├── README.md
├── data
├── adult
│ ├── adult.data
│ ├── adult.names
│ └── adult.test
└── census-income
│ ├── census-income.data.gz
│ ├── census-income.names
│ └── census-income.test.gz
├── essm.py
├── example1.ipynb
├── example2.ipynb
├── example3.ipynb
├── mmoe.py
├── ple.py
├── ple_cgc.py
└── shared_bottom.py
/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ## Multi-task Learning Models for Recommender Systems
4 |
5 | This project is developed based on [DeepCTR](https://github.com/shenweichen/DeepCTR) :https://github.com/shenweichen/DeepCTR.
6 |
7 | You can easy to use the code to design your multi task learning model for multi regression or classification tasks.
8 |
9 |
10 |
11 | | Model | Description | Paper |
12 | | :-------------------------------: | :----------------------------: | :----------------------------------------------------------: |
13 | | [Shared-Bottom](shared_bottom.py) | Shared-Bottom | [Multitask learning](http://reports-archive.adm.cs.cmu.edu/anon/1997/CMU-CS-97-203.pdf)(1998) |
14 | | [ESMM](essm.py) | Entire Space Multi-Task Model | [Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate](https://arxiv.org/abs/1804.07931)(SIGIR'18) |
15 | | [MMoE](mmoe.py) | Multi-gate Mixture-of-Experts | [Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts](https://dl.acm.org/doi/abs/10.1145/3219819.3220007)(KDD'18) |
16 | | [CGC](ple_cgc.py) | Customized Gate Control | [Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations](https://dl.acm.org/doi/10.1145/3383313.3412236)(RecSys '20) |
17 | | [PLE](ple.py) | Progressive Layered Extraction | [Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations](https://dl.acm.org/doi/10.1145/3383313.3412236)(RecSys '20) |
18 |
19 |
20 |
21 | ## Quick Start
22 |
23 | ~~~python
24 | from ple import PLE
25 |
26 | model = PLE(dnn_feature_columns, num_tasks=2, task_types=['binary', 'regression'],
27 | task_names=['task 1','task 2'], num_levels=2, num_experts_specific=8,
28 | num_experts_shared=4, expert_dnn_units=[64,64], gate_dnn_units=[16,16],
29 | tower_dnn_units_lists=[[32,32],[32,32]])
30 |
31 | model.compile("adam", loss=["binary_crossentropy", "mean_squared_error"], metrics=['AUC','mae'])
32 |
33 | model.fit(X_train, [y_task1, y_task2], batch_size=256, epochs=5, verbose=2)
34 |
35 | pred_ans = model.predict(X_test, batch_size=256)
36 |
37 | ~~~
38 |
39 |
40 |
41 | ### [Example 1](example1.ipynb)
42 |
43 | Dataset: http://archive.ics.uci.edu/ml/machine-learning-databases/adult/
44 |
45 | Task 1: (Classification) aims to predict whether the income exceeds 50K.
46 |
47 | Task 2: (Classification) aims to predict this person’s marital status is never married.
48 |
49 |
50 |
51 | Dataset: https://archive.ics.uci.edu/ml/machine-learning-databases/census-income-mld/
52 |
53 | ### [Example 2](example2.ipynb)
54 |
55 | Census-income Dataset contains 299,285 samples and 40 features extracted from the 1994 census database.
56 |
57 | **[Group 1](example2.ipynb)**
58 |
59 | Task 1: (Classification) aims to predict whether the income exceeds 50K.
60 |
61 | Task 2: (Classification) aims to predict this person’s marital status is never married.
62 |
63 | **[Group 2](example3.ipynb)**
64 |
65 | Task 1: (Classification) aims to predict whether the education level is at least college.
66 |
67 | Task 2: (Classification) aims to predict this person’s marital status is never married.
68 |
69 | **Experiment Setup** (follow MMOE paper) :
70 |
71 | ```python
72 | #Parameters
73 | learning_rate = 0.01 #Adam
74 | batch_size = 1024
75 |
76 | #ESMM
77 | Tower Network: hidden_size=8
78 |
79 | #Shared-Bottom
80 | Bottom Network: hidden_size = 16
81 | Tower Network: hidden_size=8
82 |
83 | #MMOE
84 | num_experts = 8
85 | Expert Network: hidden_size=16
86 | Tower Network: hidden_size=8
87 |
88 | #CGC
89 | num_experts_specific=4
90 | num_experts_shared=4
91 | Expert Network: hidden_size=16
92 | Tower Network: hidden_size=8
93 |
94 | #PLE
95 | num_level = 2
96 | ```
97 |
98 | **Experiment Results (AUC)**
99 |
100 | | Model | Group1
Income | Group1
Marital Stat | Group2
Education | Group2
Marital Stat |
101 | | :-------------------------------: | :----------------: | :----------------------: | --------------------- | ------------------------- |
102 | | [Shared-Bottom](shared_bottom.py) | 0.9478 | 0.9947 | **0.8745** | 0.9945 |
103 | | [ESMM](essm.py) | 0.9439 | 0.9904 | 0.8601 | 0.982 |
104 | | [MMoE](mmoe.py) | 0.9463 | 0.9937 | 0.8734 | 0.9946 |
105 | | [CGC](ple_cgc.py) | 0.9471 | 0.9947 | 0.8736 | **0.9946** |
106 | | [PLE](ple.py) | **0.948** | **0.9947** | 0.8737 | 0.9945 |
107 |
108 | Notes: We do not implement a hyper-parameter tuner as MMoE paper done. In ESSM experiment, we treat task 2 as CTR and task 1 as CTCVR.
109 |
110 |
111 |
112 | ## Shared-Bottom & MMOE
113 |
114 |
115 |
116 | 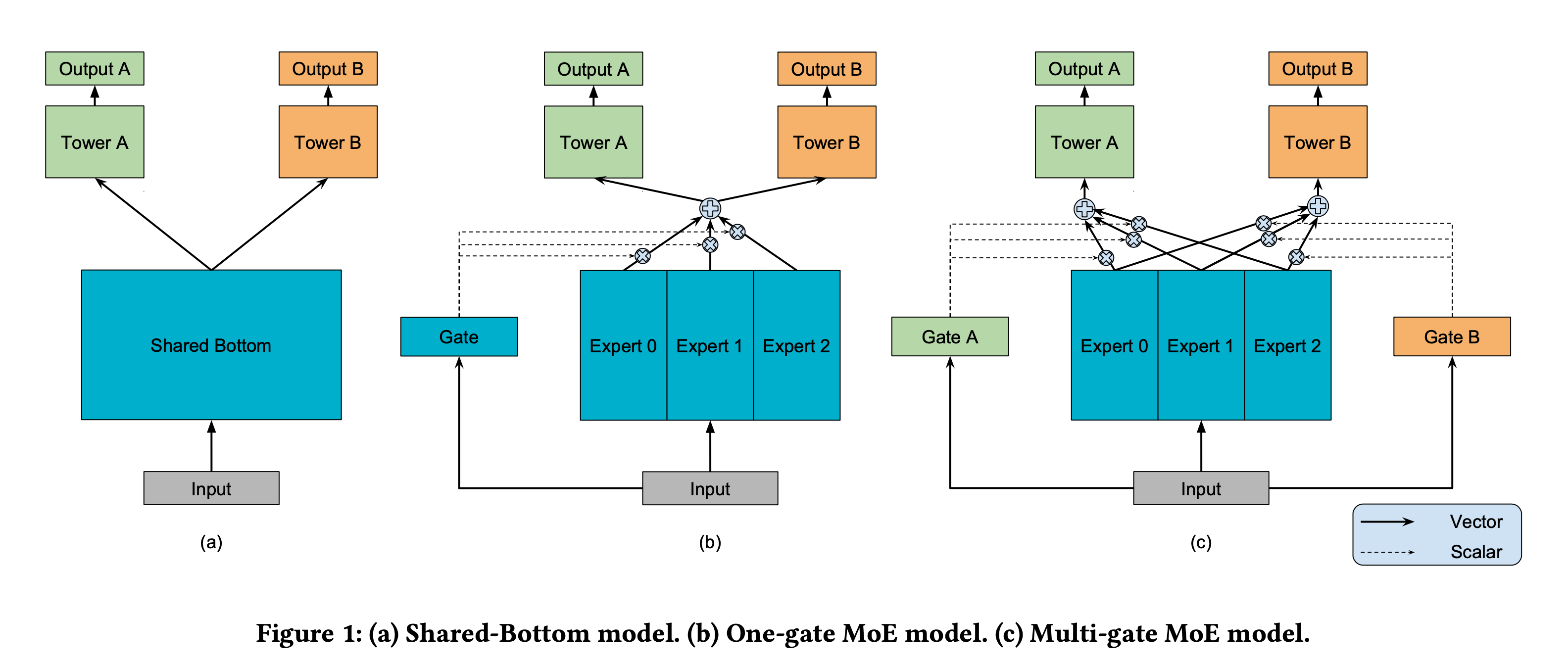
117 |
118 |
119 |
120 |
121 |
122 | ## ESMM
123 |
124 | 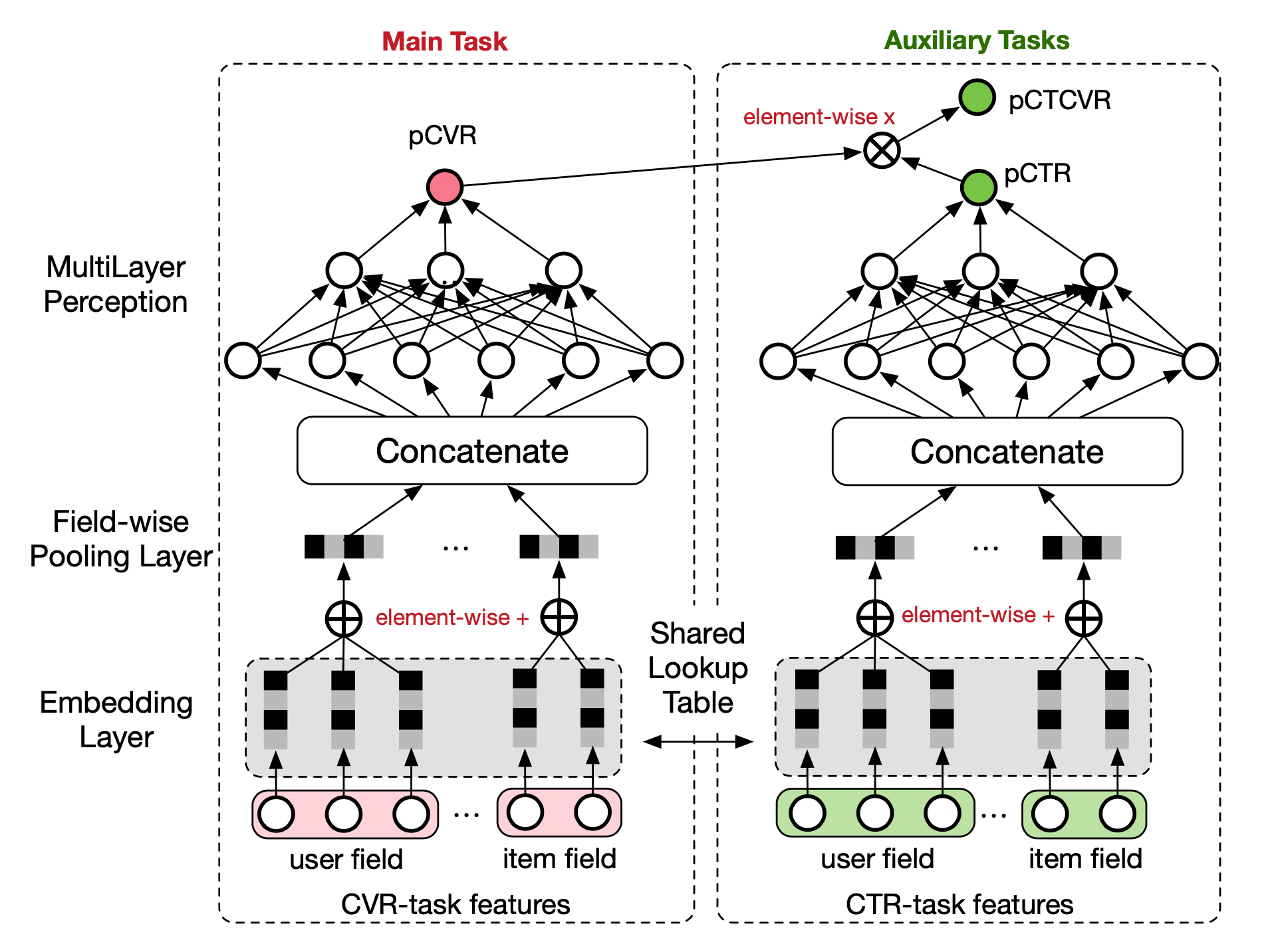
125 |
126 | ## CGC
127 |
128 | 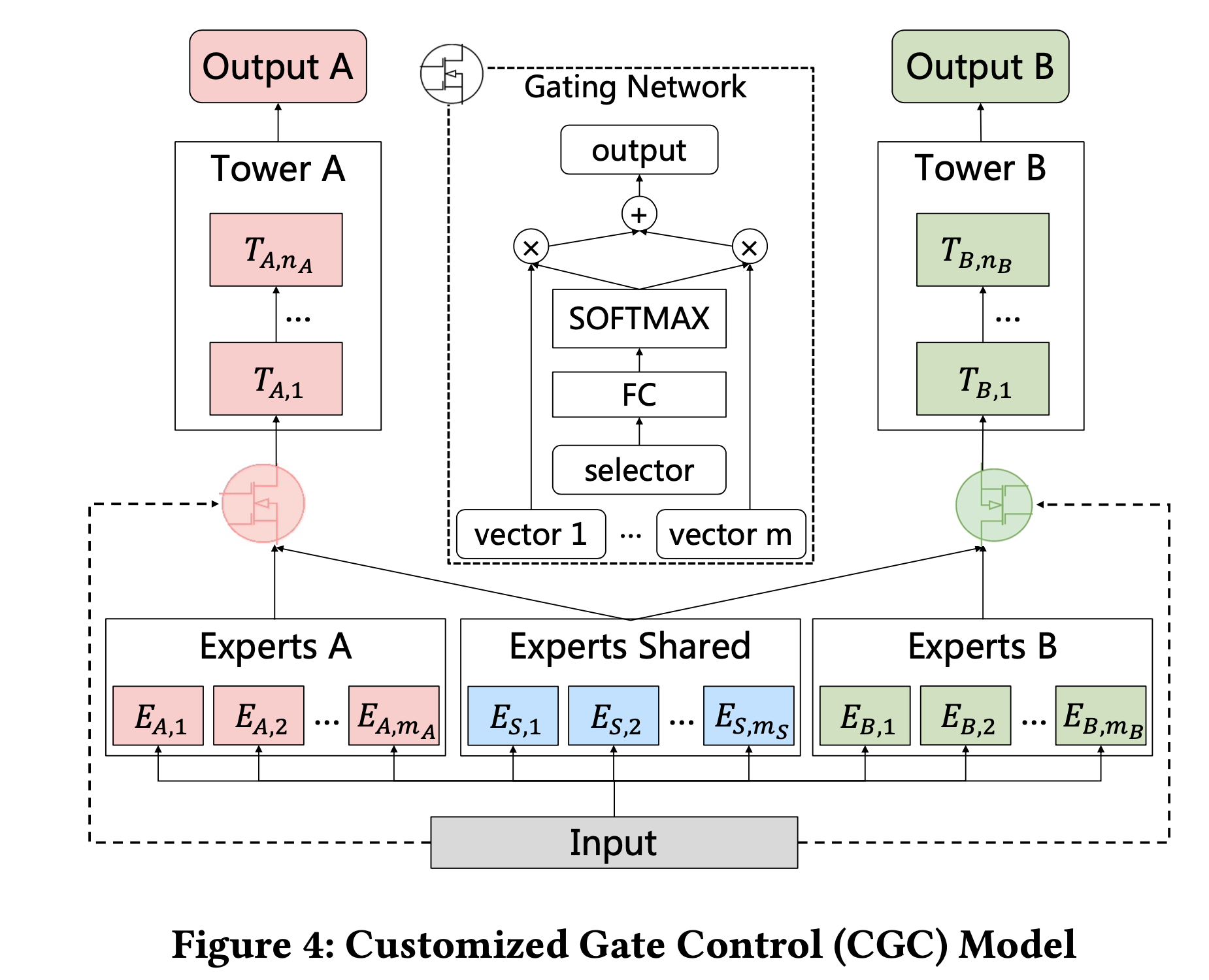
129 |
130 | ## PLE
131 |
132 | 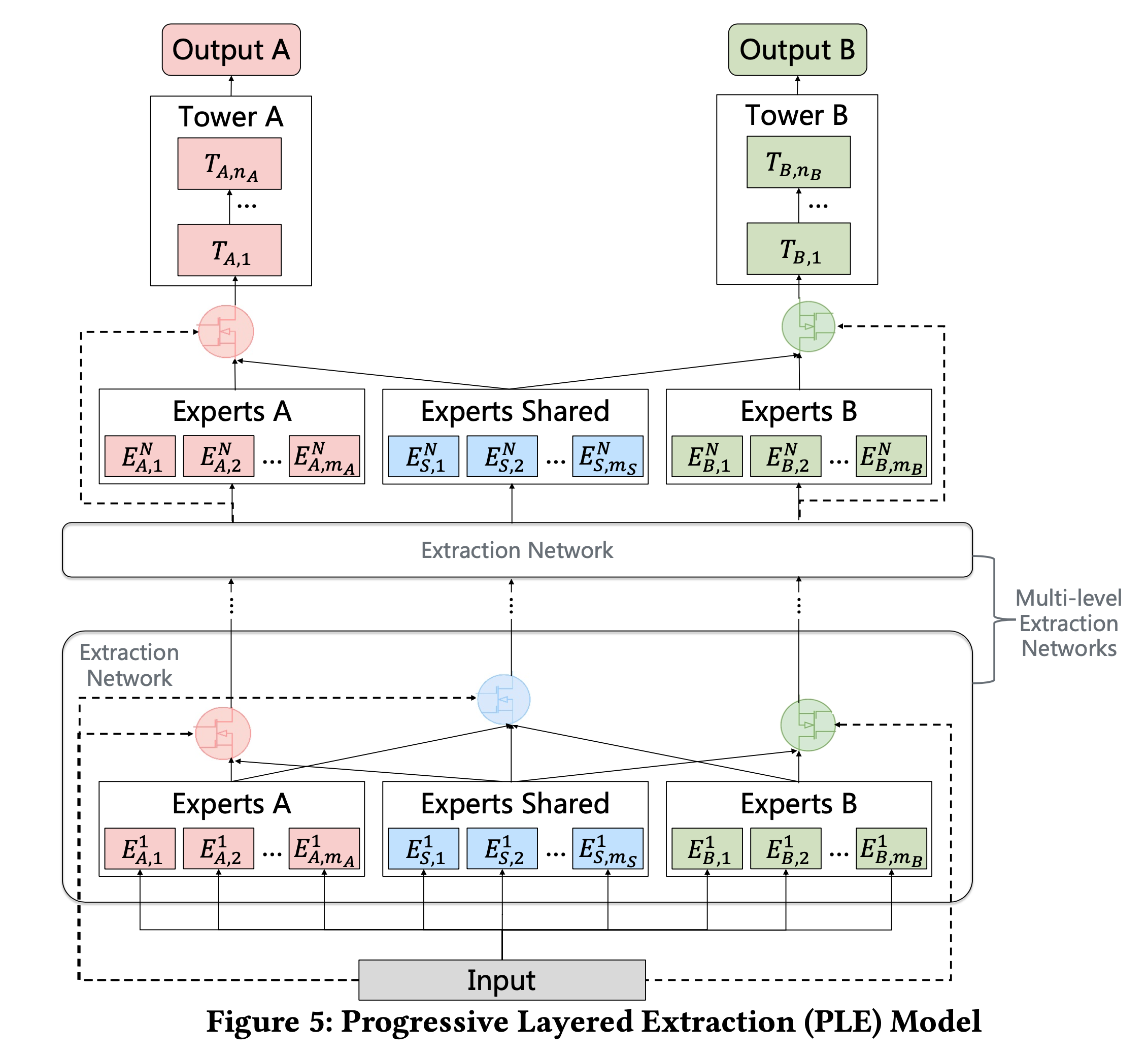
133 |
134 |
--------------------------------------------------------------------------------
/data/adult/adult.names:
--------------------------------------------------------------------------------
1 | | This data was extracted from the census bureau database found at
2 | | http://www.census.gov/ftp/pub/DES/www/welcome.html
3 | | Donor: Ronny Kohavi and Barry Becker,
4 | | Data Mining and Visualization
5 | | Silicon Graphics.
6 | | e-mail: ronnyk@sgi.com for questions.
7 | | Split into train-test using MLC++ GenCVFiles (2/3, 1/3 random).
8 | | 48842 instances, mix of continuous and discrete (train=32561, test=16281)
9 | | 45222 if instances with unknown values are removed (train=30162, test=15060)
10 | | Duplicate or conflicting instances : 6
11 | | Class probabilities for adult.all file
12 | | Probability for the label '>50K' : 23.93% / 24.78% (without unknowns)
13 | | Probability for the label '<=50K' : 76.07% / 75.22% (without unknowns)
14 | |
15 | | Extraction was done by Barry Becker from the 1994 Census database. A set of
16 | | reasonably clean records was extracted using the following conditions:
17 | | ((AAGE>16) && (AGI>100) && (AFNLWGT>1)&& (HRSWK>0))
18 | |
19 | | Prediction task is to determine whether a person makes over 50K
20 | | a year.
21 | |
22 | | First cited in:
23 | | @inproceedings{kohavi-nbtree,
24 | | author={Ron Kohavi},
25 | | title={Scaling Up the Accuracy of Naive-Bayes Classifiers: a
26 | | Decision-Tree Hybrid},
27 | | booktitle={Proceedings of the Second International Conference on
28 | | Knowledge Discovery and Data Mining},
29 | | year = 1996,
30 | | pages={to appear}}
31 | |
32 | | Error Accuracy reported as follows, after removal of unknowns from
33 | | train/test sets):
34 | | C4.5 : 84.46+-0.30
35 | | Naive-Bayes: 83.88+-0.30
36 | | NBTree : 85.90+-0.28
37 | |
38 | |
39 | | Following algorithms were later run with the following error rates,
40 | | all after removal of unknowns and using the original train/test split.
41 | | All these numbers are straight runs using MLC++ with default values.
42 | |
43 | | Algorithm Error
44 | | -- ---------------- -----
45 | | 1 C4.5 15.54
46 | | 2 C4.5-auto 14.46
47 | | 3 C4.5 rules 14.94
48 | | 4 Voted ID3 (0.6) 15.64
49 | | 5 Voted ID3 (0.8) 16.47
50 | | 6 T2 16.84
51 | | 7 1R 19.54
52 | | 8 NBTree 14.10
53 | | 9 CN2 16.00
54 | | 10 HOODG 14.82
55 | | 11 FSS Naive Bayes 14.05
56 | | 12 IDTM (Decision table) 14.46
57 | | 13 Naive-Bayes 16.12
58 | | 14 Nearest-neighbor (1) 21.42
59 | | 15 Nearest-neighbor (3) 20.35
60 | | 16 OC1 15.04
61 | | 17 Pebls Crashed. Unknown why (bounds WERE increased)
62 | |
63 | | Conversion of original data as follows:
64 | | 1. Discretized agrossincome into two ranges with threshold 50,000.
65 | | 2. Convert U.S. to US to avoid periods.
66 | | 3. Convert Unknown to "?"
67 | | 4. Run MLC++ GenCVFiles to generate data,test.
68 | |
69 | | Description of fnlwgt (final weight)
70 | |
71 | | The weights on the CPS files are controlled to independent estimates of the
72 | | civilian noninstitutional population of the US. These are prepared monthly
73 | | for us by Population Division here at the Census Bureau. We use 3 sets of
74 | | controls.
75 | | These are:
76 | | 1. A single cell estimate of the population 16+ for each state.
77 | | 2. Controls for Hispanic Origin by age and sex.
78 | | 3. Controls by Race, age and sex.
79 | |
80 | | We use all three sets of controls in our weighting program and "rake" through
81 | | them 6 times so that by the end we come back to all the controls we used.
82 | |
83 | | The term estimate refers to population totals derived from CPS by creating
84 | | "weighted tallies" of any specified socio-economic characteristics of the
85 | | population.
86 | |
87 | | People with similar demographic characteristics should have
88 | | similar weights. There is one important caveat to remember
89 | | about this statement. That is that since the CPS sample is
90 | | actually a collection of 51 state samples, each with its own
91 | | probability of selection, the statement only applies within
92 | | state.
93 |
94 |
95 | >50K, <=50K.
96 |
97 | age: continuous.
98 | workclass: Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Without-pay, Never-worked.
99 | fnlwgt: continuous.
100 | education: Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc, 9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool.
101 | education-num: continuous.
102 | marital-status: Married-civ-spouse, Divorced, Never-married, Separated, Widowed, Married-spouse-absent, Married-AF-spouse.
103 | occupation: Tech-support, Craft-repair, Other-service, Sales, Exec-managerial, Prof-specialty, Handlers-cleaners, Machine-op-inspct, Adm-clerical, Farming-fishing, Transport-moving, Priv-house-serv, Protective-serv, Armed-Forces.
104 | relationship: Wife, Own-child, Husband, Not-in-family, Other-relative, Unmarried.
105 | race: White, Asian-Pac-Islander, Amer-Indian-Eskimo, Other, Black.
106 | sex: Female, Male.
107 | capital-gain: continuous.
108 | capital-loss: continuous.
109 | hours-per-week: continuous.
110 | native-country: United-States, Cambodia, England, Puerto-Rico, Canada, Germany, Outlying-US(Guam-USVI-etc), India, Japan, Greece, South, China, Cuba, Iran, Honduras, Philippines, Italy, Poland, Jamaica, Vietnam, Mexico, Portugal, Ireland, France, Dominican-Republic, Laos, Ecuador, Taiwan, Haiti, Columbia, Hungary, Guatemala, Nicaragua, Scotland, Thailand, Yugoslavia, El-Salvador, Trinadad&Tobago, Peru, Hong, Holand-Netherlands.
111 |
--------------------------------------------------------------------------------
/data/census-income/census-income.data.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/morningsky/multi_task_learning/2c7c7cec5bb45dbfb213bc0496c9bde8283ba100/data/census-income/census-income.data.gz
--------------------------------------------------------------------------------
/data/census-income/census-income.names:
--------------------------------------------------------------------------------
1 | | This data was extracted from the census bureau database found at
2 | | http://www.census.gov/ftp/pub/DES/www/welcome.html
3 | | Donor: Terran Lane and Ronny Kohavi
4 | | Data Mining and Visualization
5 | | Silicon Graphics.
6 | | e-mail: terran@ecn.purdue.edu, ronnyk@sgi.com for questions.
7 | |
8 | | The data was split into train/test in approximately 2/3, 1/3
9 | | proportions using MineSet's MIndUtil mineset-to-mlc.
10 | |
11 | | Prediction task is to determine the income level for the person
12 | | represented by the record. Incomes have been binned at the $50K
13 | | level to present a binary classification problem, much like the
14 | | original UCI/ADULT database. The goal field of this data, however,
15 | | was drawn from the "total person income" field rather than the
16 | | "adjusted gross income" and may, therefore, behave differently than the
17 | | orginal ADULT goal field.
18 | |
19 | | More information detailing the meaning of the attributes can be
20 | | found in http://www.bls.census.gov/cps/cpsmain.htm
21 | | To make use of the data descriptions at this site, the following mappings
22 | | to the Census Bureau's internal database column names will be needed:
23 | |
24 | | age AAGE
25 | | class of worker ACLSWKR
26 | | industry code ADTIND
27 | | occupation code ADTOCC
28 | | adjusted gross income AGI
29 | | education AHGA
30 | | wage per hour AHRSPAY
31 | | enrolled in edu inst last wk AHSCOL
32 | | marital status AMARITL
33 | | major industry code AMJIND
34 | | major occupation code AMJOCC
35 | | mace ARACE
36 | | hispanic Origin AREORGN
37 | | sex ASEX
38 | | member of a labor union AUNMEM
39 | | reason for unemployment AUNTYPE
40 | | full or part time employment stat AWKSTAT
41 | | capital gains CAPGAIN
42 | | capital losses CAPLOSS
43 | | divdends from stocks DIVVAL
44 | | federal income tax liability FEDTAX
45 | | tax filer status FILESTAT
46 | | region of previous residence GRINREG
47 | | state of previous residence GRINST
48 | | detailed household and family stat HHDFMX
49 | | detailed household summary in household HHDREL
50 | | instance weight MARSUPWT
51 | | migration code-change in msa MIGMTR1
52 | | migration code-change in reg MIGMTR3
53 | | migration code-move within reg MIGMTR4
54 | | live in this house 1 year ago MIGSAME
55 | | migration prev res in sunbelt MIGSUN
56 | | num persons worked for employer NOEMP
57 | | family members under 18 PARENT
58 | | total person earnings PEARNVAL
59 | | country of birth father PEFNTVTY
60 | | country of birth mother PEMNTVTY
61 | | country of birth self PENATVTY
62 | | citizenship PRCITSHP
63 | | total person income PTOTVAL
64 | | own business or self employed SEOTR
65 | | taxable income amount TAXINC
66 | | fill inc questionnaire for veteran's admin VETQVA
67 | | veterans benefits VETYN
68 | | weeks worked in year WKSWORK
69 | |
70 | | Basic statistics for this data set:
71 | |
72 | | Number of instances data = 199523
73 | | Duplicate or conflicting instances : 46716
74 | | Number of instances in test = 99762
75 | | Duplicate or conflicting instances : 20936
76 | | Class probabilities for income-projected.test file
77 | | Probability for the label '- 50000' : 93.80%
78 | | Probability for the label '50000+' : 6.20%
79 | | Majority accuracy: 93.80% on value - 50000
80 | | Number of attributes = 40 (continuous : 7 nominal : 33)
81 | | Information about .data file :
82 | | 91 distinct values for attribute #0 (age) continuous
83 | | 9 distinct values for attribute #1 (class of worker) nominal
84 | | 52 distinct values for attribute #2 (detailed industry recode) nominal
85 | | 47 distinct values for attribute #3 (detailed occupation recode) nominal
86 | | 17 distinct values for attribute #4 (education) nominal
87 | | 1240 distinct values for attribute #5 (wage per hour) continuous
88 | | 3 distinct values for attribute #6 (enroll in edu inst last wk) nominal
89 | | 7 distinct values for attribute #7 (marital stat) nominal
90 | | 24 distinct values for attribute #8 (major industry code) nominal
91 | | 15 distinct values for attribute #9 (major occupation code) nominal
92 | | 5 distinct values for attribute #10 (race) nominal
93 | | 10 distinct values for attribute #11 (hispanic origin) nominal
94 | | 2 distinct values for attribute #12 (sex) nominal
95 | | 3 distinct values for attribute #13 (member of a labor union) nominal
96 | | 6 distinct values for attribute #14 (reason for unemployment) nominal
97 | | 8 distinct values for attribute #15 (full or part time employment stat) nominal
98 | | 132 distinct values for attribute #16 (capital gains) continuous
99 | | 113 distinct values for attribute #17 (capital losses) continuous
100 | | 1478 distinct values for attribute #18 (dividends from stocks) continuous
101 | | 6 distinct values for attribute #19 (tax filer stat) nominal
102 | | 6 distinct values for attribute #20 (region of previous residence) nominal
103 | | 51 distinct values for attribute #21 (state of previous residence) nominal
104 | | 38 distinct values for attribute #22 (detailed household and family stat) nominal
105 | | 8 distinct values for attribute #23 (detailed household summary in household) nominal
106 | | 10 distinct values for attribute #24 (migration code-change in msa) nominal
107 | | 9 distinct values for attribute #25 (migration code-change in reg) nominal
108 | | 10 distinct values for attribute #26 (migration code-move within reg) nominal
109 | | 3 distinct values for attribute #27 (live in this house 1 year ago) nominal
110 | | 4 distinct values for attribute #28 (migration prev res in sunbelt) nominal
111 | | 7 distinct values for attribute #29 (num persons worked for employer) continuous
112 | | 5 distinct values for attribute #30 (family members under 18) nominal
113 | | 43 distinct values for attribute #31 (country of birth father) nominal
114 | | 43 distinct values for attribute #32 (country of birth mother) nominal
115 | | 43 distinct values for attribute #33 (country of birth self) nominal
116 | | 5 distinct values for attribute #34 (citizenship) nominal
117 | | 3 distinct values for attribute #35 (own business or self employed) nominal
118 | | 3 distinct values for attribute #36 (fill inc questionnaire for veteran's admin) nominal
119 | | 3 distinct values for attribute #37 (veterans benefits) nominal
120 | | 53 distinct values for attribute #38 (weeks worked in year) continuous
121 | | 2 distinct values for attribute #39 (year) nominal
122 | |
123 | |
124 | | Error rates:
125 | | C4.5 : 4.8%
126 | | C5.0 : 4.7%
127 | | C5.0 rules : 4.7%
128 | | C5.0 boosting : 4.6%
129 | | Naive-Bayes : 23.2%
130 | |
131 | |
132 | | All commas and periods were changed to spaces
133 | | Colons were replaced with dashes.
134 | |
135 | | The instance weight indicates the number of people in the population
136 | | that each record represents due to stratified sampling.
137 | | To do real analysis and derive conclusions, this field must be used.
138 | | This attribute should *not* be used in the classifiers, so it is
139 | | set to "ignore" in this file.
140 | |
141 | - 50000, 50000+.
142 |
143 | age: continuous.
144 | class of worker: Not in universe, Federal government, Local government, Never worked, Private, Self-employed-incorporated, Self-employed-not incorporated, State government, Without pay.
145 | detailed industry recode: 0, 40, 44, 2, 43, 47, 48, 1, 11, 19, 24, 25, 32, 33, 34, 35, 36, 37, 38, 39, 4, 42, 45, 5, 15, 16, 22, 29, 31, 50, 14, 17, 18, 28, 3, 30, 41, 46, 51, 12, 13, 21, 23, 26, 6, 7, 9, 49, 27, 8, 10, 20.
146 | detailed occupation recode: 0, 12, 31, 44, 19, 32, 10, 23, 26, 28, 29, 42, 40, 34, 14, 36, 38, 2, 20, 25, 37, 41, 27, 24, 30, 43, 33, 16, 45, 17, 35, 22, 18, 39, 3, 15, 13, 46, 8, 21, 9, 4, 6, 5, 1, 11, 7.
147 | education: Children, 7th and 8th grade, 9th grade, 10th grade, High school graduate, 11th grade, 12th grade no diploma, 5th or 6th grade, Less than 1st grade, Bachelors degree(BA AB BS), 1st 2nd 3rd or 4th grade, Some college but no degree, Masters degree(MA MS MEng MEd MSW MBA), Associates degree-occup /vocational, Associates degree-academic program, Doctorate degree(PhD EdD), Prof school degree (MD DDS DVM LLB JD).
148 | wage per hour: continuous.
149 | enroll in edu inst last wk: Not in universe, High school, College or university.
150 | marital stat: Never married, Married-civilian spouse present, Married-spouse absent, Separated, Divorced, Widowed, Married-A F spouse present.
151 | major industry code: Not in universe or children, Entertainment, Social services, Agriculture, Education, Public administration, Manufacturing-durable goods, Manufacturing-nondurable goods, Wholesale trade, Retail trade, Finance insurance and real estate, Private household services, Business and repair services, Personal services except private HH, Construction, Medical except hospital, Other professional services, Transportation, Utilities and sanitary services, Mining, Communications, Hospital services, Forestry and fisheries, Armed Forces.
152 | major occupation code: Not in universe, Professional specialty, Other service, Farming forestry and fishing, Sales, Adm support including clerical, Protective services, Handlers equip cleaners etc , Precision production craft & repair, Technicians and related support, Machine operators assmblrs & inspctrs, Transportation and material moving, Executive admin and managerial, Private household services, Armed Forces.
153 | race: White, Black, Other, Amer Indian Aleut or Eskimo, Asian or Pacific Islander.
154 | hispanic origin: Mexican (Mexicano), Mexican-American, Puerto Rican, Central or South American, All other, Other Spanish, Chicano, Cuban, Do not know, NA.
155 | sex: Female, Male.
156 | member of a labor union: Not in universe, No, Yes.
157 | reason for unemployment: Not in universe, Re-entrant, Job loser - on layoff, New entrant, Job leaver, Other job loser.
158 | full or part time employment stat: Children or Armed Forces, Full-time schedules, Unemployed part- time, Not in labor force, Unemployed full-time, PT for non-econ reasons usually FT, PT for econ reasons usually PT, PT for econ reasons usually FT.
159 | capital gains: continuous.
160 | capital losses: continuous.
161 | dividends from stocks: continuous.
162 | tax filer stat: Nonfiler, Joint one under 65 & one 65+, Joint both under 65, Single, Head of household, Joint both 65+.
163 | region of previous residence: Not in universe, South, Northeast, West, Midwest, Abroad.
164 | state of previous residence: Not in universe, Utah, Michigan, North Carolina, North Dakota, Virginia, Vermont, Wyoming, West Virginia, Pennsylvania, Abroad, Oregon, California, Iowa, Florida, Arkansas, Texas, South Carolina, Arizona, Indiana, Tennessee, Maine, Alaska, Ohio, Montana, Nebraska, Mississippi, District of Columbia, Minnesota, Illinois, Kentucky, Delaware, Colorado, Maryland, Wisconsin, New Hampshire, Nevada, New York, Georgia, Oklahoma, New Mexico, South Dakota, Missouri, Kansas, Connecticut, Louisiana, Alabama, Massachusetts, Idaho, New Jersey.
165 | detailed household and family stat: Child <18 never marr not in subfamily, Other Rel <18 never marr child of subfamily RP, Other Rel <18 never marr not in subfamily, Grandchild <18 never marr child of subfamily RP, Grandchild <18 never marr not in subfamily, Secondary individual, In group quarters, Child under 18 of RP of unrel subfamily, RP of unrelated subfamily, Spouse of householder, Householder, Other Rel <18 never married RP of subfamily, Grandchild <18 never marr RP of subfamily, Child <18 never marr RP of subfamily, Child <18 ever marr not in subfamily, Other Rel <18 ever marr RP of subfamily, Child <18 ever marr RP of subfamily, Nonfamily householder, Child <18 spouse of subfamily RP, Other Rel <18 spouse of subfamily RP, Other Rel <18 ever marr not in subfamily, Grandchild <18 ever marr not in subfamily, Child 18+ never marr Not in a subfamily, Grandchild 18+ never marr not in subfamily, Child 18+ ever marr RP of subfamily, Other Rel 18+ never marr not in subfamily, Child 18+ never marr RP of subfamily, Other Rel 18+ ever marr RP of subfamily, Other Rel 18+ never marr RP of subfamily, Other Rel 18+ spouse of subfamily RP, Other Rel 18+ ever marr not in subfamily, Child 18+ ever marr Not in a subfamily, Grandchild 18+ ever marr not in subfamily, Child 18+ spouse of subfamily RP, Spouse of RP of unrelated subfamily, Grandchild 18+ ever marr RP of subfamily, Grandchild 18+ never marr RP of subfamily, Grandchild 18+ spouse of subfamily RP.
166 | detailed household summary in household: Child under 18 never married, Other relative of householder, Nonrelative of householder, Spouse of householder, Householder, Child under 18 ever married, Group Quarters- Secondary individual, Child 18 or older.
167 | | instance weight: ignore.
168 | instance weight: continuous.
169 | migration code-change in msa: Not in universe, Nonmover, MSA to MSA, NonMSA to nonMSA, MSA to nonMSA, NonMSA to MSA, Abroad to MSA, Not identifiable, Abroad to nonMSA.
170 | migration code-change in reg: Not in universe, Nonmover, Same county, Different county same state, Different state same division, Abroad, Different region, Different division same region.
171 | migration code-move within reg: Not in universe, Nonmover, Same county, Different county same state, Different state in West, Abroad, Different state in Midwest, Different state in South, Different state in Northeast.
172 | live in this house 1 year ago: Not in universe under 1 year old, Yes, No.
173 | migration prev res in sunbelt: Not in universe, Yes, No.
174 | num persons worked for employer: continuous.
175 | family members under 18: Both parents present, Neither parent present, Mother only present, Father only present, Not in universe.
176 | country of birth father: Mexico, United-States, Puerto-Rico, Dominican-Republic, Jamaica, Cuba, Portugal, Nicaragua, Peru, Ecuador, Guatemala, Philippines, Canada, Columbia, El-Salvador, Japan, England, Trinadad&Tobago, Honduras, Germany, Taiwan, Outlying-U S (Guam USVI etc), India, Vietnam, China, Hong Kong, Cambodia, France, Laos, Haiti, South Korea, Iran, Greece, Italy, Poland, Thailand, Yugoslavia, Holand-Netherlands, Ireland, Scotland, Hungary, Panama.
177 | country of birth mother: India, Mexico, United-States, Puerto-Rico, Dominican-Republic, England, Honduras, Peru, Guatemala, Columbia, El-Salvador, Philippines, France, Ecuador, Nicaragua, Cuba, Outlying-U S (Guam USVI etc), Jamaica, South Korea, China, Germany, Yugoslavia, Canada, Vietnam, Japan, Cambodia, Ireland, Laos, Haiti, Portugal, Taiwan, Holand-Netherlands, Greece, Italy, Poland, Thailand, Trinadad&Tobago, Hungary, Panama, Hong Kong, Scotland, Iran.
178 | country of birth self: United-States, Mexico, Puerto-Rico, Peru, Canada, South Korea, India, Japan, Haiti, El-Salvador, Dominican-Republic, Portugal, Columbia, England, Thailand, Cuba, Laos, Panama, China, Germany, Vietnam, Italy, Honduras, Outlying-U S (Guam USVI etc), Hungary, Philippines, Poland, Ecuador, Iran, Guatemala, Holand-Netherlands, Taiwan, Nicaragua, France, Jamaica, Scotland, Yugoslavia, Hong Kong, Trinadad&Tobago, Greece, Cambodia, Ireland.
179 | citizenship: Native- Born in the United States, Foreign born- Not a citizen of U S , Native- Born in Puerto Rico or U S Outlying, Native- Born abroad of American Parent(s), Foreign born- U S citizen by naturalization.
180 | own business or self employed: 0, 2, 1.
181 | fill inc questionnaire for veteran's admin: Not in universe, Yes, No.
182 | veterans benefits: 0, 2, 1.
183 | weeks worked in year: continuous.
184 | year: 94, 95.
185 |
--------------------------------------------------------------------------------
/data/census-income/census-income.test.gz:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/morningsky/multi_task_learning/2c7c7cec5bb45dbfb213bc0496c9bde8283ba100/data/census-income/census-income.test.gz
--------------------------------------------------------------------------------
/essm.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 |
3 | from deepctr.feature_column import build_input_features, input_from_feature_columns
4 | from deepctr.layers.core import PredictionLayer, DNN
5 | from deepctr.layers.utils import combined_dnn_input
6 |
7 |
8 | def ESSM(dnn_feature_columns, task_type='binary', task_names=['ctr', 'ctcvr'],
9 | tower_dnn_units_lists=[[128, 128],[128, 128]], l2_reg_embedding=0.00001, l2_reg_dnn=0,
10 | seed=1024, dnn_dropout=0,dnn_activation='relu', dnn_use_bn=False):
11 | """Instantiates the Entire Space Multi-Task Model architecture.
12 |
13 | :param dnn_feature_columns: An iterable containing all the features used by deep part of the model.
14 | :param task_type: str, indicating the loss of each tasks, ``"binary"`` for binary logloss or ``"regression"`` for regression loss.
15 | :param task_names: list of str, indicating the predict target of each tasks. default value is ['ctr', 'ctcvr']
16 |
17 | :param tower_dnn_units_lists: list, list of positive integer, the length must be equal to 2, the layer number and units in each layer of task-specific DNN
18 |
19 | :param l2_reg_embedding: float. L2 regularizer strength applied to embedding vector
20 | :param l2_reg_dnn: float. L2 regularizer strength applied to DNN
21 | :param seed: integer ,to use as random seed.
22 | :param dnn_dropout: float in [0,1), the probability we will drop out a given DNN coordinate.
23 | :param dnn_activation: Activation function to use in DNN
24 | :param dnn_use_bn: bool. Whether use BatchNormalization before activation or not in DNN
25 | :return: A Keras model instance.
26 | """
27 | if len(task_names)!=2:
28 | raise ValueError("the length of task_names must be equal to 2")
29 |
30 | if len(tower_dnn_units_lists)!=2:
31 | raise ValueError("the length of tower_dnn_units_lists must be equal to 2")
32 |
33 | features = build_input_features(dnn_feature_columns)
34 | inputs_list = list(features.values())
35 |
36 | sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns, l2_reg_embedding,seed)
37 |
38 | dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
39 |
40 | ctr_output = DNN(tower_dnn_units_lists[0], dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input)
41 | cvr_output = DNN(tower_dnn_units_lists[1], dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input)
42 |
43 | ctr_logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(ctr_output)
44 | cvr_logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(cvr_output)
45 |
46 | ctr_pred = PredictionLayer(task_type, name=task_names[0])(ctr_logit)
47 | cvr_pred = PredictionLayer(task_type)(cvr_logit)
48 |
49 | ctcvr_pred = tf.keras.layers.Multiply(name=task_names[1])([ctr_pred, cvr_pred]) #CTCVR = CTR * CVR
50 |
51 | model = tf.keras.models.Model(inputs=inputs_list, outputs=[ctr_pred, ctcvr_pred])
52 | return model
--------------------------------------------------------------------------------
/example1.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "metadata": {
3 | "language_info": {
4 | "codemirror_mode": {
5 | "name": "ipython",
6 | "version": 3
7 | },
8 | "file_extension": ".py",
9 | "mimetype": "text/x-python",
10 | "name": "python",
11 | "nbconvert_exporter": "python",
12 | "pygments_lexer": "ipython3",
13 | "version": "3.7.9"
14 | },
15 | "orig_nbformat": 2,
16 | "kernelspec": {
17 | "name": "python379jvsc74a57bd0890a3aa13989506a4f157c210d7e888dcd9c9bfc264e152253245030dde69647",
18 | "display_name": "Python 3.7.9 64-bit ('base': conda)"
19 | }
20 | },
21 | "nbformat": 4,
22 | "nbformat_minor": 2,
23 | "cells": [
24 | {
25 | "cell_type": "code",
26 | "execution_count": 1,
27 | "metadata": {},
28 | "outputs": [],
29 | "source": [
30 | "import numpy as np\n",
31 | "import pandas as pd\n",
32 | "from deepctr.feature_column import SparseFeat, DenseFeat,get_feature_names\n",
33 | "from sklearn.preprocessing import LabelEncoder, MinMaxScaler\n",
34 | "from sklearn.metrics import roc_auc_score\n",
35 | "\n",
36 | "import warnings\n",
37 | "warnings.filterwarnings('ignore')"
38 | ]
39 | },
40 | {
41 | "source": [
42 | "### task 1 aims to predict whether the income exceeds 50K, \n",
43 | "### task 2 aims to predict whether this person’s marital status is never married."
44 | ],
45 | "cell_type": "markdown",
46 | "metadata": {}
47 | },
48 | {
49 | "cell_type": "code",
50 | "execution_count": 2,
51 | "metadata": {},
52 | "outputs": [],
53 | "source": [
54 | "CENSUS_COLUMNS = ['age','workclass','fnlwgt','education','education_num','marital_status','occupation','relationship','race','gender','capital_gain','capital_loss','hours_per_week','native_country','income_bracket']\n",
55 | "\n",
56 | "df_train = pd.read_csv('./data/adult.data',header=None,names=CENSUS_COLUMNS)\n",
57 | "df_test = pd.read_csv('./data/adult.test',header=None,names=CENSUS_COLUMNS)\n",
58 | "data = pd.concat([df_train, df_test], axis=0)\n",
59 | "\n",
60 | "#take task1 as ctr task, take task2 as ctcvr task.\n",
61 | "data['ctr_label'] = data['income_bracket'].map({' >50K.':1, ' >50K':1, ' <=50K.':0, ' <=50K':0})\n",
62 | "data['ctcvr_label'] = data['marital_status'].apply(lambda x: 1 if x==' Never-married' else 0)\n",
63 | "data.drop(labels=['marital_status', 'income_bracket'], axis=1, inplace=True)\n"
64 | ]
65 | },
66 | {
67 | "cell_type": "code",
68 | "execution_count": 3,
69 | "metadata": {},
70 | "outputs": [],
71 | "source": [
72 | "#define dense and sparse features\n",
73 | "columns = data.columns.values.tolist()\n",
74 | "dense_features = ['fnlwgt', 'education_num', 'capital_gain', 'capital_loss', 'hours_per_week']\n",
75 | "sparse_features = [col for col in columns if col not in dense_features and col not in ['ctr_label', 'ctcvr_label']]\n",
76 | "\n",
77 | "data[sparse_features] = data[sparse_features].fillna('-1', )\n",
78 | "data[dense_features] = data[dense_features].fillna(0, )\n",
79 | "mms = MinMaxScaler(feature_range=(0, 1))\n",
80 | "data[dense_features] = mms.fit_transform(data[dense_features])\n",
81 | " \n",
82 | "for feat in sparse_features:\n",
83 | " lbe = LabelEncoder()\n",
84 | " data[feat] = lbe.fit_transform(data[feat])\n",
85 | " \n",
86 | "fixlen_feature_columns = [SparseFeat(feat, data[feat].max()+1, embedding_dim=16)for feat in sparse_features] \\\n",
87 | "+ [DenseFeat(feat, 1,) for feat in dense_features]\n",
88 | "\n",
89 | "dnn_feature_columns = fixlen_feature_columns\n",
90 | "\n",
91 | "feature_names = get_feature_names(dnn_feature_columns)"
92 | ]
93 | },
94 | {
95 | "cell_type": "code",
96 | "execution_count": 4,
97 | "metadata": {},
98 | "outputs": [],
99 | "source": [
100 | "#train test split\n",
101 | "n_train = df_train.shape[0]\n",
102 | "train = data[:n_train]\n",
103 | "test = data[n_train:]\n",
104 | "train_model_input = {name: train[name] for name in feature_names}\n",
105 | "test_model_input = {name: test[name] for name in feature_names}"
106 | ]
107 | },
108 | {
109 | "cell_type": "code",
110 | "execution_count": 5,
111 | "metadata": {},
112 | "outputs": [
113 | {
114 | "output_type": "stream",
115 | "name": "stdout",
116 | "text": [
117 | "Epoch 1/5\n",
118 | "128/128 - 0s - loss: 1.0419 - ctr_loss: 0.5610 - ctcvr_loss: 0.4810 - ctr_auc: 0.6276 - ctcvr_auc_1: 0.8919\n",
119 | "Epoch 2/5\n",
120 | "128/128 - 0s - loss: 0.8686 - ctr_loss: 0.5013 - ctcvr_loss: 0.3672 - ctr_auc: 0.7799 - ctcvr_auc_1: 0.9552\n",
121 | "Epoch 3/5\n",
122 | "128/128 - 0s - loss: 0.8580 - ctr_loss: 0.4925 - ctcvr_loss: 0.3655 - ctr_auc: 0.7902 - ctcvr_auc_1: 0.9566\n",
123 | "Epoch 4/5\n",
124 | "128/128 - 0s - loss: 0.8529 - ctr_loss: 0.4879 - ctcvr_loss: 0.3650 - ctr_auc: 0.7945 - ctcvr_auc_1: 0.9564\n",
125 | "Epoch 5/5\n",
126 | "128/128 - 0s - loss: 0.8496 - ctr_loss: 0.4852 - ctcvr_loss: 0.3643 - ctr_auc: 0.7993 - ctcvr_auc_1: 0.9569\n",
127 | "test CTR AUC 0.7838\n",
128 | "test CTCVR AUC 0.9559\n"
129 | ]
130 | }
131 | ],
132 | "source": [
133 | "#Test ESSM Model\n",
134 | "from essm import ESSM\n",
135 | "model = ESSM(dnn_feature_columns, task_type='binary', task_names=['ctr', 'ctcvr'],\n",
136 | " tower_dnn_units_lists=[[64, 64],[64, 64]])\n",
137 | "model.compile(\"adam\", loss=[\"binary_crossentropy\", \"binary_crossentropy\"],\n",
138 | " metrics=['AUC'])\n",
139 | "\n",
140 | "history = model.fit(train_model_input, [train['ctr_label'].values, train['ctcvr_label'].values],batch_size=256, epochs=5, verbose=2, validation_split=0.0 )\n",
141 | "\n",
142 | "pred_ans = model.predict(test_model_input, batch_size=256)\n",
143 | "\n",
144 | "print(\"test CTR AUC\", round(roc_auc_score(test['ctr_label'], pred_ans[0]), 4))\n",
145 | "print(\"test CTCVR AUC\", round(roc_auc_score(test['ctcvr_label'], pred_ans[1]), 4))"
146 | ]
147 | },
148 | {
149 | "cell_type": "code",
150 | "execution_count": 6,
151 | "metadata": {},
152 | "outputs": [
153 | {
154 | "output_type": "stream",
155 | "name": "stdout",
156 | "text": [
157 | "Epoch 1/5\n",
158 | "128/128 - 0s - loss: 0.7820 - income_loss: 0.4126 - marital_loss: 0.3693 - income_auc: 0.8222 - marital_auc_1: 0.8928\n",
159 | "Epoch 2/5\n",
160 | "128/128 - 0s - loss: 0.5554 - income_loss: 0.3248 - marital_loss: 0.2305 - income_auc: 0.9031 - marital_auc_1: 0.9619\n",
161 | "Epoch 3/5\n",
162 | "128/128 - 0s - loss: 0.5454 - income_loss: 0.3156 - marital_loss: 0.2298 - income_auc: 0.9088 - marital_auc_1: 0.9622\n",
163 | "Epoch 4/5\n",
164 | "128/128 - 0s - loss: 0.5408 - income_loss: 0.3133 - marital_loss: 0.2274 - income_auc: 0.9098 - marital_auc_1: 0.9628\n",
165 | "Epoch 5/5\n",
166 | "128/128 - 0s - loss: 0.5341 - income_loss: 0.3086 - marital_loss: 0.2254 - income_auc: 0.9130 - marital_auc_1: 0.9635\n",
167 | "test income AUC 0.9098\n",
168 | "test marital AUC 0.9635\n"
169 | ]
170 | }
171 | ],
172 | "source": [
173 | "#Test Shared_Bottom Model\n",
174 | "from shared_bottom import Shared_Bottom\n",
175 | "task_names = ['income', 'marital']\n",
176 | "model = Shared_Bottom(dnn_feature_columns, num_tasks=2, task_types= ['binary', 'binary'], task_names=task_names, bottom_dnn_units=[128, 128], tower_dnn_units_lists=[[64,32], [64,32]])\n",
177 | "\n",
178 | "model.compile(\"adam\", loss=[\"binary_crossentropy\", \"binary_crossentropy\"], metrics=['AUC'])\n",
179 | "history = model.fit(train_model_input, [train['ctr_label'].values, train['ctcvr_label'].values],batch_size=256, epochs=5, verbose=2, validation_split=0.0 )\n",
180 | "\n",
181 | "pred_ans = model.predict(test_model_input, batch_size=256)\n",
182 | "\n",
183 | "print(\"test income AUC\", round(roc_auc_score(test['ctr_label'], pred_ans[0]), 4))\n",
184 | "print(\"test marital AUC\", round(roc_auc_score(test['ctcvr_label'], pred_ans[1]), 4))"
185 | ]
186 | },
187 | {
188 | "cell_type": "code",
189 | "execution_count": 7,
190 | "metadata": {},
191 | "outputs": [
192 | {
193 | "output_type": "stream",
194 | "name": "stdout",
195 | "text": [
196 | "Epoch 1/5\n",
197 | "128/128 - 1s - loss: 0.8637 - income_loss: 0.4493 - marital_loss: 0.4144 - income_auc: 0.7824 - marital_auc_1: 0.8558\n",
198 | "Epoch 2/5\n",
199 | "128/128 - 1s - loss: 0.5618 - income_loss: 0.3302 - marital_loss: 0.2316 - income_auc: 0.9004 - marital_auc_1: 0.9614\n",
200 | "Epoch 3/5\n",
201 | "128/128 - 1s - loss: 0.5508 - income_loss: 0.3216 - marital_loss: 0.2292 - income_auc: 0.9054 - marital_auc_1: 0.9622\n",
202 | "Epoch 4/5\n",
203 | "128/128 - 1s - loss: 0.5384 - income_loss: 0.3135 - marital_loss: 0.2248 - income_auc: 0.9102 - marital_auc_1: 0.9636\n",
204 | "Epoch 5/5\n",
205 | "128/128 - 1s - loss: 0.5359 - income_loss: 0.3118 - marital_loss: 0.2240 - income_auc: 0.9108 - marital_auc_1: 0.9639\n",
206 | "test income AUC 0.9091\n",
207 | "test marital AUC 0.9638\n"
208 | ]
209 | }
210 | ],
211 | "source": [
212 | "from mmoe import MMOE\n",
213 | "\n",
214 | "model = MMOE(dnn_feature_columns, num_tasks=2, task_types=['binary', 'binary'], task_names=task_names, \n",
215 | "num_experts=8, expert_dnn_units=[64,64], gate_dnn_units=[32,32], tower_dnn_units_lists=[[32,32],[32,32]])\n",
216 | "model.compile(\"adam\", loss=[\"binary_crossentropy\", \"binary_crossentropy\"], metrics=['AUC'])\n",
217 | "\n",
218 | "history = model.fit(train_model_input, [train['ctr_label'].values, train['ctcvr_label'].values], batch_size=256, epochs=5, verbose=2, validation_split=0.0 )\n",
219 | "\n",
220 | "pred_ans = model.predict(test_model_input, batch_size=256)\n",
221 | "print(\"test income AUC\", round(roc_auc_score(test['ctr_label'], pred_ans[0]), 4))\n",
222 | "print(\"test marital AUC\", round(roc_auc_score(test['ctcvr_label'], pred_ans[1]), 4))"
223 | ]
224 | },
225 | {
226 | "cell_type": "code",
227 | "execution_count": 9,
228 | "metadata": {},
229 | "outputs": [
230 | {
231 | "output_type": "stream",
232 | "name": "stdout",
233 | "text": [
234 | "Epoch 1/5\n",
235 | "128/128 - 2s - loss: 0.8721 - income_loss: 0.4423 - marital_loss: 0.4297 - income_auc: 0.7902 - marital_auc_1: 0.8538\n",
236 | "Epoch 2/5\n",
237 | "128/128 - 2s - loss: 0.5631 - income_loss: 0.3310 - marital_loss: 0.2321 - income_auc: 0.8995 - marital_auc_1: 0.9613\n",
238 | "Epoch 3/5\n",
239 | "128/128 - 2s - loss: 0.5461 - income_loss: 0.3194 - marital_loss: 0.2266 - income_auc: 0.9066 - marital_auc_1: 0.9631\n",
240 | "Epoch 4/5\n",
241 | "128/128 - 2s - loss: 0.5412 - income_loss: 0.3151 - marital_loss: 0.2260 - income_auc: 0.9091 - marital_auc_1: 0.9632\n",
242 | "Epoch 5/5\n",
243 | "128/128 - 2s - loss: 0.5386 - income_loss: 0.3131 - marital_loss: 0.2254 - income_auc: 0.9102 - marital_auc_1: 0.9635\n",
244 | "test income AUC 0.9094\n",
245 | "test marital AUC 0.9636\n"
246 | ]
247 | }
248 | ],
249 | "source": [
250 | "from ple_cgc import PLE_CGC\n",
251 | "\n",
252 | "model = PLE_CGC(dnn_feature_columns, num_tasks=2, task_types=['binary', 'binary'], task_names=task_names, \n",
253 | "num_experts_specific=8, num_experts_shared=4, expert_dnn_units=[64,64], gate_dnn_units=[16,16], tower_dnn_units_lists=[[32,32],[32,32]])\n",
254 | "model.compile(\"adam\", loss=[\"binary_crossentropy\", \"binary_crossentropy\"], metrics=['AUC'])\n",
255 | "\n",
256 | "history = model.fit(train_model_input, [train['ctr_label'].values, train['ctcvr_label'].values], batch_size=256, epochs=5, verbose=2, validation_split=0.0 )\n",
257 | "\n",
258 | "pred_ans = model.predict(test_model_input, batch_size=256)\n",
259 | "print(\"test income AUC\", round(roc_auc_score(test['ctr_label'], pred_ans[0]), 4))\n",
260 | "print(\"test marital AUC\", round(roc_auc_score(test['ctcvr_label'], pred_ans[1]), 4))"
261 | ]
262 | },
263 | {
264 | "cell_type": "code",
265 | "execution_count": 10,
266 | "metadata": {},
267 | "outputs": [
268 | {
269 | "output_type": "stream",
270 | "name": "stdout",
271 | "text": [
272 | "Epoch 1/5\n",
273 | "128/128 - 3s - loss: 0.9043 - income_loss: 0.4642 - marital_loss: 0.4401 - income_auc: 0.7619 - marital_auc_1: 0.8424\n",
274 | "Epoch 2/5\n",
275 | "128/128 - 3s - loss: 0.5665 - income_loss: 0.3339 - marital_loss: 0.2325 - income_auc: 0.8979 - marital_auc_1: 0.9610\n",
276 | "Epoch 3/5\n",
277 | "128/128 - 4s - loss: 0.5454 - income_loss: 0.3203 - marital_loss: 0.2250 - income_auc: 0.9061 - marital_auc_1: 0.9636\n",
278 | "Epoch 4/5\n",
279 | "128/128 - 5s - loss: 0.5354 - income_loss: 0.3111 - marital_loss: 0.2242 - income_auc: 0.9116 - marital_auc_1: 0.9638\n",
280 | "Epoch 5/5\n",
281 | "128/128 - 4s - loss: 0.5319 - income_loss: 0.3090 - marital_loss: 0.2228 - income_auc: 0.9124 - marital_auc_1: 0.9643\n",
282 | "test income AUC 0.9103\n",
283 | "test marital AUC 0.9635\n"
284 | ]
285 | }
286 | ],
287 | "source": [
288 | "from ple import PLE\n",
289 | "\n",
290 | "model = PLE(dnn_feature_columns, num_tasks=2, task_types=['binary', 'binary'], task_names=task_names, \n",
291 | "num_levels=2, num_experts_specific=8, num_experts_shared=4, expert_dnn_units=[64,64], gate_dnn_units=[16,16], tower_dnn_units_lists=[[32,32],[32,32]])\n",
292 | "model.compile(\"adam\", loss=[\"binary_crossentropy\", \"binary_crossentropy\"], metrics=['AUC'])\n",
293 | "\n",
294 | "history = model.fit(train_model_input, [train['ctr_label'].values, train['ctcvr_label'].values], batch_size=256, epochs=5, verbose=2, validation_split=0.0 )\n",
295 | "\n",
296 | "pred_ans = model.predict(test_model_input, batch_size=256)\n",
297 | "print(\"test income AUC\", round(roc_auc_score(test['ctr_label'], pred_ans[0]), 4))\n",
298 | "print(\"test marital AUC\", round(roc_auc_score(test['ctcvr_label'], pred_ans[1]), 4))"
299 | ]
300 | }
301 | ]
302 | }
--------------------------------------------------------------------------------
/example2.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "metadata": {
3 | "language_info": {
4 | "codemirror_mode": {
5 | "name": "ipython",
6 | "version": 3
7 | },
8 | "file_extension": ".py",
9 | "mimetype": "text/x-python",
10 | "name": "python",
11 | "nbconvert_exporter": "python",
12 | "pygments_lexer": "ipython3",
13 | "version": "3.7.9"
14 | },
15 | "orig_nbformat": 2,
16 | "kernelspec": {
17 | "name": "python3",
18 | "display_name": "Python 3.7.9 64-bit ('base': conda)"
19 | },
20 | "interpreter": {
21 | "hash": "890a3aa13989506a4f157c210d7e888dcd9c9bfc264e152253245030dde69647"
22 | }
23 | },
24 | "nbformat": 4,
25 | "nbformat_minor": 2,
26 | "cells": [
27 | {
28 | "cell_type": "code",
29 | "execution_count": 9,
30 | "metadata": {},
31 | "outputs": [],
32 | "source": [
33 | "import numpy as np\n",
34 | "import pandas as pd\n",
35 | "from deepctr.feature_column import SparseFeat, DenseFeat,get_feature_names\n",
36 | "from sklearn.preprocessing import LabelEncoder, MinMaxScaler\n",
37 | "from sklearn.metrics import roc_auc_score\n",
38 | "import tensorflow as tf\n",
39 | "import warnings\n",
40 | "warnings.filterwarnings('ignore')"
41 | ]
42 | },
43 | {
44 | "source": [
45 | "### task 1 aims to predict whether the income exceeds 50K, \n",
46 | "### task 2 aims to predict whether this person’s marital status is never married."
47 | ],
48 | "cell_type": "markdown",
49 | "metadata": {}
50 | },
51 | {
52 | "cell_type": "code",
53 | "execution_count": 22,
54 | "metadata": {},
55 | "outputs": [],
56 | "source": [
57 | "column_names = ['age', 'class_worker', 'det_ind_code', 'det_occ_code', 'education', 'wage_per_hour', 'hs_college',\n",
58 | " 'marital_stat', 'major_ind_code', 'major_occ_code', 'race', 'hisp_origin', 'sex', 'union_member',\n",
59 | " 'unemp_reason', 'full_or_part_emp', 'capital_gains', 'capital_losses', 'stock_dividends',\n",
60 | " 'tax_filer_stat', 'region_prev_res', 'state_prev_res', 'det_hh_fam_stat', 'det_hh_summ',\n",
61 | " 'instance_weight', 'mig_chg_msa', 'mig_chg_reg', 'mig_move_reg', 'mig_same', 'mig_prev_sunbelt',\n",
62 | " 'num_emp', 'fam_under_18', 'country_father', 'country_mother', 'country_self', 'citizenship',\n",
63 | " 'own_or_self', 'vet_question', 'vet_benefits', 'weeks_worked', 'year', 'income_50k']\n",
64 | "df_train = pd.read_csv('./data/census-income/census-income.data',header=None,names=column_names)\n",
65 | "df_test = pd.read_csv('./data/census-income/census-income.test',header=None,names=column_names)\n",
66 | "data = pd.concat([df_train, df_test], axis=0)"
67 | ]
68 | },
69 | {
70 | "cell_type": "code",
71 | "execution_count": 23,
72 | "metadata": {},
73 | "outputs": [
74 | {
75 | "output_type": "execute_result",
76 | "data": {
77 | "text/plain": [
78 | " - 50000. 280717\n",
79 | " 50000+. 18568\n",
80 | "Name: income_50k, dtype: int64"
81 | ]
82 | },
83 | "metadata": {},
84 | "execution_count": 23
85 | }
86 | ],
87 | "source": [
88 | "#task 1 label:'income_50k'\n",
89 | "data['income_50k'].value_counts()"
90 | ]
91 | },
92 | {
93 | "cell_type": "code",
94 | "execution_count": 24,
95 | "metadata": {},
96 | "outputs": [
97 | {
98 | "output_type": "execute_result",
99 | "data": {
100 | "text/plain": [
101 | " Never married 129628\n",
102 | " Married-civilian spouse present 126315\n",
103 | " Divorced 19160\n",
104 | " Widowed 15788\n",
105 | " Separated 5156\n",
106 | " Married-spouse absent 2234\n",
107 | " Married-A F spouse present 1004\n",
108 | "Name: marital_stat, dtype: int64"
109 | ]
110 | },
111 | "metadata": {},
112 | "execution_count": 24
113 | }
114 | ],
115 | "source": [
116 | "#task 2 label: 'marital_stat'\n",
117 | "data['marital_stat'].value_counts()"
118 | ]
119 | },
120 | {
121 | "cell_type": "code",
122 | "execution_count": 25,
123 | "metadata": {},
124 | "outputs": [],
125 | "source": [
126 | "#change the label to binary classification\n",
127 | "data['label_income'] = data['income_50k'].map({' - 50000.':0, ' 50000+.':1})\n",
128 | "data['label_marital'] = data['marital_stat'].apply(lambda x: 1 if x==' Never married' else 0)\n",
129 | "data.drop(labels=['income_50k', 'marital_stat'], axis=1, inplace=True)"
130 | ]
131 | },
132 | {
133 | "cell_type": "code",
134 | "execution_count": 26,
135 | "metadata": {},
136 | "outputs": [],
137 | "source": [
138 | "#define dense and sparse features. \n",
139 | "#the functions used here can reference https://deepctr-torch.readthedocs.io/en/latest/Quick-Start.html\n",
140 | "columns = data.columns.values.tolist()\n",
141 | "sparse_features = ['class_worker', 'det_ind_code', 'det_occ_code', 'education', 'hs_college', 'major_ind_code',\n",
142 | " 'major_occ_code', 'race', 'hisp_origin', 'sex', 'union_member', 'unemp_reason',\n",
143 | " 'full_or_part_emp', 'tax_filer_stat', 'region_prev_res', 'state_prev_res', 'det_hh_fam_stat',\n",
144 | " 'det_hh_summ', 'mig_chg_msa', 'mig_chg_reg', 'mig_move_reg', 'mig_same', 'mig_prev_sunbelt',\n",
145 | " 'fam_under_18', 'country_father', 'country_mother', 'country_self', 'citizenship',\n",
146 | " 'vet_question']\n",
147 | "dense_features = [col for col in columns if col not in sparse_features and col not in ['label_income', 'label_marital']]\n",
148 | "\n",
149 | "data[sparse_features] = data[sparse_features].fillna('-1', )\n",
150 | "data[dense_features] = data[dense_features].fillna(0, )\n",
151 | "mms = MinMaxScaler(feature_range=(0, 1))\n",
152 | "data[dense_features] = mms.fit_transform(data[dense_features])\n",
153 | " \n",
154 | "for feat in sparse_features:\n",
155 | " lbe = LabelEncoder()\n",
156 | " data[feat] = lbe.fit_transform(data[feat])\n",
157 | " \n",
158 | "fixlen_feature_columns = [SparseFeat(feat, data[feat].max()+1, embedding_dim=4)for feat in sparse_features] \\\n",
159 | " + [DenseFeat(feat, 1,) for feat in dense_features]\n",
160 | "\n",
161 | "dnn_feature_columns = fixlen_feature_columns\n",
162 | "feature_names = get_feature_names(dnn_feature_columns)"
163 | ]
164 | },
165 | {
166 | "cell_type": "code",
167 | "execution_count": 41,
168 | "metadata": {},
169 | "outputs": [],
170 | "source": [
171 | "# Split the test dataset into 1:1 validation to test according to the MMOE paper\n",
172 | "# validation_split = n_val/len(train) = 0.2\n",
173 | "n_train = df_train.shape[0]\n",
174 | "n_val = df_test.shape[0]//2\n",
175 | "train = data[:n_train+n_val]\n",
176 | "test = data[n_train+n_val:]\n",
177 | "\n",
178 | "train_model_input = {name: train[name] for name in feature_names}\n",
179 | "test_model_input = {name: test[name] for name in feature_names}"
180 | ]
181 | },
182 | {
183 | "cell_type": "code",
184 | "execution_count": 63,
185 | "metadata": {},
186 | "outputs": [
187 | {
188 | "output_type": "stream",
189 | "name": "stdout",
190 | "text": [
191 | "Epoch 1/100\n",
192 | "195/195 - 4s - loss: 0.3384 - label_income_loss: 0.1546 - label_marital_loss: 0.1833 - label_income_auc: 0.9027 - label_marital_auc_1: 0.9789 - val_loss: 0.2262 - val_label_income_loss: 0.1299 - val_label_marital_loss: 0.0957 - val_label_income_auc: 0.9370 - val_label_marital_auc_1: 0.9940\n",
193 | "Epoch 2/100\n",
194 | "195/195 - 2s - loss: 0.2226 - label_income_loss: 0.1266 - label_marital_loss: 0.0954 - label_income_auc: 0.9391 - label_marital_auc_1: 0.9939 - val_loss: 0.2219 - val_label_income_loss: 0.1267 - val_label_marital_loss: 0.0945 - val_label_income_auc: 0.9444 - val_label_marital_auc_1: 0.9942\n",
195 | "Epoch 3/100\n",
196 | "195/195 - 2s - loss: 0.2191 - label_income_loss: 0.1246 - label_marital_loss: 0.0938 - label_income_auc: 0.9407 - label_marital_auc_1: 0.9942 - val_loss: 0.2172 - val_label_income_loss: 0.1229 - val_label_marital_loss: 0.0936 - val_label_income_auc: 0.9446 - val_label_marital_auc_1: 0.9943\n",
197 | "Epoch 4/100\n",
198 | "195/195 - 2s - loss: 0.2151 - label_income_loss: 0.1227 - label_marital_loss: 0.0917 - label_income_auc: 0.9430 - label_marital_auc_1: 0.9944 - val_loss: 0.2169 - val_label_income_loss: 0.1219 - val_label_marital_loss: 0.0942 - val_label_income_auc: 0.9458 - val_label_marital_auc_1: 0.9944\n",
199 | "Epoch 5/100\n",
200 | "195/195 - 1s - loss: 0.2139 - label_income_loss: 0.1223 - label_marital_loss: 0.0908 - label_income_auc: 0.9436 - label_marital_auc_1: 0.9945 - val_loss: 0.2170 - val_label_income_loss: 0.1221 - val_label_marital_loss: 0.0941 - val_label_income_auc: 0.9455 - val_label_marital_auc_1: 0.9944\n",
201 | "Epoch 6/100\n",
202 | "195/195 - 1s - loss: 0.2133 - label_income_loss: 0.1220 - label_marital_loss: 0.0903 - label_income_auc: 0.9434 - label_marital_auc_1: 0.9945 - val_loss: 0.2158 - val_label_income_loss: 0.1217 - val_label_marital_loss: 0.0932 - val_label_income_auc: 0.9461 - val_label_marital_auc_1: 0.9945\n",
203 | "Epoch 7/100\n",
204 | "195/195 - 1s - loss: 0.2119 - label_income_loss: 0.1213 - label_marital_loss: 0.0896 - label_income_auc: 0.9443 - label_marital_auc_1: 0.9946 - val_loss: 0.2144 - val_label_income_loss: 0.1229 - val_label_marital_loss: 0.0905 - val_label_income_auc: 0.9443 - val_label_marital_auc_1: 0.9945\n",
205 | "Epoch 8/100\n",
206 | "195/195 - 1s - loss: 0.2103 - label_income_loss: 0.1207 - label_marital_loss: 0.0886 - label_income_auc: 0.9452 - label_marital_auc_1: 0.9947 - val_loss: 0.2136 - val_label_income_loss: 0.1220 - val_label_marital_loss: 0.0906 - val_label_income_auc: 0.9452 - val_label_marital_auc_1: 0.9945\n",
207 | "Epoch 9/100\n",
208 | "195/195 - 1s - loss: 0.2101 - label_income_loss: 0.1209 - label_marital_loss: 0.0882 - label_income_auc: 0.9452 - label_marital_auc_1: 0.9948 - val_loss: 0.2140 - val_label_income_loss: 0.1225 - val_label_marital_loss: 0.0905 - val_label_income_auc: 0.9458 - val_label_marital_auc_1: 0.9945\n",
209 | "Epoch 10/100\n",
210 | "195/195 - 1s - loss: 0.2094 - label_income_loss: 0.1203 - label_marital_loss: 0.0881 - label_income_auc: 0.9457 - label_marital_auc_1: 0.9948 - val_loss: 0.2123 - val_label_income_loss: 0.1210 - val_label_marital_loss: 0.0902 - val_label_income_auc: 0.9461 - val_label_marital_auc_1: 0.9946\n",
211 | "Epoch 11/100\n",
212 | "195/195 - 1s - loss: 0.2097 - label_income_loss: 0.1207 - label_marital_loss: 0.0879 - label_income_auc: 0.9452 - label_marital_auc_1: 0.9948 - val_loss: 0.2122 - val_label_income_loss: 0.1209 - val_label_marital_loss: 0.0902 - val_label_income_auc: 0.9463 - val_label_marital_auc_1: 0.9946\n",
213 | "Epoch 12/100\n",
214 | "195/195 - 1s - loss: 0.2088 - label_income_loss: 0.1197 - label_marital_loss: 0.0880 - label_income_auc: 0.9462 - label_marital_auc_1: 0.9948 - val_loss: 0.2147 - val_label_income_loss: 0.1215 - val_label_marital_loss: 0.0921 - val_label_income_auc: 0.9458 - val_label_marital_auc_1: 0.9944\n",
215 | "Epoch 13/100\n",
216 | "195/195 - 1s - loss: 0.2084 - label_income_loss: 0.1198 - label_marital_loss: 0.0875 - label_income_auc: 0.9460 - label_marital_auc_1: 0.9949 - val_loss: 0.2117 - val_label_income_loss: 0.1210 - val_label_marital_loss: 0.0896 - val_label_income_auc: 0.9461 - val_label_marital_auc_1: 0.9946\n",
217 | "Epoch 14/100\n",
218 | "195/195 - 2s - loss: 0.2081 - label_income_loss: 0.1195 - label_marital_loss: 0.0874 - label_income_auc: 0.9463 - label_marital_auc_1: 0.9949 - val_loss: 0.2117 - val_label_income_loss: 0.1206 - val_label_marital_loss: 0.0900 - val_label_income_auc: 0.9474 - val_label_marital_auc_1: 0.9946\n",
219 | "Epoch 15/100\n",
220 | "195/195 - 1s - loss: 0.2082 - label_income_loss: 0.1194 - label_marital_loss: 0.0877 - label_income_auc: 0.9465 - label_marital_auc_1: 0.9948 - val_loss: 0.2135 - val_label_income_loss: 0.1200 - val_label_marital_loss: 0.0922 - val_label_income_auc: 0.9460 - val_label_marital_auc_1: 0.9946\n",
221 | "Epoch 16/100\n",
222 | "195/195 - 1s - loss: 0.2077 - label_income_loss: 0.1188 - label_marital_loss: 0.0876 - label_income_auc: 0.9470 - label_marital_auc_1: 0.9948 - val_loss: 0.2117 - val_label_income_loss: 0.1202 - val_label_marital_loss: 0.0903 - val_label_income_auc: 0.9465 - val_label_marital_auc_1: 0.9946\n",
223 | "Epoch 17/100\n",
224 | "195/195 - 2s - loss: 0.2071 - label_income_loss: 0.1185 - label_marital_loss: 0.0873 - label_income_auc: 0.9471 - label_marital_auc_1: 0.9949 - val_loss: 0.2115 - val_label_income_loss: 0.1201 - val_label_marital_loss: 0.0902 - val_label_income_auc: 0.9464 - val_label_marital_auc_1: 0.9946\n",
225 | "Epoch 18/100\n",
226 | "195/195 - 1s - loss: 0.2073 - label_income_loss: 0.1191 - label_marital_loss: 0.0869 - label_income_auc: 0.9465 - label_marital_auc_1: 0.9949 - val_loss: 0.2106 - val_label_income_loss: 0.1196 - val_label_marital_loss: 0.0898 - val_label_income_auc: 0.9472 - val_label_marital_auc_1: 0.9946\n",
227 | "Epoch 19/100\n",
228 | "195/195 - 1s - loss: 0.2060 - label_income_loss: 0.1180 - label_marital_loss: 0.0867 - label_income_auc: 0.9475 - label_marital_auc_1: 0.9950 - val_loss: 0.2118 - val_label_income_loss: 0.1198 - val_label_marital_loss: 0.0907 - val_label_income_auc: 0.9459 - val_label_marital_auc_1: 0.9944\n",
229 | "Epoch 20/100\n",
230 | "195/195 - 1s - loss: 0.2061 - label_income_loss: 0.1178 - label_marital_loss: 0.0870 - label_income_auc: 0.9475 - label_marital_auc_1: 0.9949 - val_loss: 0.2116 - val_label_income_loss: 0.1193 - val_label_marital_loss: 0.0911 - val_label_income_auc: 0.9474 - val_label_marital_auc_1: 0.9946\n",
231 | "Epoch 21/100\n",
232 | "195/195 - 1s - loss: 0.2056 - label_income_loss: 0.1179 - label_marital_loss: 0.0864 - label_income_auc: 0.9481 - label_marital_auc_1: 0.9950 - val_loss: 0.2108 - val_label_income_loss: 0.1194 - val_label_marital_loss: 0.0900 - val_label_income_auc: 0.9464 - val_label_marital_auc_1: 0.9946\n",
233 | "Epoch 22/100\n",
234 | "195/195 - 1s - loss: 0.2054 - label_income_loss: 0.1178 - label_marital_loss: 0.0863 - label_income_auc: 0.9476 - label_marital_auc_1: 0.9950 - val_loss: 0.2116 - val_label_income_loss: 0.1202 - val_label_marital_loss: 0.0901 - val_label_income_auc: 0.9475 - val_label_marital_auc_1: 0.9946\n",
235 | "Epoch 23/100\n",
236 | "195/195 - 1s - loss: 0.2052 - label_income_loss: 0.1175 - label_marital_loss: 0.0864 - label_income_auc: 0.9481 - label_marital_auc_1: 0.9950 - val_loss: 0.2125 - val_label_income_loss: 0.1192 - val_label_marital_loss: 0.0919 - val_label_income_auc: 0.9468 - val_label_marital_auc_1: 0.9945\n",
237 | "Epoch 24/100\n",
238 | "195/195 - 1s - loss: 0.2049 - label_income_loss: 0.1173 - label_marital_loss: 0.0863 - label_income_auc: 0.9484 - label_marital_auc_1: 0.9950 - val_loss: 0.2099 - val_label_income_loss: 0.1192 - val_label_marital_loss: 0.0895 - val_label_income_auc: 0.9468 - val_label_marital_auc_1: 0.9947\n",
239 | "Epoch 25/100\n",
240 | "195/195 - 1s - loss: 0.2044 - label_income_loss: 0.1171 - label_marital_loss: 0.0859 - label_income_auc: 0.9483 - label_marital_auc_1: 0.9950 - val_loss: 0.2115 - val_label_income_loss: 0.1200 - val_label_marital_loss: 0.0902 - val_label_income_auc: 0.9460 - val_label_marital_auc_1: 0.9946\n",
241 | "Epoch 26/100\n",
242 | "195/195 - 1s - loss: 0.2048 - label_income_loss: 0.1175 - label_marital_loss: 0.0858 - label_income_auc: 0.9479 - label_marital_auc_1: 0.9950 - val_loss: 0.2105 - val_label_income_loss: 0.1195 - val_label_marital_loss: 0.0897 - val_label_income_auc: 0.9464 - val_label_marital_auc_1: 0.9947\n",
243 | "Epoch 27/100\n",
244 | "195/195 - 1s - loss: 0.2041 - label_income_loss: 0.1170 - label_marital_loss: 0.0857 - label_income_auc: 0.9482 - label_marital_auc_1: 0.9951 - val_loss: 0.2120 - val_label_income_loss: 0.1198 - val_label_marital_loss: 0.0907 - val_label_income_auc: 0.9460 - val_label_marital_auc_1: 0.9946\n",
245 | "Epoch 28/100\n",
246 | "195/195 - 2s - loss: 0.2040 - label_income_loss: 0.1168 - label_marital_loss: 0.0858 - label_income_auc: 0.9489 - label_marital_auc_1: 0.9951 - val_loss: 0.2105 - val_label_income_loss: 0.1191 - val_label_marital_loss: 0.0900 - val_label_income_auc: 0.9462 - val_label_marital_auc_1: 0.9946\n",
247 | "Epoch 29/100\n",
248 | "195/195 - 1s - loss: 0.2038 - label_income_loss: 0.1168 - label_marital_loss: 0.0855 - label_income_auc: 0.9485 - label_marital_auc_1: 0.9951 - val_loss: 0.2105 - val_label_income_loss: 0.1196 - val_label_marital_loss: 0.0896 - val_label_income_auc: 0.9461 - val_label_marital_auc_1: 0.9946\n",
249 | "Epoch 30/100\n",
250 | "195/195 - 2s - loss: 0.2040 - label_income_loss: 0.1168 - label_marital_loss: 0.0857 - label_income_auc: 0.9486 - label_marital_auc_1: 0.9951 - val_loss: 0.2109 - val_label_income_loss: 0.1192 - val_label_marital_loss: 0.0903 - val_label_income_auc: 0.9469 - val_label_marital_auc_1: 0.9946\n",
251 | "Epoch 31/100\n",
252 | "195/195 - 2s - loss: 0.2037 - label_income_loss: 0.1167 - label_marital_loss: 0.0856 - label_income_auc: 0.9487 - label_marital_auc_1: 0.9951 - val_loss: 0.2111 - val_label_income_loss: 0.1193 - val_label_marital_loss: 0.0903 - val_label_income_auc: 0.9471 - val_label_marital_auc_1: 0.9946\n",
253 | "Epoch 32/100\n",
254 | "195/195 - 2s - loss: 0.2035 - label_income_loss: 0.1163 - label_marital_loss: 0.0858 - label_income_auc: 0.9491 - label_marital_auc_1: 0.9951 - val_loss: 0.2110 - val_label_income_loss: 0.1195 - val_label_marital_loss: 0.0900 - val_label_income_auc: 0.9471 - val_label_marital_auc_1: 0.9946\n",
255 | "Epoch 33/100\n",
256 | "195/195 - 2s - loss: 0.2034 - label_income_loss: 0.1165 - label_marital_loss: 0.0853 - label_income_auc: 0.9489 - label_marital_auc_1: 0.9951 - val_loss: 0.2153 - val_label_income_loss: 0.1239 - val_label_marital_loss: 0.0899 - val_label_income_auc: 0.9453 - val_label_marital_auc_1: 0.9946\n",
257 | "Epoch 34/100\n",
258 | "Restoring model weights from the end of the best epoch.\n",
259 | "195/195 - 1s - loss: 0.2036 - label_income_loss: 0.1165 - label_marital_loss: 0.0856 - label_income_auc: 0.9488 - label_marital_auc_1: 0.9951 - val_loss: 0.2121 - val_label_income_loss: 0.1195 - val_label_marital_loss: 0.0911 - val_label_income_auc: 0.9470 - val_label_marital_auc_1: 0.9945\n",
260 | "Epoch 00034: early stopping\n",
261 | "test income AUC 0.9478\n",
262 | "test marital AUC 0.9947\n"
263 | ]
264 | }
265 | ],
266 | "source": [
267 | "#Test Shared_Bottom Model\n",
268 | "from shared_bottom import Shared_Bottom\n",
269 | "\n",
270 | "model = Shared_Bottom(dnn_feature_columns, num_tasks=2, task_types= ['binary', 'binary'], task_names=['label_income','label_marital'], bottom_dnn_units=[16], tower_dnn_units_lists=[[8],[8]])\n",
271 | "\n",
272 | "early_stopping_monitor = tf.keras.callbacks.EarlyStopping(monitor='val_loss',min_delta=0, patience=10, verbose=1,\n",
273 | " mode='min',baseline=None,restore_best_weights=True)\n",
274 | "\n",
275 | "model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), loss=[\"binary_crossentropy\", \"binary_crossentropy\"], metrics=['AUC'])\n",
276 | "history = model.fit(train_model_input, [train['label_income'].values, train['label_marital'].values],batch_size=1024, epochs=100, verbose=2,validation_split=0.2, callbacks=[early_stopping_monitor])\n",
277 | "pred_ans = model.predict(test_model_input, batch_size=1024)\n",
278 | "\n",
279 | "print(\"test income AUC\", round(roc_auc_score(test['label_income'], pred_ans[0]), 4))\n",
280 | "print(\"test marital AUC\", round(roc_auc_score(test['label_marital'], pred_ans[1]), 4))"
281 | ]
282 | },
283 | {
284 | "cell_type": "code",
285 | "execution_count": 60,
286 | "metadata": {},
287 | "outputs": [
288 | {
289 | "output_type": "stream",
290 | "name": "stdout",
291 | "text": [
292 | "Epoch 1/100\n",
293 | "195/195 - 2s - loss: 0.3644 - label_marital_loss: 0.1804 - label_income_loss: 0.1834 - label_marital_auc: 0.9814 - label_income_auc_1: 0.8624 - val_loss: 0.2874 - val_label_marital_loss: 0.1343 - val_label_income_loss: 0.1523 - val_label_marital_auc: 0.9886 - val_label_income_auc_1: 0.9238\n",
294 | "Epoch 2/100\n",
295 | "195/195 - 2s - loss: 0.2795 - label_marital_loss: 0.1298 - label_income_loss: 0.1488 - label_marital_auc: 0.9900 - label_income_auc_1: 0.9260 - val_loss: 0.2768 - val_label_marital_loss: 0.1243 - val_label_income_loss: 0.1516 - val_label_marital_auc: 0.9909 - val_label_income_auc_1: 0.9303\n",
296 | "Epoch 3/100\n",
297 | "195/195 - 2s - loss: 0.2712 - label_marital_loss: 0.1250 - label_income_loss: 0.1452 - label_marital_auc: 0.9906 - label_income_auc_1: 0.9307 - val_loss: 0.2712 - val_label_marital_loss: 0.1249 - val_label_income_loss: 0.1454 - val_label_marital_auc: 0.9910 - val_label_income_auc_1: 0.9352\n",
298 | "Epoch 4/100\n",
299 | "195/195 - 2s - loss: 0.2671 - label_marital_loss: 0.1230 - label_income_loss: 0.1432 - label_marital_auc: 0.9907 - label_income_auc_1: 0.9334 - val_loss: 0.2689 - val_label_marital_loss: 0.1252 - val_label_income_loss: 0.1428 - val_label_marital_auc: 0.9909 - val_label_income_auc_1: 0.9338\n",
300 | "Epoch 5/100\n",
301 | "195/195 - 2s - loss: 0.2646 - label_marital_loss: 0.1221 - label_income_loss: 0.1415 - label_marital_auc: 0.9907 - label_income_auc_1: 0.9358 - val_loss: 0.2673 - val_label_marital_loss: 0.1196 - val_label_income_loss: 0.1467 - val_label_marital_auc: 0.9912 - val_label_income_auc_1: 0.9341\n",
302 | "Epoch 6/100\n",
303 | "195/195 - 2s - loss: 0.2626 - label_marital_loss: 0.1216 - label_income_loss: 0.1401 - label_marital_auc: 0.9906 - label_income_auc_1: 0.9376 - val_loss: 0.2671 - val_label_marital_loss: 0.1158 - val_label_income_loss: 0.1503 - val_label_marital_auc: 0.9908 - val_label_income_auc_1: 0.9375\n",
304 | "Epoch 7/100\n",
305 | "195/195 - 1s - loss: 0.2618 - label_marital_loss: 0.1211 - label_income_loss: 0.1397 - label_marital_auc: 0.9906 - label_income_auc_1: 0.9382 - val_loss: 0.2683 - val_label_marital_loss: 0.1226 - val_label_income_loss: 0.1447 - val_label_marital_auc: 0.9890 - val_label_income_auc_1: 0.9351\n",
306 | "Epoch 8/100\n",
307 | "195/195 - 1s - loss: 0.2604 - label_marital_loss: 0.1204 - label_income_loss: 0.1390 - label_marital_auc: 0.9907 - label_income_auc_1: 0.9391 - val_loss: 0.2679 - val_label_marital_loss: 0.1289 - val_label_income_loss: 0.1380 - val_label_marital_auc: 0.9905 - val_label_income_auc_1: 0.9413\n",
308 | "Epoch 9/100\n",
309 | "195/195 - 1s - loss: 0.2596 - label_marital_loss: 0.1204 - label_income_loss: 0.1382 - label_marital_auc: 0.9907 - label_income_auc_1: 0.9401 - val_loss: 0.2629 - val_label_marital_loss: 0.1195 - val_label_income_loss: 0.1424 - val_label_marital_auc: 0.9904 - val_label_income_auc_1: 0.9355\n",
310 | "Epoch 10/100\n",
311 | "195/195 - 1s - loss: 0.2588 - label_marital_loss: 0.1199 - label_income_loss: 0.1379 - label_marital_auc: 0.9907 - label_income_auc_1: 0.9401 - val_loss: 0.2622 - val_label_marital_loss: 0.1211 - val_label_income_loss: 0.1401 - val_label_marital_auc: 0.9907 - val_label_income_auc_1: 0.9396\n",
312 | "Epoch 11/100\n",
313 | "195/195 - 1s - loss: 0.2580 - label_marital_loss: 0.1189 - label_income_loss: 0.1380 - label_marital_auc: 0.9909 - label_income_auc_1: 0.9398 - val_loss: 0.2610 - val_label_marital_loss: 0.1220 - val_label_income_loss: 0.1379 - val_label_marital_auc: 0.9900 - val_label_income_auc_1: 0.9397\n",
314 | "Epoch 12/100\n",
315 | "195/195 - 1s - loss: 0.2570 - label_marital_loss: 0.1189 - label_income_loss: 0.1370 - label_marital_auc: 0.9908 - label_income_auc_1: 0.9412 - val_loss: 0.2616 - val_label_marital_loss: 0.1184 - val_label_income_loss: 0.1421 - val_label_marital_auc: 0.9904 - val_label_income_auc_1: 0.9389\n",
316 | "Epoch 13/100\n",
317 | "195/195 - 1s - loss: 0.2566 - label_marital_loss: 0.1185 - label_income_loss: 0.1370 - label_marital_auc: 0.9908 - label_income_auc_1: 0.9411 - val_loss: 0.2611 - val_label_marital_loss: 0.1199 - val_label_income_loss: 0.1400 - val_label_marital_auc: 0.9908 - val_label_income_auc_1: 0.9396\n",
318 | "Epoch 14/100\n",
319 | "195/195 - 1s - loss: 0.2560 - label_marital_loss: 0.1180 - label_income_loss: 0.1368 - label_marital_auc: 0.9909 - label_income_auc_1: 0.9414 - val_loss: 0.2608 - val_label_marital_loss: 0.1247 - val_label_income_loss: 0.1350 - val_label_marital_auc: 0.9902 - val_label_income_auc_1: 0.9416\n",
320 | "Epoch 15/100\n",
321 | "195/195 - 1s - loss: 0.2557 - label_marital_loss: 0.1181 - label_income_loss: 0.1364 - label_marital_auc: 0.9908 - label_income_auc_1: 0.9417 - val_loss: 0.2604 - val_label_marital_loss: 0.1215 - val_label_income_loss: 0.1378 - val_label_marital_auc: 0.9911 - val_label_income_auc_1: 0.9411\n",
322 | "Epoch 16/100\n",
323 | "195/195 - 1s - loss: 0.2556 - label_marital_loss: 0.1179 - label_income_loss: 0.1364 - label_marital_auc: 0.9908 - label_income_auc_1: 0.9415 - val_loss: 0.2600 - val_label_marital_loss: 0.1165 - val_label_income_loss: 0.1423 - val_label_marital_auc: 0.9904 - val_label_income_auc_1: 0.9407\n",
324 | "Epoch 17/100\n",
325 | "195/195 - 1s - loss: 0.2551 - label_marital_loss: 0.1174 - label_income_loss: 0.1365 - label_marital_auc: 0.9910 - label_income_auc_1: 0.9416 - val_loss: 0.2592 - val_label_marital_loss: 0.1171 - val_label_income_loss: 0.1409 - val_label_marital_auc: 0.9909 - val_label_income_auc_1: 0.9405\n",
326 | "Epoch 18/100\n",
327 | "195/195 - 1s - loss: 0.2548 - label_marital_loss: 0.1173 - label_income_loss: 0.1363 - label_marital_auc: 0.9909 - label_income_auc_1: 0.9418 - val_loss: 0.2616 - val_label_marital_loss: 0.1145 - val_label_income_loss: 0.1459 - val_label_marital_auc: 0.9917 - val_label_income_auc_1: 0.9329\n",
328 | "Epoch 19/100\n",
329 | "195/195 - 1s - loss: 0.2547 - label_marital_loss: 0.1176 - label_income_loss: 0.1359 - label_marital_auc: 0.9910 - label_income_auc_1: 0.9421 - val_loss: 0.2622 - val_label_marital_loss: 0.1116 - val_label_income_loss: 0.1493 - val_label_marital_auc: 0.9918 - val_label_income_auc_1: 0.9388\n",
330 | "Epoch 20/100\n",
331 | "195/195 - 1s - loss: 0.2540 - label_marital_loss: 0.1168 - label_income_loss: 0.1359 - label_marital_auc: 0.9911 - label_income_auc_1: 0.9422 - val_loss: 0.2589 - val_label_marital_loss: 0.1180 - val_label_income_loss: 0.1397 - val_label_marital_auc: 0.9911 - val_label_income_auc_1: 0.9415\n",
332 | "Epoch 21/100\n",
333 | "195/195 - 1s - loss: 0.2542 - label_marital_loss: 0.1170 - label_income_loss: 0.1359 - label_marital_auc: 0.9910 - label_income_auc_1: 0.9419 - val_loss: 0.2614 - val_label_marital_loss: 0.1210 - val_label_income_loss: 0.1391 - val_label_marital_auc: 0.9914 - val_label_income_auc_1: 0.9417\n",
334 | "Epoch 22/100\n",
335 | "195/195 - 1s - loss: 0.2538 - label_marital_loss: 0.1169 - label_income_loss: 0.1356 - label_marital_auc: 0.9911 - label_income_auc_1: 0.9428 - val_loss: 0.2605 - val_label_marital_loss: 0.1224 - val_label_income_loss: 0.1368 - val_label_marital_auc: 0.9902 - val_label_income_auc_1: 0.9423\n",
336 | "Epoch 23/100\n",
337 | "195/195 - 1s - loss: 0.2535 - label_marital_loss: 0.1165 - label_income_loss: 0.1356 - label_marital_auc: 0.9912 - label_income_auc_1: 0.9425 - val_loss: 0.2597 - val_label_marital_loss: 0.1172 - val_label_income_loss: 0.1411 - val_label_marital_auc: 0.9910 - val_label_income_auc_1: 0.9416\n",
338 | "Epoch 24/100\n",
339 | "195/195 - 1s - loss: 0.2540 - label_marital_loss: 0.1168 - label_income_loss: 0.1358 - label_marital_auc: 0.9911 - label_income_auc_1: 0.9423 - val_loss: 0.2596 - val_label_marital_loss: 0.1176 - val_label_income_loss: 0.1406 - val_label_marital_auc: 0.9905 - val_label_income_auc_1: 0.9416\n",
340 | "Epoch 25/100\n",
341 | "195/195 - 1s - loss: 0.2531 - label_marital_loss: 0.1164 - label_income_loss: 0.1353 - label_marital_auc: 0.9912 - label_income_auc_1: 0.9432 - val_loss: 0.2597 - val_label_marital_loss: 0.1223 - val_label_income_loss: 0.1360 - val_label_marital_auc: 0.9896 - val_label_income_auc_1: 0.9403\n",
342 | "Epoch 26/100\n",
343 | "195/195 - 1s - loss: 0.2528 - label_marital_loss: 0.1161 - label_income_loss: 0.1353 - label_marital_auc: 0.9912 - label_income_auc_1: 0.9429 - val_loss: 0.2602 - val_label_marital_loss: 0.1172 - val_label_income_loss: 0.1417 - val_label_marital_auc: 0.9903 - val_label_income_auc_1: 0.9416\n",
344 | "Epoch 27/100\n",
345 | "195/195 - 1s - loss: 0.2535 - label_marital_loss: 0.1165 - label_income_loss: 0.1356 - label_marital_auc: 0.9911 - label_income_auc_1: 0.9426 - val_loss: 0.2618 - val_label_marital_loss: 0.1196 - val_label_income_loss: 0.1409 - val_label_marital_auc: 0.9919 - val_label_income_auc_1: 0.9400\n",
346 | "Epoch 28/100\n",
347 | "195/195 - 1s - loss: 0.2529 - label_marital_loss: 0.1164 - label_income_loss: 0.1352 - label_marital_auc: 0.9912 - label_income_auc_1: 0.9432 - val_loss: 0.2587 - val_label_marital_loss: 0.1206 - val_label_income_loss: 0.1367 - val_label_marital_auc: 0.9904 - val_label_income_auc_1: 0.9432\n",
348 | "Epoch 29/100\n",
349 | "195/195 - 1s - loss: 0.2526 - label_marital_loss: 0.1163 - label_income_loss: 0.1349 - label_marital_auc: 0.9911 - label_income_auc_1: 0.9433 - val_loss: 0.2597 - val_label_marital_loss: 0.1183 - val_label_income_loss: 0.1400 - val_label_marital_auc: 0.9916 - val_label_income_auc_1: 0.9426\n",
350 | "Epoch 30/100\n",
351 | "195/195 - 1s - loss: 0.2523 - label_marital_loss: 0.1159 - label_income_loss: 0.1350 - label_marital_auc: 0.9912 - label_income_auc_1: 0.9432 - val_loss: 0.2598 - val_label_marital_loss: 0.1242 - val_label_income_loss: 0.1342 - val_label_marital_auc: 0.9905 - val_label_income_auc_1: 0.9430\n",
352 | "Epoch 31/100\n",
353 | "195/195 - 1s - loss: 0.2524 - label_marital_loss: 0.1160 - label_income_loss: 0.1350 - label_marital_auc: 0.9913 - label_income_auc_1: 0.9428 - val_loss: 0.2593 - val_label_marital_loss: 0.1232 - val_label_income_loss: 0.1347 - val_label_marital_auc: 0.9902 - val_label_income_auc_1: 0.9428\n",
354 | "Epoch 32/100\n",
355 | "195/195 - 1s - loss: 0.2522 - label_marital_loss: 0.1162 - label_income_loss: 0.1346 - label_marital_auc: 0.9912 - label_income_auc_1: 0.9441 - val_loss: 0.2602 - val_label_marital_loss: 0.1163 - val_label_income_loss: 0.1425 - val_label_marital_auc: 0.9907 - val_label_income_auc_1: 0.9394\n",
356 | "Epoch 33/100\n",
357 | "195/195 - 1s - loss: 0.2526 - label_marital_loss: 0.1163 - label_income_loss: 0.1348 - label_marital_auc: 0.9912 - label_income_auc_1: 0.9434 - val_loss: 0.2591 - val_label_marital_loss: 0.1198 - val_label_income_loss: 0.1379 - val_label_marital_auc: 0.9910 - val_label_income_auc_1: 0.9423\n",
358 | "Epoch 34/100\n",
359 | "195/195 - 1s - loss: 0.2522 - label_marital_loss: 0.1160 - label_income_loss: 0.1347 - label_marital_auc: 0.9912 - label_income_auc_1: 0.9435 - val_loss: 0.2595 - val_label_marital_loss: 0.1226 - val_label_income_loss: 0.1355 - val_label_marital_auc: 0.9906 - val_label_income_auc_1: 0.9423\n",
360 | "Epoch 35/100\n",
361 | "195/195 - 1s - loss: 0.2521 - label_marital_loss: 0.1160 - label_income_loss: 0.1347 - label_marital_auc: 0.9912 - label_income_auc_1: 0.9434 - val_loss: 0.2593 - val_label_marital_loss: 0.1222 - val_label_income_loss: 0.1356 - val_label_marital_auc: 0.9910 - val_label_income_auc_1: 0.9438\n",
362 | "Epoch 36/100\n",
363 | "195/195 - 1s - loss: 0.2519 - label_marital_loss: 0.1157 - label_income_loss: 0.1348 - label_marital_auc: 0.9913 - label_income_auc_1: 0.9436 - val_loss: 0.2609 - val_label_marital_loss: 0.1147 - val_label_income_loss: 0.1448 - val_label_marital_auc: 0.9910 - val_label_income_auc_1: 0.9422\n",
364 | "Epoch 37/100\n",
365 | "195/195 - 1s - loss: 0.2522 - label_marital_loss: 0.1159 - label_income_loss: 0.1349 - label_marital_auc: 0.9913 - label_income_auc_1: 0.9436 - val_loss: 0.2615 - val_label_marital_loss: 0.1223 - val_label_income_loss: 0.1377 - val_label_marital_auc: 0.9916 - val_label_income_auc_1: 0.9397\n",
366 | "Epoch 38/100\n",
367 | "Restoring model weights from the end of the best epoch.\n",
368 | "195/195 - 1s - loss: 0.2522 - label_marital_loss: 0.1160 - label_income_loss: 0.1347 - label_marital_auc: 0.9912 - label_income_auc_1: 0.9435 - val_loss: 0.2588 - val_label_marital_loss: 0.1210 - val_label_income_loss: 0.1363 - val_label_marital_auc: 0.9902 - val_label_income_auc_1: 0.9430\n",
369 | "Epoch 00038: early stopping\n",
370 | "test marital AUC 0.9904\n",
371 | "test income AUC 0.9439\n"
372 | ]
373 | }
374 | ],
375 | "source": [
376 | "#Test ESSM Model\n",
377 | "from essm import ESSM\n",
378 | "#take marital as ctr task, take income as ctcvr task\n",
379 | "model = ESSM(dnn_feature_columns, task_type='binary', task_names=['label_marital', 'label_income'],\n",
380 | " tower_dnn_units_lists=[[8],[8]])\n",
381 | "\n",
382 | "early_stopping_monitor = tf.keras.callbacks.EarlyStopping(monitor='val_loss',min_delta=0, patience=10, verbose=1,\n",
383 | " mode='min',baseline=None,restore_best_weights=True)\n",
384 | "model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), loss=[\"binary_crossentropy\", \"binary_crossentropy\"], metrics=['AUC'])\n",
385 | "history = model.fit(train_model_input, [train['label_marital'].values, train['label_income'].values],batch_size=1024, epochs=100, verbose=2, validation_split=0.2, callbacks=[early_stopping_monitor])\n",
386 | "\n",
387 | "pred_ans = model.predict(test_model_input, batch_size=1024)\n",
388 | "\n",
389 | "print(\"test marital AUC\", round(roc_auc_score(test['label_marital'], pred_ans[0]), 4))\n",
390 | "print(\"test income AUC\", round(roc_auc_score(test['label_income'], pred_ans[1]), 4))"
391 | ]
392 | },
393 | {
394 | "cell_type": "code",
395 | "execution_count": 59,
396 | "metadata": {},
397 | "outputs": [
398 | {
399 | "output_type": "stream",
400 | "name": "stdout",
401 | "text": [
402 | "Epoch 1/100\n",
403 | "195/195 - 4s - loss: 0.3040 - income_loss: 0.1597 - marital_loss: 0.1438 - income_auc: 0.8942 - marital_auc_1: 0.9867 - val_loss: 0.2277 - val_income_loss: 0.1288 - val_marital_loss: 0.0983 - val_income_auc: 0.9418 - val_marital_auc_1: 0.9942\n",
404 | "Epoch 2/100\n",
405 | "195/195 - 2s - loss: 0.2197 - income_loss: 0.1248 - marital_loss: 0.0942 - income_auc: 0.9413 - marital_auc_1: 0.9941 - val_loss: 0.2157 - val_income_loss: 0.1217 - val_marital_loss: 0.0933 - val_income_auc: 0.9454 - val_marital_auc_1: 0.9943\n",
406 | "Epoch 3/100\n",
407 | "195/195 - 3s - loss: 0.2162 - income_loss: 0.1232 - marital_loss: 0.0923 - income_auc: 0.9425 - marital_auc_1: 0.9943 - val_loss: 0.2147 - val_income_loss: 0.1214 - val_marital_loss: 0.0926 - val_income_auc: 0.9456 - val_marital_auc_1: 0.9944\n",
408 | "Epoch 4/100\n",
409 | "195/195 - 2s - loss: 0.2127 - income_loss: 0.1213 - marital_loss: 0.0906 - income_auc: 0.9444 - marital_auc_1: 0.9945 - val_loss: 0.2125 - val_income_loss: 0.1207 - val_marital_loss: 0.0910 - val_income_auc: 0.9466 - val_marital_auc_1: 0.9946\n",
410 | "Epoch 5/100\n",
411 | "195/195 - 2s - loss: 0.2104 - income_loss: 0.1202 - marital_loss: 0.0894 - income_auc: 0.9454 - marital_auc_1: 0.9947 - val_loss: 0.2124 - val_income_loss: 0.1211 - val_marital_loss: 0.0904 - val_income_auc: 0.9456 - val_marital_auc_1: 0.9947\n",
412 | "Epoch 6/100\n",
413 | "195/195 - 2s - loss: 0.2096 - income_loss: 0.1199 - marital_loss: 0.0888 - income_auc: 0.9458 - marital_auc_1: 0.9947 - val_loss: 0.2146 - val_income_loss: 0.1215 - val_marital_loss: 0.0923 - val_income_auc: 0.9456 - val_marital_auc_1: 0.9946\n",
414 | "Epoch 7/100\n",
415 | "195/195 - 3s - loss: 0.2086 - income_loss: 0.1193 - marital_loss: 0.0883 - income_auc: 0.9460 - marital_auc_1: 0.9948 - val_loss: 0.2116 - val_income_loss: 0.1216 - val_marital_loss: 0.0891 - val_income_auc: 0.9454 - val_marital_auc_1: 0.9947\n",
416 | "Epoch 8/100\n",
417 | "195/195 - 2s - loss: 0.2067 - income_loss: 0.1185 - marital_loss: 0.0873 - income_auc: 0.9470 - marital_auc_1: 0.9949 - val_loss: 0.2110 - val_income_loss: 0.1209 - val_marital_loss: 0.0892 - val_income_auc: 0.9463 - val_marital_auc_1: 0.9947\n",
418 | "Epoch 9/100\n",
419 | "195/195 - 2s - loss: 0.2059 - income_loss: 0.1178 - marital_loss: 0.0870 - income_auc: 0.9475 - marital_auc_1: 0.9949 - val_loss: 0.2111 - val_income_loss: 0.1205 - val_marital_loss: 0.0896 - val_income_auc: 0.9468 - val_marital_auc_1: 0.9948\n",
420 | "Epoch 10/100\n",
421 | "195/195 - 2s - loss: 0.2047 - income_loss: 0.1173 - marital_loss: 0.0863 - income_auc: 0.9480 - marital_auc_1: 0.9950 - val_loss: 0.2105 - val_income_loss: 0.1205 - val_marital_loss: 0.0889 - val_income_auc: 0.9461 - val_marital_auc_1: 0.9947\n",
422 | "Epoch 11/100\n",
423 | "195/195 - 2s - loss: 0.2038 - income_loss: 0.1168 - marital_loss: 0.0858 - income_auc: 0.9487 - marital_auc_1: 0.9951 - val_loss: 0.2132 - val_income_loss: 0.1208 - val_marital_loss: 0.0912 - val_income_auc: 0.9459 - val_marital_auc_1: 0.9946\n",
424 | "Epoch 12/100\n",
425 | "195/195 - 2s - loss: 0.2030 - income_loss: 0.1164 - marital_loss: 0.0853 - income_auc: 0.9490 - marital_auc_1: 0.9951 - val_loss: 0.2109 - val_income_loss: 0.1206 - val_marital_loss: 0.0890 - val_income_auc: 0.9463 - val_marital_auc_1: 0.9947\n",
426 | "Epoch 13/100\n",
427 | "195/195 - 2s - loss: 0.2015 - income_loss: 0.1152 - marital_loss: 0.0850 - income_auc: 0.9503 - marital_auc_1: 0.9952 - val_loss: 0.2134 - val_income_loss: 0.1221 - val_marital_loss: 0.0900 - val_income_auc: 0.9450 - val_marital_auc_1: 0.9947\n",
428 | "Epoch 14/100\n",
429 | "195/195 - 2s - loss: 0.2007 - income_loss: 0.1148 - marital_loss: 0.0845 - income_auc: 0.9503 - marital_auc_1: 0.9952 - val_loss: 0.2130 - val_income_loss: 0.1215 - val_marital_loss: 0.0902 - val_income_auc: 0.9448 - val_marital_auc_1: 0.9946\n",
430 | "Epoch 15/100\n",
431 | "195/195 - 2s - loss: 0.1993 - income_loss: 0.1135 - marital_loss: 0.0843 - income_auc: 0.9519 - marital_auc_1: 0.9952 - val_loss: 0.2136 - val_income_loss: 0.1215 - val_marital_loss: 0.0907 - val_income_auc: 0.9446 - val_marital_auc_1: 0.9946\n",
432 | "Epoch 16/100\n",
433 | "195/195 - 2s - loss: 0.1985 - income_loss: 0.1132 - marital_loss: 0.0837 - income_auc: 0.9519 - marital_auc_1: 0.9953 - val_loss: 0.2140 - val_income_loss: 0.1216 - val_marital_loss: 0.0908 - val_income_auc: 0.9450 - val_marital_auc_1: 0.9946\n",
434 | "Epoch 17/100\n",
435 | "195/195 - 2s - loss: 0.1970 - income_loss: 0.1124 - marital_loss: 0.0829 - income_auc: 0.9527 - marital_auc_1: 0.9954 - val_loss: 0.2144 - val_income_loss: 0.1223 - val_marital_loss: 0.0905 - val_income_auc: 0.9439 - val_marital_auc_1: 0.9946\n",
436 | "Epoch 18/100\n",
437 | "195/195 - 2s - loss: 0.1968 - income_loss: 0.1123 - marital_loss: 0.0828 - income_auc: 0.9527 - marital_auc_1: 0.9954 - val_loss: 0.2143 - val_income_loss: 0.1220 - val_marital_loss: 0.0906 - val_income_auc: 0.9442 - val_marital_auc_1: 0.9946\n",
438 | "Epoch 19/100\n",
439 | "195/195 - 2s - loss: 0.1957 - income_loss: 0.1111 - marital_loss: 0.0829 - income_auc: 0.9540 - marital_auc_1: 0.9954 - val_loss: 0.2169 - val_income_loss: 0.1227 - val_marital_loss: 0.0925 - val_income_auc: 0.9448 - val_marital_auc_1: 0.9943\n",
440 | "Epoch 20/100\n",
441 | "Restoring model weights from the end of the best epoch.\n",
442 | "195/195 - 2s - loss: 0.1943 - income_loss: 0.1102 - marital_loss: 0.0823 - income_auc: 0.9547 - marital_auc_1: 0.9955 - val_loss: 0.2153 - val_income_loss: 0.1219 - val_marital_loss: 0.0916 - val_income_auc: 0.9439 - val_marital_auc_1: 0.9944\n",
443 | "Epoch 00020: early stopping\n",
444 | "test income AUC 0.9463\n",
445 | "test marital AUC 0.9947\n"
446 | ]
447 | }
448 | ],
449 | "source": [
450 | "from mmoe import MMOE\n",
451 | "model = MMOE(dnn_feature_columns, num_tasks=2, task_types=['binary', 'binary'], task_names=['income','marital'], \n",
452 | " num_experts=8, expert_dnn_units=[16], gate_dnn_units=None, tower_dnn_units_lists=[[8],[8]])\n",
453 | "\n",
454 | "model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), loss=[\"binary_crossentropy\", \"binary_crossentropy\"],metrics=['AUC'])\n",
455 | "\n",
456 | "early_stopping_monitor = tf.keras.callbacks.EarlyStopping(monitor='val_loss',min_delta=0, patience=10, verbose=1,\n",
457 | " mode='min',baseline=None,restore_best_weights=True)\n",
458 | "\n",
459 | "history = model.fit(train_model_input, [train['label_income'].values, train['label_marital'].values], \n",
460 | " batch_size=1024, epochs=100, verbose=2, validation_split=0.2, callbacks=[early_stopping_monitor])\n",
461 | "\n",
462 | "pred_ans = model.predict(test_model_input, batch_size=1024)\n",
463 | "print(\"test income AUC\", round(roc_auc_score(test['label_income'], pred_ans[0]), 4))\n",
464 | "print(\"test marital AUC\", round(roc_auc_score(test['label_marital'], pred_ans[1]), 4))"
465 | ]
466 | },
467 | {
468 | "cell_type": "code",
469 | "execution_count": 64,
470 | "metadata": {},
471 | "outputs": [
472 | {
473 | "output_type": "stream",
474 | "name": "stdout",
475 | "text": [
476 | "Epoch 1/100\n",
477 | "390/390 - 4s - loss: 0.2645 - income_loss: 0.1430 - marital_loss: 0.1210 - income_auc: 0.9185 - marital_auc_1: 0.9904 - val_loss: 0.2250 - val_income_loss: 0.1235 - val_marital_loss: 0.1010 - val_income_auc: 0.9436 - val_marital_auc_1: 0.9940\n",
478 | "Epoch 2/100\n",
479 | "390/390 - 3s - loss: 0.2177 - income_loss: 0.1241 - marital_loss: 0.0930 - income_auc: 0.9415 - marital_auc_1: 0.9942 - val_loss: 0.2138 - val_income_loss: 0.1212 - val_marital_loss: 0.0918 - val_income_auc: 0.9447 - val_marital_auc_1: 0.9944\n",
480 | "Epoch 3/100\n",
481 | "390/390 - 4s - loss: 0.2132 - income_loss: 0.1222 - marital_loss: 0.0902 - income_auc: 0.9431 - marital_auc_1: 0.9945 - val_loss: 0.2147 - val_income_loss: 0.1225 - val_marital_loss: 0.0913 - val_income_auc: 0.9446 - val_marital_auc_1: 0.9944\n",
482 | "Epoch 4/100\n",
483 | "390/390 - 4s - loss: 0.2118 - income_loss: 0.1214 - marital_loss: 0.0895 - income_auc: 0.9442 - marital_auc_1: 0.9946 - val_loss: 0.2124 - val_income_loss: 0.1208 - val_marital_loss: 0.0907 - val_income_auc: 0.9451 - val_marital_auc_1: 0.9945\n",
484 | "Epoch 5/100\n",
485 | "390/390 - 4s - loss: 0.2094 - income_loss: 0.1205 - marital_loss: 0.0880 - income_auc: 0.9446 - marital_auc_1: 0.9948 - val_loss: 0.2112 - val_income_loss: 0.1209 - val_marital_loss: 0.0892 - val_income_auc: 0.9473 - val_marital_auc_1: 0.9947\n",
486 | "Epoch 6/100\n",
487 | "390/390 - 4s - loss: 0.2086 - income_loss: 0.1200 - marital_loss: 0.0875 - income_auc: 0.9454 - marital_auc_1: 0.9949 - val_loss: 0.2127 - val_income_loss: 0.1204 - val_marital_loss: 0.0911 - val_income_auc: 0.9463 - val_marital_auc_1: 0.9946\n",
488 | "Epoch 7/100\n",
489 | "390/390 - 3s - loss: 0.2072 - income_loss: 0.1190 - marital_loss: 0.0870 - income_auc: 0.9467 - marital_auc_1: 0.9949 - val_loss: 0.2113 - val_income_loss: 0.1210 - val_marital_loss: 0.0891 - val_income_auc: 0.9460 - val_marital_auc_1: 0.9948\n",
490 | "Epoch 8/100\n",
491 | "390/390 - 3s - loss: 0.2063 - income_loss: 0.1185 - marital_loss: 0.0865 - income_auc: 0.9471 - marital_auc_1: 0.9950 - val_loss: 0.2109 - val_income_loss: 0.1201 - val_marital_loss: 0.0894 - val_income_auc: 0.9465 - val_marital_auc_1: 0.9947\n",
492 | "Epoch 9/100\n",
493 | "390/390 - 3s - loss: 0.2046 - income_loss: 0.1174 - marital_loss: 0.0858 - income_auc: 0.9483 - marital_auc_1: 0.9951 - val_loss: 0.2109 - val_income_loss: 0.1200 - val_marital_loss: 0.0895 - val_income_auc: 0.9469 - val_marital_auc_1: 0.9947\n",
494 | "Epoch 10/100\n",
495 | "390/390 - 3s - loss: 0.2033 - income_loss: 0.1165 - marital_loss: 0.0853 - income_auc: 0.9492 - marital_auc_1: 0.9951 - val_loss: 0.2175 - val_income_loss: 0.1258 - val_marital_loss: 0.0902 - val_income_auc: 0.9424 - val_marital_auc_1: 0.9946\n",
496 | "Epoch 11/100\n",
497 | "390/390 - 5s - loss: 0.2029 - income_loss: 0.1164 - marital_loss: 0.0849 - income_auc: 0.9497 - marital_auc_1: 0.9952 - val_loss: 0.2148 - val_income_loss: 0.1229 - val_marital_loss: 0.0902 - val_income_auc: 0.9447 - val_marital_auc_1: 0.9946\n",
498 | "Epoch 12/100\n",
499 | "390/390 - 5s - loss: 0.2009 - income_loss: 0.1153 - marital_loss: 0.0839 - income_auc: 0.9506 - marital_auc_1: 0.9953 - val_loss: 0.2163 - val_income_loss: 0.1232 - val_marital_loss: 0.0914 - val_income_auc: 0.9430 - val_marital_auc_1: 0.9946\n",
500 | "Epoch 13/100\n",
501 | "390/390 - 3s - loss: 0.2002 - income_loss: 0.1147 - marital_loss: 0.0836 - income_auc: 0.9511 - marital_auc_1: 0.9953 - val_loss: 0.2161 - val_income_loss: 0.1237 - val_marital_loss: 0.0906 - val_income_auc: 0.9427 - val_marital_auc_1: 0.9946\n",
502 | "Epoch 14/100\n",
503 | "390/390 - 3s - loss: 0.1984 - income_loss: 0.1136 - marital_loss: 0.0829 - income_auc: 0.9525 - marital_auc_1: 0.9954 - val_loss: 0.2178 - val_income_loss: 0.1224 - val_marital_loss: 0.0934 - val_income_auc: 0.9431 - val_marital_auc_1: 0.9944\n",
504 | "Epoch 15/100\n",
505 | "390/390 - 3s - loss: 0.1977 - income_loss: 0.1131 - marital_loss: 0.0826 - income_auc: 0.9530 - marital_auc_1: 0.9954 - val_loss: 0.2166 - val_income_loss: 0.1226 - val_marital_loss: 0.0920 - val_income_auc: 0.9432 - val_marital_auc_1: 0.9944\n",
506 | "Epoch 16/100\n",
507 | "390/390 - 3s - loss: 0.1962 - income_loss: 0.1124 - marital_loss: 0.0818 - income_auc: 0.9536 - marital_auc_1: 0.9955 - val_loss: 0.2171 - val_income_loss: 0.1229 - val_marital_loss: 0.0921 - val_income_auc: 0.9427 - val_marital_auc_1: 0.9944\n",
508 | "Epoch 17/100\n",
509 | "390/390 - 3s - loss: 0.1946 - income_loss: 0.1112 - marital_loss: 0.0812 - income_auc: 0.9546 - marital_auc_1: 0.9956 - val_loss: 0.2225 - val_income_loss: 0.1240 - val_marital_loss: 0.0963 - val_income_auc: 0.9421 - val_marital_auc_1: 0.9943\n",
510 | "Epoch 18/100\n",
511 | "Restoring model weights from the end of the best epoch.\n",
512 | "390/390 - 3s - loss: 0.1932 - income_loss: 0.1104 - marital_loss: 0.0806 - income_auc: 0.9562 - marital_auc_1: 0.9956 - val_loss: 0.2213 - val_income_loss: 0.1250 - val_marital_loss: 0.0940 - val_income_auc: 0.9404 - val_marital_auc_1: 0.9942\n",
513 | "Epoch 00018: early stopping\n",
514 | "test income AUC 0.9471\n",
515 | "test marital AUC 0.9947\n"
516 | ]
517 | }
518 | ],
519 | "source": [
520 | "from ple_cgc import PLE_CGC\n",
521 | "\n",
522 | "model = PLE_CGC(dnn_feature_columns, num_tasks=2, task_types=['binary', 'binary'], task_names=['income','marital'], \n",
523 | " num_experts_specific=4, num_experts_shared=4, expert_dnn_units=[16], gate_dnn_units=None, tower_dnn_units_lists=[[8],[8]])\n",
524 | "\n",
525 | "model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), loss=[\"binary_crossentropy\", \"binary_crossentropy\"], metrics=['AUC'])\n",
526 | "\n",
527 | "early_stopping_monitor = tf.keras.callbacks.EarlyStopping(monitor='val_loss',min_delta=0,patience=10, verbose=1,\n",
528 | " mode='min',baseline=None,restore_best_weights=True)\n",
529 | "\n",
530 | "history = model.fit(train_model_input, [train['label_income'].values, train['label_marital'].values], \n",
531 | " batch_size=512, epochs=100, verbose=2, validation_split=0.2, callbacks=[early_stopping_monitor])\n",
532 | "\n",
533 | "pred_ans = model.predict(test_model_input, batch_size=512)\n",
534 | "print(\"test income AUC\", round(roc_auc_score(test['label_income'], pred_ans[0]), 4))\n",
535 | "print(\"test marital AUC\", round(roc_auc_score(test['label_marital'], pred_ans[1]), 4))"
536 | ]
537 | },
538 | {
539 | "cell_type": "code",
540 | "execution_count": 57,
541 | "metadata": {},
542 | "outputs": [
543 | {
544 | "output_type": "stream",
545 | "name": "stdout",
546 | "text": [
547 | "Epoch 1/100\n",
548 | "195/195 - 5s - loss: 0.3415 - income_loss: 0.1676 - marital_loss: 0.1734 - income_auc: 0.8845 - marital_auc_1: 0.9802 - val_loss: 0.2316 - val_income_loss: 0.1314 - val_marital_loss: 0.0996 - val_income_auc: 0.9406 - val_marital_auc_1: 0.9941\n",
549 | "Epoch 2/100\n",
550 | "195/195 - 3s - loss: 0.2241 - income_loss: 0.1294 - marital_loss: 0.0941 - income_auc: 0.9398 - marital_auc_1: 0.9941 - val_loss: 0.2211 - val_income_loss: 0.1278 - val_marital_loss: 0.0927 - val_income_auc: 0.9435 - val_marital_auc_1: 0.9943\n",
551 | "Epoch 3/100\n",
552 | "195/195 - 3s - loss: 0.2199 - income_loss: 0.1262 - marital_loss: 0.0930 - income_auc: 0.9423 - marital_auc_1: 0.9942 - val_loss: 0.2193 - val_income_loss: 0.1269 - val_marital_loss: 0.0916 - val_income_auc: 0.9439 - val_marital_auc_1: 0.9944\n",
553 | "Epoch 4/100\n",
554 | "195/195 - 3s - loss: 0.2155 - income_loss: 0.1239 - marital_loss: 0.0909 - income_auc: 0.9436 - marital_auc_1: 0.9945 - val_loss: 0.2139 - val_income_loss: 0.1223 - val_marital_loss: 0.0908 - val_income_auc: 0.9454 - val_marital_auc_1: 0.9945\n",
555 | "Epoch 5/100\n",
556 | "195/195 - 3s - loss: 0.2115 - income_loss: 0.1213 - marital_loss: 0.0893 - income_auc: 0.9445 - marital_auc_1: 0.9947 - val_loss: 0.2138 - val_income_loss: 0.1211 - val_marital_loss: 0.0918 - val_income_auc: 0.9473 - val_marital_auc_1: 0.9946\n",
557 | "Epoch 6/100\n",
558 | "195/195 - 3s - loss: 0.2093 - income_loss: 0.1200 - marital_loss: 0.0884 - income_auc: 0.9453 - marital_auc_1: 0.9948 - val_loss: 0.2132 - val_income_loss: 0.1224 - val_marital_loss: 0.0898 - val_income_auc: 0.9458 - val_marital_auc_1: 0.9947\n",
559 | "Epoch 7/100\n",
560 | "195/195 - 3s - loss: 0.2073 - income_loss: 0.1185 - marital_loss: 0.0878 - income_auc: 0.9470 - marital_auc_1: 0.9949 - val_loss: 0.2103 - val_income_loss: 0.1203 - val_marital_loss: 0.0890 - val_income_auc: 0.9469 - val_marital_auc_1: 0.9948\n",
561 | "Epoch 8/100\n",
562 | "195/195 - 3s - loss: 0.2059 - income_loss: 0.1179 - marital_loss: 0.0869 - income_auc: 0.9473 - marital_auc_1: 0.9949 - val_loss: 0.2112 - val_income_loss: 0.1203 - val_marital_loss: 0.0898 - val_income_auc: 0.9459 - val_marital_auc_1: 0.9947\n",
563 | "Epoch 9/100\n",
564 | "195/195 - 3s - loss: 0.2049 - income_loss: 0.1172 - marital_loss: 0.0865 - income_auc: 0.9481 - marital_auc_1: 0.9950 - val_loss: 0.2105 - val_income_loss: 0.1193 - val_marital_loss: 0.0901 - val_income_auc: 0.9476 - val_marital_auc_1: 0.9947\n",
565 | "Epoch 10/100\n",
566 | "195/195 - 3s - loss: 0.2035 - income_loss: 0.1164 - marital_loss: 0.0859 - income_auc: 0.9488 - marital_auc_1: 0.9951 - val_loss: 0.2103 - val_income_loss: 0.1194 - val_marital_loss: 0.0896 - val_income_auc: 0.9471 - val_marital_auc_1: 0.9947\n",
567 | "Epoch 11/100\n",
568 | "195/195 - 3s - loss: 0.2018 - income_loss: 0.1152 - marital_loss: 0.0853 - income_auc: 0.9500 - marital_auc_1: 0.9951 - val_loss: 0.2108 - val_income_loss: 0.1206 - val_marital_loss: 0.0889 - val_income_auc: 0.9457 - val_marital_auc_1: 0.9947\n",
569 | "Epoch 12/100\n",
570 | "195/195 - 3s - loss: 0.2004 - income_loss: 0.1143 - marital_loss: 0.0847 - income_auc: 0.9510 - marital_auc_1: 0.9952 - val_loss: 0.2110 - val_income_loss: 0.1200 - val_marital_loss: 0.0896 - val_income_auc: 0.9461 - val_marital_auc_1: 0.9947\n",
571 | "Epoch 13/100\n",
572 | "195/195 - 3s - loss: 0.1991 - income_loss: 0.1130 - marital_loss: 0.0845 - income_auc: 0.9523 - marital_auc_1: 0.9952 - val_loss: 0.2118 - val_income_loss: 0.1207 - val_marital_loss: 0.0896 - val_income_auc: 0.9447 - val_marital_auc_1: 0.9947\n",
573 | "Epoch 14/100\n",
574 | "195/195 - 3s - loss: 0.1973 - income_loss: 0.1120 - marital_loss: 0.0837 - income_auc: 0.9532 - marital_auc_1: 0.9953 - val_loss: 0.2132 - val_income_loss: 0.1205 - val_marital_loss: 0.0910 - val_income_auc: 0.9457 - val_marital_auc_1: 0.9944\n",
575 | "Epoch 15/100\n",
576 | "195/195 - 3s - loss: 0.1962 - income_loss: 0.1112 - marital_loss: 0.0833 - income_auc: 0.9538 - marital_auc_1: 0.9953 - val_loss: 0.2157 - val_income_loss: 0.1226 - val_marital_loss: 0.0914 - val_income_auc: 0.9441 - val_marital_auc_1: 0.9944\n",
577 | "Epoch 16/100\n",
578 | "195/195 - 3s - loss: 0.1940 - income_loss: 0.1097 - marital_loss: 0.0825 - income_auc: 0.9558 - marital_auc_1: 0.9954 - val_loss: 0.2150 - val_income_loss: 0.1218 - val_marital_loss: 0.0914 - val_income_auc: 0.9441 - val_marital_auc_1: 0.9944\n",
579 | "Epoch 17/100\n",
580 | "195/195 - 3s - loss: 0.1928 - income_loss: 0.1090 - marital_loss: 0.0819 - income_auc: 0.9561 - marital_auc_1: 0.9955 - val_loss: 0.2182 - val_income_loss: 0.1234 - val_marital_loss: 0.0929 - val_income_auc: 0.9424 - val_marital_auc_1: 0.9942\n",
581 | "Epoch 18/100\n",
582 | "195/195 - 4s - loss: 0.1906 - income_loss: 0.1078 - marital_loss: 0.0809 - income_auc: 0.9575 - marital_auc_1: 0.9956 - val_loss: 0.2190 - val_income_loss: 0.1245 - val_marital_loss: 0.0925 - val_income_auc: 0.9407 - val_marital_auc_1: 0.9944\n",
583 | "Epoch 19/100\n",
584 | "195/195 - 3s - loss: 0.1894 - income_loss: 0.1066 - marital_loss: 0.0808 - income_auc: 0.9589 - marital_auc_1: 0.9956 - val_loss: 0.2187 - val_income_loss: 0.1240 - val_marital_loss: 0.0926 - val_income_auc: 0.9423 - val_marital_auc_1: 0.9943\n",
585 | "Epoch 20/100\n",
586 | "Restoring model weights from the end of the best epoch.\n",
587 | "195/195 - 4s - loss: 0.1871 - income_loss: 0.1050 - marital_loss: 0.0799 - income_auc: 0.9598 - marital_auc_1: 0.9957 - val_loss: 0.2248 - val_income_loss: 0.1273 - val_marital_loss: 0.0953 - val_income_auc: 0.9384 - val_marital_auc_1: 0.9939\n",
588 | "Epoch 00020: early stopping\n",
589 | "test income AUC 0.948\n",
590 | "test marital AUC 0.9947\n"
591 | ]
592 | }
593 | ],
594 | "source": [
595 | "from ple import PLE\n",
596 | "\n",
597 | "model = PLE(dnn_feature_columns, num_tasks=2, task_types=['binary', 'binary'], task_names=['income','marital'], \n",
598 | " num_levels=2, num_experts_specific=4, num_experts_shared=4, expert_dnn_units=[16], gate_dnn_units=None, tower_dnn_units_lists=[[8],[8]])\n",
599 | "model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), loss=[\"binary_crossentropy\", \"binary_crossentropy\"], metrics=['AUC'])\n",
600 | "\n",
601 | "early_stopping_monitor = tf.keras.callbacks.EarlyStopping(monitor='val_loss',min_delta=0,patience=10, verbose=1,\n",
602 | " mode='min',baseline=None,restore_best_weights=True)\n",
603 | "\n",
604 | "history = model.fit(train_model_input, [train['label_income'].values, train['label_marital'].values], \n",
605 | " batch_size=1024, epochs=100, verbose=2, validation_split=0.2, callbacks=[early_stopping_monitor])\n",
606 | "\n",
607 | "pred_ans = model.predict(test_model_input, batch_size=1024)\n",
608 | "print(\"test income AUC\", round(roc_auc_score(test['label_income'], pred_ans[0]), 4))\n",
609 | "print(\"test marital AUC\", round(roc_auc_score(test['label_marital'], pred_ans[1]), 4))"
610 | ]
611 | }
612 | ]
613 | }
--------------------------------------------------------------------------------
/example3.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "metadata": {
3 | "language_info": {
4 | "codemirror_mode": {
5 | "name": "ipython",
6 | "version": 3
7 | },
8 | "file_extension": ".py",
9 | "mimetype": "text/x-python",
10 | "name": "python",
11 | "nbconvert_exporter": "python",
12 | "pygments_lexer": "ipython3",
13 | "version": "3.7.9"
14 | },
15 | "orig_nbformat": 2,
16 | "kernelspec": {
17 | "name": "python3",
18 | "display_name": "Python 3.7.9 64-bit ('base': conda)"
19 | },
20 | "interpreter": {
21 | "hash": "890a3aa13989506a4f157c210d7e888dcd9c9bfc264e152253245030dde69647"
22 | }
23 | },
24 | "nbformat": 4,
25 | "nbformat_minor": 2,
26 | "cells": [
27 | {
28 | "cell_type": "code",
29 | "execution_count": 1,
30 | "metadata": {},
31 | "outputs": [],
32 | "source": [
33 | "import numpy as np\n",
34 | "import pandas as pd\n",
35 | "from deepctr.feature_column import SparseFeat, DenseFeat,get_feature_names\n",
36 | "from sklearn.preprocessing import LabelEncoder, MinMaxScaler\n",
37 | "from sklearn.metrics import roc_auc_score\n",
38 | "import tensorflow as tf\n",
39 | "import warnings\n",
40 | "warnings.filterwarnings('ignore')"
41 | ]
42 | },
43 | {
44 | "cell_type": "code",
45 | "execution_count": null,
46 | "metadata": {},
47 | "outputs": [],
48 | "source": []
49 | },
50 | {
51 | "source": [
52 | "### task 1 aims to predict whether the education level is at least college;\n",
53 | "### task 2 aims to predict whether this person’s marital status is never married."
54 | ],
55 | "cell_type": "markdown",
56 | "metadata": {}
57 | },
58 | {
59 | "cell_type": "code",
60 | "execution_count": 3,
61 | "metadata": {},
62 | "outputs": [],
63 | "source": [
64 | "column_names = ['age', 'class_worker', 'det_ind_code', 'det_occ_code', 'education', 'wage_per_hour', 'hs_college',\n",
65 | " 'marital_stat', 'major_ind_code', 'major_occ_code', 'race', 'hisp_origin', 'sex', 'union_member',\n",
66 | " 'unemp_reason', 'full_or_part_emp', 'capital_gains', 'capital_losses', 'stock_dividends',\n",
67 | " 'tax_filer_stat', 'region_prev_res', 'state_prev_res', 'det_hh_fam_stat', 'det_hh_summ',\n",
68 | " 'instance_weight', 'mig_chg_msa', 'mig_chg_reg', 'mig_move_reg', 'mig_same', 'mig_prev_sunbelt',\n",
69 | " 'num_emp', 'fam_under_18', 'country_father', 'country_mother', 'country_self', 'citizenship',\n",
70 | " 'own_or_self', 'vet_question', 'vet_benefits', 'weeks_worked', 'year', 'income_50k']\n",
71 | "df_train = pd.read_csv('./data/census-income/census-income.data',header=None,names=column_names)\n",
72 | "df_test = pd.read_csv('./data/census-income/census-income.test',header=None,names=column_names)\n",
73 | "data = pd.concat([df_train, df_test], axis=0)"
74 | ]
75 | },
76 | {
77 | "cell_type": "code",
78 | "execution_count": 4,
79 | "metadata": {},
80 | "outputs": [
81 | {
82 | "output_type": "execute_result",
83 | "data": {
84 | "text/plain": [
85 | " High school graduate 72554\n",
86 | " Children 70864\n",
87 | " Some college but no degree 41774\n",
88 | " Bachelors degree(BA AB BS) 29750\n",
89 | " 7th and 8th grade 12156\n",
90 | " 10th grade 11370\n",
91 | " 11th grade 10399\n",
92 | " Masters degree(MA MS MEng MEd MSW MBA) 9847\n",
93 | " 9th grade 9335\n",
94 | " Associates degree-occup /vocational 8048\n",
95 | " Associates degree-academic program 6442\n",
96 | " 5th or 6th grade 4991\n",
97 | " 12th grade no diploma 3263\n",
98 | " 1st 2nd 3rd or 4th grade 2705\n",
99 | " Prof school degree (MD DDS DVM LLB JD) 2669\n",
100 | " Doctorate degree(PhD EdD) 1883\n",
101 | " Less than 1st grade 1235\n",
102 | "Name: education, dtype: int64"
103 | ]
104 | },
105 | "metadata": {},
106 | "execution_count": 4
107 | }
108 | ],
109 | "source": [
110 | "#task 1 label 'education' predict whether the education level is at least college\n",
111 | "data['education'].value_counts()"
112 | ]
113 | },
114 | {
115 | "cell_type": "code",
116 | "execution_count": 24,
117 | "metadata": {},
118 | "outputs": [
119 | {
120 | "output_type": "execute_result",
121 | "data": {
122 | "text/plain": [
123 | " Never married 129628\n",
124 | " Married-civilian spouse present 126315\n",
125 | " Divorced 19160\n",
126 | " Widowed 15788\n",
127 | " Separated 5156\n",
128 | " Married-spouse absent 2234\n",
129 | " Married-A F spouse present 1004\n",
130 | "Name: marital_stat, dtype: int64"
131 | ]
132 | },
133 | "metadata": {},
134 | "execution_count": 24
135 | }
136 | ],
137 | "source": [
138 | "#task 2 label: 'marital_stat'\n",
139 | "data['marital_stat'].value_counts()"
140 | ]
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": 17,
145 | "metadata": {},
146 | "outputs": [],
147 | "source": [
148 | "#change the label to binary classification\n",
149 | "college = [' Some college but no degree', ' Bachelors degree(BA AB BS)', ' Masters degree(MA MS MEng MEd MSW MBA)', ' Prof school degree (MD DDS DVM LLB JD)', ' Doctorate degree(PhD EdD)']\n",
150 | "\n",
151 | "data['label_education'] = data['education'].apply(lambda x: 1 if x in college else 0)\n",
152 | "data['label_marital'] = data['marital_stat'].apply(lambda x: 1 if x==' Never married' else 0)\n",
153 | "data.drop(labels=['education', 'marital_stat'], axis=1, inplace=True)"
154 | ]
155 | },
156 | {
157 | "cell_type": "code",
158 | "execution_count": 20,
159 | "metadata": {},
160 | "outputs": [],
161 | "source": [
162 | "#define dense and sparse features. \n",
163 | "#the functions used here can reference https://deepctr-torch.readthedocs.io/en/latest/Quick-Start.html\n",
164 | "columns = data.columns.values.tolist()\n",
165 | "sparse_features = ['class_worker', 'det_ind_code', 'det_occ_code', 'hs_college', 'major_ind_code',\n",
166 | " 'major_occ_code', 'race', 'hisp_origin', 'sex', 'union_member', 'unemp_reason',\n",
167 | " 'full_or_part_emp', 'tax_filer_stat', 'region_prev_res', 'state_prev_res', 'det_hh_fam_stat',\n",
168 | " 'det_hh_summ', 'mig_chg_msa', 'mig_chg_reg', 'mig_move_reg', 'mig_same', 'mig_prev_sunbelt',\n",
169 | " 'fam_under_18', 'country_father', 'country_mother', 'country_self', 'citizenship',\n",
170 | " 'vet_question', 'income_50k']\n",
171 | "dense_features = [col for col in columns if col not in sparse_features and col not in ['label_education', 'label_marital']]\n",
172 | "\n",
173 | "data[sparse_features] = data[sparse_features].fillna('-1', )\n",
174 | "data[dense_features] = data[dense_features].fillna(0, )\n",
175 | "mms = MinMaxScaler(feature_range=(0, 1))\n",
176 | "data[dense_features] = mms.fit_transform(data[dense_features])\n",
177 | " \n",
178 | "for feat in sparse_features:\n",
179 | " lbe = LabelEncoder()\n",
180 | " data[feat] = lbe.fit_transform(data[feat])\n",
181 | " \n",
182 | "fixlen_feature_columns = [SparseFeat(feat, data[feat].max()+1, embedding_dim=4)for feat in sparse_features] \\\n",
183 | " + [DenseFeat(feat, 1,) for feat in dense_features]\n",
184 | "\n",
185 | "dnn_feature_columns = fixlen_feature_columns\n",
186 | "feature_names = get_feature_names(dnn_feature_columns)"
187 | ]
188 | },
189 | {
190 | "cell_type": "code",
191 | "execution_count": 21,
192 | "metadata": {},
193 | "outputs": [],
194 | "source": [
195 | "# Split the test dataset into 1:1 validation to test according to the MMOE paper\n",
196 | "# validation_split = n_val/len(train) = 0.2\n",
197 | "n_train = df_train.shape[0]\n",
198 | "n_val = df_test.shape[0]//2\n",
199 | "train = data[:n_train+n_val]\n",
200 | "test = data[n_train+n_val:]\n",
201 | "\n",
202 | "train_model_input = {name: train[name] for name in feature_names}\n",
203 | "test_model_input = {name: test[name] for name in feature_names}"
204 | ]
205 | },
206 | {
207 | "cell_type": "code",
208 | "execution_count": 24,
209 | "metadata": {},
210 | "outputs": [
211 | {
212 | "output_type": "stream",
213 | "name": "stdout",
214 | "text": [
215 | "Epoch 1/100\n",
216 | "195/195 - 2s - loss: 0.5787 - label_education_loss: 0.4041 - label_marital_loss: 0.1742 - label_education_auc: 0.8528 - label_marital_auc_1: 0.9797 - val_loss: 0.4874 - val_label_education_loss: 0.3896 - val_label_marital_loss: 0.0971 - val_label_education_auc: 0.8680 - val_label_marital_auc_1: 0.9939\n",
217 | "Epoch 2/100\n",
218 | "195/195 - 1s - loss: 0.4797 - label_education_loss: 0.3828 - label_marital_loss: 0.0962 - label_education_auc: 0.8717 - label_marital_auc_1: 0.9939 - val_loss: 0.4835 - val_label_education_loss: 0.3849 - val_label_marital_loss: 0.0978 - val_label_education_auc: 0.8692 - val_label_marital_auc_1: 0.9939\n",
219 | "Epoch 3/100\n",
220 | "195/195 - 1s - loss: 0.4771 - label_education_loss: 0.3818 - label_marital_loss: 0.0944 - label_education_auc: 0.8724 - label_marital_auc_1: 0.9941 - val_loss: 0.4817 - val_label_education_loss: 0.3870 - val_label_marital_loss: 0.0938 - val_label_education_auc: 0.8703 - val_label_marital_auc_1: 0.9942\n",
221 | "Epoch 4/100\n",
222 | "195/195 - 1s - loss: 0.4737 - label_education_loss: 0.3798 - label_marital_loss: 0.0930 - label_education_auc: 0.8741 - label_marital_auc_1: 0.9942 - val_loss: 0.4793 - val_label_education_loss: 0.3853 - val_label_marital_loss: 0.0930 - val_label_education_auc: 0.8708 - val_label_marital_auc_1: 0.9942\n",
223 | "Epoch 5/100\n",
224 | "195/195 - 1s - loss: 0.4725 - label_education_loss: 0.3788 - label_marital_loss: 0.0926 - label_education_auc: 0.8747 - label_marital_auc_1: 0.9942 - val_loss: 0.4778 - val_label_education_loss: 0.3834 - val_label_marital_loss: 0.0934 - val_label_education_auc: 0.8713 - val_label_marital_auc_1: 0.9942\n",
225 | "Epoch 6/100\n",
226 | "195/195 - 1s - loss: 0.4717 - label_education_loss: 0.3784 - label_marital_loss: 0.0921 - label_education_auc: 0.8751 - label_marital_auc_1: 0.9943 - val_loss: 0.4784 - val_label_education_loss: 0.3830 - val_label_marital_loss: 0.0943 - val_label_education_auc: 0.8710 - val_label_marital_auc_1: 0.9942\n",
227 | "Epoch 7/100\n",
228 | "195/195 - 1s - loss: 0.4698 - label_education_loss: 0.3776 - label_marital_loss: 0.0911 - label_education_auc: 0.8758 - label_marital_auc_1: 0.9944 - val_loss: 0.4829 - val_label_education_loss: 0.3824 - val_label_marital_loss: 0.0994 - val_label_education_auc: 0.8713 - val_label_marital_auc_1: 0.9941\n",
229 | "Epoch 8/100\n",
230 | "195/195 - 1s - loss: 0.4692 - label_education_loss: 0.3772 - label_marital_loss: 0.0908 - label_education_auc: 0.8761 - label_marital_auc_1: 0.9945 - val_loss: 0.4754 - val_label_education_loss: 0.3821 - val_label_marital_loss: 0.0921 - val_label_education_auc: 0.8718 - val_label_marital_auc_1: 0.9943\n",
231 | "Epoch 9/100\n",
232 | "195/195 - 1s - loss: 0.4686 - label_education_loss: 0.3771 - label_marital_loss: 0.0903 - label_education_auc: 0.8761 - label_marital_auc_1: 0.9945 - val_loss: 0.4777 - val_label_education_loss: 0.3835 - val_label_marital_loss: 0.0930 - val_label_education_auc: 0.8709 - val_label_marital_auc_1: 0.9942\n",
233 | "Epoch 10/100\n",
234 | "195/195 - 1s - loss: 0.4675 - label_education_loss: 0.3762 - label_marital_loss: 0.0899 - label_education_auc: 0.8769 - label_marital_auc_1: 0.9946 - val_loss: 0.4776 - val_label_education_loss: 0.3839 - val_label_marital_loss: 0.0924 - val_label_education_auc: 0.8718 - val_label_marital_auc_1: 0.9943\n",
235 | "Epoch 11/100\n",
236 | "195/195 - 1s - loss: 0.4675 - label_education_loss: 0.3764 - label_marital_loss: 0.0898 - label_education_auc: 0.8767 - label_marital_auc_1: 0.9946 - val_loss: 0.4761 - val_label_education_loss: 0.3828 - val_label_marital_loss: 0.0919 - val_label_education_auc: 0.8715 - val_label_marital_auc_1: 0.9944\n",
237 | "Epoch 12/100\n",
238 | "195/195 - 1s - loss: 0.4671 - label_education_loss: 0.3758 - label_marital_loss: 0.0899 - label_education_auc: 0.8773 - label_marital_auc_1: 0.9946 - val_loss: 0.4757 - val_label_education_loss: 0.3825 - val_label_marital_loss: 0.0919 - val_label_education_auc: 0.8723 - val_label_marital_auc_1: 0.9944\n",
239 | "Epoch 13/100\n",
240 | "195/195 - 1s - loss: 0.4659 - label_education_loss: 0.3754 - label_marital_loss: 0.0891 - label_education_auc: 0.8777 - label_marital_auc_1: 0.9946 - val_loss: 0.4767 - val_label_education_loss: 0.3837 - val_label_marital_loss: 0.0916 - val_label_education_auc: 0.8722 - val_label_marital_auc_1: 0.9944\n",
241 | "Epoch 14/100\n",
242 | "195/195 - 1s - loss: 0.4661 - label_education_loss: 0.3752 - label_marital_loss: 0.0895 - label_education_auc: 0.8776 - label_marital_auc_1: 0.9946 - val_loss: 0.4734 - val_label_education_loss: 0.3804 - val_label_marital_loss: 0.0916 - val_label_education_auc: 0.8730 - val_label_marital_auc_1: 0.9944\n",
243 | "Epoch 15/100\n",
244 | "195/195 - 1s - loss: 0.4661 - label_education_loss: 0.3755 - label_marital_loss: 0.0892 - label_education_auc: 0.8775 - label_marital_auc_1: 0.9946 - val_loss: 0.4752 - val_label_education_loss: 0.3819 - val_label_marital_loss: 0.0919 - val_label_education_auc: 0.8726 - val_label_marital_auc_1: 0.9944\n",
245 | "Epoch 16/100\n",
246 | "195/195 - 1s - loss: 0.4652 - label_education_loss: 0.3751 - label_marital_loss: 0.0886 - label_education_auc: 0.8778 - label_marital_auc_1: 0.9947 - val_loss: 0.4784 - val_label_education_loss: 0.3834 - val_label_marital_loss: 0.0936 - val_label_education_auc: 0.8717 - val_label_marital_auc_1: 0.9944\n",
247 | "Epoch 17/100\n",
248 | "195/195 - 1s - loss: 0.4648 - label_education_loss: 0.3749 - label_marital_loss: 0.0885 - label_education_auc: 0.8779 - label_marital_auc_1: 0.9947 - val_loss: 0.4761 - val_label_education_loss: 0.3824 - val_label_marital_loss: 0.0922 - val_label_education_auc: 0.8724 - val_label_marital_auc_1: 0.9944\n",
249 | "Epoch 18/100\n",
250 | "195/195 - 1s - loss: 0.4651 - label_education_loss: 0.3750 - label_marital_loss: 0.0886 - label_education_auc: 0.8779 - label_marital_auc_1: 0.9947 - val_loss: 0.4747 - val_label_education_loss: 0.3815 - val_label_marital_loss: 0.0917 - val_label_education_auc: 0.8734 - val_label_marital_auc_1: 0.9944\n",
251 | "Epoch 19/100\n",
252 | "195/195 - 1s - loss: 0.4645 - label_education_loss: 0.3747 - label_marital_loss: 0.0883 - label_education_auc: 0.8781 - label_marital_auc_1: 0.9947 - val_loss: 0.4744 - val_label_education_loss: 0.3813 - val_label_marital_loss: 0.0915 - val_label_education_auc: 0.8731 - val_label_marital_auc_1: 0.9944\n",
253 | "Epoch 20/100\n",
254 | "195/195 - 1s - loss: 0.4643 - label_education_loss: 0.3742 - label_marital_loss: 0.0885 - label_education_auc: 0.8785 - label_marital_auc_1: 0.9947 - val_loss: 0.4728 - val_label_education_loss: 0.3805 - val_label_marital_loss: 0.0907 - val_label_education_auc: 0.8735 - val_label_marital_auc_1: 0.9945\n",
255 | "Epoch 21/100\n",
256 | "195/195 - 1s - loss: 0.4633 - label_education_loss: 0.3737 - label_marital_loss: 0.0881 - label_education_auc: 0.8790 - label_marital_auc_1: 0.9948 - val_loss: 0.4736 - val_label_education_loss: 0.3807 - val_label_marital_loss: 0.0913 - val_label_education_auc: 0.8729 - val_label_marital_auc_1: 0.9944\n",
257 | "Epoch 22/100\n",
258 | "195/195 - 1s - loss: 0.4627 - label_education_loss: 0.3733 - label_marital_loss: 0.0878 - label_education_auc: 0.8792 - label_marital_auc_1: 0.9948 - val_loss: 0.4743 - val_label_education_loss: 0.3814 - val_label_marital_loss: 0.0913 - val_label_education_auc: 0.8738 - val_label_marital_auc_1: 0.9944\n",
259 | "Epoch 23/100\n",
260 | "195/195 - 1s - loss: 0.4631 - label_education_loss: 0.3733 - label_marital_loss: 0.0882 - label_education_auc: 0.8792 - label_marital_auc_1: 0.9948 - val_loss: 0.4727 - val_label_education_loss: 0.3795 - val_label_marital_loss: 0.0916 - val_label_education_auc: 0.8739 - val_label_marital_auc_1: 0.9944\n",
261 | "Epoch 24/100\n",
262 | "195/195 - 1s - loss: 0.4620 - label_education_loss: 0.3729 - label_marital_loss: 0.0875 - label_education_auc: 0.8795 - label_marital_auc_1: 0.9949 - val_loss: 0.4754 - val_label_education_loss: 0.3828 - val_label_marital_loss: 0.0909 - val_label_education_auc: 0.8718 - val_label_marital_auc_1: 0.9945\n",
263 | "Epoch 25/100\n",
264 | "195/195 - 1s - loss: 0.4620 - label_education_loss: 0.3727 - label_marital_loss: 0.0877 - label_education_auc: 0.8797 - label_marital_auc_1: 0.9948 - val_loss: 0.4751 - val_label_education_loss: 0.3804 - val_label_marital_loss: 0.0931 - val_label_education_auc: 0.8734 - val_label_marital_auc_1: 0.9944\n",
265 | "Epoch 26/100\n",
266 | "195/195 - 1s - loss: 0.4618 - label_education_loss: 0.3728 - label_marital_loss: 0.0874 - label_education_auc: 0.8795 - label_marital_auc_1: 0.9949 - val_loss: 0.4747 - val_label_education_loss: 0.3818 - val_label_marital_loss: 0.0913 - val_label_education_auc: 0.8734 - val_label_marital_auc_1: 0.9944\n",
267 | "Epoch 27/100\n",
268 | "195/195 - 1s - loss: 0.4618 - label_education_loss: 0.3725 - label_marital_loss: 0.0876 - label_education_auc: 0.8798 - label_marital_auc_1: 0.9949 - val_loss: 0.4765 - val_label_education_loss: 0.3827 - val_label_marital_loss: 0.0921 - val_label_education_auc: 0.8742 - val_label_marital_auc_1: 0.9944\n",
269 | "Epoch 28/100\n",
270 | "195/195 - 1s - loss: 0.4618 - label_education_loss: 0.3725 - label_marital_loss: 0.0875 - label_education_auc: 0.8797 - label_marital_auc_1: 0.9949 - val_loss: 0.4773 - val_label_education_loss: 0.3816 - val_label_marital_loss: 0.0939 - val_label_education_auc: 0.8735 - val_label_marital_auc_1: 0.9944\n",
271 | "Epoch 29/100\n",
272 | "195/195 - 1s - loss: 0.4610 - label_education_loss: 0.3720 - label_marital_loss: 0.0873 - label_education_auc: 0.8802 - label_marital_auc_1: 0.9949 - val_loss: 0.4738 - val_label_education_loss: 0.3808 - val_label_marital_loss: 0.0913 - val_label_education_auc: 0.8736 - val_label_marital_auc_1: 0.9944\n",
273 | "Epoch 30/100\n",
274 | "195/195 - 1s - loss: 0.4610 - label_education_loss: 0.3721 - label_marital_loss: 0.0871 - label_education_auc: 0.8802 - label_marital_auc_1: 0.9949 - val_loss: 0.4733 - val_label_education_loss: 0.3803 - val_label_marital_loss: 0.0913 - val_label_education_auc: 0.8738 - val_label_marital_auc_1: 0.9945\n",
275 | "Epoch 31/100\n",
276 | "195/195 - 1s - loss: 0.4610 - label_education_loss: 0.3720 - label_marital_loss: 0.0873 - label_education_auc: 0.8803 - label_marital_auc_1: 0.9949 - val_loss: 0.4773 - val_label_education_loss: 0.3820 - val_label_marital_loss: 0.0935 - val_label_education_auc: 0.8717 - val_label_marital_auc_1: 0.9944\n",
277 | "Epoch 32/100\n",
278 | "195/195 - 1s - loss: 0.4609 - label_education_loss: 0.3719 - label_marital_loss: 0.0872 - label_education_auc: 0.8803 - label_marital_auc_1: 0.9949 - val_loss: 0.4729 - val_label_education_loss: 0.3806 - val_label_marital_loss: 0.0905 - val_label_education_auc: 0.8729 - val_label_marital_auc_1: 0.9945\n",
279 | "Epoch 33/100\n",
280 | "Restoring model weights from the end of the best epoch.\n",
281 | "195/195 - 1s - loss: 0.4604 - label_education_loss: 0.3715 - label_marital_loss: 0.0871 - label_education_auc: 0.8806 - label_marital_auc_1: 0.9949 - val_loss: 0.4737 - val_label_education_loss: 0.3802 - val_label_marital_loss: 0.0917 - val_label_education_auc: 0.8733 - val_label_marital_auc_1: 0.9944\n",
282 | "Epoch 00033: early stopping\n",
283 | "test inceducationome AUC 0.8745\n",
284 | "test marital AUC 0.9945\n"
285 | ]
286 | }
287 | ],
288 | "source": [
289 | "#Test Shared_Bottom Model\n",
290 | "from shared_bottom import Shared_Bottom\n",
291 | "\n",
292 | "model = Shared_Bottom(dnn_feature_columns, num_tasks=2, task_types= ['binary', 'binary'], task_names=['label_education','label_marital'], bottom_dnn_units=[16], tower_dnn_units_lists=[[8],[8]])\n",
293 | "\n",
294 | "early_stopping_monitor = tf.keras.callbacks.EarlyStopping(monitor='val_loss',min_delta=0, patience=10, verbose=1,\n",
295 | " mode='min',baseline=None,restore_best_weights=True)\n",
296 | "\n",
297 | "model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), loss=[\"binary_crossentropy\", \"binary_crossentropy\"], metrics=['AUC'])\n",
298 | "history = model.fit(train_model_input, [train['label_education'].values, train['label_marital'].values],batch_size=1024, epochs=100, verbose=2,validation_split=0.2, callbacks=[early_stopping_monitor])\n",
299 | "pred_ans = model.predict(test_model_input, batch_size=1024)\n",
300 | "\n",
301 | "print(\"test education AUC\", round(roc_auc_score(test['label_education'], pred_ans[0]), 4))\n",
302 | "print(\"test marital AUC\", round(roc_auc_score(test['label_marital'], pred_ans[1]), 4))"
303 | ]
304 | },
305 | {
306 | "cell_type": "code",
307 | "execution_count": 25,
308 | "metadata": {},
309 | "outputs": [
310 | {
311 | "output_type": "stream",
312 | "name": "stdout",
313 | "text": [
314 | "Epoch 1/100\n",
315 | "195/195 - 2s - loss: 0.7163 - label_marital_loss: 0.2452 - label_education_loss: 0.4707 - label_marital_auc: 0.9735 - label_education_auc_1: 0.8243 - val_loss: 0.6675 - val_label_marital_loss: 0.2073 - val_label_education_loss: 0.4596 - val_label_marital_auc: 0.9805 - val_label_education_auc_1: 0.8511\n",
316 | "Epoch 2/100\n",
317 | "195/195 - 1s - loss: 0.6627 - label_marital_loss: 0.2101 - label_education_loss: 0.4519 - label_marital_auc: 0.9825 - label_education_auc_1: 0.8526 - val_loss: 0.6612 - val_label_marital_loss: 0.2185 - val_label_education_loss: 0.4420 - val_label_marital_auc: 0.9833 - val_label_education_auc_1: 0.8568\n",
318 | "Epoch 3/100\n",
319 | "195/195 - 1s - loss: 0.6567 - label_marital_loss: 0.2062 - label_education_loss: 0.4497 - label_marital_auc: 0.9833 - label_education_auc_1: 0.8562 - val_loss: 0.6606 - val_label_marital_loss: 0.2140 - val_label_education_loss: 0.4457 - val_label_marital_auc: 0.9825 - val_label_education_auc_1: 0.8621\n",
320 | "Epoch 4/100\n",
321 | "195/195 - 1s - loss: 0.6546 - label_marital_loss: 0.2047 - label_education_loss: 0.4491 - label_marital_auc: 0.9835 - label_education_auc_1: 0.8574 - val_loss: 0.6552 - val_label_marital_loss: 0.2091 - val_label_education_loss: 0.4452 - val_label_marital_auc: 0.9819 - val_label_education_auc_1: 0.8545\n",
322 | "Epoch 5/100\n",
323 | "195/195 - 1s - loss: 0.6537 - label_marital_loss: 0.2041 - label_education_loss: 0.4487 - label_marital_auc: 0.9835 - label_education_auc_1: 0.8579 - val_loss: 0.6539 - val_label_marital_loss: 0.1985 - val_label_education_loss: 0.4544 - val_label_marital_auc: 0.9843 - val_label_education_auc_1: 0.8576\n",
324 | "Epoch 6/100\n",
325 | "195/195 - 1s - loss: 0.6510 - label_marital_loss: 0.2030 - label_education_loss: 0.4470 - label_marital_auc: 0.9839 - label_education_auc_1: 0.8598 - val_loss: 0.6529 - val_label_marital_loss: 0.2004 - val_label_education_loss: 0.4515 - val_label_marital_auc: 0.9829 - val_label_education_auc_1: 0.8587\n",
326 | "Epoch 7/100\n",
327 | "195/195 - 1s - loss: 0.6501 - label_marital_loss: 0.2027 - label_education_loss: 0.4463 - label_marital_auc: 0.9837 - label_education_auc_1: 0.8606 - val_loss: 0.6533 - val_label_marital_loss: 0.2056 - val_label_education_loss: 0.4466 - val_label_marital_auc: 0.9841 - val_label_education_auc_1: 0.8598\n",
328 | "Epoch 8/100\n",
329 | "195/195 - 1s - loss: 0.6491 - label_marital_loss: 0.2023 - label_education_loss: 0.4457 - label_marital_auc: 0.9838 - label_education_auc_1: 0.8610 - val_loss: 0.6527 - val_label_marital_loss: 0.2051 - val_label_education_loss: 0.4465 - val_label_marital_auc: 0.9833 - val_label_education_auc_1: 0.8622\n",
330 | "Epoch 9/100\n",
331 | "195/195 - 1s - loss: 0.6485 - label_marital_loss: 0.2019 - label_education_loss: 0.4455 - label_marital_auc: 0.9837 - label_education_auc_1: 0.8612 - val_loss: 0.6519 - val_label_marital_loss: 0.2005 - val_label_education_loss: 0.4502 - val_label_marital_auc: 0.9822 - val_label_education_auc_1: 0.8588\n",
332 | "Epoch 10/100\n",
333 | "195/195 - 1s - loss: 0.6473 - label_marital_loss: 0.2014 - label_education_loss: 0.4447 - label_marital_auc: 0.9838 - label_education_auc_1: 0.8623 - val_loss: 0.6514 - val_label_marital_loss: 0.2020 - val_label_education_loss: 0.4483 - val_label_marital_auc: 0.9832 - val_label_education_auc_1: 0.8593\n",
334 | "Epoch 11/100\n",
335 | "195/195 - 1s - loss: 0.6473 - label_marital_loss: 0.2013 - label_education_loss: 0.4448 - label_marital_auc: 0.9837 - label_education_auc_1: 0.8620 - val_loss: 0.6538 - val_label_marital_loss: 0.2091 - val_label_education_loss: 0.4435 - val_label_marital_auc: 0.9838 - val_label_education_auc_1: 0.8633\n",
336 | "Epoch 12/100\n",
337 | "195/195 - 1s - loss: 0.6475 - label_marital_loss: 0.2016 - label_education_loss: 0.4446 - label_marital_auc: 0.9835 - label_education_auc_1: 0.8620 - val_loss: 0.6517 - val_label_marital_loss: 0.2100 - val_label_education_loss: 0.4404 - val_label_marital_auc: 0.9819 - val_label_education_auc_1: 0.8594\n",
338 | "Epoch 13/100\n",
339 | "195/195 - 1s - loss: 0.6468 - label_marital_loss: 0.2014 - label_education_loss: 0.4441 - label_marital_auc: 0.9837 - label_education_auc_1: 0.8627 - val_loss: 0.6511 - val_label_marital_loss: 0.2040 - val_label_education_loss: 0.4458 - val_label_marital_auc: 0.9839 - val_label_education_auc_1: 0.8581\n",
340 | "Epoch 14/100\n",
341 | "195/195 - 1s - loss: 0.6463 - label_marital_loss: 0.2013 - label_education_loss: 0.4437 - label_marital_auc: 0.9836 - label_education_auc_1: 0.8630 - val_loss: 0.6513 - val_label_marital_loss: 0.2071 - val_label_education_loss: 0.4429 - val_label_marital_auc: 0.9813 - val_label_education_auc_1: 0.8579\n",
342 | "Epoch 15/100\n",
343 | "195/195 - 1s - loss: 0.6462 - label_marital_loss: 0.2010 - label_education_loss: 0.4438 - label_marital_auc: 0.9836 - label_education_auc_1: 0.8629 - val_loss: 0.6510 - val_label_marital_loss: 0.2000 - val_label_education_loss: 0.4498 - val_label_marital_auc: 0.9828 - val_label_education_auc_1: 0.8549\n",
344 | "Epoch 16/100\n",
345 | "195/195 - 1s - loss: 0.6459 - label_marital_loss: 0.2012 - label_education_loss: 0.4434 - label_marital_auc: 0.9834 - label_education_auc_1: 0.8631 - val_loss: 0.6504 - val_label_marital_loss: 0.2034 - val_label_education_loss: 0.4457 - val_label_marital_auc: 0.9814 - val_label_education_auc_1: 0.8606\n",
346 | "Epoch 17/100\n",
347 | "195/195 - 1s - loss: 0.6452 - label_marital_loss: 0.2006 - label_education_loss: 0.4432 - label_marital_auc: 0.9837 - label_education_auc_1: 0.8635 - val_loss: 0.6513 - val_label_marital_loss: 0.2087 - val_label_education_loss: 0.4412 - val_label_marital_auc: 0.9810 - val_label_education_auc_1: 0.8619\n",
348 | "Epoch 18/100\n",
349 | "195/195 - 1s - loss: 0.6453 - label_marital_loss: 0.2009 - label_education_loss: 0.4430 - label_marital_auc: 0.9835 - label_education_auc_1: 0.8637 - val_loss: 0.6509 - val_label_marital_loss: 0.2025 - val_label_education_loss: 0.4470 - val_label_marital_auc: 0.9829 - val_label_education_auc_1: 0.8610\n",
350 | "Epoch 19/100\n",
351 | "195/195 - 1s - loss: 0.6446 - label_marital_loss: 0.2005 - label_education_loss: 0.4426 - label_marital_auc: 0.9837 - label_education_auc_1: 0.8641 - val_loss: 0.6522 - val_label_marital_loss: 0.2069 - val_label_education_loss: 0.4438 - val_label_marital_auc: 0.9790 - val_label_education_auc_1: 0.8611\n",
352 | "Epoch 20/100\n",
353 | "195/195 - 1s - loss: 0.6454 - label_marital_loss: 0.2009 - label_education_loss: 0.4429 - label_marital_auc: 0.9833 - label_education_auc_1: 0.8636 - val_loss: 0.6540 - val_label_marital_loss: 0.1985 - val_label_education_loss: 0.4541 - val_label_marital_auc: 0.9844 - val_label_education_auc_1: 0.8624\n",
354 | "Epoch 21/100\n",
355 | "195/195 - 1s - loss: 0.6447 - label_marital_loss: 0.2006 - label_education_loss: 0.4427 - label_marital_auc: 0.9836 - label_education_auc_1: 0.8640 - val_loss: 0.6524 - val_label_marital_loss: 0.2077 - val_label_education_loss: 0.4432 - val_label_marital_auc: 0.9842 - val_label_education_auc_1: 0.8616\n",
356 | "Epoch 22/100\n",
357 | "195/195 - 1s - loss: 0.6445 - label_marital_loss: 0.2006 - label_education_loss: 0.4424 - label_marital_auc: 0.9834 - label_education_auc_1: 0.8643 - val_loss: 0.6510 - val_label_marital_loss: 0.2090 - val_label_education_loss: 0.4405 - val_label_marital_auc: 0.9836 - val_label_education_auc_1: 0.8589\n",
358 | "Epoch 23/100\n",
359 | "195/195 - 1s - loss: 0.6445 - label_marital_loss: 0.2005 - label_education_loss: 0.4425 - label_marital_auc: 0.9835 - label_education_auc_1: 0.8641 - val_loss: 0.6517 - val_label_marital_loss: 0.2070 - val_label_education_loss: 0.4432 - val_label_marital_auc: 0.9828 - val_label_education_auc_1: 0.8554\n",
360 | "Epoch 24/100\n",
361 | "195/195 - 1s - loss: 0.6443 - label_marital_loss: 0.2003 - label_education_loss: 0.4424 - label_marital_auc: 0.9835 - label_education_auc_1: 0.8641 - val_loss: 0.6531 - val_label_marital_loss: 0.2036 - val_label_education_loss: 0.4479 - val_label_marital_auc: 0.9847 - val_label_education_auc_1: 0.8616\n",
362 | "Epoch 25/100\n",
363 | "195/195 - 1s - loss: 0.6443 - label_marital_loss: 0.2008 - label_education_loss: 0.4419 - label_marital_auc: 0.9833 - label_education_auc_1: 0.8647 - val_loss: 0.6512 - val_label_marital_loss: 0.1997 - val_label_education_loss: 0.4499 - val_label_marital_auc: 0.9841 - val_label_education_auc_1: 0.8561\n",
364 | "Epoch 26/100\n",
365 | "Restoring model weights from the end of the best epoch.\n",
366 | "195/195 - 1s - loss: 0.6441 - label_marital_loss: 0.2004 - label_education_loss: 0.4421 - label_marital_auc: 0.9836 - label_education_auc_1: 0.8646 - val_loss: 0.6510 - val_label_marital_loss: 0.2037 - val_label_education_loss: 0.4458 - val_label_marital_auc: 0.9835 - val_label_education_auc_1: 0.8552\n",
367 | "Epoch 00026: early stopping\n",
368 | "test education AUC 0.982\n",
369 | "test income AUC 0.8601\n"
370 | ]
371 | }
372 | ],
373 | "source": [
374 | "#Test ESSM Model\n",
375 | "from essm import ESSM\n",
376 | "#take marital as ctr task, take income as ctcvr task\n",
377 | "model = ESSM(dnn_feature_columns, task_type='binary', task_names=['label_marital', 'label_education'],\n",
378 | " tower_dnn_units_lists=[[8],[8]])\n",
379 | "\n",
380 | "early_stopping_monitor = tf.keras.callbacks.EarlyStopping(monitor='val_loss',min_delta=0, patience=10, verbose=1,\n",
381 | " mode='min',baseline=None,restore_best_weights=True)\n",
382 | "model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), loss=[\"binary_crossentropy\", \"binary_crossentropy\"], metrics=['AUC'])\n",
383 | "history = model.fit(train_model_input, [train['label_marital'].values, train['label_education'].values],batch_size=1024, epochs=100, verbose=2, validation_split=0.2, callbacks=[early_stopping_monitor])\n",
384 | "\n",
385 | "pred_ans = model.predict(test_model_input, batch_size=1024)\n",
386 | "\n",
387 | "print(\"test education AUC\", round(roc_auc_score(test['label_marital'], pred_ans[0]), 4))\n",
388 | "print(\"test income AUC\", round(roc_auc_score(test['label_education'], pred_ans[1]), 4))"
389 | ]
390 | },
391 | {
392 | "cell_type": "code",
393 | "execution_count": 26,
394 | "metadata": {},
395 | "outputs": [
396 | {
397 | "output_type": "stream",
398 | "name": "stdout",
399 | "text": [
400 | "Epoch 1/100\n",
401 | "195/195 - 3s - loss: 0.5466 - label_education_loss: 0.4058 - label_marital_loss: 0.1404 - label_education_auc: 0.8513 - label_marital_auc_1: 0.9872 - val_loss: 0.4881 - val_label_education_loss: 0.3849 - val_label_marital_loss: 0.1026 - val_label_education_auc: 0.8691 - val_label_marital_auc_1: 0.9938\n",
402 | "Epoch 2/100\n",
403 | "195/195 - 2s - loss: 0.4790 - label_education_loss: 0.3819 - label_marital_loss: 0.0964 - label_education_auc: 0.8722 - label_marital_auc_1: 0.9938 - val_loss: 0.4842 - val_label_education_loss: 0.3830 - val_label_marital_loss: 0.1004 - val_label_education_auc: 0.8713 - val_label_marital_auc_1: 0.9940\n",
404 | "Epoch 3/100\n",
405 | "195/195 - 2s - loss: 0.4747 - label_education_loss: 0.3800 - label_marital_loss: 0.0938 - label_education_auc: 0.8739 - label_marital_auc_1: 0.9941 - val_loss: 0.4779 - val_label_education_loss: 0.3836 - val_label_marital_loss: 0.0934 - val_label_education_auc: 0.8715 - val_label_marital_auc_1: 0.9942\n",
406 | "Epoch 4/100\n",
407 | "195/195 - 2s - loss: 0.4711 - label_education_loss: 0.3783 - label_marital_loss: 0.0918 - label_education_auc: 0.8752 - label_marital_auc_1: 0.9944 - val_loss: 0.4753 - val_label_education_loss: 0.3822 - val_label_marital_loss: 0.0921 - val_label_education_auc: 0.8716 - val_label_marital_auc_1: 0.9943\n",
408 | "Epoch 5/100\n",
409 | "195/195 - 2s - loss: 0.4698 - label_education_loss: 0.3776 - label_marital_loss: 0.0911 - label_education_auc: 0.8758 - label_marital_auc_1: 0.9945 - val_loss: 0.4817 - val_label_education_loss: 0.3858 - val_label_marital_loss: 0.0949 - val_label_education_auc: 0.8710 - val_label_marital_auc_1: 0.9942\n",
410 | "Epoch 6/100\n",
411 | "195/195 - 2s - loss: 0.4680 - label_education_loss: 0.3766 - label_marital_loss: 0.0902 - label_education_auc: 0.8764 - label_marital_auc_1: 0.9946 - val_loss: 0.4743 - val_label_education_loss: 0.3814 - val_label_marital_loss: 0.0917 - val_label_education_auc: 0.8722 - val_label_marital_auc_1: 0.9944\n",
412 | "Epoch 7/100\n",
413 | "195/195 - 2s - loss: 0.4662 - label_education_loss: 0.3756 - label_marital_loss: 0.0894 - label_education_auc: 0.8773 - label_marital_auc_1: 0.9946 - val_loss: 0.4760 - val_label_education_loss: 0.3818 - val_label_marital_loss: 0.0931 - val_label_education_auc: 0.8726 - val_label_marital_auc_1: 0.9944\n",
414 | "Epoch 8/100\n",
415 | "195/195 - 2s - loss: 0.4656 - label_education_loss: 0.3755 - label_marital_loss: 0.0888 - label_education_auc: 0.8773 - label_marital_auc_1: 0.9947 - val_loss: 0.4747 - val_label_education_loss: 0.3819 - val_label_marital_loss: 0.0915 - val_label_education_auc: 0.8726 - val_label_marital_auc_1: 0.9944\n",
416 | "Epoch 9/100\n",
417 | "195/195 - 2s - loss: 0.4637 - label_education_loss: 0.3742 - label_marital_loss: 0.0881 - label_education_auc: 0.8783 - label_marital_auc_1: 0.9948 - val_loss: 0.4738 - val_label_education_loss: 0.3809 - val_label_marital_loss: 0.0915 - val_label_education_auc: 0.8728 - val_label_marital_auc_1: 0.9944\n",
418 | "Epoch 10/100\n",
419 | "195/195 - 2s - loss: 0.4624 - label_education_loss: 0.3733 - label_marital_loss: 0.0876 - label_education_auc: 0.8789 - label_marital_auc_1: 0.9949 - val_loss: 0.4737 - val_label_education_loss: 0.3809 - val_label_marital_loss: 0.0914 - val_label_education_auc: 0.8728 - val_label_marital_auc_1: 0.9945\n",
420 | "Epoch 11/100\n",
421 | "195/195 - 2s - loss: 0.4605 - label_education_loss: 0.3718 - label_marital_loss: 0.0872 - label_education_auc: 0.8802 - label_marital_auc_1: 0.9949 - val_loss: 0.4743 - val_label_education_loss: 0.3811 - val_label_marital_loss: 0.0916 - val_label_education_auc: 0.8724 - val_label_marital_auc_1: 0.9943\n",
422 | "Epoch 12/100\n",
423 | "195/195 - 2s - loss: 0.4598 - label_education_loss: 0.3714 - label_marital_loss: 0.0867 - label_education_auc: 0.8802 - label_marital_auc_1: 0.9950 - val_loss: 0.4750 - val_label_education_loss: 0.3821 - val_label_marital_loss: 0.0913 - val_label_education_auc: 0.8722 - val_label_marital_auc_1: 0.9945\n",
424 | "Epoch 13/100\n",
425 | "195/195 - 2s - loss: 0.4579 - label_education_loss: 0.3700 - label_marital_loss: 0.0862 - label_education_auc: 0.8814 - label_marital_auc_1: 0.9950 - val_loss: 0.4754 - val_label_education_loss: 0.3819 - val_label_marital_loss: 0.0917 - val_label_education_auc: 0.8721 - val_label_marital_auc_1: 0.9943\n",
426 | "Epoch 14/100\n",
427 | "195/195 - 2s - loss: 0.4573 - label_education_loss: 0.3696 - label_marital_loss: 0.0859 - label_education_auc: 0.8817 - label_marital_auc_1: 0.9951 - val_loss: 0.4770 - val_label_education_loss: 0.3831 - val_label_marital_loss: 0.0921 - val_label_education_auc: 0.8721 - val_label_marital_auc_1: 0.9943\n",
428 | "Epoch 15/100\n",
429 | "195/195 - 2s - loss: 0.4556 - label_education_loss: 0.3684 - label_marital_loss: 0.0854 - label_education_auc: 0.8827 - label_marital_auc_1: 0.9951 - val_loss: 0.4773 - val_label_education_loss: 0.3824 - val_label_marital_loss: 0.0930 - val_label_education_auc: 0.8724 - val_label_marital_auc_1: 0.9943\n",
430 | "Epoch 16/100\n",
431 | "195/195 - 2s - loss: 0.4538 - label_education_loss: 0.3670 - label_marital_loss: 0.0849 - label_education_auc: 0.8835 - label_marital_auc_1: 0.9952 - val_loss: 0.4767 - val_label_education_loss: 0.3829 - val_label_marital_loss: 0.0918 - val_label_education_auc: 0.8719 - val_label_marital_auc_1: 0.9944\n",
432 | "Epoch 17/100\n",
433 | "195/195 - 2s - loss: 0.4527 - label_education_loss: 0.3665 - label_marital_loss: 0.0842 - label_education_auc: 0.8839 - label_marital_auc_1: 0.9952 - val_loss: 0.4790 - val_label_education_loss: 0.3828 - val_label_marital_loss: 0.0941 - val_label_education_auc: 0.8715 - val_label_marital_auc_1: 0.9942\n",
434 | "Epoch 18/100\n",
435 | "195/195 - 2s - loss: 0.4515 - label_education_loss: 0.3652 - label_marital_loss: 0.0842 - label_education_auc: 0.8848 - label_marital_auc_1: 0.9953 - val_loss: 0.4831 - val_label_education_loss: 0.3868 - val_label_marital_loss: 0.0942 - val_label_education_auc: 0.8710 - val_label_marital_auc_1: 0.9943\n",
436 | "Epoch 19/100\n",
437 | "195/195 - 2s - loss: 0.4502 - label_education_loss: 0.3643 - label_marital_loss: 0.0837 - label_education_auc: 0.8856 - label_marital_auc_1: 0.9953 - val_loss: 0.4798 - val_label_education_loss: 0.3846 - val_label_marital_loss: 0.0929 - val_label_education_auc: 0.8715 - val_label_marital_auc_1: 0.9942\n",
438 | "Epoch 20/100\n",
439 | "Restoring model weights from the end of the best epoch.\n",
440 | "195/195 - 2s - loss: 0.4493 - label_education_loss: 0.3634 - label_marital_loss: 0.0837 - label_education_auc: 0.8861 - label_marital_auc_1: 0.9953 - val_loss: 0.4842 - val_label_education_loss: 0.3868 - val_label_marital_loss: 0.0951 - val_label_education_auc: 0.8706 - val_label_marital_auc_1: 0.9942\n",
441 | "Epoch 00020: early stopping\n",
442 | "test education AUC 0.8734\n",
443 | "test marital AUC 0.9946\n"
444 | ]
445 | }
446 | ],
447 | "source": [
448 | "from mmoe import MMOE\n",
449 | "model = MMOE(dnn_feature_columns, num_tasks=2, task_types=['binary', 'binary'], task_names=['label_education','label_marital'], \n",
450 | " num_experts=8, expert_dnn_units=[16], gate_dnn_units=None, tower_dnn_units_lists=[[8],[8]])\n",
451 | "\n",
452 | "model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), loss=[\"binary_crossentropy\", \"binary_crossentropy\"],metrics=['AUC'])\n",
453 | "\n",
454 | "early_stopping_monitor = tf.keras.callbacks.EarlyStopping(monitor='val_loss',min_delta=0, patience=10, verbose=1,\n",
455 | " mode='min',baseline=None,restore_best_weights=True)\n",
456 | "\n",
457 | "history = model.fit(train_model_input, [train['label_education'].values, train['label_marital'].values], \n",
458 | " batch_size=1024, epochs=100, verbose=2, validation_split=0.2, callbacks=[early_stopping_monitor])\n",
459 | "\n",
460 | "pred_ans = model.predict(test_model_input, batch_size=1024)\n",
461 | "print(\"test education AUC\", round(roc_auc_score(test['label_education'], pred_ans[0]), 4))\n",
462 | "print(\"test marital AUC\", round(roc_auc_score(test['label_marital'], pred_ans[1]), 4))"
463 | ]
464 | },
465 | {
466 | "cell_type": "code",
467 | "execution_count": 27,
468 | "metadata": {},
469 | "outputs": [
470 | {
471 | "output_type": "stream",
472 | "name": "stdout",
473 | "text": [
474 | "Epoch 1/100\n",
475 | "195/195 - 3s - loss: 0.5478 - label_education_loss: 0.4071 - label_marital_loss: 0.1402 - label_education_auc: 0.8507 - label_marital_auc_1: 0.9874 - val_loss: 0.4842 - val_label_education_loss: 0.3847 - val_label_marital_loss: 0.0989 - val_label_education_auc: 0.8697 - val_label_marital_auc_1: 0.9938\n",
476 | "Epoch 2/100\n",
477 | "195/195 - 2s - loss: 0.4765 - label_education_loss: 0.3807 - label_marital_loss: 0.0950 - label_education_auc: 0.8735 - label_marital_auc_1: 0.9940 - val_loss: 0.4790 - val_label_education_loss: 0.3833 - val_label_marital_loss: 0.0949 - val_label_education_auc: 0.8709 - val_label_marital_auc_1: 0.9941\n",
478 | "Epoch 3/100\n",
479 | "195/195 - 2s - loss: 0.4733 - label_education_loss: 0.3790 - label_marital_loss: 0.0935 - label_education_auc: 0.8749 - label_marital_auc_1: 0.9942 - val_loss: 0.4772 - val_label_education_loss: 0.3822 - val_label_marital_loss: 0.0940 - val_label_education_auc: 0.8716 - val_label_marital_auc_1: 0.9942\n",
480 | "Epoch 4/100\n",
481 | "195/195 - 2s - loss: 0.4717 - label_education_loss: 0.3779 - label_marital_loss: 0.0928 - label_education_auc: 0.8756 - label_marital_auc_1: 0.9943 - val_loss: 0.4768 - val_label_education_loss: 0.3826 - val_label_marital_loss: 0.0932 - val_label_education_auc: 0.8717 - val_label_marital_auc_1: 0.9943\n",
482 | "Epoch 5/100\n",
483 | "195/195 - 2s - loss: 0.4687 - label_education_loss: 0.3767 - label_marital_loss: 0.0909 - label_education_auc: 0.8767 - label_marital_auc_1: 0.9945 - val_loss: 0.4751 - val_label_education_loss: 0.3808 - val_label_marital_loss: 0.0932 - val_label_education_auc: 0.8728 - val_label_marital_auc_1: 0.9943\n",
484 | "Epoch 6/100\n",
485 | "195/195 - 2s - loss: 0.4662 - label_education_loss: 0.3752 - label_marital_loss: 0.0898 - label_education_auc: 0.8778 - label_marital_auc_1: 0.9946 - val_loss: 0.4740 - val_label_education_loss: 0.3805 - val_label_marital_loss: 0.0923 - val_label_education_auc: 0.8733 - val_label_marital_auc_1: 0.9944\n",
486 | "Epoch 7/100\n",
487 | "195/195 - 2s - loss: 0.4647 - label_education_loss: 0.3743 - label_marital_loss: 0.0892 - label_education_auc: 0.8785 - label_marital_auc_1: 0.9947 - val_loss: 0.4740 - val_label_education_loss: 0.3816 - val_label_marital_loss: 0.0911 - val_label_education_auc: 0.8730 - val_label_marital_auc_1: 0.9945\n",
488 | "Epoch 8/100\n",
489 | "195/195 - 2s - loss: 0.4626 - label_education_loss: 0.3730 - label_marital_loss: 0.0883 - label_education_auc: 0.8795 - label_marital_auc_1: 0.9948 - val_loss: 0.4740 - val_label_education_loss: 0.3806 - val_label_marital_loss: 0.0920 - val_label_education_auc: 0.8728 - val_label_marital_auc_1: 0.9943\n",
490 | "Epoch 9/100\n",
491 | "195/195 - 2s - loss: 0.4610 - label_education_loss: 0.3718 - label_marital_loss: 0.0878 - label_education_auc: 0.8804 - label_marital_auc_1: 0.9948 - val_loss: 0.4759 - val_label_education_loss: 0.3817 - val_label_marital_loss: 0.0927 - val_label_education_auc: 0.8725 - val_label_marital_auc_1: 0.9941\n",
492 | "Epoch 10/100\n",
493 | "195/195 - 2s - loss: 0.4588 - label_education_loss: 0.3703 - label_marital_loss: 0.0869 - label_education_auc: 0.8815 - label_marital_auc_1: 0.9949 - val_loss: 0.4751 - val_label_education_loss: 0.3816 - val_label_marital_loss: 0.0920 - val_label_education_auc: 0.8719 - val_label_marital_auc_1: 0.9944\n",
494 | "Epoch 11/100\n",
495 | "195/195 - 2s - loss: 0.4576 - label_education_loss: 0.3696 - label_marital_loss: 0.0864 - label_education_auc: 0.8821 - label_marital_auc_1: 0.9950 - val_loss: 0.4794 - val_label_education_loss: 0.3818 - val_label_marital_loss: 0.0960 - val_label_education_auc: 0.8715 - val_label_marital_auc_1: 0.9943\n",
496 | "Epoch 12/100\n",
497 | "195/195 - 2s - loss: 0.4559 - label_education_loss: 0.3684 - label_marital_loss: 0.0858 - label_education_auc: 0.8829 - label_marital_auc_1: 0.9951 - val_loss: 0.4771 - val_label_education_loss: 0.3826 - val_label_marital_loss: 0.0926 - val_label_education_auc: 0.8716 - val_label_marital_auc_1: 0.9943\n",
498 | "Epoch 13/100\n",
499 | "195/195 - 2s - loss: 0.4541 - label_education_loss: 0.3668 - label_marital_loss: 0.0854 - label_education_auc: 0.8840 - label_marital_auc_1: 0.9951 - val_loss: 0.4800 - val_label_education_loss: 0.3841 - val_label_marital_loss: 0.0940 - val_label_education_auc: 0.8711 - val_label_marital_auc_1: 0.9942\n",
500 | "Epoch 14/100\n",
501 | "195/195 - 2s - loss: 0.4520 - label_education_loss: 0.3656 - label_marital_loss: 0.0845 - label_education_auc: 0.8848 - label_marital_auc_1: 0.9952 - val_loss: 0.4791 - val_label_education_loss: 0.3832 - val_label_marital_loss: 0.0939 - val_label_education_auc: 0.8712 - val_label_marital_auc_1: 0.9940\n",
502 | "Epoch 15/100\n",
503 | "195/195 - 2s - loss: 0.4499 - label_education_loss: 0.3642 - label_marital_loss: 0.0836 - label_education_auc: 0.8859 - label_marital_auc_1: 0.9953 - val_loss: 0.4813 - val_label_education_loss: 0.3843 - val_label_marital_loss: 0.0949 - val_label_education_auc: 0.8710 - val_label_marital_auc_1: 0.9940\n",
504 | "Epoch 16/100\n",
505 | "195/195 - 2s - loss: 0.4494 - label_education_loss: 0.3635 - label_marital_loss: 0.0837 - label_education_auc: 0.8862 - label_marital_auc_1: 0.9953 - val_loss: 0.4822 - val_label_education_loss: 0.3844 - val_label_marital_loss: 0.0956 - val_label_education_auc: 0.8715 - val_label_marital_auc_1: 0.9940\n",
506 | "Epoch 17/100\n",
507 | "Restoring model weights from the end of the best epoch.\n",
508 | "195/195 - 2s - loss: 0.4469 - label_education_loss: 0.3618 - label_marital_loss: 0.0829 - label_education_auc: 0.8877 - label_marital_auc_1: 0.9954 - val_loss: 0.4854 - val_label_education_loss: 0.3860 - val_label_marital_loss: 0.0971 - val_label_education_auc: 0.8694 - val_label_marital_auc_1: 0.9939\n",
509 | "Epoch 00017: early stopping\n",
510 | "test education AUC 0.8736\n",
511 | "test marital AUC 0.9946\n"
512 | ]
513 | }
514 | ],
515 | "source": [
516 | "from ple_cgc import PLE_CGC\n",
517 | "\n",
518 | "model = PLE_CGC(dnn_feature_columns, num_tasks=2, task_types=['binary', 'binary'], task_names=['label_education','label_marital'], \n",
519 | " num_experts_specific=4, num_experts_shared=4, expert_dnn_units=[16], gate_dnn_units=None, tower_dnn_units_lists=[[8],[8]])\n",
520 | "\n",
521 | "model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), loss=[\"binary_crossentropy\", \"binary_crossentropy\"], metrics=['AUC'])\n",
522 | "\n",
523 | "early_stopping_monitor = tf.keras.callbacks.EarlyStopping(monitor='val_loss',min_delta=0,patience=10, verbose=1,\n",
524 | " mode='min',baseline=None,restore_best_weights=True)\n",
525 | "\n",
526 | "history = model.fit(train_model_input, [train['label_education'].values, train['label_marital'].values], \n",
527 | " batch_size=1024, epochs=100, verbose=2, validation_split=0.2, callbacks=[early_stopping_monitor])\n",
528 | "\n",
529 | "pred_ans = model.predict(test_model_input, batch_size=1024)\n",
530 | "print(\"test education AUC\", round(roc_auc_score(test['label_education'], pred_ans[0]), 4))\n",
531 | "print(\"test marital AUC\", round(roc_auc_score(test['label_marital'], pred_ans[1]), 4))"
532 | ]
533 | },
534 | {
535 | "cell_type": "code",
536 | "execution_count": 28,
537 | "metadata": {},
538 | "outputs": [
539 | {
540 | "output_type": "stream",
541 | "name": "stdout",
542 | "text": [
543 | "Epoch 1/100\n",
544 | "195/195 - 4s - loss: 0.8963 - label_education_loss: 0.4108 - label_marital_loss: 0.4851 - label_education_auc: 0.8497 - label_marital_auc_1: 0.8235 - val_loss: 0.5634 - val_label_education_loss: 0.3849 - val_label_marital_loss: 0.1778 - val_label_education_auc: 0.8693 - val_label_marital_auc_1: 0.9852\n",
545 | "Epoch 2/100\n",
546 | "195/195 - 3s - loss: 0.5222 - label_education_loss: 0.3811 - label_marital_loss: 0.1403 - label_education_auc: 0.8728 - label_marital_auc_1: 0.9881 - val_loss: 0.5060 - val_label_education_loss: 0.3831 - val_label_marital_loss: 0.1221 - val_label_education_auc: 0.8707 - val_label_marital_auc_1: 0.9903\n",
547 | "Epoch 3/100\n",
548 | "195/195 - 3s - loss: 0.4935 - label_education_loss: 0.3795 - label_marital_loss: 0.1131 - label_education_auc: 0.8743 - label_marital_auc_1: 0.9927 - val_loss: 0.4915 - val_label_education_loss: 0.3826 - val_label_marital_loss: 0.1080 - val_label_education_auc: 0.8716 - val_label_marital_auc_1: 0.9939\n",
549 | "Epoch 4/100\n",
550 | "195/195 - 3s - loss: 0.4820 - label_education_loss: 0.3774 - label_marital_loss: 0.1036 - label_education_auc: 0.8760 - label_marital_auc_1: 0.9941 - val_loss: 0.4855 - val_label_education_loss: 0.3823 - val_label_marital_loss: 0.1022 - val_label_education_auc: 0.8729 - val_label_marital_auc_1: 0.9941\n",
551 | "Epoch 5/100\n",
552 | "195/195 - 3s - loss: 0.4761 - label_education_loss: 0.3765 - label_marital_loss: 0.0985 - label_education_auc: 0.8767 - label_marital_auc_1: 0.9944 - val_loss: 0.4827 - val_label_education_loss: 0.3819 - val_label_marital_loss: 0.0996 - val_label_education_auc: 0.8732 - val_label_marital_auc_1: 0.9942\n",
553 | "Epoch 6/100\n",
554 | "195/195 - 5s - loss: 0.4719 - label_education_loss: 0.3753 - label_marital_loss: 0.0954 - label_education_auc: 0.8776 - label_marital_auc_1: 0.9946 - val_loss: 0.4799 - val_label_education_loss: 0.3809 - val_label_marital_loss: 0.0978 - val_label_education_auc: 0.8729 - val_label_marital_auc_1: 0.9944\n",
555 | "Epoch 7/100\n",
556 | "195/195 - 3s - loss: 0.4675 - label_education_loss: 0.3733 - label_marital_loss: 0.0929 - label_education_auc: 0.8789 - label_marital_auc_1: 0.9947 - val_loss: 0.4811 - val_label_education_loss: 0.3818 - val_label_marital_loss: 0.0980 - val_label_education_auc: 0.8731 - val_label_marital_auc_1: 0.9941\n",
557 | "Epoch 8/100\n",
558 | "195/195 - 3s - loss: 0.4660 - label_education_loss: 0.3725 - label_marital_loss: 0.0921 - label_education_auc: 0.8797 - label_marital_auc_1: 0.9947 - val_loss: 0.4773 - val_label_education_loss: 0.3806 - val_label_marital_loss: 0.0952 - val_label_education_auc: 0.8732 - val_label_marital_auc_1: 0.9943\n",
559 | "Epoch 9/100\n",
560 | "195/195 - 3s - loss: 0.4631 - label_education_loss: 0.3711 - label_marital_loss: 0.0905 - label_education_auc: 0.8806 - label_marital_auc_1: 0.9948 - val_loss: 0.4791 - val_label_education_loss: 0.3820 - val_label_marital_loss: 0.0955 - val_label_education_auc: 0.8729 - val_label_marital_auc_1: 0.9942\n",
561 | "Epoch 10/100\n",
562 | "195/195 - 3s - loss: 0.4610 - label_education_loss: 0.3695 - label_marital_loss: 0.0898 - label_education_auc: 0.8817 - label_marital_auc_1: 0.9948 - val_loss: 0.4791 - val_label_education_loss: 0.3827 - val_label_marital_loss: 0.0948 - val_label_education_auc: 0.8720 - val_label_marital_auc_1: 0.9942\n",
563 | "Epoch 11/100\n",
564 | "195/195 - 3s - loss: 0.4581 - label_education_loss: 0.3678 - label_marital_loss: 0.0886 - label_education_auc: 0.8830 - label_marital_auc_1: 0.9950 - val_loss: 0.4802 - val_label_education_loss: 0.3829 - val_label_marital_loss: 0.0955 - val_label_education_auc: 0.8724 - val_label_marital_auc_1: 0.9942\n",
565 | "Epoch 12/100\n",
566 | "195/195 - 3s - loss: 0.4554 - label_education_loss: 0.3660 - label_marital_loss: 0.0875 - label_education_auc: 0.8843 - label_marital_auc_1: 0.9951 - val_loss: 0.4831 - val_label_education_loss: 0.3852 - val_label_marital_loss: 0.0960 - val_label_education_auc: 0.8717 - val_label_marital_auc_1: 0.9940\n",
567 | "Epoch 13/100\n",
568 | "195/195 - 3s - loss: 0.4519 - label_education_loss: 0.3644 - label_marital_loss: 0.0855 - label_education_auc: 0.8853 - label_marital_auc_1: 0.9951 - val_loss: 0.4829 - val_label_education_loss: 0.3849 - val_label_marital_loss: 0.0960 - val_label_education_auc: 0.8705 - val_label_marital_auc_1: 0.9938\n",
569 | "Epoch 14/100\n",
570 | "195/195 - 3s - loss: 0.4497 - label_education_loss: 0.3626 - label_marital_loss: 0.0850 - label_education_auc: 0.8867 - label_marital_auc_1: 0.9951 - val_loss: 0.4853 - val_label_education_loss: 0.3879 - val_label_marital_loss: 0.0952 - val_label_education_auc: 0.8692 - val_label_marital_auc_1: 0.9939\n",
571 | "Epoch 15/100\n",
572 | "195/195 - 3s - loss: 0.4474 - label_education_loss: 0.3612 - label_marital_loss: 0.0840 - label_education_auc: 0.8875 - label_marital_auc_1: 0.9953 - val_loss: 0.4855 - val_label_education_loss: 0.3870 - val_label_marital_loss: 0.0963 - val_label_education_auc: 0.8711 - val_label_marital_auc_1: 0.9937\n",
573 | "Epoch 16/100\n",
574 | "195/195 - 3s - loss: 0.4448 - label_education_loss: 0.3591 - label_marital_loss: 0.0834 - label_education_auc: 0.8890 - label_marital_auc_1: 0.9953 - val_loss: 0.4877 - val_label_education_loss: 0.3892 - val_label_marital_loss: 0.0961 - val_label_education_auc: 0.8677 - val_label_marital_auc_1: 0.9939\n",
575 | "Epoch 17/100\n",
576 | "195/195 - 3s - loss: 0.4427 - label_education_loss: 0.3574 - label_marital_loss: 0.0829 - label_education_auc: 0.8901 - label_marital_auc_1: 0.9954 - val_loss: 0.4894 - val_label_education_loss: 0.3898 - val_label_marital_loss: 0.0972 - val_label_education_auc: 0.8676 - val_label_marital_auc_1: 0.9937\n",
577 | "Epoch 18/100\n",
578 | "Restoring model weights from the end of the best epoch.\n",
579 | "195/195 - 3s - loss: 0.4400 - label_education_loss: 0.3555 - label_marital_loss: 0.0820 - label_education_auc: 0.8916 - label_marital_auc_1: 0.9955 - val_loss: 0.4951 - val_label_education_loss: 0.3952 - val_label_marital_loss: 0.0974 - val_label_education_auc: 0.8669 - val_label_marital_auc_1: 0.9936\n",
580 | "Epoch 00018: early stopping\n",
581 | "test education AUC 0.8737\n",
582 | "test marital AUC 0.9945\n"
583 | ]
584 | }
585 | ],
586 | "source": [
587 | "from ple import PLE\n",
588 | "\n",
589 | "model = PLE(dnn_feature_columns, num_tasks=2, task_types=['binary', 'binary'], task_names=['label_education','label_marital'], \n",
590 | " num_levels=2, num_experts_specific=4, num_experts_shared=4, expert_dnn_units=[16], gate_dnn_units=None, tower_dnn_units_lists=[[8],[8]])\n",
591 | "model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), loss=[\"binary_crossentropy\", \"binary_crossentropy\"], metrics=['AUC'])\n",
592 | "\n",
593 | "early_stopping_monitor = tf.keras.callbacks.EarlyStopping(monitor='val_loss',min_delta=0,patience=10, verbose=1,\n",
594 | " mode='min',baseline=None,restore_best_weights=True)\n",
595 | "\n",
596 | "history = model.fit(train_model_input, [train['label_education'].values, train['label_marital'].values], \n",
597 | " batch_size=1024, epochs=100, verbose=2, validation_split=0.2, callbacks=[early_stopping_monitor])\n",
598 | "\n",
599 | "pred_ans = model.predict(test_model_input, batch_size=1024)\n",
600 | "print(\"test education AUC\", round(roc_auc_score(test['label_education'], pred_ans[0]), 4))2\n",
601 | "print(\"test marital AUC\", round(roc_auc_score(test['label_marital'], pred_ans[1]), 4))"
602 | ]
603 | }
604 | ]
605 | }
--------------------------------------------------------------------------------
/mmoe.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 |
3 | from deepctr.feature_column import build_input_features, input_from_feature_columns
4 | from deepctr.layers.core import PredictionLayer, DNN
5 | from deepctr.layers.utils import combined_dnn_input
6 |
7 | def MMOE(dnn_feature_columns, num_tasks, task_types, task_names, num_experts=4,
8 | expert_dnn_units=[32,32], gate_dnn_units=None, tower_dnn_units_lists=[[16,8],[16,8]],
9 | l2_reg_embedding=1e-5, l2_reg_dnn=0, seed=1024, dnn_dropout=0, dnn_activation='relu', dnn_use_bn=False):
10 | """Instantiates the Multi-gate Mixture-of-Experts multi-task learning architecture.
11 |
12 | :param dnn_feature_columns: An iterable containing all the features used by deep part of the model.
13 | :param num_tasks: integer, number of tasks, equal to number of outputs, must be greater than 1.
14 | :param task_types: list of str, indicating the loss of each tasks, ``"binary"`` for binary logloss, ``"regression"`` for regression loss. e.g. ['binary', 'regression']
15 | :param task_names: list of str, indicating the predict target of each tasks
16 |
17 | :param num_experts: integer, number of experts.
18 | :param expert_dnn_units: list, list of positive integer, its length must be greater than 1, the layer number and units in each layer of expert DNN
19 | :param gate_dnn_units: list, list of positive integer or None, the layer number and units in each layer of gate DNN, default value is None. e.g.[8, 8].
20 | :param tower_dnn_units_lists: list, list of positive integer list, its length must be euqal to num_tasks, the layer number and units in each layer of task-specific DNN
21 |
22 | :param l2_reg_embedding: float. L2 regularizer strength applied to embedding vector
23 | :param l2_reg_dnn: float. L2 regularizer strength applied to DNN
24 | :param seed: integer ,to use as random seed.
25 | :param dnn_dropout: float in [0,1), the probability we will drop out a given DNN coordinate.
26 | :param dnn_activation: Activation function to use in DNN
27 | :param dnn_use_bn: bool. Whether use BatchNormalization before activation or not in DNN
28 | :return: a Keras model instance
29 | """
30 |
31 | if num_tasks <= 1:
32 | raise ValueError("num_tasks must be greater than 1")
33 |
34 | if len(task_types) != num_tasks:
35 | raise ValueError("num_tasks must be equal to the length of task_types")
36 |
37 | for task_type in task_types:
38 | if task_type not in ['binary', 'regression']:
39 | raise ValueError("task must be binary or regression, {} is illegal".format(task_type))
40 |
41 | if num_tasks != len(tower_dnn_units_lists):
42 | raise ValueError("the length of tower_dnn_units_lists must be euqal to num_tasks")
43 |
44 | features = build_input_features(dnn_feature_columns)
45 |
46 | inputs_list = list(features.values())
47 |
48 | sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns,
49 | l2_reg_embedding, seed)
50 | dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
51 |
52 | #build expert layer
53 | expert_outs = []
54 | for i in range(num_experts):
55 | expert_network = DNN(expert_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='expert_'+str(i))(dnn_input)
56 | expert_outs.append(expert_network)
57 | expert_concat = tf.keras.layers.concatenate(expert_outs, axis=1, name='expert_concat')
58 | expert_concat = tf.keras.layers.Reshape([num_experts, expert_dnn_units[-1]], name='expert_reshape')(expert_concat) #(num_experts, output dim of expert_network)
59 |
60 | mmoe_outs = []
61 | for i in range(num_tasks): #one mmoe layer: nums_tasks = num_gates
62 | #build gate layers
63 | if gate_dnn_units!=None:
64 | gate_network = DNN(gate_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='gate_'+task_names[i])(dnn_input)
65 | gate_input = gate_network
66 | else: #in origin paper, gate is one Dense layer with softmax.
67 | gate_input = dnn_input
68 | gate_out = tf.keras.layers.Dense(num_experts, use_bias=False, activation='softmax', name='gate_softmax_'+task_names[i])(gate_input)
69 | gate_out = tf.tile(tf.expand_dims(gate_out, axis=-1), [1, 1, expert_dnn_units[-1]]) #let the shape of gate_out be (num_experts, output dim of expert_network)
70 |
71 | #gate multiply the expert
72 | gate_mul_expert = tf.keras.layers.Multiply(name='gate_mul_expert_'+task_names[i])([expert_concat, gate_out])
73 | gate_mul_expert = tf.math.reduce_sum(gate_mul_expert, axis=1) #sum pooling in the expert ndim
74 | mmoe_outs.append(gate_mul_expert)
75 |
76 | task_outs = []
77 | for task_type, task_name, tower_dnn, mmoe_out in zip(task_types, task_names, tower_dnn_units_lists, mmoe_outs):
78 | #build tower layer
79 | tower_output = DNN(tower_dnn, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='tower_'+task_name)(mmoe_out)
80 |
81 | logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(tower_output)
82 | output = PredictionLayer(task_type, name=task_name)(logit)
83 | task_outs.append(output)
84 |
85 | model = tf.keras.models.Model(inputs=inputs_list, outputs=task_outs)
86 | return model
--------------------------------------------------------------------------------
/ple.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 |
3 | from deepctr.feature_column import build_input_features, input_from_feature_columns
4 | from deepctr.layers.core import PredictionLayer, DNN
5 | from deepctr.layers.utils import combined_dnn_input
6 |
7 | def PLE(dnn_feature_columns, num_tasks, task_types, task_names, num_levels=2, num_experts_specific=8, num_experts_shared=4,
8 | expert_dnn_units=[64,64], gate_dnn_units=None, tower_dnn_units_lists=[[16,16],[16,16]],
9 | l2_reg_embedding=1e-5, l2_reg_dnn=0, seed=1024, dnn_dropout=0, dnn_activation='relu', dnn_use_bn=False):
10 | """Instantiates the multi level of Customized Gate Control of Progressive Layered Extraction architecture.
11 |
12 | :param dnn_feature_columns: An iterable containing all the features used by deep part of the model.
13 | :param num_tasks: integer, number of tasks, equal to number of outputs, must be greater than 1.
14 | :param task_types: list of str, indicating the loss of each tasks, ``"binary"`` for binary logloss, ``"regression"`` for regression loss. e.g. ['binary', 'regression']
15 | :param task_names: list of str, indicating the predict target of each tasks
16 |
17 | :param num_levels: integer, number of CGC levels.
18 | :param num_experts_specific: integer, number of task-specific experts.
19 | :param num_experts_shared: integer, number of task-shared experts.
20 |
21 | :param expert_dnn_units: list, list of positive integer, its length must be greater than 1, the layer number and units in each layer of expert DNN.
22 | :param gate_dnn_units: list, list of positive integer or None, the layer number and units in each layer of gate DNN, default value is None. e.g.[8, 8].
23 | :param tower_dnn_units_lists: list, list of positive integer list, its length must be euqal to num_tasks, the layer number and units in each layer of task-specific DNN.
24 |
25 | :param l2_reg_embedding: float. L2 regularizer strength applied to embedding vector.
26 | :param l2_reg_dnn: float. L2 regularizer strength applied to DNN.
27 | :param seed: integer ,to use as random seed.
28 | :param dnn_dropout: float in [0,1), the probability we will drop out a given DNN coordinate.
29 | :param dnn_activation: Activation function to use in DNN.
30 | :param dnn_use_bn: bool. Whether use BatchNormalization before activation or not in DNN.
31 | :return: a Keras model instance.
32 | """
33 |
34 | if num_tasks <= 1:
35 | raise ValueError("num_tasks must be greater than 1")
36 | if len(task_types) != num_tasks:
37 | raise ValueError("num_tasks must be equal to the length of task_types")
38 |
39 | for task_type in task_types:
40 | if task_type not in ['binary', 'regression']:
41 | raise ValueError("task must be binary or regression, {} is illegal".format(task_type))
42 |
43 | if num_tasks != len(tower_dnn_units_lists):
44 | raise ValueError("the length of tower_dnn_units_lists must be euqal to num_tasks")
45 |
46 | features = build_input_features(dnn_feature_columns)
47 |
48 | inputs_list = list(features.values())
49 |
50 | sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns,
51 | l2_reg_embedding, seed)
52 | dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
53 |
54 | #single Extraction Layer
55 | def cgc_net(inputs, level_name, is_last=False):
56 | #inputs: [task1, task2, ... taskn, shared task]
57 | expert_outputs = []
58 | #build task-specific expert layer
59 | for i in range(num_tasks):
60 | for j in range(num_experts_specific):
61 | expert_network = DNN(expert_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name=level_name+'task_'+task_names[i]+'_expert_specific_'+str(j))(inputs[i])
62 | expert_outputs.append(expert_network)
63 |
64 | #build task-shared expert layer
65 | for i in range(num_experts_shared):
66 | expert_network = DNN(expert_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name=level_name+'expert_shared_'+str(i))(inputs[-1])
67 | expert_outputs.append(expert_network)
68 |
69 | #task_specific gate (count = num_tasks)
70 | cgc_outs = []
71 | for i in range(num_tasks):
72 | #concat task-specific expert and task-shared expert
73 | cur_expert_num = num_experts_specific + num_experts_shared
74 | cur_experts = expert_outputs[i * num_experts_specific:(i + 1) * num_experts_specific] + expert_outputs[-int(num_experts_shared):] #task_specific + task_shared
75 |
76 | expert_concat = tf.keras.layers.concatenate(cur_experts, axis=1, name=level_name+'expert_concat_specific_'+task_names[i])
77 | expert_concat = tf.keras.layers.Reshape([cur_expert_num, expert_dnn_units[-1]], name=level_name+'expert_reshape_specific_'+task_names[i])(expert_concat)
78 |
79 | #build gate layers
80 | if gate_dnn_units!=None:
81 | gate_network = DNN(gate_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name=level_name+'gate_specific_'+task_names[i])(inputs[i]) #gate[i] for task input[i]
82 | gate_input = gate_network
83 | else: #in origin paper, gate is one Dense layer with softmax.
84 | gate_input = dnn_input
85 | gate_out = tf.keras.layers.Dense(cur_expert_num, use_bias=False, activation='softmax', name=level_name+'gate_softmax_specific_'+task_names[i])(gate_input)
86 | gate_out = tf.tile(tf.expand_dims(gate_out, axis=-1), [1, 1, expert_dnn_units[-1]])
87 |
88 | #gate multiply the expert
89 | gate_mul_expert = tf.keras.layers.Multiply(name=level_name+'gate_mul_expert_specific_'+task_names[i])([expert_concat, gate_out])
90 | gate_mul_expert = tf.math.reduce_sum(gate_mul_expert, axis=1) #sum pooling in the expert ndim
91 | cgc_outs.append(gate_mul_expert)
92 |
93 | #task_shared gate, if the level not in last, add one shared gate
94 | if not is_last:
95 | cur_expert_num = num_tasks * num_experts_specific + num_experts_shared
96 | cur_experts = expert_outputs #all the expert include task-specific expert and task-shared expert
97 |
98 | expert_concat = tf.keras.layers.concatenate(cur_experts, axis=1, name=level_name+'expert_concat_shared_'+task_names[i])
99 | expert_concat = tf.keras.layers.Reshape([cur_expert_num, expert_dnn_units[-1]], name=level_name+'expert_reshape_shared_'+task_names[i])(expert_concat)
100 |
101 | #build gate layers
102 | if gate_dnn_units!=None:
103 | gate_network = DNN(gate_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name=level_name+'gate_shared_'+str(i))(inputs[-1]) #gate for shared task input
104 | gate_input = gate_network
105 | else: #in origin paper, gate is one Dense layer with softmax.
106 | gate_input = dnn_input
107 |
108 | gate_out = tf.keras.layers.Dense(cur_expert_num, use_bias=False, activation='softmax', name=level_name+'gate_softmax_shared_'+str(i))(gate_input)
109 | gate_out = tf.tile(tf.expand_dims(gate_out, axis=-1), [1, 1, expert_dnn_units[-1]])
110 |
111 | #gate multiply the expert
112 | gate_mul_expert = tf.keras.layers.Multiply(name=level_name+'gate_mul_expert_shared_'+task_names[i])([expert_concat, gate_out])
113 | gate_mul_expert = tf.math.reduce_sum(gate_mul_expert, axis=1) #sum pooling in the expert ndim
114 | cgc_outs.append(gate_mul_expert)
115 | return cgc_outs
116 |
117 | #build Progressive Layered Extraction
118 | ple_inputs = [dnn_input]*(num_tasks+1) #[task1, task2, ... taskn, shared task]
119 | ple_outputs = []
120 | for i in range(num_levels):
121 | if i == num_levels-1: #the last level
122 | ple_outputs = cgc_net(inputs=ple_inputs, level_name='level_'+str(i)+'_', is_last=True)
123 | break
124 | else:
125 | ple_outputs = cgc_net(inputs=ple_inputs, level_name='level_'+str(i)+'_', is_last=False)
126 | ple_inputs = ple_outputs
127 |
128 | task_outs = []
129 | for task_type, task_name, tower_dnn, ple_out in zip(task_types, task_names, tower_dnn_units_lists, ple_outputs):
130 | #build tower layer
131 | tower_output = DNN(tower_dnn, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='tower_'+task_name)(ple_out)
132 | logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(tower_output)
133 | output = PredictionLayer(task_type, name=task_name)(logit)
134 | task_outs.append(output)
135 |
136 | model = tf.keras.models.Model(inputs=inputs_list, outputs=task_outs)
137 | return model
--------------------------------------------------------------------------------
/ple_cgc.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 |
3 | from deepctr.feature_column import build_input_features, input_from_feature_columns
4 | from deepctr.layers.core import PredictionLayer, DNN
5 | from deepctr.layers.utils import combined_dnn_input
6 |
7 | def PLE_CGC(dnn_feature_columns, num_tasks, task_types, task_names, num_experts_specific=8, num_experts_shared=4,
8 | expert_dnn_units=[64,64], gate_dnn_units=None, tower_dnn_units_lists=[[16,16],[16,16]],
9 | l2_reg_embedding=1e-5, l2_reg_dnn=0, seed=1024, dnn_dropout=0, dnn_activation='relu', dnn_use_bn=False):
10 | """Instantiates the Customized Gate Control block of Progressive Layered Extraction architecture.
11 |
12 | :param dnn_feature_columns: An iterable containing all the features used by deep part of the model.
13 | :param num_tasks: integer, number of tasks, equal to number of outputs, must be greater than 1.
14 | :param task_types: list of str, indicating the loss of each tasks, ``"binary"`` for binary logloss, ``"regression"`` for regression loss. e.g. ['binary', 'regression']
15 | :param task_names: list of str, indicating the predict target of each tasks
16 |
17 | :param num_experts_specific: integer, number of task-specific experts.
18 | :param num_experts_shared: integer, number of task-shared experts.
19 |
20 | :param expert_dnn_units: list, list of positive integer, its length must be greater than 1, the layer number and units in each layer of expert DNN
21 | :param gate_dnn_units: list, list of positive integer or None, the layer number and units in each layer of gate DNN, default value is None. e.g.[8, 8].
22 | :param tower_dnn_units_lists: list, list of positive integer list, its length must be euqal to num_tasks, the layer number and units in each layer of task-specific DNN
23 |
24 | :param l2_reg_embedding: float. L2 regularizer strength applied to embedding vector
25 | :param l2_reg_dnn: float. L2 regularizer strength applied to DNN
26 | :param seed: integer ,to use as random seed.
27 | :param dnn_dropout: float in [0,1), the probability we will drop out a given DNN coordinate.
28 | :param dnn_activation: Activation function to use in DNN
29 | :param dnn_use_bn: bool. Whether use BatchNormalization before activation or not in DNN
30 | :return: a Keras model instance
31 | """
32 |
33 | if num_tasks <= 1:
34 | raise ValueError("num_tasks must be greater than 1")
35 | if len(task_types) != num_tasks:
36 | raise ValueError("num_tasks must be equal to the length of task_types")
37 |
38 | for task_type in task_types:
39 | if task_type not in ['binary', 'regression']:
40 | raise ValueError("task must be binary or regression, {} is illegal".format(task_type))
41 |
42 | if num_tasks != len(tower_dnn_units_lists):
43 | raise ValueError("the length of tower_dnn_units_lists must be euqal to num_tasks")
44 |
45 | features = build_input_features(dnn_feature_columns)
46 |
47 | inputs_list = list(features.values())
48 |
49 | sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns,
50 | l2_reg_embedding, seed)
51 | dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
52 |
53 | expert_outputs = []
54 | #build task-specific expert layer
55 | for i in range(num_tasks):
56 | for j in range(num_experts_specific):
57 | expert_network = DNN(expert_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='task_'+task_names[i]+'_expert_specific_'+str(j))(dnn_input)
58 | expert_outputs.append(expert_network)
59 |
60 | #build task-shared expert layer
61 | for i in range(num_experts_shared):
62 | expert_network = DNN(expert_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='expert_shared_'+str(i))(dnn_input)
63 | expert_outputs.append(expert_network)
64 |
65 | #build one Extraction Layer
66 | cgc_outs = []
67 | for i in range(num_tasks):
68 | #concat task-specific expert and task-shared expert
69 | cur_expert_num = num_experts_specific + num_experts_shared
70 | cur_experts = expert_outputs[i * num_experts_specific:(i + 1) * num_experts_specific] + expert_outputs[-int(num_experts_shared):] #task_specific + task_shared
71 | expert_concat = tf.keras.layers.concatenate(cur_experts, axis=1, name='expert_concat_'+task_names[i])
72 | expert_concat = tf.keras.layers.Reshape([cur_expert_num, expert_dnn_units[-1]], name='expert_reshape_'+task_names[i])(expert_concat)
73 |
74 | #build gate layers
75 | if gate_dnn_units!=None:
76 | gate_network = DNN(gate_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='gate_'+task_names[i])(dnn_input)
77 | gate_input = gate_network
78 | else: #in origin paper, gate is one Dense layer with softmax.
79 | gate_input = dnn_input
80 |
81 | gate_out = tf.keras.layers.Dense(cur_expert_num, use_bias=False, activation='softmax', name='gate_softmax_'+task_names[i])(gate_input)
82 | gate_out = tf.tile(tf.expand_dims(gate_out, axis=-1), [1, 1, expert_dnn_units[-1]])
83 |
84 | #gate multiply the expert
85 | gate_mul_expert = tf.keras.layers.Multiply(name='gate_mul_expert_'+task_names[i])([expert_concat, gate_out])
86 | gate_mul_expert = tf.math.reduce_sum(gate_mul_expert, axis=1) #sum pooling in the expert ndim
87 | cgc_outs.append(gate_mul_expert)
88 |
89 | task_outs = []
90 | for task_type, task_name, tower_dnn, cgc_out in zip(task_types, task_names, tower_dnn_units_lists, cgc_outs):
91 | #build tower layer
92 | tower_output = DNN(tower_dnn, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='tower_'+task_name)(cgc_out)
93 | logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(tower_output)
94 | output = PredictionLayer(task_type, name=task_name)(logit)
95 | task_outs.append(output)
96 |
97 | model = tf.keras.models.Model(inputs=inputs_list, outputs=task_outs)
98 | return model
--------------------------------------------------------------------------------
/shared_bottom.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 |
3 | from deepctr.feature_column import build_input_features, input_from_feature_columns
4 | from deepctr.layers.core import PredictionLayer, DNN
5 | from deepctr.layers.utils import combined_dnn_input
6 |
7 | def Shared_Bottom(dnn_feature_columns, num_tasks, task_types, task_names,
8 | bottom_dnn_units=[128, 128], tower_dnn_units_lists=[[64,32], [64,32]],
9 | l2_reg_embedding=0.00001, l2_reg_dnn=0, seed=1024, dnn_dropout=0,dnn_activation='relu', dnn_use_bn=False):
10 | """Instantiates the Shared_Bottom multi-task learning Network architecture.
11 |
12 | :param dnn_feature_columns: An iterable containing all the features used by deep part of the model.
13 | :param num_tasks: integer, number of tasks, equal to number of outputs, must be greater than 1.
14 | :param task_types: list of str, indicating the loss of each tasks, ``"binary"`` for binary logloss or ``"regression"`` for regression loss. e.g. ['binary', 'regression']
15 | :param task_names: list of str, indicating the predict target of each tasks
16 |
17 | :param bottom_dnn_units: list,list of positive integer or empty list, the layer number and units in each layer of shared-bottom DNN
18 | :param tower_dnn_units_lists: list, list of positive integer list, its length must be euqal to num_tasks, the layer number and units in each layer of task-specific DNN
19 |
20 | :param l2_reg_embedding: float. L2 regularizer strength applied to embedding vector
21 | :param l2_reg_dnn: float. L2 regularizer strength applied to DNN
22 | :param seed: integer ,to use as random seed.
23 | :param dnn_dropout: float in [0,1), the probability we will drop out a given DNN coordinate.
24 | :param dnn_activation: Activation function to use in DNN
25 | :param dnn_use_bn: bool. Whether use BatchNormalization before activation or not in DNN
26 | :return: A Keras model instance.
27 | """
28 | if num_tasks <= 1:
29 | raise ValueError("num_tasks must be greater than 1")
30 | if len(task_types) != num_tasks:
31 | raise ValueError("num_tasks must be equal to the length of task_types")
32 |
33 | for task_type in task_types:
34 | if task_type not in ['binary', 'regression']:
35 | raise ValueError("task must be binary or regression, {} is illegal".format(task_type))
36 |
37 | if num_tasks != len(tower_dnn_units_lists):
38 | raise ValueError("the length of tower_dnn_units_lists must be euqal to num_tasks")
39 |
40 | features = build_input_features(dnn_feature_columns)
41 | inputs_list = list(features.values())
42 |
43 | sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns, l2_reg_embedding,seed)
44 |
45 | dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
46 | shared_bottom_output = DNN(bottom_dnn_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input)
47 |
48 | tasks_output = []
49 | for task_type, task_name, tower_dnn in zip(task_types, task_names, tower_dnn_units_lists):
50 | tower_output = DNN(tower_dnn, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed, name='tower_'+task_name)(shared_bottom_output)
51 |
52 | logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(tower_output)
53 | output = PredictionLayer(task_type, name=task_name)(logit) #regression->keep, binary classification->sigmoid
54 | tasks_output.append(output)
55 |
56 | model = tf.keras.models.Model(inputs=inputs_list, outputs=tasks_output)
57 | return model
--------------------------------------------------------------------------------