├── LICENSE
├── README.md
├── requirements.txt
└── scripts
├── benchmark
├── README.md
├── benchmark.py
├── data_utils.py
├── model_utils.py
├── performance_evaluator.py
├── requirements.txt
├── scripts
│ └── benchmark_7B
│ │ ├── gemini.sh
│ │ └── gemini_auto.sh
└── test_ci.sh
├── convert_hf_to_gguf.py
├── finetune
├── chat_finetune
│ └── finetune.py
├── instruct_finetune
│ ├── dpo_finetune.sh
│ └── sft_finetune.sh
└── reason_finetune
│ └── train_7b.sh
├── inference
└── inference.py
└── train
├── attn.py
├── pretrain.py
└── requirements.txt
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright 2024 moxin-org
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | Moxin LLM
2 | Moxin is a family of fully open-source and reproducible LLMs
3 | Technical Report | Base Model | Chat Model | Instruct Model | Reasoning Model
4 |
5 |
6 | ## Introduction
7 |
8 | Generative AI (GAI) offers unprecedented opportunities for research and innovation, but its commercialization has raised concerns about transparency, reproducibility, and safety. Many open GAI models lack the necessary components for full understanding and reproducibility, and some use restrictive licenses whilst claiming to be “open-source”. To address these concerns, we follow the [Model Openness Framework (MOF)](https://arxiv.org/pdf/2403.13784), a ranked classification system that rates machine learning models based on their completeness and openness, following principles of open science, open source, open data, and open access.
9 |
10 | By promoting transparency and reproducibility, the MOF combats “openwashing” practices and establishes completeness and openness as primary criteria alongside the core tenets of responsible AI. Wide adoption of the MOF will foster a more open AI ecosystem, benefiting research, innovation, and adoption of state-of-the-art models.
11 |
12 | We follow MOF to release the datasets during training, the training scripts, and the trained models.
13 |
14 |
15 |
16 | ## Model
17 | You can download our [Moxin-7B-Base](https://huggingface.co/moxin-org/moxin-llm-7b), [Moxin-7B-Chat](https://huggingface.co/moxin-org/moxin-chat-7b), [Moxin-7B-Instruct](https://huggingface.co/moxin-org/moxin-instruct-7b) and [Moxin-7B-Reasoning](https://huggingface.co/moxin-org/moxin-reasoning-7b) models.
18 |
19 |
20 |
21 |
22 |
23 | ## Evaluation
24 |
25 | ### Base Model Evaluation
26 |
27 | We test the performance of our base model with [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness). The evaluation results on common datasets are shown below. We test on AI2 Reasoning Challenge (25-shot), HellaSwag (10-shot), MMLU (5-shot), and Winogrande (5-shot). We release the Moxin-7B-Enhanced as our base model. We further finetune our base model on Tulu v2 to obtain our chat model.
28 |
29 | | Models | ARC-C | Hellaswag | MMLU | WinoGrade | Ave |
30 | |:----------------------:|:-----:|:---------:|:-----:|:---------:|:-----:|
31 | | Mistral-7B | 57.59 | 83.25 | 62.42 | 78.77 | 70.51 |
32 | | LLaMA 3.1-8B | 54.61 | 81.95 | 65.16 | 77.35 | 69.77 |
33 | | LLaMA 3-8B | 55.46 | 82.09 | 65.29 | 77.82 | 70.17 |
34 | | LLaMA 2-7B | 49.74 | 78.94 | 45.89 | 74.27 | 62.21 |
35 | | Qwen 2-7B | 57.68 | 80.76 | 70.42 | 77.43 | 71.57 |
36 | | Gemma-7b | 56.48 | 82.31 | 63.02 | 78.3 | 70.03 |
37 | | Internlm2.5-7b | 54.78 | 79.7 | 68.17 | 80.9 | 70.89 |
38 | | Baichuan2-7B | 47.87 | 73.89 | 54.13 | 70.8 | 61.67 |
39 | | Yi-1.5-9B | 58.36 | 80.36 | 69.54 | 77.53 | 71.48 |
40 | | Moxin-7B-Original | 53.75 | 75.46 | 59.43 | 70.32 | 64.74 |
41 | | Moxin-7B-Enhanced (Moxin-7B-Base)| 59.47 | 83.08 | 60.97 | 78.69 | 70.55 |
42 |
43 |
44 | We also test the zero shot performance on AI2 Reasoning Challenge (0-shot), AI2 Reasoning Easy (0-shot), HellaSwag (0-shot), PIQA (0-shot) and Winogrande (0-shot). The results are shown below.
45 |
46 | | Models | HellaSwag | WinoGrade | PIQA | ARC-E | ARC-C | Ave |
47 | |:-----------------: |:---------: |:---------: |:-----: |:-----: |:-----: |:-----: |
48 | | Mistral-7B | 80.39 | 73.4 | 82.15 | 78.28 | 52.22 | 73.29 |
49 | | LLaMA 2-7B | 75.99 | 69.06 | 79.11 | 74.54 | 46.42 | 69.02 |
50 | | LLaMA 2-13B | 79.37 | 72.22 | 80.52 | 77.4 | 49.06 | 71.71 |
51 | | LLaMA 3.1-8B | 78.92 | 74.19 | 81.12 | 81.06 | 53.67 | 73.79 |
52 | | Gemma-7b | 80.45 | 73.72 | 80.9 | 79.97 | 54.1 | 73.83 |
53 | | Qwen v2-7B | 78.9 | 72.38 | 79.98 | 74.71 | 50.09 | 71.21 |
54 | | Internlm2.5-7b | 79.14 | 77.9 | 80.52 | 76.16 | 51.37 | 73.02 |
55 | | Baichuan2-7B | 72.25 | 67.17 | 77.26 | 72.98 | 42.15 | 66.36 |
56 | | Yi-1.5-9B | 77.86 | 73.01 | 80.74 | 79.04 | 55.03 | 73.14 |
57 | | Deepseek-7b | 76.13 | 69.77 | 79.76 | 71.04 | 44.8 | 68.3 |
58 | | Moxin-7B-Original | 72.06 | 66.31 | 78.07 | 71.47 | 48.15 | 67.21 |
59 | | Moxin-7B-Enhanced (Moxin-7B-Base) | 80.03 | 75.17 | 82.24 | 81.12 | 58.64 | 75.44 |
60 |
61 |
62 |
63 | ### Instruct Model Evaluation
64 |
65 | Our instruct model is trained with [Tulu 3](https://allenai.org/blog/tulu-3-technical). The evaluations are demonstrated below. We evaluate with [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness) and [OLMES](https://github.com/allenai/olmes).
66 |
67 | We test on AI2 Reasoning Challenge (25-shot), HellaSwag (10-shot), MMLU (5-shot), and Winogrande (5-shot).
68 | |Model |ARC-C| Hellaswag| MMLU |WinoGrade| Ave|
69 | |:-----------------: |:---------: |:---------: |:-----: |:-----: |:-----: |
70 | |Mistral 8B Instruct| 62.63 |80.61 |64.16| 79.08| 71.62|
71 | |Llama3.1 8B Instruct| 60.32 |80 |68.18 |77.27| 71.44|
72 | |Qwen2.5 7B Instruct| 66.72 |81.54| 71.3 |74.59| 73.54|
73 | |Moxin-7B-SFT| 60.11 |83.43| 60.56| 77.56| 70.42|
74 | |Moxin-7B-DPO (Moxin-7B-Instruct) | 64.76 |87.19| 58.36| 76.32| 71.66|
75 |
76 |
77 | We also test the zero shot performance on AI2 Reasoning Challenge (0-shot), AI2 Reasoning Easy (0-shot), HellaSwag (0-shot), PIQA (0-shot) and Winogrande (0-shot). The results are shown below.
78 | |Models | HellaSwag | WinoGrade | PIQA | ARC-E | ARC-C | Ave |
79 | |:-----------------: |:---------: |:---------: |:-----: |:-----: |:-----: |:-----: |
80 | |Mistral 8B Instruct | 79.08 | 73.56 | 82.26 | 79.88 | 56.57 | 74.27 |
81 | | Llama3.1 8B Instruct | 79.21| 74.19 |80.79 |79.71 |55.03 |73.79|
82 | |Qwen2.5 7B Instruct | 80.5 | 71.03 | 80.47 | 81.31 | 55.12 | 73.69 |
83 | |Moxin-7B-SFT |81.44 |73.09 |81.07 |79.8 |54.67| 74.01|
84 | |Moxin-7B-DPO (Moxin-7B-Instruct) | 85.7 | 73.24 | 81.56 |81.1 |58.02| 75.92|
85 |
86 |
87 |
88 |
89 | The evaluation results with OLMES are shown below.
90 | |Models/Datasets |GSM8K |MATH |Humaneval |Humaneval plus |MMLU |PopQA |BBH |TruthfulQA| Ave|
91 | |:-----------------: |:---------: |:---------: |:-----: |:-----: |:-----: |:-----: |:-----: |:-----: |:-----: |
92 | |Qwen2.5 7B Instruct |83.8 |14.8 |93.1 |89.7 |76.6 |18.1 |21.7 |63.1| 57.61|
93 | |Gemma2 9B Instruct| 79.7 |29.8 |71.7 |67 |74.6 |28.3 |2.5 |61.4 |51.88|
94 | |Moxin-7B-DPO (Moxin-7B-Instruct) |81.19| 36.42| 82.86| 77.18 |60.85 |23.85 |57.44| 55.27 |59.38|
95 |
96 |
97 | ### Reasoning Model Evaluation
98 |
99 | Our reasoning model is trained with [DeepScaleR](https://github.com/agentica-project/rllm). The evaluation on math datasets are demonstrated below.
100 |
101 | |Models/Datasets |MATH 500 |AMC |Minerva Math |OlympiadBench |Ave|
102 | |:-----------------: |:---------: |:---------: |:-----: |:-----: |:-----: |
103 | |Qwen2.5-Math-7B-Base |52.4 |52.5 |12.9 |16.4| 33.55|
104 | |Qwen2.5-Math-7B-Base + 8K MATH SFT |54.6 |22.5| 32.7| 19.6| 32.35|
105 | |Llama-3.1-70B-Instruct| 64.6 |30.1 |35.3| 31.9| 40.48|
106 | |Moxin-7B-RL-DeepScaleR| 68 |57.5 |16.9| 30.4 |43.2|
107 |
108 |
109 | ## Inference
110 |
111 | You can use the following code to run inference with the model. The model is saved under './model/' directory. Change the model directory accordingly or use the Huggingface link.
112 |
113 | ```
114 | import torch
115 | from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
116 |
117 | torch.backends.cuda.enable_mem_efficient_sdp(False)
118 | torch.backends.cuda.enable_flash_sdp(False)
119 |
120 | model_name = 'moxin-org/moxin-7b'
121 | tokenizer = AutoTokenizer.from_pretrained(model_name)
122 | model = AutoModelForCausalLM.from_pretrained(
123 | model_name,
124 | torch_dtype=torch.bfloat16,
125 | device_map="auto",
126 | trust_remote_code=True,
127 | )
128 |
129 | pipe = pipeline(
130 | "text-generation",
131 | model=model,
132 | tokenizer = tokenizer,
133 | torch_dtype=torch.bfloat16,
134 | device_map="auto"
135 | )
136 |
137 | prompt = "Can you explain the concept of regularization in machine learning?"
138 |
139 | sequences = pipe(
140 | prompt,
141 | do_sample=True,
142 | max_new_tokens=100,
143 | temperature=0.7,
144 | top_k=50,
145 | top_p=0.95,
146 | num_return_sequences=1,
147 | )
148 | print(sequences[0]['generated_text'])
149 | ```
150 |
151 | ### Convert to GGUF
152 |
153 |
154 | Build a typical deep learning environment with pytorch. Then use the script covert_hf_to_gguf.py to convert the hf model to GGUF.
155 | ```
156 | python covert_hf_to_gguf.py path_to_model_directory/
157 | ```
158 | Then, you can experiment with this gguf model following [llama.cpp](https://github.com/ggerganov/llama.cpp).
159 |
160 |
161 |
162 | ## Reinforcement Learning with GRPO
163 |
164 | To enhance the CoT capabilities of our model, we adopt RL techniques similar to DeepSeek R1. We first use high quality reasoning data to SFT our instruct model. The reasoning data mainly includes Openthoughts and OpenR1-Math-220k. Next, we adopt the RL techniques in DeepSeek R1, i.e., GRPO to finetune our model with RL. We adopt the [DeepScaleR](https://github.com/agentica-project/rllm) as our RL training framework.
165 |
166 | We first use high quality reasoning data to SFT our instruct (DPO) model.
167 | + Dataset: [OpenThoughts](https://huggingface.co/datasets/open-thoughts/OpenThoughts-114k) and [OpenR1-Math-220k](https://huggingface.co/datasets/open-r1/OpenR1-Math-220k)
168 | + Framework: [open-instruct](https://github.com/allenai/open-instruct)
169 | + Configuration: [Llama-3.1-Tulu-3-8B-SFT](https://github.com/allenai/open-instruct/blob/main/docs/tulu3.md)
170 |
171 | Refer to 'scripts/finetune/instruct_finetune/sft_finetune.sh' for more details.
172 |
173 | Next, we adopt GRPO to finetune our model with RL.
174 | + Framework, configuration and Dataset: [DeepScaleR](https://github.com/agentica-project/rllm)
175 |
176 | Refer to 'scripts/finetune/reason_finetune/train_7b.sh' for more details.
177 |
178 | ## Post-Training with Tülu 3
179 |
180 | The open-source Tülu 3 dataset and framework are adopted for the model post-training. For our post-training, with our base model, we follow Tülu 3 to perform supervised finetuning (SFT) and then Direct Preference Optimization (DPO).
181 |
182 | Specifically, we use the Tülu 3 SFT Mixture dataset from Tülu 3 to train our base model with the SFT training method for two epochs and obtain our SFT model, following the default training configuration of the Tülu 3 8B SFT model.
183 | + Dataset: [Tülu 3 SFT Mixture](https://huggingface.co/datasets/allenai/tulu-3-sft-mixture)
184 | + Framework: [open-instruct](https://github.com/allenai/open-instruct)
185 | + Configuration: [Llama-3.1-Tulu-3-8B-SFT](https://github.com/allenai/open-instruct/blob/main/docs/tulu3.md)
186 |
187 | Refer to 'scripts/finetune/instruct_finetune/sft_finetune.sh' for more details.
188 |
189 | Next, we continue to train our SFT model on the Tülu 3 8B Preference Mixture dataset from Tülu 3 with the DPO training method to obtain our DPO model, following the same training configuration of the Tülu 3 8B DPO model.
190 | + Dataset: [Tülu 3 8B Preference Mixture](https://huggingface.co/datasets/allenai/llama-3.1-tulu-3-8b-preference-mixture)
191 | + Framework: [open-instruct](https://github.com/allenai/open-instruct)
192 | + Configuration: [Llama-3.1-Tulu-3-8B-DPO](https://github.com/allenai/open-instruct/blob/main/docs/tulu3.md)
193 |
194 | Refer to 'scripts/finetune/instruct_finetune/dpo_finetune.sh' for more details.
195 |
196 |
197 | ## Pre-Training Environment
198 |
199 | #### 1. Dataset config
200 | To prepare the dataset, it needs to install the following package,
201 |
202 |
203 | ```
204 | pip install datasets
205 | ```
206 |
207 | #### 2. Cuda install
208 |
209 | We use cuda 11.7. Other cuda versions may also work.
210 | ```
211 | get https://developer.download.nvidia.com/compute/cuda/11.7.0/local_installers/cuda_11.7.0_515.43.04_linux.run
212 | sudo sh cuda_11.7.0_515.43.04_linux.run
213 | ```
214 |
215 | #### 3. Install pytorch
216 |
217 | We use pytorch 2.0.0.
218 | ```
219 | conda create --name llm_train python==3.10
220 | conda activate llm_train
221 | pip install torch==2.0.0 torchvision==0.15.1 torchaudio==2.0.1
222 | ```
223 |
224 | #### 4. Install other packages
225 |
226 | To install other packages, follow the requirements.txt
227 | ```
228 | pip install -r requirements.txt
229 | ```
230 |
231 | #### 5. Install flash attention
232 |
233 | We use flash-attention 2.2.1.
234 | ```
235 | git clone https://github.com/Dao-AILab/flash-attention.git
236 | cd flash-attention/
237 | git checkout a1576ad ## flash-attention 2.2.1
238 | python setup.py install
239 | cd ./csrc
240 | cd fused_dense_lib && pip install -v .
241 | cd ../xentropy && pip install -v .
242 | cd ../rotary && pip install -v .
243 | cd ../layer_norm && pip install -v .
244 | ```
245 |
246 |
247 | ## Pretrain Datasets
248 |
249 |
250 | To use the [SlimPajama dataset](https://huggingface.co/datasets/cerebras/SlimPajama-627B) for pretraining, you can download the dataset using Hugging Face datasets:
251 | ```
252 | import datasets
253 | ds = datasets.load_dataset("cerebras/SlimPajama-627B")
254 | ```
255 | SlimPajama is the largest extensively deduplicated, multi-corpora, open-source dataset for training large language models. SlimPajama was created by cleaning and deduplicating the 1.2T token RedPajama dataset from Together. By filtering out low quality data and duplicates, it removes 49.6% of bytes, slimming down the RedPajama dataset from 1210B to 627B tokens. SlimPajama offers the highest quality and most compute efficient data to train on for runs up to 627B tokens. When upsampled, SlimPajama is expected to perform equal to or better than RedPajama-1T when training at trillion token scale.
256 |
257 |
258 | To use the [stack-dedup dataset](https://huggingface.co/datasets/bigcode/the-stack-dedup) for pretraining, you can download the dataset using Hugging Face datasets:
259 | ```
260 | from datasets import load_dataset
261 |
262 | # full dataset (3TB of data)
263 | ds = load_dataset("bigcode/the-stack-dedup", split="train")
264 |
265 | # specific language (e.g. Dockerfiles)
266 | ds = load_dataset("bigcode/the-stack-dedup", data_dir="data/dockerfile", split="train")
267 |
268 | # dataset streaming (will only download the data as needed)
269 | ds = load_dataset("bigcode/the-stack-dedup", streaming=True, split="train")
270 | for sample in iter(ds): print(sample["content"])
271 | ```
272 | The Stack contains over 6TB of permissively-licensed source code files covering 358 programming languages. The dataset was created as part of the BigCode Project, an open scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs). The Stack serves as a pre-training dataset for Code LLMs, i.e., code-generating AI systems which enable the synthesis of programs from natural language descriptions as well as other from code snippets. This is the near-deduplicated version with 3TB data.
273 |
274 | You can find more details about the DCLM-baseline dataset on the [homepage](https://huggingface.co/datasets/mlfoundations/dclm-baseline-1.0).
275 |
276 | ## Pre-Training
277 |
278 | We follow the [ColossalAI](https://github.com/hpcaitech/ColossalAI) framework to train the LLM model. Colossal-AI provides a collection of parallel components for the training. It aims to support to write the distributed deep learning models just like how you write your model on your laptop. It provides user-friendly tools to kickstart distributed training and inference in a few lines.
279 |
280 | We provide a few examples to show how to run benchmark or pretraining based on Colossal-AI.
281 |
282 | ### 1. Training LLM
283 |
284 | You can find the shell scripts in 'scripts/train_7B' directory. The main command should be in the format of:
285 | ```
286 | colossalai run --nproc_per_node YOUR_GPU_PER_NODE --hostfile YOUR_HOST_FILE \
287 | benchmark.py --OTHER_CONFIGURATIONS
288 | ```
289 |
290 | #### a. Running on a sinlge node
291 | we provide an example to run the training on a single node as below,
292 | ```
293 | colossalai run --nproc_per_node 1 pretrain.py \
294 | --config 7b \
295 | --dataset togethercomputer/RedPajama-Data-1T-Sample \
296 | --batch_size 1 \
297 | --num_epochs 5 \
298 | --save_interval 5000 \
299 | --max_length 2048 \
300 | --save_dir output-checkpoints \
301 | --plugin zero2_cpu \
302 | --lr 2e-5 \
303 | --expanded_model hpcai-tech/Colossal-LLaMA-2-7b-base
304 | ```
305 | In the example, it uses the sample dataset 'togethercomputer/RedPajama-Data-1T-Sample' for training. It trains the 7B model 'hpcai-tech/Colossal-LLaMA-2-7b-base'. You can refer the main file 'run.sh' and 'pretrain.py' for more details. To start the training, run the following,
306 | ```bash
307 | bash run.sh
308 | ```
309 |
310 | #### b. Running on a sinlge node
311 |
312 | we provide an example to run the training on multiple nodes as below,
313 | ```
314 | srun colossalai run --num_nodes 8 --nproc_per_node 8 pretrain.py \
315 | --config 7b \
316 | --dataset cerebras/SlimPajama-627B \
317 | --batch_size 1 \
318 | --num_epochs 10 \
319 | --save_interval 50000 \
320 | --max_length 2048 \
321 | --save_dir output-checkpoints \
322 | --flash_attention \
323 | --plugin zero2_cpu \
324 | --lr 1e-5 \
325 | --expanded_model hpcai-tech/Colossal-LLaMA-2-7b-base
326 | ```
327 | It uses 8 nodes. Put your host file (`hosts.txt`) in this directory with your real host ip or host name.
328 | Here is a sample `hosts.txt`:
329 | ```text
330 | hostname1
331 | hostname2
332 | hostname3
333 | ...
334 | hostname8
335 | ```
336 | You can refer to the main file 'run-multi-server.sh' and 'pretrain.py' for more details. To start the training, run the following,
337 |
338 | ```bash
339 | bash run-multi-server.sh
340 | ```
341 |
342 | ### 2. Benchmark
343 |
344 |
345 | You can find the shell scripts in 'scripts/benchmark_7B' directory. The benchmark mainly test the throughput of the LLM, without actual model training. The main command should be in the format of:
346 | ```
347 | colossalai run --nproc_per_node YOUR_GPU_PER_NODE --hostfile YOUR_HOST_FILE \
348 | benchmark.py --OTHER_CONFIGURATIONS
349 | ```
350 |
351 | Here we will show an example of how to run training llama pretraining with 'gemini, batch_size=16, sequence_length=4096, gradient_checkpoint=True, flash_attn=True'.
352 |
353 | #### a. Running environment
354 |
355 | This experiment was performed on 4 computing nodes with 32 L40S GPUs in total for LLaMA-2 7B. The nodes are connected with RDMA and GPUs within one node are fully connected with NVLink.
356 |
357 | #### b. Running command
358 |
359 | ```bash
360 | cd scripts/benchmark_7B
361 | ```
362 |
363 | First, put your host file (`hosts.txt`) in this directory with your real host ip or host name.
364 |
365 | Here is a sample `hosts.txt`:
366 | ```text
367 | hostname1
368 | hostname2
369 | hostname3
370 | hostname4
371 | ```
372 |
373 | Then add environment variables to script if needed.
374 |
375 | Finally, run the following command to start training:
376 |
377 | ```bash
378 | bash gemini.sh
379 | ```
380 |
381 |
382 | ## Citation
383 |
384 | ```
385 | @article{zhao2024fully,
386 | title={Fully Open Source Moxin-7B Technical Report},
387 | author={Zhao, Pu and Shen, Xuan and Kong, Zhenglun and Shen, Yixin and Chang, Sung-En and Rupprecht, Timothy and Lu, Lei and Nan, Enfu and Yang, Changdi and He, Yumei and others},
388 | journal={arXiv preprint arXiv:2412.06845},
389 | year={2024}
390 | }
391 | ```
392 |
393 |
394 |
395 |
396 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | absl-py==2.1.0
2 | aiohttp==3.9.3
3 | aiosignal==1.3.1
4 | annotated-types==0.6.0
5 | async-timeout==4.0.3
6 | attrs==23.2.0
7 | bcrypt==4.1.2
8 | beautifulsoup4==4.12.3
9 | cachetools==5.3.3
10 | certifi==2024.2.2
11 | cffi==1.16.0
12 | cfgv==3.4.0
13 | charset-normalizer==3.3.2
14 | click==8.1.7
15 | cmake==3.29.0.1
16 | colossalai==0.3.6
17 | contexttimer==0.3.3
18 | cryptography==42.0.5
19 | datasets==2.18.0
20 | decorator==5.1.1
21 | Deprecated==1.2.14
22 | dill==0.3.8
23 | distlib==0.3.8
24 | einops==0.7.0
25 | fabric==3.2.2
26 | filelock==3.13.3
27 | flash-attn==2.2.1
28 | frozenlist==1.4.1
29 | fsspec==2024.2.0
30 | google==3.0.0
31 | google-auth==2.29.0
32 | google-auth-oauthlib==1.0.0
33 | grpcio==1.62.1
34 | huggingface-hub==0.22.2
35 | identify==2.5.35
36 | idna==3.6
37 | invoke==2.2.0
38 | Jinja2==3.1.3
39 | jsonschema==4.21.1
40 | jsonschema-specifications==2023.12.1
41 | lit==18.1.2
42 | Markdown==3.6
43 | markdown-it-py==3.0.0
44 | MarkupSafe==2.1.5
45 | mdurl==0.1.2
46 | mpmath==1.3.0
47 | msgpack==1.0.8
48 | multidict==6.0.5
49 | multiprocess==0.70.16
50 | networkx== 3.3
51 | ninja==1.11.1.1
52 | nodeenv==1.8.0
53 | numpy==1.26.4
54 | nvidia-cublas-cu11==11.10.3.66
55 | nvidia-cublas-cu12==12.1.3.1
56 | nvidia-cuda-cupti-cu11==11.7.101
57 | nvidia-cuda-cupti-cu12==12.1.105
58 | nvidia-cuda-nvrtc-cu11==11.7.99
59 | nvidia-cuda-nvrtc-cu12==12.1.105
60 | nvidia-cuda-runtime-cu11==11.7.99
61 | nvidia-cuda-runtime-cu12==12.1.105
62 | nvidia-cudnn-cu11==8.5.0.96
63 | nvidia-cudnn-cu12==8.9.2.26
64 | nvidia-cufft-cu11==10.9.0.58
65 | nvidia-cufft-cu12==11.0.2.54
66 | nvidia-curand-cu11==10.2.10.91
67 | nvidia-curand-cu12==10.3.2.106
68 | nvidia-cusolver-cu11==11.4.0.1
69 | nvidia-cusolver-cu12==11.4.5.107
70 | nvidia-cusparse-cu11==11.7.4.91
71 | nvidia-cusparse-cu12==12.1.0.106
72 | nvidia-nccl-cu11==2.14.3
73 | nvidia-nccl-cu12==2.19.3
74 | nvidia-nvjitlink-cu12==12.4.127
75 | nvidia-nvtx-cu11==11.7.91
76 | nvidia-nvtx-cu12==12.1.105
77 | oauthlib==3.2.2
78 | packaging==24.0
79 | pandas==2.2.1
80 | paramiko==3.4.0
81 | pip==23.3.1
82 | platformdirs==4.2.0
83 | pre-commit==3.7.0
84 | protobuf==5.26.1
85 | psutil==5.9.8
86 | pyarrow==15.0.2
87 | pyarrow-hotfix==0.6
88 | pyasn1==0.6.0
89 | pyasn1_modules==0.4.0
90 | pycparser==2.22
91 | pydantic==2.6.4
92 | pydantic_core==2.16.3
93 | Pygments==2.17.2
94 | PyNaCl==1.5.0
95 | python-dateutil==2.9.0.post0
96 | pytz==2024.1
97 | PyYAML==6.0.1
98 | ray==2.10.0
99 | referencing==0.34.0
100 | regex==2023.12.25
101 | requests==2.31.0
102 | requests-oauthlib==2.0.0
103 | rich==13.7.1
104 | rpds-py==0.18.0
105 | rsa==4.9
106 | safetensors==0.4.2
107 | sentencepiece==0.1.99
108 | setuptools==68.2.2
109 | six==1.16.0
110 | soupsieve==2.5
111 | sympy==1.12
112 | tensorboard==2.14.0
113 | tensorboard-data-server==0.7.2
114 | tokenizers==0.13.3
115 | torch==2.0.0
116 | tqdm==4.66.2
117 | transformers==4.34.0
118 | triton==2.0.0
119 | typing_extensions==4.11.0
120 | tzdata==2024.1
121 | urllib3==2.2.1
122 | virtualenv==20.25.1
123 | Werkzeug==3.0.2
124 | wheel==0.41.2
125 | wrapt==1.16.0
126 | xxhash==3.4.1
127 | yarl==1.9.4
128 |
--------------------------------------------------------------------------------
/scripts/benchmark/README.md:
--------------------------------------------------------------------------------
1 | # Pretraining LLaMA-1/2/3: best practices for building LLaMA-1/2/3-like base models
2 | ### LLaMA3
3 |
4 | 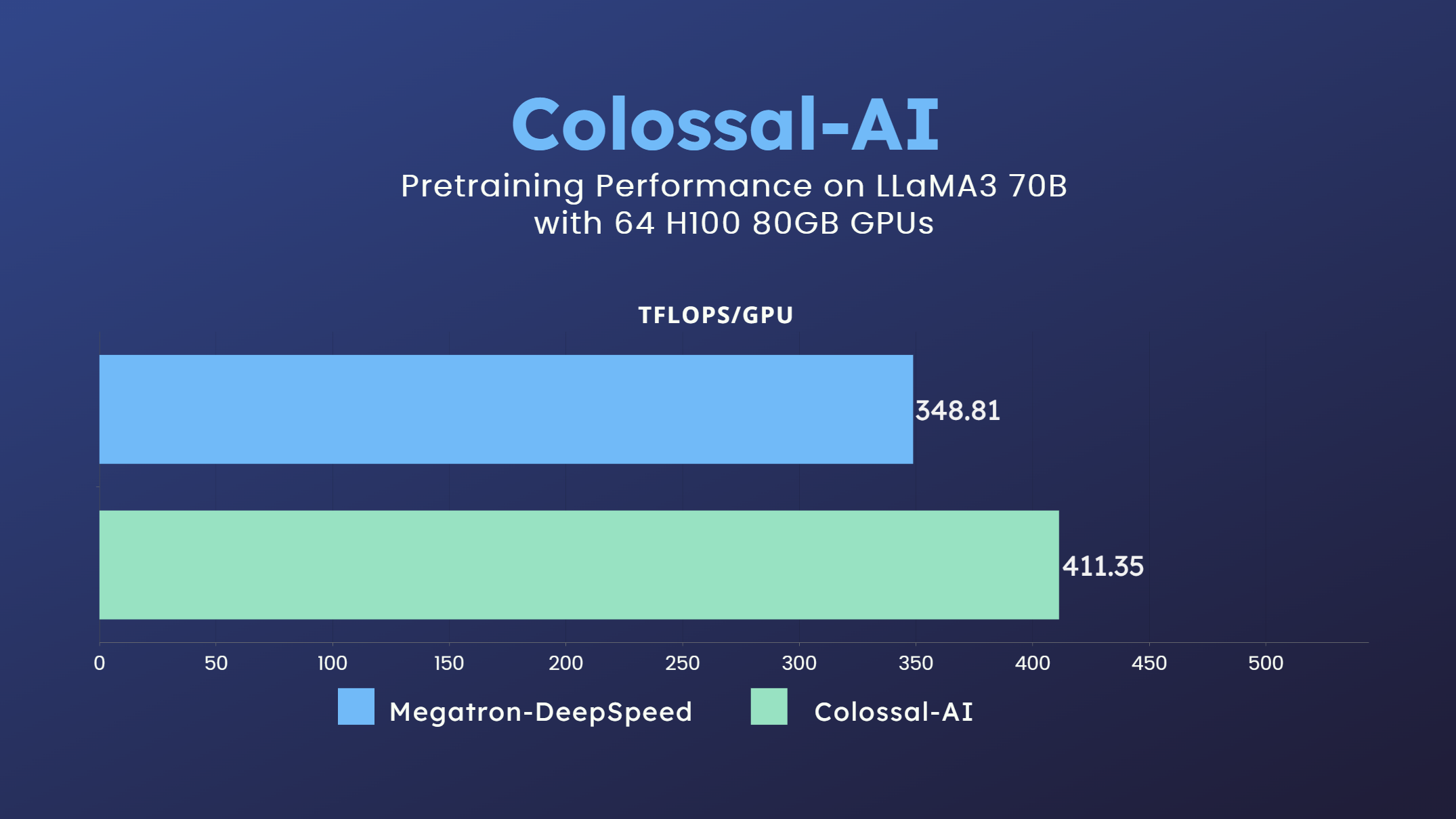 5 |
5 |
6 |
7 | - 70 billion parameter LLaMA3 model training accelerated by 18%
8 |
9 | ### LLaMA2
10 |
11 | 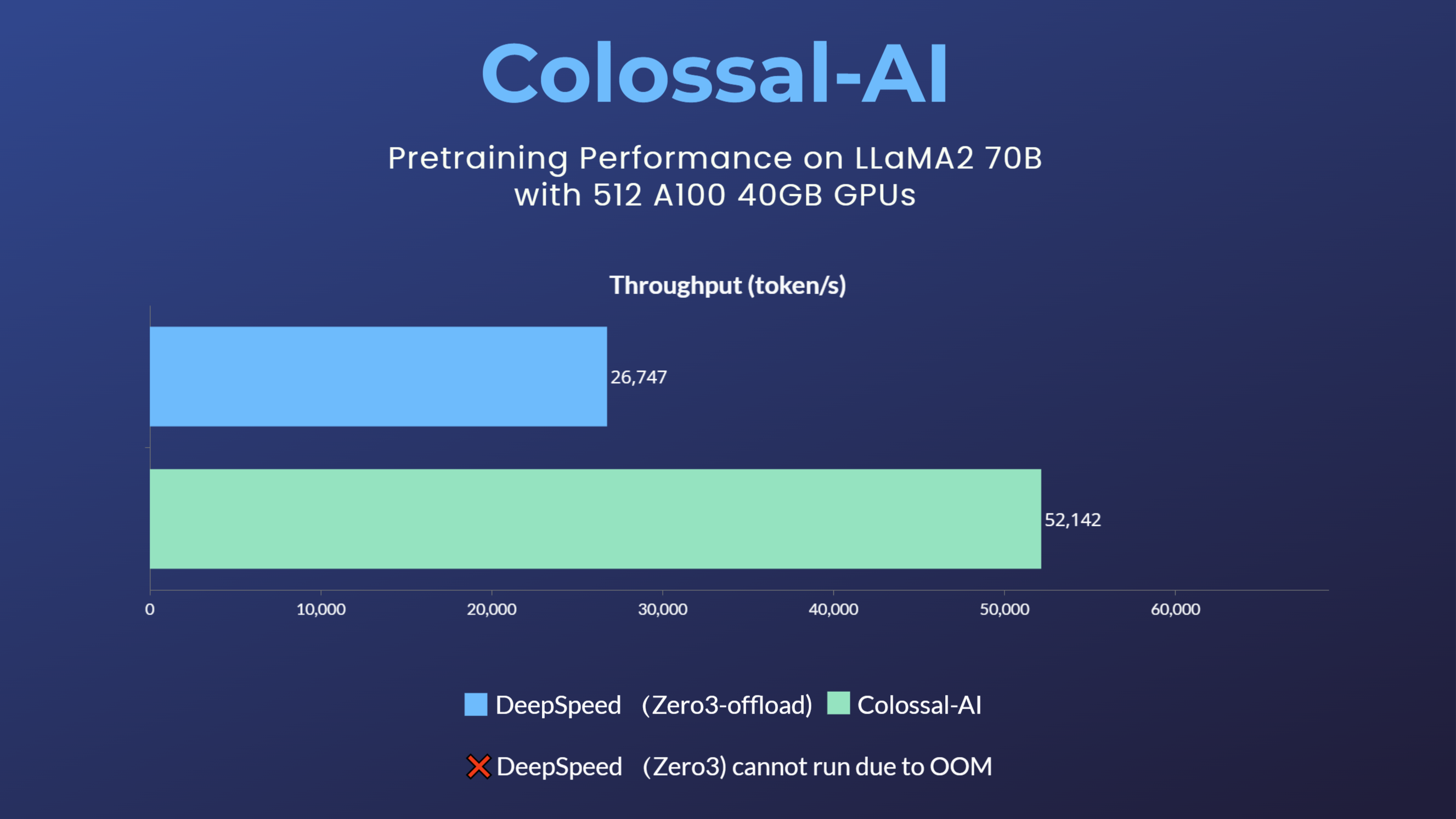 12 |
12 |
13 |
14 | - 70 billion parameter LLaMA2 model training accelerated by 195%
15 | [[blog]](https://www.hpc-ai.tech/blog/70b-llama2-training)
16 |
17 | ### LLaMA1
18 |
19 |  20 |
20 |
21 |
22 | - 65-billion-parameter large model pretraining accelerated by 38%
23 | [[blog]](https://www.hpc-ai.tech/blog/large-model-pretraining)
24 |
25 | ## Usage
26 |
27 | > ⚠ This example only has benchmarking script. For training/finetuning, please refer to the [applications/Colossal-LLaMA](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Colossal-LLaMA).
28 |
29 | ### 1. Installation
30 |
31 | Please install the latest ColossalAI from source.
32 |
33 | ```bash
34 | BUILD_EXT=1 pip install -U git+https://github.com/hpcaitech/ColossalAI
35 | ```
36 |
37 | Then install other dependencies.
38 |
39 | ```bash
40 | pip install -r requirements.txt
41 | ```
42 |
43 | ### 4. Shell Script Examples
44 |
45 | For your convenience, we provide some shell scripts to run benchmark with various configurations.
46 |
47 | You can find them in `scripts/benchmark_7B` and `scripts/benchmark_70B` directory. The main command should be in the format of:
48 | ```bash
49 | colossalai run --nproc_per_node YOUR_GPU_PER_NODE --hostfile YOUR_HOST_FILE \
50 | benchmark.py --OTHER_CONFIGURATIONS
51 | ```
52 | Here we will show an example of how to run training
53 | llama pretraining with `gemini, batch_size=16, sequence_length=4096, gradient_checkpoint=True, flash_attn=True`.
54 |
55 | #### a. Running environment
56 | This experiment was performed on 4 computing nodes with 32 A800/H800 80GB GPUs in total for LLaMA-1 65B or LLaMA-2 70B. The nodes are
57 | connected with RDMA and GPUs within one node are fully connected with NVLink.
58 |
59 | #### b. Running command
60 |
61 | ```bash
62 | cd scripts/benchmark_7B
63 | ```
64 |
65 | First, put your host file (`hosts.txt`) in this directory with your real host ip or host name.
66 |
67 | Here is a sample `hosts.txt`:
68 | ```text
69 | hostname1
70 | hostname2
71 | hostname3
72 | hostname4
73 | ```
74 |
75 | Then add environment variables to script if needed.
76 |
77 | Finally, run the following command to start training:
78 |
79 | ```bash
80 | bash gemini.sh
81 | ```
82 |
83 | If you encounter out-of-memory(OOM) error during training with script `gemini.sh`, changing to script `gemini_auto.sh` might be a solution, since gemini_auto will set a upper limit on GPU memory usage through offloading part of the model parameters and optimizer states back to CPU memory. But there's a trade-off: `gemini_auto.sh` will be a bit slower, since more data are transmitted between CPU and GPU.
84 |
85 | #### c. Results
86 | If you run the above command successfully, you will get the following results:
87 | `max memory usage: 55491.10 MB, throughput: 24.26 samples/s, TFLOPS/GPU: 167.43`.
88 |
89 |
90 | ## Reference
91 | ```
92 | @article{bian2021colossal,
93 | title={Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training},
94 | author={Bian, Zhengda and Liu, Hongxin and Wang, Boxiang and Huang, Haichen and Li, Yongbin and Wang, Chuanrui and Cui, Fan and You, Yang},
95 | journal={arXiv preprint arXiv:2110.14883},
96 | year={2021}
97 | }
98 | ```
99 |
100 | ```bibtex
101 | @software{openlm2023openllama,
102 | author = {Geng, Xinyang and Liu, Hao},
103 | title = {OpenLLaMA: An Open Reproduction of LLaMA},
104 | month = May,
105 | year = 2023,
106 | url = {https://github.com/openlm-research/open_llama}
107 | }
108 | ```
109 |
110 | ```bibtex
111 | @software{together2023redpajama,
112 | author = {Together Computer},
113 | title = {RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset},
114 | month = April,
115 | year = 2023,
116 | url = {https://github.com/togethercomputer/RedPajama-Data}
117 | }
118 | ```
119 |
120 | ```bibtex
121 | @article{touvron2023llama,
122 | title={Llama: Open and efficient foundation language models},
123 | author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{\'e}e and Rozi{\`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and others},
124 | journal={arXiv preprint arXiv:2302.13971},
125 | year={2023}
126 | }
127 | ```
128 |
--------------------------------------------------------------------------------
/scripts/benchmark/benchmark.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import resource
3 | import time
4 | from contextlib import nullcontext
5 |
6 | import torch
7 | from data_utils import RandomDataset
8 | from model_utils import format_numel_str, get_model_numel
9 | from performance_evaluator import PerformanceEvaluator, get_profile_context
10 | from torch.distributed.fsdp.fully_sharded_data_parallel import CPUOffload, MixedPrecision
11 | from tqdm import tqdm
12 | from transformers import AutoConfig, AutoModelForCausalLM
13 | from transformers.models.llama.configuration_llama import LlamaConfig
14 |
15 | import colossalai
16 | from colossalai.accelerator import get_accelerator
17 | from colossalai.booster import Booster
18 | from colossalai.booster.plugin import GeminiPlugin, HybridParallelPlugin, TorchFSDPPlugin
19 | from colossalai.cluster import DistCoordinator
20 | from colossalai.lazy import LazyInitContext
21 | from colossalai.nn.optimizer import HybridAdam
22 | from colossalai.shardformer import PipelineGradientCheckpointConfig
23 |
24 | # ==============================
25 | # Constants
26 | # ==============================
27 |
28 | MODEL_CONFIGS = {
29 | "7b": LlamaConfig(max_position_embeddings=4096),
30 | "13b": LlamaConfig(
31 | hidden_size=5120,
32 | intermediate_size=13824,
33 | num_hidden_layers=40,
34 | num_attention_heads=40,
35 | max_position_embeddings=4096,
36 | ),
37 | "70b": LlamaConfig(
38 | hidden_size=8192,
39 | intermediate_size=28672,
40 | num_hidden_layers=80,
41 | num_attention_heads=64,
42 | max_position_embeddings=4096,
43 | num_key_value_heads=8,
44 | ),
45 | }
46 |
47 |
48 | def main():
49 | # ==============================
50 | # Parse Arguments
51 | # ==============================
52 | parser = argparse.ArgumentParser()
53 | parser.add_argument("-c", "--config", type=str, default="7b", help="Model configuration")
54 | parser.add_argument(
55 | "-p",
56 | "--plugin",
57 | choices=["gemini", "gemini_auto", "fsdp", "fsdp_cpu", "3d", "3d_cpu"],
58 | default="gemini",
59 | help="Choose which plugin to use",
60 | )
61 | parser.add_argument("-b", "--batch_size", type=int, default=2, help="Batch size")
62 | parser.add_argument("-s", "--num_steps", type=int, default=5, help="Number of steps to run")
63 | parser.add_argument("-i", "--ignore_steps", type=int, default=2, help="Number of steps to ignore")
64 | parser.add_argument("-g", "--grad_checkpoint", action="store_true", help="Use gradient checkpointing")
65 | parser.add_argument("-l", "--max_length", type=int, default=4096, help="Max sequence length")
66 | parser.add_argument(
67 | "-w", "--warmup_ratio", type=float, default=0.8, help="warm up ratio of non-model data. Only for gemini-auto"
68 | )
69 | parser.add_argument("-m", "--memory_limit", type=int, help="Gemini memory limit in mb")
70 | parser.add_argument("-x", "--xformers", action="store_true", help="Use xformers")
71 | parser.add_argument("--shard_param_frac", type=float, default=1.0, help="Shard param fraction. Only for gemini")
72 | parser.add_argument("--offload_optim_frac", type=float, default=0.0, help="Offload optim fraction. Only for gemini")
73 | parser.add_argument("--offload_param_frac", type=float, default=0.0, help="Offload param fraction. Only for gemini")
74 | parser.add_argument("--tp", type=int, default=1, help="Tensor parallel size")
75 | parser.add_argument("--extra_dp", type=int, default=1, help="Extra data parallel size, used for Gemini")
76 | parser.add_argument("--pp", type=int, default=1, help="Pipeline parallel size")
77 | parser.add_argument("--mbs", type=int, default=1, help="Micro batch size of pipeline parallel")
78 | parser.add_argument("--zero", type=int, default=0, help="Zero Stage when hybrid plugin is enabled")
79 | parser.add_argument("--custom-ckpt", action="store_true", help="Customize checkpoint", default=False)
80 | parser.add_argument("--profile", action="store_true", help="Enable profiling", default=False)
81 | parser.add_argument(
82 | "--disable-async-reduce", action="store_true", help="Disable the asynchronous reduce operation", default=False
83 | )
84 | parser.add_argument("--prefetch_num", type=int, default=0, help="chunk prefetch max number")
85 | args = parser.parse_args()
86 |
87 | colossalai.launch_from_torch()
88 | coordinator = DistCoordinator()
89 |
90 | def empty_init():
91 | pass
92 |
93 | # ckpt config for LLaMA3-70B on 64 H100 GPUs
94 | hybrid_kwargs = (
95 | {
96 | "gradient_checkpoint_config": PipelineGradientCheckpointConfig(
97 | num_ckpt_layers_per_stage=[19, 19, 19, 13],
98 | ),
99 | "num_layers_per_stage": [19, 20, 20, 21],
100 | }
101 | if args.custom_ckpt
102 | else {}
103 | )
104 |
105 | # ==============================
106 | # Initialize Booster
107 | # ==============================
108 | use_empty_init = True
109 | if args.plugin == "gemini":
110 | plugin = GeminiPlugin(
111 | precision="bf16",
112 | shard_param_frac=args.shard_param_frac,
113 | offload_optim_frac=args.offload_optim_frac,
114 | offload_param_frac=args.offload_param_frac,
115 | tp_size=args.tp,
116 | extra_dp_size=args.extra_dp,
117 | enable_fused_normalization=torch.cuda.is_available(),
118 | enable_flash_attention=args.xformers,
119 | max_prefetch=args.prefetch_num,
120 | enable_async_reduce=not args.disable_async_reduce,
121 | )
122 | elif args.plugin == "gemini_auto":
123 | plugin = GeminiPlugin(
124 | placement_policy="auto",
125 | precision="bf16",
126 | warmup_non_model_data_ratio=args.warmup_ratio,
127 | tp_size=args.tp,
128 | extra_dp_size=args.extra_dp,
129 | enable_fused_normalization=torch.cuda.is_available(),
130 | max_prefetch=args.prefetch_num,
131 | enable_async_reduce=not args.disable_async_reduce,
132 | enable_flash_attention=args.xformers,
133 | )
134 | elif args.plugin == "fsdp":
135 | if use_empty_init:
136 | plugin = TorchFSDPPlugin(
137 | mixed_precision=MixedPrecision(
138 | param_dtype=torch.float16,
139 | reduce_dtype=torch.float16,
140 | buffer_dtype=torch.float16,
141 | ),
142 | param_init_fn=empty_init(),
143 | )
144 | else:
145 | plugin = TorchFSDPPlugin(
146 | mixed_precision=MixedPrecision(
147 | param_dtype=torch.float16,
148 | reduce_dtype=torch.float16,
149 | buffer_dtype=torch.float16,
150 | )
151 | )
152 | elif args.plugin == "fsdp_cpu":
153 | if use_empty_init:
154 | plugin = TorchFSDPPlugin(
155 | mixed_precision=MixedPrecision(
156 | param_dtype=torch.float16,
157 | reduce_dtype=torch.float16,
158 | buffer_dtype=torch.float16,
159 | ),
160 | cpu_offload=CPUOffload(offload_params=True),
161 | param_init_fn=empty_init(),
162 | )
163 | else:
164 | plugin = TorchFSDPPlugin(
165 | mixed_precision=MixedPrecision(
166 | param_dtype=torch.float16,
167 | reduce_dtype=torch.float16,
168 | buffer_dtype=torch.float16,
169 | ),
170 | cpu_offload=CPUOffload(offload_params=True),
171 | )
172 | elif args.plugin == "3d":
173 | plugin = HybridParallelPlugin(
174 | tp_size=args.tp,
175 | pp_size=args.pp,
176 | zero_stage=args.zero,
177 | enable_fused_normalization=torch.cuda.is_available(),
178 | enable_flash_attention=args.xformers,
179 | microbatch_size=args.mbs,
180 | precision="bf16",
181 | dp_outside=False,
182 | **hybrid_kwargs,
183 | )
184 | elif args.plugin == "3d_cpu":
185 | plugin = HybridParallelPlugin(
186 | tp_size=args.tp,
187 | pp_size=args.pp,
188 | zero_stage=args.zero,
189 | cpu_offload=True,
190 | enable_fused_normalization=torch.cuda.is_available(),
191 | enable_flash_attention=args.xformers,
192 | microbatch_size=args.mbs,
193 | initial_scale=2**8,
194 | precision="bf16",
195 | )
196 | else:
197 | raise ValueError(f"Unknown plugin {args.plugin}")
198 |
199 | booster = Booster(plugin=plugin)
200 |
201 | # ==============================
202 | # Initialize Dataset and Dataloader
203 | # ==============================
204 | dp_size = getattr(plugin, "dp_size", coordinator.world_size)
205 |
206 | if args.config in MODEL_CONFIGS:
207 | config = MODEL_CONFIGS[args.config]
208 | else:
209 | config = AutoConfig.from_pretrained(args.config, trust_remote_code=True)
210 | dataset = RandomDataset(
211 | num_samples=args.batch_size * args.num_steps * dp_size, max_length=args.max_length, vocab_size=config.vocab_size
212 | )
213 | dataloader = plugin.prepare_dataloader(dataset, batch_size=args.batch_size, shuffle=True, drop_last=True)
214 |
215 | # ==============================
216 | # Initialize Model and Optimizer
217 | # ==============================
218 | init_ctx = (
219 | LazyInitContext(default_device=get_accelerator().get_current_device())
220 | if isinstance(plugin, (GeminiPlugin, HybridParallelPlugin))
221 | else nullcontext()
222 | )
223 |
224 | init_kwargs = {}
225 | if config.model_type == "chatglm":
226 | init_kwargs["empty_init"] = False
227 |
228 | with init_ctx:
229 | model = AutoModelForCausalLM.from_config(config, trust_remote_code=True, **init_kwargs)
230 |
231 | if args.grad_checkpoint:
232 | model.gradient_checkpointing_enable()
233 | if config.model_type == "chatglm":
234 | model.transformer.encoder.gradient_checkpointing = True
235 |
236 | model_numel = get_model_numel(model)
237 | coordinator.print_on_master(f"Model params: {format_numel_str(model_numel)}")
238 | performance_evaluator = PerformanceEvaluator(
239 | model_numel,
240 | model.config.num_hidden_layers,
241 | model.config.hidden_size,
242 | model.config.vocab_size,
243 | args.grad_checkpoint,
244 | args.ignore_steps,
245 | dp_world_size=dp_size,
246 | )
247 |
248 | optimizer = HybridAdam(model.parameters())
249 | torch.set_default_dtype(torch.bfloat16)
250 | model, optimizer, _, dataloader, _ = booster.boost(model, optimizer, dataloader=dataloader)
251 | torch.set_default_dtype(torch.float)
252 | coordinator.print_on_master(
253 | f"Booster init max CUDA memory: {get_accelerator().max_memory_allocated()/1024**2:.2f} MB"
254 | )
255 | coordinator.print_on_master(
256 | f"Booster init max CPU memory: {resource.getrusage(resource.RUSAGE_SELF).ru_maxrss/1024:.2f} MB"
257 | )
258 |
259 | with get_profile_context(
260 | args.profile,
261 | 1,
262 | len(dataloader) - 1,
263 | save_dir=f"profile/{time.strftime('%H:%M', time.localtime())}-{args.plugin}-llama-{args.config}",
264 | ) as prof:
265 | if isinstance(plugin, HybridParallelPlugin) and args.pp > 1:
266 | data_iter = iter(dataloader)
267 | for step in tqdm(range(len(dataloader)), desc="Step", disable=not coordinator.is_master()):
268 | performance_evaluator.on_step_start(step)
269 | booster.execute_pipeline(
270 | data_iter,
271 | model,
272 | criterion=lambda outputs, inputs: outputs[0],
273 | optimizer=optimizer,
274 | return_loss=False,
275 | )
276 | optimizer.step()
277 | optimizer.zero_grad()
278 | performance_evaluator.on_step_end(input_ids=torch.empty(args.batch_size, args.max_length))
279 | prof.step()
280 | else:
281 | for step, batch in enumerate(tqdm(dataloader, desc="Step", disable=not coordinator.is_master())):
282 | performance_evaluator.on_step_start(step)
283 | outputs = model(**batch)
284 | loss = outputs[0]
285 | booster.backward(loss, optimizer)
286 | optimizer.step()
287 | optimizer.zero_grad()
288 | performance_evaluator.on_step_end(**batch)
289 | prof.step()
290 |
291 | performance_evaluator.on_fit_end()
292 | coordinator.print_on_master(f"Max CUDA memory usage: {get_accelerator().max_memory_allocated()/1024**2:.2f} MB")
293 |
294 |
295 | if __name__ == "__main__":
296 | main()
297 |
--------------------------------------------------------------------------------
/scripts/benchmark/data_utils.py:
--------------------------------------------------------------------------------
1 | import json
2 | import random
3 | from typing import Iterator, Optional
4 |
5 | import numpy as np
6 | import torch
7 | from torch.distributed import ProcessGroup
8 | from torch.distributed.distributed_c10d import _get_default_group
9 | from torch.utils.data import DataLoader, Dataset, DistributedSampler
10 |
11 | from colossalai.accelerator import get_accelerator
12 |
13 |
14 | class StatefulDistributedSampler(DistributedSampler):
15 | def __init__(
16 | self,
17 | dataset: Dataset,
18 | num_replicas: Optional[int] = None,
19 | rank: Optional[int] = None,
20 | shuffle: bool = True,
21 | seed: int = 0,
22 | drop_last: bool = False,
23 | ) -> None:
24 | super().__init__(dataset, num_replicas, rank, shuffle, seed, drop_last)
25 | self.start_index: int = 0
26 |
27 | def __iter__(self) -> Iterator:
28 | iterator = super().__iter__()
29 | indices = list(iterator)
30 | indices = indices[self.start_index :]
31 | return iter(indices)
32 |
33 | def __len__(self) -> int:
34 | return self.num_samples - self.start_index
35 |
36 | def set_start_index(self, start_index: int) -> None:
37 | self.start_index = start_index
38 |
39 |
40 | def prepare_dataloader(
41 | dataset,
42 | batch_size,
43 | shuffle=False,
44 | seed=1024,
45 | drop_last=False,
46 | pin_memory=False,
47 | num_workers=0,
48 | process_group: Optional[ProcessGroup] = None,
49 | **kwargs,
50 | ):
51 | r"""
52 | Prepare a dataloader for distributed training. The dataloader will be wrapped by
53 | `torch.utils.data.DataLoader` and `StatefulDistributedSampler`.
54 |
55 |
56 | Args:
57 | dataset (`torch.utils.data.Dataset`): The dataset to be loaded.
58 | shuffle (bool, optional): Whether to shuffle the dataset. Defaults to False.
59 | seed (int, optional): Random worker seed for sampling, defaults to 1024.
60 | add_sampler: Whether to add ``DistributedDataParallelSampler`` to the dataset. Defaults to True.
61 | drop_last (bool, optional): Set to True to drop the last incomplete batch, if the dataset size
62 | is not divisible by the batch size. If False and the size of dataset is not divisible by
63 | the batch size, then the last batch will be smaller, defaults to False.
64 | pin_memory (bool, optional): Whether to pin memory address in CPU memory. Defaults to False.
65 | num_workers (int, optional): Number of worker threads for this dataloader. Defaults to 0.
66 | kwargs (dict): optional parameters for ``torch.utils.data.DataLoader``, more details could be found in
67 | `DataLoader `_.
68 |
69 | Returns:
70 | :class:`torch.utils.data.DataLoader`: A DataLoader used for training or testing.
71 | """
72 | _kwargs = kwargs.copy()
73 | process_group = process_group or _get_default_group()
74 | sampler = StatefulDistributedSampler(
75 | dataset, num_replicas=process_group.size(), rank=process_group.rank(), shuffle=shuffle
76 | )
77 |
78 | # Deterministic dataloader
79 | def seed_worker(worker_id):
80 | worker_seed = seed
81 | np.random.seed(worker_seed)
82 | torch.manual_seed(worker_seed)
83 | random.seed(worker_seed)
84 |
85 | return DataLoader(
86 | dataset,
87 | batch_size=batch_size,
88 | sampler=sampler,
89 | worker_init_fn=seed_worker,
90 | drop_last=drop_last,
91 | pin_memory=pin_memory,
92 | num_workers=num_workers,
93 | **_kwargs,
94 | )
95 |
96 |
97 | def load_json(file_path: str):
98 | with open(file_path, "r") as f:
99 | return json.load(f)
100 |
101 |
102 | def save_json(data, file_path: str):
103 | with open(file_path, "w") as f:
104 | json.dump(data, f, indent=4)
105 |
106 |
107 | class RandomDataset(Dataset):
108 | def __init__(self, num_samples: int = 1000, max_length: int = 2048, vocab_size: int = 32000):
109 | self.num_samples = num_samples
110 | self.max_length = max_length
111 | self.input_ids = torch.randint(
112 | 0, vocab_size, (num_samples, max_length), device=get_accelerator().get_current_device()
113 | )
114 | self.attention_mask = torch.ones_like(self.input_ids)
115 |
116 | def __len__(self):
117 | return self.num_samples
118 |
119 | def __getitem__(self, idx):
120 | return {
121 | "input_ids": self.input_ids[idx],
122 | "attention_mask": self.attention_mask[idx],
123 | "labels": self.input_ids[idx],
124 | }
125 |
--------------------------------------------------------------------------------
/scripts/benchmark/model_utils.py:
--------------------------------------------------------------------------------
1 | from contextlib import contextmanager
2 |
3 | import torch
4 | import torch.nn as nn
5 |
6 |
7 | @contextmanager
8 | def low_precision_init(target_dtype: torch.dtype = torch.float16):
9 | dtype = torch.get_default_dtype()
10 | try:
11 | torch.set_default_dtype(target_dtype)
12 | yield
13 | finally:
14 | torch.set_default_dtype(dtype)
15 |
16 |
17 | def get_model_numel(model: nn.Module) -> int:
18 | return sum(p.numel() for p in model.parameters())
19 |
20 |
21 | def format_numel_str(numel: int) -> str:
22 | B = 1024**3
23 | M = 1024**2
24 | K = 1024
25 | if numel >= B:
26 | return f"{numel / B:.2f} B"
27 | elif numel >= M:
28 | return f"{numel / M:.2f} M"
29 | elif numel >= K:
30 | return f"{numel / K:.2f} K"
31 | else:
32 | return f"{numel}"
33 |
--------------------------------------------------------------------------------
/scripts/benchmark/performance_evaluator.py:
--------------------------------------------------------------------------------
1 | from time import time
2 | from typing import Optional
3 |
4 | import torch
5 | import torch.distributed as dist
6 | from torch import Tensor
7 | from torch.profiler import ProfilerActivity, profile, schedule, tensorboard_trace_handler
8 |
9 | from colossalai.accelerator import get_accelerator
10 | from colossalai.cluster import DistCoordinator
11 |
12 |
13 | def divide(x: float, y: float) -> float:
14 | if y == 0:
15 | return float("inf")
16 | elif y == float("inf"):
17 | return float("nan")
18 | return x / y
19 |
20 |
21 | @torch.no_grad()
22 | def all_reduce_mean(x: float, world_size: int) -> float:
23 | if world_size == 1:
24 | return x
25 | tensor = torch.tensor([x], device=get_accelerator().get_current_device())
26 | dist.all_reduce(tensor)
27 | tensor = tensor / world_size
28 | return tensor.item()
29 |
30 |
31 | def get_profile_context(enable_flag, warmup_steps, active_steps, save_dir):
32 | class DummyProfiler:
33 | def __init__(self):
34 | self.step_number = 0
35 |
36 | def step(self):
37 | self.step_number += 1
38 |
39 | def __enter__(self):
40 | return self
41 |
42 | def __exit__(self, exc_type, exc_value, traceback):
43 | pass
44 |
45 | if enable_flag:
46 | return profile(
47 | activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
48 | schedule=schedule(wait=0, warmup=warmup_steps, active=active_steps),
49 | on_trace_ready=tensorboard_trace_handler(save_dir),
50 | record_shapes=True,
51 | profile_memory=True,
52 | with_stack=True,
53 | )
54 | else:
55 | return DummyProfiler()
56 |
57 |
58 | class Timer:
59 | def __init__(self) -> None:
60 | self.start_time: Optional[float] = None
61 | self.duration: float = 0.0
62 |
63 | def start(self) -> None:
64 | self.start_time = time()
65 |
66 | def end(self) -> None:
67 | assert self.start_time is not None
68 | self.duration += time() - self.start_time
69 | self.start_time = None
70 |
71 | def reset(self) -> None:
72 | self.duration = 0.0
73 |
74 |
75 | class PerformanceEvaluator:
76 | """
77 | Callback for valuate the performance of the model.
78 | Args:
79 | actor_num_params: The number of parameters of the actor model.
80 | critic_num_params: The number of parameters of the critic model.
81 | initial_model_num_params: The number of parameters of the initial model.
82 | reward_model_num_params: The number of parameters of the reward model.
83 | enable_grad_checkpoint: Whether to enable gradient checkpointing.
84 | ignore_episodes: The number of episodes to ignore when calculating the performance.
85 | """
86 |
87 | def __init__(
88 | self,
89 | model_numel: int,
90 | num_layers: int,
91 | hidden_size: int,
92 | vocab_size: int,
93 | enable_grad_checkpoint: bool = False,
94 | ignore_steps: int = 0,
95 | dp_world_size: Optional[int] = None,
96 | ) -> None:
97 | self.model_numel = model_numel
98 | self.enable_grad_checkpoint = enable_grad_checkpoint
99 | self.ignore_steps = ignore_steps
100 | self.num_layers = num_layers
101 | self.hidden_size = hidden_size
102 | self.vocab_size = vocab_size
103 |
104 | self.coordinator = DistCoordinator()
105 | self.dp_world_size = dp_world_size or self.coordinator.world_size
106 | self.disable: bool = False
107 | self.timer = Timer()
108 | self.num_samples: int = 0
109 | self.flop_megatron = 0
110 | self.flop: int = 0
111 |
112 | def on_step_start(self, step: int) -> None:
113 | self.disable = self.ignore_steps > 0 and step < self.ignore_steps
114 | if self.disable:
115 | return
116 | get_accelerator().synchronize()
117 | self.timer.start()
118 |
119 | def on_step_end(self, input_ids: Tensor, **kwargs) -> None:
120 | if self.disable:
121 | return
122 | get_accelerator().synchronize()
123 | self.timer.end()
124 |
125 | batch_size, seq_len = input_ids.shape
126 |
127 | self.num_samples += batch_size
128 | checkpoint_activations_factor = 3 + int(self.enable_grad_checkpoint)
129 | self.flop_megatron += (
130 | 24 * checkpoint_activations_factor * batch_size * seq_len * self.num_layers * (self.hidden_size**2)
131 | ) * (
132 | 1.0 + (seq_len / (6.0 * self.hidden_size)) + (self.vocab_size / (16.0 * self.num_layers * self.hidden_size))
133 | )
134 | self.flop += batch_size * seq_len * self.model_numel * 2 * (3 + int(self.enable_grad_checkpoint))
135 |
136 | def on_fit_end(self) -> None:
137 | avg_duration = all_reduce_mean(self.timer.duration, self.coordinator.world_size)
138 | avg_throughput = self.num_samples * self.dp_world_size / (avg_duration + 1e-12)
139 | mp_world_size = self.coordinator.world_size // self.dp_world_size
140 | avg_tflops_per_gpu_megatron = self.flop_megatron / 1e12 / (avg_duration + 1e-12) / mp_world_size
141 | avg_tflops_per_gpu = self.flop / 1e12 / (avg_duration + 1e-12) / mp_world_size
142 | self.coordinator.print_on_master(
143 | f"num_samples: {self.num_samples}, dp_world_size: {self.dp_world_size}, flop_megatron: {self.flop_megatron}, flop: {self.flop}, avg_duration: {avg_duration}, "
144 | f"avg_throughput: {avg_throughput}"
145 | )
146 | self.coordinator.print_on_master(
147 | f"Throughput: {avg_throughput:.2f} samples/sec, TFLOPS per GPU by Megatron: {avg_tflops_per_gpu_megatron:.2f}, TFLOPS per GPU: {avg_tflops_per_gpu:.2f}"
148 | )
149 |
--------------------------------------------------------------------------------
/scripts/benchmark/requirements.txt:
--------------------------------------------------------------------------------
1 | colossalai>=0.3.6
2 | datasets
3 | numpy
4 | tqdm
5 | transformers
6 | flash-attn>=2.0.0
7 | SentencePiece==0.1.99
8 | tensorboard==2.14.0
9 |
--------------------------------------------------------------------------------
/scripts/benchmark/scripts/benchmark_7B/gemini.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | ################
4 | #Load your environments and modules here
5 | ################
6 |
7 | HOSTFILE=$(realpath hosts.txt)
8 |
9 | cd ../..
10 |
11 | export OMP_NUM_THREADS=8
12 |
13 | colossalai run --nproc_per_node 8 --hostfile $HOSTFILE benchmark.py -g -x -b 16
14 |
--------------------------------------------------------------------------------
/scripts/benchmark/scripts/benchmark_7B/gemini_auto.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | ################
4 | #Load your environments and modules here
5 | ################
6 |
7 | HOSTFILE=$(realpath hosts.txt)
8 |
9 | cd ../..
10 |
11 | export OMP_NUM_THREADS=8
12 |
13 | colossalai run --nproc_per_node 8 --hostfile $HOSTFILE benchmark.py -p gemini_auto -g -x -b 16
14 |
--------------------------------------------------------------------------------
/scripts/benchmark/test_ci.sh:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/moxin-org/Moxin-LLM/2ff78a7875c613d1fa2198f6d398813e9caf402e/scripts/benchmark/test_ci.sh
--------------------------------------------------------------------------------
/scripts/finetune/chat_finetune/finetune.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | import resource
4 | from contextlib import nullcontext
5 | from functools import partial
6 | from typing import Optional, Tuple
7 |
8 | import torch
9 | import torch.distributed as dist
10 | import torch.nn as nn
11 | from attn import replace_with_flash_attention
12 |
13 | # xuan ========================================
14 | import sys; sys.path.append("..")
15 | # ========================================
16 |
17 | # datasets 2.18.0
18 | # fsspec 2024.2.0
19 |
20 | from data_utils import load_json, prepare_dataloader, save_json
21 | from datasets import load_dataset, load_from_disk # , save_to_disk
22 | from torch.optim import Optimizer
23 | from torch.optim.lr_scheduler import _LRScheduler
24 | from torch.utils.tensorboard import SummaryWriter
25 | from tqdm import tqdm
26 | from transformers.models.llama.configuration_llama import LlamaConfig
27 | from transformers.models.llama.modeling_llama import LlamaForCausalLM
28 | from transformers.models.llama.tokenization_llama import LlamaTokenizer
29 |
30 | import colossalai
31 | from colossalai.accelerator import get_accelerator
32 | from colossalai.booster import Booster
33 | from colossalai.booster.plugin import GeminiPlugin, HybridParallelPlugin, LowLevelZeroPlugin
34 | from colossalai.cluster import DistCoordinator
35 | from colossalai.lazy import LazyInitContext
36 | from colossalai.nn.lr_scheduler import CosineAnnealingWarmupLR
37 | from colossalai.nn.optimizer import HybridAdam
38 |
39 | MODEL_CONFIGS = {
40 | "7b": LlamaConfig(max_position_embeddings=4096),
41 | "13b": LlamaConfig(
42 | hidden_size=5120,
43 | intermediate_size=13824,
44 | num_hidden_layers=40,
45 | num_attention_heads=40,
46 | max_position_embeddings=4096,
47 | ),
48 | "70b": LlamaConfig(
49 | hidden_size=8192,
50 | intermediate_size=28672,
51 | num_hidden_layers=80,
52 | num_attention_heads=64,
53 | max_position_embeddings=4096,
54 | num_key_value_heads=8,
55 | ),
56 | }
57 |
58 |
59 | def get_model_numel(model: nn.Module) -> int:
60 | return sum(p.numel() for p in model.parameters())
61 |
62 |
63 | def format_numel_str(numel: int) -> str:
64 | B = 1024 ** 3
65 | M = 1024 ** 2
66 | K = 1024
67 | if numel >= B:
68 | return f"{numel / B:.2f} B"
69 | elif numel >= M:
70 | return f"{numel / M:.2f} M"
71 | elif numel >= K:
72 | return f"{numel / K:.2f} K"
73 | else:
74 | return f"{numel}"
75 |
76 |
77 | def tokenize_batch_for_pretrain(batch, tokenizer: Optional[LlamaTokenizer] = None, max_length: int = 2048):
78 | texts = [sample["text"] for sample in batch]
79 | data = tokenizer(texts, return_tensors="pt", padding="max_length", truncation=True, max_length=max_length)
80 | data = {k: v.cuda() for k, v in data.items()}
81 | data["labels"] = data["input_ids"].clone()
82 | return data
83 |
84 |
85 | def all_reduce_mean(tensor: torch.Tensor) -> torch.Tensor:
86 | dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
87 | tensor = tensor.data
88 | tensor.div_(dist.get_world_size())
89 | return tensor
90 |
91 |
92 | def save(
93 | booster: Booster,
94 | model: nn.Module,
95 | optimizer: Optimizer,
96 | lr_scheduler: _LRScheduler,
97 | epoch: int,
98 | step: int,
99 | batch_size: int,
100 | coordinator: DistCoordinator,
101 | save_dir: str,
102 | ):
103 | save_dir = os.path.join(save_dir, f"epoch{epoch}-step{step}")
104 | os.makedirs(os.path.join(save_dir, "model"), exist_ok=True)
105 |
106 | booster.save_model(model, os.path.join(save_dir, "model"), shard=True)
107 | booster.save_optimizer(optimizer, os.path.join(save_dir, "optimizer"), shard=True)
108 | booster.save_lr_scheduler(lr_scheduler, os.path.join(save_dir, "lr_scheduler"))
109 | running_states = {
110 | "epoch": epoch,
111 | "step": step,
112 | "sample_start_index": step * batch_size,
113 | }
114 | if coordinator.is_master():
115 | save_json(running_states, os.path.join(save_dir, "running_states.json"))
116 |
117 |
118 | def load(
119 | booster: Booster, model: nn.Module, optimizer: Optimizer, lr_scheduler: _LRScheduler, load_dir: str
120 | ) -> Tuple[int, int, int]:
121 | booster.load_model(model, os.path.join(load_dir, "model"))
122 | # booster.load_optimizer(optimizer, os.path.join(load_dir, "optimizer"))
123 | # booster.load_lr_scheduler(lr_scheduler, os.path.join(load_dir, "lr_scheduler"))
124 | running_states = load_json(os.path.join(load_dir, "running_states.json"))
125 | return running_states["epoch"], running_states["step"], running_states["sample_start_index"]
126 |
127 |
128 | def _criterion(outputs, inputs):
129 | return outputs.loss
130 |
131 |
132 | def encode_with_prompt_completion_format(example, tokenizer, max_seq_length):
133 | '''
134 | Here we assume each example has 'prompt' and 'completion' fields.
135 | We concatenate prompt and completion and tokenize them together because otherwise prompt will be padded/trancated
136 | and it doesn't make sense to follow directly with the completion.
137 | '''
138 | # if prompt doesn't end with space and completion doesn't start with space, add space
139 | if not example['prompt'].endswith((' ', '\n', '\t')) and not example['completion'].startswith((' ', '\n', '\t')):
140 | example_text = example['prompt'] + ' ' + example['completion']
141 | else:
142 | example_text = example['prompt'] + example['completion']
143 | example_text = example_text + tokenizer.eos_token
144 | tokenized_example = tokenizer(example_text, return_tensors='pt', max_length=max_seq_length, truncation=True)
145 | input_ids = tokenized_example.input_ids
146 | labels = input_ids.clone()
147 | tokenized_prompt = tokenizer(example['prompt'], return_tensors='pt', max_length=max_seq_length, truncation=True)
148 | # mask the prompt part for avoiding loss
149 | labels[:, :tokenized_prompt.input_ids.shape[1]] = -100
150 | attention_mask = torch.ones_like(input_ids)
151 | return {
152 | 'input_ids': input_ids.flatten(),
153 | 'labels': labels.flatten(),
154 | 'attention_mask': attention_mask.flatten(),
155 | }
156 |
157 |
158 | def encode_with_messages_format(example, tokenizer, max_seq_length):
159 | '''
160 | Here we assume each example has a 'messages' field Each message is a dict with 'role' and 'content' fields.
161 | We concatenate all messages with the roles as delimiters and tokenize them together.
162 | '''
163 | messages = example['messages']
164 | if len(messages) == 0:
165 | raise ValueError('messages field is empty.')
166 |
167 | def _concat_messages(messages):
168 | message_text = ""
169 | for message in messages:
170 | if message["role"] == "system":
171 | message_text += "<|system|>\n" + message["content"].strip() + "\n"
172 | elif message["role"] == "user":
173 | message_text += "<|user|>\n" + message["content"].strip() + "\n"
174 | elif message["role"] == "assistant":
175 | message_text += "<|assistant|>\n" + message["content"].strip() + tokenizer.eos_token + "\n"
176 | else:
177 | raise ValueError("Invalid role: {}".format(message["role"]))
178 | return message_text
179 |
180 | example_text = _concat_messages(messages).strip()
181 | tokenized_example = tokenizer(example_text, return_tensors='pt', max_length=max_seq_length, truncation=True)
182 | input_ids = tokenized_example.input_ids
183 | labels = input_ids.clone()
184 |
185 | # mask the non-assistant part for avoiding loss
186 | for message_idx, message in enumerate(messages):
187 | if message["role"] != "assistant":
188 | if message_idx == 0:
189 | message_start_idx = 0
190 | else:
191 | message_start_idx = tokenizer(
192 | _concat_messages(messages[:message_idx]), return_tensors='pt', max_length=max_seq_length,
193 | truncation=True
194 | ).input_ids.shape[1]
195 | if message_idx < len(messages) - 1 and messages[message_idx + 1]["role"] == "assistant":
196 | # here we also ignore the role of the assistant
197 | messages_so_far = _concat_messages(messages[:message_idx + 1]) + "<|assistant|>\n"
198 | else:
199 | messages_so_far = _concat_messages(messages[:message_idx + 1])
200 | message_end_idx = tokenizer(
201 | messages_so_far,
202 | return_tensors='pt',
203 | max_length=max_seq_length,
204 | truncation=True
205 | ).input_ids.shape[1]
206 | labels[:, message_start_idx:message_end_idx] = -100
207 |
208 | if message_end_idx >= max_seq_length:
209 | break
210 |
211 | attention_mask = torch.ones_like(input_ids)
212 | return {
213 | 'input_ids': input_ids.flatten(),
214 | 'labels': labels.flatten(),
215 | 'attention_mask': attention_mask.flatten(),
216 | }
217 |
218 |
219 | def main():
220 | # ==============================
221 | # Parse Arguments
222 | # ==============================
223 | parser = argparse.ArgumentParser()
224 | parser.add_argument("-c", "--config", type=str, default="7b", help="Model configuration")
225 | parser.add_argument(
226 | "-p",
227 | "--plugin",
228 | choices=["gemini", "gemini_auto", "zero2", "zero2_cpu", "hybrid_parallel"],
229 | default="gemini",
230 | help="Choose which plugin to use",
231 | )
232 | parser.add_argument("-e", "--num_epochs", type=int, default=1, help="Number of epochs")
233 | parser.add_argument("-b", "--batch_size", type=int, default=2, help="Local batch size")
234 | parser.add_argument("--lr", type=float, default=3e-4, help="Learning rate")
235 | parser.add_argument("--data_path", type=str, default="workspace/datasets/tulu_v2.jsonl", help="dataset path")
236 | parser.add_argument("-w", "--weigth_decay", type=float, default=0.1, help="Weight decay")
237 | parser.add_argument("-s", "--warmup_steps", type=int, default=2000, help="Warmup steps")
238 | parser.add_argument("-g", "--grad_checkpoint", action="store_true", help="Use gradient checkpointing")
239 | parser.add_argument("-l", "--max_length", type=int, default=4096, help="Max sequence length")
240 | parser.add_argument("-x", "--mixed_precision", default="fp16", choices=["fp16", "bf16"], help="Mixed precision")
241 | parser.add_argument("-i", "--save_interval", type=int, default=1000, help="Save interval")
242 | parser.add_argument("-o", "--save_dir", type=str, default="checkpoint", help="Checkpoint directory")
243 | parser.add_argument("-f", "--load", type=str, default=None, help="Load checkpoint")
244 | parser.add_argument("--grad_clip", type=float, default=1.0, help="Gradient clipping")
245 | parser.add_argument("-t", "--tensorboard_dir", type=str, default="tb_logs", help="Tensorboard directory")
246 | parser.add_argument("-a", "--flash_attention", action="store_true", help="Use Flash Attention")
247 |
248 | # xuan ================================================================================
249 | parser.add_argument("--accumulation_steps", default=16, help="accumulation steps")
250 | parser.add_argument("--expanded_model", default="", help="model path")
251 | parser.add_argument("--tokenizer_path", default="", help="model path")
252 | # ================================================================================
253 |
254 | args = parser.parse_args()
255 |
256 | # ==============================
257 | # Initialize Distributed Training
258 | # ==============================
259 | colossalai.launch_from_torch({})
260 | coordinator = DistCoordinator()
261 |
262 | # ==============================
263 | # Initialize Booster
264 | # ==============================
265 | if args.plugin == "gemini":
266 | plugin = GeminiPlugin(precision=args.mixed_precision, initial_scale=2 ** 16, max_norm=args.grad_clip)
267 | elif args.plugin == "gemini_auto":
268 | plugin = GeminiPlugin(
269 | precision=args.mixed_precision, placement_policy="auto", initial_scale=2 ** 16, max_norm=args.grad_clip
270 | )
271 | elif args.plugin == "zero2":
272 | plugin = LowLevelZeroPlugin(
273 | stage=2, precision=args.mixed_precision, initial_scale=2 ** 16, max_norm=args.grad_clip
274 | )
275 | elif args.plugin == "zero2_cpu":
276 | plugin = LowLevelZeroPlugin(
277 | stage=2, precision=args.mixed_precision, initial_scale=2 ** 16, cpu_offload=True, max_norm=args.grad_clip
278 | )
279 | elif args.plugin == "hybrid_parallel":
280 | plugin = HybridParallelPlugin(
281 | tp_size=4,
282 | pp_size=2,
283 | num_microbatches=None,
284 | microbatch_size=1,
285 | enable_jit_fused=False,
286 | zero_stage=0,
287 | precision=args.mixed_precision,
288 | initial_scale=1,
289 | )
290 | else:
291 | raise ValueError(f"Unknown plugin {args.plugin}")
292 |
293 | booster = Booster(plugin=plugin)
294 |
295 | use_pipeline = isinstance(booster.plugin, HybridParallelPlugin) and booster.plugin.pp_size > 1
296 | is_pp_last_stage = use_pipeline and booster.plugin.stage_manager.is_last_stage()
297 | print_flag = (not use_pipeline and coordinator.is_master()) or (use_pipeline and is_pp_last_stage)
298 |
299 | # ==============================
300 | # Initialize Tensorboard
301 | # ==============================
302 | if print_flag:
303 | os.makedirs(args.tensorboard_dir, exist_ok=True)
304 | writer = SummaryWriter(args.tensorboard_dir)
305 |
306 | # ==============================
307 | # Initialize Tokenizer, Dataset and Dataloader
308 | # ==============================
309 | from transformers import AutoTokenizer
310 | tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_path, use_fast=False)
311 | tokenizer.pad_token = tokenizer.unk_token
312 | # ================================================================
313 |
314 |
315 | train_file = args.data_path
316 |
317 | data_files = {}
318 | dataset_args = {}
319 | if train_file is not None:
320 | data_files["train"] = train_file
321 | raw_datasets = load_dataset(
322 | "json",
323 | data_files=data_files,
324 | **dataset_args,
325 | )
326 |
327 | # Preprocessing the datasets.
328 | if "prompt" in raw_datasets["train"].column_names and "completion" in raw_datasets["train"].column_names:
329 | encode_function = partial(
330 | encode_with_prompt_completion_format,
331 | tokenizer=tokenizer,
332 | max_seq_length=args.max_length,
333 | )
334 | elif "messages" in raw_datasets["train"].column_names:
335 | encode_function = partial(
336 | encode_with_messages_format,
337 | tokenizer=tokenizer,
338 | max_seq_length=args.max_length,
339 | )
340 | else:
341 | raise ValueError("You need to have either 'prompt'&'completion' or 'messages' in your column names.")
342 |
343 | # with accelerator.main_process_first():
344 | # if coordinator.is_master():
345 | lm_datasets = raw_datasets.map(
346 | encode_function,
347 | batched=False,
348 | num_proc=16,
349 | load_from_cache_file=True,
350 | remove_columns=[name for name in raw_datasets["train"].column_names if
351 | name not in ["input_ids", "labels", "attention_mask"]],
352 | desc="Tokenizing and reformatting instruction data",
353 | )
354 | lm_datasets.set_format(type="pt")
355 | lm_datasets = lm_datasets.filter(lambda example: (example['labels'] != -100).any())
356 |
357 |
358 | dist.barrier()
359 |
360 | train_dataset = lm_datasets["train"]
361 |
362 | train_ds = train_dataset
363 |
364 | # ==============================
365 | # Initialize Model, Optimizer and LR Scheduler
366 | # ==============================
367 | config = MODEL_CONFIGS[args.config]
368 |
369 | init_ctx = (
370 | LazyInitContext(default_device=get_accelerator().get_current_device())
371 | if isinstance(plugin, GeminiPlugin)
372 | else nullcontext()
373 | )
374 |
375 | with init_ctx:
376 |
377 | from transformers import AutoModelForCausalLM, AutoConfig
378 | model = AutoModelForCausalLM.from_pretrained(args.expanded_model, torch_dtype=torch.float16)#, device_map='cpu')
379 |
380 | for name, weight in model.named_parameters():
381 | weight.requires_grad = True
382 |
383 | from transformers import DataCollatorForSeq2Seq
384 | dataloader = prepare_dataloader(
385 | lm_datasets["train"],
386 | batch_size=args.batch_size,
387 | shuffle=True,
388 | drop_last=True,
389 | collate_fn=DataCollatorForSeq2Seq(tokenizer=tokenizer, model=model, padding="longest"),
390 | )
391 | # =======================================================================
392 |
393 | if args.grad_checkpoint:
394 | model.gradient_checkpointing_enable()
395 |
396 | model_numel = get_model_numel(model)
397 | coordinator.print_on_master(f"Model params: {format_numel_str(model_numel)}")
398 |
399 | optimizer = HybridAdam(model.parameters(), lr=args.lr, betas=(0.9, 0.95), weight_decay=args.weigth_decay)
400 |
401 | lr_scheduler = CosineAnnealingWarmupLR(
402 | optimizer, total_steps=args.num_epochs * len(dataloader), warmup_steps=args.warmup_steps, eta_min=0.1 * args.lr
403 | )
404 | default_dtype = torch.float16 if args.mixed_precision == "fp16" else torch.bfloat16
405 | torch.set_default_dtype(default_dtype)
406 | model, optimizer, _, dataloader, lr_scheduler = booster.boost(
407 | model, optimizer, dataloader=dataloader, lr_scheduler=lr_scheduler
408 | )
409 | torch.set_default_dtype(torch.float)
410 |
411 | coordinator.print_on_master(f"Booster init max CUDA memory: {torch.cuda.max_memory_allocated() / 1024 ** 2:.2f} MB")
412 | coordinator.print_on_master(
413 | f"Booster init max CPU memory: {resource.getrusage(resource.RUSAGE_SELF).ru_maxrss / 1024:.2f} MB"
414 | )
415 |
416 | # load checkpoint if specified
417 | start_epoch = 0
418 | start_step = 0
419 | sampler_start_idx = 0
420 | if args.load is not None:
421 | coordinator.print_on_master("Loading checkpoint")
422 | start_epoch, start_step, sampler_start_idx = load(booster, model, optimizer, lr_scheduler, args.load)
423 | coordinator.print_on_master(f"Loaded checkpoint {args.load} at epoch {start_epoch} step {start_step}")
424 |
425 | num_steps_per_epoch = len(dataloader)
426 |
427 | # if resume training, set the sampler start index to the correct value
428 | dataloader.sampler.set_start_index(sampler_start_idx)
429 | for epoch in range(start_epoch, args.num_epochs):
430 | dataloader.sampler.set_epoch(epoch)
431 | dataloader_iter = iter(dataloader)
432 |
433 | for step in range(start_step, num_steps_per_epoch):
434 | if use_pipeline:
435 | outputs = booster.execute_pipeline(dataloader_iter, model, _criterion, optimizer, return_loss=True)
436 | loss = outputs["loss"]
437 | else:
438 | batch = next(dataloader_iter)
439 | batch = batch.to(get_accelerator().get_current_device())
440 | outputs = model(**batch)
441 | loss = outputs[0]
442 | booster.backward(loss, optimizer)
443 |
444 | if (step + 1) % args.accumulation_steps == 0:
445 | optimizer.step() # Update parameters
446 | lr_scheduler.step()
447 | optimizer.zero_grad() # Reset gradients
448 |
449 | if step + 1 == num_steps_per_epoch - 1:
450 | optimizer.step()
451 | lr_scheduler.step()
452 | optimizer.zero_grad()
453 |
454 | if not use_pipeline:
455 | all_reduce_mean(loss)
456 |
457 | if print_flag:
458 | writer.add_scalar("loss", loss.item(), epoch * num_steps_per_epoch + step)
459 | print("Epoch: {}, step: {}, loss: {:.3f}".format(
460 | epoch,
461 | epoch * num_steps_per_epoch + step,
462 | loss.item()
463 | ))
464 |
465 | if args.save_interval > 0 and (step + 1) % args.save_interval == 0:
466 | coordinator.print_on_master(f"Saving checkpoint")
467 | save(
468 | booster,
469 | model,
470 | optimizer,
471 | lr_scheduler,
472 | epoch,
473 | step + 1,
474 | args.batch_size,
475 | coordinator,
476 | args.save_dir,
477 | )
478 | coordinator.print_on_master(f"Saved checkpoint at epoch {epoch} step {step + 1}")
479 | # the continue epochs are not resumed, so we need to reset the sampler start index and start step
480 | dataloader.sampler.set_start_index(0)
481 | start_step = 0
482 |
483 | coordinator.print_on_master(f"Max CUDA memory usage: {torch.cuda.max_memory_allocated() / 1024 ** 2:.2f} MB")
484 |
485 |
486 | if __name__ == "__main__":
487 | main()
488 |
--------------------------------------------------------------------------------
/scripts/finetune/instruct_finetune/dpo_finetune.sh:
--------------------------------------------------------------------------------
1 |
2 |
3 | accelerate launch \
4 | --mixed_precision bf16 \
5 | --num_machines 1 \
6 | --num_processes 8 \
7 | --use_deepspeed \
8 | --deepspeed_config_file configs/ds_configs/stage3_no_offloading_accelerate.conf open_instruct/dpo_tune.py \
9 | --model_name_or_path output/sft_7b \
10 | --use_flash_attn \
11 | --tokenizer_name output/sft_7b \
12 | --max_seq_length 2048 \
13 | --preprocessing_num_workers 16 \
14 | --per_device_train_batch_size 1 \
15 | --gradient_accumulation_steps 16 \
16 | --learning_rate 5e-07 \
17 | --lr_scheduler_type linear \
18 | --warmup_ratio 0.1 \
19 | --weight_decay 0.0 \
20 | --num_train_epochs 1 \
21 | --output_dir output/dpo_7b \
22 | --with_tracking \
23 | --report_to wandb \
24 | --logging_steps 1 \
25 | --model_revision main \
26 | --gradient_checkpointing \
27 | --dataset_mixer_list allenai/llama-3.1-tulu-3-8b-preference-mixture 1.0 \
28 | --use_slow_tokenizer \
29 | --use_lora False \
30 | --dpo_loss_type dpo_norm \
31 | --dpo_beta 5 \
32 | --checkpointing_steps 1000 \
33 | --exp_name tulu-3-7b-dpo
34 |
35 |
36 |
37 |
--------------------------------------------------------------------------------
/scripts/finetune/instruct_finetune/sft_finetune.sh:
--------------------------------------------------------------------------------
1 |
2 | # modify the following `MACHINE_RANK`, `MAIN_PROCESS_IP`,
3 | # `NUM_MACHINES`, `NUM_PROCESSES`, `PER_DEVICE_TRAIN_BATCH_SIZE`,
4 | # `GRADIENT_ACCUMULATION_STEPS` according to your setup
5 | MACHINE_RANK=0
6 | MAIN_PROCESS_IP=localhost
7 | NUM_MACHINES=8
8 | NUM_PROCESSES=64
9 | PER_DEVICE_TRAIN_BATCH_SIZE=1
10 | GRADIENT_ACCUMULATION_STEPS=2
11 | accelerate launch \
12 | --mixed_precision bf16 \
13 | --num_machines 8 \
14 | --num_processes 64 \
15 | --machine_rank $MACHINE_RANK \
16 | --main_process_ip $MAIN_PROCESS_IP \
17 | --main_process_port 29400 \
18 | --use_deepspeed \
19 | --deepspeed_config_file configs/ds_configs/stage3_no_offloading_accelerate.conf \
20 | --deepspeed_multinode_launcher standard open_instruct/finetune.py \
21 | --model_name_or_path moxin-org/moxin-llm-7b \
22 | --tokenizer_name moxin-org/moxin-llm-7b \
23 | --use_slow_tokenizer \
24 | --use_flash_attn \
25 | --max_seq_length 4096 \
26 | --preprocessing_num_workers 128 \
27 | --per_device_train_batch_size $PER_DEVICE_TRAIN_BATCH_SIZE \
28 | --gradient_accumulation_steps $GRADIENT_ACCUMULATION_STEPS \
29 | --learning_rate 5e-06 \
30 | --lr_scheduler_type linear \
31 | --warmup_ratio 0.03 \
32 | --weight_decay 0.0 \
33 | --num_train_epochs 2 \
34 | --output_dir output/sft_7b \
35 | --with_tracking \
36 | --report_to wandb \
37 | --logging_steps 1 \
38 | --reduce_loss sum \
39 | --model_revision main \
40 | --dataset_mixer_list allenai/tulu-3-sft-mixture 1.0 \
41 | --checkpointing_steps epoch \
42 | --dataset_mix_dir output/sft_7b \
43 | --exp_name tulu-3-7b-sft \
44 | --seed 123
45 |
46 |
--------------------------------------------------------------------------------
/scripts/finetune/reason_finetune/train_7b.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -x
3 |
4 | # Warning: Export VLLM_ATTENTION_BACKEND on every machine before starting Ray cluster.
5 | # vLLM without XFORMERS will results in CUDA errors.
6 | export VLLM_ATTENTION_BACKEND=XFORMERS
7 |
8 | # Parse command line arguments
9 | while [[ $# -gt 0 ]]; do
10 | case $1 in
11 | --model)
12 | MODEL_PATH="$2"
13 | shift 2
14 | ;;
15 | *)
16 | break
17 | ;;
18 | esac
19 | done
20 |
21 | # Set default model path if not provided
22 | if [ -z "$MODEL_PATH" ]; then
23 | MODEL_PATH="deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B"
24 | fi
25 |
26 | # Train over a single node, 8 A100-80GB GPUs.
27 | python3 -m verl.trainer.main_ppo \
28 | algorithm.adv_estimator=grpo \
29 | data.train_files=$HOME/workspace/data/train.parquet \
30 | data.val_files=$HOME/workspace/data/aime.parquet \
31 | data.train_batch_size=64 \
32 | data.val_batch_size=256 \
33 | data.max_prompt_length=1024 \
34 | data.max_response_length=16384 \
35 | actor_rollout_ref.model.path=$MODEL_PATH \
36 | actor_rollout_ref.actor.optim.lr=1e-6 \
37 | actor_rollout_ref.model.use_remove_padding=True \
38 | actor_rollout_ref.actor.ppo_mini_batch_size=64 \
39 | actor_rollout_ref.actor.ppo_micro_batch_size=32 \
40 | actor_rollout_ref.actor.use_dynamic_bsz=True \
41 | actor_rollout_ref.actor.ppo_max_token_len_per_gpu=32768 \
42 | actor_rollout_ref.actor.use_kl_loss=True \
43 | actor_rollout_ref.actor.kl_loss_coef=0.001 \
44 | actor_rollout_ref.actor.kl_loss_type=low_var_kl \
45 | actor_rollout_ref.actor.ulysses_sequence_parallel_size=1 \
46 | actor_rollout_ref.model.enable_gradient_checkpointing=True \
47 | actor_rollout_ref.actor.fsdp_config.param_offload=False \
48 | actor_rollout_ref.actor.fsdp_config.grad_offload=False \
49 | actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
50 | actor_rollout_ref.rollout.tensor_model_parallel_size=1 \
51 | actor_rollout_ref.rollout.name=vllm \
52 | actor_rollout_ref.rollout.temperature=0.6 \
53 | actor_rollout_ref.rollout.val_temperature=0.6 \
54 | actor_rollout_ref.rollout.gpu_memory_utilization=0.8 \
55 | actor_rollout_ref.rollout.n=8 \
56 | actor_rollout_ref.rollout.n_val=8 \
57 | actor_rollout_ref.ref.fsdp_config.param_offload=True \
58 | algorithm.kl_ctrl.kl_coef=0.001 \
59 | trainer.critic_warmup=0 \
60 | trainer.logger=['console','wandb'] \
61 | trainer.project_name='deepscaler' \
62 | trainer.experiment_name='deepscaler-7b-16k' \
63 | +trainer.val_before_train=True \
64 | trainer.n_gpus_per_node=8 \
65 | trainer.nnodes=1 \
66 | trainer.save_freq=20 \
67 | trainer.test_freq=20 \
68 | trainer.default_hdfs_dir=null \
69 | trainer.total_epochs=30 "${@:1}"
70 |
71 |
--------------------------------------------------------------------------------
/scripts/inference/inference.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
3 |
4 | model_name = './model'
5 | tokenizer = AutoTokenizer.from_pretrained(model_name)
6 | model = AutoModelForCausalLM.from_pretrained(
7 | model_name,
8 | torch_dtype=torch.bfloat16,
9 | device_map="auto",
10 | trust_remote_code=True,
11 | )
12 |
13 | pipe = pipeline(
14 | "text-generation",
15 | model=model,
16 | tokenizer = tokenizer,
17 | torch_dtype=torch.bfloat16,
18 | device_map="auto"
19 | )
20 |
21 |
22 |
23 | prompt = "Can you explain the concept of regularization in machine learning?"
24 |
25 | sequences = pipe(
26 | prompt,
27 | do_sample=True,
28 | max_new_tokens=100,
29 | temperature=0.7,
30 | top_k=50,
31 | top_p=0.95,
32 | num_return_sequences=1,
33 | )
34 | print(sequences[0]['generated_text'])
35 |
36 |
--------------------------------------------------------------------------------
/scripts/train/attn.py:
--------------------------------------------------------------------------------
1 | import math
2 | from types import MethodType
3 | from typing import Optional, Tuple
4 |
5 | import torch
6 | import torch.nn as nn
7 | import torch.nn.functional as F
8 | from einops import rearrange
9 | from transformers.models.llama.configuration_llama import LlamaConfig
10 | from transformers.models.llama.modeling_llama import (
11 | LlamaAttention,
12 | LlamaForCausalLM,
13 | LlamaModel,
14 | LlamaRMSNorm,
15 | apply_rotary_pos_emb,
16 | repeat_kv,
17 | )
18 |
19 | from colossalai.accelerator import get_accelerator
20 | from colossalai.logging import get_dist_logger
21 |
22 | logger = get_dist_logger()
23 |
24 | if get_accelerator().name == "cuda":
25 | from flash_attn.bert_padding import pad_input, unpad_input
26 | from flash_attn.flash_attn_interface import flash_attn_func, flash_attn_varlen_kvpacked_func
27 | from flash_attn.ops.rms_norm import rms_norm
28 |
29 | def _prepare_decoder_attention_mask(
30 | self: LlamaModel,
31 | attention_mask: torch.BoolTensor,
32 | input_shape: torch.Size,
33 | inputs_embeds: torch.Tensor,
34 | past_key_values_length: int,
35 | ) -> Optional[torch.Tensor]:
36 | """
37 | Decoder attetion mask
38 | """
39 | if past_key_values_length > 0 and attention_mask is not None:
40 | attention_mask = torch.cat(
41 | tensors=(
42 | torch.full(
43 | size=(input_shape[0], past_key_values_length),
44 | fill_value=True,
45 | dtype=attention_mask.dtype,
46 | device=attention_mask.device,
47 | ),
48 | attention_mask,
49 | ),
50 | dim=-1,
51 | ) # (bsz, past_key_values_length + q_len)
52 | if attention_mask is not None and torch.all(attention_mask):
53 | return None # Faster
54 | return attention_mask
55 |
56 | def attention_forward(
57 | self: LlamaAttention,
58 | hidden_states: torch.Tensor,
59 | attention_mask: Optional[torch.Tensor] = None,
60 | position_ids: Optional[torch.LongTensor] = None,
61 | past_key_value: Optional[Tuple[torch.Tensor]] = None,
62 | output_attentions: bool = False,
63 | use_cache: bool = False,
64 | **kwargs,
65 | ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
66 | """
67 | Re-define LLaMA-2 `LlamaAttention` forward method using flash-attention.
68 | """
69 | if output_attentions:
70 | logger.warning(
71 | "Argument `output_attentions` is not supported for flash-attention patched `LlamaAttention`, "
72 | "return `None` instead."
73 | )
74 |
75 | bsz, q_len, _ = hidden_states.size()
76 |
77 | if self.config.pretraining_tp > 1:
78 | q_slicing, kv_slicing = (
79 | dim // self.config.pretraining_tp
80 | for dim in (
81 | self.num_heads * self.head_dim,
82 | self.num_key_value_heads * self.head_dim,
83 | )
84 | ) # `Tuple[int, int]`
85 | q_slices, k_slices, v_slices = (
86 | proj.weight.split(slicing, dim=0)
87 | for proj, slicing in (
88 | (self.q_proj, q_slicing),
89 | (self.k_proj, kv_slicing),
90 | (self.v_proj, kv_slicing),
91 | )
92 | ) # Tuple[Tuple[torch.Tensor], Tuple[torch.Tensor], Tuple[torch.Tensor]]
93 | q, k, v = (
94 | torch.cat(
95 | [F.linear(hidden_states, slices[i]) for i in range(self.config.pretraining_tp)],
96 | dim=-1,
97 | )
98 | for slices in (q_slices, k_slices, v_slices)
99 | )
100 | # `Tuple[torch.Tensor, torch.Tensor, torch.Tensor]` of shape:
101 | # (bsz, q_len, num_heads * head_dim),
102 | # (bsz, q_len, num_key_value_heads * head_dim),
103 | # (bsz, q_len, num_key_value_heads * head_dim)
104 | else:
105 | q, k, v = (proj(hidden_states) for proj in (self.q_proj, self.k_proj, self.v_proj))
106 | # `Tuple[torch.Tensor, torch.Tensor, torch.Tensor]` of shape:
107 | # (bsz, q_len, num_heads * head_dim),
108 | # (bsz, q_len, num_key_value_heads * head_dim),
109 | # (bsz, q_len, num_key_value_heads * head_dim)
110 |
111 | # (bsz, q_len, num_heads * head_dim) -> (bsz, num_heads, q_len, head_dim);
112 | # (bsz, q_len, num_key_value_heads * head_dim) -> (bsz, num_key_value_heads, q_len, head_dim);
113 | # (bsz, q_len, num_key_value_heads * head_dim) -> (bsz, num_key_value_heads, q_len, head_dim)
114 | q, k, v = (
115 | states.view(bsz, q_len, num_heads, self.head_dim).transpose(1, 2)
116 | for states, num_heads in (
117 | (q, self.num_heads),
118 | (k, self.num_key_value_heads),
119 | (v, self.num_key_value_heads),
120 | )
121 | )
122 | kv_len = k.shape[-2] # initially, `kv_len` == `q_len`
123 | past_kv_len = 0
124 | if past_key_value is not None:
125 | # if `past_key_value` is not None, `kv_len` > `q_len`.
126 | past_kv_len = past_key_value[0].shape[-2]
127 | kv_len += past_kv_len
128 |
129 | # two `torch.Tensor` objs of shape (1, 1, kv_len, head_dim)
130 | cos, sin = self.rotary_emb(v, seq_len=kv_len)
131 | # (bsz, num_heads, q_len, head_dim), (bsz, num_key_value_heads, q_len, head_dim)
132 | q, k = apply_rotary_pos_emb(q=q, k=k, cos=cos, sin=sin, position_ids=position_ids)
133 | if past_key_value is not None:
134 | # reuse k, v, self_attention
135 | k = torch.cat([past_key_value[0], k], dim=2)
136 | v = torch.cat([past_key_value[1], v], dim=2)
137 |
138 | past_key_value = (k, v) if use_cache else None
139 |
140 | # repeat k/v heads if n_kv_heads < n_heads
141 | k = repeat_kv(hidden_states=k, n_rep=self.num_key_value_groups)
142 | # (bsz, num_key_value_heads, q_len, head_dim) -> (bsz, num_heads, q_len, head_dim)
143 | v = repeat_kv(hidden_states=v, n_rep=self.num_key_value_groups)
144 | # (bsz, num_key_value_heads, q_len, head_dim) -> (bsz, num_heads, q_len, head_dim)
145 |
146 | key_padding_mask = attention_mask
147 | # (bsz, num_heads, q_len, head_dim) -> (bsz, q_len, num_heads, head_dim)
148 | q, k, v = (states.transpose(1, 2) for states in (q, k, v))
149 |
150 | if past_kv_len > 0:
151 | q = torch.cat(
152 | tensors=(
153 | torch.full(
154 | size=(bsz, past_kv_len, self.num_heads, self.head_dim),
155 | fill_value=0.0,
156 | dtype=q.dtype,
157 | device=q.device,
158 | ),
159 | q,
160 | ),
161 | dim=1,
162 | ) # (bsz, past_kv_len + q_len, num_heads, head_dim)
163 |
164 | if key_padding_mask is None:
165 | # (bsz, past_kv_len + q_len, num_heads, head_dim)
166 | output = flash_attn_func(q=q, k=k, v=v, dropout_p=0.0, softmax_scale=None, causal=True) # (bsz, )
167 | output = rearrange(
168 | output, pattern="... h d -> ... (h d)"
169 | ) # (bsz, past_kv_len + q_len, num_heads * head_dim)
170 | else:
171 | q, indices, cu_q_lens, max_q_len = unpad_input(hidden_states=q, attention_mask=key_padding_mask)
172 | kv, _, cu_kv_lens, max_kv_len = unpad_input(
173 | hidden_states=torch.stack(tensors=(k, v), dim=2),
174 | attention_mask=key_padding_mask,
175 | )
176 | output_unpad = flash_attn_varlen_kvpacked_func(
177 | q=q,
178 | kv=kv,
179 | cu_seqlens_q=cu_q_lens,
180 | cu_seqlens_k=cu_kv_lens,
181 | max_seqlen_q=max_q_len,
182 | max_seqlen_k=max_kv_len,
183 | dropout_p=0.0,
184 | softmax_scale=None,
185 | causal=True,
186 | )
187 | output = pad_input(
188 | hidden_states=rearrange(output_unpad, pattern="nnz h d -> nnz (h d)"),
189 | indices=indices,
190 | batch=bsz,
191 | seqlen=past_kv_len + q_len,
192 | ) # (bsz, past_kv_len + q_len, num_heads * head_dim)
193 |
194 | if past_kv_len > 0:
195 | # Strip off the zero query outputs.
196 | output = output[:, past_kv_len:, ...] # (bsz, q_len, num_heads * head_dim)
197 | output = self.o_proj(output) # (bsz, q_len, hidden_size)
198 | return output, None, past_key_value
199 |
200 | def rms_norm_forward(self: LlamaRMSNorm, hidden_states: torch.Tensor) -> torch.Tensor:
201 | """
202 | Formard function for RMS Norm
203 | """
204 | return rms_norm(x=hidden_states, weight=self.weight, epsilon=self.variance_epsilon)
205 |
206 | def replace_with_flash_attention(model: LlamaForCausalLM) -> None:
207 | for name, module in model.named_modules():
208 | if isinstance(module, LlamaAttention):
209 | module.forward = MethodType(attention_forward, module)
210 | if isinstance(module, LlamaModel):
211 | module._prepare_decoder_attention_mask = MethodType(_prepare_decoder_attention_mask, module)
212 | if isinstance(module, LlamaRMSNorm):
213 | module.forward = MethodType(rms_norm_forward, module)
214 |
215 | elif get_accelerator().name == "npu":
216 | import torch_npu
217 |
218 | class NPULlamaAttention(LlamaAttention):
219 | use_flash: bool = True
220 |
221 | def __init__(self, config: LlamaConfig):
222 | super().__init__(config)
223 | self.setup()
224 |
225 | def setup(self):
226 | self._softmax_scale = 1 / math.sqrt(self.head_dim)
227 |
228 | def forward(
229 | self,
230 | hidden_states: torch.Tensor,
231 | attention_mask: Optional[torch.Tensor] = None,
232 | position_ids: Optional[torch.LongTensor] = None,
233 | past_key_value: Optional[Tuple[torch.Tensor]] = None,
234 | output_attentions: bool = False,
235 | use_cache: bool = False,
236 | ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
237 | bsz, q_len, _ = hidden_states.size()
238 |
239 | if self.config.pretraining_tp > 1:
240 | key_value_slicing = (self.num_key_value_heads * self.head_dim) // self.config.pretraining_tp
241 | query_slices = self.q_proj.weight.split(
242 | (self.num_heads * self.head_dim) // self.config.pretraining_tp, dim=0
243 | )
244 | key_slices = self.k_proj.weight.split(key_value_slicing, dim=0)
245 | value_slices = self.v_proj.weight.split(key_value_slicing, dim=0)
246 |
247 | query_states = [F.linear(hidden_states, query_slices[i]) for i in range(self.config.pretraining_tp)]
248 | query_states = torch.cat(query_states, dim=-1)
249 |
250 | key_states = [F.linear(hidden_states, key_slices[i]) for i in range(self.config.pretraining_tp)]
251 | key_states = torch.cat(key_states, dim=-1)
252 |
253 | value_states = [F.linear(hidden_states, value_slices[i]) for i in range(self.config.pretraining_tp)]
254 | value_states = torch.cat(value_states, dim=-1)
255 |
256 | else:
257 | query_states = self.q_proj(hidden_states)
258 | key_states = self.k_proj(hidden_states)
259 | value_states = self.v_proj(hidden_states)
260 |
261 | query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
262 | key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
263 | value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
264 |
265 | kv_seq_len = key_states.shape[-2]
266 | if past_key_value is not None:
267 | kv_seq_len += past_key_value[0].shape[-2]
268 | cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
269 | query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
270 |
271 | if past_key_value is not None:
272 | # reuse k, v, self_attention
273 | key_states = torch.cat([past_key_value[0], key_states], dim=2)
274 | value_states = torch.cat([past_key_value[1], value_states], dim=2)
275 |
276 | past_key_value = (key_states, value_states) if use_cache else None
277 |
278 | key_states = repeat_kv(key_states, self.num_key_value_groups)
279 | value_states = repeat_kv(value_states, self.num_key_value_groups)
280 |
281 | if not self.use_flash:
282 | attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
283 |
284 | if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
285 | raise ValueError(
286 | f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
287 | f" {attn_weights.size()}"
288 | )
289 |
290 | if attention_mask is not None:
291 | if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
292 | raise ValueError(
293 | f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
294 | )
295 | attn_weights = attn_weights + attention_mask
296 |
297 | # upcast attention to fp32
298 | attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
299 | attn_output = torch.matmul(attn_weights, value_states)
300 | else:
301 | attn_output, *_ = torch_npu.npu_fusion_attention(
302 | query_states,
303 | key_states,
304 | value_states,
305 | self.num_heads,
306 | "BNSD",
307 | atten_mask=attention_mask.bool(),
308 | scale=self._softmax_scale,
309 | padding_mask=None,
310 | pre_tockens=65535,
311 | next_tockens=0,
312 | keep_prob=1.0,
313 | inner_precise=0,
314 | )
315 |
316 | if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
317 | raise ValueError(
318 | f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
319 | f" {attn_output.size()}"
320 | )
321 |
322 | attn_output = attn_output.transpose(1, 2).contiguous()
323 | attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
324 |
325 | if self.config.pretraining_tp > 1:
326 | attn_output = attn_output.split(self.hidden_size // self.config.pretraining_tp, dim=2)
327 | o_proj_slices = self.o_proj.weight.split(self.hidden_size // self.config.pretraining_tp, dim=1)
328 | attn_output = sum(
329 | [F.linear(attn_output[i], o_proj_slices[i]) for i in range(self.config.pretraining_tp)]
330 | )
331 | else:
332 | attn_output = self.o_proj(attn_output)
333 |
334 | if not output_attentions:
335 | attn_weights = None
336 |
337 | return attn_output, attn_weights, past_key_value
338 |
339 | class NPURMSNorm(LlamaRMSNorm):
340 | def forward(self, hidden_states):
341 | return torch_npu.npu_rms_norm(hidden_states, self.weight, epsilon=self.variance_epsilon)[0]
342 |
343 | def replace_with_flash_attention(model: LlamaForCausalLM) -> None:
344 | for name, module in model.named_modules():
345 | if isinstance(module, LlamaAttention):
346 | module.__class__ = NPULlamaAttention
347 | module.setup()
348 | if isinstance(module, LlamaRMSNorm):
349 | module.__class__ = NPURMSNorm
350 |
--------------------------------------------------------------------------------
/scripts/train/pretrain.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | import resource
4 | from contextlib import nullcontext
5 | from functools import partial
6 | from typing import Optional, Tuple
7 |
8 | import torch
9 | import torch.distributed as dist
10 | import torch.nn as nn
11 | from attn import replace_with_flash_attention
12 |
13 |
14 | import sys
15 | sys.path.append("..")
16 |
17 | # datasets 2.18.0
18 | # fsspec 2024.2.0
19 |
20 | from data_utils import load_json, prepare_dataloader, save_json
21 | from datasets import load_dataset, load_from_disk
22 | from torch.optim import Optimizer
23 | from torch.optim.lr_scheduler import _LRScheduler
24 | from torch.utils.tensorboard import SummaryWriter
25 | from tqdm import tqdm
26 | from transformers.models.llama.configuration_llama import LlamaConfig
27 | from transformers.models.llama.modeling_llama import LlamaForCausalLM
28 | from transformers.models.llama.tokenization_llama import LlamaTokenizer
29 |
30 | import colossalai
31 | from colossalai.accelerator import get_accelerator
32 | from colossalai.booster import Booster
33 | from colossalai.booster.plugin import GeminiPlugin, HybridParallelPlugin, LowLevelZeroPlugin
34 | from colossalai.cluster import DistCoordinator
35 | from colossalai.lazy import LazyInitContext
36 | from colossalai.nn.lr_scheduler import CosineAnnealingWarmupLR
37 | from colossalai.nn.optimizer import HybridAdam
38 |
39 | MODEL_CONFIGS = {
40 | "7b": LlamaConfig(max_position_embeddings=4096),
41 | "13b": LlamaConfig(
42 | hidden_size=5120,
43 | intermediate_size=13824,
44 | num_hidden_layers=40,
45 | num_attention_heads=40,
46 | max_position_embeddings=4096,
47 | ),
48 | "70b": LlamaConfig(
49 | hidden_size=8192,
50 | intermediate_size=28672,
51 | num_hidden_layers=80,
52 | num_attention_heads=64,
53 | max_position_embeddings=4096,
54 | num_key_value_heads=8,
55 | ),
56 | }
57 |
58 |
59 | def get_model_numel(model: nn.Module) -> int:
60 | return sum(p.numel() for p in model.parameters())
61 |
62 |
63 | def format_numel_str(numel: int) -> str:
64 | B = 1024**3
65 | M = 1024**2
66 | K = 1024
67 | if numel >= B:
68 | return f"{numel / B:.2f} B"
69 | elif numel >= M:
70 | return f"{numel / M:.2f} M"
71 | elif numel >= K:
72 | return f"{numel / K:.2f} K"
73 | else:
74 | return f"{numel}"
75 |
76 |
77 | def tokenize_batch_for_pretrain(batch, tokenizer: Optional[LlamaTokenizer] = None, max_length: int = 2048):
78 | texts = [sample["text"] for sample in batch]
79 | data = tokenizer(texts, return_tensors="pt", padding="max_length", truncation=True, max_length=max_length)
80 | data = {k: v.cuda() for k, v in data.items()}
81 | data["labels"] = data["input_ids"].clone()
82 | return data
83 |
84 |
85 | def all_reduce_mean(tensor: torch.Tensor) -> torch.Tensor:
86 | dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
87 | tensor = tensor.data
88 | tensor.div_(dist.get_world_size())
89 | return tensor
90 |
91 |
92 | def save(
93 | booster: Booster,
94 | model: nn.Module,
95 | optimizer: Optimizer,
96 | lr_scheduler: _LRScheduler,
97 | epoch: int,
98 | step: int,
99 | batch_size: int,
100 | coordinator: DistCoordinator,
101 | save_dir: str,
102 | ):
103 | save_dir = os.path.join(save_dir, f"epoch{epoch}-step{step}")
104 | os.makedirs(os.path.join(save_dir, "model"), exist_ok=True)
105 |
106 | booster.save_model(model, os.path.join(save_dir, "model"), shard=True)
107 | booster.save_optimizer(optimizer, os.path.join(save_dir, "optimizer"), shard=True)
108 | booster.save_lr_scheduler(lr_scheduler, os.path.join(save_dir, "lr_scheduler"))
109 | running_states = {
110 | "epoch": epoch,
111 | "step": step,
112 | "sample_start_index": step * batch_size,
113 | }
114 | if coordinator.is_master():
115 | save_json(running_states, os.path.join(save_dir, "running_states.json"))
116 |
117 |
118 | def load(
119 | booster: Booster, model: nn.Module, optimizer: Optimizer, lr_scheduler: _LRScheduler, load_dir: str
120 | ) -> Tuple[int, int, int]:
121 | booster.load_model(model, os.path.join(load_dir, "model"))
122 |
123 | running_states = load_json(os.path.join(load_dir, "running_states.json"))
124 | return running_states["epoch"], running_states["step"], running_states["sample_start_index"]
125 |
126 |
127 | def _criterion(outputs, inputs):
128 | return outputs.loss
129 |
130 |
131 | def main():
132 | # ==============================
133 | # Parse Arguments
134 | # ==============================
135 | parser = argparse.ArgumentParser()
136 | parser.add_argument("-c", "--config", type=str, default="7b", help="Model configuration")
137 | parser.add_argument(
138 | "-p",
139 | "--plugin",
140 | choices=["gemini", "gemini_auto", "zero2", "zero2_cpu", "hybrid_parallel"],
141 | default="gemini",
142 | help="Choose which plugin to use",
143 | )
144 | parser.add_argument(
145 | "-d", "--dataset", type=str, default="togethercomputer/RedPajama-Data-1T-Sample", help="Data set path"
146 | )
147 | parser.add_argument("--cache_path", type=str, default="workspace/.cache/huggingface/datasets", help="cache path")
148 | parser.add_argument("-e", "--num_epochs", type=int, default=1, help="Number of epochs")
149 | parser.add_argument("-b", "--batch_size", type=int, default=2, help="Local batch size")
150 | parser.add_argument("--lr", type=float, default=3e-4, help="Learning rate")
151 | parser.add_argument("-w", "--weigth_decay", type=float, default=0.1, help="Weight decay")
152 | parser.add_argument("-s", "--warmup_steps", type=int, default=2000, help="Warmup steps")
153 | parser.add_argument("-g", "--grad_checkpoint", action="store_true", help="Use gradient checkpointing")
154 | parser.add_argument("-l", "--max_length", type=int, default=4096, help="Max sequence length")
155 | parser.add_argument("-x", "--mixed_precision", default="fp16", choices=["fp16", "bf16"], help="Mixed precision")
156 | parser.add_argument("-i", "--save_interval", type=int, default=1000, help="Save interval")
157 | parser.add_argument("-o", "--save_dir", type=str, default="checkpoint", help="Checkpoint directory")
158 | parser.add_argument("-f", "--load", type=str, default=None, help="Load checkpoint")
159 | parser.add_argument("--grad_clip", type=float, default=1.0, help="Gradient clipping")
160 | parser.add_argument("-t", "--tensorboard_dir", type=str, default="tb_logs", help="Tensorboard directory")
161 | parser.add_argument("-a", "--flash_attention", action="store_true", help="Use Flash Attention")
162 |
163 | parser.add_argument("--accumulation_steps", default=8, help="accumulation steps")
164 | parser.add_argument("--expanded_model", default="", help="model path")
165 |
166 |
167 | args = parser.parse_args()
168 |
169 | # ==============================
170 | # Initialize Distributed Training
171 | # ==============================
172 | colossalai.launch_from_torch({})
173 | coordinator = DistCoordinator()
174 |
175 | # ==============================
176 | # Initialize Booster
177 | # ==============================
178 | if args.plugin == "gemini":
179 | plugin = GeminiPlugin(precision=args.mixed_precision, initial_scale=2**16, max_norm=args.grad_clip)
180 | elif args.plugin == "gemini_auto":
181 | plugin = GeminiPlugin(
182 | precision=args.mixed_precision, placement_policy="auto", initial_scale=2**16, max_norm=args.grad_clip
183 | )
184 | elif args.plugin == "zero2":
185 | plugin = LowLevelZeroPlugin(
186 | stage=2, precision=args.mixed_precision, initial_scale=2**16, max_norm=args.grad_clip
187 | )
188 | elif args.plugin == "zero2_cpu":
189 | plugin = LowLevelZeroPlugin(
190 | stage=2, precision=args.mixed_precision, initial_scale=2**16, cpu_offload=True, max_norm=args.grad_clip
191 | )
192 | elif args.plugin == "hybrid_parallel":
193 | plugin = HybridParallelPlugin(
194 | tp_size=4,
195 | pp_size=2,
196 | num_microbatches=None,
197 | microbatch_size=1,
198 | enable_jit_fused=False,
199 | zero_stage=0,
200 | precision=args.mixed_precision,
201 | initial_scale=1,
202 | )
203 | else:
204 | raise ValueError(f"Unknown plugin {args.plugin}")
205 |
206 | booster = Booster(plugin=plugin)
207 |
208 | use_pipeline = isinstance(booster.plugin, HybridParallelPlugin) and booster.plugin.pp_size > 1
209 | is_pp_last_stage = use_pipeline and booster.plugin.stage_manager.is_last_stage()
210 | print_flag = (not use_pipeline and coordinator.is_master()) or (use_pipeline and is_pp_last_stage)
211 |
212 | # ==============================
213 | # Initialize Tensorboard
214 | # ==============================
215 | if print_flag:
216 | os.makedirs(args.tensorboard_dir, exist_ok=True)
217 | writer = SummaryWriter(args.tensorboard_dir)
218 |
219 | # ==============================
220 | # Initialize Tokenizer, Dataset and Dataloader
221 | # ==============================
222 |
223 | from transformers import AutoTokenizer
224 | tokenizer = AutoTokenizer.from_pretrained(args.expanded_model, use_fast=False)
225 | tokenizer.pad_token = tokenizer.unk_token
226 | tokenizer.padding_side = 'left'
227 | # ================================================================
228 |
229 | dataset = load_dataset(args.dataset, cache_dir=args.cache_path)
230 |
231 | train_ds = dataset["train"]
232 | dataloader = prepare_dataloader(
233 | train_ds,
234 | batch_size=args.batch_size,
235 | shuffle=True,
236 | drop_last=True,
237 | collate_fn=partial(tokenize_batch_for_pretrain, tokenizer=tokenizer, max_length=args.max_length),
238 | )
239 |
240 | # ==============================
241 | # Initialize Model, Optimizer and LR Scheduler
242 | # ==============================
243 | config = MODEL_CONFIGS[args.config]
244 | init_ctx = (
245 | LazyInitContext(default_device=get_accelerator().get_current_device())
246 | if isinstance(plugin, GeminiPlugin)
247 | else nullcontext()
248 | )
249 |
250 | with init_ctx:
251 |
252 | model = LlamaForCausalLM.from_pretrained(args.expanded_model, torch_dtype=torch.float16)
253 |
254 | if args.grad_checkpoint:
255 | model.gradient_checkpointing_enable()
256 | if args.flash_attention:
257 | replace_with_flash_attention(model)
258 |
259 | model_numel = get_model_numel(model)
260 | coordinator.print_on_master(f"Model params: {format_numel_str(model_numel)}")
261 |
262 | optimizer = HybridAdam(model.parameters(), lr=args.lr, betas=(0.9, 0.95), weight_decay=args.weigth_decay)
263 |
264 | lr_scheduler = CosineAnnealingWarmupLR(
265 | optimizer, total_steps=args.num_epochs * len(dataloader), warmup_steps=args.warmup_steps, eta_min=0.1 * args.lr
266 | )
267 | default_dtype = torch.float16 if args.mixed_precision == "fp16" else torch.bfloat16
268 | torch.set_default_dtype(default_dtype)
269 | model, optimizer, _, dataloader, lr_scheduler = booster.boost(
270 | model, optimizer, dataloader=dataloader, lr_scheduler=lr_scheduler
271 | )
272 | torch.set_default_dtype(torch.float)
273 |
274 | coordinator.print_on_master(f"Booster init max CUDA memory: {torch.cuda.max_memory_allocated()/1024**2:.2f} MB")
275 | coordinator.print_on_master(
276 | f"Booster init max CPU memory: {resource.getrusage(resource.RUSAGE_SELF).ru_maxrss/1024:.2f} MB"
277 | )
278 |
279 | # load checkpoint if specified
280 | start_epoch = 0
281 | start_step = 0
282 | sampler_start_idx = 0
283 | if args.load is not None:
284 | coordinator.print_on_master("Loading checkpoint")
285 | start_epoch, start_step, sampler_start_idx = load(booster, model, optimizer, lr_scheduler, args.load)
286 | coordinator.print_on_master(f"Loaded checkpoint {args.load} at epoch {start_epoch} step {start_step}")
287 |
288 | num_steps_per_epoch = len(dataloader)
289 |
290 | dataloader.sampler.set_start_index(sampler_start_idx)
291 | for epoch in range(start_epoch, args.num_epochs):
292 | dataloader.sampler.set_epoch(epoch)
293 | dataloader_iter = iter(dataloader)
294 |
295 | for step in range(start_step, num_steps_per_epoch):
296 | if use_pipeline:
297 | outputs = booster.execute_pipeline(dataloader_iter, model, _criterion, optimizer, return_loss=True)
298 | loss = outputs["loss"]
299 | else:
300 | batch = next(dataloader_iter)
301 | outputs = model(**batch)
302 | loss = outputs[0]
303 | booster.backward(loss, optimizer)
304 |
305 | if (step + 1) % args.accumulation_steps == 0:
306 | optimizer.step() # Update parameters
307 | lr_scheduler.step()
308 | optimizer.zero_grad() # Reset gradients
309 |
310 | if step + 1 == num_steps_per_epoch - 1:
311 | optimizer.step()
312 | lr_scheduler.step()
313 | optimizer.zero_grad()
314 |
315 | if not use_pipeline:
316 | all_reduce_mean(loss)
317 |
318 | if print_flag:
319 | writer.add_scalar("loss", loss.item(), epoch * num_steps_per_epoch + step)
320 | print("Epoch: {}, step: {}, loss: {:.3f}".format(
321 | epoch,
322 | epoch * num_steps_per_epoch + step,
323 | loss.item()
324 | ))
325 |
326 | if args.save_interval > 0 and (step + 1) % args.save_interval == 0:
327 | coordinator.print_on_master(f"Saving checkpoint")
328 | save(
329 | booster,
330 | model,
331 | optimizer,
332 | lr_scheduler,
333 | epoch,
334 | step + 1,
335 | args.batch_size,
336 | coordinator,
337 | args.save_dir,
338 | )
339 | coordinator.print_on_master(f"Saved checkpoint at epoch {epoch} step {step + 1}")
340 | dataloader.sampler.set_start_index(0)
341 | start_step = 0
342 |
343 | coordinator.print_on_master(f"Max CUDA memory usage: {torch.cuda.max_memory_allocated()/1024**2:.2f} MB")
344 |
345 |
346 | if __name__ == "__main__":
347 | main()
348 |
--------------------------------------------------------------------------------
/scripts/train/requirements.txt:
--------------------------------------------------------------------------------
1 | absl-py==2.1.0
2 | aiohttp==3.9.3
3 | aiosignal==1.3.1
4 | annotated-types==0.6.0
5 | async-timeout==4.0.3
6 | attrs==23.2.0
7 | bcrypt==4.1.2
8 | beautifulsoup4==4.12.3
9 | cachetools==5.3.3
10 | certifi==2024.2.2
11 | cffi==1.16.0
12 | cfgv==3.4.0
13 | charset-normalizer==3.3.2
14 | click==8.1.7
15 | cmake==3.29.0.1
16 | colossalai==0.3.6
17 | contexttimer==0.3.3
18 | cryptography==42.0.5
19 | datasets==2.18.0
20 | decorator==5.1.1
21 | Deprecated==1.2.14
22 | dill==0.3.8
23 | distlib==0.3.8
24 | einops==0.7.0
25 | fabric==3.2.2
26 | filelock==3.13.3
27 | flash-attn==2.2.1
28 | frozenlist==1.4.1
29 | fsspec==2024.2.0
30 | google==3.0.0
31 | google-auth==2.29.0
32 | google-auth-oauthlib==1.0.0
33 | grpcio==1.62.1
34 | huggingface-hub==0.22.2
35 | identify==2.5.35
36 | idna==3.6
37 | invoke==2.2.0
38 | Jinja2==3.1.3
39 | jsonschema==4.21.1
40 | jsonschema-specifications==2023.12.1
41 | lit==18.1.2
42 | Markdown==3.6
43 | markdown-it-py==3.0.0
44 | MarkupSafe==2.1.5
45 | mdurl==0.1.2
46 | mpmath==1.3.0
47 | msgpack==1.0.8
48 | multidict==6.0.5
49 | multiprocess==0.70.16
50 | networkx== 3.3
51 | ninja==1.11.1.1
52 | nodeenv==1.8.0
53 | numpy==1.26.4
54 | nvidia-cublas-cu11==11.10.3.66
55 | nvidia-cublas-cu12==12.1.3.1
56 | nvidia-cuda-cupti-cu11==11.7.101
57 | nvidia-cuda-cupti-cu12==12.1.105
58 | nvidia-cuda-nvrtc-cu11==11.7.99
59 | nvidia-cuda-nvrtc-cu12==12.1.105
60 | nvidia-cuda-runtime-cu11==11.7.99
61 | nvidia-cuda-runtime-cu12==12.1.105
62 | nvidia-cudnn-cu11==8.5.0.96
63 | nvidia-cudnn-cu12==8.9.2.26
64 | nvidia-cufft-cu11==10.9.0.58
65 | nvidia-cufft-cu12==11.0.2.54
66 | nvidia-curand-cu11==10.2.10.91
67 | nvidia-curand-cu12==10.3.2.106
68 | nvidia-cusolver-cu11==11.4.0.1
69 | nvidia-cusolver-cu12==11.4.5.107
70 | nvidia-cusparse-cu11==11.7.4.91
71 | nvidia-cusparse-cu12==12.1.0.106
72 | nvidia-nccl-cu11==2.14.3
73 | nvidia-nccl-cu12==2.19.3
74 | nvidia-nvjitlink-cu12==12.4.127
75 | nvidia-nvtx-cu11==11.7.91
76 | nvidia-nvtx-cu12==12.1.105
77 | oauthlib==3.2.2
78 | packaging==24.0
79 | pandas==2.2.1
80 | paramiko==3.4.0
81 | pip==23.3.1
82 | platformdirs==4.2.0
83 | pre-commit==3.7.0
84 | protobuf==5.26.1
85 | psutil==5.9.8
86 | pyarrow==15.0.2
87 | pyarrow-hotfix==0.6
88 | pyasn1==0.6.0
89 | pyasn1_modules==0.4.0
90 | pycparser==2.22
91 | pydantic==2.6.4
92 | pydantic_core==2.16.3
93 | Pygments==2.17.2
94 | PyNaCl==1.5.0
95 | python-dateutil==2.9.0.post0
96 | pytz==2024.1
97 | PyYAML==6.0.1
98 | ray==2.10.0
99 | referencing==0.34.0
100 | regex==2023.12.25
101 | requests==2.31.0
102 | requests-oauthlib==2.0.0
103 | rich==13.7.1
104 | rpds-py==0.18.0
105 | rsa==4.9
106 | safetensors==0.4.2
107 | sentencepiece==0.1.99
108 | setuptools==68.2.2
109 | six==1.16.0
110 | soupsieve==2.5
111 | sympy==1.12
112 | tensorboard==2.14.0
113 | tensorboard-data-server==0.7.2
114 | tokenizers==0.13.3
115 | torch==2.0.0
116 | tqdm==4.66.2
117 | transformers==4.33.3
118 | triton==2.0.0
119 | typing_extensions==4.11.0
120 | tzdata==2024.1
121 | urllib3==2.2.1
122 | virtualenv==20.25.1
123 | Werkzeug==3.0.2
124 | wheel==0.41.2
125 | wrapt==1.16.0
126 | xxhash==3.4.1
127 | yarl==1.9.4
128 |
--------------------------------------------------------------------------------