├── Claude_3_5_Sonnet_to_gpt_4o_mini_Conversion.ipynb
├── Instruct_Prompt_>_Base_Model_Prompt_Converter.ipynb
├── LICENSE
├── Llama_3_1_405B_>_8B_Conversion.ipynb
├── README.md
├── XL_to_XS_conversion.ipynb
├── claude_prompt_engineer.ipynb
├── gpt_planner.ipynb
├── gpt_prompt_engineer.ipynb
├── gpt_prompt_engineer_Classification_Version.ipynb
└── opus_to_haiku_conversion.ipynb
/Claude_3_5_Sonnet_to_gpt_4o_mini_Conversion.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "id": "view-in-github",
7 | "colab_type": "text"
8 | },
9 | "source": [
10 | " "
11 | ]
12 | },
13 | {
14 | "cell_type": "markdown",
15 | "metadata": {
16 | "id": "WljjH8K3s7kG"
17 | },
18 | "source": [
19 | "# Claude 3.5 Sonnet to gpt-4o-mini - part of the `gpt-prompt-engineer` repo\n",
20 | "\n",
21 | "This notebook gives you the ability to go from Claude 3.5 Sonnet to GPT-4o-mini -- reducing costs massively while keeping quality high.\n",
22 | "\n",
23 | "By Matt Shumer (https://twitter.com/mattshumer_)\n",
24 | "\n",
25 | "Github repo: https://github.com/mshumer/gpt-prompt-engineer"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": null,
31 | "metadata": {
32 | "id": "dQmMZdkG_RA5"
33 | },
34 | "outputs": [],
35 | "source": [
36 | "!pip install openai\n",
37 | "\n",
38 | "OPENAI_API_KEY = \"YOUR API KEY HERE\" # enter your OpenAI API key here\n",
39 | "ANTHROPIC_API_KEY = \"YOUR API KEY HERE\" # enter your Anthropic API key here"
40 | ]
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": null,
45 | "metadata": {
46 | "id": "wXeqMQpzzosx"
47 | },
48 | "outputs": [],
49 | "source": [
50 | "import re\n",
51 | "import json\n",
52 | "import requests\n",
53 | "from openai import OpenAI\n",
54 | "\n",
55 | "client = OpenAI(api_key=OPENAI_API_KEY)\n",
56 | "\n",
57 | "def generate_candidate_prompts(task, prompt_example, response_example):\n",
58 | " headers = {\n",
59 | " \"x-api-key\": ANTHROPIC_API_KEY,\n",
60 | " \"anthropic-version\": \"2023-06-01\",\n",
61 | " \"content-type\": \"application/json\"\n",
62 | " }\n",
63 | "\n",
64 | " data = {\n",
65 | " \"model\": 'claude-3-5-sonnet-20240620',\n",
66 | " \"max_tokens\": 4000,\n",
67 | " \"temperature\": .5,\n",
68 | " \"system\": \"\"\"Given an example training sample, create seven additional samples for the same task that are even better. Each example should contain a and a .\n",
69 | "\n",
70 | "\n",
71 | "1. Ensure the new examples are diverse and unique from one another.\n",
72 | "2. They should all be perfect. If you make a mistake, this system won't work.\n",
73 | "\n",
74 | "\n",
75 | "Respond in this format:\n",
76 | "\n",
77 | "\n",
78 | "\n",
79 | "PUT_PROMPT_HERE\n",
80 | "\n",
81 | "\n",
82 | "PUT_RESPONSE_HERE\n",
83 | "\n",
84 | "\n",
85 | "\n",
86 | "\n",
87 | "\n",
88 | "PUT_PROMPT_HERE\n",
89 | "\n",
90 | "\n",
91 | "PUT_RESPONSE_HERE\n",
92 | "\n",
93 | "\n",
94 | "\n",
95 | "...\n",
96 | "\"\"\",\n",
97 | " \"messages\": [\n",
98 | " {\"role\": \"user\", \"content\": f\"\"\"{task}\n",
99 | "\n",
100 | "\n",
101 | "{prompt_example}\n",
102 | "\n",
103 | "\n",
104 | "\n",
105 | "{response_example}\n",
106 | "\"\"\"},\n",
107 | " ]\n",
108 | " }\n",
109 | "\n",
110 | "\n",
111 | " response = requests.post(\"https://api.anthropic.com/v1/messages\", headers=headers, json=data)\n",
112 | "\n",
113 | " response_text = response.json()['content'][0]['text']\n",
114 | "\n",
115 | " # Parse out the prompts and responses\n",
116 | " prompts_and_responses = []\n",
117 | " examples = re.findall(r'(.*?)', response_text, re.DOTALL)\n",
118 | " for example in examples:\n",
119 | " prompt = re.findall(r'(.*?)', example, re.DOTALL)[0].strip()\n",
120 | " response = re.findall(r'(.*?)', example, re.DOTALL)[0].strip()\n",
121 | " prompts_and_responses.append({'prompt': prompt, 'response': response})\n",
122 | "\n",
123 | " return prompts_and_responses\n",
124 | "\n",
125 | "def generate_system_prompt(task, prompt_examples):\n",
126 | " headers = {\n",
127 | " \"x-api-key\": ANTHROPIC_API_KEY,\n",
128 | " \"anthropic-version\": \"2023-06-01\",\n",
129 | " \"content-type\": \"application/json\"\n",
130 | " }\n",
131 | "\n",
132 | " data = {\n",
133 | " \"model\": 'claude-3-5-sonnet-20240620',\n",
134 | " \"max_tokens\": 1000,\n",
135 | " \"temperature\": .5,\n",
136 | " \"system\": \"\"\"Given a user-description of their a set of prompt / response pairs (it'll be in JSON for easy reading) for the types of outputs we want to generate given inputs, write a fantastic system prompt that describes the task to be done perfectly.\n",
137 | "\n",
138 | "\n",
139 | "1. Do this perfectly.\n",
140 | "2. Respond only with the system prompt, and nothing else. No other text will be allowed.\n",
141 | "\n",
142 | "\n",
143 | "Respond in this format:\n",
144 | "\n",
145 | "WRITE_SYSTEM_PROMPT_HERE\n",
146 | "\"\"\",\n",
147 | " \"messages\": [\n",
148 | " {\"role\": \"user\", \"content\": f\"\"\"{task}\n",
149 | "\n",
150 | "\n",
151 | "{str(prompt_examples)}\n",
152 | "\"\"\"},\n",
153 | " ]\n",
154 | " }\n",
155 | "\n",
156 | "\n",
157 | " response = requests.post(\"https://api.anthropic.com/v1/messages\", headers=headers, json=data)\n",
158 | "\n",
159 | " response_text = response.json()['content'][0]['text']\n",
160 | "\n",
161 | " # Parse out the prompt\n",
162 | " system_prompt = response_text.split('')[1].split('')[0].strip()\n",
163 | "\n",
164 | " return system_prompt\n",
165 | "\n",
166 | "def test_mini(generated_examples, prompt_example, system_prompt):\n",
167 | " messages = [{\"role\": \"system\", \"content\": system_prompt}]\n",
168 | "\n",
169 | " for example in generated_examples:\n",
170 | " messages.append({\"role\": \"user\", \"content\": example['prompt']})\n",
171 | " messages.append({\"role\": \"assistant\", \"content\": example['response']})\n",
172 | "\n",
173 | " messages.append({\"role\": \"user\", \"content\": prompt_example.strip()})\n",
174 | "\n",
175 | " response = client.chat.completions.create(\n",
176 | " model=\"gpt-4o-mini\",\n",
177 | " messages=messages,\n",
178 | " max_tokens=2000,\n",
179 | " temperature=0.5\n",
180 | " )\n",
181 | "\n",
182 | " response_text = response.choices[0].message.content\n",
183 | "\n",
184 | " return response_text\n",
185 | "\n",
186 | "def run_mini_conversion_process(task, prompt_example, response_example):\n",
187 | " print('Generating the prompts / responses...')\n",
188 | " # Generate candidate prompts\n",
189 | " generated_examples = generate_candidate_prompts(task, prompt_example, response_example)\n",
190 | "\n",
191 | " print('Prompts / responses generated. Now generating system prompt...')\n",
192 | "\n",
193 | " # Generate the system prompt\n",
194 | " system_prompt = generate_system_prompt(task, generated_examples)\n",
195 | "\n",
196 | " print('System prompt generated:', system_prompt)\n",
197 | "\n",
198 | " print('\\n\\nTesting the new prompt on GPT-4o-mini, using your input example...')\n",
199 | " # Test the generated examples and system prompt with the GPT-4o-mini model\n",
200 | " mini_response = test_mini(generated_examples, prompt_example, system_prompt)\n",
201 | "\n",
202 | " print('GPT-4o-mini responded with:')\n",
203 | " print(mini_response)\n",
204 | "\n",
205 | " print('\\n\\n!! CHECK THE FILE DIRECTORY, THE PROMPT IS NOW SAVED THERE !!')\n",
206 | "\n",
207 | " # Create a dictionary with all the relevant information\n",
208 | " result = {\n",
209 | " \"task\": task,\n",
210 | " \"initial_prompt_example\": prompt_example,\n",
211 | " \"initial_response_example\": response_example,\n",
212 | " \"generated_examples\": generated_examples,\n",
213 | " \"system_prompt\": system_prompt,\n",
214 | " \"mini_response\": mini_response\n",
215 | " }\n",
216 | "\n",
217 | " # Save the GPT-4o-mini prompt to a Python file\n",
218 | " with open(\"gpt4o_mini_prompt.py\", \"w\") as file:\n",
219 | " file.write('system_prompt = \"\"\"' + system_prompt + '\"\"\"\\n\\n')\n",
220 | "\n",
221 | " file.write('messages = [\\n')\n",
222 | " for example in generated_examples:\n",
223 | " file.write(' {\"role\": \"user\", \"content\": \"\"\"' + example['prompt'] + '\"\"\"},\\n')\n",
224 | " file.write(' {\"role\": \"assistant\", \"content\": \"\"\"' + example['response'] + '\"\"\"},\\n')\n",
225 | "\n",
226 | " file.write(' {\"role\": \"user\", \"content\": \"\"\"' + prompt_example.strip() + '\"\"\"}\\n')\n",
227 | " file.write(']\\n')\n",
228 | "\n",
229 | " return result"
230 | ]
231 | },
232 | {
233 | "cell_type": "markdown",
234 | "source": [
235 | "## Fill in your task, prompt_example, and response_example here. Make sure you keep the quality really high here... this is the most important step!"
236 | ],
237 | "metadata": {
238 | "id": "ZujTAzhuBMea"
239 | }
240 | },
241 | {
242 | "cell_type": "code",
243 | "source": [
244 | "task = \"refactoring complex code\"\n",
245 | "\n",
246 | "prompt_example = \"\"\"def calculate_total(prices, tax, discount, shipping_fee, gift_wrap_fee, membership_discount):\n",
247 | "\n",
248 | " total = 0\n",
249 | "\n",
250 | " for i in range(len(prices)):\n",
251 | "\n",
252 | " total += prices[i]\n",
253 | "\n",
254 | " if membership_discount != 0:\n",
255 | "\n",
256 | " total = total - (total * (membership_discount / 100))\n",
257 | "\n",
258 | " if discount != 0:\n",
259 | "\n",
260 | " total = total - (total * (discount / 100))\n",
261 | "\n",
262 | " total = total + (total * (tax / 100))\n",
263 | "\n",
264 | " if total < 50:\n",
265 | "\n",
266 | " total += shipping_fee\n",
267 | "\n",
268 | " else:\n",
269 | "\n",
270 | " total += shipping_fee / 2\n",
271 | "\n",
272 | " if gift_wrap_fee != 0:\n",
273 | "\n",
274 | " total += gift_wrap_fee * len(prices)\n",
275 | "\n",
276 | " if total > 1000:\n",
277 | "\n",
278 | " total -= 50\n",
279 | "\n",
280 | " elif total > 500:\n",
281 | "\n",
282 | " total -= 25\n",
283 | "\n",
284 | " total = round(total, 2)\n",
285 | "\n",
286 | " if total < 0:\n",
287 | "\n",
288 | " total = 0\n",
289 | "\n",
290 | " return total\"\"\"\n",
291 | "\n",
292 | "response_example = \"\"\"def calculate_total(prices, tax_rate, discount_rate, shipping_fee, gift_wrap_fee, membership_discount_rate):\n",
293 | "\n",
294 | " def apply_percentage_discount(amount, percentage):\n",
295 | "\n",
296 | " return amount * (1 - percentage / 100)\n",
297 | "\n",
298 | " def calculate_shipping_fee(total):\n",
299 | "\n",
300 | " return shipping_fee if total < 50 else shipping_fee / 2\n",
301 | "\n",
302 | " def apply_tier_discount(total):\n",
303 | "\n",
304 | " if total > 1000:\n",
305 | "\n",
306 | " return total - 50\n",
307 | "\n",
308 | " elif total > 500:\n",
309 | "\n",
310 | " return total - 25\n",
311 | "\n",
312 | " return total\n",
313 | "\n",
314 | " subtotal = sum(prices)\n",
315 | "\n",
316 | " subtotal = apply_percentage_discount(subtotal, membership_discount_rate)\n",
317 | "\n",
318 | " subtotal = apply_percentage_discount(subtotal, discount_rate)\n",
319 | "\n",
320 | "\n",
321 | "\n",
322 | " total = subtotal * (1 + tax_rate / 100)\n",
323 | "\n",
324 | " total += calculate_shipping_fee(total)\n",
325 | "\n",
326 | " total += gift_wrap_fee * len(prices)\n",
327 | "\n",
328 | "\n",
329 | "\n",
330 | " total = apply_tier_discount(total)\n",
331 | "\n",
332 | " total = max(0, round(total, 2))\n",
333 | "\n",
334 | "\n",
335 | "\n",
336 | " return total\"\"\""
337 | ],
338 | "metadata": {
339 | "id": "XSZqqOoQ-5_E"
340 | },
341 | "execution_count": null,
342 | "outputs": []
343 | },
344 | {
345 | "cell_type": "markdown",
346 | "source": [
347 | "### Now, let's run this system and get our new prompt! At the end, you'll see a new file pop up in the directory that contains everything you'll need to reduce your costs while keeping quality high w/ gpt-4o-mini!"
348 | ],
349 | "metadata": {
350 | "id": "cMO3cJzWA-O0"
351 | }
352 | },
353 | {
354 | "cell_type": "code",
355 | "source": [
356 | "result = run_mini_conversion_process(task, prompt_example, response_example)"
357 | ],
358 | "metadata": {
359 | "id": "O-Bn0rupAJqb"
360 | },
361 | "execution_count": null,
362 | "outputs": []
363 | }
364 | ],
365 | "metadata": {
366 | "colab": {
367 | "provenance": [],
368 | "include_colab_link": true
369 | },
370 | "kernelspec": {
371 | "display_name": "Python 3",
372 | "name": "python3"
373 | },
374 | "language_info": {
375 | "codemirror_mode": {
376 | "name": "ipython",
377 | "version": 3
378 | },
379 | "file_extension": ".py",
380 | "mimetype": "text/x-python",
381 | "name": "python",
382 | "nbconvert_exporter": "python",
383 | "pygments_lexer": "ipython3",
384 | "version": "3.8.8"
385 | }
386 | },
387 | "nbformat": 4,
388 | "nbformat_minor": 0
389 | }
--------------------------------------------------------------------------------
/Instruct_Prompt_>_Base_Model_Prompt_Converter.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyMiPidmyxX9dj90NyYRBkK/",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "Part of the `gpt-prompt-engineer` repo.\n",
33 | "\n",
34 | "Created by [Matt Shumer](https://twitter.com/mattshumer_)."
35 | ],
36 | "metadata": {
37 | "id": "eskBstij58XV"
38 | }
39 | },
40 | {
41 | "cell_type": "code",
42 | "source": [
43 | "!pip install anthropic\n",
44 | "\n",
45 | "import requests\n",
46 | "import anthropic\n",
47 | "\n",
48 | "ANTHROPIC_API_KEY = \"YOUR API KEY\" # Replace with your Anthropic API key\n",
49 | "OCTO_API_KEY = \"YOUR API KEY\" # Replace with your OctoAI API key\n",
50 | "\n",
51 | "client = anthropic.Anthropic(\n",
52 | " api_key=ANTHROPIC_API_KEY,\n",
53 | ")"
54 | ],
55 | "metadata": {
56 | "id": "vSYmdogL6GVF"
57 | },
58 | "execution_count": null,
59 | "outputs": []
60 | },
61 | {
62 | "cell_type": "markdown",
63 | "source": [
64 | "## Let's generate the converted prompt"
65 | ],
66 | "metadata": {
67 | "id": "z7yjKs_Y6ar8"
68 | }
69 | },
70 | {
71 | "cell_type": "code",
72 | "source": [
73 | "original_instruct_prompt = \"\"\"write an essay about frogs\"\"\" ## place your prompt to convert here\n",
74 | "\n",
75 | "message = client.messages.create(\n",
76 | " model=\"claude-3-opus-20240229\",\n",
77 | " max_tokens=1000,\n",
78 | " temperature=0.4,\n",
79 | " system=\"Given a prompt designed for an assistant model, convert it to be used with a base model. Use code as a trick to do this well.\",\n",
80 | " messages=[\n",
81 | " {\n",
82 | " \"role\": \"user\",\n",
83 | " \"content\": [\n",
84 | " {\n",
85 | " \"type\": \"text\",\n",
86 | " \"text\": \"Prompt to convert:\\n\\nApril 8, 2024 — Cohere recently announced the launch of Command R+, a cutting-edge addition to its R-series of large language models (LLMs). In this blog post, Cohere CEO Aidan Gomez delves into how this new model is poised to enhance enterprise-grade AI applications through enhanced efficiency, accuracy, and a robust partnership with Microsoft Azure.\\nToday, we’re introducing Command R+, our most powerful, scalable large language model (LLM) purpose-built to excel at real-world enterprise use cases. Command R+ joins our R-series of LLMs focused on balancing high efficiency with strong accuracy, enabling businesses to move beyond proof-of-concept, and into production with AI.\\nCommand R+, like our recently launched Command R model, features a 128k-token context window and is designed to offer best-in-class:\\nAdvanced Retrieval Augmented Generation (RAG) with citation to reduce hallucinations\\nMultilingual coverage in 10 key languages to support global business operations\\nTool Use to automate sophisticated business processes\\nOur latest model builds on the key strengths of Command R and further improves performance across the board. Command R+ outperforms similar models in the scalable market category, and is competitive with significantly more expensive models on key business-critical capabilities. We achieve this while providing the same commitment to data privacy and security that we’re known for.\\nAs we continue to serve the global enterprise community, we are proud to announce a new collaboration with Microsoft Azure to accelerate enterprise AI adoption.\\n“The collaboration with Cohere underscores our dedication to leading the charge in the AI revolution, bringing the innovative Command R+ model to Azure AI,” said John Montgomery, CVP of Azure AI Platform at Microsoft. “This partnership exemplifies our commitment to providing a comprehensive suite of AI tools that empower businesses to achieve more while adhering to the highest standards of security and compliance. Together, we’re setting new benchmarks for what’s possible in enterprise AI, fostering a future where technology amplifies human capability and innovation.”\\n--\\nGive me three good headlines\\n\"\n",
87 | " }\n",
88 | " ]\n",
89 | " },\n",
90 | " {\n",
91 | " \"role\": \"assistant\",\n",
92 | " \"content\": [\n",
93 | " {\n",
94 | " \"type\": \"text\",\n",
95 | " \"text\": \"\\nimport ai\\n\\ndef generate_headlines(press_release):\\n prompt = f\\\"\\\"\\\"Given the following press release, generate a Python list containing three compelling, informative headlines for a news article or blog post covering this announcement. \\n\\n Each headline should:\\n - Be no more than 20 words \\n - Capture the key points about the new Command R+ model and Cohere's partnership with Microsoft Azure\\n\\n Press Release:\\n \\\\\\\"\\\\\\\"\\\\\\\"{press_release}\\\\\\\"\\\\\\\"\\\\\\\"\\n \\n Respond with the Python list containing the three headlines, with each headline surrounded by double quotes.\\\"\\\"\\\"\\n\\n return ai.generate(prompt)\\n\\npress_release = \\\"\\\"\\\"\\nApril 8, 2024 — Cohere recently announced the launch of Command R+, a cutting-edge addition to its R-series of large language models (LLMs). In this blog post, Cohere CEO Aidan Gomez delves into how this new model is poised to enhance enterprise-grade AI applications through enhanced efficiency, accuracy, and a robust partnership with Microsoft Azure.\\n\\nToday, we're introducing Command R+, our most powerful, scalable large language model (LLM) purpose-built to excel at real-world enterprise use cases. Command R+ joins our R-series of LLMs focused on balancing high efficiency with strong accuracy, enabling businesses to move beyond proof-of-concept, and into production with AI.\\n\\nCommand R+, like our recently launched Command R model, features a 128k-token context window and is designed to offer best-in-class:\\n\\nAdvanced Retrieval Augmented Generation (RAG) with citation to reduce hallucinations\\nMultilingual coverage in 10 key languages to support global business operations \\nTool Use to automate sophisticated business processes\\nOur latest model builds on the key strengths of Command R and further improves performance across the board. Command R+ outperforms similar models in the scalable market category, and is competitive with significantly more expensive models on key business-critical capabilities. We achieve this while providing the same commitment to data privacy and security that we're known for.\\n\\nAs we continue to serve the global enterprise community, we are proud to announce a new collaboration with Microsoft Azure to accelerate enterprise AI adoption.\\n\\n\\\"The collaboration with Cohere underscores our dedication to leading the charge in the AI revolution, bringing the innovative Command R+ model to Azure AI,\\\" said John Montgomery, CVP of Azure AI Platform at Microsoft. \\\"This partnership exemplifies our commitment to providing a comprehensive suite of AI tools that empower businesses to achieve more while adhering to the highest standards of security and compliance. Together, we're setting new benchmarks for what's possible in enterprise AI, fostering a future where technology amplifies human capability and innovation.\\\"\\n\\\"\\\"\\\"\\n\\nprint(generate_headlines(press_release))\\n\\nOutput:\\n\\\"\\\"\\\"\\n[\\n\"\n",
96 | " }\n",
97 | " ]\n",
98 | " },\n",
99 | " {\n",
100 | " \"role\": \"user\",\n",
101 | " \"content\": [\n",
102 | " {\n",
103 | " \"type\": \"text\",\n",
104 | " \"text\": \"Prompt to convert:\\n\\nSpend Less Time in Bird Library\\nMake this shorter.\\n\"\n",
105 | " }\n",
106 | " ]\n",
107 | " },\n",
108 | " {\n",
109 | " \"role\": \"assistant\",\n",
110 | " \"content\": [\n",
111 | " {\n",
112 | " \"type\": \"text\",\n",
113 | " \"text\": \"\\nimport ai\\n\\ndef shorten_text(input_text):\\n prompt = f\\\"\\\"\\\"Shorten the following text while preserving the key meaning. Ensure the text you generate is shorter than the original:\\n\\n Text: \\\"{input_text}\\\"\\n \\n Respond with the shortened text string inside quotes.\\\"\\\"\\\"\\n\\n return ai.generate(prompt)\\n\\ntext = \\\"Spend Less Time in Bird Library\\\"\\n\\nprint('The shortened text is: ', shorten_text(input_text))\\n\\nOutput:\\n\\\"\\\"\\\"\\n\\nThe shortened text is: \\\", \\\"\\n\"\n",
114 | " }\n",
115 | " ]\n",
116 | " },\n",
117 | " {\n",
118 | " \"role\": \"user\",\n",
119 | " \"content\": [\n",
120 | " {\n",
121 | " \"type\": \"text\",\n",
122 | " \"text\": \"Prompt to convert:\\n\\npip uninstall -y transformers && pip uninstall -y flash-attn && pip install flash-attn && pip install git+https://github.com/huggingface/transformers && git clone https://github.com/OpenAccess-AI-Collective/axolotl && cd axolotl && pip3 install -e .[flash-attn] && pip3 install -U git+https://github.com/huggingface/peft.git && pip uninstall -y deepspeed && pip install -U deepspeed && pip install accelerate && pip uninstall -y deepspeed && pip install deepspeed==0.13.1 && conda install --name py3.10 mpi4py\\nHow do I run this but use the specific branch dbrx of axolotl?\\n\"\n",
123 | " }\n",
124 | " ]\n",
125 | " },\n",
126 | " {\n",
127 | " \"role\": \"assistant\",\n",
128 | " \"content\": [\n",
129 | " {\n",
130 | " \"type\": \"text\",\n",
131 | " \"text\": \"\\nimport ai\\n\\ndef modify_commands(commands):\\n prompt = f\\\"\\\"\\\"Given the following series of shell commands:\\n\\n ```\\n {commands}\\n ```\\n \\n Modify the commands to clone the specific 'dbrx' branch of the 'axolotl' repository instead of the default branch.\\n\\n Respond with the updated series of commands.\\\"\\\"\\\"\\n\\n return ai.generate(prompt)\\n\\ncommands = \\\"\\\"\\\"\\npip uninstall -y transformers && pip uninstall -y flash-attn && pip install flash-attn && pip install git+https://github.com/huggingface/transformers && git clone https://github.com/OpenAccess-AI-Collective/axolotl && cd axolotl && pip3 install -e .[flash-attn] && pip3 install -U git+https://github.com/huggingface/peft.git && pip uninstall -y deepspeed && pip install -U deepspeed && pip install accelerate && pip uninstall -y deepspeed && pip install deepspeed==0.13.1 && conda install --name py3.10 mpi4py\\n\\\"\\\"\\\"\\n\\nprint(modify_commands(commands))\\n\\nOutput:\\n\\\"\\\"\\\"\\n\"\n",
132 | " }\n",
133 | " ]\n",
134 | " },\n",
135 | " {\n",
136 | " \"role\": \"user\",\n",
137 | " \"content\": [\n",
138 | " {\n",
139 | " \"type\": \"text\",\n",
140 | " \"text\": f\"Prompt to convert:\\n\\n{original_instruct_prompt.strip()}\\n\"\n",
141 | " }\n",
142 | " ]\n",
143 | " },\n",
144 | " {\n",
145 | " \"role\": \"assistant\",\n",
146 | " \"content\": [\n",
147 | " {\n",
148 | " \"type\": \"text\",\n",
149 | " \"text\": \"\"\n",
150 | " }\n",
151 | " ]\n",
152 | " },\n",
153 | " ]\n",
154 | ")\n",
155 | "converted_prompt = message.content[0].text.split('')[0].strip()\n",
156 | "\n",
157 | "print(converted_prompt)"
158 | ],
159 | "metadata": {
160 | "id": "Qbzawzrt6dfQ"
161 | },
162 | "execution_count": null,
163 | "outputs": []
164 | },
165 | {
166 | "cell_type": "markdown",
167 | "source": [
168 | "## Use OctoAI's Mixtral 8x22B endpoint to test your prompt"
169 | ],
170 | "metadata": {
171 | "id": "CemDevtNS34g"
172 | }
173 | },
174 | {
175 | "cell_type": "code",
176 | "execution_count": null,
177 | "metadata": {
178 | "id": "SxSB1loL3g8P"
179 | },
180 | "outputs": [],
181 | "source": [
182 | "def generate_octo(prompt, max_tokens, temperature):\n",
183 | " url = \"https://text.octoai.run/v1/completions\"\n",
184 | " headers = {\n",
185 | " \"Content-Type\": \"application/json\",\n",
186 | " \"Authorization\": f\"Bearer {OCTO_API_KEY}\"\n",
187 | " }\n",
188 | " data = {\n",
189 | " \"model\": \"mixtral-8x22b\",\n",
190 | " \"prompt\": prompt,\n",
191 | " \"max_tokens\": max_tokens,\n",
192 | " \"temperature\": temperature,\n",
193 | " }\n",
194 | "\n",
195 | " response = requests.post(url, headers=headers, json=data)\n",
196 | "\n",
197 | " if response.status_code == 200:\n",
198 | " result = response.json()\n",
199 | " else:\n",
200 | " print(f\"Request failed with status code: {response.status_code}\")\n",
201 | " print(f\"Error message: {response.text}\")\n",
202 | "\n",
203 | " return response.json()['choices'][0]['text']\n",
204 | "\n",
205 | "print(generate_octo(converted_prompt, 500, .6).strip())"
206 | ]
207 | }
208 | ]
209 | }
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2023 mshumer
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/Llama_3_1_405B_>_8B_Conversion.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "include_colab_link": true
8 | },
9 | "kernelspec": {
10 | "name": "python3",
11 | "display_name": "Python 3"
12 | },
13 | "language_info": {
14 | "name": "python"
15 | }
16 | },
17 | "cells": [
18 | {
19 | "cell_type": "markdown",
20 | "metadata": {
21 | "id": "view-in-github",
22 | "colab_type": "text"
23 | },
24 | "source": [
25 | ""
26 | ]
27 | },
28 | {
29 | "cell_type": "markdown",
30 | "source": [
31 | "# Llama 3.1 405B to Llama 3.1 8B - part of the `gpt-prompt-engineer` repo\n",
32 | "\n",
33 | "This notebook gives you the ability to go from Llama 3.1 405B to Llama 3.1 8B -- reducing costs massively while keeping quality high.\n",
34 | "\n",
35 | "This is powered by OctoAI inference. You'll need to sign up for OctoAI and get an API key to continue.\n",
36 | "\n",
37 | "By Matt Shumer (https://twitter.com/mattshumer_) and Ben Hamm (https://www.linkedin.com/in/hammben/)\n",
38 | "\n",
39 | "Github repo: https://github.com/mshumer/gpt-prompt-engineer\n",
40 | "\n"
41 | ],
42 | "metadata": {
43 | "id": "2Jyodln24Bda"
44 | }
45 | },
46 | {
47 | "cell_type": "code",
48 | "execution_count": null,
49 | "metadata": {
50 | "id": "oeDuRwSk3tG6"
51 | },
52 | "outputs": [],
53 | "source": [
54 | "!pip install openai"
55 | ]
56 | },
57 | {
58 | "cell_type": "markdown",
59 | "source": [
60 | "Get your OctoAI API key at: https://octo.ai"
61 | ],
62 | "metadata": {
63 | "id": "ULGwpuIi6Rm0"
64 | }
65 | },
66 | {
67 | "cell_type": "code",
68 | "source": [
69 | "import os\n",
70 | "\n",
71 | "os.environ[\"OCTOAI_API_KEY\"] = \"PLACE YOUR KEY HERE\""
72 | ],
73 | "metadata": {
74 | "id": "xXqMwX5U6Qac"
75 | },
76 | "execution_count": null,
77 | "outputs": []
78 | },
79 | {
80 | "cell_type": "code",
81 | "source": [
82 | "from IPython.display import HTML, display\n",
83 | "import re\n",
84 | "import json\n",
85 | "import os\n",
86 | "from openai import OpenAI\n",
87 | "\n",
88 | "def set_css():\n",
89 | " display(HTML('''\n",
90 | " \n",
95 | " '''))\n",
96 | "get_ipython().events.register('pre_run_cell', set_css)\n",
97 | "\n",
98 | "# Initialize the OpenAI client with custom base URL\n",
99 | "client = OpenAI(\n",
100 | " base_url=\"https://text.octoai.run/v1\",\n",
101 | " api_key=os.environ['OCTOAI_API_KEY'],\n",
102 | ")\n",
103 | "\n",
104 | "# Define model names\n",
105 | "small_model = \"meta-llama-3.1-8b-instruct\"\n",
106 | "big_model = \"meta-llama-3.1-405b-instruct\"\n",
107 | "\n",
108 | "def generate_candidate_prompts(task, prompt_example, response_example):\n",
109 | " system_prompt = \"\"\"Given an example training sample, create seven additional samples for the same task that are even better. Each example should contain a and a .\n",
110 | "\n",
111 | "\n",
112 | "1. Ensure the new examples are diverse and unique from one another.\n",
113 | "2. They should all be perfect. If you make a mistake, this system won't work.\n",
114 | "\n",
115 | "\n",
116 | "Respond in this format:\n",
117 | "\n",
118 | "\n",
119 | "\n",
120 | "PUT_PROMPT_HERE\n",
121 | "\n",
122 | "\n",
123 | "PUT_RESPONSE_HERE\n",
124 | "\n",
125 | "\n",
126 | "\n",
127 | "\n",
128 | "\n",
129 | "PUT_PROMPT_HERE\n",
130 | "\n",
131 | "\n",
132 | "PUT_RESPONSE_HERE\n",
133 | "\n",
134 | "\n",
135 | "\n",
136 | "...\n",
137 | "\"\"\"\n",
138 | "\n",
139 | " user_content = f\"\"\"{task}\n",
140 | "\n",
141 | "\n",
142 | "{prompt_example}\n",
143 | "\n",
144 | "\n",
145 | "\n",
146 | "{response_example}\n",
147 | "\"\"\"\n",
148 | "\n",
149 | " response = client.chat.completions.create(\n",
150 | " model=big_model,\n",
151 | " messages=[\n",
152 | " {\"role\": \"system\", \"content\": system_prompt},\n",
153 | " {\"role\": \"user\", \"content\": user_content}\n",
154 | " ],\n",
155 | " max_tokens=4000,\n",
156 | " temperature=0.5\n",
157 | " )\n",
158 | "\n",
159 | " response_text = response.choices[0].message.content\n",
160 | "\n",
161 | " # Parse out the prompts and responses\n",
162 | " prompts_and_responses = []\n",
163 | " examples = re.findall(r'(.*?)', response_text, re.DOTALL)\n",
164 | " for example in examples:\n",
165 | " prompt = re.findall(r'(.*?)', example, re.DOTALL)[0].strip()\n",
166 | " response = re.findall(r'(.*?)', example, re.DOTALL)[0].strip()\n",
167 | " prompts_and_responses.append({'prompt': prompt, 'response': response})\n",
168 | "\n",
169 | " return prompts_and_responses\n",
170 | "\n",
171 | "def generate_system_prompt(task, prompt_examples):\n",
172 | " system_prompt = \"\"\"Given a user-description of their a set of prompt / response pairs (it'll be in JSON for easy reading) for the types of outputs we want to generate given inputs, write a fantastic system prompt that describes the task to be done perfectly.\n",
173 | "\n",
174 | "\n",
175 | "1. Do this perfectly.\n",
176 | "2. Respond only with the system prompt, and nothing else. No other text will be allowed.\n",
177 | "\n",
178 | "\n",
179 | "Respond in this format:\n",
180 | "\n",
181 | "WRITE_SYSTEM_PROMPT_HERE\n",
182 | "\"\"\"\n",
183 | "\n",
184 | " user_content = f\"\"\"{task}\n",
185 | "\n",
186 | "\n",
187 | "{str(prompt_examples)}\n",
188 | "\"\"\"\n",
189 | "\n",
190 | " response = client.chat.completions.create(\n",
191 | " model=big_model,\n",
192 | " messages=[\n",
193 | " {\"role\": \"system\", \"content\": system_prompt},\n",
194 | " {\"role\": \"user\", \"content\": user_content}\n",
195 | " ],\n",
196 | " max_tokens=1000,\n",
197 | " temperature=0.5\n",
198 | " )\n",
199 | "\n",
200 | " response_text = response.choices[0].message.content\n",
201 | "\n",
202 | " # Parse out the prompt\n",
203 | " generated_system_prompt = response_text.split('')[1].split('')[0].strip()\n",
204 | "\n",
205 | " return generated_system_prompt\n",
206 | "\n",
207 | "def test_small_model(generated_examples, prompt_example, system_prompt):\n",
208 | " messages = [{\"role\": \"system\", \"content\": system_prompt}]\n",
209 | "\n",
210 | " for example in generated_examples:\n",
211 | " messages.append({\"role\": \"user\", \"content\": example['prompt']})\n",
212 | " messages.append({\"role\": \"assistant\", \"content\": example['response']})\n",
213 | "\n",
214 | " messages.append({\"role\": \"user\", \"content\": prompt_example.strip()})\n",
215 | "\n",
216 | " response = client.chat.completions.create(\n",
217 | " model=small_model,\n",
218 | " messages=messages,\n",
219 | " max_tokens=2000,\n",
220 | " temperature=0.5\n",
221 | " )\n",
222 | "\n",
223 | " response_text = response.choices[0].message.content\n",
224 | "\n",
225 | " return response_text\n",
226 | "\n",
227 | "def run_conversion_process(task, prompt_example, response_example):\n",
228 | " print('Generating the prompts / responses...')\n",
229 | " # Generate candidate prompts\n",
230 | " generated_examples = generate_candidate_prompts(task, prompt_example, response_example)\n",
231 | "\n",
232 | " print('Prompts / responses generated. Now generating system prompt...')\n",
233 | "\n",
234 | " # Generate the system prompt\n",
235 | " system_prompt = generate_system_prompt(task, generated_examples)\n",
236 | "\n",
237 | " print('System prompt generated:', system_prompt)\n",
238 | "\n",
239 | " print(f'\\n\\nTesting the new prompt on {small_model}, using your input example...')\n",
240 | " # Test the generated examples and system prompt with the small model\n",
241 | " small_model_response = test_small_model(generated_examples, prompt_example, system_prompt)\n",
242 | "\n",
243 | " print(f'{small_model} responded with:')\n",
244 | " print(small_model_response)\n",
245 | "\n",
246 | " print('\\n\\n!! CHECK THE FILE DIRECTORY, THE PROMPT IS NOW SAVED THERE !!')\n",
247 | "\n",
248 | " # Create a dictionary with all the relevant information\n",
249 | " result = {\n",
250 | " \"task\": task,\n",
251 | " \"initial_prompt_example\": prompt_example,\n",
252 | " \"initial_response_example\": response_example,\n",
253 | " \"generated_examples\": generated_examples,\n",
254 | " \"system_prompt\": system_prompt,\n",
255 | " \"small_model_response\": small_model_response\n",
256 | " }\n",
257 | "\n",
258 | " # Save the small model prompt to a Python file\n",
259 | " with open(\"small_model_prompt.py\", \"w\") as file:\n",
260 | " file.write('system_prompt = \"\"\"' + system_prompt + '\"\"\"\\n\\n')\n",
261 | "\n",
262 | " file.write('messages = [\\n')\n",
263 | " for example in generated_examples:\n",
264 | " file.write(' {\"role\": \"user\", \"content\": \"\"\"' + example['prompt'] + '\"\"\"},\\n')\n",
265 | " file.write(' {\"role\": \"assistant\", \"content\": \"\"\"' + example['response'] + '\"\"\"},\\n')\n",
266 | "\n",
267 | " file.write(' {\"role\": \"user\", \"content\": \"\"\"' + prompt_example.strip() + '\"\"\"}\\n')\n",
268 | " file.write(']\\n')\n",
269 | "\n",
270 | " return result"
271 | ],
272 | "metadata": {
273 | "id": "ylWOvJEG4N3I"
274 | },
275 | "execution_count": null,
276 | "outputs": []
277 | },
278 | {
279 | "cell_type": "markdown",
280 | "source": [
281 | "# Fill in your task, prompt_example, and response_example here. Make sure you keep the quality really high here... this is the most important step!"
282 | ],
283 | "metadata": {
284 | "id": "y8PCYOdO4ZYF"
285 | }
286 | },
287 | {
288 | "cell_type": "code",
289 | "source": [
290 | "task = \"refactoring complex code\"\n",
291 | "\n",
292 | "prompt_example = \"\"\"def calculate_total(prices, tax, discount, shipping_fee, gift_wrap_fee, membership_discount):\n",
293 | "\n",
294 | " total = 0\n",
295 | "\n",
296 | " for i in range(len(prices)):\n",
297 | "\n",
298 | " total += prices[i]\n",
299 | "\n",
300 | " if membership_discount != 0:\n",
301 | "\n",
302 | " total = total - (total * (membership_discount / 100))\n",
303 | "\n",
304 | " if discount != 0:\n",
305 | "\n",
306 | " total = total - (total * (discount / 100))\n",
307 | "\n",
308 | " total = total + (total * (tax / 100))\n",
309 | "\n",
310 | " if total < 50:\n",
311 | "\n",
312 | " total += shipping_fee\n",
313 | "\n",
314 | " else:\n",
315 | "\n",
316 | " total += shipping_fee / 2\n",
317 | "\n",
318 | " if gift_wrap_fee != 0:\n",
319 | "\n",
320 | " total += gift_wrap_fee * len(prices)\n",
321 | "\n",
322 | " if total > 1000:\n",
323 | "\n",
324 | " total -= 50\n",
325 | "\n",
326 | " elif total > 500:\n",
327 | "\n",
328 | " total -= 25\n",
329 | "\n",
330 | " total = round(total, 2)\n",
331 | "\n",
332 | " if total < 0:\n",
333 | "\n",
334 | " total = 0\n",
335 | "\n",
336 | " return total\"\"\"\n",
337 | "\n",
338 | "response_example = \"\"\"def calculate_total(prices, tax_rate, discount_rate, shipping_fee, gift_wrap_fee, membership_discount_rate):\n",
339 | "\n",
340 | " def apply_percentage_discount(amount, percentage):\n",
341 | "\n",
342 | " return amount * (1 - percentage / 100)\n",
343 | "\n",
344 | " def calculate_shipping_fee(total):\n",
345 | "\n",
346 | " return shipping_fee if total < 50 else shipping_fee / 2\n",
347 | "\n",
348 | " def apply_tier_discount(total):\n",
349 | "\n",
350 | " if total > 1000:\n",
351 | "\n",
352 | " return total - 50\n",
353 | "\n",
354 | " elif total > 500:\n",
355 | "\n",
356 | " return total - 25\n",
357 | "\n",
358 | " return total\n",
359 | "\n",
360 | " subtotal = sum(prices)\n",
361 | "\n",
362 | " subtotal = apply_percentage_discount(subtotal, membership_discount_rate)\n",
363 | "\n",
364 | " subtotal = apply_percentage_discount(subtotal, discount_rate)\n",
365 | "\n",
366 | "\n",
367 | "\n",
368 | " total = subtotal * (1 + tax_rate / 100)\n",
369 | "\n",
370 | " total += calculate_shipping_fee(total)\n",
371 | "\n",
372 | " total += gift_wrap_fee * len(prices)\n",
373 | "\n",
374 | "\n",
375 | "\n",
376 | " total = apply_tier_discount(total)\n",
377 | "\n",
378 | " total = max(0, round(total, 2))\n",
379 | "\n",
380 | "\n",
381 | "\n",
382 | " return total\"\"\""
383 | ],
384 | "metadata": {
385 | "id": "zdPBIjMc4YIj"
386 | },
387 | "execution_count": null,
388 | "outputs": []
389 | },
390 | {
391 | "cell_type": "markdown",
392 | "source": [
393 | "# Now, let's run this system and get our new prompt! At the end, you'll see a new file pop up in the directory that contains everything you'll need to reduce your costs while keeping quality high w/ Llama 3.1 8B!"
394 | ],
395 | "metadata": {
396 | "id": "xu8WkKy44eRF"
397 | }
398 | },
399 | {
400 | "cell_type": "code",
401 | "source": [
402 | "result = run_conversion_process(task, prompt_example, response_example)"
403 | ],
404 | "metadata": {
405 | "id": "VxDzg8944eBB"
406 | },
407 | "execution_count": null,
408 | "outputs": []
409 | }
410 | ]
411 | }
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # gpt-prompt-engineer
2 | [](https://twitter.com/mattshumer_) [](https://colab.research.google.com/github/mshumer/gpt-prompt-engineer/blob/main/gpt_prompt_engineer.ipynb) [](https://colab.research.google.com/drive/16NLMjqyuUWxcokE_NF6RwHD8grwEeoaJ?usp=sharing)
3 |
4 | ## Overview
5 |
6 | Prompt engineering is kind of like alchemy. There's no clear way to predict what will work best. It's all about experimenting until you find the right prompt. `gpt-prompt-engineer` is a tool that takes this experimentation to a whole new level.
7 |
8 | **Simply input a description of your task and some test cases, and the system will generate, test, and rank a multitude of prompts to find the ones that perform the best.**
9 |
10 | ## *New 3/20/24: The Claude 3 Opus Version*
11 | I've added a new version of gpt-prompt-engineer that takes full advantage of Anthropic's Claude 3 Opus model. This version auto-generates test cases and allows for the user to define multiple input variables, making it even more powerful and flexible. Try it out with the claude-prompt-engineer.ipynb notebook in the repo!
12 |
13 | ## *New 3/20/24: Claude 3 Opus -> Haiku Conversion Version*
14 | This notebook enables you to build lightning-fast, performant AI systems at a fraction of the typical cost. By using Claude 3 Opus to establish the latent space and Claude 3 Haiku for the actual generation, you can achieve amazing results. The process works by leveraging Opus to produce a collection of top-notch examples, which are then used to guide Haiku in generating output of comparable quality while dramatically reducing both latency and cost per generation. Try it out with the opus-to-haiku-conversion.ipynb notebook in the repo!
15 |
16 | ## Features
17 |
18 | - **Prompt Generation**: Using GPT-4, GPT-3.5-Turbo, or Claude 3 Opus, `gpt-prompt-engineer` can generate a variety of possible prompts based on a provided use-case and test cases.
19 |
20 | - **Prompt Testing**: The real magic happens after the generation. The system tests each prompt against all the test cases, comparing their performance and ranking them using an ELO rating system.
21 |
"
11 | ]
12 | },
13 | {
14 | "cell_type": "markdown",
15 | "metadata": {
16 | "id": "WljjH8K3s7kG"
17 | },
18 | "source": [
19 | "# Claude 3.5 Sonnet to gpt-4o-mini - part of the `gpt-prompt-engineer` repo\n",
20 | "\n",
21 | "This notebook gives you the ability to go from Claude 3.5 Sonnet to GPT-4o-mini -- reducing costs massively while keeping quality high.\n",
22 | "\n",
23 | "By Matt Shumer (https://twitter.com/mattshumer_)\n",
24 | "\n",
25 | "Github repo: https://github.com/mshumer/gpt-prompt-engineer"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": null,
31 | "metadata": {
32 | "id": "dQmMZdkG_RA5"
33 | },
34 | "outputs": [],
35 | "source": [
36 | "!pip install openai\n",
37 | "\n",
38 | "OPENAI_API_KEY = \"YOUR API KEY HERE\" # enter your OpenAI API key here\n",
39 | "ANTHROPIC_API_KEY = \"YOUR API KEY HERE\" # enter your Anthropic API key here"
40 | ]
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": null,
45 | "metadata": {
46 | "id": "wXeqMQpzzosx"
47 | },
48 | "outputs": [],
49 | "source": [
50 | "import re\n",
51 | "import json\n",
52 | "import requests\n",
53 | "from openai import OpenAI\n",
54 | "\n",
55 | "client = OpenAI(api_key=OPENAI_API_KEY)\n",
56 | "\n",
57 | "def generate_candidate_prompts(task, prompt_example, response_example):\n",
58 | " headers = {\n",
59 | " \"x-api-key\": ANTHROPIC_API_KEY,\n",
60 | " \"anthropic-version\": \"2023-06-01\",\n",
61 | " \"content-type\": \"application/json\"\n",
62 | " }\n",
63 | "\n",
64 | " data = {\n",
65 | " \"model\": 'claude-3-5-sonnet-20240620',\n",
66 | " \"max_tokens\": 4000,\n",
67 | " \"temperature\": .5,\n",
68 | " \"system\": \"\"\"Given an example training sample, create seven additional samples for the same task that are even better. Each example should contain a and a .\n",
69 | "\n",
70 | "\n",
71 | "1. Ensure the new examples are diverse and unique from one another.\n",
72 | "2. They should all be perfect. If you make a mistake, this system won't work.\n",
73 | "\n",
74 | "\n",
75 | "Respond in this format:\n",
76 | "\n",
77 | "\n",
78 | "\n",
79 | "PUT_PROMPT_HERE\n",
80 | "\n",
81 | "\n",
82 | "PUT_RESPONSE_HERE\n",
83 | "\n",
84 | "\n",
85 | "\n",
86 | "\n",
87 | "\n",
88 | "PUT_PROMPT_HERE\n",
89 | "\n",
90 | "\n",
91 | "PUT_RESPONSE_HERE\n",
92 | "\n",
93 | "\n",
94 | "\n",
95 | "...\n",
96 | "\"\"\",\n",
97 | " \"messages\": [\n",
98 | " {\"role\": \"user\", \"content\": f\"\"\"{task}\n",
99 | "\n",
100 | "\n",
101 | "{prompt_example}\n",
102 | "\n",
103 | "\n",
104 | "\n",
105 | "{response_example}\n",
106 | "\"\"\"},\n",
107 | " ]\n",
108 | " }\n",
109 | "\n",
110 | "\n",
111 | " response = requests.post(\"https://api.anthropic.com/v1/messages\", headers=headers, json=data)\n",
112 | "\n",
113 | " response_text = response.json()['content'][0]['text']\n",
114 | "\n",
115 | " # Parse out the prompts and responses\n",
116 | " prompts_and_responses = []\n",
117 | " examples = re.findall(r'(.*?)', response_text, re.DOTALL)\n",
118 | " for example in examples:\n",
119 | " prompt = re.findall(r'(.*?)', example, re.DOTALL)[0].strip()\n",
120 | " response = re.findall(r'(.*?)', example, re.DOTALL)[0].strip()\n",
121 | " prompts_and_responses.append({'prompt': prompt, 'response': response})\n",
122 | "\n",
123 | " return prompts_and_responses\n",
124 | "\n",
125 | "def generate_system_prompt(task, prompt_examples):\n",
126 | " headers = {\n",
127 | " \"x-api-key\": ANTHROPIC_API_KEY,\n",
128 | " \"anthropic-version\": \"2023-06-01\",\n",
129 | " \"content-type\": \"application/json\"\n",
130 | " }\n",
131 | "\n",
132 | " data = {\n",
133 | " \"model\": 'claude-3-5-sonnet-20240620',\n",
134 | " \"max_tokens\": 1000,\n",
135 | " \"temperature\": .5,\n",
136 | " \"system\": \"\"\"Given a user-description of their a set of prompt / response pairs (it'll be in JSON for easy reading) for the types of outputs we want to generate given inputs, write a fantastic system prompt that describes the task to be done perfectly.\n",
137 | "\n",
138 | "\n",
139 | "1. Do this perfectly.\n",
140 | "2. Respond only with the system prompt, and nothing else. No other text will be allowed.\n",
141 | "\n",
142 | "\n",
143 | "Respond in this format:\n",
144 | "\n",
145 | "WRITE_SYSTEM_PROMPT_HERE\n",
146 | "\"\"\",\n",
147 | " \"messages\": [\n",
148 | " {\"role\": \"user\", \"content\": f\"\"\"{task}\n",
149 | "\n",
150 | "\n",
151 | "{str(prompt_examples)}\n",
152 | "\"\"\"},\n",
153 | " ]\n",
154 | " }\n",
155 | "\n",
156 | "\n",
157 | " response = requests.post(\"https://api.anthropic.com/v1/messages\", headers=headers, json=data)\n",
158 | "\n",
159 | " response_text = response.json()['content'][0]['text']\n",
160 | "\n",
161 | " # Parse out the prompt\n",
162 | " system_prompt = response_text.split('')[1].split('')[0].strip()\n",
163 | "\n",
164 | " return system_prompt\n",
165 | "\n",
166 | "def test_mini(generated_examples, prompt_example, system_prompt):\n",
167 | " messages = [{\"role\": \"system\", \"content\": system_prompt}]\n",
168 | "\n",
169 | " for example in generated_examples:\n",
170 | " messages.append({\"role\": \"user\", \"content\": example['prompt']})\n",
171 | " messages.append({\"role\": \"assistant\", \"content\": example['response']})\n",
172 | "\n",
173 | " messages.append({\"role\": \"user\", \"content\": prompt_example.strip()})\n",
174 | "\n",
175 | " response = client.chat.completions.create(\n",
176 | " model=\"gpt-4o-mini\",\n",
177 | " messages=messages,\n",
178 | " max_tokens=2000,\n",
179 | " temperature=0.5\n",
180 | " )\n",
181 | "\n",
182 | " response_text = response.choices[0].message.content\n",
183 | "\n",
184 | " return response_text\n",
185 | "\n",
186 | "def run_mini_conversion_process(task, prompt_example, response_example):\n",
187 | " print('Generating the prompts / responses...')\n",
188 | " # Generate candidate prompts\n",
189 | " generated_examples = generate_candidate_prompts(task, prompt_example, response_example)\n",
190 | "\n",
191 | " print('Prompts / responses generated. Now generating system prompt...')\n",
192 | "\n",
193 | " # Generate the system prompt\n",
194 | " system_prompt = generate_system_prompt(task, generated_examples)\n",
195 | "\n",
196 | " print('System prompt generated:', system_prompt)\n",
197 | "\n",
198 | " print('\\n\\nTesting the new prompt on GPT-4o-mini, using your input example...')\n",
199 | " # Test the generated examples and system prompt with the GPT-4o-mini model\n",
200 | " mini_response = test_mini(generated_examples, prompt_example, system_prompt)\n",
201 | "\n",
202 | " print('GPT-4o-mini responded with:')\n",
203 | " print(mini_response)\n",
204 | "\n",
205 | " print('\\n\\n!! CHECK THE FILE DIRECTORY, THE PROMPT IS NOW SAVED THERE !!')\n",
206 | "\n",
207 | " # Create a dictionary with all the relevant information\n",
208 | " result = {\n",
209 | " \"task\": task,\n",
210 | " \"initial_prompt_example\": prompt_example,\n",
211 | " \"initial_response_example\": response_example,\n",
212 | " \"generated_examples\": generated_examples,\n",
213 | " \"system_prompt\": system_prompt,\n",
214 | " \"mini_response\": mini_response\n",
215 | " }\n",
216 | "\n",
217 | " # Save the GPT-4o-mini prompt to a Python file\n",
218 | " with open(\"gpt4o_mini_prompt.py\", \"w\") as file:\n",
219 | " file.write('system_prompt = \"\"\"' + system_prompt + '\"\"\"\\n\\n')\n",
220 | "\n",
221 | " file.write('messages = [\\n')\n",
222 | " for example in generated_examples:\n",
223 | " file.write(' {\"role\": \"user\", \"content\": \"\"\"' + example['prompt'] + '\"\"\"},\\n')\n",
224 | " file.write(' {\"role\": \"assistant\", \"content\": \"\"\"' + example['response'] + '\"\"\"},\\n')\n",
225 | "\n",
226 | " file.write(' {\"role\": \"user\", \"content\": \"\"\"' + prompt_example.strip() + '\"\"\"}\\n')\n",
227 | " file.write(']\\n')\n",
228 | "\n",
229 | " return result"
230 | ]
231 | },
232 | {
233 | "cell_type": "markdown",
234 | "source": [
235 | "## Fill in your task, prompt_example, and response_example here. Make sure you keep the quality really high here... this is the most important step!"
236 | ],
237 | "metadata": {
238 | "id": "ZujTAzhuBMea"
239 | }
240 | },
241 | {
242 | "cell_type": "code",
243 | "source": [
244 | "task = \"refactoring complex code\"\n",
245 | "\n",
246 | "prompt_example = \"\"\"def calculate_total(prices, tax, discount, shipping_fee, gift_wrap_fee, membership_discount):\n",
247 | "\n",
248 | " total = 0\n",
249 | "\n",
250 | " for i in range(len(prices)):\n",
251 | "\n",
252 | " total += prices[i]\n",
253 | "\n",
254 | " if membership_discount != 0:\n",
255 | "\n",
256 | " total = total - (total * (membership_discount / 100))\n",
257 | "\n",
258 | " if discount != 0:\n",
259 | "\n",
260 | " total = total - (total * (discount / 100))\n",
261 | "\n",
262 | " total = total + (total * (tax / 100))\n",
263 | "\n",
264 | " if total < 50:\n",
265 | "\n",
266 | " total += shipping_fee\n",
267 | "\n",
268 | " else:\n",
269 | "\n",
270 | " total += shipping_fee / 2\n",
271 | "\n",
272 | " if gift_wrap_fee != 0:\n",
273 | "\n",
274 | " total += gift_wrap_fee * len(prices)\n",
275 | "\n",
276 | " if total > 1000:\n",
277 | "\n",
278 | " total -= 50\n",
279 | "\n",
280 | " elif total > 500:\n",
281 | "\n",
282 | " total -= 25\n",
283 | "\n",
284 | " total = round(total, 2)\n",
285 | "\n",
286 | " if total < 0:\n",
287 | "\n",
288 | " total = 0\n",
289 | "\n",
290 | " return total\"\"\"\n",
291 | "\n",
292 | "response_example = \"\"\"def calculate_total(prices, tax_rate, discount_rate, shipping_fee, gift_wrap_fee, membership_discount_rate):\n",
293 | "\n",
294 | " def apply_percentage_discount(amount, percentage):\n",
295 | "\n",
296 | " return amount * (1 - percentage / 100)\n",
297 | "\n",
298 | " def calculate_shipping_fee(total):\n",
299 | "\n",
300 | " return shipping_fee if total < 50 else shipping_fee / 2\n",
301 | "\n",
302 | " def apply_tier_discount(total):\n",
303 | "\n",
304 | " if total > 1000:\n",
305 | "\n",
306 | " return total - 50\n",
307 | "\n",
308 | " elif total > 500:\n",
309 | "\n",
310 | " return total - 25\n",
311 | "\n",
312 | " return total\n",
313 | "\n",
314 | " subtotal = sum(prices)\n",
315 | "\n",
316 | " subtotal = apply_percentage_discount(subtotal, membership_discount_rate)\n",
317 | "\n",
318 | " subtotal = apply_percentage_discount(subtotal, discount_rate)\n",
319 | "\n",
320 | "\n",
321 | "\n",
322 | " total = subtotal * (1 + tax_rate / 100)\n",
323 | "\n",
324 | " total += calculate_shipping_fee(total)\n",
325 | "\n",
326 | " total += gift_wrap_fee * len(prices)\n",
327 | "\n",
328 | "\n",
329 | "\n",
330 | " total = apply_tier_discount(total)\n",
331 | "\n",
332 | " total = max(0, round(total, 2))\n",
333 | "\n",
334 | "\n",
335 | "\n",
336 | " return total\"\"\""
337 | ],
338 | "metadata": {
339 | "id": "XSZqqOoQ-5_E"
340 | },
341 | "execution_count": null,
342 | "outputs": []
343 | },
344 | {
345 | "cell_type": "markdown",
346 | "source": [
347 | "### Now, let's run this system and get our new prompt! At the end, you'll see a new file pop up in the directory that contains everything you'll need to reduce your costs while keeping quality high w/ gpt-4o-mini!"
348 | ],
349 | "metadata": {
350 | "id": "cMO3cJzWA-O0"
351 | }
352 | },
353 | {
354 | "cell_type": "code",
355 | "source": [
356 | "result = run_mini_conversion_process(task, prompt_example, response_example)"
357 | ],
358 | "metadata": {
359 | "id": "O-Bn0rupAJqb"
360 | },
361 | "execution_count": null,
362 | "outputs": []
363 | }
364 | ],
365 | "metadata": {
366 | "colab": {
367 | "provenance": [],
368 | "include_colab_link": true
369 | },
370 | "kernelspec": {
371 | "display_name": "Python 3",
372 | "name": "python3"
373 | },
374 | "language_info": {
375 | "codemirror_mode": {
376 | "name": "ipython",
377 | "version": 3
378 | },
379 | "file_extension": ".py",
380 | "mimetype": "text/x-python",
381 | "name": "python",
382 | "nbconvert_exporter": "python",
383 | "pygments_lexer": "ipython3",
384 | "version": "3.8.8"
385 | }
386 | },
387 | "nbformat": 4,
388 | "nbformat_minor": 0
389 | }
--------------------------------------------------------------------------------
/Instruct_Prompt_>_Base_Model_Prompt_Converter.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyMiPidmyxX9dj90NyYRBkK/",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "source": [
32 | "Part of the `gpt-prompt-engineer` repo.\n",
33 | "\n",
34 | "Created by [Matt Shumer](https://twitter.com/mattshumer_)."
35 | ],
36 | "metadata": {
37 | "id": "eskBstij58XV"
38 | }
39 | },
40 | {
41 | "cell_type": "code",
42 | "source": [
43 | "!pip install anthropic\n",
44 | "\n",
45 | "import requests\n",
46 | "import anthropic\n",
47 | "\n",
48 | "ANTHROPIC_API_KEY = \"YOUR API KEY\" # Replace with your Anthropic API key\n",
49 | "OCTO_API_KEY = \"YOUR API KEY\" # Replace with your OctoAI API key\n",
50 | "\n",
51 | "client = anthropic.Anthropic(\n",
52 | " api_key=ANTHROPIC_API_KEY,\n",
53 | ")"
54 | ],
55 | "metadata": {
56 | "id": "vSYmdogL6GVF"
57 | },
58 | "execution_count": null,
59 | "outputs": []
60 | },
61 | {
62 | "cell_type": "markdown",
63 | "source": [
64 | "## Let's generate the converted prompt"
65 | ],
66 | "metadata": {
67 | "id": "z7yjKs_Y6ar8"
68 | }
69 | },
70 | {
71 | "cell_type": "code",
72 | "source": [
73 | "original_instruct_prompt = \"\"\"write an essay about frogs\"\"\" ## place your prompt to convert here\n",
74 | "\n",
75 | "message = client.messages.create(\n",
76 | " model=\"claude-3-opus-20240229\",\n",
77 | " max_tokens=1000,\n",
78 | " temperature=0.4,\n",
79 | " system=\"Given a prompt designed for an assistant model, convert it to be used with a base model. Use code as a trick to do this well.\",\n",
80 | " messages=[\n",
81 | " {\n",
82 | " \"role\": \"user\",\n",
83 | " \"content\": [\n",
84 | " {\n",
85 | " \"type\": \"text\",\n",
86 | " \"text\": \"Prompt to convert:\\n\\nApril 8, 2024 — Cohere recently announced the launch of Command R+, a cutting-edge addition to its R-series of large language models (LLMs). In this blog post, Cohere CEO Aidan Gomez delves into how this new model is poised to enhance enterprise-grade AI applications through enhanced efficiency, accuracy, and a robust partnership with Microsoft Azure.\\nToday, we’re introducing Command R+, our most powerful, scalable large language model (LLM) purpose-built to excel at real-world enterprise use cases. Command R+ joins our R-series of LLMs focused on balancing high efficiency with strong accuracy, enabling businesses to move beyond proof-of-concept, and into production with AI.\\nCommand R+, like our recently launched Command R model, features a 128k-token context window and is designed to offer best-in-class:\\nAdvanced Retrieval Augmented Generation (RAG) with citation to reduce hallucinations\\nMultilingual coverage in 10 key languages to support global business operations\\nTool Use to automate sophisticated business processes\\nOur latest model builds on the key strengths of Command R and further improves performance across the board. Command R+ outperforms similar models in the scalable market category, and is competitive with significantly more expensive models on key business-critical capabilities. We achieve this while providing the same commitment to data privacy and security that we’re known for.\\nAs we continue to serve the global enterprise community, we are proud to announce a new collaboration with Microsoft Azure to accelerate enterprise AI adoption.\\n“The collaboration with Cohere underscores our dedication to leading the charge in the AI revolution, bringing the innovative Command R+ model to Azure AI,” said John Montgomery, CVP of Azure AI Platform at Microsoft. “This partnership exemplifies our commitment to providing a comprehensive suite of AI tools that empower businesses to achieve more while adhering to the highest standards of security and compliance. Together, we’re setting new benchmarks for what’s possible in enterprise AI, fostering a future where technology amplifies human capability and innovation.”\\n--\\nGive me three good headlines\\n\"\n",
87 | " }\n",
88 | " ]\n",
89 | " },\n",
90 | " {\n",
91 | " \"role\": \"assistant\",\n",
92 | " \"content\": [\n",
93 | " {\n",
94 | " \"type\": \"text\",\n",
95 | " \"text\": \"\\nimport ai\\n\\ndef generate_headlines(press_release):\\n prompt = f\\\"\\\"\\\"Given the following press release, generate a Python list containing three compelling, informative headlines for a news article or blog post covering this announcement. \\n\\n Each headline should:\\n - Be no more than 20 words \\n - Capture the key points about the new Command R+ model and Cohere's partnership with Microsoft Azure\\n\\n Press Release:\\n \\\\\\\"\\\\\\\"\\\\\\\"{press_release}\\\\\\\"\\\\\\\"\\\\\\\"\\n \\n Respond with the Python list containing the three headlines, with each headline surrounded by double quotes.\\\"\\\"\\\"\\n\\n return ai.generate(prompt)\\n\\npress_release = \\\"\\\"\\\"\\nApril 8, 2024 — Cohere recently announced the launch of Command R+, a cutting-edge addition to its R-series of large language models (LLMs). In this blog post, Cohere CEO Aidan Gomez delves into how this new model is poised to enhance enterprise-grade AI applications through enhanced efficiency, accuracy, and a robust partnership with Microsoft Azure.\\n\\nToday, we're introducing Command R+, our most powerful, scalable large language model (LLM) purpose-built to excel at real-world enterprise use cases. Command R+ joins our R-series of LLMs focused on balancing high efficiency with strong accuracy, enabling businesses to move beyond proof-of-concept, and into production with AI.\\n\\nCommand R+, like our recently launched Command R model, features a 128k-token context window and is designed to offer best-in-class:\\n\\nAdvanced Retrieval Augmented Generation (RAG) with citation to reduce hallucinations\\nMultilingual coverage in 10 key languages to support global business operations \\nTool Use to automate sophisticated business processes\\nOur latest model builds on the key strengths of Command R and further improves performance across the board. Command R+ outperforms similar models in the scalable market category, and is competitive with significantly more expensive models on key business-critical capabilities. We achieve this while providing the same commitment to data privacy and security that we're known for.\\n\\nAs we continue to serve the global enterprise community, we are proud to announce a new collaboration with Microsoft Azure to accelerate enterprise AI adoption.\\n\\n\\\"The collaboration with Cohere underscores our dedication to leading the charge in the AI revolution, bringing the innovative Command R+ model to Azure AI,\\\" said John Montgomery, CVP of Azure AI Platform at Microsoft. \\\"This partnership exemplifies our commitment to providing a comprehensive suite of AI tools that empower businesses to achieve more while adhering to the highest standards of security and compliance. Together, we're setting new benchmarks for what's possible in enterprise AI, fostering a future where technology amplifies human capability and innovation.\\\"\\n\\\"\\\"\\\"\\n\\nprint(generate_headlines(press_release))\\n\\nOutput:\\n\\\"\\\"\\\"\\n[\\n\"\n",
96 | " }\n",
97 | " ]\n",
98 | " },\n",
99 | " {\n",
100 | " \"role\": \"user\",\n",
101 | " \"content\": [\n",
102 | " {\n",
103 | " \"type\": \"text\",\n",
104 | " \"text\": \"Prompt to convert:\\n\\nSpend Less Time in Bird Library\\nMake this shorter.\\n\"\n",
105 | " }\n",
106 | " ]\n",
107 | " },\n",
108 | " {\n",
109 | " \"role\": \"assistant\",\n",
110 | " \"content\": [\n",
111 | " {\n",
112 | " \"type\": \"text\",\n",
113 | " \"text\": \"\\nimport ai\\n\\ndef shorten_text(input_text):\\n prompt = f\\\"\\\"\\\"Shorten the following text while preserving the key meaning. Ensure the text you generate is shorter than the original:\\n\\n Text: \\\"{input_text}\\\"\\n \\n Respond with the shortened text string inside quotes.\\\"\\\"\\\"\\n\\n return ai.generate(prompt)\\n\\ntext = \\\"Spend Less Time in Bird Library\\\"\\n\\nprint('The shortened text is: ', shorten_text(input_text))\\n\\nOutput:\\n\\\"\\\"\\\"\\n\\nThe shortened text is: \\\", \\\"\\n\"\n",
114 | " }\n",
115 | " ]\n",
116 | " },\n",
117 | " {\n",
118 | " \"role\": \"user\",\n",
119 | " \"content\": [\n",
120 | " {\n",
121 | " \"type\": \"text\",\n",
122 | " \"text\": \"Prompt to convert:\\n\\npip uninstall -y transformers && pip uninstall -y flash-attn && pip install flash-attn && pip install git+https://github.com/huggingface/transformers && git clone https://github.com/OpenAccess-AI-Collective/axolotl && cd axolotl && pip3 install -e .[flash-attn] && pip3 install -U git+https://github.com/huggingface/peft.git && pip uninstall -y deepspeed && pip install -U deepspeed && pip install accelerate && pip uninstall -y deepspeed && pip install deepspeed==0.13.1 && conda install --name py3.10 mpi4py\\nHow do I run this but use the specific branch dbrx of axolotl?\\n\"\n",
123 | " }\n",
124 | " ]\n",
125 | " },\n",
126 | " {\n",
127 | " \"role\": \"assistant\",\n",
128 | " \"content\": [\n",
129 | " {\n",
130 | " \"type\": \"text\",\n",
131 | " \"text\": \"\\nimport ai\\n\\ndef modify_commands(commands):\\n prompt = f\\\"\\\"\\\"Given the following series of shell commands:\\n\\n ```\\n {commands}\\n ```\\n \\n Modify the commands to clone the specific 'dbrx' branch of the 'axolotl' repository instead of the default branch.\\n\\n Respond with the updated series of commands.\\\"\\\"\\\"\\n\\n return ai.generate(prompt)\\n\\ncommands = \\\"\\\"\\\"\\npip uninstall -y transformers && pip uninstall -y flash-attn && pip install flash-attn && pip install git+https://github.com/huggingface/transformers && git clone https://github.com/OpenAccess-AI-Collective/axolotl && cd axolotl && pip3 install -e .[flash-attn] && pip3 install -U git+https://github.com/huggingface/peft.git && pip uninstall -y deepspeed && pip install -U deepspeed && pip install accelerate && pip uninstall -y deepspeed && pip install deepspeed==0.13.1 && conda install --name py3.10 mpi4py\\n\\\"\\\"\\\"\\n\\nprint(modify_commands(commands))\\n\\nOutput:\\n\\\"\\\"\\\"\\n\"\n",
132 | " }\n",
133 | " ]\n",
134 | " },\n",
135 | " {\n",
136 | " \"role\": \"user\",\n",
137 | " \"content\": [\n",
138 | " {\n",
139 | " \"type\": \"text\",\n",
140 | " \"text\": f\"Prompt to convert:\\n\\n{original_instruct_prompt.strip()}\\n\"\n",
141 | " }\n",
142 | " ]\n",
143 | " },\n",
144 | " {\n",
145 | " \"role\": \"assistant\",\n",
146 | " \"content\": [\n",
147 | " {\n",
148 | " \"type\": \"text\",\n",
149 | " \"text\": \"\"\n",
150 | " }\n",
151 | " ]\n",
152 | " },\n",
153 | " ]\n",
154 | ")\n",
155 | "converted_prompt = message.content[0].text.split('')[0].strip()\n",
156 | "\n",
157 | "print(converted_prompt)"
158 | ],
159 | "metadata": {
160 | "id": "Qbzawzrt6dfQ"
161 | },
162 | "execution_count": null,
163 | "outputs": []
164 | },
165 | {
166 | "cell_type": "markdown",
167 | "source": [
168 | "## Use OctoAI's Mixtral 8x22B endpoint to test your prompt"
169 | ],
170 | "metadata": {
171 | "id": "CemDevtNS34g"
172 | }
173 | },
174 | {
175 | "cell_type": "code",
176 | "execution_count": null,
177 | "metadata": {
178 | "id": "SxSB1loL3g8P"
179 | },
180 | "outputs": [],
181 | "source": [
182 | "def generate_octo(prompt, max_tokens, temperature):\n",
183 | " url = \"https://text.octoai.run/v1/completions\"\n",
184 | " headers = {\n",
185 | " \"Content-Type\": \"application/json\",\n",
186 | " \"Authorization\": f\"Bearer {OCTO_API_KEY}\"\n",
187 | " }\n",
188 | " data = {\n",
189 | " \"model\": \"mixtral-8x22b\",\n",
190 | " \"prompt\": prompt,\n",
191 | " \"max_tokens\": max_tokens,\n",
192 | " \"temperature\": temperature,\n",
193 | " }\n",
194 | "\n",
195 | " response = requests.post(url, headers=headers, json=data)\n",
196 | "\n",
197 | " if response.status_code == 200:\n",
198 | " result = response.json()\n",
199 | " else:\n",
200 | " print(f\"Request failed with status code: {response.status_code}\")\n",
201 | " print(f\"Error message: {response.text}\")\n",
202 | "\n",
203 | " return response.json()['choices'][0]['text']\n",
204 | "\n",
205 | "print(generate_octo(converted_prompt, 500, .6).strip())"
206 | ]
207 | }
208 | ]
209 | }
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2023 mshumer
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/Llama_3_1_405B_>_8B_Conversion.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "include_colab_link": true
8 | },
9 | "kernelspec": {
10 | "name": "python3",
11 | "display_name": "Python 3"
12 | },
13 | "language_info": {
14 | "name": "python"
15 | }
16 | },
17 | "cells": [
18 | {
19 | "cell_type": "markdown",
20 | "metadata": {
21 | "id": "view-in-github",
22 | "colab_type": "text"
23 | },
24 | "source": [
25 | ""
26 | ]
27 | },
28 | {
29 | "cell_type": "markdown",
30 | "source": [
31 | "# Llama 3.1 405B to Llama 3.1 8B - part of the `gpt-prompt-engineer` repo\n",
32 | "\n",
33 | "This notebook gives you the ability to go from Llama 3.1 405B to Llama 3.1 8B -- reducing costs massively while keeping quality high.\n",
34 | "\n",
35 | "This is powered by OctoAI inference. You'll need to sign up for OctoAI and get an API key to continue.\n",
36 | "\n",
37 | "By Matt Shumer (https://twitter.com/mattshumer_) and Ben Hamm (https://www.linkedin.com/in/hammben/)\n",
38 | "\n",
39 | "Github repo: https://github.com/mshumer/gpt-prompt-engineer\n",
40 | "\n"
41 | ],
42 | "metadata": {
43 | "id": "2Jyodln24Bda"
44 | }
45 | },
46 | {
47 | "cell_type": "code",
48 | "execution_count": null,
49 | "metadata": {
50 | "id": "oeDuRwSk3tG6"
51 | },
52 | "outputs": [],
53 | "source": [
54 | "!pip install openai"
55 | ]
56 | },
57 | {
58 | "cell_type": "markdown",
59 | "source": [
60 | "Get your OctoAI API key at: https://octo.ai"
61 | ],
62 | "metadata": {
63 | "id": "ULGwpuIi6Rm0"
64 | }
65 | },
66 | {
67 | "cell_type": "code",
68 | "source": [
69 | "import os\n",
70 | "\n",
71 | "os.environ[\"OCTOAI_API_KEY\"] = \"PLACE YOUR KEY HERE\""
72 | ],
73 | "metadata": {
74 | "id": "xXqMwX5U6Qac"
75 | },
76 | "execution_count": null,
77 | "outputs": []
78 | },
79 | {
80 | "cell_type": "code",
81 | "source": [
82 | "from IPython.display import HTML, display\n",
83 | "import re\n",
84 | "import json\n",
85 | "import os\n",
86 | "from openai import OpenAI\n",
87 | "\n",
88 | "def set_css():\n",
89 | " display(HTML('''\n",
90 | " \n",
95 | " '''))\n",
96 | "get_ipython().events.register('pre_run_cell', set_css)\n",
97 | "\n",
98 | "# Initialize the OpenAI client with custom base URL\n",
99 | "client = OpenAI(\n",
100 | " base_url=\"https://text.octoai.run/v1\",\n",
101 | " api_key=os.environ['OCTOAI_API_KEY'],\n",
102 | ")\n",
103 | "\n",
104 | "# Define model names\n",
105 | "small_model = \"meta-llama-3.1-8b-instruct\"\n",
106 | "big_model = \"meta-llama-3.1-405b-instruct\"\n",
107 | "\n",
108 | "def generate_candidate_prompts(task, prompt_example, response_example):\n",
109 | " system_prompt = \"\"\"Given an example training sample, create seven additional samples for the same task that are even better. Each example should contain a and a .\n",
110 | "\n",
111 | "\n",
112 | "1. Ensure the new examples are diverse and unique from one another.\n",
113 | "2. They should all be perfect. If you make a mistake, this system won't work.\n",
114 | "\n",
115 | "\n",
116 | "Respond in this format:\n",
117 | "\n",
118 | "\n",
119 | "\n",
120 | "PUT_PROMPT_HERE\n",
121 | "\n",
122 | "\n",
123 | "PUT_RESPONSE_HERE\n",
124 | "\n",
125 | "\n",
126 | "\n",
127 | "\n",
128 | "\n",
129 | "PUT_PROMPT_HERE\n",
130 | "\n",
131 | "\n",
132 | "PUT_RESPONSE_HERE\n",
133 | "\n",
134 | "\n",
135 | "\n",
136 | "...\n",
137 | "\"\"\"\n",
138 | "\n",
139 | " user_content = f\"\"\"{task}\n",
140 | "\n",
141 | "\n",
142 | "{prompt_example}\n",
143 | "\n",
144 | "\n",
145 | "\n",
146 | "{response_example}\n",
147 | "\"\"\"\n",
148 | "\n",
149 | " response = client.chat.completions.create(\n",
150 | " model=big_model,\n",
151 | " messages=[\n",
152 | " {\"role\": \"system\", \"content\": system_prompt},\n",
153 | " {\"role\": \"user\", \"content\": user_content}\n",
154 | " ],\n",
155 | " max_tokens=4000,\n",
156 | " temperature=0.5\n",
157 | " )\n",
158 | "\n",
159 | " response_text = response.choices[0].message.content\n",
160 | "\n",
161 | " # Parse out the prompts and responses\n",
162 | " prompts_and_responses = []\n",
163 | " examples = re.findall(r'(.*?)', response_text, re.DOTALL)\n",
164 | " for example in examples:\n",
165 | " prompt = re.findall(r'(.*?)', example, re.DOTALL)[0].strip()\n",
166 | " response = re.findall(r'(.*?)', example, re.DOTALL)[0].strip()\n",
167 | " prompts_and_responses.append({'prompt': prompt, 'response': response})\n",
168 | "\n",
169 | " return prompts_and_responses\n",
170 | "\n",
171 | "def generate_system_prompt(task, prompt_examples):\n",
172 | " system_prompt = \"\"\"Given a user-description of their a set of prompt / response pairs (it'll be in JSON for easy reading) for the types of outputs we want to generate given inputs, write a fantastic system prompt that describes the task to be done perfectly.\n",
173 | "\n",
174 | "\n",
175 | "1. Do this perfectly.\n",
176 | "2. Respond only with the system prompt, and nothing else. No other text will be allowed.\n",
177 | "\n",
178 | "\n",
179 | "Respond in this format:\n",
180 | "\n",
181 | "WRITE_SYSTEM_PROMPT_HERE\n",
182 | "\"\"\"\n",
183 | "\n",
184 | " user_content = f\"\"\"{task}\n",
185 | "\n",
186 | "\n",
187 | "{str(prompt_examples)}\n",
188 | "\"\"\"\n",
189 | "\n",
190 | " response = client.chat.completions.create(\n",
191 | " model=big_model,\n",
192 | " messages=[\n",
193 | " {\"role\": \"system\", \"content\": system_prompt},\n",
194 | " {\"role\": \"user\", \"content\": user_content}\n",
195 | " ],\n",
196 | " max_tokens=1000,\n",
197 | " temperature=0.5\n",
198 | " )\n",
199 | "\n",
200 | " response_text = response.choices[0].message.content\n",
201 | "\n",
202 | " # Parse out the prompt\n",
203 | " generated_system_prompt = response_text.split('')[1].split('')[0].strip()\n",
204 | "\n",
205 | " return generated_system_prompt\n",
206 | "\n",
207 | "def test_small_model(generated_examples, prompt_example, system_prompt):\n",
208 | " messages = [{\"role\": \"system\", \"content\": system_prompt}]\n",
209 | "\n",
210 | " for example in generated_examples:\n",
211 | " messages.append({\"role\": \"user\", \"content\": example['prompt']})\n",
212 | " messages.append({\"role\": \"assistant\", \"content\": example['response']})\n",
213 | "\n",
214 | " messages.append({\"role\": \"user\", \"content\": prompt_example.strip()})\n",
215 | "\n",
216 | " response = client.chat.completions.create(\n",
217 | " model=small_model,\n",
218 | " messages=messages,\n",
219 | " max_tokens=2000,\n",
220 | " temperature=0.5\n",
221 | " )\n",
222 | "\n",
223 | " response_text = response.choices[0].message.content\n",
224 | "\n",
225 | " return response_text\n",
226 | "\n",
227 | "def run_conversion_process(task, prompt_example, response_example):\n",
228 | " print('Generating the prompts / responses...')\n",
229 | " # Generate candidate prompts\n",
230 | " generated_examples = generate_candidate_prompts(task, prompt_example, response_example)\n",
231 | "\n",
232 | " print('Prompts / responses generated. Now generating system prompt...')\n",
233 | "\n",
234 | " # Generate the system prompt\n",
235 | " system_prompt = generate_system_prompt(task, generated_examples)\n",
236 | "\n",
237 | " print('System prompt generated:', system_prompt)\n",
238 | "\n",
239 | " print(f'\\n\\nTesting the new prompt on {small_model}, using your input example...')\n",
240 | " # Test the generated examples and system prompt with the small model\n",
241 | " small_model_response = test_small_model(generated_examples, prompt_example, system_prompt)\n",
242 | "\n",
243 | " print(f'{small_model} responded with:')\n",
244 | " print(small_model_response)\n",
245 | "\n",
246 | " print('\\n\\n!! CHECK THE FILE DIRECTORY, THE PROMPT IS NOW SAVED THERE !!')\n",
247 | "\n",
248 | " # Create a dictionary with all the relevant information\n",
249 | " result = {\n",
250 | " \"task\": task,\n",
251 | " \"initial_prompt_example\": prompt_example,\n",
252 | " \"initial_response_example\": response_example,\n",
253 | " \"generated_examples\": generated_examples,\n",
254 | " \"system_prompt\": system_prompt,\n",
255 | " \"small_model_response\": small_model_response\n",
256 | " }\n",
257 | "\n",
258 | " # Save the small model prompt to a Python file\n",
259 | " with open(\"small_model_prompt.py\", \"w\") as file:\n",
260 | " file.write('system_prompt = \"\"\"' + system_prompt + '\"\"\"\\n\\n')\n",
261 | "\n",
262 | " file.write('messages = [\\n')\n",
263 | " for example in generated_examples:\n",
264 | " file.write(' {\"role\": \"user\", \"content\": \"\"\"' + example['prompt'] + '\"\"\"},\\n')\n",
265 | " file.write(' {\"role\": \"assistant\", \"content\": \"\"\"' + example['response'] + '\"\"\"},\\n')\n",
266 | "\n",
267 | " file.write(' {\"role\": \"user\", \"content\": \"\"\"' + prompt_example.strip() + '\"\"\"}\\n')\n",
268 | " file.write(']\\n')\n",
269 | "\n",
270 | " return result"
271 | ],
272 | "metadata": {
273 | "id": "ylWOvJEG4N3I"
274 | },
275 | "execution_count": null,
276 | "outputs": []
277 | },
278 | {
279 | "cell_type": "markdown",
280 | "source": [
281 | "# Fill in your task, prompt_example, and response_example here. Make sure you keep the quality really high here... this is the most important step!"
282 | ],
283 | "metadata": {
284 | "id": "y8PCYOdO4ZYF"
285 | }
286 | },
287 | {
288 | "cell_type": "code",
289 | "source": [
290 | "task = \"refactoring complex code\"\n",
291 | "\n",
292 | "prompt_example = \"\"\"def calculate_total(prices, tax, discount, shipping_fee, gift_wrap_fee, membership_discount):\n",
293 | "\n",
294 | " total = 0\n",
295 | "\n",
296 | " for i in range(len(prices)):\n",
297 | "\n",
298 | " total += prices[i]\n",
299 | "\n",
300 | " if membership_discount != 0:\n",
301 | "\n",
302 | " total = total - (total * (membership_discount / 100))\n",
303 | "\n",
304 | " if discount != 0:\n",
305 | "\n",
306 | " total = total - (total * (discount / 100))\n",
307 | "\n",
308 | " total = total + (total * (tax / 100))\n",
309 | "\n",
310 | " if total < 50:\n",
311 | "\n",
312 | " total += shipping_fee\n",
313 | "\n",
314 | " else:\n",
315 | "\n",
316 | " total += shipping_fee / 2\n",
317 | "\n",
318 | " if gift_wrap_fee != 0:\n",
319 | "\n",
320 | " total += gift_wrap_fee * len(prices)\n",
321 | "\n",
322 | " if total > 1000:\n",
323 | "\n",
324 | " total -= 50\n",
325 | "\n",
326 | " elif total > 500:\n",
327 | "\n",
328 | " total -= 25\n",
329 | "\n",
330 | " total = round(total, 2)\n",
331 | "\n",
332 | " if total < 0:\n",
333 | "\n",
334 | " total = 0\n",
335 | "\n",
336 | " return total\"\"\"\n",
337 | "\n",
338 | "response_example = \"\"\"def calculate_total(prices, tax_rate, discount_rate, shipping_fee, gift_wrap_fee, membership_discount_rate):\n",
339 | "\n",
340 | " def apply_percentage_discount(amount, percentage):\n",
341 | "\n",
342 | " return amount * (1 - percentage / 100)\n",
343 | "\n",
344 | " def calculate_shipping_fee(total):\n",
345 | "\n",
346 | " return shipping_fee if total < 50 else shipping_fee / 2\n",
347 | "\n",
348 | " def apply_tier_discount(total):\n",
349 | "\n",
350 | " if total > 1000:\n",
351 | "\n",
352 | " return total - 50\n",
353 | "\n",
354 | " elif total > 500:\n",
355 | "\n",
356 | " return total - 25\n",
357 | "\n",
358 | " return total\n",
359 | "\n",
360 | " subtotal = sum(prices)\n",
361 | "\n",
362 | " subtotal = apply_percentage_discount(subtotal, membership_discount_rate)\n",
363 | "\n",
364 | " subtotal = apply_percentage_discount(subtotal, discount_rate)\n",
365 | "\n",
366 | "\n",
367 | "\n",
368 | " total = subtotal * (1 + tax_rate / 100)\n",
369 | "\n",
370 | " total += calculate_shipping_fee(total)\n",
371 | "\n",
372 | " total += gift_wrap_fee * len(prices)\n",
373 | "\n",
374 | "\n",
375 | "\n",
376 | " total = apply_tier_discount(total)\n",
377 | "\n",
378 | " total = max(0, round(total, 2))\n",
379 | "\n",
380 | "\n",
381 | "\n",
382 | " return total\"\"\""
383 | ],
384 | "metadata": {
385 | "id": "zdPBIjMc4YIj"
386 | },
387 | "execution_count": null,
388 | "outputs": []
389 | },
390 | {
391 | "cell_type": "markdown",
392 | "source": [
393 | "# Now, let's run this system and get our new prompt! At the end, you'll see a new file pop up in the directory that contains everything you'll need to reduce your costs while keeping quality high w/ Llama 3.1 8B!"
394 | ],
395 | "metadata": {
396 | "id": "xu8WkKy44eRF"
397 | }
398 | },
399 | {
400 | "cell_type": "code",
401 | "source": [
402 | "result = run_conversion_process(task, prompt_example, response_example)"
403 | ],
404 | "metadata": {
405 | "id": "VxDzg8944eBB"
406 | },
407 | "execution_count": null,
408 | "outputs": []
409 | }
410 | ]
411 | }
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # gpt-prompt-engineer
2 | [](https://twitter.com/mattshumer_) [](https://colab.research.google.com/github/mshumer/gpt-prompt-engineer/blob/main/gpt_prompt_engineer.ipynb) [](https://colab.research.google.com/drive/16NLMjqyuUWxcokE_NF6RwHD8grwEeoaJ?usp=sharing)
3 |
4 | ## Overview
5 |
6 | Prompt engineering is kind of like alchemy. There's no clear way to predict what will work best. It's all about experimenting until you find the right prompt. `gpt-prompt-engineer` is a tool that takes this experimentation to a whole new level.
7 |
8 | **Simply input a description of your task and some test cases, and the system will generate, test, and rank a multitude of prompts to find the ones that perform the best.**
9 |
10 | ## *New 3/20/24: The Claude 3 Opus Version*
11 | I've added a new version of gpt-prompt-engineer that takes full advantage of Anthropic's Claude 3 Opus model. This version auto-generates test cases and allows for the user to define multiple input variables, making it even more powerful and flexible. Try it out with the claude-prompt-engineer.ipynb notebook in the repo!
12 |
13 | ## *New 3/20/24: Claude 3 Opus -> Haiku Conversion Version*
14 | This notebook enables you to build lightning-fast, performant AI systems at a fraction of the typical cost. By using Claude 3 Opus to establish the latent space and Claude 3 Haiku for the actual generation, you can achieve amazing results. The process works by leveraging Opus to produce a collection of top-notch examples, which are then used to guide Haiku in generating output of comparable quality while dramatically reducing both latency and cost per generation. Try it out with the opus-to-haiku-conversion.ipynb notebook in the repo!
15 |
16 | ## Features
17 |
18 | - **Prompt Generation**: Using GPT-4, GPT-3.5-Turbo, or Claude 3 Opus, `gpt-prompt-engineer` can generate a variety of possible prompts based on a provided use-case and test cases.
19 |
20 | - **Prompt Testing**: The real magic happens after the generation. The system tests each prompt against all the test cases, comparing their performance and ranking them using an ELO rating system.
21 |  22 |
23 | - **ELO Rating System**: Each prompt starts with an ELO rating of 1200. As they compete against each other in generating responses to the test cases, their ELO ratings change based on their performance. This way, you can easily see which prompts are the most effective.
24 |
25 | - **Classification Version**: The `gpt-prompt-engineer -- Classification Version` notebook is designed to handle classification tasks. It evaluates the correctness of a test case by matching it to the expected output ('true' or 'false') and provides a table with scores for each prompt.
26 |
22 |
23 | - **ELO Rating System**: Each prompt starts with an ELO rating of 1200. As they compete against each other in generating responses to the test cases, their ELO ratings change based on their performance. This way, you can easily see which prompts are the most effective.
24 |
25 | - **Classification Version**: The `gpt-prompt-engineer -- Classification Version` notebook is designed to handle classification tasks. It evaluates the correctness of a test case by matching it to the expected output ('true' or 'false') and provides a table with scores for each prompt.
26 | 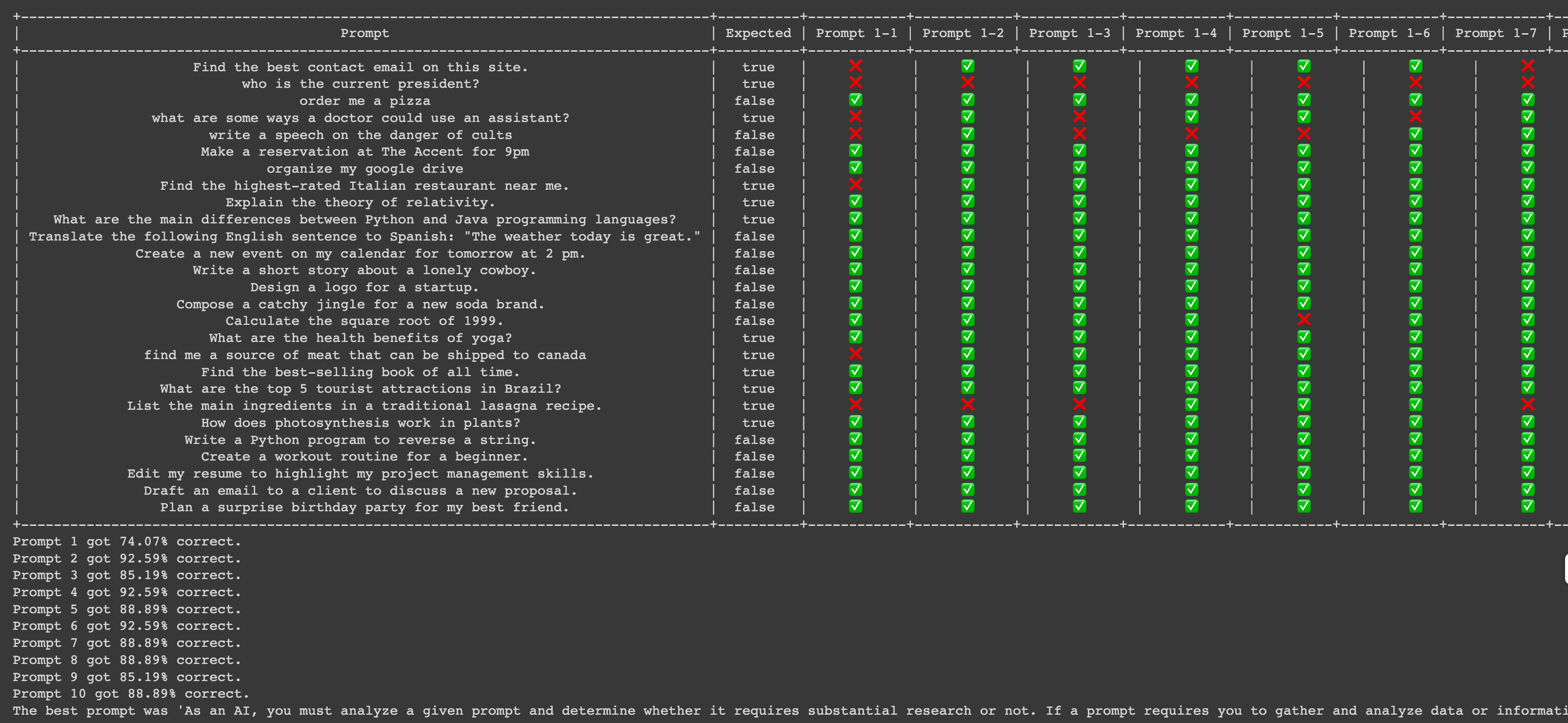 27 |
28 | - **Claude 3 Version**: The claude-prompt-engineer notebook is designed to work with Anthropic's Claude 3 Opus model. It auto-generates test cases and allows for multiple input variables, making it even more powerful and flexible.
29 |
30 | - **Claude 3 Opus -> Haiku Conversion Version**: Designed to preserve Opus' quality for your use-case while getting the speed + cost benefits of using Haiku.
31 |
32 | - **[Weights & Biases](https://wandb.ai/site/prompts) Logging**: Optional logging to [Weights & Biases](https://wandb.ai/site) of your configs such as temperature and max tokens, the system and user prompts for each part, the test cases used and the final ranked ELO rating for each candidate prompt. Set `use_wandb` to `True` to use.
33 |
34 | - **[Portkey](https://portkey.ai)**: Optional tool to log and trace all the prompt chains and their responses. Set `use_portkey` to `True` to use.
35 |
36 | ## Setup
37 | 1. [Open the notebook in Google Colab](https://colab.research.google.com/github/mshumer/gpt-prompt-engineer/blob/main/gpt_prompt_engineer.ipynb) or in a local Jupyter notebook. For classification, use [this one.](https://colab.research.google.com/drive/16NLMjqyuUWxcokE_NF6RwHD8grwEeoaJ?usp=sharing). For the Claude 3 version, use [this one.](https://colab.research.google.com/drive/1likU_S4VfkzoLMPfVdMs3E54cn_W6I7o?usp=sharing)
38 |
39 | 2. Add your OpenAI API key to the line `openai.api_key = "ADD YOUR KEY HERE"`. If you're using the Claude 3 version, add your Anthropic API key to the line `ANTHROPIC_API_KEY = "ADD YOUR KEY HERE"`.
40 |
41 | ## How to Use
42 |
43 | 1. If you are using the GPT-4 version, define your use-case and test cases. The use-case is a description of what you want the AI to do. Test cases are specific prompts that you would like the AI to respond to. For example:
44 |
45 | ```
46 | description = "Given a prompt, generate a landing page headline." # this style of description tends to work well
47 |
48 | test_cases = [
49 | {
50 | 'prompt': 'Promoting an innovative new fitness app, Smartly',
51 | },
52 | {
53 | 'prompt': 'Why a vegan diet is beneficial for your health',
54 | },
55 | {
56 | 'prompt': 'Introducing a new online course on digital marketing',
57 | },
58 | {
59 | 'prompt': 'Launching a new line of eco-friendly clothing',
60 | },
61 | {
62 | 'prompt': 'Promoting a new travel blog focusing on budget travel',
63 | },
64 | {
65 | 'prompt': 'Advertising a new software for efficient project management',
66 | },
67 | {
68 | 'prompt': 'Introducing a new book on mastering Python programming',
69 | },
70 | {
71 | 'prompt': 'Promoting a new online platform for learning languages',
72 | },
73 | {
74 | 'prompt': 'Advertising a new service for personalized meal plans',
75 | },
76 | {
77 | 'prompt': 'Launching a new app for mental health and mindfulness',
78 | }
79 | ]
80 | ```
81 |
82 | For the classification version, your test cases should be in the format:
83 |
84 | ```
85 | test_cases = [
86 | {
87 | 'prompt': 'I had a great day!',
88 | 'output': 'true'
89 | },
90 | {
91 | 'prompt': 'I am feeling gloomy.',
92 | 'output': 'false'
93 | },
94 | // add more test cases here
95 | ]
96 | ```
97 |
98 | For the Claude 3 version, you can define input variables in addition to the use-case description:
99 |
100 | ```
101 | description = "Given a prompt, generate a personalized email response."
102 |
103 | input_variables = [
104 | {"variable": "SENDER_NAME", "description": "The name of the person who sent the email."},
105 | {"variable": "RECIPIENT_NAME", "description": "The name of the person receiving the email."},
106 | {"variable": "TOPIC", "description": "The main topic or subject of the email. One to two sentences."}
107 | ]
108 | ```
109 |
110 | The test cases will be auto-generated based on the use-case description and input variables.
111 |
112 | 3. Choose how many prompts to generate. Keep in mind, this can get expensive if you generate many prompts. 10 is a good starting point.
113 |
114 | 4. Call `generate_optimal_prompt(description, test_cases, number_of_prompts)` to generate a list of potential prompts, and test and rate their performance. For the classification version, just run the last cell. For the Claude 3 version, call `generate_optimal_prompt(description, input_variables, num_test_cases, number_of_prompts, use_wandb)`.
115 |
116 | 5. The final ELO ratings will be printed in a table, sorted in descending order. The higher the rating, the better the prompt.
117 |
27 |
28 | - **Claude 3 Version**: The claude-prompt-engineer notebook is designed to work with Anthropic's Claude 3 Opus model. It auto-generates test cases and allows for multiple input variables, making it even more powerful and flexible.
29 |
30 | - **Claude 3 Opus -> Haiku Conversion Version**: Designed to preserve Opus' quality for your use-case while getting the speed + cost benefits of using Haiku.
31 |
32 | - **[Weights & Biases](https://wandb.ai/site/prompts) Logging**: Optional logging to [Weights & Biases](https://wandb.ai/site) of your configs such as temperature and max tokens, the system and user prompts for each part, the test cases used and the final ranked ELO rating for each candidate prompt. Set `use_wandb` to `True` to use.
33 |
34 | - **[Portkey](https://portkey.ai)**: Optional tool to log and trace all the prompt chains and their responses. Set `use_portkey` to `True` to use.
35 |
36 | ## Setup
37 | 1. [Open the notebook in Google Colab](https://colab.research.google.com/github/mshumer/gpt-prompt-engineer/blob/main/gpt_prompt_engineer.ipynb) or in a local Jupyter notebook. For classification, use [this one.](https://colab.research.google.com/drive/16NLMjqyuUWxcokE_NF6RwHD8grwEeoaJ?usp=sharing). For the Claude 3 version, use [this one.](https://colab.research.google.com/drive/1likU_S4VfkzoLMPfVdMs3E54cn_W6I7o?usp=sharing)
38 |
39 | 2. Add your OpenAI API key to the line `openai.api_key = "ADD YOUR KEY HERE"`. If you're using the Claude 3 version, add your Anthropic API key to the line `ANTHROPIC_API_KEY = "ADD YOUR KEY HERE"`.
40 |
41 | ## How to Use
42 |
43 | 1. If you are using the GPT-4 version, define your use-case and test cases. The use-case is a description of what you want the AI to do. Test cases are specific prompts that you would like the AI to respond to. For example:
44 |
45 | ```
46 | description = "Given a prompt, generate a landing page headline." # this style of description tends to work well
47 |
48 | test_cases = [
49 | {
50 | 'prompt': 'Promoting an innovative new fitness app, Smartly',
51 | },
52 | {
53 | 'prompt': 'Why a vegan diet is beneficial for your health',
54 | },
55 | {
56 | 'prompt': 'Introducing a new online course on digital marketing',
57 | },
58 | {
59 | 'prompt': 'Launching a new line of eco-friendly clothing',
60 | },
61 | {
62 | 'prompt': 'Promoting a new travel blog focusing on budget travel',
63 | },
64 | {
65 | 'prompt': 'Advertising a new software for efficient project management',
66 | },
67 | {
68 | 'prompt': 'Introducing a new book on mastering Python programming',
69 | },
70 | {
71 | 'prompt': 'Promoting a new online platform for learning languages',
72 | },
73 | {
74 | 'prompt': 'Advertising a new service for personalized meal plans',
75 | },
76 | {
77 | 'prompt': 'Launching a new app for mental health and mindfulness',
78 | }
79 | ]
80 | ```
81 |
82 | For the classification version, your test cases should be in the format:
83 |
84 | ```
85 | test_cases = [
86 | {
87 | 'prompt': 'I had a great day!',
88 | 'output': 'true'
89 | },
90 | {
91 | 'prompt': 'I am feeling gloomy.',
92 | 'output': 'false'
93 | },
94 | // add more test cases here
95 | ]
96 | ```
97 |
98 | For the Claude 3 version, you can define input variables in addition to the use-case description:
99 |
100 | ```
101 | description = "Given a prompt, generate a personalized email response."
102 |
103 | input_variables = [
104 | {"variable": "SENDER_NAME", "description": "The name of the person who sent the email."},
105 | {"variable": "RECIPIENT_NAME", "description": "The name of the person receiving the email."},
106 | {"variable": "TOPIC", "description": "The main topic or subject of the email. One to two sentences."}
107 | ]
108 | ```
109 |
110 | The test cases will be auto-generated based on the use-case description and input variables.
111 |
112 | 3. Choose how many prompts to generate. Keep in mind, this can get expensive if you generate many prompts. 10 is a good starting point.
113 |
114 | 4. Call `generate_optimal_prompt(description, test_cases, number_of_prompts)` to generate a list of potential prompts, and test and rate their performance. For the classification version, just run the last cell. For the Claude 3 version, call `generate_optimal_prompt(description, input_variables, num_test_cases, number_of_prompts, use_wandb)`.
115 |
116 | 5. The final ELO ratings will be printed in a table, sorted in descending order. The higher the rating, the better the prompt.
117 |  118 |
119 | For the classification version, the scores for each prompt will be printed in a table (see the image above).
120 |
121 | ## Contributions are welcome! Some ideas:
122 | - have a number of different system prompt generators that create different styles of prompts, to cover more ground (ex. examples, verbose, short, markdown, etc.)
123 | - automatically generate the test cases
124 | - expand the classification version to support more than two classes using tiktoken
125 |
126 | ## License
127 |
128 | This project is [MIT](https://github.com/your_username/your_repository/blob/master/LICENSE) licensed.
129 |
130 | ## Contact
131 |
132 | Matt Shumer - [@mattshumer_](https://twitter.com/mattshumer_)
133 |
134 | Project Link: [https://github.com/mshumer/gpt-prompt-engineer](url)
135 |
136 | Lastly, if you want to try something even cooler than this, sign up for [HyperWrite Personal Assistant](https://app.hyperwriteai.com/personalassistant) (most of my time is spent on this). It's basically an AI with access to real-time information that a) is incredible at writing naturally, and b) can operate your web browser to complete tasks for you.
137 |
138 | Head to [ShumerPrompt](https://ShumerPrompt.com), my "Github for Prompts"!
139 |
--------------------------------------------------------------------------------
/XL_to_XS_conversion.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "id": "view-in-github"
7 | },
8 | "source": [
9 | ""
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {
15 | "id": "WljjH8K3s7kG"
16 | },
17 | "source": [
18 | "# XL to XS - Prompt Engineering for Smaller Models\n",
19 | "\n",
20 | "This notebook gives you the ability to go from a large model to smaller model -- reducing costs massively while keeping quality high.\n",
21 | "\n",
22 | "This extends the Opus to Haiku notebook ( in [`gpt-prompt-engineer`]((https://github.com/mshumer/gpt-prompt-engineer)) repo by [Matt Shumer](https://twitter.com/mattshumer_)) to cover any large and small model combination using Portkey's [AI Gateway](https://github.com/portkey-ai/gateway)"
23 | ]
24 | },
25 | {
26 | "cell_type": "code",
27 | "execution_count": null,
28 | "metadata": {
29 | "id": "dQmMZdkG_RA5"
30 | },
31 | "outputs": [],
32 | "source": [
33 | "import requests\n",
34 | "\n",
35 | "PORTKEY_API_KEY = \"\" # Configure your AI Gateway Key (https://app.portkey.ai/signup)\n",
36 | "\n",
37 | "PROVIDER = \"\" # Any of `openai`, `anthropic`, `azure-openai`, `anyscale`, `mistral`, `gemini` and more\n",
38 | "PROVIDER_API_KEY = \"\" # Enter the API key of the provider used above\n",
39 | "LARGE_MODEL = \"\" # The large model to use\n",
40 | "\n",
41 | "\n",
42 | "# If you want to use a different provider for the smaller model, uncomment these 2 lines\n",
43 | "# SMALL_PROVIDER = \"\" # Any of `openai`, `anthropic`, `azure-openai`, `anyscale`, `mistral`, `gemini`\n",
44 | "# SMALL_PROVIDER_API_KEY = \"\"\n",
45 | "\n",
46 | "SMALL_MODEL = \"\" # The small model to use"
47 | ]
48 | },
49 | {
50 | "cell_type": "markdown",
51 | "metadata": {
52 | "id": "B84V9aohvCbr"
53 | },
54 | "source": [
55 | "### Portkey Client Init\n",
56 | "\n",
57 | "Using Portkey clients for the large and small models. The gateway will allow us to make calls to any model without chaning our code."
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "source": [
63 | "!pip install portkey_ai"
64 | ],
65 | "metadata": {
66 | "id": "BfTZMUNwwhxe"
67 | },
68 | "execution_count": null,
69 | "outputs": []
70 | },
71 | {
72 | "cell_type": "code",
73 | "execution_count": null,
74 | "metadata": {
75 | "cellView": "form",
76 | "id": "wXeqMQpzzosx"
77 | },
78 | "outputs": [],
79 | "source": [
80 | "#@title Run this to prep the main functions\n",
81 | "\n",
82 | "from portkey_ai import Portkey\n",
83 | "\n",
84 | "client_large = Portkey(\n",
85 | " Authorization= \"Bearer \"+PROVIDER_API_KEY,\n",
86 | " provider=PROVIDER,\n",
87 | " api_key=PORTKEY_API_KEY,\n",
88 | " metadata={\"_user\": \"gpt-prompt-engineer\"},\n",
89 | " config={\"cache\": {\"mode\": \"simple\"}}\n",
90 | ")\n",
91 | "\n",
92 | "try:\n",
93 | " authorization_token = \"Bearer \" + SMALL_PROVIDER_API_KEY\n",
94 | "except NameError:\n",
95 | " authorization_token = \"Bearer \" + PROVIDER_API_KEY\n",
96 | "\n",
97 | "try:\n",
98 | " provider_name = SMALL_PROVIDER\n",
99 | "except NameError:\n",
100 | " provider_name = PROVIDER\n",
101 | "\n",
102 | "client_small = Portkey(\n",
103 | " Authorization=authorization_token,\n",
104 | " provider=provider_name,\n",
105 | " api_key=PORTKEY_API_KEY, # Ensure this is defined and contains the correct API key.\n",
106 | " metadata={\"_user\": \"gpt-prompt-engineer\"},\n",
107 | " config={\"cache\": {\"mode\": \"simple\"}}\n",
108 | ")\n",
109 | "\n",
110 | "import json\n",
111 | "import re\n",
112 | "\n",
113 | "def generate_candidate_prompts(task, prompt_example, response_example):\n",
114 | " messages = [{\n",
115 | " \"role\": \"system\",\n",
116 | " \"content\":\"\"\"Given an example training sample, create seven additional samples for the same task that are even better. Each example should contain a and a .\n",
117 | "\n",
118 | "\n",
119 | "1. Ensure the new examples are diverse and unique from one another.\n",
120 | "2. They should all be perfect. If you make a mistake, this system won't work.\n",
121 | "\n",
122 | "\n",
123 | "Respond in this format:\n",
124 | "\n",
125 | "\n",
126 | "\n",
127 | "PUT_PROMPT_HERE\n",
128 | "\n",
129 | "\n",
130 | "PUT_RESPONSE_HERE\n",
131 | "\n",
132 | "\n",
133 | "\n",
134 | "\n",
135 | "\n",
136 | "PUT_PROMPT_HERE\n",
137 | "\n",
138 | "\n",
139 | "PUT_RESPONSE_HERE\n",
140 | "\n",
141 | "\n",
142 | "\n",
143 | "...\n",
144 | "\"\"\"\n",
145 | " }, {\n",
146 | " \"role\": \"user\",\n",
147 | " \"content\": f\"\"\"{task}\n",
148 | "\n",
149 | "\n",
150 | "{prompt_example}\n",
151 | "\n",
152 | "\n",
153 | "\n",
154 | "{response_example}\n",
155 | "\"\"\"},\n",
156 | " ]\n",
157 | "\n",
158 | " response = client_large.chat.completions.create(\n",
159 | " model=LARGE_MODEL,\n",
160 | " max_tokens=4000,\n",
161 | " temperature=0.5,\n",
162 | " messages=messages\n",
163 | " )\n",
164 | " response_text = response.choices[0]['message']['content']\n",
165 | "\n",
166 | " # Parse out the prompts and responses\n",
167 | " prompts_and_responses = []\n",
168 | " examples = re.findall(r'(.*?)', response_text, re.DOTALL)\n",
169 | " for example in examples:\n",
170 | " prompt = re.findall(r'(.*?)', example, re.DOTALL)[0].strip()\n",
171 | " response = re.findall(r'(.*?)', example, re.DOTALL)[0].strip()\n",
172 | " prompts_and_responses.append({'prompt': prompt, 'response': response})\n",
173 | "\n",
174 | " return prompts_and_responses\n",
175 | "\n",
176 | "def generate_system_prompt(task, prompt_examples):\n",
177 | " messages = [\n",
178 | " {\"role\": \"system\", \"content\": \"\"\"Given a user-description of their a set of prompt / response pairs (it'll be in JSON for easy reading) for the types of outputs we want to generate given inputs, write a fantastic system prompt that describes the task to be done perfectly.\n",
179 | "\n",
180 | "\n",
181 | "1. Do this perfectly.\n",
182 | "2. Respond only with the system prompt, and nothing else. No other text will be allowed.\n",
183 | "\n",
184 | "\n",
185 | "Respond in this format:\n",
186 | "\n",
187 | "WRITE_SYSTEM_PROMPT_HERE\n",
188 | "\"\"\"\n",
189 | " },\n",
190 | " {\"role\": \"user\", \"content\": f\"\"\"{task}\n",
191 | "\n",
192 | "\n",
193 | "{str(prompt_examples)}\n",
194 | "\"\"\"\n",
195 | " }]\n",
196 | "\n",
197 | " response = client_large.chat.completions.create(\n",
198 | " model=LARGE_MODEL,\n",
199 | " max_tokens=1000,\n",
200 | " temperature=0.5,\n",
201 | " messages=messages\n",
202 | " )\n",
203 | " response_text = response.choices[0]['message']['content']\n",
204 | "\n",
205 | " # Parse out the prompt\n",
206 | " system_prompt = response_text.split('')[1].split('')[0].strip()\n",
207 | "\n",
208 | " return system_prompt\n",
209 | "\n",
210 | "def test_haiku(generated_examples, prompt_example, system_prompt):\n",
211 | " messages = [{\"role\": \"system\", \"content\": system_prompt}]\n",
212 | "\n",
213 | " for example in generated_examples:\n",
214 | " messages.append({\"role\": \"user\", \"content\": example['prompt']})\n",
215 | " messages.append({\"role\": \"assistant\", \"content\": example['response']})\n",
216 | "\n",
217 | " messages.append({\"role\": \"user\", \"content\": prompt_example.strip()})\n",
218 | "\n",
219 | " response = client_small.chat.completions.create(\n",
220 | " model = SMALL_MODEL,\n",
221 | " max_tokens=2000,\n",
222 | " temperature=0.5,\n",
223 | " messages=messages\n",
224 | " )\n",
225 | " response_text = response.choices[0]['message']['content']\n",
226 | "\n",
227 | " return response_text\n",
228 | "\n",
229 | "def run_haiku_conversion_process(task, prompt_example, response_example):\n",
230 | "\n",
231 | " print('Generating the prompts / responses...')\n",
232 | " # Generate candidate prompts\n",
233 | " generated_examples = generate_candidate_prompts(task, prompt_example, response_example)\n",
234 | "\n",
235 | " print('Prompts / responses generated. Now generating system prompt...')\n",
236 | "\n",
237 | " # Generate the system prompt\n",
238 | " system_prompt = generate_system_prompt(task, generated_examples)\n",
239 | "\n",
240 | " print('System prompt generated:', system_prompt)\n",
241 | "\n",
242 | "\n",
243 | " print('\\n\\nTesting the new prompt on '+SMALL_MODEL+', using your input example...')\n",
244 | " # Test the generated examples and system prompt with the Haiku model\n",
245 | " small_model_response = test_haiku(generated_examples, prompt_example, system_prompt)\n",
246 | "\n",
247 | " print(SMALL_MODEL+' responded with:')\n",
248 | " print(small_model_response)\n",
249 | "\n",
250 | " print('\\n\\n!! CHECK THE FILE DIRECTORY, THE PROMPT IS NOW SAVED THERE !!')\n",
251 | "\n",
252 | " # Create a dictionary with all the relevant information\n",
253 | " result = {\n",
254 | " \"task\": task,\n",
255 | " \"initial_prompt_example\": prompt_example,\n",
256 | " \"initial_response_example\": response_example,\n",
257 | " \"generated_examples\": generated_examples,\n",
258 | " \"system_prompt\": system_prompt,\n",
259 | " \"small_model_response\": small_model_response\n",
260 | " }\n",
261 | "\n",
262 | " # Save the Haiku prompt to a Python file\n",
263 | " with open(\"haiku_prompt.py\", \"w\") as file:\n",
264 | " file.write('system_prompt = \"\"\"' + system_prompt + '\"\"\"\\n\\n')\n",
265 | "\n",
266 | " file.write('messages = [\\n')\n",
267 | " for example in generated_examples:\n",
268 | " file.write(' {\"role\": \"user\", \"content\": \"\"\"' + example['prompt'] + '\"\"\"},\\n')\n",
269 | " file.write(' {\"role\": \"assistant\", \"content\": \"\"\"' + example['response'] + '\"\"\"},\\n')\n",
270 | "\n",
271 | " file.write(' {\"role\": \"user\", \"content\": \"\"\"' + prompt_example.strip() + '\"\"\"}\\n')\n",
272 | " file.write(']\\n')\n",
273 | "\n",
274 | " return result"
275 | ]
276 | },
277 | {
278 | "cell_type": "markdown",
279 | "metadata": {
280 | "id": "ZujTAzhuBMea"
281 | },
282 | "source": [
283 | "## Fill in your task, prompt_example, and response_example here.\n",
284 | "Make sure you keep the quality really high here... this is the most important step!"
285 | ]
286 | },
287 | {
288 | "cell_type": "code",
289 | "execution_count": null,
290 | "metadata": {
291 | "id": "XSZqqOoQ-5_E"
292 | },
293 | "outputs": [],
294 | "source": [
295 | "task = \"refactoring complex code\"\n",
296 | "\n",
297 | "prompt_example = \"\"\"def calculate_total(prices, tax, discount, shipping_fee, gift_wrap_fee, membership_discount):\n",
298 | "\n",
299 | " total = 0\n",
300 | "\n",
301 | " for i in range(len(prices)):\n",
302 | "\n",
303 | " total += prices[i]\n",
304 | "\n",
305 | " if membership_discount != 0:\n",
306 | "\n",
307 | " total = total - (total * (membership_discount / 100))\n",
308 | "\n",
309 | " if discount != 0:\n",
310 | "\n",
311 | " total = total - (total * (discount / 100))\n",
312 | "\n",
313 | " total = total + (total * (tax / 100))\n",
314 | "\n",
315 | " if total < 50:\n",
316 | "\n",
317 | " total += shipping_fee\n",
318 | "\n",
319 | " else:\n",
320 | "\n",
321 | " total += shipping_fee / 2\n",
322 | "\n",
323 | " if gift_wrap_fee != 0:\n",
324 | "\n",
325 | " total += gift_wrap_fee * len(prices)\n",
326 | "\n",
327 | " if total > 1000:\n",
328 | "\n",
329 | " total -= 50\n",
330 | "\n",
331 | " elif total > 500:\n",
332 | "\n",
333 | " total -= 25\n",
334 | "\n",
335 | " total = round(total, 2)\n",
336 | "\n",
337 | " if total < 0:\n",
338 | "\n",
339 | " total = 0\n",
340 | "\n",
341 | " return total\"\"\"\n",
342 | "\n",
343 | "response_example = \"\"\"def calculate_total(prices, tax_rate, discount_rate, shipping_fee, gift_wrap_fee, membership_discount_rate):\n",
344 | "\n",
345 | " def apply_percentage_discount(amount, percentage):\n",
346 | "\n",
347 | " return amount * (1 - percentage / 100)\n",
348 | "\n",
349 | " def calculate_shipping_fee(total):\n",
350 | "\n",
351 | " return shipping_fee if total < 50 else shipping_fee / 2\n",
352 | "\n",
353 | " def apply_tier_discount(total):\n",
354 | "\n",
355 | " if total > 1000:\n",
356 | "\n",
357 | " return total - 50\n",
358 | "\n",
359 | " elif total > 500:\n",
360 | "\n",
361 | " return total - 25\n",
362 | "\n",
363 | " return total\n",
364 | "\n",
365 | " subtotal = sum(prices)\n",
366 | "\n",
367 | " subtotal = apply_percentage_discount(subtotal, membership_discount_rate)\n",
368 | "\n",
369 | " subtotal = apply_percentage_discount(subtotal, discount_rate)\n",
370 | "\n",
371 | "\n",
372 | "\n",
373 | " total = subtotal * (1 + tax_rate / 100)\n",
374 | "\n",
375 | " total += calculate_shipping_fee(total)\n",
376 | "\n",
377 | " total += gift_wrap_fee * len(prices)\n",
378 | "\n",
379 | "\n",
380 | "\n",
381 | " total = apply_tier_discount(total)\n",
382 | "\n",
383 | " total = max(0, round(total, 2))\n",
384 | "\n",
385 | "\n",
386 | "\n",
387 | " return total\"\"\""
388 | ]
389 | },
390 | {
391 | "cell_type": "markdown",
392 | "metadata": {
393 | "id": "cMO3cJzWA-O0"
394 | },
395 | "source": [
396 | "### Now, let's run this system and get our new prompt!\n",
397 | "At the end, you'll see a new file pop up in the directory that contains everything you'll need to reduce your costs while keeping quality high w/ Haiku!"
398 | ]
399 | },
400 | {
401 | "cell_type": "code",
402 | "execution_count": null,
403 | "metadata": {
404 | "id": "O-Bn0rupAJqb",
405 | "outputId": "52d922bc-8d93-4bff-e26b-42c8c99166a5"
406 | },
407 | "outputs": [
408 | {
409 | "name": "stdout",
410 | "output_type": "stream",
411 | "text": [
412 | "Generating the prompts / responses...\n",
413 | "Prompts / responses generated. Now generating system prompt...\n",
414 | "System prompt generated: You are an expert code refactoring assistant. Your task is to take a given piece of code and refactor it to be more concise, efficient, and maintainable while preserving its original functionality. Focus on improving code readability, eliminating redundancies, optimizing performance, and applying best practices and design patterns where appropriate. Provide a clear, refactored version of the code that showcases your expertise in writing clean, high-quality code.\n",
415 | "\n",
416 | "\n",
417 | "Testing the new prompt on claude-3-haiku-20240307, using your input example...\n",
418 | "claude-3-haiku-20240307 responded with:\n",
419 | "def calculate_total(prices, tax, discount, shipping_fee, gift_wrap_fee, membership_discount):\n",
420 | " subtotal = sum(prices)\n",
421 | " \n",
422 | " if membership_discount:\n",
423 | " subtotal *= (1 - membership_discount / 100)\n",
424 | " \n",
425 | " if discount:\n",
426 | " subtotal *= (1 - discount / 100)\n",
427 | " \n",
428 | " total = subtotal * (1 + tax / 100)\n",
429 | " \n",
430 | " if total < 50:\n",
431 | " total += shipping_fee\n",
432 | " else:\n",
433 | " total += shipping_fee / 2\n",
434 | " \n",
435 | " total += gift_wrap_fee * len(prices)\n",
436 | " \n",
437 | " if total > 1000:\n",
438 | " total -= 50\n",
439 | " elif total > 500:\n",
440 | " total -= 25\n",
441 | " \n",
442 | " return max(round(total, 2), 0)\n",
443 | "\n",
444 | "\n",
445 | "!! CHECK THE FILE DIRECTORY, THE PROMPT IS NOW SAVED THERE !!\n"
446 | ]
447 | }
448 | ],
449 | "source": [
450 | "result = run_haiku_conversion_process(task, prompt_example, response_example)"
451 | ]
452 | },
453 | {
454 | "cell_type": "markdown",
455 | "source": [
456 | "### View logs on Portkey\n",
457 | "Go to the logs tab in Portkey to inspect the 3 calls made and the results returned. Note that cache is enabled in the calls, so all calls after the first one would return instantaneously."
458 | ],
459 | "metadata": {
460 | "id": "-nUxJhF-wG2x"
461 | }
462 | }
463 | ],
464 | "metadata": {
465 | "colab": {
466 | "provenance": []
467 | },
468 | "kernelspec": {
469 | "display_name": "Python 3 (ipykernel)",
470 | "language": "python",
471 | "name": "python3"
472 | },
473 | "language_info": {
474 | "codemirror_mode": {
475 | "name": "ipython",
476 | "version": 3
477 | },
478 | "file_extension": ".py",
479 | "mimetype": "text/x-python",
480 | "name": "python",
481 | "nbconvert_exporter": "python",
482 | "pygments_lexer": "ipython3",
483 | "version": "3.10.9"
484 | }
485 | },
486 | "nbformat": 4,
487 | "nbformat_minor": 0
488 | }
--------------------------------------------------------------------------------
/claude_prompt_engineer.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "id": "view-in-github",
7 | "colab_type": "text"
8 | },
9 | "source": [
10 | ""
11 | ]
12 | },
13 | {
14 | "cell_type": "markdown",
15 | "metadata": {
16 | "id": "WljjH8K3s7kG"
17 | },
18 | "source": [
19 | "# claude-prompt-engineer\n",
20 | "By Matt Shumer (https://twitter.com/mattshumer_)\n",
21 | "\n",
22 | "Github repo: https://github.com/mshumer/gpt-prompt-engineer\n",
23 | "\n",
24 | "Generate an optimal prompt for a given task.\n",
25 | "\n",
26 | "To generate a prompt:\n",
27 | "1. In the first cell, add in your Anthropic key.\n",
28 | "2. If you want, adjust your settings in the `Adjust settings here` cell\n",
29 | "2. In the last cell, fill in the description of your task, the variables the system should account for.\n",
30 | "3. Run all the cells! The AI will generate a number of candidate prompts, and test them all to find the best one!"
31 | ]
32 | },
33 | {
34 | "cell_type": "code",
35 | "execution_count": null,
36 | "metadata": {
37 | "id": "JqB2ZUD8lgek",
38 | "colab": {
39 | "base_uri": "https://localhost:8080/"
40 | },
41 | "outputId": "8d8d2146-5c61-4f8d-f6fa-9701740a7aea"
42 | },
43 | "outputs": [
44 | {
45 | "output_type": "stream",
46 | "name": "stdout",
47 | "text": [
48 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m2.2/2.2 MB\u001b[0m \u001b[31m8.3 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
49 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m195.4/195.4 kB\u001b[0m \u001b[31m15.1 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
50 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m263.5/263.5 kB\u001b[0m \u001b[31m11.1 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
51 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m62.7/62.7 kB\u001b[0m \u001b[31m2.7 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
52 | "\u001b[?25h"
53 | ]
54 | }
55 | ],
56 | "source": [
57 | "!pip install prettytable tqdm tenacity wandb -qq"
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "execution_count": null,
63 | "metadata": {
64 | "id": "dQmMZdkG_RA5"
65 | },
66 | "outputs": [],
67 | "source": [
68 | "from prettytable import PrettyTable\n",
69 | "import time\n",
70 | "import requests\n",
71 | "from tqdm import tqdm\n",
72 | "import itertools\n",
73 | "import wandb\n",
74 | "from tenacity import retry, stop_after_attempt, wait_exponential\n",
75 | "\n",
76 | "ANTHROPIC_API_KEY = \"ADD YOUR KEY HERE\" # enter your Anthropic API key here\n",
77 | "\n",
78 | "use_wandb = False # set to True if you want to use wandb to log your config and results"
79 | ]
80 | },
81 | {
82 | "cell_type": "markdown",
83 | "source": [
84 | "## Adjust settings here"
85 | ],
86 | "metadata": {
87 | "id": "uzDKqEFd5wI5"
88 | }
89 | },
90 | {
91 | "cell_type": "code",
92 | "execution_count": null,
93 | "metadata": {
94 | "id": "nIklSQohlgel"
95 | },
96 | "outputs": [],
97 | "source": [
98 | "# K is a constant factor that determines how much ratings change\n",
99 | "K = 32\n",
100 | "\n",
101 | "CANDIDATE_MODEL = 'claude-3-opus-20240229'\n",
102 | "CANDIDATE_MODEL_TEMPERATURE = 0.9\n",
103 | "\n",
104 | "GENERATION_MODEL = 'claude-3-opus-20240229'\n",
105 | "GENERATION_MODEL_TEMPERATURE = 0.8\n",
106 | "GENERATION_MODEL_MAX_TOKENS = 800\n",
107 | "\n",
108 | "TEST_CASE_MODEL = 'claude-3-opus-20240229'\n",
109 | "TEST_CASE_MODEL_TEMPERATURE = .8\n",
110 | "\n",
111 | "NUMBER_OF_TEST_CASES = 10 # this determines how many test cases to generate... the higher, the more expensive, but the better the results will be\n",
112 | "\n",
113 | "N_RETRIES = 3 # number of times to retry a call to the ranking model if it fails\n",
114 | "RANKING_MODEL = 'claude-3-opus-20240229'\n",
115 | "RANKING_MODEL_TEMPERATURE = 0.5\n",
116 | "\n",
117 | "NUMBER_OF_PROMPTS = 5 # this determines how many candidate prompts to generate... the higher, the more expensive, but the better the results will be\n",
118 | "\n",
119 | "WANDB_PROJECT_NAME = \"claude-prompt-eng\" # used if use_wandb is True, Weights &| Biases project name\n",
120 | "WANDB_RUN_NAME = None # used if use_wandb is True, optionally set the Weights & Biases run name to identify this run"
121 | ]
122 | },
123 | {
124 | "cell_type": "code",
125 | "execution_count": null,
126 | "metadata": {
127 | "id": "HyIsyixwlgel"
128 | },
129 | "outputs": [],
130 | "source": [
131 | "def start_wandb_run():\n",
132 | " # start a new wandb run and log the config\n",
133 | " wandb.init(\n",
134 | " project=WANDB_PROJECT_NAME,\n",
135 | " name=WANDB_RUN_NAME,\n",
136 | " config={\n",
137 | " \"K\": K,\n",
138 | " \"candiate_model\": CANDIDATE_MODEL,\n",
139 | " \"candidate_model_temperature\": CANDIDATE_MODEL_TEMPERATURE,\n",
140 | " \"generation_model\": GENERATION_MODEL,\n",
141 | " \"generation_model_temperature\": GENERATION_MODEL_TEMPERATURE,\n",
142 | " \"generation_model_max_tokens\": GENERATION_MODEL_MAX_TOKENS,\n",
143 | " \"n_retries\": N_RETRIES,\n",
144 | " \"ranking_model\": RANKING_MODEL,\n",
145 | " \"ranking_model_temperature\": RANKING_MODEL_TEMPERATURE,\n",
146 | " \"number_of_prompts\": NUMBER_OF_PROMPTS\n",
147 | " })\n",
148 | "\n",
149 | " return"
150 | ]
151 | },
152 | {
153 | "cell_type": "code",
154 | "execution_count": null,
155 | "metadata": {
156 | "id": "Zk_2Uut-lgel"
157 | },
158 | "outputs": [],
159 | "source": [
160 | "# Optional logging to Weights & Biases to reocrd the configs, prompts and results\n",
161 | "if use_wandb:\n",
162 | " start_wandb_run()"
163 | ]
164 | },
165 | {
166 | "cell_type": "code",
167 | "execution_count": null,
168 | "metadata": {
169 | "id": "wXeqMQpzzosx"
170 | },
171 | "outputs": [],
172 | "source": [
173 | "import json\n",
174 | "import re\n",
175 | "\n",
176 | "def remove_first_line(test_string):\n",
177 | " if test_string.startswith(\"Here\") and test_string.split(\"\\n\")[0].strip().endswith(\":\"):\n",
178 | " return re.sub(r'^.*\\n', '', test_string, count=1)\n",
179 | " return test_string\n",
180 | "\n",
181 | "def generate_candidate_prompts(description, input_variables, test_cases, number_of_prompts):\n",
182 | " headers = {\n",
183 | " \"x-api-key\": ANTHROPIC_API_KEY,\n",
184 | " \"anthropic-version\": \"2023-06-01\",\n",
185 | " \"content-type\": \"application/json\"\n",
186 | " }\n",
187 | "\n",
188 | " variable_descriptions = \"\\n\".join(f\"{var['variable']}: {var['description']}\" for var in input_variables)\n",
189 | "\n",
190 | " data = {\n",
191 | " \"model\": CANDIDATE_MODEL,\n",
192 | " \"max_tokens\": 1500,\n",
193 | " \"temperature\": CANDIDATE_MODEL_TEMPERATURE,\n",
194 | " \"system\": f\"\"\"Your job is to generate system prompts for Claude 3, given a description of the use-case, some test cases/input variable examples that will help you understand what the prompt will need to be good at.\n",
195 | "The prompts you will be generating will be for freeform tasks, such as generating a landing page headline, an intro paragraph, solving a math problem, etc.\n",
196 | "In your generated prompt, you should describe how the AI should behave in plain English. Include what it will see, and what it's allowed to output.\n",
197 | "Make sure to incorporate the provided input variable placeholders into the prompt, using placeholders like {{{{VARIABLE_NAME}}}} for each variable. Ensure you place placeholders inside four squiggly lines like {{{{VARIABLE_NAME}}}}. At inference time/test time, we will slot the variables into the prompt, like a template.\n",
198 | "Be creative with prompts to get the best possible results. The AI knows it's an AI -- you don't need to tell it this.\n",
199 | "You will be graded based on the performance of your prompt... but don't cheat! You cannot include specifics about the test cases in your prompt. Any prompts with examples will be disqualified.\n",
200 | "Here are the input variables and their descriptions:\n",
201 | "{variable_descriptions}\n",
202 | "Most importantly, output NOTHING but the prompt (with the variables contained in it like {{{{VARIABLE_NAME}}}}). Do not include anything else in your message.\"\"\",\n",
203 | " \"messages\": [\n",
204 | " {\"role\": \"user\", \"content\": f\"Here are some test cases:`{test_cases}`\\n\\nHere is the description of the use-case: `{description.strip()}`\\n\\nRespond with your flexible system prompt, and nothing else. Be creative, and remember, the goal is not to complete the task, but write a prompt that will complete the task.\"},\n",
205 | " ]\n",
206 | " }\n",
207 | "\n",
208 | " prompts = []\n",
209 | "\n",
210 | " for i in range(number_of_prompts):\n",
211 | " response = requests.post(\"https://api.anthropic.com/v1/messages\", headers=headers, json=data)\n",
212 | "\n",
213 | " message = response.json()\n",
214 | "\n",
215 | " response_text = message['content'][0]['text']\n",
216 | "\n",
217 | " prompts.append(remove_first_line(response_text))\n",
218 | "\n",
219 | " return prompts\n",
220 | "\n",
221 | "def expected_score(r1, r2):\n",
222 | " return 1 / (1 + 10**((r2 - r1) / 400))\n",
223 | "\n",
224 | "def update_elo(r1, r2, score1):\n",
225 | " e1 = expected_score(r1, r2)\n",
226 | " e2 = expected_score(r2, r1)\n",
227 | " return r1 + K * (score1 - e1), r2 + K * ((1 - score1) - e2)\n",
228 | "\n",
229 | "# Get Score - retry up to N_RETRIES times, waiting exponentially between retries.\n",
230 | "@retry(stop=stop_after_attempt(N_RETRIES), wait=wait_exponential(multiplier=1, min=4, max=70))\n",
231 | "def get_score(description, test_case, pos1, pos2, input_variables, ranking_model_name, ranking_model_temperature):\n",
232 | " headers = {\n",
233 | " \"x-api-key\": ANTHROPIC_API_KEY,\n",
234 | " \"anthropic-version\": \"2023-06-01\",\n",
235 | " \"content-type\": \"application/json\"\n",
236 | " }\n",
237 | "\n",
238 | " variable_values = \"\\n\".join(f\"{var['variable']}: {test_case.get(var['variable'], '')}\" for var in input_variables)\n",
239 | "\n",
240 | " data = {\n",
241 | " \"model\": RANKING_MODEL,\n",
242 | " \"max_tokens\": 1,\n",
243 | " \"temperature\": ranking_model_temperature,\n",
244 | " \"system\": f\"\"\"Your job is to rank the quality of two outputs generated by different prompts. The prompts are used to generate a response for a given task.\n",
245 | "You will be provided with the task description, input variable values, and two generations - one for each system prompt.\n",
246 | "Rank the generations in order of quality. If Generation A is better, respond with 'A'. If Generation B is better, respond with 'B'.\n",
247 | "Remember, to be considered 'better', a generation must not just be good, it must be noticeably superior to the other.\n",
248 | "Also, keep in mind that you are a very harsh critic. Only rank a generation as better if it truly impresses you more than the other.\n",
249 | "Respond with your ranking ('A' or 'B'), and nothing else. Be fair and unbiased in your judgement.\"\"\",\n",
250 | " \"messages\": [\n",
251 | " {\"role\": \"user\", \"content\": f\"\"\"Task: {description.strip()}\n",
252 | "Variables: {test_case['variables']}\n",
253 | "Generation A: {remove_first_line(pos1)}\n",
254 | "Generation B: {remove_first_line(pos2)}\"\"\"},\n",
255 | " ]\n",
256 | " }\n",
257 | "\n",
258 | " response = requests.post(\"https://api.anthropic.com/v1/messages\", headers=headers, json=data)\n",
259 | "\n",
260 | " message = response.json()\n",
261 | "\n",
262 | " score = message['content'][0]['text']\n",
263 | "\n",
264 | " return score\n",
265 | "\n",
266 | "@retry(stop=stop_after_attempt(N_RETRIES), wait=wait_exponential(multiplier=1, min=4, max=70))\n",
267 | "def get_generation(prompt, test_case, input_variables):\n",
268 | " headers = {\n",
269 | " \"x-api-key\": ANTHROPIC_API_KEY,\n",
270 | " \"anthropic-version\": \"2023-06-01\",\n",
271 | " \"content-type\": \"application/json\"\n",
272 | " }\n",
273 | "\n",
274 | "\n",
275 | " # Replace variable placeholders in the prompt with their actual values from the test case\n",
276 | " for var_dict in test_case['variables']:\n",
277 | " for variable_name, variable_value in var_dict.items():\n",
278 | " prompt = prompt.replace(f\"{{{{{variable_name}}}}}\", variable_value)\n",
279 | "\n",
280 | " data = {\n",
281 | " \"model\": GENERATION_MODEL,\n",
282 | " \"max_tokens\": GENERATION_MODEL_MAX_TOKENS,\n",
283 | " \"temperature\": GENERATION_MODEL_TEMPERATURE,\n",
284 | " \"system\": 'Complete the task perfectly.',\n",
285 | " \"messages\": [\n",
286 | " {\"role\": \"user\", \"content\": prompt},\n",
287 | " ]\n",
288 | " }\n",
289 | "\n",
290 | " response = requests.post(\"https://api.anthropic.com/v1/messages\", headers=headers, json=data)\n",
291 | "\n",
292 | " message = response.json()\n",
293 | "\n",
294 | " generation = message['content'][0]['text']\n",
295 | "\n",
296 | " return generation\n",
297 | "\n",
298 | "def test_candidate_prompts(test_cases, description, input_variables, prompts):\n",
299 | " # Initialize each prompt with an ELO rating of 1200\n",
300 | " prompt_ratings = {prompt: 1200 for prompt in prompts}\n",
301 | "\n",
302 | " # Calculate total rounds for progress bar\n",
303 | " total_rounds = len(test_cases) * len(prompts) * (len(prompts) - 1) // 2\n",
304 | "\n",
305 | " # Initialize progress bar\n",
306 | " pbar = tqdm(total=total_rounds, ncols=70)\n",
307 | "\n",
308 | " # For each pair of prompts\n",
309 | " for prompt1, prompt2 in itertools.combinations(prompts, 2):\n",
310 | " # For each test case\n",
311 | " for test_case in test_cases:\n",
312 | " # Update progress bar\n",
313 | " pbar.update()\n",
314 | "\n",
315 | " # Generate outputs for each prompt\n",
316 | " generation1 = get_generation(prompt1, test_case, input_variables)\n",
317 | " generation2 = get_generation(prompt2, test_case, input_variables)\n",
318 | "\n",
319 | " # Rank the outputs\n",
320 | " score1 = get_score(description, test_case, generation1, generation2, input_variables, RANKING_MODEL, RANKING_MODEL_TEMPERATURE)\n",
321 | " score2 = get_score(description, test_case, generation2, generation1, input_variables, RANKING_MODEL, RANKING_MODEL_TEMPERATURE)\n",
322 | "\n",
323 | " # Convert scores to numeric values\n",
324 | " score1 = 1 if score1 == 'A' else 0 if score1 == 'B' else 0.5\n",
325 | " score2 = 1 if score2 == 'B' else 0 if score2 == 'A' else 0.5\n",
326 | "\n",
327 | " # Average the scores\n",
328 | " score = (score1 + score2) / 2\n",
329 | "\n",
330 | " # Update ELO ratings\n",
331 | " r1, r2 = prompt_ratings[prompt1], prompt_ratings[prompt2]\n",
332 | " r1, r2 = update_elo(r1, r2, score)\n",
333 | " prompt_ratings[prompt1], prompt_ratings[prompt2] = r1, r2\n",
334 | "\n",
335 | " # Print the winner of this round\n",
336 | " if score > 0.5:\n",
337 | " print(f\"Winner: {prompt1}\")\n",
338 | " elif score < 0.5:\n",
339 | " print(f\"Winner: {prompt2}\")\n",
340 | " else:\n",
341 | " print(\"Draw\")\n",
342 | "\n",
343 | " # Close progress bar\n",
344 | " pbar.close()\n",
345 | "\n",
346 | " return prompt_ratings\n",
347 | "\n",
348 | "def generate_optimal_prompt(description, input_variables, num_test_cases=10, number_of_prompts=10, use_wandb=False):\n",
349 | " if use_wandb:\n",
350 | " wandb_table = wandb.Table(columns=[\"Prompt\", \"Ranking\"] + [var[\"variable\"] for var in input_variables])\n",
351 | " if wandb.run is None:\n",
352 | " start_wandb_run()\n",
353 | "\n",
354 | " test_cases = generate_test_cases(description, input_variables, num_test_cases)\n",
355 | " prompts = generate_candidate_prompts(description, input_variables, test_cases, number_of_prompts)\n",
356 | " print('Here are the possible prompts:', prompts)\n",
357 | " prompt_ratings = test_candidate_prompts(test_cases, description, input_variables, prompts)\n",
358 | "\n",
359 | " table = PrettyTable()\n",
360 | " table.field_names = [\"Prompt\", \"Rating\"] + [var[\"variable\"] for var in input_variables]\n",
361 | " for prompt, rating in sorted(prompt_ratings.items(), key=lambda item: item[1], reverse=True):\n",
362 | " # Use the first test case as an example for displaying the input variables\n",
363 | " example_test_case = test_cases[0]\n",
364 | " table.add_row([prompt, rating] + [example_test_case.get(var[\"variable\"], \"\") for var in input_variables])\n",
365 | " if use_wandb:\n",
366 | " wandb_table.add_data(prompt, rating, *[example_test_case.get(var[\"variable\"], \"\") for var in input_variables])\n",
367 | "\n",
368 | " if use_wandb:\n",
369 | " wandb.log({\"prompt_ratings\": wandb_table})\n",
370 | " wandb.finish()\n",
371 | " print(table)\n",
372 | "\n",
373 | "def generate_test_cases(description, input_variables, num_test_cases):\n",
374 | " headers = {\n",
375 | " \"x-api-key\": ANTHROPIC_API_KEY,\n",
376 | " \"anthropic-version\": \"2023-06-01\",\n",
377 | " \"content-type\": \"application/json\"\n",
378 | " }\n",
379 | "\n",
380 | " variable_descriptions = \"\\n\".join(f\"{var['variable']}: {var['description']}\" for var in input_variables)\n",
381 | "\n",
382 | " data = {\n",
383 | " \"model\": CANDIDATE_MODEL,\n",
384 | " \"max_tokens\": 1500,\n",
385 | " \"temperature\": CANDIDATE_MODEL_TEMPERATURE,\n",
386 | " \"system\": f\"\"\"You are an expert at generating test cases for evaluating AI-generated content.\n",
387 | "Your task is to generate a list of {num_test_cases} test case prompts based on the given description and input variables.\n",
388 | "Each test case should be a JSON object with a 'test_design' field containing the overall idea of this test case, and a list of additional JSONs for each input variable, called 'variables'.\n",
389 | "The test cases should be diverse, covering a range of topics and styles relevant to the description.\n",
390 | "Here are the input variables and their descriptions:\n",
391 | "{variable_descriptions}\n",
392 | "Return the test cases as a JSON list, with no other text or explanation.\"\"\",\n",
393 | " \"messages\": [\n",
394 | " {\"role\": \"user\", \"content\": f\"Description: {description.strip()}\\n\\nGenerate the test cases. Make sure they are really, really great and diverse:\"},\n",
395 | " ]\n",
396 | " }\n",
397 | "\n",
398 | " response = requests.post(\"https://api.anthropic.com/v1/messages\", headers=headers, json=data)\n",
399 | " message = response.json()\n",
400 | "\n",
401 | " response_text = message['content'][0]['text']\n",
402 | "\n",
403 | " test_cases = json.loads(response_text)\n",
404 | "\n",
405 | " print('Here are the test cases:', test_cases)\n",
406 | "\n",
407 | " return test_cases"
408 | ]
409 | },
410 | {
411 | "cell_type": "markdown",
412 | "metadata": {
413 | "id": "MJSSKFfV_X9F"
414 | },
415 | "source": [
416 | "# In the cell below, fill in your description and input variables"
417 | ]
418 | },
419 | {
420 | "cell_type": "code",
421 | "execution_count": null,
422 | "metadata": {
423 | "id": "vCZvLyDepxFP"
424 | },
425 | "outputs": [],
426 | "source": [
427 | "## Example usage\n",
428 | "description = \"Given a prompt, generate a personalized email response.\" # this style of description tends to work well\n",
429 | "\n",
430 | "input_variables = [\n",
431 | " {\"variable\": \"SENDER_NAME\", \"description\": \"The name of the person who sent the email.\"},\n",
432 | " {\"variable\": \"RECIPIENT_NAME\", \"description\": \"The name of the person receiving the email.\"},\n",
433 | " {\"variable\": \"TOPIC\", \"description\": \"The main topic or subject of the email. One to two sentences.\"}\n",
434 | "]"
435 | ]
436 | },
437 | {
438 | "cell_type": "code",
439 | "source": [
440 | "if use_wandb:\n",
441 | " wandb.config.update({\"description\": description,\n",
442 | " \"input_variables\": input_variables,\n",
443 | " \"num_test_cases\": NUMBER_OF_TEST_CASES,\n",
444 | " \"number_of_prompts\": NUMBER_OF_PROMPTS})"
445 | ],
446 | "metadata": {
447 | "id": "4gxg9uf_vIlr"
448 | },
449 | "execution_count": null,
450 | "outputs": []
451 | },
452 | {
453 | "cell_type": "markdown",
454 | "source": [
455 | "## Run this cell to start the prompt engineering process!"
456 | ],
457 | "metadata": {
458 | "id": "Mo9B4x4R_YVl"
459 | }
460 | },
461 | {
462 | "cell_type": "code",
463 | "execution_count": null,
464 | "metadata": {
465 | "id": "7rWjcL2hlgen"
466 | },
467 | "outputs": [],
468 | "source": [
469 | "generate_optimal_prompt(description, input_variables, NUMBER_OF_TEST_CASES, NUMBER_OF_PROMPTS, use_wandb)"
470 | ]
471 | }
472 | ],
473 | "metadata": {
474 | "colab": {
475 | "provenance": [],
476 | "include_colab_link": true
477 | },
478 | "kernelspec": {
479 | "display_name": "Python 3",
480 | "name": "python3"
481 | },
482 | "language_info": {
483 | "codemirror_mode": {
484 | "name": "ipython",
485 | "version": 3
486 | },
487 | "file_extension": ".py",
488 | "mimetype": "text/x-python",
489 | "name": "python",
490 | "nbconvert_exporter": "python",
491 | "pygments_lexer": "ipython3",
492 | "version": "3.8.8"
493 | }
494 | },
495 | "nbformat": 4,
496 | "nbformat_minor": 0
497 | }
--------------------------------------------------------------------------------
/gpt_planner.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyMdDMDSqfgffWcCf0zTS8yd",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "code",
31 | "source": [
32 | "!pip install openai\n",
33 | "\n",
34 | "OPENAI_API_KEY = \"YOUR API KEY\""
35 | ],
36 | "metadata": {
37 | "id": "nNAx9eT3ule2"
38 | },
39 | "execution_count": null,
40 | "outputs": []
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": null,
45 | "metadata": {
46 | "id": "tf_S5R1Muafd"
47 | },
48 | "outputs": [],
49 | "source": [
50 | "import openai\n",
51 | "import random\n",
52 | "\n",
53 | "client = openai.OpenAI(api_key=OPENAI_API_KEY)\n",
54 | "\n",
55 | "def generate_plans(user_query, n=5):\n",
56 | " \"\"\"Generate multiple plans using GPT-4o-Mini.\"\"\"\n",
57 | " response = client.chat.completions.create(\n",
58 | " model=\"gpt-4o-mini\",\n",
59 | " messages=[\n",
60 | " {\"role\": \"system\", \"content\": \"You are a strategic reasoner. Given a user query, create a detailed plan to address it and then respond to the user. You will do so by using and tags. The user will only see what is in , the is just a scratchpad for you to figure out the best approach to satisfy the user's request. First, plan inside tags, and then write your .\"},\n",
61 | " {\"role\": \"user\", \"content\": user_query}\n",
62 | " ],\n",
63 | " n=n,\n",
64 | " temperature=0.7,\n",
65 | " max_tokens=500,\n",
66 | " stop=['']\n",
67 | " )\n",
68 | " return [choice.message.content.replace('', '') for choice in response.choices]\n",
69 | "\n",
70 | "def evaluate_plans(plans, user_query):\n",
71 | " \"\"\"Evaluate plans using a tournament ranking system.\"\"\"\n",
72 | " def compare_plans(plan1, plan2):\n",
73 | " response = client.chat.completions.create(\n",
74 | " model=\"gpt-4o-mini\",\n",
75 | " messages=[\n",
76 | " {\"role\": \"system\", \"content\": \"You are a judge evaluating two plans. Choose the better plan based on effectiveness, feasibility, and relevance to the user's query.\"},\n",
77 | " {\"role\": \"user\", \"content\": f\"User Query: {user_query}\\n\\nPlan 1: {plan1}\\n\\nPlan 2: {plan2}\\n\\nWhich plan is better? Respond with either '1' or '2'.\"}\n",
78 | " ],\n",
79 | " temperature=0.2,\n",
80 | " max_tokens=10\n",
81 | " )\n",
82 | " return 1 if response.choices[0].message.content.strip() == \"1\" else 2\n",
83 | "\n",
84 | " # Tournament ranking — to improve, run twice with swapped positions for each plan combo for greater precision, and parallelize for speed\n",
85 | " winners = plans\n",
86 | " while len(winners) > 1:\n",
87 | " next_round = []\n",
88 | " for i in range(0, len(winners), 2):\n",
89 | " if i + 1 < len(winners):\n",
90 | " winner = winners[i] if compare_plans(winners[i], winners[i+1]) == 1 else winners[i+1]\n",
91 | " next_round.append(winner)\n",
92 | " else:\n",
93 | " next_round.append(winners[i])\n",
94 | " winners = next_round\n",
95 | "\n",
96 | " return winners[0]\n",
97 | "\n",
98 | "def generate_response(best_plan, user_query):\n",
99 | " \"\"\"Generate the final response based on the best plan.\"\"\"\n",
100 | " response = client.chat.completions.create(\n",
101 | " model=\"gpt-4o-mini\",\n",
102 | " messages=[\n",
103 | " {\"role\": \"system\", \"content\": \"You are a helpful assistant. Use the given plan to create a detailed and high-quality response to the user's query.\"},\n",
104 | " {\"role\": \"user\", \"content\": f\"User Query: {user_query}\\n\\nPlan: {best_plan}\\n\\nGenerate a detailed response based on this plan.\"}\n",
105 | " ],\n",
106 | " temperature=0.5,\n",
107 | " max_tokens=2000\n",
108 | " )\n",
109 | " return response.choices[0].message.content\n",
110 | "\n",
111 | "def improved_ai_output(user_query, num_plans=20):\n",
112 | " \"\"\"Main function to improve AI output quality.\"\"\"\n",
113 | " print(\"Generating plans...\")\n",
114 | " plans = generate_plans(user_query, n=num_plans)\n",
115 | "\n",
116 | " print(\"Evaluating plans...\")\n",
117 | " best_plan = evaluate_plans(plans, user_query)\n",
118 | "\n",
119 | " print(\"Generating final response...\")\n",
120 | " final_response = generate_response(best_plan, user_query)\n",
121 | "\n",
122 | " return {\n",
123 | " \"user_query\": user_query,\n",
124 | " \"best_plan\": best_plan,\n",
125 | " \"final_response\": final_response\n",
126 | " }\n",
127 | "\n",
128 | "if __name__ == \"__main__\":\n",
129 | " user_query = \"How do I get a computer out of a bootloop?\"\n",
130 | " result = improved_ai_output(user_query)\n",
131 | "\n",
132 | " print(\"\\nUser Query:\", result[\"user_query\"])\n",
133 | " print(\"\\nBest Plan:\", result[\"best_plan\"])\n",
134 | " print(\"\\nFinal Response:\", result[\"final_response\"])"
135 | ]
136 | }
137 | ]
138 | }
--------------------------------------------------------------------------------
/gpt_prompt_engineer.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "attachments": {},
5 | "cell_type": "markdown",
6 | "metadata": {
7 | "colab_type": "text",
8 | "id": "view-in-github"
9 | },
10 | "source": [
11 | ""
12 | ]
13 | },
14 | {
15 | "attachments": {},
16 | "cell_type": "markdown",
17 | "metadata": {
18 | "id": "WljjH8K3s7kG"
19 | },
20 | "source": [
21 | "# gpt-prompt-engineer\n",
22 | "By Matt Shumer (https://twitter.com/mattshumer_)\n",
23 | "\n",
24 | "Github repo: https://github.com/mshumer/gpt-prompt-engineer\n",
25 | "\n",
26 | "Generate an optimal prompt for a given task.\n",
27 | "\n",
28 | "To generate a prompt:\n",
29 | "1. In the first cell, add in your OpenAI key.\n",
30 | "2. If you don't have GPT-4 access, change `model='gpt-4'` in the second cell to `model='gpt-3.5-turbo'`. If you do have access, skip this step.\n",
31 | "2. In the last cell, fill in the description of your task, up to 15 test cases, and the number of prompts to generate.\n",
32 | "3. Run all the cells! The AI will generate a number of candidate prompts, and test them all to find the best one!"
33 | ]
34 | },
35 | {
36 | "cell_type": "code",
37 | "execution_count": null,
38 | "metadata": {},
39 | "outputs": [],
40 | "source": [
41 | "!pip install openai==0.28 prettytable tqdm tenacity wandb -qq"
42 | ]
43 | },
44 | {
45 | "cell_type": "code",
46 | "execution_count": null,
47 | "metadata": {
48 | "id": "dQmMZdkG_RA5"
49 | },
50 | "outputs": [],
51 | "source": [
52 | "from prettytable import PrettyTable\n",
53 | "import time\n",
54 | "import openai\n",
55 | "from tqdm import tqdm\n",
56 | "import itertools\n",
57 | "import wandb\n",
58 | "from tenacity import retry, stop_after_attempt, wait_exponential\n",
59 | "\n",
60 | "openai.api_key = \"ADD YOUR KEY HERE\" # enter your OpenAI API key here\n",
61 | "\n",
62 | "use_wandb = False # set to True if you want to use wandb to log your config and results\n",
63 | "\n",
64 | "use_portkey = False #set to True if you want to use Portkey to log all the prompt chains and their responses Check https://portkey.ai/"
65 | ]
66 | },
67 | {
68 | "cell_type": "code",
69 | "execution_count": 8,
70 | "metadata": {},
71 | "outputs": [],
72 | "source": [
73 | "system_gen_system_prompt = \"\"\"Your job is to generate system prompts for GPT-4, given a description of the use-case and some test cases.\n",
74 | "\n",
75 | "The prompts you will be generating will be for freeform tasks, such as generating a landing page headline, an intro paragraph, solving a math problem, etc.\n",
76 | "\n",
77 | "In your generated prompt, you should describe how the AI should behave in plain English. Include what it will see, and what it's allowed to output. Be creative with prompts to get the best possible results. The AI knows it's an AI -- you don't need to tell it this.\n",
78 | "\n",
79 | "You will be graded based on the performance of your prompt... but don't cheat! You cannot include specifics about the test cases in your prompt. Any prompts with examples will be disqualified.\n",
80 | "\n",
81 | "Most importantly, output NOTHING but the prompt. Do not include anything else in your message.\"\"\"\n",
82 | "\n",
83 | "\n",
84 | "ranking_system_prompt = \"\"\"Your job is to rank the quality of two outputs generated by different prompts. The prompts are used to generate a response for a given task.\n",
85 | "\n",
86 | "You will be provided with the task description, the test prompt, and two generations - one for each system prompt.\n",
87 | "\n",
88 | "Rank the generations in order of quality. If Generation A is better, respond with 'A'. If Generation B is better, respond with 'B'.\n",
89 | "\n",
90 | "Remember, to be considered 'better', a generation must not just be good, it must be noticeably superior to the other.\n",
91 | "\n",
92 | "Also, keep in mind that you are a very harsh critic. Only rank a generation as better if it truly impresses you more than the other.\n",
93 | "\n",
94 | "Respond with your ranking, and nothing else. Be fair and unbiased in your judgement.\"\"\""
95 | ]
96 | },
97 | {
98 | "cell_type": "code",
99 | "execution_count": null,
100 | "metadata": {},
101 | "outputs": [],
102 | "source": [
103 | "# K is a constant factor that determines how much ratings change\n",
104 | "K = 32\n",
105 | "\n",
106 | "CANDIDATE_MODEL = 'gpt-4'\n",
107 | "CANDIDATE_MODEL_TEMPERATURE = 0.9\n",
108 | "\n",
109 | "GENERATION_MODEL = 'gpt-3.5-turbo'\n",
110 | "GENERATION_MODEL_TEMPERATURE = 0.8\n",
111 | "GENERATION_MODEL_MAX_TOKENS = 60\n",
112 | "\n",
113 | "N_RETRIES = 3 # number of times to retry a call to the ranking model if it fails\n",
114 | "RANKING_MODEL = 'gpt-3.5-turbo'\n",
115 | "RANKING_MODEL_TEMPERATURE = 0.5\n",
116 | "\n",
117 | "NUMBER_OF_PROMPTS = 10 # this determines how many candidate prompts to generate... the higher, the more expensive, but the better the results will be\n",
118 | "\n",
119 | "WANDB_PROJECT_NAME = \"gpt-prompt-eng\" # used if use_wandb is True, Weights &| Biases project name\n",
120 | "WANDB_RUN_NAME = None # used if use_wandb is True, optionally set the Weights & Biases run name to identify this run\n",
121 | "\n",
122 | "PORTKEY_API = \"\" # used if use_portkey is True. Get api key here: https://app.portkey.ai/ (click on profile photo on top left)\n",
123 | "PORTKEY_TRACE = \"prompt_engineer_test_run\" # used if use_portkey is True. Trace each run with a separate ID to differentiate prompt chains\n",
124 | "HEADERS = {} # don't change. headers will auto populate if use_portkey is true."
125 | ]
126 | },
127 | {
128 | "cell_type": "code",
129 | "execution_count": null,
130 | "metadata": {},
131 | "outputs": [],
132 | "source": [
133 | "def start_wandb_run():\n",
134 | " # start a new wandb run and log the config\n",
135 | " wandb.init(\n",
136 | " project=WANDB_PROJECT_NAME, \n",
137 | " name=WANDB_RUN_NAME,\n",
138 | " config={\n",
139 | " \"K\": K,\n",
140 | " \"system_gen_system_prompt\": system_gen_system_prompt, \n",
141 | " \"ranking_system_prompt\": ranking_system_prompt,\n",
142 | " \"candidate_model\": CANDIDATE_MODEL,\n",
143 | " \"candidate_model_temperature\": CANDIDATE_MODEL_TEMPERATURE,\n",
144 | " \"generation_model\": GENERATION_MODEL,\n",
145 | " \"generation_model_temperature\": GENERATION_MODEL_TEMPERATURE,\n",
146 | " \"generation_model_max_tokens\": GENERATION_MODEL_MAX_TOKENS,\n",
147 | " \"n_retries\": N_RETRIES,\n",
148 | " \"ranking_model\": RANKING_MODEL,\n",
149 | " \"ranking_model_temperature\": RANKING_MODEL_TEMPERATURE,\n",
150 | " \"number_of_prompts\": NUMBER_OF_PROMPTS\n",
151 | " })\n",
152 | " \n",
153 | " return "
154 | ]
155 | },
156 | {
157 | "cell_type": "code",
158 | "execution_count": null,
159 | "metadata": {},
160 | "outputs": [],
161 | "source": [
162 | "# Optional logging to Weights & Biases to reocrd the configs, prompts and results\n",
163 | "if use_wandb:\n",
164 | " start_wandb_run()"
165 | ]
166 | },
167 | {
168 | "cell_type": "code",
169 | "execution_count": null,
170 | "metadata": {},
171 | "outputs": [],
172 | "source": [
173 | "def start_portkey_run():\n",
174 | " # define Portkey headers to start logging all prompts & their responses\n",
175 | " openai.api_base=\"https://api.portkey.ai/v1/proxy\"\n",
176 | " HEADERS = {\n",
177 | " \"x-portkey-api-key\": PORTKEY_API, \n",
178 | " \"x-portkey-mode\": \"proxy openai\",\n",
179 | " \"x-portkey-trace-id\": PORTKEY_TRACE,\n",
180 | " #\"x-portkey-retry-count\": 5 # perform automatic retries with exponential backoff if the OpenAI requests fails\n",
181 | " } \n",
182 | " return HEADERS"
183 | ]
184 | },
185 | {
186 | "cell_type": "code",
187 | "execution_count": null,
188 | "metadata": {},
189 | "outputs": [],
190 | "source": [
191 | "# Optional prompt & responses logging\n",
192 | "if use_portkey:\n",
193 | " HEADERS=start_portkey_run()"
194 | ]
195 | },
196 | {
197 | "cell_type": "code",
198 | "execution_count": 13,
199 | "metadata": {
200 | "id": "wXeqMQpzzosx"
201 | },
202 | "outputs": [],
203 | "source": [
204 | "def generate_candidate_prompts(description, test_cases, number_of_prompts):\n",
205 | " outputs = openai.ChatCompletion.create(\n",
206 | " model=CANDIDATE_MODEL, # change this to gpt-3.5-turbo if you don't have GPT-4 access\n",
207 | " messages=[\n",
208 | " {\"role\": \"system\", \"content\": system_gen_system_prompt},\n",
209 | " {\"role\": \"user\", \"content\": f\"Here are some test cases:`{test_cases}`\\n\\nHere is the description of the use-case: `{description.strip()}`\\n\\nRespond with your prompt, and nothing else. Be creative.\"}\n",
210 | " ],\n",
211 | " temperature=CANDIDATE_MODEL_TEMPERATURE,\n",
212 | " n=number_of_prompts,\n",
213 | " headers=HEADERS)\n",
214 | "\n",
215 | " prompts = []\n",
216 | "\n",
217 | " for i in outputs.choices:\n",
218 | " prompts.append(i.message.content)\n",
219 | " return prompts\n",
220 | "\n",
221 | "def expected_score(r1, r2):\n",
222 | " return 1 / (1 + 10**((r2 - r1) / 400))\n",
223 | "\n",
224 | "def update_elo(r1, r2, score1):\n",
225 | " e1 = expected_score(r1, r2)\n",
226 | " e2 = expected_score(r2, r1)\n",
227 | " return r1 + K * (score1 - e1), r2 + K * ((1 - score1) - e2)\n",
228 | "\n",
229 | "# Get Score - retry up to N_RETRIES times, waiting exponentially between retries.\n",
230 | "@retry(stop=stop_after_attempt(N_RETRIES), wait=wait_exponential(multiplier=1, min=4, max=70))\n",
231 | "def get_score(description, test_case, pos1, pos2, ranking_model_name, ranking_model_temperature): \n",
232 | " score = openai.ChatCompletion.create(\n",
233 | " model=ranking_model_name,\n",
234 | " messages=[\n",
235 | " {\"role\": \"system\", \"content\": ranking_system_prompt},\n",
236 | " {\"role\": \"user\", \"content\": f\"\"\"Task: {description.strip()}\n",
237 | "Prompt: {test_case['prompt']}\n",
238 | "Generation A: {pos1}\n",
239 | "Generation B: {pos2}\"\"\"}\n",
240 | " ],\n",
241 | " logit_bias={\n",
242 | " '32': 100, # 'A' token\n",
243 | " '33': 100, # 'B' token\n",
244 | " },\n",
245 | " max_tokens=1,\n",
246 | " temperature=ranking_model_temperature,\n",
247 | " headers=HEADERS,\n",
248 | " ).choices[0].message.content\n",
249 | " return score\n",
250 | "\n",
251 | "@retry(stop=stop_after_attempt(N_RETRIES), wait=wait_exponential(multiplier=1, min=4, max=70))\n",
252 | "def get_generation(prompt, test_case):\n",
253 | " generation = openai.ChatCompletion.create(\n",
254 | " model=GENERATION_MODEL,\n",
255 | " messages=[\n",
256 | " {\"role\": \"system\", \"content\": prompt},\n",
257 | " {\"role\": \"user\", \"content\": f\"{test_case['prompt']}\"}\n",
258 | " ],\n",
259 | " max_tokens=GENERATION_MODEL_MAX_TOKENS,\n",
260 | " temperature=GENERATION_MODEL_TEMPERATURE,\n",
261 | " headers=HEADERS,\n",
262 | " ).choices[0].message.content\n",
263 | " return generation\n",
264 | "\n",
265 | "def test_candidate_prompts(test_cases, description, prompts):\n",
266 | " # Initialize each prompt with an ELO rating of 1200\n",
267 | " prompt_ratings = {prompt: 1200 for prompt in prompts}\n",
268 | "\n",
269 | " # Calculate total rounds for progress bar\n",
270 | " total_rounds = len(test_cases) * len(prompts) * (len(prompts) - 1) // 2\n",
271 | "\n",
272 | " # Initialize progress bar\n",
273 | " pbar = tqdm(total=total_rounds, ncols=70)\n",
274 | "\n",
275 | " # For each pair of prompts\n",
276 | " for prompt1, prompt2 in itertools.combinations(prompts, 2):\n",
277 | " # For each test case\n",
278 | " for test_case in test_cases:\n",
279 | " # Update progress bar\n",
280 | " pbar.update()\n",
281 | "\n",
282 | " # Generate outputs for each prompt\n",
283 | " generation1 = get_generation(prompt1, test_case)\n",
284 | " generation2 = get_generation(prompt2, test_case)\n",
285 | "\n",
286 | " # Rank the outputs\n",
287 | " score1 = get_score(description, test_case, generation1, generation2, RANKING_MODEL, RANKING_MODEL_TEMPERATURE)\n",
288 | " score2 = get_score(description, test_case, generation2, generation1, RANKING_MODEL, RANKING_MODEL_TEMPERATURE)\n",
289 | "\n",
290 | " # Convert scores to numeric values\n",
291 | " score1 = 1 if score1 == 'A' else 0 if score1 == 'B' else 0.5\n",
292 | " score2 = 1 if score2 == 'B' else 0 if score2 == 'A' else 0.5\n",
293 | "\n",
294 | " # Average the scores\n",
295 | " score = (score1 + score2) / 2\n",
296 | "\n",
297 | " # Update ELO ratings\n",
298 | " r1, r2 = prompt_ratings[prompt1], prompt_ratings[prompt2]\n",
299 | " r1, r2 = update_elo(r1, r2, score)\n",
300 | " prompt_ratings[prompt1], prompt_ratings[prompt2] = r1, r2\n",
301 | "\n",
302 | " # Print the winner of this round\n",
303 | " if score > 0.5:\n",
304 | " print(f\"Winner: {prompt1}\")\n",
305 | " elif score < 0.5:\n",
306 | " print(f\"Winner: {prompt2}\")\n",
307 | " else:\n",
308 | " print(\"Draw\")\n",
309 | "\n",
310 | " # Close progress bar\n",
311 | " pbar.close()\n",
312 | "\n",
313 | " return prompt_ratings\n",
314 | "\n",
315 | "\n",
316 | "def generate_optimal_prompt(description, test_cases, number_of_prompts=10, use_wandb=False): \n",
317 | " if use_wandb:\n",
318 | " wandb_table = wandb.Table(columns=[\"Prompt\", \"Ranking\"])\n",
319 | " if wandb.run is None:\n",
320 | " start_wandb_run()\n",
321 | "\n",
322 | " prompts = generate_candidate_prompts(description, test_cases, number_of_prompts)\n",
323 | " prompt_ratings = test_candidate_prompts(test_cases, description, prompts)\n",
324 | "\n",
325 | " # Print the final ELO ratingsz\n",
326 | " table = PrettyTable()\n",
327 | " table.field_names = [\"Prompt\", \"Rating\"]\n",
328 | " for prompt, rating in sorted(prompt_ratings.items(), key=lambda item: item[1], reverse=True):\n",
329 | " table.add_row([prompt, rating])\n",
330 | " if use_wandb:\n",
331 | " wandb_table.add_data(prompt, rating)\n",
332 | "\n",
333 | " if use_wandb: # log the results to a Weights & Biases table and finsih the run\n",
334 | " wandb.log({\"prompt_ratings\": wandb_table})\n",
335 | " wandb.finish()\n",
336 | " print(table)"
337 | ]
338 | },
339 | {
340 | "attachments": {},
341 | "cell_type": "markdown",
342 | "metadata": {
343 | "id": "MJSSKFfV_X9F"
344 | },
345 | "source": [
346 | "# In the cell below, fill in your description and test cases"
347 | ]
348 | },
349 | {
350 | "cell_type": "code",
351 | "execution_count": null,
352 | "metadata": {
353 | "id": "vCZvLyDepxFP"
354 | },
355 | "outputs": [],
356 | "source": [
357 | "description = \"Given a prompt, generate a landing page headline.\" # this style of description tends to work well\n",
358 | "\n",
359 | "test_cases = [\n",
360 | " {\n",
361 | " 'prompt': 'Promoting an innovative new fitness app, Smartly',\n",
362 | " },\n",
363 | " {\n",
364 | " 'prompt': 'Why a vegan diet is beneficial for your health',\n",
365 | " },\n",
366 | " {\n",
367 | " 'prompt': 'Introducing a new online course on digital marketing',\n",
368 | " },\n",
369 | " {\n",
370 | " 'prompt': 'Launching a new line of eco-friendly clothing',\n",
371 | " },\n",
372 | " {\n",
373 | " 'prompt': 'Promoting a new travel blog focusing on budget travel',\n",
374 | " },\n",
375 | " {\n",
376 | " 'prompt': 'Advertising a new software for efficient project management',\n",
377 | " },\n",
378 | " {\n",
379 | " 'prompt': 'Introducing a new book on mastering Python programming',\n",
380 | " },\n",
381 | " {\n",
382 | " 'prompt': 'Promoting a new online platform for learning languages',\n",
383 | " },\n",
384 | " {\n",
385 | " 'prompt': 'Advertising a new service for personalized meal plans',\n",
386 | " },\n",
387 | " {\n",
388 | " 'prompt': 'Launching a new app for mental health and mindfulness',\n",
389 | " }\n",
390 | "]\n",
391 | "\n",
392 | "if use_wandb:\n",
393 | " wandb.config.update({\"description\": description, \n",
394 | " \"test_cases\": test_cases})"
395 | ]
396 | },
397 | {
398 | "cell_type": "code",
399 | "execution_count": null,
400 | "metadata": {},
401 | "outputs": [],
402 | "source": [
403 | "generate_optimal_prompt(description, test_cases, NUMBER_OF_PROMPTS, use_wandb)"
404 | ]
405 | }
406 | ],
407 | "metadata": {
408 | "colab": {
409 | "authorship_tag": "ABX9TyPMYK+Pn5QaRzPmh3T5a9ca",
410 | "include_colab_link": true,
411 | "provenance": []
412 | },
413 | "kernelspec": {
414 | "display_name": "Python 3",
415 | "name": "python3"
416 | },
417 | "language_info": {
418 | "codemirror_mode": {
419 | "name": "ipython",
420 | "version": 3
421 | },
422 | "file_extension": ".py",
423 | "mimetype": "text/x-python",
424 | "name": "python",
425 | "nbconvert_exporter": "python",
426 | "pygments_lexer": "ipython3",
427 | "version": "3.8.8"
428 | }
429 | },
430 | "nbformat": 4,
431 | "nbformat_minor": 0
432 | }
433 |
--------------------------------------------------------------------------------
/gpt_prompt_engineer_Classification_Version.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "attachments": {},
5 | "cell_type": "markdown",
6 | "metadata": {
7 | "colab_type": "text",
8 | "id": "view-in-github"
9 | },
10 | "source": [
11 | ""
12 | ]
13 | },
14 | {
15 | "attachments": {},
16 | "cell_type": "markdown",
17 | "metadata": {
18 | "id": "L0Ey7JZ5iLo1"
19 | },
20 | "source": [
21 | "# gpt-prompt-engineer -- Classification Version\n",
22 | "By Matt Shumer (https://twitter.com/mattshumer_)\n",
23 | "\n",
24 | "Github repo: https://github.com/mshumer/gpt-prompt-engineer\n",
25 | "\n",
26 | "Generate an optimal prompt for a given classification task that can be evaluated with 'true'/'false' outputs.\n",
27 | "\n",
28 | "You just need to describe the task clearly, and provide some test cases (for example, if we're classifying statements as 'happy' or not, a 'true' test case could be \"I had a great day!\", and a 'false' test case could be \"I am feeling gloomy.\").\n",
29 | "\n",
30 | "To generate a prompt:\n",
31 | "1. In the first cell, add in your OpenAI key.\n",
32 | "2. If you don't have GPT-4 access, change `CANDIDATE_MODEL='gpt-4'` in the second cell to `CANDIDATE_MODEL='gpt-3.5-turbo'`. If you do have access, skip this step.\n",
33 | "2. In the last cell, fill in the description of your task, as many test cases as you want (test cases are example prompts and their expected output), and the number of prompts to generate.\n",
34 | "3. Run all the cells! The AI will generate a number of candidate prompts, and test them all to find the best one!\n",
35 | "\n",
36 | "🪄🐝 To use [Weights & Biases logging](https://wandb.ai/site/prompts) to your LLM configs and the generated prompt outputs, just set `use_wandb = True`.\n",
37 | "\n",
38 | "🪄🔮 To use [Portkey](https://docs.portke.ai) for logging and tracing prompt chains and responses, just set `use_portkey = True`."
39 | ]
40 | },
41 | {
42 | "cell_type": "code",
43 | "execution_count": null,
44 | "metadata": {},
45 | "outputs": [],
46 | "source": [
47 | "!pip install openai prettytable tqdm tenacity wandb -qq"
48 | ]
49 | },
50 | {
51 | "cell_type": "code",
52 | "execution_count": 6,
53 | "metadata": {
54 | "id": "UW3ztLRsolnk"
55 | },
56 | "outputs": [],
57 | "source": [
58 | "from prettytable import PrettyTable\n",
59 | "import time\n",
60 | "import wandb\n",
61 | "import openai\n",
62 | "from tenacity import retry, stop_after_attempt, wait_exponential\n",
63 | "\n",
64 | "openai.api_key = \"ADD YOUR KEY HERE\" # enter your OpenAI API key here\n",
65 | "\n",
66 | "use_wandb = True # set to True if you want to use wandb to log your config and results\n",
67 | "\n",
68 | "use_portkey = False #set to True if you want to use Portkey to log all the prompt chains and their responses Check https://portkey.ai/"
69 | ]
70 | },
71 | {
72 | "cell_type": "code",
73 | "execution_count": 30,
74 | "metadata": {},
75 | "outputs": [],
76 | "source": [
77 | "candidate_gen_system_prompt = \"\"\"Your job is to generate system prompts for GPT-4, given a description of the use-case and some test cases.\n",
78 | "\n",
79 | "The prompts you will be generating will be for classifiers, with 'true' and 'false' being the only possible outputs.\n",
80 | "\n",
81 | "In your generated prompt, you should describe how the AI should behave in plain English. Include what it will see, and what it's allowed to output. Be creative in with prompts to get the best possible results. The AI knows it's an AI -- you don't need to tell it this.\n",
82 | "\n",
83 | "You will be graded based on the performance of your prompt... but don't cheat! You cannot include specifics about the test cases in your prompt. Any prompts with examples will be disqualified.\n",
84 | "\n",
85 | "Most importantly, output NOTHING but the prompt. Do not include anything else in your message.\"\"\""
86 | ]
87 | },
88 | {
89 | "cell_type": "code",
90 | "execution_count": 31,
91 | "metadata": {},
92 | "outputs": [],
93 | "source": [
94 | "CANDIDATE_MODEL = 'gpt-4'\n",
95 | "CANDIDATE_MODEL_TEMPERATURE = 0.9\n",
96 | "\n",
97 | "EVAL_MODEL = 'gpt-3.5-turbo'\n",
98 | "EVAL_MODEL_TEMPERATURE = 0\n",
99 | "EVAL_MODEL_MAX_TOKENS = 1\n",
100 | "\n",
101 | "NUMBER_OF_PROMPTS = 10 # this determines how many candidate prompts to generate... the higher, the more expensive\n",
102 | "\n",
103 | "N_RETRIES = 3 # number of times to retry a call to the ranking model if it fails\n",
104 | "\n",
105 | "WANDB_PROJECT_NAME = \"gpt-prompt-eng\" # used if use_wandb is True, Weights &| Biases project name\n",
106 | "WANDB_RUN_NAME = None # used if use_wandb is True, optionally set the Weights & Biases run name to identify this run\n",
107 | "\n",
108 | "PORTKEY_API = \"\" # used if use_portkey is True. Get api key here: https://app.portkey.ai/ (click on profile photo on top left)\n",
109 | "PORTKEY_TRACE = \"prompt_engineer_classification_test_run\" # used if use_portkey is True. Trace each run with a separate ID to differentiate prompt chains\n",
110 | "HEADERS = {} # don't change. headers will auto populate if use_portkey is true."
111 | ]
112 | },
113 | {
114 | "cell_type": "code",
115 | "execution_count": 32,
116 | "metadata": {},
117 | "outputs": [],
118 | "source": [
119 | "def start_wandb_run():\n",
120 | " # start a new wandb run and log the config\n",
121 | " wandb.init(\n",
122 | " project=WANDB_PROJECT_NAME, \n",
123 | " name=WANDB_RUN_NAME,\n",
124 | " config={\n",
125 | " \"candidate_gen_system_prompt\": candidate_gen_system_prompt, \n",
126 | " \"candiate_model\": CANDIDATE_MODEL,\n",
127 | " \"candidate_model_temperature\": CANDIDATE_MODEL_TEMPERATURE,\n",
128 | " \"generation_model\": EVAL_MODEL,\n",
129 | " \"generation_model_temperature\": EVAL_MODEL_TEMPERATURE,\n",
130 | " \"generation_model_max_tokens\": EVAL_MODEL_MAX_TOKENS,\n",
131 | " \"n_retries\": N_RETRIES,\n",
132 | " \"number_of_prompts\": NUMBER_OF_PROMPTS\n",
133 | " })\n",
134 | " \n",
135 | " return "
136 | ]
137 | },
138 | {
139 | "cell_type": "code",
140 | "execution_count": null,
141 | "metadata": {},
142 | "outputs": [],
143 | "source": [
144 | "# Optional logging to Weights & Biases to reocrd the configs, prompts and results\n",
145 | "if use_wandb:\n",
146 | " start_wandb_run()"
147 | ]
148 | },
149 | {
150 | "cell_type": "code",
151 | "execution_count": null,
152 | "metadata": {},
153 | "outputs": [],
154 | "source": [
155 | "def start_portkey_run():\n",
156 | " # define Portkey headers to start logging all prompts & their responses\n",
157 | " openai.api_base=\"https://api.portkey.ai/v1/proxy\"\n",
158 | " HEADERS = {\n",
159 | " \"x-portkey-api-key\": PORTKEY_API, \n",
160 | " \"x-portkey-mode\": \"proxy openai\",\n",
161 | " \"x-portkey-trace-id\": PORTKEY_TRACE,\n",
162 | " #\"x-portkey-retry-count\": 5 # perform automatic retries with exponential backoff if the OpenAI requests fails\n",
163 | " } \n",
164 | " return HEADERS"
165 | ]
166 | },
167 | {
168 | "cell_type": "code",
169 | "execution_count": null,
170 | "metadata": {},
171 | "outputs": [],
172 | "source": [
173 | "# Optional prompt & responses logging\n",
174 | "if use_portkey:\n",
175 | " HEADERS=start_portkey_run()"
176 | ]
177 | },
178 | {
179 | "cell_type": "code",
180 | "execution_count": 34,
181 | "metadata": {
182 | "id": "KTRFiBhSouz8"
183 | },
184 | "outputs": [],
185 | "source": [
186 | "# Get Score - retry up to N_RETRIES times, waiting exponentially between retries.\n",
187 | "@retry(stop=stop_after_attempt(N_RETRIES), wait=wait_exponential(multiplier=1, min=4, max=70))\n",
188 | "def generate_candidate_prompts(description, test_cases, number_of_prompts):\n",
189 | " outputs = openai.ChatCompletion.create(\n",
190 | " model=CANDIDATE_MODEL,\n",
191 | " messages=[\n",
192 | " {\"role\": \"system\", \"content\": candidate_gen_system_prompt},\n",
193 | " {\"role\": \"user\", \"content\": f\"Here are some test cases:`{test_cases}`\\n\\nHere is the description of the use-case: `{description.strip()}`\\n\\nRespond with your prompt, and nothing else. Be creative.\"}\n",
194 | " ],\n",
195 | " temperature=CANDIDATE_MODEL_TEMPERATURE,\n",
196 | " n=number_of_prompts,\n",
197 | " headers=HEADERS)\n",
198 | "\n",
199 | " prompts = []\n",
200 | "\n",
201 | " for i in outputs.choices:\n",
202 | " prompts.append(i.message.content)\n",
203 | " return prompts"
204 | ]
205 | },
206 | {
207 | "cell_type": "code",
208 | "execution_count": 43,
209 | "metadata": {
210 | "id": "w4ltgxntszwK"
211 | },
212 | "outputs": [],
213 | "source": [
214 | "def test_candidate_prompts(test_cases, prompts):\n",
215 | " prompt_results = {prompt: {'correct': 0, 'total': 0} for prompt in prompts}\n",
216 | "\n",
217 | " # Initialize the table\n",
218 | " table = PrettyTable()\n",
219 | " table_field_names = [\"Prompt\", \"Expected\"] + [f\"Prompt {i+1}-{j+1}\" for j, prompt in enumerate(prompts) for i in range(prompts.count(prompt))]\n",
220 | " table.field_names = table_field_names\n",
221 | "\n",
222 | " # Wrap the text in the \"Prompt\" column\n",
223 | " table.max_width[\"Prompt\"] = 100\n",
224 | "\n",
225 | " if use_wandb:\n",
226 | " wandb_table = wandb.Table(columns=table_field_names)\n",
227 | " if wandb.run is None:\n",
228 | " start_wandb_run()\n",
229 | "\n",
230 | " for test_case in test_cases:\n",
231 | " row = [test_case['prompt'], test_case['answer']]\n",
232 | " for prompt in prompts:\n",
233 | " x = openai.ChatCompletion.create(\n",
234 | " model=EVAL_MODEL,\n",
235 | " messages=[\n",
236 | " {\"role\": \"system\", \"content\": prompt},\n",
237 | " {\"role\": \"user\", \"content\": f\"{test_case['prompt']}\"}\n",
238 | " ],\n",
239 | " logit_bias={\n",
240 | " '1904': 100, # 'true' token\n",
241 | " '3934': 100, # 'false' token\n",
242 | " },\n",
243 | " max_tokens=EVAL_MODEL_MAX_TOKENS,\n",
244 | " temperature=EVAL_MODEL_TEMPERATURE,\n",
245 | " headers=HEADERS\n",
246 | " ).choices[0].message.content\n",
247 | "\n",
248 | "\n",
249 | " status = \"✅\" if x == test_case['answer'] else \"❌\"\n",
250 | " row.append(status)\n",
251 | "\n",
252 | " # Update model results\n",
253 | " if x == test_case['answer']:\n",
254 | " prompt_results[prompt]['correct'] += 1\n",
255 | " prompt_results[prompt]['total'] += 1\n",
256 | "\n",
257 | " table.add_row(row)\n",
258 | " if use_wandb:\n",
259 | " wandb_table.add_data(*row)\n",
260 | "\n",
261 | " print(table)\n",
262 | "\n",
263 | " # Calculate and print the percentage of correct answers and average time for each model\n",
264 | " best_prompt = None\n",
265 | " best_percentage = 0\n",
266 | " if use_wandb:\n",
267 | " prompts_results_table = wandb.Table(columns=[\"Prompt Number\", \"Prompt\", \"Percentage\", \"Correct\", \"Total\"])\n",
268 | " \n",
269 | " for i, prompt in enumerate(prompts):\n",
270 | " correct = prompt_results[prompt]['correct']\n",
271 | " total = prompt_results[prompt]['total']\n",
272 | " percentage = (correct / total) * 100\n",
273 | " print(f\"Prompt {i+1} got {percentage:.2f}% correct.\")\n",
274 | " if use_wandb:\n",
275 | " prompts_results_table.add_data(i, prompt, percentage, correct, total)\n",
276 | " if percentage > best_percentage:\n",
277 | " best_percentage = percentage\n",
278 | " best_prompt = prompt\n",
279 | "\n",
280 | " if use_wandb: # log the results to a Weights & Biases table and finsih the run\n",
281 | " wandb.log({\"prompt_results\": prompts_results_table})\n",
282 | " best_prompt_table = wandb.Table(columns=[\"Best Prompt\", \"Best Percentage\"])\n",
283 | " best_prompt_table.add_data(best_prompt, best_percentage)\n",
284 | " wandb.log({\"best_prompt\": best_prompt_table})\n",
285 | " wandb.log({\"prompt_ratings\": wandb_table})\n",
286 | " wandb.finish()\n",
287 | "\n",
288 | " print(f\"The best prompt was '{best_prompt}' with a correctness of {best_percentage:.2f}%.\")"
289 | ]
290 | },
291 | {
292 | "cell_type": "code",
293 | "execution_count": 44,
294 | "metadata": {
295 | "id": "SBJEi1hkrT9T"
296 | },
297 | "outputs": [],
298 | "source": [
299 | "test_cases = [\n",
300 | " {\n",
301 | " 'prompt': 'Find the best contact email on this site.',\n",
302 | " 'answer': 'true'\n",
303 | " },\n",
304 | " {\n",
305 | " 'prompt': 'who is the current president?',\n",
306 | " 'answer': 'true'\n",
307 | " },\n",
308 | " {\n",
309 | " 'prompt': 'order me a pizza',\n",
310 | " 'answer': 'false'\n",
311 | " },\n",
312 | " {\n",
313 | " 'prompt': 'what are some ways a doctor could use an assistant?',\n",
314 | " 'answer': 'true'\n",
315 | " },\n",
316 | " {\n",
317 | " 'prompt': 'write a speech on the danger of cults',\n",
318 | " 'answer': 'false'\n",
319 | " },\n",
320 | " {\n",
321 | " 'prompt': 'Make a reservation at The Accent for 9pm',\n",
322 | " 'answer': 'false'\n",
323 | " },\n",
324 | " {\n",
325 | " 'prompt': 'organize my google drive',\n",
326 | " 'answer': 'false'\n",
327 | " },\n",
328 | " {\n",
329 | " 'prompt': 'Find the highest-rated Italian restaurant near me.',\n",
330 | " 'answer': 'true'\n",
331 | " },\n",
332 | " {\n",
333 | " 'prompt': 'Explain the theory of relativity.',\n",
334 | " 'answer': 'true'\n",
335 | " },\n",
336 | " {\n",
337 | " 'prompt': 'What are the main differences between Python and Java programming languages?',\n",
338 | " 'answer': 'true'\n",
339 | " },\n",
340 | " {\n",
341 | " 'prompt': 'Translate the following English sentence to Spanish: \"The weather today is great.\"',\n",
342 | " 'answer': 'false'\n",
343 | " },\n",
344 | " {\n",
345 | " 'prompt': 'Create a new event on my calendar for tomorrow at 2 pm.',\n",
346 | " 'answer': 'false'\n",
347 | " },\n",
348 | " {\n",
349 | " 'prompt': 'Write a short story about a lonely cowboy.',\n",
350 | " 'answer': 'false'\n",
351 | " },\n",
352 | " {\n",
353 | " 'prompt': 'Design a logo for a startup.',\n",
354 | " 'answer': 'false'\n",
355 | " },\n",
356 | " {\n",
357 | " 'prompt': 'Compose a catchy jingle for a new soda brand.',\n",
358 | " 'answer': 'false'\n",
359 | " },\n",
360 | " {\n",
361 | " 'prompt': 'Calculate the square root of 1999.',\n",
362 | " 'answer': 'false'\n",
363 | " },\n",
364 | " {\n",
365 | " 'prompt': 'What are the health benefits of yoga?',\n",
366 | " 'answer': 'true'\n",
367 | " },\n",
368 | " {\n",
369 | " 'prompt': 'find me a source of meat that can be shipped to canada',\n",
370 | " 'answer': 'true'\n",
371 | " },\n",
372 | " {\n",
373 | " 'prompt': 'Find the best-selling book of all time.',\n",
374 | " 'answer': 'true'\n",
375 | " },\n",
376 | " {\n",
377 | " 'prompt': 'What are the top 5 tourist attractions in Brazil?',\n",
378 | " 'answer': 'true'\n",
379 | " },\n",
380 | " {\n",
381 | " 'prompt': 'List the main ingredients in a traditional lasagna recipe.',\n",
382 | " 'answer': 'true'\n",
383 | " },\n",
384 | " {\n",
385 | " 'prompt': 'How does photosynthesis work in plants?',\n",
386 | " 'answer': 'true'\n",
387 | " },\n",
388 | " {\n",
389 | " 'prompt': 'Write a Python program to reverse a string.',\n",
390 | " 'answer': 'false'\n",
391 | " },\n",
392 | " {\n",
393 | " 'prompt': 'Create a workout routine for a beginner.',\n",
394 | " 'answer': 'false'\n",
395 | " },\n",
396 | " {\n",
397 | " 'prompt': 'Edit my resume to highlight my project management skills.',\n",
398 | " 'answer': 'false'\n",
399 | " },\n",
400 | " {\n",
401 | " 'prompt': 'Draft an email to a client to discuss a new proposal.',\n",
402 | " 'answer': 'false'\n",
403 | " },\n",
404 | " {\n",
405 | " 'prompt': 'Plan a surprise birthday party for my best friend.',\n",
406 | " 'answer': 'false'\n",
407 | " }]"
408 | ]
409 | },
410 | {
411 | "cell_type": "code",
412 | "execution_count": 46,
413 | "metadata": {},
414 | "outputs": [],
415 | "source": [
416 | "description = \"Decide if a task is research-heavy.\" # describe the classification task clearly\n",
417 | "\n",
418 | "# If Weights & Biases is enabled, log the description and test cases too\n",
419 | "if use_wandb:\n",
420 | " if wandb.run is None:\n",
421 | " start_wandb_run()\n",
422 | " wandb.config.update({\"description\": description, \n",
423 | " \"test_cases\": test_cases})\n",
424 | "\n",
425 | "candidate_prompts = generate_candidate_prompts(description, test_cases, NUMBER_OF_PROMPTS)\n",
426 | "test_candidate_prompts(test_cases, candidate_prompts)"
427 | ]
428 | }
429 | ],
430 | "metadata": {
431 | "colab": {
432 | "authorship_tag": "ABX9TyMvbQztC95mJY9x+Gc/uEm+",
433 | "include_colab_link": true,
434 | "provenance": []
435 | },
436 | "kernelspec": {
437 | "display_name": "Python 3",
438 | "name": "python3"
439 | },
440 | "language_info": {
441 | "codemirror_mode": {
442 | "name": "ipython",
443 | "version": 3
444 | },
445 | "file_extension": ".py",
446 | "mimetype": "text/x-python",
447 | "name": "python",
448 | "nbconvert_exporter": "python",
449 | "pygments_lexer": "ipython3",
450 | "version": "3.11.2"
451 | }
452 | },
453 | "nbformat": 4,
454 | "nbformat_minor": 0
455 | }
456 |
--------------------------------------------------------------------------------
/opus_to_haiku_conversion.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "id": "view-in-github",
7 | "colab_type": "text"
8 | },
9 | "source": [
10 | ""
11 | ]
12 | },
13 | {
14 | "cell_type": "markdown",
15 | "metadata": {
16 | "id": "WljjH8K3s7kG"
17 | },
18 | "source": [
19 | "# opus-to-haiku - part of the `gpt-prompt-engineer` repo\n",
20 | "\n",
21 | "This notebook gives you the ability to go from Claude Opus to Claude Haiku -- reducing costs massively while keeping quality high.\n",
22 | "\n",
23 | "By Matt Shumer (https://twitter.com/mattshumer_)\n",
24 | "\n",
25 | "Github repo: https://github.com/mshumer/gpt-prompt-engineer"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": null,
31 | "metadata": {
32 | "id": "dQmMZdkG_RA5"
33 | },
34 | "outputs": [],
35 | "source": [
36 | "import requests\n",
37 | "\n",
38 | "ANTHROPIC_API_KEY = \"YOUR API KEY HERE\" # enter your Anthropic API key here"
39 | ]
40 | },
41 | {
42 | "cell_type": "code",
43 | "execution_count": null,
44 | "metadata": {
45 | "id": "wXeqMQpzzosx",
46 | "cellView": "form"
47 | },
48 | "outputs": [],
49 | "source": [
50 | "#@title Run this to prep the main functions\n",
51 | "\n",
52 | "import json\n",
53 | "import re\n",
54 | "\n",
55 | "def generate_candidate_prompts(task, prompt_example, response_example):\n",
56 | " headers = {\n",
57 | " \"x-api-key\": ANTHROPIC_API_KEY,\n",
58 | " \"anthropic-version\": \"2023-06-01\",\n",
59 | " \"content-type\": \"application/json\"\n",
60 | " }\n",
61 | "\n",
62 | " data = {\n",
63 | " \"model\": 'claude-3-opus-20240229',\n",
64 | " \"max_tokens\": 4000,\n",
65 | " \"temperature\": .5,\n",
66 | " \"system\": \"\"\"Given an example training sample, create seven additional samples for the same task that are even better. Each example should contain a and a .\n",
67 | "\n",
68 | "\n",
69 | "1. Ensure the new examples are diverse and unique from one another.\n",
70 | "2. They should all be perfect. If you make a mistake, this system won't work.\n",
71 | "\n",
72 | "\n",
73 | "Respond in this format:\n",
74 | "\n",
75 | "\n",
76 | "\n",
77 | "PUT_PROMPT_HERE\n",
78 | "\n",
79 | "\n",
80 | "PUT_RESPONSE_HERE\n",
81 | "\n",
82 | "\n",
83 | "\n",
84 | "\n",
85 | "\n",
86 | "PUT_PROMPT_HERE\n",
87 | "\n",
88 | "\n",
89 | "PUT_RESPONSE_HERE\n",
90 | "\n",
91 | "\n",
92 | "\n",
93 | "...\n",
94 | "\"\"\",\n",
95 | " \"messages\": [\n",
96 | " {\"role\": \"user\", \"content\": f\"\"\"{task}\n",
97 | "\n",
98 | "\n",
99 | "{prompt_example}\n",
100 | "\n",
101 | "\n",
102 | "\n",
103 | "{response_example}\n",
104 | "\"\"\"},\n",
105 | " ]\n",
106 | " }\n",
107 | "\n",
108 | "\n",
109 | " response = requests.post(\"https://api.anthropic.com/v1/messages\", headers=headers, json=data)\n",
110 | "\n",
111 | " response_text = response.json()['content'][0]['text']\n",
112 | "\n",
113 | " # Parse out the prompts and responses\n",
114 | " prompts_and_responses = []\n",
115 | " examples = re.findall(r'(.*?)', response_text, re.DOTALL)\n",
116 | " for example in examples:\n",
117 | " prompt = re.findall(r'(.*?)', example, re.DOTALL)[0].strip()\n",
118 | " response = re.findall(r'(.*?)', example, re.DOTALL)[0].strip()\n",
119 | " prompts_and_responses.append({'prompt': prompt, 'response': response})\n",
120 | "\n",
121 | " return prompts_and_responses\n",
122 | "\n",
123 | "def generate_system_prompt(task, prompt_examples):\n",
124 | " headers = {\n",
125 | " \"x-api-key\": ANTHROPIC_API_KEY,\n",
126 | " \"anthropic-version\": \"2023-06-01\",\n",
127 | " \"content-type\": \"application/json\"\n",
128 | " }\n",
129 | "\n",
130 | " data = {\n",
131 | " \"model\": 'claude-3-opus-20240229',\n",
132 | " \"max_tokens\": 1000,\n",
133 | " \"temperature\": .5,\n",
134 | " \"system\": \"\"\"Given a user-description of their a set of prompt / response pairs (it'll be in JSON for easy reading) for the types of outputs we want to generate given inputs, write a fantastic system prompt that describes the task to be done perfectly.\n",
135 | "\n",
136 | "\n",
137 | "1. Do this perfectly.\n",
138 | "2. Respond only with the system prompt, and nothing else. No other text will be allowed.\n",
139 | "\n",
140 | "\n",
141 | "Respond in this format:\n",
142 | "\n",
143 | "WRITE_SYSTEM_PROMPT_HERE\n",
144 | "\"\"\",\n",
145 | " \"messages\": [\n",
146 | " {\"role\": \"user\", \"content\": f\"\"\"{task}\n",
147 | "\n",
148 | "\n",
149 | "{str(prompt_examples)}\n",
150 | "\"\"\"},\n",
151 | " ]\n",
152 | " }\n",
153 | "\n",
154 | "\n",
155 | " response = requests.post(\"https://api.anthropic.com/v1/messages\", headers=headers, json=data)\n",
156 | "\n",
157 | " response_text = response.json()['content'][0]['text']\n",
158 | "\n",
159 | " # Parse out the prompt\n",
160 | " system_prompt = response_text.split('')[1].split('')[0].strip()\n",
161 | "\n",
162 | " return system_prompt\n",
163 | "\n",
164 | "def test_haiku(generated_examples, prompt_example, system_prompt):\n",
165 | " headers = {\n",
166 | " \"x-api-key\": ANTHROPIC_API_KEY,\n",
167 | " \"anthropic-version\": \"2023-06-01\",\n",
168 | " \"content-type\": \"application/json\"\n",
169 | " }\n",
170 | "\n",
171 | " messages = []\n",
172 | "\n",
173 | " for example in generated_examples:\n",
174 | " messages.append({\"role\": \"user\", \"content\": example['prompt']})\n",
175 | " messages.append({\"role\": \"assistant\", \"content\": example['response']})\n",
176 | "\n",
177 | " messages.append({\"role\": \"user\", \"content\": prompt_example.strip()})\n",
178 | "\n",
179 | " data = {\n",
180 | " \"model\": 'claude-3-haiku-20240307',\n",
181 | " \"max_tokens\": 2000,\n",
182 | " \"temperature\": .5,\n",
183 | " \"system\": system_prompt,\n",
184 | " \"messages\": messages,\n",
185 | " }\n",
186 | "\n",
187 | "\n",
188 | " response = requests.post(\"https://api.anthropic.com/v1/messages\", headers=headers, json=data)\n",
189 | "\n",
190 | " response_text = response.json()['content'][0]['text']\n",
191 | "\n",
192 | " return response_text\n",
193 | "\n",
194 | "def run_haiku_conversion_process(task, prompt_example, response_example):\n",
195 | "\n",
196 | " print('Generating the prompts / responses...')\n",
197 | " # Generate candidate prompts\n",
198 | " generated_examples = generate_candidate_prompts(task, prompt_example, response_example)\n",
199 | "\n",
200 | " print('Prompts / responses generated. Now generating system prompt...')\n",
201 | "\n",
202 | " # Generate the system prompt\n",
203 | " system_prompt = generate_system_prompt(task, generated_examples)\n",
204 | "\n",
205 | " print('System prompt generated:', system_prompt)\n",
206 | "\n",
207 | "\n",
208 | " print('\\n\\nTesting the new prompt on Haiku, using your input example...')\n",
209 | " # Test the generated examples and system prompt with the Haiku model\n",
210 | " haiku_response = test_haiku(generated_examples, prompt_example, system_prompt)\n",
211 | "\n",
212 | " print('Haiku responded with:')\n",
213 | " print(haiku_response)\n",
214 | "\n",
215 | " print('\\n\\n!! CHECK THE FILE DIRECTORY, THE PROMPT IS NOW SAVED THERE !!')\n",
216 | "\n",
217 | " # Create a dictionary with all the relevant information\n",
218 | " result = {\n",
219 | " \"task\": task,\n",
220 | " \"initial_prompt_example\": prompt_example,\n",
221 | " \"initial_response_example\": response_example,\n",
222 | " \"generated_examples\": generated_examples,\n",
223 | " \"system_prompt\": system_prompt,\n",
224 | " \"haiku_response\": haiku_response\n",
225 | " }\n",
226 | "\n",
227 | " # Save the Haiku prompt to a Python file\n",
228 | " with open(\"haiku_prompt.py\", \"w\") as file:\n",
229 | " file.write('system_prompt = \"\"\"' + system_prompt + '\"\"\"\\n\\n')\n",
230 | "\n",
231 | " file.write('messages = [\\n')\n",
232 | " for example in generated_examples:\n",
233 | " file.write(' {\"role\": \"user\", \"content\": \"\"\"' + example['prompt'] + '\"\"\"},\\n')\n",
234 | " file.write(' {\"role\": \"assistant\", \"content\": \"\"\"' + example['response'] + '\"\"\"},\\n')\n",
235 | "\n",
236 | " file.write(' {\"role\": \"user\", \"content\": \"\"\"' + prompt_example.strip() + '\"\"\"}\\n')\n",
237 | " file.write(']\\n')\n",
238 | "\n",
239 | " return result"
240 | ]
241 | },
242 | {
243 | "cell_type": "markdown",
244 | "source": [
245 | "## Fill in your task, prompt_example, and response_example here. Make sure you keep the quality really high here... this is the most important step!"
246 | ],
247 | "metadata": {
248 | "id": "ZujTAzhuBMea"
249 | }
250 | },
251 | {
252 | "cell_type": "code",
253 | "source": [
254 | "task = \"refactoring complex code\"\n",
255 | "\n",
256 | "prompt_example = \"\"\"def calculate_total(prices, tax, discount, shipping_fee, gift_wrap_fee, membership_discount):\n",
257 | "\n",
258 | " total = 0\n",
259 | "\n",
260 | " for i in range(len(prices)):\n",
261 | "\n",
262 | " total += prices[i]\n",
263 | "\n",
264 | " if membership_discount != 0:\n",
265 | "\n",
266 | " total = total - (total * (membership_discount / 100))\n",
267 | "\n",
268 | " if discount != 0:\n",
269 | "\n",
270 | " total = total - (total * (discount / 100))\n",
271 | "\n",
272 | " total = total + (total * (tax / 100))\n",
273 | "\n",
274 | " if total < 50:\n",
275 | "\n",
276 | " total += shipping_fee\n",
277 | "\n",
278 | " else:\n",
279 | "\n",
280 | " total += shipping_fee / 2\n",
281 | "\n",
282 | " if gift_wrap_fee != 0:\n",
283 | "\n",
284 | " total += gift_wrap_fee * len(prices)\n",
285 | "\n",
286 | " if total > 1000:\n",
287 | "\n",
288 | " total -= 50\n",
289 | "\n",
290 | " elif total > 500:\n",
291 | "\n",
292 | " total -= 25\n",
293 | "\n",
294 | " total = round(total, 2)\n",
295 | "\n",
296 | " if total < 0:\n",
297 | "\n",
298 | " total = 0\n",
299 | "\n",
300 | " return total\"\"\"\n",
301 | "\n",
302 | "response_example = \"\"\"def calculate_total(prices, tax_rate, discount_rate, shipping_fee, gift_wrap_fee, membership_discount_rate):\n",
303 | "\n",
304 | " def apply_percentage_discount(amount, percentage):\n",
305 | "\n",
306 | " return amount * (1 - percentage / 100)\n",
307 | "\n",
308 | " def calculate_shipping_fee(total):\n",
309 | "\n",
310 | " return shipping_fee if total < 50 else shipping_fee / 2\n",
311 | "\n",
312 | " def apply_tier_discount(total):\n",
313 | "\n",
314 | " if total > 1000:\n",
315 | "\n",
316 | " return total - 50\n",
317 | "\n",
318 | " elif total > 500:\n",
319 | "\n",
320 | " return total - 25\n",
321 | "\n",
322 | " return total\n",
323 | "\n",
324 | " subtotal = sum(prices)\n",
325 | "\n",
326 | " subtotal = apply_percentage_discount(subtotal, membership_discount_rate)\n",
327 | "\n",
328 | " subtotal = apply_percentage_discount(subtotal, discount_rate)\n",
329 | "\n",
330 | "\n",
331 | "\n",
332 | " total = subtotal * (1 + tax_rate / 100)\n",
333 | "\n",
334 | " total += calculate_shipping_fee(total)\n",
335 | "\n",
336 | " total += gift_wrap_fee * len(prices)\n",
337 | "\n",
338 | "\n",
339 | "\n",
340 | " total = apply_tier_discount(total)\n",
341 | "\n",
342 | " total = max(0, round(total, 2))\n",
343 | "\n",
344 | "\n",
345 | "\n",
346 | " return total\"\"\""
347 | ],
348 | "metadata": {
349 | "id": "XSZqqOoQ-5_E"
350 | },
351 | "execution_count": null,
352 | "outputs": []
353 | },
354 | {
355 | "cell_type": "markdown",
356 | "source": [
357 | "### Now, let's run this system and get our new prompt! At the end, you'll see a new file pop up in the directory that contains everything you'll need to reduce your costs while keeping quality high w/ Haiku!"
358 | ],
359 | "metadata": {
360 | "id": "cMO3cJzWA-O0"
361 | }
362 | },
363 | {
364 | "cell_type": "code",
365 | "source": [
366 | "result = run_haiku_conversion_process(task, prompt_example, response_example)"
367 | ],
368 | "metadata": {
369 | "id": "O-Bn0rupAJqb"
370 | },
371 | "execution_count": null,
372 | "outputs": []
373 | }
374 | ],
375 | "metadata": {
376 | "colab": {
377 | "provenance": [],
378 | "include_colab_link": true
379 | },
380 | "kernelspec": {
381 | "display_name": "Python 3",
382 | "name": "python3"
383 | },
384 | "language_info": {
385 | "codemirror_mode": {
386 | "name": "ipython",
387 | "version": 3
388 | },
389 | "file_extension": ".py",
390 | "mimetype": "text/x-python",
391 | "name": "python",
392 | "nbconvert_exporter": "python",
393 | "pygments_lexer": "ipython3",
394 | "version": "3.8.8"
395 | }
396 | },
397 | "nbformat": 4,
398 | "nbformat_minor": 0
399 | }
--------------------------------------------------------------------------------
118 |
119 | For the classification version, the scores for each prompt will be printed in a table (see the image above).
120 |
121 | ## Contributions are welcome! Some ideas:
122 | - have a number of different system prompt generators that create different styles of prompts, to cover more ground (ex. examples, verbose, short, markdown, etc.)
123 | - automatically generate the test cases
124 | - expand the classification version to support more than two classes using tiktoken
125 |
126 | ## License
127 |
128 | This project is [MIT](https://github.com/your_username/your_repository/blob/master/LICENSE) licensed.
129 |
130 | ## Contact
131 |
132 | Matt Shumer - [@mattshumer_](https://twitter.com/mattshumer_)
133 |
134 | Project Link: [https://github.com/mshumer/gpt-prompt-engineer](url)
135 |
136 | Lastly, if you want to try something even cooler than this, sign up for [HyperWrite Personal Assistant](https://app.hyperwriteai.com/personalassistant) (most of my time is spent on this). It's basically an AI with access to real-time information that a) is incredible at writing naturally, and b) can operate your web browser to complete tasks for you.
137 |
138 | Head to [ShumerPrompt](https://ShumerPrompt.com), my "Github for Prompts"!
139 |
--------------------------------------------------------------------------------
/XL_to_XS_conversion.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "id": "view-in-github"
7 | },
8 | "source": [
9 | ""
10 | ]
11 | },
12 | {
13 | "cell_type": "markdown",
14 | "metadata": {
15 | "id": "WljjH8K3s7kG"
16 | },
17 | "source": [
18 | "# XL to XS - Prompt Engineering for Smaller Models\n",
19 | "\n",
20 | "This notebook gives you the ability to go from a large model to smaller model -- reducing costs massively while keeping quality high.\n",
21 | "\n",
22 | "This extends the Opus to Haiku notebook ( in [`gpt-prompt-engineer`]((https://github.com/mshumer/gpt-prompt-engineer)) repo by [Matt Shumer](https://twitter.com/mattshumer_)) to cover any large and small model combination using Portkey's [AI Gateway](https://github.com/portkey-ai/gateway)"
23 | ]
24 | },
25 | {
26 | "cell_type": "code",
27 | "execution_count": null,
28 | "metadata": {
29 | "id": "dQmMZdkG_RA5"
30 | },
31 | "outputs": [],
32 | "source": [
33 | "import requests\n",
34 | "\n",
35 | "PORTKEY_API_KEY = \"\" # Configure your AI Gateway Key (https://app.portkey.ai/signup)\n",
36 | "\n",
37 | "PROVIDER = \"\" # Any of `openai`, `anthropic`, `azure-openai`, `anyscale`, `mistral`, `gemini` and more\n",
38 | "PROVIDER_API_KEY = \"\" # Enter the API key of the provider used above\n",
39 | "LARGE_MODEL = \"\" # The large model to use\n",
40 | "\n",
41 | "\n",
42 | "# If you want to use a different provider for the smaller model, uncomment these 2 lines\n",
43 | "# SMALL_PROVIDER = \"\" # Any of `openai`, `anthropic`, `azure-openai`, `anyscale`, `mistral`, `gemini`\n",
44 | "# SMALL_PROVIDER_API_KEY = \"\"\n",
45 | "\n",
46 | "SMALL_MODEL = \"\" # The small model to use"
47 | ]
48 | },
49 | {
50 | "cell_type": "markdown",
51 | "metadata": {
52 | "id": "B84V9aohvCbr"
53 | },
54 | "source": [
55 | "### Portkey Client Init\n",
56 | "\n",
57 | "Using Portkey clients for the large and small models. The gateway will allow us to make calls to any model without chaning our code."
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "source": [
63 | "!pip install portkey_ai"
64 | ],
65 | "metadata": {
66 | "id": "BfTZMUNwwhxe"
67 | },
68 | "execution_count": null,
69 | "outputs": []
70 | },
71 | {
72 | "cell_type": "code",
73 | "execution_count": null,
74 | "metadata": {
75 | "cellView": "form",
76 | "id": "wXeqMQpzzosx"
77 | },
78 | "outputs": [],
79 | "source": [
80 | "#@title Run this to prep the main functions\n",
81 | "\n",
82 | "from portkey_ai import Portkey\n",
83 | "\n",
84 | "client_large = Portkey(\n",
85 | " Authorization= \"Bearer \"+PROVIDER_API_KEY,\n",
86 | " provider=PROVIDER,\n",
87 | " api_key=PORTKEY_API_KEY,\n",
88 | " metadata={\"_user\": \"gpt-prompt-engineer\"},\n",
89 | " config={\"cache\": {\"mode\": \"simple\"}}\n",
90 | ")\n",
91 | "\n",
92 | "try:\n",
93 | " authorization_token = \"Bearer \" + SMALL_PROVIDER_API_KEY\n",
94 | "except NameError:\n",
95 | " authorization_token = \"Bearer \" + PROVIDER_API_KEY\n",
96 | "\n",
97 | "try:\n",
98 | " provider_name = SMALL_PROVIDER\n",
99 | "except NameError:\n",
100 | " provider_name = PROVIDER\n",
101 | "\n",
102 | "client_small = Portkey(\n",
103 | " Authorization=authorization_token,\n",
104 | " provider=provider_name,\n",
105 | " api_key=PORTKEY_API_KEY, # Ensure this is defined and contains the correct API key.\n",
106 | " metadata={\"_user\": \"gpt-prompt-engineer\"},\n",
107 | " config={\"cache\": {\"mode\": \"simple\"}}\n",
108 | ")\n",
109 | "\n",
110 | "import json\n",
111 | "import re\n",
112 | "\n",
113 | "def generate_candidate_prompts(task, prompt_example, response_example):\n",
114 | " messages = [{\n",
115 | " \"role\": \"system\",\n",
116 | " \"content\":\"\"\"Given an example training sample, create seven additional samples for the same task that are even better. Each example should contain a and a .\n",
117 | "\n",
118 | "\n",
119 | "1. Ensure the new examples are diverse and unique from one another.\n",
120 | "2. They should all be perfect. If you make a mistake, this system won't work.\n",
121 | "\n",
122 | "\n",
123 | "Respond in this format:\n",
124 | "\n",
125 | "\n",
126 | "\n",
127 | "PUT_PROMPT_HERE\n",
128 | "\n",
129 | "\n",
130 | "PUT_RESPONSE_HERE\n",
131 | "\n",
132 | "\n",
133 | "\n",
134 | "\n",
135 | "\n",
136 | "PUT_PROMPT_HERE\n",
137 | "\n",
138 | "\n",
139 | "PUT_RESPONSE_HERE\n",
140 | "\n",
141 | "\n",
142 | "\n",
143 | "...\n",
144 | "\"\"\"\n",
145 | " }, {\n",
146 | " \"role\": \"user\",\n",
147 | " \"content\": f\"\"\"{task}\n",
148 | "\n",
149 | "\n",
150 | "{prompt_example}\n",
151 | "\n",
152 | "\n",
153 | "\n",
154 | "{response_example}\n",
155 | "\"\"\"},\n",
156 | " ]\n",
157 | "\n",
158 | " response = client_large.chat.completions.create(\n",
159 | " model=LARGE_MODEL,\n",
160 | " max_tokens=4000,\n",
161 | " temperature=0.5,\n",
162 | " messages=messages\n",
163 | " )\n",
164 | " response_text = response.choices[0]['message']['content']\n",
165 | "\n",
166 | " # Parse out the prompts and responses\n",
167 | " prompts_and_responses = []\n",
168 | " examples = re.findall(r'(.*?)', response_text, re.DOTALL)\n",
169 | " for example in examples:\n",
170 | " prompt = re.findall(r'(.*?)', example, re.DOTALL)[0].strip()\n",
171 | " response = re.findall(r'(.*?)', example, re.DOTALL)[0].strip()\n",
172 | " prompts_and_responses.append({'prompt': prompt, 'response': response})\n",
173 | "\n",
174 | " return prompts_and_responses\n",
175 | "\n",
176 | "def generate_system_prompt(task, prompt_examples):\n",
177 | " messages = [\n",
178 | " {\"role\": \"system\", \"content\": \"\"\"Given a user-description of their a set of prompt / response pairs (it'll be in JSON for easy reading) for the types of outputs we want to generate given inputs, write a fantastic system prompt that describes the task to be done perfectly.\n",
179 | "\n",
180 | "\n",
181 | "1. Do this perfectly.\n",
182 | "2. Respond only with the system prompt, and nothing else. No other text will be allowed.\n",
183 | "\n",
184 | "\n",
185 | "Respond in this format:\n",
186 | "\n",
187 | "WRITE_SYSTEM_PROMPT_HERE\n",
188 | "\"\"\"\n",
189 | " },\n",
190 | " {\"role\": \"user\", \"content\": f\"\"\"{task}\n",
191 | "\n",
192 | "\n",
193 | "{str(prompt_examples)}\n",
194 | "\"\"\"\n",
195 | " }]\n",
196 | "\n",
197 | " response = client_large.chat.completions.create(\n",
198 | " model=LARGE_MODEL,\n",
199 | " max_tokens=1000,\n",
200 | " temperature=0.5,\n",
201 | " messages=messages\n",
202 | " )\n",
203 | " response_text = response.choices[0]['message']['content']\n",
204 | "\n",
205 | " # Parse out the prompt\n",
206 | " system_prompt = response_text.split('')[1].split('')[0].strip()\n",
207 | "\n",
208 | " return system_prompt\n",
209 | "\n",
210 | "def test_haiku(generated_examples, prompt_example, system_prompt):\n",
211 | " messages = [{\"role\": \"system\", \"content\": system_prompt}]\n",
212 | "\n",
213 | " for example in generated_examples:\n",
214 | " messages.append({\"role\": \"user\", \"content\": example['prompt']})\n",
215 | " messages.append({\"role\": \"assistant\", \"content\": example['response']})\n",
216 | "\n",
217 | " messages.append({\"role\": \"user\", \"content\": prompt_example.strip()})\n",
218 | "\n",
219 | " response = client_small.chat.completions.create(\n",
220 | " model = SMALL_MODEL,\n",
221 | " max_tokens=2000,\n",
222 | " temperature=0.5,\n",
223 | " messages=messages\n",
224 | " )\n",
225 | " response_text = response.choices[0]['message']['content']\n",
226 | "\n",
227 | " return response_text\n",
228 | "\n",
229 | "def run_haiku_conversion_process(task, prompt_example, response_example):\n",
230 | "\n",
231 | " print('Generating the prompts / responses...')\n",
232 | " # Generate candidate prompts\n",
233 | " generated_examples = generate_candidate_prompts(task, prompt_example, response_example)\n",
234 | "\n",
235 | " print('Prompts / responses generated. Now generating system prompt...')\n",
236 | "\n",
237 | " # Generate the system prompt\n",
238 | " system_prompt = generate_system_prompt(task, generated_examples)\n",
239 | "\n",
240 | " print('System prompt generated:', system_prompt)\n",
241 | "\n",
242 | "\n",
243 | " print('\\n\\nTesting the new prompt on '+SMALL_MODEL+', using your input example...')\n",
244 | " # Test the generated examples and system prompt with the Haiku model\n",
245 | " small_model_response = test_haiku(generated_examples, prompt_example, system_prompt)\n",
246 | "\n",
247 | " print(SMALL_MODEL+' responded with:')\n",
248 | " print(small_model_response)\n",
249 | "\n",
250 | " print('\\n\\n!! CHECK THE FILE DIRECTORY, THE PROMPT IS NOW SAVED THERE !!')\n",
251 | "\n",
252 | " # Create a dictionary with all the relevant information\n",
253 | " result = {\n",
254 | " \"task\": task,\n",
255 | " \"initial_prompt_example\": prompt_example,\n",
256 | " \"initial_response_example\": response_example,\n",
257 | " \"generated_examples\": generated_examples,\n",
258 | " \"system_prompt\": system_prompt,\n",
259 | " \"small_model_response\": small_model_response\n",
260 | " }\n",
261 | "\n",
262 | " # Save the Haiku prompt to a Python file\n",
263 | " with open(\"haiku_prompt.py\", \"w\") as file:\n",
264 | " file.write('system_prompt = \"\"\"' + system_prompt + '\"\"\"\\n\\n')\n",
265 | "\n",
266 | " file.write('messages = [\\n')\n",
267 | " for example in generated_examples:\n",
268 | " file.write(' {\"role\": \"user\", \"content\": \"\"\"' + example['prompt'] + '\"\"\"},\\n')\n",
269 | " file.write(' {\"role\": \"assistant\", \"content\": \"\"\"' + example['response'] + '\"\"\"},\\n')\n",
270 | "\n",
271 | " file.write(' {\"role\": \"user\", \"content\": \"\"\"' + prompt_example.strip() + '\"\"\"}\\n')\n",
272 | " file.write(']\\n')\n",
273 | "\n",
274 | " return result"
275 | ]
276 | },
277 | {
278 | "cell_type": "markdown",
279 | "metadata": {
280 | "id": "ZujTAzhuBMea"
281 | },
282 | "source": [
283 | "## Fill in your task, prompt_example, and response_example here.\n",
284 | "Make sure you keep the quality really high here... this is the most important step!"
285 | ]
286 | },
287 | {
288 | "cell_type": "code",
289 | "execution_count": null,
290 | "metadata": {
291 | "id": "XSZqqOoQ-5_E"
292 | },
293 | "outputs": [],
294 | "source": [
295 | "task = \"refactoring complex code\"\n",
296 | "\n",
297 | "prompt_example = \"\"\"def calculate_total(prices, tax, discount, shipping_fee, gift_wrap_fee, membership_discount):\n",
298 | "\n",
299 | " total = 0\n",
300 | "\n",
301 | " for i in range(len(prices)):\n",
302 | "\n",
303 | " total += prices[i]\n",
304 | "\n",
305 | " if membership_discount != 0:\n",
306 | "\n",
307 | " total = total - (total * (membership_discount / 100))\n",
308 | "\n",
309 | " if discount != 0:\n",
310 | "\n",
311 | " total = total - (total * (discount / 100))\n",
312 | "\n",
313 | " total = total + (total * (tax / 100))\n",
314 | "\n",
315 | " if total < 50:\n",
316 | "\n",
317 | " total += shipping_fee\n",
318 | "\n",
319 | " else:\n",
320 | "\n",
321 | " total += shipping_fee / 2\n",
322 | "\n",
323 | " if gift_wrap_fee != 0:\n",
324 | "\n",
325 | " total += gift_wrap_fee * len(prices)\n",
326 | "\n",
327 | " if total > 1000:\n",
328 | "\n",
329 | " total -= 50\n",
330 | "\n",
331 | " elif total > 500:\n",
332 | "\n",
333 | " total -= 25\n",
334 | "\n",
335 | " total = round(total, 2)\n",
336 | "\n",
337 | " if total < 0:\n",
338 | "\n",
339 | " total = 0\n",
340 | "\n",
341 | " return total\"\"\"\n",
342 | "\n",
343 | "response_example = \"\"\"def calculate_total(prices, tax_rate, discount_rate, shipping_fee, gift_wrap_fee, membership_discount_rate):\n",
344 | "\n",
345 | " def apply_percentage_discount(amount, percentage):\n",
346 | "\n",
347 | " return amount * (1 - percentage / 100)\n",
348 | "\n",
349 | " def calculate_shipping_fee(total):\n",
350 | "\n",
351 | " return shipping_fee if total < 50 else shipping_fee / 2\n",
352 | "\n",
353 | " def apply_tier_discount(total):\n",
354 | "\n",
355 | " if total > 1000:\n",
356 | "\n",
357 | " return total - 50\n",
358 | "\n",
359 | " elif total > 500:\n",
360 | "\n",
361 | " return total - 25\n",
362 | "\n",
363 | " return total\n",
364 | "\n",
365 | " subtotal = sum(prices)\n",
366 | "\n",
367 | " subtotal = apply_percentage_discount(subtotal, membership_discount_rate)\n",
368 | "\n",
369 | " subtotal = apply_percentage_discount(subtotal, discount_rate)\n",
370 | "\n",
371 | "\n",
372 | "\n",
373 | " total = subtotal * (1 + tax_rate / 100)\n",
374 | "\n",
375 | " total += calculate_shipping_fee(total)\n",
376 | "\n",
377 | " total += gift_wrap_fee * len(prices)\n",
378 | "\n",
379 | "\n",
380 | "\n",
381 | " total = apply_tier_discount(total)\n",
382 | "\n",
383 | " total = max(0, round(total, 2))\n",
384 | "\n",
385 | "\n",
386 | "\n",
387 | " return total\"\"\""
388 | ]
389 | },
390 | {
391 | "cell_type": "markdown",
392 | "metadata": {
393 | "id": "cMO3cJzWA-O0"
394 | },
395 | "source": [
396 | "### Now, let's run this system and get our new prompt!\n",
397 | "At the end, you'll see a new file pop up in the directory that contains everything you'll need to reduce your costs while keeping quality high w/ Haiku!"
398 | ]
399 | },
400 | {
401 | "cell_type": "code",
402 | "execution_count": null,
403 | "metadata": {
404 | "id": "O-Bn0rupAJqb",
405 | "outputId": "52d922bc-8d93-4bff-e26b-42c8c99166a5"
406 | },
407 | "outputs": [
408 | {
409 | "name": "stdout",
410 | "output_type": "stream",
411 | "text": [
412 | "Generating the prompts / responses...\n",
413 | "Prompts / responses generated. Now generating system prompt...\n",
414 | "System prompt generated: You are an expert code refactoring assistant. Your task is to take a given piece of code and refactor it to be more concise, efficient, and maintainable while preserving its original functionality. Focus on improving code readability, eliminating redundancies, optimizing performance, and applying best practices and design patterns where appropriate. Provide a clear, refactored version of the code that showcases your expertise in writing clean, high-quality code.\n",
415 | "\n",
416 | "\n",
417 | "Testing the new prompt on claude-3-haiku-20240307, using your input example...\n",
418 | "claude-3-haiku-20240307 responded with:\n",
419 | "def calculate_total(prices, tax, discount, shipping_fee, gift_wrap_fee, membership_discount):\n",
420 | " subtotal = sum(prices)\n",
421 | " \n",
422 | " if membership_discount:\n",
423 | " subtotal *= (1 - membership_discount / 100)\n",
424 | " \n",
425 | " if discount:\n",
426 | " subtotal *= (1 - discount / 100)\n",
427 | " \n",
428 | " total = subtotal * (1 + tax / 100)\n",
429 | " \n",
430 | " if total < 50:\n",
431 | " total += shipping_fee\n",
432 | " else:\n",
433 | " total += shipping_fee / 2\n",
434 | " \n",
435 | " total += gift_wrap_fee * len(prices)\n",
436 | " \n",
437 | " if total > 1000:\n",
438 | " total -= 50\n",
439 | " elif total > 500:\n",
440 | " total -= 25\n",
441 | " \n",
442 | " return max(round(total, 2), 0)\n",
443 | "\n",
444 | "\n",
445 | "!! CHECK THE FILE DIRECTORY, THE PROMPT IS NOW SAVED THERE !!\n"
446 | ]
447 | }
448 | ],
449 | "source": [
450 | "result = run_haiku_conversion_process(task, prompt_example, response_example)"
451 | ]
452 | },
453 | {
454 | "cell_type": "markdown",
455 | "source": [
456 | "### View logs on Portkey\n",
457 | "Go to the logs tab in Portkey to inspect the 3 calls made and the results returned. Note that cache is enabled in the calls, so all calls after the first one would return instantaneously."
458 | ],
459 | "metadata": {
460 | "id": "-nUxJhF-wG2x"
461 | }
462 | }
463 | ],
464 | "metadata": {
465 | "colab": {
466 | "provenance": []
467 | },
468 | "kernelspec": {
469 | "display_name": "Python 3 (ipykernel)",
470 | "language": "python",
471 | "name": "python3"
472 | },
473 | "language_info": {
474 | "codemirror_mode": {
475 | "name": "ipython",
476 | "version": 3
477 | },
478 | "file_extension": ".py",
479 | "mimetype": "text/x-python",
480 | "name": "python",
481 | "nbconvert_exporter": "python",
482 | "pygments_lexer": "ipython3",
483 | "version": "3.10.9"
484 | }
485 | },
486 | "nbformat": 4,
487 | "nbformat_minor": 0
488 | }
--------------------------------------------------------------------------------
/claude_prompt_engineer.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "id": "view-in-github",
7 | "colab_type": "text"
8 | },
9 | "source": [
10 | ""
11 | ]
12 | },
13 | {
14 | "cell_type": "markdown",
15 | "metadata": {
16 | "id": "WljjH8K3s7kG"
17 | },
18 | "source": [
19 | "# claude-prompt-engineer\n",
20 | "By Matt Shumer (https://twitter.com/mattshumer_)\n",
21 | "\n",
22 | "Github repo: https://github.com/mshumer/gpt-prompt-engineer\n",
23 | "\n",
24 | "Generate an optimal prompt for a given task.\n",
25 | "\n",
26 | "To generate a prompt:\n",
27 | "1. In the first cell, add in your Anthropic key.\n",
28 | "2. If you want, adjust your settings in the `Adjust settings here` cell\n",
29 | "2. In the last cell, fill in the description of your task, the variables the system should account for.\n",
30 | "3. Run all the cells! The AI will generate a number of candidate prompts, and test them all to find the best one!"
31 | ]
32 | },
33 | {
34 | "cell_type": "code",
35 | "execution_count": null,
36 | "metadata": {
37 | "id": "JqB2ZUD8lgek",
38 | "colab": {
39 | "base_uri": "https://localhost:8080/"
40 | },
41 | "outputId": "8d8d2146-5c61-4f8d-f6fa-9701740a7aea"
42 | },
43 | "outputs": [
44 | {
45 | "output_type": "stream",
46 | "name": "stdout",
47 | "text": [
48 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m2.2/2.2 MB\u001b[0m \u001b[31m8.3 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
49 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m195.4/195.4 kB\u001b[0m \u001b[31m15.1 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
50 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m263.5/263.5 kB\u001b[0m \u001b[31m11.1 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
51 | "\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m62.7/62.7 kB\u001b[0m \u001b[31m2.7 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n",
52 | "\u001b[?25h"
53 | ]
54 | }
55 | ],
56 | "source": [
57 | "!pip install prettytable tqdm tenacity wandb -qq"
58 | ]
59 | },
60 | {
61 | "cell_type": "code",
62 | "execution_count": null,
63 | "metadata": {
64 | "id": "dQmMZdkG_RA5"
65 | },
66 | "outputs": [],
67 | "source": [
68 | "from prettytable import PrettyTable\n",
69 | "import time\n",
70 | "import requests\n",
71 | "from tqdm import tqdm\n",
72 | "import itertools\n",
73 | "import wandb\n",
74 | "from tenacity import retry, stop_after_attempt, wait_exponential\n",
75 | "\n",
76 | "ANTHROPIC_API_KEY = \"ADD YOUR KEY HERE\" # enter your Anthropic API key here\n",
77 | "\n",
78 | "use_wandb = False # set to True if you want to use wandb to log your config and results"
79 | ]
80 | },
81 | {
82 | "cell_type": "markdown",
83 | "source": [
84 | "## Adjust settings here"
85 | ],
86 | "metadata": {
87 | "id": "uzDKqEFd5wI5"
88 | }
89 | },
90 | {
91 | "cell_type": "code",
92 | "execution_count": null,
93 | "metadata": {
94 | "id": "nIklSQohlgel"
95 | },
96 | "outputs": [],
97 | "source": [
98 | "# K is a constant factor that determines how much ratings change\n",
99 | "K = 32\n",
100 | "\n",
101 | "CANDIDATE_MODEL = 'claude-3-opus-20240229'\n",
102 | "CANDIDATE_MODEL_TEMPERATURE = 0.9\n",
103 | "\n",
104 | "GENERATION_MODEL = 'claude-3-opus-20240229'\n",
105 | "GENERATION_MODEL_TEMPERATURE = 0.8\n",
106 | "GENERATION_MODEL_MAX_TOKENS = 800\n",
107 | "\n",
108 | "TEST_CASE_MODEL = 'claude-3-opus-20240229'\n",
109 | "TEST_CASE_MODEL_TEMPERATURE = .8\n",
110 | "\n",
111 | "NUMBER_OF_TEST_CASES = 10 # this determines how many test cases to generate... the higher, the more expensive, but the better the results will be\n",
112 | "\n",
113 | "N_RETRIES = 3 # number of times to retry a call to the ranking model if it fails\n",
114 | "RANKING_MODEL = 'claude-3-opus-20240229'\n",
115 | "RANKING_MODEL_TEMPERATURE = 0.5\n",
116 | "\n",
117 | "NUMBER_OF_PROMPTS = 5 # this determines how many candidate prompts to generate... the higher, the more expensive, but the better the results will be\n",
118 | "\n",
119 | "WANDB_PROJECT_NAME = \"claude-prompt-eng\" # used if use_wandb is True, Weights &| Biases project name\n",
120 | "WANDB_RUN_NAME = None # used if use_wandb is True, optionally set the Weights & Biases run name to identify this run"
121 | ]
122 | },
123 | {
124 | "cell_type": "code",
125 | "execution_count": null,
126 | "metadata": {
127 | "id": "HyIsyixwlgel"
128 | },
129 | "outputs": [],
130 | "source": [
131 | "def start_wandb_run():\n",
132 | " # start a new wandb run and log the config\n",
133 | " wandb.init(\n",
134 | " project=WANDB_PROJECT_NAME,\n",
135 | " name=WANDB_RUN_NAME,\n",
136 | " config={\n",
137 | " \"K\": K,\n",
138 | " \"candiate_model\": CANDIDATE_MODEL,\n",
139 | " \"candidate_model_temperature\": CANDIDATE_MODEL_TEMPERATURE,\n",
140 | " \"generation_model\": GENERATION_MODEL,\n",
141 | " \"generation_model_temperature\": GENERATION_MODEL_TEMPERATURE,\n",
142 | " \"generation_model_max_tokens\": GENERATION_MODEL_MAX_TOKENS,\n",
143 | " \"n_retries\": N_RETRIES,\n",
144 | " \"ranking_model\": RANKING_MODEL,\n",
145 | " \"ranking_model_temperature\": RANKING_MODEL_TEMPERATURE,\n",
146 | " \"number_of_prompts\": NUMBER_OF_PROMPTS\n",
147 | " })\n",
148 | "\n",
149 | " return"
150 | ]
151 | },
152 | {
153 | "cell_type": "code",
154 | "execution_count": null,
155 | "metadata": {
156 | "id": "Zk_2Uut-lgel"
157 | },
158 | "outputs": [],
159 | "source": [
160 | "# Optional logging to Weights & Biases to reocrd the configs, prompts and results\n",
161 | "if use_wandb:\n",
162 | " start_wandb_run()"
163 | ]
164 | },
165 | {
166 | "cell_type": "code",
167 | "execution_count": null,
168 | "metadata": {
169 | "id": "wXeqMQpzzosx"
170 | },
171 | "outputs": [],
172 | "source": [
173 | "import json\n",
174 | "import re\n",
175 | "\n",
176 | "def remove_first_line(test_string):\n",
177 | " if test_string.startswith(\"Here\") and test_string.split(\"\\n\")[0].strip().endswith(\":\"):\n",
178 | " return re.sub(r'^.*\\n', '', test_string, count=1)\n",
179 | " return test_string\n",
180 | "\n",
181 | "def generate_candidate_prompts(description, input_variables, test_cases, number_of_prompts):\n",
182 | " headers = {\n",
183 | " \"x-api-key\": ANTHROPIC_API_KEY,\n",
184 | " \"anthropic-version\": \"2023-06-01\",\n",
185 | " \"content-type\": \"application/json\"\n",
186 | " }\n",
187 | "\n",
188 | " variable_descriptions = \"\\n\".join(f\"{var['variable']}: {var['description']}\" for var in input_variables)\n",
189 | "\n",
190 | " data = {\n",
191 | " \"model\": CANDIDATE_MODEL,\n",
192 | " \"max_tokens\": 1500,\n",
193 | " \"temperature\": CANDIDATE_MODEL_TEMPERATURE,\n",
194 | " \"system\": f\"\"\"Your job is to generate system prompts for Claude 3, given a description of the use-case, some test cases/input variable examples that will help you understand what the prompt will need to be good at.\n",
195 | "The prompts you will be generating will be for freeform tasks, such as generating a landing page headline, an intro paragraph, solving a math problem, etc.\n",
196 | "In your generated prompt, you should describe how the AI should behave in plain English. Include what it will see, and what it's allowed to output.\n",
197 | "Make sure to incorporate the provided input variable placeholders into the prompt, using placeholders like {{{{VARIABLE_NAME}}}} for each variable. Ensure you place placeholders inside four squiggly lines like {{{{VARIABLE_NAME}}}}. At inference time/test time, we will slot the variables into the prompt, like a template.\n",
198 | "Be creative with prompts to get the best possible results. The AI knows it's an AI -- you don't need to tell it this.\n",
199 | "You will be graded based on the performance of your prompt... but don't cheat! You cannot include specifics about the test cases in your prompt. Any prompts with examples will be disqualified.\n",
200 | "Here are the input variables and their descriptions:\n",
201 | "{variable_descriptions}\n",
202 | "Most importantly, output NOTHING but the prompt (with the variables contained in it like {{{{VARIABLE_NAME}}}}). Do not include anything else in your message.\"\"\",\n",
203 | " \"messages\": [\n",
204 | " {\"role\": \"user\", \"content\": f\"Here are some test cases:`{test_cases}`\\n\\nHere is the description of the use-case: `{description.strip()}`\\n\\nRespond with your flexible system prompt, and nothing else. Be creative, and remember, the goal is not to complete the task, but write a prompt that will complete the task.\"},\n",
205 | " ]\n",
206 | " }\n",
207 | "\n",
208 | " prompts = []\n",
209 | "\n",
210 | " for i in range(number_of_prompts):\n",
211 | " response = requests.post(\"https://api.anthropic.com/v1/messages\", headers=headers, json=data)\n",
212 | "\n",
213 | " message = response.json()\n",
214 | "\n",
215 | " response_text = message['content'][0]['text']\n",
216 | "\n",
217 | " prompts.append(remove_first_line(response_text))\n",
218 | "\n",
219 | " return prompts\n",
220 | "\n",
221 | "def expected_score(r1, r2):\n",
222 | " return 1 / (1 + 10**((r2 - r1) / 400))\n",
223 | "\n",
224 | "def update_elo(r1, r2, score1):\n",
225 | " e1 = expected_score(r1, r2)\n",
226 | " e2 = expected_score(r2, r1)\n",
227 | " return r1 + K * (score1 - e1), r2 + K * ((1 - score1) - e2)\n",
228 | "\n",
229 | "# Get Score - retry up to N_RETRIES times, waiting exponentially between retries.\n",
230 | "@retry(stop=stop_after_attempt(N_RETRIES), wait=wait_exponential(multiplier=1, min=4, max=70))\n",
231 | "def get_score(description, test_case, pos1, pos2, input_variables, ranking_model_name, ranking_model_temperature):\n",
232 | " headers = {\n",
233 | " \"x-api-key\": ANTHROPIC_API_KEY,\n",
234 | " \"anthropic-version\": \"2023-06-01\",\n",
235 | " \"content-type\": \"application/json\"\n",
236 | " }\n",
237 | "\n",
238 | " variable_values = \"\\n\".join(f\"{var['variable']}: {test_case.get(var['variable'], '')}\" for var in input_variables)\n",
239 | "\n",
240 | " data = {\n",
241 | " \"model\": RANKING_MODEL,\n",
242 | " \"max_tokens\": 1,\n",
243 | " \"temperature\": ranking_model_temperature,\n",
244 | " \"system\": f\"\"\"Your job is to rank the quality of two outputs generated by different prompts. The prompts are used to generate a response for a given task.\n",
245 | "You will be provided with the task description, input variable values, and two generations - one for each system prompt.\n",
246 | "Rank the generations in order of quality. If Generation A is better, respond with 'A'. If Generation B is better, respond with 'B'.\n",
247 | "Remember, to be considered 'better', a generation must not just be good, it must be noticeably superior to the other.\n",
248 | "Also, keep in mind that you are a very harsh critic. Only rank a generation as better if it truly impresses you more than the other.\n",
249 | "Respond with your ranking ('A' or 'B'), and nothing else. Be fair and unbiased in your judgement.\"\"\",\n",
250 | " \"messages\": [\n",
251 | " {\"role\": \"user\", \"content\": f\"\"\"Task: {description.strip()}\n",
252 | "Variables: {test_case['variables']}\n",
253 | "Generation A: {remove_first_line(pos1)}\n",
254 | "Generation B: {remove_first_line(pos2)}\"\"\"},\n",
255 | " ]\n",
256 | " }\n",
257 | "\n",
258 | " response = requests.post(\"https://api.anthropic.com/v1/messages\", headers=headers, json=data)\n",
259 | "\n",
260 | " message = response.json()\n",
261 | "\n",
262 | " score = message['content'][0]['text']\n",
263 | "\n",
264 | " return score\n",
265 | "\n",
266 | "@retry(stop=stop_after_attempt(N_RETRIES), wait=wait_exponential(multiplier=1, min=4, max=70))\n",
267 | "def get_generation(prompt, test_case, input_variables):\n",
268 | " headers = {\n",
269 | " \"x-api-key\": ANTHROPIC_API_KEY,\n",
270 | " \"anthropic-version\": \"2023-06-01\",\n",
271 | " \"content-type\": \"application/json\"\n",
272 | " }\n",
273 | "\n",
274 | "\n",
275 | " # Replace variable placeholders in the prompt with their actual values from the test case\n",
276 | " for var_dict in test_case['variables']:\n",
277 | " for variable_name, variable_value in var_dict.items():\n",
278 | " prompt = prompt.replace(f\"{{{{{variable_name}}}}}\", variable_value)\n",
279 | "\n",
280 | " data = {\n",
281 | " \"model\": GENERATION_MODEL,\n",
282 | " \"max_tokens\": GENERATION_MODEL_MAX_TOKENS,\n",
283 | " \"temperature\": GENERATION_MODEL_TEMPERATURE,\n",
284 | " \"system\": 'Complete the task perfectly.',\n",
285 | " \"messages\": [\n",
286 | " {\"role\": \"user\", \"content\": prompt},\n",
287 | " ]\n",
288 | " }\n",
289 | "\n",
290 | " response = requests.post(\"https://api.anthropic.com/v1/messages\", headers=headers, json=data)\n",
291 | "\n",
292 | " message = response.json()\n",
293 | "\n",
294 | " generation = message['content'][0]['text']\n",
295 | "\n",
296 | " return generation\n",
297 | "\n",
298 | "def test_candidate_prompts(test_cases, description, input_variables, prompts):\n",
299 | " # Initialize each prompt with an ELO rating of 1200\n",
300 | " prompt_ratings = {prompt: 1200 for prompt in prompts}\n",
301 | "\n",
302 | " # Calculate total rounds for progress bar\n",
303 | " total_rounds = len(test_cases) * len(prompts) * (len(prompts) - 1) // 2\n",
304 | "\n",
305 | " # Initialize progress bar\n",
306 | " pbar = tqdm(total=total_rounds, ncols=70)\n",
307 | "\n",
308 | " # For each pair of prompts\n",
309 | " for prompt1, prompt2 in itertools.combinations(prompts, 2):\n",
310 | " # For each test case\n",
311 | " for test_case in test_cases:\n",
312 | " # Update progress bar\n",
313 | " pbar.update()\n",
314 | "\n",
315 | " # Generate outputs for each prompt\n",
316 | " generation1 = get_generation(prompt1, test_case, input_variables)\n",
317 | " generation2 = get_generation(prompt2, test_case, input_variables)\n",
318 | "\n",
319 | " # Rank the outputs\n",
320 | " score1 = get_score(description, test_case, generation1, generation2, input_variables, RANKING_MODEL, RANKING_MODEL_TEMPERATURE)\n",
321 | " score2 = get_score(description, test_case, generation2, generation1, input_variables, RANKING_MODEL, RANKING_MODEL_TEMPERATURE)\n",
322 | "\n",
323 | " # Convert scores to numeric values\n",
324 | " score1 = 1 if score1 == 'A' else 0 if score1 == 'B' else 0.5\n",
325 | " score2 = 1 if score2 == 'B' else 0 if score2 == 'A' else 0.5\n",
326 | "\n",
327 | " # Average the scores\n",
328 | " score = (score1 + score2) / 2\n",
329 | "\n",
330 | " # Update ELO ratings\n",
331 | " r1, r2 = prompt_ratings[prompt1], prompt_ratings[prompt2]\n",
332 | " r1, r2 = update_elo(r1, r2, score)\n",
333 | " prompt_ratings[prompt1], prompt_ratings[prompt2] = r1, r2\n",
334 | "\n",
335 | " # Print the winner of this round\n",
336 | " if score > 0.5:\n",
337 | " print(f\"Winner: {prompt1}\")\n",
338 | " elif score < 0.5:\n",
339 | " print(f\"Winner: {prompt2}\")\n",
340 | " else:\n",
341 | " print(\"Draw\")\n",
342 | "\n",
343 | " # Close progress bar\n",
344 | " pbar.close()\n",
345 | "\n",
346 | " return prompt_ratings\n",
347 | "\n",
348 | "def generate_optimal_prompt(description, input_variables, num_test_cases=10, number_of_prompts=10, use_wandb=False):\n",
349 | " if use_wandb:\n",
350 | " wandb_table = wandb.Table(columns=[\"Prompt\", \"Ranking\"] + [var[\"variable\"] for var in input_variables])\n",
351 | " if wandb.run is None:\n",
352 | " start_wandb_run()\n",
353 | "\n",
354 | " test_cases = generate_test_cases(description, input_variables, num_test_cases)\n",
355 | " prompts = generate_candidate_prompts(description, input_variables, test_cases, number_of_prompts)\n",
356 | " print('Here are the possible prompts:', prompts)\n",
357 | " prompt_ratings = test_candidate_prompts(test_cases, description, input_variables, prompts)\n",
358 | "\n",
359 | " table = PrettyTable()\n",
360 | " table.field_names = [\"Prompt\", \"Rating\"] + [var[\"variable\"] for var in input_variables]\n",
361 | " for prompt, rating in sorted(prompt_ratings.items(), key=lambda item: item[1], reverse=True):\n",
362 | " # Use the first test case as an example for displaying the input variables\n",
363 | " example_test_case = test_cases[0]\n",
364 | " table.add_row([prompt, rating] + [example_test_case.get(var[\"variable\"], \"\") for var in input_variables])\n",
365 | " if use_wandb:\n",
366 | " wandb_table.add_data(prompt, rating, *[example_test_case.get(var[\"variable\"], \"\") for var in input_variables])\n",
367 | "\n",
368 | " if use_wandb:\n",
369 | " wandb.log({\"prompt_ratings\": wandb_table})\n",
370 | " wandb.finish()\n",
371 | " print(table)\n",
372 | "\n",
373 | "def generate_test_cases(description, input_variables, num_test_cases):\n",
374 | " headers = {\n",
375 | " \"x-api-key\": ANTHROPIC_API_KEY,\n",
376 | " \"anthropic-version\": \"2023-06-01\",\n",
377 | " \"content-type\": \"application/json\"\n",
378 | " }\n",
379 | "\n",
380 | " variable_descriptions = \"\\n\".join(f\"{var['variable']}: {var['description']}\" for var in input_variables)\n",
381 | "\n",
382 | " data = {\n",
383 | " \"model\": CANDIDATE_MODEL,\n",
384 | " \"max_tokens\": 1500,\n",
385 | " \"temperature\": CANDIDATE_MODEL_TEMPERATURE,\n",
386 | " \"system\": f\"\"\"You are an expert at generating test cases for evaluating AI-generated content.\n",
387 | "Your task is to generate a list of {num_test_cases} test case prompts based on the given description and input variables.\n",
388 | "Each test case should be a JSON object with a 'test_design' field containing the overall idea of this test case, and a list of additional JSONs for each input variable, called 'variables'.\n",
389 | "The test cases should be diverse, covering a range of topics and styles relevant to the description.\n",
390 | "Here are the input variables and their descriptions:\n",
391 | "{variable_descriptions}\n",
392 | "Return the test cases as a JSON list, with no other text or explanation.\"\"\",\n",
393 | " \"messages\": [\n",
394 | " {\"role\": \"user\", \"content\": f\"Description: {description.strip()}\\n\\nGenerate the test cases. Make sure they are really, really great and diverse:\"},\n",
395 | " ]\n",
396 | " }\n",
397 | "\n",
398 | " response = requests.post(\"https://api.anthropic.com/v1/messages\", headers=headers, json=data)\n",
399 | " message = response.json()\n",
400 | "\n",
401 | " response_text = message['content'][0]['text']\n",
402 | "\n",
403 | " test_cases = json.loads(response_text)\n",
404 | "\n",
405 | " print('Here are the test cases:', test_cases)\n",
406 | "\n",
407 | " return test_cases"
408 | ]
409 | },
410 | {
411 | "cell_type": "markdown",
412 | "metadata": {
413 | "id": "MJSSKFfV_X9F"
414 | },
415 | "source": [
416 | "# In the cell below, fill in your description and input variables"
417 | ]
418 | },
419 | {
420 | "cell_type": "code",
421 | "execution_count": null,
422 | "metadata": {
423 | "id": "vCZvLyDepxFP"
424 | },
425 | "outputs": [],
426 | "source": [
427 | "## Example usage\n",
428 | "description = \"Given a prompt, generate a personalized email response.\" # this style of description tends to work well\n",
429 | "\n",
430 | "input_variables = [\n",
431 | " {\"variable\": \"SENDER_NAME\", \"description\": \"The name of the person who sent the email.\"},\n",
432 | " {\"variable\": \"RECIPIENT_NAME\", \"description\": \"The name of the person receiving the email.\"},\n",
433 | " {\"variable\": \"TOPIC\", \"description\": \"The main topic or subject of the email. One to two sentences.\"}\n",
434 | "]"
435 | ]
436 | },
437 | {
438 | "cell_type": "code",
439 | "source": [
440 | "if use_wandb:\n",
441 | " wandb.config.update({\"description\": description,\n",
442 | " \"input_variables\": input_variables,\n",
443 | " \"num_test_cases\": NUMBER_OF_TEST_CASES,\n",
444 | " \"number_of_prompts\": NUMBER_OF_PROMPTS})"
445 | ],
446 | "metadata": {
447 | "id": "4gxg9uf_vIlr"
448 | },
449 | "execution_count": null,
450 | "outputs": []
451 | },
452 | {
453 | "cell_type": "markdown",
454 | "source": [
455 | "## Run this cell to start the prompt engineering process!"
456 | ],
457 | "metadata": {
458 | "id": "Mo9B4x4R_YVl"
459 | }
460 | },
461 | {
462 | "cell_type": "code",
463 | "execution_count": null,
464 | "metadata": {
465 | "id": "7rWjcL2hlgen"
466 | },
467 | "outputs": [],
468 | "source": [
469 | "generate_optimal_prompt(description, input_variables, NUMBER_OF_TEST_CASES, NUMBER_OF_PROMPTS, use_wandb)"
470 | ]
471 | }
472 | ],
473 | "metadata": {
474 | "colab": {
475 | "provenance": [],
476 | "include_colab_link": true
477 | },
478 | "kernelspec": {
479 | "display_name": "Python 3",
480 | "name": "python3"
481 | },
482 | "language_info": {
483 | "codemirror_mode": {
484 | "name": "ipython",
485 | "version": 3
486 | },
487 | "file_extension": ".py",
488 | "mimetype": "text/x-python",
489 | "name": "python",
490 | "nbconvert_exporter": "python",
491 | "pygments_lexer": "ipython3",
492 | "version": "3.8.8"
493 | }
494 | },
495 | "nbformat": 4,
496 | "nbformat_minor": 0
497 | }
--------------------------------------------------------------------------------
/gpt_planner.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "authorship_tag": "ABX9TyMdDMDSqfgffWcCf0zTS8yd",
8 | "include_colab_link": true
9 | },
10 | "kernelspec": {
11 | "name": "python3",
12 | "display_name": "Python 3"
13 | },
14 | "language_info": {
15 | "name": "python"
16 | }
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {
22 | "id": "view-in-github",
23 | "colab_type": "text"
24 | },
25 | "source": [
26 | ""
27 | ]
28 | },
29 | {
30 | "cell_type": "code",
31 | "source": [
32 | "!pip install openai\n",
33 | "\n",
34 | "OPENAI_API_KEY = \"YOUR API KEY\""
35 | ],
36 | "metadata": {
37 | "id": "nNAx9eT3ule2"
38 | },
39 | "execution_count": null,
40 | "outputs": []
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": null,
45 | "metadata": {
46 | "id": "tf_S5R1Muafd"
47 | },
48 | "outputs": [],
49 | "source": [
50 | "import openai\n",
51 | "import random\n",
52 | "\n",
53 | "client = openai.OpenAI(api_key=OPENAI_API_KEY)\n",
54 | "\n",
55 | "def generate_plans(user_query, n=5):\n",
56 | " \"\"\"Generate multiple plans using GPT-4o-Mini.\"\"\"\n",
57 | " response = client.chat.completions.create(\n",
58 | " model=\"gpt-4o-mini\",\n",
59 | " messages=[\n",
60 | " {\"role\": \"system\", \"content\": \"You are a strategic reasoner. Given a user query, create a detailed plan to address it and then respond to the user. You will do so by using and tags. The user will only see what is in , the is just a scratchpad for you to figure out the best approach to satisfy the user's request. First, plan inside tags, and then write your .\"},\n",
61 | " {\"role\": \"user\", \"content\": user_query}\n",
62 | " ],\n",
63 | " n=n,\n",
64 | " temperature=0.7,\n",
65 | " max_tokens=500,\n",
66 | " stop=['']\n",
67 | " )\n",
68 | " return [choice.message.content.replace('', '') for choice in response.choices]\n",
69 | "\n",
70 | "def evaluate_plans(plans, user_query):\n",
71 | " \"\"\"Evaluate plans using a tournament ranking system.\"\"\"\n",
72 | " def compare_plans(plan1, plan2):\n",
73 | " response = client.chat.completions.create(\n",
74 | " model=\"gpt-4o-mini\",\n",
75 | " messages=[\n",
76 | " {\"role\": \"system\", \"content\": \"You are a judge evaluating two plans. Choose the better plan based on effectiveness, feasibility, and relevance to the user's query.\"},\n",
77 | " {\"role\": \"user\", \"content\": f\"User Query: {user_query}\\n\\nPlan 1: {plan1}\\n\\nPlan 2: {plan2}\\n\\nWhich plan is better? Respond with either '1' or '2'.\"}\n",
78 | " ],\n",
79 | " temperature=0.2,\n",
80 | " max_tokens=10\n",
81 | " )\n",
82 | " return 1 if response.choices[0].message.content.strip() == \"1\" else 2\n",
83 | "\n",
84 | " # Tournament ranking — to improve, run twice with swapped positions for each plan combo for greater precision, and parallelize for speed\n",
85 | " winners = plans\n",
86 | " while len(winners) > 1:\n",
87 | " next_round = []\n",
88 | " for i in range(0, len(winners), 2):\n",
89 | " if i + 1 < len(winners):\n",
90 | " winner = winners[i] if compare_plans(winners[i], winners[i+1]) == 1 else winners[i+1]\n",
91 | " next_round.append(winner)\n",
92 | " else:\n",
93 | " next_round.append(winners[i])\n",
94 | " winners = next_round\n",
95 | "\n",
96 | " return winners[0]\n",
97 | "\n",
98 | "def generate_response(best_plan, user_query):\n",
99 | " \"\"\"Generate the final response based on the best plan.\"\"\"\n",
100 | " response = client.chat.completions.create(\n",
101 | " model=\"gpt-4o-mini\",\n",
102 | " messages=[\n",
103 | " {\"role\": \"system\", \"content\": \"You are a helpful assistant. Use the given plan to create a detailed and high-quality response to the user's query.\"},\n",
104 | " {\"role\": \"user\", \"content\": f\"User Query: {user_query}\\n\\nPlan: {best_plan}\\n\\nGenerate a detailed response based on this plan.\"}\n",
105 | " ],\n",
106 | " temperature=0.5,\n",
107 | " max_tokens=2000\n",
108 | " )\n",
109 | " return response.choices[0].message.content\n",
110 | "\n",
111 | "def improved_ai_output(user_query, num_plans=20):\n",
112 | " \"\"\"Main function to improve AI output quality.\"\"\"\n",
113 | " print(\"Generating plans...\")\n",
114 | " plans = generate_plans(user_query, n=num_plans)\n",
115 | "\n",
116 | " print(\"Evaluating plans...\")\n",
117 | " best_plan = evaluate_plans(plans, user_query)\n",
118 | "\n",
119 | " print(\"Generating final response...\")\n",
120 | " final_response = generate_response(best_plan, user_query)\n",
121 | "\n",
122 | " return {\n",
123 | " \"user_query\": user_query,\n",
124 | " \"best_plan\": best_plan,\n",
125 | " \"final_response\": final_response\n",
126 | " }\n",
127 | "\n",
128 | "if __name__ == \"__main__\":\n",
129 | " user_query = \"How do I get a computer out of a bootloop?\"\n",
130 | " result = improved_ai_output(user_query)\n",
131 | "\n",
132 | " print(\"\\nUser Query:\", result[\"user_query\"])\n",
133 | " print(\"\\nBest Plan:\", result[\"best_plan\"])\n",
134 | " print(\"\\nFinal Response:\", result[\"final_response\"])"
135 | ]
136 | }
137 | ]
138 | }
--------------------------------------------------------------------------------
/gpt_prompt_engineer.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "attachments": {},
5 | "cell_type": "markdown",
6 | "metadata": {
7 | "colab_type": "text",
8 | "id": "view-in-github"
9 | },
10 | "source": [
11 | ""
12 | ]
13 | },
14 | {
15 | "attachments": {},
16 | "cell_type": "markdown",
17 | "metadata": {
18 | "id": "WljjH8K3s7kG"
19 | },
20 | "source": [
21 | "# gpt-prompt-engineer\n",
22 | "By Matt Shumer (https://twitter.com/mattshumer_)\n",
23 | "\n",
24 | "Github repo: https://github.com/mshumer/gpt-prompt-engineer\n",
25 | "\n",
26 | "Generate an optimal prompt for a given task.\n",
27 | "\n",
28 | "To generate a prompt:\n",
29 | "1. In the first cell, add in your OpenAI key.\n",
30 | "2. If you don't have GPT-4 access, change `model='gpt-4'` in the second cell to `model='gpt-3.5-turbo'`. If you do have access, skip this step.\n",
31 | "2. In the last cell, fill in the description of your task, up to 15 test cases, and the number of prompts to generate.\n",
32 | "3. Run all the cells! The AI will generate a number of candidate prompts, and test them all to find the best one!"
33 | ]
34 | },
35 | {
36 | "cell_type": "code",
37 | "execution_count": null,
38 | "metadata": {},
39 | "outputs": [],
40 | "source": [
41 | "!pip install openai==0.28 prettytable tqdm tenacity wandb -qq"
42 | ]
43 | },
44 | {
45 | "cell_type": "code",
46 | "execution_count": null,
47 | "metadata": {
48 | "id": "dQmMZdkG_RA5"
49 | },
50 | "outputs": [],
51 | "source": [
52 | "from prettytable import PrettyTable\n",
53 | "import time\n",
54 | "import openai\n",
55 | "from tqdm import tqdm\n",
56 | "import itertools\n",
57 | "import wandb\n",
58 | "from tenacity import retry, stop_after_attempt, wait_exponential\n",
59 | "\n",
60 | "openai.api_key = \"ADD YOUR KEY HERE\" # enter your OpenAI API key here\n",
61 | "\n",
62 | "use_wandb = False # set to True if you want to use wandb to log your config and results\n",
63 | "\n",
64 | "use_portkey = False #set to True if you want to use Portkey to log all the prompt chains and their responses Check https://portkey.ai/"
65 | ]
66 | },
67 | {
68 | "cell_type": "code",
69 | "execution_count": 8,
70 | "metadata": {},
71 | "outputs": [],
72 | "source": [
73 | "system_gen_system_prompt = \"\"\"Your job is to generate system prompts for GPT-4, given a description of the use-case and some test cases.\n",
74 | "\n",
75 | "The prompts you will be generating will be for freeform tasks, such as generating a landing page headline, an intro paragraph, solving a math problem, etc.\n",
76 | "\n",
77 | "In your generated prompt, you should describe how the AI should behave in plain English. Include what it will see, and what it's allowed to output. Be creative with prompts to get the best possible results. The AI knows it's an AI -- you don't need to tell it this.\n",
78 | "\n",
79 | "You will be graded based on the performance of your prompt... but don't cheat! You cannot include specifics about the test cases in your prompt. Any prompts with examples will be disqualified.\n",
80 | "\n",
81 | "Most importantly, output NOTHING but the prompt. Do not include anything else in your message.\"\"\"\n",
82 | "\n",
83 | "\n",
84 | "ranking_system_prompt = \"\"\"Your job is to rank the quality of two outputs generated by different prompts. The prompts are used to generate a response for a given task.\n",
85 | "\n",
86 | "You will be provided with the task description, the test prompt, and two generations - one for each system prompt.\n",
87 | "\n",
88 | "Rank the generations in order of quality. If Generation A is better, respond with 'A'. If Generation B is better, respond with 'B'.\n",
89 | "\n",
90 | "Remember, to be considered 'better', a generation must not just be good, it must be noticeably superior to the other.\n",
91 | "\n",
92 | "Also, keep in mind that you are a very harsh critic. Only rank a generation as better if it truly impresses you more than the other.\n",
93 | "\n",
94 | "Respond with your ranking, and nothing else. Be fair and unbiased in your judgement.\"\"\""
95 | ]
96 | },
97 | {
98 | "cell_type": "code",
99 | "execution_count": null,
100 | "metadata": {},
101 | "outputs": [],
102 | "source": [
103 | "# K is a constant factor that determines how much ratings change\n",
104 | "K = 32\n",
105 | "\n",
106 | "CANDIDATE_MODEL = 'gpt-4'\n",
107 | "CANDIDATE_MODEL_TEMPERATURE = 0.9\n",
108 | "\n",
109 | "GENERATION_MODEL = 'gpt-3.5-turbo'\n",
110 | "GENERATION_MODEL_TEMPERATURE = 0.8\n",
111 | "GENERATION_MODEL_MAX_TOKENS = 60\n",
112 | "\n",
113 | "N_RETRIES = 3 # number of times to retry a call to the ranking model if it fails\n",
114 | "RANKING_MODEL = 'gpt-3.5-turbo'\n",
115 | "RANKING_MODEL_TEMPERATURE = 0.5\n",
116 | "\n",
117 | "NUMBER_OF_PROMPTS = 10 # this determines how many candidate prompts to generate... the higher, the more expensive, but the better the results will be\n",
118 | "\n",
119 | "WANDB_PROJECT_NAME = \"gpt-prompt-eng\" # used if use_wandb is True, Weights &| Biases project name\n",
120 | "WANDB_RUN_NAME = None # used if use_wandb is True, optionally set the Weights & Biases run name to identify this run\n",
121 | "\n",
122 | "PORTKEY_API = \"\" # used if use_portkey is True. Get api key here: https://app.portkey.ai/ (click on profile photo on top left)\n",
123 | "PORTKEY_TRACE = \"prompt_engineer_test_run\" # used if use_portkey is True. Trace each run with a separate ID to differentiate prompt chains\n",
124 | "HEADERS = {} # don't change. headers will auto populate if use_portkey is true."
125 | ]
126 | },
127 | {
128 | "cell_type": "code",
129 | "execution_count": null,
130 | "metadata": {},
131 | "outputs": [],
132 | "source": [
133 | "def start_wandb_run():\n",
134 | " # start a new wandb run and log the config\n",
135 | " wandb.init(\n",
136 | " project=WANDB_PROJECT_NAME, \n",
137 | " name=WANDB_RUN_NAME,\n",
138 | " config={\n",
139 | " \"K\": K,\n",
140 | " \"system_gen_system_prompt\": system_gen_system_prompt, \n",
141 | " \"ranking_system_prompt\": ranking_system_prompt,\n",
142 | " \"candidate_model\": CANDIDATE_MODEL,\n",
143 | " \"candidate_model_temperature\": CANDIDATE_MODEL_TEMPERATURE,\n",
144 | " \"generation_model\": GENERATION_MODEL,\n",
145 | " \"generation_model_temperature\": GENERATION_MODEL_TEMPERATURE,\n",
146 | " \"generation_model_max_tokens\": GENERATION_MODEL_MAX_TOKENS,\n",
147 | " \"n_retries\": N_RETRIES,\n",
148 | " \"ranking_model\": RANKING_MODEL,\n",
149 | " \"ranking_model_temperature\": RANKING_MODEL_TEMPERATURE,\n",
150 | " \"number_of_prompts\": NUMBER_OF_PROMPTS\n",
151 | " })\n",
152 | " \n",
153 | " return "
154 | ]
155 | },
156 | {
157 | "cell_type": "code",
158 | "execution_count": null,
159 | "metadata": {},
160 | "outputs": [],
161 | "source": [
162 | "# Optional logging to Weights & Biases to reocrd the configs, prompts and results\n",
163 | "if use_wandb:\n",
164 | " start_wandb_run()"
165 | ]
166 | },
167 | {
168 | "cell_type": "code",
169 | "execution_count": null,
170 | "metadata": {},
171 | "outputs": [],
172 | "source": [
173 | "def start_portkey_run():\n",
174 | " # define Portkey headers to start logging all prompts & their responses\n",
175 | " openai.api_base=\"https://api.portkey.ai/v1/proxy\"\n",
176 | " HEADERS = {\n",
177 | " \"x-portkey-api-key\": PORTKEY_API, \n",
178 | " \"x-portkey-mode\": \"proxy openai\",\n",
179 | " \"x-portkey-trace-id\": PORTKEY_TRACE,\n",
180 | " #\"x-portkey-retry-count\": 5 # perform automatic retries with exponential backoff if the OpenAI requests fails\n",
181 | " } \n",
182 | " return HEADERS"
183 | ]
184 | },
185 | {
186 | "cell_type": "code",
187 | "execution_count": null,
188 | "metadata": {},
189 | "outputs": [],
190 | "source": [
191 | "# Optional prompt & responses logging\n",
192 | "if use_portkey:\n",
193 | " HEADERS=start_portkey_run()"
194 | ]
195 | },
196 | {
197 | "cell_type": "code",
198 | "execution_count": 13,
199 | "metadata": {
200 | "id": "wXeqMQpzzosx"
201 | },
202 | "outputs": [],
203 | "source": [
204 | "def generate_candidate_prompts(description, test_cases, number_of_prompts):\n",
205 | " outputs = openai.ChatCompletion.create(\n",
206 | " model=CANDIDATE_MODEL, # change this to gpt-3.5-turbo if you don't have GPT-4 access\n",
207 | " messages=[\n",
208 | " {\"role\": \"system\", \"content\": system_gen_system_prompt},\n",
209 | " {\"role\": \"user\", \"content\": f\"Here are some test cases:`{test_cases}`\\n\\nHere is the description of the use-case: `{description.strip()}`\\n\\nRespond with your prompt, and nothing else. Be creative.\"}\n",
210 | " ],\n",
211 | " temperature=CANDIDATE_MODEL_TEMPERATURE,\n",
212 | " n=number_of_prompts,\n",
213 | " headers=HEADERS)\n",
214 | "\n",
215 | " prompts = []\n",
216 | "\n",
217 | " for i in outputs.choices:\n",
218 | " prompts.append(i.message.content)\n",
219 | " return prompts\n",
220 | "\n",
221 | "def expected_score(r1, r2):\n",
222 | " return 1 / (1 + 10**((r2 - r1) / 400))\n",
223 | "\n",
224 | "def update_elo(r1, r2, score1):\n",
225 | " e1 = expected_score(r1, r2)\n",
226 | " e2 = expected_score(r2, r1)\n",
227 | " return r1 + K * (score1 - e1), r2 + K * ((1 - score1) - e2)\n",
228 | "\n",
229 | "# Get Score - retry up to N_RETRIES times, waiting exponentially between retries.\n",
230 | "@retry(stop=stop_after_attempt(N_RETRIES), wait=wait_exponential(multiplier=1, min=4, max=70))\n",
231 | "def get_score(description, test_case, pos1, pos2, ranking_model_name, ranking_model_temperature): \n",
232 | " score = openai.ChatCompletion.create(\n",
233 | " model=ranking_model_name,\n",
234 | " messages=[\n",
235 | " {\"role\": \"system\", \"content\": ranking_system_prompt},\n",
236 | " {\"role\": \"user\", \"content\": f\"\"\"Task: {description.strip()}\n",
237 | "Prompt: {test_case['prompt']}\n",
238 | "Generation A: {pos1}\n",
239 | "Generation B: {pos2}\"\"\"}\n",
240 | " ],\n",
241 | " logit_bias={\n",
242 | " '32': 100, # 'A' token\n",
243 | " '33': 100, # 'B' token\n",
244 | " },\n",
245 | " max_tokens=1,\n",
246 | " temperature=ranking_model_temperature,\n",
247 | " headers=HEADERS,\n",
248 | " ).choices[0].message.content\n",
249 | " return score\n",
250 | "\n",
251 | "@retry(stop=stop_after_attempt(N_RETRIES), wait=wait_exponential(multiplier=1, min=4, max=70))\n",
252 | "def get_generation(prompt, test_case):\n",
253 | " generation = openai.ChatCompletion.create(\n",
254 | " model=GENERATION_MODEL,\n",
255 | " messages=[\n",
256 | " {\"role\": \"system\", \"content\": prompt},\n",
257 | " {\"role\": \"user\", \"content\": f\"{test_case['prompt']}\"}\n",
258 | " ],\n",
259 | " max_tokens=GENERATION_MODEL_MAX_TOKENS,\n",
260 | " temperature=GENERATION_MODEL_TEMPERATURE,\n",
261 | " headers=HEADERS,\n",
262 | " ).choices[0].message.content\n",
263 | " return generation\n",
264 | "\n",
265 | "def test_candidate_prompts(test_cases, description, prompts):\n",
266 | " # Initialize each prompt with an ELO rating of 1200\n",
267 | " prompt_ratings = {prompt: 1200 for prompt in prompts}\n",
268 | "\n",
269 | " # Calculate total rounds for progress bar\n",
270 | " total_rounds = len(test_cases) * len(prompts) * (len(prompts) - 1) // 2\n",
271 | "\n",
272 | " # Initialize progress bar\n",
273 | " pbar = tqdm(total=total_rounds, ncols=70)\n",
274 | "\n",
275 | " # For each pair of prompts\n",
276 | " for prompt1, prompt2 in itertools.combinations(prompts, 2):\n",
277 | " # For each test case\n",
278 | " for test_case in test_cases:\n",
279 | " # Update progress bar\n",
280 | " pbar.update()\n",
281 | "\n",
282 | " # Generate outputs for each prompt\n",
283 | " generation1 = get_generation(prompt1, test_case)\n",
284 | " generation2 = get_generation(prompt2, test_case)\n",
285 | "\n",
286 | " # Rank the outputs\n",
287 | " score1 = get_score(description, test_case, generation1, generation2, RANKING_MODEL, RANKING_MODEL_TEMPERATURE)\n",
288 | " score2 = get_score(description, test_case, generation2, generation1, RANKING_MODEL, RANKING_MODEL_TEMPERATURE)\n",
289 | "\n",
290 | " # Convert scores to numeric values\n",
291 | " score1 = 1 if score1 == 'A' else 0 if score1 == 'B' else 0.5\n",
292 | " score2 = 1 if score2 == 'B' else 0 if score2 == 'A' else 0.5\n",
293 | "\n",
294 | " # Average the scores\n",
295 | " score = (score1 + score2) / 2\n",
296 | "\n",
297 | " # Update ELO ratings\n",
298 | " r1, r2 = prompt_ratings[prompt1], prompt_ratings[prompt2]\n",
299 | " r1, r2 = update_elo(r1, r2, score)\n",
300 | " prompt_ratings[prompt1], prompt_ratings[prompt2] = r1, r2\n",
301 | "\n",
302 | " # Print the winner of this round\n",
303 | " if score > 0.5:\n",
304 | " print(f\"Winner: {prompt1}\")\n",
305 | " elif score < 0.5:\n",
306 | " print(f\"Winner: {prompt2}\")\n",
307 | " else:\n",
308 | " print(\"Draw\")\n",
309 | "\n",
310 | " # Close progress bar\n",
311 | " pbar.close()\n",
312 | "\n",
313 | " return prompt_ratings\n",
314 | "\n",
315 | "\n",
316 | "def generate_optimal_prompt(description, test_cases, number_of_prompts=10, use_wandb=False): \n",
317 | " if use_wandb:\n",
318 | " wandb_table = wandb.Table(columns=[\"Prompt\", \"Ranking\"])\n",
319 | " if wandb.run is None:\n",
320 | " start_wandb_run()\n",
321 | "\n",
322 | " prompts = generate_candidate_prompts(description, test_cases, number_of_prompts)\n",
323 | " prompt_ratings = test_candidate_prompts(test_cases, description, prompts)\n",
324 | "\n",
325 | " # Print the final ELO ratingsz\n",
326 | " table = PrettyTable()\n",
327 | " table.field_names = [\"Prompt\", \"Rating\"]\n",
328 | " for prompt, rating in sorted(prompt_ratings.items(), key=lambda item: item[1], reverse=True):\n",
329 | " table.add_row([prompt, rating])\n",
330 | " if use_wandb:\n",
331 | " wandb_table.add_data(prompt, rating)\n",
332 | "\n",
333 | " if use_wandb: # log the results to a Weights & Biases table and finsih the run\n",
334 | " wandb.log({\"prompt_ratings\": wandb_table})\n",
335 | " wandb.finish()\n",
336 | " print(table)"
337 | ]
338 | },
339 | {
340 | "attachments": {},
341 | "cell_type": "markdown",
342 | "metadata": {
343 | "id": "MJSSKFfV_X9F"
344 | },
345 | "source": [
346 | "# In the cell below, fill in your description and test cases"
347 | ]
348 | },
349 | {
350 | "cell_type": "code",
351 | "execution_count": null,
352 | "metadata": {
353 | "id": "vCZvLyDepxFP"
354 | },
355 | "outputs": [],
356 | "source": [
357 | "description = \"Given a prompt, generate a landing page headline.\" # this style of description tends to work well\n",
358 | "\n",
359 | "test_cases = [\n",
360 | " {\n",
361 | " 'prompt': 'Promoting an innovative new fitness app, Smartly',\n",
362 | " },\n",
363 | " {\n",
364 | " 'prompt': 'Why a vegan diet is beneficial for your health',\n",
365 | " },\n",
366 | " {\n",
367 | " 'prompt': 'Introducing a new online course on digital marketing',\n",
368 | " },\n",
369 | " {\n",
370 | " 'prompt': 'Launching a new line of eco-friendly clothing',\n",
371 | " },\n",
372 | " {\n",
373 | " 'prompt': 'Promoting a new travel blog focusing on budget travel',\n",
374 | " },\n",
375 | " {\n",
376 | " 'prompt': 'Advertising a new software for efficient project management',\n",
377 | " },\n",
378 | " {\n",
379 | " 'prompt': 'Introducing a new book on mastering Python programming',\n",
380 | " },\n",
381 | " {\n",
382 | " 'prompt': 'Promoting a new online platform for learning languages',\n",
383 | " },\n",
384 | " {\n",
385 | " 'prompt': 'Advertising a new service for personalized meal plans',\n",
386 | " },\n",
387 | " {\n",
388 | " 'prompt': 'Launching a new app for mental health and mindfulness',\n",
389 | " }\n",
390 | "]\n",
391 | "\n",
392 | "if use_wandb:\n",
393 | " wandb.config.update({\"description\": description, \n",
394 | " \"test_cases\": test_cases})"
395 | ]
396 | },
397 | {
398 | "cell_type": "code",
399 | "execution_count": null,
400 | "metadata": {},
401 | "outputs": [],
402 | "source": [
403 | "generate_optimal_prompt(description, test_cases, NUMBER_OF_PROMPTS, use_wandb)"
404 | ]
405 | }
406 | ],
407 | "metadata": {
408 | "colab": {
409 | "authorship_tag": "ABX9TyPMYK+Pn5QaRzPmh3T5a9ca",
410 | "include_colab_link": true,
411 | "provenance": []
412 | },
413 | "kernelspec": {
414 | "display_name": "Python 3",
415 | "name": "python3"
416 | },
417 | "language_info": {
418 | "codemirror_mode": {
419 | "name": "ipython",
420 | "version": 3
421 | },
422 | "file_extension": ".py",
423 | "mimetype": "text/x-python",
424 | "name": "python",
425 | "nbconvert_exporter": "python",
426 | "pygments_lexer": "ipython3",
427 | "version": "3.8.8"
428 | }
429 | },
430 | "nbformat": 4,
431 | "nbformat_minor": 0
432 | }
433 |
--------------------------------------------------------------------------------
/gpt_prompt_engineer_Classification_Version.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "attachments": {},
5 | "cell_type": "markdown",
6 | "metadata": {
7 | "colab_type": "text",
8 | "id": "view-in-github"
9 | },
10 | "source": [
11 | ""
12 | ]
13 | },
14 | {
15 | "attachments": {},
16 | "cell_type": "markdown",
17 | "metadata": {
18 | "id": "L0Ey7JZ5iLo1"
19 | },
20 | "source": [
21 | "# gpt-prompt-engineer -- Classification Version\n",
22 | "By Matt Shumer (https://twitter.com/mattshumer_)\n",
23 | "\n",
24 | "Github repo: https://github.com/mshumer/gpt-prompt-engineer\n",
25 | "\n",
26 | "Generate an optimal prompt for a given classification task that can be evaluated with 'true'/'false' outputs.\n",
27 | "\n",
28 | "You just need to describe the task clearly, and provide some test cases (for example, if we're classifying statements as 'happy' or not, a 'true' test case could be \"I had a great day!\", and a 'false' test case could be \"I am feeling gloomy.\").\n",
29 | "\n",
30 | "To generate a prompt:\n",
31 | "1. In the first cell, add in your OpenAI key.\n",
32 | "2. If you don't have GPT-4 access, change `CANDIDATE_MODEL='gpt-4'` in the second cell to `CANDIDATE_MODEL='gpt-3.5-turbo'`. If you do have access, skip this step.\n",
33 | "2. In the last cell, fill in the description of your task, as many test cases as you want (test cases are example prompts and their expected output), and the number of prompts to generate.\n",
34 | "3. Run all the cells! The AI will generate a number of candidate prompts, and test them all to find the best one!\n",
35 | "\n",
36 | "🪄🐝 To use [Weights & Biases logging](https://wandb.ai/site/prompts) to your LLM configs and the generated prompt outputs, just set `use_wandb = True`.\n",
37 | "\n",
38 | "🪄🔮 To use [Portkey](https://docs.portke.ai) for logging and tracing prompt chains and responses, just set `use_portkey = True`."
39 | ]
40 | },
41 | {
42 | "cell_type": "code",
43 | "execution_count": null,
44 | "metadata": {},
45 | "outputs": [],
46 | "source": [
47 | "!pip install openai prettytable tqdm tenacity wandb -qq"
48 | ]
49 | },
50 | {
51 | "cell_type": "code",
52 | "execution_count": 6,
53 | "metadata": {
54 | "id": "UW3ztLRsolnk"
55 | },
56 | "outputs": [],
57 | "source": [
58 | "from prettytable import PrettyTable\n",
59 | "import time\n",
60 | "import wandb\n",
61 | "import openai\n",
62 | "from tenacity import retry, stop_after_attempt, wait_exponential\n",
63 | "\n",
64 | "openai.api_key = \"ADD YOUR KEY HERE\" # enter your OpenAI API key here\n",
65 | "\n",
66 | "use_wandb = True # set to True if you want to use wandb to log your config and results\n",
67 | "\n",
68 | "use_portkey = False #set to True if you want to use Portkey to log all the prompt chains and their responses Check https://portkey.ai/"
69 | ]
70 | },
71 | {
72 | "cell_type": "code",
73 | "execution_count": 30,
74 | "metadata": {},
75 | "outputs": [],
76 | "source": [
77 | "candidate_gen_system_prompt = \"\"\"Your job is to generate system prompts for GPT-4, given a description of the use-case and some test cases.\n",
78 | "\n",
79 | "The prompts you will be generating will be for classifiers, with 'true' and 'false' being the only possible outputs.\n",
80 | "\n",
81 | "In your generated prompt, you should describe how the AI should behave in plain English. Include what it will see, and what it's allowed to output. Be creative in with prompts to get the best possible results. The AI knows it's an AI -- you don't need to tell it this.\n",
82 | "\n",
83 | "You will be graded based on the performance of your prompt... but don't cheat! You cannot include specifics about the test cases in your prompt. Any prompts with examples will be disqualified.\n",
84 | "\n",
85 | "Most importantly, output NOTHING but the prompt. Do not include anything else in your message.\"\"\""
86 | ]
87 | },
88 | {
89 | "cell_type": "code",
90 | "execution_count": 31,
91 | "metadata": {},
92 | "outputs": [],
93 | "source": [
94 | "CANDIDATE_MODEL = 'gpt-4'\n",
95 | "CANDIDATE_MODEL_TEMPERATURE = 0.9\n",
96 | "\n",
97 | "EVAL_MODEL = 'gpt-3.5-turbo'\n",
98 | "EVAL_MODEL_TEMPERATURE = 0\n",
99 | "EVAL_MODEL_MAX_TOKENS = 1\n",
100 | "\n",
101 | "NUMBER_OF_PROMPTS = 10 # this determines how many candidate prompts to generate... the higher, the more expensive\n",
102 | "\n",
103 | "N_RETRIES = 3 # number of times to retry a call to the ranking model if it fails\n",
104 | "\n",
105 | "WANDB_PROJECT_NAME = \"gpt-prompt-eng\" # used if use_wandb is True, Weights &| Biases project name\n",
106 | "WANDB_RUN_NAME = None # used if use_wandb is True, optionally set the Weights & Biases run name to identify this run\n",
107 | "\n",
108 | "PORTKEY_API = \"\" # used if use_portkey is True. Get api key here: https://app.portkey.ai/ (click on profile photo on top left)\n",
109 | "PORTKEY_TRACE = \"prompt_engineer_classification_test_run\" # used if use_portkey is True. Trace each run with a separate ID to differentiate prompt chains\n",
110 | "HEADERS = {} # don't change. headers will auto populate if use_portkey is true."
111 | ]
112 | },
113 | {
114 | "cell_type": "code",
115 | "execution_count": 32,
116 | "metadata": {},
117 | "outputs": [],
118 | "source": [
119 | "def start_wandb_run():\n",
120 | " # start a new wandb run and log the config\n",
121 | " wandb.init(\n",
122 | " project=WANDB_PROJECT_NAME, \n",
123 | " name=WANDB_RUN_NAME,\n",
124 | " config={\n",
125 | " \"candidate_gen_system_prompt\": candidate_gen_system_prompt, \n",
126 | " \"candiate_model\": CANDIDATE_MODEL,\n",
127 | " \"candidate_model_temperature\": CANDIDATE_MODEL_TEMPERATURE,\n",
128 | " \"generation_model\": EVAL_MODEL,\n",
129 | " \"generation_model_temperature\": EVAL_MODEL_TEMPERATURE,\n",
130 | " \"generation_model_max_tokens\": EVAL_MODEL_MAX_TOKENS,\n",
131 | " \"n_retries\": N_RETRIES,\n",
132 | " \"number_of_prompts\": NUMBER_OF_PROMPTS\n",
133 | " })\n",
134 | " \n",
135 | " return "
136 | ]
137 | },
138 | {
139 | "cell_type": "code",
140 | "execution_count": null,
141 | "metadata": {},
142 | "outputs": [],
143 | "source": [
144 | "# Optional logging to Weights & Biases to reocrd the configs, prompts and results\n",
145 | "if use_wandb:\n",
146 | " start_wandb_run()"
147 | ]
148 | },
149 | {
150 | "cell_type": "code",
151 | "execution_count": null,
152 | "metadata": {},
153 | "outputs": [],
154 | "source": [
155 | "def start_portkey_run():\n",
156 | " # define Portkey headers to start logging all prompts & their responses\n",
157 | " openai.api_base=\"https://api.portkey.ai/v1/proxy\"\n",
158 | " HEADERS = {\n",
159 | " \"x-portkey-api-key\": PORTKEY_API, \n",
160 | " \"x-portkey-mode\": \"proxy openai\",\n",
161 | " \"x-portkey-trace-id\": PORTKEY_TRACE,\n",
162 | " #\"x-portkey-retry-count\": 5 # perform automatic retries with exponential backoff if the OpenAI requests fails\n",
163 | " } \n",
164 | " return HEADERS"
165 | ]
166 | },
167 | {
168 | "cell_type": "code",
169 | "execution_count": null,
170 | "metadata": {},
171 | "outputs": [],
172 | "source": [
173 | "# Optional prompt & responses logging\n",
174 | "if use_portkey:\n",
175 | " HEADERS=start_portkey_run()"
176 | ]
177 | },
178 | {
179 | "cell_type": "code",
180 | "execution_count": 34,
181 | "metadata": {
182 | "id": "KTRFiBhSouz8"
183 | },
184 | "outputs": [],
185 | "source": [
186 | "# Get Score - retry up to N_RETRIES times, waiting exponentially between retries.\n",
187 | "@retry(stop=stop_after_attempt(N_RETRIES), wait=wait_exponential(multiplier=1, min=4, max=70))\n",
188 | "def generate_candidate_prompts(description, test_cases, number_of_prompts):\n",
189 | " outputs = openai.ChatCompletion.create(\n",
190 | " model=CANDIDATE_MODEL,\n",
191 | " messages=[\n",
192 | " {\"role\": \"system\", \"content\": candidate_gen_system_prompt},\n",
193 | " {\"role\": \"user\", \"content\": f\"Here are some test cases:`{test_cases}`\\n\\nHere is the description of the use-case: `{description.strip()}`\\n\\nRespond with your prompt, and nothing else. Be creative.\"}\n",
194 | " ],\n",
195 | " temperature=CANDIDATE_MODEL_TEMPERATURE,\n",
196 | " n=number_of_prompts,\n",
197 | " headers=HEADERS)\n",
198 | "\n",
199 | " prompts = []\n",
200 | "\n",
201 | " for i in outputs.choices:\n",
202 | " prompts.append(i.message.content)\n",
203 | " return prompts"
204 | ]
205 | },
206 | {
207 | "cell_type": "code",
208 | "execution_count": 43,
209 | "metadata": {
210 | "id": "w4ltgxntszwK"
211 | },
212 | "outputs": [],
213 | "source": [
214 | "def test_candidate_prompts(test_cases, prompts):\n",
215 | " prompt_results = {prompt: {'correct': 0, 'total': 0} for prompt in prompts}\n",
216 | "\n",
217 | " # Initialize the table\n",
218 | " table = PrettyTable()\n",
219 | " table_field_names = [\"Prompt\", \"Expected\"] + [f\"Prompt {i+1}-{j+1}\" for j, prompt in enumerate(prompts) for i in range(prompts.count(prompt))]\n",
220 | " table.field_names = table_field_names\n",
221 | "\n",
222 | " # Wrap the text in the \"Prompt\" column\n",
223 | " table.max_width[\"Prompt\"] = 100\n",
224 | "\n",
225 | " if use_wandb:\n",
226 | " wandb_table = wandb.Table(columns=table_field_names)\n",
227 | " if wandb.run is None:\n",
228 | " start_wandb_run()\n",
229 | "\n",
230 | " for test_case in test_cases:\n",
231 | " row = [test_case['prompt'], test_case['answer']]\n",
232 | " for prompt in prompts:\n",
233 | " x = openai.ChatCompletion.create(\n",
234 | " model=EVAL_MODEL,\n",
235 | " messages=[\n",
236 | " {\"role\": \"system\", \"content\": prompt},\n",
237 | " {\"role\": \"user\", \"content\": f\"{test_case['prompt']}\"}\n",
238 | " ],\n",
239 | " logit_bias={\n",
240 | " '1904': 100, # 'true' token\n",
241 | " '3934': 100, # 'false' token\n",
242 | " },\n",
243 | " max_tokens=EVAL_MODEL_MAX_TOKENS,\n",
244 | " temperature=EVAL_MODEL_TEMPERATURE,\n",
245 | " headers=HEADERS\n",
246 | " ).choices[0].message.content\n",
247 | "\n",
248 | "\n",
249 | " status = \"✅\" if x == test_case['answer'] else \"❌\"\n",
250 | " row.append(status)\n",
251 | "\n",
252 | " # Update model results\n",
253 | " if x == test_case['answer']:\n",
254 | " prompt_results[prompt]['correct'] += 1\n",
255 | " prompt_results[prompt]['total'] += 1\n",
256 | "\n",
257 | " table.add_row(row)\n",
258 | " if use_wandb:\n",
259 | " wandb_table.add_data(*row)\n",
260 | "\n",
261 | " print(table)\n",
262 | "\n",
263 | " # Calculate and print the percentage of correct answers and average time for each model\n",
264 | " best_prompt = None\n",
265 | " best_percentage = 0\n",
266 | " if use_wandb:\n",
267 | " prompts_results_table = wandb.Table(columns=[\"Prompt Number\", \"Prompt\", \"Percentage\", \"Correct\", \"Total\"])\n",
268 | " \n",
269 | " for i, prompt in enumerate(prompts):\n",
270 | " correct = prompt_results[prompt]['correct']\n",
271 | " total = prompt_results[prompt]['total']\n",
272 | " percentage = (correct / total) * 100\n",
273 | " print(f\"Prompt {i+1} got {percentage:.2f}% correct.\")\n",
274 | " if use_wandb:\n",
275 | " prompts_results_table.add_data(i, prompt, percentage, correct, total)\n",
276 | " if percentage > best_percentage:\n",
277 | " best_percentage = percentage\n",
278 | " best_prompt = prompt\n",
279 | "\n",
280 | " if use_wandb: # log the results to a Weights & Biases table and finsih the run\n",
281 | " wandb.log({\"prompt_results\": prompts_results_table})\n",
282 | " best_prompt_table = wandb.Table(columns=[\"Best Prompt\", \"Best Percentage\"])\n",
283 | " best_prompt_table.add_data(best_prompt, best_percentage)\n",
284 | " wandb.log({\"best_prompt\": best_prompt_table})\n",
285 | " wandb.log({\"prompt_ratings\": wandb_table})\n",
286 | " wandb.finish()\n",
287 | "\n",
288 | " print(f\"The best prompt was '{best_prompt}' with a correctness of {best_percentage:.2f}%.\")"
289 | ]
290 | },
291 | {
292 | "cell_type": "code",
293 | "execution_count": 44,
294 | "metadata": {
295 | "id": "SBJEi1hkrT9T"
296 | },
297 | "outputs": [],
298 | "source": [
299 | "test_cases = [\n",
300 | " {\n",
301 | " 'prompt': 'Find the best contact email on this site.',\n",
302 | " 'answer': 'true'\n",
303 | " },\n",
304 | " {\n",
305 | " 'prompt': 'who is the current president?',\n",
306 | " 'answer': 'true'\n",
307 | " },\n",
308 | " {\n",
309 | " 'prompt': 'order me a pizza',\n",
310 | " 'answer': 'false'\n",
311 | " },\n",
312 | " {\n",
313 | " 'prompt': 'what are some ways a doctor could use an assistant?',\n",
314 | " 'answer': 'true'\n",
315 | " },\n",
316 | " {\n",
317 | " 'prompt': 'write a speech on the danger of cults',\n",
318 | " 'answer': 'false'\n",
319 | " },\n",
320 | " {\n",
321 | " 'prompt': 'Make a reservation at The Accent for 9pm',\n",
322 | " 'answer': 'false'\n",
323 | " },\n",
324 | " {\n",
325 | " 'prompt': 'organize my google drive',\n",
326 | " 'answer': 'false'\n",
327 | " },\n",
328 | " {\n",
329 | " 'prompt': 'Find the highest-rated Italian restaurant near me.',\n",
330 | " 'answer': 'true'\n",
331 | " },\n",
332 | " {\n",
333 | " 'prompt': 'Explain the theory of relativity.',\n",
334 | " 'answer': 'true'\n",
335 | " },\n",
336 | " {\n",
337 | " 'prompt': 'What are the main differences between Python and Java programming languages?',\n",
338 | " 'answer': 'true'\n",
339 | " },\n",
340 | " {\n",
341 | " 'prompt': 'Translate the following English sentence to Spanish: \"The weather today is great.\"',\n",
342 | " 'answer': 'false'\n",
343 | " },\n",
344 | " {\n",
345 | " 'prompt': 'Create a new event on my calendar for tomorrow at 2 pm.',\n",
346 | " 'answer': 'false'\n",
347 | " },\n",
348 | " {\n",
349 | " 'prompt': 'Write a short story about a lonely cowboy.',\n",
350 | " 'answer': 'false'\n",
351 | " },\n",
352 | " {\n",
353 | " 'prompt': 'Design a logo for a startup.',\n",
354 | " 'answer': 'false'\n",
355 | " },\n",
356 | " {\n",
357 | " 'prompt': 'Compose a catchy jingle for a new soda brand.',\n",
358 | " 'answer': 'false'\n",
359 | " },\n",
360 | " {\n",
361 | " 'prompt': 'Calculate the square root of 1999.',\n",
362 | " 'answer': 'false'\n",
363 | " },\n",
364 | " {\n",
365 | " 'prompt': 'What are the health benefits of yoga?',\n",
366 | " 'answer': 'true'\n",
367 | " },\n",
368 | " {\n",
369 | " 'prompt': 'find me a source of meat that can be shipped to canada',\n",
370 | " 'answer': 'true'\n",
371 | " },\n",
372 | " {\n",
373 | " 'prompt': 'Find the best-selling book of all time.',\n",
374 | " 'answer': 'true'\n",
375 | " },\n",
376 | " {\n",
377 | " 'prompt': 'What are the top 5 tourist attractions in Brazil?',\n",
378 | " 'answer': 'true'\n",
379 | " },\n",
380 | " {\n",
381 | " 'prompt': 'List the main ingredients in a traditional lasagna recipe.',\n",
382 | " 'answer': 'true'\n",
383 | " },\n",
384 | " {\n",
385 | " 'prompt': 'How does photosynthesis work in plants?',\n",
386 | " 'answer': 'true'\n",
387 | " },\n",
388 | " {\n",
389 | " 'prompt': 'Write a Python program to reverse a string.',\n",
390 | " 'answer': 'false'\n",
391 | " },\n",
392 | " {\n",
393 | " 'prompt': 'Create a workout routine for a beginner.',\n",
394 | " 'answer': 'false'\n",
395 | " },\n",
396 | " {\n",
397 | " 'prompt': 'Edit my resume to highlight my project management skills.',\n",
398 | " 'answer': 'false'\n",
399 | " },\n",
400 | " {\n",
401 | " 'prompt': 'Draft an email to a client to discuss a new proposal.',\n",
402 | " 'answer': 'false'\n",
403 | " },\n",
404 | " {\n",
405 | " 'prompt': 'Plan a surprise birthday party for my best friend.',\n",
406 | " 'answer': 'false'\n",
407 | " }]"
408 | ]
409 | },
410 | {
411 | "cell_type": "code",
412 | "execution_count": 46,
413 | "metadata": {},
414 | "outputs": [],
415 | "source": [
416 | "description = \"Decide if a task is research-heavy.\" # describe the classification task clearly\n",
417 | "\n",
418 | "# If Weights & Biases is enabled, log the description and test cases too\n",
419 | "if use_wandb:\n",
420 | " if wandb.run is None:\n",
421 | " start_wandb_run()\n",
422 | " wandb.config.update({\"description\": description, \n",
423 | " \"test_cases\": test_cases})\n",
424 | "\n",
425 | "candidate_prompts = generate_candidate_prompts(description, test_cases, NUMBER_OF_PROMPTS)\n",
426 | "test_candidate_prompts(test_cases, candidate_prompts)"
427 | ]
428 | }
429 | ],
430 | "metadata": {
431 | "colab": {
432 | "authorship_tag": "ABX9TyMvbQztC95mJY9x+Gc/uEm+",
433 | "include_colab_link": true,
434 | "provenance": []
435 | },
436 | "kernelspec": {
437 | "display_name": "Python 3",
438 | "name": "python3"
439 | },
440 | "language_info": {
441 | "codemirror_mode": {
442 | "name": "ipython",
443 | "version": 3
444 | },
445 | "file_extension": ".py",
446 | "mimetype": "text/x-python",
447 | "name": "python",
448 | "nbconvert_exporter": "python",
449 | "pygments_lexer": "ipython3",
450 | "version": "3.11.2"
451 | }
452 | },
453 | "nbformat": 4,
454 | "nbformat_minor": 0
455 | }
456 |
--------------------------------------------------------------------------------
/opus_to_haiku_conversion.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "id": "view-in-github",
7 | "colab_type": "text"
8 | },
9 | "source": [
10 | ""
11 | ]
12 | },
13 | {
14 | "cell_type": "markdown",
15 | "metadata": {
16 | "id": "WljjH8K3s7kG"
17 | },
18 | "source": [
19 | "# opus-to-haiku - part of the `gpt-prompt-engineer` repo\n",
20 | "\n",
21 | "This notebook gives you the ability to go from Claude Opus to Claude Haiku -- reducing costs massively while keeping quality high.\n",
22 | "\n",
23 | "By Matt Shumer (https://twitter.com/mattshumer_)\n",
24 | "\n",
25 | "Github repo: https://github.com/mshumer/gpt-prompt-engineer"
26 | ]
27 | },
28 | {
29 | "cell_type": "code",
30 | "execution_count": null,
31 | "metadata": {
32 | "id": "dQmMZdkG_RA5"
33 | },
34 | "outputs": [],
35 | "source": [
36 | "import requests\n",
37 | "\n",
38 | "ANTHROPIC_API_KEY = \"YOUR API KEY HERE\" # enter your Anthropic API key here"
39 | ]
40 | },
41 | {
42 | "cell_type": "code",
43 | "execution_count": null,
44 | "metadata": {
45 | "id": "wXeqMQpzzosx",
46 | "cellView": "form"
47 | },
48 | "outputs": [],
49 | "source": [
50 | "#@title Run this to prep the main functions\n",
51 | "\n",
52 | "import json\n",
53 | "import re\n",
54 | "\n",
55 | "def generate_candidate_prompts(task, prompt_example, response_example):\n",
56 | " headers = {\n",
57 | " \"x-api-key\": ANTHROPIC_API_KEY,\n",
58 | " \"anthropic-version\": \"2023-06-01\",\n",
59 | " \"content-type\": \"application/json\"\n",
60 | " }\n",
61 | "\n",
62 | " data = {\n",
63 | " \"model\": 'claude-3-opus-20240229',\n",
64 | " \"max_tokens\": 4000,\n",
65 | " \"temperature\": .5,\n",
66 | " \"system\": \"\"\"Given an example training sample, create seven additional samples for the same task that are even better. Each example should contain a and a .\n",
67 | "\n",
68 | "\n",
69 | "1. Ensure the new examples are diverse and unique from one another.\n",
70 | "2. They should all be perfect. If you make a mistake, this system won't work.\n",
71 | "\n",
72 | "\n",
73 | "Respond in this format:\n",
74 | "\n",
75 | "\n",
76 | "\n",
77 | "PUT_PROMPT_HERE\n",
78 | "\n",
79 | "\n",
80 | "PUT_RESPONSE_HERE\n",
81 | "\n",
82 | "\n",
83 | "\n",
84 | "\n",
85 | "\n",
86 | "PUT_PROMPT_HERE\n",
87 | "\n",
88 | "\n",
89 | "PUT_RESPONSE_HERE\n",
90 | "\n",
91 | "\n",
92 | "\n",
93 | "...\n",
94 | "\"\"\",\n",
95 | " \"messages\": [\n",
96 | " {\"role\": \"user\", \"content\": f\"\"\"{task}\n",
97 | "\n",
98 | "\n",
99 | "{prompt_example}\n",
100 | "\n",
101 | "\n",
102 | "\n",
103 | "{response_example}\n",
104 | "\"\"\"},\n",
105 | " ]\n",
106 | " }\n",
107 | "\n",
108 | "\n",
109 | " response = requests.post(\"https://api.anthropic.com/v1/messages\", headers=headers, json=data)\n",
110 | "\n",
111 | " response_text = response.json()['content'][0]['text']\n",
112 | "\n",
113 | " # Parse out the prompts and responses\n",
114 | " prompts_and_responses = []\n",
115 | " examples = re.findall(r'(.*?)', response_text, re.DOTALL)\n",
116 | " for example in examples:\n",
117 | " prompt = re.findall(r'(.*?)', example, re.DOTALL)[0].strip()\n",
118 | " response = re.findall(r'(.*?)', example, re.DOTALL)[0].strip()\n",
119 | " prompts_and_responses.append({'prompt': prompt, 'response': response})\n",
120 | "\n",
121 | " return prompts_and_responses\n",
122 | "\n",
123 | "def generate_system_prompt(task, prompt_examples):\n",
124 | " headers = {\n",
125 | " \"x-api-key\": ANTHROPIC_API_KEY,\n",
126 | " \"anthropic-version\": \"2023-06-01\",\n",
127 | " \"content-type\": \"application/json\"\n",
128 | " }\n",
129 | "\n",
130 | " data = {\n",
131 | " \"model\": 'claude-3-opus-20240229',\n",
132 | " \"max_tokens\": 1000,\n",
133 | " \"temperature\": .5,\n",
134 | " \"system\": \"\"\"Given a user-description of their a set of prompt / response pairs (it'll be in JSON for easy reading) for the types of outputs we want to generate given inputs, write a fantastic system prompt that describes the task to be done perfectly.\n",
135 | "\n",
136 | "\n",
137 | "1. Do this perfectly.\n",
138 | "2. Respond only with the system prompt, and nothing else. No other text will be allowed.\n",
139 | "\n",
140 | "\n",
141 | "Respond in this format:\n",
142 | "\n",
143 | "WRITE_SYSTEM_PROMPT_HERE\n",
144 | "\"\"\",\n",
145 | " \"messages\": [\n",
146 | " {\"role\": \"user\", \"content\": f\"\"\"{task}\n",
147 | "\n",
148 | "\n",
149 | "{str(prompt_examples)}\n",
150 | "\"\"\"},\n",
151 | " ]\n",
152 | " }\n",
153 | "\n",
154 | "\n",
155 | " response = requests.post(\"https://api.anthropic.com/v1/messages\", headers=headers, json=data)\n",
156 | "\n",
157 | " response_text = response.json()['content'][0]['text']\n",
158 | "\n",
159 | " # Parse out the prompt\n",
160 | " system_prompt = response_text.split('')[1].split('')[0].strip()\n",
161 | "\n",
162 | " return system_prompt\n",
163 | "\n",
164 | "def test_haiku(generated_examples, prompt_example, system_prompt):\n",
165 | " headers = {\n",
166 | " \"x-api-key\": ANTHROPIC_API_KEY,\n",
167 | " \"anthropic-version\": \"2023-06-01\",\n",
168 | " \"content-type\": \"application/json\"\n",
169 | " }\n",
170 | "\n",
171 | " messages = []\n",
172 | "\n",
173 | " for example in generated_examples:\n",
174 | " messages.append({\"role\": \"user\", \"content\": example['prompt']})\n",
175 | " messages.append({\"role\": \"assistant\", \"content\": example['response']})\n",
176 | "\n",
177 | " messages.append({\"role\": \"user\", \"content\": prompt_example.strip()})\n",
178 | "\n",
179 | " data = {\n",
180 | " \"model\": 'claude-3-haiku-20240307',\n",
181 | " \"max_tokens\": 2000,\n",
182 | " \"temperature\": .5,\n",
183 | " \"system\": system_prompt,\n",
184 | " \"messages\": messages,\n",
185 | " }\n",
186 | "\n",
187 | "\n",
188 | " response = requests.post(\"https://api.anthropic.com/v1/messages\", headers=headers, json=data)\n",
189 | "\n",
190 | " response_text = response.json()['content'][0]['text']\n",
191 | "\n",
192 | " return response_text\n",
193 | "\n",
194 | "def run_haiku_conversion_process(task, prompt_example, response_example):\n",
195 | "\n",
196 | " print('Generating the prompts / responses...')\n",
197 | " # Generate candidate prompts\n",
198 | " generated_examples = generate_candidate_prompts(task, prompt_example, response_example)\n",
199 | "\n",
200 | " print('Prompts / responses generated. Now generating system prompt...')\n",
201 | "\n",
202 | " # Generate the system prompt\n",
203 | " system_prompt = generate_system_prompt(task, generated_examples)\n",
204 | "\n",
205 | " print('System prompt generated:', system_prompt)\n",
206 | "\n",
207 | "\n",
208 | " print('\\n\\nTesting the new prompt on Haiku, using your input example...')\n",
209 | " # Test the generated examples and system prompt with the Haiku model\n",
210 | " haiku_response = test_haiku(generated_examples, prompt_example, system_prompt)\n",
211 | "\n",
212 | " print('Haiku responded with:')\n",
213 | " print(haiku_response)\n",
214 | "\n",
215 | " print('\\n\\n!! CHECK THE FILE DIRECTORY, THE PROMPT IS NOW SAVED THERE !!')\n",
216 | "\n",
217 | " # Create a dictionary with all the relevant information\n",
218 | " result = {\n",
219 | " \"task\": task,\n",
220 | " \"initial_prompt_example\": prompt_example,\n",
221 | " \"initial_response_example\": response_example,\n",
222 | " \"generated_examples\": generated_examples,\n",
223 | " \"system_prompt\": system_prompt,\n",
224 | " \"haiku_response\": haiku_response\n",
225 | " }\n",
226 | "\n",
227 | " # Save the Haiku prompt to a Python file\n",
228 | " with open(\"haiku_prompt.py\", \"w\") as file:\n",
229 | " file.write('system_prompt = \"\"\"' + system_prompt + '\"\"\"\\n\\n')\n",
230 | "\n",
231 | " file.write('messages = [\\n')\n",
232 | " for example in generated_examples:\n",
233 | " file.write(' {\"role\": \"user\", \"content\": \"\"\"' + example['prompt'] + '\"\"\"},\\n')\n",
234 | " file.write(' {\"role\": \"assistant\", \"content\": \"\"\"' + example['response'] + '\"\"\"},\\n')\n",
235 | "\n",
236 | " file.write(' {\"role\": \"user\", \"content\": \"\"\"' + prompt_example.strip() + '\"\"\"}\\n')\n",
237 | " file.write(']\\n')\n",
238 | "\n",
239 | " return result"
240 | ]
241 | },
242 | {
243 | "cell_type": "markdown",
244 | "source": [
245 | "## Fill in your task, prompt_example, and response_example here. Make sure you keep the quality really high here... this is the most important step!"
246 | ],
247 | "metadata": {
248 | "id": "ZujTAzhuBMea"
249 | }
250 | },
251 | {
252 | "cell_type": "code",
253 | "source": [
254 | "task = \"refactoring complex code\"\n",
255 | "\n",
256 | "prompt_example = \"\"\"def calculate_total(prices, tax, discount, shipping_fee, gift_wrap_fee, membership_discount):\n",
257 | "\n",
258 | " total = 0\n",
259 | "\n",
260 | " for i in range(len(prices)):\n",
261 | "\n",
262 | " total += prices[i]\n",
263 | "\n",
264 | " if membership_discount != 0:\n",
265 | "\n",
266 | " total = total - (total * (membership_discount / 100))\n",
267 | "\n",
268 | " if discount != 0:\n",
269 | "\n",
270 | " total = total - (total * (discount / 100))\n",
271 | "\n",
272 | " total = total + (total * (tax / 100))\n",
273 | "\n",
274 | " if total < 50:\n",
275 | "\n",
276 | " total += shipping_fee\n",
277 | "\n",
278 | " else:\n",
279 | "\n",
280 | " total += shipping_fee / 2\n",
281 | "\n",
282 | " if gift_wrap_fee != 0:\n",
283 | "\n",
284 | " total += gift_wrap_fee * len(prices)\n",
285 | "\n",
286 | " if total > 1000:\n",
287 | "\n",
288 | " total -= 50\n",
289 | "\n",
290 | " elif total > 500:\n",
291 | "\n",
292 | " total -= 25\n",
293 | "\n",
294 | " total = round(total, 2)\n",
295 | "\n",
296 | " if total < 0:\n",
297 | "\n",
298 | " total = 0\n",
299 | "\n",
300 | " return total\"\"\"\n",
301 | "\n",
302 | "response_example = \"\"\"def calculate_total(prices, tax_rate, discount_rate, shipping_fee, gift_wrap_fee, membership_discount_rate):\n",
303 | "\n",
304 | " def apply_percentage_discount(amount, percentage):\n",
305 | "\n",
306 | " return amount * (1 - percentage / 100)\n",
307 | "\n",
308 | " def calculate_shipping_fee(total):\n",
309 | "\n",
310 | " return shipping_fee if total < 50 else shipping_fee / 2\n",
311 | "\n",
312 | " def apply_tier_discount(total):\n",
313 | "\n",
314 | " if total > 1000:\n",
315 | "\n",
316 | " return total - 50\n",
317 | "\n",
318 | " elif total > 500:\n",
319 | "\n",
320 | " return total - 25\n",
321 | "\n",
322 | " return total\n",
323 | "\n",
324 | " subtotal = sum(prices)\n",
325 | "\n",
326 | " subtotal = apply_percentage_discount(subtotal, membership_discount_rate)\n",
327 | "\n",
328 | " subtotal = apply_percentage_discount(subtotal, discount_rate)\n",
329 | "\n",
330 | "\n",
331 | "\n",
332 | " total = subtotal * (1 + tax_rate / 100)\n",
333 | "\n",
334 | " total += calculate_shipping_fee(total)\n",
335 | "\n",
336 | " total += gift_wrap_fee * len(prices)\n",
337 | "\n",
338 | "\n",
339 | "\n",
340 | " total = apply_tier_discount(total)\n",
341 | "\n",
342 | " total = max(0, round(total, 2))\n",
343 | "\n",
344 | "\n",
345 | "\n",
346 | " return total\"\"\""
347 | ],
348 | "metadata": {
349 | "id": "XSZqqOoQ-5_E"
350 | },
351 | "execution_count": null,
352 | "outputs": []
353 | },
354 | {
355 | "cell_type": "markdown",
356 | "source": [
357 | "### Now, let's run this system and get our new prompt! At the end, you'll see a new file pop up in the directory that contains everything you'll need to reduce your costs while keeping quality high w/ Haiku!"
358 | ],
359 | "metadata": {
360 | "id": "cMO3cJzWA-O0"
361 | }
362 | },
363 | {
364 | "cell_type": "code",
365 | "source": [
366 | "result = run_haiku_conversion_process(task, prompt_example, response_example)"
367 | ],
368 | "metadata": {
369 | "id": "O-Bn0rupAJqb"
370 | },
371 | "execution_count": null,
372 | "outputs": []
373 | }
374 | ],
375 | "metadata": {
376 | "colab": {
377 | "provenance": [],
378 | "include_colab_link": true
379 | },
380 | "kernelspec": {
381 | "display_name": "Python 3",
382 | "name": "python3"
383 | },
384 | "language_info": {
385 | "codemirror_mode": {
386 | "name": "ipython",
387 | "version": 3
388 | },
389 | "file_extension": ".py",
390 | "mimetype": "text/x-python",
391 | "name": "python",
392 | "nbconvert_exporter": "python",
393 | "pygments_lexer": "ipython3",
394 | "version": "3.8.8"
395 | }
396 | },
397 | "nbformat": 4,
398 | "nbformat_minor": 0
399 | }
--------------------------------------------------------------------------------