├── dataset
├── __init__.py
├── __pycache__
│ ├── scaler.cpython-39.pyc
│ ├── __init__.cpython-39.pyc
│ ├── preprocess.cpython-39.pyc
│ ├── quaternion.cpython-39.pyc
│ └── dance_dataset.cpython-39.pyc
├── preprocess.py
├── quaternion.py
├── masks.py
├── scaler.py
└── dance_dataset.py
├── data
├── audio_extraction
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-39.pyc
│ │ ├── both_features.cpython-39.pyc
│ │ ├── jukebox_features.cpython-39.pyc
│ │ └── baseline_features.cpython-39.pyc
│ ├── jukebox_features.py
│ └── baseline_features.py
├── download_dataset.sh
├── splits
│ ├── crossmodal_test.txt
│ ├── ignore_list.txt
│ └── crossmodal_train.txt
├── filter_split_data.py
├── create_dataset.py
└── slice.py
├── figs
└── model_00.png
├── .idea
├── misc.xml
├── .gitignore
├── inspectionProfiles
│ └── profiles_settings.xml
├── modules.xml
└── DGSDP-main.iml
├── train.py
├── eval
├── eval_pfc.py
├── beat_align_score.py
├── features
│ ├── kinetic.py
│ ├── utils.py
│ ├── manual_new.py
│ └── manual.py
└── metrics_diversity.py
├── model
├── utils.py
├── adan.py
├── rotary_embedding_torch.py
├── style_CLIP.py
├── model.py
└── diffusion.py
├── args.py
├── README.md
├── test.py
├── vis.py
└── DGSDP.py
/dataset/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/data/audio_extraction/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/figs/model_00.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mucunzhuzhu/DGSDP/HEAD/figs/model_00.png
--------------------------------------------------------------------------------
/dataset/__pycache__/scaler.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mucunzhuzhu/DGSDP/HEAD/dataset/__pycache__/scaler.cpython-39.pyc
--------------------------------------------------------------------------------
/dataset/__pycache__/__init__.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mucunzhuzhu/DGSDP/HEAD/dataset/__pycache__/__init__.cpython-39.pyc
--------------------------------------------------------------------------------
/dataset/__pycache__/preprocess.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mucunzhuzhu/DGSDP/HEAD/dataset/__pycache__/preprocess.cpython-39.pyc
--------------------------------------------------------------------------------
/dataset/__pycache__/quaternion.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mucunzhuzhu/DGSDP/HEAD/dataset/__pycache__/quaternion.cpython-39.pyc
--------------------------------------------------------------------------------
/dataset/__pycache__/dance_dataset.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mucunzhuzhu/DGSDP/HEAD/dataset/__pycache__/dance_dataset.cpython-39.pyc
--------------------------------------------------------------------------------
/data/audio_extraction/__pycache__/__init__.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mucunzhuzhu/DGSDP/HEAD/data/audio_extraction/__pycache__/__init__.cpython-39.pyc
--------------------------------------------------------------------------------
/data/audio_extraction/__pycache__/both_features.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mucunzhuzhu/DGSDP/HEAD/data/audio_extraction/__pycache__/both_features.cpython-39.pyc
--------------------------------------------------------------------------------
/data/audio_extraction/__pycache__/jukebox_features.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mucunzhuzhu/DGSDP/HEAD/data/audio_extraction/__pycache__/jukebox_features.cpython-39.pyc
--------------------------------------------------------------------------------
/data/audio_extraction/__pycache__/baseline_features.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/mucunzhuzhu/DGSDP/HEAD/data/audio_extraction/__pycache__/baseline_features.cpython-39.pyc
--------------------------------------------------------------------------------
/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
--------------------------------------------------------------------------------
/.idea/.gitignore:
--------------------------------------------------------------------------------
1 | # Default ignored files
2 | /shelf/
3 | /workspace.xml
4 | # Editor-based HTTP Client requests
5 | /httpRequests/
6 | # Datasource local storage ignored files
7 | /dataSources/
8 | /dataSources.local.xml
9 |
--------------------------------------------------------------------------------
/.idea/inspectionProfiles/profiles_settings.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/train.py:
--------------------------------------------------------------------------------
1 | from args import parse_train_opt
2 | from DGSDP import DGSDP
3 |
4 |
5 | def train(opt):
6 | model = DGSDP(opt.feature_type)
7 | model.train_loop(opt)
8 |
9 |
10 | if __name__ == "__main__":
11 | opt = parse_train_opt()
12 | train(opt)
13 |
--------------------------------------------------------------------------------
/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/data/download_dataset.sh:
--------------------------------------------------------------------------------
1 | wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1RzqSbSnbMEwLUagV0GThfpm9JJXePGkV' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=1RzqSbSnbMEwLUagV0GThfpm9JJXePGkV" -O edge_aistpp.zip && rm -rf /tmp/cookies.txt
2 | unzip edge_aistpp.zip
--------------------------------------------------------------------------------
/.idea/DGSDP-main.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
--------------------------------------------------------------------------------
/data/splits/crossmodal_test.txt:
--------------------------------------------------------------------------------
1 | gLH_sBM_cAll_d17_mLH4_ch02
2 | gLH_sBM_cAll_d18_mLH4_ch02
3 | gKR_sBM_cAll_d30_mKR2_ch02
4 | gKR_sBM_cAll_d28_mKR2_ch02
5 | gBR_sBM_cAll_d04_mBR0_ch02
6 | gBR_sBM_cAll_d05_mBR0_ch02
7 | gLO_sBM_cAll_d13_mLO2_ch02
8 | gLO_sBM_cAll_d15_mLO2_ch02
9 | gJB_sBM_cAll_d08_mJB5_ch02
10 | gJB_sBM_cAll_d09_mJB5_ch02
11 | gWA_sBM_cAll_d26_mWA0_ch02
12 | gWA_sBM_cAll_d25_mWA0_ch02
13 | gJS_sBM_cAll_d03_mJS3_ch02
14 | gJS_sBM_cAll_d01_mJS3_ch02
15 | gMH_sBM_cAll_d24_mMH3_ch02
16 | gMH_sBM_cAll_d22_mMH3_ch02
17 | gHO_sBM_cAll_d20_mHO5_ch02
18 | gHO_sBM_cAll_d21_mHO5_ch02
19 | gPO_sBM_cAll_d10_mPO1_ch02
20 | gPO_sBM_cAll_d11_mPO1_ch02
--------------------------------------------------------------------------------
/data/audio_extraction/jukebox_features.py:
--------------------------------------------------------------------------------
1 | import os
2 | from functools import partial
3 | from pathlib import Path
4 |
5 | import jukemirlib
6 | import numpy as np
7 | from tqdm import tqdm
8 |
9 | FPS = 30
10 | LAYER = 66
11 |
12 |
13 | def extract(fpath, skip_completed=True, dest_dir="aist_juke_feats"):
14 | os.makedirs(dest_dir, exist_ok=True)
15 | audio_name = Path(fpath).stem
16 | save_path = os.path.join(dest_dir, audio_name + ".npy")
17 |
18 | if os.path.exists(save_path) and skip_completed:
19 | return
20 |
21 | audio = jukemirlib.load_audio(fpath)
22 | reps = jukemirlib.extract(audio, layers=[LAYER], downsample_target_rate=FPS)
23 |
24 | #np.save(save_path, reps[LAYER])
25 | return reps[LAYER], save_path
26 |
27 |
28 | def extract_folder(src, dest):
29 | fpaths = Path(src).glob("*")
30 | fpaths = sorted(list(fpaths))
31 | extract_ = partial(extract, skip_completed=False, dest_dir=dest)
32 | for fpath in tqdm(fpaths):
33 | rep, path = extract_(fpath)
34 | np.save(path, rep)
35 |
36 |
37 | if __name__ == "__main__":
38 | import argparse
39 |
40 | parser = argparse.ArgumentParser()
41 |
42 | parser.add_argument("--src", help="source path to AIST++ audio files")
43 | parser.add_argument("--dest", help="dest path to audio features")
44 |
45 | args = parser.parse_args()
46 |
47 | extract_folder(args.src, args.dest)
48 |
--------------------------------------------------------------------------------
/data/splits/ignore_list.txt:
--------------------------------------------------------------------------------
1 | gBR_sFM_cAll_d05_mBR5_ch14
2 | gBR_sFM_cAll_d06_mBR5_ch19
3 | gBR_sFM_cAll_d04_mBR4_ch07
4 | gBR_sFM_cAll_d05_mBR4_ch13
5 | gBR_sBM_cAll_d04_mBR0_ch08
6 | gBR_sBM_cAll_d04_mBR0_ch07
7 | gBR_sBM_cAll_d04_mBR0_ch10
8 | gBR_sBM_cAll_d05_mBR0_ch07
9 | gJB_sBM_cAll_d07_mJB2_ch06
10 | gJB_sBM_cAll_d07_mJB3_ch01
11 | gJB_sBM_cAll_d07_mJB3_ch05
12 | gJB_sBM_cAll_d08_mJB0_ch07
13 | gJB_sBM_cAll_d08_mJB0_ch09
14 | gJB_sBM_cAll_d08_mJB1_ch09
15 | gJB_sFM_cAll_d08_mJB3_ch11
16 | gJB_sBM_cAll_d08_mJB5_ch07
17 | gJB_sBM_cAll_d09_mJB2_ch07
18 | gJB_sBM_cAll_d09_mJB3_ch07
19 | gJB_sBM_cAll_d09_mJB4_ch06
20 | gJB_sBM_cAll_d09_mJB4_ch07
21 | gJB_sBM_cAll_d09_mJB4_ch09
22 | gJB_sBM_cAll_d09_mJB5_ch09
23 | gJS_sFM_cAll_d01_mJS0_ch01
24 | gJS_sFM_cAll_d01_mJS1_ch02
25 | gJS_sFM_cAll_d02_mJS0_ch08
26 | gJS_sFM_cAll_d03_mJS0_ch01
27 | gJS_sBM_cAll_d03_mJS3_ch10
28 | gKR_sBM_cAll_d30_mKR5_ch02
29 | gKR_sBM_cAll_d30_mKR5_ch01
30 | gHO_sFM_cAll_d20_mHO5_ch13
31 | gWA_sBM_cAll_d27_mWA4_ch02
32 | gWA_sBM_cAll_d27_mWA4_ch08
33 | gWA_sFM_cAll_d26_mWA2_ch10
34 | gWA_sBM_cAll_d25_mWA3_ch04
35 | gWA_sFM_cAll_d27_mWA1_ch16
36 | gWA_sBM_cAll_d25_mWA1_ch04
37 | gWA_sBM_cAll_d27_mWA5_ch01
38 | gWA_sBM_cAll_d27_mWA5_ch08
39 | gWA_sBM_cAll_d27_mWA3_ch01
40 | gWA_sBM_cAll_d27_mWA2_ch08
41 | gWA_sBM_cAll_d26_mWA1_ch01
42 | gWA_sBM_cAll_d26_mWA0_ch09
43 | gWA_sBM_cAll_d27_mWA2_ch01
44 | gWA_sBM_cAll_d25_mWA2_ch04
45 | gWA_sBM_cAll_d25_mWA2_ch03
46 |
47 |
--------------------------------------------------------------------------------
/data/filter_split_data.py:
--------------------------------------------------------------------------------
1 | import glob
2 | import os
3 | import pickle
4 | import shutil
5 | from pathlib import Path
6 |
7 |
8 | def fileToList(f):
9 | out = open(f, "r").readlines()
10 | out = [x.strip() for x in out]
11 | out = [x for x in out if len(x)]
12 | out = [x for x in out if len(x)]
13 | return out
14 |
15 |
16 | filter_list = set(fileToList("splits/ignore_list.txt"))
17 | train_list = set(fileToList("splits/crossmodal_train.txt"))
18 | test_list = set(fileToList("splits/crossmodal_test.txt"))
19 |
20 |
21 | def split_data(dataset_path):
22 | # train - test split
23 | for split_list, split_name in zip([train_list, test_list], ["train", "test"]):
24 | Path(f"{split_name}/motions").mkdir(parents=True, exist_ok=True)
25 | Path(f"{split_name}/wavs").mkdir(parents=True, exist_ok=True)
26 | for sequence in split_list:
27 | if sequence in filter_list:
28 | continue
29 | motion = f"{dataset_path}/motions/{sequence}.pkl"
30 | wav = f"{dataset_path}/wavs/{sequence}.wav"
31 | assert os.path.isfile(motion)
32 | assert os.path.isfile(wav)
33 | motion_data = pickle.load(open(motion, "rb"))
34 | trans = motion_data["smpl_trans"]
35 | pose = motion_data["smpl_poses"]
36 | scale = motion_data["smpl_scaling"]
37 | out_data = {"pos": trans, "q": pose, "scale": scale}
38 | pickle.dump(out_data, open(f"{split_name}/motions/{sequence}.pkl", "wb"))
39 | shutil.copyfile(wav, f"{split_name}/wavs/{sequence}.wav")
40 |
--------------------------------------------------------------------------------
/data/create_dataset.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | from pathlib import Path
4 |
5 | from audio_extraction.baseline_features import \
6 | extract_folder as baseline_extract
7 | from audio_extraction.jukebox_features import extract_folder as jukebox_extract
8 | from filter_split_data import *
9 | from slice import *
10 |
11 |
12 | def create_dataset(opt):
13 | # split the data according to the splits files
14 | print("Creating train / test split")
15 | split_data(opt.dataset_folder)
16 | # slice motions/music into sliding windows to create training dataset
17 | print("Slicing train data") #
18 | slice_aistpp(f"train/motions", f"train/wavs")
19 | print("Slicing test data")
20 | slice_aistpp(f"test/motions", f"test/wavs")
21 | # process dataset to extract audio features
22 | if opt.extract_baseline:
23 | print("Extracting baseline features")
24 | baseline_extract("train/wavs_sliced", "train/baseline_feats")
25 | baseline_extract("test/wavs_sliced", "test/baseline_feats")
26 | if opt.extract_jukebox:
27 | print("Extracting jukebox features")
28 | jukebox_extract("train/wavs_sliced", "train/jukebox_feats")
29 | jukebox_extract("test/wavs_sliced", "test/jukebox_feats")
30 |
31 |
32 | def parse_opt():
33 | parser = argparse.ArgumentParser()
34 | parser.add_argument("--stride", type=float, default=0.5)
35 | parser.add_argument("--length", type=float, default=5.0, help="checkpoint")
36 | parser.add_argument(
37 | "--dataset_folder",
38 | type=str,
39 | default="edge_aistpp",
40 | help="folder containing motions and music",
41 | )
42 | parser.add_argument("--extract-baseline", action="store_true")
43 | parser.add_argument("--extract-jukebox", action="store_true")
44 | opt = parser.parse_args()
45 | return opt
46 |
47 |
48 | if __name__ == "__main__":
49 | opt = parse_opt()
50 | create_dataset(opt)
51 |
--------------------------------------------------------------------------------
/dataset/preprocess.py:
--------------------------------------------------------------------------------
1 | import glob
2 | import os
3 | import re
4 | from pathlib import Path
5 |
6 | import torch
7 |
8 | from .scaler import MinMaxScaler
9 |
10 |
11 | def increment_path(path, exist_ok=False, sep="", mkdir=False):
12 | # Increment file or directory path, i.e. runs/exp --> runs/exp{sep}2, runs/exp{sep}3, ... etc.
13 | path = Path(path) # os-agnostic
14 | if path.exists() and not exist_ok:
15 | suffix = path.suffix
16 | path = path.with_suffix("")
17 | dirs = glob.glob(f"{path}{sep}*") # similar paths
18 | matches = [re.search(rf"%s{sep}(\d+)" % path.stem, d) for d in dirs]
19 | i = [int(m.groups()[0]) for m in matches if m] # indices
20 | n = max(i) + 1 if i else 2 # increment number
21 | path = Path(f"{path}{sep}{n}{suffix}") # update path
22 | dir = path if path.suffix == "" else path.parent # directory
23 | if not dir.exists() and mkdir:
24 | dir.mkdir(parents=True, exist_ok=True) # make directory
25 | return path
26 |
27 |
28 | class Normalizer:
29 | def __init__(self, data):
30 | flat = data.reshape(-1, data.shape[-1])
31 | self.scaler = MinMaxScaler((-1, 1), clip=True)
32 | self.scaler.fit(flat)
33 |
34 | def normalize(self, x):
35 | batch, seq, ch = x.shape
36 | x = x.reshape(-1, ch)
37 | return self.scaler.transform(x).reshape((batch, seq, ch))
38 |
39 | def unnormalize(self, x):
40 | batch, seq, ch = x.shape
41 | x = x.reshape(-1, ch)
42 | x = torch.clip(x, -1, 1) # clip to force compatibility
43 | return self.scaler.inverse_transform(x).reshape((batch, seq, ch))
44 |
45 |
46 | def vectorize_many(data):
47 | # given a list of batch x seqlen x joints? x channels, flatten all to batch x seqlen x -1, concatenate
48 | batch_size = data[0].shape[0]
49 | seq_len = data[0].shape[1]
50 |
51 | out = [x.reshape(batch_size, seq_len, -1).contiguous() for x in data]
52 |
53 | global_pose_vec_gt = torch.cat(out, dim=2)
54 | return global_pose_vec_gt
55 |
--------------------------------------------------------------------------------
/dataset/quaternion.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from pytorch3d.transforms import (axis_angle_to_matrix, matrix_to_axis_angle,
3 | matrix_to_quaternion, matrix_to_rotation_6d,
4 | quaternion_to_matrix, rotation_6d_to_matrix)
5 |
6 |
7 | def quat_to_6v(q):
8 | assert q.shape[-1] == 4
9 | mat = quaternion_to_matrix(q)
10 | mat = matrix_to_rotation_6d(mat)
11 | return mat
12 |
13 |
14 | def quat_from_6v(q):
15 | assert q.shape[-1] == 6
16 | mat = rotation_6d_to_matrix(q)
17 | quat = matrix_to_quaternion(mat)
18 | return quat
19 |
20 |
21 | def ax_to_6v(q):
22 | assert q.shape[-1] == 3
23 | mat = axis_angle_to_matrix(q)
24 | mat = matrix_to_rotation_6d(mat)
25 | return mat
26 |
27 |
28 | def ax_from_6v(q):
29 | assert q.shape[-1] == 6
30 | mat = rotation_6d_to_matrix(q)
31 | ax = matrix_to_axis_angle(mat)
32 | return ax
33 |
34 |
35 | def quat_slerp(x, y, a): # merged = quat_slerp(left, right, slerp_weight)
36 | """
37 | Performs spherical linear interpolation (SLERP) between x and y, with proportion a
38 |
39 | :param x: quaternion tensor (N, S, J, 4)
40 | :param y: quaternion tensor (N, S, J, 4)
41 | :param a: interpolation weight (S, )
42 | :return: tensor of interpolation results
43 | """
44 | len = torch.sum(x * y, axis=-1)
45 |
46 | neg = len < 0.0
47 | len[neg] = -len[neg]
48 | y[neg] = -y[neg]
49 |
50 | a = torch.zeros_like(x[..., 0]) + a
51 |
52 | amount0 = torch.zeros_like(a)
53 | amount1 = torch.zeros_like(a)
54 |
55 | linear = (1.0 - len) < 0.01
56 | omegas = torch.arccos(len[~linear])
57 | sinoms = torch.sin(omegas)
58 |
59 | amount0[linear] = 1.0 - a[linear]
60 | amount0[~linear] = torch.sin((1.0 - a[~linear]) * omegas) / sinoms
61 |
62 | amount1[linear] = a[linear]
63 | amount1[~linear] = torch.sin(a[~linear] * omegas) / sinoms
64 |
65 | # reshape
66 | amount0 = amount0[..., None]
67 | amount1 = amount1[..., None]
68 |
69 | res = amount0 * x + amount1 * y
70 |
71 | return res
72 |
--------------------------------------------------------------------------------
/eval/eval_pfc.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import glob
3 | import os
4 | import pickle
5 | import random
6 |
7 | import numpy as np
8 | from tqdm import tqdm
9 |
10 |
11 | def calc_physical_score(dir):
12 | scores = []
13 | names = []
14 | accelerations = []
15 | up_dir = 2 # z is up
16 | flat_dirs = [i for i in range(3) if i != up_dir]
17 | DT = 1 / 30
18 |
19 | it = glob.glob(os.path.join(dir, "*.pkl"))
20 | if len(it) > 1000:
21 | it = random.sample(it, 1000)
22 | for pkl in tqdm(it):
23 | info = pickle.load(open(pkl, "rb"))
24 | joint3d = info["full_pose"]
25 | joint3d = joint3d.reshape(-1,24,3)
26 | root_v = (joint3d[1:, 0, :] - joint3d[:-1, 0, :]) / DT
27 | root_a = (root_v[1:] - root_v[:-1]) / DT
28 | # clamp the up-direction of root acceleration
29 | root_a[:, up_dir] = np.maximum(root_a[:, up_dir], 0) #
30 | # l2 norm
31 | root_a = np.linalg.norm(root_a, axis=-1)
32 | scaling = root_a.max()
33 | root_a /= scaling
34 |
35 | foot_idx = [7, 10, 8, 11]
36 | feet = joint3d[:, foot_idx]
37 | foot_v = np.linalg.norm(
38 | feet[2:, :, flat_dirs] - feet[1:-1, :, flat_dirs], axis=-1
39 | ) # (S-2, 4) horizontal velocity
40 | foot_mins = np.zeros((len(foot_v), 2))
41 | foot_mins[:, 0] = np.minimum(foot_v[:, 0], foot_v[:, 1])
42 | foot_mins[:, 1] = np.minimum(foot_v[:, 2], foot_v[:, 3])
43 |
44 | foot_loss = (
45 | foot_mins[:, 0] * foot_mins[:, 1] * root_a
46 | ) # min leftv * min rightv * root_a (S-2,)
47 | foot_loss = foot_loss.mean()
48 | scores.append(foot_loss)
49 | names.append(pkl)
50 | accelerations.append(foot_mins[:, 0].mean())
51 |
52 | out = np.mean(scores) * 10000
53 | print(f"{dir} has a mean PFC of {out}")
54 |
55 |
56 | def parse_eval_opt():
57 | parser = argparse.ArgumentParser()
58 | parser.add_argument(
59 | "--motion_path",
60 | type=str,
61 | default="./motions",
62 | help="Where to load saved motions",
63 | )
64 | opt = parser.parse_args()
65 | return opt
66 |
67 |
68 | if __name__ == "__main__":
69 | opt = parse_eval_opt()
70 | opt.motion_path = "eval/motions"
71 |
72 | calc_physical_score(opt.motion_path)
--------------------------------------------------------------------------------
/dataset/masks.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | smpl_joints = [
4 | "root", # 0
5 | "lhip",
6 | "rhip",
7 | "belly", # 1 2 3
8 | "lknee",
9 | "rknee",
10 | "spine", # 4 5 6
11 | "lankle",
12 | "rankle",
13 | "chest", # 7 8 9
14 | "ltoes",
15 | "rtoes",
16 | "neck", # 10 11 12
17 | "linshoulder",
18 | "rinshoulder", # 13 14
19 | "head",
20 | "lshoulder",
21 | "rshoulder", # 15 16 17
22 | "lelbow",
23 | "relbow", # 18 19
24 | "lwrist",
25 | "rwrist", # 20 21
26 | "lhand",
27 | "rhand", # 22 23
28 | ]
29 |
30 |
31 | def joint_indices_to_channel_indices(indices):
32 | out = []
33 | for index in indices:
34 | out += list(range(3 + 3 * index, 3 + 3 * index + 3))
35 | return out
36 |
37 |
38 | def get_first_last_mask(posq_batch, start_width=1, end_width=1):
39 | # an array in batch x seq_len x channels
40 | # return a mask that is ones in the first and last row (or first/last WIDTH rows) in the sequence direction
41 | mask = torch.zeros_like(posq_batch)
42 | mask[..., :start_width, :] = 1
43 | mask[..., -end_width:, :] = 1
44 | return mask
45 |
46 |
47 | def get_first_mask(posq_batch, start_width=1):
48 | # an array in batch x seq_len x channels
49 | # return a mask that is ones in the first and last row (or first/last WIDTH rows) in the sequence direction
50 | mask = torch.zeros_like(posq_batch)
51 | mask[..., :start_width, :] = 1
52 | return mask
53 |
54 |
55 | def get_middle_mask(posq_batch, start=0, end=-1):
56 | # an array in batch x seq_len x channels
57 | # return a mask that is ones in the first and last row (or first/last WIDTH rows) in the sequence direction
58 | mask = torch.zeros_like(posq_batch)
59 | mask[..., start:end, :] = 1
60 | return mask
61 |
62 |
63 | def lowerbody_mask(posq_batch):
64 | # an array in batch x seq_len x channels
65 | # return a mask that is ones in the first and last row (or first/last WIDTH rows) in the sequence direction
66 | mask = torch.zeros_like(posq_batch)
67 | lowerbody_indices = [0, 1, 2, 4, 5, 7, 8, 10, 11]
68 | root_traj_indices = [0, 1, 2]
69 | lowerbody_indices = (
70 | joint_indices_to_channel_indices(lowerbody_indices) + root_traj_indices
71 | ) # plus root traj
72 | mask[..., :, lowerbody_indices] = 1
73 | return mask
74 |
75 |
76 | def upperbody_mask(posq_batch):
77 | # an array in batch x seq_len x channels
78 | # return a mask that is ones in the first and last row (or first/last WIDTH rows) in the sequence direction
79 | mask = torch.zeros_like(posq_batch)
80 | upperbody_indices = [0, 3, 6, 9, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]
81 | root_traj_indices = [0, 1, 2]
82 | upperbody_indices = (
83 | joint_indices_to_channel_indices(upperbody_indices) + root_traj_indices
84 | ) # plus root traj
85 | mask[..., :, upperbody_indices] = 1
86 | return mask
87 |
--------------------------------------------------------------------------------
/dataset/scaler.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 |
4 | def _handle_zeros_in_scale(scale, copy=True, constant_mask=None):
5 | # if we are fitting on 1D arrays, scale might be a scalar
6 | if constant_mask is None:
7 | # Detect near constant values to avoid dividing by a very small
8 | # value that could lead to surprising results and numerical
9 | # stability issues.
10 | constant_mask = scale < 10 * torch.finfo(scale.dtype).eps
11 |
12 | if copy:
13 | # New array to avoid side-effects
14 | scale = scale.clone()
15 | scale[constant_mask] = 1.0
16 | return scale
17 |
18 |
19 | class MinMaxScaler:
20 | _parameter_constraints: dict = {
21 | "feature_range": [tuple],
22 | "copy": ["boolean"],
23 | "clip": ["boolean"],
24 | }
25 |
26 | def __init__(self, feature_range=(0, 1), *, copy=True, clip=False):
27 | self.feature_range = feature_range
28 | self.copy = copy
29 | self.clip = clip
30 |
31 | def _reset(self):
32 | """Reset internal data-dependent state of the scaler, if necessary.
33 | __init__ parameters are not touched.
34 | """
35 | # Checking one attribute is enough, because they are all set together
36 | # in partial_fit
37 | if hasattr(self, "scale_"):
38 | del self.scale_
39 | del self.min_
40 | del self.n_samples_seen_
41 | del self.data_min_
42 | del self.data_max_
43 | del self.data_range_
44 |
45 | def fit(self, X):
46 | # Reset internal state before fitting
47 | self._reset()
48 | return self.partial_fit(X)
49 |
50 | def partial_fit(self, X):
51 | feature_range = self.feature_range
52 | if feature_range[0] >= feature_range[1]:
53 | raise ValueError(
54 | "Minimum of desired feature range must be smaller than maximum. Got %s."
55 | % str(feature_range)
56 | )
57 |
58 | data_min = torch.min(X, axis=0)[0]
59 | data_max = torch.max(X, axis=0)[0]
60 |
61 | self.n_samples_seen_ = X.shape[0]
62 |
63 | data_range = data_max - data_min
64 | self.scale_ = (feature_range[1] - feature_range[0]) / _handle_zeros_in_scale(
65 | data_range, copy=True
66 | )
67 | self.min_ = feature_range[0] - data_min * self.scale_
68 | self.data_min_ = data_min
69 | self.data_max_ = data_max
70 | self.data_range_ = data_range
71 | return self
72 |
73 | def transform(self, X):
74 | X *= self.scale_.to(X.device)
75 | X += self.min_.to(X.device)
76 | if self.clip:
77 | torch.clip(X, self.feature_range[0], self.feature_range[1], out=X)
78 | return X
79 |
80 | def inverse_transform(self, X):
81 | X -= self.min_[-X.shape[1] :].to(X.device)
82 | X /= self.scale_[-X.shape[1] :].to(X.device)
83 | return X
84 |
--------------------------------------------------------------------------------
/data/slice.py:
--------------------------------------------------------------------------------
1 | import glob
2 | import os
3 | import pickle
4 |
5 | import librosa as lr
6 | import numpy as np
7 | import soundfile as sf
8 | from tqdm import tqdm
9 |
10 |
11 | def slice_audio(audio_file, stride, length, out_dir):
12 | # stride, length in seconds
13 | audio, sr = lr.load(audio_file, sr=None)
14 | file_name = os.path.splitext(os.path.basename(audio_file))[0]
15 | start_idx = 0
16 | idx = 0
17 | window = int(length * sr)
18 | stride_step = int(stride * sr)
19 | while start_idx <= len(audio) - window:
20 | audio_slice = audio[start_idx : start_idx + window]
21 | sf.write(f"{out_dir}/{file_name}_slice{idx}.wav", audio_slice, sr)
22 | start_idx += stride_step
23 | idx += 1
24 | return idx
25 |
26 |
27 | def slice_motion(motion_file, stride, length, num_slices, out_dir):
28 | motion = pickle.load(open(motion_file, "rb"))
29 | pos, q = motion["pos"], motion["q"]
30 | scale = motion["scale"][0]
31 | file_name = os.path.splitext(os.path.basename(motion_file))[0]
32 | # normalize root position
33 | pos /= scale
34 | start_idx = 0
35 | window = int(length * 60)
36 | stride_step = int(stride * 60)
37 | slice_count = 0
38 | # slice until done or until matching audio slices
39 | while start_idx <= len(pos) - window and slice_count < num_slices:
40 | pos_slice, q_slice = (
41 | pos[start_idx : start_idx + window],
42 | q[start_idx : start_idx + window],
43 | )
44 | out = {"pos": pos_slice, "q": q_slice}
45 | pickle.dump(out, open(f"{out_dir}/{file_name}_slice{slice_count}.pkl", "wb"))
46 | start_idx += stride_step
47 | slice_count += 1
48 | return slice_count
49 |
50 |
51 | def slice_aistpp(motion_dir, wav_dir, stride=0.5, length=5):
52 | wavs = sorted(glob.glob(f"{wav_dir}/*.wav"))
53 | motions = sorted(glob.glob(f"{motion_dir}/*.pkl"))
54 | wav_out = wav_dir + "_sliced_"+ str(stride)
55 | motion_out = motion_dir + "_sliced_" + str(stride)
56 | os.makedirs(wav_out, exist_ok=True)
57 | os.makedirs(motion_out, exist_ok=True)
58 | assert len(wavs) == len(motions)
59 | for wav, motion in tqdm(zip(wavs, motions)):
60 | # make sure name is matching
61 | m_name = os.path.splitext(os.path.basename(motion))[0]
62 | w_name = os.path.splitext(os.path.basename(wav))[0]
63 | assert m_name == w_name, str((motion, wav))
64 | audio_slices = slice_audio(wav, stride, length, wav_out) # 3
65 | motion_slices = slice_motion(motion, stride, length, audio_slices, motion_out)
66 | # make sure the slices line up
67 | assert audio_slices == motion_slices, str(
68 | (wav, motion, audio_slices, motion_slices)
69 | )
70 |
71 |
72 | def slice_audio_folder(wav_dir, stride=0.5, length=5):
73 | wavs = sorted(glob.glob(f"{wav_dir}/*.wav"))
74 | wav_out = wav_dir + "_sliced"
75 | os.makedirs(wav_out, exist_ok=True)
76 | for wav in tqdm(wavs):
77 | audio_slices = slice_audio(wav, stride, length, wav_out)
78 |
--------------------------------------------------------------------------------
/model/utils.py:
--------------------------------------------------------------------------------
1 | import math
2 |
3 | import numpy as np
4 | import torch
5 | from einops import rearrange, reduce, repeat
6 | from einops.layers.torch import Rearrange
7 | from torch import nn
8 |
9 |
10 | # absolute positional embedding used for vanilla transformer sequential data
11 | class PositionalEncoding(nn.Module):
12 | def __init__(self, d_model, dropout=0.1, max_len=500, batch_first=False):
13 | super().__init__()
14 | self.batch_first = batch_first
15 |
16 | self.dropout = nn.Dropout(p=dropout)
17 |
18 | pe = torch.zeros(max_len, d_model)
19 | position = torch.arange(0, max_len).unsqueeze(1)
20 | div_term = torch.exp(torch.arange(0, d_model, 2) * (-np.log(10000.0) / d_model))
21 | pe[:, 0::2] = torch.sin(position * div_term)
22 | pe[:, 1::2] = torch.cos(position * div_term)
23 | pe = pe.unsqueeze(0).transpose(0, 1)
24 |
25 | self.register_buffer("pe", pe)
26 |
27 | def forward(self, x):
28 | if self.batch_first:
29 | x = x + self.pe.permute(1, 0, 2)[:, : x.shape[1], :]
30 | else:
31 | x = x + self.pe[: x.shape[0], :]
32 | return self.dropout(x)
33 |
34 |
35 | # very similar positional embedding used for diffusion timesteps
36 | class SinusoidalPosEmb(nn.Module):
37 | def __init__(self, dim):
38 | super().__init__()
39 | self.dim = dim
40 |
41 | def forward(self, x):
42 | device = x.device
43 | half_dim = self.dim // 2
44 | emb = math.log(10000) / (half_dim - 1)
45 | emb = torch.exp(torch.arange(half_dim, device=device) * -emb)
46 | emb = x[:, None] * emb[None, :]
47 | emb = torch.cat((emb.sin(), emb.cos()), dim=-1)
48 | return emb
49 |
50 |
51 | # dropout mask
52 | def prob_mask_like(shape, prob, device):
53 | if prob == 1:
54 | return torch.ones(shape, device=device, dtype=torch.bool)
55 | elif prob == 0:
56 | return torch.zeros(shape, device=device, dtype=torch.bool)
57 | else:
58 | return torch.zeros(shape, device=device).float().uniform_(0, 1) < prob
59 |
60 |
61 | def extract(a, t, x_shape):
62 | b, *_ = t.shape
63 | out = a.gather(-1, t)
64 | return out.reshape(b, *((1,) * (len(x_shape) - 1)))
65 |
66 | def make_beta_schedule(
67 | schedule, n_timestep, linear_start=1e-4, linear_end=2e-2, cosine_s=8e-3
68 | ):
69 | if schedule == "linear":
70 | betas = (
71 | torch.linspace(
72 | linear_start ** 0.5, linear_end ** 0.5, n_timestep, dtype=torch.float64
73 | )
74 | ** 2
75 | )
76 |
77 | elif schedule == "cosine":
78 | timesteps = (
79 | torch.arange(n_timestep + 1, dtype=torch.float64) / n_timestep + cosine_s
80 | )
81 | alphas = timesteps / (1 + cosine_s) * np.pi / 2
82 | alphas = torch.cos(alphas).pow(2)
83 | alphas = alphas / alphas[0]
84 | betas = 1 - alphas[1:] / alphas[:-1]
85 | betas = np.clip(betas, a_min=0, a_max=0.999)
86 |
87 | elif schedule == "sqrt_linear":
88 | betas = torch.linspace(
89 | linear_start, linear_end, n_timestep, dtype=torch.float64
90 | )
91 | elif schedule == "sqrt":
92 | betas = (
93 | torch.linspace(linear_start, linear_end, n_timestep, dtype=torch.float64)
94 | ** 0.5
95 | )
96 | else:
97 | raise ValueError(f"schedule '{schedule}' unknown.")
98 | return betas.numpy()
99 |
--------------------------------------------------------------------------------
/data/audio_extraction/baseline_features.py:
--------------------------------------------------------------------------------
1 | import os
2 | from functools import partial
3 | from pathlib import Path
4 |
5 | import librosa
6 | import librosa as lr
7 | import numpy as np
8 | from tqdm import tqdm
9 |
10 | FPS = 30
11 | HOP_LENGTH = 512
12 | SR = FPS * HOP_LENGTH
13 | EPS = 1e-6
14 |
15 |
16 | def _get_tempo(audio_name):
17 | """Get tempo (BPM) for a music by parsing music name."""
18 |
19 |
20 | # a lot of stuff, only take the 5th element
21 | audio_name = audio_name.split("_")[4]
22 |
23 | assert len(audio_name) == 4
24 | if audio_name[0:3] in [
25 | "mBR",
26 | "mPO",
27 | "mLO",
28 | "mMH",
29 | "mLH",
30 | "mWA",
31 | "mKR",
32 | "mJS",
33 | "mJB",
34 | ]:
35 | return int(audio_name[3]) * 10 + 80
36 | elif audio_name[0:3] == "mHO":
37 | return int(audio_name[3]) * 5 + 110
38 | else:
39 | assert False, audio_name
40 |
41 |
42 | def extract(fpath, skip_completed=True, dest_dir="aist_baseline_feats"):
43 | os.makedirs(dest_dir, exist_ok=True)
44 | audio_name = Path(fpath).stem
45 | save_path = os.path.join(dest_dir, audio_name + ".npy")
46 |
47 | if os.path.exists(save_path) and skip_completed:
48 | return
49 |
50 | data, _ = librosa.load(fpath, sr=SR)
51 |
52 | envelope = librosa.onset.onset_strength(y=data, sr=SR)
53 | mfcc = librosa.feature.mfcc(y=data, sr=SR, n_mfcc=20).T
54 | chroma = librosa.feature.chroma_cens(
55 | y=data, sr=SR, hop_length=HOP_LENGTH, n_chroma=12
56 | ).T
57 |
58 | peak_idxs = librosa.onset.onset_detect(
59 | onset_envelope=envelope.flatten(), sr=SR, hop_length=HOP_LENGTH
60 | )
61 | peak_onehot = np.zeros_like(envelope, dtype=np.float32)
62 | peak_onehot[peak_idxs] = 1.0 # (seq_len,)
63 |
64 | try:
65 | start_bpm = _get_tempo(audio_name)
66 | except:
67 | # determine manually
68 | start_bpm = lr.beat.tempo(y=lr.load(fpath)[0])[0]
69 |
70 | tempo, beat_idxs = librosa.beat.beat_track(
71 | onset_envelope=envelope,
72 | sr=SR,
73 | hop_length=HOP_LENGTH,
74 | start_bpm=start_bpm,
75 | tightness=100,
76 | )
77 | beat_onehot = np.zeros_like(envelope, dtype=np.float32)
78 | beat_onehot[beat_idxs] = 1.0 # (seq_len,)
79 |
80 | audio_feature = np.concatenate(
81 | [envelope[:, None], mfcc, chroma, peak_onehot[:, None], beat_onehot[:, None]],
82 | axis=-1,
83 | ) # envelope:1, mfcc:20, chroma:12, peak_onehot:1, beat_onehot:1
84 |
85 | # chop to ensure exact shape
86 | audio_feature = audio_feature[:5 * FPS]
87 | assert (audio_feature.shape[0] - 5 * FPS) == 0, f"expected output to be ~5s, but was {audio_feature.shape[0] / FPS}"
88 |
89 | #np.save(save_path, audio_feature)
90 | return audio_feature, save_path
91 |
92 |
93 | def extract_folder(src, dest):
94 | fpaths = Path(src).glob("*")
95 | fpaths = sorted(list(fpaths))
96 | extract_ = partial(extract, skip_completed=False, dest_dir=dest)
97 | for fpath in tqdm(fpaths):
98 | rep, path = extract_(fpath)
99 | np.save(path, rep)
100 |
101 |
102 | if __name__ == "__main__":
103 | import argparse
104 |
105 | parser = argparse.ArgumentParser()
106 |
107 | parser.add_argument("--src", help="source path to AIST++ audio files")
108 | parser.add_argument("--dest", help="dest path to audio features")
109 |
110 | args = parser.parse_args()
111 |
112 | extract_folder(args.src, args.dest)
113 |
114 |
--------------------------------------------------------------------------------
/model/adan.py:
--------------------------------------------------------------------------------
1 | import math
2 |
3 | import torch
4 | from torch.optim import Optimizer
5 |
6 |
7 | def exists(val):
8 | return val is not None
9 |
10 |
11 | class Adan(Optimizer):
12 | def __init__(
13 | self,
14 | params,
15 | lr=1e-3,
16 | betas=(0.02, 0.08, 0.01),
17 | eps=1e-8,
18 | weight_decay=0,
19 | restart_cond: callable = None,
20 | ):
21 | assert len(betas) == 3
22 |
23 | defaults = dict(
24 | lr=lr,
25 | betas=betas,
26 | eps=eps,
27 | weight_decay=weight_decay,
28 | restart_cond=restart_cond,
29 | )
30 |
31 | super().__init__(params, defaults)
32 |
33 | def step(self, closure=None):
34 | loss = None
35 |
36 | if exists(closure):
37 | loss = closure()
38 |
39 | for group in self.param_groups:
40 |
41 | lr = group["lr"]
42 | beta1, beta2, beta3 = group["betas"]
43 | weight_decay = group["weight_decay"]
44 | eps = group["eps"]
45 | restart_cond = group["restart_cond"]
46 |
47 | for p in group["params"]:
48 | if not exists(p.grad):
49 | continue
50 |
51 | data, grad = p.data, p.grad.data
52 | assert not grad.is_sparse
53 |
54 | state = self.state[p]
55 |
56 | if len(state) == 0:
57 | state["step"] = 0
58 | state["prev_grad"] = torch.zeros_like(grad)
59 | state["m"] = torch.zeros_like(grad)
60 | state["v"] = torch.zeros_like(grad)
61 | state["n"] = torch.zeros_like(grad)
62 |
63 | step, m, v, n, prev_grad = (
64 | state["step"],
65 | state["m"],
66 | state["v"],
67 | state["n"],
68 | state["prev_grad"],
69 | )
70 |
71 | if step > 0:
72 | prev_grad = state["prev_grad"]
73 |
74 | # main algorithm
75 |
76 | m.mul_(1 - beta1).add_(grad, alpha=beta1)
77 |
78 | grad_diff = grad - prev_grad
79 |
80 | v.mul_(1 - beta2).add_(grad_diff, alpha=beta2)
81 |
82 | next_n = (grad + (1 - beta2) * grad_diff) ** 2
83 |
84 | n.mul_(1 - beta3).add_(next_n, alpha=beta3)
85 |
86 | # bias correction terms
87 |
88 | step += 1
89 |
90 | correct_m, correct_v, correct_n = map(
91 | lambda n: 1 / (1 - (1 - n) ** step), (beta1, beta2, beta3)
92 | )
93 |
94 | # gradient step
95 |
96 | def grad_step_(data, m, v, n):
97 | weighted_step_size = lr / (n * correct_n).sqrt().add_(eps)
98 |
99 | denom = 1 + weight_decay * lr
100 |
101 | data.addcmul_(
102 | weighted_step_size,
103 | (m * correct_m + (1 - beta2) * v * correct_v),
104 | value=-1.0,
105 | ).div_(denom)
106 |
107 | grad_step_(data, m, v, n)
108 |
109 | # restart condition
110 |
111 | if exists(restart_cond) and restart_cond(state):
112 | m.data.copy_(grad)
113 | v.zero_()
114 | n.data.copy_(grad ** 2)
115 |
116 | grad_step_(data, m, v, n)
117 |
118 | # set new incremented step
119 |
120 | prev_grad.copy_(grad)
121 | state["step"] = step
122 |
123 | return loss
124 |
125 |
126 |
--------------------------------------------------------------------------------
/args.py:
--------------------------------------------------------------------------------
1 | import argparse
2 |
3 |
4 | def parse_train_opt():
5 | parser = argparse.ArgumentParser()
6 | parser.add_argument("--project", default="runs/train", help="project/name")
7 | parser.add_argument("--exp_name", default="exp", help="save to project/name")
8 | parser.add_argument("--data_path", type=str, default="/data/zhuying/PAMD-main/data/", help="raw data path")
9 | parser.add_argument(
10 | "--processed_data_dir",
11 | type=str,
12 | default="data/dataset_backups/",
13 | help="Dataset backup path",
14 | )
15 | parser.add_argument(
16 | "--render_dir", type=str, default="renders/", help="Sample render path"
17 | )
18 |
19 | parser.add_argument("--feature_type", type=str, default="jukebox")
20 | parser.add_argument(
21 | "--wandb_pj_name", type=str, default="EDGE", help="project name"
22 | )
23 | parser.add_argument("--batch_size", type=int, default=64, help="batch size")
24 | parser.add_argument("--epochs", type=int, default=2000)
25 | parser.add_argument(
26 | "--force_reload", action="store_true", help="force reloads the datasets"
27 | )
28 | parser.add_argument(
29 | "--no_cache", action="store_true", help="don't reuse / cache loaded dataset"
30 | )
31 | parser.add_argument(
32 | "--save_interval",
33 | type=int,
34 | default=100,
35 | help='Log model after every "save_period" epoch',
36 | )
37 | parser.add_argument("--ema_interval", type=int, default=1, help="ema every x steps")
38 | parser.add_argument(
39 | "--checkpoint", type=str, default="", help="trained checkpoint path (optional)"
40 | )
41 | opt = parser.parse_args()
42 | return opt
43 |
44 |
45 | def parse_test_opt():
46 | parser = argparse.ArgumentParser()
47 | parser.add_argument("--data_path", type=str, default="/data/zhuying/PAMD-main/data/", help="raw data path")
48 | parser.add_argument(
49 | "--force_reload", action="store_true", help="force reloads the datasets"
50 | )
51 | parser.add_argument(
52 | "--edit_render_dir", type=str, default="renders_edit", help="Sample render path"
53 | )
54 | parser.add_argument("--feature_type", type=str, default="jukebox")
55 | parser.add_argument("--out_length", type=float, default=30, help="max. length of output, in seconds")
56 | parser.add_argument(
57 | "--processed_data_dir",
58 | type=str,
59 | default="data/dataset_backups/",
60 | help="Dataset backup path",
61 | )
62 | parser.add_argument(
63 | "--render_dir", type=str, default="renders/", help="Sample render path"
64 | )
65 | parser.add_argument(
66 | "--checkpoint", type=str, default="checkpoint.pt", help="checkpoint"
67 | )
68 | parser.add_argument(
69 | "--music_dir",
70 | type=str,
71 | default="data/test/wavs",
72 | help="folder containing input music",
73 | )
74 | parser.add_argument(
75 | "--save_motions", action="store_true", help="Saves the motions for evaluation"
76 | )
77 | parser.add_argument(
78 | "--motion_save_dir",
79 | type=str,
80 | default="eval/motions",
81 | help="Where to save the motions",
82 | )
83 | parser.add_argument(
84 | "--cache_features",
85 | action="store_true",
86 | help="Save the jukebox features for later reuse",
87 | )
88 | parser.add_argument(
89 | "--no_render",
90 | action="store_true",
91 | help="Don't render the video",
92 | )
93 | parser.add_argument(
94 | "--use_cached_features",
95 | action="store_true",
96 | help="Use precomputed features instead of music folder",
97 | )
98 | parser.add_argument(
99 | "--feature_cache_dir",
100 | type=str,
101 | default="cached_features/",
102 | help="Where to save/load the features",
103 | )
104 | opt = parser.parse_args()
105 | return opt
106 |
--------------------------------------------------------------------------------
/eval/beat_align_score.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import pickle
3 | from features.kinetic import extract_kinetic_features
4 | from features.manual_new import extract_manual_features
5 | from scipy import linalg
6 | import json
7 | # kinetic, manual
8 | import os
9 | from scipy.ndimage import gaussian_filter as G
10 | from scipy.signal import argrelextrema
11 | import glob
12 | import matplotlib.pyplot as plt
13 | import random
14 |
15 | from tqdm import tqdm
16 |
17 | music_root = './test_wavs_sliced/baseline_feats'
18 |
19 | def get_mb(key, length=None):
20 | path = os.path.join(music_root, key)
21 | with open(path) as f:
22 | # print(path)
23 | sample_dict = json.loads(f.read())
24 | if length is not None:
25 | beats = np.array(sample_dict['music_array'])[:, 53][:][:length]
26 | else:
27 | beats = np.array(sample_dict['music_array'])[:, 53]
28 |
29 | beats = beats.astype(bool)
30 | beat_axis = np.arange(len(beats))
31 | beat_axis = beat_axis[beats]
32 |
33 | # fig, ax = plt.subplots()
34 | # ax.set_xticks(beat_axis, minor=True)
35 | # # ax.set_xticks([0.3, 0.55, 0.7], minor=True)
36 | # ax.xaxis.grid(color='deeppink', linestyle='--', linewidth=1.5, which='minor')
37 | # ax.xaxis.grid(True, which='minor')
38 |
39 | # print(len(beats))
40 | return beat_axis
41 |
42 |
43 | def get_mb2(key, length=None):
44 | path = os.path.join(music_root, key)
45 | if length is not None:
46 | beats = np.load(path)[:, 34][:][:length]
47 | else:
48 | beats = np.load(path)[:, 34]
49 | beats = beats.astype(bool)
50 | beat_axis = np.arange(len(beats))
51 | beat_axis = beat_axis[beats]
52 |
53 | return beat_axis
54 |
55 |
56 | def calc_db(keypoints, name=''):
57 | keypoints = np.array(keypoints).reshape(-1, 24, 3)
58 | kinetic_vel = np.mean(np.sqrt(np.sum((keypoints[1:] - keypoints[:-1]) ** 2, axis=2)), axis=1)
59 | kinetic_vel = G(kinetic_vel, 5)
60 | motion_beats = argrelextrema(kinetic_vel, np.less)
61 | return motion_beats, len(kinetic_vel)
62 |
63 |
64 | def BA(music_beats, motion_beats):
65 | ba = 0
66 | for bb in music_beats:
67 | ba += np.exp(-np.min((motion_beats[0] - bb) ** 2) / 2 / 9)
68 | return (ba / len(music_beats))
69 |
70 |
71 | def calc_ba_score(root):
72 | ba_scores = []
73 |
74 | it = glob.glob(os.path.join(root, "*.pkl"))
75 | if len(it) > 1000:
76 | it = random.sample(it, 1000)
77 | for pkl in tqdm(it):
78 | print('pkl',pkl)
79 | info = pickle.load(open(pkl, "rb"))
80 | joint3d = info["full_pose"]
81 |
82 | joint3d = joint3d.reshape(-1,72)
83 |
84 | # for pkl in os.listdir(root):
85 | # # print(pkl)
86 | # if os.path.isdir(os.path.join(root, pkl)):
87 | # continue
88 | # joint3d = np.load(os.path.join(root, pkl), allow_pickle=True).item()['pred_position'][:,
89 | # :] # shape:(length+1,72)
90 |
91 | dance_beats, length = calc_db(joint3d, pkl)
92 | print('length',length)
93 | pkl= os.path.basename(pkl)
94 | pkl_split = pkl.split('.')[0].split('_')[1] + '_' + pkl.split('.')[0].split('_')[2] + '_' + \
95 | pkl.split('.')[0].split('_')[3] + '_' + pkl.split('.')[0].split('_')[4] + '_' + \
96 | pkl.split('.')[0].split('_')[5] + '_' + pkl.split('.')[0].split('_')[6]
97 | pkl_split2 = pkl.split('.')[0].split('_')[1]+'_'+pkl.split('.')[0].split('_')[2]+ '_'+\
98 | pkl.split('.')[0].split('_')[3]+'_'+pkl.split('.')[0].split('_')[4]+'_'+\
99 | pkl.split('.')[0].split('_')[5]+'_'+pkl.split('.')[0].split('_')[6]+'_' + \
100 | pkl.split('.')[0].split('_')[7]
101 | # music_beats = get_mb(pkl_split + '.json', length)
102 | music_beats = get_mb2(pkl_split +'/'+pkl_split2 +'.npy', length)
103 | ba_scores.append(BA(music_beats, dance_beats))
104 |
105 | return np.mean(ba_scores)
106 |
107 |
108 | if __name__ == '__main__':
109 | pred_root = 'eval/motions'
110 | print(calc_ba_score(pred_root))
111 |
--------------------------------------------------------------------------------
/model/rotary_embedding_torch.py:
--------------------------------------------------------------------------------
1 | from inspect import isfunction
2 | from math import log, pi
3 |
4 | import torch
5 | from einops import rearrange, repeat
6 | from torch import einsum, nn
7 |
8 | # helper functions
9 |
10 |
11 | def exists(val):
12 | return val is not None
13 |
14 |
15 | def broadcat(tensors, dim=-1):
16 | num_tensors = len(tensors)
17 | shape_lens = set(list(map(lambda t: len(t.shape), tensors)))
18 | assert len(shape_lens) == 1, "tensors must all have the same number of dimensions"
19 | shape_len = list(shape_lens)[0]
20 |
21 | dim = (dim + shape_len) if dim < 0 else dim
22 | dims = list(zip(*map(lambda t: list(t.shape), tensors)))
23 |
24 | expandable_dims = [(i, val) for i, val in enumerate(dims) if i != dim]
25 | assert all(
26 | [*map(lambda t: len(set(t[1])) <= 2, expandable_dims)]
27 | ), "invalid dimensions for broadcastable concatentation"
28 | max_dims = list(map(lambda t: (t[0], max(t[1])), expandable_dims))
29 | expanded_dims = list(map(lambda t: (t[0], (t[1],) * num_tensors), max_dims))
30 | expanded_dims.insert(dim, (dim, dims[dim]))
31 | expandable_shapes = list(zip(*map(lambda t: t[1], expanded_dims)))
32 | tensors = list(map(lambda t: t[0].expand(*t[1]), zip(tensors, expandable_shapes)))
33 | return torch.cat(tensors, dim=dim)
34 |
35 |
36 | # rotary embedding helper functions
37 |
38 |
39 | def rotate_half(x):
40 | x = rearrange(x, "... (d r) -> ... d r", r=2)
41 | x1, x2 = x.unbind(dim=-1)
42 | x = torch.stack((-x2, x1), dim=-1)
43 | return rearrange(x, "... d r -> ... (d r)")
44 |
45 |
46 | def apply_rotary_emb(freqs, t, start_index=0):
47 | freqs = freqs.to(t)
48 | rot_dim = freqs.shape[-1]
49 | end_index = start_index + rot_dim
50 | assert (
51 | rot_dim <= t.shape[-1]
52 | ), f"feature dimension {t.shape[-1]} is not of sufficient size to rotate in all the positions {rot_dim}"
53 | t_left, t, t_right = (
54 | t[..., :start_index],
55 | t[..., start_index:end_index],
56 | t[..., end_index:],
57 | )
58 | t = (t * freqs.cos()) + (rotate_half(t) * freqs.sin())
59 | return torch.cat((t_left, t, t_right), dim=-1)
60 |
61 |
62 | # learned rotation helpers
63 |
64 |
65 | def apply_learned_rotations(rotations, t, start_index=0, freq_ranges=None):
66 | if exists(freq_ranges):
67 | rotations = einsum("..., f -> ... f", rotations, freq_ranges)
68 | rotations = rearrange(rotations, "... r f -> ... (r f)")
69 |
70 | rotations = repeat(rotations, "... n -> ... (n r)", r=2)
71 | return apply_rotary_emb(rotations, t, start_index=start_index)
72 |
73 |
74 | # classes
75 |
76 |
77 | class RotaryEmbedding(nn.Module):
78 | def __init__(
79 | self,
80 | dim,
81 | custom_freqs=None,
82 | freqs_for="lang",
83 | theta=10000,
84 | max_freq=10,
85 | num_freqs=1,
86 | learned_freq=False,
87 | ):
88 | super().__init__()
89 | if exists(custom_freqs):
90 | freqs = custom_freqs
91 | elif freqs_for == "lang":
92 | freqs = 1.0 / (
93 | theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim)
94 | )
95 | elif freqs_for == "pixel":
96 | freqs = torch.linspace(1.0, max_freq / 2, dim // 2) * pi
97 | elif freqs_for == "constant":
98 | freqs = torch.ones(num_freqs).float()
99 | else:
100 | raise ValueError(f"unknown modality {freqs_for}")
101 |
102 | self.cache = dict()
103 |
104 | if learned_freq:
105 | self.freqs = nn.Parameter(freqs)
106 | else:
107 | self.register_buffer("freqs", freqs)
108 |
109 | def rotate_queries_or_keys(self, t, seq_dim=-2):
110 | device = t.device
111 | seq_len = t.shape[seq_dim]
112 | freqs = self.forward(
113 | lambda: torch.arange(seq_len, device=device), cache_key=seq_len
114 | )
115 | return apply_rotary_emb(freqs, t)
116 |
117 | def forward(self, t, cache_key=None):
118 | if exists(cache_key) and cache_key in self.cache:
119 | return self.cache[cache_key]
120 |
121 | if isfunction(t):
122 | t = t()
123 |
124 | freqs = self.freqs
125 |
126 | freqs = torch.einsum("..., f -> ... f", t.type(freqs.dtype), freqs)
127 | freqs = repeat(freqs, "... n -> ... (n r)", r=2)
128 |
129 | if exists(cache_key):
130 | self.cache[cache_key] = freqs
131 |
132 | return freqs
133 |
--------------------------------------------------------------------------------
/eval/features/kinetic.py:
--------------------------------------------------------------------------------
1 | # BSD License
2 |
3 | # For fairmotion software
4 |
5 | # Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
6 | # Modified by Ruilong Li
7 |
8 | # Redistribution and use in source and binary forms, with or without modification,
9 | # are permitted provided that the following conditions are met:
10 |
11 | # * Redistributions of source code must retain the above copyright notice, this
12 | # list of conditions and the following disclaimer.
13 |
14 | # * Redistributions in binary form must reproduce the above copyright notice,
15 | # this list of conditions and the following disclaimer in the documentation
16 | # and/or other materials provided with the distribution.
17 |
18 | # * Neither the name Facebook nor the names of its contributors may be used to
19 | # endorse or promote products derived from this software without specific
20 | # prior written permission.
21 |
22 | # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
23 | # ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
24 | # WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
25 | # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR
26 | # ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
27 | # (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
28 | # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON
29 | # ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
30 | # (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
31 | # SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
32 | import numpy as np
33 | from . import utils as feat_utils
34 |
35 |
36 | def extract_kinetic_features(positions):
37 | assert len(positions.shape) == 3 # (seq_len, n_joints, 3)
38 | features = KineticFeatures(positions)
39 | kinetic_feature_vector = []
40 | for i in range(positions.shape[1]):
41 | feature_vector = np.hstack(
42 | [
43 | features.average_kinetic_energy_horizontal(i),
44 | features.average_kinetic_energy_vertical(i),
45 | features.average_energy_expenditure(i),
46 | ]
47 | )
48 | kinetic_feature_vector.extend(feature_vector)
49 | kinetic_feature_vector = np.array(kinetic_feature_vector, dtype=np.float32)
50 | return kinetic_feature_vector
51 |
52 |
53 | class KineticFeatures:
54 | def __init__(
55 | self, positions, frame_time=1./60, up_vec="y", sliding_window=2
56 | ):
57 | self.positions = positions
58 | self.frame_time = frame_time
59 | self.up_vec = up_vec
60 | self.sliding_window = sliding_window
61 |
62 | def average_kinetic_energy(self, joint):
63 | average_kinetic_energy = 0
64 | for i in range(1, len(self.positions)):
65 | average_velocity = feat_utils.calc_average_velocity(
66 | self.positions, i, joint, self.sliding_window, self.frame_time
67 | )
68 | average_kinetic_energy += average_velocity ** 2
69 | average_kinetic_energy = average_kinetic_energy / (
70 | len(self.positions) - 1.0
71 | )
72 | return average_kinetic_energy
73 |
74 | def average_kinetic_energy_horizontal(self, joint):
75 | val = 0
76 | for i in range(1, len(self.positions)):
77 | average_velocity = feat_utils.calc_average_velocity_horizontal(
78 | self.positions,
79 | i,
80 | joint,
81 | self.sliding_window,
82 | self.frame_time,
83 | self.up_vec,
84 | )
85 | val += average_velocity ** 2
86 | val = val / (len(self.positions) - 1.0)
87 | return val
88 |
89 | def average_kinetic_energy_vertical(self, joint):
90 | val = 0
91 | for i in range(1, len(self.positions)):
92 | average_velocity = feat_utils.calc_average_velocity_vertical(
93 | self.positions,
94 | i,
95 | joint,
96 | self.sliding_window,
97 | self.frame_time,
98 | self.up_vec,
99 | )
100 | val += average_velocity ** 2
101 | val = val / (len(self.positions) - 1.0)
102 | return val
103 |
104 | def average_energy_expenditure(self, joint):
105 | val = 0.0
106 | for i in range(1, len(self.positions)):
107 | val += feat_utils.calc_average_acceleration(
108 | self.positions, i, joint, self.sliding_window, self.frame_time
109 | )
110 | val = val / (len(self.positions) - 1.0)
111 | return val
112 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | ## Controllable Dance Generation with Style-Guided Motion Diffusion
2 | **[Controllable Dance Generation with Style-Guided Motion Diffusion](https://arxiv.org/abs/2406.07871)**, [Arxiv](https://arxiv.org/abs/2406.07871)
3 | **[Flexible Music-Conditioned Dance Generation with Style Description Prompts](https://arxiv.org/abs/2406.07871v1)**
4 |
5 | ### Demo Videos of Dance Generation
6 |
7 |
15 |
16 | **Demo Videos of Dance Generation: (a) Dance Generation; (b) Long Dance Generation**
17 |
18 | *Abstract: Dance plays an important role as an artistic form and expression in human culture, yet the creation of dance remains a challenging task. Most dance generation methods primarily rely solely on music, seldom taking into consideration intrinsic attributes such as music style or genre. In this work, we introduce Flexible Dance Generation with Style Description Prompts (DGSDP), a diffusion-based framework for suitable for diversified tasks of dance generation by fully leveraging the semantics of music style. The core component of this framework is Music-Conditioned Style-Aware Diffusion (MCSAD), which comprises a Transformer-based network and a music Style Modulation module. The MCSAD seemly integrates music conditions and style description prompts into the dance generation framework, ensuring that generated dances are consistent with the music content and style. To facilitate flexible dance generation and accommodate different tasks, a spatial-temporal masking strategy is effectively applied in the backward diffusion process. The proposed framework successfully generates realistic dance sequences that are accurately aligned with music for a variety of tasks such as long-term generation, dance in-betweening, dance inpainting, and etc. We hope that this work has the potential to inspire dance generation and creation, with promising applications in entertainment, art, and education.*
19 |
20 | 
21 |
22 |
23 | ## Requirements
24 | * We follow the environment configuration of [EDGE](https://github.com/Stanford-TML/EDGE)
25 |
26 | ## Chekpoint
27 | * Download the saved model checkpoint from [Google Drive](https://drive.google.com/file/d/1qYEY45m3paDEXfBqpBWGCYaqvZS-Z60k/view?usp=drive_link).
28 |
29 | ## Dataset Download
30 | Download and process the AIST++ dataset (wavs and motion only) using:
31 | ```.bash
32 | cd data
33 | bash download_dataset.sh
34 | python create_dataset.py --extract-baseline --extract-jukebox
35 | ```
36 | This will process the dataset to match the settings used in the paper. The data processing will take ~24 hrs and ~50 GB to precompute all the Jukebox features for the dataset.
37 |
38 | ## Training
39 | Run model/style_CLIP.py to generate semantic features.
40 | ```.bash
41 | cd model
42 | python style_CLIP.py
43 | ```
44 | Then, run the training script, e.g.
45 | ```.bash
46 | cd ../
47 | accelerate launch train.py --batch_size 128 --epochs 2000 --feature_type jukebox --learning_rate 0.0002
48 | ```
49 | to train the model with the settings from the paper. The training will log progress to `wandb` and intermittently produce sample outputs to visualize learning.
50 |
51 | ## Testing and Evaluation
52 | Download the long music from [Google Drive](https://drive.google.com/file/d/1d2sqwQfW3f4XcNyYx3oWXdDQphrhfokj/view?usp=drive_link).
53 |
54 | Evaluate your model's outputs with the Beat Align Score, PFC, FID, Diversity score proposed in the paper:
55 | 1. Generate ~1k samples, saving the joint positions with the `--save_motions` argument
56 | 2. Run the evaluation script
57 | ```.bash
58 | python test.py --music_dir custom_music/ --save_motions
59 | python eval/beat_align_score.py
60 | python eval/eval_pfc.py
61 | python eval/metrics_diveristy.py
62 | ```
63 |
64 | ## Citation
65 | ```
66 | @misc{wang2025controllabledancegenerationstyleguided,
67 | title={Controllable Dance Generation with Style-Guided Motion Diffusion},
68 | author={Hongsong Wang and Ying Zhu and Xin Geng and Liang Wang},
69 | year={2025},
70 | eprint={2406.07871},
71 | archivePrefix={arXiv},
72 | primaryClass={cs.CV},
73 | url={https://arxiv.org/abs/2406.07871},
74 | }
75 |
76 | @article{wang2024flexible,
77 | title={Flexible Music-Conditioned Dance Generation with Style Description Prompts},
78 | author={Wang, Hongsong and Zhu, Yin and Geng, Xin},
79 | journal={arXiv preprint arXiv:2406.07871},
80 | year={2024}
81 | }
82 | ```
83 |
--------------------------------------------------------------------------------
/model/style_CLIP.py:
--------------------------------------------------------------------------------
1 | # from transformers import BertTokenizer, BertModel
2 | import os
3 | import pickle
4 | from pathlib import Path
5 |
6 | from transformers import AutoModel,AutoTokenizer
7 | import torch
8 |
9 | import clip
10 | import random
11 |
12 | device = "cuda" if torch.cuda.is_available() else "cpu"
13 |
14 | clip_model, clip_preprocess = clip.load("ViT-B/32", device=device, jit=False) # Must set jit=False for training
15 | clip_model.eval()
16 | for p in clip_model.parameters():
17 | p.requires_grad = False
18 |
19 |
20 |
21 | # 输入文本
22 | text=[]
23 | text.append("Breakdance, also known as B-boying or breaking, is an energetic and acrobatic style of dance that originated in the streets of New York City. It combines intricate footwork, power moves, freezes, and energetic spins on the floor. Breakdancers showcase their strength, agility, and creativity through explosive movements and impressive stunts. This dynamic dance style has become a global phenomenon, inspiring dancers worldwide to push their physical limits and express themselves through the art of breaking.")
24 | text.append("House dance is a vibrant and soulful style that originated in the underground clubs of Chicago and New York City. It combines elements of disco, funk, and hip-hop, creating a unique fusion of footwork, fluid movements, and intricate rhythms. House dancers often freestyle to electronic music, allowing their bodies to flow with the infectious beats. With its emphasis on individual expression and improvisation, house dance embodies the spirit of freedom and community within the dance culture.")
25 | text.append("Jazz ballet, also known as contemporary jazz, is a fusion of classical ballet technique and the expressive nature of jazz dance. It combines the grace and precision of ballet with the rhythmic and syncopated movements of jazz. Jazz ballet dancers exhibit a strong sense of musicality, emphasizing body isolations, turns, jumps, and extensions. This versatile dance style allows for both structured choreography and personal interpretation, making it a popular choice for dancers seeking a balance between technique and creative expression.")
26 | text.append("Street Jazz is a dance form that combines elements of street dance and jazz dance. It embodies the characteristics of street culture and urban vibes, emphasizing freedom, individuality, and a sense of rhythm. The dance steps of Street Jazz include fluid body movements, sharp footwork, and dynamic spins. Dancers express themselves freely on stage, showcasing their personality and sense of style through dance. Street Jazz is suitable for individuals who enjoy dancing, have a passion for street culture, and seek to express their individuality.")
27 | text.append("Krump is an expressive and aggressive street dance style that originated in the neighborhoods of Los Angeles. It is characterized by its intense and energetic movements, including chest pops, stomps, arm swings, and exaggerated facial expressions. Krump dancers use their bodies as a form of personal expression, channeling their emotions and energy into powerful and raw performances. This urban dance form serves as an outlet for self-expression and has evolved into a community-driven movement promoting positivity and self-empowerment.")
28 | text.append("Los Angeles-style hip-hop dance, also known as LA-style, is a fusion of various street dance styles that emerged from the urban communities of Los Angeles. It combines elements of popping, locking, breaking, and freestyle, creating a dynamic and diverse dance form. LA-style dancers showcase their unique styles and personalities through intricate body isolations, fluid movements, and sharp hits. This dance style embodies the vibrant and eclectic culture of Los Angeles and has influenced the global hip-hop dance scene.")
29 | text.append("Locking is a funk-based dance style that originated in the 1970s. It is characterized by its distinctive moves known as locks, which involve freezing in certain positions and then quickly transitioning to the next. Locking combines funky footwork, energetic arm gestures, and exaggerated body movements, creating a playful and entertaining dance form. Lockers often incorporate humor and showmanship into their performances, making it a popular style for entertainment purposes.")
30 | text.append("Middle Hip-Hop is a dance form that combines various elements of street dance, including popping and locking, with the rhythms and beats of hip-hop music. It requires a great deal of rhythm, coordination, and control. Middle Hip-Hop features energetic and dynamic movements, such as intricate footwork, isolations, and body waves. Dancers express themselves through their movements, delivering a powerful and engaging performance that captivates audiences. Middle Hip-Hop provides a great way for individuals to enhance their overall fitness, build confidence, and express their creativity.")
31 | text.append("Popular dance encompasses a wide range of contemporary dance styles that are widely enjoyed and accessible to the general public. It includes various genres such as commercial dance, music video choreography, and social dances like line dancing or party dances. Popular dancers often adapt and fuse different dance styles, creating visually appealing routines that resonate with a broad audience. This dance category reflects the ever-evolving trends and influences in popular culture.")
32 | text.append("Waacking, also known as punking or whacking, is a dance style that originated in the LGBTQ+ clubs of 1970s Los Angeles. It is characterized by its fluid arm movements, dramatic poses, and expressive storytelling through dance. Waacking requires precision, musicality, and personality to convey emotions and narratives. Dancers often use props like fans or scarves to enhance their performances. This dance form celebrates individuality, self-expression, and the liberation of one's true self.")
33 |
34 | style=[]
35 | style.append("mBR")
36 | style.append("mHO")
37 | style.append("mJB")
38 | style.append("mJS")
39 | style.append("mKR")
40 | style.append("mLH")
41 | style.append("mLO")
42 | style.append("mMH")
43 | style.append("mPO")
44 | style.append("mWA")
45 |
46 | features ={}
47 |
48 | for i in range(len(text)):
49 | t = clip.tokenize([text[i]], truncate=True).cuda()
50 | feature = clip_model.encode_text(t).cpu().float().reshape(-1)
51 |
52 | # print(features)
53 | print(feature.shape) # (1,768)
54 | features.update({style[i]:feature})
55 |
56 | save_path = "../data/style_clip"
57 | Path(save_path).mkdir(parents=True, exist_ok=True)
58 | outname = style[i] +'.pkl'
59 | pickle.dump(
60 | {
61 | style[i]:feature
62 | },
63 | open(os.path.join(save_path, outname), "wb"),
64 | )
65 |
66 |
67 |
68 | style_features = []
69 | for i in range(len(style)):
70 | path = '../data/style_clip/' + style[i] + '.pkl'
71 | with open(path, 'rb') as f:
72 | data = pickle.load(f)
73 | print(data[style[i]].shape)
74 | style_features.append(data[style[i]])
75 |
--------------------------------------------------------------------------------
/test.py:
--------------------------------------------------------------------------------
1 | import glob
2 | import os
3 | import pickle
4 | from functools import cmp_to_key
5 | from pathlib import Path
6 | from tempfile import TemporaryDirectory
7 | import random
8 |
9 | import jukemirlib
10 | import numpy as np
11 | import torch
12 | from tqdm import tqdm
13 |
14 | from args import parse_test_opt
15 | from data.slice import slice_audio
16 | from DGSDP import DGSDP
17 | from data.audio_extraction.baseline_features import extract as baseline_extract
18 | from data.audio_extraction.jukebox_features import extract as juke_extract
19 |
20 | # sort filenames that look like songname_slice{number}.ext
21 | key_func = lambda x: int(os.path.splitext(x)[0].split("_")[-1].split("slice")[-1])
22 |
23 | random.seed(123)
24 |
25 | def stringintcmp_(a, b):
26 | aa, bb = "".join(a.split("_")[:-1]), "".join(b.split("_")[:-1])
27 | ka, kb = key_func(a), key_func(b)
28 | if aa < bb:
29 | return -1
30 | if aa > bb:
31 | return 1
32 | if ka < kb:
33 | return -1
34 | if ka > kb:
35 | return 1
36 | return 0
37 |
38 |
39 | stringintkey = cmp_to_key(stringintcmp_)
40 |
41 |
42 | def test(opt):
43 | # feature_func = juke_extract if opt.feature_type == "jukebox" else baseline_extract
44 | if opt.feature_type == "jukebox":
45 | feature_func = juke_extract
46 | elif opt.feature_type == "baseline":
47 | feature_func = baseline_extract
48 |
49 | sample_length = opt.out_length
50 | sample_length = 5
51 | sample_size = int(sample_length / 2.5) - 1 # 11
52 |
53 | temp_dir_list = []
54 | all_cond = []
55 | all_filenames = []
56 | if opt.use_cached_features:
57 | print("Using precomputed features")
58 | # all subdirectories
59 | dir_list = glob.glob(os.path.join(opt.feature_cache_dir, "*/"))
60 | for dir in dir_list:
61 | file_list = sorted(glob.glob(f"{dir}/*.wav"), key=stringintkey)
62 | juke_file_list = sorted(glob.glob(f"{dir}/*.npy"), key=stringintkey)
63 | # print('dir',dir)
64 | # print('len(file_list)',len(file_list))
65 | # print('len(juke_file_list)',len(juke_file_list))
66 | assert len(file_list) == len(juke_file_list)
67 | # random chunk after sanity check
68 | rand_idx = random.randint(0, len(file_list) - sample_size)
69 | file_list = file_list[rand_idx : rand_idx + sample_size]
70 | juke_file_list = juke_file_list[rand_idx : rand_idx + sample_size]
71 | cond_list = [np.load(x) for x in juke_file_list]
72 | all_filenames.append(file_list)
73 | all_cond.append(torch.from_numpy(np.array(cond_list)))
74 | else:
75 | print("Computing features for input music")
76 | for wav_file in glob.glob(os.path.join(opt.music_dir, "*.wav")):
77 | # create temp folder (or use the cache folder if specified)
78 | if opt.cache_features:
79 | songname = os.path.splitext(os.path.basename(wav_file))[0]
80 | save_dir = os.path.join(opt.feature_cache_dir, songname)
81 | Path(save_dir).mkdir(parents=True, exist_ok=True)
82 | dirname = save_dir
83 | else:
84 | temp_dir = TemporaryDirectory()
85 | temp_dir_list.append(temp_dir)
86 | dirname = temp_dir.name
87 | # slice the audio file
88 | print(f"Slicing {wav_file}")
89 | slice_audio(wav_file, 2.5, 5.0, dirname)
90 | file_list = sorted(glob.glob(f"{dirname}/*.wav"), key=stringintkey)
91 | # randomly sample a chunk of length at most sample_size
92 | rand_idx = random.randint(0, len(file_list) - sample_size)
93 | cond_list = []
94 | # generate juke representations
95 | print(f"Computing features for {wav_file}")
96 | for idx, file in enumerate(tqdm(file_list)):
97 | # if not caching then only calculate for the interested range
98 | if (not opt.cache_features) and (not (rand_idx <= idx < rand_idx + sample_size)):
99 | continue
100 | # audio = jukemirlib.load_audio(file)
101 | # reps = jukemirlib.extract(
102 | # audio, layers=[66], downsample_target_rate=30
103 | # )[66]
104 | reps, _ = feature_func(file)
105 | # save reps
106 | if opt.cache_features:
107 | featurename = os.path.splitext(file)[0] + ".npy"
108 | np.save(featurename, reps)
109 | # if in the random range, put it into the list of reps we want
110 | # to actually use for generation
111 | if rand_idx <= idx < rand_idx + sample_size:
112 | cond_list.append(reps)
113 | cond_list = torch.from_numpy(np.array(cond_list))
114 | all_cond.append(cond_list)
115 | all_filenames.append(file_list[rand_idx : rand_idx + sample_size])
116 |
117 | print("len(all_cond)",len(all_cond))
118 |
119 | model = DGSDP(opt.feature_type, opt.checkpoint)
120 | model.eval()
121 |
122 | # directory for optionally saving the dances for eval
123 | fk_out = None
124 | if opt.save_motions:
125 | fk_out = opt.motion_save_dir
126 |
127 | print("Generating dances")
128 | for i in range(len(all_cond)):
129 | styles = []
130 | for j in range(len(all_filenames[i])):
131 | wav = os.path.basename(all_filenames[i][j])
132 | style = wav.split('_')[4]
133 | style = style[:-1]
134 | styles.append(style)
135 |
136 | style_features = []
137 | for j in range(len(styles)):
138 | path = './data/style_clip/' + styles[j] + '.pkl'
139 | with open(path, 'rb') as f:
140 | data = pickle.load(f)
141 | style_features.append(data[styles[j]])
142 |
143 | style_features = torch.tensor([item.cpu().detach().numpy() for item in style_features]).cuda()
144 | batchsize, original_dim = style_features.size()
145 | style_tensor = style_features.unsqueeze(1).expand(batchsize, 150, original_dim)
146 | print("style_tensor.shape",style_tensor.shape)
147 | style_tensor = style_tensor.detach().cpu()
148 | # style_tensor = style_tensor.to(self.accelerator.device)
149 | all_cond[i] = torch.cat((all_cond[i], style_tensor), dim=-1)
150 |
151 | data_tuple = None, all_cond[i], all_filenames[i]
152 | model.render_sample(
153 | data_tuple, "test", opt.render_dir, render_count=-1, fk_out=fk_out, render=not opt.no_render # render = True
154 | )
155 | print("Done")
156 | torch.cuda.empty_cache()
157 | for temp_dir in temp_dir_list:
158 | temp_dir.cleanup()
159 |
160 |
161 | if __name__ == "__main__":
162 | opt = parse_test_opt()
163 | # opt.use_cached_features = True
164 | # opt.feature_cache_dir = "cached_features"
165 | # opt.save_motions = True
166 | # opt.motion_save_dir = "SMPL-to-FBX/motions"
167 | test(opt)
168 |
169 | # opt = parse_test_opt()
170 | # motion_save_dir = opt.motion_save_dir
171 | # for i in range(100):
172 | # opt.motion_save_dir = motion_save_dir + '_' +str(i)
173 | # test(opt)
174 |
175 |
176 |
--------------------------------------------------------------------------------
/eval/features/utils.py:
--------------------------------------------------------------------------------
1 | # BSD License
2 |
3 | # For fairmotion software
4 |
5 | # Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
6 |
7 | # Redistribution and use in source and binary forms, with or without modification,
8 | # are permitted provided that the following conditions are met:
9 |
10 | # * Redistributions of source code must retain the above copyright notice, this
11 | # list of conditions and the following disclaimer.
12 |
13 | # * Redistributions in binary form must reproduce the above copyright notice,
14 | # this list of conditions and the following disclaimer in the documentation
15 | # and/or other materials provided with the distribution.
16 |
17 | # * Neither the name Facebook nor the names of its contributors may be used to
18 | # endorse or promote products derived from this software without specific
19 | # prior written permission.
20 |
21 | # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
22 | # ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
23 | # WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 | # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR
25 | # ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
26 | # (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
27 | # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON
28 | # ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
29 | # (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
30 | # SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
31 | import numpy as np
32 |
33 |
34 | def distance_between_points(a, b):
35 | return np.linalg.norm(np.array(a) - np.array(b))
36 |
37 |
38 | def distance_from_plane(a, b, c, p, threshold):
39 | ba = np.array(b) - np.array(a)
40 | ca = np.array(c) - np.array(a)
41 | cross = np.cross(ca, ba)
42 |
43 | pa = np.array(p) - np.array(a)
44 | return np.dot(cross, pa) / np.linalg.norm(cross) > threshold
45 |
46 |
47 | def distance_from_plane_normal(n1, n2, a, p, threshold):
48 | normal = np.array(n2) - np.array(n1)
49 | pa = np.array(p) - np.array(a)
50 | return np.dot(normal, pa) / np.linalg.norm(normal) > threshold
51 |
52 |
53 | def angle_within_range(j1, j2, k1, k2, range):
54 | j = np.array(j2) - np.array(j1)
55 | k = np.array(k2) - np.array(k1)
56 |
57 | angle = np.arccos(np.dot(j, k) / (np.linalg.norm(j) * np.linalg.norm(k)))
58 | angle = np.degrees(angle)
59 |
60 | if angle > range[0] and angle < range[1]:
61 | return True
62 | else:
63 | return False
64 |
65 |
66 | def velocity_direction_above_threshold(
67 | j1, j1_prev, j2, j2_prev, p, p_prev, threshold, time_per_frame=1 / 120.0
68 | ):
69 | velocity = (
70 | np.array(p) - np.array(j1) - (np.array(p_prev) - np.array(j1_prev))
71 | )
72 | direction = np.array(j2) - np.array(j1)
73 |
74 | velocity_along_direction = np.dot(velocity, direction) / np.linalg.norm(
75 | direction
76 | )
77 | velocity_along_direction = velocity_along_direction / time_per_frame
78 | return velocity_along_direction > threshold
79 |
80 |
81 | def velocity_direction_above_threshold_normal(
82 | j1, j1_prev, j2, j3, p, p_prev, threshold, time_per_frame=1 / 120.0
83 | ):
84 | velocity = (
85 | np.array(p) - np.array(j1) - (np.array(p_prev) - np.array(j1_prev))
86 | )
87 | j31 = np.array(j3) - np.array(j1)
88 | j21 = np.array(j2) - np.array(j1)
89 | direction = np.cross(j31, j21)
90 |
91 | velocity_along_direction = np.dot(velocity, direction) / np.linalg.norm(
92 | direction
93 | )
94 | velocity_along_direction = velocity_along_direction / time_per_frame
95 | return velocity_along_direction > threshold
96 |
97 |
98 | def velocity_above_threshold(p, p_prev, threshold, time_per_frame=1 / 120.0):
99 | velocity = np.linalg.norm(np.array(p) - np.array(p_prev)) / time_per_frame
100 | return velocity > threshold
101 |
102 |
103 | def calc_average_velocity(positions, i, joint_idx, sliding_window, frame_time):
104 | current_window = 0
105 | average_velocity = np.zeros(len(positions[0][joint_idx]))
106 | for j in range(-sliding_window, sliding_window + 1):
107 | if i + j - 1 < 0 or i + j >= len(positions):
108 | continue
109 | average_velocity += (
110 | positions[i + j][joint_idx] - positions[i + j - 1][joint_idx]
111 | )
112 | current_window += 1
113 | return np.linalg.norm(average_velocity / (current_window * frame_time))
114 |
115 |
116 | def calc_average_acceleration(
117 | positions, i, joint_idx, sliding_window, frame_time
118 | ):
119 | current_window = 0
120 | average_acceleration = np.zeros(len(positions[0][joint_idx]))
121 | for j in range(-sliding_window, sliding_window + 1):
122 | if i + j - 1 < 0 or i + j + 1 >= len(positions):
123 | continue
124 | v2 = (
125 | positions[i + j + 1][joint_idx] - positions[i + j][joint_idx]
126 | ) / frame_time
127 | v1 = (
128 | positions[i + j][joint_idx]
129 | - positions[i + j - 1][joint_idx] / frame_time
130 | )
131 | average_acceleration += (v2 - v1) / frame_time
132 | current_window += 1
133 | return np.linalg.norm(average_acceleration / current_window)
134 |
135 |
136 | def calc_average_velocity_horizontal(
137 | positions, i, joint_idx, sliding_window, frame_time, up_vec="z"
138 | ):
139 | current_window = 0
140 | average_velocity = np.zeros(len(positions[0][joint_idx]))
141 | for j in range(-sliding_window, sliding_window + 1):
142 | if i + j - 1 < 0 or i + j >= len(positions):
143 | continue
144 | average_velocity += (
145 | positions[i + j][joint_idx] - positions[i + j - 1][joint_idx]
146 | )
147 | current_window += 1
148 | if up_vec == "y":
149 | average_velocity = np.array(
150 | [average_velocity[0], average_velocity[2]]
151 | ) / (current_window * frame_time)
152 | elif up_vec == "z":
153 | average_velocity = np.array(
154 | [average_velocity[0], average_velocity[1]]
155 | ) / (current_window * frame_time)
156 | else:
157 | raise NotImplementedError
158 | return np.linalg.norm(average_velocity)
159 |
160 |
161 | def calc_average_velocity_vertical(
162 | positions, i, joint_idx, sliding_window, frame_time, up_vec
163 | ):
164 | current_window = 0
165 | average_velocity = np.zeros(len(positions[0][joint_idx]))
166 | for j in range(-sliding_window, sliding_window + 1):
167 | if i + j - 1 < 0 or i + j >= len(positions):
168 | continue
169 | average_velocity += (
170 | positions[i + j][joint_idx] - positions[i + j - 1][joint_idx]
171 | )
172 | current_window += 1
173 | if up_vec == "y":
174 | average_velocity = np.array([average_velocity[1]]) / (
175 | current_window * frame_time
176 | )
177 | elif up_vec == "z":
178 | average_velocity = np.array([average_velocity[2]]) / (
179 | current_window * frame_time
180 | )
181 | else:
182 | raise NotImplementedError
183 | return np.linalg.norm(average_velocity)
--------------------------------------------------------------------------------
/eval/features/manual_new.py:
--------------------------------------------------------------------------------
1 | # BSD License
2 |
3 | # For fairmotion software
4 |
5 | # Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
6 | # Modified by Ruilong Li
7 |
8 | # Redistribution and use in source and binary forms, with or without modification,
9 | # are permitted provided that the following conditions are met:
10 |
11 | # * Redistributions of source code must retain the above copyright notice, this
12 | # list of conditions and the following disclaimer.
13 |
14 | # * Redistributions in binary form must reproduce the above copyright notice,
15 | # this list of conditions and the following disclaimer in the documentation
16 | # and/or other materials provided with the distribution.
17 |
18 | # * Neither the name Facebook nor the names of its contributors may be used to
19 | # endorse or promote products derived from this software without specific
20 | # prior written permission.
21 |
22 | # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
23 | # ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
24 | # WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
25 | # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR
26 | # ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
27 | # (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
28 | # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON
29 | # ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
30 | # (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
31 | # SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
32 | import numpy as np
33 | from . import utils as feat_utils
34 |
35 |
36 | SMPL_JOINT_NAMES = [
37 | "root",
38 | "lhip", "rhip", "belly",
39 | "lknee", "rknee", "spine",
40 | "lankle", "rankle", "chest",
41 | "ltoes", "rtoes", "neck",
42 | "linshoulder", "rinshoulder",
43 | "head", "lshoulder", "rshoulder",
44 | "lelbow", "relbow",
45 | "lwrist", "rwrist",
46 | "lhand", "rhand",
47 | ]
48 |
49 |
50 | def extract_manual_features(positions):
51 | assert len(positions.shape) == 3 # (seq_len, n_joints, 3)
52 | features = []
53 | f = ManualFeatures(positions)
54 | for _ in range(1, positions.shape[0]):
55 | pose_features = []
56 | pose_features.append(
57 | f.f_nmove("neck", "rhip", "lhip", "rwrist", 1.8 * f.hl)
58 | )
59 | pose_features.append(
60 | f.f_nmove("neck", "lhip", "rhip", "lwrist", 1.8 * f.hl)
61 | )
62 | pose_features.append(
63 | f.f_nplane("chest", "neck", "neck", "rwrist", 0.2 * f.hl)
64 | )
65 | pose_features.append(
66 | f.f_nplane("chest", "neck", "neck", "lwrist", 0.2 * f.hl)
67 | )
68 | pose_features.append(
69 | f.f_move("belly", "chest", "chest", "rwrist", 1.8 * f.hl)
70 | )
71 | pose_features.append(
72 | f.f_move("belly", "chest", "chest", "lwrist", 1.8 * f.hl)
73 | )
74 | pose_features.append(
75 | f.f_angle("relbow", "rshoulder", "relbow", "rwrist", [0, 110])
76 | )
77 | pose_features.append(
78 | f.f_angle("lelbow", "lshoulder", "lelbow", "lwrist", [0, 110])
79 | )
80 | pose_features.append(
81 | f.f_nplane(
82 | "lshoulder", "rshoulder", "lwrist", "rwrist", 2.5 * f.sw
83 | )
84 | )
85 | pose_features.append(
86 | f.f_move("lwrist", "rwrist", "rwrist", "lwrist", 1.4 * f.hl)
87 | )
88 | pose_features.append(
89 | f.f_move("rwrist", "root", "lwrist", "root", 1.4 * f.hl)
90 | )
91 | pose_features.append(
92 | f.f_move("lwrist", "root", "rwrist", "root", 1.4 * f.hl)
93 | )
94 | pose_features.append(f.f_fast("rwrist", 2.5 * f.hl))
95 | pose_features.append(f.f_fast("lwrist", 2.5 * f.hl))
96 | pose_features.append(
97 | f.f_plane("root", "lhip", "ltoes", "rankle", 0.38 * f.hl)
98 | )
99 | pose_features.append(
100 | f.f_plane("root", "rhip", "rtoes", "lankle", 0.38 * f.hl)
101 | )
102 | pose_features.append(
103 | f.f_nplane("zero", "y_unit", "y_min", "rankle", 1.2 * f.hl)
104 | )
105 | pose_features.append(
106 | f.f_nplane("zero", "y_unit", "y_min", "lankle", 1.2 * f.hl)
107 | )
108 | pose_features.append(
109 | f.f_nplane("lhip", "rhip", "lankle", "rankle", 2.1 * f.hw)
110 | )
111 | pose_features.append(
112 | f.f_angle("rknee", "rhip", "rknee", "rankle", [0, 110])
113 | )
114 | pose_features.append(
115 | f.f_angle("lknee", "lhip", "lknee", "lankle", [0, 110])
116 | )
117 | pose_features.append(f.f_fast("rankle", 2.5 * f.hl))
118 | pose_features.append(f.f_fast("lankle", 2.5 * f.hl))
119 | pose_features.append(
120 | f.f_angle("neck", "root", "rshoulder", "relbow", [25, 180])
121 | )
122 | pose_features.append(
123 | f.f_angle("neck", "root", "lshoulder", "lelbow", [25, 180])
124 | )
125 | pose_features.append(
126 | f.f_angle("neck", "root", "rhip", "rknee", [50, 180])
127 | )
128 | pose_features.append(
129 | f.f_angle("neck", "root", "lhip", "lknee", [50, 180])
130 | )
131 | pose_features.append(
132 | f.f_plane("rankle", "neck", "lankle", "root", 0.5 * f.hl)
133 | )
134 | pose_features.append(
135 | f.f_angle("neck", "root", "zero", "y_unit", [70, 110])
136 | )
137 | pose_features.append(
138 | f.f_nplane("zero", "minus_y_unit", "y_min", "rwrist", -1.2 * f.hl)
139 | )
140 | pose_features.append(
141 | f.f_nplane("zero", "minus_y_unit", "y_min", "lwrist", -1.2 * f.hl)
142 | )
143 | pose_features.append(f.f_fast("root", 2.3 * f.hl))
144 | features.append(pose_features)
145 | f.next_frame()
146 | features = np.array(features, dtype=np.float32).mean(axis=0)
147 | return features
148 |
149 |
150 | class ManualFeatures:
151 | def __init__(self, positions, joint_names=SMPL_JOINT_NAMES):
152 | self.positions = positions
153 | self.joint_names = joint_names
154 | self.frame_num = 1
155 |
156 | # humerus length
157 | self.hl = feat_utils.distance_between_points(
158 | [1.99113488e-01, 2.36807942e-01, -1.80702247e-02], # "lshoulder",
159 | [4.54445392e-01, 2.21158922e-01, -4.10167128e-02], # "lelbow"
160 | )
161 | # shoulder width
162 | self.sw = feat_utils.distance_between_points(
163 | [1.99113488e-01, 2.36807942e-01, -1.80702247e-02], # "lshoulder"
164 | [-1.91692337e-01, 2.36928746e-01, -1.23055102e-02,], # "rshoulder"
165 | )
166 | # hip width
167 | self.hw = feat_utils.distance_between_points(
168 | [5.64076714e-02, -3.23069185e-01, 1.09197125e-02], # "lhip"
169 | [-6.24834076e-02, -3.31302464e-01, 1.50412619e-02], # "rhip"
170 | )
171 |
172 | def next_frame(self):
173 | self.frame_num += 1
174 |
175 | def transform_and_fetch_position(self, j):
176 | if j == "y_unit":
177 | return [0, 1, 0]
178 | elif j == "minus_y_unit":
179 | return [0, -1, 0]
180 | elif j == "zero":
181 | return [0, 0, 0]
182 | elif j == "y_min":
183 | return [
184 | 0,
185 | min(
186 | [y for (_, y, _) in self.positions[self.frame_num]]
187 | ),
188 | 0,
189 | ]
190 | return self.positions[self.frame_num][
191 | self.joint_names.index(j)
192 | ]
193 |
194 | def transform_and_fetch_prev_position(self, j):
195 | return self.positions[self.frame_num - 1][
196 | self.joint_names.index(j)
197 | ]
198 |
199 | def f_move(self, j1, j2, j3, j4, range):
200 | j1_prev, j2_prev, j3_prev, j4_prev = [
201 | self.transform_and_fetch_prev_position(j) for j in [j1, j2, j3, j4]
202 | ]
203 | j1, j2, j3, j4 = [
204 | self.transform_and_fetch_position(j) for j in [j1, j2, j3, j4]
205 | ]
206 | return feat_utils.velocity_direction_above_threshold(
207 | j1, j1_prev, j2, j2_prev, j3, j3_prev, range,
208 | )
209 |
210 | def f_nmove(self, j1, j2, j3, j4, range):
211 | j1_prev, j2_prev, j3_prev, j4_prev = [
212 | self.transform_and_fetch_prev_position(j) for j in [j1, j2, j3, j4]
213 | ]
214 | j1, j2, j3, j4 = [
215 | self.transform_and_fetch_position(j) for j in [j1, j2, j3, j4]
216 | ]
217 | return feat_utils.velocity_direction_above_threshold_normal(
218 | j1, j1_prev, j2, j3, j4, j4_prev, range
219 | )
220 |
221 | def f_plane(self, j1, j2, j3, j4, threshold):
222 | j1, j2, j3, j4 = [
223 | self.transform_and_fetch_position(j) for j in [j1, j2, j3, j4]
224 | ]
225 | return feat_utils.distance_from_plane(j1, j2, j3, j4, threshold)
226 |
227 | #
228 | def f_nplane(self, j1, j2, j3, j4, threshold):
229 | j1, j2, j3, j4 = [
230 | self.transform_and_fetch_position(j) for j in [j1, j2, j3, j4]
231 | ]
232 | return feat_utils.distance_from_plane_normal(j1, j2, j3, j4, threshold)
233 |
234 | # relative
235 | def f_angle(self, j1, j2, j3, j4, range):
236 | j1, j2, j3, j4 = [
237 | self.transform_and_fetch_position(j) for j in [j1, j2, j3, j4]
238 | ]
239 | return feat_utils.angle_within_range(j1, j2, j3, j4, range)
240 |
241 | # non-relative
242 | def f_fast(self, j1, threshold):
243 | j1_prev = self.transform_and_fetch_prev_position(j1)
244 | j1 = self.transform_and_fetch_position(j1)
245 | return feat_utils.velocity_above_threshold(j1, j1_prev, threshold)
246 |
--------------------------------------------------------------------------------
/eval/features/manual.py:
--------------------------------------------------------------------------------
1 | # BSD License
2 |
3 | # For fairmotion software
4 |
5 | # Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
6 | # Modified by Ruilong Li
7 |
8 | # Redistribution and use in source and binary forms, with or without modification,
9 | # are permitted provided that the following conditions are met:
10 |
11 | # * Redistributions of source code must retain the above copyright notice, this
12 | # list of conditions and the following disclaimer.
13 |
14 | # * Redistributions in binary form must reproduce the above copyright notice,
15 | # this list of conditions and the following disclaimer in the documentation
16 | # and/or other materials provided with the distribution.
17 |
18 | # * Neither the name Facebook nor the names of its contributors may be used to
19 | # endorse or promote products derived from this software without specific
20 | # prior written permission.
21 |
22 | # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
23 | # ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
24 | # WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
25 | # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR
26 | # ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
27 | # (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
28 | # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON
29 | # ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
30 | # (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
31 | # SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
32 | import numpy as np
33 | from . import utils as feat_utils
34 |
35 |
36 | # SMPL_JOINT_NAMES = [
37 | # "root",
38 | # "lhip", "lknee", "lankle", "ltoes",
39 | # "rhip", "rknee", "rankle", "rtoes",
40 | # "belly", "spine", "chest", "neck", "head",
41 | # "linshoulder", "lshoulder", "lelbow", "lwrist",
42 | # "rinshoulder", "rshoulder", "relbow", "rwrist"
43 | # ]
44 |
45 |
46 |
47 | SMPL_JOINT_NAMES = [
48 | "root",
49 | "lhip", "rhip", "belly",
50 | "lknee", "rknee", "spine",
51 | "lankle", "rankle", "chest",
52 | "ltoes", "rtoes", "neck", "linshoulder", "rinshoulder",
53 | "head", "lshoulder", "rshoulder",
54 | "lelbow", "relbow",
55 | "lwrist", "rwrist"
56 | ]
57 |
58 |
59 | def extract_manual_features(positions):
60 | assert len(positions.shape) == 3 # (seq_len, n_joints, 3)
61 | features = []
62 | f = ManualFeatures(positions)
63 | for _ in range(1, positions.shape[0]):
64 | pose_features = []
65 | pose_features.append(
66 | f.f_nmove("neck", "rhip", "lhip", "rwrist", 1.8 * f.hl)
67 | )
68 | pose_features.append(
69 | f.f_nmove("neck", "lhip", "rhip", "lwrist", 1.8 * f.hl)
70 | )
71 | pose_features.append(
72 | f.f_nplane("chest", "neck", "neck", "rwrist", 0.2 * f.hl)
73 | )
74 | pose_features.append(
75 | f.f_nplane("chest", "neck", "neck", "lwrist", 0.2 * f.hl)
76 | )
77 | pose_features.append(
78 | f.f_move("belly", "chest", "chest", "rwrist", 1.8 * f.hl)
79 | )
80 | pose_features.append(
81 | f.f_move("belly", "chest", "chest", "lwrist", 1.8 * f.hl)
82 | )
83 | pose_features.append(
84 | f.f_angle("relbow", "rshoulder", "relbow", "rwrist", [0, 110])
85 | )
86 | pose_features.append(
87 | f.f_angle("lelbow", "lshoulder", "lelbow", "lwrist", [0, 110])
88 | )
89 | pose_features.append(
90 | f.f_nplane(
91 | "lshoulder", "rshoulder", "lwrist", "rwrist", 2.5 * f.sw
92 | )
93 | )
94 | pose_features.append(
95 | f.f_move("lwrist", "rwrist", "rwrist", "lwrist", 1.4 * f.hl)
96 | )
97 | pose_features.append(
98 | f.f_move("rwrist", "root", "lwrist", "root", 1.4 * f.hl)
99 | )
100 | pose_features.append(
101 | f.f_move("lwrist", "root", "rwrist", "root", 1.4 * f.hl)
102 | )
103 | pose_features.append(f.f_fast("rwrist", 2.5 * f.hl))
104 | pose_features.append(f.f_fast("lwrist", 2.5 * f.hl))
105 | pose_features.append(
106 | f.f_plane("root", "lhip", "ltoes", "rankle", 0.38 * f.hl)
107 | )
108 | pose_features.append(
109 | f.f_plane("root", "rhip", "rtoes", "lankle", 0.38 * f.hl)
110 | )
111 | pose_features.append(
112 | f.f_nplane("zero", "y_unit", "y_min", "rankle", 1.2 * f.hl)
113 | )
114 | pose_features.append(
115 | f.f_nplane("zero", "y_unit", "y_min", "lankle", 1.2 * f.hl)
116 | )
117 | pose_features.append(
118 | f.f_nplane("lhip", "rhip", "lankle", "rankle", 2.1 * f.hw)
119 | )
120 | pose_features.append(
121 | f.f_angle("rknee", "rhip", "rknee", "rankle", [0, 110])
122 | )
123 | pose_features.append(
124 | f.f_angle("lknee", "lhip", "lknee", "lankle", [0, 110])
125 | )
126 | pose_features.append(f.f_fast("rankle", 2.5 * f.hl))
127 | pose_features.append(f.f_fast("lankle", 2.5 * f.hl))
128 | pose_features.append(
129 | f.f_angle("neck", "root", "rshoulder", "relbow", [25, 180])
130 | )
131 | pose_features.append(
132 | f.f_angle("neck", "root", "lshoulder", "lelbow", [25, 180])
133 | )
134 | pose_features.append(
135 | f.f_angle("neck", "root", "rhip", "rknee", [50, 180])
136 | )
137 | pose_features.append(
138 | f.f_angle("neck", "root", "lhip", "lknee", [50, 180])
139 | )
140 | pose_features.append(
141 | f.f_plane("rankle", "neck", "lankle", "root", 0.5 * f.hl)
142 | )
143 | pose_features.append(
144 | f.f_angle("neck", "root", "zero", "y_unit", [70, 110])
145 | )
146 | pose_features.append(
147 | f.f_nplane("zero", "minus_y_unit", "y_min", "rwrist", -1.2 * f.hl)
148 | )
149 | pose_features.append(
150 | f.f_nplane("zero", "minus_y_unit", "y_min", "lwrist", -1.2 * f.hl)
151 | )
152 | pose_features.append(f.f_fast("root", 2.3 * f.hl))
153 | features.append(pose_features)
154 | f.next_frame()
155 | features = np.array(features, dtype=np.float32).mean(axis=0)
156 | return features
157 |
158 |
159 | class ManualFeatures:
160 | def __init__(self, positions, joint_names=SMPL_JOINT_NAMES):
161 | self.positions = positions
162 | self.joint_names = joint_names
163 | self.frame_num = 1
164 |
165 | # humerus length
166 | self.hl = feat_utils.distance_between_points(
167 | [0.00121265, 0.37817603, 0.03681623], # "lshoulder",
168 | [0.19911349, 0.23680794, -0.01807022], # "lelbow"
169 | )
170 | # shoulder width
171 | self.sw = feat_utils.distance_between_points(
172 | [0.00121265, 0.37817603, 0.03681623], # "lshoulder"
173 | [-0.45181984, 0.2225595, -0.04357424], # "rshoulder"
174 | )
175 | # hip width
176 | self.hw = feat_utils.distance_between_points(
177 | [0.05640767, -0.32306919, 0.01091971], # "lhip"
178 | [-0.10574003, -0.7149903, 0.01019822], # "rhip"
179 | )
180 |
181 | def next_frame(self):
182 | self.frame_num += 1
183 |
184 | def transform_and_fetch_position(self, j):
185 | if j == "y_unit":
186 | return [0, 1, 0]
187 | elif j == "minus_y_unit":
188 | return [0, -1, 0]
189 | elif j == "zero":
190 | return [0, 0, 0]
191 | elif j == "y_min":
192 | return [
193 | 0,
194 | min(
195 | [y for (_, y, _) in self.positions[self.frame_num]]
196 | ),
197 | 0,
198 | ]
199 | return self.positions[self.frame_num][
200 | self.joint_names.index(j)
201 | ]
202 |
203 | def transform_and_fetch_prev_position(self, j):
204 | return self.positions[self.frame_num - 1][
205 | self.joint_names.index(j)
206 | ]
207 |
208 | def f_move(self, j1, j2, j3, j4, range):
209 | j1_prev, j2_prev, j3_prev, j4_prev = [
210 | self.transform_and_fetch_prev_position(j) for j in [j1, j2, j3, j4]
211 | ]
212 | j1, j2, j3, j4 = [
213 | self.transform_and_fetch_position(j) for j in [j1, j2, j3, j4]
214 | ]
215 | return feat_utils.velocity_direction_above_threshold(
216 | j1, j1_prev, j2, j2_prev, j3, j3_prev, range
217 | )
218 |
219 | def f_nmove(self, j1, j2, j3, j4, range):
220 | j1_prev, j2_prev, j3_prev, j4_prev = [
221 | self.transform_and_fetch_prev_position(j) for j in [j1, j2, j3, j4]
222 | ]
223 | j1, j2, j3, j4 = [
224 | self.transform_and_fetch_position(j) for j in [j1, j2, j3, j4]
225 | ]
226 | return feat_utils.velocity_direction_above_threshold_normal(
227 | j1, j1_prev, j2, j3, j4, j4_prev, range
228 | )
229 |
230 | def f_plane(self, j1, j2, j3, j4, threshold):
231 | j1, j2, j3, j4 = [
232 | self.transform_and_fetch_position(j) for j in [j1, j2, j3, j4]
233 | ]
234 | return feat_utils.distance_from_plane(j1, j2, j3, j4, threshold)
235 |
236 | def f_nplane(self, j1, j2, j3, j4, threshold):
237 | j1, j2, j3, j4 = [
238 | self.transform_and_fetch_position(j) for j in [j1, j2, j3, j4]
239 | ]
240 | return feat_utils.distance_from_plane_normal(j1, j2, j3, j4, threshold)
241 |
242 | def f_angle(self, j1, j2, j3, j4, range):
243 | j1, j2, j3, j4 = [
244 | self.transform_and_fetch_position(j) for j in [j1, j2, j3, j4]
245 | ]
246 | return feat_utils.angle_within_range(j1, j2, j3, j4, range)
247 |
248 | def f_fast(self, j1, threshold):
249 | j1_prev = self.transform_and_fetch_prev_position(j1)
250 | j1 = self.transform_and_fetch_position(j1)
251 | return feat_utils.velocity_above_threshold(j1, j1_prev, threshold)
252 |
--------------------------------------------------------------------------------
/eval/metrics_diversity.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import pickle
3 | # from aist_plusplus.features.kinetic import extract_kinetic_features
4 | # from aist_plusplus.features.manual import extract_manual_features
5 | from features.kinetic import extract_kinetic_features
6 | from features.manual_new import extract_manual_features
7 | from scipy import linalg
8 |
9 | # kinetic, manual
10 | import os
11 | import glob
12 | import matplotlib.pyplot as plt
13 | import random
14 |
15 | from tqdm import tqdm
16 |
17 | def normalize2(feat, feat2):
18 | mean = feat.mean(axis=0)
19 | std = feat.std(axis=0)
20 |
21 | return (feat - mean) / (std + 1e-10), (feat2 - mean) / (std + 1e-10)
22 |
23 |
24 | def normalize(feat):
25 | mean = feat.mean(axis=0)
26 | std = feat.std(axis=0)
27 |
28 | return (feat - mean) / (std + 1e-10)
29 |
30 |
31 | def quantized_metrics(predicted_pkl_root, gt_pkl_root):
32 |
33 |
34 | pred_features_k = []
35 | pred_features_m = []
36 | gt_freatures_k = []
37 | gt_freatures_m = []
38 |
39 |
40 | pred_features_k = [np.load(os.path.join(predicted_pkl_root, 'kinetic_features', pkl)) for pkl in os.listdir(os.path.join(predicted_pkl_root, 'kinetic_features'))]
41 | pred_features_m = [np.load(os.path.join(predicted_pkl_root, 'manual_features_new', pkl)) for pkl in os.listdir(os.path.join(predicted_pkl_root, 'manual_features_new'))]
42 |
43 | gt_freatures_k = [np.load(os.path.join(gt_pkl_root, 'kinetic_features', pkl)) for pkl in os.listdir(os.path.join(gt_pkl_root, 'kinetic_features'))]
44 | gt_freatures_m = [np.load(os.path.join(gt_pkl_root, 'manual_features_new', pkl)) for pkl in os.listdir(os.path.join(gt_pkl_root, 'manual_features_new'))]
45 |
46 |
47 |
48 |
49 | pred_features_k = np.stack(pred_features_k) # Nx72 p40
50 | pred_features_m = np.stack(pred_features_m) # Nx32
51 | gt_freatures_k = np.stack(gt_freatures_k) # N' x 72 N' >> N
52 | gt_freatures_m = np.stack(gt_freatures_m) #
53 |
54 |
55 |
56 | gt_freatures_k, pred_features_k = normalize2(gt_freatures_k, pred_features_k)
57 | gt_freatures_m, pred_features_m = normalize2(gt_freatures_m, pred_features_m)
58 |
59 |
60 |
61 |
62 | # print(pred_features_k.mean(axis=0))
63 | # print(pred_features_m.mean(axis=0))
64 | # print(pred_features_k.std(axis=0))
65 | # print(pred_features_m.std(axis=0))
66 |
67 | print('Calculating metrics')
68 |
69 | fid_k = calc_fid(pred_features_k, gt_freatures_k)
70 | fid_m = calc_fid(pred_features_m, gt_freatures_m)
71 |
72 | div_k_gt = calculate_avg_distance(gt_freatures_k)
73 | div_m_gt = calculate_avg_distance(gt_freatures_m)
74 | div_k = calculate_avg_distance(pred_features_k)
75 | div_m = calculate_avg_distance(pred_features_m)
76 |
77 |
78 | metrics = {'fid_k': fid_k, 'fid_m': fid_m, 'div_k': div_k, 'div_m' : div_m, 'div_k_gt': div_k_gt, 'div_m_gt': div_m_gt}
79 | return metrics
80 |
81 |
82 | def calc_fid(kps_gen, kps_gt):
83 |
84 | print(kps_gen.shape)
85 | print(kps_gt.shape)
86 |
87 | # kps_gen = kps_gen[:20, :]
88 |
89 | mu_gen = np.mean(kps_gen, axis=0)
90 | sigma_gen = np.cov(kps_gen, rowvar=False)
91 |
92 | mu_gt = np.mean(kps_gt, axis=0)
93 | sigma_gt = np.cov(kps_gt, rowvar=False)
94 |
95 | mu1,mu2,sigma1,sigma2 = mu_gen, mu_gt, sigma_gen, sigma_gt
96 |
97 | diff = mu1 - mu2
98 | eps = 1e-5
99 | # Product might be almost singular
100 | covmean, _ = linalg.sqrtm(sigma1.dot(sigma2), disp=False)
101 | if not np.isfinite(covmean).all():
102 | msg = ('fid calculation produces singular product; '
103 | 'adding %s to diagonal of cov estimates') % eps
104 | print(msg)
105 | offset = np.eye(sigma1.shape[0]) * eps
106 | covmean = linalg.sqrtm((sigma1 + offset).dot(sigma2 + offset))
107 |
108 | # Numerical error might give slight imaginary component
109 | if np.iscomplexobj(covmean):
110 | if not np.allclose(np.diagonal(covmean).imag, 0, atol=1e-3):
111 | m = np.max(np.abs(covmean.imag))
112 | # raise ValueError('Imaginary component {}'.format(m))
113 | covmean = covmean.real
114 |
115 | tr_covmean = np.trace(covmean)
116 |
117 | return (diff.dot(diff) + np.trace(sigma1)
118 | + np.trace(sigma2) - 2 * tr_covmean)
119 |
120 |
121 | def calc_diversity(feats):
122 | feat_array = np.array(feats)
123 | n, c = feat_array.shape
124 | diff = np.array([feat_array] * n) - feat_array.reshape(n, 1, c)
125 | return np.sqrt(np.sum(diff**2, axis=2)).sum() / n / (n-1)
126 |
127 | def calculate_avg_distance(feature_list, mean=None, std=None):
128 | feature_list = np.stack(feature_list)
129 | n = feature_list.shape[0]
130 | # normalize the scale
131 | if (mean is not None) and (std is not None):
132 | feature_list = (feature_list - mean) / std
133 | dist = 0
134 | for i in range(n):
135 | for j in range(i + 1, n):
136 | dist += np.linalg.norm(feature_list[i] - feature_list[j])
137 | dist /= (n * n - n) / 2
138 | return dist
139 |
140 | def calc_and_save_feats(root):
141 | if not os.path.exists(os.path.join(root, 'kinetic_features')):
142 | os.mkdir(os.path.join(root, 'kinetic_features'))
143 | if not os.path.exists(os.path.join(root, 'manual_features_new')):
144 | os.mkdir(os.path.join(root, 'manual_features_new'))
145 |
146 | # gt_list = []
147 | pred_list = []
148 |
149 | it = glob.glob(os.path.join(root, "*.pkl"))
150 | if len(it) > 1000:
151 | it = random.sample(it, 1000)
152 | for pkl in tqdm(it):
153 | if os.path.isdir(os.path.join(root, pkl)):
154 | continue
155 | info = pickle.load(open(pkl, "rb"))
156 | joint3d = info["full_pose"]
157 |
158 | joint3d = joint3d.reshape(-1, 72)
159 | joint3d = joint3d[:1200,:]
160 |
161 | # for pkl in os.listdir(root):
162 | # print(pkl)
163 | # if os.path.isdir(os.path.join(root, pkl)):
164 | # continue
165 | # joint3d = np.load(os.path.join(root, pkl), allow_pickle=True).item()['pred_position'][:1200,:]
166 |
167 | # print(extract_manual_features(joint3d.reshape(-1, 24, 3)))
168 | roott = joint3d[:1, :3] # the root Tx72 (Tx(24x3))
169 | # print(roott)
170 | joint3d = joint3d - np.tile(roott, (1, 24)) # Calculate relative offset with respect to root
171 | # print('==============after fix root ============')
172 | # print(extract_manual_features(joint3d.reshape(-1, 24, 3)))
173 | # print('==============bla============')
174 | # print(extract_manual_features(joint3d.reshape(-1, 24, 3)))
175 | # np_dance[:, :3] = root
176 | # print('pkl',pkl)
177 | # pkl_split = pkl.split('.')[0].split('_')[1] + '_' + pkl.split('.')[0].split('_')[2] + '_' + \
178 | # pkl.split('.')[0].split('_')[3] + '_' + pkl.split('.')[0].split('_')[4] + '_' + \
179 | # pkl.split('.')[0].split('_')[5] + '_' + pkl.split('.')[0].split('_')[6]
180 | pkl = os.path.basename(pkl)
181 | print('pkl', pkl)
182 | pkl_split = pkl.split('.')[0].split('_')[1] + '_' + pkl.split('.')[0].split('_')[2] + '_' + \
183 | pkl.split('.')[0].split('_')[3] + '_' + pkl.split('.')[0].split('_')[4] + '_' + \
184 | pkl.split('.')[0].split('_')[5] + '_' + pkl.split('.')[0].split('_')[6] \
185 | + '_' + pkl.split('.')[0].split('_')[7]
186 | np.save(os.path.join(root, 'kinetic_features', pkl_split), extract_kinetic_features(joint3d.reshape(-1, 24, 3)))
187 | np.save(os.path.join(root, 'manual_features_new', pkl_split), extract_manual_features(joint3d.reshape(-1, 24, 3)))
188 |
189 |
190 | def calc_and_save_feats_gt(root):
191 | if not os.path.exists(os.path.join(root, 'kinetic_features')):
192 | os.mkdir(os.path.join(root, 'kinetic_features'))
193 | if not os.path.exists(os.path.join(root, 'manual_features_new')):
194 | os.mkdir(os.path.join(root, 'manual_features_new'))
195 |
196 | # gt_list = []
197 | pred_list = []
198 |
199 | it = glob.glob(os.path.join(root, "*.pkl"))
200 | if len(it) > 1000:
201 | it = random.sample(it, 1000)
202 | for pkl in tqdm(it):
203 | if os.path.isdir(os.path.join(root, pkl)):
204 | continue
205 | info = pickle.load(open(pkl, "rb"))
206 | joint3d = info["full_pose"]
207 |
208 | joint3d = joint3d.reshape(-1, 72)
209 | joint3d = joint3d[:1200, :]
210 |
211 | # for pkl in os.listdir(root):
212 | # print(pkl)
213 | # if os.path.isdir(os.path.join(root, pkl)):
214 | # continue
215 | # joint3d = np.load(os.path.join(root, pkl), allow_pickle=True).item()['pred_position'][:1200,:]
216 |
217 | # print(extract_manual_features(joint3d.reshape(-1, 24, 3)))
218 | roott = joint3d[:1, :3] # the root Tx72 (Tx(24x3))
219 | # print(roott)
220 | joint3d = joint3d - np.tile(roott, (1, 24)) # Calculate relative offset with respect to root
221 | # print('==============after fix root ============')
222 | # print(extract_manual_features(joint3d.reshape(-1, 24, 3)))
223 | # print('==============bla============')
224 | # print(extract_manual_features(joint3d.reshape(-1, 24, 3)))
225 | # np_dance[:, :3] = root
226 | # print('pkl',pkl)
227 | # pkl_split = pkl.split('.')[0].split('_')[1] + '_' + pkl.split('.')[0].split('_')[2] + '_' + \
228 | # pkl.split('.')[0].split('_')[3] + '_' + pkl.split('.')[0].split('_')[4] + '_' + \
229 | # pkl.split('.')[0].split('_')[5] + '_' + pkl.split('.')[0].split('_')[6]
230 | pkl = os.path.basename(pkl)
231 | print('pkl', pkl)
232 | pkl_split = pkl.split('.')[0]
233 | np.save(os.path.join(root, 'kinetic_features', pkl_split), extract_kinetic_features(joint3d.reshape(-1, 24, 3)))
234 | np.save(os.path.join(root, 'manual_features_new', pkl_split),
235 | extract_manual_features(joint3d.reshape(-1, 24, 3)))
236 |
237 | if __name__ == '__main__':
238 | gt_root = './test_motions_sliced_smpl3'
239 | pred_root = 'eval/motions'
240 | print('Calculating and saving features')
241 | # calc_and_save_feats_gt(gt_root)
242 | # calc_and_save_feats(pred_root)
243 | print('Calculating metrics')
244 | print(quantized_metrics(pred_root, gt_root))
245 |
246 |
--------------------------------------------------------------------------------
/dataset/dance_dataset.py:
--------------------------------------------------------------------------------
1 | import glob
2 | import os
3 | import pickle
4 | import random
5 | from functools import cmp_to_key
6 | from pathlib import Path
7 | from typing import Any
8 |
9 | import numpy as np
10 | import torch
11 | from pytorch3d.transforms import (RotateAxisAngle, axis_angle_to_quaternion,
12 | quaternion_multiply,
13 | quaternion_to_axis_angle)
14 | from torch.utils.data import Dataset
15 |
16 | from dataset.preprocess import Normalizer, vectorize_many
17 | from dataset.quaternion import ax_to_6v
18 | from vis import SMPLSkeleton
19 |
20 |
21 | class AISTPPDataset(Dataset):
22 | def __init__(
23 | self,
24 | data_path: str,
25 | backup_path: str,
26 | train: bool,
27 | feature_type: str = "jukebox",
28 | normalizer: Any = None,
29 | data_len: int = -1,
30 | include_contacts: bool = True,
31 | force_reload: bool = False,
32 | ):
33 | print('feature_type:',feature_type)
34 | self.data_path = data_path
35 | self.raw_fps = 60
36 | self.data_fps = 30
37 | assert self.data_fps <= self.raw_fps
38 | self.data_stride = self.raw_fps // self.data_fps
39 |
40 | self.train = train
41 | self.name = "Train" if self.train else "Test"
42 | self.feature_type = feature_type
43 |
44 | self.normalizer = normalizer
45 | self.data_len = data_len
46 |
47 | pickle_name = "processed_train_data.pkl" if train else "processed_test_data.pkl"
48 |
49 | backup_path = Path(backup_path)
50 | backup_path.mkdir(parents=True, exist_ok=True)
51 | # save normalizer
52 | if not train:
53 | pickle.dump(
54 | normalizer, open(os.path.join(backup_path, "normalizer.pkl"), "wb")
55 | )
56 | # load raw data
57 | if not force_reload and pickle_name in os.listdir(backup_path):
58 | print("Using cached dataset...")
59 | with open(os.path.join(backup_path, pickle_name), "rb") as f:
60 | data = pickle.load(f)
61 | else:
62 | print("Loading dataset...")
63 | data = self.load_aistpp() # Call this last
64 | with open(os.path.join(backup_path, pickle_name), "wb") as f:
65 | pickle.dump(data, f, pickle.HIGHEST_PROTOCOL)
66 |
67 | print(
68 | f"Loaded {self.name} Dataset With Dimensions: Pos: {data['pos'].shape}, Q: {data['q'].shape}"
69 | )
70 |
71 | # process data, convert to 6dof etc
72 | pose_input = self.process_dataset(data["pos"], data["q"])
73 | self.data = {
74 | "pose": pose_input, #(batch_size, seq_len, 151)
75 | "filenames": data["filenames"],
76 | "wavs": data["wavs"],
77 | }
78 | assert len(pose_input) == len(data["filenames"])
79 | self.length = len(pose_input)
80 |
81 | def __len__(self):
82 | return self.length
83 |
84 | def __getitem__(self, idx):
85 | filename_ = self.data["filenames"][idx]
86 | feature = torch.from_numpy(np.load(filename_))
87 | print('feature.shape', feature.shape)
88 | return self.data["pose"][idx], feature, filename_, self.data["wavs"][idx]
89 |
90 | def load_aistpp(self):
91 | # open data path
92 | split_data_path = os.path.join(
93 | self.data_path, "train" if self.train else "test"
94 | )
95 |
96 | # Structure:
97 | # data
98 | # |- train
99 | # | |- motion_sliced
100 | # | |- wav_sliced
101 | # | |- baseline_features
102 | # | |- jukebox_features
103 | # | |- motions
104 | # | |- wavs
105 |
106 | motion_path = os.path.join(split_data_path, "motions_sliced")
107 | sound_path = os.path.join(split_data_path, f"{self.feature_type}_feats")
108 | wav_path = os.path.join(split_data_path, f"wavs_sliced")
109 | # sort motions and sounds
110 | motions = sorted(glob.glob(os.path.join(motion_path, "*.pkl")))
111 | features = sorted(glob.glob(os.path.join(sound_path, "*.npy")))
112 | wavs = sorted(glob.glob(os.path.join(wav_path, "*.wav")))
113 |
114 | # stack the motions and features together
115 | all_pos = []
116 | all_q = []
117 | all_names = []
118 | all_wavs = []
119 | assert len(motions) == len(features)
120 | for motion, feature, wav in zip(motions, features, wavs):
121 | # make sure name is matching
122 | m_name = os.path.splitext(os.path.basename(motion))[0]
123 | f_name = os.path.splitext(os.path.basename(feature))[0]
124 | w_name = os.path.splitext(os.path.basename(wav))[0]
125 | assert m_name == f_name == w_name, str((motion, feature, wav))
126 | # load motion
127 | data = pickle.load(open(motion, "rb"))
128 | pos = data["pos"]
129 | q = data["q"]
130 | all_pos.append(pos)
131 | all_q.append(q)
132 | all_names.append(feature)
133 | all_wavs.append(wav)
134 |
135 | all_pos = np.array(all_pos) # N x seq x 3
136 | all_q = np.array(all_q) # N x seq x (joint * 3)
137 | # downsample the motions to the data fps
138 | print(all_pos.shape)
139 | all_pos = all_pos[:, :: self.data_stride, :]
140 | all_q = all_q[:, :: self.data_stride, :]
141 | data = {"pos": all_pos, "q": all_q, "filenames": all_names, "wavs": all_wavs}
142 | return data
143 |
144 | def process_dataset(self, root_pos, local_q):
145 | # FK skeleton
146 | smpl = SMPLSkeleton()
147 | # to Tensor
148 | root_pos = torch.Tensor(root_pos)
149 | local_q = torch.Tensor(local_q)
150 | # to ax
151 | bs, sq, c = local_q.shape
152 | local_q = local_q.reshape((bs, sq, -1, 3))
153 |
154 | root_q = local_q[:, :, :1, :] # sequence x 1 x 3
155 | root_q_quat = axis_angle_to_quaternion(root_q)
156 | rotation = torch.Tensor(
157 | [0.7071068, 0.7071068, 0, 0]
158 | ) # 90 degrees about the x axis
159 | root_q_quat = quaternion_multiply(rotation, root_q_quat)
160 | root_q = quaternion_to_axis_angle(root_q_quat)
161 | local_q[:, :, :1, :] = root_q
162 |
163 | # don't forget to rotate the root position too
164 | pos_rotation = RotateAxisAngle(90, axis="X", degrees=True)
165 | root_pos = pos_rotation.transform_points(
166 | root_pos
167 | ) # basically (y, z) -> (-z, y), expressed as a rotation for readability
168 |
169 | # do FK
170 | positions = smpl.forward(local_q, root_pos) # batch x sequence x 24 x 3
171 |
172 | feet = positions[:, :, (7, 8, 10, 11)]
173 | feetv = torch.zeros(feet.shape[:3])
174 | feetv[:, :-1] = (feet[:, 1:] - feet[:, :-1]).norm(dim=-1)
175 | contacts = (feetv < 0.01).to(local_q) # cast to right dtype
176 |
177 | # to 6d
178 | local_q = ax_to_6v(local_q)
179 |
180 | # now, flatten everything into: batch x sequence x [...]
181 | l = [contacts, root_pos, local_q] # [4,3,24*6]
182 | global_pose_vec_input = vectorize_many(l).float().detach()
183 |
184 | # normalize the data. Both train and test need the same normalizer.
185 | if self.train:
186 | self.normalizer = Normalizer(global_pose_vec_input)
187 | else:
188 | assert self.normalizer is not None
189 | global_pose_vec_input = self.normalizer.normalize(global_pose_vec_input)
190 |
191 | assert not torch.isnan(global_pose_vec_input).any()
192 | data_name = "Train" if self.train else "Test"
193 |
194 | # cut the dataset
195 | if self.data_len > 0:
196 | global_pose_vec_input = global_pose_vec_input[: self.data_len]
197 |
198 | global_pose_vec_input = global_pose_vec_input
199 |
200 | print(f"{data_name} Dataset Motion Features Dim: {global_pose_vec_input.shape}")
201 |
202 | return global_pose_vec_input
203 |
204 |
205 | class OrderedMusicDataset(Dataset):
206 | def __init__(
207 | self,
208 | data_path: str,
209 | train: bool = False,
210 | feature_type: str = "baseline",
211 | data_name: str = "aist",
212 | ):
213 | self.data_path = data_path
214 | self.data_fps = 30
215 | self.feature_type = feature_type
216 | self.test_list = set(
217 | [
218 | "mLH4",
219 | "mKR2",
220 | "mBR0",
221 | "mLO2",
222 | "mJB5",
223 | "mWA0",
224 | "mJS3",
225 | "mMH3",
226 | "mHO5",
227 | "mPO1",
228 | ]
229 | )
230 | self.train = train
231 |
232 | # if not aist, then set train to true to ignore test split logic
233 | self.data_name = data_name
234 | if self.data_name != "aist":
235 | self.train = True
236 |
237 | self.data = self.load_music() # Call this last
238 |
239 | def __len__(self):
240 | return len(self.data)
241 |
242 | def __getitem__(self, idx):
243 | return None
244 |
245 | def get_batch(self, batch_size, idx=None):
246 | key = random.choice(self.keys) if idx is None else self.keys[idx]
247 | seq = self.data[key]
248 | if len(seq) <= batch_size:
249 | seq_slice = seq
250 | else:
251 | max_start = len(seq) - batch_size
252 | start = random.randint(0, max_start)
253 | seq_slice = seq[start : start + batch_size]
254 |
255 | # now we have a batch of filenames
256 | filenames = [os.path.join(self.music_path, x + ".npy") for x in seq_slice]
257 | # get the features
258 | features = np.array([np.load(x) for x in filenames])
259 |
260 | return torch.Tensor(features), seq_slice
261 |
262 | def load_music(self):
263 | # open data path
264 | split_data_path = os.path.join(self.data_path)
265 | music_path = os.path.join(
266 | split_data_path,
267 | f"{self.data_name}_baseline_feats"
268 | if self.feature_type == "baseline"
269 | else f"{self.data_name}_juke_feats/juke_66",
270 | )
271 | self.music_path = music_path
272 | # get the music filenames strided, with each subsequent item 5 slices (2.5 seconds) apart
273 | all_names = []
274 |
275 | key_func = lambda x: int(x.split("_")[-1].split("e")[-1])
276 |
277 | def stringintcmp(a, b):
278 | aa, bb = "".join(a.split("_")[:-1]), "".join(b.split("_")[:-1])
279 | ka, kb = key_func(a), key_func(b)
280 | if aa < bb:
281 | return -1
282 | if aa > bb:
283 | return 1
284 | if ka < kb:
285 | return -1
286 | if ka > kb:
287 | return 1
288 | return 0
289 |
290 | for features in glob.glob(os.path.join(music_path, "*.npy")):
291 | fname = os.path.splitext(os.path.basename(features))[0]
292 | all_names.append(fname)
293 | all_names = sorted(all_names, key=cmp_to_key(stringintcmp))
294 | data_dict = {}
295 | for name in all_names:
296 | k = "".join(name.split("_")[:-1])
297 | if (self.train and k in self.test_list) or (
298 | (not self.train) and k not in self.test_list
299 | ):
300 | continue
301 | data_dict[k] = data_dict.get(k, []) + [name]
302 | self.keys = sorted(list(data_dict.keys()))
303 | return data_dict
304 |
--------------------------------------------------------------------------------
/vis.py:
--------------------------------------------------------------------------------
1 | import os
2 | from pathlib import Path
3 | from tempfile import TemporaryDirectory
4 | from tempfile import mkdtemp
5 |
6 | import librosa as lr
7 | import matplotlib.animation as animation
8 | import matplotlib.pyplot as plt
9 | import numpy as np
10 | import soundfile as sf
11 | import torch
12 | from matplotlib import cm
13 | from matplotlib.colors import ListedColormap
14 | from pytorch3d.transforms import (axis_angle_to_quaternion, quaternion_apply,
15 | quaternion_multiply)
16 | from tqdm import tqdm
17 |
18 | smpl_joints = [
19 | "root", # 0
20 | "lhip", # 1
21 | "rhip", # 2
22 | "belly", # 3
23 | "lknee", # 4
24 | "rknee", # 5
25 | "spine", # 6
26 | "lankle",# 7
27 | "rankle",# 8
28 | "chest", # 9
29 | "ltoes", # 10
30 | "rtoes", # 11
31 | "neck", # 12
32 | "linshoulder", # 13
33 | "rinshoulder", # 14
34 | "head", # 15
35 | "lshoulder", # 16
36 | "rshoulder", # 17
37 | "lelbow", # 18
38 | "relbow", # 19
39 | "lwrist", # 20
40 | "rwrist", # 21
41 | "lhand", # 22
42 | "rhand", # 23
43 | ]
44 |
45 | smpl_parents = [
46 | -1,
47 | 0,
48 | 0,
49 | 0,
50 | 1,
51 | 2,
52 | 3,
53 | 4,
54 | 5,
55 | 6,
56 | 7,
57 | 8,
58 | 9,
59 | 9,
60 | 9,
61 | 12,
62 | 13,
63 | 14,
64 | 16,
65 | 17,
66 | 18,
67 | 19,
68 | 20,
69 | 21,
70 | ]
71 |
72 | smpl_offsets = [
73 | [0.0, 0.0, 0.0],
74 | [0.05858135, -0.08228004, -0.01766408],
75 | [-0.06030973, -0.09051332, -0.01354254],
76 | [0.00443945, 0.12440352, -0.03838522],
77 | [0.04345142, -0.38646945, 0.008037],
78 | [-0.04325663, -0.38368791, -0.00484304],
79 | [0.00448844, 0.1379564, 0.02682033],
80 | [-0.01479032, -0.42687458, -0.037428],
81 | [0.01905555, -0.4200455, -0.03456167],
82 | [-0.00226458, 0.05603239, 0.00285505],
83 | [0.04105436, -0.06028581, 0.12204243],
84 | [-0.03483987, -0.06210566, 0.13032329],
85 | [-0.0133902, 0.21163553, -0.03346758],
86 | [0.07170245, 0.11399969, -0.01889817],
87 | [-0.08295366, 0.11247234, -0.02370739],
88 | [0.01011321, 0.08893734, 0.05040987],
89 | [0.12292141, 0.04520509, -0.019046],
90 | [-0.11322832, 0.04685326, -0.00847207],
91 | [0.2553319, -0.01564902, -0.02294649],
92 | [-0.26012748, -0.01436928, -0.03126873],
93 | [0.26570925, 0.01269811, -0.00737473],
94 | [-0.26910836, 0.00679372, -0.00602676],
95 | [0.08669055, -0.01063603, -0.01559429],
96 | [-0.0887537, -0.00865157, -0.01010708],
97 | ]
98 |
99 |
100 | def set_line_data_3d(line, x):
101 | line.set_data(x[:, :2].T)
102 | line.set_3d_properties(x[:, 2])
103 |
104 |
105 | def set_scatter_data_3d(scat, x, c):
106 | scat.set_offsets(x[:, :2])
107 | scat.set_3d_properties(x[:, 2], "z")
108 | scat.set_facecolors([c])
109 |
110 |
111 | def get_axrange(poses):
112 | pose = poses[0]
113 | x_min = pose[:, 0].min()
114 | x_max = pose[:, 0].max()
115 |
116 | y_min = pose[:, 1].min()
117 | y_max = pose[:, 1].max()
118 |
119 | z_min = pose[:, 2].min()
120 | z_max = pose[:, 2].max()
121 |
122 | xdiff = x_max - x_min
123 | ydiff = y_max - y_min
124 | zdiff = z_max - z_min
125 |
126 | biggestdiff = max([xdiff, ydiff, zdiff])
127 | return biggestdiff
128 |
129 |
130 | def plot_single_pose(num, poses, lines, ax, axrange, scat, contact):
131 | pose = poses[num]
132 | static = contact[num]
133 | indices = [7, 8, 10, 11]
134 |
135 | for i, (point, idx) in enumerate(zip(scat, indices)):
136 | position = pose[idx : idx + 1]
137 | color = "r" if static[i] else "g"
138 | set_scatter_data_3d(point, position, color)
139 |
140 | for i, (p, line) in enumerate(zip(smpl_parents, lines)):
141 | # don't plot root
142 | if i == 0:
143 | continue
144 | # stack to create a line
145 | data = np.stack((pose[i], pose[p]), axis=0)
146 | set_line_data_3d(line, data)
147 |
148 | if num == 0:
149 | if isinstance(axrange, int):
150 | axrange = (axrange, axrange, axrange)
151 | xcenter, ycenter, zcenter = 0, 0, 2.5
152 | stepx, stepy, stepz = axrange[0] / 2, axrange[1] / 2, axrange[2] / 2
153 |
154 | x_min, x_max = xcenter - stepx, xcenter + stepx # 0-1.5, 0+1.5
155 | y_min, y_max = ycenter - stepy, ycenter + stepy # 0-1.5, 0+1.5
156 | z_min, z_max = zcenter - stepz, zcenter + stepz # 2.5-2.5=1, 2.5+1.5=4
157 |
158 | ax.set_xlim(x_min, x_max)
159 | ax.set_ylim(y_min, y_max)
160 | ax.set_zlim(z_min, z_max)
161 |
162 |
163 | def skeleton_render(
164 | poses,
165 | epoch=0,
166 | out="renders",
167 | name="",
168 | sound=True,
169 | stitch=False,
170 | sound_folder="ood_sliced",
171 | contact=None,
172 | render=True
173 | ):
174 | if render:
175 | # generate the pose with FK
176 | Path(out).mkdir(parents=True, exist_ok=True)
177 | num_steps = poses.shape[0]
178 |
179 | fig = plt.figure()
180 | ax = fig.add_subplot(projection="3d")
181 |
182 | point = np.array([0, 0, 1])
183 | normal = np.array([0, 0, 1])
184 | d = -point.dot(normal)
185 | xx, yy = np.meshgrid(np.linspace(-1.5, 1.5, 2), np.linspace(-1.5, 1.5, 2))
186 | z = (-normal[0] * xx - normal[1] * yy - d) * 1.0 / normal[2]
187 | # plot the plane
188 | ax.plot_surface(xx, yy, z, zorder=-11, cmap=cm.twilight)
189 | lines = [
190 | ax.plot([], [], [], zorder=10, linewidth=1.5)[0]
191 | for _ in smpl_parents
192 | ]
193 | scat = [
194 | ax.scatter([], [], [], zorder=10, s=0, cmap=ListedColormap(["r", "g", "b"]))
195 | for _ in range(4)
196 | ]
197 | axrange = 3
198 |
199 | # create contact labels
200 | feet = poses[:, (7, 8, 10, 11)]
201 | feetv = np.zeros(feet.shape[:2])
202 | feetv[:-1] = np.linalg.norm(feet[1:] - feet[:-1], axis=-1)
203 | if contact is None:
204 | contact = feetv < 0.01
205 | else:
206 | contact = contact > 0.95
207 |
208 | # Creating the Animation object
209 | anim = animation.FuncAnimation(
210 | fig,
211 | plot_single_pose,
212 | num_steps,
213 | fargs=(poses, lines, ax, axrange, scat, contact),
214 | interval=1000 // 30,
215 | )
216 | if sound:
217 | # make a temporary directory to save the intermediate gif in
218 | if render:
219 | temp_dir = TemporaryDirectory()
220 | gifname = os.path.join(temp_dir.name, f"{epoch}.gif")
221 | anim.save(gifname)
222 |
223 | # stitch wavs
224 | if stitch:
225 | assert type(name) == list # must be a list of names to do stitching
226 | name_ = [os.path.splitext(x)[0] + ".wav" for x in name]
227 | audio, sr = lr.load(name_[0], sr=None)
228 | ll, half = len(audio), len(audio) // 2
229 | total_wav = np.zeros(ll + half * (len(name_) - 1))
230 | total_wav[:ll] = audio
231 | idx = ll
232 | for n_ in name_[1:]:
233 | audio, sr = lr.load(n_, sr=None)
234 | total_wav[idx : idx + half] = audio[half:]
235 | idx += half
236 | # save a dummy spliced audio
237 | audioname = f"{temp_dir.name}/tempsound.wav" if render else os.path.join(out, f'{epoch}_{"_".join(os.path.splitext(os.path.basename(name[0]))[0].split("_")[:-1])}.wav')
238 | sf.write(audioname, total_wav, sr)
239 | outname = os.path.join(
240 | out,
241 | f'{epoch}_{"_".join(os.path.splitext(os.path.basename(name[0]))[0].split("_")[:-1])}.mp4',
242 | )
243 | else:
244 | assert type(name) == str
245 | assert name != "", "Must provide an audio filename"
246 | audioname = name
247 | outname = os.path.join(
248 | out, f"{epoch}_{os.path.splitext(os.path.basename(name))[0]}.mp4"
249 | )
250 | if render:
251 | out = os.system(
252 | f"ffmpeg -loglevel error -stream_loop 0 -y -i {gifname} -i {audioname} -shortest -c:v libx264 -crf 26 -c:a aac -q:a 4 {outname}"
253 | )
254 | else:
255 | if render:
256 | # actually save the gif
257 | path = os.path.normpath(name)
258 | pathparts = path.split(os.sep)
259 | gifname = os.path.join(out, f"{pathparts[-1][:-4]}.gif")
260 | anim.save(gifname, savefig_kwargs={"transparent": True, "facecolor": "none"},)
261 | plt.close()
262 |
263 |
264 | class SMPLSkeleton:
265 | def __init__(
266 | self, device=None,
267 | ):
268 | offsets = smpl_offsets
269 | parents = smpl_parents
270 | assert len(offsets) == len(parents)
271 | self._offsets = torch.Tensor(offsets).to(device)
272 | self._parents = np.array(parents)
273 | self._compute_metadata()
274 |
275 | def _compute_metadata(self):
276 | self._has_children = np.zeros(len(self._parents)).astype(bool)
277 | for i, parent in enumerate(self._parents):
278 | if parent != -1:
279 | self._has_children[parent] = True
280 |
281 | self._children = []
282 | for i, parent in enumerate(self._parents):
283 | self._children.append([])
284 | for i, parent in enumerate(self._parents):
285 | if parent != -1:
286 | self._children[parent].append(i)
287 |
288 | def forward(self, rotations, root_positions):
289 | """
290 | Perform forward kinematics using the given trajectory and local rotations.
291 | Arguments (where N = batch size, L = sequence length, J = number of joints):
292 | -- rotations: (N, L, J, 3) tensor of axis-angle rotations describing the local rotations of each joint.
293 | -- root_positions: (N, L, 3) tensor describing the root joint positions.
294 | """
295 | assert len(rotations.shape) == 4
296 | assert len(root_positions.shape) == 3
297 | # transform from axis angle to quaternion
298 | rotations = axis_angle_to_quaternion(rotations)
299 |
300 | positions_world = []
301 | rotations_world = []
302 |
303 | expanded_offsets = self._offsets.expand(
304 | rotations.shape[0], # batch_size
305 | rotations.shape[1],
306 | self._offsets.shape[0],
307 | self._offsets.shape[1],
308 | )
309 |
310 | # Parallelize along the batch and time dimensions
311 | for i in range(self._offsets.shape[0]):
312 | if self._parents[i] == -1:
313 | positions_world.append(root_positions)
314 | rotations_world.append(rotations[:, :, 0])
315 | else:
316 | positions_world.append(
317 | quaternion_apply(
318 | rotations_world[self._parents[i]], expanded_offsets[:, :, i]
319 | )
320 | + positions_world[self._parents[i]]
321 | )
322 | if self._has_children[i]:
323 | rotations_world.append(
324 | quaternion_multiply(
325 | rotations_world[self._parents[i]], rotations[:, :, i]
326 | )
327 | )
328 | else:
329 | # This joint is a terminal node -> it would be useless to compute the transformation
330 | rotations_world.append(None)
331 |
332 | return torch.stack(positions_world, dim=3).permute(0, 1, 3, 2)
333 |
--------------------------------------------------------------------------------
/DGSDP.py:
--------------------------------------------------------------------------------
1 | import multiprocessing
2 | import os
3 | import pickle
4 | from functools import partial
5 | from pathlib import Path
6 |
7 | import numpy as np
8 | import torch
9 | import torch.nn.functional as F
10 | import wandb
11 | from accelerate import Accelerator, DistributedDataParallelKwargs
12 | from accelerate.state import AcceleratorState
13 | from torch.utils.data import DataLoader
14 | from tqdm import tqdm
15 |
16 | from dataset.dance_dataset import AISTPPDataset
17 | from dataset.preprocess import increment_path
18 | from model.adan import Adan
19 | from model.diffusion import GaussianDiffusion
20 | from model.model import DanceDecoder
21 | from vis import SMPLSkeleton
22 |
23 |
24 | def wrap(x):
25 | return {f"module.{key}": value for key, value in x.items()}
26 |
27 |
28 | def maybe_wrap(x, num):
29 | return x if num == 1 else wrap(x)
30 |
31 |
32 | class DGSDP:
33 | def __init__(
34 | self,
35 | feature_type,
36 | checkpoint_path="",
37 | normalizer=None,
38 | EMA=True,
39 | learning_rate=0.0002,
40 | weight_decay=0.02,
41 | ):
42 | ddp_kwargs = DistributedDataParallelKwargs(find_unused_parameters=True)
43 | self.accelerator = Accelerator(kwargs_handlers=[ddp_kwargs])
44 | print("self.accelerator.device",self.accelerator.device)
45 | state = AcceleratorState()
46 | num_processes = state.num_processes
47 | self.feature_type = feature_type
48 | use_baseline_feats = feature_type == "baseline"
49 | use_both_feats = feature_type == "both"
50 |
51 | pos_dim = 3
52 | rot_dim = 24 * 6 # 24 joints, 6dof
53 | self.repr_dim = repr_dim = pos_dim + rot_dim + 4
54 |
55 | # feature_dim = 35 if use_baseline_feats else 4800
56 | if use_baseline_feats:
57 | feature_dim = 35+512
58 | else:
59 | feature_dim = 4800+512
60 |
61 | horizon_seconds = 5
62 | FPS = 30
63 | self.horizon = horizon = horizon_seconds * FPS
64 |
65 | self.accelerator.wait_for_everyone()
66 |
67 | checkpoint = None
68 | if checkpoint_path != "":
69 | checkpoint = torch.load(
70 | checkpoint_path, map_location=self.accelerator.device
71 | )
72 | self.normalizer = checkpoint["normalizer"]
73 |
74 | model = DanceDecoder(
75 | nfeats=repr_dim,
76 | seq_len=horizon,
77 | latent_dim=512,
78 | ff_size=1024,
79 | num_layers=8,
80 | num_heads=8,
81 | dropout=0.1,
82 | cond_feature_dim=feature_dim,
83 | activation=F.gelu,
84 | )
85 |
86 | smpl = SMPLSkeleton(self.accelerator.device)
87 | diffusion = GaussianDiffusion(
88 | model,
89 | horizon,
90 | repr_dim,
91 | smpl,
92 | schedule="cosine",
93 | n_timestep=1000,
94 | predict_epsilon=False,
95 | loss_type="l2",
96 | use_p2=False,
97 | cond_drop_prob=0.25,
98 | guidance_weight=2,
99 | )
100 |
101 | print(
102 | "Model has {} parameters".format(sum(y.numel() for y in model.parameters()))
103 | )
104 |
105 | self.model = self.accelerator.prepare(model)
106 | self.diffusion = diffusion.to(self.accelerator.device)
107 | optim = Adan(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
108 | self.optim = self.accelerator.prepare(optim)
109 |
110 | if checkpoint_path != "":
111 | self.model.load_state_dict(
112 | maybe_wrap(
113 | checkpoint["ema_state_dict" if EMA else "model_state_dict"],
114 | num_processes,
115 | )
116 | )
117 |
118 | def eval(self):
119 | self.diffusion.eval()
120 |
121 | def train(self):
122 | self.diffusion.train()
123 |
124 | def prepare(self, objects):
125 | return self.accelerator.prepare(*objects)
126 |
127 | def train_loop(self, opt):
128 | # load datasets
129 | train_tensor_dataset_path = os.path.join(
130 | opt.processed_data_dir, f"train_tensor_dataset.pkl"
131 | )
132 | test_tensor_dataset_path = os.path.join(
133 | opt.processed_data_dir, f"test_tensor_dataset.pkl"
134 | )
135 | if (
136 | not opt.no_cache
137 | and os.path.isfile(train_tensor_dataset_path)
138 | and os.path.isfile(test_tensor_dataset_path)
139 | ):
140 | print('use train_tensor_dataset.pkl and test_tensor_dataset.pkl')
141 | train_dataset = pickle.load(open(train_tensor_dataset_path, "rb"))
142 | test_dataset = pickle.load(open(test_tensor_dataset_path, "rb"))
143 | else:
144 | train_dataset = AISTPPDataset(
145 | data_path=opt.data_path,
146 | backup_path=opt.processed_data_dir,
147 | train=True,
148 | feature_type= self.feature_type,
149 | force_reload=opt.force_reload,
150 | )
151 | test_dataset = AISTPPDataset(
152 | data_path=opt.data_path, # data/
153 | backup_path=opt.processed_data_dir,# data/dataset_backups/
154 | train=False,
155 | feature_type=self.feature_type,
156 | normalizer=train_dataset.normalizer,
157 | force_reload=opt.force_reload,
158 | )
159 | # cache the dataset in case
160 | if self.accelerator.is_main_process:
161 | pickle.dump(train_dataset, open(train_tensor_dataset_path, "wb"))
162 | pickle.dump(test_dataset, open(test_tensor_dataset_path, "wb"))
163 |
164 | # set normalizer
165 | self.normalizer = test_dataset.normalizer
166 |
167 | # data loaders
168 | # decide number of workers based on cpu count
169 | num_cpus = multiprocessing.cpu_count()
170 | train_data_loader = DataLoader(
171 | train_dataset,
172 | batch_size=opt.batch_size,
173 | shuffle=True,
174 | num_workers=min(int(num_cpus * 0.75), 32),
175 | pin_memory=True,
176 | drop_last=True,
177 | )
178 | test_data_loader = DataLoader(
179 | test_dataset,
180 | batch_size=opt.batch_size,
181 | shuffle=True,
182 | num_workers=2,
183 | pin_memory=True,
184 | drop_last=True,
185 | )
186 |
187 | train_data_loader = self.accelerator.prepare(train_data_loader)
188 | # boot up multi-gpu training. test dataloader is only on main process
189 | load_loop = (
190 | partial(tqdm, position=1, desc="Batch")
191 | if self.accelerator.is_main_process
192 | else lambda x: x
193 | )
194 | if self.accelerator.is_main_process:
195 | save_dir = str(increment_path(Path(opt.project) / opt.exp_name))
196 | opt.exp_name = save_dir.split("/")[-1]
197 | wandb.init(project=opt.wandb_pj_name, name=opt.exp_name)
198 | save_dir = Path(save_dir)
199 | wdir = save_dir / "weights"
200 | wdir.mkdir(parents=True, exist_ok=True)
201 |
202 | self.accelerator.wait_for_everyone()
203 | for epoch in range(1, opt.epochs + 1):
204 | print('epoch', epoch)
205 | avg_loss = 0
206 | avg_vloss = 0
207 | avg_fkloss = 0
208 | avg_footloss = 0
209 | # train
210 | self.train()
211 | for step, (x, cond, filename, wavnames) in enumerate(
212 | load_loop(train_data_loader)
213 | ):
214 | styles = []
215 | for i in range(len(wavnames)):
216 | wav = os.path.basename(wavnames[i])
217 | style = wav.split('_')[4]
218 | style = style[:-1]
219 | styles.append(style)
220 | # print(styles)
221 |
222 | style_features = []
223 | for i in range(len(styles)):
224 | path = './data/style_clip/' + styles[i] + '.pkl'
225 | with open(path, 'rb') as f:
226 | data = pickle.load(f)
227 | style_features.append(data[styles[i]])
228 | # print(style_features)
229 | style_features = torch.tensor([item.cpu().detach().numpy() for item in style_features]).cuda()
230 | batchsize, original_dim = style_features.size()
231 | style_tensor = style_features.unsqueeze(1).expand(batchsize, self.horizon, original_dim)
232 |
233 | style_tensor = style_tensor.to(self.accelerator.device)
234 | cond = cond.to(self.accelerator.device)
235 | cond = torch.cat((cond, style_tensor), dim=-1)
236 |
237 | total_loss, (loss, v_loss, fk_loss, foot_loss) = self.diffusion(
238 | x, cond, t_override=None
239 | )
240 | self.optim.zero_grad()
241 | self.accelerator.backward(total_loss)
242 |
243 | self.optim.step()
244 |
245 | # ema update and train loss update only on main
246 | if self.accelerator.is_main_process:
247 | avg_loss += loss.detach().cpu().numpy()
248 | avg_vloss += v_loss.detach().cpu().numpy()
249 | avg_fkloss += fk_loss.detach().cpu().numpy()
250 | avg_footloss += foot_loss.detach().cpu().numpy()
251 | if step % opt.ema_interval == 0:
252 | self.diffusion.ema.update_model_average(
253 | self.diffusion.master_model, self.diffusion.model
254 | )
255 | # Save model
256 | if (epoch % opt.save_interval) == 0:
257 | # everyone waits here for the val loop to finish ( don't start next train epoch early)
258 | self.accelerator.wait_for_everyone()
259 | # save only if on main thread
260 | if self.accelerator.is_main_process:
261 | self.eval()
262 | # log
263 | avg_loss /= len(train_data_loader)
264 | avg_vloss /= len(train_data_loader)
265 | avg_fkloss /= len(train_data_loader)
266 | avg_footloss /= len(train_data_loader)
267 | log_dict = {
268 | "Train Loss": avg_loss,
269 | "V Loss": avg_vloss,
270 | "FK Loss": avg_fkloss,
271 | "Foot Loss": avg_footloss,
272 | }
273 | wandb.log(log_dict)
274 | ckpt = {
275 | "ema_state_dict": self.diffusion.master_model.state_dict(),
276 | "model_state_dict": self.accelerator.unwrap_model(
277 | self.model
278 | ).state_dict(),
279 | "optimizer_state_dict": self.optim.state_dict(),
280 | "normalizer": self.normalizer,
281 | }
282 | torch.save(ckpt, os.path.join(wdir, f"train-{epoch}.pt"))
283 | # generate a sample
284 | render_count = 2
285 | shape = (render_count, self.horizon, self.repr_dim) # shape = (2,150,151)
286 | print("Generating Sample")
287 | # draw a music from the test dataset
288 | (x, cond, filename, wavnames) = next(iter(test_data_loader))
289 | cond = cond.to(self.accelerator.device)
290 |
291 | styles = []
292 | for i in range(len(wavnames)):
293 | wav = os.path.basename(wavnames[i])
294 | style = wav.split('_')[4]
295 | style = style[:-1]
296 | styles.append(style)
297 | # print(styles)
298 |
299 | style_features = []
300 | for i in range(len(styles)):
301 | path = './data/style_clip/' + styles[i] + '.pkl'
302 | with open(path, 'rb') as f:
303 | data = pickle.load(f)
304 | style_features.append(data[styles[i]])
305 | # print(style_features)
306 | style_features = torch.tensor([item.cpu().detach().numpy() for item in style_features]).cuda()
307 | batchsize, original_dim = style_features.size()
308 | style_tensor = style_features.unsqueeze(1).expand(batchsize, self.horizon, original_dim)
309 | style_tensor = style_tensor.to(self.accelerator.device)
310 | cond = torch.cat((cond, style_tensor), dim=-1)
311 |
312 |
313 |
314 | self.diffusion.render_sample(
315 | shape,
316 | cond[:render_count],
317 | self.normalizer,
318 | epoch,
319 | os.path.join(opt.render_dir, "train_" + opt.exp_name),
320 | # fk_out= "eval/motions",
321 | name=wavnames[:render_count],
322 | sound=True,
323 | )
324 | print(f"[MODEL SAVED at Epoch {epoch}]")
325 | if self.accelerator.is_main_process:
326 | wandb.run.finish()
327 |
328 | def render_sample(
329 | self, data_tuple, label, render_dir, render_count=-1, fk_out=None, render=True
330 | ):
331 | _, cond, wavname = data_tuple
332 |
333 | assert len(cond.shape) == 3
334 | if render_count < 0:
335 | render_count = len(cond)
336 | shape = (render_count, self.horizon, self.repr_dim)
337 | cond = cond.to(self.accelerator.device)
338 | self.diffusion.render_sample(
339 | shape,
340 | cond[:render_count],
341 | self.normalizer,
342 | label,
343 | render_dir,
344 | name=wavname[:render_count],
345 | sound=True,
346 | mode="long",
347 | fk_out=fk_out,
348 | render=render
349 | )
350 |
--------------------------------------------------------------------------------
/model/model.py:
--------------------------------------------------------------------------------
1 | from typing import Any, Callable, List, Optional, Union
2 |
3 | import numpy as np
4 | import torch
5 | import torch.nn as nn
6 | from einops import rearrange, reduce, repeat
7 | from einops.layers.torch import Rearrange, Reduce
8 | from torch import Tensor
9 | from torch.nn import functional as F
10 |
11 | from model.rotary_embedding_torch import RotaryEmbedding
12 | from model.utils import PositionalEncoding, SinusoidalPosEmb, prob_mask_like
13 |
14 |
15 | class StyleNorm(nn.Module):
16 | def __init__(self, dim=768, eps=1e-8):
17 | super().__init__()
18 |
19 | self.scale = dim ** -0.5
20 | self.eps = eps
21 |
22 | def forward(self, x, style):
23 | b, d = style.shape
24 | style = style.reshape(b, 1, d)
25 | norm = torch.norm(x, dim=-1, keepdim=True) * self.scale
26 | return x / norm.clamp(min=self.eps) * style
27 |
28 | class DenseFiLM(nn.Module):
29 | """Feature-wise linear modulation (FiLM) generator."""
30 |
31 | def __init__(self, embed_channels):
32 | super().__init__()
33 | self.embed_channels = embed_channels
34 | self.block = nn.Sequential(
35 | nn.Mish(), nn.Linear(embed_channels, embed_channels * 2)
36 | )
37 |
38 | def forward(self, position):
39 | pos_encoding = self.block(position)
40 | pos_encoding = rearrange(pos_encoding, "b c -> b 1 c")
41 | scale_shift = pos_encoding.chunk(2, dim=-1)
42 | return scale_shift
43 |
44 |
45 | def featurewise_affine(x, scale_shift):
46 | scale, shift = scale_shift
47 | return (scale + 1) * x + shift
48 |
49 |
50 | class TransformerEncoderLayer(nn.Module):
51 | def __init__(
52 | self,
53 | d_model: int,
54 | nhead: int,
55 | dim_feedforward: int = 2048,
56 | dropout: float = 0.1,
57 | activation: Union[str, Callable[[Tensor], Tensor]] = F.relu,
58 | layer_norm_eps: float = 1e-5,
59 | batch_first: bool = False,
60 | norm_first: bool = True,
61 | device=None,
62 | dtype=None,
63 | rotary=None,
64 | ) -> None:
65 | super().__init__()
66 | self.d_model = d_model
67 | self.self_attn = nn.MultiheadAttention(
68 | d_model, nhead, dropout=dropout, batch_first=batch_first
69 | )
70 | # Implementation of Feedforward model
71 | self.linear1 = nn.Linear(d_model, dim_feedforward)
72 | self.dropout = nn.Dropout(dropout)
73 | self.linear2 = nn.Linear(dim_feedforward, d_model)
74 |
75 | self.norm_first = norm_first
76 | self.norm1 = nn.LayerNorm(d_model, eps=layer_norm_eps)
77 | self.norm2 = nn.LayerNorm(d_model, eps=layer_norm_eps)
78 | self.dropout1 = nn.Dropout(dropout)
79 | self.dropout2 = nn.Dropout(dropout)
80 | self.activation = activation
81 |
82 | self.rotary = rotary
83 | self.use_rotary = rotary is not None
84 |
85 | def forward(
86 | self,
87 | src: Tensor, # (11,150,512)
88 | src_mask: Optional[Tensor] = None,
89 | src_key_padding_mask: Optional[Tensor] = None,
90 | ) -> Tensor:
91 | x = src
92 | if self.norm_first:
93 | x = x + self._sa_block(self.norm1(x),src_mask, src_key_padding_mask)
94 | x = x + self._ff_block(self.norm2(x))
95 | else:
96 | x = self.norm1(x + self._sa_block(x, src_mask, src_key_padding_mask))
97 | x = self.norm2(x + self._ff_block(x))
98 |
99 |
100 | return x
101 |
102 | # self-attention block
103 | def _sa_block(
104 | self, x: Tensor, attn_mask: Optional[Tensor], key_padding_mask: Optional[Tensor]
105 | ) -> Tensor:
106 | qk = self.rotary.rotate_queries_or_keys(x) if self.use_rotary else x
107 | x = self.self_attn(
108 | qk,
109 | qk,
110 | x,
111 | attn_mask=attn_mask,
112 | key_padding_mask=key_padding_mask,
113 | need_weights=False,
114 | )[0]
115 | return self.dropout1(x)
116 |
117 | # feed forward block
118 | def _ff_block(self, x: Tensor) -> Tensor:
119 | x = self.linear2(self.dropout(self.activation(self.linear1(x))))
120 | return self.dropout2(x)
121 |
122 |
123 | class FiLMTransformerDecoderLayer(
124 | nn.Module):
125 | def __init__(
126 | self,
127 | d_model: int,
128 | nhead: int,
129 | dim_feedforward=2048,
130 | dropout=0.1,
131 | activation=F.relu,
132 | layer_norm_eps=1e-5,
133 | batch_first=False,
134 | norm_first=True,
135 | device=None,
136 | dtype=None,
137 | rotary=None,
138 | ):
139 | super().__init__()
140 | self.self_attn = nn.MultiheadAttention(
141 | d_model, nhead, dropout=dropout, batch_first=batch_first
142 | )
143 | self.multihead_attn = nn.MultiheadAttention(
144 | d_model, nhead, dropout=dropout, batch_first=batch_first
145 | )
146 | # Feedforward
147 | self.linear1 = nn.Linear(d_model, dim_feedforward)
148 | self.dropout = nn.Dropout(dropout)
149 | self.linear2 = nn.Linear(dim_feedforward, d_model)
150 |
151 | self.norm_first = norm_first
152 | self.norm1 = nn.LayerNorm(d_model, eps=layer_norm_eps)
153 | self.norm2 = nn.LayerNorm( d_model, eps=layer_norm_eps)
154 | self.norm3 = nn.LayerNorm(d_model, eps=layer_norm_eps)
155 | self.dropout1 = nn.Dropout(dropout)
156 | self.dropout2 = nn.Dropout(dropout)
157 | self.dropout3 = nn.Dropout(dropout)
158 | self.activation = activation
159 |
160 | self.film1 = DenseFiLM(d_model)
161 | self.film2 = DenseFiLM(d_model)
162 | self.film3 = DenseFiLM(d_model)
163 |
164 | self.style = StyleNorm(d_model)
165 |
166 | self.rotary = rotary
167 | self.use_rotary = rotary is not None
168 |
169 | # x, cond, t
170 | def forward(
171 | self,
172 | tgt,
173 | memory,
174 | t,
175 | style,
176 | tgt_mask=None,
177 | memory_mask=None,
178 | tgt_key_padding_mask=None,
179 | memory_key_padding_mask=None,
180 | ):
181 | x = tgt
182 | if self.norm_first:
183 | # self-attention -> film -> residual
184 | x_1 = self._sa_block(self.norm1(x), tgt_mask, tgt_key_padding_mask)
185 | x = x + featurewise_affine(x_1, self.film1(t))
186 | # cross-attention -> film -> residual
187 | x_2 = self._mha_block(
188 | self.norm2(x), memory, memory_mask, memory_key_padding_mask
189 | )
190 | x = x + featurewise_affine(x_2, self.film2(t))
191 | # feedforward -> film -> residual
192 | x = x + self.style(x,style)
193 | x_3 = self._ff_block(self.norm3(x))
194 | x = x + featurewise_affine(x_3, self.film3(t))
195 | else:
196 | x = self.norm1(
197 | x
198 | + featurewise_affine(
199 | self._sa_block(x, tgt_mask, tgt_key_padding_mask), self.film1(t)
200 | )
201 | )
202 | x = self.norm2(
203 | x
204 | + featurewise_affine(
205 | self._mha_block(x, memory, memory_mask, memory_key_padding_mask),
206 | self.film2(t),
207 | )
208 | )
209 | x = x + self.style(x, style)
210 | x = self.norm3(x + featurewise_affine(self._ff_block(x), self.film3(t)))
211 | return x
212 |
213 | # self-attention block
214 | # qkv
215 | def _sa_block(self, x, attn_mask, key_padding_mask):
216 | qk = self.rotary.rotate_queries_or_keys(x) if self.use_rotary else x
217 | x = self.self_attn(
218 | qk,
219 | qk,
220 | x,
221 | attn_mask=attn_mask,
222 | key_padding_mask=key_padding_mask,
223 | need_weights=False,
224 | )[0]
225 | return self.dropout1(x)
226 |
227 | # multihead attention block
228 | # qkv
229 | def _mha_block(self, x, mem, attn_mask, key_padding_mask):
230 | q = self.rotary.rotate_queries_or_keys(x) if self.use_rotary else x
231 | k = self.rotary.rotate_queries_or_keys(mem) if self.use_rotary else mem
232 | x = self.multihead_attn(
233 | q,
234 | k,
235 | mem,
236 | attn_mask=attn_mask,
237 | key_padding_mask=key_padding_mask,
238 | need_weights=False,
239 | )[0]
240 | return self.dropout2(x)
241 |
242 | # feed forward block
243 | def _ff_block(self, x):
244 | x = self.linear2(self.dropout(self.activation(self.linear1(x))))
245 | return self.dropout3(x)
246 |
247 |
248 | class DecoderLayerStack(nn.Module):
249 | def __init__(self, stack):
250 | super().__init__()
251 | self.stack = stack
252 |
253 | def forward(self, x, cond, t,style):
254 | for layer in self.stack:
255 | x = layer(x, cond, t,style)
256 | return x
257 |
258 |
259 | class DanceDecoder(nn.Module):
260 | def __init__(
261 | self,
262 | nfeats: int,
263 | seq_len: int = 150,
264 | latent_dim: int = 256,
265 | ff_size: int = 1024,
266 | num_layers: int = 4,
267 | num_heads: int = 4,
268 | dropout: float = 0.1,
269 | cond_feature_dim: int = 4800,
270 | activation: Callable[[Tensor], Tensor] = F.gelu,
271 | use_rotary=True,
272 | **kwargs
273 | ) -> None:
274 |
275 | super().__init__()
276 |
277 | self.genre_dim = 512
278 |
279 | self.latent_dim = latent_dim
280 |
281 | output_feats = nfeats
282 |
283 | # positional embeddings
284 | self.rotary = None
285 | self.abs_pos_encoding = nn.Identity()
286 | # if rotary, replace absolute embedding with a rotary embedding instance (absolute becomes an identity)
287 | if use_rotary:
288 | self.rotary = RotaryEmbedding(dim=latent_dim)
289 | else:
290 | self.abs_pos_encoding = PositionalEncoding(
291 | latent_dim, dropout, batch_first=True
292 | )
293 |
294 | # time embedding processing
295 | self.time_mlp = nn.Sequential(
296 | SinusoidalPosEmb(latent_dim), # learned?
297 | nn.Linear(latent_dim, latent_dim * 4),
298 | nn.Mish(),
299 | )
300 |
301 | self.to_time_cond = nn.Sequential(nn.Linear(latent_dim * 4, latent_dim), )
302 |
303 | self.to_time_tokens = nn.Sequential(
304 | nn.Linear(latent_dim * 4, latent_dim * 2), # 2 time tokens
305 | Rearrange("b (r d) -> b r d", r=2),
306 | )
307 |
308 | # null embeddings for guidance dropout
309 | self.null_cond_embed = nn.Parameter(torch.randn(1, seq_len, latent_dim))
310 | self.null_cond_hidden = nn.Parameter(torch.randn(1, latent_dim))
311 |
312 | self.norm_cond = nn.LayerNorm(latent_dim)
313 |
314 | # input projection
315 | self.input_projection = nn.Linear(nfeats, latent_dim)
316 | self.cond_encoder = nn.Sequential()
317 | for _ in range(2):
318 | self.cond_encoder.append(
319 | TransformerEncoderLayer(
320 | d_model=latent_dim,
321 | nhead=num_heads,
322 | dim_feedforward=ff_size,
323 | dropout=dropout,
324 | activation=activation,
325 | batch_first=True,
326 | rotary=self.rotary,
327 | )
328 | )
329 | # conditional projection
330 | self.cond_projection = nn.Linear(cond_feature_dim-self.genre_dim, latent_dim)
331 | self.genre_projection = nn.Linear(self.genre_dim,latent_dim)
332 | self.non_attn_cond_projection = nn.Sequential(
333 | nn.LayerNorm(latent_dim),
334 | nn.Linear(latent_dim, latent_dim),
335 | nn.SiLU(),
336 | nn.Linear(latent_dim, latent_dim),
337 | )
338 | # decoder
339 | # FiLM Transformer
340 | decoderstack = nn.ModuleList([])
341 | for _ in range(num_layers):
342 | decoderstack.append(
343 | FiLMTransformerDecoderLayer(
344 | latent_dim,
345 | num_heads,
346 | dim_feedforward=ff_size,
347 | dropout=dropout,
348 | activation=activation,
349 | batch_first=True,
350 | rotary=self.rotary,
351 | )
352 | )
353 |
354 | self.seqTransDecoder = DecoderLayerStack(decoderstack)
355 |
356 | self.final_layer = nn.Linear(latent_dim, output_feats)
357 |
358 | def guided_forward(self, x, cond_embed, times, guidance_weight):
359 | unc = self.forward(x, cond_embed, times, cond_drop_prob=1)
360 | conditioned = self.forward(x, cond_embed, times, cond_drop_prob=0)
361 | return unc + (conditioned - unc) * guidance_weight
362 |
363 | def forward(
364 | self, x: Tensor, cond_embed: Tensor, times: Tensor, cond_drop_prob: float = 0.0
365 | ):
366 | batch_size, device = x.shape[0], x.device
367 | x = self.input_projection(x)
368 | # add the positional embeddings of the input sequence to provide temporal information
369 | x = self.abs_pos_encoding(x)
370 |
371 | # create music conditional embedding with conditional dropout
372 | keep_mask = prob_mask_like((batch_size,), 1 - cond_drop_prob, device=device)
373 | keep_mask_embed = rearrange(keep_mask,
374 | "b -> b 1 1")
375 | keep_mask_hidden = rearrange(keep_mask,
376 | "b -> b 1")
377 |
378 | genre = cond_embed[:, :, -512:]
379 | cond_embed = cond_embed[:, :, :-512]
380 |
381 | genre = genre[:,0,:]
382 | genre_embed = self.genre_projection(genre)
383 |
384 | cond_tokens = self.cond_projection(cond_embed)
385 |
386 | cond_tokens = self.abs_pos_encoding(cond_tokens)
387 | cond_tokens = self.cond_encoder(cond_tokens)
388 | null_cond_embed = self.null_cond_embed.to(cond_tokens.dtype)
389 | cond_tokens = torch.where(keep_mask_embed, cond_tokens,
390 | null_cond_embed)
391 |
392 |
393 | mean_pooled_cond_tokens = cond_tokens.mean(
394 | dim=-2)
395 | cond_hidden = self.non_attn_cond_projection(
396 | mean_pooled_cond_tokens)
397 |
398 | t_hidden = self.time_mlp(times)
399 |
400 | # project to attention and FiLM conditioning
401 | t = self.to_time_cond(t_hidden)
402 | t_tokens = self.to_time_tokens(
403 | t_hidden)
404 |
405 | # FiLM conditioning
406 | null_cond_hidden = self.null_cond_hidden.to(t.dtype)
407 | cond_hidden = torch.where(keep_mask_hidden, cond_hidden,
408 | null_cond_hidden)
409 | t += cond_hidden
410 | # cross-attention conditioning
411 |
412 | c = torch.cat((cond_tokens, t_tokens),
413 | dim=-2)
414 | cond_tokens = self.norm_cond(
415 | c)
416 |
417 | # Pass through the transformer decoder
418 | # attending to the conditional embedding
419 | output = self.seqTransDecoder(x, cond_tokens, t, style=genre_embed)
420 |
421 | output = self.final_layer(output)
422 | return output
423 |
--------------------------------------------------------------------------------
/model/diffusion.py:
--------------------------------------------------------------------------------
1 | import copy
2 | import os
3 | import pickle
4 | from pathlib import Path
5 | from functools import partial
6 |
7 | import numpy as np
8 | import torch
9 | import torch.nn as nn
10 | import torch.nn.functional as F
11 | from einops import reduce
12 | from p_tqdm import p_map
13 | from pytorch3d.transforms import (axis_angle_to_quaternion,
14 | quaternion_to_axis_angle)
15 | from tqdm import tqdm
16 |
17 | from dataset.quaternion import ax_from_6v, quat_slerp
18 | from vis import skeleton_render
19 |
20 | from .utils import extract, make_beta_schedule
21 |
22 | torch.manual_seed(123)
23 |
24 | def identity(t, *args, **kwargs):
25 | return t
26 |
27 |
28 | class EMA:
29 | def __init__(self, beta):
30 | super().__init__()
31 | self.beta = beta
32 |
33 | def update_model_average(self, ma_model, current_model):
34 | for current_params, ma_params in zip(
35 | current_model.parameters(), ma_model.parameters()
36 | ):
37 | old_weight, up_weight = ma_params.data, current_params.data
38 | ma_params.data = self.update_average(old_weight, up_weight)
39 |
40 | def update_average(self, old, new):
41 | if old is None:
42 | return new
43 | return old * self.beta + (1 - self.beta) * new
44 |
45 |
46 | class GaussianDiffusion(nn.Module):
47 | def __init__(
48 | self,
49 | model,
50 | horizon,
51 | repr_dim,
52 | smpl,
53 | n_timestep=1000,
54 | schedule="linear",
55 | loss_type="l1",
56 | clip_denoised=True,
57 | predict_epsilon=True,
58 | guidance_weight=3,
59 | use_p2=False,
60 | cond_drop_prob=0.2,
61 | ):
62 | super().__init__()
63 | self.horizon = horizon
64 | self.transition_dim = repr_dim
65 | self.model = model
66 | self.ema = EMA(0.9999)
67 | self.master_model = copy.deepcopy(self.model)
68 |
69 | self.cond_drop_prob = cond_drop_prob
70 |
71 | # make a SMPL instance for FK module
72 | self.smpl = smpl
73 |
74 | betas = torch.Tensor(
75 | make_beta_schedule(schedule=schedule, n_timestep=n_timestep)
76 | )
77 | alphas = 1.0 - betas
78 | alphas_cumprod = torch.cumprod(alphas, axis=0)
79 | alphas_cumprod_prev = torch.cat([torch.ones(1), alphas_cumprod[:-1]])
80 |
81 | self.n_timestep = int(n_timestep)
82 | self.clip_denoised = clip_denoised
83 | self.predict_epsilon = predict_epsilon
84 |
85 | self.register_buffer("betas", betas)
86 | self.register_buffer("alphas_cumprod", alphas_cumprod)
87 | self.register_buffer("alphas_cumprod_prev", alphas_cumprod_prev)
88 |
89 | self.guidance_weight = guidance_weight
90 |
91 | # calculations for diffusion q(x_t | x_{t-1}) and others
92 | self.register_buffer("sqrt_alphas_cumprod", torch.sqrt(alphas_cumprod))
93 | self.register_buffer(
94 | "sqrt_one_minus_alphas_cumprod", torch.sqrt(1.0 - alphas_cumprod)
95 | )
96 | self.register_buffer(
97 | "log_one_minus_alphas_cumprod", torch.log(1.0 - alphas_cumprod)
98 | )
99 | self.register_buffer(
100 | "sqrt_recip_alphas_cumprod", torch.sqrt(1.0 / alphas_cumprod)
101 | )
102 | self.register_buffer(
103 | "sqrt_recipm1_alphas_cumprod", torch.sqrt(1.0 / alphas_cumprod - 1)
104 | )
105 |
106 | # calculations for posterior q(x_{t-1} | x_t, x_0)
107 | posterior_variance = (
108 | betas * (1.0 - alphas_cumprod_prev) / (1.0 - alphas_cumprod)
109 | )
110 | self.register_buffer("posterior_variance", posterior_variance)
111 |
112 | ## log calculation clipped because the posterior variance
113 | ## is 0 at the beginning of the diffusion chain
114 | self.register_buffer(
115 | "posterior_log_variance_clipped",
116 | torch.log(torch.clamp(posterior_variance, min=1e-20)),
117 | )
118 | self.register_buffer(
119 | "posterior_mean_coef1",
120 | betas * np.sqrt(alphas_cumprod_prev) / (1.0 - alphas_cumprod),
121 | )
122 | self.register_buffer(
123 | "posterior_mean_coef2",
124 | (1.0 - alphas_cumprod_prev) * np.sqrt(alphas) / (1.0 - alphas_cumprod),
125 | )
126 |
127 | # p2 weighting
128 | self.p2_loss_weight_k = 1
129 | self.p2_loss_weight_gamma = 0.5 if use_p2 else 0
130 | self.register_buffer(
131 | "p2_loss_weight",
132 | (self.p2_loss_weight_k + alphas_cumprod / (1 - alphas_cumprod))
133 | ** -self.p2_loss_weight_gamma,
134 | )
135 |
136 | ## get loss coefficients and initialize objective
137 | self.loss_fn = F.mse_loss if loss_type == "l2" else F.l1_loss
138 |
139 | # ------------------------------------------ sampling ------------------------------------------#
140 |
141 | def predict_start_from_noise(self, x_t, t, noise): # predict_start_from_noise
142 | """
143 | if self.predict_epsilon, model output is (scaled) noise;
144 | otherwise, model predicts x0 directly
145 | """
146 | if self.predict_epsilon:
147 | return (
148 | extract(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t
149 | - extract(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * noise
150 | )
151 | else:
152 | return noise
153 |
154 | def predict_noise_from_start(self, x_t, t, x0):
155 | return (
156 | (extract(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t - x0) / \
157 | extract(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape)
158 | )
159 |
160 | def model_predictions(self, x, cond, t, weight=None, clip_x_start = False):
161 | weight = weight if weight is not None else self.guidance_weight
162 | model_output = self.model.guided_forward(x, cond, t, weight)
163 | maybe_clip = partial(torch.clamp, min = -1., max = 1.) if clip_x_start else identity
164 | x_start = model_output
165 | x_start = maybe_clip(x_start)
166 | pred_noise = self.predict_noise_from_start(x, t, x_start)
167 | return pred_noise, x_start
168 |
169 | def q_posterior(self, x_start, x_t, t):
170 | posterior_mean = (
171 | extract(self.posterior_mean_coef1, t, x_t.shape) * x_start
172 | + extract(self.posterior_mean_coef2, t, x_t.shape) * x_t
173 | )
174 | posterior_variance = extract(self.posterior_variance, t, x_t.shape)
175 | posterior_log_variance_clipped = extract(
176 | self.posterior_log_variance_clipped, t, x_t.shape
177 | )
178 | return posterior_mean, posterior_variance, posterior_log_variance_clipped
179 |
180 | def p_mean_variance(self, x, cond, t):
181 | # guidance clipping
182 | if t[0] > 1.0 * self.n_timestep:
183 | weight = min(self.guidance_weight, 0)
184 | elif t[0] < 0.1 * self.n_timestep:
185 | weight = min(self.guidance_weight, 1)
186 | else:
187 | weight = self.guidance_weight
188 |
189 | x_recon = self.predict_start_from_noise(
190 | x, t=t, noise=self.model.guided_forward(x, cond, t, weight)
191 | )
192 |
193 | if self.clip_denoised:
194 | x_recon.clamp_(-1.0, 1.0)
195 | else:
196 | assert RuntimeError()
197 |
198 | model_mean, posterior_variance, posterior_log_variance = self.q_posterior(
199 | x_start=x_recon, x_t=x, t=t
200 | )
201 | return model_mean, posterior_variance, posterior_log_variance, x_recon
202 |
203 | @torch.no_grad()
204 | def p_sample(self, x, cond, t):
205 | b, *_, device = *x.shape, x.device
206 | model_mean, _, model_log_variance, x_start = self.p_mean_variance(
207 | x=x, cond=cond, t=t
208 | )
209 | noise = torch.randn_like(model_mean)
210 | # no noise when t == 0
211 | nonzero_mask = (1 - (t == 0).float()).reshape(
212 | b, *((1,) * (len(noise.shape) - 1))
213 | )
214 | x_out = model_mean + nonzero_mask * (0.5 * model_log_variance).exp() * noise
215 | return x_out, x_start
216 |
217 | @torch.no_grad()
218 | def p_sample_loop(
219 | self,
220 | shape,
221 | cond,
222 | noise=None,
223 | constraint=None,
224 | return_diffusion=False,
225 | start_point=None,
226 | ):
227 | device = self.betas.device
228 |
229 | # default to diffusion over whole timescale
230 | start_point = self.n_timestep if start_point is None else start_point
231 | batch_size = shape[0]
232 | x = torch.randn(shape, device=device) if noise is None else noise.to(device)
233 | cond = cond.to(device)
234 |
235 | if return_diffusion:
236 | diffusion = [x]
237 |
238 |
239 | for i in tqdm(reversed(range(0, start_point))):
240 | # fill with i
241 | timesteps = torch.full((batch_size,), i, device=device, dtype=torch.long)
242 | x, _ = self.p_sample(x, cond, timesteps)
243 |
244 | if return_diffusion:
245 | diffusion.append(x)
246 | if return_diffusion:
247 | return x, diffusion
248 | else:
249 | return x
250 |
251 | @torch.no_grad()
252 | def ddim_sample(self, shape, cond, **kwargs):
253 | batch, device, total_timesteps, sampling_timesteps, eta = shape[0], self.betas.device, self.n_timestep, 50, 1
254 |
255 | times = torch.linspace(-1, total_timesteps - 1, steps=sampling_timesteps + 1) # [-1, 0, 1, 2, ..., T-1] when sampling_timesteps == total_timesteps
256 | times = list(reversed(times.int().tolist()))
257 | time_pairs = list(zip(times[:-1], times[1:])) # [(T-1, T-2), (T-2, T-3), ..., (1, 0), (0, -1)]
258 |
259 | x = torch.randn(shape, device = device)
260 | cond = cond.to(device)
261 |
262 | x_start = None
263 |
264 | for time, time_next in tqdm(time_pairs, desc = 'sampling loop time step'):
265 | time_cond = torch.full((batch,), time, device=device, dtype=torch.long)
266 | pred_noise, x_start, *_ = self.model_predictions(x, cond, time_cond, clip_x_start = self.clip_denoised)
267 |
268 | if time_next < 0:
269 | x = x_start
270 | continue
271 | alpha = self.alphas_cumprod[time]
272 | alpha_next = self.alphas_cumprod[time_next]
273 |
274 |
275 | sigma = eta * ((1 - alpha / alpha_next) * (1 - alpha_next) / (1 - alpha)).sqrt()
276 | c = (1 - alpha_next - sigma ** 2).sqrt()
277 |
278 | noise = torch.randn_like(x)
279 | x = x_start * alpha_next.sqrt() + \
280 | c * pred_noise + \
281 | sigma * noise
282 | return x
283 |
284 | @torch.no_grad()
285 | def long_ddim_sample(self, shape, cond, **kwargs):
286 | batch, device, total_timesteps, sampling_timesteps, eta = shape[0], self.betas.device, self.n_timestep, 50, 1 #
287 |
288 | if batch == 1:
289 | return self.ddim_sample(shape, cond)
290 |
291 | times = torch.linspace(-1, total_timesteps - 1, steps=sampling_timesteps + 1)
292 | times = list(reversed(times.int().tolist())) # [999,979,959,...19,-1]
293 | weights = np.clip(np.linspace(0, self.guidance_weight * 2, sampling_timesteps), None, self.guidance_weight)
294 | time_pairs = list(zip(times[:-1], times[1:], weights))
295 |
296 |
297 | x = torch.randn(shape, device = device)
298 | cond = cond.to(device)
299 |
300 | assert batch > 1
301 | assert x.shape[1] % 2 == 0
302 | half = x.shape[1] // 2
303 |
304 | x_start = None
305 |
306 |
307 |
308 | for time, time_next, weight in tqdm(time_pairs, desc = 'sampling loop time step'):
309 | time_cond = torch.full((batch,), time, device=device, dtype=torch.long)
310 | pred_noise, x_start, *_ = self.model_predictions(x, cond, time_cond, weight=weight, clip_x_start = self.clip_denoised)
311 |
312 | if time_next < 0:
313 | x = x_start
314 | continue
315 |
316 | alpha = self.alphas_cumprod[time]
317 | alpha_next = self.alphas_cumprod[time_next]
318 |
319 | sigma = eta * ((1 - alpha / alpha_next) * (1 - alpha_next) / (1 - alpha)).sqrt()
320 | c = (1 - alpha_next - sigma ** 2).sqrt()
321 |
322 | noise = torch.randn_like(x)
323 |
324 | x = x_start * alpha_next.sqrt() + \
325 | c * pred_noise + \
326 | sigma * noise
327 |
328 | if time > 0:
329 | # the first half of each sequence is the second half of the previous one
330 | x[1:, :half] = x[:-1, half:]
331 | return x
332 |
333 | @torch.no_grad()
334 | def inpaint_loop(
335 | self,
336 | shape,
337 | cond,
338 | noise=None,
339 | constraint=None,
340 | return_diffusion=False,
341 | start_point=None,
342 | ):
343 | device = self.betas.device
344 | batch_size = shape[0]
345 | x = torch.randn(shape, device=device) if noise is None else noise.to(device)
346 | cond = cond.to(device)
347 | if return_diffusion:
348 | diffusion = [x]
349 | mask = constraint["mask"].to(device) # batch x horizon x channels
350 | value = constraint["value"].to(device) # batch x horizon x channels
351 |
352 | start_point = self.n_timestep if start_point is None else start_point
353 |
354 | for i in tqdm(reversed(range(0, start_point))):
355 | # fill with i
356 | timesteps = torch.full((batch_size,), i, device=device, dtype=torch.long)
357 | # sample x from step i to step i-1
358 | x, _ = self.p_sample(x, cond, timesteps)
359 | # enforce constraint between each denoising step
360 | value_ = self.q_sample(value, timesteps - 1) if (i > 0) else x
361 | x = value_ * mask + (1.0 - mask) * x
362 | if return_diffusion:
363 | diffusion.append(x)
364 |
365 | if return_diffusion:
366 | return x, diffusion
367 | else:
368 | return x
369 |
370 | @torch.no_grad()
371 | def long_inpaint_loop(
372 | self,
373 | shape,
374 | cond,
375 | noise=None,
376 | constraint=None,
377 | return_diffusion=False,
378 | start_point=None,
379 | ):
380 | device = self.betas.device
381 |
382 | batch_size = shape[0]
383 | x = torch.randn(shape, device=device) if noise is None else noise.to(device)
384 | cond = cond.to(device)
385 | if return_diffusion:
386 | diffusion = [x]
387 |
388 | assert x.shape[1] % 2 == 0
389 |
390 | if batch_size == 1:
391 | # there's no continuation to do, just do normal
392 | return self.p_sample_loop(
393 | shape,
394 | cond,
395 | noise=noise,
396 | constraint=constraint,
397 | return_diffusion=return_diffusion,
398 | start_point=start_point,
399 | )
400 |
401 | assert batch_size > 1
402 | half = x.shape[1] // 2
403 |
404 | start_point = self.n_timestep if start_point is None else start_point
405 |
406 | for i in tqdm(reversed(range(0, start_point))):
407 | # fill with i
408 | timesteps = torch.full((batch_size,), i, device=device, dtype=torch.long)
409 |
410 | # sample x from step i to step i-1
411 | x, _ = self.p_sample(x, cond, timesteps)
412 | # enforce constraint between each denoising step
413 | if i > 0:
414 | # the first half of each sequence is the second half of the previous one
415 | x[1:, :half] = x[:-1, half:]
416 |
417 | if return_diffusion:
418 | diffusion.append(x)
419 |
420 | if return_diffusion:
421 | return x, diffusion
422 | else:
423 | return x
424 |
425 | @torch.no_grad()
426 | def conditional_sample(
427 | self, shape, cond, constraint=None, *args, horizon=None, **kwargs
428 | ):
429 | """
430 | conditions : [ (time, state), ... ]
431 | """
432 | device = self.betas.device
433 | horizon = horizon or self.horizon
434 |
435 | return self.p_sample_loop(shape, cond, *args, **kwargs)
436 |
437 | # ------------------------------------------ training ------------------------------------------#
438 |
439 | def q_sample(self, x_start, t, noise=None):
440 | if noise is None:
441 | noise = torch.randn_like(x_start)
442 |
443 | sample = (
444 | extract(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start
445 | + extract(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise
446 | )
447 |
448 | return sample
449 |
450 | def p_losses(self, x_start, cond, t):
451 | noise = torch.randn_like(x_start)
452 |
453 | x_noisy = self.q_sample(x_start=x_start, t=t, noise=noise)
454 |
455 | # reconstruct
456 | x_recon = self.model(x_noisy, cond, t, cond_drop_prob=self.cond_drop_prob)
457 | assert noise.shape == x_recon.shape
458 |
459 |
460 | model_out = x_recon
461 | if self.predict_epsilon: # False
462 | target = noise
463 | else:
464 | target = x_start
465 |
466 | # full reconstruction loss
467 | loss = self.loss_fn(model_out, target, reduction="none")
468 | loss = reduce(loss, "b ... -> b (...)", "mean")
469 |
470 | loss = loss * extract(self.p2_loss_weight, t, loss.shape)
471 |
472 | # split off contact from the rest
473 | model_contact, model_out = torch.split(
474 | model_out, (4, model_out.shape[2] - 4), dim=2
475 | )
476 | target_contact, target = torch.split(target, (4, target.shape[2] - 4), dim=2)
477 |
478 | # velocity loss
479 | target_v = target[:, 1:] - target[:, :-1]
480 | model_out_v = model_out[:, 1:] - model_out[:, :-1]
481 | v_loss = self.loss_fn(model_out_v, target_v, reduction="none")
482 | v_loss = reduce(v_loss, "b ... -> b (...)", "mean")
483 | v_loss = v_loss * extract(self.p2_loss_weight, t, v_loss.shape)
484 |
485 | # FK loss
486 | b, s, c = model_out.shape
487 | # unnormalize
488 | # model_out = self.normalizer.unnormalize(model_out)
489 | # target = self.normalizer.unnormalize(target)
490 | # X, Q
491 | model_x = model_out[:, :, :3]
492 | model_q = ax_from_6v(model_out[:, :, 3:].reshape(b, s, -1, 6))
493 | target_x = target[:, :, :3]
494 | target_q = ax_from_6v(target[:, :, 3:].reshape(b, s, -1, 6))
495 |
496 | # perform FK
497 | model_xp = self.smpl.forward(model_q, model_x)
498 | target_xp = self.smpl.forward(target_q, target_x)
499 |
500 | fk_loss = self.loss_fn(model_xp, target_xp, reduction="none")
501 | fk_loss = reduce(fk_loss, "b ... -> b (...)", "mean")
502 | fk_loss = fk_loss * extract(self.p2_loss_weight, t, fk_loss.shape)
503 |
504 | # foot skate loss
505 | foot_idx = [7, 8, 10, 11]
506 |
507 | # find static indices consistent with model's own predictions
508 | static_idx = model_contact > 0.95
509 | model_feet = model_xp[:, :, foot_idx]
510 | model_foot_v = torch.zeros_like(model_feet)
511 | model_foot_v[:, :-1] = (
512 | model_feet[:, 1:, :, :] - model_feet[:, :-1, :, :]
513 | ) # (N, S-1, 4, 3)
514 | model_foot_v[~static_idx] = 0
515 | foot_loss = self.loss_fn(
516 | model_foot_v, torch.zeros_like(model_foot_v), reduction="none"
517 | )
518 |
519 | foot_loss = reduce(foot_loss, "b ... -> b (...)", "mean")
520 |
521 | losses = (
522 | 0.636 * loss.mean(),
523 | 2.964 * v_loss.mean(),
524 | 0.646 * fk_loss.mean(),
525 | 10.942 * foot_loss.mean(),
526 | )
527 | return sum(losses), losses
528 |
529 | def loss(self, x, cond, t_override=None):
530 | batch_size = len(x)
531 |
532 | if t_override is None:
533 | t = torch.randint(0, self.n_timestep, (batch_size,), device=x.device).long()
534 | else:
535 | t = torch.full((batch_size,), t_override, device=x.device).long()
536 |
537 | return self.p_losses(x, cond, t)
538 |
539 | def forward(self, x, cond, t_override=None):
540 | return self.loss(x, cond, t_override)
541 |
542 | def partial_denoise(self, x, cond, t):
543 | x_noisy = self.noise_to_t(x, t)
544 |
545 | return self.p_sample_loop(x.shape, cond, noise=x_noisy, start_point=t)
546 |
547 | def noise_to_t(self, x, timestep):
548 | batch_size = len(x)
549 |
550 | t = torch.full((batch_size,), timestep, device=x.device).long()
551 |
552 | return self.q_sample(x, t) if timestep > 0 else x
553 |
554 |
555 | def render_sample(
556 | self,
557 | shape,
558 | cond,
559 | normalizer,
560 | epoch,
561 | render_out,
562 | fk_out=None,
563 | name=None,
564 | sound=True,
565 | mode="normal",
566 | noise=None,
567 | constraint=None,
568 | sound_folder="ood_sliced",
569 | start_point=None,
570 | render=True
571 | ):
572 | print('self.guidance_weight',self.guidance_weight)
573 |
574 | if isinstance(shape, tuple):
575 | if mode == "inpaint":
576 | func_class = self.inpaint_loop
577 | elif mode == "normal":
578 | func_class = self.ddim_sample
579 | elif mode == "long":
580 | func_class = self.long_ddim_sample
581 | else:
582 | assert False, "Unrecognized inference mode"
583 | samples = (
584 | func_class(
585 | shape,
586 | cond,
587 | noise=noise,
588 | constraint=constraint,
589 | start_point=start_point,
590 | )
591 | .detach()
592 | .cpu()
593 | )
594 | else:
595 | samples = shape
596 |
597 | samples = normalizer.unnormalize(samples)
598 |
599 | if samples.shape[2] == 151:
600 | sample_contact, samples = torch.split(
601 | samples, (4, samples.shape[2] - 4), dim=2
602 | )
603 | else:
604 | sample_contact = None
605 | # do the FK all at once
606 | b, s, c = samples.shape
607 | pos = samples[:, :, :3].to(cond.device)
608 | q = samples[:, :, 3:].reshape(b, s, 24, 6)
609 | # go 6d to ax
610 | q = ax_from_6v(q).to(cond.device)
611 |
612 | if mode == "long":
613 | b, s, c1, c2 = q.shape
614 | assert s % 2 == 0
615 | half = s // 2
616 | if b > 1:
617 | # if long mode, stitch position using linear interp
618 | fade_out = torch.ones((1, s, 1)).to(pos.device)
619 | fade_in = torch.ones((1, s, 1)).to(pos.device)
620 | fade_out[:, half:, :] = torch.linspace(1, 0, half)[None, :, None].to(
621 | pos.device
622 | )
623 | fade_in[:, :half, :] = torch.linspace(0, 1, half)[None, :, None].to(
624 | pos.device
625 | )
626 | pos[:-1] *= fade_out
627 | pos[1:] *= fade_in
628 |
629 | full_pos = torch.zeros((s + half * (b - 1), 3)).to(pos.device)
630 | idx = 0
631 | for pos_slice in pos:
632 | full_pos[idx : idx + s] += pos_slice
633 | idx += half
634 |
635 | # stitch joint angles with slerp
636 | slerp_weight = torch.linspace(0, 1, half)[None, :, None].to(pos.device)
637 |
638 | left, right = q[:-1, half:], q[1:, :half]
639 | # convert to quat
640 | left, right = (
641 | axis_angle_to_quaternion(left),
642 | axis_angle_to_quaternion(right),
643 | )
644 | merged = quat_slerp(left, right, slerp_weight)
645 | # convert back
646 | merged = quaternion_to_axis_angle(merged)
647 |
648 | full_q = torch.zeros((s + half * (b - 1), c1, c2)).to(pos.device)
649 | full_q[:half] += q[0, :half]
650 | idx = half
651 | for q_slice in merged:
652 | full_q[idx : idx + half] += q_slice
653 | idx += half
654 | full_q[idx : idx + half] += q[-1, half:]
655 | # unsqueeze for fk
656 | full_pos = full_pos.unsqueeze(0)
657 | full_q = full_q.unsqueeze(0)
658 | else:
659 | full_pos = pos
660 | full_q = q
661 | full_pose = (
662 | self.smpl.forward(full_q, full_pos).detach().cpu().numpy()
663 | ) # b, s, 24, 3
664 | # squeeze the batch dimension away and render
665 | '''
666 | skeleton_render(
667 | full_pose[0], #{Tensor:(900,24,3)}
668 | epoch=f"{epoch}",
669 | out=render_out, # 'renders/'
670 | name=name, # {list:11}
671 | sound=sound, # True
672 | stitch=True,
673 | sound_folder=sound_folder, # ood_sliced
674 | render=render # True
675 | )
676 | '''
677 | if fk_out is not None:
678 | outname = f'{epoch}_{"_".join(os.path.splitext(os.path.basename(name[0]))[0].split("_"))}.pkl'
679 | Path(fk_out).mkdir(parents=True, exist_ok=True)
680 | pickle.dump(
681 | {
682 | "smpl_poses": full_q.squeeze(0).reshape((-1, 72)).cpu().numpy(),
683 | "smpl_trans": full_pos.squeeze(0).cpu().numpy(),
684 | "full_pose": full_pose[0],
685 | },
686 | open(os.path.join(fk_out, outname), "wb"),
687 | )
688 | return
689 |
690 | poses = self.smpl.forward(q, pos).detach().cpu().numpy()
691 | sample_contact = (
692 | sample_contact.detach().cpu().numpy()
693 | if sample_contact is not None
694 | else None
695 | )
696 |
697 | def inner(xx):
698 | num, pose = xx
699 | filename = name[num] if name is not None else None
700 | contact = sample_contact[num] if sample_contact is not None else None
701 | skeleton_render(
702 | pose,
703 | epoch=f"e{epoch}_b{num}",
704 | out=render_out,
705 | name=filename,
706 | sound=sound,
707 | contact=contact,
708 | )
709 |
710 | p_map(inner, enumerate(poses))
711 |
712 | if fk_out is not None and mode != "long":
713 | Path(fk_out).mkdir(parents=True, exist_ok=True)
714 | for num, (qq, pos_, filename, pose) in enumerate(zip(q, pos, name, poses)):
715 | path = os.path.normpath(filename)
716 | pathparts = path.split(os.sep)
717 | pathparts[-1] = pathparts[-1].replace("npy", "wav")
718 | # path is like "data/train/features/name"
719 | pathparts[2] = "wav_sliced"
720 | audioname = os.path.join(*pathparts)
721 | outname = f"{epoch}_{num}_{pathparts[-1][:-4]}.pkl"
722 | pickle.dump(
723 | {
724 | "smpl_poses": qq.reshape((-1, 72)).cpu().numpy(),
725 | "smpl_trans": pos_.cpu().numpy(),
726 | "full_pose": pose,
727 | },
728 | open(f"{fk_out}/{outname}", "wb"),
729 | )
730 |
--------------------------------------------------------------------------------
/data/splits/crossmodal_train.txt:
--------------------------------------------------------------------------------
1 | gWA_sFM_cAll_d25_mWA4_ch05
2 | gWA_sFM_cAll_d25_mWA2_ch03
3 | gWA_sFM_cAll_d27_mWA2_ch21
4 | gWA_sFM_cAll_d25_mWA5_ch07
5 | gWA_sFM_cAll_d27_mWA2_ch17
6 | gWA_sFM_cAll_d25_mWA5_ch06
7 | gWA_sFM_cAll_d26_mWA5_ch13
8 | gWA_sFM_cAll_d26_mWA2_ch10
9 | gWA_sFM_cAll_d25_mWA1_ch02
10 | gWA_sFM_cAll_d27_mWA3_ch18
11 | gWA_sFM_cAll_d26_mWA1_ch09
12 | gWA_sFM_cAll_d27_mWA4_ch19
13 | gWA_sFM_cAll_d26_mWA3_ch14
14 | gWA_sFM_cAll_d27_mWA5_ch20
15 | gWA_sFM_cAll_d27_mWA1_ch16
16 | gWA_sFM_cAll_d25_mWA3_ch04
17 | gWA_sFM_cAll_d26_mWA4_ch12
18 | gWA_sFM_cAll_d26_mWA3_ch11
19 | gLH_sBM_cAll_d18_mLH2_ch06
20 | gLH_sBM_cAll_d17_mLH0_ch09
21 | gLH_sBM_cAll_d17_mLH1_ch09
22 | gLH_sBM_cAll_d16_mLH2_ch04
23 | gLH_sFM_cAll_d17_mLH5_ch13
24 | gLH_sFM_cAll_d17_mLH2_ch10
25 | gLH_sBM_cAll_d18_mLH2_ch09
26 | gLH_sFM_cAll_d17_mLH3_ch11
27 | gLH_sBM_cAll_d17_mLH5_ch06
28 | gLH_sBM_cAll_d18_mLH2_ch08
29 | gLH_sBM_cAll_d16_mLH0_ch08
30 | gLH_sFM_cAll_d16_mLH3_ch07
31 | gLH_sBM_cAll_d16_mLH1_ch03
32 | gLH_sBM_cAll_d18_mLH3_ch05
33 | gLH_sBM_cAll_d17_mLH5_ch09
34 | gLH_sBM_cAll_d18_mLH2_ch07
35 | gLH_sFM_cAll_d18_mLH3_ch18
36 | gLH_sBM_cAll_d17_mLH5_ch03
37 | gLH_sBM_cAll_d17_mLH1_ch10
38 | gLH_sBM_cAll_d16_mLH0_ch10
39 | gLH_sFM_cAll_d18_mLH2_ch17
40 | gLH_sBM_cAll_d17_mLH0_ch07
41 | gLH_sBM_cAll_d17_mLH5_ch07
42 | gLH_sBM_cAll_d16_mLH0_ch03
43 | gLH_sBM_cAll_d18_mLH3_ch07
44 | gLH_sBM_cAll_d17_mLH0_ch08
45 | gLH_sBM_cAll_d16_mLH2_ch03
46 | gLH_sBM_cAll_d17_mLH1_ch06
47 | gLH_sFM_cAll_d16_mLH3_ch04
48 | gLH_sBM_cAll_d16_mLH2_ch05
49 | gLH_sBM_cAll_d16_mLH2_ch08
50 | gLH_sBM_cAll_d16_mLH2_ch07
51 | gLH_sBM_cAll_d16_mLH0_ch09
52 | gLH_sBM_cAll_d17_mLH5_ch10
53 | gLH_sBM_cAll_d18_mLH2_ch03
54 | gLH_sBM_cAll_d18_mLH5_ch07
55 | gLH_sBM_cAll_d16_mLH3_ch05
56 | gLH_sFM_cAll_d17_mLH0_ch08
57 | gLH_sBM_cAll_d18_mLH5_ch10
58 | gLH_sBM_cAll_d17_mLH5_ch08
59 | gLH_sBM_cAll_d16_mLH3_ch09
60 | gLH_sBM_cAll_d16_mLH3_ch04
61 | gLH_sFM_cAll_d16_mLH0_ch01
62 | gLH_sBM_cAll_d16_mLH0_ch07
63 | gLH_sBM_cAll_d18_mLH2_ch05
64 | gLH_sBM_cAll_d18_mLH2_ch04
65 | gLH_sBM_cAll_d16_mLH0_ch05
66 | gLH_sFM_cAll_d16_mLH1_ch02
67 | gLH_sBM_cAll_d18_mLH5_ch04
68 | gLH_sBM_cAll_d16_mLH3_ch03
69 | gLH_sBM_cAll_d16_mLH2_ch09
70 | gLH_sBM_cAll_d16_mLH1_ch04
71 | gLH_sBM_cAll_d18_mLH3_ch10
72 | gLH_sBM_cAll_d16_mLH3_ch06
73 | gLH_sBM_cAll_d16_mLH1_ch09
74 | gLH_sBM_cAll_d16_mLH3_ch07
75 | gLH_sBM_cAll_d18_mLH5_ch09
76 | gLH_sBM_cAll_d18_mLH3_ch09
77 | gLH_sBM_cAll_d18_mLH2_ch10
78 | gLH_sBM_cAll_d17_mLH5_ch05
79 | gLH_sBM_cAll_d16_mLH0_ch06
80 | gLH_sBM_cAll_d18_mLH3_ch03
81 | gLH_sBM_cAll_d17_mLH0_ch04
82 | gLH_sBM_cAll_d17_mLH1_ch07
83 | gLH_sBM_cAll_d17_mLH1_ch04
84 | gLH_sFM_cAll_d16_mLH2_ch03
85 | gLH_sBM_cAll_d17_mLH0_ch03
86 | gLH_sBM_cAll_d17_mLH1_ch08
87 | gLH_sFM_cAll_d18_mLH0_ch21
88 | gLH_sBM_cAll_d17_mLH1_ch03
89 | gLH_sBM_cAll_d16_mLH1_ch06
90 | gLH_sBM_cAll_d17_mLH0_ch06
91 | gLH_sBM_cAll_d18_mLH3_ch08
92 | gLH_sBM_cAll_d16_mLH3_ch08
93 | gLH_sBM_cAll_d16_mLH1_ch08
94 | gLH_sFM_cAll_d18_mLH5_ch20
95 | gLH_sBM_cAll_d18_mLH5_ch03
96 | gLH_sFM_cAll_d16_mLH5_ch06
97 | gLH_sBM_cAll_d16_mLH1_ch05
98 | gLH_sBM_cAll_d16_mLH1_ch07
99 | gLH_sFM_cAll_d17_mLH0_ch14
100 | gLH_sBM_cAll_d18_mLH5_ch05
101 | gLH_sFM_cAll_d18_mLH1_ch16
102 | gLH_sBM_cAll_d17_mLH5_ch04
103 | gLH_sBM_cAll_d17_mLH0_ch10
104 | gLH_sFM_cAll_d18_mLH0_ch15
105 | gLH_sBM_cAll_d18_mLH3_ch06
106 | gLH_sBM_cAll_d16_mLH1_ch10
107 | gLH_sFM_cAll_d17_mLH1_ch09
108 | gLH_sBM_cAll_d16_mLH2_ch06
109 | gLH_sBM_cAll_d16_mLH3_ch10
110 | gLH_sBM_cAll_d18_mLH5_ch06
111 | gLH_sBM_cAll_d17_mLH0_ch05
112 | gLH_sBM_cAll_d18_mLH3_ch04
113 | gLH_sBM_cAll_d18_mLH5_ch08
114 | gLH_sBM_cAll_d17_mLH1_ch05
115 | gLH_sBM_cAll_d16_mLH2_ch10
116 | gLH_sBM_cAll_d16_mLH0_ch04
117 | gKR_sFM_cAll_d28_mKR3_ch07
118 | gKR_sBM_cAll_d29_mKR0_ch03
119 | gKR_sBM_cAll_d28_mKR3_ch10
120 | gKR_sFM_cAll_d28_mKR0_ch01
121 | gKR_sBM_cAll_d29_mKR0_ch10
122 | gKR_sBM_cAll_d30_mKR3_ch09
123 | gKR_sBM_cAll_d28_mKR0_ch09
124 | gKR_sBM_cAll_d28_mKR1_ch05
125 | gKR_sFM_cAll_d29_mKR5_ch14
126 | gKR_sBM_cAll_d29_mKR5_ch08
127 | gKR_sFM_cAll_d28_mKR4_ch05
128 | gKR_sBM_cAll_d29_mKR4_ch09
129 | gKR_sBM_cAll_d30_mKR3_ch10
130 | gKR_sBM_cAll_d28_mKR0_ch03
131 | gKR_sBM_cAll_d28_mKR1_ch09
132 | gKR_sBM_cAll_d29_mKR0_ch07
133 | gKR_sBM_cAll_d28_mKR3_ch04
134 | gKR_sBM_cAll_d28_mKR3_ch05
135 | gKR_sBM_cAll_d30_mKR4_ch03
136 | gKR_sFM_cAll_d29_mKR1_ch09
137 | gKR_sFM_cAll_d30_mKR4_ch19
138 | gKR_sBM_cAll_d29_mKR4_ch07
139 | gKR_sBM_cAll_d30_mKR5_ch04
140 | gKR_sBM_cAll_d29_mKR0_ch04
141 | gKR_sBM_cAll_d29_mKR5_ch10
142 | gKR_sFM_cAll_d30_mKR3_ch18
143 | gKR_sFM_cAll_d30_mKR0_ch15
144 | gKR_sBM_cAll_d30_mKR3_ch07
145 | gKR_sBM_cAll_d30_mKR4_ch04
146 | gKR_sBM_cAll_d29_mKR0_ch06
147 | gKR_sBM_cAll_d28_mKR1_ch06
148 | gKR_sBM_cAll_d28_mKR3_ch07
149 | gKR_sBM_cAll_d29_mKR1_ch06
150 | gKR_sBM_cAll_d30_mKR5_ch03
151 | gKR_sBM_cAll_d29_mKR5_ch04
152 | gKR_sBM_cAll_d30_mKR4_ch09
153 | gKR_sBM_cAll_d29_mKR0_ch05
154 | gKR_sBM_cAll_d30_mKR3_ch05
155 | gKR_sFM_cAll_d28_mKR1_ch02
156 | gKR_sBM_cAll_d29_mKR5_ch07
157 | gKR_sBM_cAll_d28_mKR3_ch08
158 | gKR_sBM_cAll_d29_mKR4_ch04
159 | gKR_sBM_cAll_d29_mKR5_ch03
160 | gKR_sFM_cAll_d30_mKR5_ch20
161 | gKR_sBM_cAll_d30_mKR3_ch03
162 | gKR_sBM_cAll_d29_mKR5_ch05
163 | gKR_sBM_cAll_d30_mKR3_ch08
164 | gKR_sBM_cAll_d29_mKR1_ch10
165 | gKR_sBM_cAll_d28_mKR1_ch03
166 | gKR_sBM_cAll_d30_mKR3_ch06
167 | gKR_sBM_cAll_d28_mKR0_ch07
168 | gKR_sBM_cAll_d28_mKR0_ch08
169 | gKR_sFM_cAll_d29_mKR5_ch13
170 | gKR_sBM_cAll_d29_mKR1_ch03
171 | gKR_sBM_cAll_d28_mKR1_ch07
172 | gKR_sBM_cAll_d30_mKR5_ch10
173 | gKR_sBM_cAll_d28_mKR3_ch03
174 | gKR_sBM_cAll_d29_mKR4_ch05
175 | gKR_sBM_cAll_d28_mKR0_ch06
176 | gKR_sBM_cAll_d29_mKR1_ch09
177 | gKR_sBM_cAll_d30_mKR5_ch07
178 | gKR_sBM_cAll_d29_mKR4_ch03
179 | gKR_sBM_cAll_d29_mKR4_ch10
180 | gKR_sBM_cAll_d30_mKR3_ch04
181 | gKR_sBM_cAll_d30_mKR4_ch05
182 | gKR_sBM_cAll_d29_mKR4_ch06
183 | gKR_sBM_cAll_d28_mKR3_ch06
184 | gKR_sBM_cAll_d28_mKR1_ch08
185 | gKR_sBM_cAll_d29_mKR1_ch05
186 | gKR_sBM_cAll_d29_mKR0_ch09
187 | gKR_sBM_cAll_d30_mKR4_ch10
188 | gKR_sBM_cAll_d29_mKR5_ch06
189 | gKR_sBM_cAll_d29_mKR5_ch09
190 | gKR_sFM_cAll_d29_mKR3_ch11
191 | gKR_sBM_cAll_d28_mKR0_ch04
192 | gKR_sBM_cAll_d30_mKR4_ch08
193 | gKR_sFM_cAll_d30_mKR3_ch21
194 | gKR_sBM_cAll_d30_mKR5_ch06
195 | gKR_sBM_cAll_d30_mKR4_ch06
196 | gKR_sBM_cAll_d28_mKR0_ch05
197 | gKR_sBM_cAll_d30_mKR5_ch08
198 | gKR_sFM_cAll_d28_mKR5_ch06
199 | gKR_sBM_cAll_d29_mKR0_ch08
200 | gKR_sBM_cAll_d28_mKR1_ch10
201 | gKR_sBM_cAll_d30_mKR5_ch05
202 | gKR_sBM_cAll_d29_mKR1_ch08
203 | gKR_sBM_cAll_d29_mKR1_ch07
204 | gKR_sBM_cAll_d29_mKR1_ch04
205 | gKR_sBM_cAll_d28_mKR3_ch09
206 | gKR_sBM_cAll_d30_mKR4_ch07
207 | gKR_sBM_cAll_d30_mKR5_ch09
208 | gKR_sFM_cAll_d28_mKR3_ch04
209 | gKR_sBM_cAll_d29_mKR4_ch08
210 | gKR_sFM_cAll_d29_mKR0_ch08
211 | gKR_sFM_cAll_d29_mKR4_ch12
212 | gKR_sBM_cAll_d28_mKR1_ch04
213 | gKR_sBM_cAll_d28_mKR0_ch10
214 | gKR_sFM_cAll_d30_mKR1_ch16
215 | gBR_sBM_cAll_d06_mBR4_ch10
216 | gBR_sBM_cAll_d04_mBR1_ch05
217 | gBR_sBM_cAll_d04_mBR2_ch08
218 | gBR_sBM_cAll_d06_mBR3_ch03
219 | gBR_sBM_cAll_d06_mBR2_ch04
220 | gBR_sFM_cAll_d06_mBR1_ch15
221 | gBR_sFM_cAll_d06_mBR4_ch18
222 | gBR_sBM_cAll_d05_mBR4_ch10
223 | gBR_sBM_cAll_d06_mBR2_ch09
224 | gBR_sBM_cAll_d06_mBR2_ch05
225 | gBR_sBM_cAll_d05_mBR4_ch09
226 | gBR_sBM_cAll_d05_mBR4_ch07
227 | gBR_sFM_cAll_d04_mBR5_ch06
228 | gBR_sBM_cAll_d05_mBR4_ch08
229 | gBR_sBM_cAll_d05_mBR1_ch09
230 | gBR_sFM_cAll_d05_mBR4_ch13
231 | gBR_sBM_cAll_d05_mBR1_ch05
232 | gBR_sBM_cAll_d06_mBR5_ch10
233 | gBR_sBM_cAll_d05_mBR5_ch09
234 | gBR_sBM_cAll_d06_mBR4_ch07
235 | gBR_sBM_cAll_d04_mBR3_ch05
236 | gBR_sBM_cAll_d04_mBR1_ch04
237 | gBR_sFM_cAll_d05_mBR3_ch10
238 | gBR_sBM_cAll_d04_mBR2_ch05
239 | gBR_sFM_cAll_d05_mBR1_ch08
240 | gBR_sFM_cAll_d04_mBR2_ch03
241 | gBR_sBM_cAll_d06_mBR2_ch07
242 | gBR_sBM_cAll_d04_mBR1_ch09
243 | gBR_sBM_cAll_d05_mBR1_ch07
244 | gBR_sBM_cAll_d05_mBR4_ch03
245 | gBR_sBM_cAll_d06_mBR3_ch09
246 | gBR_sBM_cAll_d04_mBR3_ch04
247 | gBR_sBM_cAll_d04_mBR3_ch10
248 | gBR_sFM_cAll_d06_mBR3_ch17
249 | gBR_sBM_cAll_d06_mBR5_ch08
250 | gBR_sBM_cAll_d05_mBR4_ch04
251 | gBR_sFM_cAll_d04_mBR4_ch07
252 | gBR_sBM_cAll_d06_mBR2_ch08
253 | gBR_sBM_cAll_d04_mBR3_ch09
254 | gBR_sFM_cAll_d06_mBR2_ch16
255 | gBR_sBM_cAll_d05_mBR5_ch07
256 | gBR_sBM_cAll_d05_mBR4_ch06
257 | gBR_sBM_cAll_d06_mBR3_ch05
258 | gBR_sBM_cAll_d05_mBR1_ch06
259 | gBR_sBM_cAll_d06_mBR4_ch06
260 | gBR_sFM_cAll_d04_mBR1_ch02
261 | gBR_sFM_cAll_d05_mBR4_ch11
262 | gBR_sBM_cAll_d04_mBR3_ch06
263 | gBR_sFM_cAll_d06_mBR4_ch20
264 | gBR_sBM_cAll_d06_mBR5_ch07
265 | gBR_sBM_cAll_d04_mBR2_ch10
266 | gBR_sBM_cAll_d05_mBR5_ch10
267 | gBR_sBM_cAll_d06_mBR3_ch08
268 | gBR_sFM_cAll_d06_mBR5_ch19
269 | gBR_sBM_cAll_d06_mBR3_ch04
270 | gBR_sBM_cAll_d05_mBR1_ch04
271 | gBR_sBM_cAll_d05_mBR5_ch03
272 | gBR_sBM_cAll_d05_mBR5_ch04
273 | gBR_sBM_cAll_d06_mBR5_ch04
274 | gBR_sBM_cAll_d04_mBR3_ch07
275 | gBR_sFM_cAll_d04_mBR3_ch04
276 | gBR_sBM_cAll_d05_mBR1_ch08
277 | gBR_sFM_cAll_d05_mBR2_ch09
278 | gBR_sBM_cAll_d04_mBR2_ch09
279 | gBR_sBM_cAll_d05_mBR5_ch08
280 | gBR_sBM_cAll_d04_mBR2_ch03
281 | gBR_sBM_cAll_d04_mBR2_ch07
282 | gBR_sBM_cAll_d05_mBR5_ch06
283 | gBR_sBM_cAll_d05_mBR5_ch05
284 | gBR_sBM_cAll_d06_mBR4_ch03
285 | gBR_sBM_cAll_d05_mBR4_ch05
286 | gBR_sBM_cAll_d06_mBR4_ch08
287 | gBR_sBM_cAll_d06_mBR4_ch05
288 | gBR_sBM_cAll_d06_mBR2_ch10
289 | gBR_sBM_cAll_d06_mBR4_ch04
290 | gBR_sBM_cAll_d06_mBR2_ch03
291 | gBR_sBM_cAll_d05_mBR1_ch03
292 | gBR_sBM_cAll_d06_mBR5_ch06
293 | gBR_sBM_cAll_d06_mBR2_ch06
294 | gBR_sBM_cAll_d04_mBR1_ch10
295 | gBR_sBM_cAll_d04_mBR1_ch08
296 | gBR_sBM_cAll_d04_mBR1_ch06
297 | gBR_sBM_cAll_d06_mBR3_ch07
298 | gBR_sBM_cAll_d06_mBR3_ch06
299 | gBR_sBM_cAll_d04_mBR3_ch08
300 | gBR_sFM_cAll_d04_mBR4_ch05
301 | gBR_sBM_cAll_d04_mBR2_ch04
302 | gBR_sBM_cAll_d06_mBR4_ch09
303 | gBR_sBM_cAll_d05_mBR1_ch10
304 | gBR_sFM_cAll_d06_mBR5_ch21
305 | gBR_sFM_cAll_d05_mBR5_ch12
306 | gBR_sBM_cAll_d06_mBR5_ch03
307 | gBR_sBM_cAll_d04_mBR3_ch03
308 | gBR_sFM_cAll_d05_mBR5_ch14
309 | gBR_sBM_cAll_d04_mBR2_ch06
310 | gBR_sBM_cAll_d04_mBR1_ch03
311 | gBR_sBM_cAll_d06_mBR5_ch09
312 | gBR_sBM_cAll_d06_mBR3_ch10
313 | gBR_sBM_cAll_d04_mBR1_ch07
314 | gBR_sBM_cAll_d06_mBR5_ch05
315 | gPO_sFM_cAll_d12_mPO0_ch15
316 | gPO_sFM_cAll_d12_mPO5_ch20
317 | gPO_sFM_cAll_d12_mPO4_ch19
318 | gPO_sFM_cAll_d10_mPO5_ch06
319 | gPO_sFM_cAll_d11_mPO2_ch10
320 | gPO_sFM_cAll_d11_mPO4_ch12
321 | gPO_sFM_cAll_d10_mPO4_ch05
322 | gPO_sFM_cAll_d10_mPO3_ch07
323 | gPO_sFM_cAll_d11_mPO0_ch08
324 | gPO_sFM_cAll_d12_mPO5_ch21
325 | gPO_sFM_cAll_d12_mPO3_ch18
326 | gPO_sFM_cAll_d12_mPO2_ch17
327 | gPO_sFM_cAll_d11_mPO2_ch14
328 | gPO_sFM_cAll_d11_mPO3_ch11
329 | gPO_sFM_cAll_d11_mPO5_ch13
330 | gLO_sFM_cAll_d15_mLO4_ch21
331 | gLO_sFM_cAll_d13_mLO4_ch05
332 | gLO_sFM_cAll_d15_mLO4_ch19
333 | gLO_sFM_cAll_d13_mLO0_ch01
334 | gLO_sFM_cAll_d14_mLO3_ch11
335 | gLO_sFM_cAll_d14_mLO4_ch12
336 | gLO_sFM_cAll_d14_mLO5_ch13
337 | gLO_sFM_cAll_d14_mLO0_ch08
338 | gLO_sFM_cAll_d13_mLO4_ch07
339 | gLO_sFM_cAll_d13_mLO3_ch04
340 | gLO_sFM_cAll_d13_mLO5_ch06
341 | gLO_sFM_cAll_d14_mLO5_ch14
342 | gLO_sFM_cAll_d14_mLO1_ch09
343 | gLO_sFM_cAll_d15_mLO3_ch18
344 | gLO_sFM_cAll_d15_mLO5_ch20
345 | gLO_sFM_cAll_d13_mLO1_ch02
346 | gLO_sFM_cAll_d15_mLO0_ch15
347 | gLO_sFM_cAll_d15_mLO1_ch16
348 | gJB_sBM_cAll_d08_mJB4_ch05
349 | gJB_sBM_cAll_d07_mJB1_ch09
350 | gJB_sBM_cAll_d09_mJB2_ch04
351 | gJB_sBM_cAll_d07_mJB1_ch10
352 | gJB_sBM_cAll_d07_mJB2_ch08
353 | gJB_sBM_cAll_d08_mJB4_ch04
354 | gJB_sBM_cAll_d09_mJB4_ch03
355 | gJB_sBM_cAll_d08_mJB4_ch06
356 | gJB_sBM_cAll_d08_mJB4_ch10
357 | gJB_sFM_cAll_d09_mJB4_ch19
358 | gJB_sBM_cAll_d08_mJB4_ch08
359 | gJB_sBM_cAll_d09_mJB2_ch10
360 | gJB_sBM_cAll_d09_mJB3_ch05
361 | gJB_sBM_cAll_d07_mJB2_ch04
362 | gJB_sBM_cAll_d07_mJB3_ch07
363 | gJB_sFM_cAll_d07_mJB4_ch05
364 | gJB_sBM_cAll_d07_mJB2_ch10
365 | gJB_sBM_cAll_d07_mJB0_ch09
366 | gJB_sBM_cAll_d07_mJB2_ch09
367 | gJB_sBM_cAll_d07_mJB0_ch08
368 | gJB_sFM_cAll_d07_mJB1_ch02
369 | gJB_sFM_cAll_d07_mJB2_ch03
370 | gJB_sBM_cAll_d07_mJB0_ch10
371 | gJB_sBM_cAll_d07_mJB0_ch07
372 | gJB_sBM_cAll_d09_mJB2_ch09
373 | gJB_sBM_cAll_d08_mJB1_ch07
374 | gJB_sFM_cAll_d08_mJB2_ch10
375 | gJB_sBM_cAll_d08_mJB1_ch05
376 | gJB_sBM_cAll_d09_mJB3_ch10
377 | gJB_sBM_cAll_d09_mJB2_ch07
378 | gJB_sBM_cAll_d08_mJB0_ch08
379 | gJB_sBM_cAll_d07_mJB1_ch06
380 | gJB_sBM_cAll_d08_mJB4_ch07
381 | gJB_sBM_cAll_d07_mJB3_ch03
382 | gJB_sBM_cAll_d08_mJB0_ch04
383 | gJB_sBM_cAll_d09_mJB2_ch05
384 | gJB_sBM_cAll_d09_mJB2_ch06
385 | gJB_sFM_cAll_d07_mJB0_ch01
386 | gJB_sBM_cAll_d08_mJB0_ch07
387 | gJB_sBM_cAll_d09_mJB4_ch08
388 | gJB_sFM_cAll_d09_mJB1_ch16
389 | gJB_sBM_cAll_d09_mJB3_ch03
390 | gJB_sBM_cAll_d08_mJB1_ch10
391 | gJB_sFM_cAll_d08_mJB1_ch09
392 | gJB_sBM_cAll_d08_mJB1_ch03
393 | gJB_sBM_cAll_d09_mJB3_ch07
394 | gJB_sBM_cAll_d07_mJB2_ch05
395 | gJB_sBM_cAll_d08_mJB0_ch06
396 | gJB_sBM_cAll_d08_mJB0_ch09
397 | gJB_sBM_cAll_d08_mJB1_ch06
398 | gJB_sBM_cAll_d07_mJB3_ch09
399 | gJB_sFM_cAll_d08_mJB0_ch08
400 | gJB_sBM_cAll_d09_mJB2_ch03
401 | gJB_sBM_cAll_d09_mJB4_ch07
402 | gJB_sBM_cAll_d07_mJB0_ch03
403 | gJB_sBM_cAll_d09_mJB4_ch05
404 | gJB_sBM_cAll_d07_mJB0_ch05
405 | gJB_sBM_cAll_d07_mJB3_ch10
406 | gJB_sBM_cAll_d09_mJB3_ch09
407 | gJB_sBM_cAll_d08_mJB4_ch03
408 | gJB_sBM_cAll_d07_mJB3_ch08
409 | gJB_sBM_cAll_d07_mJB3_ch05
410 | gJB_sFM_cAll_d08_mJB3_ch11
411 | gJB_sBM_cAll_d07_mJB3_ch04
412 | gJB_sFM_cAll_d07_mJB3_ch07
413 | gJB_sBM_cAll_d07_mJB1_ch07
414 | gJB_sBM_cAll_d09_mJB3_ch04
415 | gJB_sBM_cAll_d07_mJB0_ch06
416 | gJB_sFM_cAll_d09_mJB1_ch21
417 | gJB_sBM_cAll_d09_mJB2_ch08
418 | gJB_sBM_cAll_d07_mJB0_ch04
419 | gJB_sBM_cAll_d07_mJB1_ch04
420 | gJB_sBM_cAll_d08_mJB0_ch10
421 | gJB_sBM_cAll_d07_mJB2_ch06
422 | gJB_sBM_cAll_d07_mJB2_ch07
423 | gJB_sBM_cAll_d09_mJB4_ch04
424 | gJB_sBM_cAll_d08_mJB1_ch04
425 | gJB_sFM_cAll_d07_mJB3_ch04
426 | gJB_sFM_cAll_d08_mJB4_ch12
427 | gJB_sBM_cAll_d08_mJB1_ch08
428 | gJB_sBM_cAll_d08_mJB0_ch03
429 | gJB_sBM_cAll_d08_mJB4_ch09
430 | gJB_sBM_cAll_d09_mJB4_ch06
431 | gJB_sBM_cAll_d08_mJB0_ch05
432 | gJB_sBM_cAll_d08_mJB1_ch09
433 | gJB_sBM_cAll_d07_mJB3_ch06
434 | gJB_sBM_cAll_d07_mJB1_ch08
435 | gJB_sBM_cAll_d07_mJB1_ch03
436 | gJB_sFM_cAll_d09_mJB0_ch15
437 | gJB_sBM_cAll_d09_mJB3_ch06
438 | gJB_sFM_cAll_d09_mJB3_ch18
439 | gJB_sBM_cAll_d09_mJB4_ch09
440 | gJB_sBM_cAll_d07_mJB1_ch05
441 | gJB_sBM_cAll_d07_mJB2_ch03
442 | gJB_sFM_cAll_d09_mJB2_ch17
443 | gJB_sBM_cAll_d09_mJB4_ch10
444 | gJB_sBM_cAll_d09_mJB3_ch08
445 | gWA_sBM_cAll_d27_mWA2_ch05
446 | gWA_sBM_cAll_d25_mWA2_ch08
447 | gWA_sBM_cAll_d26_mWA5_ch03
448 | gWA_sBM_cAll_d25_mWA3_ch07
449 | gWA_sBM_cAll_d27_mWA5_ch06
450 | gWA_sBM_cAll_d27_mWA4_ch04
451 | gWA_sBM_cAll_d25_mWA1_ch09
452 | gWA_sBM_cAll_d25_mWA2_ch09
453 | gWA_sBM_cAll_d25_mWA2_ch05
454 | gWA_sBM_cAll_d26_mWA5_ch09
455 | gWA_sBM_cAll_d27_mWA5_ch07
456 | gWA_sBM_cAll_d27_mWA5_ch08
457 | gWA_sBM_cAll_d26_mWA1_ch10
458 | gWA_sBM_cAll_d26_mWA1_ch09
459 | gWA_sBM_cAll_d26_mWA4_ch10
460 | gWA_sBM_cAll_d26_mWA1_ch08
461 | gWA_sBM_cAll_d26_mWA1_ch05
462 | gWA_sBM_cAll_d25_mWA3_ch10
463 | gWA_sBM_cAll_d26_mWA1_ch07
464 | gWA_sBM_cAll_d26_mWA4_ch05
465 | gWA_sBM_cAll_d27_mWA5_ch10
466 | gWA_sBM_cAll_d25_mWA1_ch08
467 | gWA_sBM_cAll_d27_mWA5_ch04
468 | gWA_sBM_cAll_d25_mWA2_ch03
469 | gWA_sBM_cAll_d26_mWA5_ch10
470 | gWA_sBM_cAll_d26_mWA4_ch07
471 | gWA_sBM_cAll_d27_mWA2_ch09
472 | gWA_sBM_cAll_d27_mWA4_ch06
473 | gWA_sBM_cAll_d27_mWA5_ch03
474 | gWA_sBM_cAll_d27_mWA4_ch05
475 | gWA_sBM_cAll_d26_mWA4_ch08
476 | gWA_sBM_cAll_d27_mWA3_ch05
477 | gWA_sBM_cAll_d25_mWA1_ch07
478 | gWA_sBM_cAll_d27_mWA4_ch03
479 | gWA_sBM_cAll_d25_mWA2_ch06
480 | gWA_sBM_cAll_d26_mWA5_ch08
481 | gWA_sBM_cAll_d27_mWA2_ch06
482 | gWA_sBM_cAll_d27_mWA2_ch10
483 | gWA_sBM_cAll_d26_mWA4_ch06
484 | gWA_sBM_cAll_d26_mWA4_ch04
485 | gWA_sBM_cAll_d27_mWA4_ch08
486 | gWA_sBM_cAll_d25_mWA1_ch04
487 | gWA_sBM_cAll_d25_mWA1_ch03
488 | gWA_sBM_cAll_d25_mWA2_ch04
489 | gWA_sBM_cAll_d25_mWA2_ch07
490 | gWA_sBM_cAll_d27_mWA5_ch05
491 | gWA_sBM_cAll_d27_mWA2_ch08
492 | gWA_sBM_cAll_d25_mWA3_ch04
493 | gWA_sBM_cAll_d26_mWA1_ch04
494 | gWA_sBM_cAll_d25_mWA1_ch10
495 | gWA_sBM_cAll_d26_mWA5_ch04
496 | gWA_sBM_cAll_d27_mWA3_ch09
497 | gWA_sBM_cAll_d26_mWA4_ch03
498 | gWA_sBM_cAll_d26_mWA4_ch09
499 | gWA_sBM_cAll_d25_mWA2_ch10
500 | gWA_sBM_cAll_d26_mWA5_ch06
501 | gWA_sBM_cAll_d27_mWA3_ch08
502 | gWA_sBM_cAll_d26_mWA5_ch07
503 | gWA_sBM_cAll_d26_mWA1_ch06
504 | gWA_sBM_cAll_d25_mWA1_ch06
505 | gWA_sBM_cAll_d27_mWA4_ch09
506 | gWA_sBM_cAll_d27_mWA4_ch07
507 | gWA_sBM_cAll_d26_mWA1_ch03
508 | gWA_sBM_cAll_d25_mWA3_ch08
509 | gWA_sBM_cAll_d27_mWA4_ch10
510 | gWA_sBM_cAll_d27_mWA5_ch09
511 | gWA_sBM_cAll_d25_mWA3_ch09
512 | gWA_sBM_cAll_d27_mWA3_ch04
513 | gWA_sBM_cAll_d27_mWA3_ch06
514 | gWA_sBM_cAll_d25_mWA3_ch06
515 | gWA_sBM_cAll_d25_mWA3_ch05
516 | gWA_sBM_cAll_d25_mWA3_ch03
517 | gWA_sBM_cAll_d27_mWA2_ch03
518 | gWA_sBM_cAll_d25_mWA1_ch05
519 | gWA_sBM_cAll_d27_mWA2_ch07
520 | gWA_sBM_cAll_d26_mWA5_ch05
521 | gWA_sBM_cAll_d27_mWA3_ch10
522 | gWA_sBM_cAll_d27_mWA3_ch07
523 | gWA_sBM_cAll_d27_mWA3_ch03
524 | gWA_sBM_cAll_d27_mWA2_ch04
525 | gJS_sBM_cAll_d03_mJS2_ch08
526 | gJS_sBM_cAll_d02_mJS5_ch07
527 | gJS_sBM_cAll_d02_mJS0_ch07
528 | gJS_sBM_cAll_d02_mJS0_ch09
529 | gJS_sBM_cAll_d01_mJS1_ch05
530 | gJS_sBM_cAll_d03_mJS4_ch06
531 | gJS_sBM_cAll_d01_mJS0_ch03
532 | gJS_sBM_cAll_d01_mJS0_ch09
533 | gJS_sFM_cAll_d02_mJS5_ch10
534 | gJS_sBM_cAll_d01_mJS1_ch03
535 | gJS_sFM_cAll_d01_mJS2_ch03
536 | gJS_sFM_cAll_d02_mJS0_ch08
537 | gJS_sBM_cAll_d01_mJS1_ch10
538 | gJS_sBM_cAll_d03_mJS2_ch03
539 | gJS_sBM_cAll_d03_mJS5_ch10
540 | gJS_sFM_cAll_d01_mJS4_ch05
541 | gJS_sFM_cAll_d03_mJS1_ch02
542 | gJS_sBM_cAll_d03_mJS2_ch07
543 | gJS_sBM_cAll_d03_mJS4_ch09
544 | gJS_sFM_cAll_d03_mJS2_ch03
545 | gJS_sBM_cAll_d01_mJS0_ch05
546 | gJS_sBM_cAll_d01_mJS2_ch03
547 | gJS_sBM_cAll_d01_mJS0_ch06
548 | gJS_sBM_cAll_d02_mJS1_ch10
549 | gJS_sBM_cAll_d01_mJS2_ch07
550 | gJS_sBM_cAll_d03_mJS5_ch08
551 | gJS_sFM_cAll_d01_mJS5_ch06
552 | gJS_sBM_cAll_d02_mJS5_ch03
553 | gJS_sBM_cAll_d02_mJS5_ch06
554 | gJS_sBM_cAll_d02_mJS0_ch03
555 | gJS_sBM_cAll_d01_mJS0_ch04
556 | gJS_sBM_cAll_d02_mJS5_ch09
557 | gJS_sBM_cAll_d03_mJS4_ch07
558 | gJS_sBM_cAll_d01_mJS2_ch09
559 | gJS_sBM_cAll_d03_mJS5_ch04
560 | gJS_sBM_cAll_d02_mJS5_ch05
561 | gJS_sFM_cAll_d01_mJS0_ch01
562 | gJS_sBM_cAll_d03_mJS4_ch04
563 | gJS_sBM_cAll_d02_mJS1_ch07
564 | gJS_sBM_cAll_d03_mJS4_ch05
565 | gJS_sFM_cAll_d01_mJS1_ch02
566 | gJS_sBM_cAll_d01_mJS1_ch09
567 | gJS_sBM_cAll_d02_mJS4_ch03
568 | gJS_sBM_cAll_d01_mJS0_ch08
569 | gJS_sBM_cAll_d01_mJS2_ch08
570 | gJS_sBM_cAll_d03_mJS5_ch07
571 | gJS_sFM_cAll_d02_mJS1_ch11
572 | gJS_sBM_cAll_d03_mJS5_ch03
573 | gJS_sFM_cAll_d02_mJS4_ch09
574 | gJS_sBM_cAll_d03_mJS2_ch10
575 | gJS_sBM_cAll_d02_mJS5_ch08
576 | gJS_sBM_cAll_d02_mJS5_ch04
577 | gJS_sBM_cAll_d02_mJS4_ch07
578 | gJS_sFM_cAll_d02_mJS1_ch02
579 | gJS_sBM_cAll_d03_mJS5_ch05
580 | gJS_sBM_cAll_d02_mJS0_ch04
581 | gJS_sBM_cAll_d01_mJS0_ch10
582 | gJS_sBM_cAll_d02_mJS0_ch05
583 | gJS_sBM_cAll_d02_mJS5_ch10
584 | gJS_sBM_cAll_d02_mJS4_ch10
585 | gJS_sBM_cAll_d03_mJS5_ch09
586 | gJS_sBM_cAll_d02_mJS0_ch06
587 | gJS_sFM_cAll_d03_mJS5_ch14
588 | gJS_sBM_cAll_d03_mJS4_ch08
589 | gJS_sBM_cAll_d02_mJS4_ch09
590 | gJS_sFM_cAll_d02_mJS2_ch03
591 | gJS_sBM_cAll_d03_mJS2_ch04
592 | gJS_sBM_cAll_d03_mJS5_ch06
593 | gJS_sBM_cAll_d02_mJS1_ch09
594 | gJS_sBM_cAll_d02_mJS1_ch06
595 | gJS_sBM_cAll_d02_mJS4_ch04
596 | gJS_sBM_cAll_d01_mJS0_ch07
597 | gJS_sBM_cAll_d02_mJS0_ch08
598 | gJS_sBM_cAll_d01_mJS1_ch08
599 | gJS_sBM_cAll_d01_mJS2_ch05
600 | gJS_sBM_cAll_d01_mJS2_ch04
601 | gJS_sFM_cAll_d03_mJS4_ch12
602 | gJS_sBM_cAll_d02_mJS4_ch06
603 | gJS_sBM_cAll_d02_mJS1_ch08
604 | gJS_sBM_cAll_d01_mJS1_ch07
605 | gJS_sBM_cAll_d03_mJS2_ch05
606 | gJS_sBM_cAll_d02_mJS0_ch10
607 | gJS_sBM_cAll_d01_mJS1_ch04
608 | gJS_sBM_cAll_d02_mJS1_ch05
609 | gJS_sBM_cAll_d02_mJS1_ch03
610 | gJS_sFM_cAll_d01_mJS1_ch07
611 | gJS_sBM_cAll_d01_mJS2_ch10
612 | gJS_sBM_cAll_d03_mJS4_ch03
613 | gJS_sBM_cAll_d02_mJS4_ch05
614 | gJS_sFM_cAll_d03_mJS0_ch01
615 | gJS_sBM_cAll_d03_mJS4_ch10
616 | gJS_sBM_cAll_d03_mJS2_ch06
617 | gJS_sBM_cAll_d02_mJS1_ch04
618 | gJS_sFM_cAll_d03_mJS5_ch13
619 | gJS_sBM_cAll_d03_mJS2_ch09
620 | gJS_sBM_cAll_d01_mJS2_ch06
621 | gJS_sBM_cAll_d02_mJS4_ch08
622 | gJS_sBM_cAll_d01_mJS1_ch06
623 | gMH_sBM_cAll_d23_mMH4_ch07
624 | gMH_sBM_cAll_d23_mMH0_ch07
625 | gMH_sBM_cAll_d23_mMH4_ch09
626 | gMH_sBM_cAll_d23_mMH0_ch09
627 | gMH_sBM_cAll_d23_mMH1_ch07
628 | gMH_sBM_cAll_d24_mMH4_ch07
629 | gMH_sBM_cAll_d22_mMH2_ch04
630 | gMH_sBM_cAll_d24_mMH5_ch04
631 | gMH_sBM_cAll_d23_mMH1_ch06
632 | gMH_sBM_cAll_d22_mMH2_ch09
633 | gMH_sBM_cAll_d24_mMH5_ch05
634 | gMH_sBM_cAll_d23_mMH1_ch05
635 | gMH_sBM_cAll_d22_mMH1_ch09
636 | gMH_sBM_cAll_d24_mMH2_ch09
637 | gMH_sBM_cAll_d24_mMH5_ch09
638 | gMH_sBM_cAll_d24_mMH2_ch06
639 | gMH_sBM_cAll_d22_mMH0_ch05
640 | gMH_sBM_cAll_d23_mMH5_ch04
641 | gMH_sBM_cAll_d22_mMH0_ch06
642 | gMH_sBM_cAll_d24_mMH4_ch04
643 | gMH_sBM_cAll_d22_mMH1_ch08
644 | gMH_sBM_cAll_d22_mMH0_ch04
645 | gMH_sBM_cAll_d24_mMH2_ch03
646 | gMH_sBM_cAll_d24_mMH4_ch03
647 | gMH_sBM_cAll_d22_mMH1_ch03
648 | gMH_sBM_cAll_d24_mMH2_ch10
649 | gMH_sBM_cAll_d22_mMH1_ch07
650 | gMH_sBM_cAll_d23_mMH5_ch08
651 | gMH_sBM_cAll_d24_mMH2_ch05
652 | gMH_sBM_cAll_d23_mMH5_ch07
653 | gMH_sBM_cAll_d23_mMH5_ch09
654 | gMH_sBM_cAll_d23_mMH1_ch08
655 | gMH_sBM_cAll_d24_mMH5_ch10
656 | gMH_sBM_cAll_d23_mMH5_ch10
657 | gMH_sBM_cAll_d24_mMH2_ch08
658 | gMH_sBM_cAll_d23_mMH1_ch04
659 | gMH_sBM_cAll_d23_mMH4_ch05
660 | gMH_sBM_cAll_d23_mMH4_ch06
661 | gMH_sBM_cAll_d22_mMH0_ch10
662 | gMH_sBM_cAll_d24_mMH5_ch08
663 | gMH_sBM_cAll_d23_mMH1_ch10
664 | gMH_sBM_cAll_d22_mMH0_ch09
665 | gMH_sBM_cAll_d23_mMH4_ch10
666 | gMH_sBM_cAll_d22_mMH2_ch08
667 | gMH_sBM_cAll_d24_mMH5_ch03
668 | gMH_sBM_cAll_d23_mMH4_ch08
669 | gMH_sBM_cAll_d23_mMH5_ch05
670 | gMH_sBM_cAll_d22_mMH2_ch03
671 | gMH_sBM_cAll_d23_mMH5_ch06
672 | gMH_sBM_cAll_d22_mMH2_ch10
673 | gMH_sBM_cAll_d22_mMH1_ch10
674 | gMH_sBM_cAll_d23_mMH1_ch03
675 | gMH_sBM_cAll_d23_mMH0_ch05
676 | gMH_sBM_cAll_d23_mMH4_ch03
677 | gMH_sBM_cAll_d22_mMH0_ch03
678 | gMH_sBM_cAll_d22_mMH1_ch04
679 | gMH_sBM_cAll_d22_mMH0_ch07
680 | gMH_sBM_cAll_d24_mMH4_ch05
681 | gMH_sBM_cAll_d22_mMH2_ch06
682 | gMH_sBM_cAll_d24_mMH4_ch06
683 | gMH_sBM_cAll_d24_mMH5_ch07
684 | gMH_sBM_cAll_d23_mMH0_ch06
685 | gMH_sBM_cAll_d23_mMH0_ch03
686 | gMH_sBM_cAll_d23_mMH0_ch10
687 | gMH_sBM_cAll_d22_mMH2_ch05
688 | gMH_sBM_cAll_d22_mMH2_ch07
689 | gMH_sBM_cAll_d24_mMH4_ch08
690 | gMH_sBM_cAll_d24_mMH4_ch10
691 | gMH_sBM_cAll_d24_mMH4_ch09
692 | gMH_sBM_cAll_d22_mMH1_ch06
693 | gMH_sBM_cAll_d24_mMH2_ch04
694 | gMH_sBM_cAll_d23_mMH5_ch03
695 | gMH_sBM_cAll_d22_mMH1_ch05
696 | gMH_sBM_cAll_d23_mMH0_ch04
697 | gMH_sBM_cAll_d23_mMH4_ch04
698 | gMH_sBM_cAll_d24_mMH2_ch07
699 | gMH_sBM_cAll_d22_mMH0_ch08
700 | gMH_sBM_cAll_d23_mMH0_ch08
701 | gMH_sBM_cAll_d23_mMH1_ch09
702 | gMH_sBM_cAll_d24_mMH5_ch06
703 | gHO_sBM_cAll_d19_mHO0_ch04
704 | gHO_sBM_cAll_d19_mHO1_ch08
705 | gHO_sBM_cAll_d19_mHO1_ch05
706 | gHO_sBM_cAll_d21_mHO4_ch10
707 | gHO_sBM_cAll_d20_mHO1_ch03
708 | gHO_sBM_cAll_d20_mHO0_ch10
709 | gHO_sBM_cAll_d19_mHO2_ch10
710 | gHO_sFM_cAll_d19_mHO1_ch02
711 | gHO_sBM_cAll_d19_mHO0_ch08
712 | gHO_sBM_cAll_d21_mHO4_ch03
713 | gHO_sBM_cAll_d19_mHO0_ch03
714 | gHO_sBM_cAll_d19_mHO3_ch09
715 | gHO_sBM_cAll_d19_mHO2_ch07
716 | gHO_sBM_cAll_d19_mHO2_ch04
717 | gHO_sBM_cAll_d21_mHO2_ch05
718 | gHO_sFM_cAll_d20_mHO2_ch10
719 | gHO_sBM_cAll_d20_mHO4_ch10
720 | gHO_sBM_cAll_d19_mHO0_ch09
721 | gHO_sBM_cAll_d21_mHO3_ch07
722 | gHO_sBM_cAll_d19_mHO0_ch05
723 | gHO_sBM_cAll_d19_mHO1_ch04
724 | gHO_sBM_cAll_d21_mHO3_ch08
725 | gHO_sFM_cAll_d21_mHO2_ch17
726 | gHO_sFM_cAll_d20_mHO4_ch12
727 | gHO_sBM_cAll_d19_mHO3_ch03
728 | gHO_sBM_cAll_d21_mHO4_ch07
729 | gHO_sBM_cAll_d21_mHO4_ch09
730 | gHO_sFM_cAll_d20_mHO3_ch11
731 | gHO_sBM_cAll_d20_mHO1_ch08
732 | gHO_sBM_cAll_d21_mHO3_ch09
733 | gHO_sBM_cAll_d21_mHO3_ch04
734 | gHO_sBM_cAll_d20_mHO0_ch03
735 | gHO_sBM_cAll_d19_mHO3_ch06
736 | gHO_sBM_cAll_d21_mHO4_ch06
737 | gHO_sFM_cAll_d20_mHO3_ch14
738 | gHO_sFM_cAll_d19_mHO0_ch01
739 | gHO_sBM_cAll_d21_mHO4_ch04
740 | gHO_sBM_cAll_d19_mHO0_ch10
741 | gHO_sBM_cAll_d20_mHO4_ch08
742 | gHO_sBM_cAll_d20_mHO4_ch05
743 | gHO_sBM_cAll_d19_mHO3_ch04
744 | gHO_sBM_cAll_d20_mHO1_ch04
745 | gHO_sBM_cAll_d19_mHO1_ch07
746 | gHO_sBM_cAll_d20_mHO0_ch07
747 | gHO_sBM_cAll_d21_mHO2_ch08
748 | gHO_sBM_cAll_d19_mHO2_ch05
749 | gHO_sBM_cAll_d19_mHO0_ch06
750 | gHO_sFM_cAll_d19_mHO3_ch04
751 | gHO_sBM_cAll_d19_mHO1_ch10
752 | gHO_sBM_cAll_d19_mHO2_ch06
753 | gHO_sBM_cAll_d21_mHO3_ch03
754 | gHO_sFM_cAll_d21_mHO3_ch21
755 | gHO_sBM_cAll_d21_mHO2_ch09
756 | gHO_sBM_cAll_d20_mHO0_ch06
757 | gHO_sFM_cAll_d21_mHO1_ch16
758 | gHO_sBM_cAll_d20_mHO0_ch08
759 | gHO_sBM_cAll_d20_mHO1_ch10
760 | gHO_sBM_cAll_d20_mHO4_ch09
761 | gHO_sBM_cAll_d21_mHO2_ch06
762 | gHO_sBM_cAll_d19_mHO1_ch03
763 | gHO_sBM_cAll_d20_mHO4_ch06
764 | gHO_sBM_cAll_d19_mHO1_ch06
765 | gHO_sBM_cAll_d20_mHO0_ch09
766 | gHO_sFM_cAll_d20_mHO0_ch08
767 | gHO_sBM_cAll_d20_mHO1_ch09
768 | gHO_sFM_cAll_d20_mHO1_ch09
769 | gHO_sFM_cAll_d21_mHO0_ch15
770 | gHO_sBM_cAll_d19_mHO0_ch07
771 | gHO_sBM_cAll_d20_mHO1_ch05
772 | gHO_sBM_cAll_d20_mHO4_ch07
773 | gHO_sBM_cAll_d20_mHO0_ch05
774 | gHO_sBM_cAll_d19_mHO2_ch09
775 | gHO_sBM_cAll_d20_mHO1_ch07
776 | gHO_sBM_cAll_d20_mHO4_ch04
777 | gHO_sBM_cAll_d21_mHO3_ch05
778 | gHO_sBM_cAll_d19_mHO3_ch10
779 | gHO_sFM_cAll_d19_mHO2_ch03
780 | gHO_sBM_cAll_d21_mHO3_ch06
781 | gHO_sFM_cAll_d19_mHO4_ch05
782 | gHO_sBM_cAll_d21_mHO2_ch04
783 | gHO_sBM_cAll_d19_mHO3_ch05
784 | gHO_sBM_cAll_d19_mHO2_ch03
785 | gHO_sBM_cAll_d21_mHO4_ch05
786 | gHO_sBM_cAll_d19_mHO1_ch09
787 | gHO_sBM_cAll_d21_mHO2_ch07
788 | gHO_sBM_cAll_d19_mHO3_ch07
789 | gHO_sBM_cAll_d21_mHO2_ch03
790 | gHO_sFM_cAll_d21_mHO4_ch19
791 | gHO_sBM_cAll_d20_mHO4_ch03
792 | gHO_sBM_cAll_d20_mHO1_ch06
793 | gHO_sBM_cAll_d19_mHO3_ch08
794 | gHO_sFM_cAll_d21_mHO3_ch18
795 | gHO_sBM_cAll_d21_mHO2_ch10
796 | gHO_sBM_cAll_d21_mHO3_ch10
797 | gHO_sBM_cAll_d19_mHO2_ch08
798 | gHO_sBM_cAll_d20_mHO0_ch04
799 | gHO_sFM_cAll_d19_mHO2_ch07
800 | gHO_sBM_cAll_d21_mHO4_ch08
801 | gLO_sBM_cAll_d15_mLO5_ch03
802 | gLO_sBM_cAll_d13_mLO3_ch06
803 | gLO_sBM_cAll_d14_mLO1_ch04
804 | gLO_sBM_cAll_d15_mLO3_ch10
805 | gLO_sBM_cAll_d14_mLO1_ch05
806 | gLO_sBM_cAll_d14_mLO1_ch10
807 | gLO_sBM_cAll_d14_mLO0_ch03
808 | gLO_sBM_cAll_d15_mLO4_ch05
809 | gLO_sBM_cAll_d13_mLO3_ch07
810 | gLO_sBM_cAll_d15_mLO5_ch06
811 | gLO_sBM_cAll_d15_mLO4_ch03
812 | gLO_sBM_cAll_d15_mLO3_ch09
813 | gLO_sBM_cAll_d14_mLO0_ch08
814 | gLO_sBM_cAll_d15_mLO4_ch06
815 | gLO_sBM_cAll_d14_mLO1_ch03
816 | gLO_sBM_cAll_d15_mLO4_ch08
817 | gLO_sBM_cAll_d14_mLO4_ch08
818 | gLO_sBM_cAll_d14_mLO5_ch03
819 | gLO_sBM_cAll_d13_mLO0_ch06
820 | gLO_sBM_cAll_d14_mLO1_ch09
821 | gLO_sBM_cAll_d15_mLO5_ch10
822 | gLO_sBM_cAll_d15_mLO4_ch04
823 | gLO_sBM_cAll_d14_mLO1_ch07
824 | gLO_sBM_cAll_d15_mLO5_ch09
825 | gLO_sBM_cAll_d15_mLO5_ch07
826 | gLO_sBM_cAll_d13_mLO3_ch08
827 | gLO_sBM_cAll_d15_mLO3_ch04
828 | gLO_sBM_cAll_d13_mLO1_ch06
829 | gLO_sBM_cAll_d15_mLO3_ch03
830 | gLO_sBM_cAll_d14_mLO4_ch06
831 | gLO_sBM_cAll_d15_mLO5_ch04
832 | gLO_sBM_cAll_d14_mLO4_ch10
833 | gLO_sBM_cAll_d14_mLO0_ch06
834 | gLO_sBM_cAll_d14_mLO5_ch04
835 | gLO_sBM_cAll_d14_mLO0_ch07
836 | gLO_sBM_cAll_d15_mLO3_ch06
837 | gLO_sBM_cAll_d13_mLO3_ch09
838 | gLO_sBM_cAll_d14_mLO4_ch03
839 | gLO_sBM_cAll_d14_mLO5_ch10
840 | gLO_sBM_cAll_d14_mLO4_ch09
841 | gLO_sBM_cAll_d14_mLO0_ch04
842 | gLO_sBM_cAll_d13_mLO3_ch10
843 | gLO_sBM_cAll_d15_mLO4_ch07
844 | gLO_sBM_cAll_d13_mLO1_ch05
845 | gLO_sBM_cAll_d13_mLO1_ch09
846 | gLO_sBM_cAll_d15_mLO3_ch07
847 | gLO_sBM_cAll_d13_mLO0_ch04
848 | gLO_sBM_cAll_d15_mLO5_ch05
849 | gLO_sBM_cAll_d14_mLO0_ch05
850 | gLO_sBM_cAll_d13_mLO1_ch04
851 | gLO_sBM_cAll_d13_mLO3_ch04
852 | gLO_sBM_cAll_d13_mLO3_ch05
853 | gLO_sBM_cAll_d14_mLO0_ch10
854 | gLO_sBM_cAll_d13_mLO1_ch03
855 | gLO_sBM_cAll_d13_mLO3_ch03
856 | gLO_sBM_cAll_d14_mLO1_ch06
857 | gLO_sBM_cAll_d14_mLO0_ch09
858 | gLO_sBM_cAll_d14_mLO4_ch04
859 | gLO_sBM_cAll_d14_mLO5_ch05
860 | gLO_sBM_cAll_d14_mLO5_ch08
861 | gLO_sBM_cAll_d13_mLO0_ch05
862 | gLO_sBM_cAll_d13_mLO1_ch08
863 | gLO_sBM_cAll_d15_mLO5_ch08
864 | gLO_sBM_cAll_d14_mLO5_ch06
865 | gLO_sBM_cAll_d13_mLO0_ch07
866 | gLO_sBM_cAll_d14_mLO5_ch07
867 | gLO_sBM_cAll_d13_mLO1_ch10
868 | gLO_sBM_cAll_d15_mLO3_ch08
869 | gLO_sBM_cAll_d14_mLO5_ch09
870 | gLO_sBM_cAll_d15_mLO4_ch10
871 | gLO_sBM_cAll_d15_mLO3_ch05
872 | gLO_sBM_cAll_d14_mLO4_ch05
873 | gLO_sBM_cAll_d14_mLO4_ch07
874 | gLO_sBM_cAll_d13_mLO0_ch03
875 | gLO_sBM_cAll_d13_mLO0_ch10
876 | gLO_sBM_cAll_d13_mLO1_ch07
877 | gLO_sBM_cAll_d13_mLO0_ch08
878 | gLO_sBM_cAll_d15_mLO4_ch09
879 | gLO_sBM_cAll_d13_mLO0_ch09
880 | gLO_sBM_cAll_d14_mLO1_ch08
881 | gMH_sFM_cAll_d24_mMH2_ch17
882 | gMH_sFM_cAll_d22_mMH5_ch06
883 | gMH_sFM_cAll_d22_mMH1_ch02
884 | gMH_sFM_cAll_d22_mMH1_ch07
885 | gMH_sFM_cAll_d22_mMH0_ch01
886 | gMH_sFM_cAll_d23_mMH1_ch09
887 | gMH_sFM_cAll_d22_mMH2_ch03
888 | gMH_sFM_cAll_d23_mMH0_ch14
889 | gMH_sFM_cAll_d23_mMH5_ch13
890 | gMH_sFM_cAll_d23_mMH4_ch12
891 | gMH_sFM_cAll_d24_mMH5_ch20
892 | gMH_sFM_cAll_d23_mMH2_ch10
893 | gMH_sFM_cAll_d24_mMH2_ch21
894 | gMH_sFM_cAll_d22_mMH4_ch05
895 | gMH_sFM_cAll_d24_mMH1_ch16
896 | gMH_sFM_cAll_d24_mMH0_ch15
897 | gMH_sFM_cAll_d24_mMH4_ch19
898 | gMH_sFM_cAll_d23_mMH0_ch08
899 | gPO_sBM_cAll_d10_mPO0_ch09
900 | gPO_sBM_cAll_d12_mPO4_ch07
901 | gPO_sBM_cAll_d11_mPO5_ch04
902 | gPO_sBM_cAll_d12_mPO2_ch04
903 | gPO_sBM_cAll_d12_mPO3_ch09
904 | gPO_sBM_cAll_d12_mPO5_ch05
905 | gPO_sBM_cAll_d12_mPO4_ch05
906 | gPO_sBM_cAll_d12_mPO2_ch08
907 | gPO_sBM_cAll_d12_mPO5_ch07
908 | gPO_sBM_cAll_d12_mPO4_ch04
909 | gPO_sBM_cAll_d11_mPO4_ch05
910 | gPO_sBM_cAll_d12_mPO3_ch05
911 | gPO_sBM_cAll_d10_mPO2_ch09
912 | gPO_sFM_cAll_d10_mPO2_ch03
913 | gPO_sBM_cAll_d11_mPO4_ch07
914 | gPO_sBM_cAll_d12_mPO4_ch09
915 | gPO_sBM_cAll_d10_mPO0_ch07
916 | gPO_sBM_cAll_d12_mPO3_ch07
917 | gPO_sBM_cAll_d10_mPO3_ch07
918 | gPO_sBM_cAll_d11_mPO5_ch05
919 | gPO_sBM_cAll_d12_mPO4_ch08
920 | gPO_sBM_cAll_d10_mPO2_ch06
921 | gPO_sBM_cAll_d11_mPO4_ch03
922 | gPO_sBM_cAll_d10_mPO0_ch08
923 | gPO_sBM_cAll_d12_mPO5_ch10
924 | gPO_sBM_cAll_d12_mPO4_ch03
925 | gPO_sBM_cAll_d12_mPO2_ch09
926 | gPO_sBM_cAll_d10_mPO2_ch04
927 | gPO_sBM_cAll_d11_mPO4_ch06
928 | gPO_sBM_cAll_d10_mPO3_ch05
929 | gPO_sBM_cAll_d10_mPO3_ch04
930 | gPO_sBM_cAll_d10_mPO3_ch03
931 | gPO_sBM_cAll_d12_mPO3_ch03
932 | gPO_sBM_cAll_d11_mPO5_ch06
933 | gPO_sBM_cAll_d10_mPO2_ch05
934 | gPO_sBM_cAll_d11_mPO5_ch03
935 | gPO_sBM_cAll_d12_mPO2_ch03
936 | gPO_sBM_cAll_d12_mPO2_ch05
937 | gPO_sBM_cAll_d10_mPO2_ch10
938 | gPO_sBM_cAll_d10_mPO2_ch08
939 | gPO_sBM_cAll_d12_mPO5_ch04
940 | gPO_sBM_cAll_d12_mPO5_ch03
941 | gPO_sBM_cAll_d12_mPO2_ch07
942 | gPO_sBM_cAll_d10_mPO3_ch09
943 | gPO_sBM_cAll_d11_mPO0_ch05
944 | gPO_sBM_cAll_d11_mPO0_ch08
945 | gPO_sBM_cAll_d11_mPO4_ch08
946 | gPO_sBM_cAll_d12_mPO2_ch10
947 | gPO_sBM_cAll_d12_mPO3_ch06
948 | gPO_sBM_cAll_d11_mPO4_ch10
949 | gPO_sBM_cAll_d11_mPO0_ch06
950 | gPO_sBM_cAll_d12_mPO5_ch08
951 | gPO_sBM_cAll_d10_mPO0_ch10
952 | gPO_sBM_cAll_d12_mPO5_ch06
953 | gPO_sBM_cAll_d10_mPO2_ch03
954 | gPO_sBM_cAll_d12_mPO2_ch06
955 | gPO_sBM_cAll_d10_mPO3_ch10
956 | gPO_sFM_cAll_d10_mPO0_ch01
957 | gPO_sBM_cAll_d11_mPO4_ch04
958 | gPO_sBM_cAll_d11_mPO0_ch07
959 | gPO_sBM_cAll_d10_mPO3_ch08
960 | gPO_sBM_cAll_d12_mPO3_ch08
961 | gPO_sBM_cAll_d11_mPO5_ch10
962 | gPO_sBM_cAll_d10_mPO2_ch07
963 | gPO_sBM_cAll_d10_mPO0_ch04
964 | gPO_sBM_cAll_d11_mPO5_ch08
965 | gPO_sBM_cAll_d10_mPO0_ch05
966 | gPO_sBM_cAll_d11_mPO0_ch09
967 | gPO_sBM_cAll_d10_mPO3_ch06
968 | gPO_sBM_cAll_d10_mPO0_ch03
969 | gPO_sBM_cAll_d12_mPO4_ch06
970 | gPO_sBM_cAll_d12_mPO3_ch10
971 | gPO_sBM_cAll_d11_mPO0_ch10
972 | gPO_sBM_cAll_d11_mPO5_ch07
973 | gPO_sBM_cAll_d11_mPO0_ch04
974 | gPO_sBM_cAll_d12_mPO3_ch04
975 | gPO_sBM_cAll_d11_mPO5_ch09
976 | gPO_sBM_cAll_d12_mPO5_ch09
977 | gPO_sBM_cAll_d12_mPO4_ch10
978 | gPO_sBM_cAll_d11_mPO0_ch03
979 | gPO_sBM_cAll_d11_mPO4_ch09
980 | gPO_sBM_cAll_d10_mPO0_ch06
--------------------------------------------------------------------------------
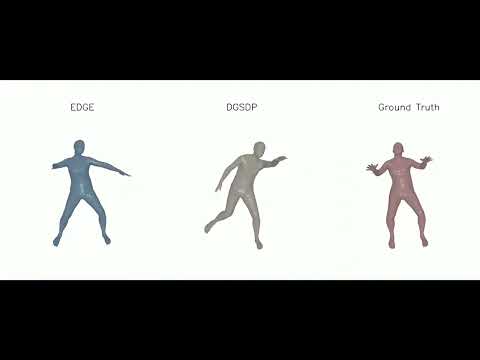 10 |
11 |
12 |
10 |
11 |
12 | 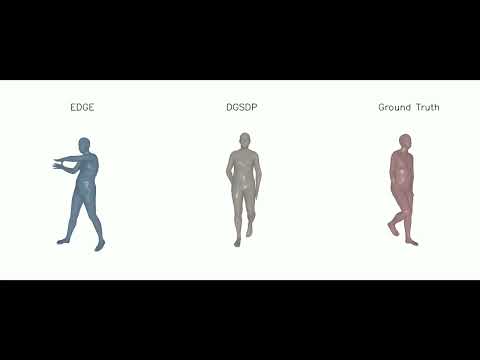 13 |
14 |
13 |
14 |