├── LICENSE
├── README.md
├── a3c.py
├── a3c_ale.py
├── ale.py
├── async.py
├── copy_param.py
├── demo_a3c_ale.py
├── demo_a3c_doom.py
├── doom_env.py
├── dqn_head.py
├── dqn_phi.py
├── environment.py
├── init_like_torch.py
├── nonbias_weight_decay.py
├── plot_scores.py
├── policy.py
├── policy_output.py
├── prepare_output_dir.py
├── random_seed.py
├── rmsprop_async.py
├── run_a3c.py
├── train_a3c_doom.py
├── trained_model
├── breakout_ff
│ ├── 80000000_finish.h5
│ ├── animation.gif
│ ├── scores.txt
│ └── scores.txt.png
└── space_invaders_lstm
│ ├── 80000000_finish.h5
│ ├── animation.gif
│ ├── scores.txt
│ └── scores.txt.png
└── v_function.py
/LICENSE:
--------------------------------------------------------------------------------
1 | The MIT License (MIT)
2 |
3 | Copyright (c) 2016 Yasuhiro Fujita
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Async-RL
2 |
3 | *(2017/02/25) Now the A3C implementation in this repository has been ported into [ChainerRL](https://github.com/pfnet/chainerrl), a Chainer-based deep reinforcement learning library, with some enhancement such as support for continuous actions by Gaussian policies and n-step Q-learning, so I recommend using it instead of this repository.*
4 |
5 | 
6 | 
7 |
8 | This is a repository where I attempt to reproduce the results of [Asynchronous Methods for Deep Reinforcement Learning](http://arxiv.org/abs/1602.01783). Currently I have only replicated A3C FF/LSTM for Atari.
9 |
10 | Any feedback is welcome :)
11 |
12 | ## Supported Features
13 |
14 | - A3C FF/LSTM (only for discrete action space)
15 | - Atari environment
16 | - ViZDoom environment (experimental)
17 |
18 | ## Current Status
19 |
20 | ### A3C FF
21 |
22 | I trained A3C FF for ALE's Breakout with 36 processes (AWS EC2 c4.8xlarge) for 80 million training steps, which took about 17 hours. The mean and median of scores of test runs along training are plotted below. Ten test runs for every 1 million training steps (counted by the global shared counter). The results seems slightly worse than theirs.
23 |
24 | 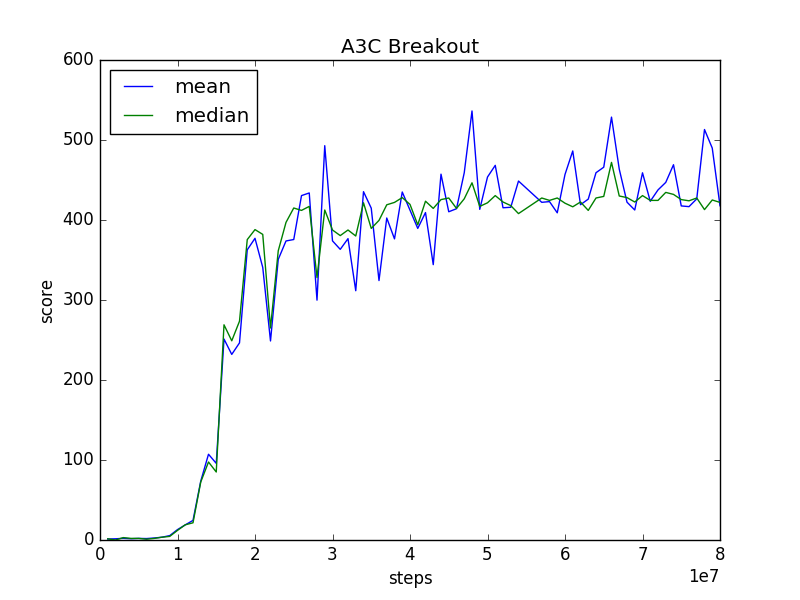 25 |
26 | The trained model is uploaded at `trained_model/breakout_ff/80000000_finish.h5`, so you can make it to play Breakout by the following command:
27 |
28 | ```
29 | python demo_a3c_ale.py trained_model/breakout_ff/80000000_finish.h5
30 | ```
31 |
32 | The animation gif above is the episode I cherry-picked from 10 demo runs using that model.
33 |
34 | ### A3C LSTM
35 |
36 | I also trained A3C LSTM for ALE's Space Invaders in the same manner with A3C FF. Training A3C LSTM took about 24 hours for 80 million training steps.
37 |
38 |
25 |
26 | The trained model is uploaded at `trained_model/breakout_ff/80000000_finish.h5`, so you can make it to play Breakout by the following command:
27 |
28 | ```
29 | python demo_a3c_ale.py trained_model/breakout_ff/80000000_finish.h5
30 | ```
31 |
32 | The animation gif above is the episode I cherry-picked from 10 demo runs using that model.
33 |
34 | ### A3C LSTM
35 |
36 | I also trained A3C LSTM for ALE's Space Invaders in the same manner with A3C FF. Training A3C LSTM took about 24 hours for 80 million training steps.
37 |
38 | 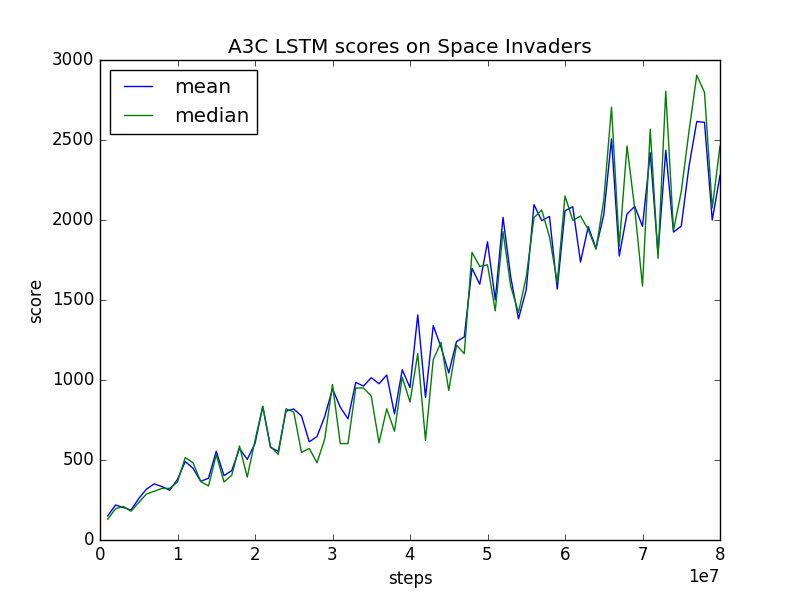 39 |
40 | The trained model is uploaded at `trained_model/space_invaders_lstm/80000000_finish.h5`, so you can make it to play Space Invaders by the following command:
41 |
42 | ```
43 | python demo_a3c_ale.py trained_model/space_invaders_lstm/80000000_finish.h5 --use-lstm
44 | ```
45 |
46 | The animation gif above is the episode I cherry-picked from 10 demo runs using that model.
47 |
48 | ### Implementation details
49 |
50 | I received a confirmation about their implementation details and some hyperparameters by e-mail from Dr. Mnih. I summarized them in the wiki: https://github.com/muupan/async-rl/wiki
51 |
52 | ## Requirements
53 |
54 | - Python 3.5.1
55 | - chainer 1.8.1
56 | - cached-property 1.3.0
57 | - h5py 2.5.0
58 | - Arcade-Learning-Environment
59 |
60 | ## Training
61 |
62 | ```
63 | python a3c_ale.py [--use-lstm]
64 | ```
65 |
66 | `a3c_ale.py` will save best-so-far models and test scores into the output directory.
67 |
68 | Unfortunately it seems this script has some bug now. Please see the issues [#5](https://github.com/muupan/async-rl/issues/5) and [#6](https://github.com/muupan/async-rl/issues/6). I'm trying to fix it.
69 |
70 | ## Evaluation
71 |
72 | ```
73 | python demo_a3c_ale.py [--use-lstm]
74 | ```
75 |
76 | ## Similar Projects
77 |
78 | - https://github.com/miyosuda/async_deep_reinforce
79 |
--------------------------------------------------------------------------------
/a3c.py:
--------------------------------------------------------------------------------
1 | import copy
2 | from logging import getLogger
3 | import os
4 |
5 | import numpy as np
6 | import chainer
7 | from chainer import serializers
8 | from chainer import functions as F
9 |
10 | import copy_param
11 |
12 | logger = getLogger(__name__)
13 |
14 |
15 | class A3CModel(chainer.Link):
16 |
17 | def pi_and_v(self, state, keep_same_state=False):
18 | raise NotImplementedError()
19 |
20 | def reset_state(self):
21 | pass
22 |
23 | def unchain_backward(self):
24 | pass
25 |
26 |
27 | class A3C(object):
28 | """A3C: Asynchronous Advantage Actor-Critic.
29 |
30 | See http://arxiv.org/abs/1602.01783
31 | """
32 |
33 | def __init__(self, model, optimizer, t_max, gamma, beta=1e-2,
34 | process_idx=0, clip_reward=True, phi=lambda x: x,
35 | pi_loss_coef=1.0, v_loss_coef=0.5,
36 | keep_loss_scale_same=False):
37 |
38 | # Globally shared model
39 | self.shared_model = model
40 |
41 | # Thread specific model
42 | self.model = copy.deepcopy(self.shared_model)
43 |
44 | self.optimizer = optimizer
45 | self.t_max = t_max
46 | self.gamma = gamma
47 | self.beta = beta
48 | self.process_idx = process_idx
49 | self.clip_reward = clip_reward
50 | self.phi = phi
51 | self.pi_loss_coef = pi_loss_coef
52 | self.v_loss_coef = v_loss_coef
53 | self.keep_loss_scale_same = keep_loss_scale_same
54 |
55 | self.t = 0
56 | self.t_start = 0
57 | self.past_action_log_prob = {}
58 | self.past_action_entropy = {}
59 | self.past_states = {}
60 | self.past_rewards = {}
61 | self.past_values = {}
62 |
63 | def sync_parameters(self):
64 | copy_param.copy_param(target_link=self.model,
65 | source_link=self.shared_model)
66 |
67 | def act(self, state, reward, is_state_terminal):
68 |
69 | if self.clip_reward:
70 | reward = np.clip(reward, -1, 1)
71 |
72 | if not is_state_terminal:
73 | statevar = chainer.Variable(np.expand_dims(self.phi(state), 0))
74 |
75 | self.past_rewards[self.t - 1] = reward
76 |
77 | if (is_state_terminal and self.t_start < self.t) \
78 | or self.t - self.t_start == self.t_max:
79 |
80 | assert self.t_start < self.t
81 |
82 | if is_state_terminal:
83 | R = 0
84 | else:
85 | _, vout = self.model.pi_and_v(statevar, keep_same_state=True)
86 | R = float(vout.data)
87 |
88 | pi_loss = 0
89 | v_loss = 0
90 | for i in reversed(range(self.t_start, self.t)):
91 | R *= self.gamma
92 | R += self.past_rewards[i]
93 | v = self.past_values[i]
94 | if self.process_idx == 0:
95 | logger.debug('s:%s v:%s R:%s',
96 | self.past_states[i].data.sum(), v.data, R)
97 | advantage = R - v
98 | # Accumulate gradients of policy
99 | log_prob = self.past_action_log_prob[i]
100 | entropy = self.past_action_entropy[i]
101 |
102 | # Log probability is increased proportionally to advantage
103 | pi_loss -= log_prob * float(advantage.data)
104 | # Entropy is maximized
105 | pi_loss -= self.beta * entropy
106 | # Accumulate gradients of value function
107 |
108 | v_loss += (v - R) ** 2 / 2
109 |
110 | if self.pi_loss_coef != 1.0:
111 | pi_loss *= self.pi_loss_coef
112 |
113 | if self.v_loss_coef != 1.0:
114 | v_loss *= self.v_loss_coef
115 |
116 | # Normalize the loss of sequences truncated by terminal states
117 | if self.keep_loss_scale_same and \
118 | self.t - self.t_start < self.t_max:
119 | factor = self.t_max / (self.t - self.t_start)
120 | pi_loss *= factor
121 | v_loss *= factor
122 |
123 | if self.process_idx == 0:
124 | logger.debug('pi_loss:%s v_loss:%s', pi_loss.data, v_loss.data)
125 |
126 | total_loss = pi_loss + F.reshape(v_loss, pi_loss.data.shape)
127 |
128 | # Compute gradients using thread-specific model
129 | self.model.zerograds()
130 | total_loss.backward()
131 | # Copy the gradients to the globally shared model
132 | self.shared_model.zerograds()
133 | copy_param.copy_grad(
134 | target_link=self.shared_model, source_link=self.model)
135 | # Update the globally shared model
136 | if self.process_idx == 0:
137 | norm = self.optimizer.compute_grads_norm()
138 | logger.debug('grad norm:%s', norm)
139 | self.optimizer.update()
140 | if self.process_idx == 0:
141 | logger.debug('update')
142 |
143 | self.sync_parameters()
144 | self.model.unchain_backward()
145 |
146 | self.past_action_log_prob = {}
147 | self.past_action_entropy = {}
148 | self.past_states = {}
149 | self.past_rewards = {}
150 | self.past_values = {}
151 |
152 | self.t_start = self.t
153 |
154 | if not is_state_terminal:
155 | self.past_states[self.t] = statevar
156 | pout, vout = self.model.pi_and_v(statevar)
157 | self.past_action_log_prob[self.t] = pout.sampled_actions_log_probs
158 | self.past_action_entropy[self.t] = pout.entropy
159 | self.past_values[self.t] = vout
160 | self.t += 1
161 | if self.process_idx == 0:
162 | logger.debug('t:%s entropy:%s, probs:%s',
163 | self.t, pout.entropy.data, pout.probs.data)
164 | return pout.action_indices[0]
165 | else:
166 | self.model.reset_state()
167 | return None
168 |
169 | def load_model(self, model_filename):
170 | """Load a network model form a file
171 | """
172 | serializers.load_hdf5(model_filename, self.model)
173 | copy_param.copy_param(target_link=self.model,
174 | source_link=self.shared_model)
175 | opt_filename = model_filename + '.opt'
176 | if os.path.exists(opt_filename):
177 | print('WARNING: {0} was not found, so loaded only a model'.format(
178 | opt_filename))
179 | serializers.load_hdf5(model_filename + '.opt', self.optimizer)
180 |
181 | def save_model(self, model_filename):
182 | """Save a network model to a file
183 | """
184 | serializers.save_hdf5(model_filename, self.model)
185 | serializers.save_hdf5(model_filename + '.opt', self.optimizer)
186 |
--------------------------------------------------------------------------------
/a3c_ale.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import copy
3 | import multiprocessing as mp
4 | import os
5 | import sys
6 | import statistics
7 | import time
8 |
9 | import chainer
10 | from chainer import links as L
11 | from chainer import functions as F
12 | import numpy as np
13 |
14 | import policy
15 | import v_function
16 | import dqn_head
17 | import a3c
18 | import ale
19 | import random_seed
20 | import async
21 | import rmsprop_async
22 | from prepare_output_dir import prepare_output_dir
23 | from nonbias_weight_decay import NonbiasWeightDecay
24 | from init_like_torch import init_like_torch
25 | from dqn_phi import dqn_phi
26 |
27 |
28 | class A3CFF(chainer.ChainList, a3c.A3CModel):
29 |
30 | def __init__(self, n_actions):
31 | self.head = dqn_head.NIPSDQNHead()
32 | self.pi = policy.FCSoftmaxPolicy(
33 | self.head.n_output_channels, n_actions)
34 | self.v = v_function.FCVFunction(self.head.n_output_channels)
35 | super().__init__(self.head, self.pi, self.v)
36 | init_like_torch(self)
37 |
38 | def pi_and_v(self, state, keep_same_state=False):
39 | out = self.head(state)
40 | return self.pi(out), self.v(out)
41 |
42 |
43 | class A3CLSTM(chainer.ChainList, a3c.A3CModel):
44 |
45 | def __init__(self, n_actions):
46 | self.head = dqn_head.NIPSDQNHead()
47 | self.pi = policy.FCSoftmaxPolicy(
48 | self.head.n_output_channels, n_actions)
49 | self.v = v_function.FCVFunction(self.head.n_output_channels)
50 | self.lstm = L.LSTM(self.head.n_output_channels,
51 | self.head.n_output_channels)
52 | super().__init__(self.head, self.lstm, self.pi, self.v)
53 | init_like_torch(self)
54 |
55 | def pi_and_v(self, state, keep_same_state=False):
56 | out = self.head(state)
57 | if keep_same_state:
58 | prev_h, prev_c = self.lstm.h, self.lstm.c
59 | out = self.lstm(out)
60 | self.lstm.h, self.lstm.c = prev_h, prev_c
61 | else:
62 | out = self.lstm(out)
63 | return self.pi(out), self.v(out)
64 |
65 | def reset_state(self):
66 | self.lstm.reset_state()
67 |
68 | def unchain_backward(self):
69 | self.lstm.h.unchain_backward()
70 | self.lstm.c.unchain_backward()
71 |
72 |
73 | def eval_performance(rom, p_func, n_runs):
74 | assert n_runs > 1, 'Computing stdev requires at least two runs'
75 | scores = []
76 | for i in range(n_runs):
77 | env = ale.ALE(rom, treat_life_lost_as_terminal=False)
78 | test_r = 0
79 | while not env.is_terminal:
80 | s = chainer.Variable(np.expand_dims(dqn_phi(env.state), 0))
81 | pout = p_func(s)
82 | a = pout.action_indices[0]
83 | test_r += env.receive_action(a)
84 | scores.append(test_r)
85 | print('test_{}:'.format(i), test_r)
86 | mean = statistics.mean(scores)
87 | median = statistics.median(scores)
88 | stdev = statistics.stdev(scores)
89 | return mean, median, stdev
90 |
91 |
92 | def train_loop(process_idx, counter, max_score, args, agent, env, start_time):
93 | try:
94 |
95 | total_r = 0
96 | episode_r = 0
97 | global_t = 0
98 | local_t = 0
99 |
100 | while True:
101 |
102 | # Get and increment the global counter
103 | with counter.get_lock():
104 | counter.value += 1
105 | global_t = counter.value
106 | local_t += 1
107 |
108 | if global_t > args.steps:
109 | break
110 |
111 | agent.optimizer.lr = (
112 | args.steps - global_t - 1) / args.steps * args.lr
113 |
114 | total_r += env.reward
115 | episode_r += env.reward
116 |
117 | action = agent.act(env.state, env.reward, env.is_terminal)
118 |
119 | if env.is_terminal:
120 | if process_idx == 0:
121 | print('{} global_t:{} local_t:{} lr:{} episode_r:{}'.format(
122 | args.outdir, global_t, local_t, agent.optimizer.lr, episode_r))
123 | episode_r = 0
124 | env.initialize()
125 | else:
126 | env.receive_action(action)
127 |
128 | if global_t % args.eval_frequency == 0:
129 | # Evaluation
130 |
131 | # We must use a copy of the model because test runs can change
132 | # the hidden states of the model
133 | test_model = copy.deepcopy(agent.model)
134 | test_model.reset_state()
135 |
136 | def p_func(s):
137 | pout, _ = test_model.pi_and_v(s)
138 | test_model.unchain_backward()
139 | return pout
140 | mean, median, stdev = eval_performance(
141 | args.rom, p_func, args.eval_n_runs)
142 | with open(os.path.join(args.outdir, 'scores.txt'), 'a+') as f:
143 | elapsed = time.time() - start_time
144 | record = (global_t, elapsed, mean, median, stdev)
145 | print('\t'.join(str(x) for x in record), file=f)
146 | with max_score.get_lock():
147 | if mean > max_score.value:
148 | # Save the best model so far
149 | print('The best score is updated {} -> {}'.format(
150 | max_score.value, mean))
151 | filename = os.path.join(
152 | args.outdir, '{}.h5'.format(global_t))
153 | agent.save_model(filename)
154 | print('Saved the current best model to {}'.format(
155 | filename))
156 | max_score.value = mean
157 |
158 | except KeyboardInterrupt:
159 | if process_idx == 0:
160 | # Save the current model before being killed
161 | agent.save_model(os.path.join(
162 | args.outdir, '{}_keyboardinterrupt.h5'.format(global_t)))
163 | print('Saved the current model to {}'.format(
164 | args.outdir), file=sys.stderr)
165 | raise
166 |
167 | if global_t == args.steps + 1:
168 | # Save the final model
169 | agent.save_model(
170 | os.path.join(args.outdir, '{}_finish.h5'.format(args.steps)))
171 | print('Saved the final model to {}'.format(args.outdir))
172 |
173 |
174 | def train_loop_with_profile(process_idx, counter, max_score, args, agent, env,
175 | start_time):
176 | import cProfile
177 | cmd = 'train_loop(process_idx, counter, max_score, args, agent, env, ' \
178 | 'start_time)'
179 | cProfile.runctx(cmd, globals(), locals(),
180 | 'profile-{}.out'.format(os.getpid()))
181 |
182 |
183 | def main():
184 |
185 | # Prevent numpy from using multiple threads
186 | os.environ['OMP_NUM_THREADS'] = '1'
187 |
188 | import logging
189 | logging.basicConfig(level=logging.DEBUG)
190 |
191 | parser = argparse.ArgumentParser()
192 | parser.add_argument('processes', type=int)
193 | parser.add_argument('rom', type=str)
194 | parser.add_argument('--seed', type=int, default=None)
195 | parser.add_argument('--outdir', type=str, default=None)
196 | parser.add_argument('--use-sdl', action='store_true')
197 | parser.add_argument('--t-max', type=int, default=5)
198 | parser.add_argument('--beta', type=float, default=1e-2)
199 | parser.add_argument('--profile', action='store_true')
200 | parser.add_argument('--steps', type=int, default=8 * 10 ** 7)
201 | parser.add_argument('--lr', type=float, default=7e-4)
202 | parser.add_argument('--eval-frequency', type=int, default=10 ** 6)
203 | parser.add_argument('--eval-n-runs', type=int, default=10)
204 | parser.add_argument('--weight-decay', type=float, default=0.0)
205 | parser.add_argument('--use-lstm', action='store_true')
206 | parser.set_defaults(use_sdl=False)
207 | parser.set_defaults(use_lstm=False)
208 | args = parser.parse_args()
209 |
210 | if args.seed is not None:
211 | random_seed.set_random_seed(args.seed)
212 |
213 | args.outdir = prepare_output_dir(args, args.outdir)
214 |
215 | print('Output files are saved in {}'.format(args.outdir))
216 |
217 | n_actions = ale.ALE(args.rom).number_of_actions
218 |
219 | def model_opt():
220 | if args.use_lstm:
221 | model = A3CLSTM(n_actions)
222 | else:
223 | model = A3CFF(n_actions)
224 | opt = rmsprop_async.RMSpropAsync(lr=7e-4, eps=1e-1, alpha=0.99)
225 | opt.setup(model)
226 | opt.add_hook(chainer.optimizer.GradientClipping(40))
227 | if args.weight_decay > 0:
228 | opt.add_hook(NonbiasWeightDecay(args.weight_decay))
229 | return model, opt
230 |
231 | model, opt = model_opt()
232 |
233 | shared_params = async.share_params_as_shared_arrays(model)
234 | shared_states = async.share_states_as_shared_arrays(opt)
235 |
236 | max_score = mp.Value('f', np.finfo(np.float32).min)
237 | counter = mp.Value('l', 0)
238 | start_time = time.time()
239 |
240 | # Write a header line first
241 | with open(os.path.join(args.outdir, 'scores.txt'), 'a+') as f:
242 | column_names = ('steps', 'elapsed', 'mean', 'median', 'stdev')
243 | print('\t'.join(column_names), file=f)
244 |
245 | def run_func(process_idx):
246 | env = ale.ALE(args.rom, use_sdl=args.use_sdl)
247 | model, opt = model_opt()
248 | async.set_shared_params(model, shared_params)
249 | async.set_shared_states(opt, shared_states)
250 |
251 | agent = a3c.A3C(model, opt, args.t_max, 0.99, beta=args.beta,
252 | process_idx=process_idx, phi=dqn_phi)
253 |
254 | if args.profile:
255 | train_loop_with_profile(process_idx, counter, max_score,
256 | args, agent, env, start_time)
257 | else:
258 | train_loop(process_idx, counter, max_score,
259 | args, agent, env, start_time)
260 |
261 | async.run_async(args.processes, run_func)
262 |
263 |
264 | if __name__ == '__main__':
265 | main()
266 |
--------------------------------------------------------------------------------
/ale.py:
--------------------------------------------------------------------------------
1 | import collections
2 | import os
3 | import sys
4 |
5 | import numpy as np
6 | from ale_python_interface import ALEInterface
7 | import cv2
8 |
9 | import environment
10 |
11 |
12 | class ALE(environment.EpisodicEnvironment):
13 | """Arcade Learning Environment.
14 | """
15 |
16 | def __init__(self, rom_filename, seed=None, use_sdl=False, n_last_screens=4,
17 | frame_skip=4, treat_life_lost_as_terminal=True,
18 | crop_or_scale='scale', max_start_nullops=30,
19 | record_screen_dir=None):
20 | self.n_last_screens = n_last_screens
21 | self.treat_life_lost_as_terminal = treat_life_lost_as_terminal
22 | self.crop_or_scale = crop_or_scale
23 | self.max_start_nullops = max_start_nullops
24 |
25 | ale = ALEInterface()
26 | if seed is not None:
27 | assert seed >= 0 and seed < 2 ** 16, \
28 | "ALE's random seed must be represented by unsigned int"
29 | else:
30 | # Use numpy's random state
31 | seed = np.random.randint(0, 2 ** 16)
32 | ale.setInt(b'random_seed', seed)
33 | ale.setFloat(b'repeat_action_probability', 0.0)
34 | ale.setBool(b'color_averaging', False)
35 | if record_screen_dir is not None:
36 | ale.setString(b'record_screen_dir', str.encode(record_screen_dir))
37 | self.frame_skip = frame_skip
38 | if use_sdl:
39 | if 'DISPLAY' not in os.environ:
40 | raise RuntimeError(
41 | 'Please set DISPLAY environment variable for use_sdl=True')
42 | # SDL settings below are from the ALE python example
43 | if sys.platform == 'darwin':
44 | import pygame
45 | pygame.init()
46 | ale.setBool(b'sound', False) # Sound doesn't work on OSX
47 | elif sys.platform.startswith('linux'):
48 | ale.setBool(b'sound', True)
49 | ale.setBool(b'display_screen', True)
50 | ale.loadROM(str.encode(rom_filename))
51 |
52 | assert ale.getFrameNumber() == 0
53 |
54 |
55 | self.ale = ale
56 | self.legal_actions = ale.getMinimalActionSet()
57 | self.initialize()
58 |
59 | def current_screen(self):
60 | # Max of two consecutive frames
61 | assert self.last_raw_screen is not None
62 | rgb_img = np.maximum(self.ale.getScreenRGB(), self.last_raw_screen)
63 | # Make sure the last raw screen is used only once
64 | self.last_raw_screen = None
65 | assert rgb_img.shape == (210, 160, 3)
66 | # RGB -> Luminance
67 | img = rgb_img[:, :, 0] * 0.2126 + rgb_img[:, :, 1] * \
68 | 0.0722 + rgb_img[:, :, 2] * 0.7152
69 | img = img.astype(np.uint8)
70 | if img.shape == (250, 160):
71 | raise RuntimeError("This ROM is for PAL. Please use ROMs for NTSC")
72 | assert img.shape == (210, 160)
73 | if self.crop_or_scale == 'crop':
74 | # Shrink (210, 160) -> (110, 84)
75 | img = cv2.resize(img, (84, 110),
76 | interpolation=cv2.INTER_LINEAR)
77 | assert img.shape == (110, 84)
78 | # Crop (110, 84) -> (84, 84)
79 | unused_height = 110 - 84
80 | bottom_crop = 8
81 | top_crop = unused_height - bottom_crop
82 | img = img[top_crop: 110 - bottom_crop, :]
83 | elif self.crop_or_scale == 'scale':
84 | img = cv2.resize(img, (84, 84),
85 | interpolation=cv2.INTER_LINEAR)
86 | else:
87 | raise RuntimeError('crop_or_scale must be either crop or scale')
88 | assert img.shape == (84, 84)
89 | return img
90 |
91 | @property
92 | def state(self):
93 | assert len(self.last_screens) == 4
94 | return list(self.last_screens)
95 |
96 | @property
97 | def is_terminal(self):
98 | if self.treat_life_lost_as_terminal:
99 | return self.lives_lost or self.ale.game_over()
100 | else:
101 | return self.ale.game_over()
102 |
103 | @property
104 | def reward(self):
105 | return self._reward
106 |
107 | @property
108 | def number_of_actions(self):
109 | return len(self.legal_actions)
110 |
111 | def receive_action(self, action):
112 | assert not self.is_terminal
113 |
114 | rewards = []
115 | for i in range(4):
116 |
117 | # Last screeen must be stored before executing the 4th action
118 | if i == 3:
119 | self.last_raw_screen = self.ale.getScreenRGB()
120 |
121 | rewards.append(self.ale.act(self.legal_actions[action]))
122 |
123 | # Check if lives are lost
124 | if self.lives > self.ale.lives():
125 | self.lives_lost = True
126 | else:
127 | self.lives_lost = False
128 | self.lives = self.ale.lives()
129 |
130 | if self.is_terminal:
131 | break
132 |
133 | # We must have last screen here unless it's terminal
134 | if not self.is_terminal:
135 | self.last_screens.append(self.current_screen())
136 |
137 | self._reward = sum(rewards)
138 |
139 | return self._reward
140 |
141 | def initialize(self):
142 |
143 | if self.ale.game_over():
144 | self.ale.reset_game()
145 |
146 | if self.max_start_nullops > 0:
147 | n_nullops = np.random.randint(0, self.max_start_nullops + 1)
148 | for _ in range(n_nullops):
149 | self.ale.act(0)
150 |
151 | self._reward = 0
152 |
153 | self.last_raw_screen = self.ale.getScreenRGB()
154 |
155 | self.last_screens = collections.deque(
156 | [np.zeros((84, 84), dtype=np.uint8)] * 3 +
157 | [self.current_screen()],
158 | maxlen=self.n_last_screens)
159 |
160 | self.lives_lost = False
161 | self.lives = self.ale.lives()
162 |
--------------------------------------------------------------------------------
/async.py:
--------------------------------------------------------------------------------
1 | import multiprocessing as mp
2 | import os
3 | import random
4 |
5 | import chainer
6 | import numpy as np
7 |
8 | import random_seed
9 |
10 |
11 | def set_shared_params(a, b):
12 | """
13 | Args:
14 | a (chainer.Link): link whose params are to be replaced
15 | b (dict): dict that consists of (param_name, multiprocessing.Array)
16 | """
17 | assert isinstance(a, chainer.Link)
18 | for param_name, param in a.namedparams():
19 | if param_name in b:
20 | shared_param = b[param_name]
21 | param.data = np.frombuffer(
22 | shared_param, dtype=param.data.dtype).reshape(param.data.shape)
23 |
24 |
25 | def set_shared_states(a, b):
26 | assert isinstance(a, chainer.Optimizer)
27 | assert hasattr(a, 'target'), 'Optimizer.setup must be called first'
28 | for state_name, shared_state in b.items():
29 | for param_name, param in shared_state.items():
30 | old_param = a._states[state_name][param_name]
31 | a._states[state_name][param_name] = np.frombuffer(
32 | param,
33 | dtype=old_param.dtype).reshape(old_param.shape)
34 |
35 |
36 | def extract_params_as_shared_arrays(link):
37 | assert isinstance(link, chainer.Link)
38 | shared_arrays = {}
39 | for param_name, param in link.namedparams():
40 | shared_arrays[param_name] = mp.RawArray('f', param.data.ravel())
41 | return shared_arrays
42 |
43 |
44 | def share_params_as_shared_arrays(link):
45 | shared_arrays = extract_params_as_shared_arrays(link)
46 | set_shared_params(link, shared_arrays)
47 | return shared_arrays
48 |
49 |
50 | def share_states_as_shared_arrays(link):
51 | shared_arrays = extract_states_as_shared_arrays(link)
52 | set_shared_states(link, shared_arrays)
53 | return shared_arrays
54 |
55 |
56 | def extract_states_as_shared_arrays(optimizer):
57 | assert isinstance(optimizer, chainer.Optimizer)
58 | assert hasattr(optimizer, 'target'), 'Optimizer.setup must be called first'
59 | shared_arrays = {}
60 | for state_name, state in optimizer._states.items():
61 | shared_arrays[state_name] = {}
62 | for param_name, param in state.items():
63 | shared_arrays[state_name][
64 | param_name] = mp.RawArray('f', param.ravel())
65 | return shared_arrays
66 |
67 |
68 | def run_async(n_process, run_func):
69 | """Run experiments asynchronously.
70 |
71 | Args:
72 | n_process (int): number of processes
73 | run_func: function that will be run in parallel
74 | """
75 |
76 | processes = []
77 |
78 | def set_seed_and_run(process_idx, run_func):
79 | random_seed.set_random_seed(np.random.randint(0, 2 ** 32))
80 | run_func(process_idx)
81 |
82 | for process_idx in range(n_process):
83 | processes.append(mp.Process(target=set_seed_and_run, args=(
84 | process_idx, run_func)))
85 |
86 | for p in processes:
87 | p.start()
88 |
89 | for p in processes:
90 | p.join()
91 |
--------------------------------------------------------------------------------
/copy_param.py:
--------------------------------------------------------------------------------
1 | def copy_param(target_link, source_link):
2 | """Copy parameters of a link to another link.
3 | """
4 | target_params = dict(target_link.namedparams())
5 | for param_name, param in source_link.namedparams():
6 | target_params[param_name].data[:] = param.data
7 |
8 |
9 | def copy_grad(target_link, source_link):
10 | """Copy gradients of a link to another link.
11 | """
12 | target_params = dict(target_link.namedparams())
13 | for param_name, param in source_link.namedparams():
14 | target_params[param_name].grad[:] = param.grad
15 |
--------------------------------------------------------------------------------
/demo_a3c_ale.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 |
4 | import numpy as np
5 | import chainer
6 | from chainer import serializers
7 |
8 | import ale
9 | import random_seed
10 | from dqn_phi import dqn_phi
11 | from a3c_ale import A3CFF
12 | from a3c_ale import A3CLSTM
13 |
14 |
15 | def eval_performance(rom, model, deterministic=False, use_sdl=False,
16 | record_screen_dir=None):
17 | env = ale.ALE(rom, treat_life_lost_as_terminal=False, use_sdl=use_sdl,
18 | record_screen_dir=record_screen_dir)
19 | model.reset_state()
20 | test_r = 0
21 | while not env.is_terminal:
22 | s = chainer.Variable(np.expand_dims(dqn_phi(env.state), 0))
23 | pout = model.pi_and_v(s)[0]
24 | model.unchain_backward()
25 | if deterministic:
26 | a = pout.most_probable_actions[0]
27 | else:
28 | a = pout.action_indices[0]
29 | test_r += env.receive_action(a)
30 | return test_r
31 |
32 |
33 | def main():
34 |
35 | import logging
36 | logging.basicConfig(level=logging.DEBUG)
37 |
38 | parser = argparse.ArgumentParser()
39 | parser.add_argument('rom', type=str)
40 | parser.add_argument('model', type=str)
41 | parser.add_argument('--seed', type=int, default=0)
42 | parser.add_argument('--use-sdl', action='store_true')
43 | parser.add_argument('--n-runs', type=int, default=10)
44 | parser.add_argument('--deterministic', action='store_true')
45 | parser.add_argument('--record-screen-dir', type=str, default=None)
46 | parser.add_argument('--use-lstm', action='store_true')
47 | parser.set_defaults(use_sdl=False)
48 | parser.set_defaults(use_lstm=False)
49 | parser.set_defaults(deterministic=False)
50 | args = parser.parse_args()
51 |
52 | random_seed.set_random_seed(args.seed)
53 |
54 | n_actions = ale.ALE(args.rom).number_of_actions
55 |
56 | # Load an A3C-DQN model
57 | if args.use_lstm:
58 | model = A3CLSTM(n_actions)
59 | else:
60 | model = A3CFF(n_actions)
61 | serializers.load_hdf5(args.model, model)
62 |
63 | scores = []
64 | for i in range(args.n_runs):
65 | episode_record_dir = None
66 | if args.record_screen_dir is not None:
67 | episode_record_dir = os.path.join(args.record_screen_dir, str(i))
68 | os.makedirs(episode_record_dir)
69 | score = eval_performance(
70 | args.rom, model, deterministic=args.deterministic,
71 | use_sdl=args.use_sdl, record_screen_dir=episode_record_dir)
72 | print('Run {}: {}'.format(i, score))
73 | scores.append(score)
74 | print('Average: {}'.format(sum(scores) / args.n_runs))
75 |
76 |
77 | if __name__ == '__main__':
78 | main()
79 |
--------------------------------------------------------------------------------
/demo_a3c_doom.py:
--------------------------------------------------------------------------------
1 | import argparse
2 |
3 | import chainer
4 | from chainer import serializers
5 | import numpy as np
6 |
7 | import random_seed
8 | import doom_env
9 | from train_a3c_doom import phi, A3CFF, A3CLSTM
10 |
11 |
12 | def eval_single_run(env, model, phi, deterministic=False):
13 | model.reset_state()
14 | test_r = 0
15 | obs = env.reset()
16 | done = False
17 | while not done:
18 | s = chainer.Variable(np.expand_dims(phi(obs), 0))
19 | pout = model.pi_and_v(s)[0]
20 | model.unchain_backward()
21 | if deterministic:
22 | a = pout.most_probable_actions[0]
23 | else:
24 | a = pout.action_indices[0]
25 | obs, r, done, info = env.step(a)
26 | test_r += r
27 | return test_r
28 |
29 |
30 | def eval_single_random_run(env):
31 | test_r = 0
32 | obs = env.reset()
33 | done = False
34 | while not done:
35 | a = np.random.randint(env.n_actions)
36 | obs, r, done, info = env.step(a)
37 | test_r += r
38 | return test_r
39 |
40 |
41 | def main():
42 | import logging
43 | logging.basicConfig(level=logging.DEBUG)
44 |
45 | parser = argparse.ArgumentParser()
46 | parser.add_argument('model', type=str)
47 | parser.add_argument('--seed', type=int, default=0)
48 | parser.add_argument('--sleep', type=float, default=0)
49 | parser.add_argument('--scenario', type=str, default='basic')
50 | parser.add_argument('--n-runs', type=int, default=10)
51 | parser.add_argument('--use-lstm', action='store_true')
52 | parser.add_argument('--window-visible', action='store_true')
53 | parser.add_argument('--deterministic', action='store_true')
54 | parser.add_argument('--random', action='store_true')
55 | parser.set_defaults(window_visible=False)
56 | parser.set_defaults(use_lstm=False)
57 | parser.set_defaults(deterministic=False)
58 | parser.set_defaults(random=False)
59 | args = parser.parse_args()
60 |
61 | random_seed.set_random_seed(args.seed)
62 |
63 | n_actions = doom_env.DoomEnv(
64 | window_visible=False, scenario=args.scenario).n_actions
65 |
66 | if not args.random:
67 | if args.use_lstm:
68 | model = A3CLSTM(n_actions)
69 | else:
70 | model = A3CFF(n_actions)
71 | serializers.load_hdf5(args.model, model)
72 |
73 | scores = []
74 | env = doom_env.DoomEnv(window_visible=args.window_visible,
75 | scenario=args.scenario,
76 | sleep=args.sleep)
77 | for i in range(args.n_runs):
78 | if args.random:
79 | score = eval_single_random_run(env)
80 | else:
81 | score = eval_single_run(
82 | env, model, phi, deterministic=args.deterministic)
83 | print('Run {}: {}'.format(i, score))
84 | scores.append(score)
85 | print('Average: {}'.format(sum(scores) / args.n_runs))
86 |
87 |
88 | if __name__ == '__main__':
89 | main()
90 |
--------------------------------------------------------------------------------
/doom_env.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import time
4 |
5 | import numpy as np
6 |
7 |
8 | class DoomEnv(object):
9 |
10 | def __init__(self, vizdoom_dir=os.path.expanduser('~/ViZDoom'),
11 | window_visible=True, scenario='basic', skipcount=10,
12 | resolution_width=640, sleep=0.0, seed=None):
13 |
14 | self.skipcount = skipcount
15 | self.sleep = sleep
16 |
17 | sys.path.append(os.path.join(vizdoom_dir, "examples/python"))
18 | from vizdoom import DoomGame
19 | from vizdoom import ScreenFormat
20 | from vizdoom import ScreenResolution
21 |
22 | game = DoomGame()
23 |
24 | if seed is not None:
25 | assert seed >= 0 and seed < 2 ** 16, \
26 | "ViZDoom's random seed must be represented by unsigned int"
27 | else:
28 | # Use numpy's random state
29 | seed = np.random.randint(0, 2 ** 16)
30 | game.set_seed(seed)
31 |
32 | # Load a config file
33 | game.load_config(os.path.join(
34 | vizdoom_dir, "examples", 'config', scenario + '.cfg'))
35 |
36 | # Replace default relative paths with actual paths
37 | game.set_vizdoom_path(os.path.join(vizdoom_dir, "bin/vizdoom"))
38 | game.set_doom_game_path(
39 | os.path.join(vizdoom_dir, 'scenarios/freedoom2.wad'))
40 | game.set_doom_scenario_path(
41 | os.path.join(vizdoom_dir, 'scenarios', scenario + '.wad'))
42 |
43 | # Set screen settings
44 | resolutions = {640: ScreenResolution.RES_640X480,
45 | 320: ScreenResolution.RES_320X240,
46 | 160: ScreenResolution.RES_160X120}
47 | game.set_screen_resolution(resolutions[resolution_width])
48 | game.set_screen_format(ScreenFormat.RGB24)
49 | game.set_window_visible(window_visible)
50 | game.set_sound_enabled(window_visible)
51 |
52 | game.init()
53 | self.game = game
54 |
55 | # Use one-hot actions
56 | self.n_actions = game.get_available_buttons_size()
57 | self.actions = []
58 | for i in range(self.n_actions):
59 | self.actions.append([i == j for j in range(self.n_actions)])
60 |
61 | def reset(self):
62 | self.game.new_episode()
63 | return self.game.get_state()
64 |
65 | def step(self, action):
66 | r = self.game.make_action(self.actions[action], self.skipcount)
67 | r /= 100
68 | time.sleep(self.sleep * self.skipcount)
69 | return self.game.get_state(), r, self.game.is_episode_finished(), None
70 |
--------------------------------------------------------------------------------
/dqn_head.py:
--------------------------------------------------------------------------------
1 | import chainer
2 | from chainer import functions as F
3 | from chainer import links as L
4 |
5 |
6 | class NatureDQNHead(chainer.ChainList):
7 | """DQN's head (Nature version)"""
8 |
9 | def __init__(self, n_input_channels=4, n_output_channels=512,
10 | activation=F.relu, bias=0.1):
11 | self.n_input_channels = n_input_channels
12 | self.activation = activation
13 | self.n_output_channels = n_output_channels
14 |
15 | layers = [
16 | L.Convolution2D(n_input_channels, 32, 8, stride=4, bias=bias),
17 | L.Convolution2D(32, 64, 4, stride=2, bias=bias),
18 | L.Convolution2D(64, 64, 3, stride=1, bias=bias),
19 | L.Linear(3136, n_output_channels, bias=bias),
20 | ]
21 |
22 | super(NatureDQNHead, self).__init__(*layers)
23 |
24 | def __call__(self, state):
25 | h = state
26 | for layer in self:
27 | h = self.activation(layer(h))
28 | return h
29 |
30 |
31 | class NIPSDQNHead(chainer.ChainList):
32 | """DQN's head (NIPS workshop version)"""
33 |
34 | def __init__(self, n_input_channels=4, n_output_channels=256,
35 | activation=F.relu, bias=0.1):
36 | self.n_input_channels = n_input_channels
37 | self.activation = activation
38 | self.n_output_channels = n_output_channels
39 |
40 | layers = [
41 | L.Convolution2D(n_input_channels, 16, 8, stride=4, bias=bias),
42 | L.Convolution2D(16, 32, 4, stride=2, bias=bias),
43 | L.Linear(2592, n_output_channels, bias=bias),
44 | ]
45 |
46 | super(NIPSDQNHead, self).__init__(*layers)
47 |
48 | def __call__(self, state):
49 | h = state
50 | for layer in self:
51 | h = self.activation(layer(h))
52 | return h
53 |
--------------------------------------------------------------------------------
/dqn_phi.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 |
4 | def dqn_phi(screens):
5 | """Phi (feature extractor) of DQN for ALE
6 | Args:
7 | screens: List of N screen objects. Each screen object must be
8 | numpy.ndarray whose dtype is numpy.uint8.
9 | Returns:
10 | numpy.ndarray
11 | """
12 | assert len(screens) == 4
13 | assert screens[0].dtype == np.uint8
14 | raw_values = np.asarray(screens, dtype=np.float32)
15 | # [0,255] -> [0, 1]
16 | raw_values /= 255.0
17 | return raw_values
18 |
--------------------------------------------------------------------------------
/environment.py:
--------------------------------------------------------------------------------
1 | class Environment(object):
2 | """RL learning environment
3 | """
4 |
5 | @property
6 | def state(self):
7 | pass
8 |
9 | @property
10 | def reward(self):
11 | pass
12 |
13 | def receive_action(self, action):
14 | pass
15 |
16 | class EpisodicEnvironment(Environment):
17 |
18 | def initialize(self):
19 | """
20 | Initialize the internal state
21 | """
22 | pass
23 |
24 | @property
25 | def is_terminal(self):
26 | pass
27 |
28 |
--------------------------------------------------------------------------------
/init_like_torch.py:
--------------------------------------------------------------------------------
1 | from chainer import links as L
2 | import numpy as np
3 |
4 |
5 | def init_like_torch(link):
6 | # Mimic torch's default parameter initialization
7 | # TODO(muupan): Use chainer's initializers when it is merged
8 | for l in link.links():
9 | if isinstance(l, L.Linear):
10 | out_channels, in_channels = l.W.data.shape
11 | stdv = 1 / np.sqrt(in_channels)
12 | l.W.data[:] = np.random.uniform(-stdv, stdv, size=l.W.data.shape)
13 | if l.b is not None:
14 | l.b.data[:] = np.random.uniform(-stdv, stdv,
15 | size=l.b.data.shape)
16 | elif isinstance(l, L.Convolution2D):
17 | out_channels, in_channels, kh, kw = l.W.data.shape
18 | stdv = 1 / np.sqrt(in_channels * kh * kw)
19 | l.W.data[:] = np.random.uniform(-stdv, stdv, size=l.W.data.shape)
20 | if l.b is not None:
21 | l.b.data[:] = np.random.uniform(-stdv, stdv,
22 | size=l.b.data.shape)
23 |
--------------------------------------------------------------------------------
/nonbias_weight_decay.py:
--------------------------------------------------------------------------------
1 | from chainer import cuda
2 |
3 |
4 | class NonbiasWeightDecay(object):
5 |
6 | """Optimizer hook function for weight decay regularization.
7 |
8 | """
9 | name = 'NonbiasWeightDecay'
10 |
11 | def __init__(self, rate):
12 | self.rate = rate
13 |
14 | def __call__(self, opt):
15 | if cuda.available:
16 | kernel = cuda.elementwise(
17 | 'T p, T decay', 'T g', 'g += decay * p', 'weight_decay')
18 |
19 | rate = self.rate
20 | for name, param in opt.target.namedparams():
21 | if name == 'b' or name.endswith('/b'):
22 | continue
23 | p, g = param.data, param.grad
24 | with cuda.get_device(p) as dev:
25 | if int(dev) == -1:
26 | g += rate * p
27 | else:
28 | kernel(p, rate, g)
29 |
--------------------------------------------------------------------------------
/plot_scores.py:
--------------------------------------------------------------------------------
1 | import argparse
2 |
3 | import matplotlib.pyplot as plt
4 | import pandas as pd
5 |
6 |
7 | def main():
8 | parser = argparse.ArgumentParser()
9 | parser.add_argument('scores', type=str, help='specify path of scores.txt')
10 | parser.add_argument('--title', type=str, default=None)
11 | args = parser.parse_args()
12 |
13 | scores = pd.read_csv(args.scores, delimiter='\t')
14 | for col in ['mean', 'median']:
15 | plt.plot(scores['steps'], scores[col], label=col)
16 | if args.title is not None:
17 | plt.title(args.title)
18 | plt.xlabel('steps')
19 | plt.ylabel('score')
20 | plt.legend(loc='best')
21 | fig_fname = args.scores + '.png'
22 | plt.savefig(fig_fname)
23 | print('Saved a figure as {}'.format(fig_fname))
24 |
25 | if __name__ == '__main__':
26 | main()
27 |
--------------------------------------------------------------------------------
/policy.py:
--------------------------------------------------------------------------------
1 | from logging import getLogger
2 | logger = getLogger(__name__)
3 |
4 | import chainer
5 | from chainer import functions as F
6 | from chainer import links as L
7 |
8 | import policy_output
9 |
10 |
11 | class Policy(object):
12 | """Abstract policy class."""
13 |
14 | def __call__(self, state):
15 | raise NotImplementedError
16 |
17 |
18 | class SoftmaxPolicy(Policy):
19 | """Abstract softmax policy class."""
20 |
21 | def compute_logits(self, state):
22 | """
23 | Returns:
24 | ~chainer.Variable: logits of actions
25 | """
26 | raise NotImplementedError
27 |
28 | def __call__(self, state):
29 | return policy_output.SoftmaxPolicyOutput(self.compute_logits(state))
30 |
31 |
32 | class FCSoftmaxPolicy(chainer.ChainList, SoftmaxPolicy):
33 | """Softmax policy that consists of FC layers and rectifiers"""
34 |
35 | def __init__(self, n_input_channels, n_actions,
36 | n_hidden_layers=0, n_hidden_channels=None):
37 | self.n_input_channels = n_input_channels
38 | self.n_actions = n_actions
39 | self.n_hidden_layers = n_hidden_layers
40 | self.n_hidden_channels = n_hidden_channels
41 |
42 | layers = []
43 | if n_hidden_layers > 0:
44 | layers.append(L.Linear(n_input_channels, n_hidden_channels))
45 | for i in range(n_hidden_layers - 1):
46 | layers.append(L.Linear(n_hidden_channels, n_hidden_channels))
47 | layers.append(L.Linear(n_hidden_channels, n_actions))
48 | else:
49 | layers.append(L.Linear(n_input_channels, n_actions))
50 |
51 | super(FCSoftmaxPolicy, self).__init__(*layers)
52 |
53 | def compute_logits(self, state):
54 | h = state
55 | for layer in self[:-1]:
56 | h = F.relu(layer(h))
57 | h = self[-1](h)
58 | return h
59 |
60 |
61 | class GaussianPolicy(Policy):
62 | """Abstract Gaussian policy class.
63 | """
64 | pass
65 |
--------------------------------------------------------------------------------
/policy_output.py:
--------------------------------------------------------------------------------
1 | import chainer
2 | from chainer import functions as F
3 | from cached_property import cached_property
4 | import numpy as np
5 |
6 |
7 | class PolicyOutput(object):
8 | """Struct that holds policy output and subproducts."""
9 | pass
10 |
11 |
12 | def _sample_discrete_actions(batch_probs):
13 | """Sample a batch of actions from a batch of action probabilities.
14 |
15 | Args:
16 | batch_probs (ndarray): batch of action probabilities BxA
17 | Returns:
18 | List consisting of sampled actions
19 | """
20 | action_indices = []
21 |
22 | # Subtract a tiny value from probabilities in order to avoid
23 | # "ValueError: sum(pvals[:-1]) > 1.0" in numpy.multinomial
24 | batch_probs = batch_probs - np.finfo(np.float32).epsneg
25 |
26 | for i in range(batch_probs.shape[0]):
27 | histogram = np.random.multinomial(1, batch_probs[i])
28 | action_indices.append(int(np.nonzero(histogram)[0]))
29 | return action_indices
30 |
31 |
32 | class SoftmaxPolicyOutput(PolicyOutput):
33 |
34 | def __init__(self, logits):
35 | self.logits = logits
36 |
37 | @cached_property
38 | def most_probable_actions(self):
39 | return np.argmax(self.probs.data, axis=1)
40 |
41 | @cached_property
42 | def probs(self):
43 | return F.softmax(self.logits)
44 |
45 | @cached_property
46 | def log_probs(self):
47 | return F.log_softmax(self.logits)
48 |
49 | @cached_property
50 | def action_indices(self):
51 | return _sample_discrete_actions(self.probs.data)
52 |
53 | @cached_property
54 | def sampled_actions_log_probs(self):
55 | return F.select_item(
56 | self.log_probs,
57 | chainer.Variable(np.asarray(self.action_indices, dtype=np.int32)))
58 |
59 | @cached_property
60 | def entropy(self):
61 | return - F.sum(self.probs * self.log_probs, axis=1)
62 |
--------------------------------------------------------------------------------
/prepare_output_dir.py:
--------------------------------------------------------------------------------
1 | import os
2 | import tempfile
3 | import json
4 | import subprocess
5 |
6 |
7 | def prepare_output_dir(args, user_specified_dir=None):
8 | """Prepare output directory.
9 |
10 | An output directory is created if it does not exist. Then the following
11 | infomation is saved into the directory:
12 | args.txt: command-line arguments
13 | git-status.txt: result of `git status`
14 | git-log.txt: result of `git log`
15 | git-diff.txt: result of `git diff`
16 |
17 | Args:
18 | args: dict that describes command-line arguments
19 | user_specified_dir: directory path
20 | """
21 | if user_specified_dir is not None:
22 | if os.path.exists(user_specified_dir):
23 | if not os.path.isdir(user_specified_dir):
24 | raise RuntimeError(
25 | '{} is not a directory'.format(user_specified_dir))
26 | else:
27 | os.makedirs(user_specified_dir)
28 | outdir = user_specified_dir
29 | else:
30 | outdir = tempfile.mkdtemp()
31 |
32 | # Save all the arguments
33 | with open(os.path.join(outdir, 'args.txt'), 'w') as f:
34 | f.write(json.dumps(vars(args)))
35 |
36 | # Save `git status`
37 | with open(os.path.join(outdir, 'git-status.txt'), 'w') as f:
38 | f.write(subprocess.getoutput('git status'))
39 |
40 | # Save `git log`
41 | with open(os.path.join(outdir, 'git-log.txt'), 'w') as f:
42 | f.write(subprocess.getoutput('git log'))
43 |
44 | # Save `git diff`
45 | with open(os.path.join(outdir, 'git-diff.txt'), 'w') as f:
46 | f.write(subprocess.getoutput('git diff'))
47 |
48 | return outdir
49 |
--------------------------------------------------------------------------------
/random_seed.py:
--------------------------------------------------------------------------------
1 | import random
2 | import numpy as np
3 |
4 |
5 | def set_random_seed(seed):
6 | random.seed(seed)
7 | np.random.seed(seed)
8 |
--------------------------------------------------------------------------------
/rmsprop_async.py:
--------------------------------------------------------------------------------
1 | import numpy
2 |
3 | from chainer import cuda
4 | from chainer import optimizer
5 |
6 |
7 | class RMSpropAsync(optimizer.GradientMethod):
8 |
9 | """RMSprop for asynchronous methods.
10 |
11 | The only difference from chainer.optimizers.RMSprop in that the epsilon is
12 | outside the square root."""
13 |
14 | def __init__(self, lr=0.01, alpha=0.99, eps=1e-8):
15 | self.lr = lr
16 | self.alpha = alpha
17 | self.eps = eps
18 |
19 | def init_state(self, param, state):
20 | xp = cuda.get_array_module(param.data)
21 | state['ms'] = xp.zeros_like(param.data)
22 |
23 | def update_one_cpu(self, param, state):
24 | ms = state['ms']
25 | grad = param.grad
26 |
27 | ms *= self.alpha
28 | ms += (1 - self.alpha) * grad * grad
29 | param.data -= self.lr * grad / numpy.sqrt(ms + self.eps)
30 |
31 | def update_one_gpu(self, param, state):
32 | cuda.elementwise(
33 | 'T grad, T lr, T alpha, T eps',
34 | 'T param, T ms',
35 | '''ms = alpha * ms + (1 - alpha) * grad * grad;
36 | param -= lr * grad / sqrt(ms + eps);''',
37 | 'rmsprop')(param.grad, self.lr, self.alpha, self.eps,
38 | param.data, state['ms'])
39 |
--------------------------------------------------------------------------------
/run_a3c.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import copy
3 | import multiprocessing as mp
4 | import os
5 | import sys
6 | import statistics
7 | import time
8 |
9 | import chainer
10 | from chainer import links as L
11 | from chainer import functions as F
12 | import cv2
13 | import numpy as np
14 |
15 | import a3c
16 | import random_seed
17 | import async
18 | from prepare_output_dir import prepare_output_dir
19 |
20 |
21 | def eval_performance(process_idx, make_env, model, phi, n_runs):
22 | assert n_runs > 1, 'Computing stdev requires at least two runs'
23 | scores = []
24 | for i in range(n_runs):
25 | model.reset_state()
26 | env = make_env(process_idx, test=True)
27 | obs = env.reset()
28 | done = False
29 | test_r = 0
30 | while not done:
31 | s = chainer.Variable(np.expand_dims(phi(obs), 0))
32 | pout, _ = model.pi_and_v(s)
33 | a = pout.action_indices[0]
34 | obs, r, done, info = env.step(a)
35 | test_r += r
36 | scores.append(test_r)
37 | print('test_{}:'.format(i), test_r)
38 | mean = statistics.mean(scores)
39 | median = statistics.median(scores)
40 | stdev = statistics.stdev(scores)
41 | return mean, median, stdev
42 |
43 |
44 | def train_loop(process_idx, counter, make_env, max_score, args, agent, env,
45 | start_time, outdir):
46 | try:
47 |
48 | total_r = 0
49 | episode_r = 0
50 | global_t = 0
51 | local_t = 0
52 | obs = env.reset()
53 | r = 0
54 | done = False
55 |
56 | while True:
57 |
58 | # Get and increment the global counter
59 | with counter.get_lock():
60 | counter.value += 1
61 | global_t = counter.value
62 | local_t += 1
63 |
64 | if global_t > args.steps:
65 | break
66 |
67 | agent.optimizer.lr = (
68 | args.steps - global_t - 1) / args.steps * args.lr
69 |
70 | total_r += r
71 | episode_r += r
72 |
73 | a = agent.act(obs, r, done)
74 |
75 | if done:
76 | if process_idx == 0:
77 | print('{} global_t:{} local_t:{} lr:{} r:{}'.format(
78 | outdir, global_t, local_t, agent.optimizer.lr,
79 | episode_r))
80 | episode_r = 0
81 | obs = env.reset()
82 | r = 0
83 | done = False
84 | else:
85 | obs, r, done, info = env.step(a)
86 |
87 | if global_t % args.eval_frequency == 0:
88 | # Evaluation
89 |
90 | # We must use a copy of the model because test runs can change
91 | # the hidden states of the model
92 | test_model = copy.deepcopy(agent.model)
93 | test_model.reset_state()
94 |
95 | mean, median, stdev = eval_performance(
96 | process_idx, make_env, test_model, agent.phi,
97 | args.eval_n_runs)
98 | with open(os.path.join(outdir, 'scores.txt'), 'a+') as f:
99 | elapsed = time.time() - start_time
100 | record = (global_t, elapsed, mean, median, stdev)
101 | print('\t'.join(str(x) for x in record), file=f)
102 | with max_score.get_lock():
103 | if mean > max_score.value:
104 | # Save the best model so far
105 | print('The best score is updated {} -> {}'.format(
106 | max_score.value, mean))
107 | filename = os.path.join(
108 | outdir, '{}.h5'.format(global_t))
109 | agent.save_model(filename)
110 | print('Saved the current best model to {}'.format(
111 | filename))
112 | max_score.value = mean
113 |
114 | except KeyboardInterrupt:
115 | if process_idx == 0:
116 | # Save the current model before being killed
117 | agent.save_model(os.path.join(
118 | outdir, '{}_keyboardinterrupt.h5'.format(global_t)))
119 | print('Saved the current model to {}'.format(
120 | outdir), file=sys.stderr)
121 | raise
122 |
123 | if global_t == args.steps + 1:
124 | # Save the final model
125 | agent.save_model(
126 | os.path.join(args.outdir, '{}_finish.h5'.format(args.steps)))
127 | print('Saved the final model to {}'.format(args.outdir))
128 |
129 |
130 | def train_loop_with_profile(process_idx, counter, make_env, max_score, args,
131 | agent, env, start_time, outdir):
132 | import cProfile
133 | cmd = 'train_loop(process_idx, counter, make_env, max_score, args, ' \
134 | 'agent, env, start_time)'
135 | cProfile.runctx(cmd, globals(), locals(),
136 | 'profile-{}.out'.format(os.getpid()))
137 |
138 |
139 | def run_a3c(processes, make_env, model_opt, phi, t_max=1, beta=1e-2,
140 | profile=False, steps=8 * 10 ** 7, eval_frequency=10 ** 6,
141 | eval_n_runs=10, args={}):
142 |
143 | # Prevent numpy from using multiple threads
144 | os.environ['OMP_NUM_THREADS'] = '1'
145 |
146 | outdir = prepare_output_dir(args, None)
147 |
148 | print('Output files are saved in {}'.format(outdir))
149 |
150 | n_actions = 20 * 20
151 |
152 | model, opt = model_opt()
153 |
154 | shared_params = async.share_params_as_shared_arrays(model)
155 | shared_states = async.share_states_as_shared_arrays(opt)
156 |
157 | max_score = mp.Value('f', np.finfo(np.float32).min)
158 | counter = mp.Value('l', 0)
159 | start_time = time.time()
160 |
161 | # Write a header line first
162 | with open(os.path.join(outdir, 'scores.txt'), 'a+') as f:
163 | column_names = ('steps', 'elapsed', 'mean', 'median', 'stdev')
164 | print('\t'.join(column_names), file=f)
165 |
166 | def run_func(process_idx):
167 | env = make_env(process_idx, test=False)
168 | model, opt = model_opt()
169 | async.set_shared_params(model, shared_params)
170 | async.set_shared_states(opt, shared_states)
171 |
172 | agent = a3c.A3C(model, opt, t_max, 0.99, beta=beta,
173 | process_idx=process_idx, phi=phi)
174 |
175 | if profile:
176 | train_loop_with_profile(process_idx, counter, make_env, max_score,
177 | args, agent, env, start_time,
178 | outdir=outdir)
179 | else:
180 | train_loop(process_idx, counter, make_env, max_score,
181 | args, agent, env, start_time, outdir=outdir)
182 |
183 | async.run_async(processes, run_func)
184 |
--------------------------------------------------------------------------------
/train_a3c_doom.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import multiprocessing as mp
3 |
4 | import chainer
5 | from chainer import links as L
6 | from chainer import functions as F
7 | import cv2
8 | import numpy as np
9 |
10 | import policy
11 | import v_function
12 | import dqn_head
13 | import a3c
14 | import random_seed
15 | import rmsprop_async
16 | from init_like_torch import init_like_torch
17 | import run_a3c
18 | import doom_env
19 |
20 |
21 | def phi(obs):
22 | resized = cv2.resize(obs.image_buffer, (84, 84))
23 | return resized.transpose(2, 0, 1).astype(np.float32) / 255
24 |
25 |
26 | class A3CFF(chainer.ChainList, a3c.A3CModel):
27 |
28 | def __init__(self, n_actions):
29 | self.head = dqn_head.NIPSDQNHead(n_input_channels=3)
30 | self.pi = policy.FCSoftmaxPolicy(
31 | self.head.n_output_channels, n_actions)
32 | self.v = v_function.FCVFunction(self.head.n_output_channels)
33 | super().__init__(self.head, self.pi, self.v)
34 | init_like_torch(self)
35 |
36 | def pi_and_v(self, state, keep_same_state=False):
37 | out = self.head(state)
38 | return self.pi(out), self.v(out)
39 |
40 |
41 | class A3CLSTM(chainer.ChainList, a3c.A3CModel):
42 |
43 | def __init__(self, n_actions):
44 | self.head = dqn_head.NIPSDQNHead(n_input_channels=3)
45 | self.pi = policy.FCSoftmaxPolicy(
46 | self.head.n_output_channels, n_actions)
47 | self.v = v_function.FCVFunction(self.head.n_output_channels)
48 | self.lstm = L.LSTM(self.head.n_output_channels,
49 | self.head.n_output_channels)
50 | super().__init__(self.head, self.lstm, self.pi, self.v)
51 | init_like_torch(self)
52 |
53 | def pi_and_v(self, state, keep_same_state=False):
54 | out = self.head(state)
55 | if keep_same_state:
56 | prev_h, prev_c = self.lstm.h, self.lstm.c
57 | out = self.lstm(out)
58 | self.lstm.h, self.lstm.c = prev_h, prev_c
59 | else:
60 | out = self.lstm(out)
61 | return self.pi(out), self.v(out)
62 |
63 | def reset_state(self):
64 | self.lstm.reset_state()
65 |
66 | def unchain_backward(self):
67 | self.lstm.h.unchain_backward()
68 | self.lstm.c.unchain_backward()
69 |
70 |
71 | def main():
72 | import logging
73 | logging.basicConfig(level=logging.DEBUG)
74 |
75 | parser = argparse.ArgumentParser()
76 | parser.add_argument('processes', type=int)
77 | parser.add_argument('--seed', type=int, default=None)
78 | parser.add_argument('--outdir', type=str, default=None)
79 | parser.add_argument('--scenario', type=str, default='basic')
80 | parser.add_argument('--t-max', type=int, default=5)
81 | parser.add_argument('--beta', type=float, default=1e-2)
82 | parser.add_argument('--profile', action='store_true')
83 | parser.add_argument('--steps', type=int, default=8 * 10 ** 7)
84 | parser.add_argument('--lr', type=float, default=7e-4)
85 | parser.add_argument('--eval-frequency', type=int, default=10 ** 5)
86 | parser.add_argument('--eval-n-runs', type=int, default=10)
87 | parser.add_argument('--use-lstm', action='store_true')
88 | parser.add_argument('--window-visible', action='store_true')
89 | parser.set_defaults(window_visible=False)
90 | parser.set_defaults(use_lstm=False)
91 | args = parser.parse_args()
92 |
93 | if args.seed is not None:
94 | random_seed.set_random_seed(args.seed)
95 |
96 | # Simultaneously launching multiple vizdoom processes makes program stuck,
97 | # so use the global lock
98 | env_lock = mp.Lock()
99 |
100 | def make_env(process_idx, test):
101 | with env_lock:
102 | return doom_env.DoomEnv(window_visible=args.window_visible,
103 | scenario=args.scenario)
104 |
105 | n_actions = 3
106 |
107 | def model_opt():
108 | if args.use_lstm:
109 | model = A3CLSTM(n_actions)
110 | else:
111 | model = A3CFF(n_actions)
112 | opt = rmsprop_async.RMSpropAsync(lr=args.lr, eps=1e-1, alpha=0.99)
113 | opt.setup(model)
114 | opt.add_hook(chainer.optimizer.GradientClipping(40))
115 | return model, opt
116 |
117 | run_a3c.run_a3c(args.processes, make_env, model_opt, phi, t_max=args.t_max,
118 | beta=args.beta, profile=args.profile, steps=args.steps,
119 | eval_frequency=args.eval_frequency,
120 | eval_n_runs=args.eval_n_runs, args=args)
121 |
122 |
123 | if __name__ == '__main__':
124 | main()
125 |
--------------------------------------------------------------------------------
/trained_model/breakout_ff/80000000_finish.h5:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/muupan/async-rl/5c5844fe7d62055ef911c7abfa6200fb30f6db84/trained_model/breakout_ff/80000000_finish.h5
--------------------------------------------------------------------------------
/trained_model/breakout_ff/animation.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/muupan/async-rl/5c5844fe7d62055ef911c7abfa6200fb30f6db84/trained_model/breakout_ff/animation.gif
--------------------------------------------------------------------------------
/trained_model/breakout_ff/scores.txt:
--------------------------------------------------------------------------------
1 | steps elapsed mean median stdev
2 | 1000000 799.1865322589874 1.2 1.5 1.1352924243950933
3 | 2000000 1575.7219505310059 1.5 0.0 2.273030282830976
4 | 3000000 2359.6249346733093 2.1 3.0 1.911950719959998
5 | 4000000 3109.272673845291 1.6 2.0 1.4298407059684812
6 | 5000000 3859.516502380371 2.0 2.0 2.0548046676563256
7 | 6000000 4602.4465317726135 1.8 1.0 1.9888578520235065
8 | 7000000 5348.210222244263 2.5 2.0 0.97182531580755
9 | 8000000 6110.1892149448395 3.5 3.5 2.173067468400883
10 | 9000000 6861.104922533035 5.5 4.5 4.503085362035432
11 | 10000000 7619.673486471176 13.0 12.0 4.2946995755750415
12 | 11000000 8378.648483276367 18.9 19.0 5.586690532964138
13 | 12000000 9167.731533527374 24.5 21.5 11.057928276932246
14 | 13000000 10027.934562683105 73.6 72.5 26.95757984521443
15 | 14000000 10791.431033372879 107.2 97.5 50.78888767349716
16 | 15000000 11552.96664738655 95.8 85.0 71.8374708785201
17 | 16000000 12357.831614017487 251.2 269.0 65.97945808271608
18 | 17000000 13152.097360610962 232.0 249.0 99.43395351242508
19 | 18000000 13918.015005588531 246.4 273.5 100.97216338069506
20 | 19000000 14744.782504558563 362.7 375.5 51.497680638171566
21 | 20000000 15498.439815044403 377.1 388.0 41.420472662145656
22 | 21000000 16318.818217515945 340.7 382.0 113.92204937295209
23 | 22000000 17040.97575569153 248.8 265.0 116.37468224088377
24 | 23000000 17841.953941345215 350.8 361.5 51.100771901106235
25 | 24000000 18606.147523880005 373.8 397.0 61.31847646146759
26 | 25000000 19452.10493350029 375.6 415.0 100.00577761087385
27 | 26000000 20231.817700862885 430.5 412.0 77.02849400636681
28 | 27000000 21134.255215406418 433.8 417.0 100.2505749498614
29 | 28000000 21763.75692296028 299.8 328.0 119.36014596356878
30 | 29000000 22626.56786084175 492.9 412.5 183.22023784384615
31 | 30000000 23399.90938782692 373.9 387.5 211.82091492579292
32 | 31000000 24072.50167989731 363.3 380.5 82.33542507464342
33 | 32000000 24852.809225320816 376.7 387.5 55.63581979664221
34 | 33000000 25615.238379001617 311.6 380.0 137.93412276236154
35 | 34000000 26598.047915697098 435.4 421.5 53.74879843618212
36 | 35000000 27231.892096042633 414.8 389.5 138.989847750754
37 | 36000000 27887.654467582703 324.3 399.5 157.67339661464771
38 | 37000000 28814.492196321487 402.5 419.0 49.80907993975038
39 | 38000000 29534.802098751068 376.4 422.0 109.01804132038573
40 | 39000000 30364.29454421997 435.0 428.0 104.94654724085865
41 | 40000000 31047.65421795845 412.3 419.5 18.1906569425076
42 | 41000000 31737.017671108246 389.5 394.0 65.46457905700694
43 | 42000000 32467.050805568695 409.3 423.5 48.087998040629174
44 | 43000000 33230.65163731575 344.2 414.5 133.11799277332872
45 | 44000000 34009.13779783249 457.3 425.5 115.42294206766502
46 | 45000000 34763.50703406334 410.3 427.5 40.996070272378276
47 | 46000000 35484.54351043701 414.1 414.5 12.269655432995844
48 | 47000000 36283.29621911049 459.1 426.5 145.52010170419754
49 | 48000000 37148.736817359924 536.3 446.5 175.72140197230132
50 | 49000000 37665.218223810196 413.3 417.0 13.216572088774676
51 | 50000000 38502.0075905323 453.7 421.5 133.0806355393434
52 | 51000000 39192.341354846954 468.3 430.5 124.23816733283786
53 | 52000000 40030.84110355377 415.3 422.5 17.888854382299364
54 | 53000000 40686.36572384834 415.9 418.0 73.99316785277469
55 | 54000000 41383.44816946983 448.7 408.0 133.6006071177157
56 | 57000000 43803.362179756165 422.1 427.5 50.61060494929233
57 | 58000000 44451.59215736389 423.0 424.5 17.10100711784088
58 | 59000000 45240.43768501282 409.0 427.5 46.401628323918885
59 | 60000000 46110.308336257935 456.9 421.0 139.6896957943252
60 | 61000000 46937.206632852554 486.3 416.5 196.8372424110844
61 | 62000000 47675.98979473114 419.1 422.5 37.495036708580216
62 | 63000000 48513.08631014824 426.1 412.0 33.69289407443521
63 | 64000000 49318.95145368576 459.1 427.5 151.07352882325583
64 | 65000000 50040.2566986084 466.0 429.5 99.69509070717129
65 | 66000000 50993.864820718765 528.6 472.0 226.0335275032347
66 | 67000000 51737.7411031723 463.6 430.0 127.71774435144954
67 | 68000000 52501.34305858612 422.3 428.0 68.30169999511156
68 | 69000000 53283.210359334946 412.5 422.5 122.31948150460562
69 | 70000000 54116.87993979454 459.0 430.5 146.60832172833847
70 | 71000000 54859.40275526047 423.4 424.5 27.162883172119678
71 | 72000000 55693.9102909565 437.6 424.5 45.792284648544594
72 | 73000000 56525.86289215088 447.0 434.5 49.416596402423345
73 | 74000000 57244.09581017494 469.1 432.0 151.229369575563
74 | 75000000 58063.31164121628 417.6 425.5 31.931175988365975
75 | 76000000 58799.664543151855 416.7 424.0 20.144202364176373
76 | 77000000 59633.22558784485 426.4 427.5 10.490207073477837
77 | 78000000 60394.60213589668 513.1 413.0 195.16229713298168
78 | 79000000 61230.48169326782 489.9 425.0 165.88714369849293
79 | 80000000 61839.64669966698 417.8 422.0 21.627143439052077
80 |
--------------------------------------------------------------------------------
/trained_model/breakout_ff/scores.txt.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/muupan/async-rl/5c5844fe7d62055ef911c7abfa6200fb30f6db84/trained_model/breakout_ff/scores.txt.png
--------------------------------------------------------------------------------
/trained_model/space_invaders_lstm/80000000_finish.h5:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/muupan/async-rl/5c5844fe7d62055ef911c7abfa6200fb30f6db84/trained_model/space_invaders_lstm/80000000_finish.h5
--------------------------------------------------------------------------------
/trained_model/space_invaders_lstm/animation.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/muupan/async-rl/5c5844fe7d62055ef911c7abfa6200fb30f6db84/trained_model/space_invaders_lstm/animation.gif
--------------------------------------------------------------------------------
/trained_model/space_invaders_lstm/scores.txt:
--------------------------------------------------------------------------------
1 | steps elapsed mean median stdev
2 | 1000000 1176.0026223659515 150.5 130.0 71.23708459940106
3 | 2000000 2279.606765270233 218.5 195.0 82.63204920341475
4 | 3000000 3405.7928512096405 203.0 210.0 32.076297929918425
5 | 4000000 4499.463195800781 187.0 180.0 57.4552966323481
6 | 5000000 5575.656061410904 259.0 235.0 136.459192109257
7 | 6000000 6694.54666686058 318.0 287.5 179.53953448877058
8 | 7000000 7828.923171281815 351.0 305.0 181.62537757091596
9 | 8000000 8827.748558998108 333.5 322.5 114.26212554181431
10 | 9000000 9897.704538345337 311.0 322.5 131.90484785969352
11 | 10000000 10987.551244974136 379.0 362.5 88.49984306326324
12 | 11000000 12111.16355252266 490.5 515.0 97.39524286808538
13 | 12000000 13139.165969610214 448.5 482.5 113.38356729849936
14 | 13000000 14198.187840223312 367.0 365.0 54.324130099902305
15 | 14000000 15247.866738319397 386.0 337.5 125.80408048496147
16 | 15000000 16321.860386371613 555.0 532.5 211.18712081942877
17 | 16000000 17356.161630392075 402.5 362.5 84.63155439905378
18 | 17000000 18419.353372573853 433.5 405.0 148.38107845828742
19 | 18000000 19517.881631851196 572.5 587.5 170.18372425117508
20 | 19000000 20565.545799016953 504.0 392.5 223.69125547901461
21 | 20000000 21651.335790395737 603.0 622.5 203.74548393086462
22 | 21000000 22765.650399684906 834.5 835.0 298.63997276542426
23 | 22000000 23780.1443631649 579.0 585.0 249.15189476836548
24 | 23000000 24812.381363153458 553.5 535.0 160.07029705726168
25 | 24000000 25943.478595733643 805.5 820.0 266.4420929374503
26 | 25000000 27022.40669798851 819.0 800.0 356.03370626950476
27 | 26000000 28154.23360300064 775.0 547.5 532.2123636294068
28 | 27000000 29255.90105676651 613.5 572.5 229.7226588736949
29 | 28000000 30400.700807094574 646.5 482.5 406.20910050531035
30 | 29000000 31572.145109176636 772.0 632.5 334.54944826338203
31 | 30000000 32690.86220598221 945.0 972.5 311.4839036326311
32 | 31000000 33758.00896549225 830.5 602.5 442.72797015272886
33 | 32000000 34861.88159298897 757.0 602.5 344.4415770489968
34 | 33000000 35916.9765996933 985.0 950.0 397.50611455814254
35 | 34000000 37010.65085887909 962.0 950.0 381.9118571956973
36 | 35000000 38139.09030032158 1014.5 900.0 490.8521501769482
37 | 36000000 39226.673714637756 976.5 607.5 536.9515289525158
38 | 37000000 40325.832810640335 1031.0 820.0 501.2639579658162
39 | 38000000 41391.046285390854 788.0 680.0 318.21725632376103
40 | 39000000 42567.62489628792 1064.0 1017.5 455.73384045222423
41 | 40000000 43663.877554655075 952.5 862.5 410.55687114508805
42 | 41000000 44881.854682445526 1406.5 1165.0 795.8889160345599
43 | 42000000 45882.31720352173 891.0 622.5 492.4586841102059
44 | 43000000 47044.14443182945 1340.0 1127.5 765.2740975914737
45 | 44000000 48123.50830435753 1205.5 1235.0 508.775490761888
46 | 45000000 49227.012467861176 1044.5 935.0 557.8751851644078
47 | 46000000 50345.83370089531 1240.5 1217.5 541.9278857314258
48 | 47000000 51417.79047751427 1269.0 1165.0 778.919479507064
49 | 48000000 52607.29307818413 1698.0 1797.5 543.8198231032039
50 | 49000000 53671.907301187515 1598.5 1710.0 466.9347444296211
51 | 50000000 54812.021178245544 1863.5 1720.0 510.8873000313605
52 | 51000000 55892.94242429733 1501.0 1432.5 484.23364424854066
53 | 52000000 57041.53133392334 2016.0 1927.5 670.7657315834394
54 | 53000000 58073.72801113129 1643.0 1585.0 496.4887824625156
55 | 54000000 59165.362850666046 1382.0 1422.5 681.1395680116602
56 | 55000000 60335.68020105362 1565.0 1645.0 475.94350738530113
57 | 56000000 61488.63900256157 2096.0 2015.0 365.1468502153924
58 | 57000000 62582.88352417946 1996.0 2062.5 504.8751220736558
59 | 58000000 63649.29801917076 2022.0 1895.0 680.4051080871683
60 | 59000000 64736.771109342575 1568.0 1610.0 177.81388522209895
61 | 60000000 65917.98326063156 2057.5 2150.0 778.325303313324
62 | 61000000 66951.23457431793 2082.5 1997.5 567.936078171557
63 | 62000000 68049.10905337334 1737.0 2025.0 718.3592416054797
64 | 63000000 69085.28632044792 1959.0 1940.0 356.23650071889665
65 | 64000000 70181.8262295723 1822.5 1817.5 756.8144128883616
66 | 65000000 71294.90933918953 2032.0 2122.5 683.3585361205996
67 | 66000000 72485.66170525551 2507.0 2705.0 515.5051460029817
68 | 67000000 73494.54617547989 1775.0 1837.5 858.5064550330029
69 | 68000000 74578.25437927246 2038.0 2462.5 922.8434320078352
70 | 69000000 75629.58755373955 2085.0 2070.0 778.1209560358996
71 | 70000000 76678.21772170067 1960.5 1587.5 915.0818117645123
72 | 71000000 77790.33036136627 2420.5 2567.5 455.76827689322806
73 | 72000000 78800.69010519981 1789.0 1760.0 604.4639498486792
74 | 73000000 79914.5376329422 2436.0 2805.0 706.0327345259724
75 | 74000000 80936.40157341957 1924.5 1935.0 821.6191669840447
76 | 75000000 81944.25549578667 1962.0 2177.5 869.6238011666628
77 | 76000000 83064.10873103142 2335.5 2555.0 695.3314557341221
78 | 77000000 84099.02462172508 2615.0 2905.0 847.9648839689321
79 | 78000000 85200.52754330635 2610.5 2797.5 532.5382093751061
80 | 79000000 86191.62391448021 1999.5 2075.0 919.0981388779377
81 | 80000000 87095.2680015564 2278.0 2462.5 637.1908836622055
82 |
--------------------------------------------------------------------------------
/trained_model/space_invaders_lstm/scores.txt.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/muupan/async-rl/5c5844fe7d62055ef911c7abfa6200fb30f6db84/trained_model/space_invaders_lstm/scores.txt.png
--------------------------------------------------------------------------------
/v_function.py:
--------------------------------------------------------------------------------
1 | import chainer
2 | from chainer import functions as F
3 | from chainer import links as L
4 |
5 |
6 | class VFunction(object):
7 | pass
8 |
9 |
10 | class FCVFunction(chainer.ChainList, VFunction):
11 |
12 | def __init__(self, n_input_channels, n_hidden_layers=0,
13 | n_hidden_channels=None):
14 | self.n_input_channels = n_input_channels
15 | self.n_hidden_layers = n_hidden_layers
16 | self.n_hidden_channels = n_hidden_channels
17 |
18 | layers = []
19 | if n_hidden_layers > 0:
20 | layers.append(L.Linear(n_input_channels, n_hidden_channels))
21 | for i in range(n_hidden_layers - 1):
22 | layers.append(L.Linear(n_hidden_channels, n_hidden_channels))
23 | layers.append(L.Linear(n_hidden_channels, 1))
24 | else:
25 | layers.append(L.Linear(n_input_channels, 1))
26 |
27 | super(FCVFunction, self).__init__(*layers)
28 |
29 | def __call__(self, state):
30 | h = state
31 | for layer in self[:-1]:
32 | h = F.relu(layer(h))
33 | h = self[-1](h)
34 | return h
35 |
--------------------------------------------------------------------------------
39 |
40 | The trained model is uploaded at `trained_model/space_invaders_lstm/80000000_finish.h5`, so you can make it to play Space Invaders by the following command:
41 |
42 | ```
43 | python demo_a3c_ale.py trained_model/space_invaders_lstm/80000000_finish.h5 --use-lstm
44 | ```
45 |
46 | The animation gif above is the episode I cherry-picked from 10 demo runs using that model.
47 |
48 | ### Implementation details
49 |
50 | I received a confirmation about their implementation details and some hyperparameters by e-mail from Dr. Mnih. I summarized them in the wiki: https://github.com/muupan/async-rl/wiki
51 |
52 | ## Requirements
53 |
54 | - Python 3.5.1
55 | - chainer 1.8.1
56 | - cached-property 1.3.0
57 | - h5py 2.5.0
58 | - Arcade-Learning-Environment
59 |
60 | ## Training
61 |
62 | ```
63 | python a3c_ale.py [--use-lstm]
64 | ```
65 |
66 | `a3c_ale.py` will save best-so-far models and test scores into the output directory.
67 |
68 | Unfortunately it seems this script has some bug now. Please see the issues [#5](https://github.com/muupan/async-rl/issues/5) and [#6](https://github.com/muupan/async-rl/issues/6). I'm trying to fix it.
69 |
70 | ## Evaluation
71 |
72 | ```
73 | python demo_a3c_ale.py [--use-lstm]
74 | ```
75 |
76 | ## Similar Projects
77 |
78 | - https://github.com/miyosuda/async_deep_reinforce
79 |
--------------------------------------------------------------------------------
/a3c.py:
--------------------------------------------------------------------------------
1 | import copy
2 | from logging import getLogger
3 | import os
4 |
5 | import numpy as np
6 | import chainer
7 | from chainer import serializers
8 | from chainer import functions as F
9 |
10 | import copy_param
11 |
12 | logger = getLogger(__name__)
13 |
14 |
15 | class A3CModel(chainer.Link):
16 |
17 | def pi_and_v(self, state, keep_same_state=False):
18 | raise NotImplementedError()
19 |
20 | def reset_state(self):
21 | pass
22 |
23 | def unchain_backward(self):
24 | pass
25 |
26 |
27 | class A3C(object):
28 | """A3C: Asynchronous Advantage Actor-Critic.
29 |
30 | See http://arxiv.org/abs/1602.01783
31 | """
32 |
33 | def __init__(self, model, optimizer, t_max, gamma, beta=1e-2,
34 | process_idx=0, clip_reward=True, phi=lambda x: x,
35 | pi_loss_coef=1.0, v_loss_coef=0.5,
36 | keep_loss_scale_same=False):
37 |
38 | # Globally shared model
39 | self.shared_model = model
40 |
41 | # Thread specific model
42 | self.model = copy.deepcopy(self.shared_model)
43 |
44 | self.optimizer = optimizer
45 | self.t_max = t_max
46 | self.gamma = gamma
47 | self.beta = beta
48 | self.process_idx = process_idx
49 | self.clip_reward = clip_reward
50 | self.phi = phi
51 | self.pi_loss_coef = pi_loss_coef
52 | self.v_loss_coef = v_loss_coef
53 | self.keep_loss_scale_same = keep_loss_scale_same
54 |
55 | self.t = 0
56 | self.t_start = 0
57 | self.past_action_log_prob = {}
58 | self.past_action_entropy = {}
59 | self.past_states = {}
60 | self.past_rewards = {}
61 | self.past_values = {}
62 |
63 | def sync_parameters(self):
64 | copy_param.copy_param(target_link=self.model,
65 | source_link=self.shared_model)
66 |
67 | def act(self, state, reward, is_state_terminal):
68 |
69 | if self.clip_reward:
70 | reward = np.clip(reward, -1, 1)
71 |
72 | if not is_state_terminal:
73 | statevar = chainer.Variable(np.expand_dims(self.phi(state), 0))
74 |
75 | self.past_rewards[self.t - 1] = reward
76 |
77 | if (is_state_terminal and self.t_start < self.t) \
78 | or self.t - self.t_start == self.t_max:
79 |
80 | assert self.t_start < self.t
81 |
82 | if is_state_terminal:
83 | R = 0
84 | else:
85 | _, vout = self.model.pi_and_v(statevar, keep_same_state=True)
86 | R = float(vout.data)
87 |
88 | pi_loss = 0
89 | v_loss = 0
90 | for i in reversed(range(self.t_start, self.t)):
91 | R *= self.gamma
92 | R += self.past_rewards[i]
93 | v = self.past_values[i]
94 | if self.process_idx == 0:
95 | logger.debug('s:%s v:%s R:%s',
96 | self.past_states[i].data.sum(), v.data, R)
97 | advantage = R - v
98 | # Accumulate gradients of policy
99 | log_prob = self.past_action_log_prob[i]
100 | entropy = self.past_action_entropy[i]
101 |
102 | # Log probability is increased proportionally to advantage
103 | pi_loss -= log_prob * float(advantage.data)
104 | # Entropy is maximized
105 | pi_loss -= self.beta * entropy
106 | # Accumulate gradients of value function
107 |
108 | v_loss += (v - R) ** 2 / 2
109 |
110 | if self.pi_loss_coef != 1.0:
111 | pi_loss *= self.pi_loss_coef
112 |
113 | if self.v_loss_coef != 1.0:
114 | v_loss *= self.v_loss_coef
115 |
116 | # Normalize the loss of sequences truncated by terminal states
117 | if self.keep_loss_scale_same and \
118 | self.t - self.t_start < self.t_max:
119 | factor = self.t_max / (self.t - self.t_start)
120 | pi_loss *= factor
121 | v_loss *= factor
122 |
123 | if self.process_idx == 0:
124 | logger.debug('pi_loss:%s v_loss:%s', pi_loss.data, v_loss.data)
125 |
126 | total_loss = pi_loss + F.reshape(v_loss, pi_loss.data.shape)
127 |
128 | # Compute gradients using thread-specific model
129 | self.model.zerograds()
130 | total_loss.backward()
131 | # Copy the gradients to the globally shared model
132 | self.shared_model.zerograds()
133 | copy_param.copy_grad(
134 | target_link=self.shared_model, source_link=self.model)
135 | # Update the globally shared model
136 | if self.process_idx == 0:
137 | norm = self.optimizer.compute_grads_norm()
138 | logger.debug('grad norm:%s', norm)
139 | self.optimizer.update()
140 | if self.process_idx == 0:
141 | logger.debug('update')
142 |
143 | self.sync_parameters()
144 | self.model.unchain_backward()
145 |
146 | self.past_action_log_prob = {}
147 | self.past_action_entropy = {}
148 | self.past_states = {}
149 | self.past_rewards = {}
150 | self.past_values = {}
151 |
152 | self.t_start = self.t
153 |
154 | if not is_state_terminal:
155 | self.past_states[self.t] = statevar
156 | pout, vout = self.model.pi_and_v(statevar)
157 | self.past_action_log_prob[self.t] = pout.sampled_actions_log_probs
158 | self.past_action_entropy[self.t] = pout.entropy
159 | self.past_values[self.t] = vout
160 | self.t += 1
161 | if self.process_idx == 0:
162 | logger.debug('t:%s entropy:%s, probs:%s',
163 | self.t, pout.entropy.data, pout.probs.data)
164 | return pout.action_indices[0]
165 | else:
166 | self.model.reset_state()
167 | return None
168 |
169 | def load_model(self, model_filename):
170 | """Load a network model form a file
171 | """
172 | serializers.load_hdf5(model_filename, self.model)
173 | copy_param.copy_param(target_link=self.model,
174 | source_link=self.shared_model)
175 | opt_filename = model_filename + '.opt'
176 | if os.path.exists(opt_filename):
177 | print('WARNING: {0} was not found, so loaded only a model'.format(
178 | opt_filename))
179 | serializers.load_hdf5(model_filename + '.opt', self.optimizer)
180 |
181 | def save_model(self, model_filename):
182 | """Save a network model to a file
183 | """
184 | serializers.save_hdf5(model_filename, self.model)
185 | serializers.save_hdf5(model_filename + '.opt', self.optimizer)
186 |
--------------------------------------------------------------------------------
/a3c_ale.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import copy
3 | import multiprocessing as mp
4 | import os
5 | import sys
6 | import statistics
7 | import time
8 |
9 | import chainer
10 | from chainer import links as L
11 | from chainer import functions as F
12 | import numpy as np
13 |
14 | import policy
15 | import v_function
16 | import dqn_head
17 | import a3c
18 | import ale
19 | import random_seed
20 | import async
21 | import rmsprop_async
22 | from prepare_output_dir import prepare_output_dir
23 | from nonbias_weight_decay import NonbiasWeightDecay
24 | from init_like_torch import init_like_torch
25 | from dqn_phi import dqn_phi
26 |
27 |
28 | class A3CFF(chainer.ChainList, a3c.A3CModel):
29 |
30 | def __init__(self, n_actions):
31 | self.head = dqn_head.NIPSDQNHead()
32 | self.pi = policy.FCSoftmaxPolicy(
33 | self.head.n_output_channels, n_actions)
34 | self.v = v_function.FCVFunction(self.head.n_output_channels)
35 | super().__init__(self.head, self.pi, self.v)
36 | init_like_torch(self)
37 |
38 | def pi_and_v(self, state, keep_same_state=False):
39 | out = self.head(state)
40 | return self.pi(out), self.v(out)
41 |
42 |
43 | class A3CLSTM(chainer.ChainList, a3c.A3CModel):
44 |
45 | def __init__(self, n_actions):
46 | self.head = dqn_head.NIPSDQNHead()
47 | self.pi = policy.FCSoftmaxPolicy(
48 | self.head.n_output_channels, n_actions)
49 | self.v = v_function.FCVFunction(self.head.n_output_channels)
50 | self.lstm = L.LSTM(self.head.n_output_channels,
51 | self.head.n_output_channels)
52 | super().__init__(self.head, self.lstm, self.pi, self.v)
53 | init_like_torch(self)
54 |
55 | def pi_and_v(self, state, keep_same_state=False):
56 | out = self.head(state)
57 | if keep_same_state:
58 | prev_h, prev_c = self.lstm.h, self.lstm.c
59 | out = self.lstm(out)
60 | self.lstm.h, self.lstm.c = prev_h, prev_c
61 | else:
62 | out = self.lstm(out)
63 | return self.pi(out), self.v(out)
64 |
65 | def reset_state(self):
66 | self.lstm.reset_state()
67 |
68 | def unchain_backward(self):
69 | self.lstm.h.unchain_backward()
70 | self.lstm.c.unchain_backward()
71 |
72 |
73 | def eval_performance(rom, p_func, n_runs):
74 | assert n_runs > 1, 'Computing stdev requires at least two runs'
75 | scores = []
76 | for i in range(n_runs):
77 | env = ale.ALE(rom, treat_life_lost_as_terminal=False)
78 | test_r = 0
79 | while not env.is_terminal:
80 | s = chainer.Variable(np.expand_dims(dqn_phi(env.state), 0))
81 | pout = p_func(s)
82 | a = pout.action_indices[0]
83 | test_r += env.receive_action(a)
84 | scores.append(test_r)
85 | print('test_{}:'.format(i), test_r)
86 | mean = statistics.mean(scores)
87 | median = statistics.median(scores)
88 | stdev = statistics.stdev(scores)
89 | return mean, median, stdev
90 |
91 |
92 | def train_loop(process_idx, counter, max_score, args, agent, env, start_time):
93 | try:
94 |
95 | total_r = 0
96 | episode_r = 0
97 | global_t = 0
98 | local_t = 0
99 |
100 | while True:
101 |
102 | # Get and increment the global counter
103 | with counter.get_lock():
104 | counter.value += 1
105 | global_t = counter.value
106 | local_t += 1
107 |
108 | if global_t > args.steps:
109 | break
110 |
111 | agent.optimizer.lr = (
112 | args.steps - global_t - 1) / args.steps * args.lr
113 |
114 | total_r += env.reward
115 | episode_r += env.reward
116 |
117 | action = agent.act(env.state, env.reward, env.is_terminal)
118 |
119 | if env.is_terminal:
120 | if process_idx == 0:
121 | print('{} global_t:{} local_t:{} lr:{} episode_r:{}'.format(
122 | args.outdir, global_t, local_t, agent.optimizer.lr, episode_r))
123 | episode_r = 0
124 | env.initialize()
125 | else:
126 | env.receive_action(action)
127 |
128 | if global_t % args.eval_frequency == 0:
129 | # Evaluation
130 |
131 | # We must use a copy of the model because test runs can change
132 | # the hidden states of the model
133 | test_model = copy.deepcopy(agent.model)
134 | test_model.reset_state()
135 |
136 | def p_func(s):
137 | pout, _ = test_model.pi_and_v(s)
138 | test_model.unchain_backward()
139 | return pout
140 | mean, median, stdev = eval_performance(
141 | args.rom, p_func, args.eval_n_runs)
142 | with open(os.path.join(args.outdir, 'scores.txt'), 'a+') as f:
143 | elapsed = time.time() - start_time
144 | record = (global_t, elapsed, mean, median, stdev)
145 | print('\t'.join(str(x) for x in record), file=f)
146 | with max_score.get_lock():
147 | if mean > max_score.value:
148 | # Save the best model so far
149 | print('The best score is updated {} -> {}'.format(
150 | max_score.value, mean))
151 | filename = os.path.join(
152 | args.outdir, '{}.h5'.format(global_t))
153 | agent.save_model(filename)
154 | print('Saved the current best model to {}'.format(
155 | filename))
156 | max_score.value = mean
157 |
158 | except KeyboardInterrupt:
159 | if process_idx == 0:
160 | # Save the current model before being killed
161 | agent.save_model(os.path.join(
162 | args.outdir, '{}_keyboardinterrupt.h5'.format(global_t)))
163 | print('Saved the current model to {}'.format(
164 | args.outdir), file=sys.stderr)
165 | raise
166 |
167 | if global_t == args.steps + 1:
168 | # Save the final model
169 | agent.save_model(
170 | os.path.join(args.outdir, '{}_finish.h5'.format(args.steps)))
171 | print('Saved the final model to {}'.format(args.outdir))
172 |
173 |
174 | def train_loop_with_profile(process_idx, counter, max_score, args, agent, env,
175 | start_time):
176 | import cProfile
177 | cmd = 'train_loop(process_idx, counter, max_score, args, agent, env, ' \
178 | 'start_time)'
179 | cProfile.runctx(cmd, globals(), locals(),
180 | 'profile-{}.out'.format(os.getpid()))
181 |
182 |
183 | def main():
184 |
185 | # Prevent numpy from using multiple threads
186 | os.environ['OMP_NUM_THREADS'] = '1'
187 |
188 | import logging
189 | logging.basicConfig(level=logging.DEBUG)
190 |
191 | parser = argparse.ArgumentParser()
192 | parser.add_argument('processes', type=int)
193 | parser.add_argument('rom', type=str)
194 | parser.add_argument('--seed', type=int, default=None)
195 | parser.add_argument('--outdir', type=str, default=None)
196 | parser.add_argument('--use-sdl', action='store_true')
197 | parser.add_argument('--t-max', type=int, default=5)
198 | parser.add_argument('--beta', type=float, default=1e-2)
199 | parser.add_argument('--profile', action='store_true')
200 | parser.add_argument('--steps', type=int, default=8 * 10 ** 7)
201 | parser.add_argument('--lr', type=float, default=7e-4)
202 | parser.add_argument('--eval-frequency', type=int, default=10 ** 6)
203 | parser.add_argument('--eval-n-runs', type=int, default=10)
204 | parser.add_argument('--weight-decay', type=float, default=0.0)
205 | parser.add_argument('--use-lstm', action='store_true')
206 | parser.set_defaults(use_sdl=False)
207 | parser.set_defaults(use_lstm=False)
208 | args = parser.parse_args()
209 |
210 | if args.seed is not None:
211 | random_seed.set_random_seed(args.seed)
212 |
213 | args.outdir = prepare_output_dir(args, args.outdir)
214 |
215 | print('Output files are saved in {}'.format(args.outdir))
216 |
217 | n_actions = ale.ALE(args.rom).number_of_actions
218 |
219 | def model_opt():
220 | if args.use_lstm:
221 | model = A3CLSTM(n_actions)
222 | else:
223 | model = A3CFF(n_actions)
224 | opt = rmsprop_async.RMSpropAsync(lr=7e-4, eps=1e-1, alpha=0.99)
225 | opt.setup(model)
226 | opt.add_hook(chainer.optimizer.GradientClipping(40))
227 | if args.weight_decay > 0:
228 | opt.add_hook(NonbiasWeightDecay(args.weight_decay))
229 | return model, opt
230 |
231 | model, opt = model_opt()
232 |
233 | shared_params = async.share_params_as_shared_arrays(model)
234 | shared_states = async.share_states_as_shared_arrays(opt)
235 |
236 | max_score = mp.Value('f', np.finfo(np.float32).min)
237 | counter = mp.Value('l', 0)
238 | start_time = time.time()
239 |
240 | # Write a header line first
241 | with open(os.path.join(args.outdir, 'scores.txt'), 'a+') as f:
242 | column_names = ('steps', 'elapsed', 'mean', 'median', 'stdev')
243 | print('\t'.join(column_names), file=f)
244 |
245 | def run_func(process_idx):
246 | env = ale.ALE(args.rom, use_sdl=args.use_sdl)
247 | model, opt = model_opt()
248 | async.set_shared_params(model, shared_params)
249 | async.set_shared_states(opt, shared_states)
250 |
251 | agent = a3c.A3C(model, opt, args.t_max, 0.99, beta=args.beta,
252 | process_idx=process_idx, phi=dqn_phi)
253 |
254 | if args.profile:
255 | train_loop_with_profile(process_idx, counter, max_score,
256 | args, agent, env, start_time)
257 | else:
258 | train_loop(process_idx, counter, max_score,
259 | args, agent, env, start_time)
260 |
261 | async.run_async(args.processes, run_func)
262 |
263 |
264 | if __name__ == '__main__':
265 | main()
266 |
--------------------------------------------------------------------------------
/ale.py:
--------------------------------------------------------------------------------
1 | import collections
2 | import os
3 | import sys
4 |
5 | import numpy as np
6 | from ale_python_interface import ALEInterface
7 | import cv2
8 |
9 | import environment
10 |
11 |
12 | class ALE(environment.EpisodicEnvironment):
13 | """Arcade Learning Environment.
14 | """
15 |
16 | def __init__(self, rom_filename, seed=None, use_sdl=False, n_last_screens=4,
17 | frame_skip=4, treat_life_lost_as_terminal=True,
18 | crop_or_scale='scale', max_start_nullops=30,
19 | record_screen_dir=None):
20 | self.n_last_screens = n_last_screens
21 | self.treat_life_lost_as_terminal = treat_life_lost_as_terminal
22 | self.crop_or_scale = crop_or_scale
23 | self.max_start_nullops = max_start_nullops
24 |
25 | ale = ALEInterface()
26 | if seed is not None:
27 | assert seed >= 0 and seed < 2 ** 16, \
28 | "ALE's random seed must be represented by unsigned int"
29 | else:
30 | # Use numpy's random state
31 | seed = np.random.randint(0, 2 ** 16)
32 | ale.setInt(b'random_seed', seed)
33 | ale.setFloat(b'repeat_action_probability', 0.0)
34 | ale.setBool(b'color_averaging', False)
35 | if record_screen_dir is not None:
36 | ale.setString(b'record_screen_dir', str.encode(record_screen_dir))
37 | self.frame_skip = frame_skip
38 | if use_sdl:
39 | if 'DISPLAY' not in os.environ:
40 | raise RuntimeError(
41 | 'Please set DISPLAY environment variable for use_sdl=True')
42 | # SDL settings below are from the ALE python example
43 | if sys.platform == 'darwin':
44 | import pygame
45 | pygame.init()
46 | ale.setBool(b'sound', False) # Sound doesn't work on OSX
47 | elif sys.platform.startswith('linux'):
48 | ale.setBool(b'sound', True)
49 | ale.setBool(b'display_screen', True)
50 | ale.loadROM(str.encode(rom_filename))
51 |
52 | assert ale.getFrameNumber() == 0
53 |
54 |
55 | self.ale = ale
56 | self.legal_actions = ale.getMinimalActionSet()
57 | self.initialize()
58 |
59 | def current_screen(self):
60 | # Max of two consecutive frames
61 | assert self.last_raw_screen is not None
62 | rgb_img = np.maximum(self.ale.getScreenRGB(), self.last_raw_screen)
63 | # Make sure the last raw screen is used only once
64 | self.last_raw_screen = None
65 | assert rgb_img.shape == (210, 160, 3)
66 | # RGB -> Luminance
67 | img = rgb_img[:, :, 0] * 0.2126 + rgb_img[:, :, 1] * \
68 | 0.0722 + rgb_img[:, :, 2] * 0.7152
69 | img = img.astype(np.uint8)
70 | if img.shape == (250, 160):
71 | raise RuntimeError("This ROM is for PAL. Please use ROMs for NTSC")
72 | assert img.shape == (210, 160)
73 | if self.crop_or_scale == 'crop':
74 | # Shrink (210, 160) -> (110, 84)
75 | img = cv2.resize(img, (84, 110),
76 | interpolation=cv2.INTER_LINEAR)
77 | assert img.shape == (110, 84)
78 | # Crop (110, 84) -> (84, 84)
79 | unused_height = 110 - 84
80 | bottom_crop = 8
81 | top_crop = unused_height - bottom_crop
82 | img = img[top_crop: 110 - bottom_crop, :]
83 | elif self.crop_or_scale == 'scale':
84 | img = cv2.resize(img, (84, 84),
85 | interpolation=cv2.INTER_LINEAR)
86 | else:
87 | raise RuntimeError('crop_or_scale must be either crop or scale')
88 | assert img.shape == (84, 84)
89 | return img
90 |
91 | @property
92 | def state(self):
93 | assert len(self.last_screens) == 4
94 | return list(self.last_screens)
95 |
96 | @property
97 | def is_terminal(self):
98 | if self.treat_life_lost_as_terminal:
99 | return self.lives_lost or self.ale.game_over()
100 | else:
101 | return self.ale.game_over()
102 |
103 | @property
104 | def reward(self):
105 | return self._reward
106 |
107 | @property
108 | def number_of_actions(self):
109 | return len(self.legal_actions)
110 |
111 | def receive_action(self, action):
112 | assert not self.is_terminal
113 |
114 | rewards = []
115 | for i in range(4):
116 |
117 | # Last screeen must be stored before executing the 4th action
118 | if i == 3:
119 | self.last_raw_screen = self.ale.getScreenRGB()
120 |
121 | rewards.append(self.ale.act(self.legal_actions[action]))
122 |
123 | # Check if lives are lost
124 | if self.lives > self.ale.lives():
125 | self.lives_lost = True
126 | else:
127 | self.lives_lost = False
128 | self.lives = self.ale.lives()
129 |
130 | if self.is_terminal:
131 | break
132 |
133 | # We must have last screen here unless it's terminal
134 | if not self.is_terminal:
135 | self.last_screens.append(self.current_screen())
136 |
137 | self._reward = sum(rewards)
138 |
139 | return self._reward
140 |
141 | def initialize(self):
142 |
143 | if self.ale.game_over():
144 | self.ale.reset_game()
145 |
146 | if self.max_start_nullops > 0:
147 | n_nullops = np.random.randint(0, self.max_start_nullops + 1)
148 | for _ in range(n_nullops):
149 | self.ale.act(0)
150 |
151 | self._reward = 0
152 |
153 | self.last_raw_screen = self.ale.getScreenRGB()
154 |
155 | self.last_screens = collections.deque(
156 | [np.zeros((84, 84), dtype=np.uint8)] * 3 +
157 | [self.current_screen()],
158 | maxlen=self.n_last_screens)
159 |
160 | self.lives_lost = False
161 | self.lives = self.ale.lives()
162 |
--------------------------------------------------------------------------------
/async.py:
--------------------------------------------------------------------------------
1 | import multiprocessing as mp
2 | import os
3 | import random
4 |
5 | import chainer
6 | import numpy as np
7 |
8 | import random_seed
9 |
10 |
11 | def set_shared_params(a, b):
12 | """
13 | Args:
14 | a (chainer.Link): link whose params are to be replaced
15 | b (dict): dict that consists of (param_name, multiprocessing.Array)
16 | """
17 | assert isinstance(a, chainer.Link)
18 | for param_name, param in a.namedparams():
19 | if param_name in b:
20 | shared_param = b[param_name]
21 | param.data = np.frombuffer(
22 | shared_param, dtype=param.data.dtype).reshape(param.data.shape)
23 |
24 |
25 | def set_shared_states(a, b):
26 | assert isinstance(a, chainer.Optimizer)
27 | assert hasattr(a, 'target'), 'Optimizer.setup must be called first'
28 | for state_name, shared_state in b.items():
29 | for param_name, param in shared_state.items():
30 | old_param = a._states[state_name][param_name]
31 | a._states[state_name][param_name] = np.frombuffer(
32 | param,
33 | dtype=old_param.dtype).reshape(old_param.shape)
34 |
35 |
36 | def extract_params_as_shared_arrays(link):
37 | assert isinstance(link, chainer.Link)
38 | shared_arrays = {}
39 | for param_name, param in link.namedparams():
40 | shared_arrays[param_name] = mp.RawArray('f', param.data.ravel())
41 | return shared_arrays
42 |
43 |
44 | def share_params_as_shared_arrays(link):
45 | shared_arrays = extract_params_as_shared_arrays(link)
46 | set_shared_params(link, shared_arrays)
47 | return shared_arrays
48 |
49 |
50 | def share_states_as_shared_arrays(link):
51 | shared_arrays = extract_states_as_shared_arrays(link)
52 | set_shared_states(link, shared_arrays)
53 | return shared_arrays
54 |
55 |
56 | def extract_states_as_shared_arrays(optimizer):
57 | assert isinstance(optimizer, chainer.Optimizer)
58 | assert hasattr(optimizer, 'target'), 'Optimizer.setup must be called first'
59 | shared_arrays = {}
60 | for state_name, state in optimizer._states.items():
61 | shared_arrays[state_name] = {}
62 | for param_name, param in state.items():
63 | shared_arrays[state_name][
64 | param_name] = mp.RawArray('f', param.ravel())
65 | return shared_arrays
66 |
67 |
68 | def run_async(n_process, run_func):
69 | """Run experiments asynchronously.
70 |
71 | Args:
72 | n_process (int): number of processes
73 | run_func: function that will be run in parallel
74 | """
75 |
76 | processes = []
77 |
78 | def set_seed_and_run(process_idx, run_func):
79 | random_seed.set_random_seed(np.random.randint(0, 2 ** 32))
80 | run_func(process_idx)
81 |
82 | for process_idx in range(n_process):
83 | processes.append(mp.Process(target=set_seed_and_run, args=(
84 | process_idx, run_func)))
85 |
86 | for p in processes:
87 | p.start()
88 |
89 | for p in processes:
90 | p.join()
91 |
--------------------------------------------------------------------------------
/copy_param.py:
--------------------------------------------------------------------------------
1 | def copy_param(target_link, source_link):
2 | """Copy parameters of a link to another link.
3 | """
4 | target_params = dict(target_link.namedparams())
5 | for param_name, param in source_link.namedparams():
6 | target_params[param_name].data[:] = param.data
7 |
8 |
9 | def copy_grad(target_link, source_link):
10 | """Copy gradients of a link to another link.
11 | """
12 | target_params = dict(target_link.namedparams())
13 | for param_name, param in source_link.namedparams():
14 | target_params[param_name].grad[:] = param.grad
15 |
--------------------------------------------------------------------------------
/demo_a3c_ale.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 |
4 | import numpy as np
5 | import chainer
6 | from chainer import serializers
7 |
8 | import ale
9 | import random_seed
10 | from dqn_phi import dqn_phi
11 | from a3c_ale import A3CFF
12 | from a3c_ale import A3CLSTM
13 |
14 |
15 | def eval_performance(rom, model, deterministic=False, use_sdl=False,
16 | record_screen_dir=None):
17 | env = ale.ALE(rom, treat_life_lost_as_terminal=False, use_sdl=use_sdl,
18 | record_screen_dir=record_screen_dir)
19 | model.reset_state()
20 | test_r = 0
21 | while not env.is_terminal:
22 | s = chainer.Variable(np.expand_dims(dqn_phi(env.state), 0))
23 | pout = model.pi_and_v(s)[0]
24 | model.unchain_backward()
25 | if deterministic:
26 | a = pout.most_probable_actions[0]
27 | else:
28 | a = pout.action_indices[0]
29 | test_r += env.receive_action(a)
30 | return test_r
31 |
32 |
33 | def main():
34 |
35 | import logging
36 | logging.basicConfig(level=logging.DEBUG)
37 |
38 | parser = argparse.ArgumentParser()
39 | parser.add_argument('rom', type=str)
40 | parser.add_argument('model', type=str)
41 | parser.add_argument('--seed', type=int, default=0)
42 | parser.add_argument('--use-sdl', action='store_true')
43 | parser.add_argument('--n-runs', type=int, default=10)
44 | parser.add_argument('--deterministic', action='store_true')
45 | parser.add_argument('--record-screen-dir', type=str, default=None)
46 | parser.add_argument('--use-lstm', action='store_true')
47 | parser.set_defaults(use_sdl=False)
48 | parser.set_defaults(use_lstm=False)
49 | parser.set_defaults(deterministic=False)
50 | args = parser.parse_args()
51 |
52 | random_seed.set_random_seed(args.seed)
53 |
54 | n_actions = ale.ALE(args.rom).number_of_actions
55 |
56 | # Load an A3C-DQN model
57 | if args.use_lstm:
58 | model = A3CLSTM(n_actions)
59 | else:
60 | model = A3CFF(n_actions)
61 | serializers.load_hdf5(args.model, model)
62 |
63 | scores = []
64 | for i in range(args.n_runs):
65 | episode_record_dir = None
66 | if args.record_screen_dir is not None:
67 | episode_record_dir = os.path.join(args.record_screen_dir, str(i))
68 | os.makedirs(episode_record_dir)
69 | score = eval_performance(
70 | args.rom, model, deterministic=args.deterministic,
71 | use_sdl=args.use_sdl, record_screen_dir=episode_record_dir)
72 | print('Run {}: {}'.format(i, score))
73 | scores.append(score)
74 | print('Average: {}'.format(sum(scores) / args.n_runs))
75 |
76 |
77 | if __name__ == '__main__':
78 | main()
79 |
--------------------------------------------------------------------------------
/demo_a3c_doom.py:
--------------------------------------------------------------------------------
1 | import argparse
2 |
3 | import chainer
4 | from chainer import serializers
5 | import numpy as np
6 |
7 | import random_seed
8 | import doom_env
9 | from train_a3c_doom import phi, A3CFF, A3CLSTM
10 |
11 |
12 | def eval_single_run(env, model, phi, deterministic=False):
13 | model.reset_state()
14 | test_r = 0
15 | obs = env.reset()
16 | done = False
17 | while not done:
18 | s = chainer.Variable(np.expand_dims(phi(obs), 0))
19 | pout = model.pi_and_v(s)[0]
20 | model.unchain_backward()
21 | if deterministic:
22 | a = pout.most_probable_actions[0]
23 | else:
24 | a = pout.action_indices[0]
25 | obs, r, done, info = env.step(a)
26 | test_r += r
27 | return test_r
28 |
29 |
30 | def eval_single_random_run(env):
31 | test_r = 0
32 | obs = env.reset()
33 | done = False
34 | while not done:
35 | a = np.random.randint(env.n_actions)
36 | obs, r, done, info = env.step(a)
37 | test_r += r
38 | return test_r
39 |
40 |
41 | def main():
42 | import logging
43 | logging.basicConfig(level=logging.DEBUG)
44 |
45 | parser = argparse.ArgumentParser()
46 | parser.add_argument('model', type=str)
47 | parser.add_argument('--seed', type=int, default=0)
48 | parser.add_argument('--sleep', type=float, default=0)
49 | parser.add_argument('--scenario', type=str, default='basic')
50 | parser.add_argument('--n-runs', type=int, default=10)
51 | parser.add_argument('--use-lstm', action='store_true')
52 | parser.add_argument('--window-visible', action='store_true')
53 | parser.add_argument('--deterministic', action='store_true')
54 | parser.add_argument('--random', action='store_true')
55 | parser.set_defaults(window_visible=False)
56 | parser.set_defaults(use_lstm=False)
57 | parser.set_defaults(deterministic=False)
58 | parser.set_defaults(random=False)
59 | args = parser.parse_args()
60 |
61 | random_seed.set_random_seed(args.seed)
62 |
63 | n_actions = doom_env.DoomEnv(
64 | window_visible=False, scenario=args.scenario).n_actions
65 |
66 | if not args.random:
67 | if args.use_lstm:
68 | model = A3CLSTM(n_actions)
69 | else:
70 | model = A3CFF(n_actions)
71 | serializers.load_hdf5(args.model, model)
72 |
73 | scores = []
74 | env = doom_env.DoomEnv(window_visible=args.window_visible,
75 | scenario=args.scenario,
76 | sleep=args.sleep)
77 | for i in range(args.n_runs):
78 | if args.random:
79 | score = eval_single_random_run(env)
80 | else:
81 | score = eval_single_run(
82 | env, model, phi, deterministic=args.deterministic)
83 | print('Run {}: {}'.format(i, score))
84 | scores.append(score)
85 | print('Average: {}'.format(sum(scores) / args.n_runs))
86 |
87 |
88 | if __name__ == '__main__':
89 | main()
90 |
--------------------------------------------------------------------------------
/doom_env.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import time
4 |
5 | import numpy as np
6 |
7 |
8 | class DoomEnv(object):
9 |
10 | def __init__(self, vizdoom_dir=os.path.expanduser('~/ViZDoom'),
11 | window_visible=True, scenario='basic', skipcount=10,
12 | resolution_width=640, sleep=0.0, seed=None):
13 |
14 | self.skipcount = skipcount
15 | self.sleep = sleep
16 |
17 | sys.path.append(os.path.join(vizdoom_dir, "examples/python"))
18 | from vizdoom import DoomGame
19 | from vizdoom import ScreenFormat
20 | from vizdoom import ScreenResolution
21 |
22 | game = DoomGame()
23 |
24 | if seed is not None:
25 | assert seed >= 0 and seed < 2 ** 16, \
26 | "ViZDoom's random seed must be represented by unsigned int"
27 | else:
28 | # Use numpy's random state
29 | seed = np.random.randint(0, 2 ** 16)
30 | game.set_seed(seed)
31 |
32 | # Load a config file
33 | game.load_config(os.path.join(
34 | vizdoom_dir, "examples", 'config', scenario + '.cfg'))
35 |
36 | # Replace default relative paths with actual paths
37 | game.set_vizdoom_path(os.path.join(vizdoom_dir, "bin/vizdoom"))
38 | game.set_doom_game_path(
39 | os.path.join(vizdoom_dir, 'scenarios/freedoom2.wad'))
40 | game.set_doom_scenario_path(
41 | os.path.join(vizdoom_dir, 'scenarios', scenario + '.wad'))
42 |
43 | # Set screen settings
44 | resolutions = {640: ScreenResolution.RES_640X480,
45 | 320: ScreenResolution.RES_320X240,
46 | 160: ScreenResolution.RES_160X120}
47 | game.set_screen_resolution(resolutions[resolution_width])
48 | game.set_screen_format(ScreenFormat.RGB24)
49 | game.set_window_visible(window_visible)
50 | game.set_sound_enabled(window_visible)
51 |
52 | game.init()
53 | self.game = game
54 |
55 | # Use one-hot actions
56 | self.n_actions = game.get_available_buttons_size()
57 | self.actions = []
58 | for i in range(self.n_actions):
59 | self.actions.append([i == j for j in range(self.n_actions)])
60 |
61 | def reset(self):
62 | self.game.new_episode()
63 | return self.game.get_state()
64 |
65 | def step(self, action):
66 | r = self.game.make_action(self.actions[action], self.skipcount)
67 | r /= 100
68 | time.sleep(self.sleep * self.skipcount)
69 | return self.game.get_state(), r, self.game.is_episode_finished(), None
70 |
--------------------------------------------------------------------------------
/dqn_head.py:
--------------------------------------------------------------------------------
1 | import chainer
2 | from chainer import functions as F
3 | from chainer import links as L
4 |
5 |
6 | class NatureDQNHead(chainer.ChainList):
7 | """DQN's head (Nature version)"""
8 |
9 | def __init__(self, n_input_channels=4, n_output_channels=512,
10 | activation=F.relu, bias=0.1):
11 | self.n_input_channels = n_input_channels
12 | self.activation = activation
13 | self.n_output_channels = n_output_channels
14 |
15 | layers = [
16 | L.Convolution2D(n_input_channels, 32, 8, stride=4, bias=bias),
17 | L.Convolution2D(32, 64, 4, stride=2, bias=bias),
18 | L.Convolution2D(64, 64, 3, stride=1, bias=bias),
19 | L.Linear(3136, n_output_channels, bias=bias),
20 | ]
21 |
22 | super(NatureDQNHead, self).__init__(*layers)
23 |
24 | def __call__(self, state):
25 | h = state
26 | for layer in self:
27 | h = self.activation(layer(h))
28 | return h
29 |
30 |
31 | class NIPSDQNHead(chainer.ChainList):
32 | """DQN's head (NIPS workshop version)"""
33 |
34 | def __init__(self, n_input_channels=4, n_output_channels=256,
35 | activation=F.relu, bias=0.1):
36 | self.n_input_channels = n_input_channels
37 | self.activation = activation
38 | self.n_output_channels = n_output_channels
39 |
40 | layers = [
41 | L.Convolution2D(n_input_channels, 16, 8, stride=4, bias=bias),
42 | L.Convolution2D(16, 32, 4, stride=2, bias=bias),
43 | L.Linear(2592, n_output_channels, bias=bias),
44 | ]
45 |
46 | super(NIPSDQNHead, self).__init__(*layers)
47 |
48 | def __call__(self, state):
49 | h = state
50 | for layer in self:
51 | h = self.activation(layer(h))
52 | return h
53 |
--------------------------------------------------------------------------------
/dqn_phi.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 |
4 | def dqn_phi(screens):
5 | """Phi (feature extractor) of DQN for ALE
6 | Args:
7 | screens: List of N screen objects. Each screen object must be
8 | numpy.ndarray whose dtype is numpy.uint8.
9 | Returns:
10 | numpy.ndarray
11 | """
12 | assert len(screens) == 4
13 | assert screens[0].dtype == np.uint8
14 | raw_values = np.asarray(screens, dtype=np.float32)
15 | # [0,255] -> [0, 1]
16 | raw_values /= 255.0
17 | return raw_values
18 |
--------------------------------------------------------------------------------
/environment.py:
--------------------------------------------------------------------------------
1 | class Environment(object):
2 | """RL learning environment
3 | """
4 |
5 | @property
6 | def state(self):
7 | pass
8 |
9 | @property
10 | def reward(self):
11 | pass
12 |
13 | def receive_action(self, action):
14 | pass
15 |
16 | class EpisodicEnvironment(Environment):
17 |
18 | def initialize(self):
19 | """
20 | Initialize the internal state
21 | """
22 | pass
23 |
24 | @property
25 | def is_terminal(self):
26 | pass
27 |
28 |
--------------------------------------------------------------------------------
/init_like_torch.py:
--------------------------------------------------------------------------------
1 | from chainer import links as L
2 | import numpy as np
3 |
4 |
5 | def init_like_torch(link):
6 | # Mimic torch's default parameter initialization
7 | # TODO(muupan): Use chainer's initializers when it is merged
8 | for l in link.links():
9 | if isinstance(l, L.Linear):
10 | out_channels, in_channels = l.W.data.shape
11 | stdv = 1 / np.sqrt(in_channels)
12 | l.W.data[:] = np.random.uniform(-stdv, stdv, size=l.W.data.shape)
13 | if l.b is not None:
14 | l.b.data[:] = np.random.uniform(-stdv, stdv,
15 | size=l.b.data.shape)
16 | elif isinstance(l, L.Convolution2D):
17 | out_channels, in_channels, kh, kw = l.W.data.shape
18 | stdv = 1 / np.sqrt(in_channels * kh * kw)
19 | l.W.data[:] = np.random.uniform(-stdv, stdv, size=l.W.data.shape)
20 | if l.b is not None:
21 | l.b.data[:] = np.random.uniform(-stdv, stdv,
22 | size=l.b.data.shape)
23 |
--------------------------------------------------------------------------------
/nonbias_weight_decay.py:
--------------------------------------------------------------------------------
1 | from chainer import cuda
2 |
3 |
4 | class NonbiasWeightDecay(object):
5 |
6 | """Optimizer hook function for weight decay regularization.
7 |
8 | """
9 | name = 'NonbiasWeightDecay'
10 |
11 | def __init__(self, rate):
12 | self.rate = rate
13 |
14 | def __call__(self, opt):
15 | if cuda.available:
16 | kernel = cuda.elementwise(
17 | 'T p, T decay', 'T g', 'g += decay * p', 'weight_decay')
18 |
19 | rate = self.rate
20 | for name, param in opt.target.namedparams():
21 | if name == 'b' or name.endswith('/b'):
22 | continue
23 | p, g = param.data, param.grad
24 | with cuda.get_device(p) as dev:
25 | if int(dev) == -1:
26 | g += rate * p
27 | else:
28 | kernel(p, rate, g)
29 |
--------------------------------------------------------------------------------
/plot_scores.py:
--------------------------------------------------------------------------------
1 | import argparse
2 |
3 | import matplotlib.pyplot as plt
4 | import pandas as pd
5 |
6 |
7 | def main():
8 | parser = argparse.ArgumentParser()
9 | parser.add_argument('scores', type=str, help='specify path of scores.txt')
10 | parser.add_argument('--title', type=str, default=None)
11 | args = parser.parse_args()
12 |
13 | scores = pd.read_csv(args.scores, delimiter='\t')
14 | for col in ['mean', 'median']:
15 | plt.plot(scores['steps'], scores[col], label=col)
16 | if args.title is not None:
17 | plt.title(args.title)
18 | plt.xlabel('steps')
19 | plt.ylabel('score')
20 | plt.legend(loc='best')
21 | fig_fname = args.scores + '.png'
22 | plt.savefig(fig_fname)
23 | print('Saved a figure as {}'.format(fig_fname))
24 |
25 | if __name__ == '__main__':
26 | main()
27 |
--------------------------------------------------------------------------------
/policy.py:
--------------------------------------------------------------------------------
1 | from logging import getLogger
2 | logger = getLogger(__name__)
3 |
4 | import chainer
5 | from chainer import functions as F
6 | from chainer import links as L
7 |
8 | import policy_output
9 |
10 |
11 | class Policy(object):
12 | """Abstract policy class."""
13 |
14 | def __call__(self, state):
15 | raise NotImplementedError
16 |
17 |
18 | class SoftmaxPolicy(Policy):
19 | """Abstract softmax policy class."""
20 |
21 | def compute_logits(self, state):
22 | """
23 | Returns:
24 | ~chainer.Variable: logits of actions
25 | """
26 | raise NotImplementedError
27 |
28 | def __call__(self, state):
29 | return policy_output.SoftmaxPolicyOutput(self.compute_logits(state))
30 |
31 |
32 | class FCSoftmaxPolicy(chainer.ChainList, SoftmaxPolicy):
33 | """Softmax policy that consists of FC layers and rectifiers"""
34 |
35 | def __init__(self, n_input_channels, n_actions,
36 | n_hidden_layers=0, n_hidden_channels=None):
37 | self.n_input_channels = n_input_channels
38 | self.n_actions = n_actions
39 | self.n_hidden_layers = n_hidden_layers
40 | self.n_hidden_channels = n_hidden_channels
41 |
42 | layers = []
43 | if n_hidden_layers > 0:
44 | layers.append(L.Linear(n_input_channels, n_hidden_channels))
45 | for i in range(n_hidden_layers - 1):
46 | layers.append(L.Linear(n_hidden_channels, n_hidden_channels))
47 | layers.append(L.Linear(n_hidden_channels, n_actions))
48 | else:
49 | layers.append(L.Linear(n_input_channels, n_actions))
50 |
51 | super(FCSoftmaxPolicy, self).__init__(*layers)
52 |
53 | def compute_logits(self, state):
54 | h = state
55 | for layer in self[:-1]:
56 | h = F.relu(layer(h))
57 | h = self[-1](h)
58 | return h
59 |
60 |
61 | class GaussianPolicy(Policy):
62 | """Abstract Gaussian policy class.
63 | """
64 | pass
65 |
--------------------------------------------------------------------------------
/policy_output.py:
--------------------------------------------------------------------------------
1 | import chainer
2 | from chainer import functions as F
3 | from cached_property import cached_property
4 | import numpy as np
5 |
6 |
7 | class PolicyOutput(object):
8 | """Struct that holds policy output and subproducts."""
9 | pass
10 |
11 |
12 | def _sample_discrete_actions(batch_probs):
13 | """Sample a batch of actions from a batch of action probabilities.
14 |
15 | Args:
16 | batch_probs (ndarray): batch of action probabilities BxA
17 | Returns:
18 | List consisting of sampled actions
19 | """
20 | action_indices = []
21 |
22 | # Subtract a tiny value from probabilities in order to avoid
23 | # "ValueError: sum(pvals[:-1]) > 1.0" in numpy.multinomial
24 | batch_probs = batch_probs - np.finfo(np.float32).epsneg
25 |
26 | for i in range(batch_probs.shape[0]):
27 | histogram = np.random.multinomial(1, batch_probs[i])
28 | action_indices.append(int(np.nonzero(histogram)[0]))
29 | return action_indices
30 |
31 |
32 | class SoftmaxPolicyOutput(PolicyOutput):
33 |
34 | def __init__(self, logits):
35 | self.logits = logits
36 |
37 | @cached_property
38 | def most_probable_actions(self):
39 | return np.argmax(self.probs.data, axis=1)
40 |
41 | @cached_property
42 | def probs(self):
43 | return F.softmax(self.logits)
44 |
45 | @cached_property
46 | def log_probs(self):
47 | return F.log_softmax(self.logits)
48 |
49 | @cached_property
50 | def action_indices(self):
51 | return _sample_discrete_actions(self.probs.data)
52 |
53 | @cached_property
54 | def sampled_actions_log_probs(self):
55 | return F.select_item(
56 | self.log_probs,
57 | chainer.Variable(np.asarray(self.action_indices, dtype=np.int32)))
58 |
59 | @cached_property
60 | def entropy(self):
61 | return - F.sum(self.probs * self.log_probs, axis=1)
62 |
--------------------------------------------------------------------------------
/prepare_output_dir.py:
--------------------------------------------------------------------------------
1 | import os
2 | import tempfile
3 | import json
4 | import subprocess
5 |
6 |
7 | def prepare_output_dir(args, user_specified_dir=None):
8 | """Prepare output directory.
9 |
10 | An output directory is created if it does not exist. Then the following
11 | infomation is saved into the directory:
12 | args.txt: command-line arguments
13 | git-status.txt: result of `git status`
14 | git-log.txt: result of `git log`
15 | git-diff.txt: result of `git diff`
16 |
17 | Args:
18 | args: dict that describes command-line arguments
19 | user_specified_dir: directory path
20 | """
21 | if user_specified_dir is not None:
22 | if os.path.exists(user_specified_dir):
23 | if not os.path.isdir(user_specified_dir):
24 | raise RuntimeError(
25 | '{} is not a directory'.format(user_specified_dir))
26 | else:
27 | os.makedirs(user_specified_dir)
28 | outdir = user_specified_dir
29 | else:
30 | outdir = tempfile.mkdtemp()
31 |
32 | # Save all the arguments
33 | with open(os.path.join(outdir, 'args.txt'), 'w') as f:
34 | f.write(json.dumps(vars(args)))
35 |
36 | # Save `git status`
37 | with open(os.path.join(outdir, 'git-status.txt'), 'w') as f:
38 | f.write(subprocess.getoutput('git status'))
39 |
40 | # Save `git log`
41 | with open(os.path.join(outdir, 'git-log.txt'), 'w') as f:
42 | f.write(subprocess.getoutput('git log'))
43 |
44 | # Save `git diff`
45 | with open(os.path.join(outdir, 'git-diff.txt'), 'w') as f:
46 | f.write(subprocess.getoutput('git diff'))
47 |
48 | return outdir
49 |
--------------------------------------------------------------------------------
/random_seed.py:
--------------------------------------------------------------------------------
1 | import random
2 | import numpy as np
3 |
4 |
5 | def set_random_seed(seed):
6 | random.seed(seed)
7 | np.random.seed(seed)
8 |
--------------------------------------------------------------------------------
/rmsprop_async.py:
--------------------------------------------------------------------------------
1 | import numpy
2 |
3 | from chainer import cuda
4 | from chainer import optimizer
5 |
6 |
7 | class RMSpropAsync(optimizer.GradientMethod):
8 |
9 | """RMSprop for asynchronous methods.
10 |
11 | The only difference from chainer.optimizers.RMSprop in that the epsilon is
12 | outside the square root."""
13 |
14 | def __init__(self, lr=0.01, alpha=0.99, eps=1e-8):
15 | self.lr = lr
16 | self.alpha = alpha
17 | self.eps = eps
18 |
19 | def init_state(self, param, state):
20 | xp = cuda.get_array_module(param.data)
21 | state['ms'] = xp.zeros_like(param.data)
22 |
23 | def update_one_cpu(self, param, state):
24 | ms = state['ms']
25 | grad = param.grad
26 |
27 | ms *= self.alpha
28 | ms += (1 - self.alpha) * grad * grad
29 | param.data -= self.lr * grad / numpy.sqrt(ms + self.eps)
30 |
31 | def update_one_gpu(self, param, state):
32 | cuda.elementwise(
33 | 'T grad, T lr, T alpha, T eps',
34 | 'T param, T ms',
35 | '''ms = alpha * ms + (1 - alpha) * grad * grad;
36 | param -= lr * grad / sqrt(ms + eps);''',
37 | 'rmsprop')(param.grad, self.lr, self.alpha, self.eps,
38 | param.data, state['ms'])
39 |
--------------------------------------------------------------------------------
/run_a3c.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import copy
3 | import multiprocessing as mp
4 | import os
5 | import sys
6 | import statistics
7 | import time
8 |
9 | import chainer
10 | from chainer import links as L
11 | from chainer import functions as F
12 | import cv2
13 | import numpy as np
14 |
15 | import a3c
16 | import random_seed
17 | import async
18 | from prepare_output_dir import prepare_output_dir
19 |
20 |
21 | def eval_performance(process_idx, make_env, model, phi, n_runs):
22 | assert n_runs > 1, 'Computing stdev requires at least two runs'
23 | scores = []
24 | for i in range(n_runs):
25 | model.reset_state()
26 | env = make_env(process_idx, test=True)
27 | obs = env.reset()
28 | done = False
29 | test_r = 0
30 | while not done:
31 | s = chainer.Variable(np.expand_dims(phi(obs), 0))
32 | pout, _ = model.pi_and_v(s)
33 | a = pout.action_indices[0]
34 | obs, r, done, info = env.step(a)
35 | test_r += r
36 | scores.append(test_r)
37 | print('test_{}:'.format(i), test_r)
38 | mean = statistics.mean(scores)
39 | median = statistics.median(scores)
40 | stdev = statistics.stdev(scores)
41 | return mean, median, stdev
42 |
43 |
44 | def train_loop(process_idx, counter, make_env, max_score, args, agent, env,
45 | start_time, outdir):
46 | try:
47 |
48 | total_r = 0
49 | episode_r = 0
50 | global_t = 0
51 | local_t = 0
52 | obs = env.reset()
53 | r = 0
54 | done = False
55 |
56 | while True:
57 |
58 | # Get and increment the global counter
59 | with counter.get_lock():
60 | counter.value += 1
61 | global_t = counter.value
62 | local_t += 1
63 |
64 | if global_t > args.steps:
65 | break
66 |
67 | agent.optimizer.lr = (
68 | args.steps - global_t - 1) / args.steps * args.lr
69 |
70 | total_r += r
71 | episode_r += r
72 |
73 | a = agent.act(obs, r, done)
74 |
75 | if done:
76 | if process_idx == 0:
77 | print('{} global_t:{} local_t:{} lr:{} r:{}'.format(
78 | outdir, global_t, local_t, agent.optimizer.lr,
79 | episode_r))
80 | episode_r = 0
81 | obs = env.reset()
82 | r = 0
83 | done = False
84 | else:
85 | obs, r, done, info = env.step(a)
86 |
87 | if global_t % args.eval_frequency == 0:
88 | # Evaluation
89 |
90 | # We must use a copy of the model because test runs can change
91 | # the hidden states of the model
92 | test_model = copy.deepcopy(agent.model)
93 | test_model.reset_state()
94 |
95 | mean, median, stdev = eval_performance(
96 | process_idx, make_env, test_model, agent.phi,
97 | args.eval_n_runs)
98 | with open(os.path.join(outdir, 'scores.txt'), 'a+') as f:
99 | elapsed = time.time() - start_time
100 | record = (global_t, elapsed, mean, median, stdev)
101 | print('\t'.join(str(x) for x in record), file=f)
102 | with max_score.get_lock():
103 | if mean > max_score.value:
104 | # Save the best model so far
105 | print('The best score is updated {} -> {}'.format(
106 | max_score.value, mean))
107 | filename = os.path.join(
108 | outdir, '{}.h5'.format(global_t))
109 | agent.save_model(filename)
110 | print('Saved the current best model to {}'.format(
111 | filename))
112 | max_score.value = mean
113 |
114 | except KeyboardInterrupt:
115 | if process_idx == 0:
116 | # Save the current model before being killed
117 | agent.save_model(os.path.join(
118 | outdir, '{}_keyboardinterrupt.h5'.format(global_t)))
119 | print('Saved the current model to {}'.format(
120 | outdir), file=sys.stderr)
121 | raise
122 |
123 | if global_t == args.steps + 1:
124 | # Save the final model
125 | agent.save_model(
126 | os.path.join(args.outdir, '{}_finish.h5'.format(args.steps)))
127 | print('Saved the final model to {}'.format(args.outdir))
128 |
129 |
130 | def train_loop_with_profile(process_idx, counter, make_env, max_score, args,
131 | agent, env, start_time, outdir):
132 | import cProfile
133 | cmd = 'train_loop(process_idx, counter, make_env, max_score, args, ' \
134 | 'agent, env, start_time)'
135 | cProfile.runctx(cmd, globals(), locals(),
136 | 'profile-{}.out'.format(os.getpid()))
137 |
138 |
139 | def run_a3c(processes, make_env, model_opt, phi, t_max=1, beta=1e-2,
140 | profile=False, steps=8 * 10 ** 7, eval_frequency=10 ** 6,
141 | eval_n_runs=10, args={}):
142 |
143 | # Prevent numpy from using multiple threads
144 | os.environ['OMP_NUM_THREADS'] = '1'
145 |
146 | outdir = prepare_output_dir(args, None)
147 |
148 | print('Output files are saved in {}'.format(outdir))
149 |
150 | n_actions = 20 * 20
151 |
152 | model, opt = model_opt()
153 |
154 | shared_params = async.share_params_as_shared_arrays(model)
155 | shared_states = async.share_states_as_shared_arrays(opt)
156 |
157 | max_score = mp.Value('f', np.finfo(np.float32).min)
158 | counter = mp.Value('l', 0)
159 | start_time = time.time()
160 |
161 | # Write a header line first
162 | with open(os.path.join(outdir, 'scores.txt'), 'a+') as f:
163 | column_names = ('steps', 'elapsed', 'mean', 'median', 'stdev')
164 | print('\t'.join(column_names), file=f)
165 |
166 | def run_func(process_idx):
167 | env = make_env(process_idx, test=False)
168 | model, opt = model_opt()
169 | async.set_shared_params(model, shared_params)
170 | async.set_shared_states(opt, shared_states)
171 |
172 | agent = a3c.A3C(model, opt, t_max, 0.99, beta=beta,
173 | process_idx=process_idx, phi=phi)
174 |
175 | if profile:
176 | train_loop_with_profile(process_idx, counter, make_env, max_score,
177 | args, agent, env, start_time,
178 | outdir=outdir)
179 | else:
180 | train_loop(process_idx, counter, make_env, max_score,
181 | args, agent, env, start_time, outdir=outdir)
182 |
183 | async.run_async(processes, run_func)
184 |
--------------------------------------------------------------------------------
/train_a3c_doom.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import multiprocessing as mp
3 |
4 | import chainer
5 | from chainer import links as L
6 | from chainer import functions as F
7 | import cv2
8 | import numpy as np
9 |
10 | import policy
11 | import v_function
12 | import dqn_head
13 | import a3c
14 | import random_seed
15 | import rmsprop_async
16 | from init_like_torch import init_like_torch
17 | import run_a3c
18 | import doom_env
19 |
20 |
21 | def phi(obs):
22 | resized = cv2.resize(obs.image_buffer, (84, 84))
23 | return resized.transpose(2, 0, 1).astype(np.float32) / 255
24 |
25 |
26 | class A3CFF(chainer.ChainList, a3c.A3CModel):
27 |
28 | def __init__(self, n_actions):
29 | self.head = dqn_head.NIPSDQNHead(n_input_channels=3)
30 | self.pi = policy.FCSoftmaxPolicy(
31 | self.head.n_output_channels, n_actions)
32 | self.v = v_function.FCVFunction(self.head.n_output_channels)
33 | super().__init__(self.head, self.pi, self.v)
34 | init_like_torch(self)
35 |
36 | def pi_and_v(self, state, keep_same_state=False):
37 | out = self.head(state)
38 | return self.pi(out), self.v(out)
39 |
40 |
41 | class A3CLSTM(chainer.ChainList, a3c.A3CModel):
42 |
43 | def __init__(self, n_actions):
44 | self.head = dqn_head.NIPSDQNHead(n_input_channels=3)
45 | self.pi = policy.FCSoftmaxPolicy(
46 | self.head.n_output_channels, n_actions)
47 | self.v = v_function.FCVFunction(self.head.n_output_channels)
48 | self.lstm = L.LSTM(self.head.n_output_channels,
49 | self.head.n_output_channels)
50 | super().__init__(self.head, self.lstm, self.pi, self.v)
51 | init_like_torch(self)
52 |
53 | def pi_and_v(self, state, keep_same_state=False):
54 | out = self.head(state)
55 | if keep_same_state:
56 | prev_h, prev_c = self.lstm.h, self.lstm.c
57 | out = self.lstm(out)
58 | self.lstm.h, self.lstm.c = prev_h, prev_c
59 | else:
60 | out = self.lstm(out)
61 | return self.pi(out), self.v(out)
62 |
63 | def reset_state(self):
64 | self.lstm.reset_state()
65 |
66 | def unchain_backward(self):
67 | self.lstm.h.unchain_backward()
68 | self.lstm.c.unchain_backward()
69 |
70 |
71 | def main():
72 | import logging
73 | logging.basicConfig(level=logging.DEBUG)
74 |
75 | parser = argparse.ArgumentParser()
76 | parser.add_argument('processes', type=int)
77 | parser.add_argument('--seed', type=int, default=None)
78 | parser.add_argument('--outdir', type=str, default=None)
79 | parser.add_argument('--scenario', type=str, default='basic')
80 | parser.add_argument('--t-max', type=int, default=5)
81 | parser.add_argument('--beta', type=float, default=1e-2)
82 | parser.add_argument('--profile', action='store_true')
83 | parser.add_argument('--steps', type=int, default=8 * 10 ** 7)
84 | parser.add_argument('--lr', type=float, default=7e-4)
85 | parser.add_argument('--eval-frequency', type=int, default=10 ** 5)
86 | parser.add_argument('--eval-n-runs', type=int, default=10)
87 | parser.add_argument('--use-lstm', action='store_true')
88 | parser.add_argument('--window-visible', action='store_true')
89 | parser.set_defaults(window_visible=False)
90 | parser.set_defaults(use_lstm=False)
91 | args = parser.parse_args()
92 |
93 | if args.seed is not None:
94 | random_seed.set_random_seed(args.seed)
95 |
96 | # Simultaneously launching multiple vizdoom processes makes program stuck,
97 | # so use the global lock
98 | env_lock = mp.Lock()
99 |
100 | def make_env(process_idx, test):
101 | with env_lock:
102 | return doom_env.DoomEnv(window_visible=args.window_visible,
103 | scenario=args.scenario)
104 |
105 | n_actions = 3
106 |
107 | def model_opt():
108 | if args.use_lstm:
109 | model = A3CLSTM(n_actions)
110 | else:
111 | model = A3CFF(n_actions)
112 | opt = rmsprop_async.RMSpropAsync(lr=args.lr, eps=1e-1, alpha=0.99)
113 | opt.setup(model)
114 | opt.add_hook(chainer.optimizer.GradientClipping(40))
115 | return model, opt
116 |
117 | run_a3c.run_a3c(args.processes, make_env, model_opt, phi, t_max=args.t_max,
118 | beta=args.beta, profile=args.profile, steps=args.steps,
119 | eval_frequency=args.eval_frequency,
120 | eval_n_runs=args.eval_n_runs, args=args)
121 |
122 |
123 | if __name__ == '__main__':
124 | main()
125 |
--------------------------------------------------------------------------------
/trained_model/breakout_ff/80000000_finish.h5:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/muupan/async-rl/5c5844fe7d62055ef911c7abfa6200fb30f6db84/trained_model/breakout_ff/80000000_finish.h5
--------------------------------------------------------------------------------
/trained_model/breakout_ff/animation.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/muupan/async-rl/5c5844fe7d62055ef911c7abfa6200fb30f6db84/trained_model/breakout_ff/animation.gif
--------------------------------------------------------------------------------
/trained_model/breakout_ff/scores.txt:
--------------------------------------------------------------------------------
1 | steps elapsed mean median stdev
2 | 1000000 799.1865322589874 1.2 1.5 1.1352924243950933
3 | 2000000 1575.7219505310059 1.5 0.0 2.273030282830976
4 | 3000000 2359.6249346733093 2.1 3.0 1.911950719959998
5 | 4000000 3109.272673845291 1.6 2.0 1.4298407059684812
6 | 5000000 3859.516502380371 2.0 2.0 2.0548046676563256
7 | 6000000 4602.4465317726135 1.8 1.0 1.9888578520235065
8 | 7000000 5348.210222244263 2.5 2.0 0.97182531580755
9 | 8000000 6110.1892149448395 3.5 3.5 2.173067468400883
10 | 9000000 6861.104922533035 5.5 4.5 4.503085362035432
11 | 10000000 7619.673486471176 13.0 12.0 4.2946995755750415
12 | 11000000 8378.648483276367 18.9 19.0 5.586690532964138
13 | 12000000 9167.731533527374 24.5 21.5 11.057928276932246
14 | 13000000 10027.934562683105 73.6 72.5 26.95757984521443
15 | 14000000 10791.431033372879 107.2 97.5 50.78888767349716
16 | 15000000 11552.96664738655 95.8 85.0 71.8374708785201
17 | 16000000 12357.831614017487 251.2 269.0 65.97945808271608
18 | 17000000 13152.097360610962 232.0 249.0 99.43395351242508
19 | 18000000 13918.015005588531 246.4 273.5 100.97216338069506
20 | 19000000 14744.782504558563 362.7 375.5 51.497680638171566
21 | 20000000 15498.439815044403 377.1 388.0 41.420472662145656
22 | 21000000 16318.818217515945 340.7 382.0 113.92204937295209
23 | 22000000 17040.97575569153 248.8 265.0 116.37468224088377
24 | 23000000 17841.953941345215 350.8 361.5 51.100771901106235
25 | 24000000 18606.147523880005 373.8 397.0 61.31847646146759
26 | 25000000 19452.10493350029 375.6 415.0 100.00577761087385
27 | 26000000 20231.817700862885 430.5 412.0 77.02849400636681
28 | 27000000 21134.255215406418 433.8 417.0 100.2505749498614
29 | 28000000 21763.75692296028 299.8 328.0 119.36014596356878
30 | 29000000 22626.56786084175 492.9 412.5 183.22023784384615
31 | 30000000 23399.90938782692 373.9 387.5 211.82091492579292
32 | 31000000 24072.50167989731 363.3 380.5 82.33542507464342
33 | 32000000 24852.809225320816 376.7 387.5 55.63581979664221
34 | 33000000 25615.238379001617 311.6 380.0 137.93412276236154
35 | 34000000 26598.047915697098 435.4 421.5 53.74879843618212
36 | 35000000 27231.892096042633 414.8 389.5 138.989847750754
37 | 36000000 27887.654467582703 324.3 399.5 157.67339661464771
38 | 37000000 28814.492196321487 402.5 419.0 49.80907993975038
39 | 38000000 29534.802098751068 376.4 422.0 109.01804132038573
40 | 39000000 30364.29454421997 435.0 428.0 104.94654724085865
41 | 40000000 31047.65421795845 412.3 419.5 18.1906569425076
42 | 41000000 31737.017671108246 389.5 394.0 65.46457905700694
43 | 42000000 32467.050805568695 409.3 423.5 48.087998040629174
44 | 43000000 33230.65163731575 344.2 414.5 133.11799277332872
45 | 44000000 34009.13779783249 457.3 425.5 115.42294206766502
46 | 45000000 34763.50703406334 410.3 427.5 40.996070272378276
47 | 46000000 35484.54351043701 414.1 414.5 12.269655432995844
48 | 47000000 36283.29621911049 459.1 426.5 145.52010170419754
49 | 48000000 37148.736817359924 536.3 446.5 175.72140197230132
50 | 49000000 37665.218223810196 413.3 417.0 13.216572088774676
51 | 50000000 38502.0075905323 453.7 421.5 133.0806355393434
52 | 51000000 39192.341354846954 468.3 430.5 124.23816733283786
53 | 52000000 40030.84110355377 415.3 422.5 17.888854382299364
54 | 53000000 40686.36572384834 415.9 418.0 73.99316785277469
55 | 54000000 41383.44816946983 448.7 408.0 133.6006071177157
56 | 57000000 43803.362179756165 422.1 427.5 50.61060494929233
57 | 58000000 44451.59215736389 423.0 424.5 17.10100711784088
58 | 59000000 45240.43768501282 409.0 427.5 46.401628323918885
59 | 60000000 46110.308336257935 456.9 421.0 139.6896957943252
60 | 61000000 46937.206632852554 486.3 416.5 196.8372424110844
61 | 62000000 47675.98979473114 419.1 422.5 37.495036708580216
62 | 63000000 48513.08631014824 426.1 412.0 33.69289407443521
63 | 64000000 49318.95145368576 459.1 427.5 151.07352882325583
64 | 65000000 50040.2566986084 466.0 429.5 99.69509070717129
65 | 66000000 50993.864820718765 528.6 472.0 226.0335275032347
66 | 67000000 51737.7411031723 463.6 430.0 127.71774435144954
67 | 68000000 52501.34305858612 422.3 428.0 68.30169999511156
68 | 69000000 53283.210359334946 412.5 422.5 122.31948150460562
69 | 70000000 54116.87993979454 459.0 430.5 146.60832172833847
70 | 71000000 54859.40275526047 423.4 424.5 27.162883172119678
71 | 72000000 55693.9102909565 437.6 424.5 45.792284648544594
72 | 73000000 56525.86289215088 447.0 434.5 49.416596402423345
73 | 74000000 57244.09581017494 469.1 432.0 151.229369575563
74 | 75000000 58063.31164121628 417.6 425.5 31.931175988365975
75 | 76000000 58799.664543151855 416.7 424.0 20.144202364176373
76 | 77000000 59633.22558784485 426.4 427.5 10.490207073477837
77 | 78000000 60394.60213589668 513.1 413.0 195.16229713298168
78 | 79000000 61230.48169326782 489.9 425.0 165.88714369849293
79 | 80000000 61839.64669966698 417.8 422.0 21.627143439052077
80 |
--------------------------------------------------------------------------------
/trained_model/breakout_ff/scores.txt.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/muupan/async-rl/5c5844fe7d62055ef911c7abfa6200fb30f6db84/trained_model/breakout_ff/scores.txt.png
--------------------------------------------------------------------------------
/trained_model/space_invaders_lstm/80000000_finish.h5:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/muupan/async-rl/5c5844fe7d62055ef911c7abfa6200fb30f6db84/trained_model/space_invaders_lstm/80000000_finish.h5
--------------------------------------------------------------------------------
/trained_model/space_invaders_lstm/animation.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/muupan/async-rl/5c5844fe7d62055ef911c7abfa6200fb30f6db84/trained_model/space_invaders_lstm/animation.gif
--------------------------------------------------------------------------------
/trained_model/space_invaders_lstm/scores.txt:
--------------------------------------------------------------------------------
1 | steps elapsed mean median stdev
2 | 1000000 1176.0026223659515 150.5 130.0 71.23708459940106
3 | 2000000 2279.606765270233 218.5 195.0 82.63204920341475
4 | 3000000 3405.7928512096405 203.0 210.0 32.076297929918425
5 | 4000000 4499.463195800781 187.0 180.0 57.4552966323481
6 | 5000000 5575.656061410904 259.0 235.0 136.459192109257
7 | 6000000 6694.54666686058 318.0 287.5 179.53953448877058
8 | 7000000 7828.923171281815 351.0 305.0 181.62537757091596
9 | 8000000 8827.748558998108 333.5 322.5 114.26212554181431
10 | 9000000 9897.704538345337 311.0 322.5 131.90484785969352
11 | 10000000 10987.551244974136 379.0 362.5 88.49984306326324
12 | 11000000 12111.16355252266 490.5 515.0 97.39524286808538
13 | 12000000 13139.165969610214 448.5 482.5 113.38356729849936
14 | 13000000 14198.187840223312 367.0 365.0 54.324130099902305
15 | 14000000 15247.866738319397 386.0 337.5 125.80408048496147
16 | 15000000 16321.860386371613 555.0 532.5 211.18712081942877
17 | 16000000 17356.161630392075 402.5 362.5 84.63155439905378
18 | 17000000 18419.353372573853 433.5 405.0 148.38107845828742
19 | 18000000 19517.881631851196 572.5 587.5 170.18372425117508
20 | 19000000 20565.545799016953 504.0 392.5 223.69125547901461
21 | 20000000 21651.335790395737 603.0 622.5 203.74548393086462
22 | 21000000 22765.650399684906 834.5 835.0 298.63997276542426
23 | 22000000 23780.1443631649 579.0 585.0 249.15189476836548
24 | 23000000 24812.381363153458 553.5 535.0 160.07029705726168
25 | 24000000 25943.478595733643 805.5 820.0 266.4420929374503
26 | 25000000 27022.40669798851 819.0 800.0 356.03370626950476
27 | 26000000 28154.23360300064 775.0 547.5 532.2123636294068
28 | 27000000 29255.90105676651 613.5 572.5 229.7226588736949
29 | 28000000 30400.700807094574 646.5 482.5 406.20910050531035
30 | 29000000 31572.145109176636 772.0 632.5 334.54944826338203
31 | 30000000 32690.86220598221 945.0 972.5 311.4839036326311
32 | 31000000 33758.00896549225 830.5 602.5 442.72797015272886
33 | 32000000 34861.88159298897 757.0 602.5 344.4415770489968
34 | 33000000 35916.9765996933 985.0 950.0 397.50611455814254
35 | 34000000 37010.65085887909 962.0 950.0 381.9118571956973
36 | 35000000 38139.09030032158 1014.5 900.0 490.8521501769482
37 | 36000000 39226.673714637756 976.5 607.5 536.9515289525158
38 | 37000000 40325.832810640335 1031.0 820.0 501.2639579658162
39 | 38000000 41391.046285390854 788.0 680.0 318.21725632376103
40 | 39000000 42567.62489628792 1064.0 1017.5 455.73384045222423
41 | 40000000 43663.877554655075 952.5 862.5 410.55687114508805
42 | 41000000 44881.854682445526 1406.5 1165.0 795.8889160345599
43 | 42000000 45882.31720352173 891.0 622.5 492.4586841102059
44 | 43000000 47044.14443182945 1340.0 1127.5 765.2740975914737
45 | 44000000 48123.50830435753 1205.5 1235.0 508.775490761888
46 | 45000000 49227.012467861176 1044.5 935.0 557.8751851644078
47 | 46000000 50345.83370089531 1240.5 1217.5 541.9278857314258
48 | 47000000 51417.79047751427 1269.0 1165.0 778.919479507064
49 | 48000000 52607.29307818413 1698.0 1797.5 543.8198231032039
50 | 49000000 53671.907301187515 1598.5 1710.0 466.9347444296211
51 | 50000000 54812.021178245544 1863.5 1720.0 510.8873000313605
52 | 51000000 55892.94242429733 1501.0 1432.5 484.23364424854066
53 | 52000000 57041.53133392334 2016.0 1927.5 670.7657315834394
54 | 53000000 58073.72801113129 1643.0 1585.0 496.4887824625156
55 | 54000000 59165.362850666046 1382.0 1422.5 681.1395680116602
56 | 55000000 60335.68020105362 1565.0 1645.0 475.94350738530113
57 | 56000000 61488.63900256157 2096.0 2015.0 365.1468502153924
58 | 57000000 62582.88352417946 1996.0 2062.5 504.8751220736558
59 | 58000000 63649.29801917076 2022.0 1895.0 680.4051080871683
60 | 59000000 64736.771109342575 1568.0 1610.0 177.81388522209895
61 | 60000000 65917.98326063156 2057.5 2150.0 778.325303313324
62 | 61000000 66951.23457431793 2082.5 1997.5 567.936078171557
63 | 62000000 68049.10905337334 1737.0 2025.0 718.3592416054797
64 | 63000000 69085.28632044792 1959.0 1940.0 356.23650071889665
65 | 64000000 70181.8262295723 1822.5 1817.5 756.8144128883616
66 | 65000000 71294.90933918953 2032.0 2122.5 683.3585361205996
67 | 66000000 72485.66170525551 2507.0 2705.0 515.5051460029817
68 | 67000000 73494.54617547989 1775.0 1837.5 858.5064550330029
69 | 68000000 74578.25437927246 2038.0 2462.5 922.8434320078352
70 | 69000000 75629.58755373955 2085.0 2070.0 778.1209560358996
71 | 70000000 76678.21772170067 1960.5 1587.5 915.0818117645123
72 | 71000000 77790.33036136627 2420.5 2567.5 455.76827689322806
73 | 72000000 78800.69010519981 1789.0 1760.0 604.4639498486792
74 | 73000000 79914.5376329422 2436.0 2805.0 706.0327345259724
75 | 74000000 80936.40157341957 1924.5 1935.0 821.6191669840447
76 | 75000000 81944.25549578667 1962.0 2177.5 869.6238011666628
77 | 76000000 83064.10873103142 2335.5 2555.0 695.3314557341221
78 | 77000000 84099.02462172508 2615.0 2905.0 847.9648839689321
79 | 78000000 85200.52754330635 2610.5 2797.5 532.5382093751061
80 | 79000000 86191.62391448021 1999.5 2075.0 919.0981388779377
81 | 80000000 87095.2680015564 2278.0 2462.5 637.1908836622055
82 |
--------------------------------------------------------------------------------
/trained_model/space_invaders_lstm/scores.txt.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/muupan/async-rl/5c5844fe7d62055ef911c7abfa6200fb30f6db84/trained_model/space_invaders_lstm/scores.txt.png
--------------------------------------------------------------------------------
/v_function.py:
--------------------------------------------------------------------------------
1 | import chainer
2 | from chainer import functions as F
3 | from chainer import links as L
4 |
5 |
6 | class VFunction(object):
7 | pass
8 |
9 |
10 | class FCVFunction(chainer.ChainList, VFunction):
11 |
12 | def __init__(self, n_input_channels, n_hidden_layers=0,
13 | n_hidden_channels=None):
14 | self.n_input_channels = n_input_channels
15 | self.n_hidden_layers = n_hidden_layers
16 | self.n_hidden_channels = n_hidden_channels
17 |
18 | layers = []
19 | if n_hidden_layers > 0:
20 | layers.append(L.Linear(n_input_channels, n_hidden_channels))
21 | for i in range(n_hidden_layers - 1):
22 | layers.append(L.Linear(n_hidden_channels, n_hidden_channels))
23 | layers.append(L.Linear(n_hidden_channels, 1))
24 | else:
25 | layers.append(L.Linear(n_input_channels, 1))
26 |
27 | super(FCVFunction, self).__init__(*layers)
28 |
29 | def __call__(self, state):
30 | h = state
31 | for layer in self[:-1]:
32 | h = F.relu(layer(h))
33 | h = self[-1](h)
34 | return h
35 |
--------------------------------------------------------------------------------