├── README.md
├── bus_train.py
├── images
├── ag.png
└── ftl.png
├── isic_train.py
├── losses.py
├── newmodels.py
└── utils.py
/README.md:
--------------------------------------------------------------------------------
1 | # Focal Tversky Attention U-Net
2 |
3 | This repo contains the code accompanying our paper [A novel focal Tversky loss function and improved Attention U-Net for lesion segmentation](https://arxiv.org/abs/1810.07842) accepted at [ISBI 2019](https://biomedicalimaging.org/2019/).
4 |
5 | **TL;DR** We propose a generalized focal loss function based on the Tversky index to address the issue of data imbalance in medical image segmentation. Additionally, we incorporate architectural changes that benefit small lesion segmentation.
6 |
7 | ### Some differences from the paper
8 | Figure 1 in the paper is parametrized by the function 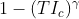 which is incorrectly depicted in Equation 4.
9 |
10 | The code in this repository follows the parametrization: 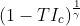 which is in line with Equation 4. I apologize for the confusion! Both parametrizations have the same effect on the gradients however I found the latter one to be more stable and so that is the loss function presented in this repo.
11 |
12 |  13 |
14 | We utilize attention gating in this repo which follows from [Ozan Oktan and his collaborators](https://arxiv.org/abs/1804.03999). The workflow is depicted below:
15 |
13 |
14 | We utilize attention gating in this repo which follows from [Ozan Oktan and his collaborators](https://arxiv.org/abs/1804.03999). The workflow is depicted below:
15 |  16 |
17 | ### Training
18 | Training files for the ISIC2018 and BUS2017 Dataset B have been added.
19 | If training with ISIC2018, create 4 folders: `orig_raw` (not used in this code), `orig_gt`, `resized-train`, `resized-gt`, for full
20 | resolution input images, ground truth and resized images at `192x256` resolution, respectively.
21 |
22 | If training with BUS2017, create 2 folders: `original` and `gt` for input data and ground truth data. In the `bus_train.py` script, images
23 | will be resampled to `128x128` resolution.
24 |
25 | ### Citation
26 | If you find this code useful, please consider citing our work:
27 | ```
28 | @article{focal-unet,
29 | title={A novel Focal Tversky loss function with improved Attention U-Net for lesion segmentation},
30 | author={Abraham, Nabila and Khan, Naimul Mefraz},
31 | journal={arXiv preprint arXiv:1810.07842},
32 | year={2018}
33 | }
34 | ```
35 |
36 |
--------------------------------------------------------------------------------
/bus_train.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | @author: Nabilla Abraham
4 | """
5 | import os
6 | import cv2
7 | import numpy as np
8 | import tensorflow as tf
9 | import matplotlib.pyplot as plt
10 |
11 | from keras.models import Model
12 | from keras.layers import Input, concatenate, Conv2D, MaxPooling2D, Conv2DTranspose
13 | from keras.layers import Activation, add, multiply, Lambda
14 | from keras.layers import AveragePooling2D, average, UpSampling2D, Dropout
15 | from keras.optimizers import Adam, SGD, RMSprop
16 | from keras.initializers import glorot_normal, random_normal, random_uniform
17 | from keras.callbacks import ModelCheckpoint, TensorBoard, EarlyStopping
18 | from keras import backend as K
19 | from keras.layers.normalization import BatchNormalization
20 |
21 | from sklearn.metrics import roc_curve, auc, precision_recall_curve # roc curve tools
22 | from sklearn.model_selection import train_test_split
23 |
24 | import losses
25 | import utils
26 | import newmodels
27 |
28 | from keras.backend.tensorflow_backend import set_session
29 | config = tf.ConfigProto()
30 | config.gpu_options.per_process_gpu_memory_fraction = 0.7
31 | set_session(tf.Session(config=config))
32 |
33 | img_row = 128
34 | img_col = 128
35 | img_size = 128
36 | img_chan = 1
37 | epochnum = 100
38 | batchnum = 16
39 | input_size = (img_row, img_col, img_chan)
40 |
41 | sgd = SGD(lr=0.01, momentum=0.9)
42 |
43 | curr_dir = os.getcwd()
44 | img_dir = os.path.join(curr_dir, 'original')
45 | gt_dir = os.path.join(curr_dir, 'gt')
46 |
47 | img_list = os.listdir(img_dir)
48 | gt_list = os.listdir(gt_dir)
49 |
50 | num_imgs = len(img_list)
51 |
52 | orig_imgs = []
53 | orig_gts = []
54 | imgs = np.zeros((num_imgs, img_row, img_col))
55 | gts = np.zeros_like(imgs)
56 |
57 | for i in range(num_imgs):
58 | tmp_img = plt.imread(os.path.join(img_dir, img_list[i]))
59 | tmp_gt = plt.imread(os.path.join(gt_dir, img_list[i]))
60 | orig_imgs.append(tmp_img)
61 | orig_gts.append(tmp_gt)
62 |
63 | imgs[i] = cv2.resize(tmp_img, (img_col,img_row), interpolation=cv2.INTER_NEAREST)
64 | gts[i] = cv2.resize(tmp_gt,(img_col,img_row), interpolation=cv2.INTER_NEAREST)
65 |
66 | indices = np.arange(0,num_imgs,1)
67 |
68 | imgs_train, imgs_test, \
69 | imgs_mask_train, orig_imgs_mask_test,\
70 | trainIdx, testIdx = train_test_split(imgs,gts, indices,test_size=0.25)
71 |
72 | imgs_train = np.expand_dims(imgs_train, axis=3)
73 | imgs_mask_train = np.expand_dims(imgs_mask_train,axis=3)
74 | imgs_test = np.expand_dims(imgs_test, axis=3)
75 |
76 | filepath="weights.hdf5"
77 | checkpoint = ModelCheckpoint(filepath, monitor='val_dsc',
78 | verbose=1, save_best_only=True,
79 | save_weights_only=True, mode='max')
80 | gt1 = imgs_mask_train[:,::8,::8,:]
81 | gt2 = imgs_mask_train[:,::4,::4,:]
82 | gt3 = imgs_mask_train[:,::2,::2,:]
83 | gt4 = imgs_mask_train
84 | gt_train = [gt1,gt2,gt3,gt4]
85 |
86 | model = newmodels.unet(sgd, input_size, losses.tversky_loss)
87 | hist = model.fit(imgs_train, imgs_mask_train, validation_split=0.15,
88 | shuffle=True, epochs=epochnum, batch_size=batchnum,
89 | verbose=True, callbacks=[checkpoint])#, callbacks=[estop,tb])
90 | h = hist.history
91 | utils.plot(h, epochnum, batchnum, img_col, 0)
92 |
93 | num_test = len(imgs_test)
94 | _,_,_,preds = model.predict(imgs_test)
95 | #preds = model.predict(imgs_test)
96 |
97 | preds_up=[]
98 | dsc = np.zeros((num_test,1))
99 | recall = np.zeros_like(dsc)
100 | tn = np.zeros_like(dsc)
101 | prec = np.zeros_like(dsc)
102 |
103 | thresh = 0.5
104 |
105 | for i in range(num_test):
106 | gt = orig_gts[testIdx[i]]
107 | preds_up.append(cv2.resize(preds[i], (gt.shape[1], gt.shape[0]), interpolation=cv2.INTER_NEAREST))
108 | dsc[i] = utils.check_preds(preds_up[i] > thresh, gt)
109 | recall[i], _, prec[i] = utils.auc(gt, preds_up[i] >thresh)
110 |
111 | print('-'*30)
112 | print('At threshold =', thresh)
113 | print('\n DSC \t\t{0:^.3f} \n Recall \t{1:^.3f} \n Precision\t{2:^.3f}'.format(
114 | np.sum(dsc)/num_test,
115 | np.sum(recall)/num_test,
116 | np.sum(prec)/num_test ))
117 |
118 | model.load_weights("weights.hdf5")
119 | _,_,_,preds = model.predict(imgs_test)
120 | #preds = model.predict(imgs_test) #use this if model is unet
121 |
122 | preds_up=[]
123 | dsc = np.zeros((num_test,1))
124 | recall = np.zeros_like(dsc)
125 | tn = np.zeros_like(dsc)
126 | prec = np.zeros_like(dsc)
127 |
128 | for i in range(num_test):
129 | gt = orig_gts[testIdx[i]]
130 | preds_up.append(cv2.resize(preds[i], (gt.shape[1], gt.shape[0]), interpolation=cv2.INTER_NEAREST))
131 | dsc[i] = utils.check_preds(preds_up[i] > thresh, gt)
132 | recall[i], _, prec[i] = utils.auc(gt, preds_up[i] >thresh)
133 |
134 | print('-'*30)
135 | print('USING HDF5 MODEL', thresh)
136 | print('\n DSC \t\t{0:^.3f} \n Recall \t{1:^.3f} \n Precision\t{2:^.3f}'.format(
137 | np.sum(dsc)/num_test,
138 | np.sum(recall)/num_test,
139 | np.sum(prec)/num_test ))
140 |
141 | # check to see how much accuracy we've lost by upsampling the predictions by comparing to
142 | # the original shapes used for training
143 | for i in range(num_test):
144 | gt = orig_imgs_mask_test[i]
145 | dsc[i] = utils.check_preds(np.squeeze(preds[i]) > thresh, gt)
146 | recall[i], _, prec[i] = utils.auc(gt, np.squeeze(preds[i]) >thresh)
147 |
148 | print('-'*30)
149 | print('Without resizing the preds =', thresh)
150 | print('\n DSC \t\t{0:^.3f} \n Recall \t{1:^.3f} \n Precision\t{2:^.3f}'.format(
151 | np.sum(dsc)/num_test,
152 | np.sum(recall)/num_test,
153 | np.sum(prec)/num_test ))
154 |
155 | idx = np.random.randint(0,num_test)
156 | gt_plot = orig_gts[testIdx[idx]]
157 | plt.figure(dpi=200)
158 | plt.subplot(121)
159 | plt.imshow(np.squeeze(gt_plot), cmap='gray')
160 | plt.title('Original Img {}'.format(idx))
161 | plt.subplot(122)
162 | plt.imshow(np.squeeze(preds_up[idx]), cmap='gray')
163 | plt.title('Ground Truth {}'.format(idx))
164 |
165 | y_true = orig_imgs_mask_test.ravel()
166 | y_preds = preds.ravel()
167 | precision, recall, thresholds = precision_recall_curve(y_true, y_preds)
168 | plt.figure(20)
169 | plt.plot(recall,precision)
170 |
--------------------------------------------------------------------------------
/images/ag.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nabsabraham/focal-tversky-unet/347d39117c24540400dfe80d106d2fb06d2b99e1/images/ag.png
--------------------------------------------------------------------------------
/images/ftl.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nabsabraham/focal-tversky-unet/347d39117c24540400dfe80d106d2fb06d2b99e1/images/ftl.png
--------------------------------------------------------------------------------
/isic_train.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Sun Oct 14 17:16:54 2018
4 |
5 | @author: Nabila Abraham
6 | """
7 |
8 | import os
9 | import cv2
10 | import numpy as np
11 | import tensorflow as tf
12 | import matplotlib.pyplot as plt
13 |
14 | from keras.models import Model
15 | from keras.layers import Input, concatenate, Conv2D, MaxPooling2D, Conv2DTranspose
16 | from keras.layers import Activation, add, multiply, Lambda
17 | from keras.layers import AveragePooling2D, average, UpSampling2D, Dropout
18 | from keras.optimizers import Adam, SGD, RMSprop
19 | from keras.initializers import glorot_normal, random_normal, random_uniform
20 | from keras.callbacks import ModelCheckpoint, TensorBoard, EarlyStopping
21 | from keras import backend as K
22 | from keras.layers.normalization import BatchNormalization
23 |
24 | from sklearn.metrics import roc_curve, auc, precision_recall_curve # roc curve tools
25 | from sklearn.model_selection import train_test_split
26 |
27 | import losses
28 | import utils
29 | import newmodels
30 |
31 | img_row = 192
32 | img_col = 256
33 | img_chan = 3
34 | epochnum = 50
35 | batchnum = 16
36 | smooth = 1.
37 | input_size = (img_row, img_col, img_chan)
38 |
39 | sgd = SGD(lr=0.01, momentum=0.90, decay=1e-6)
40 | adam = Adam(lr=1e-3)
41 |
42 | curr_dir = os.getcwd()
43 | train_dir = os.path.join(curr_dir, 'resized_train')
44 | gt_dir = os.path.join(curr_dir, 'resized_gt')
45 | orig_dir = os.path.join(curr_dir, 'orig_gt')
46 |
47 | img_list = os.listdir(train_dir)
48 | num_imgs = len(img_list)
49 |
50 | orig_data = np.zeros((num_imgs, img_row, img_col, img_chan))
51 | orig_masks = np.zeros((num_imgs, img_row, img_col,1))
52 |
53 | for idx,img_name in enumerate(img_list):
54 | orig_data[idx] = plt.imread(os.path.join(train_dir, img_name))
55 | orig_masks[idx,:,:,0] = plt.imread(os.path.join(gt_dir, img_name.split('.')[0] + "_segmentation.png"))
56 |
57 | indices = np.arange(0,num_imgs,1)
58 |
59 | imgs_train, imgs_test, \
60 | imgs_mask_train, orig_imgs_mask_test,\
61 | trainIdx, testIdx = train_test_split(orig_data,orig_masks, indices,test_size=0.25)
62 |
63 | imgs_train /= 255
64 | imgs_test /=255
65 |
66 | estop = EarlyStopping(monitor='val_loss', min_delta=0.001, patience=5, mode='auto')
67 | filepath="weights.hdf5"
68 | checkpoint = ModelCheckpoint(filepath, monitor='val_final_dsc',
69 | verbose=1, save_best_only=True,
70 | save_weights_only=True, mode='max')
71 | gt1 = imgs_mask_train[:,::8,::8,:]
72 | gt2 = imgs_mask_train[:,::4,::4,:]
73 | gt3 = imgs_mask_train[:,::2,::2,:]
74 | gt4 = imgs_mask_train
75 | gt_train = [gt1,gt2,gt3,gt4]
76 |
77 | model = newmodels.attn_reg(sgd, input_size, losses.focal_tversky)
78 | hist = model.fit(imgs_train, gt_train, validation_split=0.15,
79 | shuffle=True, epochs=epochnum, batch_size=batchnum,
80 | verbose=True, callbacks=[checkpoint])#, callbacks=[estop,tb])
81 | h = hist.history
82 | utils.plot(h, epochnum, batchnum, img_col, 1)
83 |
84 | num_test = len(imgs_test)
85 | _,_,_,preds = model.predict(imgs_test)
86 | #preds = model.predict(imgs_test) #use this if the model is unet
87 |
88 | preds_up=[]
89 | dsc = np.zeros((num_test,1))
90 | recall = np.zeros_like(dsc)
91 | tn = np.zeros_like(dsc)
92 | prec = np.zeros_like(dsc)
93 |
94 | thresh = 0.5
95 |
96 | # check the predictions from the trained model
97 | for i in range(num_test):
98 | #gt = orig_masks[testIdx[i]]
99 | name = img_list[testIdx[i]]
100 | gt = plt.imread(os.path.join(orig_dir, name.split('.')[0] + "_segmentation.png"))
101 |
102 | pred_up = cv2.resize(preds[i], (gt.shape[1], gt.shape[0]), interpolation=cv2.INTER_NEAREST)
103 | dsc[i] = utils.check_preds(pred_up > thresh, gt)
104 | recall[i], _, prec[i] = utils.auc(gt, pred_up >thresh)
105 |
106 | print('-'*30)
107 | print('At threshold =', thresh)
108 | print('\n DSC \t\t{0:^.3f} \n Recall \t{1:^.3f} \n Precision\t{2:^.3f}'.format(
109 | np.sum(dsc)/num_test,
110 | np.sum(recall)/num_test,
111 | np.sum(prec)/num_test ))
112 |
113 | # check the predictions with the best saved model from checkpoint
114 | model.load_weights("weights.hdf5")
115 | _,_,_,preds = model.predict(imgs_test)
116 | #preds = model.predict(imgs_test) #use this if the model is unet
117 |
118 | preds_up=[]
119 | dsc = np.zeros((num_test,1))
120 | recall = np.zeros_like(dsc)
121 | tn = np.zeros_like(dsc)
122 | prec = np.zeros_like(dsc)
123 |
124 | for i in range(num_test):
125 | #gt = orig_masks[testIdx[i]]
126 | name = img_list[testIdx[i]]
127 | gt = plt.imread(os.path.join(orig_dir, name.split('.')[0] + "_segmentation.png"))
128 |
129 | pred_up = cv2.resize(preds[i], (gt.shape[1], gt.shape[0]), interpolation=cv2.INTER_NEAREST)
130 | dsc[i] = utils.check_preds(pred_up > thresh, gt)
131 | recall[i], _, prec[i] = utils.auc(gt, pred_up >thresh)
132 |
133 | print('-'*30)
134 | print('USING HDF5 saved model at thresh=', thresh)
135 | print('\n DSC \t\t{0:^.3f} \n Recall \t{1:^.3f} \n Precision\t{2:^.3f}'.format(
136 | np.sum(dsc)/num_test,
137 | np.sum(recall)/num_test,
138 | np.sum(prec)/num_test ))
139 |
140 | #plot precision-recall
141 | y_true = orig_imgs_mask_test.ravel()
142 | y_preds = preds.ravel()
143 | precision, recall, thresholds = precision_recall_curve(y_true, y_preds)
144 | plt.figure(20)
145 | plt.plot(recall,precision)
146 |
147 |
--------------------------------------------------------------------------------
/losses.py:
--------------------------------------------------------------------------------
1 | from keras.losses import binary_crossentropy
2 | import keras.backend as K
3 | import tensorflow as tf
4 |
5 | epsilon = 1e-5
6 | smooth = 1
7 |
8 | def dsc(y_true, y_pred):
9 | smooth = 1.
10 | y_true_f = K.flatten(y_true)
11 | y_pred_f = K.flatten(y_pred)
12 | intersection = K.sum(y_true_f * y_pred_f)
13 | score = (2. * intersection + smooth) / (K.sum(y_true_f) + K.sum(y_pred_f) + smooth)
14 | return score
15 |
16 | def dice_loss(y_true, y_pred):
17 | loss = 1 - dsc(y_true, y_pred)
18 | return loss
19 |
20 | def bce_dice_loss(y_true, y_pred):
21 | loss = binary_crossentropy(y_true, y_pred) + dice_loss(y_true, y_pred)
22 | return loss
23 |
24 | def confusion(y_true, y_pred):
25 | smooth=1
26 | y_pred_pos = K.clip(y_pred, 0, 1)
27 | y_pred_neg = 1 - y_pred_pos
28 | y_pos = K.clip(y_true, 0, 1)
29 | y_neg = 1 - y_pos
30 | tp = K.sum(y_pos * y_pred_pos)
31 | fp = K.sum(y_neg * y_pred_pos)
32 | fn = K.sum(y_pos * y_pred_neg)
33 | prec = (tp + smooth)/(tp+fp+smooth)
34 | recall = (tp+smooth)/(tp+fn+smooth)
35 | return prec, recall
36 |
37 | def tp(y_true, y_pred):
38 | smooth = 1
39 | y_pred_pos = K.round(K.clip(y_pred, 0, 1))
40 | y_pos = K.round(K.clip(y_true, 0, 1))
41 | tp = (K.sum(y_pos * y_pred_pos) + smooth)/ (K.sum(y_pos) + smooth)
42 | return tp
43 |
44 | def tn(y_true, y_pred):
45 | smooth = 1
46 | y_pred_pos = K.round(K.clip(y_pred, 0, 1))
47 | y_pred_neg = 1 - y_pred_pos
48 | y_pos = K.round(K.clip(y_true, 0, 1))
49 | y_neg = 1 - y_pos
50 | tn = (K.sum(y_neg * y_pred_neg) + smooth) / (K.sum(y_neg) + smooth )
51 | return tn
52 |
53 | def tversky(y_true, y_pred):
54 | y_true_pos = K.flatten(y_true)
55 | y_pred_pos = K.flatten(y_pred)
56 | true_pos = K.sum(y_true_pos * y_pred_pos)
57 | false_neg = K.sum(y_true_pos * (1-y_pred_pos))
58 | false_pos = K.sum((1-y_true_pos)*y_pred_pos)
59 | alpha = 0.7
60 | return (true_pos + smooth)/(true_pos + alpha*false_neg + (1-alpha)*false_pos + smooth)
61 |
62 | def tversky_loss(y_true, y_pred):
63 | return 1 - tversky(y_true,y_pred)
64 |
65 | def focal_tversky(y_true,y_pred):
66 | pt_1 = tversky(y_true, y_pred)
67 | gamma = 0.75
68 | return K.pow((1-pt_1), gamma)
69 |
--------------------------------------------------------------------------------
/newmodels.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Tue Oct 9 18:54:57 2018
4 |
5 | @author: Nabila Abraham
6 | """
7 | import cv2
8 | import time
9 | import os
10 | import h5py
11 |
12 | from keras.models import Model
13 | from keras.layers import Input, concatenate, Conv2D, MaxPooling2D, Conv2DTranspose
14 | from keras.layers import Activation, add, multiply, Lambda
15 | from keras.layers import AveragePooling2D, average, UpSampling2D, Dropout
16 | from keras.optimizers import Adam, SGD, RMSprop
17 | from keras.initializers import glorot_normal, random_normal, random_uniform
18 | from keras.callbacks import ModelCheckpoint, TensorBoard, EarlyStopping
19 |
20 | from keras import backend as K
21 | from keras.layers.normalization import BatchNormalization
22 | from keras.applications import VGG19, densenet
23 | from keras.models import load_model
24 |
25 | import numpy as np
26 | import tensorflow as tf
27 | import losses
28 | import matplotlib.pyplot as plt
29 | from sklearn.metrics import roc_curve, auc, precision_recall_curve # roc curve tools
30 | from sklearn.model_selection import train_test_split
31 |
32 | K.set_image_data_format('channels_last') # TF dimension ordering in this code
33 | kinit = 'glorot_normal'
34 |
35 | def unet(opt,input_size, lossfxn):
36 |
37 | inputs = Input(shape=input_size)
38 | conv1 = UnetConv2D(inputs, 32, is_batchnorm=True, name='conv1')
39 | pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
40 |
41 | conv2 = UnetConv2D(pool1, 64, is_batchnorm=True, name='conv2')
42 | pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
43 |
44 | conv3 = UnetConv2D(pool2, 128, is_batchnorm=True, name='conv3')
45 | pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
46 |
47 | conv4 = UnetConv2D(pool3, 256, is_batchnorm=True, name='conv4')
48 | pool4 = MaxPooling2D(pool_size=(2, 2))(conv4)
49 |
50 | conv5 = Conv2D(512, (3, 3), activation='relu', kernel_initializer=kinit, padding='same')(pool4)
51 | conv5 = Conv2D(512, (3, 3), activation='relu', kernel_initializer=kinit, padding='same')(conv5)
52 |
53 | up6 = concatenate([Conv2DTranspose(256, (2, 2), strides=(2, 2), kernel_initializer=kinit, padding='same')(conv5), conv4], axis=3)
54 | conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(up6)
55 | conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv6)
56 |
57 | up7 = concatenate([Conv2DTranspose(128, (2, 2), strides=(2, 2), padding='same')(conv6), conv3], axis=3)
58 | conv7 = Conv2D(128, (3, 3), activation='relu', kernel_initializer=kinit, padding='same')(up7)
59 | conv7 = Conv2D(128, (3, 3), activation='relu', kernel_initializer=kinit, padding='same')(conv7)
60 |
61 | up8 = concatenate([Conv2DTranspose(64, (2, 2), strides=(2, 2), kernel_initializer=kinit, padding='same')(conv7), conv2], axis=3)
62 | conv8 = Conv2D(64, (3, 3), activation='relu', kernel_initializer=kinit, padding='same')(up8)
63 |
64 | up9 = concatenate([Conv2DTranspose(32, (2, 2), strides=(2, 2), kernel_initializer=kinit, padding='same')(conv8), conv1], axis=3)
65 | conv9 = Conv2D(32, (3, 3), activation='relu', kernel_initializer=kinit, padding='same')(up9)
66 | conv9 = Conv2D(32, (3, 3), activation='relu', kernel_initializer=kinit, padding='same')(conv9)
67 | conv10 = Conv2D(1, (1, 1), activation='sigmoid', name='final')(conv9)
68 |
69 | model = Model(inputs=[inputs], outputs=[conv10])
70 | model.compile(optimizer=opt, loss=lossfxn, metrics=[losses.dsc,losses.tp,losses.tn])
71 | return model
72 |
73 | def expend_as(tensor, rep,name):
74 | my_repeat = Lambda(lambda x, repnum: K.repeat_elements(x, repnum, axis=3), arguments={'repnum': rep}, name='psi_up'+name)(tensor)
75 | return my_repeat
76 |
77 |
78 | def AttnGatingBlock(x, g, inter_shape, name):
79 | ''' take g which is the spatially smaller signal, do a conv to get the same
80 | number of feature channels as x (bigger spatially)
81 | do a conv on x to also get same geature channels (theta_x)
82 | then, upsample g to be same size as x
83 | add x and g (concat_xg)
84 | relu, 1x1 conv, then sigmoid then upsample the final - this gives us attn coefficients'''
85 |
86 | shape_x = K.int_shape(x) # 32
87 | shape_g = K.int_shape(g) # 16
88 |
89 | theta_x = Conv2D(inter_shape, (2, 2), strides=(2, 2), padding='same', name='xl'+name)(x) # 16
90 | shape_theta_x = K.int_shape(theta_x)
91 |
92 | phi_g = Conv2D(inter_shape, (1, 1), padding='same')(g)
93 | upsample_g = Conv2DTranspose(inter_shape, (3, 3),strides=(shape_theta_x[1] // shape_g[1], shape_theta_x[2] // shape_g[2]),padding='same', name='g_up'+name)(phi_g) # 16
94 |
95 | concat_xg = add([upsample_g, theta_x])
96 | act_xg = Activation('relu')(concat_xg)
97 | psi = Conv2D(1, (1, 1), padding='same', name='psi'+name)(act_xg)
98 | sigmoid_xg = Activation('sigmoid')(psi)
99 | shape_sigmoid = K.int_shape(sigmoid_xg)
100 | upsample_psi = UpSampling2D(size=(shape_x[1] // shape_sigmoid[1], shape_x[2] // shape_sigmoid[2]))(sigmoid_xg) # 32
101 |
102 | upsample_psi = expend_as(upsample_psi, shape_x[3], name)
103 | y = multiply([upsample_psi, x], name='q_attn'+name)
104 |
105 | result = Conv2D(shape_x[3], (1, 1), padding='same',name='q_attn_conv'+name)(y)
106 | result_bn = BatchNormalization(name='q_attn_bn'+name)(result)
107 | return result_bn
108 |
109 | def UnetConv2D(input, outdim, is_batchnorm, name):
110 | x = Conv2D(outdim, (3, 3), strides=(1, 1), kernel_initializer=kinit, padding="same", name=name+'_1')(input)
111 | if is_batchnorm:
112 | x =BatchNormalization(name=name + '_1_bn')(x)
113 | x = Activation('relu',name=name + '_1_act')(x)
114 |
115 | x = Conv2D(outdim, (3, 3), strides=(1, 1), kernel_initializer=kinit, padding="same", name=name+'_2')(x)
116 | if is_batchnorm:
117 | x = BatchNormalization(name=name + '_2_bn')(x)
118 | x = Activation('relu', name=name + '_2_act')(x)
119 | return x
120 |
121 |
122 | def UnetGatingSignal(input, is_batchnorm, name):
123 | ''' this is simply 1x1 convolution, bn, activation '''
124 | shape = K.int_shape(input)
125 | x = Conv2D(shape[3] * 1, (1, 1), strides=(1, 1), padding="same", kernel_initializer=kinit, name=name + '_conv')(input)
126 | if is_batchnorm:
127 | x = BatchNormalization(name=name + '_bn')(x)
128 | x = Activation('relu', name = name + '_act')(x)
129 | return x
130 |
131 | # plain old attention gates in u-net, NO multi-input, NO deep supervision
132 | def attn_unet(opt,input_size, lossfxn):
133 | inputs = Input(shape=input_size)
134 | conv1 = UnetConv2D(inputs, 32, is_batchnorm=True, name='conv1')
135 | pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
136 |
137 | conv2 = UnetConv2D(pool1, 32, is_batchnorm=True, name='conv2')
138 | pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
139 |
140 | conv3 = UnetConv2D(pool2, 64, is_batchnorm=True, name='conv3')
141 | #conv3 = Dropout(0.2,name='drop_conv3')(conv3)
142 | pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
143 |
144 | conv4 = UnetConv2D(pool3, 64, is_batchnorm=True, name='conv4')
145 | #conv4 = Dropout(0.2, name='drop_conv4')(conv4)
146 | pool4 = MaxPooling2D(pool_size=(2, 2))(conv4)
147 |
148 | center = UnetConv2D(pool4, 128, is_batchnorm=True, name='center')
149 |
150 | g1 = UnetGatingSignal(center, is_batchnorm=True, name='g1')
151 | attn1 = AttnGatingBlock(conv4, g1, 128, '_1')
152 | up1 = concatenate([Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(center), attn1], name='up1')
153 |
154 | g2 = UnetGatingSignal(up1, is_batchnorm=True, name='g2')
155 | attn2 = AttnGatingBlock(conv3, g2, 64, '_2')
156 | up2 = concatenate([Conv2DTranspose(64, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up1), attn2], name='up2')
157 |
158 | g3 = UnetGatingSignal(up1, is_batchnorm=True, name='g3')
159 | attn3 = AttnGatingBlock(conv2, g3, 32, '_3')
160 | up3 = concatenate([Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up2), attn3], name='up3')
161 |
162 | up4 = concatenate([Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up3), conv1], name='up4')
163 | out = Conv2D(1, (1, 1), activation='sigmoid', kernel_initializer=kinit, name='final')(up4)
164 |
165 | model = Model(inputs=[inputs], outputs=[out])
166 | model.compile(optimizer=opt, loss=lossfxn, metrics=[losses.dsc,losses.tp,losses.tn])
167 | return model
168 |
169 |
170 | #regular attention unet with deep supervision - exactly from paper (my intepretation)
171 | def attn_reg_ds(opt,input_size, lossfxn):
172 |
173 | img_input = Input(shape=input_size, name='input_scale1')
174 |
175 | conv1 = UnetConv2D(img_input, 32, is_batchnorm=True, name='conv1')
176 | pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
177 |
178 | conv2 = UnetConv2D(pool1, 64, is_batchnorm=True, name='conv2')
179 | pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
180 |
181 | conv3 = UnetConv2D(pool2, 128, is_batchnorm=True, name='conv3')
182 | #conv3 = Dropout(0.2,name='drop_conv3')(conv3)
183 | pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
184 |
185 | conv4 = UnetConv2D(pool3, 64, is_batchnorm=True, name='conv4')
186 | #conv4 = Dropout(0.2, name='drop_conv4')(conv4)
187 | pool4 = MaxPooling2D(pool_size=(2, 2))(conv4)
188 |
189 | center = UnetConv2D(pool4, 512, is_batchnorm=True, name='center')
190 |
191 | g1 = UnetGatingSignal(center, is_batchnorm=True, name='g1')
192 | attn1 = AttnGatingBlock(conv4, g1, 128, '_1')
193 | up1 = concatenate([Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(center), attn1], name='up1')
194 |
195 | g2 = UnetGatingSignal(up1, is_batchnorm=True, name='g2')
196 | attn2 = AttnGatingBlock(conv3, g2, 64, '_2')
197 | up2 = concatenate([Conv2DTranspose(64, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up1), attn2], name='up2')
198 |
199 | g3 = UnetGatingSignal(up1, is_batchnorm=True, name='g3')
200 | attn3 = AttnGatingBlock(conv2, g3, 32, '_3')
201 | up3 = concatenate([Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up2), attn3], name='up3')
202 |
203 | up4 = concatenate([Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up3), conv1], name='up4')
204 |
205 | conv6 = UnetConv2D(up1, 256, is_batchnorm=True, name='conv6')
206 | conv7 = UnetConv2D(up2, 128, is_batchnorm=True, name='conv7')
207 | conv8 = UnetConv2D(up3, 64, is_batchnorm=True, name='conv8')
208 | conv9 = UnetConv2D(up4, 32, is_batchnorm=True, name='conv9')
209 |
210 | out6 = Conv2D(1, (1, 1), activation='sigmoid', name='pred1')(conv6)
211 | out7 = Conv2D(1, (1, 1), activation='sigmoid', name='pred2')(conv7)
212 | out8 = Conv2D(1, (1, 1), activation='sigmoid', name='pred3')(conv8)
213 | out9 = Conv2D(1, (1, 1), activation='sigmoid', name='final')(conv9)
214 |
215 | model = Model(inputs=[img_input], outputs=[out6, out7, out8, out9])
216 |
217 | loss = {'pred1':lossfxn,
218 | 'pred2':lossfxn,
219 | 'pred3':lossfxn,
220 | 'final': lossfxn}
221 |
222 | loss_weights = {'pred1':1,
223 | 'pred2':1,
224 | 'pred3':1,
225 | 'final':1}
226 | model.compile(optimizer=opt, loss=loss, loss_weights=loss_weights,
227 | metrics=[losses.dsc])
228 | return model
229 |
230 |
231 | #model proposed in my paper - improved attention u-net with multi-scale input pyramid and deep supervision
232 |
233 | def attn_reg(opt,input_size, lossfxn):
234 |
235 | img_input = Input(shape=input_size, name='input_scale1')
236 | scale_img_2 = AveragePooling2D(pool_size=(2, 2), name='input_scale2')(img_input)
237 | scale_img_3 = AveragePooling2D(pool_size=(2, 2), name='input_scale3')(scale_img_2)
238 | scale_img_4 = AveragePooling2D(pool_size=(2, 2), name='input_scale4')(scale_img_3)
239 |
240 | conv1 = UnetConv2D(img_input, 32, is_batchnorm=True, name='conv1')
241 | pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
242 |
243 | input2 = Conv2D(64, (3, 3), padding='same', activation='relu', name='conv_scale2')(scale_img_2)
244 | input2 = concatenate([input2, pool1], axis=3)
245 | conv2 = UnetConv2D(input2, 64, is_batchnorm=True, name='conv2')
246 | pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
247 |
248 | input3 = Conv2D(128, (3, 3), padding='same', activation='relu', name='conv_scale3')(scale_img_3)
249 | input3 = concatenate([input3, pool2], axis=3)
250 | conv3 = UnetConv2D(input3, 128, is_batchnorm=True, name='conv3')
251 | pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
252 |
253 | input4 = Conv2D(256, (3, 3), padding='same', activation='relu', name='conv_scale4')(scale_img_4)
254 | input4 = concatenate([input4, pool3], axis=3)
255 | conv4 = UnetConv2D(input4, 64, is_batchnorm=True, name='conv4')
256 | pool4 = MaxPooling2D(pool_size=(2, 2))(conv4)
257 |
258 | center = UnetConv2D(pool4, 512, is_batchnorm=True, name='center')
259 |
260 | g1 = UnetGatingSignal(center, is_batchnorm=True, name='g1')
261 | attn1 = AttnGatingBlock(conv4, g1, 128, '_1')
262 | up1 = concatenate([Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(center), attn1], name='up1')
263 |
264 | g2 = UnetGatingSignal(up1, is_batchnorm=True, name='g2')
265 | attn2 = AttnGatingBlock(conv3, g2, 64, '_2')
266 | up2 = concatenate([Conv2DTranspose(64, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up1), attn2], name='up2')
267 |
268 | g3 = UnetGatingSignal(up1, is_batchnorm=True, name='g3')
269 | attn3 = AttnGatingBlock(conv2, g3, 32, '_3')
270 | up3 = concatenate([Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up2), attn3], name='up3')
271 |
272 | up4 = concatenate([Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up3), conv1], name='up4')
273 |
274 | conv6 = UnetConv2D(up1, 256, is_batchnorm=True, name='conv6')
275 | conv7 = UnetConv2D(up2, 128, is_batchnorm=True, name='conv7')
276 | conv8 = UnetConv2D(up3, 64, is_batchnorm=True, name='conv8')
277 | conv9 = UnetConv2D(up4, 32, is_batchnorm=True, name='conv9')
278 |
279 | out6 = Conv2D(1, (1, 1), activation='sigmoid', name='pred1')(conv6)
280 | out7 = Conv2D(1, (1, 1), activation='sigmoid', name='pred2')(conv7)
281 | out8 = Conv2D(1, (1, 1), activation='sigmoid', name='pred3')(conv8)
282 | out9 = Conv2D(1, (1, 1), activation='sigmoid', name='final')(conv9)
283 |
284 | model = Model(inputs=[img_input], outputs=[out6, out7, out8, out9])
285 |
286 | loss = {'pred1':lossfxn,
287 | 'pred2':lossfxn,
288 | 'pred3':lossfxn,
289 | 'final': losses.tversky_loss}
290 |
291 | loss_weights = {'pred1':1,
292 | 'pred2':1,
293 | 'pred3':1,
294 | 'final':1}
295 | model.compile(optimizer=opt, loss=loss, loss_weights=loss_weights,
296 | metrics=[losses.dsc])
297 | return model
298 |
299 |
--------------------------------------------------------------------------------
/utils.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Wed Aug 29 15:12:49 2018
4 |
5 | @author: Nabila Abraham
6 | """
7 | import numpy as np
8 | import matplotlib.pyplot as plt
9 |
10 |
11 | def plot(hist, epochnum, batchnum, name, is_attnnet=0):
12 | plt.figure()
13 |
14 | if is_attnnet==True:
15 | train_loss = hist['final_loss']
16 | val_loss = hist['val_final_loss']
17 | acc = hist['final_dsc']
18 | val_acc = hist['val_final_dsc']
19 | else:
20 | train_loss = hist['loss']
21 | val_loss = hist['val_loss']
22 | acc = hist['dsc']
23 | val_acc = hist['val_dsc']
24 |
25 | epochs = np.arange(1, len(train_loss)+1,1)
26 | plt.plot(epochs,train_loss, 'b', label='Training Loss')
27 | plt.plot(epochs,val_loss, 'r', label='Validation Loss')
28 | plt.grid(color='gray', linestyle='--')
29 | plt.legend()
30 | plt.title('LOSS Model={}, Epochs={}, Batch={}'.format(name,epochnum, batchnum))
31 | plt.xlabel('Epochs')
32 | plt.ylabel('Loss')
33 |
34 | plt.figure()
35 | plt.plot(epochs, acc, 'b', label='Training Dice Coefficient')
36 | plt.plot(epochs, val_acc, 'r', label='Validation Dice Coefficient')
37 | plt.grid(color='gray', linestyle='--')
38 | plt.legend()
39 | plt.title('DSC Model={}, Epochs={}, Batch={}'.format(name,epochnum, batchnum))
40 | plt.xlabel('Epochs')
41 | plt.ylabel('Dice')
42 |
43 |
44 | def check_preds(ypred, ytrue):
45 | smooth = 1
46 | pred = np.ndarray.flatten(np.clip(ypred,0,1))
47 | gt = np.ndarray.flatten(np.clip(ytrue,0,1))
48 | intersection = np.sum(pred * gt)
49 | union = np.sum(pred) + np.sum(gt)
50 | return np.round((2 * intersection + smooth)/(union + smooth),decimals=5)
51 |
52 | def confusion(y_true, y_pred):
53 | smooth = 1
54 | y_pred_pos = np.round(np.clip(y_pred, 0, 1))
55 | y_pred_neg = 1 - y_pred_pos
56 | y_pos = np.round(np.clip(y_true, 0, 1))
57 | y_neg = 1 - y_pos
58 | tp = (np.sum(y_pos * y_pred_pos) + smooth) / (np.sum(y_pos) + smooth)
59 | tn = (np.sum(y_neg * y_pred_neg) + smooth) / (np.sum(y_neg) + smooth)
60 | return [tp, tn]
61 |
62 | def auc(y_true, y_pred):
63 | smooth = 1
64 | y_pred_pos = np.round(np.clip(y_pred, 0, 1))
65 | y_pred_neg = 1 - y_pred_pos
66 | y_pos = np.round(np.clip(y_true, 0, 1))
67 | y_neg = 1 - y_pos
68 | tp = np.sum(y_pos * y_pred_pos)
69 | tn = np.sum(y_neg * y_pred_neg)
70 | fp = np.sum(y_neg * y_pred_pos)
71 | fn = np.sum(y_pos * y_pred_neg)
72 | tpr = (tp + smooth) / (tp + fn + smooth) #recall
73 | tnr = (tn + smooth) / (tn + fp + smooth)
74 | prec = (tp + smooth) / (tp + fp + smooth) #precision
75 | return [tpr, tnr, prec]
--------------------------------------------------------------------------------
16 |
17 | ### Training
18 | Training files for the ISIC2018 and BUS2017 Dataset B have been added.
19 | If training with ISIC2018, create 4 folders: `orig_raw` (not used in this code), `orig_gt`, `resized-train`, `resized-gt`, for full
20 | resolution input images, ground truth and resized images at `192x256` resolution, respectively.
21 |
22 | If training with BUS2017, create 2 folders: `original` and `gt` for input data and ground truth data. In the `bus_train.py` script, images
23 | will be resampled to `128x128` resolution.
24 |
25 | ### Citation
26 | If you find this code useful, please consider citing our work:
27 | ```
28 | @article{focal-unet,
29 | title={A novel Focal Tversky loss function with improved Attention U-Net for lesion segmentation},
30 | author={Abraham, Nabila and Khan, Naimul Mefraz},
31 | journal={arXiv preprint arXiv:1810.07842},
32 | year={2018}
33 | }
34 | ```
35 |
36 |
--------------------------------------------------------------------------------
/bus_train.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | @author: Nabilla Abraham
4 | """
5 | import os
6 | import cv2
7 | import numpy as np
8 | import tensorflow as tf
9 | import matplotlib.pyplot as plt
10 |
11 | from keras.models import Model
12 | from keras.layers import Input, concatenate, Conv2D, MaxPooling2D, Conv2DTranspose
13 | from keras.layers import Activation, add, multiply, Lambda
14 | from keras.layers import AveragePooling2D, average, UpSampling2D, Dropout
15 | from keras.optimizers import Adam, SGD, RMSprop
16 | from keras.initializers import glorot_normal, random_normal, random_uniform
17 | from keras.callbacks import ModelCheckpoint, TensorBoard, EarlyStopping
18 | from keras import backend as K
19 | from keras.layers.normalization import BatchNormalization
20 |
21 | from sklearn.metrics import roc_curve, auc, precision_recall_curve # roc curve tools
22 | from sklearn.model_selection import train_test_split
23 |
24 | import losses
25 | import utils
26 | import newmodels
27 |
28 | from keras.backend.tensorflow_backend import set_session
29 | config = tf.ConfigProto()
30 | config.gpu_options.per_process_gpu_memory_fraction = 0.7
31 | set_session(tf.Session(config=config))
32 |
33 | img_row = 128
34 | img_col = 128
35 | img_size = 128
36 | img_chan = 1
37 | epochnum = 100
38 | batchnum = 16
39 | input_size = (img_row, img_col, img_chan)
40 |
41 | sgd = SGD(lr=0.01, momentum=0.9)
42 |
43 | curr_dir = os.getcwd()
44 | img_dir = os.path.join(curr_dir, 'original')
45 | gt_dir = os.path.join(curr_dir, 'gt')
46 |
47 | img_list = os.listdir(img_dir)
48 | gt_list = os.listdir(gt_dir)
49 |
50 | num_imgs = len(img_list)
51 |
52 | orig_imgs = []
53 | orig_gts = []
54 | imgs = np.zeros((num_imgs, img_row, img_col))
55 | gts = np.zeros_like(imgs)
56 |
57 | for i in range(num_imgs):
58 | tmp_img = plt.imread(os.path.join(img_dir, img_list[i]))
59 | tmp_gt = plt.imread(os.path.join(gt_dir, img_list[i]))
60 | orig_imgs.append(tmp_img)
61 | orig_gts.append(tmp_gt)
62 |
63 | imgs[i] = cv2.resize(tmp_img, (img_col,img_row), interpolation=cv2.INTER_NEAREST)
64 | gts[i] = cv2.resize(tmp_gt,(img_col,img_row), interpolation=cv2.INTER_NEAREST)
65 |
66 | indices = np.arange(0,num_imgs,1)
67 |
68 | imgs_train, imgs_test, \
69 | imgs_mask_train, orig_imgs_mask_test,\
70 | trainIdx, testIdx = train_test_split(imgs,gts, indices,test_size=0.25)
71 |
72 | imgs_train = np.expand_dims(imgs_train, axis=3)
73 | imgs_mask_train = np.expand_dims(imgs_mask_train,axis=3)
74 | imgs_test = np.expand_dims(imgs_test, axis=3)
75 |
76 | filepath="weights.hdf5"
77 | checkpoint = ModelCheckpoint(filepath, monitor='val_dsc',
78 | verbose=1, save_best_only=True,
79 | save_weights_only=True, mode='max')
80 | gt1 = imgs_mask_train[:,::8,::8,:]
81 | gt2 = imgs_mask_train[:,::4,::4,:]
82 | gt3 = imgs_mask_train[:,::2,::2,:]
83 | gt4 = imgs_mask_train
84 | gt_train = [gt1,gt2,gt3,gt4]
85 |
86 | model = newmodels.unet(sgd, input_size, losses.tversky_loss)
87 | hist = model.fit(imgs_train, imgs_mask_train, validation_split=0.15,
88 | shuffle=True, epochs=epochnum, batch_size=batchnum,
89 | verbose=True, callbacks=[checkpoint])#, callbacks=[estop,tb])
90 | h = hist.history
91 | utils.plot(h, epochnum, batchnum, img_col, 0)
92 |
93 | num_test = len(imgs_test)
94 | _,_,_,preds = model.predict(imgs_test)
95 | #preds = model.predict(imgs_test)
96 |
97 | preds_up=[]
98 | dsc = np.zeros((num_test,1))
99 | recall = np.zeros_like(dsc)
100 | tn = np.zeros_like(dsc)
101 | prec = np.zeros_like(dsc)
102 |
103 | thresh = 0.5
104 |
105 | for i in range(num_test):
106 | gt = orig_gts[testIdx[i]]
107 | preds_up.append(cv2.resize(preds[i], (gt.shape[1], gt.shape[0]), interpolation=cv2.INTER_NEAREST))
108 | dsc[i] = utils.check_preds(preds_up[i] > thresh, gt)
109 | recall[i], _, prec[i] = utils.auc(gt, preds_up[i] >thresh)
110 |
111 | print('-'*30)
112 | print('At threshold =', thresh)
113 | print('\n DSC \t\t{0:^.3f} \n Recall \t{1:^.3f} \n Precision\t{2:^.3f}'.format(
114 | np.sum(dsc)/num_test,
115 | np.sum(recall)/num_test,
116 | np.sum(prec)/num_test ))
117 |
118 | model.load_weights("weights.hdf5")
119 | _,_,_,preds = model.predict(imgs_test)
120 | #preds = model.predict(imgs_test) #use this if model is unet
121 |
122 | preds_up=[]
123 | dsc = np.zeros((num_test,1))
124 | recall = np.zeros_like(dsc)
125 | tn = np.zeros_like(dsc)
126 | prec = np.zeros_like(dsc)
127 |
128 | for i in range(num_test):
129 | gt = orig_gts[testIdx[i]]
130 | preds_up.append(cv2.resize(preds[i], (gt.shape[1], gt.shape[0]), interpolation=cv2.INTER_NEAREST))
131 | dsc[i] = utils.check_preds(preds_up[i] > thresh, gt)
132 | recall[i], _, prec[i] = utils.auc(gt, preds_up[i] >thresh)
133 |
134 | print('-'*30)
135 | print('USING HDF5 MODEL', thresh)
136 | print('\n DSC \t\t{0:^.3f} \n Recall \t{1:^.3f} \n Precision\t{2:^.3f}'.format(
137 | np.sum(dsc)/num_test,
138 | np.sum(recall)/num_test,
139 | np.sum(prec)/num_test ))
140 |
141 | # check to see how much accuracy we've lost by upsampling the predictions by comparing to
142 | # the original shapes used for training
143 | for i in range(num_test):
144 | gt = orig_imgs_mask_test[i]
145 | dsc[i] = utils.check_preds(np.squeeze(preds[i]) > thresh, gt)
146 | recall[i], _, prec[i] = utils.auc(gt, np.squeeze(preds[i]) >thresh)
147 |
148 | print('-'*30)
149 | print('Without resizing the preds =', thresh)
150 | print('\n DSC \t\t{0:^.3f} \n Recall \t{1:^.3f} \n Precision\t{2:^.3f}'.format(
151 | np.sum(dsc)/num_test,
152 | np.sum(recall)/num_test,
153 | np.sum(prec)/num_test ))
154 |
155 | idx = np.random.randint(0,num_test)
156 | gt_plot = orig_gts[testIdx[idx]]
157 | plt.figure(dpi=200)
158 | plt.subplot(121)
159 | plt.imshow(np.squeeze(gt_plot), cmap='gray')
160 | plt.title('Original Img {}'.format(idx))
161 | plt.subplot(122)
162 | plt.imshow(np.squeeze(preds_up[idx]), cmap='gray')
163 | plt.title('Ground Truth {}'.format(idx))
164 |
165 | y_true = orig_imgs_mask_test.ravel()
166 | y_preds = preds.ravel()
167 | precision, recall, thresholds = precision_recall_curve(y_true, y_preds)
168 | plt.figure(20)
169 | plt.plot(recall,precision)
170 |
--------------------------------------------------------------------------------
/images/ag.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nabsabraham/focal-tversky-unet/347d39117c24540400dfe80d106d2fb06d2b99e1/images/ag.png
--------------------------------------------------------------------------------
/images/ftl.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nabsabraham/focal-tversky-unet/347d39117c24540400dfe80d106d2fb06d2b99e1/images/ftl.png
--------------------------------------------------------------------------------
/isic_train.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Sun Oct 14 17:16:54 2018
4 |
5 | @author: Nabila Abraham
6 | """
7 |
8 | import os
9 | import cv2
10 | import numpy as np
11 | import tensorflow as tf
12 | import matplotlib.pyplot as plt
13 |
14 | from keras.models import Model
15 | from keras.layers import Input, concatenate, Conv2D, MaxPooling2D, Conv2DTranspose
16 | from keras.layers import Activation, add, multiply, Lambda
17 | from keras.layers import AveragePooling2D, average, UpSampling2D, Dropout
18 | from keras.optimizers import Adam, SGD, RMSprop
19 | from keras.initializers import glorot_normal, random_normal, random_uniform
20 | from keras.callbacks import ModelCheckpoint, TensorBoard, EarlyStopping
21 | from keras import backend as K
22 | from keras.layers.normalization import BatchNormalization
23 |
24 | from sklearn.metrics import roc_curve, auc, precision_recall_curve # roc curve tools
25 | from sklearn.model_selection import train_test_split
26 |
27 | import losses
28 | import utils
29 | import newmodels
30 |
31 | img_row = 192
32 | img_col = 256
33 | img_chan = 3
34 | epochnum = 50
35 | batchnum = 16
36 | smooth = 1.
37 | input_size = (img_row, img_col, img_chan)
38 |
39 | sgd = SGD(lr=0.01, momentum=0.90, decay=1e-6)
40 | adam = Adam(lr=1e-3)
41 |
42 | curr_dir = os.getcwd()
43 | train_dir = os.path.join(curr_dir, 'resized_train')
44 | gt_dir = os.path.join(curr_dir, 'resized_gt')
45 | orig_dir = os.path.join(curr_dir, 'orig_gt')
46 |
47 | img_list = os.listdir(train_dir)
48 | num_imgs = len(img_list)
49 |
50 | orig_data = np.zeros((num_imgs, img_row, img_col, img_chan))
51 | orig_masks = np.zeros((num_imgs, img_row, img_col,1))
52 |
53 | for idx,img_name in enumerate(img_list):
54 | orig_data[idx] = plt.imread(os.path.join(train_dir, img_name))
55 | orig_masks[idx,:,:,0] = plt.imread(os.path.join(gt_dir, img_name.split('.')[0] + "_segmentation.png"))
56 |
57 | indices = np.arange(0,num_imgs,1)
58 |
59 | imgs_train, imgs_test, \
60 | imgs_mask_train, orig_imgs_mask_test,\
61 | trainIdx, testIdx = train_test_split(orig_data,orig_masks, indices,test_size=0.25)
62 |
63 | imgs_train /= 255
64 | imgs_test /=255
65 |
66 | estop = EarlyStopping(monitor='val_loss', min_delta=0.001, patience=5, mode='auto')
67 | filepath="weights.hdf5"
68 | checkpoint = ModelCheckpoint(filepath, monitor='val_final_dsc',
69 | verbose=1, save_best_only=True,
70 | save_weights_only=True, mode='max')
71 | gt1 = imgs_mask_train[:,::8,::8,:]
72 | gt2 = imgs_mask_train[:,::4,::4,:]
73 | gt3 = imgs_mask_train[:,::2,::2,:]
74 | gt4 = imgs_mask_train
75 | gt_train = [gt1,gt2,gt3,gt4]
76 |
77 | model = newmodels.attn_reg(sgd, input_size, losses.focal_tversky)
78 | hist = model.fit(imgs_train, gt_train, validation_split=0.15,
79 | shuffle=True, epochs=epochnum, batch_size=batchnum,
80 | verbose=True, callbacks=[checkpoint])#, callbacks=[estop,tb])
81 | h = hist.history
82 | utils.plot(h, epochnum, batchnum, img_col, 1)
83 |
84 | num_test = len(imgs_test)
85 | _,_,_,preds = model.predict(imgs_test)
86 | #preds = model.predict(imgs_test) #use this if the model is unet
87 |
88 | preds_up=[]
89 | dsc = np.zeros((num_test,1))
90 | recall = np.zeros_like(dsc)
91 | tn = np.zeros_like(dsc)
92 | prec = np.zeros_like(dsc)
93 |
94 | thresh = 0.5
95 |
96 | # check the predictions from the trained model
97 | for i in range(num_test):
98 | #gt = orig_masks[testIdx[i]]
99 | name = img_list[testIdx[i]]
100 | gt = plt.imread(os.path.join(orig_dir, name.split('.')[0] + "_segmentation.png"))
101 |
102 | pred_up = cv2.resize(preds[i], (gt.shape[1], gt.shape[0]), interpolation=cv2.INTER_NEAREST)
103 | dsc[i] = utils.check_preds(pred_up > thresh, gt)
104 | recall[i], _, prec[i] = utils.auc(gt, pred_up >thresh)
105 |
106 | print('-'*30)
107 | print('At threshold =', thresh)
108 | print('\n DSC \t\t{0:^.3f} \n Recall \t{1:^.3f} \n Precision\t{2:^.3f}'.format(
109 | np.sum(dsc)/num_test,
110 | np.sum(recall)/num_test,
111 | np.sum(prec)/num_test ))
112 |
113 | # check the predictions with the best saved model from checkpoint
114 | model.load_weights("weights.hdf5")
115 | _,_,_,preds = model.predict(imgs_test)
116 | #preds = model.predict(imgs_test) #use this if the model is unet
117 |
118 | preds_up=[]
119 | dsc = np.zeros((num_test,1))
120 | recall = np.zeros_like(dsc)
121 | tn = np.zeros_like(dsc)
122 | prec = np.zeros_like(dsc)
123 |
124 | for i in range(num_test):
125 | #gt = orig_masks[testIdx[i]]
126 | name = img_list[testIdx[i]]
127 | gt = plt.imread(os.path.join(orig_dir, name.split('.')[0] + "_segmentation.png"))
128 |
129 | pred_up = cv2.resize(preds[i], (gt.shape[1], gt.shape[0]), interpolation=cv2.INTER_NEAREST)
130 | dsc[i] = utils.check_preds(pred_up > thresh, gt)
131 | recall[i], _, prec[i] = utils.auc(gt, pred_up >thresh)
132 |
133 | print('-'*30)
134 | print('USING HDF5 saved model at thresh=', thresh)
135 | print('\n DSC \t\t{0:^.3f} \n Recall \t{1:^.3f} \n Precision\t{2:^.3f}'.format(
136 | np.sum(dsc)/num_test,
137 | np.sum(recall)/num_test,
138 | np.sum(prec)/num_test ))
139 |
140 | #plot precision-recall
141 | y_true = orig_imgs_mask_test.ravel()
142 | y_preds = preds.ravel()
143 | precision, recall, thresholds = precision_recall_curve(y_true, y_preds)
144 | plt.figure(20)
145 | plt.plot(recall,precision)
146 |
147 |
--------------------------------------------------------------------------------
/losses.py:
--------------------------------------------------------------------------------
1 | from keras.losses import binary_crossentropy
2 | import keras.backend as K
3 | import tensorflow as tf
4 |
5 | epsilon = 1e-5
6 | smooth = 1
7 |
8 | def dsc(y_true, y_pred):
9 | smooth = 1.
10 | y_true_f = K.flatten(y_true)
11 | y_pred_f = K.flatten(y_pred)
12 | intersection = K.sum(y_true_f * y_pred_f)
13 | score = (2. * intersection + smooth) / (K.sum(y_true_f) + K.sum(y_pred_f) + smooth)
14 | return score
15 |
16 | def dice_loss(y_true, y_pred):
17 | loss = 1 - dsc(y_true, y_pred)
18 | return loss
19 |
20 | def bce_dice_loss(y_true, y_pred):
21 | loss = binary_crossentropy(y_true, y_pred) + dice_loss(y_true, y_pred)
22 | return loss
23 |
24 | def confusion(y_true, y_pred):
25 | smooth=1
26 | y_pred_pos = K.clip(y_pred, 0, 1)
27 | y_pred_neg = 1 - y_pred_pos
28 | y_pos = K.clip(y_true, 0, 1)
29 | y_neg = 1 - y_pos
30 | tp = K.sum(y_pos * y_pred_pos)
31 | fp = K.sum(y_neg * y_pred_pos)
32 | fn = K.sum(y_pos * y_pred_neg)
33 | prec = (tp + smooth)/(tp+fp+smooth)
34 | recall = (tp+smooth)/(tp+fn+smooth)
35 | return prec, recall
36 |
37 | def tp(y_true, y_pred):
38 | smooth = 1
39 | y_pred_pos = K.round(K.clip(y_pred, 0, 1))
40 | y_pos = K.round(K.clip(y_true, 0, 1))
41 | tp = (K.sum(y_pos * y_pred_pos) + smooth)/ (K.sum(y_pos) + smooth)
42 | return tp
43 |
44 | def tn(y_true, y_pred):
45 | smooth = 1
46 | y_pred_pos = K.round(K.clip(y_pred, 0, 1))
47 | y_pred_neg = 1 - y_pred_pos
48 | y_pos = K.round(K.clip(y_true, 0, 1))
49 | y_neg = 1 - y_pos
50 | tn = (K.sum(y_neg * y_pred_neg) + smooth) / (K.sum(y_neg) + smooth )
51 | return tn
52 |
53 | def tversky(y_true, y_pred):
54 | y_true_pos = K.flatten(y_true)
55 | y_pred_pos = K.flatten(y_pred)
56 | true_pos = K.sum(y_true_pos * y_pred_pos)
57 | false_neg = K.sum(y_true_pos * (1-y_pred_pos))
58 | false_pos = K.sum((1-y_true_pos)*y_pred_pos)
59 | alpha = 0.7
60 | return (true_pos + smooth)/(true_pos + alpha*false_neg + (1-alpha)*false_pos + smooth)
61 |
62 | def tversky_loss(y_true, y_pred):
63 | return 1 - tversky(y_true,y_pred)
64 |
65 | def focal_tversky(y_true,y_pred):
66 | pt_1 = tversky(y_true, y_pred)
67 | gamma = 0.75
68 | return K.pow((1-pt_1), gamma)
69 |
--------------------------------------------------------------------------------
/newmodels.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Tue Oct 9 18:54:57 2018
4 |
5 | @author: Nabila Abraham
6 | """
7 | import cv2
8 | import time
9 | import os
10 | import h5py
11 |
12 | from keras.models import Model
13 | from keras.layers import Input, concatenate, Conv2D, MaxPooling2D, Conv2DTranspose
14 | from keras.layers import Activation, add, multiply, Lambda
15 | from keras.layers import AveragePooling2D, average, UpSampling2D, Dropout
16 | from keras.optimizers import Adam, SGD, RMSprop
17 | from keras.initializers import glorot_normal, random_normal, random_uniform
18 | from keras.callbacks import ModelCheckpoint, TensorBoard, EarlyStopping
19 |
20 | from keras import backend as K
21 | from keras.layers.normalization import BatchNormalization
22 | from keras.applications import VGG19, densenet
23 | from keras.models import load_model
24 |
25 | import numpy as np
26 | import tensorflow as tf
27 | import losses
28 | import matplotlib.pyplot as plt
29 | from sklearn.metrics import roc_curve, auc, precision_recall_curve # roc curve tools
30 | from sklearn.model_selection import train_test_split
31 |
32 | K.set_image_data_format('channels_last') # TF dimension ordering in this code
33 | kinit = 'glorot_normal'
34 |
35 | def unet(opt,input_size, lossfxn):
36 |
37 | inputs = Input(shape=input_size)
38 | conv1 = UnetConv2D(inputs, 32, is_batchnorm=True, name='conv1')
39 | pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
40 |
41 | conv2 = UnetConv2D(pool1, 64, is_batchnorm=True, name='conv2')
42 | pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
43 |
44 | conv3 = UnetConv2D(pool2, 128, is_batchnorm=True, name='conv3')
45 | pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
46 |
47 | conv4 = UnetConv2D(pool3, 256, is_batchnorm=True, name='conv4')
48 | pool4 = MaxPooling2D(pool_size=(2, 2))(conv4)
49 |
50 | conv5 = Conv2D(512, (3, 3), activation='relu', kernel_initializer=kinit, padding='same')(pool4)
51 | conv5 = Conv2D(512, (3, 3), activation='relu', kernel_initializer=kinit, padding='same')(conv5)
52 |
53 | up6 = concatenate([Conv2DTranspose(256, (2, 2), strides=(2, 2), kernel_initializer=kinit, padding='same')(conv5), conv4], axis=3)
54 | conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(up6)
55 | conv6 = Conv2D(256, (3, 3), activation='relu', padding='same')(conv6)
56 |
57 | up7 = concatenate([Conv2DTranspose(128, (2, 2), strides=(2, 2), padding='same')(conv6), conv3], axis=3)
58 | conv7 = Conv2D(128, (3, 3), activation='relu', kernel_initializer=kinit, padding='same')(up7)
59 | conv7 = Conv2D(128, (3, 3), activation='relu', kernel_initializer=kinit, padding='same')(conv7)
60 |
61 | up8 = concatenate([Conv2DTranspose(64, (2, 2), strides=(2, 2), kernel_initializer=kinit, padding='same')(conv7), conv2], axis=3)
62 | conv8 = Conv2D(64, (3, 3), activation='relu', kernel_initializer=kinit, padding='same')(up8)
63 |
64 | up9 = concatenate([Conv2DTranspose(32, (2, 2), strides=(2, 2), kernel_initializer=kinit, padding='same')(conv8), conv1], axis=3)
65 | conv9 = Conv2D(32, (3, 3), activation='relu', kernel_initializer=kinit, padding='same')(up9)
66 | conv9 = Conv2D(32, (3, 3), activation='relu', kernel_initializer=kinit, padding='same')(conv9)
67 | conv10 = Conv2D(1, (1, 1), activation='sigmoid', name='final')(conv9)
68 |
69 | model = Model(inputs=[inputs], outputs=[conv10])
70 | model.compile(optimizer=opt, loss=lossfxn, metrics=[losses.dsc,losses.tp,losses.tn])
71 | return model
72 |
73 | def expend_as(tensor, rep,name):
74 | my_repeat = Lambda(lambda x, repnum: K.repeat_elements(x, repnum, axis=3), arguments={'repnum': rep}, name='psi_up'+name)(tensor)
75 | return my_repeat
76 |
77 |
78 | def AttnGatingBlock(x, g, inter_shape, name):
79 | ''' take g which is the spatially smaller signal, do a conv to get the same
80 | number of feature channels as x (bigger spatially)
81 | do a conv on x to also get same geature channels (theta_x)
82 | then, upsample g to be same size as x
83 | add x and g (concat_xg)
84 | relu, 1x1 conv, then sigmoid then upsample the final - this gives us attn coefficients'''
85 |
86 | shape_x = K.int_shape(x) # 32
87 | shape_g = K.int_shape(g) # 16
88 |
89 | theta_x = Conv2D(inter_shape, (2, 2), strides=(2, 2), padding='same', name='xl'+name)(x) # 16
90 | shape_theta_x = K.int_shape(theta_x)
91 |
92 | phi_g = Conv2D(inter_shape, (1, 1), padding='same')(g)
93 | upsample_g = Conv2DTranspose(inter_shape, (3, 3),strides=(shape_theta_x[1] // shape_g[1], shape_theta_x[2] // shape_g[2]),padding='same', name='g_up'+name)(phi_g) # 16
94 |
95 | concat_xg = add([upsample_g, theta_x])
96 | act_xg = Activation('relu')(concat_xg)
97 | psi = Conv2D(1, (1, 1), padding='same', name='psi'+name)(act_xg)
98 | sigmoid_xg = Activation('sigmoid')(psi)
99 | shape_sigmoid = K.int_shape(sigmoid_xg)
100 | upsample_psi = UpSampling2D(size=(shape_x[1] // shape_sigmoid[1], shape_x[2] // shape_sigmoid[2]))(sigmoid_xg) # 32
101 |
102 | upsample_psi = expend_as(upsample_psi, shape_x[3], name)
103 | y = multiply([upsample_psi, x], name='q_attn'+name)
104 |
105 | result = Conv2D(shape_x[3], (1, 1), padding='same',name='q_attn_conv'+name)(y)
106 | result_bn = BatchNormalization(name='q_attn_bn'+name)(result)
107 | return result_bn
108 |
109 | def UnetConv2D(input, outdim, is_batchnorm, name):
110 | x = Conv2D(outdim, (3, 3), strides=(1, 1), kernel_initializer=kinit, padding="same", name=name+'_1')(input)
111 | if is_batchnorm:
112 | x =BatchNormalization(name=name + '_1_bn')(x)
113 | x = Activation('relu',name=name + '_1_act')(x)
114 |
115 | x = Conv2D(outdim, (3, 3), strides=(1, 1), kernel_initializer=kinit, padding="same", name=name+'_2')(x)
116 | if is_batchnorm:
117 | x = BatchNormalization(name=name + '_2_bn')(x)
118 | x = Activation('relu', name=name + '_2_act')(x)
119 | return x
120 |
121 |
122 | def UnetGatingSignal(input, is_batchnorm, name):
123 | ''' this is simply 1x1 convolution, bn, activation '''
124 | shape = K.int_shape(input)
125 | x = Conv2D(shape[3] * 1, (1, 1), strides=(1, 1), padding="same", kernel_initializer=kinit, name=name + '_conv')(input)
126 | if is_batchnorm:
127 | x = BatchNormalization(name=name + '_bn')(x)
128 | x = Activation('relu', name = name + '_act')(x)
129 | return x
130 |
131 | # plain old attention gates in u-net, NO multi-input, NO deep supervision
132 | def attn_unet(opt,input_size, lossfxn):
133 | inputs = Input(shape=input_size)
134 | conv1 = UnetConv2D(inputs, 32, is_batchnorm=True, name='conv1')
135 | pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
136 |
137 | conv2 = UnetConv2D(pool1, 32, is_batchnorm=True, name='conv2')
138 | pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
139 |
140 | conv3 = UnetConv2D(pool2, 64, is_batchnorm=True, name='conv3')
141 | #conv3 = Dropout(0.2,name='drop_conv3')(conv3)
142 | pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
143 |
144 | conv4 = UnetConv2D(pool3, 64, is_batchnorm=True, name='conv4')
145 | #conv4 = Dropout(0.2, name='drop_conv4')(conv4)
146 | pool4 = MaxPooling2D(pool_size=(2, 2))(conv4)
147 |
148 | center = UnetConv2D(pool4, 128, is_batchnorm=True, name='center')
149 |
150 | g1 = UnetGatingSignal(center, is_batchnorm=True, name='g1')
151 | attn1 = AttnGatingBlock(conv4, g1, 128, '_1')
152 | up1 = concatenate([Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(center), attn1], name='up1')
153 |
154 | g2 = UnetGatingSignal(up1, is_batchnorm=True, name='g2')
155 | attn2 = AttnGatingBlock(conv3, g2, 64, '_2')
156 | up2 = concatenate([Conv2DTranspose(64, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up1), attn2], name='up2')
157 |
158 | g3 = UnetGatingSignal(up1, is_batchnorm=True, name='g3')
159 | attn3 = AttnGatingBlock(conv2, g3, 32, '_3')
160 | up3 = concatenate([Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up2), attn3], name='up3')
161 |
162 | up4 = concatenate([Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up3), conv1], name='up4')
163 | out = Conv2D(1, (1, 1), activation='sigmoid', kernel_initializer=kinit, name='final')(up4)
164 |
165 | model = Model(inputs=[inputs], outputs=[out])
166 | model.compile(optimizer=opt, loss=lossfxn, metrics=[losses.dsc,losses.tp,losses.tn])
167 | return model
168 |
169 |
170 | #regular attention unet with deep supervision - exactly from paper (my intepretation)
171 | def attn_reg_ds(opt,input_size, lossfxn):
172 |
173 | img_input = Input(shape=input_size, name='input_scale1')
174 |
175 | conv1 = UnetConv2D(img_input, 32, is_batchnorm=True, name='conv1')
176 | pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
177 |
178 | conv2 = UnetConv2D(pool1, 64, is_batchnorm=True, name='conv2')
179 | pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
180 |
181 | conv3 = UnetConv2D(pool2, 128, is_batchnorm=True, name='conv3')
182 | #conv3 = Dropout(0.2,name='drop_conv3')(conv3)
183 | pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
184 |
185 | conv4 = UnetConv2D(pool3, 64, is_batchnorm=True, name='conv4')
186 | #conv4 = Dropout(0.2, name='drop_conv4')(conv4)
187 | pool4 = MaxPooling2D(pool_size=(2, 2))(conv4)
188 |
189 | center = UnetConv2D(pool4, 512, is_batchnorm=True, name='center')
190 |
191 | g1 = UnetGatingSignal(center, is_batchnorm=True, name='g1')
192 | attn1 = AttnGatingBlock(conv4, g1, 128, '_1')
193 | up1 = concatenate([Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(center), attn1], name='up1')
194 |
195 | g2 = UnetGatingSignal(up1, is_batchnorm=True, name='g2')
196 | attn2 = AttnGatingBlock(conv3, g2, 64, '_2')
197 | up2 = concatenate([Conv2DTranspose(64, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up1), attn2], name='up2')
198 |
199 | g3 = UnetGatingSignal(up1, is_batchnorm=True, name='g3')
200 | attn3 = AttnGatingBlock(conv2, g3, 32, '_3')
201 | up3 = concatenate([Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up2), attn3], name='up3')
202 |
203 | up4 = concatenate([Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up3), conv1], name='up4')
204 |
205 | conv6 = UnetConv2D(up1, 256, is_batchnorm=True, name='conv6')
206 | conv7 = UnetConv2D(up2, 128, is_batchnorm=True, name='conv7')
207 | conv8 = UnetConv2D(up3, 64, is_batchnorm=True, name='conv8')
208 | conv9 = UnetConv2D(up4, 32, is_batchnorm=True, name='conv9')
209 |
210 | out6 = Conv2D(1, (1, 1), activation='sigmoid', name='pred1')(conv6)
211 | out7 = Conv2D(1, (1, 1), activation='sigmoid', name='pred2')(conv7)
212 | out8 = Conv2D(1, (1, 1), activation='sigmoid', name='pred3')(conv8)
213 | out9 = Conv2D(1, (1, 1), activation='sigmoid', name='final')(conv9)
214 |
215 | model = Model(inputs=[img_input], outputs=[out6, out7, out8, out9])
216 |
217 | loss = {'pred1':lossfxn,
218 | 'pred2':lossfxn,
219 | 'pred3':lossfxn,
220 | 'final': lossfxn}
221 |
222 | loss_weights = {'pred1':1,
223 | 'pred2':1,
224 | 'pred3':1,
225 | 'final':1}
226 | model.compile(optimizer=opt, loss=loss, loss_weights=loss_weights,
227 | metrics=[losses.dsc])
228 | return model
229 |
230 |
231 | #model proposed in my paper - improved attention u-net with multi-scale input pyramid and deep supervision
232 |
233 | def attn_reg(opt,input_size, lossfxn):
234 |
235 | img_input = Input(shape=input_size, name='input_scale1')
236 | scale_img_2 = AveragePooling2D(pool_size=(2, 2), name='input_scale2')(img_input)
237 | scale_img_3 = AveragePooling2D(pool_size=(2, 2), name='input_scale3')(scale_img_2)
238 | scale_img_4 = AveragePooling2D(pool_size=(2, 2), name='input_scale4')(scale_img_3)
239 |
240 | conv1 = UnetConv2D(img_input, 32, is_batchnorm=True, name='conv1')
241 | pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
242 |
243 | input2 = Conv2D(64, (3, 3), padding='same', activation='relu', name='conv_scale2')(scale_img_2)
244 | input2 = concatenate([input2, pool1], axis=3)
245 | conv2 = UnetConv2D(input2, 64, is_batchnorm=True, name='conv2')
246 | pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
247 |
248 | input3 = Conv2D(128, (3, 3), padding='same', activation='relu', name='conv_scale3')(scale_img_3)
249 | input3 = concatenate([input3, pool2], axis=3)
250 | conv3 = UnetConv2D(input3, 128, is_batchnorm=True, name='conv3')
251 | pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
252 |
253 | input4 = Conv2D(256, (3, 3), padding='same', activation='relu', name='conv_scale4')(scale_img_4)
254 | input4 = concatenate([input4, pool3], axis=3)
255 | conv4 = UnetConv2D(input4, 64, is_batchnorm=True, name='conv4')
256 | pool4 = MaxPooling2D(pool_size=(2, 2))(conv4)
257 |
258 | center = UnetConv2D(pool4, 512, is_batchnorm=True, name='center')
259 |
260 | g1 = UnetGatingSignal(center, is_batchnorm=True, name='g1')
261 | attn1 = AttnGatingBlock(conv4, g1, 128, '_1')
262 | up1 = concatenate([Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(center), attn1], name='up1')
263 |
264 | g2 = UnetGatingSignal(up1, is_batchnorm=True, name='g2')
265 | attn2 = AttnGatingBlock(conv3, g2, 64, '_2')
266 | up2 = concatenate([Conv2DTranspose(64, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up1), attn2], name='up2')
267 |
268 | g3 = UnetGatingSignal(up1, is_batchnorm=True, name='g3')
269 | attn3 = AttnGatingBlock(conv2, g3, 32, '_3')
270 | up3 = concatenate([Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up2), attn3], name='up3')
271 |
272 | up4 = concatenate([Conv2DTranspose(32, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up3), conv1], name='up4')
273 |
274 | conv6 = UnetConv2D(up1, 256, is_batchnorm=True, name='conv6')
275 | conv7 = UnetConv2D(up2, 128, is_batchnorm=True, name='conv7')
276 | conv8 = UnetConv2D(up3, 64, is_batchnorm=True, name='conv8')
277 | conv9 = UnetConv2D(up4, 32, is_batchnorm=True, name='conv9')
278 |
279 | out6 = Conv2D(1, (1, 1), activation='sigmoid', name='pred1')(conv6)
280 | out7 = Conv2D(1, (1, 1), activation='sigmoid', name='pred2')(conv7)
281 | out8 = Conv2D(1, (1, 1), activation='sigmoid', name='pred3')(conv8)
282 | out9 = Conv2D(1, (1, 1), activation='sigmoid', name='final')(conv9)
283 |
284 | model = Model(inputs=[img_input], outputs=[out6, out7, out8, out9])
285 |
286 | loss = {'pred1':lossfxn,
287 | 'pred2':lossfxn,
288 | 'pred3':lossfxn,
289 | 'final': losses.tversky_loss}
290 |
291 | loss_weights = {'pred1':1,
292 | 'pred2':1,
293 | 'pred3':1,
294 | 'final':1}
295 | model.compile(optimizer=opt, loss=loss, loss_weights=loss_weights,
296 | metrics=[losses.dsc])
297 | return model
298 |
299 |
--------------------------------------------------------------------------------
/utils.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Created on Wed Aug 29 15:12:49 2018
4 |
5 | @author: Nabila Abraham
6 | """
7 | import numpy as np
8 | import matplotlib.pyplot as plt
9 |
10 |
11 | def plot(hist, epochnum, batchnum, name, is_attnnet=0):
12 | plt.figure()
13 |
14 | if is_attnnet==True:
15 | train_loss = hist['final_loss']
16 | val_loss = hist['val_final_loss']
17 | acc = hist['final_dsc']
18 | val_acc = hist['val_final_dsc']
19 | else:
20 | train_loss = hist['loss']
21 | val_loss = hist['val_loss']
22 | acc = hist['dsc']
23 | val_acc = hist['val_dsc']
24 |
25 | epochs = np.arange(1, len(train_loss)+1,1)
26 | plt.plot(epochs,train_loss, 'b', label='Training Loss')
27 | plt.plot(epochs,val_loss, 'r', label='Validation Loss')
28 | plt.grid(color='gray', linestyle='--')
29 | plt.legend()
30 | plt.title('LOSS Model={}, Epochs={}, Batch={}'.format(name,epochnum, batchnum))
31 | plt.xlabel('Epochs')
32 | plt.ylabel('Loss')
33 |
34 | plt.figure()
35 | plt.plot(epochs, acc, 'b', label='Training Dice Coefficient')
36 | plt.plot(epochs, val_acc, 'r', label='Validation Dice Coefficient')
37 | plt.grid(color='gray', linestyle='--')
38 | plt.legend()
39 | plt.title('DSC Model={}, Epochs={}, Batch={}'.format(name,epochnum, batchnum))
40 | plt.xlabel('Epochs')
41 | plt.ylabel('Dice')
42 |
43 |
44 | def check_preds(ypred, ytrue):
45 | smooth = 1
46 | pred = np.ndarray.flatten(np.clip(ypred,0,1))
47 | gt = np.ndarray.flatten(np.clip(ytrue,0,1))
48 | intersection = np.sum(pred * gt)
49 | union = np.sum(pred) + np.sum(gt)
50 | return np.round((2 * intersection + smooth)/(union + smooth),decimals=5)
51 |
52 | def confusion(y_true, y_pred):
53 | smooth = 1
54 | y_pred_pos = np.round(np.clip(y_pred, 0, 1))
55 | y_pred_neg = 1 - y_pred_pos
56 | y_pos = np.round(np.clip(y_true, 0, 1))
57 | y_neg = 1 - y_pos
58 | tp = (np.sum(y_pos * y_pred_pos) + smooth) / (np.sum(y_pos) + smooth)
59 | tn = (np.sum(y_neg * y_pred_neg) + smooth) / (np.sum(y_neg) + smooth)
60 | return [tp, tn]
61 |
62 | def auc(y_true, y_pred):
63 | smooth = 1
64 | y_pred_pos = np.round(np.clip(y_pred, 0, 1))
65 | y_pred_neg = 1 - y_pred_pos
66 | y_pos = np.round(np.clip(y_true, 0, 1))
67 | y_neg = 1 - y_pos
68 | tp = np.sum(y_pos * y_pred_pos)
69 | tn = np.sum(y_neg * y_pred_neg)
70 | fp = np.sum(y_neg * y_pred_pos)
71 | fn = np.sum(y_pos * y_pred_neg)
72 | tpr = (tp + smooth) / (tp + fn + smooth) #recall
73 | tnr = (tn + smooth) / (tn + fp + smooth)
74 | prec = (tp + smooth) / (tp + fp + smooth) #precision
75 | return [tpr, tnr, prec]
--------------------------------------------------------------------------------