├── .gitignore
├── README.md
├── deps.edn
├── project.clj
└── src
├── assets
└── index.html
├── log4j2.properties
└── soupscraper
└── core.clj
/.gitignore:
--------------------------------------------------------------------------------
1 | .cpcache
2 | .nrepl-port
3 | log
4 | soup
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | ## Update 2020-07-21: Pssst, it still works
2 |
3 | Soup.io is officially ~dead~ in new hands now, but old servers haven’t been turned off yet. So apparently you still have a chance of backing up your soup.
4 |
5 | Here’s how:
6 |
7 | 1. [Edit your hosts file](https://support.rackspace.com/how-to/modify-your-hosts-file/) ([instructions for macOS](https://www.imore.com/how-edit-your-macs-hosts-file-and-why-you-would-want)) and add the following entries:
8 |
9 | ```
10 | 45.153.143.247 soup.io
11 | 45.153.143.247 www.soup.io
12 | 45.153.143.247 YOURSOUP.soup.io
13 | 45.153.143.248 asset.soup.io
14 | ```
15 |
16 | Put in your soup’s name in place of `YOURSOUP`.
17 |
18 | 2. Follow the instructions below.
19 |
20 | # soupscraper
21 |
22 | _Dej, mam umierajoncom zupe_
23 |
24 | soupscraper is a downloader for Soup.io. Here’s a screencast of the local copy that it can generate for you:
25 |
26 | 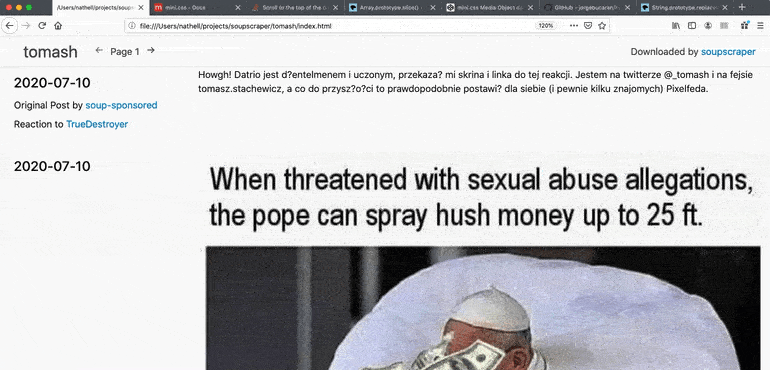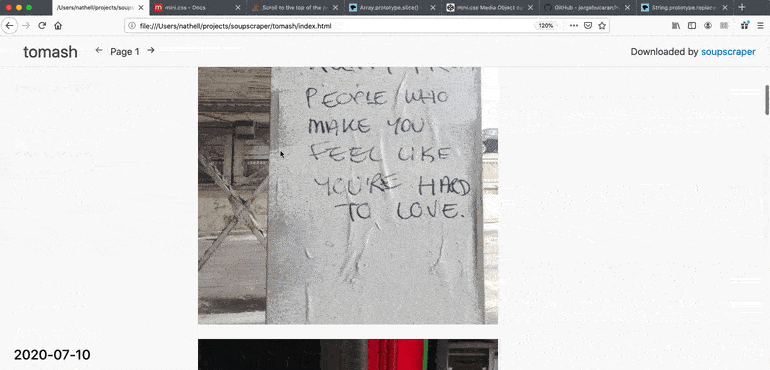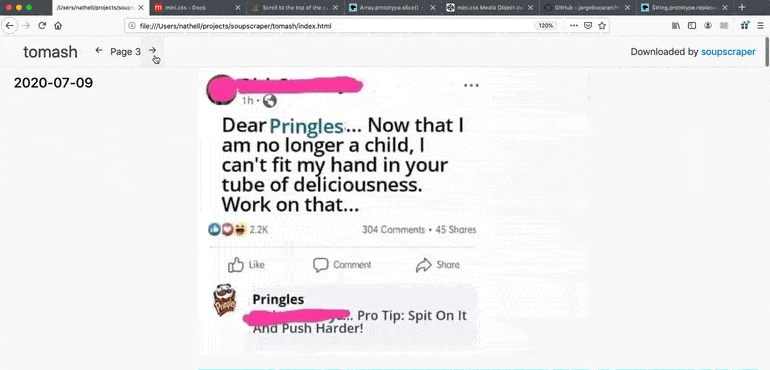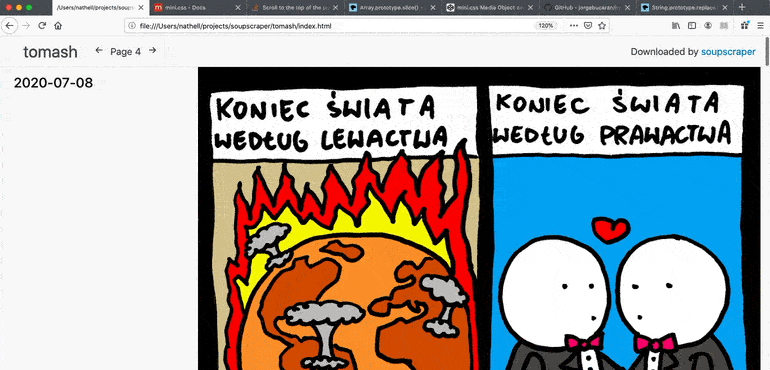
27 |
28 | See an example [here](http://soup.tomash.eu/archive/).
29 |
30 | ## Usage
31 |
32 | 1. [Install Clojure](https://clojure.org/guides/getting_started#_clojure_installer_and_cli_tools)
33 | 2. Clone this repo, cd to the main directory
34 | 3. `clojure -A:run` to see the options
35 | 4. `clojure -A:run https://yoursoup.soup.io` or just `clojure -A:run yoursoup` to do the full magic
36 |
37 | If you want to just download a few pages, add the `--earliest` (or `-e`) option. For example: `clojure -A:run -e 2020-07-01 yoursoup` will skip simulating infinite scroll as soon as it encounters posts from June 2020 or earlier.
38 |
39 | ### Without installing Clojure
40 |
41 | 1. Install Java if you haven’t already (tested on JRE 11, any version >=8 should work)
42 | 2. [Download the jar](https://github.com/nathell/soupscraper/releases)
43 | 3. Follow step 3 or 4 above, replacing `clojure -A:run` with `java -Djdk.tls.client.protocols=TLSv1,TLSv1.1,TLSv1.2 -jar soupscraper-0.1.jar`
44 |
45 | For example:
46 |
47 | ```
48 | java -Djdk.tls.client.protocols=TLSv1,TLSv1.1,TLSv1.2 -jar soupscraper-20200717.jar yoursoup
49 | ```
50 |
51 | ## FAQ
52 |
53 | **I’m on Windows! How can I run this?**
54 |
55 | Use the “Without installing Clojure” approach above.
56 |
57 | **I ran this and it completed, where’s my soup?**
58 |
59 | In `soup`. Unless you change the output directory with `--output-dir`.
60 |
61 | **There’s some shit in `~/skyscraper-data` which takes up a lot of space!**
62 |
63 | Yes, there’s a bunch of files there; you can’t easily view them. Technically, they’re HTMLs and assets, stored as [netstrings](https://cr.yp.to/proto/netstrings.txt), and preceded by another netstring corresponding to HTTP headers as obtained from server, in [edn](https://github.com/edn-format/edn) format.
64 |
65 | There are several upsides for having a local cache of this kind.
66 |
67 | - You can abort the program at any time, and restart it later. It won’t redownload stuff; rather, it will reuse what it’s already downloaded.
68 |
69 | - Once you’ve downloaded it, it’s there. When Soup.io finally goes dead, it will continue to be there, and you’ll be able to re-run future versions of the program.
70 |
71 | If you’re super happy about your output in `soup`, you can delete `~/skyscraper-data`, but be aware that from then on you’ll need to redownload everything if you want to update your output.
72 |
73 | **It’s hung / doing something weird!**
74 |
75 | Try to abort it (^C) and restart. It’s safe.
76 |
77 | If you continue to have problems, there’s some logs in `log/`. Create an issue in this repo and attach the logs, possibly trimming them. I’ll see what I can do, but can’t promise anything.
78 |
79 | **How’d you write this?**
80 |
81 | It uses my scraping framework, [Skyscraper](https://github.com/nathell/skyscraper). Check it out.
82 |
83 | ## License
84 |
85 | Copyright 2020, Daniel Janus and contributors
86 |
87 | Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
88 |
89 | The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
90 |
91 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
92 |
--------------------------------------------------------------------------------
/deps.edn:
--------------------------------------------------------------------------------
1 | {:paths ["src"]
2 | :deps {cheshire {:mvn/version "5.10.0"}
3 | clojure.java-time {:mvn/version "0.3.2"}
4 | org.apache.logging.log4j/log4j-api {:mvn/version "2.13.3"}
5 | org.apache.logging.log4j/log4j-core {:mvn/version "2.13.3"}
6 | org.apache.logging.log4j/log4j-1.2-api {:mvn/version "2.13.3"}
7 | org.clojure/clojure {:mvn/version "1.10.1"}
8 | org.clojure/tools.cli {:mvn/version "1.0.194"}
9 | skyscraper {:mvn/version "0.3.0"}}
10 | :aliases {:run {:main-opts ["-m" "soupscraper.core"]
11 | ;; looks like Java 11 has problems with TLS 1.3, see https://jira.atlassian.com/browse/JRASERVER-70189
12 | :jvm-opts ["-Djdk.tls.client.protocols=TLSv1,TLSv1.1,TLSv1.2"]}}}
13 |
--------------------------------------------------------------------------------
/project.clj:
--------------------------------------------------------------------------------
1 | ;; I really wanted it to be a Leiningen-less project and use something
2 | ;; like uberdeps for the uberjar, but apparently there’s no escape,
3 | ;; because of this:
4 | ;; https://www.arctype.co/blog/resolve-log4j2-conflicts-in-uberjars
5 |
6 | (defproject soupscraper "0.1.0-SNAPSHOT"
7 | :main soupscraper.core
8 | :plugins [[lein-tools-deps "0.4.5"] ; at least let's not repeat deps
9 | [arctype/log4j2-plugins-cache "1.0.0"]] ; apply the workaround
10 | :lein-tools-deps/config {:config-files [:install :user :project]}
11 | :manifest {"Multi-Release" "true"} ; otherwise it'll complain, see https://stackoverflow.com/questions/53049346/is-log4j2-compatible-with-java-11
12 | :middleware [lein-tools-deps.plugin/resolve-dependencies-with-deps-edn
13 | leiningen.log4j2-plugins-cache/middleware])
14 |
--------------------------------------------------------------------------------
/src/assets/index.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
15 |
16 |
137 |
138 |
139 |
140 |
141 |
142 |
--------------------------------------------------------------------------------
/src/log4j2.properties:
--------------------------------------------------------------------------------
1 | rootLogger.level = warn
2 | rootLogger.appenderRef.rolling.ref = fileLogger
3 |
4 | property.basePath = ./log/
5 | status = error
6 |
7 | appender.rolling.type = RollingFile
8 | appender.rolling.name = fileLogger
9 | appender.rolling.fileName=${basePath}/clj-http.log
10 | appender.rolling.filePattern=${basePath}clj-http_%d{yyyyMMdd}.log.gz
11 | appender.rolling.layout.type = PatternLayout
12 | appender.rolling.layout.pattern = [%d{ISO8601}][%-5p][%-25c{1.}] %marker%m%n
13 | appender.rolling.policies.type = Policies
14 |
--------------------------------------------------------------------------------
/src/soupscraper/core.clj:
--------------------------------------------------------------------------------
1 | (ns soupscraper.core
2 | (:require [cheshire.core :as json]
3 | [clojure.core.async :as async]
4 | [clojure.java.io :as io]
5 | [clojure.string :as string]
6 | [clojure.tools.cli :as cli]
7 | [java-time]
8 | [skyscraper.cache :as cache]
9 | [skyscraper.core :as core :refer [defprocessor]]
10 | [skyscraper.context :as context]
11 | [taoensso.timbre :as log :refer [warnf]]
12 | [taoensso.timbre.appenders.core :as appenders])
13 | (:gen-class))
14 |
15 | ;; logic c/o tomash, cf https://github.com/UlanaXY/BowlOfSoup/pull/1
16 | (defn fullsize-asset-url [url]
17 | (when url
18 | (if-let [[_ a b c ext] (re-find #"^https://asset.soup.io/asset/(\d+)/([0-9a-f]+)_([0-9a-f]+)_[0-9]+\.(.*)$" url)]
19 | (format "http://asset.soup.io/asset/%s/%s_%s.%s" a b c ext)
20 | (string/replace url "https://" "http://"))))
21 |
22 | (defn asset-info [type url]
23 | (let [url (fullsize-asset-url url)
24 | [_ prefix asset-id ext] (re-find #"^http://asset.soup.io/asset/(\d+)/([0-9a-f_]+)\.(.*)$" url)]
25 | {:type type
26 | :prefix prefix
27 | :asset-id asset-id
28 | :ext ext
29 | :url url
30 | :processor :asset}))
31 |
32 | (let [formatter (-> (java-time/formatter "MMM dd yyyy HH:mm:ss z")
33 | (.withLocale java.util.Locale/ENGLISH))]
34 | (defn parse-post-date [date]
35 | (try
36 | (java-time/java-date (java-time/instant formatter date))
37 | (catch Exception e
38 | (warnf "Could not parse date: %s" date)
39 | nil))))
40 |
41 | (defn parse-user-container [span]
42 | (or (reaver/text (reaver/select span ".name"))
43 | (reaver/attr (reaver/select span "a img") :title)))
44 |
45 | (defn parse-reaction [li]
46 | {:user (parse-user-container (reaver/select li ".toggle1 .user_container"))
47 | :link (reaver/attr (reaver/select li ".original_link") :href)
48 | :type (string/trim (reaver/text (reaver/select li ".toggle1 .info")))})
49 |
50 | (defn parse-tag [a]
51 | (reaver/text a))
52 |
53 | (defn parse-post [div]
54 | (if-let [content (reaver/select div ".content")]
55 | (let [imagebox (reaver/select content "a.lightbox")
56 | imagedirect (reaver/select content ".imagecontainer > img")
57 | body (reaver/select content ".body")
58 | cite (reaver/select content ".content > cite")
59 | description (reaver/select content ".description")
60 | h3 (reaver/select content ".content > h3")
61 | video (reaver/select content ".embed video")
62 | id (subs (reaver/attr div :id) 4)
63 | time (reaver/select div ".time > abbr")
64 | reactions (reaver/select div ".reactions li")
65 | reposts (reaver/select div ".reposted_by .user_container")
66 | tags (reaver/select div ".tags a")
67 | tv (reaver/select div ".post_video > .content-container .tv_promo")
68 | link (reaver/select div ".post_link > .content-container .content h3 a")]
69 | (merge {:id id
70 | :post div
71 | :date (when time (parse-post-date (reaver/attr time :title)))
72 | :reactions (mapv parse-reaction reactions)
73 | :reposts (mapv parse-user-container reposts)
74 | :tags (mapv parse-tag tags)}
75 | (cond
76 | tv {:type :video, :url (str "/tv/show?id=" id), :processor :tv}
77 | video (if-let [src-url (reaver/attr video :src)]
78 | (asset-info :video src-url)
79 | (do
80 | (warnf "[parse-post] no video src: %s" video)
81 | {:type :unable-to-parse, :post div}))
82 | link {:type :link, :link-title (reaver/text link), :link-url (reaver/attr link :href)}
83 | imagebox (asset-info :image (reaver/attr imagebox :href))
84 | imagedirect (asset-info :image (reaver/attr imagedirect :src))
85 | body {:type :text}
86 | :otherwise nil)
87 | (when h3 {:title (reaver/text h3)})
88 | (when cite {:cite (.html cite)})
89 | (when description {:content (.html description)})
90 | (when body {:content (.html body)})
91 | (when (reaver/select div ".ad-marker") {:sponsored true})))
92 | (do
93 | (warnf "[parse-post] no content: %s", div)
94 | {:type :unable-to-parse, :post div})))
95 |
96 | (def months ["January" "February" "March" "April" "May" "June" "July" "August" "September" "October"
97 | "November" "December"])
98 |
99 | (defn yyyymmdd [h2]
100 | (format "%s-%02d-%s"
101 | (reaver/text (reaver/select h2 ".y"))
102 | (inc (.indexOf months (reaver/text (reaver/select h2 ".m"))))
103 | (reaver/text (reaver/select h2 ".d"))))
104 |
105 | (defn matches? [selector element]
106 | (and (instance? org.jsoup.nodes.Element element)
107 | (= (first (reaver/select element selector)) element)))
108 |
109 |
110 | (defn date->yyyy-mm-dd [date]
111 | (some-> date java-time/instant str (subs 0 10)))
112 |
113 | (defn propagate
114 | "Given a key `k` and a seq of maps `s`, goes through `s` and if an
115 | element doesn't contain `k`, assocs it to the last-seen value.
116 |
117 | (propagate :b [{:a 1 :b 2} {:a 2} {:a 3} {:a 4 :b 5}])
118 | ;=> [{:a 1 :b 2} {:a 2 :b 2} {:a 3 :b 2} {:a 4 :b 5}]"
119 | [k [fst & rst :as s]]
120 | (loop [acc [fst]
121 | to-go rst
122 | seen? (contains? fst k)
123 | last-val (get fst k)]
124 | (if-not (seq to-go)
125 | acc
126 | (let [[fst & rst] to-go
127 | has? (contains? fst k)]
128 | (recur (conj acc (if (or has? (not seen?))
129 | fst
130 | (assoc fst k last-val)))
131 | rst
132 | (or seen? (contains? fst k))
133 | (if has? (get fst k) last-val))))))
134 |
135 | (def as-far-as (atom nil))
136 | (def total-assets (atom 0))
137 |
138 | (defn matches? [selector element]
139 | (and (instance? org.jsoup.nodes.Element element)
140 | (= (first (reaver/select element selector)) element)))
141 |
142 | (defn parse-post-or-date [node]
143 | (condp matches? node
144 | "h2.date" {:date-from-header (yyyymmdd node)}
145 | "div.post" (parse-post node)
146 | nil))
147 |
148 | (defn fixup-date [post]
149 | (if (:date post)
150 | post
151 | (assoc post :date (clojure.instant/read-instant-date (:date-from-header post)))))
152 |
153 | (defn parse-posts-and-dates [document]
154 | (when-let [nodes (some-> (reaver/select document "#first_batch") first .childNodes)]
155 | (->> nodes
156 | (map parse-post-or-date)
157 | (remove nil?)
158 | (propagate :date-from-header)
159 | (filter :type)
160 | (map fixup-date)
161 | (map-indexed #(assoc %2 :num-on-page (- %1))))))
162 |
163 | (defn parse-json [headers body]
164 | (json/parse-string (core/parse-string headers body) true))
165 |
166 | (defprocessor :soup
167 | :cache-template "soup/:soup/list/:since"
168 | :process-fn (fn [document {:keys [earliest pages-only] :as context}]
169 | (let [posts (parse-posts-and-dates document)
170 | earliest-on-page (->> posts (map :date) sort first date->yyyy-mm-dd)
171 | moar (-> (reaver/select document "#load_more a") (reaver/attr :href))]
172 | (when pages-only
173 | (swap! total-assets + (count (filter #(= (:processor %) :asset) posts))))
174 | (swap! as-far-as #(or earliest-on-page %))
175 | (concat
176 | (when (and moar (or (not earliest) (>= (compare earliest-on-page earliest) 0)))
177 | (let [since (second (re-find #"/since/(\d+)" moar))]
178 | [{:processor :soup, :since since, :url moar}]))
179 | (when-not pages-only posts)))))
180 |
181 | (defprocessor :tv
182 | :cache-template "soup/:soup/tv/:id"
183 | :parse-fn parse-json
184 | :process-fn (fn [document context]
185 | (try
186 | (let [[type id] (string/split (-> document first second) #":")]
187 | {:tv-type type, :tv-id id})
188 | (catch Exception _
189 | {:type :unable-to-parse, :tv-data document}))))
190 |
191 | (defprocessor :asset
192 | :cache-template "soup/:soup/assets/:prefix/:asset-id"
193 | :parse-fn (fn [headers body] body)
194 | :process-fn (fn [document context]
195 | {:downloaded true}))
196 |
197 | (defn download-error-handler
198 | [error options context]
199 | (let [{:keys [status]} (ex-data error)
200 | retry? (or (nil? status) (>= status 500) (= status 429))]
201 | (cond
202 | (= status 404)
203 | (do
204 | (warnf "[download] %s 404'd, dumping in empty file" (:url context))
205 | (core/respond-with {:headers {"content-type" "text/plain"}
206 | :body (byte-array 0)}
207 | options context))
208 |
209 | retry?
210 | (do
211 | (if (= status 429)
212 | (do
213 | (warnf "[download] Unexpected error %s, retrying after a nap" error)
214 | (Thread/sleep 5000))
215 | (warnf "[download] Unexpected error %s, retrying" error))
216 | [context])
217 |
218 | :otherwise
219 | (do
220 | (warnf "[download] Unexpected error %s, giving up" error)
221 | (core/signal-error error context)))))
222 |
223 | (defn seed [{:keys [soup earliest pages-only]}]
224 | [{:url (format "https://%s.soup.io" soup),
225 | :soup soup,
226 | :since "latest",
227 | :processor :soup,
228 | :earliest earliest,
229 | :pages-only pages-only}])
230 |
231 | (defn scrape-args [opts]
232 | [(seed opts)
233 | :parse-fn core/parse-reaver
234 | :parallelism 1
235 | ;; :max-connections 1
236 | :html-cache true
237 | :download-error-handler download-error-handler
238 | :sleep (:sleep opts)
239 | :http-options {:redirect-strategy :lax
240 | :as :byte-array
241 | :connection-timeout (:connection-timeout opts)
242 | :socket-timeout (:socket-timeout opts)}
243 | :item-chan (:item-chan opts)])
244 |
245 | (defn scrape [opts]
246 | (apply core/scrape (scrape-args opts)))
247 |
248 | (defn scrape! [opts]
249 | (apply core/scrape! (scrape-args opts)))
250 |
251 | (def cli-options
252 | [["-e" "--earliest DATE" "Skip posts older than DATE, in YYYY-MM-DD format"]
253 | ["-o" "--output-dir DIRECTORY" "Save soup data in DIRECTORY" :default "soup"]
254 | [nil "--connection-timeout MS" "Connection timeout in milliseconds"
255 | :default 60000
256 | :parse-fn #(Long/parseLong %)
257 | :validate [pos? "Must be a positive number"]]
258 | [nil "--socket-timeout MS" "Socket timeout in milliseconds"
259 | :default 60000
260 | :parse-fn #(Long/parseLong %)
261 | :validate [pos? "Must be a positive number"]]])
262 |
263 | (log/set-level! :info)
264 | (log/merge-config! {:appenders {:println {:enabled? false}
265 | :spit (appenders/spit-appender {:fname "log/skyscraper.log"})}})
266 |
267 | ;; some touching of Skyscraper internals here; you're not supposed to understand this
268 | (defn pages-reporter [item-chan]
269 | (async/thread
270 | (loop [i 1]
271 | (when-let [items (async/> orig-posts
305 | (sort-by (juxt :date :since :num-on-page) (comp - compare))
306 | (map #(select-keys % [:asset-id :cite :content :date :ext :id :prefix
307 | :reactions :reposts :sponsored :tags :title :type
308 | :tv-id :tv-type :link-title :link-url]))
309 | distinct)]
310 | {:soup-name (-> orig-posts first :soup)
311 | :posts posts}))
312 |
313 | (defn generate-local-copy [{:keys [output-dir] :as opts} posts]
314 | (let [json-file (str output-dir "/soup.json")
315 | js-file (str output-dir "/soup.js")
316 | index-file (str output-dir "/index.html")
317 | cache (cache/fs core/html-cache-dir)]
318 | (io/make-parents (io/file json-file))
319 | (println "Saving assets (this may take a while)...")
320 | (doseq [{:keys [soup asset-id prefix ext]} posts
321 | :when asset-id
322 | :let [in-key (format "soup/%s/assets/%s/%s" soup prefix asset-id)
323 | out-file (format "%s/assets/%s/%s.%s" output-dir prefix asset-id ext)
324 | {:keys [blob]} (cache/load-blob cache in-key)]]
325 | (io/make-parents out-file)
326 | (with-open [in (io/input-stream blob)]
327 | (with-open [out (io/output-stream out-file)]
328 | (io/copy in out))))
329 | (println "Generating viewable soup...")
330 | (let [json (json/generate-string (soup-data posts))]
331 | (spit json-file json)
332 | (spit js-file (str "window.soup=" json))
333 | (with-open [in (io/input-stream (io/resource "assets/index.html"))]
334 | (with-open [out (io/output-stream index-file)]
335 | (io/copy in out))))))
336 |
337 | (defn download-soup [opts]
338 | (println "Downloading infiniscroll pages...")
339 | (let [item-chan (async/chan)]
340 | (pages-reporter item-chan)
341 | (scrape! (assoc opts :sleep 1000 :item-chan item-chan :pages-only true)))
342 | (println "\nDownloading assets...")
343 | (let [item-chan (async/chan)]
344 | (assets-reporter item-chan)
345 | (scrape! (assoc opts :item-chan item-chan)))
346 | (println "\nGenerating local copy...")
347 | (generate-local-copy opts (scrape opts)))
348 |
349 | (defn sanitize-soup [soup-name-or-url]
350 | (when soup-name-or-url
351 | (or (last (re-find #"^(https?://)?([^.]+)\.soup\.io" soup-name-or-url))
352 | soup-name-or-url)))
353 |
354 | (defn validate-args [args]
355 | (let [{:keys [options arguments errors summary] :as res} (cli/parse-opts args cli-options)
356 | soup (sanitize-soup (first arguments))]
357 | (cond
358 | errors (println (string/join "\n" errors))
359 | soup (assoc options :soup soup)
360 | :else (print-usage summary))))
361 |
362 | (defn -main [& args]
363 | (println "This is Soupscraper v0.1.0")
364 | (when-let [opts (validate-args args)]
365 | (download-soup opts))
366 | (System/exit 0))
367 |
--------------------------------------------------------------------------------