4 | This folder contains code for the blog posts published on the Neptune blog.
5 |
6 |
7 |
Table of Contents
8 |
9 |
10 |
11 | | Title | Blog | Code | Neptune
12 | | --- | :---: | :---: | :---:
13 | | MLOps For Time Series Prediction: Binance Trading Tutorial | [![blog]](https://neptune.ai/blog/mlops-pipeline-for-time-series-prediction-tutorial) | [![github]](./binance-trading-neptune-master) | [![neptune]](https://app.neptune.ai/o/community/org/mlops-pipeline-for-time-series-prediction/runs/table?viewId=standard-view)
14 | | How to build a RAG system using LangChain | [![blog]](https://neptune.ai/blog/building-and-evaluating-rag-system-using-langchain-ragas-neptune) | [![github]](./HOW_TO_BUILD_A_RAG_SYSTEM_USING_LANGCHAIN/) | [![neptune]](https://app.neptune.ai/o/community/org/building-RAG-using-LangChain/runs/table?viewId=standard-view)
15 |
16 |
17 |
18 | #### Notice something wrong?
19 | Drop us an email at marketing@neptune.ai.
20 |
21 |
22 | [blog]: https://neptune.ai/wp-content/uploads/2023/06/file_icon.svg "Read the blog"
23 | [neptune]: https://neptune.ai/wp-content/uploads/2023/01/Signet-svg-16x16-1.svg "Explore Neptune example project"
24 | [github]: https://neptune.ai/wp-content/uploads/2023/06/Github-Monochrome-1.svg "See code on GitHub"
25 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/azure-ml/scripts/get_latest_model_prod.py:
--------------------------------------------------------------------------------
1 | import logging
2 | import os
3 |
4 | import neptune
5 | from neptune.exceptions import ModelNotFound
6 |
7 | NEPTUNE_PROJECT = "common/project-time-series-forecasting" # change to your own Neptune project
8 |
9 | os.environ["NEPTUNE_PROJECT"] = NEPTUNE_PROJECT
10 |
11 |
12 | def download_latest_prod_model():
13 | model_key = "PRO"
14 | project_key = "TSF"
15 |
16 | try:
17 | model = neptune.init_model(
18 | with_id=f"{project_key}-{model_key}", # Your model ID here
19 | )
20 | model_versions_table = model.fetch_model_versions_table().to_pandas()
21 | production_model_table = model_versions_table[
22 | model_versions_table["sys/stage"] == "production"
23 | ]
24 | prod_model_id = production_model_table["sys/id"].tolist()[0]
25 |
26 | except ModelNotFound:
27 | logging.info(
28 | f"The model with the provided key `{model_key}` doesn't exist in the `{project_key}` project."
29 | )
30 |
31 | # (neptune) Download the lastest model checkpoint from model registry
32 | prod_model = neptune.init_model_version(with_id=prod_model_id)
33 |
34 | # (Neptune) Get model weights from training stage
35 | prod_model["serialized_model"].download()
36 |
37 | logging.info(
38 | f"Model to be deployed: {prod_model_id}. Model has been downloaded and is ready for deployment."
39 | )
40 |
41 |
42 | if __name__ == "__main__":
43 | download_latest_prod_model()
44 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/azure-ml/README.md:
--------------------------------------------------------------------------------
1 | # Azure Machine Learning how-to
2 |
3 | This project is an example integration between Azure DevOps and Azure ML services with Neptune.
4 |
5 | ## Environment preparation
6 |
7 | ### Azure ML
8 |
9 | To run the example, first create a compute cluster and a custom environment in your Azure ML environment. You can do that by executing the `./dependencies/build_compute_cluster.py` and `./dependencies/build_environment.py` scripts.
10 |
11 | Note that you will need to fill
12 |
13 | ```
14 | AZURE_SUBSCRIPTION_ID = ""
15 | AZUREML_RESOURCE_GROUP_NAME = ""
16 | AZUREML_WORKSPACE_NAME = ""
17 | ```
18 | with values representing your environment.
19 |
20 | ### Azure DevOps
21 |
22 | For Azure DevOps Pipelines to be able to successfully create and execute Azure ML Pipelines, create the following secrets as per `./azure-ci/azure-pipelines.yaml` in your Azure DevOps Pipeline via the UI:
23 |
24 | ```
25 | AZURE_TENANT_ID: $(tenant)
26 | AZURE_CLIENT_ID: $(client)
27 | AZURE_CLIENT_SECRET: $(secret)
28 | NEPTUNE_API_TOKEN: $(neptune-sa-token)
29 | ```
30 |
31 | ## The example
32 | The example is focused around creation of an Azure DevOps CI/CD pipeline that would be able to test the Azure ML Pipeline and then deploy it for operational purposes. The following picture shows the resulting AzureML pipeline:
33 |
34 |
35 |
36 |
37 |
--------------------------------------------------------------------------------
/how-to-guides/data-versioning/datasets/tables/test.csv:
--------------------------------------------------------------------------------
1 | sepal.length,sepal.width,petal.length,petal.width,variety
2 | 6.2,3.4,5.4,2.3,Virginica
3 | 6.4,2.7,5.3,1.9,Virginica
4 | 5.1,3.4,1.5,0.2,Setosa
5 | 5.8,2.7,3.9,1.2,Versicolor
6 | 4.8,3.1,1.6,0.2,Setosa
7 | 5.6,2.8,4.9,2.0,Virginica
8 | 5.9,3.0,4.2,1.5,Versicolor
9 | 7.6,3.0,6.6,2.1,Virginica
10 | 6.4,3.2,4.5,1.5,Versicolor
11 | 6.1,2.6,5.6,1.4,Virginica
12 | 6.7,2.5,5.8,1.8,Virginica
13 | 6.9,3.2,5.7,2.3,Virginica
14 | 5.6,3.0,4.1,1.3,Versicolor
15 | 5.0,3.4,1.5,0.2,Setosa
16 | 6.8,3.0,5.5,2.1,Virginica
17 | 6.6,3.0,4.4,1.4,Versicolor
18 | 6.5,2.8,4.6,1.5,Versicolor
19 | 5.8,2.7,5.1,1.9,Virginica
20 | 6.0,3.4,4.5,1.6,Versicolor
21 | 6.3,3.4,5.6,2.4,Virginica
22 | 7.7,3.0,6.1,2.3,Virginica
23 | 7.7,2.8,6.7,2.0,Virginica
24 | 5.7,2.9,4.2,1.3,Versicolor
25 | 5.5,2.3,4.0,1.3,Versicolor
26 | 6.2,2.9,4.3,1.3,Versicolor
27 | 4.9,3.1,1.5,0.2,Setosa
28 | 6.4,3.1,5.5,1.8,Virginica
29 | 5.7,2.6,3.5,1.0,Versicolor
30 | 4.7,3.2,1.3,0.2,Setosa
31 | 5.7,2.8,4.5,1.3,Versicolor
32 | 6.3,2.7,4.9,1.8,Virginica
33 | 4.9,3.6,1.4,0.1,Setosa
34 | 4.6,3.1,1.5,0.2,Setosa
35 | 5.2,2.7,3.9,1.4,Versicolor
36 | 5.2,3.5,1.5,0.2,Setosa
37 | 5.5,3.5,1.3,0.2,Setosa
38 | 5.0,3.6,1.4,0.2,Setosa
39 | 7.1,3.0,5.9,2.1,Virginica
40 | 6.3,2.8,5.1,1.5,Virginica
41 | 6.3,2.5,5.0,1.9,Virginica
42 | 5.1,3.5,1.4,0.2,Setosa
43 | 5.6,2.7,4.2,1.3,Versicolor
44 | 5.0,3.4,1.6,0.4,Setosa
45 | 5.1,2.5,3.0,1.1,Versicolor
46 | 4.6,3.6,1.0,0.2,Setosa
47 | 6.7,3.0,5.0,1.7,Versicolor
48 | 6.9,3.1,5.1,2.3,Virginica
49 | 6.3,2.3,4.4,1.3,Versicolor
50 | 4.9,3.1,1.5,0.1,Setosa
51 | 7.9,3.8,6.4,2.0,Virginica
52 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/transformers/scripts/Neptune_Transformers_report_to.py:
--------------------------------------------------------------------------------
1 | from datasets import load_dataset
2 | from evaluate import load
3 | from transformers import (
4 | AutoModelForSequenceClassification,
5 | AutoTokenizer,
6 | Trainer,
7 | TrainingArguments,
8 | )
9 |
10 | task = "cola"
11 | model_checkpoint = "prajjwal1/bert-tiny"
12 | batch_size = 16
13 | dataset = load_dataset("glue", task)
14 | metric = load("glue", task)
15 | num_labels = 2
16 |
17 | tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)
18 |
19 |
20 | def preprocess_function(examples):
21 | return tokenizer(examples["sentence"], truncation=True)
22 |
23 |
24 | encoded_dataset = dataset.map(preprocess_function, batched=True)
25 |
26 | model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=num_labels)
27 | model_name = model_checkpoint.split("/")[-1]
28 |
29 | args = TrainingArguments(
30 | f"{model_name}-finetuned-{task}",
31 | eval_strategy="epoch",
32 | save_strategy="epoch",
33 | save_safetensors=False,
34 | learning_rate=1e-6,
35 | per_device_train_batch_size=batch_size,
36 | per_device_eval_batch_size=batch_size,
37 | num_train_epochs=2,
38 | weight_decay=0.05,
39 | load_best_model_at_end=True,
40 | report_to="neptune",
41 | )
42 |
43 | validation_key = "validation"
44 |
45 | trainer = Trainer(
46 | model,
47 | args,
48 | train_dataset=encoded_dataset["train"],
49 | eval_dataset=encoded_dataset[validation_key],
50 | tokenizer=tokenizer,
51 | )
52 |
53 | trainer.train()
54 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/prophet/scripts/Neptune_prophet_more_options.py:
--------------------------------------------------------------------------------
1 | import matplotlib
2 | import neptune
3 | import neptune.integrations.prophet as npt_utils
4 | import pandas as pd
5 | from prophet import Prophet
6 |
7 | # To prevent `RuntimeError: main thread is not in main loop` error
8 | matplotlib.use("Agg")
9 |
10 | run = neptune.init_run(
11 | project="common/fbprophet-integration",
12 | api_token=neptune.ANONYMOUS_API_TOKEN,
13 | tags=["prophet", "script", "more options"], # optional
14 | )
15 |
16 | df = pd.read_csv(
17 | "https://raw.githubusercontent.com/facebook/prophet/master/examples/example_wp_log_R.csv"
18 | )
19 |
20 | # Market capacity
21 | df["cap"] = 8.5
22 |
23 |
24 | def nfl_sunday(ds) -> int:
25 | date = pd.to_datetime(ds)
26 | return 1 if date.weekday() == 6 and (date.month > 8 or date.month < 2) else 0
27 |
28 |
29 | df["nfl_sunday"] = df.ds.apply(nfl_sunday)
30 |
31 | model = Prophet()
32 | model.add_regressor("nfl_sunday")
33 | model.fit(df)
34 |
35 | forecast = model.predict(df)
36 |
37 | # Log Prophet plots to Neptune
38 | run["forecast_plots"] = npt_utils.create_forecast_plots(model, forecast, log_interactive=False)
39 | run["forecast_components"] = npt_utils.get_forecast_components(model, forecast)
40 | run["residual_diagnostics_plot"] = npt_utils.create_residual_diagnostics_plots(
41 | forecast, df.y, log_interactive=False
42 | )
43 |
44 | # Log Prophet model configuration
45 | run["model_config"] = npt_utils.get_model_config(model)
46 |
47 | # Log Prophet serialized model
48 | run["model"] = npt_utils.get_serialized_model(model)
49 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/optuna/scripts/Neptune_Optuna_integration_log_after_study.py:
--------------------------------------------------------------------------------
1 | import lightgbm as lgb
2 | import neptune
3 | import neptune.integrations.optuna as optuna_utils
4 | import optuna
5 | from sklearn.datasets import load_breast_cancer
6 | from sklearn.metrics import roc_auc_score
7 | from sklearn.model_selection import train_test_split
8 |
9 |
10 | def objective(trial):
11 | data, target = load_breast_cancer(return_X_y=True)
12 | train_x, test_x, train_y, test_y = train_test_split(data, target, test_size=0.25)
13 | dtrain = lgb.Dataset(train_x, label=train_y)
14 |
15 | param = {
16 | "verbose": -1,
17 | "objective": "binary",
18 | "metric": "binary_logloss",
19 | "num_leaves": trial.suggest_int("num_leaves", 2, 256),
20 | "feature_fraction": trial.suggest_float("feature_fraction", 0.2, 1.0, step=0.1),
21 | "bagging_fraction": trial.suggest_float("bagging_fraction", 0.2, 1.0, step=0.1),
22 | "min_child_samples": trial.suggest_int("min_child_samples", 3, 100),
23 | }
24 |
25 | gbm = lgb.train(param, dtrain)
26 | preds = gbm.predict(test_x)
27 | return roc_auc_score(test_y, preds)
28 |
29 |
30 | # Create a Neptune run
31 | run = neptune.init_run(
32 | api_token=neptune.ANONYMOUS_API_TOKEN,
33 | project="common/optuna",
34 | tags=["log-after-study", "study", "script"],
35 | )
36 |
37 | # Pass NeptuneCallback to Optuna Study .optimize()
38 | study = optuna.create_study(direction="maximize")
39 | study.optimize(objective, n_trials=5)
40 |
41 | # Log Optuna Study metadata
42 | optuna_utils.log_study_metadata(study, run)
43 |
--------------------------------------------------------------------------------
/how-to-guides/sequential-pipelines/scripts/data_preprocessing.py:
--------------------------------------------------------------------------------
1 | import neptune
2 | from sklearn.datasets import fetch_lfw_people
3 |
4 | from utils import *
5 |
6 | # Download dataset
7 | dataset = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
8 |
9 | # (Neptune) Create a new run
10 | run = neptune.init_run(
11 | monitoring_namespace="monitoring/preprocessing",
12 | dependencies="requirements.txt",
13 | )
14 |
15 | # Get dataset details
16 | dataset_config = {
17 | "target_names": str(dataset.target_names.tolist()),
18 | "n_classes": dataset.target_names.shape[0],
19 | "n_samples": dataset.images.shape[0],
20 | "height": dataset.images.shape[1],
21 | "width": dataset.images.shape[2],
22 | }
23 |
24 | # (Neptune) Set up "preprocessing" namespace inside the run.
25 | # This will be the base namespace where all the preprocessing metadata is logged.
26 | preprocessing_handler = run["preprocessing"]
27 |
28 | # (Neptune) Log dataset details
29 | preprocessing_handler["dataset/config"] = dataset_config
30 |
31 | # Preprocess dataset
32 | dataset_transform = Preprocessing(
33 | dataset,
34 | dataset_config["n_samples"],
35 | dataset_config["target_names"],
36 | dataset_config["n_classes"],
37 | (dataset_config["height"], dataset_config["width"]),
38 | )
39 | path_to_scaler = dataset_transform.scale_data()
40 | path_to_features = dataset_transform.create_and_save_features(data_filename="features")
41 | dataset_transform.describe()
42 |
43 | # (Neptune) Log scaler and features files
44 | preprocessing_handler["dataset/scaler"].upload(path_to_scaler)
45 | preprocessing_handler["dataset/features"].upload(path_to_features)
46 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/xgboost/scripts/Neptune_XGBoost_train.py:
--------------------------------------------------------------------------------
1 | # To fix the random RuntimeError: main thread is not in main loop error in Windows
2 | import matplotlib.pyplot as plt
3 | import neptune
4 | import xgboost as xgb
5 | from neptune.integrations.xgboost import NeptuneCallback
6 | from sklearn.datasets import fetch_california_housing
7 | from sklearn.model_selection import train_test_split
8 |
9 | plt.switch_backend("agg")
10 |
11 | # Create run
12 | run = neptune.init_run(
13 | project="common/xgboost-integration",
14 | api_token=neptune.ANONYMOUS_API_TOKEN,
15 | name="xgb-train",
16 | tags=["xgb-integration", "train"],
17 | )
18 |
19 | # Create neptune callback
20 | neptune_callback = NeptuneCallback(run=run, log_tree=[0, 1, 2, 3])
21 |
22 | # Prepare data
23 | X, y = fetch_california_housing(return_X_y=True)
24 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
25 | dtrain = xgb.DMatrix(X_train, label=y_train)
26 | dval = xgb.DMatrix(X_test, label=y_test)
27 |
28 | # Define parameters
29 | model_params = {
30 | "eta": 0.7,
31 | "gamma": 0.001,
32 | "max_depth": 9,
33 | "objective": "reg:squarederror",
34 | "eval_metric": ["mae", "rmse"],
35 | }
36 | evals = [(dtrain, "train"), (dval, "valid")]
37 | num_round = 57
38 |
39 | # Train the model and log metadata to the run in Neptune
40 | xgb.train(
41 | params=model_params,
42 | dtrain=dtrain,
43 | num_boost_round=num_round,
44 | evals=evals,
45 | callbacks=[
46 | neptune_callback,
47 | xgb.callback.LearningRateScheduler(lambda epoch: 0.99**epoch),
48 | xgb.callback.EarlyStopping(rounds=30),
49 | ],
50 | )
51 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/optuna/scripts/Neptune_Optuna_integration_quickstart.py:
--------------------------------------------------------------------------------
1 | import lightgbm as lgb
2 | import neptune
3 | import neptune.integrations.optuna as optuna_utils
4 | import optuna
5 | from sklearn.datasets import load_breast_cancer
6 | from sklearn.metrics import roc_auc_score
7 | from sklearn.model_selection import train_test_split
8 |
9 |
10 | def objective(trial):
11 | data, target = load_breast_cancer(return_X_y=True)
12 | train_x, test_x, train_y, test_y = train_test_split(data, target, test_size=0.25)
13 | dtrain = lgb.Dataset(train_x, label=train_y)
14 |
15 | param = {
16 | "verbose": -1,
17 | "objective": "binary",
18 | "metric": "binary_logloss",
19 | "num_leaves": trial.suggest_int("num_leaves", 2, 256),
20 | "feature_fraction": trial.suggest_float("feature_fraction", 0.2, 1.0, step=0.1),
21 | "bagging_fraction": trial.suggest_float("bagging_fraction", 0.2, 1.0, step=0.1),
22 | "min_child_samples": trial.suggest_int("min_child_samples", 3, 100),
23 | }
24 |
25 | gbm = lgb.train(param, dtrain)
26 | preds = gbm.predict(test_x)
27 | return roc_auc_score(test_y, preds)
28 |
29 |
30 | # Create a Neptune run
31 | run = neptune.init_run(
32 | api_token=neptune.ANONYMOUS_API_TOKEN,
33 | project="common/optuna",
34 | tags=["quickstart", "study", "script"],
35 | )
36 |
37 | # Create a NeptuneCallback for Optuna
38 | neptune_callback = optuna_utils.NeptuneCallback(run)
39 |
40 | # Pass NeptuneCallback to Optuna Study .optimize()
41 | study = optuna.create_study(direction="maximize")
42 | study.optimize(objective, n_trials=5, callbacks=[neptune_callback])
43 |
44 | # Stop logging to a Neptune run
45 | run.stop()
46 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/kedro/scripts/spaceflights-pandas/src/spaceflights_pandas/__main__.py:
--------------------------------------------------------------------------------
1 | """Spaceflights Pandas file for ensuring the package is executable
2 | as `spaceflights-pandas` and `python -m spaceflights_pandas`
3 | """
4 | import importlib
5 | from pathlib import Path
6 |
7 | from kedro.framework.cli.utils import KedroCliError, load_entry_points
8 | from kedro.framework.project import configure_project
9 |
10 |
11 | def _find_run_command(package_name):
12 | try:
13 | project_cli = importlib.import_module(f"{package_name}.cli")
14 | # fail gracefully if cli.py does not exist
15 | except ModuleNotFoundError as exc:
16 | if f"{package_name}.cli" not in str(exc):
17 | raise
18 | plugins = load_entry_points("project")
19 | run = _find_run_command_in_plugins(plugins) if plugins else None
20 | if run:
21 | # use run command from installed plugin if it exists
22 | return run
23 | # use run command from the framework project
24 | from kedro.framework.cli.project import run
25 |
26 | return run
27 | # fail badly if cli.py exists, but has no `cli` in it
28 | if not hasattr(project_cli, "cli"):
29 | raise KedroCliError(f"Cannot load commands from {package_name}.cli")
30 | return project_cli.run
31 |
32 |
33 | def _find_run_command_in_plugins(plugins):
34 | for group in plugins:
35 | if "run" in group.commands:
36 | return group.commands["run"]
37 |
38 |
39 | def main(*args, **kwargs):
40 | package_name = Path(__file__).parent.name
41 | configure_project(package_name)
42 | run = _find_run_command(package_name)
43 | run(*args, **kwargs)
44 |
45 |
46 | if __name__ == "__main__":
47 | main()
48 |
--------------------------------------------------------------------------------
/community-code/binance-trading-neptune-master/.github/workflows/main.yml:
--------------------------------------------------------------------------------
1 | # This is a basic workflow to help you get started with Actions
2 |
3 | name: Tests
4 |
5 | # Controls when the workflow will run
6 | on:
7 | # Triggers the workflow on push or pull request events but only for the "master" branch
8 | push:
9 | branches: [ "master", "production" ]
10 |
11 | # A workflow run is made up of one or more jobs that can run sequentially or in parallel
12 | jobs:
13 | # This workflow contains a single job called "build"
14 | build:
15 | # The type of runner that the job will run on
16 | runs-on: ubuntu-latest
17 |
18 | # Steps represent a sequence of tasks that will be executed as part of the job
19 | steps:
20 | # Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it
21 | - uses: actions/checkout@v3
22 | - uses: actions/setup-python@v4.0.0
23 | with:
24 | python-version: 3.7
25 | # Runs a set of commands using the runners shell
26 | - name: Install requirements
27 | run: |
28 | python -m pip install --upgrade pip
29 | pip install -r requirements.txt
30 | - name: Install talib
31 | run: |
32 | wget http://prdownloads.sourceforge.net/ta-lib/ta-lib-0.4.0-src.tar.gz \
33 | && sudo tar -xzf ta-lib-0.4.0-src.tar.gz \
34 | && sudo rm ta-lib-0.4.0-src.tar.gz \
35 | && cd ta-lib/ \
36 | && sudo ./configure --prefix=/usr \
37 | && sudo make \
38 | && sudo make install \
39 | && cd ~ \
40 | && sudo rm -rf ta-lib/ \
41 | && pip install ta-lib
42 | - name: Run test
43 | run: |
44 | cd src
45 | pytest main.py
46 |
--------------------------------------------------------------------------------
/how-to-guides/monitor-ml-runs/scripts/Monitor_ML_runs_live.py:
--------------------------------------------------------------------------------
1 | import neptune
2 | from tensorflow import keras
3 |
4 | run = neptune.init_run(project="common/quickstarts", api_token=neptune.ANONYMOUS_API_TOKEN)
5 |
6 | params = {
7 | "epoch_nr": 10,
8 | "batch_size": 256,
9 | "lr": 0.005,
10 | "momentum": 0.4,
11 | "use_nesterov": True,
12 | "unit_nr": 256,
13 | "dropout": 0.05,
14 | }
15 |
16 | mnist = keras.datasets.mnist
17 | (x_train, y_train), (x_test, y_test) = mnist.load_data()
18 |
19 | model = keras.models.Sequential(
20 | [
21 | keras.layers.Flatten(),
22 | keras.layers.Dense(params["unit_nr"], activation=keras.activations.relu),
23 | keras.layers.Dropout(params["dropout"]),
24 | keras.layers.Dense(10, activation=keras.activations.softmax),
25 | ]
26 | )
27 |
28 | optimizer = keras.optimizers.SGD(
29 | learning_rate=params["lr"],
30 | momentum=params["momentum"],
31 | nesterov=params["use_nesterov"],
32 | )
33 |
34 | model.compile(optimizer=optimizer, loss="sparse_categorical_crossentropy", metrics=["accuracy"])
35 |
36 |
37 | # log metrics during training
38 | class NeptuneLogger(keras.callbacks.Callback):
39 | def on_batch_end(self, batch, logs=None):
40 | if logs is None:
41 | logs = {}
42 | for log_name, log_value in logs.items():
43 | run[f"batch/{log_name}"].append(log_value)
44 |
45 | def on_epoch_end(self, epoch, logs=None):
46 | if logs is None:
47 | logs = {}
48 | for log_name, log_value in logs.items():
49 | run[f"epoch/{log_name}"].append(log_value)
50 |
51 |
52 | model.fit(
53 | x_train,
54 | y_train,
55 | epochs=params["epoch_nr"],
56 | batch_size=params["batch_size"],
57 | callbacks=[NeptuneLogger()],
58 | )
59 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/optuna/scripts/Neptune_Optuna_integration_load_study.py:
--------------------------------------------------------------------------------
1 | import lightgbm as lgb
2 | import neptune
3 | import neptune.integrations.optuna as optuna_utils
4 | from sklearn.datasets import load_breast_cancer
5 | from sklearn.metrics import roc_auc_score
6 | from sklearn.model_selection import train_test_split
7 |
8 |
9 | def objective(trial):
10 | data, target = load_breast_cancer(return_X_y=True)
11 | train_x, test_x, train_y, test_y = train_test_split(data, target, test_size=0.25)
12 | dtrain = lgb.Dataset(train_x, label=train_y)
13 |
14 | param = {
15 | "verbose": -1,
16 | "objective": "binary",
17 | "metric": "binary_logloss",
18 | "num_leaves": trial.suggest_int("num_leaves", 2, 256),
19 | "feature_fraction": trial.suggest_float("feature_fraction", 0.2, 1.0, step=0.1),
20 | "bagging_fraction": trial.suggest_float("bagging_fraction", 0.2, 1.0, step=0.1),
21 | "min_child_samples": trial.suggest_int("min_child_samples", 3, 100),
22 | }
23 |
24 | gbm = lgb.train(param, dtrain)
25 | preds = gbm.predict(test_x)
26 | return roc_auc_score(test_y, preds)
27 |
28 |
29 | # Fetch an existing Neptune run where you logged the Optuna Study
30 | run = neptune.init_run(
31 | api_token=neptune.ANONYMOUS_API_TOKEN,
32 | project="common/optuna",
33 | with_id="NEP1-32623",
34 | monitoring_namespace="monitoring",
35 | ) # you can pass your credentials and run ID here
36 |
37 | # Load the Optuna Study from Neptune run
38 | study = optuna_utils.load_study_from_run(run)
39 |
40 | # Continue logging to the existing Neptune run
41 | neptune_callback = optuna_utils.NeptuneCallback(run)
42 | study.optimize(objective, n_trials=2, callbacks=[neptune_callback])
43 |
44 | # Stop logging to a Neptune run
45 | run.stop()
46 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/evidently/scripts/Neptune_Evidently_reports.py:
--------------------------------------------------------------------------------
1 | import neptune
2 | from evidently.metric_preset import DataDriftPreset
3 | from evidently.report import Report
4 | from evidently.test_preset import DataStabilityTestPreset
5 | from evidently.test_suite import TestSuite
6 | from neptune.utils import stringify_unsupported
7 | from sklearn import datasets
8 |
9 | # Load sample data
10 | iris_frame = datasets.load_iris(as_frame=True).frame
11 |
12 | # Run Evidently test suites and reports
13 | data_stability = TestSuite(
14 | tests=[
15 | DataStabilityTestPreset(),
16 | ]
17 | )
18 | data_stability.run(
19 | current_data=iris_frame.iloc[:60],
20 | reference_data=iris_frame.iloc[60:],
21 | column_mapping=None,
22 | )
23 |
24 | data_drift_report = Report(
25 | metrics=[
26 | DataDriftPreset(),
27 | ]
28 | )
29 | data_drift_report.run(
30 | current_data=iris_frame.iloc[:60],
31 | reference_data=iris_frame.iloc[60:],
32 | column_mapping=None,
33 | )
34 |
35 | # (Neptune) Start a run
36 | run = neptune.init_run(
37 | api_token=neptune.ANONYMOUS_API_TOKEN, # replace with your own
38 | project="common/evidently-support", # replace with your own
39 | tags=["reports"], # (optional) replace with your own
40 | )
41 |
42 | # (Neptune) Save and upload reports as HTML
43 | data_stability.save_html("data_stability.html")
44 | data_drift_report.save_html("data_drift_report.html")
45 |
46 | run["data_stability/report"].upload("data_stability.html")
47 | run["data_drift/report"].upload("data_drift_report.html")
48 |
49 | # (Neptune) Save reports as dict
50 |
51 | run["data_stability"] = stringify_unsupported(data_stability.as_dict())
52 | run["data_drift"] = stringify_unsupported(data_drift_report.as_dict())
53 |
54 | # (Neptune) Stop logging
55 | run.stop()
56 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/kedro/scripts/spaceflights-pandas/pyproject.toml:
--------------------------------------------------------------------------------
1 | [build-system]
2 | requires = ["setuptools"]
3 | build-backend = "setuptools.build_meta"
4 |
5 | [project]
6 | name = "spaceflights_pandas"
7 | readme = "README.md"
8 | dynamic = ["dependencies", "version"]
9 |
10 | [project.scripts]
11 | spaceflights-pandas = "spaceflights_pandas.__main__:main"
12 |
13 | [project.entry-points."kedro.hooks"]
14 |
15 | [project.optional-dependencies]
16 | docs = [
17 | "docutils<0.18.0",
18 | "sphinx~=3.4.3",
19 | "sphinx_rtd_theme==0.5.1",
20 | "nbsphinx==0.8.1",
21 | "sphinx-autodoc-typehints==1.11.1",
22 | "sphinx_copybutton==0.3.1",
23 | "ipykernel>=5.3, <7.0",
24 | "Jinja2<3.1.0",
25 | "myst-parser~=0.17.2",
26 | ]
27 |
28 | [tool.setuptools.dynamic]
29 | dependencies = {file = "requirements.txt"}
30 | version = {attr = "spaceflights_pandas.__version__"}
31 |
32 | [tool.setuptools.packages.find]
33 | where = ["src"]
34 | namespaces = false
35 |
36 | [tool.kedro]
37 | package_name = "spaceflights_pandas"
38 | project_name = "Spaceflights Pandas"
39 | kedro_init_version = "0.19.2"
40 | tools = ['None']
41 | example_pipeline = "False"
42 | source_dir = "src"
43 |
44 | [tool.pytest.ini_options]
45 | addopts = """
46 | --cov-report term-missing \
47 | --cov src/spaceflights_pandas -ra"""
48 |
49 | [tool.coverage.report]
50 | fail_under = 0
51 | show_missing = true
52 | exclude_lines = ["pragma: no cover", "raise NotImplementedError"]
53 |
54 | [tool.ruff.format]
55 | docstring-code-format = true
56 |
57 | [tool.ruff]
58 | line-length = 88
59 | show-fixes = true
60 | select = [
61 | "F", # Pyflakes
62 | "W", # pycodestyle
63 | "E", # pycodestyle
64 | "I", # isort
65 | "UP", # pyupgrade
66 | "PL", # Pylint
67 | "T201", # Print Statement
68 | ]
69 | ignore = ["E501"] # Ruff format takes care of line-too-long
70 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/lightgbm/scripts/Neptune_LightGBM_train_summary.py:
--------------------------------------------------------------------------------
1 | import lightgbm as lgb
2 | import neptune
3 | import numpy as np
4 | from neptune.integrations.lightgbm import NeptuneCallback, create_booster_summary
5 | from sklearn.datasets import load_digits
6 | from sklearn.model_selection import train_test_split
7 |
8 | # Create run
9 | run = neptune.init_run(
10 | project="common/lightgbm-integration",
11 | api_token=neptune.ANONYMOUS_API_TOKEN,
12 | name="train-cls",
13 | tags=["lgbm-integration", "train", "cls"],
14 | )
15 |
16 | # Create neptune callback
17 | neptune_callback = NeptuneCallback(run=run)
18 |
19 | # Prepare data
20 | X, y = load_digits(return_X_y=True)
21 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
22 | lgb_train = lgb.Dataset(X_train, y_train)
23 | lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
24 |
25 | # Define parameters
26 | params = {
27 | "boosting_type": "gbdt",
28 | "objective": "multiclass",
29 | "num_class": 10,
30 | "metric": ["multi_logloss", "multi_error"],
31 | "num_leaves": 21,
32 | "learning_rate": 0.05,
33 | "feature_fraction": 0.9,
34 | "bagging_fraction": 0.8,
35 | "bagging_freq": 5,
36 | "max_depth": 12,
37 | }
38 |
39 | # Train the model
40 | gbm = lgb.train(
41 | params,
42 | lgb_train,
43 | num_boost_round=200,
44 | valid_sets=[lgb_train, lgb_eval],
45 | valid_names=["training", "validation"],
46 | callbacks=[neptune_callback],
47 | )
48 |
49 | y_pred = np.argmax(gbm.predict(X_test), axis=1)
50 |
51 | # Log summary metadata to the same run under the "lgbm_summary" namespace
52 | run["lgbm_summary"] = create_booster_summary(
53 | booster=gbm,
54 | log_trees=True,
55 | list_trees=[0, 1, 2, 3, 4],
56 | log_confusion_matrix=True,
57 | y_pred=y_pred,
58 | y_true=y_test,
59 | )
60 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/azure-ml/dependencies/build_environment.py:
--------------------------------------------------------------------------------
1 | import logging
2 | import os
3 |
4 | from azure.ai.ml import MLClient
5 | from azure.ai.ml.entities import Environment
6 | from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
7 |
8 | CUSTOM_ENV_NAME = "neptune-example"
9 | DEPENDENCIES_DIR = "./dependencies"
10 |
11 | AZURE_SUBSCRIPTION_ID = ""
12 | AZUREML_RESOURCE_GROUP_NAME = ""
13 | AZUREML_WORKSPACE_NAME = ""
14 |
15 |
16 | def main():
17 | try:
18 | credential = DefaultAzureCredential()
19 | # Check if given credential can get token successfully.
20 | credential.get_token("https://management.azure.com/.default")
21 | except Exception as ex:
22 | # Fall back to InteractiveBrowserCredential in case DefaultAzureCredential does not work
23 | credential = InteractiveBrowserCredential()
24 |
25 | # Get a handle to the workspace
26 | ml_client = MLClient(
27 | credential=credential,
28 | subscription_id=AZURE_SUBSCRIPTION_ID,
29 | resource_group_name=AZUREML_RESOURCE_GROUP_NAME,
30 | workspace_name=AZUREML_WORKSPACE_NAME,
31 | )
32 |
33 | pipeline_job_env = Environment(
34 | name=CUSTOM_ENV_NAME,
35 | description="Custom environment for Neptune Example",
36 | tags={"scikit-learn": "0.24.2"},
37 | conda_file=os.path.join(DEPENDENCIES_DIR, "conda.yml"),
38 | image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
39 | version="0.1.0",
40 | )
41 | pipeline_job_env = ml_client.environments.create_or_update(pipeline_job_env)
42 |
43 | logging.info(
44 | f"Environment with name {pipeline_job_env.name} is registered to workspace, the environment version is {pipeline_job_env.version}"
45 | )
46 |
47 |
48 | if __name__ == "__main__":
49 | main()
50 |
--------------------------------------------------------------------------------
/community-code/binance-trading-neptune-master/Dockerfile:
--------------------------------------------------------------------------------
1 | FROM ubuntu:22.10
2 |
3 | ARG PATH="/root/miniconda3/bin:${PATH}"
4 | ENV PATH="/root/miniconda3/bin:${PATH}"
5 |
6 | ARG BINANCE_TESTNET_API
7 | ARG BINANCE_TESTNET_SECRET
8 | ARG NEPTUNE_API_TOKEN
9 | ARG NEPTUNE_PROJECT
10 | ARG AWS_ACCESS_KEY_ID
11 | ARG AWS_SECRET_ACCESS_KEY
12 |
13 | ENV BINANCE_TESTNET_API=${BINANCE_TESTNET_API}
14 | ENV BINANCE_TESTNET_SECRET=${BINANCE_TESTNET_SECRET}
15 | ENV NEPTUNE_API_TOKEN=${NEPTUNE_API_TOKEN}
16 | ENV NEPTUNE_PROJECT=${NEPTUNE_PROJECT}
17 | ENV AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID}
18 | ENV AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY}
19 |
20 | ENV VAR_NAME=$VAR_NAME
21 |
22 |
23 | RUN apt update \
24 | && apt install -y python3-dev wget cron gcc vim build-essential
25 |
26 | RUN wget https://repo.anaconda.com/miniconda/Miniconda3-py37_4.9.2-Linux-x86_64.sh \
27 | && mkdir root/.conda \
28 | && sh Miniconda3-py37_4.9.2-Linux-x86_64.sh -b \
29 | && rm -f Miniconda3-py37_4.9.2-Linux-x86_64.sh
30 |
31 | RUN conda create -y -n env python=3.7
32 |
33 | COPY . binance_trading/
34 |
35 | RUN /bin/bash -c " source activate env \
36 | && wget http://prdownloads.sourceforge.net/ta-lib/ta-lib-0.4.0-src.tar.gz \
37 | && tar -xzf ta-lib-0.4.0-src.tar.gz \
38 | && rm ta-lib-0.4.0-src.tar.gz \
39 | && cd ta-lib/ \
40 | && ./configure --prefix=/usr \
41 | && make \
42 | && make install \
43 | && cd ~ \
44 | && rm -rf ta-lib/ \
45 | && pip install ta-lib"
46 |
47 | RUN /bin/bash -c "source activate env \
48 | && pip install --upgrade pip \
49 | && pip install -r binance_trading/requirements.txt"
50 |
51 |
52 | COPY cron-job /etc/cron.d/cron-job
53 |
54 | # Give execution rights on the cron job
55 | RUN chmod 0644 /etc/cron.d/cron-job
56 |
57 | # Apply cron job
58 | RUN /usr/bin/crontab /etc/cron.d/cron-job
59 |
60 | # Run the command on container startup
61 | CMD printenv > /etc/environment && cron -f
--------------------------------------------------------------------------------
/integrations-and-supported-tools/lightgbm/scripts/Neptune_LightGBM_sklearn_api.py:
--------------------------------------------------------------------------------
1 | import lightgbm as lgb
2 | import neptune
3 | from neptune.integrations.lightgbm import NeptuneCallback, create_booster_summary
4 | from sklearn.datasets import load_digits
5 | from sklearn.model_selection import train_test_split
6 |
7 | # Create run
8 | run = neptune.init_run(
9 | project="common/lightgbm-integration",
10 | api_token=neptune.ANONYMOUS_API_TOKEN,
11 | name="sklearn-api-cls",
12 | tags=["lgbm-integration", "sklearn-api", "cls"],
13 | )
14 |
15 | # Create neptune callback
16 | neptune_callback = NeptuneCallback(run=run)
17 |
18 | # Prepare data
19 | X, y = load_digits(return_X_y=True)
20 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
21 | lgb_train = lgb.Dataset(X_train, y_train)
22 | lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
23 |
24 | # Define parameters
25 | params = {
26 | "boosting_type": "gbdt",
27 | "objective": "multiclass",
28 | "num_class": 10,
29 | "num_leaves": 21,
30 | "learning_rate": 0.05,
31 | "feature_fraction": 0.9,
32 | "bagging_fraction": 0.8,
33 | "bagging_freq": 5,
34 | "max_depth": 12,
35 | "n_estimators": 207,
36 | }
37 |
38 | # Create instance of the classifier object
39 | gbm = lgb.LGBMClassifier(**params)
40 |
41 | # Fit model and log metadata
42 | gbm.fit(
43 | X_train,
44 | y_train,
45 | eval_set=[(X_train, y_train), (X_test, y_test)],
46 | eval_names=["training", "validation"],
47 | eval_metric=["multi_logloss", "multi_error"],
48 | callbacks=[neptune_callback],
49 | )
50 |
51 | y_pred = gbm.predict(X_test)
52 |
53 | # Log summary metadata to the same run under the "lgbm_summary" namespace
54 | run["lgbm_summary"] = create_booster_summary(
55 | booster=gbm,
56 | log_trees=True,
57 | list_trees=[0, 1, 2, 3, 4],
58 | log_confusion_matrix=True,
59 | y_pred=y_pred,
60 | y_true=y_test,
61 | )
62 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/transformers/scripts/Neptune_Transformers.py:
--------------------------------------------------------------------------------
1 | import neptune
2 | from datasets import load_dataset
3 | from evaluate import load
4 | from transformers import (
5 | AutoModelForSequenceClassification,
6 | AutoTokenizer,
7 | Trainer,
8 | TrainingArguments,
9 | )
10 | from transformers.integrations import NeptuneCallback
11 |
12 | # Set the environment variables `NEPTUNE_API_TOKEN` and `NEPTUNE_PROJECT`.
13 | run = neptune.init_run()
14 |
15 | task = "cola"
16 | model_checkpoint = "prajjwal1/bert-tiny"
17 | batch_size = 16
18 | dataset = load_dataset("glue", task)
19 | metric = load("glue", task)
20 | num_labels = 2
21 |
22 | tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)
23 |
24 |
25 | def preprocess_function(examples):
26 | return tokenizer(examples["sentence"], truncation=True)
27 |
28 |
29 | encoded_dataset = dataset.map(preprocess_function, batched=True)
30 |
31 | model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=num_labels)
32 | model_name = model_checkpoint.split("/")[-1]
33 |
34 | args = TrainingArguments(
35 | f"{model_name}-finetuned-{task}",
36 | eval_strategy="epoch",
37 | save_strategy="epoch",
38 | save_safetensors=False,
39 | learning_rate=2e-6,
40 | per_device_train_batch_size=batch_size,
41 | per_device_eval_batch_size=batch_size,
42 | num_train_epochs=2,
43 | weight_decay=0.005,
44 | load_best_model_at_end=True,
45 | report_to="none",
46 | )
47 |
48 | validation_key = "validation"
49 |
50 | neptune_callback = NeptuneCallback(
51 | run=run,
52 | log_checkpoints=None, # Update to "last" or "best" if you want to log model checkpoints to Neptune
53 | )
54 |
55 | trainer = Trainer(
56 | model,
57 | args,
58 | train_dataset=encoded_dataset["train"],
59 | eval_dataset=encoded_dataset[validation_key],
60 | callbacks=[neptune_callback],
61 | tokenizer=tokenizer,
62 | )
63 |
64 | trainer.train()
65 |
--------------------------------------------------------------------------------
/.sourcery.yaml:
--------------------------------------------------------------------------------
1 | # 🪄 This is your project's Sourcery configuration file.
2 |
3 | # You can use it to get Sourcery working in the way you want, such as
4 | # ignoring specific refactorings, skipping directories in your project,
5 | # or writing custom rules.
6 |
7 | # 📚 For a complete reference to this file, see the documentation at
8 | # https://docs.sourcery.ai/Configuration/Project-Settings/
9 |
10 | # This file was auto-generated by Sourcery on 2022-12-21 at 13:39.
11 |
12 | version: "1" # The schema version of this config file
13 |
14 | ignore: # A list of paths or files which Sourcery will ignore.
15 | - .git
16 | - venv
17 | - .venv
18 | - env
19 | - .env
20 | - .tox
21 |
22 | rule_settings:
23 | enable:
24 | - default
25 | disable: [] # A list of rule IDs Sourcery will never suggest.
26 | rule_types:
27 | - refactoring
28 | - suggestion
29 | - comment
30 | python_version: "3.9" # A string specifying the lowest Python version your project supports. Sourcery will not suggest refactorings requiring a higher Python version.
31 |
32 | # rules: # A list of custom rules Sourcery will include in its analysis.
33 | # - id: no-print-statements
34 | # description: Do not use print statements in the test directory.
35 | # pattern: print(...)
36 | # replacement:
37 | # condition:
38 | # explanation:
39 | # paths:
40 | # include:
41 | # - test
42 | # exclude:
43 | # - conftest.py
44 | # tests: []
45 | # tags: []
46 |
47 | # rule_tags: {} # Additional rule tags.
48 |
49 | # metrics:
50 | # quality_threshold: 25.0
51 |
52 | # github:
53 | # labels: []
54 | # ignore_labels:
55 | # - sourcery-ignore
56 | # request_review: author
57 | # sourcery_branch: sourcery/{base_branch}
58 |
59 | # clone_detection:
60 | # min_lines: 3
61 | # min_duplicates: 2
62 | # identical_clones_only: false
63 |
64 | # proxy:
65 | # url:
66 | # ssl_certs_file:
67 | # no_ssl_verify: false
68 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/kedro/scripts/spaceflights-pandas/src/spaceflights_pandas/settings.py:
--------------------------------------------------------------------------------
1 | """Project settings. There is no need to edit this file unless you want to change values
2 | from the Kedro defaults. For further information, including these default values, see
3 | https://docs.kedro.org/en/stable/kedro_project_setup/settings.html."""
4 |
5 | # Instantiated project hooks.
6 | # For example, after creating a hooks.py and defining a ProjectHooks class there, do
7 | # from spaceflights_pandas.hooks import ProjectHooks
8 |
9 | # Hooks are executed in a Last-In-First-Out (LIFO) order.
10 | # HOOKS = (ProjectHooks(),)
11 |
12 | # Installed plugins for which to disable hook auto-registration.
13 | # DISABLE_HOOKS_FOR_PLUGINS = ("kedro-viz",)
14 |
15 | # Class that manages storing KedroSession data.
16 | # from kedro.framework.session.store import BaseSessionStore
17 | # SESSION_STORE_CLASS = BaseSessionStore
18 | # Keyword arguments to pass to the `SESSION_STORE_CLASS` constructor.
19 | # SESSION_STORE_ARGS = {
20 | # "path": "./sessions"
21 | # }
22 |
23 | # Directory that holds configuration.
24 | # CONF_SOURCE = "conf"
25 |
26 | # Class that manages how configuration is loaded.
27 | from kedro.config import OmegaConfigLoader # noqa: E402
28 |
29 | CONFIG_LOADER_CLASS = OmegaConfigLoader
30 | # Keyword arguments to pass to the `CONFIG_LOADER_CLASS` constructor.
31 | CONFIG_LOADER_ARGS = {
32 | "base_env": "base",
33 | "default_run_env": "local",
34 | "config_patterns": {
35 | # "spark" : ["spark*/"],
36 | # "parameters": ["parameters*", "parameters*/**", "**/parameters*"],
37 | "credentials_neptune": ["credentials_neptune*"],
38 | "neptune": ["neptune*"],
39 | },
40 | }
41 |
42 | # Class that manages Kedro's library components.
43 | # from kedro.framework.context import KedroContext
44 | # CONTEXT_CLASS = KedroContext
45 |
46 | # Class that manages the Data Catalog.
47 | # from kedro.io import DataCatalog
48 | # DATA_CATALOG_CLASS = DataCatalog
49 |
--------------------------------------------------------------------------------
/use-cases/time-series-forecasting/walmart-sales/scripts/model.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | from lightning import LightningModule
4 |
5 |
6 | class LSTMRegressor(LightningModule):
7 | def __init__(
8 | self,
9 | n_features,
10 | hidden_dim,
11 | n_layers,
12 | criterion,
13 | dropout,
14 | learning_rate,
15 | seq_len,
16 | batch_first=True,
17 | ):
18 | super().__init__()
19 |
20 | self.save_hyperparameters()
21 |
22 | # loss
23 | self.criterion = criterion
24 |
25 | # lr
26 | self.learning_rate = learning_rate
27 |
28 | # n_features
29 | self.n_features = n_features
30 |
31 | # n_layers
32 | self.n_layers = n_layers
33 |
34 | # hidden_dim
35 | self.hidden_dim = hidden_dim
36 |
37 | # Model
38 | self.lstm = nn.LSTM(
39 | input_size=n_features,
40 | hidden_size=hidden_dim,
41 | num_layers=n_layers,
42 | batch_first=batch_first,
43 | dropout=dropout,
44 | )
45 | self.regressor = nn.Linear(hidden_dim, 1)
46 |
47 | def forward(self, x):
48 | output, _ = self.lstm(x)
49 | return self.regressor(output[:, -1, :])
50 |
51 | def configure_optimizers(self):
52 | return torch.optim.Adam(self.parameters(), lr=self.learning_rate)
53 |
54 | def training_step(self, batch, batch_idx):
55 | return self._batch_step(batch, loss_name="train_loss")
56 |
57 | def validation_step(self, batch, batch_idx):
58 | return self._batch_step(batch, loss_name="val_loss")
59 |
60 | def _batch_step(self, batch, loss_name):
61 | x, y = batch
62 | y_hat = self(x)
63 | loss = self.criterion(y_hat, y)
64 | self.log(loss_name, loss, on_step=True, on_epoch=True, prog_bar=True)
65 | return loss
66 |
67 | def predict(self, test_loader):
68 | with torch.no_grad():
69 | x_test, y_test = next(iter(test_loader))
70 | self.eval()
71 | yhat = self(x_test)
72 |
73 | return yhat.detach().data.numpy(), y_test.detach().data.numpy()
74 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/catalyst/scripts/Neptune_Catalyst.py:
--------------------------------------------------------------------------------
1 | import os
2 | from collections import OrderedDict
3 |
4 | import neptune
5 | from catalyst import dl
6 | from torch import nn, optim
7 | from torch.utils.data import DataLoader
8 | from torchvision.datasets import MNIST
9 | from torchvision.transforms import ToTensor
10 |
11 | # Prepare hparams
12 | my_hparams = {"lr": 0.07, "batch_size": 32}
13 |
14 | # Prepare model, criterion, optimizer and data loaders
15 | model = nn.Sequential(nn.Flatten(), nn.Linear(28 * 28, 10))
16 | criterion = nn.CrossEntropyLoss()
17 | optimizer = optim.Adam(model.parameters(), my_hparams["lr"])
18 | loaders = OrderedDict(
19 | {
20 | "training": DataLoader(
21 | MNIST(os.getcwd(), train=True, download=True, transform=ToTensor()),
22 | batch_size=my_hparams["batch_size"],
23 | ),
24 | "validation": DataLoader(
25 | MNIST(os.getcwd(), train=False, download=True, transform=ToTensor()),
26 | batch_size=my_hparams["batch_size"],
27 | ),
28 | }
29 | )
30 |
31 | # Create runner
32 | my_runner = dl.SupervisedRunner()
33 |
34 | # Create NeptuneLogger
35 | neptune_logger = dl.NeptuneLogger(
36 | api_token=neptune.ANONYMOUS_API_TOKEN,
37 | project="common/catalyst-integration",
38 | tags=["docs-example", "quickstart"],
39 | )
40 |
41 | # Train the model, pass neptune_logger
42 | my_runner.train(
43 | model=model,
44 | criterion=criterion,
45 | optimizer=optimizer,
46 | loggers={"neptune": neptune_logger},
47 | loaders=loaders,
48 | num_epochs=5,
49 | callbacks=[
50 | dl.AccuracyCallback(input_key="logits", target_key="targets", topk=[1]),
51 | dl.CheckpointCallback(
52 | logdir="checkpoints",
53 | loader_key="validation",
54 | metric_key="loss",
55 | minimize=True,
56 | ),
57 | ],
58 | hparams=my_hparams,
59 | valid_loader="validation",
60 | valid_metric="loss",
61 | minimize_valid_metric=True,
62 | )
63 |
64 | # Log best model
65 | my_runner.log_artifact(
66 | path_to_artifact="./checkpoints/model.best.pth",
67 | tag="best_model",
68 | scope="experiment",
69 | )
70 |
--------------------------------------------------------------------------------
/how-to-guides/sequential-pipelines/scripts/model_promotion.py:
--------------------------------------------------------------------------------
1 | import neptune
2 | from neptune.exceptions import ModelNotFound
3 |
4 | from utils import *
5 |
6 | model_name = "pickled_model"
7 |
8 | # (Neptune) Get latest model from training stage
9 | model_key = "PIPELINES"
10 | project_key = "PIP"
11 |
12 | try:
13 | model = neptune.init_model(
14 | with_id=f"{project_key}-{model_key}", # Your model ID here
15 | )
16 | model_versions_table = model.fetch_model_versions_table().to_pandas()
17 | staging_model_table = model_versions_table[model_versions_table["sys/stage"] == "staging"]
18 | challenger_model_id = staging_model_table["sys/id"].tolist()[0]
19 | production_model_table = model_versions_table[model_versions_table["sys/stage"] == "production"]
20 | champion_model_id = production_model_table["sys/id"].tolist()[0]
21 |
22 | except ModelNotFound:
23 | print(
24 | f"The model with the provided key `{model_key}` doesn't exist in the `{project_key}` project."
25 | )
26 |
27 | # (neptune) Download the lastest model checkpoint from model registry
28 | challenger = neptune.init_model_version(with_id=challenger_model_id)
29 | champion = neptune.init_model_version(with_id=champion_model_id)
30 |
31 | # (Neptune) Get model weights from training stage
32 | challenger["model"][model_name].download()
33 | champion["model"][model_name].download()
34 |
35 | # (Neptune) Move model to production
36 | challenger_score = challenger["metrics/validation/scores/class_0"].fetch()
37 | champion_score = champion["metrics/validation/scores/class_0"].fetch()
38 |
39 | print(
40 | f"Challenger score: {challenger_score['fbeta_score']}\nChampion score: {champion_score['fbeta_score']}"
41 | )
42 | if challenger_score["fbeta_score"] > champion_score["fbeta_score"]:
43 | print(
44 | f"Promoting challenger model {challenger_model_id} to production and archiving current champion model {champion_model_id}"
45 | )
46 | challenger.change_stage("production")
47 | champion.change_stage("archived")
48 | else:
49 | print(
50 | f"Challenger model {challenger_model_id} underperforms champion {champion_model_id}. Archiving."
51 | )
52 | challenger.change_stage("archived")
53 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/skorch/scripts/Neptune_Skorch.py:
--------------------------------------------------------------------------------
1 | import neptune
2 | import numpy as np
3 | import torch
4 | import torch.nn.functional as F
5 | from sklearn.datasets import fetch_openml
6 | from sklearn.model_selection import train_test_split
7 | from skorch import NeuralNetClassifier
8 | from skorch.callbacks import NeptuneLogger
9 | from torch import nn
10 |
11 | # Define hyper-parameters
12 | params = {
13 | "batch_size": 2,
14 | "lr": 0.1,
15 | "max_epochs": 10,
16 | }
17 |
18 | # Load data
19 | mnist = fetch_openml("mnist_784", as_frame=False, cache=False)
20 |
21 | # Preprocess data
22 | X = mnist.data.astype("float32")
23 | y = mnist.target.astype("int64")
24 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
25 |
26 | # Build a neural network with PyTorch
27 | device = "cuda" if torch.cuda.is_available() else "cpu"
28 | mnist_dim = X.shape[1]
29 | hidden_dim = int(mnist_dim / 8)
30 | output_dim = len(np.unique(mnist.target))
31 |
32 |
33 | class ClassifierModule(nn.Module):
34 | def __init__(
35 | self,
36 | input_dim=mnist_dim,
37 | hidden_dim=hidden_dim,
38 | output_dim=output_dim,
39 | dropout=0.5,
40 | ):
41 | super(ClassifierModule, self).__init__()
42 | self.dropout = nn.Dropout(dropout)
43 |
44 | self.hidden = nn.Linear(input_dim, hidden_dim)
45 | self.output = nn.Linear(hidden_dim, output_dim)
46 |
47 | def forward(self, X, **kwargs):
48 | X = F.relu(self.hidden(X))
49 | X = self.dropout(X)
50 | X = F.softmax(self.output(X), dim=-1)
51 | return X
52 |
53 |
54 | # (Neptune) Initialize Neptune run
55 | run = neptune.init_run(api_token=neptune.ANONYMOUS_API_TOKEN, project="common/skorch-integration")
56 | # (Neptune) Create NeptuneLogger
57 | neptune_logger = NeptuneLogger(run, close_after_train=False)
58 |
59 | # Initialize a trainer and pass neptune_logger
60 | net = NeuralNetClassifier(
61 | ClassifierModule,
62 | max_epochs=params["max_epochs"],
63 | lr=params["lr"],
64 | device=device,
65 | callbacks=[neptune_logger],
66 | )
67 |
68 | # Train the model log metadata to the Neptune run
69 | net.fit(X_train, y_train)
70 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/mlflow/scripts/train_keras_mlflow.py:
--------------------------------------------------------------------------------
1 | """Trains and evaluate a simple MLP
2 | on the Reuters newswire topic classification task.
3 | """
4 | # The following import and function call are the only additions to code required
5 | # to automatically log metrics and parameters to MLflow.
6 | import mlflow
7 | import numpy as np
8 | from tensorflow import keras
9 | from tensorflow.keras.datasets import reuters
10 | from tensorflow.keras.layers import Activation, Dense, Dropout
11 | from tensorflow.keras.models import Sequential
12 | from tensorflow.keras.preprocessing.text import Tokenizer
13 |
14 | mlflow.tensorflow.autolog()
15 |
16 | max_words = 1000
17 | batch_size = 32
18 | epochs = 5
19 |
20 | print("Loading data...")
21 | (x_train, y_train), (x_test, y_test) = reuters.load_data(num_words=max_words, test_split=0.2)
22 |
23 | print(len(x_train), "train sequences")
24 | print(len(x_test), "test sequences")
25 |
26 | num_classes = np.max(y_train) + 1
27 | print(num_classes, "classes")
28 |
29 | print("Vectorizing sequence data...")
30 | tokenizer = Tokenizer(num_words=max_words)
31 | x_train = tokenizer.sequences_to_matrix(x_train, mode="binary")
32 | x_test = tokenizer.sequences_to_matrix(x_test, mode="binary")
33 | print("x_train shape:", x_train.shape)
34 | print("x_test shape:", x_test.shape)
35 |
36 | print("Convert class vector to binary class matrix (for use with categorical_crossentropy)")
37 | y_train = keras.utils.to_categorical(y_train, num_classes)
38 | y_test = keras.utils.to_categorical(y_test, num_classes)
39 | print("y_train shape:", y_train.shape)
40 | print("y_test shape:", y_test.shape)
41 |
42 | print("Building model...")
43 | model = Sequential()
44 | model.add(Dense(512, input_shape=(max_words,)))
45 | model.add(Activation("relu"))
46 | model.add(Dropout(0.5))
47 | model.add(Dense(num_classes))
48 | model.add(Activation("softmax"))
49 |
50 | model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
51 |
52 | history = model.fit(
53 | x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_split=0.1
54 | )
55 | score = model.evaluate(x_test, y_test, batch_size=batch_size, verbose=1)
56 | print("Test score:", score[0])
57 | print("Test accuracy:", score[1])
58 |
--------------------------------------------------------------------------------
/how-to-guides/hello-neptune/scripts/hello_neptune.py:
--------------------------------------------------------------------------------
1 | import neptune
2 |
3 | # Initialize Neptune and create a new run
4 | run = neptune.init_run(
5 | project="common/quickstarts",
6 | api_token=neptune.ANONYMOUS_API_TOKEN,
7 | tags=["quickstart", "script"],
8 | dependencies="infer", # to infer dependencies. You can also pass the path to the requirements.txt file
9 | )
10 |
11 | # log single value
12 | run["seed"] = 0.42
13 |
14 | # log series of values
15 | from random import random
16 |
17 | epochs = 10
18 | offset = random() / 5
19 |
20 | for epoch in range(epochs):
21 | acc = 1 - 2**-epoch - random() / (epoch + 1) - offset
22 | loss = 2**-epoch + random() / (epoch + 1) + offset
23 |
24 | run["accuracy"].append(acc)
25 | run["loss"].append(loss)
26 |
27 | # Upload single image to Neptune
28 | run["single_image"].upload("sample.png") # You can upload native images as-is
29 |
30 | # Load MNIST dataset
31 | from tensorflow.keras.datasets import mnist
32 |
33 | (x_train, y_train), (x_test, y_test) = mnist.load_data()
34 |
35 | # Upload a series of images to Neptune
36 | from neptune.types import File
37 |
38 | for i in range(10):
39 | run["image_series"].append(
40 | File.as_image(
41 | x_train[i]
42 | ), # You can upload arrays as images using Neptune's File.as_image() method
43 | name=str(y_train[i]),
44 | )
45 |
46 | # Save the run ID to resume the run later
47 | run_id = run["sys/id"].fetch()
48 |
49 | # Stop logging
50 | run.stop()
51 |
52 | # Reinitialize an already logged run
53 | run = neptune.init_run(
54 | project="common/quickstarts",
55 | api_token=neptune.ANONYMOUS_API_TOKEN,
56 | with_id=run_id, # ID of the run you want to re-initialize
57 | mode="read-only", # To prevent accidental overwrite of already logged data
58 | )
59 |
60 | # Download metadata from reinitialized run
61 | print(f"Logged seed: {run['seed'].fetch()}")
62 | print(f"Logged accuracies:\n{run['accuracy'].fetch_values()}")
63 | run["single_image"].download("downloaded_single_image.png")
64 | print("Image downloaded to downloaded_single_image.png")
65 | run["image_series"].download("downloaded_image_series")
66 | print("Image series downloaded to downloaded_image_series folder")
67 |
68 | # Stop the run
69 | run.stop()
70 |
--------------------------------------------------------------------------------
/use-cases/time-series-forecasting/walmart-sales/scripts/run_ml_baseline.py:
--------------------------------------------------------------------------------
1 | import sys
2 |
3 | import matplotlib.pyplot as plt
4 | import neptune
5 | import pandas as pd
6 | import seaborn as sns
7 | import xgboost as xgb
8 | from neptune.integrations.xgboost import NeptuneCallback
9 | from neptune.types import File
10 | from sklearn.metrics import mean_absolute_error, mean_squared_error
11 |
12 | sys.path.append("../")
13 | from utils import *
14 |
15 | sns.set()
16 | plt.rcParams["figure.figsize"] = 15, 8
17 | plt.rcParams["image.cmap"] = "viridis"
18 | plt.ioff()
19 |
20 | # (neptune) Initialize Neptune run
21 | run = neptune.init_run(
22 | tags=["baseline", "xgboost", "walmart-sales"],
23 | name="XGBoost",
24 | )
25 | neptune_callback = NeptuneCallback(run=run, log_tree=[0, 1, 2, 3])
26 |
27 | # Load dataset
28 | DATA_PATH = "../dataset"
29 | df = load_data(DATA_PATH)
30 |
31 | # Normalize sales data
32 | df_normalized = normalize_data(df, "Weekly_Sales")
33 |
34 | # Encode categorical data
35 | df_encoded = df_normalized.copy()
36 | df_encoded = encode_categorical_data(df_encoded)
37 |
38 | # Create Lagged features
39 | df_encoded = create_lags(df_encoded)
40 |
41 | # Get train data
42 | X_train, X_valid, y_train, y_valid = get_train_data(
43 | df_encoded[df_encoded.Dept == 1], ["Weekly_Sales", "Date", "Year"]
44 | )
45 |
46 | # Train model
47 | model = xgb.XGBRegressor(callbacks=[neptune_callback]).fit(
48 | X_train,
49 | y_train,
50 | )
51 |
52 | # Calculate scores
53 | model_score = model.score(X_valid, y_valid)
54 | y_pred = model.predict(X_valid)
55 | rmse = mean_squared_error(y_valid, y_pred, squared=False)
56 | mae = mean_absolute_error(y_valid, y_pred)
57 |
58 | # (neptune) Log scores
59 | run["training/val/r2"] = model_score
60 | run["training/val/rmse"] = rmse
61 | run["training/val/mae"] = mae
62 |
63 | # Visualize predictions
64 | df_result = pd.DataFrame(
65 | data={
66 | "y_valid": y_valid.values,
67 | "y_pred": y_pred,
68 | "Week": df_encoded.loc[X_valid.index].Week,
69 | },
70 | index=X_valid.index,
71 | )
72 | df_result = df_result.set_index("Week")
73 |
74 | plt.figure()
75 | preds_plot = sns.lineplot(data=df_result)
76 |
77 | # (neptune) Log predictions visualizations
78 | run["training/plots/ypred_vs_y_valid"].upload(File.as_image(preds_plot.figure))
79 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/kedro/scripts/spaceflights-pandas/src/spaceflights_pandas/pipelines/data_science/nodes.py:
--------------------------------------------------------------------------------
1 | import logging
2 | from typing import Dict, Tuple
3 |
4 | import matplotlib.pyplot as plt
5 | import neptune
6 | import pandas as pd
7 | from sklearn.linear_model import LinearRegression
8 | from sklearn.metrics import r2_score
9 | from sklearn.model_selection import train_test_split
10 |
11 |
12 | def split_data(data: pd.DataFrame, parameters: Dict) -> Tuple:
13 | """Splits data into features and targets training and test sets.
14 |
15 | Args:
16 | data: Data containing features and target.
17 | parameters: Parameters defined in parameters/data_science.yml.
18 | Returns:
19 | Split data.
20 | """
21 | X = data[parameters["features"]]
22 | y = data["price"]
23 | X_train, X_test, y_train, y_test = train_test_split(
24 | X, y, test_size=parameters["test_size"], random_state=parameters["random_state"]
25 | )
26 | return X_train, X_test, y_train, y_test
27 |
28 |
29 | def train_model(X_train: pd.DataFrame, y_train: pd.Series) -> LinearRegression:
30 | """Trains the linear regression model.
31 |
32 | Args:
33 | X_train: Training data of independent features.
34 | y_train: Training data for price.
35 |
36 | Returns:
37 | Trained model.
38 | """
39 | regressor = LinearRegression()
40 | regressor.fit(X_train, y_train)
41 | return regressor
42 |
43 |
44 | def evaluate_model(
45 | regressor: LinearRegression,
46 | X_test: pd.DataFrame,
47 | y_test: pd.Series,
48 | neptune_run: neptune.handler.Handler,
49 | ):
50 | """Calculates and logs the coefficient of determination.
51 |
52 | Args:
53 | regressor: Trained model.
54 | X_test: Testing data of independent features.
55 | y_test: Testing data for price.
56 | """
57 | y_pred = regressor.predict(X_test)
58 | score = r2_score(y_test, y_pred)
59 | logger = logging.getLogger(__name__)
60 | logger.info("Model has a coefficient R^2 of %.3f on test data.", score)
61 |
62 | fig = plt.figure()
63 | plt.scatter(y_test.values, y_pred, alpha=0.2)
64 | plt.xlabel("Actuals")
65 | plt.ylabel("Predictions")
66 |
67 | if neptune_run:
68 | neptune_run["nodes/evaluate_model_node/score"] = score
69 | neptune_run["nodes/evaluate_model_node/actual_vs_prediction"].upload(fig)
70 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/kedro/scripts/spaceflights-pandas/src/spaceflights_pandas/pipelines/data_processing/nodes.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 |
3 |
4 | def _is_true(x: pd.Series) -> pd.Series:
5 | return x == "t"
6 |
7 |
8 | def _parse_percentage(x: pd.Series) -> pd.Series:
9 | x = x.str.replace("%", "")
10 | x = x.astype(float) / 100
11 | return x
12 |
13 |
14 | def _parse_money(x: pd.Series) -> pd.Series:
15 | x = x.str.replace("$", "").str.replace(",", "")
16 | x = x.astype(float)
17 | return x
18 |
19 |
20 | def preprocess_companies(companies: pd.DataFrame) -> pd.DataFrame:
21 | """Preprocesses the data for companies.
22 |
23 | Args:
24 | companies: Raw data.
25 | Returns:
26 | Preprocessed data, with `company_rating` converted to a float and
27 | `iata_approved` converted to boolean.
28 | """
29 | companies["iata_approved"] = _is_true(companies["iata_approved"])
30 | companies["company_rating"] = _parse_percentage(companies["company_rating"])
31 | return companies
32 |
33 |
34 | def preprocess_shuttles(shuttles: pd.DataFrame) -> pd.DataFrame:
35 | """Preprocesses the data for shuttles.
36 |
37 | Args:
38 | shuttles: Raw data.
39 | Returns:
40 | Preprocessed data, with `price` converted to a float and `d_check_complete`,
41 | `moon_clearance_complete` converted to boolean.
42 | """
43 | shuttles["d_check_complete"] = _is_true(shuttles["d_check_complete"])
44 | shuttles["moon_clearance_complete"] = _is_true(shuttles["moon_clearance_complete"])
45 | shuttles["price"] = _parse_money(shuttles["price"])
46 | return shuttles
47 |
48 |
49 | def create_model_input_table(
50 | shuttles: pd.DataFrame, companies: pd.DataFrame, reviews: pd.DataFrame
51 | ) -> pd.DataFrame:
52 | """Combines all data to create a model input table.
53 |
54 | Args:
55 | shuttles: Preprocessed data for shuttles.
56 | companies: Preprocessed data for companies.
57 | reviews: Raw data for reviews.
58 | Returns:
59 | Model input table.
60 |
61 | """
62 | rated_shuttles = shuttles.merge(reviews, left_on="id", right_on="shuttle_id")
63 | rated_shuttles = rated_shuttles.drop("id", axis=1)
64 | model_input_table = rated_shuttles.merge(companies, left_on="company_id", right_on="id")
65 | model_input_table = model_input_table.dropna()
66 | return model_input_table
67 |
--------------------------------------------------------------------------------
/how-to-guides/data-versioning/datasets/tables/train_v2.csv:
--------------------------------------------------------------------------------
1 | sepal.length,sepal.width,petal.length,petal.width,variety
2 | 6.1,2.8,4.7,1.2,Versicolor
3 | 6.5,3.0,5.5,1.8,Virginica
4 | 6.1,3.0,4.9,1.8,Virginica
5 | 5.5,2.6,4.4,1.2,Versicolor
6 | 5.1,3.8,1.9,0.4,Setosa
7 | 5.2,3.4,1.4,0.2,Setosa
8 | 6.3,3.3,6.0,2.5,Virginica
9 | 6.4,2.8,5.6,2.2,Virginica
10 | 5.9,3.0,5.1,1.8,Virginica
11 | 6.8,3.2,5.9,2.3,Virginica
12 | 6.2,2.8,4.8,1.8,Virginica
13 | 6.1,2.8,4.0,1.3,Versicolor
14 | 5.7,4.4,1.5,0.4,Setosa
15 | 5.1,3.8,1.6,0.2,Setosa
16 | 5.0,3.5,1.6,0.6,Setosa
17 | 4.4,2.9,1.4,0.2,Setosa
18 | 4.5,2.3,1.3,0.3,Setosa
19 | 6.5,3.0,5.2,2.0,Virginica
20 | 6.0,2.7,5.1,1.6,Versicolor
21 | 5.0,3.2,1.2,0.2,Setosa
22 | 6.8,2.8,4.8,1.4,Versicolor
23 | 5.0,3.0,1.6,0.2,Setosa
24 | 5.1,3.5,1.4,0.3,Setosa
25 | 6.7,3.0,5.2,2.3,Virginica
26 | 7.7,3.8,6.7,2.2,Virginica
27 | 5.0,3.3,1.4,0.2,Setosa
28 | 4.8,3.0,1.4,0.1,Setosa
29 | 5.4,3.9,1.3,0.4,Setosa
30 | 5.8,4.0,1.2,0.2,Setosa
31 | 6.9,3.1,4.9,1.5,Versicolor
32 | 5.6,2.5,3.9,1.1,Versicolor
33 | 6.3,2.9,5.6,1.8,Virginica
34 | 5.0,2.0,3.5,1.0,Versicolor
35 | 5.6,2.9,3.6,1.3,Versicolor
36 | 6.0,3.0,4.8,1.8,Virginica
37 | 4.9,3.0,1.4,0.2,Setosa
38 | 6.4,2.9,4.3,1.3,Versicolor
39 | 5.8,2.7,5.1,1.9,Virginica
40 | 5.4,3.0,4.5,1.5,Versicolor
41 | 6.7,3.1,4.4,1.4,Versicolor
42 | 6.0,2.9,4.5,1.5,Versicolor
43 | 5.7,2.5,5.0,2.0,Virginica
44 | 6.9,3.1,5.4,2.1,Virginica
45 | 5.1,3.8,1.5,0.3,Setosa
46 | 4.8,3.0,1.4,0.3,Setosa
47 | 4.7,3.2,1.6,0.2,Setosa
48 | 6.7,3.3,5.7,2.1,Virginica
49 | 5.0,2.3,3.3,1.0,Versicolor
50 | 5.1,3.7,1.5,0.4,Setosa
51 | 6.0,2.2,5.0,1.5,Virginica
52 | 5.7,2.8,4.1,1.3,Versicolor
53 | 5.1,3.3,1.7,0.5,Setosa
54 | 7.2,3.0,5.8,1.6,Virginica
55 | 6.6,2.9,4.6,1.3,Versicolor
56 | 6.7,3.3,5.7,2.5,Virginica
57 | 5.9,3.2,4.8,1.8,Versicolor
58 | 7.0,3.2,4.7,1.4,Versicolor
59 | 6.7,3.1,5.6,2.4,Virginica
60 | 7.2,3.6,6.1,2.5,Virginica
61 | 6.2,2.2,4.5,1.5,Versicolor
62 | 5.6,3.0,4.5,1.5,Versicolor
63 | 6.3,3.3,4.7,1.6,Versicolor
64 | 5.8,2.7,4.1,1.0,Versicolor
65 | 5.7,3.8,1.7,0.3,Setosa
66 | 7.3,2.9,6.3,1.8,Virginica
67 | 5.5,4.2,1.4,0.2,Setosa
68 | 5.4,3.4,1.7,0.2,Setosa
69 | 5.5,2.4,3.8,1.1,Versicolor
70 | 4.6,3.4,1.4,0.3,Setosa
71 | 6.5,3.2,5.1,2.0,Virginica
72 | 6.7,3.1,4.7,1.5,Versicolor
73 | 5.4,3.9,1.7,0.4,Setosa
74 | 6.4,2.8,5.6,2.1,Virginica
75 | 5.3,3.7,1.5,0.2,Setosa
76 | 7.4,2.8,6.1,1.9,Virginica
77 | 5.8,2.8,5.1,2.4,Virginica
78 | 5.2,4.1,1.5,0.1,Setosa
79 | 6.0,2.2,4.0,1.0,Versicolor
80 | 4.3,3.0,1.1,0.1,Setosa
81 | 4.9,2.4,3.3,1.0,Versicolor
82 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/kedro/scripts/spaceflights-pandas/conf/base/catalog.yml:
--------------------------------------------------------------------------------
1 | # Here you can define all your data sets by using simple YAML syntax.
2 | #
3 | # Documentation for this file format can be found in "The Data Catalog"
4 | # Link: https://docs.kedro.org/en/stable/data/data_catalog.html
5 | #
6 | # We support interacting with a variety of data stores including local file systems, cloud, network and HDFS
7 | #
8 | # An example data set definition can look as follows:
9 | #
10 | #bikes:
11 | # type: pandas.CSVDataset
12 | # filepath: "data/01_raw/bikes.csv"
13 | #
14 | #weather:
15 | # type: spark.SparkDataset
16 | # filepath: s3a://your_bucket/data/01_raw/weather*
17 | # file_format: csv
18 | # credentials: dev_s3
19 | # load_args:
20 | # header: True
21 | # inferSchema: True
22 | # save_args:
23 | # sep: '|'
24 | # header: True
25 | #
26 | #scooters:
27 | # type: pandas.SQLTableDataset
28 | # credentials: scooters_credentials
29 | # table_name: scooters
30 | # load_args:
31 | # index_col: ['name']
32 | # columns: ['name', 'gear']
33 | # save_args:
34 | # if_exists: 'replace'
35 | # # if_exists: 'fail'
36 | # # if_exists: 'append'
37 | #
38 | # The Data Catalog supports being able to reference the same file using two different Dataset implementations
39 | # (transcoding), templating and a way to reuse arguments that are frequently repeated. See more here:
40 | # https://docs.kedro.org/en/stable/data/data_catalog.html
41 |
42 | companies:
43 | type: pandas.CSVDataset
44 | filepath: data/01_raw/companies.csv
45 |
46 | companies@neptune:
47 | type: kedro_neptune.NeptuneFileDataset
48 | filepath: data/01_raw/companies.csv
49 |
50 | reviews:
51 | type: pandas.CSVDataset
52 | filepath: data/01_raw/reviews.csv
53 |
54 | shuttles:
55 | type: pandas.ExcelDataset
56 | filepath: data/01_raw/shuttles.xlsx
57 | load_args:
58 | engine: openpyxl
59 |
60 | preprocessed_companies:
61 | type: pandas.ParquetDataset
62 | filepath: data/02_intermediate/preprocessed_companies.pq
63 |
64 | preprocessed_shuttles:
65 | type: pandas.ParquetDataset
66 | filepath: data/02_intermediate/preprocessed_shuttles.pq
67 |
68 | model_input_table:
69 | type: pandas.ParquetDataset
70 | filepath: data/03_primary/model_input_table.pq
71 |
72 | regressor:
73 | type: pickle.PickleDataset
74 | filepath: data/06_models/regressor.pickle
75 | versioned: true
76 |
77 | example_csv_file:
78 | type: kedro_neptune.NeptuneFileDataset
79 | filepath: data/01_raw/companies.csv
80 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/azure-ml/dependencies/build_compute_cluster.py:
--------------------------------------------------------------------------------
1 | import logging
2 |
3 | from azure.ai.ml import MLClient
4 | from azure.ai.ml.entities import AmlCompute
5 | from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
6 |
7 | AZURE_SUBSCRIPTION_ID = ""
8 | AZUREML_RESOURCE_GROUP_NAME = ""
9 | AZUREML_WORKSPACE_NAME = ""
10 |
11 |
12 | def create_compute_cluster() -> None:
13 | try:
14 | credential = DefaultAzureCredential()
15 | credential.get_token("https://management.azure.com/.default")
16 | except Exception as ex:
17 | credential = InteractiveBrowserCredential()
18 |
19 | ml_client = MLClient(
20 | credential=credential,
21 | subscription_id=AZURE_SUBSCRIPTION_ID,
22 | resource_group_name=AZUREML_RESOURCE_GROUP_NAME,
23 | workspace_name=AZUREML_WORKSPACE_NAME,
24 | )
25 |
26 | cpu_compute_target = "cpu-cluster"
27 |
28 | try:
29 | # let's see if the compute target already exists
30 | cpu_cluster = ml_client.compute.get(cpu_compute_target)
31 | logging.info(
32 | f"You already have a cluster named {cpu_compute_target}, we'll reuse it as is."
33 | )
34 |
35 | except Exception:
36 | logging.info("Creating a new cpu compute target...")
37 |
38 | # Let's create the Azure ML compute object with the intended parameters
39 | cpu_cluster = AmlCompute(
40 | # Name assigned to the compute cluster
41 | name="cpu-cluster",
42 | # Azure ML Compute is the on-demand VM service
43 | type="amlcompute",
44 | # VM Family
45 | size="STANDARD_NC6",
46 | # Minimum running nodes when there is no job running
47 | min_instances=0,
48 | # Nodes in cluster
49 | max_instances=4,
50 | # How many seconds will the node running after the job termination
51 | idle_time_before_scale_down=180,
52 | # Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
53 | tier="Dedicated",
54 | )
55 |
56 | # Now, we pass the object to MLClient's create_or_update method
57 | cpu_cluster = ml_client.begin_create_or_update(cpu_cluster)
58 |
59 | logging.info(
60 | f"AMLCompute with name {cpu_cluster.name} is created, the compute size is {cpu_cluster.size}"
61 | )
62 |
63 |
64 | if __name__ == "__main__":
65 | create_compute_cluster()
66 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/azure-ml/scripts/model_promotion.py:
--------------------------------------------------------------------------------
1 | import logging
2 | import os
3 |
4 | import neptune
5 | from neptune.exceptions import ModelNotFound
6 |
7 | NEPTUNE_PROJECT = "common/project-time-series-forecasting" # change to your own Neptune project
8 |
9 | os.environ["NEPTUNE_PROJECT"] = "common/project-time-series-forecasting"
10 |
11 |
12 | def promote_model():
13 | # (Neptune) Get latest model from training stage
14 | model_key = "PRO"
15 | project_key = "TSF"
16 |
17 | try:
18 | model = neptune.init_model(
19 | with_id=f"{project_key}-{model_key}", # Your model ID here
20 | )
21 | model_versions_table = model.fetch_model_versions_table().to_pandas()
22 | staging_model_table = model_versions_table[model_versions_table["sys/stage"] == "staging"]
23 | challenger_model_id = staging_model_table["sys/id"].tolist()[0]
24 | production_model_table = model_versions_table[
25 | model_versions_table["sys/stage"] == "production"
26 | ]
27 | champion_model_id = production_model_table["sys/id"].tolist()[0]
28 |
29 | except ModelNotFound:
30 | logging.info(
31 | f"The model with the provided key `{model_key}` doesn't exist in the `{project_key}` project."
32 | )
33 |
34 | # (neptune) Download the lastest model checkpoint from model registry
35 | challenger = neptune.init_model_version(with_id=challenger_model_id)
36 | champion = neptune.init_model_version(with_id=champion_model_id)
37 |
38 | # (Neptune) Get model weights from training stage
39 | challenger["serialized_model"].download()
40 | champion["serialized_model"].download()
41 |
42 | # (Neptune) Move model to production
43 | challenger_score = challenger["scores"].fetch()
44 | champion_score = champion["scores"].fetch()
45 |
46 | logging.info(
47 | f"Challenger score: {challenger_score['rmse']}\nChampion score: {champion_score['rmse']}"
48 | )
49 | if challenger_score["rmse"] < champion_score["rmse"]:
50 | logging.info(
51 | f"Promoting challenger model {challenger_model_id} to production and archiving current champion model {champion_model_id}"
52 | )
53 | challenger.change_stage("production")
54 | champion.change_stage("archived")
55 | else:
56 | logging.info(
57 | f"Challenger model {challenger_model_id} underperforms champion {champion_model_id}. Archiving."
58 | )
59 | challenger.change_stage("archived")
60 |
61 |
62 | if __name__ == "__main__":
63 | promote_model()
64 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/keras/scripts/Neptune_Keras_more_options.py:
--------------------------------------------------------------------------------
1 | # Import libraries
2 | import neptune
3 | import tensorflow as tf
4 | from neptune.integrations.tensorflow_keras import NeptuneCallback
5 | from neptune.types import File
6 | from tensorflow.keras.callbacks import ModelCheckpoint
7 |
8 | # Prepare dataset
9 | mnist = tf.keras.datasets.mnist
10 | (x_train, y_train), (x_test, y_test) = mnist.load_data()
11 |
12 | # Build and compile model
13 | params = {"lr": 0.005, "momentum": 0.7, "epochs": 15, "batch_size": 256}
14 |
15 | model = tf.keras.models.Sequential(
16 | [
17 | tf.keras.layers.Flatten(),
18 | tf.keras.layers.Dense(256, activation=tf.keras.activations.relu),
19 | tf.keras.layers.Dropout(0.5),
20 | tf.keras.layers.Dense(10, activation=tf.keras.activations.softmax),
21 | ]
22 | )
23 |
24 | optimizer = tf.keras.optimizers.SGD(learning_rate=params["lr"], momentum=params["momentum"])
25 |
26 | model.compile(optimizer=optimizer, loss="sparse_categorical_crossentropy", metrics=["accuracy"])
27 |
28 | # Initialize Keras' ModelCheckpoint
29 | checkpoint_cbk = ModelCheckpoint(
30 | "checkpoints/ep{epoch:02d}-acc{accuracy:.3f}.keras",
31 | save_best_only=False,
32 | save_weights_only=False,
33 | save_freq="epoch",
34 | )
35 |
36 | # (Neptune) Initialize run
37 | run = neptune.init_run(
38 | project="common/tf-keras-integration",
39 | api_token=neptune.ANONYMOUS_API_TOKEN,
40 | tags=["script", "more options"],
41 | )
42 |
43 | # (Neptune) log hyper-parameters
44 | run["hyper-parameters"] = params
45 |
46 | # (Neptune) Initialize NeptuneCallback to log metrics during training
47 | neptune_cbk = NeptuneCallback(
48 | run=run,
49 | log_on_batch=True,
50 | log_model_diagram=False, # Requires pydot to be installed
51 | )
52 |
53 | # Fit model with callbacks
54 | model.fit(
55 | x_train,
56 | y_train,
57 | epochs=params["epochs"],
58 | batch_size=params["batch_size"],
59 | callbacks=[neptune_cbk, checkpoint_cbk],
60 | )
61 |
62 | # (Neptune) Upload model checkpoints
63 | run["checkpoints"].upload_files("checkpoints")
64 |
65 | # (Neptune) Upload final model
66 | model.save("my_model.keras")
67 |
68 | run["saved_model"].upload("my_model.keras")
69 |
70 | # (Neptune) log test images with prediction
71 | for image, label in zip(x_test[:10], y_test[:10]):
72 | prediction = model.predict(image[None], verbose=0)
73 | predicted = prediction.argmax()
74 | desc = f"label : {label} | predicted : {predicted}"
75 | run["visualization/test_prediction"].append(File.as_image(image), description=desc)
76 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/kedro/scripts/spaceflights-pandas/.gitignore:
--------------------------------------------------------------------------------
1 | ##########################
2 | # KEDRO PROJECT
3 |
4 | # ignore all local configuration
5 | conf/local/**
6 | !conf/local/.gitkeep
7 |
8 | # ignore potentially sensitive credentials files
9 | conf/**/*credentials*
10 |
11 | # ignore everything in the following folders
12 | data/**
13 |
14 | # except their sub-folders
15 | !data/**/
16 |
17 | # also keep all .gitkeep files
18 | !.gitkeep
19 |
20 | # keep also the example dataset
21 | !data/01_raw/*
22 |
23 |
24 | ##########################
25 | # Common files
26 |
27 | # IntelliJ
28 | .idea/
29 | *.iml
30 | out/
31 | .idea_modules/
32 |
33 | ### macOS
34 | *.DS_Store
35 | .AppleDouble
36 | .LSOverride
37 | .Trashes
38 |
39 | # Vim
40 | *~
41 | .*.swo
42 | .*.swp
43 |
44 | # emacs
45 | *~
46 | \#*\#
47 | /.emacs.desktop
48 | /.emacs.desktop.lock
49 | *.elc
50 |
51 | # JIRA plugin
52 | atlassian-ide-plugin.xml
53 |
54 | # C extensions
55 | *.so
56 |
57 | ### Python template
58 | # Byte-compiled / optimized / DLL files
59 | __pycache__/
60 | *.py[cod]
61 | *$py.class
62 |
63 | # Distribution / packaging
64 | .Python
65 | build/
66 | develop-eggs/
67 | dist/
68 | downloads/
69 | eggs/
70 | .eggs/
71 | lib/
72 | lib64/
73 | parts/
74 | sdist/
75 | var/
76 | wheels/
77 | *.egg-info/
78 | .installed.cfg
79 | *.egg
80 | MANIFEST
81 |
82 | # PyInstaller
83 | # Usually these files are written by a python script from a template
84 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
85 | *.manifest
86 | *.spec
87 |
88 | # Installer logs
89 | pip-log.txt
90 | pip-delete-this-directory.txt
91 |
92 | # Unit test / coverage reports
93 | htmlcov/
94 | .tox/
95 | .coverage
96 | .coverage.*
97 | .cache
98 | nosetests.xml
99 | coverage.xml
100 | *.cover
101 | .hypothesis/
102 |
103 | # Translations
104 | *.mo
105 | *.pot
106 |
107 | # Django stuff:
108 | *.log
109 | .static_storage/
110 | .media/
111 | local_settings.py
112 |
113 | # Flask stuff:
114 | instance/
115 | .webassets-cache
116 |
117 | # Scrapy stuff:
118 | .scrapy
119 |
120 | # Sphinx documentation
121 | docs/_build/
122 |
123 | # PyBuilder
124 | target/
125 |
126 | # Jupyter Notebook
127 | .ipynb_checkpoints
128 |
129 | # pyenv
130 | .python-version
131 |
132 | # celery beat schedule file
133 | celerybeat-schedule
134 |
135 | # SageMath parsed files
136 | *.sage.py
137 |
138 | # Environments
139 | .env
140 | .venv
141 | env/
142 | venv/
143 | ENV/
144 | env.bak/
145 | venv.bak/
146 |
147 | # mkdocs documentation
148 | /site
149 |
150 | # mypy
151 | .mypy_cache/
152 |
--------------------------------------------------------------------------------
/how-to-guides/neptune-docker/scripts/training.py:
--------------------------------------------------------------------------------
1 | import neptune
2 | import torch
3 | import torch.nn as nn
4 | import torch.optim as optim
5 | from neptune.utils import stringify_unsupported
6 | from torchvision import datasets, transforms
7 |
8 | # Initialize Neptune and create a new Neptune run
9 | run = neptune.init_run(project="common/showroom", tags="Neptune Docker")
10 |
11 | data_dir = "data/CIFAR10"
12 | compressed_ds = "./data/CIFAR10/cifar-10-python.tar.gz"
13 | data_tfms = {
14 | "train": transforms.Compose(
15 | [
16 | transforms.RandomHorizontalFlip(),
17 | transforms.ToTensor(),
18 | transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
19 | ]
20 | )
21 | }
22 |
23 | params = {
24 | "lr": 1e-2,
25 | "batch_size": 128,
26 | "input_size": 32 * 32 * 3,
27 | "n_classes": 10,
28 | "model_filename": "basemodel",
29 | }
30 |
31 |
32 | class BaseModel(nn.Module):
33 | def __init__(self, input_size, hidden_dim, n_classes):
34 | super(BaseModel, self).__init__()
35 | self.main = nn.Sequential(
36 | nn.Linear(input_size, hidden_dim * 2),
37 | nn.ReLU(),
38 | nn.Linear(hidden_dim * 2, hidden_dim),
39 | nn.ReLU(),
40 | nn.Linear(hidden_dim, hidden_dim // 2),
41 | nn.ReLU(),
42 | nn.Linear(hidden_dim // 2, n_classes),
43 | )
44 |
45 | def forward(self, input):
46 | x = input.view(-1, 32 * 32 * 3)
47 | return self.main(x)
48 |
49 |
50 | trainset = datasets.CIFAR10(data_dir, transform=data_tfms["train"], download=True)
51 | trainloader = torch.utils.data.DataLoader(trainset, batch_size=params["batch_size"], shuffle=True)
52 | dataset_size = {"train": len(trainset)}
53 |
54 | model = BaseModel(params["input_size"], params["input_size"], params["n_classes"])
55 | criterion = nn.CrossEntropyLoss()
56 | optimizer = optim.SGD(model.parameters(), lr=params["lr"])
57 |
58 | # Log config & parameters
59 | run["config/dataset/path"] = data_dir
60 | run["config/dataset/transforms"] = stringify_unsupported(data_tfms)
61 | run["config/dataset/size"] = dataset_size
62 | run["config/params"] = params
63 |
64 | # Log losses & metrics
65 | for i, (x, y) in enumerate(trainloader, 0):
66 | optimizer.zero_grad()
67 | outputs = model.forward(x)
68 | _, preds = torch.max(outputs, 1)
69 | loss = criterion(outputs, y)
70 | acc = (torch.sum(preds == y.data)) / len(x)
71 |
72 | # Log batch loss
73 | run["metrics/training/batch/loss"].append(loss)
74 |
75 | # Log batch accuracy
76 | run["metrics/training/batch/acc"].append(acc)
77 |
78 | loss.backward()
79 | optimizer.step()
80 |
--------------------------------------------------------------------------------
/how-to-guides/data-versioning/datasets/tables/train_sampled.csv:
--------------------------------------------------------------------------------
1 | sepal.length,sepal.width,petal.length,petal.width,variety
2 | 5.6,2.9,3.6,1.3,Versicolor
3 | 6.4,2.8,5.6,2.1,Virginica
4 | 5.8,4.0,1.2,0.2,Setosa
5 | 4.4,2.9,1.4,0.2,Setosa
6 | 5.5,2.4,3.8,1.1,Versicolor
7 | 5.7,2.5,5.0,2.0,Virginica
8 | 5.0,3.2,1.2,0.2,Setosa
9 | 4.8,3.4,1.6,0.2,Setosa
10 | 5.4,3.4,1.5,0.4,Setosa
11 | 5.0,2.3,3.3,1.0,Versicolor
12 | 5.1,3.8,1.9,0.4,Setosa
13 | 6.3,3.3,6.0,2.5,Virginica
14 | 7.4,2.8,6.1,1.9,Virginica
15 | 5.7,4.4,1.5,0.4,Setosa
16 | 6.3,3.3,4.7,1.6,Versicolor
17 | 6.3,2.9,5.6,1.8,Virginica
18 | 5.4,3.9,1.3,0.4,Setosa
19 | 5.7,3.8,1.7,0.3,Setosa
20 | 6.4,3.2,5.3,2.3,Virginica
21 | 5.4,3.0,4.5,1.5,Versicolor
22 | 5.8,2.7,5.1,1.9,Virginica
23 | 5.1,3.7,1.5,0.4,Setosa
24 | 6.2,2.2,4.5,1.5,Versicolor
25 | 6.9,3.1,4.9,1.5,Versicolor
26 | 6.9,3.1,5.4,2.1,Virginica
27 | 6.1,2.8,4.0,1.3,Versicolor
28 | 4.5,2.3,1.3,0.3,Setosa
29 | 7.3,2.9,6.3,1.8,Virginica
30 | 7.2,3.2,6.0,1.8,Virginica
31 | 6.0,2.7,5.1,1.6,Versicolor
32 | 5.5,2.5,4.0,1.3,Versicolor
33 | 6.7,3.1,5.6,2.4,Virginica
34 | 4.4,3.2,1.3,0.2,Setosa
35 | 6.7,3.1,4.7,1.5,Versicolor
36 | 5.7,3.0,4.2,1.2,Versicolor
37 | 6.1,3.0,4.6,1.4,Versicolor
38 | 4.4,3.0,1.3,0.2,Setosa
39 | 5.9,3.0,5.1,1.8,Virginica
40 | 6.8,3.2,5.9,2.3,Virginica
41 | 5.0,3.0,1.6,0.2,Setosa
42 | 6.1,2.9,4.7,1.4,Versicolor
43 | 6.0,2.9,4.5,1.5,Versicolor
44 | 6.4,2.8,5.6,2.2,Virginica
45 | 4.7,3.2,1.6,0.2,Setosa
46 | 6.7,3.1,4.4,1.4,Versicolor
47 | 5.2,4.1,1.5,0.1,Setosa
48 | 5.1,3.8,1.5,0.3,Setosa
49 | 4.8,3.0,1.4,0.1,Setosa
50 | 6.4,2.9,4.3,1.3,Versicolor
51 | 5.0,3.5,1.6,0.6,Setosa
52 | 6.5,3.2,5.1,2.0,Virginica
53 | 4.3,3.0,1.1,0.1,Setosa
54 | 5.8,2.7,4.1,1.0,Versicolor
55 | 5.0,3.3,1.4,0.2,Setosa
56 | 7.0,3.2,4.7,1.4,Versicolor
57 | 4.6,3.4,1.4,0.3,Setosa
58 | 5.8,2.8,5.1,2.4,Virginica
59 | 5.4,3.4,1.7,0.2,Setosa
60 | 4.9,2.4,3.3,1.0,Versicolor
61 | 6.7,3.3,5.7,2.1,Virginica
62 | 6.0,2.2,5.0,1.5,Virginica
63 | 5.5,2.4,3.7,1.0,Versicolor
64 | 6.7,3.3,5.7,2.5,Virginica
65 | 7.2,3.0,5.8,1.6,Virginica
66 | 5.4,3.9,1.7,0.4,Setosa
67 | 5.0,2.0,3.5,1.0,Versicolor
68 | 5.1,3.5,1.4,0.3,Setosa
69 | 4.9,3.0,1.4,0.2,Setosa
70 | 6.0,2.2,4.0,1.0,Versicolor
71 | 7.7,3.8,6.7,2.2,Virginica
72 | 5.6,2.5,3.9,1.1,Versicolor
73 | 4.8,3.4,1.9,0.2,Setosa
74 | 6.5,3.0,5.2,2.0,Virginica
75 | 5.7,2.8,4.1,1.3,Versicolor
76 | 5.1,3.8,1.6,0.2,Setosa
77 | 5.1,3.3,1.7,0.5,Setosa
78 | 5.3,3.7,1.5,0.2,Setosa
79 | 6.5,3.0,5.5,1.8,Virginica
80 | 6.3,2.5,4.9,1.5,Versicolor
81 | 6.1,3.0,4.9,1.8,Virginica
82 | 5.4,3.7,1.5,0.2,Setosa
83 | 5.9,3.2,4.8,1.8,Versicolor
84 | 4.6,3.2,1.4,0.2,Setosa
85 | 7.2,3.6,6.1,2.5,Virginica
86 | 5.5,4.2,1.4,0.2,Setosa
87 | 7.7,2.6,6.9,2.3,Virginica
88 | 5.6,3.0,4.5,1.5,Versicolor
89 | 5.8,2.6,4.0,1.2,Versicolor
90 | 6.0,3.0,4.8,1.8,Virginica
91 | 6.8,2.8,4.8,1.4,Versicolor
92 |
--------------------------------------------------------------------------------
/.github/workflows/adhoc-test.yml:
--------------------------------------------------------------------------------
1 | name: Adhoc tests
2 | on:
3 | workflow_dispatch:
4 | inputs:
5 | path:
6 | description:
7 | "Path of the notebook/script to test, relative to the repo root.
8 | For scripts, this should be the path of the `scripts` folder"
9 | required: true
10 | type: string
11 | python_version:
12 | description: "Python version"
13 | required: true
14 | default: "3.10"
15 | type: choice
16 | options:
17 | - "3.9"
18 | - "3.10"
19 | - "3.11"
20 | - "3.12"
21 | - "3.13"
22 | os:
23 | description: "Windows/Ubuntu/MacOS"
24 | required: true
25 | default: "ubuntu-latest"
26 | type: choice
27 | options:
28 | - ubuntu-latest
29 | - macos-13
30 | - windows-latest
31 | env:
32 | PYTHONIOENCODING: utf-8
33 | PYTHONLEGACYWINDOWSSTDIO: utf-8
34 | jobs:
35 | run-tests:
36 | runs-on: ${{ inputs.os }}
37 | steps:
38 | - uses: actions/checkout@main
39 | - uses: actions/setup-python@main
40 | with:
41 | python-version: ${{ inputs.python_version }}
42 | cache: "pip"
43 | - name: Upgrade pip
44 | run: python -m pip install --upgrade pip
45 | - name: Install setuptools for python>=3.12
46 | if: inputs.python_version >= 3.12
47 | run: pip install -U setuptools
48 | - name: Install libomp on MacOS
49 | if: inputs.os == 'macos-13'
50 | run: brew install libomp
51 | - name: Test scripts
52 | if: endsWith(inputs.path, 'scripts')
53 | uses: nick-fields/retry@v3
54 | env:
55 | NEPTUNE_API_TOKEN: "ANONYMOUS"
56 | AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
57 | AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_ACCESS_KEY_ID }}
58 | with:
59 | timeout_minutes: 60
60 | max_attempts: 2
61 | command: |
62 | cd ${{ inputs.path }}
63 | bash run_examples.sh
64 | - name: Test notebooks
65 | if: endsWith(inputs.path, '.ipynb')
66 | uses: nick-fields/retry@v3
67 | env:
68 | NEPTUNE_API_TOKEN: "ANONYMOUS"
69 | AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
70 | AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_ACCESS_KEY_ID }}
71 | with:
72 | timeout_minutes: 60
73 | max_attempts: 2
74 | command: |
75 | pip install -U -r requirements.txt
76 | ipython ${{ inputs.path }}
77 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/sacred/scripts/Neptune_Sacred.py:
--------------------------------------------------------------------------------
1 | import neptune
2 | import torch
3 | import torch.nn as nn
4 | import torch.optim as optim
5 | from neptune.integrations.sacred import NeptuneObserver
6 | from sacred import Experiment
7 | from torchvision import datasets, transforms
8 |
9 | if torch.device("cuda:0"):
10 | torch.cuda.empty_cache()
11 |
12 | # Initialize Neptune and create new Neptune run
13 | neptune_run = neptune.init_run(
14 | project="common/sacred-integration",
15 | api_token=neptune.ANONYMOUS_API_TOKEN,
16 | tags="basic",
17 | )
18 |
19 | # Add NeptuneObserver() to your sacred experiment's observers
20 | ex = Experiment("image_classification")
21 | ex.observers.append(NeptuneObserver(run=neptune_run))
22 |
23 |
24 | class BaseModel(nn.Module):
25 | def __init__(self, input_sz=32 * 32 * 3, n_classes=10):
26 | super(BaseModel, self).__init__()
27 | self.lin = nn.Linear(input_sz, n_classes)
28 |
29 | def forward(self, input):
30 | x = input.view(-1, 32 * 32 * 3)
31 | return self.lin(x)
32 |
33 |
34 | # Log hyperparameters
35 | @ex.config
36 | def cfg():
37 | data_dir = "data/CIFAR10"
38 | data_tfms = {
39 | "train": transforms.Compose(
40 | [
41 | transforms.RandomHorizontalFlip(),
42 | transforms.ToTensor(),
43 | transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
44 | ]
45 | )
46 | }
47 | lr = 1e-2
48 | bs = 128
49 | n_classes = 10
50 | input_sz = 32 * 32 * 3
51 | device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
52 |
53 |
54 | # Log loss and metrics
55 | @ex.main
56 | def run(data_dir, data_tfms, input_sz, n_classes, lr, bs, device, _run):
57 | trainset = datasets.CIFAR10(data_dir, transform=data_tfms["train"], download=True)
58 | trainloader = torch.utils.data.DataLoader(trainset, batch_size=bs, shuffle=True)
59 | model = BaseModel(input_sz, n_classes).to(device)
60 | criterion = nn.CrossEntropyLoss()
61 | optimizer = optim.SGD(model.parameters(), lr=lr)
62 | for i, (x, y) in enumerate(trainloader, 0):
63 | x, y = x.to(device), y.to(device)
64 | optimizer.zero_grad()
65 | outputs = model.forward(x)
66 | _, preds = torch.max(outputs, 1)
67 | loss = criterion(outputs, y)
68 | acc = (torch.sum(preds == y.data)) / len(x)
69 |
70 | # Log loss
71 | ex.log_scalar("training/batch/loss", loss)
72 | # Log accuracy
73 | ex.log_scalar("training/batch/acc", acc)
74 |
75 | loss.backward()
76 | optimizer.step()
77 |
78 | return {"final_loss": loss.item(), "final_acc": acc.cpu().item()}
79 |
80 |
81 | # Run you experiment and explore metadata in the Neptune app
82 | ex.run()
83 |
--------------------------------------------------------------------------------
/how-to-guides/data-versioning/scripts/Compare_model_training_runs_on_dataset_versions.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 |
3 | import neptune
4 | import pandas as pd
5 | import requests
6 | from sklearn.ensemble import RandomForestClassifier
7 |
8 | # Download dataset
9 |
10 | dataset_path = Path.relative_to(Path.absolute(Path(__file__)).parent, Path.cwd())
11 |
12 | for file in ["train.csv", "test.csv", "train_v2.csv"]:
13 | r = requests.get(
14 | f"https://raw.githubusercontent.com/neptune-ai/examples/main/how-to-guides/data-versioning/datasets/tables/{file}",
15 | allow_redirects=True,
16 | )
17 |
18 | open(dataset_path.joinpath(file), "wb").write(r.content)
19 |
20 |
21 | TRAIN_DATASET_PATH = str(dataset_path.joinpath("train.csv"))
22 | TEST_DATASET_PATH = str(dataset_path.joinpath("test.csv"))
23 |
24 |
25 | params = {
26 | "n_estimators": 7,
27 | "max_depth": 2,
28 | "max_features": 2,
29 | }
30 |
31 |
32 | def train_model(params, train_path, test_path):
33 | train = pd.read_csv(train_path)
34 | test = pd.read_csv(test_path)
35 |
36 | FEATURE_COLUMNS = ["sepal.length", "sepal.width", "petal.length", "petal.width"]
37 | TARGET_COLUMN = ["variety"]
38 | X_train, y_train = train[FEATURE_COLUMNS], train[TARGET_COLUMN]
39 | X_test, y_test = test[FEATURE_COLUMNS], test[TARGET_COLUMN]
40 |
41 | rf = RandomForestClassifier(**params)
42 | rf.fit(X_train, y_train)
43 |
44 | return rf.score(X_test, y_test)
45 |
46 |
47 | #
48 | # Run model training and log dataset version, parameter and test score to Neptune
49 | #
50 |
51 | # Create Neptune run and start logging
52 | run = neptune.init_run(project="common/data-versioning", api_token=neptune.ANONYMOUS_API_TOKEN)
53 |
54 | # Track dataset version
55 | run["datasets/train"].track_files(TRAIN_DATASET_PATH)
56 | run["datasets/test"].track_files(TEST_DATASET_PATH)
57 |
58 | # Log parameters
59 | run["parameters"] = params
60 |
61 | # Calculate and log test score
62 | score = train_model(params, TRAIN_DATASET_PATH, TEST_DATASET_PATH)
63 | run["metrics/test_score"] = score
64 |
65 | # Stop logging to the active Neptune run
66 | run.stop()
67 |
68 | #
69 | # Change the training data
70 | # Run model training log dataset version, parameter and test score to Neptune
71 | #
72 |
73 | TRAIN_DATASET_PATH = str(dataset_path.joinpath("train_v2.csv"))
74 |
75 | # Create a new Neptune run and start logging
76 | new_run = neptune.init_run(project="common/data-versioning", api_token=neptune.ANONYMOUS_API_TOKEN)
77 |
78 | # Log dataset versions
79 | new_run["datasets/train"].track_files(TRAIN_DATASET_PATH)
80 | new_run["datasets/test"].track_files(TEST_DATASET_PATH)
81 |
82 | # Log parameters
83 | new_run["parameters"] = params
84 |
85 | # Calculate and log test score
86 | score = train_model(params, TRAIN_DATASET_PATH, TEST_DATASET_PATH)
87 | new_run["metrics/test_score"] = score
88 |
89 | # Stop logging to the active Neptune run
90 | new_run.stop()
91 |
92 | #
93 | # Go to Neptune to see how the datasets changed between training runs!
94 | #
95 |
--------------------------------------------------------------------------------
/utils/migration_tools/from_another_project/README.md:
--------------------------------------------------------------------------------
1 | # Exporting runs
2 |
3 | This script allows you to export runs from one project to another within the same or different workspaces.
4 |
5 | ## Instructions
6 |
7 | To use the script, follow these steps:
8 |
9 | 1. Execute `runs_migrator.py`.
10 | 2. Enter the source and target project names using the format `WORKSPACE_NAME/PROJECT_NAME`. A private target project will be created if it does not already exist.
11 | 3. Enter your API tokens from the source and target workspaces.
12 | 4. Enter the number of workers to use to copy the metadata. Leave blank to let `ThreadPoolExecutor` decide.
13 | 5. The script will generate run logs in the working directory. You can modify this location by editing the `logging.basicConfig()` function.
14 | 6. The source run of a migrated run can be idenfied from the `old_sys/run_id` field of the migrated run.
15 |
16 | ## Note
17 |
18 | There are a few things to keep in mind when using this script:
19 |
20 | - Avoid creating new runs in the source project while the script is running as these might not be copied.
21 | - Currently, only run metadata is copied. Project and model metadata are not copied†.
22 | - All runs from the source project will be copied to the target project. It is not possible to filter runs currently†.
23 | - Most of the namespaces from the source runs will be retained in the target runs, except for the following:
24 | - `sys` namespace:
25 | - The `state` field cannot be copied.
26 | - The `description`, `name`, `custom_run_id`, `tags`, and `group_tags` fields are copied to the `sys` namespace in the target run.
27 | - All other fields are copied to a new `old_sys` namespace in the target run.
28 | - The `source_code/git` namespace cannot be copied.
29 | - The relative time x-axis in copied charts is based on the `sys/creation_time` of the source runs. Since this field is read-only, the relative time will be negative in the copied charts, as the logging time occurred before the creation time of the target run.
30 | - The hash of tracked artifacts may change between the source and target runs.
31 | - File metadata is stored in the `.tmp_%Y%m%d%H%M%S` folder in the working directory. This folder can be deleted after the migration and sanity checks.
32 |
33 | † Support for these can be added based on feedback
34 |
35 | ## Support
36 |
37 | If you encounter any bugs or have feature requests, please submit them as [GitHub Issues](https://github.com/neptune-ai/examples/issues).
38 |
39 | ## License
40 |
41 | Copyright (c) 2024, Neptune Labs Sp. z o.o.
42 |
43 | Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0
44 |
45 | Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
46 | See the License for the specific language governing permissions and limitations under the License.
47 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/skorch/scripts/Neptune_Skorch_more_options.py:
--------------------------------------------------------------------------------
1 | import neptune
2 | import numpy as np
3 | import torch
4 | import torch.nn.functional as F
5 | from neptune.types import File
6 | from sklearn.datasets import fetch_openml
7 | from sklearn.metrics import accuracy_score
8 | from sklearn.model_selection import train_test_split
9 | from skorch import NeuralNetClassifier
10 | from skorch.callbacks import Checkpoint, NeptuneLogger
11 | from torch import nn
12 |
13 | # Define hyper-parameters
14 | params = {
15 | "batch_size": 2,
16 | "lr": 0.1,
17 | "max_epochs": 10,
18 | }
19 |
20 | # Load data
21 | mnist = fetch_openml("mnist_784", as_frame=False, cache=False)
22 |
23 | # Preprocess data
24 | X = mnist.data.astype("float32")
25 | y = mnist.target.astype("int64")
26 |
27 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
28 |
29 | # Build a neural network with PyTorch
30 | device = "cuda" if torch.cuda.is_available() else "cpu"
31 | mnist_dim = X.shape[1]
32 | hidden_dim = int(mnist_dim / 8)
33 | output_dim = len(np.unique(mnist.target))
34 |
35 |
36 | class ClassifierModule(nn.Module):
37 | def __init__(
38 | self,
39 | input_dim=mnist_dim,
40 | hidden_dim=hidden_dim,
41 | output_dim=output_dim,
42 | dropout=0.5,
43 | ):
44 | super(ClassifierModule, self).__init__()
45 | self.dropout = nn.Dropout(dropout)
46 |
47 | self.hidden = nn.Linear(input_dim, hidden_dim)
48 | self.output = nn.Linear(hidden_dim, output_dim)
49 |
50 | def forward(self, X, **kwargs):
51 | X = F.relu(self.hidden(X))
52 | X = self.dropout(X)
53 | X = F.softmax(self.output(X), dim=-1)
54 | return X
55 |
56 |
57 | # (Neptune) Initialize Neptune run
58 | run = neptune.init_run(api_token=neptune.ANONYMOUS_API_TOKEN, project="common/skorch-integration")
59 | # (Neptune) Create NeptuneLogger
60 | neptune_logger = NeptuneLogger(run, close_after_train=False)
61 |
62 | # Initialize checkpoint callback
63 | checkpoint_dirname = "./checkpoints"
64 | checkpoint = Checkpoint(dirname=checkpoint_dirname)
65 |
66 | # Initialize a trainer and pass neptune_logger
67 | net = NeuralNetClassifier(
68 | ClassifierModule,
69 | max_epochs=params["max_epochs"],
70 | lr=params["lr"],
71 | device=device,
72 | callbacks=[neptune_logger, checkpoint],
73 | )
74 |
75 | # Train the model and log metadata to the Neptune run
76 | net.fit(X_train, y_train)
77 |
78 | # (Neptune) Log model weights
79 | neptune_logger.run["training/model/checkpoints"].upload_files(checkpoint_dirname)
80 |
81 | # (Neptune) Log test score
82 | y_pred = net.predict(X_test)
83 | neptune_logger.run["training/test/acc"] = accuracy_score(y_test, y_pred)
84 |
85 | # (Neptune) Log misclassified images
86 | error_mask = y_pred != y_test
87 | for x, y_hat, y in zip(X_test[error_mask], y_pred[error_mask], y_test[error_mask]):
88 | x_reshaped = x.reshape(28, 28)
89 | neptune_logger.run["training/test/misclassified_images"].append(
90 | File.as_image(x_reshaped), description=f"y_pred={y_hat}, y_true={y}"
91 | )
92 |
--------------------------------------------------------------------------------
/how-to-guides/data-versioning/datasets/tables/train.csv:
--------------------------------------------------------------------------------
1 | sepal.length,sepal.width,petal.length,petal.width,variety
2 | 6.0,2.7,5.1,1.6,Versicolor
3 | 4.9,3.0,1.4,0.2,Setosa
4 | 5.0,3.2,1.2,0.2,Setosa
5 | 5.0,2.3,3.3,1.0,Versicolor
6 | 5.4,3.9,1.7,0.4,Setosa
7 | 7.2,3.2,6.0,1.8,Virginica
8 | 4.6,3.2,1.4,0.2,Setosa
9 | 5.7,3.0,4.2,1.2,Versicolor
10 | 6.3,2.9,5.6,1.8,Virginica
11 | 7.3,2.9,6.3,1.8,Virginica
12 | 4.8,3.4,1.6,0.2,Setosa
13 | 6.7,3.1,4.4,1.4,Versicolor
14 | 6.1,2.8,4.7,1.2,Versicolor
15 | 6.4,2.8,5.6,2.2,Virginica
16 | 6.1,2.8,4.0,1.3,Versicolor
17 | 7.7,2.6,6.9,2.3,Virginica
18 | 6.3,3.3,6.0,2.5,Virginica
19 | 5.0,3.0,1.6,0.2,Setosa
20 | 6.8,3.2,5.9,2.3,Virginica
21 | 5.6,2.9,3.6,1.3,Versicolor
22 | 5.6,2.5,3.9,1.1,Versicolor
23 | 6.6,2.9,4.6,1.3,Versicolor
24 | 4.8,3.0,1.4,0.3,Setosa
25 | 5.9,3.2,4.8,1.8,Versicolor
26 | 6.2,2.2,4.5,1.5,Versicolor
27 | 4.5,2.3,1.3,0.3,Setosa
28 | 6.5,3.2,5.1,2.0,Virginica
29 | 5.8,2.7,4.1,1.0,Versicolor
30 | 5.4,3.0,4.5,1.5,Versicolor
31 | 5.5,2.5,4.0,1.3,Versicolor
32 | 6.1,3.0,4.9,1.8,Virginica
33 | 5.5,2.4,3.7,1.0,Versicolor
34 | 4.4,3.2,1.3,0.2,Setosa
35 | 5.4,3.7,1.5,0.2,Setosa
36 | 5.0,3.5,1.6,0.6,Setosa
37 | 4.3,3.0,1.1,0.1,Setosa
38 | 5.5,4.2,1.4,0.2,Setosa
39 | 6.0,2.2,5.0,1.5,Virginica
40 | 7.4,2.8,6.1,1.9,Virginica
41 | 5.1,3.8,1.5,0.3,Setosa
42 | 6.9,3.1,5.4,2.1,Virginica
43 | 5.0,3.5,1.3,0.3,Setosa
44 | 7.2,3.0,5.8,1.6,Virginica
45 | 5.1,3.5,1.4,0.3,Setosa
46 | 7.0,3.2,4.7,1.4,Versicolor
47 | 5.7,3.8,1.7,0.3,Setosa
48 | 5.7,2.5,5.0,2.0,Virginica
49 | 4.6,3.4,1.4,0.3,Setosa
50 | 5.1,3.3,1.7,0.5,Setosa
51 | 5.1,3.8,1.9,0.4,Setosa
52 | 5.7,4.4,1.5,0.4,Setosa
53 | 6.0,3.0,4.8,1.8,Virginica
54 | 5.4,3.4,1.7,0.2,Setosa
55 | 4.7,3.2,1.6,0.2,Setosa
56 | 5.6,3.0,4.5,1.5,Versicolor
57 | 6.1,3.0,4.6,1.4,Versicolor
58 | 5.8,2.8,5.1,2.4,Virginica
59 | 5.3,3.7,1.5,0.2,Setosa
60 | 6.4,3.2,5.3,2.3,Virginica
61 | 6.7,3.3,5.7,2.5,Virginica
62 | 5.7,2.8,4.1,1.3,Versicolor
63 | 5.1,3.7,1.5,0.4,Setosa
64 | 4.4,2.9,1.4,0.2,Setosa
65 | 6.2,2.8,4.8,1.8,Virginica
66 | 4.9,2.5,4.5,1.7,Virginica
67 | 5.5,2.6,4.4,1.2,Versicolor
68 | 6.3,2.5,4.9,1.5,Versicolor
69 | 6.1,2.9,4.7,1.4,Versicolor
70 | 6.5,3.0,5.2,2.0,Virginica
71 | 5.0,3.3,1.4,0.2,Setosa
72 | 7.7,3.8,6.7,2.2,Virginica
73 | 6.4,2.9,4.3,1.3,Versicolor
74 | 6.5,3.0,5.5,1.8,Virginica
75 | 6.5,3.0,5.8,2.2,Virginica
76 | 6.9,3.1,4.9,1.5,Versicolor
77 | 5.1,3.8,1.6,0.2,Setosa
78 | 4.4,3.0,1.3,0.2,Setosa
79 | 6.7,3.0,5.2,2.3,Virginica
80 | 5.8,2.7,5.1,1.9,Virginica
81 | 5.0,2.0,3.5,1.0,Versicolor
82 | 4.9,2.4,3.3,1.0,Versicolor
83 | 6.7,3.1,5.6,2.4,Virginica
84 | 6.7,3.3,5.7,2.1,Virginica
85 | 5.2,3.4,1.4,0.2,Setosa
86 | 6.4,2.8,5.6,2.1,Virginica
87 | 4.8,3.4,1.9,0.2,Setosa
88 | 5.4,3.9,1.3,0.4,Setosa
89 | 4.8,3.0,1.4,0.1,Setosa
90 | 6.8,2.8,4.8,1.4,Versicolor
91 | 7.2,3.6,6.1,2.5,Virginica
92 | 5.8,2.6,4.0,1.2,Versicolor
93 | 5.2,4.1,1.5,0.1,Setosa
94 | 5.5,2.4,3.8,1.1,Versicolor
95 | 5.8,4.0,1.2,0.2,Setosa
96 | 6.3,3.3,4.7,1.6,Versicolor
97 | 6.7,3.1,4.7,1.5,Versicolor
98 | 6.0,2.9,4.5,1.5,Versicolor
99 | 5.9,3.0,5.1,1.8,Virginica
100 | 5.4,3.4,1.5,0.4,Setosa
101 | 6.0,2.2,4.0,1.0,Versicolor
102 |
--------------------------------------------------------------------------------
/how-to-guides/reproduce-run/scripts/old_run.py:
--------------------------------------------------------------------------------
1 | import neptune
2 | import torch
3 | import torch.nn as nn
4 | import torch.optim as optim
5 | from neptune.utils import stringify_unsupported
6 | from torchvision import datasets, transforms
7 |
8 | ###################################################################
9 | # (Neptune) Step 1: Initialize Neptune and create new Neptune run #
10 | ###################################################################
11 | run = neptune.init_run(
12 | project="common/showroom",
13 | tags="Basic script",
14 | api_token=neptune.ANONYMOUS_API_TOKEN,
15 | )
16 |
17 | # Experiment Config
18 | data_dir = "data/CIFAR10"
19 | compressed_ds = "./data/CIFAR10/cifar-10-python.tar.gz"
20 | data_tfms = {
21 | "train": transforms.Compose(
22 | [
23 | transforms.RandomHorizontalFlip(),
24 | transforms.ToTensor(),
25 | transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
26 | ]
27 | )
28 | }
29 |
30 | params = {
31 | "lr": 1e-2,
32 | "bs": 128,
33 | "input_sz": 32 * 32 * 3,
34 | "n_classes": 10,
35 | "model_filename": "basemodel",
36 | }
37 |
38 |
39 | # Model & Dataset
40 | class BaseModel(nn.Module):
41 | def __init__(self, input_sz, hidden_dim, n_classes):
42 | super(BaseModel, self).__init__()
43 | self.main = nn.Sequential(
44 | nn.Linear(input_sz, hidden_dim * 2),
45 | nn.ReLU(),
46 | nn.Linear(hidden_dim * 2, hidden_dim),
47 | nn.ReLU(),
48 | nn.Linear(hidden_dim, hidden_dim // 2),
49 | nn.ReLU(),
50 | nn.Linear(hidden_dim // 2, n_classes),
51 | )
52 |
53 | def forward(self, input):
54 | x = input.view(-1, 32 * 32 * 3)
55 | return self.main(x)
56 |
57 |
58 | trainset = datasets.CIFAR10(data_dir, transform=data_tfms["train"], download=True)
59 | trainloader = torch.utils.data.DataLoader(
60 | trainset, batch_size=params["bs"], shuffle=True, num_workers=0
61 | )
62 | dataset_size = {"train": len(trainset)}
63 |
64 | # Instatiate model, criterion and optimizer
65 | model = BaseModel(params["input_sz"], params["input_sz"], params["n_classes"])
66 | criterion = nn.CrossEntropyLoss()
67 | optimizer = optim.SGD(model.parameters(), lr=params["lr"])
68 |
69 | ###############################################
70 | # (Neptune) Step 2: Log config & pararameters #
71 | ###############################################
72 | run["config/dataset/path"] = data_dir
73 | run["config/dataset/transforms"] = stringify_unsupported(data_tfms)
74 | run["config/dataset/size"] = dataset_size
75 | run["config/params"] = stringify_unsupported(params)
76 |
77 | ##########################################
78 | # (Neptune) Step 3: Log losses & metrics #
79 | ##########################################
80 | for i, (x, y) in enumerate(trainloader, 0):
81 | optimizer.zero_grad()
82 | outputs = model.forward(x)
83 | _, preds = torch.max(outputs, 1)
84 | loss = criterion(outputs, y)
85 | acc = (torch.sum(preds == y.data)) / len(x)
86 |
87 | run["training/batch/loss"].append(loss)
88 |
89 | run["training/batch/acc"].append(acc)
90 |
91 | loss.backward()
92 | optimizer.step()
93 |
--------------------------------------------------------------------------------
/how-to-guides/data-versioning/scripts/Organize_and_share_dataset_versions.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 |
3 | import neptune
4 | import pandas as pd
5 | import requests
6 | from sklearn.ensemble import RandomForestClassifier
7 |
8 | # Download dataset
9 | dataset_path = Path.relative_to(Path.absolute(Path(__file__)).parent, Path.cwd())
10 |
11 | for file in ["train_sampled.csv", "test.csv"]:
12 | r = requests.get(
13 | f"https://raw.githubusercontent.com/neptune-ai/examples/main/how-to-guides/data-versioning/datasets/tables/{file}",
14 | allow_redirects=True,
15 | )
16 |
17 | open(dataset_path.joinpath(file), "wb").write(r.content)
18 |
19 | # Initialize Neptune project
20 | project = neptune.init_project(
21 | project="common/data-versioning", api_token=neptune.ANONYMOUS_API_TOKEN
22 | )
23 |
24 | # Create a few versions of a dataset and save them to Neptune
25 | train = pd.read_csv(str(dataset_path.joinpath("train.csv")))
26 |
27 | for i in range(5):
28 | train_sample = train.sample(frac=0.5 + 0.1 * i)
29 | train_sample.to_csv(str(dataset_path.joinpath("train_sampled.csv")), index=None)
30 | project[f"datasets/train_sampled/v{i}"].track_files(
31 | str(dataset_path.joinpath("train_sampled.csv")), wait=True
32 | )
33 |
34 | print(project.get_structure())
35 |
36 |
37 | # Get the latest version of the dataset and save it as 'latest'
38 |
39 |
40 | def get_latest_version():
41 | artifact_name = project.get_structure()["datasets"]["train_sampled"].keys()
42 | versions = [int(version.replace("v", "")) for version in artifact_name if version != "latest"]
43 | return max(versions)
44 |
45 |
46 | latest_version = get_latest_version()
47 | print("latest version", latest_version)
48 |
49 | project["datasets/train_sampled/latest"].assign(
50 | project[f"datasets/train_sampled/v{latest_version}"].fetch(), wait=True
51 | )
52 |
53 | print(project.get_structure()["datasets"])
54 |
55 | # Create a Neptune run
56 | run = neptune.init_run(project="common/data-versioning", api_token=neptune.ANONYMOUS_API_TOKEN)
57 |
58 | # Assert that you are training on the latest dataset
59 | TRAIN_DATASET_PATH = str(dataset_path.joinpath("train_sampled.csv"))
60 | run["datasets/train"].track_files(TRAIN_DATASET_PATH, wait=True)
61 |
62 | assert run["datasets/train"].fetch_hash() == project["datasets/train_sampled/latest"].fetch_hash()
63 |
64 | TEST_DATASET_PATH = str(dataset_path.joinpath("test.csv"))
65 |
66 | # Log parameters
67 | params = {
68 | "n_estimators": 8,
69 | "max_depth": 3,
70 | "max_features": 2,
71 | }
72 | run["parameters"] = params
73 |
74 | # Train the model
75 | train = pd.read_csv(TRAIN_DATASET_PATH)
76 | test = pd.read_csv(TEST_DATASET_PATH)
77 |
78 | FEATURE_COLUMNS = ["sepal.length", "sepal.width", "petal.length", "petal.width"]
79 | TARGET_COLUMN = ["variety"]
80 | X_train, y_train = train[FEATURE_COLUMNS], train[TARGET_COLUMN]
81 | X_test, y_test = test[FEATURE_COLUMNS], test[TARGET_COLUMN]
82 |
83 | rf = RandomForestClassifier(**params)
84 | rf.fit(X_train, y_train)
85 |
86 | # Save the score
87 | score = rf.score(X_test, y_test)
88 | run["metrics/test_score"] = score
89 |
90 | #
91 | # Go to the Neptune app to see datasets logged at the Project level!
92 | #
93 |
--------------------------------------------------------------------------------
/community-code/binance-trading-neptune-master/.github/workflows/deploy.yml:
--------------------------------------------------------------------------------
1 | name: Deploy to Amazon ECS
2 |
3 | on:
4 | # push:
5 | branches:
6 | - production
7 |
8 | env:
9 | AWS_REGION: us-east-1 # set this to your preferred AWS region, e.g. us-west-1
10 | ECR_REPOSITORY: neptune-repo # set this to your Amazon ECR repository name
11 | ECS_SERVICE: ecs-neptune-service # set this to your Amazon ECS service name
12 | ECS_CLUSTER: ecs-neptune-cluster # set this to your Amazon ECS cluster name
13 | ECS_TASK_DEFINITION: task-definition.json # set this to the path to your Amazon ECS task definition
14 | # file, e.g. .aws/task-definition.json
15 | CONTAINER_NAME: neptune-repo # set this to the name of the container in the
16 | # containerDefinitions section of your task definition
17 |
18 | jobs:
19 | deploy:
20 | name: Deploy
21 | runs-on: ubuntu-latest
22 | environment: production
23 |
24 | steps:
25 | - name: Checkout
26 | uses: actions/checkout@v3
27 |
28 | - name: Configure AWS credentials
29 | uses: aws-actions/configure-aws-credentials@13d241b293754004c80624b5567555c4a39ffbe3
30 | with:
31 | aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
32 | aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
33 | aws-region: ${{ env.AWS_REGION }}
34 |
35 | - name: Login to Amazon ECR
36 | id: login-ecr
37 | uses: aws-actions/amazon-ecr-login@aaf69d68aa3fb14c1d5a6be9ac61fe15b48453a2
38 |
39 | - name: Build, tag, and push image to Amazon ECR
40 | id: build-image
41 | env:
42 | ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }}
43 | IMAGE_TAG: ${{ github.sha }}
44 | BINANCE_TESTNET_API: ${{ secrets.BINANCE_TESTNET_API }}
45 | BINANCE_TESTNET_SECRET: ${{ secrets.BINANCE_TESTNET_SECRET }}
46 | NEPTUNE_API_TOKEN: ${{ secrets.NEPTUNE_API_TOKEN }}
47 | NEPTUNE_PROJECT: ${{ secrets.NEPTUNE_PROJECT }}
48 | AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
49 | AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
50 | run: |
51 | # Build a docker container and
52 | # push it to ECR so that it can
53 | # be deployed to ECS.
54 | docker build --build-arg NEPTUNE_API_TOKEN=$NEPTUNE_API_TOKEN \
55 | --build-arg NEPTUNE_PROJECT=$NEPTUNE_PROJECT \
56 | --build-arg BINANCE_TESTNET_API=$BINANCE_TESTNET_API \
57 | --build-arg BINANCE_TESTNET_SECRET=$BINANCE_TESTNET_SECRET \
58 | --build-arg AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID \
59 | --build-arg AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY \
60 | -t $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG .
61 | docker push $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG
62 | echo "::set-output name=image::$ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG"
63 |
64 | - name: Fill in the new image ID in the Amazon ECS task definition
65 | id: task-def
66 | uses: aws-actions/amazon-ecs-render-task-definition@97587c9d45a4930bf0e3da8dd2feb2a463cf4a3a
67 | with:
68 | task-definition: task-definition.json
69 | container-name: ${{ env.CONTAINER_NAME }}
70 | image: ${{ steps.build-image.outputs.image }}
71 |
72 | - name: Deploy Amazon ECS task definition
73 | uses: aws-actions/amazon-ecs-deploy-task-definition@de0132cf8cdedb79975c6d42b77eb7ea193cf28e
74 | with:
75 | task-definition: ${{ steps.task-def.outputs.task-definition }}
76 | service: ${{ env.ECS_SERVICE }}
77 | cluster: ${{ env.ECS_CLUSTER }}
78 | wait-for-service-stability: true
--------------------------------------------------------------------------------
/integrations-and-supported-tools/fastai/scripts/Neptune_fastai_more_options.py:
--------------------------------------------------------------------------------
1 | import neptune
2 | import torch
3 | from fastai.callback.all import SaveModelCallback
4 | from fastai.vision.all import (
5 | ImageDataLoaders,
6 | URLs,
7 | accuracy,
8 | resnet18,
9 | untar_data,
10 | vision_learner,
11 | )
12 | from neptune.integrations.fastai import NeptuneCallback
13 | from neptune.types import File
14 |
15 | run = neptune.init_run(
16 | project="common/fastai-integration",
17 | api_token=neptune.ANONYMOUS_API_TOKEN,
18 | tags="more options",
19 | )
20 |
21 | path = untar_data(URLs.MNIST_TINY)
22 | dls = ImageDataLoaders.from_csv(path, num_workers=0)
23 |
24 | # Single & Multi phase logging
25 |
26 | # 1. (Neptune) Log a single training phase
27 | learn = vision_learner(dls, resnet18, metrics=accuracy)
28 | learn.fit_one_cycle(1, cbs=[NeptuneCallback(run=run, base_namespace="experiment_1")])
29 | learn.fit_one_cycle(2)
30 |
31 | # 2. (Neptune) Log all training phases of the learner
32 | learn = vision_learner(dls, resnet18, cbs=[NeptuneCallback(run=run, base_namespace="experiment_2")])
33 | learn.fit_one_cycle(1)
34 |
35 | # Log model weights
36 |
37 | # Add SaveModelCallback
38 | """ You can log your model weight files
39 | during single training or all training phases
40 | add SavemodelCallback() to the callbacks' list
41 | of your learner or fit method."""
42 |
43 | # 1.(Neptune) Log Every N epochs
44 | n = 2
45 | learn = vision_learner(
46 | dls,
47 | resnet18,
48 | metrics=accuracy,
49 | cbs=[
50 | SaveModelCallback(every_epoch=n),
51 | NeptuneCallback(run=run, base_namespace="experiment_3", upload_saved_models="all"),
52 | ],
53 | )
54 |
55 | learn.fit_one_cycle(5)
56 |
57 | # 2. (Neptune) Best Model
58 | learn = vision_learner(
59 | dls,
60 | resnet18,
61 | metrics=accuracy,
62 | cbs=[SaveModelCallback(), NeptuneCallback(run=run, base_namespace="experiment_4")],
63 | )
64 | learn.fit_one_cycle(5)
65 |
66 | # 3. (Neptune) Pickling and logging the learner
67 | """ Remove the NeptuneCallback class before pickling the learner object
68 | to avoid errors due to pickle's inability to pickle local objects
69 | (i.e., nested functions or methods)"""
70 |
71 | pickled_learner = "learner.pkl"
72 | base_namespace = "experiment_5"
73 | neptune_cbk = NeptuneCallback(run=run, base_namespace=base_namespace)
74 | learn = vision_learner(
75 | dls,
76 | resnet18,
77 | metrics=accuracy,
78 | cbs=[neptune_cbk],
79 | )
80 | learn.fit_one_cycle(1) # training
81 | learn.remove_cb(neptune_cbk) # remove NeptuneCallback
82 | learn.export(f"./{pickled_learner}") # export learner
83 | run[f"{base_namespace}/pickled_learner"].upload(pickled_learner) # (Neptune) upload pickled learner
84 | learn.add_cb(neptune_cbk) # add NeptuneCallback back again
85 | learn.fit_one_cycle(1) # continue training
86 |
87 |
88 | # (Neptune) Log images
89 | batch = dls.one_batch()
90 | for i, (x, y) in enumerate(dls.decode_batch(batch)):
91 | # Neptune supports torch tensors
92 | # fastai uses their own tensor type name TensorImage
93 | # so you have to convert it back to torch.Tensor
94 | run["images/one_batch"].append(
95 | File.as_image(x.as_subclass(torch.Tensor).permute(2, 1, 0)),
96 | name=f"{i}",
97 | description=f"Label: {y}",
98 | )
99 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/optuna/scripts/Neptune_Optuna_integration_log_study_and_trial_level.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | import lightgbm as lgb
4 | import neptune
5 | import neptune.integrations.optuna as optuna_utils
6 | import optuna
7 | from sklearn.datasets import load_breast_cancer
8 | from sklearn.metrics import roc_auc_score
9 | from sklearn.model_selection import train_test_split
10 |
11 | # To connect to the Neptune app, you need to tell Neptune who you are (`api_token`) and where to send the data (`project`).
12 | # **By default, this script logs to the public project `common/optuna` as an anonymous user.**
13 | # Note: Public projects are cleaned regularly, so anonymous runs are only stored temporarily.
14 |
15 | # %%### Log to public project
16 | os.environ["NEPTUNE_API_TOKEN"] = neptune.ANONYMOUS_API_TOKEN
17 | os.environ["NEPTUNE_PROJECT"] = "common/optuna"
18 |
19 | # **To Log to your own project instead**
20 | # Uncomment the code block below:
21 |
22 | # from getpass import getpass
23 | # os.environ["NEPTUNE_API_TOKEN"]=getpass("Enter your Neptune API token: ")
24 | # os.environ["NEPTUNE_PROJECT"]="workspace-name/project-name", # replace with your own
25 |
26 |
27 | # create an objective function that logs each trial as a separate Neptune run
28 | def objective_with_logging(trial):
29 | data, target = load_breast_cancer(return_X_y=True)
30 | train_x, test_x, train_y, test_y = train_test_split(data, target, test_size=0.25)
31 | dtrain = lgb.Dataset(train_x, label=train_y)
32 |
33 | param = {
34 | "verbose": -1,
35 | "objective": "binary",
36 | "metric": "binary_logloss",
37 | "num_leaves": trial.suggest_int("num_leaves", 2, 256),
38 | "feature_fraction": trial.suggest_float("feature_fraction", 0.2, 1.0, step=0.1),
39 | "bagging_fraction": trial.suggest_float("bagging_fraction", 0.2, 1.0, step=0.1),
40 | "min_child_samples": trial.suggest_int("min_child_samples", 3, 100),
41 | }
42 |
43 | # create a trial-level run
44 | run_trial_level = neptune.init_run(tags=["trial", "script"])
45 |
46 | # log study name and trial number to trial-level run
47 | run_trial_level["sys/group_tags"].add([study.study_name])
48 | run_trial_level["trial/number"] = trial.number
49 |
50 | # log parameters of a trial-level run
51 | run_trial_level["trial/parameters"] = param
52 |
53 | # run model training
54 | gbm = lgb.train(param, dtrain)
55 | preds = gbm.predict(test_x)
56 | accuracy = roc_auc_score(test_y, preds)
57 |
58 | # log score of a trial-level run
59 | run_trial_level["trial/score"] = accuracy
60 |
61 | # stop trial-level run
62 | run_trial_level.stop()
63 |
64 | return accuracy
65 |
66 |
67 | # create an Optuna study
68 | study = optuna.create_study(direction="maximize")
69 |
70 | # create a study-level run
71 | run_study_level = neptune.init_run(tags=["study", "script"])
72 |
73 | # add study name as a group tag to the study-level run
74 | run_study_level["sys/group_tags"].add([study.study_name])
75 |
76 | # create a study-level NeptuneCallback
77 | neptune_callback = optuna_utils.NeptuneCallback(run_study_level)
78 |
79 | # pass NeptuneCallback to the Study
80 | study.optimize(objective_with_logging, n_trials=5, callbacks=[neptune_callback])
81 |
82 | # stop study-level run
83 | run_study_level.stop()
84 |
85 | # Go to the Neptune app to filter and see all the runs for this run ID
86 |
--------------------------------------------------------------------------------
/use-cases/time-series-forecasting/walmart-sales/notebooks/project_metadata.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "attachments": {},
5 | "cell_type": "markdown",
6 | "metadata": {},
7 | "source": [
8 | "# Updating project metadata\n",
9 | "A _project_ in Neptune typically represents one machine learning task. A project can contain runs, models, model versions, and project-level metadata.\n",
10 | "\n",
11 | "Project metadata helps you maintain a single source of truth for runs and models tracked in the project.\n",
12 | "\n",
13 | "Learn more about logging to the project metadata here: https://docs.neptune.ai/logging/project_metadata/"
14 | ]
15 | },
16 | {
17 | "cell_type": "code",
18 | "execution_count": null,
19 | "metadata": {},
20 | "outputs": [],
21 | "source": [
22 | "! pip install -U neptune"
23 | ]
24 | },
25 | {
26 | "cell_type": "code",
27 | "execution_count": null,
28 | "metadata": {},
29 | "outputs": [],
30 | "source": [
31 | "import neptune"
32 | ]
33 | },
34 | {
35 | "cell_type": "code",
36 | "execution_count": null,
37 | "metadata": {
38 | "tags": []
39 | },
40 | "outputs": [],
41 | "source": [
42 | "try:\n",
43 | " from pathlib import Path\n",
44 | "\n",
45 | " DATA_PATH = str(Path(__file__).parent.parent.joinpath(\"dataset\"))\n",
46 | "except NameError:\n",
47 | " DATA_PATH = \"../dataset\""
48 | ]
49 | },
50 | {
51 | "cell_type": "code",
52 | "execution_count": null,
53 | "metadata": {},
54 | "outputs": [
55 | {
56 | "name": "stdout",
57 | "output_type": "stream",
58 | "text": [
59 | "https://app.neptune.ai/common/project-time-series-forecasting/\n",
60 | "Shutting down background jobs, please wait a moment...\n",
61 | "Done!\n",
62 | "Waiting for the remaining 3 operations to synchronize with Neptune. Do not kill this process.\n",
63 | "All 3 operations synced, thanks for waiting!\n",
64 | "Explore the metadata in the Neptune app:\n",
65 | "https://app.neptune.ai/common/project-time-series-forecasting/metadata\n"
66 | ]
67 | }
68 | ],
69 | "source": [
70 | "with neptune.init_project(project=\"common/project-time-series-forecasting\") as project:\n",
71 | " project[\"sales-forecasting/brief\"] = \"Walmart sales forecast\"\n",
72 | " project[\"sales-forecasting/dataset\"].track_files(DATA_PATH)\n",
73 | " project[\"sales-forecasting/code\"] = (\n",
74 | " \"https://github.com/neptune-ai/examples/tree/main/use-cases/time-series-forecasting\"\n",
75 | " )"
76 | ]
77 | }
78 | ],
79 | "metadata": {
80 | "keep_output": true,
81 | "kernelspec": {
82 | "display_name": "py38",
83 | "language": "python",
84 | "name": "python3"
85 | },
86 | "language_info": {
87 | "codemirror_mode": {
88 | "name": "ipython",
89 | "version": 3
90 | },
91 | "file_extension": ".py",
92 | "mimetype": "text/x-python",
93 | "name": "python",
94 | "nbconvert_exporter": "python",
95 | "pygments_lexer": "ipython3",
96 | "version": "3.8.15"
97 | },
98 | "vscode": {
99 | "interpreter": {
100 | "hash": "a9715cf0b0024f6e1c62cb31a4f1f43970eb41991212681878768b4bfe53050a"
101 | }
102 | }
103 | },
104 | "nbformat": 4,
105 | "nbformat_minor": 2
106 | }
107 |
--------------------------------------------------------------------------------
/integrations-and-supported-tools/mlflow/scripts/mlflow_neptune_plugin.py:
--------------------------------------------------------------------------------
1 | # The data set used in this example is from http://archive.ics.uci.edu/ml/datasets/Wine+Quality
2 | # P. Cortez, A. Cerdeira, F. Almeida, T. Matos and J. Reis.
3 | # Modeling wine preferences by data mining from physicochemical properties. In Decision Support Systems, Elsevier, 47(4):547-553, 2009.
4 |
5 | import logging
6 | import sys
7 | import warnings
8 | from urllib.parse import urlparse
9 |
10 | import mlflow
11 | import mlflow.sklearn
12 | import numpy as np
13 | import pandas as pd
14 | from mlflow.models.signature import infer_signature
15 | from neptune import ANONYMOUS_API_TOKEN
16 | from neptune_mlflow_plugin import create_neptune_tracking_uri
17 | from sklearn.linear_model import ElasticNet
18 | from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
19 | from sklearn.model_selection import train_test_split
20 |
21 | logging.basicConfig(level=logging.WARN)
22 | logger = logging.getLogger(__name__)
23 |
24 | # (Neptune) Create Neptune tracking URI
25 | neptune_uri = create_neptune_tracking_uri(
26 | api_token=ANONYMOUS_API_TOKEN, # Replace with your own
27 | project="common/mlflow-integration", # Replace with your own
28 | tags=["mlflow", "plugin", "script"], # (optional) use your own
29 | )
30 |
31 | # (Neptune) Use Neptune tracking URI to log MLflow runs
32 | mlflow.set_tracking_uri(neptune_uri)
33 |
34 |
35 | def eval_metrics(actual, pred):
36 | rmse = np.sqrt(mean_squared_error(actual, pred))
37 | mae = mean_absolute_error(actual, pred)
38 | r2 = r2_score(actual, pred)
39 | return rmse, mae, r2
40 |
41 |
42 | if __name__ == "__main__":
43 | warnings.filterwarnings("ignore")
44 | np.random.seed(40)
45 |
46 | # Read the wine-quality csv file from the URL
47 | csv_url = (
48 | "https://raw.githubusercontent.com/mlflow/mlflow/master/tests/datasets/winequality-red.csv"
49 | )
50 | try:
51 | data = pd.read_csv(csv_url, sep=";")
52 | except Exception as e:
53 | raise Exception(f"Unable to download training data. Error: {e}")
54 |
55 | # Split the data into training and test sets. (0.75, 0.25) split.
56 | train, test = train_test_split(data)
57 |
58 | # The predicted column is "quality" which is a scalar from [3, 9]
59 | train_x = train.drop(["quality"], axis=1)
60 | test_x = test.drop(["quality"], axis=1)
61 | train_y = train[["quality"]]
62 | test_y = test[["quality"]]
63 |
64 | alpha = 0.5
65 | l1_ratio = 0.5
66 |
67 | with mlflow.start_run():
68 | lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)
69 | lr.fit(train_x, train_y)
70 |
71 | predicted_qualities = lr.predict(test_x)
72 |
73 | (rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
74 |
75 | print("Elasticnet model (alpha={:f}, l1_ratio={:f}):".format(alpha, l1_ratio))
76 | print(f" RMSE: {rmse}")
77 | print(f" MAE: {mae}")
78 | print(f" R2: {r2}")
79 |
80 | mlflow.log_param("alpha", alpha)
81 | mlflow.log_param("l1_ratio", l1_ratio)
82 | mlflow.log_metric("rmse", rmse)
83 | mlflow.log_metric("r2", r2)
84 | mlflow.log_metric("mae", mae)
85 |
86 | predictions = lr.predict(train_x)
87 | signature = infer_signature(train_x, predictions)
88 |
89 | # Model registry does not work with Neptune URI
90 | mlflow.sklearn.log_model(lr, "model", signature=signature)
91 |
--------------------------------------------------------------------------------
/how-to-guides/sequential-pipelines/scripts/model_training.py:
--------------------------------------------------------------------------------
1 | import neptune
2 | import neptune.integrations.sklearn as npt_utils
3 | from neptune.exceptions import NeptuneModelKeyAlreadyExistsError
4 | from neptune.utils import stringify_unsupported
5 | from scipy.stats import loguniform
6 | from sklearn.model_selection import RandomizedSearchCV
7 | from sklearn.svm import SVC
8 |
9 | from utils import get_data_features
10 |
11 | # (Neptune) Create a new run
12 | run = neptune.init_run(
13 | monitoring_namespace="monitoring/training",
14 | )
15 |
16 | # (Neptune) Fetch features from preprocessing stage
17 | run["preprocessing/dataset/features"].download()
18 |
19 | # (Neptune) Set up "training" namespace inside the run.
20 | # This will be the base namespace where all the training metadata is logged.
21 | training_handler = run["training"]
22 |
23 | # Get features
24 | dataset = get_data_features("features.npz")
25 | X_train, y_train, X_test, y_test = dataset["data"]
26 | X_train_pca, X_test_pca = dataset["features"]
27 |
28 | # Train a SVM classification model
29 | print("Fitting the classifier to the training set")
30 | param_grid = {
31 | "C": loguniform(1e3, 1e5),
32 | "gamma": loguniform(1e-4, 1e-1),
33 | }
34 |
35 | # Train a SVM classification model
36 | clf = RandomizedSearchCV(
37 | SVC(kernel="rbf", class_weight="balanced", probability=True), param_grid, n_iter=10
38 | )
39 | clf = clf.fit(X_train_pca, y_train)
40 |
41 | print("Best model found by grid search:")
42 | print(clf.best_estimator_)
43 |
44 | # (Neptune) Log model params
45 | training_handler["params"] = stringify_unsupported(npt_utils.get_estimator_params(clf))
46 |
47 | # (Neptune) Log model scores
48 | training_handler["metrics/scores"] = npt_utils.get_scores(clf, X_train_pca, y_train)
49 |
50 | # (Neptune) Log pickled model
51 | model_name = "pickled_model"
52 | training_handler["model"][model_name] = npt_utils.get_pickled_model(clf)
53 |
54 | # (Neptune) Initializing a Model and Model version
55 | model_key = "PIPELINES"
56 | project_key = run["sys/id"].fetch().split("-")[0]
57 |
58 | try:
59 | model = neptune.init_model(key=model_key)
60 | model.wait()
61 | print("Creating a new model version...")
62 | model_version = neptune.init_model_version(model=f"{project_key}-{model_key}")
63 |
64 | except NeptuneModelKeyAlreadyExistsError:
65 | print(f"A model with the provided key {model_key} already exists in this project.")
66 | print("Creating a new model version...")
67 | model_version = neptune.init_model_version(
68 | model=f"{project_key}-{model_key}",
69 | )
70 |
71 | # (Neptune) Log model version details to run
72 | model_version.wait()
73 | training_handler["model/model_version/id"] = model_version["sys/id"].fetch()
74 | training_handler["model/model_version/model_id"] = model_version["sys/model_id"].fetch()
75 | training_handler["model/model_version/url"] = model_version.get_url()
76 |
77 | # (Neptune) Log run details
78 | model_version["run/id"] = run["sys/id"].fetch()
79 | model_version["run/name"] = run["sys/name"].fetch()
80 | model_version["run/url"] = run.get_url()
81 |
82 | # (Neptune) Log training scores from run
83 | run.wait()
84 | model_scores = training_handler["metrics/scores"].fetch()
85 | model_version["metrics/training/scores"] = model_scores
86 |
87 | # (Neptune) Download pickled model from run
88 | training_handler["model"][model_name].download()
89 |
90 | # (Neptune) Upload pickled model to model registry
91 | model_version["model"][model_name].upload("pickled_model.pkl")
92 |
--------------------------------------------------------------------------------
 3 |
3 | 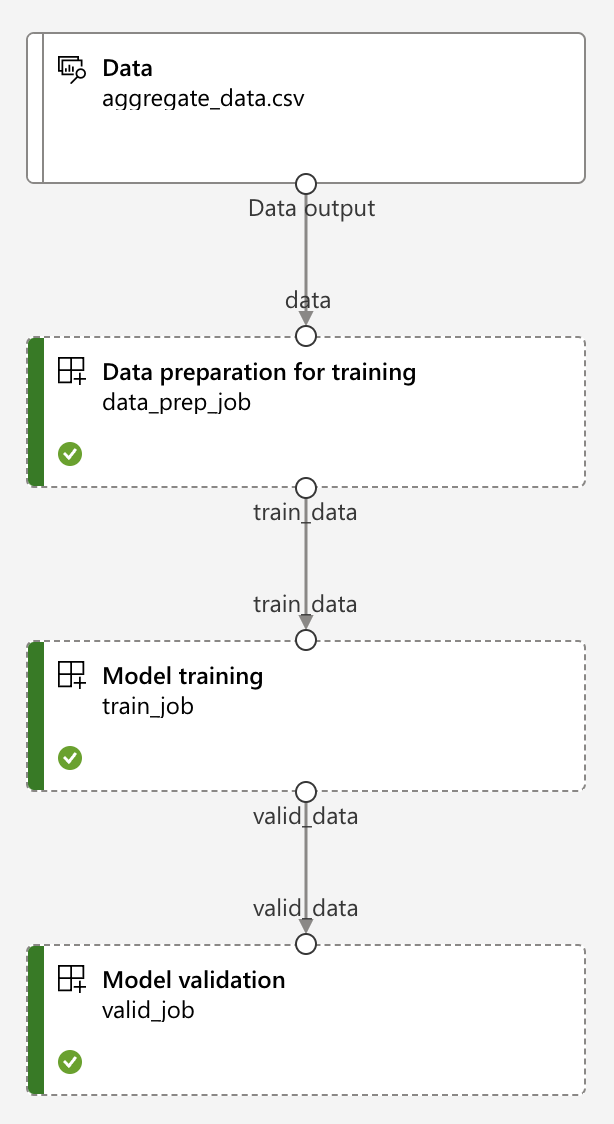 36 |
36 |