├── .gitignore
├── Architecture.png
├── Home.py
├── Libs.py
├── README.md
├── demo
├── Chat.mov
├── CreateQuestions.mov
├── QnA.mov
├── Suggest_Writing.mov
└── Summary.mov
├── pages
├── 0_Summary_Document.py
├── 1_Question_Anwers_Document.py
├── 2_Create_Multi_Choice.py
├── 3_Improve_Writing.py
├── 4_Rewrite_Essay.py
└── 5_Search.py
├── requirements.txt
└── samples
├── 2022DemandForecastingBasedMachineLearning.pdf
├── Data-struture.pdf
├── DeepAR.pdf
└── Financial_Time_Series_Forecasting_Algorithm_Based_.pdf
/.gitignore:
--------------------------------------------------------------------------------
1 | *.pyc
2 | stock_ticker_database.db
3 | *venv
--------------------------------------------------------------------------------
/Architecture.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nguyendinhthi0705/Study-Assistant/fe52ec6778a64bf84be74f042a1c21c677ffed2d/Architecture.png
--------------------------------------------------------------------------------
/Home.py:
--------------------------------------------------------------------------------
1 | import streamlit as st
2 | import Libs as glib
3 | import json
4 |
5 | st.set_page_config(page_title="Home")
6 |
7 |
8 | st.markdown("Ask me anything as below samples:")
9 | st.markdown("Top 10 interview questions for OOP in Java")
10 | st.markdown("Write a recursive function.")
11 | st.markdown("Phân biệt giữa classifcation and object detection trong computer vision.")
12 | st.markdown("Thuật toán nào được dùng để xây dựng hệ thống recommendation.")
13 |
14 | input_text = st.text_input("Input your question")
15 | if input_text:
16 | with st.chat_message("user"):
17 | st.markdown(input_text)
18 | response = glib.call_claude_sonet_stream(input_text)
19 | st.write_stream(response)
20 |
21 |
22 |
23 |
24 |
25 |
26 |
--------------------------------------------------------------------------------
/Libs.py:
--------------------------------------------------------------------------------
1 | import os
2 | import boto3, json
3 | from dotenv import load_dotenv
4 | from langchain_community.retrievers import AmazonKnowledgeBasesRetriever
5 | from langchain.chains import RetrievalQA
6 | from langchain_community.chat_models import BedrockChat
7 | from langchain_core.prompts import ChatPromptTemplate
8 | from langchain_core.runnables import RunnablePassthrough
9 | from langchain_core.output_parsers import StrOutputParser
10 |
11 | load_dotenv()
12 |
13 | def call_claude_sonet_stream(prompt):
14 |
15 | prompt_config = {
16 | "anthropic_version": "bedrock-2023-05-31",
17 | "max_tokens": 2000,
18 | "temperature": 0,
19 | "top_k": 0,
20 | "messages": [
21 | {
22 | "role": "user",
23 | "content": [
24 | {"type": "text", "text": prompt},
25 | ],
26 | }
27 | ],
28 | }
29 |
30 | body = json.dumps(prompt_config)
31 |
32 | modelId = "anthropic.claude-3-sonnet-20240229-v1:0"
33 | accept = "application/json"
34 | contentType = "application/json"
35 |
36 | bedrock = boto3.client(service_name="bedrock-runtime")
37 | response = bedrock.invoke_model_with_response_stream(
38 | body=body, modelId=modelId, accept=accept, contentType=contentType
39 | )
40 |
41 | stream = response['body']
42 | if stream:
43 | for event in stream:
44 | chunk = event.get('chunk')
45 | if chunk:
46 | delta = json.loads(chunk.get('bytes').decode()).get("delta")
47 | if delta:
48 | yield delta.get("text")
49 |
50 | def rewrite_document(input_text):
51 | prompt = """Your name is good writer. You need to rewrite content:
52 | \n\nHuman: here is the content
53 | """ + str(input_text) + """
54 | \n\nAssistant: """
55 | return call_claude_sonet_stream(prompt)
56 |
57 |
58 | def summary_stream(input_text):
59 | prompt = f"""Based on the provided context, create summary the lecture
60 | \n\nHuman: here is the content
61 | """ + str(input_text) + """
62 | \n\nAssistant: """
63 | return call_claude_sonet_stream(prompt)
64 |
65 | def query_document(question, docs):
66 | prompt = """Human: here is the content:
67 | """ + str(docs) + """
68 | Question: """ + question + """
69 | \n\nAssistant: """
70 |
71 | return call_claude_sonet_stream(prompt)
72 |
73 | def create_questions(input_text):
74 | system_prompt = """You are an expert in creating high-quality multiple-choice quesitons and answer pairs
75 | based on a given context. Based on the given context (e.g a passage, a paragraph, or a set of information), you should:
76 | 1. Come up with thought-provoking multiple-choice questions that assess the reader's understanding of the context.
77 | 2. The questions should be clear and concise.
78 | 3. The answer options should be logical and relevant to the context.
79 |
80 | The multiple-choice questions and answer pairs should be in a bulleted list:
81 | 1) Question:
82 |
83 | A) Option 1
84 |
85 | B) Option 2
86 |
87 | C) Option 3
88 |
89 | Answer: A) Option 1
90 |
91 |
92 | Continue with additional questions and answer pairs as needed.
93 |
94 | MAKE SURE TO INCLUDE THE FULL CORRECT ANSWER AT THE END, NO EXPLANATION NEEDED:"""
95 |
96 | prompt = f"""{system_prompt}. Based on the provided context, create 10 multiple-choice questions and answer pairs
97 | \n\nHuman: here is the content
98 | """ + str(input_text) + """
99 | \n\nAssistant: """
100 | return call_claude_sonet_stream(prompt)
101 |
102 | def suggest_writing_document(input_text):
103 | prompt = """Your name is good writer. You need to suggest and correct mistake in the essay:
104 | \n\nHuman: here is the content
105 | """ + str(input_text) + """
106 | \n\nAssistant: """
107 | return call_claude_sonet_stream(prompt)
108 |
109 | def search(question, callback):
110 | retriever = AmazonKnowledgeBasesRetriever(
111 | knowledge_base_id="JAHBTIXPHK",
112 | retrieval_config={"vectorSearchConfiguration": {"numberOfResults": 1}},
113 |
114 | )
115 |
116 | model_kwargs_claude = {"max_tokens": 1000}
117 | llm = BedrockChat(model_id="anthropic.claude-3-sonnet-20240229-v1:0"
118 | , model_kwargs=model_kwargs_claude
119 | , streaming=True
120 | , callbacks=[callback])
121 |
122 | chain = RetrievalQA.from_chain_type(
123 | llm=llm, retriever=retriever, return_source_documents=True
124 | )
125 | return chain.invoke(question)
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Overview Study-Assistant
2 | This is a simple demo of Amazon Bedrock and Anthropic Claude 3 Sonnet model with langchain and streamlit. For more detail please reference the following link:
3 | - https://aws.amazon.com/bedrock/
4 | - Claude 3
5 | # To view demo and sample data:
6 | Access folder demo for demo video
7 | Access folder samples for sample videos
8 |
9 | # To Setup
10 | Setup Python
11 | Setup Python Env
12 | Setup AWS CLI
13 | > git clone https://github.com/nguyendinhthi0705/Study-Assistant.git
14 | > cd Study-Assistant
15 | > pip3 install -r requirements.txt
16 | > streamlit run Home.py --server.port 8080
17 |
18 | # Architecture
19 | 
20 |
21 | # Learn more about prompt and Claude 3
22 | Introduction to prompt design
23 | Model Card
24 |
25 | # Demo
26 |
27 | ## A Simple Chat
28 | [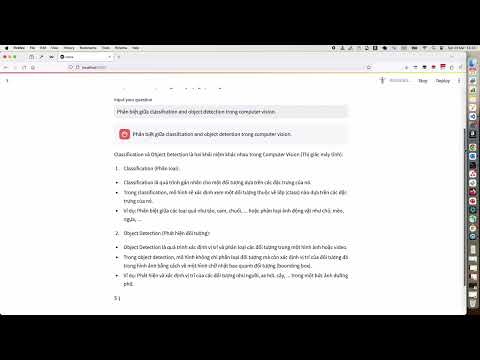](https://www.youtube.com/watch?v=PdX7i0A4a-M)]
29 |
30 | ## Questions and Anwsers
31 | [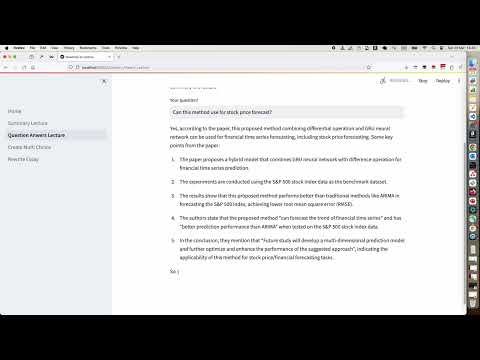](https://www.youtube.com/watch?v=ciJfAhyRjTI)]
32 |
33 | ## Summary a Lecture
34 | [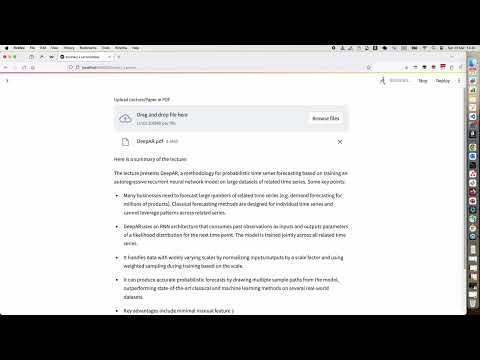](https://www.youtube.com/watch?v=5JpeWmbHMi0)]
35 |
36 | ## Create Multi Choice Questions
37 | [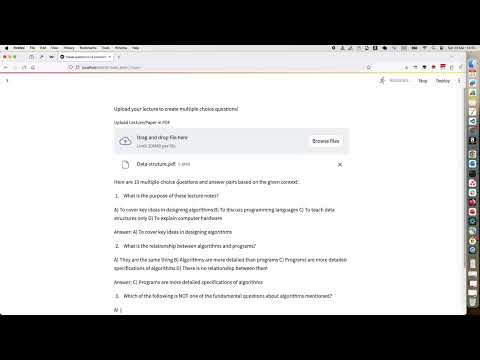](https://www.youtube.com/watch?v=AE9gj19a9t0)]
38 |
39 | ## Suggest a Better Writing
40 | [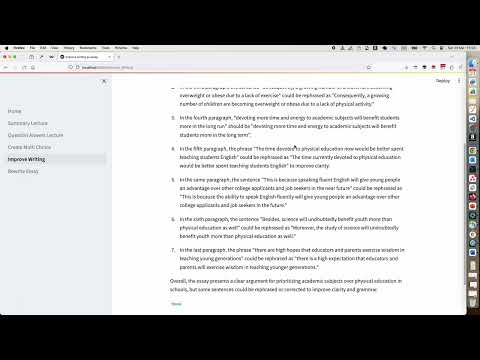](https://www.youtube.com/watch?v=7xBR5rtcp30)]
41 |
42 |
43 |
--------------------------------------------------------------------------------
/demo/Chat.mov:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nguyendinhthi0705/Study-Assistant/fe52ec6778a64bf84be74f042a1c21c677ffed2d/demo/Chat.mov
--------------------------------------------------------------------------------
/demo/CreateQuestions.mov:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nguyendinhthi0705/Study-Assistant/fe52ec6778a64bf84be74f042a1c21c677ffed2d/demo/CreateQuestions.mov
--------------------------------------------------------------------------------
/demo/QnA.mov:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nguyendinhthi0705/Study-Assistant/fe52ec6778a64bf84be74f042a1c21c677ffed2d/demo/QnA.mov
--------------------------------------------------------------------------------
/demo/Suggest_Writing.mov:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nguyendinhthi0705/Study-Assistant/fe52ec6778a64bf84be74f042a1c21c677ffed2d/demo/Suggest_Writing.mov
--------------------------------------------------------------------------------
/demo/Summary.mov:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nguyendinhthi0705/Study-Assistant/fe52ec6778a64bf84be74f042a1c21c677ffed2d/demo/Summary.mov
--------------------------------------------------------------------------------
/pages/0_Summary_Document.py:
--------------------------------------------------------------------------------
1 | import streamlit as st
2 | import Libs as glib
3 | from PyPDF2 import PdfReader
4 | import Libs as glib
5 |
6 | st.set_page_config(page_title="Summary a Lecture/Paper")
7 |
8 | uploaded_file = st.file_uploader("Upload Lecture/Paper in PDF")
9 | docs = []
10 |
11 | if uploaded_file is not None:
12 | reader = PdfReader(uploaded_file)
13 | for page in reader.pages:
14 | docs.append(page.extract_text())
15 |
16 | response = glib.summary_stream(docs)
17 | st.write_stream(response)
18 |
--------------------------------------------------------------------------------
/pages/1_Question_Anwers_Document.py:
--------------------------------------------------------------------------------
1 | import streamlit as st
2 | import Libs as glib
3 | from PyPDF2 import PdfReader
4 | import Libs as glib
5 |
6 |
7 | st.set_page_config(page_title="Questions on Lecture")
8 |
9 | uploaded_file = st.file_uploader("Upload Your Lecture in PDF")
10 | docs = []
11 |
12 | st.markdown("Ask me anything as below samples:")
13 | st.markdown("Summary the lecture")
14 |
15 | input_text = st.text_input("Your question!")
16 | if uploaded_file is not None and input_text:
17 | reader = PdfReader(uploaded_file)
18 | for page in reader.pages:
19 | docs.append(page.extract_text())
20 |
21 | response = glib.query_document(input_text, docs)
22 | st.write_stream(response)
23 |
24 |
25 |
--------------------------------------------------------------------------------
/pages/2_Create_Multi_Choice.py:
--------------------------------------------------------------------------------
1 | import streamlit as st
2 | import Libs as glib
3 | from PyPDF2 import PdfReader
4 | import Libs as glib
5 |
6 | st.set_page_config(page_title="Create question for a Lecture/Paper")
7 |
8 | st.markdown("Upload your lecture to create multiple choice questions!")
9 | uploaded_file = st.file_uploader("Upload Lecture/Paper in PDF")
10 | docs = []
11 |
12 | if uploaded_file is not None:
13 | reader = PdfReader(uploaded_file)
14 | for page in reader.pages:
15 | docs.append(page.extract_text())
16 |
17 | response = glib.create_questions(docs)
18 | st.write_stream(response)
19 |
--------------------------------------------------------------------------------
/pages/3_Improve_Writing.py:
--------------------------------------------------------------------------------
1 | import streamlit as st
2 | import Libs as glib
3 |
4 | st.set_page_config(page_title="Improve writing an essay")
5 |
6 |
7 | input_text = st.text_area("Input your whole or apart of your essay")
8 | if input_text:
9 | response = glib.suggest_writing_document(input_text)
10 | st.write_stream(response)
11 |
12 |
--------------------------------------------------------------------------------
/pages/4_Rewrite_Essay.py:
--------------------------------------------------------------------------------
1 | import streamlit as st
2 | import Libs as glib
3 |
4 | st.set_page_config(page_title="Rewrite an Essay")
5 |
6 |
7 | input_text = st.text_area("Input your whole or apart of your essay")
8 | if input_text:
9 | response = glib.rewrite_document(input_text)
10 | st.write_stream(response)
11 |
12 |
--------------------------------------------------------------------------------
/pages/5_Search.py:
--------------------------------------------------------------------------------
1 | import streamlit as st
2 | import Libs as glib
3 | from langchain.callbacks import StreamlitCallbackHandler
4 |
5 | st.set_page_config(page_title="Search Knowledge base")
6 | st.markdown("Một số bệnh phổ biến của trẻ em là gì?")
7 | st.markdown("Tóm tắt tài chính apple?")
8 |
9 | input_text = st.text_input("Search Knowledge base")
10 | if input_text:
11 | st_callback = StreamlitCallbackHandler(st.container())
12 | response = glib.search(input_text, st_callback)
13 | st.write(response["result"])
14 | st.write(response)
15 |
16 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | transformers
2 | Pillow
3 | pypdf
4 | jq
5 | langchain
6 | streamlit
7 | boto3
8 | awscli
9 | pandas-datareader
10 | langchain-experimental
11 | bs4
12 | setuptools
13 | PyPDF2
14 | pypdf
15 | langchain_community
16 | python-dotenv
17 | botocore
--------------------------------------------------------------------------------
/samples/2022DemandForecastingBasedMachineLearning.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nguyendinhthi0705/Study-Assistant/fe52ec6778a64bf84be74f042a1c21c677ffed2d/samples/2022DemandForecastingBasedMachineLearning.pdf
--------------------------------------------------------------------------------
/samples/Data-struture.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nguyendinhthi0705/Study-Assistant/fe52ec6778a64bf84be74f042a1c21c677ffed2d/samples/Data-struture.pdf
--------------------------------------------------------------------------------
/samples/DeepAR.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nguyendinhthi0705/Study-Assistant/fe52ec6778a64bf84be74f042a1c21c677ffed2d/samples/DeepAR.pdf
--------------------------------------------------------------------------------
/samples/Financial_Time_Series_Forecasting_Algorithm_Based_.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nguyendinhthi0705/Study-Assistant/fe52ec6778a64bf84be74f042a1c21c677ffed2d/samples/Financial_Time_Series_Forecasting_Algorithm_Based_.pdf
--------------------------------------------------------------------------------