├── .gitignore
├── LICENSE
├── README.md
├── __init__.py
├── configs
└── config.ini
├── evaluation
├── __init__.py
├── evaluate_el.py
├── evaluate_inference.py
└── evaluate_types.py
├── models
├── __init__.py
├── base.py
├── batch_normalizer.py
└── figer_model
│ ├── __init__.py
│ ├── coherence_model.py
│ ├── coldStart.py
│ ├── context_encoder.py
│ ├── el_model.py
│ ├── entity_posterior.py
│ ├── joint_context.py
│ ├── labeling_model.py
│ ├── loss_optim.py
│ └── wiki_desc.py
├── neuralel.py
├── neuralel_jsonl.py
├── neuralel_tadir.py
├── overview.png
├── readers
├── Mention.py
├── __init__.py
├── config.py
├── crosswikis_test.py
├── inference_reader.py
├── test_reader.py
├── textanno_test_reader.py
├── utils.py
└── vocabloader.py
└── requirements.txt
/.gitignore:
--------------------------------------------------------------------------------
1 | logs/
2 | deprecated/
3 | test.py
4 | readers/crosswikis_test.py
5 |
6 | # Byte-compiled / optimized / DLL files
7 | __pycache__/
8 | *.py[cod]
9 | *$py.class
10 |
11 | # C extensions
12 | *.so
13 |
14 | # Distribution / packaging
15 | .Python
16 | env/
17 | build/
18 | develop-eggs/
19 | dist/
20 | downloads/
21 | eggs/
22 | .eggs/
23 | lib/
24 | lib64/
25 | parts/
26 | sdist/
27 | var/
28 | *.egg-info/
29 | .installed.cfg
30 | *.egg
31 |
32 | # PyInstaller
33 | # Usually these files are written by a python script from a template
34 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
35 | *.manifest
36 | *.spec
37 |
38 | # Installer logs
39 | pip-log.txt
40 | pip-delete-this-directory.txt
41 |
42 | # Unit test / coverage reports
43 | htmlcov/
44 | .tox/
45 | .coverage
46 | .coverage.*
47 | .cache
48 | nosetests.xml
49 | coverage.xml
50 | *,cover
51 | .hypothesis/
52 |
53 | # Translations
54 | *.mo
55 | *.pot
56 |
57 | # Django stuff:
58 | *.log
59 | local_settings.py
60 |
61 | # Flask stuff:
62 | instance/
63 | .webassets-cache
64 |
65 | # Scrapy stuff:
66 | .scrapy
67 |
68 | # Sphinx documentation
69 | docs/_build/
70 |
71 | # PyBuilder
72 | target/
73 |
74 | # IPython Notebook
75 | .ipynb_checkpoints
76 |
77 | # pyenv
78 | .python-version
79 |
80 | # celery beat schedule file
81 | celerybeat-schedule
82 |
83 | # dotenv
84 | .env
85 |
86 | # virtualenv
87 | venv/
88 | ENV/
89 |
90 | # Spyder project settings
91 | .spyderproject
92 |
93 | # Rope project settings
94 | .ropeproject
95 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright [yyyy] [name of copyright owner]
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | Neural Entity Linking
2 | =====================
3 | Code for paper
4 | "[Entity Linking via Joint Encoding of Types, Descriptions, and Context](http://cogcomp.org/page/publication_view/817)", EMNLP '17
5 |
6 | 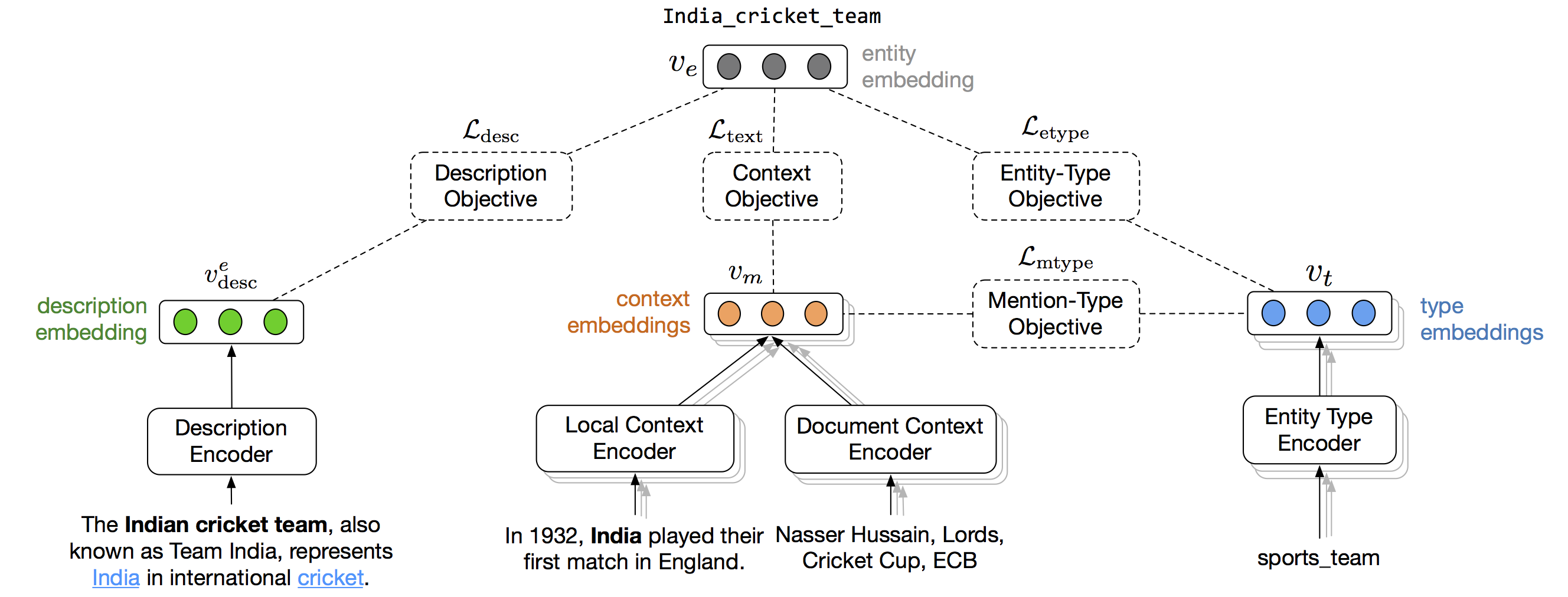 7 |
8 | ## Abstract
9 | For accurate entity linking, we need to capture the various information aspects of an entity, such as its description in a KB, contexts in which it is mentioned, and structured knowledge. Further, a linking system should work on texts from different domains without requiring domain-specific training data or hand-engineered features.
10 | In this work we present a neural, modular entity linking system that learns a unified dense representation for each entity using multiple sources of information, such as its description, contexts around its mentions, and fine-grained types. We show that the resulting entity linking system is effective at combining these sources, and performs competitively, sometimes out-performing current state-of-art-systems across datasets, without requiring any domain-specific training data or hand-engineered features. We also show that our model can effectively "embed" entities that are new to the KB, and is able to link its mentions accurately.
11 |
12 | ### Requirements
13 | * Python 3.4
14 | * Tensorflow 0.11 / 0.12
15 | * numpy
16 | * [CogComp-NLPy](https://github.com/CogComp/cogcomp-nlpy)
17 | * [Resources](https://drive.google.com/open?id=0Bz-t37BfgoTuSEtXOTI1SEF3VnM) - Pretrained models, vectors, etc.
18 |
19 | ### How to run inference
20 | 1. Clone the [code repository](https://github.com/nitishgupta/neural-el/)
21 | 1. Download the [resources folder](https://drive.google.com/open?id=0Bz-t37BfgoTuSEtXOTI1SEF3VnM).
22 | 2. In `config/config.ini` set the correct path to the resources folder you just downloaded
23 | 3. Run using:
24 | ```
25 | python3 neuralel.py --config=configs/config.ini --model_path=PATH_TO_MODEL_IN_RESOURCES --mode=inference
26 | ```
27 | The file `sampletest.txt` in the resources folder contains the text to be entity-linked. Currently we only support linking for a single document. Make sure the text in `sampletest.txt` is a single doc in a single line.
28 |
29 | ### Installing cogcomp-nlpy
30 | [CogComp-NLPy](https://github.com/CogComp/cogcomp-nlpy) is needed to detect named-entity mentions using NER. To install:
31 | ```
32 | pip install cython
33 | pip install ccg_nlpy
34 | ```
35 |
36 | ### Installing Tensorflow (CPU Version)
37 | To install tensorflow 0.12:
38 | ```
39 | export TF_BINARY_URL=https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.12.1-cp34-cp34m-linux_x86_64.whl
40 | (Regular) pip install --upgrade $TF_BINARY_URL
41 | (Conda) pip install --ignore-installed --upgrade $TF_BINARY_URL
42 | ```
43 |
--------------------------------------------------------------------------------
/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nitishgupta/neural-el/8c7c278acefa66238a75e805511ff26a567fd4e0/__init__.py
--------------------------------------------------------------------------------
/configs/config.ini:
--------------------------------------------------------------------------------
1 | [DEFAULT]
2 | resources_dir: /shared/bronte/ngupta19/neural-el_resources
3 |
4 | vocab_dir: ${resources_dir}/vocab
5 |
6 | word_vocab_pkl:${vocab_dir}/word_vocab.pkl
7 | kwnwid_vocab_pkl:${vocab_dir}/knwn_wid_vocab.pkl
8 | label_vocab_pkl:${vocab_dir}/label_vocab.pkl
9 | cohstringG9_vocab_pkl:${vocab_dir}/cohstringG9_vocab.pkl
10 | widWiktitle_pkl:${vocab_dir}/wid2Wikititle.pkl
11 |
12 | # One CWIKIs PATH NEEDED
13 | crosswikis_pruned_pkl: ${resources_dir}/crosswikis.pruned.pkl
14 |
15 |
16 | glove_pkl: ${resources_dir}/glove.pkl
17 | glove_word_vocab_pkl:${vocab_dir}/glove_word_vocab.pkl
18 |
19 | # Should be removed
20 | test_file: ${resources_dir}/sampletest.txt
21 |
--------------------------------------------------------------------------------
/evaluation/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nitishgupta/neural-el/8c7c278acefa66238a75e805511ff26a567fd4e0/evaluation/__init__.py
--------------------------------------------------------------------------------
/evaluation/evaluate_el.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import numpy as np
4 |
5 | coarsetypes = set(["location", "person", "organization", "event"])
6 | coarseTypeIds = set([1,5,10,25])
7 |
8 |
9 | def computeMaxPriorContextJointEntities(
10 | WIDS_list, wikiTitles_list, condProbs_list, contextProbs_list,
11 | condContextJointProbs_list, verbose):
12 |
13 | assert (len(wikiTitles_list) == len(condProbs_list) ==
14 | len(contextProbs_list) == len(condContextJointProbs_list))
15 | numMens = len(wikiTitles_list)
16 | numWithCorrectInCand = 0
17 | accCond = 0
18 | accCont = 0
19 | accJoint = 0
20 |
21 | # [[(trueWT, maxPrWT, maxContWT, maxJWT), (trueWID, maxPrWID, maxContWID, maxJWID)]]
22 | evaluationWikiTitles = []
23 |
24 | sortedContextWTs = []
25 |
26 | for (WIDS, wTs, cProbs, contProbs, jointProbs) in zip(WIDS_list,
27 | wikiTitles_list,
28 | condProbs_list,
29 | contextProbs_list,
30 | condContextJointProbs_list):
31 | if wTs[0] == "":
32 | evaluationWikiTitles.append([tuple([""]*4), tuple([""]*4)])
33 |
34 | else:
35 | numWithCorrectInCand += 1
36 | trueWID = WIDS[0]
37 | trueEntity = wTs[0]
38 | tCondProb = cProbs[0]
39 | tContProb = contProbs[0]
40 | tJointProb = jointProbs[0]
41 |
42 | maxCondEntity_idx = np.argmax(cProbs)
43 | maxCondWID = WIDS[maxCondEntity_idx]
44 | maxCondEntity = wTs[maxCondEntity_idx]
45 | maxCondProb = cProbs[maxCondEntity_idx]
46 | if trueEntity == maxCondEntity and maxCondProb!=0.0:
47 | accCond+= 1
48 |
49 | maxContEntity_idx = np.argmax(contProbs)
50 | maxContWID = WIDS[maxContEntity_idx]
51 | maxContEntity = wTs[maxContEntity_idx]
52 | maxContProb = contProbs[maxContEntity_idx]
53 | if maxContEntity == trueEntity and maxContProb!=0.0:
54 | accCont+= 1
55 |
56 | contProbs_sortIdxs = np.argsort(contProbs).tolist()[::-1]
57 | sortContWTs = [wTs[i] for i in contProbs_sortIdxs]
58 | sortedContextWTs.append(sortContWTs)
59 |
60 | maxJointEntity_idx = np.argmax(jointProbs)
61 | maxJointWID = WIDS[maxJointEntity_idx]
62 | maxJointEntity = wTs[maxJointEntity_idx]
63 | maxJointProb = jointProbs[maxJointEntity_idx]
64 | maxJointCprob = cProbs[maxJointEntity_idx]
65 | maxJointContP = contProbs[maxJointEntity_idx]
66 | if maxJointEntity == trueEntity and maxJointProb!=0:
67 | accJoint+= 1
68 |
69 | predWTs = (trueEntity, maxCondEntity, maxContEntity, maxJointEntity)
70 | predWIDs = (trueWID, maxCondWID, maxContWID, maxJointWID)
71 | evaluationWikiTitles.append([predWTs, predWIDs])
72 |
73 | if verbose:
74 | print("True: {} c:{:.3f} cont:{:.3f} J:{:.3f}".format(
75 | trueEntity, tCondProb, tContProb, tJointProb))
76 | print("Pred: {} c:{:.3f} cont:{:.3f} J:{:.3f}".format(
77 | maxJointEntity, maxJointCprob, maxJointContP, maxJointProb))
78 | print("maxPrior: {} p:{:.3f} maxCont:{} p:{:.3f}".format(
79 | maxCondEntity, maxCondProb, maxContEntity, maxContProb))
80 | #AllMentionsProcessed
81 | if numWithCorrectInCand != 0:
82 | accCond = accCond/float(numWithCorrectInCand)
83 | accCont = accCont/float(numWithCorrectInCand)
84 | accJoint = accJoint/float(numWithCorrectInCand)
85 | else:
86 | accCond = 0.0
87 | accCont = 0.0
88 | accJoint = 0.0
89 |
90 | print("Total Mentions : {} In Knwn Mentions : {}".format(
91 | numMens, numWithCorrectInCand))
92 | print("Priors Accuracy: {:.3f} Context Accuracy: {:.3f} Joint Accuracy: {:.3f}".format(
93 | (accCond), accCont, accJoint))
94 |
95 | assert len(evaluationWikiTitles) == numMens
96 |
97 | return (evaluationWikiTitles, sortedContextWTs)
98 |
99 |
100 | def convertWidIdxs2WikiTitlesAndWIDs(widIdxs_list, idx2knwid, wid2WikiTitle):
101 | wikiTitles_list = []
102 | WIDS_list = []
103 | for widIdxs in widIdxs_list:
104 | wids = [idx2knwid[wididx] for wididx in widIdxs]
105 | wikititles = [wid2WikiTitle[idx2knwid[wididx]] for wididx in widIdxs]
106 | WIDS_list.append(wids)
107 | wikiTitles_list.append(wikititles)
108 |
109 | return (WIDS_list, wikiTitles_list)
110 |
111 |
112 | def _normalizeProbList(probList):
113 | norm_probList = []
114 | for probs in probList:
115 | s = sum(probs)
116 | if s != 0.0:
117 | n_p = [p/s for p in probs]
118 | norm_probList.append(n_p)
119 | else:
120 | norm_probList.append(probs)
121 | return norm_probList
122 |
123 |
124 | def computeFinalEntityProbs(condProbs_list, contextProbs_list, alpha=0.5):
125 | condContextJointProbs_list = []
126 | condProbs_list = _normalizeProbList(condProbs_list)
127 | contextProbs_list = _normalizeProbList(contextProbs_list)
128 |
129 | for (cprobs, contprobs) in zip(condProbs_list, contextProbs_list):
130 | #condcontextprobs = [(alpha*x + (1-alpha)*y) for (x,y) in zip(cprobs, contprobs)]
131 | condcontextprobs = [(x + y - x*y) for (x,y) in zip(cprobs, contprobs)]
132 | sum_condcontextprobs = sum(condcontextprobs)
133 | if sum_condcontextprobs != 0.0:
134 | condcontextprobs = [float(x)/sum_condcontextprobs for x in condcontextprobs]
135 | condContextJointProbs_list.append(condcontextprobs)
136 | return condContextJointProbs_list
137 |
138 |
139 | def computeFinalEntityScores(condProbs_list, contextProbs_list, alpha=0.5):
140 | condContextJointProbs_list = []
141 | condProbs_list = _normalizeProbList(condProbs_list)
142 | #contextProbs_list = _normalizeProbList(contextProbs_list)
143 |
144 | for (cprobs, contprobs) in zip(condProbs_list, contextProbs_list):
145 | condcontextprobs = [(alpha*x + (1-alpha)*y) for (x,y) in zip(cprobs, contprobs)]
146 | sum_condcontextprobs = sum(condcontextprobs)
147 | if sum_condcontextprobs != 0.0:
148 | condcontextprobs = [float(x)/sum_condcontextprobs for x in condcontextprobs]
149 | condContextJointProbs_list.append(condcontextprobs)
150 | return condContextJointProbs_list
151 |
152 |
153 | ##############################################################################
154 |
155 | def evaluateEL(condProbs_list, widIdxs_list, contextProbs_list,
156 | idx2knwid, wid2WikiTitle, verbose=False):
157 | ''' Prior entity prob, True and candidate entity WIDs, Predicted ent. prob.
158 | using context for each of te 30 candidates. First element in the candidates is
159 | the true entity.
160 | Args:
161 | For each mention:
162 | condProbs_list: List of prior probs for 30 candidates.
163 | widIdxs_list: List of candidate widIdxs probs for 30 candidates.
164 | contextProbss_list: List of candidate prob. using context
165 | idx2knwid: Map for widIdx -> WID
166 | wid2WikiTitle: Map from WID -> WikiTitle
167 | wid2TypeLabels: Map from WID -> List of Types
168 | '''
169 | print("Evaluating E-Linking ... ")
170 | (WIDS_list, wikiTitles_list) = convertWidIdxs2WikiTitlesAndWIDs(
171 | widIdxs_list, idx2knwid, wid2WikiTitle)
172 |
173 | alpha = 0.5
174 | #for alpha in alpha_range:
175 | print("Alpha : {}".format(alpha))
176 | jointProbs_list = computeFinalEntityProbs(
177 | condProbs_list, contextProbs_list, alpha=alpha)
178 |
179 | # evaluationWikiTitles:
180 | # For each mention [(trWT, maxPWT, maxCWT, maxJWT), (trWID, ...)]
181 | (evaluationWikiTitles,
182 | sortedContextWTs) = computeMaxPriorContextJointEntities(
183 | WIDS_list, wikiTitles_list, condProbs_list, contextProbs_list,
184 | jointProbs_list, verbose)
185 |
186 |
187 | '''
188 | condContextJointScores_list = computeFinalEntityScores(
189 | condProbs_list, contextProbs_list, alpha=alpha)
190 |
191 | evaluationWikiTitles = computeMaxPriorContextJointEntities(
192 | WIDS_list, wikiTitles_list, condProbs_list, contextProbs_list,
193 | condContextJointScores_list, verbose)
194 | '''
195 |
196 | return (jointProbs_list, evaluationWikiTitles, sortedContextWTs)
197 |
198 | ##############################################################################
199 |
200 |
201 | def f1(p,r):
202 | if p == 0.0 and r == 0.0:
203 | return 0.0
204 | return (float(2*p*r))/(p + r)
205 |
206 |
207 | def strict_pred(true_label_batch, pred_score_batch):
208 | ''' Calculates strict precision/recall/f1 given truth and predicted scores
209 | args
210 | true_label_batch: Binary Numpy matrix of [num_instances, num_labels]
211 | pred_score_batch: Real [0,1] numpy matrix of [num_instances, num_labels]
212 |
213 | return:
214 | correct_preds: Number of correct strict preds
215 | precision : correct_preds / num_instances
216 | '''
217 | (true_labels, pred_labels) = types_convert_mat_to_sets(
218 | true_label_batch, pred_score_batch)
219 |
220 | num_instanes = len(true_labels)
221 | correct_preds = 0
222 | for i in range(0, num_instanes):
223 | if true_labels[i] == pred_labels[i]:
224 | correct_preds += 1
225 | #endfor
226 | precision = recall = float(correct_preds)/num_instanes
227 |
228 | return correct_preds, precision
229 |
230 |
231 | def correct_context_prediction(entity_posterior_scores, batch_size):
232 | bool_array = np.equal(np.argmax(entity_posterior_scores, axis=1),
233 | [0]*batch_size)
234 | correct_preds = np.sum(bool_array)
235 | return correct_preds
236 |
--------------------------------------------------------------------------------
/evaluation/evaluate_inference.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import numpy as np
4 |
5 |
6 | def computeMaxPriorContextJointEntities(
7 | WIDS_list, wikiTitles_list, condProbs_list, contextProbs_list,
8 | condContextJointProbs_list, verbose):
9 |
10 | assert (len(wikiTitles_list) == len(condProbs_list) ==
11 | len(contextProbs_list) == len(condContextJointProbs_list))
12 | numMens = len(wikiTitles_list)
13 |
14 | evaluationWikiTitles = []
15 | sortedContextWTs = []
16 | for (WIDS, wTs,
17 | cProbs, contProbs, jointProbs) in zip(WIDS_list,
18 | wikiTitles_list,
19 | condProbs_list,
20 | contextProbs_list,
21 | condContextJointProbs_list):
22 | # if wTs[0] == "":
23 | # evaluationWikiTitles.append([tuple([""]*3),
24 | # tuple([""]*3)])
25 | # else:
26 | maxCondEntity_idx = np.argmax(cProbs)
27 | maxCondWID = WIDS[maxCondEntity_idx]
28 | maxCondEntity = wTs[maxCondEntity_idx]
29 | maxCondProb = cProbs[maxCondEntity_idx]
30 |
31 | maxContEntity_idx = np.argmax(contProbs)
32 | maxContWID = WIDS[maxContEntity_idx]
33 | maxContEntity = wTs[maxContEntity_idx]
34 | maxContProb = contProbs[maxContEntity_idx]
35 |
36 | contProbs_sortIdxs = np.argsort(contProbs).tolist()[::-1]
37 | sortContWTs = [wTs[i] for i in contProbs_sortIdxs]
38 | sortedContextWTs.append(sortContWTs)
39 |
40 | maxJointEntity_idx = np.argmax(jointProbs)
41 | maxJointWID = WIDS[maxJointEntity_idx]
42 | maxJointEntity = wTs[maxJointEntity_idx]
43 | maxJointProb = jointProbs[maxJointEntity_idx]
44 | maxJointCprob = cProbs[maxJointEntity_idx]
45 | maxJointContP = contProbs[maxJointEntity_idx]
46 |
47 | predWTs = (maxCondEntity, maxContEntity, maxJointEntity)
48 | predWIDs = (maxCondWID, maxContWID, maxJointWID)
49 | predProbs = (maxCondProb, maxContProb, maxJointProb)
50 | evaluationWikiTitles.append([predWTs, predWIDs, predProbs])
51 |
52 | assert len(evaluationWikiTitles) == numMens
53 |
54 | return (evaluationWikiTitles, sortedContextWTs)
55 |
56 | def convertWidIdxs2WikiTitlesAndWIDs(widIdxs_list, idx2knwid, wid2WikiTitle):
57 | wikiTitles_list = []
58 | WIDS_list = []
59 | for widIdxs in widIdxs_list:
60 | wids = [idx2knwid[wididx] for wididx in widIdxs]
61 | wikititles = [wid2WikiTitle[idx2knwid[wididx]] for wididx in widIdxs]
62 | WIDS_list.append(wids)
63 | wikiTitles_list.append(wikititles)
64 |
65 | return (WIDS_list, wikiTitles_list)
66 |
67 | def _normalizeProbList(probList):
68 | norm_probList = []
69 | for probs in probList:
70 | s = sum(probs)
71 | if s != 0.0:
72 | n_p = [p/s for p in probs]
73 | norm_probList.append(n_p)
74 | else:
75 | norm_probList.append(probs)
76 | return norm_probList
77 |
78 |
79 | def computeFinalEntityProbs(condProbs_list, contextProbs_list):
80 | condContextJointProbs_list = []
81 | condProbs_list = _normalizeProbList(condProbs_list)
82 | contextProbs_list = _normalizeProbList(contextProbs_list)
83 |
84 | for (cprobs, contprobs) in zip(condProbs_list, contextProbs_list):
85 | condcontextprobs = [(x + y - x*y) for (x,y) in zip(cprobs, contprobs)]
86 | sum_condcontextprobs = sum(condcontextprobs)
87 | if sum_condcontextprobs != 0.0:
88 | condcontextprobs = [float(x)/sum_condcontextprobs for x in condcontextprobs]
89 | condContextJointProbs_list.append(condcontextprobs)
90 | return condContextJointProbs_list
91 |
92 |
93 | def computeFinalEntityScores(condProbs_list, contextProbs_list, alpha=0.5):
94 | condContextJointProbs_list = []
95 | condProbs_list = _normalizeProbList(condProbs_list)
96 | #contextProbs_list = _normalizeProbList(contextProbs_list)
97 |
98 | for (cprobs, contprobs) in zip(condProbs_list, contextProbs_list):
99 | condcontextprobs = [(alpha*x + (1-alpha)*y) for (x,y) in zip(cprobs, contprobs)]
100 | sum_condcontextprobs = sum(condcontextprobs)
101 | if sum_condcontextprobs != 0.0:
102 | condcontextprobs = [float(x)/sum_condcontextprobs for x in condcontextprobs]
103 | condContextJointProbs_list.append(condcontextprobs)
104 | return condContextJointProbs_list
105 |
106 |
107 | #############################################################################
108 |
109 |
110 | def evaluateEL(condProbs_list, widIdxs_list, contextProbs_list,
111 | idx2knwid, wid2WikiTitle, verbose=False):
112 | ''' Prior entity prob, True and candidate entity WIDs, Predicted ent. prob.
113 | using context for each of te 30 candidates. First element in the candidates
114 | is the true entity.
115 | Args:
116 | For each mention:
117 | condProbs_list: List of prior probs for 30 candidates.
118 | widIdxs_list: List of candidate widIdxs probs for 30 candidates.
119 | contextProbss_list: List of candidate prob. using context
120 | idx2knwid: Map for widIdx -> WID
121 | wid2WikiTitle: Map from WID -> WikiTitle
122 | '''
123 | # print("Evaluating E-Linking ... ")
124 | (WIDS_list, wikiTitles_list) = convertWidIdxs2WikiTitlesAndWIDs(
125 | widIdxs_list, idx2knwid, wid2WikiTitle)
126 |
127 | jointProbs_list = computeFinalEntityProbs(condProbs_list,
128 | contextProbs_list)
129 |
130 | (evaluationWikiTitles,
131 | sortedContextWTs) = computeMaxPriorContextJointEntities(
132 | WIDS_list, wikiTitles_list, condProbs_list, contextProbs_list,
133 | jointProbs_list, verbose)
134 |
135 | return (jointProbs_list, evaluationWikiTitles, sortedContextWTs)
136 |
137 | ##############################################################################
138 |
139 |
140 | def f1(p,r):
141 | if p == 0.0 and r == 0.0:
142 | return 0.0
143 | return (float(2*p*r))/(p + r)
144 |
145 |
146 | def strict_pred(true_label_batch, pred_score_batch):
147 | ''' Calculates strict precision/recall/f1 given truth and predicted scores
148 | args
149 | true_label_batch: Binary Numpy matrix of [num_instances, num_labels]
150 | pred_score_batch: Real [0,1] numpy matrix of [num_instances, num_labels]
151 |
152 | return:
153 | correct_preds: Number of correct strict preds
154 | precision : correct_preds / num_instances
155 | '''
156 | (true_labels, pred_labels) = types_convert_mat_to_sets(
157 | true_label_batch, pred_score_batch)
158 |
159 | num_instanes = len(true_labels)
160 | correct_preds = 0
161 | for i in range(0, num_instanes):
162 | if true_labels[i] == pred_labels[i]:
163 | correct_preds += 1
164 | #endfor
165 | precision = recall = float(correct_preds)/num_instanes
166 |
167 | return correct_preds, precision
168 |
169 |
170 | def correct_context_prediction(entity_posterior_scores, batch_size):
171 | bool_array = np.equal(np.argmax(entity_posterior_scores, axis=1),
172 | [0]*batch_size)
173 | correct_preds = np.sum(bool_array)
174 | return correct_preds
175 |
--------------------------------------------------------------------------------
/evaluation/evaluate_types.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import numpy as np
4 |
5 | coarsetypes = set(["location", "person", "organization", "event"])
6 | coarseTypeIds = set([1,5,10,25])
7 |
8 | def _convertTypeMatToTypeSets(typesscore_mat, idx2label, threshold):
9 | ''' Gets true labels and pred scores in numpy matrix and converts to list
10 | args
11 | true_label_batch: Binary Numpy matrix of [num_instances, num_labels]
12 | pred_score_batch: Real [0,1] numpy matrix of [num_instances, num_labels]
13 |
14 | return:
15 | true_labels: List of list of true label (indices) for batch of instances
16 | pred_labels : List of list of pred label (indices) for batch of instances
17 | (threshold = 0.5)
18 | '''
19 | labels = []
20 | for i in typesscore_mat:
21 | # i in array of label_vals for i-th example
22 | labels_i = []
23 | max_idx = -1
24 | max_val = -1
25 | for (label_idx, val) in enumerate(i):
26 | if val >= threshold:
27 | labels_i.append(idx2label[label_idx])
28 | if val > max_val:
29 | max_idx = label_idx
30 | max_val = val
31 | if len(labels_i) == 0:
32 | labels_i.append(idx2label[max_idx])
33 | labels.append(set(labels_i))
34 |
35 | '''
36 | assert 0.0 < threshold <= 1.0
37 | boolmat = typesscore_mat >= threshold
38 | boollist = boolmat.tolist()
39 | num_instanes = len(boollist)
40 | labels = []
41 | for i in range(0, num_instanes):
42 | labels_i = [idx2label[i] for i, x in enumerate(boollist[i]) if x]
43 | labels.append(set(labels_i))
44 | ##
45 | '''
46 | return labels
47 |
48 | def convertTypesScoreMatLists_TypeSets(typeScoreMat_list, idx2label, threshold):
49 | '''
50 | Take list of type scores numpy mat (per batch) as ouput from Tensorflow.
51 | Convert into list of type sets for each mention based on the thresold
52 |
53 | Return:
54 | typeSets_list: Size=num_instances. Each instance is set of type labels for mention
55 | '''
56 |
57 | typeSets_list = []
58 | for typeScoreMat in typeScoreMat_list:
59 | typeLabels_list = _convertTypeMatToTypeSets(typeScoreMat,
60 | idx2label, threshold)
61 | typeSets_list.extend(typeLabels_list)
62 | return typeSets_list
63 |
64 |
65 | def typesPredictionStats(pred_labels, true_labels):
66 | '''
67 | args
68 | true_label_batch: Binary Numpy matrix of [num_instances, num_labels]
69 | pred_score_batch: Real [0,1] numpy matrix of [num_instances, num_labels]
70 | '''
71 |
72 | # t_hat \interesect t
73 | t_intersect = 0
74 | t_hat_count = 0
75 | t_count = 0
76 | t_t_hat_exact = 0
77 | loose_macro_p = 0.0
78 | loose_macro_r = 0.0
79 | num_instances = len(true_labels)
80 | for i in range(0, num_instances):
81 | intersect = len(true_labels[i].intersection(pred_labels[i]))
82 | t_h_c = len(pred_labels[i])
83 | t_c = len(true_labels[i])
84 | t_intersect += intersect
85 | t_hat_count += t_h_c
86 | t_count += t_c
87 | exact = 1 if (true_labels[i] == pred_labels[i]) else 0
88 | t_t_hat_exact += exact
89 | if len(pred_labels[i]) > 0:
90 | loose_macro_p += intersect / float(t_h_c)
91 | if len(true_labels[i]) > 0:
92 | loose_macro_r += intersect / float(t_c)
93 |
94 | return (t_intersect, t_t_hat_exact, t_hat_count, t_count,
95 | loose_macro_p, loose_macro_r)
96 |
97 | def typesEvaluationMetrics(pred_TypeSetsList, true_TypeSetsList):
98 | num_instances = len(true_TypeSetsList)
99 | (t_i, t_th_exact, t_h_c, t_c, l_m_p, l_m_r) = typesPredictionStats(
100 | pred_labels=pred_TypeSetsList, true_labels=true_TypeSetsList)
101 | strict = float(t_th_exact)/float(num_instances)
102 | loose_macro_p = l_m_p / float(num_instances)
103 | loose_macro_r = l_m_r / float(num_instances)
104 | loose_macro_f = f1(loose_macro_p, loose_macro_r)
105 | if t_h_c > 0:
106 | loose_micro_p = float(t_i)/float(t_h_c)
107 | else:
108 | loose_micro_p = 0
109 | if t_c > 0:
110 | loose_micro_r = float(t_i)/float(t_c)
111 | else:
112 | loose_micro_r = 0
113 | loose_micro_f = f1(loose_micro_p, loose_micro_r)
114 |
115 | return (strict, loose_macro_p, loose_macro_r, loose_macro_f, loose_micro_p,
116 | loose_micro_r, loose_micro_f)
117 |
118 |
119 | def performTypingEvaluation(predLabelScoresnumpymat_list, idx2label):
120 | '''
121 | Args: List of numpy mat, one for ech batch, for true and pred type scores
122 | trueLabelScoresnumpymat_list: List of score matrices output by tensorflow
123 | predLabelScoresnumpymat_list: List of score matrices output by tensorflow
124 | '''
125 | pred_TypeSetsList = convertTypesScoreMatLists_TypeSets(
126 | typeScoreMat_list=predLabelScoresnumpymat_list, idx2label=idx2label,
127 | threshold=0.75)
128 |
129 | return pred_TypeSetsList
130 |
131 |
132 | def evaluate(predLabelScoresnumpymat_list, idx2label):
133 | # print("Evaluating Typing ... ")
134 | pred_TypeSetsList = convertTypesScoreMatLists_TypeSets(
135 | typeScoreMat_list=predLabelScoresnumpymat_list, idx2label=idx2label,
136 | threshold=0.75)
137 |
138 | return pred_TypeSetsList
139 |
140 |
141 | def f1(p,r):
142 | if p == 0.0 and r == 0.0:
143 | return 0.0
144 | return (float(2*p*r))/(p + r)
145 |
146 |
147 | def strict_pred(true_label_batch, pred_score_batch):
148 | ''' Calculates strict precision/recall/f1 given truth and predicted scores
149 | args
150 | true_label_batch: Binary Numpy matrix of [num_instances, num_labels]
151 | pred_score_batch: Real [0,1] numpy matrix of [num_instances, num_labels]
152 |
153 | return:
154 | correct_preds: Number of correct strict preds
155 | precision : correct_preds / num_instances
156 | '''
157 | (true_labels, pred_labels) = types_convert_mat_to_sets(
158 | true_label_batch, pred_score_batch)
159 |
160 | num_instanes = len(true_labels)
161 | correct_preds = 0
162 | for i in range(0, num_instanes):
163 | if true_labels[i] == pred_labels[i]:
164 | correct_preds += 1
165 | #endfor
166 | precision = recall = float(correct_preds)/num_instanes
167 |
168 | return correct_preds, precision
169 |
170 | def correct_context_prediction(entity_posterior_scores, batch_size):
171 | bool_array = np.equal(np.argmax(entity_posterior_scores, axis=1),
172 | [0]*batch_size)
173 | correct_preds = np.sum(bool_array)
174 | return correct_preds
175 |
--------------------------------------------------------------------------------
/models/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nitishgupta/neural-el/8c7c278acefa66238a75e805511ff26a567fd4e0/models/__init__.py
--------------------------------------------------------------------------------
/models/base.py:
--------------------------------------------------------------------------------
1 | import os
2 | from glob import glob
3 | import tensorflow as tf
4 |
5 | class Model(object):
6 | """Abstract object representing an Reader model."""
7 | def __init__(self):
8 | pass
9 |
10 | # def get_model_dir(self):
11 | # model_dir = self.dataset
12 | # for attr in self._attrs:
13 | # if hasattr(self, attr):
14 | # model_dir += "/%s=%s" % (attr, getattr(self, attr))
15 | # return model_dir
16 |
17 | def get_model_dir(self, attrs=None):
18 | model_dir = self.dataset
19 | if attrs == None:
20 | attrs = self._attrs
21 | for attr in attrs:
22 | if hasattr(self, attr):
23 | model_dir += "/%s=%s" % (attr, getattr(self, attr))
24 | return model_dir
25 |
26 | def get_log_dir(self, root_log_dir, attrs=None):
27 | model_dir = self.get_model_dir(attrs=attrs)
28 | log_dir = os.path.join(root_log_dir, model_dir)
29 | if not os.path.exists(log_dir):
30 | os.makedirs(log_dir)
31 | return log_dir
32 |
33 | def save(self, saver, checkpoint_dir, attrs=None, global_step=None):
34 | print(" [*] Saving checkpoints...")
35 | model_name = type(self).__name__
36 | model_dir = self.get_model_dir(attrs=attrs)
37 |
38 | checkpoint_dir = os.path.join(checkpoint_dir, model_dir)
39 | if not os.path.exists(checkpoint_dir):
40 | os.makedirs(checkpoint_dir)
41 | saver.save(self.sess, os.path.join(checkpoint_dir, model_name),
42 | global_step=global_step)
43 | print(" [*] Saving done...")
44 |
45 | def initialize(self, log_dir="./logs"):
46 | self.merged_sum = tf.merge_all_summaries()
47 | self.writer = tf.train.SummaryWriter(log_dir, self.sess.graph_def)
48 |
49 | tf.initialize_all_variables().run()
50 | self.load(self.checkpoint_dir)
51 |
52 | start_iter = self.step.eval()
53 |
54 | def load(self, saver, checkpoint_dir, attrs=None):
55 | print(" [*] Loading checkpoints...")
56 | model_dir = self.get_model_dir(attrs=attrs)
57 | # /checkpointdir/attrs=values/
58 | checkpoint_dir = os.path.join(checkpoint_dir, model_dir)
59 | print(" [#] Checkpoint Dir : {}".format(checkpoint_dir))
60 | ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
61 | if ckpt and ckpt.model_checkpoint_path:
62 | ckpt_name = os.path.basename(ckpt.model_checkpoint_path)
63 | print("ckpt_name: {}".format(ckpt_name))
64 | saver.restore(self.sess, os.path.join(checkpoint_dir, ckpt_name))
65 | print(" [*] Load SUCCESS")
66 | return True
67 | else:
68 | print(" [!] Load failed...")
69 | return False
70 |
71 | def loadCKPTPath(self, saver, ckptPath=None):
72 | assert ckptPath != None
73 | print(" [#] CKPT Path : {}".format(ckptPath))
74 | if os.path.exists(ckptPath):
75 | saver.restore(self.sess, ckptPath)
76 | print(" [*] Load SUCCESS")
77 | return True
78 | else:
79 | print(" [*] CKPT Path doesn't exist")
80 | return False
81 |
82 | def loadSpecificCKPT(self, saver, checkpoint_dir, ckptName=None, attrs=None):
83 | assert ckptName != None
84 | model_dir = self.get_model_dir(attrs=attrs)
85 | checkpoint_dir = os.path.join(checkpoint_dir, model_dir)
86 | checkpoint_path = os.path.join(checkpoint_dir, ckptName)
87 | print(" [#] CKPT Path : {}".format(checkpoint_path))
88 | if os.path.exists(checkpoint_path):
89 | saver.restore(self.sess, checkpoint_path)
90 |
91 | print(" [*] Load SUCCESS")
92 | return True
93 | else:
94 | print(" [*] CKPT Path doesn't exist")
95 | return False
96 |
97 |
98 |
99 | def collect_scope(self, scope_name, graph=None, var_type=tf.GraphKeys.VARIABLES):
100 | if graph == None:
101 | graph = tf.get_default_graph()
102 |
103 | var_list = graph.get_collection(var_type, scope=scope_name)
104 |
105 | assert_str = "No variable exists with name_scope '{}'".format(scope_name)
106 | assert len(var_list) != 0, assert_str
107 |
108 | return var_list
109 |
110 | def get_scope_var_name_set(self, var_name):
111 | clean_var_num = var_name.split(":")[0]
112 | scopes_names = clean_var_num.split("/")
113 | return set(scopes_names)
114 |
115 |
116 | def scope_vars_list(self, scope_name, var_list):
117 | scope_var_list = []
118 | for var in var_list:
119 | scope_var_name = self.get_scope_var_name_set(var.name)
120 | if scope_name in scope_var_name:
121 | scope_var_list.append(var)
122 | return scope_var_list
123 |
--------------------------------------------------------------------------------
/models/batch_normalizer.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | #from tensorflow.python import control_flow_ops
3 | from tensorflow.python.ops import control_flow_ops
4 |
5 | class BatchNorm():
6 | def __init__(self,
7 | input,
8 | training,
9 | decay=0.95,
10 | epsilon=1e-4,
11 | name='bn',
12 | reuse_vars=False):
13 |
14 | self.decay = decay
15 | self.epsilon = epsilon
16 | self.batchnorm(input, training, name, reuse_vars)
17 |
18 | def batchnorm(self, input, training, name, reuse_vars):
19 | with tf.variable_scope(name, reuse=reuse_vars) as bn:
20 | rank = len(input.get_shape().as_list())
21 | in_dim = input.get_shape().as_list()[-1]
22 |
23 | if rank == 2:
24 | self.axes = [0]
25 | elif rank == 4:
26 | self.axes = [0, 1, 2]
27 | else:
28 | raise ValueError('Input tensor must have rank 2 or 4.')
29 |
30 | self.offset = tf.get_variable(
31 | 'offset',
32 | shape=[in_dim],
33 | initializer=tf.constant_initializer(0.0))
34 |
35 | self.scale = tf.get_variable(
36 | 'scale',
37 | shape=[in_dim],
38 | initializer=tf.constant_initializer(1.0))
39 |
40 | self.ema = tf.train.ExponentialMovingAverage(decay=self.decay)
41 |
42 | self.output = tf.cond(training,
43 | lambda: self.get_normalizer(input, True),
44 | lambda: self.get_normalizer(input, False))
45 |
46 | def get_normalizer(self, input, train_flag):
47 | if train_flag:
48 | self.mean, self.variance = tf.nn.moments(input, self.axes)
49 | # Fixes numerical instability if variance ~= 0, and it goes negative
50 | v = tf.nn.relu(self.variance)
51 | ema_apply_op = self.ema.apply([self.mean, self.variance])
52 | with tf.control_dependencies([ema_apply_op]):
53 | self.output_training = tf.nn.batch_normalization(
54 | input, self.mean, v, self.offset, self.scale,
55 | self.epsilon, 'normalizer_train'),
56 | return self.output_training
57 | else:
58 | self.output_test = tf.nn.batch_normalization(
59 | input, self.ema.average(self.mean),
60 | self.ema.average(self.variance), self.offset, self.scale,
61 | self.epsilon, 'normalizer_test')
62 | return self.output_test
63 |
64 | def get_batch_moments(self):
65 | return self.mean, self.variance
66 |
67 | def get_ema_moments(self):
68 | return self.ema.average(self.mean), self.ema.average(self.variance)
69 |
70 | def get_offset_scale(self):
71 | return self.offset, self.scale
72 |
--------------------------------------------------------------------------------
/models/figer_model/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nitishgupta/neural-el/8c7c278acefa66238a75e805511ff26a567fd4e0/models/figer_model/__init__.py
--------------------------------------------------------------------------------
/models/figer_model/coherence_model.py:
--------------------------------------------------------------------------------
1 | import time
2 | import numpy as np
3 | import tensorflow as tf
4 |
5 | from models.base import Model
6 |
7 | class CoherenceModel(Model):
8 | '''
9 | Input is sparse tensor of mention strings in mention's document.
10 | Pass through feed forward and get a coherence representation
11 | (keep same as context_encoded_dim)
12 | '''
13 |
14 | def __init__(self, num_layers, batch_size, input_size,
15 | coherence_indices, coherence_values, coherence_matshape,
16 | context_encoded_dim, scope_name, device,
17 | dropout_keep_prob=1.0):
18 |
19 | # Num of layers in the encoder and decoder network
20 | self.num_layers = num_layers
21 | self.input_size = input_size
22 | self.context_encoded_dim = context_encoded_dim
23 | self.dropout_keep_prob = dropout_keep_prob
24 | self.batch_size = batch_size
25 |
26 | with tf.variable_scope(scope_name) as s, tf.device(device) as d:
27 | coherence_inp_tensor = tf.SparseTensor(coherence_indices,
28 | coherence_values,
29 | coherence_matshape)
30 |
31 | # Feed-forward Net for coherence_representation
32 | # Layer 1
33 | self.trans_weights = tf.get_variable(
34 | name="coherence_layer_0",
35 | shape=[self.input_size, self.context_encoded_dim],
36 | initializer=tf.random_normal_initializer(
37 | mean=0.0,
38 | stddev=1.0/(100.0)))
39 |
40 | # [B, context_encoded_dim]
41 | coherence_encoded = tf.sparse_tensor_dense_matmul(
42 | coherence_inp_tensor, self.trans_weights)
43 | coherence_encoded = tf.nn.relu(coherence_encoded)
44 |
45 | # Hidden Layers. NumLayers >= 2
46 | self.hidden_layers = []
47 | for i in range(1, self.num_layers):
48 | weight_matrix = tf.get_variable(
49 | name="coherence_layer_"+str(i),
50 | shape=[self.context_encoded_dim, self.context_encoded_dim],
51 | initializer=tf.random_normal_initializer(
52 | mean=0.0,
53 | stddev=1.0/(100.0)))
54 | self.hidden_layers.append(weight_matrix)
55 |
56 | for i in range(1, self.num_layers):
57 | coherence_encoded = tf.nn.dropout(
58 | coherence_encoded, keep_prob=self.dropout_keep_prob)
59 | coherence_encoded = tf.matmul(coherence_encoded,
60 | self.hidden_layers[i-1])
61 | coherence_encoded = tf.nn.relu(coherence_encoded)
62 |
63 | self.coherence_encoded = tf.nn.dropout(
64 | coherence_encoded, keep_prob=self.dropout_keep_prob)
65 |
--------------------------------------------------------------------------------
/models/figer_model/coldStart.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import tensorflow as tf
4 | import numpy as np
5 |
6 | import readers.utils as utils
7 | from evaluation import evaluate
8 | from evaluation import evaluate_el
9 | from evaluation import evaluate_types
10 | from models.base import Model
11 | from models.figer_model.context_encoder import ContextEncoderModel
12 | from models.figer_model.coherence_model import CoherenceModel
13 | from models.figer_model.wiki_desc import WikiDescModel
14 | from models.figer_model.joint_context import JointContextModel
15 | from models.figer_model.labeling_model import LabelingModel
16 | from models.figer_model.entity_posterior import EntityPosterior
17 | from models.figer_model.loss_optim import LossOptim
18 |
19 |
20 | class ColdStart(object):
21 | def __init__(self, figermodel):
22 | print("###### ENTERED THE COLD WORLD OF THE UNKNOWN ##############")
23 | # Object of the WikiELModel Class
24 | self.fm = figermodel
25 | self.coldDir = self.fm.reader.coldDir
26 | coldWid2DescVecs_pkl = os.path.join(self.coldDir, "coldwid2descvecs.pkl")
27 | self.coldWid2DescVecs = utils.load(coldWid2DescVecs_pkl)
28 | self.num_cold_entities = self.fm.reader.num_cold_entities
29 | self.batch_size = self.fm.batch_size
30 | (self.coldwid2idx,
31 | self.idx2coldwid) = (self.fm.reader.coldwid2idx, self.fm.reader.idx2coldwid)
32 |
33 | def _makeDescLossGraph(self):
34 | with tf.variable_scope("cold") as s:
35 | with tf.device(self.fm.device_placements['gpu']) as d:
36 | tf.set_random_seed(1)
37 |
38 | self.coldEnEmbsToAssign = tf.placeholder(
39 | tf.float32, [self.num_cold_entities, 200], name="coldEmbsAssignment")
40 |
41 | self.coldEnEmbs = tf.get_variable(
42 | name="cold_entity_embeddings",
43 | shape=[self.num_cold_entities, 200],
44 | initializer=tf.random_normal_initializer(mean=-0.25,
45 | stddev=1.0/(100.0)))
46 |
47 | self.assignColdEmbs = self.coldEnEmbs.assign(self.coldEnEmbsToAssign)
48 |
49 | self.trueColdEnIds = tf.placeholder(
50 | tf.int32, [self.batch_size], name="true_entities_idxs")
51 |
52 | # Should be a list of zeros
53 | self.softTrueIdxs = tf.placeholder(
54 | tf.int32, [self.batch_size], name="softmaxTrueEnsIdxs")
55 |
56 | # [B, D]
57 | self.trueColdEmb = tf.nn.embedding_lookup(
58 | self.coldEnEmbs, self.trueColdEnIds)
59 | # [B, 1, D]
60 | self.trueColdEmb_exp = tf.expand_dims(
61 | input=self.trueColdEmb, dim=1)
62 |
63 | self.label_scores = tf.matmul(self.trueColdEmb,
64 | self.fm.labeling_model.label_weights)
65 |
66 | self.labeling_losses = tf.nn.sigmoid_cross_entropy_with_logits(
67 | logits=self.label_scores,
68 | targets=self.fm.labels_batch,
69 | name="labeling_loss")
70 |
71 | self.labelingLoss = tf.reduce_sum(
72 | self.labeling_losses) / tf.to_float(self.batch_size)
73 |
74 | # [B, D]
75 | self.descEncoded = self.fm.wikidescmodel.desc_encoded
76 |
77 | ## Maximize sigmoid of dot-prod between true emb. and desc encoding
78 | descLosses = -tf.sigmoid(tf.reduce_sum(tf.mul(self.trueColdEmb, self.descEncoded), 1))
79 | self.descLoss = tf.reduce_sum(descLosses)/tf.to_float(self.batch_size)
80 |
81 |
82 | # L-2 Norm Loss
83 | self.trueEmbNormLoss = tf.reduce_sum(
84 | tf.square(self.trueColdEmb))/(tf.to_float(self.batch_size))
85 |
86 |
87 | ''' Concat trueColdEmb_exp to negKnownEmbs so that 0 is the true entity.
88 | Dotprod this emb matrix with descEncoded to get scores and apply softmax
89 | '''
90 |
91 | self.trcoldvars = self.fm.scope_vars_list(scope_name="cold",
92 | var_list=tf.trainable_variables())
93 |
94 | print("Vars in Training")
95 | for var in self.trcoldvars:
96 | print(var.name)
97 |
98 |
99 | self.optimizer = tf.train.AdamOptimizer(
100 | learning_rate=self.fm.learning_rate,
101 | name='AdamCold_')
102 |
103 | self.total_labeling_loss = self.labelingLoss + self.trueEmbNormLoss
104 | self.label_gvs = self.optimizer.compute_gradients(
105 | loss=self.total_labeling_loss, var_list=self.trcoldvars)
106 | self.labeling_optim_op = self.optimizer.apply_gradients(self.label_gvs)
107 |
108 | self.total_loss = self.labelingLoss + 100*self.descLoss + self.trueEmbNormLoss
109 | self.comb_gvs = self.optimizer.compute_gradients(
110 | loss=self.total_loss, var_list=self.trcoldvars)
111 | self.combined_optim_op = self.optimizer.apply_gradients(self.comb_gvs)
112 |
113 |
114 | self.allcoldvars = self.fm.scope_vars_list(scope_name="cold",
115 | var_list=tf.all_variables())
116 |
117 | print("All Vars in Cold")
118 | for var in self.allcoldvars:
119 | print(var.name)
120 |
121 | print("Loaded and graph made")
122 | ### GRAPH COMPLETE ###
123 |
124 | #############################################################################
125 | def _trainColdEmbFromTypes(self, epochsToTrain=5):
126 | print("Training Cold Entity Embeddings from Typing Info")
127 |
128 | epochsDone = self.fm.reader.val_epochs
129 |
130 | while self.fm.reader.val_epochs < epochsToTrain:
131 | (left_batch, left_lengths,
132 | right_batch, right_lengths,
133 | wids_batch,
134 | labels_batch, coherence_batch,
135 | wid_idxs_batch, wid_cprobs_batch) = self.fm.reader._next_padded_batch(data_type=1)
136 |
137 | trueColdWidIdxsBatch = []
138 | trueColdWidDescWordVecBatch = []
139 | for wid in wids_batch:
140 | trueColdWidIdxsBatch.append(self.coldwid2idx[wid])
141 | trueColdWidDescWordVecBatch.append(self.coldWid2DescVecs[wid])
142 |
143 | feed_dict = {self.trueColdEnIds: trueColdWidIdxsBatch,
144 | self.fm.labels_batch: labels_batch}
145 |
146 | fetch_tensor = [self.labelingLoss, self.trueEmbNormLoss]
147 |
148 | (fetches, _) = self.fm.sess.run([fetch_tensor,
149 | self.labeling_optim_op],
150 | feed_dict=feed_dict)
151 |
152 | labelingLoss = fetches[0]
153 | trueEmbNormLoss = fetches[1]
154 |
155 | print("LL : {} NormLoss : {}".format(labelingLoss, trueEmbNormLoss))
156 |
157 | newedone = self.fm.reader.val_epochs
158 | if newedone > epochsDone:
159 | print("Epochs : {}".format(newedone))
160 | epochsDone = newedone
161 |
162 | #############################################################################
163 | def _trainColdEmbFromTypesAndDesc(self, epochsToTrain=5):
164 | print("Training Cold Entity Embeddings from Typing Info")
165 |
166 | epochsDone = self.fm.reader.val_epochs
167 |
168 | while self.fm.reader.val_epochs < epochsToTrain:
169 | (left_batch, left_lengths,
170 | right_batch, right_lengths,
171 | wids_batch,
172 | labels_batch, coherence_batch,
173 | wid_idxs_batch, wid_cprobs_batch) = self.fm.reader._next_padded_batch(data_type=1)
174 |
175 | trueColdWidIdxsBatch = []
176 | trueColdWidDescWordVecBatch = []
177 | for wid in wids_batch:
178 | trueColdWidIdxsBatch.append(self.coldwid2idx[wid])
179 | trueColdWidDescWordVecBatch.append(self.coldWid2DescVecs[wid])
180 |
181 | feed_dict = {self.fm.wikidesc_batch: trueColdWidDescWordVecBatch,
182 | self.trueColdEnIds: trueColdWidIdxsBatch,
183 | self.fm.labels_batch: labels_batch}
184 |
185 | fetch_tensor = [self.labelingLoss, self.descLoss, self.trueEmbNormLoss]
186 |
187 | (fetches,_) = self.fm.sess.run([fetch_tensor,
188 | self.combined_optim_op],
189 | feed_dict=feed_dict)
190 |
191 | labelingLoss = fetches[0]
192 | descLoss = fetches[1]
193 | normLoss = fetches[2]
194 |
195 | print("L : {} D : {} NormLoss : {}".format(labelingLoss, descLoss, normLoss))
196 |
197 | newedone = self.fm.reader.val_epochs
198 | if newedone > epochsDone:
199 | print("Epochs : {}".format(newedone))
200 | epochsDone = newedone
201 |
202 | #############################################################################
203 |
204 | def runEval(self):
205 | print("Running Evaluations")
206 | self.fm.reader.reset_validation()
207 | correct = 0
208 | total = 0
209 | totnew = 0
210 | correctnew = 0
211 | while self.fm.reader.val_epochs < 1:
212 | (left_batch, left_lengths,
213 | right_batch, right_lengths,
214 | wids_batch,
215 | labels_batch, coherence_batch,
216 | wid_idxs_batch,
217 | wid_cprobs_batch) = self.fm.reader._next_padded_batch(data_type=1)
218 |
219 | trueColdWidIdxsBatch = []
220 |
221 | for wid in wids_batch:
222 | trueColdWidIdxsBatch.append(self.coldwid2idx[wid])
223 |
224 | feed_dict = {self.fm.sampled_entity_ids: wid_idxs_batch,
225 | self.fm.left_context_embeddings: left_batch,
226 | self.fm.right_context_embeddings: right_batch,
227 | self.fm.left_lengths: left_lengths,
228 | self.fm.right_lengths: right_lengths,
229 | self.fm.coherence_indices: coherence_batch[0],
230 | self.fm.coherence_values: coherence_batch[1],
231 | self.fm.coherence_matshape: coherence_batch[2],
232 | self.trueColdEnIds: trueColdWidIdxsBatch}
233 |
234 | fetch_tensor = [self.trueColdEmb,
235 | self.fm.joint_context_encoded,
236 | self.fm.posterior_model.sampled_entity_embeddings,
237 | self.fm.posterior_model.entity_scores]
238 |
239 | fetched_vals = self.fm.sess.run(fetch_tensor, feed_dict=feed_dict)
240 | [trueColdEmbs, # [B, D]
241 | context_encoded, # [B, D]
242 | neg_entity_embeddings, # [B, N, D]
243 | neg_entity_scores] = fetched_vals # [B, N]
244 |
245 | # [B]
246 | trueColdWidScores = np.sum(trueColdEmbs*context_encoded, axis=1)
247 | entity_scores = neg_entity_scores
248 | entity_scores[:,0] = trueColdWidScores
249 | context_entity_scores = np.exp(entity_scores)/np.sum(np.exp(entity_scores))
250 |
251 | maxIdxs = np.argmax(context_entity_scores, axis=1)
252 | for i in range(0, self.batch_size):
253 | total += 1
254 | if maxIdxs[i] == 0:
255 | correct += 1
256 |
257 | scores_withpriors = context_entity_scores + wid_cprobs_batch
258 |
259 | maxIdxs = np.argmax(scores_withpriors, axis=1)
260 | for i in range(0, self.batch_size):
261 | totnew += 1
262 | if maxIdxs[i] == 0:
263 | correctnew += 1
264 |
265 | print("Context T : {} C : {}".format(total, correct))
266 | print("WPriors T : {} C : {}".format(totnew, correctnew))
267 |
268 | ##############################################################################
269 |
270 | def typeBasedColdEmbExp(self, ckptName="FigerModel-20001"):
271 | ''' Train cold embeddings using wiki desc loss
272 | '''
273 | saver = tf.train.Saver(var_list=tf.all_variables())
274 |
275 | print("Loading Model ... ")
276 | if ckptName == None:
277 | print("Given CKPT Name")
278 | sys.exit()
279 | else:
280 | load_status = self.fm.loadSpecificCKPT(
281 | saver=saver, checkpoint_dir=self.fm.checkpoint_dir,
282 | ckptName=ckptName, attrs=self.fm._attrs)
283 | if not load_status:
284 | print("No model to load. Exiting")
285 | sys.exit(0)
286 |
287 | self._makeDescLossGraph()
288 | self.fm.sess.run(tf.initialize_variables(self.allcoldvars))
289 | self._trainColdEmbFromTypes(epochsToTrain=5)
290 |
291 | self.runEval()
292 |
293 | ##############################################################################
294 |
295 | def typeAndWikiDescBasedColdEmbExp(self, ckptName="FigerModel-20001"):
296 | ''' Train cold embeddings using wiki desc loss
297 | '''
298 | saver = tf.train.Saver(var_list=tf.all_variables())
299 |
300 | print("Loading Model ... ")
301 | if ckptName == None:
302 | print("Given CKPT Name")
303 | sys.exit()
304 | else:
305 | load_status = self.fm.loadSpecificCKPT(
306 | saver=saver, checkpoint_dir=self.fm.checkpoint_dir,
307 | ckptName=ckptName, attrs=self.fm._attrs)
308 | if not load_status:
309 | print("No model to load. Exiting")
310 | sys.exit(0)
311 |
312 | self._makeDescLossGraph()
313 | self.fm.sess.run(tf.initialize_variables(self.allcoldvars))
314 | self._trainColdEmbFromTypesAndDesc(epochsToTrain=5)
315 |
316 | self.runEval()
317 |
318 | # EVALUATION FOR COLD START WHEN INITIALIZING COLD EMB FROM WIKI DESC ENCODING
319 | def wikiDescColdEmbExp(self, ckptName="FigerModel-20001"):
320 | ''' Assign cold entity embeddings as wiki desc encoding
321 | '''
322 | assert self.batch_size == 1
323 | print("Loaded Cold Start Class. ")
324 | print("Size of cold entities : {}".format(len(self.coldWid2DescVecs)))
325 |
326 | saver = tf.train.Saver(var_list=tf.all_variables(), max_to_keep=5)
327 |
328 | print("Loading Model ... ")
329 | if ckptName == None:
330 | print("Given CKPT Name")
331 | sys.exit()
332 | else:
333 | load_status = self.fm.loadSpecificCKPT(
334 | saver=saver, checkpoint_dir=self.fm.checkpoint_dir,
335 | ckptName=ckptName, attrs=self.fm._attrs)
336 | if not load_status:
337 | print("No model to load. Exiting")
338 | sys.exit(0)
339 |
340 | iter_done = self.fm.global_step.eval()
341 | print("[#] Model loaded with iterations done: %d" % iter_done)
342 |
343 | self._makeDescLossGraph()
344 | self.fm.sess.run(tf.initialize_variables(self.allcoldvars))
345 |
346 | # Fill with encoded desc. in order of idx2coldwid
347 | print("Getting Encoded Description Vectors")
348 | descEncodedMatrix = []
349 | for idx in range(0, len(self.idx2coldwid)):
350 | wid = self.idx2coldwid[idx]
351 | desc_vec = self.coldWid2DescVecs[wid]
352 | feed_dict = {self.fm.wikidesc_batch: [desc_vec]}
353 | desc_encoded = self.fm.sess.run(self.fm.wikidescmodel.desc_encoded,
354 | feed_dict=feed_dict)
355 | descEncodedMatrix.append(desc_encoded[0])
356 |
357 | print("Initialization Experiment")
358 | self.runEval()
359 |
360 | print("Assigning Cold Embeddings from Wiki Desc Encoder ...")
361 | self.fm.sess.run(self.assignColdEmbs,
362 | feed_dict={self.coldEnEmbsToAssign:descEncodedMatrix})
363 |
364 | print("After assigning based on Wiki Encoder")
365 | self.runEval()
366 |
367 | ##############################################################################
368 |
--------------------------------------------------------------------------------
/models/figer_model/context_encoder.py:
--------------------------------------------------------------------------------
1 | import time
2 | import tensorflow as tf
3 | import numpy as np
4 |
5 | from models.base import Model
6 |
7 | class ContextEncoderModel(Model):
8 | """Run Forward and Backward LSTM and concatenate last outputs to get
9 | context representation"""
10 |
11 | def __init__(self, num_layers, batch_size, lstm_size,
12 | left_embed_batch, left_lengths, right_embed_batch, right_lengths,
13 | context_encoded_dim, scope_name, device, dropout_keep_prob=1.0):
14 |
15 | self.num_layers = num_layers # Num of layers in the encoder and decoder network
16 | self.num_lstm_layers = 1
17 |
18 | # Left / Right Context Dim.
19 | # Context Representation Dim : 2*lstm_size
20 | self.lstm_size = lstm_size
21 | self.dropout_keep_prob = dropout_keep_prob
22 | self.batch_size = batch_size
23 | self.context_encoded_dim = context_encoded_dim
24 | self.left_context_embeddings = left_embed_batch
25 | self.right_context_embeddings = right_embed_batch
26 |
27 | with tf.variable_scope(scope_name) as sc, tf.device(device) as d:
28 | with tf.variable_scope("left_encoder") as s:
29 | l_encoder_cell = tf.nn.rnn_cell.BasicLSTMCell(
30 | self.lstm_size, state_is_tuple=True)
31 |
32 | l_dropout_cell = tf.nn.rnn_cell.DropoutWrapper(
33 | cell=l_encoder_cell,
34 | input_keep_prob=self.dropout_keep_prob,
35 | output_keep_prob=self.dropout_keep_prob)
36 |
37 | self.left_encoder = tf.nn.rnn_cell.MultiRNNCell(
38 | [l_dropout_cell] * self.num_lstm_layers, state_is_tuple=True)
39 |
40 | self.left_outputs, self.left_states = tf.nn.dynamic_rnn(
41 | cell=self.left_encoder, inputs=self.left_context_embeddings,
42 | sequence_length=left_lengths, dtype=tf.float32)
43 |
44 | with tf.variable_scope("right_encoder") as s:
45 | r_encoder_cell = tf.nn.rnn_cell.BasicLSTMCell(
46 | self.lstm_size, state_is_tuple=True)
47 |
48 | r_dropout_cell = tf.nn.rnn_cell.DropoutWrapper(
49 | cell=r_encoder_cell,
50 | input_keep_prob=self.dropout_keep_prob,
51 | output_keep_prob=self.dropout_keep_prob)
52 |
53 | self.right_encoder = tf.nn.rnn_cell.MultiRNNCell(
54 | [r_dropout_cell] * self.num_lstm_layers, state_is_tuple=True)
55 |
56 | self.right_outputs, self.right_states = tf.nn.dynamic_rnn(
57 | cell=self.right_encoder,
58 | inputs=self.right_context_embeddings,
59 | sequence_length=right_lengths, dtype=tf.float32)
60 |
61 | # Left Context Encoded
62 | # [B, LSTM_DIM]
63 | self.left_last_output = self.get_last_output(
64 | outputs=self.left_outputs, lengths=left_lengths,
65 | name="left_context_encoded")
66 |
67 | # Right Context Encoded
68 | # [B, LSTM_DIM]
69 | self.right_last_output = self.get_last_output(
70 | outputs=self.right_outputs, lengths=right_lengths,
71 | name="right_context_encoded")
72 |
73 | # Context Encoded Vector
74 | self.context_lstm_encoded = tf.concat(
75 | 1, [self.left_last_output, self.right_last_output],
76 | name='context_lstm_encoded')
77 |
78 | # Linear Transformation to get context_encoded_dim
79 | # Layer 1
80 | self.trans_weights = tf.get_variable(
81 | name="context_trans_weights",
82 | shape=[2*self.lstm_size, self.context_encoded_dim],
83 | initializer=tf.random_normal_initializer(
84 | mean=0.0,
85 | stddev=1.0/(100.0)))
86 |
87 | # [B, context_encoded_dim]
88 | context_encoded = tf.matmul(self.context_lstm_encoded,
89 | self.trans_weights)
90 | context_encoded = tf.nn.relu(context_encoded)
91 |
92 | self.hidden_layers = []
93 | for i in range(1, self.num_layers):
94 | weight_matrix = tf.get_variable(
95 | name="context_hlayer_"+str(i),
96 | shape=[self.context_encoded_dim, self.context_encoded_dim],
97 | initializer=tf.random_normal_initializer(
98 | mean=0.0,
99 | stddev=1.0/(100.0)))
100 | self.hidden_layers.append(weight_matrix)
101 |
102 | for i in range(1, self.num_layers):
103 | context_encoded = tf.nn.dropout(
104 | context_encoded, keep_prob=self.dropout_keep_prob)
105 | context_encoded = tf.matmul(context_encoded,
106 | self.hidden_layers[i-1])
107 | context_encoded = tf.nn.relu(context_encoded)
108 |
109 | self.context_encoded = tf.nn.dropout(
110 | context_encoded, keep_prob=self.dropout_keep_prob)
111 |
112 | def get_last_output(self, outputs, lengths, name):
113 | reverse_output = tf.reverse_sequence(input=outputs,
114 | seq_lengths=tf.to_int64(lengths),
115 | seq_dim=1,
116 | batch_dim=0)
117 | en_last_output = tf.slice(input_=reverse_output,
118 | begin=[0,0,0],
119 | size=[self.batch_size, 1, -1])
120 | # [batch_size, h_dim]
121 | encoder_last_output = tf.reshape(en_last_output,
122 | shape=[self.batch_size, -1],
123 | name=name)
124 |
125 | return encoder_last_output
126 |
--------------------------------------------------------------------------------
/models/figer_model/entity_posterior.py:
--------------------------------------------------------------------------------
1 | import time
2 | import tensorflow as tf
3 | import numpy as np
4 |
5 | from models.base import Model
6 |
7 | class EntityPosterior(Model):
8 | """Entity Embeddings and Posterior Calculation"""
9 |
10 | def __init__(self, batch_size, num_knwn_entities, context_encoded_dim,
11 | context_encoded, entity_ids, scope_name,
12 | device_embeds, device_gpu):
13 |
14 | ''' Defines the entity posterior estimation graph.
15 | Makes entity embeddings variable, gets encoded context and candidate
16 | entities and gets entity scores using dot-prod.
17 |
18 | Input :
19 | context_encoded_dim: D - dims in which context is encoded
20 | context_encoded: [B, D]
21 | entity_ids: [B, N]. If supervised, first is the correct entity, and
22 | rest N-1 the candidates. For unsupervised, all N are candidates.
23 | num_knwn_entities: Number of entities with supervised data.
24 | Defines:
25 | entity_embeddings: [num_knwn_entities, D]
26 | Output:
27 | entity_scores: [B,N] matrix of context scores
28 | '''
29 |
30 | self.batch_size = batch_size
31 | self.num_knwn_entities = num_knwn_entities
32 |
33 | with tf.variable_scope(scope_name) as s:
34 | with tf.device(device_embeds) as d:
35 | self.knwn_entity_embeddings = tf.get_variable(
36 | name="known_entity_embeddings",
37 | shape=[self.num_knwn_entities, context_encoded_dim],
38 | initializer=tf.random_normal_initializer(mean=0.0,
39 | stddev=1.0/(100.0)))
40 | with tf.device(device_gpu) as g:
41 | # [B, N, D]
42 | self.sampled_entity_embeddings = tf.nn.embedding_lookup(
43 | self.knwn_entity_embeddings, entity_ids)
44 |
45 | # # Negative Samples for Description CNN - [B, D]
46 | trueentity_embeddings = tf.slice(
47 | self.sampled_entity_embeddings, [0,0,0],
48 | [self.batch_size, 1, context_encoded_dim])
49 | self.trueentity_embeddings = tf.reshape(
50 | trueentity_embeddings, [self.batch_size,
51 | context_encoded_dim])
52 |
53 | # Negative Samples for Description CNN
54 | negentity_embeddings = tf.slice(
55 | self.sampled_entity_embeddings, [0,1,0],
56 | [self.batch_size, 1, context_encoded_dim])
57 | self.negentity_embeddings = tf.reshape(
58 | negentity_embeddings, [self.batch_size,
59 | context_encoded_dim])
60 |
61 | # [B, 1, D]
62 | context_encoded_expanded = tf.expand_dims(
63 | input=context_encoded, dim=1)
64 |
65 | # [B, N]
66 | self.entity_scores = tf.reduce_sum(tf.mul(
67 | self.sampled_entity_embeddings, context_encoded_expanded), 2)
68 |
69 | # SOFTMAX
70 | # [B, N]
71 | self.entity_posteriors = tf.nn.softmax(
72 | self.entity_scores, name="entity_post_softmax")
73 |
74 | def loss_graph(self, true_entity_ids, scope_name, device_gpu):
75 | ''' true_entity_ids : [B] is the true ids in the sampled [B,N] matrix
76 | In entity_ids, [?, 0] is the true entity therefore this should be
77 | a vector of zeros
78 | '''
79 | with tf.variable_scope(scope_name) as s, tf.device(device_gpu) as d:
80 | # CROSS ENTROPY LOSS
81 | self.crossentropy_losses = \
82 | tf.nn.sparse_softmax_cross_entropy_with_logits(
83 | logits=self.entity_scores,
84 | labels=true_entity_ids,
85 | name="entity_posterior_loss")
86 |
87 | self.posterior_loss = tf.reduce_sum(
88 | self.crossentropy_losses) / tf.to_float(self.batch_size)
89 |
--------------------------------------------------------------------------------
/models/figer_model/joint_context.py:
--------------------------------------------------------------------------------
1 | import time
2 | import tensorflow as tf
3 | import numpy as np
4 |
5 | from models.base import Model
6 |
7 | class JointContextModel(Model):
8 | """Entity Embeddings and Posterior Calculation"""
9 |
10 | def __init__(self, num_layers, context_encoded_dim, text_encoded,
11 | coherence_encoded, scope_name, device, dropout_keep_prob):
12 |
13 | ''' Get context text and coherence encoded and combine into one repr.
14 | Input:
15 | text_encoded: Encoded vector for bi-LSTM. [context_encoded_dim]
16 | coherence_encoded: Encoded vector from sparse coherence FF [context_encoded_dim]
17 |
18 | Output:
19 | joint_encoded_vector: [context_encoded_dim]
20 | '''
21 | self.num_layers = num_layers
22 | self.dropout_keep_prob = dropout_keep_prob
23 | with tf.variable_scope(scope_name) as s:
24 | with tf.device(device) as d:
25 | self.joint_weights = tf.get_variable(
26 | name="joint_context_layer",
27 | shape=[2*context_encoded_dim, context_encoded_dim],
28 | initializer=tf.random_normal_initializer(mean=0.0,
29 | stddev=1.0/(100.0)))
30 |
31 | self.text_coh_concat = tf.concat(
32 | 1, [text_encoded, coherence_encoded], name='text_coh_concat')
33 |
34 | context_encoded = tf.matmul(self.text_coh_concat, self.joint_weights)
35 | context_encoded = tf.nn.relu(context_encoded)
36 |
37 | self.hidden_layers = []
38 | for i in range(1, self.num_layers):
39 | weight_matrix = tf.get_variable(
40 | name="joint_context_hlayer_"+str(i),
41 | shape=[context_encoded_dim, context_encoded_dim],
42 | initializer=tf.random_normal_initializer(
43 | mean=0.0,
44 | stddev=1.0/(100.0)))
45 | self.hidden_layers.append(weight_matrix)
46 |
47 | for i in range(1, self.num_layers):
48 | context_encoded = tf.nn.dropout(context_encoded, keep_prob=self.dropout_keep_prob)
49 | context_encoded = tf.matmul(context_encoded, self.hidden_layers[i-1])
50 | context_encoded = tf.nn.relu(context_encoded)
51 |
52 | self.context_encoded = tf.nn.dropout(context_encoded, keep_prob=self.dropout_keep_prob)
53 |
--------------------------------------------------------------------------------
/models/figer_model/labeling_model.py:
--------------------------------------------------------------------------------
1 | import time
2 | import tensorflow as tf
3 | import numpy as np
4 |
5 | from models.base import Model
6 |
7 | class LabelingModel(Model):
8 | """Unsupervised Clustering using Discrete-State VAE"""
9 |
10 | def __init__(self, batch_size, num_labels, context_encoded_dim,
11 | true_entity_embeddings,
12 | word_embed_dim, context_encoded, mention_embed, scope_name, device):
13 |
14 | self.batch_size = batch_size
15 | self.num_labels = num_labels
16 | self.word_embed_dim = word_embed_dim
17 |
18 | with tf.variable_scope(scope_name) as s, tf.device(device) as d:
19 | if mention_embed == None:
20 | self.label_weights = tf.get_variable(
21 | name="label_weights",
22 | shape=[context_encoded_dim, num_labels],
23 | initializer=tf.random_normal_initializer(mean=0.0,
24 | stddev=1.0/(100.0)))
25 | else:
26 | context_encoded = tf.concat(
27 | 1, [context_encoded, mention_embed], name='con_ment_repr')
28 | self.label_weights = tf.get_variable(
29 | name="label_weights",
30 | shape=[context_encoded_dim+word_embed_dim, num_labels],
31 | initializer=tf.random_normal_initializer(mean=0.0,
32 | stddev=1.0/(100.0)))
33 |
34 | # [B, L]
35 | self.label_scores = tf.matmul(context_encoded, self.label_weights)
36 | self.label_probs = tf.sigmoid(self.label_scores)
37 |
38 | ### PREDICT TYPES FROM ENTITIES
39 | #true_entity_embeddings = tf.nn.dropout(true_entity_embeddings, keep_prob=0.5)
40 | self.entity_label_scores = tf.matmul(true_entity_embeddings, self.label_weights)
41 | self.entity_label_probs = tf.sigmoid(self.label_scores)
42 |
43 |
44 | def loss_graph(self, true_label_ids, scope_name, device_gpu):
45 | with tf.variable_scope(scope_name) as s, tf.device(device_gpu) as d:
46 | # [B, L]
47 | self.cross_entropy_losses = tf.nn.sigmoid_cross_entropy_with_logits(
48 | logits=self.label_scores,
49 | targets=true_label_ids,
50 | name="labeling_loss")
51 |
52 | self.labeling_loss = tf.reduce_sum(
53 | self.cross_entropy_losses) / tf.to_float(self.batch_size)
54 |
55 |
56 | self.enlabel_cross_entropy_losses = tf.nn.sigmoid_cross_entropy_with_logits(
57 | logits=self.entity_label_scores,
58 | targets=true_label_ids,
59 | name="entity_labeling_loss")
60 |
61 | self.entity_labeling_loss = tf.reduce_sum(
62 | self.enlabel_cross_entropy_losses) / tf.to_float(self.batch_size)
63 |
--------------------------------------------------------------------------------
/models/figer_model/loss_optim.py:
--------------------------------------------------------------------------------
1 | import os
2 | import numpy as np
3 | import tensorflow as tf
4 |
5 | from models.base import Model
6 |
7 |
8 | class LossOptim(object):
9 | def __init__(self, figermodel):
10 | ''' Houses utility functions to facilitate training/pre-training'''
11 |
12 | # Object of the WikiELModel Class
13 | self.figermodel = figermodel
14 |
15 | def make_loss_graph(self):
16 | self.figermodel.labeling_model.loss_graph(
17 | true_label_ids=self.figermodel.labels_batch,
18 | scope_name=self.figermodel.labeling_loss_scope,
19 | device_gpu=self.figermodel.device_placements['gpu'])
20 |
21 | self.figermodel.posterior_model.loss_graph(
22 | true_entity_ids=self.figermodel.true_entity_ids,
23 | scope_name=self.figermodel.posterior_loss_scope,
24 | device_gpu=self.figermodel.device_placements['gpu'])
25 |
26 | if self.figermodel.useCNN:
27 | self.figermodel.wikidescmodel.loss_graph(
28 | true_entity_ids=self.figermodel.true_entity_ids,
29 | scope_name=self.figermodel.wikidesc_loss_scope,
30 | device_gpu=self.figermodel.device_placements['gpu'])
31 |
32 | def optimizer(self, optimizer_name, name):
33 | if optimizer_name == 'adam':
34 | optimizer = tf.train.AdamOptimizer(
35 | learning_rate=self.figermodel.learning_rate,
36 | name='Adam_'+name)
37 | elif optimizer_name == 'adagrad':
38 | optimizer = tf.train.AdagradOptimizer(
39 | learning_rate=self.figermodel.learning_rate,
40 | name='Adagrad_'+name)
41 | elif optimizer_name == 'adadelta':
42 | optimizer = tf.train.AdadeltaOptimizer(
43 | learning_rate=self.figermodel.learning_rate,
44 | name='Adadelta_'+name)
45 | elif optimizer_name == 'sgd':
46 | optimizer = tf.train.GradientDescentOptimizer(
47 | learning_rate=self.figermodel.learning_rate,
48 | name='SGD_'+name)
49 | elif optimizer_name == 'momentum':
50 | optimizer = tf.train.MomentumOptimizer(
51 | learning_rate=self.figermodel.learning_rate,
52 | momentum=0.9,
53 | name='Momentum_'+name)
54 | else:
55 | print("OPTIMIZER WRONG. HOW DID YOU GET HERE!!")
56 | sys.exit(0)
57 | return optimizer
58 |
59 | def weight_regularization(self, trainable_vars):
60 | vars_to_regularize = []
61 | regularization_loss = 0
62 | for var in trainable_vars:
63 | if "_weights" in var.name:
64 | regularization_loss += tf.nn.l2_loss(var)
65 | vars_to_regularize.append(var)
66 |
67 | print("L2 - Regularization for Variables:")
68 | self.figermodel.print_variables_in_collection(vars_to_regularize)
69 | return regularization_loss
70 |
71 | def label_optimization(self, trainable_vars, optim_scope):
72 | # Typing Loss
73 | if self.figermodel.typing:
74 | self.labeling_loss = self.figermodel.labeling_model.labeling_loss
75 | else:
76 | self.labeling_loss = tf.constant(0.0)
77 |
78 | if self.figermodel.entyping:
79 | self.entity_labeling_loss = \
80 | self.figermodel.labeling_model.entity_labeling_loss
81 | else:
82 | self.entity_labeling_loss = tf.constant(0.0)
83 |
84 | # Posterior Loss
85 | if self.figermodel.el:
86 | self.posterior_loss = \
87 | self.figermodel.posterior_model.posterior_loss
88 | else:
89 | self.posterior_loss = tf.constant(0.0)
90 |
91 | if self.figermodel.useCNN:
92 | self.wikidesc_loss = self.figermodel.wikidescmodel.wikiDescLoss
93 | else:
94 | self.wikidesc_loss = tf.constant(0.0)
95 |
96 | # _ = tf.scalar_summary("loss_typing", self.labeling_loss)
97 | # _ = tf.scalar_summary("loss_posterior", self.posterior_loss)
98 | # _ = tf.scalar_summary("loss_wikidesc", self.wikidesc_loss)
99 |
100 | self.total_loss = (self.labeling_loss + self.posterior_loss +
101 | self.wikidesc_loss + self.entity_labeling_loss)
102 |
103 | # Weight Regularization
104 | # self.regularization_loss = self.weight_regularization(
105 | # trainable_vars)
106 | # self.total_loss += (self.figermodel.reg_constant *
107 | # self.regularization_loss)
108 |
109 | # Scalar Summaries
110 | # _ = tf.scalar_summary("loss_regularized", self.total_loss)
111 | # _ = tf.scalar_summary("loss_labeling", self.labeling_loss)
112 |
113 | with tf.variable_scope(optim_scope) as s, \
114 | tf.device(self.figermodel.device_placements['gpu']) as d:
115 | self.optimizer = self.optimizer(
116 | optimizer_name=self.figermodel.optimizer, name="opt")
117 | self.gvs = self.optimizer.compute_gradients(
118 | loss=self.total_loss, var_list=trainable_vars)
119 | # self.clipped_gvs = self.clip_gradients(self.gvs)
120 | self.optim_op = self.optimizer.apply_gradients(self.gvs)
121 |
122 | def clip_gradients(self, gvs):
123 | clipped_gvs = []
124 | for (g,v) in gvs:
125 | if self.figermodel.embeddings_scope in v.name:
126 | clipped_gvalues = tf.clip_by_norm(g.values, 30)
127 | clipped_index_slices = tf.IndexedSlices(
128 | values=clipped_gvalues,
129 | indices=g.indices)
130 | clipped_gvs.append((clipped_index_slices, v))
131 | else:
132 | clipped_gvs.append((tf.clip_by_norm(g, 1), v))
133 | return clipped_gvs
134 |
--------------------------------------------------------------------------------
/models/figer_model/wiki_desc.py:
--------------------------------------------------------------------------------
1 | import time
2 | import numpy as np
3 | import tensorflow as tf
4 |
5 | from models.base import Model
6 |
7 | class WikiDescModel(Model):
8 | '''
9 | Input is sparse tensor of mention strings in mention's document.
10 | Pass through feed forward and get a coherence representation
11 | (keep same as context_encoded_dim)
12 | '''
13 |
14 | def __init__(self, desc_batch, trueentity_embs, negentity_embs, allentity_embs,
15 | batch_size, doclength, wordembeddim, filtersize, desc_encoded_dim,
16 | scope_name, device, dropout_keep_prob=1.0):
17 |
18 | # [B, doclength, wordembeddim]
19 | self.desc_batch = desc_batch
20 | self.batch_size = batch_size
21 | self.doclength = doclength
22 | self.wordembeddim = wordembeddim
23 | self.filtersize = filtersize
24 | self.desc_encoded_dim = desc_encoded_dim # Output dim of desc
25 | self.dropout_keep_prob = dropout_keep_prob
26 |
27 | # [B, K] - target of the CNN network and Negative sampled Entities
28 | self.trueentity_embs = trueentity_embs
29 | self.negentity_embs = negentity_embs
30 | self.allentity_embs = allentity_embs
31 |
32 | # [B, DL, WD, 1] - 1 to specify one channel
33 | self.desc_batch_expanded = tf.expand_dims(self.desc_batch, -1)
34 | # [F, WD, 1, K]
35 | self.filter_shape = [self.filtersize, self.wordembeddim, 1, self.desc_encoded_dim]
36 |
37 |
38 | with tf.variable_scope(scope_name) as scope, tf.device(device) as device:
39 | W = tf.Variable(tf.truncated_normal(self.filter_shape, stddev=0.1), name="W_conv")
40 | conv = tf.nn.conv2d(self.desc_batch_expanded,
41 | W,
42 | strides=[1, 1, 1, 1],
43 | padding="VALID",
44 | name="desc_conv")
45 |
46 | conv = tf.nn.relu(conv, name="conv_relu")
47 | conv = tf.nn.dropout(conv, keep_prob=self.dropout_keep_prob)
48 |
49 | # [B, (doclength-F+1), 1, K]
50 | # [B,K] - Global Average Pooling
51 | self.desc_encoded = tf.reduce_mean(conv, reduction_indices=[1,2])
52 |
53 | # [B, 1, K]
54 | self.desc_encoded_expand = tf.expand_dims(
55 | input=self.desc_encoded, dim=1)
56 |
57 | # [B, N]
58 | self.desc_scores = tf.reduce_sum(tf.mul(
59 | self.allentity_embs, self.desc_encoded_expand), 2)
60 |
61 | self.desc_posteriors = tf.nn.softmax(self.desc_scores,
62 | name="entity_post_softmax")
63 |
64 | ########### end def __init__ ##########################################
65 |
66 | def loss_graph(self, true_entity_ids, scope_name, device_gpu):
67 |
68 | with tf.variable_scope(scope_name) as s, tf.device(device_gpu) as d:
69 | self.crossentropy_losses = tf.nn.sparse_softmax_cross_entropy_with_logits(
70 | logits=self.desc_scores,
71 | labels=true_entity_ids,
72 | name="desc_posterior_loss")
73 |
74 | self.wikiDescLoss = tf.reduce_sum(
75 | self.crossentropy_losses) / tf.to_float(self.batch_size)
76 |
77 |
78 | '''
79 | # Maximize cosine distance between true_entity_embeddings and encoded_description
80 | # max CosineDis(self.trueentity_embs, self.desc_encoded)
81 |
82 | # [B, 1] - NOT [B] Due to keep_dims
83 | trueen_emb_norm = tf.sqrt(
84 | tf.reduce_sum(tf.square(self.trueentity_embs), 1, keep_dims=True))
85 | # [B, K]
86 | true_emb_normalized = self.trueentity_embs / trueen_emb_norm
87 |
88 | # [B, 1] - NOT [B] Due to keep_dims
89 | negen_emb_norm = tf.sqrt(
90 | tf.reduce_sum(tf.square(self.negentity_embs), 1, keep_dims=True))
91 | # [B, K]
92 | neg_emb_normalized = self.negentity_embs / negen_emb_norm
93 |
94 |
95 | # [B, 1] - NOT [B] Due to keep_dims
96 | desc_enc_norm = tf.sqrt(
97 | tf.reduce_sum(tf.square(self.desc_encoded), 1, keep_dims=True))
98 | # [B, K]
99 | desc_end_normalized = self.desc_encoded / desc_enc_norm
100 |
101 | # [B]
102 | self.true_cosDist = tf.reduce_mean(tf.mul(true_emb_normalized, desc_end_normalized))
103 |
104 | self.neg_cosDist = tf.reduce_mean(tf.mul(neg_emb_normalized, desc_end_normalized))
105 |
106 | # Loss = -ve dot_prod because distance has to be decreased
107 | #self.wikiDescLoss = self.neg_cosDist - self.true_cosDist
108 | '''
109 |
--------------------------------------------------------------------------------
/neuralel.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import copy
4 | import pprint
5 | import numpy as np
6 | import tensorflow as tf
7 |
8 | from readers.inference_reader import InferenceReader
9 | from readers.test_reader import TestDataReader
10 | from models.figer_model.el_model import ELModel
11 | from readers.config import Config
12 | from readers.vocabloader import VocabLoader
13 |
14 | np.set_printoptions(threshold=np.inf)
15 | np.set_printoptions(precision=7)
16 |
17 | pp = pprint.PrettyPrinter()
18 |
19 | flags = tf.app.flags
20 | flags.DEFINE_integer("max_steps", 32000, "Maximum of iteration [450000]")
21 | flags.DEFINE_integer("pretraining_steps", 32000, "Number of steps to run pretraining")
22 | flags.DEFINE_float("learning_rate", 0.005, "Learning rate of adam optimizer [0.001]")
23 | flags.DEFINE_string("model_path", "", "Path to trained model")
24 | flags.DEFINE_string("dataset", "el-figer", "The name of dataset [ptb]")
25 | flags.DEFINE_string("checkpoint_dir", "/tmp",
26 | "Directory name to save the checkpoints [checkpoints]")
27 | flags.DEFINE_integer("batch_size", 1, "Batch Size for training and testing")
28 | flags.DEFINE_integer("word_embed_dim", 300, "Word Embedding Size")
29 | flags.DEFINE_integer("context_encoded_dim", 100, "Context Encoded Dim")
30 | flags.DEFINE_integer("context_encoder_num_layers", 1, "Num of Layers in context encoder network")
31 | flags.DEFINE_integer("context_encoder_lstmsize", 100, "Size of context encoder hidden layer")
32 | flags.DEFINE_integer("coherence_numlayers", 1, "Number of layers in the Coherence FF")
33 | flags.DEFINE_integer("jointff_numlayers", 1, "Number of layers in the Coherence FF")
34 | flags.DEFINE_integer("num_cand_entities", 30, "Num CrossWikis entity candidates")
35 | flags.DEFINE_float("reg_constant", 0.00, "Regularization constant for NN weight regularization")
36 | flags.DEFINE_float("dropout_keep_prob", 0.6, "Dropout Keep Probability")
37 | flags.DEFINE_float("wordDropoutKeep", 0.6, "Word Dropout Keep Probability")
38 | flags.DEFINE_float("cohDropoutKeep", 0.4, "Coherence Dropout Keep Probability")
39 | flags.DEFINE_boolean("decoder_bool", True, "Decoder bool")
40 | flags.DEFINE_string("mode", 'inference', "Mode to run")
41 | flags.DEFINE_boolean("strict_context", False, "Strict Context exludes mention surface")
42 | flags.DEFINE_boolean("pretrain_wordembed", True, "Use Word2Vec Embeddings")
43 | flags.DEFINE_boolean("coherence", True, "Use Coherence")
44 | flags.DEFINE_boolean("typing", True, "Perform joint typing")
45 | flags.DEFINE_boolean("el", True, "Perform joint typing")
46 | flags.DEFINE_boolean("textcontext", True, "Use text context from LSTM")
47 | flags.DEFINE_boolean("useCNN", False, "Use wiki descp. CNN")
48 | flags.DEFINE_boolean("glove", True, "Use Glove Embeddings")
49 | flags.DEFINE_boolean("entyping", False, "Use Entity Type Prediction")
50 | flags.DEFINE_integer("WDLength", 100, "Length of wiki description")
51 | flags.DEFINE_integer("Fsize", 5, "For CNN filter size")
52 |
53 | flags.DEFINE_string("optimizer", 'adam', "Optimizer to use. adagrad, adadelta or adam")
54 |
55 | flags.DEFINE_string("config", 'configs/config.ini',
56 | "VocabConfig Filepath")
57 | flags.DEFINE_string("test_out_fp", "", "Write Test Prediction Data")
58 |
59 | FLAGS = flags.FLAGS
60 |
61 |
62 | def FLAGS_check(FLAGS):
63 | if not (FLAGS.textcontext and FLAGS.coherence):
64 | print("*** Local and Document context required ***")
65 | sys.exit(0)
66 | assert os.path.exists(FLAGS.model_path), "Model path doesn't exist."
67 |
68 |
69 | def main(_):
70 | pp.pprint(flags.FLAGS.__flags)
71 |
72 | FLAGS_check(FLAGS)
73 |
74 | config = Config(FLAGS.config, verbose=False)
75 | vocabloader = VocabLoader(config)
76 |
77 | if FLAGS.mode == 'inference':
78 | FLAGS.dropout_keep_prob = 1.0
79 | FLAGS.wordDropoutKeep = 1.0
80 | FLAGS.cohDropoutKeep = 1.0
81 |
82 | reader = InferenceReader(config=config,
83 | vocabloader=vocabloader,
84 | test_mens_file=config.test_file,
85 | num_cands=FLAGS.num_cand_entities,
86 | batch_size=FLAGS.batch_size,
87 | strict_context=FLAGS.strict_context,
88 | pretrain_wordembed=FLAGS.pretrain_wordembed,
89 | coherence=FLAGS.coherence)
90 | docta = reader.ccgdoc
91 | model_mode = 'inference'
92 |
93 | elif FLAGS.mode == 'test':
94 | FLAGS.dropout_keep_prob = 1.0
95 | FLAGS.wordDropoutKeep = 1.0
96 | FLAGS.cohDropoutKeep = 1.0
97 |
98 | reader = TestDataReader(config=config,
99 | vocabloader=vocabloader,
100 | test_mens_file=config.test_file,
101 | num_cands=30,
102 | batch_size=FLAGS.batch_size,
103 | strict_context=FLAGS.strict_context,
104 | pretrain_wordembed=FLAGS.pretrain_wordembed,
105 | coherence=FLAGS.coherence)
106 | model_mode = 'test'
107 |
108 | else:
109 | print("MODE in FLAGS is incorrect : {}".format(FLAGS.mode))
110 | sys.exit()
111 |
112 | config_proto = tf.ConfigProto()
113 | config_proto.allow_soft_placement = True
114 | config_proto.gpu_options.allow_growth=True
115 | sess = tf.Session(config=config_proto)
116 |
117 |
118 | with sess.as_default():
119 | model = ELModel(
120 | sess=sess, reader=reader, dataset=FLAGS.dataset,
121 | max_steps=FLAGS.max_steps,
122 | pretrain_max_steps=FLAGS.pretraining_steps,
123 | word_embed_dim=FLAGS.word_embed_dim,
124 | context_encoded_dim=FLAGS.context_encoded_dim,
125 | context_encoder_num_layers=FLAGS.context_encoder_num_layers,
126 | context_encoder_lstmsize=FLAGS.context_encoder_lstmsize,
127 | coherence_numlayers=FLAGS.coherence_numlayers,
128 | jointff_numlayers=FLAGS.jointff_numlayers,
129 | learning_rate=FLAGS.learning_rate,
130 | dropout_keep_prob=FLAGS.dropout_keep_prob,
131 | reg_constant=FLAGS.reg_constant,
132 | checkpoint_dir=FLAGS.checkpoint_dir,
133 | optimizer=FLAGS.optimizer,
134 | mode=model_mode,
135 | strict=FLAGS.strict_context,
136 | pretrain_word_embed=FLAGS.pretrain_wordembed,
137 | typing=FLAGS.typing,
138 | el=FLAGS.el,
139 | coherence=FLAGS.coherence,
140 | textcontext=FLAGS.textcontext,
141 | useCNN=FLAGS.useCNN,
142 | WDLength=FLAGS.WDLength,
143 | Fsize=FLAGS.Fsize,
144 | entyping=FLAGS.entyping)
145 |
146 | if FLAGS.mode == 'inference':
147 | print("Doing inference")
148 | (predTypScNPmat_list,
149 | widIdxs_list,
150 | priorProbs_list,
151 | textProbs_list,
152 | jointProbs_list,
153 | evWTs_list,
154 | pred_TypeSetsList) = model.inference(ckptpath=FLAGS.model_path)
155 |
156 | numMentionsInference = len(widIdxs_list)
157 | numMentionsReader = 0
158 | for sent_idx in reader.sentidx2ners:
159 | numMentionsReader += len(reader.sentidx2ners[sent_idx])
160 | assert numMentionsInference == numMentionsReader
161 |
162 | mentionnum = 0
163 | entityTitleList = []
164 | for sent_idx in reader.sentidx2ners:
165 | nerDicts = reader.sentidx2ners[sent_idx]
166 | sentence = ' '.join(reader.sentences_tokenized[sent_idx])
167 | for s, ner in nerDicts:
168 | [evWTs, evWIDS, evProbs] = evWTs_list[mentionnum]
169 | predTypes = pred_TypeSetsList[mentionnum]
170 | print(reader.bracketMentionInSentence(sentence, ner))
171 | print("Prior: {} {}, Context: {} {}, Joint: {} {}".format(
172 | evWTs[0], evProbs[0], evWTs[1], evProbs[1],
173 | evWTs[2], evProbs[2]))
174 |
175 | entityTitleList.append(evWTs[2])
176 | print("Predicted Entity Types : {}".format(predTypes))
177 | print("\n")
178 | mentionnum += 1
179 |
180 | elview = copy.deepcopy(docta.view_dictionary['NER_CONLL'])
181 | elview.view_name = 'ENG_NEURAL_EL'
182 | for i, cons in enumerate(elview.cons_list):
183 | cons['label'] = entityTitleList[i]
184 |
185 | docta.view_dictionary['ENG_NEURAL_EL'] = elview
186 |
187 | print("elview.cons_list")
188 | print(elview.cons_list)
189 | print("\n")
190 |
191 | for v in docta.as_json['views']:
192 | print(v)
193 | print("\n")
194 |
195 | elif FLAGS.mode == 'test':
196 | print("Testing on Data ")
197 | (widIdxs_list, condProbs_list, contextProbs_list,
198 | condContextJointProbs_list, evWTs,
199 | sortedContextWTs) = model.dataset_test(ckptpath=FLAGS.model_path)
200 |
201 | print(len(widIdxs_list))
202 | print(len(condProbs_list))
203 | print(len(contextProbs_list))
204 | print(len(condContextJointProbs_list))
205 | print(len(reader.mentions))
206 |
207 |
208 | print("Writing Test Predictions: {}".format(FLAGS.test_out_fp))
209 | with open(FLAGS.test_out_fp, 'w') as f:
210 | for (wididxs, pps, mps, jps) in zip(widIdxs_list,
211 | condProbs_list,
212 | contextProbs_list,
213 | condContextJointProbs_list):
214 |
215 | mentionPred = ""
216 |
217 | for (wididx, prp, mp, jp) in zip(wididxs, pps, mps, jps):
218 | wit = reader.widIdx2WikiTitle(wididx)
219 | mentionPred += wit + " " + str(prp) + " " + \
220 | str(mp) + " " + str(jp)
221 | mentionPred += "\t"
222 |
223 | mentionPred = mentionPred.strip() + "\n"
224 |
225 | f.write(mentionPred)
226 |
227 | print("Done writing. Can Exit.")
228 |
229 | else:
230 | print("WRONG MODE!")
231 | sys.exit(0)
232 |
233 |
234 |
235 |
236 |
237 | sys.exit()
238 |
239 | if __name__ == '__main__':
240 | tf.app.run()
241 |
--------------------------------------------------------------------------------
/neuralel_jsonl.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import copy
4 | import json
5 | import pprint
6 | import numpy as np
7 | import tensorflow as tf
8 | from os import listdir
9 | from os.path import isfile, join
10 |
11 | from ccg_nlpy.core.view import View
12 | from ccg_nlpy.core.text_annotation import TextAnnotation
13 | from ccg_nlpy.local_pipeline import LocalPipeline
14 | from readers.textanno_test_reader import TextAnnoTestReader
15 | from models.figer_model.el_model import ELModel
16 | from readers.config import Config
17 | from readers.vocabloader import VocabLoader
18 |
19 | np.set_printoptions(threshold=np.inf)
20 | np.set_printoptions(precision=7)
21 |
22 | pp = pprint.PrettyPrinter()
23 |
24 | flags = tf.app.flags
25 | flags.DEFINE_integer("max_steps", 32000, "Maximum of iteration [450000]")
26 | flags.DEFINE_integer("pretraining_steps", 32000, "Number of steps to run pretraining")
27 | flags.DEFINE_float("learning_rate", 0.005, "Learning rate of adam optimizer [0.001]")
28 | flags.DEFINE_string("model_path", "", "Path to trained model")
29 | flags.DEFINE_string("dataset", "el-figer", "The name of dataset [ptb]")
30 | flags.DEFINE_string("checkpoint_dir", "/tmp",
31 | "Directory name to save the checkpoints [checkpoints]")
32 | flags.DEFINE_integer("batch_size", 1, "Batch Size for training and testing")
33 | flags.DEFINE_integer("word_embed_dim", 300, "Word Embedding Size")
34 | flags.DEFINE_integer("context_encoded_dim", 100, "Context Encoded Dim")
35 | flags.DEFINE_integer("context_encoder_num_layers", 1, "Num of Layers in context encoder network")
36 | flags.DEFINE_integer("context_encoder_lstmsize", 100, "Size of context encoder hidden layer")
37 | flags.DEFINE_integer("coherence_numlayers", 1, "Number of layers in the Coherence FF")
38 | flags.DEFINE_integer("jointff_numlayers", 1, "Number of layers in the Coherence FF")
39 | flags.DEFINE_integer("num_cand_entities", 30, "Num CrossWikis entity candidates")
40 | flags.DEFINE_float("reg_constant", 0.00, "Regularization constant for NN weight regularization")
41 | flags.DEFINE_float("dropout_keep_prob", 0.6, "Dropout Keep Probability")
42 | flags.DEFINE_float("wordDropoutKeep", 0.6, "Word Dropout Keep Probability")
43 | flags.DEFINE_float("cohDropoutKeep", 0.4, "Coherence Dropout Keep Probability")
44 | flags.DEFINE_boolean("decoder_bool", True, "Decoder bool")
45 | flags.DEFINE_string("mode", 'inference', "Mode to run")
46 | flags.DEFINE_boolean("strict_context", False, "Strict Context exludes mention surface")
47 | flags.DEFINE_boolean("pretrain_wordembed", True, "Use Word2Vec Embeddings")
48 | flags.DEFINE_boolean("coherence", True, "Use Coherence")
49 | flags.DEFINE_boolean("typing", True, "Perform joint typing")
50 | flags.DEFINE_boolean("el", True, "Perform joint typing")
51 | flags.DEFINE_boolean("textcontext", True, "Use text context from LSTM")
52 | flags.DEFINE_boolean("useCNN", False, "Use wiki descp. CNN")
53 | flags.DEFINE_boolean("glove", True, "Use Glove Embeddings")
54 | flags.DEFINE_boolean("entyping", False, "Use Entity Type Prediction")
55 | flags.DEFINE_integer("WDLength", 100, "Length of wiki description")
56 | flags.DEFINE_integer("Fsize", 5, "For CNN filter size")
57 |
58 | flags.DEFINE_string("optimizer", 'adam', "Optimizer to use. adagrad, adadelta or adam")
59 |
60 | flags.DEFINE_string("config", 'configs/config.ini',
61 | "VocabConfig Filepath")
62 | flags.DEFINE_string("test_out_fp", "", "Write Test Prediction Data")
63 |
64 | flags.DEFINE_string("input_jsonl", "", "Input containing documents in jsonl")
65 | flags.DEFINE_string("output_jsonl", "", "Output in jsonl format")
66 | flags.DEFINE_string("doc_key", "", "Key in input_jsonl containing documents")
67 | flags.DEFINE_boolean("pretokenized", False, "Is the input text pretokenized")
68 |
69 | FLAGS = flags.FLAGS
70 |
71 | localpipeline = LocalPipeline()
72 |
73 |
74 | def FLAGS_check(FLAGS):
75 | if not (FLAGS.textcontext and FLAGS.coherence):
76 | print("*** Local and Document context required ***")
77 | sys.exit(0)
78 | assert os.path.exists(FLAGS.model_path), "Model path doesn't exist."
79 |
80 | assert(FLAGS.mode == 'ta'), "Only mode == ta allowed"
81 |
82 |
83 | def main(_):
84 | pp.pprint(flags.FLAGS.__flags)
85 |
86 | FLAGS_check(FLAGS)
87 |
88 | config = Config(FLAGS.config, verbose=False)
89 | vocabloader = VocabLoader(config)
90 |
91 | FLAGS.dropout_keep_prob = 1.0
92 | FLAGS.wordDropoutKeep = 1.0
93 | FLAGS.cohDropoutKeep = 1.0
94 |
95 | input_jsonl = FLAGS.input_jsonl
96 | output_jsonl = FLAGS.output_jsonl
97 | doc_key = FLAGS.doc_key
98 |
99 | reader = TextAnnoTestReader(
100 | config=config,
101 | vocabloader=vocabloader,
102 | num_cands=30,
103 | batch_size=FLAGS.batch_size,
104 | strict_context=FLAGS.strict_context,
105 | pretrain_wordembed=FLAGS.pretrain_wordembed,
106 | coherence=FLAGS.coherence)
107 | model_mode = 'test'
108 |
109 | config_proto = tf.ConfigProto()
110 | config_proto.allow_soft_placement = True
111 | config_proto.gpu_options.allow_growth=True
112 | sess = tf.Session(config=config_proto)
113 |
114 |
115 | with sess.as_default():
116 | model = ELModel(
117 | sess=sess, reader=reader, dataset=FLAGS.dataset,
118 | max_steps=FLAGS.max_steps,
119 | pretrain_max_steps=FLAGS.pretraining_steps,
120 | word_embed_dim=FLAGS.word_embed_dim,
121 | context_encoded_dim=FLAGS.context_encoded_dim,
122 | context_encoder_num_layers=FLAGS.context_encoder_num_layers,
123 | context_encoder_lstmsize=FLAGS.context_encoder_lstmsize,
124 | coherence_numlayers=FLAGS.coherence_numlayers,
125 | jointff_numlayers=FLAGS.jointff_numlayers,
126 | learning_rate=FLAGS.learning_rate,
127 | dropout_keep_prob=FLAGS.dropout_keep_prob,
128 | reg_constant=FLAGS.reg_constant,
129 | checkpoint_dir=FLAGS.checkpoint_dir,
130 | optimizer=FLAGS.optimizer,
131 | mode=model_mode,
132 | strict=FLAGS.strict_context,
133 | pretrain_word_embed=FLAGS.pretrain_wordembed,
134 | typing=FLAGS.typing,
135 | el=FLAGS.el,
136 | coherence=FLAGS.coherence,
137 | textcontext=FLAGS.textcontext,
138 | useCNN=FLAGS.useCNN,
139 | WDLength=FLAGS.WDLength,
140 | Fsize=FLAGS.Fsize,
141 | entyping=FLAGS.entyping)
142 |
143 | model.load_ckpt_model(ckptpath=FLAGS.model_path)
144 |
145 | erroneous_files = 0
146 |
147 | outf = open(output_jsonl, 'w')
148 | inpf = open(input_jsonl, 'r')
149 |
150 | for line in inpf:
151 | jsonobj = json.loads(line)
152 | doctext = jsonobj[doc_key]
153 | ta = localpipeline.doc(doctext, pretokenized=FLAGS.pretokenized)
154 | _ = ta.get_ner_conll
155 |
156 | # Make instances for this document
157 | reader.new_ta(ta)
158 |
159 | (predTypScNPmat_list,
160 | widIdxs_list,
161 | priorProbs_list,
162 | textProbs_list,
163 | jointProbs_list,
164 | evWTs_list,
165 | pred_TypeSetsList) = model.inference_run()
166 |
167 | wiki_view = copy.deepcopy(reader.textanno.get_view("NER_CONLL"))
168 | docta = reader.textanno
169 |
170 | el_cons_list = wiki_view.cons_list
171 | numMentionsInference = len(widIdxs_list)
172 |
173 | assert len(el_cons_list) == numMentionsInference
174 |
175 | out_dict = {doc_key: doctext}
176 | el_mentions = []
177 |
178 | mentionnum = 0
179 | for ner_cons in el_cons_list:
180 | # ner_cons is a dict
181 | mentiondict = {}
182 | mentiondict['tokens'] = ner_cons['tokens']
183 | mentiondict['end'] = ner_cons['end']
184 | mentiondict['start'] = ner_cons['start']
185 |
186 | priorScoreMap = {}
187 | contextScoreMap = {}
188 | jointScoreMap = {}
189 |
190 | (wididxs, pps, mps, jps) = (widIdxs_list[mentionnum],
191 | priorProbs_list[mentionnum],
192 | textProbs_list[mentionnum],
193 | jointProbs_list[mentionnum])
194 |
195 | maxJointProb = 0.0
196 | maxJointEntity = ""
197 | for (wididx, prp, mp, jp) in zip(wididxs, pps, mps, jps):
198 | wT = reader.widIdx2WikiTitle(wididx)
199 | priorScoreMap[wT] = prp
200 | contextScoreMap[wT] = mp
201 | jointScoreMap[wT] = jp
202 |
203 | if jp > maxJointProb:
204 | maxJointProb = jp
205 | maxJointEntity = wT
206 |
207 | mentiondict["jointScoreMap"] = jointScoreMap
208 | mentiondict["contextScoreMap"] = contextScoreMap
209 | mentiondict["priorScoreMap"] = priorScoreMap
210 |
211 | # add max scoring entity as label
212 | mentiondict["label"] = maxJointEntity
213 | mentiondict["score"] = maxJointProb
214 |
215 | mentionnum += 1
216 |
217 | el_mentions.append(mentiondict)
218 |
219 | out_dict['nel'] = el_mentions
220 | outstr = json.dumps(out_dict)
221 | outf.write(outstr)
222 | outf.write("\n")
223 |
224 | outf.close()
225 | inpf.close()
226 |
227 | print("Number of erroneous files: {}".format(erroneous_files))
228 | print("Annotation completed. Program can be exited safely.")
229 | sys.exit()
230 |
231 | if __name__ == '__main__':
232 | tf.app.run()
233 |
--------------------------------------------------------------------------------
/neuralel_tadir.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import copy
4 | import json
5 | import pprint
6 | import numpy as np
7 | import tensorflow as tf
8 | from os import listdir
9 | from os.path import isfile, join
10 |
11 | from ccg_nlpy.core.view import View
12 | from ccg_nlpy.core.text_annotation import TextAnnotation
13 |
14 | from readers.inference_reader import InferenceReader
15 | from readers.test_reader import TestDataReader
16 | from readers.textanno_test_reader import TextAnnoTestReader
17 | from models.figer_model.el_model import ELModel
18 | from readers.config import Config
19 | from readers.vocabloader import VocabLoader
20 |
21 | np.set_printoptions(threshold=np.inf)
22 | np.set_printoptions(precision=7)
23 |
24 | pp = pprint.PrettyPrinter()
25 |
26 | flags = tf.app.flags
27 | flags.DEFINE_integer("max_steps", 32000, "Maximum of iteration [450000]")
28 | flags.DEFINE_integer("pretraining_steps", 32000, "Number of steps to run pretraining")
29 | flags.DEFINE_float("learning_rate", 0.005, "Learning rate of adam optimizer [0.001]")
30 | flags.DEFINE_string("model_path", "", "Path to trained model")
31 | flags.DEFINE_string("dataset", "el-figer", "The name of dataset [ptb]")
32 | flags.DEFINE_string("checkpoint_dir", "/tmp",
33 | "Directory name to save the checkpoints [checkpoints]")
34 | flags.DEFINE_integer("batch_size", 1, "Batch Size for training and testing")
35 | flags.DEFINE_integer("word_embed_dim", 300, "Word Embedding Size")
36 | flags.DEFINE_integer("context_encoded_dim", 100, "Context Encoded Dim")
37 | flags.DEFINE_integer("context_encoder_num_layers", 1, "Num of Layers in context encoder network")
38 | flags.DEFINE_integer("context_encoder_lstmsize", 100, "Size of context encoder hidden layer")
39 | flags.DEFINE_integer("coherence_numlayers", 1, "Number of layers in the Coherence FF")
40 | flags.DEFINE_integer("jointff_numlayers", 1, "Number of layers in the Coherence FF")
41 | flags.DEFINE_integer("num_cand_entities", 30, "Num CrossWikis entity candidates")
42 | flags.DEFINE_float("reg_constant", 0.00, "Regularization constant for NN weight regularization")
43 | flags.DEFINE_float("dropout_keep_prob", 0.6, "Dropout Keep Probability")
44 | flags.DEFINE_float("wordDropoutKeep", 0.6, "Word Dropout Keep Probability")
45 | flags.DEFINE_float("cohDropoutKeep", 0.4, "Coherence Dropout Keep Probability")
46 | flags.DEFINE_boolean("decoder_bool", True, "Decoder bool")
47 | flags.DEFINE_string("mode", 'inference', "Mode to run")
48 | flags.DEFINE_boolean("strict_context", False, "Strict Context exludes mention surface")
49 | flags.DEFINE_boolean("pretrain_wordembed", True, "Use Word2Vec Embeddings")
50 | flags.DEFINE_boolean("coherence", True, "Use Coherence")
51 | flags.DEFINE_boolean("typing", True, "Perform joint typing")
52 | flags.DEFINE_boolean("el", True, "Perform joint typing")
53 | flags.DEFINE_boolean("textcontext", True, "Use text context from LSTM")
54 | flags.DEFINE_boolean("useCNN", False, "Use wiki descp. CNN")
55 | flags.DEFINE_boolean("glove", True, "Use Glove Embeddings")
56 | flags.DEFINE_boolean("entyping", False, "Use Entity Type Prediction")
57 | flags.DEFINE_integer("WDLength", 100, "Length of wiki description")
58 | flags.DEFINE_integer("Fsize", 5, "For CNN filter size")
59 |
60 | flags.DEFINE_string("optimizer", 'adam', "Optimizer to use. adagrad, adadelta or adam")
61 |
62 | flags.DEFINE_string("config", 'configs/config.ini',
63 | "VocabConfig Filepath")
64 | flags.DEFINE_string("test_out_fp", "", "Write Test Prediction Data")
65 |
66 | flags.DEFINE_string("tadirpath", "", "Director containing all the text-annos")
67 | flags.DEFINE_string("taoutdirpath", "", "Director containing all the text-annos")
68 |
69 |
70 |
71 | FLAGS = flags.FLAGS
72 |
73 |
74 | def FLAGS_check(FLAGS):
75 | if not (FLAGS.textcontext and FLAGS.coherence):
76 | print("*** Local and Document context required ***")
77 | sys.exit(0)
78 | assert os.path.exists(FLAGS.model_path), "Model path doesn't exist."
79 |
80 | assert(FLAGS.mode == 'ta'), "Only mode == ta allowed"
81 |
82 |
83 | def getAllTAFilePaths(FLAGS):
84 | tadir = FLAGS.tadirpath
85 | taoutdirpath = FLAGS.taoutdirpath
86 | onlyfiles = [f for f in listdir(tadir) if isfile(join(tadir, f))]
87 | ta_files = [os.path.join(tadir, fname) for fname in onlyfiles]
88 |
89 | output_ta_files = [os.path.join(taoutdirpath, fname) for fname in onlyfiles]
90 |
91 | return (ta_files, output_ta_files)
92 |
93 |
94 | def main(_):
95 | pp.pprint(flags.FLAGS.__flags)
96 |
97 | FLAGS_check(FLAGS)
98 |
99 | config = Config(FLAGS.config, verbose=False)
100 | vocabloader = VocabLoader(config)
101 |
102 | FLAGS.dropout_keep_prob = 1.0
103 | FLAGS.wordDropoutKeep = 1.0
104 | FLAGS.cohDropoutKeep = 1.0
105 |
106 | (intput_ta_files, output_ta_files) = getAllTAFilePaths(FLAGS)
107 |
108 | print("TOTAL NUMBER OF TAS : {}".format(len(intput_ta_files)))
109 |
110 | reader = TextAnnoTestReader(
111 | config=config,
112 | vocabloader=vocabloader,
113 | num_cands=30,
114 | batch_size=FLAGS.batch_size,
115 | strict_context=FLAGS.strict_context,
116 | pretrain_wordembed=FLAGS.pretrain_wordembed,
117 | coherence=FLAGS.coherence,
118 | nerviewname="NER")
119 |
120 | model_mode = 'test'
121 |
122 | config_proto = tf.ConfigProto()
123 | config_proto.allow_soft_placement = True
124 | config_proto.gpu_options.allow_growth=True
125 | sess = tf.Session(config=config_proto)
126 |
127 |
128 | with sess.as_default():
129 | model = ELModel(
130 | sess=sess, reader=reader, dataset=FLAGS.dataset,
131 | max_steps=FLAGS.max_steps,
132 | pretrain_max_steps=FLAGS.pretraining_steps,
133 | word_embed_dim=FLAGS.word_embed_dim,
134 | context_encoded_dim=FLAGS.context_encoded_dim,
135 | context_encoder_num_layers=FLAGS.context_encoder_num_layers,
136 | context_encoder_lstmsize=FLAGS.context_encoder_lstmsize,
137 | coherence_numlayers=FLAGS.coherence_numlayers,
138 | jointff_numlayers=FLAGS.jointff_numlayers,
139 | learning_rate=FLAGS.learning_rate,
140 | dropout_keep_prob=FLAGS.dropout_keep_prob,
141 | reg_constant=FLAGS.reg_constant,
142 | checkpoint_dir=FLAGS.checkpoint_dir,
143 | optimizer=FLAGS.optimizer,
144 | mode=model_mode,
145 | strict=FLAGS.strict_context,
146 | pretrain_word_embed=FLAGS.pretrain_wordembed,
147 | typing=FLAGS.typing,
148 | el=FLAGS.el,
149 | coherence=FLAGS.coherence,
150 | textcontext=FLAGS.textcontext,
151 | useCNN=FLAGS.useCNN,
152 | WDLength=FLAGS.WDLength,
153 | Fsize=FLAGS.Fsize,
154 | entyping=FLAGS.entyping)
155 |
156 | model.load_ckpt_model(ckptpath=FLAGS.model_path)
157 |
158 | print("Total files: {}".format(len(output_ta_files)))
159 | erroneous_files = 0
160 | for in_ta_path, out_ta_path in zip(intput_ta_files, output_ta_files):
161 | # print("Running the inference for : {}".format(in_ta_path))
162 | try:
163 | reader.new_test_file(in_ta_path)
164 | except:
165 | print("Error reading : {}".format(in_ta_path))
166 | erroneous_files += 1
167 | continue
168 |
169 | (predTypScNPmat_list,
170 | widIdxs_list,
171 | priorProbs_list,
172 | textProbs_list,
173 | jointProbs_list,
174 | evWTs_list,
175 | pred_TypeSetsList) = model.inference_run()
176 |
177 | # model.inference(ckptpath=FLAGS.model_path)
178 |
179 | wiki_view = copy.deepcopy(reader.textanno.get_view("NER"))
180 | docta = reader.textanno
181 |
182 | el_cons_list = wiki_view.cons_list
183 | numMentionsInference = len(widIdxs_list)
184 |
185 | # print("Number of mentions in model: {}".format(len(widIdxs_list)))
186 | # print("Number of NER mention: {}".format(len(el_cons_list)))
187 |
188 | assert len(el_cons_list) == numMentionsInference
189 |
190 | mentionnum = 0
191 | for ner_cons in el_cons_list:
192 | priorScoreMap = {}
193 | contextScoreMap = {}
194 | jointScoreMap = {}
195 |
196 | (wididxs, pps, mps, jps) = (widIdxs_list[mentionnum],
197 | priorProbs_list[mentionnum],
198 | textProbs_list[mentionnum],
199 | jointProbs_list[mentionnum])
200 |
201 | maxJointProb = 0.0
202 | maxJointEntity = ""
203 | for (wididx, prp, mp, jp) in zip(wididxs, pps, mps, jps):
204 | wT = reader.widIdx2WikiTitle(wididx)
205 | priorScoreMap[wT] = prp
206 | contextScoreMap[wT] = mp
207 | jointScoreMap[wT] = jp
208 |
209 | if jp > maxJointProb:
210 | maxJointProb = jp
211 | maxJointEntity = wT
212 |
213 |
214 | ''' add labels2score map here '''
215 | ner_cons["jointScoreMap"] = jointScoreMap
216 | ner_cons["contextScoreMap"] = contextScoreMap
217 | ner_cons["priorScoreMap"] = priorScoreMap
218 |
219 | # add max scoring entity as label
220 | ner_cons["label"] = maxJointEntity
221 | ner_cons["score"] = maxJointProb
222 |
223 | mentionnum += 1
224 |
225 | wiki_view.view_name = "NEUREL"
226 | docta.view_dictionary["NEUREL"] = wiki_view
227 |
228 | docta_json = docta.as_json
229 | json.dump(docta_json, open(out_ta_path, "w"), indent=True)
230 |
231 | print("Number of erroneous files: {}".format(erroneous_files))
232 | print("Annotation completed. Program can be exited safely.")
233 | sys.exit()
234 |
235 | if __name__ == '__main__':
236 | tf.app.run()
237 |
--------------------------------------------------------------------------------
/overview.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nitishgupta/neural-el/8c7c278acefa66238a75e805511ff26a567fd4e0/overview.png
--------------------------------------------------------------------------------
/readers/Mention.py:
--------------------------------------------------------------------------------
1 | start_word = "
7 |
8 | ## Abstract
9 | For accurate entity linking, we need to capture the various information aspects of an entity, such as its description in a KB, contexts in which it is mentioned, and structured knowledge. Further, a linking system should work on texts from different domains without requiring domain-specific training data or hand-engineered features.
10 | In this work we present a neural, modular entity linking system that learns a unified dense representation for each entity using multiple sources of information, such as its description, contexts around its mentions, and fine-grained types. We show that the resulting entity linking system is effective at combining these sources, and performs competitively, sometimes out-performing current state-of-art-systems across datasets, without requiring any domain-specific training data or hand-engineered features. We also show that our model can effectively "embed" entities that are new to the KB, and is able to link its mentions accurately.
11 |
12 | ### Requirements
13 | * Python 3.4
14 | * Tensorflow 0.11 / 0.12
15 | * numpy
16 | * [CogComp-NLPy](https://github.com/CogComp/cogcomp-nlpy)
17 | * [Resources](https://drive.google.com/open?id=0Bz-t37BfgoTuSEtXOTI1SEF3VnM) - Pretrained models, vectors, etc.
18 |
19 | ### How to run inference
20 | 1. Clone the [code repository](https://github.com/nitishgupta/neural-el/)
21 | 1. Download the [resources folder](https://drive.google.com/open?id=0Bz-t37BfgoTuSEtXOTI1SEF3VnM).
22 | 2. In `config/config.ini` set the correct path to the resources folder you just downloaded
23 | 3. Run using:
24 | ```
25 | python3 neuralel.py --config=configs/config.ini --model_path=PATH_TO_MODEL_IN_RESOURCES --mode=inference
26 | ```
27 | The file `sampletest.txt` in the resources folder contains the text to be entity-linked. Currently we only support linking for a single document. Make sure the text in `sampletest.txt` is a single doc in a single line.
28 |
29 | ### Installing cogcomp-nlpy
30 | [CogComp-NLPy](https://github.com/CogComp/cogcomp-nlpy) is needed to detect named-entity mentions using NER. To install:
31 | ```
32 | pip install cython
33 | pip install ccg_nlpy
34 | ```
35 |
36 | ### Installing Tensorflow (CPU Version)
37 | To install tensorflow 0.12:
38 | ```
39 | export TF_BINARY_URL=https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.12.1-cp34-cp34m-linux_x86_64.whl
40 | (Regular) pip install --upgrade $TF_BINARY_URL
41 | (Conda) pip install --ignore-installed --upgrade $TF_BINARY_URL
42 | ```
43 |
--------------------------------------------------------------------------------
/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nitishgupta/neural-el/8c7c278acefa66238a75e805511ff26a567fd4e0/__init__.py
--------------------------------------------------------------------------------
/configs/config.ini:
--------------------------------------------------------------------------------
1 | [DEFAULT]
2 | resources_dir: /shared/bronte/ngupta19/neural-el_resources
3 |
4 | vocab_dir: ${resources_dir}/vocab
5 |
6 | word_vocab_pkl:${vocab_dir}/word_vocab.pkl
7 | kwnwid_vocab_pkl:${vocab_dir}/knwn_wid_vocab.pkl
8 | label_vocab_pkl:${vocab_dir}/label_vocab.pkl
9 | cohstringG9_vocab_pkl:${vocab_dir}/cohstringG9_vocab.pkl
10 | widWiktitle_pkl:${vocab_dir}/wid2Wikititle.pkl
11 |
12 | # One CWIKIs PATH NEEDED
13 | crosswikis_pruned_pkl: ${resources_dir}/crosswikis.pruned.pkl
14 |
15 |
16 | glove_pkl: ${resources_dir}/glove.pkl
17 | glove_word_vocab_pkl:${vocab_dir}/glove_word_vocab.pkl
18 |
19 | # Should be removed
20 | test_file: ${resources_dir}/sampletest.txt
21 |
--------------------------------------------------------------------------------
/evaluation/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nitishgupta/neural-el/8c7c278acefa66238a75e805511ff26a567fd4e0/evaluation/__init__.py
--------------------------------------------------------------------------------
/evaluation/evaluate_el.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import numpy as np
4 |
5 | coarsetypes = set(["location", "person", "organization", "event"])
6 | coarseTypeIds = set([1,5,10,25])
7 |
8 |
9 | def computeMaxPriorContextJointEntities(
10 | WIDS_list, wikiTitles_list, condProbs_list, contextProbs_list,
11 | condContextJointProbs_list, verbose):
12 |
13 | assert (len(wikiTitles_list) == len(condProbs_list) ==
14 | len(contextProbs_list) == len(condContextJointProbs_list))
15 | numMens = len(wikiTitles_list)
16 | numWithCorrectInCand = 0
17 | accCond = 0
18 | accCont = 0
19 | accJoint = 0
20 |
21 | # [[(trueWT, maxPrWT, maxContWT, maxJWT), (trueWID, maxPrWID, maxContWID, maxJWID)]]
22 | evaluationWikiTitles = []
23 |
24 | sortedContextWTs = []
25 |
26 | for (WIDS, wTs, cProbs, contProbs, jointProbs) in zip(WIDS_list,
27 | wikiTitles_list,
28 | condProbs_list,
29 | contextProbs_list,
30 | condContextJointProbs_list):
31 | if wTs[0] == "":
32 | evaluationWikiTitles.append([tuple([""]*4), tuple([""]*4)])
33 |
34 | else:
35 | numWithCorrectInCand += 1
36 | trueWID = WIDS[0]
37 | trueEntity = wTs[0]
38 | tCondProb = cProbs[0]
39 | tContProb = contProbs[0]
40 | tJointProb = jointProbs[0]
41 |
42 | maxCondEntity_idx = np.argmax(cProbs)
43 | maxCondWID = WIDS[maxCondEntity_idx]
44 | maxCondEntity = wTs[maxCondEntity_idx]
45 | maxCondProb = cProbs[maxCondEntity_idx]
46 | if trueEntity == maxCondEntity and maxCondProb!=0.0:
47 | accCond+= 1
48 |
49 | maxContEntity_idx = np.argmax(contProbs)
50 | maxContWID = WIDS[maxContEntity_idx]
51 | maxContEntity = wTs[maxContEntity_idx]
52 | maxContProb = contProbs[maxContEntity_idx]
53 | if maxContEntity == trueEntity and maxContProb!=0.0:
54 | accCont+= 1
55 |
56 | contProbs_sortIdxs = np.argsort(contProbs).tolist()[::-1]
57 | sortContWTs = [wTs[i] for i in contProbs_sortIdxs]
58 | sortedContextWTs.append(sortContWTs)
59 |
60 | maxJointEntity_idx = np.argmax(jointProbs)
61 | maxJointWID = WIDS[maxJointEntity_idx]
62 | maxJointEntity = wTs[maxJointEntity_idx]
63 | maxJointProb = jointProbs[maxJointEntity_idx]
64 | maxJointCprob = cProbs[maxJointEntity_idx]
65 | maxJointContP = contProbs[maxJointEntity_idx]
66 | if maxJointEntity == trueEntity and maxJointProb!=0:
67 | accJoint+= 1
68 |
69 | predWTs = (trueEntity, maxCondEntity, maxContEntity, maxJointEntity)
70 | predWIDs = (trueWID, maxCondWID, maxContWID, maxJointWID)
71 | evaluationWikiTitles.append([predWTs, predWIDs])
72 |
73 | if verbose:
74 | print("True: {} c:{:.3f} cont:{:.3f} J:{:.3f}".format(
75 | trueEntity, tCondProb, tContProb, tJointProb))
76 | print("Pred: {} c:{:.3f} cont:{:.3f} J:{:.3f}".format(
77 | maxJointEntity, maxJointCprob, maxJointContP, maxJointProb))
78 | print("maxPrior: {} p:{:.3f} maxCont:{} p:{:.3f}".format(
79 | maxCondEntity, maxCondProb, maxContEntity, maxContProb))
80 | #AllMentionsProcessed
81 | if numWithCorrectInCand != 0:
82 | accCond = accCond/float(numWithCorrectInCand)
83 | accCont = accCont/float(numWithCorrectInCand)
84 | accJoint = accJoint/float(numWithCorrectInCand)
85 | else:
86 | accCond = 0.0
87 | accCont = 0.0
88 | accJoint = 0.0
89 |
90 | print("Total Mentions : {} In Knwn Mentions : {}".format(
91 | numMens, numWithCorrectInCand))
92 | print("Priors Accuracy: {:.3f} Context Accuracy: {:.3f} Joint Accuracy: {:.3f}".format(
93 | (accCond), accCont, accJoint))
94 |
95 | assert len(evaluationWikiTitles) == numMens
96 |
97 | return (evaluationWikiTitles, sortedContextWTs)
98 |
99 |
100 | def convertWidIdxs2WikiTitlesAndWIDs(widIdxs_list, idx2knwid, wid2WikiTitle):
101 | wikiTitles_list = []
102 | WIDS_list = []
103 | for widIdxs in widIdxs_list:
104 | wids = [idx2knwid[wididx] for wididx in widIdxs]
105 | wikititles = [wid2WikiTitle[idx2knwid[wididx]] for wididx in widIdxs]
106 | WIDS_list.append(wids)
107 | wikiTitles_list.append(wikititles)
108 |
109 | return (WIDS_list, wikiTitles_list)
110 |
111 |
112 | def _normalizeProbList(probList):
113 | norm_probList = []
114 | for probs in probList:
115 | s = sum(probs)
116 | if s != 0.0:
117 | n_p = [p/s for p in probs]
118 | norm_probList.append(n_p)
119 | else:
120 | norm_probList.append(probs)
121 | return norm_probList
122 |
123 |
124 | def computeFinalEntityProbs(condProbs_list, contextProbs_list, alpha=0.5):
125 | condContextJointProbs_list = []
126 | condProbs_list = _normalizeProbList(condProbs_list)
127 | contextProbs_list = _normalizeProbList(contextProbs_list)
128 |
129 | for (cprobs, contprobs) in zip(condProbs_list, contextProbs_list):
130 | #condcontextprobs = [(alpha*x + (1-alpha)*y) for (x,y) in zip(cprobs, contprobs)]
131 | condcontextprobs = [(x + y - x*y) for (x,y) in zip(cprobs, contprobs)]
132 | sum_condcontextprobs = sum(condcontextprobs)
133 | if sum_condcontextprobs != 0.0:
134 | condcontextprobs = [float(x)/sum_condcontextprobs for x in condcontextprobs]
135 | condContextJointProbs_list.append(condcontextprobs)
136 | return condContextJointProbs_list
137 |
138 |
139 | def computeFinalEntityScores(condProbs_list, contextProbs_list, alpha=0.5):
140 | condContextJointProbs_list = []
141 | condProbs_list = _normalizeProbList(condProbs_list)
142 | #contextProbs_list = _normalizeProbList(contextProbs_list)
143 |
144 | for (cprobs, contprobs) in zip(condProbs_list, contextProbs_list):
145 | condcontextprobs = [(alpha*x + (1-alpha)*y) for (x,y) in zip(cprobs, contprobs)]
146 | sum_condcontextprobs = sum(condcontextprobs)
147 | if sum_condcontextprobs != 0.0:
148 | condcontextprobs = [float(x)/sum_condcontextprobs for x in condcontextprobs]
149 | condContextJointProbs_list.append(condcontextprobs)
150 | return condContextJointProbs_list
151 |
152 |
153 | ##############################################################################
154 |
155 | def evaluateEL(condProbs_list, widIdxs_list, contextProbs_list,
156 | idx2knwid, wid2WikiTitle, verbose=False):
157 | ''' Prior entity prob, True and candidate entity WIDs, Predicted ent. prob.
158 | using context for each of te 30 candidates. First element in the candidates is
159 | the true entity.
160 | Args:
161 | For each mention:
162 | condProbs_list: List of prior probs for 30 candidates.
163 | widIdxs_list: List of candidate widIdxs probs for 30 candidates.
164 | contextProbss_list: List of candidate prob. using context
165 | idx2knwid: Map for widIdx -> WID
166 | wid2WikiTitle: Map from WID -> WikiTitle
167 | wid2TypeLabels: Map from WID -> List of Types
168 | '''
169 | print("Evaluating E-Linking ... ")
170 | (WIDS_list, wikiTitles_list) = convertWidIdxs2WikiTitlesAndWIDs(
171 | widIdxs_list, idx2knwid, wid2WikiTitle)
172 |
173 | alpha = 0.5
174 | #for alpha in alpha_range:
175 | print("Alpha : {}".format(alpha))
176 | jointProbs_list = computeFinalEntityProbs(
177 | condProbs_list, contextProbs_list, alpha=alpha)
178 |
179 | # evaluationWikiTitles:
180 | # For each mention [(trWT, maxPWT, maxCWT, maxJWT), (trWID, ...)]
181 | (evaluationWikiTitles,
182 | sortedContextWTs) = computeMaxPriorContextJointEntities(
183 | WIDS_list, wikiTitles_list, condProbs_list, contextProbs_list,
184 | jointProbs_list, verbose)
185 |
186 |
187 | '''
188 | condContextJointScores_list = computeFinalEntityScores(
189 | condProbs_list, contextProbs_list, alpha=alpha)
190 |
191 | evaluationWikiTitles = computeMaxPriorContextJointEntities(
192 | WIDS_list, wikiTitles_list, condProbs_list, contextProbs_list,
193 | condContextJointScores_list, verbose)
194 | '''
195 |
196 | return (jointProbs_list, evaluationWikiTitles, sortedContextWTs)
197 |
198 | ##############################################################################
199 |
200 |
201 | def f1(p,r):
202 | if p == 0.0 and r == 0.0:
203 | return 0.0
204 | return (float(2*p*r))/(p + r)
205 |
206 |
207 | def strict_pred(true_label_batch, pred_score_batch):
208 | ''' Calculates strict precision/recall/f1 given truth and predicted scores
209 | args
210 | true_label_batch: Binary Numpy matrix of [num_instances, num_labels]
211 | pred_score_batch: Real [0,1] numpy matrix of [num_instances, num_labels]
212 |
213 | return:
214 | correct_preds: Number of correct strict preds
215 | precision : correct_preds / num_instances
216 | '''
217 | (true_labels, pred_labels) = types_convert_mat_to_sets(
218 | true_label_batch, pred_score_batch)
219 |
220 | num_instanes = len(true_labels)
221 | correct_preds = 0
222 | for i in range(0, num_instanes):
223 | if true_labels[i] == pred_labels[i]:
224 | correct_preds += 1
225 | #endfor
226 | precision = recall = float(correct_preds)/num_instanes
227 |
228 | return correct_preds, precision
229 |
230 |
231 | def correct_context_prediction(entity_posterior_scores, batch_size):
232 | bool_array = np.equal(np.argmax(entity_posterior_scores, axis=1),
233 | [0]*batch_size)
234 | correct_preds = np.sum(bool_array)
235 | return correct_preds
236 |
--------------------------------------------------------------------------------
/evaluation/evaluate_inference.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import numpy as np
4 |
5 |
6 | def computeMaxPriorContextJointEntities(
7 | WIDS_list, wikiTitles_list, condProbs_list, contextProbs_list,
8 | condContextJointProbs_list, verbose):
9 |
10 | assert (len(wikiTitles_list) == len(condProbs_list) ==
11 | len(contextProbs_list) == len(condContextJointProbs_list))
12 | numMens = len(wikiTitles_list)
13 |
14 | evaluationWikiTitles = []
15 | sortedContextWTs = []
16 | for (WIDS, wTs,
17 | cProbs, contProbs, jointProbs) in zip(WIDS_list,
18 | wikiTitles_list,
19 | condProbs_list,
20 | contextProbs_list,
21 | condContextJointProbs_list):
22 | # if wTs[0] == "":
23 | # evaluationWikiTitles.append([tuple([""]*3),
24 | # tuple([""]*3)])
25 | # else:
26 | maxCondEntity_idx = np.argmax(cProbs)
27 | maxCondWID = WIDS[maxCondEntity_idx]
28 | maxCondEntity = wTs[maxCondEntity_idx]
29 | maxCondProb = cProbs[maxCondEntity_idx]
30 |
31 | maxContEntity_idx = np.argmax(contProbs)
32 | maxContWID = WIDS[maxContEntity_idx]
33 | maxContEntity = wTs[maxContEntity_idx]
34 | maxContProb = contProbs[maxContEntity_idx]
35 |
36 | contProbs_sortIdxs = np.argsort(contProbs).tolist()[::-1]
37 | sortContWTs = [wTs[i] for i in contProbs_sortIdxs]
38 | sortedContextWTs.append(sortContWTs)
39 |
40 | maxJointEntity_idx = np.argmax(jointProbs)
41 | maxJointWID = WIDS[maxJointEntity_idx]
42 | maxJointEntity = wTs[maxJointEntity_idx]
43 | maxJointProb = jointProbs[maxJointEntity_idx]
44 | maxJointCprob = cProbs[maxJointEntity_idx]
45 | maxJointContP = contProbs[maxJointEntity_idx]
46 |
47 | predWTs = (maxCondEntity, maxContEntity, maxJointEntity)
48 | predWIDs = (maxCondWID, maxContWID, maxJointWID)
49 | predProbs = (maxCondProb, maxContProb, maxJointProb)
50 | evaluationWikiTitles.append([predWTs, predWIDs, predProbs])
51 |
52 | assert len(evaluationWikiTitles) == numMens
53 |
54 | return (evaluationWikiTitles, sortedContextWTs)
55 |
56 | def convertWidIdxs2WikiTitlesAndWIDs(widIdxs_list, idx2knwid, wid2WikiTitle):
57 | wikiTitles_list = []
58 | WIDS_list = []
59 | for widIdxs in widIdxs_list:
60 | wids = [idx2knwid[wididx] for wididx in widIdxs]
61 | wikititles = [wid2WikiTitle[idx2knwid[wididx]] for wididx in widIdxs]
62 | WIDS_list.append(wids)
63 | wikiTitles_list.append(wikititles)
64 |
65 | return (WIDS_list, wikiTitles_list)
66 |
67 | def _normalizeProbList(probList):
68 | norm_probList = []
69 | for probs in probList:
70 | s = sum(probs)
71 | if s != 0.0:
72 | n_p = [p/s for p in probs]
73 | norm_probList.append(n_p)
74 | else:
75 | norm_probList.append(probs)
76 | return norm_probList
77 |
78 |
79 | def computeFinalEntityProbs(condProbs_list, contextProbs_list):
80 | condContextJointProbs_list = []
81 | condProbs_list = _normalizeProbList(condProbs_list)
82 | contextProbs_list = _normalizeProbList(contextProbs_list)
83 |
84 | for (cprobs, contprobs) in zip(condProbs_list, contextProbs_list):
85 | condcontextprobs = [(x + y - x*y) for (x,y) in zip(cprobs, contprobs)]
86 | sum_condcontextprobs = sum(condcontextprobs)
87 | if sum_condcontextprobs != 0.0:
88 | condcontextprobs = [float(x)/sum_condcontextprobs for x in condcontextprobs]
89 | condContextJointProbs_list.append(condcontextprobs)
90 | return condContextJointProbs_list
91 |
92 |
93 | def computeFinalEntityScores(condProbs_list, contextProbs_list, alpha=0.5):
94 | condContextJointProbs_list = []
95 | condProbs_list = _normalizeProbList(condProbs_list)
96 | #contextProbs_list = _normalizeProbList(contextProbs_list)
97 |
98 | for (cprobs, contprobs) in zip(condProbs_list, contextProbs_list):
99 | condcontextprobs = [(alpha*x + (1-alpha)*y) for (x,y) in zip(cprobs, contprobs)]
100 | sum_condcontextprobs = sum(condcontextprobs)
101 | if sum_condcontextprobs != 0.0:
102 | condcontextprobs = [float(x)/sum_condcontextprobs for x in condcontextprobs]
103 | condContextJointProbs_list.append(condcontextprobs)
104 | return condContextJointProbs_list
105 |
106 |
107 | #############################################################################
108 |
109 |
110 | def evaluateEL(condProbs_list, widIdxs_list, contextProbs_list,
111 | idx2knwid, wid2WikiTitle, verbose=False):
112 | ''' Prior entity prob, True and candidate entity WIDs, Predicted ent. prob.
113 | using context for each of te 30 candidates. First element in the candidates
114 | is the true entity.
115 | Args:
116 | For each mention:
117 | condProbs_list: List of prior probs for 30 candidates.
118 | widIdxs_list: List of candidate widIdxs probs for 30 candidates.
119 | contextProbss_list: List of candidate prob. using context
120 | idx2knwid: Map for widIdx -> WID
121 | wid2WikiTitle: Map from WID -> WikiTitle
122 | '''
123 | # print("Evaluating E-Linking ... ")
124 | (WIDS_list, wikiTitles_list) = convertWidIdxs2WikiTitlesAndWIDs(
125 | widIdxs_list, idx2knwid, wid2WikiTitle)
126 |
127 | jointProbs_list = computeFinalEntityProbs(condProbs_list,
128 | contextProbs_list)
129 |
130 | (evaluationWikiTitles,
131 | sortedContextWTs) = computeMaxPriorContextJointEntities(
132 | WIDS_list, wikiTitles_list, condProbs_list, contextProbs_list,
133 | jointProbs_list, verbose)
134 |
135 | return (jointProbs_list, evaluationWikiTitles, sortedContextWTs)
136 |
137 | ##############################################################################
138 |
139 |
140 | def f1(p,r):
141 | if p == 0.0 and r == 0.0:
142 | return 0.0
143 | return (float(2*p*r))/(p + r)
144 |
145 |
146 | def strict_pred(true_label_batch, pred_score_batch):
147 | ''' Calculates strict precision/recall/f1 given truth and predicted scores
148 | args
149 | true_label_batch: Binary Numpy matrix of [num_instances, num_labels]
150 | pred_score_batch: Real [0,1] numpy matrix of [num_instances, num_labels]
151 |
152 | return:
153 | correct_preds: Number of correct strict preds
154 | precision : correct_preds / num_instances
155 | '''
156 | (true_labels, pred_labels) = types_convert_mat_to_sets(
157 | true_label_batch, pred_score_batch)
158 |
159 | num_instanes = len(true_labels)
160 | correct_preds = 0
161 | for i in range(0, num_instanes):
162 | if true_labels[i] == pred_labels[i]:
163 | correct_preds += 1
164 | #endfor
165 | precision = recall = float(correct_preds)/num_instanes
166 |
167 | return correct_preds, precision
168 |
169 |
170 | def correct_context_prediction(entity_posterior_scores, batch_size):
171 | bool_array = np.equal(np.argmax(entity_posterior_scores, axis=1),
172 | [0]*batch_size)
173 | correct_preds = np.sum(bool_array)
174 | return correct_preds
175 |
--------------------------------------------------------------------------------
/evaluation/evaluate_types.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import numpy as np
4 |
5 | coarsetypes = set(["location", "person", "organization", "event"])
6 | coarseTypeIds = set([1,5,10,25])
7 |
8 | def _convertTypeMatToTypeSets(typesscore_mat, idx2label, threshold):
9 | ''' Gets true labels and pred scores in numpy matrix and converts to list
10 | args
11 | true_label_batch: Binary Numpy matrix of [num_instances, num_labels]
12 | pred_score_batch: Real [0,1] numpy matrix of [num_instances, num_labels]
13 |
14 | return:
15 | true_labels: List of list of true label (indices) for batch of instances
16 | pred_labels : List of list of pred label (indices) for batch of instances
17 | (threshold = 0.5)
18 | '''
19 | labels = []
20 | for i in typesscore_mat:
21 | # i in array of label_vals for i-th example
22 | labels_i = []
23 | max_idx = -1
24 | max_val = -1
25 | for (label_idx, val) in enumerate(i):
26 | if val >= threshold:
27 | labels_i.append(idx2label[label_idx])
28 | if val > max_val:
29 | max_idx = label_idx
30 | max_val = val
31 | if len(labels_i) == 0:
32 | labels_i.append(idx2label[max_idx])
33 | labels.append(set(labels_i))
34 |
35 | '''
36 | assert 0.0 < threshold <= 1.0
37 | boolmat = typesscore_mat >= threshold
38 | boollist = boolmat.tolist()
39 | num_instanes = len(boollist)
40 | labels = []
41 | for i in range(0, num_instanes):
42 | labels_i = [idx2label[i] for i, x in enumerate(boollist[i]) if x]
43 | labels.append(set(labels_i))
44 | ##
45 | '''
46 | return labels
47 |
48 | def convertTypesScoreMatLists_TypeSets(typeScoreMat_list, idx2label, threshold):
49 | '''
50 | Take list of type scores numpy mat (per batch) as ouput from Tensorflow.
51 | Convert into list of type sets for each mention based on the thresold
52 |
53 | Return:
54 | typeSets_list: Size=num_instances. Each instance is set of type labels for mention
55 | '''
56 |
57 | typeSets_list = []
58 | for typeScoreMat in typeScoreMat_list:
59 | typeLabels_list = _convertTypeMatToTypeSets(typeScoreMat,
60 | idx2label, threshold)
61 | typeSets_list.extend(typeLabels_list)
62 | return typeSets_list
63 |
64 |
65 | def typesPredictionStats(pred_labels, true_labels):
66 | '''
67 | args
68 | true_label_batch: Binary Numpy matrix of [num_instances, num_labels]
69 | pred_score_batch: Real [0,1] numpy matrix of [num_instances, num_labels]
70 | '''
71 |
72 | # t_hat \interesect t
73 | t_intersect = 0
74 | t_hat_count = 0
75 | t_count = 0
76 | t_t_hat_exact = 0
77 | loose_macro_p = 0.0
78 | loose_macro_r = 0.0
79 | num_instances = len(true_labels)
80 | for i in range(0, num_instances):
81 | intersect = len(true_labels[i].intersection(pred_labels[i]))
82 | t_h_c = len(pred_labels[i])
83 | t_c = len(true_labels[i])
84 | t_intersect += intersect
85 | t_hat_count += t_h_c
86 | t_count += t_c
87 | exact = 1 if (true_labels[i] == pred_labels[i]) else 0
88 | t_t_hat_exact += exact
89 | if len(pred_labels[i]) > 0:
90 | loose_macro_p += intersect / float(t_h_c)
91 | if len(true_labels[i]) > 0:
92 | loose_macro_r += intersect / float(t_c)
93 |
94 | return (t_intersect, t_t_hat_exact, t_hat_count, t_count,
95 | loose_macro_p, loose_macro_r)
96 |
97 | def typesEvaluationMetrics(pred_TypeSetsList, true_TypeSetsList):
98 | num_instances = len(true_TypeSetsList)
99 | (t_i, t_th_exact, t_h_c, t_c, l_m_p, l_m_r) = typesPredictionStats(
100 | pred_labels=pred_TypeSetsList, true_labels=true_TypeSetsList)
101 | strict = float(t_th_exact)/float(num_instances)
102 | loose_macro_p = l_m_p / float(num_instances)
103 | loose_macro_r = l_m_r / float(num_instances)
104 | loose_macro_f = f1(loose_macro_p, loose_macro_r)
105 | if t_h_c > 0:
106 | loose_micro_p = float(t_i)/float(t_h_c)
107 | else:
108 | loose_micro_p = 0
109 | if t_c > 0:
110 | loose_micro_r = float(t_i)/float(t_c)
111 | else:
112 | loose_micro_r = 0
113 | loose_micro_f = f1(loose_micro_p, loose_micro_r)
114 |
115 | return (strict, loose_macro_p, loose_macro_r, loose_macro_f, loose_micro_p,
116 | loose_micro_r, loose_micro_f)
117 |
118 |
119 | def performTypingEvaluation(predLabelScoresnumpymat_list, idx2label):
120 | '''
121 | Args: List of numpy mat, one for ech batch, for true and pred type scores
122 | trueLabelScoresnumpymat_list: List of score matrices output by tensorflow
123 | predLabelScoresnumpymat_list: List of score matrices output by tensorflow
124 | '''
125 | pred_TypeSetsList = convertTypesScoreMatLists_TypeSets(
126 | typeScoreMat_list=predLabelScoresnumpymat_list, idx2label=idx2label,
127 | threshold=0.75)
128 |
129 | return pred_TypeSetsList
130 |
131 |
132 | def evaluate(predLabelScoresnumpymat_list, idx2label):
133 | # print("Evaluating Typing ... ")
134 | pred_TypeSetsList = convertTypesScoreMatLists_TypeSets(
135 | typeScoreMat_list=predLabelScoresnumpymat_list, idx2label=idx2label,
136 | threshold=0.75)
137 |
138 | return pred_TypeSetsList
139 |
140 |
141 | def f1(p,r):
142 | if p == 0.0 and r == 0.0:
143 | return 0.0
144 | return (float(2*p*r))/(p + r)
145 |
146 |
147 | def strict_pred(true_label_batch, pred_score_batch):
148 | ''' Calculates strict precision/recall/f1 given truth and predicted scores
149 | args
150 | true_label_batch: Binary Numpy matrix of [num_instances, num_labels]
151 | pred_score_batch: Real [0,1] numpy matrix of [num_instances, num_labels]
152 |
153 | return:
154 | correct_preds: Number of correct strict preds
155 | precision : correct_preds / num_instances
156 | '''
157 | (true_labels, pred_labels) = types_convert_mat_to_sets(
158 | true_label_batch, pred_score_batch)
159 |
160 | num_instanes = len(true_labels)
161 | correct_preds = 0
162 | for i in range(0, num_instanes):
163 | if true_labels[i] == pred_labels[i]:
164 | correct_preds += 1
165 | #endfor
166 | precision = recall = float(correct_preds)/num_instanes
167 |
168 | return correct_preds, precision
169 |
170 | def correct_context_prediction(entity_posterior_scores, batch_size):
171 | bool_array = np.equal(np.argmax(entity_posterior_scores, axis=1),
172 | [0]*batch_size)
173 | correct_preds = np.sum(bool_array)
174 | return correct_preds
175 |
--------------------------------------------------------------------------------
/models/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nitishgupta/neural-el/8c7c278acefa66238a75e805511ff26a567fd4e0/models/__init__.py
--------------------------------------------------------------------------------
/models/base.py:
--------------------------------------------------------------------------------
1 | import os
2 | from glob import glob
3 | import tensorflow as tf
4 |
5 | class Model(object):
6 | """Abstract object representing an Reader model."""
7 | def __init__(self):
8 | pass
9 |
10 | # def get_model_dir(self):
11 | # model_dir = self.dataset
12 | # for attr in self._attrs:
13 | # if hasattr(self, attr):
14 | # model_dir += "/%s=%s" % (attr, getattr(self, attr))
15 | # return model_dir
16 |
17 | def get_model_dir(self, attrs=None):
18 | model_dir = self.dataset
19 | if attrs == None:
20 | attrs = self._attrs
21 | for attr in attrs:
22 | if hasattr(self, attr):
23 | model_dir += "/%s=%s" % (attr, getattr(self, attr))
24 | return model_dir
25 |
26 | def get_log_dir(self, root_log_dir, attrs=None):
27 | model_dir = self.get_model_dir(attrs=attrs)
28 | log_dir = os.path.join(root_log_dir, model_dir)
29 | if not os.path.exists(log_dir):
30 | os.makedirs(log_dir)
31 | return log_dir
32 |
33 | def save(self, saver, checkpoint_dir, attrs=None, global_step=None):
34 | print(" [*] Saving checkpoints...")
35 | model_name = type(self).__name__
36 | model_dir = self.get_model_dir(attrs=attrs)
37 |
38 | checkpoint_dir = os.path.join(checkpoint_dir, model_dir)
39 | if not os.path.exists(checkpoint_dir):
40 | os.makedirs(checkpoint_dir)
41 | saver.save(self.sess, os.path.join(checkpoint_dir, model_name),
42 | global_step=global_step)
43 | print(" [*] Saving done...")
44 |
45 | def initialize(self, log_dir="./logs"):
46 | self.merged_sum = tf.merge_all_summaries()
47 | self.writer = tf.train.SummaryWriter(log_dir, self.sess.graph_def)
48 |
49 | tf.initialize_all_variables().run()
50 | self.load(self.checkpoint_dir)
51 |
52 | start_iter = self.step.eval()
53 |
54 | def load(self, saver, checkpoint_dir, attrs=None):
55 | print(" [*] Loading checkpoints...")
56 | model_dir = self.get_model_dir(attrs=attrs)
57 | # /checkpointdir/attrs=values/
58 | checkpoint_dir = os.path.join(checkpoint_dir, model_dir)
59 | print(" [#] Checkpoint Dir : {}".format(checkpoint_dir))
60 | ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
61 | if ckpt and ckpt.model_checkpoint_path:
62 | ckpt_name = os.path.basename(ckpt.model_checkpoint_path)
63 | print("ckpt_name: {}".format(ckpt_name))
64 | saver.restore(self.sess, os.path.join(checkpoint_dir, ckpt_name))
65 | print(" [*] Load SUCCESS")
66 | return True
67 | else:
68 | print(" [!] Load failed...")
69 | return False
70 |
71 | def loadCKPTPath(self, saver, ckptPath=None):
72 | assert ckptPath != None
73 | print(" [#] CKPT Path : {}".format(ckptPath))
74 | if os.path.exists(ckptPath):
75 | saver.restore(self.sess, ckptPath)
76 | print(" [*] Load SUCCESS")
77 | return True
78 | else:
79 | print(" [*] CKPT Path doesn't exist")
80 | return False
81 |
82 | def loadSpecificCKPT(self, saver, checkpoint_dir, ckptName=None, attrs=None):
83 | assert ckptName != None
84 | model_dir = self.get_model_dir(attrs=attrs)
85 | checkpoint_dir = os.path.join(checkpoint_dir, model_dir)
86 | checkpoint_path = os.path.join(checkpoint_dir, ckptName)
87 | print(" [#] CKPT Path : {}".format(checkpoint_path))
88 | if os.path.exists(checkpoint_path):
89 | saver.restore(self.sess, checkpoint_path)
90 |
91 | print(" [*] Load SUCCESS")
92 | return True
93 | else:
94 | print(" [*] CKPT Path doesn't exist")
95 | return False
96 |
97 |
98 |
99 | def collect_scope(self, scope_name, graph=None, var_type=tf.GraphKeys.VARIABLES):
100 | if graph == None:
101 | graph = tf.get_default_graph()
102 |
103 | var_list = graph.get_collection(var_type, scope=scope_name)
104 |
105 | assert_str = "No variable exists with name_scope '{}'".format(scope_name)
106 | assert len(var_list) != 0, assert_str
107 |
108 | return var_list
109 |
110 | def get_scope_var_name_set(self, var_name):
111 | clean_var_num = var_name.split(":")[0]
112 | scopes_names = clean_var_num.split("/")
113 | return set(scopes_names)
114 |
115 |
116 | def scope_vars_list(self, scope_name, var_list):
117 | scope_var_list = []
118 | for var in var_list:
119 | scope_var_name = self.get_scope_var_name_set(var.name)
120 | if scope_name in scope_var_name:
121 | scope_var_list.append(var)
122 | return scope_var_list
123 |
--------------------------------------------------------------------------------
/models/batch_normalizer.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | #from tensorflow.python import control_flow_ops
3 | from tensorflow.python.ops import control_flow_ops
4 |
5 | class BatchNorm():
6 | def __init__(self,
7 | input,
8 | training,
9 | decay=0.95,
10 | epsilon=1e-4,
11 | name='bn',
12 | reuse_vars=False):
13 |
14 | self.decay = decay
15 | self.epsilon = epsilon
16 | self.batchnorm(input, training, name, reuse_vars)
17 |
18 | def batchnorm(self, input, training, name, reuse_vars):
19 | with tf.variable_scope(name, reuse=reuse_vars) as bn:
20 | rank = len(input.get_shape().as_list())
21 | in_dim = input.get_shape().as_list()[-1]
22 |
23 | if rank == 2:
24 | self.axes = [0]
25 | elif rank == 4:
26 | self.axes = [0, 1, 2]
27 | else:
28 | raise ValueError('Input tensor must have rank 2 or 4.')
29 |
30 | self.offset = tf.get_variable(
31 | 'offset',
32 | shape=[in_dim],
33 | initializer=tf.constant_initializer(0.0))
34 |
35 | self.scale = tf.get_variable(
36 | 'scale',
37 | shape=[in_dim],
38 | initializer=tf.constant_initializer(1.0))
39 |
40 | self.ema = tf.train.ExponentialMovingAverage(decay=self.decay)
41 |
42 | self.output = tf.cond(training,
43 | lambda: self.get_normalizer(input, True),
44 | lambda: self.get_normalizer(input, False))
45 |
46 | def get_normalizer(self, input, train_flag):
47 | if train_flag:
48 | self.mean, self.variance = tf.nn.moments(input, self.axes)
49 | # Fixes numerical instability if variance ~= 0, and it goes negative
50 | v = tf.nn.relu(self.variance)
51 | ema_apply_op = self.ema.apply([self.mean, self.variance])
52 | with tf.control_dependencies([ema_apply_op]):
53 | self.output_training = tf.nn.batch_normalization(
54 | input, self.mean, v, self.offset, self.scale,
55 | self.epsilon, 'normalizer_train'),
56 | return self.output_training
57 | else:
58 | self.output_test = tf.nn.batch_normalization(
59 | input, self.ema.average(self.mean),
60 | self.ema.average(self.variance), self.offset, self.scale,
61 | self.epsilon, 'normalizer_test')
62 | return self.output_test
63 |
64 | def get_batch_moments(self):
65 | return self.mean, self.variance
66 |
67 | def get_ema_moments(self):
68 | return self.ema.average(self.mean), self.ema.average(self.variance)
69 |
70 | def get_offset_scale(self):
71 | return self.offset, self.scale
72 |
--------------------------------------------------------------------------------
/models/figer_model/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nitishgupta/neural-el/8c7c278acefa66238a75e805511ff26a567fd4e0/models/figer_model/__init__.py
--------------------------------------------------------------------------------
/models/figer_model/coherence_model.py:
--------------------------------------------------------------------------------
1 | import time
2 | import numpy as np
3 | import tensorflow as tf
4 |
5 | from models.base import Model
6 |
7 | class CoherenceModel(Model):
8 | '''
9 | Input is sparse tensor of mention strings in mention's document.
10 | Pass through feed forward and get a coherence representation
11 | (keep same as context_encoded_dim)
12 | '''
13 |
14 | def __init__(self, num_layers, batch_size, input_size,
15 | coherence_indices, coherence_values, coherence_matshape,
16 | context_encoded_dim, scope_name, device,
17 | dropout_keep_prob=1.0):
18 |
19 | # Num of layers in the encoder and decoder network
20 | self.num_layers = num_layers
21 | self.input_size = input_size
22 | self.context_encoded_dim = context_encoded_dim
23 | self.dropout_keep_prob = dropout_keep_prob
24 | self.batch_size = batch_size
25 |
26 | with tf.variable_scope(scope_name) as s, tf.device(device) as d:
27 | coherence_inp_tensor = tf.SparseTensor(coherence_indices,
28 | coherence_values,
29 | coherence_matshape)
30 |
31 | # Feed-forward Net for coherence_representation
32 | # Layer 1
33 | self.trans_weights = tf.get_variable(
34 | name="coherence_layer_0",
35 | shape=[self.input_size, self.context_encoded_dim],
36 | initializer=tf.random_normal_initializer(
37 | mean=0.0,
38 | stddev=1.0/(100.0)))
39 |
40 | # [B, context_encoded_dim]
41 | coherence_encoded = tf.sparse_tensor_dense_matmul(
42 | coherence_inp_tensor, self.trans_weights)
43 | coherence_encoded = tf.nn.relu(coherence_encoded)
44 |
45 | # Hidden Layers. NumLayers >= 2
46 | self.hidden_layers = []
47 | for i in range(1, self.num_layers):
48 | weight_matrix = tf.get_variable(
49 | name="coherence_layer_"+str(i),
50 | shape=[self.context_encoded_dim, self.context_encoded_dim],
51 | initializer=tf.random_normal_initializer(
52 | mean=0.0,
53 | stddev=1.0/(100.0)))
54 | self.hidden_layers.append(weight_matrix)
55 |
56 | for i in range(1, self.num_layers):
57 | coherence_encoded = tf.nn.dropout(
58 | coherence_encoded, keep_prob=self.dropout_keep_prob)
59 | coherence_encoded = tf.matmul(coherence_encoded,
60 | self.hidden_layers[i-1])
61 | coherence_encoded = tf.nn.relu(coherence_encoded)
62 |
63 | self.coherence_encoded = tf.nn.dropout(
64 | coherence_encoded, keep_prob=self.dropout_keep_prob)
65 |
--------------------------------------------------------------------------------
/models/figer_model/coldStart.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import tensorflow as tf
4 | import numpy as np
5 |
6 | import readers.utils as utils
7 | from evaluation import evaluate
8 | from evaluation import evaluate_el
9 | from evaluation import evaluate_types
10 | from models.base import Model
11 | from models.figer_model.context_encoder import ContextEncoderModel
12 | from models.figer_model.coherence_model import CoherenceModel
13 | from models.figer_model.wiki_desc import WikiDescModel
14 | from models.figer_model.joint_context import JointContextModel
15 | from models.figer_model.labeling_model import LabelingModel
16 | from models.figer_model.entity_posterior import EntityPosterior
17 | from models.figer_model.loss_optim import LossOptim
18 |
19 |
20 | class ColdStart(object):
21 | def __init__(self, figermodel):
22 | print("###### ENTERED THE COLD WORLD OF THE UNKNOWN ##############")
23 | # Object of the WikiELModel Class
24 | self.fm = figermodel
25 | self.coldDir = self.fm.reader.coldDir
26 | coldWid2DescVecs_pkl = os.path.join(self.coldDir, "coldwid2descvecs.pkl")
27 | self.coldWid2DescVecs = utils.load(coldWid2DescVecs_pkl)
28 | self.num_cold_entities = self.fm.reader.num_cold_entities
29 | self.batch_size = self.fm.batch_size
30 | (self.coldwid2idx,
31 | self.idx2coldwid) = (self.fm.reader.coldwid2idx, self.fm.reader.idx2coldwid)
32 |
33 | def _makeDescLossGraph(self):
34 | with tf.variable_scope("cold") as s:
35 | with tf.device(self.fm.device_placements['gpu']) as d:
36 | tf.set_random_seed(1)
37 |
38 | self.coldEnEmbsToAssign = tf.placeholder(
39 | tf.float32, [self.num_cold_entities, 200], name="coldEmbsAssignment")
40 |
41 | self.coldEnEmbs = tf.get_variable(
42 | name="cold_entity_embeddings",
43 | shape=[self.num_cold_entities, 200],
44 | initializer=tf.random_normal_initializer(mean=-0.25,
45 | stddev=1.0/(100.0)))
46 |
47 | self.assignColdEmbs = self.coldEnEmbs.assign(self.coldEnEmbsToAssign)
48 |
49 | self.trueColdEnIds = tf.placeholder(
50 | tf.int32, [self.batch_size], name="true_entities_idxs")
51 |
52 | # Should be a list of zeros
53 | self.softTrueIdxs = tf.placeholder(
54 | tf.int32, [self.batch_size], name="softmaxTrueEnsIdxs")
55 |
56 | # [B, D]
57 | self.trueColdEmb = tf.nn.embedding_lookup(
58 | self.coldEnEmbs, self.trueColdEnIds)
59 | # [B, 1, D]
60 | self.trueColdEmb_exp = tf.expand_dims(
61 | input=self.trueColdEmb, dim=1)
62 |
63 | self.label_scores = tf.matmul(self.trueColdEmb,
64 | self.fm.labeling_model.label_weights)
65 |
66 | self.labeling_losses = tf.nn.sigmoid_cross_entropy_with_logits(
67 | logits=self.label_scores,
68 | targets=self.fm.labels_batch,
69 | name="labeling_loss")
70 |
71 | self.labelingLoss = tf.reduce_sum(
72 | self.labeling_losses) / tf.to_float(self.batch_size)
73 |
74 | # [B, D]
75 | self.descEncoded = self.fm.wikidescmodel.desc_encoded
76 |
77 | ## Maximize sigmoid of dot-prod between true emb. and desc encoding
78 | descLosses = -tf.sigmoid(tf.reduce_sum(tf.mul(self.trueColdEmb, self.descEncoded), 1))
79 | self.descLoss = tf.reduce_sum(descLosses)/tf.to_float(self.batch_size)
80 |
81 |
82 | # L-2 Norm Loss
83 | self.trueEmbNormLoss = tf.reduce_sum(
84 | tf.square(self.trueColdEmb))/(tf.to_float(self.batch_size))
85 |
86 |
87 | ''' Concat trueColdEmb_exp to negKnownEmbs so that 0 is the true entity.
88 | Dotprod this emb matrix with descEncoded to get scores and apply softmax
89 | '''
90 |
91 | self.trcoldvars = self.fm.scope_vars_list(scope_name="cold",
92 | var_list=tf.trainable_variables())
93 |
94 | print("Vars in Training")
95 | for var in self.trcoldvars:
96 | print(var.name)
97 |
98 |
99 | self.optimizer = tf.train.AdamOptimizer(
100 | learning_rate=self.fm.learning_rate,
101 | name='AdamCold_')
102 |
103 | self.total_labeling_loss = self.labelingLoss + self.trueEmbNormLoss
104 | self.label_gvs = self.optimizer.compute_gradients(
105 | loss=self.total_labeling_loss, var_list=self.trcoldvars)
106 | self.labeling_optim_op = self.optimizer.apply_gradients(self.label_gvs)
107 |
108 | self.total_loss = self.labelingLoss + 100*self.descLoss + self.trueEmbNormLoss
109 | self.comb_gvs = self.optimizer.compute_gradients(
110 | loss=self.total_loss, var_list=self.trcoldvars)
111 | self.combined_optim_op = self.optimizer.apply_gradients(self.comb_gvs)
112 |
113 |
114 | self.allcoldvars = self.fm.scope_vars_list(scope_name="cold",
115 | var_list=tf.all_variables())
116 |
117 | print("All Vars in Cold")
118 | for var in self.allcoldvars:
119 | print(var.name)
120 |
121 | print("Loaded and graph made")
122 | ### GRAPH COMPLETE ###
123 |
124 | #############################################################################
125 | def _trainColdEmbFromTypes(self, epochsToTrain=5):
126 | print("Training Cold Entity Embeddings from Typing Info")
127 |
128 | epochsDone = self.fm.reader.val_epochs
129 |
130 | while self.fm.reader.val_epochs < epochsToTrain:
131 | (left_batch, left_lengths,
132 | right_batch, right_lengths,
133 | wids_batch,
134 | labels_batch, coherence_batch,
135 | wid_idxs_batch, wid_cprobs_batch) = self.fm.reader._next_padded_batch(data_type=1)
136 |
137 | trueColdWidIdxsBatch = []
138 | trueColdWidDescWordVecBatch = []
139 | for wid in wids_batch:
140 | trueColdWidIdxsBatch.append(self.coldwid2idx[wid])
141 | trueColdWidDescWordVecBatch.append(self.coldWid2DescVecs[wid])
142 |
143 | feed_dict = {self.trueColdEnIds: trueColdWidIdxsBatch,
144 | self.fm.labels_batch: labels_batch}
145 |
146 | fetch_tensor = [self.labelingLoss, self.trueEmbNormLoss]
147 |
148 | (fetches, _) = self.fm.sess.run([fetch_tensor,
149 | self.labeling_optim_op],
150 | feed_dict=feed_dict)
151 |
152 | labelingLoss = fetches[0]
153 | trueEmbNormLoss = fetches[1]
154 |
155 | print("LL : {} NormLoss : {}".format(labelingLoss, trueEmbNormLoss))
156 |
157 | newedone = self.fm.reader.val_epochs
158 | if newedone > epochsDone:
159 | print("Epochs : {}".format(newedone))
160 | epochsDone = newedone
161 |
162 | #############################################################################
163 | def _trainColdEmbFromTypesAndDesc(self, epochsToTrain=5):
164 | print("Training Cold Entity Embeddings from Typing Info")
165 |
166 | epochsDone = self.fm.reader.val_epochs
167 |
168 | while self.fm.reader.val_epochs < epochsToTrain:
169 | (left_batch, left_lengths,
170 | right_batch, right_lengths,
171 | wids_batch,
172 | labels_batch, coherence_batch,
173 | wid_idxs_batch, wid_cprobs_batch) = self.fm.reader._next_padded_batch(data_type=1)
174 |
175 | trueColdWidIdxsBatch = []
176 | trueColdWidDescWordVecBatch = []
177 | for wid in wids_batch:
178 | trueColdWidIdxsBatch.append(self.coldwid2idx[wid])
179 | trueColdWidDescWordVecBatch.append(self.coldWid2DescVecs[wid])
180 |
181 | feed_dict = {self.fm.wikidesc_batch: trueColdWidDescWordVecBatch,
182 | self.trueColdEnIds: trueColdWidIdxsBatch,
183 | self.fm.labels_batch: labels_batch}
184 |
185 | fetch_tensor = [self.labelingLoss, self.descLoss, self.trueEmbNormLoss]
186 |
187 | (fetches,_) = self.fm.sess.run([fetch_tensor,
188 | self.combined_optim_op],
189 | feed_dict=feed_dict)
190 |
191 | labelingLoss = fetches[0]
192 | descLoss = fetches[1]
193 | normLoss = fetches[2]
194 |
195 | print("L : {} D : {} NormLoss : {}".format(labelingLoss, descLoss, normLoss))
196 |
197 | newedone = self.fm.reader.val_epochs
198 | if newedone > epochsDone:
199 | print("Epochs : {}".format(newedone))
200 | epochsDone = newedone
201 |
202 | #############################################################################
203 |
204 | def runEval(self):
205 | print("Running Evaluations")
206 | self.fm.reader.reset_validation()
207 | correct = 0
208 | total = 0
209 | totnew = 0
210 | correctnew = 0
211 | while self.fm.reader.val_epochs < 1:
212 | (left_batch, left_lengths,
213 | right_batch, right_lengths,
214 | wids_batch,
215 | labels_batch, coherence_batch,
216 | wid_idxs_batch,
217 | wid_cprobs_batch) = self.fm.reader._next_padded_batch(data_type=1)
218 |
219 | trueColdWidIdxsBatch = []
220 |
221 | for wid in wids_batch:
222 | trueColdWidIdxsBatch.append(self.coldwid2idx[wid])
223 |
224 | feed_dict = {self.fm.sampled_entity_ids: wid_idxs_batch,
225 | self.fm.left_context_embeddings: left_batch,
226 | self.fm.right_context_embeddings: right_batch,
227 | self.fm.left_lengths: left_lengths,
228 | self.fm.right_lengths: right_lengths,
229 | self.fm.coherence_indices: coherence_batch[0],
230 | self.fm.coherence_values: coherence_batch[1],
231 | self.fm.coherence_matshape: coherence_batch[2],
232 | self.trueColdEnIds: trueColdWidIdxsBatch}
233 |
234 | fetch_tensor = [self.trueColdEmb,
235 | self.fm.joint_context_encoded,
236 | self.fm.posterior_model.sampled_entity_embeddings,
237 | self.fm.posterior_model.entity_scores]
238 |
239 | fetched_vals = self.fm.sess.run(fetch_tensor, feed_dict=feed_dict)
240 | [trueColdEmbs, # [B, D]
241 | context_encoded, # [B, D]
242 | neg_entity_embeddings, # [B, N, D]
243 | neg_entity_scores] = fetched_vals # [B, N]
244 |
245 | # [B]
246 | trueColdWidScores = np.sum(trueColdEmbs*context_encoded, axis=1)
247 | entity_scores = neg_entity_scores
248 | entity_scores[:,0] = trueColdWidScores
249 | context_entity_scores = np.exp(entity_scores)/np.sum(np.exp(entity_scores))
250 |
251 | maxIdxs = np.argmax(context_entity_scores, axis=1)
252 | for i in range(0, self.batch_size):
253 | total += 1
254 | if maxIdxs[i] == 0:
255 | correct += 1
256 |
257 | scores_withpriors = context_entity_scores + wid_cprobs_batch
258 |
259 | maxIdxs = np.argmax(scores_withpriors, axis=1)
260 | for i in range(0, self.batch_size):
261 | totnew += 1
262 | if maxIdxs[i] == 0:
263 | correctnew += 1
264 |
265 | print("Context T : {} C : {}".format(total, correct))
266 | print("WPriors T : {} C : {}".format(totnew, correctnew))
267 |
268 | ##############################################################################
269 |
270 | def typeBasedColdEmbExp(self, ckptName="FigerModel-20001"):
271 | ''' Train cold embeddings using wiki desc loss
272 | '''
273 | saver = tf.train.Saver(var_list=tf.all_variables())
274 |
275 | print("Loading Model ... ")
276 | if ckptName == None:
277 | print("Given CKPT Name")
278 | sys.exit()
279 | else:
280 | load_status = self.fm.loadSpecificCKPT(
281 | saver=saver, checkpoint_dir=self.fm.checkpoint_dir,
282 | ckptName=ckptName, attrs=self.fm._attrs)
283 | if not load_status:
284 | print("No model to load. Exiting")
285 | sys.exit(0)
286 |
287 | self._makeDescLossGraph()
288 | self.fm.sess.run(tf.initialize_variables(self.allcoldvars))
289 | self._trainColdEmbFromTypes(epochsToTrain=5)
290 |
291 | self.runEval()
292 |
293 | ##############################################################################
294 |
295 | def typeAndWikiDescBasedColdEmbExp(self, ckptName="FigerModel-20001"):
296 | ''' Train cold embeddings using wiki desc loss
297 | '''
298 | saver = tf.train.Saver(var_list=tf.all_variables())
299 |
300 | print("Loading Model ... ")
301 | if ckptName == None:
302 | print("Given CKPT Name")
303 | sys.exit()
304 | else:
305 | load_status = self.fm.loadSpecificCKPT(
306 | saver=saver, checkpoint_dir=self.fm.checkpoint_dir,
307 | ckptName=ckptName, attrs=self.fm._attrs)
308 | if not load_status:
309 | print("No model to load. Exiting")
310 | sys.exit(0)
311 |
312 | self._makeDescLossGraph()
313 | self.fm.sess.run(tf.initialize_variables(self.allcoldvars))
314 | self._trainColdEmbFromTypesAndDesc(epochsToTrain=5)
315 |
316 | self.runEval()
317 |
318 | # EVALUATION FOR COLD START WHEN INITIALIZING COLD EMB FROM WIKI DESC ENCODING
319 | def wikiDescColdEmbExp(self, ckptName="FigerModel-20001"):
320 | ''' Assign cold entity embeddings as wiki desc encoding
321 | '''
322 | assert self.batch_size == 1
323 | print("Loaded Cold Start Class. ")
324 | print("Size of cold entities : {}".format(len(self.coldWid2DescVecs)))
325 |
326 | saver = tf.train.Saver(var_list=tf.all_variables(), max_to_keep=5)
327 |
328 | print("Loading Model ... ")
329 | if ckptName == None:
330 | print("Given CKPT Name")
331 | sys.exit()
332 | else:
333 | load_status = self.fm.loadSpecificCKPT(
334 | saver=saver, checkpoint_dir=self.fm.checkpoint_dir,
335 | ckptName=ckptName, attrs=self.fm._attrs)
336 | if not load_status:
337 | print("No model to load. Exiting")
338 | sys.exit(0)
339 |
340 | iter_done = self.fm.global_step.eval()
341 | print("[#] Model loaded with iterations done: %d" % iter_done)
342 |
343 | self._makeDescLossGraph()
344 | self.fm.sess.run(tf.initialize_variables(self.allcoldvars))
345 |
346 | # Fill with encoded desc. in order of idx2coldwid
347 | print("Getting Encoded Description Vectors")
348 | descEncodedMatrix = []
349 | for idx in range(0, len(self.idx2coldwid)):
350 | wid = self.idx2coldwid[idx]
351 | desc_vec = self.coldWid2DescVecs[wid]
352 | feed_dict = {self.fm.wikidesc_batch: [desc_vec]}
353 | desc_encoded = self.fm.sess.run(self.fm.wikidescmodel.desc_encoded,
354 | feed_dict=feed_dict)
355 | descEncodedMatrix.append(desc_encoded[0])
356 |
357 | print("Initialization Experiment")
358 | self.runEval()
359 |
360 | print("Assigning Cold Embeddings from Wiki Desc Encoder ...")
361 | self.fm.sess.run(self.assignColdEmbs,
362 | feed_dict={self.coldEnEmbsToAssign:descEncodedMatrix})
363 |
364 | print("After assigning based on Wiki Encoder")
365 | self.runEval()
366 |
367 | ##############################################################################
368 |
--------------------------------------------------------------------------------
/models/figer_model/context_encoder.py:
--------------------------------------------------------------------------------
1 | import time
2 | import tensorflow as tf
3 | import numpy as np
4 |
5 | from models.base import Model
6 |
7 | class ContextEncoderModel(Model):
8 | """Run Forward and Backward LSTM and concatenate last outputs to get
9 | context representation"""
10 |
11 | def __init__(self, num_layers, batch_size, lstm_size,
12 | left_embed_batch, left_lengths, right_embed_batch, right_lengths,
13 | context_encoded_dim, scope_name, device, dropout_keep_prob=1.0):
14 |
15 | self.num_layers = num_layers # Num of layers in the encoder and decoder network
16 | self.num_lstm_layers = 1
17 |
18 | # Left / Right Context Dim.
19 | # Context Representation Dim : 2*lstm_size
20 | self.lstm_size = lstm_size
21 | self.dropout_keep_prob = dropout_keep_prob
22 | self.batch_size = batch_size
23 | self.context_encoded_dim = context_encoded_dim
24 | self.left_context_embeddings = left_embed_batch
25 | self.right_context_embeddings = right_embed_batch
26 |
27 | with tf.variable_scope(scope_name) as sc, tf.device(device) as d:
28 | with tf.variable_scope("left_encoder") as s:
29 | l_encoder_cell = tf.nn.rnn_cell.BasicLSTMCell(
30 | self.lstm_size, state_is_tuple=True)
31 |
32 | l_dropout_cell = tf.nn.rnn_cell.DropoutWrapper(
33 | cell=l_encoder_cell,
34 | input_keep_prob=self.dropout_keep_prob,
35 | output_keep_prob=self.dropout_keep_prob)
36 |
37 | self.left_encoder = tf.nn.rnn_cell.MultiRNNCell(
38 | [l_dropout_cell] * self.num_lstm_layers, state_is_tuple=True)
39 |
40 | self.left_outputs, self.left_states = tf.nn.dynamic_rnn(
41 | cell=self.left_encoder, inputs=self.left_context_embeddings,
42 | sequence_length=left_lengths, dtype=tf.float32)
43 |
44 | with tf.variable_scope("right_encoder") as s:
45 | r_encoder_cell = tf.nn.rnn_cell.BasicLSTMCell(
46 | self.lstm_size, state_is_tuple=True)
47 |
48 | r_dropout_cell = tf.nn.rnn_cell.DropoutWrapper(
49 | cell=r_encoder_cell,
50 | input_keep_prob=self.dropout_keep_prob,
51 | output_keep_prob=self.dropout_keep_prob)
52 |
53 | self.right_encoder = tf.nn.rnn_cell.MultiRNNCell(
54 | [r_dropout_cell] * self.num_lstm_layers, state_is_tuple=True)
55 |
56 | self.right_outputs, self.right_states = tf.nn.dynamic_rnn(
57 | cell=self.right_encoder,
58 | inputs=self.right_context_embeddings,
59 | sequence_length=right_lengths, dtype=tf.float32)
60 |
61 | # Left Context Encoded
62 | # [B, LSTM_DIM]
63 | self.left_last_output = self.get_last_output(
64 | outputs=self.left_outputs, lengths=left_lengths,
65 | name="left_context_encoded")
66 |
67 | # Right Context Encoded
68 | # [B, LSTM_DIM]
69 | self.right_last_output = self.get_last_output(
70 | outputs=self.right_outputs, lengths=right_lengths,
71 | name="right_context_encoded")
72 |
73 | # Context Encoded Vector
74 | self.context_lstm_encoded = tf.concat(
75 | 1, [self.left_last_output, self.right_last_output],
76 | name='context_lstm_encoded')
77 |
78 | # Linear Transformation to get context_encoded_dim
79 | # Layer 1
80 | self.trans_weights = tf.get_variable(
81 | name="context_trans_weights",
82 | shape=[2*self.lstm_size, self.context_encoded_dim],
83 | initializer=tf.random_normal_initializer(
84 | mean=0.0,
85 | stddev=1.0/(100.0)))
86 |
87 | # [B, context_encoded_dim]
88 | context_encoded = tf.matmul(self.context_lstm_encoded,
89 | self.trans_weights)
90 | context_encoded = tf.nn.relu(context_encoded)
91 |
92 | self.hidden_layers = []
93 | for i in range(1, self.num_layers):
94 | weight_matrix = tf.get_variable(
95 | name="context_hlayer_"+str(i),
96 | shape=[self.context_encoded_dim, self.context_encoded_dim],
97 | initializer=tf.random_normal_initializer(
98 | mean=0.0,
99 | stddev=1.0/(100.0)))
100 | self.hidden_layers.append(weight_matrix)
101 |
102 | for i in range(1, self.num_layers):
103 | context_encoded = tf.nn.dropout(
104 | context_encoded, keep_prob=self.dropout_keep_prob)
105 | context_encoded = tf.matmul(context_encoded,
106 | self.hidden_layers[i-1])
107 | context_encoded = tf.nn.relu(context_encoded)
108 |
109 | self.context_encoded = tf.nn.dropout(
110 | context_encoded, keep_prob=self.dropout_keep_prob)
111 |
112 | def get_last_output(self, outputs, lengths, name):
113 | reverse_output = tf.reverse_sequence(input=outputs,
114 | seq_lengths=tf.to_int64(lengths),
115 | seq_dim=1,
116 | batch_dim=0)
117 | en_last_output = tf.slice(input_=reverse_output,
118 | begin=[0,0,0],
119 | size=[self.batch_size, 1, -1])
120 | # [batch_size, h_dim]
121 | encoder_last_output = tf.reshape(en_last_output,
122 | shape=[self.batch_size, -1],
123 | name=name)
124 |
125 | return encoder_last_output
126 |
--------------------------------------------------------------------------------
/models/figer_model/entity_posterior.py:
--------------------------------------------------------------------------------
1 | import time
2 | import tensorflow as tf
3 | import numpy as np
4 |
5 | from models.base import Model
6 |
7 | class EntityPosterior(Model):
8 | """Entity Embeddings and Posterior Calculation"""
9 |
10 | def __init__(self, batch_size, num_knwn_entities, context_encoded_dim,
11 | context_encoded, entity_ids, scope_name,
12 | device_embeds, device_gpu):
13 |
14 | ''' Defines the entity posterior estimation graph.
15 | Makes entity embeddings variable, gets encoded context and candidate
16 | entities and gets entity scores using dot-prod.
17 |
18 | Input :
19 | context_encoded_dim: D - dims in which context is encoded
20 | context_encoded: [B, D]
21 | entity_ids: [B, N]. If supervised, first is the correct entity, and
22 | rest N-1 the candidates. For unsupervised, all N are candidates.
23 | num_knwn_entities: Number of entities with supervised data.
24 | Defines:
25 | entity_embeddings: [num_knwn_entities, D]
26 | Output:
27 | entity_scores: [B,N] matrix of context scores
28 | '''
29 |
30 | self.batch_size = batch_size
31 | self.num_knwn_entities = num_knwn_entities
32 |
33 | with tf.variable_scope(scope_name) as s:
34 | with tf.device(device_embeds) as d:
35 | self.knwn_entity_embeddings = tf.get_variable(
36 | name="known_entity_embeddings",
37 | shape=[self.num_knwn_entities, context_encoded_dim],
38 | initializer=tf.random_normal_initializer(mean=0.0,
39 | stddev=1.0/(100.0)))
40 | with tf.device(device_gpu) as g:
41 | # [B, N, D]
42 | self.sampled_entity_embeddings = tf.nn.embedding_lookup(
43 | self.knwn_entity_embeddings, entity_ids)
44 |
45 | # # Negative Samples for Description CNN - [B, D]
46 | trueentity_embeddings = tf.slice(
47 | self.sampled_entity_embeddings, [0,0,0],
48 | [self.batch_size, 1, context_encoded_dim])
49 | self.trueentity_embeddings = tf.reshape(
50 | trueentity_embeddings, [self.batch_size,
51 | context_encoded_dim])
52 |
53 | # Negative Samples for Description CNN
54 | negentity_embeddings = tf.slice(
55 | self.sampled_entity_embeddings, [0,1,0],
56 | [self.batch_size, 1, context_encoded_dim])
57 | self.negentity_embeddings = tf.reshape(
58 | negentity_embeddings, [self.batch_size,
59 | context_encoded_dim])
60 |
61 | # [B, 1, D]
62 | context_encoded_expanded = tf.expand_dims(
63 | input=context_encoded, dim=1)
64 |
65 | # [B, N]
66 | self.entity_scores = tf.reduce_sum(tf.mul(
67 | self.sampled_entity_embeddings, context_encoded_expanded), 2)
68 |
69 | # SOFTMAX
70 | # [B, N]
71 | self.entity_posteriors = tf.nn.softmax(
72 | self.entity_scores, name="entity_post_softmax")
73 |
74 | def loss_graph(self, true_entity_ids, scope_name, device_gpu):
75 | ''' true_entity_ids : [B] is the true ids in the sampled [B,N] matrix
76 | In entity_ids, [?, 0] is the true entity therefore this should be
77 | a vector of zeros
78 | '''
79 | with tf.variable_scope(scope_name) as s, tf.device(device_gpu) as d:
80 | # CROSS ENTROPY LOSS
81 | self.crossentropy_losses = \
82 | tf.nn.sparse_softmax_cross_entropy_with_logits(
83 | logits=self.entity_scores,
84 | labels=true_entity_ids,
85 | name="entity_posterior_loss")
86 |
87 | self.posterior_loss = tf.reduce_sum(
88 | self.crossentropy_losses) / tf.to_float(self.batch_size)
89 |
--------------------------------------------------------------------------------
/models/figer_model/joint_context.py:
--------------------------------------------------------------------------------
1 | import time
2 | import tensorflow as tf
3 | import numpy as np
4 |
5 | from models.base import Model
6 |
7 | class JointContextModel(Model):
8 | """Entity Embeddings and Posterior Calculation"""
9 |
10 | def __init__(self, num_layers, context_encoded_dim, text_encoded,
11 | coherence_encoded, scope_name, device, dropout_keep_prob):
12 |
13 | ''' Get context text and coherence encoded and combine into one repr.
14 | Input:
15 | text_encoded: Encoded vector for bi-LSTM. [context_encoded_dim]
16 | coherence_encoded: Encoded vector from sparse coherence FF [context_encoded_dim]
17 |
18 | Output:
19 | joint_encoded_vector: [context_encoded_dim]
20 | '''
21 | self.num_layers = num_layers
22 | self.dropout_keep_prob = dropout_keep_prob
23 | with tf.variable_scope(scope_name) as s:
24 | with tf.device(device) as d:
25 | self.joint_weights = tf.get_variable(
26 | name="joint_context_layer",
27 | shape=[2*context_encoded_dim, context_encoded_dim],
28 | initializer=tf.random_normal_initializer(mean=0.0,
29 | stddev=1.0/(100.0)))
30 |
31 | self.text_coh_concat = tf.concat(
32 | 1, [text_encoded, coherence_encoded], name='text_coh_concat')
33 |
34 | context_encoded = tf.matmul(self.text_coh_concat, self.joint_weights)
35 | context_encoded = tf.nn.relu(context_encoded)
36 |
37 | self.hidden_layers = []
38 | for i in range(1, self.num_layers):
39 | weight_matrix = tf.get_variable(
40 | name="joint_context_hlayer_"+str(i),
41 | shape=[context_encoded_dim, context_encoded_dim],
42 | initializer=tf.random_normal_initializer(
43 | mean=0.0,
44 | stddev=1.0/(100.0)))
45 | self.hidden_layers.append(weight_matrix)
46 |
47 | for i in range(1, self.num_layers):
48 | context_encoded = tf.nn.dropout(context_encoded, keep_prob=self.dropout_keep_prob)
49 | context_encoded = tf.matmul(context_encoded, self.hidden_layers[i-1])
50 | context_encoded = tf.nn.relu(context_encoded)
51 |
52 | self.context_encoded = tf.nn.dropout(context_encoded, keep_prob=self.dropout_keep_prob)
53 |
--------------------------------------------------------------------------------
/models/figer_model/labeling_model.py:
--------------------------------------------------------------------------------
1 | import time
2 | import tensorflow as tf
3 | import numpy as np
4 |
5 | from models.base import Model
6 |
7 | class LabelingModel(Model):
8 | """Unsupervised Clustering using Discrete-State VAE"""
9 |
10 | def __init__(self, batch_size, num_labels, context_encoded_dim,
11 | true_entity_embeddings,
12 | word_embed_dim, context_encoded, mention_embed, scope_name, device):
13 |
14 | self.batch_size = batch_size
15 | self.num_labels = num_labels
16 | self.word_embed_dim = word_embed_dim
17 |
18 | with tf.variable_scope(scope_name) as s, tf.device(device) as d:
19 | if mention_embed == None:
20 | self.label_weights = tf.get_variable(
21 | name="label_weights",
22 | shape=[context_encoded_dim, num_labels],
23 | initializer=tf.random_normal_initializer(mean=0.0,
24 | stddev=1.0/(100.0)))
25 | else:
26 | context_encoded = tf.concat(
27 | 1, [context_encoded, mention_embed], name='con_ment_repr')
28 | self.label_weights = tf.get_variable(
29 | name="label_weights",
30 | shape=[context_encoded_dim+word_embed_dim, num_labels],
31 | initializer=tf.random_normal_initializer(mean=0.0,
32 | stddev=1.0/(100.0)))
33 |
34 | # [B, L]
35 | self.label_scores = tf.matmul(context_encoded, self.label_weights)
36 | self.label_probs = tf.sigmoid(self.label_scores)
37 |
38 | ### PREDICT TYPES FROM ENTITIES
39 | #true_entity_embeddings = tf.nn.dropout(true_entity_embeddings, keep_prob=0.5)
40 | self.entity_label_scores = tf.matmul(true_entity_embeddings, self.label_weights)
41 | self.entity_label_probs = tf.sigmoid(self.label_scores)
42 |
43 |
44 | def loss_graph(self, true_label_ids, scope_name, device_gpu):
45 | with tf.variable_scope(scope_name) as s, tf.device(device_gpu) as d:
46 | # [B, L]
47 | self.cross_entropy_losses = tf.nn.sigmoid_cross_entropy_with_logits(
48 | logits=self.label_scores,
49 | targets=true_label_ids,
50 | name="labeling_loss")
51 |
52 | self.labeling_loss = tf.reduce_sum(
53 | self.cross_entropy_losses) / tf.to_float(self.batch_size)
54 |
55 |
56 | self.enlabel_cross_entropy_losses = tf.nn.sigmoid_cross_entropy_with_logits(
57 | logits=self.entity_label_scores,
58 | targets=true_label_ids,
59 | name="entity_labeling_loss")
60 |
61 | self.entity_labeling_loss = tf.reduce_sum(
62 | self.enlabel_cross_entropy_losses) / tf.to_float(self.batch_size)
63 |
--------------------------------------------------------------------------------
/models/figer_model/loss_optim.py:
--------------------------------------------------------------------------------
1 | import os
2 | import numpy as np
3 | import tensorflow as tf
4 |
5 | from models.base import Model
6 |
7 |
8 | class LossOptim(object):
9 | def __init__(self, figermodel):
10 | ''' Houses utility functions to facilitate training/pre-training'''
11 |
12 | # Object of the WikiELModel Class
13 | self.figermodel = figermodel
14 |
15 | def make_loss_graph(self):
16 | self.figermodel.labeling_model.loss_graph(
17 | true_label_ids=self.figermodel.labels_batch,
18 | scope_name=self.figermodel.labeling_loss_scope,
19 | device_gpu=self.figermodel.device_placements['gpu'])
20 |
21 | self.figermodel.posterior_model.loss_graph(
22 | true_entity_ids=self.figermodel.true_entity_ids,
23 | scope_name=self.figermodel.posterior_loss_scope,
24 | device_gpu=self.figermodel.device_placements['gpu'])
25 |
26 | if self.figermodel.useCNN:
27 | self.figermodel.wikidescmodel.loss_graph(
28 | true_entity_ids=self.figermodel.true_entity_ids,
29 | scope_name=self.figermodel.wikidesc_loss_scope,
30 | device_gpu=self.figermodel.device_placements['gpu'])
31 |
32 | def optimizer(self, optimizer_name, name):
33 | if optimizer_name == 'adam':
34 | optimizer = tf.train.AdamOptimizer(
35 | learning_rate=self.figermodel.learning_rate,
36 | name='Adam_'+name)
37 | elif optimizer_name == 'adagrad':
38 | optimizer = tf.train.AdagradOptimizer(
39 | learning_rate=self.figermodel.learning_rate,
40 | name='Adagrad_'+name)
41 | elif optimizer_name == 'adadelta':
42 | optimizer = tf.train.AdadeltaOptimizer(
43 | learning_rate=self.figermodel.learning_rate,
44 | name='Adadelta_'+name)
45 | elif optimizer_name == 'sgd':
46 | optimizer = tf.train.GradientDescentOptimizer(
47 | learning_rate=self.figermodel.learning_rate,
48 | name='SGD_'+name)
49 | elif optimizer_name == 'momentum':
50 | optimizer = tf.train.MomentumOptimizer(
51 | learning_rate=self.figermodel.learning_rate,
52 | momentum=0.9,
53 | name='Momentum_'+name)
54 | else:
55 | print("OPTIMIZER WRONG. HOW DID YOU GET HERE!!")
56 | sys.exit(0)
57 | return optimizer
58 |
59 | def weight_regularization(self, trainable_vars):
60 | vars_to_regularize = []
61 | regularization_loss = 0
62 | for var in trainable_vars:
63 | if "_weights" in var.name:
64 | regularization_loss += tf.nn.l2_loss(var)
65 | vars_to_regularize.append(var)
66 |
67 | print("L2 - Regularization for Variables:")
68 | self.figermodel.print_variables_in_collection(vars_to_regularize)
69 | return regularization_loss
70 |
71 | def label_optimization(self, trainable_vars, optim_scope):
72 | # Typing Loss
73 | if self.figermodel.typing:
74 | self.labeling_loss = self.figermodel.labeling_model.labeling_loss
75 | else:
76 | self.labeling_loss = tf.constant(0.0)
77 |
78 | if self.figermodel.entyping:
79 | self.entity_labeling_loss = \
80 | self.figermodel.labeling_model.entity_labeling_loss
81 | else:
82 | self.entity_labeling_loss = tf.constant(0.0)
83 |
84 | # Posterior Loss
85 | if self.figermodel.el:
86 | self.posterior_loss = \
87 | self.figermodel.posterior_model.posterior_loss
88 | else:
89 | self.posterior_loss = tf.constant(0.0)
90 |
91 | if self.figermodel.useCNN:
92 | self.wikidesc_loss = self.figermodel.wikidescmodel.wikiDescLoss
93 | else:
94 | self.wikidesc_loss = tf.constant(0.0)
95 |
96 | # _ = tf.scalar_summary("loss_typing", self.labeling_loss)
97 | # _ = tf.scalar_summary("loss_posterior", self.posterior_loss)
98 | # _ = tf.scalar_summary("loss_wikidesc", self.wikidesc_loss)
99 |
100 | self.total_loss = (self.labeling_loss + self.posterior_loss +
101 | self.wikidesc_loss + self.entity_labeling_loss)
102 |
103 | # Weight Regularization
104 | # self.regularization_loss = self.weight_regularization(
105 | # trainable_vars)
106 | # self.total_loss += (self.figermodel.reg_constant *
107 | # self.regularization_loss)
108 |
109 | # Scalar Summaries
110 | # _ = tf.scalar_summary("loss_regularized", self.total_loss)
111 | # _ = tf.scalar_summary("loss_labeling", self.labeling_loss)
112 |
113 | with tf.variable_scope(optim_scope) as s, \
114 | tf.device(self.figermodel.device_placements['gpu']) as d:
115 | self.optimizer = self.optimizer(
116 | optimizer_name=self.figermodel.optimizer, name="opt")
117 | self.gvs = self.optimizer.compute_gradients(
118 | loss=self.total_loss, var_list=trainable_vars)
119 | # self.clipped_gvs = self.clip_gradients(self.gvs)
120 | self.optim_op = self.optimizer.apply_gradients(self.gvs)
121 |
122 | def clip_gradients(self, gvs):
123 | clipped_gvs = []
124 | for (g,v) in gvs:
125 | if self.figermodel.embeddings_scope in v.name:
126 | clipped_gvalues = tf.clip_by_norm(g.values, 30)
127 | clipped_index_slices = tf.IndexedSlices(
128 | values=clipped_gvalues,
129 | indices=g.indices)
130 | clipped_gvs.append((clipped_index_slices, v))
131 | else:
132 | clipped_gvs.append((tf.clip_by_norm(g, 1), v))
133 | return clipped_gvs
134 |
--------------------------------------------------------------------------------
/models/figer_model/wiki_desc.py:
--------------------------------------------------------------------------------
1 | import time
2 | import numpy as np
3 | import tensorflow as tf
4 |
5 | from models.base import Model
6 |
7 | class WikiDescModel(Model):
8 | '''
9 | Input is sparse tensor of mention strings in mention's document.
10 | Pass through feed forward and get a coherence representation
11 | (keep same as context_encoded_dim)
12 | '''
13 |
14 | def __init__(self, desc_batch, trueentity_embs, negentity_embs, allentity_embs,
15 | batch_size, doclength, wordembeddim, filtersize, desc_encoded_dim,
16 | scope_name, device, dropout_keep_prob=1.0):
17 |
18 | # [B, doclength, wordembeddim]
19 | self.desc_batch = desc_batch
20 | self.batch_size = batch_size
21 | self.doclength = doclength
22 | self.wordembeddim = wordembeddim
23 | self.filtersize = filtersize
24 | self.desc_encoded_dim = desc_encoded_dim # Output dim of desc
25 | self.dropout_keep_prob = dropout_keep_prob
26 |
27 | # [B, K] - target of the CNN network and Negative sampled Entities
28 | self.trueentity_embs = trueentity_embs
29 | self.negentity_embs = negentity_embs
30 | self.allentity_embs = allentity_embs
31 |
32 | # [B, DL, WD, 1] - 1 to specify one channel
33 | self.desc_batch_expanded = tf.expand_dims(self.desc_batch, -1)
34 | # [F, WD, 1, K]
35 | self.filter_shape = [self.filtersize, self.wordembeddim, 1, self.desc_encoded_dim]
36 |
37 |
38 | with tf.variable_scope(scope_name) as scope, tf.device(device) as device:
39 | W = tf.Variable(tf.truncated_normal(self.filter_shape, stddev=0.1), name="W_conv")
40 | conv = tf.nn.conv2d(self.desc_batch_expanded,
41 | W,
42 | strides=[1, 1, 1, 1],
43 | padding="VALID",
44 | name="desc_conv")
45 |
46 | conv = tf.nn.relu(conv, name="conv_relu")
47 | conv = tf.nn.dropout(conv, keep_prob=self.dropout_keep_prob)
48 |
49 | # [B, (doclength-F+1), 1, K]
50 | # [B,K] - Global Average Pooling
51 | self.desc_encoded = tf.reduce_mean(conv, reduction_indices=[1,2])
52 |
53 | # [B, 1, K]
54 | self.desc_encoded_expand = tf.expand_dims(
55 | input=self.desc_encoded, dim=1)
56 |
57 | # [B, N]
58 | self.desc_scores = tf.reduce_sum(tf.mul(
59 | self.allentity_embs, self.desc_encoded_expand), 2)
60 |
61 | self.desc_posteriors = tf.nn.softmax(self.desc_scores,
62 | name="entity_post_softmax")
63 |
64 | ########### end def __init__ ##########################################
65 |
66 | def loss_graph(self, true_entity_ids, scope_name, device_gpu):
67 |
68 | with tf.variable_scope(scope_name) as s, tf.device(device_gpu) as d:
69 | self.crossentropy_losses = tf.nn.sparse_softmax_cross_entropy_with_logits(
70 | logits=self.desc_scores,
71 | labels=true_entity_ids,
72 | name="desc_posterior_loss")
73 |
74 | self.wikiDescLoss = tf.reduce_sum(
75 | self.crossentropy_losses) / tf.to_float(self.batch_size)
76 |
77 |
78 | '''
79 | # Maximize cosine distance between true_entity_embeddings and encoded_description
80 | # max CosineDis(self.trueentity_embs, self.desc_encoded)
81 |
82 | # [B, 1] - NOT [B] Due to keep_dims
83 | trueen_emb_norm = tf.sqrt(
84 | tf.reduce_sum(tf.square(self.trueentity_embs), 1, keep_dims=True))
85 | # [B, K]
86 | true_emb_normalized = self.trueentity_embs / trueen_emb_norm
87 |
88 | # [B, 1] - NOT [B] Due to keep_dims
89 | negen_emb_norm = tf.sqrt(
90 | tf.reduce_sum(tf.square(self.negentity_embs), 1, keep_dims=True))
91 | # [B, K]
92 | neg_emb_normalized = self.negentity_embs / negen_emb_norm
93 |
94 |
95 | # [B, 1] - NOT [B] Due to keep_dims
96 | desc_enc_norm = tf.sqrt(
97 | tf.reduce_sum(tf.square(self.desc_encoded), 1, keep_dims=True))
98 | # [B, K]
99 | desc_end_normalized = self.desc_encoded / desc_enc_norm
100 |
101 | # [B]
102 | self.true_cosDist = tf.reduce_mean(tf.mul(true_emb_normalized, desc_end_normalized))
103 |
104 | self.neg_cosDist = tf.reduce_mean(tf.mul(neg_emb_normalized, desc_end_normalized))
105 |
106 | # Loss = -ve dot_prod because distance has to be decreased
107 | #self.wikiDescLoss = self.neg_cosDist - self.true_cosDist
108 | '''
109 |
--------------------------------------------------------------------------------
/neuralel.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import copy
4 | import pprint
5 | import numpy as np
6 | import tensorflow as tf
7 |
8 | from readers.inference_reader import InferenceReader
9 | from readers.test_reader import TestDataReader
10 | from models.figer_model.el_model import ELModel
11 | from readers.config import Config
12 | from readers.vocabloader import VocabLoader
13 |
14 | np.set_printoptions(threshold=np.inf)
15 | np.set_printoptions(precision=7)
16 |
17 | pp = pprint.PrettyPrinter()
18 |
19 | flags = tf.app.flags
20 | flags.DEFINE_integer("max_steps", 32000, "Maximum of iteration [450000]")
21 | flags.DEFINE_integer("pretraining_steps", 32000, "Number of steps to run pretraining")
22 | flags.DEFINE_float("learning_rate", 0.005, "Learning rate of adam optimizer [0.001]")
23 | flags.DEFINE_string("model_path", "", "Path to trained model")
24 | flags.DEFINE_string("dataset", "el-figer", "The name of dataset [ptb]")
25 | flags.DEFINE_string("checkpoint_dir", "/tmp",
26 | "Directory name to save the checkpoints [checkpoints]")
27 | flags.DEFINE_integer("batch_size", 1, "Batch Size for training and testing")
28 | flags.DEFINE_integer("word_embed_dim", 300, "Word Embedding Size")
29 | flags.DEFINE_integer("context_encoded_dim", 100, "Context Encoded Dim")
30 | flags.DEFINE_integer("context_encoder_num_layers", 1, "Num of Layers in context encoder network")
31 | flags.DEFINE_integer("context_encoder_lstmsize", 100, "Size of context encoder hidden layer")
32 | flags.DEFINE_integer("coherence_numlayers", 1, "Number of layers in the Coherence FF")
33 | flags.DEFINE_integer("jointff_numlayers", 1, "Number of layers in the Coherence FF")
34 | flags.DEFINE_integer("num_cand_entities", 30, "Num CrossWikis entity candidates")
35 | flags.DEFINE_float("reg_constant", 0.00, "Regularization constant for NN weight regularization")
36 | flags.DEFINE_float("dropout_keep_prob", 0.6, "Dropout Keep Probability")
37 | flags.DEFINE_float("wordDropoutKeep", 0.6, "Word Dropout Keep Probability")
38 | flags.DEFINE_float("cohDropoutKeep", 0.4, "Coherence Dropout Keep Probability")
39 | flags.DEFINE_boolean("decoder_bool", True, "Decoder bool")
40 | flags.DEFINE_string("mode", 'inference', "Mode to run")
41 | flags.DEFINE_boolean("strict_context", False, "Strict Context exludes mention surface")
42 | flags.DEFINE_boolean("pretrain_wordembed", True, "Use Word2Vec Embeddings")
43 | flags.DEFINE_boolean("coherence", True, "Use Coherence")
44 | flags.DEFINE_boolean("typing", True, "Perform joint typing")
45 | flags.DEFINE_boolean("el", True, "Perform joint typing")
46 | flags.DEFINE_boolean("textcontext", True, "Use text context from LSTM")
47 | flags.DEFINE_boolean("useCNN", False, "Use wiki descp. CNN")
48 | flags.DEFINE_boolean("glove", True, "Use Glove Embeddings")
49 | flags.DEFINE_boolean("entyping", False, "Use Entity Type Prediction")
50 | flags.DEFINE_integer("WDLength", 100, "Length of wiki description")
51 | flags.DEFINE_integer("Fsize", 5, "For CNN filter size")
52 |
53 | flags.DEFINE_string("optimizer", 'adam', "Optimizer to use. adagrad, adadelta or adam")
54 |
55 | flags.DEFINE_string("config", 'configs/config.ini',
56 | "VocabConfig Filepath")
57 | flags.DEFINE_string("test_out_fp", "", "Write Test Prediction Data")
58 |
59 | FLAGS = flags.FLAGS
60 |
61 |
62 | def FLAGS_check(FLAGS):
63 | if not (FLAGS.textcontext and FLAGS.coherence):
64 | print("*** Local and Document context required ***")
65 | sys.exit(0)
66 | assert os.path.exists(FLAGS.model_path), "Model path doesn't exist."
67 |
68 |
69 | def main(_):
70 | pp.pprint(flags.FLAGS.__flags)
71 |
72 | FLAGS_check(FLAGS)
73 |
74 | config = Config(FLAGS.config, verbose=False)
75 | vocabloader = VocabLoader(config)
76 |
77 | if FLAGS.mode == 'inference':
78 | FLAGS.dropout_keep_prob = 1.0
79 | FLAGS.wordDropoutKeep = 1.0
80 | FLAGS.cohDropoutKeep = 1.0
81 |
82 | reader = InferenceReader(config=config,
83 | vocabloader=vocabloader,
84 | test_mens_file=config.test_file,
85 | num_cands=FLAGS.num_cand_entities,
86 | batch_size=FLAGS.batch_size,
87 | strict_context=FLAGS.strict_context,
88 | pretrain_wordembed=FLAGS.pretrain_wordembed,
89 | coherence=FLAGS.coherence)
90 | docta = reader.ccgdoc
91 | model_mode = 'inference'
92 |
93 | elif FLAGS.mode == 'test':
94 | FLAGS.dropout_keep_prob = 1.0
95 | FLAGS.wordDropoutKeep = 1.0
96 | FLAGS.cohDropoutKeep = 1.0
97 |
98 | reader = TestDataReader(config=config,
99 | vocabloader=vocabloader,
100 | test_mens_file=config.test_file,
101 | num_cands=30,
102 | batch_size=FLAGS.batch_size,
103 | strict_context=FLAGS.strict_context,
104 | pretrain_wordembed=FLAGS.pretrain_wordembed,
105 | coherence=FLAGS.coherence)
106 | model_mode = 'test'
107 |
108 | else:
109 | print("MODE in FLAGS is incorrect : {}".format(FLAGS.mode))
110 | sys.exit()
111 |
112 | config_proto = tf.ConfigProto()
113 | config_proto.allow_soft_placement = True
114 | config_proto.gpu_options.allow_growth=True
115 | sess = tf.Session(config=config_proto)
116 |
117 |
118 | with sess.as_default():
119 | model = ELModel(
120 | sess=sess, reader=reader, dataset=FLAGS.dataset,
121 | max_steps=FLAGS.max_steps,
122 | pretrain_max_steps=FLAGS.pretraining_steps,
123 | word_embed_dim=FLAGS.word_embed_dim,
124 | context_encoded_dim=FLAGS.context_encoded_dim,
125 | context_encoder_num_layers=FLAGS.context_encoder_num_layers,
126 | context_encoder_lstmsize=FLAGS.context_encoder_lstmsize,
127 | coherence_numlayers=FLAGS.coherence_numlayers,
128 | jointff_numlayers=FLAGS.jointff_numlayers,
129 | learning_rate=FLAGS.learning_rate,
130 | dropout_keep_prob=FLAGS.dropout_keep_prob,
131 | reg_constant=FLAGS.reg_constant,
132 | checkpoint_dir=FLAGS.checkpoint_dir,
133 | optimizer=FLAGS.optimizer,
134 | mode=model_mode,
135 | strict=FLAGS.strict_context,
136 | pretrain_word_embed=FLAGS.pretrain_wordembed,
137 | typing=FLAGS.typing,
138 | el=FLAGS.el,
139 | coherence=FLAGS.coherence,
140 | textcontext=FLAGS.textcontext,
141 | useCNN=FLAGS.useCNN,
142 | WDLength=FLAGS.WDLength,
143 | Fsize=FLAGS.Fsize,
144 | entyping=FLAGS.entyping)
145 |
146 | if FLAGS.mode == 'inference':
147 | print("Doing inference")
148 | (predTypScNPmat_list,
149 | widIdxs_list,
150 | priorProbs_list,
151 | textProbs_list,
152 | jointProbs_list,
153 | evWTs_list,
154 | pred_TypeSetsList) = model.inference(ckptpath=FLAGS.model_path)
155 |
156 | numMentionsInference = len(widIdxs_list)
157 | numMentionsReader = 0
158 | for sent_idx in reader.sentidx2ners:
159 | numMentionsReader += len(reader.sentidx2ners[sent_idx])
160 | assert numMentionsInference == numMentionsReader
161 |
162 | mentionnum = 0
163 | entityTitleList = []
164 | for sent_idx in reader.sentidx2ners:
165 | nerDicts = reader.sentidx2ners[sent_idx]
166 | sentence = ' '.join(reader.sentences_tokenized[sent_idx])
167 | for s, ner in nerDicts:
168 | [evWTs, evWIDS, evProbs] = evWTs_list[mentionnum]
169 | predTypes = pred_TypeSetsList[mentionnum]
170 | print(reader.bracketMentionInSentence(sentence, ner))
171 | print("Prior: {} {}, Context: {} {}, Joint: {} {}".format(
172 | evWTs[0], evProbs[0], evWTs[1], evProbs[1],
173 | evWTs[2], evProbs[2]))
174 |
175 | entityTitleList.append(evWTs[2])
176 | print("Predicted Entity Types : {}".format(predTypes))
177 | print("\n")
178 | mentionnum += 1
179 |
180 | elview = copy.deepcopy(docta.view_dictionary['NER_CONLL'])
181 | elview.view_name = 'ENG_NEURAL_EL'
182 | for i, cons in enumerate(elview.cons_list):
183 | cons['label'] = entityTitleList[i]
184 |
185 | docta.view_dictionary['ENG_NEURAL_EL'] = elview
186 |
187 | print("elview.cons_list")
188 | print(elview.cons_list)
189 | print("\n")
190 |
191 | for v in docta.as_json['views']:
192 | print(v)
193 | print("\n")
194 |
195 | elif FLAGS.mode == 'test':
196 | print("Testing on Data ")
197 | (widIdxs_list, condProbs_list, contextProbs_list,
198 | condContextJointProbs_list, evWTs,
199 | sortedContextWTs) = model.dataset_test(ckptpath=FLAGS.model_path)
200 |
201 | print(len(widIdxs_list))
202 | print(len(condProbs_list))
203 | print(len(contextProbs_list))
204 | print(len(condContextJointProbs_list))
205 | print(len(reader.mentions))
206 |
207 |
208 | print("Writing Test Predictions: {}".format(FLAGS.test_out_fp))
209 | with open(FLAGS.test_out_fp, 'w') as f:
210 | for (wididxs, pps, mps, jps) in zip(widIdxs_list,
211 | condProbs_list,
212 | contextProbs_list,
213 | condContextJointProbs_list):
214 |
215 | mentionPred = ""
216 |
217 | for (wididx, prp, mp, jp) in zip(wididxs, pps, mps, jps):
218 | wit = reader.widIdx2WikiTitle(wididx)
219 | mentionPred += wit + " " + str(prp) + " " + \
220 | str(mp) + " " + str(jp)
221 | mentionPred += "\t"
222 |
223 | mentionPred = mentionPred.strip() + "\n"
224 |
225 | f.write(mentionPred)
226 |
227 | print("Done writing. Can Exit.")
228 |
229 | else:
230 | print("WRONG MODE!")
231 | sys.exit(0)
232 |
233 |
234 |
235 |
236 |
237 | sys.exit()
238 |
239 | if __name__ == '__main__':
240 | tf.app.run()
241 |
--------------------------------------------------------------------------------
/neuralel_jsonl.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import copy
4 | import json
5 | import pprint
6 | import numpy as np
7 | import tensorflow as tf
8 | from os import listdir
9 | from os.path import isfile, join
10 |
11 | from ccg_nlpy.core.view import View
12 | from ccg_nlpy.core.text_annotation import TextAnnotation
13 | from ccg_nlpy.local_pipeline import LocalPipeline
14 | from readers.textanno_test_reader import TextAnnoTestReader
15 | from models.figer_model.el_model import ELModel
16 | from readers.config import Config
17 | from readers.vocabloader import VocabLoader
18 |
19 | np.set_printoptions(threshold=np.inf)
20 | np.set_printoptions(precision=7)
21 |
22 | pp = pprint.PrettyPrinter()
23 |
24 | flags = tf.app.flags
25 | flags.DEFINE_integer("max_steps", 32000, "Maximum of iteration [450000]")
26 | flags.DEFINE_integer("pretraining_steps", 32000, "Number of steps to run pretraining")
27 | flags.DEFINE_float("learning_rate", 0.005, "Learning rate of adam optimizer [0.001]")
28 | flags.DEFINE_string("model_path", "", "Path to trained model")
29 | flags.DEFINE_string("dataset", "el-figer", "The name of dataset [ptb]")
30 | flags.DEFINE_string("checkpoint_dir", "/tmp",
31 | "Directory name to save the checkpoints [checkpoints]")
32 | flags.DEFINE_integer("batch_size", 1, "Batch Size for training and testing")
33 | flags.DEFINE_integer("word_embed_dim", 300, "Word Embedding Size")
34 | flags.DEFINE_integer("context_encoded_dim", 100, "Context Encoded Dim")
35 | flags.DEFINE_integer("context_encoder_num_layers", 1, "Num of Layers in context encoder network")
36 | flags.DEFINE_integer("context_encoder_lstmsize", 100, "Size of context encoder hidden layer")
37 | flags.DEFINE_integer("coherence_numlayers", 1, "Number of layers in the Coherence FF")
38 | flags.DEFINE_integer("jointff_numlayers", 1, "Number of layers in the Coherence FF")
39 | flags.DEFINE_integer("num_cand_entities", 30, "Num CrossWikis entity candidates")
40 | flags.DEFINE_float("reg_constant", 0.00, "Regularization constant for NN weight regularization")
41 | flags.DEFINE_float("dropout_keep_prob", 0.6, "Dropout Keep Probability")
42 | flags.DEFINE_float("wordDropoutKeep", 0.6, "Word Dropout Keep Probability")
43 | flags.DEFINE_float("cohDropoutKeep", 0.4, "Coherence Dropout Keep Probability")
44 | flags.DEFINE_boolean("decoder_bool", True, "Decoder bool")
45 | flags.DEFINE_string("mode", 'inference', "Mode to run")
46 | flags.DEFINE_boolean("strict_context", False, "Strict Context exludes mention surface")
47 | flags.DEFINE_boolean("pretrain_wordembed", True, "Use Word2Vec Embeddings")
48 | flags.DEFINE_boolean("coherence", True, "Use Coherence")
49 | flags.DEFINE_boolean("typing", True, "Perform joint typing")
50 | flags.DEFINE_boolean("el", True, "Perform joint typing")
51 | flags.DEFINE_boolean("textcontext", True, "Use text context from LSTM")
52 | flags.DEFINE_boolean("useCNN", False, "Use wiki descp. CNN")
53 | flags.DEFINE_boolean("glove", True, "Use Glove Embeddings")
54 | flags.DEFINE_boolean("entyping", False, "Use Entity Type Prediction")
55 | flags.DEFINE_integer("WDLength", 100, "Length of wiki description")
56 | flags.DEFINE_integer("Fsize", 5, "For CNN filter size")
57 |
58 | flags.DEFINE_string("optimizer", 'adam', "Optimizer to use. adagrad, adadelta or adam")
59 |
60 | flags.DEFINE_string("config", 'configs/config.ini',
61 | "VocabConfig Filepath")
62 | flags.DEFINE_string("test_out_fp", "", "Write Test Prediction Data")
63 |
64 | flags.DEFINE_string("input_jsonl", "", "Input containing documents in jsonl")
65 | flags.DEFINE_string("output_jsonl", "", "Output in jsonl format")
66 | flags.DEFINE_string("doc_key", "", "Key in input_jsonl containing documents")
67 | flags.DEFINE_boolean("pretokenized", False, "Is the input text pretokenized")
68 |
69 | FLAGS = flags.FLAGS
70 |
71 | localpipeline = LocalPipeline()
72 |
73 |
74 | def FLAGS_check(FLAGS):
75 | if not (FLAGS.textcontext and FLAGS.coherence):
76 | print("*** Local and Document context required ***")
77 | sys.exit(0)
78 | assert os.path.exists(FLAGS.model_path), "Model path doesn't exist."
79 |
80 | assert(FLAGS.mode == 'ta'), "Only mode == ta allowed"
81 |
82 |
83 | def main(_):
84 | pp.pprint(flags.FLAGS.__flags)
85 |
86 | FLAGS_check(FLAGS)
87 |
88 | config = Config(FLAGS.config, verbose=False)
89 | vocabloader = VocabLoader(config)
90 |
91 | FLAGS.dropout_keep_prob = 1.0
92 | FLAGS.wordDropoutKeep = 1.0
93 | FLAGS.cohDropoutKeep = 1.0
94 |
95 | input_jsonl = FLAGS.input_jsonl
96 | output_jsonl = FLAGS.output_jsonl
97 | doc_key = FLAGS.doc_key
98 |
99 | reader = TextAnnoTestReader(
100 | config=config,
101 | vocabloader=vocabloader,
102 | num_cands=30,
103 | batch_size=FLAGS.batch_size,
104 | strict_context=FLAGS.strict_context,
105 | pretrain_wordembed=FLAGS.pretrain_wordembed,
106 | coherence=FLAGS.coherence)
107 | model_mode = 'test'
108 |
109 | config_proto = tf.ConfigProto()
110 | config_proto.allow_soft_placement = True
111 | config_proto.gpu_options.allow_growth=True
112 | sess = tf.Session(config=config_proto)
113 |
114 |
115 | with sess.as_default():
116 | model = ELModel(
117 | sess=sess, reader=reader, dataset=FLAGS.dataset,
118 | max_steps=FLAGS.max_steps,
119 | pretrain_max_steps=FLAGS.pretraining_steps,
120 | word_embed_dim=FLAGS.word_embed_dim,
121 | context_encoded_dim=FLAGS.context_encoded_dim,
122 | context_encoder_num_layers=FLAGS.context_encoder_num_layers,
123 | context_encoder_lstmsize=FLAGS.context_encoder_lstmsize,
124 | coherence_numlayers=FLAGS.coherence_numlayers,
125 | jointff_numlayers=FLAGS.jointff_numlayers,
126 | learning_rate=FLAGS.learning_rate,
127 | dropout_keep_prob=FLAGS.dropout_keep_prob,
128 | reg_constant=FLAGS.reg_constant,
129 | checkpoint_dir=FLAGS.checkpoint_dir,
130 | optimizer=FLAGS.optimizer,
131 | mode=model_mode,
132 | strict=FLAGS.strict_context,
133 | pretrain_word_embed=FLAGS.pretrain_wordembed,
134 | typing=FLAGS.typing,
135 | el=FLAGS.el,
136 | coherence=FLAGS.coherence,
137 | textcontext=FLAGS.textcontext,
138 | useCNN=FLAGS.useCNN,
139 | WDLength=FLAGS.WDLength,
140 | Fsize=FLAGS.Fsize,
141 | entyping=FLAGS.entyping)
142 |
143 | model.load_ckpt_model(ckptpath=FLAGS.model_path)
144 |
145 | erroneous_files = 0
146 |
147 | outf = open(output_jsonl, 'w')
148 | inpf = open(input_jsonl, 'r')
149 |
150 | for line in inpf:
151 | jsonobj = json.loads(line)
152 | doctext = jsonobj[doc_key]
153 | ta = localpipeline.doc(doctext, pretokenized=FLAGS.pretokenized)
154 | _ = ta.get_ner_conll
155 |
156 | # Make instances for this document
157 | reader.new_ta(ta)
158 |
159 | (predTypScNPmat_list,
160 | widIdxs_list,
161 | priorProbs_list,
162 | textProbs_list,
163 | jointProbs_list,
164 | evWTs_list,
165 | pred_TypeSetsList) = model.inference_run()
166 |
167 | wiki_view = copy.deepcopy(reader.textanno.get_view("NER_CONLL"))
168 | docta = reader.textanno
169 |
170 | el_cons_list = wiki_view.cons_list
171 | numMentionsInference = len(widIdxs_list)
172 |
173 | assert len(el_cons_list) == numMentionsInference
174 |
175 | out_dict = {doc_key: doctext}
176 | el_mentions = []
177 |
178 | mentionnum = 0
179 | for ner_cons in el_cons_list:
180 | # ner_cons is a dict
181 | mentiondict = {}
182 | mentiondict['tokens'] = ner_cons['tokens']
183 | mentiondict['end'] = ner_cons['end']
184 | mentiondict['start'] = ner_cons['start']
185 |
186 | priorScoreMap = {}
187 | contextScoreMap = {}
188 | jointScoreMap = {}
189 |
190 | (wididxs, pps, mps, jps) = (widIdxs_list[mentionnum],
191 | priorProbs_list[mentionnum],
192 | textProbs_list[mentionnum],
193 | jointProbs_list[mentionnum])
194 |
195 | maxJointProb = 0.0
196 | maxJointEntity = ""
197 | for (wididx, prp, mp, jp) in zip(wididxs, pps, mps, jps):
198 | wT = reader.widIdx2WikiTitle(wididx)
199 | priorScoreMap[wT] = prp
200 | contextScoreMap[wT] = mp
201 | jointScoreMap[wT] = jp
202 |
203 | if jp > maxJointProb:
204 | maxJointProb = jp
205 | maxJointEntity = wT
206 |
207 | mentiondict["jointScoreMap"] = jointScoreMap
208 | mentiondict["contextScoreMap"] = contextScoreMap
209 | mentiondict["priorScoreMap"] = priorScoreMap
210 |
211 | # add max scoring entity as label
212 | mentiondict["label"] = maxJointEntity
213 | mentiondict["score"] = maxJointProb
214 |
215 | mentionnum += 1
216 |
217 | el_mentions.append(mentiondict)
218 |
219 | out_dict['nel'] = el_mentions
220 | outstr = json.dumps(out_dict)
221 | outf.write(outstr)
222 | outf.write("\n")
223 |
224 | outf.close()
225 | inpf.close()
226 |
227 | print("Number of erroneous files: {}".format(erroneous_files))
228 | print("Annotation completed. Program can be exited safely.")
229 | sys.exit()
230 |
231 | if __name__ == '__main__':
232 | tf.app.run()
233 |
--------------------------------------------------------------------------------
/neuralel_tadir.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import copy
4 | import json
5 | import pprint
6 | import numpy as np
7 | import tensorflow as tf
8 | from os import listdir
9 | from os.path import isfile, join
10 |
11 | from ccg_nlpy.core.view import View
12 | from ccg_nlpy.core.text_annotation import TextAnnotation
13 |
14 | from readers.inference_reader import InferenceReader
15 | from readers.test_reader import TestDataReader
16 | from readers.textanno_test_reader import TextAnnoTestReader
17 | from models.figer_model.el_model import ELModel
18 | from readers.config import Config
19 | from readers.vocabloader import VocabLoader
20 |
21 | np.set_printoptions(threshold=np.inf)
22 | np.set_printoptions(precision=7)
23 |
24 | pp = pprint.PrettyPrinter()
25 |
26 | flags = tf.app.flags
27 | flags.DEFINE_integer("max_steps", 32000, "Maximum of iteration [450000]")
28 | flags.DEFINE_integer("pretraining_steps", 32000, "Number of steps to run pretraining")
29 | flags.DEFINE_float("learning_rate", 0.005, "Learning rate of adam optimizer [0.001]")
30 | flags.DEFINE_string("model_path", "", "Path to trained model")
31 | flags.DEFINE_string("dataset", "el-figer", "The name of dataset [ptb]")
32 | flags.DEFINE_string("checkpoint_dir", "/tmp",
33 | "Directory name to save the checkpoints [checkpoints]")
34 | flags.DEFINE_integer("batch_size", 1, "Batch Size for training and testing")
35 | flags.DEFINE_integer("word_embed_dim", 300, "Word Embedding Size")
36 | flags.DEFINE_integer("context_encoded_dim", 100, "Context Encoded Dim")
37 | flags.DEFINE_integer("context_encoder_num_layers", 1, "Num of Layers in context encoder network")
38 | flags.DEFINE_integer("context_encoder_lstmsize", 100, "Size of context encoder hidden layer")
39 | flags.DEFINE_integer("coherence_numlayers", 1, "Number of layers in the Coherence FF")
40 | flags.DEFINE_integer("jointff_numlayers", 1, "Number of layers in the Coherence FF")
41 | flags.DEFINE_integer("num_cand_entities", 30, "Num CrossWikis entity candidates")
42 | flags.DEFINE_float("reg_constant", 0.00, "Regularization constant for NN weight regularization")
43 | flags.DEFINE_float("dropout_keep_prob", 0.6, "Dropout Keep Probability")
44 | flags.DEFINE_float("wordDropoutKeep", 0.6, "Word Dropout Keep Probability")
45 | flags.DEFINE_float("cohDropoutKeep", 0.4, "Coherence Dropout Keep Probability")
46 | flags.DEFINE_boolean("decoder_bool", True, "Decoder bool")
47 | flags.DEFINE_string("mode", 'inference', "Mode to run")
48 | flags.DEFINE_boolean("strict_context", False, "Strict Context exludes mention surface")
49 | flags.DEFINE_boolean("pretrain_wordembed", True, "Use Word2Vec Embeddings")
50 | flags.DEFINE_boolean("coherence", True, "Use Coherence")
51 | flags.DEFINE_boolean("typing", True, "Perform joint typing")
52 | flags.DEFINE_boolean("el", True, "Perform joint typing")
53 | flags.DEFINE_boolean("textcontext", True, "Use text context from LSTM")
54 | flags.DEFINE_boolean("useCNN", False, "Use wiki descp. CNN")
55 | flags.DEFINE_boolean("glove", True, "Use Glove Embeddings")
56 | flags.DEFINE_boolean("entyping", False, "Use Entity Type Prediction")
57 | flags.DEFINE_integer("WDLength", 100, "Length of wiki description")
58 | flags.DEFINE_integer("Fsize", 5, "For CNN filter size")
59 |
60 | flags.DEFINE_string("optimizer", 'adam', "Optimizer to use. adagrad, adadelta or adam")
61 |
62 | flags.DEFINE_string("config", 'configs/config.ini',
63 | "VocabConfig Filepath")
64 | flags.DEFINE_string("test_out_fp", "", "Write Test Prediction Data")
65 |
66 | flags.DEFINE_string("tadirpath", "", "Director containing all the text-annos")
67 | flags.DEFINE_string("taoutdirpath", "", "Director containing all the text-annos")
68 |
69 |
70 |
71 | FLAGS = flags.FLAGS
72 |
73 |
74 | def FLAGS_check(FLAGS):
75 | if not (FLAGS.textcontext and FLAGS.coherence):
76 | print("*** Local and Document context required ***")
77 | sys.exit(0)
78 | assert os.path.exists(FLAGS.model_path), "Model path doesn't exist."
79 |
80 | assert(FLAGS.mode == 'ta'), "Only mode == ta allowed"
81 |
82 |
83 | def getAllTAFilePaths(FLAGS):
84 | tadir = FLAGS.tadirpath
85 | taoutdirpath = FLAGS.taoutdirpath
86 | onlyfiles = [f for f in listdir(tadir) if isfile(join(tadir, f))]
87 | ta_files = [os.path.join(tadir, fname) for fname in onlyfiles]
88 |
89 | output_ta_files = [os.path.join(taoutdirpath, fname) for fname in onlyfiles]
90 |
91 | return (ta_files, output_ta_files)
92 |
93 |
94 | def main(_):
95 | pp.pprint(flags.FLAGS.__flags)
96 |
97 | FLAGS_check(FLAGS)
98 |
99 | config = Config(FLAGS.config, verbose=False)
100 | vocabloader = VocabLoader(config)
101 |
102 | FLAGS.dropout_keep_prob = 1.0
103 | FLAGS.wordDropoutKeep = 1.0
104 | FLAGS.cohDropoutKeep = 1.0
105 |
106 | (intput_ta_files, output_ta_files) = getAllTAFilePaths(FLAGS)
107 |
108 | print("TOTAL NUMBER OF TAS : {}".format(len(intput_ta_files)))
109 |
110 | reader = TextAnnoTestReader(
111 | config=config,
112 | vocabloader=vocabloader,
113 | num_cands=30,
114 | batch_size=FLAGS.batch_size,
115 | strict_context=FLAGS.strict_context,
116 | pretrain_wordembed=FLAGS.pretrain_wordembed,
117 | coherence=FLAGS.coherence,
118 | nerviewname="NER")
119 |
120 | model_mode = 'test'
121 |
122 | config_proto = tf.ConfigProto()
123 | config_proto.allow_soft_placement = True
124 | config_proto.gpu_options.allow_growth=True
125 | sess = tf.Session(config=config_proto)
126 |
127 |
128 | with sess.as_default():
129 | model = ELModel(
130 | sess=sess, reader=reader, dataset=FLAGS.dataset,
131 | max_steps=FLAGS.max_steps,
132 | pretrain_max_steps=FLAGS.pretraining_steps,
133 | word_embed_dim=FLAGS.word_embed_dim,
134 | context_encoded_dim=FLAGS.context_encoded_dim,
135 | context_encoder_num_layers=FLAGS.context_encoder_num_layers,
136 | context_encoder_lstmsize=FLAGS.context_encoder_lstmsize,
137 | coherence_numlayers=FLAGS.coherence_numlayers,
138 | jointff_numlayers=FLAGS.jointff_numlayers,
139 | learning_rate=FLAGS.learning_rate,
140 | dropout_keep_prob=FLAGS.dropout_keep_prob,
141 | reg_constant=FLAGS.reg_constant,
142 | checkpoint_dir=FLAGS.checkpoint_dir,
143 | optimizer=FLAGS.optimizer,
144 | mode=model_mode,
145 | strict=FLAGS.strict_context,
146 | pretrain_word_embed=FLAGS.pretrain_wordembed,
147 | typing=FLAGS.typing,
148 | el=FLAGS.el,
149 | coherence=FLAGS.coherence,
150 | textcontext=FLAGS.textcontext,
151 | useCNN=FLAGS.useCNN,
152 | WDLength=FLAGS.WDLength,
153 | Fsize=FLAGS.Fsize,
154 | entyping=FLAGS.entyping)
155 |
156 | model.load_ckpt_model(ckptpath=FLAGS.model_path)
157 |
158 | print("Total files: {}".format(len(output_ta_files)))
159 | erroneous_files = 0
160 | for in_ta_path, out_ta_path in zip(intput_ta_files, output_ta_files):
161 | # print("Running the inference for : {}".format(in_ta_path))
162 | try:
163 | reader.new_test_file(in_ta_path)
164 | except:
165 | print("Error reading : {}".format(in_ta_path))
166 | erroneous_files += 1
167 | continue
168 |
169 | (predTypScNPmat_list,
170 | widIdxs_list,
171 | priorProbs_list,
172 | textProbs_list,
173 | jointProbs_list,
174 | evWTs_list,
175 | pred_TypeSetsList) = model.inference_run()
176 |
177 | # model.inference(ckptpath=FLAGS.model_path)
178 |
179 | wiki_view = copy.deepcopy(reader.textanno.get_view("NER"))
180 | docta = reader.textanno
181 |
182 | el_cons_list = wiki_view.cons_list
183 | numMentionsInference = len(widIdxs_list)
184 |
185 | # print("Number of mentions in model: {}".format(len(widIdxs_list)))
186 | # print("Number of NER mention: {}".format(len(el_cons_list)))
187 |
188 | assert len(el_cons_list) == numMentionsInference
189 |
190 | mentionnum = 0
191 | for ner_cons in el_cons_list:
192 | priorScoreMap = {}
193 | contextScoreMap = {}
194 | jointScoreMap = {}
195 |
196 | (wididxs, pps, mps, jps) = (widIdxs_list[mentionnum],
197 | priorProbs_list[mentionnum],
198 | textProbs_list[mentionnum],
199 | jointProbs_list[mentionnum])
200 |
201 | maxJointProb = 0.0
202 | maxJointEntity = ""
203 | for (wididx, prp, mp, jp) in zip(wididxs, pps, mps, jps):
204 | wT = reader.widIdx2WikiTitle(wididx)
205 | priorScoreMap[wT] = prp
206 | contextScoreMap[wT] = mp
207 | jointScoreMap[wT] = jp
208 |
209 | if jp > maxJointProb:
210 | maxJointProb = jp
211 | maxJointEntity = wT
212 |
213 |
214 | ''' add labels2score map here '''
215 | ner_cons["jointScoreMap"] = jointScoreMap
216 | ner_cons["contextScoreMap"] = contextScoreMap
217 | ner_cons["priorScoreMap"] = priorScoreMap
218 |
219 | # add max scoring entity as label
220 | ner_cons["label"] = maxJointEntity
221 | ner_cons["score"] = maxJointProb
222 |
223 | mentionnum += 1
224 |
225 | wiki_view.view_name = "NEUREL"
226 | docta.view_dictionary["NEUREL"] = wiki_view
227 |
228 | docta_json = docta.as_json
229 | json.dump(docta_json, open(out_ta_path, "w"), indent=True)
230 |
231 | print("Number of erroneous files: {}".format(erroneous_files))
232 | print("Annotation completed. Program can be exited safely.")
233 | sys.exit()
234 |
235 | if __name__ == '__main__':
236 | tf.app.run()
237 |
--------------------------------------------------------------------------------
/overview.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nitishgupta/neural-el/8c7c278acefa66238a75e805511ff26a567fd4e0/overview.png
--------------------------------------------------------------------------------
/readers/Mention.py:
--------------------------------------------------------------------------------
1 | start_word = ""
2 | end_word = ""
3 | unk_word = ""
4 |
5 |
6 | class Mention(object):
7 | def __init__(self, mention_line):
8 | ''' mention_line : Is the string line stored for each mention
9 | mid wid wikititle start_token end_token surface tokenized_sentence
10 | all_types
11 | '''
12 | mention_line = mention_line.strip()
13 | split = mention_line.split("\t")
14 | (self.mid, self.wid, self.wikititle) = split[0:3]
15 | self.start_token = int(split[3]) + 1 # Adding in the start
16 | self.end_token = int(split[4]) + 1
17 | self.surface = split[5]
18 | self.sent_tokens = [start_word]
19 | self.sent_tokens.extend(split[6].split(" "))
20 | self.sent_tokens.append(end_word)
21 | self.types = split[7].split(" ")
22 | if len(split) > 8: # If no mention surface words in coherence
23 | if split[8].strip() == "":
24 | self.coherence = [unk_word]
25 | else:
26 | self.coherence = split[8].split(" ")
27 | if len(split) == 10:
28 | self.docid = split[9]
29 |
30 | assert self.end_token <= (len(self.sent_tokens) - 1), "Line : %s" % mention_line
31 | #enddef
32 |
33 | def toString(self):
34 | outstr = self.wid + "\t"
35 | outstr += self.wikititle + "\t"
36 | for i in range(1, len(self.sent_tokens)):
37 | outstr += self.sent_tokens[i] + " "
38 |
39 | outstr = outstr.strip()
40 | return outstr
41 |
42 | #endclass
43 |
--------------------------------------------------------------------------------
/readers/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nitishgupta/neural-el/8c7c278acefa66238a75e805511ff26a567fd4e0/readers/__init__.py
--------------------------------------------------------------------------------
/readers/config.py:
--------------------------------------------------------------------------------
1 | import pprint
2 | import configparser
3 |
4 | pp = pprint.PrettyPrinter()
5 |
6 | class Config(object):
7 | def __init__(self, paths_config, verbose=False):
8 | config = configparser.ConfigParser()
9 | config._interpolation = configparser.ExtendedInterpolation()
10 | config.read(paths_config)
11 | print(paths_config)
12 |
13 | c = config['DEFAULT']
14 |
15 | d = {}
16 | for k in c:
17 | d[k] = c[k]
18 |
19 | self.resources_dir = d['resources_dir']
20 |
21 | self.vocab_dir = d['vocab_dir']
22 |
23 | # Word2Vec Vocab to Idxs
24 | self.word_vocab_pkl = d['word_vocab_pkl']
25 | # Wid2Idx for Known Entities ~ 620K (readers.train.vocab.py)
26 | self.kwnwid_vocab_pkl = d['kwnwid_vocab_pkl']
27 | # FIGER Type label 2 idx (readers.train.vocab.py)
28 | self.label_vocab_pkl = d['label_vocab_pkl']
29 | # EntityWid: [FIGER Type Labels]
30 | # CoherenceStr2Idx at various thresholds (readers.train.vocab.py)
31 | self.cohstringG9_vocab_pkl = d['cohstringg9_vocab_pkl']
32 |
33 | # wid2Wikititle for whole KB ~ 3.18M (readers.train.vocab.py)
34 | self.widWiktitle_pkl = d['widwiktitle_pkl']
35 |
36 | self.crosswikis_pruned_pkl = d['crosswikis_pruned_pkl']
37 |
38 | self.glove_pkl = d['glove_pkl']
39 | self.glove_word_vocab_pkl = d['glove_word_vocab_pkl']
40 |
41 | self.test_file = d['test_file']
42 |
43 | if verbose:
44 | pp.pprint(d)
45 |
46 | #endinit
47 |
48 | if __name__=='__main__':
49 | c = Config("configs/allnew_mentions_config.ini", verbose=True)
50 |
--------------------------------------------------------------------------------
/readers/crosswikis_test.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import time
4 | from readers.config import Config
5 | from readers.vocabloader import VocabLoader
6 | from readers import utils
7 |
8 |
9 |
10 | class CrosswikisTest(object):
11 | def __init__(self, config, vocabloader):
12 | print("Loading Crosswikis")
13 | # self.crosswikis = vocabloader.loadCrosswikis()
14 |
15 | stime = time.time()
16 | self.crosswikis = utils.load(config.crosswikis_pruned_pkl)
17 | ttime = time.time() - stime
18 | print("Crosswikis Loaded. Size : {}".format(len(self.crosswikis)))
19 | print("Time taken : {} secs".format(ttime))
20 |
21 | (self.knwid2idx, self.idx2knwid) = vocabloader.getKnwnWidVocab()
22 | print("Size of known wids : {}".format(len(self.knwid2idx)))
23 |
24 | def test(self):
25 | print("Test starting")
26 | maxCands = 0
27 | minCands = 0
28 | notKnownWid = False
29 | smallSurface = 0
30 | notSortedProbs = 0
31 | for surface, c_cprobs in self.crosswikis.items():
32 | notSorted = False
33 | numCands = len(c_cprobs)
34 | if numCands < minCands:
35 | minCands = numCands
36 | if numCands > maxCands:
37 | maxCands = numCands
38 |
39 | prob_prv = 10.0
40 | for (wid, prob) in c_cprobs:
41 | if wid not in self.knwid2idx:
42 | notKnownWid = True
43 | if prob_prv < prob:
44 | notSorted = True
45 | prob_prv = prob
46 |
47 | if notSorted:
48 | notSortedProbs += 1
49 |
50 | if len(surface) <= 1:
51 | smallSurface += 1
52 |
53 | print("Max Cands : {}".format(maxCands))
54 | print("min Cands : {}".format(minCands))
55 | print("Not Known Wid : {}".format(notKnownWid))
56 | print("small surfaces {}".format(smallSurface))
57 | print("Not Sorted Probs {}".format(notSortedProbs))
58 |
59 | def test_pruned(self):
60 | print("Test starting")
61 | maxCands = 0
62 | minCands = 30
63 | notKnownWid = False
64 | smallSurface = 0
65 | notSortedProbs = 0
66 | for surface, c_cprobs in self.crosswikis.items():
67 | notSorted = False
68 | (wids, probs) = c_cprobs
69 | numCands = len(wids)
70 | if numCands < minCands:
71 | minCands = numCands
72 | if numCands > maxCands:
73 | maxCands = numCands
74 |
75 | prob_prv = 10.0
76 | for (wid, prob) in zip(wids, probs):
77 | if wid not in self.knwid2idx:
78 | notKnownWid = True
79 | if prob_prv < prob:
80 | notSorted = True
81 | prob_prv = prob
82 |
83 | if notSorted:
84 | notSortedProbs += 1
85 |
86 | if len(surface) <= 1:
87 | smallSurface += 1
88 |
89 | print("Max Cands : {}".format(maxCands))
90 | print("min Cands : {}".format(minCands))
91 | print("Not Known Wid : {}".format(notKnownWid))
92 | print("small surfaces {}".format(smallSurface))
93 | print("Not Sorted Probs {}".format(notSortedProbs))
94 |
95 | def makeCWKnown(self, cwOutPath):
96 | cw = {}
97 | MAXCAND = 30
98 | surfacesProcessed = 0
99 | for surface, c_cprobs in self.crosswikis.items():
100 | surfacesProcessed += 1
101 | if surfacesProcessed % 1000000 == 0:
102 | print("Surfaces Processed : {}".format(surfacesProcessed))
103 |
104 | if len(c_cprobs) == 0:
105 | continue
106 | if len(surface) <= 1:
107 | continue
108 | candsAdded = 0
109 | c_probs = ([], [])
110 | # cw[surface] = ([], [])
111 | for (wid, prob) in c_cprobs:
112 | if candsAdded == 30:
113 | break
114 | if wid in self.knwid2idx:
115 | c_probs[0].append(wid)
116 | c_probs[1].append(prob)
117 | candsAdded += 1
118 | if candsAdded != 0:
119 | cw[surface] = c_probs
120 | print("Processed")
121 | print("Size of CW : {}".format(len(cw)))
122 | utils.save(cwOutPath, cw)
123 | print("Saved pruned CW")
124 |
125 |
126 |
127 | if __name__ == '__main__':
128 | configpath = "configs/config.ini"
129 | config = Config(configpath, verbose=False)
130 | vocabloader = VocabLoader(config)
131 | cwikistest = CrosswikisTest(config, vocabloader)
132 | cwikistest.test_pruned()
133 | # cwikistest.makeCWKnown(os.path.join(config.resources_dir,
134 | # "crosswikis.pruned.pkl"))
135 | import os
136 | import sys
137 | import time
138 | from readers.config import Config
139 | from readers.vocabloader import VocabLoader
140 | from readers import utils
141 |
142 |
143 |
144 | class CrosswikisTest(object):
145 | def __init__(self, config, vocabloader):
146 | print("Loading Crosswikis")
147 | # self.crosswikis = vocabloader.loadCrosswikis()
148 |
149 | stime = time.time()
150 | self.crosswikis = utils.load(config.crosswikis_pruned_pkl)
151 | ttime = time.time() - stime
152 | print("Crosswikis Loaded. Size : {}".format(len(self.crosswikis)))
153 | print("Time taken : {} secs".format(ttime))
154 |
155 | (self.knwid2idx, self.idx2knwid) = vocabloader.getKnwnWidVocab()
156 | print("Size of known wids : {}".format(len(self.knwid2idx)))
157 |
158 | def test(self):
159 | print("Test starting")
160 | maxCands = 0
161 | minCands = 0
162 | notKnownWid = False
163 | smallSurface = 0
164 | notSortedProbs = 0
165 | for surface, c_cprobs in self.crosswikis.items():
166 | notSorted = False
167 | numCands = len(c_cprobs)
168 | if numCands < minCands:
169 | minCands = numCands
170 | if numCands > maxCands:
171 | maxCands = numCands
172 |
173 | prob_prv = 10.0
174 | for (wid, prob) in c_cprobs:
175 | if wid not in self.knwid2idx:
176 | notKnownWid = True
177 | if prob_prv < prob:
178 | notSorted = True
179 | prob_prv = prob
180 |
181 | if notSorted:
182 | notSortedProbs += 1
183 |
184 | if len(surface) <= 1:
185 | smallSurface += 1
186 |
187 | print("Max Cands : {}".format(maxCands))
188 | print("min Cands : {}".format(minCands))
189 | print("Not Known Wid : {}".format(notKnownWid))
190 | print("small surfaces {}".format(smallSurface))
191 | print("Not Sorted Probs {}".format(notSortedProbs))
192 |
193 | def test_pruned(self):
194 | print("Test starting")
195 | maxCands = 0
196 | minCands = 30
197 | notKnownWid = False
198 | smallSurface = 0
199 | notSortedProbs = 0
200 | for surface, c_cprobs in self.crosswikis.items():
201 | notSorted = False
202 | (wids, probs) = c_cprobs
203 | numCands = len(wids)
204 | if numCands < minCands:
205 | minCands = numCands
206 | if numCands > maxCands:
207 | maxCands = numCands
208 |
209 | prob_prv = 10.0
210 | for (wid, prob) in zip(wids, probs):
211 | if wid not in self.knwid2idx:
212 | notKnownWid = True
213 | if prob_prv < prob:
214 | notSorted = True
215 | prob_prv = prob
216 |
217 | if notSorted:
218 | notSortedProbs += 1
219 |
220 | if len(surface) <= 1:
221 | smallSurface += 1
222 |
223 | print("Max Cands : {}".format(maxCands))
224 | print("min Cands : {}".format(minCands))
225 | print("Not Known Wid : {}".format(notKnownWid))
226 | print("small surfaces {}".format(smallSurface))
227 | print("Not Sorted Probs {}".format(notSortedProbs))
228 |
229 | def makeCWKnown(self, cwOutPath):
230 | cw = {}
231 | MAXCAND = 30
232 | surfacesProcessed = 0
233 | for surface, c_cprobs in self.crosswikis.items():
234 | surfacesProcessed += 1
235 | if surfacesProcessed % 1000000 == 0:
236 | print("Surfaces Processed : {}".format(surfacesProcessed))
237 |
238 | if len(c_cprobs) == 0:
239 | continue
240 | if len(surface) <= 1:
241 | continue
242 | candsAdded = 0
243 | c_probs = ([], [])
244 | # cw[surface] = ([], [])
245 | for (wid, prob) in c_cprobs:
246 | if candsAdded == 30:
247 | break
248 | if wid in self.knwid2idx:
249 | c_probs[0].append(wid)
250 | c_probs[1].append(prob)
251 | candsAdded += 1
252 | if candsAdded != 0:
253 | cw[surface] = c_probs
254 | print("Processed")
255 | print("Size of CW : {}".format(len(cw)))
256 | utils.save(cwOutPath, cw)
257 | print("Saved pruned CW")
258 |
259 |
260 |
261 | if __name__ == '__main__':
262 | configpath = "configs/config.ini"
263 | config = Config(configpath, verbose=False)
264 | vocabloader = VocabLoader(config)
265 | cwikistest = CrosswikisTest(config, vocabloader)
266 | cwikistest.test_pruned()
267 | # cwikistest.makeCWKnown(os.path.join(config.resources_dir,
268 | # "crosswikis.pruned.pkl"))
269 |
--------------------------------------------------------------------------------
/readers/inference_reader.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import time
3 | import numpy as np
4 | import readers.utils as utils
5 | from readers.Mention import Mention
6 | from readers.config import Config
7 | from readers.vocabloader import VocabLoader
8 | from ccg_nlpy import remote_pipeline
9 |
10 | start_word = ""
11 | end_word = ""
12 |
13 | class InferenceReader(object):
14 | def __init__(self, config, vocabloader, test_mens_file,
15 | num_cands, batch_size, strict_context=True,
16 | pretrain_wordembed=True, coherence=True):
17 | self.pipeline = remote_pipeline.RemotePipeline(
18 | server_api='http://macniece.seas.upenn.edu:4001')
19 | self.typeOfReader = "inference"
20 | self.start_word = start_word
21 | self.end_word = end_word
22 | self.unk_word = 'unk' # In tune with word2vec
23 | self.unk_wid = ""
24 | self.tr_sup = 'tr_sup'
25 | self.tr_unsup = 'tr_unsup'
26 | self.pretrain_wordembed = pretrain_wordembed
27 | self.coherence = coherence
28 |
29 | # Word Vocab
30 | (self.word2idx, self.idx2word) = vocabloader.getGloveWordVocab()
31 | self.num_words = len(self.idx2word)
32 |
33 | # Label Vocab
34 | (self.label2idx, self.idx2label) = vocabloader.getLabelVocab()
35 | self.num_labels = len(self.idx2label)
36 |
37 | # Known WID Vocab
38 | (self.knwid2idx, self.idx2knwid) = vocabloader.getKnwnWidVocab()
39 | self.num_knwn_entities = len(self.idx2knwid)
40 |
41 | # Wid2Wikititle Map
42 | self.wid2WikiTitle = vocabloader.getWID2Wikititle()
43 |
44 | # Coherence String Vocab
45 | print("Loading Coherence Strings Dicts ... ")
46 | (self.cohG92idx, self.idx2cohG9) = utils.load(
47 | config.cohstringG9_vocab_pkl)
48 | self.num_cohstr = len(self.idx2cohG9)
49 |
50 | # Crosswikis
51 | print("Loading Crosswikis dict. (takes ~2 mins to load)")
52 | self.crosswikis = utils.load(config.crosswikis_pruned_pkl)
53 | print("Crosswikis loaded. Size: {}".format(len(self.crosswikis)))
54 |
55 | if self.pretrain_wordembed:
56 | stime = time.time()
57 | self.word2vec = vocabloader.loadGloveVectors()
58 | print("[#] Glove Vectors loaded!")
59 | ttime = (time.time() - stime)/float(60)
60 |
61 |
62 | print("[#] Test Mentions File : {}".format(test_mens_file))
63 |
64 | print("[#] Loading test file and preprocessing ... ")
65 | self.processTestDoc(test_mens_file)
66 | self.mention_lines = self.convertSent2NerToMentionLines()
67 | self.mentions = []
68 | for line in self.mention_lines:
69 | m = Mention(line)
70 | self.mentions.append(m)
71 |
72 | self.men_idx = 0
73 | self.num_mens = len(self.mentions)
74 | self.epochs = 0
75 | print( "[#] Test Mentions : {}".format(self.num_mens))
76 |
77 | self.batch_size = batch_size
78 | print("[#] Batch Size: %d" % self.batch_size)
79 | self.num_cands = num_cands
80 | self.strict_context = strict_context
81 |
82 | print("\n[#]LOADING COMPLETE")
83 | #******************* END __init__ *********************************
84 |
85 | def get_vector(self, word):
86 | if word in self.word2vec:
87 | return self.word2vec[word]
88 | else:
89 | return self.word2vec['unk']
90 |
91 | def reset_test(self):
92 | self.men_idx = 0
93 | self.epochs = 0
94 |
95 | def processTestDoc(self, test_mens_file):
96 | with open(test_mens_file, 'r') as f:
97 | lines = f.read().strip().split("\n")
98 | assert len(lines) == 1, "Only support inference for single doc"
99 | self.doctext = lines[0].strip()
100 | self.ccgdoc = self.pipeline.doc(self.doctext)
101 | # List of tokens
102 | self.doc_tokens = self.ccgdoc.get_tokens
103 | # sent_end_token_indices : contains index for the starting of the
104 | # next sentence.
105 | self.sent_end_token_indices = \
106 | self.ccgdoc.get_sentence_end_token_indices
107 | # List of tokenized sentences
108 | self.sentences_tokenized = []
109 | for i in range(0, len(self.sent_end_token_indices)):
110 | start = self.sent_end_token_indices[i-1] if i != 0 else 0
111 | end = self.sent_end_token_indices[i]
112 | sent_tokens = self.doc_tokens[start:end]
113 | self.sentences_tokenized.append(sent_tokens)
114 |
115 | # List of ner dicts from ccg pipeline
116 | self.ner_cons_list = []
117 | try:
118 | self.ner_cons_list = self.ccgdoc.get_ner_conll.cons_list
119 | except:
120 | print("NO NAMED ENTITIES IN THE DOC. EXITING")
121 |
122 | # SentIdx : [(tokenized_sent, ner_dict)]
123 | self.sentidx2ners = {}
124 | for ner in self.ner_cons_list:
125 | found = False
126 | # idx = sentIdx, j = sentEndTokenIdx
127 | for idx, j in enumerate(self.sent_end_token_indices):
128 | sent_start_token = self.sent_end_token_indices[idx-1] \
129 | if idx != 0 else 0
130 | # ner['end'] is the idx of the token after ner
131 | if ner['end'] < j:
132 | if idx not in self.sentidx2ners:
133 | self.sentidx2ners[idx] = []
134 | ner['start'] = ner['start'] - sent_start_token
135 | ner['end'] = ner['end'] - sent_start_token - 1
136 | self.sentidx2ners[idx].append(
137 | (self.sentences_tokenized[idx], ner))
138 | found = True
139 | if found:
140 | break
141 |
142 | def convertSent2NerToMentionLines(self):
143 | '''Convert NERs from document to list of mention strings'''
144 | mentions = []
145 | # Make Document Context String for whole document
146 | cohStr = ""
147 | for sent_idx, s_nerDicts in self.sentidx2ners.items():
148 | for s, ner in s_nerDicts:
149 | cohStr += ner['tokens'].replace(' ', '_') + ' '
150 |
151 | cohStr = cohStr.strip()
152 |
153 | for idx in range(0, len(self.sentences_tokenized)):
154 | if idx in self.sentidx2ners:
155 | sentence = ' '.join(self.sentences_tokenized[idx])
156 | s_nerDicts = self.sentidx2ners[idx]
157 | for s, ner in s_nerDicts:
158 | mention = "%s\t%s\t%s" % ("unk_mid", "unk_wid", "unkWT")
159 | mention = mention + str('\t') + str(ner['start'])
160 | mention = mention + '\t' + str(ner['end'])
161 | mention = mention + '\t' + str(ner['tokens'])
162 | mention = mention + '\t' + sentence
163 | mention = mention + '\t' + "UNK_TYPES"
164 | mention = mention + '\t' + cohStr
165 | mentions.append(mention)
166 | return mentions
167 |
168 | def bracketMentionInSentence(self, s, nerDict):
169 | tokens = s.split(" ")
170 | start = nerDict['start']
171 | end = nerDict['end']
172 | tokens.insert(start, '[[')
173 | tokens.insert(end + 2, ']]')
174 | return ' '.join(tokens)
175 |
176 | def _read_mention(self):
177 | mention = self.mentions[self.men_idx]
178 | self.men_idx += 1
179 | if self.men_idx == self.num_mens:
180 | self.men_idx = 0
181 | self.epochs += 1
182 | return mention
183 |
184 | def _next_batch(self):
185 | ''' Data : wikititle \t mid \t wid \t start \t end \t tokens \t labels
186 | start and end are inclusive
187 | '''
188 | # Sentence = s1 ... m1 ... mN, ... sN.
189 | # Left Batch = s1 ... m1 ... mN
190 | # Right Batch = sN ... mN ... m1
191 | (left_batch, right_batch) = ([], [])
192 |
193 | coh_indices = []
194 | coh_values = []
195 | if self.coherence:
196 | coh_matshape = [self.batch_size, self.num_cohstr]
197 | else:
198 | coh_matshape = []
199 |
200 | # Candidate WID idxs and their cprobs
201 | # First element is always true wid
202 | (wid_idxs_batch, wid_cprobs_batch) = ([], [])
203 |
204 | while len(left_batch) < self.batch_size:
205 | batch_el = len(left_batch)
206 | m = self._read_mention()
207 |
208 | # for label in m.types:
209 | # if label in self.label2idx:
210 | # labelidx = self.label2idx[label]
211 | # labels_batch[batch_el][labelidx] = 1.0
212 |
213 | cohFound = False # If no coherence mention is found, add unk
214 | if self.coherence:
215 | cohidxs = [] # Indexes in the [B, NumCoh] matrix
216 | cohvals = [] # 1.0 to indicate presence
217 | for cohstr in m.coherence:
218 | if cohstr in self.cohG92idx:
219 | cohidx = self.cohG92idx[cohstr]
220 | cohidxs.append([batch_el, cohidx])
221 | cohvals.append(1.0)
222 | cohFound = True
223 | if cohFound:
224 | coh_indices.extend(cohidxs)
225 | coh_values.extend(cohvals)
226 | else:
227 | cohidx = self.cohG92idx[self.unk_word]
228 | coh_indices.append([batch_el, cohidx])
229 | coh_values.append(1.0)
230 |
231 | # Left and Right context includes mention surface
232 | left_tokens = m.sent_tokens[0:m.end_token+1]
233 | right_tokens = m.sent_tokens[m.start_token:][::-1]
234 |
235 | # Strict left and right context
236 | if self.strict_context:
237 | left_tokens = m.sent_tokens[0:m.start_token]
238 | right_tokens = m.sent_tokens[m.end_token+1:][::-1]
239 | # Left and Right context includes mention surface
240 | else:
241 | left_tokens = m.sent_tokens[0:m.end_token+1]
242 | right_tokens = m.sent_tokens[m.start_token:][::-1]
243 |
244 | if not self.pretrain_wordembed:
245 | left_idxs = [self.convert_word2idx(word)
246 | for word in left_tokens]
247 | right_idxs = [self.convert_word2idx(word)
248 | for word in right_tokens]
249 | else:
250 | left_idxs = left_tokens
251 | right_idxs = right_tokens
252 |
253 | left_batch.append(left_idxs)
254 | right_batch.append(right_idxs)
255 |
256 | # wids : [true_knwn_idx, cand1_idx, cand2_idx, ..., unk_idx]
257 | # wid_cprobs : [cwikis probs or 0.0 for unks]
258 | (wid_idxs, wid_cprobs) = self.make_candidates_cprobs(m)
259 | wid_idxs_batch.append(wid_idxs)
260 | wid_cprobs_batch.append(wid_cprobs)
261 |
262 | coherence_batch = (coh_indices, coh_values, coh_matshape)
263 |
264 | return (left_batch, right_batch,
265 | coherence_batch, wid_idxs_batch, wid_cprobs_batch)
266 |
267 | def print_test_batch(self, mention, wid_idxs, wid_cprobs):
268 | print("Surface : {} WID : {} WT: {}".format(
269 | mention.surface, mention.wid, self.wid2WikiTitle[mention.wid]))
270 | print(mention.wid in self.knwid2idx)
271 | for (idx,cprob) in zip(wid_idxs, wid_cprobs):
272 | print("({} : {:0.5f})".format(
273 | self.wid2WikiTitle[self.idx2knwid[idx]], cprob), end=" ")
274 | print("\n")
275 |
276 | def make_candidates_cprobs(self, m):
277 | # Fill num_cands now
278 | surface = utils._getLnrm(m.surface)
279 | if surface in self.crosswikis:
280 | # Pruned crosswikis has only known wids and 30 cands at max
281 | candwids_cprobs = self.crosswikis[surface][0:self.num_cands-1]
282 | (wids, wid_cprobs) = candwids_cprobs
283 | wid_idxs = [self.knwid2idx[wid] for wid in wids]
284 |
285 | # All possible candidates added now. Pad with unks
286 | assert len(wid_idxs) == len(wid_cprobs)
287 | remain = self.num_cands - len(wid_idxs)
288 | wid_idxs.extend([0]*remain)
289 | wid_cprobs.extend([0.0]*remain)
290 |
291 | return (wid_idxs, wid_cprobs)
292 |
293 | def embed_batch(self, batch):
294 | ''' Input is a padded batch of left or right contexts containing words
295 | Dimensions should be [B, padded_length]
296 | Output:
297 | Embed the word idxs using pretrain word embedding
298 | '''
299 | output_batch = []
300 | for sent in batch:
301 | word_embeddings = [self.get_vector(word) for word in sent]
302 | output_batch.append(word_embeddings)
303 | return output_batch
304 |
305 | def embed_mentions_batch(self, mentions_batch):
306 | ''' Input is batch of mention tokens as a list of list of tokens.
307 | Output: For each mention, average word embeddings '''
308 | embedded_mentions_batch = []
309 | for m_tokens in mentions_batch:
310 | outvec = np.zeros(300, dtype=float)
311 | for word in m_tokens:
312 | outvec += self.get_vector(word)
313 | outvec = outvec / len(m_tokens)
314 | embedded_mentions_batch.append(outvec)
315 | return embedded_mentions_batch
316 |
317 | def pad_batch(self, batch):
318 | if not self.pretrain_wordembed:
319 | pad_unit = self.word2idx[self.unk_word]
320 | else:
321 | pad_unit = self.unk_word
322 |
323 | lengths = [len(i) for i in batch]
324 | max_length = max(lengths)
325 | for i in range(0, len(batch)):
326 | batch[i].extend([pad_unit]*(max_length - lengths[i]))
327 | return (batch, lengths)
328 |
329 | def _next_padded_batch(self):
330 | (left_batch, right_batch,
331 | coherence_batch,
332 | wid_idxs_batch, wid_cprobs_batch) = self._next_batch()
333 |
334 | (left_batch, left_lengths) = self.pad_batch(left_batch)
335 | (right_batch, right_lengths) = self.pad_batch(right_batch)
336 |
337 | if self.pretrain_wordembed:
338 | left_batch = self.embed_batch(left_batch)
339 | right_batch = self.embed_batch(right_batch)
340 |
341 | return (left_batch, left_lengths, right_batch, right_lengths,
342 | coherence_batch, wid_idxs_batch, wid_cprobs_batch)
343 |
344 | def convert_word2idx(self, word):
345 | if word in self.word2idx:
346 | return self.word2idx[word]
347 | else:
348 | return self.word2idx[self.unk_word]
349 |
350 | def next_test_batch(self):
351 | return self._next_padded_batch()
352 |
353 | def widIdx2WikiTitle(self, widIdx):
354 | wid = self.idx2knwid[widIdx]
355 | wikiTitle = self.wid2WikiTitle[wid]
356 | return wikiTitle
357 |
358 | if __name__ == '__main__':
359 | sttime = time.time()
360 | batch_size = 2
361 | num_batch = 1000
362 | configpath = "configs/all_mentions_config.ini"
363 | config = Config(configpath, verbose=False)
364 | vocabloader = VocabLoader(config)
365 | b = InferenceReader(config=config,
366 | vocabloader=vocabloader,
367 | test_mens_file=config.test_file,
368 | num_cands=30,
369 | batch_size=batch_size,
370 | strict_context=False,
371 | pretrain_wordembed=True,
372 | coherence=True)
373 |
374 | stime = time.time()
375 |
376 | i = 0
377 | total_instances = 0
378 | while b.epochs < 1:
379 | (left_batch, left_lengths, right_batch, right_lengths,
380 | coherence_batch, wid_idxs_batch,
381 | wid_cprobs_batch) = b.next_test_batch()
382 | if i % 100 == 0:
383 | etime = time.time()
384 | t=etime-stime
385 | print("{} done. Time taken : {} seconds".format(i, t))
386 | i += 1
387 | etime = time.time()
388 | t=etime-stime
389 | tt = etime - sttime
390 | print("Total Instances : {}".format(total_instances))
391 | print("Batching time (in secs) to make %d batches of size %d : %7.4f seconds" % (i, batch_size, t))
392 | print("Total time (in secs) to make %d batches of size %d : %7.4f seconds" % (i, batch_size, tt))
393 |
--------------------------------------------------------------------------------
/readers/test_reader.py:
--------------------------------------------------------------------------------
1 | import time
2 | import numpy as np
3 | import readers.utils as utils
4 | from readers.Mention import Mention
5 | from readers.config import Config
6 | from readers.vocabloader import VocabLoader
7 |
8 | start_word = ""
9 | end_word = ""
10 |
11 | class TestDataReader(object):
12 | def __init__(self, config, vocabloader, test_mens_file,
13 | num_cands, batch_size, strict_context=True,
14 | pretrain_wordembed=True, coherence=True,
15 | glove=True):
16 | print("Loading Test Reader: {}".format(test_mens_file))
17 | self.typeOfReader="test"
18 | self.start_word = start_word
19 | self.end_word = end_word
20 | self.unk_word = 'unk' # In tune with word2vec
21 | self.unk_wid = ""
22 | # self.useKnownEntitesOnly = True
23 | self.pretrain_wordembed = pretrain_wordembed
24 | self.coherence = coherence
25 |
26 | # Word Vocab
27 | (self.word2idx, self.idx2word) = vocabloader.getGloveWordVocab()
28 | self.num_words = len(self.idx2word)
29 | print(" [#] Word vocab loaded. Size of vocab : {}".format(
30 | self.num_words))
31 |
32 | # Label Vocab
33 | (self.label2idx, self.idx2label) = vocabloader.getLabelVocab()
34 | self.num_labels = len(self.idx2label)
35 | print(" [#] Label vocab loaded. Number of labels : {}".format(
36 | self.num_labels))
37 |
38 | # Known WID Vocab
39 | (self.knwid2idx, self.idx2knwid) = vocabloader.getKnwnWidVocab()
40 | self.num_knwn_entities = len(self.idx2knwid)
41 | print(" [#] Loaded. Num of known wids : {}".format(
42 | self.num_knwn_entities))
43 |
44 | # Wid2Wikititle Map
45 | self.wid2WikiTitle = vocabloader.getWID2Wikititle()
46 | print(" [#] Size of Wid2Wikititle: {}".format(len(
47 | self.wid2WikiTitle)))
48 |
49 | # # Wid2TypeLabels Map
50 | # self.wid2TypeLabels = vocabloader.getWID2TypeLabels()
51 | # print(" [#] Total number of Wids : {}".format(len(
52 | # self.wid2TypeLabels)))
53 |
54 | # Coherence String Vocab
55 | print("Loading Coherence Strings Dicts ... ")
56 | (self.cohG92idx, self.idx2cohG9) = utils.load(
57 | config.cohstringG9_vocab_pkl)
58 | self.num_cohstr = len(self.idx2cohG9)
59 | print(" [#] Number of Coherence Strings in Vocab : {}".format(
60 | self.num_cohstr))
61 |
62 | # Known WID Description Vectors
63 | # self.kwnwid2descvecs = vocabloader.loadKnownWIDDescVecs()
64 | # print(" [#] Size of kwn wid desc vecs dict : {}".format(
65 | # len(self.kwnwid2descvecs)))
66 |
67 | # # Crosswikis
68 | # print("[#] Loading training/val crosswikis dictionary ... ")
69 | # self.test_kwnen_cwikis = vocabloader.getTestKnwEnCwiki()
70 | # self.test_allen_cwikis = vocabloader.getTestAllEnCwiki()
71 |
72 | # Crosswikis
73 | print("Loading Crosswikis dict. (takes ~2 mins to load)")
74 | self.crosswikis = utils.load(config.crosswikis_pruned_pkl)
75 | # self.crosswikis = {}
76 | print("Crosswikis loaded. Size: {}".format(len(self.crosswikis)))
77 |
78 | if self.pretrain_wordembed:
79 | stime = time.time()
80 | self.word2vec = vocabloader.loadGloveVectors()
81 | print("[#] Glove Vectors loaded!")
82 | ttime = (time.time() - stime)/float(60)
83 | print("[#] Time to load vectors : {} mins".format(ttime))
84 |
85 | print("[#] Test Mentions File : {}".format(test_mens_file))
86 |
87 | print("[#] Pre-loading test mentions ... ")
88 | self.mentions = utils.make_mentions_from_file(test_mens_file)
89 | self.men_idx = 0
90 | self.num_mens = len(self.mentions)
91 | self.epochs = 0
92 | print( "[#] Test Mentions : {}".format(self.num_mens))
93 |
94 | self.batch_size = batch_size
95 | print("[#] Batch Size: %d" % self.batch_size)
96 | self.num_cands = num_cands
97 | self.strict_context = strict_context
98 |
99 | print("\n[#]LOADING COMPLETE")
100 | # ******************* END __init__ *******************************
101 |
102 | def get_vector(self, word):
103 | if word in self.word2vec:
104 | return self.word2vec[word]
105 | else:
106 | return self.word2vec['unk']
107 |
108 | def reset_test(self):
109 | self.men_idx = 0
110 | self.epochs = 0
111 |
112 | def _read_mention(self):
113 | mention = self.mentions[self.men_idx]
114 | self.men_idx += 1
115 | if self.men_idx == self.num_mens:
116 | self.men_idx = 0
117 | self.epochs += 1
118 | return mention
119 |
120 | def _next_batch(self):
121 | ''' Data : wikititle \t mid \t wid \t start \t end \t tokens \t labels
122 | start and end are inclusive
123 | '''
124 | # Sentence = s1 ... m1 ... mN, ... sN.
125 | # Left Batch = s1 ... m1 ... mN
126 | # Right Batch = sN ... mN ... m1
127 | (left_batch, right_batch) = ([], [])
128 |
129 | # Labels : Vector of 0s and 1s of size = number of labels = 113
130 | labels_batch = np.zeros([self.batch_size, self.num_labels])
131 |
132 | coh_indices = []
133 | coh_values = []
134 | if self.coherence:
135 | coh_matshape = [self.batch_size, self.num_cohstr]
136 | else:
137 | coh_matshape = []
138 |
139 | # Wiki Description: [B, N=100, D=300]
140 | # truewid_descvec_batch = []
141 |
142 | # Candidate WID idxs and their cprobs
143 | # First element is always true wid
144 | (wid_idxs_batch, wid_cprobs_batch) = ([], [])
145 |
146 | while len(left_batch) < self.batch_size:
147 | batch_el = len(left_batch)
148 | m = self._read_mention()
149 |
150 | for label in m.types:
151 | if label in self.label2idx:
152 | labelidx = self.label2idx[label]
153 | labels_batch[batch_el][labelidx] = 1.0
154 | #labels
155 |
156 | cohFound = False # If no coherence mention is found, then add unk
157 | if self.coherence:
158 | cohidxs = [] # Indexes in the [B, NumCoh] matrix
159 | cohvals = [] # 1.0 to indicate presence
160 | for cohstr in m.coherence:
161 | if cohstr in self.cohG92idx:
162 | cohidx = self.cohG92idx[cohstr]
163 | cohidxs.append([batch_el, cohidx])
164 | cohvals.append(1.0)
165 | cohFound = True
166 | if cohFound:
167 | coh_indices.extend(cohidxs)
168 | coh_values.extend(cohvals)
169 | else:
170 | cohidx = self.cohG92idx[self.unk_word]
171 | coh_indices.append([batch_el, cohidx])
172 | coh_values.append(1.0)
173 |
174 | # cohFound = False # If no coherence mention found, then add unk
175 | # if self.coherence:
176 | # for cohstr in m.coherence:
177 | # if cohstr in self.cohG92idx:
178 | # cohidx = self.cohG92idx[cohstr]
179 | # coh_indices.append([batch_el, cohidx])
180 | # coh_values.append(1.0)
181 | # cohFound = True
182 | # if not cohFound:
183 | # cohidx = self.cohG92idx[self.unk_word]
184 | # coh_indices.append([batch_el, cohidx])
185 | # coh_values.append(1.0)
186 |
187 | # Left and Right context includes mention surface
188 | left_tokens = m.sent_tokens[0:m.end_token+1]
189 | right_tokens = m.sent_tokens[m.start_token:][::-1]
190 |
191 | # Strict left and right context
192 | if self.strict_context:
193 | left_tokens = m.sent_tokens[0:m.start_token]
194 | right_tokens = m.sent_tokens[m.end_token+1:][::-1]
195 | # Left and Right context includes mention surface
196 | else:
197 | left_tokens = m.sent_tokens[0:m.end_token+1]
198 | right_tokens = m.sent_tokens[m.start_token:][::-1]
199 |
200 | if not self.pretrain_wordembed:
201 | left_idxs = [self.convert_word2idx(word)
202 | for word in left_tokens]
203 | right_idxs = [self.convert_word2idx(word)
204 | for word in right_tokens]
205 | else:
206 | left_idxs = left_tokens
207 | right_idxs = right_tokens
208 |
209 | left_batch.append(left_idxs)
210 | right_batch.append(right_idxs)
211 |
212 | # if m.wid in self.knwid2idx:
213 | # truewid_descvec_batch.append(self.kwnwid2descvecs[m.wid])
214 | # else:
215 | # truewid_descvec_batch.append(
216 | # self.kwnwid2descvecs[self.unk_wid])
217 |
218 | # wids : [true_knwn_idx, cand1_idx, cand2_idx, ..., unk_idx]
219 | # wid_cprobs : [cwikis probs or 0.0 for unks]
220 | (wid_idxs, wid_cprobs) = self.make_candidates_cprobs(m)
221 | wid_idxs_batch.append(wid_idxs)
222 | wid_cprobs_batch.append(wid_cprobs)
223 |
224 | # self.print_test_batch(m, wid_idxs, wid_cprobs)
225 | # print(m.docid)
226 |
227 | #end batch making
228 | coherence_batch = (coh_indices, coh_values, coh_matshape)
229 |
230 | # return (left_batch, right_batch, truewid_descvec_batch, labels_batch,
231 | # coherence_batch, wid_idxs_batch, wid_cprobs_batch)
232 | return (left_batch, right_batch, labels_batch,
233 | coherence_batch, wid_idxs_batch, wid_cprobs_batch)
234 |
235 | def print_test_batch(self, mention, wid_idxs, wid_cprobs):
236 | print("Surface : {} WID : {} WT: {}".format(
237 | mention.surface, mention.wid, self.wid2WikiTitle[mention.wid]))
238 | print(mention.wid in self.knwid2idx)
239 | for (idx,cprob) in zip(wid_idxs, wid_cprobs):
240 | print("({} : {:0.5f})".format(
241 | self.wid2WikiTitle[self.idx2knwid[idx]], cprob), end=" ")
242 | print("\n")
243 |
244 | def make_candidates_cprobs(self, m):
245 | # First wid_idx is true entity
246 | #if self.useKnownEntitesOnly:
247 | if m.wid in self.knwid2idx:
248 | wid_idxs = [self.knwid2idx[m.wid]]
249 | else:
250 | wid_idxs = [self.knwid2idx[self.unk_wid]]
251 | # else:
252 | # ''' Todo: Set wids_idxs[0] in a way to incorporate all entities'''
253 | # wids_idxs = [0]
254 |
255 | # This prob will be updated when going over cwikis candidates
256 | wid_cprobs = [0.0]
257 |
258 | # Crosswikis to use based on Known / All entities
259 | # if self.useKnownEntitesOnly:
260 | cwiki_dict = self.crosswikis
261 | # else:
262 | # cwiki_dict = self.test_all_cwikis
263 |
264 | # Indexing dict to use
265 | # Todo: When changed to all entities, indexing will change
266 | wid2idx = self.knwid2idx
267 |
268 | # Fill num_cands now
269 | surface = utils._getLnrm(m.surface)
270 | if surface in cwiki_dict:
271 | candwids_cprobs = cwiki_dict[surface][0:self.num_cands-1]
272 | (candwids, candwid_cprobs) = candwids_cprobs
273 | for (c, p) in zip(candwids, candwid_cprobs):
274 | if c in wid2idx:
275 | if c == m.wid: # Update cprob for true if in known set
276 | wid_cprobs[0] = p
277 | else:
278 | wid_idxs.append(wid2idx[c])
279 | wid_cprobs.append(p)
280 | # All possible candidates added now. Pad with unks
281 | assert len(wid_idxs) == len(wid_cprobs)
282 | remain = self.num_cands - len(wid_idxs)
283 | wid_idxs.extend([0]*remain)
284 | wid_cprobs.extend([0.0]*remain)
285 |
286 | wid_idxs = wid_idxs[0:self.num_cands]
287 | wid_cprobs = wid_cprobs[0:self.num_cands]
288 |
289 | return (wid_idxs, wid_cprobs)
290 |
291 | def embed_batch(self, batch):
292 | ''' Input is a padded batch of left or right contexts containing words
293 | Dimensions should be [B, padded_length]
294 | Output:
295 | Embed the word idxs using pretrain word embedding
296 | '''
297 | output_batch = []
298 | for sent in batch:
299 | word_embeddings = [self.get_vector(word) for word in sent]
300 | output_batch.append(word_embeddings)
301 | return output_batch
302 |
303 | def embed_mentions_batch(self, mentions_batch):
304 | ''' Input is batch of mention tokens as a list of list of tokens.
305 | Output: For each mention, average word embeddings '''
306 | embedded_mentions_batch = []
307 | for m_tokens in mentions_batch:
308 | outvec = np.zeros(300, dtype=float)
309 | for word in m_tokens:
310 | outvec += self.get_vector(word)
311 | outvec = outvec / len(m_tokens)
312 | embedded_mentions_batch.append(outvec)
313 | return embedded_mentions_batch
314 |
315 | def pad_batch(self, batch):
316 | if not self.pretrain_wordembed:
317 | pad_unit = self.word2idx[self.unk_word]
318 | else:
319 | pad_unit = self.unk_word
320 |
321 | lengths = [len(i) for i in batch]
322 | max_length = max(lengths)
323 | for i in range(0, len(batch)):
324 | batch[i].extend([pad_unit]*(max_length - lengths[i]))
325 | return (batch, lengths)
326 |
327 | def _next_padded_batch(self):
328 | # (left_batch, right_batch, truewid_descvec_batch,
329 | # labels_batch, coherence_batch,
330 | # wid_idxs_batch, wid_cprobs_batch) = self._next_batch()
331 | (left_batch, right_batch,
332 | labels_batch, coherence_batch,
333 | wid_idxs_batch, wid_cprobs_batch) = self._next_batch()
334 |
335 | (left_batch, left_lengths) = self.pad_batch(left_batch)
336 | (right_batch, right_lengths) = self.pad_batch(right_batch)
337 |
338 | if self.pretrain_wordembed:
339 | left_batch = self.embed_batch(left_batch)
340 | right_batch = self.embed_batch(right_batch)
341 |
342 | return (left_batch, left_lengths, right_batch, right_lengths,
343 | labels_batch, coherence_batch,
344 | wid_idxs_batch, wid_cprobs_batch)
345 |
346 | def convert_word2idx(self, word):
347 | if word in self.word2idx:
348 | return self.word2idx[word]
349 | else:
350 | return self.word2idx[self.unk_word]
351 |
352 | def next_test_batch(self):
353 | return self._next_padded_batch()
354 |
355 |
356 | def debugWIDIdxsBatch(self, wid_idxs_batch):
357 | WikiTitles = []
358 | for widxs in wid_idxs_batch:
359 | wits = [self.wid2WikiTitle[self.idx2knwid[wididx]] for wididx in widxs]
360 | WikiTitles.append(wits)
361 |
362 | return WikiTitles
363 |
364 | def widIdx2WikiTitle(self, widIdx):
365 | wid = self.idx2knwid[widIdx]
366 | wikiTitle = self.wid2WikiTitle[wid]
367 | return wikiTitle
368 |
369 |
370 | if __name__ == '__main__':
371 | sttime = time.time()
372 | batch_size = 1
373 | num_batch = 1000
374 | configpath = "configs/config.ini"
375 | config = Config(configpath, verbose=False)
376 | vocabloader = VocabLoader(config)
377 | b = TestDataReader(config=config,
378 | vocabloader=vocabloader,
379 | test_mens_file=config.test_file,
380 | num_cands=30,
381 | batch_size=batch_size,
382 | strict_context=False,
383 | pretrain_wordembed=False,
384 | coherence=False)
385 |
386 | stime = time.time()
387 |
388 | i = 0
389 | kwn = 0
390 | total_instances = 0
391 | while b.epochs < 1:
392 | (left_batch, left_lengths,
393 | right_batch, right_lengths,
394 | labels_batch, coherence_batch,
395 | wid_idxs_batch, wid_cprobs_batch) = b.next_test_batch()
396 |
397 | print(b.debugWIDIdxsBatch(wid_idxs_batch))
398 | print(wid_cprobs_batch)
399 |
400 | if i % 100 == 0:
401 | etime = time.time()
402 | t=etime-stime
403 | print("{} done. Time taken : {} seconds".format(i, t))
404 | i += 1
405 | etime = time.time()
406 | t=etime-stime
407 | tt = etime - sttime
408 | print("Batching time (in secs) to make %d batches of size %d : %7.4f seconds" % (i, batch_size, t))
409 | print("Total time (in secs) to make %d batches of size %d : %7.4f seconds" % (i, batch_size, tt))
410 |
--------------------------------------------------------------------------------
/readers/textanno_test_reader.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import time
3 | import numpy as np
4 | import readers.utils as utils
5 | from readers.Mention import Mention
6 | from readers.config import Config
7 | from readers.vocabloader import VocabLoader
8 | import ccg_nlpy
9 | from ccg_nlpy.core.text_annotation import TextAnnotation
10 |
11 | start_word = ""
12 | end_word = ""
13 |
14 | # Reader for Text Annotations
15 | class TextAnnoTestReader(object):
16 | def __init__(self, config, vocabloader,
17 | num_cands, batch_size, strict_context=True,
18 | pretrain_wordembed=True, coherence=True,
19 | nerviewname="NER_CONLL"):
20 | self.typeOfReader = "inference"
21 | self.start_word = start_word
22 | self.end_word = end_word
23 | self.unk_word = 'unk' # In tune with word2vec
24 | self.unk_wid = ""
25 | self.tr_sup = 'tr_sup'
26 | self.tr_unsup = 'tr_unsup'
27 | self.pretrain_wordembed = pretrain_wordembed
28 | self.coherence = coherence
29 | self.nerviewname = nerviewname
30 |
31 | # Word Vocab
32 | (self.word2idx, self.idx2word) = vocabloader.getGloveWordVocab()
33 | self.num_words = len(self.idx2word)
34 |
35 | # Label Vocab
36 | (self.label2idx, self.idx2label) = vocabloader.getLabelVocab()
37 | self.num_labels = len(self.idx2label)
38 |
39 | # Known WID Vocab
40 | (self.knwid2idx, self.idx2knwid) = vocabloader.getKnwnWidVocab()
41 | self.num_knwn_entities = len(self.idx2knwid)
42 |
43 | # Wid2Wikititle Map
44 | self.wid2WikiTitle = vocabloader.getWID2Wikititle()
45 |
46 | # Coherence String Vocab
47 | print("Loading Coherence Strings Dicts ... ")
48 | (self.cohG92idx, self.idx2cohG9) = utils.load(
49 | config.cohstringG9_vocab_pkl)
50 | self.num_cohstr = len(self.idx2cohG9)
51 |
52 | # Crosswikis
53 | print("Loading Crosswikis dict. (takes ~2 mins to load)")
54 | self.crosswikis = utils.load(config.crosswikis_pruned_pkl)
55 | print("Crosswikis loaded. Size: {}".format(len(self.crosswikis)))
56 |
57 | if self.pretrain_wordembed:
58 | stime = time.time()
59 | self.word2vec = vocabloader.loadGloveVectors()
60 | print("[#] Glove Vectors loaded!")
61 | ttime = (time.time() - stime)/float(60)
62 |
63 |
64 | # print("[#] Test Mentions File : {}".format(test_mens_file))
65 |
66 | # print("[#] Loading test file and preprocessing ... ")
67 | # with open(test_mens_file, 'r') as f:
68 | # tajsonstr = f.read()
69 | # ta = TextAnnotation(json_str=tajsonstr)
70 | #
71 | # (sentences_tokenized, modified_ner_cons_list) = self.processTestDoc(ta)
72 | #
73 | # self.mention_lines = self.convertSent2NerToMentionLines(
74 | # sentences_tokenized, modified_ner_cons_list)
75 | #
76 | # self.mentions = []
77 | # for line in self.mention_lines:
78 | # m = Mention(line)
79 | # self.mentions.append(m)
80 |
81 | self.men_idx = 0
82 | # self.num_mens = len(self.mentions)
83 | self.epochs = 0
84 | # print( "[#] Test Mentions : {}".format(self.num_mens))
85 |
86 | self.batch_size = batch_size
87 | print("[#] Batch Size: %d" % self.batch_size)
88 | self.num_cands = num_cands
89 | self.strict_context = strict_context
90 |
91 | print("\n[#]LOADING COMPLETE")
92 | #******************* END __init__ *********************************
93 |
94 | def new_test_file(self, test_mens_file):
95 | self.test_mens_file = test_mens_file
96 |
97 | with open(test_mens_file, 'r') as f:
98 | tajsonstr = f.read()
99 | ta = TextAnnotation(json_str=tajsonstr)
100 | self.textanno = ta
101 |
102 | (sentences_tokenized, modified_ner_cons_list) = self.processTestDoc(ta)
103 |
104 | self.mention_lines = self.convertSent2NerToMentionLines(
105 | sentences_tokenized, modified_ner_cons_list)
106 |
107 | self.mentions = []
108 | for line in self.mention_lines:
109 | m = Mention(line)
110 | self.mentions.append(m)
111 |
112 | self.men_idx = 0
113 | self.num_mens = len(self.mentions)
114 | self.epochs = 0
115 |
116 | def new_tajsonstr(self, tajsonstr):
117 | """ tajsonstr is a json str of a TA """
118 | ta = TextAnnotation(json_str=tajsonstr)
119 | self.new_ta(ta)
120 |
121 | def new_ta(self, ta):
122 | self.textanno = ta
123 |
124 | (sentences_tokenized, modified_ner_cons_list) = self.processTestDoc(ta)
125 |
126 | self.mention_lines = self.convertSent2NerToMentionLines(
127 | sentences_tokenized, modified_ner_cons_list)
128 |
129 | self.mentions = []
130 | for line in self.mention_lines:
131 | m = Mention(line)
132 | self.mentions.append(m)
133 |
134 | self.men_idx = 0
135 | self.num_mens = len(self.mentions)
136 | self.epochs = 0
137 |
138 |
139 |
140 | def get_vector(self, word):
141 | if word in self.word2vec:
142 | return self.word2vec[word]
143 | else:
144 | return self.word2vec['unk']
145 |
146 | def reset_test(self):
147 | self.men_idx = 0
148 | self.epochs = 0
149 |
150 | def processTestDoc(self, ccgdoc):
151 | doc_tokens = ccgdoc.get_tokens
152 | # sent_end_token_indices : contains index for the starting of the
153 | # next sentence.
154 | sent_end_token_indices = \
155 | ccgdoc.get_sentence_end_token_indices
156 | # List of tokenized sentences
157 | sentences_tokenized = []
158 | for i in range(0, len(sent_end_token_indices)):
159 | start = sent_end_token_indices[i-1] if i != 0 else 0
160 | end = sent_end_token_indices[i]
161 | sent_tokens = doc_tokens[start:end]
162 | sentences_tokenized.append(sent_tokens)
163 |
164 | # List of ner dicts from ccg pipeline
165 | ner_cons_list = []
166 | try:
167 | ner_cons_list = ccgdoc.get_view(self.nerviewname).cons_list
168 | except:
169 | print("NO NAMED ENTITIES IN THE DOC. EXITING")
170 |
171 | modified_ner_cons_list = []
172 |
173 | for orig_ner in ner_cons_list:
174 | ner = orig_ner.copy()
175 | # ner['end'] = ner['end'] + 1
176 | # ner['tokens'] = ' '.join(doc_tokens[ner['start']:ner['end']])
177 |
178 | found = False
179 | # idx = sentIdx, j = sentEndTokenIdx
180 | for idx, j in enumerate(sent_end_token_indices):
181 | sent_start_token = sent_end_token_indices[idx-1] \
182 | if idx != 0 else 0
183 | # ner['end'] is the idx of the token after ner
184 | if ner['end'] <= j:
185 | ner['start'] = ner['start'] - sent_start_token
186 | ner['end'] = ner['end'] - sent_start_token - 1
187 | ner['sent_idx'] = idx
188 |
189 | modified_ner_cons_list.append(ner)
190 |
191 | found = True
192 | if found:
193 | break
194 | return (sentences_tokenized, modified_ner_cons_list)
195 |
196 | def convertSent2NerToMentionLines(self, sentences_tokenized,
197 | modified_ner_cons_list):
198 | '''Convert NERs from document to list of mention strings'''
199 | mentions = []
200 | # Make Document Context String for whole document
201 | cohStr = ""
202 | # for sent_idx, s_nerDicts in sentidx2ners.items():
203 | # for s, ner in s_nerDicts:
204 | # cohStr += ner['tokens'].replace(' ', '_') + ' '
205 |
206 | for ner_men in modified_ner_cons_list:
207 | cohStr += ner_men['tokens'].replace(' ', '_') + ' '
208 |
209 | cohStr = cohStr.strip()
210 |
211 | for ner_men in modified_ner_cons_list:
212 | idx = ner_men['sent_idx']
213 | sentence = ' '.join(sentences_tokenized[idx])
214 |
215 | mention = "%s\t%s\t%s" % ("unk_mid", "unk_wid", "unkWT")
216 | mention = mention + '\t' + str(ner_men['start'])
217 | mention = mention + '\t' + str(ner_men['end'])
218 | mention = mention + '\t' + str(ner_men['tokens'])
219 | mention = mention + '\t' + sentence
220 | mention = mention + '\t' + "UNK_TYPES"
221 | mention = mention + '\t' + cohStr
222 | mentions.append(mention)
223 | return mentions
224 |
225 | def bracketMentionInSentence(self, s, nerDict):
226 | tokens = s.split(" ")
227 | start = nerDict['start']
228 | end = nerDict['end']
229 | tokens.insert(start, '[[')
230 | tokens.insert(end + 2, ']]')
231 | return ' '.join(tokens)
232 |
233 | def _read_mention(self):
234 | mention = self.mentions[self.men_idx]
235 | self.men_idx += 1
236 | if self.men_idx == self.num_mens:
237 | self.men_idx = 0
238 | self.epochs += 1
239 | return mention
240 |
241 | def _next_batch(self):
242 | ''' Data : wikititle \t mid \t wid \t start \t end \t tokens \t labels
243 | start and end are inclusive
244 | '''
245 | # Sentence = s1 ... m1 ... mN, ... sN.
246 | # Left Batch = s1 ... m1 ... mN
247 | # Right Batch = sN ... mN ... m1
248 | (left_batch, right_batch) = ([], [])
249 |
250 | coh_indices = []
251 | coh_values = []
252 | if self.coherence:
253 | coh_matshape = [self.batch_size, self.num_cohstr]
254 | else:
255 | coh_matshape = []
256 |
257 | # Candidate WID idxs and their cprobs
258 | # First element is always true wid
259 | (wid_idxs_batch, wid_cprobs_batch) = ([], [])
260 |
261 | while len(left_batch) < self.batch_size:
262 | batch_el = len(left_batch)
263 | m = self._read_mention()
264 |
265 | # for label in m.types:
266 | # if label in self.label2idx:
267 | # labelidx = self.label2idx[label]
268 | # labels_batch[batch_el][labelidx] = 1.0
269 |
270 | cohFound = False # If no coherence mention is found, add unk
271 | if self.coherence:
272 | cohidxs = [] # Indexes in the [B, NumCoh] matrix
273 | cohvals = [] # 1.0 to indicate presence
274 | for cohstr in m.coherence:
275 | if cohstr in self.cohG92idx:
276 | cohidx = self.cohG92idx[cohstr]
277 | cohidxs.append([batch_el, cohidx])
278 | cohvals.append(1.0)
279 | cohFound = True
280 | if cohFound:
281 | coh_indices.extend(cohidxs)
282 | coh_values.extend(cohvals)
283 | else:
284 | cohidx = self.cohG92idx[self.unk_word]
285 | coh_indices.append([batch_el, cohidx])
286 | coh_values.append(1.0)
287 |
288 | # Left and Right context includes mention surface
289 | left_tokens = m.sent_tokens[0:m.end_token+1]
290 | right_tokens = m.sent_tokens[m.start_token:][::-1]
291 |
292 | # Strict left and right context
293 | if self.strict_context:
294 | left_tokens = m.sent_tokens[0:m.start_token]
295 | right_tokens = m.sent_tokens[m.end_token+1:][::-1]
296 | # Left and Right context includes mention surface
297 | else:
298 | left_tokens = m.sent_tokens[0:m.end_token+1]
299 | right_tokens = m.sent_tokens[m.start_token:][::-1]
300 |
301 | if not self.pretrain_wordembed:
302 | left_idxs = [self.convert_word2idx(word)
303 | for word in left_tokens]
304 | right_idxs = [self.convert_word2idx(word)
305 | for word in right_tokens]
306 | else:
307 | left_idxs = left_tokens
308 | right_idxs = right_tokens
309 |
310 | left_batch.append(left_idxs)
311 | right_batch.append(right_idxs)
312 |
313 | # wids : [true_knwn_idx, cand1_idx, cand2_idx, ..., unk_idx]
314 | # wid_cprobs : [cwikis probs or 0.0 for unks]
315 | (wid_idxs, wid_cprobs) = self.make_candidates_cprobs(m)
316 | wid_idxs_batch.append(wid_idxs)
317 | wid_cprobs_batch.append(wid_cprobs)
318 |
319 | coherence_batch = (coh_indices, coh_values, coh_matshape)
320 |
321 | return (left_batch, right_batch,
322 | coherence_batch, wid_idxs_batch, wid_cprobs_batch)
323 |
324 | def print_test_batch(self, mention, wid_idxs, wid_cprobs):
325 | print("Surface : {} WID : {} WT: {}".format(
326 | mention.surface, mention.wid, self.wid2WikiTitle[mention.wid]))
327 | print(mention.wid in self.knwid2idx)
328 | for (idx,cprob) in zip(wid_idxs, wid_cprobs):
329 | print("({} : {:0.5f})".format(
330 | self.wid2WikiTitle[self.idx2knwid[idx]], cprob), end=" ")
331 | print("\n")
332 |
333 | def make_candidates_cprobs(self, m):
334 | # Fill num_cands now
335 | surface = utils._getLnrm(m.surface)
336 | wid_idxs = []
337 | wid_cprobs = []
338 |
339 | # print(surface)
340 | if surface in self.crosswikis:
341 | # Pruned crosswikis has only known wids and 30 cands at max
342 | candwids_cprobs = self.crosswikis[surface][0:self.num_cands-1]
343 | (wids, wid_cprobs) = candwids_cprobs
344 | wid_idxs = [self.knwid2idx[wid] for wid in wids]
345 |
346 | # All possible candidates added now. Pad with unks
347 |
348 | # assert len(wid_idxs) == len(wid_cprobs)
349 | remain = self.num_cands - len(wid_idxs)
350 | wid_idxs.extend([0]*remain)
351 | remain = self.num_cands - len(wid_cprobs)
352 | wid_cprobs.extend([0.0]*remain)
353 |
354 | return (wid_idxs, wid_cprobs)
355 |
356 | def embed_batch(self, batch):
357 | ''' Input is a padded batch of left or right contexts containing words
358 | Dimensions should be [B, padded_length]
359 | Output:
360 | Embed the word idxs using pretrain word embedding
361 | '''
362 | output_batch = []
363 | for sent in batch:
364 | word_embeddings = [self.get_vector(word) for word in sent]
365 | output_batch.append(word_embeddings)
366 | return output_batch
367 |
368 | def embed_mentions_batch(self, mentions_batch):
369 | ''' Input is batch of mention tokens as a list of list of tokens.
370 | Output: For each mention, average word embeddings '''
371 | embedded_mentions_batch = []
372 | for m_tokens in mentions_batch:
373 | outvec = np.zeros(300, dtype=float)
374 | for word in m_tokens:
375 | outvec += self.get_vector(word)
376 | outvec = outvec / len(m_tokens)
377 | embedded_mentions_batch.append(outvec)
378 | return embedded_mentions_batch
379 |
380 | def pad_batch(self, batch):
381 | if not self.pretrain_wordembed:
382 | pad_unit = self.word2idx[self.unk_word]
383 | else:
384 | pad_unit = self.unk_word
385 |
386 | lengths = [len(i) for i in batch]
387 | max_length = max(lengths)
388 | for i in range(0, len(batch)):
389 | batch[i].extend([pad_unit]*(max_length - lengths[i]))
390 | return (batch, lengths)
391 |
392 | def _next_padded_batch(self):
393 | (left_batch, right_batch,
394 | coherence_batch,
395 | wid_idxs_batch, wid_cprobs_batch) = self._next_batch()
396 |
397 | (left_batch, left_lengths) = self.pad_batch(left_batch)
398 | (right_batch, right_lengths) = self.pad_batch(right_batch)
399 |
400 | if self.pretrain_wordembed:
401 | left_batch = self.embed_batch(left_batch)
402 | right_batch = self.embed_batch(right_batch)
403 |
404 | return (left_batch, left_lengths, right_batch, right_lengths,
405 | coherence_batch, wid_idxs_batch, wid_cprobs_batch)
406 |
407 | def convert_word2idx(self, word):
408 | if word in self.word2idx:
409 | return self.word2idx[word]
410 | else:
411 | return self.word2idx[self.unk_word]
412 |
413 | def next_test_batch(self):
414 | return self._next_padded_batch()
415 |
416 | def widIdx2WikiTitle(self, widIdx):
417 | wid = self.idx2knwid[widIdx]
418 | wikiTitle = self.wid2WikiTitle[wid]
419 | return wikiTitle
420 |
421 | if __name__ == '__main__':
422 | sttime = time.time()
423 | batch_size = 2
424 | num_batch = 1000
425 | configpath = "configs/all_mentions_config.ini"
426 | config = Config(configpath, verbose=False)
427 | vocabloader = VocabLoader(config)
428 | b = TextAnnoTestReader(config=config,
429 | vocabloader=vocabloader,
430 | num_cands=30,
431 | batch_size=batch_size,
432 | strict_context=False,
433 | pretrain_wordembed=True,
434 | coherence=True)
435 |
436 | stime = time.time()
437 |
438 | i = 0
439 | total_instances = 0
440 | while b.epochs < 1:
441 | (left_batch, left_lengths, right_batch, right_lengths,
442 | coherence_batch, wid_idxs_batch,
443 | wid_cprobs_batch) = b.next_test_batch()
444 | if i % 100 == 0:
445 | etime = time.time()
446 | t=etime-stime
447 | print("{} done. Time taken : {} seconds".format(i, t))
448 | i += 1
449 | etime = time.time()
450 | t=etime-stime
451 | tt = etime - sttime
452 | print("Total Instances : {}".format(total_instances))
453 | print("Batching time (in secs) to make %d batches of size %d : %7.4f seconds" % (i, batch_size, t))
454 | print("Total time (in secs) to make %d batches of size %d : %7.4f seconds" % (i, batch_size, tt))
455 |
--------------------------------------------------------------------------------
/readers/utils.py:
--------------------------------------------------------------------------------
1 | import re
2 | import os
3 | import gc
4 | import sys
5 | import math
6 | import time
7 | import pickle
8 | import random
9 | import unicodedata
10 | import collections
11 | import numpy as np
12 |
13 | from readers.Mention import Mention
14 |
15 | def save(fname, obj):
16 | with open(fname, 'wb') as f:
17 | pickle.dump(obj, f)
18 |
19 | def load(fname):
20 | with open(fname, 'rb') as f:
21 | return pickle.load(f)
22 |
23 | def _getLnrm(arg):
24 | """Normalizes the given arg by stripping it of diacritics, lowercasing, and
25 | removing all non-alphanumeric characters.
26 | """
27 | arg = ''.join(
28 | [c for c in unicodedata.normalize('NFD', arg) if unicodedata.category(c) != 'Mn'])
29 | arg = arg.lower()
30 | arg = ''.join(
31 | [c for c in arg if c in set('abcdefghijklmnopqrstuvwxyz0123456789')])
32 | return arg
33 |
34 | def load_crosswikis(crosswikis_pkl):
35 | stime = time.time()
36 | print("[#] Loading normalized crosswikis dictionary ... ")
37 | crosswikis_dict = load(crosswikis_pkl)
38 | ttime = (time.time() - stime)/60.0
39 | print(" [#] Crosswikis dictionary loaded!. Time: {0:2.4f} mins. Size : {1}".format(
40 | ttime, len(crosswikis_dict)))
41 | return crosswikis_dict
42 | #end
43 |
44 | def load_widSet(
45 | widWikititle_file="/save/ngupta19/freebase/types_xiao/wid.WikiTitle"):
46 | print("Loading WIDs in the KB ... ")
47 | wids = set()
48 | with open(widWikititle_file, 'r') as f:
49 | text = f.read()
50 | lines = text.strip().split("\n")
51 | for line in lines:
52 | wids.add(line.split("\t")[0].strip())
53 |
54 | print("Loaded all WIDs : {}".format(len(wids)))
55 | return wids
56 |
57 | def make_mentions_from_file(mens_file, verbose=False):
58 | stime = time.time()
59 | with open(mens_file, 'r') as f:
60 | mention_lines = f.read().strip().split("\n")
61 | mentions = []
62 | for line in mention_lines:
63 | mentions.append(Mention(line))
64 | ttime = (time.time() - stime)
65 | if verbose:
66 | filename = mens_file.split("/")[-1]
67 | print(" ## Time in loading {} mens : {} secs".format(mens_file, ttime))
68 | return mentions
69 |
70 |
71 | def get_mention_files(mentions_dir):
72 | mention_files = []
73 | for (dirpath, dirnames, filenames) in os.walk(mentions_dir):
74 | mention_files.extend(filenames)
75 | break
76 | #endfor
77 | return mention_files
78 |
79 |
80 | def decrSortedDict(dict):
81 | # Returns a list of tuples (key, value) in decreasing order of the values
82 | return sorted(dict.items(), key=lambda kv: kv[1], reverse=True)
83 |
84 | if __name__=="__main__":
85 | measureCrossWikisEntityConverage("/save/ngupta19/crosswikis/crosswikis.normalized.pkl")
86 |
--------------------------------------------------------------------------------
/readers/vocabloader.py:
--------------------------------------------------------------------------------
1 | import re
2 | import os
3 | import gc
4 | import sys
5 | import time
6 | import math
7 | import pickle
8 | import random
9 | import pprint
10 | import unicodedata
11 | import configparser
12 | import collections
13 | import numpy as np
14 | import readers.utils as utils
15 | from readers.config import Config
16 |
17 | class VocabLoader(object):
18 | def __init__(self, config):
19 | self.initialize_all_dicts()
20 | self.config = config
21 |
22 | def initialize_all_dicts(self):
23 | (self.word2idx, self.idx2word) = (None, None)
24 | (self.label2idx, self.idx2label) = (None, None)
25 | (self.knwid2idx, self.idx2knwid) = (None, None)
26 | self.wid2Wikititle = None
27 | self.wid2TypeLabels = None
28 | (self.test_knwen_cwikis, self.test_allen_cwikis) = (None, None)
29 | self.cwikis_slice = None
30 | self.glove2vec = None
31 | (self.gword2idx, self.gidx2word) = (None, None)
32 | self.crosswikis = None
33 |
34 | def loadCrosswikis(self):
35 | if self.crosswikis == None:
36 | if not os.path.exists(self.config.crosswikis_pkl):
37 | print("Crosswikis pkl missing")
38 | sys.exit()
39 | self.crosswikis = utils.load(self.config.crosswikis_pkl)
40 | return self.crosswikis
41 |
42 | def getWordVocab(self):
43 | if self.word2idx == None or self.idx2word == None:
44 | if not os.path.exists(self.config.word_vocab_pkl):
45 | print("Word Vocab PKL missing")
46 | sys.exit()
47 | print("Loading Word Vocabulary")
48 | (self.word2idx, self.idx2word) = utils.load(self.config.word_vocab_pkl)
49 | return (self.word2idx, self.idx2word)
50 |
51 | def getLabelVocab(self):
52 | if self.label2idx == None or self.idx2label == None:
53 | if not os.path.exists(self.config.label_vocab_pkl):
54 | print("Label Vocab PKL missing")
55 | sys.exit()
56 | print("Loading Type Label Vocabulary")
57 | (self.label2idx, self.idx2label) = utils.load(self.config.label_vocab_pkl)
58 | return (self.label2idx, self.idx2label)
59 |
60 | def getKnwnWidVocab(self):
61 | if self.knwid2idx == None or self.idx2knwid == None:
62 | if not os.path.exists(self.config.kwnwid_vocab_pkl):
63 | print("Known Entities Vocab PKL missing")
64 | sys.exit()
65 | print("Loading Known Entity Vocabulary ... ")
66 | (self.knwid2idx, self.idx2knwid) = utils.load(self.config.kwnwid_vocab_pkl)
67 | return (self.knwid2idx, self.idx2knwid)
68 |
69 | def getTestKnwEnCwiki(self):
70 | if self.test_knwen_cwikis == None:
71 | if not os.path.exists(self.config.test_kwnen_cwikis_pkl):
72 | print("Test Known Entity CWikis Dict missing")
73 | sys.exit()
74 | print("Loading Test Data Known Entity CWIKI")
75 | self.test_knwen_cwikis = utils.load(self.config.test_kwnen_cwikis_pkl)
76 | return self.test_knwen_cwikis
77 |
78 | def getTestAllEnCwiki(self):
79 | if self.test_allen_cwikis == None:
80 | if not os.path.exists(self.config.test_allen_cwikis_pkl):
81 | print("Test All Entity CWikis Dict missing")
82 | sys.exit()
83 | print("Loading Test Data All Entity CWIKI")
84 | self.test_allen_cwikis = utils.load(self.config.test_allen_cwikis_pkl)
85 | return self.test_allen_cwikis
86 |
87 | def getCrosswikisSlice(self):
88 | if self.cwikis_slice == None:
89 | if not os.path.exists(self.config.crosswikis_slice):
90 | print("CWikis Slice Dict missing")
91 | sys.exit()
92 | print("Loading CWIKI Slice")
93 | self.cwikis_slice = utils.load(self.config.crosswikis_slice)
94 | return self.cwikis_slice
95 |
96 | def getWID2Wikititle(self):
97 | if self.wid2Wikititle == None:
98 | if not os.path.exists(self.config.widWiktitle_pkl):
99 | print("wid2Wikititle pkl missing")
100 | sys.exit()
101 | print("Loading wid2Wikititle")
102 | self.wid2Wikititle = utils.load(self.config.widWiktitle_pkl)
103 | return self.wid2Wikititle
104 |
105 | def getWID2TypeLabels(self):
106 | if self.wid2TypeLabels == None:
107 | if not os.path.exists(self.config.wid2typelabels_vocab_pkl):
108 | print("wid2TypeLabels pkl missing")
109 | sys.exit()
110 | print("Loading wid2TypeLabels")
111 | self.wid2TypeLabels = utils.load(self.config.wid2typelabels_vocab_pkl)
112 | return self.wid2TypeLabels
113 |
114 | def loadGloveVectors(self):
115 | if self.glove2vec == None:
116 | if not os.path.exists(self.config.glove_pkl):
117 | print("Glove_Vectors_PKL doesnot exist")
118 | sys.exit()
119 | print("Loading Glove Word Vectors")
120 | self.glove2vec = utils.load(self.config.glove_pkl)
121 | return self.glove2vec
122 |
123 | def getGloveWordVocab(self):
124 | if self.gword2idx == None or self.gidx2word == None:
125 | if not os.path.exists(self.config.glove_word_vocab_pkl):
126 | print("Glove Word Vocab PKL missing")
127 | sys.exit()
128 | print("Loading Glove Word Vocabulary")
129 | (self.gword2idx, self.gidx2word) = utils.load(self.config.glove_word_vocab_pkl)
130 | return (self.gword2idx, self.gidx2word)
131 |
132 | if __name__=='__main__':
133 | config = Config("configs/wcoh_config.ini")
134 | a = VocabLoader(config)
135 | a.loadWord2Vec()
136 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | # Requirements automatically generated by pigar.
2 | # https://github.com/Damnever/pigar
3 |
4 | # readers/inference_reader.py: 8
5 | ccg_nlpy == 0.11.0
6 |
7 | # evaluation/evaluate_inference.py: 3
8 | # evaluation/evaluate_types.py: 3
9 | # models/figer_model/coherence_model.py: 2
10 | # models/figer_model/coldStart.py: 4
11 | # models/figer_model/context_encoder.py: 3
12 | # models/figer_model/el_model.py: 3
13 | # models/figer_model/entity_posterior.py: 3
14 | # models/figer_model/joint_context.py: 3
15 | # models/figer_model/labeling_model.py: 3
16 | # models/figer_model/loss_optim.py: 2
17 | # models/figer_model/wiki_desc.py: 2
18 | # neuralel.py: 4
19 | # readers/inference_reader.py: 3
20 | # readers/utils.py: 11
21 | # readers/vocabloader.py: 13
22 | numpy == 1.11.3
23 |
24 | # models/base.py: 3
25 | # models/batch_normalizer.py: 1,3
26 | # models/figer_model/coherence_model.py: 3
27 | # models/figer_model/coldStart.py: 3
28 | # models/figer_model/context_encoder.py: 2
29 | # models/figer_model/el_model.py: 2
30 | # models/figer_model/entity_posterior.py: 2
31 | # models/figer_model/joint_context.py: 2
32 | # models/figer_model/labeling_model.py: 2
33 | # models/figer_model/loss_optim.py: 3
34 | # models/figer_model/wiki_desc.py: 3
35 | # neuralel.py: 5
36 | tensorflow == 0.12.1
37 |
--------------------------------------------------------------------------------