├── .gitignore
├── LICENSE
├── README.md
├── benchmark
├── bench.py
├── big-test.txt
├── sentences.txt
├── single-words.txt
├── tweets.txt
└── word-pairs.txt
├── demo.py
├── eld
├── __init__.py
├── languageData.py
├── languageDetector.py
├── languageResult.py
├── languageSubset.py
├── resources
│ ├── avg_score.py
│ └── ngrams
│ │ ├── ngramsL60.py
│ │ ├── ngramsM60.py
│ │ └── subset
│ │ ├── ngramsM60-1_2rrx014rx6ypsas6tplo1gtcnmiv5mz.py
│ │ └── ngramsM60-6_5ijqhj4oecs310zqtm8u9pgmd9ox2yd.py
├── subsetResult.py
└── tests
│ ├── data
│ └── big-test.txt
│ ├── test_detector.py
│ └── test_subset.py
├── misc
├── sentences_avg_py.png
├── table_accuracy_py.svg
└── table_time_py.svg
└── pyproject.toml
/.gitignore:
--------------------------------------------------------------------------------
1 | __pycache__/
2 | *.pyc
3 | /.idea/
4 | build/
5 | dist/
6 | *.egg-info/
7 | *.egg
8 | .pytest_cache/
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 |
2 | Apache License
3 | Version 2.0, January 2004
4 | http://www.apache.org/licenses/
5 |
6 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
7 |
8 | 1. Definitions.
9 |
10 | "License" shall mean the terms and conditions for use, reproduction,
11 | and distribution as defined by Sections 1 through 9 of this document.
12 |
13 | "Licensor" shall mean the copyright owner or entity authorized by
14 | the copyright owner that is granting the License.
15 |
16 | "Legal Entity" shall mean the union of the acting entity and all
17 | other entities that control, are controlled by, or are under common
18 | control with that entity. For the purposes of this definition,
19 | "control" means (i) the power, direct or indirect, to cause the
20 | direction or management of such entity, whether by contract or
21 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
22 | outstanding shares, or (iii) beneficial ownership of such entity.
23 |
24 | "You" (or "Your") shall mean an individual or Legal Entity
25 | exercising permissions granted by this License.
26 |
27 | "Source" form shall mean the preferred form for making modifications,
28 | including but not limited to software source code, documentation
29 | source, and configuration files.
30 |
31 | "Object" form shall mean any form resulting from mechanical
32 | transformation or translation of a Source form, including but
33 | not limited to compiled object code, generated documentation,
34 | and conversions to other media types.
35 |
36 | "Work" shall mean the work of authorship, whether in Source or
37 | Object form, made available under the License, as indicated by a
38 | copyright notice that is included in or attached to the work
39 | (an example is provided in the Appendix below).
40 |
41 | "Derivative Works" shall mean any work, whether in Source or Object
42 | form, that is based on (or derived from) the Work and for which the
43 | editorial revisions, annotations, elaborations, or other modifications
44 | represent, as a whole, an original work of authorship. For the purposes
45 | of this License, Derivative Works shall not include works that remain
46 | separable from, or merely link (or bind by name) to the interfaces of,
47 | the Work and Derivative Works thereof.
48 |
49 | "Contribution" shall mean any work of authorship, including
50 | the original version of the Work and any modifications or additions
51 | to that Work or Derivative Works thereof, that is intentionally
52 | submitted to Licensor for inclusion in the Work by the copyright owner
53 | or by an individual or Legal Entity authorized to submit on behalf of
54 | the copyright owner. For the purposes of this definition, "submitted"
55 | means any form of electronic, verbal, or written communication sent
56 | to the Licensor or its representatives, including but not limited to
57 | communication on electronic mailing lists, source code control systems,
58 | and issue tracking systems that are managed by, or on behalf of, the
59 | Licensor for the purpose of discussing and improving the Work, but
60 | excluding communication that is conspicuously marked or otherwise
61 | designated in writing by the copyright owner as "Not a Contribution."
62 |
63 | "Contributor" shall mean Licensor and any individual or Legal Entity
64 | on behalf of whom a Contribution has been received by Licensor and
65 | subsequently incorporated within the Work.
66 |
67 | 2. Grant of Copyright License. Subject to the terms and conditions of
68 | this License, each Contributor hereby grants to You a perpetual,
69 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
70 | copyright license to reproduce, prepare Derivative Works of,
71 | publicly display, publicly perform, sublicense, and distribute the
72 | Work and such Derivative Works in Source or Object form.
73 |
74 | 3. Grant of Patent License. Subject to the terms and conditions of
75 | this License, each Contributor hereby grants to You a perpetual,
76 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
77 | (except as stated in this section) patent license to make, have made,
78 | use, offer to sell, sell, import, and otherwise transfer the Work,
79 | where such license applies only to those patent claims licensable
80 | by such Contributor that are necessarily infringed by their
81 | Contribution(s) alone or by combination of their Contribution(s)
82 | with the Work to which such Contribution(s) was submitted. If You
83 | institute patent litigation against any entity (including a
84 | cross-claim or counterclaim in a lawsuit) alleging that the Work
85 | or a Contribution incorporated within the Work constitutes direct
86 | or contributory patent infringement, then any patent licenses
87 | granted to You under this License for that Work shall terminate
88 | as of the date such litigation is filed.
89 |
90 | 4. Redistribution. You may reproduce and distribute copies of the
91 | Work or Derivative Works thereof in any medium, with or without
92 | modifications, and in Source or Object form, provided that You
93 | meet the following conditions:
94 |
95 | (a) You must give any other recipients of the Work or
96 | Derivative Works a copy of this License; and
97 |
98 | (b) You must cause any modified files to carry prominent notices
99 | stating that You changed the files; and
100 |
101 | (c) You must retain, in the Source form of any Derivative Works
102 | that You distribute, all copyright, patent, trademark, and
103 | attribution notices from the Source form of the Work,
104 | excluding those notices that do not pertain to any part of
105 | the Derivative Works; and
106 |
107 | (d) If the Work includes a "NOTICE" text file as part of its
108 | distribution, then any Derivative Works that You distribute must
109 | include a readable copy of the attribution notices contained
110 | within such NOTICE file, excluding those notices that do not
111 | pertain to any part of the Derivative Works, in at least one
112 | of the following places: within a NOTICE text file distributed
113 | as part of the Derivative Works; within the Source form or
114 | documentation, if provided along with the Derivative Works; or,
115 | within a display generated by the Derivative Works, if and
116 | wherever such third-party notices normally appear. The contents
117 | of the NOTICE file are for informational purposes only and
118 | do not modify the License. You may add Your own attribution
119 | notices within Derivative Works that You distribute, alongside
120 | or as an addendum to the NOTICE text from the Work, provided
121 | that such additional attribution notices cannot be construed
122 | as modifying the License.
123 |
124 | You may add Your own copyright statement to Your modifications and
125 | may provide additional or different license terms and conditions
126 | for use, reproduction, or distribution of Your modifications, or
127 | for any such Derivative Works as a whole, provided Your use,
128 | reproduction, and distribution of the Work otherwise complies with
129 | the conditions stated in this License.
130 |
131 | 5. Submission of Contributions. Unless You explicitly state otherwise,
132 | any Contribution intentionally submitted for inclusion in the Work
133 | by You to the Licensor shall be under the terms and conditions of
134 | this License, without any additional terms or conditions.
135 | Notwithstanding the above, nothing herein shall supersede or modify
136 | the terms of any separate license agreement you may have executed
137 | with Licensor regarding such Contributions.
138 |
139 | 6. Trademarks. This License does not grant permission to use the trade
140 | names, trademarks, service marks, or product names of the Licensor,
141 | except as required for reasonable and customary use in describing the
142 | origin of the Work and reproducing the content of the NOTICE file.
143 |
144 | 7. Disclaimer of Warranty. Unless required by applicable law or
145 | agreed to in writing, Licensor provides the Work (and each
146 | Contributor provides its Contributions) on an "AS IS" BASIS,
147 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
148 | implied, including, without limitation, any warranties or conditions
149 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
150 | PARTICULAR PURPOSE. You are solely responsible for determining the
151 | appropriateness of using or redistributing the Work and assume any
152 | risks associated with Your exercise of permissions under this License.
153 |
154 | 8. Limitation of Liability. In no event and under no legal theory,
155 | whether in tort (including negligence), contract, or otherwise,
156 | unless required by applicable law (such as deliberate and grossly
157 | negligent acts) or agreed to in writing, shall any Contributor be
158 | liable to You for damages, including any direct, indirect, special,
159 | incidental, or consequential damages of any character arising as a
160 | result of this License or out of the use or inability to use the
161 | Work (including but not limited to damages for loss of goodwill,
162 | work stoppage, computer failure or malfunction, or any and all
163 | other commercial damages or losses), even if such Contributor
164 | has been advised of the possibility of such damages.
165 |
166 | 9. Accepting Warranty or Additional Liability. While redistributing
167 | the Work or Derivative Works thereof, You may choose to offer,
168 | and charge a fee for, acceptance of support, warranty, indemnity,
169 | or other liability obligations and/or rights consistent with this
170 | License. However, in accepting such obligations, You may act only
171 | on Your own behalf and on Your sole responsibility, not on behalf
172 | of any other Contributor, and only if You agree to indemnify,
173 | defend, and hold each Contributor harmless for any liability
174 | incurred by, or claims asserted against, such Contributor by reason
175 | of your accepting any such warranty or additional liability.
176 |
177 | END OF TERMS AND CONDITIONS
178 |
179 | APPENDIX: How to apply the Apache License to your work.
180 |
181 | To apply the Apache License to your work, attach the following
182 | boilerplate notice, with the fields enclosed by brackets "[]"
183 | replaced with your own identifying information. (Don't include
184 | the brackets!) The text should be enclosed in the appropriate
185 | comment syntax for the file format. We also recommend that a
186 | file or class name and description of purpose be included on the
187 | same "printed page" as the copyright notice for easier
188 | identification within third-party archives.
189 |
190 | Copyright 2023 Nito T.M.
191 | Author URL: https://github.com/nitotm
192 |
193 | Licensed under the Apache License, Version 2.0 (the "License");
194 | you may not use this file except in compliance with the License.
195 | You may obtain a copy of the License at
196 |
197 | http://www.apache.org/licenses/LICENSE-2.0
198 |
199 | Unless required by applicable law or agreed to in writing, software
200 | distributed under the License is distributed on an "AS IS" BASIS,
201 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
202 | See the License for the specific language governing permissions and
203 | limitations under the License.
204 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Efficient Language Detector
2 |
3 |
10 |
11 | Efficient language detector (*Nito-ELD* or *ELD*) is a fast and accurate language detector, is one of the fastest non compiled detectors, while its accuracy is within the range of the heaviest and slowest detectors.
12 |
13 | It's 100% Python, easy installation and no dependencies other than `regex`.
14 | ELD is also available in [Javascript](https://github.com/nitotm/efficient-language-detector-js) and [PHP](https://github.com/nitotm/efficient-language-detector).
15 |
16 | > This is the first version of a port made from the original version in PHP, the structure might not be definitive, the code can be optimized. My knowledge of Python is basic, feel free to suggest improvements.
17 |
18 | 1. [Installation](#installation)
19 | 2. [How to use](#how-to-use)
20 | 3. [Benchmarks](#benchmarks)
21 | 4. [Languages](#languages)
22 |
23 | ## Installation
24 |
25 | ```bash
26 | $ pip install eld
27 | ```
28 | Alternatively, download / clone the files can work too, by changing the import path.
29 |
30 | ## How to use?
31 |
32 | ```python
33 | from eld import LanguageDetector
34 | detector = LanguageDetector()
35 | ```
36 | `detect()` expects a UTF-8 string, and returns an object, with a 'language' variable, which is either an *ISO 639-1 code* or `None`
37 | ```python
38 | print(detector.detect('Hola, cómo te llamas?'))
39 | # Object { language: "es", scores(): {"es": 0.53, "et": 0.21, ...}, is_reliable(): True }
40 | # Object { language: None|str, scores(): None|dict, is_reliable(): bool }
41 |
42 | print(detector.detect('Hola, cómo te llamas?').language)
43 | # "es"
44 |
45 | # if clean_text(True), detect() removes Urls, domains, emails, alphanumerical & numbers
46 | detector.clean_text(True) # Default is False
47 | ```
48 | - To reduce the languages to be detected, there are 3 different options, they only need to be executed once. (Check available [languages](#languages) below)
49 | ```python
50 | lang_subset = ['en', 'es', 'fr', 'it', 'nl', 'de']
51 |
52 | # Option 1
53 | # with dynamic_lang_subset(), detect() executes normally, and then filters excluded languages
54 | detector.dynamic_lang_subset(lang_subset)
55 | # Returns an object with a list named 'languages', with the validated languages or 'None'
56 |
57 | # Option 2. lang_subset() Will first remove the excluded languages, from the n-grams database
58 | # For a single detection is slower than dynamic_lang_subset(), but for several will be faster
59 | # If save option is true (default), the new Ngrams subset will be stored, and loaded next call
60 | detector.lang_subset(lang_subset) # lang_subset(langs, save=True)
61 | # Returns object {success: True, languages: ['de', 'en', ...], error: None, file: 'ngramsM60...'}
62 |
63 | # To remove either dynamic_lang_subset() or lang_subset(), call the methods with None as argument
64 | detector.lang_subset(None)
65 |
66 | # Finally the optimal way to regularly use a language subset: we create the instance with a file
67 | # The file in the argument can be a subset by lang_subset() or another database like 'ngramsL60'
68 | langSubsetDetect = LanguageDetector('ngramsL60')
69 | ```
70 |
71 | ## Benchmarks
72 |
73 | I compared *ELD* with a different variety of detectors, since the interesting part is the algorithm.
74 |
75 | | URL | Version | Language |
76 | |:----------------------------------------------------------|:-------------|:-----------|
77 | | https://github.com/nitotm/efficient-language-detector-py/ | 0.9.0 | Python |
78 | | https://github.com/nitotm/efficient-language-detector/ | 1.0.0 | PHP |
79 | | https://github.com/pemistahl/lingua-py | 1.3.2 | Python |
80 | | https://github.com/CLD2Owners/cld2 | Aug 21, 2015 | C++ |
81 | | https://github.com/google/cld3 | Aug 28, 2020 | C++ |
82 | | https://github.com/wooorm/franc | 6.1.0 | Javascript |
83 |
84 | Benchmarks: **Tweets**: *760KB*, short sentences of 140 chars max.; **Big test**: *10MB*, sentences in all 60 languages supported; **Sentences**: *8MB*, this is the *Lingua* sentences test, minus unsupported languages.
85 | Short sentences is what *ELD* and most detectors focus on, as very short text is unreliable, but I included the *Lingua* **Word pairs** *1.5MB*, and **Single words** *880KB* tests to see how they all compare beyond their reliable limits.
86 |
87 | These are the results, first, accuracy and then execution time.
88 |
89 |
100 |
101 |
102 |
114 |
115 |
116 | 1.Lingua could have a small advantage as it participates with 54 languages, 6 less.
117 | 2.CLD2 and CLD3, return a list of languages, the ones not included in this test where discarded, but usually they return one language, I believe they have a disadvantage.
118 | Also, I confirm the results of CLD2 for short text are correct, contrary to the test on the *Lingua* page, they did not use the parameter "bestEffort = True", their benchmark for CLD2 is unfair.
119 |
120 | *Lingua* is the average accuracy winner, but at what cost, the same test that in *ELD* or *CLD2* is below 10 seconds, in Lingua takes more than 5 hours! It acts like a brute-force software.
121 | Also, its lead comes from single and pair words, which are unreliable regardless.
122 |
123 | The Python version of *NITO-ELD* is not the fastest but is still considered fast, as it is faster than any other non compiled detector tested.
124 |
125 | I added *ELD-L* for comparison, which has a 2.3x bigger database, but only increases execution time marginally, a testament to the efficiency of the algorithm. *ELD-L* is not the main database as it does not improve language detection in sentences.
126 |
127 | Here is the average, per benchmark, of Tweets, Big test & Sentences.
128 |
129 | 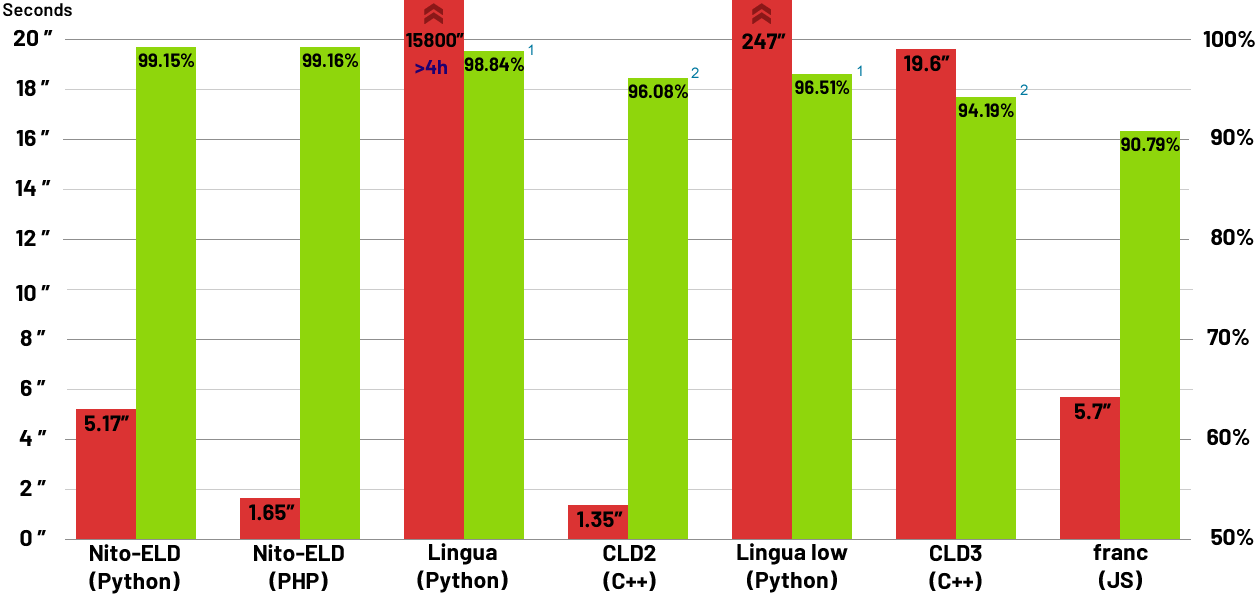
130 |
141 |
142 | ## Languages
143 |
144 | These are the *ISO 639-1 codes* of the 60 supported languages for *Nito-ELD* v1
145 |
146 | > 'am', 'ar', 'az', 'be', 'bg', 'bn', 'ca', 'cs', 'da', 'de', 'el', 'en', 'es', 'et', 'eu', 'fa', 'fi', 'fr', 'gu', 'he', 'hi', 'hr', 'hu', 'hy', 'is', 'it', 'ja', 'ka', 'kn', 'ko', 'ku', 'lo', 'lt', 'lv', 'ml', 'mr', 'ms', 'nl', 'no', 'or', 'pa', 'pl', 'pt', 'ro', 'ru', 'sk', 'sl', 'sq', 'sr', 'sv', 'ta', 'te', 'th', 'tl', 'tr', 'uk', 'ur', 'vi', 'yo', 'zh'
147 |
148 | Full name languages:
149 |
150 | > Amharic, Arabic, Azerbaijani (Latin), Belarusian, Bulgarian, Bengali, Catalan, Czech, Danish, German, Greek, English, Spanish, Estonian, Basque, Persian, Finnish, French, Gujarati, Hebrew, Hindi, Croatian, Hungarian, Armenian, Icelandic, Italian, Japanese, Georgian, Kannada, Korean, Kurdish (Arabic), Lao, Lithuanian, Latvian, Malayalam, Marathi, Malay (Latin), Dutch, Norwegian, Oriya, Punjabi, Polish, Portuguese, Romanian, Russian, Slovak, Slovene, Albanian, Serbian (Cyrillic), Swedish, Tamil, Telugu, Thai, Tagalog, Turkish, Ukrainian, Urdu, Vietnamese, Yoruba, Chinese
151 |
152 | ## Future improvements
153 |
154 | - Train from bigger datasets, and more languages.
155 | - The tokenizer could separate characters from languages that have their own alphabet, potentially improving accuracy and reducing the N-grams database. Retraining and testing is needed.
156 |
157 | **Donate / Hire**
158 | If you wish to Donate for open source improvements, Hire me for private modifications / upgrades, or to Contact me, use the following link: https://linktr.ee/nitotm
--------------------------------------------------------------------------------
/benchmark/bench.py:
--------------------------------------------------------------------------------
1 | import time
2 | import os
3 | import sys
4 |
5 | # Make sure local package is imported instead of pip package
6 | project_root = os.path.abspath(os.path.join(os.path.dirname(__file__), '..'))
7 | sys.path.insert(0, project_root) # prioritize the local package
8 | # sys.path.append('../..')
9 |
10 | from eld.languageDetector import LanguageDetector
11 |
12 | langDetect = LanguageDetector()
13 | print(f"ELD version: {langDetect.VERSION}\n")
14 |
15 | files = ['tweets.txt', 'big-test.txt', 'sentences.txt', 'word-pairs.txt', 'single-words.txt']
16 | durations = []
17 |
18 | for file in files:
19 | content = open(file, encoding="utf-8").read()
20 | lines = content.strip().split("\n")
21 | texts = []
22 |
23 | for line in lines:
24 | values = line.split("\t")
25 | texts.append([values[1], values[0]])
26 |
27 | total = len(texts)
28 | correct = 0
29 | duration = 0
30 |
31 | for text in texts:
32 | start = time.time()
33 | language = langDetect.detect(text[0]).language
34 | duration += time.time() - start
35 | if language == text[1]:
36 | correct += 1
37 | durations.append(duration)
38 | print(f"{file} - Correct ratio: {round((correct / total) * 100, 2)}% Time: {duration}\n")
39 |
40 | average = sum(durations) / len(durations) if len(durations) > 0 else 1
41 | print(f"Average duration: {average}\n")
42 |
43 | # tweets.txt - Correct ratio: 99.28% Time: 0.9556999206542969
44 | # big-test.txt - Correct ratio: 99.41% Time: 7.8356194496154785
45 | # sentences.txt - Correct ratio: 98.77% Time: 6.7327587604522705
46 | # word-pairs.txt - Correct ratio: 87.55% Time: 2.636420488357544
47 | # single-words.txt - Correct ratio: 73.31% Time: 2.12335205078125
48 |
--------------------------------------------------------------------------------
/demo.py:
--------------------------------------------------------------------------------
1 | # Copyright 2023 Nito T.M.
2 | # License https://www.apache.org/licenses/LICENSE-2.0 Apache-2.0
3 | # Author Nito T.M. (https://github.com/nitotm)
4 | # Package pypi.org/project/eld/
5 |
6 | from eld import LanguageDetector
7 |
8 | detector = LanguageDetector()
9 |
10 | # detect() expects a UTF-8 string, returns an object, with a 'language' variable : ISO 639-1 code or null
11 | print(detector.detect('Hola, cómo te llamas?'))
12 | # Object { language: "es", scores(): {"es": 0.53, "et": 0.21, ...}, is_reliable(): True }
13 | # Object { language: None|str, scores(): None|dict, is_reliable(): bool }
14 | print(detector.detect('Hola, cómo te llamas?').language)
15 | # "es"
16 |
17 | # clean_text(True) Removes Urls, domains, emails, alphanumerical & numbers
18 | detector.clean_text(True) # Default is False
19 |
20 | # To reduce the languages to be detected, there are 3 different options, they only need to be executed once.
21 | # This is the complete list on languages for ELD v1, using ISO 639-1 codes:
22 | # ['am', 'ar', 'az', 'be', 'bg', 'bn', 'ca', 'cs', 'da', 'de', 'el', 'en', 'es', 'et', 'eu', 'fa', 'fi', 'fr', 'gu',
23 | # 'he', 'hi', 'hr', 'hu', 'hy', 'is', 'it', 'ja', 'ka', 'kn', 'ko', 'ku', 'lo', 'lt', 'lv', 'ml', 'mr', 'ms', 'nl',
24 | # 'no', 'or', 'pa', 'pl', 'pt', 'ro', 'ru', 'sk', 'sl', 'sq', 'sr', 'sv', 'ta', 'te', 'th', 'tl', 'tr', 'uk', 'ur',
25 | # 'vi', 'yo', 'zh']
26 |
27 | lang_subset = ['en', 'es', 'fr', 'it', 'nl', 'de']
28 |
29 | # Option 1. With dynamic_lang_subset(), detect() executes normally, but at the end will filter the excluded languages.
30 | detector.dynamic_lang_subset(lang_subset)
31 | # Returns an object with a list named 'languages', with the validated languages or 'None'
32 |
33 | # to remove the subset
34 | detector.dynamic_lang_subset(None)
35 |
36 | # Option 2. lang_subset(langs,save=True) Will previously remove the excluded languages form the Ngrams database; for
37 | # a single detection might be slower than dynamic_lang_subset(), but for several strings will be faster. If 'save'
38 | # option is true (default), the new ngrams subset will be stored and cached for next time.
39 | detector.lang_subset(lang_subset)
40 | # Returns object {success: True, languages: ['de', 'en', ...], error: None, file: 'ngramsM60...'}
41 |
42 | # to remove the subset
43 | detector.lang_subset(None)
44 |
45 | print(detector.VERSION)
46 |
47 | # Finally the optimal way to regularly use the same language subset, will be to add as an argument the file stored
48 | # (and returned) by lang_subset(), when creating an instance of the class. In this case the subset Ngrams database will
49 | # be loaded directly, and not the default database. Also, you can use this option to load different ngram databases
50 | # stored at eld/resources/ngrams
51 | langSubsetDetect = LanguageDetector('ngramsM60-6_5ijqhj4oecs310zqtm8u9pgmd9ox2yd')
52 |
--------------------------------------------------------------------------------
/eld/__init__.py:
--------------------------------------------------------------------------------
1 | from eld.languageDetector import LanguageDetector
2 |
--------------------------------------------------------------------------------
/eld/languageData.py:
--------------------------------------------------------------------------------
1 | # Copyright 2023 Nito T.M.
2 | # License https://www.apache.org/licenses/LICENSE-2.0 Apache-2.0
3 | # Author Nito T.M. (https://github.com/nitotm)
4 | # Package pypi.org/project/eld/
5 |
6 | import importlib.util
7 | import os
8 |
9 |
10 | class LanguageData:
11 | def __init__(self):
12 | from .resources.avg_score import avg_score
13 | self.avg_score = avg_score
14 | self.ngrams = {}
15 | self.lang_score = []
16 | self.lang_codes = {}
17 | self.type = ''
18 | self.folder = os.path.dirname(__file__) + '/resources/ngrams/'
19 |
20 | # ISO 639-1 codes, for the 60 languages set.
21 | # ['am', 'ar', 'az', 'be', 'bg', 'bn', 'ca', 'cs', 'da', 'de', 'el', 'en', 'es', 'et', 'eu', 'fa', 'fi', 'fr', 'gu',
22 | # 'he', 'hi', 'hr', 'hu', 'hy', 'is', 'it', 'ja', 'ka', 'kn', 'ko', 'ku', 'lo', 'lt', 'lv', 'ml', 'mr', 'ms', 'nl',
23 | # 'no', 'or', 'pa', 'pl', 'pt', 'ro', 'ru', 'sk', 'sl', 'sq', 'sr', 'sv', 'ta', 'te', 'th', 'tl', 'tr', 'uk', 'ur',
24 | # 'vi', 'yo', 'zh']
25 |
26 | # ['Amharic', 'Arabic', 'Azerbaijani (Latin)', 'Belarusian', 'Bulgarian', 'Bengali', 'Catalan', 'Czech', 'Danish',
27 | # 'German', 'Greek', 'English', 'Spanish', 'Estonian', 'Basque', 'Persian', 'Finnish', 'French', 'Gujarati',
28 | # 'Hebrew', 'Hindi', 'Croatian', 'Hungarian', 'Armenian', 'Icelandic', 'Italian', 'Japanese', 'Georgian', 'Kannada',
29 | # 'Korean', 'Kurdish (Arabic)', 'Lao', 'Lithuanian', 'Latvian', 'Malayalam', 'Marathi', 'Malay (Latin)', 'Dutch',
30 | # 'Norwegian', 'Oriya', 'Punjabi', 'Polish', 'Portuguese', 'Romanian', 'Russian', 'Slovak', 'Slovene', 'Albanian',
31 | # 'Serbian (Cyrillic)', 'Swedish', 'Tamil', 'Telugu', 'Thai', 'Tagalog', 'Turkish', 'Ukrainian', 'Urdu',
32 | # 'Vietnamese', 'Yoruba', 'Chinese']
33 |
34 | def load_ngrams(self, subset_file=''):
35 | if subset_file == '':
36 | from .resources.ngrams.ngramsM60 import ngrams_data
37 | else:
38 | # module = importlib.import_module('.ngrams.' + subset_file)
39 | file_path = self.folder + subset_file + '.py'
40 | if not os.path.exists(file_path):
41 | file_path = self.folder + 'subset/' + subset_file + '.py'
42 | spec = importlib.util.spec_from_file_location(subset_file, file_path)
43 | module = importlib.util.module_from_spec(spec)
44 | spec.loader.exec_module(module)
45 | ngrams_data = module.ngrams_data
46 |
47 | self.ngrams = ngrams_data['ngrams']
48 | self.lang_score = [0] * (max(ngrams_data['languages'].keys()) + 1)
49 | self.type = ngrams_data['type']
50 | self.lang_codes = ngrams_data['languages']
51 |
52 |
53 | languageData = LanguageData()
54 |
--------------------------------------------------------------------------------
/eld/languageDetector.py:
--------------------------------------------------------------------------------
1 | # Copyright 2023 Nito T.M.
2 | # License https://www.apache.org/licenses/LICENSE-2.0 Apache-2.0
3 | # Author Nito T.M. (https://github.com/nitotm)
4 | # Package pypi.org/project/eld/
5 |
6 | import regex as re
7 |
8 | from eld.languageData import languageData
9 | from eld.languageSubset import LanguageSubset
10 | from eld.languageResult import LanguageResult
11 |
12 |
13 | class LanguageDetector(LanguageSubset):
14 | def __init__(self, subset_file=''):
15 | super().__init__()
16 | languageData.load_ngrams(subset_file)
17 | self.__do_clean_text = False
18 | self.VERSION = '1.0.8' # Has to match pyproject.toml version
19 |
20 | def detect(self, text):
21 | """
22 | Returns the language detected for a given UTF-8 string, as an ISO 639-1 code
23 | LanguageResult object { language = 'es', scores() = {'es': 0.5, 'et': 0.2}, is_reliable() = True }
24 |
25 | Args:
26 | text (str): UTF-8 string
27 |
28 | Returns:
29 | object LanguageResult: language (str or None), scores() (dict or None), is_reliable() (bool)
30 | """
31 | if not isinstance(text, str):
32 | raise TypeError("Input 'text' must be a string.")
33 | if self.__do_clean_text:
34 | # Removes Urls, emails, alphanumerical & numbers
35 | text = get_clean_txt(text)
36 | text = _normalize_text(text)
37 | byte_ngrams = _get_byte_ngrams(text)
38 | num_ngrams = len(byte_ngrams)
39 | results = _calculate_scores(byte_ngrams, num_ngrams)
40 |
41 | if results:
42 | if self.subset:
43 | results = LanguageSubset._filter_lang_subset(self, results)
44 | results.sort(key=lambda x: -x[1])
45 | return LanguageResult(results, num_ngrams)
46 | return LanguageResult()
47 |
48 | def clean_text(self, set_bool):
49 | self.__do_clean_text = (True if set_bool else False)
50 |
51 |
52 | def _tokenizer(txt):
53 | return filter(None, re.split(b'\x20', txt))
54 |
55 |
56 | def get_clean_txt(txt):
57 | """Removes parts of a string, that may be considered as "noise" for language detection"""
58 | # Remove URLS
59 | txt = re.sub(r'[hw]((ttps?://(www\.)?)|ww\.)([^\s/?\.#-]+\.?)+(\/\S*)?', ' ', txt, flags=re.IGNORECASE)
60 | # Remove emails
61 | txt = re.sub(r'[a-zA-Z0-9.!$%&?+_`-]+@[A-Za-z0-9.-]+\.[A-Za-z0-9-]{2,64}', ' ', txt)
62 | # Remove .com domains
63 | txt = re.sub(r'([A-Za-z0-9-]+\.)+com(\/\S*|[^\pL])', ' ', txt)
64 | # Remove alphanumerical/number codes
65 | txt = re.sub(r'[a-zA-Z]*[0-9]+[a-zA-Z0-9]*', ' ', txt)
66 | return txt
67 |
68 |
69 | def _normalize_text(text):
70 | """Normalize special characters/word separators"""
71 | text = re.sub(r'[^\pL]+(? 350:
77 | # Cut to first whitespace after 350 byte length offset
78 | text = text[0:min(380, (text.find(b'\x20', 350) or 350))]
79 | return text
80 |
81 |
82 | def _calculate_scores(byte_ngrams, num_ngrams):
83 | """Calculate scores for each language from the given Ngrams"""
84 | lang_score = languageData.lang_score[:]
85 | for bytes_, frequency in byte_ngrams.items():
86 | if bytes_ in languageData.ngrams:
87 | lang_count = len(languageData.ngrams[bytes_])
88 | # Ngram score multiplier, the fewer languages found the more relevancy. Formula can be fine-tuned.
89 | if lang_count == 1:
90 | relevancy = 27 # Handpicked relevance multiplier, trial-error
91 | elif lang_count < 16:
92 | relevancy = (16 - lang_count) / 2 + 1
93 | else:
94 | relevancy = 1
95 |
96 | # Most time-consuming loop, do only the strictly necessary inside
97 | for lang, global_frequency in languageData.ngrams[bytes_].items():
98 | lang_score[lang] += (global_frequency / frequency if frequency > global_frequency
99 | else frequency / global_frequency) * relevancy + 2
100 | # This divisor will produce a final score between 0 - ~1, score could be >1. Can be improved.
101 | result_divisor = num_ngrams * 3.2
102 | results = []
103 | for lang in range(len(lang_score)):
104 | if lang_score[lang]:
105 | results.append([lang, lang_score[lang] / result_divisor]) # * languageData.scoreNormalizer[lang]
106 | return results
107 |
108 |
109 | def _get_byte_ngrams(txt):
110 | """Gets Ngrams from a given string"""
111 | byte_grams = {}
112 | count_ngrams = 0
113 |
114 | for word in _tokenizer(txt):
115 | length = len(word)
116 |
117 | if length > 70:
118 | length = 70
119 | x = 0
120 | for j in range(0, length - 4, 3):
121 | this_bytes = (b' ' if j == 0 else b'') + word[j:j + 4]
122 | byte_grams[this_bytes] = (1 + byte_grams[this_bytes] if this_bytes in byte_grams else 1)
123 | count_ngrams += 1
124 | x = 1
125 |
126 | this_bytes = (b' ' if x == 0 else b'') + word[length - 4 if length != 3 else 0:] + b' '
127 | byte_grams[this_bytes] = (1 + byte_grams[this_bytes] if this_bytes in byte_grams else 1)
128 | count_ngrams += 1
129 |
130 | # Frequency is multiplied by 15000 at the ngrams database. A reduced number (13200) seems to work better.
131 | # Linear formulas were tried, decreasing the multiplier for fewer ngram strings, no meaningful improvement.
132 | for bytes_, count in byte_grams.items():
133 | byte_grams[bytes_] = count / count_ngrams * 13200
134 |
135 | return byte_grams
136 |
--------------------------------------------------------------------------------
/eld/languageResult.py:
--------------------------------------------------------------------------------
1 | # Copyright 2023 Nito T.M.
2 | # License https://www.apache.org/licenses/LICENSE-2.0 Apache-2.0
3 | # Author Nito T.M. (https://github.com/nitotm)
4 | # Package pypi.org/project/eld/
5 |
6 | import json
7 | from eld.languageData import languageData
8 |
9 |
10 | class LanguageResult:
11 | def __init__(self, results=None, num_ngrams=None):
12 | self.language = (languageData.lang_codes[results[0][0]] if results else None)
13 | self.__results = results
14 | self.__num_ngrams = num_ngrams
15 |
16 | def __str__(self):
17 | return json.dumps({'
 101 |
102 |
114 |
101 |
102 |
114 |  115 |
116 | 1. Lingua could have a small advantage as it participates with 54 languages, 6 less.
117 | 2. CLD2 and CLD3, return a list of languages, the ones not included in this test where discarded, but usually they return one language, I believe they have a disadvantage.
118 | Also, I confirm the results of CLD2 for short text are correct, contrary to the test on the *Lingua* page, they did not use the parameter "bestEffort = True", their benchmark for CLD2 is unfair.
119 |
120 | *Lingua* is the average accuracy winner, but at what cost, the same test that in *ELD* or *CLD2* is below 10 seconds, in Lingua takes more than 5 hours! It acts like a brute-force software.
121 | Also, its lead comes from single and pair words, which are unreliable regardless.
122 |
123 | The Python version of *NITO-ELD* is not the fastest but is still considered fast, as it is faster than any other non compiled detector tested.
124 |
125 | I added *ELD-L* for comparison, which has a 2.3x bigger database, but only increases execution time marginally, a testament to the efficiency of the algorithm. *ELD-L* is not the main database as it does not improve language detection in sentences.
126 |
127 | Here is the average, per benchmark, of Tweets, Big test & Sentences.
128 |
129 | 
130 |
141 |
142 | ## Languages
143 |
144 | These are the *ISO 639-1 codes* of the 60 supported languages for *Nito-ELD* v1
145 |
146 | > 'am', 'ar', 'az', 'be', 'bg', 'bn', 'ca', 'cs', 'da', 'de', 'el', 'en', 'es', 'et', 'eu', 'fa', 'fi', 'fr', 'gu', 'he', 'hi', 'hr', 'hu', 'hy', 'is', 'it', 'ja', 'ka', 'kn', 'ko', 'ku', 'lo', 'lt', 'lv', 'ml', 'mr', 'ms', 'nl', 'no', 'or', 'pa', 'pl', 'pt', 'ro', 'ru', 'sk', 'sl', 'sq', 'sr', 'sv', 'ta', 'te', 'th', 'tl', 'tr', 'uk', 'ur', 'vi', 'yo', 'zh'
147 |
148 | Full name languages:
149 |
150 | > Amharic, Arabic, Azerbaijani (Latin), Belarusian, Bulgarian, Bengali, Catalan, Czech, Danish, German, Greek, English, Spanish, Estonian, Basque, Persian, Finnish, French, Gujarati, Hebrew, Hindi, Croatian, Hungarian, Armenian, Icelandic, Italian, Japanese, Georgian, Kannada, Korean, Kurdish (Arabic), Lao, Lithuanian, Latvian, Malayalam, Marathi, Malay (Latin), Dutch, Norwegian, Oriya, Punjabi, Polish, Portuguese, Romanian, Russian, Slovak, Slovene, Albanian, Serbian (Cyrillic), Swedish, Tamil, Telugu, Thai, Tagalog, Turkish, Ukrainian, Urdu, Vietnamese, Yoruba, Chinese
151 |
152 | ## Future improvements
153 |
154 | - Train from bigger datasets, and more languages.
155 | - The tokenizer could separate characters from languages that have their own alphabet, potentially improving accuracy and reducing the N-grams database. Retraining and testing is needed.
156 |
157 | **Donate / Hire**
158 | If you wish to Donate for open source improvements, Hire me for private modifications / upgrades, or to Contact me, use the following link: https://linktr.ee/nitotm
--------------------------------------------------------------------------------
/benchmark/bench.py:
--------------------------------------------------------------------------------
1 | import time
2 | import os
3 | import sys
4 |
5 | # Make sure local package is imported instead of pip package
6 | project_root = os.path.abspath(os.path.join(os.path.dirname(__file__), '..'))
7 | sys.path.insert(0, project_root) # prioritize the local package
8 | # sys.path.append('../..')
9 |
10 | from eld.languageDetector import LanguageDetector
11 |
12 | langDetect = LanguageDetector()
13 | print(f"ELD version: {langDetect.VERSION}\n")
14 |
15 | files = ['tweets.txt', 'big-test.txt', 'sentences.txt', 'word-pairs.txt', 'single-words.txt']
16 | durations = []
17 |
18 | for file in files:
19 | content = open(file, encoding="utf-8").read()
20 | lines = content.strip().split("\n")
21 | texts = []
22 |
23 | for line in lines:
24 | values = line.split("\t")
25 | texts.append([values[1], values[0]])
26 |
27 | total = len(texts)
28 | correct = 0
29 | duration = 0
30 |
31 | for text in texts:
32 | start = time.time()
33 | language = langDetect.detect(text[0]).language
34 | duration += time.time() - start
35 | if language == text[1]:
36 | correct += 1
37 | durations.append(duration)
38 | print(f"{file} - Correct ratio: {round((correct / total) * 100, 2)}% Time: {duration}\n")
39 |
40 | average = sum(durations) / len(durations) if len(durations) > 0 else 1
41 | print(f"Average duration: {average}\n")
42 |
43 | # tweets.txt - Correct ratio: 99.28% Time: 0.9556999206542969
44 | # big-test.txt - Correct ratio: 99.41% Time: 7.8356194496154785
45 | # sentences.txt - Correct ratio: 98.77% Time: 6.7327587604522705
46 | # word-pairs.txt - Correct ratio: 87.55% Time: 2.636420488357544
47 | # single-words.txt - Correct ratio: 73.31% Time: 2.12335205078125
48 |
--------------------------------------------------------------------------------
/demo.py:
--------------------------------------------------------------------------------
1 | # Copyright 2023 Nito T.M.
2 | # License https://www.apache.org/licenses/LICENSE-2.0 Apache-2.0
3 | # Author Nito T.M. (https://github.com/nitotm)
4 | # Package pypi.org/project/eld/
5 |
6 | from eld import LanguageDetector
7 |
8 | detector = LanguageDetector()
9 |
10 | # detect() expects a UTF-8 string, returns an object, with a 'language' variable : ISO 639-1 code or null
11 | print(detector.detect('Hola, cómo te llamas?'))
12 | # Object { language: "es", scores(): {"es": 0.53, "et": 0.21, ...}, is_reliable(): True }
13 | # Object { language: None|str, scores(): None|dict, is_reliable(): bool }
14 | print(detector.detect('Hola, cómo te llamas?').language)
15 | # "es"
16 |
17 | # clean_text(True) Removes Urls, domains, emails, alphanumerical & numbers
18 | detector.clean_text(True) # Default is False
19 |
20 | # To reduce the languages to be detected, there are 3 different options, they only need to be executed once.
21 | # This is the complete list on languages for ELD v1, using ISO 639-1 codes:
22 | # ['am', 'ar', 'az', 'be', 'bg', 'bn', 'ca', 'cs', 'da', 'de', 'el', 'en', 'es', 'et', 'eu', 'fa', 'fi', 'fr', 'gu',
23 | # 'he', 'hi', 'hr', 'hu', 'hy', 'is', 'it', 'ja', 'ka', 'kn', 'ko', 'ku', 'lo', 'lt', 'lv', 'ml', 'mr', 'ms', 'nl',
24 | # 'no', 'or', 'pa', 'pl', 'pt', 'ro', 'ru', 'sk', 'sl', 'sq', 'sr', 'sv', 'ta', 'te', 'th', 'tl', 'tr', 'uk', 'ur',
25 | # 'vi', 'yo', 'zh']
26 |
27 | lang_subset = ['en', 'es', 'fr', 'it', 'nl', 'de']
28 |
29 | # Option 1. With dynamic_lang_subset(), detect() executes normally, but at the end will filter the excluded languages.
30 | detector.dynamic_lang_subset(lang_subset)
31 | # Returns an object with a list named 'languages', with the validated languages or 'None'
32 |
33 | # to remove the subset
34 | detector.dynamic_lang_subset(None)
35 |
36 | # Option 2. lang_subset(langs,save=True) Will previously remove the excluded languages form the Ngrams database; for
37 | # a single detection might be slower than dynamic_lang_subset(), but for several strings will be faster. If 'save'
38 | # option is true (default), the new ngrams subset will be stored and cached for next time.
39 | detector.lang_subset(lang_subset)
40 | # Returns object {success: True, languages: ['de', 'en', ...], error: None, file: 'ngramsM60...'}
41 |
42 | # to remove the subset
43 | detector.lang_subset(None)
44 |
45 | print(detector.VERSION)
46 |
47 | # Finally the optimal way to regularly use the same language subset, will be to add as an argument the file stored
48 | # (and returned) by lang_subset(), when creating an instance of the class. In this case the subset Ngrams database will
49 | # be loaded directly, and not the default database. Also, you can use this option to load different ngram databases
50 | # stored at eld/resources/ngrams
51 | langSubsetDetect = LanguageDetector('ngramsM60-6_5ijqhj4oecs310zqtm8u9pgmd9ox2yd')
52 |
--------------------------------------------------------------------------------
/eld/__init__.py:
--------------------------------------------------------------------------------
1 | from eld.languageDetector import LanguageDetector
2 |
--------------------------------------------------------------------------------
/eld/languageData.py:
--------------------------------------------------------------------------------
1 | # Copyright 2023 Nito T.M.
2 | # License https://www.apache.org/licenses/LICENSE-2.0 Apache-2.0
3 | # Author Nito T.M. (https://github.com/nitotm)
4 | # Package pypi.org/project/eld/
5 |
6 | import importlib.util
7 | import os
8 |
9 |
10 | class LanguageData:
11 | def __init__(self):
12 | from .resources.avg_score import avg_score
13 | self.avg_score = avg_score
14 | self.ngrams = {}
15 | self.lang_score = []
16 | self.lang_codes = {}
17 | self.type = ''
18 | self.folder = os.path.dirname(__file__) + '/resources/ngrams/'
19 |
20 | # ISO 639-1 codes, for the 60 languages set.
21 | # ['am', 'ar', 'az', 'be', 'bg', 'bn', 'ca', 'cs', 'da', 'de', 'el', 'en', 'es', 'et', 'eu', 'fa', 'fi', 'fr', 'gu',
22 | # 'he', 'hi', 'hr', 'hu', 'hy', 'is', 'it', 'ja', 'ka', 'kn', 'ko', 'ku', 'lo', 'lt', 'lv', 'ml', 'mr', 'ms', 'nl',
23 | # 'no', 'or', 'pa', 'pl', 'pt', 'ro', 'ru', 'sk', 'sl', 'sq', 'sr', 'sv', 'ta', 'te', 'th', 'tl', 'tr', 'uk', 'ur',
24 | # 'vi', 'yo', 'zh']
25 |
26 | # ['Amharic', 'Arabic', 'Azerbaijani (Latin)', 'Belarusian', 'Bulgarian', 'Bengali', 'Catalan', 'Czech', 'Danish',
27 | # 'German', 'Greek', 'English', 'Spanish', 'Estonian', 'Basque', 'Persian', 'Finnish', 'French', 'Gujarati',
28 | # 'Hebrew', 'Hindi', 'Croatian', 'Hungarian', 'Armenian', 'Icelandic', 'Italian', 'Japanese', 'Georgian', 'Kannada',
29 | # 'Korean', 'Kurdish (Arabic)', 'Lao', 'Lithuanian', 'Latvian', 'Malayalam', 'Marathi', 'Malay (Latin)', 'Dutch',
30 | # 'Norwegian', 'Oriya', 'Punjabi', 'Polish', 'Portuguese', 'Romanian', 'Russian', 'Slovak', 'Slovene', 'Albanian',
31 | # 'Serbian (Cyrillic)', 'Swedish', 'Tamil', 'Telugu', 'Thai', 'Tagalog', 'Turkish', 'Ukrainian', 'Urdu',
32 | # 'Vietnamese', 'Yoruba', 'Chinese']
33 |
34 | def load_ngrams(self, subset_file=''):
35 | if subset_file == '':
36 | from .resources.ngrams.ngramsM60 import ngrams_data
37 | else:
38 | # module = importlib.import_module('.ngrams.' + subset_file)
39 | file_path = self.folder + subset_file + '.py'
40 | if not os.path.exists(file_path):
41 | file_path = self.folder + 'subset/' + subset_file + '.py'
42 | spec = importlib.util.spec_from_file_location(subset_file, file_path)
43 | module = importlib.util.module_from_spec(spec)
44 | spec.loader.exec_module(module)
45 | ngrams_data = module.ngrams_data
46 |
47 | self.ngrams = ngrams_data['ngrams']
48 | self.lang_score = [0] * (max(ngrams_data['languages'].keys()) + 1)
49 | self.type = ngrams_data['type']
50 | self.lang_codes = ngrams_data['languages']
51 |
52 |
53 | languageData = LanguageData()
54 |
--------------------------------------------------------------------------------
/eld/languageDetector.py:
--------------------------------------------------------------------------------
1 | # Copyright 2023 Nito T.M.
2 | # License https://www.apache.org/licenses/LICENSE-2.0 Apache-2.0
3 | # Author Nito T.M. (https://github.com/nitotm)
4 | # Package pypi.org/project/eld/
5 |
6 | import regex as re
7 |
8 | from eld.languageData import languageData
9 | from eld.languageSubset import LanguageSubset
10 | from eld.languageResult import LanguageResult
11 |
12 |
13 | class LanguageDetector(LanguageSubset):
14 | def __init__(self, subset_file=''):
15 | super().__init__()
16 | languageData.load_ngrams(subset_file)
17 | self.__do_clean_text = False
18 | self.VERSION = '1.0.8' # Has to match pyproject.toml version
19 |
20 | def detect(self, text):
21 | """
22 | Returns the language detected for a given UTF-8 string, as an ISO 639-1 code
23 | LanguageResult object { language = 'es', scores() = {'es': 0.5, 'et': 0.2}, is_reliable() = True }
24 |
25 | Args:
26 | text (str): UTF-8 string
27 |
28 | Returns:
29 | object LanguageResult: language (str or None), scores() (dict or None), is_reliable() (bool)
30 | """
31 | if not isinstance(text, str):
32 | raise TypeError("Input 'text' must be a string.")
33 | if self.__do_clean_text:
34 | # Removes Urls, emails, alphanumerical & numbers
35 | text = get_clean_txt(text)
36 | text = _normalize_text(text)
37 | byte_ngrams = _get_byte_ngrams(text)
38 | num_ngrams = len(byte_ngrams)
39 | results = _calculate_scores(byte_ngrams, num_ngrams)
40 |
41 | if results:
42 | if self.subset:
43 | results = LanguageSubset._filter_lang_subset(self, results)
44 | results.sort(key=lambda x: -x[1])
45 | return LanguageResult(results, num_ngrams)
46 | return LanguageResult()
47 |
48 | def clean_text(self, set_bool):
49 | self.__do_clean_text = (True if set_bool else False)
50 |
51 |
52 | def _tokenizer(txt):
53 | return filter(None, re.split(b'\x20', txt))
54 |
55 |
56 | def get_clean_txt(txt):
57 | """Removes parts of a string, that may be considered as "noise" for language detection"""
58 | # Remove URLS
59 | txt = re.sub(r'[hw]((ttps?://(www\.)?)|ww\.)([^\s/?\.#-]+\.?)+(\/\S*)?', ' ', txt, flags=re.IGNORECASE)
60 | # Remove emails
61 | txt = re.sub(r'[a-zA-Z0-9.!$%&?+_`-]+@[A-Za-z0-9.-]+\.[A-Za-z0-9-]{2,64}', ' ', txt)
62 | # Remove .com domains
63 | txt = re.sub(r'([A-Za-z0-9-]+\.)+com(\/\S*|[^\pL])', ' ', txt)
64 | # Remove alphanumerical/number codes
65 | txt = re.sub(r'[a-zA-Z]*[0-9]+[a-zA-Z0-9]*', ' ', txt)
66 | return txt
67 |
68 |
69 | def _normalize_text(text):
70 | """Normalize special characters/word separators"""
71 | text = re.sub(r'[^\pL]+(? 350:
77 | # Cut to first whitespace after 350 byte length offset
78 | text = text[0:min(380, (text.find(b'\x20', 350) or 350))]
79 | return text
80 |
81 |
82 | def _calculate_scores(byte_ngrams, num_ngrams):
83 | """Calculate scores for each language from the given Ngrams"""
84 | lang_score = languageData.lang_score[:]
85 | for bytes_, frequency in byte_ngrams.items():
86 | if bytes_ in languageData.ngrams:
87 | lang_count = len(languageData.ngrams[bytes_])
88 | # Ngram score multiplier, the fewer languages found the more relevancy. Formula can be fine-tuned.
89 | if lang_count == 1:
90 | relevancy = 27 # Handpicked relevance multiplier, trial-error
91 | elif lang_count < 16:
92 | relevancy = (16 - lang_count) / 2 + 1
93 | else:
94 | relevancy = 1
95 |
96 | # Most time-consuming loop, do only the strictly necessary inside
97 | for lang, global_frequency in languageData.ngrams[bytes_].items():
98 | lang_score[lang] += (global_frequency / frequency if frequency > global_frequency
99 | else frequency / global_frequency) * relevancy + 2
100 | # This divisor will produce a final score between 0 - ~1, score could be >1. Can be improved.
101 | result_divisor = num_ngrams * 3.2
102 | results = []
103 | for lang in range(len(lang_score)):
104 | if lang_score[lang]:
105 | results.append([lang, lang_score[lang] / result_divisor]) # * languageData.scoreNormalizer[lang]
106 | return results
107 |
108 |
109 | def _get_byte_ngrams(txt):
110 | """Gets Ngrams from a given string"""
111 | byte_grams = {}
112 | count_ngrams = 0
113 |
114 | for word in _tokenizer(txt):
115 | length = len(word)
116 |
117 | if length > 70:
118 | length = 70
119 | x = 0
120 | for j in range(0, length - 4, 3):
121 | this_bytes = (b' ' if j == 0 else b'') + word[j:j + 4]
122 | byte_grams[this_bytes] = (1 + byte_grams[this_bytes] if this_bytes in byte_grams else 1)
123 | count_ngrams += 1
124 | x = 1
125 |
126 | this_bytes = (b' ' if x == 0 else b'') + word[length - 4 if length != 3 else 0:] + b' '
127 | byte_grams[this_bytes] = (1 + byte_grams[this_bytes] if this_bytes in byte_grams else 1)
128 | count_ngrams += 1
129 |
130 | # Frequency is multiplied by 15000 at the ngrams database. A reduced number (13200) seems to work better.
131 | # Linear formulas were tried, decreasing the multiplier for fewer ngram strings, no meaningful improvement.
132 | for bytes_, count in byte_grams.items():
133 | byte_grams[bytes_] = count / count_ngrams * 13200
134 |
135 | return byte_grams
136 |
--------------------------------------------------------------------------------
/eld/languageResult.py:
--------------------------------------------------------------------------------
1 | # Copyright 2023 Nito T.M.
2 | # License https://www.apache.org/licenses/LICENSE-2.0 Apache-2.0
3 | # Author Nito T.M. (https://github.com/nitotm)
4 | # Package pypi.org/project/eld/
5 |
6 | import json
7 | from eld.languageData import languageData
8 |
9 |
10 | class LanguageResult:
11 | def __init__(self, results=None, num_ngrams=None):
12 | self.language = (languageData.lang_codes[results[0][0]] if results else None)
13 | self.__results = results
14 | self.__num_ngrams = num_ngrams
15 |
16 | def __str__(self):
17 | return json.dumps({'
115 |
116 | 1. Lingua could have a small advantage as it participates with 54 languages, 6 less.
117 | 2. CLD2 and CLD3, return a list of languages, the ones not included in this test where discarded, but usually they return one language, I believe they have a disadvantage.
118 | Also, I confirm the results of CLD2 for short text are correct, contrary to the test on the *Lingua* page, they did not use the parameter "bestEffort = True", their benchmark for CLD2 is unfair.
119 |
120 | *Lingua* is the average accuracy winner, but at what cost, the same test that in *ELD* or *CLD2* is below 10 seconds, in Lingua takes more than 5 hours! It acts like a brute-force software.
121 | Also, its lead comes from single and pair words, which are unreliable regardless.
122 |
123 | The Python version of *NITO-ELD* is not the fastest but is still considered fast, as it is faster than any other non compiled detector tested.
124 |
125 | I added *ELD-L* for comparison, which has a 2.3x bigger database, but only increases execution time marginally, a testament to the efficiency of the algorithm. *ELD-L* is not the main database as it does not improve language detection in sentences.
126 |
127 | Here is the average, per benchmark, of Tweets, Big test & Sentences.
128 |
129 | 
130 |
141 |
142 | ## Languages
143 |
144 | These are the *ISO 639-1 codes* of the 60 supported languages for *Nito-ELD* v1
145 |
146 | > 'am', 'ar', 'az', 'be', 'bg', 'bn', 'ca', 'cs', 'da', 'de', 'el', 'en', 'es', 'et', 'eu', 'fa', 'fi', 'fr', 'gu', 'he', 'hi', 'hr', 'hu', 'hy', 'is', 'it', 'ja', 'ka', 'kn', 'ko', 'ku', 'lo', 'lt', 'lv', 'ml', 'mr', 'ms', 'nl', 'no', 'or', 'pa', 'pl', 'pt', 'ro', 'ru', 'sk', 'sl', 'sq', 'sr', 'sv', 'ta', 'te', 'th', 'tl', 'tr', 'uk', 'ur', 'vi', 'yo', 'zh'
147 |
148 | Full name languages:
149 |
150 | > Amharic, Arabic, Azerbaijani (Latin), Belarusian, Bulgarian, Bengali, Catalan, Czech, Danish, German, Greek, English, Spanish, Estonian, Basque, Persian, Finnish, French, Gujarati, Hebrew, Hindi, Croatian, Hungarian, Armenian, Icelandic, Italian, Japanese, Georgian, Kannada, Korean, Kurdish (Arabic), Lao, Lithuanian, Latvian, Malayalam, Marathi, Malay (Latin), Dutch, Norwegian, Oriya, Punjabi, Polish, Portuguese, Romanian, Russian, Slovak, Slovene, Albanian, Serbian (Cyrillic), Swedish, Tamil, Telugu, Thai, Tagalog, Turkish, Ukrainian, Urdu, Vietnamese, Yoruba, Chinese
151 |
152 | ## Future improvements
153 |
154 | - Train from bigger datasets, and more languages.
155 | - The tokenizer could separate characters from languages that have their own alphabet, potentially improving accuracy and reducing the N-grams database. Retraining and testing is needed.
156 |
157 | **Donate / Hire**
158 | If you wish to Donate for open source improvements, Hire me for private modifications / upgrades, or to Contact me, use the following link: https://linktr.ee/nitotm
--------------------------------------------------------------------------------
/benchmark/bench.py:
--------------------------------------------------------------------------------
1 | import time
2 | import os
3 | import sys
4 |
5 | # Make sure local package is imported instead of pip package
6 | project_root = os.path.abspath(os.path.join(os.path.dirname(__file__), '..'))
7 | sys.path.insert(0, project_root) # prioritize the local package
8 | # sys.path.append('../..')
9 |
10 | from eld.languageDetector import LanguageDetector
11 |
12 | langDetect = LanguageDetector()
13 | print(f"ELD version: {langDetect.VERSION}\n")
14 |
15 | files = ['tweets.txt', 'big-test.txt', 'sentences.txt', 'word-pairs.txt', 'single-words.txt']
16 | durations = []
17 |
18 | for file in files:
19 | content = open(file, encoding="utf-8").read()
20 | lines = content.strip().split("\n")
21 | texts = []
22 |
23 | for line in lines:
24 | values = line.split("\t")
25 | texts.append([values[1], values[0]])
26 |
27 | total = len(texts)
28 | correct = 0
29 | duration = 0
30 |
31 | for text in texts:
32 | start = time.time()
33 | language = langDetect.detect(text[0]).language
34 | duration += time.time() - start
35 | if language == text[1]:
36 | correct += 1
37 | durations.append(duration)
38 | print(f"{file} - Correct ratio: {round((correct / total) * 100, 2)}% Time: {duration}\n")
39 |
40 | average = sum(durations) / len(durations) if len(durations) > 0 else 1
41 | print(f"Average duration: {average}\n")
42 |
43 | # tweets.txt - Correct ratio: 99.28% Time: 0.9556999206542969
44 | # big-test.txt - Correct ratio: 99.41% Time: 7.8356194496154785
45 | # sentences.txt - Correct ratio: 98.77% Time: 6.7327587604522705
46 | # word-pairs.txt - Correct ratio: 87.55% Time: 2.636420488357544
47 | # single-words.txt - Correct ratio: 73.31% Time: 2.12335205078125
48 |
--------------------------------------------------------------------------------
/demo.py:
--------------------------------------------------------------------------------
1 | # Copyright 2023 Nito T.M.
2 | # License https://www.apache.org/licenses/LICENSE-2.0 Apache-2.0
3 | # Author Nito T.M. (https://github.com/nitotm)
4 | # Package pypi.org/project/eld/
5 |
6 | from eld import LanguageDetector
7 |
8 | detector = LanguageDetector()
9 |
10 | # detect() expects a UTF-8 string, returns an object, with a 'language' variable : ISO 639-1 code or null
11 | print(detector.detect('Hola, cómo te llamas?'))
12 | # Object { language: "es", scores(): {"es": 0.53, "et": 0.21, ...}, is_reliable(): True }
13 | # Object { language: None|str, scores(): None|dict, is_reliable(): bool }
14 | print(detector.detect('Hola, cómo te llamas?').language)
15 | # "es"
16 |
17 | # clean_text(True) Removes Urls, domains, emails, alphanumerical & numbers
18 | detector.clean_text(True) # Default is False
19 |
20 | # To reduce the languages to be detected, there are 3 different options, they only need to be executed once.
21 | # This is the complete list on languages for ELD v1, using ISO 639-1 codes:
22 | # ['am', 'ar', 'az', 'be', 'bg', 'bn', 'ca', 'cs', 'da', 'de', 'el', 'en', 'es', 'et', 'eu', 'fa', 'fi', 'fr', 'gu',
23 | # 'he', 'hi', 'hr', 'hu', 'hy', 'is', 'it', 'ja', 'ka', 'kn', 'ko', 'ku', 'lo', 'lt', 'lv', 'ml', 'mr', 'ms', 'nl',
24 | # 'no', 'or', 'pa', 'pl', 'pt', 'ro', 'ru', 'sk', 'sl', 'sq', 'sr', 'sv', 'ta', 'te', 'th', 'tl', 'tr', 'uk', 'ur',
25 | # 'vi', 'yo', 'zh']
26 |
27 | lang_subset = ['en', 'es', 'fr', 'it', 'nl', 'de']
28 |
29 | # Option 1. With dynamic_lang_subset(), detect() executes normally, but at the end will filter the excluded languages.
30 | detector.dynamic_lang_subset(lang_subset)
31 | # Returns an object with a list named 'languages', with the validated languages or 'None'
32 |
33 | # to remove the subset
34 | detector.dynamic_lang_subset(None)
35 |
36 | # Option 2. lang_subset(langs,save=True) Will previously remove the excluded languages form the Ngrams database; for
37 | # a single detection might be slower than dynamic_lang_subset(), but for several strings will be faster. If 'save'
38 | # option is true (default), the new ngrams subset will be stored and cached for next time.
39 | detector.lang_subset(lang_subset)
40 | # Returns object {success: True, languages: ['de', 'en', ...], error: None, file: 'ngramsM60...'}
41 |
42 | # to remove the subset
43 | detector.lang_subset(None)
44 |
45 | print(detector.VERSION)
46 |
47 | # Finally the optimal way to regularly use the same language subset, will be to add as an argument the file stored
48 | # (and returned) by lang_subset(), when creating an instance of the class. In this case the subset Ngrams database will
49 | # be loaded directly, and not the default database. Also, you can use this option to load different ngram databases
50 | # stored at eld/resources/ngrams
51 | langSubsetDetect = LanguageDetector('ngramsM60-6_5ijqhj4oecs310zqtm8u9pgmd9ox2yd')
52 |
--------------------------------------------------------------------------------
/eld/__init__.py:
--------------------------------------------------------------------------------
1 | from eld.languageDetector import LanguageDetector
2 |
--------------------------------------------------------------------------------
/eld/languageData.py:
--------------------------------------------------------------------------------
1 | # Copyright 2023 Nito T.M.
2 | # License https://www.apache.org/licenses/LICENSE-2.0 Apache-2.0
3 | # Author Nito T.M. (https://github.com/nitotm)
4 | # Package pypi.org/project/eld/
5 |
6 | import importlib.util
7 | import os
8 |
9 |
10 | class LanguageData:
11 | def __init__(self):
12 | from .resources.avg_score import avg_score
13 | self.avg_score = avg_score
14 | self.ngrams = {}
15 | self.lang_score = []
16 | self.lang_codes = {}
17 | self.type = ''
18 | self.folder = os.path.dirname(__file__) + '/resources/ngrams/'
19 |
20 | # ISO 639-1 codes, for the 60 languages set.
21 | # ['am', 'ar', 'az', 'be', 'bg', 'bn', 'ca', 'cs', 'da', 'de', 'el', 'en', 'es', 'et', 'eu', 'fa', 'fi', 'fr', 'gu',
22 | # 'he', 'hi', 'hr', 'hu', 'hy', 'is', 'it', 'ja', 'ka', 'kn', 'ko', 'ku', 'lo', 'lt', 'lv', 'ml', 'mr', 'ms', 'nl',
23 | # 'no', 'or', 'pa', 'pl', 'pt', 'ro', 'ru', 'sk', 'sl', 'sq', 'sr', 'sv', 'ta', 'te', 'th', 'tl', 'tr', 'uk', 'ur',
24 | # 'vi', 'yo', 'zh']
25 |
26 | # ['Amharic', 'Arabic', 'Azerbaijani (Latin)', 'Belarusian', 'Bulgarian', 'Bengali', 'Catalan', 'Czech', 'Danish',
27 | # 'German', 'Greek', 'English', 'Spanish', 'Estonian', 'Basque', 'Persian', 'Finnish', 'French', 'Gujarati',
28 | # 'Hebrew', 'Hindi', 'Croatian', 'Hungarian', 'Armenian', 'Icelandic', 'Italian', 'Japanese', 'Georgian', 'Kannada',
29 | # 'Korean', 'Kurdish (Arabic)', 'Lao', 'Lithuanian', 'Latvian', 'Malayalam', 'Marathi', 'Malay (Latin)', 'Dutch',
30 | # 'Norwegian', 'Oriya', 'Punjabi', 'Polish', 'Portuguese', 'Romanian', 'Russian', 'Slovak', 'Slovene', 'Albanian',
31 | # 'Serbian (Cyrillic)', 'Swedish', 'Tamil', 'Telugu', 'Thai', 'Tagalog', 'Turkish', 'Ukrainian', 'Urdu',
32 | # 'Vietnamese', 'Yoruba', 'Chinese']
33 |
34 | def load_ngrams(self, subset_file=''):
35 | if subset_file == '':
36 | from .resources.ngrams.ngramsM60 import ngrams_data
37 | else:
38 | # module = importlib.import_module('.ngrams.' + subset_file)
39 | file_path = self.folder + subset_file + '.py'
40 | if not os.path.exists(file_path):
41 | file_path = self.folder + 'subset/' + subset_file + '.py'
42 | spec = importlib.util.spec_from_file_location(subset_file, file_path)
43 | module = importlib.util.module_from_spec(spec)
44 | spec.loader.exec_module(module)
45 | ngrams_data = module.ngrams_data
46 |
47 | self.ngrams = ngrams_data['ngrams']
48 | self.lang_score = [0] * (max(ngrams_data['languages'].keys()) + 1)
49 | self.type = ngrams_data['type']
50 | self.lang_codes = ngrams_data['languages']
51 |
52 |
53 | languageData = LanguageData()
54 |
--------------------------------------------------------------------------------
/eld/languageDetector.py:
--------------------------------------------------------------------------------
1 | # Copyright 2023 Nito T.M.
2 | # License https://www.apache.org/licenses/LICENSE-2.0 Apache-2.0
3 | # Author Nito T.M. (https://github.com/nitotm)
4 | # Package pypi.org/project/eld/
5 |
6 | import regex as re
7 |
8 | from eld.languageData import languageData
9 | from eld.languageSubset import LanguageSubset
10 | from eld.languageResult import LanguageResult
11 |
12 |
13 | class LanguageDetector(LanguageSubset):
14 | def __init__(self, subset_file=''):
15 | super().__init__()
16 | languageData.load_ngrams(subset_file)
17 | self.__do_clean_text = False
18 | self.VERSION = '1.0.8' # Has to match pyproject.toml version
19 |
20 | def detect(self, text):
21 | """
22 | Returns the language detected for a given UTF-8 string, as an ISO 639-1 code
23 | LanguageResult object { language = 'es', scores() = {'es': 0.5, 'et': 0.2}, is_reliable() = True }
24 |
25 | Args:
26 | text (str): UTF-8 string
27 |
28 | Returns:
29 | object LanguageResult: language (str or None), scores() (dict or None), is_reliable() (bool)
30 | """
31 | if not isinstance(text, str):
32 | raise TypeError("Input 'text' must be a string.")
33 | if self.__do_clean_text:
34 | # Removes Urls, emails, alphanumerical & numbers
35 | text = get_clean_txt(text)
36 | text = _normalize_text(text)
37 | byte_ngrams = _get_byte_ngrams(text)
38 | num_ngrams = len(byte_ngrams)
39 | results = _calculate_scores(byte_ngrams, num_ngrams)
40 |
41 | if results:
42 | if self.subset:
43 | results = LanguageSubset._filter_lang_subset(self, results)
44 | results.sort(key=lambda x: -x[1])
45 | return LanguageResult(results, num_ngrams)
46 | return LanguageResult()
47 |
48 | def clean_text(self, set_bool):
49 | self.__do_clean_text = (True if set_bool else False)
50 |
51 |
52 | def _tokenizer(txt):
53 | return filter(None, re.split(b'\x20', txt))
54 |
55 |
56 | def get_clean_txt(txt):
57 | """Removes parts of a string, that may be considered as "noise" for language detection"""
58 | # Remove URLS
59 | txt = re.sub(r'[hw]((ttps?://(www\.)?)|ww\.)([^\s/?\.#-]+\.?)+(\/\S*)?', ' ', txt, flags=re.IGNORECASE)
60 | # Remove emails
61 | txt = re.sub(r'[a-zA-Z0-9.!$%&?+_`-]+@[A-Za-z0-9.-]+\.[A-Za-z0-9-]{2,64}', ' ', txt)
62 | # Remove .com domains
63 | txt = re.sub(r'([A-Za-z0-9-]+\.)+com(\/\S*|[^\pL])', ' ', txt)
64 | # Remove alphanumerical/number codes
65 | txt = re.sub(r'[a-zA-Z]*[0-9]+[a-zA-Z0-9]*', ' ', txt)
66 | return txt
67 |
68 |
69 | def _normalize_text(text):
70 | """Normalize special characters/word separators"""
71 | text = re.sub(r'[^\pL]+(? 350:
77 | # Cut to first whitespace after 350 byte length offset
78 | text = text[0:min(380, (text.find(b'\x20', 350) or 350))]
79 | return text
80 |
81 |
82 | def _calculate_scores(byte_ngrams, num_ngrams):
83 | """Calculate scores for each language from the given Ngrams"""
84 | lang_score = languageData.lang_score[:]
85 | for bytes_, frequency in byte_ngrams.items():
86 | if bytes_ in languageData.ngrams:
87 | lang_count = len(languageData.ngrams[bytes_])
88 | # Ngram score multiplier, the fewer languages found the more relevancy. Formula can be fine-tuned.
89 | if lang_count == 1:
90 | relevancy = 27 # Handpicked relevance multiplier, trial-error
91 | elif lang_count < 16:
92 | relevancy = (16 - lang_count) / 2 + 1
93 | else:
94 | relevancy = 1
95 |
96 | # Most time-consuming loop, do only the strictly necessary inside
97 | for lang, global_frequency in languageData.ngrams[bytes_].items():
98 | lang_score[lang] += (global_frequency / frequency if frequency > global_frequency
99 | else frequency / global_frequency) * relevancy + 2
100 | # This divisor will produce a final score between 0 - ~1, score could be >1. Can be improved.
101 | result_divisor = num_ngrams * 3.2
102 | results = []
103 | for lang in range(len(lang_score)):
104 | if lang_score[lang]:
105 | results.append([lang, lang_score[lang] / result_divisor]) # * languageData.scoreNormalizer[lang]
106 | return results
107 |
108 |
109 | def _get_byte_ngrams(txt):
110 | """Gets Ngrams from a given string"""
111 | byte_grams = {}
112 | count_ngrams = 0
113 |
114 | for word in _tokenizer(txt):
115 | length = len(word)
116 |
117 | if length > 70:
118 | length = 70
119 | x = 0
120 | for j in range(0, length - 4, 3):
121 | this_bytes = (b' ' if j == 0 else b'') + word[j:j + 4]
122 | byte_grams[this_bytes] = (1 + byte_grams[this_bytes] if this_bytes in byte_grams else 1)
123 | count_ngrams += 1
124 | x = 1
125 |
126 | this_bytes = (b' ' if x == 0 else b'') + word[length - 4 if length != 3 else 0:] + b' '
127 | byte_grams[this_bytes] = (1 + byte_grams[this_bytes] if this_bytes in byte_grams else 1)
128 | count_ngrams += 1
129 |
130 | # Frequency is multiplied by 15000 at the ngrams database. A reduced number (13200) seems to work better.
131 | # Linear formulas were tried, decreasing the multiplier for fewer ngram strings, no meaningful improvement.
132 | for bytes_, count in byte_grams.items():
133 | byte_grams[bytes_] = count / count_ngrams * 13200
134 |
135 | return byte_grams
136 |
--------------------------------------------------------------------------------
/eld/languageResult.py:
--------------------------------------------------------------------------------
1 | # Copyright 2023 Nito T.M.
2 | # License https://www.apache.org/licenses/LICENSE-2.0 Apache-2.0
3 | # Author Nito T.M. (https://github.com/nitotm)
4 | # Package pypi.org/project/eld/
5 |
6 | import json
7 | from eld.languageData import languageData
8 |
9 |
10 | class LanguageResult:
11 | def __init__(self, results=None, num_ngrams=None):
12 | self.language = (languageData.lang_codes[results[0][0]] if results else None)
13 | self.__results = results
14 | self.__num_ngrams = num_ngrams
15 |
16 | def __str__(self):
17 | return json.dumps({'