6 | 404! - Go home
7 |
8 | );
9 |
10 | export default NotFoundPage;
--------------------------------------------------------------------------------
/app-ui/src/components/SideBar.js:
--------------------------------------------------------------------------------
1 | import React from 'react';
2 | import { Link } from 'react-router-dom';
3 | import Drawer from '@material-ui/core/Drawer';
4 | import List from '@material-ui/core/List';
5 | import ListItem from '@material-ui/core/ListItem';
6 | import Divider from '@material-ui/core/Divider';
7 | import { withStyles } from '@material-ui/core/styles';
8 | import ListItemText from '@material-ui/core/ListItemText';
9 | import { PROJECT_TYPES } from './constants';
10 |
11 | const drawerWidth = 150;
12 |
13 | const styles = theme => ({
14 | drawer: {
15 | width: drawerWidth,
16 | flexShrink: 0
17 | },
18 | listItemRoot1: {
19 | "&.MuiListItem-root": {
20 | backgroundColor: 'red',
21 | color: 'white'
22 | }
23 | },
24 | listItemRoot2: {
25 | "&.MuiListItem-root": {
26 | backgroundColor: 'green',
27 | color: 'white'
28 | }
29 | },
30 | });
31 |
32 |
33 | class SideBar extends React.Component {
34 |
35 | render() {
36 | const { classes, ...rest } = this.props;
37 |
38 | return (
39 |
71 | )
72 | }
73 | }
74 |
75 | export default withStyles(styles)(SideBar);
76 | export { drawerWidth };
--------------------------------------------------------------------------------
/app-ui/src/components/constants.js:
--------------------------------------------------------------------------------
1 | const PROJECT_TYPES = { classification: "classification",
2 | ner: "ner",
3 | entity_disambiguation: "entity_disambiguation"};
4 |
5 | const PROJECT_TYPES_ABBREV = { classification: "classification",
6 | ner: "NER",
7 | entity_disambiguation: "entity linking"};
8 |
9 | const WIKI_DOCS_FILE_FORMAT = "";
10 | const DOCS_TEXT_FILE_FORMAT = "";
11 | const DOCS_CLASSNAME_FILE_FORMAT = "";
12 | const DOCS_MENTIONS_FILE_FORMAT = "";
13 | const DOCS_KB_FILE_FORMAT = "";
14 |
15 | const FILE_TYPE_DOCUMENTS = "documents";
16 | const FILE_TYPE_DOCUMENTS_WIKI = "documents_wiki";
17 | const FILE_TYPE_KB = "kb";
18 |
19 | const DEFAULT_WIKI_COLUMN = "url";
20 | const DEFAULT_TEXT_COLUMN = "text";
21 | const DEFAULT_CLASS_NAME_COLUMN = "label";
22 | const DEFAULT_MENTIONS_COLUMNS = ["text", "mentions"];
23 | const DEFAULT_KB_COLUMNS = ["name", "description"];
24 |
25 | export { PROJECT_TYPES,
26 | PROJECT_TYPES_ABBREV,
27 | DOCS_MENTIONS_FILE_FORMAT,
28 | DOCS_KB_FILE_FORMAT,
29 | DOCS_TEXT_FILE_FORMAT,
30 | DOCS_CLASSNAME_FILE_FORMAT,
31 | FILE_TYPE_DOCUMENTS,
32 | FILE_TYPE_KB,
33 | FILE_TYPE_DOCUMENTS_WIKI,
34 | DEFAULT_TEXT_COLUMN,
35 | DEFAULT_CLASS_NAME_COLUMN,
36 | DEFAULT_MENTIONS_COLUMNS,
37 | DEFAULT_KB_COLUMNS,
38 | DEFAULT_WIKI_COLUMN,
39 | WIKI_DOCS_FILE_FORMAT };
40 |
--------------------------------------------------------------------------------
/app-ui/src/components/file-upload/UploadFileButton.js:
--------------------------------------------------------------------------------
1 | import React from 'react';
2 | import Button from '@material-ui/core/Button';
3 | import CircularProgress from '@material-ui/core/CircularProgress';
4 |
5 | export const UploadFileButton = (props) => {
6 | console.log("Inside UploadFileButton", props);
7 | if(!props.loading){
8 | return (
9 |
20 | )
21 | }else{
22 | return (
23 |
55 |
63 |
64 |
65 |
73 |
74 |
75 |
83 |
84 |
85 | )
86 | }
87 | }
88 |
89 | export default withStyles(styles)(Text);
--------------------------------------------------------------------------------
/app-ui/src/components/label-page/supervised/classification/MainArea.js:
--------------------------------------------------------------------------------
1 | import React from 'react';
2 | import Paper from '@material-ui/core/Paper';
3 | import Grid from '@material-ui/core/Grid';
4 | import Typography from '@material-ui/core/Typography';
5 | import Navigation from './Navigation';
6 | import { withStyles } from '@material-ui/core/styles';
7 |
8 |
9 |
10 | const styles = theme => ({
11 | paper: {
12 | width: 'auto',
13 | minHeight: '200px',
14 | padding: theme.spacing(1),
15 | margin: theme.spacing(5)
16 | },
17 | container: {
18 | width: '80%',
19 | minHeight: '200px',
20 | padding: theme.spacing(1),
21 | margin: theme.spacing(5)
22 | },
23 | });
24 |
25 | // for message and inside main area
26 | const Container = (props) => {
27 | const { classes, ...rest } = props;
28 | return (
65 |
66 |
67 |
68 |
107 |
108 |
109 | )
110 | }
111 |
112 | export default PerformanceTable;
--------------------------------------------------------------------------------
/app-ui/src/components/project-summary/supervised/ProjectDataDrawers.js:
--------------------------------------------------------------------------------
1 | import React from 'react';
2 | import RuleTable from './RuleTable';
3 | import LabelTable from './LabelTable';
4 | import PerformanceTable from './PerformanceTable';
5 | import AppBar from '@material-ui/core/AppBar';
6 | import Tabs from '@material-ui/core/Tabs';
7 | import Tab from '@material-ui/core/Tab';
8 | import CircularProgress from '@material-ui/core/CircularProgress';
9 | import FileDownloadButton from '../common/FileDownloadButton';
10 | import DownloadUnlabeledDataButton from '../common/DownloadUnlabeledDataButton';
11 | import ExportRulesButton from './ExportRulesButton';
12 |
13 |
14 | class ProjectDataDrawers extends React.Component{
15 |
16 | state = {
17 | tab: 0
18 | }
19 |
20 | setTabValue = (e, value) => {
21 | this.setState({tab: value});
22 | }
23 |
24 | render(){
25 | if(!this.props.loading){
26 | return (
27 | 66 |
28 |
29 |
30 |
32 |
33 |
34 | {this.state.tab == 0 &&
35 |
52 |
53 | )
54 | }
55 | else{
56 | return (
57 |
58 |
62 | )
63 | }
64 | }
65 | }
66 |
67 | export default ProjectDataDrawers;
--------------------------------------------------------------------------------
/app-ui/src/components/project-summary/supervised/RuleTable.js:
--------------------------------------------------------------------------------
1 | import React from 'react';
2 | import { PROJECT_TYPES } from '../../constants';
3 | import RuleTableClassification from './classification/RuleTableClassification';
4 | import RuleTableNER from './ner/RuleTableNER';
5 |
6 |
7 | const RuleTable = (props) => {
8 | if(props.projectType == PROJECT_TYPES["classification"]){
9 | return (
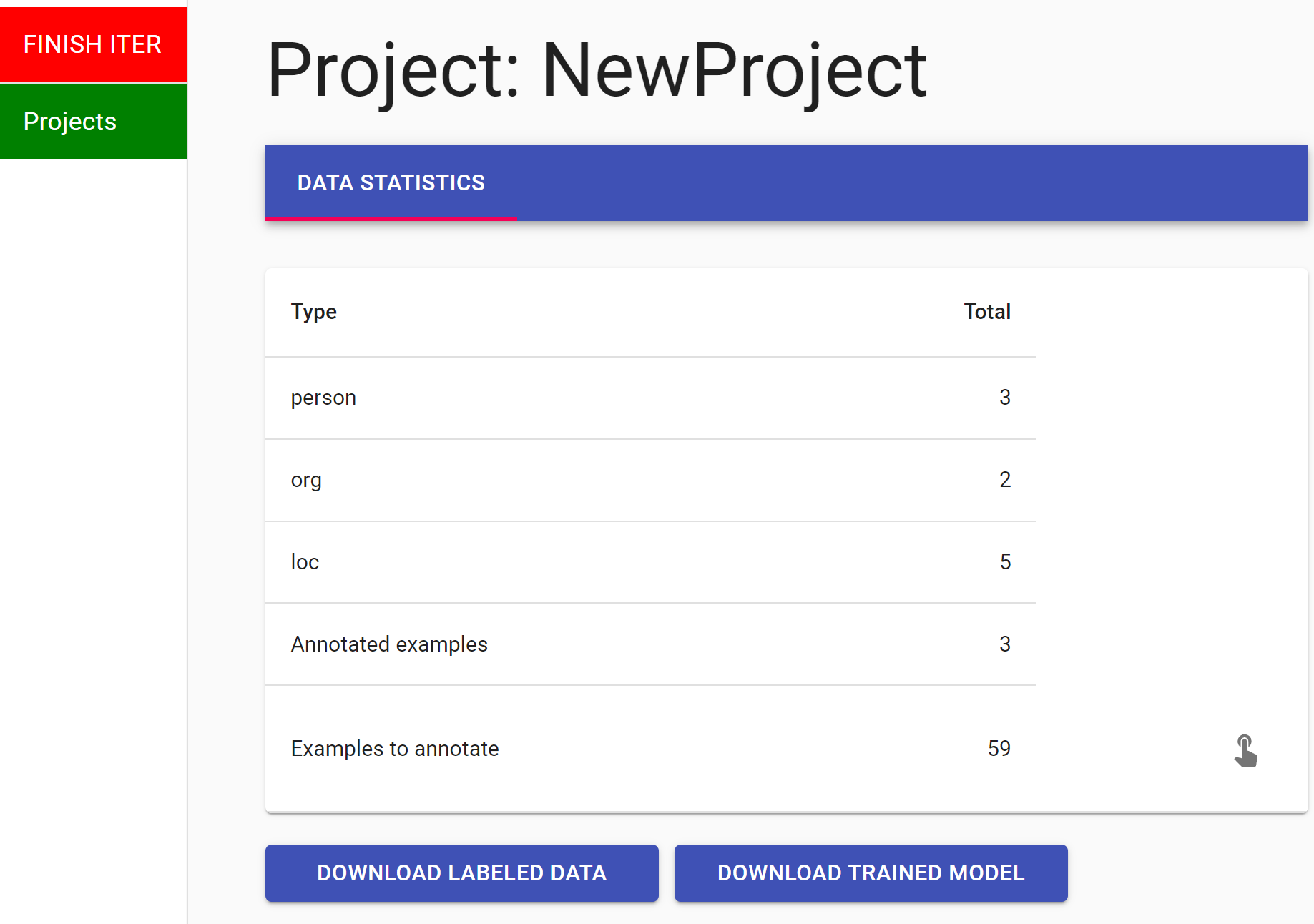
10 | Selecting best unlabeled examples for the next annotation iteration...
59 | 60 |
75 |
76 |
77 |
101 |
102 |
103 | )
104 | }
105 |
106 | export default LabelTableClassification;
--------------------------------------------------------------------------------
/app-ui/src/components/project-summary/supervised/ner/LabelTableNER.js:
--------------------------------------------------------------------------------
1 | import React from 'react';
2 | import { makeStyles } from '@material-ui/core/styles';
3 | import Table from '@material-ui/core/Table';
4 | import TableHead from '@material-ui/core/TableHead';
5 | import TableBody from '@material-ui/core/TableBody';
6 | import TableCell from '@material-ui/core/TableCell';
7 | import TableContainer from '@material-ui/core/TableContainer';
8 | import TableRow from '@material-ui/core/TableRow';
9 | import Paper from '@material-ui/core/Paper';
10 | import TouchAppIcon from '@material-ui/icons/TouchApp';
11 | import IconButton from '@material-ui/core/IconButton';
12 | import Tooltip from '@material-ui/core/Tooltip';
13 |
14 |
15 | const useStyles = makeStyles({
16 | tablecell: {
17 | fontSize: '80%'
18 | }
19 | });
20 |
21 | const useStyles2 = makeStyles({
22 | tablecell: {
23 | fontSize: '80%',
24 | fontWeight: 'bold',
25 | color: '#0089de'
26 | }
27 | });
28 |
29 | const StyledTableCell = (props) => {
30 | const classes = useStyles();
31 | return (
32 |
119 |
120 |
121 |
152 |
153 |
154 | )
155 | }
156 |
157 | export default LabelTableNER;
--------------------------------------------------------------------------------
/app-ui/src/components/projects/Projects.js:
--------------------------------------------------------------------------------
1 | import React from 'react';
2 | import AddIcon from '@material-ui/icons/Add';
3 | import IconButton from '@material-ui/core/IconButton';
4 | import { withStyles } from '@material-ui/core/styles';
5 | import { Link } from 'react-router-dom';
6 | import Card from '@material-ui/core/Card';
7 | import CardContent from '@material-ui/core/CardContent';
8 | import Typography from '@material-ui/core/Typography';
9 | import Grid from '@material-ui/core/Grid';
10 | import { trimString } from '../../utils';
11 | import { PROJECT_TYPES_ABBREV } from '../constants';
12 |
13 | const MAX_PROJECT_NAME_LENGTH = 20;
14 |
15 | const styles = theme => ({
16 | button_root: {
17 | height: '100%',
18 | width: '100%'
19 | },
20 | icon_root: {
21 | height: '50%',
22 | width: '50%'
23 | },
24 | card: {
25 | height: '150px',
26 | width: '150px',
27 | justifyContent: 'center',
28 | display: 'flex',
29 | alignItems: 'center',
30 | position: 'relative'
31 | },
32 | container: {
33 | marginTop: '20px'
34 | },
35 | main_div: {
36 | margin: '20px'
37 | },
38 | new_banner: { position: 'absolute',
39 | top: '10px',
40 | right: '10px' ,
41 | color: theme.palette.secondary.main,
42 | fontWeight: 'bold'}
43 | });
44 |
45 | const Container = (props) => {
46 | const { classes, ...rest } = props;
47 | return (
64 | {PROJECT_TYPES_ABBREV[props.projectType]}
65 |
66 |
134 | My projects
135 |
137 | )
138 | }
139 | }
140 |
141 | export default withStyles(styles)(Projects);
--------------------------------------------------------------------------------
/app-ui/src/components/rules/main-page/ImportRuleCard.js:
--------------------------------------------------------------------------------
1 | import Card from '@material-ui/core/Card';
2 | import CardContent from '@material-ui/core/CardContent';
3 | import CardActionArea from '@material-ui/core/CardActionArea';
4 | import Typography from '@material-ui/core/Typography';
5 | import React from 'react';
6 | import $ from 'jquery';
7 | import { Redirect } from 'react-router-dom';
8 | import uuid from 'react-uuid';
9 | import CircularProgress from '@material-ui/core/CircularProgress';
10 |
11 |
12 |
13 | const IMPORT_PARAMS = {
14 | totalAttempts: 16,
15 | timeAttemptms: 15000
16 | }
17 |
18 | class ImportRuleCard extends React.Component{
19 | state = {toProjectSummary: false,
20 | importingLoading: false}
21 |
22 | importRulesEndPoint = (selectedFile,
23 | projectName,
24 | importId,
25 | attemptNum,
26 | polling) => {
27 | const data = new FormData();
28 | console.log("Inside importRulesEndPoint", attemptNum, polling, selectedFile);
29 | data.append('file', selectedFile);
30 | data.append('project_name', projectName);
31 | data.append('polling', polling);
32 | data.append('import_id', importId);
33 |
34 | $.ajax({
35 | url : '/api/import-rules',
36 | type : 'POST',
37 | data : data,
38 | processData: false, // tell jQuery not to process the data
39 | contentType: false, // tell jQuery not to set contentType,
40 | timeout: 60000,
41 | success : function(data) {
42 | console.log("import rules data: ", data);
43 | const jsonData = JSON.parse(data);
44 | console.log("jsonData", jsonData);
45 | const importIdFromServer = jsonData.id;
46 |
47 | if(!importIdFromServer){
48 | if(attemptNum < IMPORT_PARAMS.totalAttempts){
49 | setTimeout(() => this.importRulesEndPoint(
50 | selectedFile,
51 | projectName,
52 | importId,
53 | attemptNum+1,
54 | true),
55 | IMPORT_PARAMS.timeAttemptms);
56 | }
57 | else{
58 | alert("Server timed out");
59 | this.setState( {importingLoading: false} );
60 | }
61 | }
62 | else{
63 | var today = new Date();
64 | console.log("Rules imported successfully", today.toLocaleString());
65 | this.setState( {toProjectSummary: true,
66 | importingLoading: false} );
67 | }
68 | }.bind(this),
69 | error: function (xmlhttprequest, textstatus, message) {
70 | console.log("Error", textstatus, message);
71 | if(textstatus==="timeout" & attemptNum < IMPORT_PARAMS.totalAttempts) {
72 | setTimeout(() => this.importRulesEndPoint(
73 | selectedFile,
74 | projectName,
75 | importId,
76 | attemptNum+1,
77 | true),
78 | IMPORT_PARAMS.timeAttemptms);
79 | }
80 | else{
81 | alert("Error importing rules");
82 | this.setState( {importingLoading: false} );
83 | }
84 | }.bind(this)
85 | });
86 |
87 | this.setState( {importingLoading: true} );
88 | }
89 |
90 | importRules = (e, projectName) => {
91 | e.preventDefault;
92 | const selectedFile = e.target.files[0];
93 | if(!selectedFile){
94 | alert("Need to select file!");
95 | }else{
96 | this.importRulesEndPoint(selectedFile,
97 | projectName,
98 | uuid(),
99 | 0,
100 | false);
101 | }
102 | e.target.value = null;
103 | }
104 |
105 | render() {
106 |
107 | if(this.state.toProjectSummary === true) {
108 | return 75 |
88 |
123 | )
124 | }
125 |
126 | export default RuleMain;
--------------------------------------------------------------------------------
/app-ui/src/components/rules/rule-forms/base/CaseSensitive.js:
--------------------------------------------------------------------------------
1 | import React from 'react';
2 | import OptionSelection from './OptionSelection';
3 |
4 |
5 | const CaseSensitive = () => {
6 | return (
7 |
93 |
94 | Add rules.
95 |
96 |
97 | {
98 | rules.map((rule, index) => (
99 | -
100 |
104 |
111 | ))
112 | }
113 | -
114 |
120 |
121 |
122 |
24 |
25 | {props.addText &&
26 | -
27 |
Then it's most likely class:
28 |
29 | }
30 | -
31 |
option.name}
35 | onChange={props.setClass}
36 | style={{ width: 300 }}
37 | renderInput={(params) =>
43 |
44 |
45 | )
46 | }
47 |
48 | export default ClassDefinitionBox;
--------------------------------------------------------------------------------
/app-ui/src/components/rules/rule-forms/base/ContainOrDoesNotContain.js:
--------------------------------------------------------------------------------
1 | import React from 'react';
2 | import OptionSelection from './OptionSelection';
3 |
4 |
5 | const ContainOrDoesNotContain = () => {
6 | return (
7 |
7 | {
8 | props.options.map((option, index) => (
9 |
21 | )
22 | }
23 |
24 | export default OptionSelection;
--------------------------------------------------------------------------------
/app-ui/src/components/rules/rule-forms/base/RuleSubmit.js:
--------------------------------------------------------------------------------
1 | import React from 'react';
2 | import InputField from '../base/InputField';
3 | import RuleSubmitButton from '../base/RuleSubmitButton';
4 | import Grid from '@material-ui/core/Grid';
5 |
6 |
7 | const Container = (props) => {
8 | const { classes, ...rest } = props;
9 | return (
10 |
16 |
17 |
18 | ))
19 | }
20 |
25 |
37 | );
38 | }
39 |
40 | if(props.projectType == PROJECT_TYPES.ner){
41 | console.log("Inside LabelComponent", props);
42 |
43 | let entities;
44 | if(props.currentDisplayedLabels){
45 | entities = props.currentDisplayedLabels.map((x, ind) => x && props.classNames[x.entityId]);
46 | console.log("Inside MainArea,", entities);
47 | entities = _.uniqBy(entities, 'id');
48 | }else{
49 | entities = [];
50 | }
51 |
52 | console.log("Inside MainArea,", entities);
53 | const EntitySet = new Set(entities.map((x, ind) => x.id))
54 |
55 | // all the entities that are not in the text and will populate the search
56 | const otherEntities = props.classNames.filter(x => !EntitySet.has(x.id));
57 |
58 | return (
59 |
60 |
73 | )
74 | }
75 | };
76 |
77 |
78 | export default LabelComponent;
79 |
--------------------------------------------------------------------------------
/app-ui/src/components/search/Result.js:
--------------------------------------------------------------------------------
1 | import PropTypes from "prop-types";
2 | import React from "react";
3 |
4 | import { appendClassName, getUrlSanitizer } from "@elastic/react-search-ui-views/lib/view-helpers";
5 | import { isFieldValueWrapper } from "@elastic/react-search-ui-views/lib/types/FieldValueWrapper";
6 |
7 |
8 | const DISPLAYED_FIELDS = ["id", "text"]
9 |
10 | function getFieldType(result, field, type) {
11 | if (result[field]) return result[field][type];
12 | }
13 |
14 | function getRaw(result, field) {
15 | return getFieldType(result, field, "raw");
16 | }
17 |
18 | function getSnippet(result, field) {
19 | return getFieldType(result, field, "snippet");
20 | }
21 |
22 | function htmlEscape(str) {
23 | if (!str) return "";
24 |
25 | return String(str)
26 | .replace(/&/g, "&")
27 | .replace(/"/g, """)
28 | .replace(/'/g, "'")
29 | .replace(//g, ">");
31 | }
32 |
33 | function getEscapedField(result, field) {
34 | // Fallback to raw values here, because non-string fields
35 | // will not have a snippet fallback. Raw values MUST be html escaped.
36 | const safeField =
37 | getSnippet(result, field) || htmlEscape(getRaw(result, field));
38 | return Array.isArray(safeField) ? safeField.join(", ") : safeField;
39 | }
40 |
41 | function getField(result, field) {
42 | // Fallback to raw values here, because non-string fields
43 | // will not have a snippet fallback. Raw values MUST be html escaped.
44 | const safeField =
45 | getSnippet(result, field) || getRaw(result, field);
46 | return Array.isArray(safeField) ? safeField.join(", ") : `${safeField}`;
47 | }
48 |
49 | function getEscapedFields(result) {
50 | return Object.keys(result).reduce((acc, field) => {
51 | // If we receive an arbitrary value from the response, we may not properly
52 | // handle it, so we should filter out arbitrary values here.
53 | //
54 | // I.e.,
55 | // Arbitrary value: "_metaField: '1939191'"
56 | // vs.
57 | // FieldValueWrapper: "_metaField: {raw: '1939191'}"
58 | if (!isFieldValueWrapper(result[field])) return acc;
59 | // return { ...acc, [field]: getEscapedField(result, field) };
60 | return { ...acc, [field]: getField(result, field) };
61 | }, {});
62 | }
63 |
64 | function Result({
65 | className,
66 | result,
67 | onClickLink,
68 | titleField,
69 | urlField,
70 | labelComponent,
71 | getSearchTextComponent,
72 | ...rest
73 | }) {
74 | const fields = Object.fromEntries(DISPLAYED_FIELDS.map(k => [k, getEscapedFields(result)[k]]));
75 | console.log("Inside Result", result, fields);
76 | const title = getEscapedField(result, titleField);
77 | const url = getUrlSanitizer(URL, location)(getRaw(result, urlField));
78 |
79 | return (
80 |
100 |
109 | {labelComponent}
110 | -
101 | {Object.entries(fields).map(([fieldName, fieldValue]) => (
102 |
- 103 | {fieldName}{" "} 104 | {getSearchTextComponent(fieldValue)} 105 | 106 | ))} 107 |
36 | {props.withText && props.addAppliedRuleFilter(x['id']))}
53 | onDelete={props.removeAppliedRuleFilter && (() => props.removeAppliedRuleFilter(x['id']))}
54 | />)}
55 |
56 | {props.rules.length > MAX_FILTERS_DISPLAYED_UNDERNEATH &&
57 |
58 | More
59 |
71 |
72 | }
73 |
74 |
75 | );
76 | }
77 |
78 | export default withStyles(styles)(RuleFilters);
--------------------------------------------------------------------------------
/app-ui/src/components/search/buildRequest.js:
--------------------------------------------------------------------------------
1 |
2 | function buildFrom(current, resultsPerPage) {
3 | if (!current || !resultsPerPage) return;
4 | return (current - 1) * resultsPerPage;
5 | }
6 |
7 | function buildMatch(searchTerm) {
8 | return searchTerm
9 | ? {
10 | multi_match: {
11 | query: searchTerm,
12 | fields: ["text"]
13 | }
14 | }
15 | : { match_all: {} };
16 | }
17 |
18 |
19 | function buildRuleFilter(appliedRuleFilters) {
20 | return appliedRuleFilters.map((rule) => {
21 | return ({
22 | "nested": {
23 | "path": "rules",
24 | "query": {
25 | "bool": {
26 | "must": [
27 | {
28 | "match": {
29 | "rules.rule_id": rule.id
30 | }
31 | }
32 | ]
33 | }
34 | }
35 | }
36 | })
37 | })
38 | }
39 |
40 | function buildTableFilter() {
41 | return {
42 | "match": {
43 | "is_table": {
44 | "query": "true"
45 | }
46 | }
47 | }
48 | }
49 |
50 | function buildFilters(appliedRuleFilters, filterTables){
51 | let ruleFilters = buildRuleFilter(appliedRuleFilters);
52 | if(filterTables){
53 | return ruleFilters.concat(buildTableFilter())
54 | }
55 | return ruleFilters;
56 | }
57 |
58 | /*
59 | Converts current application state to an Elasticsearch request.
60 | When implementing an onSearch Handler in Search UI, the handler needs to take the
61 | current state of the application and convert it to an API request.
62 | For instance, there is a "current" property in the application state that you receive
63 | in this handler. The "current" property represents the current page in pagination. This
64 | method converts our "current" property to Elasticsearch's "from" parameter.
65 | This "current" property is a "page" offset, while Elasticsearch's "from" parameter
66 | is a "item" offset. In other words, for a set of 100 results and a page size
67 | of 10, if our "current" value is "4", then the equivalent Elasticsearch "from" value
68 | would be "40". This method does that conversion.
69 | We then do similar things for searchTerm, filters, sort, etc.
70 | */
71 | export default function buildRequest(state) {
72 | const {
73 | current,
74 | resultsPerPage,
75 | searchTerm,
76 | appliedRuleFilters,
77 | filterTables
78 | } = state;
79 |
80 | const match = buildMatch(searchTerm);
81 | const filters = buildFilters(appliedRuleFilters, filterTables);
82 | const size = resultsPerPage;
83 | const from = buildFrom(current, resultsPerPage);
84 |
85 | const body = {
86 | // Static query Configuration
87 | // --------------------------
88 | // https://www.elastic.co/guide/en/elasticsearch/reference/7.x/search-request-highlighting.html
89 | highlight: {
90 | number_of_fragments: 0,
91 | fields: {
92 | text: {}
93 | }
94 | },
95 | //https://www.elastic.co/guide/en/elasticsearch/reference/7.x/search-request-source-filtering.html#search-request-source-filtering
96 | _source: ["id", "text", "manual_label.*"],
97 |
98 | // Dynamic values based on current Search UI state
99 | // --------------------------
100 | // https://www.elastic.co/guide/en/elasticsearch/reference/7.x/full-text-queries.html
101 | query: {
102 | bool: {
103 | must: filters.concat(match)
104 | }
105 | },
106 | // https://www.elastic.co/guide/en/elasticsearch/reference/7.x/search-request-from-size.html
107 | ...(size && { size }),
108 | ...(from && { from })
109 | };
110 |
111 | console.log("Inside buildRequest", state, body, filters);
112 |
113 | return body;
114 | }
--------------------------------------------------------------------------------
/app-ui/src/components/search/buildState.js:
--------------------------------------------------------------------------------
1 | import { renameKeysToCamelCase } from '../utils';
2 |
3 |
4 | function buildTotalPages(resultsPerPage, totalResults) {
5 | if (!resultsPerPage) return 0;
6 | if (totalResults === 0) return 1;
7 | return Math.ceil(totalResults / resultsPerPage);
8 | }
9 |
10 | function buildTotalResults(hits) {
11 | return hits.total.value;
12 | }
13 |
14 | function getHighlight(hit, fieldName) {
15 | if (
16 | !hit.highlight ||
17 | !hit.highlight[fieldName] ||
18 | hit.highlight[fieldName].length < 1
19 | ) {
20 | return;
21 | }
22 |
23 | return hit.highlight[fieldName][0];
24 | }
25 |
26 | function buildResults(hits) {
27 | const addEachKeyValueToObject = (acc, [key, value]) => ({
28 | ...acc,
29 | [key]: value
30 | });
31 |
32 | const toObject = (value, snippet) => {
33 | return { raw: value, ...(snippet && { snippet }) };
34 | };
35 |
36 | return hits.map(record => {
37 | return Object.entries(record._source)
38 | .map(([fieldName, fieldValue]) => [
39 | fieldName,
40 | toObject(fieldValue, getHighlight(record, fieldName))
41 | ])
42 | .reduce(addEachKeyValueToObject, {});
43 | });
44 | }
45 |
46 | /*
47 | Converts an Elasticsearch response to new application state
48 | When implementing an onSearch Handler in Search UI, the handler needs to convert
49 | search results into a new application state that Search UI understands.
50 | For instance, Elasticsearch returns "hits" for search results. This maps to
51 | the "results" property in application state, which requires a specific format. So this
52 | file iterates through "hits" and reformats them to "results" that Search UI
53 | understands.
54 | We do similar things for facets and totals.
55 | */
56 | export default function buildState(response, resultsPerPage) {
57 | const results = buildResults(response.hits.hits);
58 | const modifiedResults = renameKeysToCamelCase(results);
59 | const modifiedResultsArray = Object.keys(modifiedResults).map(function (key) { return modifiedResults[key]; });
60 |
61 | const totalResults = buildTotalResults(response.hits);
62 | const totalPages = buildTotalPages(resultsPerPage, totalResults);
63 |
64 | console.log("Running renameKeysToCamelCase, ", results, modifiedResults, modifiedResultsArray, totalResults,
65 | totalPages);
66 |
67 | return {
68 | results: modifiedResultsArray,
69 | totalPages,
70 | totalResults
71 | };
72 | }
--------------------------------------------------------------------------------
/app-ui/src/components/search/getSearchTextComponent.js:
--------------------------------------------------------------------------------
1 | import React from "react";
2 | import Typography from '@material-ui/core/Typography';
3 | import HighlightableText from '../label-page/supervised/ner/HighlightableText';
4 | import { PROJECT_TYPES } from '../constants';
5 |
6 |
7 | function getSearchTextComponent(fieldValue,
8 | projectType,
9 | classNames,
10 | currentSelectedEntityId,
11 | currentDisplayedLabels,
12 | addTextSpan,
13 | deleteTextSpan) {
14 | if(projectType==PROJECT_TYPES.classification){
15 | return (
16 |
20 | )
21 | }
22 |
23 | if(projectType==PROJECT_TYPES.ner){
24 | const entityColourMap = classNames.reduce(function(obj, itm) {
25 | obj[itm['id']] = itm['colour'];
26 |
27 | return obj;
28 | }, {});
29 |
30 | const content = fieldValue.replace(//g, '').replace(/<\/em>/g, '');
31 | return (
32 | {"Filters:"}
} 37 | {props.hasTables && !props.filterTables &&
62 | NEW
63 |
64 | }
65 |
111 |
123 | )
124 | }
125 | }
126 |
127 | export default withStyles(styles)(WelcomePage);
128 |
--------------------------------------------------------------------------------
/app-ui/src/routers/ProjectStartPage.js:
--------------------------------------------------------------------------------
1 | import React from 'react';
2 | import ProjectMain from '../components/project-summary/ProjectMain';
3 | import FileUploadMain from '../components/file-upload/FileUploadMain';
4 | import NotFoundPage from '../components/NotFoundPage';
5 | import ProjectParamsPage from '../components/set-project-params/ProjectParamsPage';
6 |
7 |
8 | class ProjectStartPage extends React.Component {
9 |
10 | constructor(props){
11 | super(props);
12 | this.props.setAllProjectVars(this.props.uri);
13 |
14 | console.log("Inside ProjectStartPage", this.props);
15 | }
16 |
17 | componentDidUpdate(prevProps, prevState) {
18 | console.log("ProjectStartPage did update", prevState, prevProps, this.props);
19 | }
20 |
21 | render() {
22 | if(!this.props.projectName){
23 | return
113 |
114 | FAMIE: A Fast Active Learning Framework for Multilingual Information Extraction
115 |
116 |
122 |