├── .gitattributes
├── .gitignore
├── Cache
├── Redis.md
└── redis.png
├── Linux
├── AWK.md
├── LinuxIO模型.md
├── Linux命令.md
├── Linux命令2.md
├── Nginx.md
├── README.md
├── Sed.md
├── Vim.md
├── crontab.md
├── crontab.png
├── hard.png
├── inode.md
├── lanmp.md
├── shell.md
└── 进程和线程.md
├── MQ
├── README.md
├── images
│ ├── 20140220173559828
│ ├── 20151201162724900.jpg
│ ├── 20151201162752176.jpg
│ ├── 20151201162825775.jpg
│ ├── 20151201162841986.jpg
│ ├── 20151201162903057.jpg
│ ├── 20151201162920224.jpg
│ ├── 20160516173232943
│ ├── 20160516173308130
│ ├── 20161018130024488
│ ├── 20161018144117548
│ ├── 20161103174653291.jpg
│ ├── 20161103182929513.jpg
│ ├── 20161103182938987.jpg
│ ├── 306976-20160728104237622-1486261669.png
│ ├── 306976-20160728104255372-2049742072.png
│ ├── 306976-20160728104309934-1385658660.png
│ ├── 52im_1.png
│ ├── 61c6fd8e58722d438da19445c8016395.png
│ ├── 820332-20160124211106000-2080222350.png
│ ├── 820332-20160124211115703-218873208.png
│ ├── 820332-20160124211131625-1083908699.png
│ ├── 820332-20160124220821515-1142658553.jpg
│ ├── 820332-20160124220830750-1886187340.jpg
│ ├── 91a956e890623d5f05b3dac013d8dd3a.png
│ ├── Decorator.jpg
│ ├── Pic90.gif
│ ├── a0d2f7ae4bc26ac1b0534660b51af7b9.png
│ ├── addea89be214fa66a0d45db711da4f91.png
│ ├── f88e45bdce945fe93c31d68df4059146.png
│ ├── uml6.png
│ ├── v63YbyA.png
│ ├── vi-vim-cheat-sheet-sch1.gif
│ └── vim-vi-workmodel.png
├── question.md
└── rabbitmq.md
├── MongoDb
└── MongoDB.md
├── Mysql
├── MySQL三范式.md
├── MySQL优化.md
├── MySQL索引原理及慢查询优化.md
├── README.md
├── SQL标准.md
├── explain.md
├── mysql.md
├── 事务.md
├── 存储引擎.md
├── 索引.md
└── 锁.md
├── PHP
├── PHP-FPM配置选项.md
├── PHP-Zval结构.md
├── PHP7-HashTable.md
├── PHP手册笔记
│ ├── 0.php在unix平台安装.md
│ ├── 1.基本语法.md
│ ├── 10.错误和异常处理.md
│ ├── 2-变量和常量.md
│ ├── 3-运算符.md
│ ├── 4.流程控制.md
│ ├── 5.函数.md
│ ├── 6.面向对象(OOP).md
│ ├── 7.面向对象(OOP).md
│ ├── 8.面向对象(OOP).md
│ └── 9.命名空间.md
├── PHP运行原理.md
├── README.md
├── php7.md
└── 正则表达式.md
├── README.md
├── SUMMARY.md
├── _config.yml
├── book.json
├── mirror
├── mm_reward_qrcode.jpg
├── 操作系统
├── Readme.md
└── 进程和线程.md
├── 数据结构
├── Leetcode经典二叉树题目集合.md
├── README.md
├── images
│ ├── Node.jpg
│ ├── array.jpg
│ └── doubleLink.jpg
├── 二叉树基本操作.md
├── 堆栈.md
├── 字符串.md
├── 散列表.md
├── 数组.md
└── 链表.md
├── 架构和系统设计
├── API设计.md
└── README.md
├── 版本控制器
├── Git.md
├── Git_removeCommits.md
├── REAME.md
└── gitcheat.jpg
├── 算法
├── Readme.md
├── 二分查找.md
└── 动态规划.md
├── 计算机网络
├── HTTP2.md
├── HTTPS.md
├── HTTP协议.md
├── IP协议.md
├── README.md
├── TCP协议.md
├── UDP协议.md
├── Webscokt.md
└── images
│ ├── 01.png
│ ├── 02.png
│ ├── 04.png
│ ├── 5.png
│ ├── 6.png
│ ├── http2.png
│ ├── https.png
│ ├── tcp-2.png
│ ├── tcp-byte-stream.png
│ ├── tcp-four-disconnect-1-1.png
│ ├── tcp-four-disconnect-1-2.png
│ ├── tcp-four-disconnect-1.png
│ ├── tcp-four-disconnect-2-1.png
│ ├── tcp-four-disconnect-2-2.png
│ ├── tcp-four-disconnect-3-1.png
│ ├── tcp-four-disconnect-3-2.png
│ ├── tcp-four-disconnect-4-1.png
│ ├── tcp-four-disconnect-4-2.png
│ ├── tcp-four-disconnect.png
│ ├── tcp-handshake-1-1.png
│ ├── tcp-handshake-1.png
│ ├── tcp-handshake-2-1.png
│ ├── tcp-handshake-2.png
│ ├── tcp-handshake-3-1.png
│ ├── tcp-handshake-3.png
│ ├── tcp-ip-header-map.png
│ ├── tcp-ip-protocal.png
│ ├── tcp-packets-header.png
│ ├── tcp-three-way-handshake.png
│ ├── tcp-three-way-handshake2.png
│ ├── tcp-wireshark.png
│ ├── udp-1.png
│ ├── udp-2.png
│ └── udp-3.png
├── 设计模式
├── Behavioral.md
├── Creational.md
├── README.md
└── Structural.md
└── 面试
├── 01.png
├── 01离职原因回答.md
├── 02写简历.md
├── 03裸辞应对.md
├── 04面试提问.md
├── 05谈薪资.md
├── README.md
├── 笔试题.md
├── 笔试题2.md
├── 笔试题3.md
├── 笔试题4.md
└── 面试总结.md
/.gitattributes:
--------------------------------------------------------------------------------
1 | *.md linguist-language=php
2 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | /node_modules
2 | /vendor
3 | /.idea
4 | /.vscode
5 | /.vagrant
6 | .env
7 | /_book
--------------------------------------------------------------------------------
/Cache/Redis.md:
--------------------------------------------------------------------------------
1 | ## redis
2 |
3 | redis是一个开源的支持多种数据类型的key=>value的存储数据库。支持字符串、列表、集合、有序集合、哈希五种类型
4 |
5 | 图片过大,请下载到本地打开
6 |
7 | 
8 |
9 | ### redis 和memcache区别
10 |
11 | 1. Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储。
12 |
13 | 2. Redis支持数据的备份,即master-slave模式的数据备份。
14 |
15 | 3. Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
16 |
17 |
18 |
19 | ### redis五种类型
20 |
21 | #### 字符串
22 |
23 | > set 、get、append、strlen
24 |
25 | ### 列表
26 |
27 | > lpush lpop rpop rpush llen lrem lset
28 |
29 | #### 集合
30 |
31 | > sadd、smembers、sdiff、spop 、srem、scard
32 |
33 | #### 有序集合
34 |
35 | > zadd、 zcount、zrem、zrank、
36 |
37 | #### 哈希
38 |
39 | > hset、hget、hmget、hmset、hkeys、hlen、hsetnx、hvals
40 |
41 |
42 | ### redis 各种类型的场景使用
43 |
44 | - string 就是存储简单的key=>value的字符串
45 | - list 使用场景。做先进先出的消费队列
46 | - set 进行集合过滤重复元素
47 | - zset 有序集合,排行榜 TOP N
48 | - hash 适合存储一组数据,比如用户的信息 以用户id为键,里面记录用户的昵称等信息。
--------------------------------------------------------------------------------
/Cache/redis.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/Cache/redis.png
--------------------------------------------------------------------------------
/Linux/AWK.md:
--------------------------------------------------------------------------------
1 | ## AWK题目练习
2 |
3 | ### awk工作原理
4 |
5 | ## AWK工作原理
6 |
7 | - 第一步:执行BEGIN{action;… }语句块中的语句
8 | - 第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{action;… }语句块,它逐行扫描文件,从第
9 | 一行到最后一行重复这个过程,直到文件全部被读取完毕。
10 | - 第三步:当读至输入流末尾时,执行END{action;…}语句块BEGIN语句块在awk开始从输入流中读取行之前被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中END语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块pattern语句块中的通用命令是最重要的部分,也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行, awk读取的每一行都会执行该语句块
11 |
12 | ### awk 内置变量
13 |
14 | ARGC 命令行参数个数
15 |
16 | ARGV 命令行参数排列
17 |
18 | ENVIRON 支持队列中系统环境变量的使用
19 |
20 | FILENAME awk浏览文件名
21 |
22 | FNR 浏览文件的记录数
23 |
24 | FS 设置输入域分隔符,等价于命令行-F选项
25 |
26 | NF 浏览记录的域个数
27 |
28 | NR 已读的记录数
29 |
30 | OFS 输出域分隔符
31 |
32 | ORS 输出例句分隔符
33 |
34 | RS 控制记录分隔符
35 |
36 | 1. 打印出/etc/passwd中个的第一个域,并在前面追加"账号"
37 |
38 | ```shell
39 | cat /etc/passwd | awk -F ":" '{print "账号"$1}'
40 | ```
41 |
42 | 2. 打印出/etc/passwd 第三个域和第四个域
43 |
44 | ```shell
45 | cat /etc/passwd | awk -F ":" '{print $3,$4}'
46 | ```
47 |
48 | 3. 匹配/etc/passwd 第三域大于100的显示出完整信息
49 |
50 | ```shell
51 | cat /etc/passwd | awk -F ":" '{if($3 > 100) {print $0}}'
52 | ```
53 |
54 | 4. 打印行号小于15的,并且最后一域匹配bash的信息.
55 |
56 | NR表示行号。NF表示最后一个域 ~ 正则匹配符号。 // 正则表达式开始和结束符号
57 |
58 | ```shell
59 | cat /etc/passwd | awk -F ":" '{if($NR < 15 && $NF~/bash/) {print $0}}'
60 | ```
61 |
62 | 5. 打印出第三域数字之和
63 |
64 | ```SHELL
65 | awk -F ":" 'BEGIN{sum =0} {sum = sum+$3} END {print sum}'
66 | ```
67 |
68 | 6. 请匹配passwd最后一段域bash结尾的信息,有多少条
69 |
70 | ```shell
71 | awk -F ":" '{if( $NF~/bash/) {i++}} END {print i }'
72 | ```
73 |
74 | 7. 请同时匹配passwd文件中,带mail和bash的关键字的信息
75 |
76 | ```shell
77 | cat /etc/passwd | awk -F ":" '{if( $NF~/bash/ || $NF~/mail/) {print $0}} '
78 | ```
79 |
80 | 8. 统计/etc/fstab文件中每个文件系统类型出现的次数
81 |
82 | /^UUID/:模式匹配以UUID开头的行
83 |
84 | fs[$3]++:定义fs[]为关联数组下标是每条记录的第3个字段,数组的值是出现的次数
85 |
86 | for(i in fs){print i,fs[i]}:在每条记录都处理完之后,用for循环遍历数组,打印下标(文件类型)和数组元素值(文件类型出现的次数)
87 |
88 | ```shell
89 | awk '/^UUID/{fs[$3]++}END{for(i in fs){print i,fs[i]}}' /etc/fstab
90 | ```
91 |
92 | ### nginx日志分析
93 |
94 | 日志格式
95 |
96 | `'$remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" "$http_x_forwarded_for"' `
97 |
98 | **日志记录:**27.189.231.39 - - [09/Apr/2016:17:21:23 +0800] "GET /Public/index/images/icon_pre.png HTTP/1.1" 200 44668 "http://www.test.com/Public/index/css/global.css" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36" "-"
99 |
100 | - 统计日志最多的10个IP
101 |
102 | ```shell
103 | awk '{arr[$1]++} END {for(i in arr) {print arr[i]}}' access.log | sort -k1 -nr | head -n10
104 | ```
105 |
106 | - 统计日志访问次数大于100次的IP
107 |
108 | ```shell
109 | awk '{arr[$1]++} END{for (i in arr) {if(arr[i] > 100){print $i}}}' access.log
110 | ```
111 |
112 | - 统计2016年4月9日内访问最多的10个ip
113 |
114 | ```shell
115 | awk '$4>="[09/Apr/2016:00:00:00" && $4<="[09/Apr/2016:23:59:59" {arr[i]++} END{print arr[i]}' |sort -k1 -nr|head -n10
116 | ```
117 |
118 | - 统计访问最多的十个页面
119 |
120 | ```shell
121 | awk '{a[$7]++}END{for(i in a)print a[i],i|"sort -k1 -nr|head -n10"}' access.log
122 | ```
123 |
124 | - 统计访问状态为404的ip出现的次数
125 |
126 | ```shell
127 | awk '{if($9~/404/)a[$1" "$9]++}END{for(i in a)print i,a[i]}' access.log
128 | ```
129 |
130 |
--------------------------------------------------------------------------------
/Linux/LinuxIO模型.md:
--------------------------------------------------------------------------------
1 | ## 概念说明
2 |
3 | ### 1. 内核空间、用户空间
4 |
5 | 操作系统的核心是内核,独立于其他应用程序,可以访问底层会保护的硬件,Linux**为了防止用户进程直接操作内核**,将虚拟地址空间,分成了用户空间和内核空间,用户空间就是用户进程所在的空间。
6 |
7 | ### 2. 进程切换
8 |
9 | 为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换。因此可以说,任何进程都是在操作系统内核的支持下运行的,是与内核紧密相关的
10 |
11 | 从一个进程的运行转到另一个进程上运行,这个过程中经过下面这些变化:
12 |
13 | > 1. 保存处理机上下文,包括程序计数器和其他寄存器。
14 | > 2. 更新PCB信息。
15 | > 3. 把进程的PCB移入相应的队列,如就绪、在某事件阻塞等队列。
16 | > 4. 选择另一个进程执行,并更新其PCB。
17 | > 5. 更新内存管理的数据结构。
18 | > 6. 恢复处理机上下文。
19 |
20 |
21 |
22 | ### 3. 进程的阻塞
23 |
24 | > 正在执行的进程,由于期待的某些事件未发生,如请求系统资源失败、等待某种操作的完成、新数据尚未到达或无新工作做等,则由系统自动执行阻塞原语(Block),使自己由运行状态变为阻塞状态。可见,进程的阻塞是进程自身的一种主动行为,也因此只有处于运行态的进程(获得CPU),才可能将其转为阻塞状态。`当进程进入阻塞状态,是不占用CPU资源的`。
25 |
26 | ### 4. 进程缓存区、内核缓冲区
27 |
28 | 缓冲区的出现是为了减少频繁的系统调用,由于系统调用需要保存之前的进程数据和状态等信息,而结束调用之后回来还需要回复之前的信息,为了减少这种耗时耗性能的调用于是出现了缓冲区。在linux系统中,每个进程有自己独立的缓冲区,叫做**进程缓冲区**,而系统内核也有个缓冲区叫做**内核缓冲区**。
29 |
30 | **操作系统使用read函数把数据从内核缓冲区复制到进程缓冲区,write把数据从进程缓冲区复制到内核缓冲区中**
31 |
32 | ### 5. 文件描述符fd
33 |
34 | 文件描述符(File descriptor)是计算机科学中的一个术语,`是一个用于表述指向文件的引用的抽象化概念`。 文件描述符在形式上是一个非负整数。实际上,`它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表`。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开
35 |
36 | ## Linx/Unix 5种IO模型
37 |
38 | 当一个io发生时候的,涉及到的步骤和对象
39 |
40 | 以网络socket的 read为例子。
41 |
42 | 涉及到的对象
43 |
44 | - 一个是调用这个IO的process (or thread) (用户进程)
45 | - 一个就是系统内核(kernel)
46 |
47 | 经历的步骤
48 |
49 | - 等待数据准备,比如accept(), recv()等待数据
50 | - 将数据从内核拷贝到进程中, 比如 accept()接受到请求,recv()接收连接发送的数据后需要复制到内核,再从内核复制到进程**用户空间**
51 |
52 | ### 阻塞IO
53 |
54 | 
55 |
56 | > 当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据(对于网络IO来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到**操作系统内核的缓冲区**中是需要一个过程的。而在用户进程这边,整个进程会被阻塞(当然,是进程自己选择的阻塞)。当kernel一直等到数据准备好了,它就会**将数据从kernel中拷贝到用户内存**,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
57 |
58 |
59 |
60 | ### 非阻塞IO
61 |
62 | 
63 |
64 | 当用户进程发出read操作时,如果kernel中的数据还没有准备好,**那么它并不会block用户进程,而是立刻返回一个error**。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回
65 |
66 | ### I/O 多路复用( IO multiplexing)
67 |
68 | IO multiplexing就是我们说的select,poll,epoll,有些地方也称这种IO方式为event driven IO。select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。
69 |
70 | 
71 |
72 | 在一个调用中阻塞`select`,等待数据报套接字可读。当`select` 返回套接字可读时,我们然后调用`recvfrom` 将数据报复制到我们的应用程序缓冲区中 .使用`select`需要两次系统调用而不是一次
73 |
74 | 在IO multiplexing Model中,实际中,**对于每一个socket,一般都设置成为non-blocking,因为只有设置成non-blocking 才能使单个线程/进程不被阻塞(或者说锁住),可以继续处理其他socket。如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。**
75 |
76 | ### 异步 I/O
77 |
78 | 
79 |
80 | 用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了
81 |
82 | ### 异步、同步、阻塞、非阻塞
83 |
84 | 同步就是一个任务的完成需要依赖另外一个任务时,只有等待被依赖的任务完成后,依赖的任务才能算完成,这是一种可靠的任务序列
85 |
86 | 异步是不需要等待被依赖的任务完成,只是通知被依赖的任务要完成什么工作,依赖的任务也立即执行,只要自己完成了整个任务就算完成了
87 |
88 | 阻塞调用是指调用结果返回之前,当前线程会被挂起,一直处于等待消息通知,不能够执行其他业务
89 |
90 | 非阻塞调用指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回
91 |
92 | 异步、同步是发生在用户空间内,当用户发起一个IO的调用的时候,同步的时候,如果这个操作比较耗时间,会阻塞后面的流程
93 |
94 | ```php
95 | file_get_contents("http://www.qq.com/");
96 | echo "end";
97 | ```
98 |
99 | 调用read的操作的时候。后面的操作echo 会等待上面的结果完成,才能继续。
100 |
101 |
102 |
103 | ```php
104 | aysnc_read("http://www.qq.com",function($data){
105 | echo $data;
106 | })
107 | echo "end";
108 | ```
109 |
110 | 这个aysnc_read 是一个异步读的操作,当读的时候,底下的操作不会阻塞住,会先输出end。当数据到达的时候,再echo $data;
111 |
112 | 阻塞、非阻塞、发生在内核和用户空间之间。阻塞是指操作系统会挂起进程,直到数据准备好,非阻塞、操作系统不阻塞,当前进程可以继续执行。
113 |
114 | 举例说明
115 |
116 | - 阻塞io
117 |
118 | 张三去书店买书,然后问书店问老板,有没有《红楼梦》,老板说我查下,这个查询的时间,比较长,然后张三啥都不能干,就在等着。直到老板告诉它,找到了。然后买了这个书,走了。张三的操作都是同步阻塞的,必须等待老板的结果,下面的操作才能执行。
119 |
120 | - 非阻塞IO
121 |
122 | 还是张三去买书,老板去查询。这是时候,张三可以玩手机,然后隔段时间问,找到了没有,张三的进程没有被阻塞。但是这个任务是同步的,必须等待这个结果。就是老板没有告诉张三结果,张三是不能离开干其他的事。这个过程是同步非阻塞的。
123 |
124 | - 异步IO
125 |
126 | 张三去买书。然后去书店问老板有没有了。老板需要查询,张三告诉老板自己的手机号,找到了打电话给我,然后就去干其他的事了。这个过程是异步的。张三的进程没有被阻塞在这个买书的环节上。这就是异步非阻塞。
--------------------------------------------------------------------------------
/Linux/Linux命令.md:
--------------------------------------------------------------------------------
1 | 在linux终端,面对命令不知道怎么用,或不记得命令的拼写及参数时,我们需要求助于系统的帮助文档; linux系统内置的帮助文档很详细,通常能解决我们的问题,我们需要掌握如何正确的去使用它们;
2 |
3 | 比如可是使用 --help 查看帮助选项。如 `ls --help`
4 |
5 | ## 文件和目录管理
6 |
7 | ### 创建和删除
8 |
9 | - 创建:mkdir
10 | - 删除:rm
11 | - 删除非空目录:rm -rf file目录
12 | - 删除日志 rm *log (等价: $find ./ -name “*log” -exec rm {} ;)
13 | - 移动:mv
14 | - 复制:cp (复制目录:cp -r )
15 | - 创建文件 touch
16 |
17 | ### 查看
18 |
19 | - 显示当前目录下的文件 **ls**
20 | - 按时间排序,以列表的方式显示目录项 **ls -lrt**
21 |
22 | ```shell
23 | ls -l
24 | ```
25 |
26 | - 查看文件内容 cat 可以加more 、less控制输出的内容的大小
27 |
28 | ```shell
29 | cat a.text
30 | cat a.text | more
31 | cat a.text| less
32 | ```
33 |
34 | ### 权限
35 |
36 | - 改变文件的拥有者 chown
37 | - 改变文件读、写、执行等属性 chmod
38 | - 递归子目录修改: chown -R tuxapp source/
39 | - 增加脚本可执行权限: chmod a+x myscript
40 |
41 | ### 管道和重定向
42 |
43 | - 批处理命令连接执行,使用 |
44 | - 串联: 使用分号 ;
45 | - 前面成功,则执行后面一条,否则,不执行:&&
46 | - 前面失败,则后一条执行: ||
47 |
48 | ```shell
49 | ls /proc && echo suss! || echo failed.
50 | cat access.log >> test.log
51 | ```
52 |
53 | ## 文本处理
54 |
55 | ### 文件查找 find
56 |
57 | find 参数很多,本文只介绍几个常用的
58 |
59 | -name 按名字查找
60 |
61 | -type 按类型
62 |
63 | -atime 访问时间
64 |
65 | ```shell
66 | find . -atime 7 -type f -print
67 | find . -type d -print //只列出所有目录
68 | find / -name "hello.c" 查找hello.c文件
69 | ```
70 |
71 |
72 | ### 文本查找 grep
73 |
74 | ```
75 | grep match_patten file // 默认访问匹配行
76 | ```
77 |
78 | 常用参数
79 |
80 | - -o 只输出匹配的文本行 **VS** -v 只输出没有匹配的文本行
81 |
82 | - -c 统计文件中包含文本的次数
83 |
84 | `grep -c “text” filename`
85 |
86 | - -n 打印匹配的行号
87 |
88 | - -i 搜索时忽略大小写
89 |
90 | - -l 只打印文件名
91 |
92 | ```shell
93 | grep "class" . -R -n # 在多级目录中对文本递归搜索(程序员搜代码的最爱)
94 | cat LOG.* | tr a-z A-Z | grep "FROM " | grep "WHERE" > b #将日志中的所有带where条件的sql查找查找出来
95 | ```
96 |
97 | ### 文本替换 sed
98 |
99 | ```shell
100 | sed [options] 'command' file(s)
101 | ```
102 |
103 | - 首处替换
104 |
105 | ```
106 | sed 's/text/replace_text/' file //替换每一行的第一处匹配的text
107 | ```
108 |
109 | - 全局替换
110 |
111 | ```
112 | sed 's/text/replace_text/g' file
113 | ```
114 |
115 | 默认替换后,输出替换后的内容,如果需要直接替换原文件,使用-i:
116 |
117 | ```
118 | sed -i 's/text/repalce_text/g' file
119 | ```
120 |
121 | - 移除空白行
122 |
123 | ```
124 | sed '/^$/d' file
125 | ```
126 |
127 | ```shell
128 | sed 's/book/books/' file #替换文本中的字符串:
129 | sed 's/book/books/g' file
130 | sed '/^$/d' file #删除空白行
131 | ```
132 |
133 | ### 数据流处理awk
134 |
135 | 详细教程可以查看 http://awk.readthedocs.io/en/latest/chapter-one.html
136 |
137 | ```shell
138 | awk ' BEGIN{ statements } statements2 END{ statements } '
139 | ```
140 |
141 | 工作流程
142 |
143 | 1.执行begin中语句块;
144 |
145 | 2.从文件或stdin中读入一行,然后执行statements2,重复这个过程,直到文件全部被读取完毕;
146 |
147 | 3.执行end语句块;
148 |
149 | **特殊变量**
150 |
151 | NR:表示记录数量,在执行过程中对应当前行号;
152 |
153 | NF:表示字段数量,在执行过程总对应当前行的字段数;
154 |
155 | $0:这个变量包含执行过程中当前行的文本内容;
156 |
157 | $1:第一个字段的文本内容;
158 |
159 | $2:第二个字段的文本内容;
160 |
161 | ```shell
162 | awk '{print $2, $3}' file
163 | # 日志格式:'$remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" "$http_x_forwarded_for"'
164 | #统计日志中访问最多的10个IP
165 | awk '{a[$1]++}END{for(i in a)print a[i],i|"sort -k1 -nr|head -n10"}' access.log
166 |
167 | ```
168 |
169 | ### 排序 sort
170 |
171 | - -n 按数字进行排序 VS -d 按字典序进行排序
172 | - -r 逆序排序
173 | - -k N 指定按第N列排序
174 |
175 | ```shell
176 | sort -nrk 1 data.txt
177 | sort -bd data // 忽略像空格之类的前导空白字符
178 | ```
179 |
180 | ### 去重uniq
181 |
182 | - 消除重复行
183 |
184 | ```
185 | sort unsort.txt | uniq
186 | ```
187 |
188 | ### 统计 wc
189 |
190 | ```shell
191 | wc -l file // 统计行数
192 | wc -w file // 统计单词数
193 | wc -c file // 统计字符数
194 | ```
195 |
196 |
--------------------------------------------------------------------------------
/Linux/Linux命令2.md:
--------------------------------------------------------------------------------
1 | ## 磁盘管理
2 |
3 | 查看磁盘空间利用大小
4 |
5 | ```shell
6 | df -h
7 | ```
8 |
9 | 查看当前目录所占空间大小
10 |
11 | ```shell
12 | du -sh
13 | ```
14 |
15 | ## 打包和解压
16 |
17 | 在linux中打包和压缩和分两步来实现的
18 |
19 | tar、zip命令
20 |
21 | 打包是将多个文件归并到一个文件:
22 |
23 | ```shell
24 | tar -cvf etc.tar /etc <==仅打包,不压缩!
25 | gzip demo.txt #压缩
26 | zip -q -r html.zip /home/Blinux/html #打包压缩成zip文件
27 | ```
28 |
29 | 解压
30 |
31 | ```shell
32 | tar -zxvf xx.tar.gz
33 | unzip test.zip# 解压zip文件
34 | ```
35 |
36 | ## 进程管理
37 |
38 | ### 查看进程 ps
39 |
40 | ```shell
41 | ps -ef # 查询正在运行的进程信息
42 | ps -A | grep nginx #查看进程中的nginx
43 | top #显示进程信息,并实时更新
44 | lsof -p 23295 #查询指定的进程ID(23295)打开的文件:
45 | ```
46 |
47 | ### 杀死进程 kill
48 |
49 | ```shell
50 | # 杀死指定PID的进程 (PID为Process ID)
51 | kill 1111
52 | #杀死相关进程
53 | kill -9 3434
54 | ```
55 |
56 | ## 查看网络服务和端口
57 |
58 | netstat 命令用于显示各种网络相关信息,如网络连接,路由表,接口状态 (Interface Statistics),masquerade 连接,多播成员 (Multicast Memberships) 等等。
59 |
60 | 列出所有端口 (包括监听和未监听的):
61 |
62 | ```shell
63 | netstat -a
64 |
65 | ```
66 |
67 | 列出所有 tcp 端口:
68 |
69 | ```shell
70 | netstat -at
71 |
72 | ```
73 |
74 | 列出所有有监听的服务状态:
75 |
76 | ```shell
77 | netstat -l
78 | ```
79 |
80 | ## 查看内存free
81 |
82 | 缺省时free的单位为KB
83 |
84 | ```shell
85 | $ free
86 | total used free shared buffers cached
87 | Mem: 8175320 6159248 2016072 0 310208 5243680
88 | -/+ buffers/cache: 605360 7569960
89 | Swap: 6881272 16196 6865076
90 | ```
91 |
92 | free的输出一共有四行,第四行为交换区的信息,分别是交换的总量(total),使用量(used)和有多少空闲的交换区(free),这个比较清楚,不说太多
--------------------------------------------------------------------------------
/Linux/README.md:
--------------------------------------------------------------------------------
1 | ## 操作系统概述
2 |
3 | 操作系统,英文名称Operating System,简称OS,是计算机系统中必不可少的基础系统软件,它是应用程序运行以及用户操作必备的基础环境支撑,是计算机系统的核心。
4 |
5 | 操作系统的作用是管理和控制计算机系统中的硬件和软件资源,例如,它负责直接管理计算机系统的各种硬件资源,如对CPU、内存、磁盘等的管理,同时对系统资源所需的优先次序进行管理。操作系统还可以控制设备的输入、输出以及操作网络与管理文件系统等事务。同时,它也负责对计算机系统中各类软件资源的管理。例如各类应用软件的安装、设置运行环境等。操作系统与计算机硬件软件关系图如下。
6 |
7 | 
8 |
9 | ### 内核态和用户态
10 |
11 | 操作系统为了管理内存。将内存分为**内核空间**(内核态)和**用户空间**。内存空间和用户空间之间有隔离。程序需要访问系统资源必须向内核空间进行申请。由内核把数据读取到用户空间。
12 |
13 | Linux操作系统中主要采用了0和3两个特权级,分别对应的就是内核态和用户态。运行于用户态的进程可以执行的操作和访问的资源都会受到极大的限制,而运行在内核态的进程则可以执行任何操作并且在资源的使用上没有限制。很多程序开始时运行于用户态,但在执行的过程中,一些操作需要在内核权限下才能执行,这就涉及到一个从用户态切换到内核态的过程
14 |
15 | 应用程序访问内核,一般有两种调用方式:系统调用和库函数调用
16 |
17 | **系统调用**:应用程序直接调用操作系统提供的接口 如write 函数
18 |
19 | **库函数调用**:应用程序通过一些库函数直接调用 如 fwrite
20 |
21 | 系统调用(英语:system call),指运行在用户空间的应用程序向操作系统内核请求某些服务的调用过程。 系统调用提供了用户程序与操作系统之间的接口。一般来说,系统调用都在内核态执行。由于系统调用不考虑平台差异性,由内核直接提供,因而移植性较差(几乎无移植性)。
22 |
23 | 库函数(library function),是由用户或组织自己开发的,具有一定功能的函数集合,一般具有较好平台移植性,通过库文件(静态库或动态库)向程序员提供功能性调用。程序员无需关心平台差异,由库来屏蔽平台差异性。
24 |
25 | | 函数库调用 | 系统调用 |
26 | | ----------------------------- | ----------------------- |
27 | | 平台移植性好 | 依赖于内核,不保证移植性 |
28 | | 调用函数库中的一段程序(或函数) | 调用系统内核的服务 |
29 | | 一个普通功能函数的调用 | 是操作系统的一个入口点 |
30 | | 在**用户空间**执行 | 在**内核空间**执行 |
31 | | 它的运行时间属于“用户时间” | 它的运行时间属于“系统”时间 |
32 | | 属于过程调用,调用开销较小 | 在用户空间和内核上下文环境间切换,开销较大 |
33 | | 库函数数量较多 | UNIX中大约有90个系统调用,较少 |
34 | | 典型的C函数库调用:printf scanf malloc | 典型的系统调用:fork open write |
35 |
36 | **用户空间即上层应用程序的活动空间**,应用程序的执行必须依托于内核提供的资源,包括CPU资源、存储资源、I/O资源等。为了使上层应用能够访问到这些资源,内核必须为上层应用提供访问的接口:即系统调用
37 |
38 | ## Linux和Unix
39 |
40 | Unix系统于1969年在AT&T的贝尔实验室诞生,20世纪70年代,它逐步盛行,这期间,又产生了一个比较重要的分支,就是大约1977年诞生的BSD(Berkeley Software Distribution)系统。从BSD系统开始,各大厂商及商业公司开始了根据自身公司的硬件架构,并以BSD系统为基础进行Unix系统的研发,从而产生了各种版本的Unix系统.
41 |
42 | 70年代中后期,由于各厂商和商业公司开发的Unix及内置软件都是针对自己公司特定的硬件,因此在其他公司的硬件上基本无法直接运行,而且当时没有人对开发基于x86架构的CPU的系统感兴趣。另外,70年代末,Unix又面临了突如其来的被AT&T回收版权的重大问题,特别是要求禁止对学生群体提供Unix系统源代码,这样的问题一度引起了当时Unix业界的恐慌,也因此产生了商业纠纷。
43 |
44 | Linux系统的诞生开始于1991年芬兰赫尔辛基大学的一位计算机系的学生,名字为**Linus Torvalds**。在大学期间,他接触到了学校的Unix系统,但是当时的Unix系统仅为一台主机,且对应了多个终端,使用时存在操作等待时间很长等一些不爽的问题,无法满足年轻的Linus Torvalds的使用需求。因此他就萌生了自己开发一个Unix的想法,于是不久,他就找到了前文提到的谭邦宁教授开发的用于教学的Minix操作系统,他把Minix安装到了他的I386个人计算机上。此后,Torvalds又开始陆续阅读了Minix系统的源代码,从Minix系统中学到了很多重要的系统核心程序设计理念和设计思想,从而逐步开始了Linux系统雏形的设计和开发。
45 |
46 | ## GNU和GPL
47 |
48 | GNU的全称为**GNU's not unix**,意思是"GNU不是UNIX",GNU计划,又称革奴计划,是由Richard Stallman在1984年公开发起的,是FSF的主要项目。这个项目的目标是建立一套完全自由的和可移植的类Unix操作系统。
49 |
50 | GNU类Unix操作系统是由一系列应用程序、系统库和开发工具构成的软件集合,例如:Emacs编辑软件、gcc编译软件、bash命令解释程序和编程语言,以及gawk(GNU's awk)等,并加上了用于资源分配和硬件管理的内核。
51 |
52 | 到1991年Linux内核发布的时候,GNU项目已经完成了除系统内核之外的各种必备软件的开发。在Linux Torvalds和其他开发人员的努力下,GNU项目的部分组件又运行到了Linux内核之上,例如:GNU项目里的Emacs、gcc、bash、gawk等,至今都是Linux系统中很重要的基础软件。所以linux 又叫**GNU/Linux**
53 |
54 | GPL全称为General Public License,中文名为通用公共许可,是一个最著名的开源许可协议,开源社区最著名的Linux内核就是在GPL许可下发布的。GPL许可是由自由软件基金会(Free Software foundation)创建的。
--------------------------------------------------------------------------------
/Linux/Sed.md:
--------------------------------------------------------------------------------
1 | ## sed
2 |
3 | sed:Stream Editor文本流编辑,sed是一个“非交互式的”面向字符流的编辑器。能同时处理多个文件多行的内容,可以不对原文件改动,把整个文件输入到屏幕,可以把只匹配到模式的内容输入到屏幕上。还可以对原文件改动,但是不会再屏幕上返回结果。
4 |
5 | **sed命令的语法格式:**
6 |
7 | sed的命令格式: `sed [option] 'sed command'filename`
8 |
9 | sed的脚本格式:`sed [option] -f 'sed script'filename`
10 |
11 | **sed命令的选项(option):**
12 |
13 | -n :只打印模式匹配的行
14 |
15 | -e :直接在命令行模式上进行sed动作编辑,此为默认选项
16 |
17 | -f :将sed的动作写在一个文件内,用–f filename 执行filename内的sed动作
18 |
19 | -r :支持扩展表达式
20 |
21 | -i :直接修改文件内容
22 |
23 | **sed在文件中查询文本的方式:**
24 |
25 | **1)使用行号,可以是一个简单数字,或是一个行号范围**
26 |
27 | | x | x为行号 |
28 | | ----------------- | ---------------------------- |
29 | | x,y | 表示行号从x到y |
30 | | /pattern | 查询包含模式的行 |
31 | | /pattern /pattern | 查询包含两个模式的行 |
32 | | pattern/,x | 在给定行号上查询包含模式的行 |
33 | | x,/pattern/ | 通过行号和模式查询匹配的行 |
34 | | x,y! | 查询不包含指定行号x和y的行 |
35 |
36 | **sed的编辑命令(sed command):**
37 |
38 | | p | 打印匹配行(和-n选项一起合用) |
39 | | ---------- | ------------------------------------------------------------ |
40 | | = | 显示文件行号 |
41 | | a\ | 在定位行号后附加新文本信息 |
42 | | i\ | 在定位行号后插入新文本信息 |
43 | | d | 删除定位行 |
44 | | c\ | 用新文本替换定位文本 |
45 | | w filename | 写文本到一个文件,类似输出重定向 > |
46 | | r filename | 从另一个文件中读文本,类似输入重定向 < |
47 | | s | 使用替换模式替换相应模式 |
48 | | q | 第一个模式匹配完成后退出或立即退出 |
49 | | l | 显示与八进制ACSII代码等价的控制符 |
50 | | {} | 在定位行执行的命令组,用分号隔开 |
51 | | n | 从另一个文件中读文本下一行,并从下一条命令而不是第一条命令开始对其的处理 |
52 | | N | 在数据流中添加下一行以创建用于处理的多行组 |
53 | | g | 将模式2粘贴到/pattern n/ |
54 | | y | 传送字符,替换单个字符 |
55 |
56 | | 操作符 | 名字 | 效果 |
57 | | --------------------------------- | --------- | ------------------------------------------------------------ |
58 | | `[地址范围]/p` | 打印 | 打印[指定的地址范围] `3,5/p` |
59 | | `[地址范围]/d` | 删除 | 删除[指定的地址范围] |
60 | | `s/pattern1/pattern2/` | 替换 | 将指定行中, 将第一个匹配到的pattern1, 替换为pattern2. |
61 | | `[地址范围]/s/pattern1/pattern2/` | 替换 | 在`*地址范围*`指定的每一行中, 将第一个匹配到的pattern1, 替换为pattern2. |
62 | | `[地址范围]/y/pattern1/pattern2/` | transform | 在`*地址范围*`指定的每一行中, 将pattern1中的每个匹配到pattern2的字符都使用pattern2的相应字符作替换. (等价于tr命令) |
63 | | `g` | 全局 | 在每个匹配的输入行中, 将*每个*模式匹配都作相应的操作. (译者注: 不只局限于第一个匹配) |
64 |
65 | - 过滤PHP.ini中空行和注释
66 |
67 | ```shell
68 | sed -n '/^;/!p{/^$/!p}' php.ini
69 | ```
70 |
71 | - 打印指定行数的内容
72 |
73 | ```shell
74 | sed -n '3,6'p php.ini
75 | ```
76 |
77 | - 打印匹配行
78 |
79 | ```shell
80 | sed -n '/php/p' php.ini
81 | ```
82 |
83 | ### 替换 s
84 |
85 | ```shell
86 | sed -n 's/php/PHP/g' php.ini #把php 替换成PHP
87 | ```
88 |
89 | ### 追加 a\
90 |
91 | 对源文件追加 加-i
92 |
93 | ```shell
94 | sed '/^test/a\this is a test line' file #将 this is a test line 追加到 以test 开头的行后面:
95 | sed '/^test/i\this is begin/' #将this is end 追加到匹配的行头
96 | ```
97 |
98 | - 行尾追加字符
99 |
100 | ```shell
101 | sed '/php/s/$/ PHP/' php.ini
102 | ```
103 |
104 | - 行首追加
105 |
106 | ```shell
107 | sed 's/^/START/'
108 | ```
109 |
110 | ### 删除 d
111 |
112 | ```shell
113 | sed '/^$/d' file #删除空白
114 | sed '1,10d' file # 删除1-10行
115 | sed '/^$/' file #删除空白行
116 | sed '/^PHP/d' file #删除PHP开头的行
117 | ```
118 |
119 |
--------------------------------------------------------------------------------
/Linux/Vim.md:
--------------------------------------------------------------------------------
1 | ## vim
2 |
3 | vim是一个类似vi编辑器的。有一个段子:程序员分为三类,一种是用`vim`的 一种是用`emacs` ,剩下的一种是用其他编辑器的。可见vim的流传度。vim的设计理解,是命令的组合。就是完全不用鼠标。通过命令就可以。比如我们在其他编辑器。如果跑到多少行,我们可能需要滚动鼠标。但是vim就在命令行模式下就完成了。先上一个图
4 |
5 | 
6 |
7 | ### VIM的模式
8 |
9 | vim的模式有三种:分别为命令模式,输入模式、尾行模式
10 |
11 | 
12 |
13 | #### 1. 命令模式
14 |
15 | 默认用vim打开一个文件的时候,就是进入了命令模式。在这个模式下。可以通过各种命令组合操作文本编辑器
16 |
17 | #### 2. 输入模式
18 |
19 | 输入模式,就是和我们正常的编辑器一样。可以在这个模式下。编辑修改打开文件的内容
20 |
21 | 在命令模式下。按`i`键。就是输入模式。按`ESC` 退出输入模式,进入到命令模式
22 |
23 | #### 3. 尾行模式
24 |
25 | 在命令模式下`:` 进入尾行。尾行模式下命令也非常多。主要包括文件的查找,保存等
26 |
27 | ### VIM命令模式下的快捷键
28 |
29 | 介绍一些常用的快捷键。
30 |
31 | 上下左右键可能跟我们之前的不一样。一般游戏爱好者的上下左右是wsad。但是在vim就是hjkl。
32 |
33 | | 移动光标的方法 | |
34 | | ------------------------------------------------------------ | ------------------------------------------------------------ |
35 | | h 或 向左箭头键(←) | 光标向左移动一个字符 |
36 | | j 或 向下箭头键(↓) | 光标向下移动一个字符 |
37 | | k 或 向上箭头键(↑) | 光标向上移动一个字符 |
38 | | l 或 向右箭头键(→) | 光标向右移动一个字符 |
39 | | 如果你将右手放在键盘上的话,你会发现 hjkl 是排列在一起的,因此可以使用这四个按钮来移动光标。 如果想要进行多次移动的话,例如向下移动 30 行,可以使用 "30j" 或 "30↓" 的组合按键, 亦即加上想要进行的次数(数字)后,按下动作即可! | |
40 | | [Ctrl] + [f] | 屏幕『向下』移动一页,相当于 [Page Down]按键 (常用) |
41 | | [Ctrl] + [b] | 屏幕『向上』移动一页,相当于 [Page Up] 按键 (常用) |
42 | | [Ctrl] + [d] | 屏幕『向下』移动半页 |
43 | | [Ctrl] + [u] | 屏幕『向上』移动半页 |
44 | | + | 光标移动到非空格符的下一行 |
45 | | - | 光标移动到非空格符的上一行 |
46 | | | |
47 | | 0 或功能键[Home] | 这是数字『 0 』:移动到这一行的最前面字符处 (常用) |
48 | | $ 或功能键[End] | 移动到这一行的最后面字符处(常用) |
49 | | H | 光标移动到这个屏幕的最上方那一行的第一个字符 |
50 | | M | 光标移动到这个屏幕的中央那一行的第一个字符 |
51 | | L | 光标移动到这个屏幕的最下方那一行的第一个字符 |
52 | | G | 移动到这个档案的最后一行(常用) |
53 | | nG | n 为数字。移动到这个档案的第 n 行。例如 20G 则会移动到这个档案的第 20 行(可配合 :set nu) |
54 | | gg | 移动到这个档案的第一行,相当于 1G 啊! (常用) |
55 | | x, X | 在一行字当中,x 为向后删除一个字符 (相当于 [del] 按键), X 为向前删除一个字符(相当于 [backspace] 亦即是退格键) (常用) |
56 | | -------- | ------------------------------------------------------------ |
57 | | nx | n 为数字,连续向后删除 n 个字符。举例来说,我要连续删除 10 个字符, 『10x』。 |
58 | | **dd** | 删除游标所在的那一整行(常用) |
59 | | **ndd** | n 为数字。删除光标所在的向下 n 行,例如 20dd 则是删除 20 行 (常用) |
60 | | d1G | 删除光标所在到第一行的所有数据 |
61 | | dG | 删除光标所在到最后一行的所有数据 |
62 | | d$ | 删除游标所在处,到该行的最后一个字符 |
63 | | d0 | 那个是数字的 0 ,删除游标所在处,到该行的最前面一个字符 |
64 | | **yy** | 复制游标所在的那一行(常用) |
65 | | **nyy** | n 为数字。复制光标所在的向下 n 行,例如 20yy 则是复制 20 行(常用) |
66 | | y1G | 复制游标所在行到第一行的所有数据 |
67 | | yG | 复制游标所在行到最后一行的所有数据 |
68 | | y0 | 复制光标所在的那个字符到该行行首的所有数据 |
69 | | y$ | 复制光标所在的那个字符到该行行尾的所有数据 |
70 | | **p, P** | p 为将已复制的数据在光标下一行贴上,P 则为贴在游标上一行! 举例来说,我目前光标在第 20 行,且已经复制了 10 行数据。则按下 p 后, 那 10 行数据会贴在原本的 20 行之后,亦即由 21 行开始贴。但如果是按下 P 呢? 那么原本的第 20 行会被推到变成 30 行。 (常用) |
71 | | J | 将光标所在行与下一行的数据结合成同一行 |
72 | | c | 重复删除多个数据,例如向下删除 10 行,[ 10cj ] |
73 | | u | 复原前一个动作。(常用) |
74 | | [Ctrl]+r | 重做上一个动作。(常用) |
75 |
76 | ### 进入编辑模式的命令
77 |
78 | - `i` i 为『从目前光标所在处输入』 insert
79 | - `I` I 为『在目前所在行的第一个非空格符处开始输入』
80 | - `a` a 为『从目前光标所在的下一个字符处开始输入』 append
81 | - A 为『从光标所在行的最后一个字符处开始输入』。(常用)
82 | - `ESC` 退回到命令模式
83 |
84 |
85 |
86 | ### 尾行模式下的命令
87 |
88 | - `:w` 将编辑的数据写入硬盘档案中
89 | - `:w!`若文件属性为『只读』时,强制写入该档案
90 | - `:q` 退出文件
91 | - `:q!` 不保存退出
92 | - `:wq ` 保存退出
93 | - `:wq!` 强制保存退出
94 |
95 |
96 |
97 |
--------------------------------------------------------------------------------
/Linux/crontab.md:
--------------------------------------------------------------------------------
1 | ## crontab 定时任务
2 |
3 | 通过crontab 命令,我们可以在固定的间隔时间执行指定的系统指令或 shell script脚本。时间间隔的单位可以是分钟、小时、日、月、周及以上的任意组合。这个命令非常适合周期性的日志分析或数据备份等工作。
4 |
5 | ## crontab的文件格式
6 |
7 | 分 时 日 月 星期 要运行的命令
8 |
9 | - 第1列分钟0~59
10 | - 第2列小时0~23(0表示子夜)
11 | - 第3列日1~31
12 | - 第4列月1~12
13 | - 第5列星期0~7(0和7表示星期天)
14 | - 第6列要运行的命令
15 |
16 | 
17 |
18 | ### 实例
19 |
20 | ```shell
21 | * * * * * echo "hello" #每1分钟执行hello
22 | 3,15 * * * * myCommand #每小时第三分钟和第十五分钟执行
23 | 3,15 8-11 * * * myCommand# 在上午8点到11点的第3和第15分钟执行
24 | 3,15 8-11 */2 * * myCommand #每隔两天的上午8点到11点的第3和第15分钟执行
25 | 30 21 * * * /etc/init.d/smb restart #每晚的21:30重启smb
26 | 0 23 * * 6 /etc/init.d/smb restart #每星期六的晚上11 : 00 pm重启smb
27 | ```
28 |
29 | **注意事项**
30 |
31 | 新创建的cron job,不会马上执行,至少要过2分钟才执行。如果重启cron则马上执行。
32 |
33 | 当crontab失效时,可以尝试/etc/init.d/crond restart解决问题。或者查看日志看某个job有没有执行/报错tail -f /var/log/cron。
34 |
35 | ```
36 | $service cron restart
37 | ```
38 |
--------------------------------------------------------------------------------
/Linux/crontab.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/Linux/crontab.png
--------------------------------------------------------------------------------
/Linux/hard.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/Linux/hard.png
--------------------------------------------------------------------------------
/Linux/inode.md:
--------------------------------------------------------------------------------
1 | ## inode
2 |
3 | 我们文件数据存储在硬盘上,硬盘最小的单位是扇区,一个扇区是512个字节。操作系统读取硬盘每次读取4Kb。成为一个块。文件都存在块中。同时操作系统还会有一个区域记录文件的基本信息。这个基本信息成为文件的**元信息**。
4 |
5 | ### 一、inode信息
6 |
7 | 元信息存储的位置成为inode、中文名索引节点(index node)
8 |
9 | inode包括的文件信息如下
10 |
11 | * 文件的字节数
12 |
13 | * 文件拥有者的User ID
14 |
15 | * 文件的Group ID
16 |
17 | * 文件的读、写、执行权限
18 |
19 | * 文件的时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间。
20 |
21 | * 链接数,即有多少文件名指向这个inode
22 |
23 | * 文件数据block的位置
24 |
25 | ### 二、inode大小
26 |
27 | inode也是存储在硬盘上。需要耗费硬盘空间。
28 |
29 | 每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode
30 |
31 | 可以使用
32 |
33 | ```shell
34 | df -i
35 | Filesystem Inodes IUsed IFree IUse% Mounted on
36 | /dev/vda1 2621440 262203 2359237 11% /
37 | tmpfs 128788 2 128786 1% /dev/shm
38 |
39 | ```
40 |
41 | ### 三、inode id
42 |
43 | 每个inode都有一个id。操作系统根据这个id识别文件
44 |
45 | 类似人的身份证号。我们通过识别身份证来区别人。人名只是一个称号。
46 |
47 | 打开文件,一般会有三步,
48 |
49 | - 找到inode 的id
50 | - 获取**inode**信息
51 | - 找到文件数据所在的块。读取内容
52 |
53 | ### 四、目录文件
54 |
55 | 目录也是一种文件。linux一切都是文件。目录文件的读权限(r)和写权限(w),都是针对目录文件本身。由于目录文件内只有文件名和inode号码
56 |
57 | ### 五、硬链接
58 |
59 | 一般情况,文件名和**inode** id是一对 一的关系。但是linux下允许多个文件名指向一个**innode** id
60 |
61 | 可以用不同的文件名访问同样的内容;对文件内容进行修改,会影响到所有文件名。这种情况就被称为"硬链接"(hard link)。
62 |
63 | 
64 |
65 | ```shell
66 | ln 源文件 目标文件
67 | ```
68 |
69 | 运行上面这条命令以后,源文件与目标文件的inode号码相同,都指向同一个inode。inode信息中有一项叫做"链接数",记录指向该inode的文件名总数,这时就会增加1。
70 |
71 | 这个就像PHP的zval结构。zval中含有一个refcount 和一个is_ref.当有引用的时候。会让ref_count+1.is_ref设置1。
72 |
73 |
74 |
75 | ### 六、软链接
76 |
77 | 文件A和文件B的inode号码虽然不一样,但是文件A的内容是文件B的路径。读取文件A时,系统会自动将访问者导向文件B。因此,无论打开哪一个文件,最终读取的都是文件B。这时,文件A就称为文件B的"软链接"(soft link)或者"符号链接(symbolic link)。这种就是类似windows下的快捷方式。
78 |
79 | ```shell
80 | ln -s 源文文件或目录 目标文件或目录
81 | ```
82 |
83 |
--------------------------------------------------------------------------------
/Linux/lanmp.md:
--------------------------------------------------------------------------------
1 | ## LAMP环境的配置
2 |
3 | 安装环境 centos6.x.root权限下操作。安装顺序为Apache、PHP、MySQL
4 |
5 | ### 1. 安装gcc编译器以及相关工具
6 |
7 | ```shell
8 | yum -y install gcc gcc-c++ autoconf automake libtool pcre pcre-devel
9 | ```
10 |
11 | ### 2. 安装apache2.4.12
12 |
13 | apacehe 依赖apr和apr-util
14 |
15 | - apache2.4.12 的源码包[http://mirrors.cnnic.cn/apache//httpd/httpd-2.4.12.tar.gz](http://mirrors.cnnic.cn/apache//httpd/httpd-2.4.12.tar.gz)
16 | - APR 1.5.2 源码包下载地址 [http://mirrors.cnnic.cn/apache//apr/apr-1.5.2.tar.gz](http://mirrors.cnnic.cn/apache//apr/apr-1.5.2.tar.gz "http://mirrors.cnnic.cn/apache//apr/apr-1.5.2.tar.gz")
17 | - APR-util 1.5.4 源码包下载地址 [http://mirrors.cnnic.cn/apache//apr/apr-util-1.5.4.tar.gz](http://mirrors.cnnic.cn/apache//apr/apr-util-1.5.4.tar.gz)
18 |
19 | #### 2.1 编译安装apr和ap-util
20 |
21 | ```shell
22 | tar -zxf apr-1.4.5.tar.gz
23 | cd apr-1.4.5
24 | ./configure --prefix=/usr/local/apr
25 | make && make install
26 | #编译util
27 | tar zxvf apr-util-1.5.4.tar.gz
28 | cd apr-util-1.5.4
29 | ./configure --prefix=/usr/local/apr-util --with-apr=/usr/local/apr/bin/apr-1-config
30 | make && make install
31 | ```
32 |
33 | #### 2.2 编译Apache
34 |
35 | ```shell
36 | tar zxvf tar zxvf httpd-2.4.12.tar.gz
37 | cd httpd-2.4.12
38 | ./configure --prefix=/usr/local/apache \
39 | --enable-so \
40 | --with-apr=/usr/local/apr \
41 | --with-apr-util=/usr/local/apr-util \
42 | -enable-modules=all \
43 | --enable-rewrite \
44 | --enable-mods-shared=all \
45 | >make && make install
46 | ```
47 |
48 | #### 2.3 添加服务脚本放行80端口
49 |
50 | ```shell
51 | cp /usr/local/apache/bin/apachectl /etc/init.d/httpd
52 | #放开80端口
53 | vi /etc/sysconfig/iptables
54 | #增加以下内容
55 | -A INPUT -m state --state NEW -m tcp -p tcp --dport 80 -j ACCEPT
56 | #重启防火墙
57 | service iptables restart
58 | ```
59 |
60 | ### 3. 安装PHP
61 |
62 | #### 3.1 安装前准备
63 |
64 | 安装php拓展所需要的依赖。如gd库、zlib、curl等
65 |
66 | ```shell
67 | yum -y install libmcrypt-devel mhash-devel libxslt-devel \
68 | libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel libxml2 libxml2-devel \
69 | zlib zlib-devel glibc glibc-devel glib2 glib2-devel bzip2 bzip2-devel \
70 | ncurses ncurses-devel curl curl-devel e2fsprogs e2fsprogs-devel \
71 | krb5 krb5-devel libidn libidn-devel openssl openssl-devel
72 | ```
73 |
74 | #### 3.2 编译PHP
75 |
76 | 下载php的源码包.从国内的搜狐镜像下载[http://mirrors.sohu.com/](http://mirrors.sohu.com/)
77 |
78 | http://mirrors.sohu.com/php/php-7.2.1.tar.gz
79 |
80 | ```shell
81 | wget -c http://mirrors.sohu.com/php/php-7.2.1.tar.gz
82 | tar zxvf php-7.2.1.tar.gz
83 | cd php-7.2.1
84 |
85 | ./configure --prefix=/usr/local/php \
86 | --enable-mbstring --with-curl \
87 | --with-bz2 --with-zlib \
88 | --enable-pcntl \
89 | --with-mhash --enable-zip \
90 | --with-mysqli=mysqlnd \
91 | --with-pdo-mysql=mysqlnd \
92 | --with-gd --with-jpeg-dir --with-freetype-dir --with-png-dir \
93 | --with-apxs2=/usr/local/apache/bin/apxs \
94 | ```
95 |
96 | #### 3.3整合PHP和Apache
97 |
98 | - 编辑apache配置文件
99 |
100 | ```shell
101 | vim /usr/local/apache/conf/httpd.conf
102 | #增加以下信息
103 | AddType application/x-httpd-php .php
104 | ```
105 |
106 | - 更改默认页地址
107 |
108 | ```shell
109 |
110 | DirectoryIndex index.html
111 |
112 | #改为
113 |
114 | DirectoryIndex index.php index.html
115 |
116 | ```
117 |
118 | - 重启apache
119 |
120 | ```SHELL
121 | service httpd restart
122 | ```
--------------------------------------------------------------------------------
/Linux/进程和线程.md:
--------------------------------------------------------------------------------
1 | ## 进程和线程的区别
2 |
3 | 进程是一次程序运行的活动。进程有自己的pid,堆栈空间等资源。
4 |
5 | 线程是进程里面的一个实体。是CPU调度的基本单位。它比进程更小。线程本身不拥有系统资源。只拥有自己的程序计数器、堆栈、寄存器。和同一个进程中的其他线程共享进程中的内存。
6 |
7 | 线程开销小。进程切换开销比较大。进程切换,上下文。
8 |
9 | 进程是cpu资源分配的最小单位,线程是cpu调度的最小单位。
--------------------------------------------------------------------------------
/MQ/README.md:
--------------------------------------------------------------------------------
1 | ## 消息队列(Message Queue)
2 |
3 | “消息”是在两台计算机间传送的数据单位。消息可以非常简单,例如只包含文本字符串;也可以更复杂 ,包括对象等。
4 |
5 | 队列是一种数据结构,先进先出,保证了顺序性。
6 |
7 | 生产者:发送消息的一端。用于把消息写入到队列中
8 |
9 | 消费者:从消息队列中,依次读取每条消息的一端。
10 |
11 | 消息队列中间件是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题。实现高性能,高可用,可伸缩和最终一致性架构。是大型分布式系统不可缺少的中间件。
12 |
13 | 目前在生产环境,使用较多的消息队列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ等。
14 |
15 | ### 应用场景
16 |
17 | #### 1. 异步处理
18 |
19 | 场景说明:用户注册后,需要发注册邮件和注册短信。传统的做法有两种 1.串行的方式;2.并行方式
20 |
21 | (1)串行方式:将注册信息写入数据库成功后,发送注册邮件,再发送注册短信。以上三个任务全部完成后,返回给客户端
22 |
23 | 
24 |
25 | (2)并行方式:将注册信息写入数据库成功后,发送注册邮件的同时,发送注册短信。以上三个任务完成后,返回给客户端。与串行的差别是,并行的方式可以提高处理的时间
26 |
27 | 
28 |
29 | 假设三个业务节点每个使用50毫秒钟,不考虑网络等其他开销,则串行方式的时间是150毫秒,并行的时间可能是100毫秒。
30 |
31 | 因为CPU在单位时间内处理的请求数是一定的,假设CPU1秒内吞吐量是100次。则串行方式1秒内CPU可处理的请求量是7次(1000/150)。并行方式处理的请求量是10次(1000/100)
32 |
33 |
34 |
35 | 引入消息队列,将不是必须的业务逻辑,异步处理。改造后的架构如下:
36 |
37 | 
38 |
39 | 按照以上约定,用户的响应时间相当于是注册信息写入数据库的时间,也就是50毫秒。注册邮件,发送短信写入消息队列后,直接返回,因此写入消息队列的速度很快,基本可以忽略,因此用户的响应时间可能是50毫秒。因此架构改变后,系统的吞吐量提高到每秒20 QPS。比串行提高了3倍,比并行提高了两倍
40 |
41 | #### 2. 应用解耦
42 |
43 | 场景说明:用户下单后,订单系统需要通知库存系统。传统的做法是,订单系统调用库存系统的接口。如下图:
44 |
45 | 
46 |
47 | 传统模式的缺点:
48 |
49 | 1) 假如库存系统无法访问,则订单减库存将失败,从而导致订单失败;
50 |
51 | 2) 订单系统与库存系统耦合;
52 |
53 | 如何解决以上问题呢?引入应用消息队列后的方案,如下图
54 |
55 | 
56 |
57 | - 订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功。
58 | - 库存系统:订阅下单的消息,采用拉/推的方式,获取下单信息,库存系统根据下单信息,进行库存操作。
59 | - 假如:在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦。
60 |
61 | #### 3. 流量削峰
62 |
63 | 流量削锋也是消息队列中的常用场景,一般在秒杀或团抢活动中使用广泛。
64 |
65 | 应用场景:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列。
66 |
67 | 1. 可以控制活动的人数;
68 | 2. 可以缓解短时间内高流量压垮应用;
69 |
70 | 
71 |
72 | 1. 用户的请求,服务器接收后,首先写入消息队列。假如消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面;
73 | 2. 秒杀业务根据消息队列中的请求信息,再做后续处理。
74 |
75 | #### 4. 日志处理
76 |
77 | 日志处理是指将消息队列用在日志处理中,比如Kafka的应用,解决大量日志传输的问题。架构简化如下:
78 |
79 | 
80 |
81 | - 日志采集客户端,负责日志数据采集,定时写受写入Kafka队列;
82 | - Kafka消息队列,负责日志数据的接收,存储和转发;
83 | - 日志处理应用:订阅并消费kafka队列中的日志数据;
84 |
85 | #### 5. 消息通讯
86 |
87 | 消息通讯是指,消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等。
88 |
89 | 点对点通讯:
90 |
91 | 
92 |
93 | 客户端A和客户端B使用同一队列,进行消息通讯。
94 |
95 | 聊天室通讯:
96 |
97 | 
98 |
99 | 客户端A,客户端B,客户端N订阅同一主题,进行消息发布和接收。实现类似聊天室效果。
100 |
101 | 以上实际是消息队列的两种消息模式,点对点或发布订阅模式。
102 |
103 | ### 消息中间件实例
104 |
105 | #### 电商系统
106 |
107 | 
108 |
109 | 消息队列采用高可用,可持久化的消息中间件。比如Active MQ,Rabbit MQ,Rocket Mq。
110 |
111 | (1)应用将主干逻辑处理完成后,写入消息队列。消息发送是否成功可以开启消息的确认模式。(消息队列返回消息接收成功状态后,应用再返回,这样保障消息的完整性)
112 |
113 | (2)扩展流程(发短信,配送处理)订阅队列消息。采用推或拉的方式获取消息并处理。
114 |
115 | (3)消息将应用解耦的同时,带来了数据一致性问题,可以采用最终一致性方式解决。比如主数据写入数据库,扩展应用根据消息队列,并结合数据库方式实现基于消息队列的后续处理。
116 |
117 | #### 日志收集系统
118 |
119 | 
120 |
121 | 分为Zookeeper注册中心,日志收集客户端,Kafka集群和Storm集群(OtherApp)四部分组成。
122 |
123 | - Zookeeper注册中心,提出负载均衡和地址查找服务
124 | - 日志收集客户端,用于采集应用系统的日志,并将数据推送到kafka队列
125 | - Kafka集群:接收,路由,存储,转发等消息处理
126 |
127 | Storm集群:与OtherApp处于同一级别,采用拉的方式消费队列中的数据
128 |
129 | ### 消息模型
130 |
131 | JMS标准中,有两种消息模型P2P(Point to Point),Publish/Subscribe(Pub/Sub)。
132 |
133 | #### P2P(点对点)模式
134 |
135 | 
136 |
137 | P2P模式包含三个角色:消息队列(Queue),发送者(Sender),接收者(Receiver)。每个消息都被发送到一个特定的队列,接收者从队列中获取消息。队列保留着消息,直到他们被消费或超时。
138 |
139 | P2P的特点
140 |
141 | - 每个消息只有一个消费者(Consumer)(即一旦被消费,消息就不再在消息队列中)
142 | - 发送者和接收者之间在时间上没有依赖性,也就是说当发送者发送了消息之后,不管接收者有没有正在运行,它不会影响到消息被发送到队列
143 | - 接收者在成功接收消息之后需向队列应答成功
144 |
145 | 如果希望发送的每个消息都会被成功处理的话,那么需要P2P模式
146 |
147 | #### Pub/sub模式
148 |
149 | 消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。
150 |
151 | 
152 |
153 | 包含三个角色主题(Topic),发布者(Publisher),订阅者(Subscriber) 多个发布者将消息发送到Topic,系统将这些消息传递给多个订阅者。
154 |
155 | Pub/Sub的特点
156 |
157 | - 每个消息可以有多个消费者
158 | - 发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息
159 | - 为了消费消息,订阅者必须保持运行的状态
160 |
161 | 为了缓和这样严格的时间相关性,JMS允许订阅者创建一个可持久化的订阅。这样,即使订阅者没有被激活(运行),它也能接收到发布者的消息。
162 |
163 | 如果希望发送的消息可以不被做任何处理、或者只被一个消息者处理、或者可以被多个消费者处理的话,那么可以采用Pub/Sub模型
164 |
165 | ### 流行模型对比
166 |
167 | 传统企业型消息队列ActiveMQ遵循了JMS规范,实现了点对点和发布订阅模型,但其他流行的消息队列RabbitMQ、Kafka并没有遵循JMS规范。
168 |
169 | #### RabbitMQ
170 |
171 | RabbitMQ实现了AQMP协议,AQMP协议定义了消息路由规则和方式。生产端通过路由规则发送消息到不同queue,消费端根据queue名称消费消息。 RabbitMQ既支持内存队列也支持持久化队列,消费端为推模型,消费状态和订阅关系由服务端负责维护,消息消费完后立即删除,不保留历史消息。
172 |
173 | (1)点对点
174 | 生产端发送一条消息通过路由投递到Queue,只有一个消费者能消费到。
175 |
176 | 
177 | (2)多订阅
178 | 当RabbitMQ需要支持多订阅时,发布者发送的消息通过路由同时写到多个Queue,不同订阅组消费不同的Queue。所以支持多订阅时,消息会多个拷贝。
179 |
180 | 
181 |
182 | #### Kafka
183 |
184 | Kafka只支持**消息持久化**,消费端为拉模型,消费状态和订阅关系由客户端端负责维护,消息消费完后不会立即删除,会保留历史消息。因此支持多订阅时,消息只会存储一份就可以了。但是可能产生重复消费的情况。
185 |
186 | (1)点对点&多订阅 发布者生产一条消息到topic中,不同订阅组消费此消息。 
--------------------------------------------------------------------------------
/MQ/images/20140220173559828:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/20140220173559828
--------------------------------------------------------------------------------
/MQ/images/20151201162724900.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/20151201162724900.jpg
--------------------------------------------------------------------------------
/MQ/images/20151201162752176.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/20151201162752176.jpg
--------------------------------------------------------------------------------
/MQ/images/20151201162825775.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/20151201162825775.jpg
--------------------------------------------------------------------------------
/MQ/images/20151201162841986.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/20151201162841986.jpg
--------------------------------------------------------------------------------
/MQ/images/20151201162903057.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/20151201162903057.jpg
--------------------------------------------------------------------------------
/MQ/images/20151201162920224.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/20151201162920224.jpg
--------------------------------------------------------------------------------
/MQ/images/20160516173232943:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/20160516173232943
--------------------------------------------------------------------------------
/MQ/images/20160516173308130:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/20160516173308130
--------------------------------------------------------------------------------
/MQ/images/20161018130024488:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/20161018130024488
--------------------------------------------------------------------------------
/MQ/images/20161018144117548:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/20161018144117548
--------------------------------------------------------------------------------
/MQ/images/20161103174653291.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/20161103174653291.jpg
--------------------------------------------------------------------------------
/MQ/images/20161103182929513.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/20161103182929513.jpg
--------------------------------------------------------------------------------
/MQ/images/20161103182938987.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/20161103182938987.jpg
--------------------------------------------------------------------------------
/MQ/images/306976-20160728104237622-1486261669.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/306976-20160728104237622-1486261669.png
--------------------------------------------------------------------------------
/MQ/images/306976-20160728104255372-2049742072.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/306976-20160728104255372-2049742072.png
--------------------------------------------------------------------------------
/MQ/images/306976-20160728104309934-1385658660.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/306976-20160728104309934-1385658660.png
--------------------------------------------------------------------------------
/MQ/images/52im_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/52im_1.png
--------------------------------------------------------------------------------
/MQ/images/61c6fd8e58722d438da19445c8016395.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/61c6fd8e58722d438da19445c8016395.png
--------------------------------------------------------------------------------
/MQ/images/820332-20160124211106000-2080222350.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/820332-20160124211106000-2080222350.png
--------------------------------------------------------------------------------
/MQ/images/820332-20160124211115703-218873208.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/820332-20160124211115703-218873208.png
--------------------------------------------------------------------------------
/MQ/images/820332-20160124211131625-1083908699.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/820332-20160124211131625-1083908699.png
--------------------------------------------------------------------------------
/MQ/images/820332-20160124220821515-1142658553.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/820332-20160124220821515-1142658553.jpg
--------------------------------------------------------------------------------
/MQ/images/820332-20160124220830750-1886187340.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/820332-20160124220830750-1886187340.jpg
--------------------------------------------------------------------------------
/MQ/images/91a956e890623d5f05b3dac013d8dd3a.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/91a956e890623d5f05b3dac013d8dd3a.png
--------------------------------------------------------------------------------
/MQ/images/Decorator.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/Decorator.jpg
--------------------------------------------------------------------------------
/MQ/images/Pic90.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/Pic90.gif
--------------------------------------------------------------------------------
/MQ/images/a0d2f7ae4bc26ac1b0534660b51af7b9.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/a0d2f7ae4bc26ac1b0534660b51af7b9.png
--------------------------------------------------------------------------------
/MQ/images/addea89be214fa66a0d45db711da4f91.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/addea89be214fa66a0d45db711da4f91.png
--------------------------------------------------------------------------------
/MQ/images/f88e45bdce945fe93c31d68df4059146.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/f88e45bdce945fe93c31d68df4059146.png
--------------------------------------------------------------------------------
/MQ/images/uml6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/uml6.png
--------------------------------------------------------------------------------
/MQ/images/v63YbyA.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/v63YbyA.png
--------------------------------------------------------------------------------
/MQ/images/vi-vim-cheat-sheet-sch1.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/vi-vim-cheat-sheet-sch1.gif
--------------------------------------------------------------------------------
/MQ/images/vim-vi-workmodel.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/MQ/images/vim-vi-workmodel.png
--------------------------------------------------------------------------------
/MQ/question.md:
--------------------------------------------------------------------------------
1 | 1. 消息队列的作用
2 | - 流量消峰
3 | 并发量大的时间,所有的请求直接怼到数据库,造成数据库连接异常,将请求写进消息队列,后面的系统再从消息队列依次来取出。
4 | - 异步
5 | 一些非必要的业务逻辑以同步的方式运行,太耗费时间。改成异步,可以提高系统的响应时间。
6 | - 解耦
7 | 将消息写入消息队列,需要消息的系统自己从消息队列中订阅。从而使该系统不需要改代码。
8 | 2. 如何保证消息队列高可用
9 | 集群
10 | 3. 如何保证消息不被重复消费
11 | 那造成重复消费的原因?,就是因为网络传输等等故障,确认信息没有传送到消息队列,导致消息队列不知道自己已经消费过该消息了,再次将消息分发给其他的消费者。
12 | 消费前做检测,比如写库成功的时候,写入到redis中,再次消费的时候如果redis已存在,则不进行消费
13 | 4. 如何保证消费的可靠性传输?
14 | 其实这个可靠性传输,每种MQ都要从三个角度来分析:
15 |
16 | - 生产者弄丢数据
17 |
18 | 从生产者弄丢数据这个角度来看,RabbitMQ提供transaction和confirm模式来确保生产者不丢消息
19 | - 消息队列弄丢数据
20 |
21 | 处理消息队列丢数据的情况,一般是开启持久化磁盘的配置。这个持久化配置可以和confirm机制配合使用
22 | - 消费者弄丢数据
23 |
24 | 消费者丢数据一般是因为采用了自动确认消息模式。这种模式下,消费者会自动确认收到信息。这时rabbitMQ会立即将消息删除,这种情况下,如果消费者出现异常而未能处理消息,就会丢失该消息。
25 | 手动确认消息
26 |
--------------------------------------------------------------------------------
/MQ/rabbitmq.md:
--------------------------------------------------------------------------------
1 | ## RabbitMQ 消息队列
2 |
3 | > RabbitMQ是流行的开源消息队列系统,用erlang语言开发,完整的实现了AMPQ(高级消息队列协议)
4 |
5 | ## AMQP协议
6 |
7 | > AMQP,是应用层协议的一个开放标准,为面向消息的中间件设计。消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在,同样,消息使用者也不用知道发送者的存在。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全
8 |
9 | ## 系统架构
10 |
11 |
12 |
13 | 
14 | 消息队列的使用过程大概如下:
15 |
16 | (1)客户端连接到消息队列服务器,打开一个channel。
17 | (2)客户端声明一个exchange,并设置相关属性。
18 | (3)客户端声明一个queue,并设置相关属性。
19 | (4)客户端使用routing key,在exchange和queue之间建立好绑定关系。
20 | (5)客户端投递消息到exchange。exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里
21 |
22 | ## Rabbitmq中几个概念的解释
23 |
24 | - **生产者 **
25 |
26 | 
27 |
28 | 生产者就是产生消息并向RabbitMq队列发送消息
29 |
30 | - **消费者**
31 |
32 | 
33 |
34 | 等待RabbitMq消息到来并处理消息
35 |
36 | - **Queue**(队列)
37 |
38 | 
39 | Queue(队列), 依存于RabbitMQ内部,消息存在队列中。它指定消息按什么规则,路由到哪个队列
40 |
41 | - **交换器(exchange)**
42 |
43 | 
44 |
45 | 生产者将消息发送到Exchange(交换器),由Exchange将消息路由到一个或多个Queue中.它指定消息按什么规则,路由到哪个队列
46 |
47 | - **binding 绑定**
48 |
49 | 
50 |
51 | 它的作用就是把exchange和queue按照路由规则绑定起来
52 |
53 | - routing key 路由关键字
54 |
55 | exchange根据这个关键字将消息投放到对应的队列中去。
56 |
57 | - **Binding key**
58 |
59 | 在绑定(Binding)Exchange与Queue的同时,一般会指定一个binding key;生产者将消息发送给Exchange时,一般会指定一个routing key;当binding key与routing key相匹配时,消息将会被路由到对应的Queue中
60 |
61 | - **虚拟主机**
62 |
63 | 一个虚拟主机持有一组交换机、队列和绑定。隔离不同的队列和用户的权限管理。
64 |
65 | 
66 |
67 | - **channel 消息通道**
68 |
69 | 在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务
70 |
71 | -Exchange type 交换模式
72 |
73 | RabbitMQ提供了四种Exchange模式:fanout,direct,topic,header
74 |
75 | 一、 **Fanout**
76 |
77 | 
78 |
79 | 它采取广播模式,消息进来时,将会被投递到与改交换机绑定的所有队列中。
80 | 所有发送到Fanout Exchange的消息都会被转发到与该Exchange 绑定(Binding)的所有Queue上.Fanout Exchange 不需要处理RouteKey 。只需要简单的将队列绑定到exchange
81 |
82 | 二、**Direct **
83 |
84 | 
85 |
86 | Direct模式,消息传递时,RouteKey必须完全匹配,才会被队列接收,否则该消息会被抛弃。
87 |
88 | 三. **Topic **
89 |
90 | 
91 |
92 | Exchange 将RouteKey 和某Topic 进行模糊匹配。此时队列需要绑定一个Topic。可以使用通配符进行模糊匹配,符号“#”匹配一个或多个词,符号“*”匹配不多不少一个词。因此“log.#”能够匹配到“log.info.oa”,但是“log.*” 只会匹配到“log.error
--------------------------------------------------------------------------------
/Mysql/MySQL三范式.md:
--------------------------------------------------------------------------------
1 | ## mysql三范式
2 |
3 |
4 |
5 | ### 第一范式:属性原子性不可分割
6 |
7 | 第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值。
8 |
9 | 比如 在一个用户表 存在一个字段班级叫3年级2班。这个属性就不符合第一范式。这个字段可以分成3年级、2班
10 |
11 | ### 第二范式:非主键字段和主键直接关联
12 |
13 | 第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
14 |
15 | 比如订单表
16 |
17 | 
18 |
19 | 在这个表中,存在订单信息和用户信息,和订单不是直接相关的
20 |
21 | ### 第三范式:消除依赖传递
22 |
23 | 如果某一属性依赖于其他非主键属性,而其他非主键属性又依赖于主键,那么这个属性就是间接依赖于主键,这被称作传递依赖于主属性。 **通俗解释就是一张表最多只存两层同类型信息**
24 |
25 |
26 |
27 | ## 反三范式
28 |
29 | 没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,提高读性能,就必须降低范式标准,适当保留冗余数据。具体做法是: 在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,减少了查询时的关联,提高查询效率,因为在数据库的操作中查询的比例要远远大于DML的比例。但是反范式化一定要适度,并且在原本已满足三范式的基础上再做调整的
30 |
31 |
32 |
--------------------------------------------------------------------------------
/Mysql/MySQL优化.md:
--------------------------------------------------------------------------------
1 | ## mysql优化
2 |
3 | - 不要查询不需要的列
4 |
5 | - 不要在多表关联返回全部的列
6 |
7 | - 不要select *
8 |
9 | - 不要重复查询,应当写入缓存
10 |
11 | - 尽量使用关联查询来替代子查询。
12 |
13 | - 尽量使用索引优化。如果不使用索引。mysql则使用临时表或者文件排序。如果不关心结果集的顺序,可以使用order by null 禁用文件排序。
14 |
15 | - 优化分页查询,最简单的就是利用覆盖索引扫描。而不是查询所有的列
16 |
17 | - 应尽量避免在 where 子句中使用 !=或<> 操作符,否则将引擎放弃使用索引而进行全表扫描。
18 |
19 | - 对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引
20 |
21 | - 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
22 |
23 | ```sql
24 | select * from user where name is null
25 | ```
26 |
27 | - 尽量不要使用前缀%
28 |
29 | ```sql
30 | select * from user where name like '%a'
31 | ```
32 |
33 | - 应尽量避免在 where 子句中对字段进行表达式操作
34 |
35 | - 应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描
36 |
37 | - 很多时候用 exists 代替 in 是一个好的选择
38 |
39 |
40 | ## btree索引
41 |
42 | B-TREE索引适合全键值、键值范围、前缀查找。
43 |
44 | 全值匹配,是匹配所有的列进行匹配、
45 |
46 | 匹配最左前缀。比如 a=1&b=2 那么会用到a的索引
47 |
48 | 匹配列前缀。 比如 abc abcd %abc
49 |
50 | 匹配范围 比如 in(3,5)
51 |
52 | ### 限制
53 |
54 | - 如果不是左前缀开始查找,无法使用索引 比如 %aa
55 |
56 | - 不能跳过索引的列。
57 |
58 | - 需要中,含有某个列的范围查找,后面的所有字段都不会用到索引
59 |
60 | ### 索引的优点
61 |
62 | 1、减少服务器扫描表的次数
63 |
64 | 2、避免排序和临时表
65 |
66 | 3、将随机io变成顺序io
67 |
68 | ### 高性能索引策略
69 |
70 | - 1、使用独立的列,而不是计算的列
71 |
72 | where num+1 =10 //bad
73 |
74 | where num = 9 //good
75 |
76 | - 2、使用前缀索引
77 | - 3、多列索引,应该保证左序优先
78 | - 4、覆盖索引
79 | - 5、选择合适的索引顺序
80 |
81 | 不考虑排序和分组的情况。在选择性最高的列上,放索引,
82 |
83 | - 6、使用索引扫描来排序
84 |
85 | mysql有两种方式生成有序的结果,一种是排序操作,一种是按索引顺序扫描,如果explain处理的type列的值是index。则说明mysql使用了索引
86 |
87 | 只有当索引的列顺序和order by子句的顺序一致的时候,并且所有的顺序都一致的时候。mysql才能使用索引进行排序。
88 |
89 | ### 不能使用索引的情况
90 |
91 | - 1.查询使用了两种排序方向
92 |
93 | ```sql
94 | select * from user where login_time > '2018-01-01' order by id des ,username asc #
95 | ```
96 |
97 | - 2.order by中含有了一个没有 索引的列
98 |
99 | ```sql
100 | select * from user where name = '11' order by age desc; //age 没有索引
101 | ```
102 |
103 | - 3.where 和 order by 无法形成最左前缀
104 |
105 | - 索引列的第一列是范围条件
106 |
107 | - 在索引列上有多个等于条件,这也是一种范围。不能使用索引
108 |
109 | https://blog.csdn.net/samjustin1/article/details/52212421
110 |
111 |
112 |
--------------------------------------------------------------------------------
/Mysql/README.md:
--------------------------------------------------------------------------------
1 | ## MySQL知识整理
2 |
3 | - [事务](https://github.com/xianyunyh/PHP-Interview/blob/master/Mysql/%E4%BA%8B%E5%8A%A1.md)
4 |
5 | - [字段类型]()
6 |
7 | 
8 |
9 | - char/varchar/text/longtext
10 | - enum/set
11 | - int[4]/smallint[2]/tinyint[1]/bigint[8]
12 | - double/float
13 | - datetime/date/timestamp
14 | - bit
15 |
16 | - [三范式](https://github.com/xianyunyh/PHP-Interview/blob/master/Mysql/MySQL%E4%B8%89%E8%8C%83%E5%BC%8F.md)
17 |
18 | - [存储引擎](https://github.com/xianyunyh/PHP-Interview/blob/master/Mysql/%E5%AD%98%E5%82%A8%E5%BC%95%E6%93%8E.md)
19 |
20 | - [索引]()
21 |
22 | - [聚集索引和非聚集索引区别](https://blog.csdn.net/zc474235918/article/details/50580639)
23 |
24 | - [索引的分类](https://www.cnblogs.com/luyucheng/p/6289714.html)
25 |
26 | - [mysql优化](http://www.cnblogs.com/luyucheng/p/6323477.html)
27 |
28 | - [sql优化]()
29 | - [explain](https://github.com/xianyunyh/PHP-Interview/blob/master/Mysql/MySQL%E3%80%90explain%E3%80%91.md)
30 | - [慢查询]()
31 | - [配置优化](http://www.cnblogs.com/luyucheng/p/6340076.html)
32 | - [主从配置]()
33 | - [索引优化](https://github.com/xianyunyh/PHP-Interview/blob/master/Mysql/MySQL%E4%BC%98%E5%8C%96.md)
34 |
35 | - [锁]()
36 |
37 | - [mysql共享锁与排他锁](http://www.cnblogs.com/boblogsbo/p/5602122.html)
38 | - [乐观锁和悲观锁]()
39 | - [死锁](https://www.cnblogs.com/sivkun/p/7518540.html)
40 |
41 |
42 | ### 阅读资料
43 |
44 | - [MySQL索引背后的数据结构及算法原理](http://blog.codinglabs.org/articles/theory-of-mysql-index.html)
45 |
46 | - [MySQL索引原理及慢查询优化](https://tech.meituan.com/mysql-index.html)
47 |
48 | - [InnoDB备忘录 - Next-Key Lock](http://zhongmingmao.me/2017/05/19/innodb-next-key-lock/)
49 |
50 | - [MySQL主从复制与读写分离](https://www.cnblogs.com/luckcs/articles/2543607.html)
51 |
52 |
--------------------------------------------------------------------------------
/Mysql/SQL标准.md:
--------------------------------------------------------------------------------
1 | **SQL 分类:**
2 |
3 | **SQL 语句主要可以划分为以下 4 个类别。**
4 |
5 | **DDL(Data Definition Languages)语句:**数据定义语言,这些语句定义了不同的数据段、数据库、表、列、索引等数据库对象的定义。常用的语句关键字主要包括 create、drop、alter等。
6 |
7 | ```sql
8 | CREATE TABLE [IF NOT EXISTS] tbl_name (
9 | column type
10 | [ NULL | NOT NULL ] [ UNIQUE ] [ DEFAULT value ]
11 | [column_constraint_clause | PRIMARY KEY } [ ... ] ]
12 | [, PRIMARY KEY ( column [, ...] ) ]
13 | [, CHECK ( condition ) ]
14 | [, table constraint ]
15 | )
16 |
17 | DROP [TEMPORARY] TABLE [IF EXISTS]
18 | tbl_name [, tbl_name] ...
19 | [RESTRICT | CASCADE]
20 |
21 | ALTER TABLE table [ * ]
22 | ADD [] column type
23 | ALTER TABLE table [ * ]
24 | DROP [ COLUMN ] column
25 | ALTER TABLE table [ * ]
26 | MODIFY [] column { DEFAULT value | DROP DEFAULT }
27 | ALTER TABLE table [ * ]
28 | MODIFY [] column column_constraint
29 | ALTER TABLE table [ * ]
30 | RENAME [] column TO newcolumn
31 | ALTER TABLE table
32 | RENAME TO newtable
33 | ALTER TABLE table
34 | ADD table_constraint
35 | ALTER INDEX index_name {VISIBLE | INVISIBLE}
36 | ```
37 |
38 | **DQL(Data Query Language SELECT )数据查询语言,select语句。**
39 |
40 | ```sql
41 | SELECT
42 | [ALL | DISTINCT | DISTINCTROW ]
43 | [HIGH_PRIORITY]
44 | [STRAIGHT_JOIN]
45 | [SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
46 | [SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
47 | select_expr [, select_expr ...]
48 | [FROM table_references
49 | [PARTITION partition_list]
50 | [WHERE where_condition]
51 | [GROUP BY {col_name | expr | position}
52 | [ASC | DESC], ... [WITH ROLLUP]]
53 | [HAVING where_condition]
54 | [WINDOW window_name AS (window_spec)
55 | [, window_name AS (window_spec)] ...]
56 | [ORDER BY {col_name | expr | position}
57 | [ASC | DESC], ...]
58 | [LIMIT {[offset,] row_count | row_count OFFSET offset}]
59 | [INTO OUTFILE 'file_name'
60 | [CHARACTER SET charset_name]
61 | export_options
62 | | INTO DUMPFILE 'file_name'
63 | | INTO var_name [, var_name]]
64 | [FOR UPDATE | LOCK IN SHARE MODE]]
65 | [FOR {UPDATE | SHARE} [OF tbl_name [, tbl_name] ...] [NOWAIT | SKIP LOCKED]
66 | | LOCK IN SHARE MODE]]
67 | ```
68 |
69 | **DML(Data Manipulation Language)语句:**数据操纵语句,用于添加、删除、更新和查询数据库记录,并检查数据完整性,常用的语句关键字主要包括 insert、delete、udpate 。(增添改)
70 |
71 | ```sql
72 | INSERT INTO tbl_name [ ( column [, ...] ) ]
73 | { VALUES ( expression [, ...] ) | SELECT query }
74 | //demo
75 | INSERT INTO tbl_name (col1,col2) VALUES(15,col1*2);
76 | ```
77 |
78 | ```sql
79 | DELETE FROM table
80 | [ WHERE condition ]
81 | [ORDER BY ...]
82 | [LIMIT row_count]
83 | ```
84 |
85 | ```sql
86 | UPDATE table SET col = expression [,...]
87 | [ FROM fromlist ]
88 | [ WHERE condition ]
89 | [ORDER BY ...]
90 | [LIMIT row_count]
91 | ```
92 |
93 | **DCL(Data Control Language)语句:**数据控制语句,用于控制不同数据段直接的许可和访问级别的语句。这些语句定义了数据库、表、字段、用户的访问权限和安全级别。主要的语句关键字包括 grant、revoke 等。
94 |
95 | ```sql
96 | GRANT
97 | priv_type [(column_list)]
98 | [, priv_type [(column_list)]] ...
99 | ON [object_type] priv_level
100 | TO user_or_role [, user_or_role] ...
101 | [WITH GRANT OPTION]
102 |
103 | GRANT PROXY ON user_or_role
104 | TO user_or_role [, user_or_role] ...
105 | [WITH GRANT OPTION]
106 |
107 | GRANT role [, role] ...
108 | TO user_or_role [, user_or_role] ...
109 | [WITH ADMIN OPTION]
110 |
111 | object_type: {
112 | TABLE
113 | | FUNCTION
114 | | PROCEDURE
115 | }
116 |
117 | priv_level: {
118 |
119 | | db_name.*
120 | | db_name.tbl_name
121 | | tbl_name
122 | | db_name.routine_name
123 | }
124 |
125 | user_or_role: {
126 | user
127 | | role
128 | }
129 | GRANT ALL ON db1.* TO 'jeffrey'@'localhost';
130 | ```
131 |
132 | 参考资料:
133 |
134 | SQL92 http://owen.sj.ca.us/rkowen/howto/sql92F.html
135 |
136 | MySql文档 https://dev.mysql.com/doc/refman/8.0/en/sql-syntax.html
137 |
--------------------------------------------------------------------------------
/Mysql/explain.md:
--------------------------------------------------------------------------------
1 | 调用explain
2 |
3 | explain可以查看查询计划的信息,
4 |
5 | 如果sql语句中包含子查询,mysql依然会执行子查询,将结果放到一个临时表中。然后完成外层的优化查询
6 |
7 |
8 | ## EXPLAIN中的列
9 |
10 | explain中总是有相同的列。
11 |
12 | ### id 列
13 | 这个id包含一个标号,标识select所属的行。如果语句中没有子查询或者联合,id唯一。
14 |
15 | mysql将查询分为简单查询和复杂查询,复杂查询分为子查询、派生表(FROM中的子查询)、union查询。
16 |
17 | ### select_type 列
18 |
19 | 这一列显示对应的行是简单查询还是复杂查询。,如果是简单 查询 就是simple。如果是复杂查询,则是以下的几种值
20 |
21 | 1. SUBQUERY
22 |
23 | 包含在select列表中的select
24 |
25 | ```sql
26 | select (select id from user) from user
27 | ```
28 |
29 | 2. DERIVED
30 |
31 | DERIVED值用来表示包含在from子查询中的select。
32 |
33 | ```sql
34 | select id from (select id from user where id >100);
35 | ```
36 |
37 | 3. UNION
38 |
39 | 在union中的第二个值和select 都被标记为union
40 |
41 | 4. union result
42 |
43 | 用来从临时表检索结果的select被标记为union result
44 |
45 |
46 | ### table 列
47 |
48 | 对应访问的表。
49 |
50 |
51 | ### type 列
52 |
53 | mysql决定查找表中的行
54 |
55 | - all
56 |
57 | 全表扫描。
58 |
59 | - index
60 |
61 | 跟全表扫描一样,只是按照索引的顺序进行。优点避免了排序,缺点就是按照整个索引读取整个表的开销。
62 |
63 | - range
64 |
65 | 范围扫描。就是一个有限制的索引扫描,开始于索引的一点,结束到匹配的值。比如 between 或者where 带有 范围的条件
66 |
67 | - ref
68 |
69 | 这是一种索引访问,返回匹配到某个单个值的行,一般是非唯一索引或者非唯一索引的前缀索引。
70 |
71 | - eq_ref
72 |
73 | 使用这种索引查找,一般是通过唯一索引或者主键索引查找的时候看到
74 |
75 | - const system
76 |
77 | mysql对查询的部分进行优化转成一个常量的时候,比如把一行中的主键放入到where条件中
78 |
79 | ```sql
80 |
81 | select * from user where name = id ;
82 | ```
83 | - null
84 |
85 | mysql在优化阶段分解查询语句,在执行阶段不用访问表或者访问索引。
86 |
87 | ### possible_keys
88 |
89 | 这列显示的是mysql可以使用的索引
90 |
91 | ### key 列
92 |
93 | 决定了mysql 采用哪个索引来对表的访问。
94 |
95 | ### key_len 列
96 |
97 | mysql在索引使用的字节数
98 |
99 | ### ref列
100 |
101 | 显示之前的表在key列记录的索引,中,查找值所用的列或常量。
102 |
103 | ### rows 列
104 |
105 | 估算查到需要结果的而读取到的行数。
106 |
107 | ### fiteread 列
108 |
109 | 查询记录和总记录的一个百分比
110 |
111 | ### extra 列
112 |
113 | 额外的信息
114 |
115 | - using index 使用覆盖索引
116 | - using where
117 | - using temproary 使用临时表
118 | - using filesort 使用文件排序
119 | -
--------------------------------------------------------------------------------
/Mysql/mysql.md:
--------------------------------------------------------------------------------
1 | 复习mysql,整理的资料和笔记
2 |
3 | - [SQL标准](https://github.com/xianyunyh/PHP-Interview/tree/master/Mysql/SQL标准.md)
4 |
5 | - [数据库三范式](https://github.com/xianyunyh/PHP-Interview/tree/master/Mysql/MySQL三范式.md)
6 |
7 | - [存储引擎](https://github.com/xianyunyh/PHP-Interview/blob/master/Mysql/%E5%AD%98%E5%82%A8%E5%BC%95%E6%93%8E.md)
8 |
9 | - [事务](https://github.com/xianyunyh/PHP-Interview/tree/master/Mysql/事务.md)
10 |
11 | - [explain](https://github.com/xianyunyh/PHP-Interview/tree/master/Mysql/MySQL【explain】.md)
12 |
13 | - [索引](https://github.com/xianyunyh/PHP-Interview/tree/master/Mysql/索引.md)
14 |
15 | - [MySQL优化](https://github.com/xianyunyh/PHP-Interview/blob/master/Mysql/MySQL%E4%BC%98%E5%8C%96.md)
16 |
17 | - [MySQL索引原理及慢查询优化](https://github.com/xianyunyh/PHP-Interview/tree/master/Mysql/MySQL索引原理及慢查询优化.md)
18 |
19 | 参考资料:
20 |
21 | - [聚簇索引和聚簇索引介绍](https://www.cnblogs.com/Jessy/p/3543063.html)
22 |
23 | - [MySQL笔记](https://github.com/CyC2018/Interview-Notebook/blob/master/notes/MySQL.md)
24 |
25 |
26 |
--------------------------------------------------------------------------------
/Mysql/事务.md:
--------------------------------------------------------------------------------
1 | ## 数据库事务的四个特性**ACID**
2 |
3 | **原子性【Atomicity】**
4 |
5 | 原子性指的指的就是这个操作,要么全部成功,要么全部失败回滚。不存在其他的情况。
6 |
7 | **一致性(Consistency)**
8 |
9 | 一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
10 |
11 | 举个例子。就是A和B的钱是1000元,A给你100元,无论最后双方转了多少次,总的钱一定是1000元。
12 |
13 | **隔离性(Isolation)**
14 |
15 | 隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离
16 |
17 | **持久性(Durability)**
18 |
19 | 持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
20 |
21 | ## 并发操作几个问题
22 |
23 | 在事务的并发操作中可能会出现脏读,不可重复读,幻读。
24 |
25 | ### **脏读**
26 |
27 | 脏读是指在一个事务处理过程里读取了另一个未提交的事务中的数据。
28 |
29 | 比如A转账给B100元,然后还没有提交成功,这个时候,你用B用手机付款,这个事务读取到这个100了。然后就行了扣款,B读到的这个数据就是脏数据。因为A没有提交,可能会撤销。
30 |
31 | ### 不可重复读
32 |
33 | 不可重复读是指在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了。不可重复读一般是update操作
34 |
35 | 举例:比如A事务 读取了一个记录,然后此时B事务修改了这个记录会提交了,A事务再进行读取的时候就会跟之前的记录不一样。 会产生我们说的ABA问题。
36 |
37 | ### 幻读
38 |
39 | 幻读是事务非独立执行时发生的一种现象。例如事务T1对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作,这时事务T2又对这个表中插入了一行数据项,而这个数据项的数值还是为“1”并且提交给数据库。而操作事务T1的用户如果再查看刚刚修改的数据,会发现还有一行没有修改,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。 幻读一般是insert操作
40 |
41 | 举例:程序员某一天去消费,花了2千元,然后他的妻子去查看他今天的消费记录(全表扫描FTS,妻子事务开启),看到确实是花了2千元,就在这个时候,程序员花了1万买了一部电脑,即新增INSERT了一条消费记录,并提交。当妻子打印程序员的消费记录清单时(妻子事务提交),发现花了1.2万元,似乎出现了幻觉,这就是幻读。
42 |
43 | ## 四种隔离
44 |
45 | 数据库事务的隔离级别有4种,由低到高分别为Read uncommitted 、Read committed 、Repeatable read 、Serializable 。
46 |
47 | **Read uncommitted 未提交读**
48 |
49 | 最低的隔离,就是可以读取到未提交的数据。会产生**脏读**。
50 |
51 | A给B转账1000元。开启事务,还没提交。 此时B查看自己余额多了1000元。但是突然A输错了密码。放弃了转款,回滚。此时这个B看到1000元就是一个脏数据,因为事务没有提交完成。
52 |
53 | **Read committed 提交读**
54 |
55 | 就是一个事务要等另一个事务提交后才能读取数据。
56 |
57 | 比如A的卡里有1000元。去请吃饭花付钱需要花900元。然后此时他媳妇B取出了500.当结账的时候,就会出现付款失败。出现这种情况,就是因为出现了B取钱的时候,没有等待A刷卡这个事务完成,而自己的事务开始读取和提交了数据。
58 |
59 | Repeatable read 重复读
60 |
61 | 重复读,就是在开始读取数据(事务开启)时,不再允许修改操作。MySQL默认的事务隔离级别是Rr 重复读
62 |
63 | 比如上面的例子。当A进行付款的时候,B取款的操作就应该等待,不允许进行修改。
64 |
65 | **Serializable 序列化**
66 |
67 | Serializable 是最高的事务隔离级别,在该级别下,事务串行化顺序执行,可以避免脏读、不可重复读与幻读。但是这种事务隔离级别效率低下,比较耗数据库性能,一般不使用。
68 |
69 | 序列化就是将并行的操作。改成顺序执行。
70 |
--------------------------------------------------------------------------------
/Mysql/存储引擎.md:
--------------------------------------------------------------------------------
1 | **MySQL常用的四种引擎**
2 |
3 | (1):MyISAM存储引擎
4 |
5 | 不支持事务、也不支持外键,优势是访问速度快,对事务完整性没有 要求或者以select,insert为主的应用基本上可以用这个引擎来创建表
6 |
7 | 支持3种不同的存储格式,分别是:静态表;动态表;压缩表
8 |
9 | 静态表:表中的字段都是非变长字段,这样每个记录都是固定长度的,优点存储非常迅速,容易缓存,出现故障容易恢复;缺点是占用的空间通常比动态表多(因为存储时会按照列的宽度定义补足空格)ps:在取数据的时候,默认会把字段后面的空格去掉,如果不注意会把数据本身带的空格也会忽略。
10 |
11 | 动态表:记录不是固定长度的,这样存储的优点是占用的空间相对较少;缺点:频繁的更新、删除数据容易产生碎片,需要定期执行OPTIMIZE TABLE或者myisamchk-r命令来改善性能
12 |
13 | 压缩表:因为每个记录是被单独压缩的,所以只有非常小的访问开支
14 |
15 | MyISAM的表存储成3个文件。文件的名字与表名相同。拓展名为_frm_、_MYD_、_MYI_。其实,frm文件存储表的结构;MYD文件存储数据,是MYData的缩写;MYI文件存储索引,是MYIndex的缩写。
16 |
17 | MyISAM:只支持表级锁,只支持表级锁,用户在操作myisam表时,select,update,delete,insert语句都会给表自动加锁。
18 |
19 | **(2)InnoDB存储引擎**
20 |
21 | 该存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比MyISAM引擎,写的处理效率会差一些,并且会占用更多的磁盘空间以保留数据和索引。
22 | InnoDB存储引擎的特点:支持自动增长列,支持外键约束,支持事务
23 |
24 | InnoDB中,创建的表的表结构存储在_.frm_文件中(我觉得是frame的缩写吧)。数据和索引存储在innodb\_data\_home\_dir和innodb\_data\_file\_path定义的表空间中
25 |
26 | InnoDB:支持事务和行级锁,是innodb的最大特色。行锁大幅度提高了多用户并发操作的新能。
27 |
28 | **(3):MEMORY存储引擎**
29 |
30 | Memory存储引擎使用存在于内存中的内容来创建表。每个memory表只实际对应一个磁盘文件,格式是.frm。memory类型的表访问非常的快,因为它的数据是放在内存中的,并且默认使用HASH索引,但是一旦服务关闭,表中的数据就会丢失掉。
31 | MEMORY存储引擎的表可以选择使用BTREE索引或者HASH索引,两种不同类型的索引有其不同的使用范围
32 |
33 | Hash索引优点:
34 | Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
35 | Hash索引缺点: 那么不精确查找呢,也很明显,因为hash算法是基于等值计算的,所以对于“like”等范围查找hash索引无效,不支持;
36 |
37 | Memory类型的存储引擎主要用于哪些内容变化不频繁的代码表,或者作为统计操作的中间结果表,便于高效地对中间结果进行分析并得到最终的统计结果,。对存储引擎为memory的表进行更新操作要谨慎,因为数据并没有实际写入到磁盘中,所以一定要对下次重新启动服务后如何获得这些修改后的数据有所考虑。
38 |
39 | **4)MERGE存储引擎**
40 |
41 | Merge存储引擎是一组MyISAM表的组合,这些MyISAM表必须结构完全相同,merge表本身并没有数据,对merge类型的表可以进行查询,更新,删除操作,这些操作实际上是对内部的MyISAM表进行的。
42 |
43 |
44 |
--------------------------------------------------------------------------------
/Mysql/索引.md:
--------------------------------------------------------------------------------
1 | ## 索引分类
2 |
3 | **从物理存储角度**
4 |
5 | 1. 聚集索引(clustered index)
6 |
7 | 2. 非聚集索引(non-clustered index)、 二级索引
8 |
9 | **从逻辑角度**
10 |
11 | 1. 主键索引:主键索引是一种特殊的唯一索引,不允许有空值
12 |
13 | 2. 普通索引或者单列索引
14 |
15 | 3. 多列索引(联合索引):复合索引指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用复合索引时遵循最左前缀集合
16 |
17 | 4. 唯一索引或者非唯一索引
18 |
19 | 5. 空间索引:空间索引是对空间数据类型的字段建立的索引,MYSQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING、POLYGON。
20 | MYSQL使用SPATIAL关键字进行扩展,使得能够用于创建正规索引类型的语法创建空间索引。创建空间索引的列,必须将其声明为NOT NULL,空间索引只能在存储引擎为MYISAM的表中创建
21 |
22 | **从数据结构角度**
23 |
24 | 1. B-Tree索引
25 |
26 | 2. Hash索引:
27 | a 仅仅能满足"=","IN"和"<=>"查询,不能使用范围查询
28 | b 其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引
29 | c 只有Memory存储引擎显示支持hash索引
30 |
31 | 3. FULLTEXT索引(现在MyISAM和InnoDB引擎都支持了)
32 |
33 | 4. R-Tree索引
34 |
35 |
36 |
37 | ## 聚簇索引(cluster index)
38 |
39 | **聚簇索引、聚集索引 一个意思**。
40 |
41 | 指索引项的排序方式和表中数据记录排序方式一致的索引。一个表至少有一个聚集索引。
42 |
43 | 1. 如果表设置了主键,则主键就是聚簇索引
44 |
45 | 2. 如果表没有主键,则会默认第一个NOT NULL,且唯一(UNIQUE)的列作为聚簇索引
46 |
47 | 3. 以上都没有,则会默认创建一个隐藏的row_id作为聚簇索引
48 |
49 | InnoDB的聚簇索引的叶子节点存储的是行记录(其实是页结构,一个页包含多行数据),InnoDB必须要有至少一个聚簇索引。
50 |
51 | 由此可见,使用聚簇索引查询会很快,因为可以直接定位到行记录。
52 |
53 | > InnoDB的聚簇索引的叶子节点存储的是行记录(其实是页结构,一个页包含多行数据),InnoDB必须要有至少一个聚簇索引。
54 | >
55 | > 由此可见,使用聚簇索引查询会很快,因为可以直接定位到行记录。
56 |
57 | ## 普通索引
58 |
59 | 普通索引也叫**二级索引**,除聚簇索引外的索引,即非聚簇索引。
60 |
61 | InnoDB的普通索引叶子节点存储的是主键(聚簇索引)的值,而MyISAM的普通索引存储的是记录指针。
62 |
63 | ```mysql
64 | mysql> create table user(
65 | -> id int(10) auto_increment,
66 | -> name varchar(30),
67 | -> age tinyint(4),
68 | -> primary key (id),
69 | -> index idx_age (age)
70 | -> )engine=innodb charset=utf8mb4;
71 | insert into user(name,age) values('张三',30);
72 | insert into user(name,age) values('李四',20);
73 | insert into user(name,age) values('王五',40);
74 | insert into user(name,age) values('刘八',10);
75 | ```
76 |
77 |
78 |
79 | ### 聚簇索引的结构
80 |
81 | > 叶子节点存储行信息
82 |
83 | 
84 |
85 | ### 非聚簇索引结构
86 |
87 | > 非聚簇索引,其叶子节点存储的是聚簇索引的的值
88 |
89 | 
90 |
91 | ```sql
92 | select * from user where id =1
93 | select * from user where age = 20
94 | ```
95 |
96 | 对于聚簇索引查询,需要扫描聚簇索引,一次即可扫描到记录,
97 |
98 | 对于非聚簇索引,利用非非聚簇索引,扫到聚簇索引的值,然后会再次到聚簇索引中查找,
99 |
100 | ### 回表查询
101 |
102 | 先通过普通索引的值定位聚簇索引值,再通过聚簇索引的值定位行记录数据,需要扫描两次索引B+树,它的性能较扫一遍索引树更低。这个过程叫做回表
103 |
104 | ### 索引覆盖
105 |
106 | 查询的结果字段包含所有索引信息,不会回表,比如
107 |
108 | ```sql
109 | select id,age from user where age = 10
110 | ```
111 |
112 | 当age索引一次扫描到聚簇索引的值的时候,正好得到了所有的结果,避免了回表操作。
113 |
114 | 实现: 将被查询的字段,建立到联合索引里去。
115 |
116 | 可以通过`explain` ,查看extra字段。如果是`use index` 则使用了索引,如果是`null` 则进行了回表
117 |
118 | - count 优化
119 | - 列查询优化
120 | - 分页查询优化
121 |
122 |
123 |
124 | ## 索引下推
125 |
126 | 索引下推(index condition pushdown) 指的是Mysql需要一个表中检索数据的时候,会使用索引过滤掉不符合条件的数据,然后再返回给客户端
127 |
128 | ```sql
129 | "select * from user where username like '张%' and age > 10"
130 | ```
131 |
132 | **没有ICP**
133 |
134 | 根据(username,age)联合索引查询所有满足名称以“张”开头的索引,然后回表查询出相应的全行数据,然后再筛选出满足年龄小于等于10的用户数据
135 |
136 | 1,获取下一行,首先读索引元组,然后使用索引去查找并读取所有的行
137 |
138 | 2,根据WHERE条件部分,判断数据是否符合。根据判断结果接受或拒绝该行
139 |
140 | **使用ICP**
141 |
142 | 这个过程则会变成这样:
143 |
144 | 根据(username,age)联合索引查询所有满足名称以“张”开头的索引,然后直接再筛选出年龄小于等于10的索引,之后再回表查询全行数据
145 |
146 | 
147 |
148 | 1,获取下一行的索引元组(不是所有行)
149 |
150 | 2,根据WHERE条件部分,判断是否可以只通过索引列满足条件。如果不满足,则获取下一行索引元组
151 |
152 | 3,如果满足条件,则通过索引元组去查询并读取所有的行
153 |
154 | 4,根据遗留的WHERE子句中的条件,在当前表中进行判断,根据判断结果接受或者拒绝改行
155 |
156 | 
157 |
158 | ICP默认启动。可以通过optimizer_switch系统变量去控制它是否开启:
159 |
160 | ```ini
161 | SET optimizer_switch = 'index_condition_pushdown=off';
162 | SET optimizer_switch = 'index_condition_pushdown=on';
163 | ```
164 |
--------------------------------------------------------------------------------
/Mysql/锁.md:
--------------------------------------------------------------------------------
1 | ## 乐观锁
2 | 乐观锁是指操作数据库时(更新操作),想法很乐观,认为这次的操作不会导致冲突,在操作数据时,并不进行任何其他的特殊处理(也就是不加锁),而在进行更新后,再去判断是否有冲突了。通常的做法,是在表中加个版本字段,更新的时候和读取的时候做比对。如果一致则进行修改。
3 | ```sql
4 | select v,name from table where id =1 ;// 假设v = 1
5 |
6 | update table set name ="test" and v = v+1 where id = 1 and v =1;// 如果v之前有过修改,则此次修改失败。
7 | ```
8 | ## 悲观锁
9 | 与乐观锁相对应的就是悲观锁了。悲观锁就是在操作数据时,认为此操作会出现数据冲突,所以在进行每次操作时都要通过获取锁才能进行对相同数据的操作,所以悲观锁需要耗费较多的时间。另外与乐观锁相对应的,悲观锁是由数据库自己实现了的,要用的时候,我们直接调用数据库的相关语句就可以
10 | ### 共享锁 [读锁]
11 |
12 | 共享锁指的就是对于多个不同的事务,对同一个资源共享同一个锁。相当于对于同一把门,它拥有多个钥匙一样。就像这样,你家有一个大门,大门的钥匙有好几把,你有一把,你女朋友有一把,你们都可能通过这把钥匙进入你们家,这个就是所谓的共享锁。
13 | ```sql
14 | begin
15 | select id from `table` where id = 1 lock in share mode;
16 |
17 | # 第二个客户端
18 | update `table` set name = "ddte" where id =1 ;//报错 第一个事务没提交
19 | ```
20 | ### 排它锁 [写锁]
21 | 排它锁与共享锁相对应,就是指对于多个不同的事务,对同一个资源只能有一把锁。
22 |
23 | 与共享锁类型,在需要执行的语句后面加上for update就可以了(对于Innodb引擎语句后面加上for update表示把此行数据锁定,MyISAM则是锁定整个表。)
24 | ```sql
25 | select …… for update;
26 | ```
27 | ## MVCC
28 |
29 | mysql的innodb采用的是行锁,而且采用了多版本并发控制来提高读操作的性能。
30 |
31 | MVVC (Multi-Version Concurrency Control) (注:与MVCC相对的,是基于锁的并发控制,Lock-Based Concurrency Control)是一种基于多版本的并发控制协议,只有在InnoDB引擎下存在。MVCC是为了实现事务的隔离性,通过版本号,避免同一数据在不同事务间的竞争,你可以把它当成基于多版本号的一种乐观锁。当然,这种乐观锁只在事务级别未提交锁和已提交锁时才会生效。MVCC最大的好处,相信也是耳熟能详:读不加锁,读写不冲突。在读多写少的OLTP应用中,读写不冲突是非常重要的,极大的增加了系统的并发性能
32 |
33 | ### 实现方式
34 | InnoDB在每行数据都增加两个隐藏字段,一个记录创建的版本号,一个记录删除的版本号。
35 | 版本链
36 |
37 | 在InnoDB引擎表中,它的聚簇索引记录中有两个必要的隐藏列:
38 |
39 | - trx_id
40 | 这个id用来存储的每次对某条聚簇索引记录进行修改的时候的事务id。
41 | - roll_pointer
42 | 每次对哪条聚簇索引记录有修改的时候,都会把老版本写入undo日志中。这个roll_pointer就是存了一个指针,它指向这条聚簇索引记录的上一个版本的位置,通过它来获得上一个版本的记录信息。(注意插入操作的undo日志没有这个属性,因为它没有老版本)
43 |
44 | | id | name | trx_id | roll_pointer |
45 | | ---- | ---- | ------ | ------------ |
46 | | 1 | 1 | 50 | 49 |
47 | | | | | |
48 |
49 | 在多版本并发控制中,为了保证数据操作在多线程过程中,保证事务隔离的机制,降低锁竞争的压力,保证较高的并发量。在每开启一个事务时,会生成一个事务的版本号,被操作的数据会生成一条新的数据行(临时),但是在提交前对其他事务是不可见的,对于数据的更新(包括增删改)操作成功,会将这个版本号更新到数据的行中,事务提交成功,将新的版本号更新到此数据行中,这样保证了每个事务操作的数据,都是互不影响的,也不存在锁的问题。
50 | ### MVVC下的CRUD
51 | - SELECT:
52 | 当隔离级别是REPEATABLE READ时select操作,InnoDB必须每行数据来保证它符合两个条件:
53 | 1、InnoDB必须找到一个行的版本,它至少要和事务的版本一样老(也即它的版本号不大于事务的版本号)。这保证了不管是事务开始之前,或者事务创建时,或者修改了这行数据的时候,这行数据是存在的。
54 | 2、这行数据的删除版本必须是未定义的或者比事务版本要大。这可以保证在事务开始之前这行数据没有被删除。
55 | 符合这两个条件的行可能会被当作查询结果而返回。
56 |
57 |
58 | - INSERT:InnoDB为这个新行记录当前的系统版本号。
59 |
60 | - DELETE:InnoDB将当前的系统版本号设置为这一行的删除ID。
61 | - UPDATE:InnoDB会写一个这行数据的新拷贝,这个拷贝的版本为当前的系统版本号。它同时也会将这个版本号写到旧行的删除版本里。
62 |
63 | 这种额外的记录所带来的结果就是对于大多数查询来说根本就不需要获得一个锁。他们只是简单地以最快的速度来读取数据,确保只选择符合条件的行。这个方案的缺点在于存储引擎必须为每一行存储更多的数据,做更多的检查工作,处理更多的善后操作。
64 | MVCC只工作在REPEATABLE READ和READ COMMITED隔离级别下。READ UNCOMMITED不是MVCC兼容的,因为查询不能找到适合他们事务版本的行版本;它们每次都只能读到最新的版本。SERIABLABLE也不与MVCC兼容,因为读操作会锁定他们返回的每一行数据。
--------------------------------------------------------------------------------
/PHP/PHP-FPM配置选项.md:
--------------------------------------------------------------------------------
1 | ## PHP-FPM
2 |
3 | FPM(FastCGI 进程管理器)用于替换 PHP FastCGI 的大部分附加功能,对于高负载网站是非常有用的。
4 |
5 | 它的功能包括:
6 |
7 | - 支持平滑停止/启动的高级进程管理功能;
8 | - 可以工作于不同的 uid/gid/chroot 环境下,并监听不同的端口和使用不同的 php.ini 配置文件(可取代 safe_mode 的设置);
9 | - stdout 和 stderr 日志记录;
10 | - 在发生意外情况的时候能够重新启动并缓存被破坏的 opcode;
11 | - 文件上传优化支持;
12 | - "慢日志" - 记录脚本(不仅记录文件名,还记录 PHP backtrace 信息,可以使用 ptrace或者类似工具读取和分析远程进程的运行数据)运行所导致的异常缓慢;
13 | - [fastcgi_finish_request()](http://php.net/manual/zh/function.fastcgi-finish-request.php) - 特殊功能:用于在请求完成和刷新数据后,继续在后台执行耗时的工作(录入视频转换、统计处理等);
14 | - 动态/静态子进程产生;
15 | - 基本 SAPI 运行状态信息(类似Apache的 mod_status);
16 | - 基于 php.ini 的配置文件。
17 |
18 | ### 全局配置选项
19 |
20 | - pid
21 |
22 | pid文件的位置
23 |
24 | - error_log
25 |
26 | 错误日志的位置
27 |
28 | - log_level
29 |
30 | 错误的级别 alert 、error、warning、notice、debug、默认是notice
31 |
32 | - syslog.facility
33 |
34 | 设置何种程序记录消息 默认daemon
35 |
36 | - syslog.ident
37 |
38 | 为每条消息 添加前缀
39 |
40 | - emergency_restart_interval
41 |
42 | 如果子进程在 *emergency_restart_interval* 设定的时间内收到该参数设定次数的 SIGSEGV 或者 SIGBUS退出信息号,则FPM会重新启动。0 表示“关闭该功能”。默认值:0(关闭)
43 |
44 | - process_control_timeout
45 |
46 | 设置子进程接受主进程复用信号的超时时间 可用单位:s(秒),m(分),h(小时)或者 d(天)。默认单位:s(秒)。默认值:0(关闭)。
47 |
48 | - process_max
49 |
50 | fork的最大的fpm的进程数
51 |
52 | - process.priority
53 |
54 | 设置master进程的nice(2) 优先级
55 |
56 | - daemonize
57 |
58 | 设置php-fpm后台运行。默认是yes
59 |
60 | - rlimit_core
61 |
62 | 设置master 进程打开的core最大的尺寸
63 |
64 | - events.mechaism
65 |
66 | 设置fpm的使用的事件机制 select、pool、epoll、kqueue (*BSD)、port (Solaris )
67 |
68 | - systemd_interval
69 |
70 | 使用systemd集成的fpm时,设置间歇秒数
71 |
72 | ### 运行时配置
73 |
74 | - listen
75 |
76 | 设置接受的fastcgi请求的地址可用格式为:'ip:port','port','/path/to/unix/socket'。每个进程池都需要设置
77 |
78 | - listen.backlog
79 |
80 | 设置backlog的最大值
81 |
82 | - listen.allowed_clients
83 |
84 | 设置允许链接到fastcgi的ip地址
85 |
86 | - listen.owner listen.group listen.mode
87 |
88 | 设置权限
89 |
90 | - user group
91 |
92 | fpm运行的Unix用户 必须设置的
93 |
94 | - pm
95 |
96 | 设置进程管理器如何管理子进程
97 |
98 | - static 子进程是固定的 = *pm.max_children*
99 | - *ondemand* 进程在有需求时才产生
100 | - *dynamic* 子进程的数量在下面配置的基础上动态设置 *pm.max_children*,*pm.start_servers*,*pm.min_spare_servers*,*pm.max_spare_servers*。
101 |
102 | - pm.max_children
103 |
104 | pm设置为staic时。表示创建的子进程的数量。
105 |
106 | pm为dynamic时,表示最大可创建的进程数
107 |
108 | - pm.start_servers
109 |
110 | 设置启动时创建的子进程的数目。仅在 *pm* 设置为 *dynamic* 时使用 。就是初始化创建的进程数
111 |
112 | - pm.min_spare_servers
113 |
114 | 设置空闲进程的最大数目
115 |
116 | - pm.process_idle_timeout
117 |
118 | 秒。多久之后结束空闲进程
119 |
120 | - pm.max_requests
121 |
122 | 设置每个子进程重生之前的服务的请求数。
123 |
124 | - pm.status_path
125 |
126 | fpm状态的页面的地址
127 |
128 | - ping.path
129 |
130 | fpm监控页面的ping的地址
131 |
132 | - ping.resource
133 |
134 | 用于定于ping请求的返回响应 默认是pong
135 |
136 | - request_terminate_timeout
137 |
138 | 设置单个请求的超时中止时间。
139 |
140 | - request_slowlog_timeout
141 |
142 | 当一个请求该设置的超时时间后,就会将对应的 PHP 调用堆栈信息完整写入到慢日志中
143 |
144 | - slowlog
145 |
146 | 慢请求的记录日志
147 |
148 | - rlimit_files
149 |
150 | 设置打开文件描述符的限制
151 |
152 | - access.log
153 |
154 | 访问日志
155 |
156 | - access.format
157 |
158 | acces log的格式
159 |
160 | ### 优化
161 |
162 | #### 内核调优
163 |
164 | - 调整linux内核打开文件的数量。
165 |
166 | ```shell
167 | echo `ulimit -HSn 65536` >> /etc/profile
168 | echo `ulimit -HSn 65536` >> /etc/rc.local
169 | source /etc/profile
170 | ```
171 |
172 | #### PHP-FPM配置调优
173 |
174 | - 进程数调整
175 |
176 | >pm.max_children = 300; **静态方式**下开启的php-fpm进程数量
177 | >
178 | >pm.start_servers = 20; **动态方式**下的起始php-fpm进程数量
179 | >
180 | >pm.min_spare_servers = 5; **动态方式**下的最小php-fpm进程数量
181 | >
182 | >pm.max_spare_servers = 35; **动态方式**下的最大php-fpm进程数量
183 | >
184 | >request_slowlog_timeout = 2; 开启慢日志
185 | >slowlog = log/$pool.log.slow; 慢日志路径
186 | >
187 | >rlimit_files = 1024; 增加php-fpm打开文件描述符的限制
188 |
189 | **一般来说一台服务器正常情况下每一个php-cgi所耗费的内存在20M左右 。**
190 |
191 | 用内存/20 就大概算出最大的进程数。
192 |
193 | 一般初始化的进程有一个类似的公式
194 |
195 | ```
196 | start_servers = min_spare_servers + (max_spare_servers - min_spare_servers) / 2;
197 | ```
198 |
199 |
200 |
201 | 如果长时间没有得到处理的请求就会出现504 Gateway Time-out这个错误,而正在处理的很累的那几个php-cgi如果遇到了问题就会出现502 Bad gateway这个错误
202 |
203 | - **最大请求数**
204 |
205 | 最大处理请求数是指一个php-fpm的worker进程在处理多少个请求后就终止掉,master进程会重新respawn一个新的。
206 |
207 | 这个配置的主要目的是避免php解释器或程序引用的第三方库造成的内存泄露。
208 |
209 | pm.max_requests = 10240
210 |
211 | - 最长执行时间
212 |
213 | 最大执行时间在php.ini和php-fpm.conf里都可以配置,配置项分别为max_execution_time和request_terminate_timeout。
214 |
215 |
--------------------------------------------------------------------------------
/PHP/PHP7-HashTable.md:
--------------------------------------------------------------------------------
1 | 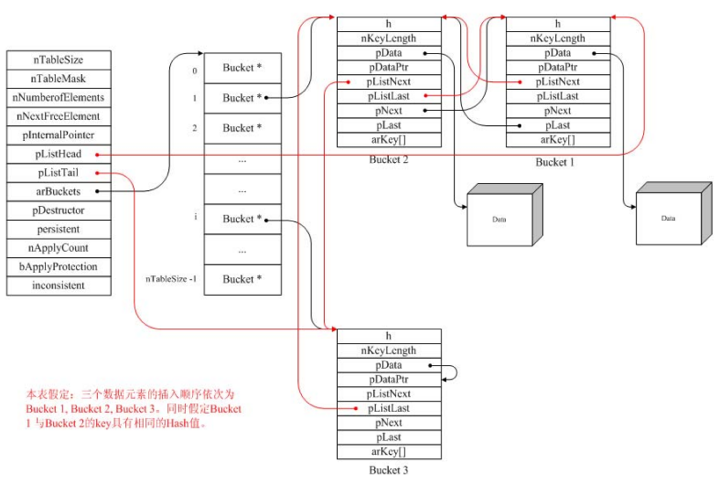
2 |
3 | 上图是PHP5 hashtable的实现
4 |
5 | 新的zval结构
6 |
7 | ```c
8 | struct _zval_struct {
9 | zend_value value;
10 | union {
11 | struct {
12 | ZEND_ENDIAN_LOHI_4(
13 | zend_uchar type,
14 | zend_uchar type_flags,
15 | zend_uchar const_flags,
16 | zend_uchar reserved
17 | )
18 | } v;
19 | uint32_t type_info;
20 | } u1;
21 | union {
22 | uint32_t var_flags;
23 | uint32_t next; /* hash collision chain */
24 | uint32_t cache_slot; /* literal cache slot */
25 | uint32_t lineno; /* line number (for ast nodes) */
26 | } u2;
27 | };
28 | ```
29 |
30 | 按照posix标准,一般整形对应的*_t类型为: 1字节 uint8_t 2字节 uint16_t 4字节 uint32_t 8字节 uint64_t
31 |
32 | PHP7中的zval结构包括三个部分。第一个是value。zend_value是一个联合体。保存任何类型的数据
33 |
34 | 第二部分是是四个字节的typeinfo.包含真正变量的类型。
35 |
36 | 第三部分是一个联合体。也是4个字节。辅助字段。
37 |
38 | 新的zval的实现不再使用引用计算。避免了两次计数/
39 |
40 | 新版HashTable的实现
41 |
42 | ```c
43 | # 老版本
44 | typedef struct bucket {
45 | ulong h; /* Used for numeric indexing */
46 | uint nKeyLength;
47 | void *pData;
48 | void *pDataPtr;
49 | struct bucket *pListNext; /* 指向哈希链表中下一个元素 */
50 | struct bucket *pListLast; /* 指向哈希链表中的前一个元素 */
51 | struct bucket *pNext; /* 相同哈希值的下一个元素(哈希冲突用) */
52 | struct bucket *pLast; /* 相同哈希值的上一个元素(哈希冲突用) */
53 | const char *arKey;
54 |
55 | } Bucket;
56 |
57 |
58 |
59 | # PHP7
60 |
61 | typedef struct _Bucket {
62 | zval val;
63 | zend_ulong h; /* hash value (or numeric index) */
64 | zend_string *key; /* string key or NULL for numerics */
65 | } Bucket;
66 | ```
67 |
68 | 新的**HashTable**中,hash链表的构建工作由 **HashTable->arHash** 来承担,而解决hash冲突的链表则被放到了**_zval_struct**了
69 |
70 | h 是hash的值。key 是字符串 val 是值。
71 |
72 | 比如arr["hello"] = "111"; hash(hello) = h hello =k
73 |
74 | 111 = val
75 |
76 | ```c
77 | typedef struct _HashTable {
78 | union {
79 | struct {
80 | ZEND_ENDIAN_LOHI_3(
81 | zend_uchar flags,
82 | zend_uchar nApplyCount, /* 循环遍历保护 */
83 | uint16_t reserve)
84 | } v;
85 | uint32_t flags;
86 | } u;
87 |
88 | uint32_t nTableSize; /* hash表的大小 */
89 | uint32_t nTableMask; /* 掩码,用于根据hash值计算存储位置,永远等于nTableSize-1 */
90 | uint32_t nNumUsed; /* arData数组已经使用的数量 */
91 | uint32_t nNumOfElements; /* hash表中元素个数 */
92 | uint32_t nInternalPointer; /* 用于HashTable遍历 */
93 | zend_long nNextFreeElement; /* 下一个空闲可用位置的数字索引 */
94 | Bucket *arData; /* 存放实际数据 */
95 | uint32_t *arHash; /* Hash表 */
96 | dtor_func_t pDestructor; /* 析构函数 */
97 |
98 | } HashTable;
99 | ```
100 |
101 | HashTable中另外一个非常重要的值`arData`,这个值指向存储元素数组的第一个Bucket
102 |
103 | HashTable中有两个非常相近的值:`nNumUsed`、`nNumOfElements`,`nNumOfElements`表示哈希表已有元素数,那这个值不跟`nNumUsed`一样吗?为什么要定义两个呢?实际上它们有不同的含义,当将一个元素从哈希表删除时并不会将对应的Bucket移除,而是将Bucket存储的zval标示为`IS_UNDEF`,只有扩容时发现nNumOfElements与nNumUsed相差达到一定数量(这个数量是:`ht->nNumUsed - ht->nNumOfElements > (ht->nNumOfElements >> 5)`)时才会将已删除的元素全部移除,重新构建哈希表。所以`nNumUsed`>=`nNumOfElements`。
104 |
105 | arData数组保存了所有的buckets(也就是数组的元素),这个数组被分配的内存大小为2的幂次方,它被保存在nTableSize这个字段(最小值为8)。数组中实际保存的元素的个数被保存在nNumOfElements这个字段。注意这个数组直接包含Bucket结构。老的Hashtable的实现是使用一个指针数组来保存分开分配的buckets,这意味着需要更多的分配和释放操作(alloc/frees),需要为冗余信息及额外的指针分配内存。
106 |
107 | ### hashtable 查找
108 |
109 | arHash这个数组,这个数组由unit32_t类型的值组成。arHash数组跟arData的大小一样(都是nTableSize),并且都被分配了一段连续的内存区块。
110 |
111 | hash函数(DJBX33A用于字符串的键,DJBX33A是PHP用到的一种hash算法)返回的hash值一般是32位或者64位的整型数,这个数有点大,不能直接作为hash数组的索引。首先通过求余操作将这个数调整到hashtable的大小的范围之内。 求余是通过计算hash & (ht->nTableSize - 1)
112 |
113 | 参考资料
114 |
115 | - [http://gywbd.github.io/posts/2014/12/php7-new-hashtable-implementation.html](http://gywbd.github.io/posts/2014/12/php7-new-hashtable-implementation.html)
116 | - [https://blog.csdn.net/pangudashu/article/details/53419992](https://blog.csdn.net/pangudashu/article/details/53419992)
117 | - [https://blog.csdn.net/heiyeshuwu/article/details/44259865](https://blog.csdn.net/heiyeshuwu/article/details/44259865)
--------------------------------------------------------------------------------
/PHP/PHP手册笔记/0.php在unix平台安装.md:
--------------------------------------------------------------------------------
1 | 在unix平台下安装PHP的方法有 使用配置喝编译过程或者使用预编译的包。编译需要的知识和软件
2 |
3 | - 基础的 Unix 技能(有能力操作“make”和一种 C 语言编译器)
4 | - 一个 ANSI C 语言编译器
5 | - 一个 web 服务器
6 | - 任何模块特需的组件(例如 GD 和 PDF 库等)
7 | - autoconf: 2.13+(PHP < 5.4.0),2.59+(PHP >= 5.4.0)
8 | - automake: 1.4+
9 | - libtool: 1.4.x+(除了 1.4.2)
10 | - re2c: 版本 0.13.4 或更高
11 | - flex: 版本 2.5.4(PHP <= 5.2)
12 | - bison: 版本 1.28(建议),1.35 或 1.75
13 |
14 |
15 |
16 | ## PHP和Apache的安装整合
17 |
18 | 以下只是简单安装,很多配置选项可以查到对应的文档
19 |
20 | apache文档
21 |
22 | [apache文档]: http://httpd.apache.org/docs/current/
--------------------------------------------------------------------------------
/PHP/PHP手册笔记/1.基本语法.md:
--------------------------------------------------------------------------------
1 | ## 基本语法
2 |
3 | php的标记使用`` 也可以使用`` (需要打开短标签) 建议使用前者
4 |
5 | > 文件末尾的 PHP 代码段结束标记可以不要,有些情况下当使用 [include](http://php.net/manual/zh/function.include.php) 或者 [require](http://php.net/manual/zh/function.require.php) 时省略掉会更好些,这样不期望的空白符就不会出现在文件末尾,之后仍然可以输出响应标头。在使用输出缓冲时也很便利,就不会看到由包含文件生成的不期望的空白符
6 |
7 | ```php
8 |
24 | ```
25 |
26 | ## 数据类型
27 |
28 | 四种标量类型:
29 |
30 | - [boolean](http://php.net/manual/zh/language.types.boolean.php)(布尔型)
31 | - [integer](http://php.net/manual/zh/language.types.integer.php)(整型)
32 | - [float](http://php.net/manual/zh/language.types.float.php)(浮点型,也称作 [double](http://php.net/manual/zh/language.types.float.php))
33 | - [string](http://php.net/manual/zh/language.types.string.php)(字符串)
34 |
35 | 三种复合类型:
36 |
37 | - [array](http://php.net/manual/zh/language.types.array.php)(数组)
38 | - [object](http://php.net/manual/zh/language.types.object.php)(对象)
39 | - [callable](http://php.net/manual/zh/language.types.callable.php)(可调用)
40 |
41 | 最后是两种特殊类型:
42 |
43 | - [resource](http://php.net/manual/zh/language.types.resource.php)(资源)
44 | - [NULL](http://php.net/manual/zh/language.types.null.php)(无类型)
45 |
46 |
47 |
48 | ### 1.布尔类型 Boolean
49 |
50 | 布尔类型只有true和false两个值
51 |
52 | 以下的值会认为是false。其他之外的都是true
53 |
54 | - [布尔](http://php.net/manual/zh/language.types.boolean.php)值 **FALSE** 本身
55 | - [整型](http://php.net/manual/zh/language.types.integer.php)值 0(零)
56 | - [浮点型](http://php.net/manual/zh/language.types.float.php)值 0.0(零)
57 | - 空[字符串](http://php.net/manual/zh/language.types.string.php),以及[字符串](http://php.net/manual/zh/language.types.string.php) "0"
58 | - 不包括任何元素的[数组](http://php.net/manual/zh/language.types.array.php)
59 | - 特殊类型 [NULL](http://php.net/manual/zh/language.types.null.php)(包括尚未赋值的变量)
60 | - 从空标记生成的 [SimpleXML](http://php.net/manual/zh/ref.simplexml.php) 对象
61 |
62 | ```php
63 | var_dump((bool)'false') //true #字符串false
64 | var_dump((bool) false) //false #布尔值false
65 | ```
66 |
67 | ### 2. 整型int
68 |
69 | 整型值可以使用十进制,十六进制,八进制或二进制表示,前面可以加上可选的符号(- 或者 +)
70 |
71 | 自 PHP 4.4.0 和 PHP 5.0.5后,整型最大值可以用常量 **PHP_INT_MAX** 来表示,最小值可以在 PHP 7.0.0 及以后的版本中用常量 **PHP_INT_MIN**
72 |
73 | ```php
74 | 123
75 | -123
76 | 0123 #八进制
77 | 0x123 #十六进制
78 | ```
79 |
80 | 给定的一个数超出了 [integer](http://php.net/manual/zh/language.types.integer.php) 的范围,将会被解释为 [float](http://php.net/manual/zh/language.types.float.php)。同样如果执行的运算结果超出了 [integer](http://php.net/manual/zh/language.types.integer.php) 范围,也会返回 [float](http://php.net/manual/zh/language.types.float.php)
81 |
82 | 从其他类型转换成整型
83 |
84 | - 布尔值转整型 **false** 产生 0 **true** 产生 1
85 |
86 | - 从浮点型转换 向下取整 0.5 转换成 0
87 |
88 | - 字符串转整型
89 |
90 | > 如果该字符串没有包含 '.','e' 或 'E' 并且其数字值在整型的范围之内(由 **PHP_INT_MAX** 所定义),该字符串将被当成 [integer](http://php.net/manual/zh/language.types.integer.php) 来取值。其它所有情况下都被作为 [float](http://php.net/manual/zh/language.types.float.php) 来取值。该字符串的开始部分决定了它的值。如果该字符串以合法的数值开始,则使用该数值。否则其值为 0(零)。合法数值由可选的正负号,后面跟着一个或多个数字(可能有小数点),再跟着可选的指数部分。指数部分由 'e' 或 'E' 后面跟着一个或多个数字构成
91 |
92 | ```php
93 | bob3+1 //1
94 | 3bob+1 //4
95 |
96 | ```
97 |
98 | ### 3. 浮点数float
99 |
100 | 浮点数,也就是我们说的小数。由于浮点数的精度有限。尽管取决于系统,PHP 通常使用 IEEE 754 双精度格式,则由于取整而导致的最大相对误差为 1.11e-16
101 |
102 | **永远不要比较两个浮点数的值**
103 |
104 |
105 |
106 | ### 4.字符串string
107 |
108 | 字符串由一些字符组成。字符串有四种表示方法
109 |
110 | - 单引号
111 |
112 | 单引号是最简单的表示方法。在C语言中 单个字符用单引号表示。单引号的变量不解析.表达一个单引号自身,需在它的前面加个反斜线(*\*)来转义
113 |
114 | ```php
115 | $a = 'abc';
116 | $b = '$a';//$a
117 | $c = "$a"; //abc
118 | ```
119 |
120 |
121 |
122 | - 双引号
123 |
124 | 双引号非转义任何其它字符都会导致反斜线被显示出来。\*\\{$var}* 中的反斜线还不会被显示出来。
125 |
126 | - heredoc
127 |
128 | heredoc 结构是一种提供一个开始标记和一个结束标记。方便书写大段的字符串。结束标记必须**顶格写**。
129 |
130 | 类似双引号。单引号不转义。变量解析
131 |
132 | ```php
133 |
142 | ```
143 |
144 |
145 |
146 | - nowdoc
147 |
148 | Nowdoc 结构是类似于单引号字符串的。Nowdoc 结构很象 heredoc 结构,但是 nowdoc 中不进行解析操作 nowdoc前需要加上单引号。
149 |
150 | ```php
151 | value.通过数组可以实现丰富的数据类型,如字典、列表、集合、栈等。
181 |
182 | 定义数组
183 |
184 | ```php
185 | $arr = array(1,2,3);
186 | //简写 php5.4+
187 | $arr2 = [1,2,3];
188 | $arr2[1];
189 | $arr3 = ["key"=>"value"];
190 |
191 | $arr3["key"];
192 | ```
193 |
194 | PHP 将自动使用之前用过的最大 INT键名加上 1 作为新的键名.PHP 实际并不区分索引数组和关联数组。
195 |
196 |
197 |
198 | ### 6. 对象object
199 |
200 | 创建一个新的对象的时候,使用new 关键字
201 |
202 | ```
203 | class obj {}
204 | $a = new obj();
205 | ```
206 |
207 |
208 |
209 | ### 7.资源类型resource
210 |
211 | 资源类型是保持外部的一个引用。如数据库的链接,文件的句柄等。
212 |
213 | ```php
214 | $fp = fopen("./a.log");//resource
215 |
216 | ```
217 |
218 |
219 |
220 | ### 8. NULL类型
221 |
222 | 当一个变量没有被赋值,那么该变量的值就是null。以下的情况是一个变量被认为是null
223 |
224 | - 被赋值成null
225 | - 未赋值
226 | - 被unset
227 |
228 | ```php
229 | $a = null // null
230 | $b;//var_dump($b); null
231 | $c = 1;
232 | unset($c);//var_dump($c); null
233 | ```
234 |
235 | ### 9. 回调 callback
236 |
237 | ```php
238 | function test(){
239 | echo "echo";
240 | }
241 | call_user_function('test');
242 | ```
243 |
244 |
--------------------------------------------------------------------------------
/PHP/PHP手册笔记/10.错误和异常处理.md:
--------------------------------------------------------------------------------
1 | ## 错误和异常
2 |
3 | 在编码的时候,我们无时无刻会遇到错误和异常,所以我们需要处理这些错误。
4 |
5 | php的错误类型有
6 |
7 | - E_ERROR 致命的错误。会中断程序的执行
8 | - E_WARNING 警告。不会中断程序
9 | - E_NOTICE 通知,运行时通知。表示脚本遇到可能会表现为错误的情况
10 | - E_PARSE 解析错误,一般是语法错误。
11 | - E_STRICT PHP 对代码的修改建议
12 | - E_DEPRECATED 将会对在未来版本中可能无法正常工作的代码给出警告
13 |
14 | ### 错误
15 |
16 | 在开发模式中,我们一般需要打开**error_reporting** 设置为**E_ALL**。然后把**display_errors** 设置为on
17 |
18 | 如果需要记录错误日志,则需要配置log_errors.
19 |
20 | 开发者可以 通过set_error_handle()自己接管错误。
21 |
22 | ```php
23 |
24 | set_error_handle(function($errno,$errstr,$errfile,$errline){
25 |
26 | })
27 |
28 | /**
29 | * throw exceptions based on E_* error types
30 | */
31 | set_error_handler(function ($err_severity, $err_msg, $err_file, $err_line, array $err_context)
32 | {
33 | // error was suppressed with the @-operator
34 | if (0 === error_reporting()) { return false;}
35 | switch($err_severity)
36 | {
37 | case E_ERROR: throw new ErrorException ($err_msg, 0, $err_severity, $err_file, $err_line);
38 | case E_WARNING: throw new WarningException ($err_msg, 0, $err_severity, $err_file, $err_line);
39 | case E_PARSE: throw new ParseException ($err_msg, 0, $err_severity, $err_file, $err_line);
40 | case E_NOTICE: throw new NoticeException ($err_msg, 0, $err_severity, $err_file, $err_line);
41 | case E_CORE_ERROR: throw new CoreErrorException ($err_msg, 0, $err_severity, $err_file, $err_line);
42 | case E_CORE_WARNING: throw new CoreWarningException ($err_msg, 0, $err_severity, $err_file, $err_line);
43 | case E_COMPILE_ERROR: throw new CompileErrorException ($err_msg, 0, $err_severity, $err_file, $err_line);
44 | case E_COMPILE_WARNING: throw new CoreWarningException ($err_msg, 0, $err_severity, $err_file, $err_line);
45 | case E_USER_ERROR: throw new UserErrorException ($err_msg, 0, $err_severity, $err_file, $err_line);
46 | case E_USER_WARNING: throw new UserWarningException ($err_msg, 0, $err_severity, $err_file, $err_line);
47 | case E_USER_NOTICE: throw new UserNoticeException ($err_msg, 0, $err_severity, $err_file, $err_line);
48 | case E_STRICT: throw new StrictException ($err_msg, 0, $err_severity, $err_file, $err_line);
49 | case E_RECOVERABLE_ERROR: throw new RecoverableErrorException ($err_msg, 0, $err_severity, $err_file, $err_line);
50 | case E_DEPRECATED: throw new DeprecatedException ($err_msg, 0, $err_severity, $err_file, $err_line);
51 | case E_USER_DEPRECATED: throw new UserDeprecatedException ($err_msg, 0, $err_severity, $err_file, $err_line);
52 | }
53 | });
54 |
55 | class WarningException extends ErrorException {}
56 | class ParseException extends ErrorException {}
57 | class NoticeException extends ErrorException {}
58 | class CoreErrorException extends ErrorException {}
59 | class CoreWarningException extends ErrorException {}
60 | class CompileErrorException extends ErrorException {}
61 | class CompileWarningException extends ErrorException {}
62 | class UserErrorException extends ErrorException {}
63 | class UserWarningException extends ErrorException {}
64 | class UserNoticeException extends ErrorException {}
65 | class StrictException extends ErrorException {}
66 | class RecoverableErrorException extends ErrorException {}
67 | class DeprecatedException extends ErrorException {}
68 | class UserDeprecatedException extends ErrorException {}
69 | ```
70 |
71 | #### PHP7的错误处理
72 |
73 | PHP 7 改变了大多数错误的报告方式。error可以通过exception异常进行捕获到.不能通过try catch捕获。但是可以通过注册到set_exception_handle捕获。
74 |
75 | - Throwable
76 | - Error
77 | - Exception
78 |
79 | ```php
80 | try
81 | {
82 | // Code that may throw an Exception or Error.
83 | }
84 | catch (Throwable $t)
85 | {
86 | // Executed only in PHP 7, will not match in PHP 5
87 | }
88 | catch (Exception $e)
89 | {
90 | // Executed only in PHP 5, will not be reached in PHP 7
91 | }
92 | ```
93 |
94 | ### 异常
95 |
96 | 捕获异常可以通过try catch 语句
97 |
98 | ```php
99 | try{
100 | //异常的代码
101 | }catch (Exception $e){
102 | //处理异常
103 | }finally{
104 | //最后执行的
105 | }
106 | ```
107 |
108 |
--------------------------------------------------------------------------------
/PHP/PHP手册笔记/2-变量和常量.md:
--------------------------------------------------------------------------------
1 | ## 变量
2 |
3 | php中的变量是以 `$` 开头的。变量名区分大小写。合法的变量名是字母或者下划线开头,后面跟着任意数量的字母,数字,或者下划线
4 |
5 | 在此所说的字母是 a-z,A-Z,以及 ASCII 字符从 127 到 255(*0x7f-0xff*)
6 |
7 | 变量默认总是传值赋值
8 |
9 | ```php
10 | $a $_a $张三 // 合法的
11 | $2aaa //非法的
12 | $a = 123;
13 | ```
14 |
15 |
16 |
17 | ### 变量的作用域
18 |
19 | 在最外层定义的是全局变量。在全局都有效。在函数内部的成为局部变量。只有函数内部可以访问。使用static修饰的变量,是静态变量。静态变量不会被销毁。只有等程序运行结束后才被回收.
20 |
21 | **$this 是一个特殊的变量。不能定位成this变量**
22 |
23 | ```php
24 |
47 | ```
48 |
49 |
50 |
51 | 确定变量的类型。php提供了以下函数
52 |
53 | ```php
54 | gettype() is_bool() is_string() is_object() is_array();
55 | ```
56 |
57 | ## 常量
58 |
59 | 常量一般是定义之后不能再更改的变量。传统上使用大写字母来定义常量.合法的常量命名跟变量一致。只是不需要加 `$` 符号。
60 |
61 | ```php
62 | IS_DEBUG;
63 | define("IS_DEBUG",0);
64 | ```
65 |
66 | #### 魔术常量
67 |
68 | 魔术常量是php内置的。可能跟着代码的变化而变化。一般魔术常量 以双下划线开始 双下划线结束。
69 |
70 | ```php
71 | __LINE__
72 | __DIR__
73 | __FILE__
74 | __CLASS__
75 | ```
76 |
77 |
78 |
79 | ## 表达式
80 |
81 | 最精确的定义一个表达式的方式就是“任何有值的东西”。最简单的表达式。常量和变量。
82 |
83 | ```php
84 | $a;
85 | ;// 空表达式
86 | $a = 1;//赋值表达式
87 |
88 | function f(){} //函数表达式
89 | $a>1 //比较表达式
90 |
91 | ```
92 |
93 |
--------------------------------------------------------------------------------
/PHP/PHP手册笔记/4.流程控制.md:
--------------------------------------------------------------------------------
1 | ### if else
2 |
3 | ```php
4 | if($a) {
5 |
6 | }
7 |
8 | if($a == 1) {
9 |
10 | } else{
11 |
12 | }
13 |
14 | if($a == 1) {
15 | echo '1';
16 | }else if($a == 2) {
17 | echo '2';
18 | }else{
19 | echo 'other';
20 | }
21 |
22 | #简写 不推荐
23 | if ($a == 1):
24 | echo "1";
25 | else:
26 | echo "else";
27 | endif;
28 | ```
29 |
30 | ### switch
31 |
32 | *switch* 语句类似于具有同一个表达式的一系列 *if* 语句。很多场合下需要把同一个变量(或表达式)与很多不同的值比较,并根据它等于哪个值来执行不同的代码.**每个case分支的break不能省去,如果省去,则会往下执行**
33 |
34 | ```php
35 | if($a == 1) {
36 | echo '1';
37 | }else if($a == 2) {
38 | echo '2';
39 | }else{
40 | echo 'other';
41 | }
42 | # swtich
43 | switch ($a) {
44 | case 1:
45 | echo '1';
46 | break;
47 | case 2:
48 | echo '2';
49 | break;
50 | default:
51 | echo 'othre';
52 | break;
53 | }
54 | ```
55 |
56 |
57 |
58 | ### while 、do while
59 |
60 | *while* 循环是 PHP 中最简单的循环类型.只要表达式是true是一直执行,直到条件为false为止.
61 |
62 | *do-while* 循环和 *while* 循环非常相似,区别在于表达式的值是在每次循环结束时检查而不是开始时。和一般的 *while* 循环主要的区别是 *do-while*的循环语句保证会执行一次(表达式的真值在每次循环结束后检查)
63 |
64 | ```php
65 | $a = 10;
66 | while($a>1) {
67 | echo $a--;//1098765432
68 | }
69 | #do while
70 | $b = 1;
71 | do{
72 | echo $b; //1
73 | }while($b>1)
74 | ```
75 |
76 |
77 |
78 | ### for、foreach
79 |
80 | *for* 循环是 PHP 中最复杂的循环结构。它的行为和 C 语言的相似
81 |
82 | ```
83 | for (expr1; expr2; expr3)
84 | statement
85 |
86 | ```
87 |
88 | 第一个表达式(expr1)在循环开始前无条件求值(并执行)一次。
89 |
90 | expr2 在每次循环开始前求值。如果值为 **TRUE**,则继续循环,执行嵌套的循环语句。如果值为 **FALSE**,则终止循环。
91 |
92 | expr3 在每次循环之后被求值(并执行)。
93 |
94 | ```php
95 | $people = Array(
96 | Array('name' => 'Kalle', 'salt' => 856412),
97 | Array('name' => 'Pierre', 'salt' => 215863)
98 | );
99 |
100 | for($i = 0; $i < count($people); ++$i)
101 | {
102 | $people[$i]['salt'] = rand(000000, 999999);
103 | }
104 | //每次都计算count 代码执行慢 可以使用中间变量
105 |
106 | $count = count($people);
107 | for($i = 0; $i < $count; ++$i)
108 | {
109 | $people[$i]['salt'] = rand(000000, 999999);
110 | }
111 | ```
112 |
113 | *foreach* 语法结构提供了遍历数组的简单方式。*foreach* 仅能够应用于数组和对象
114 |
115 | ```php
116 | foreach($array as $key=>$value) {
117 |
118 | }
119 | # 简写
120 | foreach($array as $key=>$value):
121 |
122 | endforeach;
123 | #引用修改 数组最后一个元素的 $value 引用在 foreach 循环之后仍会保留。建议使用 unset() 来将其销毁。
124 |
125 | foreach (array(1, 2, 3, 4) as &$value) {
126 | $value = $value * 2;
127 | }
128 | unset($value);
129 | ```
130 |
131 | ### break 、continue
132 |
133 | *break* 结束当前 *for*,*foreach*,*while*,*do-while* 或者 *switch* 结构的执行。break后面可以跟一个数字。表示跳出几重循环
134 |
135 | ```php
136 | for($i = 0; $i < 10; $i++) {
137 | if($i==5){
138 | break;
139 | }
140 | echo $i;
141 | }
142 | //01234
143 | for($i=0;$i<10;$i++) {
144 | for($j=0;$j<5;$j++) {
145 | if($j == 2) {
146 | break 2; #跳出两层循环
147 | }
148 | }
149 | }
150 | ```
151 |
152 | ***continue*** 在循环结构用用来跳过本次循环中剩余的代码并在条件求值为真时开始执行下一次循环
153 |
154 | ***continue*** 接受一个可选的数字参数来决定跳过几重循环到循环结尾。默认值是 *1*,即跳到当前循环末尾
155 |
156 | ```php
157 | for($i = 0; $i < 10; $i++) {
158 | if($i==5){
159 | continue;
160 | }
161 | echo $i;
162 | }
163 | // 012346789
164 | ```
165 |
166 |
167 |
168 | ### declare
169 |
170 | *declare* 结构用来设定一段代码的执行指令。*declare* 的语法和其它流程控制结构相似
171 |
172 | 目前只认识两个指令:*ticks* encoding
173 |
174 | Tick(时钟周期)是一个在 *declare* 代码段中解释器每执行 N 条可计时的低级语句就会发生的事件。N 的值是在 *declare* 中的 *directive* 部分用`ticks=N` 来指定的
175 |
176 | encoding 指令来对每段脚本指定其编码方式。
177 |
178 | ```php
179 | declare(ticks=1);
180 |
181 | // A function called on each tick event
182 | function tick_handler()
183 | {
184 | echo "tick_handler() called\n";
185 | }
186 |
187 | register_tick_function('tick_handler');
188 |
189 | $a = 1;
190 |
191 | if ($a > 0) {
192 | $a += 2;
193 | print($a);
194 | }
195 | declare(encoding='ISO-8859-1');
196 | ```
197 |
198 |
199 |
200 | ### return
201 |
202 | 在函数中使用return 将结束函数的执行。
203 |
204 | **return** 是语言结构而不是函数,因此其参数没有必要用括号将其括起来。通常都不用括号,实际上也应该不用,这样可以降低 PHP 的负担。
205 |
206 | ```php
207 | function f(){
208 | return 1;
209 | echo '11';//不会执行
210 | }
211 |
212 | #a.php
213 |
217 |
218 | #b.php
219 |
223 | // ba
224 | ```
225 |
226 | ### include 、require
227 |
228 | include(path) 会按照给定的参数 进行查找,如果没有找到就到include_path中查找。如果还没有找到,那么就会抛出一个警告。
229 |
230 | 如果定义了路径——不管是绝对路径(在 Windows 下以盘符或者 *\* 开头,在 Unix/Linux 下以 */* 开头)还是当前目录的相对路径。include_path就会被忽略。
231 |
232 | require 和include查找文件基本上一致。只是require会抛出一个error错误终止代码的执行。
233 |
234 | require 和include是一个语言构造器而不是一个函数
235 |
236 | ```php
237 | include 'a.php';
238 | echo "hello";
239 | # 会输出hello
240 |
241 | require 'a.php';
242 | echo "hello";
243 | # 抛出一个error hello不会输出。
244 | ```
245 |
246 | ### include_once 、require_once
247 |
248 | *include_once* 、require_once 语句在脚本执行期间包含并运行指定文件.如果该文件中已经被包含过,则不会再次包含
249 |
250 | include_once 会抛出warning 。require_once 会抛出error
251 |
252 |
253 |
254 | ### goto
255 |
256 | goto操作符并不常用。用来跳转程序的一个位置。目标位置只能位于同一个文件和作用域
257 |
258 | 无法跳出一个函数或类方法,也无法跳入到另一个函数。也无法跳入到任何循环或者 switch 结构中
259 |
260 | ```php
261 |
271 | ```
272 |
273 |
--------------------------------------------------------------------------------
/PHP/PHP手册笔记/5.函数.md:
--------------------------------------------------------------------------------
1 | ## 函数
2 |
3 | 函数是将特定的代码放到一个区间里,方便下次的调用。
4 |
5 | 函数名和 PHP 中的其它标识符命名规则相同。有效的函数名以字母或下划线打头,后面跟字母,数字或下划线。
6 |
7 | PHP 中的所有函数和类都具有全局作用域。PHP 不支持函数重载,也不可能取消定义或者重定义已声明的函数。
8 |
9 | 函数名是大小写无关的
10 |
11 | 要避免递归函数/方法调用超过 100-200 层,因为可能会使堆栈崩溃从而使当前脚本终止
12 |
13 | ```php
14 | function 函数名字(参数){
15 | //函数体
16 | }
17 | ```
18 |
19 | ### 函数参数
20 |
21 | 可以通过参数传递外部的信息到函数内部。
22 |
23 | 支持引用传递参数、默认参数
24 |
25 | ```php
26 | $a = 100;
27 | function fn($arg) {
28 | echo $arg;
29 | }
30 | fn($a);//100
31 |
32 | #引用传递
33 | function fn(&$arg){
34 | $arg = 10;
35 | }
36 | fn($a);
37 | echo $a;//10;
38 | # 默认值
39 | $a = 100;
40 | function fn($arg = 10){
41 | echo $arg;
42 | }
43 | fn($a);//100
44 | fn();//10
45 | ```
46 |
47 | #### **类型声明**
48 |
49 | 类型声明允许函数在调用时要求参数为特定类型。 如果给出的值类型不对,那么将会产生一个错误
50 |
51 | 目前支持的类型有类名、接口名、self、array、callable、bool、int、float、string
52 |
53 | ```php
54 | function fn(int $a){
55 | echo $a;
56 | }
57 | $c = "hello";
58 | fn($c);//error
59 | ```
60 |
61 | #### **严格类型**
62 |
63 | 默认情况下,如果能做到的话,PHP将会强迫错误类型的值转为函数期望的标量类型
64 |
65 | 但是在严格模式下,php不会转换。
66 |
67 | ```php
68 | declare(strict_types=1);
69 | function fn(int $a){
70 | echo $a;
71 | }
72 | $c = '1';//string
73 | fn($c);//
74 | ```
75 |
76 | #### **可变参数**
77 |
78 | PHP 在用户自定义函数中支持可变数量的参数列表。在 PHP 5.6 及以上的版本中,由 *...* 语法实现
79 |
80 | ```php
81 | function fn(...$arg){
82 | foreach($arg as $v){
83 | echo $v;
84 | }
85 | }
86 | fn(1,2,3,4);
87 | ```
88 |
89 |
90 |
91 | ### 返回值
92 |
93 | 函数的返回值可以通过return 返回。
94 |
95 | ```php
96 | function fn(){
97 | return "hello";
98 | }
99 | ```
100 |
101 | #### 返回值类型
102 |
103 | 可以限制返回值的类型
104 |
105 | ```php
106 | declare(strict_types=1);
107 | function($a):float {
108 | return 1.1;
109 | }
110 | ```
111 |
112 | ### 可变函数
113 |
114 | PHP 支持可变函数的概念。这意味着如果一个变量名后有圆括号,PHP 将寻找与变量的值同名的函数,并且尝试执行它。可变函数可以用来实现包括回调函数
115 |
116 | ```php
117 | function f(){
118 | echo "1";
119 | }
120 | $a = 'f';
121 |
122 | $a();//1
123 | ```
124 |
125 | ### 匿名函数
126 |
127 | 匿名函数(Anonymous functions),也叫闭包函数(*closures*),允许 临时创建一个没有指定名称的函数。最经常用作回调函数 参数的值。当然,也有其它应用的情况。
128 |
129 | 闭包可以从父作用域中继承变量。 任何此类变量都应该用 *use* 语言结构传递进去
130 |
131 |
132 |
133 | ```php
134 | (function (){
135 | echo '匿名函数';
136 | })();
137 |
138 | #传递参数
139 |
140 | $a = function ($arg) {
141 | echo $arg;
142 | }
143 | $arg = 'hello';
144 |
145 | $a($arg);//hello;
146 |
147 | # 传递外部作用域变量
148 | $arg = 'arg';
149 | $f = function() use($arg){
150 | echo $arg;
151 | }
152 | $f();
153 | ```
154 |
155 |
--------------------------------------------------------------------------------
/PHP/PHP手册笔记/6.面向对象(OOP).md:
--------------------------------------------------------------------------------
1 | ## 面向对象
2 |
3 | 类:现实世界或思维世界中的实体在计算机中的反映,它将数据以及这些数据上的操作封装在一起。比如人类、动物类
4 |
5 | 对象: 具有类类型的变量。比如人类中的张三这就是一个对象。他有人类的特性,比如说话写字等。
6 |
7 | 属性:类型的特征 比如人的名字、年龄、身高都是人的特征属性。
8 |
9 | 方法:方法是将一些操作封装起来的过程。类似函数。
10 |
11 | 继承:从父类那获得特征。比如人从父亲那继承了父亲的姓名。
12 |
13 | ### class (类)
14 |
15 | 每个类的定义都以关键字 *class* 开头,后面跟着类名,后面跟着一对花括号,里面包含有类的属性与方法的定义
16 |
17 | 类名是非php保留字以外的合法的标签。合法的类名和变量一样。字母、下划线开头,后面跟任意字母或数字。
18 |
19 | 自 PHP 5.5 起,关键词 *class* 也可用于类名的解析。使用 *ClassName::class* 你可以获取一个字符串
20 |
21 | ```php
22 | class Person {
23 | public $name;
24 | public $age;
25 |
26 | public function say(){
27 | echo "hello";
28 | }
29 | }
30 | echo Person::class;//Person 如果带命名空间。则会加上命名空间
31 |
32 | ```
33 |
34 | 要创建一个对象。使用new关键字
35 |
36 | ```php
37 | $zhang = new Person();
38 | $zhang->name = '张三';
39 | ```
40 |
41 | ### extends (继承)
42 |
43 | 一个类可以在声明中用 *extends* 关键字继承另一个类的方法和属性。PHP不支持多重继承,一个类只能继承一个基类。
44 |
45 | 被继承的方法和属性可以通过用同样的名字重新声明被覆盖。如果父类的方法使用了final。则不会被覆盖。
46 |
47 | 当覆盖方法时,参数必须保持一致否则 PHP 将发出 **E_STRICT** 级别的错误信息。但构造函数例外,构造函数可在被覆盖时使用不同的参数
48 |
49 | ```php
50 | class Boy extends Person {
51 |
52 | }
53 | ```
54 |
55 | ### 类常量
56 |
57 | 在类中始终保持不变的值定义为常量。在定义和使用常量的时候不需要使用 $ 符号
58 |
59 | 类常量是一个定值。类常量使用const 定义。访问的时候使用**self::**访问类常量
60 |
61 | ```php
62 | class C{
63 | const PI = 3.1415926;
64 | public function test(){
65 | echo self::PI;
66 | }
67 | }
68 | ```
69 |
70 | ### 自动加载
71 |
72 | 使用自动加载可以让我们不用一个个去include 类文件
73 |
74 | 自动加载不可用于 PHP 的 CLI
75 |
76 | ```php
77 | spl_autoload_register(function($class){
78 | require $class.".php";
79 | })
80 | ```
81 |
82 | ### 构造函数、析构函数
83 |
84 | 构造函数在对象创建的时候,会被调用。适合初始化工作。
85 |
86 | 如果子类中定义了构造函数则不会隐式调用其父类的构造函数。要执行父类的构造函数,需要在子类的构造函数中调用**parent::__construct()**
87 |
88 | 析构函数在到某个对象的所有引用都被删除或者当对象被显式销毁时执行
89 |
90 | 试图在析构函数(在脚本终止时被调用)中抛出一个异常会导致致命错误。
91 |
92 | ```php
93 | class P{
94 | public function __construct(){
95 | echo "construct";
96 | }
97 | public function __destruct(){
98 | echo "destruct";
99 | }
100 | }
101 |
102 | $p = new P();// construct;
103 | unset($p);//destruct;
104 |
105 |
106 | ```
107 |
108 | ### 访问控制
109 |
110 | 对属性或方法的访问控制,是通过在前面添加关键字 *public*(公有),*protected*(受保护)或 *private*(私有)来实现的。
111 |
112 | public 修饰的 可以在任何地方访问到
113 |
114 | protected修饰的只能在子类或该类中访问
115 |
116 | private修饰的只能在该类中访问。
117 |
118 | ```php
119 | class A{
120 | public $name = 'a';
121 | protected $age = 10;
122 | private $money = 100;
123 | }
124 | class B extends A{
125 | public function test(){
126 | echo $this->age;//a
127 |
128 | }
129 | public function testPrivate(){
130 | echo $this->money;
131 | }
132 | }
133 | $b = new B();
134 | echo $b->name;//a
135 | echo $b->test();//10
136 | # 不可访问
137 | echo $b->age;//error;
138 | #子类不能访问
139 | echo $b->testPrivate();//error
140 | ```
141 |
142 | ### 范围解析操作符(::)
143 |
144 | 范围解析操作符(也可称作 Paamayim Nekudotayim)或者更简单地说是一对冒号,可以用于访问静态成员,类常量。还可以用于覆盖类中的属性和方法。
145 |
146 | self,parent 和 static 这三个特殊的关键字是用于在类定义的内部对其属性或方法进行访问的
147 |
148 | 当一个子类覆盖其父类中的方法时,PHP 不会调用父类中已被覆盖的方法。是否调用父类的方法取决于子类。使用self调用父类,使用$this 调用本类。
149 |
150 | ```php
151 | class A{
152 | public $name = 'a';
153 | protected $age = 10;
154 | private $money = 100;
155 | }
156 | class B extends A{
157 | public static $s = 's';
158 | const PI = 111;
159 | public function test(){
160 | echo $this->age;// 10
161 |
162 | }
163 |
164 | public static function testStatic(){
165 | echo self::$s;
166 | }
167 | public function testConst(){
168 | echo self::PI;
169 | }
170 | public function testPrivate(){
171 | echo $this->money;
172 | }
173 | }
174 | # self 和 $this
175 | class ParentClass {
176 | function test() {
177 | self::who(); // will output 'parent'
178 | $this->who(); // will output 'child'
179 | }
180 |
181 | function who() {
182 | echo 'parent';
183 | }
184 | }
185 |
186 | class ChildClass extends ParentClass {
187 | function who() {
188 | echo 'child';
189 | }
190 | }
191 |
192 | $obj = new ChildClass();
193 | $obj->test();//
194 | ```
195 |
196 | ### static 静态关键字
197 |
198 | 声明类属性或方法为静态,就可以不实例化类而直接访问。静态属性不能通过一个类已实例化的对象来访问(但静态方法可以)
199 |
200 | 静态属性不可以由对象通过 -> 操作符来访问。静态属性只能被初始化为文字或常量。静态属性不随着对象的销毁而销毁。
201 |
202 | ```php
203 | class P{
204 | $a = "world";
205 | public static function test(){
206 | echo "hello".self::$a;
207 | }
208 | }
209 | p::test();
210 | ```
211 |
212 |
--------------------------------------------------------------------------------
/PHP/PHP手册笔记/8.面向对象(OOP).md:
--------------------------------------------------------------------------------
1 | ### 重写、重载
2 |
3 | override是重写(覆盖)了一个方法,以实现不同的功能。一般是用于子类在继承父类时,重写(重新实现)父类中的方法。
4 |
5 | **重写(覆盖)的规则**:
6 | 1、重写方法的参数列表必须完全与被重写的方法的相同,否则不能称其为重写而是重载.
7 | 2、重写方法的访问修饰符一定要大于被重写方法的访问修饰符(public>protected>default>private)。
8 | 3、重写的方法的返回值必须和被重写的方法的返回一致;
9 | 4、重写的方法所抛出的异常必须和被重写方法的所抛出的异常一致,或者是其子类;
10 | 5、被重写的方法不能为**private**,否则在其子类中只是新定义了一个方法,并没有对其进行重写
11 |
12 | 6、静态方法不能被重写为非静态的方法(会编译出错)。
13 |
14 | overload是重载,一般是用于在一个类内实现若干重载的方法,这些方法的名称相同而参数形式不同。
15 |
16 | **重载的规则**:
17 | 1、在使用重载时只能通过相同的方法名、不同的参数形式实现。不同的参数类型可以是不同的参数类型,不同的参数个数,不同的参数顺序(参数类型必须不一样);
18 | 2、不能通过访问权限、返回类型、抛出的异常进行重载;
19 | 3、方法的异常类型和数目不会对重载造成影响;
20 |
21 | PHP所提供的"重载"(overloading)是指动态地"创建"类属性和方法。我们是通过魔术方法(magic methods)来实现的。
22 |
23 | ```php
24 | class A{
25 | public function test(){
26 | echo "11";
27 | }
28 | }
29 |
30 | class B extends A{
31 | #重写父类的方法
32 | public function test(){
33 | echo "22";
34 | }
35 | }
36 |
37 | class C{
38 | public function __call($name,$args) {
39 | echo $name;
40 | }
41 | public function __callStatic($name, $arguments){}
42 | }
43 | ```
44 |
45 | ### 多态
46 |
47 | 多态:同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果。在运行时,可以通过指向基类的指针,来调用实现派生类中的方法。
48 |
49 | ```php
50 | abstract class animal{
51 | abstract function fun();
52 | }
53 | class cat extends animal{
54 | function fun(){
55 | echo "cat say miaomiao...";
56 | }
57 | }
58 | class dog extends animal{
59 | function fun(){
60 | echo "dog say wangwang...";
61 | }
62 | }
63 | function work($obj){
64 | if($obj instanceof animal){
65 | $obj -> fun();
66 | }else{
67 | echo "no function";
68 | }
69 | }
70 | work(new dog());
71 | work(new cat());
72 | ```
73 |
74 | ### 遍历对象
75 |
76 | 遍历对象可以使用foreach遍历可见属性。或者实现iterator接口
77 |
78 | ```php
79 | class MyClass
80 | {
81 | public $var1 = 'value 1';
82 | public $var2 = 'value 2';
83 | public $var3 = 'value 3';
84 |
85 | protected $protected = 'protected var';
86 | private $private = 'private var';
87 |
88 | }
89 | $c = new MyClass();
90 |
91 | foreach ($c as $key=>$v) {
92 | echo $key."=>"$v;
93 | }
94 |
95 | ```
96 |
97 | ### 魔术方法
98 |
99 | - __construct 初始化调用
100 | - __desturct 对象销毁时调用
101 | - __call 访问一个不存在的方法的时候调用
102 | - __callStatic 访问一个不存在的静态方法调用
103 | - __get() 访问一个不存在的属性调用
104 | - __set() 修改一个不存在的属性调用
105 | - __isset() 使用isset判断一个高属性的时候调用
106 | - __toString() 当一个对象以一个字符串返回时候触发调用
107 | - __invoke()当把一个对象当初函数去调用的时候 触发
108 |
109 |
110 |
111 | ### final
112 |
113 | final 最终的,如果一个类被定位成final 这个类不能被继承。如果一个方法被定义一个final。这个方法不能被覆盖。
114 |
115 | final不能修饰属性。
116 |
117 | ```php
118 | class A{
119 | final public function test(){}
120 | }
121 |
122 | Class B extends A{
123 | public function test(){ //error
124 |
125 | }
126 | }
127 | ```
128 |
129 | ### 对象复制、对象比较
130 |
131 | 对象复制可以通过 **clone** 关键字来完成
132 |
133 | 当对象被复制后,PHP 5 会对对象的所有属性执行一个浅复制(shallow copy)。所有的引用属性 仍然会是一个指向原来的变量的引用。
134 |
135 | ```php
136 | class A{
137 |
138 | public $name = "hello";
139 | }
140 |
141 | $a = new A();
142 |
143 | $b = clone $a;
144 | ```
145 |
146 | 当使用比较运算符(*==*)比较两个对象变量时,比较的原则是:如果两个对象的属性和属性值 都相等,而且两个对象是同一个类的实例,那么这两个对象变量相等。
147 |
148 | 而如果使用全等运算符(*===*),这两个对象变量一定要指向某个类的同一个实例(即同一个对象)
149 |
150 | ### 类型约束
151 |
152 | 函数的参数可以指定必须为对象(在函数原型里面指定类的名字),接口,数组
153 |
154 | ```php
155 | function Test(A $a){}
156 | ```
157 |
158 | ### 后期静态绑定
159 |
160 | “后期绑定”的意思是说,*static::* 不再被解析为定义当前方法所在的类,而是在实际运行时计算的。也可以称之为“静态绑定”,因为它可以用于(但不限于)静态方法的调用
161 |
162 | **self的限制**
163 |
164 | 使用 *self::* 或者 *__CLASS__* 对当前类的静态引用,取决于定义当前方法所在的类
165 |
166 | ```php
167 |
168 | class A {
169 | public static function who() {
170 | echo __CLASS__;
171 | }
172 | public static function test() {
173 | self::who();
174 | }
175 | }
176 |
177 | class B extends A {
178 | public static function who() {
179 | echo __CLASS__;
180 | }
181 | }//
182 |
183 | B::test();//A
184 | #静态绑定语法
185 | class A {
186 | public static function who() {
187 | echo __CLASS__;
188 | }
189 | public static function test() {
190 | static::who();
191 | }
192 | }
193 |
194 | class B extends A {
195 | public static function who() {
196 | echo __CLASS__;
197 | }
198 | }//
199 |
200 | B::test();//B
201 | ## 实现ar model
202 | class Model
203 | {
204 | public static function find()
205 | {
206 | echo static::$name;
207 | }
208 | }
209 |
210 | class Product extends Model
211 | {
212 | protected static $name = 'Product';
213 | }
214 |
215 | Product::find();
216 | ```
217 |
218 | ### 对象和引用
219 |
220 | > PHP 的引用是别名,就是两个不同的变量名字指向相同的内容。在 PHP 5,一个对象变量已经不再保存整个对象的值。只是保存一个标识符来访问真正的对象内容。 当对象作为参数传递,作为结果返回,或者赋值给另外一个变量,另外一个变量跟原来的不是引用的关系,只是他们都保存着同一个标识符的拷贝,这个标识符指向同一个对象的真正内容。
221 |
222 | ```php
223 | class A {
224 | public $foo = 1;
225 | }
226 |
227 | $a = new A;
228 | $b = $a; // $a ,$b都是同一个标识符的拷贝
229 | // ($a) = ($b) =
230 | $b->foo = 2;
231 | echo $a->foo."\n";
232 | ```
233 |
234 | ### 对象序列化
235 |
236 | 在会话中存储对象。使用serialize序列化。
--------------------------------------------------------------------------------
/PHP/PHP手册笔记/9.命名空间.md:
--------------------------------------------------------------------------------
1 | ## 命名空间
2 |
3 | 命名空间简单的说就是类似文件的路径。为了解决命名冲突的问题产生的。比如在我们的代码中经常遇到以下问题。
4 |
5 | 自己在一个目录写了一个类叫A. 另外一个人也写了一个类叫A。就会产生一个冲突。最初的框架,比如ci框架,都是类的名字前面加上一CI_的前缀防止命名冲突。
6 |
7 | 命令空间的思想来源于路径。比如在一个/www/目录下不能存在两个相同的文件。但是可以文件放在/www/a/ 、/www/b下面,这样两个文件就不会冲突。同理命名空间。如果在\www\a\A、\www\b\A 这两个类也可以可以同时存在的。
8 |
9 | 命名空间的定义使用**namespace** 定义。只有类(包括抽象类和traits)、接口、函数和常量受到命名空间的影响。
10 |
11 | 命名空间的定义必须在脚本的首行。不能有bom,否则会出错。
12 |
13 | 定义子命名空间用\分割。
14 |
15 | 也可以在一个文件定义多个命名空间。但是一般不这么做。
16 |
17 | ```php
18 | namespace app;
19 | #子命名空间
20 | namespace app\model;
21 |
22 |
23 | namespace app {
24 | function test(){}
25 | }
26 | namespace app2{
27 | function test(){}
28 | }
29 | namespace {
30 | app\test();
31 | app2\test();
32 | }
33 |
34 | ```
35 |
36 | ### 命名空间基础
37 |
38 | 命名空间和路径原理相似。所以有相对、绝对
39 |
40 | - 非限定名称、不包含前缀的类名称。类似a.php 比如include('a.php')
41 |
42 | ```php
43 | $a = new Test();// 如果这个文件定义的命名空间是app。那么就是访问的 app\Test类。
44 | ```
45 |
46 | - 限定名称,或包含前缀 类似 文件路径中的 a/c.php这种形式
47 |
48 | ```php
49 | $a = new model\Test(); //如果该文件的命名空间是app。则访问的就是app\model\Test
50 | ```
51 |
52 | - 完全限制 类似文件中的绝对路径 /www/a.php
53 |
54 | ```php
55 | $a = new \app\Test();
56 | ```
57 |
58 | ### 别名和导入
59 |
60 | 命名空间支持别名和引入外部的名字
61 |
62 | 所有支持命名空间的PHP版本支持三种别名或导入方式:为类名称使用别名、为接口使用别名或为命名空间名称使用别名
63 |
64 |
65 |
66 | ```php
67 | namespace a;
68 | use app\model;
69 | use app\test\model as model2;
70 |
71 | ```
72 |
73 | ### 全局命名空间
74 |
75 | 如果没有定义任何命名空间,所有的类与函数的定义都是在全局空间,与 PHP 引入命名空间概念前一样。在名称前加上前缀 *\\* 表示该名称是全局空间中的名称
76 |
77 | ```php
78 | namespace app;
79 |
80 | function test(){
81 | new \Redis();
82 | }
83 | ```
84 |
85 |
86 |
87 | ### 名词解析
88 |
89 | ```php
90 | namespace A;
91 | use B\D, C\E as F;
92 |
93 | // 函数调用
94 |
95 | foo(); // 首先尝试调用定义在命名空间"A"中的函数foo()
96 | // 再尝试调用全局函数 "foo"
97 |
98 | \foo(); // 调用全局空间函数 "foo"
99 |
100 | my\foo(); // 调用定义在命名空间"A\my"中函数 "foo"
101 |
102 | F(); // 首先尝试调用定义在命名空间"A"中的函数 "F"
103 | // 再尝试调用全局函数 "F"
104 |
105 | // 类引用
106 |
107 | new B(); // 创建命名空间 "A" 中定义的类 "B" 的一个对象
108 | // 如果未找到,则尝试自动装载类 "A\B"
109 |
110 | new D(); // 使用导入规则,创建命名空间 "B" 中定义的类 "D" 的一个对象
111 | // 如果未找到,则尝试自动装载类 "B\D"
112 |
113 | new F(); // 使用导入规则,创建命名空间 "C" 中定义的类 "E" 的一个对象
114 | // 如果未找到,则尝试自动装载类 "C\E"
115 |
116 | new \B(); // 创建定义在全局空间中的类 "B" 的一个对象
117 | // 如果未发现,则尝试自动装载类 "B"
118 |
119 | new \D(); // 创建定义在全局空间中的类 "D" 的一个对象
120 | // 如果未发现,则尝试自动装载类 "D"
121 |
122 | new \F(); // 创建定义在全局空间中的类 "F" 的一个对象
123 | // 如果未发现,则尝试自动装载类 "F"
124 |
125 | // 调用另一个命名空间中的静态方法或命名空间函数
126 |
127 | B\foo(); // 调用命名空间 "A\B" 中函数 "foo"
128 |
129 | B::foo(); // 调用命名空间 "A" 中定义的类 "B" 的 "foo" 方法
130 | // 如果未找到类 "A\B" ,则尝试自动装载类 "A\B"
131 |
132 | D::foo(); // 使用导入规则,调用命名空间 "B" 中定义的类 "D" 的 "foo" 方法
133 | // 如果类 "B\D" 未找到,则尝试自动装载类 "B\D"
134 |
135 | \B\foo(); // 调用命名空间 "B" 中的函数 "foo"
136 |
137 | \B::foo(); // 调用全局空间中的类 "B" 的 "foo" 方法
138 | // 如果类 "B" 未找到,则尝试自动装载类 "B"
139 |
140 | // 当前命名空间中的静态方法或函数
141 |
142 | A\B::foo(); // 调用命名空间 "A\A" 中定义的类 "B" 的 "foo" 方法
143 | // 如果类 "A\A\B" 未找到,则尝试自动装载类 "A\A\B"
144 |
145 | \A\B::foo(); // 调用命名空间 "A\B" 中定义的类 "B" 的 "foo" 方法
146 | // 如果类 "A\B" 未找到,则尝试自动装载类 "A\B"
147 | ```
148 |
149 |
--------------------------------------------------------------------------------
/PHP/README.md:
--------------------------------------------------------------------------------
1 | ## PHP
2 |
3 | - [手册笔记](https://github.com/xianyunyh/studynotes/tree/master/PHP/PHP%E6%89%8B%E5%86%8C%E7%AC%94%E8%AE%B0)
4 | - [官方文档](http://php.net/manual/zh/langref.php)
5 | - [数组函数]()
6 | - [字符串函数]()
7 | - [垃圾回收机制]()
8 | - [面向对象]()
9 |
10 | - 封装
11 | - 继承
12 | - 多态
13 | - [zval结构]()
14 | - [魔术方法]()
15 | - [抽象类和接口]()
16 | - [MVC]()
17 | - [访问修饰符]()
18 | - [正则表达式]()
19 | - [FPM、FastCGI]()
20 | - [PSR规范](https://github.com/PizzaLiu/PHP-FIG)
21 | - **PSR 1 基本代码规范**
22 | - **PSR 2 代码风格指南**
23 | - **PSR 3 日志接口**
24 | - **PSR 4 改进的自动加载**
25 |
26 | ### Zval 引用计数
27 |
28 | 在php5中,每个变量都存在一个叫zval的结构中,这个结构包括变量的类型和变量的值。第一个是is_ref,表示是不是引用集合,php通过这个把引用变量和普通变量区分开,还有一个字段叫`ref_count` 表示这个zval容器的个数。
29 |
30 | PHP5
31 |
32 | ```c_cpp
33 | struct _zval_struct {
34 | union {
35 | long lval;
36 | double dval;
37 | struct {
38 | char *val;
39 | int len;
40 | } str;
41 | HashTable *ht;
42 | zend_object_value obj;
43 | zend_ast *ast;
44 | } value;
45 | zend_uint refcount__gc;
46 | zend_uchar type;
47 | zend_uchar is_ref__gc;
48 | };
49 | ```
50 |
51 | 复合类型的变量把他们的成员属性都存在自己的符号表里。
52 |
53 | ```pph
54 | 'life', 'number' => 42 );
56 | xdebug_debug_zval( 'a' );
57 | ?>
58 | a: (refcount=1, is_ref=0)=array (
59 | 'meaning' => (refcount=1, is_ref=0)='life',
60 | 'number' => (refcount=1, is_ref=0)=42
61 | )
62 | ```
63 |
64 | ### 回收周期
65 |
66 | 我们先要建立一些基本规则,如果一个引用计数增加,它将继续被使用,当然就不再在垃圾中。如果引用计数减少到零,所在变量容器将被清除(free)。就是说,仅仅在引用计数减少到非零值时,才会产生垃圾周期(garbage cycle)。其次,在一个垃圾周期中,通过检查引用计数是否减1,并且检查哪些变量容器的引用次数是零,来发现哪部分是垃圾
67 |
68 | ### 面向对象
69 |
70 | 1. 封装性:
71 |
72 | 也称为信息隐藏,就是将一个类的使用和实现分开,只保留部分接口和方法与外部联系,或者说只公开了一些供开发人员使用的方法。
73 | 于是开发人员只需要关注这个类如何使用,而不用去关心其具体的实现过程,这样就能实现MVC分工合作,也能有效避免程序间相互依赖,
74 | 实现代码模块间松藕合。
75 |
76 | 2. 继承性:
77 | 就是子类自动继承其父级类中的属性和方法,并可以可以添加新的属性和方法或者对部分属性和方法进行重写。继承增加了代码的可重用性。
78 | php只支持单继承,也就是说一个子类只能有一个父类。
79 |
80 | 3. 多态性:
81 | 子类继承了来自父级类中的属性和方法,并对其中部分方法进行重写。
82 | 于是多个子类中虽然都具有同一个方法,但是这些子类实例化的对象调用这些相同的方法后却可以获得完全不同的结果,这种技术就是多态性。
83 | 多态性增强了软件的灵活性。
84 |
85 | ### 访问权限修饰符
86 |
87 | - public 公开的。任何地方都能访问
88 | - protected 保护的、只能在本类和子类中访问
89 | - private 私有的。只能在本类调用
90 | - final 最终的。被修饰的方法或者类,不能被继承或者重写
91 | - static 静态
92 |
93 | ### 接口和抽象类区别
94 |
95 | - 接口使用interface声明,抽象类使用abstract
96 | - 抽象类可以包含属性方法。接口不能包含成员属性、
97 | - 接口不能包含非抽象方法
98 |
99 |
100 |
101 | ### CSRF XSS
102 |
103 | CSRF,跨站请求伪造,攻击方伪装用户身份发送请求从而窃取信息或者破坏系统。
104 |
105 | 讲述基本原理:用户访问A网站登陆并生成了cookie,再访问B网站,如果A网站存在CSRF漏洞,此时B网站给A网站的请求(此时相当于是用户访问),A网站会认为是用户发的请求,从而B网站就成功伪装了你的身份,因此叫跨站脚本攻击。
106 |
107 | CSRF防范:
108 |
109 | 1.合理规范api请求方式,GET,POST
110 |
111 | 2.对POST请求加token令牌验证,生成一个随机码并存入session,表单中带上这个随机码,提交的时候服务端进行验证随机码是否相同。
112 |
113 | XSS,跨站脚本攻击。
114 |
115 | 防范:不相信任何输入,过滤输入。
116 |
117 | ### CGI、FastCGI、FPM
118 |
119 | CGI全称是“公共网关接口”(Common Gateway Interface),HTTP服务器与你的或其它机器上的程序进行“交谈”的一种工具,其程序须运行在网络服务器上。
120 |
121 | CGI是HTTP Server和一个独立的进程之间的协议,把**HTTP Request的Header设置成进程的环境变量**,HTTP Request的正文设置成进程的标准输入,而进程的标准输出就是HTTP Response包括Header和正文。
122 |
123 | FastCGI像是一个常驻(long-live)型的CGI,它可以一直执行着,只要激活后,不会每次都要花费时间去fork一次(这是CGI最为人诟病的fork-and-execute 模式)。它还支持分布式的运算,即 FastCGI 程序可以在网站服务器以外的主机上执行并且接受来自其它网站服务器来的请求。
124 |
125 | Fpm是一个实现了Fastcgi协议的程序,用来管理Fastcgi起的进程的,即能够调度php-cgi进程的程序
126 |
127 | #### FastCGI特点
128 |
129 | 1. FastCGI具有语言无关性.
130 | 2. FastCGI在进程中的应用程序,独立于核心web服务器运行,提供了一个比API更安全的环境。APIs把应用程序的代码与核心的web服务器链接在一起,这意味着在一个错误的API的应用程序可能会损坏其他应用程序或核心服务器。 恶意的API的应用程序代码甚至可以窃取另一个应用程序或核心服务器的密钥。
131 | 3. FastCGI技术目前支持语言有:C/C++、Java、Perl、Tcl、Python、SmallTalk、Ruby等。相关模块在Apache, ISS, Lighttpd等流行的服务器上也是可用的。
132 | 4. FastCGI的不依赖于任何Web服务器的内部架构,因此即使服务器技术的变化, FastCGI依然稳定不变。
133 |
134 | #### FastCGI的工作原理
135 |
136 | 1. Web Server启动时载入FastCGI进程管理器(IIS ISAPI或Apache Module)
137 | 2. FastCGI进程管理器自身初始化,启动多个CGI解释器进程(可见多个php-cgi)并等待来自Web Server的连接。
138 | 3. 当客户端请求到达Web Server时,FastCGI进程管理器选择并连接到一个CGI解释器。Web server将CGI环境变量和标准输入发送到FastCGI子进程php-cgi。
139 | 4. FastCGI子进程完成处理后将标准输出和错误信息从同一连接返回Web Server。当FastCGI子进程关闭连接时,请求便告处理完成。FastCGI子进程接着等待并处理来自FastCGI进程管理器(运行在Web Server中)的下一个连接。 在CGI模式中,php-cgi在此便退出了。
140 |
141 |
--------------------------------------------------------------------------------
/PHP/正则表达式.md:
--------------------------------------------------------------------------------
1 | ## 正则表达式
2 |
3 | 在编写处理字符串的程序或网页时,经常有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。
4 |
5 | **常用元字符**
6 |
7 | | 代码 | 说明 |
8 | | ---- | ------------------------------------------------------------ |
9 | | . | 匹配除换行符以外的任意字符 |
10 | | \w | 匹配字母或数字或下划线 |
11 | | \s | 匹配任意的空白符(space) |
12 | | \d | 匹配数字 |
13 | | \b | 匹配单词的开始或结束 |
14 | | ^ | 匹配字符串的开始 |
15 | | $ | 匹配字符串的结束 |
16 | | \un | 匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(©)。 |
17 |
18 | **常用限定符**
19 |
20 | | 代码/语法 | 说明 |
21 | | --------- | ------------------------------------------------------------ |
22 | | * | 重复零次或更多次 |
23 | | + | 重复一次或更多次 |
24 | | ? | 重复零次或一次 |
25 | | {n} | 重复n次 |
26 | | {n,} | 重复n次或更多次 |
27 | | {n,m} | 重复n-m次 |
28 | | x\|y | 匹配x或y。例如,“`z|food`"能匹配"`z`"或"`food`"。"`(z|f)ood`"则匹配"`zood`"或"`food`"。 |
29 | | [a-z] | 字符范围。匹配指定范围内的任意字符。例如,“`[a-z]`"可以匹配"`a`"到"`z`"范围内的任意小写字母字符 |
30 | | | |
31 |
32 | **常用反义词**
33 |
34 | | 代码/语法 | 说明 |
35 | | --------- | ------------------------------------------ |
36 | | \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
37 | | \S | 匹配任意不是空白符的字符 |
38 | | \D | 匹配任意非数字的字符 |
39 | | \B | 匹配不是单词开头或结束的位置 |
40 | | [^x] | 匹配除了x以外的任意字符 |
41 | | [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
42 |
43 | ## 常见的正则表达式
44 |
45 | | Unicode编码中的汉字范围 | `/^[\u2E80-\u9FFF]+$/` |
46 | | ---------------------------- | ------------------------------------------------- |
47 | | URL | ` ^((https|http)?:\/\/)[^\s]+ ` |
48 | | 电子邮箱 | /^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/ |
49 | | 中国大陆身份证号(15位或18位) | \d{15}(\d\d[0-9xX])? |
50 | | QQ号码 | [1-9]\d{4,11} |
51 | | 空白行 | \s |
52 | | 删除代码\\注释 | (?PHP面试准备的资料
2 |
3 | 这个项目是自己准备面试整理的资料。可能包括PHP、MySQL等资料。方便自己以后查阅,会不定期更新,如果错误,请指出,谢谢。欢迎大家提交PR,谢谢大家的star
4 |
5 | 可以通过[https://xianyunyh.gitbooks.io/php-interview/](https://xianyunyh.gitbooks.io/php-interview/)预览。欢迎有精力的朋友完善一下。谢谢。
6 |
7 |
8 | ### 目录
9 |
10 | - [Linux](Linux/REAMDE.md)
11 | - [操作系统简述](操作系统/Readme.md)
12 | - [进程和线程](Linux/进程和线程.md)
13 | - [Linux基本命令](https://github.com/xianyunyh/PHP-Interview/blob/master/Linux/Linux%E5%91%BD%E4%BB%A4.md)
14 | - [Crontab](Linux/crontab.md)
15 | - [Shell](Linux/shell.md)
16 | - [Linux-Inode介绍](Linux/inode.md)
17 | - [VIM编辑器](Linux/Vim.md)
18 | - [Lnmp/Lamp](Linux/lanmp.md)
19 | - [LinuxIO模型.md](Linux/LinuxIO模型.md)
20 |
21 | - [数据库](Mysql/README.md)
22 |
23 | - [MySQL](Mysql/README.md)
24 |
25 | - [Mongodb](MongoDb/MongoDB.md)
26 |
27 | - [计算机网络](计算机网络/README.md)
28 |
29 | - [IP协议](计算机网络/IP协议.md)
30 |
31 | - [TCP协议](计算机网络/TCP协议.md)
32 | - [UDP协议](计算机网络/UDP协议.md)
33 | - [HTTP协议](计算机网络/HTTP协议)
34 | - [HTTPS/HTTP2/HTTP](计算机网络/HTTP2.md)
35 |
36 | - [版本控制器](版本控制器/Git.md)
37 |
38 | - [Git](版本控制器/Git.md)
39 | - [SVN]()
40 |
41 | - [数据结构](数据结构/README.md)
42 |
43 | - [数组](数据结构/数组.md)
44 | - [链表](数据结构/链表.md)
45 | - [队列](数据结构/队列.md)
46 | - [栈](数据结构/栈.md)
47 | - [堆](数据结构/堆.md)
48 | - [集合](数据结构/集合.md)
49 | - [树](数据结构/树.md)
50 | - [二叉树 ]()
51 | - [二叉查找树]()
52 | - [红黑树]()
53 | - [B-Tree、B+Tree]()
54 | - [图]()
55 |
56 | - [算法](算法/README.md)
57 |
58 | - [排序算法]()
59 | - [冒泡排序](https://github.com/PuShaoWei/arithmetic-php/blob/master/package/Sort/BubbleSort.php)
60 | - [选择排序](https://github.com/PuShaoWei/arithmetic-php/blob/master/package/Sort/SelectSort.php)
61 | - [插入排序](https://github.com/PuShaoWei/arithmetic-php/blob/master/package/Sort/InsertSort.php)
62 | - [快速排序](https://github.com/PuShaoWei/arithmetic-php/blob/master/package/Sort/QuickSort.php)
63 | - [堆排序](https://github.com/PuShaoWei/arithmetic-php/blob/master/package/Sort/HeapSort.php)
64 | - [归并排序](https://github.com/PuShaoWei/arithmetic-php/blob/master/package/Sort/MergeSort.php)
65 | - [查找算法]()
66 | - [二分查找](https://github.com/PuShaoWei/arithmetic-php/blob/master/package/Query/BinaryQuery.php)
67 | - [hash]()
68 | - [KPM](https://github.com/PuShaoWei/arithmetic-php/blob/master/package/Query/Kmp.php)
69 | - [其他]()
70 | - 布隆过滤器
71 | - 贪心算法
72 | - 回溯算法
73 | - 动态规划
74 | - 最小生成树
75 | - 最短路径
76 | - 推荐算法
77 | - 深度优先、广度优先
78 | - [编程之法:面试和算法心得](https://wizardforcel.gitbooks.io/the-art-of-programming-by-july/content/03.02.html)
79 |
80 | - [消息队列](MQ/README.md)
81 |
82 | - [RabbitMQ](MQ/rabbitmq.md)
83 | - [ActiveMq]()
84 | - [Nsq]()
85 | - [kafka]()
86 |
87 | - [缓存系统]()
88 |
89 | - [Redis](Cache/Redis.md)
90 | - [Memcache]()
91 |
92 | - [PHP](PHP/README.md)
93 |
94 | - [PHP7](PHP/php7.md)
95 | - [面向对象OOP]()
96 | - [Zval](https://github.com/xianyunyh/PHP-Interview/blob/master/PHP/PHP-Zval%E7%BB%93%E6%9E%84.md)
97 | - [HashTable](https://github.com/xianyunyh/PHP-Interview/blob/master/PHP/PHP7-HashTable.md)
98 | - [Swoole]()
99 |
100 | - [设计模式](设计模式/README.md)
101 |
102 | - [面试](面试/README.md)
103 |
104 |
105 | ## 生成自己的Gitbook
106 |
107 | ```bash
108 | $ npm install gitbook-cli -g
109 | $ git clone https://github.com/xianyunyh/PHP-Interview
110 | $ cd PHP-Interview
111 | $ gitbook serve # 本地预览
112 | $ gitbook build # 生成静态的html
113 | ```
114 |
115 | ## 推荐阅读资料
116 | - [PHP函数库](http://overapi.com/php)
117 | - [PHP7内核剖析](https://github.com/pangudashu/php7-internal)
118 | - [php7-internal](https://github.com/laruence/php7-internal)
119 | - [PHP7-HashTable](http://nikic.github.io/2014/12/22/PHPs-new-hashtable-implementation.html)
120 | - [PHP7-zval](http://nikic.github.io/2015/05/05/Internal-value-representation-in-PHP-7-part-1.html)
121 | - [PHP中的变化](https://github.com/tpunt/PHP7-Reference)
122 | - [PHP资源集合](https://github.com/ziadoz/awesome-php)
123 | - [设计模式PHP实现](https://github.com/domnikl/DesignPatternsPHP)
124 | - [Swoole](https://www.swoole.com/)
125 | - [程序员的内功-算法和数据结构](http://www.cnblogs.com/jingmoxukong/p/4329079.html)
126 | - [数据结构和算法](http://www.cnblogs.com/skywang12345/p/3603935.html)
127 | - [剑指offer-PHP实现](https://blog.csdn.net/column/details/15795.html)
128 |
129 | ## 致谢
130 |
131 | - [OMGZui](https://github.com/OMGZui)
132 | - [fymmx](https://github.com/fymmx)
133 |
134 |
135 |
136 | 如果这个系列的文章,对您有所帮助,您可以选择打赏一下作者。谢谢!
137 |
138 | 
139 |
--------------------------------------------------------------------------------
/SUMMARY.md:
--------------------------------------------------------------------------------
1 | # Summary
2 |
3 | ## LNMP
4 | * [Linux部分](Linux/README.md)
5 | * [Linux基本操作命令](Linux/Linux命令.md)
6 | * [Linux网络相关命令](Linux/Linux命令2.md)
7 | * [Crontab计划任务](Linux/crontab.md)
8 | * [Inode介绍](Linux/inode.md)
9 | * [Shell](Linux/shell.md)
10 | * [Sed命令](Linux/Sed练习.md)
11 | * [Awk命令](Linux/AWK练习.md)
12 | * [IO模型](Linux/LinuxIO模型.md)
13 | * [LAMP/LNMP](Linux/lanmp.md)
14 | * [MySQL部分](Mysql/README.md)
15 | * [SQL语法](Mysql/SQL标准.md)
16 | * [数据库范式](Mysql/MySQL三范式.md)
17 | * [存储引擎](Mysql/存储引擎.md)
18 | * [事务](Mysql/事务.md)
19 | * [索引](Mysql/索引.md)
20 | * [explain分析SQL](Mysql/explain.md)
21 | * [MySQL优化](Mysql/MySQL优化.md)
22 | * [MySQL索引原理及慢查询优化](Mysql/MySQL索引原理及慢查询优化.md)
23 | * [MongoDB](MongoDb/MongoDB.md)
24 | * [PHP](PHP/README.md)
25 | * [PHP7](PHP/php7.md)
26 | * [面向对象OOP](https://github.com/xianyunyh/PHP-Interview/blob/master)
27 | * [Zval结构](PHP/PHP-Zval结构.md)
28 | * [HashTable](PHP/PHP7-HashTable.md)
29 | * [Swoole](https://swoole.com)
30 | * [PHP运行原理](PHP/PHP运行原理.md)
31 | * [正则表达式](PHP/正则表达式.md)
32 | * [PHP-FPM](PHP/PHP-FPM配置选项.md)
33 |
34 | ## 操作系统和网络
35 | * [计算机网络](计算机网络/README.md)
36 | * [IP协议](计算机网络/IP协议.md)
37 | * [TCP协议](计算机网络/TCP协议.md)
38 | * [UDP协议](计算机网络/UDP协议.md)
39 | * [HTTP协议](计算机网络/HTTP协议.md)
40 | * [HTTPS协议](计算机网络/HTTPS.md)
41 | * [HTTP2协议](计算机网络/HTTP2.md)
42 | * [Webscokt](计算机网络/Webscokt.md)
43 | * [版本控制器](版本控制器/Git.md)
44 | * [Git](版本控制器/Git.md)
45 | * SVN
46 |
47 | ## 数据结构和算法
48 | * [数据结构](数据结构/README.md)
49 | * [数组](数据结构/数组.md)
50 | * 链表
51 | * 单链表
52 | * 双链表
53 | * 队列
54 | * 栈
55 | * 堆
56 | * 集合
57 | * 树
58 | * 二叉树
59 | * 二叉查找树
60 | * 红黑树
61 | * B-Tree、B+Tree
62 | * [图](https://github.com/xianyunyh/PHP-Interview/blob/master)
63 | * [算法](算法/Readme.md)
64 | * [排序算法](算法/Readme.md)
65 | * [冒泡排序](https://github.com/PuShaoWei/arithmetic-php/blob/master/package/Sort/BubbleSort.php)
66 | * [选择排序](https://github.com/PuShaoWei/arithmetic-php/blob/master/package/Sort/SelectSort.php)
67 | * [插入排序](https://github.com/PuShaoWei/arithmetic-php/blob/master/package/Sort/InsertSort.php)
68 | * [快速排序](https://github.com/PuShaoWei/arithmetic-php/blob/master/package/Sort/QuickSort.php)
69 | * [堆排序](https://github.com/PuShaoWei/arithmetic-php/blob/master/package/Sort/HeapSort.php)
70 | * [归并排序](https://github.com/PuShaoWei/arithmetic-php/blob/master/package/Sort/MergeSort.php)
71 | * 查找算法
72 | * [二分查找](https://github.com/PuShaoWei/arithmetic-php/blob/master/package/Query/BinaryQuery.php)
73 | * [hash](https://github.com/xianyunyh/PHP-Interview/blob/master)
74 | * [KPM](https://github.com/PuShaoWei/arithmetic-php/blob/master/package/Query/Kmp.php)
75 | * 其他
76 | * 布隆过滤器
77 | * 贪心算法
78 | * 回溯算法
79 | * 动态规划
80 | * 最小生成树
81 | * 最短路径
82 | * 推荐算法
83 | * 深度优先、广度优先
84 | * [编程之法:面试和算法心得](https://wizardforcel.gitbooks.io/the-art-of-programming-by-july/content/03.02.html)
85 | * [剑指offer-PHP实现](https://blog.csdn.net/column/details/15795.html)
86 |
87 | ## 系统设计和架构
88 | * [架构和系统设计](架构和系统设计/README.md)
89 | * [消息队列](MQ/README.md)
90 | * [RabbitMQ](MQ/rabbitmq.md)
91 | * ActiveMq
92 | * Nsq
93 | * kafka
94 | * 缓存系统
95 | * [Redis](Cache/Redis.md)
96 | * Memcache
97 | * [设计模式](设计模式/README.md)
98 | * [创造型](设计模式/Creational.md)
99 | * [行为型](设计模式/Behavioral.md)
100 | * [结构型](设计模式/Structural.md)
101 | * [PHP实现23种设计模式](https://github.com/domnikl/DesignPatternsPHP)
102 |
103 | ## 面试
104 | * [裸辞应对](面试/03裸辞应对.md)
105 | * [写简历](面试/02写简历.md)
106 | * [笔试](面试/笔试题.md)
107 | * [笔试题1](面试/笔试题.md)
108 | * [笔试题2](面试/笔试题2.md)
109 | * [笔试题3](面试/笔试题3.md)
110 | * [笔试题4](面试/笔试题4.md)
111 | * [面试问答](面试/01离职原因回答.md)
112 | * [离职原因](面试/01离职原因回答.md)
113 | * [面试提问](面试/04面试提问.md)
114 |
115 |
--------------------------------------------------------------------------------
/_config.yml:
--------------------------------------------------------------------------------
1 | theme: jekyll-theme-tactile
--------------------------------------------------------------------------------
/book.json:
--------------------------------------------------------------------------------
1 | {
2 | "title": "PHP知识整理",
3 | "description": "PHP知识整理",
4 | "language": "zh-hans",
5 | "extension": null,
6 | "generator": "site",
7 | "gitbook": "3.x.x",
8 | "plugins": [
9 | "github",
10 | "anchors",
11 | "theme-comscore",
12 | "expandable-chapters-small",
13 | "search-plus",
14 | "-search"
15 | ],
16 | "pluginsConfig": {
17 | "github": {
18 | "url": "https://github.com/xianyunyh/PHP-Interview"
19 | },
20 | "theme-default": {
21 | "showLevel": true
22 | },
23 | "search-pro": {
24 | "cutWordLib": "nodejieba",
25 | "defineWord" : ["Gitbook Use"]
26 | }
27 | },
28 | "links": {
29 | "gitbook": false,
30 | "sharing": {
31 | "google": false,
32 | "facebook": false,
33 | "twitter": false,
34 | "all": false
35 | }
36 | }
37 | }
--------------------------------------------------------------------------------
/mm_reward_qrcode.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/mm_reward_qrcode.jpg
--------------------------------------------------------------------------------
/操作系统/Readme.md:
--------------------------------------------------------------------------------
1 |
2 | # 操作系统概论
3 |
4 | 操作系统是一种计算机软件。在硬件之上,应用程序之下。主要功能就是管理底下的计算机硬件,并为上层的应用程序提供统一的接口。
5 |
6 | 
7 |
8 | **系统调用**:应用程序直接调用操作系统提供的接口 如write 函数
9 |
10 | **库函数调用**:应用程序通过一些库函数直接调用 如 fwrite
11 |
12 | ## 内核态和用户态
13 |
14 | 操作系统为了管理内存。将内存分为**内核空间**(内核态)和**用户空间**。内存空间和用户空间之间有隔离。
15 |
16 | **用户空间即上层应用程序的活动空间**,应用程序的执行必须依托于内核提供的资源,包括CPU资源、存储资源、I/O资源等。为了使上层应用能够访问到这些资源,内核必须为上层应用提供访问的接口:即系统调用
17 |
18 |
19 |
20 |
21 |
22 | 
23 |
24 | 内核从本质上看是一种软件——控制计算机的硬件资源,并提供上层应用程序运行的环境。
25 |
26 | shell就是外壳。类似一种胶水的功能。可以通过shell访问内核。
27 |
28 | 内核态与用户态是指CPU的运行状态(即特权级别),每个进程的每种CPU状态都有其运行上下文,运行上下文就包括了当前状态所使用的空间,CPU访问的逻辑地址(即空间)通过地址映射表映射到相应的物理地址(即物理内存)。在Linux系统中,进程的用户空间是独立的,而内核空间是公用的,进程切换时,用户空间切换,内核空间不变。
29 |
30 | 对于多数CPU而言,处于内核态时,可以访问所有地址空间,而处于用户态时,就只能访问用户空间了。
31 |
32 |
33 |
34 | ## 用户态和内核态切换
35 |
36 | 操作系统的资源是有限的,如果访问资源的操作过多,必然会消耗过多的资源,而且如果不对这些操作加以区分,很可能造成资源访问的冲突。
37 |
38 | 为了减少有限资源的访问和使用冲突,Unix/Linux的设计哲学之一就是:对不同的操作赋予不同的执行等级,就是所谓特权的概念
39 |
40 | Linux操作系统中主要采用了0和3两个特权级,分别对应的就是内核态和用户态。运行于用户态的进程可以执行的操作和访问的资源都会受到极大的限制,而运行在内核态的进程则可以执行任何操作并且在资源的使用上没有限制。很多程序开始时运行于用户态,但在执行的过程中,一些操作需要在内核权限下才能执行,这就涉及到一个从用户态切换到内核态的过程
41 |
42 | 
43 |
44 |
45 |
46 | ## 库函数调用和系统调用的区别
47 |
48 | 
49 |
50 | 系统调用(英语:system call),指运行在用户空间的应用程序向操作系统内核请求某些服务的调用过程。 系统调用提供了用户程序与操作系统之间的接口。一般来说,系统调用都在内核态执行。由于系统调用不考虑平台差异性,由内核直接提供,因而移植性较差(几乎无移植性)。
51 |
52 | 库函数(library function),是由用户或组织自己开发的,具有一定功能的函数集合,一般具有较好平台移植性,通过库文件(静态库或动态库)向程序员提供功能性调用。程序员无需关心平台差异,由库来屏蔽平台差异性。
53 |
54 | | 函数库调用 | 系统调用 |
55 | | ----------------------------- | ----------------------- |
56 | | 平台移植性好 | 依赖于内核,不保证移植性 |
57 | | 调用函数库中的一段程序(或函数) | 调用系统内核的服务 |
58 | | 一个普通功能函数的调用 | 是操作系统的一个入口点 |
59 | | 在**用户空间**执行 | 在**内核空间**执行 |
60 | | 它的运行时间属于“用户时间” | 它的运行时间属于“系统”时间 |
61 | | 属于过程调用,调用开销较小 | 在用户空间和内核上下文环境间切换,开销较大 |
62 | | 库函数数量较多 | UNIX中大约有90个系统调用,较少 |
63 | | 典型的C函数库调用:printf scanf malloc | 典型的系统调用:fork open write |
64 |
65 | 
66 |
67 | 读写IO通常是大量的数据(这种大量是相对于底层驱动的系统调用所实现的数据操作单位而言),使用库函数调用可以大大减少系统调用的次数。这是因为缓冲区技术。在用户空间和内核空间,对文件操作都使用了缓冲区,当内核缓冲区写满之后或写结束之后才将内核缓冲区内容写到文件对应的硬件媒介中。
68 |
69 | **不带缓冲指的是每个read和write这些文件I/O操作都调用的是系统调用,属于内核态的操作**
70 |
71 | 诸如fread和fwrite这些标准I/O操作属于用户态操作,具体是库函数的实现,需要借助用户缓冲区来实现
72 |
73 | 更多内容可以参考 [操作系统](https://github.com/xianyunyh/studynotes/tree/master/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F)
--------------------------------------------------------------------------------
/操作系统/进程和线程.md:
--------------------------------------------------------------------------------
1 | ## 进程和线程的区别
2 |
3 | 进程是一次程序运行的活动。进程有自己的pid,堆栈空间等资源。
4 |
5 | 线程是进程里面的一个实体。是CPU调度的基本单位。它比进程更小。线程本身不拥有系统资源。只拥有自己的程序计数器、堆栈、寄存器。和同一个进程中的其他线程共享进程中的内存。
6 |
7 | 线程开销小。进程切换开销比较大。进程切换,上下文。
8 |
9 | 进程是cpu资源分配的最小单位,线程是cpu调度的最小单位。
--------------------------------------------------------------------------------
/数据结构/README.md:
--------------------------------------------------------------------------------
1 | ## 数据结构
2 |
3 | 数据结构具体指同一类数据元素中,各元素之间的相互关系,包括三个组成成分,**数据的逻辑结构**,**数据的存储结构**和**数据运算结构**。
4 |
5 | ### 数据(Data)
6 |
7 | - 数据是客观事物的符号表示,在计算机科学中指的是所有能输入到计算机中并被计算机程序处理的符号的总称。
8 |
9 | - 数据元素(Data Element) :是数据的基本单位,在程序中通常作为一个整体来进行考虑和处理。一个数据元素可由若干个数据项(Data Item)组成。
10 |
11 | - 数据项(Data Item) : 是数据的不可分割的最小单位。数据项是对客观事物某一方面特性的数据描述。
12 |
13 | - 数据对象(Data Object) :是性质相同的数据元素的集合,是数据的一个子集。如字符集合C={‘A’,’B’,’C,…} 。
14 |
15 | - 数据结构 :相互之间具有一定联系的数据元素的集合。
16 |
17 | - 数据的逻辑结构 : 数据元素之间的相互关系称为逻辑结构。
18 |
19 | - 数据操作 : 对数据要进行的运算
20 |
21 | - 数据类型(Data Type):指的是一个值的集合和定义在该值集上的一组操作的总称。
22 |
23 |
24 | ### 数据的逻辑结构
25 |
26 | - 集合:结构中数据元素之间除了“属于同一个集合"外,再也没有其他的关系
27 | - 线性结构:结构中的数据元素存在一对一的关系
28 | - 树形结构:结构中的数据元素存在一对多的关系
29 | - 网状或者图状结构:结构中的数据元素存在多对多的关系
30 |
31 | ### 数据的存储结构
32 |
33 | 由数据元素之间的关系在计算机中有两种不同的表示方法——顺序表示和非顺序表示,从则导出两种储存方式,顺序储存结构和链式储存结构
34 |
35 | - 顺序存储结构:用数据元素在存储器中的相对位置来表示数据元素之间的逻辑结构(关系),数据元素存放的地址是连续的
36 | - 链式存储结构:在每一个数据元素中增加一个存放另一个元素地址的指针(pointer),用该指针来表示数据元素之间的逻辑结构(关系),数据元素存放的地址是否连续没有要求
37 | - 索引存储方法:除建立存储结点信息外,还建立附加的索引表来标识结点的地址
38 |
39 | 数据的逻辑结构和物理结构是密不可分的两个方面,一个算法的设计取决于所选定的逻辑结构,而算法的实现依赖于所采用的存储结构
40 |
41 | ## 常见数据结构
42 |
43 | ### 数组
44 |
45 | > 把具有相同类型的若干变量按有序的形式组织起来。这些按序排列的同类数据元素的集合称为数组
46 |
47 | 两个特点:相同类型、有序
48 |
49 | 这个数组不等于PHP的数组。PHP数组本质是一个哈希表。通过数组实现
50 |
51 | 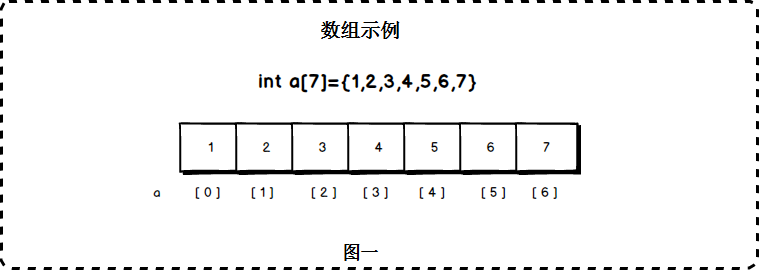
52 |
53 | ### 链表
54 |
55 | 链表是一种物理存储单元上非连续、非顺序的存储结构 ,由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。 PHP SPL标准库中有SplDoublyLinkedList (双向链表)
56 |
57 | 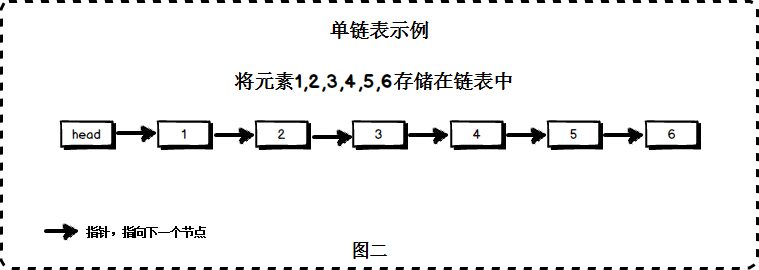
58 |
59 | 链表的操作:插入、遍历、查找、删除
60 |
61 | ```php
62 | $dlist=new SplDoublyLinkedList();
63 | $dlist->push(1);//追加到末端
64 | $dlist->add(1,3);//在index=1添加
65 | //遍历
66 | for($dlist->rewind();$dlist->valid();$dlist->next()){
67 | echo $dlist->current()."
";
68 | }
69 |
70 | ```
71 |
72 | ### 栈
73 |
74 | > 是只能在某一端插入和删除的特殊[**线性表**]。它按照**先进后出**的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出来)。
75 |
76 | PHP中SPL标准库中有对应的实现 [SplStack ](http://php.net/manual/zh/class.splstack.php)
77 |
78 | 栈的两个操作 出栈pop、入栈push
79 |
80 | ```php
81 | $q = new SplStack();
82 | $q[] = 1;
83 | $q[] = 2;
84 | $q[] = 3;
85 | $q->push(4);
86 | $q->push(5);
87 | echo $q->pop();//5
88 | ```
89 |
90 | ### 队列
91 |
92 | > 一种特殊的[线性表],它只允许在表的[前端](front)进行删除操作,而在表的末端(rear)进行插入操作。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列是按照“先进先出”或“后进后出”FIFO的原则组织数据的。队列中没有元素时,称为空队列。
93 |
94 | PHP SPL标准库中有[SplQueue ](http://php.net/manual/zh/class.splqueue.php)
95 |
96 | 队列的两个操作 入队列enqueue、出队列dequeue
97 |
98 | ```php
99 | $q = new SplQueue();
100 | $q->enqueue(array("FooBar", "foo"));
101 | $q->enqueue(array("FooBar", "bar"));
102 | $q->enqueue(array("FooBar", "msg", "Hi there!"));
103 |
104 | $f = $q->dequeue();
105 | ```
106 |
107 | ### 树
108 |
109 | 它是由n(n>=1)个有限节点组成一个具有层次关系的[集合]。是一对多的关系。
110 |
111 | (1)有且仅有一个结点 K0,他对于关系N来说没有前驱,称K0为树的根结点。简称为根(root))。
112 |
113 | (2)除K0外,K中的每个结点,对于关系N来说有且仅有一个前驱。
114 |
115 | (3)K中各结点,对关系N来说可以有m个后继(m>=0)。
116 |
117 | 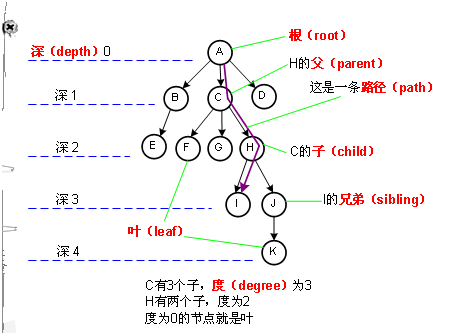
118 |
119 | #### 1. 二叉树
120 |
121 | 除了叶以外的结点,都有两个子。(叶就是在它和根的路径上,没有比他更远的结点了,也可以理解为,只有一个结点和它相连,并且它不是根,那么他就是叶)
122 |
123 | #### 2. 二叉搜索树
124 |
125 | 二叉搜索树,也称有序二叉树,排序二叉树,是指一棵空树或者具有下列性质的二叉树:
126 |
127 | 1. 若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
128 | 2. 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
129 | 3. 任意节点的左、右子树也分别为二叉查找树。
130 | 4. 没有键值相等的节点。
131 |
132 | #### 3. 树的遍历
133 |
134 | - 先序遍历 访问根结点——》访问左子树——》访问右子树
135 | - 中序遍历 先访问左子树,再访问根,再访问右子树。
136 | - 后序遍历 访问根结点——》访问右子树——》访问左子树
137 |
138 | ### 堆
139 |
140 | 堆是一种特殊的树形数据结构,每个结点都有一个值。通常我们所说的堆的数据结构,是指二叉堆。堆的特点是根结点的值最小(或最大),且根结点的两个子树也是一个堆。 比如我们查找top N 就可以用堆
141 |
142 | 
143 |
144 |
145 |
146 | PHP中有堆的实现SplMaxHeap (大端堆)、SplMaxHeap (小端堆)
147 |
148 | ### 散列表【HashTable】
149 |
150 | K=>V结构。若结构中存在关键字和K相等的记录,则必定在f(K)的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系f为散列函数(Hash function),按这个思想建立的表为[散列表]。
151 |
152 | #### 冲突
153 |
154 | 若 key1 ≠ key2 ,而 f(key1) = f(key2),这种情况称为**冲突**(Collision)。
155 |
156 | #### 构造哈希函数
157 |
158 | 常见的构造哈希表的方法有 5 种:
159 |
160 | **(1)直接定址法**
161 |
162 | 说白了,就是小学时学过的**一元一次方程**。
163 |
164 | 即 f(key) = a * key + b。其中,a和b 是常数。
165 |
166 | **(2)数字分析法**
167 |
168 | 假设关键字是R进制数(如十进制)。并且哈希表中**可能出现的关键字都是事先知道的**,则可选取关键字的若干数位组成哈希地址。
169 |
170 | 选取的原则是使得到的哈希地址尽量避免冲突,即所选数位上的数字尽可能是随机的。
171 |
172 | **(3)平方取中法**
173 |
174 | 取关键字平方后的中间几位为哈希地址。通常在选定哈希函数时不一定能知道关键字的全部情况,仅取其中的几位为地址不一定合适;
175 |
176 | 而一个数平方后的中间几位数和数的每一位都相关, 由此得到的哈希地址随机性更大。取的位数由表长决定。
177 |
178 | **(4)除留余数法**
179 |
180 | 取关键字被某个**不大于哈希表表长** m 的数 p 除后所得的余数为哈希地址。
181 |
182 | 即 f(key) = key % p (p ≤ m)
183 |
184 | 这是一种**最简单、最常用**的方法,它不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。
185 |
186 | 注意:p的选择很重要,如果选的不好,容易产生冲突。根据经验,**一般情况下可以选p为素数**。
187 |
188 | ### 冲突解决
189 |
190 | **1)开放定址法**
191 |
192 | 如果两个数据元素的哈希值相同,则在哈希表中为后插入的数据元素另外选择一个表项。 当程序查找哈希表时,如果没有在第一个对应的哈希表项中找到符合查找要求的数据元素,程序就会继续往后查找,直到找到一个符合查找要求的数据元素,或者遇到一个空的表项
193 |
194 | **2)拉链法**
195 |
196 | 将哈希值相同的数据元素存放在一个链表中,在查找哈希表的过程中,当查找到这个链表时,必须采用线性查找方法。在这种方法中,哈希表中每个单元存放的不再是记录本身,而是相应同义词单链表的头指针。
197 |
198 | ### 图
199 |
200 | 图是由结点的有穷集合V和边的集合E组成。其中,为了与树形结构加以[区别],在图结构中常常将结点称为顶点,边是顶点的有序偶对,若两个顶点之间存在一条边,就表示这两个顶点具有相邻关系。
201 |
202 | 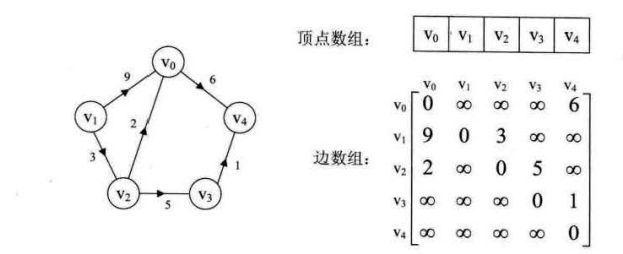
203 |
204 |
205 |
206 | 学习资料:
207 |
208 | - [https://visualgo.net/en](https://visualgo.net/en)
209 |
210 | - [http://www.cnblogs.com/jingmoxukong/p/4329079.html](http://www.cnblogs.com/jingmoxukong/p/4329079.html)
211 |
212 | - [https://www.studytonight.com/data-structures/introduction-to-data-structures](https://www.studytonight.com/data-structures/introduction-to-data-structures)
213 |
214 | - [https://www.tutorialspoint.com/data_structures_algorithms/index.htm](https://www.tutorialspoint.com/data_structures_algorithms/index.htm)
215 |
216 |
217 |
218 |
--------------------------------------------------------------------------------
/数据结构/images/Node.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/数据结构/images/Node.jpg
--------------------------------------------------------------------------------
/数据结构/images/array.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/数据结构/images/array.jpg
--------------------------------------------------------------------------------
/数据结构/images/doubleLink.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/数据结构/images/doubleLink.jpg
--------------------------------------------------------------------------------
/数据结构/堆栈.md:
--------------------------------------------------------------------------------
1 | ## :数据结构线性表之堆栈
2 |
3 | #### php-leetcode之路 [Leetcode-php](https://github.com/wuqinqiang/leetcode-php)
4 |
5 |
6 |  7 |
8 |
9 | ### :pencil2:一.栈的特点
10 | **栈是仅限在栈顶进行插入和删除的线性表.对栈来说,表尾端称之为栈顶,表头端称之为栈底.假设栈S=(a1,a2,a3,a4,a5....an),那么a1为栈的栈底,an为栈顶元素.对栈的操作是按照后进先出的原则,因此栈又称之为(LIFO)数据结构.**
11 |
12 | ### :pencil2:二.栈的表示和实现
13 | **和线性表类似,栈也有两种存储的方式.顺序栈,即栈的存储是利用一组连续的存储单元依次存放自栈底到栈顶的元素.同时还要定义指针top指向栈顶元素在顺序栈中的位置.通常的做法是top=0表示空栈.一般在使用栈的过程中难以预料所需要的空间大小.所以预先分配大小的容量,当栈的使用空间不够时,再进行动态的扩容.top作为栈顶的指针,初始的时候指向栈底,当有元素入栈时,top自增,当从栈中删除一个元素时,top--,然后删除元素,所以top始终指向栈顶的下一个空位置.**
14 | ```php
15 | LOC(ai+1)=LOC(ai)+L //申明 这里的i,i+1是下标
16 | ```
17 | **线性结构的顺序表示以元素在计算机中的物理位置相邻来表示逻辑位置相邻,相邻两个元素之间的位置以物理位置的角度分析就是相差一位,只要确定了存储线性表的起始位,那么我们就能任意存储线性表中元素,下图具体表示**
18 |
19 |
20 |
7 |
8 |
9 | ### :pencil2:一.栈的特点
10 | **栈是仅限在栈顶进行插入和删除的线性表.对栈来说,表尾端称之为栈顶,表头端称之为栈底.假设栈S=(a1,a2,a3,a4,a5....an),那么a1为栈的栈底,an为栈顶元素.对栈的操作是按照后进先出的原则,因此栈又称之为(LIFO)数据结构.**
11 |
12 | ### :pencil2:二.栈的表示和实现
13 | **和线性表类似,栈也有两种存储的方式.顺序栈,即栈的存储是利用一组连续的存储单元依次存放自栈底到栈顶的元素.同时还要定义指针top指向栈顶元素在顺序栈中的位置.通常的做法是top=0表示空栈.一般在使用栈的过程中难以预料所需要的空间大小.所以预先分配大小的容量,当栈的使用空间不够时,再进行动态的扩容.top作为栈顶的指针,初始的时候指向栈底,当有元素入栈时,top自增,当从栈中删除一个元素时,top--,然后删除元素,所以top始终指向栈顶的下一个空位置.**
14 | ```php
15 | LOC(ai+1)=LOC(ai)+L //申明 这里的i,i+1是下标
16 | ```
17 | **线性结构的顺序表示以元素在计算机中的物理位置相邻来表示逻辑位置相邻,相邻两个元素之间的位置以物理位置的角度分析就是相差一位,只要确定了存储线性表的起始位,那么我们就能任意存储线性表中元素,下图具体表示**
18 |
19 |
20 |  21 |
22 |
23 | ### :pencil2:三.栈的使用场景
24 | **栈的使用场景很多,例如idea的撤销回退功能,浏览器前进和后退功能.数制的转换,表达式求值,八皇后.......**
25 | ### :pencil2:四.用栈实现代码
26 | ```php
27 |
28 | /**
29 | * 使用栈实现十进制转8精制,其他转换类似
30 | */
31 | function tenChageEight($num)
32 | {
33 | $data=[];
34 | while($num) {
35 | $val = $num % 8;
36 | $num = intval(floor($num / 8));
37 | array_unshift($data, $val);
38 | }
39 | $data2=[];
40 | while(!empty($data)){
41 | array_push($data2,array_shift($data));
42 | }
43 | return implode($data2);
44 | }
45 | var_dump(tenChageEight(1348));
46 | ```
47 | ****
48 | ```php
49 |
50 | class Stack
51 | {
52 | private $stack=[];
53 | private $size=0;
54 | public function __construct($size)
55 | {
56 | $this->size=$size;
57 | }
58 |
59 | /**
60 | *推入栈顶
61 | */
62 | public function push($value)
63 | {
64 | if(count($this->stack)>=$this->size){
65 | return false;
66 | }
67 | array_unshift($this->stack,$value);
68 |
69 | }
70 | /**
71 | *出栈
72 | */
73 | public function pop()
74 | {
75 | if($this->size==0){
76 | return false;
77 | }
78 | array_shift($this->stack);
79 | }
80 | /**
81 | *获取栈顶元素
82 | */
83 | public function top()
84 | {
85 | if($this->size==0){
86 | return false;
87 | }
88 | return current($this->stack);
89 | }
90 |
91 | public function data()
92 | {
93 | return $this->stack;
94 | }
95 |
96 | }
97 |
98 | $stack=new Stack(10);
99 | $stack->push(2);
100 | $stack->push(10);
101 | $stack->push(8);
102 | $stack->pop();
103 | var_dump($stack->top());
104 | var_dump($stack->data());
105 | ```
106 | ### 联系
107 |
108 |
109 |
21 |
22 |
23 | ### :pencil2:三.栈的使用场景
24 | **栈的使用场景很多,例如idea的撤销回退功能,浏览器前进和后退功能.数制的转换,表达式求值,八皇后.......**
25 | ### :pencil2:四.用栈实现代码
26 | ```php
27 |
28 | /**
29 | * 使用栈实现十进制转8精制,其他转换类似
30 | */
31 | function tenChageEight($num)
32 | {
33 | $data=[];
34 | while($num) {
35 | $val = $num % 8;
36 | $num = intval(floor($num / 8));
37 | array_unshift($data, $val);
38 | }
39 | $data2=[];
40 | while(!empty($data)){
41 | array_push($data2,array_shift($data));
42 | }
43 | return implode($data2);
44 | }
45 | var_dump(tenChageEight(1348));
46 | ```
47 | ****
48 | ```php
49 |
50 | class Stack
51 | {
52 | private $stack=[];
53 | private $size=0;
54 | public function __construct($size)
55 | {
56 | $this->size=$size;
57 | }
58 |
59 | /**
60 | *推入栈顶
61 | */
62 | public function push($value)
63 | {
64 | if(count($this->stack)>=$this->size){
65 | return false;
66 | }
67 | array_unshift($this->stack,$value);
68 |
69 | }
70 | /**
71 | *出栈
72 | */
73 | public function pop()
74 | {
75 | if($this->size==0){
76 | return false;
77 | }
78 | array_shift($this->stack);
79 | }
80 | /**
81 | *获取栈顶元素
82 | */
83 | public function top()
84 | {
85 | if($this->size==0){
86 | return false;
87 | }
88 | return current($this->stack);
89 | }
90 |
91 | public function data()
92 | {
93 | return $this->stack;
94 | }
95 |
96 | }
97 |
98 | $stack=new Stack(10);
99 | $stack->push(2);
100 | $stack->push(10);
101 | $stack->push(8);
102 | $stack->pop();
103 | var_dump($stack->top());
104 | var_dump($stack->data());
105 | ```
106 | ### 联系
107 |
108 |
109 |  110 |
111 |
112 |
113 |
114 |
115 |
116 |
--------------------------------------------------------------------------------
/数据结构/字符串.md:
--------------------------------------------------------------------------------
1 | ##旋转字符串
2 | 给定一个字符串,要求把字符串前面的若干个字符移动到字符串的尾部,如把字符串“abcdef”前面的2个字符'a'和'b'移动到字符串的尾部,使得原字符串变成字符串“cdefab”。请写一个函数完成此功能,要求对长度为n的字符串操作的时间复杂度为 O(n),空间复杂度为 O(1)。
3 | ###解法一:暴力移位法
4 | ```php
5 | function move(&$str , $n){
6 | for ($i = 0; $i<$n; $i++){
7 | LeftShiftOne($str);
8 | }
9 | }
10 |
11 | function LeftShiftOne(&$str){
12 | $len = strlen($str);
13 | $last = $str[$len - 1];
14 | for ($i = 0; $i<$len-1; $i++){
15 | $str[$i - 1] =$str[$i];
16 | }
17 | $str[$len-2] = $last;
18 | }
19 | $str = "abcd";
20 | move($str, 4);
21 |
22 | ```
23 | 时间复杂度为O(m n),空间复杂度为O(1),空间复杂度符合题目要求,但时间复杂度不符合,所以,我们得需要寻找其他更好的办法来降低时间复杂度。
24 | ###解法二:三步反转法
25 | 对于这个问题,换一个角度思考一下。
26 | 将一个字符串分成X和Y两个部分,在每部分字符串上定义反转操作,如X^T,即把X的所有字符反转(如,X="abc",那么X^T="cba"),那么就得到下面的结论:(X^TY^T)^T=YX,显然就解决了字符串的反转问题。
27 | 例如,字符串 abcdef ,若要让def翻转到abc的前头,只要按照下述3个步骤操作即可:
28 | - 首先将原字符串分为两个部分,即X:abc,Y:def;
29 | - 将X反转,X->X^T,即得:abc->cba;将Y反转,Y->Y^T,即得:def->fed。
30 | - 反转上述步骤得到的结果字符串X^TY^T,即反转字符串cbafed的两部分(cba和fed)给予反转,cbafed得到defabc,形式化表示为(X^TY^T)^T=YX,这就实现了整个反转。
31 | ```php
32 |
33 | /**
34 | * 旋转字符串
35 | * @param $str
36 | * @param $start
37 | * @param $end
38 | */
39 | function ReverseString(&$str, $start, $end){
40 | while($start < $end){
41 | $t = $str[$start];
42 | $str[$start++] = $str[$end];
43 | $str[$end--] = $t;
44 | }
45 | }
46 |
47 |
48 | /**
49 | * @param $str
50 | * @param $n 字符串长度
51 | * @param $m 移动位数
52 | */
53 | function LeftRotateString(&$str, $n, $m){
54 | $m %= $n;
55 | ReverseString($str, 0, $m-1);
56 | ReverseString($str, $m, $n-1);
57 | ReverseString($str, 0, $n-1);
58 |
59 | }
60 |
61 | $str = "abcd";
62 | LeftRotateString($str, strlen($str), 1);
63 | ```
64 |
65 | 这就是把字符串分为两个部分,先各自反转再整体反转的方法,时间复杂度为O(n),空间复杂度为O(1),达到了题目的要求。
--------------------------------------------------------------------------------
/数据结构/散列表.md:
--------------------------------------------------------------------------------
1 | ## 数据结构之散列表
2 | #### php-leetcode之路 [Leetcode-php](https://github.com/wuqinqiang/leetcode-php)
3 |
4 |
110 |
111 |
112 |
113 |
114 |
115 |
116 |
--------------------------------------------------------------------------------
/数据结构/字符串.md:
--------------------------------------------------------------------------------
1 | ##旋转字符串
2 | 给定一个字符串,要求把字符串前面的若干个字符移动到字符串的尾部,如把字符串“abcdef”前面的2个字符'a'和'b'移动到字符串的尾部,使得原字符串变成字符串“cdefab”。请写一个函数完成此功能,要求对长度为n的字符串操作的时间复杂度为 O(n),空间复杂度为 O(1)。
3 | ###解法一:暴力移位法
4 | ```php
5 | function move(&$str , $n){
6 | for ($i = 0; $i<$n; $i++){
7 | LeftShiftOne($str);
8 | }
9 | }
10 |
11 | function LeftShiftOne(&$str){
12 | $len = strlen($str);
13 | $last = $str[$len - 1];
14 | for ($i = 0; $i<$len-1; $i++){
15 | $str[$i - 1] =$str[$i];
16 | }
17 | $str[$len-2] = $last;
18 | }
19 | $str = "abcd";
20 | move($str, 4);
21 |
22 | ```
23 | 时间复杂度为O(m n),空间复杂度为O(1),空间复杂度符合题目要求,但时间复杂度不符合,所以,我们得需要寻找其他更好的办法来降低时间复杂度。
24 | ###解法二:三步反转法
25 | 对于这个问题,换一个角度思考一下。
26 | 将一个字符串分成X和Y两个部分,在每部分字符串上定义反转操作,如X^T,即把X的所有字符反转(如,X="abc",那么X^T="cba"),那么就得到下面的结论:(X^TY^T)^T=YX,显然就解决了字符串的反转问题。
27 | 例如,字符串 abcdef ,若要让def翻转到abc的前头,只要按照下述3个步骤操作即可:
28 | - 首先将原字符串分为两个部分,即X:abc,Y:def;
29 | - 将X反转,X->X^T,即得:abc->cba;将Y反转,Y->Y^T,即得:def->fed。
30 | - 反转上述步骤得到的结果字符串X^TY^T,即反转字符串cbafed的两部分(cba和fed)给予反转,cbafed得到defabc,形式化表示为(X^TY^T)^T=YX,这就实现了整个反转。
31 | ```php
32 |
33 | /**
34 | * 旋转字符串
35 | * @param $str
36 | * @param $start
37 | * @param $end
38 | */
39 | function ReverseString(&$str, $start, $end){
40 | while($start < $end){
41 | $t = $str[$start];
42 | $str[$start++] = $str[$end];
43 | $str[$end--] = $t;
44 | }
45 | }
46 |
47 |
48 | /**
49 | * @param $str
50 | * @param $n 字符串长度
51 | * @param $m 移动位数
52 | */
53 | function LeftRotateString(&$str, $n, $m){
54 | $m %= $n;
55 | ReverseString($str, 0, $m-1);
56 | ReverseString($str, $m, $n-1);
57 | ReverseString($str, 0, $n-1);
58 |
59 | }
60 |
61 | $str = "abcd";
62 | LeftRotateString($str, strlen($str), 1);
63 | ```
64 |
65 | 这就是把字符串分为两个部分,先各自反转再整体反转的方法,时间复杂度为O(n),空间复杂度为O(1),达到了题目的要求。
--------------------------------------------------------------------------------
/数据结构/散列表.md:
--------------------------------------------------------------------------------
1 | ## 数据结构之散列表
2 | #### php-leetcode之路 [Leetcode-php](https://github.com/wuqinqiang/leetcode-php)
3 |
4 |  5 |
6 |
7 | ### :pencil2:一.散列表的介绍
8 | **散列表也叫哈希表,在前面的各种数据结构中(数组,链表,树等),记录在结构中的相对位置是随机的,和记录的关键字不存在确定的关系。在顺序结构中,顺序查找,比较的结果是'='或者'!=',在二分查找,二叉排序树比较的关系是'>','=‘,’<‘,查找的效率依赖于查找过程中比较的次数。**
9 | **什么样的方法能使得理想情况下不需要进行任何比较,通过一次存储就能得到所查的记录。答案就是记录存储位置和关键字之间的对应关系。**
10 |
11 |
12 |
5 |
6 |
7 | ### :pencil2:一.散列表的介绍
8 | **散列表也叫哈希表,在前面的各种数据结构中(数组,链表,树等),记录在结构中的相对位置是随机的,和记录的关键字不存在确定的关系。在顺序结构中,顺序查找,比较的结果是'='或者'!=',在二分查找,二叉排序树比较的关系是'>','=‘,’<‘,查找的效率依赖于查找过程中比较的次数。**
9 | **什么样的方法能使得理想情况下不需要进行任何比较,通过一次存储就能得到所查的记录。答案就是记录存储位置和关键字之间的对应关系。**
10 |
11 |
12 |  13 |
14 |
15 | **我们记录了存储位置和关键字的对应关系h,因此在查找的过程中,只要根据对应关系h找到给定值k的像h(k),如果结构中存在关建字和k相等的记录,那么肯定是存储在h(k)的位置上,就像上图k1..k5的一样,我们称这个对应关系h为散列函数或者是哈希函数。**
16 | ****
17 | **从上面的例子可以看出:**
18 |
19 | **1.散列函数是一个映像,因此设定散列函数可以非常灵活。**
20 |
21 | **2.从图中可以看出,k2 != k5 ,但是h(k2)===h(k5),这就是散列冲突。**
22 |
23 | ### :pencil2:二.散列冲突
24 |
25 |
26 |
13 |
14 |
15 | **我们记录了存储位置和关键字的对应关系h,因此在查找的过程中,只要根据对应关系h找到给定值k的像h(k),如果结构中存在关建字和k相等的记录,那么肯定是存储在h(k)的位置上,就像上图k1..k5的一样,我们称这个对应关系h为散列函数或者是哈希函数。**
16 | ****
17 | **从上面的例子可以看出:**
18 |
19 | **1.散列函数是一个映像,因此设定散列函数可以非常灵活。**
20 |
21 | **2.从图中可以看出,k2 != k5 ,但是h(k2)===h(k5),这就是散列冲突。**
22 |
23 | ### :pencil2:二.散列冲突
24 |
25 |
26 |  27 |
28 |
29 | **我们看当前例子,关键字 John Smith !=Sandra Dee,但是通过散列函数之后h(John Smith)===h(Sandra Dee),他们的位置都在散列表01这个位置,但是这个位置只能存储一个记录,那多出来的记录存放在哪里?**
30 |
31 | **正因为散列函数是一个映像,我们在构造散列函数的时候,只能去分析关键字的特性,选择一个恰当的散列函数来避免冲突的发生。一般情况下,冲突只能尽可能的减少,而不能完全避免。**
32 |
33 | ### :pencil2:三.散列函数的构造
34 | **先来看看什么是好的散列函数。如果对于关键字集合中任意一个,经过散列函数映射到地址集合中任何一个位置的概率都是相等的,就可以称为均匀散列函数。**
35 |
36 | **1.直接定址法**
37 |
38 | **取关键字或者关键字的某个线性函数值为哈希地址。**
39 |
40 | **h(key)=key或者h(key)=a*key+b a,b为常量。比如说做一个地区年龄段的人数统计,我们就可以把年龄1-100作为关键字,现在你要查38岁的人口数时只需要h(38)=???。**
41 | ****
42 |
43 | **2.数字分析法**
44 |
45 | **要通过具体的数字分析,找出关键字集合的特点和关系,通过这组关系构造一个散列函数。**
46 | ****
47 | **3.平方取中法**
48 |
49 | **取关键字平方后的中间几位为哈希地址,因为一般情况下,选定哈希函数时并不一定知道关键字的全部情况,取哪几位也不一定合适,而一个平方后的中间几位数和数的每一位都有关,由此使随机分布的关键字得到的哈希地址也是随机的。**
50 | ****
51 | **4.折叠法**
52 |
53 | **将关键字分割成位数相同的几部分,然后取这几部分的叠加和,也就是舍去它的进位,作为他的哈希地址。**
54 | ****
55 | **5.除留余数法**
56 | **取关键字被某个不大于散列表表长m的数(暂且称之为p)除后所得余数为哈希地址。**
57 | ```php
58 | h(key)=key MOD p, p<=m
59 | ```
60 | **以上都偏于理论,具体的使用需要视情况而定,通常,考虑的因素有以下几点**
61 |
62 | **1.计算散列函数所需的时间**
63 |
64 | **2.关键字的长度**
65 |
66 | **3.哈希表的大小**
67 |
68 | **4.关键字的分布情况**
69 |
70 | **5.记录查找的频率**
71 |
72 | ### :pencil2:四.处理冲突
73 | **之前说过,散列函数可以减少冲突,但是不能避免,这时候我们就需要处理冲突。**
74 |
75 | **1.开放寻址法**
76 |
77 | **简单的来说,下图中当前哈希表的长度是8,现在已填入关键字1,9,3,4,5的记录,假如当前我们需要再填入关键字10这条记录。通过散列函数得出h(3)===h(10),但是此时哈希地址2已被3占领。现在我们咋么处理?**
78 |
79 | **线性探测再散列得到下一个地址3,发现3也被占领,再求下一个地址4,还被占领,直到5这个位置时,处理冲突过程结束,把当前h(10)记录在地址为5的位置即可。也可以使用二次探测再散列或者伪随机再散列都是属于开放寻址法。**
80 |
81 |
82 |
27 |
28 |
29 | **我们看当前例子,关键字 John Smith !=Sandra Dee,但是通过散列函数之后h(John Smith)===h(Sandra Dee),他们的位置都在散列表01这个位置,但是这个位置只能存储一个记录,那多出来的记录存放在哪里?**
30 |
31 | **正因为散列函数是一个映像,我们在构造散列函数的时候,只能去分析关键字的特性,选择一个恰当的散列函数来避免冲突的发生。一般情况下,冲突只能尽可能的减少,而不能完全避免。**
32 |
33 | ### :pencil2:三.散列函数的构造
34 | **先来看看什么是好的散列函数。如果对于关键字集合中任意一个,经过散列函数映射到地址集合中任何一个位置的概率都是相等的,就可以称为均匀散列函数。**
35 |
36 | **1.直接定址法**
37 |
38 | **取关键字或者关键字的某个线性函数值为哈希地址。**
39 |
40 | **h(key)=key或者h(key)=a*key+b a,b为常量。比如说做一个地区年龄段的人数统计,我们就可以把年龄1-100作为关键字,现在你要查38岁的人口数时只需要h(38)=???。**
41 | ****
42 |
43 | **2.数字分析法**
44 |
45 | **要通过具体的数字分析,找出关键字集合的特点和关系,通过这组关系构造一个散列函数。**
46 | ****
47 | **3.平方取中法**
48 |
49 | **取关键字平方后的中间几位为哈希地址,因为一般情况下,选定哈希函数时并不一定知道关键字的全部情况,取哪几位也不一定合适,而一个平方后的中间几位数和数的每一位都有关,由此使随机分布的关键字得到的哈希地址也是随机的。**
50 | ****
51 | **4.折叠法**
52 |
53 | **将关键字分割成位数相同的几部分,然后取这几部分的叠加和,也就是舍去它的进位,作为他的哈希地址。**
54 | ****
55 | **5.除留余数法**
56 | **取关键字被某个不大于散列表表长m的数(暂且称之为p)除后所得余数为哈希地址。**
57 | ```php
58 | h(key)=key MOD p, p<=m
59 | ```
60 | **以上都偏于理论,具体的使用需要视情况而定,通常,考虑的因素有以下几点**
61 |
62 | **1.计算散列函数所需的时间**
63 |
64 | **2.关键字的长度**
65 |
66 | **3.哈希表的大小**
67 |
68 | **4.关键字的分布情况**
69 |
70 | **5.记录查找的频率**
71 |
72 | ### :pencil2:四.处理冲突
73 | **之前说过,散列函数可以减少冲突,但是不能避免,这时候我们就需要处理冲突。**
74 |
75 | **1.开放寻址法**
76 |
77 | **简单的来说,下图中当前哈希表的长度是8,现在已填入关键字1,9,3,4,5的记录,假如当前我们需要再填入关键字10这条记录。通过散列函数得出h(3)===h(10),但是此时哈希地址2已被3占领。现在我们咋么处理?**
78 |
79 | **线性探测再散列得到下一个地址3,发现3也被占领,再求下一个地址4,还被占领,直到5这个位置时,处理冲突过程结束,把当前h(10)记录在地址为5的位置即可。也可以使用二次探测再散列或者伪随机再散列都是属于开放寻址法。**
80 |
81 |
82 |  83 |
84 |
85 | ****
86 |
87 | **2.再散列法**
88 |
89 | **即在同义词产生地址冲突时计算另一个散列函数的地址,直到冲突不再发生,这种方法毋庸置疑,增加了计算的时间。**
90 | ****
91 | **3.链地址法**
92 |
93 | **将所有关键字为同义词的记录存储在同一个线性链表中。初始状态是一个空指针。凡是通过关键字计算出地址一样的记录都插入到当前位置的链表中,在链表中插入的位置可以是表头,表尾,或者表中,以保持同义词在同一个线性表中按关键字有序。**
94 |
95 |
96 |
83 |
84 |
85 | ****
86 |
87 | **2.再散列法**
88 |
89 | **即在同义词产生地址冲突时计算另一个散列函数的地址,直到冲突不再发生,这种方法毋庸置疑,增加了计算的时间。**
90 | ****
91 | **3.链地址法**
92 |
93 | **将所有关键字为同义词的记录存储在同一个线性链表中。初始状态是一个空指针。凡是通过关键字计算出地址一样的记录都插入到当前位置的链表中,在链表中插入的位置可以是表头,表尾,或者表中,以保持同义词在同一个线性表中按关键字有序。**
94 |
95 |
96 |  97 |
98 |
99 | ****
100 |
101 | **4.建立一个公共溢出区**
102 |
103 | **假设散列函数的值域为[0,m-1],则设置向量HashTable[0,m-1]为基本表,每一个分量存储一个记录,另外设置向量OverTable[0,v]为溢出表。所有关键字和基本表中关键字为同义词的记录,不管它们由哈希函数得到的哈希地址是什么,一旦发生冲突,都填入溢出表中。**
104 | ****
105 | ### 联系
106 |
107 |
108 |
109 |
110 |
111 |
112 |
113 |
114 |
115 |
--------------------------------------------------------------------------------
/数据结构/数组.md:
--------------------------------------------------------------------------------
1 | ## 数组
2 |
3 | 数组是一组包含有序元素的集合。这里的数组和PHP中的数组不一样。php的数组,是一个HashTable。
4 |
5 | 数组的特点
6 |
7 | - 元素在内存中的顺序是连续的
8 |
9 | - 数组里面的元素的数据类型都是一样的。就是一个数组不能存储两个类型
10 |
11 | - 数组的下标是整形。
12 |
13 | ```c_cpp
14 | char a[5] = "hello";
15 | ```
16 |
17 | 
18 |
19 |
20 | 数组的几种操作
21 |
22 | - find|delete 查找对应元素 时间复杂度是O(n). 根据下标查询,时间复杂度是O(1)
23 |
24 |
25 |
26 |
27 |
--------------------------------------------------------------------------------
/数据结构/链表.md:
--------------------------------------------------------------------------------
1 | ## 链表
2 |
3 | 由于数组在插入和删除操作,都需要后面的结点。内存需要预先分配,扩容不易。
4 |
5 | 所以有了链表。链表包含一个指向下一个节点的指针和一个自己data域
6 |
7 | > 链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列节点组成,这些节点不必在内存中相连。每个节点由数据部分Data和链部分Next,Next指向下一个节点,这样当添加或者删除时,只需要改变相关节点的Next的指向,效率很高。
8 |
9 | ```c_cpp
10 | struct Node {
11 | void * data;
12 | Node *next;
13 | } Node
14 | ```
15 |
16 | 头指针:指向链表链表第一个元素的指针
17 |
18 | 头结点:就是一个含有空的数据域的结点。作为标识。
19 |
20 | 链表的结构
21 |
22 | 
23 |
24 | 单链表的操作
25 |
26 | - 查找
27 |
28 | 查找元素的时间复杂度依然是O(n)。需要从头节点遍历。
29 |
30 | - 插入
31 |
32 | 插入一个新的元素到指定的位置,只需要改变前面元素的next指针指向该元素。不需要移动后面的元素。时间复杂度为0(n)
33 |
34 | - 删除
35 |
36 | 删除一个元素的,只需要记住这个元素的前一个元素和后面一个元素。删掉这个元素后,采用覆盖的方法,实现删除。时间复杂度为O(1)
37 |
38 | ### 双链表
39 |
40 | 双链表是包含两个两个指针域和一个data域的链表结构。这样我们可以从两个方向遍历。
41 |
42 | ```c_cpp
43 | struct doubleLink {
44 | void *data;
45 | struct doubleLink next;
46 | struct doubleLink prev;
47 | }
48 | ```
49 |
50 |
51 |
52 | ### 链表相关的面试题
53 |
54 | 链表是一种基础的数据结构,也是面试中常考的,
55 |
56 | - 判断单链表是否有环
57 |
58 | 可以使用快慢指针来。如果有环,则两个指针会相遇。
59 |
60 | - 已知两个单链表相交,求他们的第一个交点
61 |
62 | 思路:由于两个单链表相交,那么他们的尾节点一定是相同的。遍历两个链表,求出各个长度。然后求出两个链表的差N,然后让长的链表,先走N,慢的链表再同步走。当两个节点相同时。就是一个第一个交点
63 |
64 | - 快速找到未知长度单链表的中间节点
65 |
66 | 思路1:最简单的方法,遍历一次单链表,然后求出长度。然后除以2。找到位置,然后再遍历一次。时间复杂度是O((3N/2))
67 |
68 | 思路2:快慢指针,快的指针比慢指针多走一倍,然后快的指针走到尾,慢指针恰好在中间。
69 |
70 | - 约瑟夫环
71 |
72 | > 在罗马人占领乔塔帕特后,39个犹太人与Josephus及他的朋友躲到一个洞中,39个犹太人决定宁愿死也不要被敌人抓到,于是决定了一个自杀方式,41个人排成一个圆圈,由第1个人开始报数,每报数到第3人该人就必须自杀,然后再由下一个重新报数,直到所有人都自杀身亡为止。然而Josephus和他的朋友并不想遵从,Josephus要他的朋友先假装遵从,他将朋友与自己安排在第16个与第31个位置,于是逃过了这场死亡游戏。
73 |
74 | 思路:可以使用循环链表的方法。
75 |
--------------------------------------------------------------------------------
/架构和系统设计/API设计.md:
--------------------------------------------------------------------------------
1 | ## REST API
2 |
3 | REST(Representational State Transfer)表述性状态转换,**REST指的是一组架构约束条件和原则** 。
4 |
5 | 使用URL定位资源,用HTTP动词(GET,POST,PUT,DELETE)描述操作。
6 |
7 | ### 基本概念
8 |
9 | - 资源
10 |
11 | > 资源就是网络上的一个实体,一段文本,一张图片或者一首歌曲。资源总是要通过一种载体来反应它的内容。文本可以用TXT,也可以用HTML或者XML、图片可以用JPG格式或者PNG格式,JSON是现在最常用的资源表现形式。
12 |
13 | - 统一资源接口
14 |
15 | > 统一接口。RESTful风格的数据元操CRUD(create,read,update,delete)分别对应HTTP方法:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源,这样就统一了数据操作的接口。
16 |
17 | - GET 获取资源
18 | - PUT更新资源
19 | - POST 新增资源
20 | - DELETE 删除
21 |
22 | - URI
23 |
24 | > URI。可以用一个URI(统一资源定位符)指向资源,即每个URI都对应一个特定的资源。要获取这个资源访问它的URI就可以,因此URI就成了每一个资源的地址或识别符。一般的,每个资源至少有一个URI与之对应,最典型的URI就是URL。
25 |
26 | - 无状态
27 |
28 | > 所谓无状态即所有的资源都可以URI定位,而且这个定位与其他资源无关,也不会因为其他资源的变化而变化。有状态和无状态的区别,举个例子说明一下,例如要查询员工工资的步骤为第一步:登录系统。第二步:进入查询工资的页面。第三步:搜索该员工。第四步:点击姓名查看工资。这样的操作流程就是有状态的,查询工资的每一个步骤都依赖于前一个步骤,只要前置操作不成功,后续操作就无法执行。如果输入一个URL就可以得到指定员工的工资,则这种情况就是无状态的,因为获取工资不依赖于其他资源或状态,且这种情况下,员工工资是一个资源,由一个URL与之对应可以通过HTTP中的GET方法得到资源,这就是典型的RESTful风格。
29 |
30 |
31 |
32 | ### 设计风格
33 |
34 | - 协议
35 |
36 | API接口通讯,一般是通过HTTP[s]协议。
37 |
38 | - 域名
39 |
40 | 域名应单独部署到对应的域名。
41 |
42 | ```php
43 | api.github.com
44 | ```
45 |
46 | - 版本控制
47 |
48 | ```
49 | api.github.com/v1/
50 | ```
51 |
52 | - 路径规则
53 |
54 | 路径中,不要出现动词。比如getUsers。复数表示获取集合数组
55 |
56 | ```
57 | /v1/user/10 获取id为10的用户
58 | /v1/users 获取所有用户
59 | ```
60 |
61 | - HTTP请求方式表示动作
62 |
63 | - GET 表示获取资源
64 | - PUT 更新资源
65 | - POST新增资源
66 | - DELETE 删除资源
67 |
68 | ```
69 | GET /users
70 | PUT /user/10
71 | POST /user/10
72 | DELETE /user/10
73 | ```
74 |
75 | - 过滤信息
76 |
77 | 如果记录过多,可以使用分页过滤信息
78 |
79 | - ?limit=10 指定返回记录的数量
80 | - ?offset=10:指定返回记录的开始位置。
81 | - ?page=2&per_page=100:指定第几页,以及每页的记录数。
82 | - ?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序
83 | - ?producy_type=1:指定筛选条件
84 |
85 | - 异常响应
86 |
87 | 当 RESTful API 接口出现非 2xx 的 HTTP 错误码响应时,采用全局的异常结构响应信息。
88 |
89 |
--------------------------------------------------------------------------------
/架构和系统设计/README.md:
--------------------------------------------------------------------------------
1 | ## 架构和设计
2 |
3 | 架构和设计是面试中经常用到的,一是考察你的知识面,而是考察你接触的系统的复杂程序。本文可能介绍一些相关的问题。
4 |
5 | ### 1. 数据库结构设计
6 |
7 | - 主从复制
8 | - 分库分表
9 | - 双主互备
10 | - 数据库中间件
11 |
12 |
13 |
14 | 为了解决单表数据过多,一般会采取分片【分库分表】水平切分,分片会产生路由,上层应用要知道数据在哪一个库中。
15 |
16 | 路由规则常用的有三种方法
17 |
18 | - range 范围
19 |
20 | - 哈希
21 | - 路由服务
22 |
23 | #### 可用性
24 |
25 | 为了解决单点的故障,一般引入**主从复制**,也就是垂直分割。
26 |
27 | 采取**双主互备**【keplived】,冗余写库,双主当主从用
28 |
29 | 解决同步冲突,有两种常见解决方案
30 |
31 | - 两个写库设置不同的初始化,相同步长增加id
32 | - 业务层自己生成唯一的id,保证数据不冲突
33 |
34 | #### 一致性
35 |
36 | 主从数据库的一致性,通常有两种解决方案:
37 |
38 | - 中间件
39 |
40 | 中间件屏蔽了集群了,对外伪装成一个server。
41 |
42 | - 强制读主
43 |
44 | ### SESSION架构设计
45 |
46 | 服务器为每个用户创建一个会话,存储用户的相关信息,以便多次请求能够定位到同一个上下文。 只要用户不重启浏览器,会话就一直存在。
47 |
48 | - session同步法:多台web-server相互同步数据
49 | - 客户端存储法:一个用户只存储自己的数据
50 | - 反向代理hash一致性:四层hash和七层hash都可以做,保证一个用户的请求落在一台web-server上
51 | - 后端统一存储:web-server重启和扩容,session也不会丢失
52 |
53 | ## 缓存架构设计
54 |
55 | 淘汰缓存机制
56 |
57 | (1)淘汰缓存是一种通用的缓存处理方式
58 |
59 | (2)先**淘汰缓存,再写数据库**的时序是毋庸置疑的
60 |
61 | (3)服务化是向业务方屏蔽底层数据库与缓存复杂性的一种通用方式
62 |
63 |
64 |
65 | 设计一个缓存系统,不得不要考虑的问题就是:缓存穿透、缓存击穿与失效时的雪崩效应
66 |
67 | ### 缓存穿透
68 |
69 | 缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
70 |
71 | ### 缓存穿透解决方案
72 |
73 | 有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数 据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
74 |
75 | ### 缓存雪崩
76 |
77 | 缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
78 |
79 | ### 缓存雪崩解决方案
80 |
81 | 缓存失效时的雪崩效应对底层系统的冲击非常可怕。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线 程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。这里分享一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
82 |
83 | ### 缓存击穿
84 |
85 | 对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
86 |
87 | 缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
88 |
89 | ### 缓存击穿 解决方案
90 |
91 | #### 1.使用互斥锁(mutex key)
92 |
93 | 业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
94 |
95 | SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。在redis2.6.1之前版本未实现setnx的过期时间
96 |
97 | #### 2. "提前"使用互斥锁(mutex key):
98 |
99 | 在value内部设置1个超时值(timeout1), timeout1比实际的memcache timeout(timeout2)小。当从cache读取到timeout1发现它已经过期时候,马上延长timeout1并重新设置到cache。然后再从数据库加载数据并设置到cache中
100 |
101 | #### 3. "永远不过期":
102 |
103 | 这里的“永远不过期”包含两层意思:
104 |
105 | > (1) 从redis上看,确实没有设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。
106 | >
107 | > (2) 从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期
108 |
109 | 从实战看,这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,但是对于一般的互联网功能来说这个还是可以忍受。
110 |
111 | #### 4. 资源保护:
112 |
113 | 采用netflix的hystrix,可以做资源的隔离保护主线程池,如果把这个应用到缓存的构建也未尝不可。
114 |
115 | 四种解决方案:没有最佳只有最合适
116 |
117 | | 解决方案 | 优点 | 缺点 |
118 | | ----------------------------- | -------------------------------------------------------- | ------------------------------------------------------------ |
119 | | 简单分布式互斥锁(mutex key) | 1. 思路简单 2. 保证一致性 | 1. 代码复杂度增大 2. 存在死锁的风险 3. 存在线程池阻塞的风险 |
120 | | “提前”使用互斥锁 | 1. 保证一致性 | 同上 |
121 | | 不过期(本文) | 1. 异步构建缓存,不会阻塞线程池 | 1. 不保证一致性。 2. 代码复杂度增大(每个value都要维护一个timekey)。 3. 占用一定的内存空间(每个value都要维护一个timekey)。 |
122 | | 资源隔离组件hystrix(本文) | 1. hystrix技术成熟,有效保证后端。 2. hystrix监控强大。 | 1. 部分访问存在降级策略。 |
123 |
124 |
--------------------------------------------------------------------------------
/版本控制器/Git.md:
--------------------------------------------------------------------------------
1 | # Git
2 |
3 | - 创建git仓库
4 |
5 | 当前目录下多了一个.git的目录,这个目录是Git来跟踪管理版本库的
6 |
7 | ```
8 | git init
9 | ```
10 |
11 | - 工作区状态
12 |
13 | ```
14 | git status //查看状态
15 | git diff //比较差异
16 | ```
17 |
18 | - 版本回退
19 |
20 | HEAD指向的版本就是当前版本,因此,Git允许我们在版本的历史之间穿梭
21 | ```
22 | git log //查看提交的记录
23 | git reflog //查看命令操作的记录
24 | git reset --hard HEAD//回退到Head的工作区
25 | ```
26 |
27 | - 工作区、暂存区
28 |
29 | 工作区就是当前操作的目录。当你使用git add的时候就是把文件加到暂存区。commit之后就是把暂存区的文件提交到分支中
30 |
31 | 版本库记录着差异。
32 |
33 | 
34 |
35 | - 撤销修改
36 |
37 | 命令git checkout -- readme.txt意思就是,把readme.txt文件在工作区的修改全部撤销,这里有两种情况:
38 |
39 | 一种是readme.txt自修改后还没有被放到暂存区,现在,撤销修改就回到和版本库一模一样的状态;
40 |
41 | 一种是readme.txt已经添加到暂存区后,又作了修改,现在,撤销修改就回到添加到暂存区后的状态。
42 |
43 | 用命令
44 |
45 | ```
46 | git reset HEAD file
47 | ```
48 | 可以把暂存区的修改撤销掉(unstage),重新放回工作区。使用 HEAD表示最新的状态
49 |
50 | - 删除文件
51 |
52 |
53 | 使用git rm file 可以删除版本库中的文件
54 |
55 | ```
56 | git rm read.txt
57 |
58 | git checkout -- read.txt //从版本库中恢复
59 |
60 | ```
61 |
62 | - 远程仓库
63 |
64 | 添加远程仓库
65 |
66 | origin 是仓库名字。是git的默认的
67 | ```
68 | git remote add origin 仓库地址
69 | git remote -v 查看远程仓库
70 | git push -u origin master //将本地master和orgin分支关联。
71 | git clone 仓库地址 //clone 一个远程仓库到本地
72 | git checkout -b branch-name origin/branch-name,//本地和远程分支的名称最好一致
73 | git branch --set-upstream branch-name origin/branch-name //建立本地分支和远程分支的关联,
74 | git pull orgin master //从远程分支抓取
75 | ```
76 |
77 | ## git分支
78 |
79 | master 是git 默认的分支,也叫主分支。每一次提交在分支上形成了一个时间线。HEAD指向该分支
80 |
81 | 
82 |
83 | - 创建分支
84 |
85 | ```
86 | git branch dev //创建分支
87 | git checkout dev //切换分支
88 | git branch //命令会列出所有分支
89 | git checkout -b dev //创建并切换到dev分支
90 | ```
91 | HEAD指针指向了dev
92 | 
93 |
94 | - 合并分支
95 |
96 | 合并某分支到当前分支:git merge
97 | ```
98 | git checkout master
99 | git merge dev
100 | ```
101 |
102 | - 删除分支
103 |
104 | ```
105 | git branch -d dev
106 | git branch -D //强行删除
107 |
108 | ```
109 |
110 | ## 工作区暂存
111 |
112 | 将工作区暂时保存起来 不提交到暂存区。
113 |
114 | ```
115 | git stash //保存工作区
116 |
117 | git stash list //查看保存的工作区
118 | git stash pop
119 | git stash apply //恢复保存的工作区
120 | git stach drop //删除保存的工作区
121 | ```
122 |
123 | ## tag标签
124 |
125 | ```
126 | git tag v1.0 //打标签
127 | git tag // 列出所有的标签
128 | git tag commit_id //给特定的commit_id打标签
129 | git tag -a v1.0 -m "tag1" //打带说明的标签
130 | ```
131 |
132 | - 操作标签
133 |
134 | - 删除标签
135 |
136 | ```
137 | git tag -d v1.0
138 | ```
139 | - 推送标签到远程分支
140 |
141 | ```
142 | git push orgin v1.0
143 | git push origin --tags// 推送所有的标签到远程分支
144 | git push origin :refs/tags/v0.9 //删除远程分支的标签
145 | ```
146 | ### 配置git
147 |
148 | 初次使用 需要配置自己的信息,
149 |
150 | ```
151 | git config --global user.name "John Doe"
152 | git config --global user.email johndoe@example.com
153 | ```
154 |
155 |
156 | - 配置忽略文件
157 |
158 | .gitignore文件本身要放到版本库里,并且可以对.gitignore做版本管理!
159 |
160 | 忽略文件的原则是:
161 |
162 | 1. 忽略操作系统自动生成的文件,比如缩略图等;
163 | 2. 、可执行文件等,也就是如果一个文件是通过另一个文件自动生成的,那自动生成的文件就没必要放进版本库,比如Java编译产生的.class文件
164 |
165 | 3. 忽略你自己的带有敏感信息的配置文件,比如存放口令的配置文件。
166 |
167 |
168 | - 设置别名
169 |
170 | 别名就是把一些复杂的命令简化 类似svn co等之类的
171 |
172 | ```shell
173 | git config --global alias.co checkout
174 | git config --global alias.ci commit
175 | git config --global alias.br branch
176 | git config --global alias.unstage 'reset HEAD'
177 | git config --global alias.last 'log -1'
178 | git config --global alias.lg "log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit"
179 | ```
180 |
181 | - 当前项目配置
182 |
183 | 每个仓库的Git配置文件都放在.git/config文件中:
184 |
185 | ```ini
186 | [core]
187 | repositoryformatversion = 0
188 | filemode = true
189 | bare = false
190 | logallrefupdates = true
191 | ignorecase = true
192 | precomposeunicode = true
193 | [remote "origin"]
194 | url = git@github.com:xianyunyh/PHP-Interview
195 | fetch = +refs/heads/*:refs/remotes/origin/*
196 | [branch "master"]
197 | remote = origin
198 | merge = refs/heads/master
199 | [alias]
200 | last = log -1
201 | ```
202 |
203 | 当前用户的Git配置文件放在用户主目录下的一个隐藏文件.gitconfig中
204 |
205 | ```ini
206 | [alias]
207 | co = checkout
208 | ci = commit
209 | br = branch
210 | st = status
211 | [user]
212 | name = Your Name
213 | email = your@email.com
214 | ```
215 |
--------------------------------------------------------------------------------
/版本控制器/Git_removeCommits.md:
--------------------------------------------------------------------------------
1 | 在 Git 开发中通常会控制主干分支的质量,但有时还是会把错误的代码合入到远程主干。 虽然可以 直接回滚远程分支](https://harttle.land/2018/03/12/reset-origin-without-force-push.html), 但有时新的代码也已经合入,直接回滚后最近的提交都要重新操作。 那么有没有只移除某些 Commit 的方式呢?可以一次 [revert](https://git-scm.com/docs/git-revert) 操作来完成。
2 |
3 | # 一个例子
4 |
5 | 考虑这个例子,我们提交了 6 个版本,其中 3-4 包含了错误的代码需要被回滚掉。 同时希望不影响到后续的 5-6。
6 |
7 | ```
8 | * 982d4f6 (HEAD -> master) version 6
9 | * 54cc9dc version 5
10 | * 551c408 version 4, harttle screwed it up again
11 | * 7e345c9 version 3, harttle screwed it up
12 | * f7742cd version 2
13 | * 6c4db3f version 1
14 | ```
15 |
16 | 这种情况在团队协作的开发中会很常见:可能是流程或认为原因不小心合入了错误的代码, 也可能是合入一段时间后才发现存在问题。 总之已经存在后续提交,使得直接回滚不太现实。
17 |
18 | 下面的部分就开始介绍具体操作了,同时我们假设远程分支是受保护的(不允许 Force Push)。 思路是从产生一个新的 Commit 撤销之前的错误提交。
19 |
20 | # git revert
21 |
22 | 使用 `git revert ` 可以撤销指定的提交, 要撤销一串提交可以用 `..` 语法。 注意这是一个前开后闭区间,即不包括 commit1,但包括 commit2。
23 |
24 | ```
25 | git revert --no-commit f7742cd..551c408
26 | git commit -a -m 'This reverts commit 7e345c9 and 551c408'
27 | ```
28 |
29 | 其中 `f7742cd` 是 version 2,`551c408` 是 version 4,这样被移除的是 version 3 和 version 4。 注意 revert 命令会对每个撤销的 commit 进行一次提交,`--no-commit` 后可以最后一起手动提交。
30 |
31 | 此时 Git 记录是这样的:
32 |
33 | ```
34 | * 8fef80a (HEAD -> master) This reverts commit 7e345c9 and 551c408
35 | * 982d4f6 version 6
36 | * 54cc9dc version 5
37 | * 551c408 version 4, harttle screwed it up again
38 | * 7e345c9 version 3, harttle screwed it up
39 | * f7742cd version 2
40 | * 6c4db3f version 1
41 | ```
42 |
43 | 现在的 HEAD(`8fef80a`)就是我们想要的版本,把它 Push 到远程即可。
44 |
45 | # 确认 diff
46 |
47 | 如果你像不确定是否符合预期,毕竟批量干掉了别人一堆 Commit,可以做一下 diff 来确认。 首先产生 version 4(`551c408`)与 version 6(`982d4f6`)的 diff,这些是我们想要保留的:
48 |
49 | ```
50 | git diff 551c408..982d4f6
51 | ```
52 |
53 | 然后再产生 version 2(`f7742cd`)与当前状态(HEAD)的 diff:
54 |
55 | ```
56 | git diff f7742cd..HEAD
57 | ```
58 |
59 | 如果 version 3, version 4 都被 version 6 撤销的话,上述两个 diff 为空。 可以人工确认一下,或者 grep 掉 description 之后做一次 diff。 下面介绍的另一种方法可以容易地确认 diff。
60 |
61 | # 另外一种方式
62 |
63 | 类似 [安全回滚远程分支](https://harttle.land/2018/03/12/reset-origin-without-force-push.html), 我们先回到 version 2,让它合并 version 4 同时代码不变, 再合并 version 5, version 6。
64 |
65 | ```
66 | # 从 version 2 切分支出来
67 | git checkout -b fixing f7742cd
68 | # 合并 version 4,保持代码不变
69 | git merge -s ours 551c408
70 | # 合并 version 5, version 6
71 | git merge master
72 | ```
73 |
74 | 上述分支操作可以从 [分支管理](https://harttle.land/2016/09/02/git-workflow-branch.html) 一文了解。 至此,`fixing` 分支已经移除了 version 3 和 version 4 的代码,图示如下:
75 |
76 | ```
77 | * 3cb9f8a (HEAD -> v2) Merge branch 'master' into v2
78 | |\
79 | | * 982d4f6 (master) version 6
80 | | * 54cc9dc version 5
81 | * | c669557 Merge commit '551c408' into v2
82 | |\ \
83 | | |/
84 | | * 551c408 version 4, harttle screwed it up again
85 | | * 7e345c9 version 3, harttle screwed it up
86 | |/
87 | * f7742cd version 2
88 | * 6c4db3f version 1
89 | ```
90 |
91 | 可以简单 diff 一下来确认效果:
92 |
93 | ```
94 | # 第一次 merge 结果与 version 2 的 diff,应为空
95 | git diff f7742cd..c669557
96 | # 第二次 merge 的内容,应包含 version 5 和 version 6 的改动
97 | git diff c669557..3cb9f8a
98 | ```
99 |
100 | 现在的 `HEAD`(即 `fixing` 分支)就是我们想要的版本,可以把它 Push 到远程了。 注意由于现在处于 `fixing` 分支, 需要 [Push 时指定远程分支](https://harttle.land/2016/09/05/git-workflow-remote.html) 为 `master`。
101 |
--------------------------------------------------------------------------------
/版本控制器/REAME.md:
--------------------------------------------------------------------------------
1 | Git是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。
2 |
3 | Git 是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。
4 |
5 | Git 与常用的版本控制工具 CVS, Subversion 等不同,它采用了分布式版本库的方式,不必服务器端软件支持。
6 |
7 | - [快速入门](https://github.com/xianyunyh/PHP-Interview/blob/master/%E7%89%88%E6%9C%AC%E6%8E%A7%E5%88%B6%E5%99%A8/Git.md)
8 |
9 | ## Git 与 SVN 区别
10 |
11 | GIT不仅仅是个版本控制系统,它也是个内容管理系统(CMS),工作管理系统等。
12 |
13 | 如果你是一个具有使用SVN背景的人,你需要做一定的思想转换,来适应GIT提供的一些概念和特征。
14 |
15 | Git 与 SVN 区别点:
16 |
17 | - 1、GIT是分布式的,SVN不是:这是GIT和其它非分布式的版本控制系统,例如SVN,CVS等,最核心的区别。
18 | - 2、GIT把内容按元数据方式存储,而SVN是按文件:所有的资源控制系统都是把文件的元信息隐藏在一个类似.svn,.cvs等的文件夹里。
19 | - 3、GIT分支和SVN的分支不同:分支在SVN中一点不特别,就是版本库中的另外的一个目录。
20 | - 4、GIT没有一个全局的版本号,而SVN有:目前为止这是跟SVN相比GIT缺少的最大的一个特征。
21 | - 5、GIT的内容完整性要优于SVN:GIT的内容存储使用的是SHA-1哈希算法。这能确保代码内容的完整性,确保在遇到磁盘故障和网络问题时降低对版本库的破坏。
22 |
23 |
24 |
25 |
26 | **git学习资料**
27 |
28 | - [廖雪峰的git教程](https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000)
29 | - [猴子都能看懂的git教程](https://backlog.com/git-tutorial/cn/)
30 | - [高质量的git教程](https://github.com/geeeeeeeeek/git-recipes/wiki)
--------------------------------------------------------------------------------
/版本控制器/gitcheat.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/版本控制器/gitcheat.jpg
--------------------------------------------------------------------------------
/算法/Readme.md:
--------------------------------------------------------------------------------
1 | ## 算法
2 |
3 | > 算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。如果一个算法有缺陷,或不适合于某个问题,执行这个算法将不会解决这个问题。不同的算法可能用不同的时间、空间或效率来完成同样的任务。一个算法的优劣可以用空间复杂度与时间复杂度来衡量。
4 |
5 | ### 算法的特征
6 |
7 | - 有穷性
8 |
9 | 算法的有穷性是指算法必须能在执行有限个步骤之后终止;
10 |
11 | - 确定性
12 |
13 | 算法的每一步骤必须有确切的定义;
14 |
15 | - 输入
16 |
17 | 一个算法有0个或多个输入
18 |
19 | - 输出
20 |
21 | 一个算法有一个或多个输出,以反映对输入数据加工后的结果
22 |
23 | - 可行性
24 |
25 | 算法中执行的任何计算步骤都是可以被分解为基本的可执行的操作步
26 |
27 | ### 时间复杂度
28 |
29 | 时间复杂度是执行算法所需要的工作量,一般来说,计算机算法是问题规模n 的函数f(n),算法的时间复杂度也因此记做。
30 |
31 | `T(n)=Ο(f(n))`
32 |
33 | 因此,问题的规模n 越大,算法执行的时间的增长率与f(n) 的增长率正相关
34 |
35 | ### 空间复杂度
36 |
37 | 算法的空间复杂度是指算法需要消耗的内存空间。其计算和表示方法与时间 复杂度类似。
38 |
39 | 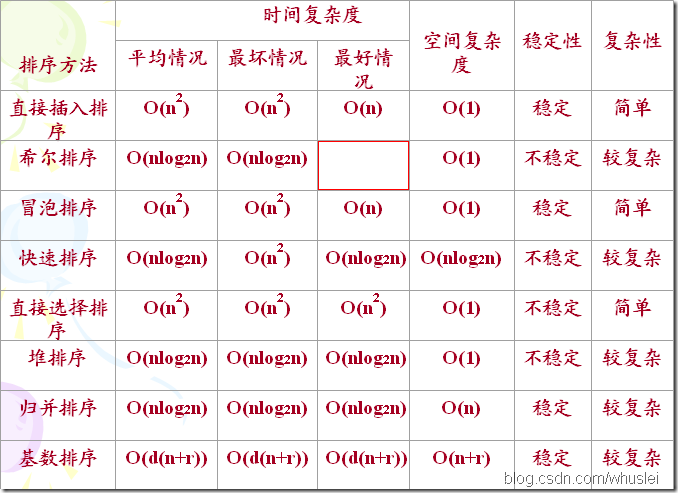
40 |
41 | ### 常见算法
42 |
43 | #### 排序算法
44 |
45 | - [冒泡排序](https://github.com/xianyunyh/arithmetic-php/blob/master/package/Sort/BubbleSort.php)
46 |
47 | ```php
48 | function BubbleSort(array $container)
49 | {
50 | $count = count($container);
51 | for ($j = 1; $j < $count; $j++) {
52 | for ($i = 0; $i < $count - $j; $i++) {
53 | if ($container[$i] > $container[$i + 1]) {
54 | $temp = $container[$i];
55 | $container[$i] = $container[$i + 1];
56 | $container[$i + 1] = $temp;
57 | }
58 | }
59 | }
60 | return $container;
61 | }
62 | ```
63 | - [插入排序](https://github.com/xianyunyh/arithmetic-php/blob/master/package/Sort/InsertSort.php)
64 |
65 | ```php
66 | function InsertSort(array $container)
67 | {
68 | $count = count($container);
69 | for ($i = 1; $i < $count; $i++){
70 | $temp = $container[$i];
71 | $j = $i - 1;
72 | // Init
73 | while($j >= 0 && $container[$j] > $temp){
74 | $container[$j+1] = $container[$j];
75 | $j--;
76 | }
77 | if($i != $j+1)
78 | $container[$j+1] = $temp;
79 | }
80 | return $container;
81 | }
82 | ```
83 |
84 | - [希尔排序](https://github.com/xianyunyh/arithmetic-php/blob/master/package/Sort/ShellSort.php)
85 |
86 | ```php
87 | function ShellSort(array $container)
88 | {
89 | $count = count($container);
90 | for ($increment = intval($count / 2); $increment > 0; $increment = intval($increment / 2)) {
91 | for ($i = $increment; $i < $count; $i++) {
92 | $temp = $container[$i];
93 | for ($j = $i; $j >= $increment; $j -= $increment) {
94 | if ($temp < $container[$j - $increment]) {
95 | $container[$j] = $container[$j - $increment];
96 | } else {
97 | break;
98 | }
99 | }
100 | $container[$j] = $temp;
101 | }
102 | }
103 | return $container;
104 | }
105 | ```
106 |
107 |
108 |
109 | - [选择排序](https://github.com/xianyunyh/arithmetic-php/blob/master/package/Sort/SelectSort.php)
110 |
111 | ```php
112 | function SelectSort(array $container)
113 | {
114 | $count = count($container);
115 | for ($i = 0; $i < $count; $i++){
116 | $k = $i;
117 | for ($j = $i + 1; $j < $count; $j++){
118 | if($container[$j] < $container[$k]){
119 | $k = $j;
120 | }
121 | }
122 | if($k != $i){
123 | $temp = $container[$i];
124 | $container[$i] = $container[$k];
125 | $container[$k] = $temp;
126 | }
127 | }
128 | return $container;
129 | }
130 | ```
131 |
132 | - [快速排序](https://github.com/xianyunyh/arithmetic-php/blob/master/package/Sort/QuickSort.php)
133 |
134 | > 快速排序(Quicksort)是对冒泡排序的一种改进。他的基本思想是:通过一趟排序将待排记录分割成独立的两部分,其中一部分的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行快速排序,整个排序过程可以递归进行,以达到整个序列有序的目的。
135 |
136 | ```php
137 | function QuickSort(&$arr,$low,$high)
138 | {
139 | if ($low < $high) {
140 | $middle = getMiddle($arr,$low,$high);
141 | QuickSort($arr,$low,$middle-1);
142 | QuickSort($arr,$middle+1,$high);
143 | }
144 | }
145 |
146 | function getMiddle (&$arr,$low,$high)
147 | {
148 | $temp = $arr[$low];
149 | while ($low < $high) {
150 | while($low < $high && $temp <= $arr[$high]) {
151 | $high --;
152 | }
153 | $arr[$low] = $arr[$high];
154 | while ($low < $high && $temp >= $arr[$low]) {
155 | $low ++;
156 | }
157 | $arr[$high] = $arr[$low];
158 | }
159 | $arr[$low] = $temp;
160 | return $low;
161 | }
162 | ```
163 |
164 | - 归并排序
165 | - 堆排序
166 |
167 | #### 查找算法
168 |
169 | - 顺序查找
170 |
171 | ```php
172 | function find($array ,$target) {
173 | foreach ($array as $key=>$value) {
174 | if($value === $target) {
175 | return key;
176 | }
177 | }
178 | return false;
179 | }
180 | ```
181 |
182 | - 有序查找(二分查找)
183 |
184 | ```php
185 | function BinaryQueryRecursive(array $container, $search, $low = 0, $top = 'default')
186 | {
187 | $top == 'default' && $top = count($container);
188 | if ($low <= $top) {
189 | $mid = intval(floor($low + $top) / 2);
190 | if (!isset($container[$mid])) {
191 | return false;
192 | }
193 | if ($container[$mid] == $search) {
194 | return $mid;
195 | }
196 | if ($container[$mid] < $search) {
197 | return BinaryQueryRecursive($container, $search, $mid + 1, $top);
198 | } else {
199 | return BinaryQueryRecursive($container, $search, $low, $mid - 1);
200 | }
201 | }
202 | }
203 | ```
204 |
205 | - 动态查找(BST)
206 | - 哈希表 O(1)
207 |
208 | ### 算法的思想
209 |
210 | - 迭代
211 | - 递归
212 | - 动态规划
213 | - 回溯
214 | - 分治
215 | - 贪心
216 |
217 | ### 算法相关的面试题
218 |
219 | - 字符串
220 |
221 | - 查找字符串中的字符
222 | - 翻转字符串
223 |
224 | - 排序
225 |
226 | - 冒泡排序
227 | - 快速排序
228 | - 归并排序
229 |
230 | - 链表
231 |
232 | - 翻转链表
233 | - 链表有没有环
234 |
235 | - 二叉搜索树
236 |
237 | - 二叉树的深度
238 | - 二叉树的遍历
239 | - 重建二叉树
240 |
241 |
242 |
243 |
244 |
--------------------------------------------------------------------------------
/算法/二分查找.md:
--------------------------------------------------------------------------------
1 | ## :算法之排序二分查找
2 | ### php-leetcode之路 [Leetcode-php](https://github.com/wuqinqiang/leetcode-php)
3 |
4 | ### :pencil2:二分查找
5 |
6 |
7 |
97 |
98 |
99 | ****
100 |
101 | **4.建立一个公共溢出区**
102 |
103 | **假设散列函数的值域为[0,m-1],则设置向量HashTable[0,m-1]为基本表,每一个分量存储一个记录,另外设置向量OverTable[0,v]为溢出表。所有关键字和基本表中关键字为同义词的记录,不管它们由哈希函数得到的哈希地址是什么,一旦发生冲突,都填入溢出表中。**
104 | ****
105 | ### 联系
106 |
107 |
108 |
109 |
110 |
111 |
112 |
113 |
114 |
115 |
--------------------------------------------------------------------------------
/数据结构/数组.md:
--------------------------------------------------------------------------------
1 | ## 数组
2 |
3 | 数组是一组包含有序元素的集合。这里的数组和PHP中的数组不一样。php的数组,是一个HashTable。
4 |
5 | 数组的特点
6 |
7 | - 元素在内存中的顺序是连续的
8 |
9 | - 数组里面的元素的数据类型都是一样的。就是一个数组不能存储两个类型
10 |
11 | - 数组的下标是整形。
12 |
13 | ```c_cpp
14 | char a[5] = "hello";
15 | ```
16 |
17 | 
18 |
19 |
20 | 数组的几种操作
21 |
22 | - find|delete 查找对应元素 时间复杂度是O(n). 根据下标查询,时间复杂度是O(1)
23 |
24 |
25 |
26 |
27 |
--------------------------------------------------------------------------------
/数据结构/链表.md:
--------------------------------------------------------------------------------
1 | ## 链表
2 |
3 | 由于数组在插入和删除操作,都需要后面的结点。内存需要预先分配,扩容不易。
4 |
5 | 所以有了链表。链表包含一个指向下一个节点的指针和一个自己data域
6 |
7 | > 链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列节点组成,这些节点不必在内存中相连。每个节点由数据部分Data和链部分Next,Next指向下一个节点,这样当添加或者删除时,只需要改变相关节点的Next的指向,效率很高。
8 |
9 | ```c_cpp
10 | struct Node {
11 | void * data;
12 | Node *next;
13 | } Node
14 | ```
15 |
16 | 头指针:指向链表链表第一个元素的指针
17 |
18 | 头结点:就是一个含有空的数据域的结点。作为标识。
19 |
20 | 链表的结构
21 |
22 | 
23 |
24 | 单链表的操作
25 |
26 | - 查找
27 |
28 | 查找元素的时间复杂度依然是O(n)。需要从头节点遍历。
29 |
30 | - 插入
31 |
32 | 插入一个新的元素到指定的位置,只需要改变前面元素的next指针指向该元素。不需要移动后面的元素。时间复杂度为0(n)
33 |
34 | - 删除
35 |
36 | 删除一个元素的,只需要记住这个元素的前一个元素和后面一个元素。删掉这个元素后,采用覆盖的方法,实现删除。时间复杂度为O(1)
37 |
38 | ### 双链表
39 |
40 | 双链表是包含两个两个指针域和一个data域的链表结构。这样我们可以从两个方向遍历。
41 |
42 | ```c_cpp
43 | struct doubleLink {
44 | void *data;
45 | struct doubleLink next;
46 | struct doubleLink prev;
47 | }
48 | ```
49 |
50 |
51 |
52 | ### 链表相关的面试题
53 |
54 | 链表是一种基础的数据结构,也是面试中常考的,
55 |
56 | - 判断单链表是否有环
57 |
58 | 可以使用快慢指针来。如果有环,则两个指针会相遇。
59 |
60 | - 已知两个单链表相交,求他们的第一个交点
61 |
62 | 思路:由于两个单链表相交,那么他们的尾节点一定是相同的。遍历两个链表,求出各个长度。然后求出两个链表的差N,然后让长的链表,先走N,慢的链表再同步走。当两个节点相同时。就是一个第一个交点
63 |
64 | - 快速找到未知长度单链表的中间节点
65 |
66 | 思路1:最简单的方法,遍历一次单链表,然后求出长度。然后除以2。找到位置,然后再遍历一次。时间复杂度是O((3N/2))
67 |
68 | 思路2:快慢指针,快的指针比慢指针多走一倍,然后快的指针走到尾,慢指针恰好在中间。
69 |
70 | - 约瑟夫环
71 |
72 | > 在罗马人占领乔塔帕特后,39个犹太人与Josephus及他的朋友躲到一个洞中,39个犹太人决定宁愿死也不要被敌人抓到,于是决定了一个自杀方式,41个人排成一个圆圈,由第1个人开始报数,每报数到第3人该人就必须自杀,然后再由下一个重新报数,直到所有人都自杀身亡为止。然而Josephus和他的朋友并不想遵从,Josephus要他的朋友先假装遵从,他将朋友与自己安排在第16个与第31个位置,于是逃过了这场死亡游戏。
73 |
74 | 思路:可以使用循环链表的方法。
75 |
--------------------------------------------------------------------------------
/架构和系统设计/API设计.md:
--------------------------------------------------------------------------------
1 | ## REST API
2 |
3 | REST(Representational State Transfer)表述性状态转换,**REST指的是一组架构约束条件和原则** 。
4 |
5 | 使用URL定位资源,用HTTP动词(GET,POST,PUT,DELETE)描述操作。
6 |
7 | ### 基本概念
8 |
9 | - 资源
10 |
11 | > 资源就是网络上的一个实体,一段文本,一张图片或者一首歌曲。资源总是要通过一种载体来反应它的内容。文本可以用TXT,也可以用HTML或者XML、图片可以用JPG格式或者PNG格式,JSON是现在最常用的资源表现形式。
12 |
13 | - 统一资源接口
14 |
15 | > 统一接口。RESTful风格的数据元操CRUD(create,read,update,delete)分别对应HTTP方法:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源,这样就统一了数据操作的接口。
16 |
17 | - GET 获取资源
18 | - PUT更新资源
19 | - POST 新增资源
20 | - DELETE 删除
21 |
22 | - URI
23 |
24 | > URI。可以用一个URI(统一资源定位符)指向资源,即每个URI都对应一个特定的资源。要获取这个资源访问它的URI就可以,因此URI就成了每一个资源的地址或识别符。一般的,每个资源至少有一个URI与之对应,最典型的URI就是URL。
25 |
26 | - 无状态
27 |
28 | > 所谓无状态即所有的资源都可以URI定位,而且这个定位与其他资源无关,也不会因为其他资源的变化而变化。有状态和无状态的区别,举个例子说明一下,例如要查询员工工资的步骤为第一步:登录系统。第二步:进入查询工资的页面。第三步:搜索该员工。第四步:点击姓名查看工资。这样的操作流程就是有状态的,查询工资的每一个步骤都依赖于前一个步骤,只要前置操作不成功,后续操作就无法执行。如果输入一个URL就可以得到指定员工的工资,则这种情况就是无状态的,因为获取工资不依赖于其他资源或状态,且这种情况下,员工工资是一个资源,由一个URL与之对应可以通过HTTP中的GET方法得到资源,这就是典型的RESTful风格。
29 |
30 |
31 |
32 | ### 设计风格
33 |
34 | - 协议
35 |
36 | API接口通讯,一般是通过HTTP[s]协议。
37 |
38 | - 域名
39 |
40 | 域名应单独部署到对应的域名。
41 |
42 | ```php
43 | api.github.com
44 | ```
45 |
46 | - 版本控制
47 |
48 | ```
49 | api.github.com/v1/
50 | ```
51 |
52 | - 路径规则
53 |
54 | 路径中,不要出现动词。比如getUsers。复数表示获取集合数组
55 |
56 | ```
57 | /v1/user/10 获取id为10的用户
58 | /v1/users 获取所有用户
59 | ```
60 |
61 | - HTTP请求方式表示动作
62 |
63 | - GET 表示获取资源
64 | - PUT 更新资源
65 | - POST新增资源
66 | - DELETE 删除资源
67 |
68 | ```
69 | GET /users
70 | PUT /user/10
71 | POST /user/10
72 | DELETE /user/10
73 | ```
74 |
75 | - 过滤信息
76 |
77 | 如果记录过多,可以使用分页过滤信息
78 |
79 | - ?limit=10 指定返回记录的数量
80 | - ?offset=10:指定返回记录的开始位置。
81 | - ?page=2&per_page=100:指定第几页,以及每页的记录数。
82 | - ?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序
83 | - ?producy_type=1:指定筛选条件
84 |
85 | - 异常响应
86 |
87 | 当 RESTful API 接口出现非 2xx 的 HTTP 错误码响应时,采用全局的异常结构响应信息。
88 |
89 |
--------------------------------------------------------------------------------
/架构和系统设计/README.md:
--------------------------------------------------------------------------------
1 | ## 架构和设计
2 |
3 | 架构和设计是面试中经常用到的,一是考察你的知识面,而是考察你接触的系统的复杂程序。本文可能介绍一些相关的问题。
4 |
5 | ### 1. 数据库结构设计
6 |
7 | - 主从复制
8 | - 分库分表
9 | - 双主互备
10 | - 数据库中间件
11 |
12 |
13 |
14 | 为了解决单表数据过多,一般会采取分片【分库分表】水平切分,分片会产生路由,上层应用要知道数据在哪一个库中。
15 |
16 | 路由规则常用的有三种方法
17 |
18 | - range 范围
19 |
20 | - 哈希
21 | - 路由服务
22 |
23 | #### 可用性
24 |
25 | 为了解决单点的故障,一般引入**主从复制**,也就是垂直分割。
26 |
27 | 采取**双主互备**【keplived】,冗余写库,双主当主从用
28 |
29 | 解决同步冲突,有两种常见解决方案
30 |
31 | - 两个写库设置不同的初始化,相同步长增加id
32 | - 业务层自己生成唯一的id,保证数据不冲突
33 |
34 | #### 一致性
35 |
36 | 主从数据库的一致性,通常有两种解决方案:
37 |
38 | - 中间件
39 |
40 | 中间件屏蔽了集群了,对外伪装成一个server。
41 |
42 | - 强制读主
43 |
44 | ### SESSION架构设计
45 |
46 | 服务器为每个用户创建一个会话,存储用户的相关信息,以便多次请求能够定位到同一个上下文。 只要用户不重启浏览器,会话就一直存在。
47 |
48 | - session同步法:多台web-server相互同步数据
49 | - 客户端存储法:一个用户只存储自己的数据
50 | - 反向代理hash一致性:四层hash和七层hash都可以做,保证一个用户的请求落在一台web-server上
51 | - 后端统一存储:web-server重启和扩容,session也不会丢失
52 |
53 | ## 缓存架构设计
54 |
55 | 淘汰缓存机制
56 |
57 | (1)淘汰缓存是一种通用的缓存处理方式
58 |
59 | (2)先**淘汰缓存,再写数据库**的时序是毋庸置疑的
60 |
61 | (3)服务化是向业务方屏蔽底层数据库与缓存复杂性的一种通用方式
62 |
63 |
64 |
65 | 设计一个缓存系统,不得不要考虑的问题就是:缓存穿透、缓存击穿与失效时的雪崩效应
66 |
67 | ### 缓存穿透
68 |
69 | 缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
70 |
71 | ### 缓存穿透解决方案
72 |
73 | 有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数 据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
74 |
75 | ### 缓存雪崩
76 |
77 | 缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
78 |
79 | ### 缓存雪崩解决方案
80 |
81 | 缓存失效时的雪崩效应对底层系统的冲击非常可怕。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线 程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。这里分享一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
82 |
83 | ### 缓存击穿
84 |
85 | 对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
86 |
87 | 缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
88 |
89 | ### 缓存击穿 解决方案
90 |
91 | #### 1.使用互斥锁(mutex key)
92 |
93 | 业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
94 |
95 | SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。在redis2.6.1之前版本未实现setnx的过期时间
96 |
97 | #### 2. "提前"使用互斥锁(mutex key):
98 |
99 | 在value内部设置1个超时值(timeout1), timeout1比实际的memcache timeout(timeout2)小。当从cache读取到timeout1发现它已经过期时候,马上延长timeout1并重新设置到cache。然后再从数据库加载数据并设置到cache中
100 |
101 | #### 3. "永远不过期":
102 |
103 | 这里的“永远不过期”包含两层意思:
104 |
105 | > (1) 从redis上看,确实没有设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。
106 | >
107 | > (2) 从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期
108 |
109 | 从实战看,这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,但是对于一般的互联网功能来说这个还是可以忍受。
110 |
111 | #### 4. 资源保护:
112 |
113 | 采用netflix的hystrix,可以做资源的隔离保护主线程池,如果把这个应用到缓存的构建也未尝不可。
114 |
115 | 四种解决方案:没有最佳只有最合适
116 |
117 | | 解决方案 | 优点 | 缺点 |
118 | | ----------------------------- | -------------------------------------------------------- | ------------------------------------------------------------ |
119 | | 简单分布式互斥锁(mutex key) | 1. 思路简单 2. 保证一致性 | 1. 代码复杂度增大 2. 存在死锁的风险 3. 存在线程池阻塞的风险 |
120 | | “提前”使用互斥锁 | 1. 保证一致性 | 同上 |
121 | | 不过期(本文) | 1. 异步构建缓存,不会阻塞线程池 | 1. 不保证一致性。 2. 代码复杂度增大(每个value都要维护一个timekey)。 3. 占用一定的内存空间(每个value都要维护一个timekey)。 |
122 | | 资源隔离组件hystrix(本文) | 1. hystrix技术成熟,有效保证后端。 2. hystrix监控强大。 | 1. 部分访问存在降级策略。 |
123 |
124 |
--------------------------------------------------------------------------------
/版本控制器/Git.md:
--------------------------------------------------------------------------------
1 | # Git
2 |
3 | - 创建git仓库
4 |
5 | 当前目录下多了一个.git的目录,这个目录是Git来跟踪管理版本库的
6 |
7 | ```
8 | git init
9 | ```
10 |
11 | - 工作区状态
12 |
13 | ```
14 | git status //查看状态
15 | git diff //比较差异
16 | ```
17 |
18 | - 版本回退
19 |
20 | HEAD指向的版本就是当前版本,因此,Git允许我们在版本的历史之间穿梭
21 | ```
22 | git log //查看提交的记录
23 | git reflog //查看命令操作的记录
24 | git reset --hard HEAD//回退到Head的工作区
25 | ```
26 |
27 | - 工作区、暂存区
28 |
29 | 工作区就是当前操作的目录。当你使用git add的时候就是把文件加到暂存区。commit之后就是把暂存区的文件提交到分支中
30 |
31 | 版本库记录着差异。
32 |
33 | 
34 |
35 | - 撤销修改
36 |
37 | 命令git checkout -- readme.txt意思就是,把readme.txt文件在工作区的修改全部撤销,这里有两种情况:
38 |
39 | 一种是readme.txt自修改后还没有被放到暂存区,现在,撤销修改就回到和版本库一模一样的状态;
40 |
41 | 一种是readme.txt已经添加到暂存区后,又作了修改,现在,撤销修改就回到添加到暂存区后的状态。
42 |
43 | 用命令
44 |
45 | ```
46 | git reset HEAD file
47 | ```
48 | 可以把暂存区的修改撤销掉(unstage),重新放回工作区。使用 HEAD表示最新的状态
49 |
50 | - 删除文件
51 |
52 |
53 | 使用git rm file 可以删除版本库中的文件
54 |
55 | ```
56 | git rm read.txt
57 |
58 | git checkout -- read.txt //从版本库中恢复
59 |
60 | ```
61 |
62 | - 远程仓库
63 |
64 | 添加远程仓库
65 |
66 | origin 是仓库名字。是git的默认的
67 | ```
68 | git remote add origin 仓库地址
69 | git remote -v 查看远程仓库
70 | git push -u origin master //将本地master和orgin分支关联。
71 | git clone 仓库地址 //clone 一个远程仓库到本地
72 | git checkout -b branch-name origin/branch-name,//本地和远程分支的名称最好一致
73 | git branch --set-upstream branch-name origin/branch-name //建立本地分支和远程分支的关联,
74 | git pull orgin master //从远程分支抓取
75 | ```
76 |
77 | ## git分支
78 |
79 | master 是git 默认的分支,也叫主分支。每一次提交在分支上形成了一个时间线。HEAD指向该分支
80 |
81 | 
82 |
83 | - 创建分支
84 |
85 | ```
86 | git branch dev //创建分支
87 | git checkout dev //切换分支
88 | git branch //命令会列出所有分支
89 | git checkout -b dev //创建并切换到dev分支
90 | ```
91 | HEAD指针指向了dev
92 | 
93 |
94 | - 合并分支
95 |
96 | 合并某分支到当前分支:git merge
97 | ```
98 | git checkout master
99 | git merge dev
100 | ```
101 |
102 | - 删除分支
103 |
104 | ```
105 | git branch -d dev
106 | git branch -D //强行删除
107 |
108 | ```
109 |
110 | ## 工作区暂存
111 |
112 | 将工作区暂时保存起来 不提交到暂存区。
113 |
114 | ```
115 | git stash //保存工作区
116 |
117 | git stash list //查看保存的工作区
118 | git stash pop
119 | git stash apply //恢复保存的工作区
120 | git stach drop //删除保存的工作区
121 | ```
122 |
123 | ## tag标签
124 |
125 | ```
126 | git tag v1.0 //打标签
127 | git tag // 列出所有的标签
128 | git tag commit_id //给特定的commit_id打标签
129 | git tag -a v1.0 -m "tag1" //打带说明的标签
130 | ```
131 |
132 | - 操作标签
133 |
134 | - 删除标签
135 |
136 | ```
137 | git tag -d v1.0
138 | ```
139 | - 推送标签到远程分支
140 |
141 | ```
142 | git push orgin v1.0
143 | git push origin --tags// 推送所有的标签到远程分支
144 | git push origin :refs/tags/v0.9 //删除远程分支的标签
145 | ```
146 | ### 配置git
147 |
148 | 初次使用 需要配置自己的信息,
149 |
150 | ```
151 | git config --global user.name "John Doe"
152 | git config --global user.email johndoe@example.com
153 | ```
154 |
155 |
156 | - 配置忽略文件
157 |
158 | .gitignore文件本身要放到版本库里,并且可以对.gitignore做版本管理!
159 |
160 | 忽略文件的原则是:
161 |
162 | 1. 忽略操作系统自动生成的文件,比如缩略图等;
163 | 2. 、可执行文件等,也就是如果一个文件是通过另一个文件自动生成的,那自动生成的文件就没必要放进版本库,比如Java编译产生的.class文件
164 |
165 | 3. 忽略你自己的带有敏感信息的配置文件,比如存放口令的配置文件。
166 |
167 |
168 | - 设置别名
169 |
170 | 别名就是把一些复杂的命令简化 类似svn co等之类的
171 |
172 | ```shell
173 | git config --global alias.co checkout
174 | git config --global alias.ci commit
175 | git config --global alias.br branch
176 | git config --global alias.unstage 'reset HEAD'
177 | git config --global alias.last 'log -1'
178 | git config --global alias.lg "log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit"
179 | ```
180 |
181 | - 当前项目配置
182 |
183 | 每个仓库的Git配置文件都放在.git/config文件中:
184 |
185 | ```ini
186 | [core]
187 | repositoryformatversion = 0
188 | filemode = true
189 | bare = false
190 | logallrefupdates = true
191 | ignorecase = true
192 | precomposeunicode = true
193 | [remote "origin"]
194 | url = git@github.com:xianyunyh/PHP-Interview
195 | fetch = +refs/heads/*:refs/remotes/origin/*
196 | [branch "master"]
197 | remote = origin
198 | merge = refs/heads/master
199 | [alias]
200 | last = log -1
201 | ```
202 |
203 | 当前用户的Git配置文件放在用户主目录下的一个隐藏文件.gitconfig中
204 |
205 | ```ini
206 | [alias]
207 | co = checkout
208 | ci = commit
209 | br = branch
210 | st = status
211 | [user]
212 | name = Your Name
213 | email = your@email.com
214 | ```
215 |
--------------------------------------------------------------------------------
/版本控制器/Git_removeCommits.md:
--------------------------------------------------------------------------------
1 | 在 Git 开发中通常会控制主干分支的质量,但有时还是会把错误的代码合入到远程主干。 虽然可以 直接回滚远程分支](https://harttle.land/2018/03/12/reset-origin-without-force-push.html), 但有时新的代码也已经合入,直接回滚后最近的提交都要重新操作。 那么有没有只移除某些 Commit 的方式呢?可以一次 [revert](https://git-scm.com/docs/git-revert) 操作来完成。
2 |
3 | # 一个例子
4 |
5 | 考虑这个例子,我们提交了 6 个版本,其中 3-4 包含了错误的代码需要被回滚掉。 同时希望不影响到后续的 5-6。
6 |
7 | ```
8 | * 982d4f6 (HEAD -> master) version 6
9 | * 54cc9dc version 5
10 | * 551c408 version 4, harttle screwed it up again
11 | * 7e345c9 version 3, harttle screwed it up
12 | * f7742cd version 2
13 | * 6c4db3f version 1
14 | ```
15 |
16 | 这种情况在团队协作的开发中会很常见:可能是流程或认为原因不小心合入了错误的代码, 也可能是合入一段时间后才发现存在问题。 总之已经存在后续提交,使得直接回滚不太现实。
17 |
18 | 下面的部分就开始介绍具体操作了,同时我们假设远程分支是受保护的(不允许 Force Push)。 思路是从产生一个新的 Commit 撤销之前的错误提交。
19 |
20 | # git revert
21 |
22 | 使用 `git revert ` 可以撤销指定的提交, 要撤销一串提交可以用 `..` 语法。 注意这是一个前开后闭区间,即不包括 commit1,但包括 commit2。
23 |
24 | ```
25 | git revert --no-commit f7742cd..551c408
26 | git commit -a -m 'This reverts commit 7e345c9 and 551c408'
27 | ```
28 |
29 | 其中 `f7742cd` 是 version 2,`551c408` 是 version 4,这样被移除的是 version 3 和 version 4。 注意 revert 命令会对每个撤销的 commit 进行一次提交,`--no-commit` 后可以最后一起手动提交。
30 |
31 | 此时 Git 记录是这样的:
32 |
33 | ```
34 | * 8fef80a (HEAD -> master) This reverts commit 7e345c9 and 551c408
35 | * 982d4f6 version 6
36 | * 54cc9dc version 5
37 | * 551c408 version 4, harttle screwed it up again
38 | * 7e345c9 version 3, harttle screwed it up
39 | * f7742cd version 2
40 | * 6c4db3f version 1
41 | ```
42 |
43 | 现在的 HEAD(`8fef80a`)就是我们想要的版本,把它 Push 到远程即可。
44 |
45 | # 确认 diff
46 |
47 | 如果你像不确定是否符合预期,毕竟批量干掉了别人一堆 Commit,可以做一下 diff 来确认。 首先产生 version 4(`551c408`)与 version 6(`982d4f6`)的 diff,这些是我们想要保留的:
48 |
49 | ```
50 | git diff 551c408..982d4f6
51 | ```
52 |
53 | 然后再产生 version 2(`f7742cd`)与当前状态(HEAD)的 diff:
54 |
55 | ```
56 | git diff f7742cd..HEAD
57 | ```
58 |
59 | 如果 version 3, version 4 都被 version 6 撤销的话,上述两个 diff 为空。 可以人工确认一下,或者 grep 掉 description 之后做一次 diff。 下面介绍的另一种方法可以容易地确认 diff。
60 |
61 | # 另外一种方式
62 |
63 | 类似 [安全回滚远程分支](https://harttle.land/2018/03/12/reset-origin-without-force-push.html), 我们先回到 version 2,让它合并 version 4 同时代码不变, 再合并 version 5, version 6。
64 |
65 | ```
66 | # 从 version 2 切分支出来
67 | git checkout -b fixing f7742cd
68 | # 合并 version 4,保持代码不变
69 | git merge -s ours 551c408
70 | # 合并 version 5, version 6
71 | git merge master
72 | ```
73 |
74 | 上述分支操作可以从 [分支管理](https://harttle.land/2016/09/02/git-workflow-branch.html) 一文了解。 至此,`fixing` 分支已经移除了 version 3 和 version 4 的代码,图示如下:
75 |
76 | ```
77 | * 3cb9f8a (HEAD -> v2) Merge branch 'master' into v2
78 | |\
79 | | * 982d4f6 (master) version 6
80 | | * 54cc9dc version 5
81 | * | c669557 Merge commit '551c408' into v2
82 | |\ \
83 | | |/
84 | | * 551c408 version 4, harttle screwed it up again
85 | | * 7e345c9 version 3, harttle screwed it up
86 | |/
87 | * f7742cd version 2
88 | * 6c4db3f version 1
89 | ```
90 |
91 | 可以简单 diff 一下来确认效果:
92 |
93 | ```
94 | # 第一次 merge 结果与 version 2 的 diff,应为空
95 | git diff f7742cd..c669557
96 | # 第二次 merge 的内容,应包含 version 5 和 version 6 的改动
97 | git diff c669557..3cb9f8a
98 | ```
99 |
100 | 现在的 `HEAD`(即 `fixing` 分支)就是我们想要的版本,可以把它 Push 到远程了。 注意由于现在处于 `fixing` 分支, 需要 [Push 时指定远程分支](https://harttle.land/2016/09/05/git-workflow-remote.html) 为 `master`。
101 |
--------------------------------------------------------------------------------
/版本控制器/REAME.md:
--------------------------------------------------------------------------------
1 | Git是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。
2 |
3 | Git 是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。
4 |
5 | Git 与常用的版本控制工具 CVS, Subversion 等不同,它采用了分布式版本库的方式,不必服务器端软件支持。
6 |
7 | - [快速入门](https://github.com/xianyunyh/PHP-Interview/blob/master/%E7%89%88%E6%9C%AC%E6%8E%A7%E5%88%B6%E5%99%A8/Git.md)
8 |
9 | ## Git 与 SVN 区别
10 |
11 | GIT不仅仅是个版本控制系统,它也是个内容管理系统(CMS),工作管理系统等。
12 |
13 | 如果你是一个具有使用SVN背景的人,你需要做一定的思想转换,来适应GIT提供的一些概念和特征。
14 |
15 | Git 与 SVN 区别点:
16 |
17 | - 1、GIT是分布式的,SVN不是:这是GIT和其它非分布式的版本控制系统,例如SVN,CVS等,最核心的区别。
18 | - 2、GIT把内容按元数据方式存储,而SVN是按文件:所有的资源控制系统都是把文件的元信息隐藏在一个类似.svn,.cvs等的文件夹里。
19 | - 3、GIT分支和SVN的分支不同:分支在SVN中一点不特别,就是版本库中的另外的一个目录。
20 | - 4、GIT没有一个全局的版本号,而SVN有:目前为止这是跟SVN相比GIT缺少的最大的一个特征。
21 | - 5、GIT的内容完整性要优于SVN:GIT的内容存储使用的是SHA-1哈希算法。这能确保代码内容的完整性,确保在遇到磁盘故障和网络问题时降低对版本库的破坏。
22 |
23 |
24 |
25 |
26 | **git学习资料**
27 |
28 | - [廖雪峰的git教程](https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000)
29 | - [猴子都能看懂的git教程](https://backlog.com/git-tutorial/cn/)
30 | - [高质量的git教程](https://github.com/geeeeeeeeek/git-recipes/wiki)
--------------------------------------------------------------------------------
/版本控制器/gitcheat.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/版本控制器/gitcheat.jpg
--------------------------------------------------------------------------------
/算法/Readme.md:
--------------------------------------------------------------------------------
1 | ## 算法
2 |
3 | > 算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。如果一个算法有缺陷,或不适合于某个问题,执行这个算法将不会解决这个问题。不同的算法可能用不同的时间、空间或效率来完成同样的任务。一个算法的优劣可以用空间复杂度与时间复杂度来衡量。
4 |
5 | ### 算法的特征
6 |
7 | - 有穷性
8 |
9 | 算法的有穷性是指算法必须能在执行有限个步骤之后终止;
10 |
11 | - 确定性
12 |
13 | 算法的每一步骤必须有确切的定义;
14 |
15 | - 输入
16 |
17 | 一个算法有0个或多个输入
18 |
19 | - 输出
20 |
21 | 一个算法有一个或多个输出,以反映对输入数据加工后的结果
22 |
23 | - 可行性
24 |
25 | 算法中执行的任何计算步骤都是可以被分解为基本的可执行的操作步
26 |
27 | ### 时间复杂度
28 |
29 | 时间复杂度是执行算法所需要的工作量,一般来说,计算机算法是问题规模n 的函数f(n),算法的时间复杂度也因此记做。
30 |
31 | `T(n)=Ο(f(n))`
32 |
33 | 因此,问题的规模n 越大,算法执行的时间的增长率与f(n) 的增长率正相关
34 |
35 | ### 空间复杂度
36 |
37 | 算法的空间复杂度是指算法需要消耗的内存空间。其计算和表示方法与时间 复杂度类似。
38 |
39 | 
40 |
41 | ### 常见算法
42 |
43 | #### 排序算法
44 |
45 | - [冒泡排序](https://github.com/xianyunyh/arithmetic-php/blob/master/package/Sort/BubbleSort.php)
46 |
47 | ```php
48 | function BubbleSort(array $container)
49 | {
50 | $count = count($container);
51 | for ($j = 1; $j < $count; $j++) {
52 | for ($i = 0; $i < $count - $j; $i++) {
53 | if ($container[$i] > $container[$i + 1]) {
54 | $temp = $container[$i];
55 | $container[$i] = $container[$i + 1];
56 | $container[$i + 1] = $temp;
57 | }
58 | }
59 | }
60 | return $container;
61 | }
62 | ```
63 | - [插入排序](https://github.com/xianyunyh/arithmetic-php/blob/master/package/Sort/InsertSort.php)
64 |
65 | ```php
66 | function InsertSort(array $container)
67 | {
68 | $count = count($container);
69 | for ($i = 1; $i < $count; $i++){
70 | $temp = $container[$i];
71 | $j = $i - 1;
72 | // Init
73 | while($j >= 0 && $container[$j] > $temp){
74 | $container[$j+1] = $container[$j];
75 | $j--;
76 | }
77 | if($i != $j+1)
78 | $container[$j+1] = $temp;
79 | }
80 | return $container;
81 | }
82 | ```
83 |
84 | - [希尔排序](https://github.com/xianyunyh/arithmetic-php/blob/master/package/Sort/ShellSort.php)
85 |
86 | ```php
87 | function ShellSort(array $container)
88 | {
89 | $count = count($container);
90 | for ($increment = intval($count / 2); $increment > 0; $increment = intval($increment / 2)) {
91 | for ($i = $increment; $i < $count; $i++) {
92 | $temp = $container[$i];
93 | for ($j = $i; $j >= $increment; $j -= $increment) {
94 | if ($temp < $container[$j - $increment]) {
95 | $container[$j] = $container[$j - $increment];
96 | } else {
97 | break;
98 | }
99 | }
100 | $container[$j] = $temp;
101 | }
102 | }
103 | return $container;
104 | }
105 | ```
106 |
107 |
108 |
109 | - [选择排序](https://github.com/xianyunyh/arithmetic-php/blob/master/package/Sort/SelectSort.php)
110 |
111 | ```php
112 | function SelectSort(array $container)
113 | {
114 | $count = count($container);
115 | for ($i = 0; $i < $count; $i++){
116 | $k = $i;
117 | for ($j = $i + 1; $j < $count; $j++){
118 | if($container[$j] < $container[$k]){
119 | $k = $j;
120 | }
121 | }
122 | if($k != $i){
123 | $temp = $container[$i];
124 | $container[$i] = $container[$k];
125 | $container[$k] = $temp;
126 | }
127 | }
128 | return $container;
129 | }
130 | ```
131 |
132 | - [快速排序](https://github.com/xianyunyh/arithmetic-php/blob/master/package/Sort/QuickSort.php)
133 |
134 | > 快速排序(Quicksort)是对冒泡排序的一种改进。他的基本思想是:通过一趟排序将待排记录分割成独立的两部分,其中一部分的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行快速排序,整个排序过程可以递归进行,以达到整个序列有序的目的。
135 |
136 | ```php
137 | function QuickSort(&$arr,$low,$high)
138 | {
139 | if ($low < $high) {
140 | $middle = getMiddle($arr,$low,$high);
141 | QuickSort($arr,$low,$middle-1);
142 | QuickSort($arr,$middle+1,$high);
143 | }
144 | }
145 |
146 | function getMiddle (&$arr,$low,$high)
147 | {
148 | $temp = $arr[$low];
149 | while ($low < $high) {
150 | while($low < $high && $temp <= $arr[$high]) {
151 | $high --;
152 | }
153 | $arr[$low] = $arr[$high];
154 | while ($low < $high && $temp >= $arr[$low]) {
155 | $low ++;
156 | }
157 | $arr[$high] = $arr[$low];
158 | }
159 | $arr[$low] = $temp;
160 | return $low;
161 | }
162 | ```
163 |
164 | - 归并排序
165 | - 堆排序
166 |
167 | #### 查找算法
168 |
169 | - 顺序查找
170 |
171 | ```php
172 | function find($array ,$target) {
173 | foreach ($array as $key=>$value) {
174 | if($value === $target) {
175 | return key;
176 | }
177 | }
178 | return false;
179 | }
180 | ```
181 |
182 | - 有序查找(二分查找)
183 |
184 | ```php
185 | function BinaryQueryRecursive(array $container, $search, $low = 0, $top = 'default')
186 | {
187 | $top == 'default' && $top = count($container);
188 | if ($low <= $top) {
189 | $mid = intval(floor($low + $top) / 2);
190 | if (!isset($container[$mid])) {
191 | return false;
192 | }
193 | if ($container[$mid] == $search) {
194 | return $mid;
195 | }
196 | if ($container[$mid] < $search) {
197 | return BinaryQueryRecursive($container, $search, $mid + 1, $top);
198 | } else {
199 | return BinaryQueryRecursive($container, $search, $low, $mid - 1);
200 | }
201 | }
202 | }
203 | ```
204 |
205 | - 动态查找(BST)
206 | - 哈希表 O(1)
207 |
208 | ### 算法的思想
209 |
210 | - 迭代
211 | - 递归
212 | - 动态规划
213 | - 回溯
214 | - 分治
215 | - 贪心
216 |
217 | ### 算法相关的面试题
218 |
219 | - 字符串
220 |
221 | - 查找字符串中的字符
222 | - 翻转字符串
223 |
224 | - 排序
225 |
226 | - 冒泡排序
227 | - 快速排序
228 | - 归并排序
229 |
230 | - 链表
231 |
232 | - 翻转链表
233 | - 链表有没有环
234 |
235 | - 二叉搜索树
236 |
237 | - 二叉树的深度
238 | - 二叉树的遍历
239 | - 重建二叉树
240 |
241 |
242 |
243 |
244 |
--------------------------------------------------------------------------------
/算法/二分查找.md:
--------------------------------------------------------------------------------
1 | ## :算法之排序二分查找
2 | ### php-leetcode之路 [Leetcode-php](https://github.com/wuqinqiang/leetcode-php)
3 |
4 | ### :pencil2:二分查找
5 |
6 |
7 | 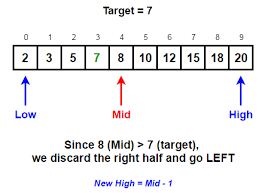 8 |
9 |
10 |
11 | **二分查找是一种常见的查找方式。在生活中有一个猜大小的例子。比如给定一个0-100的范围,让你猜出事先我所设置的数字,每次把数字的范围缩小到一半。第一次猜50,大了还是小了,继续缩小数字的范围。但是有一个前提,我们得保证我们查找的是一个有序的范围。**
12 |
13 | ****
14 |
15 | ### :pencil2:查找思想
16 |
17 | **二分查找针对的是一个有序的集合。它的查找算法有点类型分治的思想,就像上面所说的。每次我通过中间的数和指定的数进行比较,判断大小,缩小猜测的区间,最多到区间等于0的时候,结果也就是最终指定的答案。二分查找是一种高效的查找算法,它的时间复杂度是O(logn).**
18 |
19 | ****
20 |
21 | ### :pencil2:php实现二分查找
22 |
23 | **1.我们先实现一个最基础的,在一个有序数组中(数组没有重复的值)查找给定值。(迭代)**
24 |
25 | ```php
26 | function binarySerach($data,$res)
27 | {
28 | $l=0;
29 | $r=count($data)-1;
30 | while($l<=$r){
31 | // $middle=floor(($l+$r)/2);
32 | // $middle=$l+floor(($r-$l)/2);
33 | $middle=$l+(($r-$l)>>1); //使用位运算查找更高效
34 | if($data[$middle]==$res) return $middle;
35 | elseif ($data[$middle]>$res) $r=$middle-1;
36 | else $l=$middle+1;
37 | }
38 | return -1;
39 | }
40 | $data=[2,5,6,7,12,34];
41 | $res=12;
42 | var_dump(binarySerach($data,$res));
43 | ```
44 | ****
45 |
46 | **使用递归实现刚才的操作。**
47 |
48 | ```php
49 | function binarySerach($data,$res){
50 | return recursion($data,0,count($data)-1,$res);
51 | }
52 |
53 | function recursion($data,$l,$r,$res)
54 | {
55 | if($l>$r){
56 | return -1;
57 | }
58 | $middle=$l+(($r-$l)>>1);
59 | if($data[$middle]==$res) return $middle;
60 | elseif ($data[$middle]>$res) return recursion($data,$l,$middle-1,$res);
61 | else return recursion($data,$middle+1,$r,$res);
62 | }
63 | $data=[2,5,6,7,12,34];
64 | $res=12;
65 | var_dump(binarySerach($data,$res));
66 | ```
67 | ****
68 |
69 |
70 | ### :pencil2:二分查找的变形问题
71 |
72 | **上面的那个注释是在数字没有重复的情况下,现在我们来实现数组中有重复值的情况下,如何查找出第一个等于给定值的元素。其实就是在做等于判断的时候如果索引是0那么是第一个等于给定值的数,或者当前等于给定值的上一个索引值不等于给定值。**
73 |
74 | ```php
75 |
76 | function binarySerach($data,$res){
77 | $l=0;
78 | $r=count($data);
79 | while($l<=$r){
80 | $middle=$l+(($r-$l)>>1);
81 | if($data[$middle]>$res) $r=$middle-1;
82 | elseif($data[$middle]<$res) $l=$middle+1;
83 | else{
84 | if($middle==0 || $data[$middle-1] !==$res) return $middle;
85 | else $r=$middle-1;
86 | }
87 | }
88 | }
89 | $data=[2,5,6,7,8,8,10];
90 | $res=8;
91 | var_dump(binarySerach($data,$res));
92 | ```
93 | ****
94 | **查找第一个大于等于给定值的元素。**
95 | ```php
96 |
97 | //查找第一个大于等于给定值的数
98 | function binarySerach($data,$res)
99 | {
100 | $l=0;
101 | $r=count($data)-1;
102 | while($l<=$r){
103 | $middle=$l+(($r-$l)>>1);
104 | if($data[$middle]<$res) $l=$middle+1;
105 | else{
106 | if($middle==0 || $data[$middle-1]<$res ) return $middle;
107 | else $r=$middle-1;
108 | }
109 | }
110 |
111 | }
112 | $data=[2,5,6,7,8,8,10];
113 | $res=9;
114 | var_dump(binarySerach($data,$res));
115 | ```
116 | ****
117 |
118 | **针对数组是一个循环有序的数组Leetcode35题**
119 | ```php
120 |
121 | function binarySerach($data,$res)
122 | {
123 | $l=0;
124 | $r=count($data)-1;
125 | while($l<=$r){
126 | $middle=$l+(($r-$l)>>1);
127 | if($data[$middle]==$res) return $middle;
128 | elseif ($data[$middle]>$data[$r]){
129 | if($data[$l]<=$res && $data[$middle]>$res) $r=$middle-1;
130 | else $l=$middle+1;
131 | }else{
132 | if($data[$middle]<=$res && $data[$r] >$res) $r=$middle-1;
133 | else $l=$middle+1;
134 | }
135 | }
136 | }
137 | $data=[5,6,7,8,1,2,3,4];
138 | $res=7;
139 | var_dump(binarySerach($data,$res));
140 | ```
141 |
142 | **当然二分查找还有很多的应用场景,我就总结到这了。**
143 |
144 |
145 |
146 |
147 | ### 联系
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 |
157 |
--------------------------------------------------------------------------------
/计算机网络/HTTP2.md:
--------------------------------------------------------------------------------
1 | ## HTTP的基本优化
2 |
3 | 影响一个HTTP网络请求的因素主要有两个:带宽和延迟。
4 |
5 | - **带宽:**如果说我们还停留在拨号上网的阶段,带宽可能会成为一个比较严重影响请求的问题,但是现在网络基础建设已经使得带宽得到极大的提升,我们不再会担心由带宽而影响网速,那么就只剩下延迟了。
6 | - **延迟:**
7 |
8 | 1. **浏览器阻塞(HOL blocking)**:浏览器会因为一些原因阻塞请求。浏览器对于同一个域名,同时只能有 4 个连接(这个根据浏览器内核不同可能会有所差异),超过浏览器最大连接数限制,后续请求就会被阻塞。
9 | 2. **DNS 查询(DNS Lookup)**:浏览器需要知道目标服务器的 IP 才能建立连接。将域名解析为 IP 的这个系统就是 DNS。这个通常可以利用DNS缓存结果来达到减少这个时间的目的。
10 | 3. **建立连接(Initial connection)**:HTTP 是基于 TCP 协议的,浏览器最快也要在第三次握手时才能捎带 HTTP 请求报文,达到真正的建立连接,但是这些连接无法复用会导致每次请求都经历三次握手和[慢启动](http://en.wikipedia.org/wiki/Slow-start)。三次握手在高延迟的场景下影响较明显,慢启动则对文件类大请求影响较大。
11 |
12 |
13 |
14 | ## HTTP1.0和HTTP1.1的一些区别
15 |
16 | HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较为简单的网页上和网络请求上,而HTTP1.1则在1999年才开始广泛应用于现在的各大浏览器网络请求中,同时HTTP1.1也是当前使用最为广泛的HTTP协议。
17 |
18 | **主要区别主要体现在:**
19 |
20 | 1. **缓存处理,**在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
21 | 2. **带宽优化及网络连接的使用**,HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
22 | 3. **错误通知的管理**,在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
23 | 4. **Host头处理**,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
24 | 5. **长连接**,HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。以下是常见的HTTP1.0:
25 |
26 |
27 |
28 | ## **HTTP1.0和1.1现存的一些问题**
29 |
30 | 1. 上面提到过的,HTTP1.x在传输数据时,每次都需要重新建立连接,无疑增加了大量的延迟时间,特别是在移动端更为突出。
31 | 2. HTTP1.x在传输数据时,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份,这在一定程度上无法保证数据的安全性。
32 | 3. HTTP1.x在使用时,header里携带的内容过大,在一定程度上增加了传输的成本,并且每次请求header基本不怎么变化,尤其在移动端增加用户流量。
33 | 4. 虽然HTTP1.x支持了keep-alive,来弥补多次创建连接产生的延迟,但是keep-alive使用多了同样会给服务端带来大量的性能压力,并且对于单个文件被不断请求的服务(例如图片存放网站),keep-alive可能会极大的影响性能,因为它在文件被请求之后还保持了不必要的连接很长时间。
34 |
35 | ## **HTTPS与HTTP的一些区别**
36 |
37 | 1. HTTPS协议需要到CA申请证书,一般免费证书很少,需要交费。
38 | 2. HTTP协议运行在TCP之上,所有传输的内容都是明文,HTTPS运行在SSL/TLS之上,SSL/TLS运行在TCP之上,所有传输的内容都经过加密的。
39 | 3. HTTP和HTTPS使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
40 | 4. HTTPS可以有效的防止运营商劫持,解决了防劫持的一个大问题。
41 |
42 | 
43 |
44 | ## 使用SPDY加快你的网站速度
45 |
46 | SPDY的方案,大家才开始从正面看待和解决老版本HTTP协议本身的问题,SPDY可以说是综合了HTTPS和HTTP两者有点于一体的传输协议,主要解决:
47 |
48 | 1. **降低延迟**,针对HTTP高延迟的问题,SPDY优雅的采取了多路复用(multiplexing)。多路复用通过多个请求stream共享一个tcp连接的方式,解决了HOL blocking的问题,降低了延迟同时提高了带宽的利用率。
49 | 2. **请求优先级**(request prioritization)。多路复用带来一个新的问题是,在连接共享的基础之上有可能会导致关键请求被阻塞。SPDY允许给每个request设置优先级,这样重要的请求就会优先得到响应。比如浏览器加载首页,首页的html内容应该优先展示,之后才是各种静态资源文件,脚本文件等加载,这样可以保证用户能第一时间看到网页内容。
50 | 3. **header压缩**。前面提到HTTP1.x的header很多时候都是重复多余的。选择合适的压缩算法可以减小包的大小和数量。
51 | 4. **基于HTTPS的加密协议传输**,大大提高了传输数据的可靠性。
52 | 5. **服务端推送**(server push),采用了SPDY的网页,例如我的网页有一个sytle.css的请求,在客户端收到sytle.css数据的同时,服务端会将sytle.js的文件推送给客户端,当客户端再次尝试获取sytle.js时就可以直接从缓存中获取到,不用再发请求了。SPDY构成图:
53 |
54 | 
55 |
56 | SPDY位于HTTP之下,TCP和SSL之上,这样可以轻松兼容老版本的HTTP协议(将HTTP1.x的内容封装成一种新的frame格式),同时可以使用已有的SSL功能。
57 |
58 |
59 |
60 | ## HTTP2.0
61 |
62 | - **新的二进制格式**(Binary Format),HTTP1.x的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
63 | - **多路复用**(MultiPlexing),即连接共享,即每一个request都是是用作连接共享机制的。一个request对应一个id,这样一个连接上可以有多个request,每个连接的request可以随机的混杂在一起,接收方可以根据request的 id将request再归属到各自不同的服务端请求里面。**多路复用原理图**:
64 | - **header压缩,**如上文中所言,对前面提到过HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
65 | - **服务端推送**(server push),同SPDY一样,HTTP2.0也具有server push功能。目前,有大多数网站已经启用HTTP2.0,例如[YouTuBe](https://www.youtube.com/),[淘宝网](http://www.taobao.com/)等网站,利用chrome控制台可以查看是否启用H2
66 |
67 | 
68 |
69 | ```conf
70 | server {
71 | listen 443 ssl http2;
72 | server_name example.com;
73 | root /var/www/example.com/public;
74 |
75 | # SSL
76 | ssl_certificate /etc/live/example.com/fullchain.pem;
77 | ssl_certificate_key /etc/live/example.com/privkey.pem;
78 | ssl_trusted_certificate /etc/live/example.com/chain.pem;
79 |
80 | # index.html fallback
81 | location / {
82 | try_files $uri $uri/ /index.html;
83 | }
84 | }
85 |
86 | ```
--------------------------------------------------------------------------------
/计算机网络/HTTPS.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 |
--------------------------------------------------------------------------------
/计算机网络/IP协议.md:
--------------------------------------------------------------------------------
1 | ## IP协议
2 |
3 | > IP协议是TCP/IP协议簇中的核心协议,也是TCP/IP的载体。所有的TCP,UDP,ICMP及IGMP数据都以IP数据报格式传输。 IP提供**不可靠**的,**无连接**的数据传送服务。 不可靠指它不能保证IP数据报能成功到达目的地
4 |
5 | 不可靠(unreliable)的意思是它不能保证IP数据报能成功地到达目的地。IP仅提供最好的传输服务。如果发生某种错误时,如某个路由器暂时用完了缓冲区,IP有一个简单的错误处理算法:丢弃该数据报,然后发送ICMP消息报给信源端。任何要求的可靠性必须由上层来提供(如TCP)。
6 |
7 | 无连接(connectionless)这个术语的意思是IP并不维护任何关于后续数据报的状态信息。每个数据报的处理是相互独立的。这也说明,IP数据报可以不按发送顺序接收。如果一信源向相同的信宿发送两个连续的数据报(先是A,然后是B),每个数据报都是独立地进行路由选择,可能选择不同的路线,因此B可能在A到达之前先到达。
8 |
9 | 
10 |
11 |
12 |
13 | ## IP报文介绍
14 |
15 | 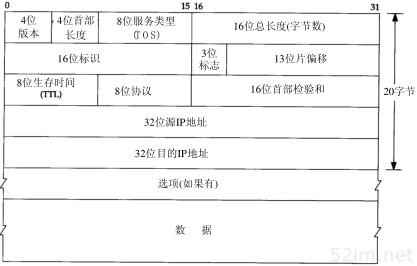
16 |
17 | - 4位版本号。包含IP数据报的版本号:ipv4为4,ipv6为6
18 | - 4位首部长度
19 | - 8位服务类型
20 | - 16位总长度
21 | - 标识字段:长度为16位,最多分配的ID值为65535个
22 |
23 |
24 |
25 |
26 |
27 | ### IP地址分类
28 |
29 | IPV4被分为五大类:ABCDE
30 |
31 | A类为:点分四组中的第一组地址范围为0~127的IP地址。已二进制来看就是“首位为0”
32 |
33 | B类:128~191.二进制首位为10
34 |
35 | C类:192~223.二进制首位为110
36 |
37 | D类:224~239.二进制首位为1110
38 |
39 | E类:240~255.二进制首位为1111
--------------------------------------------------------------------------------
/计算机网络/README.md:
--------------------------------------------------------------------------------
1 | ### 概述
2 |
3 | 网络协议通常分不同层次进行开发,每一层分别负责不同的通信功能。一个协议族,比如TCP/IP,是一组不同层次上的多个协议的组合。TCP/IP通常被认为是一个四层协议系统.
4 |
5 | 
6 |
7 | 每一层负责不同的功能:
8 |
9 | 1. **链路层**,有时也称作数据链路层或网络接口层,通常包括操作系统中的设备驱动程序和计算机中对应的网络接口卡。它们一起处理与电缆(或其他任何传输媒介)的物理接口细节。
10 | 2. **网络层**,有时也称作互联网层,处理分组在网络中的活动,例如分组的选路。在TCP/IP协议族中,网络层协议包括IP协议(网际协议),ICMP协议(Internet互联网控制报文协议),以及IGMP协议(Internet组管理协议)。
11 | 3. **运输层** 主要为两台主机上的应用程序提供端到端的通信。在TCP/IP协议族中,有两个互不相同的传输协议:TCP(传输控制协议)和UDP(用户数据报协议)。
12 | TCP为两台主机提供高可靠性的数据通信。它所做的工作包括把应用程序交给它的数据分成合适的小块交给下面的网络层,确认接收到的分组,设置发送最后确认分组的超时时钟等。由于运输层提供了高可靠性的端到端的通信,因此应用层可以忽略所有这些细节。
13 | 而另一方面,UDP则为应用层提供一种非常简单的服务。它只是把称作数据报的分组从一台主机发送到另一台主机,但并不保证该数据报能到达另一端。任何必需的可靠性必须由应用层来提供。
14 | 这两种运输层协议分别在不同的应用程序中有不同的用途,这一点将在后面看到。
15 | 4. **应用层** 负责处理特定的应用程序细节。几乎各种不同的TCP/IP实现都会提供下面这些通用的应用程序:
16 | • Telnet远程登录。• FTP文件传输协议。• SMTP简单邮件传送协议。• SNMP简单网络管理协议。
17 |
18 |
19 | 
20 |
21 |
22 |
23 | ### 互联网地址
24 |
25 | 互联网上的每个接口必须有一个唯一的Internet地址(也称作IP地址)。IP地址长32 bit。Internet地址并不采用平面形式的地址空间,如1、2、3等。IP地址具有一定的结构,五类不同的互联网地址格式如图1-5所示。
26 |
27 | 
28 |
29 | ### 用户数据封装和分用
30 |
31 | 应用程序用TCP传送数据时,数据被送入协议栈中,然后逐个通过每一层直到被当作一串比特流送入网络。其中每一层对收到的数据都要增加一些首部信息(有时还要增加尾部信息),该过程如图1-7所示。TCP传给IP的数据单元称作TCP报文段或简称为TCP段(TCP segment)。IP传给网络接口层的数据单元称作IP数据报(IP datagram)。通过以太网传输的比特流称作帧(Frame)
32 |
33 | 
34 |
35 | 当目的主机收到一个以太网数据帧时,数据就开始从协议栈中由底向上升,同时去掉各层协议加上的报文首部。每层协议盒都要去检查报文首部中的协议标识,以确定接收数据的上层协议。这个过程称作分用(Demultiplexing)
36 |
37 | 
38 |
39 | ### 端口号
40 |
41 | 服务器一般通过端口号来识别对应的应用程序。TCP和UDP采用16 bit的端口号来识别应用程序。任何TCP/IP实现所提供的服务都用知名的1~1023之间的端口号。大多数TCP/IP实现给临时端口分配1024~5000之间的端口号。大于5000的端口号是为其他服务器预留的(Internet上并不常用的服务)
42 |
43 | > 到1992年为止,知名端口号介于1~255之间。256~1023之间的端口号通常都是由Unix系统占用,以提供一些特定的Unix服务—也就是说,提供一些只有Unix系统才有的、而其他操作系统可能不提供的服务。现在IANA管理1~1023之间所有的端口号。
44 |
45 |
46 |
47 | ### 应用编程
48 |
49 | TCP/IP协议的应用程序通常采用两种应用编程接口(API):socket和TLI(运输层接口:Transport Layer Interface)
--------------------------------------------------------------------------------
/计算机网络/UDP协议.md:
--------------------------------------------------------------------------------
1 | # UDP(用户数据报协议)
2 |
3 | > 用户数据报协议(User Datagram Protocol,UDP)UDP是OSI参考模型中一种无连接的传输层协议,它主要用于不要求分组顺序到达的传输中,分组传输顺序的检查与排序由应用层完成 ,提供面向事务的简单不可靠信息传送服务。
4 |
5 |
6 | ## 一、UDP协议
7 |
8 | 1、面向事物,不是面向链接
9 |
10 | 2、UDP不提供可靠性:它把应用程序传给IP层的数据发送出去,但是并不保证它们能到达目的地
11 |
12 | 简单的可以理解UDP就是类似一个邮寄员的角色。你只要告诉它,对方的地址和电话。邮递员就把你的快递送到对应的地方,但是中间可能会丢失。对方收到没有,就不管了。
13 |
14 | ## UDP头部信息
15 |
16 | > 指定通信的源端端口号、目的端端口号、UDP长度、校验和、数据
17 |
18 | 
19 | 
20 |
21 |
22 |
23 | UDP报文各个位置详解:
24 |
25 | - 1、源端口号,16bit
26 | - 2、目的端口号:数据接收者的端口号,16bit
27 | - 3、UDP长度:UDP长度字段指的是UDP首部和UDP数据的字节长度。该字段的最小值为8字节
28 | - 4、UPD校验和:UDP检验和覆盖UDP首部和UDP数据
29 | - 5、首部长度:首部中32bit字的数目,可表示15*32bit=60字节的首部。一般首部长度为20字节。
30 | - 6、数据
31 |
32 |
33 | 使用**wireshark**抓包查看对应的字段信息。
34 |
35 | 
36 |
37 | UDP 是一个简单的传输层协议。和 TCP 相比,UDP 有下面几个显著特性:
38 |
39 | - UDP 缺乏可靠性。UDP 本身不提供确认,序列号,超时重传等机制。UDP 数据报可能在网络中被复制,被重新排序。即 UDP 不保证数据报会到达其最终目的地,也不保证各个数据报的先后顺序,也不保证每个数据报只到达一次
40 | - UDP 数据报是有长度的。每个 UDP 数据报都有长度,如果一个数据报正确地到达目的地,那么该数据报的长度将随数据一起传递给接收方。而 TCP 是一个字节流协议,没有任何(协议上的)记录边界。
41 | - UDP 是无连接的。UDP 客户和服务器之前不必存在长期的关系。UDP 发送数据报之前也不需要经过握手创建连接的过程。
42 | - UDP 支持多播和广播。
--------------------------------------------------------------------------------
/计算机网络/images/01.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/01.png
--------------------------------------------------------------------------------
/计算机网络/images/02.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/02.png
--------------------------------------------------------------------------------
/计算机网络/images/04.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/04.png
--------------------------------------------------------------------------------
/计算机网络/images/5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/5.png
--------------------------------------------------------------------------------
/计算机网络/images/6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/6.png
--------------------------------------------------------------------------------
/计算机网络/images/http2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/http2.png
--------------------------------------------------------------------------------
/计算机网络/images/https.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/https.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-2.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-byte-stream.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-byte-stream.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect-1-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect-1-1.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect-1-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect-1-2.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect-1.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect-2-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect-2-1.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect-2-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect-2-2.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect-3-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect-3-1.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect-3-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect-3-2.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect-4-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect-4-1.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect-4-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect-4-2.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-handshake-1-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-handshake-1-1.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-handshake-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-handshake-1.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-handshake-2-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-handshake-2-1.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-handshake-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-handshake-2.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-handshake-3-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-handshake-3-1.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-handshake-3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-handshake-3.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-ip-header-map.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-ip-header-map.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-ip-protocal.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-ip-protocal.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-packets-header.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-packets-header.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-three-way-handshake.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-three-way-handshake.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-three-way-handshake2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-three-way-handshake2.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-wireshark.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-wireshark.png
--------------------------------------------------------------------------------
/计算机网络/images/udp-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/udp-1.png
--------------------------------------------------------------------------------
/计算机网络/images/udp-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/udp-2.png
--------------------------------------------------------------------------------
/计算机网络/images/udp-3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/udp-3.png
--------------------------------------------------------------------------------
/设计模式/Behavioral.md:
--------------------------------------------------------------------------------
1 | ## 行为型设计模式
2 |
3 | ### 1. 观察者模式
4 |
5 | > Behavioral定义对象间一种一对多的依赖关系,使得当一个对象改变状态,则所有依赖于它的对象都会得到通知并被自动更新。
6 |
7 | Subject 被观察者。是一个接口或者是抽象类,定义被观察者必须实现的职责,它必须能偶动态地增加、取消观察者,管理观察者并通知观察者。
8 |
9 | Observer 观察者。观察者接收到消息后,即进行 update 更新操作,对接收到的信息进行处理。
10 |
11 | ConcreteSubject 具体的被观察者。定义被观察者自己的业务逻辑,同时定义对哪些事件进行通知。
12 |
13 | ConcreteObserver 具体观察者。每个观察者在接收到信息后处理的方式不同,各个观察者有自己的处理逻辑。
14 |
15 |
16 |
17 | 观察者模式简单的理解,就是当一个类改变的时候,通知另外一个类进行做出处理。比如我们用户在注册成功的时候,会发送短信提醒。我们可以利用观察者模式,实现应用的解耦。
18 |
19 | ```php
20 | //抽象主题类
21 | interface Subject
22 | {
23 | public function attach(Observer $Observer);
24 |
25 | public function detach(Observer $observer);
26 |
27 | //通知所有注册过的观察者对象
28 | public function notifyObservers();
29 | }
30 |
31 | //具体主题角色
32 |
33 |
34 | class ConcreteSubject implements Subject
35 | {
36 | private $_observers;
37 |
38 | public function __construct()
39 | {
40 | $this->_observers = array();
41 | }
42 |
43 | //增加一个观察者对象
44 | public function attach(Observer $observer)
45 | {
46 | return array_push($this->_observers,$observer);
47 | }
48 |
49 | //删除一个已经注册过的观察者对象
50 |
51 | public function detach(Observer $observer)
52 | {
53 | $index = array_search($observer,$this->_observers);
54 | if($index === false || !array_key_exists($index, $this->_observers))
55 | return false;
56 | unset($this->_observers[$index]);
57 | return true;
58 | }
59 |
60 | //通知所有注册过的观察者
61 | public function notifyObservers()
62 | {
63 | if(!is_array($this->_observers)) return false;
64 | foreach($this->_observers as $observer)
65 | {
66 | $observer->update();
67 | }
68 | return true;
69 | }
70 | }
71 |
72 |
73 | //抽象观察者角色
74 |
75 | interface Observer
76 | {
77 | //更新方法
78 | public function update();
79 | }
80 |
81 | //观察者实现
82 | class ConcreteObserver implements Observer
83 | {
84 | private $_name;
85 |
86 | public function __construct($name)
87 | {
88 | $this->_name = $name;
89 | }
90 |
91 | //更新方法
92 |
93 | public function update()
94 | {
95 | echo 'Observer'.$this->_name.' has notify';
96 | }
97 | }
98 |
99 | $Subject = new ConcreteSubject();
100 |
101 | //添加第一个观察者
102 |
103 | $observer1 = new ConcreteObserver('baixiaoshi');
104 | $Subject->attach($observer1);
105 | echo 'the first notify:';
106 | $Subject->notifyObservers();
107 |
108 | //添加第二个观察者
109 | $observer2 = new ConcreteObserver('hurong');
110 | echo '
8 |
9 |
10 |
11 | **二分查找是一种常见的查找方式。在生活中有一个猜大小的例子。比如给定一个0-100的范围,让你猜出事先我所设置的数字,每次把数字的范围缩小到一半。第一次猜50,大了还是小了,继续缩小数字的范围。但是有一个前提,我们得保证我们查找的是一个有序的范围。**
12 |
13 | ****
14 |
15 | ### :pencil2:查找思想
16 |
17 | **二分查找针对的是一个有序的集合。它的查找算法有点类型分治的思想,就像上面所说的。每次我通过中间的数和指定的数进行比较,判断大小,缩小猜测的区间,最多到区间等于0的时候,结果也就是最终指定的答案。二分查找是一种高效的查找算法,它的时间复杂度是O(logn).**
18 |
19 | ****
20 |
21 | ### :pencil2:php实现二分查找
22 |
23 | **1.我们先实现一个最基础的,在一个有序数组中(数组没有重复的值)查找给定值。(迭代)**
24 |
25 | ```php
26 | function binarySerach($data,$res)
27 | {
28 | $l=0;
29 | $r=count($data)-1;
30 | while($l<=$r){
31 | // $middle=floor(($l+$r)/2);
32 | // $middle=$l+floor(($r-$l)/2);
33 | $middle=$l+(($r-$l)>>1); //使用位运算查找更高效
34 | if($data[$middle]==$res) return $middle;
35 | elseif ($data[$middle]>$res) $r=$middle-1;
36 | else $l=$middle+1;
37 | }
38 | return -1;
39 | }
40 | $data=[2,5,6,7,12,34];
41 | $res=12;
42 | var_dump(binarySerach($data,$res));
43 | ```
44 | ****
45 |
46 | **使用递归实现刚才的操作。**
47 |
48 | ```php
49 | function binarySerach($data,$res){
50 | return recursion($data,0,count($data)-1,$res);
51 | }
52 |
53 | function recursion($data,$l,$r,$res)
54 | {
55 | if($l>$r){
56 | return -1;
57 | }
58 | $middle=$l+(($r-$l)>>1);
59 | if($data[$middle]==$res) return $middle;
60 | elseif ($data[$middle]>$res) return recursion($data,$l,$middle-1,$res);
61 | else return recursion($data,$middle+1,$r,$res);
62 | }
63 | $data=[2,5,6,7,12,34];
64 | $res=12;
65 | var_dump(binarySerach($data,$res));
66 | ```
67 | ****
68 |
69 |
70 | ### :pencil2:二分查找的变形问题
71 |
72 | **上面的那个注释是在数字没有重复的情况下,现在我们来实现数组中有重复值的情况下,如何查找出第一个等于给定值的元素。其实就是在做等于判断的时候如果索引是0那么是第一个等于给定值的数,或者当前等于给定值的上一个索引值不等于给定值。**
73 |
74 | ```php
75 |
76 | function binarySerach($data,$res){
77 | $l=0;
78 | $r=count($data);
79 | while($l<=$r){
80 | $middle=$l+(($r-$l)>>1);
81 | if($data[$middle]>$res) $r=$middle-1;
82 | elseif($data[$middle]<$res) $l=$middle+1;
83 | else{
84 | if($middle==0 || $data[$middle-1] !==$res) return $middle;
85 | else $r=$middle-1;
86 | }
87 | }
88 | }
89 | $data=[2,5,6,7,8,8,10];
90 | $res=8;
91 | var_dump(binarySerach($data,$res));
92 | ```
93 | ****
94 | **查找第一个大于等于给定值的元素。**
95 | ```php
96 |
97 | //查找第一个大于等于给定值的数
98 | function binarySerach($data,$res)
99 | {
100 | $l=0;
101 | $r=count($data)-1;
102 | while($l<=$r){
103 | $middle=$l+(($r-$l)>>1);
104 | if($data[$middle]<$res) $l=$middle+1;
105 | else{
106 | if($middle==0 || $data[$middle-1]<$res ) return $middle;
107 | else $r=$middle-1;
108 | }
109 | }
110 |
111 | }
112 | $data=[2,5,6,7,8,8,10];
113 | $res=9;
114 | var_dump(binarySerach($data,$res));
115 | ```
116 | ****
117 |
118 | **针对数组是一个循环有序的数组Leetcode35题**
119 | ```php
120 |
121 | function binarySerach($data,$res)
122 | {
123 | $l=0;
124 | $r=count($data)-1;
125 | while($l<=$r){
126 | $middle=$l+(($r-$l)>>1);
127 | if($data[$middle]==$res) return $middle;
128 | elseif ($data[$middle]>$data[$r]){
129 | if($data[$l]<=$res && $data[$middle]>$res) $r=$middle-1;
130 | else $l=$middle+1;
131 | }else{
132 | if($data[$middle]<=$res && $data[$r] >$res) $r=$middle-1;
133 | else $l=$middle+1;
134 | }
135 | }
136 | }
137 | $data=[5,6,7,8,1,2,3,4];
138 | $res=7;
139 | var_dump(binarySerach($data,$res));
140 | ```
141 |
142 | **当然二分查找还有很多的应用场景,我就总结到这了。**
143 |
144 |
145 |
146 |
147 | ### 联系
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 |
157 |
--------------------------------------------------------------------------------
/计算机网络/HTTP2.md:
--------------------------------------------------------------------------------
1 | ## HTTP的基本优化
2 |
3 | 影响一个HTTP网络请求的因素主要有两个:带宽和延迟。
4 |
5 | - **带宽:**如果说我们还停留在拨号上网的阶段,带宽可能会成为一个比较严重影响请求的问题,但是现在网络基础建设已经使得带宽得到极大的提升,我们不再会担心由带宽而影响网速,那么就只剩下延迟了。
6 | - **延迟:**
7 |
8 | 1. **浏览器阻塞(HOL blocking)**:浏览器会因为一些原因阻塞请求。浏览器对于同一个域名,同时只能有 4 个连接(这个根据浏览器内核不同可能会有所差异),超过浏览器最大连接数限制,后续请求就会被阻塞。
9 | 2. **DNS 查询(DNS Lookup)**:浏览器需要知道目标服务器的 IP 才能建立连接。将域名解析为 IP 的这个系统就是 DNS。这个通常可以利用DNS缓存结果来达到减少这个时间的目的。
10 | 3. **建立连接(Initial connection)**:HTTP 是基于 TCP 协议的,浏览器最快也要在第三次握手时才能捎带 HTTP 请求报文,达到真正的建立连接,但是这些连接无法复用会导致每次请求都经历三次握手和[慢启动](http://en.wikipedia.org/wiki/Slow-start)。三次握手在高延迟的场景下影响较明显,慢启动则对文件类大请求影响较大。
11 |
12 |
13 |
14 | ## HTTP1.0和HTTP1.1的一些区别
15 |
16 | HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较为简单的网页上和网络请求上,而HTTP1.1则在1999年才开始广泛应用于现在的各大浏览器网络请求中,同时HTTP1.1也是当前使用最为广泛的HTTP协议。
17 |
18 | **主要区别主要体现在:**
19 |
20 | 1. **缓存处理,**在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
21 | 2. **带宽优化及网络连接的使用**,HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
22 | 3. **错误通知的管理**,在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
23 | 4. **Host头处理**,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
24 | 5. **长连接**,HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。以下是常见的HTTP1.0:
25 |
26 |
27 |
28 | ## **HTTP1.0和1.1现存的一些问题**
29 |
30 | 1. 上面提到过的,HTTP1.x在传输数据时,每次都需要重新建立连接,无疑增加了大量的延迟时间,特别是在移动端更为突出。
31 | 2. HTTP1.x在传输数据时,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份,这在一定程度上无法保证数据的安全性。
32 | 3. HTTP1.x在使用时,header里携带的内容过大,在一定程度上增加了传输的成本,并且每次请求header基本不怎么变化,尤其在移动端增加用户流量。
33 | 4. 虽然HTTP1.x支持了keep-alive,来弥补多次创建连接产生的延迟,但是keep-alive使用多了同样会给服务端带来大量的性能压力,并且对于单个文件被不断请求的服务(例如图片存放网站),keep-alive可能会极大的影响性能,因为它在文件被请求之后还保持了不必要的连接很长时间。
34 |
35 | ## **HTTPS与HTTP的一些区别**
36 |
37 | 1. HTTPS协议需要到CA申请证书,一般免费证书很少,需要交费。
38 | 2. HTTP协议运行在TCP之上,所有传输的内容都是明文,HTTPS运行在SSL/TLS之上,SSL/TLS运行在TCP之上,所有传输的内容都经过加密的。
39 | 3. HTTP和HTTPS使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
40 | 4. HTTPS可以有效的防止运营商劫持,解决了防劫持的一个大问题。
41 |
42 | 
43 |
44 | ## 使用SPDY加快你的网站速度
45 |
46 | SPDY的方案,大家才开始从正面看待和解决老版本HTTP协议本身的问题,SPDY可以说是综合了HTTPS和HTTP两者有点于一体的传输协议,主要解决:
47 |
48 | 1. **降低延迟**,针对HTTP高延迟的问题,SPDY优雅的采取了多路复用(multiplexing)。多路复用通过多个请求stream共享一个tcp连接的方式,解决了HOL blocking的问题,降低了延迟同时提高了带宽的利用率。
49 | 2. **请求优先级**(request prioritization)。多路复用带来一个新的问题是,在连接共享的基础之上有可能会导致关键请求被阻塞。SPDY允许给每个request设置优先级,这样重要的请求就会优先得到响应。比如浏览器加载首页,首页的html内容应该优先展示,之后才是各种静态资源文件,脚本文件等加载,这样可以保证用户能第一时间看到网页内容。
50 | 3. **header压缩**。前面提到HTTP1.x的header很多时候都是重复多余的。选择合适的压缩算法可以减小包的大小和数量。
51 | 4. **基于HTTPS的加密协议传输**,大大提高了传输数据的可靠性。
52 | 5. **服务端推送**(server push),采用了SPDY的网页,例如我的网页有一个sytle.css的请求,在客户端收到sytle.css数据的同时,服务端会将sytle.js的文件推送给客户端,当客户端再次尝试获取sytle.js时就可以直接从缓存中获取到,不用再发请求了。SPDY构成图:
53 |
54 | 
55 |
56 | SPDY位于HTTP之下,TCP和SSL之上,这样可以轻松兼容老版本的HTTP协议(将HTTP1.x的内容封装成一种新的frame格式),同时可以使用已有的SSL功能。
57 |
58 |
59 |
60 | ## HTTP2.0
61 |
62 | - **新的二进制格式**(Binary Format),HTTP1.x的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
63 | - **多路复用**(MultiPlexing),即连接共享,即每一个request都是是用作连接共享机制的。一个request对应一个id,这样一个连接上可以有多个request,每个连接的request可以随机的混杂在一起,接收方可以根据request的 id将request再归属到各自不同的服务端请求里面。**多路复用原理图**:
64 | - **header压缩,**如上文中所言,对前面提到过HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
65 | - **服务端推送**(server push),同SPDY一样,HTTP2.0也具有server push功能。目前,有大多数网站已经启用HTTP2.0,例如[YouTuBe](https://www.youtube.com/),[淘宝网](http://www.taobao.com/)等网站,利用chrome控制台可以查看是否启用H2
66 |
67 | 
68 |
69 | ```conf
70 | server {
71 | listen 443 ssl http2;
72 | server_name example.com;
73 | root /var/www/example.com/public;
74 |
75 | # SSL
76 | ssl_certificate /etc/live/example.com/fullchain.pem;
77 | ssl_certificate_key /etc/live/example.com/privkey.pem;
78 | ssl_trusted_certificate /etc/live/example.com/chain.pem;
79 |
80 | # index.html fallback
81 | location / {
82 | try_files $uri $uri/ /index.html;
83 | }
84 | }
85 |
86 | ```
--------------------------------------------------------------------------------
/计算机网络/HTTPS.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 |
--------------------------------------------------------------------------------
/计算机网络/IP协议.md:
--------------------------------------------------------------------------------
1 | ## IP协议
2 |
3 | > IP协议是TCP/IP协议簇中的核心协议,也是TCP/IP的载体。所有的TCP,UDP,ICMP及IGMP数据都以IP数据报格式传输。 IP提供**不可靠**的,**无连接**的数据传送服务。 不可靠指它不能保证IP数据报能成功到达目的地
4 |
5 | 不可靠(unreliable)的意思是它不能保证IP数据报能成功地到达目的地。IP仅提供最好的传输服务。如果发生某种错误时,如某个路由器暂时用完了缓冲区,IP有一个简单的错误处理算法:丢弃该数据报,然后发送ICMP消息报给信源端。任何要求的可靠性必须由上层来提供(如TCP)。
6 |
7 | 无连接(connectionless)这个术语的意思是IP并不维护任何关于后续数据报的状态信息。每个数据报的处理是相互独立的。这也说明,IP数据报可以不按发送顺序接收。如果一信源向相同的信宿发送两个连续的数据报(先是A,然后是B),每个数据报都是独立地进行路由选择,可能选择不同的路线,因此B可能在A到达之前先到达。
8 |
9 | 
10 |
11 |
12 |
13 | ## IP报文介绍
14 |
15 | 
16 |
17 | - 4位版本号。包含IP数据报的版本号:ipv4为4,ipv6为6
18 | - 4位首部长度
19 | - 8位服务类型
20 | - 16位总长度
21 | - 标识字段:长度为16位,最多分配的ID值为65535个
22 |
23 |
24 |
25 |
26 |
27 | ### IP地址分类
28 |
29 | IPV4被分为五大类:ABCDE
30 |
31 | A类为:点分四组中的第一组地址范围为0~127的IP地址。已二进制来看就是“首位为0”
32 |
33 | B类:128~191.二进制首位为10
34 |
35 | C类:192~223.二进制首位为110
36 |
37 | D类:224~239.二进制首位为1110
38 |
39 | E类:240~255.二进制首位为1111
--------------------------------------------------------------------------------
/计算机网络/README.md:
--------------------------------------------------------------------------------
1 | ### 概述
2 |
3 | 网络协议通常分不同层次进行开发,每一层分别负责不同的通信功能。一个协议族,比如TCP/IP,是一组不同层次上的多个协议的组合。TCP/IP通常被认为是一个四层协议系统.
4 |
5 | 
6 |
7 | 每一层负责不同的功能:
8 |
9 | 1. **链路层**,有时也称作数据链路层或网络接口层,通常包括操作系统中的设备驱动程序和计算机中对应的网络接口卡。它们一起处理与电缆(或其他任何传输媒介)的物理接口细节。
10 | 2. **网络层**,有时也称作互联网层,处理分组在网络中的活动,例如分组的选路。在TCP/IP协议族中,网络层协议包括IP协议(网际协议),ICMP协议(Internet互联网控制报文协议),以及IGMP协议(Internet组管理协议)。
11 | 3. **运输层** 主要为两台主机上的应用程序提供端到端的通信。在TCP/IP协议族中,有两个互不相同的传输协议:TCP(传输控制协议)和UDP(用户数据报协议)。
12 | TCP为两台主机提供高可靠性的数据通信。它所做的工作包括把应用程序交给它的数据分成合适的小块交给下面的网络层,确认接收到的分组,设置发送最后确认分组的超时时钟等。由于运输层提供了高可靠性的端到端的通信,因此应用层可以忽略所有这些细节。
13 | 而另一方面,UDP则为应用层提供一种非常简单的服务。它只是把称作数据报的分组从一台主机发送到另一台主机,但并不保证该数据报能到达另一端。任何必需的可靠性必须由应用层来提供。
14 | 这两种运输层协议分别在不同的应用程序中有不同的用途,这一点将在后面看到。
15 | 4. **应用层** 负责处理特定的应用程序细节。几乎各种不同的TCP/IP实现都会提供下面这些通用的应用程序:
16 | • Telnet远程登录。• FTP文件传输协议。• SMTP简单邮件传送协议。• SNMP简单网络管理协议。
17 |
18 |
19 | 
20 |
21 |
22 |
23 | ### 互联网地址
24 |
25 | 互联网上的每个接口必须有一个唯一的Internet地址(也称作IP地址)。IP地址长32 bit。Internet地址并不采用平面形式的地址空间,如1、2、3等。IP地址具有一定的结构,五类不同的互联网地址格式如图1-5所示。
26 |
27 | 
28 |
29 | ### 用户数据封装和分用
30 |
31 | 应用程序用TCP传送数据时,数据被送入协议栈中,然后逐个通过每一层直到被当作一串比特流送入网络。其中每一层对收到的数据都要增加一些首部信息(有时还要增加尾部信息),该过程如图1-7所示。TCP传给IP的数据单元称作TCP报文段或简称为TCP段(TCP segment)。IP传给网络接口层的数据单元称作IP数据报(IP datagram)。通过以太网传输的比特流称作帧(Frame)
32 |
33 | 
34 |
35 | 当目的主机收到一个以太网数据帧时,数据就开始从协议栈中由底向上升,同时去掉各层协议加上的报文首部。每层协议盒都要去检查报文首部中的协议标识,以确定接收数据的上层协议。这个过程称作分用(Demultiplexing)
36 |
37 | 
38 |
39 | ### 端口号
40 |
41 | 服务器一般通过端口号来识别对应的应用程序。TCP和UDP采用16 bit的端口号来识别应用程序。任何TCP/IP实现所提供的服务都用知名的1~1023之间的端口号。大多数TCP/IP实现给临时端口分配1024~5000之间的端口号。大于5000的端口号是为其他服务器预留的(Internet上并不常用的服务)
42 |
43 | > 到1992年为止,知名端口号介于1~255之间。256~1023之间的端口号通常都是由Unix系统占用,以提供一些特定的Unix服务—也就是说,提供一些只有Unix系统才有的、而其他操作系统可能不提供的服务。现在IANA管理1~1023之间所有的端口号。
44 |
45 |
46 |
47 | ### 应用编程
48 |
49 | TCP/IP协议的应用程序通常采用两种应用编程接口(API):socket和TLI(运输层接口:Transport Layer Interface)
--------------------------------------------------------------------------------
/计算机网络/UDP协议.md:
--------------------------------------------------------------------------------
1 | # UDP(用户数据报协议)
2 |
3 | > 用户数据报协议(User Datagram Protocol,UDP)UDP是OSI参考模型中一种无连接的传输层协议,它主要用于不要求分组顺序到达的传输中,分组传输顺序的检查与排序由应用层完成 ,提供面向事务的简单不可靠信息传送服务。
4 |
5 |
6 | ## 一、UDP协议
7 |
8 | 1、面向事物,不是面向链接
9 |
10 | 2、UDP不提供可靠性:它把应用程序传给IP层的数据发送出去,但是并不保证它们能到达目的地
11 |
12 | 简单的可以理解UDP就是类似一个邮寄员的角色。你只要告诉它,对方的地址和电话。邮递员就把你的快递送到对应的地方,但是中间可能会丢失。对方收到没有,就不管了。
13 |
14 | ## UDP头部信息
15 |
16 | > 指定通信的源端端口号、目的端端口号、UDP长度、校验和、数据
17 |
18 | 
19 | 
20 |
21 |
22 |
23 | UDP报文各个位置详解:
24 |
25 | - 1、源端口号,16bit
26 | - 2、目的端口号:数据接收者的端口号,16bit
27 | - 3、UDP长度:UDP长度字段指的是UDP首部和UDP数据的字节长度。该字段的最小值为8字节
28 | - 4、UPD校验和:UDP检验和覆盖UDP首部和UDP数据
29 | - 5、首部长度:首部中32bit字的数目,可表示15*32bit=60字节的首部。一般首部长度为20字节。
30 | - 6、数据
31 |
32 |
33 | 使用**wireshark**抓包查看对应的字段信息。
34 |
35 | 
36 |
37 | UDP 是一个简单的传输层协议。和 TCP 相比,UDP 有下面几个显著特性:
38 |
39 | - UDP 缺乏可靠性。UDP 本身不提供确认,序列号,超时重传等机制。UDP 数据报可能在网络中被复制,被重新排序。即 UDP 不保证数据报会到达其最终目的地,也不保证各个数据报的先后顺序,也不保证每个数据报只到达一次
40 | - UDP 数据报是有长度的。每个 UDP 数据报都有长度,如果一个数据报正确地到达目的地,那么该数据报的长度将随数据一起传递给接收方。而 TCP 是一个字节流协议,没有任何(协议上的)记录边界。
41 | - UDP 是无连接的。UDP 客户和服务器之前不必存在长期的关系。UDP 发送数据报之前也不需要经过握手创建连接的过程。
42 | - UDP 支持多播和广播。
--------------------------------------------------------------------------------
/计算机网络/images/01.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/01.png
--------------------------------------------------------------------------------
/计算机网络/images/02.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/02.png
--------------------------------------------------------------------------------
/计算机网络/images/04.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/04.png
--------------------------------------------------------------------------------
/计算机网络/images/5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/5.png
--------------------------------------------------------------------------------
/计算机网络/images/6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/6.png
--------------------------------------------------------------------------------
/计算机网络/images/http2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/http2.png
--------------------------------------------------------------------------------
/计算机网络/images/https.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/https.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-2.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-byte-stream.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-byte-stream.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect-1-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect-1-1.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect-1-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect-1-2.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect-1.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect-2-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect-2-1.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect-2-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect-2-2.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect-3-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect-3-1.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect-3-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect-3-2.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect-4-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect-4-1.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect-4-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect-4-2.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-four-disconnect.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-four-disconnect.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-handshake-1-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-handshake-1-1.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-handshake-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-handshake-1.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-handshake-2-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-handshake-2-1.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-handshake-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-handshake-2.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-handshake-3-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-handshake-3-1.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-handshake-3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-handshake-3.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-ip-header-map.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-ip-header-map.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-ip-protocal.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-ip-protocal.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-packets-header.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-packets-header.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-three-way-handshake.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-three-way-handshake.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-three-way-handshake2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-three-way-handshake2.png
--------------------------------------------------------------------------------
/计算机网络/images/tcp-wireshark.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/tcp-wireshark.png
--------------------------------------------------------------------------------
/计算机网络/images/udp-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/udp-1.png
--------------------------------------------------------------------------------
/计算机网络/images/udp-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/udp-2.png
--------------------------------------------------------------------------------
/计算机网络/images/udp-3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/计算机网络/images/udp-3.png
--------------------------------------------------------------------------------
/设计模式/Behavioral.md:
--------------------------------------------------------------------------------
1 | ## 行为型设计模式
2 |
3 | ### 1. 观察者模式
4 |
5 | > Behavioral定义对象间一种一对多的依赖关系,使得当一个对象改变状态,则所有依赖于它的对象都会得到通知并被自动更新。
6 |
7 | Subject 被观察者。是一个接口或者是抽象类,定义被观察者必须实现的职责,它必须能偶动态地增加、取消观察者,管理观察者并通知观察者。
8 |
9 | Observer 观察者。观察者接收到消息后,即进行 update 更新操作,对接收到的信息进行处理。
10 |
11 | ConcreteSubject 具体的被观察者。定义被观察者自己的业务逻辑,同时定义对哪些事件进行通知。
12 |
13 | ConcreteObserver 具体观察者。每个观察者在接收到信息后处理的方式不同,各个观察者有自己的处理逻辑。
14 |
15 |
16 |
17 | 观察者模式简单的理解,就是当一个类改变的时候,通知另外一个类进行做出处理。比如我们用户在注册成功的时候,会发送短信提醒。我们可以利用观察者模式,实现应用的解耦。
18 |
19 | ```php
20 | //抽象主题类
21 | interface Subject
22 | {
23 | public function attach(Observer $Observer);
24 |
25 | public function detach(Observer $observer);
26 |
27 | //通知所有注册过的观察者对象
28 | public function notifyObservers();
29 | }
30 |
31 | //具体主题角色
32 |
33 |
34 | class ConcreteSubject implements Subject
35 | {
36 | private $_observers;
37 |
38 | public function __construct()
39 | {
40 | $this->_observers = array();
41 | }
42 |
43 | //增加一个观察者对象
44 | public function attach(Observer $observer)
45 | {
46 | return array_push($this->_observers,$observer);
47 | }
48 |
49 | //删除一个已经注册过的观察者对象
50 |
51 | public function detach(Observer $observer)
52 | {
53 | $index = array_search($observer,$this->_observers);
54 | if($index === false || !array_key_exists($index, $this->_observers))
55 | return false;
56 | unset($this->_observers[$index]);
57 | return true;
58 | }
59 |
60 | //通知所有注册过的观察者
61 | public function notifyObservers()
62 | {
63 | if(!is_array($this->_observers)) return false;
64 | foreach($this->_observers as $observer)
65 | {
66 | $observer->update();
67 | }
68 | return true;
69 | }
70 | }
71 |
72 |
73 | //抽象观察者角色
74 |
75 | interface Observer
76 | {
77 | //更新方法
78 | public function update();
79 | }
80 |
81 | //观察者实现
82 | class ConcreteObserver implements Observer
83 | {
84 | private $_name;
85 |
86 | public function __construct($name)
87 | {
88 | $this->_name = $name;
89 | }
90 |
91 | //更新方法
92 |
93 | public function update()
94 | {
95 | echo 'Observer'.$this->_name.' has notify';
96 | }
97 | }
98 |
99 | $Subject = new ConcreteSubject();
100 |
101 | //添加第一个观察者
102 |
103 | $observer1 = new ConcreteObserver('baixiaoshi');
104 | $Subject->attach($observer1);
105 | echo 'the first notify:';
106 | $Subject->notifyObservers();
107 |
108 | //添加第二个观察者
109 | $observer2 = new ConcreteObserver('hurong');
110 | echo '
second notify:';
111 | $Subject->attach($observer2);
112 |
113 | ```
114 |
115 | - 利用SPLObserver 和SplSubject
116 |
117 | ```php
118 | SplSubject {
119 | /* 方法 */
120 | abstract public void attach ( SplObserver $observer )
121 | abstract public void detach ( SplObserver $observer )
122 | abstract public void notify ( void )
123 | }
124 | SplObserver {
125 | /* 方法 */
126 | abstract public void update ( SplSubject $subject )
127 | }
128 | ```
129 |
130 | ```php
131 | /**
132 | * Subject,that who makes news
133 | */
134 | class Newspaper implements \SplSubject{
135 | private $name;
136 | private $observers = array();
137 | private $content;
138 |
139 | public function __construct($name) {
140 | $this->name = $name;
141 | }
142 |
143 | //add observer
144 | public function attach(\SplObserver $observer) {
145 | $this->observers[] = $observer;
146 | }
147 |
148 | //remove observer
149 | public function detach(\SplObserver $observer) {
150 |
151 | $key = array_search($observer,$this->observers, true);
152 | if($key){
153 | unset($this->observers[$key]);
154 | }
155 | }
156 |
157 | //set breakouts news
158 | public function breakOutNews($content) {
159 | $this->content = $content;
160 | $this->notify();
161 | }
162 |
163 | public function getContent() {
164 | return $this->content." ({$this->name})";
165 | }
166 |
167 | //notify observers(or some of them)
168 | public function notify() {
169 | foreach ($this->observers as $value) {
170 | $value->update($this);
171 | }
172 | }
173 | }
174 |
175 | /**
176 | * Observer,that who recieves news
177 | */
178 | class Reader implements SplObserver{
179 | private $name;
180 |
181 | public function __construct($name) {
182 | $this->name = $name;
183 | }
184 |
185 | public function update(\SplSubject $subject) {
186 | echo $this->name.' is reading breakout news '.$subject->getContent().'
';
187 | }
188 | }
189 |
190 | $newspaper = new Newspaper('Newyork Times');
191 |
192 | $allen = new Reader('Allen');
193 | $jim = new Reader('Jim');
194 | $linda = new Reader('Linda');
195 |
196 | //add reader
197 | $newspaper->attach($allen);
198 | $newspaper->attach($jim);
199 | $newspaper->attach($linda);
200 |
201 | //remove reader
202 | $newspaper->detach($linda);
203 |
204 | //set break outs
205 | $newspaper->breakOutNews('USA break down!');
206 | ```
207 |
208 |
209 |
210 | ## 参考资料
211 |
212 | - [http://php.net/manual/zh/class.splobserver.php#112587](http://php.net/manual/zh/class.splobserver.php#112587)
213 | - [http://designpatternsphp.readthedocs.io/en/latest/Behavioral/Observer/README.html](http://designpatternsphp.readthedocs.io/en/latest/Behavioral/Observer/README.html)
214 |
215 |
--------------------------------------------------------------------------------
/设计模式/Creational.md:
--------------------------------------------------------------------------------
1 | ## 工厂模式
2 |
3 | ### 1. 简单工厂
4 |
5 | 简单工厂就是一个工厂,只创建一个单一的类。不能创建其他的类,这就是简单工厂
6 |
7 | ```php
8 | class Factory {
9 |
10 | public function create()
11 | {
12 | return new A();
13 | }
14 | }
15 |
16 | ```
17 |
18 | 这个简单的工厂只能创建A类。
19 |
20 | ### 2. 工厂方法
21 |
22 | - [模式动机](http://design-patterns.readthedocs.io/zh_CN/latest/creational_patterns/factory_method.html#id16)
23 |
24 | 关于工厂模式的定义动机可以查阅[工厂模式](http://design-patterns.readthedocs.io/zh_CN/latest/creational_patterns/factory_method.html#id17)。
25 |
26 | 我只写下自己的理解
27 |
28 | 有些时候,我们需要一个工厂创建不同的产品。比如军工厂既能创建子弹,又能创建枪。
29 |
30 | 工厂方法模式包含如下角色:
31 |
32 | - Product:抽象产品
33 | - ConcreteProduct:具体产品
34 | - Factory:抽象工厂
35 | - ConcreteFactory:具体工厂
36 |
37 | 
38 |
39 |
40 |
41 | ```php
42 | interface Ifactory{
43 | public function create($type);
44 | }
45 |
46 | class Factory implements Ifactory{
47 | public function create($type){
48 | if($type == 'A') {
49 | return new A();
50 | } else if($type == 'B') {
51 | return new B();
52 | }
53 | }
54 | }
55 | ```
56 |
57 | ### 3. 抽象工厂
58 |
59 | [抽象工厂详细介绍](http://design-patterns.readthedocs.io/zh_CN/latest/creational_patterns/abstract_factory.html)
60 |
61 | 简单的个人理解:抽象工厂是为了创建不同的类型的产品。抽象出工厂。让不同的工厂创建不同的产品
62 |
63 | 举个例子。比如抽象军工厂。军工厂A生产枪,军工厂B生产子弹。
64 |
65 | 
66 |
67 | 代码可以参考
68 |
69 | [https://github.com/domnikl/DesignPatternsPHP/blob/master/Creational/AbstractFactory](https://github.com/domnikl/DesignPatternsPHP/blob/master/Creational/AbstractFactory)
--------------------------------------------------------------------------------
/设计模式/README.md:
--------------------------------------------------------------------------------
1 | ## 设计模式
2 |
3 | > 设计模式(Design pattern)代表了最佳的实践,通常被有经验的面向对象的软件开发人员所采用。设计模式是软件开发人员在软件开发过程中面临的一般问题的解决方案。这些解决方案是众多软件开发人员经过相当长的一段时间的试验和错误总结出来的。
4 |
5 | 设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结。使用设计模式是为了重用代码、让代码更容易被他人理解、保证代码可靠性。 毫无疑问,设计模式于己于他人于系统都是多赢的,设计模式使代码编制真正工程化,设计模式是软件工程的基石,如同大厦的一块块砖石一样。项目中合理地运用设计模式可以完美地解决很多问题,每种模式在现实中都有相应的原理来与之对应,每种模式都描述了一个在我们周围不断重复发生的问题,以及该问题的核心解决方案,这也是设计模式能被广泛应用的原因
6 |
7 | ### 设计模式的类型
8 |
9 | 根据设计模式的参考书 **Design Patterns - Elements of Reusable Object-Oriented Software(中文译名:设计模式 - 可复用的面向对象软件元素)** 中所提到的,总共有 23 种设计模式。这些模式可以分为三大类:创建型模式(Creational Patterns)、结构型模式(Structural Patterns)、行为型模式(Behavioral Patterns)
10 |
11 | | 序号 | 模式 & 描述 | 包括 |
12 | | ---- | ------------------------------------------------------------ | ------------------------------------------------------------ |
13 | | 1 | **创建型模式** 这些设计模式提供了一种在创建对象的同时隐藏创建逻辑的方式,而不是使用 new 运算符直接实例化对象。这使得程序在判断针对某个给定实例需要创建哪些对象时更加灵活。 | 工厂模式(Factory Pattern)抽象工厂模式(Abstract Factory Pattern)单例模式(Singleton Pattern)建造者模式(Builder Pattern)原型模式(Prototype Pattern) |
14 | | 2 | **结构型模式** 这些设计模式关注类和对象的组合。继承的概念被用来组合接口和定义组合对象获得新功能的方式。 | 适配器模式(Adapter Pattern)桥接模式(Bridge Pattern)过滤器模式(Filter、Criteria Pattern)组合模式(Composite Pattern)装饰器模式(Decorator Pattern)外观模式(Facade Pattern)享元模式(Flyweight Pattern)代理模式(Proxy Pattern) |
15 | | 3 | **行为型模式** 这些设计模式特别关注对象之间的通信。 | 责任链模式(Chain of Responsibility Pattern)命令模式(Command Pattern)解释器模式(Interpreter Pattern)迭代器模式(Iterator Pattern)中介者模式(Mediator Pattern)备忘录模式(Memento Pattern)观察者模式(Observer Pattern)状态模式(State Pattern)空对象模式(Null Object Pattern)策略模式(Strategy Pattern)模板模式(Template Pattern)访问者模式(Visitor Pattern) |
16 |
17 | ### 设计模式的六大原则
18 |
19 | **1、开闭原则(Open Close Principle)**
20 |
21 | 开闭原则的意思是:**对扩展开放,对修改关闭**。在程序需要进行拓展的时候,不能去修改原有的代码,实现一个热插拔的效果。简言之,是为了使程序的扩展性好,易于维护和升级。想要达到这样的效果,我们需要使用接口和抽象类,
22 |
23 | > 实现热插拔,提高扩展性。
24 |
25 | **2、里氏代换原则(Liskov Substitution Principle)**
26 |
27 | 里氏代换原则是面向对象设计的基本原则之一。 里氏代换原则中说,任何基类可以出现的地方,子类一定可以出现。LSP 是继承复用的基石,只有当派生类可以替换掉基类,且软件单位的功能不受到影响时,基类才能真正被复用,而派生类也能够在基类的基础上增加新的行为。里氏代换原则是对开闭原则的补充。实现开闭原则的关键步骤就是抽象化,而基类与子类的继承关系就是抽象化的具体实现,所以里氏代换原则是对实现抽象化的具体步骤的规范。
28 |
29 | > 实现抽象的规范,实现子父类互相替换;
30 |
31 | **3、依赖倒转原则(Dependence Inversion Principle)**
32 |
33 | 这个原则是开闭原则的基础,具体内容:针对接口编程,依赖于抽象而不依赖于具体。
34 |
35 | > 针对接口编程,实现开闭原则的基础;
36 |
37 | **4、接口隔离原则(Interface Segregation Principle)**
38 |
39 | 这个原则的意思是:使用多个隔离的接口,比使用单个接口要好。它还有另外一个意思是:降低类之间的耦合度。由此可见,其实设计模式就是从大型软件架构出发、便于升级和维护的软件设计思想,它强调降低依赖,降低耦合。
40 |
41 | > 降低耦合度,接口单独设计,互相隔离;
42 |
43 | **5、迪米特法则,又称最少知道原则(Demeter Principle)**
44 |
45 | 最少知道原则是指:一个实体应当尽量少地与其他实体之间发生相互作用,使得系统功能模块相对独立。
46 |
47 | > 功能模块尽量独立
48 |
49 | **6、合成复用原则(Composite Reuse Principle)**
50 |
51 | 合成复用原则是指:尽量使用合成/聚合的方式,而不是使用继承。
52 |
53 | > 尽量使用聚合,组合,而不是继承;
--------------------------------------------------------------------------------
/设计模式/Structural.md:
--------------------------------------------------------------------------------
1 | ## 结构型
2 |
3 | 结构型模式(Structural Pattern)描述如何将类或者对 象结合在一起形成更大的结构,就像搭积木,可以通过 简单积木的组合形成复杂的、功能更为强大的结构。
4 |
5 | ### 1. 适配器模式
6 |
7 | 适配器模式(Adapter Pattern) :将一个接口转换成客户希望的另一个接口,适配器模式使接口不兼容的那些类可以一起工作,其别名为包装器(Wrapper)。适配器模式既可以作为类结构型模式,也可以作为对象结构型模式。
8 |
9 | 适配器就是一种适配中间件,它存在于不匹配的二者之间,用于连接二者,将不匹配变得匹配,简单点理解就是平常所见的转接头,转换器之类的存在。
10 |
11 | 适配器模式包含如下角色:
12 |
13 | - Target:目标抽象类
14 | - Adapter:适配器类
15 | - Adaptee:适配者类
16 | - Client:客户类
17 |
18 | 
19 |
20 | #### 类适配器
21 |
22 | 一句话描述:Adapter类,通过**继承** src类,**实现** dst 类**接口**,完成src->dst的适配。
23 |
24 | 用电源适配器举例,我们需要5v的直流电,但是现在有的是220v的交流电。需要通过适配器转换
25 |
26 | 
27 |
28 | ```php
29 | class V220{
30 | public function output220V()
31 | {
32 | return "220";
33 | }
34 | }
35 | interface V5{
36 | public function output5V()
37 | {
38 |
39 | }
40 | }
41 |
42 | class Adapter extends V220 implements V5{
43 | //将220v转化成5v
44 | public function output5V()
45 | {
46 | $v = $this->output220V();
47 | return $v/44;
48 | }
49 | }
50 |
51 | ```
52 |
53 | 这里可能有人会问,直接写一个类,然后 返回对应的5v不就行了吗。但是我们适配器模式的是将不合适的类,通过一个接口转成合适的。你直接写一个类的话,就是增加了一个类。而不是利用原来的类的功能。
54 |
55 | #### 对象适配器
56 |
57 | 基本思路和类的适配器模式相同,只是将Adapter类作修改,这次不继承src类,而是持有src类的实例,以解决**兼容性**的问题。 即:**持有** src类,**实现** dst 类**接口**,完成src->dst的适配。 (根据“合成复用原则”,在系统中**尽量使用关联关系来替代继承关系**,因此大部分结构型模式都是对象结构型模式。)
58 |
59 | ```php
60 | class Adapter implements V5{
61 | public $v;
62 | public function __construct(V220 $v200)
63 | {
64 | $this->v = $v200
65 | }
66 | public function output5V()
67 | {
68 | if(!$this->v) {
69 | $v = $this->v->output220V();
70 | return $v/44;
71 | }
72 |
73 | return 0;
74 | }
75 | }
76 | ```
77 |
78 | 
79 |
80 | ### 2. 装饰器模式
81 |
82 | > 装饰模式(Decorator Pattern) :动态地给一个对象增加一些额外的职责(Responsibility),就增加对象功能来说,装饰模式比生成子类实现更为灵活。其别名也可以称为包装器(Wrapper),与适配器模式的别名相同,但它们适用于不同的场合。根据翻译的不同,装饰模式也有人称之为“油漆工模式”,它是一种对象结构型模式。
83 |
84 | 装饰模式包含如下角色:
85 |
86 | - Component: 抽象构件
87 | - ConcreteComponent: 具体构件
88 | - Decorator: 抽象装饰类
89 | - ConcreteDecorator: 具体装饰类
90 |
91 | 
92 |
93 |
94 |
95 | ```php
96 | interface Component{
97 | public function run(){}
98 | }
99 |
100 | class Car implements Component{
101 | public function run(){
102 | echo " I am run";
103 | }
104 | }
105 |
106 | class Decorator {
107 | public function __construct(Car $car)
108 | {
109 | $this->car = $car;
110 | }
111 | public function run()
112 | {
113 | $this->car->run();
114 | $this->fly();
115 | }
116 | protected function fly()
117 | {
118 | echo "fly";
119 | }
120 | }
121 |
122 | $car = new Car();
123 |
124 | $decorator = new Decorator();
125 |
126 | ```
127 |
128 |
129 |
130 | ### 3. 门面模式
131 |
132 | 部与一个子系统的通信必须通过一个统一的门面(Facade)对象进行,这就是门面模式
133 |
134 | 
135 | 
136 |
137 |
138 |
139 |
140 |
141 |
142 | 在这个对象图中,出现了两个角色:
143 |
144 | 门面(Facade)角色:客户端可以调用这个角色的方法。此角色知晓相关的(一个或者多个)子系统的功能和责任。在正常情况下,本角色会将所有从客户端发来的请求委派到相应的子系统去。
145 |
146 | 子系统(subsystem)角色:可以同时有一个或者多个子系统。每一个子系统都不是一个单独的类,而是一个类的集合。每一个子系统都可以被客户端直接调用,或者被门面角色调用。子系统并不知道门面的存在,对于子系统而言,门面仅仅是另外一个客户端而已。
147 |
148 | 简单的理解。就是门面模式就是解决客户端调用子系统的复杂度,为客户端提供统一的调用
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 | ### 阅读资料
157 |
158 | - [适配器模式](https://blog.csdn.net/zxt0601/article/details/52848004)
--------------------------------------------------------------------------------
/面试/01.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/no-serve-people/PHP-Interview/f9a7cfc5d30d2d491cb6c7c9c7826a1f7b69e1f9/面试/01.png
--------------------------------------------------------------------------------
/面试/01离职原因回答.md:
--------------------------------------------------------------------------------
1 | ## 离职原因回答
2 |
3 | ### 1. 外交语言
4 |
5 | 跳槽的目的,正常来说应该是**加薪**、**晋级**、**换行**,理论上三者都占才好,实际中只要有一个能满足,就算成功跳槽。
6 |
7 | 对于在职跳槽的人,尽量就这一句话“**追求更好的事业发展**”,官话为主;
8 |
9 | 对方如果问你“王先生,请问你离职的原因是什么呢?”你直接回答“**追求更好的职业发展**”即可;
10 |
11 | 对方再追问:“离职总有个理由吧,请问您辞职的理由到底是什么?”还是回答刚刚那句话“**为了追求更好的事业发展。**”这里就不咬文嚼字了,职业发展、事业发展,都一样。
12 |
13 |
14 |
15 | 总之,三种情况下的**外交语言**,你懂就行,顺便你也体会下啥叫外交语言。
16 |
17 | - 问:“请问您对美国军舰这次驶入南海岛屿12海里以内的航行自由行动,怎么看?”
18 | - **外交语言答:“我们的立场是明确的,请域外国家不要搅乱南海秩序。”**
19 | - 继续问:“这明显是对中方的不尊重和挑衅,请问你们下一步如何应对?”
20 | - **外交语言继续答:“我们的立场是一贯的,希望域外国家不要搅乱南海安宁。”**
21 |
22 | ### 2. **不说前雇主坏话**
23 |
24 |
25 |
26 | 任何前雇主、前领导、前同事的坏话,都不要说,实在对方问到你“**如何评价你的前雇主?**”你也要说它的好,说公司好,生意好,氛围好,同事好,最起码**别说他们的坏**。
27 |
28 | 如果对方追问“**既然这么好,你为何辞职?**”应对之法当然还是那几个原因:**“追求更好的职业发展”“因为个人原因”“家里有事”“是贵司通过猎头联系到我,我正好觉得这个职位更适合我......”**
29 |
30 |
31 |
32 | ### 3. **不能说自己创业过**
33 |
34 | **从负责招人的HR角度来讲**,创业的人是最不稳定的,有野心的,万一招你进来几个月不到你又创业去了,跑了,HR不是自打嘴巴?
35 |
36 | ### 4. **尽量不说裁员遭遇**
37 |
38 | **无论是自发、他发还是不可抗力(企业破产、撤资)导致的你突然失业了,都尽量不要提及自己被裁员的遭遇。**
--------------------------------------------------------------------------------
/面试/02写简历.md:
--------------------------------------------------------------------------------
1 | 简历当然是按照人来分的:应届生的简历,失业人员的简历,跳槽人士的简历
2 |
3 |
4 |
5 | **最基本的“个人信息”是最重要的,这决定了你能否进入下一轮需要精选的那50人清单**
6 |
7 | 出生日期你得将这一项改成“出生年份”
8 |
9 | 学历方面:要写你的最高学历。如果你学历不高比如是大专,则你可以写个“本科在读”
10 |
11 | **目前职位**:简历上写
12 |
13 | **目前薪资**:写你过去12个月包括各种奖金在内的月均税前工资。这点很重要,新岗位的工资都是基于你的目前工资,适当给一个增幅。
14 |
15 | **期望薪水**:
16 |
17 | 这最重要,期望薪资不能过高,也不可过低,更不能不写,你是个在职人士,目前薪资你完全了解,岂能期望薪资没有要求?你自作聪明,写个“面议”,实际上就已经错失了大多数面试的机会了。人事专员会看你的数字,是否落在她的预算区间。为了避免误判,你的期望薪资最好也写一个区间。
18 |
19 | **个人综述部分,5条即可,最重要的是某一个行业中某个专业领域的工作年数,其次你有而他人没有的资历、证书、技能、品质等**
20 |
21 | 能在强大压力下工作,可适应出差
22 |
23 | **企业招人,更主要是看此人作为合格候选者的职场综合素质,却不是简历中具体某一条你的工作内容描述**
24 |
25 |
26 |
27 | **在收到第一份Offer之后,不要急着提出辞职,而是将简历上的期望薪水调整下,在目前这个Offer的基础上,再增加30%继续投递简历,争取更好的面试机会**
28 |
29 |
30 |
31 | **新工作转正之前,不要掉以轻心,工作要上进,加加班牺牲点私人时间,也是有必要的**
32 |
33 | ## 工作经验
34 |
35 | 简写四-六个为佳。
36 |
37 | **工作经验按照时间的倒序来列出来,每家的工作经历都最好加上序列号列成条数**
38 |
39 |
--------------------------------------------------------------------------------
/面试/03裸辞应对.md:
--------------------------------------------------------------------------------
1 | 裸辞后的战略就是,**先低姿态入职,然后在职跳槽,第二个雇主才是自己真正的目标东家**。这是一种明智、理性、务实的可行策略,也叫做“曲线救国”。
2 |
3 | **简历投递出去有大概20天的滞后期**。
4 |
5 | 裸辞前的另一个准备:**3)先找一家能帮你代缴保险的公司或者中介**。
6 |
7 | ## **背景调查**
8 |
9 | 1. **离职证明,**
10 | 2. **工资证明,**
11 | 3. **上家单位顶头上司的联系方式,**
12 | 4. **上家单位的至少一位证明人及其联系电话,**
13 | 5. **上家单位人事专员或人事经理的姓名和电话,**
14 | 6. **你之前6个月的银行工资流水。**
15 |
16 |
--------------------------------------------------------------------------------
/面试/04面试提问.md:
--------------------------------------------------------------------------------
1 | ## 面试提问
2 |
3 | 面试到最后的时候,通常会让你提问。这个时候,你需要准备好几个问题。表示你有准备的。不要最后一面,不要问薪资。
4 |
5 | 1. 贵公司这个职位是新增还是接手离职员工的任务
6 |
7 | 了解公司招聘人的目的。
8 |
9 | 2. 贵公司一般的团队是多大,几个人负责一个产品或者业务?
10 |
11 | 了解公司的实力,这个一般在官网都有介绍,但是你听下里面的人介绍下,更了解里面的情况
12 |
13 | 3. 贵公司的开发中是否会使用到一些最新技术
14 |
15 | 了解公司的技术栈,更好的对自己的职业发展。
16 |
17 | 4. 贵公司之前遇到了什么样的技术难题,怎么解决的?
18 |
19 | 这个可以当作学习的例子。对方可能之前问过你之前的项目的技术难题,这个你可以反问,来学习对方的技术难题,以及方案。
20 |
21 | 5. 你觉得我有哪些需要提高的地方 ?可以给我点建议吗?
22 |
23 | 需要对方给自己简单的评价,完善自己的不足。
24 |
25 | 6. 您觉得这个职位未来几年的职业发展是怎样的
26 |
27 | 了解该职位是不是和未来的职业规划相符。间件的询问有没有晋升的机会。
--------------------------------------------------------------------------------
/面试/05谈薪资.md:
--------------------------------------------------------------------------------
1 | 谈薪资的时候,基本上是我们到了面试的最后的步骤了,这个时候,你的报价决定你以后的工作的工资的多少。也是很关键的一步,我之前面试的就是由于缺乏经验,导致自己报价低了。然后入职之后再往上加,就很难了。
2 |
3 |
4 |
5 | 在我们面试的时候,我们**尽量不要先出牌**,比如我们在填表格的时候,期望薪资, 可以写上面谈,或者写一个范围区间。不要写一个具体的数字,因为很多hr人员都会压低你的工资。比如你写的是20k,可能hr会给你18k。
6 |
7 | - 你期望的薪资是多少?
8 |
9 | **了解该公司所在地区、所属行业、公司规模等信息**,你的薪水要求应该在该公司所在地 区、行业、公司规模相应的薪水范围之内。**尽可能提供一个你期望的薪水范围,而不是具体的薪金数。** 了解具体的福利情况。好的福利可以让你的薪资加上不少。比如有的公司是15薪,然后公司稍低点,有的工资高,但是福利少。你可以权衡一下。
10 |
11 |
12 |
13 | - 你的上一份的薪资是多少?
14 |
15 | 问你这个问题的时候,是想知道和你当前薪资对比,比如你上一份是10k ,这次你报价20k,别人应该只会给你15k。所以上一份的薪资,应该和本次的报价,不是特别差别大。但是也不能一样。不然你跳槽就没不涨薪,上一份的薪资,你就应该把你的福利也加上。比如你有绩效奖金,薪资调整都加上,得到一个范围值,不要告诉具体的数值。比如你薪资15k,你加上乱七八糟的,你可以说15-18k之间。
16 |
17 | - 你认为每年的加薪幅度是多少?
18 |
19 | 提示:通常, 比较可靠的回答是: 你希望收入的增长和生活水平的提高保持一致。你还应该提到,
20 |
21 | 你的业绩将是加薪的主要因素
22 |
23 | **求职者** : 总体来说,取决于我个人的业绩和公司的业绩(盈利状况)。但一般而言,至少和生活水平的提高保持一致。
24 |
25 |
26 |
27 | 在面试过程中,我们做的准备与实际遇到的问题总会有一些出入。记得大致的原则,巧妙的随机应变。懂得自己在市场中的定位,将对薪资的确定更为有利。
28 |
--------------------------------------------------------------------------------
/面试/README.md:
--------------------------------------------------------------------------------
1 | ## 面试
2 |
3 | 这部分主要写关于面试的一些问题,如面对人事的关于离职原因的问题的回答,如何写一个简历?在面试的最后环节,怎么提问?以及一些自己搜集和整理的笔试题。
4 |
5 | - [离职原因回答](https://github.com/xianyunyh/PHP-Interview/blob/master/%E9%9D%A2%E8%AF%95/01%E7%A6%BB%E8%81%8C%E5%8E%9F%E5%9B%A0%E5%9B%9E%E7%AD%94.md)
6 |
7 | - [写简历](https://github.com/xianyunyh/PHP-Interview/blob/master/%E9%9D%A2%E8%AF%95/02%E5%86%99%E7%AE%80%E5%8E%86.md)
8 |
9 | - [裸辞应对](https://github.com/xianyunyh/PHP-Interview/blob/master/%E9%9D%A2%E8%AF%95/03%E8%A3%B8%E8%BE%9E%E5%BA%94%E5%AF%B9.md)
10 |
11 | - [面试提问](https://github.com/xianyunyh/PHP-Interview/blob/master/%E9%9D%A2%E8%AF%95/03%E9%9D%A2%E8%AF%95%E6%8F%90%E9%97%AE.md)
12 |
13 | - [笔试题](https://github.com/xianyunyh/PHP-Interview/blob/master/%E9%9D%A2%E8%AF%95/%E7%AC%94%E8%AF%95%E9%A2%98.md)
14 |
15 |
--------------------------------------------------------------------------------
/面试/笔试题4.md:
--------------------------------------------------------------------------------
1 | # 面试题
2 |
3 | 1. "\t" "\r" "\n" "\x20"
4 |
5 | 答:\t tab \r 换行 \n 回车 \x20 16进制
6 |
7 | 2. setcookie("user","value") var_dump($_COOKIE['user'])
8 |
9 | 答:null
10 |
11 | 3. `$a = 3; echo "$a",'$a',"\\\$a","$a"."$a","$a"+"$a"`
12 |
13 | 3$a\$a336
14 |
15 | 4. require include区别
16 |
17 | require 遇到错误会中断,include不会
18 |
19 | 5. private protected public const static
20 |
21 | 6. 调用父类的方法`parent::`
22 |
23 | 7. `$__GET,` `$_POST`
24 |
25 | 8. php 跳转页面
26 |
27 | header("location:");
28 |
29 | 9. 客户端ip整型
30 |
31 | ip2long
32 |
33 | 10. 什么是php-fpm
34 |
35 | FastCGI进程管理器
36 |
37 | 11. 查看进程打开的文件
38 |
39 | lsof
40 |
41 | 12. 查看io的状态
42 |
43 | iostat
44 |
45 | 13. 查看cpu的负载
46 |
47 | top
48 |
49 | 14. mysql 的增删改查
50 |
51 | 15. 聚簇索引所在的列数据是乱序的,会有什么影响。
52 |
53 | [https://www.cnblogs.com/starhu/p/6406495.html](https://www.cnblogs.com/starhu/p/6406495.html)
54 |
55 | 16. csrf xss sql注入
56 |
57 | 17. mysql主从同步的原理,什么sql语句导致mysql的主从同步失败
58 |
59 | mysql binlog
60 |
61 | 18. 拓展 活动高峰时期,cpu出现100%。你如何排查。nginx+php-fpm 数据读取redis和mysql、
62 |
63 |
64 |
65 | 19. 项目中遇到了什么问题,
66 | 20. 之前的项目有没有其他的优化方案?
67 | 21. 平时怎么学习的?
68 | 22. 未来的职业的职业方向?
69 |
--------------------------------------------------------------------------------
/面试/面试总结.md:
--------------------------------------------------------------------------------
1 | 参加了一次的面试,和面试官聊的还可以,最后让面试官对我简单评价下和给我一点建议,对方说我技术栈比较全面,但是可能缺少大型项目的锻炼,说的很对。大型项目可是自己的短板,理论的东西没有实战,只是理论。下面就记录下面试的问题。
2 |
3 |
4 |
5 | 1. 你们之前的项目的pv、uv是多少?
6 |
7 | 这个我当时实话实说了,pv并不高,高并发不存在。架构简单,因为不想瞎扯,吹那么多
8 |
9 | 2. 之前项目有没有做过集群
10 |
11 | 这个确实做过,无论是采用的阿里云的负载均衡还是自己nginx搭建的反向代理和自己用lvs+keeplived做的实验,都说了
12 |
13 | 3. 做了集群,后端的机器如何拿到前面访问的真实IP
14 |
15 | 这个通过添加header头的方式
16 |
17 | 4. 协成了解过吗?和线程的区别
18 |
19 | 用户态线程,由程序控制,开销小,线程CPU直接调度,CPU时钟切换,耗费资源
20 |
21 | 5. 分库分表做过没?采取什么样的方式
22 |
23 | 通过区间范围、hash
24 |
25 | 6. mysql分区表了解过没
26 |
27 | 了解过,但是这种一般不推荐用
28 |
29 | 7. sso单点登陆有哪些方案
30 |
31 | 这个我当时想的是统一中心认证,使用jsonp拉取登陆信息。
32 |
33 | 8. 主流的框架,都看过源码没?
34 |
35 | 看过thinkphp laravel的
36 |
37 | 9. swoole了解过没?使用过没?
38 |
39 | 这个了解过,真实项目未使用。
40 |
41 | 10. golang的协程、python的协程,的区别
42 |
43 | golang的协程goruntine
44 |
45 | 11. 对加班怎么看?
--------------------------------------------------------------------------------