├── .gitattributes
├── .gitignore
├── ClinicalBERT Deep Learning - Predicting Hospital Readmission.ipynb
├── README.md
├── attention
└── attention_visualization.ipynb
├── file_utils.py
├── images
├── equ3.png
├── fig1.png
├── fig2.png
└── tab3.png
├── modeling_readmission.py
└── preprocess.py
/.gitattributes:
--------------------------------------------------------------------------------
1 | # Auto detect text files and perform LF normalization
2 | * text=auto
3 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | .ipynb_checkpoints
2 | .DS_Store
3 | .idea
--------------------------------------------------------------------------------
/ClinicalBERT Deep Learning - Predicting Hospital Readmission.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# Install\n",
8 | "Before we begin, if you don't already have it you will need to install the following packages. Here is the install command:\n",
9 | "\n",
10 | "**transformers**: `conda install -c conda-forge transformers`\n",
11 | "\n",
12 | "It's important to note that my code differs from Kexin's because I [migrated](https://huggingface.co/transformers/migration.html) to using [HuggingFace's](https://huggingface.co/transformers/index.html) new `transformer` module instead of the formerly known as `pytorch_pretrained_bert` that the author used. "
13 | ]
14 | },
15 | {
16 | "cell_type": "markdown",
17 | "metadata": {},
18 | "source": [
19 | "# Read this article for ClinicalBERT\n",
20 | "https://arxiv.org/pdf/1904.05342.pdf\n",
21 | "They develop ClinicalBert by applying BERT (bidirectional encoder representations from transformers) to clinical notes. \n",
22 | "\n",
23 | "```\n",
24 | "@article{clinicalbert,\n",
25 | "author = {Kexin Huang and Jaan Altosaar and Rajesh Ranganath},\n",
26 | "title = {ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission},\n",
27 | "year = {2019},\n",
28 | "journal = {arXiv:1904.05342},\n",
29 | "}\n",
30 | "```\n",
31 | "\n",
32 | "# How My Work Differs from the Author's\n",
33 | "1. I am not pre-training the ClinicalBERT because the author already performed pre-training on Clinical words and the model's weights are already available.\n",
34 | "2. I am only working with early clinical notes. \"Discharge summaries have predictive power for readmission. However, discharge summaries might be written after a patient has left the hospital. Therefore, discharge summaries are not actionable since doctors cannot intervene when a patient has left the hospital. Models that dynamically predict readmission in the early stages of a patient's admission are relevant to clinicians...a maximum of the first 48 or 72 hours of a patient's notes are concatenated. These concatenated notes are used to predict readmission.\"[pg 12](https://arxiv.org/pdf/1904.05342.pdf)\n",
35 | "\n",
36 | "\n",
37 | " \n",
38 | "\n",
39 | "In this example, care providers add notes to an electronic health record during a patient’s admission, and the model dynamically updates the patient’s risk of being readmitted within a 30-day window.\n",
40 | "\n",
41 | "\n",
42 | "Boag et al. (2018) study the performance of the bag-of-words model, word2vec, and a Long Short-Term Memory Network (lstm) model combined with word2vec on various tasks such as diagnosis prediction and mortality risk estimation. Word embedding models such as word2vec are trained using the local context of individual words, but as clinical notes are long and their words are interdependent (Zhang et al., 2018), these methods cannot capture long-range dependencies.\n",
43 | "\n",
44 | "Clinical notes require capturing interactions between distant words.\n",
45 | "\n",
46 | "In this work, they develop a model that can predict readmission dynamically. **Making a prediction using a discharge summary at the end of a stay means that there are fewer opportunities to reduce the chance of readmission. To build a clinically-relevant model, we define a task for predicting readmission at any timepoint since a patient was admitted.**\n",
47 | "\n",
48 | "Medicine suffers from alarm fatigue (Sendelbach and Funk, 2013). This\n",
49 | "means useful classification rules for medicine need to have high precision (positive predictive value).\n",
50 | "\n",
51 | "Compared to a popular model of clinical text, word2vec, ClinicalBert more accurately captures clinical word similarity.\n",
52 | "\n",
53 | "ClinicalBERT is a modified BERT model: Specifically, the representations are learned\n",
54 | "using medical notes and further processed for downstream clinical tasks.\n",
55 | "* The transformer encoder architecture is based on a self-attention mechanism\n",
56 | "* The pre-training objective function for the model is defined using two unsupervised tasks: masked language modeling and next sentence prediction. \n",
57 | "* The text embeddings and model parameters are fit using stochastic optimization.\n",
58 | "\n",
59 | "
\n",
38 | "\n",
39 | "In this example, care providers add notes to an electronic health record during a patient’s admission, and the model dynamically updates the patient’s risk of being readmitted within a 30-day window.\n",
40 | "\n",
41 | "\n",
42 | "Boag et al. (2018) study the performance of the bag-of-words model, word2vec, and a Long Short-Term Memory Network (lstm) model combined with word2vec on various tasks such as diagnosis prediction and mortality risk estimation. Word embedding models such as word2vec are trained using the local context of individual words, but as clinical notes are long and their words are interdependent (Zhang et al., 2018), these methods cannot capture long-range dependencies.\n",
43 | "\n",
44 | "Clinical notes require capturing interactions between distant words.\n",
45 | "\n",
46 | "In this work, they develop a model that can predict readmission dynamically. **Making a prediction using a discharge summary at the end of a stay means that there are fewer opportunities to reduce the chance of readmission. To build a clinically-relevant model, we define a task for predicting readmission at any timepoint since a patient was admitted.**\n",
47 | "\n",
48 | "Medicine suffers from alarm fatigue (Sendelbach and Funk, 2013). This\n",
49 | "means useful classification rules for medicine need to have high precision (positive predictive value).\n",
50 | "\n",
51 | "Compared to a popular model of clinical text, word2vec, ClinicalBert more accurately captures clinical word similarity.\n",
52 | "\n",
53 | "ClinicalBERT is a modified BERT model: Specifically, the representations are learned\n",
54 | "using medical notes and further processed for downstream clinical tasks.\n",
55 | "* The transformer encoder architecture is based on a self-attention mechanism\n",
56 | "* The pre-training objective function for the model is defined using two unsupervised tasks: masked language modeling and next sentence prediction. \n",
57 | "* The text embeddings and model parameters are fit using stochastic optimization.\n",
58 | "\n",
59 | " \n",
60 | "\n",
61 | "ClinicalBert learns deep representations of clinical text using two unsupervised language modeling tasks: masked language modeling and\n",
62 | "next sentence prediction\n",
63 | "\n",
64 | "### Clinical Text Embeddings\n",
65 | "A clinical note input to ClinicalBert is represented as a collection of tokens. In ClinicalBert, a token in a clinical note is computed as\n",
66 | "the sum of the token embedding, a learned segment embedding, and a position embedding.\n",
67 | "\n",
68 | "### Pre-training ClinicalBERT\n",
69 | "The quality of learned representations of text depends on the text the model was trained on. BERT is trained on BooksCorpus and Wikipedia. However, these two datasets are distinct from clinical notes (where jargon and abbreviations are common). Also clinical notes have different syntax and grammar than common language in books or encyclopedias. It is hard to understand clinical notes without professional training.\n",
70 | "\n",
71 | "ClinicalBERT improves over BERT on the MIMIC-III corpus of clinical notes for \n",
72 | "1. Accuracy of masked language modeling a.k.a. predicting held-out tokens (86.80% vs 56.80%).\n",
73 | "2. Next sentence prediction (99.25% vs. 80.50%).\n",
74 | "The pre-training objective function based on the two tasks is the sum of the log-likelihood of the masked tokens and the log-likelihood of the binary variable indicating whether two sentences are consecutive.\n",
75 | "\n",
76 | "### Fine-tuning ClinicalBERT\n",
77 | "The model parameters are fine-tuned to maximize the log-likelihood of this binary classifier: equation (2)\n",
78 | "\n",
79 | "## Empirical Study II: 30-Day Hospital Readmission Prediction\n",
80 | "Before the author even evaluated ClinicalBERT's performance as a model of readmission, **his initial experiment showed that the original BERT suffered in performance on the masked language modeling task on the MIMIC-III data as well as the next sentence prediction tasks. This proves the need develop models tailored to clinical data such as ClinicalBERT!**\n",
81 | "\n",
82 | "
\n",
60 | "\n",
61 | "ClinicalBert learns deep representations of clinical text using two unsupervised language modeling tasks: masked language modeling and\n",
62 | "next sentence prediction\n",
63 | "\n",
64 | "### Clinical Text Embeddings\n",
65 | "A clinical note input to ClinicalBert is represented as a collection of tokens. In ClinicalBert, a token in a clinical note is computed as\n",
66 | "the sum of the token embedding, a learned segment embedding, and a position embedding.\n",
67 | "\n",
68 | "### Pre-training ClinicalBERT\n",
69 | "The quality of learned representations of text depends on the text the model was trained on. BERT is trained on BooksCorpus and Wikipedia. However, these two datasets are distinct from clinical notes (where jargon and abbreviations are common). Also clinical notes have different syntax and grammar than common language in books or encyclopedias. It is hard to understand clinical notes without professional training.\n",
70 | "\n",
71 | "ClinicalBERT improves over BERT on the MIMIC-III corpus of clinical notes for \n",
72 | "1. Accuracy of masked language modeling a.k.a. predicting held-out tokens (86.80% vs 56.80%).\n",
73 | "2. Next sentence prediction (99.25% vs. 80.50%).\n",
74 | "The pre-training objective function based on the two tasks is the sum of the log-likelihood of the masked tokens and the log-likelihood of the binary variable indicating whether two sentences are consecutive.\n",
75 | "\n",
76 | "### Fine-tuning ClinicalBERT\n",
77 | "The model parameters are fine-tuned to maximize the log-likelihood of this binary classifier: equation (2)\n",
78 | "\n",
79 | "## Empirical Study II: 30-Day Hospital Readmission Prediction\n",
80 | "Before the author even evaluated ClinicalBERT's performance as a model of readmission, **his initial experiment showed that the original BERT suffered in performance on the masked language modeling task on the MIMIC-III data as well as the next sentence prediction tasks. This proves the need develop models tailored to clinical data such as ClinicalBERT!**\n",
81 | "\n",
82 | " \n",
83 | "\n",
84 | "He finds that computing readmission probability using Equation (3) consistently outperforms predictions on each subsequence individually by 3–8%. This is because\n",
85 | "1. some subsequences (such as tokens corresponding to progress reports) do NOT contain information about readmission, whereas others do. The risk of readmission should be computed using subsequences that correlate with readmission risk, and **the effect of unimportant subsequences should be minimized**. This is accomplished by using the maximum probability over subsequences. \n",
86 | "2. Also noisy subsequences mislead the model and decrease performance. So they also include the average probability of readmission across subsequences. This leads to a trade-off between the mean and maximum probabilities of readmission in Equation (3).\n",
87 | "3. if there are a large number of subsequences for a patient with many clinical notes, there is a higher probability of having a noisy maximum probability of readmission. This means longer sequences may need to have a larger weight on the mean prediction. We include this weight as the n/c scaling factor, with c adjusting for patients with many clinical notes.\n",
88 | "Empirically, he found that c = 2 performs best on validation data.\n",
89 | "\n",
90 | "### Evaluation\n",
91 | "For validation and testing, 10% of the data is held out respectively, and 5-fold cross-validation is conducted. \n",
92 | "\n",
93 | "Each model is evaluated using three metrics:\n",
94 | "1. AUROC\n",
95 | "2. Area under the precision-recall curve\n",
96 | "3. Recall at precision of 80%: For the readmission task, false positives are important. To minimize the number of false positives and thus minimize the risk of alarm fatigue, he set the precision to 80% (in other words, 20% false positives out of the predicted positive class) and use the corresponding threshold to calculate recall. This leads to a clinically-relevant metric that enables us to build models that control the false positive rate. \n",
97 | "\n",
98 | "### Models\n",
99 | "* The training parameters are the entire encoder network, along with the classifier **`W`**\n",
100 | "* Note that the data labels are imbalanced: negative labels are subsampled to balance the positive readmit labels\n",
101 | "* ClinicalBert is trained for one epoch with batch size 4 and ee use the Adam optimizer learning rate 2 × 10−5\n",
102 | "* The ClinicalBert model settings are the same as in Section 3.\n",
103 | "* The binary classifier is a linear layer of shape 768 × 1\n",
104 | "* The maximum sequence length supported by the model is set to 512, and the model is first trained using shorter sequences.\n",
105 | "\n",
106 | "
\n",
83 | "\n",
84 | "He finds that computing readmission probability using Equation (3) consistently outperforms predictions on each subsequence individually by 3–8%. This is because\n",
85 | "1. some subsequences (such as tokens corresponding to progress reports) do NOT contain information about readmission, whereas others do. The risk of readmission should be computed using subsequences that correlate with readmission risk, and **the effect of unimportant subsequences should be minimized**. This is accomplished by using the maximum probability over subsequences. \n",
86 | "2. Also noisy subsequences mislead the model and decrease performance. So they also include the average probability of readmission across subsequences. This leads to a trade-off between the mean and maximum probabilities of readmission in Equation (3).\n",
87 | "3. if there are a large number of subsequences for a patient with many clinical notes, there is a higher probability of having a noisy maximum probability of readmission. This means longer sequences may need to have a larger weight on the mean prediction. We include this weight as the n/c scaling factor, with c adjusting for patients with many clinical notes.\n",
88 | "Empirically, he found that c = 2 performs best on validation data.\n",
89 | "\n",
90 | "### Evaluation\n",
91 | "For validation and testing, 10% of the data is held out respectively, and 5-fold cross-validation is conducted. \n",
92 | "\n",
93 | "Each model is evaluated using three metrics:\n",
94 | "1. AUROC\n",
95 | "2. Area under the precision-recall curve\n",
96 | "3. Recall at precision of 80%: For the readmission task, false positives are important. To minimize the number of false positives and thus minimize the risk of alarm fatigue, he set the precision to 80% (in other words, 20% false positives out of the predicted positive class) and use the corresponding threshold to calculate recall. This leads to a clinically-relevant metric that enables us to build models that control the false positive rate. \n",
97 | "\n",
98 | "### Models\n",
99 | "* The training parameters are the entire encoder network, along with the classifier **`W`**\n",
100 | "* Note that the data labels are imbalanced: negative labels are subsampled to balance the positive readmit labels\n",
101 | "* ClinicalBert is trained for one epoch with batch size 4 and ee use the Adam optimizer learning rate 2 × 10−5\n",
102 | "* The ClinicalBert model settings are the same as in Section 3.\n",
103 | "* The binary classifier is a linear layer of shape 768 × 1\n",
104 | "* The maximum sequence length supported by the model is set to 512, and the model is first trained using shorter sequences.\n",
105 | "\n",
106 | " \n",
107 | "\n",
108 | "Shows that ClinicalBERT outperforms it's competitors like Bag-of-words (Top 5000 TF-IDF words as features) and BiLSTM/Word2Vec in terms of precision and recall.\n",
109 | "\n",
110 | "### Readmission Prediction With Early Clinical Notes\n",
111 | "Discharge summaries have predictive power for readmission. However, discharge summaries\n",
112 | "might be written after a patient has left the hospital. Therefore, discharge summaries are\n",
113 | "not actionable since doctors cannot intervene when a patient has left the hospital. Models\n",
114 | "that dynamically predict readmission in the early stages of a patient’s admission are relevant to clinicians.\n",
115 | "\n",
116 | "> **Note** that readmission predictions from a model are not actionable if a patient has been discharged. \n",
117 | "\n",
118 | "**24-48h**\n",
119 | "* In the MIMIC-III data, admission and discharge times are available, but clinical notes do not have timestamps. This is why the table headings show a range; this range shows the cutoff time for notes fed to the model from early on in a patient’s admission. For example, in the 24–48h column, the model may only take as input a patient’s notes up to 36h because of that patient’s specific admission time.\n",
120 | "\n",
121 | "**48-72h**\n",
122 | "* For the second set of readmission prediction experiments, a maximum of the first 48 or 72 hours of a patient’s notes are concatenated. These concatenated notes are used to predict readmission. Since we separate notes into subsequences of the same length, the training set consists of all subsequences within a maximum of 72 hours, and the model is tested given only available notes within the first 48 or 72 hours of a patient’s admission.\n",
123 | "* For testing 48 or 72-hour clinical note readmission prediction, patients that are discharged within 48 or 72 hours (respectively) are filtered out.\n",
124 | "\n",
125 | "### Interpretable predictions in ClinicalBert\n",
126 | "* ClinicalBert uses several self-attention mechanisms which can be used to inspect its predictions, by visualizing terms correlated with predictions of hospital readmission.\n",
127 | " * For every clinical note input to ClinicalBert, each self-attention mechanism computes a distribution over every term in a sentence, given a query.\n",
128 | " * **A high attention weight between a query and key token means the interaction between these tokens is predictive of readmission**.\n",
129 | " * In the ClinicalBert encoder, there are 144 self-attention mechanisms (or, 12 multi-head attention mechanisms for each of the 12 transformer encoders). \n",
130 | " \n",
131 | "\n",
132 | "### Preprocessing\n",
133 | "ClinicalBert requires minimal preprocessing:\n",
134 | "1. First, words are converted to lowercase and\n",
135 | "2. line breaks are removed\n",
136 | "3. carriage returns are removed. \n",
137 | "4. De-identified the brackets \n",
138 | "5. remove special characters like ==, −−\n",
139 | "\n",
140 | "* The SpaCy sentence segmentation package is used to segment each note (Honnibal and Montani, 2017).\n",
141 | " * Since clinical notes don't follow rigid standard language grammar, we find rule-based segmentation has better results than dependency parsing-based segmentation.\n",
142 | " * Various segmentation signs that misguide rule-based segmentators are removed or replaced\n",
143 | " * For example 1.2 would be removed\n",
144 | " * M.D., dr. would be replaced with with MD, Dr\n",
145 | " * Clinical notes can include various lab results and medications that also contain numerous rule-based separators, such as 20mg, p.o., q.d.. (where q.d. means one a day and q.o. means to take by mouth. \n",
146 | " * To address this, segmentations that have less than 20 words are fused into the previous segmentation so that they are not singled out as different sentences."
147 | ]
148 | },
149 | {
150 | "cell_type": "markdown",
151 | "metadata": {},
152 | "source": [
153 | "# Preprocess.py"
154 | ]
155 | },
156 | {
157 | "cell_type": "code",
158 | "execution_count": 1,
159 | "metadata": {},
160 | "outputs": [],
161 | "source": [
162 | "import pandas as pd\n",
163 | "import numpy as np\n",
164 | "import matplotlib.pyplot as plt"
165 | ]
166 | },
167 | {
168 | "cell_type": "markdown",
169 | "metadata": {},
170 | "source": [
171 | "Convert Strings to Dates.\n",
172 | "When converting dates, it is safer to use a datetime format. \n",
173 | "Setting the errors = 'coerce' flag allows for missing dates \n",
174 | "but it sets it to NaT (not a datetime) when the string doesn't match the format."
175 | ]
176 | },
177 | {
178 | "cell_type": "code",
179 | "execution_count": 2,
180 | "metadata": {},
181 | "outputs": [],
182 | "source": [
183 | "# Load ADMISSIONS table from AWS S3 bucket\n",
184 | "bucket = 's3://mimic-iii-physionet'\n",
185 | "data_key = 'ADMISSIONS.csv.gz'\n",
186 | "data_location = 's3://{}/{}'.format(bucket, data_key)\n",
187 | "df_adm = pd.read_csv(data_location)"
188 | ]
189 | },
190 | {
191 | "cell_type": "code",
192 | "execution_count": 3,
193 | "metadata": {},
194 | "outputs": [],
195 | "source": [
196 | "# Load ADMISSIONS table\n",
197 | "# df_adm = pd.read_csv(\n",
198 | "# '/Users/nwams/Documents/Machine Learning Projects/Predicting-Hospital-Readmission-using-NLP/ADMISSIONS.csv')"
199 | ]
200 | },
201 | {
202 | "cell_type": "code",
203 | "execution_count": 4,
204 | "metadata": {},
205 | "outputs": [],
206 | "source": [
207 | "df_adm.ADMITTIME = pd.to_datetime(df_adm.ADMITTIME, format='%Y-%m-%d %H:%M:%S', errors='coerce')\n",
208 | "df_adm.DISCHTIME = pd.to_datetime(df_adm.DISCHTIME, format='%Y-%m-%d %H:%M:%S', errors='coerce')\n",
209 | "df_adm.DEATHTIME = pd.to_datetime(df_adm.DEATHTIME, format='%Y-%m-%d %H:%M:%S', errors='coerce')"
210 | ]
211 | },
212 | {
213 | "cell_type": "markdown",
214 | "metadata": {},
215 | "source": [
216 | "Get the next Unplanned admission date for each patient (if it exists).\n",
217 | "I need to get the next admission date, if it exists.\n",
218 | "First I'll verify that the dates are in order.\n",
219 | "Then I'll use the shift() function to get the next admission date."
220 | ]
221 | },
222 | {
223 | "cell_type": "code",
224 | "execution_count": 6,
225 | "metadata": {},
226 | "outputs": [],
227 | "source": [
228 | "df_adm = df_adm.sort_values(['SUBJECT_ID', 'ADMITTIME'])\n",
229 | "df_adm = df_adm.reset_index(drop=True)\n",
230 | "df_adm['NEXT_ADMITTIME'] = df_adm.groupby('SUBJECT_ID').ADMITTIME.shift(-1)\n",
231 | "df_adm['NEXT_ADMISSION_TYPE'] = df_adm.groupby('SUBJECT_ID').ADMISSION_TYPE.shift(-1)"
232 | ]
233 | },
234 | {
235 | "cell_type": "markdown",
236 | "metadata": {},
237 | "source": [
238 | "Since I want to predict unplanned re-admissions I will drop (filter out) any future admissions that are ELECTIVE \n",
239 | "so that only EMERGENCY re-admissions are measured.\n",
240 | "For rows with 'elective' admissions, replace it with NaT and NaN"
241 | ]
242 | },
243 | {
244 | "cell_type": "code",
245 | "execution_count": 7,
246 | "metadata": {},
247 | "outputs": [],
248 | "source": [
249 | "rows = df_adm.NEXT_ADMISSION_TYPE == 'ELECTIVE'\n",
250 | "df_adm.loc[rows,'NEXT_ADMITTIME'] = pd.NaT\n",
251 | "df_adm.loc[rows,'NEXT_ADMISSION_TYPE'] = np.NaN"
252 | ]
253 | },
254 | {
255 | "cell_type": "markdown",
256 | "metadata": {},
257 | "source": [
258 | "It's safer to sort right before the fill incase something I did above changed the order"
259 | ]
260 | },
261 | {
262 | "cell_type": "code",
263 | "execution_count": 8,
264 | "metadata": {},
265 | "outputs": [],
266 | "source": [
267 | "df_adm = df_adm.sort_values(['SUBJECT_ID','ADMITTIME'])"
268 | ]
269 | },
270 | {
271 | "cell_type": "markdown",
272 | "metadata": {},
273 | "source": [
274 | "Backfill in the values that I removed. So copy the ADMITTIME from the last emergency \n",
275 | "and paste it in the NEXT_ADMITTIME for the previous emergency. \n",
276 | "So I am effectively ignoring/skipping the ELECTIVE admission row completely. \n",
277 | "Doing this will allow me to calculate the days until the next admission."
278 | ]
279 | },
280 | {
281 | "cell_type": "code",
282 | "execution_count": 9,
283 | "metadata": {},
284 | "outputs": [],
285 | "source": [
286 | "# Back fill. This will take a little while.\n",
287 | "df_adm[['NEXT_ADMITTIME','NEXT_ADMISSION_TYPE']] = df_adm.groupby(['SUBJECT_ID'])[['NEXT_ADMITTIME','NEXT_ADMISSION_TYPE']].fillna(method = 'bfill')\n",
288 | "\n",
289 | "# Calculate days until next admission\n",
290 | "df_adm['DAYS_NEXT_ADMIT'] = (df_adm.NEXT_ADMITTIME - df_adm.DISCHTIME).dt.total_seconds()/(24*60*60)"
291 | ]
292 | },
293 | {
294 | "cell_type": "markdown",
295 | "metadata": {},
296 | "source": [
297 | "### Remove NEWBORN admissions\n",
298 | "According to the MIMIC site \"Newborn indicates that the HADM_ID pertains to the patient's birth.\"\n",
299 | "\n",
300 | "I will remove all NEWBORN admission types because in this project I'm not interested in studying births — my primary \n",
301 | "interest is EMERGENCY and URGENT admissions.\n",
302 | "I will remove all admissions that have a DEATHTIME because in this project I'm studying re-admissions, not mortality. \n",
303 | "And a patient who died cannot be re-admitted."
304 | ]
305 | },
306 | {
307 | "cell_type": "code",
308 | "execution_count": 10,
309 | "metadata": {},
310 | "outputs": [],
311 | "source": [
312 | "df_adm = df_adm.loc[df_adm.ADMISSION_TYPE != 'NEWBORN']\n",
313 | "df_adm = df_adm.loc[df_adm.DEATHTIME.isnull()]"
314 | ]
315 | },
316 | {
317 | "cell_type": "markdown",
318 | "metadata": {},
319 | "source": [
320 | "### Make Output Label\n",
321 | "For this problem, we are going to classify if a patient will be admitted in the next 30 days. \n",
322 | "Therefore, we need to create a variable with the output label (1 = readmitted, 0 = not readmitted)."
323 | ]
324 | },
325 | {
326 | "cell_type": "code",
327 | "execution_count": 11,
328 | "metadata": {},
329 | "outputs": [],
330 | "source": [
331 | "df_adm['OUTPUT_LABEL'] = (df_adm.DAYS_NEXT_ADMIT < 30).astype('int')\n",
332 | "df_adm['DURATION'] = (df_adm['DISCHTIME']-df_adm['ADMITTIME']).dt.total_seconds()/(24*60*60)"
333 | ]
334 | },
335 | {
336 | "cell_type": "markdown",
337 | "metadata": {},
338 | "source": [
339 | "### Load NOTEEVENTS Table"
340 | ]
341 | },
342 | {
343 | "cell_type": "code",
344 | "execution_count": 12,
345 | "metadata": {},
346 | "outputs": [
347 | {
348 | "name": "stderr",
349 | "output_type": "stream",
350 | "text": [
351 | "/home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages/IPython/core/interactiveshell.py:2785: DtypeWarning: Columns (4,5) have mixed types. Specify dtype option on import or set low_memory=False.\n",
352 | " interactivity=interactivity, compiler=compiler, result=result)\n"
353 | ]
354 | }
355 | ],
356 | "source": [
357 | "# Load ADMISSIONS table from AWS S3 bucket\n",
358 | "data_key = 'NOTEEVENTS.csv.gz'\n",
359 | "note_location = 's3://{}/{}'.format(bucket, data_key)\n",
360 | "df_notes = pd.read_csv(note_location)"
361 | ]
362 | },
363 | {
364 | "cell_type": "code",
365 | "execution_count": 15,
366 | "metadata": {},
367 | "outputs": [],
368 | "source": [
369 | "# Sort by subject_ID, HAD_ID then CHARTDATE\n",
370 | "df_notes = df_notes.sort_values(by=['SUBJECT_ID','HADM_ID','CHARTDATE'])\n",
371 | "# Merge notes table to admissions table\n",
372 | "df_adm_notes = pd.merge(df_adm[['SUBJECT_ID','HADM_ID','ADMITTIME','DISCHTIME','DAYS_NEXT_ADMIT','NEXT_ADMITTIME','ADMISSION_TYPE','DEATHTIME','OUTPUT_LABEL','DURATION']],\n",
373 | " df_notes[['SUBJECT_ID','HADM_ID','CHARTDATE','TEXT','CATEGORY']],\n",
374 | " on = ['SUBJECT_ID','HADM_ID'],\n",
375 | " how = 'left')"
376 | ]
377 | },
378 | {
379 | "cell_type": "code",
380 | "execution_count": 16,
381 | "metadata": {},
382 | "outputs": [
383 | {
384 | "name": "stderr",
385 | "output_type": "stream",
386 | "text": [
387 | "/home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages/ipykernel/__main__.py:2: UserWarning: Pandas doesn't allow columns to be created via a new attribute name - see https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute-access\n",
388 | " from ipykernel import kernelapp as app\n"
389 | ]
390 | }
391 | ],
392 | "source": [
393 | "# Grab date only, not the time\n",
394 | "df_adm_notes.ADMITTIME_C = df_adm_notes.ADMITTIME.apply(lambda x: str(x).split(' ')[0])\n",
395 | "\n",
396 | "df_adm_notes['ADMITTIME_C'] = pd.to_datetime(df_adm_notes.ADMITTIME_C, format = '%Y-%m-%d', errors = 'coerce')\n",
397 | "df_adm_notes['CHARTDATE'] = pd.to_datetime(df_adm_notes.CHARTDATE, format = '%Y-%m-%d', errors = 'coerce')"
398 | ]
399 | },
400 | {
401 | "cell_type": "markdown",
402 | "metadata": {},
403 | "source": [
404 | "Gather Discharge Summaries Only"
405 | ]
406 | },
407 | {
408 | "cell_type": "code",
409 | "execution_count": 17,
410 | "metadata": {},
411 | "outputs": [],
412 | "source": [
413 | "# Gather Discharge Summaries Only\n",
414 | "df_discharge = df_adm_notes[df_adm_notes['CATEGORY'] == 'Discharge summary']\n",
415 | "# multiple discharge summary for one admission -> after examination -> replicated summary -> replace with the last one\n",
416 | "df_discharge = (df_discharge.groupby(['SUBJECT_ID','HADM_ID']).nth(-1)).reset_index()\n",
417 | "df_discharge=df_discharge[df_discharge['TEXT'].notnull()]"
418 | ]
419 | },
420 | {
421 | "cell_type": "markdown",
422 | "metadata": {},
423 | "source": [
424 | "If Less than n days on admission notes (Early notes)"
425 | ]
426 | },
427 | {
428 | "cell_type": "code",
429 | "execution_count": 18,
430 | "metadata": {},
431 | "outputs": [],
432 | "source": [
433 | "def less_n_days_data(df_adm_notes, n):\n",
434 | " df_less_n = df_adm_notes[\n",
435 | " ((df_adm_notes['CHARTDATE'] - df_adm_notes['ADMITTIME_C']).dt.total_seconds() / (24 * 60 * 60)) < n]\n",
436 | " df_less_n = df_less_n[df_less_n['TEXT'].notnull()]\n",
437 | " # concatenate first\n",
438 | " df_concat = pd.DataFrame(df_less_n.groupby('HADM_ID')['TEXT'].apply(lambda x: \"%s\" % ' '.join(x))).reset_index()\n",
439 | " df_concat['OUTPUT_LABEL'] = df_concat['HADM_ID'].apply(\n",
440 | " lambda x: df_less_n[df_less_n['HADM_ID'] == x].OUTPUT_LABEL.values[0])\n",
441 | " \n",
442 | " return df_concat"
443 | ]
444 | },
445 | {
446 | "cell_type": "code",
447 | "execution_count": 19,
448 | "metadata": {},
449 | "outputs": [],
450 | "source": [
451 | "df_less_2 = less_n_days_data(df_adm_notes, 2)\n",
452 | "df_less_3 = less_n_days_data(df_adm_notes, 3)"
453 | ]
454 | },
455 | {
456 | "cell_type": "code",
457 | "execution_count": 20,
458 | "metadata": {},
459 | "outputs": [],
460 | "source": [
461 | "import re\n",
462 | "\n",
463 | "def preprocess1(x):\n",
464 | " y = re.sub('\\\\[(.*?)\\\\]', '', x) # remove de-identified brackets\n",
465 | " y = re.sub('[0-9]+\\.', '', y) # remove 1.2. since the segmenter segments based on this\n",
466 | " y = re.sub('dr\\.', 'doctor', y)\n",
467 | " y = re.sub('m\\.d\\.', 'md', y)\n",
468 | " y = re.sub('admission date:', '', y)\n",
469 | " y = re.sub('discharge date:', '', y)\n",
470 | " y = re.sub('--|__|==', '', y)\n",
471 | " return y"
472 | ]
473 | },
474 | {
475 | "cell_type": "code",
476 | "execution_count": 21,
477 | "metadata": {
478 | "collapsed": true
479 | },
480 | "outputs": [
481 | {
482 | "name": "stdout",
483 | "output_type": "stream",
484 | "text": [
485 | "Collecting pip\n",
486 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/00/b6/9cfa56b4081ad13874b0c6f96af8ce16cfbc1cb06bedf8e9164ce5551ec1/pip-19.3.1-py2.py3-none-any.whl (1.4MB)\n",
487 | "\u001b[K 100% |████████████████████████████████| 1.4MB 19.3MB/s ta 0:00:01\n",
488 | "\u001b[?25hInstalling collected packages: pip\n",
489 | " Found existing installation: pip 10.0.1\n",
490 | " Uninstalling pip-10.0.1:\n",
491 | " Successfully uninstalled pip-10.0.1\n",
492 | "Successfully installed pip-19.3.1\n"
493 | ]
494 | }
495 | ],
496 | "source": [
497 | "!pip install --upgrade pip"
498 | ]
499 | },
500 | {
501 | "cell_type": "code",
502 | "execution_count": 22,
503 | "metadata": {
504 | "collapsed": true
505 | },
506 | "outputs": [
507 | {
508 | "name": "stdout",
509 | "output_type": "stream",
510 | "text": [
511 | "Collecting tqdm\n",
512 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/72/c9/7fc20feac72e79032a7c8138fd0d395dc6d8812b5b9edf53c3afd0b31017/tqdm-4.41.1-py2.py3-none-any.whl (56kB)\n",
513 | "\u001b[K |████████████████████████████████| 61kB 2.3MB/s eta 0:00:011\n",
514 | "\u001b[?25hInstalling collected packages: tqdm\n",
515 | "Successfully installed tqdm-4.41.1\n"
516 | ]
517 | }
518 | ],
519 | "source": [
520 | "!pip install tqdm"
521 | ]
522 | },
523 | {
524 | "cell_type": "code",
525 | "execution_count": 23,
526 | "metadata": {},
527 | "outputs": [],
528 | "source": [
529 | "from tqdm import tqdm, trange"
530 | ]
531 | },
532 | {
533 | "cell_type": "code",
534 | "execution_count": 24,
535 | "metadata": {},
536 | "outputs": [],
537 | "source": [
538 | "def preprocessing(df_less_n):\n",
539 | " df_less_n['TEXT'] = df_less_n['TEXT'].fillna(' ')\n",
540 | " df_less_n['TEXT'] = df_less_n['TEXT'].str.replace('\\n', ' ')\n",
541 | " df_less_n['TEXT'] = df_less_n['TEXT'].str.replace('\\r', ' ')\n",
542 | " df_less_n['TEXT'] = df_less_n['TEXT'].apply(str.strip)\n",
543 | " df_less_n['TEXT'] = df_less_n['TEXT'].str.lower()\n",
544 | "\n",
545 | " df_less_n['TEXT'] = df_less_n['TEXT'].apply(lambda x: preprocess1(x))\n",
546 | "\n",
547 | " # to get 318 words chunks for readmission tasks\n",
548 | " df_len = len(df_less_n)\n",
549 | " want = pd.DataFrame({'ID': [], 'TEXT': [], 'Label': []})\n",
550 | " for i in tqdm(range(df_len)):\n",
551 | " x = df_less_n.TEXT.iloc[i].split()\n",
552 | " n = int(len(x) / 318)\n",
553 | " for j in range(n):\n",
554 | " want = want.append({'TEXT': ' '.join(x[j * 318:(j + 1) * 318]), 'Label': df_less_n.OUTPUT_LABEL.iloc[i],\n",
555 | " 'ID': df_less_n.HADM_ID.iloc[i]}, ignore_index=True)\n",
556 | " if len(x) % 318 > 10:\n",
557 | " want = want.append({'TEXT': ' '.join(x[-(len(x) % 318):]), 'Label': df_less_n.OUTPUT_LABEL.iloc[i],\n",
558 | " 'ID': df_less_n.HADM_ID.iloc[i]}, ignore_index=True)\n",
559 | "\n",
560 | " return want"
561 | ]
562 | },
563 | {
564 | "cell_type": "markdown",
565 | "metadata": {},
566 | "source": [
567 | "The preprocessing below for the Discharge, 2-Day and 3-Day stays took about 6.5 hours on my local machine (discharge=2.5hrs, 2-day=1.5 hrs and 3-day=2.5 hrs). \n",
568 | "\n",
569 | "Uncomment the lines below (I've commented it out since I've already run preprocessing and pickled the files). "
570 | ]
571 | },
572 | {
573 | "cell_type": "code",
574 | "execution_count": 25,
575 | "metadata": {},
576 | "outputs": [],
577 | "source": [
578 | "# df_discharge = preprocessing(df_discharge)\n",
579 | "# df_less_2 = preprocessing(df_less_2)\n",
580 | "# df_less_3 = preprocessing(df_less_3)"
581 | ]
582 | },
583 | {
584 | "cell_type": "code",
585 | "execution_count": 26,
586 | "metadata": {},
587 | "outputs": [],
588 | "source": [
589 | "import pickle"
590 | ]
591 | },
592 | {
593 | "cell_type": "markdown",
594 | "metadata": {},
595 | "source": [
596 | "Let's pickle it for later use. Uncomment the code below to pickle your files. "
597 | ]
598 | },
599 | {
600 | "cell_type": "code",
601 | "execution_count": 27,
602 | "metadata": {},
603 | "outputs": [],
604 | "source": [
605 | "# df_discharge.to_pickle(\"./pickle/df_discharge.pkl\")\n",
606 | "# df_less_2.to_pickle(\"./pickle/df_less_2.pkl\")\n",
607 | "# df_less_3.to_pickle(\"./pickle/df_less_3.pkl\")"
608 | ]
609 | },
610 | {
611 | "cell_type": "markdown",
612 | "metadata": {},
613 | "source": [
614 | "Load the pickled files, if needed"
615 | ]
616 | },
617 | {
618 | "cell_type": "code",
619 | "execution_count": 29,
620 | "metadata": {},
621 | "outputs": [],
622 | "source": [
623 | "df_discharge = pd.read_pickle('./pickle/df_discharge.pkl')\n",
624 | "df_less_2 = pd.read_pickle('./pickle/df_less_2.pkl')\n",
625 | "df_less_3 = pd.read_pickle('./pickle/df_less_3.pkl')"
626 | ]
627 | },
628 | {
629 | "cell_type": "code",
630 | "execution_count": 30,
631 | "metadata": {},
632 | "outputs": [
633 | {
634 | "data": {
635 | "text/plain": [
636 | "(216954, 3)"
637 | ]
638 | },
639 | "execution_count": 30,
640 | "metadata": {},
641 | "output_type": "execute_result"
642 | }
643 | ],
644 | "source": [
645 | "df_discharge.shape"
646 | ]
647 | },
648 | {
649 | "cell_type": "code",
650 | "execution_count": 31,
651 | "metadata": {},
652 | "outputs": [
653 | {
654 | "data": {
655 | "text/plain": [
656 | "(277443, 3)"
657 | ]
658 | },
659 | "execution_count": 31,
660 | "metadata": {},
661 | "output_type": "execute_result"
662 | }
663 | ],
664 | "source": [
665 | "df_less_2.shape"
666 | ]
667 | },
668 | {
669 | "cell_type": "code",
670 | "execution_count": 32,
671 | "metadata": {},
672 | "outputs": [
673 | {
674 | "data": {
675 | "text/plain": [
676 | "(385724, 3)"
677 | ]
678 | },
679 | "execution_count": 32,
680 | "metadata": {},
681 | "output_type": "execute_result"
682 | }
683 | ],
684 | "source": [
685 | "df_less_3.shape"
686 | ]
687 | },
688 | {
689 | "cell_type": "markdown",
690 | "metadata": {},
691 | "source": [
692 | "Discharge has 216,954 rows. \n",
693 | "\n",
694 | "2-Day has 277,443 rows.\n",
695 | "\n",
696 | "3-Day has 385,724 rows."
697 | ]
698 | },
699 | {
700 | "cell_type": "markdown",
701 | "metadata": {},
702 | "source": [
703 | "### Train/Test/Split\n",
704 | "An example to get the train/val/test split with random state:\n",
705 | "Note that we divide on patient admission level and share among experiments, instead of notes level.\n",
706 | "This way, since our methods run on the same set of admissions, we can see the progression of readmission scores."
707 | ]
708 | },
709 | {
710 | "cell_type": "code",
711 | "execution_count": 35,
712 | "metadata": {},
713 | "outputs": [],
714 | "source": [
715 | "readmit_ID = df_adm[df_adm.OUTPUT_LABEL == 1].HADM_ID\n",
716 | "not_readmit_ID = df_adm[df_adm.OUTPUT_LABEL == 0].HADM_ID\n",
717 | "# subsampling to get the balanced pos/neg numbers of patients for each dataset\n",
718 | "not_readmit_ID_use = not_readmit_ID.sample(n=len(readmit_ID), random_state=1)\n",
719 | "id_val_test_t = readmit_ID.sample(frac=0.2, random_state=1)\n",
720 | "id_val_test_f = not_readmit_ID_use.sample(frac=0.2, random_state=1)\n",
721 | "\n",
722 | "id_train_t = readmit_ID.drop(id_val_test_t.index)\n",
723 | "id_train_f = not_readmit_ID_use.drop(id_val_test_f.index)\n",
724 | "\n",
725 | "id_val_t = id_val_test_t.sample(frac=0.5, random_state=1)\n",
726 | "id_test_t = id_val_test_t.drop(id_val_t.index)\n",
727 | "\n",
728 | "id_val_f = id_val_test_f.sample(frac=0.5, random_state=1)\n",
729 | "id_test_f = id_val_test_f.drop(id_val_f.index)\n",
730 | "\n",
731 | "# test if there is overlap between train and test, should return \"array([], dtype=int64)\"\n",
732 | "(pd.Index(id_test_t).intersection(pd.Index(id_train_t))).values\n",
733 | "\n",
734 | "id_test = pd.concat([id_test_t, id_test_f])\n",
735 | "test_id_label = pd.DataFrame(data=list(zip(id_test, [1] * len(id_test_t) + [0] * len(id_test_f))),\n",
736 | " columns=['id', 'label'])\n",
737 | "\n",
738 | "id_val = pd.concat([id_val_t, id_val_f])\n",
739 | "val_id_label = pd.DataFrame(data=list(zip(id_val, [1] * len(id_val_t) + [0] * len(id_val_f))), columns=['id', 'label'])\n",
740 | "\n",
741 | "id_train = pd.concat([id_train_t, id_train_f])\n",
742 | "train_id_label = pd.DataFrame(data=list(zip(id_train, [1] * len(id_train_t) + [0] * len(id_train_f))),\n",
743 | " columns=['id', 'label'])"
744 | ]
745 | },
746 | {
747 | "cell_type": "markdown",
748 | "metadata": {},
749 | "source": [
750 | "### Get discharge train/val/test"
751 | ]
752 | },
753 | {
754 | "cell_type": "code",
755 | "execution_count": 36,
756 | "metadata": {},
757 | "outputs": [],
758 | "source": [
759 | "discharge_train = df_discharge[df_discharge.ID.isin(train_id_label.id)]\n",
760 | "discharge_val = df_discharge[df_discharge.ID.isin(val_id_label.id)]\n",
761 | "discharge_test = df_discharge[df_discharge.ID.isin(test_id_label.id)]"
762 | ]
763 | },
764 | {
765 | "cell_type": "markdown",
766 | "metadata": {},
767 | "source": [
768 | "### Subsampling for training\n",
769 | "Since we obtain training on patient admission level so now we have same number of pos/neg readmission but each admission is associated with different length of notes and we train on each chunks of notes, not on the admission, we need to balance the pos/neg chunks on training set. (val and test set are fine) Usually, positive admissions have longer notes, so we need find some negative chunks of notes from not_readmit_ID that we haven't used yet"
770 | ]
771 | },
772 | {
773 | "cell_type": "code",
774 | "execution_count": 37,
775 | "metadata": {},
776 | "outputs": [],
777 | "source": [
778 | "df = pd.concat([not_readmit_ID_use, not_readmit_ID])\n",
779 | "df = df.drop_duplicates(keep=False)\n",
780 | "# check to see if there are overlaps\n",
781 | "(pd.Index(df).intersection(pd.Index(not_readmit_ID_use))).values\n",
782 | "\n",
783 | "# for this set of split with random_state=1, we find we need 400 more negative training samples\n",
784 | "not_readmit_ID_more = df.sample(n=400, random_state=1)\n",
785 | "discharge_train_snippets = pd.concat([df_discharge[df_discharge.ID.isin(not_readmit_ID_more)], discharge_train])\n",
786 | "\n",
787 | "# shuffle\n",
788 | "discharge_train_snippets = discharge_train_snippets.sample(frac=1, random_state=1).reset_index(drop=True)\n",
789 | "\n",
790 | "# check if balanced\n",
791 | "discharge_train_snippets.Label.value_counts()\n",
792 | "\n",
793 | "discharge_train_snippets.to_csv('./data/discharge/train.csv')\n",
794 | "discharge_val.to_csv('./data/discharge/val.csv')\n",
795 | "discharge_test.to_csv('./data/discharge/test.csv')"
796 | ]
797 | },
798 | {
799 | "cell_type": "markdown",
800 | "metadata": {},
801 | "source": [
802 | "For the Early notes experiment: we only need to find training set for 3 days, then we can test both 3 days and 2 days. Since we split the data on patient level and experiments share admissions in order to see the progression, the 2 days training dataset is a subset of 3 days training set. So we only train 3 days and we can test/val on both 2 & 3 days or any time smaller than 3 days. This means if we train on a dataset with all the notes in n days, we can predict readmissions smaller than n days.\n",
803 | "\n",
804 | "### For 3 days note (similar to discharge)"
805 | ]
806 | },
807 | {
808 | "cell_type": "code",
809 | "execution_count": 38,
810 | "metadata": {},
811 | "outputs": [],
812 | "source": [
813 | "early_train = df_less_3[df_less_3.ID.isin(train_id_label.id)]\n",
814 | "not_readmit_ID_more = df.sample(n=500, random_state=1)\n",
815 | "early_train_snippets = pd.concat([df_less_3[df_less_3.ID.isin(not_readmit_ID_more)], early_train])\n",
816 | "# shuffle\n",
817 | "early_train_snippets = early_train_snippets.sample(frac=1, random_state=1).reset_index(drop=True)\n",
818 | "early_train_snippets.to_csv('./data/3days/train.csv')\n",
819 | "\n",
820 | "early_val = df_less_3[df_less_3.ID.isin(val_id_label.id)]\n",
821 | "early_val.to_csv('./data/3days/val.csv')\n",
822 | "\n",
823 | "# we want to test on admissions that are not discharged already. So for less than 3 days of notes experiment,\n",
824 | "# we filter out admissions discharged within 3 days\n",
825 | "actionable_ID_3days = df_adm[df_adm['DURATION'] >= 3].HADM_ID\n",
826 | "test_actionable_id_label = test_id_label[test_id_label.id.isin(actionable_ID_3days)]\n",
827 | "early_test = df_less_3[df_less_3.ID.isin(test_actionable_id_label.id)]\n",
828 | "\n",
829 | "early_test.to_csv('./data/3days/test.csv')"
830 | ]
831 | },
832 | {
833 | "cell_type": "markdown",
834 | "metadata": {},
835 | "source": [
836 | "### For 2 days notes\n",
837 | "For 2 days notes we only obtain test set. Since the model parameters are tuned on the val set of 3 days."
838 | ]
839 | },
840 | {
841 | "cell_type": "code",
842 | "execution_count": 39,
843 | "metadata": {},
844 | "outputs": [],
845 | "source": [
846 | "actionable_ID_2days = df_adm[df_adm['DURATION'] >= 2].HADM_ID\n",
847 | "test_actionable_id_label_2days = test_id_label[test_id_label.id.isin(actionable_ID_2days)]\n",
848 | "early_test_2days = df_less_2[df_less_2.ID.isin(test_actionable_id_label_2days.id)]\n",
849 | "early_test_2days.to_csv('./data/2days/test.csv')"
850 | ]
851 | },
852 | {
853 | "cell_type": "markdown",
854 | "metadata": {},
855 | "source": [
856 | "# Run Model for Predicting Readmission Using Early Notes"
857 | ]
858 | },
859 | {
860 | "cell_type": "code",
861 | "execution_count": 40,
862 | "metadata": {
863 | "collapsed": true
864 | },
865 | "outputs": [
866 | {
867 | "name": "stdout",
868 | "output_type": "stream",
869 | "text": [
870 | "Collecting torch\n",
871 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/88/95/90e8c4c31cfc67248bf944ba42029295b77159982f532c5689bcfe4e9108/torch-1.3.1-cp36-cp36m-manylinux1_x86_64.whl (734.6MB)\n",
872 | "\u001b[K |████████████████████████████████| 734.6MB 11kB/s s eta 0:00:01 |▎ | 6.8MB 3.2MB/s eta 0:03:49 |█ | 20.5MB 3.2MB/s eta 0:03:45 |█ | 23.0MB 3.2MB/s eta 0:03:44 |█▍ | 30.7MB 3.2MB/s eta 0:03:42 |█▊ | 38.4MB 3.2MB/s eta 0:03:39 |███▍ | 77.7MB 63.0MB/s eta 0:00:11 |████▎ | 99.3MB 63.0MB/s eta 0:00:11 |█████▌ | 126.0MB 40.0MB/s eta 0:00:16 |███████████▏ | 256.6MB 53.1MB/s eta 0:00:09 |████████████████▊ | 384.0MB 59.1MB/s eta 0:00:06 |█████████████████▋ | 404.2MB 59.1MB/s eta 0:00:06 |████████████████████▉ | 478.3MB 51.2MB/s eta 0:00:06\n",
873 | "\u001b[?25hRequirement already satisfied: numpy in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from torch) (1.14.3)\n",
874 | "Installing collected packages: torch\n",
875 | "Successfully installed torch-1.3.1\n"
876 | ]
877 | }
878 | ],
879 | "source": [
880 | "!pip install torch"
881 | ]
882 | },
883 | {
884 | "cell_type": "code",
885 | "execution_count": 41,
886 | "metadata": {},
887 | "outputs": [],
888 | "source": [
889 | "import torch"
890 | ]
891 | },
892 | {
893 | "cell_type": "markdown",
894 | "metadata": {},
895 | "source": [
896 | "### Device-Agnostic PyTorch code (GPU or CPU)\n",
897 | "A `torch.device` is an object representing the device on which a `torch.Tensor` is or will be allocated. [[Docs](https://pytorch.org/docs/stable/tensor_attributes.html#torch.torch.device)]. The `torch.device` contains a device type (`'cpu'` or `'cuda'`).\n",
898 | "Due to the structure of PyTorch, you may need to explicitly write device-agnostic (CPU or GPU) code [[Docs](https://pytorch.org/docs/stable/notes/cuda.html)]. The first step is to determine whether the GPU should be used or not.\n",
899 | "\n",
900 | "`torch.cuda.is_available` returns a bool indicating if CUDA is currently available [[Docs](https://pytorch.org/docs/stable/cuda.html#torch.cuda.is_available)]. \n",
901 | "\n",
902 | "I will set my values below so that my code is **Device-agnostic** but feel free to change them for your specific needs."
903 | ]
904 | },
905 | {
906 | "cell_type": "code",
907 | "execution_count": 42,
908 | "metadata": {},
909 | "outputs": [],
910 | "source": [
911 | "local_rank = -1\n",
912 | "no_cuda = False # Set flag to True to disable CUDA"
913 | ]
914 | },
915 | {
916 | "cell_type": "code",
917 | "execution_count": 43,
918 | "metadata": {},
919 | "outputs": [],
920 | "source": [
921 | "if local_rank == -1 or no_cuda:\n",
922 | " device = torch.device(\"cuda\" if torch.cuda.is_available() and not no_cuda else \"cpu\")\n",
923 | " n_gpu = torch.cuda.device_count()\n",
924 | "else:\n",
925 | " device = torch.device(\"cuda\", local_rank)\n",
926 | " n_gpu = 1\n",
927 | " # Initializes the distributed backend which will take care of sychronizing nodes/GPUs\n",
928 | " torch.distributed.init_process_group(backend='nccl')"
929 | ]
930 | },
931 | {
932 | "cell_type": "code",
933 | "execution_count": 44,
934 | "metadata": {},
935 | "outputs": [],
936 | "source": [
937 | "import logging\n",
938 | "logging.basicConfig(format = '%(asctime)s - %(levelname)s - %(name)s - %(message)s', \n",
939 | " datefmt = '%m/%d/%Y %H:%M:%S',\n",
940 | " level = logging.INFO)\n",
941 | "logger = logging.getLogger(__name__)"
942 | ]
943 | },
944 | {
945 | "cell_type": "code",
946 | "execution_count": 45,
947 | "metadata": {},
948 | "outputs": [
949 | {
950 | "name": "stderr",
951 | "output_type": "stream",
952 | "text": [
953 | "01/02/2020 22:33:27 - INFO - __main__ - device: cuda n_gpu: 1 Distributed training: False\n"
954 | ]
955 | }
956 | ],
957 | "source": [
958 | "logger.info(\"device: %s n_gpu: %d Distributed training: %r\", device, n_gpu, bool(local_rank != -1))"
959 | ]
960 | },
961 | {
962 | "cell_type": "markdown",
963 | "metadata": {},
964 | "source": [
965 | "**Accumulating gradients** just means that, before calling `optimizer.step()` to perform a step of gradient descent, we will sum the gradients of several backward operations in the `parameter.grad` tensors. \n",
966 | "\n",
967 | "Below I set the number of update steps to accumulate before performing a backward/update pass. I will set it to a default of 1. Feel free to change if needed."
968 | ]
969 | },
970 | {
971 | "cell_type": "code",
972 | "execution_count": 46,
973 | "metadata": {},
974 | "outputs": [],
975 | "source": [
976 | "gradient_accumulation_steps = 1"
977 | ]
978 | },
979 | {
980 | "cell_type": "code",
981 | "execution_count": 47,
982 | "metadata": {},
983 | "outputs": [],
984 | "source": [
985 | "if gradient_accumulation_steps < 1:\n",
986 | " raise ValueError(\"Invalid gradient_accumulation_steps parameter: {}, should be >= 1\".format(gradient_accumulation_steps))"
987 | ]
988 | },
989 | {
990 | "cell_type": "markdown",
991 | "metadata": {},
992 | "source": [
993 | "Set the default Total Batch Size for training to 32."
994 | ]
995 | },
996 | {
997 | "cell_type": "code",
998 | "execution_count": 48,
999 | "metadata": {},
1000 | "outputs": [],
1001 | "source": [
1002 | "train_batch_size = 32"
1003 | ]
1004 | },
1005 | {
1006 | "cell_type": "code",
1007 | "execution_count": 49,
1008 | "metadata": {},
1009 | "outputs": [],
1010 | "source": [
1011 | "train_batch_size = int(train_batch_size / gradient_accumulation_steps)"
1012 | ]
1013 | },
1014 | {
1015 | "cell_type": "code",
1016 | "execution_count": 50,
1017 | "metadata": {},
1018 | "outputs": [],
1019 | "source": [
1020 | "seed= 42 # random seed for initialization\n",
1021 | "do_train = False # Whether to run training\n",
1022 | "do_eval = True # Whether to run eval on the dev set.\n",
1023 | "output_dir = './result_early' # The output directory where the model checkpoints will be written"
1024 | ]
1025 | },
1026 | {
1027 | "cell_type": "code",
1028 | "execution_count": 51,
1029 | "metadata": {},
1030 | "outputs": [],
1031 | "source": [
1032 | "import os\n",
1033 | "import random"
1034 | ]
1035 | },
1036 | {
1037 | "cell_type": "markdown",
1038 | "metadata": {},
1039 | "source": [
1040 | "Create the `result_early` folder where results will go."
1041 | ]
1042 | },
1043 | {
1044 | "cell_type": "code",
1045 | "execution_count": 52,
1046 | "metadata": {},
1047 | "outputs": [],
1048 | "source": [
1049 | "random.seed(seed)\n",
1050 | "np.random.seed(seed)\n",
1051 | "torch.manual_seed(seed)\n",
1052 | "\n",
1053 | "if n_gpu > 0:\n",
1054 | " torch.cuda.manual_seed_all(seed)\n",
1055 | "\n",
1056 | "if not do_train and not do_eval:\n",
1057 | " raise ValueError(\"At least one of `do_train` or `do_eval` must be True.\")\n",
1058 | "\n",
1059 | "if os.path.exists(output_dir) and os.listdir(output_dir):\n",
1060 | " raise ValueError(\"Output directory ({}) already exists and is not empty.\".format(output_dir))\n",
1061 | "\n",
1062 | "os.makedirs(output_dir, exist_ok=True)"
1063 | ]
1064 | },
1065 | {
1066 | "cell_type": "markdown",
1067 | "metadata": {},
1068 | "source": [
1069 | "# Defining Classes Needed for Processing Readmissions"
1070 | ]
1071 | },
1072 | {
1073 | "cell_type": "code",
1074 | "execution_count": 53,
1075 | "metadata": {},
1076 | "outputs": [],
1077 | "source": [
1078 | "class InputExample(object):\n",
1079 | " \"\"\"A single training/test example for simple sequence classification.\"\"\"\n",
1080 | "\n",
1081 | " def __init__(self, guid, text_a, text_b=None, label=None):\n",
1082 | " \"\"\"Constructs a InputExample.\n",
1083 | "\n",
1084 | " Args:\n",
1085 | " guid: Unique id for the example.\n",
1086 | " text_a: string. The untokenized text of the first sequence. For single\n",
1087 | " sequence tasks, only this sequence must be specified.\n",
1088 | " text_b: (Optional) string. The untokenized text of the second sequence.\n",
1089 | " Only must be specified for sequence pair tasks.\n",
1090 | " label: (Optional) string. The label of the example. This should be\n",
1091 | " specified for train and dev examples, but not for test examples.\n",
1092 | " \"\"\"\n",
1093 | " self.guid = guid\n",
1094 | " self.text_a = text_a\n",
1095 | " self.text_b = text_b\n",
1096 | " self.label = label"
1097 | ]
1098 | },
1099 | {
1100 | "cell_type": "code",
1101 | "execution_count": 54,
1102 | "metadata": {},
1103 | "outputs": [],
1104 | "source": [
1105 | "class DataProcessor(object):\n",
1106 | " \"\"\"Base class for data converters for sequence classification data sets.\"\"\"\n",
1107 | "\n",
1108 | " def get_train_examples(self, data_dir):\n",
1109 | " \"\"\"Gets a collection of `InputExample`s for the train set.\"\"\"\n",
1110 | " raise NotImplementedError()\n",
1111 | "\n",
1112 | " def get_dev_examples(self, data_dir):\n",
1113 | " \"\"\"Gets a collection of `InputExample`s for the dev set.\"\"\"\n",
1114 | " raise NotImplementedError()\n",
1115 | "\n",
1116 | " def get_labels(self):\n",
1117 | " \"\"\"Gets the list of labels for this data set.\"\"\"\n",
1118 | " raise NotImplementedError()\n",
1119 | "\n",
1120 | " @classmethod\n",
1121 | " def _read_tsv(cls, input_file, quotechar=None):\n",
1122 | " \"\"\"Reads a tab separated value file.\"\"\"\n",
1123 | " with open(input_file, \"r\") as f:\n",
1124 | " reader = csv.reader(f, delimiter=\"\\t\", quotechar=quotechar)\n",
1125 | " lines = []\n",
1126 | " for line in reader:\n",
1127 | " lines.append(line)\n",
1128 | " return lines\n",
1129 | " \n",
1130 | " @classmethod\n",
1131 | " def _read_csv(cls, input_file):\n",
1132 | " \"\"\"Reads a comma separated value file.\"\"\"\n",
1133 | " file=pd.read_csv(input_file)\n",
1134 | " lines=zip(file.ID,file.TEXT,file.Label)\n",
1135 | " return lines"
1136 | ]
1137 | },
1138 | {
1139 | "cell_type": "code",
1140 | "execution_count": 55,
1141 | "metadata": {},
1142 | "outputs": [],
1143 | "source": [
1144 | "class readmissionProcessor(DataProcessor):\n",
1145 | " def get_train_examples(self, data_dir):\n",
1146 | " logger.info(\"LOOKING AT {}\".format(os.path.join(data_dir, \"train.csv\")))\n",
1147 | " return self._create_examples(self._read_csv(os.path.join(data_dir, \"train.csv\")), \"train\")\n",
1148 | " \n",
1149 | " def get_dev_examples(self, data_dir):\n",
1150 | " return self._create_examples(self._read_csv(os.path.join(data_dir, \"val.csv\")), \"val\")\n",
1151 | " \n",
1152 | " def get_test_examples(self, data_dir):\n",
1153 | " return self._create_examples(self._read_csv(os.path.join(data_dir, \"test.csv\")), \"test\")\n",
1154 | " \n",
1155 | " def get_labels(self):\n",
1156 | " return [\"0\", \"1\"]\n",
1157 | " \n",
1158 | " def _create_examples(self, lines, set_type):\n",
1159 | " \"\"\"Creates examples for the training and dev sets.\"\"\"\n",
1160 | " examples = []\n",
1161 | " for (i, line) in enumerate(lines):\n",
1162 | " guid = \"%s-%s\" % (set_type, i)\n",
1163 | " text_a = line[1]\n",
1164 | " label = str(int(line[2])) \n",
1165 | " examples.append(InputExample(guid=guid, text_a=text_a, text_b=None, label=label))\n",
1166 | " return examples"
1167 | ]
1168 | },
1169 | {
1170 | "cell_type": "code",
1171 | "execution_count": 56,
1172 | "metadata": {},
1173 | "outputs": [],
1174 | "source": [
1175 | "processor = readmissionProcessor()"
1176 | ]
1177 | },
1178 | {
1179 | "cell_type": "code",
1180 | "execution_count": 57,
1181 | "metadata": {},
1182 | "outputs": [],
1183 | "source": [
1184 | "label_list = processor.get_labels() # label_list = ['0', '1']"
1185 | ]
1186 | },
1187 | {
1188 | "cell_type": "code",
1189 | "execution_count": 58,
1190 | "metadata": {
1191 | "collapsed": true
1192 | },
1193 | "outputs": [
1194 | {
1195 | "name": "stdout",
1196 | "output_type": "stream",
1197 | "text": [
1198 | "Collecting transformers\n",
1199 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/50/10/aeefced99c8a59d828a92cc11d213e2743212d3641c87c82d61b035a7d5c/transformers-2.3.0-py3-none-any.whl (447kB)\n",
1200 | "\u001b[K |████████████████████████████████| 450kB 3.3MB/s eta 0:00:01\n",
1201 | "\u001b[?25hCollecting sentencepiece\n",
1202 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/74/f4/2d5214cbf13d06e7cb2c20d84115ca25b53ea76fa1f0ade0e3c9749de214/sentencepiece-0.1.85-cp36-cp36m-manylinux1_x86_64.whl (1.0MB)\n",
1203 | "\u001b[K |████████████████████████████████| 1.0MB 52.3MB/s eta 0:00:01\n",
1204 | "\u001b[?25hRequirement already satisfied: requests in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from transformers) (2.20.0)\n",
1205 | "Requirement already satisfied: tqdm in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from transformers) (4.41.1)\n",
1206 | "Collecting regex!=2019.12.17\n",
1207 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/ef/a3/7c9d57812484e43a5c4033fc4562e5aa87bd9318f48a27983717c721f22b/regex-2019.12.20-cp36-cp36m-manylinux2010_x86_64.whl (689kB)\n",
1208 | "\u001b[K |████████████████████████████████| 696kB 55.3MB/s eta 0:00:01\n",
1209 | "\u001b[?25hCollecting sacremoses\n",
1210 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/1f/8e/ed5364a06a9ba720fddd9820155cc57300d28f5f43a6fd7b7e817177e642/sacremoses-0.0.35.tar.gz (859kB)\n",
1211 | "\u001b[K |████████████████████████████████| 860kB 50.8MB/s eta 0:00:01\n",
1212 | "\u001b[?25hRequirement already satisfied: boto3 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from transformers) (1.10.19)\n",
1213 | "Requirement already satisfied: numpy in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from transformers) (1.14.3)\n",
1214 | "Requirement already satisfied: urllib3<1.25,>=1.21.1 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from requests->transformers) (1.23)\n",
1215 | "Requirement already satisfied: certifi>=2017.4.17 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from requests->transformers) (2019.9.11)\n",
1216 | "Requirement already satisfied: chardet<3.1.0,>=3.0.2 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from requests->transformers) (3.0.4)\n",
1217 | "Requirement already satisfied: idna<2.8,>=2.5 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from requests->transformers) (2.6)\n",
1218 | "Requirement already satisfied: six in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from sacremoses->transformers) (1.11.0)\n",
1219 | "Requirement already satisfied: click in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from sacremoses->transformers) (6.7)\n",
1220 | "Collecting joblib\n",
1221 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/28/5c/cf6a2b65a321c4a209efcdf64c2689efae2cb62661f8f6f4bb28547cf1bf/joblib-0.14.1-py2.py3-none-any.whl (294kB)\n",
1222 | "\u001b[K |████████████████████████████████| 296kB 52.7MB/s eta 0:00:01\n",
1223 | "\u001b[?25hRequirement already satisfied: jmespath<1.0.0,>=0.7.1 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from boto3->transformers) (0.9.4)\n",
1224 | "Requirement already satisfied: s3transfer<0.3.0,>=0.2.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from boto3->transformers) (0.2.1)\n",
1225 | "Requirement already satisfied: botocore<1.14.0,>=1.13.19 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from boto3->transformers) (1.13.19)\n",
1226 | "Requirement already satisfied: python-dateutil<2.8.1,>=2.1; python_version >= \"2.7\" in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from botocore<1.14.0,>=1.13.19->boto3->transformers) (2.7.3)\n",
1227 | "Requirement already satisfied: docutils<0.16,>=0.10 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from botocore<1.14.0,>=1.13.19->boto3->transformers) (0.14)\n",
1228 | "Building wheels for collected packages: sacremoses\n",
1229 | " Building wheel for sacremoses (setup.py) ... \u001b[?25ldone\n",
1230 | "\u001b[?25h Created wheel for sacremoses: filename=sacremoses-0.0.35-cp36-none-any.whl size=884006 sha256=c81533047bff2008d1407b012d5415316c8460895b35f513fe3719d38c786562\n",
1231 | " Stored in directory: /home/ec2-user/.cache/pip/wheels/63/2a/db/63e2909042c634ef551d0d9ac825b2b0b32dede4a6d87ddc94\n",
1232 | "Successfully built sacremoses\n",
1233 | "Installing collected packages: sentencepiece, regex, joblib, sacremoses, transformers\n",
1234 | "Successfully installed joblib-0.14.1 regex-2019.12.20 sacremoses-0.0.35 sentencepiece-0.1.85 transformers-2.3.0\n"
1235 | ]
1236 | }
1237 | ],
1238 | "source": [
1239 | "!pip install transformers"
1240 | ]
1241 | },
1242 | {
1243 | "cell_type": "code",
1244 | "execution_count": 59,
1245 | "metadata": {},
1246 | "outputs": [
1247 | {
1248 | "name": "stderr",
1249 | "output_type": "stream",
1250 | "text": [
1251 | "01/02/2020 22:33:33 - INFO - transformers.file_utils - PyTorch version 1.3.1 available.\n"
1252 | ]
1253 | }
1254 | ],
1255 | "source": [
1256 | "from transformers import BertTokenizer"
1257 | ]
1258 | },
1259 | {
1260 | "cell_type": "markdown",
1261 | "metadata": {},
1262 | "source": [
1263 | "### Tokenization\n",
1264 | "During tokenization, each word in the sentence is broken apart into smaller and smaller tokens (word pieces) until all the tokens in the dataset are recognized by the Transformer."
1265 | ]
1266 | },
1267 | {
1268 | "cell_type": "code",
1269 | "execution_count": 60,
1270 | "metadata": {
1271 | "collapsed": true
1272 | },
1273 | "outputs": [
1274 | {
1275 | "name": "stderr",
1276 | "output_type": "stream",
1277 | "text": [
1278 | "01/02/2020 22:33:38 - INFO - transformers.file_utils - https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt not found in cache or force_download set to True, downloading to /tmp/tmpr1tsrl_7\n",
1279 | "01/02/2020 22:33:38 - INFO - transformers.file_utils - copying /tmp/tmpr1tsrl_7 to cache at /home/ec2-user/.cache/torch/transformers/26bc1ad6c0ac742e9b52263248f6d0f00068293b33709fae12320c0e35ccfbbb.542ce4285a40d23a559526243235df47c5f75c197f04f37d1a0c124c32c9a084\n",
1280 | "01/02/2020 22:33:38 - INFO - transformers.file_utils - creating metadata file for /home/ec2-user/.cache/torch/transformers/26bc1ad6c0ac742e9b52263248f6d0f00068293b33709fae12320c0e35ccfbbb.542ce4285a40d23a559526243235df47c5f75c197f04f37d1a0c124c32c9a084\n",
1281 | "01/02/2020 22:33:38 - INFO - transformers.file_utils - removing temp file /tmp/tmpr1tsrl_7\n",
1282 | "01/02/2020 22:33:38 - INFO - transformers.tokenization_utils - loading file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt from cache at /home/ec2-user/.cache/torch/transformers/26bc1ad6c0ac742e9b52263248f6d0f00068293b33709fae12320c0e35ccfbbb.542ce4285a40d23a559526243235df47c5f75c197f04f37d1a0c124c32c9a084\n"
1283 | ]
1284 | }
1285 | ],
1286 | "source": [
1287 | "tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') "
1288 | ]
1289 | },
1290 | {
1291 | "cell_type": "markdown",
1292 | "metadata": {},
1293 | "source": [
1294 | "Set the input data directory. Should contain the .tsv files (or other data files) for the readmission task."
1295 | ]
1296 | },
1297 | {
1298 | "cell_type": "code",
1299 | "execution_count": 61,
1300 | "metadata": {},
1301 | "outputs": [],
1302 | "source": [
1303 | "data_dir = './data/2days/'"
1304 | ]
1305 | },
1306 | {
1307 | "cell_type": "markdown",
1308 | "metadata": {},
1309 | "source": [
1310 | "The code below is only needed if you want to pre-train ClinicalBERT. If you want to perform pre-training of BERT yourself, you should have set the variable `do_train` earlier to `True`. "
1311 | ]
1312 | },
1313 | {
1314 | "cell_type": "code",
1315 | "execution_count": 62,
1316 | "metadata": {},
1317 | "outputs": [],
1318 | "source": [
1319 | "train_examples = None\n",
1320 | "num_train_steps = None\n",
1321 | "if do_train:\n",
1322 | " train_examples = processor.get_train_examples(data_dir)\n",
1323 | " num_train_steps = int(\n",
1324 | " len(train_examples) / train_batch_size / gradient_accumulation_steps * num_train_epochs)"
1325 | ]
1326 | },
1327 | {
1328 | "cell_type": "markdown",
1329 | "metadata": {},
1330 | "source": [
1331 | "# Prepare Model\n",
1332 | "To import a custom module into Jupyter notebook, use sys.path.append because Jupyter doesn't always see/find the module you uploaded. Thanks to this Stack Overflow [answer](https://stackoverflow.com/questions/53049195/importing-custom-module-into-jupyter-notebook). "
1333 | ]
1334 | },
1335 | {
1336 | "cell_type": "code",
1337 | "execution_count": 63,
1338 | "metadata": {},
1339 | "outputs": [],
1340 | "source": [
1341 | "import sys"
1342 | ]
1343 | },
1344 | {
1345 | "cell_type": "code",
1346 | "execution_count": 64,
1347 | "metadata": {},
1348 | "outputs": [],
1349 | "source": [
1350 | "sys.path.append('./')"
1351 | ]
1352 | },
1353 | {
1354 | "cell_type": "code",
1355 | "execution_count": 66,
1356 | "metadata": {},
1357 | "outputs": [
1358 | {
1359 | "name": "stdout",
1360 | "output_type": "stream",
1361 | "text": [
1362 | "in the modeling class\n"
1363 | ]
1364 | }
1365 | ],
1366 | "source": [
1367 | "from modeling_readmission import BertForSequenceClassification"
1368 | ]
1369 | },
1370 | {
1371 | "cell_type": "markdown",
1372 | "metadata": {},
1373 | "source": [
1374 | "`bert_model` is the Bert pre-trained model selected from the list: \n",
1375 | "* bert-base-uncased\n",
1376 | "* bert-large-uncased\n",
1377 | "* bert-base-cased\n",
1378 | "* bert-base-multilingual\n",
1379 | "* bert-base-chinese"
1380 | ]
1381 | },
1382 | {
1383 | "cell_type": "markdown",
1384 | "metadata": {},
1385 | "source": [
1386 | "The main breaking change when migrating from pytorch-pretrained-bert to transformers is that the models forward method always outputs a tuple with various elements depending on the model and the configuration parameters."
1387 | ]
1388 | },
1389 | {
1390 | "cell_type": "code",
1391 | "execution_count": 67,
1392 | "metadata": {},
1393 | "outputs": [],
1394 | "source": [
1395 | "bert_model='./model/early_readmission'"
1396 | ]
1397 | },
1398 | {
1399 | "cell_type": "code",
1400 | "execution_count": 70,
1401 | "metadata": {},
1402 | "outputs": [
1403 | {
1404 | "name": "stderr",
1405 | "output_type": "stream",
1406 | "text": [
1407 | "01/02/2020 22:54:36 - INFO - modeling_readmission - loading archive file ./model/early_readmission\n",
1408 | "01/02/2020 22:54:36 - INFO - modeling_readmission - Model config {\n",
1409 | " \"attention_probs_dropout_prob\": 0.1,\n",
1410 | " \"hidden_act\": \"gelu\",\n",
1411 | " \"hidden_dropout_prob\": 0.1,\n",
1412 | " \"hidden_size\": 768,\n",
1413 | " \"initializer_range\": 0.02,\n",
1414 | " \"intermediate_size\": 3072,\n",
1415 | " \"max_position_embeddings\": 512,\n",
1416 | " \"num_attention_heads\": 12,\n",
1417 | " \"num_hidden_layers\": 12,\n",
1418 | " \"type_vocab_size\": 2,\n",
1419 | " \"vocab_size\": 30522\n",
1420 | "}\n",
1421 | "\n"
1422 | ]
1423 | }
1424 | ],
1425 | "source": [
1426 | "model = BertForSequenceClassification.from_pretrained(bert_model, 1)"
1427 | ]
1428 | },
1429 | {
1430 | "cell_type": "code",
1431 | "execution_count": 71,
1432 | "metadata": {},
1433 | "outputs": [
1434 | {
1435 | "data": {
1436 | "text/plain": [
1437 | "BertForSequenceClassification(\n",
1438 | " (bert): BertModel(\n",
1439 | " (embeddings): BertEmbeddings(\n",
1440 | " (word_embeddings): Embedding(30522, 768)\n",
1441 | " (position_embeddings): Embedding(512, 768)\n",
1442 | " (token_type_embeddings): Embedding(2, 768)\n",
1443 | " (LayerNorm): BertLayerNorm()\n",
1444 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1445 | " )\n",
1446 | " (encoder): BertEncoder(\n",
1447 | " (layer): ModuleList(\n",
1448 | " (0): BertLayer(\n",
1449 | " (attention): BertAttention(\n",
1450 | " (self): BertSelfAttention(\n",
1451 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1452 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1453 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1454 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1455 | " )\n",
1456 | " (output): BertSelfOutput(\n",
1457 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1458 | " (LayerNorm): BertLayerNorm()\n",
1459 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1460 | " )\n",
1461 | " )\n",
1462 | " (intermediate): BertIntermediate(\n",
1463 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1464 | " )\n",
1465 | " (output): BertOutput(\n",
1466 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1467 | " (LayerNorm): BertLayerNorm()\n",
1468 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1469 | " )\n",
1470 | " )\n",
1471 | " (1): BertLayer(\n",
1472 | " (attention): BertAttention(\n",
1473 | " (self): BertSelfAttention(\n",
1474 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1475 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1476 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1477 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1478 | " )\n",
1479 | " (output): BertSelfOutput(\n",
1480 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1481 | " (LayerNorm): BertLayerNorm()\n",
1482 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1483 | " )\n",
1484 | " )\n",
1485 | " (intermediate): BertIntermediate(\n",
1486 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1487 | " )\n",
1488 | " (output): BertOutput(\n",
1489 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1490 | " (LayerNorm): BertLayerNorm()\n",
1491 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1492 | " )\n",
1493 | " )\n",
1494 | " (2): BertLayer(\n",
1495 | " (attention): BertAttention(\n",
1496 | " (self): BertSelfAttention(\n",
1497 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1498 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1499 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1500 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1501 | " )\n",
1502 | " (output): BertSelfOutput(\n",
1503 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1504 | " (LayerNorm): BertLayerNorm()\n",
1505 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1506 | " )\n",
1507 | " )\n",
1508 | " (intermediate): BertIntermediate(\n",
1509 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1510 | " )\n",
1511 | " (output): BertOutput(\n",
1512 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1513 | " (LayerNorm): BertLayerNorm()\n",
1514 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1515 | " )\n",
1516 | " )\n",
1517 | " (3): BertLayer(\n",
1518 | " (attention): BertAttention(\n",
1519 | " (self): BertSelfAttention(\n",
1520 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1521 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1522 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1523 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1524 | " )\n",
1525 | " (output): BertSelfOutput(\n",
1526 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1527 | " (LayerNorm): BertLayerNorm()\n",
1528 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1529 | " )\n",
1530 | " )\n",
1531 | " (intermediate): BertIntermediate(\n",
1532 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1533 | " )\n",
1534 | " (output): BertOutput(\n",
1535 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1536 | " (LayerNorm): BertLayerNorm()\n",
1537 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1538 | " )\n",
1539 | " )\n",
1540 | " (4): BertLayer(\n",
1541 | " (attention): BertAttention(\n",
1542 | " (self): BertSelfAttention(\n",
1543 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1544 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1545 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1546 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1547 | " )\n",
1548 | " (output): BertSelfOutput(\n",
1549 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1550 | " (LayerNorm): BertLayerNorm()\n",
1551 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1552 | " )\n",
1553 | " )\n",
1554 | " (intermediate): BertIntermediate(\n",
1555 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1556 | " )\n",
1557 | " (output): BertOutput(\n",
1558 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1559 | " (LayerNorm): BertLayerNorm()\n",
1560 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1561 | " )\n",
1562 | " )\n",
1563 | " (5): BertLayer(\n",
1564 | " (attention): BertAttention(\n",
1565 | " (self): BertSelfAttention(\n",
1566 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1567 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1568 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1569 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1570 | " )\n",
1571 | " (output): BertSelfOutput(\n",
1572 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1573 | " (LayerNorm): BertLayerNorm()\n",
1574 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1575 | " )\n",
1576 | " )\n",
1577 | " (intermediate): BertIntermediate(\n",
1578 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1579 | " )\n",
1580 | " (output): BertOutput(\n",
1581 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1582 | " (LayerNorm): BertLayerNorm()\n",
1583 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1584 | " )\n",
1585 | " )\n",
1586 | " (6): BertLayer(\n",
1587 | " (attention): BertAttention(\n",
1588 | " (self): BertSelfAttention(\n",
1589 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1590 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1591 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1592 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1593 | " )\n",
1594 | " (output): BertSelfOutput(\n",
1595 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1596 | " (LayerNorm): BertLayerNorm()\n",
1597 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1598 | " )\n",
1599 | " )\n",
1600 | " (intermediate): BertIntermediate(\n",
1601 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1602 | " )\n",
1603 | " (output): BertOutput(\n",
1604 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1605 | " (LayerNorm): BertLayerNorm()\n",
1606 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1607 | " )\n",
1608 | " )\n",
1609 | " (7): BertLayer(\n",
1610 | " (attention): BertAttention(\n",
1611 | " (self): BertSelfAttention(\n",
1612 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1613 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1614 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1615 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1616 | " )\n",
1617 | " (output): BertSelfOutput(\n",
1618 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1619 | " (LayerNorm): BertLayerNorm()\n",
1620 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1621 | " )\n",
1622 | " )\n",
1623 | " (intermediate): BertIntermediate(\n",
1624 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1625 | " )\n",
1626 | " (output): BertOutput(\n",
1627 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1628 | " (LayerNorm): BertLayerNorm()\n",
1629 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1630 | " )\n",
1631 | " )\n",
1632 | " (8): BertLayer(\n",
1633 | " (attention): BertAttention(\n",
1634 | " (self): BertSelfAttention(\n",
1635 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1636 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1637 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1638 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1639 | " )\n",
1640 | " (output): BertSelfOutput(\n",
1641 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1642 | " (LayerNorm): BertLayerNorm()\n",
1643 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1644 | " )\n",
1645 | " )\n",
1646 | " (intermediate): BertIntermediate(\n",
1647 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1648 | " )\n",
1649 | " (output): BertOutput(\n",
1650 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1651 | " (LayerNorm): BertLayerNorm()\n",
1652 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1653 | " )\n",
1654 | " )\n",
1655 | " (9): BertLayer(\n",
1656 | " (attention): BertAttention(\n",
1657 | " (self): BertSelfAttention(\n",
1658 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1659 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1660 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1661 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1662 | " )\n",
1663 | " (output): BertSelfOutput(\n",
1664 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1665 | " (LayerNorm): BertLayerNorm()\n",
1666 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1667 | " )\n",
1668 | " )\n",
1669 | " (intermediate): BertIntermediate(\n",
1670 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1671 | " )\n",
1672 | " (output): BertOutput(\n",
1673 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1674 | " (LayerNorm): BertLayerNorm()\n",
1675 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1676 | " )\n",
1677 | " )\n",
1678 | " (10): BertLayer(\n",
1679 | " (attention): BertAttention(\n",
1680 | " (self): BertSelfAttention(\n",
1681 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1682 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1683 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1684 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1685 | " )\n",
1686 | " (output): BertSelfOutput(\n",
1687 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1688 | " (LayerNorm): BertLayerNorm()\n",
1689 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1690 | " )\n",
1691 | " )\n",
1692 | " (intermediate): BertIntermediate(\n",
1693 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1694 | " )\n",
1695 | " (output): BertOutput(\n",
1696 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1697 | " (LayerNorm): BertLayerNorm()\n",
1698 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1699 | " )\n",
1700 | " )\n",
1701 | " (11): BertLayer(\n",
1702 | " (attention): BertAttention(\n",
1703 | " (self): BertSelfAttention(\n",
1704 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1705 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1706 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1707 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1708 | " )\n",
1709 | " (output): BertSelfOutput(\n",
1710 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1711 | " (LayerNorm): BertLayerNorm()\n",
1712 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1713 | " )\n",
1714 | " )\n",
1715 | " (intermediate): BertIntermediate(\n",
1716 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1717 | " )\n",
1718 | " (output): BertOutput(\n",
1719 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1720 | " (LayerNorm): BertLayerNorm()\n",
1721 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1722 | " )\n",
1723 | " )\n",
1724 | " )\n",
1725 | " )\n",
1726 | " (pooler): BertPooler(\n",
1727 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1728 | " (activation): Tanh()\n",
1729 | " )\n",
1730 | " )\n",
1731 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1732 | " (classifier): Linear(in_features=768, out_features=1, bias=True)\n",
1733 | ")"
1734 | ]
1735 | },
1736 | "execution_count": 71,
1737 | "metadata": {},
1738 | "output_type": "execute_result"
1739 | }
1740 | ],
1741 | "source": [
1742 | "# Send data to the chosen device\n",
1743 | "model.to(device)"
1744 | ]
1745 | },
1746 | {
1747 | "cell_type": "markdown",
1748 | "metadata": {},
1749 | "source": [
1750 | "[`DistributedDataParallel`](https://pytorch.org/tutorials/intermediate/ddp_tutorial.html#comparison-between-dataparallel-and-distributeddataparallel) (DDP) implements data parallelism at the module level. It synchronizes gradients, parameters, and buffers. If your model is too large to fit on a single GPU, you must use model parallel to split it across multiple GPUs. DDP works with model parallel. DDP is multi-process and works for both single- and multi-machine training."
1751 | ]
1752 | },
1753 | {
1754 | "cell_type": "code",
1755 | "execution_count": 72,
1756 | "metadata": {},
1757 | "outputs": [],
1758 | "source": [
1759 | "if local_rank != -1:\n",
1760 | " model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)\n",
1761 | "elif n_gpu > 1:\n",
1762 | " model = torch.nn.DataParallel(model)"
1763 | ]
1764 | },
1765 | {
1766 | "cell_type": "markdown",
1767 | "metadata": {},
1768 | "source": [
1769 | "# Prepare the Optimizer - AdamW (Weight Decay with Adam)"
1770 | ]
1771 | },
1772 | {
1773 | "cell_type": "markdown",
1774 | "metadata": {},
1775 | "source": [
1776 | "## *** Skip this section if you're using Pre-trained BERT and have set the flag `do_train`=False"
1777 | ]
1778 | },
1779 | {
1780 | "cell_type": "markdown",
1781 | "metadata": {},
1782 | "source": [
1783 | "Training the BERT baseline model is typically done with AdamW, a variant of the Adam optimizer with weight decay as the optimizer. \n",
1784 | "\n",
1785 | ">At its heart, Adam is a simple and intuitive idea: why use the same learning rate for every parameter, when we know that some surely need to be moved further and faster than others? Since the square of recent gradients tells us how much signal we’re getting for each weight, we can just divide by that to ensure even the most sluggish weights get their chance to shine. Adam takes that idea, adds on the standard approach to momentum, and (with a little tweak to keep early batches from being biased) that’s it!...We should use **weight decay** with Adam, and not the L2 regularization that classic deep learning libraries implement [[fast.ai](https://www.fast.ai/2018/07/02/adam-weight-decay/#understanding-adamw-weight-decay-or-l2-regularization)].\n",
1786 | "\n",
1787 | "* `optimize_on_cpu` is whether to perform optimization and keep the optimizer averages on CPU.\n",
1788 | "* `learning_rate` is the initial learning rate for Adam.\n",
1789 | "* `warmup_proportion` is the proportion of training to perform linear learning rate warmup for."
1790 | ]
1791 | },
1792 | {
1793 | "cell_type": "code",
1794 | "execution_count": 73,
1795 | "metadata": {},
1796 | "outputs": [],
1797 | "source": [
1798 | "optimize_on_cpu = False\n",
1799 | "learning_rate = 5e-5\n",
1800 | "warmup_proportion = 0.1\n",
1801 | "\n",
1802 | "# num_warmup_steps = warmup_proportion * float(num_train_steps"
1803 | ]
1804 | },
1805 | {
1806 | "cell_type": "code",
1807 | "execution_count": 74,
1808 | "metadata": {},
1809 | "outputs": [],
1810 | "source": [
1811 | "global_step = 0\n",
1812 | "train_loss=100000\n",
1813 | "number_training_steps=1\n",
1814 | "global_step_check=0\n",
1815 | "train_loss_history=[]"
1816 | ]
1817 | },
1818 | {
1819 | "cell_type": "markdown",
1820 | "metadata": {},
1821 | "source": [
1822 | "Uncomment the cells below to run AdamW optimizer if training."
1823 | ]
1824 | },
1825 | {
1826 | "cell_type": "code",
1827 | "execution_count": 75,
1828 | "metadata": {},
1829 | "outputs": [],
1830 | "source": [
1831 | "# from transformers import AdamW, get_linear_schedule_with_warmup"
1832 | ]
1833 | },
1834 | {
1835 | "cell_type": "code",
1836 | "execution_count": 76,
1837 | "metadata": {},
1838 | "outputs": [],
1839 | "source": [
1840 | "# if optimize_on_cpu:\n",
1841 | "# param_optimizer = [(n, param.clone().detach().to('cpu').requires_grad_()) \\\n",
1842 | "# for n, param in model.named_parameters()]\n",
1843 | "# else:\n",
1844 | "# param_optimizer = list(model.named_parameters())\n",
1845 | "# no_decay = ['bias', 'gamma', 'beta']\n",
1846 | "# optimizer_grouped_parameters = [\n",
1847 | "# {'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay_rate': 0.01},\n",
1848 | "# {'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay_rate': 0.0}\n",
1849 | "# ]\n",
1850 | "\n",
1851 | "# optimizer = AdamW(optimizer_grouped_parameters,\n",
1852 | "# lr=learning_rate,\n",
1853 | "# correct_bias=False) # To reproduce old BertAdam specific behavior set correct_bias=False\n",
1854 | "\n",
1855 | "# # PyTorch scheduler\n",
1856 | "# scheduler = get_linear_schedule_with_warmup(optimizer, \n",
1857 | "# num_warmup_steps=num_warmup_steps,\n",
1858 | "# num_training_steps=num_training_steps) \n",
1859 | "\n",
1860 | "# if do_train:\n",
1861 | "# train_features = convert_examples_to_features(\n",
1862 | "# train_examples, label_list, max_seq_length, tokenizer)\n",
1863 | "# logger.info(\"***** Running training *****\")\n",
1864 | "# logger.info(\" Num examples = %d\", len(train_examples))\n",
1865 | "# logger.info(\" Batch size = %d\", train_batch_size)\n",
1866 | "# logger.info(\" Num steps = %d\", num_train_steps)\n",
1867 | "# all_input_ids = torch.tensor([f.input_ids for f in train_features], dtype=torch.long)\n",
1868 | "# all_input_mask = torch.tensor([f.input_mask for f in train_features], dtype=torch.long)\n",
1869 | "# all_segment_ids = torch.tensor([f.segment_ids for f in train_features], dtype=torch.long)\n",
1870 | "# all_label_ids = torch.tensor([f.label_id for f in train_features], dtype=torch.long)\n",
1871 | "# train_data = TensorDataset(all_input_ids, all_input_mask, all_segment_ids, all_label_ids)\n",
1872 | "# if local_rank == -1:\n",
1873 | "# train_sampler = RandomSampler(train_data)\n",
1874 | "# else:\n",
1875 | "# train_sampler = DistributedSampler(train_data)\n",
1876 | "# train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=train_batch_size)\n",
1877 | "# model.train()\n",
1878 | "# for epo in trange(int(num_train_epochs), desc=\"Epoch\"):\n",
1879 | "# tr_loss = 0\n",
1880 | "# nb_tr_examples, nb_tr_steps = 0, 0\n",
1881 | "# for step, batch in enumerate(train_dataloader):\n",
1882 | "# batch = tuple(t.to(device) for t in batch)\n",
1883 | "# input_ids, input_mask, segment_ids, label_ids = batch\n",
1884 | "# loss, logits = model(input_ids, segment_ids, input_mask, label_ids)\n",
1885 | "# if n_gpu > 1:\n",
1886 | "# loss = loss.mean() # mean() to average on multi-gpu.\n",
1887 | "# if gradient_accumulation_steps > 1:\n",
1888 | "# loss = loss / gradient_accumulation_steps\n",
1889 | "# loss.backward()\n",
1890 | "# train_loss_history.append(loss.item())\n",
1891 | "# tr_loss += loss.item()\n",
1892 | "# nb_tr_examples += input_ids.size(0)\n",
1893 | "# nb_tr_steps += 1\n",
1894 | "# if (step + 1) % gradient_accumulation_steps == 0:\n",
1895 | "# model.zero_grad()\n",
1896 | "# global_step += 1\n",
1897 | "\n",
1898 | "# if (step+1) % 200 == 0:\n",
1899 | "# string = 'step '+str(step+1)\n",
1900 | "# print (string)\n",
1901 | "\n",
1902 | "# train_loss=tr_loss\n",
1903 | "# global_step_check=global_step\n",
1904 | "# number_training_steps=nb_tr_steps\n",
1905 | "\n",
1906 | "# string = './pytorch_model_new_'+ readmission_mode +'.bin'\n",
1907 | "# torch.save(model.state_dict(), string)\n",
1908 | "\n",
1909 | "# fig1 = plt.figure()\n",
1910 | "# plt.plot(train_loss_history)\n",
1911 | "# fig1.savefig('loss_history.png', dpi=fig1.dpi)"
1912 | ]
1913 | },
1914 | {
1915 | "cell_type": "code",
1916 | "execution_count": 77,
1917 | "metadata": {},
1918 | "outputs": [],
1919 | "source": [
1920 | "from torch import nn # Base class for all neural network modules"
1921 | ]
1922 | },
1923 | {
1924 | "cell_type": "code",
1925 | "execution_count": 78,
1926 | "metadata": {},
1927 | "outputs": [],
1928 | "source": [
1929 | "from sklearn.metrics import roc_auc_score, precision_recall_curve, roc_curve, auc, confusion_matrix, classification_report\n",
1930 | "from sklearn.utils.fixes import signature"
1931 | ]
1932 | },
1933 | {
1934 | "cell_type": "code",
1935 | "execution_count": 79,
1936 | "metadata": {},
1937 | "outputs": [],
1938 | "source": [
1939 | "readmission_mode = 'early'"
1940 | ]
1941 | },
1942 | {
1943 | "cell_type": "code",
1944 | "execution_count": 80,
1945 | "metadata": {},
1946 | "outputs": [],
1947 | "source": [
1948 | "def vote_score(df, score, readmission_mode, output_dir):\n",
1949 | " df['pred_score'] = score\n",
1950 | " df_sort = df.sort_values(by=['ID'])\n",
1951 | " #score \n",
1952 | " temp = (df_sort.groupby(['ID'])['pred_score'].agg(max)+df_sort.groupby(['ID'])['pred_score'].agg(sum)/2)/(1+df_sort.groupby(['ID'])['pred_score'].agg(len)/2)\n",
1953 | " x = df_sort.groupby(['ID'])['Label'].agg(np.min).values\n",
1954 | " df_out = pd.DataFrame({'logits': temp.values, 'ID': x})\n",
1955 | "\n",
1956 | " fpr, tpr, thresholds = roc_curve(x, temp.values)\n",
1957 | " auc_score = auc(fpr, tpr)\n",
1958 | "\n",
1959 | " plt.figure(1)\n",
1960 | " plt.plot([0, 1], [0, 1], 'k--')\n",
1961 | " plt.plot(fpr, tpr, label='Val (area = {:.3f})'.format(auc_score))\n",
1962 | " plt.xlabel('False positive rate')\n",
1963 | " plt.ylabel('True positive rate')\n",
1964 | " plt.title('ROC curve')\n",
1965 | " plt.legend(loc='best')\n",
1966 | " plt.show()\n",
1967 | " string = 'auroc_clinicalbert_'+readmission_mode+'.png'\n",
1968 | " plt.savefig(os.path.join(output_dir, string))\n",
1969 | "\n",
1970 | " return fpr, tpr, df_out"
1971 | ]
1972 | },
1973 | {
1974 | "cell_type": "code",
1975 | "execution_count": 81,
1976 | "metadata": {},
1977 | "outputs": [],
1978 | "source": [
1979 | "def pr_curve_plot(y, y_score, readmission_mode, output_dir):\n",
1980 | " precision, recall, _ = precision_recall_curve(y, y_score)\n",
1981 | " area = auc(recall,precision)\n",
1982 | " step_kwargs = ({'step': 'post'}\n",
1983 | " if 'step' in signature(plt.fill_between).parameters\n",
1984 | " else {})\n",
1985 | " \n",
1986 | " plt.figure(2)\n",
1987 | " plt.step(recall, precision, color='b', alpha=0.2,\n",
1988 | " where='post')\n",
1989 | " plt.fill_between(recall, precision, alpha=0.2, color='b', **step_kwargs)\n",
1990 | " plt.xlabel('Recall')\n",
1991 | " plt.ylabel('Precision')\n",
1992 | " plt.ylim([0.0, 1.05])\n",
1993 | " plt.xlim([0.0, 1.0])\n",
1994 | " plt.title('Precision-Recall curve: AUC={0:0.2f}'.format(area))\n",
1995 | " \n",
1996 | " string = 'auprc_clinicalbert_'+readmission_mode+'.png'\n",
1997 | "\n",
1998 | " plt.savefig(os.path.join(output_dir, string))"
1999 | ]
2000 | },
2001 | {
2002 | "cell_type": "code",
2003 | "execution_count": 82,
2004 | "metadata": {},
2005 | "outputs": [],
2006 | "source": [
2007 | "def vote_pr_curve(df, score, readmission_mode, output_dir):\n",
2008 | " df['pred_score'] = score\n",
2009 | " df_sort = df.sort_values(by=['ID'])\n",
2010 | " #score \n",
2011 | " temp = (df_sort.groupby(['ID'])['pred_score'].agg(max)+df_sort.groupby(['ID'])['pred_score'].agg(sum)/2)/(1+df_sort.groupby(['ID'])['pred_score'].agg(len)/2)\n",
2012 | " y = df_sort.groupby(['ID'])['Label'].agg(np.min).values\n",
2013 | " \n",
2014 | " precision, recall, thres = precision_recall_curve(y, temp)\n",
2015 | " pr_thres = pd.DataFrame(data = list(zip(precision, recall, thres)), columns = ['prec','recall','thres'])\n",
2016 | " vote_df = pd.DataFrame(data = list(zip(temp, y)), columns = ['score','label'])\n",
2017 | " \n",
2018 | " pr_curve_plot(y, temp, readmission_mode, output_dir)\n",
2019 | " \n",
2020 | " temp = pr_thres[pr_thres.prec > 0.799999].reset_index()\n",
2021 | " \n",
2022 | " rp80 = 0\n",
2023 | " if temp.size == 0:\n",
2024 | " print('Test Sample too small or RP80=0')\n",
2025 | " else:\n",
2026 | " rp80 = temp.iloc[0].recall\n",
2027 | " print('Recall at Precision of 80 is {}', rp80)\n",
2028 | "\n",
2029 | " return rp80"
2030 | ]
2031 | },
2032 | {
2033 | "cell_type": "code",
2034 | "execution_count": 83,
2035 | "metadata": {},
2036 | "outputs": [],
2037 | "source": [
2038 | "def _truncate_seq_pair(tokens_a, tokens_b, max_length):\n",
2039 | " \"\"\"Truncates a sequence pair in place to the maximum length.\"\"\"\n",
2040 | "\n",
2041 | " # This is a simple heuristic which will always truncate the longer sequence\n",
2042 | " # one token at a time. This makes more sense than truncating an equal percent\n",
2043 | " # of tokens from each, since if one sequence is very short then each token\n",
2044 | " # that's truncated likely contains more information than a longer sequence.\n",
2045 | " while True:\n",
2046 | " total_length = len(tokens_a) + len(tokens_b)\n",
2047 | " if total_length <= max_length:\n",
2048 | " break\n",
2049 | " if len(tokens_a) > len(tokens_b):\n",
2050 | " tokens_a.pop()\n",
2051 | " else:\n",
2052 | " tokens_b.pop()"
2053 | ]
2054 | },
2055 | {
2056 | "cell_type": "code",
2057 | "execution_count": 84,
2058 | "metadata": {},
2059 | "outputs": [],
2060 | "source": [
2061 | "class InputFeatures(object):\n",
2062 | " \"\"\"A single set of features of data.\"\"\"\n",
2063 | "\n",
2064 | " def __init__(self, input_ids, input_mask, segment_ids, label_id):\n",
2065 | " self.input_ids = input_ids\n",
2066 | " self.input_mask = input_mask\n",
2067 | " self.segment_ids = segment_ids\n",
2068 | " self.label_id = label_id"
2069 | ]
2070 | },
2071 | {
2072 | "cell_type": "code",
2073 | "execution_count": 85,
2074 | "metadata": {},
2075 | "outputs": [],
2076 | "source": [
2077 | "def convert_examples_to_features(examples, label_list, max_seq_length, tokenizer):\n",
2078 | " \"\"\"Loads a data file into a list of `InputBatch`s.\"\"\"\n",
2079 | "\n",
2080 | " label_map = {}\n",
2081 | " for (i, label) in enumerate(label_list):\n",
2082 | " label_map[label] = i\n",
2083 | "\n",
2084 | " features = []\n",
2085 | " for (ex_index, example) in enumerate(examples):\n",
2086 | " tokens_a = tokenizer.tokenize(example.text_a)\n",
2087 | "\n",
2088 | " tokens_b = None\n",
2089 | " if example.text_b:\n",
2090 | " tokens_b = tokenizer.tokenize(example.text_b)\n",
2091 | "\n",
2092 | " if tokens_b:\n",
2093 | " # Modifies `tokens_a` and `tokens_b` in place so that the total\n",
2094 | " # length is less than the specified length.\n",
2095 | " # Account for [CLS], [SEP], [SEP] with \"- 3\"\n",
2096 | " _truncate_seq_pair(tokens_a, tokens_b, max_seq_length - 3)\n",
2097 | " else:\n",
2098 | " # Account for [CLS] and [SEP] with \"- 2\"\n",
2099 | " if len(tokens_a) > max_seq_length - 2:\n",
2100 | " tokens_a = tokens_a[0:(max_seq_length - 2)]\n",
2101 | "\n",
2102 | " # The convention in BERT is:\n",
2103 | " # (a) For sequence pairs:\n",
2104 | " # tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]\n",
2105 | " # type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1\n",
2106 | " # (b) For single sequences:\n",
2107 | " # tokens: [CLS] the dog is hairy . [SEP]\n",
2108 | " # type_ids: 0 0 0 0 0 0 0\n",
2109 | " #\n",
2110 | " # Where \"type_ids\" are used to indicate whether this is the first\n",
2111 | " # sequence or the second sequence. The embedding vectors for `type=0` and\n",
2112 | " # `type=1` were learned during pre-training and are added to the wordpiece\n",
2113 | " # embedding vector (and position vector). This is not *strictly* necessary\n",
2114 | " # since the [SEP] token unambigiously separates the sequences, but it makes\n",
2115 | " # it easier for the model to learn the concept of sequences.\n",
2116 | " #\n",
2117 | " # For classification tasks, the first vector (corresponding to [CLS]) is\n",
2118 | " # used as as the \"sentence vector\". Note that this only makes sense because\n",
2119 | " # the entire model is fine-tuned.\n",
2120 | " tokens = []\n",
2121 | " segment_ids = []\n",
2122 | " tokens.append(\"[CLS]\")\n",
2123 | " segment_ids.append(0)\n",
2124 | " for token in tokens_a:\n",
2125 | " tokens.append(token)\n",
2126 | " segment_ids.append(0)\n",
2127 | " tokens.append(\"[SEP]\")\n",
2128 | " segment_ids.append(0)\n",
2129 | "\n",
2130 | " if tokens_b:\n",
2131 | " for token in tokens_b:\n",
2132 | " tokens.append(token)\n",
2133 | " segment_ids.append(1)\n",
2134 | " tokens.append(\"[SEP]\")\n",
2135 | " segment_ids.append(1)\n",
2136 | "\n",
2137 | " input_ids = tokenizer.convert_tokens_to_ids(tokens)\n",
2138 | "\n",
2139 | " # The mask has 1 for real tokens and 0 for padding tokens. Only real tokens are attended to.\n",
2140 | " input_mask = [1] * len(input_ids)\n",
2141 | "\n",
2142 | " # Zero-pad up to the sequence length.\n",
2143 | " while len(input_ids) < max_seq_length:\n",
2144 | " input_ids.append(0)\n",
2145 | " input_mask.append(0)\n",
2146 | " segment_ids.append(0)\n",
2147 | "\n",
2148 | " assert len(input_ids) == max_seq_length\n",
2149 | " assert len(input_mask) == max_seq_length\n",
2150 | " assert len(segment_ids) == max_seq_length\n",
2151 | " #print (example.label)\n",
2152 | " label_id = label_map[example.label]\n",
2153 | " if ex_index < 5:\n",
2154 | " logger.info(\"*** Example ***\")\n",
2155 | " logger.info(\"guid: %s\" % (example.guid))\n",
2156 | " logger.info(\"tokens: %s\" % \" \".join(\n",
2157 | " [str(x) for x in tokens]))\n",
2158 | " logger.info(\"input_ids: %s\" % \" \".join([str(x) for x in input_ids]))\n",
2159 | " logger.info(\"input_mask: %s\" % \" \".join([str(x) for x in input_mask]))\n",
2160 | " logger.info(\n",
2161 | " \"segment_ids: %s\" % \" \".join([str(x) for x in segment_ids]))\n",
2162 | " logger.info(\"label: %s (id = %d)\" % (example.label, label_id))\n",
2163 | "\n",
2164 | " features.append(\n",
2165 | " InputFeatures(input_ids=input_ids,\n",
2166 | " input_mask=input_mask,\n",
2167 | " segment_ids=segment_ids,\n",
2168 | " label_id=label_id))\n",
2169 | " return features\n",
2170 | "\n"
2171 | ]
2172 | },
2173 | {
2174 | "cell_type": "markdown",
2175 | "metadata": {},
2176 | "source": [
2177 | "`max_seq_length` is the maximum total input sequence length after WordPiece tokenization. Sequences longer than this will be truncated, and sequences shorter than this will be padded.\n",
2178 | "\n",
2179 | "`eval_batch_size` is the total batch size for eval."
2180 | ]
2181 | },
2182 | {
2183 | "cell_type": "code",
2184 | "execution_count": 86,
2185 | "metadata": {},
2186 | "outputs": [],
2187 | "source": [
2188 | "max_seq_length = 128\n",
2189 | "eval_batch_size = 2"
2190 | ]
2191 | },
2192 | {
2193 | "cell_type": "code",
2194 | "execution_count": 87,
2195 | "metadata": {},
2196 | "outputs": [],
2197 | "source": [
2198 | "from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler\n",
2199 | "from torch.utils.data.distributed import DistributedSampler"
2200 | ]
2201 | },
2202 | {
2203 | "cell_type": "code",
2204 | "execution_count": 88,
2205 | "metadata": {},
2206 | "outputs": [],
2207 | "source": [
2208 | "m = nn.Sigmoid()\n",
2209 | "if do_eval:\n",
2210 | " eval_examples = processor.get_test_examples(data_dir)\n",
2211 | " eval_features = convert_examples_to_features(\n",
2212 | " eval_examples, label_list, max_seq_length, tokenizer)\n",
2213 | " logger.info(\"***** Running evaluation *****\")\n",
2214 | " logger.info(\" Num examples = %d\", len(eval_examples))\n",
2215 | " logger.info(\" Batch size = %d\", eval_batch_size)\n",
2216 | " all_input_ids = torch.tensor([f.input_ids for f in eval_features], dtype=torch.long)\n",
2217 | " all_input_mask = torch.tensor([f.input_mask for f in eval_features], dtype=torch.long)\n",
2218 | " all_segment_ids = torch.tensor([f.segment_ids for f in eval_features], dtype=torch.long)\n",
2219 | " all_label_ids = torch.tensor([f.label_id for f in eval_features], dtype=torch.long)\n",
2220 | " eval_data = TensorDataset(all_input_ids, all_input_mask, all_segment_ids, all_label_ids)\n",
2221 | " if local_rank == -1:\n",
2222 | " eval_sampler = SequentialSampler(eval_data)\n",
2223 | " else:\n",
2224 | " eval_sampler = DistributedSampler(eval_data)\n",
2225 | " eval_dataloader = DataLoader(eval_data, sampler=eval_sampler, batch_size=eval_batch_size)\n",
2226 | " model.eval()\n",
2227 | " eval_loss, eval_accuracy = 0, 0\n",
2228 | " nb_eval_steps, nb_eval_examples = 0, 0\n",
2229 | " true_labels=[]\n",
2230 | " pred_labels=[]\n",
2231 | " logits_history=[]\n",
2232 | " for input_ids, input_mask, segment_ids, label_ids in tqdm(eval_dataloader):\n",
2233 | " input_ids = input_ids.to(device)\n",
2234 | " input_mask = input_mask.to(device)\n",
2235 | " segment_ids = segment_ids.to(device)\n",
2236 | " label_ids = label_ids.to(device)\n",
2237 | " with torch.no_grad():\n",
2238 | " tmp_eval_loss, temp_logits = model(input_ids, segment_ids, input_mask, label_ids)\n",
2239 | " logits = model(input_ids,segment_ids,input_mask)\n",
2240 | "\n",
2241 | " logits = torch.squeeze(m(logits)).detach().cpu().numpy()\n",
2242 | " label_ids = label_ids.to('cpu').numpy()\n",
2243 | "\n",
2244 | " outputs = np.asarray([1 if i else 0 for i in (logits.flatten()>=0.5)])\n",
2245 | " tmp_eval_accuracy=np.sum(outputs == label_ids)\n",
2246 | "\n",
2247 | " true_labels = true_labels + label_ids.flatten().tolist()\n",
2248 | " pred_labels = pred_labels + outputs.flatten().tolist()\n",
2249 | " logits_history = logits_history + logits.flatten().tolist()\n",
2250 | "\n",
2251 | " eval_loss += tmp_eval_loss.mean().item()\n",
2252 | " eval_accuracy += tmp_eval_accuracy\n",
2253 | "\n",
2254 | " nb_eval_examples += input_ids.size(0)\n",
2255 | " nb_eval_steps += 1\n",
2256 | "\n",
2257 | " eval_loss = eval_loss / nb_eval_steps\n",
2258 | " eval_accuracy = eval_accuracy / nb_eval_examples\n",
2259 | " df = pd.DataFrame({'logits':logits_history, 'pred_label': pred_labels, 'label':true_labels})\n",
2260 | "\n",
2261 | " string = 'logits_clinicalbert_'+readmission_mode+'_chunks.csv'\n",
2262 | " df.to_csv(os.path.join(output_dir, string))\n",
2263 | "\n",
2264 | " df_test = pd.read_csv(os.path.join(data_dir, \"test.csv\"))\n",
2265 | "\n",
2266 | " fpr, tpr, df_out = vote_score(df_test, logits_history, readmission_mode, output_dir)\n",
2267 | "\n",
2268 | " string = 'logits_clinicalbert_'+readmission_mode+'_readmissions.csv'\n",
2269 | " df_out.to_csv(os.path.join(output_dir,string))\n",
2270 | "\n",
2271 | " rp80 = vote_pr_curve(df_test, logits_history, readmission_mode, output_dir)\n",
2272 | "\n",
2273 | " result = {'eval_loss': eval_loss,\n",
2274 | " 'eval_accuracy': eval_accuracy, \n",
2275 | " 'global_step': global_step_check,\n",
2276 | " 'training loss': train_loss/number_training_steps,\n",
2277 | " 'RP80': rp80}\n",
2278 | "\n",
2279 | " output_eval_file = os.path.join(output_dir, \"eval_results.txt\")\n",
2280 | " with open(output_eval_file, \"w\") as writer:\n",
2281 | " logger.info(\"***** Eval results *****\")\n",
2282 | " for key in sorted(result.keys()):\n",
2283 | " logger.info(\" %s = %s\", key, str(result[key]))\n",
2284 | " writer.write(\"%s = %s\\n\" % (key, str(result[key])))\n"
2285 | ]
2286 | },
2287 | {
2288 | "cell_type": "markdown",
2289 | "metadata": {},
2290 | "source": [
2291 | "Download entire folder from AWS sagemaker to laptop:"
2292 | ]
2293 | },
2294 | {
2295 | "cell_type": "code",
2296 | "execution_count": null,
2297 | "metadata": {},
2298 | "outputs": [
2299 | {
2300 | "name": "stdout",
2301 | "output_type": "stream",
2302 | "text": [
2303 | " adding: lost+found/ (stored 0%)\n",
2304 | " adding: model/ (stored 0%)\n",
2305 | " adding: model/early_readmission/ (stored 0%)\n",
2306 | " adding: model/early_readmission/pytorch_model.bin (deflated 7%)\n",
2307 | " adding: model/early_readmission/bert_config.json (deflated 47%)\n",
2308 | " adding: ClinicalBERT3.ipynb (deflated 67%)\n",
2309 | " adding: modeling_readmission.py (deflated 81%)\n",
2310 | " adding: data/ (stored 0%)\n",
2311 | " adding: data/3days/ (stored 0%)\n",
2312 | " adding: data/3days/train.csv (deflated 65%)\n",
2313 | " adding: data/3days/test.csv (deflated 79%)\n",
2314 | " adding: data/3days/val.csv (deflated 78%)\n",
2315 | " adding: data/discharge/ (stored 0%)\n",
2316 | " adding: data/discharge/train.csv (deflated 66%)\n",
2317 | " adding: data/discharge/test.csv (deflated 68%)\n",
2318 | " adding: data/discharge/val.csv (deflated 68%)\n",
2319 | " adding: data/2days/ (stored 0%)\n",
2320 | " adding: data/2days/test.csv (deflated 78%)\n",
2321 | " adding: pickle/ (stored 0%)\n",
2322 | " adding: pickle/df_less_3.pkl"
2323 | ]
2324 | }
2325 | ],
2326 | "source": [
2327 | "!zip -r -X ClinicalBERT3_results.zip './'"
2328 | ]
2329 | }
2330 | ],
2331 | "metadata": {
2332 | "kernelspec": {
2333 | "display_name": "Python 3",
2334 | "language": "python",
2335 | "name": "python3"
2336 | },
2337 | "language_info": {
2338 | "codemirror_mode": {
2339 | "name": "ipython",
2340 | "version": 3
2341 | },
2342 | "file_extension": ".py",
2343 | "mimetype": "text/x-python",
2344 | "name": "python",
2345 | "nbconvert_exporter": "python",
2346 | "pygments_lexer": "ipython3",
2347 | "version": "3.7.3"
2348 | },
2349 | "varInspector": {
2350 | "cols": {
2351 | "lenName": 16,
2352 | "lenType": 16,
2353 | "lenVar": 40
2354 | },
2355 | "kernels_config": {
2356 | "python": {
2357 | "delete_cmd_postfix": "",
2358 | "delete_cmd_prefix": "del ",
2359 | "library": "var_list.py",
2360 | "varRefreshCmd": "print(var_dic_list())"
2361 | },
2362 | "r": {
2363 | "delete_cmd_postfix": ") ",
2364 | "delete_cmd_prefix": "rm(",
2365 | "library": "var_list.r",
2366 | "varRefreshCmd": "cat(var_dic_list()) "
2367 | }
2368 | },
2369 | "position": {
2370 | "height": "472px",
2371 | "left": "506px",
2372 | "right": "20px",
2373 | "top": "120px",
2374 | "width": "742px"
2375 | },
2376 | "types_to_exclude": [
2377 | "module",
2378 | "function",
2379 | "builtin_function_or_method",
2380 | "instance",
2381 | "_Feature"
2382 | ],
2383 | "window_display": false
2384 | }
2385 | },
2386 | "nbformat": 4,
2387 | "nbformat_minor": 2
2388 | }
2389 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 | # ClinicalBERT: Using Deep Learning Transformer Model to Predict Hospital Readmission
3 |
4 | ClinicalBERT: Using Deep Learning Transformer Model to Predict Hospital Readmission
5 |
6 | ***Before we begin, let me point you to my GitHub [repo](https://github.com/nwams/ClinicalBERT-Deep-Learning--Predicting-Hospital-Readmission-Using-Transformer) [or Jupyter [Notebook](https://nbviewer.jupyter.org/github/nwams/ClinicalBERT-Deep-Learning--Predicting-Hospital-Readmission-Using-Transformer/blob/master/ClinicalBERT%20Deep%20Learning%20-%20Predicting%20Hospital%20Readmission.ipynb)] containing all the code used in this guide. Feel free to use the code to follow along with the guide. You can u*se [this google link](https://drive.google.com/open?id=1t8L9w-r88Q5-sfC993x2Tjt1pu--A900) to download the pretrained ClinicalBERT model along with the readmission task fine-tuned model weights.**
7 |
8 | ## Preface
9 |
10 | If you came here from my earlier work [Predicting Hospital Readmission using NLP](https://medium.com/nwamaka-imasogie/predicting-hospital-readmission-using-nlp-5f0fe6f1a705), this deep learning work won’t serve as a direct comparison for the AUROC metric because my approach is completely different in this paper. The more I dug into it, the more I discovered that the most beneficial application for clinicians is to be able to use these predictions to make adjustments **while a patient is still in the hospital** in order for Doctors to intervene and prevent them from being readmitted in the future. Therefore instead of using discharge summaries (written after a patient’s stay is over) it’s best to just feed in the early notes into the model that were gathered from within 2–3days of a patients stay.
11 |
12 | ## TLDR
13 |
14 | My results for predicting readmission **using only the first few days of notes in the intensive care unit (not discharge summaries)** are:
15 |
16 | * For 2days AUROC=0.748 and for 3days AUROC=0.758.
17 |
18 | * For 2days RP80=38.69% and for 3days RP80=38.02%.
19 |
20 | See the bottom of this article for full details.
21 |
22 | ## Introduction
23 |
24 | I recently read this great paper “ClinicalBert: Modeling Clinical Notes and Predicting Hospital Readmission” by Huang et al ([Paper](https://arxiv.org/pdf/1904.05342.pdf) & [GitHub](https://github.com/kexinhuang12345/clinicalBERT)).
25 |
26 | They develop ClinicalBert by applying BERT (bidirectional encoder representations from transformers) to clinical notes.
27 |
28 | I wanted to dissect the work and expound upon the deep learning concepts. My work will serve as a detailed annotation (along with my own code changes) and interpretation of the contents of this academic paper. I will also create visualizations to enhance explanations. And I converted it to a convenient Jupyter Notebook format.
29 |
30 | ### How my work differs from the author:
31 |
32 | 1. I am only working with **early** clinical notes (first 24–48 hrs and 48–72 hrs) because although discharge summaries have predictive power for readmission, “discharge summaries might be written after a patient has left the hospital. Therefore, discharge summaries are **not actionable** since doctors cannot intervene when a patient has left the hospital. Models that dynamically predict readmission in the early stages of a patient’s admission are relevant to clinicians…a maximum of the first 48 or 72 hours of a patient’s notes are concatenated. These concatenated notes are used to predict readmission.”[pg 12](https://arxiv.org/pdf/1904.05342.pdf). The ClinicalBERT model can predict readmission dynamically. **Making a prediction using a discharge summary at the end of a stay means that there are fewer opportunities to reduce the chance of readmission. To build a clinically-relevant model, we define a task for predicting readmission at any timepoint since a patient was admitted.**
33 |
34 | 1. My code is presented in a Jupyter Notebook rather than .py files.
35 |
36 | 1. It’s important to note that my code differs from Huang’s because I [migrated](https://huggingface.co/transformers/migration.html) to using [HuggingFace’s](https://huggingface.co/transformers/index.html) new transformer module instead of the formerly known as pytorch_pretrained_bert that the author used.
37 |
38 | 1. I do not conduct pre-training the ClinicalBERT because the author already performed pre-training on Clinical words and the model’s weights are already available [here](http://bit.ly/clinicalbert_weights).
39 |
40 | ## Brief BERT Intro
41 |
42 | **BERT** (Bidirectional Encoder Representations from Transformers) is a recent [model](https://arxiv.org/pdf/1810.04805.pdf) published in Oct 2018 by researchers at Google AI Language. It has caused a stir in the Machine Learning community by presenting state-of-the-art results in a wide variety of NLP tasks, including Question Answering (SQuAD v1.1), Natural Language Inference (MNLI), and others.
43 |
44 | ## What is ClinicalBERT?
45 |
46 | ClinicalBERT is a Bidirectional Transformer.
47 |
48 | ClinicalBERT is a modified BERT model: Specifically, the representations are learned using medical notes and further processed for downstream clinical tasks.
49 |
50 | 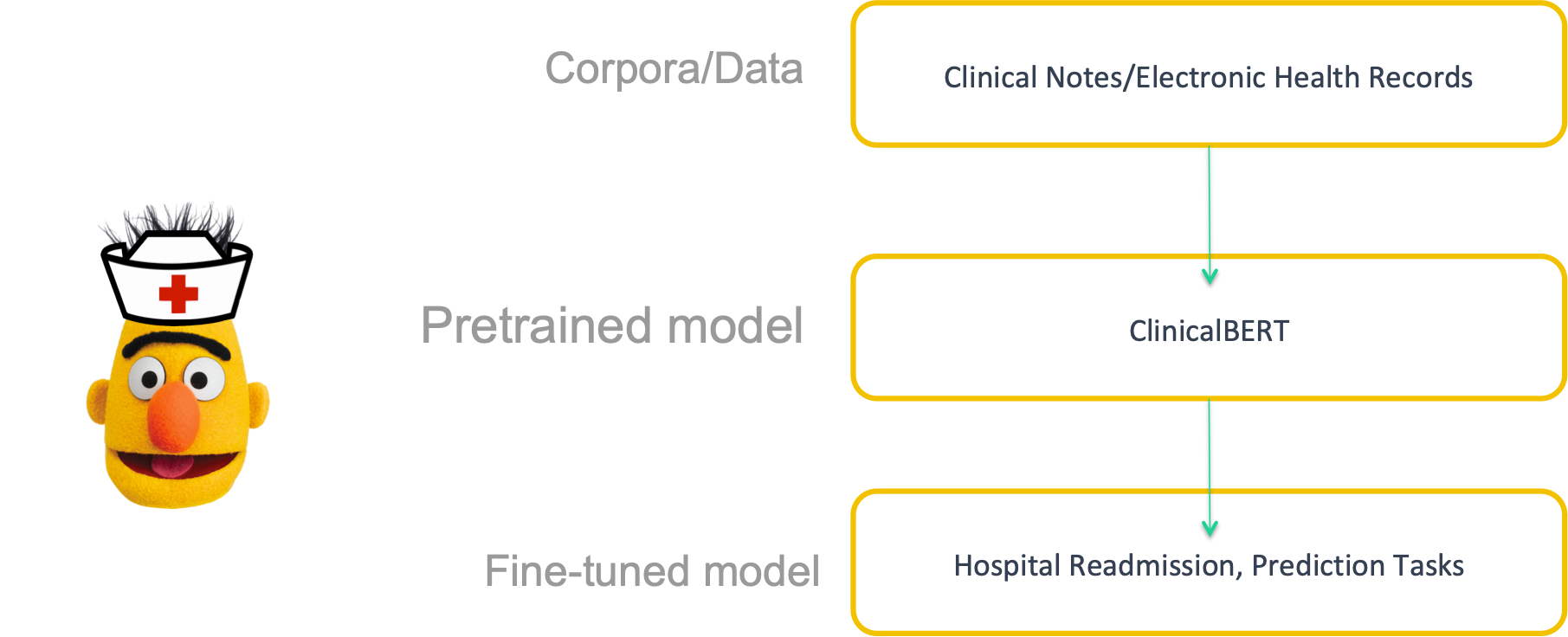*ClinicalBERT is pretrained on patient clinical notes/EHR and then can be used for downstream predictive tasks.*
51 |
52 | The diagram below illustrates how care providers add notes to an electronic health record during a patient’s admission, and the model dynamically updates the patient’s risk of being readmitted within a 30-day window.
53 |
54 | *Every day, more data gets added to an EHR. Notes like Radiology, Nursing, ECG, Physician, Discharge summary, Echo, Respiratory, Nutrition, General, Rehab Services, Social Work, Case Management, Pharmacy and Consult.*
55 |
56 | ## Why is ClinicalBERT needed?
57 |
58 | Before the author even evaluated ClinicalBERT’s performance as a model of readmission, **his initial experiment showed that the original BERT suffered in performance on the masked language modeling task on the MIMIC-III data as well as the next sentence prediction tasks. This proves the need develop models tailored to clinical data such as ClinicalBERT!**
59 |
60 | Medicine suffers from alarm fatigue. This means useful classification rules for medicine need to have high precision (positive predictive value).
61 |
62 | The quality of learned representations of text depends on the text the model was trained on. **Regular BERT is pretrained on BooksCorpus and Wikipedia**. However, these two datasets are distinct from clinical notes. Clinical notes have jargon, abbreviations and different syntax and grammar than common language in books or encyclopedias. **ClinicalBERT is trained on clinical notes/Electronic Health Records (EHR)**.
63 |
64 | Clinical notes require capturing interactions between distant words and ClinicalBert captures qualitative relationships among clinical concepts in a database of medical terms.
65 |
66 | Compared to the popular word2vec model, ClinicalBert more accurately captures clinical word similarity.
67 |
68 | ## BERT Basics
69 |
70 | ]](https://cdn-images-1.medium.com/max/2232/1*9PjJt3EkZS85Hy3H4UKeLg.png)*[[Source](https://arxiv.org/abs/1904.05342)]*
71 |
72 | Just like BERT, Clinical BERT is a trained Transformer Encoder stack.
73 |
74 | Here’s a quick refresher on the basics of how BERT works.
75 |
76 | ]](https://cdn-images-1.medium.com/max/2000/1*rAAdyehB3uXuDkrjB3Mzog.png)*[[Source](http://jalammar.github.io/illustrated-bert/)]*
77 |
78 | BERT base has 12 encoder layers.
79 |
80 | In my code I am using ***BERT base uncased***.
81 |
82 | ]](https://cdn-images-1.medium.com/max/3000/1*j9R9I4taW5P4qxaCW-7liw.png)*[[Source](http://jalammar.github.io/illustrated-bert/)]*
83 |
84 | Pretrained BERT has a max of **512 input tokens** (position embeddings). The output would be a vector for each input token. Each vector is made up of **768** float numbers (**hidden units**).
85 |
86 | ## Pre-training ClinicalBERT
87 |
88 | ClinicalBERT outperforms BERT on two unsupervised language modeling tasks evaluated on a large corpus of clinical text. In *masked language modeling* (where you mask 15% of the input tokens and using the model to predict the next tokens) and *next-sentence prediction* tasks ClinicalBERT outperforms BERT by 30 points and 18.75 points respectively.
89 |
90 | ](https://cdn-images-1.medium.com/max/3112/1*QAGvhTGhTPA0DTZms19o7g.png)*Source: [https://arxiv.org/abs/1904.05342](https://arxiv.org/abs/1904.05342)*
91 |
92 | ## Fine-tuning ClinicalBERT
93 |
94 | *ClinicalBERT can be readily adapted to downstream clinical tasks e.g. Predicting 30-Day Readmission.*
95 |
96 | In this tutorial, we will use ClinicalBERT to train a readmission classifier. Specifically, I will take the pre-trained ClinicalBERT model, add an untrained layer of neurons on the end, and train the new model.
97 |
98 | ### Advantages to Fine-Tuning
99 |
100 | You might be wondering [why](https://mccormickml.com/2019/07/22/BERT-fine-tuning/) we should do fine-tuning rather than train a specific deep learning model (BiLSTM, Word2Vec, etc.) that is well suited for the specific NLP task you need?
101 |
102 | * **Quicker Development:** The pre-trained ClinicalBERT model weights already encode a lot of information about our language. As a result, it takes much less time to train our fine-tuned model — it is as if we have already trained the bottom layers of our network extensively and only need to gently tune them while using their output as features for our classification task. For example in the original BERT paper the authors recommend only 2–4 epochs of training for fine-tuning BERT on a specific NLP task, compared to the hundreds of GPU hours needed to train the original BERT model or a LSTM from scratch!
103 |
104 | * **Less Data:** Because of the pretrained weights this method allows us to fine-tune our task on a much smaller dataset than would be required in a model that is built from scratch. A major drawback of NLP models built from scratch is that we often need a prohibitively large dataset in order to train our network to reasonable accuracy, meaning a lot of time and energy had to be put into dataset creation. By fine-tuning BERT, we are now able to get away with training a model to good performance on a much smaller amount of training data.
105 |
106 | * **Better Results:** Fine-tuning is shown to achieve state of the art results with minimal task-specific adjustments for a wide variety of tasks: classification, language inference, semantic similarity, question answering, etc. Rather than implementing custom and sometimes-obscure architectures shown to work well on a specific task, fine-tuning is shown to be a better (or at least equal) alternative.
107 |
108 | ### Fine-tuning Details
109 |
110 | ClinicalBert is fine-tuned on a task specific to clinical data: **readmission prediction**.
111 |
112 | The model is fed a patient’s clinical notes, and the patient’s risk of readmission within a 30-day window is predicted using a linear layer applied to the classification representation, hcls, learned by ClinicalBert.
113 |
114 | The model parameters are fine-tuned to **maximize the log-likelihood** of this binary classifier.
115 |
116 | Here is the probability of readmission formula:
117 |
118 | P (readmit = 1 | hcls) = σ(W hcls)
119 |
120 | * **readmit** is a binary indicator of readmission (0 or 1).
121 |
122 | * **σ** is the sigmoid function
123 |
124 | * **hcls** is a linear layer operating on the final representation for the CLS token. In other words **hcls** is the output of the model associated with the classification token.
125 |
126 | * **W** is a parameter matrix
127 |
128 | ## Setting Up
129 |
130 | Before starting you must create the following directories and files:
131 |
132 | 
133 |
134 | ### Installation
135 |
136 | Run this command to install the HuggingFace transformer module:
137 |
138 | conda install -c conda-forge transformers
139 |
140 | ## MIMIC-III Dataset on AWS S3 Bucket
141 |
142 | I used the MIMIC-III dataset that they host in the cloud in an [S3 bucket](https://physionet.org/content/mimiciii/1.4/). I found it was easiest to simply [add my AWS account number to my MIMIC-III account](https://mimic.physionet.org/gettingstarted/cloud/) and use this link s3://mimic-iii-physionet to pull the ADMISSIONS and NOTEEVENTS table into my Notebook.
143 |
144 | ## Preprocessing
145 |
146 | ClinicalBert requires minimal preprocessing:
147 |
148 | 1. First, words are converted to lowercase
149 |
150 | 1. Line breaks are removed
151 |
152 | 1. Carriage returns are removed
153 |
154 | 1. De-identified the personally identifiable info inside the brackets
155 |
156 | 1. Remove special characters like ==, −−
157 |
158 | 1. The [SpaCy](https://spacy.io/) sentence segmentation package is used to segment each note (Honnibal and Montani, 2017).
159 |
160 | Since clinical notes don’t follow rigid standard language grammar, we find rule-based segmentation has better results than dependency parsing-based segmentation. Various segmentation signs that misguide rule-based segmentators are removed or replaced.
161 |
162 | * For example 1.2 would be removed.
163 |
164 | * M.D., dr. would be replaced with with MD, Dr
165 |
166 | * Clinical notes can include various lab results and medications that also contain numerous rule-based separators, such as 20mg, p.o., q.d.. (where q.d. means one a day and q.o. means to take by mouth.
167 |
168 | * To address this, segmentations that have less than 20 words are fused into the previous segmentation so that they are not singled out as different sentences.
169 |
170 | ## AWS SageMaker — Training on a GPU
171 |
172 | I used a Notebook in AWS [Sagemaker](https://aws.amazon.com/sagemaker/) and trained on a single p2.xlarge K80 GPU (in SageMaker choose the ml.p2.xlarge). You will have to request a limit increase from AWS support before you can use a GPU. It is a manual request that’s ultimately granted by a human being and could take several hours or 1-day.
173 |
174 | Create a new Notebook in SageMaker. Then open a new Terminal (see picture below):
175 |
176 | 
177 |
178 | Copy/paste and run the script below to cd into the SageMaker directory and create the necessary folders and files:
179 |
180 | cd SageMaker/
181 |
182 | mkdir -p ./data/discharge
183 |
184 | mkdir -p ./data/3days
185 |
186 | mkdir -p ./data/2days
187 |
188 | touch ./data/discharge/train.csv
189 |
190 | touch ./data/discharge/val.csv
191 |
192 | touch ./data/discharge/test.csv
193 |
194 | touch ./data/3days/train.csv
195 |
196 | touch ./data/3days/val.csv
197 |
198 | touch ./data/3days/test.csv
199 |
200 | touch ./data/2days/test.csv
201 |
202 | Upload your Notebook that you’ve been working in on your local computer.
203 |
204 | When creating an IAM role, choose the Any S3 bucket option.
205 |
206 | 
207 |
208 | Create a /pickle directory and upload the 3 pickled files: df_discharge.pkl, df_less_2.pkl and df_less_3.pkl. This may take a few minutes because the files are 398MB, 517MB, and 733MB respectively.
209 |
210 | Then upload the modeling_readmission.py and file_utils.py files into the Jupyter home directory.
211 |
212 | Then upload the [model](https://drive.google.com/open?id=1t8L9w-r88Q5-sfC993x2Tjt1pu--A900) directory to the Jupyter home directory. You can create the directory structure using the following command: mkdir -p ./model/early_readmission. Then you can upload the 2 files pytorch_model.bin and bert_config.json into that folder. This may take a few minutes because pytorch_mode.bin is 438MB.
213 |
214 | Ultimately your Jupyter directory structure should look like this:
215 |
216 | *Note that the **result_early** folder will be created by the code (not you).*
217 |
218 | Now you can run the entire notebook.
219 |
220 | Running the entire notebook took about 8 minutes on a K80 GPU.
221 |
222 | If you’d like to save all of the files (including output) to your local computer run this line in your Jupyter Notebook: !zip -r -X ClinicalBERT3_results.zip './' then you can download it manually from your Notebook.
223 |
224 | ## Code Breakdown
225 |
226 | There’s quite a bit of code so let’s walk through the important bits. I’ll skip a lot of the preprocessing parts like cleaning, splitting training/val/test sets and subsampling that I already covered in-depth [here](https://medium.com/nwamaka-imasogie/predicting-hospital-readmission-using-nlp-5f0fe6f1a705).
227 |
228 | ### Split into 318 word chunks
229 |
230 | # to get 318 words chunks for readmission tasks
231 | df_len = len(df_less_n)
232 | want = pd.DataFrame({'ID': [], 'TEXT': [], 'Label': []})
233 | for i in tqdm(range(df_len)):
234 | x = df_less_n.TEXT.iloc[i].split()
235 | n = int(len(x) / 318)
236 | for j in range(n):
237 | want = want.append({'TEXT': ' '.join(x[j * 318:(j + 1) * 318]), 'Label': df_less_n.OUTPUT_LABEL.iloc[i],
238 | 'ID': df_less_n.HADM_ID.iloc[i]}, ignore_index=True)
239 | if len(x) % 318 > 10:
240 | want = want.append({'TEXT': ' '.join(x[-(len(x) % 318):]), 'Label': df_less_n.OUTPUT_LABEL.iloc[i],
241 | 'ID': df_less_n.HADM_ID.iloc[i]}, ignore_index=True)
242 |
243 | A patient will usually have a lot of different notes, however, the ClinicalBert model has a fixed maximum length of input sequence. We split notes into subsequences (each subsequence is the maximum length supported by the model), and define how ClinicalBert makes predictions on long sequences by binning the predictions on each subsequence.
244 |
245 | You might be wondering why we split into 318 word pieces? Because with BERT there’s a **512 maximum** sequence number of sub word unit tokens (average ~318 words). In other words, BERT uses sub word units (WordPieces) instead of the entire word as the input unit. So instead of “I am having lunch” as 4 individual words, conceptually, it might do something like “I am hav ing lun ch”.
246 |
247 | If you’d like to know more about it this [paper](https://arxiv.org/abs/1508.07909) was originally written to tackle the “out of vocab” problem but it turns out to have stronger predictive values.
248 |
249 | ### Readmission Prediction
250 |
251 | The probability of readmission for a patient is computed as follows. Assume the patient’s clinical notes are represented as *n* subsequences and fed to the model separately; the model outputs a probability for each subsequence. The **probability of readmission** is computed using the probabilities output for each of these subsequences:
252 |
253 | *Equation for Probability of Readmission where **c** is a scaling factor that controls the amount of influence of the number of subsequences **n**, and **hpatient** is the implicit representation ClinicalBert computes from the entirety of a patient’s notes. **Pnmax** is the maximum of probability of readmission across the **n** subsequences, and **Pnmean** is the mean of the probability of readmission across the **n** subsequences a patient’s notes have been split into.*
254 |
255 | Huang finds that computing readmission probability using the equation above 11consistently outperforms predictions on each subsequence individually by 3-8%. This is because:
256 |
257 | 1. Some subsequences, n, (such as tokens corresponding to progress reports) do NOT contain information about readmission, whereas others do. The risk of readmission should be computed using subsequences that correlate with readmission risk, and **the effect of unimportant subsequences should be minimized**. This is accomplished by using the maximum probability over subsequences (Pnmax).
258 |
259 | 1. Also noisy subsequences mislead the model and decrease performance. So they also include the average probability of readmission across subsequences (Pnmean). This leads to a trade-off between the mean and maximum probabilities of readmission.
260 |
261 | 1. If there are a large number of subsequences for a patient with many clinical notes, there is a higher probability of having a noisy maximum probability of readmission. This means longer sequences may need to have a larger weight on the mean prediction. We include this weight as the n/c scaling factor, with c adjusting for patients with many clinical notes. Empirically, Huang found that c=2 performs best on validation data.
262 |
263 | The formula can be found in the vote_score function in the **temp** variable Remember that the 2 is from c=2:
264 |
265 | def vote_score(df, score, readmission_mode, output_dir):
266 | df['pred_score'] = score
267 | df_sort = df.sort_values(by=['ID'])
268 | #score
269 | **temp = (df_sort.groupby(['ID'])['pred_score'].agg(max)+df_sort.groupby(['ID'])['pred_score'].agg(sum)/2)/(1+df_sort.groupby(['ID'])['pred_score'].agg(len)/2)**
270 | x = df_sort.groupby(['ID'])['Label'].agg(np.min).values
271 | df_out = pd.DataFrame({'logits': temp.values, 'ID': x})
272 |
273 | fpr, tpr, thresholds = roc_curve(x, temp.values)
274 | auc_score = auc(fpr, tpr)
275 |
276 | plt.figure(1)
277 | plt.plot([0, 1], [0, 1], 'k--')
278 | plt.plot(fpr, tpr, label='Val (area = {:.3f})'.format(auc_score))
279 | plt.xlabel('False positive rate')
280 | plt.ylabel('True positive rate')
281 | plt.title('ROC curve')
282 | plt.legend(loc='best')
283 | plt.show()
284 | string = 'auroc_clinicalbert_'+readmission_mode+'.png'
285 | plt.savefig(os.path.join(output_dir, string))
286 |
287 | return fpr, tpr, df_out
288 |
289 | ### Results
290 |
291 | For validation 10% of the data is held out, for testing 10% of the data is held out, then 5-fold cross-validation is conducted.
292 |
293 | Each model is evaluated using three metrics:
294 |
295 | 1. Area under the ROC curve (AUROC)
296 |
297 | 1. Area under the precision-recall curve (AUPRC)
298 |
299 | 1. Recall at precision of 80% (RP80): For the readmission task, false positives are important. To minimize the number of false positives and thus minimize the risk of alarm fatigue, we set the precision to 80%. In other words we set a 20% false positive rate out of the predicted positive class and use the corresponding threshold to calculate recall. This leads to a clinically-relevant metric that enables us to build models that control the false positive rate.
300 |
301 | Here is the code: https://gist.github.com/nwams/faef6411b342cf163d6c8fb6267433f9#file-clinicalbert-evaluation-py
302 |
303 | Here are the results output from Predicting Readmission on the Early Notes:
304 |
305 | 
306 |
307 | ## Interpreting Results
308 |
309 | ### Quick Review of Precision, Recall and AUROC
310 |
311 | I recommend reading Jason Brownlee’s [article](https://machinelearningmastery.com/roc-curves-and-precision-recall-curves-for-classification-in-python/).
312 |
313 | * [**Precision**](https://machinelearningmastery.com/roc-curves-and-precision-recall-curves-for-classification-in-python/) is a ratio of the number of true positives divided by the sum of the true positives and false positives. **It describes how good a model is at predicting the positive class**. It is also referred to as the positive predictive value.
314 |
315 | * **Recall**, a.k.a. sensitivity, is calculated as the ratio of the number of true positives divided by the sum of the true positives and the false negatives.
316 |
317 | 
318 |
319 | **It’s important to look at both precision and recall in cases where there is an imbalance** in the observations between the two classes. Specifically, when there are many examples of no event (class 0) and only a few examples of an event (class 1). Because usually the large number of class 0 examples means we are less interested in the skill of the model at predicting class 0 correctly, e.g. high true negatives.
320 | > The important thing to note in the calculation of precision and recall is that the calculations do not make use of the true negatives. It is only concerned with the correct prediction of the minority class, class 1.
321 |
322 | ### When to Use ROC vs. Precision-Recall Curves?
323 |
324 | The recommendations are:
325 |
326 | * ROC curves should be used when there are roughly equal numbers of observations for each class.
327 |
328 | * Precision-Recall curves should be used when there is a moderate to large class imbalance.
329 |
330 | Why? Because **ROC curves present an overly optimistic picture of the model on datasets with a class imbalance**. It’s optimistic because of the use of true negatives in the False Positive rate in the ROC Curve; however remember that the False Positive rate is carefully avoided in the Precision-Recall.
331 |
332 | ### Now back to interpreting our results
333 | > # For 2days AUROC=0.748 and for 3days AUROC=0.758.
334 | > # For 2days RP80=38.69% and for 3days RP80=38.02%.
335 |
336 | Based on [experimentation](https://arxiv.org/pdf/1904.05342.pdf#page=12), ClinicalBert outperforms results from Bag-of-Words and BILSTM baselines. Unfortunately, I didn’t find any other papers/studies that focused solely on early notes, which could’ve been a nice additional comparison point. Nevertheless, the table below shows that the outperformance can be “up to” the following:
337 |
338 | 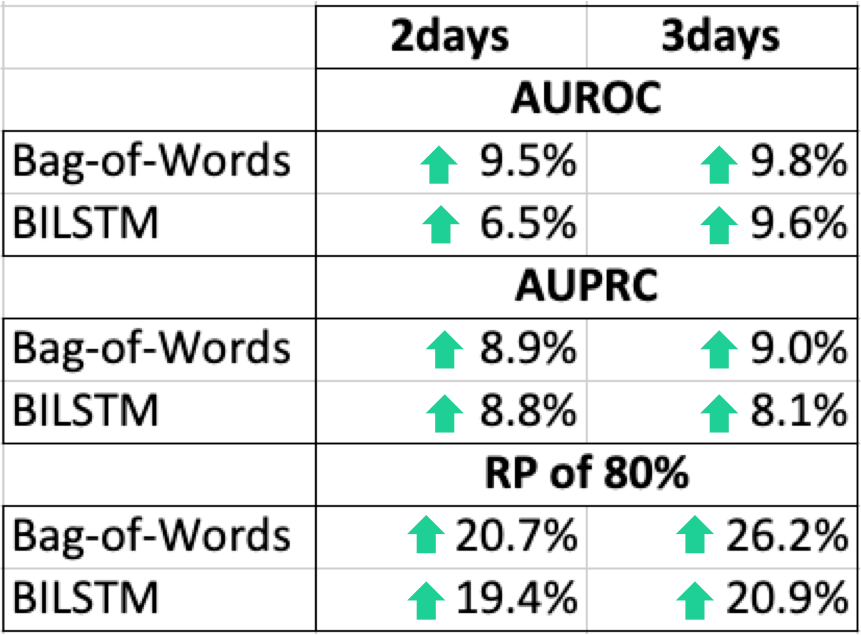*I’d like to emphasize that this only gives the upper bound on the delta of the metrics. The green arrows just indicates that ClinicalBERT has improved performance compared to Bag of Words and BILSTM in all of these metrics for both the 2-days and 3-day results.*
339 |
340 | Since we balanced the data I’ll focus on reporting the AUROC curve as the most appropriate metric instead of the AUPRC.
341 |
342 | I’ll also focus on reporting the Recall at 80% Precision metric due to the fact that it is clinically relevant (remember that alarm fatigue is a real problem in healthcare that we are intentionally trying to avoid/reduce).
343 |
344 | ClinicalBERT has more confidence compared to the other models. And at a fixed rate of false alarms, ClinicalBert recalls more patients that have been readmitted.
345 |
346 | ### 2days compared to other models:
347 |
348 | * **Up to 9.5% AUROC** compared to Bag-of-Words and **up to** **6.5% AUROC** when compared to BILSTM.
349 |
350 | * **Up to** **20.7% RP80** compared to Bag-of-words and **up to** **19.4% RP80** when compared to BILSTM.
351 |
352 | ### **3days compared to other models:**
353 |
354 | * **Up to 9.8% AUROC** compared to Bag-of-Words and **up to** **9.6% AUROC** when compared to BILSTM.
355 |
356 | * **Up to** **26.2% RP80** compared to Bag-of-words and **up to** **20.9% RP80** when compared to BILSTM.
357 |
358 | ## Self-Attention Maps — Visualizing the Results
359 |
360 | ***The code I used for creating the self-attention map in this section is [here](https://github.com/nwams/ClinicalBERT-Deep-Learning--Predicting-Hospital-Readmission-Using-Transformer/blob/master/attention/attention_visualization.ipynb).***
361 |
362 | It’s very difficult for a human to understand why a neural network made a certain prediction, and what parts of the input data did the model find most informative. Therefore Doctors may not trust output from a data-driven method.
363 |
364 | Well, visualizing the self-attention mechanism is a way to solve that problem because it allows you to see the terms correlated with predictions of hospital readmission.
365 |
366 | You might already be familiar with the popular “[Attention is All You Need](https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf)” paper that was submitted at the 2017 arXiv by the Google machine translation team. If not, check out this [animation](https://towardsdatascience.com/attn-illustrated-attention-5ec4ad276ee3) that explains attention. More intuitively, we can think **“self-attention”** as the sentence will **look at itself to determine how to represent each token.**
367 | > As the model processes each word (each position in the input sequence), self attention allows it to look at other positions in the input sequence for clues that can help lead to a better encoding for this word.
368 |
369 | — [The Illustrated Transformer](http://jalammar.github.io/illustrated-transformer/) by Jay Alammar
370 |
371 | For every clinical note input to ClinicalBert, each self-attention mechanism computes a distribution over every term in a sentence, given a query. The **self-attention equation** is:
372 |
373 | 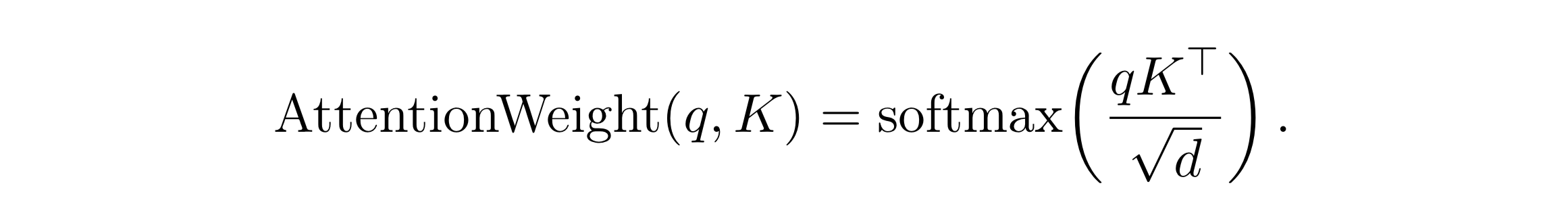*Where q is query vector, K is the key vector, d is the dimensionality of the queries and keys.*
374 |
375 | Intuitively, we can think of it like this: the query, q, represents what kind of information we are looking for, and the key, K, represent the relevance to the query.
376 |
377 | A high attention weight between a query and key token means the interaction between these tokens is predictive of readmission. In the ClinicalBert encoder, there are 144 heads (which is 12 multi-head attention mechanisms for each of the 12 encoder layers). There will be diversity in the different heads, which is what we should expect because different heads learn [different relations](https://docs.dgl.ai/en/latest/tutorials/models/4_old_wines/7_transformer.html) between word pairs. Although each head receives the same input embedding, through random initialization, each learns different focuses [[img](https://www.researchgate.net/publication/328627493_Parallel_Attention_Mechanisms_in_Neural_Machine_Translation/figures?lo=1)].
378 |
379 | The self-attention map below is just one of the self-attention heads in ClinicalBERT — it reveals which terms in clinical notes are predictive of patient readmission. The sentence he has experienced acute on chronic diastolic heart failure in the setting of volume overload due to his sepsis . is used as input that is fed into the model. This sentence is **representative** of a clinical note found in MIMIC-III. The SelfAttention equation is used to compute a distribution over tokens in this sentence, where every query token, q, is also a token in the same input sentence.
380 |
381 | 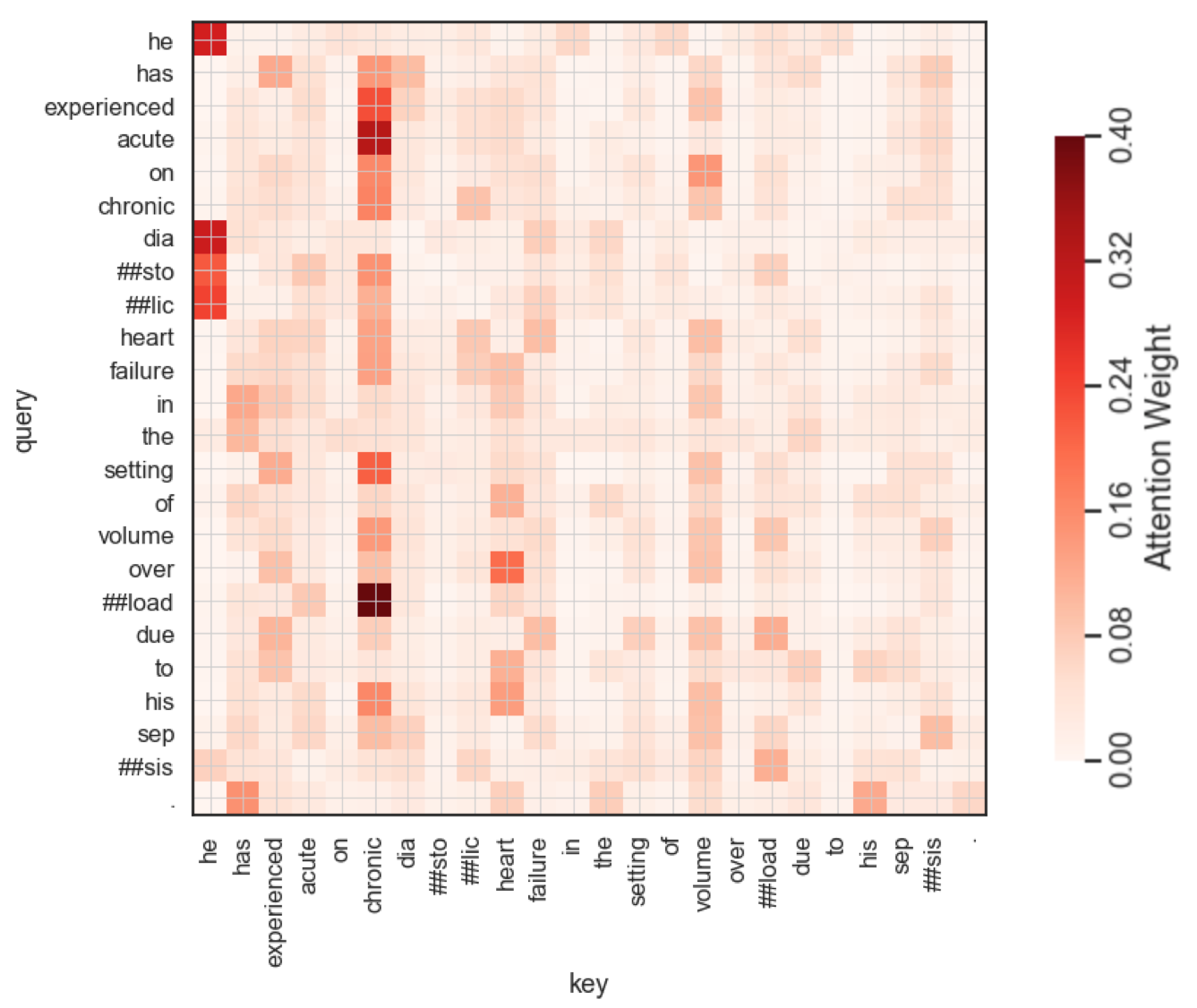*ClinicalBERT Self-Attention Map. The darker colors stand for greater weights.*
382 |
383 | Notice that the self-attention map shows a higher attention weight between the the word chronic and acute…or chronic and ###load .
384 |
385 | Intuitively, the presence of the token associated with the word “chronic” is a predictor of readmission.
386 |
387 | Remember though, there are 12 heads at each layer (144 total heads for this model). And each head is looking at different things. So looking at each head’s attention graph separately will give you an understanding of **how** the model makes predictions — but it won’t make it super easy to interpret the entire system as a “one-stop shop”. Instead, you could do some aggregation (summing up or averaging all the attention head’s weights).
388 |
389 | So if you’re a clinician looking for a “one-stop shop” understanding of the help with interpretation [exBERT](http://exbert.net/) is an interactive software tool that provides insights into the meaning of the contextual representations by matching a human-specified input to similar contexts in a large annotated dataset. By aggregating the annotations of the matching similar contexts, exBERT helps intuitively explain what each attention-head has learned [[Paper](https://arxiv.org/pdf/1910.05276.pdf)]. Although this was created for BERT, this type of tool could also be adapted to ClinicalBERT as well!
390 | > *As an aside, if you’re interested in learning more about the heads, and self-attention weights as it pertains to several BERT NLP tasks, I highly, highly, recommend this academic paper, [Revealing the Dark Secrets of BERT](https://arxiv.org/pdf/1908.08593.pdf) — it does a great job at dissecting and investigating the self-attention mechanism behind BERT-based architectures.*
391 |
392 | ## References
393 |
394 | @article{clinicalbert,
395 | author = {Kexin Huang and Jaan Altosaar and Rajesh Ranganath},
396 | title = {ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission},
397 | year = {2019},
398 | journal = {arXiv:1904.05342},
399 | }
400 |
401 | MIMIC-III, a freely accessible critical care database. Johnson AEW, Pollard TJ, Shen L, Lehman L, Feng M, Ghassemi M, Moody B, Szolovits P, Celi LA, and Mark RG. Scientific Data (2016). DOI: 10.1038/sdata.2016.35. Available at: [http://www.nature.com/articles/sdata201635](http://www.nature.com/articles/sdata201635)
402 |
--------------------------------------------------------------------------------
/file_utils.py:
--------------------------------------------------------------------------------
1 | """
2 | Utilities for working with the local dataset cache.
3 | This file is adapted from the AllenNLP library at https://github.com/allenai/allennlp
4 | Copyright by the AllenNLP authors.
5 | """
6 | from __future__ import (absolute_import, division, print_function, unicode_literals)
7 |
8 | import json
9 | import logging
10 | import os
11 | import shutil
12 | import tempfile
13 | from functools import wraps
14 | from hashlib import sha256
15 | import sys
16 | from io import open
17 |
18 | import boto3
19 | import requests
20 | from botocore.exceptions import ClientError
21 | from tqdm import tqdm
22 |
23 | try:
24 | from urllib.parse import urlparse
25 | except ImportError:
26 | from urlparse import urlparse
27 |
28 | try:
29 | from pathlib import Path
30 | PYTORCH_PRETRAINED_BERT_CACHE = Path(os.getenv('PYTORCH_PRETRAINED_BERT_CACHE',
31 | Path.home() / '.pytorch_pretrained_bert'))
32 | except (AttributeError, ImportError):
33 | PYTORCH_PRETRAINED_BERT_CACHE = os.getenv('PYTORCH_PRETRAINED_BERT_CACHE',
34 | os.path.join(os.path.expanduser("~"), '.pytorch_pretrained_bert'))
35 |
36 | logger = logging.getLogger(__name__) # pylint: disable=invalid-name
37 |
38 |
39 | def url_to_filename(url, etag=None):
40 | """
41 | Convert `url` into a hashed filename in a repeatable way.
42 | If `etag` is specified, append its hash to the url's, delimited
43 | by a period.
44 | """
45 | url_bytes = url.encode('utf-8')
46 | url_hash = sha256(url_bytes)
47 | filename = url_hash.hexdigest()
48 |
49 | if etag:
50 | etag_bytes = etag.encode('utf-8')
51 | etag_hash = sha256(etag_bytes)
52 | filename += '.' + etag_hash.hexdigest()
53 |
54 | return filename
55 |
56 |
57 | def filename_to_url(filename, cache_dir=None):
58 | """
59 | Return the url and etag (which may be ``None``) stored for `filename`.
60 | Raise ``EnvironmentError`` if `filename` or its stored metadata do not exist.
61 | """
62 | if cache_dir is None:
63 | cache_dir = PYTORCH_PRETRAINED_BERT_CACHE
64 | if sys.version_info[0] == 3 and isinstance(cache_dir, Path):
65 | cache_dir = str(cache_dir)
66 |
67 | cache_path = os.path.join(cache_dir, filename)
68 | if not os.path.exists(cache_path):
69 | raise EnvironmentError("file {} not found".format(cache_path))
70 |
71 | meta_path = cache_path + '.json'
72 | if not os.path.exists(meta_path):
73 | raise EnvironmentError("file {} not found".format(meta_path))
74 |
75 | with open(meta_path, encoding="utf-8") as meta_file:
76 | metadata = json.load(meta_file)
77 | url = metadata['url']
78 | etag = metadata['etag']
79 |
80 | return url, etag
81 |
82 |
83 | def cached_path(url_or_filename, cache_dir=None):
84 | """
85 | Given something that might be a URL (or might be a local path),
86 | determine which. If it's a URL, download the file and cache it, and
87 | return the path to the cached file. If it's already a local path,
88 | make sure the file exists and then return the path.
89 | """
90 | if cache_dir is None:
91 | cache_dir = PYTORCH_PRETRAINED_BERT_CACHE
92 | if sys.version_info[0] == 3 and isinstance(url_or_filename, Path):
93 | url_or_filename = str(url_or_filename)
94 | if sys.version_info[0] == 3 and isinstance(cache_dir, Path):
95 | cache_dir = str(cache_dir)
96 |
97 | parsed = urlparse(url_or_filename)
98 |
99 | if parsed.scheme in ('http', 'https', 's3'):
100 | # URL, so get it from the cache (downloading if necessary)
101 | return get_from_cache(url_or_filename, cache_dir)
102 | elif os.path.exists(url_or_filename):
103 | # File, and it exists.
104 | return url_or_filename
105 | elif parsed.scheme == '':
106 | # File, but it doesn't exist.
107 | raise EnvironmentError("file {} not found".format(url_or_filename))
108 | else:
109 | # Something unknown
110 | raise ValueError("unable to parse {} as a URL or as a local path".format(url_or_filename))
111 |
112 |
113 | def split_s3_path(url):
114 | """Split a full s3 path into the bucket name and path."""
115 | parsed = urlparse(url)
116 | if not parsed.netloc or not parsed.path:
117 | raise ValueError("bad s3 path {}".format(url))
118 | bucket_name = parsed.netloc
119 | s3_path = parsed.path
120 | # Remove '/' at beginning of path.
121 | if s3_path.startswith("/"):
122 | s3_path = s3_path[1:]
123 | return bucket_name, s3_path
124 |
125 |
126 | def s3_request(func):
127 | """
128 | Wrapper function for s3 requests in order to create more helpful error
129 | messages.
130 | """
131 |
132 | @wraps(func)
133 | def wrapper(url, *args, **kwargs):
134 | try:
135 | return func(url, *args, **kwargs)
136 | except ClientError as exc:
137 | if int(exc.response["Error"]["Code"]) == 404:
138 | raise EnvironmentError("file {} not found".format(url))
139 | else:
140 | raise
141 |
142 | return wrapper
143 |
144 |
145 | @s3_request
146 | def s3_etag(url):
147 | """Check ETag on S3 object."""
148 | s3_resource = boto3.resource("s3")
149 | bucket_name, s3_path = split_s3_path(url)
150 | s3_object = s3_resource.Object(bucket_name, s3_path)
151 | return s3_object.e_tag
152 |
153 |
154 | @s3_request
155 | def s3_get(url, temp_file):
156 | """Pull a file directly from S3."""
157 | s3_resource = boto3.resource("s3")
158 | bucket_name, s3_path = split_s3_path(url)
159 | s3_resource.Bucket(bucket_name).download_fileobj(s3_path, temp_file)
160 |
161 |
162 | def http_get(url, temp_file):
163 | req = requests.get(url, stream=True)
164 | content_length = req.headers.get('Content-Length')
165 | total = int(content_length) if content_length is not None else None
166 | progress = tqdm(unit="B", total=total)
167 | for chunk in req.iter_content(chunk_size=1024):
168 | if chunk: # filter out keep-alive new chunks
169 | progress.update(len(chunk))
170 | temp_file.write(chunk)
171 | progress.close()
172 |
173 |
174 | def get_from_cache(url, cache_dir=None):
175 | """
176 | Given a URL, look for the corresponding dataset in the local cache.
177 | If it's not there, download it. Then return the path to the cached file.
178 | """
179 | if cache_dir is None:
180 | cache_dir = PYTORCH_PRETRAINED_BERT_CACHE
181 | if sys.version_info[0] == 3 and isinstance(cache_dir, Path):
182 | cache_dir = str(cache_dir)
183 |
184 | if not os.path.exists(cache_dir):
185 | os.makedirs(cache_dir)
186 |
187 | # Get eTag to add to filename, if it exists.
188 | if url.startswith("s3://"):
189 | etag = s3_etag(url)
190 | else:
191 | response = requests.head(url, allow_redirects=True)
192 | if response.status_code != 200:
193 | raise IOError("HEAD request failed for url {} with status code {}"
194 | .format(url, response.status_code))
195 | etag = response.headers.get("ETag")
196 |
197 | filename = url_to_filename(url, etag)
198 |
199 | # get cache path to put the file
200 | cache_path = os.path.join(cache_dir, filename)
201 |
202 | if not os.path.exists(cache_path):
203 | # Download to temporary file, then copy to cache dir once finished.
204 | # Otherwise you get corrupt cache entries if the download gets interrupted.
205 | with tempfile.NamedTemporaryFile() as temp_file:
206 | logger.info("%s not found in cache, downloading to %s", url, temp_file.name)
207 |
208 | # GET file object
209 | if url.startswith("s3://"):
210 | s3_get(url, temp_file)
211 | else:
212 | http_get(url, temp_file)
213 |
214 | # we are copying the file before closing it, so flush to avoid truncation
215 | temp_file.flush()
216 | # shutil.copyfileobj() starts at the current position, so go to the start
217 | temp_file.seek(0)
218 |
219 | logger.info("copying %s to cache at %s", temp_file.name, cache_path)
220 | with open(cache_path, 'wb') as cache_file:
221 | shutil.copyfileobj(temp_file, cache_file)
222 |
223 | logger.info("creating metadata file for %s", cache_path)
224 | meta = {'url': url, 'etag': etag}
225 | meta_path = cache_path + '.json'
226 | with open(meta_path, 'w', encoding="utf-8") as meta_file:
227 | json.dump(meta, meta_file)
228 |
229 | logger.info("removing temp file %s", temp_file.name)
230 |
231 | return cache_path
232 |
233 |
234 | def read_set_from_file(filename):
235 | '''
236 | Extract a de-duped collection (set) of text from a file.
237 | Expected file format is one item per line.
238 | '''
239 | collection = set()
240 | with open(filename, 'r', encoding='utf-8') as file_:
241 | for line in file_:
242 | collection.add(line.rstrip())
243 | return collection
244 |
245 |
246 | def get_file_extension(path, dot=True, lower=True):
247 | ext = os.path.splitext(path)[1]
248 | ext = ext if dot else ext[1:]
249 | return ext.lower() if lower else ext
--------------------------------------------------------------------------------
/images/equ3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nwams/ClinicalBERT-Deep-Learning--Predicting-Hospital-Readmission-Using-Transformer/7c2e2b5859e8eea825c97c2d2677479786fbdd1d/images/equ3.png
--------------------------------------------------------------------------------
/images/fig1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nwams/ClinicalBERT-Deep-Learning--Predicting-Hospital-Readmission-Using-Transformer/7c2e2b5859e8eea825c97c2d2677479786fbdd1d/images/fig1.png
--------------------------------------------------------------------------------
/images/fig2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nwams/ClinicalBERT-Deep-Learning--Predicting-Hospital-Readmission-Using-Transformer/7c2e2b5859e8eea825c97c2d2677479786fbdd1d/images/fig2.png
--------------------------------------------------------------------------------
/images/tab3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nwams/ClinicalBERT-Deep-Learning--Predicting-Hospital-Readmission-Using-Transformer/7c2e2b5859e8eea825c97c2d2677479786fbdd1d/images/tab3.png
--------------------------------------------------------------------------------
/modeling_readmission.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | # Copyright 2018 The Google AI Language Team Authors and The HugginFace Inc. team.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 | """PyTorch BERT model."""
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 |
21 | import os
22 | import copy
23 | import json
24 | import math
25 | import logging
26 | import tarfile
27 | import tempfile
28 | import shutil
29 |
30 | import torch
31 | from torch import nn
32 | from torch.nn import CrossEntropyLoss, BCELoss
33 |
34 | from file_utils import cached_path
35 |
36 | print('in the modeling class')
37 |
38 | logging.basicConfig(format = '%(asctime)s - %(levelname)s - %(name)s - %(message)s',
39 | datefmt = '%m/%d/%Y %H:%M:%S',
40 | level = logging.INFO)
41 | logger = logging.getLogger(__name__)
42 |
43 | PRETRAINED_MODEL_ARCHIVE_MAP = {
44 | 'bert-base-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased.tar.gz",
45 | 'bert-large-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased.tar.gz",
46 | 'bert-base-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased.tar.gz",
47 | 'bert-base-multilingual': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual.tar.gz",
48 | 'bert-base-chinese': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese.tar.gz",
49 | }
50 | CONFIG_NAME = 'bert_config.json'
51 | WEIGHTS_NAME = 'pytorch_model.bin'
52 |
53 | def gelu(x):
54 | """Implementation of the gelu activation function.
55 | For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
56 | 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
57 | """
58 | return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
59 |
60 |
61 | def swish(x):
62 | return x * torch.sigmoid(x)
63 |
64 |
65 | ACT2FN = {"gelu": gelu, "relu": torch.nn.functional.relu, "swish": swish}
66 |
67 |
68 | class BertConfig(object):
69 | """Configuration class to store the configuration of a `BertModel`.
70 | """
71 | def __init__(self,
72 | vocab_size_or_config_json_file,
73 | hidden_size=768,
74 | num_hidden_layers=12,
75 | num_attention_heads=12,
76 | intermediate_size=3072,
77 | hidden_act="gelu",
78 | hidden_dropout_prob=0.1,
79 | attention_probs_dropout_prob=0.1,
80 | max_position_embeddings=512,
81 | type_vocab_size=2,
82 | initializer_range=0.02):
83 | """Constructs BertConfig.
84 |
85 | Args:
86 | vocab_size_or_config_json_file: Vocabulary size of `inputs_ids` in `BertModel`.
87 | hidden_size: Size of the encoder layers and the pooler layer.
88 | num_hidden_layers: Number of hidden layers in the Transformer encoder.
89 | num_attention_heads: Number of attention heads for each attention layer in
90 | the Transformer encoder.
91 | intermediate_size: The size of the "intermediate" (i.e., feed-forward)
92 | layer in the Transformer encoder.
93 | hidden_act: The non-linear activation function (function or string) in the
94 | encoder and pooler. If string, "gelu", "relu" and "swish" are supported.
95 | hidden_dropout_prob: The dropout probabilitiy for all fully connected
96 | layers in the embeddings, encoder, and pooler.
97 | attention_probs_dropout_prob: The dropout ratio for the attention
98 | probabilities.
99 | max_position_embeddings: The maximum sequence length that this model might
100 | ever be used with. Typically set this to something large just in case
101 | (e.g., 512 or 1024 or 2048).
102 | type_vocab_size: The vocabulary size of the `token_type_ids` passed into
103 | `BertModel`.
104 | initializer_range: The sttdev of the truncated_normal_initializer for
105 | initializing all weight matrices.
106 | """
107 | if isinstance(vocab_size_or_config_json_file, str):
108 | with open(vocab_size_or_config_json_file, "r") as reader:
109 | json_config = json.loads(reader.read())
110 | for key, value in json_config.items():
111 | self.__dict__[key] = value
112 | elif isinstance(vocab_size_or_config_json_file, int):
113 | self.vocab_size = vocab_size_or_config_json_file
114 | self.hidden_size = hidden_size
115 | self.num_hidden_layers = num_hidden_layers
116 | self.num_attention_heads = num_attention_heads
117 | self.hidden_act = hidden_act
118 | self.intermediate_size = intermediate_size
119 | self.hidden_dropout_prob = hidden_dropout_prob
120 | self.attention_probs_dropout_prob = attention_probs_dropout_prob
121 | self.max_position_embeddings = max_position_embeddings
122 | self.type_vocab_size = type_vocab_size
123 | self.initializer_range = initializer_range
124 | else:
125 | raise ValueError("First argument must be either a vocabulary size (int)"
126 | "or the path to a pretrained model config file (str)")
127 |
128 | @classmethod
129 | def from_dict(cls, json_object):
130 | """Constructs a `BertConfig` from a Python dictionary of parameters."""
131 | config = BertConfig(vocab_size_or_config_json_file=-1)
132 | for key, value in json_object.items():
133 | config.__dict__[key] = value
134 | return config
135 |
136 | @classmethod
137 | def from_json_file(cls, json_file):
138 | """Constructs a `BertConfig` from a json file of parameters."""
139 | with open(json_file, "r") as reader:
140 | text = reader.read()
141 | return cls.from_dict(json.loads(text))
142 |
143 | def __repr__(self):
144 | return str(self.to_json_string())
145 |
146 | def to_dict(self):
147 | """Serializes this instance to a Python dictionary."""
148 | output = copy.deepcopy(self.__dict__)
149 | return output
150 |
151 | def to_json_string(self):
152 | """Serializes this instance to a JSON string."""
153 | return json.dumps(self.to_dict(), indent=2, sort_keys=True) + "\n"
154 |
155 |
156 | class BertLayerNorm(nn.Module):
157 | def __init__(self, config, variance_epsilon=1e-12):
158 | """Construct a layernorm module in the TF style (epsilon inside the square root).
159 | """
160 | super(BertLayerNorm, self).__init__()
161 | self.gamma = nn.Parameter(torch.ones(config.hidden_size))
162 | self.beta = nn.Parameter(torch.zeros(config.hidden_size))
163 | self.variance_epsilon = variance_epsilon
164 |
165 | def forward(self, x):
166 | u = x.mean(-1, keepdim=True)
167 | s = (x - u).pow(2).mean(-1, keepdim=True)
168 | x = (x - u) / torch.sqrt(s + self.variance_epsilon)
169 | return self.gamma * x + self.beta
170 |
171 |
172 | class BertEmbeddings(nn.Module):
173 | """Construct the embeddings from word, position and token_type embeddings.
174 | """
175 | def __init__(self, config):
176 | super(BertEmbeddings, self).__init__()
177 | self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size)
178 | self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
179 | self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
180 |
181 | # self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
182 | # any TensorFlow checkpoint file
183 | self.LayerNorm = BertLayerNorm(config)
184 | self.dropout = nn.Dropout(config.hidden_dropout_prob)
185 |
186 | def forward(self, input_ids, token_type_ids=None):
187 | seq_length = input_ids.size(1)
188 | position_ids = torch.arange(seq_length, dtype=torch.long, device=input_ids.device)
189 | position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
190 | if token_type_ids is None:
191 | token_type_ids = torch.zeros_like(input_ids)
192 |
193 | words_embeddings = self.word_embeddings(input_ids)
194 | position_embeddings = self.position_embeddings(position_ids)
195 | token_type_embeddings = self.token_type_embeddings(token_type_ids)
196 |
197 | embeddings = words_embeddings + position_embeddings + token_type_embeddings
198 | embeddings = self.LayerNorm(embeddings)
199 | embeddings = self.dropout(embeddings)
200 | return embeddings
201 |
202 |
203 | class BertSelfAttention(nn.Module):
204 | def __init__(self, config):
205 | super(BertSelfAttention, self).__init__()
206 | if config.hidden_size % config.num_attention_heads != 0:
207 | raise ValueError(
208 | "The hidden size (%d) is not a multiple of the number of attention "
209 | "heads (%d)" % (config.hidden_size, config.num_attention_heads))
210 | self.num_attention_heads = config.num_attention_heads
211 | self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
212 | self.all_head_size = self.num_attention_heads * self.attention_head_size
213 |
214 | self.query = nn.Linear(config.hidden_size, self.all_head_size)
215 | self.key = nn.Linear(config.hidden_size, self.all_head_size)
216 | self.value = nn.Linear(config.hidden_size, self.all_head_size)
217 |
218 | self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
219 |
220 | def transpose_for_scores(self, x):
221 | new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
222 | x = x.view(*new_x_shape)
223 | return x.permute(0, 2, 1, 3)
224 |
225 | def forward(self, hidden_states, attention_mask):
226 | mixed_query_layer = self.query(hidden_states)
227 | mixed_key_layer = self.key(hidden_states)
228 | mixed_value_layer = self.value(hidden_states)
229 |
230 | query_layer = self.transpose_for_scores(mixed_query_layer)
231 | key_layer = self.transpose_for_scores(mixed_key_layer)
232 | value_layer = self.transpose_for_scores(mixed_value_layer)
233 |
234 | # Take the dot product between "query" and "key" to get the raw attention scores.
235 | attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
236 | attention_scores = attention_scores / math.sqrt(self.attention_head_size)
237 | # Apply the attention mask is (precomputed for all layers in BertModel forward() function)
238 | attention_scores = attention_scores + attention_mask
239 |
240 | # Normalize the attention scores to probabilities.
241 | attention_probs = nn.Softmax(dim=-1)(attention_scores)
242 |
243 | # This is actually dropping out entire tokens to attend to, which might
244 | # seem a bit unusual, but is taken from the original Transformer paper.
245 | attention_probs = self.dropout(attention_probs)
246 |
247 | context_layer = torch.matmul(attention_probs, value_layer)
248 | context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
249 | new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
250 | context_layer = context_layer.view(*new_context_layer_shape)
251 | return context_layer
252 |
253 |
254 | class BertSelfOutput(nn.Module):
255 | def __init__(self, config):
256 | super(BertSelfOutput, self).__init__()
257 | self.dense = nn.Linear(config.hidden_size, config.hidden_size)
258 | self.LayerNorm = BertLayerNorm(config)
259 | self.dropout = nn.Dropout(config.hidden_dropout_prob)
260 |
261 | def forward(self, hidden_states, input_tensor):
262 | hidden_states = self.dense(hidden_states)
263 | hidden_states = self.dropout(hidden_states)
264 | hidden_states = self.LayerNorm(hidden_states + input_tensor)
265 | return hidden_states
266 |
267 |
268 | class BertAttention(nn.Module):
269 | def __init__(self, config):
270 | super(BertAttention, self).__init__()
271 | self.self = BertSelfAttention(config)
272 | self.output = BertSelfOutput(config)
273 |
274 | def forward(self, input_tensor, attention_mask):
275 | self_output = self.self(input_tensor, attention_mask)
276 | attention_output = self.output(self_output, input_tensor)
277 | return attention_output
278 |
279 |
280 | class BertIntermediate(nn.Module):
281 | def __init__(self, config):
282 | super(BertIntermediate, self).__init__()
283 | self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
284 | self.intermediate_act_fn = ACT2FN[config.hidden_act] \
285 | if isinstance(config.hidden_act, str) else config.hidden_act
286 |
287 | def forward(self, hidden_states):
288 | hidden_states = self.dense(hidden_states)
289 | hidden_states = self.intermediate_act_fn(hidden_states)
290 | return hidden_states
291 |
292 |
293 | class BertOutput(nn.Module):
294 | def __init__(self, config):
295 | super(BertOutput, self).__init__()
296 | self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
297 | self.LayerNorm = BertLayerNorm(config)
298 | self.dropout = nn.Dropout(config.hidden_dropout_prob)
299 |
300 | def forward(self, hidden_states, input_tensor):
301 | hidden_states = self.dense(hidden_states)
302 | hidden_states = self.dropout(hidden_states)
303 | hidden_states = self.LayerNorm(hidden_states + input_tensor)
304 | return hidden_states
305 |
306 |
307 | class BertLayer(nn.Module):
308 | def __init__(self, config):
309 | super(BertLayer, self).__init__()
310 | self.attention = BertAttention(config)
311 | self.intermediate = BertIntermediate(config)
312 | self.output = BertOutput(config)
313 |
314 | def forward(self, hidden_states, attention_mask):
315 | attention_output = self.attention(hidden_states, attention_mask)
316 | intermediate_output = self.intermediate(attention_output)
317 | layer_output = self.output(intermediate_output, attention_output)
318 | return layer_output
319 |
320 |
321 | class BertEncoder(nn.Module):
322 | def __init__(self, config):
323 | super(BertEncoder, self).__init__()
324 | layer = BertLayer(config)
325 | self.layer = nn.ModuleList([copy.deepcopy(layer) for _ in range(config.num_hidden_layers)])
326 |
327 | def forward(self, hidden_states, attention_mask, output_all_encoded_layers=True):
328 | all_encoder_layers = []
329 | for layer_module in self.layer:
330 | hidden_states = layer_module(hidden_states, attention_mask)
331 | if output_all_encoded_layers:
332 | all_encoder_layers.append(hidden_states)
333 | if not output_all_encoded_layers:
334 | all_encoder_layers.append(hidden_states)
335 | return all_encoder_layers
336 |
337 |
338 | class BertPooler(nn.Module):
339 | def __init__(self, config):
340 | super(BertPooler, self).__init__()
341 | self.dense = nn.Linear(config.hidden_size, config.hidden_size)
342 | self.activation = nn.Tanh()
343 |
344 | def forward(self, hidden_states):
345 | # We "pool" the model by simply taking the hidden state corresponding
346 | # to the first token.
347 | first_token_tensor = hidden_states[:, 0]
348 | pooled_output = self.dense(first_token_tensor)
349 | pooled_output = self.activation(pooled_output)
350 | return pooled_output
351 |
352 |
353 | class BertPredictionHeadTransform(nn.Module):
354 | def __init__(self, config):
355 | super(BertPredictionHeadTransform, self).__init__()
356 | self.dense = nn.Linear(config.hidden_size, config.hidden_size)
357 | self.transform_act_fn = ACT2FN[config.hidden_act] \
358 | if isinstance(config.hidden_act, str) else config.hidden_act
359 | self.LayerNorm = BertLayerNorm(config)
360 |
361 | def forward(self, hidden_states):
362 | hidden_states = self.dense(hidden_states)
363 | hidden_states = self.transform_act_fn(hidden_states)
364 | hidden_states = self.LayerNorm(hidden_states)
365 | return hidden_states
366 |
367 |
368 | class BertLMPredictionHead(nn.Module):
369 | def __init__(self, config, bert_model_embedding_weights):
370 | super(BertLMPredictionHead, self).__init__()
371 | self.transform = BertPredictionHeadTransform(config)
372 |
373 | # The output weights are the same as the input embeddings, but there is
374 | # an output-only bias for each token.
375 | self.decoder = nn.Linear(bert_model_embedding_weights.size(1),
376 | bert_model_embedding_weights.size(0),
377 | bias=False)
378 | self.decoder.weight = bert_model_embedding_weights
379 | self.bias = nn.Parameter(torch.zeros(bert_model_embedding_weights.size(0)))
380 |
381 | def forward(self, hidden_states):
382 | hidden_states = self.transform(hidden_states)
383 | hidden_states = self.decoder(hidden_states) + self.bias
384 | return hidden_states
385 |
386 |
387 | class BertOnlyMLMHead(nn.Module):
388 | def __init__(self, config, bert_model_embedding_weights):
389 | super(BertOnlyMLMHead, self).__init__()
390 | self.predictions = BertLMPredictionHead(config, bert_model_embedding_weights)
391 |
392 | def forward(self, sequence_output):
393 | prediction_scores = self.predictions(sequence_output)
394 | return prediction_scores
395 |
396 |
397 | class BertOnlyNSPHead(nn.Module):
398 | def __init__(self, config):
399 | super(BertOnlyNSPHead, self).__init__()
400 | self.seq_relationship = nn.Linear(config.hidden_size, 2)
401 |
402 | def forward(self, pooled_output):
403 | seq_relationship_score = self.seq_relationship(pooled_output)
404 | return seq_relationship_score
405 |
406 |
407 | class BertPreTrainingHeads(nn.Module):
408 | def __init__(self, config, bert_model_embedding_weights):
409 | super(BertPreTrainingHeads, self).__init__()
410 | self.predictions = BertLMPredictionHead(config, bert_model_embedding_weights)
411 | self.seq_relationship = nn.Linear(config.hidden_size, 2)
412 |
413 | def forward(self, sequence_output, pooled_output):
414 | prediction_scores = self.predictions(sequence_output)
415 | seq_relationship_score = self.seq_relationship(pooled_output)
416 | return prediction_scores, seq_relationship_score
417 |
418 |
419 | class PreTrainedBertModel(nn.Module):
420 | """ An abstract class to handle weights initialization and
421 | a simple interface for dowloading and loading pretrained models.
422 | """
423 | def __init__(self, config, *inputs, **kwargs):
424 | super(PreTrainedBertModel, self).__init__()
425 | if not isinstance(config, BertConfig):
426 | raise ValueError(
427 | "Parameter config in `{}(config)` should be an instance of class `BertConfig`. "
428 | "To create a model from a Google pretrained model use "
429 | "`model = {}.from_pretrained(PRETRAINED_MODEL_NAME)`".format(
430 | self.__class__.__name__, self.__class__.__name__
431 | ))
432 | self.config = config
433 |
434 | def init_bert_weights(self, module):
435 | """ Initialize the weights.
436 | """
437 | if isinstance(module, (nn.Linear, nn.Embedding)):
438 | # Slightly different from the TF version which uses truncated_normal for initialization
439 | # cf https://github.com/pytorch/pytorch/pull/5617
440 | module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
441 | elif isinstance(module, BertLayerNorm):
442 | module.beta.data.normal_(mean=0.0, std=self.config.initializer_range)
443 | module.gamma.data.normal_(mean=0.0, std=self.config.initializer_range)
444 | if isinstance(module, nn.Linear) and module.bias is not None:
445 | module.bias.data.zero_()
446 |
447 | @classmethod
448 | def from_pretrained(cls, pretrained_model_name, *inputs, **kwargs):
449 | """
450 | Instantiate a PreTrainedBertModel from a pre-trained model file.
451 | Download and cache the pre-trained model file if needed.
452 |
453 | Params:
454 | pretrained_model_name: either:
455 | - a str with the name of a pre-trained model to load selected in the list of:
456 | . `bert-base-uncased`
457 | . `bert-large-uncased`
458 | . `bert-base-cased`
459 | . `bert-base-multilingual`
460 | . `bert-base-chinese`
461 | - a path or url to a pretrained model archive containing:
462 | . `bert_config.json` a configuration file for the model
463 | . `pytorch_model.bin` a PyTorch dump of a BertForPreTraining instance
464 | *inputs, **kwargs: additional input for the specific Bert class
465 | (ex: num_labels for BertForSequenceClassification)
466 | """
467 | if pretrained_model_name in PRETRAINED_MODEL_ARCHIVE_MAP:
468 | archive_file = PRETRAINED_MODEL_ARCHIVE_MAP[pretrained_model_name]
469 | else:
470 | archive_file = pretrained_model_name
471 | # redirect to the cache, if necessary
472 | try:
473 | resolved_archive_file = cached_path(archive_file)
474 | except FileNotFoundError:
475 | logger.error(
476 | "Model name '{}' was not found in model name list ({}). "
477 | "We assumed '{}' was a path or url but couldn't find any file "
478 | "associated to this path or url.".format(
479 | pretrained_model_name,
480 | ', '.join(PRETRAINED_MODEL_ARCHIVE_MAP.keys()),
481 | pretrained_model_name))
482 | return None
483 | if resolved_archive_file == archive_file:
484 | logger.info("loading archive file {}".format(archive_file))
485 | else:
486 | logger.info("loading archive file {} from cache at {}".format(
487 | archive_file, resolved_archive_file))
488 | tempdir = None
489 | if os.path.isdir(resolved_archive_file):
490 | serialization_dir = resolved_archive_file
491 | else:
492 | # Extract archive to temp dir
493 | tempdir = tempfile.mkdtemp()
494 | logger.info("extracting archive file {} to temp dir {}".format(
495 | resolved_archive_file, tempdir))
496 | with tarfile.open(resolved_archive_file, 'r:gz') as archive:
497 | archive.extractall(tempdir)
498 | serialization_dir = tempdir
499 | # Load config
500 | config_file = os.path.join(serialization_dir, CONFIG_NAME)
501 | config = BertConfig.from_json_file(config_file)
502 | logger.info("Model config {}".format(config))
503 | # Instantiate model.
504 | model = cls(config, *inputs, **kwargs)
505 | weights_path = os.path.join(serialization_dir, WEIGHTS_NAME)
506 | state_dict = torch.load(weights_path, map_location = 'cpu')
507 |
508 | missing_keys = []
509 | unexpected_keys = []
510 | error_msgs = []
511 | # copy state_dict so _load_from_state_dict can modify it
512 | metadata = getattr(state_dict, '_metadata', None)
513 | state_dict = state_dict.copy()
514 | if metadata is not None:
515 | state_dict._metadata = metadata
516 |
517 | def load(module, prefix=''):
518 | local_metadata = {} if metadata is None else metadata.get(prefix[:-1], {})
519 | module._load_from_state_dict(
520 | state_dict, prefix, local_metadata, True, missing_keys, unexpected_keys, error_msgs)
521 | for name, child in module._modules.items():
522 | if child is not None:
523 | load(child, prefix + name + '.')
524 | load(model, prefix='' if hasattr(model, 'bert') else 'bert.')
525 | if len(missing_keys) > 0:
526 | logger.info("Weights of {} not initialized from pretrained model: {}".format(
527 | model.__class__.__name__, missing_keys))
528 | if len(unexpected_keys) > 0:
529 | logger.info("Weights from pretrained model not used in {}: {}".format(
530 | model.__class__.__name__, unexpected_keys))
531 | if tempdir:
532 | # Clean up temp dir
533 | shutil.rmtree(tempdir)
534 | return model
535 |
536 |
537 | class BertModel(PreTrainedBertModel):
538 | """BERT model ("Bidirectional Embedding Representations from a Transformer").
539 |
540 | Params:
541 | config: a BertConfig class instance with the configuration to build a new model
542 |
543 | Inputs:
544 | `input_ids`: a torch.LongTensor of shape [batch_size, sequence_length]
545 | with the word token indices in the vocabulary(see the tokens preprocessing logic in the scripts
546 | `extract_features.py`, `run_classifier.py` and `run_squad.py`)
547 | `token_type_ids`: an optional torch.LongTensor of shape [batch_size, sequence_length] with the token
548 | types indices selected in [0, 1]. Type 0 corresponds to a `sentence A` and type 1 corresponds to
549 | a `sentence B` token (see BERT paper for more details).
550 | `attention_mask`: an optional torch.LongTensor of shape [batch_size, sequence_length] with indices
551 | selected in [0, 1]. It's a mask to be used if the input sequence length is smaller than the max
552 | input sequence length in the current batch. It's the mask that we typically use for attention when
553 | a batch has varying length sentences.
554 | `output_all_encoded_layers`: boolean which controls the content of the `encoded_layers` output as described below. Default: `True`.
555 |
556 | Outputs: Tuple of (encoded_layers, pooled_output)
557 | `encoded_layers`: controled by `output_all_encoded_layers` argument:
558 | - `output_all_encoded_layers=True`: outputs a list of the full sequences of encoded-hidden-states at the end
559 | of each attention block (i.e. 12 full sequences for BERT-base, 24 for BERT-large), each
560 | encoded-hidden-state is a torch.FloatTensor of size [batch_size, sequence_length, hidden_size],
561 | - `output_all_encoded_layers=False`: outputs only the full sequence of hidden-states corresponding
562 | to the last attention block,
563 | `pooled_output`: a torch.FloatTensor of size [batch_size, hidden_size] which is the output of a
564 | classifier pretrained on top of the hidden state associated to the first character of the
565 | input (`CLF`) to train on the Next-Sentence task (see BERT's paper).
566 |
567 | Example usage:
568 | ```python
569 | # Already been converted into WordPiece token ids
570 | input_ids = torch.LongTensor([[31, 51, 99], [15, 5, 0]])
571 | input_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]])
572 | token_type_ids = torch.LongTensor([[0, 0, 1], [0, 2, 0]])
573 |
574 | config = modeling.BertConfig(vocab_size=32000, hidden_size=512,
575 | num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
576 |
577 | model = modeling.BertModel(config=config)
578 | all_encoder_layers, pooled_output = model(input_ids, token_type_ids, input_mask)
579 | ```
580 | """
581 | def __init__(self, config):
582 | super(BertModel, self).__init__(config)
583 | self.embeddings = BertEmbeddings(config)
584 | self.encoder = BertEncoder(config)
585 | self.pooler = BertPooler(config)
586 | self.apply(self.init_bert_weights)
587 |
588 | def forward(self, input_ids, token_type_ids=None, attention_mask=None, output_all_encoded_layers=True):
589 | if attention_mask is None:
590 | attention_mask = torch.ones_like(input_ids)
591 | if token_type_ids is None:
592 | token_type_ids = torch.zeros_like(input_ids)
593 |
594 | # We create a 3D attention mask from a 2D tensor mask.
595 | # Sizes are [batch_size, 1, 1, to_seq_length]
596 | # So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
597 | # this attention mask is more simple than the triangular masking of causal attention
598 | # used in OpenAI GPT, we just need to prepare the broadcast dimension here.
599 | extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
600 |
601 | # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
602 | # masked positions, this operation will create a tensor which is 0.0 for
603 | # positions we want to attend and -10000.0 for masked positions.
604 | # Since we are adding it to the raw scores before the softmax, this is
605 | # effectively the same as removing these entirely.
606 | extended_attention_mask = extended_attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibility
607 | extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
608 |
609 | embedding_output = self.embeddings(input_ids, token_type_ids)
610 | encoded_layers = self.encoder(embedding_output,
611 | extended_attention_mask,
612 | output_all_encoded_layers=output_all_encoded_layers)
613 | sequence_output = encoded_layers[-1]
614 | pooled_output = self.pooler(sequence_output)
615 | if not output_all_encoded_layers:
616 | encoded_layers = encoded_layers[-1]
617 | return encoded_layers, pooled_output
618 |
619 |
620 | class BertForPreTraining(PreTrainedBertModel):
621 | """BERT model with pre-training heads.
622 | This module comprises the BERT model followed by the two pre-training heads:
623 | - the masked language modeling head, and
624 | - the next sentence classification head.
625 |
626 | Params:
627 | config: a BertConfig class instance with the configuration to build a new model.
628 |
629 | Inputs:
630 | `input_ids`: a torch.LongTensor of shape [batch_size, sequence_length]
631 | with the word token indices in the vocabulary(see the tokens preprocessing logic in the scripts
632 | `extract_features.py`, `run_classifier.py` and `run_squad.py`)
633 | `token_type_ids`: an optional torch.LongTensor of shape [batch_size, sequence_length] with the token
634 | types indices selected in [0, 1]. Type 0 corresponds to a `sentence A` and type 1 corresponds to
635 | a `sentence B` token (see BERT paper for more details).
636 | `attention_mask`: an optional torch.LongTensor of shape [batch_size, sequence_length] with indices
637 | selected in [0, 1]. It's a mask to be used if the input sequence length is smaller than the max
638 | input sequence length in the current batch. It's the mask that we typically use for attention when
639 | a batch has varying length sentences.
640 | `masked_lm_labels`: masked language modeling labels: torch.LongTensor of shape [batch_size, sequence_length]
641 | with indices selected in [-1, 0, ..., vocab_size]. All labels set to -1 are ignored (masked), the loss
642 | is only computed for the labels set in [0, ..., vocab_size]
643 | `next_sentence_label`: next sentence classification loss: torch.LongTensor of shape [batch_size]
644 | with indices selected in [0, 1].
645 | 0 => next sentence is the continuation, 1 => next sentence is a random sentence.
646 |
647 | Outputs:
648 | if `masked_lm_labels` and `next_sentence_label` are not `None`:
649 | Outputs the total_loss which is the sum of the masked language modeling loss and the next
650 | sentence classification loss.
651 | if `masked_lm_labels` or `next_sentence_label` is `None`:
652 | Outputs a tuple comprising
653 | - the masked language modeling logits, and
654 | - the next sentence classification logits.
655 |
656 | Example usage:
657 | ```python
658 | # Already been converted into WordPiece token ids
659 | input_ids = torch.LongTensor([[31, 51, 99], [15, 5, 0]])
660 | input_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]])
661 | token_type_ids = torch.LongTensor([[0, 0, 1], [0, 2, 0]])
662 |
663 | config = BertConfig(vocab_size=32000, hidden_size=512,
664 | num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
665 |
666 | model = BertForPreTraining(config)
667 | masked_lm_logits_scores, seq_relationship_logits = model(input_ids, token_type_ids, input_mask)
668 | ```
669 | """
670 | def __init__(self, config):
671 | super(BertForPreTraining, self).__init__(config)
672 | self.bert = BertModel(config)
673 | self.cls = BertPreTrainingHeads(config, self.bert.embeddings.word_embeddings.weight)
674 | self.apply(self.init_bert_weights)
675 |
676 | def forward(self, input_ids, token_type_ids=None, attention_mask=None, masked_lm_labels=None, next_sentence_label=None):
677 | sequence_output, pooled_output = self.bert(input_ids, token_type_ids, attention_mask,
678 | output_all_encoded_layers=False)
679 | prediction_scores, seq_relationship_score = self.cls(sequence_output, pooled_output)
680 |
681 | if masked_lm_labels is not None and next_sentence_label is not None:
682 | loss_fct = CrossEntropyLoss(ignore_index=-1)
683 | masked_lm_loss = loss_fct(prediction_scores, masked_lm_labels)
684 | next_sentence_loss = loss_fct(seq_relationship_score, next_sentence_label)
685 | total_loss = masked_lm_loss + next_sentence_loss
686 | return total_loss
687 | else:
688 | return prediction_scores, seq_relationship_score
689 |
690 |
691 | class BertForMaskedLM(PreTrainedBertModel):
692 | """BERT model with the masked language modeling head.
693 | This module comprises the BERT model followed by the masked language modeling head.
694 |
695 | Params:
696 | config: a BertConfig class instance with the configuration to build a new model.
697 |
698 | Inputs:
699 | `input_ids`: a torch.LongTensor of shape [batch_size, sequence_length]
700 | with the word token indices in the vocabulary(see the tokens preprocessing logic in the scripts
701 | `extract_features.py`, `run_classifier.py` and `run_squad.py`)
702 | `token_type_ids`: an optional torch.LongTensor of shape [batch_size, sequence_length] with the token
703 | types indices selected in [0, 1]. Type 0 corresponds to a `sentence A` and type 1 corresponds to
704 | a `sentence B` token (see BERT paper for more details).
705 | `attention_mask`: an optional torch.LongTensor of shape [batch_size, sequence_length] with indices
706 | selected in [0, 1]. It's a mask to be used if the input sequence length is smaller than the max
707 | input sequence length in the current batch. It's the mask that we typically use for attention when
708 | a batch has varying length sentences.
709 | `masked_lm_labels`: masked language modeling labels: torch.LongTensor of shape [batch_size, sequence_length]
710 | with indices selected in [-1, 0, ..., vocab_size]. All labels set to -1 are ignored (masked), the loss
711 | is only computed for the labels set in [0, ..., vocab_size]
712 |
713 | Outputs:
714 | if `masked_lm_labels` is `None`:
715 | Outputs the masked language modeling loss.
716 | if `masked_lm_labels` is `None`:
717 | Outputs the masked language modeling logits.
718 |
719 | Example usage:
720 | ```python
721 | # Already been converted into WordPiece token ids
722 | input_ids = torch.LongTensor([[31, 51, 99], [15, 5, 0]])
723 | input_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]])
724 | token_type_ids = torch.LongTensor([[0, 0, 1], [0, 2, 0]])
725 |
726 | config = BertConfig(vocab_size=32000, hidden_size=512,
727 | num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
728 |
729 | model = BertForMaskedLM(config)
730 | masked_lm_logits_scores = model(input_ids, token_type_ids, input_mask)
731 | ```
732 | """
733 | def __init__(self, config):
734 | super(BertForMaskedLM, self).__init__(config)
735 | self.bert = BertModel(config)
736 | self.cls = BertOnlyMLMHead(config, self.bert.embeddings.word_embeddings.weight)
737 | self.apply(self.init_bert_weights)
738 |
739 | def forward(self, input_ids, token_type_ids=None, attention_mask=None, masked_lm_labels=None):
740 | sequence_output, _ = self.bert(input_ids, token_type_ids, attention_mask,
741 | output_all_encoded_layers=False)
742 | prediction_scores = self.cls(sequence_output)
743 |
744 | if masked_lm_labels is not None:
745 | loss_fct = CrossEntropyLoss(ignore_index=-1)
746 | masked_lm_loss = loss_fct(prediction_scores, masked_lm_labels)
747 | return masked_lm_loss
748 | else:
749 | return prediction_scores
750 |
751 |
752 | class BertForNextSentencePrediction(PreTrainedBertModel):
753 | """BERT model with next sentence prediction head.
754 | This module comprises the BERT model followed by the next sentence classification head.
755 |
756 | Params:
757 | config: a BertConfig class instance with the configuration to build a new model.
758 |
759 | Inputs:
760 | `input_ids`: a torch.LongTensor of shape [batch_size, sequence_length]
761 | with the word token indices in the vocabulary(see the tokens preprocessing logic in the scripts
762 | `extract_features.py`, `run_classifier.py` and `run_squad.py`)
763 | `token_type_ids`: an optional torch.LongTensor of shape [batch_size, sequence_length] with the token
764 | types indices selected in [0, 1]. Type 0 corresponds to a `sentence A` and type 1 corresponds to
765 | a `sentence B` token (see BERT paper for more details).
766 | `attention_mask`: an optional torch.LongTensor of shape [batch_size, sequence_length] with indices
767 | selected in [0, 1]. It's a mask to be used if the input sequence length is smaller than the max
768 | input sequence length in the current batch. It's the mask that we typically use for attention when
769 | a batch has varying length sentences.
770 | `next_sentence_label`: next sentence classification loss: torch.LongTensor of shape [batch_size]
771 | with indices selected in [0, 1].
772 | 0 => next sentence is the continuation, 1 => next sentence is a random sentence.
773 |
774 | Outputs:
775 | if `next_sentence_label` is not `None`:
776 | Outputs the total_loss which is the sum of the masked language modeling loss and the next
777 | sentence classification loss.
778 | if `next_sentence_label` is `None`:
779 | Outputs the next sentence classification logits.
780 |
781 | Example usage:
782 | ```python
783 | # Already been converted into WordPiece token ids
784 | input_ids = torch.LongTensor([[31, 51, 99], [15, 5, 0]])
785 | input_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]])
786 | token_type_ids = torch.LongTensor([[0, 0, 1], [0, 2, 0]])
787 |
788 | config = BertConfig(vocab_size=32000, hidden_size=512,
789 | num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
790 |
791 | model = BertForNextSentencePrediction(config)
792 | seq_relationship_logits = model(input_ids, token_type_ids, input_mask)
793 | ```
794 | """
795 | def __init__(self, config):
796 | super(BertForNextSentencePrediction, self).__init__(config)
797 | self.bert = BertModel(config)
798 | self.cls = BertOnlyNSPHead(config)
799 | self.apply(self.init_bert_weights)
800 |
801 | def forward(self, input_ids, token_type_ids=None, attention_mask=None, next_sentence_label=None):
802 | _, pooled_output = self.bert(input_ids, token_type_ids, attention_mask,
803 | output_all_encoded_layers=False)
804 | seq_relationship_score = self.cls( pooled_output)
805 |
806 | if next_sentence_label is not None:
807 | loss_fct = CrossEntropyLoss(ignore_index=-1)
808 | next_sentence_loss = loss_fct(seq_relationship_score, next_sentence_label)
809 | return next_sentence_loss
810 | else:
811 | return seq_relationship_score
812 |
813 |
814 | class BertForSequenceClassification(PreTrainedBertModel):
815 | """BERT model for classification.
816 | This module is composed of the BERT model with a linear layer on top of
817 | the pooled output.
818 |
819 | Params:
820 | `config`: a BertConfig class instance with the configuration to build a new model.
821 | `num_labels`: the number of classes for the classifier. Default = 2.
822 |
823 | Inputs:
824 | `input_ids`: a torch.LongTensor of shape [batch_size, sequence_length]
825 | with the word token indices in the vocabulary(see the tokens preprocessing logic in the scripts
826 | `extract_features.py`, `run_classifier.py` and `run_squad.py`)
827 | `token_type_ids`: an optional torch.LongTensor of shape [batch_size, sequence_length] with the token
828 | types indices selected in [0, 1]. Type 0 corresponds to a `sentence A` and type 1 corresponds to
829 | a `sentence B` token (see BERT paper for more details).
830 | `attention_mask`: an optional torch.LongTensor of shape [batch_size, sequence_length] with indices
831 | selected in [0, 1]. It's a mask to be used if the input sequence length is smaller than the max
832 | input sequence length in the current batch. It's the mask that we typically use for attention when
833 | a batch has varying length sentences.
834 | `labels`: labels for the classification output: torch.LongTensor of shape [batch_size]
835 | with indices selected in [0, ..., num_labels].
836 |
837 | Outputs:
838 | if `labels` is not `None`:
839 | Outputs the CrossEntropy classification loss of the output with the labels.
840 | if `labels` is `None`:
841 | Outputs the classification logits.
842 |
843 | Example usage:
844 | ```python
845 | # Already been converted into WordPiece token ids
846 | input_ids = torch.LongTensor([[31, 51, 99], [15, 5, 0]])
847 | input_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]])
848 | token_type_ids = torch.LongTensor([[0, 0, 1], [0, 2, 0]])
849 |
850 | config = BertConfig(vocab_size=32000, hidden_size=512,
851 | num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
852 |
853 | num_labels = 2
854 |
855 | model = BertForSequenceClassification(config, num_labels)
856 | logits = model(input_ids, token_type_ids, input_mask)
857 | ```
858 | """
859 | def __init__(self, config, num_labels):
860 | super(BertForSequenceClassification, self).__init__(config)
861 | self.bert = BertModel(config)
862 | self.dropout = nn.Dropout(config.hidden_dropout_prob)
863 | self.classifier = nn.Linear(config.hidden_size, num_labels)
864 | self.apply(self.init_bert_weights)
865 |
866 | def forward(self, input_ids, token_type_ids=None, attention_mask=None, labels=None):
867 | _, pooled_output = self.bert(input_ids, token_type_ids, attention_mask, output_all_encoded_layers=False)
868 |
869 | pooled_output2 = self.dropout(pooled_output)
870 | logits = self.classifier(pooled_output2)
871 |
872 | if labels is not None:
873 | loss_fct = BCELoss()
874 | m = nn.Sigmoid()
875 | n = torch.squeeze(m(logits))
876 | loss = loss_fct(n, labels.float())
877 | return loss, logits
878 | else:
879 | return logits
880 |
881 |
882 | class BertForQuestionAnswering(PreTrainedBertModel):
883 | """BERT model for Question Answering (span extraction).
884 | This module is composed of the BERT model with a linear layer on top of
885 | the sequence output that computes start_logits and end_logits
886 |
887 | Params:
888 | `config`: either
889 | - a BertConfig class instance with the configuration to build a new model, or
890 | - a str with the name of a pre-trained model to load selected in the list of:
891 | . `bert-base-uncased`
892 | . `bert-large-uncased`
893 | . `bert-base-cased`
894 | . `bert-base-multilingual`
895 | . `bert-base-chinese`
896 | The pre-trained model will be downloaded and cached if needed.
897 |
898 | Inputs:
899 | `input_ids`: a torch.LongTensor of shape [batch_size, sequence_length]
900 | with the word token indices in the vocabulary(see the tokens preprocessing logic in the scripts
901 | `extract_features.py`, `run_classifier.py` and `run_squad.py`)
902 | `token_type_ids`: an optional torch.LongTensor of shape [batch_size, sequence_length] with the token
903 | types indices selected in [0, 1]. Type 0 corresponds to a `sentence A` and type 1 corresponds to
904 | a `sentence B` token (see BERT paper for more details).
905 | `attention_mask`: an optional torch.LongTensor of shape [batch_size, sequence_length] with indices
906 | selected in [0, 1]. It's a mask to be used if the input sequence length is smaller than the max
907 | input sequence length in the current batch. It's the mask that we typically use for attention when
908 | a batch has varying length sentences.
909 | `start_positions`: position of the first token for the labeled span: torch.LongTensor of shape [batch_size].
910 | Positions are clamped to the length of the sequence and position outside of the sequence are not taken
911 | into account for computing the loss.
912 | `end_positions`: position of the last token for the labeled span: torch.LongTensor of shape [batch_size].
913 | Positions are clamped to the length of the sequence and position outside of the sequence are not taken
914 | into account for computing the loss.
915 |
916 | Outputs:
917 | if `start_positions` and `end_positions` are not `None`:
918 | Outputs the total_loss which is the sum of the CrossEntropy loss for the start and end token positions.
919 | if `start_positions` or `end_positions` is `None`:
920 | Outputs a tuple of start_logits, end_logits which are the logits respectively for the start and end
921 | position tokens.
922 |
923 | Example usage:
924 | ```python
925 | # Already been converted into WordPiece token ids
926 | input_ids = torch.LongTensor([[31, 51, 99], [15, 5, 0]])
927 | input_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]])
928 | token_type_ids = torch.LongTensor([[0, 0, 1], [0, 2, 0]])
929 |
930 | config = BertConfig(vocab_size=32000, hidden_size=512,
931 | num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
932 |
933 | model = BertForQuestionAnswering(config)
934 | start_logits, end_logits = model(input_ids, token_type_ids, input_mask)
935 | ```
936 | """
937 | def __init__(self, config):
938 | super(BertForQuestionAnswering, self).__init__(config)
939 | self.bert = BertModel(config)
940 | # TODO check with Google if it's normal there is no dropout on the token classifier of SQuAD in the TF version
941 | # self.dropout = nn.Dropout(config.hidden_dropout_prob)
942 | self.qa_outputs = nn.Linear(config.hidden_size, 2)
943 | self.apply(self.init_bert_weights)
944 |
945 | def forward(self, input_ids, token_type_ids=None, attention_mask=None, start_positions=None, end_positions=None):
946 | sequence_output, _ = self.bert(input_ids, token_type_ids, attention_mask, output_all_encoded_layers=False)
947 | logits = self.qa_outputs(sequence_output)
948 | start_logits, end_logits = logits.split(1, dim=-1)
949 | start_logits = start_logits.squeeze(-1)
950 | end_logits = end_logits.squeeze(-1)
951 |
952 | if start_positions is not None and end_positions is not None:
953 | # If we are on multi-GPU, split add a dimension
954 | if len(start_positions.size()) > 1:
955 | start_positions = start_positions.squeeze(-1)
956 | if len(end_positions.size()) > 1:
957 | end_positions = end_positions.squeeze(-1)
958 | # sometimes the start/end positions are outside our model inputs, we ignore these terms
959 | ignored_index = start_logits.size(1)
960 | start_positions.clamp_(0, ignored_index)
961 | end_positions.clamp_(0, ignored_index)
962 |
963 | loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
964 | start_loss = loss_fct(start_logits, start_positions)
965 | end_loss = loss_fct(end_logits, end_positions)
966 | total_loss = (start_loss + end_loss) / 2
967 | return total_loss
968 | else:
969 | return start_logits, end_logits
970 |
--------------------------------------------------------------------------------
/preprocess.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | import numpy as np
3 | import matplotlib.pyplot as plt
4 |
5 | # Load ADMISSIONS table
6 | df_adm = pd.read_csv(
7 | '/Users/nwams/Documents/Machine Learning Projects/Predicting-Hospital-Readmission-using-NLP/ADMISSIONS.csv')
8 |
9 | '''
10 | Convert Strings to Dates.
11 | When converting dates, it is safer to use a datetime format.
12 | Setting the errors = 'coerce' flag allows for missing dates
13 | but it sets it to NaT (not a datetime) when the string doesn't match the format.
14 | '''
15 | df_adm.ADMITTIME = pd.to_datetime(df_adm.ADMITTIME, format='%Y-%m-%d %H:%M:%S', errors='coerce')
16 | df_adm.DISCHTIME = pd.to_datetime(df_adm.DISCHTIME, format='%Y-%m-%d %H:%M:%S', errors='coerce')
17 | df_adm.DEATHTIME = pd.to_datetime(df_adm.DEATHTIME, format='%Y-%m-%d %H:%M:%S', errors='coerce')
18 |
19 | '''
20 | Get the next Unplanned admission date for each patient (if it exists).
21 | I need to get the next admission date, if it exists.
22 | First I'll verify that the dates are in order.
23 | Then I'll use the shift() function to get the next admission date.
24 | '''
25 | df_adm = df_adm.sort_values(['SUBJECT_ID', 'ADMITTIME'])
26 | df_adm = df_adm.reset_index(drop=True)
27 | df_adm['NEXT_ADMITTIME'] = df_adm.groupby('SUBJECT_ID').ADMITTIME.shift(-1)
28 | df_adm['NEXT_ADMISSION_TYPE'] = df_adm.groupby('SUBJECT_ID').ADMISSION_TYPE.shift(-1)
29 |
30 | '''
31 | Since I want to predict unplanned re-admissions I will drop (filter out) any future admissions that are ELECTIVE
32 | so that only EMERGENCY re-admissions are measured.
33 | For rows with 'elective' admissions, replace it with NaT and NaN
34 | '''
35 | rows = df_adm.NEXT_ADMISSION_TYPE == 'ELECTIVE'
36 | df_adm.loc[rows,'NEXT_ADMITTIME'] = pd.NaT
37 | df_adm.loc[rows,'NEXT_ADMISSION_TYPE'] = np.NaN
38 |
39 | # It's safer to sort right before the fill incase something I did above changed the order
40 | df_adm = df_adm.sort_values(['SUBJECT_ID','ADMITTIME'])
41 |
42 | '''
43 | Backfill in the values that I removed. So copy the ADMITTIME from the last emergency
44 | and paste it in the NEXT_ADMITTIME for the previous emergency.
45 | So I am effectively ignoring/skipping the ELECTIVE admission row completely.
46 | Doing this will allow me to calculate the days until the next admission.
47 | '''
48 | # Back fill. This will take a little while.
49 | df_adm[['NEXT_ADMITTIME','NEXT_ADMISSION_TYPE']] = df_adm.groupby(['SUBJECT_ID'])[['NEXT_ADMITTIME','NEXT_ADMISSION_TYPE']].fillna(method = 'bfill')
50 |
51 | # Calculate days until next admission
52 | df_adm['DAYS_TIL_NEXT_ADMIT'] = (df_adm.NEXT_ADMITTIME - df_adm.DISCHTIME).dt.total_seconds()/(24*60*60)
53 |
54 | '''
55 | Remove NEWBORN admissions
56 | According to the MIMIC site "Newborn indicates that the HADM_ID pertains to the patient's birth."
57 |
58 | I will remove all NEWBORN admission types because in this project I'm not interested in studying births — my primary
59 | interest is EMERGENCY and URGENT admissions.
60 | I will remove all admissions that have a DEATHTIME because in this project I'm studying re-admissions, not mortality.
61 | And a patient who died cannot be re-admitted.
62 | '''
63 | df_adm = df_adm.loc[df_adm.ADMISSION_TYPE != 'NEWBORN']
64 | df_adm = df_adm.loc[df_adm.DEATHTIME.isnull()]
65 |
66 | '''
67 | Make Output Label
68 | For this problem, we are going to classify if a patient will be admitted in the next 30 days.
69 | Therefore, we need to create a variable with the output label (1 = readmitted, 0 = not readmitted).
70 | '''
71 | df_adm['OUTPUT_LABEL'] = (df_adm.DAYS_NEXT_ADMIT < 30).astype('int')
72 |
73 |
74 | # Load NOTEEVENTS Table
75 | df_notes = pd.read_csv("/Users/nwams/Documents/Machine Learning Projects/Predicting-Hospital-Readmission-using-NLP/NOTEEVENTS.csv")
76 |
77 | # Sort by subject_ID, HAD_ID then CHARTDATE
78 | df_notes = df_notes.sort_values(by=['SUBJECT_ID','HADM_ID','CHARTDATE'])
79 | # Merge notes table to admissions table
80 | df_adm_notes = pd.merge(df_adm[['SUBJECT_ID','HADM_ID','ADMITTIME','DISCHTIME','DAYS_NEXT_ADMIT','NEXT_ADMITTIME','ADMISSION_TYPE','DEATHTIME','OUTPUT_LABEL','DURATION']],
81 | df_notes[['SUBJECT_ID','HADM_ID','CHARTDATE','TEXT','CATEGORY']],
82 | on = ['SUBJECT_ID','HADM_ID'],
83 | how = 'left')
84 |
85 | # Grab date only, not the time
86 | df_adm_notes.ADMITTIME_C = df_adm_notes.ADMITTIME.apply(lambda x: str(x).split(' ')[0])
87 |
88 | df_adm_notes['ADMITTIME_C'] = pd.to_datetime(df_adm_notes.ADMITTIME_C, format = '%Y-%m-%d', errors = 'coerce')
89 | df_adm_notes['CHARTDATE'] = pd.to_datetime(df_adm_notes.CHARTDATE, format = '%Y-%m-%d', errors = 'coerce')
90 |
91 | # Gather Discharge Summaries Only
92 | df_discharge = df_adm_notes[df_adm_notes['CATEGORY'] == 'Discharge summary']
93 | # multiple discharge summary for one admission -> after examination -> replicated summary -> replace with the last one
94 | df_discharge = (df_discharge.groupby(['SUBJECT_ID','HADM_ID']).nth(-1)).reset_index()
95 | df_discharge=df_discharge[df_discharge['TEXT'].notnull()]
96 |
97 | ### If Less than n days on admission notes (Early notes)
98 | def less_n_days_data(df_adm_notes, n):
99 | df_less_n = df_adm_notes[
100 | ((df_adm_notes['CHARTDATE'] - df_adm_notes['ADMITTIME_C']).dt.total_seconds() / (24 * 60 * 60)) < n]
101 | df_less_n = df_less_n[df_less_n['TEXT'].notnull()]
102 | # concatenate first
103 | df_concat = pd.DataFrame(df_less_n.groupby('HADM_ID')['TEXT'].apply(lambda x: "%s" % ' '.join(x))).reset_index()
104 | df_concat['OUTPUT_LABEL'] = df_concat['HADM_ID'].apply(
105 | lambda x: df_less_n[df_less_n['HADM_ID'] == x].OUTPUT_LABEL.values[0])
106 |
107 | return df_concat
108 |
109 | df_less_2 = less_n_days_data(df_adm_notes, 2)
110 | df_less_3 = less_n_days_data(df_adm_notes, 3)
111 |
112 | import re
113 |
114 | def preprocess1(x):
115 | y = re.sub('\\[(.*?)\\]', '', x) # remove de-identified brackets
116 | y = re.sub('[0-9]+\.', '', y) # remove 1.2. since the segmenter segments based on this
117 | y = re.sub('dr\.', 'doctor', y)
118 | y = re.sub('m\.d\.', 'md', y)
119 | y = re.sub('admission date:', '', y)
120 | y = re.sub('discharge date:', '', y)
121 | y = re.sub('--|__|==', '', y)
122 | return y
123 |
124 | def preprocessing(df_less_n):
125 | df_less_n['TEXT'] = df_less_n['TEXT'].fillna(' ')
126 | df_less_n['TEXT'] = df_less_n['TEXT'].str.replace('\n', ' ')
127 | df_less_n['TEXT'] = df_less_n['TEXT'].str.replace('\r', ' ')
128 | df_less_n['TEXT'] = df_less_n['TEXT'].apply(str.strip)
129 | df_less_n['TEXT'] = df_less_n['TEXT'].str.lower()
130 |
131 | df_less_n['TEXT'] = df_less_n['TEXT'].apply(lambda x: preprocess1(x))
132 |
133 | # to get 318 words chunks for readmission tasks
134 | from tqdm import tqdm
135 | df_len = len(df_less_n)
136 | want = pd.DataFrame({'ID': [], 'TEXT': [], 'Label': []})
137 | for i in tqdm(range(df_len)):
138 | x = df_less_n.TEXT.iloc[i].split()
139 | n = int(len(x) / 318)
140 | for j in range(n):
141 | want = want.append({'TEXT': ' '.join(x[j * 318:(j + 1) * 318]), 'Label': df_less_n.OUTPUT_LABEL.iloc[i],
142 | 'ID': df_less_n.HADM_ID.iloc[i]}, ignore_index=True)
143 | if len(x) % 318 > 10:
144 | want = want.append({'TEXT': ' '.join(x[-(len(x) % 318):]), 'Label': df_less_n.OUTPUT_LABEL.iloc[i],
145 | 'ID': df_less_n.HADM_ID.iloc[i]}, ignore_index=True)
146 |
147 | return want
148 |
149 |
150 | df_discharge = preprocessing(df_discharge)
151 | df_less_2 = preprocessing(df_less_2)
152 | df_less_3 = preprocessing(df_less_3)
153 |
154 | ### An example to get the train/test/split with random state:
155 | ### note that we divide on patient admission level and share among experiments, instead of notes level.
156 | ### This way, since our methods run on the same set of admissions, we can see the
157 | ### progression of readmission scores.
158 |
159 | readmit_ID = df_adm[df_adm.OUTPUT_LABEL == 1].HADM_ID
160 | not_readmit_ID = df_adm[df_adm.OUTPUT_LABEL == 0].HADM_ID
161 | # subsampling to get the balanced pos/neg numbers of patients for each dataset
162 | not_readmit_ID_use = not_readmit_ID.sample(n=len(readmit_ID), random_state=1)
163 | id_val_test_t = readmit_ID.sample(frac=0.2, random_state=1)
164 | id_val_test_f = not_readmit_ID_use.sample(frac=0.2, random_state=1)
165 |
166 | id_train_t = readmit_ID.drop(id_val_test_t.index)
167 | id_train_f = not_readmit_ID_use.drop(id_val_test_f.index)
168 |
169 | id_val_t = id_val_test_t.sample(frac=0.5, random_state=1)
170 | id_test_t = id_val_test_t.drop(id_val_t.index)
171 |
172 | id_val_f = id_val_test_f.sample(frac=0.5, random_state=1)
173 | id_test_f = id_val_test_f.drop(id_val_f.index)
174 |
175 | # test if there is overlap between train and test, should return "array([], dtype=int64)"
176 | (pd.Index(id_test_t).intersection(pd.Index(id_train_t))).values
177 |
178 | id_test = pd.concat([id_test_t, id_test_f])
179 | test_id_label = pd.DataFrame(data=list(zip(id_test, [1] * len(id_test_t) + [0] * len(id_test_f))),
180 | columns=['id', 'label'])
181 |
182 | id_val = pd.concat([id_val_t, id_val_f])
183 | val_id_label = pd.DataFrame(data=list(zip(id_val, [1] * len(id_val_t) + [0] * len(id_val_f))), columns=['id', 'label'])
184 |
185 | id_train = pd.concat([id_train_t, id_train_f])
186 | train_id_label = pd.DataFrame(data=list(zip(id_train, [1] * len(id_train_t) + [0] * len(id_train_f))),
187 | columns=['id', 'label'])
188 |
189 | # get discharge train/val/test
190 |
191 | discharge_train = df_discharge[df_discharge.ID.isin(train_id_label.id)]
192 | discharge_val = df_discharge[df_discharge.ID.isin(val_id_label.id)]
193 | discharge_test = df_discharge[df_discharge.ID.isin(test_id_label.id)]
194 |
195 | # subsampling for training....since we obtain training on patient admission level so now we have same number of pos/neg readmission
196 | # but each admission is associated with different length of notes and we train on each chunks of notes, not on the admission, we need
197 | # to balance the pos/neg chunks on training set. (val and test set are fine) Usually, positive admissions have longer notes, so we need
198 | # find some negative chunks of notes from not_readmit_ID that we haven't used yet
199 |
200 | df = pd.concat([not_readmit_ID_use, not_readmit_ID])
201 | df = df.drop_duplicates(keep=False)
202 | # check to see if there are overlaps
203 | (pd.Index(df).intersection(pd.Index(not_readmit_ID_use))).values
204 |
205 | # for this set of split with random_state=1, we find we need 400 more negative training samples
206 | not_readmit_ID_more = df.sample(n=400, random_state=1)
207 | discharge_train_snippets = pd.concat([df_discharge[df_discharge.ID.isin(not_readmit_ID_more)], discharge_train])
208 |
209 | # shuffle
210 | discharge_train_snippets = discharge_train_snippets.sample(frac=1, random_state=1).reset_index(drop=True)
211 |
212 | # check if balanced
213 | discharge_train_snippets.Label.value_counts()
214 |
215 | discharge_train_snippets.to_csv('./discharge/train.csv')
216 | discharge_val.to_csv('./discharge/val.csv')
217 | discharge_test.to_csv('./discharge/test.csv')
218 |
219 | ### for Early notes experiment: we only need to find training set for 3 days, then we can test
220 | ### both 3 days and 2 days. Since we split the data on patient level and experiments share admissions
221 | ### in order to see the progression, the 2 days training dataset is a subset of 3 days training set.
222 | ### So we only train 3 days and we can test/val on both 2 & 3days or any time smaller than 3 days. This means
223 | ### if we train on a dataset with all the notes in n days, we can predict readmissions smaller than n days.
224 |
225 | # for 3 days note, similar to discharge
226 |
227 | early_train = df_less_3[df_less_3.ID.isin(train_id_label.id)]
228 | not_readmit_ID_more = df.sample(n=500, random_state=1)
229 | early_train_snippets = pd.concat([df_less_3[df_less_3.ID.isin(not_readmit_ID_more)], early_train])
230 | # shuffle
231 | early_train_snippets = early_train_snippets.sample(frac=1, random_state=1).reset_index(drop=True)
232 | early_train_snippets.to_csv('./3days/train.csv')
233 |
234 | early_val = df_less_3[df_less_3.ID.isin(val_id_label.id)]
235 | early_val.to_csv('./3days/val.csv')
236 |
237 | # we want to test on admissions that are not discharged already. So for less than 3 days of notes experiment,
238 | # we filter out admissions discharged within 3 days
239 | actionable_ID_3days = df_adm[df_adm['DURATION'] >= 3].HADM_ID
240 | test_actionable_id_label = test_id_label[test_id_label.id.isin(actionable_ID_3days)]
241 | early_test = df_less_3[df_less_3.ID.isin(test_actionable_id_label.id)]
242 |
243 | early_test.to_csv('./3days/test.csv')
244 |
245 | # for 2 days notes, we only obtain test set. Since the model parameters are tuned on the val set of 3 days
246 |
247 | actionable_ID_2days = df_adm[df_adm['DURATION'] >= 2].HADM_ID
248 |
249 | test_actionable_id_label_2days = test_id_label[test_id_label.id.isin(actionable_ID_2days)]
250 |
251 | early_test_2days = df_less_2[df_less_2.ID.isin(test_actionable_id_label_2days.id)]
252 |
253 | early_test_2days.to_csv('./2days/test.csv')
--------------------------------------------------------------------------------
\n",
107 | "\n",
108 | "Shows that ClinicalBERT outperforms it's competitors like Bag-of-words (Top 5000 TF-IDF words as features) and BiLSTM/Word2Vec in terms of precision and recall.\n",
109 | "\n",
110 | "### Readmission Prediction With Early Clinical Notes\n",
111 | "Discharge summaries have predictive power for readmission. However, discharge summaries\n",
112 | "might be written after a patient has left the hospital. Therefore, discharge summaries are\n",
113 | "not actionable since doctors cannot intervene when a patient has left the hospital. Models\n",
114 | "that dynamically predict readmission in the early stages of a patient’s admission are relevant to clinicians.\n",
115 | "\n",
116 | "> **Note** that readmission predictions from a model are not actionable if a patient has been discharged. \n",
117 | "\n",
118 | "**24-48h**\n",
119 | "* In the MIMIC-III data, admission and discharge times are available, but clinical notes do not have timestamps. This is why the table headings show a range; this range shows the cutoff time for notes fed to the model from early on in a patient’s admission. For example, in the 24–48h column, the model may only take as input a patient’s notes up to 36h because of that patient’s specific admission time.\n",
120 | "\n",
121 | "**48-72h**\n",
122 | "* For the second set of readmission prediction experiments, a maximum of the first 48 or 72 hours of a patient’s notes are concatenated. These concatenated notes are used to predict readmission. Since we separate notes into subsequences of the same length, the training set consists of all subsequences within a maximum of 72 hours, and the model is tested given only available notes within the first 48 or 72 hours of a patient’s admission.\n",
123 | "* For testing 48 or 72-hour clinical note readmission prediction, patients that are discharged within 48 or 72 hours (respectively) are filtered out.\n",
124 | "\n",
125 | "### Interpretable predictions in ClinicalBert\n",
126 | "* ClinicalBert uses several self-attention mechanisms which can be used to inspect its predictions, by visualizing terms correlated with predictions of hospital readmission.\n",
127 | " * For every clinical note input to ClinicalBert, each self-attention mechanism computes a distribution over every term in a sentence, given a query.\n",
128 | " * **A high attention weight between a query and key token means the interaction between these tokens is predictive of readmission**.\n",
129 | " * In the ClinicalBert encoder, there are 144 self-attention mechanisms (or, 12 multi-head attention mechanisms for each of the 12 transformer encoders). \n",
130 | " \n",
131 | "\n",
132 | "### Preprocessing\n",
133 | "ClinicalBert requires minimal preprocessing:\n",
134 | "1. First, words are converted to lowercase and\n",
135 | "2. line breaks are removed\n",
136 | "3. carriage returns are removed. \n",
137 | "4. De-identified the brackets \n",
138 | "5. remove special characters like ==, −−\n",
139 | "\n",
140 | "* The SpaCy sentence segmentation package is used to segment each note (Honnibal and Montani, 2017).\n",
141 | " * Since clinical notes don't follow rigid standard language grammar, we find rule-based segmentation has better results than dependency parsing-based segmentation.\n",
142 | " * Various segmentation signs that misguide rule-based segmentators are removed or replaced\n",
143 | " * For example 1.2 would be removed\n",
144 | " * M.D., dr. would be replaced with with MD, Dr\n",
145 | " * Clinical notes can include various lab results and medications that also contain numerous rule-based separators, such as 20mg, p.o., q.d.. (where q.d. means one a day and q.o. means to take by mouth. \n",
146 | " * To address this, segmentations that have less than 20 words are fused into the previous segmentation so that they are not singled out as different sentences."
147 | ]
148 | },
149 | {
150 | "cell_type": "markdown",
151 | "metadata": {},
152 | "source": [
153 | "# Preprocess.py"
154 | ]
155 | },
156 | {
157 | "cell_type": "code",
158 | "execution_count": 1,
159 | "metadata": {},
160 | "outputs": [],
161 | "source": [
162 | "import pandas as pd\n",
163 | "import numpy as np\n",
164 | "import matplotlib.pyplot as plt"
165 | ]
166 | },
167 | {
168 | "cell_type": "markdown",
169 | "metadata": {},
170 | "source": [
171 | "Convert Strings to Dates.\n",
172 | "When converting dates, it is safer to use a datetime format. \n",
173 | "Setting the errors = 'coerce' flag allows for missing dates \n",
174 | "but it sets it to NaT (not a datetime) when the string doesn't match the format."
175 | ]
176 | },
177 | {
178 | "cell_type": "code",
179 | "execution_count": 2,
180 | "metadata": {},
181 | "outputs": [],
182 | "source": [
183 | "# Load ADMISSIONS table from AWS S3 bucket\n",
184 | "bucket = 's3://mimic-iii-physionet'\n",
185 | "data_key = 'ADMISSIONS.csv.gz'\n",
186 | "data_location = 's3://{}/{}'.format(bucket, data_key)\n",
187 | "df_adm = pd.read_csv(data_location)"
188 | ]
189 | },
190 | {
191 | "cell_type": "code",
192 | "execution_count": 3,
193 | "metadata": {},
194 | "outputs": [],
195 | "source": [
196 | "# Load ADMISSIONS table\n",
197 | "# df_adm = pd.read_csv(\n",
198 | "# '/Users/nwams/Documents/Machine Learning Projects/Predicting-Hospital-Readmission-using-NLP/ADMISSIONS.csv')"
199 | ]
200 | },
201 | {
202 | "cell_type": "code",
203 | "execution_count": 4,
204 | "metadata": {},
205 | "outputs": [],
206 | "source": [
207 | "df_adm.ADMITTIME = pd.to_datetime(df_adm.ADMITTIME, format='%Y-%m-%d %H:%M:%S', errors='coerce')\n",
208 | "df_adm.DISCHTIME = pd.to_datetime(df_adm.DISCHTIME, format='%Y-%m-%d %H:%M:%S', errors='coerce')\n",
209 | "df_adm.DEATHTIME = pd.to_datetime(df_adm.DEATHTIME, format='%Y-%m-%d %H:%M:%S', errors='coerce')"
210 | ]
211 | },
212 | {
213 | "cell_type": "markdown",
214 | "metadata": {},
215 | "source": [
216 | "Get the next Unplanned admission date for each patient (if it exists).\n",
217 | "I need to get the next admission date, if it exists.\n",
218 | "First I'll verify that the dates are in order.\n",
219 | "Then I'll use the shift() function to get the next admission date."
220 | ]
221 | },
222 | {
223 | "cell_type": "code",
224 | "execution_count": 6,
225 | "metadata": {},
226 | "outputs": [],
227 | "source": [
228 | "df_adm = df_adm.sort_values(['SUBJECT_ID', 'ADMITTIME'])\n",
229 | "df_adm = df_adm.reset_index(drop=True)\n",
230 | "df_adm['NEXT_ADMITTIME'] = df_adm.groupby('SUBJECT_ID').ADMITTIME.shift(-1)\n",
231 | "df_adm['NEXT_ADMISSION_TYPE'] = df_adm.groupby('SUBJECT_ID').ADMISSION_TYPE.shift(-1)"
232 | ]
233 | },
234 | {
235 | "cell_type": "markdown",
236 | "metadata": {},
237 | "source": [
238 | "Since I want to predict unplanned re-admissions I will drop (filter out) any future admissions that are ELECTIVE \n",
239 | "so that only EMERGENCY re-admissions are measured.\n",
240 | "For rows with 'elective' admissions, replace it with NaT and NaN"
241 | ]
242 | },
243 | {
244 | "cell_type": "code",
245 | "execution_count": 7,
246 | "metadata": {},
247 | "outputs": [],
248 | "source": [
249 | "rows = df_adm.NEXT_ADMISSION_TYPE == 'ELECTIVE'\n",
250 | "df_adm.loc[rows,'NEXT_ADMITTIME'] = pd.NaT\n",
251 | "df_adm.loc[rows,'NEXT_ADMISSION_TYPE'] = np.NaN"
252 | ]
253 | },
254 | {
255 | "cell_type": "markdown",
256 | "metadata": {},
257 | "source": [
258 | "It's safer to sort right before the fill incase something I did above changed the order"
259 | ]
260 | },
261 | {
262 | "cell_type": "code",
263 | "execution_count": 8,
264 | "metadata": {},
265 | "outputs": [],
266 | "source": [
267 | "df_adm = df_adm.sort_values(['SUBJECT_ID','ADMITTIME'])"
268 | ]
269 | },
270 | {
271 | "cell_type": "markdown",
272 | "metadata": {},
273 | "source": [
274 | "Backfill in the values that I removed. So copy the ADMITTIME from the last emergency \n",
275 | "and paste it in the NEXT_ADMITTIME for the previous emergency. \n",
276 | "So I am effectively ignoring/skipping the ELECTIVE admission row completely. \n",
277 | "Doing this will allow me to calculate the days until the next admission."
278 | ]
279 | },
280 | {
281 | "cell_type": "code",
282 | "execution_count": 9,
283 | "metadata": {},
284 | "outputs": [],
285 | "source": [
286 | "# Back fill. This will take a little while.\n",
287 | "df_adm[['NEXT_ADMITTIME','NEXT_ADMISSION_TYPE']] = df_adm.groupby(['SUBJECT_ID'])[['NEXT_ADMITTIME','NEXT_ADMISSION_TYPE']].fillna(method = 'bfill')\n",
288 | "\n",
289 | "# Calculate days until next admission\n",
290 | "df_adm['DAYS_NEXT_ADMIT'] = (df_adm.NEXT_ADMITTIME - df_adm.DISCHTIME).dt.total_seconds()/(24*60*60)"
291 | ]
292 | },
293 | {
294 | "cell_type": "markdown",
295 | "metadata": {},
296 | "source": [
297 | "### Remove NEWBORN admissions\n",
298 | "According to the MIMIC site \"Newborn indicates that the HADM_ID pertains to the patient's birth.\"\n",
299 | "\n",
300 | "I will remove all NEWBORN admission types because in this project I'm not interested in studying births — my primary \n",
301 | "interest is EMERGENCY and URGENT admissions.\n",
302 | "I will remove all admissions that have a DEATHTIME because in this project I'm studying re-admissions, not mortality. \n",
303 | "And a patient who died cannot be re-admitted."
304 | ]
305 | },
306 | {
307 | "cell_type": "code",
308 | "execution_count": 10,
309 | "metadata": {},
310 | "outputs": [],
311 | "source": [
312 | "df_adm = df_adm.loc[df_adm.ADMISSION_TYPE != 'NEWBORN']\n",
313 | "df_adm = df_adm.loc[df_adm.DEATHTIME.isnull()]"
314 | ]
315 | },
316 | {
317 | "cell_type": "markdown",
318 | "metadata": {},
319 | "source": [
320 | "### Make Output Label\n",
321 | "For this problem, we are going to classify if a patient will be admitted in the next 30 days. \n",
322 | "Therefore, we need to create a variable with the output label (1 = readmitted, 0 = not readmitted)."
323 | ]
324 | },
325 | {
326 | "cell_type": "code",
327 | "execution_count": 11,
328 | "metadata": {},
329 | "outputs": [],
330 | "source": [
331 | "df_adm['OUTPUT_LABEL'] = (df_adm.DAYS_NEXT_ADMIT < 30).astype('int')\n",
332 | "df_adm['DURATION'] = (df_adm['DISCHTIME']-df_adm['ADMITTIME']).dt.total_seconds()/(24*60*60)"
333 | ]
334 | },
335 | {
336 | "cell_type": "markdown",
337 | "metadata": {},
338 | "source": [
339 | "### Load NOTEEVENTS Table"
340 | ]
341 | },
342 | {
343 | "cell_type": "code",
344 | "execution_count": 12,
345 | "metadata": {},
346 | "outputs": [
347 | {
348 | "name": "stderr",
349 | "output_type": "stream",
350 | "text": [
351 | "/home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages/IPython/core/interactiveshell.py:2785: DtypeWarning: Columns (4,5) have mixed types. Specify dtype option on import or set low_memory=False.\n",
352 | " interactivity=interactivity, compiler=compiler, result=result)\n"
353 | ]
354 | }
355 | ],
356 | "source": [
357 | "# Load ADMISSIONS table from AWS S3 bucket\n",
358 | "data_key = 'NOTEEVENTS.csv.gz'\n",
359 | "note_location = 's3://{}/{}'.format(bucket, data_key)\n",
360 | "df_notes = pd.read_csv(note_location)"
361 | ]
362 | },
363 | {
364 | "cell_type": "code",
365 | "execution_count": 15,
366 | "metadata": {},
367 | "outputs": [],
368 | "source": [
369 | "# Sort by subject_ID, HAD_ID then CHARTDATE\n",
370 | "df_notes = df_notes.sort_values(by=['SUBJECT_ID','HADM_ID','CHARTDATE'])\n",
371 | "# Merge notes table to admissions table\n",
372 | "df_adm_notes = pd.merge(df_adm[['SUBJECT_ID','HADM_ID','ADMITTIME','DISCHTIME','DAYS_NEXT_ADMIT','NEXT_ADMITTIME','ADMISSION_TYPE','DEATHTIME','OUTPUT_LABEL','DURATION']],\n",
373 | " df_notes[['SUBJECT_ID','HADM_ID','CHARTDATE','TEXT','CATEGORY']],\n",
374 | " on = ['SUBJECT_ID','HADM_ID'],\n",
375 | " how = 'left')"
376 | ]
377 | },
378 | {
379 | "cell_type": "code",
380 | "execution_count": 16,
381 | "metadata": {},
382 | "outputs": [
383 | {
384 | "name": "stderr",
385 | "output_type": "stream",
386 | "text": [
387 | "/home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages/ipykernel/__main__.py:2: UserWarning: Pandas doesn't allow columns to be created via a new attribute name - see https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute-access\n",
388 | " from ipykernel import kernelapp as app\n"
389 | ]
390 | }
391 | ],
392 | "source": [
393 | "# Grab date only, not the time\n",
394 | "df_adm_notes.ADMITTIME_C = df_adm_notes.ADMITTIME.apply(lambda x: str(x).split(' ')[0])\n",
395 | "\n",
396 | "df_adm_notes['ADMITTIME_C'] = pd.to_datetime(df_adm_notes.ADMITTIME_C, format = '%Y-%m-%d', errors = 'coerce')\n",
397 | "df_adm_notes['CHARTDATE'] = pd.to_datetime(df_adm_notes.CHARTDATE, format = '%Y-%m-%d', errors = 'coerce')"
398 | ]
399 | },
400 | {
401 | "cell_type": "markdown",
402 | "metadata": {},
403 | "source": [
404 | "Gather Discharge Summaries Only"
405 | ]
406 | },
407 | {
408 | "cell_type": "code",
409 | "execution_count": 17,
410 | "metadata": {},
411 | "outputs": [],
412 | "source": [
413 | "# Gather Discharge Summaries Only\n",
414 | "df_discharge = df_adm_notes[df_adm_notes['CATEGORY'] == 'Discharge summary']\n",
415 | "# multiple discharge summary for one admission -> after examination -> replicated summary -> replace with the last one\n",
416 | "df_discharge = (df_discharge.groupby(['SUBJECT_ID','HADM_ID']).nth(-1)).reset_index()\n",
417 | "df_discharge=df_discharge[df_discharge['TEXT'].notnull()]"
418 | ]
419 | },
420 | {
421 | "cell_type": "markdown",
422 | "metadata": {},
423 | "source": [
424 | "If Less than n days on admission notes (Early notes)"
425 | ]
426 | },
427 | {
428 | "cell_type": "code",
429 | "execution_count": 18,
430 | "metadata": {},
431 | "outputs": [],
432 | "source": [
433 | "def less_n_days_data(df_adm_notes, n):\n",
434 | " df_less_n = df_adm_notes[\n",
435 | " ((df_adm_notes['CHARTDATE'] - df_adm_notes['ADMITTIME_C']).dt.total_seconds() / (24 * 60 * 60)) < n]\n",
436 | " df_less_n = df_less_n[df_less_n['TEXT'].notnull()]\n",
437 | " # concatenate first\n",
438 | " df_concat = pd.DataFrame(df_less_n.groupby('HADM_ID')['TEXT'].apply(lambda x: \"%s\" % ' '.join(x))).reset_index()\n",
439 | " df_concat['OUTPUT_LABEL'] = df_concat['HADM_ID'].apply(\n",
440 | " lambda x: df_less_n[df_less_n['HADM_ID'] == x].OUTPUT_LABEL.values[0])\n",
441 | " \n",
442 | " return df_concat"
443 | ]
444 | },
445 | {
446 | "cell_type": "code",
447 | "execution_count": 19,
448 | "metadata": {},
449 | "outputs": [],
450 | "source": [
451 | "df_less_2 = less_n_days_data(df_adm_notes, 2)\n",
452 | "df_less_3 = less_n_days_data(df_adm_notes, 3)"
453 | ]
454 | },
455 | {
456 | "cell_type": "code",
457 | "execution_count": 20,
458 | "metadata": {},
459 | "outputs": [],
460 | "source": [
461 | "import re\n",
462 | "\n",
463 | "def preprocess1(x):\n",
464 | " y = re.sub('\\\\[(.*?)\\\\]', '', x) # remove de-identified brackets\n",
465 | " y = re.sub('[0-9]+\\.', '', y) # remove 1.2. since the segmenter segments based on this\n",
466 | " y = re.sub('dr\\.', 'doctor', y)\n",
467 | " y = re.sub('m\\.d\\.', 'md', y)\n",
468 | " y = re.sub('admission date:', '', y)\n",
469 | " y = re.sub('discharge date:', '', y)\n",
470 | " y = re.sub('--|__|==', '', y)\n",
471 | " return y"
472 | ]
473 | },
474 | {
475 | "cell_type": "code",
476 | "execution_count": 21,
477 | "metadata": {
478 | "collapsed": true
479 | },
480 | "outputs": [
481 | {
482 | "name": "stdout",
483 | "output_type": "stream",
484 | "text": [
485 | "Collecting pip\n",
486 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/00/b6/9cfa56b4081ad13874b0c6f96af8ce16cfbc1cb06bedf8e9164ce5551ec1/pip-19.3.1-py2.py3-none-any.whl (1.4MB)\n",
487 | "\u001b[K 100% |████████████████████████████████| 1.4MB 19.3MB/s ta 0:00:01\n",
488 | "\u001b[?25hInstalling collected packages: pip\n",
489 | " Found existing installation: pip 10.0.1\n",
490 | " Uninstalling pip-10.0.1:\n",
491 | " Successfully uninstalled pip-10.0.1\n",
492 | "Successfully installed pip-19.3.1\n"
493 | ]
494 | }
495 | ],
496 | "source": [
497 | "!pip install --upgrade pip"
498 | ]
499 | },
500 | {
501 | "cell_type": "code",
502 | "execution_count": 22,
503 | "metadata": {
504 | "collapsed": true
505 | },
506 | "outputs": [
507 | {
508 | "name": "stdout",
509 | "output_type": "stream",
510 | "text": [
511 | "Collecting tqdm\n",
512 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/72/c9/7fc20feac72e79032a7c8138fd0d395dc6d8812b5b9edf53c3afd0b31017/tqdm-4.41.1-py2.py3-none-any.whl (56kB)\n",
513 | "\u001b[K |████████████████████████████████| 61kB 2.3MB/s eta 0:00:011\n",
514 | "\u001b[?25hInstalling collected packages: tqdm\n",
515 | "Successfully installed tqdm-4.41.1\n"
516 | ]
517 | }
518 | ],
519 | "source": [
520 | "!pip install tqdm"
521 | ]
522 | },
523 | {
524 | "cell_type": "code",
525 | "execution_count": 23,
526 | "metadata": {},
527 | "outputs": [],
528 | "source": [
529 | "from tqdm import tqdm, trange"
530 | ]
531 | },
532 | {
533 | "cell_type": "code",
534 | "execution_count": 24,
535 | "metadata": {},
536 | "outputs": [],
537 | "source": [
538 | "def preprocessing(df_less_n):\n",
539 | " df_less_n['TEXT'] = df_less_n['TEXT'].fillna(' ')\n",
540 | " df_less_n['TEXT'] = df_less_n['TEXT'].str.replace('\\n', ' ')\n",
541 | " df_less_n['TEXT'] = df_less_n['TEXT'].str.replace('\\r', ' ')\n",
542 | " df_less_n['TEXT'] = df_less_n['TEXT'].apply(str.strip)\n",
543 | " df_less_n['TEXT'] = df_less_n['TEXT'].str.lower()\n",
544 | "\n",
545 | " df_less_n['TEXT'] = df_less_n['TEXT'].apply(lambda x: preprocess1(x))\n",
546 | "\n",
547 | " # to get 318 words chunks for readmission tasks\n",
548 | " df_len = len(df_less_n)\n",
549 | " want = pd.DataFrame({'ID': [], 'TEXT': [], 'Label': []})\n",
550 | " for i in tqdm(range(df_len)):\n",
551 | " x = df_less_n.TEXT.iloc[i].split()\n",
552 | " n = int(len(x) / 318)\n",
553 | " for j in range(n):\n",
554 | " want = want.append({'TEXT': ' '.join(x[j * 318:(j + 1) * 318]), 'Label': df_less_n.OUTPUT_LABEL.iloc[i],\n",
555 | " 'ID': df_less_n.HADM_ID.iloc[i]}, ignore_index=True)\n",
556 | " if len(x) % 318 > 10:\n",
557 | " want = want.append({'TEXT': ' '.join(x[-(len(x) % 318):]), 'Label': df_less_n.OUTPUT_LABEL.iloc[i],\n",
558 | " 'ID': df_less_n.HADM_ID.iloc[i]}, ignore_index=True)\n",
559 | "\n",
560 | " return want"
561 | ]
562 | },
563 | {
564 | "cell_type": "markdown",
565 | "metadata": {},
566 | "source": [
567 | "The preprocessing below for the Discharge, 2-Day and 3-Day stays took about 6.5 hours on my local machine (discharge=2.5hrs, 2-day=1.5 hrs and 3-day=2.5 hrs). \n",
568 | "\n",
569 | "Uncomment the lines below (I've commented it out since I've already run preprocessing and pickled the files). "
570 | ]
571 | },
572 | {
573 | "cell_type": "code",
574 | "execution_count": 25,
575 | "metadata": {},
576 | "outputs": [],
577 | "source": [
578 | "# df_discharge = preprocessing(df_discharge)\n",
579 | "# df_less_2 = preprocessing(df_less_2)\n",
580 | "# df_less_3 = preprocessing(df_less_3)"
581 | ]
582 | },
583 | {
584 | "cell_type": "code",
585 | "execution_count": 26,
586 | "metadata": {},
587 | "outputs": [],
588 | "source": [
589 | "import pickle"
590 | ]
591 | },
592 | {
593 | "cell_type": "markdown",
594 | "metadata": {},
595 | "source": [
596 | "Let's pickle it for later use. Uncomment the code below to pickle your files. "
597 | ]
598 | },
599 | {
600 | "cell_type": "code",
601 | "execution_count": 27,
602 | "metadata": {},
603 | "outputs": [],
604 | "source": [
605 | "# df_discharge.to_pickle(\"./pickle/df_discharge.pkl\")\n",
606 | "# df_less_2.to_pickle(\"./pickle/df_less_2.pkl\")\n",
607 | "# df_less_3.to_pickle(\"./pickle/df_less_3.pkl\")"
608 | ]
609 | },
610 | {
611 | "cell_type": "markdown",
612 | "metadata": {},
613 | "source": [
614 | "Load the pickled files, if needed"
615 | ]
616 | },
617 | {
618 | "cell_type": "code",
619 | "execution_count": 29,
620 | "metadata": {},
621 | "outputs": [],
622 | "source": [
623 | "df_discharge = pd.read_pickle('./pickle/df_discharge.pkl')\n",
624 | "df_less_2 = pd.read_pickle('./pickle/df_less_2.pkl')\n",
625 | "df_less_3 = pd.read_pickle('./pickle/df_less_3.pkl')"
626 | ]
627 | },
628 | {
629 | "cell_type": "code",
630 | "execution_count": 30,
631 | "metadata": {},
632 | "outputs": [
633 | {
634 | "data": {
635 | "text/plain": [
636 | "(216954, 3)"
637 | ]
638 | },
639 | "execution_count": 30,
640 | "metadata": {},
641 | "output_type": "execute_result"
642 | }
643 | ],
644 | "source": [
645 | "df_discharge.shape"
646 | ]
647 | },
648 | {
649 | "cell_type": "code",
650 | "execution_count": 31,
651 | "metadata": {},
652 | "outputs": [
653 | {
654 | "data": {
655 | "text/plain": [
656 | "(277443, 3)"
657 | ]
658 | },
659 | "execution_count": 31,
660 | "metadata": {},
661 | "output_type": "execute_result"
662 | }
663 | ],
664 | "source": [
665 | "df_less_2.shape"
666 | ]
667 | },
668 | {
669 | "cell_type": "code",
670 | "execution_count": 32,
671 | "metadata": {},
672 | "outputs": [
673 | {
674 | "data": {
675 | "text/plain": [
676 | "(385724, 3)"
677 | ]
678 | },
679 | "execution_count": 32,
680 | "metadata": {},
681 | "output_type": "execute_result"
682 | }
683 | ],
684 | "source": [
685 | "df_less_3.shape"
686 | ]
687 | },
688 | {
689 | "cell_type": "markdown",
690 | "metadata": {},
691 | "source": [
692 | "Discharge has 216,954 rows. \n",
693 | "\n",
694 | "2-Day has 277,443 rows.\n",
695 | "\n",
696 | "3-Day has 385,724 rows."
697 | ]
698 | },
699 | {
700 | "cell_type": "markdown",
701 | "metadata": {},
702 | "source": [
703 | "### Train/Test/Split\n",
704 | "An example to get the train/val/test split with random state:\n",
705 | "Note that we divide on patient admission level and share among experiments, instead of notes level.\n",
706 | "This way, since our methods run on the same set of admissions, we can see the progression of readmission scores."
707 | ]
708 | },
709 | {
710 | "cell_type": "code",
711 | "execution_count": 35,
712 | "metadata": {},
713 | "outputs": [],
714 | "source": [
715 | "readmit_ID = df_adm[df_adm.OUTPUT_LABEL == 1].HADM_ID\n",
716 | "not_readmit_ID = df_adm[df_adm.OUTPUT_LABEL == 0].HADM_ID\n",
717 | "# subsampling to get the balanced pos/neg numbers of patients for each dataset\n",
718 | "not_readmit_ID_use = not_readmit_ID.sample(n=len(readmit_ID), random_state=1)\n",
719 | "id_val_test_t = readmit_ID.sample(frac=0.2, random_state=1)\n",
720 | "id_val_test_f = not_readmit_ID_use.sample(frac=0.2, random_state=1)\n",
721 | "\n",
722 | "id_train_t = readmit_ID.drop(id_val_test_t.index)\n",
723 | "id_train_f = not_readmit_ID_use.drop(id_val_test_f.index)\n",
724 | "\n",
725 | "id_val_t = id_val_test_t.sample(frac=0.5, random_state=1)\n",
726 | "id_test_t = id_val_test_t.drop(id_val_t.index)\n",
727 | "\n",
728 | "id_val_f = id_val_test_f.sample(frac=0.5, random_state=1)\n",
729 | "id_test_f = id_val_test_f.drop(id_val_f.index)\n",
730 | "\n",
731 | "# test if there is overlap between train and test, should return \"array([], dtype=int64)\"\n",
732 | "(pd.Index(id_test_t).intersection(pd.Index(id_train_t))).values\n",
733 | "\n",
734 | "id_test = pd.concat([id_test_t, id_test_f])\n",
735 | "test_id_label = pd.DataFrame(data=list(zip(id_test, [1] * len(id_test_t) + [0] * len(id_test_f))),\n",
736 | " columns=['id', 'label'])\n",
737 | "\n",
738 | "id_val = pd.concat([id_val_t, id_val_f])\n",
739 | "val_id_label = pd.DataFrame(data=list(zip(id_val, [1] * len(id_val_t) + [0] * len(id_val_f))), columns=['id', 'label'])\n",
740 | "\n",
741 | "id_train = pd.concat([id_train_t, id_train_f])\n",
742 | "train_id_label = pd.DataFrame(data=list(zip(id_train, [1] * len(id_train_t) + [0] * len(id_train_f))),\n",
743 | " columns=['id', 'label'])"
744 | ]
745 | },
746 | {
747 | "cell_type": "markdown",
748 | "metadata": {},
749 | "source": [
750 | "### Get discharge train/val/test"
751 | ]
752 | },
753 | {
754 | "cell_type": "code",
755 | "execution_count": 36,
756 | "metadata": {},
757 | "outputs": [],
758 | "source": [
759 | "discharge_train = df_discharge[df_discharge.ID.isin(train_id_label.id)]\n",
760 | "discharge_val = df_discharge[df_discharge.ID.isin(val_id_label.id)]\n",
761 | "discharge_test = df_discharge[df_discharge.ID.isin(test_id_label.id)]"
762 | ]
763 | },
764 | {
765 | "cell_type": "markdown",
766 | "metadata": {},
767 | "source": [
768 | "### Subsampling for training\n",
769 | "Since we obtain training on patient admission level so now we have same number of pos/neg readmission but each admission is associated with different length of notes and we train on each chunks of notes, not on the admission, we need to balance the pos/neg chunks on training set. (val and test set are fine) Usually, positive admissions have longer notes, so we need find some negative chunks of notes from not_readmit_ID that we haven't used yet"
770 | ]
771 | },
772 | {
773 | "cell_type": "code",
774 | "execution_count": 37,
775 | "metadata": {},
776 | "outputs": [],
777 | "source": [
778 | "df = pd.concat([not_readmit_ID_use, not_readmit_ID])\n",
779 | "df = df.drop_duplicates(keep=False)\n",
780 | "# check to see if there are overlaps\n",
781 | "(pd.Index(df).intersection(pd.Index(not_readmit_ID_use))).values\n",
782 | "\n",
783 | "# for this set of split with random_state=1, we find we need 400 more negative training samples\n",
784 | "not_readmit_ID_more = df.sample(n=400, random_state=1)\n",
785 | "discharge_train_snippets = pd.concat([df_discharge[df_discharge.ID.isin(not_readmit_ID_more)], discharge_train])\n",
786 | "\n",
787 | "# shuffle\n",
788 | "discharge_train_snippets = discharge_train_snippets.sample(frac=1, random_state=1).reset_index(drop=True)\n",
789 | "\n",
790 | "# check if balanced\n",
791 | "discharge_train_snippets.Label.value_counts()\n",
792 | "\n",
793 | "discharge_train_snippets.to_csv('./data/discharge/train.csv')\n",
794 | "discharge_val.to_csv('./data/discharge/val.csv')\n",
795 | "discharge_test.to_csv('./data/discharge/test.csv')"
796 | ]
797 | },
798 | {
799 | "cell_type": "markdown",
800 | "metadata": {},
801 | "source": [
802 | "For the Early notes experiment: we only need to find training set for 3 days, then we can test both 3 days and 2 days. Since we split the data on patient level and experiments share admissions in order to see the progression, the 2 days training dataset is a subset of 3 days training set. So we only train 3 days and we can test/val on both 2 & 3 days or any time smaller than 3 days. This means if we train on a dataset with all the notes in n days, we can predict readmissions smaller than n days.\n",
803 | "\n",
804 | "### For 3 days note (similar to discharge)"
805 | ]
806 | },
807 | {
808 | "cell_type": "code",
809 | "execution_count": 38,
810 | "metadata": {},
811 | "outputs": [],
812 | "source": [
813 | "early_train = df_less_3[df_less_3.ID.isin(train_id_label.id)]\n",
814 | "not_readmit_ID_more = df.sample(n=500, random_state=1)\n",
815 | "early_train_snippets = pd.concat([df_less_3[df_less_3.ID.isin(not_readmit_ID_more)], early_train])\n",
816 | "# shuffle\n",
817 | "early_train_snippets = early_train_snippets.sample(frac=1, random_state=1).reset_index(drop=True)\n",
818 | "early_train_snippets.to_csv('./data/3days/train.csv')\n",
819 | "\n",
820 | "early_val = df_less_3[df_less_3.ID.isin(val_id_label.id)]\n",
821 | "early_val.to_csv('./data/3days/val.csv')\n",
822 | "\n",
823 | "# we want to test on admissions that are not discharged already. So for less than 3 days of notes experiment,\n",
824 | "# we filter out admissions discharged within 3 days\n",
825 | "actionable_ID_3days = df_adm[df_adm['DURATION'] >= 3].HADM_ID\n",
826 | "test_actionable_id_label = test_id_label[test_id_label.id.isin(actionable_ID_3days)]\n",
827 | "early_test = df_less_3[df_less_3.ID.isin(test_actionable_id_label.id)]\n",
828 | "\n",
829 | "early_test.to_csv('./data/3days/test.csv')"
830 | ]
831 | },
832 | {
833 | "cell_type": "markdown",
834 | "metadata": {},
835 | "source": [
836 | "### For 2 days notes\n",
837 | "For 2 days notes we only obtain test set. Since the model parameters are tuned on the val set of 3 days."
838 | ]
839 | },
840 | {
841 | "cell_type": "code",
842 | "execution_count": 39,
843 | "metadata": {},
844 | "outputs": [],
845 | "source": [
846 | "actionable_ID_2days = df_adm[df_adm['DURATION'] >= 2].HADM_ID\n",
847 | "test_actionable_id_label_2days = test_id_label[test_id_label.id.isin(actionable_ID_2days)]\n",
848 | "early_test_2days = df_less_2[df_less_2.ID.isin(test_actionable_id_label_2days.id)]\n",
849 | "early_test_2days.to_csv('./data/2days/test.csv')"
850 | ]
851 | },
852 | {
853 | "cell_type": "markdown",
854 | "metadata": {},
855 | "source": [
856 | "# Run Model for Predicting Readmission Using Early Notes"
857 | ]
858 | },
859 | {
860 | "cell_type": "code",
861 | "execution_count": 40,
862 | "metadata": {
863 | "collapsed": true
864 | },
865 | "outputs": [
866 | {
867 | "name": "stdout",
868 | "output_type": "stream",
869 | "text": [
870 | "Collecting torch\n",
871 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/88/95/90e8c4c31cfc67248bf944ba42029295b77159982f532c5689bcfe4e9108/torch-1.3.1-cp36-cp36m-manylinux1_x86_64.whl (734.6MB)\n",
872 | "\u001b[K |████████████████████████████████| 734.6MB 11kB/s s eta 0:00:01 |▎ | 6.8MB 3.2MB/s eta 0:03:49 |█ | 20.5MB 3.2MB/s eta 0:03:45 |█ | 23.0MB 3.2MB/s eta 0:03:44 |█▍ | 30.7MB 3.2MB/s eta 0:03:42 |█▊ | 38.4MB 3.2MB/s eta 0:03:39 |███▍ | 77.7MB 63.0MB/s eta 0:00:11 |████▎ | 99.3MB 63.0MB/s eta 0:00:11 |█████▌ | 126.0MB 40.0MB/s eta 0:00:16 |███████████▏ | 256.6MB 53.1MB/s eta 0:00:09 |████████████████▊ | 384.0MB 59.1MB/s eta 0:00:06 |█████████████████▋ | 404.2MB 59.1MB/s eta 0:00:06 |████████████████████▉ | 478.3MB 51.2MB/s eta 0:00:06\n",
873 | "\u001b[?25hRequirement already satisfied: numpy in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from torch) (1.14.3)\n",
874 | "Installing collected packages: torch\n",
875 | "Successfully installed torch-1.3.1\n"
876 | ]
877 | }
878 | ],
879 | "source": [
880 | "!pip install torch"
881 | ]
882 | },
883 | {
884 | "cell_type": "code",
885 | "execution_count": 41,
886 | "metadata": {},
887 | "outputs": [],
888 | "source": [
889 | "import torch"
890 | ]
891 | },
892 | {
893 | "cell_type": "markdown",
894 | "metadata": {},
895 | "source": [
896 | "### Device-Agnostic PyTorch code (GPU or CPU)\n",
897 | "A `torch.device` is an object representing the device on which a `torch.Tensor` is or will be allocated. [[Docs](https://pytorch.org/docs/stable/tensor_attributes.html#torch.torch.device)]. The `torch.device` contains a device type (`'cpu'` or `'cuda'`).\n",
898 | "Due to the structure of PyTorch, you may need to explicitly write device-agnostic (CPU or GPU) code [[Docs](https://pytorch.org/docs/stable/notes/cuda.html)]. The first step is to determine whether the GPU should be used or not.\n",
899 | "\n",
900 | "`torch.cuda.is_available` returns a bool indicating if CUDA is currently available [[Docs](https://pytorch.org/docs/stable/cuda.html#torch.cuda.is_available)]. \n",
901 | "\n",
902 | "I will set my values below so that my code is **Device-agnostic** but feel free to change them for your specific needs."
903 | ]
904 | },
905 | {
906 | "cell_type": "code",
907 | "execution_count": 42,
908 | "metadata": {},
909 | "outputs": [],
910 | "source": [
911 | "local_rank = -1\n",
912 | "no_cuda = False # Set flag to True to disable CUDA"
913 | ]
914 | },
915 | {
916 | "cell_type": "code",
917 | "execution_count": 43,
918 | "metadata": {},
919 | "outputs": [],
920 | "source": [
921 | "if local_rank == -1 or no_cuda:\n",
922 | " device = torch.device(\"cuda\" if torch.cuda.is_available() and not no_cuda else \"cpu\")\n",
923 | " n_gpu = torch.cuda.device_count()\n",
924 | "else:\n",
925 | " device = torch.device(\"cuda\", local_rank)\n",
926 | " n_gpu = 1\n",
927 | " # Initializes the distributed backend which will take care of sychronizing nodes/GPUs\n",
928 | " torch.distributed.init_process_group(backend='nccl')"
929 | ]
930 | },
931 | {
932 | "cell_type": "code",
933 | "execution_count": 44,
934 | "metadata": {},
935 | "outputs": [],
936 | "source": [
937 | "import logging\n",
938 | "logging.basicConfig(format = '%(asctime)s - %(levelname)s - %(name)s - %(message)s', \n",
939 | " datefmt = '%m/%d/%Y %H:%M:%S',\n",
940 | " level = logging.INFO)\n",
941 | "logger = logging.getLogger(__name__)"
942 | ]
943 | },
944 | {
945 | "cell_type": "code",
946 | "execution_count": 45,
947 | "metadata": {},
948 | "outputs": [
949 | {
950 | "name": "stderr",
951 | "output_type": "stream",
952 | "text": [
953 | "01/02/2020 22:33:27 - INFO - __main__ - device: cuda n_gpu: 1 Distributed training: False\n"
954 | ]
955 | }
956 | ],
957 | "source": [
958 | "logger.info(\"device: %s n_gpu: %d Distributed training: %r\", device, n_gpu, bool(local_rank != -1))"
959 | ]
960 | },
961 | {
962 | "cell_type": "markdown",
963 | "metadata": {},
964 | "source": [
965 | "**Accumulating gradients** just means that, before calling `optimizer.step()` to perform a step of gradient descent, we will sum the gradients of several backward operations in the `parameter.grad` tensors. \n",
966 | "\n",
967 | "Below I set the number of update steps to accumulate before performing a backward/update pass. I will set it to a default of 1. Feel free to change if needed."
968 | ]
969 | },
970 | {
971 | "cell_type": "code",
972 | "execution_count": 46,
973 | "metadata": {},
974 | "outputs": [],
975 | "source": [
976 | "gradient_accumulation_steps = 1"
977 | ]
978 | },
979 | {
980 | "cell_type": "code",
981 | "execution_count": 47,
982 | "metadata": {},
983 | "outputs": [],
984 | "source": [
985 | "if gradient_accumulation_steps < 1:\n",
986 | " raise ValueError(\"Invalid gradient_accumulation_steps parameter: {}, should be >= 1\".format(gradient_accumulation_steps))"
987 | ]
988 | },
989 | {
990 | "cell_type": "markdown",
991 | "metadata": {},
992 | "source": [
993 | "Set the default Total Batch Size for training to 32."
994 | ]
995 | },
996 | {
997 | "cell_type": "code",
998 | "execution_count": 48,
999 | "metadata": {},
1000 | "outputs": [],
1001 | "source": [
1002 | "train_batch_size = 32"
1003 | ]
1004 | },
1005 | {
1006 | "cell_type": "code",
1007 | "execution_count": 49,
1008 | "metadata": {},
1009 | "outputs": [],
1010 | "source": [
1011 | "train_batch_size = int(train_batch_size / gradient_accumulation_steps)"
1012 | ]
1013 | },
1014 | {
1015 | "cell_type": "code",
1016 | "execution_count": 50,
1017 | "metadata": {},
1018 | "outputs": [],
1019 | "source": [
1020 | "seed= 42 # random seed for initialization\n",
1021 | "do_train = False # Whether to run training\n",
1022 | "do_eval = True # Whether to run eval on the dev set.\n",
1023 | "output_dir = './result_early' # The output directory where the model checkpoints will be written"
1024 | ]
1025 | },
1026 | {
1027 | "cell_type": "code",
1028 | "execution_count": 51,
1029 | "metadata": {},
1030 | "outputs": [],
1031 | "source": [
1032 | "import os\n",
1033 | "import random"
1034 | ]
1035 | },
1036 | {
1037 | "cell_type": "markdown",
1038 | "metadata": {},
1039 | "source": [
1040 | "Create the `result_early` folder where results will go."
1041 | ]
1042 | },
1043 | {
1044 | "cell_type": "code",
1045 | "execution_count": 52,
1046 | "metadata": {},
1047 | "outputs": [],
1048 | "source": [
1049 | "random.seed(seed)\n",
1050 | "np.random.seed(seed)\n",
1051 | "torch.manual_seed(seed)\n",
1052 | "\n",
1053 | "if n_gpu > 0:\n",
1054 | " torch.cuda.manual_seed_all(seed)\n",
1055 | "\n",
1056 | "if not do_train and not do_eval:\n",
1057 | " raise ValueError(\"At least one of `do_train` or `do_eval` must be True.\")\n",
1058 | "\n",
1059 | "if os.path.exists(output_dir) and os.listdir(output_dir):\n",
1060 | " raise ValueError(\"Output directory ({}) already exists and is not empty.\".format(output_dir))\n",
1061 | "\n",
1062 | "os.makedirs(output_dir, exist_ok=True)"
1063 | ]
1064 | },
1065 | {
1066 | "cell_type": "markdown",
1067 | "metadata": {},
1068 | "source": [
1069 | "# Defining Classes Needed for Processing Readmissions"
1070 | ]
1071 | },
1072 | {
1073 | "cell_type": "code",
1074 | "execution_count": 53,
1075 | "metadata": {},
1076 | "outputs": [],
1077 | "source": [
1078 | "class InputExample(object):\n",
1079 | " \"\"\"A single training/test example for simple sequence classification.\"\"\"\n",
1080 | "\n",
1081 | " def __init__(self, guid, text_a, text_b=None, label=None):\n",
1082 | " \"\"\"Constructs a InputExample.\n",
1083 | "\n",
1084 | " Args:\n",
1085 | " guid: Unique id for the example.\n",
1086 | " text_a: string. The untokenized text of the first sequence. For single\n",
1087 | " sequence tasks, only this sequence must be specified.\n",
1088 | " text_b: (Optional) string. The untokenized text of the second sequence.\n",
1089 | " Only must be specified for sequence pair tasks.\n",
1090 | " label: (Optional) string. The label of the example. This should be\n",
1091 | " specified for train and dev examples, but not for test examples.\n",
1092 | " \"\"\"\n",
1093 | " self.guid = guid\n",
1094 | " self.text_a = text_a\n",
1095 | " self.text_b = text_b\n",
1096 | " self.label = label"
1097 | ]
1098 | },
1099 | {
1100 | "cell_type": "code",
1101 | "execution_count": 54,
1102 | "metadata": {},
1103 | "outputs": [],
1104 | "source": [
1105 | "class DataProcessor(object):\n",
1106 | " \"\"\"Base class for data converters for sequence classification data sets.\"\"\"\n",
1107 | "\n",
1108 | " def get_train_examples(self, data_dir):\n",
1109 | " \"\"\"Gets a collection of `InputExample`s for the train set.\"\"\"\n",
1110 | " raise NotImplementedError()\n",
1111 | "\n",
1112 | " def get_dev_examples(self, data_dir):\n",
1113 | " \"\"\"Gets a collection of `InputExample`s for the dev set.\"\"\"\n",
1114 | " raise NotImplementedError()\n",
1115 | "\n",
1116 | " def get_labels(self):\n",
1117 | " \"\"\"Gets the list of labels for this data set.\"\"\"\n",
1118 | " raise NotImplementedError()\n",
1119 | "\n",
1120 | " @classmethod\n",
1121 | " def _read_tsv(cls, input_file, quotechar=None):\n",
1122 | " \"\"\"Reads a tab separated value file.\"\"\"\n",
1123 | " with open(input_file, \"r\") as f:\n",
1124 | " reader = csv.reader(f, delimiter=\"\\t\", quotechar=quotechar)\n",
1125 | " lines = []\n",
1126 | " for line in reader:\n",
1127 | " lines.append(line)\n",
1128 | " return lines\n",
1129 | " \n",
1130 | " @classmethod\n",
1131 | " def _read_csv(cls, input_file):\n",
1132 | " \"\"\"Reads a comma separated value file.\"\"\"\n",
1133 | " file=pd.read_csv(input_file)\n",
1134 | " lines=zip(file.ID,file.TEXT,file.Label)\n",
1135 | " return lines"
1136 | ]
1137 | },
1138 | {
1139 | "cell_type": "code",
1140 | "execution_count": 55,
1141 | "metadata": {},
1142 | "outputs": [],
1143 | "source": [
1144 | "class readmissionProcessor(DataProcessor):\n",
1145 | " def get_train_examples(self, data_dir):\n",
1146 | " logger.info(\"LOOKING AT {}\".format(os.path.join(data_dir, \"train.csv\")))\n",
1147 | " return self._create_examples(self._read_csv(os.path.join(data_dir, \"train.csv\")), \"train\")\n",
1148 | " \n",
1149 | " def get_dev_examples(self, data_dir):\n",
1150 | " return self._create_examples(self._read_csv(os.path.join(data_dir, \"val.csv\")), \"val\")\n",
1151 | " \n",
1152 | " def get_test_examples(self, data_dir):\n",
1153 | " return self._create_examples(self._read_csv(os.path.join(data_dir, \"test.csv\")), \"test\")\n",
1154 | " \n",
1155 | " def get_labels(self):\n",
1156 | " return [\"0\", \"1\"]\n",
1157 | " \n",
1158 | " def _create_examples(self, lines, set_type):\n",
1159 | " \"\"\"Creates examples for the training and dev sets.\"\"\"\n",
1160 | " examples = []\n",
1161 | " for (i, line) in enumerate(lines):\n",
1162 | " guid = \"%s-%s\" % (set_type, i)\n",
1163 | " text_a = line[1]\n",
1164 | " label = str(int(line[2])) \n",
1165 | " examples.append(InputExample(guid=guid, text_a=text_a, text_b=None, label=label))\n",
1166 | " return examples"
1167 | ]
1168 | },
1169 | {
1170 | "cell_type": "code",
1171 | "execution_count": 56,
1172 | "metadata": {},
1173 | "outputs": [],
1174 | "source": [
1175 | "processor = readmissionProcessor()"
1176 | ]
1177 | },
1178 | {
1179 | "cell_type": "code",
1180 | "execution_count": 57,
1181 | "metadata": {},
1182 | "outputs": [],
1183 | "source": [
1184 | "label_list = processor.get_labels() # label_list = ['0', '1']"
1185 | ]
1186 | },
1187 | {
1188 | "cell_type": "code",
1189 | "execution_count": 58,
1190 | "metadata": {
1191 | "collapsed": true
1192 | },
1193 | "outputs": [
1194 | {
1195 | "name": "stdout",
1196 | "output_type": "stream",
1197 | "text": [
1198 | "Collecting transformers\n",
1199 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/50/10/aeefced99c8a59d828a92cc11d213e2743212d3641c87c82d61b035a7d5c/transformers-2.3.0-py3-none-any.whl (447kB)\n",
1200 | "\u001b[K |████████████████████████████████| 450kB 3.3MB/s eta 0:00:01\n",
1201 | "\u001b[?25hCollecting sentencepiece\n",
1202 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/74/f4/2d5214cbf13d06e7cb2c20d84115ca25b53ea76fa1f0ade0e3c9749de214/sentencepiece-0.1.85-cp36-cp36m-manylinux1_x86_64.whl (1.0MB)\n",
1203 | "\u001b[K |████████████████████████████████| 1.0MB 52.3MB/s eta 0:00:01\n",
1204 | "\u001b[?25hRequirement already satisfied: requests in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from transformers) (2.20.0)\n",
1205 | "Requirement already satisfied: tqdm in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from transformers) (4.41.1)\n",
1206 | "Collecting regex!=2019.12.17\n",
1207 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/ef/a3/7c9d57812484e43a5c4033fc4562e5aa87bd9318f48a27983717c721f22b/regex-2019.12.20-cp36-cp36m-manylinux2010_x86_64.whl (689kB)\n",
1208 | "\u001b[K |████████████████████████████████| 696kB 55.3MB/s eta 0:00:01\n",
1209 | "\u001b[?25hCollecting sacremoses\n",
1210 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/1f/8e/ed5364a06a9ba720fddd9820155cc57300d28f5f43a6fd7b7e817177e642/sacremoses-0.0.35.tar.gz (859kB)\n",
1211 | "\u001b[K |████████████████████████████████| 860kB 50.8MB/s eta 0:00:01\n",
1212 | "\u001b[?25hRequirement already satisfied: boto3 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from transformers) (1.10.19)\n",
1213 | "Requirement already satisfied: numpy in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from transformers) (1.14.3)\n",
1214 | "Requirement already satisfied: urllib3<1.25,>=1.21.1 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from requests->transformers) (1.23)\n",
1215 | "Requirement already satisfied: certifi>=2017.4.17 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from requests->transformers) (2019.9.11)\n",
1216 | "Requirement already satisfied: chardet<3.1.0,>=3.0.2 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from requests->transformers) (3.0.4)\n",
1217 | "Requirement already satisfied: idna<2.8,>=2.5 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from requests->transformers) (2.6)\n",
1218 | "Requirement already satisfied: six in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from sacremoses->transformers) (1.11.0)\n",
1219 | "Requirement already satisfied: click in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from sacremoses->transformers) (6.7)\n",
1220 | "Collecting joblib\n",
1221 | "\u001b[?25l Downloading https://files.pythonhosted.org/packages/28/5c/cf6a2b65a321c4a209efcdf64c2689efae2cb62661f8f6f4bb28547cf1bf/joblib-0.14.1-py2.py3-none-any.whl (294kB)\n",
1222 | "\u001b[K |████████████████████████████████| 296kB 52.7MB/s eta 0:00:01\n",
1223 | "\u001b[?25hRequirement already satisfied: jmespath<1.0.0,>=0.7.1 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from boto3->transformers) (0.9.4)\n",
1224 | "Requirement already satisfied: s3transfer<0.3.0,>=0.2.0 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from boto3->transformers) (0.2.1)\n",
1225 | "Requirement already satisfied: botocore<1.14.0,>=1.13.19 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from boto3->transformers) (1.13.19)\n",
1226 | "Requirement already satisfied: python-dateutil<2.8.1,>=2.1; python_version >= \"2.7\" in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from botocore<1.14.0,>=1.13.19->boto3->transformers) (2.7.3)\n",
1227 | "Requirement already satisfied: docutils<0.16,>=0.10 in /home/ec2-user/anaconda3/envs/python3/lib/python3.6/site-packages (from botocore<1.14.0,>=1.13.19->boto3->transformers) (0.14)\n",
1228 | "Building wheels for collected packages: sacremoses\n",
1229 | " Building wheel for sacremoses (setup.py) ... \u001b[?25ldone\n",
1230 | "\u001b[?25h Created wheel for sacremoses: filename=sacremoses-0.0.35-cp36-none-any.whl size=884006 sha256=c81533047bff2008d1407b012d5415316c8460895b35f513fe3719d38c786562\n",
1231 | " Stored in directory: /home/ec2-user/.cache/pip/wheels/63/2a/db/63e2909042c634ef551d0d9ac825b2b0b32dede4a6d87ddc94\n",
1232 | "Successfully built sacremoses\n",
1233 | "Installing collected packages: sentencepiece, regex, joblib, sacremoses, transformers\n",
1234 | "Successfully installed joblib-0.14.1 regex-2019.12.20 sacremoses-0.0.35 sentencepiece-0.1.85 transformers-2.3.0\n"
1235 | ]
1236 | }
1237 | ],
1238 | "source": [
1239 | "!pip install transformers"
1240 | ]
1241 | },
1242 | {
1243 | "cell_type": "code",
1244 | "execution_count": 59,
1245 | "metadata": {},
1246 | "outputs": [
1247 | {
1248 | "name": "stderr",
1249 | "output_type": "stream",
1250 | "text": [
1251 | "01/02/2020 22:33:33 - INFO - transformers.file_utils - PyTorch version 1.3.1 available.\n"
1252 | ]
1253 | }
1254 | ],
1255 | "source": [
1256 | "from transformers import BertTokenizer"
1257 | ]
1258 | },
1259 | {
1260 | "cell_type": "markdown",
1261 | "metadata": {},
1262 | "source": [
1263 | "### Tokenization\n",
1264 | "During tokenization, each word in the sentence is broken apart into smaller and smaller tokens (word pieces) until all the tokens in the dataset are recognized by the Transformer."
1265 | ]
1266 | },
1267 | {
1268 | "cell_type": "code",
1269 | "execution_count": 60,
1270 | "metadata": {
1271 | "collapsed": true
1272 | },
1273 | "outputs": [
1274 | {
1275 | "name": "stderr",
1276 | "output_type": "stream",
1277 | "text": [
1278 | "01/02/2020 22:33:38 - INFO - transformers.file_utils - https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt not found in cache or force_download set to True, downloading to /tmp/tmpr1tsrl_7\n",
1279 | "01/02/2020 22:33:38 - INFO - transformers.file_utils - copying /tmp/tmpr1tsrl_7 to cache at /home/ec2-user/.cache/torch/transformers/26bc1ad6c0ac742e9b52263248f6d0f00068293b33709fae12320c0e35ccfbbb.542ce4285a40d23a559526243235df47c5f75c197f04f37d1a0c124c32c9a084\n",
1280 | "01/02/2020 22:33:38 - INFO - transformers.file_utils - creating metadata file for /home/ec2-user/.cache/torch/transformers/26bc1ad6c0ac742e9b52263248f6d0f00068293b33709fae12320c0e35ccfbbb.542ce4285a40d23a559526243235df47c5f75c197f04f37d1a0c124c32c9a084\n",
1281 | "01/02/2020 22:33:38 - INFO - transformers.file_utils - removing temp file /tmp/tmpr1tsrl_7\n",
1282 | "01/02/2020 22:33:38 - INFO - transformers.tokenization_utils - loading file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt from cache at /home/ec2-user/.cache/torch/transformers/26bc1ad6c0ac742e9b52263248f6d0f00068293b33709fae12320c0e35ccfbbb.542ce4285a40d23a559526243235df47c5f75c197f04f37d1a0c124c32c9a084\n"
1283 | ]
1284 | }
1285 | ],
1286 | "source": [
1287 | "tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') "
1288 | ]
1289 | },
1290 | {
1291 | "cell_type": "markdown",
1292 | "metadata": {},
1293 | "source": [
1294 | "Set the input data directory. Should contain the .tsv files (or other data files) for the readmission task."
1295 | ]
1296 | },
1297 | {
1298 | "cell_type": "code",
1299 | "execution_count": 61,
1300 | "metadata": {},
1301 | "outputs": [],
1302 | "source": [
1303 | "data_dir = './data/2days/'"
1304 | ]
1305 | },
1306 | {
1307 | "cell_type": "markdown",
1308 | "metadata": {},
1309 | "source": [
1310 | "The code below is only needed if you want to pre-train ClinicalBERT. If you want to perform pre-training of BERT yourself, you should have set the variable `do_train` earlier to `True`. "
1311 | ]
1312 | },
1313 | {
1314 | "cell_type": "code",
1315 | "execution_count": 62,
1316 | "metadata": {},
1317 | "outputs": [],
1318 | "source": [
1319 | "train_examples = None\n",
1320 | "num_train_steps = None\n",
1321 | "if do_train:\n",
1322 | " train_examples = processor.get_train_examples(data_dir)\n",
1323 | " num_train_steps = int(\n",
1324 | " len(train_examples) / train_batch_size / gradient_accumulation_steps * num_train_epochs)"
1325 | ]
1326 | },
1327 | {
1328 | "cell_type": "markdown",
1329 | "metadata": {},
1330 | "source": [
1331 | "# Prepare Model\n",
1332 | "To import a custom module into Jupyter notebook, use sys.path.append because Jupyter doesn't always see/find the module you uploaded. Thanks to this Stack Overflow [answer](https://stackoverflow.com/questions/53049195/importing-custom-module-into-jupyter-notebook). "
1333 | ]
1334 | },
1335 | {
1336 | "cell_type": "code",
1337 | "execution_count": 63,
1338 | "metadata": {},
1339 | "outputs": [],
1340 | "source": [
1341 | "import sys"
1342 | ]
1343 | },
1344 | {
1345 | "cell_type": "code",
1346 | "execution_count": 64,
1347 | "metadata": {},
1348 | "outputs": [],
1349 | "source": [
1350 | "sys.path.append('./')"
1351 | ]
1352 | },
1353 | {
1354 | "cell_type": "code",
1355 | "execution_count": 66,
1356 | "metadata": {},
1357 | "outputs": [
1358 | {
1359 | "name": "stdout",
1360 | "output_type": "stream",
1361 | "text": [
1362 | "in the modeling class\n"
1363 | ]
1364 | }
1365 | ],
1366 | "source": [
1367 | "from modeling_readmission import BertForSequenceClassification"
1368 | ]
1369 | },
1370 | {
1371 | "cell_type": "markdown",
1372 | "metadata": {},
1373 | "source": [
1374 | "`bert_model` is the Bert pre-trained model selected from the list: \n",
1375 | "* bert-base-uncased\n",
1376 | "* bert-large-uncased\n",
1377 | "* bert-base-cased\n",
1378 | "* bert-base-multilingual\n",
1379 | "* bert-base-chinese"
1380 | ]
1381 | },
1382 | {
1383 | "cell_type": "markdown",
1384 | "metadata": {},
1385 | "source": [
1386 | "The main breaking change when migrating from pytorch-pretrained-bert to transformers is that the models forward method always outputs a tuple with various elements depending on the model and the configuration parameters."
1387 | ]
1388 | },
1389 | {
1390 | "cell_type": "code",
1391 | "execution_count": 67,
1392 | "metadata": {},
1393 | "outputs": [],
1394 | "source": [
1395 | "bert_model='./model/early_readmission'"
1396 | ]
1397 | },
1398 | {
1399 | "cell_type": "code",
1400 | "execution_count": 70,
1401 | "metadata": {},
1402 | "outputs": [
1403 | {
1404 | "name": "stderr",
1405 | "output_type": "stream",
1406 | "text": [
1407 | "01/02/2020 22:54:36 - INFO - modeling_readmission - loading archive file ./model/early_readmission\n",
1408 | "01/02/2020 22:54:36 - INFO - modeling_readmission - Model config {\n",
1409 | " \"attention_probs_dropout_prob\": 0.1,\n",
1410 | " \"hidden_act\": \"gelu\",\n",
1411 | " \"hidden_dropout_prob\": 0.1,\n",
1412 | " \"hidden_size\": 768,\n",
1413 | " \"initializer_range\": 0.02,\n",
1414 | " \"intermediate_size\": 3072,\n",
1415 | " \"max_position_embeddings\": 512,\n",
1416 | " \"num_attention_heads\": 12,\n",
1417 | " \"num_hidden_layers\": 12,\n",
1418 | " \"type_vocab_size\": 2,\n",
1419 | " \"vocab_size\": 30522\n",
1420 | "}\n",
1421 | "\n"
1422 | ]
1423 | }
1424 | ],
1425 | "source": [
1426 | "model = BertForSequenceClassification.from_pretrained(bert_model, 1)"
1427 | ]
1428 | },
1429 | {
1430 | "cell_type": "code",
1431 | "execution_count": 71,
1432 | "metadata": {},
1433 | "outputs": [
1434 | {
1435 | "data": {
1436 | "text/plain": [
1437 | "BertForSequenceClassification(\n",
1438 | " (bert): BertModel(\n",
1439 | " (embeddings): BertEmbeddings(\n",
1440 | " (word_embeddings): Embedding(30522, 768)\n",
1441 | " (position_embeddings): Embedding(512, 768)\n",
1442 | " (token_type_embeddings): Embedding(2, 768)\n",
1443 | " (LayerNorm): BertLayerNorm()\n",
1444 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1445 | " )\n",
1446 | " (encoder): BertEncoder(\n",
1447 | " (layer): ModuleList(\n",
1448 | " (0): BertLayer(\n",
1449 | " (attention): BertAttention(\n",
1450 | " (self): BertSelfAttention(\n",
1451 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1452 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1453 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1454 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1455 | " )\n",
1456 | " (output): BertSelfOutput(\n",
1457 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1458 | " (LayerNorm): BertLayerNorm()\n",
1459 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1460 | " )\n",
1461 | " )\n",
1462 | " (intermediate): BertIntermediate(\n",
1463 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1464 | " )\n",
1465 | " (output): BertOutput(\n",
1466 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1467 | " (LayerNorm): BertLayerNorm()\n",
1468 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1469 | " )\n",
1470 | " )\n",
1471 | " (1): BertLayer(\n",
1472 | " (attention): BertAttention(\n",
1473 | " (self): BertSelfAttention(\n",
1474 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1475 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1476 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1477 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1478 | " )\n",
1479 | " (output): BertSelfOutput(\n",
1480 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1481 | " (LayerNorm): BertLayerNorm()\n",
1482 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1483 | " )\n",
1484 | " )\n",
1485 | " (intermediate): BertIntermediate(\n",
1486 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1487 | " )\n",
1488 | " (output): BertOutput(\n",
1489 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1490 | " (LayerNorm): BertLayerNorm()\n",
1491 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1492 | " )\n",
1493 | " )\n",
1494 | " (2): BertLayer(\n",
1495 | " (attention): BertAttention(\n",
1496 | " (self): BertSelfAttention(\n",
1497 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1498 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1499 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1500 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1501 | " )\n",
1502 | " (output): BertSelfOutput(\n",
1503 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1504 | " (LayerNorm): BertLayerNorm()\n",
1505 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1506 | " )\n",
1507 | " )\n",
1508 | " (intermediate): BertIntermediate(\n",
1509 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1510 | " )\n",
1511 | " (output): BertOutput(\n",
1512 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1513 | " (LayerNorm): BertLayerNorm()\n",
1514 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1515 | " )\n",
1516 | " )\n",
1517 | " (3): BertLayer(\n",
1518 | " (attention): BertAttention(\n",
1519 | " (self): BertSelfAttention(\n",
1520 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1521 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1522 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1523 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1524 | " )\n",
1525 | " (output): BertSelfOutput(\n",
1526 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1527 | " (LayerNorm): BertLayerNorm()\n",
1528 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1529 | " )\n",
1530 | " )\n",
1531 | " (intermediate): BertIntermediate(\n",
1532 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1533 | " )\n",
1534 | " (output): BertOutput(\n",
1535 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1536 | " (LayerNorm): BertLayerNorm()\n",
1537 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1538 | " )\n",
1539 | " )\n",
1540 | " (4): BertLayer(\n",
1541 | " (attention): BertAttention(\n",
1542 | " (self): BertSelfAttention(\n",
1543 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1544 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1545 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1546 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1547 | " )\n",
1548 | " (output): BertSelfOutput(\n",
1549 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1550 | " (LayerNorm): BertLayerNorm()\n",
1551 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1552 | " )\n",
1553 | " )\n",
1554 | " (intermediate): BertIntermediate(\n",
1555 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1556 | " )\n",
1557 | " (output): BertOutput(\n",
1558 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1559 | " (LayerNorm): BertLayerNorm()\n",
1560 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1561 | " )\n",
1562 | " )\n",
1563 | " (5): BertLayer(\n",
1564 | " (attention): BertAttention(\n",
1565 | " (self): BertSelfAttention(\n",
1566 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1567 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1568 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1569 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1570 | " )\n",
1571 | " (output): BertSelfOutput(\n",
1572 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1573 | " (LayerNorm): BertLayerNorm()\n",
1574 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1575 | " )\n",
1576 | " )\n",
1577 | " (intermediate): BertIntermediate(\n",
1578 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1579 | " )\n",
1580 | " (output): BertOutput(\n",
1581 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1582 | " (LayerNorm): BertLayerNorm()\n",
1583 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1584 | " )\n",
1585 | " )\n",
1586 | " (6): BertLayer(\n",
1587 | " (attention): BertAttention(\n",
1588 | " (self): BertSelfAttention(\n",
1589 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1590 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1591 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1592 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1593 | " )\n",
1594 | " (output): BertSelfOutput(\n",
1595 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1596 | " (LayerNorm): BertLayerNorm()\n",
1597 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1598 | " )\n",
1599 | " )\n",
1600 | " (intermediate): BertIntermediate(\n",
1601 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1602 | " )\n",
1603 | " (output): BertOutput(\n",
1604 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1605 | " (LayerNorm): BertLayerNorm()\n",
1606 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1607 | " )\n",
1608 | " )\n",
1609 | " (7): BertLayer(\n",
1610 | " (attention): BertAttention(\n",
1611 | " (self): BertSelfAttention(\n",
1612 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1613 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1614 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1615 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1616 | " )\n",
1617 | " (output): BertSelfOutput(\n",
1618 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1619 | " (LayerNorm): BertLayerNorm()\n",
1620 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1621 | " )\n",
1622 | " )\n",
1623 | " (intermediate): BertIntermediate(\n",
1624 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1625 | " )\n",
1626 | " (output): BertOutput(\n",
1627 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1628 | " (LayerNorm): BertLayerNorm()\n",
1629 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1630 | " )\n",
1631 | " )\n",
1632 | " (8): BertLayer(\n",
1633 | " (attention): BertAttention(\n",
1634 | " (self): BertSelfAttention(\n",
1635 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1636 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1637 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1638 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1639 | " )\n",
1640 | " (output): BertSelfOutput(\n",
1641 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1642 | " (LayerNorm): BertLayerNorm()\n",
1643 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1644 | " )\n",
1645 | " )\n",
1646 | " (intermediate): BertIntermediate(\n",
1647 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1648 | " )\n",
1649 | " (output): BertOutput(\n",
1650 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1651 | " (LayerNorm): BertLayerNorm()\n",
1652 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1653 | " )\n",
1654 | " )\n",
1655 | " (9): BertLayer(\n",
1656 | " (attention): BertAttention(\n",
1657 | " (self): BertSelfAttention(\n",
1658 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1659 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1660 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1661 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1662 | " )\n",
1663 | " (output): BertSelfOutput(\n",
1664 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1665 | " (LayerNorm): BertLayerNorm()\n",
1666 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1667 | " )\n",
1668 | " )\n",
1669 | " (intermediate): BertIntermediate(\n",
1670 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1671 | " )\n",
1672 | " (output): BertOutput(\n",
1673 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1674 | " (LayerNorm): BertLayerNorm()\n",
1675 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1676 | " )\n",
1677 | " )\n",
1678 | " (10): BertLayer(\n",
1679 | " (attention): BertAttention(\n",
1680 | " (self): BertSelfAttention(\n",
1681 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1682 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1683 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1684 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1685 | " )\n",
1686 | " (output): BertSelfOutput(\n",
1687 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1688 | " (LayerNorm): BertLayerNorm()\n",
1689 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1690 | " )\n",
1691 | " )\n",
1692 | " (intermediate): BertIntermediate(\n",
1693 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1694 | " )\n",
1695 | " (output): BertOutput(\n",
1696 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1697 | " (LayerNorm): BertLayerNorm()\n",
1698 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1699 | " )\n",
1700 | " )\n",
1701 | " (11): BertLayer(\n",
1702 | " (attention): BertAttention(\n",
1703 | " (self): BertSelfAttention(\n",
1704 | " (query): Linear(in_features=768, out_features=768, bias=True)\n",
1705 | " (key): Linear(in_features=768, out_features=768, bias=True)\n",
1706 | " (value): Linear(in_features=768, out_features=768, bias=True)\n",
1707 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1708 | " )\n",
1709 | " (output): BertSelfOutput(\n",
1710 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1711 | " (LayerNorm): BertLayerNorm()\n",
1712 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1713 | " )\n",
1714 | " )\n",
1715 | " (intermediate): BertIntermediate(\n",
1716 | " (dense): Linear(in_features=768, out_features=3072, bias=True)\n",
1717 | " )\n",
1718 | " (output): BertOutput(\n",
1719 | " (dense): Linear(in_features=3072, out_features=768, bias=True)\n",
1720 | " (LayerNorm): BertLayerNorm()\n",
1721 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1722 | " )\n",
1723 | " )\n",
1724 | " )\n",
1725 | " )\n",
1726 | " (pooler): BertPooler(\n",
1727 | " (dense): Linear(in_features=768, out_features=768, bias=True)\n",
1728 | " (activation): Tanh()\n",
1729 | " )\n",
1730 | " )\n",
1731 | " (dropout): Dropout(p=0.1, inplace=False)\n",
1732 | " (classifier): Linear(in_features=768, out_features=1, bias=True)\n",
1733 | ")"
1734 | ]
1735 | },
1736 | "execution_count": 71,
1737 | "metadata": {},
1738 | "output_type": "execute_result"
1739 | }
1740 | ],
1741 | "source": [
1742 | "# Send data to the chosen device\n",
1743 | "model.to(device)"
1744 | ]
1745 | },
1746 | {
1747 | "cell_type": "markdown",
1748 | "metadata": {},
1749 | "source": [
1750 | "[`DistributedDataParallel`](https://pytorch.org/tutorials/intermediate/ddp_tutorial.html#comparison-between-dataparallel-and-distributeddataparallel) (DDP) implements data parallelism at the module level. It synchronizes gradients, parameters, and buffers. If your model is too large to fit on a single GPU, you must use model parallel to split it across multiple GPUs. DDP works with model parallel. DDP is multi-process and works for both single- and multi-machine training."
1751 | ]
1752 | },
1753 | {
1754 | "cell_type": "code",
1755 | "execution_count": 72,
1756 | "metadata": {},
1757 | "outputs": [],
1758 | "source": [
1759 | "if local_rank != -1:\n",
1760 | " model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)\n",
1761 | "elif n_gpu > 1:\n",
1762 | " model = torch.nn.DataParallel(model)"
1763 | ]
1764 | },
1765 | {
1766 | "cell_type": "markdown",
1767 | "metadata": {},
1768 | "source": [
1769 | "# Prepare the Optimizer - AdamW (Weight Decay with Adam)"
1770 | ]
1771 | },
1772 | {
1773 | "cell_type": "markdown",
1774 | "metadata": {},
1775 | "source": [
1776 | "## *** Skip this section if you're using Pre-trained BERT and have set the flag `do_train`=False"
1777 | ]
1778 | },
1779 | {
1780 | "cell_type": "markdown",
1781 | "metadata": {},
1782 | "source": [
1783 | "Training the BERT baseline model is typically done with AdamW, a variant of the Adam optimizer with weight decay as the optimizer. \n",
1784 | "\n",
1785 | ">At its heart, Adam is a simple and intuitive idea: why use the same learning rate for every parameter, when we know that some surely need to be moved further and faster than others? Since the square of recent gradients tells us how much signal we’re getting for each weight, we can just divide by that to ensure even the most sluggish weights get their chance to shine. Adam takes that idea, adds on the standard approach to momentum, and (with a little tweak to keep early batches from being biased) that’s it!...We should use **weight decay** with Adam, and not the L2 regularization that classic deep learning libraries implement [[fast.ai](https://www.fast.ai/2018/07/02/adam-weight-decay/#understanding-adamw-weight-decay-or-l2-regularization)].\n",
1786 | "\n",
1787 | "* `optimize_on_cpu` is whether to perform optimization and keep the optimizer averages on CPU.\n",
1788 | "* `learning_rate` is the initial learning rate for Adam.\n",
1789 | "* `warmup_proportion` is the proportion of training to perform linear learning rate warmup for."
1790 | ]
1791 | },
1792 | {
1793 | "cell_type": "code",
1794 | "execution_count": 73,
1795 | "metadata": {},
1796 | "outputs": [],
1797 | "source": [
1798 | "optimize_on_cpu = False\n",
1799 | "learning_rate = 5e-5\n",
1800 | "warmup_proportion = 0.1\n",
1801 | "\n",
1802 | "# num_warmup_steps = warmup_proportion * float(num_train_steps"
1803 | ]
1804 | },
1805 | {
1806 | "cell_type": "code",
1807 | "execution_count": 74,
1808 | "metadata": {},
1809 | "outputs": [],
1810 | "source": [
1811 | "global_step = 0\n",
1812 | "train_loss=100000\n",
1813 | "number_training_steps=1\n",
1814 | "global_step_check=0\n",
1815 | "train_loss_history=[]"
1816 | ]
1817 | },
1818 | {
1819 | "cell_type": "markdown",
1820 | "metadata": {},
1821 | "source": [
1822 | "Uncomment the cells below to run AdamW optimizer if training."
1823 | ]
1824 | },
1825 | {
1826 | "cell_type": "code",
1827 | "execution_count": 75,
1828 | "metadata": {},
1829 | "outputs": [],
1830 | "source": [
1831 | "# from transformers import AdamW, get_linear_schedule_with_warmup"
1832 | ]
1833 | },
1834 | {
1835 | "cell_type": "code",
1836 | "execution_count": 76,
1837 | "metadata": {},
1838 | "outputs": [],
1839 | "source": [
1840 | "# if optimize_on_cpu:\n",
1841 | "# param_optimizer = [(n, param.clone().detach().to('cpu').requires_grad_()) \\\n",
1842 | "# for n, param in model.named_parameters()]\n",
1843 | "# else:\n",
1844 | "# param_optimizer = list(model.named_parameters())\n",
1845 | "# no_decay = ['bias', 'gamma', 'beta']\n",
1846 | "# optimizer_grouped_parameters = [\n",
1847 | "# {'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay_rate': 0.01},\n",
1848 | "# {'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay_rate': 0.0}\n",
1849 | "# ]\n",
1850 | "\n",
1851 | "# optimizer = AdamW(optimizer_grouped_parameters,\n",
1852 | "# lr=learning_rate,\n",
1853 | "# correct_bias=False) # To reproduce old BertAdam specific behavior set correct_bias=False\n",
1854 | "\n",
1855 | "# # PyTorch scheduler\n",
1856 | "# scheduler = get_linear_schedule_with_warmup(optimizer, \n",
1857 | "# num_warmup_steps=num_warmup_steps,\n",
1858 | "# num_training_steps=num_training_steps) \n",
1859 | "\n",
1860 | "# if do_train:\n",
1861 | "# train_features = convert_examples_to_features(\n",
1862 | "# train_examples, label_list, max_seq_length, tokenizer)\n",
1863 | "# logger.info(\"***** Running training *****\")\n",
1864 | "# logger.info(\" Num examples = %d\", len(train_examples))\n",
1865 | "# logger.info(\" Batch size = %d\", train_batch_size)\n",
1866 | "# logger.info(\" Num steps = %d\", num_train_steps)\n",
1867 | "# all_input_ids = torch.tensor([f.input_ids for f in train_features], dtype=torch.long)\n",
1868 | "# all_input_mask = torch.tensor([f.input_mask for f in train_features], dtype=torch.long)\n",
1869 | "# all_segment_ids = torch.tensor([f.segment_ids for f in train_features], dtype=torch.long)\n",
1870 | "# all_label_ids = torch.tensor([f.label_id for f in train_features], dtype=torch.long)\n",
1871 | "# train_data = TensorDataset(all_input_ids, all_input_mask, all_segment_ids, all_label_ids)\n",
1872 | "# if local_rank == -1:\n",
1873 | "# train_sampler = RandomSampler(train_data)\n",
1874 | "# else:\n",
1875 | "# train_sampler = DistributedSampler(train_data)\n",
1876 | "# train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=train_batch_size)\n",
1877 | "# model.train()\n",
1878 | "# for epo in trange(int(num_train_epochs), desc=\"Epoch\"):\n",
1879 | "# tr_loss = 0\n",
1880 | "# nb_tr_examples, nb_tr_steps = 0, 0\n",
1881 | "# for step, batch in enumerate(train_dataloader):\n",
1882 | "# batch = tuple(t.to(device) for t in batch)\n",
1883 | "# input_ids, input_mask, segment_ids, label_ids = batch\n",
1884 | "# loss, logits = model(input_ids, segment_ids, input_mask, label_ids)\n",
1885 | "# if n_gpu > 1:\n",
1886 | "# loss = loss.mean() # mean() to average on multi-gpu.\n",
1887 | "# if gradient_accumulation_steps > 1:\n",
1888 | "# loss = loss / gradient_accumulation_steps\n",
1889 | "# loss.backward()\n",
1890 | "# train_loss_history.append(loss.item())\n",
1891 | "# tr_loss += loss.item()\n",
1892 | "# nb_tr_examples += input_ids.size(0)\n",
1893 | "# nb_tr_steps += 1\n",
1894 | "# if (step + 1) % gradient_accumulation_steps == 0:\n",
1895 | "# model.zero_grad()\n",
1896 | "# global_step += 1\n",
1897 | "\n",
1898 | "# if (step+1) % 200 == 0:\n",
1899 | "# string = 'step '+str(step+1)\n",
1900 | "# print (string)\n",
1901 | "\n",
1902 | "# train_loss=tr_loss\n",
1903 | "# global_step_check=global_step\n",
1904 | "# number_training_steps=nb_tr_steps\n",
1905 | "\n",
1906 | "# string = './pytorch_model_new_'+ readmission_mode +'.bin'\n",
1907 | "# torch.save(model.state_dict(), string)\n",
1908 | "\n",
1909 | "# fig1 = plt.figure()\n",
1910 | "# plt.plot(train_loss_history)\n",
1911 | "# fig1.savefig('loss_history.png', dpi=fig1.dpi)"
1912 | ]
1913 | },
1914 | {
1915 | "cell_type": "code",
1916 | "execution_count": 77,
1917 | "metadata": {},
1918 | "outputs": [],
1919 | "source": [
1920 | "from torch import nn # Base class for all neural network modules"
1921 | ]
1922 | },
1923 | {
1924 | "cell_type": "code",
1925 | "execution_count": 78,
1926 | "metadata": {},
1927 | "outputs": [],
1928 | "source": [
1929 | "from sklearn.metrics import roc_auc_score, precision_recall_curve, roc_curve, auc, confusion_matrix, classification_report\n",
1930 | "from sklearn.utils.fixes import signature"
1931 | ]
1932 | },
1933 | {
1934 | "cell_type": "code",
1935 | "execution_count": 79,
1936 | "metadata": {},
1937 | "outputs": [],
1938 | "source": [
1939 | "readmission_mode = 'early'"
1940 | ]
1941 | },
1942 | {
1943 | "cell_type": "code",
1944 | "execution_count": 80,
1945 | "metadata": {},
1946 | "outputs": [],
1947 | "source": [
1948 | "def vote_score(df, score, readmission_mode, output_dir):\n",
1949 | " df['pred_score'] = score\n",
1950 | " df_sort = df.sort_values(by=['ID'])\n",
1951 | " #score \n",
1952 | " temp = (df_sort.groupby(['ID'])['pred_score'].agg(max)+df_sort.groupby(['ID'])['pred_score'].agg(sum)/2)/(1+df_sort.groupby(['ID'])['pred_score'].agg(len)/2)\n",
1953 | " x = df_sort.groupby(['ID'])['Label'].agg(np.min).values\n",
1954 | " df_out = pd.DataFrame({'logits': temp.values, 'ID': x})\n",
1955 | "\n",
1956 | " fpr, tpr, thresholds = roc_curve(x, temp.values)\n",
1957 | " auc_score = auc(fpr, tpr)\n",
1958 | "\n",
1959 | " plt.figure(1)\n",
1960 | " plt.plot([0, 1], [0, 1], 'k--')\n",
1961 | " plt.plot(fpr, tpr, label='Val (area = {:.3f})'.format(auc_score))\n",
1962 | " plt.xlabel('False positive rate')\n",
1963 | " plt.ylabel('True positive rate')\n",
1964 | " plt.title('ROC curve')\n",
1965 | " plt.legend(loc='best')\n",
1966 | " plt.show()\n",
1967 | " string = 'auroc_clinicalbert_'+readmission_mode+'.png'\n",
1968 | " plt.savefig(os.path.join(output_dir, string))\n",
1969 | "\n",
1970 | " return fpr, tpr, df_out"
1971 | ]
1972 | },
1973 | {
1974 | "cell_type": "code",
1975 | "execution_count": 81,
1976 | "metadata": {},
1977 | "outputs": [],
1978 | "source": [
1979 | "def pr_curve_plot(y, y_score, readmission_mode, output_dir):\n",
1980 | " precision, recall, _ = precision_recall_curve(y, y_score)\n",
1981 | " area = auc(recall,precision)\n",
1982 | " step_kwargs = ({'step': 'post'}\n",
1983 | " if 'step' in signature(plt.fill_between).parameters\n",
1984 | " else {})\n",
1985 | " \n",
1986 | " plt.figure(2)\n",
1987 | " plt.step(recall, precision, color='b', alpha=0.2,\n",
1988 | " where='post')\n",
1989 | " plt.fill_between(recall, precision, alpha=0.2, color='b', **step_kwargs)\n",
1990 | " plt.xlabel('Recall')\n",
1991 | " plt.ylabel('Precision')\n",
1992 | " plt.ylim([0.0, 1.05])\n",
1993 | " plt.xlim([0.0, 1.0])\n",
1994 | " plt.title('Precision-Recall curve: AUC={0:0.2f}'.format(area))\n",
1995 | " \n",
1996 | " string = 'auprc_clinicalbert_'+readmission_mode+'.png'\n",
1997 | "\n",
1998 | " plt.savefig(os.path.join(output_dir, string))"
1999 | ]
2000 | },
2001 | {
2002 | "cell_type": "code",
2003 | "execution_count": 82,
2004 | "metadata": {},
2005 | "outputs": [],
2006 | "source": [
2007 | "def vote_pr_curve(df, score, readmission_mode, output_dir):\n",
2008 | " df['pred_score'] = score\n",
2009 | " df_sort = df.sort_values(by=['ID'])\n",
2010 | " #score \n",
2011 | " temp = (df_sort.groupby(['ID'])['pred_score'].agg(max)+df_sort.groupby(['ID'])['pred_score'].agg(sum)/2)/(1+df_sort.groupby(['ID'])['pred_score'].agg(len)/2)\n",
2012 | " y = df_sort.groupby(['ID'])['Label'].agg(np.min).values\n",
2013 | " \n",
2014 | " precision, recall, thres = precision_recall_curve(y, temp)\n",
2015 | " pr_thres = pd.DataFrame(data = list(zip(precision, recall, thres)), columns = ['prec','recall','thres'])\n",
2016 | " vote_df = pd.DataFrame(data = list(zip(temp, y)), columns = ['score','label'])\n",
2017 | " \n",
2018 | " pr_curve_plot(y, temp, readmission_mode, output_dir)\n",
2019 | " \n",
2020 | " temp = pr_thres[pr_thres.prec > 0.799999].reset_index()\n",
2021 | " \n",
2022 | " rp80 = 0\n",
2023 | " if temp.size == 0:\n",
2024 | " print('Test Sample too small or RP80=0')\n",
2025 | " else:\n",
2026 | " rp80 = temp.iloc[0].recall\n",
2027 | " print('Recall at Precision of 80 is {}', rp80)\n",
2028 | "\n",
2029 | " return rp80"
2030 | ]
2031 | },
2032 | {
2033 | "cell_type": "code",
2034 | "execution_count": 83,
2035 | "metadata": {},
2036 | "outputs": [],
2037 | "source": [
2038 | "def _truncate_seq_pair(tokens_a, tokens_b, max_length):\n",
2039 | " \"\"\"Truncates a sequence pair in place to the maximum length.\"\"\"\n",
2040 | "\n",
2041 | " # This is a simple heuristic which will always truncate the longer sequence\n",
2042 | " # one token at a time. This makes more sense than truncating an equal percent\n",
2043 | " # of tokens from each, since if one sequence is very short then each token\n",
2044 | " # that's truncated likely contains more information than a longer sequence.\n",
2045 | " while True:\n",
2046 | " total_length = len(tokens_a) + len(tokens_b)\n",
2047 | " if total_length <= max_length:\n",
2048 | " break\n",
2049 | " if len(tokens_a) > len(tokens_b):\n",
2050 | " tokens_a.pop()\n",
2051 | " else:\n",
2052 | " tokens_b.pop()"
2053 | ]
2054 | },
2055 | {
2056 | "cell_type": "code",
2057 | "execution_count": 84,
2058 | "metadata": {},
2059 | "outputs": [],
2060 | "source": [
2061 | "class InputFeatures(object):\n",
2062 | " \"\"\"A single set of features of data.\"\"\"\n",
2063 | "\n",
2064 | " def __init__(self, input_ids, input_mask, segment_ids, label_id):\n",
2065 | " self.input_ids = input_ids\n",
2066 | " self.input_mask = input_mask\n",
2067 | " self.segment_ids = segment_ids\n",
2068 | " self.label_id = label_id"
2069 | ]
2070 | },
2071 | {
2072 | "cell_type": "code",
2073 | "execution_count": 85,
2074 | "metadata": {},
2075 | "outputs": [],
2076 | "source": [
2077 | "def convert_examples_to_features(examples, label_list, max_seq_length, tokenizer):\n",
2078 | " \"\"\"Loads a data file into a list of `InputBatch`s.\"\"\"\n",
2079 | "\n",
2080 | " label_map = {}\n",
2081 | " for (i, label) in enumerate(label_list):\n",
2082 | " label_map[label] = i\n",
2083 | "\n",
2084 | " features = []\n",
2085 | " for (ex_index, example) in enumerate(examples):\n",
2086 | " tokens_a = tokenizer.tokenize(example.text_a)\n",
2087 | "\n",
2088 | " tokens_b = None\n",
2089 | " if example.text_b:\n",
2090 | " tokens_b = tokenizer.tokenize(example.text_b)\n",
2091 | "\n",
2092 | " if tokens_b:\n",
2093 | " # Modifies `tokens_a` and `tokens_b` in place so that the total\n",
2094 | " # length is less than the specified length.\n",
2095 | " # Account for [CLS], [SEP], [SEP] with \"- 3\"\n",
2096 | " _truncate_seq_pair(tokens_a, tokens_b, max_seq_length - 3)\n",
2097 | " else:\n",
2098 | " # Account for [CLS] and [SEP] with \"- 2\"\n",
2099 | " if len(tokens_a) > max_seq_length - 2:\n",
2100 | " tokens_a = tokens_a[0:(max_seq_length - 2)]\n",
2101 | "\n",
2102 | " # The convention in BERT is:\n",
2103 | " # (a) For sequence pairs:\n",
2104 | " # tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]\n",
2105 | " # type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1\n",
2106 | " # (b) For single sequences:\n",
2107 | " # tokens: [CLS] the dog is hairy . [SEP]\n",
2108 | " # type_ids: 0 0 0 0 0 0 0\n",
2109 | " #\n",
2110 | " # Where \"type_ids\" are used to indicate whether this is the first\n",
2111 | " # sequence or the second sequence. The embedding vectors for `type=0` and\n",
2112 | " # `type=1` were learned during pre-training and are added to the wordpiece\n",
2113 | " # embedding vector (and position vector). This is not *strictly* necessary\n",
2114 | " # since the [SEP] token unambigiously separates the sequences, but it makes\n",
2115 | " # it easier for the model to learn the concept of sequences.\n",
2116 | " #\n",
2117 | " # For classification tasks, the first vector (corresponding to [CLS]) is\n",
2118 | " # used as as the \"sentence vector\". Note that this only makes sense because\n",
2119 | " # the entire model is fine-tuned.\n",
2120 | " tokens = []\n",
2121 | " segment_ids = []\n",
2122 | " tokens.append(\"[CLS]\")\n",
2123 | " segment_ids.append(0)\n",
2124 | " for token in tokens_a:\n",
2125 | " tokens.append(token)\n",
2126 | " segment_ids.append(0)\n",
2127 | " tokens.append(\"[SEP]\")\n",
2128 | " segment_ids.append(0)\n",
2129 | "\n",
2130 | " if tokens_b:\n",
2131 | " for token in tokens_b:\n",
2132 | " tokens.append(token)\n",
2133 | " segment_ids.append(1)\n",
2134 | " tokens.append(\"[SEP]\")\n",
2135 | " segment_ids.append(1)\n",
2136 | "\n",
2137 | " input_ids = tokenizer.convert_tokens_to_ids(tokens)\n",
2138 | "\n",
2139 | " # The mask has 1 for real tokens and 0 for padding tokens. Only real tokens are attended to.\n",
2140 | " input_mask = [1] * len(input_ids)\n",
2141 | "\n",
2142 | " # Zero-pad up to the sequence length.\n",
2143 | " while len(input_ids) < max_seq_length:\n",
2144 | " input_ids.append(0)\n",
2145 | " input_mask.append(0)\n",
2146 | " segment_ids.append(0)\n",
2147 | "\n",
2148 | " assert len(input_ids) == max_seq_length\n",
2149 | " assert len(input_mask) == max_seq_length\n",
2150 | " assert len(segment_ids) == max_seq_length\n",
2151 | " #print (example.label)\n",
2152 | " label_id = label_map[example.label]\n",
2153 | " if ex_index < 5:\n",
2154 | " logger.info(\"*** Example ***\")\n",
2155 | " logger.info(\"guid: %s\" % (example.guid))\n",
2156 | " logger.info(\"tokens: %s\" % \" \".join(\n",
2157 | " [str(x) for x in tokens]))\n",
2158 | " logger.info(\"input_ids: %s\" % \" \".join([str(x) for x in input_ids]))\n",
2159 | " logger.info(\"input_mask: %s\" % \" \".join([str(x) for x in input_mask]))\n",
2160 | " logger.info(\n",
2161 | " \"segment_ids: %s\" % \" \".join([str(x) for x in segment_ids]))\n",
2162 | " logger.info(\"label: %s (id = %d)\" % (example.label, label_id))\n",
2163 | "\n",
2164 | " features.append(\n",
2165 | " InputFeatures(input_ids=input_ids,\n",
2166 | " input_mask=input_mask,\n",
2167 | " segment_ids=segment_ids,\n",
2168 | " label_id=label_id))\n",
2169 | " return features\n",
2170 | "\n"
2171 | ]
2172 | },
2173 | {
2174 | "cell_type": "markdown",
2175 | "metadata": {},
2176 | "source": [
2177 | "`max_seq_length` is the maximum total input sequence length after WordPiece tokenization. Sequences longer than this will be truncated, and sequences shorter than this will be padded.\n",
2178 | "\n",
2179 | "`eval_batch_size` is the total batch size for eval."
2180 | ]
2181 | },
2182 | {
2183 | "cell_type": "code",
2184 | "execution_count": 86,
2185 | "metadata": {},
2186 | "outputs": [],
2187 | "source": [
2188 | "max_seq_length = 128\n",
2189 | "eval_batch_size = 2"
2190 | ]
2191 | },
2192 | {
2193 | "cell_type": "code",
2194 | "execution_count": 87,
2195 | "metadata": {},
2196 | "outputs": [],
2197 | "source": [
2198 | "from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler\n",
2199 | "from torch.utils.data.distributed import DistributedSampler"
2200 | ]
2201 | },
2202 | {
2203 | "cell_type": "code",
2204 | "execution_count": 88,
2205 | "metadata": {},
2206 | "outputs": [],
2207 | "source": [
2208 | "m = nn.Sigmoid()\n",
2209 | "if do_eval:\n",
2210 | " eval_examples = processor.get_test_examples(data_dir)\n",
2211 | " eval_features = convert_examples_to_features(\n",
2212 | " eval_examples, label_list, max_seq_length, tokenizer)\n",
2213 | " logger.info(\"***** Running evaluation *****\")\n",
2214 | " logger.info(\" Num examples = %d\", len(eval_examples))\n",
2215 | " logger.info(\" Batch size = %d\", eval_batch_size)\n",
2216 | " all_input_ids = torch.tensor([f.input_ids for f in eval_features], dtype=torch.long)\n",
2217 | " all_input_mask = torch.tensor([f.input_mask for f in eval_features], dtype=torch.long)\n",
2218 | " all_segment_ids = torch.tensor([f.segment_ids for f in eval_features], dtype=torch.long)\n",
2219 | " all_label_ids = torch.tensor([f.label_id for f in eval_features], dtype=torch.long)\n",
2220 | " eval_data = TensorDataset(all_input_ids, all_input_mask, all_segment_ids, all_label_ids)\n",
2221 | " if local_rank == -1:\n",
2222 | " eval_sampler = SequentialSampler(eval_data)\n",
2223 | " else:\n",
2224 | " eval_sampler = DistributedSampler(eval_data)\n",
2225 | " eval_dataloader = DataLoader(eval_data, sampler=eval_sampler, batch_size=eval_batch_size)\n",
2226 | " model.eval()\n",
2227 | " eval_loss, eval_accuracy = 0, 0\n",
2228 | " nb_eval_steps, nb_eval_examples = 0, 0\n",
2229 | " true_labels=[]\n",
2230 | " pred_labels=[]\n",
2231 | " logits_history=[]\n",
2232 | " for input_ids, input_mask, segment_ids, label_ids in tqdm(eval_dataloader):\n",
2233 | " input_ids = input_ids.to(device)\n",
2234 | " input_mask = input_mask.to(device)\n",
2235 | " segment_ids = segment_ids.to(device)\n",
2236 | " label_ids = label_ids.to(device)\n",
2237 | " with torch.no_grad():\n",
2238 | " tmp_eval_loss, temp_logits = model(input_ids, segment_ids, input_mask, label_ids)\n",
2239 | " logits = model(input_ids,segment_ids,input_mask)\n",
2240 | "\n",
2241 | " logits = torch.squeeze(m(logits)).detach().cpu().numpy()\n",
2242 | " label_ids = label_ids.to('cpu').numpy()\n",
2243 | "\n",
2244 | " outputs = np.asarray([1 if i else 0 for i in (logits.flatten()>=0.5)])\n",
2245 | " tmp_eval_accuracy=np.sum(outputs == label_ids)\n",
2246 | "\n",
2247 | " true_labels = true_labels + label_ids.flatten().tolist()\n",
2248 | " pred_labels = pred_labels + outputs.flatten().tolist()\n",
2249 | " logits_history = logits_history + logits.flatten().tolist()\n",
2250 | "\n",
2251 | " eval_loss += tmp_eval_loss.mean().item()\n",
2252 | " eval_accuracy += tmp_eval_accuracy\n",
2253 | "\n",
2254 | " nb_eval_examples += input_ids.size(0)\n",
2255 | " nb_eval_steps += 1\n",
2256 | "\n",
2257 | " eval_loss = eval_loss / nb_eval_steps\n",
2258 | " eval_accuracy = eval_accuracy / nb_eval_examples\n",
2259 | " df = pd.DataFrame({'logits':logits_history, 'pred_label': pred_labels, 'label':true_labels})\n",
2260 | "\n",
2261 | " string = 'logits_clinicalbert_'+readmission_mode+'_chunks.csv'\n",
2262 | " df.to_csv(os.path.join(output_dir, string))\n",
2263 | "\n",
2264 | " df_test = pd.read_csv(os.path.join(data_dir, \"test.csv\"))\n",
2265 | "\n",
2266 | " fpr, tpr, df_out = vote_score(df_test, logits_history, readmission_mode, output_dir)\n",
2267 | "\n",
2268 | " string = 'logits_clinicalbert_'+readmission_mode+'_readmissions.csv'\n",
2269 | " df_out.to_csv(os.path.join(output_dir,string))\n",
2270 | "\n",
2271 | " rp80 = vote_pr_curve(df_test, logits_history, readmission_mode, output_dir)\n",
2272 | "\n",
2273 | " result = {'eval_loss': eval_loss,\n",
2274 | " 'eval_accuracy': eval_accuracy, \n",
2275 | " 'global_step': global_step_check,\n",
2276 | " 'training loss': train_loss/number_training_steps,\n",
2277 | " 'RP80': rp80}\n",
2278 | "\n",
2279 | " output_eval_file = os.path.join(output_dir, \"eval_results.txt\")\n",
2280 | " with open(output_eval_file, \"w\") as writer:\n",
2281 | " logger.info(\"***** Eval results *****\")\n",
2282 | " for key in sorted(result.keys()):\n",
2283 | " logger.info(\" %s = %s\", key, str(result[key]))\n",
2284 | " writer.write(\"%s = %s\\n\" % (key, str(result[key])))\n"
2285 | ]
2286 | },
2287 | {
2288 | "cell_type": "markdown",
2289 | "metadata": {},
2290 | "source": [
2291 | "Download entire folder from AWS sagemaker to laptop:"
2292 | ]
2293 | },
2294 | {
2295 | "cell_type": "code",
2296 | "execution_count": null,
2297 | "metadata": {},
2298 | "outputs": [
2299 | {
2300 | "name": "stdout",
2301 | "output_type": "stream",
2302 | "text": [
2303 | " adding: lost+found/ (stored 0%)\n",
2304 | " adding: model/ (stored 0%)\n",
2305 | " adding: model/early_readmission/ (stored 0%)\n",
2306 | " adding: model/early_readmission/pytorch_model.bin (deflated 7%)\n",
2307 | " adding: model/early_readmission/bert_config.json (deflated 47%)\n",
2308 | " adding: ClinicalBERT3.ipynb (deflated 67%)\n",
2309 | " adding: modeling_readmission.py (deflated 81%)\n",
2310 | " adding: data/ (stored 0%)\n",
2311 | " adding: data/3days/ (stored 0%)\n",
2312 | " adding: data/3days/train.csv (deflated 65%)\n",
2313 | " adding: data/3days/test.csv (deflated 79%)\n",
2314 | " adding: data/3days/val.csv (deflated 78%)\n",
2315 | " adding: data/discharge/ (stored 0%)\n",
2316 | " adding: data/discharge/train.csv (deflated 66%)\n",
2317 | " adding: data/discharge/test.csv (deflated 68%)\n",
2318 | " adding: data/discharge/val.csv (deflated 68%)\n",
2319 | " adding: data/2days/ (stored 0%)\n",
2320 | " adding: data/2days/test.csv (deflated 78%)\n",
2321 | " adding: pickle/ (stored 0%)\n",
2322 | " adding: pickle/df_less_3.pkl"
2323 | ]
2324 | }
2325 | ],
2326 | "source": [
2327 | "!zip -r -X ClinicalBERT3_results.zip './'"
2328 | ]
2329 | }
2330 | ],
2331 | "metadata": {
2332 | "kernelspec": {
2333 | "display_name": "Python 3",
2334 | "language": "python",
2335 | "name": "python3"
2336 | },
2337 | "language_info": {
2338 | "codemirror_mode": {
2339 | "name": "ipython",
2340 | "version": 3
2341 | },
2342 | "file_extension": ".py",
2343 | "mimetype": "text/x-python",
2344 | "name": "python",
2345 | "nbconvert_exporter": "python",
2346 | "pygments_lexer": "ipython3",
2347 | "version": "3.7.3"
2348 | },
2349 | "varInspector": {
2350 | "cols": {
2351 | "lenName": 16,
2352 | "lenType": 16,
2353 | "lenVar": 40
2354 | },
2355 | "kernels_config": {
2356 | "python": {
2357 | "delete_cmd_postfix": "",
2358 | "delete_cmd_prefix": "del ",
2359 | "library": "var_list.py",
2360 | "varRefreshCmd": "print(var_dic_list())"
2361 | },
2362 | "r": {
2363 | "delete_cmd_postfix": ") ",
2364 | "delete_cmd_prefix": "rm(",
2365 | "library": "var_list.r",
2366 | "varRefreshCmd": "cat(var_dic_list()) "
2367 | }
2368 | },
2369 | "position": {
2370 | "height": "472px",
2371 | "left": "506px",
2372 | "right": "20px",
2373 | "top": "120px",
2374 | "width": "742px"
2375 | },
2376 | "types_to_exclude": [
2377 | "module",
2378 | "function",
2379 | "builtin_function_or_method",
2380 | "instance",
2381 | "_Feature"
2382 | ],
2383 | "window_display": false
2384 | }
2385 | },
2386 | "nbformat": 4,
2387 | "nbformat_minor": 2
2388 | }
2389 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 | # ClinicalBERT: Using Deep Learning Transformer Model to Predict Hospital Readmission
3 |
4 | ClinicalBERT: Using Deep Learning Transformer Model to Predict Hospital Readmission
5 |
6 | ***Before we begin, let me point you to my GitHub [repo](https://github.com/nwams/ClinicalBERT-Deep-Learning--Predicting-Hospital-Readmission-Using-Transformer) [or Jupyter [Notebook](https://nbviewer.jupyter.org/github/nwams/ClinicalBERT-Deep-Learning--Predicting-Hospital-Readmission-Using-Transformer/blob/master/ClinicalBERT%20Deep%20Learning%20-%20Predicting%20Hospital%20Readmission.ipynb)] containing all the code used in this guide. Feel free to use the code to follow along with the guide. You can u*se [this google link](https://drive.google.com/open?id=1t8L9w-r88Q5-sfC993x2Tjt1pu--A900) to download the pretrained ClinicalBERT model along with the readmission task fine-tuned model weights.**
7 |
8 | ## Preface
9 |
10 | If you came here from my earlier work [Predicting Hospital Readmission using NLP](https://medium.com/nwamaka-imasogie/predicting-hospital-readmission-using-nlp-5f0fe6f1a705), this deep learning work won’t serve as a direct comparison for the AUROC metric because my approach is completely different in this paper. The more I dug into it, the more I discovered that the most beneficial application for clinicians is to be able to use these predictions to make adjustments **while a patient is still in the hospital** in order for Doctors to intervene and prevent them from being readmitted in the future. Therefore instead of using discharge summaries (written after a patient’s stay is over) it’s best to just feed in the early notes into the model that were gathered from within 2–3days of a patients stay.
11 |
12 | ## TLDR
13 |
14 | My results for predicting readmission **using only the first few days of notes in the intensive care unit (not discharge summaries)** are:
15 |
16 | * For 2days AUROC=0.748 and for 3days AUROC=0.758.
17 |
18 | * For 2days RP80=38.69% and for 3days RP80=38.02%.
19 |
20 | See the bottom of this article for full details.
21 |
22 | ## Introduction
23 |
24 | I recently read this great paper “ClinicalBert: Modeling Clinical Notes and Predicting Hospital Readmission” by Huang et al ([Paper](https://arxiv.org/pdf/1904.05342.pdf) & [GitHub](https://github.com/kexinhuang12345/clinicalBERT)).
25 |
26 | They develop ClinicalBert by applying BERT (bidirectional encoder representations from transformers) to clinical notes.
27 |
28 | I wanted to dissect the work and expound upon the deep learning concepts. My work will serve as a detailed annotation (along with my own code changes) and interpretation of the contents of this academic paper. I will also create visualizations to enhance explanations. And I converted it to a convenient Jupyter Notebook format.
29 |
30 | ### How my work differs from the author:
31 |
32 | 1. I am only working with **early** clinical notes (first 24–48 hrs and 48–72 hrs) because although discharge summaries have predictive power for readmission, “discharge summaries might be written after a patient has left the hospital. Therefore, discharge summaries are **not actionable** since doctors cannot intervene when a patient has left the hospital. Models that dynamically predict readmission in the early stages of a patient’s admission are relevant to clinicians…a maximum of the first 48 or 72 hours of a patient’s notes are concatenated. These concatenated notes are used to predict readmission.”[pg 12](https://arxiv.org/pdf/1904.05342.pdf). The ClinicalBERT model can predict readmission dynamically. **Making a prediction using a discharge summary at the end of a stay means that there are fewer opportunities to reduce the chance of readmission. To build a clinically-relevant model, we define a task for predicting readmission at any timepoint since a patient was admitted.**
33 |
34 | 1. My code is presented in a Jupyter Notebook rather than .py files.
35 |
36 | 1. It’s important to note that my code differs from Huang’s because I [migrated](https://huggingface.co/transformers/migration.html) to using [HuggingFace’s](https://huggingface.co/transformers/index.html) new transformer module instead of the formerly known as pytorch_pretrained_bert that the author used.
37 |
38 | 1. I do not conduct pre-training the ClinicalBERT because the author already performed pre-training on Clinical words and the model’s weights are already available [here](http://bit.ly/clinicalbert_weights).
39 |
40 | ## Brief BERT Intro
41 |
42 | **BERT** (Bidirectional Encoder Representations from Transformers) is a recent [model](https://arxiv.org/pdf/1810.04805.pdf) published in Oct 2018 by researchers at Google AI Language. It has caused a stir in the Machine Learning community by presenting state-of-the-art results in a wide variety of NLP tasks, including Question Answering (SQuAD v1.1), Natural Language Inference (MNLI), and others.
43 |
44 | ## What is ClinicalBERT?
45 |
46 | ClinicalBERT is a Bidirectional Transformer.
47 |
48 | ClinicalBERT is a modified BERT model: Specifically, the representations are learned using medical notes and further processed for downstream clinical tasks.
49 |
50 | *ClinicalBERT is pretrained on patient clinical notes/EHR and then can be used for downstream predictive tasks.*
51 |
52 | The diagram below illustrates how care providers add notes to an electronic health record during a patient’s admission, and the model dynamically updates the patient’s risk of being readmitted within a 30-day window.
53 |
54 | *Every day, more data gets added to an EHR. Notes like Radiology, Nursing, ECG, Physician, Discharge summary, Echo, Respiratory, Nutrition, General, Rehab Services, Social Work, Case Management, Pharmacy and Consult.*
55 |
56 | ## Why is ClinicalBERT needed?
57 |
58 | Before the author even evaluated ClinicalBERT’s performance as a model of readmission, **his initial experiment showed that the original BERT suffered in performance on the masked language modeling task on the MIMIC-III data as well as the next sentence prediction tasks. This proves the need develop models tailored to clinical data such as ClinicalBERT!**
59 |
60 | Medicine suffers from alarm fatigue. This means useful classification rules for medicine need to have high precision (positive predictive value).
61 |
62 | The quality of learned representations of text depends on the text the model was trained on. **Regular BERT is pretrained on BooksCorpus and Wikipedia**. However, these two datasets are distinct from clinical notes. Clinical notes have jargon, abbreviations and different syntax and grammar than common language in books or encyclopedias. **ClinicalBERT is trained on clinical notes/Electronic Health Records (EHR)**.
63 |
64 | Clinical notes require capturing interactions between distant words and ClinicalBert captures qualitative relationships among clinical concepts in a database of medical terms.
65 |
66 | Compared to the popular word2vec model, ClinicalBert more accurately captures clinical word similarity.
67 |
68 | ## BERT Basics
69 |
70 | ]](https://cdn-images-1.medium.com/max/2232/1*9PjJt3EkZS85Hy3H4UKeLg.png)*[[Source](https://arxiv.org/abs/1904.05342)]*
71 |
72 | Just like BERT, Clinical BERT is a trained Transformer Encoder stack.
73 |
74 | Here’s a quick refresher on the basics of how BERT works.
75 |
76 | ]](https://cdn-images-1.medium.com/max/2000/1*rAAdyehB3uXuDkrjB3Mzog.png)*[[Source](http://jalammar.github.io/illustrated-bert/)]*
77 |
78 | BERT base has 12 encoder layers.
79 |
80 | In my code I am using ***BERT base uncased***.
81 |
82 | ]](https://cdn-images-1.medium.com/max/3000/1*j9R9I4taW5P4qxaCW-7liw.png)*[[Source](http://jalammar.github.io/illustrated-bert/)]*
83 |
84 | Pretrained BERT has a max of **512 input tokens** (position embeddings). The output would be a vector for each input token. Each vector is made up of **768** float numbers (**hidden units**).
85 |
86 | ## Pre-training ClinicalBERT
87 |
88 | ClinicalBERT outperforms BERT on two unsupervised language modeling tasks evaluated on a large corpus of clinical text. In *masked language modeling* (where you mask 15% of the input tokens and using the model to predict the next tokens) and *next-sentence prediction* tasks ClinicalBERT outperforms BERT by 30 points and 18.75 points respectively.
89 |
90 | ](https://cdn-images-1.medium.com/max/3112/1*QAGvhTGhTPA0DTZms19o7g.png)*Source: [https://arxiv.org/abs/1904.05342](https://arxiv.org/abs/1904.05342)*
91 |
92 | ## Fine-tuning ClinicalBERT
93 |
94 | *ClinicalBERT can be readily adapted to downstream clinical tasks e.g. Predicting 30-Day Readmission.*
95 |
96 | In this tutorial, we will use ClinicalBERT to train a readmission classifier. Specifically, I will take the pre-trained ClinicalBERT model, add an untrained layer of neurons on the end, and train the new model.
97 |
98 | ### Advantages to Fine-Tuning
99 |
100 | You might be wondering [why](https://mccormickml.com/2019/07/22/BERT-fine-tuning/) we should do fine-tuning rather than train a specific deep learning model (BiLSTM, Word2Vec, etc.) that is well suited for the specific NLP task you need?
101 |
102 | * **Quicker Development:** The pre-trained ClinicalBERT model weights already encode a lot of information about our language. As a result, it takes much less time to train our fine-tuned model — it is as if we have already trained the bottom layers of our network extensively and only need to gently tune them while using their output as features for our classification task. For example in the original BERT paper the authors recommend only 2–4 epochs of training for fine-tuning BERT on a specific NLP task, compared to the hundreds of GPU hours needed to train the original BERT model or a LSTM from scratch!
103 |
104 | * **Less Data:** Because of the pretrained weights this method allows us to fine-tune our task on a much smaller dataset than would be required in a model that is built from scratch. A major drawback of NLP models built from scratch is that we often need a prohibitively large dataset in order to train our network to reasonable accuracy, meaning a lot of time and energy had to be put into dataset creation. By fine-tuning BERT, we are now able to get away with training a model to good performance on a much smaller amount of training data.
105 |
106 | * **Better Results:** Fine-tuning is shown to achieve state of the art results with minimal task-specific adjustments for a wide variety of tasks: classification, language inference, semantic similarity, question answering, etc. Rather than implementing custom and sometimes-obscure architectures shown to work well on a specific task, fine-tuning is shown to be a better (or at least equal) alternative.
107 |
108 | ### Fine-tuning Details
109 |
110 | ClinicalBert is fine-tuned on a task specific to clinical data: **readmission prediction**.
111 |
112 | The model is fed a patient’s clinical notes, and the patient’s risk of readmission within a 30-day window is predicted using a linear layer applied to the classification representation, hcls, learned by ClinicalBert.
113 |
114 | The model parameters are fine-tuned to **maximize the log-likelihood** of this binary classifier.
115 |
116 | Here is the probability of readmission formula:
117 |
118 | P (readmit = 1 | hcls) = σ(W hcls)
119 |
120 | * **readmit** is a binary indicator of readmission (0 or 1).
121 |
122 | * **σ** is the sigmoid function
123 |
124 | * **hcls** is a linear layer operating on the final representation for the CLS token. In other words **hcls** is the output of the model associated with the classification token.
125 |
126 | * **W** is a parameter matrix
127 |
128 | ## Setting Up
129 |
130 | Before starting you must create the following directories and files:
131 |
132 | 
133 |
134 | ### Installation
135 |
136 | Run this command to install the HuggingFace transformer module:
137 |
138 | conda install -c conda-forge transformers
139 |
140 | ## MIMIC-III Dataset on AWS S3 Bucket
141 |
142 | I used the MIMIC-III dataset that they host in the cloud in an [S3 bucket](https://physionet.org/content/mimiciii/1.4/). I found it was easiest to simply [add my AWS account number to my MIMIC-III account](https://mimic.physionet.org/gettingstarted/cloud/) and use this link s3://mimic-iii-physionet to pull the ADMISSIONS and NOTEEVENTS table into my Notebook.
143 |
144 | ## Preprocessing
145 |
146 | ClinicalBert requires minimal preprocessing:
147 |
148 | 1. First, words are converted to lowercase
149 |
150 | 1. Line breaks are removed
151 |
152 | 1. Carriage returns are removed
153 |
154 | 1. De-identified the personally identifiable info inside the brackets
155 |
156 | 1. Remove special characters like ==, −−
157 |
158 | 1. The [SpaCy](https://spacy.io/) sentence segmentation package is used to segment each note (Honnibal and Montani, 2017).
159 |
160 | Since clinical notes don’t follow rigid standard language grammar, we find rule-based segmentation has better results than dependency parsing-based segmentation. Various segmentation signs that misguide rule-based segmentators are removed or replaced.
161 |
162 | * For example 1.2 would be removed.
163 |
164 | * M.D., dr. would be replaced with with MD, Dr
165 |
166 | * Clinical notes can include various lab results and medications that also contain numerous rule-based separators, such as 20mg, p.o., q.d.. (where q.d. means one a day and q.o. means to take by mouth.
167 |
168 | * To address this, segmentations that have less than 20 words are fused into the previous segmentation so that they are not singled out as different sentences.
169 |
170 | ## AWS SageMaker — Training on a GPU
171 |
172 | I used a Notebook in AWS [Sagemaker](https://aws.amazon.com/sagemaker/) and trained on a single p2.xlarge K80 GPU (in SageMaker choose the ml.p2.xlarge). You will have to request a limit increase from AWS support before you can use a GPU. It is a manual request that’s ultimately granted by a human being and could take several hours or 1-day.
173 |
174 | Create a new Notebook in SageMaker. Then open a new Terminal (see picture below):
175 |
176 | 
177 |
178 | Copy/paste and run the script below to cd into the SageMaker directory and create the necessary folders and files:
179 |
180 | cd SageMaker/
181 |
182 | mkdir -p ./data/discharge
183 |
184 | mkdir -p ./data/3days
185 |
186 | mkdir -p ./data/2days
187 |
188 | touch ./data/discharge/train.csv
189 |
190 | touch ./data/discharge/val.csv
191 |
192 | touch ./data/discharge/test.csv
193 |
194 | touch ./data/3days/train.csv
195 |
196 | touch ./data/3days/val.csv
197 |
198 | touch ./data/3days/test.csv
199 |
200 | touch ./data/2days/test.csv
201 |
202 | Upload your Notebook that you’ve been working in on your local computer.
203 |
204 | When creating an IAM role, choose the Any S3 bucket option.
205 |
206 | 
207 |
208 | Create a /pickle directory and upload the 3 pickled files: df_discharge.pkl, df_less_2.pkl and df_less_3.pkl. This may take a few minutes because the files are 398MB, 517MB, and 733MB respectively.
209 |
210 | Then upload the modeling_readmission.py and file_utils.py files into the Jupyter home directory.
211 |
212 | Then upload the [model](https://drive.google.com/open?id=1t8L9w-r88Q5-sfC993x2Tjt1pu--A900) directory to the Jupyter home directory. You can create the directory structure using the following command: mkdir -p ./model/early_readmission. Then you can upload the 2 files pytorch_model.bin and bert_config.json into that folder. This may take a few minutes because pytorch_mode.bin is 438MB.
213 |
214 | Ultimately your Jupyter directory structure should look like this:
215 |
216 | *Note that the **result_early** folder will be created by the code (not you).*
217 |
218 | Now you can run the entire notebook.
219 |
220 | Running the entire notebook took about 8 minutes on a K80 GPU.
221 |
222 | If you’d like to save all of the files (including output) to your local computer run this line in your Jupyter Notebook: !zip -r -X ClinicalBERT3_results.zip './' then you can download it manually from your Notebook.
223 |
224 | ## Code Breakdown
225 |
226 | There’s quite a bit of code so let’s walk through the important bits. I’ll skip a lot of the preprocessing parts like cleaning, splitting training/val/test sets and subsampling that I already covered in-depth [here](https://medium.com/nwamaka-imasogie/predicting-hospital-readmission-using-nlp-5f0fe6f1a705).
227 |
228 | ### Split into 318 word chunks
229 |
230 | # to get 318 words chunks for readmission tasks
231 | df_len = len(df_less_n)
232 | want = pd.DataFrame({'ID': [], 'TEXT': [], 'Label': []})
233 | for i in tqdm(range(df_len)):
234 | x = df_less_n.TEXT.iloc[i].split()
235 | n = int(len(x) / 318)
236 | for j in range(n):
237 | want = want.append({'TEXT': ' '.join(x[j * 318:(j + 1) * 318]), 'Label': df_less_n.OUTPUT_LABEL.iloc[i],
238 | 'ID': df_less_n.HADM_ID.iloc[i]}, ignore_index=True)
239 | if len(x) % 318 > 10:
240 | want = want.append({'TEXT': ' '.join(x[-(len(x) % 318):]), 'Label': df_less_n.OUTPUT_LABEL.iloc[i],
241 | 'ID': df_less_n.HADM_ID.iloc[i]}, ignore_index=True)
242 |
243 | A patient will usually have a lot of different notes, however, the ClinicalBert model has a fixed maximum length of input sequence. We split notes into subsequences (each subsequence is the maximum length supported by the model), and define how ClinicalBert makes predictions on long sequences by binning the predictions on each subsequence.
244 |
245 | You might be wondering why we split into 318 word pieces? Because with BERT there’s a **512 maximum** sequence number of sub word unit tokens (average ~318 words). In other words, BERT uses sub word units (WordPieces) instead of the entire word as the input unit. So instead of “I am having lunch” as 4 individual words, conceptually, it might do something like “I am hav ing lun ch”.
246 |
247 | If you’d like to know more about it this [paper](https://arxiv.org/abs/1508.07909) was originally written to tackle the “out of vocab” problem but it turns out to have stronger predictive values.
248 |
249 | ### Readmission Prediction
250 |
251 | The probability of readmission for a patient is computed as follows. Assume the patient’s clinical notes are represented as *n* subsequences and fed to the model separately; the model outputs a probability for each subsequence. The **probability of readmission** is computed using the probabilities output for each of these subsequences:
252 |
253 | *Equation for Probability of Readmission where **c** is a scaling factor that controls the amount of influence of the number of subsequences **n**, and **hpatient** is the implicit representation ClinicalBert computes from the entirety of a patient’s notes. **Pnmax** is the maximum of probability of readmission across the **n** subsequences, and **Pnmean** is the mean of the probability of readmission across the **n** subsequences a patient’s notes have been split into.*
254 |
255 | Huang finds that computing readmission probability using the equation above 11consistently outperforms predictions on each subsequence individually by 3-8%. This is because:
256 |
257 | 1. Some subsequences, n, (such as tokens corresponding to progress reports) do NOT contain information about readmission, whereas others do. The risk of readmission should be computed using subsequences that correlate with readmission risk, and **the effect of unimportant subsequences should be minimized**. This is accomplished by using the maximum probability over subsequences (Pnmax).
258 |
259 | 1. Also noisy subsequences mislead the model and decrease performance. So they also include the average probability of readmission across subsequences (Pnmean). This leads to a trade-off between the mean and maximum probabilities of readmission.
260 |
261 | 1. If there are a large number of subsequences for a patient with many clinical notes, there is a higher probability of having a noisy maximum probability of readmission. This means longer sequences may need to have a larger weight on the mean prediction. We include this weight as the n/c scaling factor, with c adjusting for patients with many clinical notes. Empirically, Huang found that c=2 performs best on validation data.
262 |
263 | The formula can be found in the vote_score function in the **temp** variable Remember that the 2 is from c=2:
264 |
265 | def vote_score(df, score, readmission_mode, output_dir):
266 | df['pred_score'] = score
267 | df_sort = df.sort_values(by=['ID'])
268 | #score
269 | **temp = (df_sort.groupby(['ID'])['pred_score'].agg(max)+df_sort.groupby(['ID'])['pred_score'].agg(sum)/2)/(1+df_sort.groupby(['ID'])['pred_score'].agg(len)/2)**
270 | x = df_sort.groupby(['ID'])['Label'].agg(np.min).values
271 | df_out = pd.DataFrame({'logits': temp.values, 'ID': x})
272 |
273 | fpr, tpr, thresholds = roc_curve(x, temp.values)
274 | auc_score = auc(fpr, tpr)
275 |
276 | plt.figure(1)
277 | plt.plot([0, 1], [0, 1], 'k--')
278 | plt.plot(fpr, tpr, label='Val (area = {:.3f})'.format(auc_score))
279 | plt.xlabel('False positive rate')
280 | plt.ylabel('True positive rate')
281 | plt.title('ROC curve')
282 | plt.legend(loc='best')
283 | plt.show()
284 | string = 'auroc_clinicalbert_'+readmission_mode+'.png'
285 | plt.savefig(os.path.join(output_dir, string))
286 |
287 | return fpr, tpr, df_out
288 |
289 | ### Results
290 |
291 | For validation 10% of the data is held out, for testing 10% of the data is held out, then 5-fold cross-validation is conducted.
292 |
293 | Each model is evaluated using three metrics:
294 |
295 | 1. Area under the ROC curve (AUROC)
296 |
297 | 1. Area under the precision-recall curve (AUPRC)
298 |
299 | 1. Recall at precision of 80% (RP80): For the readmission task, false positives are important. To minimize the number of false positives and thus minimize the risk of alarm fatigue, we set the precision to 80%. In other words we set a 20% false positive rate out of the predicted positive class and use the corresponding threshold to calculate recall. This leads to a clinically-relevant metric that enables us to build models that control the false positive rate.
300 |
301 | Here is the code: https://gist.github.com/nwams/faef6411b342cf163d6c8fb6267433f9#file-clinicalbert-evaluation-py
302 |
303 | Here are the results output from Predicting Readmission on the Early Notes:
304 |
305 | 
306 |
307 | ## Interpreting Results
308 |
309 | ### Quick Review of Precision, Recall and AUROC
310 |
311 | I recommend reading Jason Brownlee’s [article](https://machinelearningmastery.com/roc-curves-and-precision-recall-curves-for-classification-in-python/).
312 |
313 | * [**Precision**](https://machinelearningmastery.com/roc-curves-and-precision-recall-curves-for-classification-in-python/) is a ratio of the number of true positives divided by the sum of the true positives and false positives. **It describes how good a model is at predicting the positive class**. It is also referred to as the positive predictive value.
314 |
315 | * **Recall**, a.k.a. sensitivity, is calculated as the ratio of the number of true positives divided by the sum of the true positives and the false negatives.
316 |
317 | 
318 |
319 | **It’s important to look at both precision and recall in cases where there is an imbalance** in the observations between the two classes. Specifically, when there are many examples of no event (class 0) and only a few examples of an event (class 1). Because usually the large number of class 0 examples means we are less interested in the skill of the model at predicting class 0 correctly, e.g. high true negatives.
320 | > The important thing to note in the calculation of precision and recall is that the calculations do not make use of the true negatives. It is only concerned with the correct prediction of the minority class, class 1.
321 |
322 | ### When to Use ROC vs. Precision-Recall Curves?
323 |
324 | The recommendations are:
325 |
326 | * ROC curves should be used when there are roughly equal numbers of observations for each class.
327 |
328 | * Precision-Recall curves should be used when there is a moderate to large class imbalance.
329 |
330 | Why? Because **ROC curves present an overly optimistic picture of the model on datasets with a class imbalance**. It’s optimistic because of the use of true negatives in the False Positive rate in the ROC Curve; however remember that the False Positive rate is carefully avoided in the Precision-Recall.
331 |
332 | ### Now back to interpreting our results
333 | > # For 2days AUROC=0.748 and for 3days AUROC=0.758.
334 | > # For 2days RP80=38.69% and for 3days RP80=38.02%.
335 |
336 | Based on [experimentation](https://arxiv.org/pdf/1904.05342.pdf#page=12), ClinicalBert outperforms results from Bag-of-Words and BILSTM baselines. Unfortunately, I didn’t find any other papers/studies that focused solely on early notes, which could’ve been a nice additional comparison point. Nevertheless, the table below shows that the outperformance can be “up to” the following:
337 |
338 | *I’d like to emphasize that this only gives the upper bound on the delta of the metrics. The green arrows just indicates that ClinicalBERT has improved performance compared to Bag of Words and BILSTM in all of these metrics for both the 2-days and 3-day results.*
339 |
340 | Since we balanced the data I’ll focus on reporting the AUROC curve as the most appropriate metric instead of the AUPRC.
341 |
342 | I’ll also focus on reporting the Recall at 80% Precision metric due to the fact that it is clinically relevant (remember that alarm fatigue is a real problem in healthcare that we are intentionally trying to avoid/reduce).
343 |
344 | ClinicalBERT has more confidence compared to the other models. And at a fixed rate of false alarms, ClinicalBert recalls more patients that have been readmitted.
345 |
346 | ### 2days compared to other models:
347 |
348 | * **Up to 9.5% AUROC** compared to Bag-of-Words and **up to** **6.5% AUROC** when compared to BILSTM.
349 |
350 | * **Up to** **20.7% RP80** compared to Bag-of-words and **up to** **19.4% RP80** when compared to BILSTM.
351 |
352 | ### **3days compared to other models:**
353 |
354 | * **Up to 9.8% AUROC** compared to Bag-of-Words and **up to** **9.6% AUROC** when compared to BILSTM.
355 |
356 | * **Up to** **26.2% RP80** compared to Bag-of-words and **up to** **20.9% RP80** when compared to BILSTM.
357 |
358 | ## Self-Attention Maps — Visualizing the Results
359 |
360 | ***The code I used for creating the self-attention map in this section is [here](https://github.com/nwams/ClinicalBERT-Deep-Learning--Predicting-Hospital-Readmission-Using-Transformer/blob/master/attention/attention_visualization.ipynb).***
361 |
362 | It’s very difficult for a human to understand why a neural network made a certain prediction, and what parts of the input data did the model find most informative. Therefore Doctors may not trust output from a data-driven method.
363 |
364 | Well, visualizing the self-attention mechanism is a way to solve that problem because it allows you to see the terms correlated with predictions of hospital readmission.
365 |
366 | You might already be familiar with the popular “[Attention is All You Need](https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf)” paper that was submitted at the 2017 arXiv by the Google machine translation team. If not, check out this [animation](https://towardsdatascience.com/attn-illustrated-attention-5ec4ad276ee3) that explains attention. More intuitively, we can think **“self-attention”** as the sentence will **look at itself to determine how to represent each token.**
367 | > As the model processes each word (each position in the input sequence), self attention allows it to look at other positions in the input sequence for clues that can help lead to a better encoding for this word.
368 |
369 | — [The Illustrated Transformer](http://jalammar.github.io/illustrated-transformer/) by Jay Alammar
370 |
371 | For every clinical note input to ClinicalBert, each self-attention mechanism computes a distribution over every term in a sentence, given a query. The **self-attention equation** is:
372 |
373 | 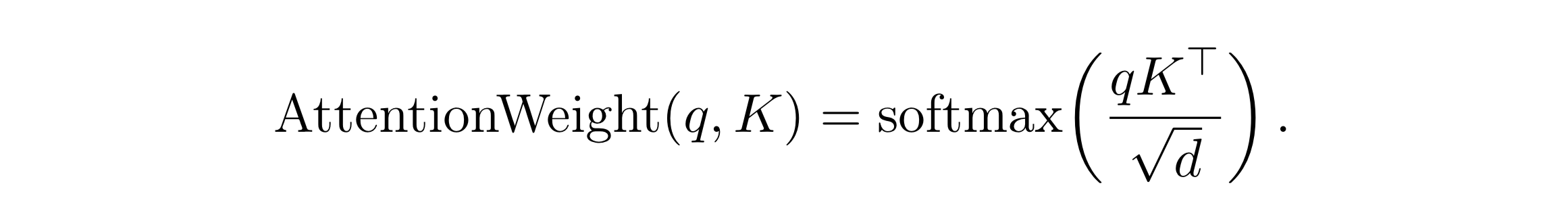*Where q is query vector, K is the key vector, d is the dimensionality of the queries and keys.*
374 |
375 | Intuitively, we can think of it like this: the query, q, represents what kind of information we are looking for, and the key, K, represent the relevance to the query.
376 |
377 | A high attention weight between a query and key token means the interaction between these tokens is predictive of readmission. In the ClinicalBert encoder, there are 144 heads (which is 12 multi-head attention mechanisms for each of the 12 encoder layers). There will be diversity in the different heads, which is what we should expect because different heads learn [different relations](https://docs.dgl.ai/en/latest/tutorials/models/4_old_wines/7_transformer.html) between word pairs. Although each head receives the same input embedding, through random initialization, each learns different focuses [[img](https://www.researchgate.net/publication/328627493_Parallel_Attention_Mechanisms_in_Neural_Machine_Translation/figures?lo=1)].
378 |
379 | The self-attention map below is just one of the self-attention heads in ClinicalBERT — it reveals which terms in clinical notes are predictive of patient readmission. The sentence he has experienced acute on chronic diastolic heart failure in the setting of volume overload due to his sepsis . is used as input that is fed into the model. This sentence is **representative** of a clinical note found in MIMIC-III. The SelfAttention equation is used to compute a distribution over tokens in this sentence, where every query token, q, is also a token in the same input sentence.
380 |
381 | *ClinicalBERT Self-Attention Map. The darker colors stand for greater weights.*
382 |
383 | Notice that the self-attention map shows a higher attention weight between the the word chronic and acute…or chronic and ###load .
384 |
385 | Intuitively, the presence of the token associated with the word “chronic” is a predictor of readmission.
386 |
387 | Remember though, there are 12 heads at each layer (144 total heads for this model). And each head is looking at different things. So looking at each head’s attention graph separately will give you an understanding of **how** the model makes predictions — but it won’t make it super easy to interpret the entire system as a “one-stop shop”. Instead, you could do some aggregation (summing up or averaging all the attention head’s weights).
388 |
389 | So if you’re a clinician looking for a “one-stop shop” understanding of the help with interpretation [exBERT](http://exbert.net/) is an interactive software tool that provides insights into the meaning of the contextual representations by matching a human-specified input to similar contexts in a large annotated dataset. By aggregating the annotations of the matching similar contexts, exBERT helps intuitively explain what each attention-head has learned [[Paper](https://arxiv.org/pdf/1910.05276.pdf)]. Although this was created for BERT, this type of tool could also be adapted to ClinicalBERT as well!
390 | > *As an aside, if you’re interested in learning more about the heads, and self-attention weights as it pertains to several BERT NLP tasks, I highly, highly, recommend this academic paper, [Revealing the Dark Secrets of BERT](https://arxiv.org/pdf/1908.08593.pdf) — it does a great job at dissecting and investigating the self-attention mechanism behind BERT-based architectures.*
391 |
392 | ## References
393 |
394 | @article{clinicalbert,
395 | author = {Kexin Huang and Jaan Altosaar and Rajesh Ranganath},
396 | title = {ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission},
397 | year = {2019},
398 | journal = {arXiv:1904.05342},
399 | }
400 |
401 | MIMIC-III, a freely accessible critical care database. Johnson AEW, Pollard TJ, Shen L, Lehman L, Feng M, Ghassemi M, Moody B, Szolovits P, Celi LA, and Mark RG. Scientific Data (2016). DOI: 10.1038/sdata.2016.35. Available at: [http://www.nature.com/articles/sdata201635](http://www.nature.com/articles/sdata201635)
402 |
--------------------------------------------------------------------------------
/file_utils.py:
--------------------------------------------------------------------------------
1 | """
2 | Utilities for working with the local dataset cache.
3 | This file is adapted from the AllenNLP library at https://github.com/allenai/allennlp
4 | Copyright by the AllenNLP authors.
5 | """
6 | from __future__ import (absolute_import, division, print_function, unicode_literals)
7 |
8 | import json
9 | import logging
10 | import os
11 | import shutil
12 | import tempfile
13 | from functools import wraps
14 | from hashlib import sha256
15 | import sys
16 | from io import open
17 |
18 | import boto3
19 | import requests
20 | from botocore.exceptions import ClientError
21 | from tqdm import tqdm
22 |
23 | try:
24 | from urllib.parse import urlparse
25 | except ImportError:
26 | from urlparse import urlparse
27 |
28 | try:
29 | from pathlib import Path
30 | PYTORCH_PRETRAINED_BERT_CACHE = Path(os.getenv('PYTORCH_PRETRAINED_BERT_CACHE',
31 | Path.home() / '.pytorch_pretrained_bert'))
32 | except (AttributeError, ImportError):
33 | PYTORCH_PRETRAINED_BERT_CACHE = os.getenv('PYTORCH_PRETRAINED_BERT_CACHE',
34 | os.path.join(os.path.expanduser("~"), '.pytorch_pretrained_bert'))
35 |
36 | logger = logging.getLogger(__name__) # pylint: disable=invalid-name
37 |
38 |
39 | def url_to_filename(url, etag=None):
40 | """
41 | Convert `url` into a hashed filename in a repeatable way.
42 | If `etag` is specified, append its hash to the url's, delimited
43 | by a period.
44 | """
45 | url_bytes = url.encode('utf-8')
46 | url_hash = sha256(url_bytes)
47 | filename = url_hash.hexdigest()
48 |
49 | if etag:
50 | etag_bytes = etag.encode('utf-8')
51 | etag_hash = sha256(etag_bytes)
52 | filename += '.' + etag_hash.hexdigest()
53 |
54 | return filename
55 |
56 |
57 | def filename_to_url(filename, cache_dir=None):
58 | """
59 | Return the url and etag (which may be ``None``) stored for `filename`.
60 | Raise ``EnvironmentError`` if `filename` or its stored metadata do not exist.
61 | """
62 | if cache_dir is None:
63 | cache_dir = PYTORCH_PRETRAINED_BERT_CACHE
64 | if sys.version_info[0] == 3 and isinstance(cache_dir, Path):
65 | cache_dir = str(cache_dir)
66 |
67 | cache_path = os.path.join(cache_dir, filename)
68 | if not os.path.exists(cache_path):
69 | raise EnvironmentError("file {} not found".format(cache_path))
70 |
71 | meta_path = cache_path + '.json'
72 | if not os.path.exists(meta_path):
73 | raise EnvironmentError("file {} not found".format(meta_path))
74 |
75 | with open(meta_path, encoding="utf-8") as meta_file:
76 | metadata = json.load(meta_file)
77 | url = metadata['url']
78 | etag = metadata['etag']
79 |
80 | return url, etag
81 |
82 |
83 | def cached_path(url_or_filename, cache_dir=None):
84 | """
85 | Given something that might be a URL (or might be a local path),
86 | determine which. If it's a URL, download the file and cache it, and
87 | return the path to the cached file. If it's already a local path,
88 | make sure the file exists and then return the path.
89 | """
90 | if cache_dir is None:
91 | cache_dir = PYTORCH_PRETRAINED_BERT_CACHE
92 | if sys.version_info[0] == 3 and isinstance(url_or_filename, Path):
93 | url_or_filename = str(url_or_filename)
94 | if sys.version_info[0] == 3 and isinstance(cache_dir, Path):
95 | cache_dir = str(cache_dir)
96 |
97 | parsed = urlparse(url_or_filename)
98 |
99 | if parsed.scheme in ('http', 'https', 's3'):
100 | # URL, so get it from the cache (downloading if necessary)
101 | return get_from_cache(url_or_filename, cache_dir)
102 | elif os.path.exists(url_or_filename):
103 | # File, and it exists.
104 | return url_or_filename
105 | elif parsed.scheme == '':
106 | # File, but it doesn't exist.
107 | raise EnvironmentError("file {} not found".format(url_or_filename))
108 | else:
109 | # Something unknown
110 | raise ValueError("unable to parse {} as a URL or as a local path".format(url_or_filename))
111 |
112 |
113 | def split_s3_path(url):
114 | """Split a full s3 path into the bucket name and path."""
115 | parsed = urlparse(url)
116 | if not parsed.netloc or not parsed.path:
117 | raise ValueError("bad s3 path {}".format(url))
118 | bucket_name = parsed.netloc
119 | s3_path = parsed.path
120 | # Remove '/' at beginning of path.
121 | if s3_path.startswith("/"):
122 | s3_path = s3_path[1:]
123 | return bucket_name, s3_path
124 |
125 |
126 | def s3_request(func):
127 | """
128 | Wrapper function for s3 requests in order to create more helpful error
129 | messages.
130 | """
131 |
132 | @wraps(func)
133 | def wrapper(url, *args, **kwargs):
134 | try:
135 | return func(url, *args, **kwargs)
136 | except ClientError as exc:
137 | if int(exc.response["Error"]["Code"]) == 404:
138 | raise EnvironmentError("file {} not found".format(url))
139 | else:
140 | raise
141 |
142 | return wrapper
143 |
144 |
145 | @s3_request
146 | def s3_etag(url):
147 | """Check ETag on S3 object."""
148 | s3_resource = boto3.resource("s3")
149 | bucket_name, s3_path = split_s3_path(url)
150 | s3_object = s3_resource.Object(bucket_name, s3_path)
151 | return s3_object.e_tag
152 |
153 |
154 | @s3_request
155 | def s3_get(url, temp_file):
156 | """Pull a file directly from S3."""
157 | s3_resource = boto3.resource("s3")
158 | bucket_name, s3_path = split_s3_path(url)
159 | s3_resource.Bucket(bucket_name).download_fileobj(s3_path, temp_file)
160 |
161 |
162 | def http_get(url, temp_file):
163 | req = requests.get(url, stream=True)
164 | content_length = req.headers.get('Content-Length')
165 | total = int(content_length) if content_length is not None else None
166 | progress = tqdm(unit="B", total=total)
167 | for chunk in req.iter_content(chunk_size=1024):
168 | if chunk: # filter out keep-alive new chunks
169 | progress.update(len(chunk))
170 | temp_file.write(chunk)
171 | progress.close()
172 |
173 |
174 | def get_from_cache(url, cache_dir=None):
175 | """
176 | Given a URL, look for the corresponding dataset in the local cache.
177 | If it's not there, download it. Then return the path to the cached file.
178 | """
179 | if cache_dir is None:
180 | cache_dir = PYTORCH_PRETRAINED_BERT_CACHE
181 | if sys.version_info[0] == 3 and isinstance(cache_dir, Path):
182 | cache_dir = str(cache_dir)
183 |
184 | if not os.path.exists(cache_dir):
185 | os.makedirs(cache_dir)
186 |
187 | # Get eTag to add to filename, if it exists.
188 | if url.startswith("s3://"):
189 | etag = s3_etag(url)
190 | else:
191 | response = requests.head(url, allow_redirects=True)
192 | if response.status_code != 200:
193 | raise IOError("HEAD request failed for url {} with status code {}"
194 | .format(url, response.status_code))
195 | etag = response.headers.get("ETag")
196 |
197 | filename = url_to_filename(url, etag)
198 |
199 | # get cache path to put the file
200 | cache_path = os.path.join(cache_dir, filename)
201 |
202 | if not os.path.exists(cache_path):
203 | # Download to temporary file, then copy to cache dir once finished.
204 | # Otherwise you get corrupt cache entries if the download gets interrupted.
205 | with tempfile.NamedTemporaryFile() as temp_file:
206 | logger.info("%s not found in cache, downloading to %s", url, temp_file.name)
207 |
208 | # GET file object
209 | if url.startswith("s3://"):
210 | s3_get(url, temp_file)
211 | else:
212 | http_get(url, temp_file)
213 |
214 | # we are copying the file before closing it, so flush to avoid truncation
215 | temp_file.flush()
216 | # shutil.copyfileobj() starts at the current position, so go to the start
217 | temp_file.seek(0)
218 |
219 | logger.info("copying %s to cache at %s", temp_file.name, cache_path)
220 | with open(cache_path, 'wb') as cache_file:
221 | shutil.copyfileobj(temp_file, cache_file)
222 |
223 | logger.info("creating metadata file for %s", cache_path)
224 | meta = {'url': url, 'etag': etag}
225 | meta_path = cache_path + '.json'
226 | with open(meta_path, 'w', encoding="utf-8") as meta_file:
227 | json.dump(meta, meta_file)
228 |
229 | logger.info("removing temp file %s", temp_file.name)
230 |
231 | return cache_path
232 |
233 |
234 | def read_set_from_file(filename):
235 | '''
236 | Extract a de-duped collection (set) of text from a file.
237 | Expected file format is one item per line.
238 | '''
239 | collection = set()
240 | with open(filename, 'r', encoding='utf-8') as file_:
241 | for line in file_:
242 | collection.add(line.rstrip())
243 | return collection
244 |
245 |
246 | def get_file_extension(path, dot=True, lower=True):
247 | ext = os.path.splitext(path)[1]
248 | ext = ext if dot else ext[1:]
249 | return ext.lower() if lower else ext
--------------------------------------------------------------------------------
/images/equ3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nwams/ClinicalBERT-Deep-Learning--Predicting-Hospital-Readmission-Using-Transformer/7c2e2b5859e8eea825c97c2d2677479786fbdd1d/images/equ3.png
--------------------------------------------------------------------------------
/images/fig1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nwams/ClinicalBERT-Deep-Learning--Predicting-Hospital-Readmission-Using-Transformer/7c2e2b5859e8eea825c97c2d2677479786fbdd1d/images/fig1.png
--------------------------------------------------------------------------------
/images/fig2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nwams/ClinicalBERT-Deep-Learning--Predicting-Hospital-Readmission-Using-Transformer/7c2e2b5859e8eea825c97c2d2677479786fbdd1d/images/fig2.png
--------------------------------------------------------------------------------
/images/tab3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/nwams/ClinicalBERT-Deep-Learning--Predicting-Hospital-Readmission-Using-Transformer/7c2e2b5859e8eea825c97c2d2677479786fbdd1d/images/tab3.png
--------------------------------------------------------------------------------
/modeling_readmission.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | # Copyright 2018 The Google AI Language Team Authors and The HugginFace Inc. team.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 | """PyTorch BERT model."""
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 |
21 | import os
22 | import copy
23 | import json
24 | import math
25 | import logging
26 | import tarfile
27 | import tempfile
28 | import shutil
29 |
30 | import torch
31 | from torch import nn
32 | from torch.nn import CrossEntropyLoss, BCELoss
33 |
34 | from file_utils import cached_path
35 |
36 | print('in the modeling class')
37 |
38 | logging.basicConfig(format = '%(asctime)s - %(levelname)s - %(name)s - %(message)s',
39 | datefmt = '%m/%d/%Y %H:%M:%S',
40 | level = logging.INFO)
41 | logger = logging.getLogger(__name__)
42 |
43 | PRETRAINED_MODEL_ARCHIVE_MAP = {
44 | 'bert-base-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased.tar.gz",
45 | 'bert-large-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased.tar.gz",
46 | 'bert-base-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased.tar.gz",
47 | 'bert-base-multilingual': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual.tar.gz",
48 | 'bert-base-chinese': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese.tar.gz",
49 | }
50 | CONFIG_NAME = 'bert_config.json'
51 | WEIGHTS_NAME = 'pytorch_model.bin'
52 |
53 | def gelu(x):
54 | """Implementation of the gelu activation function.
55 | For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
56 | 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
57 | """
58 | return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
59 |
60 |
61 | def swish(x):
62 | return x * torch.sigmoid(x)
63 |
64 |
65 | ACT2FN = {"gelu": gelu, "relu": torch.nn.functional.relu, "swish": swish}
66 |
67 |
68 | class BertConfig(object):
69 | """Configuration class to store the configuration of a `BertModel`.
70 | """
71 | def __init__(self,
72 | vocab_size_or_config_json_file,
73 | hidden_size=768,
74 | num_hidden_layers=12,
75 | num_attention_heads=12,
76 | intermediate_size=3072,
77 | hidden_act="gelu",
78 | hidden_dropout_prob=0.1,
79 | attention_probs_dropout_prob=0.1,
80 | max_position_embeddings=512,
81 | type_vocab_size=2,
82 | initializer_range=0.02):
83 | """Constructs BertConfig.
84 |
85 | Args:
86 | vocab_size_or_config_json_file: Vocabulary size of `inputs_ids` in `BertModel`.
87 | hidden_size: Size of the encoder layers and the pooler layer.
88 | num_hidden_layers: Number of hidden layers in the Transformer encoder.
89 | num_attention_heads: Number of attention heads for each attention layer in
90 | the Transformer encoder.
91 | intermediate_size: The size of the "intermediate" (i.e., feed-forward)
92 | layer in the Transformer encoder.
93 | hidden_act: The non-linear activation function (function or string) in the
94 | encoder and pooler. If string, "gelu", "relu" and "swish" are supported.
95 | hidden_dropout_prob: The dropout probabilitiy for all fully connected
96 | layers in the embeddings, encoder, and pooler.
97 | attention_probs_dropout_prob: The dropout ratio for the attention
98 | probabilities.
99 | max_position_embeddings: The maximum sequence length that this model might
100 | ever be used with. Typically set this to something large just in case
101 | (e.g., 512 or 1024 or 2048).
102 | type_vocab_size: The vocabulary size of the `token_type_ids` passed into
103 | `BertModel`.
104 | initializer_range: The sttdev of the truncated_normal_initializer for
105 | initializing all weight matrices.
106 | """
107 | if isinstance(vocab_size_or_config_json_file, str):
108 | with open(vocab_size_or_config_json_file, "r") as reader:
109 | json_config = json.loads(reader.read())
110 | for key, value in json_config.items():
111 | self.__dict__[key] = value
112 | elif isinstance(vocab_size_or_config_json_file, int):
113 | self.vocab_size = vocab_size_or_config_json_file
114 | self.hidden_size = hidden_size
115 | self.num_hidden_layers = num_hidden_layers
116 | self.num_attention_heads = num_attention_heads
117 | self.hidden_act = hidden_act
118 | self.intermediate_size = intermediate_size
119 | self.hidden_dropout_prob = hidden_dropout_prob
120 | self.attention_probs_dropout_prob = attention_probs_dropout_prob
121 | self.max_position_embeddings = max_position_embeddings
122 | self.type_vocab_size = type_vocab_size
123 | self.initializer_range = initializer_range
124 | else:
125 | raise ValueError("First argument must be either a vocabulary size (int)"
126 | "or the path to a pretrained model config file (str)")
127 |
128 | @classmethod
129 | def from_dict(cls, json_object):
130 | """Constructs a `BertConfig` from a Python dictionary of parameters."""
131 | config = BertConfig(vocab_size_or_config_json_file=-1)
132 | for key, value in json_object.items():
133 | config.__dict__[key] = value
134 | return config
135 |
136 | @classmethod
137 | def from_json_file(cls, json_file):
138 | """Constructs a `BertConfig` from a json file of parameters."""
139 | with open(json_file, "r") as reader:
140 | text = reader.read()
141 | return cls.from_dict(json.loads(text))
142 |
143 | def __repr__(self):
144 | return str(self.to_json_string())
145 |
146 | def to_dict(self):
147 | """Serializes this instance to a Python dictionary."""
148 | output = copy.deepcopy(self.__dict__)
149 | return output
150 |
151 | def to_json_string(self):
152 | """Serializes this instance to a JSON string."""
153 | return json.dumps(self.to_dict(), indent=2, sort_keys=True) + "\n"
154 |
155 |
156 | class BertLayerNorm(nn.Module):
157 | def __init__(self, config, variance_epsilon=1e-12):
158 | """Construct a layernorm module in the TF style (epsilon inside the square root).
159 | """
160 | super(BertLayerNorm, self).__init__()
161 | self.gamma = nn.Parameter(torch.ones(config.hidden_size))
162 | self.beta = nn.Parameter(torch.zeros(config.hidden_size))
163 | self.variance_epsilon = variance_epsilon
164 |
165 | def forward(self, x):
166 | u = x.mean(-1, keepdim=True)
167 | s = (x - u).pow(2).mean(-1, keepdim=True)
168 | x = (x - u) / torch.sqrt(s + self.variance_epsilon)
169 | return self.gamma * x + self.beta
170 |
171 |
172 | class BertEmbeddings(nn.Module):
173 | """Construct the embeddings from word, position and token_type embeddings.
174 | """
175 | def __init__(self, config):
176 | super(BertEmbeddings, self).__init__()
177 | self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size)
178 | self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
179 | self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
180 |
181 | # self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
182 | # any TensorFlow checkpoint file
183 | self.LayerNorm = BertLayerNorm(config)
184 | self.dropout = nn.Dropout(config.hidden_dropout_prob)
185 |
186 | def forward(self, input_ids, token_type_ids=None):
187 | seq_length = input_ids.size(1)
188 | position_ids = torch.arange(seq_length, dtype=torch.long, device=input_ids.device)
189 | position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
190 | if token_type_ids is None:
191 | token_type_ids = torch.zeros_like(input_ids)
192 |
193 | words_embeddings = self.word_embeddings(input_ids)
194 | position_embeddings = self.position_embeddings(position_ids)
195 | token_type_embeddings = self.token_type_embeddings(token_type_ids)
196 |
197 | embeddings = words_embeddings + position_embeddings + token_type_embeddings
198 | embeddings = self.LayerNorm(embeddings)
199 | embeddings = self.dropout(embeddings)
200 | return embeddings
201 |
202 |
203 | class BertSelfAttention(nn.Module):
204 | def __init__(self, config):
205 | super(BertSelfAttention, self).__init__()
206 | if config.hidden_size % config.num_attention_heads != 0:
207 | raise ValueError(
208 | "The hidden size (%d) is not a multiple of the number of attention "
209 | "heads (%d)" % (config.hidden_size, config.num_attention_heads))
210 | self.num_attention_heads = config.num_attention_heads
211 | self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
212 | self.all_head_size = self.num_attention_heads * self.attention_head_size
213 |
214 | self.query = nn.Linear(config.hidden_size, self.all_head_size)
215 | self.key = nn.Linear(config.hidden_size, self.all_head_size)
216 | self.value = nn.Linear(config.hidden_size, self.all_head_size)
217 |
218 | self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
219 |
220 | def transpose_for_scores(self, x):
221 | new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
222 | x = x.view(*new_x_shape)
223 | return x.permute(0, 2, 1, 3)
224 |
225 | def forward(self, hidden_states, attention_mask):
226 | mixed_query_layer = self.query(hidden_states)
227 | mixed_key_layer = self.key(hidden_states)
228 | mixed_value_layer = self.value(hidden_states)
229 |
230 | query_layer = self.transpose_for_scores(mixed_query_layer)
231 | key_layer = self.transpose_for_scores(mixed_key_layer)
232 | value_layer = self.transpose_for_scores(mixed_value_layer)
233 |
234 | # Take the dot product between "query" and "key" to get the raw attention scores.
235 | attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
236 | attention_scores = attention_scores / math.sqrt(self.attention_head_size)
237 | # Apply the attention mask is (precomputed for all layers in BertModel forward() function)
238 | attention_scores = attention_scores + attention_mask
239 |
240 | # Normalize the attention scores to probabilities.
241 | attention_probs = nn.Softmax(dim=-1)(attention_scores)
242 |
243 | # This is actually dropping out entire tokens to attend to, which might
244 | # seem a bit unusual, but is taken from the original Transformer paper.
245 | attention_probs = self.dropout(attention_probs)
246 |
247 | context_layer = torch.matmul(attention_probs, value_layer)
248 | context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
249 | new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
250 | context_layer = context_layer.view(*new_context_layer_shape)
251 | return context_layer
252 |
253 |
254 | class BertSelfOutput(nn.Module):
255 | def __init__(self, config):
256 | super(BertSelfOutput, self).__init__()
257 | self.dense = nn.Linear(config.hidden_size, config.hidden_size)
258 | self.LayerNorm = BertLayerNorm(config)
259 | self.dropout = nn.Dropout(config.hidden_dropout_prob)
260 |
261 | def forward(self, hidden_states, input_tensor):
262 | hidden_states = self.dense(hidden_states)
263 | hidden_states = self.dropout(hidden_states)
264 | hidden_states = self.LayerNorm(hidden_states + input_tensor)
265 | return hidden_states
266 |
267 |
268 | class BertAttention(nn.Module):
269 | def __init__(self, config):
270 | super(BertAttention, self).__init__()
271 | self.self = BertSelfAttention(config)
272 | self.output = BertSelfOutput(config)
273 |
274 | def forward(self, input_tensor, attention_mask):
275 | self_output = self.self(input_tensor, attention_mask)
276 | attention_output = self.output(self_output, input_tensor)
277 | return attention_output
278 |
279 |
280 | class BertIntermediate(nn.Module):
281 | def __init__(self, config):
282 | super(BertIntermediate, self).__init__()
283 | self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
284 | self.intermediate_act_fn = ACT2FN[config.hidden_act] \
285 | if isinstance(config.hidden_act, str) else config.hidden_act
286 |
287 | def forward(self, hidden_states):
288 | hidden_states = self.dense(hidden_states)
289 | hidden_states = self.intermediate_act_fn(hidden_states)
290 | return hidden_states
291 |
292 |
293 | class BertOutput(nn.Module):
294 | def __init__(self, config):
295 | super(BertOutput, self).__init__()
296 | self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
297 | self.LayerNorm = BertLayerNorm(config)
298 | self.dropout = nn.Dropout(config.hidden_dropout_prob)
299 |
300 | def forward(self, hidden_states, input_tensor):
301 | hidden_states = self.dense(hidden_states)
302 | hidden_states = self.dropout(hidden_states)
303 | hidden_states = self.LayerNorm(hidden_states + input_tensor)
304 | return hidden_states
305 |
306 |
307 | class BertLayer(nn.Module):
308 | def __init__(self, config):
309 | super(BertLayer, self).__init__()
310 | self.attention = BertAttention(config)
311 | self.intermediate = BertIntermediate(config)
312 | self.output = BertOutput(config)
313 |
314 | def forward(self, hidden_states, attention_mask):
315 | attention_output = self.attention(hidden_states, attention_mask)
316 | intermediate_output = self.intermediate(attention_output)
317 | layer_output = self.output(intermediate_output, attention_output)
318 | return layer_output
319 |
320 |
321 | class BertEncoder(nn.Module):
322 | def __init__(self, config):
323 | super(BertEncoder, self).__init__()
324 | layer = BertLayer(config)
325 | self.layer = nn.ModuleList([copy.deepcopy(layer) for _ in range(config.num_hidden_layers)])
326 |
327 | def forward(self, hidden_states, attention_mask, output_all_encoded_layers=True):
328 | all_encoder_layers = []
329 | for layer_module in self.layer:
330 | hidden_states = layer_module(hidden_states, attention_mask)
331 | if output_all_encoded_layers:
332 | all_encoder_layers.append(hidden_states)
333 | if not output_all_encoded_layers:
334 | all_encoder_layers.append(hidden_states)
335 | return all_encoder_layers
336 |
337 |
338 | class BertPooler(nn.Module):
339 | def __init__(self, config):
340 | super(BertPooler, self).__init__()
341 | self.dense = nn.Linear(config.hidden_size, config.hidden_size)
342 | self.activation = nn.Tanh()
343 |
344 | def forward(self, hidden_states):
345 | # We "pool" the model by simply taking the hidden state corresponding
346 | # to the first token.
347 | first_token_tensor = hidden_states[:, 0]
348 | pooled_output = self.dense(first_token_tensor)
349 | pooled_output = self.activation(pooled_output)
350 | return pooled_output
351 |
352 |
353 | class BertPredictionHeadTransform(nn.Module):
354 | def __init__(self, config):
355 | super(BertPredictionHeadTransform, self).__init__()
356 | self.dense = nn.Linear(config.hidden_size, config.hidden_size)
357 | self.transform_act_fn = ACT2FN[config.hidden_act] \
358 | if isinstance(config.hidden_act, str) else config.hidden_act
359 | self.LayerNorm = BertLayerNorm(config)
360 |
361 | def forward(self, hidden_states):
362 | hidden_states = self.dense(hidden_states)
363 | hidden_states = self.transform_act_fn(hidden_states)
364 | hidden_states = self.LayerNorm(hidden_states)
365 | return hidden_states
366 |
367 |
368 | class BertLMPredictionHead(nn.Module):
369 | def __init__(self, config, bert_model_embedding_weights):
370 | super(BertLMPredictionHead, self).__init__()
371 | self.transform = BertPredictionHeadTransform(config)
372 |
373 | # The output weights are the same as the input embeddings, but there is
374 | # an output-only bias for each token.
375 | self.decoder = nn.Linear(bert_model_embedding_weights.size(1),
376 | bert_model_embedding_weights.size(0),
377 | bias=False)
378 | self.decoder.weight = bert_model_embedding_weights
379 | self.bias = nn.Parameter(torch.zeros(bert_model_embedding_weights.size(0)))
380 |
381 | def forward(self, hidden_states):
382 | hidden_states = self.transform(hidden_states)
383 | hidden_states = self.decoder(hidden_states) + self.bias
384 | return hidden_states
385 |
386 |
387 | class BertOnlyMLMHead(nn.Module):
388 | def __init__(self, config, bert_model_embedding_weights):
389 | super(BertOnlyMLMHead, self).__init__()
390 | self.predictions = BertLMPredictionHead(config, bert_model_embedding_weights)
391 |
392 | def forward(self, sequence_output):
393 | prediction_scores = self.predictions(sequence_output)
394 | return prediction_scores
395 |
396 |
397 | class BertOnlyNSPHead(nn.Module):
398 | def __init__(self, config):
399 | super(BertOnlyNSPHead, self).__init__()
400 | self.seq_relationship = nn.Linear(config.hidden_size, 2)
401 |
402 | def forward(self, pooled_output):
403 | seq_relationship_score = self.seq_relationship(pooled_output)
404 | return seq_relationship_score
405 |
406 |
407 | class BertPreTrainingHeads(nn.Module):
408 | def __init__(self, config, bert_model_embedding_weights):
409 | super(BertPreTrainingHeads, self).__init__()
410 | self.predictions = BertLMPredictionHead(config, bert_model_embedding_weights)
411 | self.seq_relationship = nn.Linear(config.hidden_size, 2)
412 |
413 | def forward(self, sequence_output, pooled_output):
414 | prediction_scores = self.predictions(sequence_output)
415 | seq_relationship_score = self.seq_relationship(pooled_output)
416 | return prediction_scores, seq_relationship_score
417 |
418 |
419 | class PreTrainedBertModel(nn.Module):
420 | """ An abstract class to handle weights initialization and
421 | a simple interface for dowloading and loading pretrained models.
422 | """
423 | def __init__(self, config, *inputs, **kwargs):
424 | super(PreTrainedBertModel, self).__init__()
425 | if not isinstance(config, BertConfig):
426 | raise ValueError(
427 | "Parameter config in `{}(config)` should be an instance of class `BertConfig`. "
428 | "To create a model from a Google pretrained model use "
429 | "`model = {}.from_pretrained(PRETRAINED_MODEL_NAME)`".format(
430 | self.__class__.__name__, self.__class__.__name__
431 | ))
432 | self.config = config
433 |
434 | def init_bert_weights(self, module):
435 | """ Initialize the weights.
436 | """
437 | if isinstance(module, (nn.Linear, nn.Embedding)):
438 | # Slightly different from the TF version which uses truncated_normal for initialization
439 | # cf https://github.com/pytorch/pytorch/pull/5617
440 | module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
441 | elif isinstance(module, BertLayerNorm):
442 | module.beta.data.normal_(mean=0.0, std=self.config.initializer_range)
443 | module.gamma.data.normal_(mean=0.0, std=self.config.initializer_range)
444 | if isinstance(module, nn.Linear) and module.bias is not None:
445 | module.bias.data.zero_()
446 |
447 | @classmethod
448 | def from_pretrained(cls, pretrained_model_name, *inputs, **kwargs):
449 | """
450 | Instantiate a PreTrainedBertModel from a pre-trained model file.
451 | Download and cache the pre-trained model file if needed.
452 |
453 | Params:
454 | pretrained_model_name: either:
455 | - a str with the name of a pre-trained model to load selected in the list of:
456 | . `bert-base-uncased`
457 | . `bert-large-uncased`
458 | . `bert-base-cased`
459 | . `bert-base-multilingual`
460 | . `bert-base-chinese`
461 | - a path or url to a pretrained model archive containing:
462 | . `bert_config.json` a configuration file for the model
463 | . `pytorch_model.bin` a PyTorch dump of a BertForPreTraining instance
464 | *inputs, **kwargs: additional input for the specific Bert class
465 | (ex: num_labels for BertForSequenceClassification)
466 | """
467 | if pretrained_model_name in PRETRAINED_MODEL_ARCHIVE_MAP:
468 | archive_file = PRETRAINED_MODEL_ARCHIVE_MAP[pretrained_model_name]
469 | else:
470 | archive_file = pretrained_model_name
471 | # redirect to the cache, if necessary
472 | try:
473 | resolved_archive_file = cached_path(archive_file)
474 | except FileNotFoundError:
475 | logger.error(
476 | "Model name '{}' was not found in model name list ({}). "
477 | "We assumed '{}' was a path or url but couldn't find any file "
478 | "associated to this path or url.".format(
479 | pretrained_model_name,
480 | ', '.join(PRETRAINED_MODEL_ARCHIVE_MAP.keys()),
481 | pretrained_model_name))
482 | return None
483 | if resolved_archive_file == archive_file:
484 | logger.info("loading archive file {}".format(archive_file))
485 | else:
486 | logger.info("loading archive file {} from cache at {}".format(
487 | archive_file, resolved_archive_file))
488 | tempdir = None
489 | if os.path.isdir(resolved_archive_file):
490 | serialization_dir = resolved_archive_file
491 | else:
492 | # Extract archive to temp dir
493 | tempdir = tempfile.mkdtemp()
494 | logger.info("extracting archive file {} to temp dir {}".format(
495 | resolved_archive_file, tempdir))
496 | with tarfile.open(resolved_archive_file, 'r:gz') as archive:
497 | archive.extractall(tempdir)
498 | serialization_dir = tempdir
499 | # Load config
500 | config_file = os.path.join(serialization_dir, CONFIG_NAME)
501 | config = BertConfig.from_json_file(config_file)
502 | logger.info("Model config {}".format(config))
503 | # Instantiate model.
504 | model = cls(config, *inputs, **kwargs)
505 | weights_path = os.path.join(serialization_dir, WEIGHTS_NAME)
506 | state_dict = torch.load(weights_path, map_location = 'cpu')
507 |
508 | missing_keys = []
509 | unexpected_keys = []
510 | error_msgs = []
511 | # copy state_dict so _load_from_state_dict can modify it
512 | metadata = getattr(state_dict, '_metadata', None)
513 | state_dict = state_dict.copy()
514 | if metadata is not None:
515 | state_dict._metadata = metadata
516 |
517 | def load(module, prefix=''):
518 | local_metadata = {} if metadata is None else metadata.get(prefix[:-1], {})
519 | module._load_from_state_dict(
520 | state_dict, prefix, local_metadata, True, missing_keys, unexpected_keys, error_msgs)
521 | for name, child in module._modules.items():
522 | if child is not None:
523 | load(child, prefix + name + '.')
524 | load(model, prefix='' if hasattr(model, 'bert') else 'bert.')
525 | if len(missing_keys) > 0:
526 | logger.info("Weights of {} not initialized from pretrained model: {}".format(
527 | model.__class__.__name__, missing_keys))
528 | if len(unexpected_keys) > 0:
529 | logger.info("Weights from pretrained model not used in {}: {}".format(
530 | model.__class__.__name__, unexpected_keys))
531 | if tempdir:
532 | # Clean up temp dir
533 | shutil.rmtree(tempdir)
534 | return model
535 |
536 |
537 | class BertModel(PreTrainedBertModel):
538 | """BERT model ("Bidirectional Embedding Representations from a Transformer").
539 |
540 | Params:
541 | config: a BertConfig class instance with the configuration to build a new model
542 |
543 | Inputs:
544 | `input_ids`: a torch.LongTensor of shape [batch_size, sequence_length]
545 | with the word token indices in the vocabulary(see the tokens preprocessing logic in the scripts
546 | `extract_features.py`, `run_classifier.py` and `run_squad.py`)
547 | `token_type_ids`: an optional torch.LongTensor of shape [batch_size, sequence_length] with the token
548 | types indices selected in [0, 1]. Type 0 corresponds to a `sentence A` and type 1 corresponds to
549 | a `sentence B` token (see BERT paper for more details).
550 | `attention_mask`: an optional torch.LongTensor of shape [batch_size, sequence_length] with indices
551 | selected in [0, 1]. It's a mask to be used if the input sequence length is smaller than the max
552 | input sequence length in the current batch. It's the mask that we typically use for attention when
553 | a batch has varying length sentences.
554 | `output_all_encoded_layers`: boolean which controls the content of the `encoded_layers` output as described below. Default: `True`.
555 |
556 | Outputs: Tuple of (encoded_layers, pooled_output)
557 | `encoded_layers`: controled by `output_all_encoded_layers` argument:
558 | - `output_all_encoded_layers=True`: outputs a list of the full sequences of encoded-hidden-states at the end
559 | of each attention block (i.e. 12 full sequences for BERT-base, 24 for BERT-large), each
560 | encoded-hidden-state is a torch.FloatTensor of size [batch_size, sequence_length, hidden_size],
561 | - `output_all_encoded_layers=False`: outputs only the full sequence of hidden-states corresponding
562 | to the last attention block,
563 | `pooled_output`: a torch.FloatTensor of size [batch_size, hidden_size] which is the output of a
564 | classifier pretrained on top of the hidden state associated to the first character of the
565 | input (`CLF`) to train on the Next-Sentence task (see BERT's paper).
566 |
567 | Example usage:
568 | ```python
569 | # Already been converted into WordPiece token ids
570 | input_ids = torch.LongTensor([[31, 51, 99], [15, 5, 0]])
571 | input_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]])
572 | token_type_ids = torch.LongTensor([[0, 0, 1], [0, 2, 0]])
573 |
574 | config = modeling.BertConfig(vocab_size=32000, hidden_size=512,
575 | num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
576 |
577 | model = modeling.BertModel(config=config)
578 | all_encoder_layers, pooled_output = model(input_ids, token_type_ids, input_mask)
579 | ```
580 | """
581 | def __init__(self, config):
582 | super(BertModel, self).__init__(config)
583 | self.embeddings = BertEmbeddings(config)
584 | self.encoder = BertEncoder(config)
585 | self.pooler = BertPooler(config)
586 | self.apply(self.init_bert_weights)
587 |
588 | def forward(self, input_ids, token_type_ids=None, attention_mask=None, output_all_encoded_layers=True):
589 | if attention_mask is None:
590 | attention_mask = torch.ones_like(input_ids)
591 | if token_type_ids is None:
592 | token_type_ids = torch.zeros_like(input_ids)
593 |
594 | # We create a 3D attention mask from a 2D tensor mask.
595 | # Sizes are [batch_size, 1, 1, to_seq_length]
596 | # So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
597 | # this attention mask is more simple than the triangular masking of causal attention
598 | # used in OpenAI GPT, we just need to prepare the broadcast dimension here.
599 | extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
600 |
601 | # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
602 | # masked positions, this operation will create a tensor which is 0.0 for
603 | # positions we want to attend and -10000.0 for masked positions.
604 | # Since we are adding it to the raw scores before the softmax, this is
605 | # effectively the same as removing these entirely.
606 | extended_attention_mask = extended_attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibility
607 | extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
608 |
609 | embedding_output = self.embeddings(input_ids, token_type_ids)
610 | encoded_layers = self.encoder(embedding_output,
611 | extended_attention_mask,
612 | output_all_encoded_layers=output_all_encoded_layers)
613 | sequence_output = encoded_layers[-1]
614 | pooled_output = self.pooler(sequence_output)
615 | if not output_all_encoded_layers:
616 | encoded_layers = encoded_layers[-1]
617 | return encoded_layers, pooled_output
618 |
619 |
620 | class BertForPreTraining(PreTrainedBertModel):
621 | """BERT model with pre-training heads.
622 | This module comprises the BERT model followed by the two pre-training heads:
623 | - the masked language modeling head, and
624 | - the next sentence classification head.
625 |
626 | Params:
627 | config: a BertConfig class instance with the configuration to build a new model.
628 |
629 | Inputs:
630 | `input_ids`: a torch.LongTensor of shape [batch_size, sequence_length]
631 | with the word token indices in the vocabulary(see the tokens preprocessing logic in the scripts
632 | `extract_features.py`, `run_classifier.py` and `run_squad.py`)
633 | `token_type_ids`: an optional torch.LongTensor of shape [batch_size, sequence_length] with the token
634 | types indices selected in [0, 1]. Type 0 corresponds to a `sentence A` and type 1 corresponds to
635 | a `sentence B` token (see BERT paper for more details).
636 | `attention_mask`: an optional torch.LongTensor of shape [batch_size, sequence_length] with indices
637 | selected in [0, 1]. It's a mask to be used if the input sequence length is smaller than the max
638 | input sequence length in the current batch. It's the mask that we typically use for attention when
639 | a batch has varying length sentences.
640 | `masked_lm_labels`: masked language modeling labels: torch.LongTensor of shape [batch_size, sequence_length]
641 | with indices selected in [-1, 0, ..., vocab_size]. All labels set to -1 are ignored (masked), the loss
642 | is only computed for the labels set in [0, ..., vocab_size]
643 | `next_sentence_label`: next sentence classification loss: torch.LongTensor of shape [batch_size]
644 | with indices selected in [0, 1].
645 | 0 => next sentence is the continuation, 1 => next sentence is a random sentence.
646 |
647 | Outputs:
648 | if `masked_lm_labels` and `next_sentence_label` are not `None`:
649 | Outputs the total_loss which is the sum of the masked language modeling loss and the next
650 | sentence classification loss.
651 | if `masked_lm_labels` or `next_sentence_label` is `None`:
652 | Outputs a tuple comprising
653 | - the masked language modeling logits, and
654 | - the next sentence classification logits.
655 |
656 | Example usage:
657 | ```python
658 | # Already been converted into WordPiece token ids
659 | input_ids = torch.LongTensor([[31, 51, 99], [15, 5, 0]])
660 | input_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]])
661 | token_type_ids = torch.LongTensor([[0, 0, 1], [0, 2, 0]])
662 |
663 | config = BertConfig(vocab_size=32000, hidden_size=512,
664 | num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
665 |
666 | model = BertForPreTraining(config)
667 | masked_lm_logits_scores, seq_relationship_logits = model(input_ids, token_type_ids, input_mask)
668 | ```
669 | """
670 | def __init__(self, config):
671 | super(BertForPreTraining, self).__init__(config)
672 | self.bert = BertModel(config)
673 | self.cls = BertPreTrainingHeads(config, self.bert.embeddings.word_embeddings.weight)
674 | self.apply(self.init_bert_weights)
675 |
676 | def forward(self, input_ids, token_type_ids=None, attention_mask=None, masked_lm_labels=None, next_sentence_label=None):
677 | sequence_output, pooled_output = self.bert(input_ids, token_type_ids, attention_mask,
678 | output_all_encoded_layers=False)
679 | prediction_scores, seq_relationship_score = self.cls(sequence_output, pooled_output)
680 |
681 | if masked_lm_labels is not None and next_sentence_label is not None:
682 | loss_fct = CrossEntropyLoss(ignore_index=-1)
683 | masked_lm_loss = loss_fct(prediction_scores, masked_lm_labels)
684 | next_sentence_loss = loss_fct(seq_relationship_score, next_sentence_label)
685 | total_loss = masked_lm_loss + next_sentence_loss
686 | return total_loss
687 | else:
688 | return prediction_scores, seq_relationship_score
689 |
690 |
691 | class BertForMaskedLM(PreTrainedBertModel):
692 | """BERT model with the masked language modeling head.
693 | This module comprises the BERT model followed by the masked language modeling head.
694 |
695 | Params:
696 | config: a BertConfig class instance with the configuration to build a new model.
697 |
698 | Inputs:
699 | `input_ids`: a torch.LongTensor of shape [batch_size, sequence_length]
700 | with the word token indices in the vocabulary(see the tokens preprocessing logic in the scripts
701 | `extract_features.py`, `run_classifier.py` and `run_squad.py`)
702 | `token_type_ids`: an optional torch.LongTensor of shape [batch_size, sequence_length] with the token
703 | types indices selected in [0, 1]. Type 0 corresponds to a `sentence A` and type 1 corresponds to
704 | a `sentence B` token (see BERT paper for more details).
705 | `attention_mask`: an optional torch.LongTensor of shape [batch_size, sequence_length] with indices
706 | selected in [0, 1]. It's a mask to be used if the input sequence length is smaller than the max
707 | input sequence length in the current batch. It's the mask that we typically use for attention when
708 | a batch has varying length sentences.
709 | `masked_lm_labels`: masked language modeling labels: torch.LongTensor of shape [batch_size, sequence_length]
710 | with indices selected in [-1, 0, ..., vocab_size]. All labels set to -1 are ignored (masked), the loss
711 | is only computed for the labels set in [0, ..., vocab_size]
712 |
713 | Outputs:
714 | if `masked_lm_labels` is `None`:
715 | Outputs the masked language modeling loss.
716 | if `masked_lm_labels` is `None`:
717 | Outputs the masked language modeling logits.
718 |
719 | Example usage:
720 | ```python
721 | # Already been converted into WordPiece token ids
722 | input_ids = torch.LongTensor([[31, 51, 99], [15, 5, 0]])
723 | input_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]])
724 | token_type_ids = torch.LongTensor([[0, 0, 1], [0, 2, 0]])
725 |
726 | config = BertConfig(vocab_size=32000, hidden_size=512,
727 | num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
728 |
729 | model = BertForMaskedLM(config)
730 | masked_lm_logits_scores = model(input_ids, token_type_ids, input_mask)
731 | ```
732 | """
733 | def __init__(self, config):
734 | super(BertForMaskedLM, self).__init__(config)
735 | self.bert = BertModel(config)
736 | self.cls = BertOnlyMLMHead(config, self.bert.embeddings.word_embeddings.weight)
737 | self.apply(self.init_bert_weights)
738 |
739 | def forward(self, input_ids, token_type_ids=None, attention_mask=None, masked_lm_labels=None):
740 | sequence_output, _ = self.bert(input_ids, token_type_ids, attention_mask,
741 | output_all_encoded_layers=False)
742 | prediction_scores = self.cls(sequence_output)
743 |
744 | if masked_lm_labels is not None:
745 | loss_fct = CrossEntropyLoss(ignore_index=-1)
746 | masked_lm_loss = loss_fct(prediction_scores, masked_lm_labels)
747 | return masked_lm_loss
748 | else:
749 | return prediction_scores
750 |
751 |
752 | class BertForNextSentencePrediction(PreTrainedBertModel):
753 | """BERT model with next sentence prediction head.
754 | This module comprises the BERT model followed by the next sentence classification head.
755 |
756 | Params:
757 | config: a BertConfig class instance with the configuration to build a new model.
758 |
759 | Inputs:
760 | `input_ids`: a torch.LongTensor of shape [batch_size, sequence_length]
761 | with the word token indices in the vocabulary(see the tokens preprocessing logic in the scripts
762 | `extract_features.py`, `run_classifier.py` and `run_squad.py`)
763 | `token_type_ids`: an optional torch.LongTensor of shape [batch_size, sequence_length] with the token
764 | types indices selected in [0, 1]. Type 0 corresponds to a `sentence A` and type 1 corresponds to
765 | a `sentence B` token (see BERT paper for more details).
766 | `attention_mask`: an optional torch.LongTensor of shape [batch_size, sequence_length] with indices
767 | selected in [0, 1]. It's a mask to be used if the input sequence length is smaller than the max
768 | input sequence length in the current batch. It's the mask that we typically use for attention when
769 | a batch has varying length sentences.
770 | `next_sentence_label`: next sentence classification loss: torch.LongTensor of shape [batch_size]
771 | with indices selected in [0, 1].
772 | 0 => next sentence is the continuation, 1 => next sentence is a random sentence.
773 |
774 | Outputs:
775 | if `next_sentence_label` is not `None`:
776 | Outputs the total_loss which is the sum of the masked language modeling loss and the next
777 | sentence classification loss.
778 | if `next_sentence_label` is `None`:
779 | Outputs the next sentence classification logits.
780 |
781 | Example usage:
782 | ```python
783 | # Already been converted into WordPiece token ids
784 | input_ids = torch.LongTensor([[31, 51, 99], [15, 5, 0]])
785 | input_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]])
786 | token_type_ids = torch.LongTensor([[0, 0, 1], [0, 2, 0]])
787 |
788 | config = BertConfig(vocab_size=32000, hidden_size=512,
789 | num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
790 |
791 | model = BertForNextSentencePrediction(config)
792 | seq_relationship_logits = model(input_ids, token_type_ids, input_mask)
793 | ```
794 | """
795 | def __init__(self, config):
796 | super(BertForNextSentencePrediction, self).__init__(config)
797 | self.bert = BertModel(config)
798 | self.cls = BertOnlyNSPHead(config)
799 | self.apply(self.init_bert_weights)
800 |
801 | def forward(self, input_ids, token_type_ids=None, attention_mask=None, next_sentence_label=None):
802 | _, pooled_output = self.bert(input_ids, token_type_ids, attention_mask,
803 | output_all_encoded_layers=False)
804 | seq_relationship_score = self.cls( pooled_output)
805 |
806 | if next_sentence_label is not None:
807 | loss_fct = CrossEntropyLoss(ignore_index=-1)
808 | next_sentence_loss = loss_fct(seq_relationship_score, next_sentence_label)
809 | return next_sentence_loss
810 | else:
811 | return seq_relationship_score
812 |
813 |
814 | class BertForSequenceClassification(PreTrainedBertModel):
815 | """BERT model for classification.
816 | This module is composed of the BERT model with a linear layer on top of
817 | the pooled output.
818 |
819 | Params:
820 | `config`: a BertConfig class instance with the configuration to build a new model.
821 | `num_labels`: the number of classes for the classifier. Default = 2.
822 |
823 | Inputs:
824 | `input_ids`: a torch.LongTensor of shape [batch_size, sequence_length]
825 | with the word token indices in the vocabulary(see the tokens preprocessing logic in the scripts
826 | `extract_features.py`, `run_classifier.py` and `run_squad.py`)
827 | `token_type_ids`: an optional torch.LongTensor of shape [batch_size, sequence_length] with the token
828 | types indices selected in [0, 1]. Type 0 corresponds to a `sentence A` and type 1 corresponds to
829 | a `sentence B` token (see BERT paper for more details).
830 | `attention_mask`: an optional torch.LongTensor of shape [batch_size, sequence_length] with indices
831 | selected in [0, 1]. It's a mask to be used if the input sequence length is smaller than the max
832 | input sequence length in the current batch. It's the mask that we typically use for attention when
833 | a batch has varying length sentences.
834 | `labels`: labels for the classification output: torch.LongTensor of shape [batch_size]
835 | with indices selected in [0, ..., num_labels].
836 |
837 | Outputs:
838 | if `labels` is not `None`:
839 | Outputs the CrossEntropy classification loss of the output with the labels.
840 | if `labels` is `None`:
841 | Outputs the classification logits.
842 |
843 | Example usage:
844 | ```python
845 | # Already been converted into WordPiece token ids
846 | input_ids = torch.LongTensor([[31, 51, 99], [15, 5, 0]])
847 | input_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]])
848 | token_type_ids = torch.LongTensor([[0, 0, 1], [0, 2, 0]])
849 |
850 | config = BertConfig(vocab_size=32000, hidden_size=512,
851 | num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
852 |
853 | num_labels = 2
854 |
855 | model = BertForSequenceClassification(config, num_labels)
856 | logits = model(input_ids, token_type_ids, input_mask)
857 | ```
858 | """
859 | def __init__(self, config, num_labels):
860 | super(BertForSequenceClassification, self).__init__(config)
861 | self.bert = BertModel(config)
862 | self.dropout = nn.Dropout(config.hidden_dropout_prob)
863 | self.classifier = nn.Linear(config.hidden_size, num_labels)
864 | self.apply(self.init_bert_weights)
865 |
866 | def forward(self, input_ids, token_type_ids=None, attention_mask=None, labels=None):
867 | _, pooled_output = self.bert(input_ids, token_type_ids, attention_mask, output_all_encoded_layers=False)
868 |
869 | pooled_output2 = self.dropout(pooled_output)
870 | logits = self.classifier(pooled_output2)
871 |
872 | if labels is not None:
873 | loss_fct = BCELoss()
874 | m = nn.Sigmoid()
875 | n = torch.squeeze(m(logits))
876 | loss = loss_fct(n, labels.float())
877 | return loss, logits
878 | else:
879 | return logits
880 |
881 |
882 | class BertForQuestionAnswering(PreTrainedBertModel):
883 | """BERT model for Question Answering (span extraction).
884 | This module is composed of the BERT model with a linear layer on top of
885 | the sequence output that computes start_logits and end_logits
886 |
887 | Params:
888 | `config`: either
889 | - a BertConfig class instance with the configuration to build a new model, or
890 | - a str with the name of a pre-trained model to load selected in the list of:
891 | . `bert-base-uncased`
892 | . `bert-large-uncased`
893 | . `bert-base-cased`
894 | . `bert-base-multilingual`
895 | . `bert-base-chinese`
896 | The pre-trained model will be downloaded and cached if needed.
897 |
898 | Inputs:
899 | `input_ids`: a torch.LongTensor of shape [batch_size, sequence_length]
900 | with the word token indices in the vocabulary(see the tokens preprocessing logic in the scripts
901 | `extract_features.py`, `run_classifier.py` and `run_squad.py`)
902 | `token_type_ids`: an optional torch.LongTensor of shape [batch_size, sequence_length] with the token
903 | types indices selected in [0, 1]. Type 0 corresponds to a `sentence A` and type 1 corresponds to
904 | a `sentence B` token (see BERT paper for more details).
905 | `attention_mask`: an optional torch.LongTensor of shape [batch_size, sequence_length] with indices
906 | selected in [0, 1]. It's a mask to be used if the input sequence length is smaller than the max
907 | input sequence length in the current batch. It's the mask that we typically use for attention when
908 | a batch has varying length sentences.
909 | `start_positions`: position of the first token for the labeled span: torch.LongTensor of shape [batch_size].
910 | Positions are clamped to the length of the sequence and position outside of the sequence are not taken
911 | into account for computing the loss.
912 | `end_positions`: position of the last token for the labeled span: torch.LongTensor of shape [batch_size].
913 | Positions are clamped to the length of the sequence and position outside of the sequence are not taken
914 | into account for computing the loss.
915 |
916 | Outputs:
917 | if `start_positions` and `end_positions` are not `None`:
918 | Outputs the total_loss which is the sum of the CrossEntropy loss for the start and end token positions.
919 | if `start_positions` or `end_positions` is `None`:
920 | Outputs a tuple of start_logits, end_logits which are the logits respectively for the start and end
921 | position tokens.
922 |
923 | Example usage:
924 | ```python
925 | # Already been converted into WordPiece token ids
926 | input_ids = torch.LongTensor([[31, 51, 99], [15, 5, 0]])
927 | input_mask = torch.LongTensor([[1, 1, 1], [1, 1, 0]])
928 | token_type_ids = torch.LongTensor([[0, 0, 1], [0, 2, 0]])
929 |
930 | config = BertConfig(vocab_size=32000, hidden_size=512,
931 | num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
932 |
933 | model = BertForQuestionAnswering(config)
934 | start_logits, end_logits = model(input_ids, token_type_ids, input_mask)
935 | ```
936 | """
937 | def __init__(self, config):
938 | super(BertForQuestionAnswering, self).__init__(config)
939 | self.bert = BertModel(config)
940 | # TODO check with Google if it's normal there is no dropout on the token classifier of SQuAD in the TF version
941 | # self.dropout = nn.Dropout(config.hidden_dropout_prob)
942 | self.qa_outputs = nn.Linear(config.hidden_size, 2)
943 | self.apply(self.init_bert_weights)
944 |
945 | def forward(self, input_ids, token_type_ids=None, attention_mask=None, start_positions=None, end_positions=None):
946 | sequence_output, _ = self.bert(input_ids, token_type_ids, attention_mask, output_all_encoded_layers=False)
947 | logits = self.qa_outputs(sequence_output)
948 | start_logits, end_logits = logits.split(1, dim=-1)
949 | start_logits = start_logits.squeeze(-1)
950 | end_logits = end_logits.squeeze(-1)
951 |
952 | if start_positions is not None and end_positions is not None:
953 | # If we are on multi-GPU, split add a dimension
954 | if len(start_positions.size()) > 1:
955 | start_positions = start_positions.squeeze(-1)
956 | if len(end_positions.size()) > 1:
957 | end_positions = end_positions.squeeze(-1)
958 | # sometimes the start/end positions are outside our model inputs, we ignore these terms
959 | ignored_index = start_logits.size(1)
960 | start_positions.clamp_(0, ignored_index)
961 | end_positions.clamp_(0, ignored_index)
962 |
963 | loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
964 | start_loss = loss_fct(start_logits, start_positions)
965 | end_loss = loss_fct(end_logits, end_positions)
966 | total_loss = (start_loss + end_loss) / 2
967 | return total_loss
968 | else:
969 | return start_logits, end_logits
970 |
--------------------------------------------------------------------------------
/preprocess.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | import numpy as np
3 | import matplotlib.pyplot as plt
4 |
5 | # Load ADMISSIONS table
6 | df_adm = pd.read_csv(
7 | '/Users/nwams/Documents/Machine Learning Projects/Predicting-Hospital-Readmission-using-NLP/ADMISSIONS.csv')
8 |
9 | '''
10 | Convert Strings to Dates.
11 | When converting dates, it is safer to use a datetime format.
12 | Setting the errors = 'coerce' flag allows for missing dates
13 | but it sets it to NaT (not a datetime) when the string doesn't match the format.
14 | '''
15 | df_adm.ADMITTIME = pd.to_datetime(df_adm.ADMITTIME, format='%Y-%m-%d %H:%M:%S', errors='coerce')
16 | df_adm.DISCHTIME = pd.to_datetime(df_adm.DISCHTIME, format='%Y-%m-%d %H:%M:%S', errors='coerce')
17 | df_adm.DEATHTIME = pd.to_datetime(df_adm.DEATHTIME, format='%Y-%m-%d %H:%M:%S', errors='coerce')
18 |
19 | '''
20 | Get the next Unplanned admission date for each patient (if it exists).
21 | I need to get the next admission date, if it exists.
22 | First I'll verify that the dates are in order.
23 | Then I'll use the shift() function to get the next admission date.
24 | '''
25 | df_adm = df_adm.sort_values(['SUBJECT_ID', 'ADMITTIME'])
26 | df_adm = df_adm.reset_index(drop=True)
27 | df_adm['NEXT_ADMITTIME'] = df_adm.groupby('SUBJECT_ID').ADMITTIME.shift(-1)
28 | df_adm['NEXT_ADMISSION_TYPE'] = df_adm.groupby('SUBJECT_ID').ADMISSION_TYPE.shift(-1)
29 |
30 | '''
31 | Since I want to predict unplanned re-admissions I will drop (filter out) any future admissions that are ELECTIVE
32 | so that only EMERGENCY re-admissions are measured.
33 | For rows with 'elective' admissions, replace it with NaT and NaN
34 | '''
35 | rows = df_adm.NEXT_ADMISSION_TYPE == 'ELECTIVE'
36 | df_adm.loc[rows,'NEXT_ADMITTIME'] = pd.NaT
37 | df_adm.loc[rows,'NEXT_ADMISSION_TYPE'] = np.NaN
38 |
39 | # It's safer to sort right before the fill incase something I did above changed the order
40 | df_adm = df_adm.sort_values(['SUBJECT_ID','ADMITTIME'])
41 |
42 | '''
43 | Backfill in the values that I removed. So copy the ADMITTIME from the last emergency
44 | and paste it in the NEXT_ADMITTIME for the previous emergency.
45 | So I am effectively ignoring/skipping the ELECTIVE admission row completely.
46 | Doing this will allow me to calculate the days until the next admission.
47 | '''
48 | # Back fill. This will take a little while.
49 | df_adm[['NEXT_ADMITTIME','NEXT_ADMISSION_TYPE']] = df_adm.groupby(['SUBJECT_ID'])[['NEXT_ADMITTIME','NEXT_ADMISSION_TYPE']].fillna(method = 'bfill')
50 |
51 | # Calculate days until next admission
52 | df_adm['DAYS_TIL_NEXT_ADMIT'] = (df_adm.NEXT_ADMITTIME - df_adm.DISCHTIME).dt.total_seconds()/(24*60*60)
53 |
54 | '''
55 | Remove NEWBORN admissions
56 | According to the MIMIC site "Newborn indicates that the HADM_ID pertains to the patient's birth."
57 |
58 | I will remove all NEWBORN admission types because in this project I'm not interested in studying births — my primary
59 | interest is EMERGENCY and URGENT admissions.
60 | I will remove all admissions that have a DEATHTIME because in this project I'm studying re-admissions, not mortality.
61 | And a patient who died cannot be re-admitted.
62 | '''
63 | df_adm = df_adm.loc[df_adm.ADMISSION_TYPE != 'NEWBORN']
64 | df_adm = df_adm.loc[df_adm.DEATHTIME.isnull()]
65 |
66 | '''
67 | Make Output Label
68 | For this problem, we are going to classify if a patient will be admitted in the next 30 days.
69 | Therefore, we need to create a variable with the output label (1 = readmitted, 0 = not readmitted).
70 | '''
71 | df_adm['OUTPUT_LABEL'] = (df_adm.DAYS_NEXT_ADMIT < 30).astype('int')
72 |
73 |
74 | # Load NOTEEVENTS Table
75 | df_notes = pd.read_csv("/Users/nwams/Documents/Machine Learning Projects/Predicting-Hospital-Readmission-using-NLP/NOTEEVENTS.csv")
76 |
77 | # Sort by subject_ID, HAD_ID then CHARTDATE
78 | df_notes = df_notes.sort_values(by=['SUBJECT_ID','HADM_ID','CHARTDATE'])
79 | # Merge notes table to admissions table
80 | df_adm_notes = pd.merge(df_adm[['SUBJECT_ID','HADM_ID','ADMITTIME','DISCHTIME','DAYS_NEXT_ADMIT','NEXT_ADMITTIME','ADMISSION_TYPE','DEATHTIME','OUTPUT_LABEL','DURATION']],
81 | df_notes[['SUBJECT_ID','HADM_ID','CHARTDATE','TEXT','CATEGORY']],
82 | on = ['SUBJECT_ID','HADM_ID'],
83 | how = 'left')
84 |
85 | # Grab date only, not the time
86 | df_adm_notes.ADMITTIME_C = df_adm_notes.ADMITTIME.apply(lambda x: str(x).split(' ')[0])
87 |
88 | df_adm_notes['ADMITTIME_C'] = pd.to_datetime(df_adm_notes.ADMITTIME_C, format = '%Y-%m-%d', errors = 'coerce')
89 | df_adm_notes['CHARTDATE'] = pd.to_datetime(df_adm_notes.CHARTDATE, format = '%Y-%m-%d', errors = 'coerce')
90 |
91 | # Gather Discharge Summaries Only
92 | df_discharge = df_adm_notes[df_adm_notes['CATEGORY'] == 'Discharge summary']
93 | # multiple discharge summary for one admission -> after examination -> replicated summary -> replace with the last one
94 | df_discharge = (df_discharge.groupby(['SUBJECT_ID','HADM_ID']).nth(-1)).reset_index()
95 | df_discharge=df_discharge[df_discharge['TEXT'].notnull()]
96 |
97 | ### If Less than n days on admission notes (Early notes)
98 | def less_n_days_data(df_adm_notes, n):
99 | df_less_n = df_adm_notes[
100 | ((df_adm_notes['CHARTDATE'] - df_adm_notes['ADMITTIME_C']).dt.total_seconds() / (24 * 60 * 60)) < n]
101 | df_less_n = df_less_n[df_less_n['TEXT'].notnull()]
102 | # concatenate first
103 | df_concat = pd.DataFrame(df_less_n.groupby('HADM_ID')['TEXT'].apply(lambda x: "%s" % ' '.join(x))).reset_index()
104 | df_concat['OUTPUT_LABEL'] = df_concat['HADM_ID'].apply(
105 | lambda x: df_less_n[df_less_n['HADM_ID'] == x].OUTPUT_LABEL.values[0])
106 |
107 | return df_concat
108 |
109 | df_less_2 = less_n_days_data(df_adm_notes, 2)
110 | df_less_3 = less_n_days_data(df_adm_notes, 3)
111 |
112 | import re
113 |
114 | def preprocess1(x):
115 | y = re.sub('\\[(.*?)\\]', '', x) # remove de-identified brackets
116 | y = re.sub('[0-9]+\.', '', y) # remove 1.2. since the segmenter segments based on this
117 | y = re.sub('dr\.', 'doctor', y)
118 | y = re.sub('m\.d\.', 'md', y)
119 | y = re.sub('admission date:', '', y)
120 | y = re.sub('discharge date:', '', y)
121 | y = re.sub('--|__|==', '', y)
122 | return y
123 |
124 | def preprocessing(df_less_n):
125 | df_less_n['TEXT'] = df_less_n['TEXT'].fillna(' ')
126 | df_less_n['TEXT'] = df_less_n['TEXT'].str.replace('\n', ' ')
127 | df_less_n['TEXT'] = df_less_n['TEXT'].str.replace('\r', ' ')
128 | df_less_n['TEXT'] = df_less_n['TEXT'].apply(str.strip)
129 | df_less_n['TEXT'] = df_less_n['TEXT'].str.lower()
130 |
131 | df_less_n['TEXT'] = df_less_n['TEXT'].apply(lambda x: preprocess1(x))
132 |
133 | # to get 318 words chunks for readmission tasks
134 | from tqdm import tqdm
135 | df_len = len(df_less_n)
136 | want = pd.DataFrame({'ID': [], 'TEXT': [], 'Label': []})
137 | for i in tqdm(range(df_len)):
138 | x = df_less_n.TEXT.iloc[i].split()
139 | n = int(len(x) / 318)
140 | for j in range(n):
141 | want = want.append({'TEXT': ' '.join(x[j * 318:(j + 1) * 318]), 'Label': df_less_n.OUTPUT_LABEL.iloc[i],
142 | 'ID': df_less_n.HADM_ID.iloc[i]}, ignore_index=True)
143 | if len(x) % 318 > 10:
144 | want = want.append({'TEXT': ' '.join(x[-(len(x) % 318):]), 'Label': df_less_n.OUTPUT_LABEL.iloc[i],
145 | 'ID': df_less_n.HADM_ID.iloc[i]}, ignore_index=True)
146 |
147 | return want
148 |
149 |
150 | df_discharge = preprocessing(df_discharge)
151 | df_less_2 = preprocessing(df_less_2)
152 | df_less_3 = preprocessing(df_less_3)
153 |
154 | ### An example to get the train/test/split with random state:
155 | ### note that we divide on patient admission level and share among experiments, instead of notes level.
156 | ### This way, since our methods run on the same set of admissions, we can see the
157 | ### progression of readmission scores.
158 |
159 | readmit_ID = df_adm[df_adm.OUTPUT_LABEL == 1].HADM_ID
160 | not_readmit_ID = df_adm[df_adm.OUTPUT_LABEL == 0].HADM_ID
161 | # subsampling to get the balanced pos/neg numbers of patients for each dataset
162 | not_readmit_ID_use = not_readmit_ID.sample(n=len(readmit_ID), random_state=1)
163 | id_val_test_t = readmit_ID.sample(frac=0.2, random_state=1)
164 | id_val_test_f = not_readmit_ID_use.sample(frac=0.2, random_state=1)
165 |
166 | id_train_t = readmit_ID.drop(id_val_test_t.index)
167 | id_train_f = not_readmit_ID_use.drop(id_val_test_f.index)
168 |
169 | id_val_t = id_val_test_t.sample(frac=0.5, random_state=1)
170 | id_test_t = id_val_test_t.drop(id_val_t.index)
171 |
172 | id_val_f = id_val_test_f.sample(frac=0.5, random_state=1)
173 | id_test_f = id_val_test_f.drop(id_val_f.index)
174 |
175 | # test if there is overlap between train and test, should return "array([], dtype=int64)"
176 | (pd.Index(id_test_t).intersection(pd.Index(id_train_t))).values
177 |
178 | id_test = pd.concat([id_test_t, id_test_f])
179 | test_id_label = pd.DataFrame(data=list(zip(id_test, [1] * len(id_test_t) + [0] * len(id_test_f))),
180 | columns=['id', 'label'])
181 |
182 | id_val = pd.concat([id_val_t, id_val_f])
183 | val_id_label = pd.DataFrame(data=list(zip(id_val, [1] * len(id_val_t) + [0] * len(id_val_f))), columns=['id', 'label'])
184 |
185 | id_train = pd.concat([id_train_t, id_train_f])
186 | train_id_label = pd.DataFrame(data=list(zip(id_train, [1] * len(id_train_t) + [0] * len(id_train_f))),
187 | columns=['id', 'label'])
188 |
189 | # get discharge train/val/test
190 |
191 | discharge_train = df_discharge[df_discharge.ID.isin(train_id_label.id)]
192 | discharge_val = df_discharge[df_discharge.ID.isin(val_id_label.id)]
193 | discharge_test = df_discharge[df_discharge.ID.isin(test_id_label.id)]
194 |
195 | # subsampling for training....since we obtain training on patient admission level so now we have same number of pos/neg readmission
196 | # but each admission is associated with different length of notes and we train on each chunks of notes, not on the admission, we need
197 | # to balance the pos/neg chunks on training set. (val and test set are fine) Usually, positive admissions have longer notes, so we need
198 | # find some negative chunks of notes from not_readmit_ID that we haven't used yet
199 |
200 | df = pd.concat([not_readmit_ID_use, not_readmit_ID])
201 | df = df.drop_duplicates(keep=False)
202 | # check to see if there are overlaps
203 | (pd.Index(df).intersection(pd.Index(not_readmit_ID_use))).values
204 |
205 | # for this set of split with random_state=1, we find we need 400 more negative training samples
206 | not_readmit_ID_more = df.sample(n=400, random_state=1)
207 | discharge_train_snippets = pd.concat([df_discharge[df_discharge.ID.isin(not_readmit_ID_more)], discharge_train])
208 |
209 | # shuffle
210 | discharge_train_snippets = discharge_train_snippets.sample(frac=1, random_state=1).reset_index(drop=True)
211 |
212 | # check if balanced
213 | discharge_train_snippets.Label.value_counts()
214 |
215 | discharge_train_snippets.to_csv('./discharge/train.csv')
216 | discharge_val.to_csv('./discharge/val.csv')
217 | discharge_test.to_csv('./discharge/test.csv')
218 |
219 | ### for Early notes experiment: we only need to find training set for 3 days, then we can test
220 | ### both 3 days and 2 days. Since we split the data on patient level and experiments share admissions
221 | ### in order to see the progression, the 2 days training dataset is a subset of 3 days training set.
222 | ### So we only train 3 days and we can test/val on both 2 & 3days or any time smaller than 3 days. This means
223 | ### if we train on a dataset with all the notes in n days, we can predict readmissions smaller than n days.
224 |
225 | # for 3 days note, similar to discharge
226 |
227 | early_train = df_less_3[df_less_3.ID.isin(train_id_label.id)]
228 | not_readmit_ID_more = df.sample(n=500, random_state=1)
229 | early_train_snippets = pd.concat([df_less_3[df_less_3.ID.isin(not_readmit_ID_more)], early_train])
230 | # shuffle
231 | early_train_snippets = early_train_snippets.sample(frac=1, random_state=1).reset_index(drop=True)
232 | early_train_snippets.to_csv('./3days/train.csv')
233 |
234 | early_val = df_less_3[df_less_3.ID.isin(val_id_label.id)]
235 | early_val.to_csv('./3days/val.csv')
236 |
237 | # we want to test on admissions that are not discharged already. So for less than 3 days of notes experiment,
238 | # we filter out admissions discharged within 3 days
239 | actionable_ID_3days = df_adm[df_adm['DURATION'] >= 3].HADM_ID
240 | test_actionable_id_label = test_id_label[test_id_label.id.isin(actionable_ID_3days)]
241 | early_test = df_less_3[df_less_3.ID.isin(test_actionable_id_label.id)]
242 |
243 | early_test.to_csv('./3days/test.csv')
244 |
245 | # for 2 days notes, we only obtain test set. Since the model parameters are tuned on the val set of 3 days
246 |
247 | actionable_ID_2days = df_adm[df_adm['DURATION'] >= 2].HADM_ID
248 |
249 | test_actionable_id_label_2days = test_id_label[test_id_label.id.isin(actionable_ID_2days)]
250 |
251 | early_test_2days = df_less_2[df_less_2.ID.isin(test_actionable_id_label_2days.id)]
252 |
253 | early_test_2days.to_csv('./2days/test.csv')
--------------------------------------------------------------------------------