├── LICENSE
├── PPO_practice.ipynb
├── README.md
├── code
├── LICENSE
├── README.md
├── benchmarks
│ ├── README.md
│ ├── benchmark_gpt_dummy.py
│ ├── benchmark_gpt_dummy.sh
│ └── benchmark_opt_lora_dummy.py
├── chatgpt
│ ├── __init__.py
│ ├── __pycache__
│ │ └── __init__.cpython-310.pyc
│ ├── dataset
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ │ ├── __init__.cpython-310.pyc
│ │ │ ├── reward_dataset.cpython-310.pyc
│ │ │ └── utils.cpython-310.pyc
│ │ ├── reward_dataset.py
│ │ └── utils.py
│ ├── experience_maker
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ │ ├── __init__.cpython-310.pyc
│ │ │ ├── base.cpython-310.pyc
│ │ │ └── naive.cpython-310.pyc
│ │ ├── base.py
│ │ └── naive.py
│ ├── models
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ │ ├── __init__.cpython-310.pyc
│ │ │ ├── generation.cpython-310.pyc
│ │ │ ├── generation_utils.cpython-310.pyc
│ │ │ ├── lora.cpython-310.pyc
│ │ │ ├── loss.cpython-310.pyc
│ │ │ └── utils.cpython-310.pyc
│ │ ├── base
│ │ │ ├── __init__.py
│ │ │ ├── __pycache__
│ │ │ │ ├── __init__.cpython-310.pyc
│ │ │ │ ├── actor.cpython-310.pyc
│ │ │ │ ├── critic.cpython-310.pyc
│ │ │ │ └── reward_model.cpython-310.pyc
│ │ │ ├── actor.py
│ │ │ ├── critic.py
│ │ │ └── reward_model.py
│ │ ├── bloom
│ │ │ ├── __init__.py
│ │ │ ├── __pycache__
│ │ │ │ ├── __init__.cpython-310.pyc
│ │ │ │ ├── bloom_actor.cpython-310.pyc
│ │ │ │ ├── bloom_critic.cpython-310.pyc
│ │ │ │ └── bloom_rm.cpython-310.pyc
│ │ │ ├── bloom_actor.py
│ │ │ ├── bloom_critic.py
│ │ │ └── bloom_rm.py
│ │ ├── generation.py
│ │ ├── generation_utils.py
│ │ ├── gpt
│ │ │ ├── __init__.py
│ │ │ ├── __pycache__
│ │ │ │ ├── __init__.cpython-310.pyc
│ │ │ │ ├── gpt_actor.cpython-310.pyc
│ │ │ │ ├── gpt_critic.cpython-310.pyc
│ │ │ │ └── gpt_rm.cpython-310.pyc
│ │ │ ├── gpt_actor.py
│ │ │ ├── gpt_critic.py
│ │ │ └── gpt_rm.py
│ │ ├── lora.py
│ │ ├── loss.py
│ │ ├── opt
│ │ │ ├── __init__.py
│ │ │ ├── __pycache__
│ │ │ │ ├── __init__.cpython-310.pyc
│ │ │ │ ├── opt_actor.cpython-310.pyc
│ │ │ │ ├── opt_critic.cpython-310.pyc
│ │ │ │ └── opt_rm.cpython-310.pyc
│ │ │ ├── opt_actor.py
│ │ │ ├── opt_critic.py
│ │ │ └── opt_rm.py
│ │ └── utils.py
│ ├── replay_buffer
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ │ ├── __init__.cpython-310.pyc
│ │ │ ├── base.cpython-310.pyc
│ │ │ ├── naive.cpython-310.pyc
│ │ │ └── utils.cpython-310.pyc
│ │ ├── base.py
│ │ ├── naive.py
│ │ └── utils.py
│ └── trainer
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ ├── __init__.cpython-310.pyc
│ │ ├── base.cpython-310.pyc
│ │ ├── ppo.cpython-310.pyc
│ │ ├── rm.cpython-310.pyc
│ │ └── utils.cpython-310.pyc
│ │ ├── base.py
│ │ ├── callbacks
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ │ ├── __init__.cpython-310.pyc
│ │ │ ├── base.cpython-310.pyc
│ │ │ ├── performance_evaluator.cpython-310.pyc
│ │ │ └── save_checkpoint.cpython-310.pyc
│ │ ├── base.py
│ │ ├── performance_evaluator.py
│ │ └── save_checkpoint.py
│ │ ├── ppo.py
│ │ ├── rm.py
│ │ ├── strategies
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ │ ├── __init__.cpython-310.pyc
│ │ │ ├── base.cpython-310.pyc
│ │ │ ├── colossalai.cpython-310.pyc
│ │ │ ├── ddp.cpython-310.pyc
│ │ │ ├── naive.cpython-310.pyc
│ │ │ └── sampler.cpython-310.pyc
│ │ ├── base.py
│ │ ├── colossalai.py
│ │ ├── ddp.py
│ │ ├── naive.py
│ │ └── sampler.py
│ │ └── utils.py
├── examples
│ ├── README.md
│ ├── inference.py
│ ├── requirements.txt
│ ├── test_ci.sh
│ ├── train_dummy.py
│ ├── train_dummy.sh
│ ├── train_prompts.py
│ ├── train_prompts.sh
│ ├── train_reward_model.py
│ └── train_rm.sh
├── pytest.ini
├── requirements-test.txt
├── requirements.txt
├── setup.py
├── tests
│ ├── __init__.py
│ ├── test_checkpoint.py
│ └── test_data.py
├── utils.py
└── version.txt
├── data
├── stage1. domain_adaptive_pretraining
│ ├── BTS.csv
│ ├── domain_adaptive_kuksundo_pretrain.jsonl
│ ├── domain_adaptive_pretrain_ive.jsonl
│ ├── 국선도.csv
│ ├── 아이브.csv
│ └── 템플릿.csv
├── stage1. domain_instruction_tuning
│ ├── ive_instruction_test.jsonl
│ ├── ive_instruction_train.jsonl
│ ├── kuksundo_instruction_test.jsonl
│ └── kuksundo_instruction_train.jsonl
├── stage2. RM
│ ├── ive_test_rm.jsonl
│ ├── ive_train_rm.jsonl
│ ├── kuksundo_test_rm.jsonl
│ └── kuksundo_train_rm.jsonl
└── stage3. PPO
│ ├── ive_test_ppo.jsonl
│ ├── ive_train_ppo.jsonl
│ ├── kuksundo_test_ppo.jsonl
│ └── kuksundo_train_ppo.jsonl
├── mygpt_실습.ipynb
└── requirements.txt
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2023 oglee815
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # update
2 | - 2024-6-13: 데이터 생성과 학습 노트북 통합 -> 하나의 colab 노트북으로 통일
3 | - 2023-10-24: 라인 넘버 추가 및 코드 정리
4 |
5 | # mygpt-lecture
6 | 본 자료는 '나만의 데이터로 만드는 MyGPT 강의' 관련 자료입니다.
7 |
8 | 아래 자료를 참고하여 만들었습니다.
9 | https://github.com/airobotlab/KoChatGPT
10 |
11 | # 전체 목차
12 |  13 |
14 | # 실습 진행 순서
15 |
13 |
14 | # 실습 진행 순서
15 |  16 |
17 | # 학습코드
18 | [my_gpt실습.ipynb](https://colab.research.google.com/github/oglee815/mygpt-lecture/blob/main/mygpt_실습.ipynb)
19 |
20 | # 데이터 생성 코드
21 | [my_gpt실습.ipynb](https://colab.research.google.com/github/oglee815/mygpt-lecture/blob/main/mygpt_실습.ipynb)
22 | - ChatGPT API를 통해 데이터 자동 생성
23 | -
16 |
17 | # 학습코드
18 | [my_gpt실습.ipynb](https://colab.research.google.com/github/oglee815/mygpt-lecture/blob/main/mygpt_실습.ipynb)
19 |
20 | # 데이터 생성 코드
21 | [my_gpt실습.ipynb](https://colab.research.google.com/github/oglee815/mygpt-lecture/blob/main/mygpt_실습.ipynb)
22 | - ChatGPT API를 통해 데이터 자동 생성
23 | -  24 |
25 | # PPO 강화학습 연습 코드(Lunar Lander2)
26 | - [ppo_practice.ipynb](https://colab.research.google.com/github/oglee815/mygpt-lecture/blob/main/PPO_practice.ipynb)
27 | -
24 |
25 | # PPO 강화학습 연습 코드(Lunar Lander2)
26 | - [ppo_practice.ipynb](https://colab.research.google.com/github/oglee815/mygpt-lecture/blob/main/PPO_practice.ipynb)
27 | -  28 |
29 | # 학습 결과 예시
30 | - SKT-KoGPT2와 나무 위키의 '아이브' 카테고리 데이터를 기반으로 ChatGPT의 Stage 1, 2, 3를 학습 한 뒤, Stage 1의 SFT와 결과 비교
31 | -
28 |
29 | # 학습 결과 예시
30 | - SKT-KoGPT2와 나무 위키의 '아이브' 카테고리 데이터를 기반으로 ChatGPT의 Stage 1, 2, 3를 학습 한 뒤, Stage 1의 SFT와 결과 비교
31 | -  32 | - KL Penalty 덕분인지 의외로 동일한 Output을 내놓는 경우가 많음
33 |
34 | # 자료 관련 문의
35 | - 이현제, oglee815@gmail.com
36 | - h8.lee@samsung.com
37 |
--------------------------------------------------------------------------------
/code/README.md:
--------------------------------------------------------------------------------
1 | # RLHF - Colossal-AI
2 |
3 | ## Table of Contents
4 |
5 | - [What is RLHF - Colossal-AI?](#intro)
6 | - [How to Install?](#install)
7 | - [The Plan](#the-plan)
8 | - [How can you partcipate in open source?](#invitation-to-open-source-contribution)
9 | ---
10 | ## Intro
11 | Implementation of RLHF (Reinforcement Learning with Human Feedback) powered by Colossal-AI. It supports distributed training and offloading, which can fit extremly large models. More details can be found in the [blog](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt).
12 |
13 |
32 | - KL Penalty 덕분인지 의외로 동일한 Output을 내놓는 경우가 많음
33 |
34 | # 자료 관련 문의
35 | - 이현제, oglee815@gmail.com
36 | - h8.lee@samsung.com
37 |
--------------------------------------------------------------------------------
/code/README.md:
--------------------------------------------------------------------------------
1 | # RLHF - Colossal-AI
2 |
3 | ## Table of Contents
4 |
5 | - [What is RLHF - Colossal-AI?](#intro)
6 | - [How to Install?](#install)
7 | - [The Plan](#the-plan)
8 | - [How can you partcipate in open source?](#invitation-to-open-source-contribution)
9 | ---
10 | ## Intro
11 | Implementation of RLHF (Reinforcement Learning with Human Feedback) powered by Colossal-AI. It supports distributed training and offloading, which can fit extremly large models. More details can be found in the [blog](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt).
12 |
13 |
14 | 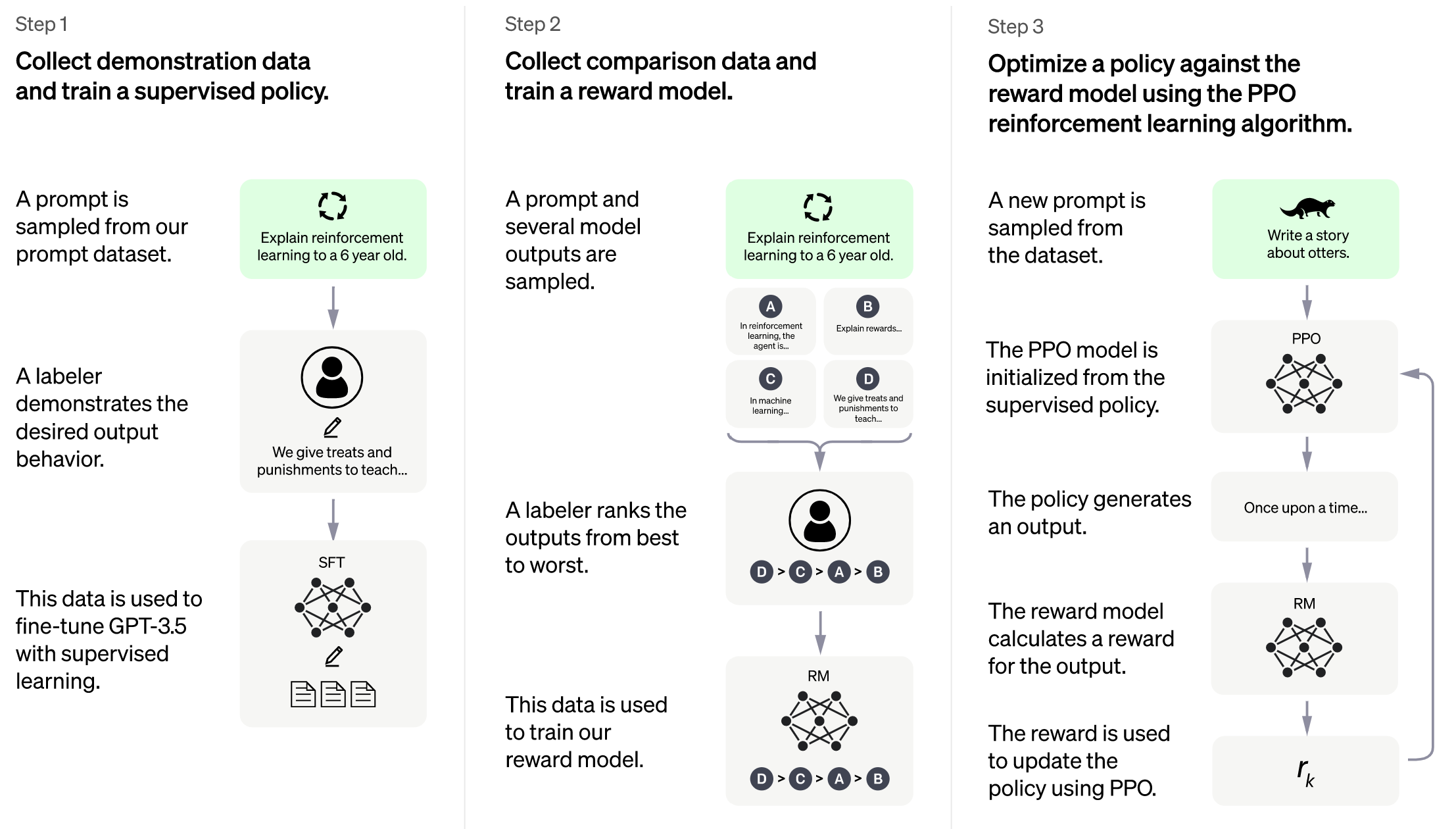 15 |
15 |
16 |
17 | ## Training process (step 3)
18 |
19 | 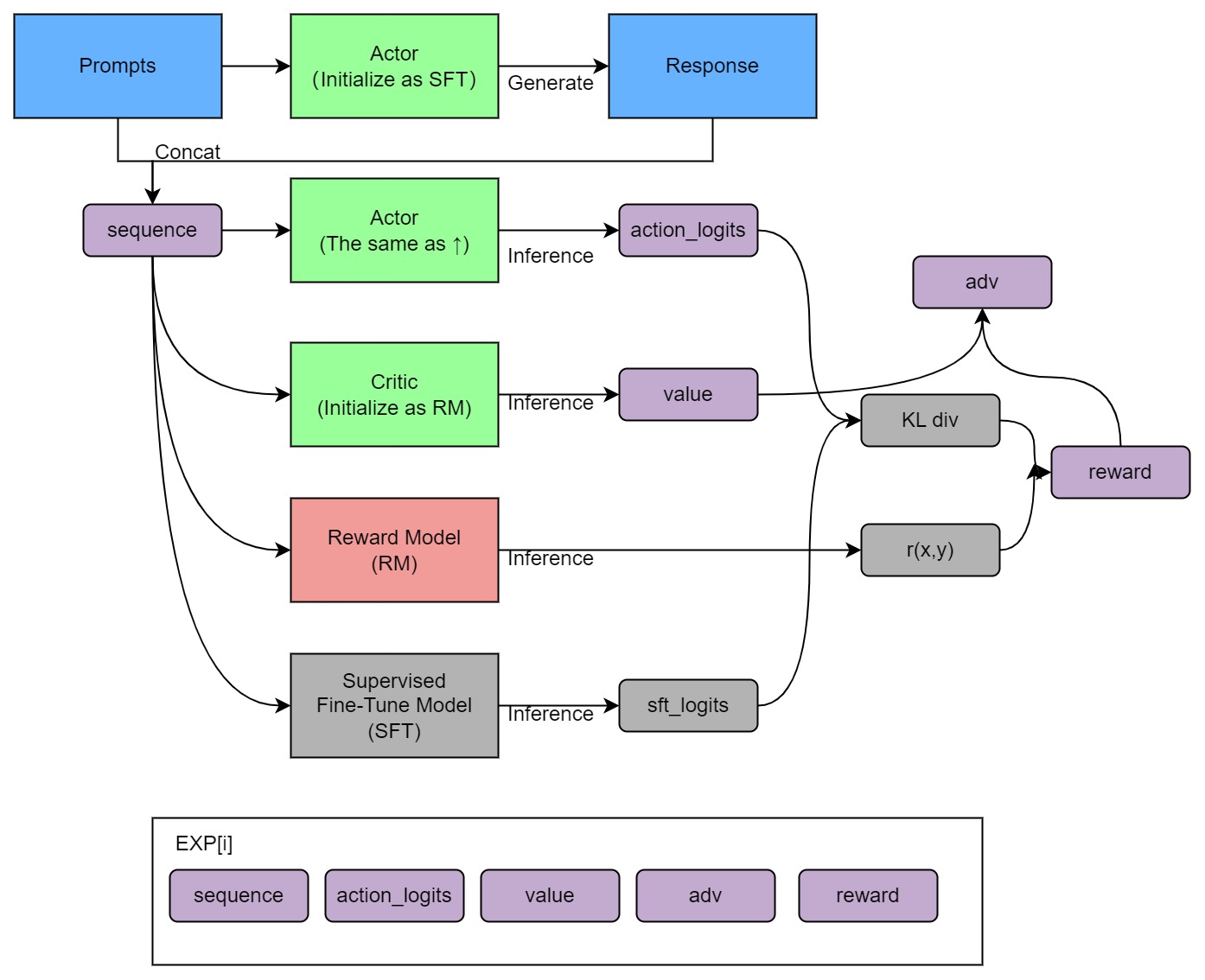 20 |
20 |
21 |
22 | 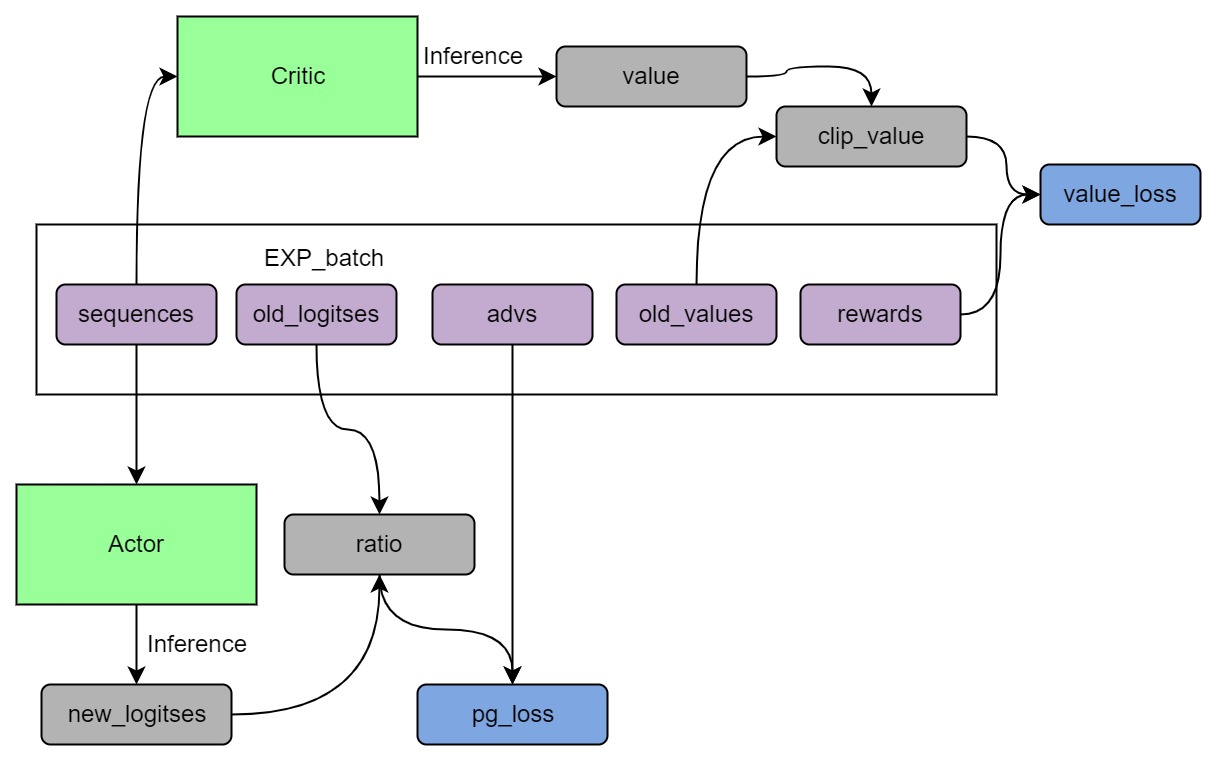 23 |
23 |
24 |
25 |
26 | ## Install
27 | ```shell
28 | pip install .
29 | ```
30 |
31 | ## Usage
32 |
33 | The main entrypoint is `Trainer`. We only support PPO trainer now. We support many training strategies:
34 |
35 | - NaiveStrategy: simplest strategy. Train on single GPU.
36 | - DDPStrategy: use `torch.nn.parallel.DistributedDataParallel`. Train on multi GPUs.
37 | - ColossalAIStrategy: use Gemini and Zero of ColossalAI. It eliminates model duplication on each GPU and supports offload. It's very useful when training large models on multi GPUs.
38 |
39 | Simplest usage:
40 |
41 | ```python
42 | from chatgpt.trainer import PPOTrainer
43 | from chatgpt.trainer.strategies import ColossalAIStrategy
44 | from chatgpt.models.gpt import GPTActor, GPTCritic
45 | from chatgpt.models.base import RewardModel
46 | from copy import deepcopy
47 | from colossalai.nn.optimizer import HybridAdam
48 |
49 | strategy = ColossalAIStrategy()
50 |
51 | with strategy.model_init_context():
52 | # init your model here
53 | # load pretrained gpt2
54 | actor = GPTActor(pretrained='gpt2')
55 | critic = GPTCritic()
56 | initial_model = deepcopy(actor).cuda()
57 | reward_model = RewardModel(deepcopy(critic.model), deepcopy(critic.value_head)).cuda()
58 |
59 | actor_optim = HybridAdam(actor.parameters(), lr=5e-6)
60 | critic_optim = HybridAdam(critic.parameters(), lr=5e-6)
61 |
62 | # prepare models and optimizers
63 | (actor, actor_optim), (critic, critic_optim), reward_model, initial_model = strategy.prepare(
64 | (actor, actor_optim), (critic, critic_optim), reward_model, initial_model)
65 |
66 | # load saved model checkpoint after preparing
67 | strategy.load_model(actor, 'actor_checkpoint.pt', strict=False)
68 | # load saved optimizer checkpoint after preparing
69 | strategy.load_optimizer(actor_optim, 'actor_optim_checkpoint.pt')
70 |
71 | trainer = PPOTrainer(strategy,
72 | actor,
73 | critic,
74 | reward_model,
75 | initial_model,
76 | actor_optim,
77 | critic_optim,
78 | ...)
79 |
80 | trainer.fit(dataset, ...)
81 |
82 | # save model checkpoint after fitting on only rank0
83 | strategy.save_model(actor, 'actor_checkpoint.pt', only_rank0=True)
84 | # save optimizer checkpoint on all ranks
85 | strategy.save_optimizer(actor_optim, 'actor_optim_checkpoint.pt', only_rank0=False)
86 | ```
87 |
88 | For more details, see `examples/`.
89 |
90 | We also support training reward model with true-world data. See `examples/train_reward_model.py`.
91 |
92 | ## FAQ
93 |
94 | ### How to save/load checkpoint
95 |
96 | To load pretrained model, you can simply use huggingface pretrained models:
97 |
98 | ```python
99 | # load OPT-350m pretrained model
100 | actor = OPTActor(pretrained='facebook/opt-350m')
101 | ```
102 |
103 | To save model checkpoint:
104 |
105 | ```python
106 | # save model checkpoint on only rank0
107 | strategy.save_model(actor, 'actor_checkpoint.pt', only_rank0=True)
108 | ```
109 |
110 | This function must be called after `strategy.prepare()`.
111 |
112 | For DDP strategy, model weights are replicated on all ranks. And for ColossalAI strategy, model weights may be sharded, but all-gather will be applied before returning state dict. You can set `only_rank0=True` for both of them, which only saves checkpoint on rank0, to save disk space usage. The checkpoint is float32.
113 |
114 | To save optimizer checkpoint:
115 |
116 | ```python
117 | # save optimizer checkpoint on all ranks
118 | strategy.save_optimizer(actor_optim, 'actor_optim_checkpoint.pt', only_rank0=False)
119 | ```
120 |
121 | For DDP strategy, optimizer states are replicated on all ranks. You can set `only_rank0=True`. But for ColossalAI strategy, optimizer states are sharded over all ranks, and no all-gather will be applied. So for ColossalAI strategy, you can only set `only_rank0=False`. That is to say, each rank will save a cehckpoint. When loading, each rank should load the corresponding part.
122 |
123 | Note that different stategy may have different shapes of optimizer checkpoint.
124 |
125 | To load model checkpoint:
126 |
127 | ```python
128 | # load saved model checkpoint after preparing
129 | strategy.load_model(actor, 'actor_checkpoint.pt', strict=False)
130 | ```
131 |
132 | To load optimizer checkpoint:
133 |
134 | ```python
135 | # load saved optimizer checkpoint after preparing
136 | strategy.load_optimizer(actor_optim, 'actor_optim_checkpoint.pt')
137 | ```
138 |
139 | ## The Plan
140 |
141 | - [x] implement PPO fine-tuning
142 | - [x] implement training reward model
143 | - [x] support LoRA
144 | - [x] support inference
145 | - [ ] open source the reward model weight
146 | - [ ] support llama from [facebook](https://github.com/facebookresearch/llama)
147 | - [ ] support BoN(best of N sample)
148 | - [ ] implement PPO-ptx fine-tuning
149 | - [ ] integrate with Ray
150 | - [ ] support more RL paradigms, like Implicit Language Q-Learning (ILQL),
151 | - [ ] support chain of throught by [langchain](https://github.com/hwchase17/langchain)
152 |
153 | ### Real-time progress
154 | You will find our progress in github project broad
155 |
156 | [Open ChatGPT](https://github.com/orgs/hpcaitech/projects/17/views/1)
157 |
158 | ## Invitation to open-source contribution
159 | Referring to the successful attempts of [BLOOM](https://bigscience.huggingface.co/) and [Stable Diffusion](https://en.wikipedia.org/wiki/Stable_Diffusion), any and all developers and partners with computing powers, datasets, models are welcome to join and build the Colossal-AI community, making efforts towards the era of big AI models from the starting point of replicating ChatGPT!
160 |
161 | You may contact us or participate in the following ways:
162 | 1. [Leaving a Star ⭐](https://github.com/hpcaitech/ColossalAI/stargazers) to show your like and support. Thanks!
163 | 2. Posting an [issue](https://github.com/hpcaitech/ColossalAI/issues/new/choose), or submitting a PR on GitHub follow the guideline in [Contributing](https://github.com/hpcaitech/ColossalAI/blob/main/CONTRIBUTING.md).
164 | 3. Join the Colossal-AI community on
165 | [Slack](https://join.slack.com/t/colossalaiworkspace/shared_invite/zt-z7b26eeb-CBp7jouvu~r0~lcFzX832w),
166 | and [WeChat(微信)](https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/WeChat.png "qrcode") to share your ideas.
167 | 4. Send your official proposal to email contact@hpcaitech.com
168 |
169 | Thanks so much to all of our amazing contributors!
170 |
171 | ## Quick Preview
172 |
173 |  174 |
174 |
175 |
176 | - Up to 7.73 times faster for single server training and 1.42 times faster for single-GPU inference
177 |
178 |
179 | 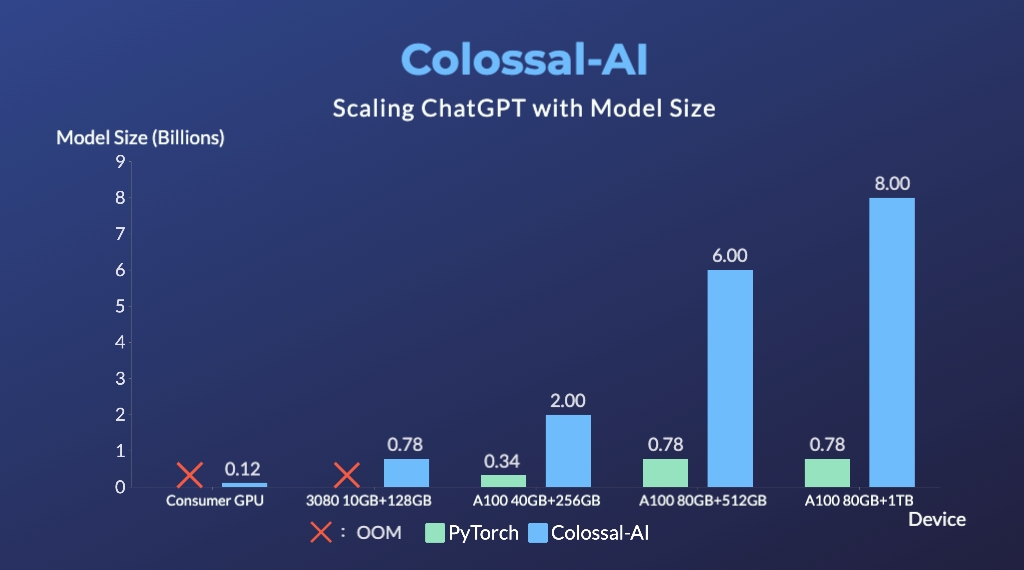 180 |
180 |
181 |
182 | - Up to 10.3x growth in model capacity on one GPU
183 | - A mini demo training process requires only 1.62GB of GPU memory (any consumer-grade GPU)
184 |
185 |
186 | 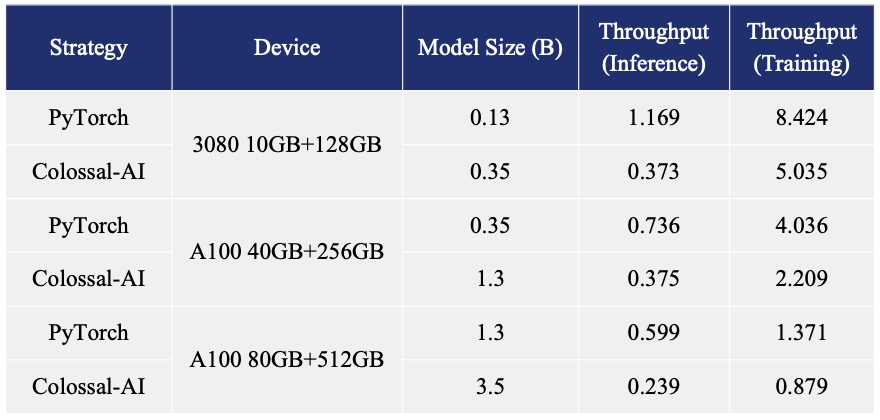 187 |
187 |
188 |
189 | - Increase the capacity of the fine-tuning model by up to 3.7 times on a single GPU
190 | - Keep in a sufficiently high running speed
191 |
192 | ## Citations
193 |
194 | ```bibtex
195 | @article{Hu2021LoRALA,
196 | title = {LoRA: Low-Rank Adaptation of Large Language Models},
197 | author = {Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Weizhu Chen},
198 | journal = {ArXiv},
199 | year = {2021},
200 | volume = {abs/2106.09685}
201 | }
202 |
203 | @article{ouyang2022training,
204 | title={Training language models to follow instructions with human feedback},
205 | author={Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and others},
206 | journal={arXiv preprint arXiv:2203.02155},
207 | year={2022}
208 | }
209 | ```
210 |
--------------------------------------------------------------------------------
/code/benchmarks/README.md:
--------------------------------------------------------------------------------
1 | # Benchmarks
2 |
3 | ## Benchmark GPT on dummy prompt data
4 |
5 | We provide various GPT models (string in parentheses is the corresponding model name used in this script):
6 |
7 | - GPT2-S (s)
8 | - GPT2-M (m)
9 | - GPT2-L (l)
10 | - GPT2-XL (xl)
11 | - GPT2-4B (4b)
12 | - GPT2-6B (6b)
13 | - GPT2-8B (8b)
14 | - GPT2-10B (10b)
15 | - GPT2-12B (12b)
16 | - GPT2-15B (15b)
17 | - GPT2-18B (18b)
18 | - GPT2-20B (20b)
19 | - GPT2-24B (24b)
20 | - GPT2-28B (28b)
21 | - GPT2-32B (32b)
22 | - GPT2-36B (36b)
23 | - GPT2-40B (40b)
24 | - GPT3 (175b)
25 |
26 | We also provide various training strategies:
27 |
28 | - ddp: torch DDP
29 | - colossalai_gemini: ColossalAI GeminiDDP with `placement_policy="cuda"`, like zero3
30 | - colossalai_gemini_cpu: ColossalAI GeminiDDP with `placement_policy="cpu"`, like zero3-offload
31 | - colossalai_zero2: ColossalAI zero2
32 | - colossalai_zero2_cpu: ColossalAI zero2-offload
33 | - colossalai_zero1: ColossalAI zero1
34 | - colossalai_zero1_cpu: ColossalAI zero1-offload
35 |
36 | We only support `torchrun` to launch now. E.g.
37 |
38 | ```shell
39 | # run GPT2-S on single-node single-GPU with min batch size
40 | torchrun --standalone --nproc_per_node 1 benchmark_gpt_dummy.py --model s --strategy ddp --experience_batch_size 1 --train_batch_size 1
41 | # run GPT2-XL on single-node 4-GPU
42 | torchrun --standalone --nproc_per_node 4 benchmark_gpt_dummy.py --model xl --strategy colossalai_zero2
43 | # run GPT3 on 8-node 8-GPU
44 | torchrun --nnodes 8 --nproc_per_node 8 \
45 | --rdzv_id=$JOB_ID --rdzv_backend=c10d --rdzv_endpoint=$HOST_NODE_ADDR \
46 | benchmark_gpt_dummy.py --model 175b --strategy colossalai_gemini
47 | ```
48 |
49 | > ⚠ Batch sizes in CLI args and outputed throughput/TFLOPS are all values of per GPU.
50 |
51 | In this benchmark, we assume the model architectures/sizes of actor and critic are the same for simplicity. But in practice, to reduce training cost, we may use a smaller critic.
52 |
53 | We also provide a simple shell script to run a set of benchmarks. But it only supports benchmark on single node. However, it's easy to run on multi-nodes by modifying launch command in this script.
54 |
55 | Usage:
56 |
57 | ```shell
58 | # run for GPUS=(1 2 4 8) x strategy=("ddp" "colossalai_zero2" "colossalai_gemini" "colossalai_zero2_cpu" "colossalai_gemini_cpu") x model=("s" "m" "l" "xl" "2b" "4b" "6b" "8b" "10b") x batch_size=(1 2 4 8 16 32 64 128 256)
59 | ./benchmark_gpt_dummy.sh
60 | # run for GPUS=2 x strategy=("ddp" "colossalai_zero2" "colossalai_gemini" "colossalai_zero2_cpu" "colossalai_gemini_cpu") x model=("s" "m" "l" "xl" "2b" "4b" "6b" "8b" "10b") x batch_size=(1 2 4 8 16 32 64 128 256)
61 | ./benchmark_gpt_dummy.sh 2
62 | # run for GPUS=2 x strategy=ddp x model=("s" "m" "l" "xl" "2b" "4b" "6b" "8b" "10b") x batch_size=(1 2 4 8 16 32 64 128 256)
63 | ./benchmark_gpt_dummy.sh 2 ddp
64 | # run for GPUS=2 x strategy=ddp x model=l x batch_size=(1 2 4 8 16 32 64 128 256)
65 | ./benchmark_gpt_dummy.sh 2 ddp l
66 | ```
67 |
68 | ## Benchmark OPT with LoRA on dummy prompt data
69 |
70 | We provide various OPT models (string in parentheses is the corresponding model name used in this script):
71 |
72 | - OPT-125M (125m)
73 | - OPT-350M (350m)
74 | - OPT-700M (700m)
75 | - OPT-1.3B (1.3b)
76 | - OPT-2.7B (2.7b)
77 | - OPT-3.5B (3.5b)
78 | - OPT-5.5B (5.5b)
79 | - OPT-6.7B (6.7b)
80 | - OPT-10B (10b)
81 | - OPT-13B (13b)
82 |
83 | We only support `torchrun` to launch now. E.g.
84 |
85 | ```shell
86 | # run OPT-125M with no lora (lora_rank=0) on single-node single-GPU with min batch size
87 | torchrun --standalone --nproc_per_node 1 benchmark_opt_lora_dummy.py --model 125m --strategy ddp --experience_batch_size 1 --train_batch_size 1 --lora_rank 0
88 | # run OPT-350M with lora_rank=4 on single-node 4-GPU
89 | torchrun --standalone --nproc_per_node 4 benchmark_opt_lora_dummy.py --model 350m --strategy colossalai_zero2 --lora_rank 4
90 | ```
91 |
92 | > ⚠ Batch sizes in CLI args and outputed throughput/TFLOPS are all values of per GPU.
93 |
94 | In this benchmark, we assume the model architectures/sizes of actor and critic are the same for simplicity. But in practice, to reduce training cost, we may use a smaller critic.
95 |
--------------------------------------------------------------------------------
/code/benchmarks/benchmark_gpt_dummy.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | from copy import deepcopy
3 |
4 | import torch
5 | import torch.distributed as dist
6 | import torch.nn as nn
7 | from chatgpt.models.base import RewardModel
8 | from chatgpt.models.gpt import GPTActor, GPTCritic
9 | from chatgpt.trainer import PPOTrainer
10 | from chatgpt.trainer.callbacks import PerformanceEvaluator
11 | from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy, Strategy
12 | from torch.optim import Adam
13 | from transformers.models.gpt2.configuration_gpt2 import GPT2Config
14 | from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
15 |
16 | from colossalai.nn.optimizer import HybridAdam
17 |
18 |
19 | def get_model_numel(model: nn.Module, strategy: Strategy) -> int:
20 | numel = sum(p.numel() for p in model.parameters())
21 | if isinstance(strategy, ColossalAIStrategy) and strategy.stage == 3 and strategy.shard_init:
22 | numel *= dist.get_world_size()
23 | return numel
24 |
25 |
26 | def preprocess_batch(samples) -> dict:
27 | input_ids = torch.stack(samples)
28 | attention_mask = torch.ones_like(input_ids, dtype=torch.long)
29 | return {'input_ids': input_ids, 'attention_mask': attention_mask}
30 |
31 |
32 | def print_rank_0(*args, **kwargs) -> None:
33 | if dist.get_rank() == 0:
34 | print(*args, **kwargs)
35 |
36 |
37 | def print_model_numel(model_dict: dict) -> None:
38 | B = 1024**3
39 | M = 1024**2
40 | K = 1024
41 | outputs = ''
42 | for name, numel in model_dict.items():
43 | outputs += f'{name}: '
44 | if numel >= B:
45 | outputs += f'{numel / B:.2f} B\n'
46 | elif numel >= M:
47 | outputs += f'{numel / M:.2f} M\n'
48 | elif numel >= K:
49 | outputs += f'{numel / K:.2f} K\n'
50 | else:
51 | outputs += f'{numel}\n'
52 | print_rank_0(outputs)
53 |
54 |
55 | def get_gpt_config(model_name: str) -> GPT2Config:
56 | model_map = {
57 | 's': GPT2Config(),
58 | 'm': GPT2Config(n_embd=1024, n_layer=24, n_head=16),
59 | 'l': GPT2Config(n_embd=1280, n_layer=36, n_head=20),
60 | 'xl': GPT2Config(n_embd=1600, n_layer=48, n_head=25),
61 | '2b': GPT2Config(n_embd=2048, n_layer=40, n_head=16),
62 | '4b': GPT2Config(n_embd=2304, n_layer=64, n_head=16),
63 | '6b': GPT2Config(n_embd=4096, n_layer=30, n_head=16),
64 | '8b': GPT2Config(n_embd=4096, n_layer=40, n_head=16),
65 | '10b': GPT2Config(n_embd=4096, n_layer=50, n_head=16),
66 | '12b': GPT2Config(n_embd=4096, n_layer=60, n_head=16),
67 | '15b': GPT2Config(n_embd=4096, n_layer=78, n_head=16),
68 | '18b': GPT2Config(n_embd=4096, n_layer=90, n_head=16),
69 | '20b': GPT2Config(n_embd=8192, n_layer=25, n_head=16),
70 | '24b': GPT2Config(n_embd=8192, n_layer=30, n_head=16),
71 | '28b': GPT2Config(n_embd=8192, n_layer=35, n_head=16),
72 | '32b': GPT2Config(n_embd=8192, n_layer=40, n_head=16),
73 | '36b': GPT2Config(n_embd=8192, n_layer=45, n_head=16),
74 | '40b': GPT2Config(n_embd=8192, n_layer=50, n_head=16),
75 | '175b': GPT2Config(n_positions=2048, n_embd=12288, n_layer=96, n_head=96),
76 | }
77 | try:
78 | return model_map[model_name]
79 | except KeyError:
80 | raise ValueError(f'Unknown model "{model_name}"')
81 |
82 |
83 | def main(args):
84 | if args.strategy == 'ddp':
85 | strategy = DDPStrategy()
86 | elif args.strategy == 'colossalai_gemini':
87 | strategy = ColossalAIStrategy(stage=3, placement_policy='cuda', initial_scale=2**5)
88 | elif args.strategy == 'colossalai_gemini_cpu':
89 | strategy = ColossalAIStrategy(stage=3, placement_policy='cpu', initial_scale=2**5)
90 | elif args.strategy == 'colossalai_zero2':
91 | strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
92 | elif args.strategy == 'colossalai_zero2_cpu':
93 | strategy = ColossalAIStrategy(stage=2, placement_policy='cpu')
94 | elif args.strategy == 'colossalai_zero1':
95 | strategy = ColossalAIStrategy(stage=1, placement_policy='cuda')
96 | elif args.strategy == 'colossalai_zero1_cpu':
97 | strategy = ColossalAIStrategy(stage=1, placement_policy='cpu')
98 | else:
99 | raise ValueError(f'Unsupported strategy "{args.strategy}"')
100 |
101 | model_config = get_gpt_config(args.model)
102 |
103 | with strategy.model_init_context():
104 | actor = GPTActor(config=model_config).cuda()
105 | critic = GPTCritic(config=model_config).cuda()
106 |
107 | initial_model = deepcopy(actor).cuda()
108 | reward_model = RewardModel(deepcopy(critic.model), deepcopy(critic.value_head)).cuda()
109 |
110 | actor_numel = get_model_numel(actor, strategy)
111 | critic_numel = get_model_numel(critic, strategy)
112 | initial_model_numel = get_model_numel(initial_model, strategy)
113 | reward_model_numel = get_model_numel(reward_model, strategy)
114 | print_model_numel({
115 | 'Actor': actor_numel,
116 | 'Critic': critic_numel,
117 | 'Initial model': initial_model_numel,
118 | 'Reward model': reward_model_numel
119 | })
120 | performance_evaluator = PerformanceEvaluator(actor_numel,
121 | critic_numel,
122 | initial_model_numel,
123 | reward_model_numel,
124 | enable_grad_checkpoint=False,
125 | ignore_episodes=1)
126 |
127 | if args.strategy.startswith('colossalai'):
128 | actor_optim = HybridAdam(actor.parameters(), lr=5e-6)
129 | critic_optim = HybridAdam(critic.parameters(), lr=5e-6)
130 | else:
131 | actor_optim = Adam(actor.parameters(), lr=5e-6)
132 | critic_optim = Adam(critic.parameters(), lr=5e-6)
133 |
134 | tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
135 | tokenizer.pad_token = tokenizer.eos_token
136 |
137 | (actor, actor_optim), (critic, critic_optim), reward_model, initial_model = strategy.prepare(
138 | (actor, actor_optim), (critic, critic_optim), reward_model, initial_model)
139 |
140 | trainer = PPOTrainer(strategy,
141 | actor,
142 | critic,
143 | reward_model,
144 | initial_model,
145 | actor_optim,
146 | critic_optim,
147 | max_epochs=args.max_epochs,
148 | train_batch_size=args.train_batch_size,
149 | experience_batch_size=args.experience_batch_size,
150 | tokenizer=preprocess_batch,
151 | max_length=512,
152 | do_sample=True,
153 | temperature=1.0,
154 | top_k=50,
155 | pad_token_id=tokenizer.pad_token_id,
156 | eos_token_id=tokenizer.eos_token_id,
157 | callbacks=[performance_evaluator])
158 |
159 | random_prompts = torch.randint(tokenizer.vocab_size, (1000, 400), device=torch.cuda.current_device())
160 | trainer.fit(random_prompts,
161 | num_episodes=args.num_episodes,
162 | max_timesteps=args.max_timesteps,
163 | update_timesteps=args.update_timesteps)
164 |
165 | print_rank_0(f'Peak CUDA mem: {torch.cuda.max_memory_allocated()/1024**3:.2f} GB')
166 |
167 |
168 | if __name__ == '__main__':
169 | parser = argparse.ArgumentParser()
170 | parser.add_argument('--model', default='s')
171 | parser.add_argument('--strategy',
172 | choices=[
173 | 'ddp', 'colossalai_gemini', 'colossalai_gemini_cpu', 'colossalai_zero2',
174 | 'colossalai_zero2_cpu', 'colossalai_zero1', 'colossalai_zero1_cpu'
175 | ],
176 | default='ddp')
177 | parser.add_argument('--num_episodes', type=int, default=3)
178 | parser.add_argument('--max_timesteps', type=int, default=8)
179 | parser.add_argument('--update_timesteps', type=int, default=8)
180 | parser.add_argument('--max_epochs', type=int, default=3)
181 | parser.add_argument('--train_batch_size', type=int, default=8)
182 | parser.add_argument('--experience_batch_size', type=int, default=8)
183 | args = parser.parse_args()
184 | main(args)
185 |
--------------------------------------------------------------------------------
/code/benchmarks/benchmark_gpt_dummy.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env bash
2 | # Usage: $0
3 | set -xu
4 |
5 | BASE=$(realpath $(dirname $0))
6 |
7 |
8 | PY_SCRIPT=${BASE}/benchmark_gpt_dummy.py
9 | export OMP_NUM_THREADS=8
10 |
11 | function tune_batch_size() {
12 | # we found when experience batch size is equal to train batch size
13 | # peak CUDA memory usage of making experience phase is less than or equal to that of training phase
14 | # thus, experience batch size can be larger than or equal to train batch size
15 | for bs in 1 2 4 8 16 32 64 128 256; do
16 | torchrun --standalone --nproc_per_node $1 $PY_SCRIPT --model $2 --strategy $3 --experience_batch_size $bs --train_batch_size $bs || return 1
17 | done
18 | }
19 |
20 | if [ $# -eq 0 ]; then
21 | num_gpus=(1 2 4 8)
22 | else
23 | num_gpus=($1)
24 | fi
25 |
26 | if [ $# -le 1 ]; then
27 | strategies=("ddp" "colossalai_zero2" "colossalai_gemini" "colossalai_zero2_cpu" "colossalai_gemini_cpu")
28 | else
29 | strategies=($2)
30 | fi
31 |
32 | if [ $# -le 2 ]; then
33 | models=("s" "m" "l" "xl" "2b" "4b" "6b" "8b" "10b")
34 | else
35 | models=($3)
36 | fi
37 |
38 |
39 | for num_gpu in ${num_gpus[@]}; do
40 | for strategy in ${strategies[@]}; do
41 | for model in ${models[@]}; do
42 | tune_batch_size $num_gpu $model $strategy || break
43 | done
44 | done
45 | done
46 |
--------------------------------------------------------------------------------
/code/benchmarks/benchmark_opt_lora_dummy.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | from copy import deepcopy
3 |
4 | import torch
5 | import torch.distributed as dist
6 | import torch.nn as nn
7 | from chatgpt.models.base import RewardModel
8 | from chatgpt.models.opt import OPTActor, OPTCritic
9 | from chatgpt.trainer import PPOTrainer
10 | from chatgpt.trainer.callbacks import PerformanceEvaluator
11 | from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy, Strategy
12 | from torch.optim import Adam
13 | from transformers import AutoTokenizer
14 | from transformers.models.opt.configuration_opt import OPTConfig
15 |
16 | from colossalai.nn.optimizer import HybridAdam
17 |
18 |
19 | def get_model_numel(model: nn.Module, strategy: Strategy) -> int:
20 | numel = sum(p.numel() for p in model.parameters())
21 | if isinstance(strategy, ColossalAIStrategy) and strategy.stage == 3 and strategy.shard_init:
22 | numel *= dist.get_world_size()
23 | return numel
24 |
25 |
26 | def preprocess_batch(samples) -> dict:
27 | input_ids = torch.stack(samples)
28 | attention_mask = torch.ones_like(input_ids, dtype=torch.long)
29 | return {'input_ids': input_ids, 'attention_mask': attention_mask}
30 |
31 |
32 | def print_rank_0(*args, **kwargs) -> None:
33 | if dist.get_rank() == 0:
34 | print(*args, **kwargs)
35 |
36 |
37 | def print_model_numel(model_dict: dict) -> None:
38 | B = 1024**3
39 | M = 1024**2
40 | K = 1024
41 | outputs = ''
42 | for name, numel in model_dict.items():
43 | outputs += f'{name}: '
44 | if numel >= B:
45 | outputs += f'{numel / B:.2f} B\n'
46 | elif numel >= M:
47 | outputs += f'{numel / M:.2f} M\n'
48 | elif numel >= K:
49 | outputs += f'{numel / K:.2f} K\n'
50 | else:
51 | outputs += f'{numel}\n'
52 | print_rank_0(outputs)
53 |
54 |
55 | def get_gpt_config(model_name: str) -> OPTConfig:
56 | model_map = {
57 | '125m': OPTConfig.from_pretrained('facebook/opt-125m'),
58 | '350m': OPTConfig(hidden_size=1024, ffn_dim=4096, num_hidden_layers=24, num_attention_heads=16),
59 | '700m': OPTConfig(hidden_size=1280, ffn_dim=5120, num_hidden_layers=36, num_attention_heads=20),
60 | '1.3b': OPTConfig.from_pretrained('facebook/opt-1.3b'),
61 | '2.7b': OPTConfig.from_pretrained('facebook/opt-2.7b'),
62 | '3.5b': OPTConfig(hidden_size=3072, ffn_dim=12288, num_hidden_layers=32, num_attention_heads=32),
63 | '5.5b': OPTConfig(hidden_size=3840, ffn_dim=15360, num_hidden_layers=32, num_attention_heads=32),
64 | '6.7b': OPTConfig.from_pretrained('facebook/opt-6.7b'),
65 | '10b': OPTConfig(hidden_size=5120, ffn_dim=20480, num_hidden_layers=32, num_attention_heads=32),
66 | '13b': OPTConfig.from_pretrained('facebook/opt-13b'),
67 | }
68 | try:
69 | return model_map[model_name]
70 | except KeyError:
71 | raise ValueError(f'Unknown model "{model_name}"')
72 |
73 |
74 | def main(args):
75 | if args.strategy == 'ddp':
76 | strategy = DDPStrategy()
77 | elif args.strategy == 'colossalai_gemini':
78 | strategy = ColossalAIStrategy(stage=3, placement_policy='cuda', initial_scale=2**5)
79 | elif args.strategy == 'colossalai_gemini_cpu':
80 | strategy = ColossalAIStrategy(stage=3, placement_policy='cpu', initial_scale=2**5)
81 | elif args.strategy == 'colossalai_zero2':
82 | strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
83 | elif args.strategy == 'colossalai_zero2_cpu':
84 | strategy = ColossalAIStrategy(stage=2, placement_policy='cpu')
85 | elif args.strategy == 'colossalai_zero1':
86 | strategy = ColossalAIStrategy(stage=1, placement_policy='cuda')
87 | elif args.strategy == 'colossalai_zero1_cpu':
88 | strategy = ColossalAIStrategy(stage=1, placement_policy='cpu')
89 | else:
90 | raise ValueError(f'Unsupported strategy "{args.strategy}"')
91 |
92 | torch.cuda.set_per_process_memory_fraction(args.cuda_mem_frac)
93 |
94 | model_config = get_gpt_config(args.model)
95 |
96 | with strategy.model_init_context():
97 | actor = OPTActor(config=model_config, lora_rank=args.lora_rank).cuda()
98 | critic = OPTCritic(config=model_config, lora_rank=args.lora_rank).cuda()
99 |
100 | initial_model = deepcopy(actor).cuda()
101 | reward_model = RewardModel(deepcopy(critic.model), deepcopy(critic.value_head)).cuda()
102 |
103 | actor_numel = get_model_numel(actor, strategy)
104 | critic_numel = get_model_numel(critic, strategy)
105 | initial_model_numel = get_model_numel(initial_model, strategy)
106 | reward_model_numel = get_model_numel(reward_model, strategy)
107 | print_model_numel({
108 | 'Actor': actor_numel,
109 | 'Critic': critic_numel,
110 | 'Initial model': initial_model_numel,
111 | 'Reward model': reward_model_numel
112 | })
113 | performance_evaluator = PerformanceEvaluator(actor_numel,
114 | critic_numel,
115 | initial_model_numel,
116 | reward_model_numel,
117 | enable_grad_checkpoint=False,
118 | ignore_episodes=1)
119 |
120 | if args.strategy.startswith('colossalai'):
121 | actor_optim = HybridAdam(actor.parameters(), lr=5e-6)
122 | critic_optim = HybridAdam(critic.parameters(), lr=5e-6)
123 | else:
124 | actor_optim = Adam(actor.parameters(), lr=5e-6)
125 | critic_optim = Adam(critic.parameters(), lr=5e-6)
126 |
127 | tokenizer = AutoTokenizer.from_pretrained('facebook/opt-350m')
128 | tokenizer.pad_token = tokenizer.eos_token
129 |
130 | (actor, actor_optim), (critic, critic_optim), reward_model, initial_model = strategy.prepare(
131 | (actor, actor_optim), (critic, critic_optim), reward_model, initial_model)
132 |
133 | trainer = PPOTrainer(strategy,
134 | actor,
135 | critic,
136 | reward_model,
137 | initial_model,
138 | actor_optim,
139 | critic_optim,
140 | max_epochs=args.max_epochs,
141 | train_batch_size=args.train_batch_size,
142 | experience_batch_size=args.experience_batch_size,
143 | tokenizer=preprocess_batch,
144 | max_length=512,
145 | do_sample=True,
146 | temperature=1.0,
147 | top_k=50,
148 | pad_token_id=tokenizer.pad_token_id,
149 | eos_token_id=tokenizer.eos_token_id,
150 | callbacks=[performance_evaluator])
151 |
152 | random_prompts = torch.randint(tokenizer.vocab_size, (1000, 400), device=torch.cuda.current_device())
153 | trainer.fit(random_prompts,
154 | num_episodes=args.num_episodes,
155 | max_timesteps=args.max_timesteps,
156 | update_timesteps=args.update_timesteps)
157 |
158 | print_rank_0(f'Peak CUDA mem: {torch.cuda.max_memory_allocated()/1024**3:.2f} GB')
159 |
160 |
161 | if __name__ == '__main__':
162 | parser = argparse.ArgumentParser()
163 | parser.add_argument('--model', default='125m')
164 | parser.add_argument('--strategy',
165 | choices=[
166 | 'ddp', 'colossalai_gemini', 'colossalai_gemini_cpu', 'colossalai_zero2',
167 | 'colossalai_zero2_cpu', 'colossalai_zero1', 'colossalai_zero1_cpu'
168 | ],
169 | default='ddp')
170 | parser.add_argument('--num_episodes', type=int, default=3)
171 | parser.add_argument('--max_timesteps', type=int, default=8)
172 | parser.add_argument('--update_timesteps', type=int, default=8)
173 | parser.add_argument('--max_epochs', type=int, default=3)
174 | parser.add_argument('--train_batch_size', type=int, default=8)
175 | parser.add_argument('--experience_batch_size', type=int, default=8)
176 | parser.add_argument('--lora_rank', type=int, default=4)
177 | parser.add_argument('--cuda_mem_frac', type=float, default=1.0)
178 | args = parser.parse_args()
179 | main(args)
180 |
--------------------------------------------------------------------------------
/code/chatgpt/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/__init__.py
--------------------------------------------------------------------------------
/code/chatgpt/__pycache__/__init__.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/__pycache__/__init__.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/dataset/__init__.py:
--------------------------------------------------------------------------------
1 | from .reward_dataset import RewardDataset
2 | from .utils import is_rank_0
3 |
4 | __all__ = ['RewardDataset', 'is_rank_0']
5 |
--------------------------------------------------------------------------------
/code/chatgpt/dataset/__pycache__/__init__.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/dataset/__pycache__/__init__.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/dataset/__pycache__/reward_dataset.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/dataset/__pycache__/reward_dataset.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/dataset/__pycache__/utils.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/dataset/__pycache__/utils.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/dataset/reward_dataset.py:
--------------------------------------------------------------------------------
1 | from typing import Callable
2 |
3 | from torch.utils.data import Dataset
4 | from tqdm import tqdm
5 |
6 | from .utils import is_rank_0
7 |
8 |
9 | class RewardDataset(Dataset):
10 | """
11 | Dataset for reward model
12 |
13 | Args:
14 | dataset: dataset for reward model
15 | tokenizer: tokenizer for reward model
16 | max_length: max length of input
17 | """
18 |
19 | def __init__(self, dataset, tokenizer: Callable, max_length: int) -> None:
20 | super().__init__()
21 | self.chosen = []
22 | self.reject = []
23 | for data in tqdm(dataset, disable=not is_rank_0()):
24 | prompt = data['prompt']
25 |
26 | chosen = prompt + data['chosen'] + tokenizer.eos_token #"<|endoftext|>"
27 | chosen_token = tokenizer(chosen,
28 | max_length=max_length,
29 | padding="max_length",
30 | truncation=True,
31 | return_tensors="pt")
32 | self.chosen.append({
33 | "input_ids": chosen_token['input_ids'],
34 | "attention_mask": chosen_token['attention_mask']
35 | })
36 |
37 | reject = prompt + data['rejected'] + tokenizer.eos_token
38 | reject_token = tokenizer(reject,
39 | max_length=max_length,
40 | padding="max_length",
41 | truncation=True,
42 | return_tensors="pt")
43 | self.reject.append({
44 | "input_ids": reject_token['input_ids'],
45 | "attention_mask": reject_token['attention_mask']
46 | })
47 |
48 | def __len__(self):
49 | length = len(self.chosen)
50 | return length
51 |
52 | def __getitem__(self, idx):
53 | return self.chosen[idx]["input_ids"], self.chosen[idx]["attention_mask"], self.reject[idx]["input_ids"], self.reject[idx]["attention_mask"]
54 |
--------------------------------------------------------------------------------
/code/chatgpt/dataset/utils.py:
--------------------------------------------------------------------------------
1 | import torch.distributed as dist
2 |
3 |
4 | def is_rank_0() -> bool:
5 | return not dist.is_initialized() or dist.get_rank() == 0
6 |
--------------------------------------------------------------------------------
/code/chatgpt/experience_maker/__init__.py:
--------------------------------------------------------------------------------
1 | from .base import Experience, ExperienceMaker
2 | from .naive import NaiveExperienceMaker
3 |
4 | __all__ = ['Experience', 'ExperienceMaker', 'NaiveExperienceMaker']
5 |
--------------------------------------------------------------------------------
/code/chatgpt/experience_maker/__pycache__/__init__.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/experience_maker/__pycache__/__init__.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/experience_maker/__pycache__/base.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/experience_maker/__pycache__/base.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/experience_maker/__pycache__/naive.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/experience_maker/__pycache__/naive.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/experience_maker/base.py:
--------------------------------------------------------------------------------
1 | from abc import ABC, abstractmethod
2 | from dataclasses import dataclass
3 | from typing import Optional
4 |
5 | import torch
6 | import torch.nn as nn
7 | from chatgpt.models.base import Actor
8 |
9 |
10 | @dataclass
11 | class Experience:
12 | """Experience is a batch of data.
13 | These data should have the the sequence length and number of actions.
14 | Left padding for sequences is applied.
15 |
16 | Shapes of each tensor:
17 | sequences: (B, S)
18 | action_log_probs: (B, A)
19 | values: (B)
20 | reward: (B)
21 | advatanges: (B)
22 | attention_mask: (B, S)
23 | action_mask: (B, A)
24 |
25 | "A" is the number of actions.
26 | """
27 | sequences: torch.Tensor
28 | action_log_probs: torch.Tensor
29 | values: torch.Tensor
30 | reward: torch.Tensor
31 | advantages: torch.Tensor
32 | attention_mask: Optional[torch.LongTensor]
33 | action_mask: Optional[torch.BoolTensor]
34 |
35 | @torch.no_grad()
36 | def to_device(self, device: torch.device) -> None:
37 | self.sequences = self.sequences.to(device)
38 | self.action_log_probs = self.action_log_probs.to(device)
39 | self.values = self.values.to(device)
40 | self.reward = self.reward.to(device)
41 | self.advantages = self.advantages.to(device)
42 | if self.attention_mask is not None:
43 | self.attention_mask = self.attention_mask.to(device)
44 | if self.action_mask is not None:
45 | self.action_mask = self.action_mask.to(device)
46 |
47 | def pin_memory(self):
48 | self.sequences = self.sequences.pin_memory()
49 | self.action_log_probs = self.action_log_probs.pin_memory()
50 | self.values = self.values.pin_memory()
51 | self.reward = self.reward.pin_memory()
52 | self.advantages = self.advantages.pin_memory()
53 | if self.attention_mask is not None:
54 | self.attention_mask = self.attention_mask.pin_memory()
55 | if self.action_mask is not None:
56 | self.action_mask = self.action_mask.pin_memory()
57 | return self
58 |
59 |
60 | class ExperienceMaker(ABC):
61 |
62 | def __init__(self,
63 | actor: Actor,
64 | critic: nn.Module,
65 | reward_model: nn.Module,
66 | initial_model: Actor,
67 | kl_coef: float = 0.1) -> None:
68 | super().__init__()
69 | self.actor = actor
70 | self.critic = critic
71 | self.reward_model = reward_model
72 | self.initial_model = initial_model
73 | self.kl_coef = kl_coef
74 |
75 | @abstractmethod
76 | def make_experience(self, input_ids: torch.Tensor, **generate_kwargs) -> Experience:
77 | pass
78 |
--------------------------------------------------------------------------------
/code/chatgpt/experience_maker/naive.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from chatgpt.models.utils import compute_reward, normalize
3 |
4 | from .base import Experience, ExperienceMaker
5 |
6 |
7 | class NaiveExperienceMaker(ExperienceMaker):
8 | """
9 | Naive experience maker.
10 | """
11 |
12 | @torch.no_grad()
13 | def make_experience(self, input_ids: torch.Tensor, **generate_kwargs) -> Experience:
14 | self.actor.eval()
15 | self.critic.eval()
16 | self.initial_model.eval()
17 | self.reward_model.eval()
18 |
19 | sequences, attention_mask, action_mask = self.actor.generate(input_ids,
20 | return_action_mask=True,
21 | **generate_kwargs)
22 | num_actions = action_mask.size(1)
23 |
24 | action_log_probs = self.actor(sequences, num_actions, attention_mask)
25 | base_action_log_probs = self.initial_model(sequences, num_actions, attention_mask)
26 | value = self.critic(sequences, action_mask, attention_mask)
27 | r = self.reward_model(sequences, attention_mask)
28 |
29 | reward = compute_reward(r, self.kl_coef, action_log_probs, base_action_log_probs, action_mask=action_mask)
30 |
31 | advantage = reward - value
32 | # TODO(ver217): maybe normalize adv
33 | if advantage.ndim == 1:
34 | advantage = advantage.unsqueeze(-1)
35 |
36 | return Experience(sequences, action_log_probs, value, reward, advantage, attention_mask, action_mask)
37 |
--------------------------------------------------------------------------------
/code/chatgpt/models/__init__.py:
--------------------------------------------------------------------------------
1 | from .base import Actor, Critic, RewardModel
2 | from .loss import PairWiseLoss, PolicyLoss, PPOPtxActorLoss, ValueLoss
3 |
4 | __all__ = ['Actor', 'Critic', 'RewardModel', 'PolicyLoss', 'ValueLoss', 'PPOPtxActorLoss', 'PairWiseLoss']
5 |
--------------------------------------------------------------------------------
/code/chatgpt/models/__pycache__/__init__.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/__pycache__/__init__.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/__pycache__/generation.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/__pycache__/generation.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/__pycache__/generation_utils.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/__pycache__/generation_utils.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/__pycache__/lora.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/__pycache__/lora.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/__pycache__/loss.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/__pycache__/loss.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/__pycache__/utils.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/__pycache__/utils.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/base/__init__.py:
--------------------------------------------------------------------------------
1 | from .actor import Actor
2 | from .critic import Critic
3 | from .reward_model import RewardModel
4 |
5 | __all__ = ['Actor', 'Critic', 'RewardModel']
6 |
--------------------------------------------------------------------------------
/code/chatgpt/models/base/__pycache__/__init__.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/base/__pycache__/__init__.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/base/__pycache__/actor.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/base/__pycache__/actor.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/base/__pycache__/critic.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/base/__pycache__/critic.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/base/__pycache__/reward_model.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/base/__pycache__/reward_model.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/base/actor.py:
--------------------------------------------------------------------------------
1 | from typing import Optional, Tuple, Union
2 |
3 | import torch
4 | import torch.nn as nn
5 | import torch.nn.functional as F
6 |
7 | from ..generation import generate
8 | from ..lora import LoRAModule
9 | from ..utils import log_probs_from_logits
10 |
11 |
12 | class Actor(LoRAModule):
13 | """
14 | Actor model base class.
15 |
16 | Args:
17 | model (nn.Module): Actor Model.
18 | lora_rank (int): LoRA rank.
19 | lora_train_bias (str): LoRA bias training mode.
20 | """
21 |
22 | def __init__(self, model: nn.Module, lora_rank: int = 0, lora_train_bias: str = 'none') -> None:
23 | super().__init__(lora_rank=lora_rank, lora_train_bias=lora_train_bias)
24 | self.model = model
25 | self.convert_to_lora()
26 |
27 | @torch.no_grad()
28 | def generate(
29 | self,
30 | input_ids: torch.Tensor,
31 | return_action_mask: bool = True,
32 | **kwargs
33 | ) -> Union[Tuple[torch.LongTensor, torch.LongTensor], Tuple[torch.LongTensor, torch.LongTensor, torch.BoolTensor]]:
34 | sequences = generate(self.model, input_ids, **kwargs)
35 | attention_mask = None
36 | pad_token_id = kwargs.get('pad_token_id', None)
37 | if pad_token_id is not None:
38 | attention_mask = sequences.not_equal(pad_token_id).to(dtype=torch.long, device=sequences.device)
39 | if not return_action_mask:
40 | return sequences, attention_mask, None
41 | input_len = input_ids.size(1)
42 | eos_token_id = kwargs.get('eos_token_id', None)
43 | if eos_token_id is None:
44 | action_mask = torch.ones_like(sequences, dtype=torch.bool)
45 | else:
46 | # left padding may be applied, only mask action
47 | action_mask = (sequences[:, input_len:] == eos_token_id).cumsum(dim=-1) == 0
48 | action_mask = F.pad(action_mask, (1 + input_len, -1), value=True) # include eos token and input
49 | action_mask[:, :input_len] = False
50 | action_mask = action_mask[:, 1:]
51 | return sequences, attention_mask, action_mask[:, -(sequences.size(1) - input_len):]
52 |
53 | def forward(self,
54 | sequences: torch.LongTensor,
55 | num_actions: int,
56 | attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
57 | """Returns action log probs
58 | """
59 | output = self.model(sequences, attention_mask=attention_mask)
60 | logits = output['logits']
61 | log_probs = log_probs_from_logits(logits[:, :-1, :], sequences[:, 1:])
62 | return log_probs[:, -num_actions:]
63 |
--------------------------------------------------------------------------------
/code/chatgpt/models/base/critic.py:
--------------------------------------------------------------------------------
1 | from typing import Optional
2 |
3 | import torch
4 | import torch.nn as nn
5 |
6 | from ..lora import LoRAModule
7 | from ..utils import masked_mean
8 |
9 |
10 | class Critic(LoRAModule):
11 | """
12 | Critic model base class.
13 |
14 | Args:
15 | model (nn.Module): Critic model.
16 | value_head (nn.Module): Value head to get value.
17 | lora_rank (int): LoRA rank.
18 | lora_train_bias (str): LoRA bias training mode.
19 | """
20 |
21 | def __init__(
22 | self,
23 | model: nn.Module,
24 | value_head: nn.Module,
25 | lora_rank: int = 0,
26 | lora_train_bias: str = 'none',
27 | use_action_mask: bool = False,
28 | ) -> None:
29 |
30 | super().__init__(lora_rank=lora_rank, lora_train_bias=lora_train_bias)
31 | self.model = model
32 | self.value_head = value_head
33 | self.use_action_mask = use_action_mask
34 | self.convert_to_lora()
35 |
36 | def forward(self,
37 | sequences: torch.LongTensor,
38 | action_mask: Optional[torch.Tensor] = None,
39 | attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
40 | outputs = self.model(sequences, attention_mask=attention_mask)
41 | last_hidden_states = outputs['last_hidden_state']
42 |
43 | values = self.value_head(last_hidden_states).squeeze(-1)
44 |
45 | if action_mask is not None and self.use_action_mask:
46 | num_actions = action_mask.size(1)
47 | prompt_mask = attention_mask[:, :-num_actions]
48 | values = values[:, :-num_actions]
49 | value = masked_mean(values, prompt_mask, dim=1)
50 | return value
51 |
52 | values = values[:, :-1]
53 | value = values.mean(dim=1)
54 | return value
55 |
--------------------------------------------------------------------------------
/code/chatgpt/models/base/reward_model.py:
--------------------------------------------------------------------------------
1 | from typing import Optional
2 |
3 | import torch
4 | import torch.nn as nn
5 |
6 | from ..lora import LoRAModule
7 |
8 |
9 | class RewardModel(LoRAModule):
10 | """
11 | Reward model base class.
12 |
13 | Args:
14 | model (nn.Module): Reward model.
15 | value_head (nn.Module): Value head to get reward score.
16 | lora_rank (int): LoRA rank.
17 | lora_train_bias (str): LoRA bias training mode.
18 | """
19 |
20 | def __init__(self,
21 | model: nn.Module,
22 | value_head: Optional[nn.Module] = None,
23 | lora_rank: int = 0,
24 | lora_train_bias: str = 'none') -> None:
25 | super().__init__(lora_rank=lora_rank, lora_train_bias=lora_train_bias)
26 | self.model = model
27 | self.convert_to_lora()
28 |
29 | if value_head is not None:
30 | if value_head.out_features != 1:
31 | raise ValueError("The value head of reward model's output dim should be 1!")
32 | self.value_head = value_head
33 | else:
34 | self.value_head = nn.Linear(model.config.n_embd, 1)
35 |
36 | def forward(self, sequences: torch.LongTensor, attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
37 | outputs = self.model(sequences, attention_mask=attention_mask)
38 | last_hidden_states = outputs['last_hidden_state']
39 | values = self.value_head(last_hidden_states)[:, :-1]
40 | value = values.mean(dim=1).squeeze(1) # ensure shape is (B)
41 | return value
42 |
--------------------------------------------------------------------------------
/code/chatgpt/models/bloom/__init__.py:
--------------------------------------------------------------------------------
1 | from .bloom_actor import BLOOMActor
2 | from .bloom_critic import BLOOMCritic
3 | from .bloom_rm import BLOOMRM
4 |
5 | __all__ = ['BLOOMActor', 'BLOOMCritic', 'BLOOMRM']
6 |
--------------------------------------------------------------------------------
/code/chatgpt/models/bloom/__pycache__/__init__.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/bloom/__pycache__/__init__.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/bloom/__pycache__/bloom_actor.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/bloom/__pycache__/bloom_actor.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/bloom/__pycache__/bloom_critic.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/bloom/__pycache__/bloom_critic.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/bloom/__pycache__/bloom_rm.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/bloom/__pycache__/bloom_rm.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/bloom/bloom_actor.py:
--------------------------------------------------------------------------------
1 | from typing import Optional
2 |
3 | import torch
4 | from transformers import BloomConfig, BloomForCausalLM, BloomModel
5 |
6 | from ..base import Actor
7 |
8 |
9 | class BLOOMActor(Actor):
10 | """
11 | BLOOM Actor model.
12 |
13 | Args:
14 | pretrained (str): Pretrained model name or path.
15 | config (BloomConfig): Model config.
16 | checkpoint (bool): Enable gradient checkpointing.
17 | lora_rank (int): LoRA rank.
18 | lora_train_bias (str): LoRA bias training mode.
19 | """
20 |
21 | def __init__(self,
22 | pretrained: str = None,
23 | config: Optional[BloomConfig] = None,
24 | checkpoint: bool = False,
25 | lora_rank: int = 0,
26 | lora_train_bias: str = 'none') -> None:
27 | if pretrained is not None:
28 | model = BloomForCausalLM.from_pretrained(pretrained)
29 | elif config is not None:
30 | model = BloomForCausalLM(config)
31 | else:
32 | model = BloomForCausalLM(BloomConfig())
33 | if checkpoint:
34 | model.gradient_checkpointing_enable()
35 | super().__init__(model, lora_rank, lora_train_bias)
36 |
--------------------------------------------------------------------------------
/code/chatgpt/models/bloom/bloom_critic.py:
--------------------------------------------------------------------------------
1 | from typing import Optional
2 |
3 | import torch
4 | import torch.nn as nn
5 | from transformers import BloomConfig, BloomForCausalLM, BloomModel
6 |
7 | from ..base import Critic
8 |
9 |
10 | class BLOOMCritic(Critic):
11 | """
12 | BLOOM Critic model.
13 |
14 | Args:
15 | pretrained (str): Pretrained model name or path.
16 | config (BloomConfig): Model config.
17 | checkpoint (bool): Enable gradient checkpointing.
18 | lora_rank (int): LoRA rank.
19 | lora_train_bias (str): LoRA bias training mode.
20 | """
21 |
22 | def __init__(self,
23 | pretrained: str = None,
24 | config: Optional[BloomConfig] = None,
25 | checkpoint: bool = False,
26 | lora_rank: int = 0,
27 | lora_train_bias: str = 'none',
28 | **kwargs) -> None:
29 | if pretrained is not None:
30 | model = BloomModel.from_pretrained(pretrained)
31 | elif config is not None:
32 | model = BloomModel(config)
33 | else:
34 | model = BloomModel(BloomConfig())
35 | if checkpoint:
36 | model.gradient_checkpointing_enable()
37 | value_head = nn.Linear(model.config.hidden_size, 1)
38 | super().__init__(model, value_head, lora_rank, lora_train_bias, **kwargs)
39 |
--------------------------------------------------------------------------------
/code/chatgpt/models/bloom/bloom_rm.py:
--------------------------------------------------------------------------------
1 | from typing import Optional
2 |
3 | import torch.nn as nn
4 | from transformers import BloomConfig, BloomForCausalLM, BloomModel
5 |
6 | from ..base import RewardModel
7 |
8 |
9 | class BLOOMRM(RewardModel):
10 | """
11 | BLOOM Reward model.
12 |
13 | Args:
14 | pretrained (str): Pretrained model name or path.
15 | config (BloomConfig): Model config.
16 | checkpoint (bool): Enable gradient checkpointing.
17 | lora_rank (int): LoRA rank.
18 | lora_train_bias (str): LoRA bias training mode.
19 | """
20 |
21 | def __init__(self,
22 | pretrained: str = None,
23 | config: Optional[BloomConfig] = None,
24 | checkpoint: bool = False,
25 | lora_rank: int = 0,
26 | lora_train_bias: str = 'none') -> None:
27 | if pretrained is not None:
28 | model = BloomModel.from_pretrained(pretrained)
29 | elif config is not None:
30 | model = BloomModel(config)
31 | else:
32 | model = BloomModel(BloomConfig())
33 | if checkpoint:
34 | model.gradient_checkpointing_enable()
35 | value_head = nn.Linear(model.config.hidden_size, 1)
36 | super().__init__(model, value_head, lora_rank, lora_train_bias)
37 |
--------------------------------------------------------------------------------
/code/chatgpt/models/generation.py:
--------------------------------------------------------------------------------
1 | from typing import Any, Callable, Optional
2 |
3 | import torch
4 | import torch.distributed as dist
5 | import torch.nn as nn
6 |
7 | try:
8 | from transformers.generation_logits_process import (
9 | LogitsProcessorList,
10 | TemperatureLogitsWarper,
11 | TopKLogitsWarper,
12 | TopPLogitsWarper,
13 | )
14 | except ImportError:
15 | from transformers.generation import LogitsProcessorList, TemperatureLogitsWarper, TopKLogitsWarper, TopPLogitsWarper
16 |
17 |
18 | def prepare_logits_processor(top_k: Optional[int] = None,
19 | top_p: Optional[float] = None,
20 | temperature: Optional[float] = None) -> LogitsProcessorList:
21 | processor_list = LogitsProcessorList()
22 | if temperature is not None and temperature != 1.0:
23 | processor_list.append(TemperatureLogitsWarper(temperature))
24 | if top_k is not None and top_k != 0:
25 | processor_list.append(TopKLogitsWarper(top_k))
26 | if top_p is not None and top_p < 1.0:
27 | processor_list.append(TopPLogitsWarper(top_p))
28 | return processor_list
29 |
30 |
31 | def _is_sequence_finished(unfinished_sequences: torch.Tensor) -> bool:
32 | if dist.is_initialized() and dist.get_world_size() > 1:
33 | # consider DP
34 | unfinished_sequences = unfinished_sequences.clone()
35 | dist.all_reduce(unfinished_sequences)
36 | return unfinished_sequences.max() == 0
37 |
38 |
39 | def sample(model: nn.Module,
40 | input_ids: torch.Tensor,
41 | max_length: int,
42 | early_stopping: bool = False,
43 | eos_token_id: Optional[int] = None,
44 | pad_token_id: Optional[int] = None,
45 | top_k: Optional[int] = None,
46 | top_p: Optional[float] = None,
47 | temperature: Optional[float] = None,
48 | prepare_inputs_fn: Optional[Callable[[torch.Tensor, Any], dict]] = None,
49 | update_model_kwargs_fn: Optional[Callable[[dict, Any], dict]] = None,
50 | **model_kwargs) -> torch.Tensor:
51 | if input_ids.size(1) >= max_length:
52 | return input_ids
53 |
54 | logits_processor = prepare_logits_processor(top_k, top_p, temperature)
55 | unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
56 |
57 | for _ in range(input_ids.size(1), max_length):
58 | model_inputs = prepare_inputs_fn(input_ids, **model_kwargs) if prepare_inputs_fn is not None else {
59 | 'input_ids': input_ids
60 | }
61 | outputs = model(**model_inputs)
62 |
63 | next_token_logits = outputs['logits'][:, -1, :]
64 | # pre-process distribution
65 | next_token_logits = logits_processor(input_ids, next_token_logits)
66 | # sample
67 | probs = torch.softmax(next_token_logits, dim=-1, dtype=torch.float)
68 | next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
69 |
70 | # finished sentences should have their next token be a padding token
71 | if eos_token_id is not None:
72 | if pad_token_id is None:
73 | raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
74 | next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)
75 |
76 | # update generated ids, model inputs for next step
77 | input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
78 | if update_model_kwargs_fn is not None:
79 | model_kwargs = update_model_kwargs_fn(outputs, **model_kwargs)
80 |
81 | # if eos_token was found in one sentence, set sentence to finished
82 | if eos_token_id is not None:
83 | unfinished_sequences = unfinished_sequences.mul((next_tokens != eos_token_id).long())
84 |
85 | # stop when each sentence is finished if early_stopping=True
86 | if early_stopping and _is_sequence_finished(unfinished_sequences):
87 | break
88 |
89 | return input_ids
90 |
91 |
92 | def generate(model: nn.Module,
93 | input_ids: torch.Tensor,
94 | max_length: int,
95 | num_beams: int = 1,
96 | do_sample: bool = True,
97 | early_stopping: bool = False,
98 | eos_token_id: Optional[int] = None,
99 | pad_token_id: Optional[int] = None,
100 | top_k: Optional[int] = None,
101 | top_p: Optional[float] = None,
102 | temperature: Optional[float] = None,
103 | prepare_inputs_fn: Optional[Callable[[torch.Tensor, Any], dict]] = None,
104 | update_model_kwargs_fn: Optional[Callable[[dict, Any], dict]] = None,
105 | **model_kwargs) -> torch.Tensor:
106 | """Generate token sequence. The returned sequence is input_ids + generated_tokens.
107 |
108 | Args:
109 | model (nn.Module): model
110 | input_ids (torch.Tensor): input sequence
111 | max_length (int): max length of the returned sequence
112 | num_beams (int, optional): number of beams. Defaults to 1.
113 | do_sample (bool, optional): whether to do sample. Defaults to True.
114 | early_stopping (bool, optional): if True, the sequence length may be smaller than max_length due to finding eos. Defaults to False.
115 | eos_token_id (Optional[int], optional): end of sequence token id. Defaults to None.
116 | pad_token_id (Optional[int], optional): pad token id. Defaults to None.
117 | top_k (Optional[int], optional): the number of highest probability vocabulary tokens to keep for top-k-filtering. Defaults to None.
118 | top_p (Optional[float], optional): If set to float < 1, only the smallest set of most probable tokens with probabilities that add up to top_p or higher are kept for generation. Defaults to None.
119 | temperature (Optional[float], optional): The value used to module the next token probabilities. Defaults to None.
120 | prepare_inputs_fn (Optional[Callable[[torch.Tensor, Any], dict]], optional): Function to preprocess model inputs. Arguments of this function should be input_ids and model_kwargs. Defaults to None.
121 | update_model_kwargs_fn (Optional[Callable[[dict, Any], dict]], optional): Function to update model_kwargs based on outputs. Arguments of this function should be outputs and model_kwargs. Defaults to None.
122 | """
123 | is_greedy_gen_mode = ((num_beams == 1) and do_sample is False)
124 | is_sample_gen_mode = ((num_beams == 1) and do_sample is True)
125 | is_beam_gen_mode = ((num_beams > 1) and do_sample is False)
126 | if is_greedy_gen_mode:
127 | # run greedy search
128 | raise NotImplementedError
129 | elif is_sample_gen_mode:
130 | # run sample
131 | return sample(model,
132 | input_ids,
133 | max_length,
134 | early_stopping=early_stopping,
135 | eos_token_id=eos_token_id,
136 | pad_token_id=pad_token_id,
137 | top_k=top_k,
138 | top_p=top_p,
139 | temperature=temperature,
140 | prepare_inputs_fn=prepare_inputs_fn,
141 | update_model_kwargs_fn=update_model_kwargs_fn,
142 | **model_kwargs)
143 | elif is_beam_gen_mode:
144 | raise NotImplementedError
145 | else:
146 | raise ValueError("Unsupported generation mode")
147 |
--------------------------------------------------------------------------------
/code/chatgpt/models/generation_utils.py:
--------------------------------------------------------------------------------
1 | from typing import Optional
2 |
3 | import torch
4 |
5 |
6 | def gpt_prepare_inputs_fn(input_ids: torch.Tensor, past: Optional[torch.Tensor] = None, **kwargs) -> dict:
7 | token_type_ids = kwargs.get("token_type_ids", None)
8 | # only last token for inputs_ids if past is defined in kwargs
9 | if past:
10 | input_ids = input_ids[:, -1].unsqueeze(-1)
11 | if token_type_ids is not None:
12 | token_type_ids = token_type_ids[:, -1].unsqueeze(-1)
13 |
14 | attention_mask = kwargs.get("attention_mask", None)
15 | position_ids = kwargs.get("position_ids", None)
16 |
17 | if attention_mask is not None and position_ids is None:
18 | # create position_ids on the fly for batch generation
19 | position_ids = attention_mask.long().cumsum(-1) - 1
20 | position_ids.masked_fill_(attention_mask == 0, 1)
21 | if past:
22 | position_ids = position_ids[:, -1].unsqueeze(-1)
23 | else:
24 | position_ids = None
25 | return {
26 | "input_ids": input_ids,
27 | "past_key_values": past,
28 | "use_cache": kwargs.get("use_cache"),
29 | "position_ids": position_ids,
30 | "attention_mask": attention_mask,
31 | "token_type_ids": token_type_ids,
32 | }
33 |
34 |
35 | def update_model_kwargs_fn(outputs: dict, **model_kwargs) -> dict:
36 | if "past_key_values" in outputs:
37 | model_kwargs["past"] = outputs["past_key_values"]
38 | else:
39 | model_kwargs["past"] = None
40 |
41 | # update token_type_ids with last value
42 | if "token_type_ids" in model_kwargs:
43 | token_type_ids = model_kwargs["token_type_ids"]
44 | model_kwargs["token_type_ids"] = torch.cat([token_type_ids, token_type_ids[:, -1].unsqueeze(-1)], dim=-1)
45 |
46 | # update attention mask
47 | if "attention_mask" in model_kwargs:
48 | attention_mask = model_kwargs["attention_mask"]
49 | model_kwargs["attention_mask"] = torch.cat(
50 | [attention_mask, attention_mask.new_ones((attention_mask.shape[0], 1))], dim=-1)
51 |
52 | return model_kwargs
53 |
54 |
55 | def opt_prepare_inputs_fn(input_ids: torch.Tensor,
56 | past: Optional[torch.Tensor] = None,
57 | attention_mask: Optional[torch.Tensor] = None,
58 | use_cache: Optional[bool] = None,
59 | **kwargs) -> dict:
60 | # if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
61 | if attention_mask is None:
62 | attention_mask = input_ids.new_ones(input_ids.shape)
63 |
64 | if past:
65 | input_ids = input_ids[:, -1:]
66 | # first step, decoder_cached_states are empty
67 | return {
68 | "input_ids": input_ids, # encoder_outputs is defined. input_ids not needed
69 | "attention_mask": attention_mask,
70 | "past_key_values": past,
71 | "use_cache": use_cache,
72 | }
73 |
74 |
75 | def bloom_prepare_inputs_fn(input_ids: torch.Tensor,
76 | past: Optional[torch.Tensor] = None,
77 | attention_mask: Optional[torch.Tensor] = None,
78 | use_cache: Optional[bool] = None,
79 | **kwargs) -> dict:
80 | # if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
81 | if attention_mask is None:
82 | attention_mask = input_ids.new_ones(input_ids.shape)
83 |
84 | if past:
85 | input_ids = input_ids[:, -1:]
86 | # first step, decoder_cached_states are empty
87 | return {
88 | "input_ids": input_ids, # encoder_outputs is defined. input_ids not needed
89 | "attention_mask": attention_mask,
90 | "past_key_values": past,
91 | "use_cache": use_cache,
92 | }
93 |
--------------------------------------------------------------------------------
/code/chatgpt/models/gpt/__init__.py:
--------------------------------------------------------------------------------
1 | from .gpt_actor import GPTActor
2 | from .gpt_critic import GPTCritic
3 | from .gpt_rm import GPTRM
4 |
5 | __all__ = ['GPTActor', 'GPTCritic', 'GPTRM']
6 |
--------------------------------------------------------------------------------
/code/chatgpt/models/gpt/__pycache__/__init__.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/gpt/__pycache__/__init__.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/gpt/__pycache__/gpt_actor.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/gpt/__pycache__/gpt_actor.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/gpt/__pycache__/gpt_critic.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/gpt/__pycache__/gpt_critic.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/gpt/__pycache__/gpt_rm.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/gpt/__pycache__/gpt_rm.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/gpt/gpt_actor.py:
--------------------------------------------------------------------------------
1 | from typing import Optional
2 |
3 | from transformers.models.gpt2.configuration_gpt2 import GPT2Config
4 | from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
5 |
6 | from ..base import Actor
7 |
8 |
9 | class GPTActor(Actor):
10 | """
11 | GPT Actor model.
12 |
13 | Args:
14 | pretrained (str): Pretrained model name or path.
15 | config (GPT2Config): Model config.
16 | checkpoint (bool): Enable gradient checkpointing.
17 | lora_rank (int): Rank of the LoRa layer.
18 | lora_train_bias (str): Bias training strategy for the LoRa layer.
19 | """
20 |
21 | def __init__(self,
22 | pretrained: Optional[str] = None,
23 | config: Optional[GPT2Config] = None,
24 | checkpoint: bool = False,
25 | lora_rank: int = 0,
26 | lora_train_bias: str = 'none') -> None:
27 | if pretrained is not None:
28 | model = GPT2LMHeadModel.from_pretrained(pretrained)
29 | elif config is not None:
30 | model = GPT2LMHeadModel(config)
31 | else:
32 | model = GPT2LMHeadModel(GPT2Config())
33 | if checkpoint:
34 | model.gradient_checkpointing_enable()
35 | super().__init__(model, lora_rank, lora_train_bias)
36 |
--------------------------------------------------------------------------------
/code/chatgpt/models/gpt/gpt_critic.py:
--------------------------------------------------------------------------------
1 | from typing import Optional
2 |
3 | import torch.nn as nn
4 | from transformers.models.gpt2.configuration_gpt2 import GPT2Config
5 | from transformers.models.gpt2.modeling_gpt2 import GPT2Model
6 |
7 | from ..base import Critic
8 |
9 |
10 | class GPTCritic(Critic):
11 | """
12 | GPT Critic model.
13 |
14 | Args:
15 | pretrained (str): Pretrained model name or path.
16 | config (GPT2Config): Model config.
17 | checkpoint (bool): Enable gradient checkpointing.
18 | lora_rank (int): Rank of the LO-RA decomposition.
19 | lora_train_bias (str): LoRA bias training mode.
20 | """
21 |
22 | def __init__(self,
23 | pretrained: Optional[str] = None,
24 | config: Optional[GPT2Config] = None,
25 | checkpoint: bool = False,
26 | lora_rank: int = 0,
27 | lora_train_bias: str = 'none') -> None:
28 | if pretrained is not None:
29 | model = GPT2Model.from_pretrained(pretrained)
30 | elif config is not None:
31 | model = GPT2Model(config)
32 | else:
33 | model = GPT2Model(GPT2Config())
34 | if checkpoint:
35 | model.gradient_checkpointing_enable()
36 | value_head = nn.Linear(model.config.n_embd, 1)
37 | super().__init__(model, value_head, lora_rank, lora_train_bias)
38 |
--------------------------------------------------------------------------------
/code/chatgpt/models/gpt/gpt_rm.py:
--------------------------------------------------------------------------------
1 | from typing import Optional
2 |
3 | import torch.nn as nn
4 | from transformers.models.gpt2.configuration_gpt2 import GPT2Config
5 | from transformers.models.gpt2.modeling_gpt2 import GPT2Model
6 |
7 | from ..base import RewardModel
8 |
9 |
10 | class GPTRM(RewardModel):
11 | """
12 | GPT Reward model.
13 |
14 | Args:
15 | pretrained (str): Pretrained model name or path.
16 | config (GPT2Config): Model config.
17 | checkpoint (bool): Enable gradient checkpointing.
18 | lora_rank (int): Rank of the low-rank approximation.
19 | lora_train_bias (str): LoRA bias training mode.
20 | """
21 |
22 | def __init__(self,
23 | pretrained: Optional[str] = None,
24 | config: Optional[GPT2Config] = None,
25 | checkpoint: bool = False,
26 | lora_rank: int = 0,
27 | lora_train_bias: str = 'none') -> None:
28 |
29 | if pretrained is not None:
30 | model = GPT2Model.from_pretrained(pretrained)
31 | elif config is not None:
32 | model = GPT2Model(config)
33 | else:
34 | model = GPT2Model(GPT2Config())
35 |
36 | if checkpoint:
37 | model.gradient_checkpointing_enable()
38 |
39 | value_head = nn.Linear(model.config.n_embd, 1)
40 | super().__init__(model, value_head, lora_rank, lora_train_bias)
41 |
--------------------------------------------------------------------------------
/code/chatgpt/models/lora.py:
--------------------------------------------------------------------------------
1 | import math
2 | from typing import Optional
3 |
4 | import loralib as lora
5 | import torch
6 | import torch.nn as nn
7 | import torch.nn.functional as F
8 |
9 |
10 | class LoraLinear(lora.LoRALayer, nn.Module):
11 | """Replace in-place ops to out-of-place ops to fit gemini. Convert a torch.nn.Linear to LoraLinear.
12 | """
13 |
14 | def __init__(
15 | self,
16 | weight: nn.Parameter,
17 | bias: Optional[nn.Parameter],
18 | r: int = 0,
19 | lora_alpha: int = 1,
20 | lora_dropout: float = 0.,
21 | fan_in_fan_out: bool = False, # Set this to True if the layer to replace stores weight like (fan_in, fan_out)
22 | merge_weights: bool = True,
23 | ):
24 | nn.Module.__init__(self)
25 | lora.LoRALayer.__init__(self,
26 | r=r,
27 | lora_alpha=lora_alpha,
28 | lora_dropout=lora_dropout,
29 | merge_weights=merge_weights)
30 | self.weight = weight
31 | self.bias = bias
32 |
33 | out_features, in_features = weight.shape
34 | self.in_features = in_features
35 | self.out_features = out_features
36 |
37 | self.fan_in_fan_out = fan_in_fan_out
38 | # Actual trainable parameters
39 | if r > 0:
40 | self.lora_A = nn.Parameter(self.weight.new_zeros((r, in_features)))
41 | self.lora_B = nn.Parameter(self.weight.new_zeros((out_features, r)))
42 | self.scaling = self.lora_alpha / self.r
43 | # Freezing the pre-trained weight matrix
44 | self.weight.requires_grad = False
45 | self.reset_parameters()
46 | if fan_in_fan_out:
47 | self.weight.data = self.weight.data.T
48 |
49 | def reset_parameters(self):
50 | if hasattr(self, 'lora_A'):
51 | # initialize A the same way as the default for nn.Linear and B to zero
52 | nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
53 | nn.init.zeros_(self.lora_B)
54 |
55 | def train(self, mode: bool = True):
56 |
57 | def T(w):
58 | return w.T if self.fan_in_fan_out else w
59 |
60 | nn.Module.train(self, mode)
61 | if self.merge_weights and self.merged:
62 | # Make sure that the weights are not merged
63 | if self.r > 0:
64 | self.weight.data -= T(self.lora_B @ self.lora_A) * self.scaling
65 | self.merged = False
66 |
67 | def eval(self):
68 |
69 | def T(w):
70 | return w.T if self.fan_in_fan_out else w
71 |
72 | nn.Module.eval(self)
73 | if self.merge_weights and not self.merged:
74 | # Merge the weights and mark it
75 | if self.r > 0:
76 | self.weight.data += T(self.lora_B @ self.lora_A) * self.scaling
77 | delattr(self, 'lora_A')
78 | delattr(self, 'lora_B')
79 | self.merged = True
80 |
81 | def forward(self, x: torch.Tensor):
82 |
83 | def T(w):
84 | return w.T if self.fan_in_fan_out else w
85 |
86 | if self.r > 0 and not self.merged:
87 | result = F.linear(x, T(self.weight), bias=self.bias)
88 | if self.r > 0:
89 | result = result + (self.lora_dropout(x) @ self.lora_A.t() @ self.lora_B.t()) * self.scaling
90 | return result
91 | else:
92 | return F.linear(x, T(self.weight), bias=self.bias)
93 |
94 |
95 | def lora_linear_wrapper(linear: nn.Linear, lora_rank: int) -> LoraLinear:
96 | assert lora_rank <= linear.in_features, f'LoRA rank ({lora_rank}) must be less than or equal to in features ({linear.in_features})'
97 | lora_linear = LoraLinear(linear.weight, linear.bias, r=lora_rank, merge_weights=False)
98 | return lora_linear
99 |
100 |
101 | def convert_to_lora_recursively(module: nn.Module, lora_rank: int) -> None:
102 | for name, child in module.named_children():
103 | if isinstance(child, nn.Linear):
104 | setattr(module, name, lora_linear_wrapper(child, lora_rank))
105 | else:
106 | convert_to_lora_recursively(child, lora_rank)
107 |
108 |
109 | class LoRAModule(nn.Module):
110 | """A LoRA module base class. All derived classes should call `convert_to_lora()` at the bottom of `__init__()`.
111 | This calss will convert all torch.nn.Linear layer to LoraLinear layer.
112 |
113 | Args:
114 | lora_rank (int, optional): LoRA rank. 0 means LoRA is not applied. Defaults to 0.
115 | lora_train_bias (str, optional): Whether LoRA train biases.
116 | 'none' means it doesn't train biases. 'all' means it trains all biases. 'lora_only' means it only trains biases of LoRA layers.
117 | Defaults to 'none'.
118 | """
119 |
120 | def __init__(self, lora_rank: int = 0, lora_train_bias: str = 'none') -> None:
121 | super().__init__()
122 | self.lora_rank = lora_rank
123 | self.lora_train_bias = lora_train_bias
124 |
125 | def convert_to_lora(self) -> None:
126 | if self.lora_rank <= 0:
127 | return
128 | convert_to_lora_recursively(self, self.lora_rank)
129 | lora.mark_only_lora_as_trainable(self, self.lora_train_bias)
130 |
131 |
--------------------------------------------------------------------------------
/code/chatgpt/models/loss.py:
--------------------------------------------------------------------------------
1 | from typing import Optional
2 |
3 | import torch
4 | import torch.nn as nn
5 |
6 | from .utils import masked_mean
7 |
8 |
9 | class GPTLMLoss(nn.Module):
10 | """
11 | GPT Language Model Loss
12 | """
13 |
14 | def __init__(self):
15 | super().__init__()
16 | self.loss = nn.CrossEntropyLoss()
17 |
18 | def forward(self, logits: torch.Tensor, labels: torch.Tensor) -> torch.Tensor:
19 | shift_logits = logits[..., :-1, :].contiguous()
20 | shift_labels = labels[..., 1:].contiguous()
21 | # Flatten the tokens
22 | return self.loss(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
23 |
24 |
25 | class PolicyLoss(nn.Module):
26 | """
27 | Policy Loss for PPO
28 | """
29 |
30 | def __init__(self, clip_eps: float = 0.2) -> None:
31 | super().__init__()
32 | self.clip_eps = clip_eps
33 |
34 | def forward(self,
35 | log_probs: torch.Tensor,
36 | old_log_probs: torch.Tensor,
37 | advantages: torch.Tensor,
38 | action_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
39 |
40 | ratio = (log_probs - old_log_probs).exp()
41 | surr1 = ratio * advantages
42 | surr2 = ratio.clamp(1 - self.clip_eps, 1 + self.clip_eps) * advantages
43 | loss = -torch.min(surr1, surr2)
44 | if action_mask is not None:
45 | loss = masked_mean(loss, action_mask)
46 | loss = loss.mean()
47 | return loss
48 |
49 |
50 | class ValueLoss(nn.Module):
51 | """
52 | Value Loss for PPO
53 | """
54 |
55 | def __init__(self, clip_eps: float = 0.4) -> None:
56 | super().__init__()
57 | self.clip_eps = clip_eps
58 |
59 | def forward(self,
60 | values: torch.Tensor,
61 | old_values: torch.Tensor,
62 | reward: torch.Tensor,
63 | action_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
64 | values_clipped = old_values + (values - old_values).clamp(-self.clip_eps, self.clip_eps)
65 | surr1 = (values_clipped - reward)**2
66 | surr2 = (values - reward)**2
67 | loss = torch.max(surr1, surr2)
68 | loss = loss.mean()
69 | return loss
70 |
71 |
72 | class PPOPtxActorLoss(nn.Module):
73 | """
74 | To Do:
75 |
76 | PPO-ptx Actor Loss
77 | """
78 |
79 | def __init__(self, policy_clip_eps: float = 0.2, pretrain_coef: float = 0.0, pretrain_loss_fn=GPTLMLoss()) -> None:
80 | super().__init__()
81 | self.pretrain_coef = pretrain_coef
82 | self.policy_loss_fn = PolicyLoss(clip_eps=policy_clip_eps)
83 | self.pretrain_loss_fn = pretrain_loss_fn
84 |
85 | def forward(self,
86 | log_probs: torch.Tensor,
87 | old_log_probs: torch.Tensor,
88 | advantages: torch.Tensor,
89 | lm_logits: torch.Tensor,
90 | lm_input_ids: torch.Tensor,
91 | action_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
92 | policy_loss = self.policy_loss_fn(log_probs, old_log_probs, advantages, action_mask=action_mask)
93 | lm_loss = self.pretrain_loss_fn(lm_logits, lm_input_ids)
94 | return policy_loss + self.pretrain_coef * lm_loss
95 |
96 |
97 | class PairWiseLoss(nn.Module):
98 | """
99 | Pairwise Loss for Reward Model
100 | """
101 |
102 | def forward(self, chosen_reward: torch.Tensor, reject_reward: torch.Tensor) -> torch.Tensor:
103 | probs = torch.sigmoid(chosen_reward - reject_reward)
104 | log_probs = torch.log(probs)
105 | loss = -log_probs.mean()
106 | return loss
107 |
--------------------------------------------------------------------------------
/code/chatgpt/models/opt/__init__.py:
--------------------------------------------------------------------------------
1 | from .opt_actor import OPTActor
2 | from .opt_critic import OPTCritic
3 | from .opt_rm import OPTRM
4 |
5 | __all__ = ['OPTActor', 'OPTCritic', 'OPTRM']
6 |
--------------------------------------------------------------------------------
/code/chatgpt/models/opt/__pycache__/__init__.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/opt/__pycache__/__init__.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/opt/__pycache__/opt_actor.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/opt/__pycache__/opt_actor.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/opt/__pycache__/opt_critic.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/opt/__pycache__/opt_critic.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/opt/__pycache__/opt_rm.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/models/opt/__pycache__/opt_rm.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/models/opt/opt_actor.py:
--------------------------------------------------------------------------------
1 | from typing import Optional
2 |
3 | from transformers.models.opt.configuration_opt import OPTConfig
4 | from transformers.models.opt.modeling_opt import OPTForCausalLM
5 |
6 | from ..base import Actor
7 |
8 |
9 | class OPTActor(Actor):
10 | """
11 | OPT Actor model.
12 |
13 | Args:
14 | pretrained (str): Pretrained model name or path.
15 | config (OPTConfig): Model config.
16 | checkpoint (bool): Enable gradient checkpointing.
17 | lora_rank (int): Rank of the low-rank approximation.
18 | lora_train_bias (str): LoRA bias training mode.
19 | """
20 |
21 | def __init__(self,
22 | pretrained: Optional[str] = None,
23 | config: Optional[OPTConfig] = None,
24 | checkpoint: bool = False,
25 | lora_rank: int = 0,
26 | lora_train_bias: str = 'none') -> None:
27 | if pretrained is not None:
28 | model = OPTForCausalLM.from_pretrained(pretrained)
29 | elif config is not None:
30 | model = OPTForCausalLM(config)
31 | else:
32 | model = OPTForCausalLM(OPTConfig())
33 | if checkpoint:
34 | model.gradient_checkpointing_enable()
35 | super().__init__(model, lora_rank, lora_train_bias)
36 |
--------------------------------------------------------------------------------
/code/chatgpt/models/opt/opt_critic.py:
--------------------------------------------------------------------------------
1 | from typing import Optional
2 |
3 | import torch.nn as nn
4 | from transformers.models.opt.configuration_opt import OPTConfig
5 | from transformers.models.opt.modeling_opt import OPTModel
6 |
7 | from ..base import Critic
8 |
9 |
10 | class OPTCritic(Critic):
11 | """
12 | OPT Critic model.
13 |
14 | Args:
15 | pretrained (str): Pretrained model name or path.
16 | config (OPTConfig): Model config.
17 | checkpoint (bool): Enable gradient checkpointing.
18 | lora_rank (int): Rank of the low-rank approximation.
19 | lora_train_bias (str): LoRA bias training mode.
20 | """
21 |
22 | def __init__(self,
23 | pretrained: Optional[str] = None,
24 | config: Optional[OPTConfig] = None,
25 | checkpoint: bool = False,
26 | lora_rank: int = 0,
27 | lora_train_bias: str = 'none',
28 | **kwargs) -> None:
29 | if pretrained is not None:
30 | model = OPTModel.from_pretrained(pretrained)
31 | elif config is not None:
32 | model = OPTModel(config)
33 | else:
34 | model = OPTModel(OPTConfig())
35 | if checkpoint:
36 | model.gradient_checkpointing_enable()
37 | value_head = nn.Linear(model.config.word_embed_proj_dim, 1)
38 | super().__init__(model, value_head, lora_rank, lora_train_bias, **kwargs)
39 |
--------------------------------------------------------------------------------
/code/chatgpt/models/opt/opt_rm.py:
--------------------------------------------------------------------------------
1 | from typing import Optional
2 |
3 | import torch.nn as nn
4 | from transformers import OPTConfig, OPTModel
5 |
6 | from ..base import RewardModel
7 |
8 |
9 | class OPTRM(RewardModel):
10 | """
11 | OPT Reward model.
12 |
13 | Args:
14 | pretrained (str): Pretrained model name or path.
15 | config (OPTConfig): Model config.
16 | checkpoint (bool): Enable gradient checkpointing.
17 | lora_rank (int): Rank of the low-rank approximation.
18 | lora_train_bias (str): LoRA bias training mode.
19 | """
20 |
21 | def __init__(self,
22 | pretrained: Optional[str] = None,
23 | config: Optional[OPTConfig] = None,
24 | checkpoint: bool = False,
25 | lora_rank: int = 0,
26 | lora_train_bias: str = 'none') -> None:
27 | if pretrained is not None:
28 | model = OPTModel.from_pretrained(pretrained)
29 | elif config is not None:
30 | model = OPTModel(config)
31 | else:
32 | model = OPTModel(OPTConfig())
33 | if checkpoint:
34 | model.gradient_checkpointing_enable()
35 |
36 | value_head = nn.Linear(model.config.word_embed_proj_dim, 1)
37 | super().__init__(model, value_head, lora_rank, lora_train_bias)
38 |
--------------------------------------------------------------------------------
/code/chatgpt/models/utils.py:
--------------------------------------------------------------------------------
1 | from typing import Optional, Union
2 |
3 | import loralib as lora
4 | import torch
5 | import torch.nn as nn
6 | import torch.nn.functional as F
7 |
8 |
9 | def compute_approx_kl(log_probs: torch.Tensor,
10 | log_probs_base: torch.Tensor,
11 | action_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
12 | """
13 | Compute the approximate KL divergence between two distributions.
14 | Schulman blog: http://joschu.net/blog/kl-approx.html
15 |
16 | Args:
17 | log_probs: Log probabilities of the new distribution.
18 | log_probs_base: Log probabilities of the base distribution.
19 | action_mask: Mask for actions.
20 | """
21 |
22 | log_ratio = log_probs - log_probs_base
23 | approx_kl = (log_ratio.exp() - 1) - log_ratio
24 | if action_mask is not None:
25 | approx_kl = masked_mean(approx_kl, action_mask, dim=1)
26 | return approx_kl
27 | approx_kl = approx_kl.mean(dim=1)
28 | return approx_kl
29 |
30 |
31 | def compute_reward(r: Union[torch.Tensor, float],
32 | kl_coef: float,
33 | log_probs: torch.Tensor,
34 | log_probs_base: torch.Tensor,
35 | action_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
36 | if kl_coef <= 0.0:
37 | return r
38 | kl = compute_approx_kl(log_probs, log_probs_base, action_mask=action_mask)
39 | reward = r - kl_coef * kl
40 | return reward
41 |
42 |
43 | def log_probs_from_logits(logits: torch.Tensor, labels: torch.Tensor) -> torch.Tensor:
44 | log_probs = F.log_softmax(logits, dim=-1)
45 | log_probs_labels = log_probs.gather(dim=-1, index=labels.unsqueeze(-1))
46 | return log_probs_labels.squeeze(-1)
47 |
48 |
49 | def masked_mean(tensor: torch.Tensor, mask: torch.Tensor, dim: int = 1) -> torch.Tensor:
50 | tensor = tensor * mask
51 | tensor = tensor.sum(dim=dim)
52 | mask_sum = mask.sum(dim=dim)
53 | mean = tensor / (mask_sum + 1e-8)
54 | return mean
55 |
56 |
57 | def masked_normalize(tensor: torch.Tensor, mask: torch.Tensor, dim: int = 1, eps: float = 1e-8) -> torch.Tensor:
58 | tensor = tensor * mask
59 | mean = masked_mean(tensor, mask, dim=dim)
60 | mean_centered = tensor - mean
61 | var = masked_mean(mean_centered**2, mask, dim=dim)
62 | return mean_centered * var.clamp(min=eps).rsqrt()
63 |
64 |
65 | def normalize(tensor: torch.Tensor, dim: int = 0, eps: float = 1e-8) -> torch.Tensor:
66 | mean = tensor.mean(dim)
67 | mean_centered = tensor - mean
68 | var = (mean_centered**2).mean(dim)
69 | norm = mean_centered * var.clamp(min=eps).rsqrt()
70 | return norm
71 |
72 |
73 | def convert_to_lora(model: nn.Module,
74 | input_size: int,
75 | output_size: int,
76 | lora_rank: int = 16,
77 | lora_alpha: int = 1,
78 | lora_dropout: float = 0.,
79 | fan_in_fan_out: bool = False,
80 | merge_weights: bool = True):
81 | if lora_rank > min(input_size, output_size):
82 | raise ValueError(f"LoRA rank {lora_rank} must be less or equal than {min(input_size, output_size)}")
83 |
84 | for name, module in model.named_modules():
85 | if isinstance(module, nn.Linear):
86 | module._modules[name] = lora.Linear(input_size,
87 | output_size,
88 | r=lora_rank,
89 | lora_alpha=lora_alpha,
90 | lora_dropout=lora_dropout,
91 | fan_in_fan_out=fan_in_fan_out,
92 | merge_weights=merge_weights)
93 |
--------------------------------------------------------------------------------
/code/chatgpt/replay_buffer/__init__.py:
--------------------------------------------------------------------------------
1 | from .base import ReplayBuffer
2 | from .naive import NaiveReplayBuffer
3 |
4 | __all__ = ['ReplayBuffer', 'NaiveReplayBuffer']
5 |
--------------------------------------------------------------------------------
/code/chatgpt/replay_buffer/__pycache__/__init__.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/replay_buffer/__pycache__/__init__.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/replay_buffer/__pycache__/base.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/replay_buffer/__pycache__/base.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/replay_buffer/__pycache__/naive.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/replay_buffer/__pycache__/naive.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/replay_buffer/__pycache__/utils.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/replay_buffer/__pycache__/utils.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/replay_buffer/base.py:
--------------------------------------------------------------------------------
1 | from abc import ABC, abstractmethod
2 | from typing import Any
3 |
4 | from chatgpt.experience_maker.base import Experience
5 |
6 |
7 | class ReplayBuffer(ABC):
8 | """Replay buffer base class. It stores experience.
9 |
10 | Args:
11 | sample_batch_size (int): Batch size when sampling.
12 | limit (int, optional): Limit of number of experience samples. A number <= 0 means unlimited. Defaults to 0.
13 | """
14 |
15 | def __init__(self, sample_batch_size: int, limit: int = 0) -> None:
16 | super().__init__()
17 | self.sample_batch_size = sample_batch_size
18 | # limit <= 0 means unlimited
19 | self.limit = limit
20 |
21 | @abstractmethod
22 | def append(self, experience: Experience) -> None:
23 | pass
24 |
25 | @abstractmethod
26 | def clear(self) -> None:
27 | pass
28 |
29 | @abstractmethod
30 | def sample(self) -> Experience:
31 | pass
32 |
33 | @abstractmethod
34 | def __len__(self) -> int:
35 | pass
36 |
37 | @abstractmethod
38 | def __getitem__(self, idx: int) -> Any:
39 | pass
40 |
41 | @abstractmethod
42 | def collate_fn(self, batch: Any) -> Experience:
43 | pass
44 |
--------------------------------------------------------------------------------
/code/chatgpt/replay_buffer/naive.py:
--------------------------------------------------------------------------------
1 | import random
2 | from typing import List
3 |
4 | import torch
5 | from chatgpt.experience_maker.base import Experience
6 |
7 | from .base import ReplayBuffer
8 | from .utils import BufferItem, make_experience_batch, split_experience_batch
9 |
10 |
11 | class NaiveReplayBuffer(ReplayBuffer):
12 | """Naive replay buffer class. It stores experience.
13 |
14 | Args:
15 | sample_batch_size (int): Batch size when sampling.
16 | limit (int, optional): Limit of number of experience samples. A number <= 0 means unlimited. Defaults to 0.
17 | cpu_offload (bool, optional): Whether to offload experience to cpu when sampling. Defaults to True.
18 | """
19 |
20 | def __init__(self, sample_batch_size: int, limit: int = 0, cpu_offload: bool = True) -> None:
21 | super().__init__(sample_batch_size, limit)
22 | self.cpu_offload = cpu_offload
23 | self.target_device = torch.device(f'cuda:{torch.cuda.current_device()}')
24 | # TODO(ver217): add prefetch
25 | self.items: List[BufferItem] = []
26 |
27 | @torch.no_grad()
28 | def append(self, experience: Experience) -> None:
29 | if self.cpu_offload:
30 | experience.to_device(torch.device('cpu'))
31 | items = split_experience_batch(experience)
32 | self.items.extend(items)
33 | if self.limit > 0:
34 | samples_to_remove = len(self.items) - self.limit
35 | if samples_to_remove > 0:
36 | self.items = self.items[samples_to_remove:]
37 |
38 | def clear(self) -> None:
39 | self.items.clear()
40 |
41 | @torch.no_grad()
42 | def sample(self) -> Experience:
43 | items = random.sample(self.items, self.sample_batch_size)
44 | experience = make_experience_batch(items)
45 | if self.cpu_offload:
46 | experience.to_device(self.target_device)
47 | return experience
48 |
49 | def __len__(self) -> int:
50 | return len(self.items)
51 |
52 | def __getitem__(self, idx: int) -> BufferItem:
53 | return self.items[idx]
54 |
55 | def collate_fn(self, batch) -> Experience:
56 | experience = make_experience_batch(batch)
57 | return experience
58 |
--------------------------------------------------------------------------------
/code/chatgpt/replay_buffer/utils.py:
--------------------------------------------------------------------------------
1 | from dataclasses import dataclass
2 | from typing import List, Optional
3 |
4 | import torch
5 | import torch.nn.functional as F
6 | from chatgpt.experience_maker.base import Experience
7 |
8 |
9 | @dataclass
10 | class BufferItem:
11 | """BufferItem is an item of experience data.
12 |
13 | Shapes of each tensor:
14 | sequences: (S)
15 | action_log_probs: (A)
16 | values: (1)
17 | reward: (1)
18 | advatanges: (1)
19 | attention_mask: (S)
20 | action_mask: (A)
21 |
22 | "A" is the number of actions.
23 | """
24 | sequences: torch.Tensor
25 | action_log_probs: torch.Tensor
26 | values: torch.Tensor
27 | reward: torch.Tensor
28 | advantages: torch.Tensor
29 | attention_mask: Optional[torch.LongTensor]
30 | action_mask: Optional[torch.BoolTensor]
31 |
32 |
33 | def split_experience_batch(experience: Experience) -> List[BufferItem]:
34 | batch_size = experience.sequences.size(0)
35 | batch_kwargs = [{} for _ in range(batch_size)]
36 | keys = ('sequences', 'action_log_probs', 'values', 'reward', 'advantages', 'attention_mask', 'action_mask')
37 | for key in keys:
38 | value = getattr(experience, key)
39 | if isinstance(value, torch.Tensor):
40 | vals = torch.unbind(value)
41 | else:
42 | # None
43 | vals = [value for _ in range(batch_size)]
44 | assert batch_size == len(vals)
45 | for i, v in enumerate(vals):
46 | batch_kwargs[i][key] = v
47 | items = [BufferItem(**kwargs) for kwargs in batch_kwargs]
48 | return items
49 |
50 |
51 | def zero_pad_sequences(sequences: List[torch.Tensor], side: str = 'left') -> torch.Tensor:
52 | assert side in ('left', 'right')
53 | max_len = max(seq.size(0) for seq in sequences)
54 | padded_sequences = []
55 | for seq in sequences:
56 | pad_len = max_len - seq.size(0)
57 | padding = (pad_len, 0) if side == 'left' else (0, pad_len)
58 | padded_sequences.append(F.pad(seq, padding))
59 | return torch.stack(padded_sequences, dim=0)
60 |
61 |
62 | def make_experience_batch(items: List[BufferItem]) -> Experience:
63 | kwargs = {}
64 | to_pad_keys = set(('action_log_probs', 'action_mask'))
65 | keys = ('sequences', 'action_log_probs', 'values', 'reward', 'advantages', 'attention_mask', 'action_mask')
66 | for key in keys:
67 | vals = [getattr(item, key) for item in items]
68 | if key in to_pad_keys:
69 | batch_data = zero_pad_sequences(vals)
70 | else:
71 | batch_data = torch.stack(vals, dim=0)
72 | kwargs[key] = batch_data
73 | return Experience(**kwargs)
74 |
--------------------------------------------------------------------------------
/code/chatgpt/trainer/__init__.py:
--------------------------------------------------------------------------------
1 | from .base import Trainer
2 | from .ppo import PPOTrainer
3 | from .rm import RewardModelTrainer
4 |
5 | __all__ = ['Trainer', 'PPOTrainer', 'RewardModelTrainer']
6 |
--------------------------------------------------------------------------------
/code/chatgpt/trainer/__pycache__/__init__.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/trainer/__pycache__/__init__.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/trainer/__pycache__/base.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/trainer/__pycache__/base.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/trainer/__pycache__/ppo.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/trainer/__pycache__/ppo.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/trainer/__pycache__/rm.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/trainer/__pycache__/rm.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/trainer/__pycache__/utils.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/trainer/__pycache__/utils.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/trainer/base.py:
--------------------------------------------------------------------------------
1 | from abc import ABC, abstractmethod
2 | from typing import Any, Callable, Dict, List, Optional, Union
3 |
4 | import torch
5 | from chatgpt.experience_maker import Experience, ExperienceMaker
6 | from chatgpt.replay_buffer import ReplayBuffer
7 | from torch import Tensor
8 | from torch.utils.data import DistributedSampler
9 | from tqdm import tqdm
10 |
11 | from .callbacks import Callback
12 | from .strategies import Strategy
13 | from .utils import is_rank_0
14 |
15 |
16 | class Trainer(ABC):
17 | """
18 | Base class for rlhf trainers.
19 |
20 | Args:
21 | strategy (Strategy):the strategy to use for training
22 | experience_maker (ExperienceMaker): the experience maker to use for produce experience to fullfill replay buffer
23 | replay_buffer (ReplayBuffer): the replay buffer to use for training
24 | experience_batch_size (int, defaults to 8): the batch size to use for experience generation
25 | max_epochs (int, defaults to 1): the number of epochs of training process
26 | tokenizer (Callable, optional): the tokenizer to use for tokenizing the input
27 | sample_replay_buffer (bool, defaults to False): whether to sample from replay buffer
28 | data_loader_pin_memory (bool, defaults to True): whether to pin memory for data loader
29 | callbacks (List[Callback], defaults to []): the callbacks to call during training process
30 | generate_kwargs (dict, optional): the kwargs to use while model generating
31 | """
32 |
33 | def __init__(self,
34 | strategy: Strategy,
35 | experience_maker: ExperienceMaker,
36 | replay_buffer: ReplayBuffer,
37 | experience_batch_size: int = 8,
38 | max_epochs: int = 1,
39 | tokenizer: Optional[Callable[[Any], dict]] = None,
40 | sample_replay_buffer: bool = False,
41 | dataloader_pin_memory: bool = True,
42 | callbacks: List[Callback] = [],
43 | **generate_kwargs) -> None:
44 | super().__init__()
45 | self.strategy = strategy
46 | self.experience_maker = experience_maker
47 | self.replay_buffer = replay_buffer
48 | self.experience_batch_size = experience_batch_size
49 | self.max_epochs = max_epochs
50 | self.tokenizer = tokenizer
51 | self.generate_kwargs = generate_kwargs
52 | self.sample_replay_buffer = sample_replay_buffer
53 | self.dataloader_pin_memory = dataloader_pin_memory
54 | self.callbacks = callbacks
55 |
56 | @abstractmethod
57 | def training_step(self, experience: Experience) -> Dict[str, Any]:
58 | pass
59 |
60 | def _make_experience(self, inputs: Union[Tensor, Dict[str, Tensor]]) -> Experience:
61 | if isinstance(inputs, Tensor):
62 | return self.experience_maker.make_experience(inputs, **self.generate_kwargs)
63 | elif isinstance(inputs, dict):
64 | return self.experience_maker.make_experience(**inputs, **self.generate_kwargs)
65 | else:
66 | raise ValueError(f'Unsupported input type "{type(inputs)}"')
67 |
68 | def _sample_prompts(self, prompts) -> list:
69 | indices = list(range(len(prompts)))
70 | sampled_indices = self.strategy.experience_sampler.choice(indices, self.experience_batch_size, replace=False)
71 | return [prompts[i] for i in sampled_indices]
72 |
73 | def _learn(self):
74 | # replay buffer may be empty at first, we should rebuild at each training
75 | if not self.sample_replay_buffer:
76 | dataloader = self.strategy.setup_dataloader(self.replay_buffer, self.dataloader_pin_memory)
77 | device = torch.cuda.current_device()
78 | if self.sample_replay_buffer:
79 | pbar = tqdm(range(self.max_epochs), desc='Train epoch', disable=not is_rank_0())
80 | for _ in pbar:
81 | experience = self.replay_buffer.sample()
82 | metrics = self.training_step(experience)
83 | pbar.set_postfix(metrics)
84 | else:
85 | for epoch in range(self.max_epochs):
86 | self._on_learn_epoch_start(epoch)
87 | if isinstance(dataloader.sampler, DistributedSampler):
88 | dataloader.sampler.set_epoch(epoch)
89 | pbar = tqdm(dataloader, desc=f'Train epoch [{epoch+1}/{self.max_epochs}]', disable=not is_rank_0())
90 | for experience in pbar:
91 | self._on_learn_batch_start()
92 | experience.to_device(device)
93 | metrics = self.training_step(experience)
94 | self._on_learn_batch_end(metrics, experience)
95 | pbar.set_postfix(metrics)
96 | self._on_learn_epoch_end(epoch)
97 |
98 | def fit(self, prompts, num_episodes: int = 50000, max_timesteps: int = 500, update_timesteps: int = 5000) -> None:
99 | time = 0
100 | sampler = self.strategy.setup_sampler(prompts)
101 | self._on_fit_start()
102 | for episode in range(num_episodes):
103 | self._on_episode_start(episode)
104 | for timestep in tqdm(range(max_timesteps),
105 | desc=f'Episode [{episode+1}/{num_episodes}]',
106 | disable=not is_rank_0()):
107 | time += 1
108 | rand_prompts = sampler.sample(self.experience_batch_size)
109 | if self.tokenizer is not None:
110 | inputs = self.tokenizer(rand_prompts)
111 | else:
112 | inputs = rand_prompts
113 | self._on_make_experience_start()
114 | experience = self._make_experience(inputs)
115 | self._on_make_experience_end(experience)
116 | self.replay_buffer.append(experience)
117 | if time % update_timesteps == 0:
118 | self._learn()
119 | self.replay_buffer.clear()
120 | self._on_episode_end(episode)
121 | self._on_fit_end()
122 |
123 | # TODO(ver217): maybe simplify these code using context
124 | def _on_fit_start(self) -> None:
125 | for callback in self.callbacks:
126 | callback.on_fit_start()
127 |
128 | def _on_fit_end(self) -> None:
129 | for callback in self.callbacks:
130 | callback.on_fit_end()
131 |
132 | def _on_episode_start(self, episode: int) -> None:
133 | for callback in self.callbacks:
134 | callback.on_episode_start(episode)
135 |
136 | def _on_episode_end(self, episode: int) -> None:
137 | for callback in self.callbacks:
138 | callback.on_episode_end(episode)
139 |
140 | def _on_make_experience_start(self) -> None:
141 | for callback in self.callbacks:
142 | callback.on_make_experience_start()
143 |
144 | def _on_make_experience_end(self, experience: Experience) -> None:
145 | for callback in self.callbacks:
146 | callback.on_make_experience_end(experience)
147 |
148 | def _on_learn_epoch_start(self, epoch: int) -> None:
149 | for callback in self.callbacks:
150 | callback.on_learn_epoch_start(epoch)
151 |
152 | def _on_learn_epoch_end(self, epoch: int) -> None:
153 | for callback in self.callbacks:
154 | callback.on_learn_epoch_end(epoch)
155 |
156 | def _on_learn_batch_start(self) -> None:
157 | for callback in self.callbacks:
158 | callback.on_learn_batch_start()
159 |
160 | def _on_learn_batch_end(self, metrics: dict, experience: Experience) -> None:
161 | for callback in self.callbacks:
162 | callback.on_learn_batch_end(metrics, experience)
163 |
--------------------------------------------------------------------------------
/code/chatgpt/trainer/callbacks/__init__.py:
--------------------------------------------------------------------------------
1 | from .base import Callback
2 | from .performance_evaluator import PerformanceEvaluator
3 | from .save_checkpoint import SaveCheckpoint
4 |
5 | __all__ = ['Callback', 'PerformanceEvaluator', 'SaveCheckpoint']
6 |
--------------------------------------------------------------------------------
/code/chatgpt/trainer/callbacks/__pycache__/__init__.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/trainer/callbacks/__pycache__/__init__.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/trainer/callbacks/__pycache__/base.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/trainer/callbacks/__pycache__/base.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/trainer/callbacks/__pycache__/performance_evaluator.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/trainer/callbacks/__pycache__/performance_evaluator.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/trainer/callbacks/__pycache__/save_checkpoint.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/trainer/callbacks/__pycache__/save_checkpoint.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/trainer/callbacks/base.py:
--------------------------------------------------------------------------------
1 | from abc import ABC
2 |
3 | from chatgpt.experience_maker import Experience
4 |
5 |
6 | class Callback(ABC):
7 | """
8 | Base callback class. It defines the interface for callbacks.
9 | """
10 |
11 | def on_fit_start(self) -> None:
12 | pass
13 |
14 | def on_fit_end(self) -> None:
15 | pass
16 |
17 | def on_episode_start(self, episode: int) -> None:
18 | pass
19 |
20 | def on_episode_end(self, episode: int) -> None:
21 | pass
22 |
23 | def on_make_experience_start(self) -> None:
24 | pass
25 |
26 | def on_make_experience_end(self, experience: Experience) -> None:
27 | pass
28 |
29 | def on_learn_epoch_start(self, epoch: int) -> None:
30 | pass
31 |
32 | def on_learn_epoch_end(self, epoch: int) -> None:
33 | pass
34 |
35 | def on_learn_batch_start(self) -> None:
36 | pass
37 |
38 | def on_learn_batch_end(self, metrics: dict, experience: Experience) -> None:
39 | pass
40 |
--------------------------------------------------------------------------------
/code/chatgpt/trainer/callbacks/performance_evaluator.py:
--------------------------------------------------------------------------------
1 | from time import time
2 | from typing import Optional
3 |
4 | import torch
5 | import torch.distributed as dist
6 | from chatgpt.experience_maker import Experience
7 |
8 | from .base import Callback
9 |
10 |
11 | def get_world_size() -> int:
12 | if dist.is_initialized():
13 | return dist.get_world_size()
14 | return 1
15 |
16 |
17 | def print_rank_0(*args, **kwargs) -> None:
18 | if not dist.is_initialized() or dist.get_rank() == 0:
19 | print(*args, **kwargs)
20 |
21 |
22 | @torch.no_grad()
23 | def all_reduce_mean(x: float, world_size: int) -> float:
24 | if world_size == 1:
25 | return x
26 | tensor = torch.tensor([x], device=torch.cuda.current_device())
27 | dist.all_reduce(tensor)
28 | tensor = tensor / world_size
29 | return tensor.item()
30 |
31 |
32 | class PerformanceEvaluator(Callback):
33 | """
34 | Callback for valuate the performance of the model.
35 | Args:
36 | actor_num_params: The number of parameters of the actor model.
37 | critic_num_params: The number of parameters of the critic model.
38 | initial_model_num_params: The number of parameters of the initial model.
39 | reward_model_num_params: The number of parameters of the reward model.
40 | enable_grad_checkpoint: Whether to enable gradient checkpointing.
41 | ignore_episodes: The number of episodes to ignore when calculating the performance.
42 | """
43 |
44 | def __init__(self,
45 | actor_num_params: int,
46 | critic_num_params: int,
47 | initial_model_num_params: int,
48 | reward_model_num_params: int,
49 | enable_grad_checkpoint: bool = False,
50 | ignore_episodes: int = 0) -> None:
51 | super().__init__()
52 | self.world_size = get_world_size()
53 | self.actor_num_params = actor_num_params
54 | self.critic_num_params = critic_num_params
55 | self.initial_model_num_params = initial_model_num_params
56 | self.reward_model_num_params = reward_model_num_params
57 | self.enable_grad_checkpoint = enable_grad_checkpoint
58 | self.ignore_episodes = ignore_episodes
59 | self.disable: bool = False
60 |
61 | self.make_experience_duration: float = 0.
62 | self.make_experience_start_time: Optional[float] = None
63 | self.make_experience_num_samples: int = 0
64 | self.make_experience_flop: int = 0
65 | self.learn_duration: float = 0.
66 | self.learn_start_time: Optional[float] = None
67 | self.learn_num_samples: int = 0
68 | self.learn_flop: int = 0
69 |
70 | def on_episode_start(self, episode: int) -> None:
71 | self.disable = self.ignore_episodes > 0 and episode < self.ignore_episodes
72 |
73 | def on_make_experience_start(self) -> None:
74 | if self.disable:
75 | return
76 | self.make_experience_start_time = time()
77 |
78 | def on_make_experience_end(self, experience: Experience) -> None:
79 | if self.disable:
80 | return
81 | self.make_experience_duration += time() - self.make_experience_start_time
82 |
83 | batch_size, seq_len = experience.sequences.shape
84 |
85 | self.make_experience_num_samples += batch_size
86 |
87 | # actor generate
88 | num_actions = experience.action_mask.size(1)
89 | input_len = seq_len - num_actions
90 | total_seq_len = (input_len + seq_len - 1) * num_actions / 2
91 | self.make_experience_flop += self.actor_num_params * batch_size * total_seq_len * 2
92 | # actor forward
93 | self.make_experience_flop += self.actor_num_params * batch_size * seq_len * 2
94 | # critic forward
95 | self.make_experience_flop += self.critic_num_params * batch_size * seq_len * 2
96 | # initial model forward
97 | self.make_experience_flop += self.initial_model_num_params * batch_size * seq_len * 2
98 | # reward model forward
99 | self.make_experience_flop += self.reward_model_num_params * batch_size * seq_len * 2
100 |
101 | def on_learn_batch_start(self) -> None:
102 | if self.disable:
103 | return
104 | self.learn_start_time = time()
105 |
106 | def on_learn_batch_end(self, metrics: dict, experience: Experience) -> None:
107 | if self.disable:
108 | return
109 | self.learn_duration += time() - self.learn_start_time
110 |
111 | batch_size, seq_len = experience.sequences.shape
112 |
113 | self.learn_num_samples += batch_size
114 |
115 | # actor forward-backward, 3 means forward(1) + backward(2)
116 | self.learn_flop += self.actor_num_params * batch_size * seq_len * 2 * (3 + int(self.enable_grad_checkpoint))
117 | # critic foward-backward
118 | self.learn_flop += self.critic_num_params * batch_size * seq_len * 2 * (3 + int(self.enable_grad_checkpoint))
119 |
120 | def on_fit_end(self) -> None:
121 | avg_make_experience_duration = all_reduce_mean(self.make_experience_duration, self.world_size)
122 | avg_learn_duration = all_reduce_mean(self.learn_duration, self.world_size)
123 |
124 | avg_make_experience_throughput = self.make_experience_num_samples / (avg_make_experience_duration + 1e-12)
125 | avg_make_experience_tflops = self.make_experience_flop / 1e12 / (avg_make_experience_duration + 1e-12)
126 |
127 | avg_learn_throughput = self.learn_num_samples / (avg_learn_duration + 1e-12)
128 | avg_learn_tflops = self.learn_flop / 1e12 / (avg_learn_duration + 1e-12)
129 |
130 | print_rank_0(
131 | f'Making experience throughput: {avg_make_experience_throughput:.3f} samples/sec, TFLOPS: {avg_make_experience_tflops:.3f}'
132 | )
133 | print_rank_0(f'Learning throughput: {avg_learn_throughput:.3f} samples/sec, TFLOPS: {avg_learn_tflops:.3f}')
134 |
--------------------------------------------------------------------------------
/code/chatgpt/trainer/callbacks/save_checkpoint.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | import torch.distributed as dist
4 | from chatgpt.trainer.strategies import ColossalAIStrategy, Strategy
5 | from chatgpt.trainer.utils import is_rank_0
6 | from torch import nn
7 | from torch.optim import Optimizer
8 |
9 | from .base import Callback
10 |
11 |
12 | class SaveCheckpoint(Callback):
13 | """
14 | The callback for saving checkpoint for chatgpt.
15 |
16 | Only support saving actor and critic model.
17 | A typical architecture of the saved checkpoint would be:
18 | - checkpoint
19 | - episode_x
20 | - actor.pt
21 | - actor-optim-rank-0.pt
22 | - actor-optim-rank-1.pt
23 | - critic.pt
24 | - critic-optim-rank-0.pt
25 | - critic-optim-rank-1.pt
26 | - ...
27 |
28 | Args:
29 | path(str): the base path you want to save checkpoint, the checkpoint would be saved at `path/checkpoint`
30 | interval(int): the interval episode of saving checkpoint
31 | strategy(Strategy): the strategy used to train
32 | actor(nn.Module): the actor model
33 | critic(nn.Module): the critic model
34 | actor_optim(Optimizer): the optimizer of actor
35 | critic_optim(Optimizer): the optimizer of critic
36 |
37 | """
38 |
39 | def __init__(self,
40 | path: str,
41 | interval: int,
42 | strategy: Strategy,
43 | actor: nn.Module = None,
44 | critic: nn.Module = None,
45 | actor_optim: Optimizer = None,
46 | critic_optim: Optimizer = None) -> None:
47 | super().__init__()
48 | self.path = os.path.join(path, 'checkpoint')
49 | self.interval = interval
50 | self.strategy = strategy
51 | self.model_dict = {'actor': [actor, actor_optim], 'critic': [critic, critic_optim]}
52 |
53 | def on_episode_end(self, episode: int) -> None:
54 | if (episode + 1) % self.interval != 0:
55 | return
56 | base_path = os.path.join(self.path, f'episode_{episode}')
57 | if not os.path.exists(base_path):
58 | os.makedirs(base_path)
59 |
60 | for model in self.model_dict.keys():
61 |
62 | # save model
63 | if self.model_dict[model][0] is None:
64 | # saving only optimizer states is meaningless, so it would be skipped
65 | continue
66 | model_path = os.path.join(base_path, f'{model}.pt')
67 | self.strategy.save_model(model=self.model_dict[model][0], path=model_path, only_rank0=True)
68 |
69 | # save optimizer
70 | if self.model_dict[model][1] is None:
71 | continue
72 | only_rank0 = not isinstance(self.strategy, ColossalAIStrategy)
73 | rank = 0 if is_rank_0() else dist.get_rank()
74 | optim_path = os.path.join(base_path, f'{model}-optim-rank-{rank}.pt')
75 | self.strategy.save_optimizer(optimizer=self.model_dict[model][1], path=optim_path, only_rank0=only_rank0)
76 |
--------------------------------------------------------------------------------
/code/chatgpt/trainer/ppo.py:
--------------------------------------------------------------------------------
1 | from typing import Any, Callable, Dict, List, Optional
2 |
3 | import torch.nn as nn
4 | from chatgpt.experience_maker import Experience, NaiveExperienceMaker
5 | from chatgpt.models.base import Actor, Critic
6 | from chatgpt.models.generation_utils import update_model_kwargs_fn
7 | from chatgpt.models.loss import PolicyLoss, ValueLoss
8 | from chatgpt.replay_buffer import NaiveReplayBuffer
9 | from torch.optim import Optimizer
10 |
11 | from .base import Trainer
12 | from .callbacks import Callback
13 | from .strategies import Strategy
14 |
15 |
16 | class PPOTrainer(Trainer):
17 | """
18 | Trainer for PPO algorithm.
19 |
20 | Args:
21 | strategy (Strategy): the strategy to use for training
22 | actor (Actor): the actor model in ppo algorithm
23 | critic (Critic): the critic model in ppo algorithm
24 | reward_model (nn.Module): the reward model in rlhf algorithm to make reward of sentences
25 | initial_model (Actor): the initial model in rlhf algorithm to generate reference logits to limit the update of actor
26 | actor_optim (Optimizer): the optimizer to use for actor model
27 | critic_optim (Optimizer): the optimizer to use for critic model
28 | kl_coef (float, defaults to 0.1): the coefficient of kl divergence loss
29 | train_batch_size (int, defaults to 8): the batch size to use for training
30 | buffer_limit (int, defaults to 0): the max_size limitaiton of replay buffer
31 | buffer_cpu_offload (bool, defaults to True): whether to offload replay buffer to cpu
32 | eps_clip (float, defaults to 0.2): the clip coefficient of policy loss
33 | value_clip (float, defaults to 0.4): the clip coefficient of value loss
34 | experience_batch_size (int, defaults to 8): the batch size to use for experience generation
35 | max_epochs (int, defaults to 1): the number of epochs of training process
36 | tokenier (Callable, optional): the tokenizer to use for tokenizing the input
37 | sample_replay_buffer (bool, defaults to False): whether to sample from replay buffer
38 | dataloader_pin_memory (bool, defaults to True): whether to pin memory for data loader
39 | callbacks (List[Callback], defaults to []): the callbacks to call during training process
40 | generate_kwargs (dict, optional): the kwargs to use while model generating
41 | """
42 |
43 | def __init__(self,
44 | strategy: Strategy,
45 | actor: Actor,
46 | critic: Critic,
47 | reward_model: nn.Module,
48 | initial_model: Actor,
49 | actor_optim: Optimizer,
50 | critic_optim: Optimizer,
51 | kl_coef: float = 0.1,
52 | train_batch_size: int = 8,
53 | buffer_limit: int = 0,
54 | buffer_cpu_offload: bool = True,
55 | eps_clip: float = 0.2,
56 | value_clip: float = 0.4,
57 | experience_batch_size: int = 8,
58 | max_epochs: int = 1,
59 | tokenizer: Optional[Callable[[Any], dict]] = None,
60 | sample_replay_buffer: bool = False,
61 | dataloader_pin_memory: bool = True,
62 | callbacks: List[Callback] = [],
63 | **generate_kwargs) -> None:
64 | experience_maker = NaiveExperienceMaker(actor, critic, reward_model, initial_model, kl_coef)
65 | replay_buffer = NaiveReplayBuffer(train_batch_size, buffer_limit, buffer_cpu_offload)
66 | generate_kwargs = _set_default_generate_kwargs(strategy, generate_kwargs, actor)
67 | super().__init__(strategy, experience_maker, replay_buffer, experience_batch_size, max_epochs, tokenizer,
68 | sample_replay_buffer, dataloader_pin_memory, callbacks, **generate_kwargs)
69 | self.actor = actor
70 | self.critic = critic
71 |
72 | self.actor_loss_fn = PolicyLoss(eps_clip)
73 | self.critic_loss_fn = ValueLoss(value_clip)
74 |
75 | self.actor_optim = actor_optim
76 | self.critic_optim = critic_optim
77 |
78 | def training_step(self, experience: Experience) -> Dict[str, float]:
79 | self.actor.train()
80 | self.critic.train()
81 |
82 | num_actions = experience.action_mask.size(1)
83 | action_log_probs = self.actor(experience.sequences, num_actions, attention_mask=experience.attention_mask)
84 | actor_loss = self.actor_loss_fn(action_log_probs,
85 | experience.action_log_probs,
86 | experience.advantages,
87 | action_mask=experience.action_mask)
88 | self.strategy.backward(actor_loss, self.actor, self.actor_optim)
89 | self.strategy.optimizer_step(self.actor_optim)
90 | self.actor_optim.zero_grad()
91 |
92 | values = self.critic(experience.sequences,
93 | action_mask=experience.action_mask,
94 | attention_mask=experience.attention_mask)
95 | critic_loss = self.critic_loss_fn(values,
96 | experience.values,
97 | experience.reward,
98 | action_mask=experience.action_mask)
99 | self.strategy.backward(critic_loss, self.critic, self.critic_optim)
100 | self.strategy.optimizer_step(self.critic_optim)
101 | self.critic_optim.zero_grad()
102 |
103 | return {'actor_loss': actor_loss.item(), 'critic_loss': critic_loss.item()}
104 |
105 |
106 | def _set_default_generate_kwargs(strategy: Strategy, generate_kwargs: dict, actor: Actor) -> None:
107 | origin_model = strategy._unwrap_actor(actor)
108 | new_kwargs = {**generate_kwargs}
109 | # use huggingface models method directly
110 | if 'prepare_inputs_fn' not in generate_kwargs and hasattr(origin_model, 'prepare_inputs_for_generation'):
111 | new_kwargs['prepare_inputs_fn'] = origin_model.prepare_inputs_for_generation
112 |
113 | if 'update_model_kwargs_fn' not in generate_kwargs:
114 | new_kwargs['update_model_kwargs_fn'] = update_model_kwargs_fn
115 |
116 | return new_kwargs
117 |
--------------------------------------------------------------------------------
/code/chatgpt/trainer/rm.py:
--------------------------------------------------------------------------------
1 | from abc import ABC
2 |
3 | import loralib as lora
4 | import torch
5 | from chatgpt.dataset import RewardDataset
6 | from chatgpt.models.loss import PairWiseLoss
7 | from torch.optim import Adam, Optimizer
8 | from torch.utils.data import DataLoader
9 | from tqdm import tqdm
10 |
11 | from .strategies import Strategy
12 | from .utils import is_rank_0
13 |
14 |
15 | class RewardModelTrainer(ABC):
16 | """
17 | Trainer to use while training reward model.
18 |
19 | Args:
20 | model (torch.nn.Module): the model to train
21 | strategy (Strategy): the strategy to use for training
22 | optim(Optimizer): the optimizer to use for training
23 | train_dataset (RewardDataset): the dataset to use for training
24 | eval_dataset (RewardDataset): the dataset to use for evaluation
25 | batch_size (int, defaults to 1): the batch size while training
26 | max_epochs (int, defaults to 2): the number of epochs to train
27 | optim_kwargs (dict, defaults to {'lr':1e-4}): the kwargs to use while initializing optimizer
28 | """
29 |
30 | def __init__(
31 | self,
32 | model,
33 | strategy: Strategy,
34 | optim: Optimizer,
35 | train_dataset: RewardDataset,
36 | eval_dataset: RewardDataset,
37 | batch_size: int = 1,
38 | max_epochs: int = 2,
39 | ) -> None:
40 | super().__init__()
41 | self.strategy = strategy
42 | self.epochs = max_epochs
43 | self.train_dataloader = DataLoader(train_dataset, batch_size=batch_size)
44 | self.eval_dataloader = DataLoader(eval_dataset, batch_size=batch_size)
45 |
46 | self.model = strategy.setup_model(model)
47 | if "DDP" in str(self.strategy):
48 | self.model = self.model.module
49 | self.loss_fn = PairWiseLoss()
50 | self.optimizer = strategy.setup_optimizer(optim, self.model)
51 |
52 | def fit(self, use_lora):
53 | epoch_bar = tqdm(range(self.epochs), desc='Train epoch', disable=not is_rank_0())
54 | for epoch in range(self.epochs):
55 | step_bar = tqdm(range(self.train_dataloader.__len__()),
56 | desc='Train step of epoch %d' % epoch,
57 | disable=not is_rank_0())
58 | # train
59 | self.model.train()
60 | for chosen_ids, c_mask, reject_ids, r_mask in self.train_dataloader:
61 | chosen_ids = chosen_ids.squeeze(1).cuda()
62 | c_mask = c_mask.squeeze(1).cuda()
63 | reject_ids = reject_ids.squeeze(1).cuda()
64 | r_mask = r_mask.squeeze(1).cuda()
65 | chosen_reward = self.model(chosen_ids, attention_mask=c_mask)
66 | reject_reward = self.model(reject_ids, attention_mask=r_mask)
67 | loss = self.loss_fn(chosen_reward, reject_reward)
68 | self.strategy.backward(loss, self.model, self.optimizer)
69 | self.strategy.optimizer_step(self.optimizer)
70 | self.optimizer.zero_grad()
71 | step_bar.update()
72 | step_bar.set_postfix({'loss': loss.item()})
73 |
74 | # eval
75 | self.model.eval()
76 | with torch.no_grad():
77 | dist = 0
78 | loss_sum = 0
79 | for chosen_ids, c_mask, reject_ids, r_mask in self.eval_dataloader:
80 | chosen_ids = chosen_ids.squeeze(1).cuda()
81 | c_mask = c_mask.squeeze(1).cuda()
82 | reject_ids = reject_ids.squeeze(1).cuda()
83 | r_mask = r_mask.squeeze(1).cuda()
84 | chosen_reward = self.model(chosen_ids, attention_mask=c_mask)
85 | reject_reward = self.model(reject_ids, attention_mask=r_mask)
86 | dist += (chosen_reward - reject_reward).mean().item()
87 | loss = self.loss_fn(chosen_reward, reject_reward)
88 | loss_sum += loss.item()
89 | dist_mean = dist / self.eval_dataloader.__len__()
90 | loss_mean = loss_sum / self.eval_dataloader.__len__()
91 | epoch_bar.update()
92 | step_bar.set_postfix({'loss': loss_mean, 'dist_mean': dist_mean})
93 | step_bar.close()
94 |
--------------------------------------------------------------------------------
/code/chatgpt/trainer/strategies/__init__.py:
--------------------------------------------------------------------------------
1 | from .base import Strategy
2 | from .colossalai import ColossalAIStrategy
3 | from .ddp import DDPStrategy
4 | from .naive import NaiveStrategy
5 |
6 | __all__ = ['Strategy', 'NaiveStrategy', 'DDPStrategy', 'ColossalAIStrategy']
7 |
--------------------------------------------------------------------------------
/code/chatgpt/trainer/strategies/__pycache__/__init__.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/trainer/strategies/__pycache__/__init__.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/trainer/strategies/__pycache__/base.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/trainer/strategies/__pycache__/base.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/trainer/strategies/__pycache__/colossalai.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/trainer/strategies/__pycache__/colossalai.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/trainer/strategies/__pycache__/ddp.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/trainer/strategies/__pycache__/ddp.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/trainer/strategies/__pycache__/naive.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/trainer/strategies/__pycache__/naive.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/trainer/strategies/__pycache__/sampler.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/chatgpt/trainer/strategies/__pycache__/sampler.cpython-310.pyc
--------------------------------------------------------------------------------
/code/chatgpt/trainer/strategies/base.py:
--------------------------------------------------------------------------------
1 | from abc import ABC, abstractmethod
2 | from contextlib import nullcontext
3 | from typing import Any, List, Tuple, Union
4 |
5 | import numpy as np
6 | import torch
7 | import torch.nn as nn
8 | from chatgpt.models.base import Actor, Critic, RewardModel
9 | from chatgpt.replay_buffer import ReplayBuffer
10 | from torch.optim import Optimizer
11 | from torch.utils.data import DataLoader
12 |
13 | from .sampler import DistributedSampler
14 |
15 | ModelOptimPair = Tuple[nn.Module, Optimizer]
16 | ModelOrModelOptimPair = Union[nn.Module, ModelOptimPair]
17 |
18 |
19 | class Strategy(ABC):
20 | """
21 | Base class for training strategies.
22 | """
23 |
24 | def __init__(self) -> None:
25 | super().__init__()
26 | self.setup_distributed()
27 |
28 | @abstractmethod
29 | def backward(self, loss: torch.Tensor, model: nn.Module, optimizer: Optimizer, **kwargs) -> None:
30 | pass
31 |
32 | @abstractmethod
33 | def optimizer_step(self, optimizer: Optimizer, **kwargs) -> None:
34 | pass
35 |
36 | @abstractmethod
37 | def setup_distributed(self) -> None:
38 | pass
39 |
40 | @abstractmethod
41 | def setup_model(self, model: nn.Module) -> nn.Module:
42 | pass
43 |
44 | @abstractmethod
45 | def setup_optimizer(self, optimizer: Optimizer, model: nn.Module) -> Optimizer:
46 | pass
47 |
48 | @abstractmethod
49 | def setup_dataloader(self, replay_buffer: ReplayBuffer, pin_memory: bool = False) -> DataLoader:
50 | pass
51 |
52 | def model_init_context(self):
53 | return nullcontext()
54 |
55 | def prepare(
56 | self, *models_or_model_optim_pairs: ModelOrModelOptimPair
57 | ) -> Union[List[ModelOrModelOptimPair], ModelOrModelOptimPair]:
58 | """Prepare models or model-optimizer-pairs based on each strategy.
59 |
60 | Example::
61 | >>> # when fine-tuning actor and critic
62 | >>> (actor, actor_optim), (critic, critic_optim), reward_model, initial_model = strategy.prepare((actor, actor_optim), (critic, critic_optim), reward_model, initial_model)
63 | >>> # or when training reward model
64 | >>> (reward_model, reward_model_optim) = strategy.prepare((reward_model, reward_model_optim))
65 | >>> # or just inference
66 | >>> actor, critic = strategy.prepare(actor, critic)
67 |
68 | Returns:
69 | Union[List[ModelOrModelOptimPair], ModelOrModelOptimPair]: Models or model-optimizer-pairs in the original order.
70 | """
71 |
72 | def prepare_model(model: nn.Module):
73 | if isinstance(model, Actor):
74 | return Actor(self.setup_model(self._unwrap_model(model)))
75 | return self.setup_model(self._unwrap_model(model))
76 |
77 | rets = []
78 | for arg in models_or_model_optim_pairs:
79 | if isinstance(arg, tuple):
80 | assert len(arg) == 2, f'Expect (model, optimizer) pair, got a tuple with size "{len(arg)}"'
81 | model, optimizer = arg
82 | model = prepare_model(model)
83 | optimizer = self.setup_optimizer(optimizer, self._unwrap_model(model))
84 | rets.append((model, optimizer))
85 | elif isinstance(arg, nn.Module):
86 | rets.append(prepare_model(arg))
87 | else:
88 | raise RuntimeError(f'Expect model or (model, optimizer) pair, got {type(arg)}')
89 |
90 | if len(rets) == 1:
91 | return rets[0]
92 | return rets
93 |
94 | @staticmethod
95 | def _unwrap_model(model: nn.Module) -> nn.Module:
96 | """Useful for saving state dict. As actor is wrapped by Actor class again in `prepare()`, we should unwrap it before saving.
97 |
98 | Args:
99 | model (nn.Module): an actor or a critic
100 | """
101 | if isinstance(model, Actor):
102 | return model.model
103 | return model
104 |
105 | @staticmethod
106 | def _unwrap_actor(actor: Actor) -> nn.Module:
107 | """Get `actor.model` from a wrapped (by `prepare()`) actor. Useful for getting original huggingface model.
108 |
109 | Args:
110 | actor (Actor): a wrapped actor
111 | """
112 | return Strategy._unwrap_model(actor)
113 |
114 | @abstractmethod
115 | def save_model(self, model: nn.Module, path: str, only_rank0: bool = False) -> None:
116 | pass
117 |
118 | @abstractmethod
119 | def load_model(self, model: nn.Module, path: str, map_location: Any = None, strict: bool = True) -> None:
120 | pass
121 |
122 | @abstractmethod
123 | def save_optimizer(self, optimizer: Optimizer, path: str, only_rank0: bool = False) -> None:
124 | pass
125 |
126 | @abstractmethod
127 | def load_optimizer(self, optimizer: Optimizer, path: str, map_location: Any = None) -> None:
128 | pass
129 |
130 | def setup_sampler(self, dataset) -> DistributedSampler:
131 | return DistributedSampler(dataset, 1, 0)
132 |
--------------------------------------------------------------------------------
/code/chatgpt/trainer/strategies/colossalai.py:
--------------------------------------------------------------------------------
1 | import warnings
2 | from typing import Optional, Union
3 |
4 | import torch
5 | import torch.distributed as dist
6 | import torch.nn as nn
7 | import torch.optim as optim
8 | from chatgpt.models.base import Actor
9 | from chatgpt.models.lora import LoraLinear
10 | from torch.optim import Optimizer
11 |
12 | import colossalai
13 | from colossalai.nn.optimizer import CPUAdam, HybridAdam
14 | from colossalai.nn.parallel import ZeroDDP, zero_model_wrapper, zero_optim_wrapper
15 | from colossalai.nn.parallel.utils import get_static_torch_model
16 | from colossalai.tensor import ProcessGroup, ShardSpec
17 | from colossalai.utils import get_current_device
18 | from colossalai.utils.model.colo_init_context import ColoInitContext
19 |
20 | from .base import Strategy
21 | from .ddp import DDPStrategy
22 |
23 |
24 | class ColossalAIStrategy(DDPStrategy):
25 | """
26 | The strategy for training with ColossalAI.
27 |
28 | Args:
29 | stage(int): The stage to use in ZeRO. Choose in (1, 2, 3)
30 | seed(int): The seed for the random number generator.
31 | shard_init(bool): Whether to shard the model parameters during initialization. Only for ZeRO-3.
32 | This is not compativle with `from_pretrained()`. We temporarily disable this and will support it in the future.
33 | placement_policy(str): The placement policy for gemini. Choose in ('cpu', 'cuda')
34 | If it is “cpu”, parameters, gradients and optimizer states will be offloaded to CPU,
35 | If it is “cuda”, they will not be offloaded, which means max CUDA memory will be used. It is the fastest.
36 | pin_memory(bool): Whether to pin the memory for the data loader. Only for ZeRO-3.
37 | force_outputs_fp32(bool): Whether to force the outputs to be fp32. Only for ZeRO-3.
38 | search_range_mb(int): The search range in MB for the chunk size. Only for ZeRO-3.
39 | hidden_dim(optional, int): The hidden dimension for the gemini. Only for ZeRO-3.
40 | min_chunk_size_mb(float): The minimum chunk size in MB. Only for ZeRO-3.
41 | gpu_margin_mem_ratio(float): The margin memory ratio for the GPU. Only for ZeRO-3.
42 | reduce_bugket_size(int): The reduce bucket size in bytes. Only for ZeRO-1 and ZeRO-2.
43 | overlap_communication(bool): Whether to overlap communication and computation. Only for ZeRO-1 and ZeRO-2.
44 | initial_scale(float): The initial scale for the optimizer.
45 | growth_factor(float): The growth factor for the optimizer.
46 | backoff_factor(float): The backoff factor for the optimizer.
47 | growth_interval(int): The growth interval for the optimizer.
48 | hysteresis(int): The hysteresis for the optimizer.
49 | min_scale(float): The minimum scale for the optimizer.
50 | max_scale(float): The maximum scale for the optimizer.
51 | max_norm(float): The maximum norm for the optimizer.
52 | norm_type(float): The norm type for the optimizer.
53 |
54 | """
55 |
56 | def __init__(
57 | self,
58 | stage: int = 3,
59 | seed: int = 42,
60 | shard_init: bool = False, # only for stage 3
61 | placement_policy: str = 'cuda',
62 | pin_memory: bool = True, # only for stage 3
63 | force_outputs_fp32: bool = False, # only for stage 3
64 | search_range_mb: int = 32, # only for stage 3
65 | hidden_dim: Optional[int] = None, # only for stage 3
66 | min_chunk_size_mb: float = 32, # only for stage 3
67 | gpu_margin_mem_ratio: float = 0.0, # only for stage 3
68 | reduce_bucket_size: int = 12 * 1024**2, # only for stage 1&2
69 | overlap_communication: bool = True, # only for stage 1&2
70 | initial_scale: float = 2**16,
71 | growth_factor: float = 2,
72 | backoff_factor: float = 0.5,
73 | growth_interval: int = 1000,
74 | hysteresis: int = 2,
75 | min_scale: float = 1,
76 | max_scale: float = 2**32,
77 | max_norm: float = 0.0,
78 | norm_type: float = 2.0) -> None:
79 | super().__init__(seed)
80 | assert placement_policy in ('cpu', 'cuda'), f'Unsupported placement policy "{placement_policy}"'
81 | self.stage = stage
82 | # TODO(ver217): support shard_init when using from_pretrained()
83 | if shard_init:
84 | warnings.warn(
85 | f'Shard init is not supported model.from_pretrained() yet. Please load weights after strategy.prepare()'
86 | )
87 | self.shard_init = shard_init
88 | self.gemini_config = dict(device=get_current_device(),
89 | placement_policy=placement_policy,
90 | pin_memory=pin_memory,
91 | force_outputs_fp32=force_outputs_fp32,
92 | strict_ddp_mode=shard_init,
93 | search_range_mb=search_range_mb,
94 | hidden_dim=hidden_dim,
95 | min_chunk_size_mb=min_chunk_size_mb)
96 | if stage == 3:
97 | self.zero_optim_config = dict(gpu_margin_mem_ratio=gpu_margin_mem_ratio)
98 | else:
99 | self.zero_optim_config = dict(reduce_bucket_size=reduce_bucket_size,
100 | overlap_communication=overlap_communication,
101 | cpu_offload=(placement_policy == 'cpu'))
102 | self.optim_kwargs = dict(initial_scale=initial_scale,
103 | growth_factor=growth_factor,
104 | backoff_factor=backoff_factor,
105 | growth_interval=growth_interval,
106 | hysteresis=hysteresis,
107 | min_scale=min_scale,
108 | max_scale=max_scale,
109 | max_norm=max_norm,
110 | norm_type=norm_type)
111 |
112 | def setup_distributed(self) -> None:
113 | colossalai.launch_from_torch({}, seed=self.seed)
114 |
115 | def model_init_context(self):
116 | if self.stage == 3:
117 | world_size = dist.get_world_size()
118 | shard_pg = ProcessGroup(tp_degree=world_size) if self.shard_init else None
119 | default_dist_spec = ShardSpec([-1], [world_size]) if self.shard_init else None
120 | return ColoInitContext(device=get_current_device(),
121 | dtype=torch.half,
122 | default_pg=shard_pg,
123 | default_dist_spec=default_dist_spec)
124 | return super().model_init_context()
125 |
126 | def setup_model(self, model: nn.Module) -> nn.Module:
127 | return zero_model_wrapper(model, zero_stage=self.stage, gemini_config=self.gemini_config)
128 |
129 | def setup_optimizer(self, optimizer: optim.Optimizer, model: nn.Module) -> optim.Optimizer:
130 | assert isinstance(optimizer, (CPUAdam, HybridAdam)), f'Unsupported optimizer {type(optimizer)}'
131 | return zero_optim_wrapper(model, optimizer, optim_config=self.zero_optim_config, **self.optim_kwargs)
132 |
133 | def backward(self, loss: torch.Tensor, model: nn.Module, optimizer: optim.Optimizer, **kwargs) -> None:
134 | optimizer.backward(loss)
135 |
136 | def optimizer_step(self, optimizer: optim.Optimizer, **kwargs) -> None:
137 | optimizer.step()
138 |
139 | @staticmethod
140 | def _unwrap_actor(actor: Actor) -> nn.Module:
141 | model: Union[nn.Module, ZeroDDP] = Strategy._unwrap_actor(actor)
142 | if isinstance(model, ZeroDDP):
143 | return model.module
144 | return model
145 |
146 | def save_model(self, model: nn.Module, path: str, only_rank0: bool = False) -> None:
147 | unwrapped_model = self._unwrap_model(model)
148 | # TODO : better way to get torch model from gemini model
149 | # to get torch model from gemini model
150 | if isinstance(unwrapped_model, ZeroDDP):
151 | state_dict = unwrapped_model.state_dict()
152 | unwrapped_model = get_static_torch_model(unwrapped_model)
153 | if only_rank0 and dist.get_rank() != 0:
154 | return
155 | unwrapped_model.load_state_dict(state_dict)
156 | # merge lora_weights into weights
157 | for module in unwrapped_model.modules():
158 | if isinstance(module, LoraLinear):
159 | module.merge_weights=True
160 | module.eval()
161 | # get state_dict and save
162 | state_dict = unwrapped_model.state_dict()
163 | if only_rank0 and dist.get_rank() != 0:
164 | return
165 | torch.save(state_dict, path)
166 |
167 | def save_optimizer(self, optimizer: Optimizer, path: str, only_rank0: bool = False) -> None:
168 | if only_rank0:
169 | raise RuntimeError(
170 | f'Optimizer states are sharded when using ColossalAIStrategy. Only rank0 is not supported.')
171 | torch.save(optimizer.state_dict(), path)
172 |
--------------------------------------------------------------------------------
/code/chatgpt/trainer/strategies/ddp.py:
--------------------------------------------------------------------------------
1 | import os
2 | import random
3 |
4 | import numpy as np
5 | import torch
6 | import torch.distributed as dist
7 | import torch.nn as nn
8 | from chatgpt.models.base import Actor
9 | from chatgpt.models.lora import LoraLinear
10 | from chatgpt.replay_buffer import ReplayBuffer
11 | from torch.nn.parallel import DistributedDataParallel as DDP
12 | from torch.optim import Optimizer
13 | from torch.utils.data import DataLoader
14 |
15 | from .base import Strategy
16 | from .naive import NaiveStrategy
17 | from .sampler import DistributedSampler
18 |
19 |
20 | class DDPStrategy(NaiveStrategy):
21 | """
22 | Strategy for distributed training using torch.distributed.
23 | """
24 |
25 | def __init__(self, seed: int = 42) -> None:
26 | self.seed = seed
27 | super().__init__()
28 |
29 | def setup_distributed(self) -> None:
30 | try:
31 | rank = int(os.environ['RANK'])
32 | local_rank = int(os.environ['LOCAL_RANK'])
33 | world_size = int(os.environ['WORLD_SIZE'])
34 | host = os.environ['MASTER_ADDR']
35 | port = int(os.environ['MASTER_PORT'])
36 | except KeyError as e:
37 | raise RuntimeError(
38 | f"Could not find {e} in the torch environment, visit https://www.colossalai.org/ for more information on launching with torch"
39 | )
40 | dist.init_process_group('nccl', init_method=f'tcp://[{host}]:{port}', world_size=world_size, rank=rank)
41 | self.set_seed(self.seed)
42 | torch.cuda.set_device(local_rank)
43 |
44 | def set_seed(self, seed: int) -> None:
45 | random.seed(seed)
46 | np.random.seed(seed)
47 | torch.manual_seed(seed)
48 |
49 | def setup_model(self, model: nn.Module) -> nn.Module:
50 | device = torch.cuda.current_device()
51 | return DDP(model, device_ids=[device])
52 |
53 | def setup_dataloader(self, replay_buffer: ReplayBuffer, pin_memory: bool = False) -> DataLoader:
54 | # DDP only mode, replay buffers on each rank are different.
55 | # sampler = DistributedSampler(replay_buffer,
56 | # num_replicas=dist.get_world_size(),
57 | # rank=dist.get_rank(),
58 | # shuffle=True,
59 | # seed=self.seed,
60 | # drop_last=True)
61 | return DataLoader(
62 | replay_buffer,
63 | batch_size=replay_buffer.sample_batch_size,
64 | # sampler=sampler,
65 | shuffle=True,
66 | drop_last=True,
67 | pin_memory=pin_memory,
68 | collate_fn=replay_buffer.collate_fn)
69 |
70 | @staticmethod
71 | def _unwrap_actor(actor: Actor) -> nn.Module:
72 | model: DDP = Strategy._unwrap_actor(actor)
73 | return model.module
74 |
75 | def save_model(self, model: nn.Module, path: str, only_rank0: bool = False) -> None:
76 | for module in model.modules():
77 | if isinstance(module, LoraLinear):
78 | module.merge_weights=True
79 | module.eval()
80 |
81 | if only_rank0 and dist.get_rank() != 0:
82 | return
83 | model = model.model.module
84 | state_dict = model.state_dict()
85 | torch.save(state_dict, path)
86 |
87 | def save_optimizer(self, optimizer: Optimizer, path: str, only_rank0: bool = False) -> None:
88 | if only_rank0 and dist.get_rank() != 0:
89 | return
90 | super().save_optimizer(optimizer, path, only_rank0)
91 |
92 | def setup_sampler(self, dataset) -> DistributedSampler:
93 | return DistributedSampler(dataset, dist.get_world_size(), dist.get_rank())
94 |
--------------------------------------------------------------------------------
/code/chatgpt/trainer/strategies/naive.py:
--------------------------------------------------------------------------------
1 | from typing import Any
2 |
3 | import torch
4 | import torch.nn as nn
5 | import torch.optim as optim
6 | from chatgpt.replay_buffer import ReplayBuffer
7 | from torch.optim import Optimizer
8 | from torch.utils.data import DataLoader
9 |
10 | from .base import Strategy
11 |
12 |
13 | class NaiveStrategy(Strategy):
14 | """
15 | Strategy for single GPU. No parallelism is used.
16 | """
17 |
18 | def backward(self, loss: torch.Tensor, model: nn.Module, optimizer: optim.Optimizer, **kwargs) -> None:
19 | loss.backward()
20 |
21 | def optimizer_step(self, optimizer: optim.Optimizer, **kwargs) -> None:
22 | optimizer.step()
23 |
24 | def setup_distributed(self) -> None:
25 | pass
26 |
27 | def setup_model(self, model: nn.Module) -> nn.Module:
28 | return model
29 |
30 | def setup_optimizer(self, optimizer: optim.Optimizer, model: nn.Module) -> optim.Optimizer:
31 | return optimizer
32 |
33 | def setup_dataloader(self, replay_buffer: ReplayBuffer, pin_memory: bool = False) -> DataLoader:
34 | return DataLoader(replay_buffer,
35 | batch_size=replay_buffer.sample_batch_size,
36 | shuffle=True,
37 | drop_last=True,
38 | pin_memory=pin_memory,
39 | collate_fn=replay_buffer.collate_fn)
40 |
41 | def save_model(self, model: nn.Module, path: str, only_rank0: bool = False) -> None:
42 | unwrapped_model = self._unwrap_model(model)
43 | torch.save(unwrapped_model.state_dict(), path)
44 |
45 | def load_model(self, model: nn.Module, path: str, map_location: Any = None, strict: bool = True) -> None:
46 | unwrapped_model = self._unwrap_model(model)
47 | state_dict = torch.load(path, map_location=map_location)
48 | unwrapped_model.load_state_dict(state_dict, strict=strict)
49 |
50 | def save_optimizer(self, optimizer: Optimizer, path: str, only_rank0: bool = False) -> None:
51 | torch.save(optimizer.state_dict(), path)
52 |
53 | def load_optimizer(self, optimizer: Optimizer, path: str, map_location: Any = None) -> None:
54 | state_dict = torch.load(path, map_location=map_location)
55 | optimizer.load_state_dict(state_dict)
56 |
--------------------------------------------------------------------------------
/code/chatgpt/trainer/strategies/sampler.py:
--------------------------------------------------------------------------------
1 | import math
2 |
3 | import numpy as np
4 |
5 |
6 | class DistributedSampler:
7 |
8 | def __init__(self, dataset, num_replicas: int, rank: int) -> None:
9 | self.dataset = dataset
10 | self.num_replicas = num_replicas
11 | self.rank = rank
12 |
13 | if len(self.dataset) % self.num_replicas != 0:
14 | self.num_samples = math.ceil(
15 | (len(self.dataset) - self.num_replicas) / self.num_replicas # type: ignore[arg-type]
16 | )
17 | else:
18 | self.num_samples = math.ceil(len(self.dataset) / self.num_replicas)
19 |
20 | self.total_size = self.num_samples * self.num_replicas
21 |
22 | indices = list(range(len(self.dataset)))
23 | indices = indices[:self.total_size]
24 | assert len(indices) == self.total_size
25 | # subsample
26 | indices = indices[self.rank:self.total_size:self.num_replicas]
27 | assert len(indices) == self.num_samples
28 | self.indices = indices
29 |
30 | def sample(self, batch_size: int) -> list:
31 | sampled_indices = np.random.choice(self.indices, batch_size, replace=False)
32 | return [self.dataset[idx] for idx in sampled_indices]
33 |
--------------------------------------------------------------------------------
/code/chatgpt/trainer/utils.py:
--------------------------------------------------------------------------------
1 | import torch.distributed as dist
2 |
3 |
4 | def is_rank_0() -> bool:
5 | return not dist.is_initialized() or dist.get_rank() == 0
6 |
--------------------------------------------------------------------------------
/code/examples/README.md:
--------------------------------------------------------------------------------
1 | # Examples
2 |
3 | ## Install requirements
4 |
5 | ```shell
6 | pip install -r requirements.txt
7 | ```
8 |
9 | ## Train the reward model (Stage 2)
10 | We use [rm-static](https://huggingface.co/datasets/Dahoas/rm-static) as dataset to train our reward model. It is a dataset of chosen & rejected response of the same prompt.
11 |
12 | You can download the dataset from huggingface automatically.
13 |
14 | Use these code to train your reward model.
15 |
16 | ```shell
17 | # Naive reward model training
18 | python train_reward_model.py --pretrain --model --strategy naive
19 | # use colossalai_zero2
20 | torchrun --standalone --nproc_per_node=2 train_reward_model.py --pretrain --model --strategy colossalai_zero2
21 | ```
22 |
23 | ## Train with dummy prompt data (Stage 3)
24 |
25 | This script supports 3 strategies:
26 |
27 | - naive
28 | - ddp
29 | - colossalai
30 |
31 | It uses random generated prompt data.
32 |
33 | Naive strategy only support single GPU training:
34 |
35 | ```shell
36 | python train_dummy.py --strategy naive
37 | # display cli help
38 | python train_dummy.py -h
39 | ```
40 |
41 | DDP strategy and ColossalAI strategy support multi GPUs training:
42 |
43 | ```shell
44 | # run DDP on 2 GPUs
45 | torchrun --standalone --nproc_per_node=2 train_dummy.py --strategy ddp
46 | # run ColossalAI on 2 GPUs
47 | torchrun --standalone --nproc_per_node=2 train_dummy.py --strategy colossalai_zero2
48 | ```
49 |
50 | ## Train with real prompt data (Stage 3)
51 |
52 | We use [awesome-chatgpt-prompts](https://huggingface.co/datasets/fka/awesome-chatgpt-prompts) as example dataset. It is a small dataset with hundreds of prompts.
53 |
54 | You should download `prompts.csv` first.
55 |
56 | This script also supports 3 strategies.
57 |
58 | ```shell
59 | # display cli help
60 | python train_dummy.py -h
61 | # run naive on 1 GPU
62 | python train_prompts.py prompts.csv --strategy naive
63 | # run DDP on 2 GPUs
64 | torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy ddp
65 | # run ColossalAI on 2 GPUs
66 | torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy colossalai_zero2
67 | ```
68 |
69 | ## Inference example(After Stage3)
70 | We support naive inference demo after training.
71 | ```shell
72 | # inference, using pretrain path to configure model
73 | python inference.py --model_path --model --pretrain
74 | # example
75 | python inference.py --model_path ./actor_checkpoint_prompts.pt --pretrain bigscience/bloom-560m --model bloom
76 | ```
77 |
78 |
79 | #### data
80 | - [x] [rm-static](https://huggingface.co/datasets/Dahoas/rm-static)
81 | - [x] [hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf)
82 | - [ ] [openai/summarize_from_feedback](https://huggingface.co/datasets/openai/summarize_from_feedback)
83 | - [ ] [openai/webgpt_comparisons](https://huggingface.co/datasets/openai/webgpt_comparisons)
84 | - [ ] [Dahoas/instruct-synthetic-prompt-responses](https://huggingface.co/datasets/Dahoas/instruct-synthetic-prompt-responses)
85 |
86 | ## Support Model
87 |
88 | ### GPT
89 | - [x] GPT2-S (s)
90 | - [x] GPT2-M (m)
91 | - [x] GPT2-L (l)
92 | - [ ] GPT2-XL (xl)
93 | - [x] GPT2-4B (4b)
94 | - [ ] GPT2-6B (6b)
95 | - [ ] GPT2-8B (8b)
96 | - [ ] GPT2-10B (10b)
97 | - [ ] GPT2-12B (12b)
98 | - [ ] GPT2-15B (15b)
99 | - [ ] GPT2-18B (18b)
100 | - [ ] GPT2-20B (20b)
101 | - [ ] GPT2-24B (24b)
102 | - [ ] GPT2-28B (28b)
103 | - [ ] GPT2-32B (32b)
104 | - [ ] GPT2-36B (36b)
105 | - [ ] GPT2-40B (40b)
106 | - [ ] GPT3 (175b)
107 |
108 | ### BLOOM
109 | - [x] [BLOOM-560m](https://huggingface.co/bigscience/bloom-560m)
110 | - [x] [BLOOM-1b1](https://huggingface.co/bigscience/bloom-1b1)
111 | - [x] [BLOOM-3b](https://huggingface.co/bigscience/bloom-3b)
112 | - [x] [BLOOM-7b](https://huggingface.co/bigscience/bloom-7b1)
113 | - [ ] BLOOM-175b
114 |
115 | ### OPT
116 | - [x] [OPT-125M](https://huggingface.co/facebook/opt-125m)
117 | - [x] [OPT-350M](https://huggingface.co/facebook/opt-350m)
118 | - [ ] [OPT-1.3B](https://huggingface.co/facebook/opt-1.3b)
119 | - [ ] [OPT-2.7B](https://huggingface.co/facebook/opt-2.7b)
120 | - [ ] [OPT-6.7B](https://huggingface.co/facebook/opt-6.7b)
121 | - [ ] [OPT-13B](https://huggingface.co/facebook/opt-13b)
122 | - [ ] [OPT-30B](https://huggingface.co/facebook/opt-30b)
123 |
--------------------------------------------------------------------------------
/code/examples/inference.py:
--------------------------------------------------------------------------------
1 | import argparse
2 |
3 | import torch
4 | from chatgpt.models.bloom import BLOOMActor
5 | from chatgpt.models.gpt import GPTActor
6 | from chatgpt.models.opt import OPTActor
7 | from transformers import AutoTokenizer
8 | from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
9 |
10 |
11 | def eval(args):
12 | # configure model
13 | if args.model == 'gpt2':
14 | actor = GPTActor(pretrained=args.pretrain).to(torch.cuda.current_device())
15 | elif args.model == 'bloom':
16 | actor = BLOOMActor(pretrained=args.pretrain).to(torch.cuda.current_device())
17 | elif args.model == 'opt':
18 | actor = OPTActor(pretrained=args.pretrain).to(torch.cuda.current_device())
19 | else:
20 | raise ValueError(f'Unsupported model "{args.model}"')
21 |
22 | state_dict = torch.load(args.model_path)
23 | actor.model.load_state_dict(state_dict)
24 |
25 | # configure tokenizer
26 | if args.model == 'gpt2':
27 | tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
28 | tokenizer.pad_token = tokenizer.eos_token
29 | elif args.model == 'bloom':
30 | tokenizer = AutoTokenizer.from_pretrained('bigscience/bloom-560m')
31 | tokenizer.pad_token = tokenizer.eos_token
32 | elif args.model == 'opt':
33 | tokenizer = AutoTokenizer.from_pretrained('facebook/opt-350m')
34 | else:
35 | raise ValueError(f'Unsupported model "{args.model}"')
36 |
37 | actor.eval()
38 | input = args.input
39 | input_ids = tokenizer.encode(input, return_tensors='pt').to(torch.cuda.current_device())
40 | outputs = actor.generate(input_ids,
41 | max_length=args.max_length,
42 | do_sample=True,
43 | top_k=50,
44 | top_p=0.95,
45 | num_return_sequences=1)
46 | output = tokenizer.batch_decode(outputs[0], skip_special_tokens=True)
47 | print(output)
48 |
49 |
50 | if __name__ == '__main__':
51 | parser = argparse.ArgumentParser()
52 | parser.add_argument('--model', default='gpt2', choices=['gpt2', 'bloom', 'opt'])
53 | # We suggest to use the pretrained model from HuggingFace, use pretrain to configure model
54 | parser.add_argument('--pretrain', type=str, default=None)
55 | parser.add_argument('--model_path', type=str, default=None)
56 | parser.add_argument('--input', type=str, default='Question: How are you ? Answer:')
57 | parser.add_argument('--max_length', type=int, default=100)
58 | args = parser.parse_args()
59 | eval(args)
60 |
--------------------------------------------------------------------------------
/code/examples/requirements.txt:
--------------------------------------------------------------------------------
1 | pandas>=1.4.1
2 |
--------------------------------------------------------------------------------
/code/examples/test_ci.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env bash
2 |
3 | set -xue
4 |
5 | if [ -z "$PROMPT_PATH" ]; then
6 | echo "Please set \$PROMPT_PATH to the path to prompts csv."
7 | exit 1
8 | fi
9 |
10 | BASE=$(realpath $(dirname $0))
11 |
12 | export OMP_NUM_THREADS=8
13 |
14 | # install requirements
15 | pip install -r ${BASE}/requirements.txt
16 |
17 | # train dummy
18 | python ${BASE}/train_dummy.py --strategy naive --num_episodes 1 \
19 | --max_timesteps 2 --update_timesteps 2 \
20 | --max_epochs 1 --train_batch_size 2 --lora_rank 4
21 |
22 | torchrun --standalone --nproc_per_node=2 ${BASE}/train_dummy.py \
23 | --strategy colossalai_gemini --num_episodes 1 --max_timesteps 2 \
24 | --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
25 | --pretrain 'facebook/opt-350m' --model opt --lora_rank 4\
26 | --save_path ${BASE}/actor_checkpoint_dummy.pt
27 | python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_dummy.pt --pretrain 'facebook/opt-350m' --model opt
28 |
29 | torchrun --standalone --nproc_per_node=2 ${BASE}/train_dummy.py \
30 | --strategy ddp --num_episodes 1 --max_timesteps 2 \
31 | --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
32 | --pretrain 'facebook/opt-350m' --model opt --lora_rank 4\
33 | --save_path ${BASE}/actor_checkpoint_dummy.pt
34 | python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_dummy.pt --pretrain 'facebook/opt-350m' --model opt
35 |
36 | torchrun --standalone --nproc_per_node=2 ${BASE}/train_dummy.py \
37 | --strategy colossalai_zero2 --num_episodes 1 --max_timesteps 2 \
38 | --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
39 | --pretrain 'gpt2' --model gpt2 --lora_rank 4\
40 | --save_path ${BASE}/actor_checkpoint_dummy.pt
41 | python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_dummy.pt --pretrain 'gpt2' --model gpt2
42 |
43 | rm -rf ${BASE}/actor_checkpoint_dummy.pt
44 |
45 | # train prompts
46 | python ${BASE}/train_prompts.py $PROMPT_PATH --strategy naive --num_episodes 1 \
47 | --max_timesteps 2 --update_timesteps 2 \
48 | --max_epochs 1 --train_batch_size 2 --lora_rank 4
49 |
50 | torchrun --standalone --nproc_per_node=2 ${BASE}/train_prompts.py $PROMPT_PATH \
51 | --strategy colossalai_zero2 --num_episodes 1 --max_timesteps 2 \
52 | --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
53 | --pretrain 'facebook/opt-350m' --model opt --lora_rank 4\
54 | --save_path ${BASE}/actor_checkpoint_prompts.pt
55 | python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_prompts.pt --pretrain 'facebook/opt-350m' --model opt
56 |
57 | torchrun --standalone --nproc_per_node=2 ${BASE}/train_prompts.py $PROMPT_PATH \
58 | --strategy ddp --num_episodes 1 --max_timesteps 2 \
59 | --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
60 | --pretrain 'gpt2' --model gpt2 --lora_rank 4\
61 | --save_path ${BASE}/actor_checkpoint_prompts.pt
62 | python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_prompts.pt --pretrain 'gpt2' --model gpt2
63 |
64 | torchrun --standalone --nproc_per_node=2 ${BASE}/train_prompts.py $PROMPT_PATH \
65 | --strategy colossalai_gemini --num_episodes 1 --max_timesteps 2 \
66 | --update_timesteps 2 --max_epochs 1 --train_batch_size 2\
67 | --pretrain 'gpt2' --model gpt2 --lora_rank 4\
68 | --save_path ${BASE}/actor_checkpoint_prompts.pt
69 | python ${BASE}/inference.py --model_path ${BASE}/actor_checkpoint_prompts.pt --pretrain 'gpt2' --model gpt2
70 |
71 | rm -rf ${BASE}/actor_checkpoint_prompts.pt
72 |
--------------------------------------------------------------------------------
/code/examples/train_dummy.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | from copy import deepcopy
3 |
4 | import torch
5 | from chatgpt.models.base import RewardModel
6 | from chatgpt.models.bloom import BLOOMActor, BLOOMCritic
7 | from chatgpt.models.gpt import GPTActor, GPTCritic
8 | from chatgpt.models.opt import OPTActor, OPTCritic
9 | from chatgpt.trainer import PPOTrainer
10 | from chatgpt.trainer.callbacks import SaveCheckpoint
11 | from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
12 | from torch.optim import Adam
13 | from transformers import AutoTokenizer, BloomTokenizerFast
14 | from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
15 |
16 | from colossalai.nn.optimizer import HybridAdam
17 |
18 |
19 | def preprocess_batch(samples):
20 | input_ids = torch.stack(samples)
21 | attention_mask = torch.ones_like(input_ids, dtype=torch.long)
22 | return {'input_ids': input_ids, 'attention_mask': attention_mask}
23 |
24 |
25 | def main(args):
26 | # configure strategy
27 | if args.strategy == 'naive':
28 | strategy = NaiveStrategy()
29 | elif args.strategy == 'ddp':
30 | strategy = DDPStrategy()
31 | elif args.strategy == 'colossalai_gemini':
32 | strategy = ColossalAIStrategy(stage=3, placement_policy='cuda', initial_scale=2**5)
33 | elif args.strategy == 'colossalai_zero2':
34 | strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
35 | else:
36 | raise ValueError(f'Unsupported strategy "{args.strategy}"')
37 |
38 | # configure model
39 | with strategy.model_init_context():
40 | if args.model == 'gpt2':
41 | actor = GPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
42 | critic = GPTCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
43 | elif args.model == 'bloom':
44 | actor = BLOOMActor(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
45 | critic = BLOOMCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
46 | elif args.model == 'opt':
47 | actor = OPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
48 | critic = OPTCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
49 | else:
50 | raise ValueError(f'Unsupported model "{args.model}"')
51 |
52 | initial_model = deepcopy(actor).to(torch.cuda.current_device())
53 | reward_model = RewardModel(deepcopy(critic.model), deepcopy(critic.value_head)).to(torch.cuda.current_device())
54 |
55 | # configure optimizer
56 | if args.strategy.startswith('colossalai'):
57 | actor_optim = HybridAdam(actor.parameters(), lr=5e-6)
58 | critic_optim = HybridAdam(critic.parameters(), lr=5e-6)
59 | else:
60 | actor_optim = Adam(actor.parameters(), lr=5e-6)
61 | critic_optim = Adam(critic.parameters(), lr=5e-6)
62 |
63 | # configure tokenizer
64 | if args.model == 'gpt2':
65 | tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
66 | tokenizer.pad_token = tokenizer.eos_token
67 | elif args.model == 'bloom':
68 | tokenizer = BloomTokenizerFast.from_pretrained(args.pretrain)
69 | tokenizer.pad_token = tokenizer.eos_token
70 | elif args.model == 'opt':
71 | tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
72 | else:
73 | raise ValueError(f'Unsupported model "{args.model}"')
74 |
75 | (actor, actor_optim), (critic, critic_optim), reward_model, initial_model = strategy.prepare(
76 | (actor, actor_optim), (critic, critic_optim), reward_model, initial_model)
77 |
78 | callbacks = []
79 | if args.save_ckpt_path:
80 | ckpt_callback = SaveCheckpoint(
81 | args.save_ckpt_path,
82 | args.save_ckpt_interval,
83 | strategy,
84 | actor,
85 | critic,
86 | actor_optim,
87 | critic_optim,
88 | )
89 | callbacks.append(ckpt_callback)
90 |
91 | # configure trainer
92 |
93 | trainer = PPOTrainer(strategy,
94 | actor,
95 | critic,
96 | reward_model,
97 | initial_model,
98 | actor_optim,
99 | critic_optim,
100 | max_epochs=args.max_epochs,
101 | train_batch_size=args.train_batch_size,
102 | tokenizer=preprocess_batch,
103 | max_length=128,
104 | do_sample=True,
105 | temperature=1.0,
106 | top_k=50,
107 | pad_token_id=tokenizer.pad_token_id,
108 | eos_token_id=tokenizer.eos_token_id,
109 | callbacks=callbacks)
110 |
111 | random_prompts = torch.randint(tokenizer.vocab_size, (1000, 64), device=torch.cuda.current_device())
112 | trainer.fit(random_prompts,
113 | num_episodes=args.num_episodes,
114 | max_timesteps=args.max_timesteps,
115 | update_timesteps=args.update_timesteps)
116 |
117 | # save model checkpoint after fitting
118 | strategy.save_model(actor, args.save_path, only_rank0=True)
119 | # save optimizer checkpoint on all ranks
120 | if args.need_optim_ckpt:
121 | strategy.save_optimizer(actor_optim,
122 | 'actor_optim_checkpoint_dummy_%d.pt' % (torch.cuda.current_device()),
123 | only_rank0=False)
124 |
125 |
126 | if __name__ == '__main__':
127 | parser = argparse.ArgumentParser()
128 | parser.add_argument('--strategy',
129 | choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
130 | default='naive')
131 | parser.add_argument('--model', type=str, default='gpt2', choices=['gpt2', 'bloom', 'opt'])
132 | parser.add_argument('--pretrain', type=str, default=None)
133 | parser.add_argument('--save_path', type=str, default='actor_checkpoint_dummy.pt')
134 | parser.add_argument('--need_optim_ckpt', type=bool, default=False)
135 | parser.add_argument('--num_episodes', type=int, default=50)
136 | parser.add_argument('--max_timesteps', type=int, default=10)
137 | parser.add_argument('--update_timesteps', type=int, default=10)
138 | parser.add_argument('--max_epochs', type=int, default=5)
139 | parser.add_argument('--train_batch_size', type=int, default=8)
140 | parser.add_argument('--experience_batch_size', type=int, default=8)
141 | parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
142 | parser.add_argument('--save_ckpt_path',
143 | type=str,
144 | default=None,
145 | help="path to save checkpoint, None means not to save")
146 | parser.add_argument('--save_ckpt_interval', type=int, default=1, help="the interval of episode to save checkpoint")
147 | args = parser.parse_args()
148 | main(args)
149 |
--------------------------------------------------------------------------------
/code/examples/train_dummy.sh:
--------------------------------------------------------------------------------
1 | set_n_least_used_CUDA_VISIBLE_DEVICES() {
2 | local n=${1:-"9999"}
3 | echo "GPU Memory Usage:"
4 | local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
5 | | tail -n +2 \
6 | | nl -v 0 \
7 | | tee /dev/tty \
8 | | sort -g -k 2 \
9 | | awk '{print $1}' \
10 | | head -n $n)
11 | export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
12 | echo "Now CUDA_VISIBLE_DEVICES is set to:"
13 | echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
14 | }
15 |
16 | set_n_least_used_CUDA_VISIBLE_DEVICES 2
17 |
18 | torchrun --standalone --nproc_per_node=2 train_dummy.py --strategy colossalai_zero2
19 |
--------------------------------------------------------------------------------
/code/examples/train_prompts.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | from copy import deepcopy
3 |
4 | import pandas as pd
5 | import torch
6 | from chatgpt.models.base import RewardModel
7 | from chatgpt.models.bloom import BLOOMActor, BLOOMCritic
8 | from chatgpt.models.gpt import GPTActor, GPTCritic
9 | from chatgpt.models.opt import OPTActor, OPTCritic
10 | from chatgpt.trainer import PPOTrainer
11 | from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
12 | from torch.optim import Adam
13 | from transformers import AutoTokenizer, BloomTokenizerFast
14 | from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
15 |
16 | from colossalai.nn.optimizer import HybridAdam
17 |
18 |
19 | def main(args):
20 | # configure strategy
21 | if args.strategy == 'naive':
22 | strategy = NaiveStrategy()
23 | elif args.strategy == 'ddp':
24 | strategy = DDPStrategy()
25 | elif args.strategy == 'colossalai_gemini':
26 | strategy = ColossalAIStrategy(stage=3, placement_policy='cuda', initial_scale=2**5)
27 | elif args.strategy == 'colossalai_zero2':
28 | strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
29 | else:
30 | raise ValueError(f'Unsupported strategy "{args.strategy}"')
31 |
32 | # configure model
33 | with strategy.model_init_context():
34 | if args.model == 'gpt2':
35 | actor = GPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
36 | critic = GPTCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
37 | elif args.model == 'bloom':
38 | actor = BLOOMActor(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
39 | critic = BLOOMCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
40 | elif args.model == 'opt':
41 | actor = OPTActor(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
42 | critic = OPTCritic(pretrained=args.pretrain, lora_rank=args.lora_rank).to(torch.cuda.current_device())
43 | else:
44 | raise ValueError(f'Unsupported model "{args.model}"')
45 |
46 | initial_model = deepcopy(actor)
47 | reward_model = RewardModel(deepcopy(critic.model), deepcopy(critic.value_head)).to(torch.cuda.current_device())
48 |
49 | # configure optimizer
50 | if args.strategy.startswith('colossalai'):
51 | actor_optim = HybridAdam(actor.parameters(), lr=5e-6)
52 | critic_optim = HybridAdam(critic.parameters(), lr=5e-6)
53 | else:
54 | actor_optim = Adam(actor.parameters(), lr=5e-6)
55 | critic_optim = Adam(critic.parameters(), lr=5e-6)
56 |
57 | # configure tokenizer
58 | if args.model == 'gpt2':
59 | tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
60 | tokenizer.pad_token = tokenizer.eos_token
61 | elif args.model == 'bloom':
62 | tokenizer = BloomTokenizerFast.from_pretrained(args.pretrain)
63 | tokenizer.pad_token = tokenizer.eos_token
64 | elif args.model == 'opt':
65 | tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
66 | else:
67 | raise ValueError(f'Unsupported model "{args.model}"')
68 |
69 | dataset = pd.read_csv(args.prompt_path)['prompt']
70 |
71 | def tokenize_fn(texts):
72 | # MUST padding to max length to ensure inputs of all ranks have the same length
73 | # Different length may lead to hang when using gemini, as different generation steps
74 | batch = tokenizer(texts, return_tensors='pt', max_length=96, padding='max_length', truncation=True)
75 | return {k: v.cuda() for k, v in batch.items()}
76 |
77 | (actor, actor_optim), (critic, critic_optim), reward_model, initial_model = strategy.prepare(
78 | (actor, actor_optim), (critic, critic_optim), reward_model, initial_model)
79 |
80 | # configure trainer
81 | trainer = PPOTrainer(
82 | strategy,
83 | actor,
84 | critic,
85 | reward_model,
86 | initial_model,
87 | actor_optim,
88 | critic_optim,
89 | max_epochs=args.max_epochs,
90 | train_batch_size=args.train_batch_size,
91 | experience_batch_size=args.experience_batch_size,
92 | tokenizer=tokenize_fn,
93 | max_length=128,
94 | do_sample=True,
95 | temperature=1.0,
96 | top_k=50,
97 | pad_token_id=tokenizer.pad_token_id,
98 | eos_token_id=tokenizer.eos_token_id,
99 | )
100 |
101 | trainer.fit(dataset,
102 | num_episodes=args.num_episodes,
103 | max_timesteps=args.max_timesteps,
104 | update_timesteps=args.update_timesteps)
105 | # save model checkpoint after fitting
106 | strategy.save_model(actor, args.save_path, only_rank0=True)
107 | # save optimizer checkpoint on all ranks
108 | if args.need_optim_ckpt:
109 | strategy.save_optimizer(actor_optim,
110 | 'actor_optim_checkpoint_prompts_%d.pt' % (torch.cuda.current_device()),
111 | only_rank0=False)
112 |
113 |
114 | if __name__ == '__main__':
115 | parser = argparse.ArgumentParser()
116 | parser.add_argument('prompt_path')
117 | parser.add_argument('--strategy',
118 | choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
119 | default='naive')
120 | parser.add_argument('--model', default='gpt2', choices=['gpt2', 'bloom', 'opt'])
121 | parser.add_argument('--pretrain', type=str, default=None)
122 | parser.add_argument('--save_path', type=str, default='actor_checkpoint_prompts.pt')
123 | parser.add_argument('--need_optim_ckpt', type=bool, default=False)
124 | parser.add_argument('--num_episodes', type=int, default=10)
125 | parser.add_argument('--max_timesteps', type=int, default=10)
126 | parser.add_argument('--update_timesteps', type=int, default=10)
127 | parser.add_argument('--max_epochs', type=int, default=5)
128 | parser.add_argument('--train_batch_size', type=int, default=8)
129 | parser.add_argument('--experience_batch_size', type=int, default=8)
130 | parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
131 | args = parser.parse_args()
132 | main(args)
133 |
--------------------------------------------------------------------------------
/code/examples/train_prompts.sh:
--------------------------------------------------------------------------------
1 | set_n_least_used_CUDA_VISIBLE_DEVICES() {
2 | local n=${1:-"9999"}
3 | echo "GPU Memory Usage:"
4 | local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
5 | | tail -n +2 \
6 | | nl -v 0 \
7 | | tee /dev/tty \
8 | | sort -g -k 2 \
9 | | awk '{print $1}' \
10 | | head -n $n)
11 | export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
12 | echo "Now CUDA_VISIBLE_DEVICES is set to:"
13 | echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
14 | }
15 |
16 | set_n_least_used_CUDA_VISIBLE_DEVICES 2
17 |
18 | torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy colossalai_zero2
19 |
--------------------------------------------------------------------------------
/code/examples/train_reward_model.py:
--------------------------------------------------------------------------------
1 | import argparse
2 |
3 | import loralib as lora
4 | import torch
5 | from chatgpt.dataset import RewardDataset
6 | from chatgpt.models.base import RewardModel
7 | from chatgpt.models.bloom import BLOOMRM
8 | from chatgpt.models.gpt import GPTRM
9 | from chatgpt.models.opt import OPTRM
10 | from chatgpt.trainer import RewardModelTrainer
11 | from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
12 | from datasets import load_dataset
13 | from torch.optim import Adam
14 | from transformers import AutoTokenizer, BloomTokenizerFast
15 | from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
16 |
17 | from colossalai.nn.optimizer import HybridAdam
18 |
19 |
20 | def train(args):
21 | # configure strategy
22 | if args.strategy == 'naive':
23 | strategy = NaiveStrategy()
24 | elif args.strategy == 'ddp':
25 | strategy = DDPStrategy()
26 | elif args.strategy == 'colossalai_gemini':
27 | strategy = ColossalAIStrategy(stage=3, placement_policy='cuda')
28 | elif args.strategy == 'colossalai_zero2':
29 | strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
30 | else:
31 | raise ValueError(f'Unsupported strategy "{args.strategy}"')
32 |
33 | # configure model
34 | with strategy.model_init_context():
35 | if args.model == 'bloom':
36 | model = BLOOMRM(pretrained=args.pretrain, lora_rank=args.lora_rank).cuda()
37 | elif args.model == 'opt':
38 | model = OPTRM(pretrained=args.pretrain, lora_rank=args.lora_rank).cuda()
39 | elif args.model == 'gpt2':
40 | model = GPTRM(pretrained=args.pretrain, lora_rank=args.lora_rank).cuda()
41 | else:
42 | raise ValueError(f'Unsupported model "{args.model}"')
43 |
44 | # configure tokenizer
45 | if args.model == 'gpt2':
46 | tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
47 | tokenizer.pad_token = tokenizer.eos_token
48 | elif args.model == 'bloom':
49 | tokenizer = BloomTokenizerFast.from_pretrained(args.pretrain)
50 | tokenizer.pad_token = tokenizer.eos_token
51 | elif args.model == 'opt':
52 | tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
53 | else:
54 | raise ValueError(f'Unsupported model "{args.model}"')
55 | tokenizer.pad_token = tokenizer.eos_token
56 |
57 | max_len = 512
58 |
59 | # configure optimizer
60 | if args.strategy.startswith('colossalai'):
61 | optim = HybridAdam(model.parameters(), lr=5e-5)
62 | else:
63 | optim = Adam(model.parameters(), lr=5e-5)
64 |
65 | # prepare for data and dataset
66 | data = load_dataset(args.dataset)
67 | train_data = data["train"]
68 | eval_data = data['test']
69 | train_dataset = RewardDataset(train_data, tokenizer, max_len)
70 | eval_dataset = RewardDataset(eval_data, tokenizer, max_len)
71 |
72 | trainer = RewardModelTrainer(model=model,
73 | strategy=strategy,
74 | optim=optim,
75 | train_dataset=train_dataset,
76 | eval_dataset=eval_dataset,
77 | batch_size=args.batch_size,
78 | max_epochs=args.max_epochs)
79 |
80 | trainer.fit(use_lora=args.lora_rank)
81 |
82 | # save model checkpoint after fitting on only rank0
83 | strategy.save_model(model, 'rm_checkpoint.pt', only_rank0=True)
84 | # save optimizer checkpoint on all ranks
85 | strategy.save_optimizer(optim, 'rm_optim_checkpoint_%d.pt' % (torch.cuda.current_device()), only_rank0=False)
86 |
87 |
88 | if __name__ == '__main__':
89 | parser = argparse.ArgumentParser()
90 | parser.add_argument('--strategy',
91 | choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'],
92 | default='naive')
93 | parser.add_argument('--model', choices=['gpt2', 'bloom', 'opt'], default='bloom')
94 | parser.add_argument('--pretrain', type=str, default=None)
95 | parser.add_argument('--dataset', type=str, default='Dahoas/rm-static')
96 | parser.add_argument('--save_path', type=str, default='rm_ckpt.pth')
97 | parser.add_argument('--max_epochs', type=int, default=1)
98 | parser.add_argument('--batch_size', type=int, default=4)
99 | parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
100 | args = parser.parse_args()
101 | train(args)
102 |
--------------------------------------------------------------------------------
/code/examples/train_rm.sh:
--------------------------------------------------------------------------------
1 | set_n_least_used_CUDA_VISIBLE_DEVICES() {
2 | local n=${1:-"9999"}
3 | echo "GPU Memory Usage:"
4 | local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv \
5 | | tail -n +2 \
6 | | nl -v 0 \
7 | | tee /dev/tty \
8 | | sort -g -k 2 \
9 | | awk '{print $1}' \
10 | | head -n $n)
11 | export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
12 | echo "Now CUDA_VISIBLE_DEVICES is set to:"
13 | echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
14 | }
15 |
16 | set_n_least_used_CUDA_VISIBLE_DEVICES 2
17 |
18 | # torchrun --standalone --nproc_per_node=2 train_reward_model.py --pretrain 'bigscience/bloomz-560m' --model 'bloom' --strategy colossalai_zero2
19 | torchrun --standalone --nproc_per_node=2 train_reward_model.py --model 'gpt2' --strategy colossalai_zero2
20 | # torchrun --standalone --nproc_per_node=2 train_reward_model.py --pretrain "facebook/opt-350m" --model 'opt' --strategy colossalai_zero2
21 |
--------------------------------------------------------------------------------
/code/pytest.ini:
--------------------------------------------------------------------------------
1 | [pytest]
2 | markers =
3 | cpu: tests which can run on CPU
4 | gpu: tests which requires a single GPU
5 | dist: tests which are run in a multi-GPU or multi-machine environment
6 | experiment: tests for experimental features
7 |
--------------------------------------------------------------------------------
/code/requirements-test.txt:
--------------------------------------------------------------------------------
1 | pytest
2 |
--------------------------------------------------------------------------------
/code/requirements.txt:
--------------------------------------------------------------------------------
1 | transformers>=4.20.1
2 | tqdm
3 | datasets
4 | loralib
5 | colossalai>=0.2.4
6 | torch
7 | langchain
8 |
--------------------------------------------------------------------------------
/code/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import find_packages, setup
2 |
3 |
4 | def fetch_requirements(path):
5 | with open(path, 'r') as fd:
6 | return [r.strip() for r in fd.readlines()]
7 |
8 |
9 | def fetch_readme():
10 | with open('README.md', encoding='utf-8') as f:
11 | return f.read()
12 |
13 |
14 | def fetch_version():
15 | with open('version.txt', 'r') as f:
16 | return f.read().strip()
17 |
18 |
19 | setup(
20 | name='chatgpt',
21 | version=fetch_version(),
22 | packages=find_packages(exclude=(
23 | 'tests',
24 | 'benchmarks',
25 | '*.egg-info',
26 | )),
27 | description='A RLFH implementation (ChatGPT) powered by ColossalAI',
28 | long_description=fetch_readme(),
29 | long_description_content_type='text/markdown',
30 | license='Apache Software License 2.0',
31 | url='https://github.com/hpcaitech/ChatGPT',
32 | install_requires=fetch_requirements('requirements.txt'),
33 | python_requires='>=3.6',
34 | classifiers=[
35 | 'Programming Language :: Python :: 3',
36 | 'License :: OSI Approved :: Apache Software License',
37 | 'Environment :: GPU :: NVIDIA CUDA',
38 | 'Topic :: Scientific/Engineering :: Artificial Intelligence',
39 | 'Topic :: System :: Distributed Computing',
40 | ],
41 | )
42 |
--------------------------------------------------------------------------------
/code/tests/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/oglee815/mygpt-lecture/ed6a506cd9605f10b5fec52e840f16f3cb46ab98/code/tests/__init__.py
--------------------------------------------------------------------------------
/code/tests/test_checkpoint.py:
--------------------------------------------------------------------------------
1 | import os
2 | import tempfile
3 | from contextlib import nullcontext
4 | from functools import partial
5 |
6 | import pytest
7 | import torch
8 | import torch.distributed as dist
9 | import torch.multiprocessing as mp
10 | from chatgpt.models.gpt import GPTActor
11 | from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy
12 | from transformers.models.gpt2.configuration_gpt2 import GPT2Config
13 |
14 | from colossalai.nn.optimizer import HybridAdam
15 | from colossalai.testing import rerun_if_address_is_in_use
16 | from colossalai.utils import free_port
17 |
18 | GPT_CONFIG = GPT2Config(n_embd=128, n_layer=4, n_head=4)
19 |
20 |
21 | def get_data(batch_size: int, seq_len: int = 10) -> dict:
22 | input_ids = torch.randint(0, 50257, (batch_size, seq_len), device='cuda')
23 | attention_mask = torch.ones_like(input_ids)
24 | return dict(input_ids=input_ids, attention_mask=attention_mask)
25 |
26 |
27 | def run_test_checkpoint(strategy):
28 | BATCH_SIZE = 2
29 |
30 | if strategy == 'ddp':
31 | strategy = DDPStrategy()
32 | elif strategy == 'colossalai_gemini':
33 | strategy = ColossalAIStrategy(stage=3, placement_policy='cuda', initial_scale=2**5)
34 | elif strategy == 'colossalai_zero2':
35 | strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
36 | else:
37 | raise ValueError(f'Unsupported strategy "{strategy}"')
38 |
39 | with strategy.model_init_context():
40 | actor = GPTActor(config=GPT_CONFIG).cuda()
41 |
42 | actor_optim = HybridAdam(actor.parameters())
43 |
44 | actor, actor_optim = strategy.prepare((actor, actor_optim))
45 |
46 | def run_step():
47 | data = get_data(BATCH_SIZE)
48 | action_mask = torch.ones_like(data['attention_mask'], dtype=torch.bool)
49 | action_log_probs = actor(data['input_ids'], action_mask.size(1), data['attention_mask'])
50 | loss = action_log_probs.sum()
51 | strategy.backward(loss, actor, actor_optim)
52 | strategy.optimizer_step(actor_optim)
53 |
54 | run_step()
55 |
56 | ctx = tempfile.TemporaryDirectory() if dist.get_rank() == 0 else nullcontext()
57 |
58 | with ctx as dirname:
59 | rank0_dirname = [dirname]
60 | dist.broadcast_object_list(rank0_dirname)
61 | rank0_dirname = rank0_dirname[0]
62 |
63 | model_path = os.path.join(rank0_dirname, 'model.pt')
64 | optim_path = os.path.join(rank0_dirname, f'optim-r{dist.get_rank()}.pt')
65 |
66 | strategy.save_model(actor, model_path, only_rank0=True)
67 | strategy.save_optimizer(actor_optim, optim_path, only_rank0=False)
68 |
69 | dist.barrier()
70 |
71 | strategy.load_model(actor, model_path, strict=False)
72 | strategy.load_optimizer(actor_optim, optim_path)
73 |
74 | dist.barrier()
75 |
76 | run_step()
77 |
78 |
79 | def run_dist(rank, world_size, port, strategy):
80 | os.environ['RANK'] = str(rank)
81 | os.environ['LOCAL_RANK'] = str(rank)
82 | os.environ['WORLD_SIZE'] = str(world_size)
83 | os.environ['MASTER_ADDR'] = 'localhost'
84 | os.environ['MASTER_PORT'] = str(port)
85 | run_test_checkpoint(strategy)
86 |
87 |
88 | @pytest.mark.dist
89 | @pytest.mark.parametrize('world_size', [2])
90 | @pytest.mark.parametrize('strategy', ['ddp', 'colossalai_zero2', 'colossalai_gemini'])
91 | @rerun_if_address_is_in_use()
92 | def test_checkpoint(world_size, strategy):
93 | run_func = partial(run_dist, world_size=world_size, port=free_port(), strategy=strategy)
94 | mp.spawn(run_func, nprocs=world_size)
95 |
96 |
97 | if __name__ == '__main__':
98 | test_checkpoint(2, 'colossalai_zero2')
99 |
--------------------------------------------------------------------------------
/code/tests/test_data.py:
--------------------------------------------------------------------------------
1 | import os
2 | from copy import deepcopy
3 | from functools import partial
4 |
5 | import pytest
6 | import torch
7 | import torch.distributed as dist
8 | import torch.multiprocessing as mp
9 | from chatgpt.experience_maker import NaiveExperienceMaker
10 | from chatgpt.models.base import RewardModel
11 | from chatgpt.models.gpt import GPTActor, GPTCritic
12 | from chatgpt.replay_buffer import NaiveReplayBuffer
13 | from chatgpt.trainer.strategies import ColossalAIStrategy, DDPStrategy
14 | from transformers.models.gpt2.configuration_gpt2 import GPT2Config
15 |
16 | from colossalai.testing import rerun_if_address_is_in_use
17 | from colossalai.utils import free_port
18 |
19 | GPT_CONFIG = GPT2Config(n_embd=128, n_layer=4, n_head=4)
20 |
21 |
22 | def get_data(batch_size: int, seq_len: int = 10) -> dict:
23 | input_ids = torch.randint(0, 50257, (batch_size, seq_len), device='cuda')
24 | attention_mask = torch.ones_like(input_ids)
25 | return dict(input_ids=input_ids, attention_mask=attention_mask)
26 |
27 |
28 | def gather_and_equal(tensor: torch.Tensor) -> bool:
29 | world_size = dist.get_world_size()
30 | outputs = [torch.empty_like(tensor) for _ in range(world_size)]
31 | dist.all_gather(outputs, tensor.contiguous())
32 | for t in outputs[1:]:
33 | if not torch.equal(outputs[0], t):
34 | return False
35 | return True
36 |
37 |
38 | def run_test_data(strategy):
39 | EXPERINCE_BATCH_SIZE = 4
40 | SAMPLE_BATCH_SIZE = 2
41 |
42 | if strategy == 'ddp':
43 | strategy = DDPStrategy()
44 | elif strategy == 'colossalai':
45 | strategy = ColossalAIStrategy(placement_policy='cuda')
46 | else:
47 | raise ValueError(f'Unsupported strategy "{strategy}"')
48 |
49 | actor = GPTActor(config=GPT_CONFIG).cuda()
50 | critic = GPTCritic(config=GPT_CONFIG).cuda()
51 |
52 | initial_model = deepcopy(actor)
53 | reward_model = RewardModel(deepcopy(critic.model)).cuda()
54 |
55 | experience_maker = NaiveExperienceMaker(actor, critic, reward_model, initial_model)
56 | replay_buffer = NaiveReplayBuffer(SAMPLE_BATCH_SIZE, cpu_offload=False)
57 |
58 | # experience of all ranks should be the same
59 | for _ in range(2):
60 | data = get_data(EXPERINCE_BATCH_SIZE)
61 | assert gather_and_equal(data['input_ids'])
62 | assert gather_and_equal(data['attention_mask'])
63 | experience = experience_maker.make_experience(**data,
64 | do_sample=True,
65 | max_length=16,
66 | eos_token_id=50256,
67 | pad_token_id=50256)
68 | assert gather_and_equal(experience.sequences)
69 | assert gather_and_equal(experience.action_log_probs)
70 | assert gather_and_equal(experience.values)
71 | assert gather_and_equal(experience.reward)
72 | assert gather_and_equal(experience.advantages)
73 | assert gather_and_equal(experience.action_mask)
74 | assert gather_and_equal(experience.attention_mask)
75 | replay_buffer.append(experience)
76 |
77 | # replay buffer's data should be the same
78 | buffer_size = torch.tensor([len(replay_buffer)], device='cuda')
79 | assert gather_and_equal(buffer_size)
80 | for item in replay_buffer.items:
81 | assert gather_and_equal(item.sequences)
82 | assert gather_and_equal(item.action_log_probs)
83 | assert gather_and_equal(item.values)
84 | assert gather_and_equal(item.reward)
85 | assert gather_and_equal(item.advantages)
86 | assert gather_and_equal(item.action_mask)
87 | assert gather_and_equal(item.attention_mask)
88 |
89 | # dataloader of each rank should have the same size and different batch
90 | dataloader = strategy.setup_dataloader(replay_buffer)
91 | dataloader_size = torch.tensor([len(dataloader)], device='cuda')
92 | assert gather_and_equal(dataloader_size)
93 | for experience in dataloader:
94 | assert not gather_and_equal(experience.sequences)
95 | assert not gather_and_equal(experience.action_log_probs)
96 | assert not gather_and_equal(experience.values)
97 | assert not gather_and_equal(experience.reward)
98 | assert not gather_and_equal(experience.advantages)
99 | # action mask and attention mask may be same
100 |
101 |
102 | def run_dist(rank, world_size, port, strategy):
103 | os.environ['RANK'] = str(rank)
104 | os.environ['LOCAL_RANK'] = str(rank)
105 | os.environ['WORLD_SIZE'] = str(world_size)
106 | os.environ['MASTER_ADDR'] = 'localhost'
107 | os.environ['MASTER_PORT'] = str(port)
108 | run_test_data(strategy)
109 |
110 |
111 | @pytest.mark.skip
112 | @pytest.mark.dist
113 | @pytest.mark.parametrize('world_size', [2])
114 | @pytest.mark.parametrize('strategy', ['ddp', 'colossalai'])
115 | @rerun_if_address_is_in_use()
116 | def test_data(world_size, strategy):
117 | run_func = partial(run_dist, world_size=world_size, port=free_port(), strategy=strategy)
118 | mp.spawn(run_func, nprocs=world_size)
119 |
120 |
121 | if __name__ == '__main__':
122 | test_data(2, 'colossalai')
123 |
--------------------------------------------------------------------------------
/code/utils.py:
--------------------------------------------------------------------------------
1 | # import
2 | # import os
3 | # os.environ["CUDA_VISIBLE_DEVICES"] = "0"
4 | import torch
5 | import torch.nn as nn
6 | from torch.utils.data import Dataset
7 | from datasets import load_dataset
8 | import transformers
9 | from transformers import AutoTokenizer, AutoConfig, AutoModelForCausalLM, pipeline
10 | from transformers import Trainer, TrainingArguments, AutoModelWithLMHead
11 | from copy import deepcopy
12 | from torch.optim import Adam
13 | from transformers import AutoTokenizer, BloomTokenizerFast
14 | from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
15 | import pandas as pd
16 | import argparse
17 | import copy
18 | import logging
19 | import json
20 | from dataclasses import dataclass, field
21 |
22 | PROMPT= "### system:사용자의 질문에 맞는 적절한 응답을 생성하세요.\n### 사용자:{instruction}\n### 응답:"
23 | # data config
24 | IGNORE_INDEX = -100
25 |
26 | def safe_save_model_for_hf_trainer(trainer: transformers.Trainer, output_dir: str):
27 | """Collects the state dict and dump to disk."""
28 | state_dict = trainer.model.state_dict()
29 | if trainer.args.should_save:
30 | cpu_state_dict = {key: value.cpu() for key, value in list(state_dict.items())}
31 | del state_dict
32 | trainer._save(output_dir, state_dict=cpu_state_dict) # noqa
33 |
34 | ## prepare data
35 | from typing import Optional, Dict, Sequence
36 | import jsonlines
37 |
38 | class SFT_dataset(Dataset):
39 | '''SFT dataset by wygo'''
40 | def __init__(self, data_path: str, tokenizer: transformers.PreTrainedTokenizer, verbose=True):
41 | super(SFT_dataset, self).__init__()
42 | logging.warning("Loading data...")
43 |
44 | # with open(data_path, "r", encoding='utf-8-sig') as json_file:
45 | # list_data_dict = json.load(json_file)
46 | # if verbose:
47 | # print('## data check ##')
48 | sources = []
49 | targets = []
50 | with jsonlines.open(data_path) as f:
51 | for example in f.iter():
52 | tmp = PROMPT.format_map(example)
53 | sources.append(tmp)
54 | targets.append(f"{example['output']}{tokenizer.eos_token}")
55 |
56 | if verbose:
57 | idx = 0
58 | print((sources[idx]))
59 | print((targets[idx]))
60 | print("Tokenizing inputs... This may take some time...")
61 |
62 | ############################################################
63 | examples = [s + t for s, t in zip(sources, targets)]
64 |
65 | # source data tokenized
66 | sources_tokenized = self._tokenize_fn(sources, tokenizer) # source만
67 | examples_tokenized = self._tokenize_fn(examples, tokenizer) # source + target
68 |
69 | ## 입력은 source, 출력은 source+target 이지만 학습은 target 부분만
70 | input_ids = examples_tokenized["input_ids"]
71 | labels = copy.deepcopy(input_ids)
72 | for label, source_len in zip(labels, sources_tokenized["input_ids_lens"]):
73 | label[:source_len] = IGNORE_INDEX # source 부분은 -100으로 채운다
74 |
75 | data_dict = dict(input_ids=input_ids, labels=labels)
76 |
77 | self.input_ids = data_dict["input_ids"]
78 | self.labels = data_dict["labels"]
79 | logging.warning("Loading data done!!: %d"%(len(self.labels)))
80 |
81 | def _tokenize_fn(self, strings: Sequence[str], tokenizer: transformers.PreTrainedTokenizer) -> Dict:
82 | """Tokenize a list of strings."""
83 | tokenized_list = [
84 | tokenizer(
85 | text,
86 | return_tensors="pt",
87 | padding="longest",
88 | max_length=tokenizer.model_max_length,
89 | truncation=True,
90 | )
91 | for text in strings
92 | ]
93 | input_ids = labels = [tokenized.input_ids[0] for tokenized in tokenized_list]
94 | input_ids_lens = labels_lens = [
95 | tokenized.input_ids.ne(tokenizer.pad_token_id).sum().item() for tokenized in tokenized_list
96 | ]
97 |
98 | return dict(
99 | input_ids=input_ids,
100 | labels=labels,
101 | input_ids_lens=input_ids_lens,
102 | labels_lens=labels_lens,
103 | )
104 |
105 |
106 | def __len__(self):
107 | return len(self.input_ids)
108 |
109 |
110 | def __getitem__(self, i) -> Dict[str, torch.Tensor]:
111 | return dict(input_ids=self.input_ids[i], labels=self.labels[i])
112 |
113 |
114 | @dataclass
115 | class DataCollatorForSupervisedDataset(object):
116 | """Collate examples for supervised fine-tuning."""
117 |
118 | tokenizer: transformers.PreTrainedTokenizer
119 |
120 | def __call__(self, instances: Sequence[Dict]) -> Dict[str, torch.Tensor]:
121 | input_ids, labels = tuple([instance[key] for instance in instances] for key in ("input_ids", "labels"))
122 | input_ids = torch.nn.utils.rnn.pad_sequence(
123 | input_ids, batch_first=True, padding_value=self.tokenizer.pad_token_id
124 | )
125 | labels = torch.nn.utils.rnn.pad_sequence(labels, batch_first=True, padding_value=IGNORE_INDEX)
126 | return dict(
127 | input_ids=input_ids,
128 | labels=labels,
129 | attention_mask=input_ids.ne(self.tokenizer.pad_token_id),
130 | )
131 |
132 | # check
133 | # print('input : %s'%train_dataset.input_ids[0])
134 | # print('output: %s'%train_dataset.labels[0])
--------------------------------------------------------------------------------
/code/version.txt:
--------------------------------------------------------------------------------
1 | 0.1.0
2 |
--------------------------------------------------------------------------------
/data/stage1. domain_adaptive_pretraining/템플릿.csv:
--------------------------------------------------------------------------------
1 | 주제,내용,길이
2 | BTS의 개요,2013년 6월 13일에 데뷔한 대한민국의 7인조 보이그룹이다.,35
3 |
--------------------------------------------------------------------------------
/data/stage1. domain_instruction_tuning/ive_instruction_test.jsonl:
--------------------------------------------------------------------------------
1 | {"instruction": "아이브의 소속사는 어떤 엔터테인먼트 기업인가요?", "output": "아이브의 소속사는 스타쉽엔터테인먼트입니다."}
2 | {"instruction": "장원영의 생년월일은 언제인가요?", "output": "장원영의 생년월일은 2004년 8월 31일입니다."}
3 | {"instruction": "아이브와 (여자)아이들은 어떤 차이점이 있나요?", "output": "아이브는 보컬의 비중이 높은 음악을 내세우고 있지만, (여자)아이들은 콘셉트추얼함과 자체 제작으로 승부를 보며 음악에 어필합니다."}
4 | {"instruction": "어떤 멤버들이 IVE의 성장을 도왔나요?", "output": "안유진과 장원영 외에도 아이즈원 출신이 아닌 새로운 멤버들이 IVE의 성장을 도왔습니다."}
5 | {"instruction": "아이브의 실력 중에서 가장 특출난 점은 무엇인가요?", "output": "아이브의 표정 연기입니다."}
6 | {"instruction": "아이브의 모든 멤버들이 곡의 스토리와 가사에 맞는 표정 연기를 잘 하나요?", "output": "네, 아이브의 모든 멤버들이 곡의 스토리와 가사에 맞는 표정 연기를 능숙하게 사용합니다."}
7 | {"instruction": "아이브의 메인보컬과 서브보컬은 누구들인가요?", "output": "메인보컬은 안유진과 리즈이고, 서브보컬은 가을, 레이, 장원영, 이서입니다."}
8 | {"instruction": "아이브의 랩 파트와 고음역대 파트는 누가 맡고 있나요?", "output": "랩 파트는 가을, 레이가 맡고, 고음역대 파트는 리즈와 안유진이 맡고 있습니다."}
9 | {"instruction": "어떤 그룹이 처음부터 비주얼을 내세웠나요?", "output": "스타쉽엔터테인먼트 그룹인 아이브가 처음부터 비주얼을 내세웠습니다."}
10 | {"instruction": "이 아티스트는 어떤 시상식에서 3개의 시상식에서 신인상과 대상을 동시 수상한 최초의 아티스트가 되었다고 언급되었나요?", "output": "이 아티스트는 2022년 11월 26일 멜론 뮤직 어워드, 11월 30일 마마 어워즈, 12월 13일 아시아 아티스트 어워즈에서 신인상과 대상을 동시에 수상하였습니다."}
11 | {"instruction": "이 아티스트가 속한 그룹은 어떤 시기에 여자 아이돌 시장의 침체기를 가져온 걸그룹으로 꼽혔나요?", "output": "이 아티스트가 속한 그룹은 약간의 침체기가 있었던 여자 아이돌 시장의 부흥을 가져온 걸그룹으로 꼽혔습니다."}
12 | {"instruction": "《After LIKE》는 어떤 수치상 한국 걸그룹 중에서 어떤 위치에 올랐나요?", "output": "두 번째로 높은 위치, Spotify 글로벌 차트 23위"}
13 | {"instruction": "\"After LIKE\"는 한국 걸그룹 중 초동 판매량 2위를 달성했나요?", "output": "네, \"After LIKE\"는 한국 걸그룹 초동 판매량 2위에 등극했습니다."}
14 | {"instruction": "IVE의 그룹명은 어떻게 결정되었나요?", "output": "IVE의 그룹명은 회사 공모를 통해 결정되었다."}
15 | {"instruction": "아이브가 첫 곡으로 연습한 노래는 무엇인가요?", "output": "피프스 하모니의 That's my girl입니다."}
16 | {"instruction": "아이브 멤버들 중 가장 어리게 태어난 멤버는 누구인가요?", "output": "이서입니다."}
17 | {"instruction": "아이브 멤버들은 어떤 애니메이션을 모르거나, 틀린 이름을 부르기도 했나요?", "output": "원영과 이서는 슬라이드폰을 열 줄 모른다든가, 이서는 마시마로를 몰라서 마시멜로라고 하기도 했습니다."}
18 | {"instruction": "가을은 이서와의 세대 차이를 어떻게 느끼고 있었나요?", "output": "가을은 이서와 크게 세대 차이를 못 느낀다고 밝혔습니다."}
19 | {"instruction": "아이브 멤버 중에서 가장 연장자는 누구인가요?", "output": "최연장자가 아닌 둘째가 리더인 걸그룹이 되었습니다."}
20 | {"instruction": "아이브 멤버 중에서 지상파 음악 방송 MC를 맡고 있던 멤버는 몇 명인가요?", "output": "아이돌 그룹 내에 지상파 음악 방송 MC를 맡고 있던 멤버가 무려 2명이었습니다."}
21 | {"instruction": "아이브의 멤버들은 가로본능 핸드폰에 대해 어떤 반응을 보였나요?", "output": "멤버들 모두가 뭔지 모르는 듯한 모습을 보였습니다."}
22 | {"instruction": "멤버들 중 MBTI가 내향형인 멤버들은 누구인가요?", "output": "장원영과 이서를 제외한 나머지 멤버들"}
23 | {"instruction": "어떤 것들이 숙소 규칙으로 정해져 있는가?", "output": "빨래 제때 가져가기, 냉장고 유통기한 음식 본인 건 본인이 버리기 등이 있다."}
24 | {"instruction": "IVE의 데뷔월 기준 유행어는 무엇인가요?", "output": "\"너무나도\", \"꽤나\", \"오히려 좋아\" 등의 유행어가 있습니다."}
25 | {"instruction": "IVE는 어떤 걸그룹의 파생 걸그룹인가요?", "output": "IVE는 엠넷의 프로듀스 101 시리즈 데뷔조 파생 걸그룹으로, 프리스틴, 구구단, 다이아 등과 함께 대표되는 걸그룹입니다."}
26 |
--------------------------------------------------------------------------------
/data/stage2. RM/ive_test_rm.jsonl:
--------------------------------------------------------------------------------
1 | {"prompt": "아이브 멤버 중에서 서울공연예술고등학교를 졸업한 멤버는 누구인가요?", "chosen": "레이, 장원영", "rejected": "누군지는 잘 모르겠어요."}
2 | {"prompt": "다른 그룹명도 고려됐던 건가요?", "chosen": "네, 멤버들은 어떤 이름이 될지 기대하며 기다리고 있었다.", "rejected": "그룹명을 정하기 위해 다양한 그룹명이 고려되었지만, 아이브가 선택되었습니다."}
3 | {"prompt": "아이브의 비주얼이 왜 유명한가요?", "chosen": "아이브는 자타공인 전원 센터급 비주얼로 유명합니다.", "rejected": "아이브의 비주얼은 논란이 있지만 다양한 스타일을 소화해내어 유명한 편입니다."}
4 | {"prompt": "아이브의 데뷔곡 《ELEVEN》은 몇 개의 음악 방송에서 1위를 차지했나요?", "chosen": "13관왕", "rejected": "한 개의 음악 방송에서 1위를 차지했어요."}
5 | {"prompt": "리즈는 어느 도시에서 태어났나요?", "chosen": "제주에서 태어났습니다.", "rejected": "상하이"}
6 | {"prompt": "멤버들의 공식색은 어떤 색들로 이루어져 있는가?", "chosen": "멤버들의 공식색은 빨간색, 주황색, 초록색, 파란색, 남색, 보라색으로 무지개 7색 중에서 노란색만 빠져 있어서 그 이유를 궁금해하는 팬들이 많다.", "rejected": "멤버들의 공식색은 하늘과 바닷물 색으로 이루어져 있다고 합니다."}
7 | {"prompt": "아이브의 랩 실력은 그룹 내에서 어떻게 평가되나요?", "chosen": "그룹 내에서 아이브의 랩 실력은 뛰어나다고 평가되고 있습니다.", "rejected": "아이브의 랩 실력은 그룹 내에서 평가가 다양하게 나뉘어요."}
8 | {"prompt": "2023년 4월 15일 방송된 아는 형님에서 이사 소식을 알렸는데, 멤버들은 새로운 숙소에서 3명씩 두 채로 나누어 살게 되었다고 하는데, 과거 숙소는 어디에 위치했나요?", "chosen": "성수동에 위치했던 것으로 보입니다.", "rejected": "전 세계 어딘가"}
9 | {"prompt": "멜론 20만 이상 하트를 보유한 아이브의 곡은 몇 개인가요?", "chosen": "멜론 20만 이상 하트를 보유한 아이브의 곡은 2곡입니다.", "rejected": "2곡"}
10 | {"prompt": "어떤 곡에서 아이브는 빠른 랩으로 호평을 받았나요?", "chosen": "에서 빠른 랩으로 호평을 받았습니다.", "rejected": "아이브는 \"11\"이라는 곡에서 빠른 랩으로 호평을 받았어요."}
11 | {"prompt": "어떻게 아이브의 표정 연기로 개개인이 더욱 돋보이게 되나요?", "chosen": "아이브의 표정 연기는 개개인을 더욱 돋보이게 만들어줍니다.", "rejected": "아이브 멤버들의 표정 연기로 인해 각자가 더 돋보이게 되는 이유는 자신들의 개성 때문이죠."}
12 | {"prompt": "아이브의 정규 1집 I've IVE로 컴백하면서 어떤 성장을 보였나요?", "chosen": "신속한 피드백 수용과 노력하는 모습으로 한 단계 성장한 라이브 실력을 보였습니다.", "rejected": "아이브의 정규 1집 I've IVE로 컴백하면서 주목할 만한 성장은 그림 그리기 실력이 향상되었다는 것입니다."}
13 | {"prompt": "아이브의 평균 비주얼은 어떤가요?", "chosen": "아이브의 평균 비주얼은 상당히 뛰어나다고 평가받고 있습니다.", "rejected": "아이브의 평균 비주얼은 평범한 수준으로 보여요."}
14 | {"prompt": "아이브 멤버 중에서 서울공연예술고등학교를 중퇴한 멤버는 누구인가요?", "chosen": "안유진", "rejected": "잘 모르겠습니다."}
15 | {"prompt": "아이브의 댄스 실력은 전문가들에게도 인정 받나요?", "chosen": "예, 아이브의 댄스 실력은 전문가들에게도 인정받고 있습니다.", "rejected": "아이브의 댄스 실력은 전문가들에게도 어느 정도 인정받고 있어요."}
16 | {"prompt": "2002년생 가을 제외하면 나머지 멤버들은 2000년대에 어떤 문화를 잘 모르는 경향이 있나요?", "chosen": "2000년대의 문화를 잘 모른다는 경향이 있습니다.", "rejected": "2002년생 가을을 제외한 나머지 멤버들은 2000년대에 IT 문화를 잘 모르는 경향이 있습니다."}
17 | {"prompt": "IZ*ONE 활동이 끝난 후 데뷔한 최초의 그룹은 어떤 그룹인가요?", "chosen": "IVE", "rejected": "그룹 A"}
18 | {"prompt": "가을이는 어떤 애완동물을 키우고 있나요?", "chosen": "가을이는 토끼를 키우고 있습니다.", "rejected": "가을이는 전 해초류를 기르고 있어요."}
19 | {"prompt": "SBS 인기가요에서 아이브는 몇 번 트리플 크라운을 수상했나요?", "chosen": "7월 3일 기준 SBS 인기가요에서도 한 번 트리플 크라운을 수상", "rejected": "5번 TMC를 수상했어요."}
20 | {"prompt": "아이브의 댄스 실력은 어떻게 평가되나요?", "chosen": "전체적으로 준수한 실력을 갖추고 있습니다.", "rejected": "아이브의 댄스 실력은 시각적으로 평가되는 경향이 있습니다."}
21 |
--------------------------------------------------------------------------------
/data/stage3. PPO/ive_test_ppo.jsonl:
--------------------------------------------------------------------------------
1 | {"prompt": "표정 연기가 무대 전반의 분위기나 이야기 전달에 어떤 영향을 미치는지 알려주세요."}
2 | {"prompt": "아이브가 향후 어떤 방식으로 발전하고 성장해 나갈 것으로 예상되는가요?"}
3 | {"prompt": "IVE의 멤버 중에서 가장 먼저 지상파 음악 방송 1위를 기록한 멤버가 누구였나요?"}
4 | {"prompt": "가족관계가 팀 내에서 언급되는 이유가 음악적 활동에 미친 영향에 대해 어떤 생각을 가지십니까?"}
5 | {"prompt": "아이브의 랩이 앞으로 그녀의 음악적 진행을 어떻게 변화시킬지 예상해 보십시오."}
6 | {"prompt": "성인이 되면서 팀 내의 역할 분담이나 관계에 변화가 있었을까요?"}
7 | {"prompt": "아이브의 댄스 실력을 보완하거나 향상시킬 수 있는 방법에는 어떤 것들이 있을까요?"}
8 | {"prompt": "아이브의 랩이 음악이나 가사에 미칠 수 있는 강력한 영향은 무엇인가요?"}
9 | {"prompt": "아이브는 다른 프로듀스 파생 걸그룹들과 다르게 데뷔조에 속한 멤버들의 인지도가 고르게 높다고 합니다. 이러한 현상이 나타나는 이유는 무엇이라고 생각하십니까?"}
10 | {"prompt": "'소녀'와 '자기애'라는 콘셉트의 마케팅 전략은 어떤 방식으로 전개되었을까요?"}
11 | {"prompt": "멤버들이 강한 포스를 뿜어내는데에는 어떤 특징이 도움이 되었을까요?"}
12 | {"prompt": "걸 크러시 콘셉트와 소녀다운 이미지를 결합시키는 과정에서 어려움을 겪은 부분은 무엇이 있었을까요?"}
13 | {"prompt": "세대 간의 차이를 긍정적이고 다양한 가치로 받아들이는데 도움을 주는 활동이 있다면, 어떤 것들이 있을까요?"}
14 | {"prompt": "각 멤버들의 취향을 반영한 단체여행을 계획할 때, 가을이 가장 먼저 제안할 곳은 어디일까요? 다른 멤버들은 그 제안에 대해 어떤 반응을 보일까요?"}
15 | {"prompt": "아이브가 한중일 아이돌 시장 등 글로벌 시장에서의 입지를 고려할 때, 어떤 전략이 필요할 것으로 보이나요?"}
16 | {"prompt": "성인이 된 후에는 어떻게 변화가 있었을까요? 예를 들어, 리더인 유진이 성인이 된 후에 리더십이나 활동에 어떤 영향을 미쳤을까요?"}
17 | {"prompt": "각 멤버의 음색과 개성을 가장 잘 드러내는 곡은 무엇인가요? 이유도 함께 궁금합니다."}
18 | {"prompt": "IVE의 음악이 2000년대 후반 ~ 2010년대 초중반의 2세대 걸그룹 노래와 공통점이 있는 이유는 무엇일까요?"}
19 | {"prompt": "멤버들의 얼굴에 있는 각각의 점은 어떤 의미가 있을까요?"}
20 | {"prompt": "멤버들이 신장 차이가 큰 영향을 미친 곡이나 활동이 있다면 무엇인가요?"}
21 |
--------------------------------------------------------------------------------
/data/stage3. PPO/kuksundo_test_ppo.jsonl:
--------------------------------------------------------------------------------
1 | {"prompt": "국선도는 어떤 사람들에게 추천되는 수련법인가요?"}
2 | {"prompt": "밝돌법이라는 이름의 유래는 무엇인가요?"}
3 | {"prompt": "국선도를 통해 건강한 몸을 유지하는 방법은 무엇인가요?"}
4 | {"prompt": "국선도를 수행하는 데 필요한 시간과 노력은 어느 정도인가요?"}
5 | {"prompt": "국선도의 목적은 무엇이고, 그것을 달성하기 위해 어떤 방법을 사용하나요?"}
6 | {"prompt": "국선도는 어떤 의지를 기르고 어떠한 미덕을 갖게 해주나요?"}
7 | {"prompt": "국선도는 어떻게 우주자연과 인간을 하나로 만드는 건가요?"}
8 | {"prompt": "국선도를 통해 어떻게 조화로운 세상을 만들 수 있는 건가요?"}
9 | {"prompt": "국선도와 국가 지도자의 도법은 어떤 관계를 가지고 있나요?"}
10 | {"prompt": "국선도의 수련 과정을 주야로 수련해야 할까요?"}
11 | {"prompt": "국선도 밝돌법을 꾸준히 수련함으로써 어떻게 체력이 증강되는지 설명해주세요."}
12 | {"prompt": "국선도를 통한 디톡스 수련법은 어떤 것이 있을까요?"}
13 | {"prompt": "스트레스관리를 위해 어떤 습관을 가질 수 있을까요?"}
14 | {"prompt": "불로장생은 어떤 원리를 기반으로 하는 것인가요?"}
15 | {"prompt": "도인도송에서 언급된 중기(中氣)의 음양(陰陽) 변화와 수화(水火)의 승강(昇降), 그리고 기혈(氣血)의 순환(循環)은 왜 중앙오십토(中央五十土)의 중기단합력(中氣團合力)에 의해 발생하는 것인지 설명해 주세요."}
16 | {"prompt": "앞서 말씀하신 것처럼, 중기(中氣)는 인체에서 하단전(下丹田)에서 발생한 기혈(氣血)이 간(肝)으로 나와 생신(生新)하는 것이라고 알고 있습니다. 이런 과정에서 중앙오십토(中央五十土)가 어떻게 작용하는지 설명해 주세요."}
17 | {"prompt": "도인도송에 따르면, 중기(中氣)단법은 우주적(宇宙的) 입장(立場)에서 오인(吾人)이 행공(行功)해야 하는 고행(苦行)이라고 합니다. 이런 고행(苦行)의 목적은 무엇인지 설명해 주세요."}
18 | {"prompt": "중기(中氣)단법을 수도(修道) 초공(初功)으로 선택하게 된 이유에 대해 설명해 주세요."}
19 | {"prompt": "선도주의가 개인적인 삶에 어떤 영향을 미칠 수 있을까요? 개인이 선도주의를 적용했을 때 어떤 변화를 기대할 수 있나요?"}
20 | {"prompt": "선도주의를 실천하기 위해서 필요한 가장 중요한 자질은 무엇인가요? 그 자질을 어떻게 갖출 수 있을까요?"}
21 | {"prompt": "국선도본원 세계본부에서 발급되는 자격증은 어떤 특징을 가지고 있나요?"}
22 | {"prompt": "국선도의 고유 권한 보존을 위해 강화된 관리 시스템이 구축되었나요? 어떤 관리 시스템이 있는지 알려주세요."}
23 | {"prompt": "기혈순환유통유통법을 할 때 힘을 주는 정도는 어떻게 결정하나요?"}
24 | {"prompt": "기혈순환유통유통법을 할 때 상상력을 이용하는 방법이 있을까요?"}
25 | {"prompt": "단전호흡이 정신적인 측면에 어떤 영향을 미치나요?"}
26 | {"prompt": "호흡법을 익히는 과정에서 주의해야 할 점이 있나요?"}
27 | {"prompt": "이 호흡법은 왜 마음을 가라앉히는 것부터 시작할까요?"}
28 | {"prompt": "아랫배 3cm 아래에서 시작되는 기운을 왜 몸을 반시계 방향으로 돌린다는 생각을 하게 될까요?"}
29 | {"prompt": "이 호흡법은 왜 힘을 건강하게 유지할 수 있는 도움이 될까요?"}
30 | {"prompt": "\"마음을 가라앉힌다\"는 말이 추상적일 수 있습니다. 도장에서는 어떤 방법을 사용하여 마음을 고요하게 만드는지 알 수 있을까요?"}
31 | {"prompt": "마음이 가라앉지 않은 상태에서 아랫배를 내밀 때 일어나는 부작용에는 어떤 것들이 있나요?"}
32 | {"prompt": "배꼽 위의 상체 중 어디라도 긴장이나 힘이 있는 상태에서 아랫배를 내밀려고 하면 어떤 일이 일어날까요?"}
33 | {"prompt": "동작을 정확하게 하는 것과 호흡에 무리가 없도록 하는 것 중 더 중요한 것은 무엇인가요?"}
34 | {"prompt": "단전행공을 통해 얻을 수 있는 신체적인 이점은 무엇인가요?"}
35 | {"prompt": "국선도의 정각도 단계의 동작 수가 많은 이유는 무엇인가요?"}
36 | {"prompt": "국선도의 정각도 단계를 통해 얻을 수 있는 이점은 무엇인가요?"}
37 | {"prompt": "중기단법을 집에서 수련할 때와 도장이나 연수원에서 특수 프로그램을 받을 때의 차이점은 무엇인가요?"}
38 | {"prompt": "중기단법을 수행하면 호흡 뿐만 아니라 다른 측면에서도 어떤 변화가 생기나요?"}
39 | {"prompt": "중기단법의 임의성이 있는 이유는 무엇일까?"}
40 | {"prompt": "원기단법에서는 어떤 유통 과정을 자주 시도하나요?"}
41 | {"prompt": "원기단법에서 축기가 왜 중요한가요?"}
42 | {"prompt": "원기단법에서의 흡지와 축기는 왜 번갈아가며 이루어져야 하나요?"}
43 | {"prompt": "국선도의 통기법을 통해 내면의 평화를 얻을 수 있나요?"}
44 | {"prompt": "국선도의 통기법은 얼마나 오래 실천해야 효과가 나타날까요?"}
45 | {"prompt": "영체와 함께 수련하는 것은 어느 단계부터 가능한 건가요?"}
46 | {"prompt": "삼합단법을 통해 우리 몸은 어떻게 이산화탄소를 배출하나요?"}
47 | {"prompt": "조리단법은 어떤 방식으로 전파되고 널리 알려지게 되었나요?"}
48 | {"prompt": "국선도의 선도법이란 무엇인가요?"}
49 | {"prompt": "국선도의 선도법은 어떻게 구성되어 있나요?"}
50 | {"prompt": "하늘과 하나가 되는 단법이 국선도의 선도법에 어떤 영향을 미치나요?"}
51 | {"prompt": "국선도의 선도법을 세우기 위해서는 어떤 조건이 필요할까요?"}
52 | {"prompt": "국선도의 선도법이 지역 사회에 미치는 영향에는 어떤 요소가 있을까요?"}
53 | {"prompt": "국선도의 삼청단법이란 무엇인가요?"}
54 | {"prompt": "삼청단법을 통해 어떤 능력을 기를 수 있나요?"}
55 | {"prompt": "삼청단법의 목표는 무엇인가요?"}
56 | {"prompt": "삼청단법을 통해 어떤 실용적인 혜택을 얻을 수 있나요?"}
57 | {"prompt": "국선도의 무진단법의 수련 과정에서 어떤 장점이 있나요?"}
58 | {"prompt": "국선도의 무진단법을 통해 수련할 때 가장 어려운 점은 무엇인가요?"}
59 | {"prompt": "국선도의 무진단법을 통해 몸과 마음을 나누는 방법에는 어떤 종류가 있을까요?"}
60 | {"prompt": "국선도의 무진단법을 통해 나눠진 몸과 마음을 다시 하나로 합치는 시기는 얼마나 걸리나요?"}
61 | {"prompt": "국선도의 장부강화운동을 꾸준히 하면 몸에 어떤 변화가 생길까요?"}
62 | {"prompt": "국선도의 진공단법을 수행하면서 정리운동의 난도가 준비운동보다 높다는데, 그 이유는 무엇인가요?"}
63 | {"prompt": "정리운동을 수행하면서 어떻게 기혈순환을 유지할 수 있을까요?"}
64 | {"prompt": "정리운동을 수행하면서 얻을 수 있는 다른 이점들이 있을까요?"}
65 | {"prompt": "국선도를 함으로써 어떤 자세 개선이 이루어질 수 있을까요?"}
66 | {"prompt": "천화법과 내기전신행법의 차이점은 무엇인가요?"}
67 | {"prompt": "천화법을 사용하는 사람들은 어떤 이유로 이를 선택하는 건가요?"}
68 | {"prompt": "천화법의 성공적인 활용 사례를 알려주세요."}
69 | {"prompt": "천화법을 사용하면 단점은 없는 것인가요?"}
70 | {"prompt": "천화법을 활용한 정책 수립의 성공적인 예시를 알려주세요."}
71 | {"prompt": "천화법을 사용한 정책이 다른 국가에 영향을 미칠 수 있는가요?"}
72 | {"prompt": "천화법의 활용은 국가의 민주주의 발전에 어떤 역할을 하는 것인가요?"}
73 | {"prompt": "국선도를 연마하기 위해 필요한 신체적인 능력은 무엇이 있을까요?"}
74 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | torch==1.13.1
2 | transformers
3 | accelerate
4 | colossalai==0.2.7
5 | openai
6 | langchain==0.0.113
7 | pandas>=1.4.1
8 | datasets
9 | jsonlines
10 | loralib
--------------------------------------------------------------------------------