├── _config.yml
├── .gitbook
└── assets
│ ├── tag.jpg
│ ├── image.png
│ ├── image (1).png
│ ├── image (10).png
│ ├── image (11).png
│ ├── image (12).png
│ ├── image (13).png
│ ├── image (14).png
│ ├── image (15).png
│ ├── image (16).png
│ ├── image (17).png
│ ├── image (2).png
│ ├── image (3).png
│ ├── image (4).png
│ ├── image (5).png
│ ├── image (6).png
│ ├── image (7).png
│ ├── image (8).png
│ ├── image (9).png
│ ├── 1577604723644.png
│ ├── 201908050916272865.jpg
│ ├── 201908050916272865 (1).jpg
│ ├── shen-du-jie-tu-xuan-ze-qu-yu-20191216153726.png
│ ├── shen-du-jie-tu-xuan-ze-qu-yu-20191216161824.png
│ ├── shen-du-jie-tu-xuan-ze-qu-yu-20191216153726 (1).png
│ └── shen-du-jie-tu-xuan-ze-qu-yu-20191216161824 (1).png
├── SUMMARY.md
├── .github
└── FUNDING.yml
├── LICENSE
├── guide.md
├── README.md
├── security.md
├── source.md
├── webpack.md
├── vue.md
├── algorithm.md
├── http.md
├── html-and-css.md
└── javascript.md
/_config.yml:
--------------------------------------------------------------------------------
1 | theme: jekyll-theme-tactile
--------------------------------------------------------------------------------
/.gitbook/assets/tag.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/tag.jpg
--------------------------------------------------------------------------------
/.gitbook/assets/image.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/image.png
--------------------------------------------------------------------------------
/.gitbook/assets/image (1).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/image (1).png
--------------------------------------------------------------------------------
/.gitbook/assets/image (10).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/image (10).png
--------------------------------------------------------------------------------
/.gitbook/assets/image (11).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/image (11).png
--------------------------------------------------------------------------------
/.gitbook/assets/image (12).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/image (12).png
--------------------------------------------------------------------------------
/.gitbook/assets/image (13).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/image (13).png
--------------------------------------------------------------------------------
/.gitbook/assets/image (14).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/image (14).png
--------------------------------------------------------------------------------
/.gitbook/assets/image (15).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/image (15).png
--------------------------------------------------------------------------------
/.gitbook/assets/image (16).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/image (16).png
--------------------------------------------------------------------------------
/.gitbook/assets/image (17).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/image (17).png
--------------------------------------------------------------------------------
/.gitbook/assets/image (2).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/image (2).png
--------------------------------------------------------------------------------
/.gitbook/assets/image (3).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/image (3).png
--------------------------------------------------------------------------------
/.gitbook/assets/image (4).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/image (4).png
--------------------------------------------------------------------------------
/.gitbook/assets/image (5).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/image (5).png
--------------------------------------------------------------------------------
/.gitbook/assets/image (6).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/image (6).png
--------------------------------------------------------------------------------
/.gitbook/assets/image (7).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/image (7).png
--------------------------------------------------------------------------------
/.gitbook/assets/image (8).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/image (8).png
--------------------------------------------------------------------------------
/.gitbook/assets/image (9).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/image (9).png
--------------------------------------------------------------------------------
/.gitbook/assets/1577604723644.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/1577604723644.png
--------------------------------------------------------------------------------
/.gitbook/assets/201908050916272865.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/201908050916272865.jpg
--------------------------------------------------------------------------------
/.gitbook/assets/201908050916272865 (1).jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/201908050916272865 (1).jpg
--------------------------------------------------------------------------------
/.gitbook/assets/shen-du-jie-tu-xuan-ze-qu-yu-20191216153726.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/shen-du-jie-tu-xuan-ze-qu-yu-20191216153726.png
--------------------------------------------------------------------------------
/.gitbook/assets/shen-du-jie-tu-xuan-ze-qu-yu-20191216161824.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/shen-du-jie-tu-xuan-ze-qu-yu-20191216161824.png
--------------------------------------------------------------------------------
/.gitbook/assets/shen-du-jie-tu-xuan-ze-qu-yu-20191216153726 (1).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/shen-du-jie-tu-xuan-ze-qu-yu-20191216153726 (1).png
--------------------------------------------------------------------------------
/.gitbook/assets/shen-du-jie-tu-xuan-ze-qu-yu-20191216161824 (1).png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/okaychen/FE-Interview-Brochure/HEAD/.gitbook/assets/shen-du-jie-tu-xuan-ze-qu-yu-20191216161824 (1).png
--------------------------------------------------------------------------------
/SUMMARY.md:
--------------------------------------------------------------------------------
1 | # Table of contents
2 |
3 | * [介绍](README.md)
4 | * [HTML/CSS](html-and-css.md)
5 | * [JavaScript](javascript.md)
6 | * [HTTP/浏览器](http.md)
7 | * [Vue框架篇](vue.md)
8 | * [构建工具篇](webpack.md)
9 | * [安全篇](security.md)
10 | * [算法篇](algorithm.md)
11 | * [求职准备](guide.md)
12 | * [资源合集](source.md)
13 | * [我的小站](https://www.chenqaq.com/)
14 |
15 |
--------------------------------------------------------------------------------
/.github/FUNDING.yml:
--------------------------------------------------------------------------------
1 | # These are supported funding model platforms
2 |
3 | github: # Replace with up to 4 GitHub Sponsors-enabled usernames e.g., [user1, user2]
4 | patreon: # Replace with a single Patreon username
5 | open_collective: # Replace with a single Open Collective username
6 | ko_fi: # Replace with a single Ko-fi username
7 | tidelift: # Replace with a single Tidelift platform-name/package-name e.g., npm/babel
8 | community_bridge: # Replace with a single Community Bridge project-name e.g., cloud-foundry
9 | liberapay: # Replace with a single Liberapay username
10 | issuehunt: # Replace with a single IssueHunt username
11 | otechie: # Replace with a single Otechie username
12 | custom: https://www.chenqaq.com/2021/03/30/00attention
13 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2019 okaychen
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/guide.md:
--------------------------------------------------------------------------------
1 | ---
2 | description: 应届生找一份前端或者互联网其他行业工作我们需要做哪些准备,注意哪些问题
3 | ---
4 |
5 | # 求职准备
6 |
7 | 
8 |
9 | * 大学或者研究生应尽早设立目标,在相对自由的氛围里找到自己真正热爱的东西
10 | * 提高自身专业知识度和综合素质,增加人生阅历
11 | * 去了解一个企业或者一个岗位JD,作为自己的发展目标
12 | * 用自己的大学或者研究生为自己准备一份简历
13 | * 简历需要什么不需要什么:
14 | * 简历是一份一页或者两页pdf,请放弃word,h5等,尽量简介大方,放弃色彩搭配黑白最佳,简洁但是要满,不要稀稀拉拉的,如果是设计岗的同学,请上传现有作品的附件或者链接
15 | * HR需要的是一份一眼就能知道你跟这个岗位很吻合的简历
16 | * 和岗位的无关的内容一概不要写,尤其不要写自己的生活兴趣爱好等,喜欢运动音乐弹个吉他什么的一类无关紧要的话,hr真的没有时间细看,不小心瞟到了会显得在凑字数
17 | * 不要造假,不要造假,不要造假,重要的事情说三遍,一旦被证实耽误的真的是你一辈子的就业前途,会被企业永久拉进黑名单,请正视这个问题,现在时间还早,不如多花时间提高,为自己准备一份合格的简历
18 | * 和岗位JD有关的关键词,多写认真写,在项目中清楚体现
19 | * 项目经历结构化,按照STAR原则去写
20 | * 跳出舒适圈,走出学校去一个企业实习
21 | * 去争取一份工作,平时应该着重培养哪些:
22 | * 如果应聘技术类的岗位:一定要写点什么,把代码量搞上去,自己发在github上面,有自己代表性的项目,如果刚好你喜欢写作,喜欢经营自己的技术博客那么恭喜你,你会是一个幸运儿,无论你从事什么行业,写作能力真的会伴随你一生
23 | * 如果你想要应聘职能类(运营,市场,销售之类)的岗位:自己要做点什么,比如自己运营一个微信号,自己发个软文,多学习,要做出点像样的成绩来
24 | * 抓住招聘季,春季招聘金三银四,秋季招聘金九银十
25 | * 分清春季和秋季招聘的区别:
26 | * 春季招聘多数是招聘本年度暑期实习生,少数是对去年秋季招聘的补招
27 | * 大三暑假的秋季招聘7月开始是毕业季招聘的核心,是为公司储备应届毕业人才
28 | * 分清暑期实习和日常实习的区别:
29 | * 暑期实习是为秋季招聘的预备人才,一般三个月以上,需要答辩成功后会有直接转正机会
30 | * 日常实习也需要到岗实习,实习时间自由一般一周4-5天,看部门缺口很少有转正机会
31 | * 投递途径:
32 | * 内推&网申
33 | * 宣讲会&网申
34 | * 正视内推
35 | * 内推只是简历投递的一种途径,你的师兄师姐在你想投递的公司可以帮你内推,也可能直接帮你把简历给部门经理,但是免不免笔试,面试结果如何他还没办法左右
36 | * 宣讲会:企业会预先安排自己的宣讲会行程,会在哪些学校进行,一般在9月进行,是介绍企业文化,人才培养计划等路演形式,分为一站式和非一站式,一站式现场收简历并且笔试,通过后一般在接下来2-3内在该学校附近就行面试,非一站式可能现场收简历,但是不会笔试面试
37 | * 招聘流程:
38 | * 提前批&正式批&补招
39 | * 提前批是在正式批次的预热,简历一般要求较高,学历,经验,能力,如果提前批你已经应聘上了心仪的公司,恭喜你,你的毕业招聘季在9月份就已经正式结束,也就是大四开学的那段时间
40 | * 正式批一般是网申批次,走正常招聘流程,不免笔试
41 | * 补招是企业对秋季招聘人才缺口的补充,在正式批结束后一段时间进行,一般在11月后
42 | * 笔试(部分提前批内推或者优秀简历免笔试)
43 | * 面试(分为三种,视频面,现场面和电话面,一般为三面,三面为HR面,技术岗三面可能都为技术面,部分有增加交叉面\)
44 | * offer流程
45 | * 意向书和offer流程
46 | * 意向书,意向书是offer前的接收意向说明,意向书少数情况会被企业"拥抱变化"
47 | * offer是用人单位单方愿意接收人才就业,应聘人才有权利拒接,无影响
48 | * 多offer选择,要综合多方面信息,比如平台大小,发展前景,薪资福利待遇,选择最心仪的
49 | * 关于录取通知书,两方和三方
50 | * 三方大四毕业季每个学校都会发,是用人单位,个人和学校三方具有法律效力的合同
51 | * 录取通知书是应聘人才愿意接收offer,需要签字生效,会写明应届生需要寄交三方,生效后任何一方违约都需要赔偿录取通知里写明的违约金
52 | * 正式接受后,一般可以选择毕业前去实习,也可以不实习自己安排余下时间等毕业申请入职
53 |
54 | > 原文地址:[浅笔墨画❀琐碎小记](https://www.chenqaq.com/2019/11/22/life-speech20191124/)
55 |
56 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 介绍
2 |
3 | 互联网发展迅猛之余也伴随着互联网寒冬,行业不景气这样的词,等毕业季去各个求职网站投简历,去各个人才市场找机会,才发现四处碰壁,作为应届求职者更需要打好基础,明确发展规划,跟上行业步伐。下面是本人2019年秋招前端面试经历,结合个人博客和牛油们面经中的高频问题以及行业前辈们复习资料的综合整理,包含基础篇、Vue框架篇、HTTP&浏览器、构建工具篇、安全篇、算法篇,欢迎交流斧正。希望大家在毕业季都能一帆风顺,从容斩获OFFER
4 |
5 | 第一版能看到什么:
6 | - 90页+PDF
7 | - 含100+前端高频面试题及其推荐解答
8 | - 资源分享常用工具优质社区团队个人博客
9 | - 如果是应届生如何规划自己从毕业到就职之路,通过哪些途径参与求职
10 |
11 | 这本小册里都能得到解答
12 |
13 | ## 计划&状态
14 |
15 | 🤤 主要面向对象:应届生求职--前端
16 |
17 | | 篇章 | 第一版预计完成 | 状态 |
18 | | :---: | :---: | :---: |
19 | | [HTML&CSS](https://github.com/okaychen/FE-Interview-Questions/blob/master/html-and-css.md) | Q20 | 😀 已完善 |
20 | | [JavaScript](https://github.com/okaychen/FE-Interview-Questions/blob/master/javascript.md) | Q25 | 😀 已完善 |
21 | | [HTTP&浏览器](https://github.com/okaychen/FE-Interview-Questions/blob/master/http.md) | Q15 | 🤔 已完善 |
22 | | [Vue篇](https://github.com/okaychen/FE-Interview-Questions/blob/master/vue.md) | Q15 | 🤔 已完善 |
23 | | [安全篇](https://github.com/okaychen/FE-Interview-Questions/blob/master/security.md) | Q10 | 🤔 已完善 |
24 | | [算法篇](https://github.com/okaychen/FE-Interview-Questions/blob/master/algorithm.md) | Q5-10 | 😀 已完善 |
25 | | [构建工具篇](https://github.com/okaychen/FE-Interview-Questions/blob/master/webpack.md) | Q5-10 | 😀 已完善 |
26 | | [求职准备](https://github.com/okaychen/FE-Interview-Brochure/blob/master/guide.md) | 求职准备 | 🤔 已完善 |
27 | | [资源合集](https://github.com/okaychen/FE-Interview-Brochure/blob/master/source.md) | 学习资源 | 🤔 已完善 |
28 |
29 | > Vue篇以Vue为主的一些框架问题,后面会考虑加上React
30 | >
31 | > 构建工具篇以前端自动化构建中的webpack为核心
32 | >
33 | > 面试官一般都会根据回答进行追问,所以小册总结上下几个问题一般具有连贯性
34 | >
35 | > 其次也正是因为是面试小册,有些问题都只是总结出较核心概念,比如浏览器解析渲染页面的过程,其实是一个很细的过程,其中滋味还需花时间细品;
36 |
37 | ## 使用姿势
38 |
39 | ### Gitbook:
40 |
41 | Gitbook:[docs.chenqaq.com](https://docs.chenqaq.com/)
42 |
43 | 
44 |
45 | > 那你说Gitbook国内访问比较慢我也不能科学上网,我是不是不适合学前端 🤣 这两好像没一点关系,我来帮你解决 👇
46 |
47 | ### Github:
48 |
49 | Github阅读:[https://github.com/okaychen/FE-Interview-Brochure](https://github.com/okaychen/FE-Interview-Brochure)
50 |
51 | > 那你说我觉得你这点总结的不对或者有更好的建议,该咋办,很简单,你给我发个issue,我会第一时间跟进
52 |
53 | 那我想下载到本地呢,打开你的git bash:
54 |
55 | ```text
56 | git clone https://github.com/okaychen/FE-Interview-Brochure.git
57 | ```
58 |
59 | 敲个回车这么简单(这里推荐一个markdown编辑器Typora)
60 |
61 | > 那你说git我也没有装呀,我太难了,我是不是不适合学前端🤣建议还是安装下
62 | >
63 | > 那你又说我就不想装,有个性,你遇到了我,我帮你解决👇
64 |
65 | ### PDF:
66 |
67 | 为了让有个性的同学也看到这份前端面试小册,我推出了方案C,90页+PDF为你准备
68 |
69 | 我已经发布了release版本:[v1.0已稳定,点击直接下载PDF](https://github.com/okaychen/FE-Interview-Brochure/releases/download/v1.0/fe-interview-brochure_v1.0.pdf)
70 |
71 | ## Change log
72 |
73 | * v1.0 Jan 9 , 2020
74 | * 完成近100+前端高频面试题以及推荐解答
75 | * 添加资源大礼包\(优质博客,平台推荐,学习资源等\)
76 |
77 | ## License
78 |
79 | [MIT](https://github.com/okaychen/FE-Interview-Questions/blob/master/LICENSE)
80 |
81 |
--------------------------------------------------------------------------------
/security.md:
--------------------------------------------------------------------------------
1 | ---
2 | description: 前端安全方面,应届生遇到的多为常识性问题,一般不具有太大难度,但是必须要了解
3 | ---
4 |
5 | # 安全篇
6 |
7 | ## 知道有哪些可能引起前端安全的问题
8 |
9 | 前端应用中常遇到的安全问题:
10 |
11 | * 跨站脚本xss
12 | * 跨站请求伪造 csrf
13 | * 网络劫持攻击
14 | * iframe滥用
15 | * 恶意第三方库
16 |
17 | ## xss攻击的分类
18 |
19 | 根据攻击来源的不同,通常分为三种:
20 |
21 | * 反射型
22 |
23 | 反射性通常发生在URL地址的参数中,常用来窃取客户端的cookie或进行钓鱼欺骗,经常在网站的搜索栏,跳转的地方被注入
24 |
25 | ```markup
26 |
27 | http://www.test.com/search.php?key=">
28 | ```
29 |
30 | * 存储型
31 |
32 | 相比反射型 XSS 的恶意代码存在 URL ⾥,存储型 XSS 的恶意代码存在数据库⾥,不需要用户去点击URL进行触发,提前将恶意代码保存在了漏洞服务器或者客户端中,站点取出后会自动解析执行
33 |
34 | * DOM型
35 |
36 | 较上面两种,DOM型取出和执行恶意代码都由浏览器端完成,属于前端自身安全漏洞
37 |
38 | ## 如何预防xss攻击
39 |
40 | xss攻击有两大要素:攻击者提交恶意代码,浏览器执行恶意代码
41 |
42 | * 针对cookie劫持,攻击者向漏洞页面写入恶意代码获取cookie,可以通过防止cookie会话劫持来防范,一般要在设置cookie时加HttpOnly,来禁止意外注入站点的恶意js代码操作Cookie造成xss攻击
43 |
44 | ```javascript
45 | // node设置httponly
46 | 'Set-Cookie' : 'SSID=EqAc1D; Expires=Wed; HttpOnly'
47 | ```
48 |
49 | * 提高攻击门槛:\(XSS Filter\)针对用户提交的数据进行有效的验证,只接受我们规定的长度或内容的提交,过滤掉其他的输入内容 或者 将特殊字符输出编码\(xss Escape\)
50 |
51 | 
52 |
53 | * xss漏洞检测poc:通过漏洞检测代码,完成自测,最小化被攻击风险
54 |
55 | ```markup
56 |
57 | )
![]() 58 |
59 |
60 |
58 |
59 |
60 | ![]() 61 | ```
62 |
63 | ## csrf简单介绍一下
64 |
65 | CSRF(Cross-site request forgery)跨站请求伪造:攻击者诱导受害者进⼊第三⽅⽹站,在第三⽅⽹站中,向被攻击⽹站发送跨站请求。利⽤受害者在被攻击⽹站已经获取的注册凭证,绕过后台的⽤户验证,达到冒充⽤户对被攻击的⽹站执⾏某项操作的⽬的,
66 |
67 | 常规的过程如下:
68 |
69 | 1. 用户打开浏览器,访问受信任网站A,输入用户名和密码请求登录网站A
70 | 2. 在用户信息通过验证后,网站A产生Cookie信息并返回给浏览器
71 | 3. 未退出网站A之前,在同一浏览器中,攻击者引诱用户进入网站B
72 | 4. 网站B接收到用户请求后,返回一些攻击性代码,并发出一个请求要求访问第三方站点A
73 | 5. 浏览器在接收到这些攻击性代码后,根据网站B的请求,在用户不知情的情况下携带Cookie信息,向网站A发出请求。网站A根据用户的Cookie信息以及用户的权限处理该请求,导致来自网站B的恶意代码被执行
74 |
75 | ## 如何预防csrf攻击
76 |
77 | CSRF通常从第三⽅⽹站发起,被攻击的⽹站⽆法防⽌攻击发⽣,只能通过增强⾃⼰⽹站针对CSRF的防护能⼒来提升安全性
78 |
79 | CSRF有两个特点:
80 |
81 | * 通常发生在第三方域名
82 | * 攻击者不能获取到cookie等信息,只是使用
83 |
84 | 针对这两点,我们可以制定专门的防护策略:
85 |
86 | * 阻止不明外域的访问
87 | * 同源检测
88 | * Samesite Cookie
89 | * 提交时要求附加文本域验证身份才可以获取信息
90 | * CSRF Token
91 | * 双重cookie验证
92 |
93 | ### 同源检测
94 |
95 | 通过使用Orgin Header确定来源域名:在部分与CSRF有关的请求中,请求的Header中会携带Origin字段,如果Origin存在,那么直接使⽤Origin中的字段确认来源域名就可以
96 |
97 | 使用Referer Header确定域名来源:根据HTTP协议,HTTP头中有一个字段叫Referer,记录了该HTTP请求的来源地址
98 |
99 | ### Samesite Cookie属性
100 |
101 | Google起草了⼀份草案来改进HTTP协议,那就是为Set-Cookie响应头新增Samesite属性,它⽤来标明这个 Cookie是个“同站 Cookie”,同站Cookie只能作为第⼀⽅Cookie,不能作为第三⽅Cookie,Samesite 有两个属性值:
102 |
103 | * Samesite=Strict: 这种称为严格模式,表明这个 Cookie 在任何情况下都不可能作为第三⽅ Cookie
104 | * Samesite=Lax: 这种称为宽松模式,⽐ Strict 放宽了点限制,假如这个请求是这种请求且同时是个GET请求,则这个Cookie可以作为第三⽅Cookie
105 |
106 | ### CSRF Token
107 |
108 | 通过csrf token验证请求的身份,是够携带正确的token,来区分正常的请求和攻击的请求
109 |
110 | CSRF Token的防护策略分为三个步骤:
111 |
112 | * 将CSRF Token输出到⻚⾯中
113 | * ⻚⾯提交的请求携带这个Token
114 | * 服务器验证Token是否
115 |
116 | ### 双重cookie验证
117 |
118 | 利⽤CSRF攻击不能获取到⽤户Cookie的特点,我们可以要求Ajax和表单请求携带⼀个Cookie中的值
119 |
120 | 双重Cookie采⽤以下流程:
121 |
122 | * 在⽤户访问⽹站⻚⾯时,向请求域名注⼊⼀个Cookie,内容为随机字符串
123 | * 在前端向后端发起请求时,取出Cookie,并添加到URL的参数中
124 | * 后端接⼝验证Cookie中的字段与URL参数中的字段是否⼀致,不⼀致则拒
125 |
126 | ## 网络劫持有哪几种
127 |
128 | 网络劫持一般分为两种:HTTP劫持和DNS劫持
129 |
130 | DNS劫持
131 |
132 | * DNS强制解析:通过修改运营商的本地DNS记录,来引导⽤户流量到缓存服务器
133 | * 302跳转的⽅式:通过监控⽹络出⼝的流量,分析判断哪些内容是可以进⾏劫持处理的,再对劫持的内存发起跳转的回复,引导⽤户获取内容
134 |
135 | HTTP劫持: 由于http明⽂传输,运营商会修改你的http响应内容\(即加⼴告\)
136 |
137 | DNS劫持由于涉嫌违法,已经被监管;针对HTTP劫持,最有效的办法就是全站HTTPS,将HTTP加密,这使得运营商⽆法获取明⽂,就⽆法劫持你的响应内容
138 |
139 | ## 中间人攻击的了解
140 |
141 | 中间人\(Man-in-the-middle attack, MITM\)是指攻击者和通讯的两端分别创建独立的联系,并交换其得到的数据,攻击者可以拦截通信双方的通话并插入新的内容
142 |
143 | 一般的过程如下:
144 |
145 | * 客户端发送请求到服务端,请求被中间⼈截获
146 | * 服务器向客户端发送公钥
147 | * 中间⼈截获公钥,保留在⾃⼰⼿上。然后⾃⼰⽣成⼀个【伪造的】公钥,发给客户端
148 | * 客户端收到伪造的公钥后,⽣成加密hash值发给服务器
149 | * 中间⼈获得加密hash值,⽤⾃⼰的私钥解密获得真秘钥,同时⽣成假的加密hash值,发给服务器
150 | * 服务器⽤私钥解密获得假密钥,然后加密数据传输给客户端
151 |
152 | > 推荐:[HTTPS中间人攻击实践](https://www.cnblogs.com/lulianqi/p/10558719.html)
153 |
154 |
--------------------------------------------------------------------------------
/source.md:
--------------------------------------------------------------------------------
1 | # 资源合集
2 |
3 | 小册高频面试题题部分到这告别一段尾声了,平时学习过程我们在不断接触一些学习资源,2019年转眼过去,下面是我大学三年前端学习过程收录的一些资源,不能说能面面俱到,但多数都是我有过接触并且得到业界认可的资源,这里做整理和分享,算是20年新年礼物给大家,希望对我和大家都有所帮助,这也是一点小小的愿望
4 |
5 | * 资源教程&官方文档
6 |
7 | | 资源教程 | 官方文档 |
8 | | :--- | :--- |
9 | | [MDN Web 文档](https://developer.mozilla.org/zh-CN/) | [TypeScript中文网](https://www.tslang.cn/docs/home.html) |
10 | | [w3school在线教程](https://www.w3school.com.cn/) | [vue生态系统](https://cn.vuejs.org/v2/guide/) |
11 | | [w3cschool](https://www.w3cschool.cn/) | [react文档](https://react.docschina.org/docs/getting-started.html) |
12 | | [菜鸟教程](https://www.w3cschool.cn/) | [webpack文档](https://webpack.docschina.org/concepts/) |
13 | | [印记中文](https://www.docschina.org/) | [node中文网](http://nodejs.cn/api/) |
14 | | [大前端](http://www.daqianduan.com/) | |
15 | | [html5tricks](https://www.html5tricks.com/) | |
16 | | [ES6入门教程](http://es6.ruanyifeng.com/) | [koajs文档](https://koa.bootcss.com/#introduction) |
17 | | [w3cpuls前端网](https://www.w3cplus.com/) | [express参考手册](http://www.expressjs.com.cn/4x/api.html) |
18 | | [WebPlatform](https://webplatform.github.io/docs/Main_Page/index.html) | [微信小程序文档](https://developers.weixin.qq.com/miniprogram/dev/framework/) |
19 | | [前端开发者手册](https://dwqs.gitbooks.io/frontenddevhandbook/content/) | [Mongodb教程](https://www.mongodb.org.cn/tutorial/) |
20 | | [JavaScript标准参考教程](http://javascript.ruanyifeng.com/#toc0) | [Mongoose 5.0文档](http://www.mongoosejs.net/) |
21 |
22 | * 开发社区&工具资源
23 |
24 | | 开发社区 | 工具资源 |
25 | | :--- | :--- |
26 | | [掘金](https://juejin.im/timeline) | [typora (markdown编辑器)](https://www.typora.io/) |
27 | | [v2ex](https://www.v2ex.com/) | [ProcessOn (在线作图)](https://www.processon.com/) |
28 | | [jsTips](http://www.jstips.co/) | [FeHeler (chrome插件,功能强大)](https://www.baidufe.com/fehelper/index/index.html) |
29 | | [Github](https://github.com/) | [Fiddler (抓包调试工具)](https://www.telerik.com/fiddler) |
30 | | [CNode](https://cnodejs.org/) | [CodePon (在线代码测试工具)](https://codepen.io/) |
31 | | | [智图 (图片在线压缩,制作webp)](https://zhitu.isux.us/) |
32 | | | [JSRun (在线代码编辑器)](http://jsrun.pro/) |
33 | | [infoQ](https://www.infoq.cn/) | [Icomoon (字体图标制作)](https://icomoon.io/) |
34 | | [segmentfault](https://segmentfault.com/) | [Iconfont (阿里矢量图库)](https://www.iconfont.cn/) |
35 | | [stackoverflow](https://stackoverflow.com/) | [墨刀 (产品设计)](https://modao.cc/) |
36 | | [smashingmagazine](https://www.smashingmagazine.com/) | [颜色搭配表](http://rainyin.com/307.html) |
37 | | [开发者头条](https://toutiao.io/posts/hot/7) | [草料二维码](https://cli.im/) |
38 | | [前端乱炖](http://www.html-js.com/) | [Github emoji](https://emoji.muan.co/) |
39 | | [中文开源社区](https://www.oschina.net/) | [Github shields](https://shields.io/) |
40 |
41 | * 博客推荐
42 |
43 | 国内以及国外开源团队:[open\_source\_team](https://github.com/niezhiyang/open_source_team)
44 |
45 | | 团队博客 | 大牛博客 |
46 | | :--- | :--- |
47 | | [淘宝FED](https://fed.taobao.org/) | [阮一峰](http://www.ruanyifeng.com/home.html) |
48 | | [百度FEX](http://fex.baidu.com/) | [张鑫旭](https://www.zhangxinxu.com/) |
49 | | [百度FEE](https://efe.baidu.com/) | [十年踪迹](https://www.h5jun.com/archives/)\(月影\) |
50 | | [腾讯AlloyTeam](http://www.alloyteam.com/) | [叶小钗](https://www.cnblogs.com/yexiaochai/) |
51 | | [腾讯IMWEB](https://imweb.io/) | [司徒正美](https://www.cnblogs.com/rubylouvre/) |
52 | | [360奇舞团](https://75.team/) | [廖雪峰](https://www.liaoxuefeng.com/) |
53 | | [京东JDC](https://jdc.jd.com/) | [chokCoco](https://www.cnblogs.com/coco1s/) |
54 | | [京东凹凸实验室](https://aotu.io/) | [汤姆大叔](https://www.cnblogs.com/TomXu/) |
55 | | [美团技术团队](https://tech.meituan.com/) | [勾三股四](https://jiongks.name/archives/) |
56 | | [饿了吗前端](https://zhuanlan.zhihu.com/ElemeFE) | [JerryQu](https://imququ.com/post/series.html) |
57 | | [有赞技术团队](https://tech.youzan.com/) | [当耐特](https://www.cnblogs.com/iamzhanglei/) |
58 | | [携程UED](http://ued.ctrip.com/) | [胖洪宇](https://jspang.com/) |
59 |
60 | 篇幅有限,不能一一列出对我技术成长有帮助的这些团队和大牛的博客,感谢这些技术大牛让我多少改变对写作的看法,更加坚持这件事,我希望我也能带着学习的视角坚持写作\(或技术或生活\),于后来之人留下哪怕很细微的帮助,到这里这份简简单单的面试小册第一版就结束了,新年新愿望,也祝福大家在新的一年里学业有成,事业顺利
61 |
62 | 那么,最后为了突出主题呢,还是要写一些对于这份小册的愿景吧:如果你是应届生\(当然,大牛除外\),正面临找前端开发的工作,或者即将成为毕业生的预备生,我相信这份前端面试小册多多少少会帮到你,在这"不景气"的"寒冬"之季,我们仍要提高自身综合素质,坚持技术生活,通过不断给自己设立小目标并实现来督促自身学习提高,2020愿我们只争朝夕不负韶华
63 |
64 |
--------------------------------------------------------------------------------
/webpack.md:
--------------------------------------------------------------------------------
1 | ---
2 | description: webpack是事实上的前端打包标准,使用较广泛,相比其他打包工具webpack更是面试中的热点
3 | ---
4 |
5 | # 构建工具篇
6 |
7 | ## 用的webpack3还是版本4,知道有哪些改进嘛
8 |
9 | webpack4是18年8月25号发布的,相比webpack3主要以下大改动:
10 |
11 | * node环境升级,不再支持node4.0及之前版本,最低node版本6.11.5
12 | * 配置增加了`mode:production/development/none`,必须指定其中一个,在不同的mode下开启了一些默认的优化手段;
13 | * 不再需要某些plugin,改为在对应生产或者开发模式下默认打开
14 |
15 | > 详细改进:[webpack Release v4.0.0](https://github.com/webpack/webpack/releases/tag/v4.0.0-beta.0?utm_source=aotu_io&utm_medium=liteo2_web)
16 |
17 | ## loader和plugin的不同
18 |
19 | * loader能让webpack处理不同的文件,然后对文件进行一些处理,编译,压缩等,最终一起打包到指定文件中(比如loader可以将sass,less文件写法转换成css,而不需要在使用其他转换工具),loader本身是一个函数,接收源文件作为参数,返回转换的结果
20 |
21 | ```javascript
22 | // build/webpack.base.conf.js
23 | module: {
24 | rules: [
25 | {
26 | test: /\.vue$/,
27 | loader: 'vue-loader',
28 | options: vueLoaderConfig
29 | },
30 | ]
31 | },
32 | ```
33 |
34 | * plugins则用于执行广泛的任务,从打包,优化,压缩,一直到重新定义环境中的变量,接口很强大,主要用来扩展webpack的功能,可以实现loader不能实现的更复杂的功能
35 |
36 | ```javascript
37 | // build/webpack.prod.conf.js
38 | plugins: [
39 | new webpack.DefinePlugin({
40 | 'process.env': env
41 | }),
42 | new UglifyJsPlugin({
43 | uglifyOptions: {
44 | compress: {
45 | warnings: false
46 | }
47 | },
48 | sourceMap: config.build.productionSourceMap,
49 | parallel: true
50 | }),
51 | ]
52 | ```
53 |
54 | ## 有手动编写过loader和plugin,说一下思路
55 |
56 | loader能把源文件经过转化后输出新的结果,一个loader遵循单一职责原则,只完成一种转换,然后链式的顺序去依次经过多个loader转换,直到得到最终结果并返回,所以在写loader时要保持其职责的单一性,同时webpack还提供了一些API供loader调用
57 |
58 | ```javascript
59 | // 一个简单的loader例子
60 | function replace(source) {
61 | // 使用正则把 @require '../style/index.css' 转换成 require('../style/index.css');
62 | return source.replace(/(\/\/ *@require) +(('|").+('|")).*/, 'require($2);');
63 | }
64 | module.exports = function (content) {
65 | return replace(content);
66 | };
67 | ```
68 |
69 | 开发plugin中最常用的两个对象是Compiler和Compilation,他们是plugin和webpack之间的桥梁
70 |
71 | * `Compiler`对象包含了webpack环境的所有配置信息,包含options,loaders,plugins这些信息,这个对象在Webpack启动时候被实例化,它是全局唯一的
72 | * `Compilation`对象包含了当前的模块资源,编译生成资源,变换的文件等。当webpack以开发模式运行时,每当检测到一个文件变化,一个新的Compilation将会被创建
73 |
74 | ```javascript
75 | // 最基础的plugin代码
76 | class BasicPlugin{
77 | // 在构造函数中获取用户给该插件传入的配置
78 | constructor(options){ }
79 | // Webpack会调用BasicPlugin实例的apply方法给插件实例传入compiler对象
80 | apply(compiler){
81 | conpiler.plugin('compilation',function(compilation){ })
82 | }
83 | }
84 | module.exports = BasicPlugin;
85 | ```
86 |
87 | ## webpack如何配置单页和多页应用
88 |
89 | 单页应用即为webpack的标准模式,直接在entry中指定单页面应用的入口即可:
90 |
91 | ```javascript
92 | module.exports = {
93 | entry: {
94 | app: './src/main.js'
95 | },
96 | }
97 | ```
98 |
99 | 多页面应用可以考虑使用webpack的`AutoWebPlugin`来完成简单的自动化构建,前提是项目目录结构要符合预先设定的规范
100 |
101 | ```javascript
102 | ├── pages
103 | │ ├── index
104 | │ │ ├── index.css // 该页面单独需要的 CSS 样式
105 | │ │ └── index.js // 该页面的入口文件
106 | │ └── login
107 | │ ├── index.css
108 | │ └── index.js
109 | ├── common.css // 所有页面都需要的公共 CSS 样式
110 | ├── google_analytics.js
111 | ├── template.html
112 | └── webpack.config.js
113 | ```
114 |
115 | ## webpack如何做到热更新
116 |
117 | webpack热更新(Hot Module Replacement),缩写为HMR,实现了不用刷新浏览器而将新变更的模块替换掉旧的模块,原理如下:
118 |
119 | 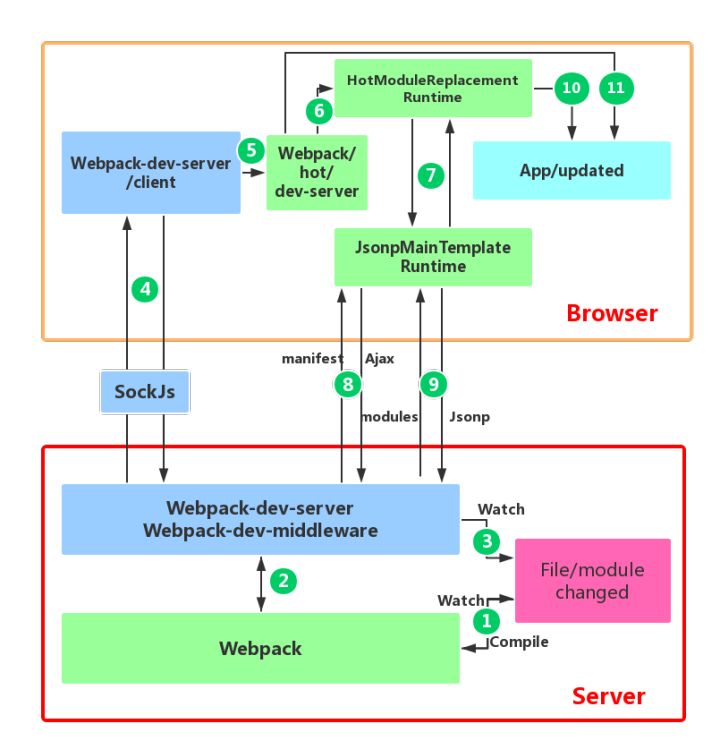
120 |
121 | server端和client端都做了处理:
122 |
123 | * webpack监听到文件变化,重新编译打包,webpack-dev-server和webpack之间接口交互(主要是webpack-dev-middleware调用webpack暴露的API对代码进行监控,并告诉webpack将打包后代码保存到内存中)
124 | * 通过sockjs(webpack-dev-server的依赖)在浏览器和服务器之间建立 一个`websocket`长连接,将webpack编译打包各阶段的信息告知浏览器端
125 | * webpack根据 webpack-dev-server/client 传给它的信息以及 dev-server的配置决定是刷新浏览器还是进⾏模块热更新,如果是模块热更新继续执行,否者刷新浏览器
126 | * HotModuleReplacement.runtime 是客户端 HMR 的中枢,它接收到上⼀步传递给他的新模块的 hash 值,它通过JsonpMainTemplate.runtime 向 server 端发送 Ajax 请求,服务端返回⼀个 json,该 json 包含了所有要更新的模块的 hash 值,获取到更新列表后,该模块再次通过 jsonp 请求,获取到最新的模块代码
127 | * HotModulePlugin 将会对新旧模块进⾏对⽐,决定是否更新模块
128 | * 当 HMR 失败后,回退到 live reload 操作,也就是进⾏浏览器刷新来获取最新打包代码
129 |
130 | > 参考:[Webpack HMR 原理解析](https://zhuanlan.zhihu.com/p/30669007)
131 |
132 | ## webpack的构建流程\(原理\)是怎样的
133 |
134 | webpack的构建流程是一个串行的过程,从启动到结束依次执行如下:
135 |
136 | * ① 初始化参数:从配置文件和shell语句中读取与合并参数,得出最终的参数
137 | * ② 开始编译:用上一步得到的参数初始化 Compiler对象,加载所有配置的插件,通过执行对象的run方法开始执行编译
138 | * ③ 确定入口:根据配置中的entry找出所有的入口文件
139 | * ④ 编译模块:从入口文件出发,调用所有配置的loader对模块进行"加载",再找出该模块依赖的模块,递归此步骤知道所有入口依赖的文件都经过处理结束
140 | * ⑤ 完成编译模块:处理结束,得到了每个模块被"加载"之后的最终内容以及他们之间的依赖关系
141 | * ⑥ 输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的chunk,再将每个chunk转换成一个单独的文件加入输出列表中
142 | * ⑦ 输出完成:确定输出内容之后,根据配置确定输出的路径和⽂件名,写⼊到⽂件系统
143 |
144 | ## 如何用webpack优化前端性能
145 |
146 | * 压缩代码:比如利用UglifyJsPlugin来对js文件压缩
147 | * CDN加速:将引用的静态资源修改为CDN上的路径。比如可以抽离出静态js,在index利用CDN引入;利⽤webpack对于 output 参数和各loader的publicPath参数来修改资源路径
148 | * 删除Tree Shaking:将代码中永远不会走到的片段删除。可以通过在启动webpack时追加参数 `--optimize-minimize` 来实现
149 | * 按照路由拆分代码,实现按需加载,提取公共代码
150 | * 优化图片,对于小图可以使用 base64 的方式写入文件中
151 |
152 |
--------------------------------------------------------------------------------
/vue.md:
--------------------------------------------------------------------------------
1 | ---
2 | description: 框架对于应届生也是较重点,除了基础的知识和部分深度问题,还要看对于技术的广度,是否有一个自己完整的技术栈,以及对于自身技术栈的认知程度
3 | ---
4 |
5 | # Vue框架篇
6 |
7 | ## 对MVVM的理解
8 |
9 | MVC的弊端:MVC即"Model-View-Controller",当视图上发生变化,通过Controller(控件)将响应传入到Model(数据源),由数据源改变View上面的数据,允许view和model直接通信,随着业务不断庞大,会出现向蜘蛛网一样难以处理的依赖关系,违背了开发应该遵循的"开放封闭原则"
10 |
11 | MVVM,萌芽于2005年微软推出的基于 Windows 的⽤户界⾯框架WPF ,前端最早的 MVVM 框架 knockout 在2010年发布
12 |
13 | 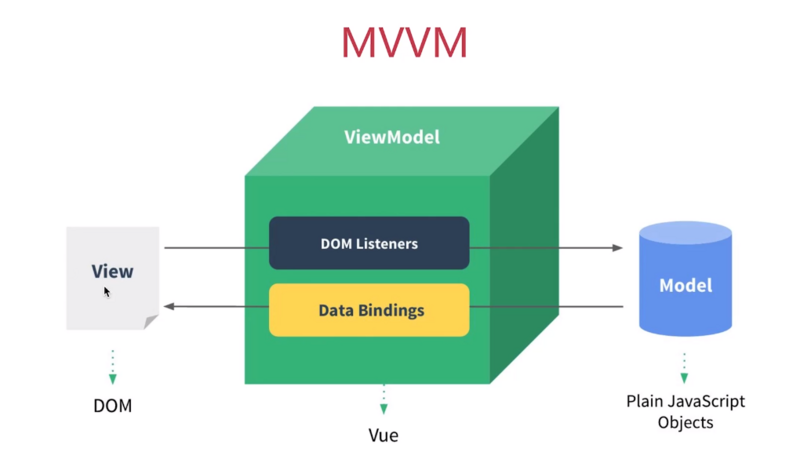
14 |
15 | 即"Model-View-ViewModel",View通过View-Model的DOM Listeners将事件绑定到Model上,而Model则通过Data Bindings来管理View中的数据,View-Model从中起到一个连接桥的作用
16 |
17 | ## vue双向数据绑定的实现
18 |
19 | vue内部利用Object.defineProperty监听数据变化,使数据具有可观测性,结合发布订阅模式,在数据发生变化时更新视图
20 |
21 | * 利用Proxy或Object.defineProperty生成的Observer针对对象/对象的属性进行"劫持",在属性发生变化后通知订阅者
22 | * 解析器Compile解析模板中的Directive\(指令\),收集指令所依赖的方法和数据,等待数据变化然后进行渲染
23 | * Watcher属于Observer和Compile桥梁,它将接收到的Observer产生的数据变化,并根据Compile提供的指令进行视图渲染,使得数据变化促使视图变化
24 |
25 | ```javascript
26 | // 简单的双向数据绑定
27 | const data = {};
28 | Object.keys(data).forEach(function(key) {
29 | Object.defineProperty(data, key, {
30 | enumerable: true,
31 | configurable: true,
32 | get: function() {
33 | console.log('get');
34 | },
35 | set: function(newVal) {
36 | // 当属性值发⽣变化时我们可以进⾏额外操作
37 | },
38 | });
39 | });
40 | ```
41 |
42 | ## Object.defineProperty和proxy的优劣区别
43 |
44 | Object.defineProperty兼容性较好,但不能直接监听数组的变化,只能监听对象的属性\(有时需要深层遍历\)
45 |
46 | 与之相比proxy的优点:
47 |
48 | * 可以直接监听数组的变化
49 | * 可以直接监听对象而非属性
50 | * proxy有多达13种的拦截方法,不限于apply、ownKeys、deleteProperty、has等等
51 | * proxy受到各大浏览器厂商的重视
52 |
53 | ## 除了数据劫持,vue为什么还需要虚拟DOM进行diff检测差异
54 |
55 | 现代前端框架主要有两种监听数据的方式:一种是pull的方式,一种是push的方式
56 |
57 | pull,其代表为react,react和vue基于双向数据绑定的依赖收集的订阅式机制不同,react是通过显式的触发函数调用来更新视图,比如setState,然后React会一层层的进行Virtual Dom Diff操作找出差异,通过较暴力diff的方式查找哪里发生变化。另一个代表是angular的脏值检测
58 |
59 | push,其代表为vue,当Vue程序初始化的时候就会对数据data进行依赖的收集,一但数据发生变化,响应式系统就会立刻得知;我们知道绑定一个数据通常就需要一个watcher,那么一旦细粒度过高会产生大量的watcher,会给增加内存以及依赖追踪的开销,而细粒度过低会无法精准检测变化,因此vue选择中细粒度方案,在组件级进行push检测的方式\(即依赖响应式系统\),在组件内部进行Virtual Dom Diff获取更加具体的差异,所以vue采用了push+pull结合的方式
60 |
61 | ## 对vue响应式系统的理解
62 |
63 | 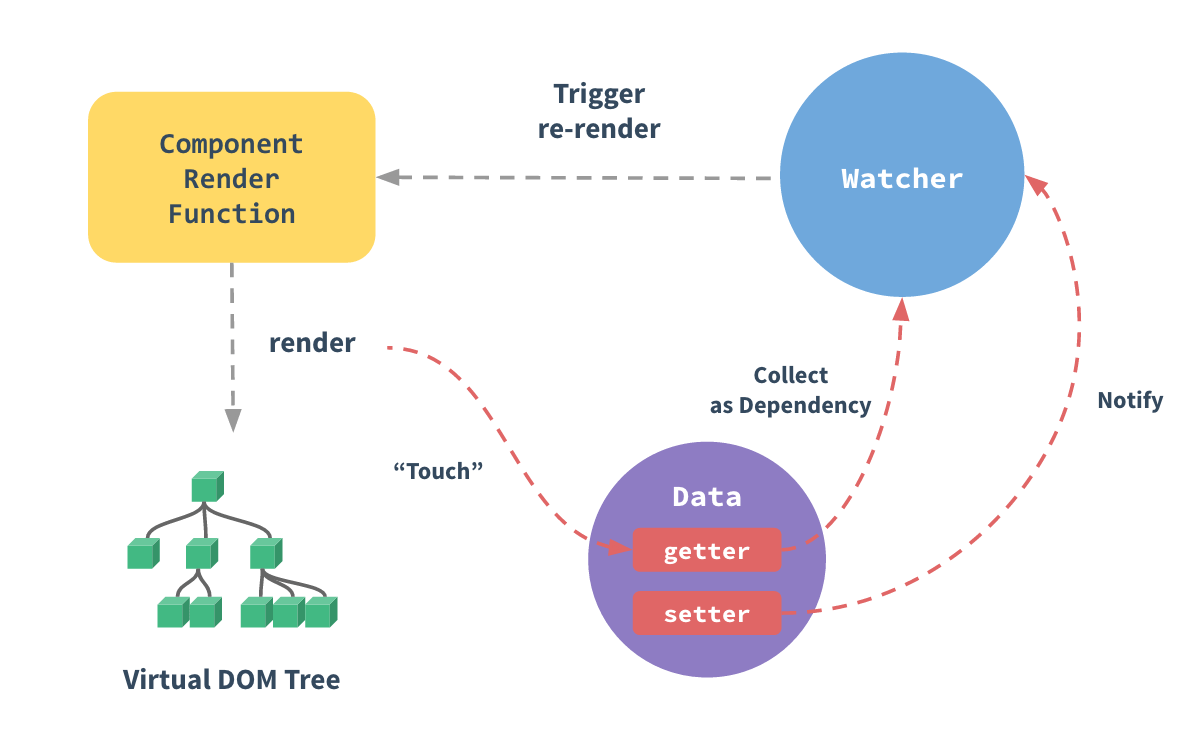
64 |
65 | 响应式系统简述:
66 |
67 | * 任何⼀个 Vue Component 都有⼀个与之对应的 Watcher 实例
68 | * Vue 的 data 上的属性会被添加 getter 和 setter 属性
69 | * 当Vue Component render函数被执⾏的时候,data上会被触碰\(touch\), 即被读,getter ⽅法会被调⽤, 此时 Vue 会去记录此 Vue component所依赖的所有data\(这⼀过程被称为依赖收集\)
70 | * data 被改动时\(主要是⽤户操作\), setter ⽅法会被调⽤, 此时 Vue 会去通知所有依赖于此 data 的组件去调⽤他们的 render 函数进⾏更新
71 |
72 | ## vue的生命周期讲一下
73 |
74 | vue 实例有⼀个完整的⽣命周期,也就是从开始创建、初始化数据、编译模版、挂载Dom -> 渲染、更新 -> 渲染、卸载等⼀系列过程,即vue实例从创建到销毁的过程,我们称这是vue的⽣命周期
75 |
76 | 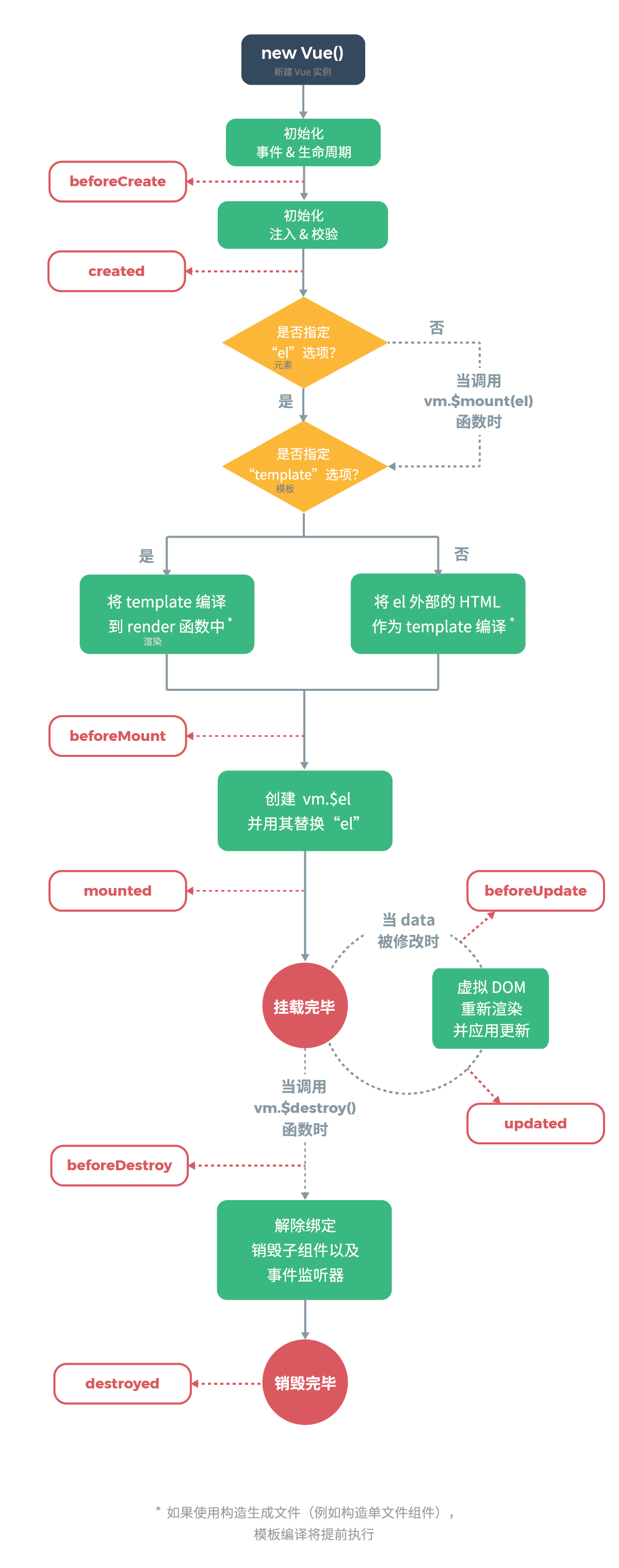
77 |
78 | 1.beforeCreate:完成实例初始化,初始化非响应式变量
79 |
80 | 2.created:实例初始化完成\(未挂载DOM\)
81 |
82 | 3.berofeMount:找到对应的template,并编译成render函数
83 |
84 | 4.mounted:完成创建vm.$el和双向绑定,完成DOM挂载
85 |
86 | 5.beforeUpdate:数据更新之前\(可在更新前访问现有的DOM\)
87 |
88 | 6.updated:完成虚拟DOM的重新渲染和打补丁
89 |
90 | 7.activated:子组件需要在每次加载时候进行某些操作,可以使用activated钩子触发
91 |
92 | 8.deactivated:keep-alive 组件被移除时使用
93 |
94 | 9.beforeDestroy:可做一些删除提示,销毁定时器,解绑全局时间 销毁插件对象
95 |
96 | 10.destroyed:当前组件已被销毁
97 |
98 | ## computed和watch有什么区别
99 |
100 | 当我们要进⾏数值计算,⽽且依赖于其他数据,我们需要使用computed
101 |
102 | 如果你需要在某个数据变化时做⼀些事情,使⽤watch来观察这个数据
103 |
104 | computed:
105 |
106 | * 1.是计算值,
107 | * 2.应用:就是简化tempalte里面计算和处理props或$emit的传值
108 | * 3.具有缓存性,页面重新渲染值不变化,计算属性会立即返回之前的计算结果,而不必再次执行函数
109 |
110 | watch:
111 |
112 | * 1.是观察的动作,
113 | * 2.应用:监听props,$emit或本组件的值执行异步操作
114 | * 3.无缓存性,页面重新渲染时值不变化也会执行
115 |
116 | ## vue指令有哪些,v-if和v-for能不能一起使用
117 |
118 | v-html,v-text,v-show,v-for,v-if v-else-if v-else,
119 |
120 | v-bind(用来动态的绑定一个或者多个特性)
121 |
122 | v-model(创建双向数据绑定)
123 |
124 | v-cloak(保持在元素上直到关联实例结束时进行编译)
125 |
126 | v-pre(用来跳过这个元素和它的子元素编译过程)
127 |
128 | > v-if和v-for能不能一起使用\(或者问v-for和v-if谁的优先级更高\):
129 | >
130 | > v-for指令的优先级要高于v-if,当处于同一节点时候,意味着v-if将分别重复运行于每个 v-for 循环中,所以应该尽量避免v-for和v-if在同一结点
131 |
132 | ## vue中的key值有什么用\(diff算法的过程\)
133 |
134 | vue采用“就地复用”策略,如果数据项的顺序被改变,Vue 将不会移动 DOM 元素来匹配数据项的顺序, 而是简单复用此处每个元素,并且确保它在特定索引下显示已被渲染过的每个元素,key 的作用主要是为了高效的更新虚拟DOM。
135 |
136 | > 虚拟dom的diff算法的过程中,先会进⾏新旧节点的⾸尾交叉对⽐,当⽆法匹配的时候会⽤新节点的 key 与旧节点进⾏⽐对,然后超出差异
137 |
138 | 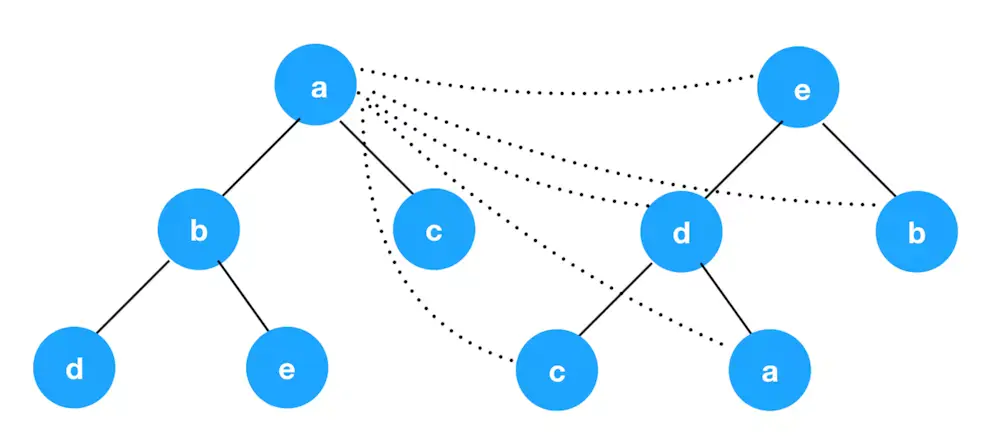
139 |
140 | vue的diff位于patch.js中,这里简单总结一下patchVnode比较的的过程,首先要判断vnode和oldVnode是否都存在,都存在并且vnode和oldVnode是同一节点时,才会进入patchVnode进行比较,结点比较五种情况:
141 |
142 | ① 引用一致,可以认为没有变化
143 |
144 | ② 文本节点的比较,如果需要修改:则会调用Node.textContent = vnode.text
145 |
146 | ③ 两个节点都有子节点,而且它们不一样:则调用updateChildren函数比较子节点
147 |
148 | ④ 只有新的节点有子节点:则调用addVnodes创建子节点
149 |
150 | ⑤ 只有老节点有子节点,则调用removeVnodes把这些子节点都删除
151 |
152 | updateChildren的过程:updateChildren用指针的方式把新旧节点的子节点的首尾节点标记,即oldStartIndex\(1\),oldEndIndex\(2\),newStartIndex\(3\), oldEndIndex\(4\)(这里简单用1 2 3 4顺序标记)即依次比较13,14,23,24,有10种左右情况分别做出对应的处理
153 |
154 | ## vue的路由实现
155 |
156 | 更新视图但不重新请求页面,是前端路由原理的核心,目前在浏览器环境主要有两种方式:
157 |
158 | * Hash 模式
159 |
160 | hash\("\#"\)符号的本来作用是加在URL指示网页中的位置:
161 |
162 | ```markup
163 | http://www.example.com/index.html#print
164 | ```
165 |
166 | `#`本身以及它后面的字符称之为hash,可通过window.location.hash属性读取,hash虽然在url中,但是却不会被包含在http请求中,也不会重新加载页面,它用来指导浏览器动作
167 |
168 | * History 模式
169 |
170 | History interface是浏览器历史记录栈提供的接口,从HTML5开始,History interface提供了2个新的方法:`pushState()`,`replaceState()`使得我们可以对浏览器历史记录栈进行修改;这两个方法有有一个特点,当调用他们修改浏览器历史栈后,虽然当前url改变了,但浏览器不会立即发送请求该url,这就为单页应用前端路由,更新视图但不重新请求页面提供了基础
171 |
172 | ## vue组件间通信的方式
173 |
174 | * props/$emit+v-on
175 |
176 | 父组件通过props的方式向子组件传递数据,而通过$emit 子组件可以向父组件通信
177 |
178 | * eventBus
179 |
180 | 通过eventBus向中心事件发送或者接收事件,所有事件都可以共用事件中心
181 |
182 | * vuex
183 |
184 | 状态管理模式,采用集中式存储管理应用的所有组件的状态,可以通过vuex管理全局的数据
185 |
186 | > 参考:[vue中8种组件通信方式](https://juejin.im/post/5d267dcdf265da1b957081a3) 只需要熟悉上面三种即可,其他基本不会用到,可以做为了解
187 |
188 | ## vue路由懒加载的方式有哪些
189 |
190 | 懒加载简单来说就是延迟加载或按需加载,即在需要的时候的时候进行加载,常用的懒加载方式有三种:即使用vue异步组件 和 ES6中的import,以及webpack的require.ensure\(\)
191 |
192 | * vue异步组件
193 |
194 | ```javascript
195 | // 路由配置,使用vue异步组件
196 | {
197 | path: '/home',
198 | name: 'home',
199 | component: resolve => require(['@/components/home'],resolve)
200 | }
201 | ```
202 |
203 | * ES6中的import
204 |
205 | ```javascript
206 | // 指定了相同的webpackChunkName,合并打包成一个js文件
207 | // 如果不指定,则分开打包
208 | const Home = () => import(/*webpackChunkName:'ImportFuncDemo'*/ '@/components/home')
209 | const Index = () => import(/*webpackChunkName:'ImportFuncDemo'*/ '@/components/index')
210 | ```
211 |
212 | * webpack推出的require.ensure\(\)
213 |
214 | ```javascript
215 | {
216 | path: '/home',
217 | name: 'home',
218 | component: r => require.ensure([], () => r(require('@/components/home')), 'demo')
219 | }
220 | ```
221 |
222 |
--------------------------------------------------------------------------------
/algorithm.md:
--------------------------------------------------------------------------------
1 | ---
2 | description: >-
3 | 算法在前端面试中也有不可忽视的重量,而且不少企业也越来越重视,这一篇只是一些普识性问题,具体到手撕某个问题可能要靠平时空闲多在LeetCode刷题;除了算法问题,可能还会有几个逻辑推理题,具体某个场景根据自己的理解和思路去答即可
4 | ---
5 |
6 | # 算法篇
7 |
8 | ## 时间复杂度分析
9 |
10 | 当问题规模数据大量增加时,重复执行的次数也必定会增加,那么我们就有必要关心执行次数是以什么样的数量级增加,这也是分析时间复杂度的意义,是一个非常重要衡量算法好快的事前估算的方法
11 |
12 | 常见的时间复杂度:
13 |
14 | * O\(1\):常数阶的复杂度,这种复杂度无论数据规模如何增长,计算时间是不变的
15 |
16 | ```javascript
17 | const increment = n => n++
18 | ```
19 |
20 | * O\(n\):线性复杂度,线性增长
21 |
22 | ```javascript
23 | // 最典型的例子就是线性查找
24 | const linearSearch = (arr,target) = {
25 | for (let i = 0;i * 比较相邻元素,如果第一个比第二个大,就交换他们两个
47 | > * 依次走访执行第一步,那么第一趟后,最后的元素应该是最大的数
48 | > * 重复走访,直到排序完成
49 |
50 | ```javascript
51 | const bubbleSort = arr => {
52 | console.time('bubbleSort耗时');
53 | let len = arr.length;
54 | for(let i = 0;iarr[j+1]){
57 | [arr[j],arr[j+1]] = [arr[j+1],arr[j]]
58 | }
59 | }
60 | }
61 | console.timeEnd('bubbleSort耗时');
62 | return arr
63 | }
64 | ```
65 |
66 | 冒泡排序改进方案:
67 |
68 | 方案一:设置一个标记变量pos,用来记录每次走访的最后一次进行交换的位置,那么下次走访之后的序列便可以不再访问
69 |
70 | ```javascript
71 | const bubbleSort_pos = arr => {
72 | console.time('bubbleSort_pos耗时')
73 | let i = arr.length - 1;
74 | while(i > 0){
75 | let pos = 0;
76 | for(var j=0;jarr[j+1]){
78 | pos = j;
79 | [arr[j],arr[j+1]] = [arr[j+1],arr[j]];
80 | }
81 | }
82 | i = pos;
83 | }
84 | console.timeEnd('bubbleSort_pos耗时')
85 | return arr;
86 | }
87 | ```
88 |
89 | 方案二:传统冒泡一趟只能找到一个最大或者最小值,我们可以考虑在利用每趟排序过程中进行正向和反向冒泡,一次可以得到一个最大值和最小值,从而使排序趟数几乎减少一半
90 |
91 | ```javascript
92 | const bubbleSort_ovonic = arr => {
93 | console.time('bubbleSort_ovonic耗时')
94 | let low = 0;
95 | let height = arr.length -1;
96 | let tmp,j;
97 | while(low < height){
98 | for(j=low;j arr[j+1]){
100 | [arr[j],arr[j+1]] = [arr[j+1],arr[j]];
101 | }
102 | }
103 | --height;
104 | for(j=height;j>low;--j){ // 反向冒泡,找到最小值
105 | if(arr[j] < arr[j-1]){
106 | [arr[j-1],arr[j]] = [arr[j],arr[j-1]]
107 | }
108 | }
109 | ++low;
110 | }
111 | console.timeEnd('bubbleSort_ovonic耗时')
112 | return arr;
113 | }
114 | ```
115 |
116 | 以上提供两种改进冒泡的思路,耗时在这只是进行粗略对比,并不完全确定好坏,相比之下改进后的冒泡时间复杂度更低,下图实例展示结果耗时更短
117 |
118 | 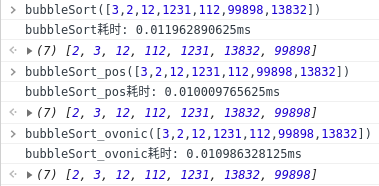
119 |
120 | * 快速排序
121 |
122 | 快速排序是分治策略的经典实现,也是对冒泡排序的改进,出现频率较高,基本思路是经过一趟排序,把数据分割成独立的两部分,其中一部分数据要比另一部分都小,然后按此方法继续排序,以达到整个序列有序,具体算法描述如下:
123 |
124 | > * 从数组中挑出一个元素作为"基准"
125 | > * 分区:所有比基准小的值放前面,而比基准大的值放后面,基准处于数列中间位置
126 | > * 按照此方法依次排序(递归),以达到序列有序
127 |
128 | ```javascript
129 | // 递归方法的其中一种形式
130 | const quickSort = (arr) => {
131 | if(arr.length <= 1){ return arr };
132 | let pivotIndex = Math.floor(arr.length/2);
133 | let pivot = arr.splice(pivotIndex,1)[0]; // 确定基准
134 | let left = [] , right = [];
135 | for(let i = 0;i * 选择一个增量序列t1,t2...tk,其中ti>tj,tk=1
151 | > * 按增量序列个数k,对序列进行k趟排序
152 | > * 每趟排序根据对应的增量ti,将待排序列分割成长度为m的若干子序列,然后分别对各子表进行直接插入排序。仅当增量因子为1时,整个序列作为一个表来处理,表长度即为整个序列的长度
153 |
154 | ```javascript
155 | const shellSort = arr => {
156 | console.time('shellSort耗时')
157 | let len = arr.length,
158 | gap = 1,
159 | temp;
160 | while(gap < len/5){ gap = gap*5+1 } // 动态定义间隔序列
161 | for(gap; gap > 0; gap = Math.floor(gap/5)){
162 | for(let i = gap;i=0&&arr[j]>temp; j-=gap){
165 | arr[j+gap] = arr[j];
166 | }
167 | arr[j+gap] = temp;
168 | }
169 | }
170 | console.timeEnd('shellSort耗时');
171 | return arr;
172 | }
173 | ```
174 |
175 | * 归并排序
176 |
177 | 归并排序不受输入数据的影响,时间复杂度始终都是O\(nlogn\),但代价是需要额外的内存空间。归并排序也是分治法的经典体现,先使子序列有序,再使子序列段间有序,若将两个有序表合并成一个有序表,称为2-路归并。实现如下:
178 |
179 | > * 将长度为n的序列,分成两个长度为n/2的子序列
180 | > * 对这两个子序列分别采用归并排序
181 | > * 将两个排序好的子序列合并成最终排序序列
182 |
183 | ```javascript
184 | const merge = (left,right) => {
185 | let result = [];
186 | while(left.length && right.length){
187 | if(left[0] <= right[0]){
188 | result.push(left.shift());
189 | }else{
190 | result.push(right.shift());
191 | }
192 | }
193 | while(left.length)
194 | result.push(left.shift());
195 |
196 | while(right.length)
197 | result.push(right.shift());
198 |
199 | return result;
200 | }
201 |
202 | const mergeSort = arr => {
203 | let len = arr.length;
204 | if(len < 2) return arr;
205 | let middle = Math.floor(len / 2),
206 | left = arr.slice(0,middle),
207 | right = arr.slice(middle);
208 |
209 | return merge(mergeSort(left),mergeSort(right));
210 | }
211 | ```
212 |
213 | ## 常见的查找算法
214 |
215 | * 线性查找
216 |
217 | 线性查找较简单,只需要简单遍历即可
218 |
219 | ```javascript
220 | const linearSearch = (arr,target) => {
221 | for(let i =0;i 实现思路如下:
235 | >
236 | > * 首先设两个指针,low表示最低索引,height表示最高索引
237 | > * 然后取中间位置索引,判断middle处的值是否是要查找的数字,是则查找结束;比所求值较小就把low设为middle+1,较大则把height设为middle-1
238 | > * 然后到新分区继续查找,直到找到或者low>height找不到要查找的值结束
239 |
240 | ```javascript
241 | const binarySearch = (arr,target) => {
242 | let height = arr.length - 1;
243 | let low = 0;
244 | while(low <= height){
245 | let middle = Math.floor((low+height)/2)
246 | if(target < arr[middle]){
247 | height = middle - 1
248 | }else if(target > arr[middle]){
249 | low = middle + 1
250 | }else{
251 | return middle
252 | }
253 | }
254 | return -1
255 | }
256 | ```
257 |
258 | 时间复杂度分析:最佳情况O\(logn\),最差情况O\(logn\),平均情况O\(logn\)
259 |
260 | > 参考:[damonare](https://github.com/damonare/Sorts)
261 |
262 | ## 二叉树的遍历方式
263 |
264 | 二叉树遍历有四种方式:先序遍历,中序遍历,后序遍历,层序遍历
265 |
266 | 前序遍历:先访问根节点,然后前序遍历左子树,再前序遍历右子树
267 |
268 | 中序遍历:先中序遍历左子树,然后访问根节点,最后遍历右子树
269 |
270 | 后序遍历:从左到右,先叶子后结点的方式遍历访问左子树,最后访问根节点
271 |
272 | 层序遍历:从根结点从上往下逐层遍历,在同一层,按从左到右的顺序对结点逐个访问
273 |
274 | ## 实现二叉树的层序遍历
275 |
276 | 有两种通用的遍历树的策略:
277 |
278 | * 深度优先遍历(DFC)
279 |
280 | 正如名字一样,深度优先遍历采用深度作为优先级,从某个确定的叶子,然后再返回根到另个分支,有细分为先序遍历,中序遍历和后序遍历
281 |
282 | * 广度优先遍历(BFC)
283 |
284 | 广度优先按照高度顺序一层一层访问整棵树,高层次的结点会比低层的结点先访问到
285 |
286 | ```javascript
287 | // 通过迭代方式实现
288 | const levelOrder = function(root) {
289 | const res = [];
290 | const stack = [{ index: 0, node: root }];
291 |
292 | while (stack.length > 0) {
293 | const { index, node } = stack.pop();
294 | if (!node) continue;
295 | res[index] = res[index] ? [...res[index], node.val] : [node.val];
296 | stack.push({ index: index + 1, node: node.right });
297 | stack.push({ index: index + 1, node: node.left });
298 | }
299 | return res;
300 | };
301 | ```
302 |
303 |
--------------------------------------------------------------------------------
/http.md:
--------------------------------------------------------------------------------
1 | ---
2 | description: HTTP/浏览器篇(第一个版本预计总结常见问题15个左右)
3 | ---
4 |
5 | # HTTP/浏览器
6 |
7 | ## 从地址栏输入URL到呈现页面
8 |
9 | 简洁来说过程如下:
10 |
11 | * 1.浏览器向`DNS`服务器请求解析该 URL 中的域名所对应的 `IP` 地址;
12 | * 2.建立`TCP`连接(三次握手);
13 | * 3.浏览器发出读取文件\(`URL` 中域名后面部分对应的文件\)的`HTTP` 请求,该请求报文作为 `TCP` 三次握手的第三个报文的数据发送给服务器;
14 | * 4.服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
15 | * 5.浏览器将该 `html` 文本并显示内容;
16 | * 6.释放 `TCP`连接(四次挥手);
17 |
18 | 浏览器解析渲染过程,见[HTML&CSS](https://github.com/okaychen/FE-Interview-Brochure/blob/master/html-and-css.md#htmlcss)
19 |
20 | ## DNS--解析顺序
21 |
22 | * 解析顺序:按照浏览器缓存,系统缓存,路由器缓存,ISP(运营商)DNS缓存,根域名服务器,顶级域名服务器,主域名服务器逐步读取,直到拿到IP地址
23 | * DNS递归查询和迭代查询:从客户端到本地DNS服务器是属于递归查询,而DNS服务器之间就是的交互查询就是迭代查询
24 |
25 | ## 建立和释放TCP连接的过程,能画一下嘛
26 |
27 | 三次握手:(SYN (同步序列编号)ACK(确认字符))
28 |
29 | * 第一次握手:Client将标志位SYN置为1,随机产生一个值seq=J,并将该数据包发送给Server,Client进入SYN\_SENT状态,等 待Server确认。
30 | * 第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN\_RCVD状态
31 | * 第三次握手:Client收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。
32 |
33 | 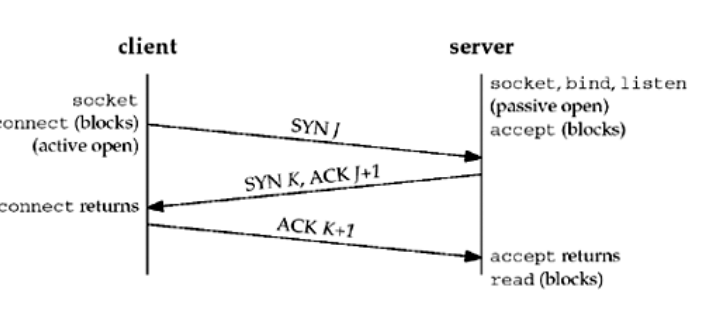
34 |
35 | 四次挥手:
36 |
37 | * 第一次挥手:Client发送一个FIN=M\(释放一个连接\),用来关闭Client到Server的数据传送,Client进入FIN\_WAIT\_1状态。
38 | * 第二次挥手:Server收到FIN后,发送一个ack=M+1给Client,确认序号为收到序号+1\(与SYN相同,一个FIN占用一个序号\),Server进入CLOSE\_WAIT状态。
39 | * 第三次挥手:Server发送一个FIN = N,用来关闭Server到Client的数据传送,Server进入LAST\_ACK状态。
40 | * 第四次挥手:Client收到FIN后,Client进入TIME\_WAIT状态,接着发送一个ACK给Server,确认序号为收到序号ack=N+1,Server进入CLOSED状态,完成四次挥手
41 |
42 | 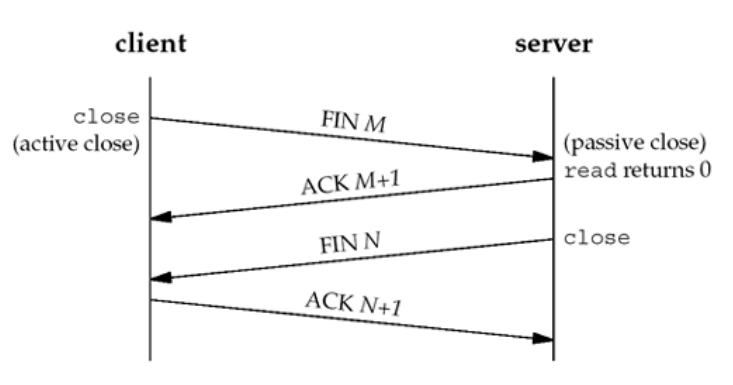
43 |
44 | > 追问:释放连接的过程是四次挥手,相比建立连接过程为什么要多一次?
45 |
46 | 因为服务端收到SYN建连报文后,可以把ACK报文和SYN报文放在一起发送。但是当关闭连接的时候,当对方收到FIN报文通知时,仅仅表示对方已经无数据发送给你了,但未必你已经发送完全部数据,这时就不能马上关闭socket,所以释放连接过程SYN包和ACK包要分开发送。
47 |
48 | ## HTTP方法知道哪些,GET和POST区别有哪些
49 |
50 | HTTP1.0定义了三种请求方法,GET,POST和HEAD方法 HTTP1.1新增六种请求方法:OPTIONS,PUT,PATCH,DELETE,TRACH和CONNECT
51 |
52 | GET和POST区别主要从三方面讲即可:表现形式,传输数据大小,安全性
53 |
54 | 首先表现形式上:GET请求的数据会附加在URL后面,以?分割多参数用&连接,由于URL采用ASCII编码,所以非ASCII字符会先编码在传输,可缓存;POST请求会把请求的数据放在请求体中,不可缓存
55 |
56 | 传输数据大小:对于GET请求,HTTP规范没有对URL长度进行限制,但是不同浏览器对URL长度加以限制,所以GET请求时,传输数据会受到URL长度的限制;POST不是URL传值,理论上无限制,但各个服务器一般会对POST传输数据大小进行限制
57 |
58 | 安全性:相比URL传值,POST利用请求体传值安全性更高
59 |
60 | > PS:还有一种GET产生一个数据包,POST产生两个数据包的说法可答可不答,并不是所有浏览器如此,铺展开解释来说就是:对GET请求,浏览器会把请求头和data一起发送,服务器响应200(返回数据),对于POST请求,浏览器会先发送header,服务器响应100后继续,浏览器再发送data,服务器响应200
61 |
62 | ## HTTP的缓存过程(强缓存和协商缓存)
63 |
64 | 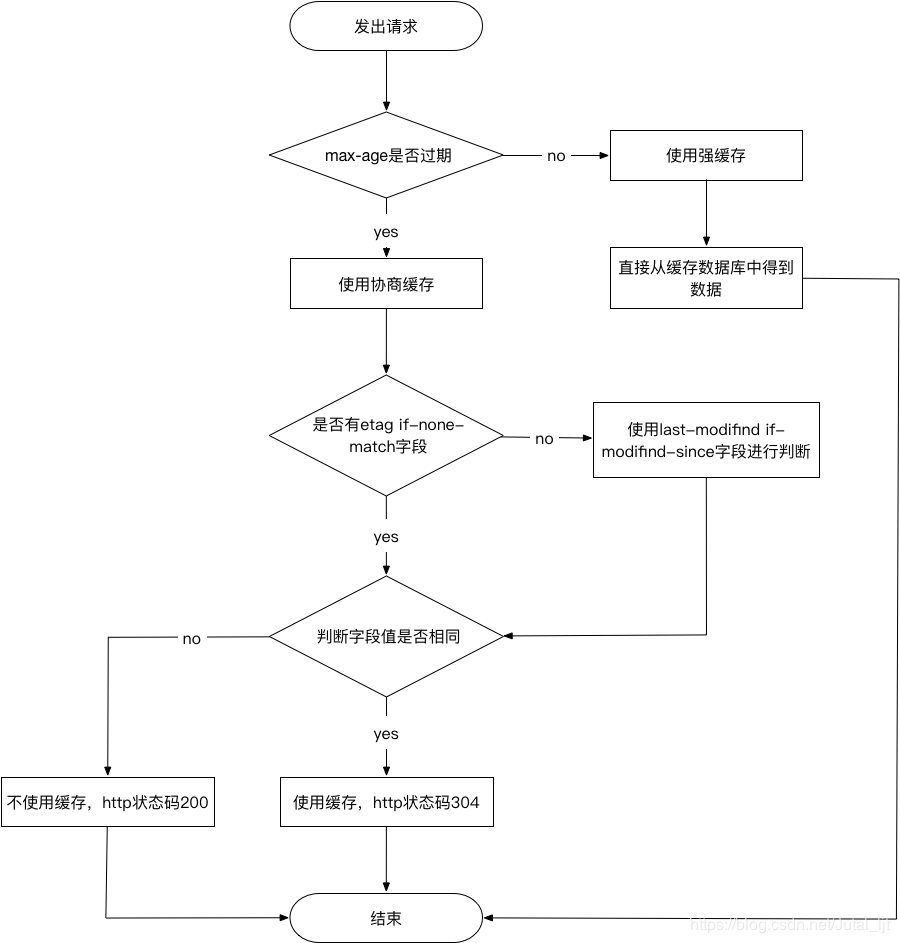
65 |
66 | 通常过程如下:
67 |
68 | * 判断是否过期(服务器会通知浏览器一个缓存时间,相关头部信息在Cache-Control和Expires中),如果时间未过期,则直接从缓存中取,即强缓存;
69 | * Cache-Control
70 | * 其中`max-age = `设置缓存存储的最大周期,超过这个时间缓存将会被认为过期,与Expires相反,时间是相对于请求的时间
71 | * public 表示响应可以被任何对象缓存,即使是通常不可缓存的内容
72 | * private 表示缓存只能被单个用户缓存,不能作为共享缓存(即代理服务器不可缓存它)
73 | * no-cache 告诉浏览器、缓存服务器,不管本地副本是否过期,使用副本前一定要到源服务器进行副本有效校验
74 | * no-store 缓存不应该存储有关客户端请求或服务器响应的任何内容
75 | * Expires
76 | * expires 字段规定了缓存的资源的过期时间,该字段时间格式使用GMT时间标准时间格式, js通过`new Date().toUTCString()`得到,由于时间期限是由服务器生成,存在着服务端和客户端的时间误差,相比cache-control优先级较低
77 |
78 | > 注:cache-control和expires谁的优先级更高也是校招面试中常问的问题(腾讯一面被问过)
79 |
80 | * 那么如果判断缓存时间已经过期,将会采用协商缓存策略
81 | * Last-Modified响应头和If-Modified-Since请求头
82 | * Last-Modified 表示资源最后的修改时间,在浏览器第一次发送HTTP请求时,服务器会返回该响应头
83 | * 那么浏览器在下次发起HTTP请求时,会带上If-Modified-Since请求头,其值就是第一次发送HTTP请求时,服务器设置在Last-Modified响应头中的值
84 | * 两种情况:如果资源最后修改时间大于If-Modified-Since,说明资源有被改动过,则响应完整的资源内容,返回状态码200;如果小于或者等于,说明资源未被修改,则响应状态码304,告知浏览器可以继续使用所保存的缓存
85 | * Etag响应头和If-None-Match请求头
86 | * Etag值为当前资源在服务器的唯一标识
87 | * 类比上面Last-Modified响应头和If-Modified-Since请求头,请求头中If-None-Match将会和资源的唯一标标识进行对比,如果不同,则说明资源被修改过,响应200;如果相同,则说明资源未改动,响应304
88 |
89 | ## 对HTTP报文结构的了解
90 |
91 | HTTP报文结构由报文首部,空行,报文主体三部分组成
92 |
93 | | 报文首部 |
94 | | :---: |
95 | | **空行** |
96 | | **报文主体** |
97 |
98 | 而HTTP报文首部则是由首部字段名和字段值键值对形式构成,如`Content-Type:text/html`
99 |
100 | HTTP首部字段通常分为4种类型:通用首部,请求首部,响应首部,实体首部
101 |
102 | * HTTP请求报文,一个HTTP请求报文由请求行(request line)、请求头部(request header)、空行和请求数据4个部分构成。**请求行**数据格式由三个部分组成:请求方法、URI、HTTP协议版本,他们之间用空格分隔
103 |
104 | ```javascript
105 | GET /index.html HTTP/1.1
106 | ```
107 |
108 | 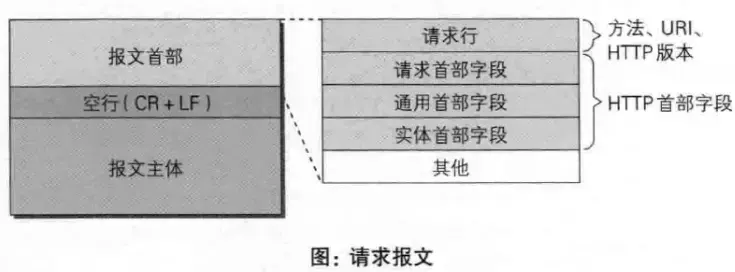
109 |
110 | * HTTP响应报文,一个HTTP响应报文由状态行(HTTP版本、状态码)、响应头部、空行和响应体4个部分构成。**状态行**主要给出响应HTTP协议的版本号、响应返回状态码、响应描述,同样是单行显示
111 |
112 | ```javascript
113 | HTTP/1.1 200 OK
114 | ```
115 |
116 | 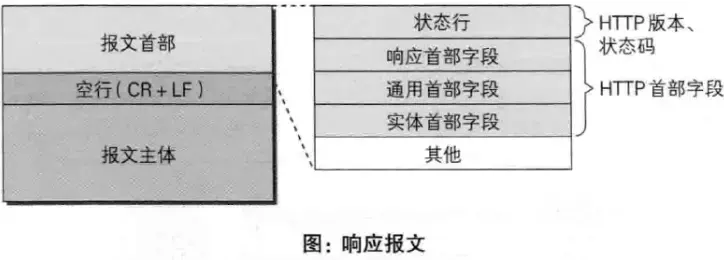
117 |
118 | ## HTTP的状态码,301和302的区别
119 |
120 | 状态码告知从服务器返回请求的状态,一般由以1~5开头的三位整数组成,
121 |
122 | 1xx:请求正在处理
123 |
124 | 2xx:成功
125 |
126 | 3xx:重定向
127 |
128 | * 301 moved permanently,永久性重定向,表示资源已被分配了新的 URL
129 | * 302 found,临时性重定向,表示资源临时被分配了新的 URL
130 | * 303 see other,表示资源存在着另⼀个 URL,应使⽤ GET ⽅法定向获取资源
131 | * 304 not modified,表示服务器允许访问资源,但因发生请求未满足条件的情况
132 | * 307 temporary redirect,临时重定向,和302含义相同
133 |
134 | 4xx:客户端错误
135 |
136 | * 400 bad request,请求报文存在语法错误
137 | * 401 unauthorized,表示发送的请求需要有通过HTTP认证的认证信息
138 | * 403 forbidden,表示对请求资源的访问被服务器拒绝
139 | * 404 not found,表示服务器上没找到请求的资源
140 | * 408 Request timeout,客户端请求超市
141 | * 409 confict,请求的资源可能引起冲突
142 |
143 | 5xx:服务器错误
144 |
145 | * 500 internal server error,表示服务器端在执行请求时发生了错误
146 | * 501 Not Implemented,请求超出服务器能力范围
147 | * 503 service unavailable,表示服务器暂时处于超负载或正在停机维护,无法处理
148 | * 505 http version not supported,服务器不支持,或者拒绝支持在请求中的使用的HTTP版本
149 |
150 | 同样是重定向,302是HTTP1.0的状态码,在HTTP1.1版本的时候为了细化302又分出来了303和307,303则明确表示客户端应采用get方法获取资源,他会把post请求变成get请求进行重定向;307则会遵照浏览器标准,不会改变post
151 |
152 | ## HTTP建立持久连接的意义
153 |
154 | HTTP持久连接也称作HTTP keep-alive,使用同一个TCP连接发送和接收多个HTTP请求,是HTTP1.1的新特性,HTTP1.1默认所有连接都是持久连接。在HTTP1.0,使用非持久连接,每个TCP连接只用于传输一个请求和响应,没有官方的keepalive操作,如果浏览器支持通常在请求和响应头中加上`Connection: Keep-Alive`
155 |
156 | 那么由于同时打开的TCP连接减少,可以减少内存和CPU的占用;其次之后也无需再次握手,也减少了后续请求的延迟
157 |
158 | ## HTTP1.1相比1.0的区别有哪些
159 |
160 | 目前通用标准是HTTP1.1,在1.0的基础上升级加了部分功能,主要从连接方式,缓存,带宽优化(断点传输),host头域,错误提示等方面做了改进和优化
161 |
162 | * 连接方式:HTTP1.0使用短连接(非持久连接);HTTP1.1默认采用带流水线的长连接(持久连接),PS:在持久连接的基础上可选的是管道化的连接
163 | * 缓存:HTTP1.1新增例如ETag,If-None-Match,Cache-Control等更多的缓存控制策略
164 | * 带宽优化:HTTP1.0在断连后不得不下载完整的包,存在一些带宽浪费的现象;HTTP1.1则支持断点续传的功能,在请求消息中加入range 头域,允许请求资源的某个部分,在响应消息中Content-Range头域中声明了返回这部分对象的偏移值和长度
165 | * host头域:在HTTP1.0中每台服务器都绑定一个唯一的ip地址,所有传递消息中的URL并没有传递主机名;HTTP1.1请求和响应消息都应支持host头域,且请求消息中没有host头域名会抛出一个错误(400 Bad Request)
166 | * 错误提示:HTTP1.1新增24个状态响应码,比如409(请求的资源与资源当前状态冲突),410(服务器上某个资源被永久性删除);相比HTTP1.0只定义了16个状态响应码
167 |
168 | ## HTTP2相比HTTP1的优势和特点
169 |
170 | HTTP2相比HTTP1.x有4大特点,二进制分帧,头部压缩,服务端推送和多路复用
171 |
172 | ①二进制分帧:HTTP2使用二进制格式传输数据,而HTTP1.x使用文本格式,二进制协议解析更高效
173 |
174 | ②头部压缩:HTTP1.x每次请求和发送都携带不常改变的,冗杂的头部数据,给网络带来额外负担;而HTTP2在客户端和服务器使用"部首表"来追踪和存储之前发送的键值对,对于相同的数据,不再每次通过每次请求和响应发送
175 |
176 | > 可以简单理解为只发送差异数据,而不是发送全部头部,从而减少头部信息量)
177 |
178 | ③服务端推送:服务端可以在发送页面HTML时主动推送其他资源,而不用等到浏览器解析到相应位置时,发起请求再响应
179 |
180 | ④多路复用:在HTTP1.x中如果想并发多个请求,需要多个TCP连接,并且浏览器为了控制资源,一般对单个域名有6-8个TCP连接数量的限制;而在HTTP2中
181 |
182 | * 同个域名所有通信都在单个连接下进行
183 | * 单个连接可以承载任意数量的双向数据流
184 | * 数据流以消息的形式发送,而消息又由一个或多个帧组成,多个帧之间可以乱序发送
185 |
186 | ## HTTPS相比HTTP的区别,讲一下HTTPS的实现过程
187 |
188 | https相比之下是安全版的http,其实就是HTTP over TSL,因为http都是使用明文传输的,对于敏感信息的传输就很不安全,https正是为了解决http存在的安全隐患而出现的
189 |
190 | https的实现也是一个较复杂的过程,将对称加密的密钥使⽤⾮对称加密的公钥进⾏加密,在保证了通信效率的同时防止窃听,同时结合CA证书以及数字签名来最大程度保证安全性:
191 |
192 | * 对称加密:通信双方都使用用一个密钥进行加密解密,比如特工接头的暗号,就属于对称加密;这种方式虽然简单性能好,但是无法解决首次把密钥发给对方的问题,容易被黑客拦截密钥
193 | * 非对称加密:由私钥+公钥组成的密钥对
194 | * 即用私钥加密的数据,只要公钥才能解密;用公钥加密的数据,只有私钥才能解密
195 | * 通信双方都有自己的一套密钥对,通信前将自己的公钥发给对方
196 | * 然后拿着这个公钥来加密数据响应给对方,等对方收到之后,再用自己的私钥进行解密
197 |
198 | 非对称加密虽然安全性更高,但是带来的问题就是速度较慢,影响性能
199 |
200 | 结合两种方式,将对称加密的密钥使用非对称加密的公钥进行加密,然后再发送出去,然后接收方使用自己的私钥进行解密得到对称加密的密钥
201 |
202 | > 但是又带来一个问题,即中间人问题:
203 | >
204 | > 如果此时在客户端和服务端之间存在一个中间人,这个中间人只需要把原本双方通信互发的公钥,换成自己的公钥,这样中间人就可以轻松解密通信双方所发送的数据
205 |
206 | 这时候就需要一个安全的第三方的颁布证书,来证明身份,防止中间攻击:所以就有了CA证书,仔细观察浏览器地址栏,会有一个"小锁"的标志,点开里面有证明身份的CA证书信息
207 |
208 | 
209 |
210 | > 但是仍然存在的一个问题是,如果中间人篡改了CA证书,那么这个证书不就无效了?所以就添加了新的保护方案:数字签名
211 |
212 | 数字签名就是用证书自带的HASH算法对证书内容进行一个HASH得到一个摘要,再用CA的私钥进行加密,最终组成数字签名
213 |
214 | > 当别人把他的证书发过来时,用同样的HASH算法得到信息摘要,然后再用CA的公钥对数字签名进行解密,得到CA创建的消息摘要,两者一对比就知道中间有没有被篡改了
215 |
216 | 通过这样的方式,https最大化保证了通信的安全性
217 |
218 | ## 对Websocket的了解,应用场景,对比HTTP
219 |
220 | Websocket和HTTP都是基于TCP协议两个不同的协议
221 |
222 | 首先Websocket是一种在单个TCP连接上进行全双工通信的协议,允许服务端主动向客户端推送数据(只需要一次握手,两者之间创建持久化连接,可进行双向数据传输);而HTTP则需要定时轮询向服务器请求,然后服务器再向客户端发送数据
223 |
224 | 其次,HTTP是一个无状态协议,缺少状态意味着后续处理需要先前数据必须重传;而Websocket需要先创建连接,这就使得其成为一种有状态的协议,之后通信时可以省略部分状态信息
225 |
226 | 应用场景:如果应用是多个用户相互交流,或者展示服务端经常变动的数据都可以考虑websocket;所以体育实况,多媒体聊天等这些都是Websocket不错的应用场景
227 |
228 | ## TCP和UDP区别有哪些
229 |
230 | | | TCP | UDP |
231 | | :---: | :---: | :---: |
232 | | 是否连接 | 面向连接 | 面向非连接 |
233 | | 传输可靠性 | 可靠 | 不可靠 |
234 | | 应用场景 | 少量数据 | 传输大量数据 |
235 | | 速度 | 慢 | 快 |
236 |
237 | * TCP是面向连接的;UDP则是无连接的,即发送数据之前不需要建立连接
238 | * TCP提供的可靠的服务,即TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;而UDP尽最大努力,不保证可靠交付
239 | * TCP面向字节流,TCP把数据看成一连串无结构的字节流;UDP是面向报文的
240 | * 每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
241 | * TCP首部开销较大,20字节;UDP只有8字节
242 | * TCP的逻辑通信信道是全双工的可靠信道;而UDP则是不可靠信道
243 |
244 | ## 前端性能优化的方案有哪些
245 |
246 | 前端性能优化七大常用的优化手段:减少请求数量,减小资源大小,优化网络连接,优化资源加载,减少回流重绘,使用更好性能的API和构建优化
247 |
248 | * 减少请求数量
249 | * 文件合并,并按需分配(公共库合并,其他页面组件按需分配)
250 | * 图片处理:使用雪碧图,将图片转码base64内嵌到HTML中,使用字体图片代替图片
251 | * 减少重定向:尽量避免使用重定向,当页面发生了重定向,就会延迟整个HTML文档的传输
252 | * 使用缓存:即利用浏览器的强缓存和协商缓存
253 | * 不使用CSS @import:CSS的@import会造成额外的请求
254 | * 避免使用空的src和href:a标签设置空的href,会重定向到当前的页面地址,form设置空的method,会提交表单到当前的页面地址
255 | * 减小资源大小
256 | * 压缩:静态资源删除无效冗余代码并压缩
257 | * webp:更小体积
258 | * 开启gzip:HTTP协议上的GZIP编码是一种用来改进WEB应用程序性能的技术
259 | * 优化网络连接
260 |
261 | * 使用CDN
262 | * 使用DNS预解析:DNS Prefetch,即DNS预解析就是根据浏览器定义的规则,提前解析之后可能会用到的域名,使解析结果缓存到`系统缓存`中,缩短DNS解析时间,来提高网站的访问速度
263 |
264 | ```javascript
265 | // 方法是在 head 标签里面写上几个 link 标签
266 |
267 |
268 | ```
269 |
270 | * 并行连接:由于在HTTP1.1协议下,chrome每个域名最大并发数是6个。使用多个域名,可以增加并发数
271 | * 管道化连接:在HTTP2协议中,可以开启管道化连接,即单条连接的多路复用
272 |
273 | * 优化资源加载
274 | * 减少重绘回流
275 | * 使用性能更好的API
276 | * 构建优化:如webpack优化
277 |
278 | > 参考:[前端性能优化的七大手段](https://www.cnblogs.com/xiaohuochai/p/9178390.html>)
279 |
280 |
--------------------------------------------------------------------------------
/html-and-css.md:
--------------------------------------------------------------------------------
1 | ---
2 | description: >-
3 | HTML&CSS篇(第一个版本该篇预计总结常见问题20个左右),HTML&CSS不少问题都能体现应届生对于前端基础的掌握程度,是应届生求职时不可忽视的重要一环
4 | ---
5 |
6 | # HTML/CSS
7 |
8 | ## 浏览器解析渲染页面过程
9 |
10 | 大致过程:
11 |
12 | HTML解析构建DOM->CSS解析构建CSSOM树->根据DOM树和CSSOM树构建render树->根据render树进行布局渲染render layer->根据计算的布局信息进行绘制
13 |
14 | 不同浏览器的内核不同,所以渲染过程其中有部分细节有不一样,以webkit主流程为例:
15 |
16 | 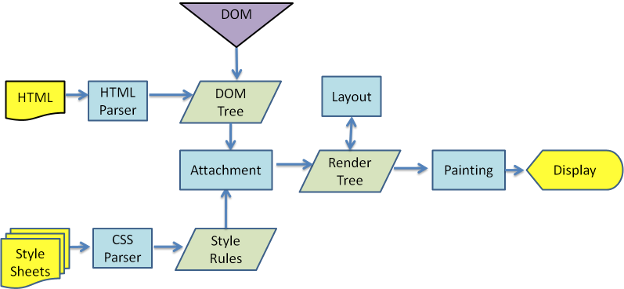
17 |
18 | 一篇很棒的文章\(需科学上网\):[How Browser Work](https://www.html5rocks.com/en/tutorials/internals/howbrowserswork/)
19 |
20 | > 编者有话说:浏览器解析渲染页面过程是一个复杂的过程,其中有不少的细节和规则,如果把上面分享的文章翻译成译文,至少有3~5页PDF左右,所以这里只能总结大致过程(作为面试回答【很可能让回答的尽可能详细】了解来说已经足够,更深入的了解可以好好读下上面那篇文章)
21 |
22 | 较详细过程:
23 |
24 | HTML解析构建DOM树:其中HTML Parser就起到了将HTML标记解析成DOM Tree的作用,HTML Parser将文本的HTML文档,提炼出关键信息,嵌套层级的树形结构,便于计算拓展;这其中也有很多的规则和操作,比如容错机制,识别特殊标签`
61 | ```
62 |
63 | ## csrf简单介绍一下
64 |
65 | CSRF(Cross-site request forgery)跨站请求伪造:攻击者诱导受害者进⼊第三⽅⽹站,在第三⽅⽹站中,向被攻击⽹站发送跨站请求。利⽤受害者在被攻击⽹站已经获取的注册凭证,绕过后台的⽤户验证,达到冒充⽤户对被攻击的⽹站执⾏某项操作的⽬的,
66 |
67 | 常规的过程如下:
68 |
69 | 1. 用户打开浏览器,访问受信任网站A,输入用户名和密码请求登录网站A
70 | 2. 在用户信息通过验证后,网站A产生Cookie信息并返回给浏览器
71 | 3. 未退出网站A之前,在同一浏览器中,攻击者引诱用户进入网站B
72 | 4. 网站B接收到用户请求后,返回一些攻击性代码,并发出一个请求要求访问第三方站点A
73 | 5. 浏览器在接收到这些攻击性代码后,根据网站B的请求,在用户不知情的情况下携带Cookie信息,向网站A发出请求。网站A根据用户的Cookie信息以及用户的权限处理该请求,导致来自网站B的恶意代码被执行
74 |
75 | ## 如何预防csrf攻击
76 |
77 | CSRF通常从第三⽅⽹站发起,被攻击的⽹站⽆法防⽌攻击发⽣,只能通过增强⾃⼰⽹站针对CSRF的防护能⼒来提升安全性
78 |
79 | CSRF有两个特点:
80 |
81 | * 通常发生在第三方域名
82 | * 攻击者不能获取到cookie等信息,只是使用
83 |
84 | 针对这两点,我们可以制定专门的防护策略:
85 |
86 | * 阻止不明外域的访问
87 | * 同源检测
88 | * Samesite Cookie
89 | * 提交时要求附加文本域验证身份才可以获取信息
90 | * CSRF Token
91 | * 双重cookie验证
92 |
93 | ### 同源检测
94 |
95 | 通过使用Orgin Header确定来源域名:在部分与CSRF有关的请求中,请求的Header中会携带Origin字段,如果Origin存在,那么直接使⽤Origin中的字段确认来源域名就可以
96 |
97 | 使用Referer Header确定域名来源:根据HTTP协议,HTTP头中有一个字段叫Referer,记录了该HTTP请求的来源地址
98 |
99 | ### Samesite Cookie属性
100 |
101 | Google起草了⼀份草案来改进HTTP协议,那就是为Set-Cookie响应头新增Samesite属性,它⽤来标明这个 Cookie是个“同站 Cookie”,同站Cookie只能作为第⼀⽅Cookie,不能作为第三⽅Cookie,Samesite 有两个属性值:
102 |
103 | * Samesite=Strict: 这种称为严格模式,表明这个 Cookie 在任何情况下都不可能作为第三⽅ Cookie
104 | * Samesite=Lax: 这种称为宽松模式,⽐ Strict 放宽了点限制,假如这个请求是这种请求且同时是个GET请求,则这个Cookie可以作为第三⽅Cookie
105 |
106 | ### CSRF Token
107 |
108 | 通过csrf token验证请求的身份,是够携带正确的token,来区分正常的请求和攻击的请求
109 |
110 | CSRF Token的防护策略分为三个步骤:
111 |
112 | * 将CSRF Token输出到⻚⾯中
113 | * ⻚⾯提交的请求携带这个Token
114 | * 服务器验证Token是否
115 |
116 | ### 双重cookie验证
117 |
118 | 利⽤CSRF攻击不能获取到⽤户Cookie的特点,我们可以要求Ajax和表单请求携带⼀个Cookie中的值
119 |
120 | 双重Cookie采⽤以下流程:
121 |
122 | * 在⽤户访问⽹站⻚⾯时,向请求域名注⼊⼀个Cookie,内容为随机字符串
123 | * 在前端向后端发起请求时,取出Cookie,并添加到URL的参数中
124 | * 后端接⼝验证Cookie中的字段与URL参数中的字段是否⼀致,不⼀致则拒
125 |
126 | ## 网络劫持有哪几种
127 |
128 | 网络劫持一般分为两种:HTTP劫持和DNS劫持
129 |
130 | DNS劫持
131 |
132 | * DNS强制解析:通过修改运营商的本地DNS记录,来引导⽤户流量到缓存服务器
133 | * 302跳转的⽅式:通过监控⽹络出⼝的流量,分析判断哪些内容是可以进⾏劫持处理的,再对劫持的内存发起跳转的回复,引导⽤户获取内容
134 |
135 | HTTP劫持: 由于http明⽂传输,运营商会修改你的http响应内容\(即加⼴告\)
136 |
137 | DNS劫持由于涉嫌违法,已经被监管;针对HTTP劫持,最有效的办法就是全站HTTPS,将HTTP加密,这使得运营商⽆法获取明⽂,就⽆法劫持你的响应内容
138 |
139 | ## 中间人攻击的了解
140 |
141 | 中间人\(Man-in-the-middle attack, MITM\)是指攻击者和通讯的两端分别创建独立的联系,并交换其得到的数据,攻击者可以拦截通信双方的通话并插入新的内容
142 |
143 | 一般的过程如下:
144 |
145 | * 客户端发送请求到服务端,请求被中间⼈截获
146 | * 服务器向客户端发送公钥
147 | * 中间⼈截获公钥,保留在⾃⼰⼿上。然后⾃⼰⽣成⼀个【伪造的】公钥,发给客户端
148 | * 客户端收到伪造的公钥后,⽣成加密hash值发给服务器
149 | * 中间⼈获得加密hash值,⽤⾃⼰的私钥解密获得真秘钥,同时⽣成假的加密hash值,发给服务器
150 | * 服务器⽤私钥解密获得假密钥,然后加密数据传输给客户端
151 |
152 | > 推荐:[HTTPS中间人攻击实践](https://www.cnblogs.com/lulianqi/p/10558719.html)
153 |
154 |
--------------------------------------------------------------------------------
/source.md:
--------------------------------------------------------------------------------
1 | # 资源合集
2 |
3 | 小册高频面试题题部分到这告别一段尾声了,平时学习过程我们在不断接触一些学习资源,2019年转眼过去,下面是我大学三年前端学习过程收录的一些资源,不能说能面面俱到,但多数都是我有过接触并且得到业界认可的资源,这里做整理和分享,算是20年新年礼物给大家,希望对我和大家都有所帮助,这也是一点小小的愿望
4 |
5 | * 资源教程&官方文档
6 |
7 | | 资源教程 | 官方文档 |
8 | | :--- | :--- |
9 | | [MDN Web 文档](https://developer.mozilla.org/zh-CN/) | [TypeScript中文网](https://www.tslang.cn/docs/home.html) |
10 | | [w3school在线教程](https://www.w3school.com.cn/) | [vue生态系统](https://cn.vuejs.org/v2/guide/) |
11 | | [w3cschool](https://www.w3cschool.cn/) | [react文档](https://react.docschina.org/docs/getting-started.html) |
12 | | [菜鸟教程](https://www.w3cschool.cn/) | [webpack文档](https://webpack.docschina.org/concepts/) |
13 | | [印记中文](https://www.docschina.org/) | [node中文网](http://nodejs.cn/api/) |
14 | | [大前端](http://www.daqianduan.com/) | |
15 | | [html5tricks](https://www.html5tricks.com/) | |
16 | | [ES6入门教程](http://es6.ruanyifeng.com/) | [koajs文档](https://koa.bootcss.com/#introduction) |
17 | | [w3cpuls前端网](https://www.w3cplus.com/) | [express参考手册](http://www.expressjs.com.cn/4x/api.html) |
18 | | [WebPlatform](https://webplatform.github.io/docs/Main_Page/index.html) | [微信小程序文档](https://developers.weixin.qq.com/miniprogram/dev/framework/) |
19 | | [前端开发者手册](https://dwqs.gitbooks.io/frontenddevhandbook/content/) | [Mongodb教程](https://www.mongodb.org.cn/tutorial/) |
20 | | [JavaScript标准参考教程](http://javascript.ruanyifeng.com/#toc0) | [Mongoose 5.0文档](http://www.mongoosejs.net/) |
21 |
22 | * 开发社区&工具资源
23 |
24 | | 开发社区 | 工具资源 |
25 | | :--- | :--- |
26 | | [掘金](https://juejin.im/timeline) | [typora (markdown编辑器)](https://www.typora.io/) |
27 | | [v2ex](https://www.v2ex.com/) | [ProcessOn (在线作图)](https://www.processon.com/) |
28 | | [jsTips](http://www.jstips.co/) | [FeHeler (chrome插件,功能强大)](https://www.baidufe.com/fehelper/index/index.html) |
29 | | [Github](https://github.com/) | [Fiddler (抓包调试工具)](https://www.telerik.com/fiddler) |
30 | | [CNode](https://cnodejs.org/) | [CodePon (在线代码测试工具)](https://codepen.io/) |
31 | | | [智图 (图片在线压缩,制作webp)](https://zhitu.isux.us/) |
32 | | | [JSRun (在线代码编辑器)](http://jsrun.pro/) |
33 | | [infoQ](https://www.infoq.cn/) | [Icomoon (字体图标制作)](https://icomoon.io/) |
34 | | [segmentfault](https://segmentfault.com/) | [Iconfont (阿里矢量图库)](https://www.iconfont.cn/) |
35 | | [stackoverflow](https://stackoverflow.com/) | [墨刀 (产品设计)](https://modao.cc/) |
36 | | [smashingmagazine](https://www.smashingmagazine.com/) | [颜色搭配表](http://rainyin.com/307.html) |
37 | | [开发者头条](https://toutiao.io/posts/hot/7) | [草料二维码](https://cli.im/) |
38 | | [前端乱炖](http://www.html-js.com/) | [Github emoji](https://emoji.muan.co/) |
39 | | [中文开源社区](https://www.oschina.net/) | [Github shields](https://shields.io/) |
40 |
41 | * 博客推荐
42 |
43 | 国内以及国外开源团队:[open\_source\_team](https://github.com/niezhiyang/open_source_team)
44 |
45 | | 团队博客 | 大牛博客 |
46 | | :--- | :--- |
47 | | [淘宝FED](https://fed.taobao.org/) | [阮一峰](http://www.ruanyifeng.com/home.html) |
48 | | [百度FEX](http://fex.baidu.com/) | [张鑫旭](https://www.zhangxinxu.com/) |
49 | | [百度FEE](https://efe.baidu.com/) | [十年踪迹](https://www.h5jun.com/archives/)\(月影\) |
50 | | [腾讯AlloyTeam](http://www.alloyteam.com/) | [叶小钗](https://www.cnblogs.com/yexiaochai/) |
51 | | [腾讯IMWEB](https://imweb.io/) | [司徒正美](https://www.cnblogs.com/rubylouvre/) |
52 | | [360奇舞团](https://75.team/) | [廖雪峰](https://www.liaoxuefeng.com/) |
53 | | [京东JDC](https://jdc.jd.com/) | [chokCoco](https://www.cnblogs.com/coco1s/) |
54 | | [京东凹凸实验室](https://aotu.io/) | [汤姆大叔](https://www.cnblogs.com/TomXu/) |
55 | | [美团技术团队](https://tech.meituan.com/) | [勾三股四](https://jiongks.name/archives/) |
56 | | [饿了吗前端](https://zhuanlan.zhihu.com/ElemeFE) | [JerryQu](https://imququ.com/post/series.html) |
57 | | [有赞技术团队](https://tech.youzan.com/) | [当耐特](https://www.cnblogs.com/iamzhanglei/) |
58 | | [携程UED](http://ued.ctrip.com/) | [胖洪宇](https://jspang.com/) |
59 |
60 | 篇幅有限,不能一一列出对我技术成长有帮助的这些团队和大牛的博客,感谢这些技术大牛让我多少改变对写作的看法,更加坚持这件事,我希望我也能带着学习的视角坚持写作\(或技术或生活\),于后来之人留下哪怕很细微的帮助,到这里这份简简单单的面试小册第一版就结束了,新年新愿望,也祝福大家在新的一年里学业有成,事业顺利
61 |
62 | 那么,最后为了突出主题呢,还是要写一些对于这份小册的愿景吧:如果你是应届生\(当然,大牛除外\),正面临找前端开发的工作,或者即将成为毕业生的预备生,我相信这份前端面试小册多多少少会帮到你,在这"不景气"的"寒冬"之季,我们仍要提高自身综合素质,坚持技术生活,通过不断给自己设立小目标并实现来督促自身学习提高,2020愿我们只争朝夕不负韶华
63 |
64 |
--------------------------------------------------------------------------------
/webpack.md:
--------------------------------------------------------------------------------
1 | ---
2 | description: webpack是事实上的前端打包标准,使用较广泛,相比其他打包工具webpack更是面试中的热点
3 | ---
4 |
5 | # 构建工具篇
6 |
7 | ## 用的webpack3还是版本4,知道有哪些改进嘛
8 |
9 | webpack4是18年8月25号发布的,相比webpack3主要以下大改动:
10 |
11 | * node环境升级,不再支持node4.0及之前版本,最低node版本6.11.5
12 | * 配置增加了`mode:production/development/none`,必须指定其中一个,在不同的mode下开启了一些默认的优化手段;
13 | * 不再需要某些plugin,改为在对应生产或者开发模式下默认打开
14 |
15 | > 详细改进:[webpack Release v4.0.0](https://github.com/webpack/webpack/releases/tag/v4.0.0-beta.0?utm_source=aotu_io&utm_medium=liteo2_web)
16 |
17 | ## loader和plugin的不同
18 |
19 | * loader能让webpack处理不同的文件,然后对文件进行一些处理,编译,压缩等,最终一起打包到指定文件中(比如loader可以将sass,less文件写法转换成css,而不需要在使用其他转换工具),loader本身是一个函数,接收源文件作为参数,返回转换的结果
20 |
21 | ```javascript
22 | // build/webpack.base.conf.js
23 | module: {
24 | rules: [
25 | {
26 | test: /\.vue$/,
27 | loader: 'vue-loader',
28 | options: vueLoaderConfig
29 | },
30 | ]
31 | },
32 | ```
33 |
34 | * plugins则用于执行广泛的任务,从打包,优化,压缩,一直到重新定义环境中的变量,接口很强大,主要用来扩展webpack的功能,可以实现loader不能实现的更复杂的功能
35 |
36 | ```javascript
37 | // build/webpack.prod.conf.js
38 | plugins: [
39 | new webpack.DefinePlugin({
40 | 'process.env': env
41 | }),
42 | new UglifyJsPlugin({
43 | uglifyOptions: {
44 | compress: {
45 | warnings: false
46 | }
47 | },
48 | sourceMap: config.build.productionSourceMap,
49 | parallel: true
50 | }),
51 | ]
52 | ```
53 |
54 | ## 有手动编写过loader和plugin,说一下思路
55 |
56 | loader能把源文件经过转化后输出新的结果,一个loader遵循单一职责原则,只完成一种转换,然后链式的顺序去依次经过多个loader转换,直到得到最终结果并返回,所以在写loader时要保持其职责的单一性,同时webpack还提供了一些API供loader调用
57 |
58 | ```javascript
59 | // 一个简单的loader例子
60 | function replace(source) {
61 | // 使用正则把 @require '../style/index.css' 转换成 require('../style/index.css');
62 | return source.replace(/(\/\/ *@require) +(('|").+('|")).*/, 'require($2);');
63 | }
64 | module.exports = function (content) {
65 | return replace(content);
66 | };
67 | ```
68 |
69 | 开发plugin中最常用的两个对象是Compiler和Compilation,他们是plugin和webpack之间的桥梁
70 |
71 | * `Compiler`对象包含了webpack环境的所有配置信息,包含options,loaders,plugins这些信息,这个对象在Webpack启动时候被实例化,它是全局唯一的
72 | * `Compilation`对象包含了当前的模块资源,编译生成资源,变换的文件等。当webpack以开发模式运行时,每当检测到一个文件变化,一个新的Compilation将会被创建
73 |
74 | ```javascript
75 | // 最基础的plugin代码
76 | class BasicPlugin{
77 | // 在构造函数中获取用户给该插件传入的配置
78 | constructor(options){ }
79 | // Webpack会调用BasicPlugin实例的apply方法给插件实例传入compiler对象
80 | apply(compiler){
81 | conpiler.plugin('compilation',function(compilation){ })
82 | }
83 | }
84 | module.exports = BasicPlugin;
85 | ```
86 |
87 | ## webpack如何配置单页和多页应用
88 |
89 | 单页应用即为webpack的标准模式,直接在entry中指定单页面应用的入口即可:
90 |
91 | ```javascript
92 | module.exports = {
93 | entry: {
94 | app: './src/main.js'
95 | },
96 | }
97 | ```
98 |
99 | 多页面应用可以考虑使用webpack的`AutoWebPlugin`来完成简单的自动化构建,前提是项目目录结构要符合预先设定的规范
100 |
101 | ```javascript
102 | ├── pages
103 | │ ├── index
104 | │ │ ├── index.css // 该页面单独需要的 CSS 样式
105 | │ │ └── index.js // 该页面的入口文件
106 | │ └── login
107 | │ ├── index.css
108 | │ └── index.js
109 | ├── common.css // 所有页面都需要的公共 CSS 样式
110 | ├── google_analytics.js
111 | ├── template.html
112 | └── webpack.config.js
113 | ```
114 |
115 | ## webpack如何做到热更新
116 |
117 | webpack热更新(Hot Module Replacement),缩写为HMR,实现了不用刷新浏览器而将新变更的模块替换掉旧的模块,原理如下:
118 |
119 | 
120 |
121 | server端和client端都做了处理:
122 |
123 | * webpack监听到文件变化,重新编译打包,webpack-dev-server和webpack之间接口交互(主要是webpack-dev-middleware调用webpack暴露的API对代码进行监控,并告诉webpack将打包后代码保存到内存中)
124 | * 通过sockjs(webpack-dev-server的依赖)在浏览器和服务器之间建立 一个`websocket`长连接,将webpack编译打包各阶段的信息告知浏览器端
125 | * webpack根据 webpack-dev-server/client 传给它的信息以及 dev-server的配置决定是刷新浏览器还是进⾏模块热更新,如果是模块热更新继续执行,否者刷新浏览器
126 | * HotModuleReplacement.runtime 是客户端 HMR 的中枢,它接收到上⼀步传递给他的新模块的 hash 值,它通过JsonpMainTemplate.runtime 向 server 端发送 Ajax 请求,服务端返回⼀个 json,该 json 包含了所有要更新的模块的 hash 值,获取到更新列表后,该模块再次通过 jsonp 请求,获取到最新的模块代码
127 | * HotModulePlugin 将会对新旧模块进⾏对⽐,决定是否更新模块
128 | * 当 HMR 失败后,回退到 live reload 操作,也就是进⾏浏览器刷新来获取最新打包代码
129 |
130 | > 参考:[Webpack HMR 原理解析](https://zhuanlan.zhihu.com/p/30669007)
131 |
132 | ## webpack的构建流程\(原理\)是怎样的
133 |
134 | webpack的构建流程是一个串行的过程,从启动到结束依次执行如下:
135 |
136 | * ① 初始化参数:从配置文件和shell语句中读取与合并参数,得出最终的参数
137 | * ② 开始编译:用上一步得到的参数初始化 Compiler对象,加载所有配置的插件,通过执行对象的run方法开始执行编译
138 | * ③ 确定入口:根据配置中的entry找出所有的入口文件
139 | * ④ 编译模块:从入口文件出发,调用所有配置的loader对模块进行"加载",再找出该模块依赖的模块,递归此步骤知道所有入口依赖的文件都经过处理结束
140 | * ⑤ 完成编译模块:处理结束,得到了每个模块被"加载"之后的最终内容以及他们之间的依赖关系
141 | * ⑥ 输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的chunk,再将每个chunk转换成一个单独的文件加入输出列表中
142 | * ⑦ 输出完成:确定输出内容之后,根据配置确定输出的路径和⽂件名,写⼊到⽂件系统
143 |
144 | ## 如何用webpack优化前端性能
145 |
146 | * 压缩代码:比如利用UglifyJsPlugin来对js文件压缩
147 | * CDN加速:将引用的静态资源修改为CDN上的路径。比如可以抽离出静态js,在index利用CDN引入;利⽤webpack对于 output 参数和各loader的publicPath参数来修改资源路径
148 | * 删除Tree Shaking:将代码中永远不会走到的片段删除。可以通过在启动webpack时追加参数 `--optimize-minimize` 来实现
149 | * 按照路由拆分代码,实现按需加载,提取公共代码
150 | * 优化图片,对于小图可以使用 base64 的方式写入文件中
151 |
152 |
--------------------------------------------------------------------------------
/vue.md:
--------------------------------------------------------------------------------
1 | ---
2 | description: 框架对于应届生也是较重点,除了基础的知识和部分深度问题,还要看对于技术的广度,是否有一个自己完整的技术栈,以及对于自身技术栈的认知程度
3 | ---
4 |
5 | # Vue框架篇
6 |
7 | ## 对MVVM的理解
8 |
9 | MVC的弊端:MVC即"Model-View-Controller",当视图上发生变化,通过Controller(控件)将响应传入到Model(数据源),由数据源改变View上面的数据,允许view和model直接通信,随着业务不断庞大,会出现向蜘蛛网一样难以处理的依赖关系,违背了开发应该遵循的"开放封闭原则"
10 |
11 | MVVM,萌芽于2005年微软推出的基于 Windows 的⽤户界⾯框架WPF ,前端最早的 MVVM 框架 knockout 在2010年发布
12 |
13 | 
14 |
15 | 即"Model-View-ViewModel",View通过View-Model的DOM Listeners将事件绑定到Model上,而Model则通过Data Bindings来管理View中的数据,View-Model从中起到一个连接桥的作用
16 |
17 | ## vue双向数据绑定的实现
18 |
19 | vue内部利用Object.defineProperty监听数据变化,使数据具有可观测性,结合发布订阅模式,在数据发生变化时更新视图
20 |
21 | * 利用Proxy或Object.defineProperty生成的Observer针对对象/对象的属性进行"劫持",在属性发生变化后通知订阅者
22 | * 解析器Compile解析模板中的Directive\(指令\),收集指令所依赖的方法和数据,等待数据变化然后进行渲染
23 | * Watcher属于Observer和Compile桥梁,它将接收到的Observer产生的数据变化,并根据Compile提供的指令进行视图渲染,使得数据变化促使视图变化
24 |
25 | ```javascript
26 | // 简单的双向数据绑定
27 | const data = {};
28 | Object.keys(data).forEach(function(key) {
29 | Object.defineProperty(data, key, {
30 | enumerable: true,
31 | configurable: true,
32 | get: function() {
33 | console.log('get');
34 | },
35 | set: function(newVal) {
36 | // 当属性值发⽣变化时我们可以进⾏额外操作
37 | },
38 | });
39 | });
40 | ```
41 |
42 | ## Object.defineProperty和proxy的优劣区别
43 |
44 | Object.defineProperty兼容性较好,但不能直接监听数组的变化,只能监听对象的属性\(有时需要深层遍历\)
45 |
46 | 与之相比proxy的优点:
47 |
48 | * 可以直接监听数组的变化
49 | * 可以直接监听对象而非属性
50 | * proxy有多达13种的拦截方法,不限于apply、ownKeys、deleteProperty、has等等
51 | * proxy受到各大浏览器厂商的重视
52 |
53 | ## 除了数据劫持,vue为什么还需要虚拟DOM进行diff检测差异
54 |
55 | 现代前端框架主要有两种监听数据的方式:一种是pull的方式,一种是push的方式
56 |
57 | pull,其代表为react,react和vue基于双向数据绑定的依赖收集的订阅式机制不同,react是通过显式的触发函数调用来更新视图,比如setState,然后React会一层层的进行Virtual Dom Diff操作找出差异,通过较暴力diff的方式查找哪里发生变化。另一个代表是angular的脏值检测
58 |
59 | push,其代表为vue,当Vue程序初始化的时候就会对数据data进行依赖的收集,一但数据发生变化,响应式系统就会立刻得知;我们知道绑定一个数据通常就需要一个watcher,那么一旦细粒度过高会产生大量的watcher,会给增加内存以及依赖追踪的开销,而细粒度过低会无法精准检测变化,因此vue选择中细粒度方案,在组件级进行push检测的方式\(即依赖响应式系统\),在组件内部进行Virtual Dom Diff获取更加具体的差异,所以vue采用了push+pull结合的方式
60 |
61 | ## 对vue响应式系统的理解
62 |
63 | 
64 |
65 | 响应式系统简述:
66 |
67 | * 任何⼀个 Vue Component 都有⼀个与之对应的 Watcher 实例
68 | * Vue 的 data 上的属性会被添加 getter 和 setter 属性
69 | * 当Vue Component render函数被执⾏的时候,data上会被触碰\(touch\), 即被读,getter ⽅法会被调⽤, 此时 Vue 会去记录此 Vue component所依赖的所有data\(这⼀过程被称为依赖收集\)
70 | * data 被改动时\(主要是⽤户操作\), setter ⽅法会被调⽤, 此时 Vue 会去通知所有依赖于此 data 的组件去调⽤他们的 render 函数进⾏更新
71 |
72 | ## vue的生命周期讲一下
73 |
74 | vue 实例有⼀个完整的⽣命周期,也就是从开始创建、初始化数据、编译模版、挂载Dom -> 渲染、更新 -> 渲染、卸载等⼀系列过程,即vue实例从创建到销毁的过程,我们称这是vue的⽣命周期
75 |
76 | 
77 |
78 | 1.beforeCreate:完成实例初始化,初始化非响应式变量
79 |
80 | 2.created:实例初始化完成\(未挂载DOM\)
81 |
82 | 3.berofeMount:找到对应的template,并编译成render函数
83 |
84 | 4.mounted:完成创建vm.$el和双向绑定,完成DOM挂载
85 |
86 | 5.beforeUpdate:数据更新之前\(可在更新前访问现有的DOM\)
87 |
88 | 6.updated:完成虚拟DOM的重新渲染和打补丁
89 |
90 | 7.activated:子组件需要在每次加载时候进行某些操作,可以使用activated钩子触发
91 |
92 | 8.deactivated:keep-alive 组件被移除时使用
93 |
94 | 9.beforeDestroy:可做一些删除提示,销毁定时器,解绑全局时间 销毁插件对象
95 |
96 | 10.destroyed:当前组件已被销毁
97 |
98 | ## computed和watch有什么区别
99 |
100 | 当我们要进⾏数值计算,⽽且依赖于其他数据,我们需要使用computed
101 |
102 | 如果你需要在某个数据变化时做⼀些事情,使⽤watch来观察这个数据
103 |
104 | computed:
105 |
106 | * 1.是计算值,
107 | * 2.应用:就是简化tempalte里面计算和处理props或$emit的传值
108 | * 3.具有缓存性,页面重新渲染值不变化,计算属性会立即返回之前的计算结果,而不必再次执行函数
109 |
110 | watch:
111 |
112 | * 1.是观察的动作,
113 | * 2.应用:监听props,$emit或本组件的值执行异步操作
114 | * 3.无缓存性,页面重新渲染时值不变化也会执行
115 |
116 | ## vue指令有哪些,v-if和v-for能不能一起使用
117 |
118 | v-html,v-text,v-show,v-for,v-if v-else-if v-else,
119 |
120 | v-bind(用来动态的绑定一个或者多个特性)
121 |
122 | v-model(创建双向数据绑定)
123 |
124 | v-cloak(保持在元素上直到关联实例结束时进行编译)
125 |
126 | v-pre(用来跳过这个元素和它的子元素编译过程)
127 |
128 | > v-if和v-for能不能一起使用\(或者问v-for和v-if谁的优先级更高\):
129 | >
130 | > v-for指令的优先级要高于v-if,当处于同一节点时候,意味着v-if将分别重复运行于每个 v-for 循环中,所以应该尽量避免v-for和v-if在同一结点
131 |
132 | ## vue中的key值有什么用\(diff算法的过程\)
133 |
134 | vue采用“就地复用”策略,如果数据项的顺序被改变,Vue 将不会移动 DOM 元素来匹配数据项的顺序, 而是简单复用此处每个元素,并且确保它在特定索引下显示已被渲染过的每个元素,key 的作用主要是为了高效的更新虚拟DOM。
135 |
136 | > 虚拟dom的diff算法的过程中,先会进⾏新旧节点的⾸尾交叉对⽐,当⽆法匹配的时候会⽤新节点的 key 与旧节点进⾏⽐对,然后超出差异
137 |
138 | 
139 |
140 | vue的diff位于patch.js中,这里简单总结一下patchVnode比较的的过程,首先要判断vnode和oldVnode是否都存在,都存在并且vnode和oldVnode是同一节点时,才会进入patchVnode进行比较,结点比较五种情况:
141 |
142 | ① 引用一致,可以认为没有变化
143 |
144 | ② 文本节点的比较,如果需要修改:则会调用Node.textContent = vnode.text
145 |
146 | ③ 两个节点都有子节点,而且它们不一样:则调用updateChildren函数比较子节点
147 |
148 | ④ 只有新的节点有子节点:则调用addVnodes创建子节点
149 |
150 | ⑤ 只有老节点有子节点,则调用removeVnodes把这些子节点都删除
151 |
152 | updateChildren的过程:updateChildren用指针的方式把新旧节点的子节点的首尾节点标记,即oldStartIndex\(1\),oldEndIndex\(2\),newStartIndex\(3\), oldEndIndex\(4\)(这里简单用1 2 3 4顺序标记)即依次比较13,14,23,24,有10种左右情况分别做出对应的处理
153 |
154 | ## vue的路由实现
155 |
156 | 更新视图但不重新请求页面,是前端路由原理的核心,目前在浏览器环境主要有两种方式:
157 |
158 | * Hash 模式
159 |
160 | hash\("\#"\)符号的本来作用是加在URL指示网页中的位置:
161 |
162 | ```markup
163 | http://www.example.com/index.html#print
164 | ```
165 |
166 | `#`本身以及它后面的字符称之为hash,可通过window.location.hash属性读取,hash虽然在url中,但是却不会被包含在http请求中,也不会重新加载页面,它用来指导浏览器动作
167 |
168 | * History 模式
169 |
170 | History interface是浏览器历史记录栈提供的接口,从HTML5开始,History interface提供了2个新的方法:`pushState()`,`replaceState()`使得我们可以对浏览器历史记录栈进行修改;这两个方法有有一个特点,当调用他们修改浏览器历史栈后,虽然当前url改变了,但浏览器不会立即发送请求该url,这就为单页应用前端路由,更新视图但不重新请求页面提供了基础
171 |
172 | ## vue组件间通信的方式
173 |
174 | * props/$emit+v-on
175 |
176 | 父组件通过props的方式向子组件传递数据,而通过$emit 子组件可以向父组件通信
177 |
178 | * eventBus
179 |
180 | 通过eventBus向中心事件发送或者接收事件,所有事件都可以共用事件中心
181 |
182 | * vuex
183 |
184 | 状态管理模式,采用集中式存储管理应用的所有组件的状态,可以通过vuex管理全局的数据
185 |
186 | > 参考:[vue中8种组件通信方式](https://juejin.im/post/5d267dcdf265da1b957081a3) 只需要熟悉上面三种即可,其他基本不会用到,可以做为了解
187 |
188 | ## vue路由懒加载的方式有哪些
189 |
190 | 懒加载简单来说就是延迟加载或按需加载,即在需要的时候的时候进行加载,常用的懒加载方式有三种:即使用vue异步组件 和 ES6中的import,以及webpack的require.ensure\(\)
191 |
192 | * vue异步组件
193 |
194 | ```javascript
195 | // 路由配置,使用vue异步组件
196 | {
197 | path: '/home',
198 | name: 'home',
199 | component: resolve => require(['@/components/home'],resolve)
200 | }
201 | ```
202 |
203 | * ES6中的import
204 |
205 | ```javascript
206 | // 指定了相同的webpackChunkName,合并打包成一个js文件
207 | // 如果不指定,则分开打包
208 | const Home = () => import(/*webpackChunkName:'ImportFuncDemo'*/ '@/components/home')
209 | const Index = () => import(/*webpackChunkName:'ImportFuncDemo'*/ '@/components/index')
210 | ```
211 |
212 | * webpack推出的require.ensure\(\)
213 |
214 | ```javascript
215 | {
216 | path: '/home',
217 | name: 'home',
218 | component: r => require.ensure([], () => r(require('@/components/home')), 'demo')
219 | }
220 | ```
221 |
222 |
--------------------------------------------------------------------------------
/algorithm.md:
--------------------------------------------------------------------------------
1 | ---
2 | description: >-
3 | 算法在前端面试中也有不可忽视的重量,而且不少企业也越来越重视,这一篇只是一些普识性问题,具体到手撕某个问题可能要靠平时空闲多在LeetCode刷题;除了算法问题,可能还会有几个逻辑推理题,具体某个场景根据自己的理解和思路去答即可
4 | ---
5 |
6 | # 算法篇
7 |
8 | ## 时间复杂度分析
9 |
10 | 当问题规模数据大量增加时,重复执行的次数也必定会增加,那么我们就有必要关心执行次数是以什么样的数量级增加,这也是分析时间复杂度的意义,是一个非常重要衡量算法好快的事前估算的方法
11 |
12 | 常见的时间复杂度:
13 |
14 | * O\(1\):常数阶的复杂度,这种复杂度无论数据规模如何增长,计算时间是不变的
15 |
16 | ```javascript
17 | const increment = n => n++
18 | ```
19 |
20 | * O\(n\):线性复杂度,线性增长
21 |
22 | ```javascript
23 | // 最典型的例子就是线性查找
24 | const linearSearch = (arr,target) = {
25 | for (let i = 0;i * 比较相邻元素,如果第一个比第二个大,就交换他们两个
47 | > * 依次走访执行第一步,那么第一趟后,最后的元素应该是最大的数
48 | > * 重复走访,直到排序完成
49 |
50 | ```javascript
51 | const bubbleSort = arr => {
52 | console.time('bubbleSort耗时');
53 | let len = arr.length;
54 | for(let i = 0;iarr[j+1]){
57 | [arr[j],arr[j+1]] = [arr[j+1],arr[j]]
58 | }
59 | }
60 | }
61 | console.timeEnd('bubbleSort耗时');
62 | return arr
63 | }
64 | ```
65 |
66 | 冒泡排序改进方案:
67 |
68 | 方案一:设置一个标记变量pos,用来记录每次走访的最后一次进行交换的位置,那么下次走访之后的序列便可以不再访问
69 |
70 | ```javascript
71 | const bubbleSort_pos = arr => {
72 | console.time('bubbleSort_pos耗时')
73 | let i = arr.length - 1;
74 | while(i > 0){
75 | let pos = 0;
76 | for(var j=0;jarr[j+1]){
78 | pos = j;
79 | [arr[j],arr[j+1]] = [arr[j+1],arr[j]];
80 | }
81 | }
82 | i = pos;
83 | }
84 | console.timeEnd('bubbleSort_pos耗时')
85 | return arr;
86 | }
87 | ```
88 |
89 | 方案二:传统冒泡一趟只能找到一个最大或者最小值,我们可以考虑在利用每趟排序过程中进行正向和反向冒泡,一次可以得到一个最大值和最小值,从而使排序趟数几乎减少一半
90 |
91 | ```javascript
92 | const bubbleSort_ovonic = arr => {
93 | console.time('bubbleSort_ovonic耗时')
94 | let low = 0;
95 | let height = arr.length -1;
96 | let tmp,j;
97 | while(low < height){
98 | for(j=low;j arr[j+1]){
100 | [arr[j],arr[j+1]] = [arr[j+1],arr[j]];
101 | }
102 | }
103 | --height;
104 | for(j=height;j>low;--j){ // 反向冒泡,找到最小值
105 | if(arr[j] < arr[j-1]){
106 | [arr[j-1],arr[j]] = [arr[j],arr[j-1]]
107 | }
108 | }
109 | ++low;
110 | }
111 | console.timeEnd('bubbleSort_ovonic耗时')
112 | return arr;
113 | }
114 | ```
115 |
116 | 以上提供两种改进冒泡的思路,耗时在这只是进行粗略对比,并不完全确定好坏,相比之下改进后的冒泡时间复杂度更低,下图实例展示结果耗时更短
117 |
118 | 
119 |
120 | * 快速排序
121 |
122 | 快速排序是分治策略的经典实现,也是对冒泡排序的改进,出现频率较高,基本思路是经过一趟排序,把数据分割成独立的两部分,其中一部分数据要比另一部分都小,然后按此方法继续排序,以达到整个序列有序,具体算法描述如下:
123 |
124 | > * 从数组中挑出一个元素作为"基准"
125 | > * 分区:所有比基准小的值放前面,而比基准大的值放后面,基准处于数列中间位置
126 | > * 按照此方法依次排序(递归),以达到序列有序
127 |
128 | ```javascript
129 | // 递归方法的其中一种形式
130 | const quickSort = (arr) => {
131 | if(arr.length <= 1){ return arr };
132 | let pivotIndex = Math.floor(arr.length/2);
133 | let pivot = arr.splice(pivotIndex,1)[0]; // 确定基准
134 | let left = [] , right = [];
135 | for(let i = 0;i * 选择一个增量序列t1,t2...tk,其中ti>tj,tk=1
151 | > * 按增量序列个数k,对序列进行k趟排序
152 | > * 每趟排序根据对应的增量ti,将待排序列分割成长度为m的若干子序列,然后分别对各子表进行直接插入排序。仅当增量因子为1时,整个序列作为一个表来处理,表长度即为整个序列的长度
153 |
154 | ```javascript
155 | const shellSort = arr => {
156 | console.time('shellSort耗时')
157 | let len = arr.length,
158 | gap = 1,
159 | temp;
160 | while(gap < len/5){ gap = gap*5+1 } // 动态定义间隔序列
161 | for(gap; gap > 0; gap = Math.floor(gap/5)){
162 | for(let i = gap;i=0&&arr[j]>temp; j-=gap){
165 | arr[j+gap] = arr[j];
166 | }
167 | arr[j+gap] = temp;
168 | }
169 | }
170 | console.timeEnd('shellSort耗时');
171 | return arr;
172 | }
173 | ```
174 |
175 | * 归并排序
176 |
177 | 归并排序不受输入数据的影响,时间复杂度始终都是O\(nlogn\),但代价是需要额外的内存空间。归并排序也是分治法的经典体现,先使子序列有序,再使子序列段间有序,若将两个有序表合并成一个有序表,称为2-路归并。实现如下:
178 |
179 | > * 将长度为n的序列,分成两个长度为n/2的子序列
180 | > * 对这两个子序列分别采用归并排序
181 | > * 将两个排序好的子序列合并成最终排序序列
182 |
183 | ```javascript
184 | const merge = (left,right) => {
185 | let result = [];
186 | while(left.length && right.length){
187 | if(left[0] <= right[0]){
188 | result.push(left.shift());
189 | }else{
190 | result.push(right.shift());
191 | }
192 | }
193 | while(left.length)
194 | result.push(left.shift());
195 |
196 | while(right.length)
197 | result.push(right.shift());
198 |
199 | return result;
200 | }
201 |
202 | const mergeSort = arr => {
203 | let len = arr.length;
204 | if(len < 2) return arr;
205 | let middle = Math.floor(len / 2),
206 | left = arr.slice(0,middle),
207 | right = arr.slice(middle);
208 |
209 | return merge(mergeSort(left),mergeSort(right));
210 | }
211 | ```
212 |
213 | ## 常见的查找算法
214 |
215 | * 线性查找
216 |
217 | 线性查找较简单,只需要简单遍历即可
218 |
219 | ```javascript
220 | const linearSearch = (arr,target) => {
221 | for(let i =0;i 实现思路如下:
235 | >
236 | > * 首先设两个指针,low表示最低索引,height表示最高索引
237 | > * 然后取中间位置索引,判断middle处的值是否是要查找的数字,是则查找结束;比所求值较小就把low设为middle+1,较大则把height设为middle-1
238 | > * 然后到新分区继续查找,直到找到或者low>height找不到要查找的值结束
239 |
240 | ```javascript
241 | const binarySearch = (arr,target) => {
242 | let height = arr.length - 1;
243 | let low = 0;
244 | while(low <= height){
245 | let middle = Math.floor((low+height)/2)
246 | if(target < arr[middle]){
247 | height = middle - 1
248 | }else if(target > arr[middle]){
249 | low = middle + 1
250 | }else{
251 | return middle
252 | }
253 | }
254 | return -1
255 | }
256 | ```
257 |
258 | 时间复杂度分析:最佳情况O\(logn\),最差情况O\(logn\),平均情况O\(logn\)
259 |
260 | > 参考:[damonare](https://github.com/damonare/Sorts)
261 |
262 | ## 二叉树的遍历方式
263 |
264 | 二叉树遍历有四种方式:先序遍历,中序遍历,后序遍历,层序遍历
265 |
266 | 前序遍历:先访问根节点,然后前序遍历左子树,再前序遍历右子树
267 |
268 | 中序遍历:先中序遍历左子树,然后访问根节点,最后遍历右子树
269 |
270 | 后序遍历:从左到右,先叶子后结点的方式遍历访问左子树,最后访问根节点
271 |
272 | 层序遍历:从根结点从上往下逐层遍历,在同一层,按从左到右的顺序对结点逐个访问
273 |
274 | ## 实现二叉树的层序遍历
275 |
276 | 有两种通用的遍历树的策略:
277 |
278 | * 深度优先遍历(DFC)
279 |
280 | 正如名字一样,深度优先遍历采用深度作为优先级,从某个确定的叶子,然后再返回根到另个分支,有细分为先序遍历,中序遍历和后序遍历
281 |
282 | * 广度优先遍历(BFC)
283 |
284 | 广度优先按照高度顺序一层一层访问整棵树,高层次的结点会比低层的结点先访问到
285 |
286 | ```javascript
287 | // 通过迭代方式实现
288 | const levelOrder = function(root) {
289 | const res = [];
290 | const stack = [{ index: 0, node: root }];
291 |
292 | while (stack.length > 0) {
293 | const { index, node } = stack.pop();
294 | if (!node) continue;
295 | res[index] = res[index] ? [...res[index], node.val] : [node.val];
296 | stack.push({ index: index + 1, node: node.right });
297 | stack.push({ index: index + 1, node: node.left });
298 | }
299 | return res;
300 | };
301 | ```
302 |
303 |
--------------------------------------------------------------------------------
/http.md:
--------------------------------------------------------------------------------
1 | ---
2 | description: HTTP/浏览器篇(第一个版本预计总结常见问题15个左右)
3 | ---
4 |
5 | # HTTP/浏览器
6 |
7 | ## 从地址栏输入URL到呈现页面
8 |
9 | 简洁来说过程如下:
10 |
11 | * 1.浏览器向`DNS`服务器请求解析该 URL 中的域名所对应的 `IP` 地址;
12 | * 2.建立`TCP`连接(三次握手);
13 | * 3.浏览器发出读取文件\(`URL` 中域名后面部分对应的文件\)的`HTTP` 请求,该请求报文作为 `TCP` 三次握手的第三个报文的数据发送给服务器;
14 | * 4.服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
15 | * 5.浏览器将该 `html` 文本并显示内容;
16 | * 6.释放 `TCP`连接(四次挥手);
17 |
18 | 浏览器解析渲染过程,见[HTML&CSS](https://github.com/okaychen/FE-Interview-Brochure/blob/master/html-and-css.md#htmlcss)
19 |
20 | ## DNS--解析顺序
21 |
22 | * 解析顺序:按照浏览器缓存,系统缓存,路由器缓存,ISP(运营商)DNS缓存,根域名服务器,顶级域名服务器,主域名服务器逐步读取,直到拿到IP地址
23 | * DNS递归查询和迭代查询:从客户端到本地DNS服务器是属于递归查询,而DNS服务器之间就是的交互查询就是迭代查询
24 |
25 | ## 建立和释放TCP连接的过程,能画一下嘛
26 |
27 | 三次握手:(SYN (同步序列编号)ACK(确认字符))
28 |
29 | * 第一次握手:Client将标志位SYN置为1,随机产生一个值seq=J,并将该数据包发送给Server,Client进入SYN\_SENT状态,等 待Server确认。
30 | * 第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN\_RCVD状态
31 | * 第三次握手:Client收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。
32 |
33 | 
34 |
35 | 四次挥手:
36 |
37 | * 第一次挥手:Client发送一个FIN=M\(释放一个连接\),用来关闭Client到Server的数据传送,Client进入FIN\_WAIT\_1状态。
38 | * 第二次挥手:Server收到FIN后,发送一个ack=M+1给Client,确认序号为收到序号+1\(与SYN相同,一个FIN占用一个序号\),Server进入CLOSE\_WAIT状态。
39 | * 第三次挥手:Server发送一个FIN = N,用来关闭Server到Client的数据传送,Server进入LAST\_ACK状态。
40 | * 第四次挥手:Client收到FIN后,Client进入TIME\_WAIT状态,接着发送一个ACK给Server,确认序号为收到序号ack=N+1,Server进入CLOSED状态,完成四次挥手
41 |
42 | 
43 |
44 | > 追问:释放连接的过程是四次挥手,相比建立连接过程为什么要多一次?
45 |
46 | 因为服务端收到SYN建连报文后,可以把ACK报文和SYN报文放在一起发送。但是当关闭连接的时候,当对方收到FIN报文通知时,仅仅表示对方已经无数据发送给你了,但未必你已经发送完全部数据,这时就不能马上关闭socket,所以释放连接过程SYN包和ACK包要分开发送。
47 |
48 | ## HTTP方法知道哪些,GET和POST区别有哪些
49 |
50 | HTTP1.0定义了三种请求方法,GET,POST和HEAD方法 HTTP1.1新增六种请求方法:OPTIONS,PUT,PATCH,DELETE,TRACH和CONNECT
51 |
52 | GET和POST区别主要从三方面讲即可:表现形式,传输数据大小,安全性
53 |
54 | 首先表现形式上:GET请求的数据会附加在URL后面,以?分割多参数用&连接,由于URL采用ASCII编码,所以非ASCII字符会先编码在传输,可缓存;POST请求会把请求的数据放在请求体中,不可缓存
55 |
56 | 传输数据大小:对于GET请求,HTTP规范没有对URL长度进行限制,但是不同浏览器对URL长度加以限制,所以GET请求时,传输数据会受到URL长度的限制;POST不是URL传值,理论上无限制,但各个服务器一般会对POST传输数据大小进行限制
57 |
58 | 安全性:相比URL传值,POST利用请求体传值安全性更高
59 |
60 | > PS:还有一种GET产生一个数据包,POST产生两个数据包的说法可答可不答,并不是所有浏览器如此,铺展开解释来说就是:对GET请求,浏览器会把请求头和data一起发送,服务器响应200(返回数据),对于POST请求,浏览器会先发送header,服务器响应100后继续,浏览器再发送data,服务器响应200
61 |
62 | ## HTTP的缓存过程(强缓存和协商缓存)
63 |
64 | 
65 |
66 | 通常过程如下:
67 |
68 | * 判断是否过期(服务器会通知浏览器一个缓存时间,相关头部信息在Cache-Control和Expires中),如果时间未过期,则直接从缓存中取,即强缓存;
69 | * Cache-Control
70 | * 其中`max-age = `设置缓存存储的最大周期,超过这个时间缓存将会被认为过期,与Expires相反,时间是相对于请求的时间
71 | * public 表示响应可以被任何对象缓存,即使是通常不可缓存的内容
72 | * private 表示缓存只能被单个用户缓存,不能作为共享缓存(即代理服务器不可缓存它)
73 | * no-cache 告诉浏览器、缓存服务器,不管本地副本是否过期,使用副本前一定要到源服务器进行副本有效校验
74 | * no-store 缓存不应该存储有关客户端请求或服务器响应的任何内容
75 | * Expires
76 | * expires 字段规定了缓存的资源的过期时间,该字段时间格式使用GMT时间标准时间格式, js通过`new Date().toUTCString()`得到,由于时间期限是由服务器生成,存在着服务端和客户端的时间误差,相比cache-control优先级较低
77 |
78 | > 注:cache-control和expires谁的优先级更高也是校招面试中常问的问题(腾讯一面被问过)
79 |
80 | * 那么如果判断缓存时间已经过期,将会采用协商缓存策略
81 | * Last-Modified响应头和If-Modified-Since请求头
82 | * Last-Modified 表示资源最后的修改时间,在浏览器第一次发送HTTP请求时,服务器会返回该响应头
83 | * 那么浏览器在下次发起HTTP请求时,会带上If-Modified-Since请求头,其值就是第一次发送HTTP请求时,服务器设置在Last-Modified响应头中的值
84 | * 两种情况:如果资源最后修改时间大于If-Modified-Since,说明资源有被改动过,则响应完整的资源内容,返回状态码200;如果小于或者等于,说明资源未被修改,则响应状态码304,告知浏览器可以继续使用所保存的缓存
85 | * Etag响应头和If-None-Match请求头
86 | * Etag值为当前资源在服务器的唯一标识
87 | * 类比上面Last-Modified响应头和If-Modified-Since请求头,请求头中If-None-Match将会和资源的唯一标标识进行对比,如果不同,则说明资源被修改过,响应200;如果相同,则说明资源未改动,响应304
88 |
89 | ## 对HTTP报文结构的了解
90 |
91 | HTTP报文结构由报文首部,空行,报文主体三部分组成
92 |
93 | | 报文首部 |
94 | | :---: |
95 | | **空行** |
96 | | **报文主体** |
97 |
98 | 而HTTP报文首部则是由首部字段名和字段值键值对形式构成,如`Content-Type:text/html`
99 |
100 | HTTP首部字段通常分为4种类型:通用首部,请求首部,响应首部,实体首部
101 |
102 | * HTTP请求报文,一个HTTP请求报文由请求行(request line)、请求头部(request header)、空行和请求数据4个部分构成。**请求行**数据格式由三个部分组成:请求方法、URI、HTTP协议版本,他们之间用空格分隔
103 |
104 | ```javascript
105 | GET /index.html HTTP/1.1
106 | ```
107 |
108 | 
109 |
110 | * HTTP响应报文,一个HTTP响应报文由状态行(HTTP版本、状态码)、响应头部、空行和响应体4个部分构成。**状态行**主要给出响应HTTP协议的版本号、响应返回状态码、响应描述,同样是单行显示
111 |
112 | ```javascript
113 | HTTP/1.1 200 OK
114 | ```
115 |
116 | 
117 |
118 | ## HTTP的状态码,301和302的区别
119 |
120 | 状态码告知从服务器返回请求的状态,一般由以1~5开头的三位整数组成,
121 |
122 | 1xx:请求正在处理
123 |
124 | 2xx:成功
125 |
126 | 3xx:重定向
127 |
128 | * 301 moved permanently,永久性重定向,表示资源已被分配了新的 URL
129 | * 302 found,临时性重定向,表示资源临时被分配了新的 URL
130 | * 303 see other,表示资源存在着另⼀个 URL,应使⽤ GET ⽅法定向获取资源
131 | * 304 not modified,表示服务器允许访问资源,但因发生请求未满足条件的情况
132 | * 307 temporary redirect,临时重定向,和302含义相同
133 |
134 | 4xx:客户端错误
135 |
136 | * 400 bad request,请求报文存在语法错误
137 | * 401 unauthorized,表示发送的请求需要有通过HTTP认证的认证信息
138 | * 403 forbidden,表示对请求资源的访问被服务器拒绝
139 | * 404 not found,表示服务器上没找到请求的资源
140 | * 408 Request timeout,客户端请求超市
141 | * 409 confict,请求的资源可能引起冲突
142 |
143 | 5xx:服务器错误
144 |
145 | * 500 internal server error,表示服务器端在执行请求时发生了错误
146 | * 501 Not Implemented,请求超出服务器能力范围
147 | * 503 service unavailable,表示服务器暂时处于超负载或正在停机维护,无法处理
148 | * 505 http version not supported,服务器不支持,或者拒绝支持在请求中的使用的HTTP版本
149 |
150 | 同样是重定向,302是HTTP1.0的状态码,在HTTP1.1版本的时候为了细化302又分出来了303和307,303则明确表示客户端应采用get方法获取资源,他会把post请求变成get请求进行重定向;307则会遵照浏览器标准,不会改变post
151 |
152 | ## HTTP建立持久连接的意义
153 |
154 | HTTP持久连接也称作HTTP keep-alive,使用同一个TCP连接发送和接收多个HTTP请求,是HTTP1.1的新特性,HTTP1.1默认所有连接都是持久连接。在HTTP1.0,使用非持久连接,每个TCP连接只用于传输一个请求和响应,没有官方的keepalive操作,如果浏览器支持通常在请求和响应头中加上`Connection: Keep-Alive`
155 |
156 | 那么由于同时打开的TCP连接减少,可以减少内存和CPU的占用;其次之后也无需再次握手,也减少了后续请求的延迟
157 |
158 | ## HTTP1.1相比1.0的区别有哪些
159 |
160 | 目前通用标准是HTTP1.1,在1.0的基础上升级加了部分功能,主要从连接方式,缓存,带宽优化(断点传输),host头域,错误提示等方面做了改进和优化
161 |
162 | * 连接方式:HTTP1.0使用短连接(非持久连接);HTTP1.1默认采用带流水线的长连接(持久连接),PS:在持久连接的基础上可选的是管道化的连接
163 | * 缓存:HTTP1.1新增例如ETag,If-None-Match,Cache-Control等更多的缓存控制策略
164 | * 带宽优化:HTTP1.0在断连后不得不下载完整的包,存在一些带宽浪费的现象;HTTP1.1则支持断点续传的功能,在请求消息中加入range 头域,允许请求资源的某个部分,在响应消息中Content-Range头域中声明了返回这部分对象的偏移值和长度
165 | * host头域:在HTTP1.0中每台服务器都绑定一个唯一的ip地址,所有传递消息中的URL并没有传递主机名;HTTP1.1请求和响应消息都应支持host头域,且请求消息中没有host头域名会抛出一个错误(400 Bad Request)
166 | * 错误提示:HTTP1.1新增24个状态响应码,比如409(请求的资源与资源当前状态冲突),410(服务器上某个资源被永久性删除);相比HTTP1.0只定义了16个状态响应码
167 |
168 | ## HTTP2相比HTTP1的优势和特点
169 |
170 | HTTP2相比HTTP1.x有4大特点,二进制分帧,头部压缩,服务端推送和多路复用
171 |
172 | ①二进制分帧:HTTP2使用二进制格式传输数据,而HTTP1.x使用文本格式,二进制协议解析更高效
173 |
174 | ②头部压缩:HTTP1.x每次请求和发送都携带不常改变的,冗杂的头部数据,给网络带来额外负担;而HTTP2在客户端和服务器使用"部首表"来追踪和存储之前发送的键值对,对于相同的数据,不再每次通过每次请求和响应发送
175 |
176 | > 可以简单理解为只发送差异数据,而不是发送全部头部,从而减少头部信息量)
177 |
178 | ③服务端推送:服务端可以在发送页面HTML时主动推送其他资源,而不用等到浏览器解析到相应位置时,发起请求再响应
179 |
180 | ④多路复用:在HTTP1.x中如果想并发多个请求,需要多个TCP连接,并且浏览器为了控制资源,一般对单个域名有6-8个TCP连接数量的限制;而在HTTP2中
181 |
182 | * 同个域名所有通信都在单个连接下进行
183 | * 单个连接可以承载任意数量的双向数据流
184 | * 数据流以消息的形式发送,而消息又由一个或多个帧组成,多个帧之间可以乱序发送
185 |
186 | ## HTTPS相比HTTP的区别,讲一下HTTPS的实现过程
187 |
188 | https相比之下是安全版的http,其实就是HTTP over TSL,因为http都是使用明文传输的,对于敏感信息的传输就很不安全,https正是为了解决http存在的安全隐患而出现的
189 |
190 | https的实现也是一个较复杂的过程,将对称加密的密钥使⽤⾮对称加密的公钥进⾏加密,在保证了通信效率的同时防止窃听,同时结合CA证书以及数字签名来最大程度保证安全性:
191 |
192 | * 对称加密:通信双方都使用用一个密钥进行加密解密,比如特工接头的暗号,就属于对称加密;这种方式虽然简单性能好,但是无法解决首次把密钥发给对方的问题,容易被黑客拦截密钥
193 | * 非对称加密:由私钥+公钥组成的密钥对
194 | * 即用私钥加密的数据,只要公钥才能解密;用公钥加密的数据,只有私钥才能解密
195 | * 通信双方都有自己的一套密钥对,通信前将自己的公钥发给对方
196 | * 然后拿着这个公钥来加密数据响应给对方,等对方收到之后,再用自己的私钥进行解密
197 |
198 | 非对称加密虽然安全性更高,但是带来的问题就是速度较慢,影响性能
199 |
200 | 结合两种方式,将对称加密的密钥使用非对称加密的公钥进行加密,然后再发送出去,然后接收方使用自己的私钥进行解密得到对称加密的密钥
201 |
202 | > 但是又带来一个问题,即中间人问题:
203 | >
204 | > 如果此时在客户端和服务端之间存在一个中间人,这个中间人只需要把原本双方通信互发的公钥,换成自己的公钥,这样中间人就可以轻松解密通信双方所发送的数据
205 |
206 | 这时候就需要一个安全的第三方的颁布证书,来证明身份,防止中间攻击:所以就有了CA证书,仔细观察浏览器地址栏,会有一个"小锁"的标志,点开里面有证明身份的CA证书信息
207 |
208 | 
209 |
210 | > 但是仍然存在的一个问题是,如果中间人篡改了CA证书,那么这个证书不就无效了?所以就添加了新的保护方案:数字签名
211 |
212 | 数字签名就是用证书自带的HASH算法对证书内容进行一个HASH得到一个摘要,再用CA的私钥进行加密,最终组成数字签名
213 |
214 | > 当别人把他的证书发过来时,用同样的HASH算法得到信息摘要,然后再用CA的公钥对数字签名进行解密,得到CA创建的消息摘要,两者一对比就知道中间有没有被篡改了
215 |
216 | 通过这样的方式,https最大化保证了通信的安全性
217 |
218 | ## 对Websocket的了解,应用场景,对比HTTP
219 |
220 | Websocket和HTTP都是基于TCP协议两个不同的协议
221 |
222 | 首先Websocket是一种在单个TCP连接上进行全双工通信的协议,允许服务端主动向客户端推送数据(只需要一次握手,两者之间创建持久化连接,可进行双向数据传输);而HTTP则需要定时轮询向服务器请求,然后服务器再向客户端发送数据
223 |
224 | 其次,HTTP是一个无状态协议,缺少状态意味着后续处理需要先前数据必须重传;而Websocket需要先创建连接,这就使得其成为一种有状态的协议,之后通信时可以省略部分状态信息
225 |
226 | 应用场景:如果应用是多个用户相互交流,或者展示服务端经常变动的数据都可以考虑websocket;所以体育实况,多媒体聊天等这些都是Websocket不错的应用场景
227 |
228 | ## TCP和UDP区别有哪些
229 |
230 | | | TCP | UDP |
231 | | :---: | :---: | :---: |
232 | | 是否连接 | 面向连接 | 面向非连接 |
233 | | 传输可靠性 | 可靠 | 不可靠 |
234 | | 应用场景 | 少量数据 | 传输大量数据 |
235 | | 速度 | 慢 | 快 |
236 |
237 | * TCP是面向连接的;UDP则是无连接的,即发送数据之前不需要建立连接
238 | * TCP提供的可靠的服务,即TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;而UDP尽最大努力,不保证可靠交付
239 | * TCP面向字节流,TCP把数据看成一连串无结构的字节流;UDP是面向报文的
240 | * 每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
241 | * TCP首部开销较大,20字节;UDP只有8字节
242 | * TCP的逻辑通信信道是全双工的可靠信道;而UDP则是不可靠信道
243 |
244 | ## 前端性能优化的方案有哪些
245 |
246 | 前端性能优化七大常用的优化手段:减少请求数量,减小资源大小,优化网络连接,优化资源加载,减少回流重绘,使用更好性能的API和构建优化
247 |
248 | * 减少请求数量
249 | * 文件合并,并按需分配(公共库合并,其他页面组件按需分配)
250 | * 图片处理:使用雪碧图,将图片转码base64内嵌到HTML中,使用字体图片代替图片
251 | * 减少重定向:尽量避免使用重定向,当页面发生了重定向,就会延迟整个HTML文档的传输
252 | * 使用缓存:即利用浏览器的强缓存和协商缓存
253 | * 不使用CSS @import:CSS的@import会造成额外的请求
254 | * 避免使用空的src和href:a标签设置空的href,会重定向到当前的页面地址,form设置空的method,会提交表单到当前的页面地址
255 | * 减小资源大小
256 | * 压缩:静态资源删除无效冗余代码并压缩
257 | * webp:更小体积
258 | * 开启gzip:HTTP协议上的GZIP编码是一种用来改进WEB应用程序性能的技术
259 | * 优化网络连接
260 |
261 | * 使用CDN
262 | * 使用DNS预解析:DNS Prefetch,即DNS预解析就是根据浏览器定义的规则,提前解析之后可能会用到的域名,使解析结果缓存到`系统缓存`中,缩短DNS解析时间,来提高网站的访问速度
263 |
264 | ```javascript
265 | // 方法是在 head 标签里面写上几个 link 标签
266 |
267 |
268 | ```
269 |
270 | * 并行连接:由于在HTTP1.1协议下,chrome每个域名最大并发数是6个。使用多个域名,可以增加并发数
271 | * 管道化连接:在HTTP2协议中,可以开启管道化连接,即单条连接的多路复用
272 |
273 | * 优化资源加载
274 | * 减少重绘回流
275 | * 使用性能更好的API
276 | * 构建优化:如webpack优化
277 |
278 | > 参考:[前端性能优化的七大手段](https://www.cnblogs.com/xiaohuochai/p/9178390.html>)
279 |
280 |
--------------------------------------------------------------------------------
/html-and-css.md:
--------------------------------------------------------------------------------
1 | ---
2 | description: >-
3 | HTML&CSS篇(第一个版本该篇预计总结常见问题20个左右),HTML&CSS不少问题都能体现应届生对于前端基础的掌握程度,是应届生求职时不可忽视的重要一环
4 | ---
5 |
6 | # HTML/CSS
7 |
8 | ## 浏览器解析渲染页面过程
9 |
10 | 大致过程:
11 |
12 | HTML解析构建DOM->CSS解析构建CSSOM树->根据DOM树和CSSOM树构建render树->根据render树进行布局渲染render layer->根据计算的布局信息进行绘制
13 |
14 | 不同浏览器的内核不同,所以渲染过程其中有部分细节有不一样,以webkit主流程为例:
15 |
16 | 
17 |
18 | 一篇很棒的文章\(需科学上网\):[How Browser Work](https://www.html5rocks.com/en/tutorials/internals/howbrowserswork/)
19 |
20 | > 编者有话说:浏览器解析渲染页面过程是一个复杂的过程,其中有不少的细节和规则,如果把上面分享的文章翻译成译文,至少有3~5页PDF左右,所以这里只能总结大致过程(作为面试回答【很可能让回答的尽可能详细】了解来说已经足够,更深入的了解可以好好读下上面那篇文章)
21 |
22 | 较详细过程:
23 |
24 | HTML解析构建DOM树:其中HTML Parser就起到了将HTML标记解析成DOM Tree的作用,HTML Parser将文本的HTML文档,提炼出关键信息,嵌套层级的树形结构,便于计算拓展;这其中也有很多的规则和操作,比如容错机制,识别特殊标签`
`等
25 |
26 | CSS解析构建CSSOM树:CSS Parser将很多个CSS文件中的样式合并解析出具有树形结构Style Rules,也叫做CSSOM。
27 |
28 | > ※其中还有一个细节是浏览器解析文档:当遇到`