├── Scratch Neural Network.ipynb
├── __init__.py
├── __pycache__
└── __init__.cpython-35.pyc
├── docs
├── Gemfile
├── License.md
├── Rakefile
├── ReadMe.md
├── _config.yml
├── _includes
│ ├── JB
│ │ ├── analytics
│ │ ├── analytics-providers
│ │ │ ├── getclicky
│ │ │ ├── google
│ │ │ └── mixpanel
│ │ ├── categories_list
│ │ ├── comments
│ │ ├── comments-providers
│ │ │ ├── disqus
│ │ │ ├── facebook
│ │ │ ├── intensedebate
│ │ │ └── livefyre
│ │ ├── liquid_raw
│ │ ├── pages_list
│ │ ├── posts_collate
│ │ ├── setup
│ │ ├── sharing
│ │ └── tags_list
│ ├── head.html
│ └── themes
│ │ └── twitter
│ │ ├── default.html
│ │ ├── page.html
│ │ ├── post.html
│ │ └── settings.yml
├── _layouts
│ ├── default.html
│ ├── page.html
│ └── post.html
├── _plugins
│ └── debug.rb
├── assets
│ ├── all_3neurons_lr_0.003_reg_0.0.gif
│ ├── all_50neurons_lr_0.003_reg_0.000001.gif
│ ├── all_50neurons_lr_0.003_reg_0.0001.gif
│ ├── chain_w1.png
│ ├── chain_w1_numbers.png
│ ├── chain_w1_numbers_final.png
│ ├── chain_w2.png
│ ├── chain_w2_detailed.png
│ ├── chain_w2_numbers.png
│ ├── code.png
│ ├── copy_values.png
│ ├── example.png
│ ├── forward.png
│ ├── h1.png
│ ├── h2.png
│ ├── initialized_network.png
│ ├── loss.png
│ ├── nonlinear_xor.png
│ ├── overview.png
│ ├── overview2.png
│ ├── themes
│ │ └── twitter
│ │ │ ├── bootstrap
│ │ │ ├── css
│ │ │ │ └── bootstrap.2.2.2.min.css
│ │ │ └── img
│ │ │ │ ├── glyphicons-halflings-white.png
│ │ │ │ └── glyphicons-halflings.png
│ │ │ └── css
│ │ │ ├── kbroman.css
│ │ │ └── style.css
│ ├── update_w1.png
│ ├── update_w2.png
│ ├── z1.png
│ └── z2.png
├── index.md
├── index_es.md
└── pages
│ ├── independent_site.md
│ ├── local_test.md
│ ├── nojekyll.md
│ ├── overview.md
│ ├── project_site.md
│ ├── resources.md
│ └── user_site.md
├── scratch_mlp.py
├── slides
└── 2017_Summer_School_LACCI.pdf
└── utils.py
/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/omar-florez/scratch_mlp/133c565e7e386b9852aa5f89c99273078594e7a7/__init__.py
--------------------------------------------------------------------------------
/__pycache__/__init__.cpython-35.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/omar-florez/scratch_mlp/133c565e7e386b9852aa5f89c99273078594e7a7/__pycache__/__init__.cpython-35.pyc
--------------------------------------------------------------------------------
/docs/Gemfile:
--------------------------------------------------------------------------------
1 | gem 'github-pages'
2 |
--------------------------------------------------------------------------------
/docs/License.md:
--------------------------------------------------------------------------------
1 | To the extent possible under law,
2 | [Karl Broman](https://github.com/kbroman)
3 | has waived all copyright and related or neighboring rights to
4 | “[simple site](https://github.com/kbroman/simple_site)”.
5 | This work is published from the United States.
6 |
7 | [](https://creativecommons.org/publicdomain/zero/1.0/)
8 |
--------------------------------------------------------------------------------
/docs/Rakefile:
--------------------------------------------------------------------------------
1 | require "rubygems"
2 | require 'rake'
3 | require 'yaml'
4 | require 'time'
5 |
6 | SOURCE = "."
7 | CONFIG = {
8 | 'version' => "0.3.0",
9 | 'themes' => File.join(SOURCE, "_includes", "themes"),
10 | 'layouts' => File.join(SOURCE, "_layouts"),
11 | 'posts' => File.join(SOURCE, "_posts"),
12 | 'post_ext' => "md",
13 | 'theme_package_version' => "0.1.0"
14 | }
15 |
16 | # Path configuration helper
17 | module JB
18 | class Path
19 | SOURCE = "."
20 | Paths = {
21 | :layouts => "_layouts",
22 | :themes => "_includes/themes",
23 | :theme_assets => "assets/themes",
24 | :theme_packages => "_theme_packages",
25 | :posts => "_posts"
26 | }
27 |
28 | def self.base
29 | SOURCE
30 | end
31 |
32 | # build a path relative to configured path settings.
33 | def self.build(path, opts = {})
34 | opts[:root] ||= SOURCE
35 | path = "#{opts[:root]}/#{Paths[path.to_sym]}/#{opts[:node]}".split("/")
36 | path.compact!
37 | File.__send__ :join, path
38 | end
39 |
40 | end #Path
41 | end #JB
42 |
43 | # Usage: rake post title="A Title" [date="2012-02-09"] [tags=[tag1, tag2]]
44 | desc "Begin a new post in #{CONFIG['posts']}"
45 | task :post do
46 | abort("rake aborted: '#{CONFIG['posts']}' directory not found.") unless FileTest.directory?(CONFIG['posts'])
47 | title = ENV["title"] || "new-post"
48 | tags = ENV["tags"] || "[]"
49 | slug = title.downcase.strip.gsub(' ', '-').gsub(/[^\w-]/, '')
50 | begin
51 | date = (ENV['date'] ? Time.parse(ENV['date']) : Time.now).strftime('%Y-%m-%d')
52 | rescue Exception => e
53 | puts "Error - date format must be YYYY-MM-DD, please check you typed it correctly!"
54 | exit -1
55 | end
56 | filename = File.join(CONFIG['posts'], "#{date}-#{slug}.#{CONFIG['post_ext']}")
57 | if File.exist?(filename)
58 | abort("rake aborted!") if ask("#{filename} already exists. Do you want to overwrite?", ['y', 'n']) == 'n'
59 | end
60 |
61 | puts "Creating new post: #{filename}"
62 | open(filename, 'w') do |post|
63 | post.puts "---"
64 | post.puts "layout: post"
65 | post.puts "title: \"#{title.gsub(/-/,' ')}\""
66 | post.puts 'description: ""'
67 | post.puts "category: "
68 | post.puts "tags: []"
69 | post.puts "---"
70 | post.puts "{% include JB/setup %}"
71 | end
72 | end # task :post
73 |
74 | # Usage: rake page name="about.html"
75 | # You can also specify a sub-directory path.
76 | # If you don't specify a file extention we create an index.html at the path specified
77 | desc "Create a new page."
78 | task :page do
79 | name = ENV["name"] || "new-page.md"
80 | filename = File.join(SOURCE, "#{name}")
81 | filename = File.join(filename, "index.html") if File.extname(filename) == ""
82 | title = File.basename(filename, File.extname(filename)).gsub(/[\W\_]/, " ").gsub(/\b\w/){$&.upcase}
83 | if File.exist?(filename)
84 | abort("rake aborted!") if ask("#{filename} already exists. Do you want to overwrite?", ['y', 'n']) == 'n'
85 | end
86 |
87 | mkdir_p File.dirname(filename)
88 | puts "Creating new page: #{filename}"
89 | open(filename, 'w') do |post|
90 | post.puts "---"
91 | post.puts "layout: page"
92 | post.puts "title: \"#{title}\""
93 | post.puts 'description: ""'
94 | post.puts "---"
95 | post.puts "{% include JB/setup %}"
96 | end
97 | end # task :page
98 |
99 | desc "Launch preview environment"
100 | task :preview do
101 | system "jekyll --auto --server"
102 | end # task :preview
103 |
104 | # Public: Alias - Maintains backwards compatability for theme switching.
105 | task :switch_theme => "theme:switch"
106 |
107 | namespace :theme do
108 |
109 | # Public: Switch from one theme to another for your blog.
110 | #
111 | # name - String, Required. name of the theme you want to switch to.
112 | # The the theme must be installed into your JB framework.
113 | #
114 | # Examples
115 | #
116 | # rake theme:switch name="the-program"
117 | #
118 | # Returns Success/failure messages.
119 | desc "Switch between Jekyll-bootstrap themes."
120 | task :switch do
121 | theme_name = ENV["name"].to_s
122 | theme_path = File.join(CONFIG['themes'], theme_name)
123 | settings_file = File.join(theme_path, "settings.yml")
124 | non_layout_files = ["settings.yml"]
125 |
126 | abort("rake aborted: name cannot be blank") if theme_name.empty?
127 | abort("rake aborted: '#{theme_path}' directory not found.") unless FileTest.directory?(theme_path)
128 | abort("rake aborted: '#{CONFIG['layouts']}' directory not found.") unless FileTest.directory?(CONFIG['layouts'])
129 |
130 | Dir.glob("#{theme_path}/*") do |filename|
131 | next if non_layout_files.include?(File.basename(filename).downcase)
132 | puts "Generating '#{theme_name}' layout: #{File.basename(filename)}"
133 |
134 | open(File.join(CONFIG['layouts'], File.basename(filename)), 'w') do |page|
135 | if File.basename(filename, ".html").downcase == "default"
136 | page.puts "---"
137 | page.puts File.read(settings_file) if File.exist?(settings_file)
138 | page.puts "---"
139 | else
140 | page.puts "---"
141 | page.puts "layout: default"
142 | page.puts "---"
143 | end
144 | page.puts "{% include JB/setup %}"
145 | page.puts "{% include themes/#{theme_name}/#{File.basename(filename)} %}"
146 | end
147 | end
148 |
149 | puts "=> Theme successfully switched!"
150 | puts "=> Reload your web-page to check it out =)"
151 | end # task :switch
152 |
153 | # Public: Install a theme using the theme packager.
154 | # Version 0.1.0 simple 1:1 file matching.
155 | #
156 | # git - String, Optional path to the git repository of the theme to be installed.
157 | # name - String, Optional name of the theme you want to install.
158 | # Passing name requires that the theme package already exist.
159 | #
160 | # Examples
161 | #
162 | # rake theme:install git="https://github.com/jekyllbootstrap/theme-twitter.git"
163 | # rake theme:install name="cool-theme"
164 | #
165 | # Returns Success/failure messages.
166 | desc "Install theme"
167 | task :install do
168 | if ENV["git"]
169 | manifest = theme_from_git_url(ENV["git"])
170 | name = manifest["name"]
171 | else
172 | name = ENV["name"].to_s.downcase
173 | end
174 |
175 | packaged_theme_path = JB::Path.build(:theme_packages, :node => name)
176 |
177 | abort("rake aborted!
178 | => ERROR: 'name' cannot be blank") if name.empty?
179 | abort("rake aborted!
180 | => ERROR: '#{packaged_theme_path}' directory not found.
181 | => Installable themes can be added via git. You can find some here: http://github.com/jekyllbootstrap
182 | => To download+install run: `rake theme:install git='[PUBLIC-CLONE-URL]'`
183 | => example : rake theme:install git='git@github.com:jekyllbootstrap/theme-the-program.git'
184 | ") unless FileTest.directory?(packaged_theme_path)
185 |
186 | manifest = verify_manifest(packaged_theme_path)
187 |
188 | # Get relative paths to packaged theme files
189 | # Exclude directories as they'll be recursively created. Exclude meta-data files.
190 | packaged_theme_files = []
191 | FileUtils.cd(packaged_theme_path) {
192 | Dir.glob("**/*.*") { |f|
193 | next if ( FileTest.directory?(f) || f =~ /^(manifest|readme|packager)/i )
194 | packaged_theme_files << f
195 | }
196 | }
197 |
198 | # Mirror each file into the framework making sure to prompt if already exists.
199 | packaged_theme_files.each do |filename|
200 | file_install_path = File.join(JB::Path.base, filename)
201 | if File.exist? file_install_path and ask("#{file_install_path} already exists. Do you want to overwrite?", ['y', 'n']) == 'n'
202 | next
203 | else
204 | mkdir_p File.dirname(file_install_path)
205 | cp_r File.join(packaged_theme_path, filename), file_install_path
206 | end
207 | end
208 |
209 | puts "=> #{name} theme has been installed!"
210 | puts "=> ---"
211 | if ask("=> Want to switch themes now?", ['y', 'n']) == 'y'
212 | system("rake switch_theme name='#{name}'")
213 | end
214 | end
215 |
216 | # Public: Package a theme using the theme packager.
217 | # The theme must be structured using valid JB API.
218 | # In other words packaging is essentially the reverse of installing.
219 | #
220 | # name - String, Required name of the theme you want to package.
221 | #
222 | # Examples
223 | #
224 | # rake theme:package name="twitter"
225 | #
226 | # Returns Success/failure messages.
227 | desc "Package theme"
228 | task :package do
229 | name = ENV["name"].to_s.downcase
230 | theme_path = JB::Path.build(:themes, :node => name)
231 | asset_path = JB::Path.build(:theme_assets, :node => name)
232 |
233 | abort("rake aborted: name cannot be blank") if name.empty?
234 | abort("rake aborted: '#{theme_path}' directory not found.") unless FileTest.directory?(theme_path)
235 | abort("rake aborted: '#{asset_path}' directory not found.") unless FileTest.directory?(asset_path)
236 |
237 | ## Mirror theme's template directory (_includes)
238 | packaged_theme_path = JB::Path.build(:themes, :root => JB::Path.build(:theme_packages, :node => name))
239 | mkdir_p packaged_theme_path
240 | cp_r theme_path, packaged_theme_path
241 |
242 | ## Mirror theme's asset directory
243 | packaged_theme_assets_path = JB::Path.build(:theme_assets, :root => JB::Path.build(:theme_packages, :node => name))
244 | mkdir_p packaged_theme_assets_path
245 | cp_r asset_path, packaged_theme_assets_path
246 |
247 | ## Log packager version
248 | packager = {"packager" => {"version" => CONFIG["theme_package_version"].to_s } }
249 | open(JB::Path.build(:theme_packages, :node => "#{name}/packager.yml"), "w") do |page|
250 | page.puts packager.to_yaml
251 | end
252 |
253 | puts "=> '#{name}' theme is packaged and available at: #{JB::Path.build(:theme_packages, :node => name)}"
254 | end
255 |
256 | end # end namespace :theme
257 |
258 | # Internal: Download and process a theme from a git url.
259 | # Notice we don't know the name of the theme until we look it up in the manifest.
260 | # So we'll have to change the folder name once we get the name.
261 | #
262 | # url - String, Required url to git repository.
263 | #
264 | # Returns theme manifest hash
265 | def theme_from_git_url(url)
266 | tmp_path = JB::Path.build(:theme_packages, :node => "_tmp")
267 | abort("rake aborted: system call to git clone failed") if !system("git clone #{url} #{tmp_path}")
268 | manifest = verify_manifest(tmp_path)
269 | new_path = JB::Path.build(:theme_packages, :node => manifest["name"])
270 | if File.exist?(new_path) && ask("=> #{new_path} theme package already exists. Override?", ['y', 'n']) == 'n'
271 | remove_dir(tmp_path)
272 | abort("rake aborted: '#{manifest["name"]}' already exists as theme package.")
273 | end
274 |
275 | remove_dir(new_path) if File.exist?(new_path)
276 | mv(tmp_path, new_path)
277 | manifest
278 | end
279 |
280 | # Internal: Process theme package manifest file.
281 | #
282 | # theme_path - String, Required. File path to theme package.
283 | #
284 | # Returns theme manifest hash
285 | def verify_manifest(theme_path)
286 | manifest_path = File.join(theme_path, "manifest.yml")
287 | manifest_file = File.open( manifest_path )
288 | abort("rake aborted: repo must contain valid manifest.yml") unless File.exist? manifest_file
289 | manifest = YAML.load( manifest_file )
290 | manifest_file.close
291 | manifest
292 | end
293 |
294 | def ask(message, valid_options)
295 | if valid_options
296 | answer = get_stdin("#{message} #{valid_options.to_s.gsub(/"/, '').gsub(/, /,'/')} ") while !valid_options.include?(answer)
297 | else
298 | answer = get_stdin(message)
299 | end
300 | answer
301 | end
302 |
303 | def get_stdin(message)
304 | print message
305 | STDIN.gets.chomp
306 | end
307 |
308 | #Load custom rake scripts
309 | Dir['_rake/*.rake'].each { |r| load r }
310 |
--------------------------------------------------------------------------------
/docs/ReadMe.md:
--------------------------------------------------------------------------------
1 |
2 | Steps to run the code:
3 | - git clone https://github.com/omar-florez/scratch_mlp/
4 | - python scratch_mlp/scratch_mlp.py
5 |
6 | >A **neural network** is a clever arrangement of linear and non-linear modules. When we choose and connect them wisely,
7 | we have a powerful tool to approximate any mathematical function. For example one that **separates classes with a non-linear
8 | decision boundary**.
9 |
10 | A topic that is not always explained in depth, despite of its intuitive and modular nature, is the
11 | **backpropagation technique** responsible for updating trainable parameters. Let’s build a neural network from scratch
12 | to see the internal functioning of a neural network using **LEGO pieces as a modular analogy**, one brick at a time.
13 |
14 | Code implementing this can be found in this repository: [https://github.com/omar-florez/scratch_mlp](https://github.com/omar-florez/scratch_mlp)
15 |
16 | ## Neural Networks as a Composition of Pieces
17 |
18 | 
19 |
20 | The above figure depicts some of the Math used for training a neural network. We will make sense of this during this article.
21 | The reader may find interesting that a neural network is a stack of modules with different purposes:
22 |
23 | - **Input X** feeds a neural network with raw data, which is stored in a matrix in which observations are rows and dimensions are columns
24 | - **Weights W1** maps input X to the first hidden layer h1. Weights W1 works then as a linear kernel
25 | - A **Sigmoid function** prevents numbers in the hidden layer from falling out of range by scaling them to 0-1. The result is an **array of
26 | neural activations** h1 = Sigmoid(WX)
27 |
28 | At this point these operations only compute a **general linear system**, which doesn’t have the capacity to model non-linear interactions.
29 | This changes when we stack one more layer, adding depth to this modular structure. The deeper the network, the more subtle non-linear
30 | interactions we can learn and more complex problems we can solve, which may explain in part the rise of deep neural models.
31 |
32 | ## Why should I read this?
33 |
34 | >If you understand the internal parts of a neural network, you will quickly know **what to change first** when things don't work
35 | and define an strategy to **test invariants** and **expected behaviors** that you know are part the algorithm. This will also
36 | be helpful when you want to **create new capabilities that are not currently implemented in the ML library** you are using.
37 |
38 | **Because debugging machine learning models is a complex task**. By experience, mathematical models don't
39 | work as expected the first try. They may give you low accuracy for new data, spend long training time or too much memory,
40 | return a large number of false negatives or NaN predictions, etc. Let me show some cases when knowing how the algorithm works
41 | can become handy:
42 |
43 | - If it **takes so much time to train**, it is maybe a good idea to increase the size of a minibatch to reduce the variance
44 | in the observations and thus to help the algorithm to converge
45 | - If you observe **NaN predictions**, the algorithm may have received large gradients producing memory overflow. Think of
46 | this as consecutive matrix multiplications that exploit after many iterations. Decreasing the learning rate will have the
47 | effect of scaling down these values. Reducing the number of layers will decrease the number of multiplications. And clipping
48 | gradients will control this problem explicitly
49 |
50 | ## Concrete Example: Learning the XOR Function
51 |
52 | >Let's open the blackbox. We will build now a neural network from scratch that learns the **XOR function**.
53 | The choice of this **non-linear function** is by no means random chance. Without backpropagation it would be hard to learn
54 | to separate classes with a **straight line**.
55 |
56 | To illustrate this important concept, note below how a straight line cannot
57 | separate 0s and 1s, the outputs of the XOR function. **Real life problems are also non-linearly separable**.
58 |
59 | 
60 |
61 | The topology of the network is simple:
62 | - **Input X** is a two dimensional vector
63 | - **Weights W1** is a 2x3 matrix with randomly initialized values
64 | - **Hidden layer h1** consists of three neurons. Each neuron receives as input a weighted sum of observations, this is the inner product
65 | highlighted in green in the below figure: **z1 = [x1, x2][w1, w2]**
66 | - **Weights W2** is a 3x2 matrix with randomly initialized values and
67 | - **Output layer h2** consists of two neurons since the XOR function returns either 0 (y1=[0,1]) or 1 (y2 = [1,0])
68 |
69 | More visually:
70 |
71 | 
72 |
73 | Let's now train the model. In our simple example the trainable parameters are weights, but be aware that current
74 | research is exploring more types of parameters to be optimized. For example shortcuts between layers, regularized distributions, topologies,
75 | residual, learning rates, etc.
76 |
77 | **Backpropagation** is a method to update the weights towards the direction (**gradient**) that minimizes a predefined error metric known as **Loss function**
78 | given a batch of labeled observations. This algorithm has been repeatedly rediscovered and is a special case of a more general technique called
79 | [automatic differentiation](https://en.wikipedia.org/wiki/Automatic_differentiation) in reverse accumulation mode.
80 |
81 | ### Network Initialization
82 |
83 | >Let's **initialize the network weights** with random numbers.
84 |
85 | {:width="1300px"}
86 |
87 | ### Forward Step:
88 |
89 | >This goal of this step is to **forward propagate** the input X to each layer of the network until computing a vector in
90 | the output layer h2.
91 |
92 | This is how it happens:
93 | - Linearly map input data X using weights W1 as a kernel:
94 |
95 |
96 | {:width="500px"}
97 |
98 | - Scale this weighted sum z1 with a Sigmoid function to get values of the first hidden layer h1. **Note that the original
99 | 2D vector is now mapped to a 3D space**.
100 |
101 |
102 | {:width="400px"}
103 |
104 | - A similar process takes place for the second layer h2. Let's compute first the **weighted sum** z2 of the
105 | first hidden layer, which is now input data.
106 |
107 |
108 | {:width="500px"}
109 |
110 | - And then compute their Sigmoid activation function. This vector [0.37166596 0.45414264] represents the **log probability**
111 | or **predicted vector** computed by the network given input X.
112 |
113 | {:width="300px"}
114 |
115 | ### Computing the Total Loss
116 |
117 | >Also known as "actual minus predicted", the goal of the loss function is to **quantify the distance between the predicted
118 | vector h2 and the actual label provided by humans y**.
119 |
120 | Note that the Loss function contains a **regularization component** that penalizes large weight values as in a Ridge
121 | regression. In other words, large squared weights values will increase the Loss function, **an error metric we indeed want to minimize**.
122 |
123 | 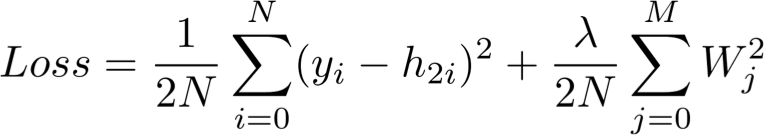{:width="500px"}
124 |
125 | ### Backward step:
126 | >The goal of this step is to **update the weights of the neural network** in a direction that minimizes its Loss function.
127 | As we will see, this is a **recursive algorithm**, which can reuse gradients previously computed and heavily relies on
128 | **differentiable functions**. Since these updates reduce the loss function, a network ‘learns’ to approximate the label
129 | of observations with known classes. A property called **generalization**.
130 |
131 | This step goes in **backward order** than the forward step. It computes first the partial derivative of the loss function
132 | with respect to the weights of the output layer (dLoss/dW2) and then the hidden layer (dLoss/dW1). Let's explain
133 | in detail each one.
134 |
135 | #### dLoss/dW2:
136 |
137 | The chain rule says that we can decompose the computation of gradients of a neural network into **differentiable pieces**:
138 |
139 | 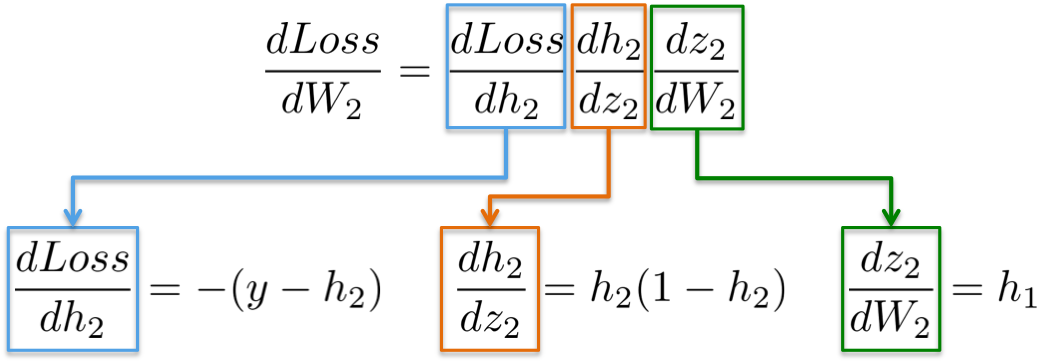{:width="500px"}
140 |
141 | As a memory helper, these are the **function definitions** used above and their **first derivatives**:
142 |
143 | | Function | First derivative |
144 | |------------------------------------------------------------ |------------------------------------------------------------|
145 | |Loss = (y-h2)^2 | dLoss/dW2 = -(y-h2) |
146 | |h2 = Sigmoid(z2) | dh2/dz2 = h2(1-h2) |
147 | |z2 = h1W2 | dz2/dW2 = h1 |
148 | |z2 = h1W2 | dz2/dh1 = W2 |
149 |
150 |
151 | More visually, we aim to update the weights W2 (in blue) in the below figure. In order to that, we need to compute
152 | three **partial derivatives along the chain**.
153 |
154 | 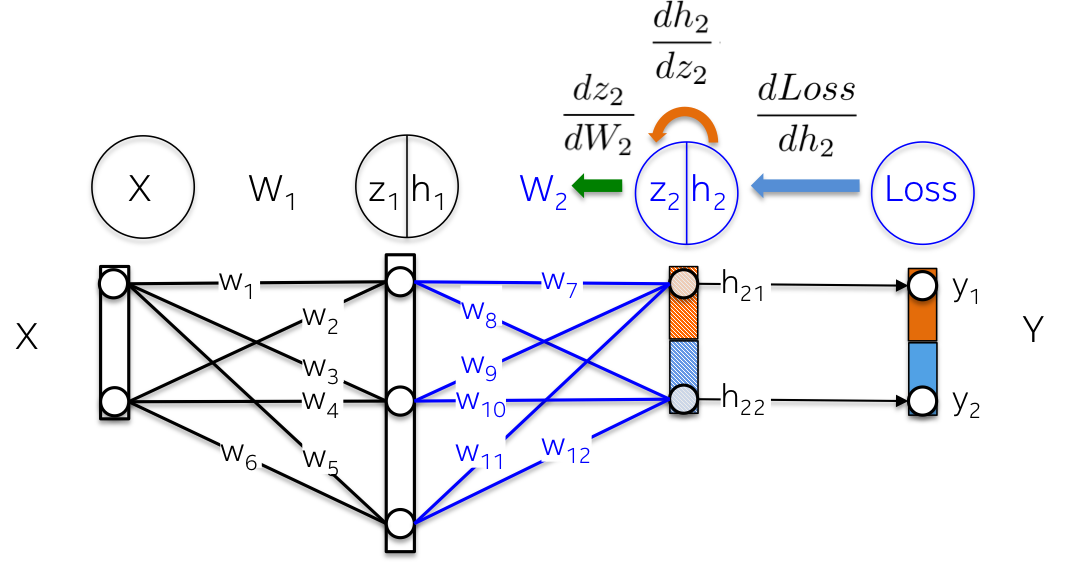{:width="500px"}
155 |
156 | Plugging in values into these partial derivatives allow us to compute gradients with respect to weights W2 as follows.
157 |
158 | 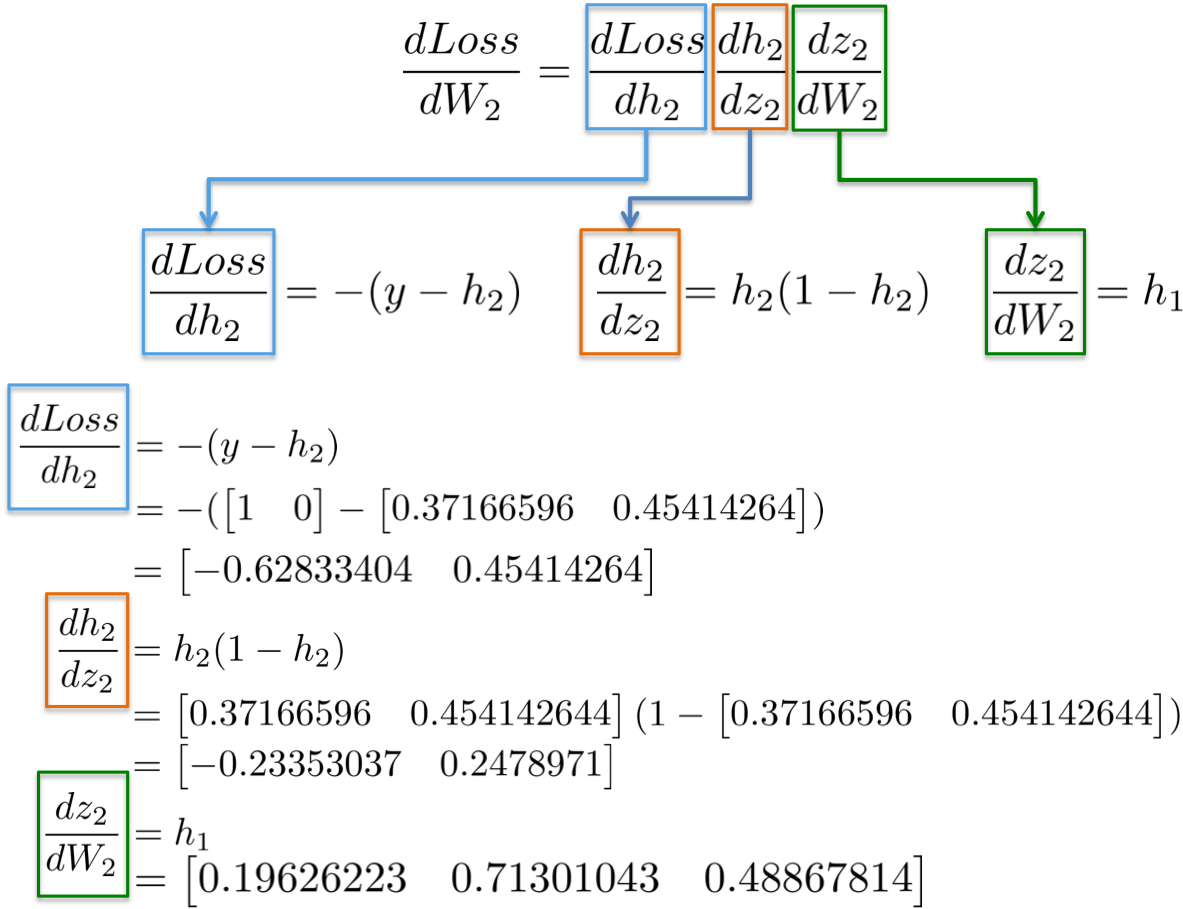{:width="600px"}
159 |
160 | The result is a 3x2 matrix dLoss/dW2, which will update the original W2 values in a direction that minimizes the Loss function.
161 |
162 | 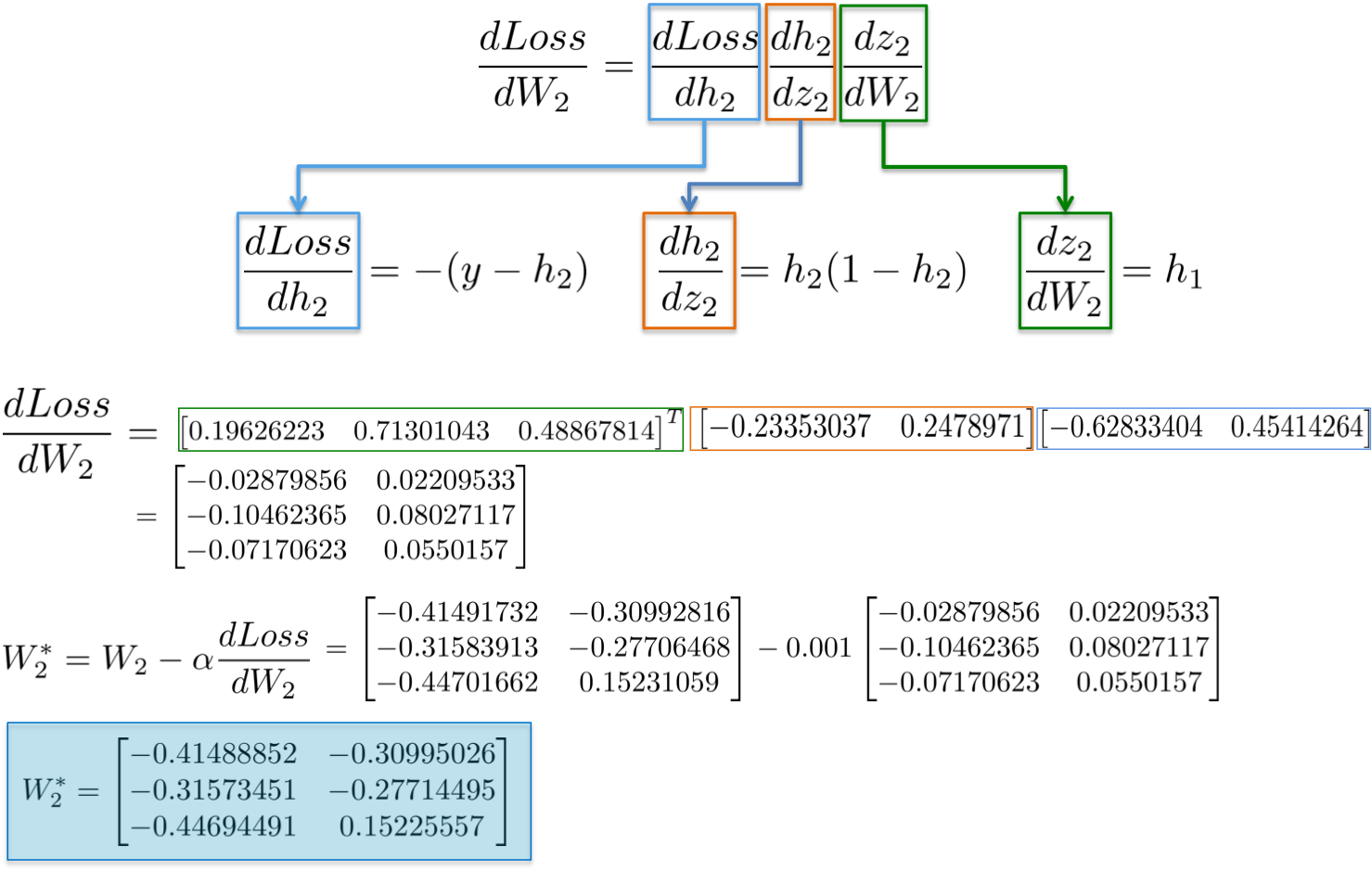{:width="700px"}
163 |
164 | #### dLoss/dW1:
165 |
166 | Computing the **chain rule** for updating the weights of the first hidden layer W1 exhibits the possibility of **reusing existing
167 | computations**.
168 |
169 | 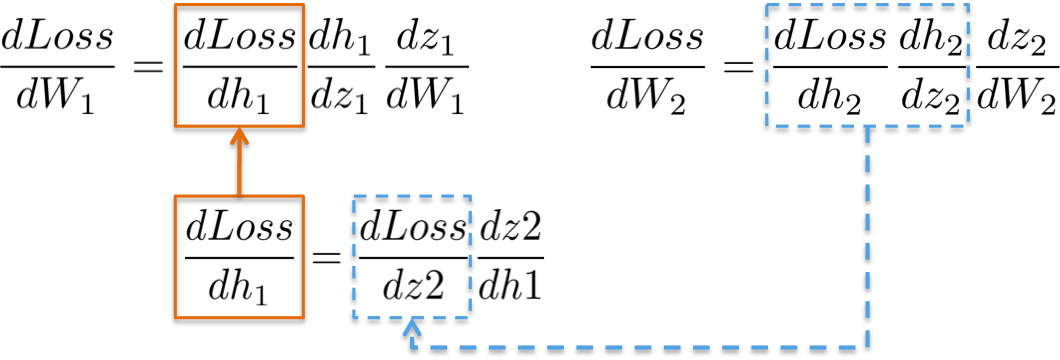{:width="500px"}
170 |
171 | More visually, the **path from the output layer to the weights W1** touches partial derivatives already computed in **latter
172 | layers**.
173 |
174 | 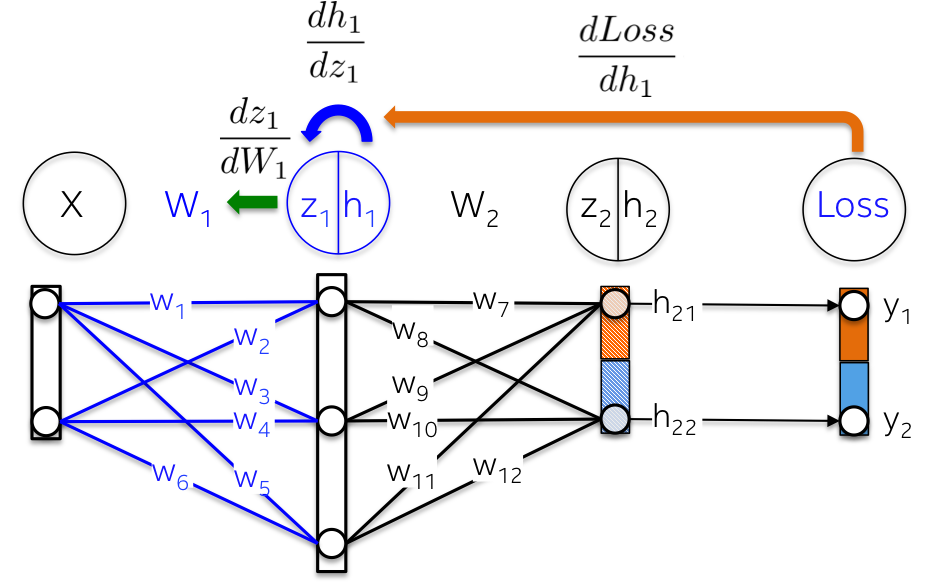{:width="500px"}
175 |
176 | For example, partial derivatives dLoss/dh2 and dh2/dz2 have been already computed as a dependency for learning weights
177 | of the output layer dLoss/dW2 in the previous section.
178 |
179 | 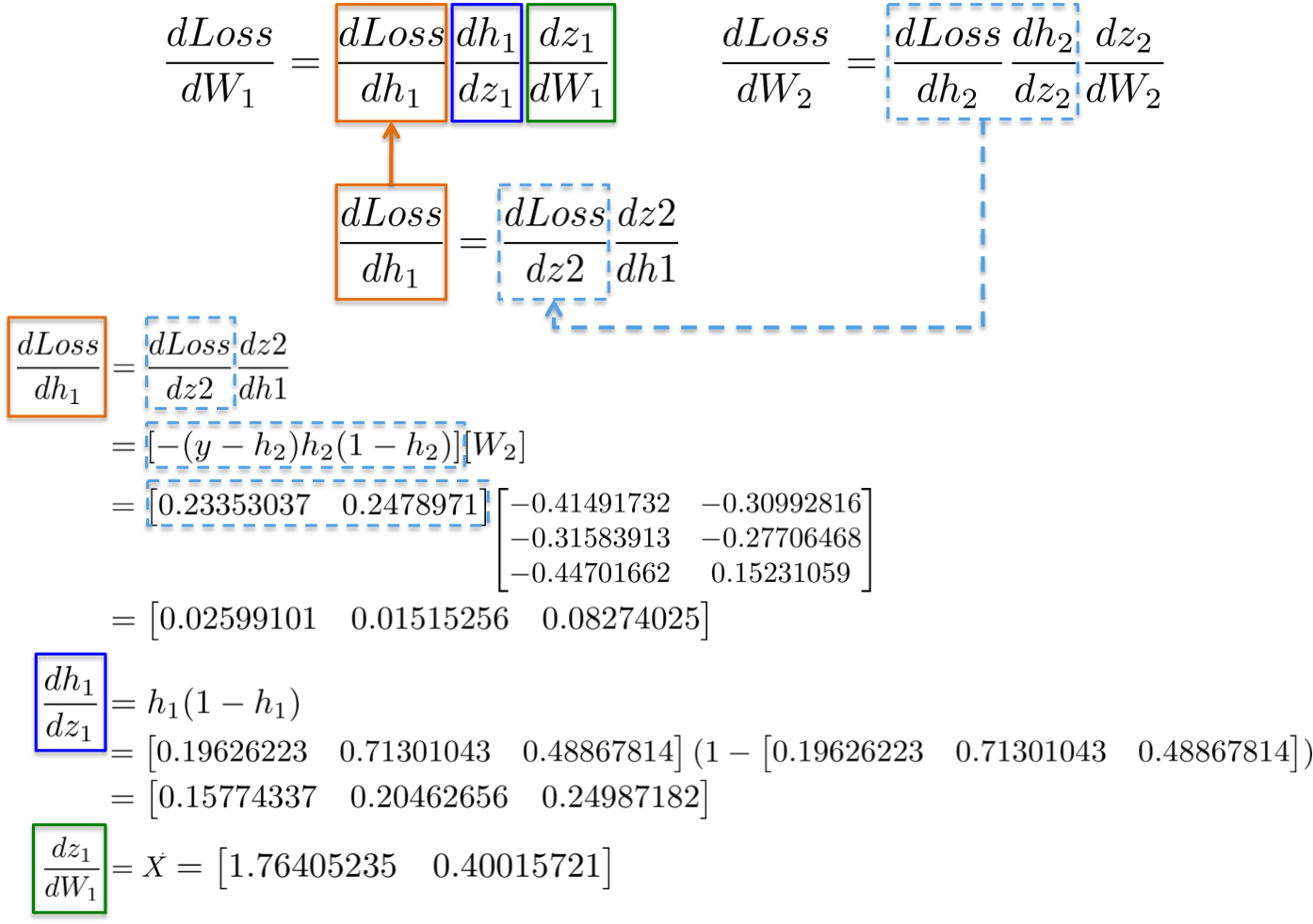{:width="700px"}
180 |
181 | Placing all derivatives together, we can execute the **chain rule** again to update the weights of the hidden layer W1:
182 |
183 | 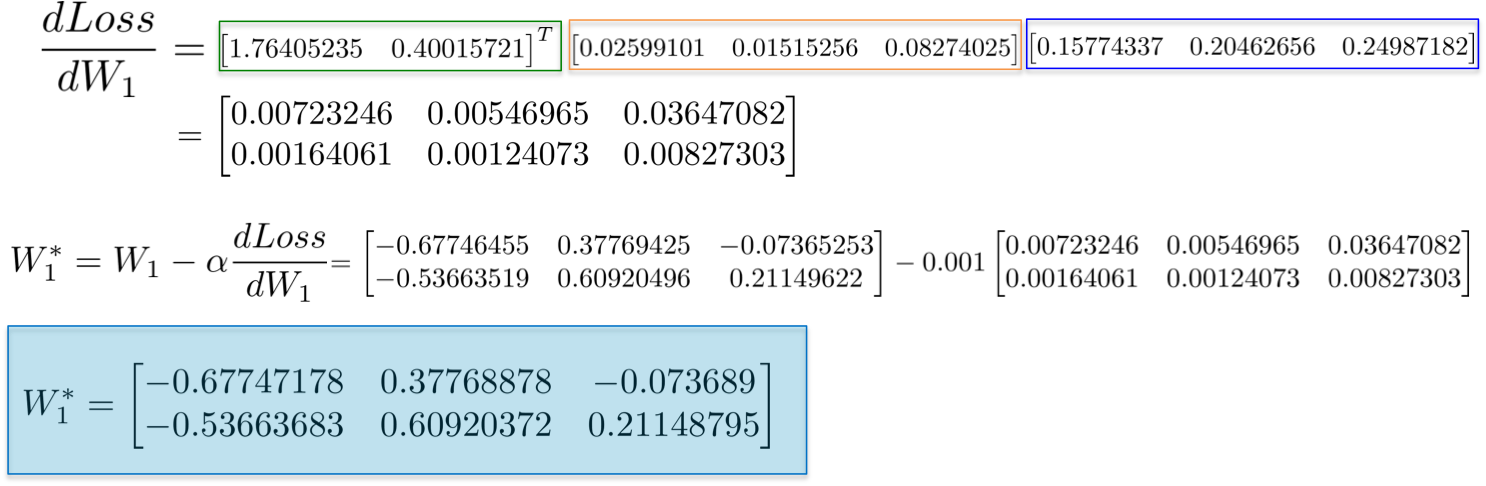{:width="700px"}
184 |
185 | Finally, we assign the new values of the weights and have completed an iteration on the training of network.
186 |
187 | 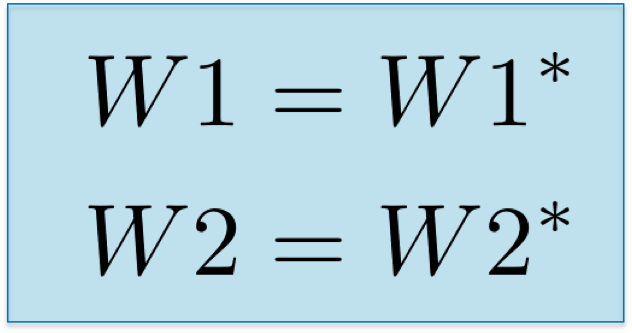{:width="150px"}
188 |
189 | ### Implementation
190 |
191 | Let's translate the above mathematical equations to code only using [Numpy](http://www.numpy.org/) as our **linear algebra engine**.
192 | Neural networks are trained in a loop in which each iteration present already **calibrated input data** to the network.
193 | In this small example, let's just consider the entire dataset in each iteration. The computations of **Forward step**,
194 | **Loss**, and **Backwards step** lead to good generalization since we update the **trainable parameters** (matrices w1 and
195 | w2 in the code) with their corresponding **gradients** (matrices dL_dw1 and dL_dw2) in every cycle.
196 | Code is stored in this repository: [https://github.com/omar-florez/scratch_mlp](https://github.com/omar-florez/scratch_mlp)
197 |
198 | 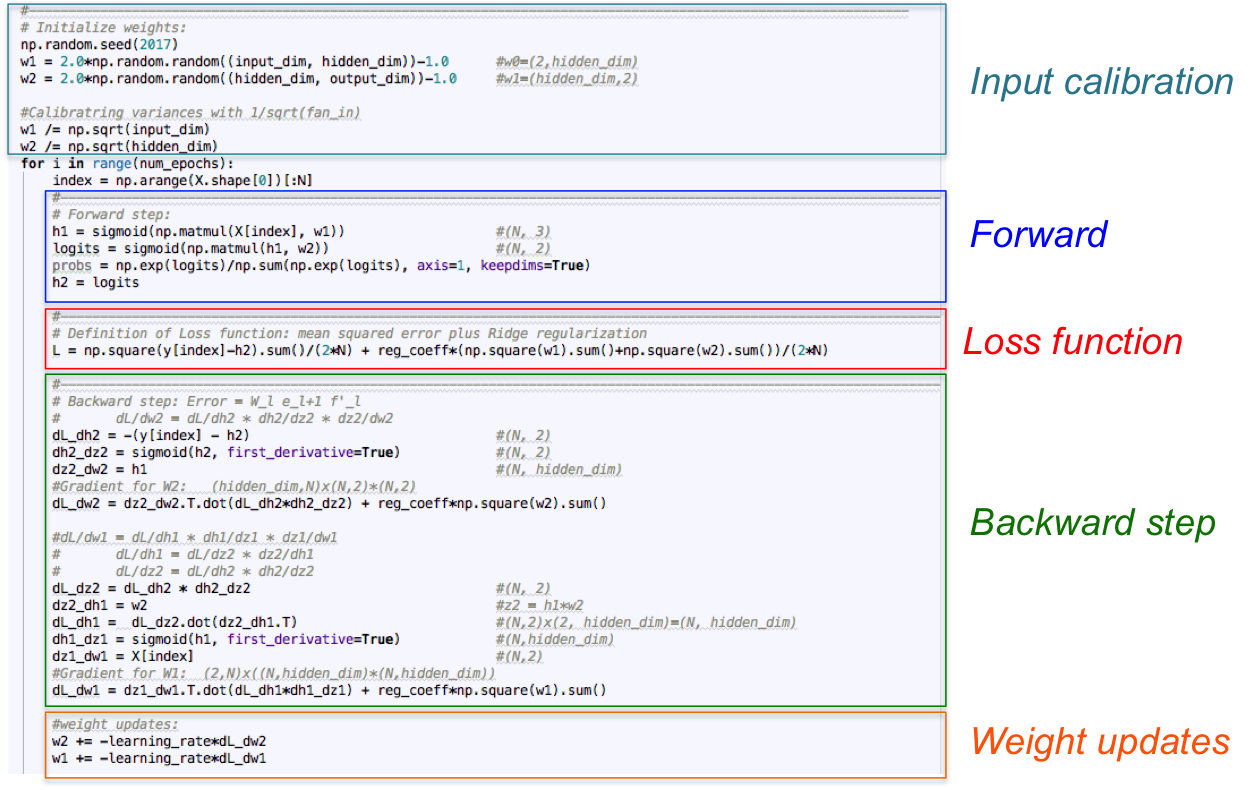
199 |
200 | ### Let's Run This!
201 |
202 | See below **some neural networks** trained to approximate the **XOR function** over many iterations.
203 |
204 | **Left plot:** Accuracy. **Central plot:** Learned decision boundary. **Right plot:** Loss function.
205 |
206 | First let's see how a neural network with **3 neurons** in the hidden layer has small capacity. This model learns to separate 2 classes
207 | with a **simple decision boundary** that starts being a straight line but then shows a non-linear behavior.
208 | The loss function in the right plot nicely gets low as training continues.
209 |
210 | 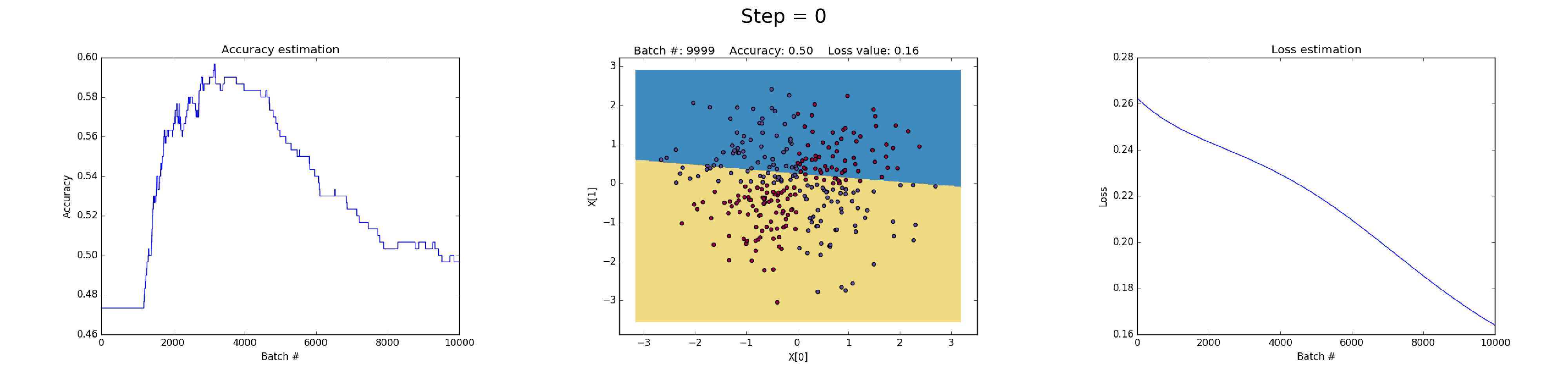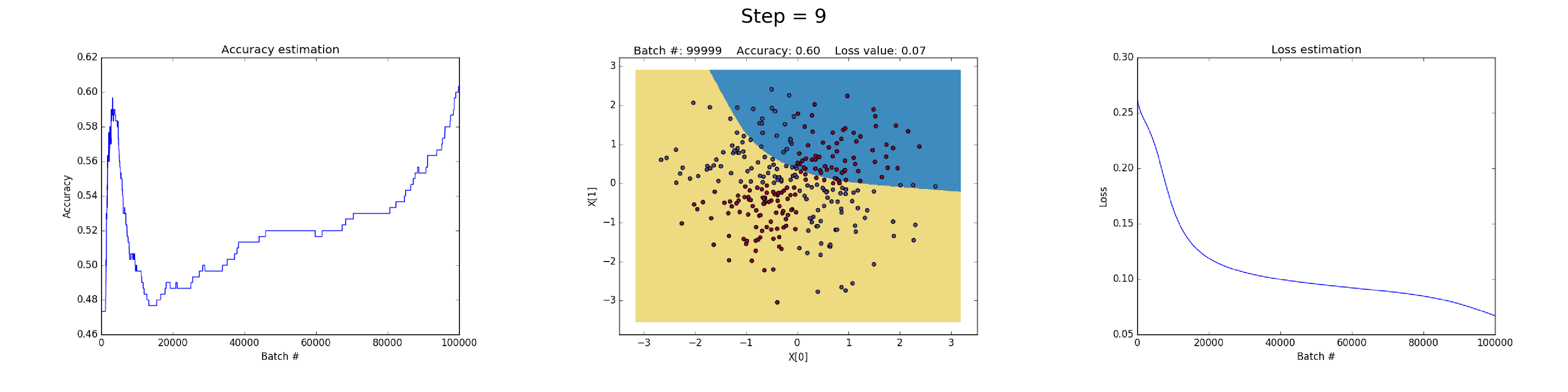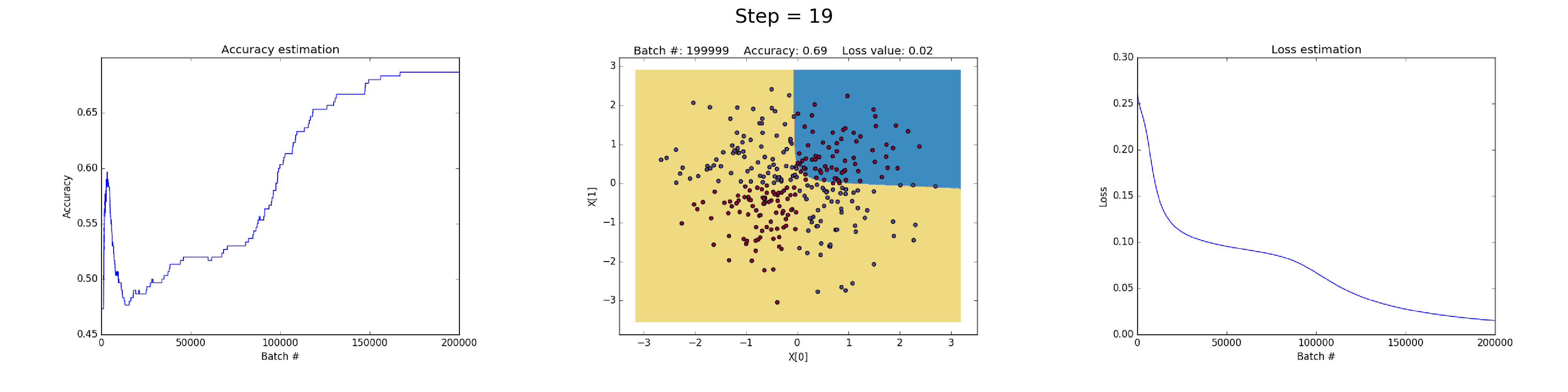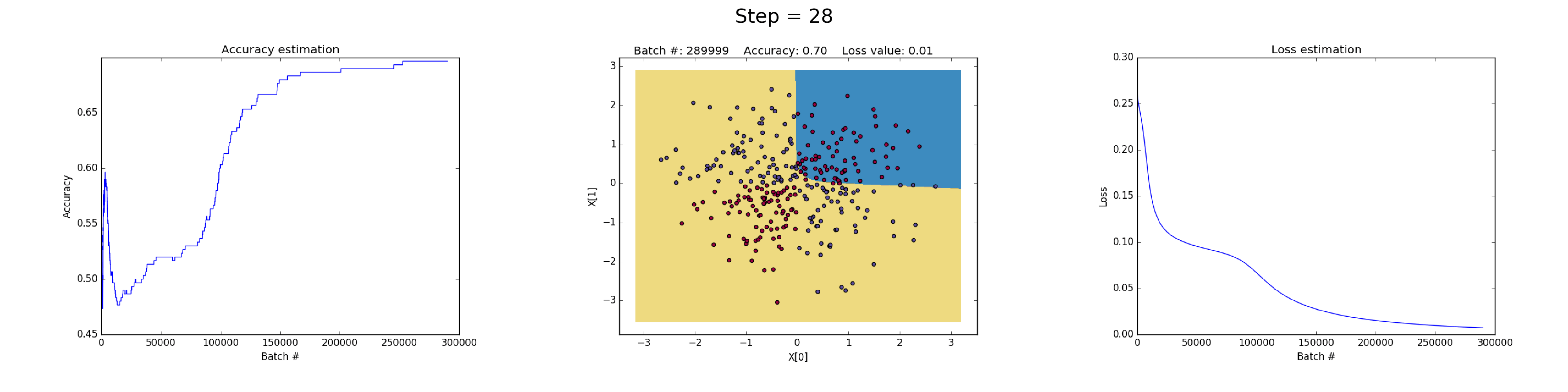
211 |
212 | Having **50 neurons** in the hidden layer notably increases model's power to learn more **complex decision boundaries**.
213 | This could not only produce more accurate results, but also **exploiting gradients**, a notable problem when training neural networks.
214 | This happens when very large gradients multiply weights during backpropagation and thus generate large updated weights.
215 | This is reason why the **Loss value suddenly increases** during the last steps of the training (step > 90).
216 | The **regularization component** of the Loss function computes the **squared values** of weights that are already very large (sum(W^2)/2N).
217 |
218 | 
219 |
220 | This problem can be avoided by **reducing the learning rate** as you can see below. Or by implementing a policy that reduces
221 | the learning rate over time. Or by enforcing a stronger regularization, maybe L1 instead of L2.
222 | **Exploiding** and **vanishing gradients** are interesting phenomenons and we will devote an entire analysis later.
223 |
224 | 
225 |
226 |
--------------------------------------------------------------------------------
/docs/_config.yml:
--------------------------------------------------------------------------------
1 | # This is the default format.
2 | # For more see: https://github.com/mojombo/jekyll/wiki/Permalinks
3 | permalink: /:categories/:year/:month/:day/:title
4 |
5 | exclude: [".rvmrc", ".rbenv-version", "ReadMe.md", "Rakefile", "changelog.md", "License.md"]
6 | highlighter: rouge
7 |
8 | # Themes are encouraged to use these universal variables
9 | # so be sure to set them if your theme uses them.
10 | #
11 | title : Omar U. Florez
12 | author :
13 | name : Omar U. Florez
14 | email : omar.florez@aggiemail.usu.edu
15 | github : omar-florez
16 | twitter : OmarUFlorez
17 | feedburner : nil
18 |
19 | # NOTE: If replacing this next line with your own URL, you likely want "https://" not "http://"
20 | production_url : https://omar-florez.github.io/scratch_mlp
21 |
22 | # Tell Github to use the kramdown markdown interpreter
23 | # (see https://help.github.com/articles/migrating-your-pages-site-from-maruku)
24 | markdown: kramdown
25 |
26 | # All Jekyll-Bootstrap specific configurations are namespaced into this hash
27 | #
28 | JB :
29 | version : 0.3.0
30 |
31 | # All links will be namespaced by BASE_PATH if defined.
32 | # Links in your website should always be prefixed with {{BASE_PATH}}
33 | # however this value will be dynamically changed depending on your deployment situation.
34 | #
35 | # CNAME (http://yourcustomdomain.com)
36 | # DO NOT SET BASE_PATH
37 | # (urls will be prefixed with "/" and work relatively)
38 | #
39 | # GitHub Pages (http://username.github.io)
40 | # DO NOT SET BASE_PATH
41 | # (urls will be prefixed with "/" and work relatively)
42 | #
43 | # GitHub Project Pages (http://username.github.io/project-name)
44 | #
45 | # A GitHub Project site exists in the `gh-pages` branch of one of your repositories.
46 | # REQUIRED! Set BASE_PATH to: http://username.github.io/project-name
47 | #
48 | # CAUTION:
49 | # - When in Localhost, your site will run from root "/" regardless of BASE_PATH
50 | # - Only the following values are falsy: ["", null, false]
51 | # - When setting BASE_PATH it must be a valid url.
52 | # This means always setting the protocol (http|https) or prefixing with "/"
53 | #
54 | # NOTE: If replacing this next line with your own URL, you likely want "https://" not "http://"
55 | BASE_PATH : https://omar-florez.github.io/scratch_mlp
56 |
57 | # By default, the asset_path is automatically defined relative to BASE_PATH plus the enabled theme.
58 | # ex: [BASE_PATH]/assets/themes/[THEME-NAME]
59 | #
60 | # Override this by defining an absolute path to assets here.
61 | # ex:
62 | # http://s3.amazonaws.com/yoursite/themes/watermelon
63 | # /assets
64 | #
65 | # ASSET_PATH : http://kbroman.org/simple_site/assets/themes/twitter
66 |
67 | # These paths are to the main pages Jekyll-Bootstrap ships with.
68 | # Some JB helpers refer to these paths; change them here if needed.
69 | #
70 | archive_path: nil
71 | categories_path : nil
72 | tags_path : nil
73 | atom_path : nil
74 | rss_path : nil
75 |
76 | # Settings for comments helper
77 | # Set 'provider' to the comment provider you want to use.
78 | # Set 'provider' to false to turn commenting off globally.
79 | #
80 | comments :
81 | provider : false
82 |
83 | # Settings for analytics helper
84 | # Set 'provider' to the analytics provider you want to use.
85 | # Set 'provider' to false to turn analytics off globally.
86 | #
87 | analytics :
88 | provider : false
89 |
90 | # Settings for sharing helper.
91 | # Sharing is for things like tweet, plusone, like, reddit buttons etc.
92 | # Set 'provider' to the sharing provider you want to use.
93 | # Set 'provider' to false to turn sharing off globally.
94 | #
95 | sharing :
96 | provider : true
97 |
98 | # Settings for all other include helpers can be defined by creating
99 | # a hash with key named for the given helper. ex:
100 | #
101 | # pages_list :
102 | # provider : "custom"
103 | #
104 | # Setting any helper's provider to 'custom' will bypass the helper code
105 | # and include your custom code. Your custom file must be defined at:
106 | # ./_includes/custom/[HELPER]
107 | # where [HELPER] is the name of the helper you are overriding.
108 |
109 | theme: jekyll-theme-leap-day
--------------------------------------------------------------------------------
/docs/_includes/JB/analytics:
--------------------------------------------------------------------------------
1 | {% if site.safe and site.JB.analytics.provider and page.JB.analytics != false %}
2 |
3 | {% case site.JB.analytics.provider %}
4 | {% when "google" %}
5 | {% include JB/analytics-providers/google %}
6 | {% when "getclicky" %}
7 | {% include JB/analytics-providers/getclicky %}
8 | {% when "mixpanel" %}
9 | {% include JB/analytics-providers/mixpanel %}
10 | {% when "custom" %}
11 | {% include custom/analytics %}
12 | {% endcase %}
13 |
14 | {% endif %}
--------------------------------------------------------------------------------
/docs/_includes/JB/analytics-providers/getclicky:
--------------------------------------------------------------------------------
1 |
12 |
13 |
--------------------------------------------------------------------------------
/docs/_includes/JB/analytics-providers/google:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/docs/_includes/JB/analytics-providers/mixpanel:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/docs/_includes/JB/categories_list:
--------------------------------------------------------------------------------
1 | {% comment %}{% endcomment %}
19 |
20 | {% if site.JB.categories_list.provider == "custom" %}
21 | {% include custom/categories_list %}
22 | {% else %}
23 | {% if categories_list.first[0] == null %}
24 | {% for category in categories_list %}
25 |