├── BasicLSTM
├── .idea
│ ├── BasicLSTM.iml
│ ├── misc.xml
│ ├── modules.xml
│ └── workspace.xml
├── main.py
└── rnn_utils.py
├── BasicRNN
├── .idea
│ ├── BasicRNN.iml
│ ├── misc.xml
│ ├── modules.xml
│ └── workspace.xml
├── main.py
└── rnn_utils.py
├── MusicGenerationProject
├── .idea
│ ├── MusicGeneration.iml
│ ├── misc.xml
│ ├── modules.xml
│ └── workspace.xml
├── Results.txt
├── __pycache__
│ ├── data_utils.cpython-35.pyc
│ ├── grammar.cpython-35.pyc
│ ├── music_utils.cpython-35.pyc
│ ├── preprocess.cpython-35.pyc
│ └── qa.cpython-35.pyc
├── data
│ └── original_metheny.mid
├── data_utils.py
├── grammar.py
├── inference_code.py
├── main.py
├── midi.py
├── music_utils.py
├── output
│ └── my_music.midi
├── preprocess.py
└── qa.py
├── README.md
├── SentimentAnalysisProject
├── .idea
│ ├── SentimentAnalysis.iml
│ ├── misc.xml
│ ├── modules.xml
│ ├── vcs.xml
│ └── workspace.xml
├── Results.txt
├── __pycache__
│ └── emo_utils.cpython-35.pyc
├── emo_utils.py
├── emojify_data.csv
├── main.py
├── test_emoji.csv
└── train_emoji.csv
└── StockPricesPredictionProject
├── .idea
├── misc.xml
├── modules.xml
├── stockPricePredictionLSTM.iml
└── workspace.xml
├── DIS.csv
├── DIS_prediction_and_actualprice.png
├── lstm_result.csv
└── pricePredictionLSTM.py
/BasicLSTM/.idea/BasicLSTM.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
--------------------------------------------------------------------------------
/BasicLSTM/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
--------------------------------------------------------------------------------
/BasicLSTM/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/BasicLSTM/.idea/workspace.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
45 |
46 |
47 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
89 |
90 |
91 |
92 |
93 |
103 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
111 |
112 |
113 |
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
131 |
132 |
133 |
134 |
135 |
136 |
137 |
138 |
139 |
140 |
141 |
142 |
143 |
144 |
145 |
146 |
147 |
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 |
157 |
158 |
159 |
160 |
161 |
162 |
163 |
164 |
165 |
166 |
167 |
168 |
169 |
170 |
171 |
172 |
173 |
174 |
175 |
176 | 1534709418862
177 |
178 |
179 | 1534709418862
180 |
181 |
182 |
183 |
184 |
185 |
186 |
187 |
188 |
189 |
190 |
191 |
192 |
193 |
194 |
195 |
196 |
197 |
198 |
199 |
200 |
201 |
202 |
203 |
204 |
205 |
206 |
207 |
208 |
209 |
210 |
211 |
212 |
213 |
214 |
215 |
216 |
217 |
218 |
219 |
220 |
221 |
222 |
223 |
224 |
225 |
226 |
227 |
228 |
229 |
230 |
231 |
232 |
233 |
234 |
--------------------------------------------------------------------------------
/BasicLSTM/main.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from rnn_utils import *
3 |
4 |
5 | def lstm_cell_forward(xt, a_prev, c_prev, parameters):
6 | """
7 | Arguments:
8 | xt -- your input data at timestep "t", numpy array of shape (n_x, m).
9 | a_prev -- Hidden state at timestep "t-1", numpy array of shape (n_a, m)
10 | c_prev -- Memory state at timestep "t-1", numpy array of shape (n_a, m)
11 | parameters -- python dictionary containing:
12 | Wf -- Weight matrix of the forget gate, numpy array of shape (n_a, n_a + n_x)
13 | bf -- Bias of the forget gate, numpy array of shape (n_a, 1)
14 | Wi -- Weight matrix of the update gate, numpy array of shape (n_a, n_a + n_x)
15 | bi -- Bias of the update gate, numpy array of shape (n_a, 1)
16 | Wc -- Weight matrix of the first "tanh", numpy array of shape (n_a, n_a + n_x)
17 | bc -- Bias of the first "tanh", numpy array of shape (n_a, 1)
18 | Wo -- Weight matrix of the output gate, numpy array of shape (n_a, n_a + n_x)
19 | bo -- Bias of the output gate, numpy array of shape (n_a, 1)
20 | Wy -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a)
21 | by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1)
22 |
23 | Returns:
24 | a_next -- next hidden state, of shape (n_a, m)
25 | c_next -- next memory state, of shape (n_a, m)
26 | yt_pred -- prediction at timestep "t", numpy array of shape (n_y, m)
27 | cache -- tuple of values needed for the backward pass, contains (a_next, c_next, a_prev, c_prev, xt, parameters)
28 |
29 | Note: ft/it/ot stand for the forget/update/output gates, cct stands for the candidate value (c tilde),
30 | c stands for the memory value
31 | """
32 |
33 | # Retrieve parameters from "parameters"
34 | Wf = parameters["Wf"]
35 | bf = parameters["bf"]
36 | Wi = parameters["Wi"]
37 | bi = parameters["bi"]
38 | Wc = parameters["Wc"]
39 | bc = parameters["bc"]
40 | Wo = parameters["Wo"]
41 | bo = parameters["bo"]
42 | Wy = parameters["Wy"]
43 | by = parameters["by"]
44 |
45 | # Retrieve dimensions from shapes of xt and Wy
46 | n_x, m = xt.shape
47 | n_y, n_a = Wy.shape
48 |
49 | # Concatenate a_prev and xt
50 | concat = np.zeros((n_a + n_x, m))
51 | concat[: n_a, :] = a_prev
52 | concat[n_a:, :] = xt
53 |
54 | # Compute values for ft, it, cct, c_next, ot, a_next
55 | ft = sigmoid(np.matmul(Wf, concat) + bf)
56 | it = sigmoid(np.matmul(Wi, concat) + bi)
57 | cct = np.tanh(np.matmul(Wc, concat) + bc)
58 | c_next = (ft * c_prev) + (it * cct)
59 | ot = sigmoid(np.matmul(Wo, concat) + bo)
60 | a_next = ot * np.tanh(c_next)
61 |
62 | # Compute prediction of the LSTM cell
63 | yt_pred = softmax(np.matmul(Wy, a_next) + by)
64 |
65 | # store values needed for backward propagation in cache
66 | cache = (a_next, c_next, a_prev, c_prev, ft, it, cct, ot, xt, parameters)
67 |
68 | return a_next, c_next, yt_pred, cache
69 |
70 |
71 | def lstm_cell_backward(da_next, dc_next, cache):
72 | """
73 | Arguments:
74 | da_next -- Gradients of next hidden state, of shape (n_a, m)
75 | dc_next -- Gradients of next cell state, of shape (n_a, m)
76 | cache -- cache storing information from the forward pass
77 |
78 | Returns:
79 | gradients -- python dictionary containing:
80 | dxt -- Gradient of input data at time-step t, of shape (n_x, m)
81 | da_prev -- Gradient w.r.t. the previous hidden state, numpy array of shape (n_a, m)
82 | dc_prev -- Gradient w.r.t. the previous memory state, of shape (n_a, m, T_x)
83 | dWf -- Gradient w.r.t. the weight matrix of the forget gate, numpy array of shape (n_a, n_a + n_x)
84 | dWi -- Gradient w.r.t. the weight matrix of the update gate, numpy array of shape (n_a, n_a + n_x)
85 | dWc -- Gradient w.r.t. the weight matrix of the memory gate, numpy array of shape (n_a, n_a + n_x)
86 | dWo -- Gradient w.r.t. the weight matrix of the output gate, numpy array of shape (n_a, n_a + n_x)
87 | dbf -- Gradient w.r.t. biases of the forget gate, of shape (n_a, 1)
88 | dbi -- Gradient w.r.t. biases of the update gate, of shape (n_a, 1)
89 | dbc -- Gradient w.r.t. biases of the memory gate, of shape (n_a, 1)
90 | dbo -- Gradient w.r.t. biases of the output gate, of shape (n_a, 1)
91 | """
92 |
93 | # Retrieve information from "cache"
94 | (a_next, c_next, a_prev, c_prev, ft, it, cct, ot, xt, parameters) = cache
95 |
96 | # Retrieve dimensions from xt's and a_next's shape
97 | n_x, m = xt.shape
98 | n_a, m = a_next.shape
99 |
100 | # Compute gates related derivatives
101 | dot = da_next * np.tanh(c_next) * ot * (1 - ot)
102 | dcct = (dc_next * it + ot * (1 - np.square(np.tanh(c_next))) * it * da_next) * (1 - np.square(cct))
103 | dit = (dc_next * cct + ot * (1 - np.square(np.tanh(c_next))) * cct * da_next) * it * (1 - it)
104 | dft = (dc_next * c_prev + ot * (1 - np.square(np.tanh(c_next))) * c_prev * da_next) * ft * (1 - ft)
105 |
106 | concat = np.concatenate((a_prev, xt), axis=0)
107 |
108 | # Compute parameters related derivatives.
109 | dWf = np.dot(dft, concat.T)
110 | dWi = np.dot(dit, concat.T)
111 | dWc = np.dot(dcct, concat.T)
112 | dWo = np.dot(dot, concat.T)
113 | dbf = np.sum(dft, axis=1, keepdims=True)
114 | dbi = np.sum(dit, axis=1, keepdims=True)
115 | dbc = np.sum(dcct, axis=1, keepdims=True)
116 | dbo = np.sum(dot, axis=1, keepdims=True)
117 |
118 | # Compute derivatives w.r.t previous hidden state, previous memory state and input. Use equations (15)-(17). (≈3 lines)
119 | da_prev = np.dot(parameters['Wf'][:, :n_a].T, dft) + np.dot(parameters['Wi'][:, :n_a].T, dit) + np.dot(
120 | parameters['Wc'][:, :n_a].T, dcct) + np.dot(parameters['Wo'][:, :n_a].T, dot)
121 | dc_prev = dc_next * ft + ot * (1 - np.square(np.tanh(c_next))) * ft * da_next
122 | dxt = np.dot(parameters['Wf'][:, n_a:].T, dft) + np.dot(parameters['Wi'][:, n_a:].T, dit) + np.dot(
123 | parameters['Wc'][:, n_a:].T, dcct) + np.dot(parameters['Wo'][:, n_a:].T, dot)
124 |
125 | # Save gradients in dictionary
126 | gradients = {"dxt": dxt, "da_prev": da_prev, "dc_prev": dc_prev, "dWf": dWf, "dbf": dbf, "dWi": dWi, "dbi": dbi,
127 | "dWc": dWc, "dbc": dbc, "dWo": dWo, "dbo": dbo}
128 |
129 | return gradients
130 |
131 | def lstm_forward(x, a0, parameters):
132 | """
133 | Arguments:
134 | x -- Input data for every time-step, of shape (n_x, m, T_x).
135 | a0 -- Initial hidden state, of shape (n_a, m)
136 | parameters -- python dictionary containing:
137 | Wf -- Weight matrix of the forget gate, numpy array of shape (n_a, n_a + n_x)
138 | bf -- Bias of the forget gate, numpy array of shape (n_a, 1)
139 | Wi -- Weight matrix of the update gate, numpy array of shape (n_a, n_a + n_x)
140 | bi -- Bias of the update gate, numpy array of shape (n_a, 1)
141 | Wc -- Weight matrix of the first "tanh", numpy array of shape (n_a, n_a + n_x)
142 | bc -- Bias of the first "tanh", numpy array of shape (n_a, 1)
143 | Wo -- Weight matrix of the output gate, numpy array of shape (n_a, n_a + n_x)
144 | bo -- Bias of the output gate, numpy array of shape (n_a, 1)
145 | Wy -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a)
146 | by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1)
147 |
148 | Returns:
149 | a -- Hidden states for every time-step, numpy array of shape (n_a, m, T_x)
150 | y -- Predictions for every time-step, numpy array of shape (n_y, m, T_x)
151 | caches -- tuple of values needed for the backward pass, contains (list of all the caches, x)
152 | """
153 |
154 | # Initialize "caches", which will track the list of all the caches
155 | caches = []
156 |
157 | # Retrieve dimensions from shapes of x and parameters['Wy']
158 | n_x, m, T_x = x.shape
159 | n_y, n_a = parameters["Wy"].shape
160 |
161 | # initialize "a", "c" and "y" with zeros
162 | a = np.zeros((n_a, m, T_x))
163 | c = a
164 | y = np.zeros((n_y, m, T_x))
165 |
166 | # Initialize a_next and c_next
167 | a_next = a0
168 | c_next = np.zeros(a_next.shape)
169 |
170 | # loop over all time-steps
171 | for t in range(T_x):
172 | # Update next hidden state, next memory state, compute the prediction, get the cache
173 | a_next, c_next, yt, cache = lstm_cell_forward(x[:, :, t], a_next, c_next, parameters)
174 | # Save the value of the new "next" hidden state in a
175 | a[:, :, t] = a_next
176 | # Save the value of the prediction in y
177 | y[:, :, t] = yt
178 | # Save the value of the next cell state
179 | c[:, :, t] = c_next
180 | # Append the cache into caches
181 | caches.append(cache)
182 |
183 | # store values needed for backward propagation in cache
184 | caches = (caches, x)
185 |
186 | return a, y, c, caches
187 |
188 |
189 | def lstm_backward(da, caches):
190 | """
191 | Arguments:
192 | da -- Gradients w.r.t the hidden states, numpy-array of shape (n_a, m, T_x)
193 | dc -- Gradients w.r.t the memory states, numpy-array of shape (n_a, m, T_x)
194 | caches -- cache storing information from the forward pass (lstm_forward)
195 |
196 | Returns:
197 | gradients -- python dictionary containing:
198 | dx -- Gradient of inputs, of shape (n_x, m, T_x)
199 | da0 -- Gradient w.r.t. the previous hidden state, numpy array of shape (n_a, m)
200 | dWf -- Gradient w.r.t. the weight matrix of the forget gate, numpy array of shape (n_a, n_a + n_x)
201 | dWi -- Gradient w.r.t. the weight matrix of the update gate, numpy array of shape (n_a, n_a + n_x)
202 | dWc -- Gradient w.r.t. the weight matrix of the memory gate, numpy array of shape (n_a, n_a + n_x)
203 | dWo -- Gradient w.r.t. the weight matrix of the save gate, numpy array of shape (n_a, n_a + n_x)
204 | dbf -- Gradient w.r.t. biases of the forget gate, of shape (n_a, 1)
205 | dbi -- Gradient w.r.t. biases of the update gate, of shape (n_a, 1)
206 | dbc -- Gradient w.r.t. biases of the memory gate, of shape (n_a, 1)
207 | dbo -- Gradient w.r.t. biases of the save gate, of shape (n_a, 1)
208 | """
209 |
210 | # Retrieve values from the first cache (t=1) of caches.
211 | (caches, x) = caches
212 | (a1, c1, a0, c0, f1, i1, cc1, o1, x1, parameters) = caches[0]
213 |
214 | # Retrieve dimensions from da's and x1's shapes
215 | n_a, m, T_x = da.shape
216 | n_x, m = x1.shape
217 |
218 | # initialize the gradients with the right sizes
219 | dx = np.zeros((n_x, m, T_x))
220 | da0 = np.zeros((n_a, m))
221 | da_prevt = np.zeros(da0.shape)
222 | dc_prevt = np.zeros(da0.shape)
223 | dWf = np.zeros((n_a, n_a + n_x))
224 | dWi = np.zeros(dWf.shape)
225 | dWc = np.zeros(dWf.shape)
226 | dWo = np.zeros(dWf.shape)
227 | dbf = np.zeros((n_a, 1))
228 | dbi = np.zeros(dbf.shape)
229 | dbc = np.zeros(dbf.shape)
230 | dbo = np.zeros(dbf.shape)
231 |
232 | # loop back over the whole sequence
233 | for t in reversed(range(T_x)):
234 | # Compute all gradients using lstm_cell_backward
235 | gradients = lstm_cell_backward(da[:, :, t], dc_prevt, caches[t])
236 | # Store or add the gradient to the parameters' previous step's gradient
237 | dx[:, :, t] = gradients["dxt"]
238 | dWf += gradients["dWf"]
239 | dWi += gradients["dWi"]
240 | dWc += gradients["dWc"]
241 | dWo += gradients["dWo"]
242 | dbf += gradients["dbf"]
243 | dbi += gradients["dbi"]
244 | dbc += gradients["dbc"]
245 | dbo += gradients["dbo"]
246 | # Set the first activation's gradient to the backpropagated gradient da_prev.
247 | da0 = gradients["da_prev"]
248 |
249 | # Store the gradients in a python dictionary
250 | gradients = {"dx": dx, "da0": da0, "dWf": dWf, "dbf": dbf, "dWi": dWi, "dbi": dbi,
251 | "dWc": dWc, "dbc": dbc, "dWo": dWo, "dbo": dbo}
252 |
253 | return gradients
254 |
--------------------------------------------------------------------------------
/BasicLSTM/rnn_utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | def softmax(x):
4 | e_x = np.exp(x - np.max(x))
5 | return e_x / e_x.sum(axis=0)
6 |
7 |
8 | def sigmoid(x):
9 | return 1 / (1 + np.exp(-x))
10 |
11 |
12 | def initialize_adam(parameters) :
13 | """
14 | Initializes v and s as two python dictionaries with:
15 | - keys: "dW1", "db1", ..., "dWL", "dbL"
16 | - values: numpy arrays of zeros of the same shape as the corresponding gradients/parameters.
17 |
18 | Arguments:
19 | parameters -- python dictionary containing your parameters.
20 | parameters["W" + str(l)] = Wl
21 | parameters["b" + str(l)] = bl
22 |
23 | Returns:
24 | v -- python dictionary that will contain the exponentially weighted average of the gradient.
25 | v["dW" + str(l)] = ...
26 | v["db" + str(l)] = ...
27 | s -- python dictionary that will contain the exponentially weighted average of the squared gradient.
28 | s["dW" + str(l)] = ...
29 | s["db" + str(l)] = ...
30 |
31 | """
32 |
33 | L = len(parameters) // 2 # number of layers in the neural networks
34 | v = {}
35 | s = {}
36 |
37 | # Initialize v, s. Input: "parameters". Outputs: "v, s".
38 | for l in range(L):
39 | v["dW" + str(l+1)] = np.zeros(parameters["W" + str(l+1)].shape)
40 | v["db" + str(l+1)] = np.zeros(parameters["b" + str(l+1)].shape)
41 | s["dW" + str(l+1)] = np.zeros(parameters["W" + str(l+1)].shape)
42 | s["db" + str(l+1)] = np.zeros(parameters["b" + str(l+1)].shape)
43 |
44 | return v, s
45 |
46 |
47 | def update_parameters_with_adam(parameters, grads, v, s, t, learning_rate = 0.01,
48 | beta1 = 0.9, beta2 = 0.999, epsilon = 1e-8):
49 | """
50 | Update parameters using Adam
51 |
52 | Arguments:
53 | parameters -- python dictionary containing your parameters:
54 | parameters['W' + str(l)] = Wl
55 | parameters['b' + str(l)] = bl
56 | grads -- python dictionary containing your gradients for each parameters:
57 | grads['dW' + str(l)] = dWl
58 | grads['db' + str(l)] = dbl
59 | v -- Adam variable, moving average of the first gradient, python dictionary
60 | s -- Adam variable, moving average of the squared gradient, python dictionary
61 | learning_rate -- the learning rate, scalar.
62 | beta1 -- Exponential decay hyperparameter for the first moment estimates
63 | beta2 -- Exponential decay hyperparameter for the second moment estimates
64 | epsilon -- hyperparameter preventing division by zero in Adam updates
65 |
66 | Returns:
67 | parameters -- python dictionary containing your updated parameters
68 | v -- Adam variable, moving average of the first gradient, python dictionary
69 | s -- Adam variable, moving average of the squared gradient, python dictionary
70 | """
71 |
72 | L = len(parameters) // 2 # number of layers in the neural networks
73 | v_corrected = {} # Initializing first moment estimate, python dictionary
74 | s_corrected = {} # Initializing second moment estimate, python dictionary
75 |
76 | # Perform Adam update on all parameters
77 | for l in range(L):
78 | # Moving average of the gradients. Inputs: "v, grads, beta1". Output: "v".
79 | v["dW" + str(l+1)] = beta1 * v["dW" + str(l+1)] + (1 - beta1) * grads["dW" + str(l+1)]
80 | v["db" + str(l+1)] = beta1 * v["db" + str(l+1)] + (1 - beta1) * grads["db" + str(l+1)]
81 |
82 | # Compute bias-corrected first moment estimate. Inputs: "v, beta1, t". Output: "v_corrected".
83 | v_corrected["dW" + str(l+1)] = v["dW" + str(l+1)] / (1 - beta1**t)
84 | v_corrected["db" + str(l+1)] = v["db" + str(l+1)] / (1 - beta1**t)
85 |
86 | # Moving average of the squared gradients. Inputs: "s, grads, beta2". Output: "s".
87 | s["dW" + str(l+1)] = beta2 * s["dW" + str(l+1)] + (1 - beta2) * (grads["dW" + str(l+1)] ** 2)
88 | s["db" + str(l+1)] = beta2 * s["db" + str(l+1)] + (1 - beta2) * (grads["db" + str(l+1)] ** 2)
89 |
90 | # Compute bias-corrected second raw moment estimate. Inputs: "s, beta2, t". Output: "s_corrected".
91 | s_corrected["dW" + str(l+1)] = s["dW" + str(l+1)] / (1 - beta2 ** t)
92 | s_corrected["db" + str(l+1)] = s["db" + str(l+1)] / (1 - beta2 ** t)
93 |
94 | # Update parameters. Inputs: "parameters, learning_rate, v_corrected, s_corrected, epsilon". Output: "parameters".
95 | parameters["W" + str(l+1)] = parameters["W" + str(l+1)] - learning_rate * v_corrected["dW" + str(l+1)] / np.sqrt(s_corrected["dW" + str(l+1)] + epsilon)
96 | parameters["b" + str(l+1)] = parameters["b" + str(l+1)] - learning_rate * v_corrected["db" + str(l+1)] / np.sqrt(s_corrected["db" + str(l+1)] + epsilon)
97 |
98 | return parameters, v, s
--------------------------------------------------------------------------------
/BasicRNN/.idea/BasicRNN.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
--------------------------------------------------------------------------------
/BasicRNN/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
--------------------------------------------------------------------------------
/BasicRNN/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/BasicRNN/.idea/workspace.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
45 |
46 |
47 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
89 |
90 |
91 |
92 |
93 |
94 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
111 |
112 |
113 |
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
131 |
132 |
133 |
134 |
135 |
136 |
137 |
138 |
139 |
140 |
141 |
142 |
143 |
144 |
145 |
146 |
147 |
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 |
157 |
158 |
159 |
160 |
161 |
162 |
163 |
164 |
165 |
166 |
167 |
168 |
169 |
170 |
171 |
172 |
173 |
174 |
175 |
176 |
177 | 1534707048731
178 |
179 |
180 | 1534707048731
181 |
182 |
183 |
184 |
185 |
186 |
187 |
188 |
189 |
190 |
191 |
192 |
193 |
194 |
195 |
196 |
197 |
198 |
199 |
200 |
201 |
202 |
203 |
204 |
205 |
206 |
207 |
208 |
209 |
210 |
211 |
212 |
213 |
214 |
215 |
216 |
217 |
218 |
219 |
220 |
221 |
222 |
223 |
224 |
225 |
226 |
227 |
228 |
229 |
230 |
231 |
232 |
233 |
234 |
235 |
--------------------------------------------------------------------------------
/BasicRNN/main.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from rnn_utils import *
3 |
4 | def rnn_cell_forward(xt, a_prev, parameters):
5 | """
6 | Arguments:
7 | xt -- your input data at timestep "t", numpy array of shape (n_x, m).
8 | a_prev -- Hidden state at timestep "t-1", numpy array of shape (n_a, m)
9 | parameters -- python dictionary containing:
10 | Wax -- Weight matrix multiplying the input, numpy array of shape (n_a, n_x)
11 | Waa -- Weight matrix multiplying the hidden state, numpy array of shape (n_a, n_a)
12 | Wya -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a)
13 | ba -- Bias, numpy array of shape (n_a, 1)
14 | by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1)
15 | Returns:
16 | a_next -- next hidden state, of shape (n_a, m)
17 | yt_pred -- prediction at timestep "t", numpy array of shape (n_y, m)
18 | cache -- tuple of values needed for the backward pass, contains (a_next, a_prev, xt, parameters)
19 | """
20 |
21 | # Retrieve parameters from "parameters"
22 | Wax = parameters["Wax"]
23 | Waa = parameters["Waa"]
24 | Wya = parameters["Wya"]
25 | ba = parameters["ba"]
26 | by = parameters["by"]
27 |
28 | # compute next activation state using the formula given above
29 | a_next = np.tanh(np.matmul(Waa, a_prev) + np.matmul(Wax, xt) + ba)
30 | # compute output of the current cell using the formula given above
31 | yt_pred = softmax(np.matmul(Wya, a_next) + by)
32 |
33 | # store values you need for backward propagation in cache
34 | cache = (a_next, a_prev, xt, parameters)
35 |
36 | return a_next, yt_pred, cache
37 |
38 |
39 | def rnn_cell_backward(da_next, cache):
40 | """
41 | Arguments:
42 | da_next -- Gradient of loss with respect to next hidden state
43 | cache -- python dictionary containing useful values (output of rnn_cell_forward())
44 |
45 | Returns:
46 | gradients -- python dictionary containing:
47 | dx -- Gradients of input data, of shape (n_x, m)
48 | da_prev -- Gradients of previous hidden state, of shape (n_a, m)
49 | dWax -- Gradients of input-to-hidden weights, of shape (n_a, n_x)
50 | dWaa -- Gradients of hidden-to-hidden weights, of shape (n_a, n_a)
51 | dba -- Gradients of bias vector, of shape (n_a, 1)
52 | """
53 |
54 | # Retrieve values from cache
55 | (a_next, a_prev, xt, parameters) = cache
56 |
57 | # Retrieve values from parameters
58 | Wax = parameters["Wax"]
59 | Waa = parameters["Waa"]
60 | Wya = parameters["Wya"]
61 | ba = parameters["ba"]
62 | by = parameters["by"]
63 |
64 | # compute the gradient of tanh with respect to a_next
65 | dtanh = (1 - a_next ** 2) * da_next
66 |
67 | # compute the gradient of the loss with respect to Wax
68 | dxt = np.dot(Wax.T, dtanh)
69 | dWax = np.dot(dtanh, xt.T)
70 |
71 | # compute the gradient with respect to Waa
72 | da_prev = np.dot(Waa.T, dtanh)
73 | dWaa = np.dot(dtanh, a_prev.T)
74 |
75 | # compute the gradient with respect to b
76 | dba = np.sum(dtanh, 1, keepdims=True)
77 |
78 | # Store the gradients in a python dictionary
79 | gradients = {"dxt": dxt, "da_prev": da_prev, "dWax": dWax, "dWaa": dWaa, "dba": dba}
80 |
81 | return gradients
82 |
83 | def rnn_forward(x, a0, parameters):
84 | """
85 | Arguments:
86 | x -- Input data for every time-step, of shape (n_x, m, T_x).
87 | a0 -- Initial hidden state, of shape (n_a, m)
88 | parameters -- python dictionary containing:
89 | Waa -- Weight matrix multiplying the hidden state, numpy array of shape (n_a, n_a)
90 | Wax -- Weight matrix multiplying the input, numpy array of shape (n_a, n_x)
91 | Wya -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a)
92 | ba -- Bias numpy array of shape (n_a, 1)
93 | by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1)
94 |
95 | Returns:
96 | a -- Hidden states for every time-step, numpy array of shape (n_a, m, T_x)
97 | y_pred -- Predictions for every time-step, numpy array of shape (n_y, m, T_x)
98 | caches -- tuple of values needed for the backward pass, contains (list of caches, x)
99 | """
100 |
101 | # Initialize "caches" which will contain the list of all caches
102 | caches = []
103 |
104 | # Retrieve dimensions from shapes of x and parameters["Wya"]
105 | n_x, m, T_x = x.shape
106 | n_y, n_a = parameters["Wya"].shape
107 |
108 | # initialize "a" and "y" with zeros
109 | a = np.zeros((n_a, m, T_x))
110 | y_pred = np.zeros((n_y, m, T_x))
111 |
112 | # Initialize a_next (≈1 line)
113 | a_next = a0
114 |
115 | # loop over all time-steps
116 | for t in range(T_x):
117 | # Update next hidden state, compute the prediction, get the cache
118 | a_next, yt_pred, cache = rnn_cell_forward(x[:, :, t], a_next, parameters)
119 | # Save the value of the new "next" hidden state in a
120 | a[:, :, t] = a_next
121 | # Save the value of the prediction in y
122 | y_pred[:, :, t] = yt_pred
123 | # Append "cache" to "caches"
124 | caches.append(cache)
125 |
126 | # store values needed for backward propagation in cache
127 | caches = (caches, x)
128 |
129 | return a, y_pred, caches
130 |
131 |
132 | def rnn_backward(da, caches):
133 | """
134 | Arguments:
135 | da -- Upstream gradients of all hidden states, of shape (n_a, m, T_x)
136 | caches -- tuple containing information from the forward pass (rnn_forward)
137 |
138 | Returns:
139 | gradients -- python dictionary containing:
140 | dx -- Gradient w.r.t. the input data, numpy-array of shape (n_x, m, T_x)
141 | da0 -- Gradient w.r.t the initial hidden state, numpy-array of shape (n_a, m)
142 | dWax -- Gradient w.r.t the input's weight matrix, numpy-array of shape (n_a, n_x)
143 | dWaa -- Gradient w.r.t the hidden state's weight matrix, numpy-arrayof shape (n_a, n_a)
144 | dba -- Gradient w.r.t the bias, of shape (n_a, 1)
145 | """
146 |
147 | # Retrieve values from the first cache (t=1) of caches
148 | (caches, x) = caches
149 | (a1, a0, x1, parameters) = caches[0]
150 |
151 | # Retrieve dimensions from da's and x1's shapes
152 | n_a, m, T_x = da.shape
153 | n_x, m = x1.shape
154 |
155 | # initialize the gradients with the right sizes
156 | dx = np.zeros((n_x, m, T_x))
157 | dWax = np.zeros((n_a, n_x))
158 | dWaa = np.zeros((n_a, n_a))
159 | dba = np.zeros((n_a, 1))
160 | da0 = np.zeros((n_a, m))
161 | da_prevt = np.zeros((n_a, m))
162 |
163 | # Loop through all the time steps
164 | for t in reversed(range(T_x)):
165 | # Compute gradients at time step t. Choose wisely the "da_next" and the "cache" to use in the backward propagation step.
166 | gradients = rnn_cell_backward(da[:, :, t] + da_prevt, caches[t])
167 | # Retrieve derivatives from gradients
168 | dxt, da_prevt, dWaxt, dWaat, dbat = gradients["dxt"], gradients["da_prev"], gradients["dWax"], gradients[
169 | "dWaa"], gradients["dba"]
170 | # Increment global derivatives w.r.t parameters by adding their derivative at time-step t
171 | dx[:, :, t] = dxt
172 | dWax += dWaxt
173 | dWaa += dWaat
174 | dba += dbat
175 |
176 | # Set da0 to the gradient of a which has been backpropagated through all time-steps
177 | da0 = da_prevt
178 |
179 | # Store the gradients in a python dictionary
180 | gradients = {"dx": dx, "da0": da0, "dWax": dWax, "dWaa": dWaa, "dba": dba}
181 |
182 | return gradients
183 |
--------------------------------------------------------------------------------
/BasicRNN/rnn_utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | def softmax(x):
4 | e_x = np.exp(x - np.max(x))
5 | return e_x / e_x.sum(axis=0)
6 |
7 |
8 | def sigmoid(x):
9 | return 1 / (1 + np.exp(-x))
10 |
11 |
12 | def initialize_adam(parameters) :
13 | """
14 | Initializes v and s as two python dictionaries with:
15 | - keys: "dW1", "db1", ..., "dWL", "dbL"
16 | - values: numpy arrays of zeros of the same shape as the corresponding gradients/parameters.
17 |
18 | Arguments:
19 | parameters -- python dictionary containing your parameters.
20 | parameters["W" + str(l)] = Wl
21 | parameters["b" + str(l)] = bl
22 |
23 | Returns:
24 | v -- python dictionary that will contain the exponentially weighted average of the gradient.
25 | v["dW" + str(l)] = ...
26 | v["db" + str(l)] = ...
27 | s -- python dictionary that will contain the exponentially weighted average of the squared gradient.
28 | s["dW" + str(l)] = ...
29 | s["db" + str(l)] = ...
30 |
31 | """
32 |
33 | L = len(parameters) // 2 # number of layers in the neural networks
34 | v = {}
35 | s = {}
36 |
37 | # Initialize v, s. Input: "parameters". Outputs: "v, s".
38 | for l in range(L):
39 | v["dW" + str(l+1)] = np.zeros(parameters["W" + str(l+1)].shape)
40 | v["db" + str(l+1)] = np.zeros(parameters["b" + str(l+1)].shape)
41 | s["dW" + str(l+1)] = np.zeros(parameters["W" + str(l+1)].shape)
42 | s["db" + str(l+1)] = np.zeros(parameters["b" + str(l+1)].shape)
43 |
44 | return v, s
45 |
46 |
47 | def update_parameters_with_adam(parameters, grads, v, s, t, learning_rate = 0.01,
48 | beta1 = 0.9, beta2 = 0.999, epsilon = 1e-8):
49 | """
50 | Update parameters using Adam
51 |
52 | Arguments:
53 | parameters -- python dictionary containing your parameters:
54 | parameters['W' + str(l)] = Wl
55 | parameters['b' + str(l)] = bl
56 | grads -- python dictionary containing your gradients for each parameters:
57 | grads['dW' + str(l)] = dWl
58 | grads['db' + str(l)] = dbl
59 | v -- Adam variable, moving average of the first gradient, python dictionary
60 | s -- Adam variable, moving average of the squared gradient, python dictionary
61 | learning_rate -- the learning rate, scalar.
62 | beta1 -- Exponential decay hyperparameter for the first moment estimates
63 | beta2 -- Exponential decay hyperparameter for the second moment estimates
64 | epsilon -- hyperparameter preventing division by zero in Adam updates
65 |
66 | Returns:
67 | parameters -- python dictionary containing your updated parameters
68 | v -- Adam variable, moving average of the first gradient, python dictionary
69 | s -- Adam variable, moving average of the squared gradient, python dictionary
70 | """
71 |
72 | L = len(parameters) // 2 # number of layers in the neural networks
73 | v_corrected = {} # Initializing first moment estimate, python dictionary
74 | s_corrected = {} # Initializing second moment estimate, python dictionary
75 |
76 | # Perform Adam update on all parameters
77 | for l in range(L):
78 | # Moving average of the gradients. Inputs: "v, grads, beta1". Output: "v".
79 | v["dW" + str(l+1)] = beta1 * v["dW" + str(l+1)] + (1 - beta1) * grads["dW" + str(l+1)]
80 | v["db" + str(l+1)] = beta1 * v["db" + str(l+1)] + (1 - beta1) * grads["db" + str(l+1)]
81 |
82 | # Compute bias-corrected first moment estimate. Inputs: "v, beta1, t". Output: "v_corrected".
83 | v_corrected["dW" + str(l+1)] = v["dW" + str(l+1)] / (1 - beta1**t)
84 | v_corrected["db" + str(l+1)] = v["db" + str(l+1)] / (1 - beta1**t)
85 |
86 | # Moving average of the squared gradients. Inputs: "s, grads, beta2". Output: "s".
87 | s["dW" + str(l+1)] = beta2 * s["dW" + str(l+1)] + (1 - beta2) * (grads["dW" + str(l+1)] ** 2)
88 | s["db" + str(l+1)] = beta2 * s["db" + str(l+1)] + (1 - beta2) * (grads["db" + str(l+1)] ** 2)
89 |
90 | # Compute bias-corrected second raw moment estimate. Inputs: "s, beta2, t". Output: "s_corrected".
91 | s_corrected["dW" + str(l+1)] = s["dW" + str(l+1)] / (1 - beta2 ** t)
92 | s_corrected["db" + str(l+1)] = s["db" + str(l+1)] / (1 - beta2 ** t)
93 |
94 | # Update parameters. Inputs: "parameters, learning_rate, v_corrected, s_corrected, epsilon". Output: "parameters".
95 | parameters["W" + str(l+1)] = parameters["W" + str(l+1)] - learning_rate * v_corrected["dW" + str(l+1)] / np.sqrt(s_corrected["dW" + str(l+1)] + epsilon)
96 | parameters["b" + str(l+1)] = parameters["b" + str(l+1)] - learning_rate * v_corrected["db" + str(l+1)] / np.sqrt(s_corrected["db" + str(l+1)] + epsilon)
97 |
98 | return parameters, v, s
--------------------------------------------------------------------------------
/MusicGenerationProject/.idea/MusicGeneration.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
--------------------------------------------------------------------------------
/MusicGenerationProject/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
--------------------------------------------------------------------------------
/MusicGenerationProject/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/MusicGenerationProject/.idea/workspace.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
77 |
78 |
79 |
88 |
89 |
90 |
91 |
92 |
93 |
94 |
95 |
96 |
97 |
98 |
99 |
100 |
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
111 |
112 |
113 |
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
139 |
140 |
141 |
142 |
143 |
144 |
145 |
146 |
147 |
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 |
157 |
158 |
159 |
160 |
161 |
162 |
163 |
164 |
165 |
166 |
167 |
168 |
169 |
170 |
171 |
172 |
173 |
174 |
175 |
176 |
177 |
178 |
179 |
180 |
181 |
182 |
183 |
184 |
185 |
186 |
187 |
188 |
189 |
190 |
191 |
192 |
193 |
194 |
195 |
196 |
197 |
198 |
199 |
200 |
201 |
202 |
203 |
204 |
205 |
206 |
207 |
208 |
209 |
210 |
211 |
212 |
213 |
214 |
215 |
216 |
217 |
218 |
219 |
220 |
221 |
222 |
223 |
224 |
225 |
226 |
227 |
228 |
229 |
230 |
231 |
232 |
233 |
234 |
235 |
236 |
237 |
238 | 1534074581875
239 |
240 |
241 | 1534074581875
242 |
243 |
244 |
245 |
246 |
247 |
248 |
249 |
250 |
251 |
252 |
253 |
254 |
255 |
256 |
257 |
258 |
259 |
260 |
261 |
262 |
263 |
264 |
265 |
266 |
267 |
268 |
269 |
270 |
271 |
272 |
273 |
274 |
275 |
276 | file://$PROJECT_DIR$/preprocess.py
277 | 9
278 |
279 |
280 |
281 |
282 |
283 |
284 |
285 |
286 |
287 |
288 |
289 |
290 |
291 |
292 |
293 |
294 |
295 |
296 |
297 |
298 |
299 |
300 |
301 |
302 |
303 |
304 |
305 |
306 |
307 |
308 |
309 |
310 |
311 |
312 |
313 |
314 |
315 |
316 |
317 |
318 |
319 |
320 |
321 |
322 |
323 |
324 |
325 |
326 |
327 |
328 |
329 |
330 |
--------------------------------------------------------------------------------
/MusicGenerationProject/__pycache__/data_utils.cpython-35.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/72975a4d872b7a9c9643b2c453378d2625bba41e/MusicGenerationProject/__pycache__/data_utils.cpython-35.pyc
--------------------------------------------------------------------------------
/MusicGenerationProject/__pycache__/grammar.cpython-35.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/72975a4d872b7a9c9643b2c453378d2625bba41e/MusicGenerationProject/__pycache__/grammar.cpython-35.pyc
--------------------------------------------------------------------------------
/MusicGenerationProject/__pycache__/music_utils.cpython-35.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/72975a4d872b7a9c9643b2c453378d2625bba41e/MusicGenerationProject/__pycache__/music_utils.cpython-35.pyc
--------------------------------------------------------------------------------
/MusicGenerationProject/__pycache__/preprocess.cpython-35.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/72975a4d872b7a9c9643b2c453378d2625bba41e/MusicGenerationProject/__pycache__/preprocess.cpython-35.pyc
--------------------------------------------------------------------------------
/MusicGenerationProject/__pycache__/qa.cpython-35.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/72975a4d872b7a9c9643b2c453378d2625bba41e/MusicGenerationProject/__pycache__/qa.cpython-35.pyc
--------------------------------------------------------------------------------
/MusicGenerationProject/data/original_metheny.mid:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/72975a4d872b7a9c9643b2c453378d2625bba41e/MusicGenerationProject/data/original_metheny.mid
--------------------------------------------------------------------------------
/MusicGenerationProject/data_utils.py:
--------------------------------------------------------------------------------
1 | from music_utils import *
2 | from preprocess import *
3 | from keras.utils import to_categorical
4 |
5 | chords, abstract_grammars = get_musical_data('data/original_metheny.mid')
6 | corpus, tones, tones_indices, indices_tones = get_corpus_data(abstract_grammars)
7 | N_tones = len(set(corpus))
8 | n_a = 64
9 | x_initializer = np.zeros((1, 1, 78))
10 | a_initializer = np.zeros((1, n_a))
11 | c_initializer = np.zeros((1, n_a))
12 |
13 | def load_music_utils():
14 | chords, abstract_grammars = get_musical_data('data/original_metheny.mid')
15 | corpus, tones, tones_indices, indices_tones = get_corpus_data(abstract_grammars)
16 | N_tones = len(set(corpus))
17 | X, Y, N_tones = data_processing(corpus, tones_indices, 60, 30)
18 | return (X, Y, N_tones, indices_tones)
19 |
20 |
21 | def generate_music(inference_model, corpus = corpus, abstract_grammars = abstract_grammars, tones = tones, tones_indices = tones_indices, indices_tones = indices_tones, T_y = 10, max_tries = 1000, diversity = 0.5):
22 | """
23 | Generates music using a model trained to learn musical patterns of a jazz soloist. Creates an audio stream
24 | to save the music and play it.
25 |
26 | Arguments:
27 | model -- Keras model Instance, output of djmodel()
28 | corpus -- musical corpus, list of 193 tones as strings (ex: 'C,0.333,')
29 | abstract_grammars -- list of grammars, on element can be: 'S,0.250, C,0.250, A,0.250,'
30 | tones -- set of unique tones, ex: 'A,0.250,' is one element of the set.
31 | tones_indices -- a python dictionary mapping unique tone (ex: A,0.250,< m2,P-4 >) into their corresponding indices (0-77)
32 | indices_tones -- a python dictionary mapping indices (0-77) into their corresponding unique tone (ex: A,0.250,< m2,P-4 >)
33 | Tx -- integer, number of time-steps used at training time
34 | temperature -- scalar value, defines how conservative/creative the model is when generating music
35 |
36 | Returns:
37 | predicted_tones -- python list containing predicted tones
38 | """
39 |
40 | # set up audio stream
41 | out_stream = stream.Stream()
42 |
43 | # Initialize chord variables
44 | curr_offset = 0.0 # variable used to write sounds to the Stream.
45 | num_chords = int(len(chords) / 3) # number of different set of chords
46 |
47 | print("Predicting new values for different set of chords.")
48 | # Loop over all 18 set of chords. At each iteration generate a sequence of tones
49 | # and use the current chords to convert it into actual sounds
50 | for i in range(1, num_chords):
51 |
52 | # Retrieve current chord from stream
53 | curr_chords = stream.Voice()
54 |
55 | # Loop over the chords of the current set of chords
56 | for j in chords[i]:
57 | # Add chord to the current chords with the adequate offset, no need to understand this
58 | curr_chords.insert((j.offset % 4), j)
59 |
60 | # Generate a sequence of tones using the model
61 | _, indices = predict_and_sample(inference_model)
62 | indices = list(indices.squeeze())
63 | pred = [indices_tones[p] for p in indices]
64 |
65 | predicted_tones = 'C,0.25 '
66 | for k in range(len(pred) - 1):
67 | predicted_tones += pred[k] + ' '
68 |
69 | predicted_tones += pred[-1]
70 |
71 | #### POST PROCESSING OF THE PREDICTED TONES ####
72 | # consider "A" and "X" as "C" tones. It is a common choice.
73 | predicted_tones = predicted_tones.replace(' A',' C').replace(' X',' C')
74 |
75 | # Pruning #1: smoothing measure
76 | predicted_tones = prune_grammar(predicted_tones)
77 |
78 | # Use predicted tones and current chords to generate sounds
79 | sounds = unparse_grammar(predicted_tones, curr_chords)
80 |
81 | # Pruning #2: removing repeated and too close together sounds
82 | sounds = prune_notes(sounds)
83 |
84 | # Quality assurance: clean up sounds
85 | sounds = clean_up_notes(sounds)
86 |
87 | # Print number of tones/notes in sounds
88 | print('Generated %s sounds using the predicted values for the set of chords ("%s") and after pruning' % (len([k for k in sounds if isinstance(k, note.Note)]), i))
89 |
90 | # Insert sounds into the output stream
91 | for m in sounds:
92 | out_stream.insert(curr_offset + m.offset, m)
93 | for mc in curr_chords:
94 | out_stream.insert(curr_offset + mc.offset, mc)
95 |
96 | curr_offset += 4.0
97 |
98 | # Initialize tempo of the output stream with 130 bit per minute
99 | out_stream.insert(0.0, tempo.MetronomeMark(number=130))
100 |
101 | # Save audio stream to fine
102 | mf = midi.translate.streamToMidiFile(out_stream)
103 | mf.open("output/my_music.midi", 'wb')
104 | mf.write()
105 | print("Your generated music is saved in output/my_music.midi")
106 | mf.close()
107 |
108 | # Play the final stream through output (see 'play' lambda function above)
109 | # play = lambda x: midi.realtime.StreamPlayer(x).play()
110 | # play(out_stream)
111 |
112 | return out_stream
113 |
114 |
115 | def predict_and_sample(inference_model, x_initializer = x_initializer, a_initializer = a_initializer,
116 | c_initializer = c_initializer):
117 | """
118 | Predicts the next value of values using the inference model.
119 |
120 | Arguments:
121 | inference_model -- Keras model instance for inference time
122 | x_initializer -- numpy array of shape (1, 1, 78), one-hot vector initializing the values generation
123 | a_initializer -- numpy array of shape (1, n_a), initializing the hidden state of the LSTM_cell
124 | c_initializer -- numpy array of shape (1, n_a), initializing the cell state of the LSTM_cel
125 | Ty -- length of the sequence you'd like to generate.
126 |
127 | Returns:
128 | results -- numpy-array of shape (Ty, 78), matrix of one-hot vectors representing the values generated
129 | indices -- numpy-array of shape (Ty, 1), matrix of indices representing the values generated
130 | """
131 |
132 | pred = inference_model.predict([x_initializer, a_initializer, c_initializer])
133 | indices = np.argmax(pred, axis = -1)
134 | results = to_categorical(indices, num_classes=78)
135 |
136 |
137 | return results, indices
138 |
--------------------------------------------------------------------------------
/MusicGenerationProject/grammar.py:
--------------------------------------------------------------------------------
1 | '''
2 | Author: Ji-Sung Kim, Evan Chow
3 | Project: jazzml / (used in) deepjazz
4 | Purpose: Extract, manipulate, process musical grammar
5 |
6 | Directly taken then cleaned up from Evan Chow's jazzml,
7 | https://github.com/evancchow/jazzml,with permission.
8 | '''
9 |
10 | from collections import OrderedDict, defaultdict
11 | from itertools import groupby
12 | from music21 import *
13 | import copy, random, pdb
14 |
15 | #from preprocess import *
16 |
17 | ''' Helper function to determine if a note is a scale tone. '''
18 | def __is_scale_tone(chord, note):
19 | # Method: generate all scales that have the chord notes th check if note is
20 | # in names
21 |
22 | # Derive major or minor scales (minor if 'other') based on the quality
23 | # of the chord.
24 | scaleType = scale.DorianScale() # i.e. minor pentatonic
25 | if chord.quality == 'major':
26 | scaleType = scale.MajorScale()
27 | # Can change later to deriveAll() for flexibility. If so then use list
28 | # comprehension of form [x for a in b for x in a].
29 | scales = scaleType.derive(chord) # use deriveAll() later for flexibility
30 | allPitches = list(set([pitch for pitch in scales.getPitches()]))
31 | allNoteNames = [i.name for i in allPitches] # octaves don't matter
32 |
33 | # Get note name. Return true if in the list of note names.
34 | noteName = note.name
35 | return (noteName in allNoteNames)
36 |
37 | ''' Helper function to determine if a note is an approach tone. '''
38 | def __is_approach_tone(chord, note):
39 | # Method: see if note is +/- 1 a chord tone.
40 |
41 | for chordPitch in chord.pitches:
42 | stepUp = chordPitch.transpose(1)
43 | stepDown = chordPitch.transpose(-1)
44 | if (note.name == stepDown.name or
45 | note.name == stepDown.getEnharmonic().name or
46 | note.name == stepUp.name or
47 | note.name == stepUp.getEnharmonic().name):
48 | return True
49 | return False
50 |
51 | ''' Helper function to determine if a note is a chord tone. '''
52 | def __is_chord_tone(lastChord, note):
53 | return (note.name in (p.name for p in lastChord.pitches))
54 |
55 | ''' Helper function to generate a chord tone. '''
56 | def __generate_chord_tone(lastChord):
57 | lastChordNoteNames = [p.nameWithOctave for p in lastChord.pitches]
58 | return note.Note(random.choice(lastChordNoteNames))
59 |
60 | ''' Helper function to generate a scale tone. '''
61 | def __generate_scale_tone(lastChord):
62 | # Derive major or minor scales (minor if 'other') based on the quality
63 | # of the lastChord.
64 | scaleType = scale.WeightedHexatonicBlues() # minor pentatonic
65 | if lastChord.quality == 'major':
66 | scaleType = scale.MajorScale()
67 | # Can change later to deriveAll() for flexibility. If so then use list
68 | # comprehension of form [x for a in b for x in a].
69 | scales = scaleType.derive(lastChord) # use deriveAll() later for flexibility
70 | allPitches = list(set([pitch for pitch in scales.getPitches()]))
71 | allNoteNames = [i.name for i in allPitches] # octaves don't matter
72 |
73 | # Return a note (no octave here) in a scale that matches the lastChord.
74 | sNoteName = random.choice(allNoteNames)
75 | lastChordSort = lastChord.sortAscending()
76 | sNoteOctave = random.choice([i.octave for i in lastChordSort.pitches])
77 | sNote = note.Note(("%s%s" % (sNoteName, sNoteOctave)))
78 | return sNote
79 |
80 | ''' Helper function to generate an approach tone. '''
81 | def __generate_approach_tone(lastChord):
82 | sNote = __generate_scale_tone(lastChord)
83 | aNote = sNote.transpose(random.choice([1, -1]))
84 | return aNote
85 |
86 | ''' Helper function to generate a random tone. '''
87 | def __generate_arbitrary_tone(lastChord):
88 | return __generate_scale_tone(lastChord) # fix later, make random note.
89 |
90 |
91 | ''' Given the notes in a measure ('measure') and the chords in that measure
92 | ('chords'), generate a list of abstract grammatical symbols to represent
93 | that measure as described in GTK's "Learning Jazz Grammars" (2009).
94 |
95 | Inputs:
96 | 1) "measure" : a stream.Voice object where each element is a
97 | note.Note or note.Rest object.
98 |
99 | >>> m1
100 |
101 | >>> m1[0]
102 |
103 | >>> m1[1]
104 |
105 |
106 | Can have instruments and other elements, removes them here.
107 |
108 | 2) "chords" : a stream.Voice object where each element is a chord.Chord.
109 |
110 | >>> c1
111 |
112 | >>> c1[0]
113 |
114 | >>> c1[1]
115 |
116 |
117 | Can have instruments and other elements, removes them here.
118 |
119 | Outputs:
120 | 1) "fullGrammar" : a string that holds the abstract grammar for measure.
121 | Format:
122 | (Remember, these are DURATIONS not offsets!)
123 | "R,0.125" : a rest element of (1/32) length, or 1/8 quarter note.
124 | "C,0.125" : chord note of (1/32) length, generated
125 | anywhere from minor 6th down to major 2nd down.
126 | (interval is not ordered). '''
127 |
128 | def parse_melody(fullMeasureNotes, fullMeasureChords):
129 | # Remove extraneous elements.x
130 | measure = copy.deepcopy(fullMeasureNotes)
131 | chords = copy.deepcopy(fullMeasureChords)
132 | measure.removeByNotOfClass([note.Note, note.Rest])
133 | chords.removeByNotOfClass([chord.Chord])
134 |
135 | # Information for the start of the measure.
136 | # 1) measureStartTime: the offset for measure's start, e.g. 476.0.
137 | # 2) measureStartOffset: how long from the measure start to the first element.
138 | measureStartTime = measure[0].offset - (measure[0].offset % 4)
139 | measureStartOffset = measure[0].offset - measureStartTime
140 |
141 | # Iterate over the notes and rests in measure, finding the grammar for each
142 | # note in the measure and adding an abstract grammatical string for it.
143 |
144 | fullGrammar = ""
145 | prevNote = None # Store previous note. Need for interval.
146 | numNonRests = 0 # Number of non-rest elements. Need for updating prevNote.
147 | for ix, nr in enumerate(measure):
148 | # Get the last chord. If no last chord, then (assuming chords is of length
149 | # >0) shift first chord in chords to the beginning of the measure.
150 | try:
151 | lastChord = [n for n in chords if n.offset <= nr.offset][-1]
152 | except IndexError:
153 | chords[0].offset = measureStartTime
154 | lastChord = [n for n in chords if n.offset <= nr.offset][-1]
155 |
156 | # FIRST, get type of note, e.g. R for Rest, C for Chord, etc.
157 | # Dealing with solo notes here. If unexpected chord: still call 'C'.
158 | elementType = ' '
159 | # R: First, check if it's a rest. Clearly a rest --> only one possibility.
160 | if isinstance(nr, note.Rest):
161 | elementType = 'R'
162 | # C: Next, check to see if note pitch is in the last chord.
163 | elif nr.name in lastChord.pitchNames or isinstance(nr, chord.Chord):
164 | elementType = 'C'
165 | # L: (Complement tone) Skip this for now.
166 | # S: Check if it's a scale tone.
167 | elif __is_scale_tone(lastChord, nr):
168 | elementType = 'S'
169 | # A: Check if it's an approach tone, i.e. +-1 halfstep chord tone.
170 | elif __is_approach_tone(lastChord, nr):
171 | elementType = 'A'
172 | # X: Otherwise, it's an arbitrary tone. Generate random note.
173 | else:
174 | elementType = 'X'
175 |
176 | # SECOND, get the length for each element. e.g. 8th note = R8, but
177 | # to simplify things you'll use the direct num, e.g. R,0.125
178 | if (ix == (len(measure)-1)):
179 | # formula for a in "a - b": start of measure (e.g. 476) + 4
180 | diff = measureStartTime + 4.0 - nr.offset
181 | else:
182 | diff = measure[ix + 1].offset - nr.offset
183 |
184 | # Combine into the note info.
185 | noteInfo = "%s,%.3f" % (elementType, nr.quarterLength) # back to diff
186 |
187 | # THIRD, get the deltas (max range up, max range down) based on where
188 | # the previous note was, +- minor 3. Skip rests (don't affect deltas).
189 | intervalInfo = ""
190 | if isinstance(nr, note.Note):
191 | numNonRests += 1
192 | if numNonRests == 1:
193 | prevNote = nr
194 | else:
195 | noteDist = interval.Interval(noteStart=prevNote, noteEnd=nr)
196 | noteDistUpper = interval.add([noteDist, "m3"])
197 | noteDistLower = interval.subtract([noteDist, "m3"])
198 | intervalInfo = ",<%s,%s>" % (noteDistUpper.directedName,
199 | noteDistLower.directedName)
200 | # print "Upper, lower: %s, %s" % (noteDistUpper,
201 | # noteDistLower)
202 | # print "Upper, lower dnames: %s, %s" % (
203 | # noteDistUpper.directedName,
204 | # noteDistLower.directedName)
205 | # print "The interval: %s" % (intervalInfo)
206 | prevNote = nr
207 |
208 | # Return. Do lazy evaluation for real-time performance.
209 | grammarTerm = noteInfo + intervalInfo
210 | fullGrammar += (grammarTerm + " ")
211 |
212 | return fullGrammar.rstrip()
213 |
214 | ''' Given a grammar string and chords for a measure, returns measure notes. '''
215 | def unparse_grammar(m1_grammar, m1_chords):
216 | m1_elements = stream.Voice()
217 | currOffset = 0.0 # for recalculate last chord.
218 | prevElement = None
219 | for ix, grammarElement in enumerate(m1_grammar.split(' ')):
220 | terms = grammarElement.split(',')
221 | currOffset += float(terms[1]) # works just fine
222 |
223 | # Case 1: it's a rest. Just append
224 | if terms[0] == 'R':
225 | rNote = note.Rest(quarterLength = float(terms[1]))
226 | m1_elements.insert(currOffset, rNote)
227 | continue
228 |
229 | # Get the last chord first so you can find chord note, scale note, etc.
230 | try:
231 | lastChord = [n for n in m1_chords if n.offset <= currOffset][-1]
232 | except IndexError:
233 | m1_chords[0].offset = 0.0
234 | lastChord = [n for n in m1_chords if n.offset <= currOffset][-1]
235 |
236 | # Case: no < > (should just be the first note) so generate from range
237 | # of lowest chord note to highest chord note (if not a chord note, else
238 | # just generate one of the actual chord notes).
239 |
240 | # Case #1: if no < > to indicate next note range. Usually this lack of < >
241 | # is for the first note (no precedent), or for rests.
242 | if (len(terms) == 2): # Case 1: if no < >.
243 | insertNote = note.Note() # default is C
244 |
245 | # Case C: chord note.
246 | if terms[0] == 'C':
247 | insertNote = __generate_chord_tone(lastChord)
248 |
249 | # Case S: scale note.
250 | elif terms[0] == 'S':
251 | insertNote = __generate_scale_tone(lastChord)
252 |
253 | # Case A: approach note.
254 | # Handle both A and X notes here for now.
255 | else:
256 | insertNote = __generate_approach_tone(lastChord)
257 |
258 | # Update the stream of generated notes
259 | insertNote.quarterLength = float(terms[1])
260 | if insertNote.octave < 4:
261 | insertNote.octave = 4
262 | m1_elements.insert(currOffset, insertNote)
263 | prevElement = insertNote
264 |
265 | # Case #2: if < > for the increment. Usually for notes after the first one.
266 | else:
267 | # Get lower, upper intervals and notes.
268 | interval1 = interval.Interval(terms[2].replace("<",''))
269 | interval2 = interval.Interval(terms[3].replace(">",''))
270 | if interval1.cents > interval2.cents:
271 | upperInterval, lowerInterval = interval1, interval2
272 | else:
273 | upperInterval, lowerInterval = interval2, interval1
274 | lowPitch = interval.transposePitch(prevElement.pitch, lowerInterval)
275 | highPitch = interval.transposePitch(prevElement.pitch, upperInterval)
276 | numNotes = int(highPitch.ps - lowPitch.ps + 1) # for range(s, e)
277 |
278 | # Case C: chord note, must be within increment (terms[2]).
279 | # First, transpose note with lowerInterval to get note that is
280 | # the lower bound. Then iterate over, and find valid notes. Then
281 | # choose randomly from those.
282 |
283 | if terms[0] == 'C':
284 | relevantChordTones = []
285 | for i in range(0, numNotes):
286 | currNote = note.Note(lowPitch.transpose(i).simplifyEnharmonic())
287 | if __is_chord_tone(lastChord, currNote):
288 | relevantChordTones.append(currNote)
289 | if len(relevantChordTones) > 1:
290 | insertNote = random.choice([i for i in relevantChordTones
291 | if i.nameWithOctave != prevElement.nameWithOctave])
292 | elif len(relevantChordTones) == 1:
293 | insertNote = relevantChordTones[0]
294 | else: # if no choices, set to prev element +-1 whole step
295 | insertNote = prevElement.transpose(random.choice([-2,2]))
296 | if insertNote.octave < 3:
297 | insertNote.octave = 3
298 | insertNote.quarterLength = float(terms[1])
299 | m1_elements.insert(currOffset, insertNote)
300 |
301 | # Case S: scale note, must be within increment.
302 | elif terms[0] == 'S':
303 | relevantScaleTones = []
304 | for i in range(0, numNotes):
305 | currNote = note.Note(lowPitch.transpose(i).simplifyEnharmonic())
306 | if __is_scale_tone(lastChord, currNote):
307 | relevantScaleTones.append(currNote)
308 | if len(relevantScaleTones) > 1:
309 | insertNote = random.choice([i for i in relevantScaleTones
310 | if i.nameWithOctave != prevElement.nameWithOctave])
311 | elif len(relevantScaleTones) == 1:
312 | insertNote = relevantScaleTones[0]
313 | else: # if no choices, set to prev element +-1 whole step
314 | insertNote = prevElement.transpose(random.choice([-2,2]))
315 | if insertNote.octave < 3:
316 | insertNote.octave = 3
317 | insertNote.quarterLength = float(terms[1])
318 | m1_elements.insert(currOffset, insertNote)
319 |
320 | # Case A: approach tone, must be within increment.
321 | # For now: handle both A and X cases.
322 | else:
323 | relevantApproachTones = []
324 | for i in range(0, numNotes):
325 | currNote = note.Note(lowPitch.transpose(i).simplifyEnharmonic())
326 | if __is_approach_tone(lastChord, currNote):
327 | relevantApproachTones.append(currNote)
328 | if len(relevantApproachTones) > 1:
329 | insertNote = random.choice([i for i in relevantApproachTones
330 | if i.nameWithOctave != prevElement.nameWithOctave])
331 | elif len(relevantApproachTones) == 1:
332 | insertNote = relevantApproachTones[0]
333 | else: # if no choices, set to prev element +-1 whole step
334 | insertNote = prevElement.transpose(random.choice([-2,2]))
335 | if insertNote.octave < 3:
336 | insertNote.octave = 3
337 | insertNote.quarterLength = float(terms[1])
338 | m1_elements.insert(currOffset, insertNote)
339 |
340 | # update the previous element.
341 | prevElement = insertNote
342 |
343 | return m1_elements
--------------------------------------------------------------------------------
/MusicGenerationProject/inference_code.py:
--------------------------------------------------------------------------------
1 | def inference_model(LSTM_cell, densor, n_x = 78, n_a = 64, Ty = 100):
2 | """
3 | Uses the trained "LSTM_cell" and "densor" from model() to generate a sequence of values.
4 |
5 | Arguments:
6 | LSTM_cell -- the trained "LSTM_cell" from model(), Keras layer object
7 | densor -- the trained "densor" from model(), Keras layer object
8 | n_x -- number of unique values
9 | n_a -- number of units in the LSTM_cell
10 | Ty -- number of time steps to generate
11 |
12 | Returns:
13 | inference_model -- Keras model instance
14 | """
15 |
16 | # Define the input of your model with a shape
17 | x0 = Input(shape=(1, n_x))
18 |
19 | # Define s0, initial hidden state for the decoder LSTM
20 | a0 = Input(shape=(n_a,), name='a0')
21 | c0 = Input(shape=(n_a,), name='c0')
22 | a = a0
23 | c = c0
24 | x = x0
25 |
26 |
27 | # Create an empty list of "outputs" to later store predicted values
28 | outputs = []
29 |
30 | # Loop over Ty and generate a value at every time step
31 | for t in range(Ty):
32 |
33 | # Perform one step of LSTM_cell
34 | a, _, c = LSTM_cell(x, initial_state=[a, c])
35 |
36 | # Apply Dense layer to the hidden state output of the LSTM_cell
37 | out = densor(a)
38 |
39 | # Append the prediction "out" to "outputs"
40 | outputs.append(out)
41 |
42 | # Set the prediction "out" to be the next input "x". You will need to use RepeatVector(1).
43 | x = RepeatVector(1)(out)
44 |
45 | # Create model instance with the correct "inputs" and "outputs"
46 | inference_model = Model(inputs=[x0, a0, c0], outputs=outputs)
47 |
48 |
49 | return inference_model
50 |
51 |
52 | inference_model = inference_model(LSTM_cell, densor)
53 |
54 |
55 | x1 = np.zeros((1, 1, 78))
56 | x1[:,:,35] = 1
57 | a1 = np.zeros((1, n_a))
58 | c1 = np.zeros((1, n_a))
59 | predicting = inference_model.predict([x1, a1, c1])
60 |
61 |
62 | indices = np.argmax(predicting, axis = -1)
63 | results = to_categorical(indices, num_classes=78)
64 |
--------------------------------------------------------------------------------
/MusicGenerationProject/main.py:
--------------------------------------------------------------------------------
1 | import sys
2 | from music21 import *
3 | import numpy as np
4 | from grammar import *
5 | from qa import *
6 | from preprocess import *
7 | from music_utils import *
8 | from data_utils import *
9 | from keras.models import load_model, Model
10 | from keras.layers import Dense, Activation, Dropout, Input, LSTM, Reshape, Lambda, RepeatVector
11 | from keras.initializers import glorot_uniform
12 | from keras.utils import to_categorical
13 | from keras.optimizers import Adam
14 | from keras import backend as K
15 |
16 |
17 | X, Y, n_values, indices_values = load_music_utils()
18 | # print('shape of X:', X.shape= (60,30,78) )
19 | # print('number of training examples:', X.shape[0]=60)
20 | # print('Tx (length of sequence):', X.shape[1]=30)
21 | # print('total # of unique values:', n_values=78)
22 | # print('Shape of Y:', Y.shape=(30,60,78))
23 |
24 | n_a = 64
25 |
26 | reshapor = Reshape((1, 78))
27 | LSTM_cell = LSTM(n_a, return_state = True)
28 | densor = Dense(n_values, activation='softmax')
29 |
30 | # First generate model
31 | def djmodel(Tx, n_a, n_values):
32 | """
33 | Implement the model
34 | Arguments:
35 | Tx -- length of the sequence in a corpus
36 | n_a -- the number of activations used in our model
37 | n_values -- number of unique values in the music data
38 |
39 | Returns:
40 | model -- a keras model with the
41 | """
42 |
43 | # Define the input of your model with a shape
44 | X = Input(shape=(Tx, n_values))
45 |
46 | # Define s0, initial hidden state for the decoder LSTM
47 | a0 = Input(shape=(n_a,), name='a0')
48 | c0 = Input(shape=(n_a,), name='c0')
49 | a = a0
50 | c = c0
51 | outputs = []
52 |
53 | for t in range(Tx):
54 | # select the "t"th time step vector from X.
55 | x = Lambda(lambda x: X[:, t, :])(X)
56 | # Use reshapor to reshape x to be (1, n_values) (≈1 line); reshapor = Reshape((1, 78))
57 | x = reshapor(x)
58 | # Perform one step of the LSTM_cell; LSTM_cell = LSTM(n_a, return_state = True)
59 | a, _, c = LSTM_cell(x, initial_state=[a, c])
60 | # Apply densor to the hidden state output of LSTM_Cell; densor = Dense(n_values, activation='softmax')
61 | out = densor(a)
62 | # add the output to "outputs"
63 | outputs.append(out)
64 |
65 | # Create model instance
66 | model = Model([X, a0, c0], outputs)
67 | return model
68 |
69 | # music inference
70 | def music_inference_model(LSTM_cell, densor, n_values=78, n_a=64, Ty=100):
71 | """
72 | Uses the trained "LSTM_cell" and "densor" from model() to generate a sequence of values.
73 |
74 | Arguments:
75 | LSTM_cell -- the trained "LSTM_cell" from model(), Keras layer object
76 | densor -- the trained "densor" from model(), Keras layer object
77 | n_values -- integer, umber of unique values
78 | n_a -- number of units in the LSTM_cell
79 | Ty -- integer, number of time steps to generate
80 |
81 | Returns:
82 | inference_model -- Keras model instance
83 | """
84 |
85 | # Define the input of your model with a shape
86 | x0 = Input(shape=(1, n_values))
87 |
88 | # Define s0, initial hidden state for the decoder LSTM
89 | a0 = Input(shape=(n_a,), name='a0')
90 | c0 = Input(shape=(n_a,), name='c0')
91 | a = a0
92 | c = c0
93 | x = x0
94 |
95 | outputs = []
96 |
97 | # Loop over Ty and generate a value at every time step
98 | for t in range(Ty):
99 | # Perform one step of LSTM_cell (≈1 line); LSTM_cell = LSTM(n_a, return_state = True)
100 | a, _, c = LSTM_cell(x, initial_state=[a, c])
101 |
102 | # Apply Dense layer to the hidden state output of the LSTM_cell; densor = Dense(n_values, activation='softmax')
103 | out = densor(a)
104 |
105 | # Append the prediction "out" to "outputs". out.shape = (None, 78)
106 | outputs.append(out)
107 |
108 | # Select the next value according to "out", and set "x" to be the one-hot representation of the
109 | # selected value, which will be passed as the input to LSTM_cell on the next step. We have provided
110 | # the line of code you need to do this.
111 | x = Lambda(one_hot)(out)
112 |
113 | # Create model instance with the correct "inputs" and "outputs"
114 | inference_model = Model([x0, a0, c0], outputs)
115 |
116 | return inference_model
117 |
118 | # Music Generation
119 | def predict_and_sample(inference_model, x_initializer=x_initializer, a_initializer=a_initializer,
120 | c_initializer=c_initializer):
121 | """
122 | Predicts the next value of values using the inference model.
123 |
124 | Arguments:
125 | inference_model -- Keras model instance for inference time
126 | x_initializer -- numpy array of shape (1, 1, 78), one-hot vector initializing the values generation
127 | a_initializer -- numpy array of shape (1, n_a), initializing the hidden state of the LSTM_cell
128 | c_initializer -- numpy array of shape (1, n_a), initializing the cell state of the LSTM_cel
129 |
130 | Returns:
131 | results -- numpy-array of shape (Ty, 78), matrix of one-hot vectors representing the values generated
132 | indices -- numpy-array of shape (Ty, 1), matrix of indices representing the values generated
133 | """
134 |
135 | # Step 1: Use your inference model to predict an output sequence given x_initializer, a_initializer and c_initializer.
136 | pred = inference_model.predict([x_initializer, a_initializer, c_initializer])
137 | # Step 2: Convert "pred" into an np.array() of indices with the maximum probabilities
138 | indices = np.argmax(pred, 2)
139 | # Step 3: Convert indices to one-hot vectors, the shape of the results should be (1, )
140 | results = to_categorical(indices, num_classes=None)
141 |
142 | return results, indices
143 |
144 | if __name__ == "__main__":
145 | # First generate model, train LSTM and densor; densor = Dense(n_values, activation='softmax'); densor is fully connected with softmax
146 | model = djmodel(Tx=30, n_a=64, n_values=78)
147 | opt = Adam(lr=0.01, beta_1=0.9, beta_2=0.999, decay=0.01)
148 | model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
149 | m = 60
150 | a0 = np.zeros((m, n_a))
151 | c0 = np.zeros((m, n_a))
152 | model.fit([X, a0, c0], list(Y), epochs=100)
153 |
154 | # Uses the trained "LSTM_cell" and "densor" from model() to generate a sequence of values.
155 | inference_model = music_inference_model(LSTM_cell, densor, n_values=78, n_a=64, Ty=50)
156 |
157 | x_initializer = np.zeros((1, 1, 78))
158 | a_initializer = np.zeros((1, n_a))
159 | c_initializer = np.zeros((1, n_a))
160 |
161 | # Music gereneration
162 | results, indices = predict_and_sample(inference_model, x_initializer, a_initializer, c_initializer)
163 |
164 | out_stream = generate_music(inference_model)
165 |
--------------------------------------------------------------------------------
/MusicGenerationProject/midi.py:
--------------------------------------------------------------------------------
1 | """
2 | File: midi.py
3 | Author: Addy771
4 | Description:
5 | A script which converts MIDI files to WAV and optionally to MP3 using ffmpeg.
6 | Works by playing each file and using the stereo mix device to record at the same time
7 | """
8 |
9 |
10 | import pyaudio # audio recording
11 | import wave # file saving
12 | import pygame # midi playback
13 | import fnmatch # name matching
14 | import os # file listing
15 |
16 |
17 | #### CONFIGURATION ####
18 |
19 | do_ffmpeg_convert = True # Uses FFmpeg to convert WAV files to MP3. Requires ffmpeg.exe in the script folder or PATH
20 | do_wav_cleanup = True # Deletes WAV files after conversion to MP3
21 | sample_rate = 44100 # Sample rate used for WAV/MP3
22 | channels = 2 # Audio channels (1 = mono, 2 = stereo)
23 | buffer = 1024 # Audio buffer size
24 | mp3_bitrate = 128 # Bitrate to save MP3 with in kbps (CBR)
25 | input_device = 1 # Which recording device to use. On my system Stereo Mix = 1
26 |
27 |
28 |
29 | # Begins playback of a MIDI file
30 | def play_music(music_file):
31 |
32 | try:
33 | pygame.mixer.music.load(music_file)
34 |
35 | except pygame.error:
36 | print ("Couldn't play %s! (%s)" % (music_file, pygame.get_error()))
37 | return
38 |
39 | pygame.mixer.music.play()
40 |
41 |
42 |
43 | # Init pygame playback
44 | bitsize = -16 # unsigned 16 bit
45 | pygame.mixer.init(sample_rate, bitsize, channels, buffer)
46 |
47 | # optional volume 0 to 1.0
48 | pygame.mixer.music.set_volume(1.0)
49 |
50 | # Init pyAudio
51 | format = pyaudio.paInt16
52 | audio = pyaudio.PyAudio()
53 |
54 |
55 |
56 | try:
57 |
58 | # Make a list of .mid files in the current directory and all subdirectories
59 | matches = []
60 | for root, dirnames, filenames in os.walk("./"):
61 | for filename in fnmatch.filter(filenames, '*.mid'):
62 | matches.append(os.path.join(root, filename))
63 |
64 | # Play each song in the list
65 | for song in matches:
66 |
67 | # Create a filename with a .wav extension
68 | file_name = os.path.splitext(os.path.basename(song))[0]
69 | new_file = file_name + '.wav'
70 |
71 | # Open the stream and start recording
72 | stream = audio.open(format=format, channels=channels, rate=sample_rate, input=True, input_device_index=input_device, frames_per_buffer=buffer)
73 |
74 | # Playback the song
75 | print("Playing " + file_name + ".mid\n")
76 | play_music(song)
77 |
78 | frames = []
79 |
80 | # Record frames while the song is playing
81 | while pygame.mixer.music.get_busy():
82 | frames.append(stream.read(buffer))
83 |
84 | # Stop recording
85 | stream.stop_stream()
86 | stream.close()
87 |
88 |
89 | # Configure wave file settings
90 | wave_file = wave.open(new_file, 'wb')
91 | wave_file.setnchannels(channels)
92 | wave_file.setsampwidth(audio.get_sample_size(format))
93 | wave_file.setframerate(sample_rate)
94 |
95 | print("Saving " + new_file)
96 |
97 | # Write the frames to the wave file
98 | wave_file.writeframes(b''.join(frames))
99 | wave_file.close()
100 |
101 | # Call FFmpeg to handle the MP3 conversion if desired
102 | if do_ffmpeg_convert:
103 | os.system('ffmpeg -i ' + new_file + ' -y -f mp3 -ab ' + str(mp3_bitrate) + 'k -ac ' + str(channels) + ' -ar ' + str(sample_rate) + ' -vn ' + file_name + '.mp3')
104 |
105 | # Delete the WAV file if desired
106 | if do_wav_cleanup:
107 | os.remove(new_file)
108 |
109 | # End PyAudio
110 | audio.terminate()
111 |
112 | except KeyboardInterrupt:
113 | # if user hits Ctrl/C then exit
114 | # (works only in console mode)
115 | pygame.mixer.music.fadeout(1000)
116 | pygame.mixer.music.stop()
117 | raise SystemExit
--------------------------------------------------------------------------------
/MusicGenerationProject/music_utils.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 | import tensorflow as tf
3 | import keras.backend as K
4 | from keras.layers import RepeatVector
5 | import sys
6 | from music21 import *
7 | import numpy as np
8 | from grammar import *
9 | from preprocess import *
10 | from qa import *
11 |
12 |
13 | def data_processing(corpus, values_indices, m = 60, Tx = 30):
14 | # cut the corpus into semi-redundant sequences of Tx values
15 | Tx = Tx
16 | N_values = len(set(corpus))
17 | np.random.seed(0)
18 | X = np.zeros((m, Tx, N_values), dtype=np.bool)
19 | Y = np.zeros((m, Tx, N_values), dtype=np.bool)
20 | for i in range(m):
21 | # for t in range(1, Tx):
22 | random_idx = np.random.choice(len(corpus) - Tx)
23 | corp_data = corpus[random_idx:(random_idx + Tx)]
24 | for j in range(Tx):
25 | idx = values_indices[corp_data[j]]
26 | if j != 0:
27 | X[i, j, idx] = 1
28 | Y[i, j-1, idx] = 1
29 |
30 | Y = np.swapaxes(Y,0,1)
31 | Y = Y.tolist()
32 | return np.asarray(X), np.asarray(Y), N_values
33 |
34 | def next_value_processing(model, next_value, x, predict_and_sample, indices_values, abstract_grammars, duration, max_tries = 1000, temperature = 0.5):
35 | """
36 | Helper function to fix the first value.
37 |
38 | Arguments:
39 | next_value -- predicted and sampled value, index between 0 and 77
40 | x -- numpy-array, one-hot encoding of next_value
41 | predict_and_sample -- predict function
42 | indices_values -- a python dictionary mapping indices (0-77) into their corresponding unique value (ex: A,0.250,< m2,P-4 >)
43 | abstract_grammars -- list of grammars, on element can be: 'S,0.250, C,0.250, A,0.250,'
44 | duration -- scalar, index of the loop in the parent function
45 | max_tries -- Maximum numbers of time trying to fix the value
46 |
47 | Returns:
48 | next_value -- process predicted value
49 | """
50 |
51 | # fix first note: must not have < > and not be a rest
52 | if (duration < 0.00001):
53 | tries = 0
54 | while (next_value.split(',')[0] == 'R' or
55 | len(next_value.split(',')) != 2):
56 | # give up after 1000 tries; random from input's first notes
57 | if tries >= max_tries:
58 | #print('Gave up on first note generation after', max_tries, 'tries')
59 | # np.random is exclusive to high
60 | rand = np.random.randint(0, len(abstract_grammars))
61 | next_value = abstract_grammars[rand].split(' ')[0]
62 | else:
63 | next_value = predict_and_sample(model, x, indices_values, temperature)
64 |
65 | tries += 1
66 |
67 | return next_value
68 |
69 |
70 | def sequence_to_matrix(sequence, values_indices):
71 | """
72 | Convert a sequence (slice of the corpus) into a matrix (numpy) of one-hot vectors corresponding
73 | to indices in values_indices
74 |
75 | Arguments:
76 | sequence -- python list
77 |
78 | Returns:
79 | x -- numpy-array of one-hot vectors
80 | """
81 | sequence_len = len(sequence)
82 | x = np.zeros((1, sequence_len, len(values_indices)))
83 | for t, value in enumerate(sequence):
84 | if (not value in values_indices): print(value)
85 | x[0, t, values_indices[value]] = 1.
86 | return x
87 |
88 | def one_hot(x):
89 | x = K.argmax(x)
90 | x = tf.one_hot(x, 78)
91 | x = RepeatVector(1)(x)
92 | return x
--------------------------------------------------------------------------------
/MusicGenerationProject/output/my_music.midi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/72975a4d872b7a9c9643b2c453378d2625bba41e/MusicGenerationProject/output/my_music.midi
--------------------------------------------------------------------------------
/MusicGenerationProject/preprocess.py:
--------------------------------------------------------------------------------
1 | '''
2 | Author: Ji-Sung Kim
3 | Project: deepjazz
4 | Purpose: Parse, cleanup and process data.
5 |
6 | Code adapted from Evan Chow's jazzml, https://github.com/evancchow/jazzml with
7 | express permission.
8 | '''
9 |
10 | from __future__ import print_function
11 |
12 | from music21 import *
13 | from collections import defaultdict, OrderedDict
14 | from itertools import groupby, zip_longest
15 |
16 | from grammar import *
17 |
18 | from grammar import parse_melody
19 | from music_utils import *
20 |
21 | #----------------------------HELPER FUNCTIONS----------------------------------#
22 |
23 | ''' Helper function to parse a MIDI file into its measures and chords '''
24 | def __parse_midi(data_fn):
25 | # Parse the MIDI data for separate melody and accompaniment parts.
26 | midi_data = converter.parse(data_fn)
27 | # Get melody part, compress into single voice.
28 | melody_stream = midi_data[5] # For Metheny piece, Melody is Part #5.
29 | melody1, melody2 = melody_stream.getElementsByClass(stream.Voice)
30 | for j in melody2:
31 | melody1.insert(j.offset, j)
32 | melody_voice = melody1
33 |
34 | for i in melody_voice:
35 | if i.quarterLength == 0.0:
36 | i.quarterLength = 0.25
37 |
38 | # Change key signature to adhere to comp_stream (1 sharp, mode = major).
39 | # Also add Electric Guitar.
40 | melody_voice.insert(0, instrument.ElectricGuitar())
41 | melody_voice.insert(0, key.KeySignature(sharps=1))
42 |
43 | # The accompaniment parts. Take only the best subset of parts from
44 | # the original data. Maybe add more parts, hand-add valid instruments.
45 | # Should add least add a string part (for sparse solos).
46 | # Verified are good parts: 0, 1, 6, 7 '''
47 | partIndices = [0, 1, 6, 7]
48 | comp_stream = stream.Voice()
49 | comp_stream.append([j.flat for i, j in enumerate(midi_data)
50 | if i in partIndices])
51 |
52 | # Full stream containing both the melody and the accompaniment.
53 | # All parts are flattened.
54 | full_stream = stream.Voice()
55 | for i in range(len(comp_stream)):
56 | full_stream.append(comp_stream[i])
57 | full_stream.append(melody_voice)
58 |
59 | # Extract solo stream, assuming you know the positions ..ByOffset(i, j).
60 | # Note that for different instruments (with stream.flat), you NEED to use
61 | # stream.Part(), not stream.Voice().
62 | # Accompanied solo is in range [478, 548)
63 | solo_stream = stream.Voice()
64 | for part in full_stream:
65 | curr_part = stream.Part()
66 | curr_part.append(part.getElementsByClass(instrument.Instrument))
67 | curr_part.append(part.getElementsByClass(tempo.MetronomeMark))
68 | curr_part.append(part.getElementsByClass(key.KeySignature))
69 | curr_part.append(part.getElementsByClass(meter.TimeSignature))
70 | curr_part.append(part.getElementsByOffset(476, 548,
71 | includeEndBoundary=True))
72 | cp = curr_part.flat
73 | solo_stream.insert(cp)
74 |
75 | # Group by measure so you can classify.
76 | # Note that measure 0 is for the time signature, metronome, etc. which have
77 | # an offset of 0.0.
78 | melody_stream = solo_stream[-1]
79 | measures = OrderedDict()
80 | offsetTuples = [(int(n.offset / 4), n) for n in melody_stream]
81 | measureNum = 0 # for now, don't use real m. nums (119, 120)
82 | for key_x, group in groupby(offsetTuples, lambda x: x[0]):
83 | measures[measureNum] = [n[1] for n in group]
84 | measureNum += 1
85 |
86 | # Get the stream of chords.
87 | # offsetTuples_chords: group chords by measure number.
88 | chordStream = solo_stream[0]
89 | chordStream.removeByClass(note.Rest)
90 | chordStream.removeByClass(note.Note)
91 | offsetTuples_chords = [(int(n.offset / 4), n) for n in chordStream]
92 |
93 | # Generate the chord structure. Use just track 1 (piano) since it is
94 | # the only instrument that has chords.
95 | # Group into 4s, just like before.
96 | chords = OrderedDict()
97 | measureNum = 0
98 | for key_x, group in groupby(offsetTuples_chords, lambda x: x[0]):
99 | chords[measureNum] = [n[1] for n in group]
100 | measureNum += 1
101 |
102 | # Fix for the below problem.
103 | # 1) Find out why len(measures) != len(chords).
104 | # ANSWER: resolves at end but melody ends 1/16 before last measure so doesn't
105 | # actually show up, while the accompaniment's beat 1 right after does.
106 | # Actually on second thought: melody/comp start on Ab, and resolve to
107 | # the same key (Ab) so could actually just cut out last measure to loop.
108 | # Decided: just cut out the last measure.
109 | del chords[len(chords) - 1]
110 | assert len(chords) == len(measures)
111 |
112 | return measures, chords
113 |
114 | ''' Helper function to get the grammatical data from given musical data. '''
115 | def __get_abstract_grammars(measures, chords):
116 | # extract grammars
117 | abstract_grammars = []
118 | for ix in range(1, len(measures)):
119 | m = stream.Voice()
120 | for i in measures[ix]:
121 | m.insert(i.offset, i)
122 | c = stream.Voice()
123 | for j in chords[ix]:
124 | c.insert(j.offset, j)
125 | parsed = parse_melody(m, c)
126 | abstract_grammars.append(parsed)
127 |
128 | return abstract_grammars
129 |
130 | #----------------------------PUBLIC FUNCTIONS----------------------------------#
131 |
132 | ''' Get musical data from a MIDI file '''
133 | def get_musical_data(data_fn):
134 |
135 | measures, chords = __parse_midi(data_fn)
136 | abstract_grammars = __get_abstract_grammars(measures, chords)
137 |
138 | return chords, abstract_grammars
139 |
140 | ''' Get corpus data from grammatical data '''
141 | def get_corpus_data(abstract_grammars):
142 | corpus = [x for sublist in abstract_grammars for x in sublist.split(' ')]
143 | values = set(corpus)
144 | val_indices = dict((v, i) for i, v in enumerate(values))
145 | indices_val = dict((i, v) for i, v in enumerate(values))
146 |
147 | return corpus, values, val_indices, indices_val
148 |
149 | '''
150 | def load_music_utils():
151 | chord_data, raw_music_data = get_musical_data('data/original_metheny.mid')
152 | music_data, values, values_indices, indices_values = get_corpus_data(raw_music_data)
153 |
154 | X, Y = data_processing(music_data, values_indices, Tx = 20, step = 3)
155 | return (X, Y)
156 | '''
157 |
--------------------------------------------------------------------------------
/MusicGenerationProject/qa.py:
--------------------------------------------------------------------------------
1 | '''
2 | Author: Ji-Sung Kim, Evan Chow
3 | Project: deepjazz
4 | Purpose: Provide pruning and cleanup functions.
5 |
6 | Code adapted from Evan Chow's jazzml, https://github.com/evancchow/jazzml
7 | with express permission.
8 | '''
9 | from itertools import zip_longest
10 | import random
11 |
12 | from music21 import *
13 |
14 | #----------------------------HELPER FUNCTIONS----------------------------------#
15 |
16 | ''' Helper function to down num to the nearest multiple of mult. '''
17 | def __roundDown(num, mult):
18 | return (float(num) - (float(num) % mult))
19 |
20 | ''' Helper function to round up num to nearest multiple of mult. '''
21 | def __roundUp(num, mult):
22 | return __roundDown(num, mult) + mult
23 |
24 | ''' Helper function that, based on if upDown < 0 or upDown >= 0, rounds number
25 | down or up respectively to nearest multiple of mult. '''
26 | def __roundUpDown(num, mult, upDown):
27 | if upDown < 0:
28 | return __roundDown(num, mult)
29 | else:
30 | return __roundUp(num, mult)
31 |
32 | ''' Helper function, from recipes, to iterate over list in chunks of n
33 | length. '''
34 | def __grouper(iterable, n, fillvalue=None):
35 | args = [iter(iterable)] * n
36 | return zip_longest(*args, fillvalue=fillvalue)
37 |
38 | #----------------------------PUBLIC FUNCTIONS----------------------------------#
39 |
40 | ''' Smooth the measure, ensuring that everything is in standard note lengths
41 | (e.g., 0.125, 0.250, 0.333 ... ). '''
42 | def prune_grammar(curr_grammar):
43 | pruned_grammar = curr_grammar.split(' ')
44 |
45 | for ix, gram in enumerate(pruned_grammar):
46 | terms = gram.split(',')
47 | terms[1] = str(__roundUpDown(float(terms[1]), 0.250,
48 | random.choice([-1, 1])))
49 | pruned_grammar[ix] = ','.join(terms)
50 | pruned_grammar = ' '.join(pruned_grammar)
51 |
52 | return pruned_grammar
53 |
54 | ''' Remove repeated notes, and notes that are too close together. '''
55 | def prune_notes(curr_notes):
56 | for n1, n2 in __grouper(curr_notes, n=2):
57 | if n2 == None: # corner case: odd-length list
58 | continue
59 | if isinstance(n1, note.Note) and isinstance(n2, note.Note):
60 | if n1.nameWithOctave == n2.nameWithOctave:
61 | curr_notes.remove(n2)
62 |
63 | return curr_notes
64 |
65 | ''' Perform quality assurance on notes '''
66 | def clean_up_notes(curr_notes):
67 | removeIxs = []
68 | for ix, m in enumerate(curr_notes):
69 | # QA1: ensure nothing is of 0 quarter note len, if so changes its len
70 | if (m.quarterLength == 0.0):
71 | m.quarterLength = 0.250
72 | # QA2: ensure no two melody notes have same offset, i.e. form a chord.
73 | # Sorted, so same offset would be consecutive notes.
74 | if (ix < (len(curr_notes) - 1)):
75 | if (m.offset == curr_notes[ix + 1].offset and
76 | isinstance(curr_notes[ix + 1], note.Note)):
77 | removeIxs.append((ix + 1))
78 | curr_notes = [i for ix, i in enumerate(curr_notes) if ix not in removeIxs]
79 |
80 | return curr_notes
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # LSTM and RNN Tutorial with Demo (with Stock/Bitcoin Time Series Prediction, Sentiment Analysis, Music Generation)
2 |
3 | There are many LSTM tutorials, courses, papers in the internet. This one summarizes all of them. In this tutorial, RNN Cell, RNN Forward and Backward Pass, LSTM Cell, LSTM Forward Pass, Sample LSTM Project: Prediction of Stock Prices Using LSTM network, Sample LSTM Project: Sentiment Analysis, Sample LSTM Project: Music Generation. It will continue to be updated over time.
4 |
5 | **Keywords: Deep Learning, LSTM, RNN, Stock/Bitcoin price prediction, Sentiment Analysis, Music Generation, Sample Code, Basic LSTM, Basic RNN**
6 |
7 | **NOTE: This tutorial is only for education purpose. It is not academic study/paper. All related references are listed at the end of the file.**
8 |
9 | # Table of Contents
10 | - [What is Deep Learning?](#whatisDL)
11 | - [What is RNN?](#whatisRNN)
12 | - [RNN Cell](#RNNCell)
13 | - [RNN Forward Pass](#RNNForward)
14 | - [RNN Backward Pass](#RNNBackward)
15 | - [RNN Problem](#RNNProblem)
16 | - [What is LSTM?](#whatisLSTM)
17 | - [LSTM Cell](#LSTMCell)
18 | - [LSTM Forward Pass](#LSTMForward)
19 | - [SAMPLE LSTM CODE: Prediction of Stock Prices Using LSTM network](#SampleStock)
20 | - [SAMPLE LSTM CODE: Sentiment Analysis](#Sentiment)
21 | - [Results](#SentimentResults)
22 | - [DataSet](#SentimentDataSet)
23 | - [Embeddings](#SentimentEmbeddings)
24 | - [LSTM Model in Sentiment Analysis](#SentimentLSTM)
25 | - [SAMPLE LSTM CODE: Music Generation](#MusicGeneration)
26 | - [How to Run Code?](#MusicHowToRunCode)
27 | - [Input File and Parameters](#MusicInput)
28 | - [LSTM Model in Music Generation](#MusicLSTM)
29 | - [Predicting and Sampling](#MusicPredictingAndSampling)
30 | - [Resources](#Resources)
31 | - [References](#References)
32 |
33 |
34 | ## What is Deep Learning (DL)?
35 |
36 | "Deep Learning is a subfield of machine learning concerned with algorithms inspired by the structure and function of the brain called artificial neural networks." There are different types of DL models: Convolutional Neural Network, Recurrent Neural Networks (RNN), Long Short Term Memory (LSTM), Restricted Boltzmann Machine (RBM), Deep Belief Networks, etc.
37 |
38 | In this tutorial, we are focusing on recurrent networks, especially LSTM. Basic RNN structure, Basic LSTM structures and Stock/Bitcoin Price Prediction Sample code are presented in the following sections.
39 |
40 |
41 | ## What is RNN?
42 |
43 | * Recurrent neural network (RNN) is a type of deep learning model that is mostly used for analysis of sequential data (time series data prediction).
44 | * There are different application areas that are used: Language model, neural machine translation, music generation, time series prediction, financial prediction, etc.
45 | * The aim of this implementation is to help to learn structure of basic RNN (RNN cell forward, RNN cell backward, etc..).
46 | * Code is adapted from Andrew Ng's Course 'Sequential models'.
47 |
48 | Code: https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/tree/master/BasicRNN
49 |
50 |
51 | ### RNN Cell
52 |
53 |
54 |
55 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
56 |
57 | ### RNN Forward Pass
58 |
59 |
60 |
61 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
62 |
63 | ### RNN Backward Pass
64 |
65 |
66 |
67 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
68 |
69 | ### RNN Problem
70 | - In theory, RNNs are absolutely capable of handling such “long-term dependencies.”
71 | - In practice, RNNs don’t seem to be able to learn them.
72 | - The problem was explored in depth by Hochreiter (1991) [German] and Bengio, et al. (1994) with [LSTM](https://www.bioinf.jku.at/publications/older/2604.pdf)
73 |
74 | ## What is LSTM?
75 |
76 | - It is a special type of RNN, capable of learning long-term dependencies.
77 |
78 | - "Long short-term memory (LSTM) units are units of a recurrent neural network (RNN). An RNN composed of LSTM units is often called an LSTM network. A common LSTM unit is composed of a cell, an input gate, an output gate and a forget gate. The cell remembers values over arbitrary time intervals and the three gates regulate the flow of information into and out of the cell"
79 |
80 | - Long Short Term Memory (LSTM) is a type of deep learning model that is mostly used for analysis of sequential data (time series data prediction).
81 |
82 | - There are different application areas that are used: Language model, Neural machine translation, Music generation, Time series prediction, Financial prediction, Robot control, Time series prediction, Speech recognition, Rhythm learning, Music composition, Grammar learning, Handwriting recognition, Human action recognition, Sign Language Translation,Time series anomaly detection, Several prediction tasks in the area of business process management, Prediction in medical care pathways, Semantic parsing, Object Co-segmentation.
83 |
84 | - LSTM was proposed in 1997 by Sepp Hochreiter and Jürgen Schmidhuber and improved in 2000 by Felix Gers' team.
85 | [Paper](https://www.bioinf.jku.at/publications/older/2604.pdf)
86 |
87 | Code: https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/tree/master/BasicLSTM
88 |
89 | ### LSTM Cell
90 |
91 |
92 |
93 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
94 |
95 | ### LSTM Forward Pass
96 |
97 |
98 |
99 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
100 |
101 |
102 | ## SAMPLE LSTM CODE: Prediction of Stock Prices Using LSTM network
103 | Stock and ETFs prices are predicted using LSTM network (Keras-Tensorflow).
104 |
105 | Code: https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/tree/master/StockPricesPredictionProject
106 |
107 | - Stock prices are downloaded from [finance.yahoo.com](https://finance.yahoo.com/). [Disneyland (DIS) Stock Price CSV file](https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Stock_Prices_Prediction/blob/master/Stock_Prices_Prediction_Example/DIS.csv).
108 | - Closed value (column[5]) is used in the network, [LSTM Code](https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Stock_Prices_Prediction/blob/master/Stock_Prices_Prediction_Example/pricePredictionLSTM.py)
109 | - Values are normalized in range (0,1).
110 | - Datasets are splitted into train and test sets, 50% test data, 50% training data.
111 | - Keras-Tensorflow is used for implementation.
112 | - LSTM network consists of 25 hidden neurons, and 1 output layer (1 dense layer).
113 | - LSTM network features input: 1 layer, output: 1 layer , hidden: 25 neurons, optimizer:adam, dropout:0.1, timestep:240, batchsize:240, epochs:1000 (features can be further optimized).
114 | - Root mean squared errors are calculated.
115 | - Output files: [lstm_results](https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Stock_Prices_Prediction/blob/master/Stock_Prices_Prediction_Example/lstm_result.csv) (consists of prediction and actual values), plot file (actual and prediction values).
116 |
117 | 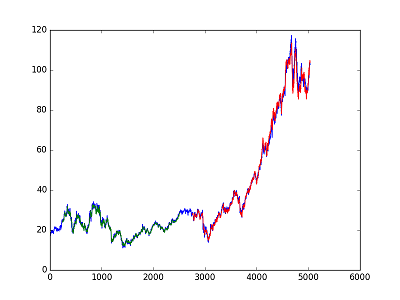
118 |
119 | ## SAMPLE LSTM CODE: Sentiment Analysis
120 |
121 | Sentiment Analysis is an analysis of the sentence, text at the document that gives us the opinion of the sentence/text. In this project, it will be implemented a model which inputs a sentence and finds the most appropriate emoji to be used with this sentence. Code is adapted from Andrew Ng's Course 'Sequential Models'.
122 |
123 | **NOTE:This project is adapted from Andrew Ng, [Sequential Models Course](https://github.com/Kulbear/deep-learning-coursera/tree/master/Sequence%20Models), [Deep Learning Specialization](https://www.coursera.org/specializations/deep-learning) for educational purpose**
124 |
125 | Code: https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/tree/master/SentimentAnalysisProject
126 |
127 | ### Results
128 |
129 | 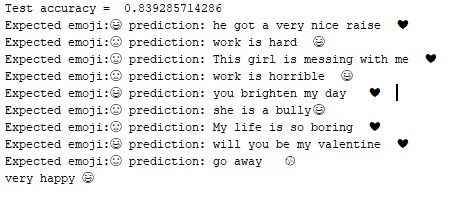
130 |
131 | ### DataSet
132 | We have a tiny dataset (X, Y) where:
133 |
134 | * X contains 127 sentences (strings)
135 | * Y contains a integer label between 0 and 4 corresponding to an emoji for each sentence
136 |
137 |
138 |
139 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
140 |
141 | ### Embeddings
142 |
143 | Glove 50 dimension, 40000 words of dictionary file is used for word embeddings. It should be downloaded from https://www.kaggle.com/watts2/glove6b50dtxt (file size = ~168MB))
144 |
145 |
146 | * word_to_index: dictionary mapping from words to their indices in the vocabulary (400,001 words, with the valid indices ranging from 0 to 400,000)
147 | * index_to_word: dictionary mapping from indices to their corresponding words in the vocabulary
148 | * word_to_vec_map: dictionary mapping words to their GloVe vector representation.
149 |
150 | ### LSTM Model in Sentiment Analysis
151 |
152 | LSTM structure is used for classification.
153 |
154 |
155 |
156 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
157 |
158 | Parameters:
159 |
160 | 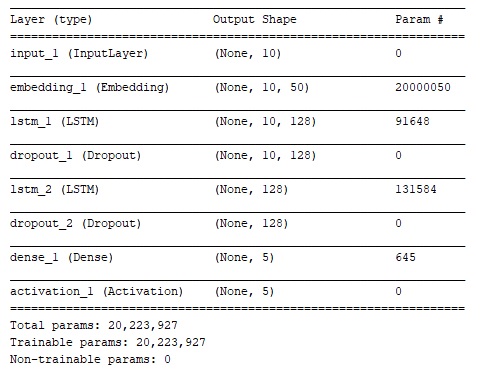
161 |
162 |
163 |
164 | ## SAMPLE LSTM CODE: Music Generation
165 |
166 | With trained DL model (LSTM), new sequences of time series data can be predicted. In this project, it will be implemented a model which inputs a sample jazz music and samples/generates a new music. Code is adapted from Andrew Ng's Course 'Sequential models'.
167 |
168 | **NOTE:This project is adapted from Andrew Ng, [Sequential Models Course](https://github.com/Kulbear/deep-learning-coursera/tree/master/Sequence%20Models), [Deep Learning Specialization](https://www.coursera.org/specializations/deep-learning) for educational purpose**
169 |
170 | Code: https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/tree/master/MusicGenerationProject
171 |
172 | ### How to Run Code?
173 | * To run code, download music21 toolkit from [http://web.mit.edu/music21/](http://web.mit.edu/music21/). "pip install music21".
174 | * Run main.py
175 |
176 |
177 | ### Input File and Parameters
178 | Model is trained with "data/original_music"
179 | * "X, Y, n_values, indices_values = load_music_utils()"
180 | * Number of training examples: 60,
181 | * Each of training examples length of sequence:30
182 | * Our music generation system will use 78 unique values.
183 |
184 | * X: This is an (m, Tx , 78) dimensional array. We have m training examples, each of which is a snippet of Tx=30Tx=30 musical values. At each time step, the input is one of 78 different possible values, represented as a one-hot vector. Thus for example, X[i,t,:] is a one-hot vector representating the value of the i-th example at time t.
185 | * Y: This is essentially the same as X, but shifted one step to the left (to the past).
186 | * n_values: The number of unique values in this dataset. This should be 78.
187 | * indices_values: python dictionary mapping from 0-77 to musical values.
188 |
189 | ### LSTM Model in Music Generation
190 | LSTM model structure is:
191 |
192 |
193 |
194 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
195 |
196 | Model is implemented with "djmodel(Tx, n_a, n_values)" function.
197 |
198 | ### Predicting and Sampling:
199 |
200 | Adding model, predicting and sampling feature, model structure is:
201 |
202 |
203 |
204 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
205 |
206 | Music Inference Model is similar trained model and it is implemented with "music_inference_model(LSTM_cell, densor, n_values = 78, n_a = 64, Ty = 100)" function. Music is generated with "redict_and_sample" function.
207 | Finally, your generated music is saved in output/my_music.midi.
208 |
209 |
210 |
211 | ## Resources:
212 | - [LSTM Original Paper](https://www.bioinf.jku.at/publications/older/2604.pdf)
213 | - Keras: [https://keras.io/](https://keras.io/)
214 | - Tensorflow: [https://www.tensorflow.org/](https://www.tensorflow.org/)
215 | - [LSTM in Detail](http://colah.github.io/posts/2015-08-Understanding-LSTMs/)
216 | - [Music Toolkit: http://web.mit.edu/music21/](http://web.mit.edu/music21/)
217 |
218 | ## References:
219 | - [Andrew Ng, Sequential Models Course, Deep Learning Specialization](https://github.com/Kulbear/deep-learning-coursera/tree/master/Sequence%20Models)
220 | - https://www.kaggle.com/pablocastilla/predict-stock-prices-with-lstm/notebook
221 | - Basic LSTM Code is adapted from Andrew Ng's Course 'Sequential models'.
222 |
223 |
224 |
225 |
226 |
--------------------------------------------------------------------------------
/SentimentAnalysisProject/.idea/SentimentAnalysis.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
--------------------------------------------------------------------------------
/SentimentAnalysisProject/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
--------------------------------------------------------------------------------
/SentimentAnalysisProject/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/SentimentAnalysisProject/.idea/vcs.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/SentimentAnalysisProject/.idea/workspace.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 |
41 |
42 |
47 |
48 |
49 |
50 |
51 |
52 |
58 |
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
89 |
90 |
91 |
92 |
93 |
94 |
95 |
96 |
97 |
98 |
99 |
100 |
101 |
102 |
103 |
104 |
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
131 |
132 |
133 |
134 |
135 |
136 |
137 |
138 |
139 |
140 |
141 |
142 |
143 |
144 |
145 |
146 |
147 |
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 |
157 |
158 |
159 |
160 |
161 |
162 |
163 |
164 |
165 |
166 |
167 |
168 |
169 |
170 |
171 |
172 |
173 |
174 |
175 |
176 |
177 |
178 |
179 |
180 |
181 |
182 |
183 |
184 |
185 |
186 |
187 |
188 |
189 |
190 |
191 |
192 |
193 |
194 |
195 |
196 |
197 |
198 |
199 |
200 |
201 |
202 |
203 |
204 |
205 |
206 |
207 |
208 |
209 |
210 |
211 |
212 |
213 | 1533669706522
214 |
215 |
216 | 1533669706522
217 |
218 |
219 |
220 |
221 |
222 |
223 |
224 |
225 |
226 |
227 |
228 |
229 |
230 |
231 |
232 |
233 |
234 |
235 |
236 |
237 |
238 |
239 |
240 |
241 |
242 |
243 |
244 |
245 |
246 |
247 |
248 |
249 |
250 |
251 |
252 |
253 |
254 |
255 |
256 |
257 |
258 |
259 |
260 |
261 |
262 |
263 |
264 |
265 |
266 |
267 |
268 |
269 |
270 |
271 |
272 |
--------------------------------------------------------------------------------
/SentimentAnalysisProject/__pycache__/emo_utils.cpython-35.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/72975a4d872b7a9c9643b2c453378d2625bba41e/SentimentAnalysisProject/__pycache__/emo_utils.cpython-35.pyc
--------------------------------------------------------------------------------
/SentimentAnalysisProject/emo_utils.py:
--------------------------------------------------------------------------------
1 | import csv
2 | import numpy as np
3 | import emoji
4 | import pandas as pd
5 | import matplotlib.pyplot as plt
6 | from sklearn.metrics import confusion_matrix
7 |
8 | def read_glove_vecs(glove_file):
9 | with open(glove_file, 'r', encoding="utf8") as f:
10 | words = set()
11 | word_to_vec_map = {}
12 | for line in f:
13 | line = line.strip().split()
14 | curr_word = line[0]
15 | words.add(curr_word)
16 | word_to_vec_map[curr_word] = np.array(line[1:], dtype=np.float64)
17 |
18 | i = 1
19 | words_to_index = {}
20 | index_to_words = {}
21 | for w in sorted(words):
22 | words_to_index[w] = i
23 | index_to_words[i] = w
24 | i = i + 1
25 | return words_to_index, index_to_words, word_to_vec_map
26 |
27 | def softmax(x):
28 | """Compute softmax values for each sets of scores in x."""
29 | e_x = np.exp(x - np.max(x))
30 | return e_x / e_x.sum()
31 |
32 |
33 | def read_csv(filename = 'emojify_data.csv'):
34 | phrase = []
35 | emoji = []
36 |
37 | with open (filename) as csvDataFile:
38 | csvReader = csv.reader(csvDataFile)
39 |
40 | for row in csvReader:
41 | phrase.append(row[0])
42 | emoji.append(row[1])
43 |
44 | X = np.asarray(phrase)
45 | Y = np.asarray(emoji, dtype=int)
46 |
47 | return X, Y
48 |
49 | def convert_to_one_hot(Y, C):
50 | Y = np.eye(C)[Y.reshape(-1)]
51 | return Y
52 |
53 |
54 | emoji_dictionary = {"0": "\u2764\uFE0F", # :heart: prints a black instead of red heart depending on the font
55 | "1": ":baseball:",
56 | "2": ":smile:",
57 | "3": ":disappointed:",
58 | "4": ":fork_and_knife:"}
59 |
60 | def label_to_emoji(label):
61 | """
62 | Converts a label (int or string) into the corresponding emoji code (string) ready to be printed
63 | """
64 | return emoji.emojize(emoji_dictionary[str(label)], use_aliases=True)
65 |
66 |
67 | def print_predictions(X, pred):
68 | print()
69 | for i in range(X.shape[0]):
70 | print(X[i], label_to_emoji(int(pred[i])))
71 |
72 |
73 | def plot_confusion_matrix(y_actu, y_pred, title='Confusion matrix', cmap=plt.cm.gray_r):
74 |
75 | df_confusion = pd.crosstab(y_actu, y_pred.reshape(y_pred.shape[0],), rownames=['Actual'], colnames=['Predicted'], margins=True)
76 |
77 | df_conf_norm = df_confusion / df_confusion.sum(axis=1)
78 |
79 | plt.matshow(df_confusion, cmap=cmap) # imshow
80 | #plt.title(title)
81 | plt.colorbar()
82 | tick_marks = np.arange(len(df_confusion.columns))
83 | plt.xticks(tick_marks, df_confusion.columns, rotation=45)
84 | plt.yticks(tick_marks, df_confusion.index)
85 | #plt.tight_layout()
86 | plt.ylabel(df_confusion.index.name)
87 | plt.xlabel(df_confusion.columns.name)
88 |
89 |
90 | def predict(X, Y, W, b, word_to_vec_map):
91 | """
92 | Given X (sentences) and Y (emoji indices), predict emojis and compute the accuracy of your model over the given set.
93 |
94 | Arguments:
95 | X -- input data containing sentences, numpy array of shape (m, None)
96 | Y -- labels, containing index of the label emoji, numpy array of shape (m, 1)
97 |
98 | Returns:
99 | pred -- numpy array of shape (m, 1) with your predictions
100 | """
101 | m = X.shape[0]
102 | pred = np.zeros((m, 1))
103 |
104 | for j in range(m): # Loop over training examples
105 |
106 | # Split jth test example (sentence) into list of lower case words
107 | words = X[j].lower().split()
108 |
109 | # Average words' vectors
110 | avg = np.zeros((50,))
111 | for w in words:
112 | avg += word_to_vec_map[w]
113 | avg = avg/len(words)
114 |
115 | # Forward propagation
116 | Z = np.dot(W, avg) + b
117 | A = softmax(Z)
118 | pred[j] = np.argmax(A)
119 |
120 | print("Accuracy: " + str(np.mean((pred[:] == Y.reshape(Y.shape[0],1)[:]))))
121 |
122 | return pred
--------------------------------------------------------------------------------
/SentimentAnalysisProject/emojify_data.csv:
--------------------------------------------------------------------------------
1 | French macaroon is so tasty,4,,
2 | work is horrible,3,,
3 | I am upset,3,, [3]
4 | throw the ball,1,, [2]
5 | Good joke,2,,
6 | what is your favorite baseball game,1,,
7 | I cooked meat,4,,
8 | stop messing around,3,,
9 | I want chinese food,4,,
10 | Let us go play baseball,1,,
11 | you are failing this exercise,3,,
12 | yesterday we lost again,3,, [4]
13 | Good job,2,,
14 | ha ha ha it was so funny,2,,
15 | I will have a cheese cake,4,,
16 | Why are you feeling bad,3,,
17 | I want to joke,2,,
18 | I never said yes for this,3,, [0]
19 | the party is cancelled,3,, [0]
20 | where is the ball,1,,
21 | I am frustrated,3,, [6]
22 | ha ha ha lol,2,,
23 | she said yes,2,,
24 | he got a raise,2,,
25 | family is all I have,0,,
26 | he can pitch really well,1,,
27 | I love to the stars and back,0,,
28 | do you like pizza ,4,, [1]
29 | You totally deserve this prize,2,,
30 | I miss you so much,0,,v2
31 | I like your jacket ,2,,
32 | she got me a present,0,,
33 | will you be my valentine,0,,
34 | you failed the midterm,3,, [6]
35 | Who is down for a restaurant,4,,
36 | valentine day is near,0,,
37 | Great so awesome,2,,
38 | do you have a ball,1,,
39 | he can not do anything,3,,
40 | he likes baseball,1,,
41 | We had such a lovely dinner tonight,0,,
42 | vegetables are healthy,4,,
43 | he is a good friend,0,, [3]
44 | never talk to me again,3,,
45 | i miss her,0,, [2]
46 | food is life,4,,
47 | I am having fun,2,,
48 | So bad that you cannot come with us,3,, [0]
49 | do you want to join me for dinner ,4,,
50 | I like to smile,2,, [0]
51 | he did an amazing job,2,,
52 | Stop shouting at me,3,,
53 | I love taking breaks,0,,
54 | You are incredibly intelligent and talented,2,,
55 | I am proud of your achievements,2,,
56 | So sad you are not coming,3,, [0]
57 | funny,2,,
58 | Stop saying bullshit,3,,
59 | Bravo for the announcement it got a lot of traction,2,,
60 | This specialization is great,2,,
61 | I was waiting for her for two hours ,3,, [7]
62 | she takes forever to get ready ,3,,
63 | My grandmother is the love of my life,0,, [4]
64 | I will celebrate soon,2,,
65 | my code is working but the grader gave me zero,3,,
66 | She is the cutest person I have ever seen,0,,
67 | he is laughing,2,,
68 | I adore my dogs,0,,
69 | I love you mum,0,, [3]
70 | great job,2,,
71 | How dare you ask that,3,,
72 | this guy was such a joke,2,,
73 | I love indian food,4,,
74 | Are you down for baseball this afternoon,1,,
75 | this is bad,3,,
76 | Your stupidity has no limit,3,,
77 | I love my dad,0,,
78 | Do you want to give me a hug,0,,
79 | this girl was mean,3,,
80 | I am excited,2,,
81 | i miss him,0,,
82 | What is wrong with you,3,,
83 | they are so kind and friendly,0,,
84 | I am so impressed by your dedication to this project,2,,
85 | we made it,2,,
86 | I am ordering food,4,,
87 | Sounds like a fun plan ha ha,2,,
88 | I am so happy for you,2,,
89 | Miss you so much,0,,
90 | I love you,0,,
91 | this joke is killing me haha,2,,
92 | You are not qualified for this position,3,,
93 | miss you my dear,0,,
94 | I want to eat,4,,
95 | I am so excited to see you after so long,2,,
96 | he is the best player,1,,
97 | What a fun moment,2,,
98 | my algorithm performs poorly,3,,
99 | Stop shouting at me,3,,
100 | her smile is so charming,2,,
101 | It is the worst day in my life,3,,
102 | he is handsome,0,,
103 | no one likes him,3,,
104 | she is attractive,0,,
105 | It was funny lol,2,,
106 | he is so cute,0,,
107 | you did well on you exam,2,,
108 | I think I will end up alone,3,,
109 | Lets have food together,4,,
110 | too bad that you were not here,3,,
111 | I want to go play,1,,
112 | you are a loser,3,,
113 | I am starving,4,,
114 | you suck,3,,
115 | Congratulations,2,,
116 | you could not solve it,3,,
117 | I lost my wallet,3,,
118 | she did not answer my text ,3,,
119 | That catcher sucks ,1,,
120 | See you at the restaurant,4,,
121 | I boiled rice,4,,
122 | I said yes,2,,
123 | candy is life ,2,,
124 | the game just finished,1,,
125 | The first base man got the ball,1,,
126 | congratulations on your acceptance,2,,
127 | The assignment is too long ,3,,
128 | lol,2,,
129 | I got humiliated by my sister,3,,
130 | I want to eat,4,,
131 | the lectures are great though ,2,,
132 | you did not do your homework,3,,
133 | The baby is adorable,0,,
134 | Bravo,2,,
135 | I missed you,0,,
136 | I am looking for a date,0,,
137 | where is the food,4,,
138 | you are awful,3,,
139 | any suggestions for dinner,4,,
140 | she is happy,2,,
141 | I am always working,3,,
142 | This is so funny,2,,
143 | you got a down grade,3,,
144 | I want to have sushi for dinner,4,,
145 | she smiles a lot,2,,
146 | The chicago cubs won again,1,,
147 | I got approved,2,,
148 | cookies are good,4,,
149 | I hate him,3,,
150 | I am going to the stadium,1,,
151 | I am very disappointed,3,,
152 | I am proud of you forever,2,,
153 | This girl is messing with me,3,,
154 | Congrats on the new job,2,,
155 | enjoy your break,2,,
156 | go away,3,,
157 | I worked during my birthday,3,,
158 | Congratulation fon have a baby,2,,
159 | I am hungry,4,,
160 | She is my dearest love,0,,
161 | she is so cute,0,,
162 | I love dogs,0,,
163 | I did not have breakfast ,3,,
164 | my dog just had a few puppies,0,,
165 | I like you a lot,0,,
166 | he had to make a home run,1,,
167 | I am at the baseball game,1,,
168 | are you serious ha ha,2,,
169 | I like to laugh,2,,
170 | Stop making this joke ha ha ha,2,,
171 | you two are cute,0,,
172 | This stupid grader is not working ,3,,
173 | What you did was awesome,2,,
174 | My life is so boring,3,,
175 | he did not answer,3,,
176 | lets exercise,1,,
177 | you brighten my day,2,,
178 | I will go dance,2,,
179 | lets brunch some day,4,,
180 | dance with me,2,,
181 | she is a bully,3,,
182 | she plays baseball,1,,
183 | I like it when people smile,2,,
--------------------------------------------------------------------------------
/SentimentAnalysisProject/main.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from keras.models import Model
3 | from keras.layers import Dense, Input, Dropout, LSTM, Activation
4 | from keras.layers.embeddings import Embedding
5 | from keras.preprocessing import sequence
6 | from keras.initializers import glorot_uniform
7 | from emo_utils import *
8 |
9 | np.random.seed(1)
10 |
11 | def sentences_to_indices(X, word_to_index, max_len):
12 | """
13 | Converts an array of sentences (strings) into an array of indices corresponding to words in the sentences.
14 | The output shape should be such that it can be given to `Embedding()`
15 |
16 | Arguments:
17 | X -- array of sentences (strings), of shape (m, 1)
18 | word_to_index -- a dictionary containing the each word mapped to its index
19 | max_len -- maximum number of words in a sentence. You can assume every sentence in X is no longer than this.
20 |
21 | Returns:
22 | X_indices -- array of indices corresponding to words in the sentences from X, of shape (m, max_len)
23 | """
24 |
25 | m = X.shape[0] # number of training examples
26 | # Initialize X_indices as a numpy matrix of zeros and the correct shape (≈ 1 line)
27 | X_indices = np.zeros((m, max_len))
28 |
29 | for i in range(m): # loop over training examples
30 | # Convert the ith training sentence in lower case and split is into words. You should get a list of words.
31 | sentence_words = (X[i].lower()).split()
32 | # Initialize j to 0
33 | j = 0
34 | # Loop over the words of sentence_words
35 | for w in sentence_words:
36 | # Set the (i,j)th entry of X_indices to the index of the correct word.
37 | X_indices[i, j] = word_to_index[w]
38 | # Increment j to j + 1
39 | j = j + 1
40 | return X_indices
41 |
42 | def pretrained_embedding_layer(word_to_vec_map, word_to_index):
43 | """
44 | Creates a Keras Embedding() layer and loads in pre-trained GloVe 50-dimensional vectors.
45 |
46 | Arguments:
47 | word_to_vec_map -- dictionary mapping words to their GloVe vector representation.
48 | word_to_index -- dictionary mapping from words to their indices in the vocabulary (400,001 words)
49 |
50 | Returns:
51 | embedding_layer -- pretrained layer Keras instance
52 | """
53 | vocab_len = len(word_to_index) + 1 # adding 1 to fit Keras embedding (requirement)
54 | emb_dim = word_to_vec_map["cucumber"].shape[0] # define dimensionality of your GloVe word vectors (= 50)
55 |
56 | # Initialize the embedding matrix as a numpy array of zeros of shape (vocab_len, dimensions of word vectors = emb_dim)
57 | emb_matrix = np.zeros((vocab_len, emb_dim))
58 |
59 | # Set each row "index" of the embedding matrix to be the word vector representation of the "index"th word of the vocabulary
60 | for word, index in word_to_index.items():
61 | emb_matrix[index, :] = word_to_vec_map[word]
62 |
63 | # Define Keras embedding layer with the correct output/input sizes, make it trainable. Use Embedding(...). Make sure to set trainable=False.
64 | embedding_layer = Embedding(vocab_len, emb_dim)
65 |
66 | # Build the embedding layer, it is required before setting the weights of the embedding layer. Do not modify the "None".
67 | embedding_layer.build((None,))
68 |
69 | # Set the weights of the embedding layer to the embedding matrix. Your layer is now pretrained.
70 | embedding_layer.set_weights([emb_matrix])
71 |
72 | return embedding_layer
73 |
74 |
75 | def SentimentAnalysis(input_shape, word_to_vec_map, word_to_index):
76 | """
77 | Function creating the Emojify-v2 model's graph.
78 |
79 | Arguments:
80 | input_shape -- shape of the input, usually (max_len,)
81 | word_to_vec_map -- dictionary mapping every word in a vocabulary into its 50-dimensional vector representation
82 | word_to_index -- dictionary mapping from words to their indices in the vocabulary (400,001 words)
83 |
84 | Returns:
85 | model -- a model instance in Keras
86 | """
87 | # Define sentence_indices as the input of the graph, it should be of shape input_shape and dtype 'int32' (as it contains indices).
88 | sentence_indices = Input(shape=input_shape, dtype=np.int32)
89 |
90 | # Create the embedding layer pretrained with GloVe Vectors (≈1 line)
91 | embedding_layer = pretrained_embedding_layer(word_to_vec_map, word_to_index)
92 |
93 | # Propagate sentence_indices through your embedding layer, you get back the embeddings
94 | embeddings = embedding_layer(sentence_indices)
95 |
96 | # Propagate the embeddings through an LSTM layer with 128-dimensional hidden state
97 | # Be careful, the returned output should be a batch of sequences.
98 | X = LSTM(128, return_sequences=True)(embeddings)
99 | # Add dropout with a probability of 0.5
100 | X = Dropout(0.5)(X)
101 | # Propagate X trough another LSTM layer with 128-dimensional hidden state
102 | # Be careful, the returned output should be a single hidden state, not a batch of sequences.
103 | X = LSTM(128)(X)
104 | # Add dropout with a probability of 0.5
105 | X = Dropout(0.5)(X)
106 | # Propagate X through a Dense layer with softmax activation to get back a batch of 5-dimensional vectors.
107 | X = Dense(5, activation='softmax')(X)
108 | # Add a softmax activation
109 | X = Activation('softmax')(X)
110 |
111 | # Create Model instance which converts sentence_indices into X.
112 | model = Model(sentence_indices, X)
113 |
114 | return model
115 |
116 |
117 | if __name__ == "__main__":
118 | # Read train and test files
119 | X_train, Y_train = read_csv('train_emoji.csv')
120 | X_test, Y_test = read_csv('test_emoji.csv')
121 | maxLen = len(max(X_train, key=len).split())
122 |
123 | # Convert one-hot-encoding type, classification =5, [1,0,0,0,0]
124 | Y_oh_train = convert_to_one_hot(Y_train, C=5)
125 | Y_oh_test = convert_to_one_hot(Y_test, C=5)
126 |
127 | # Read 50 feature dimension glove file
128 | word_to_index, index_to_word, word_to_vec_map = read_glove_vecs('glove.6B.50d.txt')
129 |
130 | # Model and model summmary
131 | model = SentimentAnalysis((maxLen,), word_to_vec_map, word_to_index)
132 | model.summary()
133 | model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
134 |
135 | X_train_indices = sentences_to_indices(X_train, word_to_index, maxLen)
136 | Y_train_oh = convert_to_one_hot(Y_train, C=5)
137 |
138 | # Train model
139 | model.fit(X_train_indices, Y_train_oh, epochs=100, batch_size=32, shuffle=True)
140 |
141 | X_test_indices = sentences_to_indices(X_test, word_to_index, max_len=maxLen)
142 | Y_test_oh = convert_to_one_hot(Y_test, C=5)
143 |
144 | # Evaluate model, loss and accuracy
145 | loss, acc = model.evaluate(X_test_indices, Y_test_oh)
146 | print()
147 | print("Test accuracy = ", acc)
148 |
149 | # Compare prediction and expected emoji
150 | C = 5
151 | y_test_oh = np.eye(C)[Y_test.reshape(-1)]
152 | X_test_indices = sentences_to_indices(X_test, word_to_index, maxLen)
153 | pred = model.predict(X_test_indices)
154 | for i in range(len(X_test)):
155 | x = X_test_indices
156 | num = np.argmax(pred[i])
157 | if (num != Y_test[i]):
158 | print('Expected emoji:' + label_to_emoji(Y_test[i]) + ' prediction: ' + X_test[i] + label_to_emoji(num).strip())
159 |
160 | # Test your sentence
161 | x_test = np.array(['very happy'])
162 | X_test_indices = sentences_to_indices(x_test, word_to_index, maxLen)
163 | print(x_test[0] + ' ' + label_to_emoji(np.argmax(model.predict(X_test_indices))))
--------------------------------------------------------------------------------
/SentimentAnalysisProject/test_emoji.csv:
--------------------------------------------------------------------------------
1 | "I want to eat ",4
2 | "he did not answer ",3
3 | "he got a very nice raise ",2
4 | "she got me a nice present ",2
5 | "ha ha ha it was so funny ",2
6 | "he is a good friend ",2
7 | "I am upset ",3
8 | "We had such a lovely dinner tonight ",2
9 | "where is the food ",4
10 | "Stop making this joke ha ha ha ",2
11 | "where is the ball ",1
12 | "work is hard ",3
13 | "This girl is messing with me ",3
14 | are you serious,3
15 | "Let us go play baseball ",1
16 | "This stupid grader is not working ",3
17 | "work is horrible ",3
18 | "Congratulation for having a baby ",2
19 | stop pissing me off,3
20 | "any suggestions for dinner ",4
21 | "I love taking breaks ",0
22 | "you brighten my day ",2
23 | "I boiled rice ",4
24 | "she is a bully ",3
25 | "Why are you feeling bad ",3
26 | "I am upset ",3
27 | give me the ball,1
28 | "My grandmother is the love of my life ",0
29 | enjoy your game,1
30 | "valentine day is near ",2
31 | "I miss you so much ",0
32 | "throw the ball ",1
33 | "My life is so boring ",3
34 | "she said yes ",2
35 | "will you be my valentine ",2
36 | "he can pitch really well ",1
37 | "dance with me ",2
38 | I am hungry,4
39 | "See you at the restaurant ",4
40 | "I like to laugh ",2
41 | I will run,1
42 | "I like your jacket ",0
43 | "i miss her ",0
44 | "what is your favorite baseball game ",1
45 | "Good job ",2
46 | "I love you to the stars and back ",0
47 | "What you did was awesome ",2
48 | "ha ha ha lol ",2
49 | "I do not want to joke ",3
50 | "go away ",3
51 | "yesterday we lost again ",3
52 | "family is all I have ",0
53 | "you are failing this exercise ",3
54 | "Good joke ",2
55 | "You deserve this nice prize ",2
56 | I did not have breakfast ,4
--------------------------------------------------------------------------------
/SentimentAnalysisProject/train_emoji.csv:
--------------------------------------------------------------------------------
1 | never talk to me again,3,,
2 | I am proud of your achievements,2,,
3 | It is the worst day in my life,3,,
4 | Miss you so much,0,, [0]
5 | food is life,4,,
6 | I love you mum,0,,
7 | Stop saying bullshit,3,,
8 | congratulations on your acceptance,2,,
9 | The assignment is too long ,3,,
10 | I want to go play,1,, [3]
11 | she did not answer my text ,3,,
12 | Your stupidity has no limit,3,,
13 | how many points did he score,1,,
14 | my algorithm performs poorly,3,,
15 | I got approved,2,,
16 | Stop shouting at me,3,,
17 | Sounds like a fun plan ha ha,2,,
18 | no one likes him,3,,
19 | the game just finished,1,, [2]
20 | I will celebrate soon,2,,
21 | So sad you are not coming,3,,
22 | She is my dearest love,0,, [1]
23 | Good job,2,, [4]
24 | It was funny lol,2,,
25 | candy is life ,2,,
26 | The chicago cubs won again,1,,
27 | I am hungry,4,,
28 | I am so excited to see you after so long,2,,
29 | you did well on you exam,2,,
30 | lets brunch some day,4,,
31 | he is so cute,0,,
32 | How dare you ask that,3,,
33 | do you want to join me for dinner ,4,,
34 | I said yes,2,,
35 | she is attractive,0,,
36 | you suck,3,,
37 | she smiles a lot,2,,
38 | he is laughing,2,,
39 | she takes forever to get ready ,3,,
40 | French macaroon is so tasty,4,,
41 | we made it,2,,
42 | I am excited,2,,
43 | I adore my dogs,0,,
44 | Congratulations,2,,
45 | this girl was mean,3,,
46 | you two are cute,0,,
47 | my code is working but the grader gave me zero,3,,
48 | this joke is killing me haha,2,,
49 | do you like pizza ,4,,
50 | you got a down grade,3,,
51 | I missed you,0,,
52 | I think I will end up alone,3,,
53 | I got humiliated by my sister,3,,
54 | you are awful,3,,
55 | I cooked meat,4,,
56 | This is so funny,2,,
57 | lets exercise,1,,
58 | he is the best player,1,,
59 | I am going to the stadium,1,, [0]
60 | You are incredibly intelligent and talented,2,,
61 | Stop shouting at me,3,,
62 | Who is your favorite player,1,,
63 | I like you a lot,0,,
64 | i miss him,0,,
65 | my dog just had a few puppies,0,,
66 | I hate him,3,,
67 | I want chinese food,4,,
68 | cookies are good,4,,
69 | her smile is so charming,2,,
70 | Bravo for the announcement it got a lot of traction,2,, [3]
71 | she plays baseball,1,,
72 | he did an amazing job,2,,
73 | The baby is adorable,0,,
74 | I was waiting for her for two hours ,3,,
75 | funny,2,,
76 | I like it when people smile,2,,
77 | I love dogs,0,,v2
78 | they are so kind and friendly,0,, [0]
79 | So bad that you cannot come with us,3,,
80 | he likes baseball,1,,
81 | I am so impressed by your dedication to this project,2,,
82 | I am at the baseball game,1,, [0]
83 | Bravo,2,,
84 | What a fun moment,2,,
85 | I want to have sushi for dinner,4,,
86 | I am very disappointed,3,,
87 | he can not do anything,3,,
88 | lol,2,,
89 | Lets have food together,4,,
90 | she is so cute,0,,
91 | miss you my dear,0,, [6]
92 | I am looking for a date,0,,
93 | I am frustrated,3,,
94 | I lost my wallet,3,,
95 | you failed the midterm,3,,
96 | ha ha ha it was so funny,2,,
97 | Do you want to give me a hug,0,,
98 | who is playing in the final,1,,
99 | she is happy,2,,
100 | You are not qualified for this position,3,,
101 | I love my dad,0,,
102 | this guy was such a joke,2,,
103 | Good joke,2,,
104 | This specialization is great,2,,
105 | you could not solve it,3,,
106 | I am so happy for you,2,,
107 | Congrats on the new job,2,,
108 | I am proud of you forever,2,,
109 | I want to eat,4,,
110 | That catcher sucks ,1,,
111 | The first base man got the ball,1,,
112 | this is bad,3,,
113 | you did not do your homework,3,,
114 | I will have a cheese cake,4,,
115 | do you have a ball,1,,
116 | the lectures are great though ,2,,
117 | Are you down for baseball this afternoon,1,,
118 | what are the rules of the game,1,,
119 | I am always working,3,,
120 | where is the stadium,1,,
121 | She is the cutest person I have ever seen,0,, [4]
122 | vegetables are healthy,4,,
123 | he is handsome,0,,
124 | too bad that you were not here,3,,
125 | you are a loser,3,,
126 | I love indian food,4,,
127 | Who is down for a restaurant,4,,
128 | he had to make a home run,1,,
129 | I am ordering food,4,,
130 | What is wrong with you,3,,
131 | I love you,0,,
132 | great job,2,,
--------------------------------------------------------------------------------
/StockPricesPredictionProject/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
--------------------------------------------------------------------------------
/StockPricesPredictionProject/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/StockPricesPredictionProject/.idea/stockPricePredictionLSTM.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
--------------------------------------------------------------------------------
/StockPricesPredictionProject/.idea/workspace.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
35 |
36 |
37 |
42 |
43 |
44 |
45 |
46 |
47 |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
80 |
81 |
82 |
83 |
93 |
94 |
95 |
96 |
97 |
98 |
99 |
100 |
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
111 |
112 |
113 |
114 |
115 |
116 |
117 |
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
126 |
127 |
128 |
129 |
130 |
131 |
132 |
133 |
134 |
135 |
136 |
137 |
138 |
139 |
140 |
141 |
142 |
143 |
144 |
145 |
146 |
147 |
148 |
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 |
157 |
158 |
159 |
160 |
161 |
162 |
163 |
164 |
165 |
166 |
167 |
168 |
169 |
170 |
171 |
172 |
173 |
174 |
175 |
176 |
177 |
178 |
179 |
180 |
181 |
182 |
183 |
184 |
185 |
186 |
187 |
188 |
189 |
190 |
191 |
192 | 1518940317469
193 |
194 |
195 | 1518940317469
196 |
197 |
198 |
199 |
200 |
201 |
202 |
203 |
204 |
205 |
206 |
207 |
208 |
209 |
210 |
211 |
212 |
213 |
214 |
215 |
216 |
217 |
218 |
219 |
220 |
221 |
222 |
223 |
224 |
225 |
226 |
227 |
228 |
229 |
230 |
231 |
232 |
233 |
234 |
235 |
236 |
237 |
238 |
239 |
240 |
241 |
242 |
--------------------------------------------------------------------------------
/StockPricesPredictionProject/DIS_prediction_and_actualprice.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/72975a4d872b7a9c9643b2c453378d2625bba41e/StockPricesPredictionProject/DIS_prediction_and_actualprice.png
--------------------------------------------------------------------------------
/StockPricesPredictionProject/pricePredictionLSTM.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import matplotlib.pyplot as plt
3 | import pandas as pd
4 | from pandas import read_csv
5 | import math
6 | from keras.models import Sequential
7 | from keras.layers import Dense
8 | from keras.layers import LSTM
9 | from sklearn.preprocessing import MinMaxScaler
10 | from sklearn.metrics import mean_squared_error
11 | from keras.layers.core import Dense, Activation, Dropout
12 | import time #helper libraries
13 |
14 | # file is downloaded from finance.yahoo.com, 1.1.1997-1.1.2017
15 | # training data = 1.1.1997 - 1.1.2007
16 | # test data = 1.1.2007 - 1.1.2017
17 | input_file="DIS.csv"
18 |
19 | # convert an array of values into a dataset matrix
20 | def create_dataset(dataset, look_back=1):
21 | dataX, dataY = [], []
22 | for i in range(len(dataset)-look_back-1):
23 | a = dataset[i:(i+look_back), 0]
24 | dataX.append(a)
25 | dataY.append(dataset[i + look_back, 0])
26 | return np.array(dataX), np.array(dataY)
27 |
28 | # fix random seed for reproducibility
29 | np.random.seed(5)
30 |
31 | # load the dataset
32 | df = read_csv(input_file, header=None, index_col=None, delimiter=',')
33 |
34 | # take close price column[5]
35 | all_y = df[5].values
36 | dataset=all_y.reshape(-1, 1)
37 |
38 | # normalize the dataset
39 | scaler = MinMaxScaler(feature_range=(0, 1))
40 | dataset = scaler.fit_transform(dataset)
41 |
42 | # split into train and test sets, 50% test data, 50% training data
43 | train_size = int(len(dataset) * 0.5)
44 | test_size = len(dataset) - train_size
45 | train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:]
46 |
47 | # reshape into X=t and Y=t+1, timestep 240
48 | look_back = 240
49 | trainX, trainY = create_dataset(train, look_back)
50 | testX, testY = create_dataset(test, look_back)
51 |
52 | # reshape input to be [samples, time steps, features]
53 | trainX = np.reshape(trainX, (trainX.shape[0], trainX.shape[1], 1))
54 | testX = np.reshape(testX, (testX.shape[0], testX.shape[1], 1))
55 |
56 | # create and fit the LSTM network, optimizer=adam, 25 neurons, dropout 0.1
57 | model = Sequential()
58 | model.add(LSTM(25, input_shape=(look_back, 1)))
59 | model.add(Dropout(0.1))
60 | model.add(Dense(1))
61 | model.compile(loss='mse', optimizer='adam')
62 | model.fit(trainX, trainY, epochs=1000, batch_size=240, verbose=1)
63 |
64 | # make predictions
65 | trainPredict = model.predict(trainX)
66 | testPredict = model.predict(testX)
67 |
68 | # invert predictions
69 | trainPredict = scaler.inverse_transform(trainPredict)
70 | trainY = scaler.inverse_transform([trainY])
71 | testPredict = scaler.inverse_transform(testPredict)
72 | testY = scaler.inverse_transform([testY])
73 |
74 | # calculate root mean squared error
75 | trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
76 | print('Train Score: %.2f RMSE' % (trainScore))
77 | testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
78 | print('Test Score: %.2f RMSE' % (testScore))
79 |
80 | # shift train predictions for plotting
81 | trainPredictPlot = np.empty_like(dataset)
82 | trainPredictPlot[:, :] = np.nan
83 | trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict
84 |
85 | # shift test predictions for plotting
86 | testPredictPlot = np.empty_like(dataset)
87 | testPredictPlot[:, :] = np.nan
88 | testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict
89 |
90 | # plot baseline and predictions
91 | plt.plot(scaler.inverse_transform(dataset))
92 | plt.plot(trainPredictPlot)
93 | print('testPrices:')
94 | testPrices=scaler.inverse_transform(dataset[test_size+look_back:])
95 |
96 | print('testPredictions:')
97 | print(testPredict)
98 |
99 | # export prediction and actual prices
100 | df = pd.DataFrame(data={"prediction": np.around(list(testPredict.reshape(-1)), decimals=2), "test_price": np.around(list(testPrices.reshape(-1)), decimals=2)})
101 | df.to_csv("lstm_result.csv", sep=';', index=None)
102 |
103 | # plot the actual price, prediction in test data=red line, actual price=blue line
104 | plt.plot(testPredictPlot)
105 | plt.show()
106 |
107 |
108 |
--------------------------------------------------------------------------------
 54 |
55 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
56 |
57 | ### RNN Forward Pass
58 |
59 |
54 |
55 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
56 |
57 | ### RNN Forward Pass
58 |
59 |  60 |
61 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
62 |
63 | ### RNN Backward Pass
64 |
65 |
60 |
61 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
62 |
63 | ### RNN Backward Pass
64 |
65 |  66 |
67 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
68 |
69 | ### RNN Problem
70 | - In theory, RNNs are absolutely capable of handling such “long-term dependencies.”
71 | - In practice, RNNs don’t seem to be able to learn them.
72 | - The problem was explored in depth by Hochreiter (1991) [German] and Bengio, et al. (1994) with [LSTM](https://www.bioinf.jku.at/publications/older/2604.pdf)
73 |
74 | ## What is LSTM?
75 |
76 | - It is a special type of RNN, capable of learning long-term dependencies.
77 |
78 | - "Long short-term memory (LSTM) units are units of a recurrent neural network (RNN). An RNN composed of LSTM units is often called an LSTM network. A common LSTM unit is composed of a cell, an input gate, an output gate and a forget gate. The cell remembers values over arbitrary time intervals and the three gates regulate the flow of information into and out of the cell"
79 |
80 | - Long Short Term Memory (LSTM) is a type of deep learning model that is mostly used for analysis of sequential data (time series data prediction).
81 |
82 | - There are different application areas that are used: Language model, Neural machine translation, Music generation, Time series prediction, Financial prediction, Robot control, Time series prediction, Speech recognition, Rhythm learning, Music composition, Grammar learning, Handwriting recognition, Human action recognition, Sign Language Translation,Time series anomaly detection, Several prediction tasks in the area of business process management, Prediction in medical care pathways, Semantic parsing, Object Co-segmentation.
83 |
84 | - LSTM was proposed in 1997 by Sepp Hochreiter and Jürgen Schmidhuber and improved in 2000 by Felix Gers' team.
85 | [Paper](https://www.bioinf.jku.at/publications/older/2604.pdf)
86 |
87 | Code: https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/tree/master/BasicLSTM
88 |
89 | ### LSTM Cell
90 |
91 |
66 |
67 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
68 |
69 | ### RNN Problem
70 | - In theory, RNNs are absolutely capable of handling such “long-term dependencies.”
71 | - In practice, RNNs don’t seem to be able to learn them.
72 | - The problem was explored in depth by Hochreiter (1991) [German] and Bengio, et al. (1994) with [LSTM](https://www.bioinf.jku.at/publications/older/2604.pdf)
73 |
74 | ## What is LSTM?
75 |
76 | - It is a special type of RNN, capable of learning long-term dependencies.
77 |
78 | - "Long short-term memory (LSTM) units are units of a recurrent neural network (RNN). An RNN composed of LSTM units is often called an LSTM network. A common LSTM unit is composed of a cell, an input gate, an output gate and a forget gate. The cell remembers values over arbitrary time intervals and the three gates regulate the flow of information into and out of the cell"
79 |
80 | - Long Short Term Memory (LSTM) is a type of deep learning model that is mostly used for analysis of sequential data (time series data prediction).
81 |
82 | - There are different application areas that are used: Language model, Neural machine translation, Music generation, Time series prediction, Financial prediction, Robot control, Time series prediction, Speech recognition, Rhythm learning, Music composition, Grammar learning, Handwriting recognition, Human action recognition, Sign Language Translation,Time series anomaly detection, Several prediction tasks in the area of business process management, Prediction in medical care pathways, Semantic parsing, Object Co-segmentation.
83 |
84 | - LSTM was proposed in 1997 by Sepp Hochreiter and Jürgen Schmidhuber and improved in 2000 by Felix Gers' team.
85 | [Paper](https://www.bioinf.jku.at/publications/older/2604.pdf)
86 |
87 | Code: https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/tree/master/BasicLSTM
88 |
89 | ### LSTM Cell
90 |
91 |  92 |
93 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
94 |
95 | ### LSTM Forward Pass
96 |
97 |
92 |
93 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
94 |
95 | ### LSTM Forward Pass
96 |
97 |  98 |
99 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
100 |
101 |
102 | ## SAMPLE LSTM CODE: Prediction of Stock Prices Using LSTM network
103 | Stock and ETFs prices are predicted using LSTM network (Keras-Tensorflow).
104 |
105 | Code: https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/tree/master/StockPricesPredictionProject
106 |
107 | - Stock prices are downloaded from [finance.yahoo.com](https://finance.yahoo.com/). [Disneyland (DIS) Stock Price CSV file](https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Stock_Prices_Prediction/blob/master/Stock_Prices_Prediction_Example/DIS.csv).
108 | - Closed value (column[5]) is used in the network, [LSTM Code](https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Stock_Prices_Prediction/blob/master/Stock_Prices_Prediction_Example/pricePredictionLSTM.py)
109 | - Values are normalized in range (0,1).
110 | - Datasets are splitted into train and test sets, 50% test data, 50% training data.
111 | - Keras-Tensorflow is used for implementation.
112 | - LSTM network consists of 25 hidden neurons, and 1 output layer (1 dense layer).
113 | - LSTM network features input: 1 layer, output: 1 layer , hidden: 25 neurons, optimizer:adam, dropout:0.1, timestep:240, batchsize:240, epochs:1000 (features can be further optimized).
114 | - Root mean squared errors are calculated.
115 | - Output files: [lstm_results](https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Stock_Prices_Prediction/blob/master/Stock_Prices_Prediction_Example/lstm_result.csv) (consists of prediction and actual values), plot file (actual and prediction values).
116 |
117 | 
118 |
119 | ## SAMPLE LSTM CODE: Sentiment Analysis
120 |
121 | Sentiment Analysis is an analysis of the sentence, text at the document that gives us the opinion of the sentence/text. In this project, it will be implemented a model which inputs a sentence and finds the most appropriate emoji to be used with this sentence. Code is adapted from Andrew Ng's Course 'Sequential Models'.
122 |
123 | **NOTE:This project is adapted from Andrew Ng, [Sequential Models Course](https://github.com/Kulbear/deep-learning-coursera/tree/master/Sequence%20Models), [Deep Learning Specialization](https://www.coursera.org/specializations/deep-learning) for educational purpose**
124 |
125 | Code: https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/tree/master/SentimentAnalysisProject
126 |
127 | ### Results
128 |
129 | 
130 |
131 | ### DataSet
132 | We have a tiny dataset (X, Y) where:
133 |
134 | * X contains 127 sentences (strings)
135 | * Y contains a integer label between 0 and 4 corresponding to an emoji for each sentence
136 |
137 |
98 |
99 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
100 |
101 |
102 | ## SAMPLE LSTM CODE: Prediction of Stock Prices Using LSTM network
103 | Stock and ETFs prices are predicted using LSTM network (Keras-Tensorflow).
104 |
105 | Code: https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/tree/master/StockPricesPredictionProject
106 |
107 | - Stock prices are downloaded from [finance.yahoo.com](https://finance.yahoo.com/). [Disneyland (DIS) Stock Price CSV file](https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Stock_Prices_Prediction/blob/master/Stock_Prices_Prediction_Example/DIS.csv).
108 | - Closed value (column[5]) is used in the network, [LSTM Code](https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Stock_Prices_Prediction/blob/master/Stock_Prices_Prediction_Example/pricePredictionLSTM.py)
109 | - Values are normalized in range (0,1).
110 | - Datasets are splitted into train and test sets, 50% test data, 50% training data.
111 | - Keras-Tensorflow is used for implementation.
112 | - LSTM network consists of 25 hidden neurons, and 1 output layer (1 dense layer).
113 | - LSTM network features input: 1 layer, output: 1 layer , hidden: 25 neurons, optimizer:adam, dropout:0.1, timestep:240, batchsize:240, epochs:1000 (features can be further optimized).
114 | - Root mean squared errors are calculated.
115 | - Output files: [lstm_results](https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Stock_Prices_Prediction/blob/master/Stock_Prices_Prediction_Example/lstm_result.csv) (consists of prediction and actual values), plot file (actual and prediction values).
116 |
117 | 
118 |
119 | ## SAMPLE LSTM CODE: Sentiment Analysis
120 |
121 | Sentiment Analysis is an analysis of the sentence, text at the document that gives us the opinion of the sentence/text. In this project, it will be implemented a model which inputs a sentence and finds the most appropriate emoji to be used with this sentence. Code is adapted from Andrew Ng's Course 'Sequential Models'.
122 |
123 | **NOTE:This project is adapted from Andrew Ng, [Sequential Models Course](https://github.com/Kulbear/deep-learning-coursera/tree/master/Sequence%20Models), [Deep Learning Specialization](https://www.coursera.org/specializations/deep-learning) for educational purpose**
124 |
125 | Code: https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/tree/master/SentimentAnalysisProject
126 |
127 | ### Results
128 |
129 | 
130 |
131 | ### DataSet
132 | We have a tiny dataset (X, Y) where:
133 |
134 | * X contains 127 sentences (strings)
135 | * Y contains a integer label between 0 and 4 corresponding to an emoji for each sentence
136 |
137 | 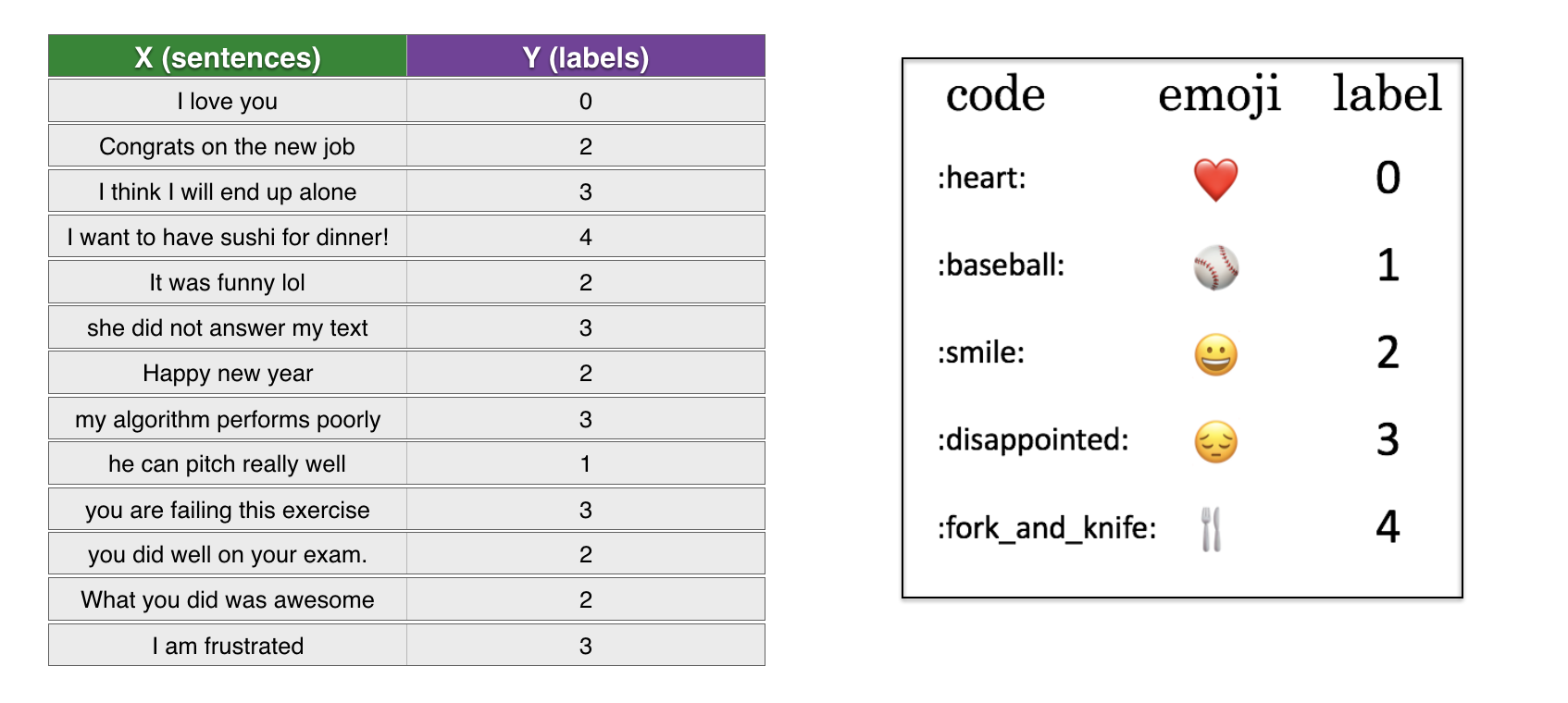 138 |
139 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
140 |
141 | ### Embeddings
142 |
143 | Glove 50 dimension, 40000 words of dictionary file is used for word embeddings. It should be downloaded from https://www.kaggle.com/watts2/glove6b50dtxt (file size = ~168MB))
144 |
145 |
146 | * word_to_index: dictionary mapping from words to their indices in the vocabulary (400,001 words, with the valid indices ranging from 0 to 400,000)
147 | * index_to_word: dictionary mapping from indices to their corresponding words in the vocabulary
148 | * word_to_vec_map: dictionary mapping words to their GloVe vector representation.
149 |
150 | ### LSTM Model in Sentiment Analysis
151 |
152 | LSTM structure is used for classification.
153 |
154 |
138 |
139 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
140 |
141 | ### Embeddings
142 |
143 | Glove 50 dimension, 40000 words of dictionary file is used for word embeddings. It should be downloaded from https://www.kaggle.com/watts2/glove6b50dtxt (file size = ~168MB))
144 |
145 |
146 | * word_to_index: dictionary mapping from words to their indices in the vocabulary (400,001 words, with the valid indices ranging from 0 to 400,000)
147 | * index_to_word: dictionary mapping from indices to their corresponding words in the vocabulary
148 | * word_to_vec_map: dictionary mapping words to their GloVe vector representation.
149 |
150 | ### LSTM Model in Sentiment Analysis
151 |
152 | LSTM structure is used for classification.
153 |
154 | 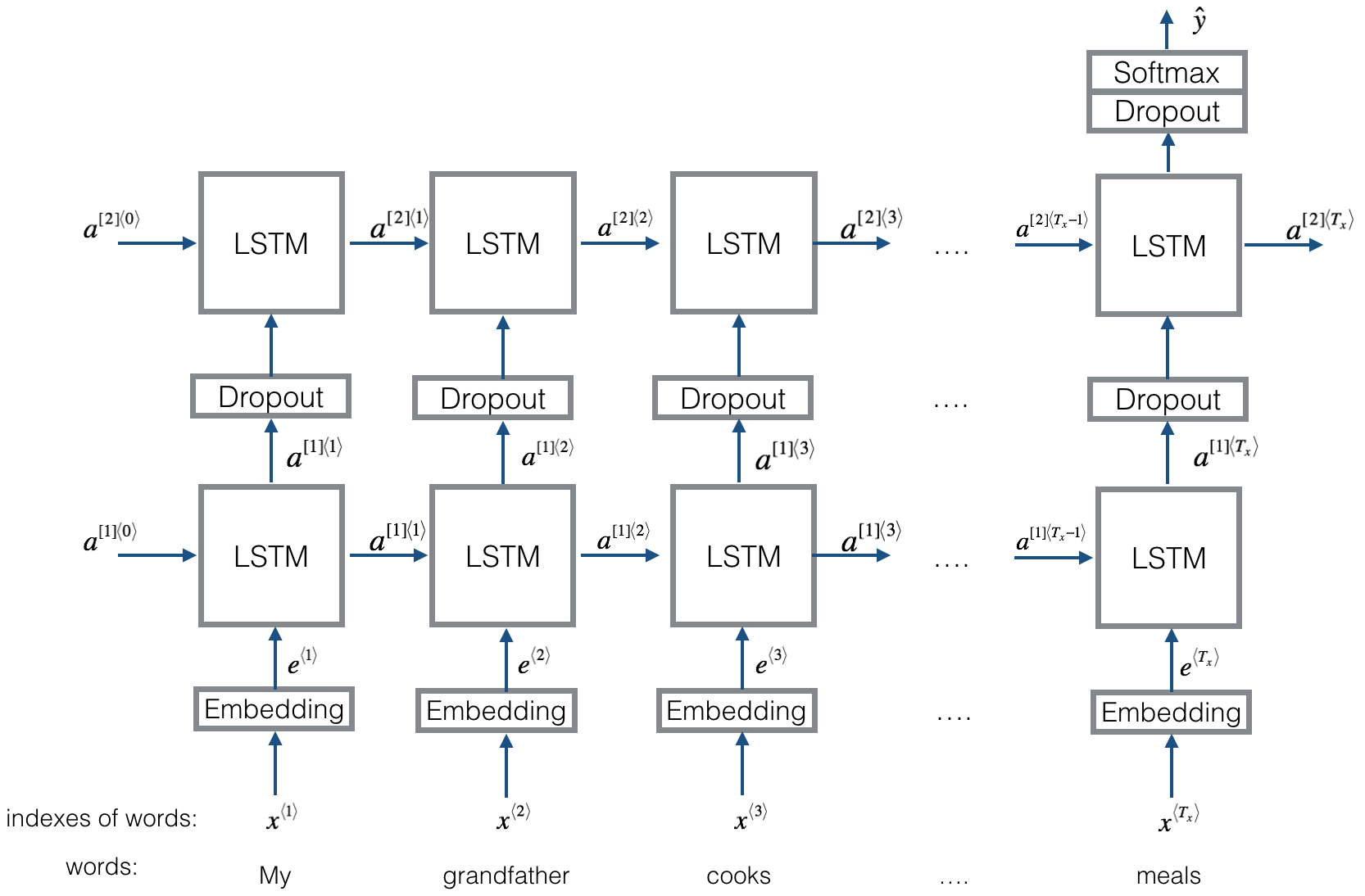 155 |
156 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
157 |
158 | Parameters:
159 |
160 | 
161 |
162 |
163 |
164 | ## SAMPLE LSTM CODE: Music Generation
165 |
166 | With trained DL model (LSTM), new sequences of time series data can be predicted. In this project, it will be implemented a model which inputs a sample jazz music and samples/generates a new music. Code is adapted from Andrew Ng's Course 'Sequential models'.
167 |
168 | **NOTE:This project is adapted from Andrew Ng, [Sequential Models Course](https://github.com/Kulbear/deep-learning-coursera/tree/master/Sequence%20Models), [Deep Learning Specialization](https://www.coursera.org/specializations/deep-learning) for educational purpose**
169 |
170 | Code: https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/tree/master/MusicGenerationProject
171 |
172 | ### How to Run Code?
173 | * To run code, download music21 toolkit from [http://web.mit.edu/music21/](http://web.mit.edu/music21/). "pip install music21".
174 | * Run main.py
175 |
176 |
177 | ### Input File and Parameters
178 | Model is trained with "data/original_music"
179 | * "X, Y, n_values, indices_values = load_music_utils()"
180 | * Number of training examples: 60,
181 | * Each of training examples length of sequence:30
182 | * Our music generation system will use 78 unique values.
183 |
184 | * X: This is an (m, Tx , 78) dimensional array. We have m training examples, each of which is a snippet of Tx=30Tx=30 musical values. At each time step, the input is one of 78 different possible values, represented as a one-hot vector. Thus for example, X[i,t,:] is a one-hot vector representating the value of the i-th example at time t.
185 | * Y: This is essentially the same as X, but shifted one step to the left (to the past).
186 | * n_values: The number of unique values in this dataset. This should be 78.
187 | * indices_values: python dictionary mapping from 0-77 to musical values.
188 |
189 | ### LSTM Model in Music Generation
190 | LSTM model structure is:
191 |
192 |
155 |
156 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
157 |
158 | Parameters:
159 |
160 | 
161 |
162 |
163 |
164 | ## SAMPLE LSTM CODE: Music Generation
165 |
166 | With trained DL model (LSTM), new sequences of time series data can be predicted. In this project, it will be implemented a model which inputs a sample jazz music and samples/generates a new music. Code is adapted from Andrew Ng's Course 'Sequential models'.
167 |
168 | **NOTE:This project is adapted from Andrew Ng, [Sequential Models Course](https://github.com/Kulbear/deep-learning-coursera/tree/master/Sequence%20Models), [Deep Learning Specialization](https://www.coursera.org/specializations/deep-learning) for educational purpose**
169 |
170 | Code: https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo/tree/master/MusicGenerationProject
171 |
172 | ### How to Run Code?
173 | * To run code, download music21 toolkit from [http://web.mit.edu/music21/](http://web.mit.edu/music21/). "pip install music21".
174 | * Run main.py
175 |
176 |
177 | ### Input File and Parameters
178 | Model is trained with "data/original_music"
179 | * "X, Y, n_values, indices_values = load_music_utils()"
180 | * Number of training examples: 60,
181 | * Each of training examples length of sequence:30
182 | * Our music generation system will use 78 unique values.
183 |
184 | * X: This is an (m, Tx , 78) dimensional array. We have m training examples, each of which is a snippet of Tx=30Tx=30 musical values. At each time step, the input is one of 78 different possible values, represented as a one-hot vector. Thus for example, X[i,t,:] is a one-hot vector representating the value of the i-th example at time t.
185 | * Y: This is essentially the same as X, but shifted one step to the left (to the past).
186 | * n_values: The number of unique values in this dataset. This should be 78.
187 | * indices_values: python dictionary mapping from 0-77 to musical values.
188 |
189 | ### LSTM Model in Music Generation
190 | LSTM model structure is:
191 |
192 | 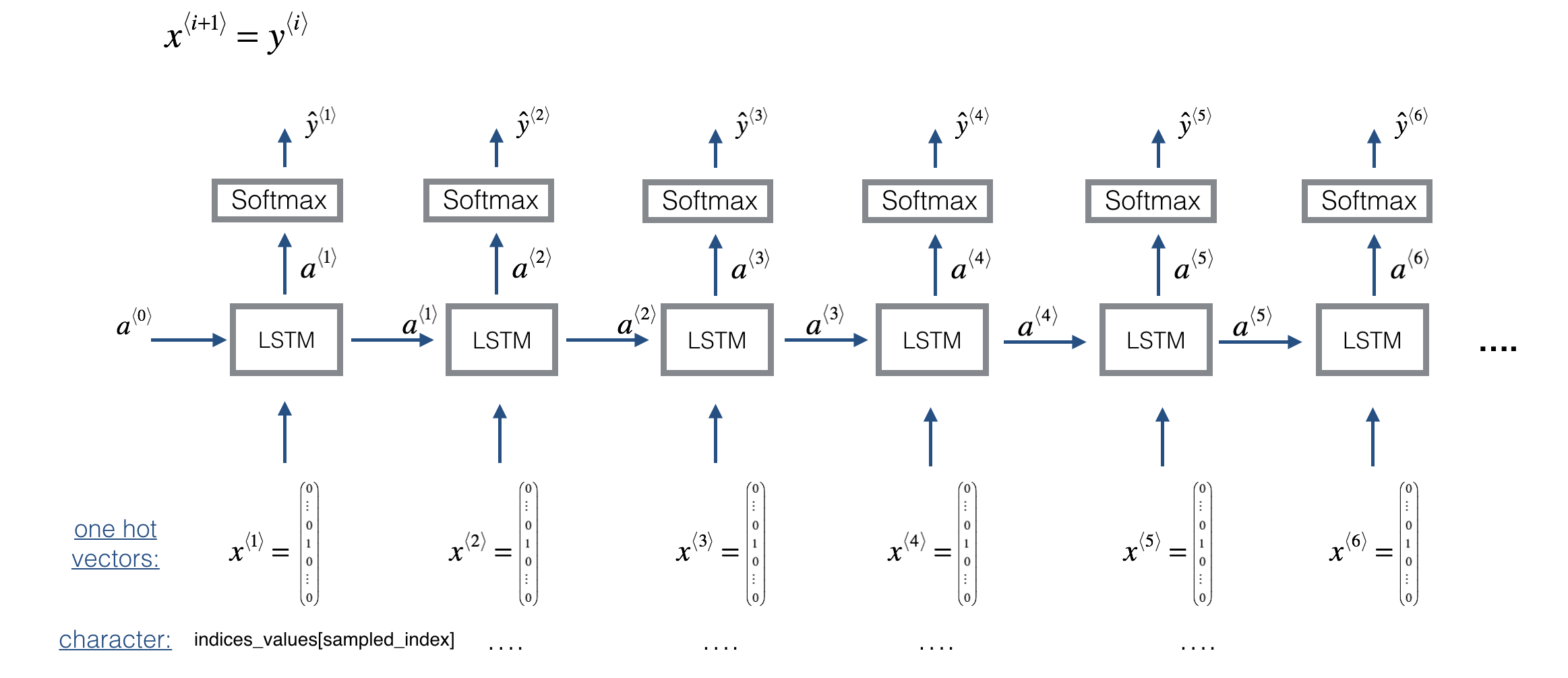 193 |
194 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
195 |
196 | Model is implemented with "djmodel(Tx, n_a, n_values)" function.
197 |
198 | ### Predicting and Sampling:
199 |
200 | Adding model, predicting and sampling feature, model structure is:
201 |
202 |
193 |
194 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
195 |
196 | Model is implemented with "djmodel(Tx, n_a, n_values)" function.
197 |
198 | ### Predicting and Sampling:
199 |
200 | Adding model, predicting and sampling feature, model structure is:
201 |
202 |  203 |
204 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
205 |
206 | Music Inference Model is similar trained model and it is implemented with "music_inference_model(LSTM_cell, densor, n_values = 78, n_a = 64, Ty = 100)" function. Music is generated with "redict_and_sample" function.
207 | Finally, your generated music is saved in output/my_music.midi.
208 |
209 |
210 |
211 | ## Resources:
212 | - [LSTM Original Paper](https://www.bioinf.jku.at/publications/older/2604.pdf)
213 | - Keras: [https://keras.io/](https://keras.io/)
214 | - Tensorflow: [https://www.tensorflow.org/](https://www.tensorflow.org/)
215 | - [LSTM in Detail](http://colah.github.io/posts/2015-08-Understanding-LSTMs/)
216 | - [Music Toolkit: http://web.mit.edu/music21/](http://web.mit.edu/music21/)
217 |
218 | ## References:
219 | - [Andrew Ng, Sequential Models Course, Deep Learning Specialization](https://github.com/Kulbear/deep-learning-coursera/tree/master/Sequence%20Models)
220 | - https://www.kaggle.com/pablocastilla/predict-stock-prices-with-lstm/notebook
221 | - Basic LSTM Code is adapted from Andrew Ng's Course 'Sequential models'.
222 |
223 |
224 |
225 |
226 |
--------------------------------------------------------------------------------
/SentimentAnalysisProject/.idea/SentimentAnalysis.iml:
--------------------------------------------------------------------------------
1 |
2 |
203 |
204 | [Andrew Ng, Sequential Models Course, Deep Learning Specialization]
205 |
206 | Music Inference Model is similar trained model and it is implemented with "music_inference_model(LSTM_cell, densor, n_values = 78, n_a = 64, Ty = 100)" function. Music is generated with "redict_and_sample" function.
207 | Finally, your generated music is saved in output/my_music.midi.
208 |
209 |
210 |
211 | ## Resources:
212 | - [LSTM Original Paper](https://www.bioinf.jku.at/publications/older/2604.pdf)
213 | - Keras: [https://keras.io/](https://keras.io/)
214 | - Tensorflow: [https://www.tensorflow.org/](https://www.tensorflow.org/)
215 | - [LSTM in Detail](http://colah.github.io/posts/2015-08-Understanding-LSTMs/)
216 | - [Music Toolkit: http://web.mit.edu/music21/](http://web.mit.edu/music21/)
217 |
218 | ## References:
219 | - [Andrew Ng, Sequential Models Course, Deep Learning Specialization](https://github.com/Kulbear/deep-learning-coursera/tree/master/Sequence%20Models)
220 | - https://www.kaggle.com/pablocastilla/predict-stock-prices-with-lstm/notebook
221 | - Basic LSTM Code is adapted from Andrew Ng's Course 'Sequential models'.
222 |
223 |
224 |
225 |
226 |
--------------------------------------------------------------------------------
/SentimentAnalysisProject/.idea/SentimentAnalysis.iml:
--------------------------------------------------------------------------------
1 |
2 |