├── .gitignore
├── .gitpod.yml
├── Dockerfile
├── LICENSE
├── README.md
├── SECURITY.md
├── advanced.md
├── cache
└── search
│ ├── 9f1f0f498f7a94591b61513c14d07116.json
│ └── f0d63bfeda464e93d5c6dfcd413ea193.json
├── docker-compose.yaml
├── images
├── google-logo.png
├── google-scraper-csv-result.png
├── google-scraper-featured-image.png
└── google-scraper-social-featured-image.png
├── local_storage.json
├── main.py
├── profiles.json
├── requirements.txt
└── src
├── __init__.py
├── google_scraper.py
├── search.py
├── utils.py
├── write_output.py
└── write_output_utils.py
/.gitignore:
--------------------------------------------------------------------------------
1 |
2 |
3 | # Byte-compiled / optimized / DLL files
4 | __pycache__/
5 | *.py[cod]
6 | *$py.class
7 |
8 | # C extensions
9 | *.so
10 |
11 | # Distribution / packaging
12 | .Python
13 | build/
14 | develop-eggs/
15 | dist/
16 | downloads/
17 | eggs/
18 | .eggs/
19 | lib/
20 | lib64/
21 | parts/
22 | sdist/
23 | var/
24 | wheels/
25 | *.egg-info/
26 | .installed.cfg
27 | *.egg
28 | MANIFEST
29 |
30 | # PyInstaller
31 | # Usually these files are written by a python script from a template
32 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
33 | *.manifest
34 | *.spec
35 |
36 | # Installer logs
37 | pip-log.txt
38 | pip-delete-this-directory.txt
39 |
40 | # Unit test / coverage reports
41 | htmlcov/
42 | .tox/
43 | .coverage
44 | .coverage.*
45 | .cache
46 | nosetests.xml
47 | coverage.xml
48 | *.cover
49 | .hypothesis/
50 | .pytest_cache/
51 |
52 | # Translations
53 | *.mo
54 | *.pot
55 |
56 | # Django stuff:
57 | local_settings.py
58 | db.sqlite3
59 |
60 | # Flask stuff:
61 | instance/
62 | .webassets-cache
63 |
64 | # Botasaurus stuff:
65 | build/
66 |
67 | # Sphinx documentation
68 | docs/_build/
69 |
70 | # PyBuilder
71 | target/
72 |
73 | # Jupyter Notebook
74 | .ipynb_checkpoints
75 |
76 | # pyenv
77 | .python-version
78 |
79 | # celery beat schedule file
80 | celerybeat-schedule
81 |
82 | # SageMath parsed files
83 | *.sage.py
84 |
85 | # Environments
86 | .env
87 | .venv
88 | env/
89 | venv/
90 | ENV/
91 | env.bak/
92 | venv.bak/
93 |
94 | # Spyder project settings
95 | .spyderproject
96 | .spyproject
97 |
98 | # Rope project settings
99 | .ropeproject
100 |
101 | # mkdocs documentation
102 | /site
103 |
104 | # mypy
105 | .mypy_cache/
106 |
107 | tasks/
108 |
109 | profiles/
110 |
111 | output/
112 |
113 |
114 | create_cache.py
115 |
116 | error_logs/
117 |
118 | gpt/
--------------------------------------------------------------------------------
/.gitpod.yml:
--------------------------------------------------------------------------------
1 | image: chetan1111/gitpod-botasaurus:3
2 |
3 | tasks:
4 | - init: pip install -r requirements.txt
--------------------------------------------------------------------------------
/Dockerfile:
--------------------------------------------------------------------------------
1 | FROM chetan1111/botasaurus:latest
2 |
3 | ENV PYTHONUNBUFFERED=1
4 |
5 | COPY requirements.txt .
6 |
7 | RUN python -m pip install -r requirements.txt
8 |
9 | RUN mkdir app
10 | WORKDIR /app
11 | COPY . /app
12 |
13 | CMD ["python", "main.py"]
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2023 Chetan Jain
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 |
4 |
✨ Google Scraper 🚀
5 |
💦 Google Scraper helps you collect search results from Google. 💦
6 |
(Programming Language - Python 3)
9 |
10 |
11 |
12 |  13 |
14 |
15 |
13 |
14 |
15 |  16 |
17 |
18 |
16 |
17 |
18 |  19 |
20 |
21 |
19 |
20 |
21 |  22 |
23 |
22 |
23 |
24 |
25 |  26 |
26 |
27 |
28 |
29 |
30 |  31 |
32 |
31 |
32 |
33 |
34 | ---
35 |
36 | ## Disclaimer for Google Scraper Project
37 |
38 | > By using Google Scraper, you agree to comply with all applicable local and international laws related to data scraping, copyright, and privacy. The developers of Google Scraper will not be held liable for any misuse of this software. It is the user's sole responsibility to ensure adherence to all relevant laws regarding data scraping, copyright, and privacy, and to use Google Scraper in an ethical and legal manner, in line with both local and international regulations.
39 |
40 | We take concerns related to the Google Scraper Project very seriously. If you have any inquiries or issues, please contact Chetan Jain at [chetan@omkar.cloud](mailto:chetan@omkar.cloud). We will take prompt and necessary action in response to your emails.
41 |
42 | ## 👉 Explore Our Other Awesome Products
43 |
44 | - ✅ [Botasaurus](https://github.com/omkarcloud/botasaurus): The All-in-One Web Scraping Framework with Anti-Detection, Parallelization, Asynchronous, and Caching Superpowers.
45 |
46 | ---
47 |
48 | Google Scraper helps you collect search results from Google.
49 |
50 | ## 🚀 Getting Started
51 |
52 | 1️⃣ **Clone the Magic 🧙♀:**
53 | ```shell
54 | git clone https://github.com/omkarcloud/google-scraper
55 | cd google-scraper
56 | ```
57 | 2️⃣ **Install Dependencies 📦:**
58 | ```shell
59 | python -m pip install -r requirements.txt
60 | ```
61 | 3️⃣ **Let the Scraping Begin 😎**:
62 | ```shell
63 | python main.py
64 | ```
65 |
66 | Find your data in the `output` directory.
67 |
68 | 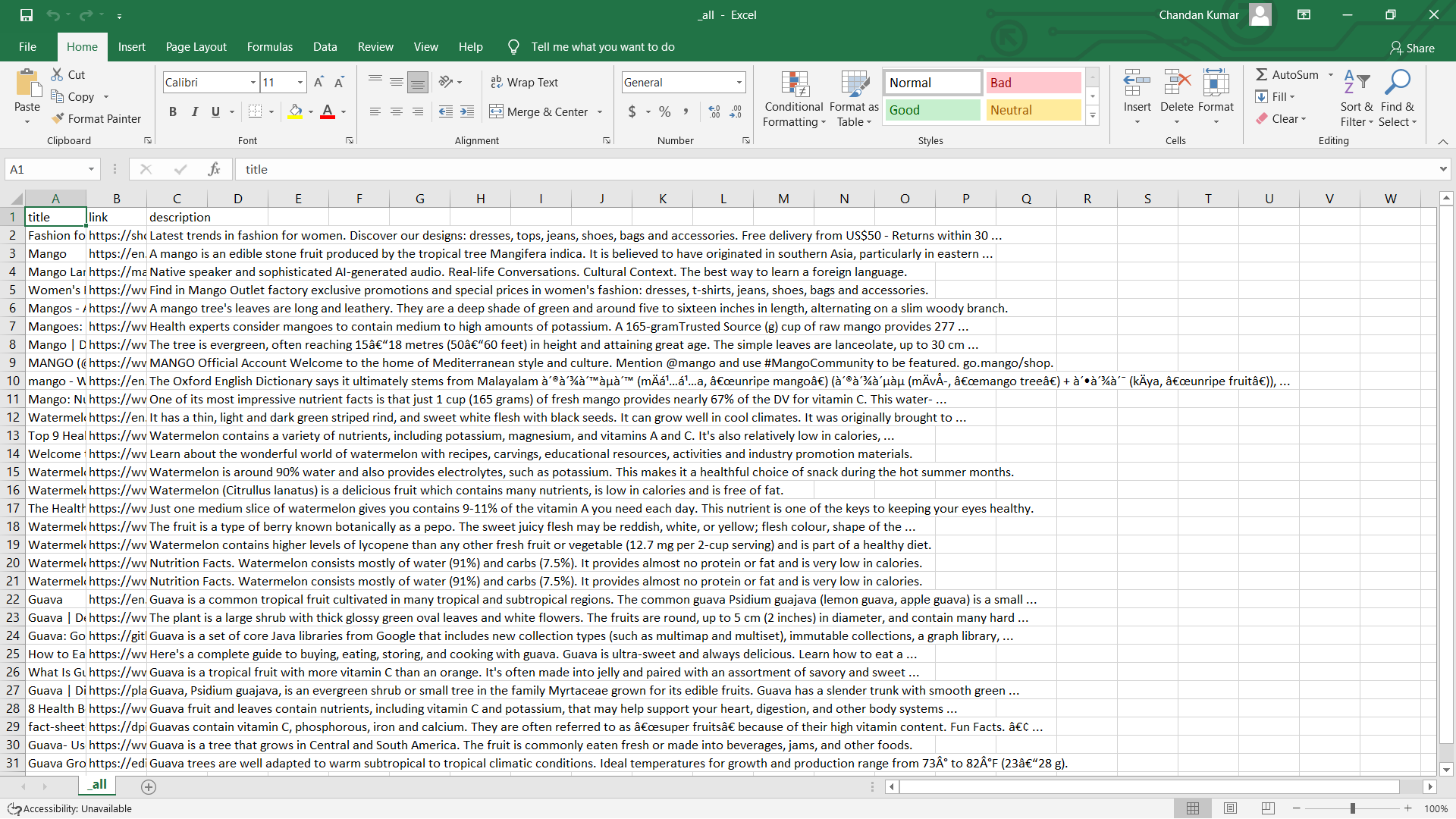
69 |
70 | *Note: If you don't have Python installed. Follow this Simple FAQ [here](https://github.com/omkarcloud/google-scraper/blob/master/advanced.md#-i-dont-have-python-installed-how-can-i-run-the-scraper) and you will have your Google data in next 5 Minutes*
71 |
72 | ## 🤔 FAQs
73 |
74 | ### ❓ How to Scrape Google?
75 |
76 | 1. Open the `main.py` file.
77 | 2. Update the `queries` list with the locations you are interested in. For example:
78 |
79 | ```python
80 | queries = [
81 | "Mango",
82 | "Watermelon",
83 | ]
84 |
85 | Google.search(queries, max=10)
86 | ```
87 |
88 | 3. Run it.
89 |
90 | ```bash
91 | python main.py
92 | ```
93 |
94 | Then find your data in the `output` directory.
95 |
96 |
97 | ### ❓ How to Scrape More Google Search Results Using Your Google API?
98 |
99 | To scrape additional data, follow these steps to use our Google API. You can make 50 requests for free:
100 |
101 | 1. Sign up on RapidAPI by visiting [this link](https://rapidapi.com/auth/sign-up).
102 |
103 | 
104 |
105 | 2. Then, subscribe to our Free Plan by visiting [this link](https://rapidapi.com/Chetan11dev/api/google-scraper/pricing).
106 |
107 | 
108 |
109 | 3. Now, copy the API key.
110 |
111 | 
112 |
113 | 4. Use it in the scraper as follows:
114 | ```python
115 | Google.search("Orange", max=10, key="YOUR_API_KEY")
116 | ```
117 |
118 | 5. Run the script, and you'll find your data in the `output` folder.
119 | ```bash
120 | python main.py
121 | ```
122 |
123 | The first 50 requests are free. After that, you can upgrade to the Pro Plan, which will get you 1000 requests for just $9.
124 |
125 |
126 | ### ❓ How did you build it?
127 |
128 | We used Botasaurus, It's an All-in-One Web Scraping Framework with Anti-Detection, Parallelization, Asynchronous, and Caching Superpowers.
129 |
130 | Botasaurus helped us cut down the development time by 50% and helped us focus only on the core extraction logic of the scraper.
131 |
132 | If you are a Web Scraper, you should learn about Botasaurus [here](https://github.com/omkarcloud/botasaurus), because Botasaurus will save you countless hours in your life as a Web Scraper.
133 |
134 |
135 |
136 |  137 |
138 |
137 |
138 |
139 |
140 |
141 | ### ❓ Need More Help or Have Additional Questions?
142 |
143 | For further help, contact us on WhatsApp. We'll be happy to help you out.
144 |
145 | [](https://api.whatsapp.com/send?phone=918295042963&text=Hi,%20I%20would%20like%20to%20learn%20more%20about%20your%20products.)
146 |
147 | ## Love It? [Star It! ⭐](https://github.com/omkarcloud/google-scraper/stargazers)
148 |
149 | ## Made with ❤️ using [Botasaurus Web Scraping Framework](https://github.com/omkarcloud/botasaurus)
--------------------------------------------------------------------------------
/SECURITY.md:
--------------------------------------------------------------------------------
1 |
2 | # Security Policy for the Google Scraper Project
3 |
4 | ## Disclaimer
5 |
6 | By using Google Scraper, you agree to comply with all applicable local and international laws related to data scraping, copyright, and privacy. The developers of Google Scraper will not be held liable for any misuse of this software. It is the user's sole responsibility to ensure adherence to all relevant laws regarding data scraping, copyright, and privacy, and to use Google Scraper in an ethical and legal manner, in line with both local and international regulations.
7 |
8 | ## 1. Reporting a Vulnerability
9 |
10 | We take the privacy and security of the Google Scraper Project very seriously. If you have discovered a security vulnerability or have concerns about the project, we appreciate your assistance in responsibly disclosing it to us.
11 |
12 | To report a security issue or express a concern, please email Chetan Jain at [chetan@omkar.cloud](mailto:chetan@omkar.cloud). We will promptly respond to your concerns.
13 |
14 | ## 2. Use at Your Own Risk
15 |
16 | This project is provided for ethical and legal purposes only. It must be used in compliance with all relevant local and international laws and is not intended for unauthorized or illegal use.
17 |
18 | ## 3. Contact
19 |
20 | For questions regarding this security policy or the security of the Google Scraper Project, please contact [chetan@omkar.cloud](mailto:chetan@omkar.cloud).
21 |
22 | The information in this `SECURITY.md` is provided "as is," without any kind of warranty.
--------------------------------------------------------------------------------
/advanced.md:
--------------------------------------------------------------------------------
1 | ## 🤔 Advanced Questions
2 |
3 | ### ❓ I don't have Python installed. How can I run the scraper?
4 |
5 | You can easily run the scraper in Gitpod, a browser-based development environment. Set it up in just 5 minutes by following these steps:
6 |
7 | 1. Visit [this link](https://gitpod.io/#https://github.com/omkarcloud/google-scraper) and sign up using your GitHub account.
8 |
9 | 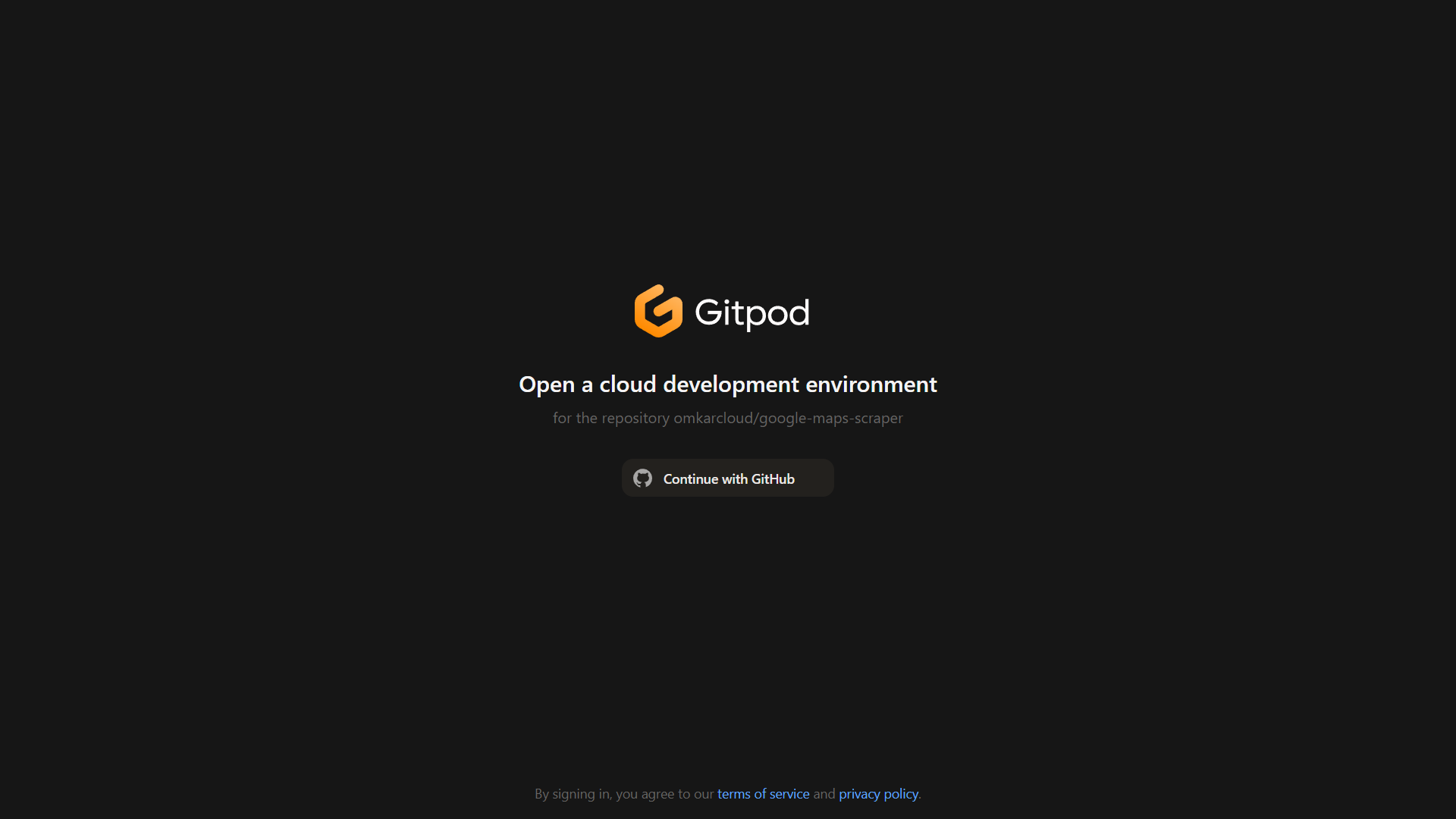
10 |
11 | 2. Once signed up, open it in Gitpod.
12 |
13 | 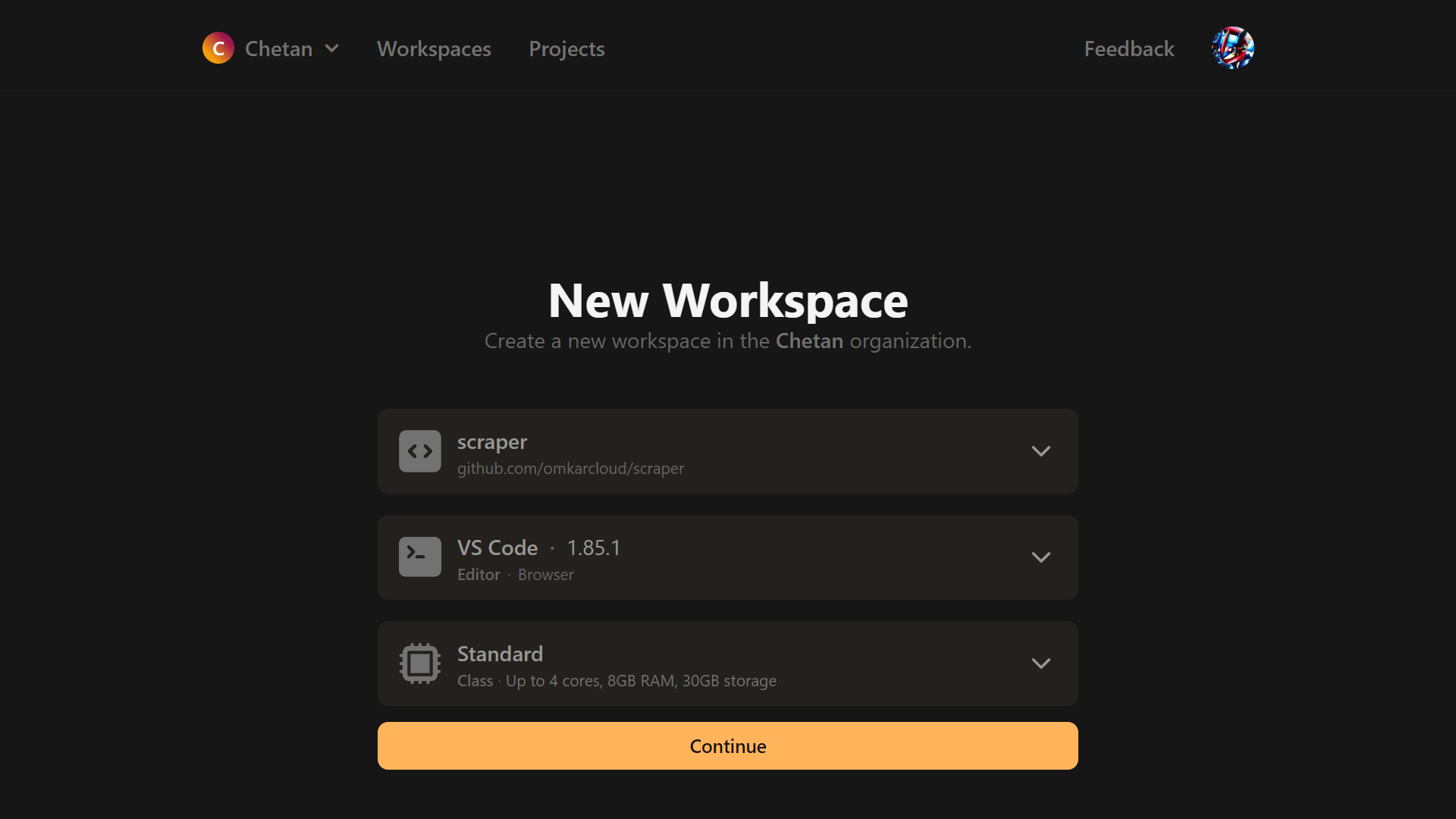
14 |
15 | 3. In the terminal, run the following command to start scraping:
16 | ```bash
17 | python main.py
18 | ```
19 |
20 | 4. Once the scraper has finished running, download the data from the `output` folder.
21 | 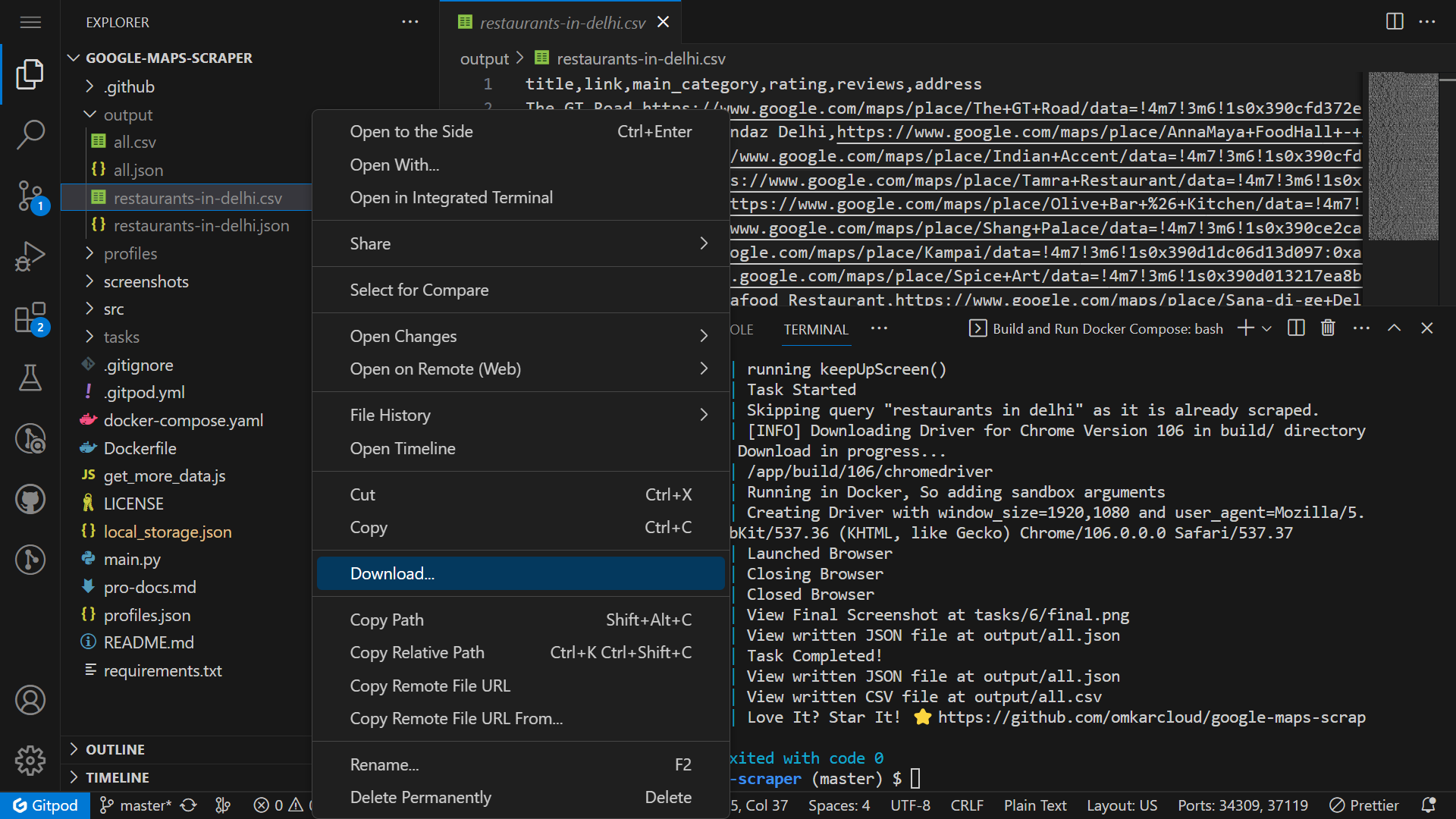
22 |
23 | ### ❓ Need More Help or Have Additional Questions?
24 |
25 | For further help, contact us on WhatsApp. We'll be happy to help you out.
26 |
27 | [](https://api.whatsapp.com/send?phone=918295042963&text=Hi,%20I%20would%20like%20to%20learn%20more%20about%20your%20products.)
28 |
29 | ## Love It? [Star It! ⭐](https://github.com/omkarcloud/google-scraper/stargazers)
30 |
31 | ## Made with ❤️ using [Botasaurus Web Scraping Framework](https://github.com/omkarcloud/botasaurus)
--------------------------------------------------------------------------------
/cache/search/9f1f0f498f7a94591b61513c14d07116.json:
--------------------------------------------------------------------------------
1 | {
2 | "data": {
3 | "count": 9,
4 | "next": "https://google-scraper.p.rapidapi.com/search/?query=watermelon&page=3",
5 | "previous": "https://google-scraper.p.rapidapi.com/search/?query=watermelon&page=1",
6 | "results": [
7 | {
8 | "title": "Watermelon",
9 | "link": "https://en.wikipedia.org/wiki/Watermelon",
10 | "description": "It has a thin, light and dark green striped rind, and sweet white flesh with black seeds. It can grow well in cool climates. It was originally brought to ..."
11 | },
12 | {
13 | "title": "Top 9 Health Benefits of Eating Watermelon",
14 | "link": "https://www.healthline.com/nutrition/watermelon-health-benefits",
15 | "description": "Watermelon contains a variety of nutrients, including potassium, magnesium, and vitamins A and C. It's also relatively low in calories, ..."
16 | },
17 | {
18 | "title": "Welcome to Watermelon.org",
19 | "link": "https://www.watermelon.org/",
20 | "description": "Learn about the wonderful world of watermelon with recipes, carvings, educational resources, activities and industry promotion materials."
21 | },
22 | {
23 | "title": "Watermelon: Health benefits, nutrition, and risks",
24 | "link": "https://www.medicalnewstoday.com/articles/266886",
25 | "description": "Watermelon is around 90% water and also provides electrolytes, such as potassium. This makes it a healthful choice of snack during the hot summer months."
26 | },
27 | {
28 | "title": "Watermelon: Health benefits, risks & nutrition facts",
29 | "link": "https://www.livescience.com/46019-watermelon-nutrition.html",
30 | "description": "Watermelon (Citrullus lanatus) is a delicious fruit which contains many nutrients, is low in calories and is free of fat."
31 | },
32 | {
33 | "title": "The Health Benefits of Watermelon",
34 | "link": "https://www.webmd.com/diet/ss/slideshow-health-benefits-of-watermelon",
35 | "description": "Just one medium slice of watermelon gives you contains 9-11% of the vitamin A you need each day. This nutrient is one of the keys to keeping your eyes healthy."
36 | },
37 | {
38 | "title": "Watermelon | Nutrition, Health Benefits, Recipes",
39 | "link": "https://www.britannica.com/plant/watermelon",
40 | "description": "The fruit is a type of berry known botanically as a pepo. The sweet juicy flesh may be reddish, white, or yellow; flesh colour, shape of the ..."
41 | },
42 | {
43 | "title": "Watermelon's Benefits",
44 | "link": "https://www.watermelon.org/nutrition/watermelons-benefits/",
45 | "description": "Watermelon contains higher levels of lycopene than any other fresh fruit or vegetable (12.7 mg per 2-cup serving) and is part of a healthy diet."
46 | },
47 | {
48 | "title": "Watermelon 101: Nutrition Facts and Health Benefits",
49 | "link": "https://www.healthline.com/nutrition/foods/watermelon",
50 | "description": "Nutrition Facts. Watermelon consists mostly of water (91%) and carbs (7.5%). It provides almost no protein or fat and is very low in calories."
51 | },
52 | {
53 | "title": "Watermelon 101: Nutrition Facts and Health Benefits",
54 | "link": "https://www.healthline.com/nutrition/foods/watermelon",
55 | "description": "Nutrition Facts. Watermelon consists mostly of water (91%) and carbs (7.5%). It provides almost no protein or fat and is very low in calories."
56 | }
57 | ]
58 | },
59 | "error": null
60 | }
--------------------------------------------------------------------------------
/cache/search/f0d63bfeda464e93d5c6dfcd413ea193.json:
--------------------------------------------------------------------------------
1 | {
2 | "data": {
3 | "count": 9,
4 | "next": "https://google-scraper.p.rapidapi.com/search/?query=mango&page=3",
5 | "previous": "https://google-scraper.p.rapidapi.com/search/?query=mango&page=1",
6 | "results": [
7 | {
8 | "title": "Fashion for Women | Mango USA",
9 | "link": "https://shop.mango.com/us",
10 | "description": "Latest trends in fashion for women. Discover our designs: dresses, tops, jeans, shoes, bags and accessories. Free delivery from US$50 - Returns within 30 ..."
11 | },
12 | {
13 | "title": "Mango",
14 | "link": "https://en.wikipedia.org/wiki/Mango",
15 | "description": "A mango is an edible stone fruit produced by the tropical tree Mangifera indica. It is believed to have originated in southern Asia, particularly in eastern ..."
16 | },
17 | {
18 | "title": "Mango Languages: Homepage",
19 | "link": "https://mangolanguages.com/",
20 | "description": "Native speaker and sophisticated AI-generated audio. Real-life Conversations. Cultural Context. The best way to learn a foreign language."
21 | },
22 | {
23 | "title": "Women's Fashion Outlet 2023 | Mango Outlet USA",
24 | "link": "https://www.mangooutlet.com/us/women",
25 | "description": "Find in Mango Outlet factory exclusive promotions and special prices in women's fashion: dresses, t-shirts, jeans, shoes, bags and accessories."
26 | },
27 | {
28 | "title": "Mangos - All You Need To Know About Mango - Mango.org",
29 | "link": "https://www.mango.org/",
30 | "description": "A mango tree's leaves are long and leathery. They are a deep shade of green and around five to sixteen inches in length, alternating on a slim woody branch."
31 | },
32 | {
33 | "title": "Mangoes: Benefits, nutrition, and recipes",
34 | "link": "https://www.medicalnewstoday.com/articles/275921",
35 | "description": "Health experts consider mangoes to contain medium to high amounts of potassium. A 165-gramTrusted Source (g) cup of raw mango provides 277 ..."
36 | },
37 | {
38 | "title": "Mango | Description, History, Cultivation, & Facts",
39 | "link": "https://www.britannica.com/plant/mango-plant-and-fruit",
40 | "description": "The tree is evergreen, often reaching 15\u201318 metres (50\u201360 feet) in height and attaining great age. The simple leaves are lanceolate, up to 30 cm ..."
41 | },
42 | {
43 | "title": "MANGO (@mango) \u2022 Instagram photos and videos",
44 | "link": "https://www.instagram.com/mango/",
45 | "description": "MANGO Official Account Welcome to the home of Mediterranean style and culture. Mention @mango and use #MangoCommunity to be featured. go.mango/shop."
46 | },
47 | {
48 | "title": "mango - Wiktionary, the free dictionary",
49 | "link": "https://en.wiktionary.org/wiki/mango",
50 | "description": "The Oxford English Dictionary says it ultimately stems from Malayalam \u0d2e\u0d3e\u0d19\u0d4d\u0d19 (m\u0101\u1e45\u1e45a, \u201cunripe mango\u201d) (\u0d2e\u0d3e\u0d35\u0d4d (m\u0101v\u016d, \u201cmango tree\u201d) + \u0d15\u0d3e\u0d2f (k\u0101ya, \u201cunripe fruit\u201d)), ..."
51 | },
52 | {
53 | "title": "Mango: Nutrition, Health Benefits, and How to Eat It",
54 | "link": "https://www.healthline.com/nutrition/mango",
55 | "description": "One of its most impressive nutrient facts is that just 1 cup (165 grams) of fresh mango provides nearly 67% of the DV for vitamin C. This water- ..."
56 | }
57 | ]
58 | },
59 | "error": null
60 | }
--------------------------------------------------------------------------------
/docker-compose.yaml:
--------------------------------------------------------------------------------
1 | version: "3"
2 | services:
3 | bot-1:
4 | restart: "no"
5 | shm_size: 800m
6 | build:
7 | dockerfile: Dockerfile
8 | context: .
9 | volumes:
10 | - ./output:/app/output
11 | - ./tasks:/app/tasks
12 | - ./profiles:/app/profiles
13 | - ./profiles.json:/app/profiles.json
14 | - ./local_storage.json:/app/local_storage.json
--------------------------------------------------------------------------------
/images/google-logo.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/omkarcloud/google-scraper/f0063eba18fa976eb3970f157a59cb0d9f04aedc/images/google-logo.png
--------------------------------------------------------------------------------
/images/google-scraper-csv-result.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/omkarcloud/google-scraper/f0063eba18fa976eb3970f157a59cb0d9f04aedc/images/google-scraper-csv-result.png
--------------------------------------------------------------------------------
/images/google-scraper-featured-image.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/omkarcloud/google-scraper/f0063eba18fa976eb3970f157a59cb0d9f04aedc/images/google-scraper-featured-image.png
--------------------------------------------------------------------------------
/images/google-scraper-social-featured-image.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/omkarcloud/google-scraper/f0063eba18fa976eb3970f157a59cb0d9f04aedc/images/google-scraper-social-featured-image.png
--------------------------------------------------------------------------------
/local_storage.json:
--------------------------------------------------------------------------------
1 | {
2 | "count": 11,
3 | "credits_used": 22
4 | }
--------------------------------------------------------------------------------
/main.py:
--------------------------------------------------------------------------------
1 | from src import Google
2 |
3 | queries = [
4 | "Mango",
5 | "Watermelon",
6 | ]
7 |
8 | Google.search(queries, max=10)
9 |
--------------------------------------------------------------------------------
/profiles.json:
--------------------------------------------------------------------------------
1 | {}
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | botasaurus
2 | casefy
3 |
--------------------------------------------------------------------------------
/src/__init__.py:
--------------------------------------------------------------------------------
1 | from .google_scraper import Google
--------------------------------------------------------------------------------
/src/google_scraper.py:
--------------------------------------------------------------------------------
1 | from typing import List,Optional, Union, Dict
2 | from botasaurus import bt
3 | from .write_output import write_output
4 |
5 | from .search import FAILED_DUE_TO_CREDITS_EXHAUSTED, FAILED_DUE_TO_NO_KEY,FAILED_DUE_TO_NOT_SUBSCRIBED, FAILED_DUE_TO_UNKNOWN_ERROR, search
6 |
7 |
8 | def clean_data(social_details):
9 | success, credits_exhausted, not_subscribed, unknown_error, no_key = [], [], [], [], []
10 |
11 | for detail in social_details:
12 | if detail.get("error") is None:
13 | success.append(detail)
14 | elif detail["error"] == FAILED_DUE_TO_CREDITS_EXHAUSTED:
15 | credits_exhausted.append(detail)
16 | elif detail["error"] == FAILED_DUE_TO_NOT_SUBSCRIBED:
17 | not_subscribed.append(detail)
18 | elif detail["error"] == FAILED_DUE_TO_UNKNOWN_ERROR:
19 | unknown_error.append(detail)
20 | elif detail["error"] == FAILED_DUE_TO_NO_KEY:
21 | no_key.append(detail)
22 |
23 | return success, credits_exhausted, not_subscribed, unknown_error, no_key
24 |
25 | def print_data_errors(credits_exhausted, not_subscribed, unknown_error, no_key):
26 |
27 | if credits_exhausted:
28 | name = "queries" if len(credits_exhausted) > 1 else "query"
29 | print(f"Could not get data for {len(credits_exhausted)} {name} due to credit exhaustion. Please consider upgrading your plan by visiting https://rapidapi.com/Chetan11dev/api/google-scraper/pricing to continue scraping data.")
30 |
31 | if not_subscribed:
32 | name = "queries" if len(not_subscribed) > 1 else "query"
33 | print(f"Could not get data for {len(not_subscribed)} {name} as you are not subscribed to Google Scraper API. Please subscribe to a free plan by visiting https://rapidapi.com/Chetan11dev/api/google-scraper/pricing")
34 |
35 | if unknown_error:
36 | name = "queries" if len(unknown_error) > 1 else "query"
37 | print(f"Could not get data for {len(unknown_error)} {name} due to Unknown Error.")
38 |
39 | if no_key:
40 | name = "queries" if len(no_key) > 1 else "query"
41 | print(f"Could not get data for {len(no_key)} {name} as you are not subscribed to Google Scraper API. Please subscribe to a free plan by visiting https://rapidapi.com/Chetan11dev/api/google-scraper/pricing")
42 |
43 |
44 | class Google:
45 |
46 | @staticmethod
47 | def search(query: Union[str, List[str]], max: Optional[int] = None, key: Optional[str] =None, use_cache: bool = True) -> Dict:
48 | """
49 | Function to scrape data from Google.
50 | :param use_cache: Boolean indicating whether to use cached data.
51 | :return: List of dictionaries with the scraped data.
52 | """
53 | cache = use_cache
54 | if isinstance(query, str):
55 | query = [query]
56 |
57 | query = [{"query":query_query, "max": max} for query_query in query]
58 | result = []
59 | for item in query:
60 | # TODO: max fixes
61 | data = item
62 | metadata = {"key": key}
63 |
64 | result_item = search(data, cache=cache, metadata=metadata)
65 |
66 | success, credits_exhausted, not_subscribed, unknown_error, no_key = clean_data([result_item])
67 | print_data_errors(credits_exhausted, not_subscribed, unknown_error, no_key)
68 |
69 | if success:
70 | data = result_item.get('data')
71 | if not data:
72 | data = {}
73 |
74 | result_item = data.get('results', [])
75 | result.extend(result_item)
76 | write_output(item['query'], result_item,None)
77 |
78 | if result:
79 | # bt.write_json(result, "result")
80 | write_output('_all',result, None, lambda x:x)
81 |
82 | search.close()
83 |
84 | return result
--------------------------------------------------------------------------------
/src/search.py:
--------------------------------------------------------------------------------
1 |
2 | from botasaurus import bt
3 | from botasaurus.cache import DontCache
4 | from botasaurus import cl
5 | from time import sleep
6 | from botasaurus import *
7 | from .utils import default_request_options
8 | import requests
9 |
10 | FAILED_DUE_TO_CREDITS_EXHAUSTED = "FAILED_DUE_TO_CREDITS_EXHAUSTED"
11 | FAILED_DUE_TO_NOT_SUBSCRIBED = "FAILED_DUE_TO_NOT_SUBSCRIBED"
12 | FAILED_DUE_TO_NO_KEY = "FAILED_DUE_TO_NO_KEY"
13 | FAILED_DUE_TO_UNKNOWN_ERROR = "FAILED_DUE_TO_UNKNOWN_ERROR"
14 |
15 | def update_credits():
16 | credits_used = bt.LocalStorage.get_item("credits_used", 0)
17 | bt.LocalStorage.set_item("credits_used", credits_used + 1)
18 |
19 | def do_request(data, retry_count=3):
20 |
21 | params = data["params"]
22 |
23 |
24 | link = params["link"]
25 | key = data["key"]
26 | # print(params)
27 | # print("link", link)
28 | if retry_count == 0:
29 | print(f"Failed to get data, after 3 retries")
30 | return {
31 | "data": None,
32 | "error":FAILED_DUE_TO_UNKNOWN_ERROR,
33 | }
34 |
35 |
36 |
37 | headers = {
38 | "X-RapidAPI-Key": key,
39 | "X-RapidAPI-Host": "google-scraper.p.rapidapi.com"
40 | }
41 |
42 |
43 | response = requests.get(link, headers=headers)
44 | response_data = response.json()
45 | if response.status_code == 200 or response.status_code == 404:
46 |
47 | message = response_data.get("message", "")
48 | if "API doesn't exists" in message:
49 | return {
50 | "data": None,
51 | "error":FAILED_DUE_TO_UNKNOWN_ERROR
52 | }
53 |
54 | update_credits()
55 | # print(response_data)
56 | # bt.write_json(response_data, "response.json")
57 | if response.status_code == 404:
58 | print(f"No data found")
59 |
60 | return {
61 | "data": response_data,
62 | "error": None
63 | }
64 |
65 | return {
66 | "data": response_data,
67 | "error": None
68 | }
69 | else:
70 |
71 | message = response_data.get("message", "")
72 |
73 | if "exceeded the MONTHLY quota" in message:
74 | return {
75 | "data": None,
76 | "error":FAILED_DUE_TO_CREDITS_EXHAUSTED
77 | }
78 | elif "exceeded the rate limit per second for your plan" in message or "many requests" in message:
79 | sleep(2)
80 | return do_request(data, retry_count - 1)
81 | elif "You are not subscribed to this API." in message:
82 | return {
83 | "data": None,
84 | "error": FAILED_DUE_TO_NOT_SUBSCRIBED
85 | }
86 |
87 | print(f"Error: {response.status_code}", response_data)
88 |
89 | return {
90 | "data": None,
91 | "error":FAILED_DUE_TO_UNKNOWN_ERROR,
92 | }
93 |
94 | @request(**default_request_options)
95 | def search(_, data, metadata):
96 | if not metadata.get('key'):
97 | return DontCache({
98 | "data": None,
99 | "error":FAILED_DUE_TO_NO_KEY
100 | })
101 | max_items = data['max']
102 | url = "https://google-scraper.p.rapidapi.com/search/"
103 | qp = {"query": data['query']}
104 | params = {**qp, 'link':cl.join_link(url, query_params=qp)}
105 |
106 | request_data = {**metadata, "params": params}
107 | result = do_request(request_data)
108 | initial_results = cl.select(result, 'data', 'results', default=[])
109 |
110 | if not cl.select(result, 'error'):
111 | more_results = cl.select(result, 'data', 'results', default=[])
112 | print(f"Got {len(more_results)} more results")
113 |
114 | while cl.select(result, 'data', 'next') and (max_items is None or len(initial_results) < max_items):
115 | next = cl.select(result, 'data', 'next')
116 |
117 | params = {**qp, 'link':next}
118 | request_data = {**metadata, "params": params}
119 | result = do_request(request_data)
120 | if result.get('error'):
121 | break
122 | more_results = cl.select(result, 'data', 'results', default=[])
123 | print(f"Got {len(more_results)} more results")
124 | initial_results.extend(more_results)
125 |
126 |
127 | if cl.select(result, 'error'):
128 | return DontCache(result)
129 | else:
130 | if max_items is not None:
131 | initial_results = initial_results[:max_items]
132 |
133 | result['data']['results'] = initial_results
134 | return result
135 |
--------------------------------------------------------------------------------
/src/utils.py:
--------------------------------------------------------------------------------
1 |
2 | default_browser_options = {
3 | "block_images": True,
4 | "reuse_driver": True,
5 | "keep_drivers_alive": True,
6 | "close_on_crash": True, # When Ready for Production change to True
7 | "headless": True, # When Ready change to True
8 | 'output': None, # When Ready for Production Uncomment
9 | }
10 |
11 | # max 5 retries add
12 | default_request_options = {
13 | "close_on_crash": True, # When Ready for Production change to True
14 | 'output': None, # When Ready for Production Uncomment
15 | "raise_exception":True,
16 | }
--------------------------------------------------------------------------------
/src/write_output.py:
--------------------------------------------------------------------------------
1 | from botasaurus import bt
2 | from botasaurus.decorators import print_filenames
3 | from .write_output_utils import kebab_case, make_folders
4 |
5 |
6 | def create_json(path, data):
7 | bt.write_json(data, path, False )
8 |
9 |
10 | def create_csv(path, data):
11 | bt.write_csv(data, path, False )
12 |
13 | def format(query_kebab, entity_type, type):
14 | return f"{query_kebab}.{type}"
15 |
16 | def create(data, selected_fields, csv_path, json_path, query_kebab,entity_type):
17 | written = []
18 |
19 | fname = json_path + format(query_kebab, entity_type,"json",)
20 | create_json(fname, data)
21 | written.append(fname)
22 |
23 | fname = csv_path + format(query_kebab, entity_type,"csv",)
24 | create_csv(fname, data)
25 | written.append(fname)
26 |
27 | print_filenames(written)
28 |
29 | def write_output(query, data, entity_type,transformer = kebab_case):
30 |
31 | query_kebab = transformer(query)
32 | make_folders(query_kebab)
33 |
34 | csv_path = f"output/{query_kebab}/csv/"
35 | json_path = f"output/{query_kebab}/json/"
36 |
37 | create(data,[], csv_path, json_path, query_kebab,entity_type)
38 |
--------------------------------------------------------------------------------
/src/write_output_utils.py:
--------------------------------------------------------------------------------
1 | from botasaurus.decorators_utils import create_directory_if_not_exists
2 | from casefy import kebabcase
3 |
4 |
5 | def kebab_case(s):
6 | return kebabcase(s)
7 |
8 | def make_folders(query_kebab):
9 | create_directory_if_not_exists(f"output/{query_kebab}/")
10 | create_directory_if_not_exists(f"output/{query_kebab}/json/")
11 | create_directory_if_not_exists(f"output/{query_kebab}/csv/")
12 |
13 | def format(query_kebab, type, name):
14 | return f"{name}-of-{query_kebab}.{type}"
15 |
16 |
--------------------------------------------------------------------------------