├── .gitignore
├── CONTRIBUTING.md
├── LICENSE
├── MANIFEST.in
├── README.md
├── README_PyPI.md
├── images
├── demo.gif
├── imgur_app.png
├── logo.png
└── reddit_app.png
├── pyproject.toml
├── requirements.txt
├── setup.cfg
└── src
└── saveddit
├── __init__.py
├── _version.py
├── configuration.py
├── multireddit_downloader.py
├── multireddit_downloader_config.py
├── saveddit.py
├── search_config.py
├── search_subreddits.py
├── submission_downloader.py
├── subreddit_downloader.py
├── subreddit_downloader_config.py
├── user_downloader.py
└── user_downloader_config.py
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 | .DS_Store
6 |
7 | # C extensions
8 | *.so
9 |
10 | # Distribution / packaging
11 | .Python
12 | build/
13 | develop-eggs/
14 | dist/
15 | downloads/
16 | eggs/
17 | .eggs/
18 | lib/
19 | lib64/
20 | parts/
21 | sdist/
22 | var/
23 | wheels/
24 | share/python-wheels/
25 | *.egg-info/
26 | .installed.cfg
27 | *.egg
28 | MANIFEST
29 |
30 | # PyInstaller
31 | # Usually these files are written by a python script from a template
32 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
33 | *.manifest
34 | *.spec
35 |
36 | # Installer logs
37 | pip-log.txt
38 | pip-delete-this-directory.txt
39 |
40 | # Unit test / coverage reports
41 | htmlcov/
42 | .tox/
43 | .nox/
44 | .coverage
45 | .coverage.*
46 | .cache
47 | nosetests.xml
48 | coverage.xml
49 | *.cover
50 | *.py,cover
51 | .hypothesis/
52 | .pytest_cache/
53 | cover/
54 |
55 | # Translations
56 | *.mo
57 | *.pot
58 |
59 | # Django stuff:
60 | *.log
61 | local_settings.py
62 | db.sqlite3
63 | db.sqlite3-journal
64 |
65 | # Flask stuff:
66 | instance/
67 | .webassets-cache
68 |
69 | # Scrapy stuff:
70 | .scrapy
71 |
72 | # Sphinx documentation
73 | docs/_build/
74 |
75 | # PyBuilder
76 | .pybuilder/
77 | target/
78 |
79 | # Jupyter Notebook
80 | .ipynb_checkpoints
81 |
82 | # IPython
83 | profile_default/
84 | ipython_config.py
85 |
86 | # pyenv
87 | # For a library or package, you might want to ignore these files since the code is
88 | # intended to run in multiple environments; otherwise, check them in:
89 | # .python-version
90 |
91 | # pipenv
92 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
93 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
94 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
95 | # install all needed dependencies.
96 | #Pipfile.lock
97 |
98 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
99 | __pypackages__/
100 |
101 | # Celery stuff
102 | celerybeat-schedule
103 | celerybeat.pid
104 |
105 | # SageMath parsed files
106 | *.sage.py
107 |
108 | # Environments
109 | .env
110 | .venv
111 | env/
112 | venv/
113 | ENV/
114 | env.bak/
115 | venv.bak/
116 |
117 | # Spyder project settings
118 | .spyderproject
119 | .spyproject
120 |
121 | # Rope project settings
122 | .ropeproject
123 |
124 | # mkdocs documentation
125 | /site
126 |
127 | # mypy
128 | .mypy_cache/
129 | .dmypy.json
130 | dmypy.json
131 |
132 | # Pyre type checker
133 | .pyre/
134 |
135 | # pytype static type analyzer
136 | .pytype/
137 |
138 | # Cython debug symbols
139 | cython_debug/
140 |
141 | # Configuration file
142 | **/user_config.yaml
--------------------------------------------------------------------------------
/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | # Contributing
2 | Contributions are welcomed. Open a pull-request or an issue.
3 |
4 | ## Code of conduct
5 | This project adheres to the [Open Code of Conduct][code-of-conduct]. By participating, you are expected to honor this code.
6 |
7 | [code-of-conduct]: https://github.com/spotify/code-of-conduct/blob/master/code-of-conduct.md
8 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2021 Pranav
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/MANIFEST.in:
--------------------------------------------------------------------------------
1 | include images/*
2 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |  3 |
3 |
4 |
5 |
6 |
7 |  8 |
9 |
10 |
8 |
9 |
10 |  11 |
12 |
11 |
12 |
13 |
14 | `saveddit` is a bulk media downloader for reddit
15 |
16 | ```console
17 | pip3 install saveddit
18 | ```
19 |
20 | ## Setting up authorization
21 |
22 | * [Register an application with Reddit](https://ssl.reddit.com/prefs/apps/)
23 | - Write down your client ID and secret from the app
24 | - More about Reddit API access [here](https://ssl.reddit.com/wiki/api)
25 | - Wiki page about Reddit OAuth2 applications [here](https://github.com/reddit-archive/reddit/wiki/OAuth2)
26 |
27 |
28 |  29 |
29 |
30 |
31 | * [Register an application with Imgur](https://api.imgur.com/oauth2/addclient)
32 | - Write down the Imgur client ID from the app
33 |
34 |
35 |  36 |
36 |
37 |
38 | These registrations will authorize you to use the Reddit and Imgur APIs to download publicly available information.
39 |
40 | ## User configuration
41 |
42 | The first time you run `saveddit`, you will see something like this:
43 |
44 | ```console
45 | foo@bar:~$ saveddit
46 | Retrieving configuration from ~/.saveddit/user_config.yaml file
47 | No configuration file found.
48 | Creating one. Would you like to edit it now?
49 | > Choose Y for yes and N for no
50 | ```
51 |
52 | Once you choose 'yes', the program will request you to enter these credentials:
53 | - Your imgur client ID
54 | - Your reddit client ID
55 | - Your reddit client secret
56 | - Your reddit username
57 |
58 | In case you choose 'no', the program will create a file which you can edit later, this is how to edit it:
59 |
60 | * Open the generated `~/.saveddit/user_config.yaml`
61 | * Update the client IDs and secrets from the previous step
62 | * If you plan on using the `user` API, add your reddit username as well
63 |
64 | ```yaml
65 | imgur_client_id: ''
66 | reddit_client_id: ''
67 | reddit_client_secret: ''
68 | reddit_username: ''
69 | ```
70 |
71 | ## Download from Subreddit
72 |
73 | ```console
74 | foo@bar:~$ saveddit subreddit -h
75 | Retrieving configuration from /Users/pranav/.saveddit/user_config.yaml file
76 |
77 | usage: saveddit subreddit [-h] [-f categories [categories ...]] [-l post_limit] [--skip-comments] [--skip-meta] [--skip-videos] -o output_path subreddits [subreddits ...]
78 |
79 | positional arguments:
80 | subreddits Names of subreddits to download, e.g., AskReddit
81 |
82 | optional arguments:
83 | -h, --help show this help message and exit
84 | -f categories [categories ...]
85 | Categories of posts to download (default: ['hot', 'new', 'rising', 'controversial', 'top', 'gilded'])
86 | -l post_limit Limit the number of submissions downloaded in each category (default: None, i.e., all submissions)
87 | --skip-comments When true, saveddit will not save comments to a comments.json file
88 | --skip-meta When true, saveddit will not save meta to a submission.json file on submissions
89 | --skip-videos When true, saveddit will not download videos (e.g., gfycat, redgifs, youtube, v.redd.it links)
90 | --all-comments When true, saveddit will download all the comments in a post instead of just downloading the top ones.)
91 | -o output_path Directory where saveddit will save downloaded content
92 | ```
93 |
94 | ```console
95 | foo@bar:~$ saveddit subreddit pics -f hot -l 5 -o ~/Desktop
96 | ```
97 |
98 | ```console
99 | foo@bar:~$ tree -L 4 ~/Desktop/www.reddit.com
100 | /Users/pranav/Desktop/www.reddit.com
101 | └── r
102 | └── pics
103 | └── hot
104 | ├── 000_Prince_Philip_Duke_of_Edinburgh_...
105 | ├── 001_Day_10_of_Nobody_Noticing_the_Ap...
106 | ├── 002_First_edited_picture
107 | ├── 003_Reorganized_a_few_months_ago_and...
108 | └── 004_Van_Gogh_inspired_rainy_street_I...
109 | ```
110 |
111 | You can download from multiple subreddits and use multiple filters:
112 |
113 | ```console
114 | foo@bar:~$ saveddit subreddit funny AskReddit -f hot top new rising -l 5 -o ~/Downloads/Reddit/.
115 | ```
116 |
117 | The downloads from each subreddit to go to a separate folder like so:
118 |
119 | ```console
120 | foo@bar:~$ tree -L 3 ~/Downloads/Reddit/www.reddit.com
121 | /Users/pranav/Downloads/Reddit/www.reddit.com
122 | └── r
123 | ├── AskReddit
124 | │ ├── hot
125 | │ ├── new
126 | │ ├── rising
127 | │ └── top
128 | └── funny
129 | ├── hot
130 | ├── new
131 | ├── rising
132 | └── top
133 | ```
134 |
135 | ## Download from anonymous Multireddit
136 |
137 | To download from an anonymous multireddit, use the `multireddit` option and pass a number of subreddit names
138 |
139 | ```console
140 | foo@bar:~$ saveddit multireddit -h
141 | usage: saveddit multireddit [-h] [-f categories [categories ...]] [-l post_limit] [--skip-comments] [--skip-meta] [--skip-videos] -o output_path subreddits [subreddits ...]
142 |
143 | positional arguments:
144 | subreddits Names of subreddits to download, e.g., aww, pics. The downloads will be stored in /www.reddit.com/m/aww+pics/.
145 |
146 | optional arguments:
147 | -h, --help show this help message and exit
148 | -f categories [categories ...]
149 | Categories of posts to download (default: ['hot', 'new', 'random_rising', 'rising', 'controversial', 'top', 'gilded'])
150 | -l post_limit Limit the number of submissions downloaded in each category (default: None, i.e., all submissions)
151 | --skip-comments When true, saveddit will not save comments to a comments.json file
152 | --skip-meta When true, saveddit will not save meta to a submission.json file on submissions
153 | --skip-videos When true, saveddit will not download videos (e.g., gfycat, redgifs, youtube, v.redd.it links)
154 | -o output_path Directory where saveddit will save downloaded content
155 | ```
156 |
157 | ```console
158 | foo@bar:~$ saveddit multireddit EarthPorn NaturePics -f hot -l 5 -o ~/Desktop
159 | ```
160 |
161 | Anonymous multireddits are saved in `www.reddit.com/m///` like so:
162 |
163 | ```console
164 | tree -L 4 ~/Desktop/www.reddit.com
165 | /Users/pranav/Desktop/www.reddit.com
166 | └── m
167 | └── EarthPorn+NaturePics
168 | └── hot
169 | ├── 000_Banning_State_Park_Minnesota_OC_...
170 | ├── 001_Misty_forest_in_the_mountains_of...
171 | ├── 002_One_of_the_highlights_of_my_last...
172 | ├── 003__OC_Japan_Kyoto_Garden_of_the_Go...
173 | └── 004_Sunset_at_Mt_Rainier_National_Pa...
174 | ```
175 |
176 | ## Download from User's page
177 |
178 | ```console
179 | foo@bar:~$ saveddit user -h
180 | usage: saveddit user [-h] users [users ...] {saved,gilded,submitted,multireddits,upvoted,comments} ...
181 |
182 | positional arguments:
183 | users Names of users to download, e.g., Poem_for_your_sprog
184 | {saved,gilded,submitted,multireddits,upvoted,comments}
185 |
186 | optional arguments:
187 | -h, --help show this help message and exit
188 | ```
189 |
190 | Here's a usage example for downloading all comments made by `Poem_for_your_sprog`
191 |
192 | ```console
193 | foo@bar:~$ saveddit user "Poem_for_your_sprog" comments -s top -l 5 -o ~/Desktop
194 | ```
195 |
196 | Here's another example for downloading `kemitche`'s multireddits:
197 |
198 | ```console
199 | foo@bar:~$ saveddit user kemitche multireddits -n reddit -f hot -l 5 -o ~/Desktop
200 | ```
201 |
202 | User-specific content is downloaded to `www.reddit.com/u//...` like so:
203 |
204 | ```console
205 | foo@bar:~$ tree ~/Desktop/www.reddit.com
206 | /Users/pranav/Desktop/www.reddit.com
207 | └── u
208 | ├── Poem_for_your_sprog
209 | │ ├── comments
210 | │ │ └── top
211 | │ │ ├── 000_Comment_my_name_is_Cow_and_wen_its_ni....json
212 | │ │ ├── 001_Comment_It_stopped_at_six_and_life....json
213 | │ │ ├── 002_Comment__Perhaps_I_could_listen_to_podca....json
214 | │ │ ├── 003_Comment__I_don_t_have_regret_for_the_thi....json
215 | │ │ └── 004_Comment__So_throw_off_the_chains_of_oppr....json
216 | │ └── user.json
217 | └── kemitche
218 | ├── m
219 | │ └── reddit
220 | │ └── hot
221 | │ ├── 000_When_posting_to_my_u_channel_NSF...
222 | │ │ ├── comments.json
223 | │ │ └── submission.json
224 | │ ├── 001_How_to_remove_popular_near_you
225 | │ │ ├── comments.json
226 | │ │ └── submission.json
227 | │ ├── 002__IOS_2021_13_0_Reddit_is_just_su...
228 | │ │ ├── comments.json
229 | │ │ └── submission.json
230 | │ ├── 003_The_Approve_User_button_should_n...
231 | │ │ ├── comments.json
232 | │ │ └── submission.json
233 | │ └── 004_non_moderators_unable_to_view_su...
234 | │ ├── comments.json
235 | │ └── submission.json
236 | └── user.json
237 | ```
238 |
239 | ## Search and Download
240 |
241 | `saveddit` support searching subreddits and downloading search results
242 |
243 | ```console
244 | foo@bar:~$ saveddit search -h
245 | usage: saveddit search [-h] -q query [-s sort] [-t time_filter] [--include-nsfw] [--skip-comments] [--skip-meta] [--skip-videos] -o output_path subreddits [subreddits ...]
246 |
247 | positional arguments:
248 | subreddits Names of subreddits to search, e.g., all, aww, pics
249 |
250 | optional arguments:
251 | -h, --help show this help message and exit
252 | -q query Search query string
253 | -s sort Sort to apply on search (default: relevance, choices: [relevance, hot, top, new, comments])
254 | -t time_filter Time filter to apply on search (default: all, choices: [all, day, hour, month, week, year])
255 | --include-nsfw When true, saveddit will include NSFW results in search
256 | --skip-comments When true, saveddit will not save comments to a comments.json file
257 | --skip-meta When true, saveddit will not save meta to a submission.json file on submissions
258 | --skip-videos When true, saveddit will not download videos (e.g., gfycat, redgifs, youtube, v.redd.it links)
259 | -o output_path Directory where saveddit will save downloaded content
260 | ```
261 |
262 | e.g.,
263 |
264 | ```console
265 | foo@bar:~$ saveddit search soccer -q "Chelsea" -o ~/Desktop
266 | ```
267 |
268 | The downloaded search results are stored in `www.reddit.com/q////.`
269 |
270 | ```console
271 | foo@bar:~$ tree -L 4 ~/Desktop/www.reddit.com/q
272 | /Users/pranav/Desktop/www.reddit.com/q
273 | └── Chelsea
274 | └── soccer
275 | └── relevance
276 | ├── 000__Official_Results_for_UEFA_Champ...
277 | ├── 001_Porto_0_1_Chelsea_Mason_Mount_32...
278 | ├── 002_Crystal_Palace_0_2_Chelsea_Chris...
279 | ├── 003_Post_Match_Thread_Chelsea_2_5_We...
280 | ├── 004_Match_Thread_Porto_vs_Chelsea_UE...
281 | ├── 005_Crystal_Palace_1_4_Chelsea_Chris...
282 | ├── 006_Porto_0_2_Chelsea_Ben_Chilwell_8...
283 | ├── 007_Post_Match_Thread_Porto_0_2_Chel...
284 | ├── 008_UCL_Quaterfinalists_are_Bayern_D...
285 | ├── 009__MD_Mino_Raiola_and_Haaland_s_fa...
286 | ├── 010_Chelsea_2_5_West_Brom_Callum_Rob...
287 | ├── 011_Chelsea_1_2_West_Brom_Matheus_Pe...
288 | ├── 012__Bild_Sport_via_Sport_Witness_Ch...
289 | ├── 013_Match_Thread_Chelsea_vs_West_Bro...
290 | ├── 014_Chelsea_1_3_West_Brom_Callum_Rob...
291 | ├── 015_Match_Thread_Chelsea_vs_Atletico...
292 | ├── 016_Stefan_Savi�\207_Atlético_Madrid_str...
293 | ├── 017_Chelsea_1_0_West_Brom_Christian_...
294 | └── 018_Alvaro_Morata_I_ve_never_had_dep...
295 | ```
296 |
297 | ## Supported Links:
298 |
299 | * Direct links to images or videos, e.g., `.png`, `.jpg`, `.mp4`, `.gif` etc.
300 | * Reddit galleries `reddit.com/gallery/...`
301 | * Reddit videos `v.redd.it/...`
302 | * Gfycat links `gfycat.com/...`
303 | * Redgif links `redgifs.com/...`
304 | * Imgur images `imgur.com/...`
305 | * Imgur albums `imgur.com/a/...` and `imgur.com/gallery/...`
306 | * Youtube links `youtube.com/...` and `yout.be/...`
307 | * These [sites](https://ytdl-org.github.io/youtube-dl/supportedsites.html) supported by `youtube-dl`
308 | * Self posts
309 | * For all other cases, `saveddit` will simply fetch the HTML of the URL
310 |
311 | ## Contributing
312 | Contributions are welcome, have a look at the [CONTRIBUTING.md](CONTRIBUTING.md) document for more information.
313 |
314 | ## License
315 | The project is available under the [MIT](https://opensource.org/licenses/MIT) license.
316 |
--------------------------------------------------------------------------------
/README_PyPI.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 | `saveddit` is a bulk media downloader for reddit
4 |
5 | ```console
6 | pip3 install saveddit
7 | ```
8 |
9 | ## Setting up authorization
10 |
11 | * [Register an application with Reddit](https://ssl.reddit.com/prefs/apps/)
12 | - Write down your client ID and secret from the app
13 | - More about Reddit API access [here](https://ssl.reddit.com/wiki/api)
14 | - Wiki page about Reddit OAuth2 applications [here](https://github.com/reddit-archive/reddit/wiki/OAuth2)
15 |
16 | 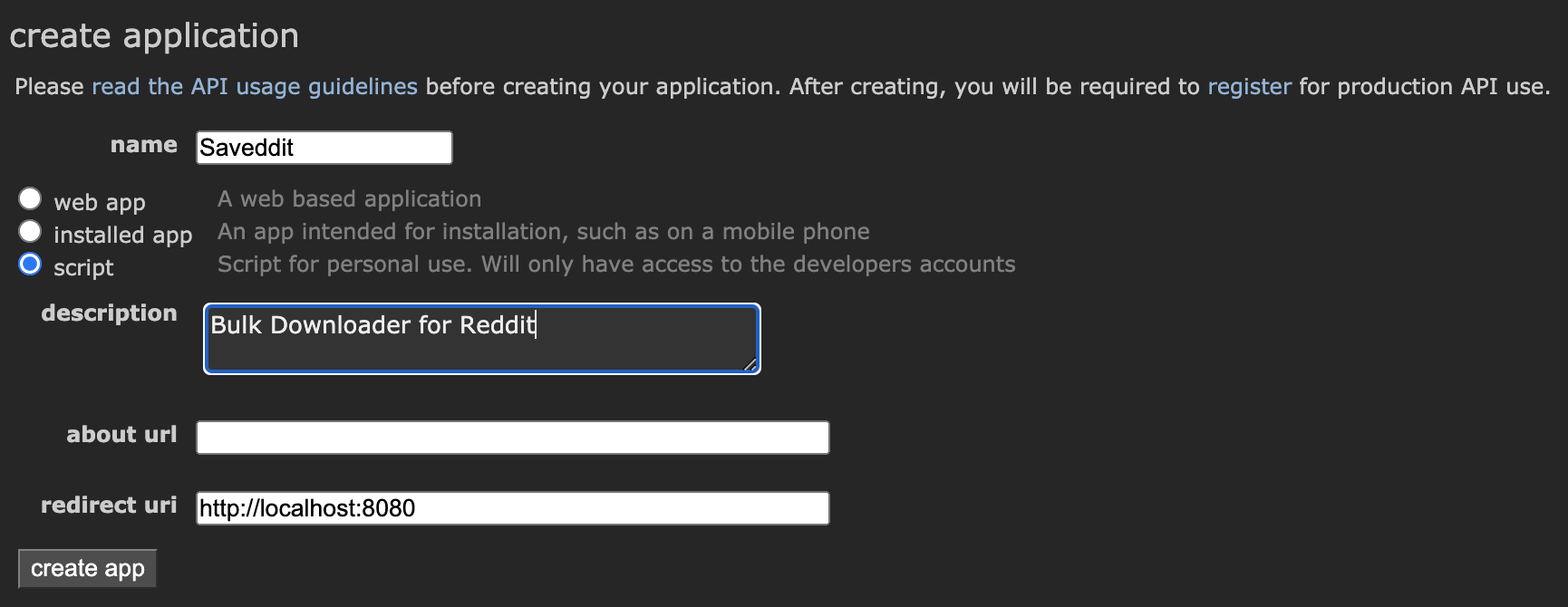
17 |
18 | * [Register an application with Imgur](https://api.imgur.com/oauth2/addclient)
19 | - Write down the Imgur client ID from the app
20 |
21 | 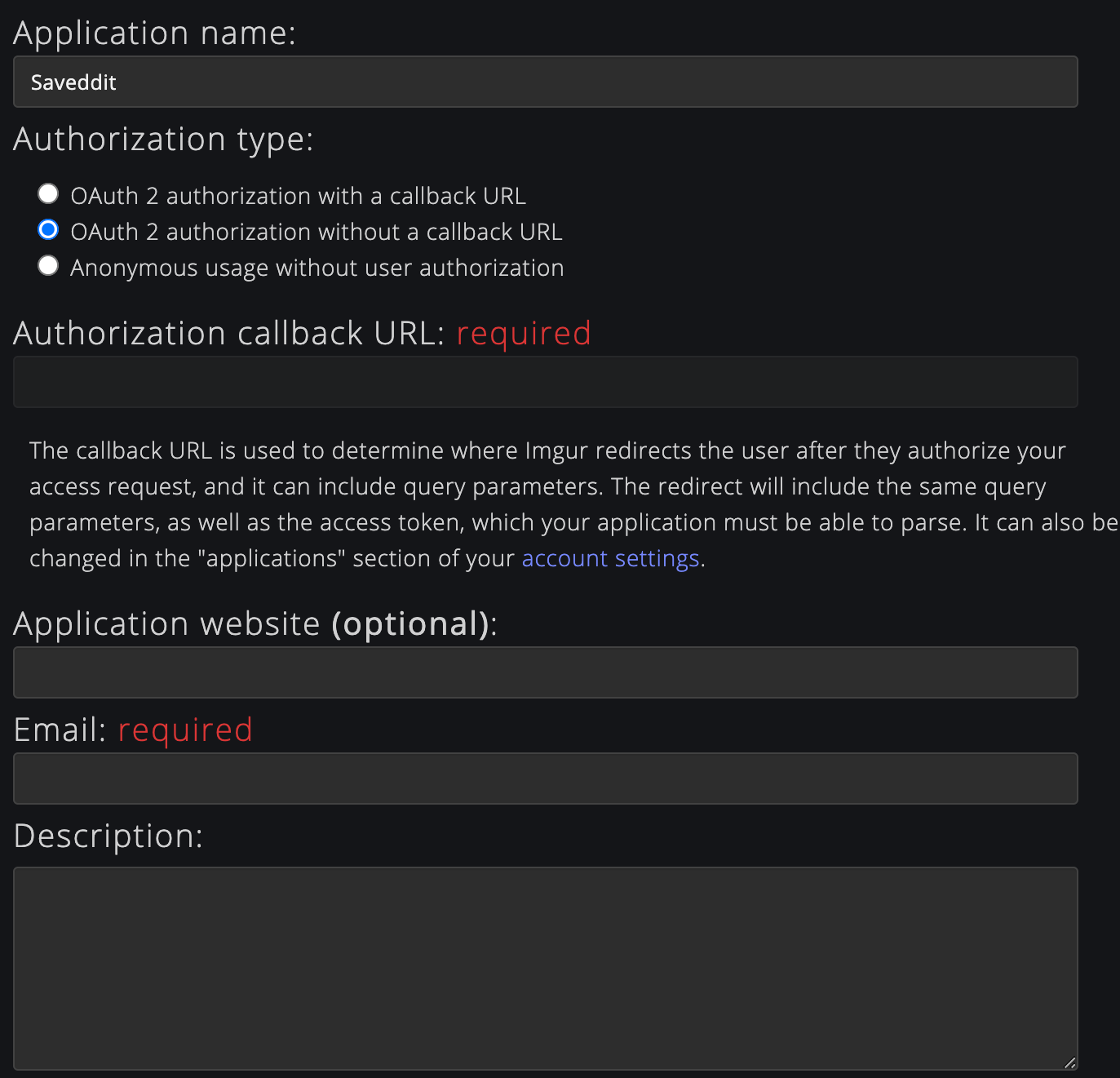
22 |
23 | These registrations will authorize you to use the Reddit and Imgur APIs to download publicly available information.
24 |
25 | ## User configuration
26 |
27 | The first time you run `saveddit`, you will see something like this:
28 |
29 | ```console
30 | foo@bar:~$ saveddit
31 | Retrieving configuration from ~/.saveddit/user_config.yaml file
32 | No configuration file found.
33 | Creating one. Would you like to edit it now?
34 | > Choose Y for yes and N for no
35 | ```
36 |
37 | Once you choose 'yes', the program will request you to enter these credentials:
38 | - Your imgur client ID
39 | - Your reddit client ID
40 | - Your reddit client secret
41 | - Your reddit username
42 |
43 | In case you choose 'no', the program will create a file which you can edit later, this is how to edit it:
44 |
45 | * Open the generated `~/.saveddit/user_config.yaml`
46 | * Update the client IDs and secrets from the previous step
47 | * If you plan on using the `user` API, add your reddit username as well
48 |
49 | ```yaml
50 | imgur_client_id: ''
51 | reddit_client_id: ''
52 | reddit_client_secret: ''
53 | reddit_username: ''
54 | ```
55 |
56 | ## Download from Subreddit
57 |
58 | ```console
59 | foo@bar:~$ saveddit subreddit -h
60 | Retrieving configuration from /Users/pranav/.saveddit/user_config.yaml file
61 |
62 | usage: saveddit subreddit [-h] [-f categories [categories ...]] [-l post_limit] [--skip-comments] [--skip-meta] [--skip-videos] -o output_path subreddits [subreddits ...]
63 |
64 | positional arguments:
65 | subreddits Names of subreddits to download, e.g., AskReddit
66 |
67 | optional arguments:
68 | -h, --help show this help message and exit
69 | -f categories [categories ...]
70 | Categories of posts to download (default: ['hot', 'new', 'rising', 'controversial', 'top', 'gilded'])
71 | -l post_limit Limit the number of submissions downloaded in each category (default: None, i.e., all submissions)
72 | --skip-comments When true, saveddit will not save comments to a comments.json file
73 | --skip-meta When true, saveddit will not save meta to a submission.json file on submissions
74 | --skip-videos When true, saveddit will not download videos (e.g., gfycat, redgifs, youtube, v.redd.it links)
75 | --all-comments When true, saveddit will download all the comments in a post instead of just downloading the top ones.)
76 | -o output_path Directory where saveddit will save downloaded content
77 | ```
78 |
79 | ```console
80 | foo@bar:~$ saveddit subreddit pics -f hot -l 5 -o ~/Desktop
81 | ```
82 |
83 | ```console
84 | foo@bar:~$ tree -L 4 ~/Desktop/www.reddit.com
85 | /Users/pranav/Desktop/www.reddit.com
86 | └── r
87 | └── pics
88 | └── hot
89 | ├── 000_Prince_Philip_Duke_of_Edinburgh_...
90 | ├── 001_Day_10_of_Nobody_Noticing_the_Ap...
91 | ├── 002_First_edited_picture
92 | ├── 003_Reorganized_a_few_months_ago_and...
93 | └── 004_Van_Gogh_inspired_rainy_street_I...
94 | ```
95 |
96 | You can download from multiple subreddits and use multiple filters:
97 |
98 | ```console
99 | foo@bar:~$ saveddit subreddit funny AskReddit -f hot top new rising -l 5 -o ~/Downloads/Reddit/.
100 | ```
101 |
102 | The downloads from each subreddit to go to a separate folder like so:
103 |
104 | ```console
105 | foo@bar:~$ tree -L 3 ~/Downloads/Reddit/www.reddit.com
106 | /Users/pranav/Downloads/Reddit/www.reddit.com
107 | └── r
108 | ├── AskReddit
109 | │ ├── hot
110 | │ ├── new
111 | │ ├── rising
112 | │ └── top
113 | └── funny
114 | ├── hot
115 | ├── new
116 | ├── rising
117 | └── top
118 | ```
119 |
120 | ## Download from anonymous Multireddit
121 |
122 | To download from an anonymous multireddit, use the `multireddit` option and pass a number of subreddit names
123 |
124 | ```console
125 | foo@bar:~$ saveddit multireddit -h
126 | usage: saveddit multireddit [-h] [-f categories [categories ...]] [-l post_limit] [--skip-comments] [--skip-meta] [--skip-videos] -o output_path subreddits [subreddits ...]
127 |
128 | positional arguments:
129 | subreddits Names of subreddits to download, e.g., aww, pics. The downloads will be stored in /www.reddit.com/m/aww+pics/.
130 |
131 | optional arguments:
132 | -h, --help show this help message and exit
133 | -f categories [categories ...]
134 | Categories of posts to download (default: ['hot', 'new', 'random_rising', 'rising', 'controversial', 'top', 'gilded'])
135 | -l post_limit Limit the number of submissions downloaded in each category (default: None, i.e., all submissions)
136 | --skip-comments When true, saveddit will not save comments to a comments.json file
137 | --skip-meta When true, saveddit will not save meta to a submission.json file on submissions
138 | --skip-videos When true, saveddit will not download videos (e.g., gfycat, redgifs, youtube, v.redd.it links)
139 | -o output_path Directory where saveddit will save downloaded content
140 | ```
141 |
142 | ```console
143 | foo@bar:~$ saveddit multireddit EarthPorn NaturePics -f hot -l 5 -o ~/Desktop
144 | ```
145 |
146 | Anonymous multireddits are saved in `www.reddit.com/m///` like so:
147 |
148 | ```console
149 | tree -L 4 ~/Desktop/www.reddit.com
150 | /Users/pranav/Desktop/www.reddit.com
151 | └── m
152 | └── EarthPorn+NaturePics
153 | └── hot
154 | ├── 000_Banning_State_Park_Minnesota_OC_...
155 | ├── 001_Misty_forest_in_the_mountains_of...
156 | ├── 002_One_of_the_highlights_of_my_last...
157 | ├── 003__OC_Japan_Kyoto_Garden_of_the_Go...
158 | └── 004_Sunset_at_Mt_Rainier_National_Pa...
159 | ```
160 |
161 | ## Download from User's page
162 |
163 | ```console
164 | foo@bar:~$ saveddit user -h
165 | usage: saveddit user [-h] users [users ...] {saved,gilded,submitted,multireddits,upvoted,comments} ...
166 |
167 | positional arguments:
168 | users Names of users to download, e.g., Poem_for_your_sprog
169 | {saved,gilded,submitted,multireddits,upvoted,comments}
170 |
171 | optional arguments:
172 | -h, --help show this help message and exit
173 | ```
174 |
175 | Here's a usage example for downloading all comments made by `Poem_for_your_sprog`
176 |
177 | ```console
178 | foo@bar:~$ saveddit user "Poem_for_your_sprog" comments -s top -l 5 -o ~/Desktop
179 | ```
180 |
181 | Here's another example for downloading `kemitche`'s multireddits:
182 |
183 | ```console
184 | foo@bar:~$ saveddit user kemitche multireddits -n reddit -f hot -l 5 -o ~/Desktop
185 | ```
186 |
187 | User-specific content is downloaded to `www.reddit.com/u//...` like so:
188 |
189 | ```console
190 | foo@bar:~$ tree ~/Desktop/www.reddit.com
191 | /Users/pranav/Desktop/www.reddit.com
192 | └── u
193 | ├── Poem_for_your_sprog
194 | │ ├── comments
195 | │ │ └── top
196 | │ │ ├── 000_Comment_my_name_is_Cow_and_wen_its_ni....json
197 | │ │ ├── 001_Comment_It_stopped_at_six_and_life....json
198 | │ │ ├── 002_Comment__Perhaps_I_could_listen_to_podca....json
199 | │ │ ├── 003_Comment__I_don_t_have_regret_for_the_thi....json
200 | │ │ └── 004_Comment__So_throw_off_the_chains_of_oppr....json
201 | │ └── user.json
202 | └── kemitche
203 | ├── m
204 | │ └── reddit
205 | │ └── hot
206 | │ ├── 000_When_posting_to_my_u_channel_NSF...
207 | │ │ ├── comments.json
208 | │ │ └── submission.json
209 | │ ├── 001_How_to_remove_popular_near_you
210 | │ │ ├── comments.json
211 | │ │ └── submission.json
212 | │ ├── 002__IOS_2021_13_0_Reddit_is_just_su...
213 | │ │ ├── comments.json
214 | │ │ └── submission.json
215 | │ ├── 003_The_Approve_User_button_should_n...
216 | │ │ ├── comments.json
217 | │ │ └── submission.json
218 | │ └── 004_non_moderators_unable_to_view_su...
219 | │ ├── comments.json
220 | │ └── submission.json
221 | └── user.json
222 | ```
223 |
224 | ## Search and Download
225 |
226 | `saveddit` support searching subreddits and downloading search results
227 |
228 | ```console
229 | foo@bar:~$ saveddit search -h
230 | usage: saveddit search [-h] -q query [-s sort] [-t time_filter] [--include-nsfw] [--skip-comments] [--skip-meta] [--skip-videos] -o output_path subreddits [subreddits ...]
231 |
232 | positional arguments:
233 | subreddits Names of subreddits to search, e.g., all, aww, pics
234 |
235 | optional arguments:
236 | -h, --help show this help message and exit
237 | -q query Search query string
238 | -s sort Sort to apply on search (default: relevance, choices: [relevance, hot, top, new, comments])
239 | -t time_filter Time filter to apply on search (default: all, choices: [all, day, hour, month, week, year])
240 | --include-nsfw When true, saveddit will include NSFW results in search
241 | --skip-comments When true, saveddit will not save comments to a comments.json file
242 | --skip-meta When true, saveddit will not save meta to a submission.json file on submissions
243 | --skip-videos When true, saveddit will not download videos (e.g., gfycat, redgifs, youtube, v.redd.it links)
244 | -o output_path Directory where saveddit will save downloaded content
245 | ```
246 |
247 | e.g.,
248 |
249 | ```console
250 | foo@bar:~$ saveddit search soccer -q "Chelsea" -o ~/Desktop
251 | ```
252 |
253 | The downloaded search results are stored in `www.reddit.com/q////.`
254 |
255 | ```console
256 | foo@bar:~$ tree -L 4 ~/Desktop/www.reddit.com/q
257 | /Users/pranav/Desktop/www.reddit.com/q
258 | └── Chelsea
259 | └── soccer
260 | └── relevance
261 | ├── 000__Official_Results_for_UEFA_Champ...
262 | ├── 001_Porto_0_1_Chelsea_Mason_Mount_32...
263 | ├── 002_Crystal_Palace_0_2_Chelsea_Chris...
264 | ├── 003_Post_Match_Thread_Chelsea_2_5_We...
265 | ├── 004_Match_Thread_Porto_vs_Chelsea_UE...
266 | ├── 005_Crystal_Palace_1_4_Chelsea_Chris...
267 | ├── 006_Porto_0_2_Chelsea_Ben_Chilwell_8...
268 | ├── 007_Post_Match_Thread_Porto_0_2_Chel...
269 | ├── 008_UCL_Quaterfinalists_are_Bayern_D...
270 | ├── 009__MD_Mino_Raiola_and_Haaland_s_fa...
271 | ├── 010_Chelsea_2_5_West_Brom_Callum_Rob...
272 | ├── 011_Chelsea_1_2_West_Brom_Matheus_Pe...
273 | ├── 012__Bild_Sport_via_Sport_Witness_Ch...
274 | ├── 013_Match_Thread_Chelsea_vs_West_Bro...
275 | ├── 014_Chelsea_1_3_West_Brom_Callum_Rob...
276 | ├── 015_Match_Thread_Chelsea_vs_Atletico...
277 | ├── 016_Stefan_Savi�\207_Atlético_Madrid_str...
278 | ├── 017_Chelsea_1_0_West_Brom_Christian_...
279 | └── 018_Alvaro_Morata_I_ve_never_had_dep...
280 | ```
281 |
282 | ## Supported Links:
283 |
284 | * Direct links to images or videos, e.g., `.png`, `.jpg`, `.mp4`, `.gif` etc.
285 | * Reddit galleries `reddit.com/gallery/...`
286 | * Reddit videos `v.redd.it/...`
287 | * Gfycat links `gfycat.com/...`
288 | * Redgif links `redgifs.com/...`
289 | * Imgur images `imgur.com/...`
290 | * Imgur albums `imgur.com/a/...` and `imgur.com/gallery/...`
291 | * Youtube links `youtube.com/...` and `yout.be/...`
292 | * These [sites](https://ytdl-org.github.io/youtube-dl/supportedsites.html) supported by `youtube-dl`
293 | * Self posts
294 | * For all other cases, `saveddit` will simply fetch the HTML of the URL
295 |
296 | ## Contributing
297 | Contributions are welcome, have a look at the [CONTRIBUTING.md](CONTRIBUTING.md) document for more information.
298 |
299 | ## License
300 | The project is available under the [MIT](https://opensource.org/licenses/MIT) license.
301 |
--------------------------------------------------------------------------------
/images/demo.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/p-ranav/saveddit/f4aa0749eec1020bb9927c6dd7fd5059a6d989af/images/demo.gif
--------------------------------------------------------------------------------
/images/imgur_app.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/p-ranav/saveddit/f4aa0749eec1020bb9927c6dd7fd5059a6d989af/images/imgur_app.png
--------------------------------------------------------------------------------
/images/logo.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/p-ranav/saveddit/f4aa0749eec1020bb9927c6dd7fd5059a6d989af/images/logo.png
--------------------------------------------------------------------------------
/images/reddit_app.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/p-ranav/saveddit/f4aa0749eec1020bb9927c6dd7fd5059a6d989af/images/reddit_app.png
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [build-system]
2 | requires = [
3 | "setuptools>=42",
4 | "wheel"
5 | ]
6 | build-backend = "setuptools.build_meta"
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | colorama==0.4.4
2 | coloredlogs==15.0
3 | verboselogs==1.7
4 | praw==7.2.0
5 | tqdm==4.60.0
6 | ffmpeg_python==0.2.0
7 | youtube_dl==2021.4.7
8 | requests==2.25.1
9 | beautifulsoup4==4.9.3
10 | PyYAML==5.4.1
11 |
--------------------------------------------------------------------------------
/setup.cfg:
--------------------------------------------------------------------------------
1 | [metadata]
2 | # replace with your username:
3 | name = saveddit
4 | version = 2.2.1
5 | author = Pranav Srinivas Kumar
6 | author_email = pranav.srinivas.kumar@gmail.com
7 | description = Bulk Downloader for Reddit
8 | long_description = file: README_PyPI.md
9 | long_description_content_type = text/markdown
10 | url = https://github.com/p-ranav/saveddit
11 | project_urls =
12 | Bug Tracker = https://github.com/p-ranav/saveddit/issues
13 | classifiers =
14 | Programming Language :: Python :: 3
15 | License :: OSI Approved :: MIT License
16 | Operating System :: OS Independent
17 |
18 | [options]
19 | package_dir =
20 | = src
21 | packages = find:
22 | python_requires = >=3.8
23 | install_requires =
24 | praw
25 | verboselogs
26 | requests
27 | colorama
28 | coloredlogs
29 | youtube_dl
30 | tqdm
31 | ffmpeg_python
32 | beautifulsoup4
33 | PyYAML
34 |
35 | [options.packages.find]
36 | where = src
37 |
38 | [options.entry_points]
39 | console_scripts =
40 | saveddit = saveddit.saveddit:main
--------------------------------------------------------------------------------
/src/saveddit/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/p-ranav/saveddit/f4aa0749eec1020bb9927c6dd7fd5059a6d989af/src/saveddit/__init__.py
--------------------------------------------------------------------------------
/src/saveddit/_version.py:
--------------------------------------------------------------------------------
1 | __version__ = "2.2.1"
--------------------------------------------------------------------------------
/src/saveddit/configuration.py:
--------------------------------------------------------------------------------
1 | import os
2 | from typing import Union
3 | import yaml
4 | import pathlib
5 | import colorama
6 | import sys
7 |
8 |
9 | class ConfigurationLoader:
10 | PURPLE = colorama.Fore.MAGENTA
11 | WHITE = colorama.Style.RESET_ALL
12 | RED = colorama.Fore.RED
13 |
14 | @staticmethod
15 | def load(path):
16 | """
17 | Loads Saveddit configuration from a configuration file.
18 | If ifle is not found, create one and exit.
19 |
20 | Arguments:
21 | path: path to user_config.yaml file
22 |
23 | Returns:
24 | A Python dictionary with Saveddit configuration info
25 | """
26 |
27 | def _create_config(_path):
28 | _STD_CONFIG = {
29 | "reddit_client_id": "",
30 | "reddit_client_secret": "",
31 | "reddit_username": "",
32 | "imgur_client_id": "",
33 | }
34 | with open(_path, "x") as _f:
35 | yaml.dump(_STD_CONFIG, _f)
36 | sys.exit(0)
37 |
38 | # Explicitly converting path to POSIX-like path (to avoid '\\' hell)
39 | print(
40 | "{notice}Retrieving configuration from {path} file{white}".format(
41 | path=path,
42 | notice=ConfigurationLoader.PURPLE,
43 | white=ConfigurationLoader.WHITE,
44 | )
45 | )
46 | path = pathlib.Path(path).absolute().as_posix()
47 |
48 | # Check if file exists. If not, create one and fill it with std config template
49 | if not os.path.exists(path):
50 | print(
51 | "{red}No configuration file found.\nCreating one. Would you like to edit it now?\n > Choose {purple}Y{red} for yes and {purple}N{red} for no.{white}".format(
52 | red=ConfigurationLoader.RED,
53 | path=path,
54 | white=ConfigurationLoader.WHITE,
55 | purple=ConfigurationLoader.PURPLE,
56 | )
57 | )
58 | getchoice = str(input("> "))
59 | if getchoice == "Y":
60 | reddit_client = str(input("Reddit Client ID: "))
61 | reddit_client_sec = str(input("Reddit Client Secret: "))
62 | reddit_user = str(input("Reddit Username: "))
63 | imgur_client = str(input("Imgur Client ID: "))
64 | STD_CONFIG = {
65 | "reddit_client_id": "{}".format(reddit_client),
66 | "reddit_client_secret": "{}".format(reddit_client_sec),
67 | "reddit_username": "{}".format(reddit_user),
68 | "imgur_client_id": "{}".format(imgur_client),
69 | }
70 | with open(path, "x") as f:
71 | yaml.dump(STD_CONFIG, f)
72 | sys.exit(0)
73 | elif getchoice == "N":
74 | print(
75 | "{red}Alright.\nPlease edit {path} with valid credentials.\nExiting{white}".format(
76 | red=ConfigurationLoader.RED,
77 | path=path,
78 | white=ConfigurationLoader.WHITE,
79 | )
80 | )
81 | _create_config(path)
82 | else:
83 | print("Invalid choice.")
84 | exit()
85 |
86 | with open(path, "r") as _f:
87 | return yaml.safe_load(_f.read())
88 |
--------------------------------------------------------------------------------
/src/saveddit/multireddit_downloader.py:
--------------------------------------------------------------------------------
1 | import coloredlogs
2 | from colorama import Fore, Style
3 | from datetime import datetime, timezone
4 | import logging
5 | import verboselogs
6 | import getpass
7 | import json
8 | import os
9 | import praw
10 | from pprint import pprint
11 | import re
12 | from saveddit.submission_downloader import SubmissionDownloader
13 | from saveddit.subreddit_downloader import SubredditDownloader
14 | from saveddit.multireddit_downloader_config import MultiredditDownloaderConfig
15 | import sys
16 | from tqdm import tqdm
17 |
18 | class MultiredditDownloader:
19 | config = SubredditDownloader.config
20 | REDDIT_CLIENT_ID = config['reddit_client_id']
21 | REDDIT_CLIENT_SECRET = config['reddit_client_secret']
22 | IMGUR_CLIENT_ID = config['imgur_client_id']
23 |
24 | def __init__(self, multireddit_names):
25 | self.logger = verboselogs.VerboseLogger(__name__)
26 | level_styles = {
27 | 'critical': {'bold': True, 'color': 'red'},
28 | 'debug': {'color': 'green'},
29 | 'error': {'color': 'red'},
30 | 'info': {'color': 'white'},
31 | 'notice': {'color': 'magenta'},
32 | 'spam': {'color': 'white', 'faint': True},
33 | 'success': {'bold': True, 'color': 'green'},
34 | 'verbose': {'color': 'blue'},
35 | 'warning': {'color': 'yellow'}
36 | }
37 | coloredlogs.install(level='SPAM', logger=self.logger,
38 | fmt='%(message)s', level_styles=level_styles)
39 |
40 | self.reddit = praw.Reddit(
41 | client_id=MultiredditDownloader.REDDIT_CLIENT_ID,
42 | client_secret=MultiredditDownloader.REDDIT_CLIENT_SECRET,
43 | user_agent="saveddit (by /u/p_ranav)"
44 | )
45 |
46 | self.multireddit_name = "+".join(multireddit_names)
47 | self.multireddit = self.reddit.subreddit(self.multireddit_name)
48 |
49 | def download(self, output_path, categories=MultiredditDownloaderConfig.DEFAULT_CATEGORIES, post_limit=MultiredditDownloaderConfig.DEFAULT_POST_LIMIT, skip_videos=False, skip_meta=False, skip_comments=False, comment_limit=0):
50 | '''
51 | categories: List of categories within the multireddit to download (see MultiredditDownloaderConfig.DEFAULT_CATEGORIES)
52 | post_limit: Number of posts to download (default: None, i.e., all posts)
53 | comment_limit: Number of comment levels to download from submission (default: `0`, i.e., only top-level comments)
54 | - to get all comments, set comment_limit to `None`
55 | '''
56 |
57 | multireddit_dir_name = self.multireddit_name
58 | if len(multireddit_dir_name) > 64:
59 | multireddit_dir_name = multireddit_dir_name[0:63]
60 | multireddit_dir_name += "..."
61 |
62 | root_dir = os.path.join(os.path.join(os.path.join(
63 | output_path, "www.reddit.com"), "m"), multireddit_dir_name)
64 | categories = categories
65 |
66 | for c in categories:
67 | self.logger.notice("Downloading from /m/" +
68 | self.multireddit_name + "/" + c + "/")
69 | category_dir = os.path.join(root_dir, c)
70 | if not os.path.exists(category_dir):
71 | os.makedirs(category_dir)
72 | category_function = getattr(self.multireddit, c)
73 |
74 | for i, submission in enumerate(category_function(limit=post_limit)):
75 | SubmissionDownloader(submission, i, self.logger, category_dir,
76 | skip_videos, skip_meta, skip_comments, comment_limit,
77 | {'imgur_client_id': MultiredditDownloader.IMGUR_CLIENT_ID})
78 |
--------------------------------------------------------------------------------
/src/saveddit/multireddit_downloader_config.py:
--------------------------------------------------------------------------------
1 | class MultiredditDownloaderConfig:
2 | DEFAULT_CATEGORIES = ["hot", "new", "random_rising", "rising",
3 | "controversial", "top", "gilded"]
4 | DEFAULT_POST_LIMIT = None
--------------------------------------------------------------------------------
/src/saveddit/saveddit.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import sys
3 | from saveddit.multireddit_downloader_config import MultiredditDownloaderConfig
4 | from saveddit.search_config import SearchConfig
5 | from saveddit.subreddit_downloader_config import SubredditDownloaderConfig
6 | from saveddit.user_downloader_config import UserDownloaderConfig
7 | from saveddit._version import __version__
8 |
9 |
10 | def asciiart():
11 | return r''' .___ .___.__ __
12 | ___________ ___ __ ____ __| _/__| _/|__|/ |_
13 | / ___/\__ \\ \/ // __ \ / __ |/ __ | | \ __\
14 | \___ \ / __ \\ /\ ___// /_/ / /_/ | | || |
15 | /____ >(____ /\_/ \___ >____ \____ | |__||__|
16 | \/ \/ \/ \/ \/
17 |
18 | Downloader for Reddit
19 | version : ''' + __version__ + '''
20 | URL : https://github.com/p-ranav/saveddit
21 | '''
22 |
23 |
24 | def check_positive(value):
25 | ivalue = int(value)
26 | if ivalue <= 0:
27 | raise argparse.ArgumentTypeError(
28 | "%s is an invalid positive int value" % value)
29 | return ivalue
30 |
31 | class UniqueAppendAction(argparse.Action):
32 | '''
33 | Class used to discard duplicates in list arguments
34 | https://stackoverflow.com/questions/9376670/python-argparse-force-a-list-item-to-be-unique
35 | '''
36 | def __call__(self, parser, namespace, values, option_string=None):
37 | unique_values = set(values)
38 | setattr(namespace, self.dest, unique_values)
39 |
40 | def main():
41 | argv = sys.argv[1:]
42 |
43 | parser = argparse.ArgumentParser(prog="saveddit")
44 | parser.add_argument('-v', '--version', action='version', version='%(prog)s ' + __version__)
45 |
46 | subparsers = parser.add_subparsers(dest="subparser_name")
47 |
48 | subreddit_parser = subparsers.add_parser('subreddit')
49 | subreddit_parser.add_argument('subreddits',
50 | metavar='subreddits',
51 | nargs='+',
52 | action=UniqueAppendAction,
53 | help='Names of subreddits to download, e.g., AskReddit')
54 | subreddit_parser.add_argument('-f',
55 | metavar='categories',
56 | default=SubredditDownloaderConfig.DEFAULT_CATEGORIES,
57 | nargs='+',
58 | action=UniqueAppendAction,
59 | help='Categories of posts to download (default: %(default)s)')
60 | subreddit_parser.add_argument('-l',
61 | default=SubredditDownloaderConfig.DEFAULT_POST_LIMIT,
62 | metavar='post_limit',
63 | type=check_positive,
64 | help='Limit the number of submissions downloaded in each category (default: %(default)s, i.e., all submissions)')
65 | subreddit_parser.add_argument('--skip-comments',
66 | default=False,
67 | action='store_true',
68 | help='When true, saveddit will not save comments to a comments.json file')
69 | subreddit_parser.add_argument('--skip-meta',
70 | default=False,
71 | action='store_true',
72 | help='When true, saveddit will not save meta to a submission.json file on submissions')
73 | subreddit_parser.add_argument('--skip-videos',
74 | default=False,
75 | action='store_true',
76 | help='When true, saveddit will not download videos (e.g., gfycat, redgifs, youtube, v.redd.it links)')
77 | subreddit_parser.add_argument('--all-comments',
78 | default=False,
79 | action='store_true',
80 | help='When true, saveddit will download all the comments in a post instead of just the top ones.')
81 | subreddit_parser.add_argument('-o',
82 | required=True,
83 | type=str,
84 | metavar='output_path',
85 | help='Directory where saveddit will save downloaded content'
86 | )
87 |
88 | multireddit_parser = subparsers.add_parser('multireddit')
89 | multireddit_parser.add_argument('subreddits',
90 | metavar='subreddits',
91 | nargs='+',
92 | action=UniqueAppendAction,
93 | help='Names of subreddits to download, e.g., aww, pics. The downloads will be stored in /www.reddit.com/m/aww+pics/.')
94 | multireddit_parser.add_argument('-f',
95 | metavar='categories',
96 | default=MultiredditDownloaderConfig.DEFAULT_CATEGORIES,
97 | nargs='+',
98 | action=UniqueAppendAction,
99 | help='Categories of posts to download (default: %(default)s)')
100 | multireddit_parser.add_argument('-l',
101 | default=MultiredditDownloaderConfig.DEFAULT_POST_LIMIT,
102 | metavar='post_limit',
103 | type=check_positive,
104 | help='Limit the number of submissions downloaded in each category (default: %(default)s, i.e., all submissions)')
105 | multireddit_parser.add_argument('--skip-comments',
106 | default=False,
107 | action='store_true',
108 | help='When true, saveddit will not save comments to a comments.json file')
109 | multireddit_parser.add_argument('--skip-meta',
110 | default=False,
111 | action='store_true',
112 | help='When true, saveddit will not save meta to a submission.json file on submissions')
113 | multireddit_parser.add_argument('--skip-videos',
114 | default=False,
115 | action='store_true',
116 | help='When true, saveddit will not download videos (e.g., gfycat, redgifs, youtube, v.redd.it links)')
117 | multireddit_parser.add_argument('-o',
118 | required=True,
119 | type=str,
120 | metavar='output_path',
121 | help='Directory where saveddit will save downloaded content'
122 | )
123 |
124 | search_parser = subparsers.add_parser('search')
125 | search_parser.add_argument('subreddits',
126 | metavar='subreddits',
127 | nargs='+',
128 | action=UniqueAppendAction,
129 | help='Names of subreddits to search, e.g., all, aww, pics')
130 | search_parser.add_argument('-q',
131 | metavar='query',
132 | required=True,
133 | help='Search query string')
134 | search_parser.add_argument('-s',
135 | metavar='sort',
136 | default=SearchConfig.DEFAULT_SORT,
137 | choices=SearchConfig.DEFAULT_SORT_CATEGORIES,
138 | help='Sort to apply on search (default: %(default)s, choices: [%(choices)s])')
139 | search_parser.add_argument('-t',
140 | metavar='time_filter',
141 | default=SearchConfig.DEFAULT_TIME_FILTER,
142 | choices=SearchConfig.DEFAULT_TIME_FILTER_CATEGORIES,
143 | help='Time filter to apply on search (default: %(default)s, choices: [%(choices)s])')
144 | search_parser.add_argument('--include-nsfw',
145 | default=False,
146 | action='store_true',
147 | help='When true, saveddit will include NSFW results in search')
148 | search_parser.add_argument('--skip-comments',
149 | default=False,
150 | action='store_true',
151 | help='When true, saveddit will not save comments to a comments.json file')
152 | search_parser.add_argument('--skip-meta',
153 | default=False,
154 | action='store_true',
155 | help='When true, saveddit will not save meta to a submission.json file on submissions')
156 | search_parser.add_argument('--skip-videos',
157 | default=False,
158 | action='store_true',
159 | help='When true, saveddit will not download videos (e.g., gfycat, redgifs, youtube, v.redd.it links)')
160 | search_parser.add_argument('-o',
161 | required=True,
162 | type=str,
163 | metavar='output_path',
164 | help='Directory where saveddit will save downloaded content'
165 | )
166 |
167 | user_parser = subparsers.add_parser('user')
168 | user_parser.add_argument('users',
169 | metavar='users',
170 | nargs='+',
171 | help='Names of users to download, e.g., Poem_for_your_sprog')
172 |
173 |
174 | user_subparsers = user_parser.add_subparsers(dest="user_subparser_name")
175 | user_subparsers.required = True
176 |
177 | # user.saved subparser
178 | saved_parser = user_subparsers.add_parser('saved')
179 | saved_parser.add_argument('--skip-meta',
180 | default=False,
181 | action='store_true',
182 | help='When true, saveddit will not save meta to a submission.json file on submissions')
183 | saved_parser.add_argument('--skip-comments',
184 | default=False,
185 | action='store_true',
186 | help='When true, saveddit will not save comments to a comments.json file')
187 | saved_parser.add_argument('--skip-videos',
188 | default=False,
189 | action='store_true',
190 | help='When true, saveddit will not download videos (e.g., gfycat, redgifs, youtube, v.redd.it links)')
191 | saved_parser.add_argument('-l',
192 | default=UserDownloaderConfig.DEFAULT_POST_LIMIT,
193 | metavar='post_limit',
194 | type=check_positive,
195 | help='Limit the number of saved submissions downloaded (default: %(default)s, i.e., all submissions)')
196 | saved_parser.add_argument('-o',
197 | required=True,
198 | type=str,
199 | metavar='output_path',
200 | help='Directory where saveddit will save downloaded content'
201 | )
202 |
203 | # user.gilded subparser
204 | gilded_parser = user_subparsers.add_parser('gilded')
205 | gilded_parser.add_argument('--skip-meta',
206 | default=False,
207 | action='store_true',
208 | help='When true, saveddit will not save meta to a submission.json file on submissions')
209 | gilded_parser.add_argument('--skip-comments',
210 | default=False,
211 | action='store_true',
212 | help='When true, saveddit will not save comments to a comments.json file')
213 | gilded_parser.add_argument('--skip-videos',
214 | default=False,
215 | action='store_true',
216 | help='When true, saveddit will not download videos (e.g., gfycat, redgifs, youtube, v.redd.it links)')
217 | gilded_parser.add_argument('-l',
218 | default=UserDownloaderConfig.DEFAULT_POST_LIMIT,
219 | metavar='post_limit',
220 | type=check_positive,
221 | help='Limit the number of saved submissions downloaded (default: %(default)s, i.e., all submissions)')
222 | gilded_parser.add_argument('-o',
223 | required=True,
224 | type=str,
225 | metavar='output_path',
226 | help='Directory where saveddit will save downloaded content'
227 | )
228 |
229 | # user.submitted subparser
230 | submitted_parser = user_subparsers.add_parser('submitted')
231 | submitted_parser.add_argument('-s',
232 | metavar='sort',
233 | default=UserDownloaderConfig.DEFAULT_SORT,
234 | choices=UserDownloaderConfig.DEFAULT_SORT_OPTIONS,
235 | help='Download submissions sorted by this option (default: %(default)s, choices: [%(choices)s])')
236 | submitted_parser.add_argument('--skip-comments',
237 | default=False,
238 | action='store_true',
239 | help='When true, saveddit will not save comments to a comments.json file for the submissions')
240 | submitted_parser.add_argument('--skip-meta',
241 | default=False,
242 | action='store_true',
243 | help='When true, saveddit will not save meta to a submission.json file on submissions')
244 | submitted_parser.add_argument('--skip-videos',
245 | default=False,
246 | action='store_true',
247 | help='When true, saveddit will not download videos (e.g., gfycat, redgifs, youtube, v.redd.it links)')
248 | submitted_parser.add_argument('-l',
249 | default=UserDownloaderConfig.DEFAULT_POST_LIMIT,
250 | metavar='post_limit',
251 | type=check_positive,
252 | help='Limit the number of submissions downloaded (default: %(default)s, i.e., all submissions)')
253 | submitted_parser.add_argument('-o',
254 | required=True,
255 | type=str,
256 | metavar='output_path',
257 | help='Directory where saveddit will save downloaded posts'
258 | )
259 |
260 | # user.multireddits subparser
261 | submitted_parser = user_subparsers.add_parser('multireddits')
262 | submitted_parser.add_argument('-n',
263 | metavar='names',
264 | default=None,
265 | nargs='+',
266 | action=UniqueAppendAction,
267 | help='Names of specific multireddits to download (default: %(default)s, i.e., all multireddits for this user)')
268 | submitted_parser.add_argument('-f',
269 | metavar='categories',
270 | default=UserDownloaderConfig.DEFAULT_CATEGORIES,
271 | nargs='+',
272 | action=UniqueAppendAction,
273 | help='Categories of posts to download (default: %(default)s)')
274 | submitted_parser.add_argument('--skip-comments',
275 | default=False,
276 | action='store_true',
277 | help='When true, saveddit will not save comments to a comments.json file for the submissions')
278 | submitted_parser.add_argument('--skip-meta',
279 | default=False,
280 | action='store_true',
281 | help='When true, saveddit will not save meta to a submission.json file on submissions')
282 | submitted_parser.add_argument('--skip-videos',
283 | default=False,
284 | action='store_true',
285 | help='When true, saveddit will not download videos (e.g., gfycat, redgifs, youtube, v.redd.it links)')
286 | submitted_parser.add_argument('-l',
287 | default=UserDownloaderConfig.DEFAULT_POST_LIMIT,
288 | metavar='post_limit',
289 | type=check_positive,
290 | help='Limit the number of submissions downloaded (default: %(default)s, i.e., all submissions)')
291 | submitted_parser.add_argument('-o',
292 | required=True,
293 | type=str,
294 | metavar='output_path',
295 | help='Directory where saveddit will save downloaded posts'
296 | )
297 |
298 | # user.upvoted subparser
299 | upvoted_parser = user_subparsers.add_parser('upvoted')
300 | upvoted_parser.add_argument('--skip-comments',
301 | default=False,
302 | action='store_true',
303 | help='When true, saveddit will not save comments to a comments.json file for the upvoted submissions')
304 | upvoted_parser.add_argument('--skip-meta',
305 | default=False,
306 | action='store_true',
307 | help='When true, saveddit will not save meta to a submission.json file on upvoted submissions')
308 | upvoted_parser.add_argument('--skip-videos',
309 | default=False,
310 | action='store_true',
311 | help='When true, saveddit will not download videos (e.g., gfycat, redgifs, youtube, v.redd.it links)')
312 | upvoted_parser.add_argument('-l',
313 | default=UserDownloaderConfig.DEFAULT_POST_LIMIT,
314 | metavar='post_limit',
315 | type=check_positive,
316 | help='Limit the number of submissions downloaded (default: %(default)s, i.e., all submissions)')
317 | upvoted_parser.add_argument('-o',
318 | required=True,
319 | type=str,
320 | metavar='output_path',
321 | help='Directory where saveddit will save downloaded posts'
322 | )
323 |
324 | # user.comments subparser
325 | comments_parser = user_subparsers.add_parser('comments')
326 | comments_parser.add_argument('-s',
327 | metavar='sort',
328 | default=UserDownloaderConfig.DEFAULT_SORT,
329 | choices=UserDownloaderConfig.DEFAULT_SORT_OPTIONS,
330 | help='Download comments sorted by this option (default: %(default)s, choices: [%(choices)s])')
331 | comments_parser.add_argument('-l',
332 | default=UserDownloaderConfig.DEFAULT_COMMENT_LIMIT,
333 | metavar='post_limit',
334 | type=check_positive,
335 | help='Limit the number of comments downloaded (default: %(default)s, i.e., all comments)')
336 | comments_parser.add_argument('-o',
337 | required=True,
338 | type=str,
339 | metavar='output_path',
340 | help='Directory where saveddit will save downloaded comments'
341 | )
342 |
343 | args = parser.parse_args(argv)
344 | print(asciiart())
345 |
346 | if args.subparser_name == "subreddit":
347 | from saveddit.subreddit_downloader import SubredditDownloader
348 | for subreddit in args.subreddits:
349 | downloader = SubredditDownloader(subreddit)
350 | downloader.download(args.o,
351 | download_all_comments=args.all_comments, categories=args.f, post_limit=args.l, skip_videos=args.skip_videos, skip_meta=args.skip_meta, skip_comments=args.skip_comments)
352 | elif args.subparser_name == "multireddit":
353 | from saveddit.multireddit_downloader import MultiredditDownloader
354 | downloader = MultiredditDownloader(args.subreddits)
355 | downloader.download(args.o,
356 | categories=args.f, post_limit=args.l, skip_videos=args.skip_videos, skip_meta=args.skip_meta, skip_comments=args.skip_comments)
357 | elif args.subparser_name == "search":
358 | from saveddit.search_subreddits import SearchSubreddits
359 | downloader = SearchSubreddits(args.subreddits)
360 | downloader.download(args)
361 | elif args.subparser_name == "user":
362 | from saveddit.user_downloader import UserDownloader
363 | downloader = UserDownloader()
364 | downloader.download_user_meta(args)
365 | if args.user_subparser_name == "comments":
366 | downloader.download_comments(args)
367 | elif args.user_subparser_name == "multireddits":
368 | downloader.download_multireddits(args)
369 | elif args.user_subparser_name == "submitted":
370 | downloader.download_submitted(args)
371 | elif args.user_subparser_name == "saved":
372 | downloader.download_saved(args)
373 | elif args.user_subparser_name == "upvoted":
374 | downloader.download_upvoted(args)
375 | elif args.user_subparser_name == "gilded":
376 | downloader.download_gilded(args)
377 | else:
378 | parser.print_help()
379 |
380 | if __name__ == "__main__":
381 | main()
382 |
--------------------------------------------------------------------------------
/src/saveddit/search_config.py:
--------------------------------------------------------------------------------
1 | class SearchConfig:
2 | DEFAULT_SORT = "relevance"
3 | DEFAULT_SORT_CATEGORIES = ["relevance", "hot", "top", "new", "comments"]
4 | DEFAULT_SYNTAX = "lucene"
5 | DEFAULT_SYNTAX_CATEGORIES = ["cloud search", "lucene", "plain"]
6 | DEFAULT_TIME_FILTER = "all"
7 | DEFAULT_TIME_FILTER_CATEGORIES = ["all", "day", "hour", "month", "week", "year"]
--------------------------------------------------------------------------------
/src/saveddit/search_subreddits.py:
--------------------------------------------------------------------------------
1 | import coloredlogs
2 | from colorama import Fore, Style
3 | from datetime import datetime, timezone
4 | import logging
5 | import verboselogs
6 | import getpass
7 | import json
8 | import os
9 | import praw
10 | from pprint import pprint
11 | import re
12 | from saveddit.submission_downloader import SubmissionDownloader
13 | from saveddit.subreddit_downloader import SubredditDownloader
14 | from saveddit.search_config import SearchConfig
15 | import sys
16 | from tqdm import tqdm
17 |
18 | class SearchSubreddits:
19 | config = SubredditDownloader.config
20 | REDDIT_CLIENT_ID = config['reddit_client_id']
21 | REDDIT_CLIENT_SECRET = config['reddit_client_secret']
22 | IMGUR_CLIENT_ID = config['imgur_client_id']
23 |
24 | REDDIT_USERNAME = None
25 | try:
26 | REDDIT_USERNAME = config['reddit_username']
27 | except Exception as e:
28 | pass
29 |
30 | REDDIT_PASSWORD = None
31 | if REDDIT_USERNAME:
32 | if sys.stdin.isatty():
33 | print("Username: " + REDDIT_USERNAME)
34 | REDDIT_PASSWORD = getpass.getpass("Password: ")
35 | else:
36 | # echo "foobar" > password
37 | # saveddit user .... < password
38 | REDDIT_PASSWORD = sys.stdin.readline().rstrip()
39 |
40 | def __init__(self, subreddit_names):
41 | self.logger = verboselogs.VerboseLogger(__name__)
42 | level_styles = {
43 | 'critical': {'bold': True, 'color': 'red'},
44 | 'debug': {'color': 'green'},
45 | 'error': {'color': 'red'},
46 | 'info': {'color': 'white'},
47 | 'notice': {'color': 'magenta'},
48 | 'spam': {'color': 'white', 'faint': True},
49 | 'success': {'bold': True, 'color': 'green'},
50 | 'verbose': {'color': 'blue'},
51 | 'warning': {'color': 'yellow'}
52 | }
53 | coloredlogs.install(level='SPAM', logger=self.logger,
54 | fmt='%(message)s', level_styles=level_styles)
55 |
56 | if not SearchSubreddits.REDDIT_USERNAME:
57 | self.logger.error("`reddit_username` in user_config.yaml is empty")
58 | self.logger.error("If you plan on using the user API of saveddit, then add your username to user_config.yaml")
59 | print("Exiting now")
60 | exit()
61 | else:
62 | if not len(SearchSubreddits.REDDIT_PASSWORD):
63 | if sys.stdin.isatty():
64 | print("Username: " + REDDIT_USERNAME)
65 | REDDIT_PASSWORD = getpass.getpass("Password: ")
66 | else:
67 | # echo "foobar" > password
68 | # saveddit user .... < password
69 | REDDIT_PASSWORD = sys.stdin.readline().rstrip()
70 |
71 | self.reddit = praw.Reddit(
72 | client_id=SearchSubreddits.REDDIT_CLIENT_ID,
73 | client_secret=SearchSubreddits.REDDIT_CLIENT_SECRET,
74 | user_agent="saveddit (by /u/p_ranav)"
75 | )
76 |
77 | self.multireddit_name = "+".join(subreddit_names)
78 | self.subreddit = self.reddit.subreddit(self.multireddit_name)
79 |
80 | def download(self, args):
81 | output_path = args.o
82 | query = args.q
83 | sort = args.s
84 | syntax = SearchConfig.DEFAULT_SYNTAX
85 | time_filter = args.t
86 | include_nsfw = args.include_nsfw
87 | skip_comments = args.skip_comments
88 | skip_videos = args.skip_videos
89 | skip_meta = args.skip_meta
90 | comment_limit = 0 # top-level comments ONLY
91 |
92 | self.logger.verbose("Searching '" + query + "' in " + self.multireddit_name + ", sorted by " + sort)
93 | if include_nsfw:
94 | self.logger.spam(" * Including NSFW results")
95 |
96 | search_dir = os.path.join(os.path.join(os.path.join(os.path.join(os.path.join(
97 | output_path, "www.reddit.com"), "q"), query), self.multireddit_name), sort)
98 |
99 | if not os.path.exists(search_dir):
100 | os.makedirs(search_dir)
101 |
102 | search_results = None
103 | if include_nsfw:
104 | search_params = {"include_over_18": "on"}
105 | search_results = self.subreddit.search(query, sort, syntax, time_filter, params=search_params)
106 | else:
107 | search_results = self.subreddit.search(query, sort, syntax, time_filter)
108 |
109 | results_found = False
110 | for i, submission in enumerate(search_results):
111 | if not results_found:
112 | results_found = True
113 | SubmissionDownloader(submission, i, self.logger, search_dir,
114 | skip_videos, skip_meta, skip_comments, comment_limit,
115 | {'imgur_client_id': SubredditDownloader.IMGUR_CLIENT_ID})
116 |
117 | if not results_found:
118 | self.logger.spam(" * No results found")
--------------------------------------------------------------------------------
/src/saveddit/submission_downloader.py:
--------------------------------------------------------------------------------
1 | from bs4 import BeautifulSoup
2 | import coloredlogs
3 | from colorama import Fore
4 | import contextlib
5 | import logging
6 | import verboselogs
7 | from datetime import datetime
8 | import os
9 | from io import StringIO
10 | import json
11 | import mimetypes
12 | import ffmpeg
13 | import praw
14 | from pprint import pprint
15 | import re
16 | import requests
17 | from tqdm import tqdm
18 | import urllib.request
19 | import youtube_dl
20 | import os
21 |
22 |
23 | class SubmissionDownloader:
24 | def __init__(self, submission, submission_index, logger, output_dir, skip_videos, skip_meta, skip_comments, comment_limit, config):
25 | self.IMGUR_CLIENT_ID = config["imgur_client_id"]
26 |
27 | self.logger = logger
28 | i = submission_index
29 | prefix_str = '#' + str(i).zfill(3) + ' '
30 | self.indent_1 = ' ' * len(prefix_str) + "* "
31 | self.indent_2 = ' ' * len(self.indent_1) + "- "
32 |
33 | has_url = getattr(submission, "url", None)
34 | if has_url:
35 | title = submission.title
36 | self.logger.verbose(prefix_str + '"' + title + '"')
37 | title = re.sub(r'\W+', '_', title)
38 |
39 | # Truncate title
40 | if len(title) > 32:
41 | title = title[0:32]
42 | if os.name == "nt":
43 | pass
44 | else:
45 | title += "..."
46 |
47 | # Prepare directory for the submission
48 | post_dir = str(i).zfill(3) + "_" + title.replace(" ", "_")
49 | submission_dir = os.path.join(output_dir, post_dir)
50 | if not os.path.exists(submission_dir):
51 | os.makedirs(submission_dir)
52 | elif os.path.exists(submission_dir):
53 | print("File exists, Skipping it.")
54 | return
55 |
56 | self.logger.spam(
57 | self.indent_1 + "Processing `" + submission.url + "`")
58 |
59 | success = False
60 |
61 | should_create_files_dir = True
62 | if skip_comments and skip_meta:
63 | should_create_files_dir = False
64 |
65 | def create_files_dir(submission_dir):
66 | if should_create_files_dir:
67 | files_dir = os.path.join(submission_dir, "files")
68 | if not os.path.exists(files_dir):
69 | os.makedirs(files_dir)
70 | return files_dir
71 | else:
72 | return submission_dir
73 |
74 | if self.is_direct_link_to_content(submission.url, [".png", ".jpg", ".jpeg", ".gif"]):
75 | files_dir = create_files_dir(submission_dir)
76 |
77 | filename = submission.url.split("/")[-1]
78 | self.logger.spam(
79 | self.indent_1 + "This is a direct link to a " + filename.split(".")[-1] + " file")
80 | save_path = os.path.join(files_dir, filename)
81 | self.download_direct_link(submission, save_path)
82 | success = True
83 | elif self.is_direct_link_to_content(submission.url, [".mp4"]):
84 | filename = submission.url.split("/")[-1]
85 | self.logger.spam(
86 | self.indent_1 + "This is a direct link to a " + filename.split(".")[-1] + " file")
87 | if not skip_videos:
88 | files_dir = create_files_dir(submission_dir)
89 | save_path = os.path.join(files_dir, filename)
90 | self.download_direct_link(submission, save_path)
91 | success = True
92 | else:
93 | self.logger.spam(self.indent_1 + "Skipping download of video content")
94 | success = True
95 | elif self.is_reddit_gallery(submission.url):
96 | files_dir = create_files_dir(submission_dir)
97 |
98 | self.logger.spam(
99 | self.indent_1 + "This is a reddit gallery")
100 | self.download_reddit_gallery(submission, files_dir, skip_videos)
101 | success = True
102 | elif self.is_reddit_video(submission.url):
103 | self.logger.spam(
104 | self.indent_1 + "This is a reddit video")
105 |
106 | if not skip_videos:
107 | files_dir = create_files_dir(submission_dir)
108 | self.download_reddit_video(submission, files_dir)
109 | success = True
110 | else:
111 | self.logger.spam(self.indent_1 + "Skipping download of video content")
112 | success = True
113 | elif self.is_gfycat_link(submission.url) or self.is_redgifs_link(submission.url):
114 | if self.is_gfycat_link(submission.url):
115 | self.logger.spam(
116 | self.indent_1 + "This is a gfycat link")
117 | else:
118 | self.logger.spam(
119 | self.indent_1 + "This is a redgif link")
120 |
121 | if not skip_videos:
122 | files_dir = create_files_dir(submission_dir)
123 | self.download_gfycat_or_redgif(submission, files_dir)
124 | success = True
125 | else:
126 | self.logger.spam(self.indent_1 + "Skipping download of video content")
127 | success = True
128 | elif self.is_imgur_album(submission.url):
129 | files_dir = create_files_dir(submission_dir)
130 |
131 | self.logger.spam(
132 | self.indent_1 + "This is an imgur album")
133 | self.download_imgur_album(submission, files_dir)
134 | success = True
135 | elif self.is_imgur_image(submission.url):
136 | files_dir = create_files_dir(submission_dir)
137 |
138 | self.logger.spam(
139 | self.indent_1 + "This is an imgur image or video")
140 | self.download_imgur_image(submission, files_dir)
141 | success = True
142 | elif self.is_self_post(submission):
143 | self.logger.spam(self.indent_1 + "This is a self-post")
144 | success = True
145 | elif (not skip_videos) and (self.is_youtube_link(submission.url) or self.is_supported_by_youtubedl(submission.url)):
146 | if self.is_youtube_link(submission.url):
147 | self.logger.spam(
148 | self.indent_1 + "This is a youtube link")
149 | else:
150 | self.logger.spam(
151 | self.indent_1 + "This link is supported by a youtube-dl extractor")
152 |
153 | if not skip_videos:
154 | files_dir = create_files_dir(submission_dir)
155 | self.download_youtube_video(submission.url, files_dir)
156 | success = True
157 | else:
158 | self.logger.spam(self.indent_1 + "Skipping download of video content")
159 | success = True
160 | else:
161 | success = True
162 |
163 | # Download submission meta
164 | if not skip_meta:
165 | self.logger.spam(self.indent_1 + "Saving submission.json")
166 | self.download_submission_meta(submission, submission_dir)
167 | else:
168 | self.logger.spam(
169 | self.indent_1 + "Skipping submissions meta")
170 |
171 | # Downlaod comments if requested
172 | if not skip_comments:
173 | if comment_limit == None:
174 | self.logger.spam(
175 | self.indent_1 + "Saving all comments to comments.json")
176 | else:
177 | self.logger.spam(
178 | self.indent_1 + "Saving top-level comments to comments.json")
179 | self.download_comments(
180 | submission, submission_dir, comment_limit)
181 | else:
182 | self.logger.spam(
183 | self.indent_1 + "Skipping comments")
184 |
185 | if success:
186 | self.logger.spam(
187 | self.indent_1 + "Saved to " + submission_dir + "\n")
188 | else:
189 | self.logger.warning(
190 | self.indent_1 + "Failed to download from link " + submission.url + "\n"
191 | )
192 |
193 | def print_formatted_error(self, e):
194 | for line in str(e).split("\n"):
195 | self.logger.error(self.indent_2 + line)
196 |
197 | def is_direct_link_to_content(self, url, supported_file_formats):
198 | url_leaf = url.split("/")[-1]
199 | return any([i in url_leaf for i in supported_file_formats]) and ".gifv" not in url_leaf
200 |
201 | def download_direct_link(self, submission, output_path):
202 | try:
203 | urllib.request.urlretrieve(submission.url, output_path)
204 | except Exception as e:
205 | self.print_formatted_error(e)
206 |
207 | def is_youtube_link(self, url):
208 | return "youtube.com" in url or "youtu.be" in url
209 |
210 | def is_supported_by_youtubedl(self, url):
211 | try:
212 | # Since youtube-dl's quiet mode is amything BUT quiet
213 | # using contextlib to redirect stdout to a local StringIO variable
214 | local_stderr = StringIO()
215 | with contextlib.redirect_stderr(local_stderr):
216 | if "flickr.com/photos" in url:
217 | return False
218 |
219 | # Try to extract info from URL
220 | try:
221 | download_options = {
222 | 'quiet': True,
223 | 'warnings': True,
224 | 'ignoreerrors': True,
225 | }
226 | ydl = youtube_dl.YoutubeDL(download_options)
227 | r = ydl.extract_info(url, download=False)
228 | except Exception as e:
229 | # No media found through youtube-dl
230 | self.logger.spam(self.indent_2 + "No media found in '" + url + "' that could be downloaded with youtube-dl")
231 | return False
232 |
233 | extractors = youtube_dl.extractor.gen_extractors()
234 | for e in extractors:
235 | if e.suitable(url) and e.IE_NAME != 'generic':
236 | return True
237 | self.logger.spam(self.indent_2 + "This link could potentially be downloaded with youtube-dl")
238 | self.logger.spam(self.indent_2 + "No media found in '" + url + "' that could be downloaded with youtube-dl")
239 | return False
240 | except Exception as e:
241 | return False
242 |
243 | def download_youtube_video(self, url, output_path):
244 | try:
245 | local_stderr = StringIO()
246 | with contextlib.redirect_stderr(local_stderr):
247 | download_options = {
248 | 'format': "299+bestaudio/298+bestaudio/137+bestaudio/136+bestaudio/best",
249 | 'quiet': True,
250 | 'warnings': True,
251 | 'ignoreerrors': True,
252 | 'nooverwrites': True,
253 | 'continuedl': True,
254 | 'outtmpl': output_path + '/%(id)s.%(ext)s'
255 | }
256 | self.logger.spam(self.indent_2 + "Downloading " +
257 | url + " with youtube-dl")
258 | with youtube_dl.YoutubeDL(download_options) as ydl:
259 | ydl.download([url])
260 | errors = local_stderr.getvalue()
261 | if not len(errors):
262 | self.logger.spam(self.indent_2 + "Finished downloading video from " +
263 | url)
264 | else:
265 | self.logger.error(self.indent_2 + errors.strip())
266 | except Exception as e:
267 | self.logger.error(self.indent_2 + "Failed to download with youtube-dl")
268 | self.print_formatted_error(e)
269 |
270 | def is_reddit_gallery(self, url):
271 | return "reddit.com/gallery" in url
272 |
273 | def download_reddit_gallery(self, submission, output_path, skip_videos):
274 | gallery_data = getattr(submission, "gallery_data", None)
275 | media_metadata = getattr(submission, "media_metadata", None)
276 | self.logger.spam(
277 | self.indent_2 + "Looking for submission.gallery_data and submission.media_metadata")
278 |
279 | if gallery_data == None and media_metadata == None:
280 | # gallery_data not in submission
281 | # could be a crosspost
282 | crosspost_parent_list = getattr(
283 | submission, "crosspost_parent_list", None)
284 | if crosspost_parent_list != None:
285 | self.logger.spam(
286 | self.indent_2 + "This is a crosspost to a reddit gallery")
287 | first_parent = crosspost_parent_list[0]
288 | gallery_data = first_parent["gallery_data"]
289 | media_metadata = first_parent["media_metadata"]
290 |
291 | if gallery_data != None and media_metadata != None:
292 | image_count = len(gallery_data["items"])
293 | self.logger.spam(self.indent_2 + "This reddit gallery has " +
294 | str(image_count) + " images")
295 | for j, item in tqdm(enumerate(gallery_data["items"]), total=image_count, bar_format='%s%s{l_bar}{bar:20}{r_bar}%s' % (self.indent_2, Fore.WHITE + Fore.LIGHTBLACK_EX, Fore.RESET)):
296 | try:
297 | media_id = item["media_id"]
298 | item_metadata = media_metadata[media_id]
299 | item_format = item_metadata['m']
300 | if "image/" in item_format or "video/" in item_format:
301 | if not os.path.exists(output_path):
302 | os.makedirs(output_path)
303 | if "image/" in item_format:
304 | item_format = item_format.split("image/")[-1]
305 | elif "video/" in item_format:
306 | item_format = item_format.split("video/")[-1]
307 | # Skip video content if requested by user
308 | if skip_videos:
309 | continue
310 | item_filename = media_id + "." + item_format
311 | item_url = item_metadata["s"]["u"]
312 | save_path = os.path.join(output_path, item_filename)
313 | try:
314 | urllib.request.urlretrieve(item_url, save_path)
315 | except Exception as e:
316 | self.print_formatted_error(e)
317 | except Exception as e:
318 | self.print_formatted_error(e)
319 |
320 | def is_reddit_video(self, url):
321 | return "v.redd.it" in url
322 |
323 | def download_reddit_video(self, submission, output_path):
324 | media = getattr(submission, "media", None)
325 | media_id = submission.url.split("v.redd.it/")[-1]
326 |
327 | self.logger.spam(self.indent_2 + "Looking for submission.media")
328 |
329 | if media == None:
330 | # link might be a crosspost
331 | crosspost_parent_list = getattr(
332 | submission, "crosspost_parent_list", None)
333 | if crosspost_parent_list != None:
334 | self.logger.spam(
335 | self.indent_2 + "This is a crosspost to a reddit video")
336 | first_parent = crosspost_parent_list[0]
337 | media = first_parent["media"]
338 |
339 | if media != None:
340 | self.logger.spam(self.indent_2 + "Downloading video component")
341 | url = media["reddit_video"]["fallback_url"]
342 | video_save_path = os.path.join(
343 | output_path, media_id + "_video.mp4")
344 | try:
345 | urllib.request.urlretrieve(url, video_save_path)
346 | except Exception as e:
347 | self.print_formatted_error(e)
348 |
349 | # Download the audio
350 | self.logger.spam(self.indent_2 + "Downloading audio component")
351 | audio_downloaded = False
352 | audio_save_path = os.path.join(
353 | output_path, media_id + "_audio.mp4")
354 | try:
355 | urllib.request.urlretrieve(
356 | submission.url + "/DASH_audio.mp4", audio_save_path)
357 | audio_downloaded = True
358 | except Exception as e:
359 | pass
360 |
361 | if audio_downloaded == True:
362 | # Merge mp4 files
363 | self.logger.spam(
364 | self.indent_2 + "Merging video & audio components with ffmpeg")
365 | output_save_path = os.path.join(output_path, media_id + ".mp4")
366 | input_video = ffmpeg.input(video_save_path)
367 | input_audio = ffmpeg.input(audio_save_path)
368 | ffmpeg.concat(input_video, input_audio, v=1, a=1)\
369 | .output(output_save_path)\
370 | .global_args('-loglevel', 'error')\
371 | .global_args('-y')\
372 | .run()
373 | self.logger.spam(self.indent_2 + "Done merging with ffmpeg")
374 | else:
375 | self.logger.spam(
376 | self.indent_2 + "This video does not have an audio component")
377 |
378 | self.logger.spam(
379 | self.indent_2 + "Sucessfully saved video")
380 |
381 | def is_gfycat_link(self, url):
382 | return "gfycat.com/" in url
383 |
384 | def is_redgifs_link(self, url):
385 | return "redgifs.com/" in url
386 |
387 | def get_gfycat_embedded_video_url(self, url):
388 | try:
389 | response = requests.get(url)
390 | data = response.text
391 | soup = BeautifulSoup(data, features="html.parser")
392 |
393 | # Cycle through all links
394 | giant_url_found = False
395 | giant_url = ""
396 | thumbs_url_found = False
397 | thumbs_url = ""
398 | for link in soup.find_all():
399 | link_src = link.get('src')
400 | src_url = str(link_src)
401 | if ".mp4" in src_url:
402 | # Looking for giant.gfycat.com
403 | if "giant." in src_url:
404 | giant_url_found = True
405 | giant_url = src_url
406 | elif "thumbs." in src_url:
407 | thumbs_url_found = True
408 | thumbs_url = src_url
409 | except Exception as e:
410 | self.print_formatted_error(e)
411 | return ""
412 |
413 | if giant_url_found:
414 | return giant_url
415 | elif thumbs_url_found:
416 | return thumbs_url
417 | else:
418 | return ""
419 |
420 | def guess_extension(self, url):
421 | response = requests.get(url)
422 | content_type = response.headers['content-type']
423 | return mimetypes.guess_extension(content_type)
424 |
425 | def get_redirect_url(self, url):
426 | r = requests.get(url)
427 | return r.url
428 |
429 | def download_gfycat_or_redgif(self, submission, output_dir):
430 | # Check if gfycat redirects to gifdeliverynetwork
431 | redirect_url = self.get_redirect_url(submission.url)
432 | if "gfycat.com" in submission.url and "gifdeliverynetwork.com" in redirect_url:
433 | self.logger.spam(
434 | self.indent_2 + "This is a gfycat link that redirects to gifdeliverynetwork.com")
435 | try:
436 | # Gfycat link that redirects to gifdeliverynetwork
437 | # True source in this case is hiding in redgifs.com
438 | response = requests.get(redirect_url)
439 | html = BeautifulSoup(response.content, features="html.parser")
440 | links = html.find_all()
441 | for i in links:
442 | if "src" in str(i):
443 | attrs = i.attrs
444 | if "src" in attrs:
445 | src = attrs["src"]
446 | if "redgifs.com/" in src:
447 | self.logger.spam(
448 | self.indent_2 + "Found embedded media at " + src)
449 | filename = src.split("/")[-1]
450 | save_path = os.path.join(output_dir, filename)
451 | try:
452 | r = requests.get(src)
453 | with open(save_path, 'wb') as outfile:
454 | outfile.write(r.content)
455 | except Exception as e:
456 | self.print_formatted_error(e)
457 | except Exception as e:
458 | self.print_formatted_error(e)
459 |
460 | self.logger.spam(
461 | self.indent_2 + "Looking for submission.preview.reddit_video_preview.fallback_url")
462 |
463 | preview = None
464 | try:
465 | preview = getattr(submission, "preview")
466 | if preview:
467 | if "reddit_video_preview" in preview:
468 | if "fallback_url" in preview["reddit_video_preview"]:
469 | self.logger.spam(self.indent_2 + "Found submission.preview.reddit_video_preview.fallback_url")
470 | fallback_url = preview["reddit_video_preview"]["fallback_url"]
471 | if "." in fallback_url.split("/")[-1]:
472 | file_format = fallback_url.split(".")[-1]
473 | filename = submission.url.split("/")[-1] + "." + file_format
474 | else:
475 | filename = submission.url.split("/")[-1] + ".mp4"
476 | save_path = os.path.join(output_dir, filename)
477 | try:
478 | urllib.request.urlretrieve(fallback_url, save_path)
479 | return
480 | except Exception as e:
481 | self.print_formatted_error(e)
482 | elif "images" in preview:
483 | if "source" in preview["images"][0]:
484 | self.logger.spam(self.indent_2 + "Found submission.preview.images instead")
485 | source_url = preview["images"][0]["source"]["url"]
486 | try:
487 | extension = self.guess_extension(source_url)
488 | filename = submission.url.split("/")[-1] + extension
489 | save_path = os.path.join(output_dir, filename)
490 | try:
491 | urllib.request.urlretrieve(source_url, save_path)
492 | except Exception as e:
493 | self.print_formatted_error(e)
494 | except Exception as e:
495 | self.print_formatted_error(e)
496 |
497 | except Exception as e:
498 | self.print_formatted_error(e)
499 |
500 | try:
501 | self.logger.spam(
502 | self.indent_2 + "Looking for submission.media_embed")
503 | media_embed = getattr(submission, "media_embed")
504 | if media_embed:
505 | content = media_embed["content"]
506 | self.logger.spam(
507 | self.indent_2 + "Found submission.media_embed")
508 | if "iframe" in content:
509 | if "gfycat.com" in submission.url:
510 | self.logger.spam(
511 | self.indent_2 + "This is an embedded video in gfycat.com")
512 | # This is likely an embedded video in gfycat
513 | video_url = self.get_gfycat_embedded_video_url(submission.url)
514 | if video_url:
515 | filename = video_url.split("/")[-1]
516 | save_path = os.path.join(output_dir, filename)
517 |
518 | self.logger.spam(
519 | self.indent_2 + "Embedded video URL: " + video_url)
520 | try:
521 | r = requests.get(video_url)
522 | with open(save_path, 'wb') as outfile:
523 | outfile.write(r.content)
524 | except Exception as e:
525 | self.print_formatted_error(e)
526 | except Exception as e:
527 | self.print_formatted_error(e)
528 |
529 | def is_imgur_album(self, url):
530 | return "imgur.com/a/" in url or "imgur.com/gallery/" in url
531 |
532 | def get_imgur_album_images_count(self, album_id):
533 | request = "https://api.imgur.com/3/album/" + album_id
534 | res = requests.get(request, headers={
535 | "Authorization": "Client-ID " + self.IMGUR_CLIENT_ID})
536 | if res.status_code == 200:
537 | return res.json()["data"]["images_count"]
538 | else:
539 | self.logger.spam(self.indent_2 + "This imgur album is empty")
540 | return 0
541 |
542 | def get_imgur_image_meta(self, image_id):
543 | request = "https://api.imgur.com/3/image/" + image_id
544 | res = requests.get(request, headers={
545 | "Authorization": "Client-ID " + self.IMGUR_CLIENT_ID})
546 | return res.json()["data"]
547 |
548 | def download_imgur_album(self, submission, output_dir):
549 | # Imgur album
550 | album_id = ""
551 | if "imgur.com/a/" in submission.url:
552 | album_id = submission.url.split("imgur.com/a/")[-1]
553 | elif "imgur.com/gallery/" in submission.url:
554 | album_id = submission.url.split("imgur.com/gallery/")[-1]
555 |
556 | self.logger.spam(self.indent_2 + "Album ID " + album_id)
557 |
558 | images_count = self.get_imgur_album_images_count(album_id)
559 | if images_count > 0:
560 | request = "https://api.imgur.com/3/album/" + album_id
561 | res = requests.get(request, headers={
562 | "Authorization": "Client-ID " + self.IMGUR_CLIENT_ID})
563 | self.logger.spam(self.indent_2 + "This imgur album has " +
564 | str(images_count) + " images")
565 | for i, image in tqdm(enumerate(res.json()["data"]["images"]), total=images_count, bar_format='%s%s{l_bar}{bar:20}{r_bar}%s' % (self.indent_2, Fore.WHITE + Fore.LIGHTBLACK_EX, Fore.RESET)):
566 | url = image["link"]
567 | filename = str(i).zfill(3) + "_" + url.split("/")[-1]
568 | save_path = os.path.join(output_dir, filename)
569 | try:
570 | if not os.path.exists(output_dir):
571 | os.makedirs(output_dir)
572 | urllib.request.urlretrieve(url, save_path)
573 | except Exception as e:
574 | self.print_formatted_error(e)
575 |
576 | def is_imgur_image(self, url):
577 | return "imgur.com" in url
578 |
579 | def download_imgur_image(self, submission, output_dir):
580 | # Other imgur content, e.g., .gifv, '.mp4', '.jpg', etc.
581 | url_leaf = submission.url.split("/")[-1]
582 | if "." in url_leaf:
583 | image_id = url_leaf.split(".")[0]
584 | else:
585 | image_id = url_leaf
586 |
587 | try:
588 | data = self.get_imgur_image_meta(image_id)
589 | url = data["link"]
590 | image_type = data["type"]
591 | if "video/" in image_type:
592 | self.logger.spam(
593 | self.indent_2 + "This is an imgur link to a video file")
594 | image_type = image_type.split("video/")[-1]
595 | elif "image/" in image_type:
596 | self.logger.spam(
597 | self.indent_2 + "This is an imgur link to an image file")
598 | image_type = image_type.split("image/")[-1]
599 |
600 | filename = image_id + "." + image_type
601 | save_path = os.path.join(output_dir, filename)
602 |
603 | urllib.request.urlretrieve(url, save_path)
604 | except Exception as e:
605 | self.print_formatted_error(e)
606 |
607 | def download_comments(self, submission, output_dir, comment_limit):
608 | # Save comments - Breath first unwrap of comment forest
609 | comments_list = []
610 | with open(os.path.join(output_dir, 'comments.json'), 'w') as file:
611 | submission.comments.replace_more(limit=comment_limit)
612 | limited_comments = submission.comments.list()
613 | if not len(limited_comments):
614 | # No comments
615 | self.logger.spam(self.indent_2 + "No comments found")
616 | return
617 |
618 | for comment in tqdm(limited_comments, total=len(limited_comments), bar_format='%s%s{l_bar}{bar:20}{r_bar}%s' % (self.indent_2, Fore.WHITE + Fore.LIGHTBLACK_EX, Fore.RESET)):
619 | comment_dict = {}
620 | try:
621 | if comment.author:
622 | comment_dict["author"] = comment.author.name
623 | else:
624 | comment_dict["author"] = None
625 | comment_dict["body"] = comment.body
626 | comment_dict["created_utc"] = int(comment.created_utc)
627 | comment_dict["distinguished"] = comment.distinguished
628 | comment_dict["downs"] = comment.downs
629 | comment_dict["edited"] = comment.edited
630 | comment_dict["id"] = comment.id
631 | comment_dict["is_submitter"] = comment.is_submitter
632 | comment_dict["link_id"] = comment.link_id
633 | comment_dict["parent_id"] = comment.parent_id
634 | comment_dict["permalink"] = comment.permalink
635 | comment_dict["score"] = comment.score
636 | comment_dict["stickied"] = comment.stickied
637 | comment_dict["subreddit_name_prefixed"] = comment.subreddit_name_prefixed
638 | comment_dict["subreddit_id"] = comment.subreddit_id
639 | comment_dict["total_awards_received"] = comment.total_awards_received
640 | comment_dict["ups"] = comment.ups
641 | except Exception as e:
642 | self.print_formatted_error(e)
643 | comments_list.append(comment_dict)
644 | file.write(json.dumps(comments_list, indent=2))
645 |
646 | def is_self_post(self, submission):
647 | return submission.is_self
648 |
649 | def download_submission_meta(self, submission, submission_dir):
650 | submission_dict = {}
651 | if submission.author:
652 | submission_dict["author"] = submission.author.name
653 | else:
654 | submission_dict["author"] = None
655 | submission_dict["created_utc"] = int(submission.created_utc)
656 | submission_dict["distinguished"] = submission.distinguished
657 | submission_dict["downs"] = submission.downs
658 | submission_dict["edited"] = submission.edited
659 | submission_dict["id"] = submission.id
660 | submission_dict["link_flair_text"] = submission.link_flair_text
661 | submission_dict["locked"] = submission.locked
662 | submission_dict["num_comments"] = submission.num_comments
663 | submission_dict["num_crossposts"] = submission.num_crossposts
664 | submission_dict["permalink"] = submission.permalink
665 | submission_dict["selftext"] = submission.selftext
666 | submission_dict["selftext"] = submission.selftext
667 | submission_dict["selftext_html"] = submission.selftext_html
668 | submission_dict["send_replies"] = submission.send_replies
669 | submission_dict["spoiler"] = submission.spoiler
670 | submission_dict["stickied"] = submission.stickied
671 | submission_dict["subreddit_name_prefixed"] = submission.subreddit_name_prefixed
672 | submission_dict["subreddit_id"] = submission.subreddit_id
673 | submission_dict["subreddit_subscribers"] = submission.subreddit_subscribers
674 | submission_dict["subreddit_type"] = submission.subreddit_type
675 | submission_dict["title"] = submission.title
676 | submission_dict["total_awards_received"] = submission.total_awards_received
677 | submission_dict["ups"] = submission.ups
678 | submission_dict["upvote_ratio"] = submission.upvote_ratio
679 | submission_dict["url"] = submission.url
680 |
681 | with open(os.path.join(submission_dir, "submission.json"), 'w') as file:
682 | file.write(json.dumps(submission_dict, indent=2))
683 |
--------------------------------------------------------------------------------
/src/saveddit/subreddit_downloader.py:
--------------------------------------------------------------------------------
1 | import coloredlogs
2 | from colorama import Fore
3 | import logging
4 | import verboselogs
5 | import os
6 | import praw
7 | from saveddit.configuration import ConfigurationLoader
8 | from saveddit.submission_downloader import SubmissionDownloader
9 | from saveddit.subreddit_downloader_config import SubredditDownloaderConfig
10 |
11 | class SubredditDownloader:
12 | app_config_dir = os.path.expanduser("~/.saveddit")
13 | if not os.path.exists(app_config_dir):
14 | os.makedirs(app_config_dir)
15 |
16 | config_file_location = os.path.expanduser("~/.saveddit/user_config.yaml")
17 | config = ConfigurationLoader.load(config_file_location)
18 |
19 | REDDIT_CLIENT_ID = config['reddit_client_id']
20 | REDDIT_CLIENT_SECRET = config['reddit_client_secret']
21 | IMGUR_CLIENT_ID = config['imgur_client_id']
22 |
23 | def __init__(self, subreddit_name):
24 | self.subreddit_name = subreddit_name
25 | reddit = praw.Reddit(
26 | client_id=SubredditDownloader.REDDIT_CLIENT_ID,
27 | client_secret=SubredditDownloader.REDDIT_CLIENT_SECRET,
28 | user_agent="saveddit (by /u/p_ranav)",
29 | )
30 | self.subreddit = reddit.subreddit(subreddit_name)
31 |
32 | self.logger = verboselogs.VerboseLogger(__name__)
33 | level_styles = {
34 | 'critical': {'bold': True, 'color': 'red'},
35 | 'debug': {'color': 'green'},
36 | 'error': {'color': 'red'},
37 | 'info': {'color': 'white'},
38 | 'notice': {'color': 'magenta'},
39 | 'spam': {'color': 'white', 'faint': True},
40 | 'success': {'bold': True, 'color': 'green'},
41 | 'verbose': {'color': 'blue'},
42 | 'warning': {'color': 'yellow'}
43 | }
44 | coloredlogs.install(level='SPAM', logger=self.logger,
45 | fmt='%(message)s', level_styles=level_styles)
46 |
47 | def download(self, output_path, download_all_comments, categories=SubredditDownloaderConfig.DEFAULT_CATEGORIES, post_limit=SubredditDownloaderConfig.DEFAULT_POST_LIMIT, skip_videos=False, skip_meta=False, skip_comments=False):
48 | '''
49 | categories: List of categories within the subreddit to download (see SubredditDownloaderConfig.DEFAULT_CATEGORIES)
50 | post_limit: Number of posts to download (default: None, i.e., all posts)
51 | comment_limit: Number of comment levels to download from submission (default: `0`, i.e., only top-level comments)
52 | - to get all comments, set comment_limit to `None`
53 | '''
54 | root_dir = os.path.join(os.path.join(os.path.join(
55 | output_path, "www.reddit.com"), "r"), self.subreddit_name)
56 | categories = categories
57 |
58 | if download_all_comments == False:
59 | comment_limit = 0
60 | elif download_all_comments == True:
61 | comment_limit = None
62 |
63 | for c in categories:
64 | self.logger.notice("Downloading from /r/" +
65 | self.subreddit_name + "/" + c + "/")
66 | category_dir = os.path.join(root_dir, c)
67 | if not os.path.exists(category_dir):
68 | os.makedirs(category_dir)
69 | category_function = getattr(self.subreddit, c)
70 |
71 | for i, submission in enumerate(category_function(limit=post_limit)):
72 | SubmissionDownloader(submission, i, self.logger, category_dir,
73 | skip_videos, skip_meta, skip_comments, comment_limit,
74 | {'imgur_client_id': SubredditDownloader.IMGUR_CLIENT_ID})
75 |
--------------------------------------------------------------------------------
/src/saveddit/subreddit_downloader_config.py:
--------------------------------------------------------------------------------
1 | class SubredditDownloaderConfig:
2 | DEFAULT_CATEGORIES = ["hot", "new", "random_rising", "rising",
3 | "controversial", "top", "gilded"]
4 | DEFAULT_POST_LIMIT = None
--------------------------------------------------------------------------------
/src/saveddit/user_downloader.py:
--------------------------------------------------------------------------------
1 | import coloredlogs
2 | from colorama import Fore, Style
3 | from datetime import datetime, timezone
4 | import logging
5 | import verboselogs
6 | import getpass
7 | import json
8 | import os
9 | import praw
10 | from pprint import pprint
11 | import re
12 | from saveddit.submission_downloader import SubmissionDownloader
13 | from saveddit.subreddit_downloader import SubredditDownloader
14 | import sys
15 | from tqdm import tqdm
16 |
17 | class UserDownloader:
18 | config = SubredditDownloader.config
19 |
20 | REDDIT_CLIENT_ID = config['reddit_client_id']
21 | REDDIT_CLIENT_SECRET = config['reddit_client_secret']
22 | REDDIT_USERNAME = None
23 | try:
24 | REDDIT_USERNAME = config['reddit_username']
25 | except Exception as e:
26 | pass
27 |
28 | REDDIT_PASSWORD = None
29 | if REDDIT_USERNAME:
30 | if sys.stdin.isatty():
31 | print("Username: " + REDDIT_USERNAME)
32 | REDDIT_PASSWORD = getpass.getpass("Password: ")
33 | else:
34 | # echo "foobar" > password
35 | # saveddit user .... < password
36 | REDDIT_PASSWORD = sys.stdin.readline().rstrip()
37 |
38 | IMGUR_CLIENT_ID = config['imgur_client_id']
39 |
40 | def __init__(self):
41 | self.logger = verboselogs.VerboseLogger(__name__)
42 | level_styles = {
43 | 'critical': {'bold': True, 'color': 'red'},
44 | 'debug': {'color': 'green'},
45 | 'error': {'color': 'red'},
46 | 'info': {'color': 'white'},
47 | 'notice': {'color': 'magenta'},
48 | 'spam': {'color': 'white', 'faint': True},
49 | 'success': {'bold': True, 'color': 'green'},
50 | 'verbose': {'color': 'blue'},
51 | 'warning': {'color': 'yellow'}
52 | }
53 | coloredlogs.install(level='SPAM', logger=self.logger,
54 | fmt='%(message)s', level_styles=level_styles)
55 |
56 | if not UserDownloader.REDDIT_USERNAME:
57 | self.logger.error("`reddit_username` in user_config.yaml is empty")
58 | self.logger.error("If you plan on using the user API of saveddit, then add your username to user_config.yaml")
59 | print("Exiting now")
60 | exit()
61 | else:
62 | if not len(UserDownloader.REDDIT_PASSWORD):
63 | if sys.stdin.isatty():
64 | print("Username: " + UserDownloader.REDDIT_USERNAME)
65 | REDDIT_PASSWORD = getpass.getpass("Password: ")
66 | else:
67 | # echo "foobar" > password
68 | # saveddit user .... < password
69 | REDDIT_PASSWORD = sys.stdin.readline().rstrip()
70 |
71 | self.reddit = praw.Reddit(
72 | client_id=UserDownloader.REDDIT_CLIENT_ID,
73 | client_secret=UserDownloader.REDDIT_CLIENT_SECRET,
74 | user_agent="saveddit (by /u/p_ranav)",
75 | username=UserDownloader.REDDIT_USERNAME,
76 | password=UserDownloader.REDDIT_PASSWORD
77 | )
78 |
79 | def download_user_meta(self, args):
80 | output_path = args.o
81 |
82 | for username in args.users:
83 | user = self.reddit.redditor(name=username)
84 |
85 | root_dir = os.path.join(os.path.join(os.path.join(
86 | output_path, "www.reddit.com"), "u"), username)
87 |
88 | if not os.path.exists(root_dir):
89 | os.makedirs(root_dir)
90 |
91 | with open(os.path.join(root_dir, 'user.json'), 'w') as file:
92 | user_dict = {}
93 | user_dict["comment_karma"] = user.comment_karma
94 | user_dict["created_utc"] = int(user.created_utc)
95 | user_dict["has_verified_email"] = user.has_verified_email
96 | user_dict["icon_img"] = user.icon_img
97 | user_dict["id"] = user.id
98 | user_dict["is_employee"] = user.is_employee
99 | user_dict["is_friend"] = user.is_friend
100 | user_dict["is_mod"] = user.is_mod
101 | user_dict["is_gold"] = user.is_gold
102 | try:
103 | user_dict["is_suspended"] = user.is_suspended
104 | except Exception as e:
105 | user_dict["is_suspended"] = None
106 | user_dict["link_karma"] = user.link_karma
107 | user_dict["name"] = user.name
108 |
109 | file.write(json.dumps(user_dict, indent=2))
110 |
111 | def download_comments(self, args):
112 | output_path = args.o
113 |
114 | for username in args.users:
115 | user = self.reddit.redditor(name=username)
116 |
117 | self.logger.notice("Downloading from /u/" + username + "/comments")
118 |
119 | root_dir = os.path.join(os.path.join(os.path.join(
120 | output_path, "www.reddit.com"), "u"), username)
121 |
122 | try:
123 | sort = args.s
124 | limit = args.l
125 |
126 | comments_dir = os.path.join(root_dir, "comments")
127 | if not os.path.exists(comments_dir):
128 | os.makedirs(comments_dir)
129 |
130 | self.logger.verbose("Downloading comments sorted by " + sort)
131 | category_function = getattr(user.comments, sort)
132 |
133 | category_dir = os.path.join(comments_dir, sort)
134 |
135 | if category_function:
136 | if not os.path.exists(category_dir):
137 | os.makedirs(category_dir)
138 | for i, comment in enumerate(category_function(limit=limit)):
139 | prefix_str = '#' + str(i).zfill(3) + ' '
140 | self.indent_1 = ' ' * len(prefix_str) + "* "
141 | self.indent_2 = ' ' * len(self.indent_1) + "- "
142 |
143 | comment_body = comment.body
144 | comment_body = comment_body[0:32]
145 | comment_body = re.sub(r'\W+', '_', comment_body)
146 | comment_filename = str(i).zfill(3) + "_Comment_" + \
147 | comment_body + "..." + ".json"
148 | self.logger.spam(self.indent_1 + comment.id + ' - "' + comment.body[0:64].replace("\n", "").replace("\r", "") + '..."')
149 |
150 | with open(os.path.join(category_dir, comment_filename), 'w') as file:
151 | comment_dict = {}
152 | try:
153 | if comment.author:
154 | comment_dict["author"] = comment.author.name
155 | else:
156 | comment_dict["author"] = None
157 | comment_dict["body"] = comment.body
158 | comment_dict["created_utc"] = int(comment.created_utc)
159 | comment_dict["distinguished"] = comment.distinguished
160 | comment_dict["downs"] = comment.downs
161 | comment_dict["edited"] = comment.edited
162 | comment_dict["id"] = comment.id
163 | comment_dict["is_submitter"] = comment.is_submitter
164 | comment_dict["link_id"] = comment.link_id
165 | comment_dict["parent_id"] = comment.parent_id
166 | comment_dict["permalink"] = comment.permalink
167 | comment_dict["score"] = comment.score
168 | comment_dict["stickied"] = comment.stickied
169 | comment_dict["subreddit_name_prefixed"] = comment.subreddit_name_prefixed
170 | comment_dict["subreddit_id"] = comment.subreddit_id
171 | comment_dict["total_awards_received"] = comment.total_awards_received
172 | comment_dict["ups"] = comment.ups
173 | file.write(json.dumps(comment_dict, indent=2))
174 | except Exception as e:
175 | self.print_formatted_error(e)
176 | except Exception as e:
177 | self.logger.error("Unable to download comments for user `" + username + "` - " + str(e))
178 |
179 | def download_multireddits(self, args):
180 | output_path = args.o
181 |
182 | for username in args.users:
183 | user = self.reddit.redditor(name=username)
184 |
185 | root_dir = os.path.join(os.path.join(os.path.join(os.path.join(
186 | output_path, "www.reddit.com"), "u"), username), "m")
187 |
188 | try:
189 | post_limit = args.l
190 | names = args.n
191 | categories = args.f
192 | skip_meta = args.skip_meta
193 | skip_videos = args.skip_videos
194 | skip_comments = args.skip_comments
195 | comment_limit = 0 # top-level comments ONLY
196 |
197 | # If names is None, download all multireddits from user's page
198 | if not names:
199 | names = [m.name.lower() for m in user.multireddits()]
200 | else:
201 | names = [n.lower() for n in names]
202 |
203 | for multireddit in user.multireddits():
204 | if multireddit.name.lower() in names:
205 | name = multireddit.name
206 | self.logger.notice("Downloading from /u/" + username + "/m/" + name)
207 | multireddit_dir = os.path.join(root_dir, name)
208 | if not os.path.exists(multireddit_dir):
209 | os.makedirs(multireddit_dir)
210 |
211 | for category in categories:
212 |
213 | self.logger.verbose("Downloading submissions sorted by " + category)
214 | category_function = getattr(multireddit, category)
215 |
216 | category_dir = os.path.join(multireddit_dir, category)
217 |
218 | if category_function:
219 | for i, s in enumerate(category_function(limit=post_limit)):
220 | try:
221 | prefix_str = '#' + str(i).zfill(3) + ' '
222 | self.indent_1 = ' ' * len(prefix_str) + "* "
223 | self.indent_2 = ' ' * len(self.indent_1) + "- "
224 | SubmissionDownloader(s, i, self.logger, category_dir, skip_videos, skip_meta, skip_comments, comment_limit,
225 | {'imgur_client_id': UserDownloader.IMGUR_CLIENT_ID})
226 | except Exception as e:
227 | self.logger.error(self.indent_2 + "Unable to download post #" + str(i) + " for user `" + username + "` from multireddit " + name + " - " + str(e))
228 | except Exception as e:
229 | self.logger.error(self.indent_1 + "Unable to download multireddit posts for user `" + username + "` - " + str(e))
230 |
231 | def download_submitted(self, args):
232 | output_path = args.o
233 |
234 | for username in args.users:
235 | user = self.reddit.redditor(name=username)
236 |
237 | self.logger.notice("Downloading from /u/" + username + "/submitted")
238 |
239 | root_dir = os.path.join(os.path.join(os.path.join(
240 | output_path, "www.reddit.com"), "u"), username)
241 |
242 | try:
243 | post_limit = args.l
244 | sort = args.s
245 | skip_meta = args.skip_meta
246 | skip_videos = args.skip_videos
247 | skip_comments = args.skip_comments
248 | comment_limit = 0 # top-level comments ONLY
249 |
250 | submitted_dir = os.path.join(root_dir, "submitted")
251 | if not os.path.exists(submitted_dir):
252 | os.makedirs(submitted_dir)
253 |
254 | self.logger.verbose("Downloading submissions sorted by " + sort)
255 | category_function = getattr(user.submissions, sort)
256 |
257 | category_dir = os.path.join(submitted_dir, sort)
258 |
259 | if category_function:
260 | for i, s in enumerate(category_function(limit=post_limit)):
261 | try:
262 | prefix_str = '#' + str(i).zfill(3) + ' '
263 | self.indent_1 = ' ' * len(prefix_str) + "* "
264 | self.indent_2 = ' ' * len(self.indent_1) + "- "
265 | SubmissionDownloader(s, i, self.logger, category_dir, skip_videos, skip_meta, skip_comments, comment_limit,
266 | {'imgur_client_id': UserDownloader.IMGUR_CLIENT_ID})
267 | except Exception as e:
268 | self.logger.error(self.indent_2 + "Unable to download post #" + str(i) + " for user `" + username + "` - " + str(e))
269 | except Exception as e:
270 | self.logger.error(self.indent_1 + "Unable to download submitted posts for user `" + username + "` - " + str(e))
271 |
272 | def download_upvoted(self, args):
273 | output_path = args.o
274 |
275 | for username in args.users:
276 | user = self.reddit.redditor(name=username)
277 |
278 | self.logger.notice("Downloading from /u/" + username + "/upvoted")
279 |
280 | root_dir = os.path.join(os.path.join(os.path.join(
281 | output_path, "www.reddit.com"), "u"), username)
282 |
283 | try:
284 | post_limit = args.l
285 | skip_meta = args.skip_meta
286 | skip_videos = args.skip_videos
287 | skip_comments = args.skip_comments
288 | comment_limit = 0 # top-level comments ONLY
289 |
290 | upvoted_dir = os.path.join(root_dir, "upvoted")
291 | if not os.path.exists(upvoted_dir):
292 | os.makedirs(upvoted_dir)
293 |
294 | for i, s in enumerate(user.upvoted(limit=post_limit)):
295 | try:
296 | prefix_str = '#' + str(i).zfill(3) + ' '
297 | self.indent_1 = ' ' * len(prefix_str) + "* "
298 | self.indent_2 = ' ' * len(self.indent_1) + "- "
299 | SubmissionDownloader(s, i, self.logger, upvoted_dir, skip_videos, skip_meta, skip_comments, comment_limit,
300 | {'imgur_client_id': UserDownloader.IMGUR_CLIENT_ID})
301 | except Exception as e:
302 | self.logger.error(self.indent_2 + "Unable to download post #" + str(i) + " for user `" + username + "` - " + str(e))
303 | except Exception as e:
304 | self.logger.error("Unable to download upvoted posts for user `" + username + "` - " + str(e))
305 |
306 | def download_saved(self, args):
307 | output_path = args.o
308 |
309 | for username in args.users:
310 | user = self.reddit.redditor(name=username)
311 |
312 | self.logger.notice("Downloading from /u/" + username + "/saved")
313 |
314 | root_dir = os.path.join(os.path.join(os.path.join(
315 | output_path, "www.reddit.com"), "u"), username)
316 |
317 | try:
318 | post_limit = args.l
319 | skip_meta = args.skip_meta
320 | skip_videos = args.skip_videos
321 | skip_comments = args.skip_comments
322 | comment_limit = 0 # top-level comments ONLY
323 |
324 | saved_dir = os.path.join(root_dir, "saved")
325 | if not os.path.exists(saved_dir):
326 | os.makedirs(saved_dir)
327 |
328 | for i, s in enumerate(user.saved(limit=post_limit)):
329 | try:
330 | prefix_str = '#' + str(i).zfill(3) + ' '
331 | self.indent_1 = ' ' * len(prefix_str) + "* "
332 | self.indent_2 = ' ' * len(self.indent_1) + "- "
333 | if isinstance(s, praw.models.Comment) and not skip_comments:
334 | self.logger.verbose(
335 | prefix_str + "Comment `" + str(s.id) + "` by " + str(s.author) + " \"" + s.body[0:32].replace("\n", "").replace("\r", "") + "...\"")
336 |
337 | comment_body = s.body
338 | comment_body = comment_body[0:32]
339 | comment_body = re.sub(r'\W+', '_', comment_body)
340 | post_dir = str(i).zfill(3) + "_Comment_" + \
341 | comment_body + "..."
342 | submission_dir = os.path.join(saved_dir, post_dir)
343 | self.download_saved_comment(s, submission_dir)
344 | elif isinstance(s, praw.models.Comment):
345 | self.logger.verbose(
346 | prefix_str + "Comment `" + str(s.id) + "` by " + str(s.author))
347 | self.logger.spam(self.indent_2 + "Skipping comment")
348 | elif isinstance(s, praw.models.Submission):
349 | SubmissionDownloader(s, i, self.logger, saved_dir, skip_videos, skip_meta, skip_comments, comment_limit,
350 | {'imgur_client_id': UserDownloader.IMGUR_CLIENT_ID})
351 | else:
352 | pass
353 | except Exception as e:
354 | self.logger.error(self.indent_2 + "Unable to download #" + str(i) + " for user `" + username + "` - " + str(e))
355 | except Exception as e:
356 | self.logger.error("Unable to download saved for user `" + username + "` - " + str(e))
357 |
358 | def download_gilded(self, args):
359 | output_path = args.o
360 |
361 | for username in args.users:
362 | user = self.reddit.redditor(name=username)
363 |
364 | self.logger.notice("Downloading from /u/" + username + "/gilded")
365 |
366 | root_dir = os.path.join(os.path.join(os.path.join(
367 | output_path, "www.reddit.com"), "u"), username)
368 |
369 | try:
370 | post_limit = args.l
371 | skip_meta = args.skip_meta
372 | skip_videos = args.skip_videos
373 | skip_comments = args.skip_comments
374 | comment_limit = 0 # top-level comments ONLY
375 |
376 | saved_dir = os.path.join(root_dir, "gilded")
377 | if not os.path.exists(saved_dir):
378 | os.makedirs(saved_dir)
379 |
380 | for i, s in enumerate(user.gilded(limit=post_limit)):
381 | try:
382 | prefix_str = '#' + str(i).zfill(3) + ' '
383 | self.indent_1 = ' ' * len(prefix_str) + "* "
384 | self.indent_2 = ' ' * len(self.indent_1) + "- "
385 | if isinstance(s, praw.models.Comment) and not skip_comments:
386 | self.logger.verbose(
387 | prefix_str + "Comment `" + str(s.id) + "` by " + str(s.author) + " \"" + s.body[0:32].replace("\n", "").replace("\r", "") + "...\"")
388 |
389 | comment_body = s.body
390 | comment_body = comment_body[0:32]
391 | comment_body = re.sub(r'\W+', '_', comment_body)
392 | post_dir = str(i).zfill(3) + "_Comment_" + \
393 | comment_body + "..."
394 | submission_dir = os.path.join(saved_dir, post_dir)
395 | self.download_saved_comment(s, submission_dir)
396 | elif isinstance(s, praw.models.Comment):
397 | self.logger.verbose(
398 | prefix_str + "Comment `" + str(s.id) + "` by " + str(s.author))
399 | self.logger.spam(self.indent_2 + "Skipping comment")
400 | elif isinstance(s, praw.models.Submission):
401 | SubmissionDownloader(s, i, self.logger, saved_dir, skip_videos, skip_meta, skip_comments, comment_limit,
402 | {'imgur_client_id': UserDownloader.IMGUR_CLIENT_ID})
403 | else:
404 | pass
405 | except Exception as e:
406 | self.logger.error(self.indent_2 + "Unable to download #" + str(i) + " for user `" + username + "` - " + str(e))
407 | except Exception as e:
408 | self.logger.error("Unable to download gilded for user `" + username + "` - " + str(e))
409 |
410 | def print_formatted_error(self, e):
411 | for line in str(e).split("\n"):
412 | self.logger.error(self.indent_2 + line)
413 |
414 | def download_saved_comment(self, comment, output_dir):
415 | if not os.path.exists(output_dir):
416 | os.makedirs(output_dir)
417 | self.logger.spam(
418 | self.indent_2 + "Saving comment.json to " + output_dir)
419 | with open(os.path.join(output_dir, 'comments.json'), 'w') as file:
420 | comment_dict = {}
421 | try:
422 | if comment.author:
423 | comment_dict["author"] = comment.author.name
424 | else:
425 | comment_dict["author"] = None
426 | comment_dict["body"] = comment.body
427 | comment_dict["created_utc"] = int(comment.created_utc)
428 | comment_dict["distinguished"] = comment.distinguished
429 | comment_dict["downs"] = comment.downs
430 | comment_dict["edited"] = comment.edited
431 | comment_dict["id"] = comment.id
432 | comment_dict["is_submitter"] = comment.is_submitter
433 | comment_dict["link_id"] = comment.link_id
434 | comment_dict["parent_id"] = comment.parent_id
435 | comment_dict["permalink"] = comment.permalink
436 | comment_dict["score"] = comment.score
437 | comment_dict["stickied"] = comment.stickied
438 | comment_dict["subreddit_name_prefixed"] = comment.subreddit_name_prefixed
439 | comment_dict["subreddit_id"] = comment.subreddit_id
440 | comment_dict["total_awards_received"] = comment.total_awards_received
441 | comment_dict["ups"] = comment.ups
442 | file.write(json.dumps(comment_dict, indent=2))
443 | self.logger.spam(
444 | self.indent_2 + "Successfully saved comment.json")
445 | except Exception as e:
446 | self.print_formatted_error(e)
--------------------------------------------------------------------------------
/src/saveddit/user_downloader_config.py:
--------------------------------------------------------------------------------
1 | class UserDownloaderConfig:
2 | DEFAULT_CATEGORIES = ["hot", "new", "random_rising", "rising",
3 | "controversial", "top", "gilded"]
4 | DEFAULT_SORT = "hot"
5 | DEFAULT_SORT_OPTIONS = ["hot", "new", "top", "controversial"]
6 | DEFAULT_POST_LIMIT = None
7 | DEFAULT_COMMENT_LIMIT = None
--------------------------------------------------------------------------------