├── __init__.py
├── envs
└── setup_env.sh
├── mpi_utils.py
├── .gitignore
├── recorder.py
├── README.md
├── cnn_policy.py
├── dynamics.py
├── vec_env.py
├── auxiliary_tasks.py
├── rollouts.py
├── utils.py
├── run.py
├── cppo_agent.py
└── wrappers.py
/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/envs/setup_env.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
--------------------------------------------------------------------------------
/mpi_utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import tensorflow as tf
3 | from mpi4py import MPI
4 |
5 |
6 | class MpiAdamOptimizer(tf.train.AdamOptimizer):
7 | """Adam optimizer that averages gradients across mpi processes."""
8 |
9 | def __init__(self, comm, **kwargs):
10 | self.comm = comm
11 | tf.train.AdamOptimizer.__init__(self, **kwargs)
12 |
13 | def compute_gradients(self, loss, var_list, **kwargs):
14 | grads_and_vars = tf.train.AdamOptimizer.compute_gradients(self, loss, var_list, **kwargs)
15 | grads_and_vars = [(g, v) for g, v in grads_and_vars if g is not None]
16 | flat_grad = tf.concat([tf.reshape(g, (-1,)) for g, v in grads_and_vars], axis=0)
17 | shapes = [v.shape.as_list() for g, v in grads_and_vars]
18 | sizes = [int(np.prod(s)) for s in shapes]
19 |
20 | _task_id, num_tasks = self.comm.Get_rank(), self.comm.Get_size()
21 | buf = np.zeros(sum(sizes), np.float32)
22 |
23 | def _collect_grads(flat_grad):
24 | self.comm.Allreduce(flat_grad, buf, op=MPI.SUM)
25 | np.divide(buf, float(num_tasks), out=buf)
26 | return buf
27 |
28 | avg_flat_grad = tf.py_func(_collect_grads, [flat_grad], tf.float32)
29 | avg_flat_grad.set_shape(flat_grad.shape)
30 | avg_grads = tf.split(avg_flat_grad, sizes, axis=0)
31 | avg_grads_and_vars = [(tf.reshape(g, v.shape), v)
32 | for g, (_, v) in zip(avg_grads, grads_and_vars)]
33 |
34 | return avg_grads_and_vars
35 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Created by .ignore support plugin (hsz.mobi)
2 | ### Python template
3 | # Byte-compiled / optimized / DLL files
4 | __pycache__/
5 | *.py[cod]
6 | *$py.class
7 |
8 | # C extensions
9 | *.so
10 |
11 | # Distribution / packaging
12 | .Python
13 | build/
14 | develop-eggs/
15 | dist/
16 | downloads/
17 | eggs/
18 | .eggs/
19 | lib/
20 | lib64/
21 | parts/
22 | sdist/
23 | var/
24 | wheels/
25 | *.egg-info/
26 | .installed.cfg
27 | *.egg
28 | MANIFEST
29 |
30 | # PyInstaller
31 | # Usually these files are written by a python script from a template
32 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
33 | *.manifest
34 | *.spec
35 |
36 | # Installer logs
37 | pip-log.txt
38 | pip-delete-this-directory.txt
39 |
40 | # Unit test / coverage reports
41 | htmlcov/
42 | .tox/
43 | .coverage
44 | .coverage.*
45 | .cache
46 | nosetests.xml
47 | coverage.xml
48 | *.cover
49 | .hypothesis/
50 | .pytest_cache/
51 |
52 | # Translations
53 | *.mo
54 | *.pot
55 |
56 | # Django stuff:
57 | *.log
58 | local_settings.py
59 | db.sqlite3
60 |
61 | # Flask stuff:
62 | instance/
63 | .webassets-cache
64 |
65 | # Scrapy stuff:
66 | .scrapy
67 |
68 | # Sphinx documentation
69 | docs/_build/
70 |
71 | # PyBuilder
72 | target/
73 |
74 | # Jupyter Notebook
75 | .ipynb_checkpoints
76 |
77 | # pyenv
78 | .python-version
79 |
80 | # celery beat schedule file
81 | celerybeat-schedule
82 |
83 | # SageMath parsed files
84 | *.sage.py
85 |
86 | # Environments
87 | .env
88 | .venv
89 | env/
90 | venv/
91 | ENV/
92 | env.bak/
93 | venv.bak/
94 |
95 | # Spyder project settings
96 | .spyderproject
97 | .spyproject
98 |
99 | # Rope project settings
100 | .ropeproject
101 |
102 | # mkdocs documentation
103 | /site
104 |
105 | # mypy
106 | .mypy_cache/
107 |
108 | .idea/
109 |
110 | .DS_Store
111 | envs/
112 | venv/
113 | logs/
114 | ml-agents/
115 | wrapper.sh
116 |
--------------------------------------------------------------------------------
/recorder.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pickle
3 |
4 | from baselines import logger
5 | from mpi4py import MPI
6 |
7 |
8 | class Recorder(object):
9 | def __init__(self, nenvs, nlumps):
10 | self.nenvs = nenvs
11 | self.nlumps = nlumps
12 | self.nenvs_per_lump = nenvs // nlumps
13 | self.acs = [[] for _ in range(nenvs)]
14 | self.int_rews = [[] for _ in range(nenvs)]
15 | self.ext_rews = [[] for _ in range(nenvs)]
16 | self.ep_infos = [{} for _ in range(nenvs)]
17 | self.filenames = [self.get_filename(i) for i in range(nenvs)]
18 | if MPI.COMM_WORLD.Get_rank() == 0:
19 | logger.info("episode recordings saved to ", self.filenames[0])
20 |
21 | def record(self, timestep, lump, acs, infos, int_rew, ext_rew, news):
22 | for out_index in range(self.nenvs_per_lump):
23 | in_index = out_index + lump * self.nenvs_per_lump
24 | if timestep == 0:
25 | self.acs[in_index].append(acs[out_index])
26 | else:
27 | if self.is_first_episode_step(in_index):
28 | try:
29 | self.ep_infos[in_index]['random_state'] = infos[out_index]['random_state']
30 | except:
31 | pass
32 |
33 | self.int_rews[in_index].append(int_rew[out_index])
34 | self.ext_rews[in_index].append(ext_rew[out_index])
35 |
36 | if news[out_index]:
37 | self.ep_infos[in_index]['ret'] = infos[out_index]['episode']['r']
38 | self.ep_infos[in_index]['len'] = infos[out_index]['episode']['l']
39 | self.dump_episode(in_index)
40 |
41 | self.acs[in_index].append(acs[out_index])
42 |
43 | def dump_episode(self, i):
44 | episode = {'acs': self.acs[i],
45 | 'int_rew': self.int_rews[i],
46 | 'info': self.ep_infos[i]}
47 | filename = self.filenames[i]
48 | if self.episode_worth_saving(i):
49 | with open(filename, 'ab') as f:
50 | pickle.dump(episode, f, protocol=-1)
51 | self.acs[i].clear()
52 | self.int_rews[i].clear()
53 | self.ext_rews[i].clear()
54 | self.ep_infos[i].clear()
55 |
56 | def episode_worth_saving(self, i):
57 | return (i == 0 and MPI.COMM_WORLD.Get_rank() == 0)
58 |
59 | def is_first_episode_step(self, i):
60 | return len(self.int_rews[i]) == 0
61 |
62 | def get_filename(self, i):
63 | filename = os.path.join(logger.get_dir(), 'env{}_{}.pk'.format(MPI.COMM_WORLD.Get_rank(), i))
64 | return filename
65 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | ## Self-Supervised Exploration via Disagreement ##
2 | #### [[Project Website]](https://pathak22.github.io/exploration-by-disagreement/) [[Demo Video]](https://youtu.be/POlrWt32_ec)
3 |
4 | [Deepak Pathak*](https://people.eecs.berkeley.edu/~pathak/), [Dhiraj Gandhi*](http://www.cs.cmu.edu/~dgandhi/), [Abhinav Gupta](http://www.cs.cmu.edu/~abhinavg/)
5 | (* equal contribution)
6 |
7 | UC Berkeley
8 | CMU
9 | Facebook AI Research
10 |
11 |
12 | 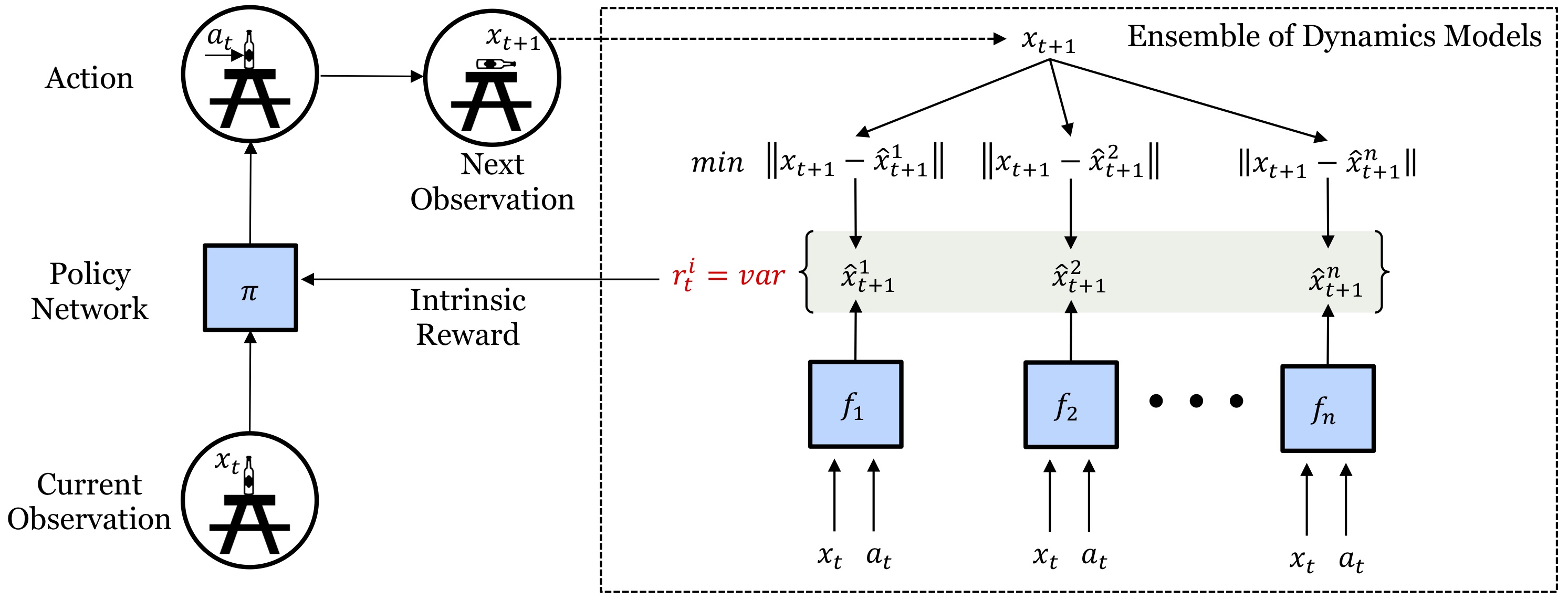 13 |
14 |
15 | This is a TensorFlow based implementation for our [paper on self-supervised exploration via disagreement](https://pathak22.github.io/exploration-by-disagreement/). In this paper, we propose a formulation for exploration inspired by the work in active learning literature. Specifically, we train an ensemble of dynamics models and incentivize the agent to explore such that the disagreement of those ensembles is maximized. This allows the agent to learn skills by exploring in a self-supervised manner without any external reward. Notably, we further leverage the disagreement objective to optimize the agent's policy in a differentiable manner, without using reinforcement learning, which results in a sample-efficient exploration. We demonstrate the efficacy of this formulation across a variety of benchmark environments including stochastic-Atari, Mujoco, Unity and a real robotic arm. If you find this work useful in your research, please cite:
16 |
17 | @inproceedings{pathak19disagreement,
18 | Author = {Pathak, Deepak and
19 | Gandhi, Dhiraj and Gupta, Abhinav},
20 | Title = {Self-Supervised Exploration via Disagreement},
21 | Booktitle = {ICML},
22 | Year = {2019}
23 | }
24 |
25 | ### Installation and Usage
26 | The following command should train a pure exploration agent on Breakout with default experiment parameters.
27 | ```bash
28 | python run.py
29 | ```
30 | To use more than one gpu/machine, use MPI (e.g. `mpiexec -n 8 python run.py` should use 1024 parallel environments to collect experience instead of the default 128 on an 8 gpu machine).
31 |
32 | ### Other helpful pointers
33 | - [Paper](https://pathak22.github.io/exploration-by-disagreement/resources/icml19.pdf)
34 | - [Project Website](https://pathak22.github.io/exploration-by-disagreement/)
35 | - [Demo Video](https://youtu.be/POlrWt32_ec)
36 |
37 | ### Acknowledgement
38 |
39 | This repository is built off the publicly released code of [Large-Scale Study of Curiosity-driven Learning, ICLR 2019](https://github.com/openai/large-scale-curiosity).
40 |
--------------------------------------------------------------------------------
/cnn_policy.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | from baselines.common.distributions import make_pdtype
3 |
4 | from utils import getsess, small_convnet, activ, fc, flatten_two_dims, unflatten_first_dim
5 |
6 |
7 | class CnnPolicy(object):
8 | def __init__(self, ob_space, ac_space, hidsize,
9 | ob_mean, ob_std, feat_dim, layernormalize, nl, scope="policy"):
10 | if layernormalize:
11 | print("Warning: policy is operating on top of layer-normed features. It might slow down the training.")
12 | self.layernormalize = layernormalize
13 | self.nl = nl
14 | self.ob_mean = ob_mean
15 | self.ob_std = ob_std
16 | with tf.variable_scope(scope):
17 | self.ob_space = ob_space
18 | self.ac_space = ac_space
19 | self.ac_pdtype = make_pdtype(ac_space)
20 | self.ph_ob = tf.placeholder(dtype=tf.int32,
21 | shape=(None, None) + ob_space.shape, name='ob')
22 | self.ph_ac = self.ac_pdtype.sample_placeholder([None, None], name='ac')
23 | self.pd = self.vpred = None
24 | self.hidsize = hidsize
25 | self.feat_dim = feat_dim
26 | self.scope = scope
27 | pdparamsize = self.ac_pdtype.param_shape()[0]
28 |
29 | sh = tf.shape(self.ph_ob)
30 | x = flatten_two_dims(self.ph_ob)
31 | self.flat_features = self.get_features(x, reuse=False)
32 | self.features = unflatten_first_dim(self.flat_features, sh)
33 |
34 | with tf.variable_scope(scope, reuse=False):
35 | x = fc(self.flat_features, units=hidsize, activation=activ)
36 | x = fc(x, units=hidsize, activation=activ)
37 | pdparam = fc(x, name='pd', units=pdparamsize, activation=None)
38 | vpred = fc(x, name='value_function_output', units=1, activation=None)
39 | pdparam = unflatten_first_dim(pdparam, sh)
40 | self.vpred = unflatten_first_dim(vpred, sh)[:, :, 0]
41 | self.pd = pd = self.ac_pdtype.pdfromflat(pdparam)
42 | self.a_samp = pd.sample()
43 | self.entropy = pd.entropy()
44 | self.nlp_samp = pd.neglogp(self.a_samp)
45 |
46 | def get_features(self, x, reuse):
47 | x_has_timesteps = (x.get_shape().ndims == 5)
48 | if x_has_timesteps:
49 | sh = tf.shape(x)
50 | x = flatten_two_dims(x)
51 |
52 | with tf.variable_scope(self.scope + "_features", reuse=reuse):
53 | x = (tf.to_float(x) - self.ob_mean) / self.ob_std
54 | x = small_convnet(x, nl=self.nl, feat_dim=self.feat_dim, last_nl=None, layernormalize=self.layernormalize)
55 |
56 | if x_has_timesteps:
57 | x = unflatten_first_dim(x, sh)
58 | return x
59 |
60 | def get_ac_value_nlp(self, ob):
61 | a, vpred, nlp = \
62 | getsess().run([self.a_samp, self.vpred, self.nlp_samp],
63 | feed_dict={self.ph_ob: ob[:, None]})
64 | return a[:, 0], vpred[:, 0], nlp[:, 0]
65 |
--------------------------------------------------------------------------------
/dynamics.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import tensorflow as tf
3 |
4 | from auxiliary_tasks import JustPixels
5 | from utils import small_convnet, flatten_two_dims, unflatten_first_dim, getsess, unet
6 |
7 |
8 | class Dynamics(object):
9 | def __init__(self, auxiliary_task, predict_from_pixels, var_output, feat_dim=None, scope='dynamics'):
10 | self.scope = scope
11 | self.auxiliary_task = auxiliary_task
12 | self.hidsize = self.auxiliary_task.hidsize
13 | self.feat_dim = feat_dim
14 | self.obs = self.auxiliary_task.obs
15 | self.last_ob = self.auxiliary_task.last_ob
16 | self.ac = self.auxiliary_task.ac
17 | self.ac_space = self.auxiliary_task.ac_space
18 | self.ob_mean = self.auxiliary_task.ob_mean
19 | self.ob_std = self.auxiliary_task.ob_std
20 | self.var_output = var_output
21 | if predict_from_pixels:
22 | self.features = self.get_features(self.obs, reuse=False)
23 | else:
24 | self.features = tf.stop_gradient(self.auxiliary_task.features)
25 |
26 | self.out_features = self.auxiliary_task.next_features
27 | with tf.variable_scope(self.scope + "_loss"):
28 | self.loss = self.get_loss()
29 | self.partial_loss = self.get_loss_partial()
30 |
31 | def get_features(self, x, reuse):
32 | nl = tf.nn.leaky_relu
33 | x_has_timesteps = (x.get_shape().ndims == 5)
34 | if x_has_timesteps:
35 | sh = tf.shape(x)
36 | x = flatten_two_dims(x)
37 | with tf.variable_scope(self.scope + "_features", reuse=reuse):
38 | x = (tf.to_float(x) - self.ob_mean) / self.ob_std
39 | x = small_convnet(x, nl=nl, feat_dim=self.feat_dim, last_nl=nl, layernormalize=False)
40 | if x_has_timesteps:
41 | x = unflatten_first_dim(x, sh)
42 | return x
43 |
44 | def get_loss(self):
45 | ac = tf.one_hot(self.ac, self.ac_space.n, axis=2)
46 | sh = tf.shape(ac)
47 | ac = flatten_two_dims(ac)
48 |
49 | def add_ac(x):
50 | return tf.concat([x, ac], axis=-1)
51 |
52 | with tf.variable_scope(self.scope):
53 | x = flatten_two_dims(self.features)
54 | x = tf.layers.dense(add_ac(x), self.hidsize, activation=tf.nn.leaky_relu)
55 |
56 | def residual(x):
57 | res = tf.layers.dense(add_ac(x), self.hidsize, activation=tf.nn.leaky_relu)
58 | res = tf.layers.dense(add_ac(res), self.hidsize, activation=None)
59 | return x + res
60 |
61 | for _ in range(4):
62 | x = residual(x)
63 | n_out_features = self.out_features.get_shape()[-1].value
64 | x = tf.layers.dense(add_ac(x), n_out_features, activation=None)
65 | x = unflatten_first_dim(x, sh)
66 | if self.var_output:
67 | return x
68 | else:
69 | return tf.reduce_mean((x - tf.stop_gradient(self.out_features)) ** 2, -1)
70 |
71 | def get_loss_partial(self):
72 | ac = tf.one_hot(self.ac, self.ac_space.n, axis=2)
73 | sh = tf.shape(ac)
74 | ac = flatten_two_dims(ac)
75 |
76 | def add_ac(x):
77 | return tf.concat([x, ac], axis=-1)
78 |
79 | with tf.variable_scope(self.scope, reuse=True):
80 | x = flatten_two_dims(self.features)
81 | x = tf.layers.dense(add_ac(x), self.hidsize, activation=tf.nn.leaky_relu)
82 |
83 | def residual(x):
84 | res = tf.layers.dense(add_ac(x), self.hidsize, activation=tf.nn.leaky_relu)
85 | res = tf.layers.dense(add_ac(res), self.hidsize, activation=None)
86 | return x + res
87 |
88 | for _ in range(4):
89 | x = residual(x)
90 | n_out_features = self.out_features.get_shape()[-1].value
91 | x = tf.layers.dense(add_ac(x), n_out_features, activation=None)
92 | x = unflatten_first_dim(x, sh)
93 | return tf.nn.dropout(tf.reduce_mean(((x - tf.stop_gradient(self.out_features)) ** 2), -1), keep_prob=0.8)
94 |
95 | def calculate_loss(self, ob, last_ob, acs):
96 | n_chunks = 8
97 | n = ob.shape[0]
98 | chunk_size = n // n_chunks
99 | assert n % n_chunks == 0
100 | sli = lambda i: slice(i * chunk_size, (i + 1) * chunk_size)
101 | return np.concatenate([getsess().run(self.loss,
102 | {self.obs: ob[sli(i)], self.last_ob: last_ob[sli(i)],
103 | self.ac: acs[sli(i)]}) for i in range(n_chunks)], 0)
104 |
105 |
106 | class UNet(Dynamics):
107 | def __init__(self, auxiliary_task, predict_from_pixels, feat_dim=None, scope='pixel_dynamics'):
108 | assert isinstance(auxiliary_task, JustPixels)
109 | assert not predict_from_pixels, "predict from pixels must be False, it's set up to predict from features that are normalized pixels."
110 | super(UNet, self).__init__(auxiliary_task=auxiliary_task,
111 | predict_from_pixels=predict_from_pixels,
112 | feat_dim=feat_dim,
113 | scope=scope)
114 |
115 | def get_features(self, x, reuse):
116 | raise NotImplementedError
117 |
118 | def get_loss(self):
119 | nl = tf.nn.leaky_relu
120 | ac = tf.one_hot(self.ac, self.ac_space.n, axis=2)
121 | sh = tf.shape(ac)
122 | ac = flatten_two_dims(ac)
123 | ac_four_dim = tf.expand_dims(tf.expand_dims(ac, 1), 1)
124 |
125 | def add_ac(x):
126 | if x.get_shape().ndims == 2:
127 | return tf.concat([x, ac], axis=-1)
128 | elif x.get_shape().ndims == 4:
129 | sh = tf.shape(x)
130 | return tf.concat(
131 | [x, ac_four_dim + tf.zeros([sh[0], sh[1], sh[2], ac_four_dim.get_shape()[3].value], tf.float32)],
132 | axis=-1)
133 |
134 | with tf.variable_scope(self.scope):
135 | x = flatten_two_dims(self.features)
136 | x = unet(x, nl=nl, feat_dim=self.feat_dim, cond=add_ac)
137 | x = unflatten_first_dim(x, sh)
138 | self.prediction_pixels = x * self.ob_std + self.ob_mean
139 | return tf.reduce_mean((x - tf.stop_gradient(self.out_features)) ** 2, [2, 3, 4])
140 |
--------------------------------------------------------------------------------
/vec_env.py:
--------------------------------------------------------------------------------
1 | """
2 | An interface for asynchronous vectorized environments.
3 | """
4 |
5 | import ctypes
6 | from abc import ABC, abstractmethod
7 | from multiprocessing import Pipe, Array, Process
8 |
9 | import gym
10 | import numpy as np
11 | from baselines import logger
12 |
13 | _NP_TO_CT = {np.float32: ctypes.c_float,
14 | np.int32: ctypes.c_int32,
15 | np.int8: ctypes.c_int8,
16 | np.uint8: ctypes.c_char,
17 | np.bool: ctypes.c_bool}
18 | _CT_TO_NP = {v: k for k, v in _NP_TO_CT.items()}
19 |
20 |
21 | class CloudpickleWrapper(object):
22 | """
23 | Uses cloudpickle to serialize contents (otherwise multiprocessing tries to use pickle)
24 | """
25 |
26 | def __init__(self, x):
27 | self.x = x
28 |
29 | def __getstate__(self):
30 | import cloudpickle
31 | return cloudpickle.dumps(self.x)
32 |
33 | def __setstate__(self, ob):
34 | import pickle
35 | self.x = pickle.loads(ob)
36 |
37 |
38 | class VecEnv(ABC):
39 | """
40 | An abstract asynchronous, vectorized environment.
41 | """
42 |
43 | def __init__(self, num_envs, observation_space, action_space):
44 | self.num_envs = num_envs
45 | self.observation_space = observation_space
46 | self.action_space = action_space
47 |
48 | @abstractmethod
49 | def reset(self):
50 | """
51 | Reset all the environments and return an array of
52 | observations, or a tuple of observation arrays.
53 |
54 | If step_async is still doing work, that work will
55 | be cancelled and step_wait() should not be called
56 | until step_async() is invoked again.
57 | """
58 | pass
59 |
60 | @abstractmethod
61 | def step_async(self, actions):
62 | """
63 | Tell all the environments to start taking a step
64 | with the given actions.
65 | Call step_wait() to get the results of the step.
66 |
67 | You should not call this if a step_async run is
68 | already pending.
69 | """
70 | pass
71 |
72 | @abstractmethod
73 | def step_wait(self):
74 | """
75 | Wait for the step taken with step_async().
76 |
77 | Returns (obs, rews, dones, infos):
78 | - obs: an array of observations, or a tuple of
79 | arrays of observations.
80 | - rews: an array of rewards
81 | - dones: an array of "episode done" booleans
82 | - infos: a sequence of info objects
83 | """
84 | pass
85 |
86 | @abstractmethod
87 | def close(self):
88 | """
89 | Clean up the environments' resources.
90 | """
91 | pass
92 |
93 | def step(self, actions):
94 | self.step_async(actions)
95 | return self.step_wait()
96 |
97 | def render(self):
98 | logger.warn('Render not defined for %s' % self)
99 |
100 |
101 | class ShmemVecEnv(VecEnv):
102 | """
103 | An AsyncEnv that uses multiprocessing to run multiple
104 | environments in parallel.
105 | """
106 |
107 | def __init__(self, env_fns, spaces=None):
108 | """
109 | If you don't specify observation_space, we'll have to create a dummy
110 | environment to get it.
111 | """
112 | if spaces:
113 | observation_space, action_space = spaces
114 | else:
115 | logger.log('Creating dummy env object to get spaces')
116 | with logger.scoped_configure(format_strs=[]):
117 | dummy = env_fns[0]()
118 | observation_space, action_space = dummy.observation_space, dummy.action_space
119 | dummy.close()
120 | del dummy
121 | VecEnv.__init__(self, len(env_fns), observation_space, action_space)
122 |
123 | obs_spaces = observation_space.spaces if isinstance(self.observation_space, gym.spaces.Tuple) else (
124 | self.observation_space,)
125 | self.obs_bufs = [tuple(Array(_NP_TO_CT[s.dtype.type], int(np.prod(s.shape))) for s in obs_spaces) for _ in
126 | env_fns]
127 | self.obs_shapes = [s.shape for s in obs_spaces]
128 | self.obs_dtypes = [s.dtype for s in obs_spaces]
129 |
130 | self.parent_pipes = []
131 | self.procs = []
132 | for env_fn, obs_buf in zip(env_fns, self.obs_bufs):
133 | wrapped_fn = CloudpickleWrapper(env_fn)
134 | parent_pipe, child_pipe = Pipe()
135 | proc = Process(target=_subproc_worker,
136 | args=(child_pipe, parent_pipe, wrapped_fn, obs_buf, self.obs_shapes))
137 | proc.daemon = True
138 | self.procs.append(proc)
139 | self.parent_pipes.append(parent_pipe)
140 | proc.start()
141 | child_pipe.close()
142 | self.waiting_step = False
143 |
144 | def reset(self):
145 | if self.waiting_step:
146 | logger.warn('Called reset() while waiting for the step to complete')
147 | self.step_wait()
148 | for pipe in self.parent_pipes:
149 | pipe.send(('reset', None))
150 | return self._decode_obses([pipe.recv() for pipe in self.parent_pipes])
151 |
152 | def step_async(self, actions):
153 | assert len(actions) == len(self.parent_pipes)
154 | for pipe, act in zip(self.parent_pipes, actions):
155 | pipe.send(('step', act))
156 |
157 | def step_wait(self):
158 | outs = [pipe.recv() for pipe in self.parent_pipes]
159 | obs, rews, dones, infos = zip(*outs)
160 | return self._decode_obses(obs), np.array(rews), np.array(dones), infos
161 |
162 | def close(self):
163 | if self.waiting_step:
164 | self.step_wait()
165 | for pipe in self.parent_pipes:
166 | pipe.send(('close', None))
167 | for pipe in self.parent_pipes:
168 | pipe.recv()
169 | pipe.close()
170 | for proc in self.procs:
171 | proc.join()
172 |
173 | def _decode_obses(self, obs):
174 | """
175 | Turn the observation responses into a single numpy
176 | array, possibly via shared memory.
177 | """
178 | obs = []
179 | for i, shape in enumerate(self.obs_shapes):
180 | bufs = [b[i] for b in self.obs_bufs]
181 | o = [np.frombuffer(b.get_obj(), dtype=self.obs_dtypes[i]).reshape(shape) for b in bufs]
182 | obs.append(np.array(o))
183 | return tuple(obs) if len(obs) > 1 else obs[0]
184 |
185 |
186 | def _subproc_worker(pipe, parent_pipe, env_fn_wrapper, obs_buf, obs_shape):
187 | """
188 | Control a single environment instance using IPC and
189 | shared memory.
190 |
191 | If obs_buf is not None, it is a shared-memory buffer
192 | for communicating observations.
193 | """
194 |
195 | def _write_obs(obs):
196 | if not isinstance(obs, tuple):
197 | obs = (obs,)
198 | for o, b, s in zip(obs, obs_buf, obs_shape):
199 | dst = b.get_obj()
200 | dst_np = np.frombuffer(dst, dtype=_CT_TO_NP[dst._type_]).reshape(s) # pylint: disable=W0212
201 | np.copyto(dst_np, o)
202 |
203 | env = env_fn_wrapper.x()
204 | parent_pipe.close()
205 | try:
206 | while True:
207 | cmd, data = pipe.recv()
208 | if cmd == 'reset':
209 | pipe.send(_write_obs(env.reset()))
210 | elif cmd == 'step':
211 | obs, reward, done, info = env.step(data)
212 | if done:
213 | obs = env.reset()
214 | pipe.send((_write_obs(obs), reward, done, info))
215 | elif cmd == 'close':
216 | pipe.send(None)
217 | break
218 | else:
219 | raise RuntimeError('Got unrecognized cmd %s' % cmd)
220 | finally:
221 | env.close()
222 |
--------------------------------------------------------------------------------
/auxiliary_tasks.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 |
3 | from utils import small_convnet, fc, activ, flatten_two_dims, unflatten_first_dim, small_deconvnet
4 |
5 |
6 | class FeatureExtractor(object):
7 | def __init__(self, policy, features_shared_with_policy, feat_dim=None, layernormalize=None,
8 | scope='feature_extractor'):
9 | self.scope = scope
10 | self.features_shared_with_policy = features_shared_with_policy
11 | self.feat_dim = feat_dim
12 | self.layernormalize = layernormalize
13 | self.policy = policy
14 | self.hidsize = policy.hidsize
15 | self.ob_space = policy.ob_space
16 | self.ac_space = policy.ac_space
17 | self.obs = self.policy.ph_ob
18 | self.ob_mean = self.policy.ob_mean
19 | self.ob_std = self.policy.ob_std
20 | with tf.variable_scope(scope):
21 | self.last_ob = tf.placeholder(dtype=tf.int32,
22 | shape=(None, 1) + self.ob_space.shape, name='last_ob')
23 | self.next_ob = tf.concat([self.obs[:, 1:], self.last_ob], 1)
24 |
25 | if features_shared_with_policy:
26 | self.features = self.policy.features
27 | self.last_features = self.policy.get_features(self.last_ob, reuse=True)
28 | else:
29 | self.features = self.get_features(self.obs, reuse=False)
30 | self.last_features = self.get_features(self.last_ob, reuse=True)
31 | self.next_features = tf.concat([self.features[:, 1:], self.last_features], 1)
32 |
33 | self.ac = self.policy.ph_ac
34 | self.scope = scope
35 |
36 | self.loss = self.get_loss()
37 |
38 | def get_features(self, x, reuse):
39 | nl = tf.nn.leaky_relu
40 | x_has_timesteps = (x.get_shape().ndims == 5)
41 | if x_has_timesteps:
42 | sh = tf.shape(x)
43 | x = flatten_two_dims(x)
44 | with tf.variable_scope(self.scope + "_features", reuse=reuse):
45 | x = (tf.to_float(x) - self.ob_mean) / self.ob_std
46 | x = small_convnet(x, nl=nl, feat_dim=self.feat_dim, last_nl=None, layernormalize=self.layernormalize)
47 | if x_has_timesteps:
48 | x = unflatten_first_dim(x, sh)
49 | return x
50 |
51 | def get_loss(self):
52 | return tf.zeros((), dtype=tf.float32)
53 |
54 |
55 | class InverseDynamics(FeatureExtractor):
56 | def __init__(self, policy, features_shared_with_policy, feat_dim=None, layernormalize=None):
57 | super(InverseDynamics, self).__init__(scope="inverse_dynamics", policy=policy,
58 | features_shared_with_policy=features_shared_with_policy,
59 | feat_dim=feat_dim, layernormalize=layernormalize)
60 |
61 | def get_loss(self):
62 | with tf.variable_scope(self.scope):
63 | x = tf.concat([self.features, self.next_features], 2)
64 | sh = tf.shape(x)
65 | x = flatten_two_dims(x)
66 | x = fc(x, units=self.policy.hidsize, activation=activ)
67 | x = fc(x, units=self.ac_space.n, activation=None)
68 | param = unflatten_first_dim(x, sh)
69 | idfpd = self.policy.ac_pdtype.pdfromflat(param)
70 | return idfpd.neglogp(self.ac)
71 |
72 |
73 | class VAE(FeatureExtractor):
74 | def __init__(self, policy, features_shared_with_policy, feat_dim=None, layernormalize=False, spherical_obs=False):
75 | assert not layernormalize, "VAE features should already have reasonable size, no need to layer normalize them"
76 | self.spherical_obs = spherical_obs
77 | super(VAE, self).__init__(scope="vae", policy=policy,
78 | features_shared_with_policy=features_shared_with_policy,
79 | feat_dim=feat_dim, layernormalize=False)
80 | self.features = tf.split(self.features, 2, -1)[0] # use mean only for features exposed to the dynamics
81 | self.next_features = tf.split(self.next_features, 2, -1)[0]
82 |
83 | def get_features(self, x, reuse):
84 | nl = tf.nn.leaky_relu
85 | x_has_timesteps = (x.get_shape().ndims == 5)
86 | if x_has_timesteps:
87 | sh = tf.shape(x)
88 | x = flatten_two_dims(x)
89 | with tf.variable_scope(self.scope + "_features", reuse=reuse):
90 | x = (tf.to_float(x) - self.ob_mean) / self.ob_std
91 | x = small_convnet(x, nl=nl, feat_dim=2 * self.feat_dim, last_nl=None, layernormalize=False)
92 | if x_has_timesteps:
93 | x = unflatten_first_dim(x, sh)
94 | return x
95 |
96 | def get_loss(self):
97 | with tf.variable_scope(self.scope):
98 | posterior_mean, posterior_scale = tf.split(self.features, 2, -1)
99 | posterior_scale = tf.nn.softplus(posterior_scale)
100 | posterior_distribution = tf.distributions.Normal(loc=posterior_mean, scale=posterior_scale)
101 |
102 | sh = tf.shape(posterior_mean)
103 | prior = tf.distributions.Normal(loc=tf.zeros(sh), scale=tf.ones(sh))
104 |
105 | posterior_kl = tf.distributions.kl_divergence(posterior_distribution, prior)
106 |
107 | posterior_kl = tf.reduce_sum(posterior_kl, [-1])
108 | assert posterior_kl.get_shape().ndims == 2
109 |
110 | posterior_sample = posterior_distribution.sample()
111 | reconstruction_distribution = self.decoder(posterior_sample)
112 | norm_obs = self.add_noise_and_normalize(self.obs)
113 | reconstruction_likelihood = reconstruction_distribution.log_prob(norm_obs)
114 | assert reconstruction_likelihood.get_shape().as_list()[2:] == [84, 84, 4]
115 | reconstruction_likelihood = tf.reduce_sum(reconstruction_likelihood, [2, 3, 4])
116 |
117 | likelihood_lower_bound = reconstruction_likelihood - posterior_kl
118 | return - likelihood_lower_bound
119 |
120 | def add_noise_and_normalize(self, x):
121 | x = tf.to_float(x) + tf.random_uniform(shape=tf.shape(x), minval=0., maxval=1.)
122 | x = (x - self.ob_mean) / self.ob_std
123 | return x
124 |
125 | def decoder(self, z):
126 | nl = tf.nn.leaky_relu
127 | z_has_timesteps = (z.get_shape().ndims == 3)
128 | if z_has_timesteps:
129 | sh = tf.shape(z)
130 | z = flatten_two_dims(z)
131 | with tf.variable_scope(self.scope + "decoder"):
132 | z = small_deconvnet(z, nl=nl, ch=4 if self.spherical_obs else 8, positional_bias=True)
133 | if z_has_timesteps:
134 | z = unflatten_first_dim(z, sh)
135 | if self.spherical_obs:
136 | scale = tf.get_variable(name="scale", shape=(), dtype=tf.float32,
137 | initializer=tf.ones_initializer())
138 | scale = tf.maximum(scale, -4.)
139 | scale = tf.nn.softplus(scale)
140 | scale = scale * tf.ones_like(z)
141 | else:
142 | z, scale = tf.split(z, 2, -1)
143 | scale = tf.nn.softplus(scale)
144 | # scale = tf.Print(scale, [scale])
145 | return tf.distributions.Normal(loc=z, scale=scale)
146 |
147 |
148 | class JustPixels(FeatureExtractor):
149 | def __init__(self, policy, features_shared_with_policy, feat_dim=None, layernormalize=None,
150 | scope='just_pixels'):
151 | assert not layernormalize
152 | assert not features_shared_with_policy
153 | super(JustPixels, self).__init__(scope=scope, policy=policy,
154 | features_shared_with_policy=False,
155 | feat_dim=None, layernormalize=None)
156 |
157 | def get_features(self, x, reuse):
158 | with tf.variable_scope(self.scope + "_features", reuse=reuse):
159 | x = (tf.to_float(x) - self.ob_mean) / self.ob_std
160 | return x
161 |
162 | def get_loss(self):
163 | return tf.zeros((), dtype=tf.float32)
164 |
--------------------------------------------------------------------------------
/rollouts.py:
--------------------------------------------------------------------------------
1 | from collections import deque, defaultdict
2 |
3 | import numpy as np
4 | from mpi4py import MPI
5 |
6 | from recorder import Recorder
7 |
8 |
9 | class Rollout(object):
10 | def __init__(self, ob_space, ac_space, nenvs, nsteps_per_seg, nsegs_per_env, nlumps, envs, policy,
11 | int_rew_coeff, ext_rew_coeff, record_rollouts, dynamics_list):
12 | self.nenvs = nenvs
13 | self.nsteps_per_seg = nsteps_per_seg
14 | self.nsegs_per_env = nsegs_per_env
15 | self.nsteps = self.nsteps_per_seg * self.nsegs_per_env
16 | self.ob_space = ob_space
17 | self.ac_space = ac_space
18 | self.nlumps = nlumps
19 | self.lump_stride = nenvs // self.nlumps
20 | self.envs = envs
21 | self.policy = policy
22 | self.dynamics_list = dynamics_list
23 |
24 | self.reward_fun = lambda ext_rew, int_rew: ext_rew_coeff * np.clip(ext_rew, -1., 1.) + int_rew_coeff * int_rew
25 |
26 | self.buf_vpreds = np.empty((nenvs, self.nsteps), np.float32)
27 | self.buf_nlps = np.empty((nenvs, self.nsteps), np.float32)
28 | self.buf_rews = np.empty((nenvs, self.nsteps), np.float32)
29 | self.buf_ext_rews = np.empty((nenvs, self.nsteps), np.float32)
30 | self.buf_acs = np.empty((nenvs, self.nsteps, *self.ac_space.shape), self.ac_space.dtype)
31 | self.buf_obs = np.empty((nenvs, self.nsteps, *self.ob_space.shape), self.ob_space.dtype)
32 | self.buf_obs_last = np.empty((nenvs, self.nsegs_per_env, *self.ob_space.shape), np.float32)
33 |
34 | self.buf_news = np.zeros((nenvs, self.nsteps), np.float32)
35 | self.buf_new_last = self.buf_news[:, 0, ...].copy()
36 | self.buf_vpred_last = self.buf_vpreds[:, 0, ...].copy()
37 |
38 | self.env_results = [None] * self.nlumps
39 | # self.prev_feat = [None for _ in range(self.nlumps)]
40 | # self.prev_acs = [None for _ in range(self.nlumps)]
41 | self.int_rew = np.zeros((nenvs,), np.float32)
42 |
43 | self.recorder = Recorder(nenvs=self.nenvs, nlumps=self.nlumps) if record_rollouts else None
44 | self.statlists = defaultdict(lambda: deque([], maxlen=100))
45 | self.stats = defaultdict(float)
46 | self.best_ext_ret = None
47 | self.all_visited_rooms = []
48 | self.all_scores = []
49 |
50 | self.step_count = 0
51 |
52 | def collect_rollout(self):
53 | self.ep_infos_new = []
54 | for t in range(self.nsteps):
55 | self.rollout_step()
56 | self.calculate_reward()
57 | self.update_info()
58 |
59 | def calculate_reward(self):
60 | int_rew = []
61 | if self.dynamics_list[0].var_output:
62 | net_output = []
63 | for dynamics in self.dynamics_list:
64 | net_output.append(dynamics.calculate_loss(ob=self.buf_obs,
65 | last_ob=self.buf_obs_last,
66 | acs=self.buf_acs))
67 |
68 | # cal variance along first dimension .. [n_dyna, n_env, n_step, feature_size]
69 | # --> [n_env, n_step,feature_size]
70 | var_output = np.var(net_output, axis=0)
71 |
72 | # cal reward by mean along second dimension .. [n_env, n_step, feature_size] --> [n_env, n_step]
73 | var_rew = np.mean(var_output, axis=-1)
74 | else:
75 | for dynamics in self.dynamics_list:
76 | int_rew.append(dynamics.calculate_loss(ob=self.buf_obs,
77 | last_ob=self.buf_obs_last,
78 | acs=self.buf_acs))
79 |
80 | # calculate the variance of the rew
81 | var_rew = np.var(int_rew, axis=0)
82 |
83 | self.buf_rews[:] = self.reward_fun(int_rew=var_rew, ext_rew=self.buf_ext_rews)
84 |
85 | def rollout_step(self):
86 | t = self.step_count % self.nsteps
87 | s = t % self.nsteps_per_seg
88 | for l in range(self.nlumps):
89 | obs, prevrews, news, infos = self.env_get(l)
90 | # if t > 0:
91 | # prev_feat = self.prev_feat[l]
92 | # prev_acs = self.prev_acs[l]
93 | for info in infos:
94 | epinfo = info.get('episode', {})
95 | mzepinfo = info.get('mz_episode', {})
96 | retroepinfo = info.get('retro_episode', {})
97 | unityepinfo = info.get("unity_episode", {})
98 | epinfo.update(unityepinfo)
99 | epinfo.update(mzepinfo)
100 | epinfo.update(retroepinfo)
101 | if epinfo:
102 | if "n_states_visited" in info:
103 | epinfo["n_states_visited"] = info["n_states_visited"]
104 | epinfo["states_visited"] = info["states_visited"]
105 | if "unity_rooms" in info:
106 | epinfo["unity_rooms"] = info["unity_rooms"]
107 | self.ep_infos_new.append((self.step_count, epinfo))
108 |
109 | sli = slice(l * self.lump_stride, (l + 1) * self.lump_stride)
110 |
111 | acs, vpreds, nlps = self.policy.get_ac_value_nlp(obs)
112 | self.env_step(l, acs)
113 |
114 | # self.prev_feat[l] = dyn_feat
115 | # self.prev_acs[l] = acs
116 | self.buf_obs[sli, t] = obs
117 | self.buf_news[sli, t] = news
118 | self.buf_vpreds[sli, t] = vpreds
119 | self.buf_nlps[sli, t] = nlps
120 | self.buf_acs[sli, t] = acs
121 | if t > 0:
122 | self.buf_ext_rews[sli, t - 1] = prevrews
123 | # if t > 0:
124 | # dyn_logp = self.policy.call_reward(prev_feat, pol_feat, prev_acs)
125 | #
126 | # int_rew = dyn_logp.reshape(-1, )
127 | #
128 | # self.int_rew[sli] = int_rew
129 | # self.buf_rews[sli, t - 1] = self.reward_fun(ext_rew=prevrews, int_rew=int_rew)
130 | if self.recorder is not None:
131 | self.recorder.record(timestep=self.step_count, lump=l, acs=acs, infos=infos, int_rew=self.int_rew[sli],
132 | ext_rew=prevrews, news=news)
133 | self.step_count += 1
134 | if s == self.nsteps_per_seg - 1:
135 | for l in range(self.nlumps):
136 | sli = slice(l * self.lump_stride, (l + 1) * self.lump_stride)
137 | nextobs, ext_rews, nextnews, _ = self.env_get(l)
138 | self.buf_obs_last[sli, t // self.nsteps_per_seg] = nextobs
139 | if t == self.nsteps - 1:
140 | self.buf_new_last[sli] = nextnews
141 | self.buf_ext_rews[sli, t] = ext_rews
142 | _, self.buf_vpred_last[sli], _ = self.policy.get_ac_value_nlp(nextobs)
143 | # dyn_logp = self.policy.call_reward(self.prev_feat[l], last_pol_feat, prev_acs)
144 | # dyn_logp = dyn_logp.reshape(-1, )
145 | # int_rew = dyn_logp
146 | #
147 | # self.int_rew[sli] = int_rew
148 | # self.buf_rews[sli, t] = self.reward_fun(ext_rew=ext_rews, int_rew=int_rew)
149 |
150 | def update_info(self):
151 | all_ep_infos = MPI.COMM_WORLD.allgather(self.ep_infos_new)
152 | all_ep_infos = sorted(sum(all_ep_infos, []), key=lambda x: x[0])
153 | if all_ep_infos:
154 | all_ep_infos = [i_[1] for i_ in all_ep_infos] # remove the step_count
155 | keys_ = all_ep_infos[0].keys()
156 | all_ep_infos = {k: [i[k] for i in all_ep_infos] for k in keys_}
157 |
158 | self.statlists['eprew'].extend(all_ep_infos['r'])
159 | self.stats['eprew_recent'] = np.mean(all_ep_infos['r'])
160 | self.statlists['eplen'].extend(all_ep_infos['l'])
161 | self.stats['epcount'] += len(all_ep_infos['l'])
162 | self.stats['tcount'] += sum(all_ep_infos['l'])
163 | if 'visited_rooms' in keys_:
164 | # Montezuma specific logging.
165 | self.stats['visited_rooms'] = sorted(list(set.union(*all_ep_infos['visited_rooms'])))
166 | self.stats['pos_count'] = np.mean(all_ep_infos['pos_count'])
167 | self.all_visited_rooms.extend(self.stats['visited_rooms'])
168 | self.all_scores.extend(all_ep_infos["r"])
169 | self.all_scores = sorted(list(set(self.all_scores)))
170 | self.all_visited_rooms = sorted(list(set(self.all_visited_rooms)))
171 | if MPI.COMM_WORLD.Get_rank() == 0:
172 | print("All visited rooms")
173 | print(self.all_visited_rooms)
174 | print("All scores")
175 | print(self.all_scores)
176 | if 'levels' in keys_:
177 | # Retro logging
178 | temp = sorted(list(set.union(*all_ep_infos['levels'])))
179 | self.all_visited_rooms.extend(temp)
180 | self.all_visited_rooms = sorted(list(set(self.all_visited_rooms)))
181 | if MPI.COMM_WORLD.Get_rank() == 0:
182 | print("All visited levels")
183 | print(self.all_visited_rooms)
184 | if "unity_rooms" in keys_:
185 | #Unity logging.
186 | temp = sorted(list(set.union(*all_ep_infos['unity_rooms'])))
187 | self.all_visited_rooms.extend(temp)
188 | self.all_visited_rooms = sorted(list(set(self.all_visited_rooms)))
189 | self.stats["n_rooms"] = len(self.all_visited_rooms)
190 | if MPI.COMM_WORLD.Get_rank() == 0:
191 | print("All visited levels")
192 | print(self.all_visited_rooms)
193 |
194 | current_max = np.max(all_ep_infos['r'])
195 | else:
196 | current_max = None
197 | self.ep_infos_new = []
198 |
199 | if current_max is not None:
200 | if (self.best_ext_ret is None) or (current_max > self.best_ext_ret):
201 | self.best_ext_ret = current_max
202 | self.current_max = current_max
203 |
204 | def env_step(self, l, acs):
205 | self.envs[l].step_async(acs)
206 | self.env_results[l] = None
207 |
208 | def env_get(self, l):
209 | if self.step_count == 0:
210 | ob = self.envs[l].reset()
211 | out = self.env_results[l] = (ob, None, np.ones(self.lump_stride, bool), {})
212 | else:
213 | if self.env_results[l] is None:
214 | out = self.env_results[l] = self.envs[l].step_wait()
215 | else:
216 | out = self.env_results[l]
217 | return out
218 |
--------------------------------------------------------------------------------
/utils.py:
--------------------------------------------------------------------------------
1 | import multiprocessing
2 | import os
3 | import platform
4 | from functools import partial
5 |
6 | import numpy as np
7 | import tensorflow as tf
8 | from baselines.common.tf_util import normc_initializer
9 | from mpi4py import MPI
10 |
11 |
12 | def bcast_tf_vars_from_root(sess, vars):
13 | """
14 | Send the root node's parameters to every worker.
15 |
16 | Arguments:
17 | sess: the TensorFlow session.
18 | vars: all parameter variables including optimizer's
19 | """
20 | rank = MPI.COMM_WORLD.Get_rank()
21 | for var in vars:
22 | if rank == 0:
23 | MPI.COMM_WORLD.bcast(sess.run(var))
24 | else:
25 | sess.run(tf.assign(var, MPI.COMM_WORLD.bcast(None)))
26 |
27 |
28 | def get_mean_and_std(array):
29 | comm = MPI.COMM_WORLD
30 | task_id, num_tasks = comm.Get_rank(), comm.Get_size()
31 | local_mean = np.array(np.mean(array))
32 | sum_of_means = np.zeros((), dtype=np.float32)
33 | comm.Allreduce(local_mean, sum_of_means, op=MPI.SUM)
34 | mean = sum_of_means / num_tasks
35 |
36 | n_array = array - mean
37 | sqs = n_array ** 2
38 | local_mean = np.array(np.mean(sqs))
39 | sum_of_means = np.zeros((), dtype=np.float32)
40 | comm.Allreduce(local_mean, sum_of_means, op=MPI.SUM)
41 | var = sum_of_means / num_tasks
42 | std = var ** 0.5
43 | return mean, std
44 |
45 |
46 | def guess_available_gpus(n_gpus=None):
47 | if n_gpus is not None:
48 | return list(range(n_gpus))
49 | if 'CUDA_VISIBLE_DEVICES' in os.environ:
50 | cuda_visible_divices = os.environ['CUDA_VISIBLE_DEVICES']
51 | cuda_visible_divices = cuda_visible_divices.split(',')
52 | return [int(n) for n in cuda_visible_divices]
53 | nvidia_dir = '/proc/driver/nvidia/gpus/'
54 | if os.path.exists(nvidia_dir):
55 | n_gpus = len(os.listdir(nvidia_dir))
56 | return list(range(n_gpus))
57 | raise Exception("Couldn't guess the available gpus on this machine")
58 |
59 |
60 | def setup_mpi_gpus():
61 | """
62 | Set CUDA_VISIBLE_DEVICES using MPI.
63 | """
64 | available_gpus = guess_available_gpus()
65 |
66 | node_id = platform.node()
67 | nodes_ordered_by_rank = MPI.COMM_WORLD.allgather(node_id)
68 | processes_outranked_on_this_node = [n for n in nodes_ordered_by_rank[:MPI.COMM_WORLD.Get_rank()] if n == node_id]
69 | local_rank = len(processes_outranked_on_this_node)
70 | os.environ['CUDA_VISIBLE_DEVICES'] = str(available_gpus[local_rank])
71 |
72 |
73 | def guess_available_cpus():
74 | return int(multiprocessing.cpu_count())
75 |
76 |
77 | def setup_tensorflow_session():
78 | num_cpu = guess_available_cpus()
79 |
80 | tf_config = tf.ConfigProto(
81 | inter_op_parallelism_threads=num_cpu,
82 | intra_op_parallelism_threads=num_cpu
83 | )
84 | # tf_config.gpu_options.allow_growth = True
85 | return tf.Session(config=tf_config)
86 |
87 |
88 | def random_agent_ob_mean_std(env, nsteps=10000):
89 | ob = np.asarray(env.reset())
90 | if MPI.COMM_WORLD.Get_rank() == 0:
91 | obs = [ob]
92 | for _ in range(nsteps):
93 | ac = env.action_space.sample()
94 | ob, _, done, _ = env.step(ac)
95 | if done:
96 | ob = env.reset()
97 | obs.append(np.asarray(ob))
98 | mean = np.mean(obs, 0).astype(np.float32)
99 | std = np.std(obs, 0).mean().astype(np.float32)
100 | else:
101 | mean = np.empty(shape=ob.shape, dtype=np.float32)
102 | std = np.empty(shape=(), dtype=np.float32)
103 | MPI.COMM_WORLD.Bcast(mean, root=0)
104 | MPI.COMM_WORLD.Bcast(std, root=0)
105 | return mean, std
106 |
107 |
108 | def layernorm(x):
109 | m, v = tf.nn.moments(x, -1, keep_dims=True)
110 | return (x - m) / (tf.sqrt(v) + 1e-8)
111 |
112 |
113 | getsess = tf.get_default_session
114 |
115 | fc = partial(tf.layers.dense, kernel_initializer=normc_initializer(1.))
116 | activ = tf.nn.relu
117 |
118 |
119 | def flatten_two_dims(x):
120 | return tf.reshape(x, [-1] + x.get_shape().as_list()[2:])
121 |
122 |
123 | def unflatten_first_dim(x, sh):
124 | return tf.reshape(x, [sh[0], sh[1]] + x.get_shape().as_list()[1:])
125 |
126 |
127 | def add_pos_bias(x):
128 | with tf.variable_scope(name_or_scope=None, default_name="pos_bias"):
129 | b = tf.get_variable(name="pos_bias", shape=[1] + x.get_shape().as_list()[1:], dtype=tf.float32,
130 | initializer=tf.zeros_initializer())
131 | return x + b
132 |
133 |
134 | def small_convnet(x, nl, feat_dim, last_nl, layernormalize, batchnorm=False):
135 | bn = tf.layers.batch_normalization if batchnorm else lambda x: x
136 | x = bn(tf.layers.conv2d(x, filters=32, kernel_size=8, strides=(4, 4), activation=nl))
137 | x = bn(tf.layers.conv2d(x, filters=64, kernel_size=4, strides=(2, 2), activation=nl))
138 | x = bn(tf.layers.conv2d(x, filters=64, kernel_size=3, strides=(1, 1), activation=nl))
139 | x = tf.reshape(x, (-1, np.prod(x.get_shape().as_list()[1:])))
140 | x = bn(fc(x, units=feat_dim, activation=None))
141 | if last_nl is not None:
142 | x = last_nl(x)
143 | if layernormalize:
144 | x = layernorm(x)
145 | return x
146 |
147 |
148 | def small_deconvnet(z, nl, ch, positional_bias):
149 | sh = (8, 8, 64)
150 | z = fc(z, np.prod(sh), activation=nl)
151 | z = tf.reshape(z, (-1, *sh))
152 | z = tf.layers.conv2d_transpose(z, 128, kernel_size=4, strides=(2, 2), activation=nl, padding='same')
153 | assert z.get_shape().as_list()[1:3] == [16, 16]
154 | z = tf.layers.conv2d_transpose(z, 64, kernel_size=8, strides=(2, 2), activation=nl, padding='same')
155 | assert z.get_shape().as_list()[1:3] == [32, 32]
156 | z = tf.layers.conv2d_transpose(z, ch, kernel_size=8, strides=(3, 3), activation=None, padding='same')
157 | assert z.get_shape().as_list()[1:3] == [96, 96]
158 | z = z[:, 6:-6, 6:-6]
159 | assert z.get_shape().as_list()[1:3] == [84, 84]
160 | if positional_bias:
161 | z = add_pos_bias(z)
162 | return z
163 |
164 |
165 | def unet(x, nl, feat_dim, cond, batchnorm=False):
166 | bn = tf.layers.batch_normalization if batchnorm else lambda x: x
167 | layers = []
168 | x = tf.pad(x, [[0, 0], [6, 6], [6, 6], [0, 0]])
169 | x = bn(tf.layers.conv2d(cond(x), filters=32, kernel_size=8, strides=(3, 3), activation=nl, padding='same'))
170 | assert x.get_shape().as_list()[1:3] == [32, 32]
171 | layers.append(x)
172 | x = bn(tf.layers.conv2d(cond(x), filters=64, kernel_size=8, strides=(2, 2), activation=nl, padding='same'))
173 | layers.append(x)
174 | assert x.get_shape().as_list()[1:3] == [16, 16]
175 | x = bn(tf.layers.conv2d(cond(x), filters=64, kernel_size=4, strides=(2, 2), activation=nl, padding='same'))
176 | layers.append(x)
177 | assert x.get_shape().as_list()[1:3] == [8, 8]
178 |
179 | x = tf.reshape(x, (-1, np.prod(x.get_shape().as_list()[1:])))
180 | x = fc(cond(x), units=feat_dim, activation=nl)
181 |
182 | def residual(x):
183 | res = bn(tf.layers.dense(cond(x), feat_dim, activation=tf.nn.leaky_relu))
184 | res = tf.layers.dense(cond(res), feat_dim, activation=None)
185 | return x + res
186 |
187 | for _ in range(4):
188 | x = residual(x)
189 |
190 | sh = (8, 8, 64)
191 | x = fc(cond(x), np.prod(sh), activation=nl)
192 | x = tf.reshape(x, (-1, *sh))
193 | x += layers.pop()
194 | x = bn(tf.layers.conv2d_transpose(cond(x), 64, kernel_size=4, strides=(2, 2), activation=nl, padding='same'))
195 | assert x.get_shape().as_list()[1:3] == [16, 16]
196 | x += layers.pop()
197 | x = bn(tf.layers.conv2d_transpose(cond(x), 32, kernel_size=8, strides=(2, 2), activation=nl, padding='same'))
198 | assert x.get_shape().as_list()[1:3] == [32, 32]
199 | x += layers.pop()
200 | x = tf.layers.conv2d_transpose(cond(x), 4, kernel_size=8, strides=(3, 3), activation=None, padding='same')
201 | assert x.get_shape().as_list()[1:3] == [96, 96]
202 | x = x[:, 6:-6, 6:-6]
203 | assert x.get_shape().as_list()[1:3] == [84, 84]
204 | assert layers == []
205 | return x
206 |
207 |
208 | def tile_images(array, n_cols=None, max_images=None, div=1):
209 | if max_images is not None:
210 | array = array[:max_images]
211 | if len(array.shape) == 4 and array.shape[3] == 1:
212 | array = array[:, :, :, 0]
213 | assert len(array.shape) in [3, 4], "wrong number of dimensions - shape {}".format(array.shape)
214 | if len(array.shape) == 4:
215 | assert array.shape[3] == 3, "wrong number of channels- shape {}".format(array.shape)
216 | if n_cols is None:
217 | n_cols = max(int(np.sqrt(array.shape[0])) // div * div, div)
218 | n_rows = int(np.ceil(float(array.shape[0]) / n_cols))
219 |
220 | def cell(i, j):
221 | ind = i * n_cols + j
222 | return array[ind] if ind < array.shape[0] else np.zeros(array[0].shape)
223 |
224 | def row(i):
225 | return np.concatenate([cell(i, j) for j in range(n_cols)], axis=1)
226 |
227 | return np.concatenate([row(i) for i in range(n_rows)], axis=0)
228 |
229 |
230 | import distutils.spawn
231 | import subprocess
232 | def save_np_as_mp4(frames, filename):
233 | print(filename)
234 | if distutils.spawn.find_executable('avconv') is not None:
235 | backend = 'avconv'
236 | elif distutils.spawn.find_executable('ffmpeg') is not None:
237 | backend = 'ffmpeg'
238 | else:
239 | raise NotImplementedError(
240 | """Found neither the ffmpeg nor avconv executables. On OS X, you can install ffmpeg via `brew install ffmpeg`. On most Ubuntu variants, `sudo apt-get install ffmpeg` should do it. On Ubuntu 14.04, however, you'll need to install avconv with `sudo apt-get install libav-tools`.""")
241 |
242 | frames_per_sec = 30
243 | h, w = frames[0].shape[:2]
244 | output_path = filename
245 | cmdline = (backend,
246 | '-nostats',
247 | '-loglevel', 'error', # suppress warnings
248 | '-y',
249 | '-r', '%d' % frames_per_sec,
250 |
251 | # input
252 | '-f', 'rawvideo',
253 | '-s:v', '{}x{}'.format(w, h),
254 | '-pix_fmt', 'rgb24',
255 | '-i', '-', # this used to be /dev/stdin, which is not Windows-friendly
256 |
257 | # output
258 | '-vcodec', 'libx264',
259 | '-pix_fmt', 'yuv420p',
260 | output_path
261 | )
262 |
263 | print('saving ', output_path)
264 | if hasattr(os, 'setsid'): # setsid not present on Windows
265 | process = subprocess.Popen(cmdline, stdin=subprocess.PIPE, preexec_fn=os.setsid)
266 | else:
267 | process = subprocess.Popen(cmdline, stdin=subprocess.PIPE)
268 | process.stdin.write(np.array(frames).tobytes())
269 | process.stdin.close()
270 | ret = process.wait()
271 | if ret != 0:
272 | print("VideoRecorder encoder exited with status {}".format(ret))
273 |
--------------------------------------------------------------------------------
/run.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | try:
3 | from OpenGL import GLU
4 | except:
5 | print("no OpenGL.GLU")
6 | import functools
7 | import os.path as osp
8 | from functools import partial
9 |
10 | import gym
11 | import tensorflow as tf
12 | from baselines import logger
13 | from baselines.bench import Monitor
14 | from baselines.common.atari_wrappers import NoopResetEnv, FrameStack
15 | from mpi4py import MPI
16 |
17 | from auxiliary_tasks import FeatureExtractor, InverseDynamics, VAE, JustPixels
18 | from cnn_policy import CnnPolicy
19 | from cppo_agent import PpoOptimizer
20 | from dynamics import Dynamics, UNet
21 | from utils import random_agent_ob_mean_std
22 | from wrappers import MontezumaInfoWrapper, make_mario_env, \
23 | make_multi_pong, AddRandomStateToInfo, MaxAndSkipEnv, ProcessFrame84, ExtraTimeLimit, \
24 | make_unity_maze, StickyActionEnv
25 |
26 | import datetime
27 |
28 |
29 | def start_experiment(**args):
30 | make_env = partial(make_env_all_params, add_monitor=True, args=args)
31 |
32 | trainer = Trainer(make_env=make_env,
33 | num_timesteps=args['num_timesteps'], hps=args,
34 | envs_per_process=args['envs_per_process'],
35 | num_dyna=args['num_dynamics'],
36 | var_output=args['var_output'])
37 | log, tf_sess = get_experiment_environment(**args)
38 | with log, tf_sess:
39 | logdir = logger.get_dir()
40 | print("results will be saved to ", logdir)
41 | trainer.train()
42 |
43 |
44 | class Trainer(object):
45 | def __init__(self, make_env, hps, num_timesteps, envs_per_process, num_dyna, var_output):
46 | self.make_env = make_env
47 | self.hps = hps
48 | self.envs_per_process = envs_per_process
49 | self.num_timesteps = num_timesteps
50 | self._set_env_vars()
51 |
52 | self.policy = CnnPolicy(
53 | scope='pol',
54 | ob_space=self.ob_space,
55 | ac_space=self.ac_space,
56 | hidsize=512,
57 | feat_dim=512,
58 | ob_mean=self.ob_mean,
59 | ob_std=self.ob_std,
60 | layernormalize=False,
61 | nl=tf.nn.leaky_relu)
62 |
63 | self.feature_extractor = {"none": FeatureExtractor,
64 | "idf": InverseDynamics,
65 | "vaesph": partial(VAE, spherical_obs=True),
66 | "vaenonsph": partial(VAE, spherical_obs=False),
67 | "pix2pix": JustPixels}[hps['feat_learning']]
68 | self.feature_extractor = self.feature_extractor(policy=self.policy,
69 | features_shared_with_policy=False,
70 | feat_dim=512,
71 | layernormalize=hps['layernorm'])
72 |
73 | self.dynamics_class = Dynamics if hps['feat_learning'] != 'pix2pix' else UNet
74 |
75 | # create dynamics list
76 | self.dynamics_list = []
77 | for i in range(num_dyna):
78 | self.dynamics_list.append(self.dynamics_class(auxiliary_task=self.feature_extractor,
79 | predict_from_pixels=hps['dyn_from_pixels'],
80 | feat_dim=512, scope='dynamics_{}'.format(i),
81 | var_output=var_output)
82 | )
83 |
84 | self.agent = PpoOptimizer(
85 | scope='ppo',
86 | ob_space=self.ob_space,
87 | ac_space=self.ac_space,
88 | stochpol=self.policy,
89 | use_news=hps['use_news'],
90 | gamma=hps['gamma'],
91 | lam=hps["lambda"],
92 | nepochs=hps['nepochs'],
93 | nminibatches=hps['nminibatches'],
94 | lr=hps['lr'],
95 | cliprange=0.1,
96 | nsteps_per_seg=hps['nsteps_per_seg'],
97 | nsegs_per_env=hps['nsegs_per_env'],
98 | ent_coef=hps['ent_coeff'],
99 | normrew=hps['norm_rew'],
100 | normadv=hps['norm_adv'],
101 | ext_coeff=hps['ext_coeff'],
102 | int_coeff=hps['int_coeff'],
103 | unity=hps["env_kind"] == "unity",
104 | dynamics_list=self.dynamics_list
105 | )
106 |
107 | self.agent.to_report['aux'] = tf.reduce_mean(self.feature_extractor.loss)
108 | self.agent.total_loss += self.agent.to_report['aux']
109 |
110 | self.agent.to_report['dyn_loss'] = tf.reduce_mean(self.dynamics_list[0].partial_loss)
111 | for i in range(1, num_dyna):
112 | self.agent.to_report['dyn_loss'] += tf.reduce_mean(self.dynamics_list[i].partial_loss)
113 |
114 | self.agent.total_loss += self.agent.to_report['dyn_loss']
115 | self.agent.to_report['feat_var'] = tf.reduce_mean(tf.nn.moments(self.feature_extractor.features, [0, 1])[1])
116 |
117 | def _set_env_vars(self):
118 | env = self.make_env(0, add_monitor=False)
119 | self.ob_space, self.ac_space = env.observation_space, env.action_space
120 | self.ob_mean, self.ob_std = random_agent_ob_mean_std(env)
121 | if self.hps["env_kind"] == "unity":
122 | env.close()
123 | # self.ob_mean, self.ob_std = 124.89177, 55.7459
124 | del env
125 | self.envs = [functools.partial(self.make_env, i) for i in range(self.envs_per_process)]
126 |
127 | def train(self):
128 | self.agent.start_interaction(self.envs, nlump=self.hps['nlumps'], dynamics_list=self.dynamics_list)
129 | while True:
130 | info = self.agent.step()
131 | if info['update']:
132 | logger.logkvs(info['update'])
133 | logger.dumpkvs()
134 | if self.agent.rollout.stats['tcount'] > self.num_timesteps:
135 | break
136 |
137 | self.agent.stop_interaction()
138 |
139 |
140 | def make_env_all_params(rank, add_monitor, args):
141 | if args["env_kind"] == 'atari':
142 | env = gym.make(args['env'])
143 | assert 'NoFrameskip' in env.spec.id
144 | if args["stickyAtari"]:
145 | env._max_episode_steps = args['max_episode_steps'] * 4
146 | env = StickyActionEnv(env)
147 | else:
148 | env = NoopResetEnv(env, noop_max=args['noop_max'])
149 | env = MaxAndSkipEnv(env, skip=4)
150 | env = ProcessFrame84(env, crop=False)
151 | env = FrameStack(env, 4)
152 | if not args["stickyAtari"]:
153 | env = ExtraTimeLimit(env, args['max_episode_steps'])
154 | if 'Montezuma' in args['env']:
155 | env = MontezumaInfoWrapper(env)
156 | env = AddRandomStateToInfo(env)
157 | elif args["env_kind"] == 'mario':
158 | env = make_mario_env()
159 | elif args["env_kind"] == "retro_multi":
160 | env = make_multi_pong()
161 | elif args["env_kind"] == 'unity':
162 | env = make_unity_maze(args["env"], seed=args["seed"], rank=rank,
163 | ext_coeff=args["ext_coeff"], recordUnityVid=args['recordUnityVid'],
164 | expID=args["unityExpID"], startLoc=args["startLoc"], door=args["door"],
165 | tv=args["tv"], testenv=args["testenv"], logdir=logger.get_dir())
166 |
167 | if add_monitor:
168 | env = Monitor(env, osp.join(logger.get_dir(), '%.2i' % rank))
169 | return env
170 |
171 |
172 | def get_experiment_environment(**args):
173 | from utils import setup_mpi_gpus, setup_tensorflow_session
174 | from baselines.common import set_global_seeds
175 | from gym.utils.seeding import hash_seed
176 | process_seed = args["seed"] + 1000 * MPI.COMM_WORLD.Get_rank()
177 | process_seed = hash_seed(process_seed, max_bytes=4)
178 | set_global_seeds(process_seed)
179 | setup_mpi_gpus()
180 |
181 | logger_context = logger.scoped_configure(dir='./logs/' +
182 | datetime.datetime.now().strftime(args["expID"] + "-openai-%Y-%m-%d-%H-%M-%S-%f"),
183 | format_strs=['stdout', 'log',
184 | 'csv', 'tensorboard']
185 | if MPI.COMM_WORLD.Get_rank() == 0 else ['log'])
186 | tf_context = setup_tensorflow_session()
187 | return logger_context, tf_context
188 |
189 |
190 | def add_environments_params(parser):
191 | parser.add_argument('--env', help='environment ID', default='BreakoutNoFrameskip-v4',
192 | type=str)
193 | parser.add_argument('--max-episode-steps', help='maximum number of timesteps for episode', default=4500, type=int)
194 | parser.add_argument('--env_kind', type=str, default="atari")
195 | parser.add_argument('--noop_max', type=int, default=30)
196 | parser.add_argument('--stickyAtari', action='store_true', default=True)
197 |
198 |
199 | def add_optimization_params(parser):
200 | parser.add_argument('--lambda', type=float, default=0.95)
201 | parser.add_argument('--gamma', type=float, default=0.99)
202 | parser.add_argument('--nminibatches', type=int, default=8)
203 | parser.add_argument('--norm_adv', type=int, default=1)
204 | parser.add_argument('--norm_rew', type=int, default=1)
205 | parser.add_argument('--lr', type=float, default=1e-4)
206 | parser.add_argument('--ent_coeff', type=float, default=0.001)
207 | parser.add_argument('--nepochs', type=int, default=3)
208 | parser.add_argument('--num_timesteps', type=int, default=int(1e8))
209 |
210 |
211 | def add_rollout_params(parser):
212 | parser.add_argument('--nsteps_per_seg', type=int, default=128)
213 | parser.add_argument('--nsegs_per_env', type=int, default=1)
214 | parser.add_argument('--envs_per_process', type=int, default=128)
215 | parser.add_argument('--nlumps', type=int, default=1)
216 |
217 |
218 | def add_unity_params(parser):
219 | parser.add_argument('--testenv', action='store_true', default=False,
220 | help='test mode: slows to real time with bigger screen')
221 | parser.add_argument('--startLoc', type=int, default=0)
222 | parser.add_argument('--door', type=int, default=1)
223 | parser.add_argument('--tv', type=int, default=2)
224 | parser.add_argument('--unityExpID', type=int, default=0)
225 | parser.add_argument('--recordUnityVid', action='store_true', default=False)
226 |
227 |
228 | if __name__ == '__main__':
229 | import argparse
230 |
231 | parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
232 | add_environments_params(parser)
233 | add_unity_params(parser)
234 | add_optimization_params(parser)
235 | add_rollout_params(parser)
236 |
237 | parser.add_argument('--exp_name', type=str, default='')
238 | parser.add_argument('--expID', type=str, default='000')
239 | parser.add_argument('--seed', help='RNG seed', type=int, default=0)
240 | parser.add_argument('--dyn_from_pixels', type=int, default=0)
241 | parser.add_argument('--use_news', type=int, default=0)
242 | parser.add_argument('--ext_coeff', type=float, default=0.)
243 | parser.add_argument('--int_coeff', type=float, default=1.)
244 | parser.add_argument('--layernorm', type=int, default=0)
245 | parser.add_argument('--feat_learning', type=str, default="none",
246 | choices=["none", "idf", "vaesph", "vaenonsph", "pix2pix"])
247 | parser.add_argument('--num_dynamics', type=int, default=5)
248 | parser.add_argument('--var_output', action='store_true', default=True)
249 |
250 |
251 | args = parser.parse_args()
252 |
253 | start_experiment(**args.__dict__)
254 |
--------------------------------------------------------------------------------
/cppo_agent.py:
--------------------------------------------------------------------------------
1 | import time
2 | import sys
3 | import os
4 |
5 | import numpy as np
6 | import tensorflow as tf
7 | from baselines.common import explained_variance
8 | from baselines.common.mpi_moments import mpi_moments
9 | from baselines.common.running_mean_std import RunningMeanStd
10 | from mpi4py import MPI
11 | from tqdm import tqdm
12 |
13 | from mpi_utils import MpiAdamOptimizer
14 | from rollouts import Rollout
15 | from utils import bcast_tf_vars_from_root, get_mean_and_std
16 | from vec_env import ShmemVecEnv as VecEnv
17 |
18 | getsess = tf.get_default_session
19 |
20 |
21 | class PpoOptimizer(object):
22 | envs = None
23 |
24 | def __init__(self, *, scope, ob_space, ac_space, stochpol,
25 | ent_coef, gamma, lam, nepochs, lr, cliprange,
26 | nminibatches,
27 | normrew, normadv, use_news, ext_coeff, int_coeff,
28 | nsteps_per_seg, nsegs_per_env, unity, dynamics_list):
29 | self.dynamics_list = dynamics_list
30 | with tf.variable_scope(scope):
31 | self.unity = unity
32 | self.use_recorder = True
33 | self.n_updates = 0
34 | self.scope = scope
35 | self.ob_space = ob_space
36 | self.ac_space = ac_space
37 | self.stochpol = stochpol
38 | self.nepochs = nepochs
39 | self.lr = lr
40 | self.cliprange = cliprange
41 | self.nsteps_per_seg = nsteps_per_seg
42 | self.nsegs_per_env = nsegs_per_env
43 | self.nminibatches = nminibatches
44 | self.gamma = gamma
45 | self.lam = lam
46 | self.normrew = normrew
47 | self.normadv = normadv
48 | self.use_news = use_news
49 | self.ext_coeff = ext_coeff
50 | self.int_coeff = int_coeff
51 | self.ph_adv = tf.placeholder(tf.float32, [None, None])
52 | self.ph_ret = tf.placeholder(tf.float32, [None, None])
53 | self.ph_rews = tf.placeholder(tf.float32, [None, None])
54 | self.ph_oldnlp = tf.placeholder(tf.float32, [None, None])
55 | self.ph_oldvpred = tf.placeholder(tf.float32, [None, None])
56 | self.ph_lr = tf.placeholder(tf.float32, [])
57 | self.ph_cliprange = tf.placeholder(tf.float32, [])
58 | neglogpac = self.stochpol.pd.neglogp(self.stochpol.ph_ac)
59 | entropy = tf.reduce_mean(self.stochpol.pd.entropy())
60 | vpred = self.stochpol.vpred
61 |
62 | vf_loss = 0.5 * tf.reduce_mean((vpred - self.ph_ret) ** 2)
63 | ratio = tf.exp(self.ph_oldnlp - neglogpac) # p_new / p_old
64 | negadv = - self.ph_adv
65 | pg_losses1 = negadv * ratio
66 | pg_losses2 = negadv * tf.clip_by_value(ratio, 1.0 - self.ph_cliprange, 1.0 + self.ph_cliprange)
67 | pg_loss_surr = tf.maximum(pg_losses1, pg_losses2)
68 | pg_loss = tf.reduce_mean(pg_loss_surr)
69 | ent_loss = (- ent_coef) * entropy
70 | approxkl = .5 * tf.reduce_mean(tf.square(neglogpac - self.ph_oldnlp))
71 | clipfrac = tf.reduce_mean(tf.to_float(tf.abs(pg_losses2 - pg_loss_surr) > 1e-6))
72 |
73 | self.total_loss = pg_loss + ent_loss + vf_loss
74 | self.to_report = {'tot': self.total_loss, 'pg': pg_loss, 'vf': vf_loss, 'ent': entropy,
75 | 'approxkl': approxkl, 'clipfrac': clipfrac}
76 |
77 | def start_interaction(self, env_fns, dynamics_list, nlump=2):
78 | self.loss_names, self._losses = zip(*list(self.to_report.items()))
79 |
80 | params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES)
81 | if MPI.COMM_WORLD.Get_size() > 1:
82 | trainer = MpiAdamOptimizer(learning_rate=self.ph_lr, comm=MPI.COMM_WORLD)
83 | else:
84 | trainer = tf.train.AdamOptimizer(learning_rate=self.ph_lr)
85 | gradsandvars = trainer.compute_gradients(self.total_loss, params)
86 | self._train = trainer.apply_gradients(gradsandvars)
87 |
88 | if MPI.COMM_WORLD.Get_rank() == 0:
89 | getsess().run(tf.variables_initializer(tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES)))
90 | bcast_tf_vars_from_root(getsess(), tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES))
91 |
92 | self.all_visited_rooms = []
93 | self.all_scores = []
94 | self.nenvs = nenvs = len(env_fns)
95 | self.nlump = nlump
96 | self.lump_stride = nenvs // self.nlump
97 | self.envs = [
98 | VecEnv(env_fns[l * self.lump_stride: (l + 1) * self.lump_stride], spaces=[self.ob_space, self.ac_space]) for
99 | l in range(self.nlump)]
100 | if self.unity:
101 | for i in tqdm(range(int(nenvs*2.5 + 10))):
102 | time.sleep(1)
103 | print('... long overdue sleep ends now')
104 | sys.stdout.flush()
105 |
106 | self.rollout = Rollout(ob_space=self.ob_space, ac_space=self.ac_space, nenvs=nenvs,
107 | nsteps_per_seg=self.nsteps_per_seg,
108 | nsegs_per_env=self.nsegs_per_env, nlumps=self.nlump,
109 | envs=self.envs,
110 | policy=self.stochpol,
111 | int_rew_coeff=self.int_coeff,
112 | ext_rew_coeff=self.ext_coeff,
113 | record_rollouts=self.use_recorder,
114 | dynamics_list=dynamics_list)
115 |
116 | self.buf_advs = np.zeros((nenvs, self.rollout.nsteps), np.float32)
117 | self.buf_rets = np.zeros((nenvs, self.rollout.nsteps), np.float32)
118 |
119 | if self.normrew:
120 | self.rff = RewardForwardFilter(self.gamma)
121 | self.rff_rms = RunningMeanStd()
122 |
123 | self.step_count = 0
124 | self.t_last_update = time.time()
125 | self.t_start = time.time()
126 |
127 | def stop_interaction(self):
128 | for env in self.envs:
129 | env.close()
130 |
131 | def calculate_advantages(self, rews, use_news, gamma, lam):
132 | nsteps = self.rollout.nsteps
133 | lastgaelam = 0
134 | for t in range(nsteps - 1, -1, -1): # nsteps-2 ... 0
135 | nextnew = self.rollout.buf_news[:, t + 1] if t + 1 < nsteps else self.rollout.buf_new_last
136 | if not use_news:
137 | nextnew = 0
138 | nextvals = self.rollout.buf_vpreds[:, t + 1] if t + 1 < nsteps else self.rollout.buf_vpred_last
139 | nextnotnew = 1 - nextnew
140 | delta = rews[:, t] + gamma * nextvals * nextnotnew - self.rollout.buf_vpreds[:, t]
141 | self.buf_advs[:, t] = lastgaelam = delta + gamma * lam * nextnotnew * lastgaelam
142 | self.buf_rets[:] = self.buf_advs + self.rollout.buf_vpreds
143 |
144 | def update(self):
145 | if self.normrew:
146 | rffs = np.array([self.rff.update(rew) for rew in self.rollout.buf_rews.T])
147 | rffs_mean, rffs_std, rffs_count = mpi_moments(rffs.ravel())
148 | self.rff_rms.update_from_moments(rffs_mean, rffs_std ** 2, rffs_count)
149 | rews = self.rollout.buf_rews / np.sqrt(self.rff_rms.var)
150 | else:
151 | rews = np.copy(self.rollout.buf_rews)
152 | self.calculate_advantages(rews=rews, use_news=self.use_news, gamma=self.gamma, lam=self.lam)
153 |
154 | info = dict(
155 | advmean=self.buf_advs.mean(),
156 | advstd=self.buf_advs.std(),
157 | retmean=self.buf_rets.mean(),
158 | retstd=self.buf_rets.std(),
159 | vpredmean=self.rollout.buf_vpreds.mean(),
160 | vpredstd=self.rollout.buf_vpreds.std(),
161 | ev=explained_variance(self.rollout.buf_vpreds.ravel(), self.buf_rets.ravel()),
162 | rew_mean=np.mean(self.rollout.buf_rews),
163 | recent_best_ext_ret=self.rollout.current_max if self.rollout.current_max is not None else 0,
164 | )
165 | if self.rollout.best_ext_ret is not None:
166 | info['best_ext_ret'] = self.rollout.best_ext_ret
167 |
168 | # store images for debugging
169 | # from PIL import Image
170 | # if not os.path.exists('logs/images/'):
171 | # os.makedirs('logs/images/')
172 | # for i in range(self.rollout.buf_obs_last.shape[0]):
173 | # obs = self.rollout.buf_obs_last[i][0]
174 | # Image.fromarray((obs*255.).astype(np.uint8)).save('logs/images/%04d.png'%i)
175 |
176 | # normalize advantages
177 | if self.normadv:
178 | m, s = get_mean_and_std(self.buf_advs)
179 | self.buf_advs = (self.buf_advs - m) / (s + 1e-7)
180 | envsperbatch = (self.nenvs * self.nsegs_per_env) // self.nminibatches
181 | envsperbatch = max(1, envsperbatch)
182 | envinds = np.arange(self.nenvs * self.nsegs_per_env)
183 |
184 | def resh(x):
185 | if self.nsegs_per_env == 1:
186 | return x
187 | sh = x.shape
188 | return x.reshape((sh[0] * self.nsegs_per_env, self.nsteps_per_seg) + sh[2:])
189 |
190 | ph_buf = [
191 | (self.stochpol.ph_ac, resh(self.rollout.buf_acs)),
192 | (self.ph_rews, resh(self.rollout.buf_rews)),
193 | (self.ph_oldvpred, resh(self.rollout.buf_vpreds)),
194 | (self.ph_oldnlp, resh(self.rollout.buf_nlps)),
195 | (self.stochpol.ph_ob, resh(self.rollout.buf_obs)),
196 | (self.ph_ret, resh(self.buf_rets)),
197 | (self.ph_adv, resh(self.buf_advs)),
198 | ]
199 | ph_buf.extend([
200 | (self.dynamics_list[0].last_ob,
201 | self.rollout.buf_obs_last.reshape([self.nenvs * self.nsegs_per_env, 1, *self.ob_space.shape]))
202 | ])
203 | mblossvals = []
204 |
205 | for _ in range(self.nepochs):
206 | np.random.shuffle(envinds)
207 | for start in range(0, self.nenvs * self.nsegs_per_env, envsperbatch):
208 | end = start + envsperbatch
209 | mbenvinds = envinds[start:end]
210 | fd = {ph: buf[mbenvinds] for (ph, buf) in ph_buf}
211 | fd.update({self.ph_lr: self.lr, self.ph_cliprange: self.cliprange})
212 | mblossvals.append(getsess().run(self._losses + (self._train,), fd)[:-1])
213 |
214 | mblossvals = [mblossvals[0]]
215 | info.update(zip(['opt_' + ln for ln in self.loss_names], np.mean([mblossvals[0]], axis=0)))
216 | info["rank"] = MPI.COMM_WORLD.Get_rank()
217 | self.n_updates += 1
218 | info["n_updates"] = self.n_updates
219 | info.update({dn: (np.mean(dvs) if len(dvs) > 0 else 0) for (dn, dvs) in self.rollout.statlists.items()})
220 | info.update(self.rollout.stats)
221 | if "states_visited" in info:
222 | info.pop("states_visited")
223 | tnow = time.time()
224 | info["ups"] = 1. / (tnow - self.t_last_update)
225 | info["total_secs"] = tnow - self.t_start
226 | info['tps'] = MPI.COMM_WORLD.Get_size() * self.rollout.nsteps * self.nenvs / (tnow - self.t_last_update)
227 | self.t_last_update = tnow
228 |
229 | return info
230 |
231 | def step(self):
232 | self.rollout.collect_rollout()
233 | update_info = self.update()
234 | return {'update': update_info}
235 |
236 | def get_var_values(self):
237 | return self.stochpol.get_var_values()
238 |
239 | def set_var_values(self, vv):
240 | self.stochpol.set_var_values(vv)
241 |
242 |
243 | class RewardForwardFilter(object):
244 | def __init__(self, gamma):
245 | self.rewems = None
246 | self.gamma = gamma
247 |
248 | def update(self, rews):
249 | if self.rewems is None:
250 | self.rewems = rews
251 | else:
252 | self.rewems = self.rewems * self.gamma + rews
253 | return self.rewems
254 |
--------------------------------------------------------------------------------
/wrappers.py:
--------------------------------------------------------------------------------
1 | import os
2 | import itertools
3 | from collections import deque
4 | from copy import copy
5 |
6 | import gym
7 | import numpy as np
8 | from PIL import Image
9 | from utils import save_np_as_mp4
10 |
11 |
12 | def unwrap(env):
13 | if hasattr(env, "unwrapped"):
14 | return env.unwrapped
15 | elif hasattr(env, "env"):
16 | return unwrap(env.env)
17 | elif hasattr(env, "leg_env"):
18 | return unwrap(env.leg_env)
19 | else:
20 | return env
21 |
22 |
23 | class MaxAndSkipEnv(gym.Wrapper):
24 | def __init__(self, env, skip=4):
25 | """Return only every `skip`-th frame"""
26 | gym.Wrapper.__init__(self, env)
27 | # most recent raw observations (for max pooling across time steps)
28 | self._obs_buffer = deque(maxlen=2)
29 | self._skip = skip
30 |
31 | def step(self, action):
32 | """Repeat action, sum reward, and max over last observations."""
33 | total_reward = 0.0
34 | done = None
35 | acc_info = {}
36 | for _ in range(self._skip):
37 | obs, reward, done, info = self.env.step(action)
38 | acc_info.update(info)
39 | self._obs_buffer.append(obs)
40 | total_reward += reward
41 | if done:
42 | break
43 | max_frame = np.max(np.stack(self._obs_buffer), axis=0)
44 |
45 | return max_frame, total_reward, done, acc_info
46 |
47 | def reset(self):
48 | """Clear past frame buffer and init. to first obs. from inner env."""
49 | self._obs_buffer.clear()
50 | obs = self.env.reset()
51 | self._obs_buffer.append(obs)
52 | return obs
53 |
54 |
55 | class ProcessFrame84(gym.ObservationWrapper):
56 | def __init__(self, env, crop=True):
57 | self.crop = crop
58 | super(ProcessFrame84, self).__init__(env)
59 | self.observation_space = gym.spaces.Box(low=0, high=255, shape=(84, 84, 1), dtype=np.uint8)
60 |
61 | def observation(self, obs):
62 | return ProcessFrame84.process(obs, crop=self.crop)
63 |
64 | @staticmethod
65 | def process(frame, crop=True):
66 | if frame.size == 210 * 160 * 3:
67 | img = np.reshape(frame, [210, 160, 3]).astype(np.float32)
68 | elif frame.size == 250 * 160 * 3:
69 | img = np.reshape(frame, [250, 160, 3]).astype(np.float32)
70 | elif frame.size == 224 * 240 * 3: # mario resolution
71 | img = np.reshape(frame, [224, 240, 3]).astype(np.float32)
72 | elif frame.size == 84 * 84 * 3: # unity maze
73 | img = frame
74 | img = img[:, :, 0] * 0.299 + img[:, :, 1] * 0.587 + img[:, :, 2] * 0.114
75 | x_t = np.reshape(img, [84, 84, 1])
76 | return x_t.astype(np.uint8)
77 | else:
78 | assert False, "Unknown resolution." + str(frame.size)
79 | img = img[:, :, 0] * 0.299 + img[:, :, 1] * 0.587 + img[:, :, 2] * 0.114
80 | size = (84, 110 if crop else 84)
81 | resized_screen = np.array(Image.fromarray(img).resize(size,
82 | resample=Image.BILINEAR), dtype=np.uint8)
83 | x_t = resized_screen[18:102, :] if crop else resized_screen
84 | x_t = np.reshape(x_t, [84, 84, 1])
85 | return x_t.astype(np.uint8)
86 |
87 |
88 | class ExtraTimeLimit(gym.Wrapper):
89 | def __init__(self, env, max_episode_steps=None):
90 | gym.Wrapper.__init__(self, env)
91 | self._max_episode_steps = max_episode_steps
92 | self._elapsed_steps = 0
93 |
94 | def step(self, action):
95 | observation, reward, done, info = self.env.step(action)
96 | self._elapsed_steps += 1
97 | if self._elapsed_steps > self._max_episode_steps:
98 | done = True
99 | return observation, reward, done, info
100 |
101 | def reset(self):
102 | self._elapsed_steps = 0
103 | return self.env.reset()
104 |
105 |
106 | class AddRandomStateToInfo(gym.Wrapper):
107 | def __init__(self, env):
108 | """Adds the random state to the info field on the first step after reset
109 | """
110 | gym.Wrapper.__init__(self, env)
111 |
112 | def step(self, action):
113 | ob, r, d, info = self.env.step(action)
114 | if self.random_state_copy is not None:
115 | info['random_state'] = self.random_state_copy
116 | self.random_state_copy = None
117 | return ob, r, d, info
118 |
119 | def reset(self, **kwargs):
120 | """ Do no-op action for a number of steps in [1, noop_max]."""
121 | self.random_state_copy = copy(self.unwrapped.np_random)
122 | return self.env.reset(**kwargs)
123 |
124 |
125 | class MontezumaInfoWrapper(gym.Wrapper):
126 | ram_map = {
127 | "room": dict(
128 | index=3,
129 | ),
130 | "x": dict(
131 | index=42,
132 | ),
133 | "y": dict(
134 | index=43,
135 | ),
136 | }
137 |
138 | def __init__(self, env):
139 | super(MontezumaInfoWrapper, self).__init__(env)
140 | self.visited = set()
141 | self.visited_rooms = set()
142 |
143 | def step(self, action):
144 | obs, rew, done, info = self.env.step(action)
145 | ram_state = unwrap(self.env).ale.getRAM()
146 | for name, properties in MontezumaInfoWrapper.ram_map.items():
147 | info[name] = ram_state[properties['index']]
148 | pos = (info['x'], info['y'], info['room'])
149 | self.visited.add(pos)
150 | self.visited_rooms.add(info["room"])
151 | if done:
152 | info['mz_episode'] = dict(pos_count=len(self.visited),
153 | visited_rooms=copy(self.visited_rooms))
154 | self.visited.clear()
155 | self.visited_rooms.clear()
156 | return obs, rew, done, info
157 |
158 | def reset(self):
159 | return self.env.reset()
160 |
161 |
162 | class MarioXReward(gym.Wrapper):
163 | def __init__(self, env):
164 | gym.Wrapper.__init__(self, env)
165 | self.current_level = [0, 0]
166 | self.visited_levels = set()
167 | self.visited_levels.add(tuple(self.current_level))
168 | self.current_max_x = 0.
169 |
170 | def reset(self):
171 | ob = self.env.reset()
172 | self.current_level = [0, 0]
173 | self.visited_levels = set()
174 | self.visited_levels.add(tuple(self.current_level))
175 | self.current_max_x = 0.
176 | return ob
177 |
178 | def step(self, action):
179 | ob, reward, done, info = self.env.step(action)
180 | levellow, levelhigh, xscrollHi, xscrollLo = \
181 | info["levelLo"], info["levelHi"], info["xscrollHi"], info["xscrollLo"]
182 | currentx = xscrollHi * 256 + xscrollLo
183 | new_level = [levellow, levelhigh]
184 | if new_level != self.current_level:
185 | self.current_level = new_level
186 | self.current_max_x = 0.
187 | reward = 0.
188 | self.visited_levels.add(tuple(self.current_level))
189 | else:
190 | if currentx > self.current_max_x:
191 | delta = currentx - self.current_max_x
192 | self.current_max_x = currentx
193 | reward = delta
194 | else:
195 | reward = 0.
196 | if done:
197 | info["levels"] = copy(self.visited_levels)
198 | info["retro_episode"] = dict(levels=copy(self.visited_levels))
199 | return ob, reward, done, info
200 |
201 |
202 | class UnityRoomCounterWrapper(gym.Wrapper):
203 | def __init__(self, env,use_ext_reward=True):
204 | gym.Wrapper.__init__(self, env)
205 | self.current_room = None
206 | self.visited_rooms = set()
207 | self.use_ext_reward = use_ext_reward
208 |
209 | def reset(self):
210 | ob = self.env.reset()
211 | self.current_room = None
212 | self.visited_rooms = set()
213 | return ob
214 |
215 |
216 | def step(self, action):
217 | ob, true_reward, done, info = self.env.step(action)
218 | reward = 0.0
219 | current_room = info["curRoom"]
220 |
221 | if self.current_room is None:
222 | self.current_room = current_room
223 | reward = 1.0
224 | self.visited_rooms.add(self.current_room)
225 |
226 | if current_room != self.current_room:
227 | self.current_room = current_room
228 | if self.current_room not in self.visited_rooms:
229 | reward = 1.0
230 | self.visited_rooms.add(self.current_room)
231 | else:
232 | reward = 0.0
233 | info = {"unity_rooms":copy(self.visited_rooms)}
234 | return ob, reward if not self.use_ext_reward else true_reward, done, info
235 |
236 |
237 | class LimitedDiscreteActions(gym.ActionWrapper):
238 | KNOWN_BUTTONS = {"A", "B"}
239 | KNOWN_SHOULDERS = {"L", "R"}
240 |
241 | '''
242 | Reproduces the action space from curiosity paper.
243 | '''
244 |
245 | def __init__(self, env, all_buttons, whitelist=KNOWN_BUTTONS | KNOWN_SHOULDERS):
246 | gym.ActionWrapper.__init__(self, env)
247 |
248 | self._num_buttons = len(all_buttons)
249 | button_keys = {i for i in range(len(all_buttons)) if all_buttons[i] in whitelist & self.KNOWN_BUTTONS}
250 | buttons = [(), *zip(button_keys), *itertools.combinations(button_keys, 2)]
251 | shoulder_keys = {i for i in range(len(all_buttons)) if all_buttons[i] in whitelist & self.KNOWN_SHOULDERS}
252 | shoulders = [(), *zip(shoulder_keys), *itertools.permutations(shoulder_keys, 2)]
253 | arrows = [(), (4,), (5,), (6,), (7,)] # (), up, down, left, right
254 | acts = []
255 | acts += arrows
256 | acts += buttons[1:]
257 | acts += [a + b for a in arrows[-2:] for b in buttons[1:]]
258 | self._actions = acts
259 | self.action_space = gym.spaces.Discrete(len(self._actions))
260 |
261 | def action(self, a):
262 | mask = np.zeros(self._num_buttons)
263 | for i in self._actions[a]:
264 | mask[i] = 1
265 | return mask
266 |
267 |
268 | class FrameSkip(gym.Wrapper):
269 | def __init__(self, env, n):
270 | gym.Wrapper.__init__(self, env)
271 | self.n = n
272 |
273 | def step(self, action):
274 | done = False
275 | totrew = 0
276 | for _ in range(self.n):
277 | ob, rew, done, info = self.env.step(action)
278 | totrew += rew
279 | if done: break
280 | return ob, totrew, done, info
281 |
282 |
283 | def make_mario_env(crop=True, frame_stack=True, clip_rewards=False):
284 | assert clip_rewards is False
285 | import gym
286 | import retro
287 | from baselines.common.atari_wrappers import FrameStack
288 |
289 | #gym.undo_logger_setup()
290 | env = retro.make('SuperMarioBros-Nes', 'Level1-1')
291 | buttons = env.buttons
292 | env = MarioXReward(env)
293 | env = FrameSkip(env, 4)
294 | env = ProcessFrame84(env, crop=crop)
295 | if frame_stack:
296 | env = FrameStack(env, 4)
297 | env = LimitedDiscreteActions(env, buttons)
298 | return env
299 |
300 |
301 | class OneChannel(gym.ObservationWrapper):
302 | def __init__(self, env, crop=True):
303 | self.crop = crop
304 | super(OneChannel, self).__init__(env)
305 | assert env.observation_space.dtype == np.uint8
306 | self.observation_space = gym.spaces.Box(low=0, high=255, shape=(84, 84, 1), dtype=np.uint8)
307 |
308 | def observation(self, obs):
309 | return obs[:, :, 2:3]
310 |
311 |
312 | class RetroALEActions(gym.ActionWrapper):
313 | def __init__(self, env, all_buttons, n_players=1):
314 | gym.ActionWrapper.__init__(self, env)
315 | self.n_players = n_players
316 | self._num_buttons = len(all_buttons)
317 | bs = [-1, 0, 4, 5, 6, 7]
318 | actions = []
319 |
320 | def update_actions(old_actions, offset=0):
321 | actions = []
322 | for b in old_actions:
323 | for button in bs:
324 | action = []
325 | action.extend(b)
326 | if button != -1:
327 | action.append(button + offset)
328 | actions.append(action)
329 | return actions
330 |
331 | current_actions = [[]]
332 | for i in range(self.n_players):
333 | current_actions = update_actions(current_actions, i * self._num_buttons)
334 | self._actions = current_actions
335 | self.action_space = gym.spaces.Discrete(len(self._actions))
336 |
337 | def action(self, a):
338 | mask = np.zeros(self._num_buttons * self.n_players)
339 | for i in self._actions[a]:
340 | mask[i] = 1
341 | return mask
342 |
343 |
344 | class NoReward(gym.Wrapper):
345 | def __init__(self, env):
346 | gym.Wrapper.__init__(self, env)
347 |
348 | def step(self, action):
349 | ob, rew, done, info = self.env.step(action)
350 | return ob, 0.0, done, info
351 |
352 |
353 | def make_multi_pong(frame_stack=True):
354 | import gym
355 | import retro
356 | from baselines.common.atari_wrappers import FrameStack
357 | gym.undo_logger_setup()
358 | game_env = env = retro.make('Pong-Atari2600', players=2)
359 | env = RetroALEActions(env, game_env.BUTTONS, n_players=2)
360 | env = NoReward(env)
361 | env = FrameSkip(env, 4)
362 | env = ProcessFrame84(env, crop=False)
363 | if frame_stack:
364 | env = FrameStack(env, 4)
365 |
366 | return env
367 |
368 |
369 | def make_unity_maze(env_id, seed=0, rank=0, expID=0, frame_stack=True,
370 | logdir=None, ext_coeff=1.0, recordUnityVid=False, **kwargs):
371 | import os
372 | import sys
373 | import time
374 | try:
375 | sys.path.insert(0, os.path.abspath("ml-agents/python/"))
376 | from unityagents import UnityEnvironment
377 | from unity_wrapper import GymWrapper
378 | except ImportError:
379 | print("Import error in unity environment. Ignore if not using unity.")
380 | pass
381 | from baselines.common.atari_wrappers import FrameStack
382 | # gym.undo_logger_setup() # deprecated in new version of gym
383 |
384 | # max 20 workers per expID, max 30 experiments per machine
385 | if rank>=0 and rank<=200:
386 | time.sleep(rank * 2)
387 | env = UnityEnvironment(file_name='envs/' + env_id,
388 | worker_id=(expID % 60) * 200 + rank)
389 | maxsteps = 3000 if 'big' in env_id else 500
390 | env = GymWrapper(env, seed=seed, rank=rank, expID=expID, maxsteps=maxsteps,
391 | **kwargs)
392 | if "big" in env_id:
393 | env = UnityRoomCounterWrapper(env, use_ext_reward=(ext_coeff != 0.0))
394 | if rank == 1 and recordUnityVid:
395 | env = RecordBestScores(env, directory=logdir, freq=1)
396 | print('Loaded environment %s with rank %d\n\n' % (env_id, rank))
397 |
398 | # env = NoReward(env)
399 | # env = FrameSkip(env, 4)
400 | env = ProcessFrame84(env, crop=False)
401 | if frame_stack:
402 | env = FrameStack(env, 4)
403 | return env
404 |
405 |
406 | class RecordBestScores(gym.Wrapper):
407 | def __init__(self, env, directory, freq=100):
408 | super(RecordBestScores, self).__init__(env)
409 | self.freq = freq
410 | self.frames = []
411 | self.highest_reward = None
412 | self.episodic_reward = 0.
413 | self.longest_length = 0
414 | self.directory = directory
415 | self.episode_number = 0
416 | if not os.path.exists(self.directory):
417 | os.makedirs(self.directory)
418 |
419 | def _step(self, action):
420 | state, reward, done, info = self.env.step(action)
421 | self.frames.append(self.env.render(mode='rgb_array'))
422 | self.episodic_reward += reward
423 | if done:
424 | if self.highest_reward == None:
425 | self.highest_reward = self.episodic_reward
426 | self._record_last_episode("high_score_")
427 | elif self.highest_reward < self.episodic_reward:
428 | self.highest_reward = self.episodic_reward
429 | self._record_last_episode("high_score_")
430 | elif self.episode_number % self.freq == 0:
431 | self._record_last_episode("random_")
432 |
433 | self.frames = []
434 | self.episodic_reward = 0
435 | self.episode_number += 1
436 | return state, reward, done, info
437 |
438 | def _record_last_episode(self, prefix=""):
439 | save_np_as_mp4(self.frames, os.path.join(self.directory, prefix+'replay{}.mp4'.format(self.episode_number)))
440 |
441 |
442 | class StickyActionEnv(gym.Wrapper):
443 | def __init__(self, env, p=0.25):
444 | super(StickyActionEnv, self).__init__(env)
445 | self.p = p
446 | self.last_action = 0
447 |
448 | def reset(self):
449 | self.last_action = 0
450 | return self.env.reset()
451 |
452 | def step(self, action):
453 | if self.unwrapped.np_random.uniform() < self.p:
454 | action = self.last_action
455 | self.last_action = action
456 | obs, reward, done, info = self.env.step(action)
457 | return obs, reward, done, info
458 |
--------------------------------------------------------------------------------
13 |
14 |
15 | This is a TensorFlow based implementation for our [paper on self-supervised exploration via disagreement](https://pathak22.github.io/exploration-by-disagreement/). In this paper, we propose a formulation for exploration inspired by the work in active learning literature. Specifically, we train an ensemble of dynamics models and incentivize the agent to explore such that the disagreement of those ensembles is maximized. This allows the agent to learn skills by exploring in a self-supervised manner without any external reward. Notably, we further leverage the disagreement objective to optimize the agent's policy in a differentiable manner, without using reinforcement learning, which results in a sample-efficient exploration. We demonstrate the efficacy of this formulation across a variety of benchmark environments including stochastic-Atari, Mujoco, Unity and a real robotic arm. If you find this work useful in your research, please cite:
16 |
17 | @inproceedings{pathak19disagreement,
18 | Author = {Pathak, Deepak and
19 | Gandhi, Dhiraj and Gupta, Abhinav},
20 | Title = {Self-Supervised Exploration via Disagreement},
21 | Booktitle = {ICML},
22 | Year = {2019}
23 | }
24 |
25 | ### Installation and Usage
26 | The following command should train a pure exploration agent on Breakout with default experiment parameters.
27 | ```bash
28 | python run.py
29 | ```
30 | To use more than one gpu/machine, use MPI (e.g. `mpiexec -n 8 python run.py` should use 1024 parallel environments to collect experience instead of the default 128 on an 8 gpu machine).
31 |
32 | ### Other helpful pointers
33 | - [Paper](https://pathak22.github.io/exploration-by-disagreement/resources/icml19.pdf)
34 | - [Project Website](https://pathak22.github.io/exploration-by-disagreement/)
35 | - [Demo Video](https://youtu.be/POlrWt32_ec)
36 |
37 | ### Acknowledgement
38 |
39 | This repository is built off the publicly released code of [Large-Scale Study of Curiosity-driven Learning, ICLR 2019](https://github.com/openai/large-scale-curiosity).
40 |
--------------------------------------------------------------------------------
/cnn_policy.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | from baselines.common.distributions import make_pdtype
3 |
4 | from utils import getsess, small_convnet, activ, fc, flatten_two_dims, unflatten_first_dim
5 |
6 |
7 | class CnnPolicy(object):
8 | def __init__(self, ob_space, ac_space, hidsize,
9 | ob_mean, ob_std, feat_dim, layernormalize, nl, scope="policy"):
10 | if layernormalize:
11 | print("Warning: policy is operating on top of layer-normed features. It might slow down the training.")
12 | self.layernormalize = layernormalize
13 | self.nl = nl
14 | self.ob_mean = ob_mean
15 | self.ob_std = ob_std
16 | with tf.variable_scope(scope):
17 | self.ob_space = ob_space
18 | self.ac_space = ac_space
19 | self.ac_pdtype = make_pdtype(ac_space)
20 | self.ph_ob = tf.placeholder(dtype=tf.int32,
21 | shape=(None, None) + ob_space.shape, name='ob')
22 | self.ph_ac = self.ac_pdtype.sample_placeholder([None, None], name='ac')
23 | self.pd = self.vpred = None
24 | self.hidsize = hidsize
25 | self.feat_dim = feat_dim
26 | self.scope = scope
27 | pdparamsize = self.ac_pdtype.param_shape()[0]
28 |
29 | sh = tf.shape(self.ph_ob)
30 | x = flatten_two_dims(self.ph_ob)
31 | self.flat_features = self.get_features(x, reuse=False)
32 | self.features = unflatten_first_dim(self.flat_features, sh)
33 |
34 | with tf.variable_scope(scope, reuse=False):
35 | x = fc(self.flat_features, units=hidsize, activation=activ)
36 | x = fc(x, units=hidsize, activation=activ)
37 | pdparam = fc(x, name='pd', units=pdparamsize, activation=None)
38 | vpred = fc(x, name='value_function_output', units=1, activation=None)
39 | pdparam = unflatten_first_dim(pdparam, sh)
40 | self.vpred = unflatten_first_dim(vpred, sh)[:, :, 0]
41 | self.pd = pd = self.ac_pdtype.pdfromflat(pdparam)
42 | self.a_samp = pd.sample()
43 | self.entropy = pd.entropy()
44 | self.nlp_samp = pd.neglogp(self.a_samp)
45 |
46 | def get_features(self, x, reuse):
47 | x_has_timesteps = (x.get_shape().ndims == 5)
48 | if x_has_timesteps:
49 | sh = tf.shape(x)
50 | x = flatten_two_dims(x)
51 |
52 | with tf.variable_scope(self.scope + "_features", reuse=reuse):
53 | x = (tf.to_float(x) - self.ob_mean) / self.ob_std
54 | x = small_convnet(x, nl=self.nl, feat_dim=self.feat_dim, last_nl=None, layernormalize=self.layernormalize)
55 |
56 | if x_has_timesteps:
57 | x = unflatten_first_dim(x, sh)
58 | return x
59 |
60 | def get_ac_value_nlp(self, ob):
61 | a, vpred, nlp = \
62 | getsess().run([self.a_samp, self.vpred, self.nlp_samp],
63 | feed_dict={self.ph_ob: ob[:, None]})
64 | return a[:, 0], vpred[:, 0], nlp[:, 0]
65 |
--------------------------------------------------------------------------------
/dynamics.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import tensorflow as tf
3 |
4 | from auxiliary_tasks import JustPixels
5 | from utils import small_convnet, flatten_two_dims, unflatten_first_dim, getsess, unet
6 |
7 |
8 | class Dynamics(object):
9 | def __init__(self, auxiliary_task, predict_from_pixels, var_output, feat_dim=None, scope='dynamics'):
10 | self.scope = scope
11 | self.auxiliary_task = auxiliary_task
12 | self.hidsize = self.auxiliary_task.hidsize
13 | self.feat_dim = feat_dim
14 | self.obs = self.auxiliary_task.obs
15 | self.last_ob = self.auxiliary_task.last_ob
16 | self.ac = self.auxiliary_task.ac
17 | self.ac_space = self.auxiliary_task.ac_space
18 | self.ob_mean = self.auxiliary_task.ob_mean
19 | self.ob_std = self.auxiliary_task.ob_std
20 | self.var_output = var_output
21 | if predict_from_pixels:
22 | self.features = self.get_features(self.obs, reuse=False)
23 | else:
24 | self.features = tf.stop_gradient(self.auxiliary_task.features)
25 |
26 | self.out_features = self.auxiliary_task.next_features
27 | with tf.variable_scope(self.scope + "_loss"):
28 | self.loss = self.get_loss()
29 | self.partial_loss = self.get_loss_partial()
30 |
31 | def get_features(self, x, reuse):
32 | nl = tf.nn.leaky_relu
33 | x_has_timesteps = (x.get_shape().ndims == 5)
34 | if x_has_timesteps:
35 | sh = tf.shape(x)
36 | x = flatten_two_dims(x)
37 | with tf.variable_scope(self.scope + "_features", reuse=reuse):
38 | x = (tf.to_float(x) - self.ob_mean) / self.ob_std
39 | x = small_convnet(x, nl=nl, feat_dim=self.feat_dim, last_nl=nl, layernormalize=False)
40 | if x_has_timesteps:
41 | x = unflatten_first_dim(x, sh)
42 | return x
43 |
44 | def get_loss(self):
45 | ac = tf.one_hot(self.ac, self.ac_space.n, axis=2)
46 | sh = tf.shape(ac)
47 | ac = flatten_two_dims(ac)
48 |
49 | def add_ac(x):
50 | return tf.concat([x, ac], axis=-1)
51 |
52 | with tf.variable_scope(self.scope):
53 | x = flatten_two_dims(self.features)
54 | x = tf.layers.dense(add_ac(x), self.hidsize, activation=tf.nn.leaky_relu)
55 |
56 | def residual(x):
57 | res = tf.layers.dense(add_ac(x), self.hidsize, activation=tf.nn.leaky_relu)
58 | res = tf.layers.dense(add_ac(res), self.hidsize, activation=None)
59 | return x + res
60 |
61 | for _ in range(4):
62 | x = residual(x)
63 | n_out_features = self.out_features.get_shape()[-1].value
64 | x = tf.layers.dense(add_ac(x), n_out_features, activation=None)
65 | x = unflatten_first_dim(x, sh)
66 | if self.var_output:
67 | return x
68 | else:
69 | return tf.reduce_mean((x - tf.stop_gradient(self.out_features)) ** 2, -1)
70 |
71 | def get_loss_partial(self):
72 | ac = tf.one_hot(self.ac, self.ac_space.n, axis=2)
73 | sh = tf.shape(ac)
74 | ac = flatten_two_dims(ac)
75 |
76 | def add_ac(x):
77 | return tf.concat([x, ac], axis=-1)
78 |
79 | with tf.variable_scope(self.scope, reuse=True):
80 | x = flatten_two_dims(self.features)
81 | x = tf.layers.dense(add_ac(x), self.hidsize, activation=tf.nn.leaky_relu)
82 |
83 | def residual(x):
84 | res = tf.layers.dense(add_ac(x), self.hidsize, activation=tf.nn.leaky_relu)
85 | res = tf.layers.dense(add_ac(res), self.hidsize, activation=None)
86 | return x + res
87 |
88 | for _ in range(4):
89 | x = residual(x)
90 | n_out_features = self.out_features.get_shape()[-1].value
91 | x = tf.layers.dense(add_ac(x), n_out_features, activation=None)
92 | x = unflatten_first_dim(x, sh)
93 | return tf.nn.dropout(tf.reduce_mean(((x - tf.stop_gradient(self.out_features)) ** 2), -1), keep_prob=0.8)
94 |
95 | def calculate_loss(self, ob, last_ob, acs):
96 | n_chunks = 8
97 | n = ob.shape[0]
98 | chunk_size = n // n_chunks
99 | assert n % n_chunks == 0
100 | sli = lambda i: slice(i * chunk_size, (i + 1) * chunk_size)
101 | return np.concatenate([getsess().run(self.loss,
102 | {self.obs: ob[sli(i)], self.last_ob: last_ob[sli(i)],
103 | self.ac: acs[sli(i)]}) for i in range(n_chunks)], 0)
104 |
105 |
106 | class UNet(Dynamics):
107 | def __init__(self, auxiliary_task, predict_from_pixels, feat_dim=None, scope='pixel_dynamics'):
108 | assert isinstance(auxiliary_task, JustPixels)
109 | assert not predict_from_pixels, "predict from pixels must be False, it's set up to predict from features that are normalized pixels."
110 | super(UNet, self).__init__(auxiliary_task=auxiliary_task,
111 | predict_from_pixels=predict_from_pixels,
112 | feat_dim=feat_dim,
113 | scope=scope)
114 |
115 | def get_features(self, x, reuse):
116 | raise NotImplementedError
117 |
118 | def get_loss(self):
119 | nl = tf.nn.leaky_relu
120 | ac = tf.one_hot(self.ac, self.ac_space.n, axis=2)
121 | sh = tf.shape(ac)
122 | ac = flatten_two_dims(ac)
123 | ac_four_dim = tf.expand_dims(tf.expand_dims(ac, 1), 1)
124 |
125 | def add_ac(x):
126 | if x.get_shape().ndims == 2:
127 | return tf.concat([x, ac], axis=-1)
128 | elif x.get_shape().ndims == 4:
129 | sh = tf.shape(x)
130 | return tf.concat(
131 | [x, ac_four_dim + tf.zeros([sh[0], sh[1], sh[2], ac_four_dim.get_shape()[3].value], tf.float32)],
132 | axis=-1)
133 |
134 | with tf.variable_scope(self.scope):
135 | x = flatten_two_dims(self.features)
136 | x = unet(x, nl=nl, feat_dim=self.feat_dim, cond=add_ac)
137 | x = unflatten_first_dim(x, sh)
138 | self.prediction_pixels = x * self.ob_std + self.ob_mean
139 | return tf.reduce_mean((x - tf.stop_gradient(self.out_features)) ** 2, [2, 3, 4])
140 |
--------------------------------------------------------------------------------
/vec_env.py:
--------------------------------------------------------------------------------
1 | """
2 | An interface for asynchronous vectorized environments.
3 | """
4 |
5 | import ctypes
6 | from abc import ABC, abstractmethod
7 | from multiprocessing import Pipe, Array, Process
8 |
9 | import gym
10 | import numpy as np
11 | from baselines import logger
12 |
13 | _NP_TO_CT = {np.float32: ctypes.c_float,
14 | np.int32: ctypes.c_int32,
15 | np.int8: ctypes.c_int8,
16 | np.uint8: ctypes.c_char,
17 | np.bool: ctypes.c_bool}
18 | _CT_TO_NP = {v: k for k, v in _NP_TO_CT.items()}
19 |
20 |
21 | class CloudpickleWrapper(object):
22 | """
23 | Uses cloudpickle to serialize contents (otherwise multiprocessing tries to use pickle)
24 | """
25 |
26 | def __init__(self, x):
27 | self.x = x
28 |
29 | def __getstate__(self):
30 | import cloudpickle
31 | return cloudpickle.dumps(self.x)
32 |
33 | def __setstate__(self, ob):
34 | import pickle
35 | self.x = pickle.loads(ob)
36 |
37 |
38 | class VecEnv(ABC):
39 | """
40 | An abstract asynchronous, vectorized environment.
41 | """
42 |
43 | def __init__(self, num_envs, observation_space, action_space):
44 | self.num_envs = num_envs
45 | self.observation_space = observation_space
46 | self.action_space = action_space
47 |
48 | @abstractmethod
49 | def reset(self):
50 | """
51 | Reset all the environments and return an array of
52 | observations, or a tuple of observation arrays.
53 |
54 | If step_async is still doing work, that work will
55 | be cancelled and step_wait() should not be called
56 | until step_async() is invoked again.
57 | """
58 | pass
59 |
60 | @abstractmethod
61 | def step_async(self, actions):
62 | """
63 | Tell all the environments to start taking a step
64 | with the given actions.
65 | Call step_wait() to get the results of the step.
66 |
67 | You should not call this if a step_async run is
68 | already pending.
69 | """
70 | pass
71 |
72 | @abstractmethod
73 | def step_wait(self):
74 | """
75 | Wait for the step taken with step_async().
76 |
77 | Returns (obs, rews, dones, infos):
78 | - obs: an array of observations, or a tuple of
79 | arrays of observations.
80 | - rews: an array of rewards
81 | - dones: an array of "episode done" booleans
82 | - infos: a sequence of info objects
83 | """
84 | pass
85 |
86 | @abstractmethod
87 | def close(self):
88 | """
89 | Clean up the environments' resources.
90 | """
91 | pass
92 |
93 | def step(self, actions):
94 | self.step_async(actions)
95 | return self.step_wait()
96 |
97 | def render(self):
98 | logger.warn('Render not defined for %s' % self)
99 |
100 |
101 | class ShmemVecEnv(VecEnv):
102 | """
103 | An AsyncEnv that uses multiprocessing to run multiple
104 | environments in parallel.
105 | """
106 |
107 | def __init__(self, env_fns, spaces=None):
108 | """
109 | If you don't specify observation_space, we'll have to create a dummy
110 | environment to get it.
111 | """
112 | if spaces:
113 | observation_space, action_space = spaces
114 | else:
115 | logger.log('Creating dummy env object to get spaces')
116 | with logger.scoped_configure(format_strs=[]):
117 | dummy = env_fns[0]()
118 | observation_space, action_space = dummy.observation_space, dummy.action_space
119 | dummy.close()
120 | del dummy
121 | VecEnv.__init__(self, len(env_fns), observation_space, action_space)
122 |
123 | obs_spaces = observation_space.spaces if isinstance(self.observation_space, gym.spaces.Tuple) else (
124 | self.observation_space,)
125 | self.obs_bufs = [tuple(Array(_NP_TO_CT[s.dtype.type], int(np.prod(s.shape))) for s in obs_spaces) for _ in
126 | env_fns]
127 | self.obs_shapes = [s.shape for s in obs_spaces]
128 | self.obs_dtypes = [s.dtype for s in obs_spaces]
129 |
130 | self.parent_pipes = []
131 | self.procs = []
132 | for env_fn, obs_buf in zip(env_fns, self.obs_bufs):
133 | wrapped_fn = CloudpickleWrapper(env_fn)
134 | parent_pipe, child_pipe = Pipe()
135 | proc = Process(target=_subproc_worker,
136 | args=(child_pipe, parent_pipe, wrapped_fn, obs_buf, self.obs_shapes))
137 | proc.daemon = True
138 | self.procs.append(proc)
139 | self.parent_pipes.append(parent_pipe)
140 | proc.start()
141 | child_pipe.close()
142 | self.waiting_step = False
143 |
144 | def reset(self):
145 | if self.waiting_step:
146 | logger.warn('Called reset() while waiting for the step to complete')
147 | self.step_wait()
148 | for pipe in self.parent_pipes:
149 | pipe.send(('reset', None))
150 | return self._decode_obses([pipe.recv() for pipe in self.parent_pipes])
151 |
152 | def step_async(self, actions):
153 | assert len(actions) == len(self.parent_pipes)
154 | for pipe, act in zip(self.parent_pipes, actions):
155 | pipe.send(('step', act))
156 |
157 | def step_wait(self):
158 | outs = [pipe.recv() for pipe in self.parent_pipes]
159 | obs, rews, dones, infos = zip(*outs)
160 | return self._decode_obses(obs), np.array(rews), np.array(dones), infos
161 |
162 | def close(self):
163 | if self.waiting_step:
164 | self.step_wait()
165 | for pipe in self.parent_pipes:
166 | pipe.send(('close', None))
167 | for pipe in self.parent_pipes:
168 | pipe.recv()
169 | pipe.close()
170 | for proc in self.procs:
171 | proc.join()
172 |
173 | def _decode_obses(self, obs):
174 | """
175 | Turn the observation responses into a single numpy
176 | array, possibly via shared memory.
177 | """
178 | obs = []
179 | for i, shape in enumerate(self.obs_shapes):
180 | bufs = [b[i] for b in self.obs_bufs]
181 | o = [np.frombuffer(b.get_obj(), dtype=self.obs_dtypes[i]).reshape(shape) for b in bufs]
182 | obs.append(np.array(o))
183 | return tuple(obs) if len(obs) > 1 else obs[0]
184 |
185 |
186 | def _subproc_worker(pipe, parent_pipe, env_fn_wrapper, obs_buf, obs_shape):
187 | """
188 | Control a single environment instance using IPC and
189 | shared memory.
190 |
191 | If obs_buf is not None, it is a shared-memory buffer
192 | for communicating observations.
193 | """
194 |
195 | def _write_obs(obs):
196 | if not isinstance(obs, tuple):
197 | obs = (obs,)
198 | for o, b, s in zip(obs, obs_buf, obs_shape):
199 | dst = b.get_obj()
200 | dst_np = np.frombuffer(dst, dtype=_CT_TO_NP[dst._type_]).reshape(s) # pylint: disable=W0212
201 | np.copyto(dst_np, o)
202 |
203 | env = env_fn_wrapper.x()
204 | parent_pipe.close()
205 | try:
206 | while True:
207 | cmd, data = pipe.recv()
208 | if cmd == 'reset':
209 | pipe.send(_write_obs(env.reset()))
210 | elif cmd == 'step':
211 | obs, reward, done, info = env.step(data)
212 | if done:
213 | obs = env.reset()
214 | pipe.send((_write_obs(obs), reward, done, info))
215 | elif cmd == 'close':
216 | pipe.send(None)
217 | break
218 | else:
219 | raise RuntimeError('Got unrecognized cmd %s' % cmd)
220 | finally:
221 | env.close()
222 |
--------------------------------------------------------------------------------
/auxiliary_tasks.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 |
3 | from utils import small_convnet, fc, activ, flatten_two_dims, unflatten_first_dim, small_deconvnet
4 |
5 |
6 | class FeatureExtractor(object):
7 | def __init__(self, policy, features_shared_with_policy, feat_dim=None, layernormalize=None,
8 | scope='feature_extractor'):
9 | self.scope = scope
10 | self.features_shared_with_policy = features_shared_with_policy
11 | self.feat_dim = feat_dim
12 | self.layernormalize = layernormalize
13 | self.policy = policy
14 | self.hidsize = policy.hidsize
15 | self.ob_space = policy.ob_space
16 | self.ac_space = policy.ac_space
17 | self.obs = self.policy.ph_ob
18 | self.ob_mean = self.policy.ob_mean
19 | self.ob_std = self.policy.ob_std
20 | with tf.variable_scope(scope):
21 | self.last_ob = tf.placeholder(dtype=tf.int32,
22 | shape=(None, 1) + self.ob_space.shape, name='last_ob')
23 | self.next_ob = tf.concat([self.obs[:, 1:], self.last_ob], 1)
24 |
25 | if features_shared_with_policy:
26 | self.features = self.policy.features
27 | self.last_features = self.policy.get_features(self.last_ob, reuse=True)
28 | else:
29 | self.features = self.get_features(self.obs, reuse=False)
30 | self.last_features = self.get_features(self.last_ob, reuse=True)
31 | self.next_features = tf.concat([self.features[:, 1:], self.last_features], 1)
32 |
33 | self.ac = self.policy.ph_ac
34 | self.scope = scope
35 |
36 | self.loss = self.get_loss()
37 |
38 | def get_features(self, x, reuse):
39 | nl = tf.nn.leaky_relu
40 | x_has_timesteps = (x.get_shape().ndims == 5)
41 | if x_has_timesteps:
42 | sh = tf.shape(x)
43 | x = flatten_two_dims(x)
44 | with tf.variable_scope(self.scope + "_features", reuse=reuse):
45 | x = (tf.to_float(x) - self.ob_mean) / self.ob_std
46 | x = small_convnet(x, nl=nl, feat_dim=self.feat_dim, last_nl=None, layernormalize=self.layernormalize)
47 | if x_has_timesteps:
48 | x = unflatten_first_dim(x, sh)
49 | return x
50 |
51 | def get_loss(self):
52 | return tf.zeros((), dtype=tf.float32)
53 |
54 |
55 | class InverseDynamics(FeatureExtractor):
56 | def __init__(self, policy, features_shared_with_policy, feat_dim=None, layernormalize=None):
57 | super(InverseDynamics, self).__init__(scope="inverse_dynamics", policy=policy,
58 | features_shared_with_policy=features_shared_with_policy,
59 | feat_dim=feat_dim, layernormalize=layernormalize)
60 |
61 | def get_loss(self):
62 | with tf.variable_scope(self.scope):
63 | x = tf.concat([self.features, self.next_features], 2)
64 | sh = tf.shape(x)
65 | x = flatten_two_dims(x)
66 | x = fc(x, units=self.policy.hidsize, activation=activ)
67 | x = fc(x, units=self.ac_space.n, activation=None)
68 | param = unflatten_first_dim(x, sh)
69 | idfpd = self.policy.ac_pdtype.pdfromflat(param)
70 | return idfpd.neglogp(self.ac)
71 |
72 |
73 | class VAE(FeatureExtractor):
74 | def __init__(self, policy, features_shared_with_policy, feat_dim=None, layernormalize=False, spherical_obs=False):
75 | assert not layernormalize, "VAE features should already have reasonable size, no need to layer normalize them"
76 | self.spherical_obs = spherical_obs
77 | super(VAE, self).__init__(scope="vae", policy=policy,
78 | features_shared_with_policy=features_shared_with_policy,
79 | feat_dim=feat_dim, layernormalize=False)
80 | self.features = tf.split(self.features, 2, -1)[0] # use mean only for features exposed to the dynamics
81 | self.next_features = tf.split(self.next_features, 2, -1)[0]
82 |
83 | def get_features(self, x, reuse):
84 | nl = tf.nn.leaky_relu
85 | x_has_timesteps = (x.get_shape().ndims == 5)
86 | if x_has_timesteps:
87 | sh = tf.shape(x)
88 | x = flatten_two_dims(x)
89 | with tf.variable_scope(self.scope + "_features", reuse=reuse):
90 | x = (tf.to_float(x) - self.ob_mean) / self.ob_std
91 | x = small_convnet(x, nl=nl, feat_dim=2 * self.feat_dim, last_nl=None, layernormalize=False)
92 | if x_has_timesteps:
93 | x = unflatten_first_dim(x, sh)
94 | return x
95 |
96 | def get_loss(self):
97 | with tf.variable_scope(self.scope):
98 | posterior_mean, posterior_scale = tf.split(self.features, 2, -1)
99 | posterior_scale = tf.nn.softplus(posterior_scale)
100 | posterior_distribution = tf.distributions.Normal(loc=posterior_mean, scale=posterior_scale)
101 |
102 | sh = tf.shape(posterior_mean)
103 | prior = tf.distributions.Normal(loc=tf.zeros(sh), scale=tf.ones(sh))
104 |
105 | posterior_kl = tf.distributions.kl_divergence(posterior_distribution, prior)
106 |
107 | posterior_kl = tf.reduce_sum(posterior_kl, [-1])
108 | assert posterior_kl.get_shape().ndims == 2
109 |
110 | posterior_sample = posterior_distribution.sample()
111 | reconstruction_distribution = self.decoder(posterior_sample)
112 | norm_obs = self.add_noise_and_normalize(self.obs)
113 | reconstruction_likelihood = reconstruction_distribution.log_prob(norm_obs)
114 | assert reconstruction_likelihood.get_shape().as_list()[2:] == [84, 84, 4]
115 | reconstruction_likelihood = tf.reduce_sum(reconstruction_likelihood, [2, 3, 4])
116 |
117 | likelihood_lower_bound = reconstruction_likelihood - posterior_kl
118 | return - likelihood_lower_bound
119 |
120 | def add_noise_and_normalize(self, x):
121 | x = tf.to_float(x) + tf.random_uniform(shape=tf.shape(x), minval=0., maxval=1.)
122 | x = (x - self.ob_mean) / self.ob_std
123 | return x
124 |
125 | def decoder(self, z):
126 | nl = tf.nn.leaky_relu
127 | z_has_timesteps = (z.get_shape().ndims == 3)
128 | if z_has_timesteps:
129 | sh = tf.shape(z)
130 | z = flatten_two_dims(z)
131 | with tf.variable_scope(self.scope + "decoder"):
132 | z = small_deconvnet(z, nl=nl, ch=4 if self.spherical_obs else 8, positional_bias=True)
133 | if z_has_timesteps:
134 | z = unflatten_first_dim(z, sh)
135 | if self.spherical_obs:
136 | scale = tf.get_variable(name="scale", shape=(), dtype=tf.float32,
137 | initializer=tf.ones_initializer())
138 | scale = tf.maximum(scale, -4.)
139 | scale = tf.nn.softplus(scale)
140 | scale = scale * tf.ones_like(z)
141 | else:
142 | z, scale = tf.split(z, 2, -1)
143 | scale = tf.nn.softplus(scale)
144 | # scale = tf.Print(scale, [scale])
145 | return tf.distributions.Normal(loc=z, scale=scale)
146 |
147 |
148 | class JustPixels(FeatureExtractor):
149 | def __init__(self, policy, features_shared_with_policy, feat_dim=None, layernormalize=None,
150 | scope='just_pixels'):
151 | assert not layernormalize
152 | assert not features_shared_with_policy
153 | super(JustPixels, self).__init__(scope=scope, policy=policy,
154 | features_shared_with_policy=False,
155 | feat_dim=None, layernormalize=None)
156 |
157 | def get_features(self, x, reuse):
158 | with tf.variable_scope(self.scope + "_features", reuse=reuse):
159 | x = (tf.to_float(x) - self.ob_mean) / self.ob_std
160 | return x
161 |
162 | def get_loss(self):
163 | return tf.zeros((), dtype=tf.float32)
164 |
--------------------------------------------------------------------------------
/rollouts.py:
--------------------------------------------------------------------------------
1 | from collections import deque, defaultdict
2 |
3 | import numpy as np
4 | from mpi4py import MPI
5 |
6 | from recorder import Recorder
7 |
8 |
9 | class Rollout(object):
10 | def __init__(self, ob_space, ac_space, nenvs, nsteps_per_seg, nsegs_per_env, nlumps, envs, policy,
11 | int_rew_coeff, ext_rew_coeff, record_rollouts, dynamics_list):
12 | self.nenvs = nenvs
13 | self.nsteps_per_seg = nsteps_per_seg
14 | self.nsegs_per_env = nsegs_per_env
15 | self.nsteps = self.nsteps_per_seg * self.nsegs_per_env
16 | self.ob_space = ob_space
17 | self.ac_space = ac_space
18 | self.nlumps = nlumps
19 | self.lump_stride = nenvs // self.nlumps
20 | self.envs = envs
21 | self.policy = policy
22 | self.dynamics_list = dynamics_list
23 |
24 | self.reward_fun = lambda ext_rew, int_rew: ext_rew_coeff * np.clip(ext_rew, -1., 1.) + int_rew_coeff * int_rew
25 |
26 | self.buf_vpreds = np.empty((nenvs, self.nsteps), np.float32)
27 | self.buf_nlps = np.empty((nenvs, self.nsteps), np.float32)
28 | self.buf_rews = np.empty((nenvs, self.nsteps), np.float32)
29 | self.buf_ext_rews = np.empty((nenvs, self.nsteps), np.float32)
30 | self.buf_acs = np.empty((nenvs, self.nsteps, *self.ac_space.shape), self.ac_space.dtype)
31 | self.buf_obs = np.empty((nenvs, self.nsteps, *self.ob_space.shape), self.ob_space.dtype)
32 | self.buf_obs_last = np.empty((nenvs, self.nsegs_per_env, *self.ob_space.shape), np.float32)
33 |
34 | self.buf_news = np.zeros((nenvs, self.nsteps), np.float32)
35 | self.buf_new_last = self.buf_news[:, 0, ...].copy()
36 | self.buf_vpred_last = self.buf_vpreds[:, 0, ...].copy()
37 |
38 | self.env_results = [None] * self.nlumps
39 | # self.prev_feat = [None for _ in range(self.nlumps)]
40 | # self.prev_acs = [None for _ in range(self.nlumps)]
41 | self.int_rew = np.zeros((nenvs,), np.float32)
42 |
43 | self.recorder = Recorder(nenvs=self.nenvs, nlumps=self.nlumps) if record_rollouts else None
44 | self.statlists = defaultdict(lambda: deque([], maxlen=100))
45 | self.stats = defaultdict(float)
46 | self.best_ext_ret = None
47 | self.all_visited_rooms = []
48 | self.all_scores = []
49 |
50 | self.step_count = 0
51 |
52 | def collect_rollout(self):
53 | self.ep_infos_new = []
54 | for t in range(self.nsteps):
55 | self.rollout_step()
56 | self.calculate_reward()
57 | self.update_info()
58 |
59 | def calculate_reward(self):
60 | int_rew = []
61 | if self.dynamics_list[0].var_output:
62 | net_output = []
63 | for dynamics in self.dynamics_list:
64 | net_output.append(dynamics.calculate_loss(ob=self.buf_obs,
65 | last_ob=self.buf_obs_last,
66 | acs=self.buf_acs))
67 |
68 | # cal variance along first dimension .. [n_dyna, n_env, n_step, feature_size]
69 | # --> [n_env, n_step,feature_size]
70 | var_output = np.var(net_output, axis=0)
71 |
72 | # cal reward by mean along second dimension .. [n_env, n_step, feature_size] --> [n_env, n_step]
73 | var_rew = np.mean(var_output, axis=-1)
74 | else:
75 | for dynamics in self.dynamics_list:
76 | int_rew.append(dynamics.calculate_loss(ob=self.buf_obs,
77 | last_ob=self.buf_obs_last,
78 | acs=self.buf_acs))
79 |
80 | # calculate the variance of the rew
81 | var_rew = np.var(int_rew, axis=0)
82 |
83 | self.buf_rews[:] = self.reward_fun(int_rew=var_rew, ext_rew=self.buf_ext_rews)
84 |
85 | def rollout_step(self):
86 | t = self.step_count % self.nsteps
87 | s = t % self.nsteps_per_seg
88 | for l in range(self.nlumps):
89 | obs, prevrews, news, infos = self.env_get(l)
90 | # if t > 0:
91 | # prev_feat = self.prev_feat[l]
92 | # prev_acs = self.prev_acs[l]
93 | for info in infos:
94 | epinfo = info.get('episode', {})
95 | mzepinfo = info.get('mz_episode', {})
96 | retroepinfo = info.get('retro_episode', {})
97 | unityepinfo = info.get("unity_episode", {})
98 | epinfo.update(unityepinfo)
99 | epinfo.update(mzepinfo)
100 | epinfo.update(retroepinfo)
101 | if epinfo:
102 | if "n_states_visited" in info:
103 | epinfo["n_states_visited"] = info["n_states_visited"]
104 | epinfo["states_visited"] = info["states_visited"]
105 | if "unity_rooms" in info:
106 | epinfo["unity_rooms"] = info["unity_rooms"]
107 | self.ep_infos_new.append((self.step_count, epinfo))
108 |
109 | sli = slice(l * self.lump_stride, (l + 1) * self.lump_stride)
110 |
111 | acs, vpreds, nlps = self.policy.get_ac_value_nlp(obs)
112 | self.env_step(l, acs)
113 |
114 | # self.prev_feat[l] = dyn_feat
115 | # self.prev_acs[l] = acs
116 | self.buf_obs[sli, t] = obs
117 | self.buf_news[sli, t] = news
118 | self.buf_vpreds[sli, t] = vpreds
119 | self.buf_nlps[sli, t] = nlps
120 | self.buf_acs[sli, t] = acs
121 | if t > 0:
122 | self.buf_ext_rews[sli, t - 1] = prevrews
123 | # if t > 0:
124 | # dyn_logp = self.policy.call_reward(prev_feat, pol_feat, prev_acs)
125 | #
126 | # int_rew = dyn_logp.reshape(-1, )
127 | #
128 | # self.int_rew[sli] = int_rew
129 | # self.buf_rews[sli, t - 1] = self.reward_fun(ext_rew=prevrews, int_rew=int_rew)
130 | if self.recorder is not None:
131 | self.recorder.record(timestep=self.step_count, lump=l, acs=acs, infos=infos, int_rew=self.int_rew[sli],
132 | ext_rew=prevrews, news=news)
133 | self.step_count += 1
134 | if s == self.nsteps_per_seg - 1:
135 | for l in range(self.nlumps):
136 | sli = slice(l * self.lump_stride, (l + 1) * self.lump_stride)
137 | nextobs, ext_rews, nextnews, _ = self.env_get(l)
138 | self.buf_obs_last[sli, t // self.nsteps_per_seg] = nextobs
139 | if t == self.nsteps - 1:
140 | self.buf_new_last[sli] = nextnews
141 | self.buf_ext_rews[sli, t] = ext_rews
142 | _, self.buf_vpred_last[sli], _ = self.policy.get_ac_value_nlp(nextobs)
143 | # dyn_logp = self.policy.call_reward(self.prev_feat[l], last_pol_feat, prev_acs)
144 | # dyn_logp = dyn_logp.reshape(-1, )
145 | # int_rew = dyn_logp
146 | #
147 | # self.int_rew[sli] = int_rew
148 | # self.buf_rews[sli, t] = self.reward_fun(ext_rew=ext_rews, int_rew=int_rew)
149 |
150 | def update_info(self):
151 | all_ep_infos = MPI.COMM_WORLD.allgather(self.ep_infos_new)
152 | all_ep_infos = sorted(sum(all_ep_infos, []), key=lambda x: x[0])
153 | if all_ep_infos:
154 | all_ep_infos = [i_[1] for i_ in all_ep_infos] # remove the step_count
155 | keys_ = all_ep_infos[0].keys()
156 | all_ep_infos = {k: [i[k] for i in all_ep_infos] for k in keys_}
157 |
158 | self.statlists['eprew'].extend(all_ep_infos['r'])
159 | self.stats['eprew_recent'] = np.mean(all_ep_infos['r'])
160 | self.statlists['eplen'].extend(all_ep_infos['l'])
161 | self.stats['epcount'] += len(all_ep_infos['l'])
162 | self.stats['tcount'] += sum(all_ep_infos['l'])
163 | if 'visited_rooms' in keys_:
164 | # Montezuma specific logging.
165 | self.stats['visited_rooms'] = sorted(list(set.union(*all_ep_infos['visited_rooms'])))
166 | self.stats['pos_count'] = np.mean(all_ep_infos['pos_count'])
167 | self.all_visited_rooms.extend(self.stats['visited_rooms'])
168 | self.all_scores.extend(all_ep_infos["r"])
169 | self.all_scores = sorted(list(set(self.all_scores)))
170 | self.all_visited_rooms = sorted(list(set(self.all_visited_rooms)))
171 | if MPI.COMM_WORLD.Get_rank() == 0:
172 | print("All visited rooms")
173 | print(self.all_visited_rooms)
174 | print("All scores")
175 | print(self.all_scores)
176 | if 'levels' in keys_:
177 | # Retro logging
178 | temp = sorted(list(set.union(*all_ep_infos['levels'])))
179 | self.all_visited_rooms.extend(temp)
180 | self.all_visited_rooms = sorted(list(set(self.all_visited_rooms)))
181 | if MPI.COMM_WORLD.Get_rank() == 0:
182 | print("All visited levels")
183 | print(self.all_visited_rooms)
184 | if "unity_rooms" in keys_:
185 | #Unity logging.
186 | temp = sorted(list(set.union(*all_ep_infos['unity_rooms'])))
187 | self.all_visited_rooms.extend(temp)
188 | self.all_visited_rooms = sorted(list(set(self.all_visited_rooms)))
189 | self.stats["n_rooms"] = len(self.all_visited_rooms)
190 | if MPI.COMM_WORLD.Get_rank() == 0:
191 | print("All visited levels")
192 | print(self.all_visited_rooms)
193 |
194 | current_max = np.max(all_ep_infos['r'])
195 | else:
196 | current_max = None
197 | self.ep_infos_new = []
198 |
199 | if current_max is not None:
200 | if (self.best_ext_ret is None) or (current_max > self.best_ext_ret):
201 | self.best_ext_ret = current_max
202 | self.current_max = current_max
203 |
204 | def env_step(self, l, acs):
205 | self.envs[l].step_async(acs)
206 | self.env_results[l] = None
207 |
208 | def env_get(self, l):
209 | if self.step_count == 0:
210 | ob = self.envs[l].reset()
211 | out = self.env_results[l] = (ob, None, np.ones(self.lump_stride, bool), {})
212 | else:
213 | if self.env_results[l] is None:
214 | out = self.env_results[l] = self.envs[l].step_wait()
215 | else:
216 | out = self.env_results[l]
217 | return out
218 |
--------------------------------------------------------------------------------
/utils.py:
--------------------------------------------------------------------------------
1 | import multiprocessing
2 | import os
3 | import platform
4 | from functools import partial
5 |
6 | import numpy as np
7 | import tensorflow as tf
8 | from baselines.common.tf_util import normc_initializer
9 | from mpi4py import MPI
10 |
11 |
12 | def bcast_tf_vars_from_root(sess, vars):
13 | """
14 | Send the root node's parameters to every worker.
15 |
16 | Arguments:
17 | sess: the TensorFlow session.
18 | vars: all parameter variables including optimizer's
19 | """
20 | rank = MPI.COMM_WORLD.Get_rank()
21 | for var in vars:
22 | if rank == 0:
23 | MPI.COMM_WORLD.bcast(sess.run(var))
24 | else:
25 | sess.run(tf.assign(var, MPI.COMM_WORLD.bcast(None)))
26 |
27 |
28 | def get_mean_and_std(array):
29 | comm = MPI.COMM_WORLD
30 | task_id, num_tasks = comm.Get_rank(), comm.Get_size()
31 | local_mean = np.array(np.mean(array))
32 | sum_of_means = np.zeros((), dtype=np.float32)
33 | comm.Allreduce(local_mean, sum_of_means, op=MPI.SUM)
34 | mean = sum_of_means / num_tasks
35 |
36 | n_array = array - mean
37 | sqs = n_array ** 2
38 | local_mean = np.array(np.mean(sqs))
39 | sum_of_means = np.zeros((), dtype=np.float32)
40 | comm.Allreduce(local_mean, sum_of_means, op=MPI.SUM)
41 | var = sum_of_means / num_tasks
42 | std = var ** 0.5
43 | return mean, std
44 |
45 |
46 | def guess_available_gpus(n_gpus=None):
47 | if n_gpus is not None:
48 | return list(range(n_gpus))
49 | if 'CUDA_VISIBLE_DEVICES' in os.environ:
50 | cuda_visible_divices = os.environ['CUDA_VISIBLE_DEVICES']
51 | cuda_visible_divices = cuda_visible_divices.split(',')
52 | return [int(n) for n in cuda_visible_divices]
53 | nvidia_dir = '/proc/driver/nvidia/gpus/'
54 | if os.path.exists(nvidia_dir):
55 | n_gpus = len(os.listdir(nvidia_dir))
56 | return list(range(n_gpus))
57 | raise Exception("Couldn't guess the available gpus on this machine")
58 |
59 |
60 | def setup_mpi_gpus():
61 | """
62 | Set CUDA_VISIBLE_DEVICES using MPI.
63 | """
64 | available_gpus = guess_available_gpus()
65 |
66 | node_id = platform.node()
67 | nodes_ordered_by_rank = MPI.COMM_WORLD.allgather(node_id)
68 | processes_outranked_on_this_node = [n for n in nodes_ordered_by_rank[:MPI.COMM_WORLD.Get_rank()] if n == node_id]
69 | local_rank = len(processes_outranked_on_this_node)
70 | os.environ['CUDA_VISIBLE_DEVICES'] = str(available_gpus[local_rank])
71 |
72 |
73 | def guess_available_cpus():
74 | return int(multiprocessing.cpu_count())
75 |
76 |
77 | def setup_tensorflow_session():
78 | num_cpu = guess_available_cpus()
79 |
80 | tf_config = tf.ConfigProto(
81 | inter_op_parallelism_threads=num_cpu,
82 | intra_op_parallelism_threads=num_cpu
83 | )
84 | # tf_config.gpu_options.allow_growth = True
85 | return tf.Session(config=tf_config)
86 |
87 |
88 | def random_agent_ob_mean_std(env, nsteps=10000):
89 | ob = np.asarray(env.reset())
90 | if MPI.COMM_WORLD.Get_rank() == 0:
91 | obs = [ob]
92 | for _ in range(nsteps):
93 | ac = env.action_space.sample()
94 | ob, _, done, _ = env.step(ac)
95 | if done:
96 | ob = env.reset()
97 | obs.append(np.asarray(ob))
98 | mean = np.mean(obs, 0).astype(np.float32)
99 | std = np.std(obs, 0).mean().astype(np.float32)
100 | else:
101 | mean = np.empty(shape=ob.shape, dtype=np.float32)
102 | std = np.empty(shape=(), dtype=np.float32)
103 | MPI.COMM_WORLD.Bcast(mean, root=0)
104 | MPI.COMM_WORLD.Bcast(std, root=0)
105 | return mean, std
106 |
107 |
108 | def layernorm(x):
109 | m, v = tf.nn.moments(x, -1, keep_dims=True)
110 | return (x - m) / (tf.sqrt(v) + 1e-8)
111 |
112 |
113 | getsess = tf.get_default_session
114 |
115 | fc = partial(tf.layers.dense, kernel_initializer=normc_initializer(1.))
116 | activ = tf.nn.relu
117 |
118 |
119 | def flatten_two_dims(x):
120 | return tf.reshape(x, [-1] + x.get_shape().as_list()[2:])
121 |
122 |
123 | def unflatten_first_dim(x, sh):
124 | return tf.reshape(x, [sh[0], sh[1]] + x.get_shape().as_list()[1:])
125 |
126 |
127 | def add_pos_bias(x):
128 | with tf.variable_scope(name_or_scope=None, default_name="pos_bias"):
129 | b = tf.get_variable(name="pos_bias", shape=[1] + x.get_shape().as_list()[1:], dtype=tf.float32,
130 | initializer=tf.zeros_initializer())
131 | return x + b
132 |
133 |
134 | def small_convnet(x, nl, feat_dim, last_nl, layernormalize, batchnorm=False):
135 | bn = tf.layers.batch_normalization if batchnorm else lambda x: x
136 | x = bn(tf.layers.conv2d(x, filters=32, kernel_size=8, strides=(4, 4), activation=nl))
137 | x = bn(tf.layers.conv2d(x, filters=64, kernel_size=4, strides=(2, 2), activation=nl))
138 | x = bn(tf.layers.conv2d(x, filters=64, kernel_size=3, strides=(1, 1), activation=nl))
139 | x = tf.reshape(x, (-1, np.prod(x.get_shape().as_list()[1:])))
140 | x = bn(fc(x, units=feat_dim, activation=None))
141 | if last_nl is not None:
142 | x = last_nl(x)
143 | if layernormalize:
144 | x = layernorm(x)
145 | return x
146 |
147 |
148 | def small_deconvnet(z, nl, ch, positional_bias):
149 | sh = (8, 8, 64)
150 | z = fc(z, np.prod(sh), activation=nl)
151 | z = tf.reshape(z, (-1, *sh))
152 | z = tf.layers.conv2d_transpose(z, 128, kernel_size=4, strides=(2, 2), activation=nl, padding='same')
153 | assert z.get_shape().as_list()[1:3] == [16, 16]
154 | z = tf.layers.conv2d_transpose(z, 64, kernel_size=8, strides=(2, 2), activation=nl, padding='same')
155 | assert z.get_shape().as_list()[1:3] == [32, 32]
156 | z = tf.layers.conv2d_transpose(z, ch, kernel_size=8, strides=(3, 3), activation=None, padding='same')
157 | assert z.get_shape().as_list()[1:3] == [96, 96]
158 | z = z[:, 6:-6, 6:-6]
159 | assert z.get_shape().as_list()[1:3] == [84, 84]
160 | if positional_bias:
161 | z = add_pos_bias(z)
162 | return z
163 |
164 |
165 | def unet(x, nl, feat_dim, cond, batchnorm=False):
166 | bn = tf.layers.batch_normalization if batchnorm else lambda x: x
167 | layers = []
168 | x = tf.pad(x, [[0, 0], [6, 6], [6, 6], [0, 0]])
169 | x = bn(tf.layers.conv2d(cond(x), filters=32, kernel_size=8, strides=(3, 3), activation=nl, padding='same'))
170 | assert x.get_shape().as_list()[1:3] == [32, 32]
171 | layers.append(x)
172 | x = bn(tf.layers.conv2d(cond(x), filters=64, kernel_size=8, strides=(2, 2), activation=nl, padding='same'))
173 | layers.append(x)
174 | assert x.get_shape().as_list()[1:3] == [16, 16]
175 | x = bn(tf.layers.conv2d(cond(x), filters=64, kernel_size=4, strides=(2, 2), activation=nl, padding='same'))
176 | layers.append(x)
177 | assert x.get_shape().as_list()[1:3] == [8, 8]
178 |
179 | x = tf.reshape(x, (-1, np.prod(x.get_shape().as_list()[1:])))
180 | x = fc(cond(x), units=feat_dim, activation=nl)
181 |
182 | def residual(x):
183 | res = bn(tf.layers.dense(cond(x), feat_dim, activation=tf.nn.leaky_relu))
184 | res = tf.layers.dense(cond(res), feat_dim, activation=None)
185 | return x + res
186 |
187 | for _ in range(4):
188 | x = residual(x)
189 |
190 | sh = (8, 8, 64)
191 | x = fc(cond(x), np.prod(sh), activation=nl)
192 | x = tf.reshape(x, (-1, *sh))
193 | x += layers.pop()
194 | x = bn(tf.layers.conv2d_transpose(cond(x), 64, kernel_size=4, strides=(2, 2), activation=nl, padding='same'))
195 | assert x.get_shape().as_list()[1:3] == [16, 16]
196 | x += layers.pop()
197 | x = bn(tf.layers.conv2d_transpose(cond(x), 32, kernel_size=8, strides=(2, 2), activation=nl, padding='same'))
198 | assert x.get_shape().as_list()[1:3] == [32, 32]
199 | x += layers.pop()
200 | x = tf.layers.conv2d_transpose(cond(x), 4, kernel_size=8, strides=(3, 3), activation=None, padding='same')
201 | assert x.get_shape().as_list()[1:3] == [96, 96]
202 | x = x[:, 6:-6, 6:-6]
203 | assert x.get_shape().as_list()[1:3] == [84, 84]
204 | assert layers == []
205 | return x
206 |
207 |
208 | def tile_images(array, n_cols=None, max_images=None, div=1):
209 | if max_images is not None:
210 | array = array[:max_images]
211 | if len(array.shape) == 4 and array.shape[3] == 1:
212 | array = array[:, :, :, 0]
213 | assert len(array.shape) in [3, 4], "wrong number of dimensions - shape {}".format(array.shape)
214 | if len(array.shape) == 4:
215 | assert array.shape[3] == 3, "wrong number of channels- shape {}".format(array.shape)
216 | if n_cols is None:
217 | n_cols = max(int(np.sqrt(array.shape[0])) // div * div, div)
218 | n_rows = int(np.ceil(float(array.shape[0]) / n_cols))
219 |
220 | def cell(i, j):
221 | ind = i * n_cols + j
222 | return array[ind] if ind < array.shape[0] else np.zeros(array[0].shape)
223 |
224 | def row(i):
225 | return np.concatenate([cell(i, j) for j in range(n_cols)], axis=1)
226 |
227 | return np.concatenate([row(i) for i in range(n_rows)], axis=0)
228 |
229 |
230 | import distutils.spawn
231 | import subprocess
232 | def save_np_as_mp4(frames, filename):
233 | print(filename)
234 | if distutils.spawn.find_executable('avconv') is not None:
235 | backend = 'avconv'
236 | elif distutils.spawn.find_executable('ffmpeg') is not None:
237 | backend = 'ffmpeg'
238 | else:
239 | raise NotImplementedError(
240 | """Found neither the ffmpeg nor avconv executables. On OS X, you can install ffmpeg via `brew install ffmpeg`. On most Ubuntu variants, `sudo apt-get install ffmpeg` should do it. On Ubuntu 14.04, however, you'll need to install avconv with `sudo apt-get install libav-tools`.""")
241 |
242 | frames_per_sec = 30
243 | h, w = frames[0].shape[:2]
244 | output_path = filename
245 | cmdline = (backend,
246 | '-nostats',
247 | '-loglevel', 'error', # suppress warnings
248 | '-y',
249 | '-r', '%d' % frames_per_sec,
250 |
251 | # input
252 | '-f', 'rawvideo',
253 | '-s:v', '{}x{}'.format(w, h),
254 | '-pix_fmt', 'rgb24',
255 | '-i', '-', # this used to be /dev/stdin, which is not Windows-friendly
256 |
257 | # output
258 | '-vcodec', 'libx264',
259 | '-pix_fmt', 'yuv420p',
260 | output_path
261 | )
262 |
263 | print('saving ', output_path)
264 | if hasattr(os, 'setsid'): # setsid not present on Windows
265 | process = subprocess.Popen(cmdline, stdin=subprocess.PIPE, preexec_fn=os.setsid)
266 | else:
267 | process = subprocess.Popen(cmdline, stdin=subprocess.PIPE)
268 | process.stdin.write(np.array(frames).tobytes())
269 | process.stdin.close()
270 | ret = process.wait()
271 | if ret != 0:
272 | print("VideoRecorder encoder exited with status {}".format(ret))
273 |
--------------------------------------------------------------------------------
/run.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | try:
3 | from OpenGL import GLU
4 | except:
5 | print("no OpenGL.GLU")
6 | import functools
7 | import os.path as osp
8 | from functools import partial
9 |
10 | import gym
11 | import tensorflow as tf
12 | from baselines import logger
13 | from baselines.bench import Monitor
14 | from baselines.common.atari_wrappers import NoopResetEnv, FrameStack
15 | from mpi4py import MPI
16 |
17 | from auxiliary_tasks import FeatureExtractor, InverseDynamics, VAE, JustPixels
18 | from cnn_policy import CnnPolicy
19 | from cppo_agent import PpoOptimizer
20 | from dynamics import Dynamics, UNet
21 | from utils import random_agent_ob_mean_std
22 | from wrappers import MontezumaInfoWrapper, make_mario_env, \
23 | make_multi_pong, AddRandomStateToInfo, MaxAndSkipEnv, ProcessFrame84, ExtraTimeLimit, \
24 | make_unity_maze, StickyActionEnv
25 |
26 | import datetime
27 |
28 |
29 | def start_experiment(**args):
30 | make_env = partial(make_env_all_params, add_monitor=True, args=args)
31 |
32 | trainer = Trainer(make_env=make_env,
33 | num_timesteps=args['num_timesteps'], hps=args,
34 | envs_per_process=args['envs_per_process'],
35 | num_dyna=args['num_dynamics'],
36 | var_output=args['var_output'])
37 | log, tf_sess = get_experiment_environment(**args)
38 | with log, tf_sess:
39 | logdir = logger.get_dir()
40 | print("results will be saved to ", logdir)
41 | trainer.train()
42 |
43 |
44 | class Trainer(object):
45 | def __init__(self, make_env, hps, num_timesteps, envs_per_process, num_dyna, var_output):
46 | self.make_env = make_env
47 | self.hps = hps
48 | self.envs_per_process = envs_per_process
49 | self.num_timesteps = num_timesteps
50 | self._set_env_vars()
51 |
52 | self.policy = CnnPolicy(
53 | scope='pol',
54 | ob_space=self.ob_space,
55 | ac_space=self.ac_space,
56 | hidsize=512,
57 | feat_dim=512,
58 | ob_mean=self.ob_mean,
59 | ob_std=self.ob_std,
60 | layernormalize=False,
61 | nl=tf.nn.leaky_relu)
62 |
63 | self.feature_extractor = {"none": FeatureExtractor,
64 | "idf": InverseDynamics,
65 | "vaesph": partial(VAE, spherical_obs=True),
66 | "vaenonsph": partial(VAE, spherical_obs=False),
67 | "pix2pix": JustPixels}[hps['feat_learning']]
68 | self.feature_extractor = self.feature_extractor(policy=self.policy,
69 | features_shared_with_policy=False,
70 | feat_dim=512,
71 | layernormalize=hps['layernorm'])
72 |
73 | self.dynamics_class = Dynamics if hps['feat_learning'] != 'pix2pix' else UNet
74 |
75 | # create dynamics list
76 | self.dynamics_list = []
77 | for i in range(num_dyna):
78 | self.dynamics_list.append(self.dynamics_class(auxiliary_task=self.feature_extractor,
79 | predict_from_pixels=hps['dyn_from_pixels'],
80 | feat_dim=512, scope='dynamics_{}'.format(i),
81 | var_output=var_output)
82 | )
83 |
84 | self.agent = PpoOptimizer(
85 | scope='ppo',
86 | ob_space=self.ob_space,
87 | ac_space=self.ac_space,
88 | stochpol=self.policy,
89 | use_news=hps['use_news'],
90 | gamma=hps['gamma'],
91 | lam=hps["lambda"],
92 | nepochs=hps['nepochs'],
93 | nminibatches=hps['nminibatches'],
94 | lr=hps['lr'],
95 | cliprange=0.1,
96 | nsteps_per_seg=hps['nsteps_per_seg'],
97 | nsegs_per_env=hps['nsegs_per_env'],
98 | ent_coef=hps['ent_coeff'],
99 | normrew=hps['norm_rew'],
100 | normadv=hps['norm_adv'],
101 | ext_coeff=hps['ext_coeff'],
102 | int_coeff=hps['int_coeff'],
103 | unity=hps["env_kind"] == "unity",
104 | dynamics_list=self.dynamics_list
105 | )
106 |
107 | self.agent.to_report['aux'] = tf.reduce_mean(self.feature_extractor.loss)
108 | self.agent.total_loss += self.agent.to_report['aux']
109 |
110 | self.agent.to_report['dyn_loss'] = tf.reduce_mean(self.dynamics_list[0].partial_loss)
111 | for i in range(1, num_dyna):
112 | self.agent.to_report['dyn_loss'] += tf.reduce_mean(self.dynamics_list[i].partial_loss)
113 |
114 | self.agent.total_loss += self.agent.to_report['dyn_loss']
115 | self.agent.to_report['feat_var'] = tf.reduce_mean(tf.nn.moments(self.feature_extractor.features, [0, 1])[1])
116 |
117 | def _set_env_vars(self):
118 | env = self.make_env(0, add_monitor=False)
119 | self.ob_space, self.ac_space = env.observation_space, env.action_space
120 | self.ob_mean, self.ob_std = random_agent_ob_mean_std(env)
121 | if self.hps["env_kind"] == "unity":
122 | env.close()
123 | # self.ob_mean, self.ob_std = 124.89177, 55.7459
124 | del env
125 | self.envs = [functools.partial(self.make_env, i) for i in range(self.envs_per_process)]
126 |
127 | def train(self):
128 | self.agent.start_interaction(self.envs, nlump=self.hps['nlumps'], dynamics_list=self.dynamics_list)
129 | while True:
130 | info = self.agent.step()
131 | if info['update']:
132 | logger.logkvs(info['update'])
133 | logger.dumpkvs()
134 | if self.agent.rollout.stats['tcount'] > self.num_timesteps:
135 | break
136 |
137 | self.agent.stop_interaction()
138 |
139 |
140 | def make_env_all_params(rank, add_monitor, args):
141 | if args["env_kind"] == 'atari':
142 | env = gym.make(args['env'])
143 | assert 'NoFrameskip' in env.spec.id
144 | if args["stickyAtari"]:
145 | env._max_episode_steps = args['max_episode_steps'] * 4
146 | env = StickyActionEnv(env)
147 | else:
148 | env = NoopResetEnv(env, noop_max=args['noop_max'])
149 | env = MaxAndSkipEnv(env, skip=4)
150 | env = ProcessFrame84(env, crop=False)
151 | env = FrameStack(env, 4)
152 | if not args["stickyAtari"]:
153 | env = ExtraTimeLimit(env, args['max_episode_steps'])
154 | if 'Montezuma' in args['env']:
155 | env = MontezumaInfoWrapper(env)
156 | env = AddRandomStateToInfo(env)
157 | elif args["env_kind"] == 'mario':
158 | env = make_mario_env()
159 | elif args["env_kind"] == "retro_multi":
160 | env = make_multi_pong()
161 | elif args["env_kind"] == 'unity':
162 | env = make_unity_maze(args["env"], seed=args["seed"], rank=rank,
163 | ext_coeff=args["ext_coeff"], recordUnityVid=args['recordUnityVid'],
164 | expID=args["unityExpID"], startLoc=args["startLoc"], door=args["door"],
165 | tv=args["tv"], testenv=args["testenv"], logdir=logger.get_dir())
166 |
167 | if add_monitor:
168 | env = Monitor(env, osp.join(logger.get_dir(), '%.2i' % rank))
169 | return env
170 |
171 |
172 | def get_experiment_environment(**args):
173 | from utils import setup_mpi_gpus, setup_tensorflow_session
174 | from baselines.common import set_global_seeds
175 | from gym.utils.seeding import hash_seed
176 | process_seed = args["seed"] + 1000 * MPI.COMM_WORLD.Get_rank()
177 | process_seed = hash_seed(process_seed, max_bytes=4)
178 | set_global_seeds(process_seed)
179 | setup_mpi_gpus()
180 |
181 | logger_context = logger.scoped_configure(dir='./logs/' +
182 | datetime.datetime.now().strftime(args["expID"] + "-openai-%Y-%m-%d-%H-%M-%S-%f"),
183 | format_strs=['stdout', 'log',
184 | 'csv', 'tensorboard']
185 | if MPI.COMM_WORLD.Get_rank() == 0 else ['log'])
186 | tf_context = setup_tensorflow_session()
187 | return logger_context, tf_context
188 |
189 |
190 | def add_environments_params(parser):
191 | parser.add_argument('--env', help='environment ID', default='BreakoutNoFrameskip-v4',
192 | type=str)
193 | parser.add_argument('--max-episode-steps', help='maximum number of timesteps for episode', default=4500, type=int)
194 | parser.add_argument('--env_kind', type=str, default="atari")
195 | parser.add_argument('--noop_max', type=int, default=30)
196 | parser.add_argument('--stickyAtari', action='store_true', default=True)
197 |
198 |
199 | def add_optimization_params(parser):
200 | parser.add_argument('--lambda', type=float, default=0.95)
201 | parser.add_argument('--gamma', type=float, default=0.99)
202 | parser.add_argument('--nminibatches', type=int, default=8)
203 | parser.add_argument('--norm_adv', type=int, default=1)
204 | parser.add_argument('--norm_rew', type=int, default=1)
205 | parser.add_argument('--lr', type=float, default=1e-4)
206 | parser.add_argument('--ent_coeff', type=float, default=0.001)
207 | parser.add_argument('--nepochs', type=int, default=3)
208 | parser.add_argument('--num_timesteps', type=int, default=int(1e8))
209 |
210 |
211 | def add_rollout_params(parser):
212 | parser.add_argument('--nsteps_per_seg', type=int, default=128)
213 | parser.add_argument('--nsegs_per_env', type=int, default=1)
214 | parser.add_argument('--envs_per_process', type=int, default=128)
215 | parser.add_argument('--nlumps', type=int, default=1)
216 |
217 |
218 | def add_unity_params(parser):
219 | parser.add_argument('--testenv', action='store_true', default=False,
220 | help='test mode: slows to real time with bigger screen')
221 | parser.add_argument('--startLoc', type=int, default=0)
222 | parser.add_argument('--door', type=int, default=1)
223 | parser.add_argument('--tv', type=int, default=2)
224 | parser.add_argument('--unityExpID', type=int, default=0)
225 | parser.add_argument('--recordUnityVid', action='store_true', default=False)
226 |
227 |
228 | if __name__ == '__main__':
229 | import argparse
230 |
231 | parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
232 | add_environments_params(parser)
233 | add_unity_params(parser)
234 | add_optimization_params(parser)
235 | add_rollout_params(parser)
236 |
237 | parser.add_argument('--exp_name', type=str, default='')
238 | parser.add_argument('--expID', type=str, default='000')
239 | parser.add_argument('--seed', help='RNG seed', type=int, default=0)
240 | parser.add_argument('--dyn_from_pixels', type=int, default=0)
241 | parser.add_argument('--use_news', type=int, default=0)
242 | parser.add_argument('--ext_coeff', type=float, default=0.)
243 | parser.add_argument('--int_coeff', type=float, default=1.)
244 | parser.add_argument('--layernorm', type=int, default=0)
245 | parser.add_argument('--feat_learning', type=str, default="none",
246 | choices=["none", "idf", "vaesph", "vaenonsph", "pix2pix"])
247 | parser.add_argument('--num_dynamics', type=int, default=5)
248 | parser.add_argument('--var_output', action='store_true', default=True)
249 |
250 |
251 | args = parser.parse_args()
252 |
253 | start_experiment(**args.__dict__)
254 |
--------------------------------------------------------------------------------
/cppo_agent.py:
--------------------------------------------------------------------------------
1 | import time
2 | import sys
3 | import os
4 |
5 | import numpy as np
6 | import tensorflow as tf
7 | from baselines.common import explained_variance
8 | from baselines.common.mpi_moments import mpi_moments
9 | from baselines.common.running_mean_std import RunningMeanStd
10 | from mpi4py import MPI
11 | from tqdm import tqdm
12 |
13 | from mpi_utils import MpiAdamOptimizer
14 | from rollouts import Rollout
15 | from utils import bcast_tf_vars_from_root, get_mean_and_std
16 | from vec_env import ShmemVecEnv as VecEnv
17 |
18 | getsess = tf.get_default_session
19 |
20 |
21 | class PpoOptimizer(object):
22 | envs = None
23 |
24 | def __init__(self, *, scope, ob_space, ac_space, stochpol,
25 | ent_coef, gamma, lam, nepochs, lr, cliprange,
26 | nminibatches,
27 | normrew, normadv, use_news, ext_coeff, int_coeff,
28 | nsteps_per_seg, nsegs_per_env, unity, dynamics_list):
29 | self.dynamics_list = dynamics_list
30 | with tf.variable_scope(scope):
31 | self.unity = unity
32 | self.use_recorder = True
33 | self.n_updates = 0
34 | self.scope = scope
35 | self.ob_space = ob_space
36 | self.ac_space = ac_space
37 | self.stochpol = stochpol
38 | self.nepochs = nepochs
39 | self.lr = lr
40 | self.cliprange = cliprange
41 | self.nsteps_per_seg = nsteps_per_seg
42 | self.nsegs_per_env = nsegs_per_env
43 | self.nminibatches = nminibatches
44 | self.gamma = gamma
45 | self.lam = lam
46 | self.normrew = normrew
47 | self.normadv = normadv
48 | self.use_news = use_news
49 | self.ext_coeff = ext_coeff
50 | self.int_coeff = int_coeff
51 | self.ph_adv = tf.placeholder(tf.float32, [None, None])
52 | self.ph_ret = tf.placeholder(tf.float32, [None, None])
53 | self.ph_rews = tf.placeholder(tf.float32, [None, None])
54 | self.ph_oldnlp = tf.placeholder(tf.float32, [None, None])
55 | self.ph_oldvpred = tf.placeholder(tf.float32, [None, None])
56 | self.ph_lr = tf.placeholder(tf.float32, [])
57 | self.ph_cliprange = tf.placeholder(tf.float32, [])
58 | neglogpac = self.stochpol.pd.neglogp(self.stochpol.ph_ac)
59 | entropy = tf.reduce_mean(self.stochpol.pd.entropy())
60 | vpred = self.stochpol.vpred
61 |
62 | vf_loss = 0.5 * tf.reduce_mean((vpred - self.ph_ret) ** 2)
63 | ratio = tf.exp(self.ph_oldnlp - neglogpac) # p_new / p_old
64 | negadv = - self.ph_adv
65 | pg_losses1 = negadv * ratio
66 | pg_losses2 = negadv * tf.clip_by_value(ratio, 1.0 - self.ph_cliprange, 1.0 + self.ph_cliprange)
67 | pg_loss_surr = tf.maximum(pg_losses1, pg_losses2)
68 | pg_loss = tf.reduce_mean(pg_loss_surr)
69 | ent_loss = (- ent_coef) * entropy
70 | approxkl = .5 * tf.reduce_mean(tf.square(neglogpac - self.ph_oldnlp))
71 | clipfrac = tf.reduce_mean(tf.to_float(tf.abs(pg_losses2 - pg_loss_surr) > 1e-6))
72 |
73 | self.total_loss = pg_loss + ent_loss + vf_loss
74 | self.to_report = {'tot': self.total_loss, 'pg': pg_loss, 'vf': vf_loss, 'ent': entropy,
75 | 'approxkl': approxkl, 'clipfrac': clipfrac}
76 |
77 | def start_interaction(self, env_fns, dynamics_list, nlump=2):
78 | self.loss_names, self._losses = zip(*list(self.to_report.items()))
79 |
80 | params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES)
81 | if MPI.COMM_WORLD.Get_size() > 1:
82 | trainer = MpiAdamOptimizer(learning_rate=self.ph_lr, comm=MPI.COMM_WORLD)
83 | else:
84 | trainer = tf.train.AdamOptimizer(learning_rate=self.ph_lr)
85 | gradsandvars = trainer.compute_gradients(self.total_loss, params)
86 | self._train = trainer.apply_gradients(gradsandvars)
87 |
88 | if MPI.COMM_WORLD.Get_rank() == 0:
89 | getsess().run(tf.variables_initializer(tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES)))
90 | bcast_tf_vars_from_root(getsess(), tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES))
91 |
92 | self.all_visited_rooms = []
93 | self.all_scores = []
94 | self.nenvs = nenvs = len(env_fns)
95 | self.nlump = nlump
96 | self.lump_stride = nenvs // self.nlump
97 | self.envs = [
98 | VecEnv(env_fns[l * self.lump_stride: (l + 1) * self.lump_stride], spaces=[self.ob_space, self.ac_space]) for
99 | l in range(self.nlump)]
100 | if self.unity:
101 | for i in tqdm(range(int(nenvs*2.5 + 10))):
102 | time.sleep(1)
103 | print('... long overdue sleep ends now')
104 | sys.stdout.flush()
105 |
106 | self.rollout = Rollout(ob_space=self.ob_space, ac_space=self.ac_space, nenvs=nenvs,
107 | nsteps_per_seg=self.nsteps_per_seg,
108 | nsegs_per_env=self.nsegs_per_env, nlumps=self.nlump,
109 | envs=self.envs,
110 | policy=self.stochpol,
111 | int_rew_coeff=self.int_coeff,
112 | ext_rew_coeff=self.ext_coeff,
113 | record_rollouts=self.use_recorder,
114 | dynamics_list=dynamics_list)
115 |
116 | self.buf_advs = np.zeros((nenvs, self.rollout.nsteps), np.float32)
117 | self.buf_rets = np.zeros((nenvs, self.rollout.nsteps), np.float32)
118 |
119 | if self.normrew:
120 | self.rff = RewardForwardFilter(self.gamma)
121 | self.rff_rms = RunningMeanStd()
122 |
123 | self.step_count = 0
124 | self.t_last_update = time.time()
125 | self.t_start = time.time()
126 |
127 | def stop_interaction(self):
128 | for env in self.envs:
129 | env.close()
130 |
131 | def calculate_advantages(self, rews, use_news, gamma, lam):
132 | nsteps = self.rollout.nsteps
133 | lastgaelam = 0
134 | for t in range(nsteps - 1, -1, -1): # nsteps-2 ... 0
135 | nextnew = self.rollout.buf_news[:, t + 1] if t + 1 < nsteps else self.rollout.buf_new_last
136 | if not use_news:
137 | nextnew = 0
138 | nextvals = self.rollout.buf_vpreds[:, t + 1] if t + 1 < nsteps else self.rollout.buf_vpred_last
139 | nextnotnew = 1 - nextnew
140 | delta = rews[:, t] + gamma * nextvals * nextnotnew - self.rollout.buf_vpreds[:, t]
141 | self.buf_advs[:, t] = lastgaelam = delta + gamma * lam * nextnotnew * lastgaelam
142 | self.buf_rets[:] = self.buf_advs + self.rollout.buf_vpreds
143 |
144 | def update(self):
145 | if self.normrew:
146 | rffs = np.array([self.rff.update(rew) for rew in self.rollout.buf_rews.T])
147 | rffs_mean, rffs_std, rffs_count = mpi_moments(rffs.ravel())
148 | self.rff_rms.update_from_moments(rffs_mean, rffs_std ** 2, rffs_count)
149 | rews = self.rollout.buf_rews / np.sqrt(self.rff_rms.var)
150 | else:
151 | rews = np.copy(self.rollout.buf_rews)
152 | self.calculate_advantages(rews=rews, use_news=self.use_news, gamma=self.gamma, lam=self.lam)
153 |
154 | info = dict(
155 | advmean=self.buf_advs.mean(),
156 | advstd=self.buf_advs.std(),
157 | retmean=self.buf_rets.mean(),
158 | retstd=self.buf_rets.std(),
159 | vpredmean=self.rollout.buf_vpreds.mean(),
160 | vpredstd=self.rollout.buf_vpreds.std(),
161 | ev=explained_variance(self.rollout.buf_vpreds.ravel(), self.buf_rets.ravel()),
162 | rew_mean=np.mean(self.rollout.buf_rews),
163 | recent_best_ext_ret=self.rollout.current_max if self.rollout.current_max is not None else 0,
164 | )
165 | if self.rollout.best_ext_ret is not None:
166 | info['best_ext_ret'] = self.rollout.best_ext_ret
167 |
168 | # store images for debugging
169 | # from PIL import Image
170 | # if not os.path.exists('logs/images/'):
171 | # os.makedirs('logs/images/')
172 | # for i in range(self.rollout.buf_obs_last.shape[0]):
173 | # obs = self.rollout.buf_obs_last[i][0]
174 | # Image.fromarray((obs*255.).astype(np.uint8)).save('logs/images/%04d.png'%i)
175 |
176 | # normalize advantages
177 | if self.normadv:
178 | m, s = get_mean_and_std(self.buf_advs)
179 | self.buf_advs = (self.buf_advs - m) / (s + 1e-7)
180 | envsperbatch = (self.nenvs * self.nsegs_per_env) // self.nminibatches
181 | envsperbatch = max(1, envsperbatch)
182 | envinds = np.arange(self.nenvs * self.nsegs_per_env)
183 |
184 | def resh(x):
185 | if self.nsegs_per_env == 1:
186 | return x
187 | sh = x.shape
188 | return x.reshape((sh[0] * self.nsegs_per_env, self.nsteps_per_seg) + sh[2:])
189 |
190 | ph_buf = [
191 | (self.stochpol.ph_ac, resh(self.rollout.buf_acs)),
192 | (self.ph_rews, resh(self.rollout.buf_rews)),
193 | (self.ph_oldvpred, resh(self.rollout.buf_vpreds)),
194 | (self.ph_oldnlp, resh(self.rollout.buf_nlps)),
195 | (self.stochpol.ph_ob, resh(self.rollout.buf_obs)),
196 | (self.ph_ret, resh(self.buf_rets)),
197 | (self.ph_adv, resh(self.buf_advs)),
198 | ]
199 | ph_buf.extend([
200 | (self.dynamics_list[0].last_ob,
201 | self.rollout.buf_obs_last.reshape([self.nenvs * self.nsegs_per_env, 1, *self.ob_space.shape]))
202 | ])
203 | mblossvals = []
204 |
205 | for _ in range(self.nepochs):
206 | np.random.shuffle(envinds)
207 | for start in range(0, self.nenvs * self.nsegs_per_env, envsperbatch):
208 | end = start + envsperbatch
209 | mbenvinds = envinds[start:end]
210 | fd = {ph: buf[mbenvinds] for (ph, buf) in ph_buf}
211 | fd.update({self.ph_lr: self.lr, self.ph_cliprange: self.cliprange})
212 | mblossvals.append(getsess().run(self._losses + (self._train,), fd)[:-1])
213 |
214 | mblossvals = [mblossvals[0]]
215 | info.update(zip(['opt_' + ln for ln in self.loss_names], np.mean([mblossvals[0]], axis=0)))
216 | info["rank"] = MPI.COMM_WORLD.Get_rank()
217 | self.n_updates += 1
218 | info["n_updates"] = self.n_updates
219 | info.update({dn: (np.mean(dvs) if len(dvs) > 0 else 0) for (dn, dvs) in self.rollout.statlists.items()})
220 | info.update(self.rollout.stats)
221 | if "states_visited" in info:
222 | info.pop("states_visited")
223 | tnow = time.time()
224 | info["ups"] = 1. / (tnow - self.t_last_update)
225 | info["total_secs"] = tnow - self.t_start
226 | info['tps'] = MPI.COMM_WORLD.Get_size() * self.rollout.nsteps * self.nenvs / (tnow - self.t_last_update)
227 | self.t_last_update = tnow
228 |
229 | return info
230 |
231 | def step(self):
232 | self.rollout.collect_rollout()
233 | update_info = self.update()
234 | return {'update': update_info}
235 |
236 | def get_var_values(self):
237 | return self.stochpol.get_var_values()
238 |
239 | def set_var_values(self, vv):
240 | self.stochpol.set_var_values(vv)
241 |
242 |
243 | class RewardForwardFilter(object):
244 | def __init__(self, gamma):
245 | self.rewems = None
246 | self.gamma = gamma
247 |
248 | def update(self, rews):
249 | if self.rewems is None:
250 | self.rewems = rews
251 | else:
252 | self.rewems = self.rewems * self.gamma + rews
253 | return self.rewems
254 |
--------------------------------------------------------------------------------
/wrappers.py:
--------------------------------------------------------------------------------
1 | import os
2 | import itertools
3 | from collections import deque
4 | from copy import copy
5 |
6 | import gym
7 | import numpy as np
8 | from PIL import Image
9 | from utils import save_np_as_mp4
10 |
11 |
12 | def unwrap(env):
13 | if hasattr(env, "unwrapped"):
14 | return env.unwrapped
15 | elif hasattr(env, "env"):
16 | return unwrap(env.env)
17 | elif hasattr(env, "leg_env"):
18 | return unwrap(env.leg_env)
19 | else:
20 | return env
21 |
22 |
23 | class MaxAndSkipEnv(gym.Wrapper):
24 | def __init__(self, env, skip=4):
25 | """Return only every `skip`-th frame"""
26 | gym.Wrapper.__init__(self, env)
27 | # most recent raw observations (for max pooling across time steps)
28 | self._obs_buffer = deque(maxlen=2)
29 | self._skip = skip
30 |
31 | def step(self, action):
32 | """Repeat action, sum reward, and max over last observations."""
33 | total_reward = 0.0
34 | done = None
35 | acc_info = {}
36 | for _ in range(self._skip):
37 | obs, reward, done, info = self.env.step(action)
38 | acc_info.update(info)
39 | self._obs_buffer.append(obs)
40 | total_reward += reward
41 | if done:
42 | break
43 | max_frame = np.max(np.stack(self._obs_buffer), axis=0)
44 |
45 | return max_frame, total_reward, done, acc_info
46 |
47 | def reset(self):
48 | """Clear past frame buffer and init. to first obs. from inner env."""
49 | self._obs_buffer.clear()
50 | obs = self.env.reset()
51 | self._obs_buffer.append(obs)
52 | return obs
53 |
54 |
55 | class ProcessFrame84(gym.ObservationWrapper):
56 | def __init__(self, env, crop=True):
57 | self.crop = crop
58 | super(ProcessFrame84, self).__init__(env)
59 | self.observation_space = gym.spaces.Box(low=0, high=255, shape=(84, 84, 1), dtype=np.uint8)
60 |
61 | def observation(self, obs):
62 | return ProcessFrame84.process(obs, crop=self.crop)
63 |
64 | @staticmethod
65 | def process(frame, crop=True):
66 | if frame.size == 210 * 160 * 3:
67 | img = np.reshape(frame, [210, 160, 3]).astype(np.float32)
68 | elif frame.size == 250 * 160 * 3:
69 | img = np.reshape(frame, [250, 160, 3]).astype(np.float32)
70 | elif frame.size == 224 * 240 * 3: # mario resolution
71 | img = np.reshape(frame, [224, 240, 3]).astype(np.float32)
72 | elif frame.size == 84 * 84 * 3: # unity maze
73 | img = frame
74 | img = img[:, :, 0] * 0.299 + img[:, :, 1] * 0.587 + img[:, :, 2] * 0.114
75 | x_t = np.reshape(img, [84, 84, 1])
76 | return x_t.astype(np.uint8)
77 | else:
78 | assert False, "Unknown resolution." + str(frame.size)
79 | img = img[:, :, 0] * 0.299 + img[:, :, 1] * 0.587 + img[:, :, 2] * 0.114
80 | size = (84, 110 if crop else 84)
81 | resized_screen = np.array(Image.fromarray(img).resize(size,
82 | resample=Image.BILINEAR), dtype=np.uint8)
83 | x_t = resized_screen[18:102, :] if crop else resized_screen
84 | x_t = np.reshape(x_t, [84, 84, 1])
85 | return x_t.astype(np.uint8)
86 |
87 |
88 | class ExtraTimeLimit(gym.Wrapper):
89 | def __init__(self, env, max_episode_steps=None):
90 | gym.Wrapper.__init__(self, env)
91 | self._max_episode_steps = max_episode_steps
92 | self._elapsed_steps = 0
93 |
94 | def step(self, action):
95 | observation, reward, done, info = self.env.step(action)
96 | self._elapsed_steps += 1
97 | if self._elapsed_steps > self._max_episode_steps:
98 | done = True
99 | return observation, reward, done, info
100 |
101 | def reset(self):
102 | self._elapsed_steps = 0
103 | return self.env.reset()
104 |
105 |
106 | class AddRandomStateToInfo(gym.Wrapper):
107 | def __init__(self, env):
108 | """Adds the random state to the info field on the first step after reset
109 | """
110 | gym.Wrapper.__init__(self, env)
111 |
112 | def step(self, action):
113 | ob, r, d, info = self.env.step(action)
114 | if self.random_state_copy is not None:
115 | info['random_state'] = self.random_state_copy
116 | self.random_state_copy = None
117 | return ob, r, d, info
118 |
119 | def reset(self, **kwargs):
120 | """ Do no-op action for a number of steps in [1, noop_max]."""
121 | self.random_state_copy = copy(self.unwrapped.np_random)
122 | return self.env.reset(**kwargs)
123 |
124 |
125 | class MontezumaInfoWrapper(gym.Wrapper):
126 | ram_map = {
127 | "room": dict(
128 | index=3,
129 | ),
130 | "x": dict(
131 | index=42,
132 | ),
133 | "y": dict(
134 | index=43,
135 | ),
136 | }
137 |
138 | def __init__(self, env):
139 | super(MontezumaInfoWrapper, self).__init__(env)
140 | self.visited = set()
141 | self.visited_rooms = set()
142 |
143 | def step(self, action):
144 | obs, rew, done, info = self.env.step(action)
145 | ram_state = unwrap(self.env).ale.getRAM()
146 | for name, properties in MontezumaInfoWrapper.ram_map.items():
147 | info[name] = ram_state[properties['index']]
148 | pos = (info['x'], info['y'], info['room'])
149 | self.visited.add(pos)
150 | self.visited_rooms.add(info["room"])
151 | if done:
152 | info['mz_episode'] = dict(pos_count=len(self.visited),
153 | visited_rooms=copy(self.visited_rooms))
154 | self.visited.clear()
155 | self.visited_rooms.clear()
156 | return obs, rew, done, info
157 |
158 | def reset(self):
159 | return self.env.reset()
160 |
161 |
162 | class MarioXReward(gym.Wrapper):
163 | def __init__(self, env):
164 | gym.Wrapper.__init__(self, env)
165 | self.current_level = [0, 0]
166 | self.visited_levels = set()
167 | self.visited_levels.add(tuple(self.current_level))
168 | self.current_max_x = 0.
169 |
170 | def reset(self):
171 | ob = self.env.reset()
172 | self.current_level = [0, 0]
173 | self.visited_levels = set()
174 | self.visited_levels.add(tuple(self.current_level))
175 | self.current_max_x = 0.
176 | return ob
177 |
178 | def step(self, action):
179 | ob, reward, done, info = self.env.step(action)
180 | levellow, levelhigh, xscrollHi, xscrollLo = \
181 | info["levelLo"], info["levelHi"], info["xscrollHi"], info["xscrollLo"]
182 | currentx = xscrollHi * 256 + xscrollLo
183 | new_level = [levellow, levelhigh]
184 | if new_level != self.current_level:
185 | self.current_level = new_level
186 | self.current_max_x = 0.
187 | reward = 0.
188 | self.visited_levels.add(tuple(self.current_level))
189 | else:
190 | if currentx > self.current_max_x:
191 | delta = currentx - self.current_max_x
192 | self.current_max_x = currentx
193 | reward = delta
194 | else:
195 | reward = 0.
196 | if done:
197 | info["levels"] = copy(self.visited_levels)
198 | info["retro_episode"] = dict(levels=copy(self.visited_levels))
199 | return ob, reward, done, info
200 |
201 |
202 | class UnityRoomCounterWrapper(gym.Wrapper):
203 | def __init__(self, env,use_ext_reward=True):
204 | gym.Wrapper.__init__(self, env)
205 | self.current_room = None
206 | self.visited_rooms = set()
207 | self.use_ext_reward = use_ext_reward
208 |
209 | def reset(self):
210 | ob = self.env.reset()
211 | self.current_room = None
212 | self.visited_rooms = set()
213 | return ob
214 |
215 |
216 | def step(self, action):
217 | ob, true_reward, done, info = self.env.step(action)
218 | reward = 0.0
219 | current_room = info["curRoom"]
220 |
221 | if self.current_room is None:
222 | self.current_room = current_room
223 | reward = 1.0
224 | self.visited_rooms.add(self.current_room)
225 |
226 | if current_room != self.current_room:
227 | self.current_room = current_room
228 | if self.current_room not in self.visited_rooms:
229 | reward = 1.0
230 | self.visited_rooms.add(self.current_room)
231 | else:
232 | reward = 0.0
233 | info = {"unity_rooms":copy(self.visited_rooms)}
234 | return ob, reward if not self.use_ext_reward else true_reward, done, info
235 |
236 |
237 | class LimitedDiscreteActions(gym.ActionWrapper):
238 | KNOWN_BUTTONS = {"A", "B"}
239 | KNOWN_SHOULDERS = {"L", "R"}
240 |
241 | '''
242 | Reproduces the action space from curiosity paper.
243 | '''
244 |
245 | def __init__(self, env, all_buttons, whitelist=KNOWN_BUTTONS | KNOWN_SHOULDERS):
246 | gym.ActionWrapper.__init__(self, env)
247 |
248 | self._num_buttons = len(all_buttons)
249 | button_keys = {i for i in range(len(all_buttons)) if all_buttons[i] in whitelist & self.KNOWN_BUTTONS}
250 | buttons = [(), *zip(button_keys), *itertools.combinations(button_keys, 2)]
251 | shoulder_keys = {i for i in range(len(all_buttons)) if all_buttons[i] in whitelist & self.KNOWN_SHOULDERS}
252 | shoulders = [(), *zip(shoulder_keys), *itertools.permutations(shoulder_keys, 2)]
253 | arrows = [(), (4,), (5,), (6,), (7,)] # (), up, down, left, right
254 | acts = []
255 | acts += arrows
256 | acts += buttons[1:]
257 | acts += [a + b for a in arrows[-2:] for b in buttons[1:]]
258 | self._actions = acts
259 | self.action_space = gym.spaces.Discrete(len(self._actions))
260 |
261 | def action(self, a):
262 | mask = np.zeros(self._num_buttons)
263 | for i in self._actions[a]:
264 | mask[i] = 1
265 | return mask
266 |
267 |
268 | class FrameSkip(gym.Wrapper):
269 | def __init__(self, env, n):
270 | gym.Wrapper.__init__(self, env)
271 | self.n = n
272 |
273 | def step(self, action):
274 | done = False
275 | totrew = 0
276 | for _ in range(self.n):
277 | ob, rew, done, info = self.env.step(action)
278 | totrew += rew
279 | if done: break
280 | return ob, totrew, done, info
281 |
282 |
283 | def make_mario_env(crop=True, frame_stack=True, clip_rewards=False):
284 | assert clip_rewards is False
285 | import gym
286 | import retro
287 | from baselines.common.atari_wrappers import FrameStack
288 |
289 | #gym.undo_logger_setup()
290 | env = retro.make('SuperMarioBros-Nes', 'Level1-1')
291 | buttons = env.buttons
292 | env = MarioXReward(env)
293 | env = FrameSkip(env, 4)
294 | env = ProcessFrame84(env, crop=crop)
295 | if frame_stack:
296 | env = FrameStack(env, 4)
297 | env = LimitedDiscreteActions(env, buttons)
298 | return env
299 |
300 |
301 | class OneChannel(gym.ObservationWrapper):
302 | def __init__(self, env, crop=True):
303 | self.crop = crop
304 | super(OneChannel, self).__init__(env)
305 | assert env.observation_space.dtype == np.uint8
306 | self.observation_space = gym.spaces.Box(low=0, high=255, shape=(84, 84, 1), dtype=np.uint8)
307 |
308 | def observation(self, obs):
309 | return obs[:, :, 2:3]
310 |
311 |
312 | class RetroALEActions(gym.ActionWrapper):
313 | def __init__(self, env, all_buttons, n_players=1):
314 | gym.ActionWrapper.__init__(self, env)
315 | self.n_players = n_players
316 | self._num_buttons = len(all_buttons)
317 | bs = [-1, 0, 4, 5, 6, 7]
318 | actions = []
319 |
320 | def update_actions(old_actions, offset=0):
321 | actions = []
322 | for b in old_actions:
323 | for button in bs:
324 | action = []
325 | action.extend(b)
326 | if button != -1:
327 | action.append(button + offset)
328 | actions.append(action)
329 | return actions
330 |
331 | current_actions = [[]]
332 | for i in range(self.n_players):
333 | current_actions = update_actions(current_actions, i * self._num_buttons)
334 | self._actions = current_actions
335 | self.action_space = gym.spaces.Discrete(len(self._actions))
336 |
337 | def action(self, a):
338 | mask = np.zeros(self._num_buttons * self.n_players)
339 | for i in self._actions[a]:
340 | mask[i] = 1
341 | return mask
342 |
343 |
344 | class NoReward(gym.Wrapper):
345 | def __init__(self, env):
346 | gym.Wrapper.__init__(self, env)
347 |
348 | def step(self, action):
349 | ob, rew, done, info = self.env.step(action)
350 | return ob, 0.0, done, info
351 |
352 |
353 | def make_multi_pong(frame_stack=True):
354 | import gym
355 | import retro
356 | from baselines.common.atari_wrappers import FrameStack
357 | gym.undo_logger_setup()
358 | game_env = env = retro.make('Pong-Atari2600', players=2)
359 | env = RetroALEActions(env, game_env.BUTTONS, n_players=2)
360 | env = NoReward(env)
361 | env = FrameSkip(env, 4)
362 | env = ProcessFrame84(env, crop=False)
363 | if frame_stack:
364 | env = FrameStack(env, 4)
365 |
366 | return env
367 |
368 |
369 | def make_unity_maze(env_id, seed=0, rank=0, expID=0, frame_stack=True,
370 | logdir=None, ext_coeff=1.0, recordUnityVid=False, **kwargs):
371 | import os
372 | import sys
373 | import time
374 | try:
375 | sys.path.insert(0, os.path.abspath("ml-agents/python/"))
376 | from unityagents import UnityEnvironment
377 | from unity_wrapper import GymWrapper
378 | except ImportError:
379 | print("Import error in unity environment. Ignore if not using unity.")
380 | pass
381 | from baselines.common.atari_wrappers import FrameStack
382 | # gym.undo_logger_setup() # deprecated in new version of gym
383 |
384 | # max 20 workers per expID, max 30 experiments per machine
385 | if rank>=0 and rank<=200:
386 | time.sleep(rank * 2)
387 | env = UnityEnvironment(file_name='envs/' + env_id,
388 | worker_id=(expID % 60) * 200 + rank)
389 | maxsteps = 3000 if 'big' in env_id else 500
390 | env = GymWrapper(env, seed=seed, rank=rank, expID=expID, maxsteps=maxsteps,
391 | **kwargs)
392 | if "big" in env_id:
393 | env = UnityRoomCounterWrapper(env, use_ext_reward=(ext_coeff != 0.0))
394 | if rank == 1 and recordUnityVid:
395 | env = RecordBestScores(env, directory=logdir, freq=1)
396 | print('Loaded environment %s with rank %d\n\n' % (env_id, rank))
397 |
398 | # env = NoReward(env)
399 | # env = FrameSkip(env, 4)
400 | env = ProcessFrame84(env, crop=False)
401 | if frame_stack:
402 | env = FrameStack(env, 4)
403 | return env
404 |
405 |
406 | class RecordBestScores(gym.Wrapper):
407 | def __init__(self, env, directory, freq=100):
408 | super(RecordBestScores, self).__init__(env)
409 | self.freq = freq
410 | self.frames = []
411 | self.highest_reward = None
412 | self.episodic_reward = 0.
413 | self.longest_length = 0
414 | self.directory = directory
415 | self.episode_number = 0
416 | if not os.path.exists(self.directory):
417 | os.makedirs(self.directory)
418 |
419 | def _step(self, action):
420 | state, reward, done, info = self.env.step(action)
421 | self.frames.append(self.env.render(mode='rgb_array'))
422 | self.episodic_reward += reward
423 | if done:
424 | if self.highest_reward == None:
425 | self.highest_reward = self.episodic_reward
426 | self._record_last_episode("high_score_")
427 | elif self.highest_reward < self.episodic_reward:
428 | self.highest_reward = self.episodic_reward
429 | self._record_last_episode("high_score_")
430 | elif self.episode_number % self.freq == 0:
431 | self._record_last_episode("random_")
432 |
433 | self.frames = []
434 | self.episodic_reward = 0
435 | self.episode_number += 1
436 | return state, reward, done, info
437 |
438 | def _record_last_episode(self, prefix=""):
439 | save_np_as_mp4(self.frames, os.path.join(self.directory, prefix+'replay{}.mp4'.format(self.episode_number)))
440 |
441 |
442 | class StickyActionEnv(gym.Wrapper):
443 | def __init__(self, env, p=0.25):
444 | super(StickyActionEnv, self).__init__(env)
445 | self.p = p
446 | self.last_action = 0
447 |
448 | def reset(self):
449 | self.last_action = 0
450 | return self.env.reset()
451 |
452 | def step(self, action):
453 | if self.unwrapped.np_random.uniform() < self.p:
454 | action = self.last_action
455 | self.last_action = action
456 | obs, reward, done, info = self.env.step(action)
457 | return obs, reward, done, info
458 |
--------------------------------------------------------------------------------