├── .gitignore
├── README.md
├── assets
├── 3dunet_arch.png
├── Decision Making in Applying Deep Learning - Page 1.svg
├── IOU_segmentation.png
├── RCNN_arch.png
├── alexnet_arch.png
├── chestxray8_arch.png
├── deepmask_arch.PNG
├── fast_rcnn_arch.png
├── faster_rcnn_arch.png
├── fcn_arch.png
├── fpn_arch.png
├── fpn_arch2.png
├── fpn_arch3.png
├── images
│ ├── 2d3d_deep3dbox.png
│ ├── 2d3d_deep3dbox_1.png
│ ├── 2d3d_deep3dbox_2.png
│ ├── 2d3d_deep3dbox_code.png
│ ├── 2d3d_deep3dbox_equivalency.png
│ ├── 2d3d_fqnet_1.png
│ ├── 2d3d_fqnet_2.png
│ ├── 2d3d_shift_rcnn_1.png
│ ├── 2d3d_shift_rcnn_2.png
│ ├── cam_conv.jpg
│ ├── disnet.png
│ ├── foresee.png
│ ├── pseudo_lidar.png
│ └── tesla_release_note_10.11.2.png
├── lstm_arch.png
├── lstm_calc.png
├── mask_rcnn_arch.png
├── mask_rcnn_arch2.png
├── multipath_arch.png
├── overfeat_bb_regressor.png
├── overfeat_efficient_sliding_window.png
├── overfeat_shift_and_stich.png
├── papers
│ ├── Devils_in_BatchNorm_yuxin_wu.pdf
│ ├── bosch_traffic_lights.pdf
│ └── schumann2018.pdf
├── polygon_rnn_arch.png
├── review_mlp_vs_transformers
│ ├── illustrated_transformers_vs_mlp.docx
│ └── illustration_mlp_vs_transformers.ipynb
├── segmentation_tasks_example.png
├── sharpmask_arch.png
├── sharpmask_head_arch.png
├── sharpmask_refinement_arch.png
├── ssd_arch.png
├── unet_arch.png
├── vgg_arch.png
├── vnet_arch.png
├── yolo9000_wordtree.png
├── yolo_arch.png
├── yolo_arch2.png
├── yolo_diagram.png
└── yolo_loss.png
├── chrono
├── 2019H1.md
├── 2019H2.md
└── ipynb
│ └── visualization_paper_reading_2019.ipynb
├── code_notes
├── _template.md
├── old_tf_notes
│ └── tf_learning_notes.md
├── openpilot.md
├── pitfalls.md
├── setup_log.md
└── simple_faster_rcnn.md
├── learning_filters
└── README.md
├── learning_pnc
├── crash_course.md
└── pnc_notes.md
├── learning_slam
├── slam_14.md
└── slam_ref.md
├── openai_orgchart
├── README.md
├── openai_orgchart.ipynb
├── openai_orgchart.txt
├── resource_allocation.png
├── skill_diversity_of_addtional_contributors.png
├── skill_diversity_of_all_contributors.png
├── top_contributors in Additional contributions.png
├── top_contributors in Long context.png
├── top_contributors.png
├── top_contributors_in_Deployment.png
├── top_contributors_in_Evaluation_analysis.png
├── top_contributors_in_Pretraining.png
├── top_contributors_in_Reinforcement_Learning_Alignment.png
├── top_contributors_in_Vision.png
└── word_cloud.png
├── paper_notes
├── 2dod_calib.md
├── 3d_gck.md
├── 3d_lanenet+.md
├── 3d_lanenet.md
├── 3d_rcnn.md
├── 3d_shapenets.md
├── 3ddl_cvpr2017.md
├── 3dod_review.md
├── 3dssd.md
├── 6d_vnet.md
├── AUNet_panoptic.md
├── M2Det.md
├── MixMatch.md
├── _template.md
├── acnet.md
├── adaptive_nms.md
├── adriver_i.md
├── afdet.md
├── aft.md
├── agg_loss.md
├── alphago.md
├── am3d.md
├── amodal_completion.md
├── anchor_detr.md
├── ap_mr.md
├── apollo_car_parts.md
├── apollo_em_planner.md
├── apollocar3d.md
├── argoverse.md
├── association_lstm.md
├── associative_embedding.md
├── astyx_dataset.md
├── astyx_radar_camera_fusion.md
├── atss.md
├── autoaugment.md
├── av20.md
├── avod.md
├── avp_slam.md
├── avp_slam_late_fusion.md
├── ba_sfm_learner.md
├── bag_of_freebies_object_detection.md
├── bag_of_tricks_classification.md
├── banet.md
├── batchnorm_pruning.md
├── bayes_od.md
├── bayesian_segnet.md
├── bayesian_yolov3.md
├── bc_sac.md
├── bev_feat_stitching.md
├── bev_od_ipm.md
├── bev_seg.md
├── bevdepth.md
├── bevdet.md
├── bevdet4d.md
├── beverse.md
├── bevformer.md
├── bevfusion.md
├── bevnet_sdca.md
├── birdgan.md
├── blendmask.md
├── bn_ffn_bn.md
├── bosch_traffic_lights.md
├── boxinst.md
├── boxy.md
├── bs3d.md
├── c3dpo.md
├── caddn.md
├── calib_modern_nn.md
├── cam2bev.md
├── cam_conv.md
├── cap.md
├── casgeo.md
├── cbam.md
├── cbgs.md
├── cbn.md
├── cc.md
├── center3d.md
├── centerfusion.md
├── centermask.md
├── centernet.md
├── centernet2.md
├── centerpoint.md
├── centertrack.md
├── centroid_voting.md
├── channel_pruning_megvii.md
├── chauffeurnet.md
├── class_balanced_loss.md
├── classical_keypoints.md
├── cluster_vo.md
├── cnn_seg.md
├── codex.md
├── complex_yolo.md
├── condinst.md
├── confluence.md
├── consistent_video_depth.md
├── contfuse.md
├── coord_conv.md
├── corenet.md
├── corner_case_multisensor.md
├── corner_case_vision_arxiv.md
├── cornernet.md
├── crf_net.md
├── crowd_det.md
├── crowdhuman.md
├── csp_pedestrian.md
├── cube_slam.md
├── cubifae_3d.md
├── cvt.md
├── d3vo.md
├── d4lcn.md
├── da_3det.md
├── dagmapper.md
├── darts.md
├── ddmp.md
├── deep3dbox.md
├── deep_active_learning_lidar.md
├── deep_boundary_extractor.md
├── deep_depth_completion_rgbd.md
├── deep_double_descent.md
├── deep_fusion_review.md
├── deep_lane_association.md
├── deep_manta.md
├── deep_optics.md
├── deep_radar_detector.md
├── deep_road_mapper.md
├── deep_signals.md
├── deep_sort.md
├── deep_structured_crosswalk.md
├── deeplidar.md
├── deepmot.md
├── deepv2d.md
├── defcn.md
├── deformable_detr.md
├── dekr.md
├── delving_bev.md
├── dense_tnt.md
├── densebox.md
├── densepose.md
├── depth_coeff.md
├── depth_from_one_line.md
├── depth_hints.md
├── detect_track.md
├── detr.md
├── detr3d.md
├── df_vo.md
├── disnet.md
├── distance_estimation_pose_radar.md
├── distant_object_radar.md
├── dl_regression_calib.md
├── dorn.md
├── dota.md
├── double_anchor.md
├── double_descent.md
├── drive_dreamer.md
├── drive_gan.md
├── drive_wm.md
├── drivegpt4.md
├── drivevlm.md
├── drl_flappy.md
├── drl_vessel_centerline.md
├── dsnt.md
├── dsp.md
├── dtp.md
├── e2e_lmd.md
├── e2e_review_hongyang.md
├── edge_aware_depth_normal.md
├── edgeconv.md
├── efficientdet.md
├── efficientnet.md
├── egonet.md
├── eudm.md
├── extreme_clicking.md
├── extremenet.md
├── faf.md
├── fairmot.md
├── fbnet.md
├── fcos.md
├── fcos3d.md
├── feature_metric.md
├── federated_learning_comm.md
├── fiery.md
├── fishing_net.md
├── fishyscape.md
├── fixres.md
├── flamingo.md
├── focal_loss.md
├── foresee_mono3dod.md
├── foveabox.md
├── fqnet.md
├── frozen_depth.md
├── frustum_pointnet.md
├── fsaf_detection.md
├── fsm.md
├── gac.md
├── gaia_1.md
├── gato.md
├── gaussian_yolov3.md
├── gen_lanenet.md
├── genie.md
├── geometric_pretraining.md
├── geonet.md
├── gfocal.md
├── gfocalv2.md
├── ghostnet.md
├── giou.md
├── glnet.md
├── gpp.md
├── gpt4.md
├── gpt4v_robotics.md
├── gradnorm.md
├── graph_spectrum.md
├── groupnorm.md
├── gs3d.md
├── guided_backprop.md
├── gupnet.md
├── h3d.md
├── hdmapnet.md
├── hevi.md
├── home.md
├── how_hard_can_it_be.md
├── hran.md
├── hugging_gpt.md
├── human_centric_annotation.md
├── insta_yolo.md
├── instance_mot_seg.md
├── instructgpt.md
├── intentnet.md
├── iou_net.md
├── joint_learned_bptp.md
├── kalman_filter.md
├── keep_hd_maps_updated_bmw.md
├── kinematic_mono3d.md
├── kitti.md
├── kitti_lane.md
├── kl_loss.md
├── km3d_net.md
├── kp2d.md
├── kp3d.md
├── lanenet.md
├── lasernet.md
├── lasernet_kl.md
├── layer_compensated_pruning.md
├── learn_depth_and_motion.md
├── learning_correspondence.md
├── learning_ood_conf.md
├── learning_to_look_around_objects.md
├── learnk.md
├── lego.md
├── lego_loam.md
├── legr.md
├── lidar_rcnn.md
├── lidar_sim.md
├── lifelong_feature_mapping_google.md
├── lift_splat_shoot.md
├── lighthead_rcnn.md
├── lingo_1.md
├── lingo_2.md
├── llm_brain.md
├── llm_vision_intel.md
├── locomotion_next_token_pred.md
├── long_term_feat_bank.md
├── lottery_ticket_hypothesis.md
├── lstr.md
├── m2bev.md
├── m2i.md
├── m3d_rpn.md
├── mae.md
├── manydepth.md
├── maptr.md
├── marc.md
├── mb_net.md
├── mebow.md
├── meinst.md
├── mfs.md
├── mgail_ad.md
├── mile.md
├── misc.md
├── mixup.md
├── mlf.md
├── mmf.md
├── mnasnet.md
├── mobilenets.md
├── mobilenets_v2.md
├── mobilenets_v3.md
├── moc.md
├── moco.md
├── monet3d.md
├── mono3d++.md
├── mono3d.md
├── mono3d_fisheye.md
├── mono_3d_tracking.md
├── mono_3dod_2d3d_constraints.md
├── mono_uncertainty.md
├── monodepth.md
├── monodepth2.md
├── monodis.md
├── monodle.md
├── monodr.md
├── monoef.md
├── monoflex.md
├── monogrnet.md
├── monogrnet_russian.md
├── monolayout.md
├── monoloco.md
├── monopair.md
├── monopsr.md
├── monoresmatch.md
├── monoscene.md
├── mot_and_sot.md
├── motionnet.md
├── movi_3d.md
├── mp3.md
├── mpdm.md
├── mpdm2.md
├── mpv_nets.md
├── mtcnn.md
├── multi_object_mono_slam.md
├── multigrid_training.md
├── multinet_raquel.md
├── multipath++.md
├── multipath.md
├── multipath_uber.md
├── mv3d.md
├── mvcnn.md
├── mvf.md
├── mvp.md
├── mvra.md
├── nas_fpn.md
├── nature_dqn_paper.md
├── neat.md
├── network_slimming.md
├── ng_ransac.md
├── nmp.md
├── non_local_net.md
├── nuplan.md
├── nuscenes.md
├── obj_dist_iccv2019.md
├── obj_motion_net.md
├── object_detection_region_decomposition.md
├── objects_without_bboxes.md
├── occ3d.md
├── occlusion_net.md
├── occupancy_networks.md
├── oft.md
├── onenet.md
├── openoccupancy.md
├── opportunities_foundation_models.md
├── out_of_data.md
├── owod.md
├── packnet.md
├── packnet_sg.md
├── palm_e.md
├── panet.md
├── panoptic_bev.md
├── panoptic_fpn.md
├── panoptic_segmentation.md
├── parametric_cont_conv.md
├── patchnet.md
├── patdnn.md
├── pdq.md
├── perceiver.md
├── perceiver_io.md
├── perceiving_humans.md
├── persformer.md
├── petr.md
├── petrv2.md
├── peudo_lidar_e2d.md
├── pie.md
├── pillar_motion.md
├── pillar_od.md
├── pix2seq.md
├── pix2seq_v2.md
├── pixels_to_graphs.md
├── pixor++.md
├── pixor.md
├── pnpnet.md
├── point_cnn.md
├── point_painting.md
├── point_pillars.md
├── point_rcnn.md
├── pointnet++.md
├── pointnet.md
├── pointrend.md
├── pointtrack++.md
├── pointtrack.md
├── polarmask.md
├── polymapper.md
├── posenet.md
├── powernorm.md
├── pp_yolo.md
├── ppgeo.md
├── prevention_dataset.md
├── prompt_craft.md
├── pruning_filters.md
├── psdet.md
├── pseudo_lidar++.md
├── pseudo_lidar.md
├── pseudo_lidar_e2e.md
├── pseudo_lidar_v3.md
├── pss.md
├── pwc_net.md
├── pyroccnet.md
├── pyva.md
├── qcnet.md
├── quo_vadis_i3d.md
├── r2_nms.md
├── radar_3d_od_fcn.md
├── radar_camera_qcom.md
├── radar_detection_pointnet.md
├── radar_fft_qcom.md
├── radar_point_semantic_seg.md
├── radar_target_detection_tsinghua.md
├── rarnet.md
├── realtime_panoptic.md
├── recurrent_retinanet.md
├── recurrent_ssd.md
├── refined_mpl.md
├── reid_surround_fisheye.md
├── rep_loss.md
├── repvgg.md
├── resnest.md
├── resnext.md
├── rethinking_pretraining.md
├── retina_face.md
├── retina_unet.md
├── retnet.md
├── review_descriptors.md
├── review_mono_3dod.md
├── rfcn.md
├── rib_centerline_philips.md
├── road_slam.md
├── road_tracer.md
├── robovqa.md
├── roi10d.md
├── roi_transformer.md
├── rolo.md
├── ror.md
├── rpt.md
├── rrpn_radar.md
├── rt1.md
├── rt2.md
├── rtm3d.md
├── rvnet.md
├── rwkv.md
├── s3dot.md
├── saycan.md
├── sc_sfm_learner.md
├── scaled_yolov4.md
├── sdflabel.md
├── self_mono_sf.md
├── semilocal_3d_lanenet.md
├── sfm_learner.md
├── sgdepth.md
├── shift_rcnn.md
├── simmim.md
├── simtrack.md
├── sknet.md
├── sku110k.md
├── slimmable_networks.md
├── slowfast.md
├── smoke.md
├── smwa.md
├── social_lstm.md
├── solo.md
├── solov2.md
├── sort.md
├── sparse_hd_maps.md
├── sparse_rcnn.md
├── sparse_to_dense.md
├── spatial_embedding.md
├── specialized_cyclists.md
├── speednet.md
├── ss3d.md
├── stitcher.md
├── stn.md
├── struct2depth.md
├── stsu.md
├── subpixel_conv.md
├── super.md
├── superpoint.md
├── surfel_gan.md
├── surroundocc.md
├── swahr.md
├── task_grouping.md
├── taskonomy.md
├── tensormask.md
├── tfl_exploting_map_korea.md
├── tfl_lidar_map_building_brazil.md
├── tfl_mapping_google.md
├── tfl_robust_japan.md
├── tfl_stanford.md
├── ti_mmwave_radar_webinar.md
├── tidybot.md
├── tlnet.md
├── tnt.md
├── to_learn_or_not.md
├── tot.md
├── towards_safe_ad.md
├── towards_safe_ad2.md
├── towards_safe_ad_calib.md
├── tpvformer.md
├── tracktor.md
├── trafficpredict.md
├── train_in_germany.md
├── transformer.md
├── transformers_are_rnns.md
├── translating_images_to_maps.md
├── trianflow.md
├── tsinghua_daimler_cyclists.md
├── tsl_frequency.md
├── tsm.md
├── tsp.md
├── twsm_net.md
├── umap.md
├── uncertainty_bdl.md
├── uncertainty_multitask.md
├── understanding_apr.md
├── uniad.md
├── unisim.md
├── universal_slimmable.md
├── unsuperpoint.md
├── ur3d.md
├── vectormapnet.md
├── ved.md
├── vehicle_centric_velocity_net.md
├── velocity_net.md
├── vg_nms.md
├── video_ldm.md
├── videogpt.md
├── vip3d.md
├── virtual_normal.md
├── vision_llm.md
├── vit.md
├── vo_monodepth.md
├── vol_vs_mvcnn.md
├── voxformer.md
├── voxnet.md
├── voxposer.md
├── vpgnet.md
├── vpn.md
├── vpt.md
├── vslam_for_ad.md
├── wayformer.md
├── waymo_dataset.md
├── what_monodepth_see.md
├── widerperson.md
├── world_dreamer.md
├── wysiwyg.md
├── yolact.md
├── yolof.md
├── yolov3.md
├── yolov4.md
└── yolov5.md
├── start
├── first_cnn_papers.md
└── first_cnn_papers_notes.md
├── talk_notes
├── andrej.md
├── cvpr_2021
│ ├── assets
│ │ ├── 8cam_setup.jpg
│ │ ├── cover.jpg
│ │ ├── data_auto_labeling.jpg
│ │ ├── depth_velocity_with_vision_1.jpg
│ │ ├── depth_velocity_with_vision_2.jpg
│ │ ├── depth_velocity_with_vision_3.jpg
│ │ ├── large_clean_diverse_data.jpg
│ │ ├── release_and_validation.jpg
│ │ ├── tesla_dataset.jpg
│ │ ├── tesla_no_radar.jpg
│ │ ├── traffic_control_warning_pmm.jpg
│ │ └── trainig_cluster.jpg
│ └── cvpr_2021.md
├── scaledml_2020
│ ├── assets
│ │ ├── bevnet.jpg
│ │ ├── env.jpg
│ │ ├── evaluation.jpg
│ │ ├── operation_vacation.jpg
│ │ ├── pedestrian_aeb.jpg
│ │ ├── stop1.jpg
│ │ ├── stop10.jpg
│ │ ├── stop11.jpg
│ │ ├── stop12.jpg
│ │ ├── stop13.jpg
│ │ ├── stop2.jpg
│ │ ├── stop3.jpg
│ │ ├── stop4.jpg
│ │ ├── stop5.jpg
│ │ ├── stop6.jpg
│ │ ├── stop7.jpg
│ │ ├── stop8.jpg
│ │ ├── stop9.jpg
│ │ ├── stop_overview.jpg
│ │ └── vidar.jpg
│ └── scaledml_2020.md
└── state_of_gpt_2023
│ ├── media
│ ├── image001.jpg
│ ├── image002.jpg
│ ├── image003.jpg
│ ├── image004.jpg
│ ├── image005.jpg
│ ├── image006.jpg
│ ├── image007.jpg
│ ├── image008.jpg
│ ├── image009.jpg
│ ├── image010.jpg
│ ├── image011.jpg
│ ├── image012.jpg
│ ├── image013.jpg
│ ├── image014.jpg
│ ├── image015.jpg
│ ├── image016.jpg
│ ├── image017.jpg
│ ├── image018.jpg
│ ├── image019.jpg
│ ├── image020.jpg
│ ├── image021.jpg
│ ├── image022.jpg
│ ├── image023.jpg
│ ├── image024.jpg
│ ├── image025.jpg
│ ├── image026.jpg
│ ├── image027.jpg
│ ├── image028.jpg
│ ├── image029.jpg
│ ├── image030.jpg
│ ├── image031.jpg
│ ├── image032.jpg
│ ├── image033.jpg
│ ├── image034.jpg
│ ├── image035.jpg
│ ├── image036.jpg
│ ├── image037.jpg
│ └── image038.jpg
│ └── state_of_gpt_2023.md
├── topics
├── topic_3d_lld.md
├── topic_bev_segmentation.md
├── topic_cls_reg.md
├── topic_crowd_detection.md
├── topic_detr.md
├── topic_occupancy_network.md
├── topic_single_stage_instance_segmentation.md
├── topic_transformers_bev.md
└── topic_vlm.md
└── trusty.md
/.gitignore:
--------------------------------------------------------------------------------
1 | # ignore numpy data file
2 | *.npy
3 | # ignore Desktop Service Store in Mac OSX
4 | .DS_Store
5 | */.DS_Store
6 | *.html
7 | # ignore ipynb checkpoints
8 | .ipynb_checkpoints
9 | # ignore ide
10 | .idea
11 |
--------------------------------------------------------------------------------
/assets/3dunet_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/3dunet_arch.png
--------------------------------------------------------------------------------
/assets/IOU_segmentation.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/IOU_segmentation.png
--------------------------------------------------------------------------------
/assets/RCNN_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/RCNN_arch.png
--------------------------------------------------------------------------------
/assets/alexnet_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/alexnet_arch.png
--------------------------------------------------------------------------------
/assets/chestxray8_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/chestxray8_arch.png
--------------------------------------------------------------------------------
/assets/deepmask_arch.PNG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/deepmask_arch.PNG
--------------------------------------------------------------------------------
/assets/fast_rcnn_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/fast_rcnn_arch.png
--------------------------------------------------------------------------------
/assets/faster_rcnn_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/faster_rcnn_arch.png
--------------------------------------------------------------------------------
/assets/fcn_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/fcn_arch.png
--------------------------------------------------------------------------------
/assets/fpn_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/fpn_arch.png
--------------------------------------------------------------------------------
/assets/fpn_arch2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/fpn_arch2.png
--------------------------------------------------------------------------------
/assets/fpn_arch3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/fpn_arch3.png
--------------------------------------------------------------------------------
/assets/images/2d3d_deep3dbox.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/images/2d3d_deep3dbox.png
--------------------------------------------------------------------------------
/assets/images/2d3d_deep3dbox_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/images/2d3d_deep3dbox_1.png
--------------------------------------------------------------------------------
/assets/images/2d3d_deep3dbox_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/images/2d3d_deep3dbox_2.png
--------------------------------------------------------------------------------
/assets/images/2d3d_deep3dbox_code.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/images/2d3d_deep3dbox_code.png
--------------------------------------------------------------------------------
/assets/images/2d3d_deep3dbox_equivalency.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/images/2d3d_deep3dbox_equivalency.png
--------------------------------------------------------------------------------
/assets/images/2d3d_fqnet_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/images/2d3d_fqnet_1.png
--------------------------------------------------------------------------------
/assets/images/2d3d_fqnet_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/images/2d3d_fqnet_2.png
--------------------------------------------------------------------------------
/assets/images/2d3d_shift_rcnn_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/images/2d3d_shift_rcnn_1.png
--------------------------------------------------------------------------------
/assets/images/2d3d_shift_rcnn_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/images/2d3d_shift_rcnn_2.png
--------------------------------------------------------------------------------
/assets/images/cam_conv.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/images/cam_conv.jpg
--------------------------------------------------------------------------------
/assets/images/disnet.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/images/disnet.png
--------------------------------------------------------------------------------
/assets/images/foresee.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/images/foresee.png
--------------------------------------------------------------------------------
/assets/images/pseudo_lidar.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/images/pseudo_lidar.png
--------------------------------------------------------------------------------
/assets/images/tesla_release_note_10.11.2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/images/tesla_release_note_10.11.2.png
--------------------------------------------------------------------------------
/assets/lstm_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/lstm_arch.png
--------------------------------------------------------------------------------
/assets/lstm_calc.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/lstm_calc.png
--------------------------------------------------------------------------------
/assets/mask_rcnn_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/mask_rcnn_arch.png
--------------------------------------------------------------------------------
/assets/mask_rcnn_arch2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/mask_rcnn_arch2.png
--------------------------------------------------------------------------------
/assets/multipath_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/multipath_arch.png
--------------------------------------------------------------------------------
/assets/overfeat_bb_regressor.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/overfeat_bb_regressor.png
--------------------------------------------------------------------------------
/assets/overfeat_efficient_sliding_window.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/overfeat_efficient_sliding_window.png
--------------------------------------------------------------------------------
/assets/overfeat_shift_and_stich.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/overfeat_shift_and_stich.png
--------------------------------------------------------------------------------
/assets/papers/Devils_in_BatchNorm_yuxin_wu.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/papers/Devils_in_BatchNorm_yuxin_wu.pdf
--------------------------------------------------------------------------------
/assets/papers/bosch_traffic_lights.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/papers/bosch_traffic_lights.pdf
--------------------------------------------------------------------------------
/assets/papers/schumann2018.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/papers/schumann2018.pdf
--------------------------------------------------------------------------------
/assets/polygon_rnn_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/polygon_rnn_arch.png
--------------------------------------------------------------------------------
/assets/review_mlp_vs_transformers/illustrated_transformers_vs_mlp.docx:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/review_mlp_vs_transformers/illustrated_transformers_vs_mlp.docx
--------------------------------------------------------------------------------
/assets/segmentation_tasks_example.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/segmentation_tasks_example.png
--------------------------------------------------------------------------------
/assets/sharpmask_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/sharpmask_arch.png
--------------------------------------------------------------------------------
/assets/sharpmask_head_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/sharpmask_head_arch.png
--------------------------------------------------------------------------------
/assets/sharpmask_refinement_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/sharpmask_refinement_arch.png
--------------------------------------------------------------------------------
/assets/ssd_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/ssd_arch.png
--------------------------------------------------------------------------------
/assets/unet_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/unet_arch.png
--------------------------------------------------------------------------------
/assets/vgg_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/vgg_arch.png
--------------------------------------------------------------------------------
/assets/vnet_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/vnet_arch.png
--------------------------------------------------------------------------------
/assets/yolo9000_wordtree.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/yolo9000_wordtree.png
--------------------------------------------------------------------------------
/assets/yolo_arch.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/yolo_arch.png
--------------------------------------------------------------------------------
/assets/yolo_arch2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/yolo_arch2.png
--------------------------------------------------------------------------------
/assets/yolo_diagram.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/yolo_diagram.png
--------------------------------------------------------------------------------
/assets/yolo_loss.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/assets/yolo_loss.png
--------------------------------------------------------------------------------
/code_notes/_template.md:
--------------------------------------------------------------------------------
1 | # [Paper Title](link_to_paper)
2 |
3 | _December 2019_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - Questions and notes on how to improve/revise the current work
18 |
19 |
--------------------------------------------------------------------------------
/code_notes/pitfalls.md:
--------------------------------------------------------------------------------
1 | # Pitfalls in Python and its libraries
2 |
3 | ## Python
4 | - Python passes by object. This is quite different from pass by reference and pass by value, as explained in the blog [here](https://robertheaton.com/2014/02/09/pythons-pass-by-object-reference-as-explained-by-philip-k-dick/) and [here](https://jeffknupp.com/blog/2012/11/13/is-python-callbyvalue-or-callbyreference-neither/).
5 | - pay attention to the trailing `,`.
6 | ```
7 | >>> a = 1
8 | >>> a
9 | 1
10 | >>> a = 1,
11 | >>> a
12 | (1,)
13 | ```
14 |
--------------------------------------------------------------------------------
/code_notes/simple_faster_rcnn.md:
--------------------------------------------------------------------------------
1 | # [simple-faster-rcnn-pytorch](https://github.com/chenyuntc/simple-faster-rcnn-pytorch/) (2.1k star)
2 |
3 | _January 2020_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - [从编程实现角度学习Faster R-CNN(附极简实现)](https://zhuanlan.zhihu.com/p/32404424)
18 |
19 |
--------------------------------------------------------------------------------
/learning_slam/slam_14.md:
--------------------------------------------------------------------------------
1 | # [视觉SLAM14讲 (14 Lectures on Visual SLAM)](https://github.com/gaoxiang12/slambook2)
2 |
3 | _January 2020_
4 |
5 | #### Chapter 1
6 | - Questions and notes on how to improve/revise the current work
7 |
8 |
--------------------------------------------------------------------------------
/openai_orgchart/resource_allocation.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/openai_orgchart/resource_allocation.png
--------------------------------------------------------------------------------
/openai_orgchart/skill_diversity_of_addtional_contributors.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/openai_orgchart/skill_diversity_of_addtional_contributors.png
--------------------------------------------------------------------------------
/openai_orgchart/skill_diversity_of_all_contributors.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/openai_orgchart/skill_diversity_of_all_contributors.png
--------------------------------------------------------------------------------
/openai_orgchart/top_contributors in Additional contributions.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/openai_orgchart/top_contributors in Additional contributions.png
--------------------------------------------------------------------------------
/openai_orgchart/top_contributors in Long context.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/openai_orgchart/top_contributors in Long context.png
--------------------------------------------------------------------------------
/openai_orgchart/top_contributors.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/openai_orgchart/top_contributors.png
--------------------------------------------------------------------------------
/openai_orgchart/top_contributors_in_Deployment.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/openai_orgchart/top_contributors_in_Deployment.png
--------------------------------------------------------------------------------
/openai_orgchart/top_contributors_in_Evaluation_analysis.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/openai_orgchart/top_contributors_in_Evaluation_analysis.png
--------------------------------------------------------------------------------
/openai_orgchart/top_contributors_in_Pretraining.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/openai_orgchart/top_contributors_in_Pretraining.png
--------------------------------------------------------------------------------
/openai_orgchart/top_contributors_in_Reinforcement_Learning_Alignment.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/openai_orgchart/top_contributors_in_Reinforcement_Learning_Alignment.png
--------------------------------------------------------------------------------
/openai_orgchart/top_contributors_in_Vision.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/openai_orgchart/top_contributors_in_Vision.png
--------------------------------------------------------------------------------
/openai_orgchart/word_cloud.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/openai_orgchart/word_cloud.png
--------------------------------------------------------------------------------
/paper_notes/2dod_calib.md:
--------------------------------------------------------------------------------
1 | # [Calibrating Uncertainties in Object Localization Task](https://arxiv.org/abs/1811.11210)
2 |
3 | _November 2019_
4 |
5 | tl;dr: Proof of concept by applying Uncertainty calibration to object detector.
6 |
7 | #### Overall impression
8 | For a more theoretical treatment refer to [accurate uncertainty via calibrated regression](dl_regression_calib.md). A more detailed application is [can we trust you](towards_safe_ad_calib.md).
9 |
10 | #### Key ideas
11 | - Validating uncertainty estimates: plot regressed aleatoric uncertainty $\sigma_i^2$ and $(b_i - \bar{b_i})^2$
12 | - To find 90% confidence interval, the upper and lower bounds are given by $\hat{P^{-1}}(r \pm 90/2)$, where $r = \hat{P(x)}$ and $\hat{P}$ is the P after calibration.
13 |
14 | #### Technical details
15 | - Summary of technical details
16 |
17 | #### Notes
18 | - Questions and notes on how to improve/revise the current work
19 |
20 |
--------------------------------------------------------------------------------
/paper_notes/3d_gck.md:
--------------------------------------------------------------------------------
1 | # [3D-GCK: Single-Shot 3D Detection of Vehicles from Monocular RGB Images via Geometrically Constrained Keypoints in Real-Time](https://arxiv.org/abs/2006.13084)
2 |
3 | _August 2020_
4 |
5 | tl;dr: Annotate and predict an 8DoF polyline for 3D perception.
6 |
7 | #### Overall impression
8 | The paper proposed a way to annotate and regress a 3D bbox, in the form of a 8 DoF polyline. This is very similar but different from [Bounding Shapes](bounding_shapes.md).
9 |
10 | This is one of the series of papers from Daimler.
11 |
12 | - [MergeBox](mb_net.md)
13 | - [Bounding Shapes](bounding_shapes.md)
14 | - [3D Geometrically constraint keypoints](3d_gck.md)
15 |
16 |
17 | #### Key ideas
18 | - Bounding shape is one 4-point and 8DoF polyline.
19 | 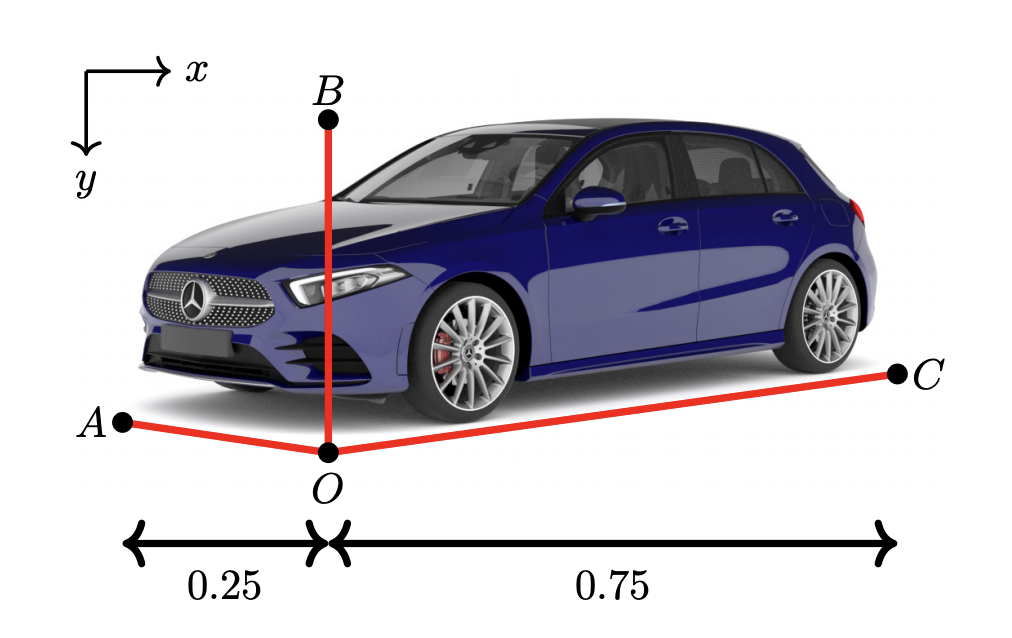
20 | - Distance is calculated with IPM.
21 |
22 | #### Technical details
23 | - Summary of technical details
24 |
25 | #### Notes
26 | - Series production cars: mass production cars
27 |
28 |
--------------------------------------------------------------------------------
/paper_notes/3d_lanenet+.md:
--------------------------------------------------------------------------------
1 | # [3D-LaneNet+: Anchor Free Lane Detection using a Semi-Local Representation](https://arxiv.org/abs/2011.01535)
2 |
3 | _November 2020_
4 |
5 | tl;dr: This is a shrunk down version of [Semilocal 3D LaneNet](semilocal_3d_lanenet.md). By design, the semi-local tile based approach is anchor free.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - Questions and notes on how to improve/revise the current work
18 |
19 |
--------------------------------------------------------------------------------
/paper_notes/3ddl_cvpr2017.md:
--------------------------------------------------------------------------------
1 | # [3D Deep Learning Tutorial at CVPR 2017](https://www.youtube.com/watch?v=8CenT_4HWyY)
2 |
3 | _Mar 2019_
4 |
5 | tl;dr: CVPR Tutorial on 3d deep learning.
6 |
7 | #### Overall impression
8 | - 3D representations:
9 | - rasterized: multiview 2d, 3d voxelized
10 | - geometric: point cloud, mesh, primitive-based CAD
--------------------------------------------------------------------------------
/paper_notes/3dod_review.md:
--------------------------------------------------------------------------------
1 | # [A Survey on 3D Object Detection Methods for Autonomous Driving Applications](http://wrap.warwick.ac.uk/114314/1/WRAP-survey-3D-object-detection-methods-autonomous-driving-applications-Arnold-2019.pdf)
2 |
3 | _October 2019_
4 |
5 | tl;dr: Summary of 3DOD methods based on monocular images, lidars and sensor fusion methods of the two.
6 |
7 | #### Overall impression
8 | The review is updated as of 2018. However there have been a lot of progress of mono 3DOD in 2019. I shall write a review of mono 3DOD soon.
9 |
10 | #### Key ideas
11 | > - The main drawback of monocular methods is the lack of depth cues, which limits detection and localization accuracy, especially for far and occluded objects.
12 |
13 | > - Most mono 3DOD methods have shifted towards a learned paradigm for RPN and second stage of of 3D model matching and reprojection to obtain 3D Box.
14 |
15 | #### Technical details
16 | - Mono
17 | - [mono3D](mono3d.md)
18 | - 3DVP
19 | - subCNN
20 | - [deepMANTA](deep_manta.md)
21 | - [deep3DBox](deep3dbox.md)
22 | - 360 panorama
23 | - Lidar
24 | - projection
25 | - VeloFCN
26 | - [Complex YOLO](complex_yolo.md)
27 | - Towards Safe (variational dropout)
28 | - BirdNet (lidar point cloud normalization)
29 | - Volumetric
30 | - 3DFCN
31 | - Vote3Deep
32 | - point net
33 | - VoxelNet
34 |
35 | - Sensor Fusion
36 | - [MV3D](mv3d.md)
37 | - [AVOD](avod.md)
38 | - [Frustum PointNet](frustum_pointnet.md)
39 |
40 | #### Notes
41 | - camera and lidar calibration with odometry
42 |
--------------------------------------------------------------------------------
/paper_notes/6d_vnet.md:
--------------------------------------------------------------------------------
1 | # [6D-VNet: End-to-end 6DoF Vehicle Pose Estimation from Monocular RGB Images](http://openaccess.thecvf.com/content_CVPRW_2019/papers/Autonomous%20Driving/Wu_6D-VNet_End-to-End_6-DoF_Vehicle_Pose_Estimation_From_Monocular_RGB_Images_CVPRW_2019_paper.pdf)
2 |
3 | _January 2020_
4 |
5 | tl;dr: Directly regress 3D distance and quaternion direction from RoIPooled features.
6 |
7 | #### Overall impression
8 | This is an extension of mask RCNN, by extending the mask head to regress fine-grained vehicle model (such as Audi Q5), quaternion and distance.
9 |
10 | #### Key ideas
11 | - Previous methods usually estimate depth via two step process: 1) regress bbox and direction 2) postprocess to estimate 3D translation via projective distance estimation. --> this requires bbox and orientation to be estimated correctly.
12 | - Robotics usually requires strict estimation of orientation but translation can be relaxed. However AD require accurate estimation of translation.
13 | - the features for regreessing fine-class and orientation (quaternion) is also concate with the translational branch to predict translation.
14 | - The target of translation is also preprocessed to essentially regress z directly. This can also be used to predict the 3D projection.
15 | $$
16 | x = (u - c_x) z / f_x \\
17 | y = (u - c_y) z / f_y
18 | $$
19 |
20 | #### Technical details
21 | - Summary of technical details
22 |
23 | #### Notes
24 | - Postprocessing DL output may suffer from error accumulation. If we work the postprocessing into label preprocessing, this could not be a problem anymore. Of course, keeping both will add to redundancy.
25 | - [github code](https://github.com/stevenwudi/6DVNET)
26 |
27 |
--------------------------------------------------------------------------------
/paper_notes/M2Det.md:
--------------------------------------------------------------------------------
1 | # [M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network](https://arxiv.org/abs/1811.04533)
2 |
3 | @YuShen1116
4 |
5 | _May 2019_
6 |
7 | #### tl;dr
8 | A new method to produce feature map for object detection.
9 |
10 | #### Overall impression
11 | Describe the overall impression of the paper.
12 | Previous methods of building feature pyramid(SSD, FPN, STDN) still have some limitations because
13 | their pyramids are built on classification backbone. This paper states a new method of generating
14 | feature pyramid, and integrated into SSD architecture.
15 | As a result, they achieves AP of 41.0 at speed of 11.8 FPS with single-scale inference strategy on
16 | MS-COCO dataset.
17 |
18 | #### Key ideas
19 | - Use Feature Fusion Modules(add figure later) to fuse the shallow and deep features(such as conv4_3 and conv5_3 of VGG)
20 | from backbone.
21 | - stack several Thinned U-shape Module and Feature Fusion Module together,
22 | to generate feature maps in different scale(from shallow to deep).
23 | - Use a scale-wise feature aggregation module to generate a multi-level feature pyramid from above features.
24 | - Apply detection layer on this pyramid.
25 |
26 |
27 | #### Notes
28 | - Not very easy to train, it costs 3 - more than 10+ days to train the whole pipeline.
29 | - I think this idea is interesting because it states that the features from classification backbone is not good enough
30 | for object detection. Modifying the features for specific task could be a good direction to try.
31 | - M2: multi-level, multi-scale features
32 |
--------------------------------------------------------------------------------
/paper_notes/_template.md:
--------------------------------------------------------------------------------
1 | # [Paper Title](link_to_paper)
2 |
3 | _November 2024_
4 |
5 | tl;dr: Summarize the the main idea of the paper with one sentence.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper. In a multi-paragraph format, this is a high-level overview of this paper, including its main contribution, advantages compared with previous methods. Also this would include drawbacks of he paper and point out future directions.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas, each formulating a bullet point. Finer grained details would belisted in nested bullet points. The main aspects to consider include, but not limited to Model architecture, data, eval.
12 |
13 | #### Technical details
14 | - Summary of technical details, such as important training details, or bugs of previous benchmarks.
15 |
16 | #### Notes
17 | - Questions and notes on how to improve/revise the current work
18 |
19 |
--------------------------------------------------------------------------------
/paper_notes/acnet.md:
--------------------------------------------------------------------------------
1 | # [ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks](https://arxiv.org/abs/1908.03930)
2 |
3 | _January 2021_
4 |
5 | tl;dr: Train with 3x3, 3x1 and 1x3, but deploy with fused 3x3.
6 |
7 | #### Overall impression
8 | This paper take the idea of BN fusion during inference to a new level, by fusing conv kernels. It has **no additional hyperparameters during training, and no additional parameters during inference, thanks to the fact that additivity holds for convolution.**
9 |
10 | It directly inspired [RepVGG](repvgg.md), a follow-up work by the same authors.
11 |
12 | #### Key ideas
13 | - Asymmetric convolution block (ACB)
14 | - During training, replace every 3x3 by 3 parallel branches, 3x3, 3x1 and 1x3.
15 | - During inference, merge the 3 branches into 1, through BN fusion and branch fusion.
16 |
17 | 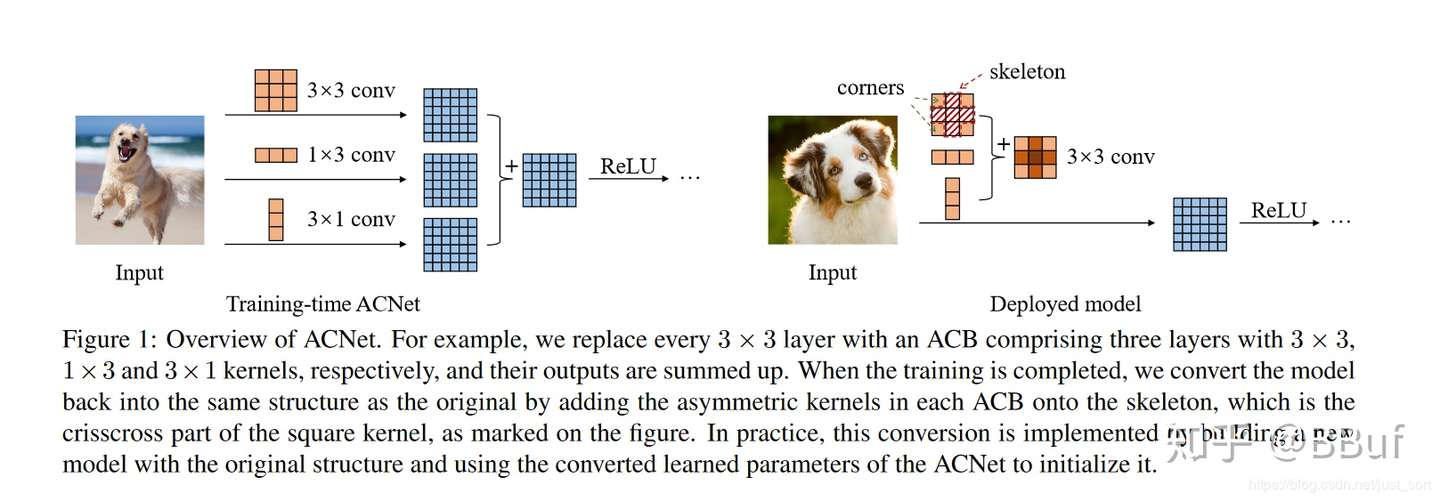
18 | - ACNet strengthens the skeleton
19 | - Skeletons are more important than corners. Removing corners causes less harm than skeletons.
20 | - ACNet aggravates this imbalance
21 | - Adding ACB to edges cannot diminish the importance of other parts. Skeleton is still very important.
22 |
23 |
24 | #### Technical details
25 | - Breaking large kernels into asymmetric convolutional kernels can save computation and increase receptive field cheaply.
26 | - ACNet can enhance the robustness toward rotational distortions. Train upright, and infer on rotated images. --> but the improvement in robustness is quite marginal.
27 |
28 | #### Notes
29 | - [Review on Zhihu](https://zhuanlan.zhihu.com/p/131282789)
30 |
31 |
--------------------------------------------------------------------------------
/paper_notes/astyx_dataset.md:
--------------------------------------------------------------------------------
1 | # [Astyx dataset: Automotive Radar Dataset for Deep Learning Based 3D Object Detection](https://www.astyx.com/fileadmin/redakteur/dokumente/Automotive_Radar_Dataset_for_Deep_learning_Based_3D_Object_Detection.PDF)
2 |
3 | _January 2020_
4 |
5 | tl;dr: Dataset with radar data from proprietary high resolution radar design.
6 |
7 | #### Overall impression
8 | Active learning scheme based on uncertainty sampling using estimated scores as approximation.
9 |
10 | #### Key ideas
11 | - Radar+camera sees more clearly than lidar+camera, for far away objects and for pedestrians. --> However even with radar, the recall is only ~0.5. Too low for real-world application.
12 |
13 | #### Technical details
14 | - Cross sensor calibration has two steps: camera lidar 2D-3D with checkerboard, and radar lidar 3D-3D relative pose estimation.
15 | - Annotation has "invisible" objects as well associated via temporal reference, but invisible in camera and lidar.
16 |
17 | #### Notes
18 | - [Dataset](https://www.astyx.com/development/astyx-hires2019-dataset.html)
19 | - [Estimation of height](https://sci-hub.tw/10.1109/RADAR.2019.8835831) in this dataset
--------------------------------------------------------------------------------
/paper_notes/astyx_radar_camera_fusion.md:
--------------------------------------------------------------------------------
1 | # [Astyx camera radar: Deep Learning Based 3D Object Detection for Automotive Radar and Camera](https://www.astyx.net/fileadmin/redakteur/dokumente/Deep_Learning_Based_3D_Object_Detection_for_Automotive_Radar_and_Camera.PDF)
2 |
3 | _January 2020_
4 |
5 | tl;dr: Camera + radar fusion based on AVOD.
6 |
7 | #### Overall impression
8 |
9 |
10 | #### Key ideas
11 | The architecture is largely based on [AVOD](avod.md). It converts radar into height and intensity maps and uses the pseudo image and camera image for region proposal.
12 |
13 | #### Technical details
14 | - Bbox encoding has 10 dim (4 pts + 2 z-values) in the original AVOD paper. However this paper said it used 14 dim.
15 | - Radar+camera does not detect perpendicular cars well. However it detects cars that align with the direction of the ego car much better.
16 |
17 |
18 |
--------------------------------------------------------------------------------
/paper_notes/ba_sfm_learner.md:
--------------------------------------------------------------------------------
1 | # [Self-Supervised Learning of Depth and Ego-motion with Differentiable Bundle Adjustment](https://arxiv.org/abs/1909.13163)
2 |
3 | _July 2020_
4 |
5 | tl;dr: Introduce [BA-Net](banet.md) into [SfM learner](sfm_learner.md).
6 |
7 | #### Overall impression
8 | The paper looks to be SOTA compared to the papers it cites. However the performance looks on par with [monodepth2](monodepth2.md). The performance is actually not as good as BA-Net on KITTI.
9 |
10 | The paper spent too much texts on explaining the existing work of [BA-Net](banet.md). The main innovation of the paper seems to be using poseNet to provide a good initial guess of the camera pose.
11 |
12 | #### Key ideas
13 | - Summaries of the key ideas
14 |
15 | #### Technical details
16 | - Summary of technical details
17 |
18 | #### Notes
19 | - Questions and notes on how to improve/revise the current work
20 |
21 |
--------------------------------------------------------------------------------
/paper_notes/batchnorm_pruning.md:
--------------------------------------------------------------------------------
1 | # [BatchNorm Pruning: Rethinking the Smaller-Norm-Less-Informative Assumption in Channel Pruning of Convolution Layers](https://arxiv.org/abs/1802.00124)
2 |
3 | _May 2020_
4 |
5 | tl;dr: Similar idea to [Network Slimming](network_slimming.md) but with more details.
6 |
7 | #### Overall impression
8 | Two questions to answer:
9 |
10 | - Can we set wt < thresh to zero. If so, under what constraints?
11 | - Can we set a global thresh to diff layers?
12 |
13 | Many previous works are norm-based pruning, which do not have solid theoretical foundation. One cannot assign different weights to the Lasso regularization to diff layers, as we can perform model reparameterization to reduce Lasso loss. In addition, in the presence of BN, any linear scaling of W will not change results.
14 |
15 |
16 | #### Key ideas
17 | - This paper (together with concurrent work of [Network Slimming](network_slimming.md)) focuses on sparsifying the gamma value in BN layer.
18 | - gamma works on top of normalized random variable and thus comparable across layers.
19 | - The impact of gamma is independent across diff layers.
20 | - A regularization term based on L1 of gamma is introduced, but scaled by a per layer factor $\lambda$. The global weight of the regularization term is $\rho$.
21 | - ISTA (Iterative Shrinkage-Thresholding Algorithm) is better than gradient descent.
22 |
23 | #### Technical details
24 | - Summary of technical details
25 |
26 | #### Notes
27 | - Questions and notes on how to improve/revise the current work
28 |
29 |
--------------------------------------------------------------------------------
/paper_notes/bev_od_ipm.md:
--------------------------------------------------------------------------------
1 | # [BEV-IPM: Deep Learning based Vehicle Position and Orientation Estimation via Inverse Perspective Mapping Image](https://ieeexplore.ieee.org/abstract/document/8814050)
2 |
3 | _October 2019_
4 |
5 | tl;dr: IPM of the pitch/role corrected camera image, and then perform 2DOD on the IPM image.
6 |
7 | #### Overall impression
8 | The paper performs 2DOD on IPM'ed image. This seems quite hard but obviously doable. The GT on BEV image seems to come from 3D GT, but the paper did not go to details about it.
9 |
10 | The detection distance is only up to ~50 meters. Beyond 50 m, it is hard to reliably detect distance and position. --> Maybe vehicle yaw are not important for cars beyond 50 meters after all?
11 |
12 | #### Key ideas
13 | - Motion cancellation using IMU (motion due to wind disturbance or fluctuation of road surface)
14 | - IPM assumptions:
15 | - road is flat
16 | - mounting position of the camera is stationary --> motion cancellation helps this.
17 | - the vehicle to be detected is on the ground
18 | - 2DOD oriented bbox detection based on YOLOv3.
19 |
20 | #### Technical details
21 | - KITTI does not label bbox smaller than 25 pixels, which translates to 60 meters according to fx=fy=721 of KITTI's intrinsics.
22 |
23 | #### Notes
24 | - [youtube demo](https://www.youtube.com/watch?v=2zvS87d1png&feature=youtu.be) the results look reasonably good, but how about occluded cases?
25 |
26 |
--------------------------------------------------------------------------------
/paper_notes/bev_seg.md:
--------------------------------------------------------------------------------
1 | # [BEV-Seg: Bird’s Eye View Semantic Segmentation Using Geometry and Semantic Point Cloud](https://arxiv.org/abs/2006.11436)
2 |
3 | _June 2020_
4 |
5 | tl;dr: Detached model to perform domain adaptation sim2real.
6 |
7 | #### Overall impression
8 | Two stage model to bridge domain gap. This is very similar to [GenLaneNet](gen_lanenet.md) for 3D LLD prediction. The idea of using semantic segmentation to bridge the sim2real gap is explored in many BEV semantic segmentation tasks such as [BEV-Seg](bev_seg.md), [CAM2BEV](cam2bev.md), [VPN](vpn.md).
9 |
10 | The first stage model already extracted away domain-dependent features and thus the second stage model can be used as is.
11 |
12 | The GT of BEV segmentation is difficult to collect in most domains. The simulated segmentation GT can be obtained in abundance with simulator such as CARLA.
13 |
14 | 
15 |
16 | #### Key ideas
17 | - **View transformation**: pixel-wise depth prediction
18 | - The first stage generates the pseudo-lidar point cloud, and render it in BEV.
19 | - This is incomplete and may have many void pixels.
20 | - Always choosing the point of lower height.
21 | - The second stage converts the BEV view of pseudo-lidar point cloud to BEV segmentation.
22 | - Fills in the void pixels
23 | - Smooth already predicted segmentation
24 | - During inference, only finetune first stage. Use second stage as is.
25 |
26 |
27 | #### Technical details
28 | - Summary of technical details
29 |
30 | #### Notes
31 | - [talk at CVPR 2020](https://youtu.be/WRH7N_GxgjE?t=1554)
32 |
33 |
--------------------------------------------------------------------------------
/paper_notes/birdgan.md:
--------------------------------------------------------------------------------
1 | # [BirdGAN: Learning 2D to 3D Lifting for Object Detection in 3D for Autonomous Vehicles](https://arxiv.org/abs/1904.08494)
2 |
3 | _October 2019_
4 |
5 | tl;dr: Learn to map 2D perspective image to BEV with GAN.
6 |
7 | #### Overall impression
8 | The performance of BirdGAN on 3D object detection has the SOTA. The AP_3D @ IoU=0.7 is ~60 for easy and ~40 for hard. This is much better than the ~10 for [ForeSeE](foresee_mono3dod.md)
9 |
10 | One major drawback is the limited forward distance BirdGAN can handle. In the clipping case, the frontal depth is only about 10 to 15 meters.
11 |
12 | Personally I feel GAN related architecture not reliable for production. The closest to production research so far is still [pseudo-lidar++](pseudo_lidar++.md).
13 |
14 | #### Key ideas
15 | - Train a GAN to translate 2D perspective image to BEV.
16 | - Use the generated BEV to perform sensor fusion in AVOD and MV3D.
17 | - Clipping further away points in lidar helps training and generates better performance --> while this also severely limited the application of the idea.
18 |
19 | #### Technical details
20 | - Summary of technical details
21 |
22 | #### Notes
23 | - Maybe the 3D AP is not what matters most in autonomous driving. Predicting closeby objects better at the cost of distant objects is not optimal for autonomous driving.
--------------------------------------------------------------------------------
/paper_notes/bs3d.md:
--------------------------------------------------------------------------------
1 | # [BS3D: Beyond Bounding Boxes: Using Bounding Shapes for Real-Time 3D Vehicle Detection from Monocular RGB Images](https://ieeexplore.ieee.org/abstract/document/8814036/)
2 |
3 | _August 2020_
4 |
5 | tl;dr: Annotate and predict a 6DoF bounding shape for 3D perception.
6 |
7 | #### Overall impression
8 | The paper proposed a way to annotate and regress a 3D bbox, in the form of a 8 DoF polyline.
9 |
10 | This is one of the series of papers from Daimler.
11 |
12 | - [MergeBox](mb_net.md)
13 | - [Bounding Shapes](bounding_shapes.md)
14 | - [3D Geometrically constraint keypoints](3d_gck.md)
15 |
16 | #### Key ideas
17 | - Bounding shape is one 4-point and 8DoF polyline.
18 | 
19 |
20 |
21 | #### Technical details
22 | - The paper normalizes dimension and 3D location to that y = 0. When real depth is recovered (via lidar, radar or stereo), the monocular perception
23 | - An object is of [Manhattan properties](https://openaccess.thecvf.com/content_cvpr_2017/papers/Gao_Exploiting_Symmetry_andor_CVPR_2017_paper.pdf) if 3 orthogonal axes can be inferred, such as cars, buses, motorbikes, trains, etc.
24 |
25 | #### Notes
26 | - 57% of all American drivers do not use turn signals when changing the lane. ([source](https://www.insurancejournal.com/news/national/2006/03/15/66496.htm))
27 |
28 |
--------------------------------------------------------------------------------
/paper_notes/c3dpo.md:
--------------------------------------------------------------------------------
1 | # [C3DPO: Canonical 3D Pose Networks for Non-Rigid Structure From Motion](https://arxiv.org/abs/1909.02533)
2 |
3 | _December 2019_
4 |
5 | tl;dr: Infer 3D pose for non-rigid objects by introducing DL to non-rigid structure-from-motion (NR-SFM).
6 |
7 | #### Overall impression
8 | C3DPO transforms closed-formed matrix decomposition problem into a DL-based parameter estimation problem. This method is faster and also can embody prior info that is not apparent in the linear model.
9 |
10 | A challenge in NR-SFM is the ambiguity of internal object deformation (or pose in this paper, non-rigid motion) and viewpoint changes (rigid motion). C3DPO introduces a canonicalization network to encourage the consistent decomposition.
11 |
12 |
13 | #### Key ideas
14 | - The main takeaway from this work: Work as many constraints as possible into loss. Use any mathematical cycle-consistency to constrain learning.
15 | - Use deep learning to supplement maths, not to replace math.
16 |
17 | #### Technical details
18 | - Summary of technical details
19 |
20 | #### Notes
21 | - Questions and notes on how to improve/revise the current work
22 |
23 |
--------------------------------------------------------------------------------
/paper_notes/cbam.md:
--------------------------------------------------------------------------------
1 | # [CBAM: Convolutional Block Attention Module](https://arxiv.org/abs/1807.06521)
2 |
3 | _May 2020_
4 |
5 | tl;dr: Improvement over SENet.
6 |
7 | #### Overall impression
8 | Channel attention module is very much like SENet but more concise. Spatial attention module concatenates mean pooling and max pooling across channels and blends them together.
9 |
10 | Each attention is then used sequentially with each feature map.
11 |
12 | 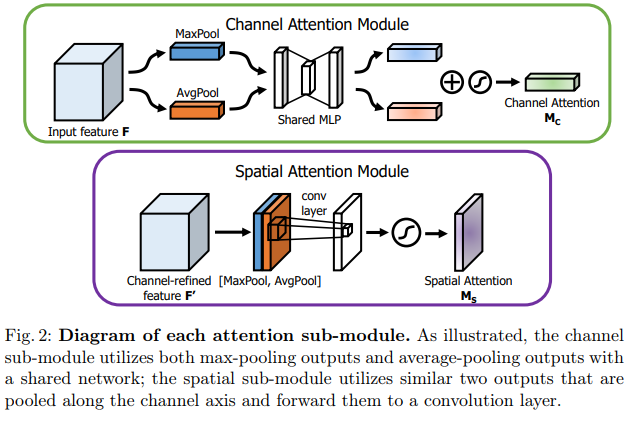
13 | 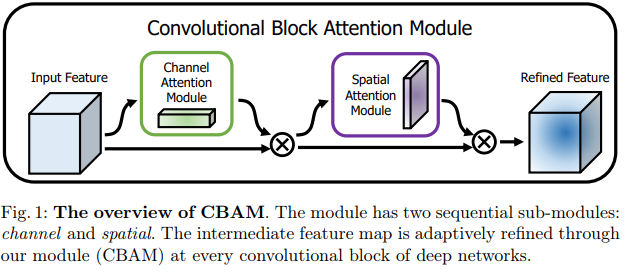
14 |
15 | The Spatial attention module is modified in [Yolov4](yolov4.md) to a point wise operation.
16 |
17 | #### Key ideas
18 | - Summaries of the key ideas
19 |
20 | #### Technical details
21 | - Summary of technical details
22 |
23 | #### Notes
24 | - Questions and notes on how to improve/revise the current work
25 |
26 |
--------------------------------------------------------------------------------
/paper_notes/cbgs.md:
--------------------------------------------------------------------------------
1 | # [CBGS: Class-balanced Grouping and Sampling for Point Cloud 3D Object Detection](https://arxiv.org/abs/1908.09492)
2 |
3 | _July 2020_
4 |
5 | tl;dr: Class rebalance of minority helps in object detection for nuscenes dataset.
6 |
7 | #### Overall impression
8 | The class balanced sampling and class-grouped heads are useful to handle imbalanced object detection.
9 |
10 | #### Key ideas
11 | - **DS sampling**:
12 | - increases sample density of rare classes to avoid gradient vanishing
13 | - count instances and samples (frames). Resample so that samples for each class is on the same order of magnitude.
14 | - **Class balanced grouping**: each group has a separate head.
15 | - Classes of similar shapes or sizes should be grouped.
16 | - Instance numbers of diff groups should be balanced properly.
17 | - Supergroups:
18 | - cars (majority classes)
19 | - truck, construction vehicle
20 | - bus, trailer
21 | - barrier
22 | - motorcycle, bicycle
23 | - pedestrian, traffic cone
24 | - Fit ground plane and plant GT back in.
25 | - Bag of tricks
26 | - Accumulate 10 frames (0.5 seconds) to form a dense lidar BEV
27 | - AdamW + [One cycle policy](https://sgugger.github.io/the-1cycle-policy.html)
28 |
29 | #### Technical details
30 | - Regress vx and vy. If bicycle speed is above a certain thresh, then it is with rider.
31 |
32 | #### Notes
33 | - Questions and notes on how to improve/revise the current work
34 |
35 |
--------------------------------------------------------------------------------
/paper_notes/cbn.md:
--------------------------------------------------------------------------------
1 | # [CBN: Cross-Iteration Batch Normalization](https://arxiv.org/abs/2002.05712)
2 |
3 | _May 2020_
4 |
5 | tl;dr: Improve batch normalization when minibatch size is small.
6 |
7 | #### Overall impression
8 | Similar to [GroupNorm](groupnorm.md) in improving performance when batch size is small. It accumulates stats over mini-batches. However, as weights are changing in each iteration, the statistics collected under those weights may become inaccurate under the new weight. A naive average will be wrong. Fortunately, weights change gradually. In Cross-Iteration Batch Normalization (CBM), it estimates those statistics from k previous iterations with the adjustment below.
9 |
10 | 
11 |
12 | #### Key ideas
13 | - Summaries of the key ideas
14 |
15 | #### Technical details
16 | - Summary of technical details
17 |
18 | #### Notes
19 | - Questions and notes on how to improve/revise the current work
20 |
21 |
--------------------------------------------------------------------------------
/paper_notes/centermask.md:
--------------------------------------------------------------------------------
1 | # [CenterMask: Single Shot Instance Segmentation With Point Representation](https://arxiv.org/abs/2004.04446)
2 |
3 | _April 2020_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 | [CenterMask](centermask.md) works almost in exactly the same way as [BlendMask](blendmask.md). See [my review on Medium](https://towardsdatascience.com/single-stage-instance-segmentation-a-review-1eeb66e0cc49).
9 |
10 | - [CenterMask](centermask.md) uses 1 prototype mask (named global saliency map) explicitly.
11 | - [CenterMask](centermask.md)'s name comes from the fact that it uses [CenterNet](centernet.md) as the backbone, while [CenterMask](centermask.md) uses the similar anchor-free one-stage [FCOS](fcos.md) as backbone.
12 |
13 |
14 | #### Key ideas
15 | - Summaries of the key ideas
16 |
17 | #### Technical details
18 | - Summary of technical details
19 |
20 | #### Notes
21 | - Questions and notes on how to improve/revise the current work
22 |
23 |
--------------------------------------------------------------------------------
/paper_notes/centroid_voting.md:
--------------------------------------------------------------------------------
1 | # [Centroid Voting: Object-Aware Centroid Voting for Monocular 3D Object Detection](https://arxiv.org/abs/2007.09836)
2 |
3 | _December 2020_
4 |
5 | tl;dr: Use bbox to guide depth prediction.
6 |
7 | #### Overall impression
8 | The paper is really a run-of-the-mill paper. The main idea is that instead of convolutional features to regress distance, use geometric prior to guide the distance prediction. The convolutional appearance features are only required to learn the residual.
9 |
10 | #### Key ideas
11 | - Based on two-stage object detector such as Faster-RCNN
12 | - The paper uses two different modules to learn appearance
13 | - GPD (geometric projection distribution): predicts 3D center location's projection in 2D image
14 | - AAM (appearance attention map): 1x1 conv attention to address occlusion or inaccuracy in RPN
15 |
16 |
17 | #### Technical details
18 | - From Table IV, it seems that the fusion from the geometric branch did not help that much. However, from Fig. 6, it seem that without geometry the performance from appearance based method alone is not good at all.
19 |
20 | #### Notes
21 | - Maybe we can use this for distance prediction.
22 |
23 |
--------------------------------------------------------------------------------
/paper_notes/class_balanced_loss.md:
--------------------------------------------------------------------------------
1 | # [Class-Balanced Loss Based on Effective Number of Samples](https://arxiv.org/abs/1901.05555)
2 |
3 | _September 2020_
4 |
5 | tl;dr: Calculate effective numbers for each class for better weighted loss.
6 |
7 | #### Overall impression
8 | This paper reminds me of [effective receptive field](https://arxiv.org/abs/1701.04128) paper from Uber ATG, which basically says the effective RF grows with sqrt(N) with deeper nets.
9 |
10 | This paper has some basic assumptions and derived a general equation to come up with the effective number for weight. The effective number of samples
11 | is defined as the volume of samples and can be calculated
12 | by a simple formula $(1−\beta^N)/(1-\beta)$, where N is the number
13 | of samples and $\beta \in [0, 1)$ is a hyperparameter.
14 |
15 | People seem to have noticed it and uses some simple heuristics to counter the effect. For example, this paper noticed using 1/N would bias the loss toward minority class and thus simply uses 1/sqrt(N) as the weighting factor, in [PyrOccNet](pyroccnet.md).
16 |
17 | #### Key ideas
18 | - Summaries of the key ideas
19 |
20 | #### Technical details
21 | - Summary of technical details
22 |
23 | #### Notes
24 | - Questions and notes on how to improve/revise the current work
25 |
26 |
--------------------------------------------------------------------------------
/paper_notes/classical_keypoints.md:
--------------------------------------------------------------------------------
1 | # Classical Keypoints
2 |
3 | _May 2020_
4 |
5 | tl;dr: A summary of classical keypoints and descriptors.
6 |
7 | #### BRIEF
8 | - [BRIEF: Binary Robust Independent Elementary Features](https://www.cs.ubc.ca/~lowe/525/papers/calonder_eccv10.pdf) ECCV 2010
9 | - The sampling pattern is randomly generated but [the same for all image patches](https://gilscvblog.com/2013/09/19/a-tutorial-on-binary-descriptors-part-2-the-brief-descriptor/#comment-328). In openCV, the [sampling sequence is pre-fixed](https://gilscvblog.com/2013/09/19/a-tutorial-on-binary-descriptors-part-2-the-brief-descriptor/#comment-1282).
10 | - patch window is 31 x 31.
11 | - [blog review on BRIEF descriptor](https://gilscvblog.com/2013/09/19/a-tutorial-on-binary-descriptors-part-2-the-brief-descriptor/)
12 |
13 | #### ORB
14 | - [ORB: an efficient alternative to SIFT or SURF](http://www.willowgarage.com/sites/default/files/orb_final.pdf) ICCV 2011
15 | - Sampling pairs should have **uncorrelation and high variance** to ensure the fixed length would encode maximum discriminative information.
16 | - ORB is improved BRIEF:
17 | - ORB uses an orientation compensation mechanism, making it rotation invariant.
18 | - ORB learns the optimal sampling pairs, whereas BRIEF uses randomly chosen sampling pairs.
19 | - [blog review on ORB](https://gilscvblog.com/2013/10/04/a-tutorial-on-binary-descriptors-part-3-the-orb-descriptor/)
20 |
21 | #### Key ideas
22 | - Summaries of the key ideas
23 |
24 | #### References
25 | - [nterest Point Detector and Feature Descriptor Survey](https://core.ac.uk/download/pdf/81870989.pdf)
--------------------------------------------------------------------------------
/paper_notes/cnn_seg.md:
--------------------------------------------------------------------------------
1 | # [Baidu's CNN seg](https://zhuanlan.zhihu.com/p/35034215)
2 |
3 | _June 2021_
4 |
5 | tl;dr: Baidu's couples centerNet + offset for instance segmentation.
6 |
7 | #### Overall impression
8 | Baidu's CNN seg has not been published but the source code are open sourced. Several reviews to go over the algorithms in details here
9 | - [apollo感知算法解析之cnn_seg](https://zhuanlan.zhihu.com/p/35034215)
10 | - [apollo感知算法lidar部分](https://www.jianshu.com/p/95a51214959b)
11 |
12 | #### Key ideas
13 | - Summaries of the key ideas
14 |
15 | #### Technical details
16 | - Summary of technical details
17 |
18 | #### Notes
19 | - Questions and notes on how to improve/revise the current work
20 |
21 |
--------------------------------------------------------------------------------
/paper_notes/coord_conv.md:
--------------------------------------------------------------------------------
1 | # [CoordConv: An intriguing failing of convolutional neural networks and the CoordConv solution](https://arxiv.org/abs/1807.03247)
2 |
3 | _August 2019_
4 |
5 | tl;dr: Predicting coordinate transformation (predicting x and y directly from image and vice versa) with Conv Nets are hard. Adding a mesh grid to input image helps this task significantly.
6 |
7 | #### Overall impression
8 | The paper results are very convincing, and the technique is super efficient. Essentially it only concats two channel meshgrid to the original input.
9 |
10 | [RoI10D](roi10d.md) cited this paper. This work also inspired [cam conv](cam_conv.md).
11 |
12 | #### Key ideas
13 | - Other coordinates works as well, such as radius and theta.
14 | - The idea can be useful for other tasks such as object detection, GAN, DRL, but not so much for classification.
15 |
16 | #### Technical details
17 | - Summary of technical details
18 |
19 | #### Notes
20 | - Uber made a [video presenting this paper](https://www.youtube.com/watch?v=8yFQc6elePA).
21 | - A concurrent paper from VGG has more theoretical analysis [Semi-convolutional Operators for Instance Segmentation](https://arxiv.org/abs/1807.10712) ECCV 2018.
22 | - This technique seems to alleviate checkerboard artifacts as well. This is a good alternative to [using bilinear upsampling](https://distill.pub/2016/deconv-checkerboard/).
--------------------------------------------------------------------------------
/paper_notes/corenet.md:
--------------------------------------------------------------------------------
1 | # [CoReNet: Coherent 3D scene reconstruction from a single RGB image](https://arxiv.org/abs/2004.12989)
2 |
3 | _March 2023_
4 |
5 | tl;dr: Ray tracing skip connection to flow 2D features to 3D volume.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - Questions and notes on how to improve/revise the current work
18 |
--------------------------------------------------------------------------------
/paper_notes/corner_case_multisensor.md:
--------------------------------------------------------------------------------
1 | # [An Application-Driven Conceptualization of Corner Cases for Perception in Highly Automated Driving](https://arxiv.org/abs/2103.03678)
2 |
3 | _September 2021_
4 |
5 | tl;dr: Multi-sensor expansion of previous work on corner cases.
6 |
7 | #### Overall impression
8 | An essential task of ML-based perception models are to reliably detect and interpret unusual new and potentially dangerous situations. A complication for the development of corner case detectors is the lack of consistent definitions, terms and corner case descriptions.
9 |
10 | Corner cases introduced not only by vision system, but also radar/lidar and sensor fusion. This is an extension from [CC-vision](corner_case_vision_arxiv.md) and [CC-vision (IV version)](corner_case_vision_iv.md).
11 |
12 | #### Key ideas
13 | - Summaries of the key ideas
14 |
15 | #### Technical details
16 | - Object level corner cases of lidar: dust or smoke cloud
17 |
18 | #### Notes
19 | - Questions and notes on how to improve/revise the current work
20 |
21 |
--------------------------------------------------------------------------------
/paper_notes/corner_case_vision_arxiv.md:
--------------------------------------------------------------------------------
1 | # [Paper Title](link_to_paper)
2 |
3 | _September 2021_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - [Review on Zhihu](https://zhuanlan.zhihu.com/p/352477803)
18 |
19 |
--------------------------------------------------------------------------------
/paper_notes/crowdhuman.md:
--------------------------------------------------------------------------------
1 | # [CrowdHuman: A Benchmark for Detecting Human in a Crowd](https://arxiv.org/abs/1805.00123)
2 |
3 | _July 2020_
4 |
5 | tl;dr: A large scale (15k training images) dataset for crowded/dense human detection.
6 |
7 | #### Overall impression
8 | Very solid technical report from megvii (face++). Related datasets: [WiderPerson](widerperson.md).
9 |
10 | Previous datasets are more likely to annotate crowd human as a whole ignored region, which cannot be counted as valid samples in training and evaluation.
11 |
12 | #### Key ideas
13 | - 22 human per image.
14 | - Full body bbox (amodal), visible bbox (only visible region), head bbox. They are bound (associated) for each human instance.
15 | - occlusion ratio can be quantified by the two bbox.
16 | - evaluation metric:
17 | - AP
18 | - mMR (average log miss rate over FP per image)
19 |
20 | #### Technical details
21 | - Image crawled from google image search engine, cleaned and annotated.
22 | - Pervious datasets (CityPerson) annotates top of the head to the middle of the feet and generated a full bbox with fixed aspect ratio of 0.41.
23 |
24 | #### Notes
25 | - [AP vs MR](ap_mr.md) in object detection.
--------------------------------------------------------------------------------
/paper_notes/d4lcn.md:
--------------------------------------------------------------------------------
1 | # [D4LCN: Learning Depth-Guided Convolutions for Monocular 3D Object Detection](https://arxiv.org/abs/1912.04799)
2 |
3 | _June 2020_
4 |
5 | tl;dr: Use depth map to generate dynamic filters for depth estimation.
6 |
7 | #### Overall impression
8 | The idea of depth aware convolution and the idea of the 2D and 3D anchor both come from [M3D RPN](m3d_rpn.md).
9 |
10 | #### Key ideas
11 | - 2D/3D anchors. Average the 3D shape that are associated with the 2D bbox. This forms the 3D anchor. This operation allows the neural network only focus on the residual adjustment from the anchors and significantly reduces the task difficulty.
12 | - Filter generation network generates **dynamic local filters**, using depth map as input.
13 | - Generate a filter volume the same size as the feature map
14 | - Shift filter volumn by 3x3 grid and average, this approximates a local filtering operation.
15 | - Each location also learns a different dilation rate.
16 | - Loss function:
17 | - Multiple loss terms weighted by focal loss style $(1-s_t)^\gamma$, where $s_t$ is the cls score of target class.
18 | - For each anchor, there are 4 (bbox) + 2 (proj 3D center) + 3 (whl) + 1 (depth) + 1 (yaw) + 3x8 (8 corners) + n_c (cls, =4) = 35 + 4 = 39 output bits. --> this formulation is similar to [M3D RPN](m3d_rpn.md) and [SS3D](ss3d.md).
19 | - corner loss helps.
20 |
21 | #### Technical details
22 | - Pseudo-lidar discards semantic information. This may be addressed by [PatchNet](patchnet.md).
23 |
24 | #### Notes
25 | - [Github repo](https://github.com/dingmyu/D4LCN)
26 | - Trident network utilizes manually defined multi-head detectors for 2D detection.
27 |
28 |
--------------------------------------------------------------------------------
/paper_notes/ddmp.md:
--------------------------------------------------------------------------------
1 | # [DDMP: Depth-conditioned Dynamic Message Propagation for Monocular 3D Object Detection](https://arxiv.org/abs/2103.16470)
2 |
3 | _June 2021_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - Questions and notes on how to improve/revise the current work
18 |
19 |
--------------------------------------------------------------------------------
/paper_notes/deep_road_mapper.md:
--------------------------------------------------------------------------------
1 | # [DeepRoadMapper: Extracting Road Topology from Aerial Images](https://openaccess.thecvf.com/content_ICCV_2017/papers/Mattyus_DeepRoadMapper_Extracting_Road_ICCV_2017_paper.pdf)
2 |
3 | _August 2020_
4 |
5 | tl;dr: Extract road topology from satellite images.
6 |
7 | #### Overall impression
8 | This is one of the first paper on extracting road network based on aerial images captured by satellite. Note that this is not HD map as it does not contain lane level information.
9 |
10 | The following work are focused on road network discovery and are NOT focused on HD maps.
11 |
12 | - [DeepRoadMapper](deep_road_mapper.md): semantic segmentation
13 | - [RoadTracer](road_tracer.md): like an DRL agent
14 | - [PolyMapper](polymapper.md): iterate every vertices of a closed polygon
15 |
16 | #### Key ideas
17 | - Semantic segmentation
18 | - Thinning
19 | - Pruning small branches, closing small loops
20 | - A* search algorithm for connecting disconnected roads.
21 |
22 | #### Technical details
23 | - Summary of technical details
24 |
25 | #### Notes
26 | - Questions and notes on how to improve/revise the current work
27 |
28 |
--------------------------------------------------------------------------------
/paper_notes/deep_signals.md:
--------------------------------------------------------------------------------
1 | # [DeepSignals: Predicting Intent of Drivers Through Visual Signals](https://arxiv.org/pdf/1905.01333.pdf)
2 |
3 | _June 2019_
4 |
5 | tl;dr: Detecting automotive signals with CNN+LSTM to decode driver intention.
6 |
7 | #### Overall impression
8 | Vehicle light detection is a rather overlooked field in autonomous driving, perhaps due to the lack of public datasets. As long as autonomous cars and human driver co-exist, the capability to decode human driver's intention through visual signal is important, for vehicle-to-vehicle communication.
9 |
10 | The paper's performance is not that good. Perhaps due to the severe imbalance in the dataset.
11 |
12 | #### Key ideas
13 | - The use of attention is quite enlightening. This eliminates the need for turn signal light recognition.
14 | - The study depend on a video of cropped patches, and trained on GT annotation. The performance degrades when sequence of real detection is used. (This might be improved via data augmentation during training.)
15 |
16 | #### Technical details
17 | - Annotation:
18 | - Intention/situation: left merge, right merge, emergency flashers, off, unknown (occluded), **brake**
19 | - left/right light: ON, OFF, unknown (occluded)
20 | - view: on, off, front, right
21 | - **brake lights: ON, OFF, unknown**
22 | - More balanced datasets
23 |
24 | #### Notes
25 | - Q: why no brake light? This need to be added to the annotation
26 | - Q: how to annotate unknown intention?
27 | - Q: how to speed up annotation? Each vehicle is needed to assign a token throughout the video (uuid).
28 | - Q: FP (off or unknown classified as any other state) is critical. We need this number as low as possible.
29 |
--------------------------------------------------------------------------------
/paper_notes/deepmot.md:
--------------------------------------------------------------------------------
1 | # [DeepMOT: A Differentiable Framework for Training Multiple Object Trackers](https://arxiv.org/abs/1906.06618)
2 |
3 | _July 2020_
4 |
5 | tl;dr: Make Hungarian algorithm differentiable.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - [从(CVPR2020)DeepMOT和MPNTracker详谈端到端的数据关联 on Zhihu](https://zhuanlan.zhihu.com/p/130293417): Review of end to end data association
18 |
19 |
--------------------------------------------------------------------------------
/paper_notes/dekr.md:
--------------------------------------------------------------------------------
1 | # [DEKR: Bottom-Up Human Pose Estimation Via Disentangled Keypoint Regression](https://arxiv.org/abs/2104.02300)
2 |
3 | _January 2022_
4 |
5 | tl;dr: Enable neural networks to focus on keypoint regions via adaptive activation and multi-branch regression for disentangled learning.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 |
15 |
16 | #### Notes
17 | - Questions and notes on how to improve/revise the current work does not
18 |
--------------------------------------------------------------------------------
/paper_notes/delving_bev.md:
--------------------------------------------------------------------------------
1 | # [Delving into the devils of bird's eye view perception]()
2 |
3 | _October 2022_
4 |
5 | tl;dr: A bag of tricks for BEV perception.
6 |
7 | #### Overall impression
8 | The review did a good job summarizing the recent progress in BEV perception, including both vision, lidar and fusion methods, covering both academia and industry, and also covers a wide range of useful tricks. This can also be cross-referenced with the leaderboard version of BEVFormer [BEVFormer++](bevformer++.md).
9 |
10 | #### Key ideas
11 | - The methods of BEV perception can be divided into two categories, depending on the BEV transformation method
12 | - 2D-to-3D: reconstruction method
13 | - 3D-to-2D: use 3D prior to sample 2D images
14 |
15 | #### Technical details
16 | - Use the evolution algorithm or annealing algorithm in NNI toolkit for parameter tuning with a evaluation dataset.
17 | - TTA tricks for competition and autolabel
18 | - WBF method
19 |
20 | #### Notes
21 | - Need to write a review blog on DETR and improved version (anchor-DETR, conditional DETR, DAB-DETR, DN_DETR, DINO, etc).
22 |
--------------------------------------------------------------------------------
/paper_notes/dense_tnt.md:
--------------------------------------------------------------------------------
1 | # [DenseTNT: End-to-end Trajectory Prediction from Dense Goal Sets](https://arxiv.org/abs/2108.09640)
2 |
3 | _February 2022_
4 |
5 | tl;dr: Anchor-free version of [TNT](tnt.md).
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - Questions and notes on how to improve/revise the current work
18 |
--------------------------------------------------------------------------------
/paper_notes/densebox.md:
--------------------------------------------------------------------------------
1 | # [DenseBox: Unifying Landmark Localization with End to End Object Detection](https://arxiv.org/pdf/1509.04874.pdf)
2 |
3 | _May 2019_
4 |
5 | tl;dr: The ground-breaking (?) paper for anchor-free box detection. This is published in 2015!
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - [关于DenseBox的八卦](https://zhuanlan.zhihu.com/p/24350950)
18 |
19 |
--------------------------------------------------------------------------------
/paper_notes/disnet.md:
--------------------------------------------------------------------------------
1 | # [DisNet: A novel method for distance estimation from monocular camera](https://project.inria.fr/ppniv18/files/2018/10/paper22.pdf)
2 |
3 | _October 2019_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 | Use bbox H, W, D (diagnal), average size of object h, w, b (breadth, along depth dimension) is good enough to regress the distance, with relative error ~10%, up to 300 meters.
9 |
10 | This method seems much more promising than the one presented in [object distance estimation](obj_dist_iccv2019.md).
11 |
12 | This idea is quite similar to the more elaborate ICCV 2019 paper [monoloco](monoloco.md).
13 |
14 | #### Key ideas
15 | - Distance of 1/W (or 1/D, 1/H) are all approximately linear with distance.
16 | 
17 |
18 | #### Technical details
19 | - 2000 bbox are used. Distance GT measured with laser scanner.
20 |
21 | #### Notes
22 | - We can add the backplane width for better estimation of depth.
23 | - The method to extract GT information from point cloud may be noisy. But how to quantify and avoid this?
--------------------------------------------------------------------------------
/paper_notes/distance_estimation_pose_radar.md:
--------------------------------------------------------------------------------
1 | # [Distance Estimation of Monocular Based on Vehicle Pose Information](https://iopscience.iop.org/article/10.1088/1742-6596/1168/3/032040/pdf)
2 |
3 | _August 2019_
4 |
5 | tl;dr: Use IMU for online calibration to get real time pose. Use radar for GT
6 |
7 | #### Overall impression
8 | The paper is a short technical report.
9 |
10 | #### Key ideas
11 | - The main idea is to estimate distance based on the bottom line of the vehicle bbox.
12 | - For this, accurate and online calibrated **roll and pitch** are needed (yaw will not chance the row position of the car in the image).
13 | - radar is used to acquire GT.
14 | - The method performs really well for **vehicles up to 30 m** (with errors of up to 0.5 m).
15 |
16 | #### Technical details
17 | - Camera, radar and IMU run at 20 Hz.
18 |
19 |
20 |
21 |
--------------------------------------------------------------------------------
/paper_notes/dota.md:
--------------------------------------------------------------------------------
1 | # [DOTA: A Large-scale Dataset for Object Detection in Aerial Images](https://vision.cornell.edu/se3/wp-content/uploads/2018/03/2666.pdf)
2 |
3 | _September 2019_
4 |
5 | tl;dr: Largest dataset for object detection in aerial images.
6 |
7 | #### Overall impression
8 | This dataset addresses a specific field called Earth Vision/Earth Observation/Remote Sensing.
9 |
10 | In aerial images, there is rarely occlusion so every object can be annotated (vs. crowd class in COCO dataset).
11 |
12 | Other than aerial image, text region detection also involves oriented bbox detection.
13 |
14 | #### Key ideas
15 | - The annotation is 8 dof quadrilateral. But essentially most of them are (or converted to) Oriented bounding box (OBB).
16 | - For horizontal bounding boxes, sometimes the overlap is too big for object detection algorithms to tell them apart (due to NMS).
17 | - Cars: Big car (trucks, etc) and small car two categories.
18 |
19 | #### Technical details
20 | - Dataset stats are analyzed to filter anomaly annotations.
21 |
22 | #### Notes
23 | - According to their implementation of the Faster RCNN (OBB), they used original anchor proposals, and reparameterized the anchor box to four corners (8 points), and then changed prediction from 4 numbers to 8 numbers. No oriented anchors were used. --> compare with [RoiTransformer](roi_transformer.md).
24 |
--------------------------------------------------------------------------------
/paper_notes/dsnt.md:
--------------------------------------------------------------------------------
1 | # [DSNT: Numerical Coordinate Regression with Convolutional Neural Networks](https://arxiv.org/abs/1801.07372)
2 |
3 | _March 2021_
4 |
5 | tl;dr: A differentiable way to transform spatial heatmaps to numerical coordinates.
6 |
7 | #### Overall impression
8 | The SOTA method for coordinate prediction is still heatmap-based keypoint regression (heatmap matching) instead of direct numerical coordinate regression.
9 |
10 | Previous method obtains numerical coordinates by applying armgax to the heatmaps, which is a non-differentiable operation. Gradient flow starts from heatmap and not the numerical coordinates. The handcrafted features in designing heatmap and the postprocess to obtain numerical coordinates leads to sub-optimal system design.
11 |
12 | DSNT proposed a way to back-propagate all the way from the predicted numerical coordinates tot he input image.
13 |
14 | DSNT can only handle one keypoint per heatmap. How to extend the work to multiple keypoints per heatmap is still open to research. --> Maybe try to impose a neighborhood.
15 |
16 | #### Key ideas
17 | - Applying a [CoordConv](coord_conv.md) layer and perform inner product of the heatmap with X and Y coordinate maps. This essentially uses mean (differentiable) to find the mode (non-differentiable) of the heatmap.
18 | - Regularization to encourage the heatmap blobs to resemble a gaussian shape.
19 |
20 | #### Technical details
21 | - An alternative way is by using a soft-argmax ([Human pose regression by combining indirect part detection and contextual information]())
22 |
23 | #### Notes
24 | - Questions and notes on how to improve/revise the current work
25 |
26 |
--------------------------------------------------------------------------------
/paper_notes/edge_aware_depth_normal.md:
--------------------------------------------------------------------------------
1 | # [Unsupervised Learning of Geometry with Edge-aware Depth-Normal Consistency](https://arxiv.org/pdf/1711.03665.pdf)
2 |
3 | _July 2019_
4 |
5 | tl;dr: Extend [SfM-Learner](sfm_learner.md) by introducing a surface normal presentation. Precursor to [LEGO](lego.md).
6 |
7 | #### Overall impression
8 | The idea is good, that we introduce a surface normal map, which at each point should be perpendicular to the depth estimation.
9 |
10 | However how to use it is a bit questionable. This work used normal map as an intermediate step (depth --> norm --> depth) and both conversion is deterministic by 3D geometry constraint. How this helps is puzzling. The result to be honest is not as good as claimed. You still see a lot of discontinuity of surface normals within the same object.
11 |
12 | This work is superceded by their CVPR 2018 spotlight paper [LEGO](lego.md).
13 |
14 |
--------------------------------------------------------------------------------
/paper_notes/efficientdet.md:
--------------------------------------------------------------------------------
1 | # [EfficientDet: Scalable and Efficient Object Detection](https://arxiv.org/abs/1911.09070)
2 |
3 | _September 2021_
4 |
5 | tl;dr: BiFPN and multidimensional scaling of object detection.
6 |
7 | #### Overall impression
8 | This paper follows up on the work of [EfficientNet](efficientnet.md). The FPN neck essentially is a multi-scale feature fusion that aims to find a transformation that can effectively aggregate different features and output a list of new features.
9 |
10 | #### Key ideas
11 | - BiFPN (bidirectional FPN) (<-- PANet <-- FPN)
12 | - [PANet](panet.md) to introduce bottom up pathway again.
13 | - **Remove nodes** from PANet that has only has one input edge.
14 | - **Add skip connection** from original input to the output node if they are at the same level
15 | - **Repeat** blocks of the above BiFPN block.
16 | - Weighted feature fusion
17 | - Baseline is to resize and sum up. Each feature may have different weight contribution (feature level attention).
18 | - Softmax works, but a linear weighting normalization may work as well.
19 | - Multidimensional/compound scaling up is more effective than single dimension scaling. Resolution, depth and width.
20 |
21 | #### Technical details
22 | - [NAS-FPN](nas_fpn.md) has repeated irregular blocks.
23 | - Simply repeating FNP blocks will not lead to much benefit. Repeating PANet blocks will be better, and repeated BiFPN yields similar results but with much less computation.
24 | - This still needs object assignemtns, like [RetinaNet](retinanet.md).
25 |
26 | #### Notes
27 | - [Github](https://github.com/google/automl)
28 |
29 |
--------------------------------------------------------------------------------
/paper_notes/fairmot.md:
--------------------------------------------------------------------------------
1 | # [FairMOT: A Simple Baseline for Multi-Object Tracking](https://arxiv.org/abs/2004.01888)
2 |
3 | _July 2020_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 | CenterNet backbone.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - [Review on Zhihu](https://zhuanlan.zhihu.com/p/126558285)
18 |
19 |
--------------------------------------------------------------------------------
/paper_notes/federated_learning_comm.md:
--------------------------------------------------------------------------------
1 | # [Federated Learning: Strategies for Improving Communication Efficiency](https://arxiv.org/abs/1610.05492)
2 |
3 | _September 2019_
4 |
5 | tl;dr: Seminal paper on federated learning: distributed machine learning approach which enables model training on a large corpus of decentralized data.
6 |
7 | #### Overall impression
8 | FL solves the problem of data privacy (critical for hospitals, financial institutes, etc).
9 |
10 | In FL, the training data is kept locally on users’ mobile devices, and the devices are used as nodes performing computation on their local data in order to update a global model.
11 |
12 | FL has its own challenge compared to distributed machine learning, due to the data imbalance, non iid data and large number of devices under unreliable connection.
13 |
14 | #### Key ideas
15 | - The main challenge in FL is the effective communication uplink for neural networks to the central server. This paper proposed two method to compress the communication.
16 | - Structured update: enforce the update to the original matrix to be a low rank matrix (easy to compress) or with a **random mask** --> I like the random mask idea better, as only a random seed is required to generate such a random mask
17 | - Sketched updates: first computes an unconstrained update, and then compress it via quantization.
18 |
19 | #### Technical details
20 | - Summary of technical details
21 |
22 | #### Notes
23 | - We can also use a common dataset and knowledge distillation for communication. The communicated is the consensus over the public dataset. (Daliang Li's idea)
24 |
--------------------------------------------------------------------------------
/paper_notes/fixres.md:
--------------------------------------------------------------------------------
1 | # [FixRes: Fixing the train-test resolution discrepancy](https://arxiv.org/abs/1906.06423)
2 |
3 | _February 2020_
4 |
5 | tl;dr: Conventional imageNet classification has a train/test resolution discrepancy (domain shift).
6 |
7 | #### Overall impression
8 | Scale invariance/equivariance is not guaranteed in CNN (only shift invariance). The same model with different test time input will yield very different statistics. The distribution of activation changes at test time, the values are not in the range that the final cls layers were trained for.
9 |
10 | In ImageNet training, conventional way is to use 10-time crop (center, four corners, and their mirrors) and test time is always central crop. This leads to a discrepancy of the statistics in training/test.
11 |
12 | Simple solution: **finetune last layer** with test time scale and resolution, as the final stage of training.
13 |
14 |
15 | #### Key ideas
16 |
17 | #### Technical details
18 | - Larger test crops yields better results.
19 | - A similar work is MultiGrain, where the p-pooling is adjusted to match the train/test-time stats.
20 | - GeM (generalized mean pooling) p-pooling: a generalization of average pooling and max pooling
21 | - cf LSE pooling in [From Image-level to Pixel-level Labeling with Convolutional Networks](https://arxiv.org/abs/1411.6228) CVPR 2015
22 | - Image/instance retrieval requires adjusting p-pooling for better accuracy
23 |
24 | #### Notes
25 | - Questions and notes on how to improve/revise the current work
26 |
27 |
--------------------------------------------------------------------------------
/paper_notes/focal_loss.md:
--------------------------------------------------------------------------------
1 | # [Focal Loss for Dense Object Detection](https://arxiv.org/abs/1708.02002)
2 |
3 | tl;dr: Focal loss solves the class imbalance problem by modifying the model with a new loss function that focuses on hard negative samples. Concretely, it modulates cross entropy loss by a L2 loss.
4 |
5 | - Focal loss can be used for classification, as shown [here](https://shaoanlu.wordpress.com/2017/08/16/applying-focal-loss-on-cats-vs-dogs-classification-task/).
6 |
7 | #### Takeaways
8 |
9 | - Imbalanced training, balanced test: When trained on imblanced data (up to 100:1), the model trained with focal loss has evenly distributed prediction error when test data is balanced.
10 |
11 | - Imbalanced training, imbalanced test: traning with focal loss yields better accuracy than trained with cross entropy. Again it has evenly distributed prediction error.
--------------------------------------------------------------------------------
/paper_notes/frozen_depth.md:
--------------------------------------------------------------------------------
1 | # [FrozenDepth: Learning the Depths of Moving People by Watching Frozen People](https://arxiv.org/abs/1904.11111)
2 |
3 | _June 2020_
4 |
5 | tl;dr: Use
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - Questions and notes on how to improve/revise the current work
18 |
19 |
--------------------------------------------------------------------------------
/paper_notes/gac.md:
--------------------------------------------------------------------------------
1 | # [GAC: Ground-aware Monocular 3D Object Detection for Autonomous Driving](https://arxiv.org/abs/2102.00690)
2 |
3 | _August 2021_
4 |
5 | tl;dr: Anchor-based method with a ground aware convolution module.
6 |
7 | #### Overall impression
8 | This paper is directly inspired by [M3D-RPN](m3d_rpn.md). It still uses anchors instead of anchor-free, and uses the postprocessing module to optimize yaw.
9 |
10 | #### Key ideas
11 | - The key idea is a ground aware convolution (GAC) module. The network predicts the offers in the vertical direction and we sample the corresponding features and depth priors from the pixels below.
12 | - Depth priors are inspired by [CoordConv](coordconv.md) and are computed with perspective geometry with ground plane assumption.
13 | 
14 |
15 | #### Technical details
16 | - Summary of technical details
17 |
18 | #### Notes
19 | - Questions and notes on how to improve/revise the current work
20 |
21 |
--------------------------------------------------------------------------------
/paper_notes/geonet.md:
--------------------------------------------------------------------------------
1 | # [GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose](https://arxiv.org/abs/1803.02276)
2 |
3 | _July 2020_
4 |
5 | tl;dr: Use ResFlowNet and consistency check to improve monodepth.
6 |
7 | #### Overall impression
8 | GeoNet decouples the pixel movement to **rigid flow** and **object motion** adaptively. The movement of static parts in a video is solely caused by camera motion. The movement of dynamic object is caused by camera motion and specific object motion.
9 |
10 | However it is still using photometric error instead of geometric error (unlike in [DeepV2D](deepv2d.md)).
11 |
12 | #### Key ideas
13 | - PoseNet and DepthNet similar to [SfM Learner](sfm_learner.md).
14 | - We will have naturally a rigid flow from depth and pose estimation.
15 | - The main idea is to use ResFlowNet to predict the **residual** flow to handle non-rigid cars.
16 | - As compared to predict global flow, predicting residual flow is easier
17 | - **Caution**: ResFlowNet is extremely good at rectifying small errors from rigid flow, but cannot predict large optical flow, and need to be addressed with additional supervision. Regressing global flow does not have this issue.
18 | - A geometric consistency check is performed to mask inconsistent loss. It is similar to that used in optical flow or left-right consistency loss in [monodepth](monodepth.md).
19 | - If warped target pixel and source pixel difference is smaller than 3 pixel or 5% error, then use the loss at that location. Otherwise mask it out.
20 |
21 | #### Technical details
22 | - Summary of technical details
23 |
24 | #### Notes
25 | - Questions and notes on how to improve/revise the current work
26 |
27 |
--------------------------------------------------------------------------------
/paper_notes/ghostnet.md:
--------------------------------------------------------------------------------
1 | # [GhostNet: More Features from Cheap Operations](https://arxiv.org/abs/1911.11907)
2 |
3 | _February 2020_
4 |
5 | tl;dr: A computationally efficient module to compress neural network by cheaply generate more feature maps
6 |
7 | #### Overall impression
8 | Instead of generating all n feature maps from all c channels in the input, generate m feature maps first (m < n), and then use cheap linear operation to generate n-m feature maps. The compression ratio is s.
9 |
10 | The linear operation is usually a 3x3 conv. Different from original 3x3 convolution which takes in all c channels in the input, the m-n are generated from each of the m features directly (injective 单摄).
11 |
12 | The paper has a very good description of compact model design, including [mobilenets](mobilenets.md), [mobilenets v2](mobilenets_v2.md), [mobilenets v3](mobilenets_v3.md).
13 |
14 | Model compression methods are usually bounded by the pretrained deep neural network taken as their baseline. The best way is to design such an efficient neural network that lends themselves to compression.
15 |
16 | #### Key ideas
17 | - Summaries of the key ideas
18 |
19 | #### Technical details
20 | - Summary of technical details
21 |
22 | #### Notes
23 | - [official github repo](https://link.zhihu.com/?target=https%3A//github.com/huawei-noah/ghostnet)
24 |
25 |
--------------------------------------------------------------------------------
/paper_notes/graph_spectrum.md:
--------------------------------------------------------------------------------
1 | # Review of Graph Spectrum Theory
2 |
3 | _Mar 2019_
4 |
5 | ### The Graph Laplacian Matrix
6 | - Incidence matrix C=C(G), each row is an edge, and each column is a vertex, the source is +1, and sink is -1.
7 | - Graph Laplacian matrix $L(G) = C^T C = D-W$. D diagonal matrix records the degrees and W is the adjacency matrix.
8 | - L(G) is symmetric, thus L(G) has real-valued, non-negative eigenvalues, and real-valued orthogonal eigenvalues.
9 | - G has K connected components iff there are k eigenvalues that are 0.
10 | - Partition vector: Let x represent a bipartition of a graph. Each element is a vertex, whether it is in one partition (+1) or the other (-1).
11 | - The number of cut edges (edges with vertices in two partitions) are $\frac{1}{4} x^T L(G) x$.
12 | - If we want to minimize the cut between partitions, then use $q_1$ as the partition vector, the # cut is then $\frac{1}{4} n \lambda_1$. The partition vector is then $\texttt{sign}(q_1)$
13 | - [Source](https://www.youtube.com/watch?v=rVnOANM0oJE)
14 |
--------------------------------------------------------------------------------
/paper_notes/groupnorm.md:
--------------------------------------------------------------------------------
1 | # [Group Normalization](https://arxiv.org/pdf/1803.08494.pdf)
2 |
3 | _Mar 2019_
4 |
5 | tl;dr: Improve batch normalization when batch size is small.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | 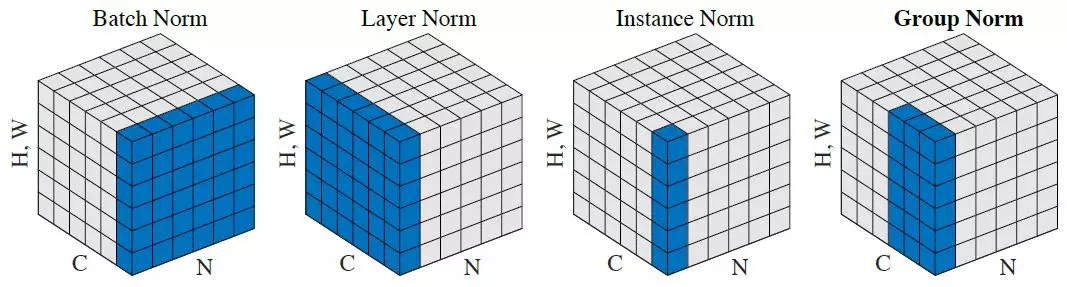
11 |
12 | #### Key ideas
13 | - Summaries of the key ideas
14 |
15 | #### Technical details
16 | - Summary of technical details
17 |
18 | #### Notes
19 | - Questions and notes on how to improve/revise the current work
20 |
21 |
--------------------------------------------------------------------------------
/paper_notes/guided_backprop.md:
--------------------------------------------------------------------------------
1 | # [Guided backprop: Striving for Simplicity: The All Convolutional Net](https://arxiv.org/pdf/1412.6806.pdf)
2 |
3 | _September 2019_
4 |
5 | tl;dr: Guided prop for visualizing CNN efficiently. Also, max pooling can be replaced by conv with larger strides.
6 |
7 | #### Overall impression
8 | Backprop visualizes contribution of pixels to a classification results via backprop, but mask out the negative gradient. This leads to less noise in the visualized saliency map as compared to vanilla backprop.
9 |
10 | The idea is summarized well in this [blog post](https://towardsdatascience.com/feature-visualisation-in-pytorch-saliency-maps-a3f99d08f78a) by the author of [FlashTorch](https://github.com/MisaOgura/flashtorch).
11 |
12 | The idea can be combined with class activation map (CAM) or grad-CAM as well. But as shown in [pytorch-cnn-visualizations](https://github.com/utkuozbulak/pytorch-cnn-visualizations), the difference between guided backprop (GB) and grad-CAM is not that big.
13 |
14 | #### Key ideas
15 | - Summaries of the key ideas
16 |
17 | #### Technical details
18 | - Summary of technical details
19 |
20 | #### Notes
21 | - Questions and notes on how to improve/revise the current work
22 |
23 |
--------------------------------------------------------------------------------
/paper_notes/h3d.md:
--------------------------------------------------------------------------------
1 | # [The H3D Dataset for Full-Surround 3D Multi-Object Detection and Tracking in Crowded Urban Scenes](https://arxiv.org/abs/1903.01568)
2 |
3 | _November 2020_
4 |
5 | tl;dr: VoxelNet + UKF for 3D detection and tracking in crowded urban scene.
6 |
7 | #### Overall impression
8 | H3D dataset includes 160 scenes, and 30k frames, at 2 Hz. Roughly 90 seconds each scene.
9 |
10 | Really crowded scenes as H3D has roughly same number of people and vehicle.
11 |
12 | #### Key ideas
13 | - Use Lidar SLAM to register multiple lidar scans to form a dense point cloud. Then static objects will only have to be labeled once instead of in a frame-by-frame fashion.
14 | - Camera is used to assist
15 | - Class annotation
16 | - 3D bbox verification after projection 3D bbox back to camera
17 | - The 2Hz annotation is propagated to 10 Hz with linear velocity model.
18 | - 3D detection with VexelNet and tracking with UKF.
19 |
20 | #### Technical details
21 | - Calibration between GPS and Lidar are done with hand-eye calibration method.
22 | - Motion blur has to be corrected, using the method from LOAM.
23 |
24 |
25 | #### Notes
26 | - Questions and notes on how to improve/revise the current work
27 |
28 |
--------------------------------------------------------------------------------
/paper_notes/hevi.md:
--------------------------------------------------------------------------------
1 | # [Egocentric Vision-based Future Vehicle Localization for Intelligent Driving Assistance Systems](https://arxiv.org/abs/1809.07408)
2 |
3 | _May 2020_
4 |
5 | tl;dr: Egocentric/first person vehicle prediction.
6 |
7 | #### Overall impression
8 | The paper introduced HEVI (Honda egocentric view intersection) dataset.
9 |
10 | First-person video or egocentric data are easier to collect, and also captures rich information about the objects performance.
11 |
12 | However the front camera has a narrow FOV and tracklets are usually short. The paper selects tracklets that are 2 seconds long. Use 1 sec history and predict 1 second future.
13 |
14 | The inclusion of dense optical flow improves results hugely. Incorporation of future ego motion is also important in reducing prediction error. Note that the future ego motion is fed as GT. During inference the system assumes future motion are from motion planning.
15 |
16 | #### Key ideas
17 | - Summaries of the key ideas
18 |
19 | #### Technical details
20 | - Motion planning is represented in BEV, with 2 DoF translation and one DoF of rotation (yaw).
21 | - HEVI classifies tracklets as easy and hard. Easy can be predicted with a **constant acceleration** model with lower than average error.
22 |
23 | #### Notes
24 | - This is quite similar to [Nvidia's demo](https://www.youtube.com/watch?v=OT_MxopvfQ0) (see also [blog here](https://blogs.nvidia.com/blog/2019/05/22/drive-labs-predicting-future-motion/?ncid=so-you-t7-90294)).
25 |
26 |
--------------------------------------------------------------------------------
/paper_notes/how_hard_can_it_be.md:
--------------------------------------------------------------------------------
1 | # [How hard can it be? Estimating the difficulty of visual search in an image](https://arxiv.org/abs/1705.08280)
2 |
3 | _July 2019_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - [Frustratingly Easy Trade-off Optimization
18 | between Single-Stage and Two-Stage Deep
19 | Object Detectors](http://openaccess.thecvf.com/content_ECCVW_2018/papers/11132/Soviany_Frustratingly_Easy_Trade-off_Optimization_between_Single-Stage_and_Two-Stage_Deep_Object_ECCVW_2018_paper.pdf) ECCV 2018
--------------------------------------------------------------------------------
/paper_notes/hugging_gpt.md:
--------------------------------------------------------------------------------
1 | # [HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face](https://arxiv.org/abs/2303.17580)
2 |
3 | _May 2023_
4 |
5 | tl;dr: Use LLM to connect various AI models to solve AI tasks.
6 |
7 | #### Overall impression
8 | API-based approach. Using AI to manage AI models, or an AI-based expert systems. The LLM such as ChatGPT acts like a switch.
9 |
10 | #### Key ideas
11 | - Four steps
12 | - Task planning (with LLM)
13 | - Model selection (with LLM)
14 | - Task execution, and return results to LLM
15 | - Response generation
16 |
17 | #### Technical details
18 | - Summary of technical details
19 |
20 | #### Notes
21 | - Questions and notes on how to improve/revise the current work
22 |
--------------------------------------------------------------------------------
/paper_notes/human_centric_annotation.md:
--------------------------------------------------------------------------------
1 | # [Human-Centric Efficiency Improvements in Image Annotation for Autonomous Driving](https://drive.google.com/file/d/1DY95vfWBLKOOZZyq8gLDd0heZ6aBSdji/view)
2 |
3 | _June 2020_
4 |
5 | tl;dr: How to generate masks with few vertices that is easy to edit by human annotator.
6 |
7 | #### Overall impression
8 | Use [extreme point clicking](extreme_clicking.md) and [DEXTR: Deep Extreme Cut](https://arxiv.org/abs/1711.09081) CVPR 2018 ([code](https://github.com/scaelles/DEXTR-PyTorch)) to improve efficiency.
9 |
10 | The task improved human annotation of semantic segmentation by almost 4x without degradation of quality.
11 |
12 | 
13 | 
14 |
15 |
16 | #### Key ideas
17 | - Summaries of the key ideas
18 |
19 | #### Technical details
20 | - Summary of technical details
21 |
22 | #### Notes
23 | - Questions and notes on how to improve/revise the current work
24 |
25 |
--------------------------------------------------------------------------------
/paper_notes/insta_yolo.md:
--------------------------------------------------------------------------------
1 | # [INSTA-YOLO: Real-Time Instance Segmentation](https://arxiv.org/abs/2102.06777)
2 |
3 | _March 2021_
4 |
5 | tl;dr: Extend yolo to perform single-stage instance segmentation.
6 |
7 | #### Overall impression
8 | Insta-yolo adopts a fixed length contour representation, and uses a
9 |
10 | Work by Valeo Egypt. Speed is very fast but quality is subpar. Looks like a run-of-the-mill paper.
11 |
12 | #### Key ideas
13 | - Represent masks by a fixed number of contour points (polygons) in Cartesian, and predict the polygons of each object instance through the center of the object.
14 | - GT generation with a deterministic algorithm (dominant points detection).
15 | - Loss
16 | - Regression loss wrt the GT generated with deterministic algo
17 | - IoU Loss to compensate for the fact that no unique representation for the object mask using fixed number of vertices.
18 | - This can also work for orientated bbox prediction.
19 |
20 | #### Technical details
21 | - Log Cosh loss: a differentiable alternative to Huber loss (smooth L1 loss).
22 |
23 | #### Notes
24 | - [On the detection of dominant points on digital curve](https://www.researchgate.net/publication/3191687_On_the_detection_of_dominant_points_on_digital_curve)
25 |
26 |
--------------------------------------------------------------------------------
/paper_notes/kalman_filter.md:
--------------------------------------------------------------------------------
1 | # [Review of Kálmán Filter](https://www.bzarg.com/p/how-a-kalman-filter-works-in-pictures/)
2 |
3 | _September 2019_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - Questions and notes on how to improve/revise the current work
18 |
19 |
--------------------------------------------------------------------------------
/paper_notes/keep_hd_maps_updated_bmw.md:
--------------------------------------------------------------------------------
1 | # [How to Keep HD Maps for Automated Driving Up To Date](http://www.lewissoft.com/pdf/ICRA2020/1484.pdf)
2 |
3 | _December 2020_
4 |
5 | tl;dr: A linklet based updating method for HD maps.
6 |
7 | #### Overall impression
8 | The authors believed that [feature based mapping](lifelong_feature_mapping_google.md) which maintains the persistence score of each feature does not allow large scale application.
9 |
10 | The central idea is to use fleet data to estimate probability of change and update the map where needed.
11 |
12 | #### Key ideas
13 | - Partition the map into linklets in the topology graph defined in SD map.
14 | - Three steps:
15 | - Change detection: detecting if a change in the map has occurred (difference between perception and map). This score is predicted by a gradient boosted tree. This updates the is_changed function F for traversed linklet.
16 | - Job creation: when the aggregated linklet change probability is larger than a certain threshold (also learned), trigger map updating.
17 | - Map updating:
18 |
19 | #### Technical details
20 | - Summary of technical details
21 |
22 | #### Notes
23 | - [TomTom](https://www.tomtom.com/blog/maps/continuous-map-processing/) has a similar method to detect changes and update map patches.
24 |
25 |
--------------------------------------------------------------------------------
/paper_notes/layer_compensated_pruning.md:
--------------------------------------------------------------------------------
1 | # [LcP: Layer-compensated Pruning for Resource-constrained Convolutional Neural Networks](https://arxiv.org/pdf/1810.00518.pdf)
2 |
3 | (NIPS 2018 [talk](https://sites.google.com/view/nips-2018-on-device-ml/schedule?authuser=0) for ML on device)
4 |
5 | _May 2019_
6 |
7 | tl;dr: Layer-wise pruning, but with layer-compensated loss.
8 |
9 | #### Overall impression
10 | Previous method approximates the pruning loss increase with the L1 or L2 of the pruned filter. This is not true. LcP first approximates the layer-wise error compensation and then uses naive pruning (global greedy pruning algorithms) to prune network.
11 |
12 | #### Key ideas
13 | - Two problems in pruning the network: how many to prune and which to prune. The first is also named layer scheduling.
14 | - Naive pruning algorithm: global iterative pruning without layer scheduling.
15 | - Two approximation in prior art of multi-filter pruning:
16 | - Approximate loss change with a ranking metric (the paper addresses this issue)
17 | - Approximate the effect of multiple filter pruning with addition of single layer pruning.
18 | - The paper assumes that the approximation error to be identical for filters in the same layer. Therefore only L latent variables $\beta_l, l=1, ..., L$ need to be approximated.
19 |
20 | #### Technical details
21 | - Summary of technical details
22 |
23 | #### Notes
24 | - Questions and notes on how to improve/revise the current work
25 |
26 |
--------------------------------------------------------------------------------
/paper_notes/lego_loam.md:
--------------------------------------------------------------------------------
1 | # [LeGO-LOAM: Lightweight and Ground-Optimized Lidar Odometry and Mapping on Variable Terrain](http://personal.stevens.edu/~benglot/Shan_Englot_IROS_2018_Preprint.pdf)
2 |
3 | _June 2020_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - [LeGO-LOAM-BOR](https://github.com/facontidavide/LeGO-LOAM-BOR/tree/speed_optimization) (optimized repo)
18 | - [LeGO-LOAM_NOTED](https://github.com/wykxwyc/LeGO-LOAM_NOTED/tree/master/src/LeGO-LOAM) (annotated repo)
19 | - [Loam slam review 知乎](https://zhuanlan.zhihu.com/p/111388877)
20 | - [Lego loam 知乎](https://zhuanlan.zhihu.com/p/115986186)
21 |
22 |
--------------------------------------------------------------------------------
/paper_notes/lidar_sim.md:
--------------------------------------------------------------------------------
1 | # [LiDARsim: Realistic LiDAR Simulation by Leveraging the Real World](https://arxiv.org/abs/2006.09348)
2 |
3 | _June 2020_
4 |
5 | tl;dr: Generate a map, then place bank of cars on it to create synthetic scenes.
6 |
7 | #### Overall impression
8 | Lidar sim is similar to [surfel GAN](surfel_gan.md) in generating synthetic dataset with real data collection.
9 |
10 | - [surfel GAN](surfel_gan.md) generates a photorealistic model
11 | - [lidar sim](lidar_sim.md) focuses on lidar data simulation, which is somewhat easier.
12 |
13 | It can allow closed-loop evaluation of the whole AD stack.
14 |
15 | #### Key ideas
16 | - Simulate ray drop patterns with U-Net structure
17 | - Minimum sim2real domain gap.
18 |
19 | #### Technical details
20 | - Chart showing the diversity of cars on the road
21 | 
22 | 
23 |
24 | #### Notes
25 | - Questions and notes on how to improve/revise the current work
26 |
27 |
--------------------------------------------------------------------------------
/paper_notes/lifelong_feature_mapping_google.md:
--------------------------------------------------------------------------------
1 | # [Towards lifelong feature-based mapping in semi-static environments](https://storage.googleapis.com/pub-tools-public-publication-data/pdf/43966.pdf)
2 |
3 | _December 2020_
4 |
5 | tl;dr: Feature persistence model to keep features in the map up to date.
6 |
7 | #### Overall impression
8 | Vanilla SLAM assumes a static world. They have to adapt in order to achieve **persistent autonomy**. This study proposed a **feature persistent model** that is based on survival analysis. It uses a recursive Bayesian estimator (persistence filter).
9 |
10 | In summary, any observation existence boosts the existence confidence, any observation of absence degrades existence conf, and lack of observation decays existence conf.
11 |
12 | This method has a good formulation but seems to be a bit heavy and does not allow large scale application. See [Keep HD map updated](keep_hd_maps_updated_bmw.md).
13 |
14 | #### Key ideas
15 | - Feature based mapping views the world as a collection of features (lines, planes, objects, or other visual interest points). Mapping is then identify and estimate their state (position, orientation, color).
16 | - In semi-static mapping we have to both add new features to the map and remove existing features from the map.
17 | - The detector is not perfect as well, so it is insufficient if a feature is still present or not. We can only update the **belief**.
18 | - The passage of time matters. An observation 5 min ago should be different from one observation 5 days ago.
19 |
20 | #### Technical details
21 | - Summary of technical details
22 |
23 | #### Notes
24 | - Questions and notes on how to improve/revise the current work
25 |
26 |
--------------------------------------------------------------------------------
/paper_notes/lingo_1.md:
--------------------------------------------------------------------------------
1 | # [LINGO-1: Exploring Natural Language for Autonomous Driving](https://wayve.ai/thinking/lingo-natural-language-autonomous-driving/)
2 |
3 | _June 2024_
4 |
5 | tl;dr: Open-loop AD commentator with LLM.
6 |
7 | #### Overall impression
8 | Lingo-1's commentary was not integrated with the driving model, and remains an open loop system. Lingo-1 is enhanced by the relase of Lingo-1X, by extending VLM model to VLX by adding referential segmentation as X. This is enhanced further by successor [Lingo-2](lingo_2.md) which is a VLA model and finally achieving close-loop.
9 |
10 | This is the first step torward a fully explanable E2E system. The language model can be coupled with the driving model, offering a nice interface to the E2E blackbox.
11 |
12 | > A critical aspect of integrating the language and driving models is grounding between them. The two main factors affecting driving performance are the ability of the language model to accurately interpret scenes using various input modalities and the proficiency of the driving model in translating mid-level reasoning into effective low-level planning.
13 |
14 | #### Key ideas
15 | - Why language?
16 | - Accelerates training
17 | - Offers explanability of E2E one model
18 | - Offers controllability of E2E one model
19 |
20 | #### Technical details
21 | - Summary of technical details, such as important training details, or bugs of previous benchmarks.
22 |
23 | #### Notes
24 | - Questions and notes on how to improve/revise the current work
25 |
26 |
--------------------------------------------------------------------------------
/paper_notes/m2bev.md:
--------------------------------------------------------------------------------
1 | # [M^2BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Birds-Eye View Representation](https://arxiv.org/abs/2204.05088)
2 |
3 | _July 2022_
4 |
5 | tl;dr: Multitask multicam with improved LSS.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - **Joint training** slightly hurts the performance of each task. We observe that the location distribution of objects and maps do not have strong correlation, e.g. many cars are not in the drivable area. --> This is also observed in [BEVFusion](bevfusion.md) and [PETRv2](petrv2.md).
15 | - **Voxel Pooling** is improved to boost efficiency and memory usage. Sinilar improvement has also been seen in [BEVDepth](bevdepth.md) and [BEVFusion](bevfusion.md).
16 |
17 | #### Notes
18 | - Questions and notes on how to improve/revise the current work
19 |
--------------------------------------------------------------------------------
/paper_notes/mae.md:
--------------------------------------------------------------------------------
1 | # [MAE: Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377)
2 |
3 | _November 2021_
4 |
5 | tl;dr: Scalable unsupervised pretraining of vision model by masked image modeling.
6 |
7 | #### Overall impression
8 | This paper is very enlightening.
9 |
10 | This paper rushed the publication of other contemporary work such as [SimMIM](simmim.md) and [iBOT](ibot.md). The clarity of the message, the depth of insight, the craft of engineering consideration, the coverage of ablation study of MAE is significantly superior to the others.
11 |
12 | #### Key ideas
13 | - Masking a high proportions of the input image yields a nontrivial and meaningful self-supervisory task.
14 | - Language and vision have very different information density.
15 | - Languages are human generated signals, highly semantic and information dense.
16 | - Asymmetric encoder and decoder
17 | - Encoder only
18 | - Saves significant computation for transformer-based backbone
19 | - Downstream tasks (object detection, instance and semantic segmentation) all surpassed supervised pretraining.
20 |
21 | #### Technical details
22 | - Summary of technical details
23 |
24 | #### Notes
25 | - Questions and notes on how to improve/revise the current work
26 |
--------------------------------------------------------------------------------
/paper_notes/mb_net.md:
--------------------------------------------------------------------------------
1 | # [MB-Net: MergeBoxes for Real-Time 3D Vehicles Detection](https://ieeexplore.ieee.org/document/8500395)
2 |
3 | _August 2020_
4 |
5 | tl;dr: Use 5DoF 2d bbox to infer 3d bbox.
6 |
7 | #### Overall impression
8 | The paper proposed a way to annotate and regress a 3D bbox, in the form of a 5 DoF bbox (MergeBox).
9 |
10 | This is one of the series of papers from Daimler.
11 |
12 | - [MergeBox](mb_net.md)
13 | - [Bounding Shapes](bounding_shapes.md)
14 | - [3D Geometrically constraint keypoints](3d_gck.md)
15 |
16 | #### Key ideas
17 | - A 5 DoF bbox to represent 3d bbox.
18 | 
19 | - 3D car size templates have to be assumed to lift the mergebox representation to 3D.
20 |
21 | #### Technical details
22 | - The authors noted that even one single template can achieve good performance for AOS (average orientation score).
23 |
24 | #### Notes
25 | - The fancy name for (cos(theta), sin(theta)) is called Biternion. The gaussian on unit circle is called von Mises distribution.
26 | - 3D annotation generally has two approaches: using lidar or 3D CAD model.
27 | - This is similar to what nvidia does by marking the visible edges of the car.
28 |
29 |
--------------------------------------------------------------------------------
/paper_notes/mfs.md:
--------------------------------------------------------------------------------
1 | # [MfS: Learning Stereo from Single Images](https://arxiv.org/abs/2008.01484)
2 |
3 | _August 2020_
4 |
5 | tl;dr: Mono for stereo. Learn stereo matching with monocular images.
6 |
7 | #### Overall impression
8 | The basic idea is to generate stereo training pair with mono depth to train stereo matching algorithms. This idea is very similar to that of Homographic Adaptation in [SuperPoint](superpoint.md), in that both generates training data and GT with known geometric transformation.
9 |
10 | This still need a stereo pair as input during inference time. The main idea is to use monodepth to predict a depth map, sharpen it, and generate a stereo pair, with known stereo matching GT.
11 |
12 | #### Key ideas
13 | - Summaries of the key ideas
14 |
15 | #### Technical details
16 | - Training uses PSMNet (pyramid stereo matching)
17 |
18 | #### Notes
19 | - [Code on github](https://github.com/nianticlabs/stereo-from-mono/)
20 |
21 |
--------------------------------------------------------------------------------
/paper_notes/mgail_ad.md:
--------------------------------------------------------------------------------
1 | # [MGAIL-AD: Hierarchical Model-Based Imitation Learning for Planning in Autonomous Driving](https://arxiv.org/abs/2210.09539)
2 |
3 | _June 2023_
4 |
5 | tl;dr: Application of MGAIL to AD. Closed loop training and eval are the key.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - Questions and notes on how to improve/revise the current work
18 |
--------------------------------------------------------------------------------
/paper_notes/mnasnet.md:
--------------------------------------------------------------------------------
1 | # [MnasNet: Platform-Aware Neural Architecture Search for Mobile](https://arxiv.org/pdf/1807.11626.pdf)
2 |
3 | _May 2019_
4 |
5 | tl;dr: Search the neighborhood of MobileNetV2.
6 |
7 | #### Overall impression
8 | One of the main challenge of NAS is its vast search space. This paper uses [MobilenetsV2](mobilenets_v2.md) as a starting point and significantly reduces the search space. M stands for mobile.
9 |
10 | The algorithm can be seen as an evolution algorithm, just a glorified for loop.
11 |
12 | The performance is overtaken by [FBNet](fbnet.md) also published at CVPR 2019, which uses differentiable optimization method instead of training a controller.
13 |
14 | #### Key ideas
15 | - Combine model Accuracy and latency into a cost function $ACC(model) \times [LAT(model)/TAR]^w$, with w ranging from -0.07 (in MobilenetsV3 Large, or MNasNet-A1) to -0.15 (in MobilenetsV3 Small). -0.07 was obtained by observing that empirically model accuracy improves by 5% when doubling latency.
16 |
17 | #### Technical details
18 | - Summary of technical details
19 |
20 | #### Notes
21 | - Questions and notes on how to improve/revise the current work
22 |
23 |
--------------------------------------------------------------------------------
/paper_notes/moc.md:
--------------------------------------------------------------------------------
1 | # [Actions as Moving Points](https://arxiv.org/abs/2001.04608)
2 |
3 | _January 2020_
4 |
5 | tl;dr: CenterNet for video object detection.
6 |
7 | #### Overall impression
8 | This extends [CenterNet](centernet.md) as Recurrent SSD extends SSD.
9 |
10 | However it is still using box-based method to generate bbox and then link them to action tublets. This is more of a bottom up approach as compared to [recurrent ssd](recurrent_ssd.md).
11 |
12 | Drawbacks and limitations: The main drawback is that it takes in K frames (K=7) frames at the same time. It is not suitable for fast online inference. It does support multiple object detection at the same time, same as CenterNet.
13 |
14 | #### Key ideas
15 | - Summaries of the key ideas
16 |
17 | #### Technical details
18 | - Summary of technical details
19 |
20 | #### Notes
21 | - [code tbd](https://github.com/mcg2019/MOC-Detector)
22 |
23 |
--------------------------------------------------------------------------------
/paper_notes/monet3d.md:
--------------------------------------------------------------------------------
1 | # [MoNet3D: Towards Accurate Monocular 3D Object Localization in Real Time](https://arxiv.org/abs/2006.16007)
2 |
3 | _November 2020_
4 |
5 | tl;dr: Encodes the local geometric consistency (spatial correlation of neighboring objects) into learning.
6 |
7 | #### Overall impression
8 | The idea is similar to enforcing certain order in prediction. It learns the second degree of information hidden in the GT labels. It incorporates prior knowledge of geometric locality as regularization in the training module. The mining of pair-wise relationship if similar to [MonoPair](monopair.md).
9 |
10 | The writing is actually quite bad with heavy use of non-standard terminology. No ablation study on the effect of this newly introduced regularization.
11 |
12 | #### Key ideas
13 | - Local similarity constraints as additional regularization. If two objects are similar (close-by) in GT, then they should be similar in prediction as well.
14 | - The similarity is defined as $s_{ij} = \exp (-\Delta u_{ij}^2 - \Delta z_{ij}^2/\lambda)$
15 | - The difference between the output for different vehicles are penalized according to this metric.
16 |
17 | #### Technical details
18 | - Summary of technical details
19 |
20 | #### Notes
21 | - Questions and notes on how to improve/revise the current work
22 |
23 |
--------------------------------------------------------------------------------
/paper_notes/mono3d++.md:
--------------------------------------------------------------------------------
1 | # [Mono3D++: Monocular 3D Vehicle Detection with Two-Scale 3D Hypotheses and Task Priors](https://arxiv.org/abs/1901.03446)
2 |
3 | _August 2019_
4 |
5 | tl;dr: Mono 3DOD based on 3D and 2D consistency, in particular landmark and shape recon.
6 |
7 | #### Overall impression
8 | The paper is written in overcomplicated math formulation. Overall not very impressive. The consistency part is quite similar to other papers such as [deep3dbox](deep3dbox.md).
9 |
10 | The morphable wire frame model is fragile and the authors did not do a thorough ablation study on its contribution. I am not sure if shape recon is a good idea, especially to handle corner cases. --> **Nobody in the literature actually talks about how to handle corner cases. This need to be acquired through engineering practice.** Maybe CV method is needed to handle the corner cases.
11 |
12 | The paper seems to use 3D depth off the shelf but it was not described in details.
13 |
14 | #### Key ideas
15 | - Learn a morphable wire model from landmarks (takes 2.5 min, deterministic). --> similar to [ROI 10D](roi10d.md).
16 | - Metrics: ALP (average localization precision). This metric only cares about center location.
17 |
18 | #### Technical details
19 | - w and h are encoded to be exponential forms because they need to be positive.
20 |
21 | #### Notes
22 | - Where does the label come from?
23 | - The wireframe model is fragile and cannot model under-represented cases.
24 | - von Mises distribution: circular Gaussian distribution
--------------------------------------------------------------------------------
/paper_notes/mono3d_fisheye.md:
--------------------------------------------------------------------------------
1 | # [Monocular 3D Object Detection in Cylindrical Images from Fisheye Cameras](https://arxiv.org/abs/2003.03759)
2 |
3 | _December 2020_
4 |
5 | tl;dr: Use cylindrical representation of fisheye images to transfer pinhole camera image to fisheye images.
6 |
7 | #### Overall impression
8 | In pinhole camera model, perceived objects become smaller as they become further away as measured by depth Z. Objects with constant Z, regardless of X and Y positions, appear similar. Pinhole camera model can only accommodate limited FoV (view angles up to 90 deg).
9 |
10 | Fisheye model, $r = f\theta$. It can represent view angles beyond 90 deg. In fisheye image, when an object moves in XY plane at the same Z, its appearance changes as well. CNN is not immediately compatible with such a fisheye raw image.
11 |
12 | One way is to convert it into a cylindrical view. An object's side and appearance remain the same as long as the $\rho$ distance keeps the same.
13 |
14 | #### Key ideas
15 | - Change fisheye raw image to cylindrical view
16 | - Interpret output z as $\rho$
17 | - Use self-supervised learning (rotation prediction, etc) and finetune on small number (<100) of samples. The fintuning even on a small number of images helps a lot.
18 | - We need finetuning as the analogy between cylindrical and perspective image (approximation that $\Delta X = \rho \Delta \phi$) breaks down for close-by objects.
19 |
20 | #### Technical details
21 | - Warping uses predefined mappings and its computation time is typically negligible (as compared to model inference time).
22 |
23 | #### Notes
24 | - Questions and notes on how to improve/revise the current work
25 |
26 |
--------------------------------------------------------------------------------
/paper_notes/mono_3dod_2d3d_constraints.md:
--------------------------------------------------------------------------------
1 | # 2D 3D contraints in Mono 3DOD
2 |
3 | _October 2019_
4 |
5 | tl;dr: Summary of the main idea. The review is published at [towarddatacience](https://towardsdatascience.com/geometric-reasoning-based-cuboid-generation-in-monocular-3d-object-detection-5ee2996270d1?source=friends_link&sk=ebead4b51a3f75476d308997dd88dd75).
6 |
7 | ### Deep 3D Box
8 | from [Deep3DBox](https://arxiv.org/pdf/1612.00496.pdf) and its [Supplementary material](https://cs.gmu.edu/~amousavi/papers/3D-Deepbox-Supplementary.pdf), and [review in 中文](https://blog.csdn.net/qq_29462849/article/details/91314777)
9 | 
10 | 
11 | 
12 | 
13 |
14 | #### Code
15 | - [2d 3d contraint code](https://github.com/lzccccc/3d-bounding-box-estimation-for-autonomous-driving/blob/master/utils/correspondece_constraint.py)
16 | - [Different implementation](https://github.com/skhadem/3D-BoundingBox/blob/master/library/Math.py)
17 | 
18 |
19 |
20 | ### FQNet
21 | from [FQNet supplementatry material](https://arxiv.org/pdf/1904.12681.pdf)
22 | 
23 | 
24 |
25 | ### Shift RCNN
26 | from [shift rcnn](https://arxiv.org/pdf/1905.09970.pdf)
27 | 
28 | 
--------------------------------------------------------------------------------
/paper_notes/mpdm2.md:
--------------------------------------------------------------------------------
1 | # [MPDM2: Multipolicy Decision-Making for Autonomous Driving via Changepoint-based Behavior Prediction](https://www.roboticsproceedings.org/rss11/p43.pdf)
2 |
3 | _June 2024_
4 |
5 | tl;dr: Improvement of MPDM in predicting the intention of other vehicles.
6 |
7 | #### Overall impression
8 | The majority is the same as the previous work [MPDM](mpdm.md). There is a follow up article on this as well [MPDM3](https://link.springer.com/article/10.1007/s10514-017-9619-z) which expands [MPDM2](mpdm2.md) with more experiments, but with the same methodology.
9 |
10 | So the main idea of MPDM is already covered in the original short paper [MPDM](mpdm.md).
11 |
12 | #### Key ideas
13 | - Motion prediction of other agents with a classical ML methods (Maximum likelihood estimation).
14 |
15 | #### Technical details
16 | - Summary of technical details, such as important training details, or bugs of previous benchmarks.
17 |
18 | #### Notes
19 | - Questions and notes on how to improve/revise the current work
20 |
21 |
--------------------------------------------------------------------------------
/paper_notes/mpv_nets.md:
--------------------------------------------------------------------------------
1 | # [MPV-Nets: Monocular Plan View Networks for Autonomous Driving](https://arxiv.org/abs/1905.06937)
2 |
3 | _September 2020_
4 |
5 | tl;dr: Project 3D object detection into BEV map to train a better driving agent.
6 |
7 | #### Overall impression
8 | Monocular 3D object detection in a way similar to [Deep3DBox](deep3dbox.md). Then the 3D object detection results are rendered into a BEV (Plan view). Having access to this plan view reduces collisions by half.
9 |
10 | #### Key ideas
11 | - Plan view is essential for planning.
12 | - In perspective view, free space and overall structure is implicit rather than explicit.
13 | - Hallucinating a top-down view of the road makes it easier to earn to drive as free and occupied spaces are explicitly represented at a constant resolution through the image.
14 | - Perception stack should generate this plan view for planning stack.
15 |
16 | #### Technical details
17 | - Summary of technical details
18 |
19 | #### Notes
20 | - Questions and notes on how to improve/revise the current work
21 |
22 |
--------------------------------------------------------------------------------
/paper_notes/mvra.md:
--------------------------------------------------------------------------------
1 | # [MVRA: Multi-View Reprojection Architecture for Orientation Estimation](http://openaccess.thecvf.com/content_ICCVW_2019/papers/ADW/Choi_Multi-View_Reprojection_Architecture_for_Orientation_Estimation_ICCVW_2019_paper.pdf)
2 |
3 | _November 2019_
4 |
5 | tl;dr: Build the 2D/3D constraints optimization into neural network and use iterative method to refine cropped cases.
6 |
7 | #### Overall impression
8 | This paper is heavily based on [deep3Dbox](deep3dbox.md) and adds a few improvement to handle corner cases.
9 |
10 | The paper has a very good introduction to mono 3DOD methods.
11 |
12 | #### Key ideas
13 | - 3D reconstruction layer: instead of solving an over-constrained equation, MVRA used a reconstruction layer to lift 2D to 3D.
14 | - **IoU loss** in perspective view, between the reprojected 3D bbox and the 2d bbox in IoU.
15 | - L2 loss in BEV loss between estimated distance and gt distance.
16 | - **Iterative orientation refinement for truncated bbox**: use only **3 constraints instead of 4**, excluding the xmin (for left truncated) or xmax (for right truncated) cars. Try pi/8 interval and find best, then try pi/32 interval to find best. After two iterations, the performance is good enough.
17 |
18 | #### Technical details
19 | - Bbox jitter to make the 3D reconstruction layer more robust.
20 |
21 | #### Notes
22 | - The use of IoU to pick the best configuration is proposed before in [Shift RCNN](shift_rcnn.md).
23 | - The BEV loss term can be used to incorporate radar into training process.
24 |
--------------------------------------------------------------------------------
/paper_notes/nature_dqn_paper.md:
--------------------------------------------------------------------------------
1 | # [Human-level control through deep reinforcement learning](https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf)
2 |
3 | _01/06/2019_
4 |
5 | tl;dr: the founding paper of DQN
6 |
7 | #### Key ideas
8 |
9 | * Approximating action values (Q) with neural nets are known to be unstable. Two tricks are used to solve this: experience replay buffer, and a periodically updated target network.
10 | * The authors tied the important ideas of adjusting representation based on reward (end-to-end learning) and replay buffer (hippocampus) with biological evidence.
11 |
12 | #### Notes/Questions
13 |
14 | * Drawbacks: It does not make much progress toward solving Montezuma's revenge.
15 |
16 | > Nevertheless, games demanding more temporally extended planning strategies still constitute a major challenge for all existing agents including DQN (for example, Montezuma’s Revenge).
17 |
18 | Overall impression: fill this out last; it should be a distilled, accessible description of your high-level thoughts on the paper.
19 |
--------------------------------------------------------------------------------
/paper_notes/nuscenes.md:
--------------------------------------------------------------------------------
1 | # [nuScenes: A multimodal dataset for autonomous driving](https://arxiv.org/abs/1903.11027)
2 |
3 | _July 2020_
4 |
5 | tl;dr: This is the first large dataset with camera, lidar and radar data.
6 |
7 | #### Overall impression
8 | The dataset is quite challenging in many aspects:
9 |
10 | - multiple country, multiple city (Boston, Singapore)
11 | - multiple weather condition
12 | - low framerate annotation (2 FPS for camera and lidar, although camera captured at 15 FPS and lidar 20 FPS). This makes tracking harder.
13 |
14 | #### Key ideas
15 | - 1000 scenes, each 20 seconds long.
16 | - Revised mAP (different from KITTI) for 3D OD.
17 | - We use the Average Precision (AP) metric [32, 26], but define a match by thresholding the 2D center distance d on the ground plane instead of intersection over union (IOU). This is done in order to decouple detection from object size and orientation but also because objects with small footprints, like pedestrians and bikes, if detected with a small translation error, give 0 IOU (Figure 7). This makes it hard to compare the performance of vision-only methods which tend to have large localization errors [69].
18 | - Same convention is used in [Argoverse](argoverse.md).
19 |
20 | #### Technical details
21 | - Summary of technical details
22 |
23 | #### Notes
24 | - Questions and notes on how to improve/revise the current work
25 |
26 |
--------------------------------------------------------------------------------
/paper_notes/occupancy_networks.md:
--------------------------------------------------------------------------------
1 | # [Occupancy Networks: Learning 3D Reconstruction in Function Space](https://arxiv.org/abs/1812.03828)
2 |
3 | _May 2023_
4 |
5 | tl;dr: Encoding the occupancy of a scene with a neural network, and can be queried at any location with arbitrary resolution.
6 |
7 | #### Overall impression
8 | In 3D there is no canonical representation which is both computationally and memory efficient yet allows for representing high-resolution geometry
9 | of arbitrary topology.
10 |
11 | Occupancy networks implicitly represent the 3D surface as the continuous decision boundary of a deep neural network classifier. Instead of predicting a voxelized representation at a fixed resolution, the network can be evaluated at arbitrary resolution. This drastically reduces the memory footprint during training.
12 |
13 | #### Key ideas
14 | - Training involves random sampling points inside the volume. Random sampling yields the best results.
15 | - During inference, a Multiresolution IsoSurface Extraction (MISE) method is used to extract isosurface of a scene.
16 |
17 | 
18 |
19 | #### Technical details
20 | - Summary of technical details
21 |
22 | #### Notes
23 | - [Official website with talk and supplementary materials](https://avg.is.mpg.de/publications/occupancy-networks)
24 |
--------------------------------------------------------------------------------
/paper_notes/opportunities_foundation_models.md:
--------------------------------------------------------------------------------
1 | # [On the Opportunities and Risks of Foundation Models](https://arxiv.org/abs/2108.07258)
2 |
3 | _November 2024_
4 |
5 | tl;dr: Nice def and summary of FM.
6 |
7 | #### Overall impression
8 | * A foundation model is any model that is trained on broad data (generally using self-supervision at scale) that can be adapted (e.g., fine-tuned) to a wide range of downstream tasks
9 | * The significance of foundation models can be summarized by two words: **emergence** and **homogenization**.
10 | * Emergence means that the behavior of a system is implicitly induced rather than explicitly constructed;
11 | * Homogenization indicates the consolidation of methodologies for building machine learning systems across a wide range of applications
12 |
13 |
14 |
15 | #### Key ideas
16 |
17 |
18 | #### Technical details
19 |
20 | #### Notes
21 |
22 |
--------------------------------------------------------------------------------
/paper_notes/panet.md:
--------------------------------------------------------------------------------
1 | # [Path Aggregation Network for Instance Segmentation](https://arxiv.org/pdf/1803.01534.pdf)
2 |
3 | _May 2019_
4 |
5 | tl;dr: Add another bottom-up layer to FPN (N-shaped) boosts Mask-RCNN performance.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - Questions and notes on how to improve/revise the current work
18 |
19 |
--------------------------------------------------------------------------------
/paper_notes/panoptic_bev.md:
--------------------------------------------------------------------------------
1 | # [PanopticBEV: Bird's-Eye-View Panoptic Segmentation Using Monocular Frontal View Images](https://arxiv.org/abs/2108.03227)
2 |
3 | _October 2021_
4 |
5 | tl;dr: Use of a vertical and a flat transformer to lift image into BEV.
6 |
7 | #### Overall impression
8 | The paper notes correctly that the notion of instance is critical to downstream. [FIERY](fiery.md) also extends the semantic segmentation idea to instance segmentation. [Panoptic BEV](panoptic_bev.md) goes one step further and does [panoptic segmentation](panoptic_segmentation.md).
9 |
10 | #### Key ideas
11 | - Backbone: resnet + [BiFPN](efficientdet.md)
12 | - At each level (P2-P5), image features are projected into a BEV by a dense transformer module (note that this transformer is not attention based).
13 | - Dense transformer module
14 | - Each dense transformer consists of a distinct vertical and flat transformer.
15 | - The vertical transformer uses a volumetric lattice to model the intermediate 3D space which is then flattened to generated the vertical BEV features. --> this vertical transformer is quite similar to that of [Lift Splat Shoot](lift_splat_shoot.md).
16 | - The flat transformer uses IPM followed by an Error Correction Module (ECM) to generate the flat BEV features.
17 | - The differentiation between flat and vertical module is by a binary semantic segmentation network.
18 |
19 | #### Technical details
20 | - Summary of technical details
21 |
22 | #### Notes
23 | - [Video](https://www.youtube.com/watch?v=HCJ1Hi_y9x8)
24 | - [Code](https://github.com/robot-learning-freiburg/PanopticBEV)
25 |
26 |
--------------------------------------------------------------------------------
/paper_notes/patdnn.md:
--------------------------------------------------------------------------------
1 | # [PatDNN: Achieving Real-Time DNN Execution on Mobile Devices with Pattern-based Weight Pruning](https://arxiv.org/abs/2001.00138)
2 |
3 | _December 2020_
4 |
5 | tl;dr: Pattern based fine-grained pruning method and use compiler to speed up inference again.
6 |
7 | #### Overall impression
8 | Current pruning methods exhibits two extremes in the design space.
9 |
10 | - Non-structured pruning is fine-grained, accurate, but not hardware friendly;
11 | - Structured pruning is coarse-grained, hardware-efficient, but with higher accuracy loss.
12 |
13 | PatDNN introduces a new dimension in design space: fine-grained pruning **patterns** (thus PatDNN) inside coarse-grained structures. The direct output is still unstructured and does not lend to speedup in HW. Then compiler is used to reorder kernels and compress weight storage and convert the unstructured network to a structured one that is more suitable for HW acceleration.
14 |
15 | 
16 | 
17 |
18 | #### Key ideas
19 | - Summaries of the key ideas
20 |
21 | #### Technical details
22 | - Summary of technical details
23 |
24 | #### Notes
25 | - [Video of talk](https://www.bilibili.com/video/BV1QK41157pV)
26 |
27 |
--------------------------------------------------------------------------------
/paper_notes/pdq.md:
--------------------------------------------------------------------------------
1 | # [Probabilistic Object Detection: Definition and Evaluation](https://arxiv.org/abs/1811.10800)
2 |
3 | _December 2019_
4 |
5 | tl;dr: Proposes a new metric for probabilistic detection.
6 |
7 | #### Overall impression
8 | Proposed a benchmark PDQ (probabilistic detection quality) to evaluate probabilistic object detectors.
9 |
10 | $$PDQ = \sqrt{DQ * LQ} $$
11 |
12 | $$DQ = \exp(-(L_{FG} + L_{BG}))$$
13 | $$L_{FG} = -\frac{1}{|GT|}\sum \log p(TP)$$
14 | $$L_{BG} = -\frac{1}{|GT|}\sum \log (1 - p(FP))$$
15 | $$LQ = p(class=y)$$
16 |
17 | #### Key ideas
18 | - Only pixels in the original mask is counted as TP. Only pixels not in the original bbox is counted as FP.
19 | - For bbox annotation, we can use the bbox as the mask.
20 |
21 | #### Technical details
22 | - Summary of technical details
23 |
24 | #### Notes
25 | - [A Mask-RCNN Baseline for Probabilistic Object Detection](https://arxiv.org/pdf/1908.03621.pdf) provides a benchmark with mask rcnn. The authors change the output of mask rcnn to probabilistic approach by
26 | - shrinking bbox by 10%
27 | - set uncertainty to 20% of width/height
28 |
29 |
--------------------------------------------------------------------------------
/paper_notes/point_cnn.md:
--------------------------------------------------------------------------------
1 | # [Paper Title](link_to_paper)
2 |
3 | _July 2019_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - Questions and notes on how to improve/revise the current work
18 |
19 |
--------------------------------------------------------------------------------
/paper_notes/pointtrack++.md:
--------------------------------------------------------------------------------
1 | # [PointTrack++ for Effective Online Multi-Object Tracking and Segmentation](https://arxiv.org/abs/2007.01549)
2 |
3 | _July 2020_
4 |
5 | tl;dr: Follow-up work of [PointTrack](pointtrack.md) for MOTS.
6 |
7 | #### Overall impression
8 | Three main contributions:
9 |
10 |
11 | #### Key ideas
12 | - Semantic segmentation map as seed map in [PointTrack](pointtrack.md) and [SpatialEmbedding](spatial_embedding.md).
13 | - Copy and paste data augmentation for crowded scenes. Need segmentation mask.
14 | - Training instance embedding:
15 | - [PointTrack](pointtrack.md) consists of D track ids, each with three crops with equal temporal space. It does not use 3 consecutive frames to increase the intra-track-id discrepancy. The space S is randomly chosen between 1 and 10.
16 | - [PointTrack++](pointtrack++.md) finds that for environment embedding, making S>2 does not converge, but for foreground 2D point cloud a large S (~12) helps to achieve a higher performance. Thus the embeddings are trained separately. Then the individual MLP weights are fixed, and a new MLP is trained to aggregate these info together.
17 |
18 | #### Technical details
19 | - Image is upsampled to twice the original size for better performance.
20 |
21 | #### Notes
22 | - Questions and notes on how to improve/revise the current work
23 |
24 |
--------------------------------------------------------------------------------
/paper_notes/polymapper.md:
--------------------------------------------------------------------------------
1 | # [PolyMapper: Topological Map Extraction From Overhead Images](https://arxiv.org/abs/1812.01497)
2 |
3 | _August 2020_
4 |
5 | tl;dr: Map buildings and roads as polygon.
6 |
7 | #### Overall impression
8 | Identify keypoints first, then starting with one arbitrary one vertex, connect them according to the Left/Right hand rule (or [Maze solving algorithm](https://en.wikipedia.org/wiki/Maze_solving_algorithm)), then there is one unique way to define the graph.
9 |
10 | The following work are focused on road network discovery and are NOT focused on HD maps.
11 |
12 | - [DeepRoadMapper](deep_road_mapper.md): semantic segmentation
13 | - [RoadTracer](road_tracer.md): like an DRL agent
14 | - [PolyMapper](hran.md): iterate every vertices of a closed polygon
15 |
16 | [Polyline loss](hran.md) and [DAGMapper](dagmapper.md) focuses on HD mapping tasks with lane-level information.
17 |
18 | Road network extraction is still very helpful for routing purposes, but lack the fine detail and accuracy needed for a safe localization and motion planning of an autonomous car.
19 |
20 | #### Key ideas
21 | - Find RoI with RPN
22 | - Identify keypoints
23 | - Connect keypoints with RNN (Conv-LSTM)
24 |
25 | #### Technical details
26 | - Summary of technical details
27 |
28 | #### Notes
29 | - Questions and notes on how to improve/revise the current work
30 |
31 |
--------------------------------------------------------------------------------
/paper_notes/posenet.md:
--------------------------------------------------------------------------------
1 | # [PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization](https://arxiv.org/abs/1505.07427)
2 |
3 | _March 2020_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | Note: this PoseNet is used for relocalization. The PoseNet mentioned in [openpilot's architecture](https://medium.com/@comma_ai/a-tour-through-openpilot-a6589a801ed0) is actually the PoseNet/Pose-CNN in [sfm Learner](sfm_learner.md).
11 |
12 | #### Key ideas
13 |
14 | #### Technical details
15 | - Summary of technical details
16 |
17 | #### Notes
18 | - Questions and notes on how to improve/revise the current work
19 |
20 |
--------------------------------------------------------------------------------
/paper_notes/pp_yolo.md:
--------------------------------------------------------------------------------
1 | # [PP-YOLO: An Effective and Efficient Implementation of Object Detector](https://arxiv.org/abs/2007.12099)
2 |
3 | _December 2020_
4 |
5 | tl;dr: A bag of tricks to train [YOLOv3](yolov3.md).
6 |
7 | #### Overall impression
8 | This paper and [YOLOv4](yolov4.md) both starts from [YOLOv3](yolov3.md) but adopts different methods. YOLOv4 explores extensively recent advances in backbones and data augmentation, while PP-YOLO adopts more training tricks. Their improvements are orthogonal.
9 |
10 | The paper is more like a cookbook/recipe, and the focus is how to stack effective tricks that hardly affect efficiency to get better performance.
11 |
12 | #### Key ideas
13 | - Bag of training tricks
14 | - Larger batch
15 | - EMA of weight
16 | - Dropblock (structured dropout) @ FPN
17 | - IoU Loss in separate branch
18 | - IoU Aware: IoU guided NMS
19 | - Grid sensitive: introduced by [YOLOv4](yolov4.md). This helps the prediction after sigmoid to get to 0 or 1 position exactly, at grid boundary.
20 | - [CoordConv](coord_conv.md)
21 | - Matrix-NMS proposed by [SOLOv2](solov2.md)
22 | - SPP: efficiently boosts receptive field.
23 |
24 | #### Technical details
25 | - Summary of technical details
26 |
27 | #### Notes
28 | - See this [review](https://mp.weixin.qq.com/s/pHOFqFihkkRVTYbkSTlG4w)
29 |
30 |
--------------------------------------------------------------------------------
/paper_notes/ppgeo.md:
--------------------------------------------------------------------------------
1 | # [PPGeo: Policy Pre-training for End-to-end Autonomous Driving via Self-supervised Geometric Modeling](https://arxiv.org/abs/2301.01006)
2 |
3 | _January 2023_
4 |
5 | tl;dr: Large scale visual pretraining for policy learning.
6 |
7 | #### Overall impression
8 | The idea is interesting: how to use large scale pretraining to extract driving relevant information. The
9 |
10 | #### Key ideas
11 | - Step1: use large scale uncalibrated driving video to train depthNet and poseNet, a la [SfMLearner](sfm_learner.md). The input is two consecutive frames at 1 Hz.
12 | - Step2: from a single image, predict the ego motion. --> This is highly questionable. It would be better to feed in multiple historical frames, and also historical ego motion information. If historical information is important for prediction tasks, why not for planning?
13 |
14 | #### Technical details
15 | - Summary of technical details
16 |
17 | #### Notes
18 | - Questions and notes on how to improve/revise the current work
19 |
--------------------------------------------------------------------------------
/paper_notes/prevention_dataset.md:
--------------------------------------------------------------------------------
1 | # [The PREVENTION dataset: a novel benchmark for PREdiction of VEhicles iNTentIONs](10.1109/ITSC.2019.8917433)
2 |
3 | _January 2020_
4 |
5 | tl;dr: Dataset for cut-in and other lane-change prediction.
6 |
7 | #### Overall impression
8 | This dataset includes tracking and sensor fusion annotation.
9 |
10 | #### Key ideas
11 | - High accuracy lateral movement of the vehicles are critical for the lane change prediction task. Symmetrically placed keypoints are traced (like BPE) automatically, with Median Flow. The tracking process is supervised.
12 | - Relative position of ego-vehicle wrt the road surface is useful to correct BEV pitch or height. The ground plane coefficients are computed with RANSAC with lidar point cloud.
13 | - Event types: Cut-in/Cut-out/Lane-change/zebra-crossing. Note: Cut-in and cut-out are actually not labeled. Only contains left and right lane changes.
14 |
15 | #### Technical details
16 | - Cameras are externally triggered by lidar at 10 Hz.
17 | - On average, one lane change event in every 20 second.
18 | - Lane detection and tracking in BEV image with moving objects removed.
19 |
20 | #### Notes
21 | - We need some metric to measure the prediction performance!
22 |
23 |
--------------------------------------------------------------------------------
/paper_notes/psdet.md:
--------------------------------------------------------------------------------
1 | # [PSDet: Efficient and Universal Parking Slot Detection](https://arxiv.org/abs/2005.05528)
2 |
3 | _December 2020_
4 |
5 | tl;dr: Parking slot detection by detecting marking point with a CenterNet-like algorithm.
6 |
7 | #### Overall impression
8 | For my future self: **Dataset is super important. Your algorithm is only going to evolve to the level your dataset KPI requires it to.**
9 |
10 | The algorithm only focuses on detecting the marking point detection and did not mention too much about the post-processing needed to combine the marking points to parking slot. It is more general in that it can detect more than T/L-shaped marking points.
11 |
12 | The paper is very poorly written, with tons of sloppy annotation and non-standard terminology.
13 |
14 | #### Key ideas
15 | - A coarse-to-fine marking point detection algorithm. Very much like [CenterNet](centernet.md).
16 | - The regression also predicts the "vertex paradigm". Basically it predicts the pattern of the connectivity among the marking points.
17 |
18 | #### Technical details
19 | - Annotated a dataset (~15k images). This is slightly bigger than [PS2.0 dataset](https://cslinzhang.github.io/deepps/) with 12k images.
20 | - The paper uses L2 loss to supervise the heatmaps and attributes. This is a bit strange as most studies uses focal loss for heatmap prediction and L1 for attribute prediction.
21 |
22 | #### Notes
23 | - Questions and notes on how to improve/revise the current work
24 |
25 |
--------------------------------------------------------------------------------
/paper_notes/pwc_net.md:
--------------------------------------------------------------------------------
1 | # [PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume](https://arxiv.org/abs/1709.02371)
2 |
3 | _June 2020_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - [Review of DL-based optical flow methods on 知乎](https://zhuanlan.zhihu.com/p/37736910)
18 |
19 |
--------------------------------------------------------------------------------
/paper_notes/pyva.md:
--------------------------------------------------------------------------------
1 | # [PYVA: Projecting Your View Attentively: Monocular Road Scene Layout Estimation via Cross-view Transformation](https://openaccess.thecvf.com/content/CVPR2021/html/Yang_Projecting_Your_View_Attentively_Monocular_Road_Scene_Layout_Estimation_via_CVPR_2021_paper.html)
2 |
3 | _September 2021_
4 |
5 | tl;dr: Transformers to lift image to BEV.
6 |
7 | #### Overall impression
8 | This paper uses a cross-attention transformer structure (although they did not spell that out explicitly) to lift image features to BEV and perform road layout and vehicle segmentation on it.
9 |
10 | It is difficult for CNN to fit a view projection model due to the locally confined receptive fields of convolutional layers. Transformers are more suitable to do this job due to the global attention mechanism.
11 |
12 | Road layout provides the crucial context information to infer the position and orientation of vehicles. The paper introduces a context-awre discriminator loss to refine the results.
13 |
14 | #### Key ideas
15 | - CVP (cycled view projection)
16 | - 2-layer MLP to project image feature X to BEV feature X', following [VPN](vpn.md)
17 | - Add cycle consistency loss to ensure the X' captures most information
18 | - CVT (cross view transformer)
19 | - X' as Query, X/X'' as key/value
20 | - Context-aware Discriminator. This follows [MonoLayout](monolayout.md) but takes it one step further.
21 | - distinguish predicted and gt vechiles
22 | - distinguish predicted and gt correlation between vehicle and road
23 |
24 | #### Technical details
25 | - Summary of technical details
26 |
27 | #### Notes
28 | - [code on Github](https://github.com/JonDoe-297/cross-view)
29 |
30 |
--------------------------------------------------------------------------------
/paper_notes/qcnet.md:
--------------------------------------------------------------------------------
1 | # [QCNet: Query-Centric Trajectory Prediction](https://openaccess.thecvf.com/content/CVPR2023/papers/Zhou_Query-Centric_Trajectory_Prediction_CVPR_2023_paper.pdf)
2 |
3 | _June 2024_
4 |
5 | tl;dr: Query centic prediction that marries agent centric and scene centric predictions.
6 |
7 | #### Overall impression
8 | Winning solution in Argoverse and Waymo datasets.
9 |
10 | #### Key ideas
11 | - Local coordinate system for each agent that leverages invariance.
12 | - Long horizon prediction in 6-8s is achieved by AR decoding of 1s each, then followed by a trajectory refiner. --> This means the target oriented approach scuh as [TNT](tnt.md) might have been too hard. [TNT](tnt.md) seems to have been proposed to maximize FDE directly.
13 |
14 | #### Technical details
15 | - Summary of technical details, such as important training details, or bugs of previous benchmarks.
16 |
17 | #### Notes
18 | - [Tech blog in Chinese by 周梓康](https://mp.weixin.qq.com/s/Aek1ThqbrKWCSMHG6Xr9eA)
19 |
20 |
--------------------------------------------------------------------------------
/paper_notes/radar_detection_pointnet.md:
--------------------------------------------------------------------------------
1 | # [2D Car Detection in Radar Data with PointNets](https://arxiv.org/abs/1904.08414)
2 |
3 | _July 2019_
4 |
5 | tl;dr: Use F-pointnet for car detection with sparse 4D radar data (x, y, $\tilde {v}_r$, $\sigma$).
6 |
7 | #### Overall impression
8 | From U of Ulm. Only one target per per car, in a controlled environment. A high precision GPS is used to create the dataset GT.
9 |
10 | This is an extension to the [radar point cloud segmentation](radar_point_semantic_seg.md).
11 |
12 | #### Key ideas
13 | - Three steps:
14 | - Patch Proposal around each point --> this proposal is quite like [point rcnn](point_rcnn.md).
15 | - Classify patch
16 | - Segment patch (point cloud segmentation)
17 | - Bbox estimation
18 |
19 | #### Technical details
20 | - Radar data often contain reflections of object parts not directly visible, like the wheel house (fender) on the opposite side.
21 | - No accumulation of data across frames like the radar point segmentation work.
22 |
23 |
24 |
--------------------------------------------------------------------------------
/paper_notes/radar_target_detection_tsinghua.md:
--------------------------------------------------------------------------------
1 | # [A study on Radar Target Detection Based on Deep Neural Networks](https://www.researchgate.net/publication/330748053_A_Study_on_Radar_Target_Detection_Based_on_Deep_Neural_Networks)
2 |
3 | _July 2019_
4 |
5 | tl;dr: Detection on RD map. Use CNN to replace CFAR (adaptive thresholding) and binary integration (time sequence processing).
6 |
7 | #### Overall impression
8 | The paper showed that there are minimum gain of CNN over CFAR under different noise levels. And it is better than binary integration for time sequence processing.
9 |
10 | #### Technical details
11 | - 61 frames, 0.5 ms frame time, 2 us per chirp.
12 | - Seems like only one object in the frame.
--------------------------------------------------------------------------------
/paper_notes/realtime_panoptic.md:
--------------------------------------------------------------------------------
1 | # [Real-Time Panoptic Segmentation From Dense Detections](https://arxiv.org/abs/1912.01202)
2 |
3 | _June 2020_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 | Weakly supervised learning to get instance segmentation is awesome!
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - [code on github](https://github.com/TRI-ML/realtime_panoptic)
18 | - [slides from CVPR](https://drive.google.com/file/d/1J3EIhQq_nVbZkwtTIc-tEcBAtQqbzOQL/view?usp=sharing)
19 |
20 |
--------------------------------------------------------------------------------
/paper_notes/recurrent_retinanet.md:
--------------------------------------------------------------------------------
1 | # [Recurrent RetinaNet: A Video Object Detection Model Based on Focal Loss](https://doi.org/10.1007/978-3-030-04212-7_44)
2 |
3 | _January 2020_
4 |
5 | tl;dr: Add recurrent LSTM to retinaNet
6 |
7 | #### Overall impression
8 | This paper is quite similar to [recurrent SSD](recurrent_SSD.md) but much less insightful. They added two layers of recurrent LSTM to the feature map before the detection head.
9 |
10 | K=5 frames
11 |
--------------------------------------------------------------------------------
/paper_notes/refined_mpl.md:
--------------------------------------------------------------------------------
1 | # [RefinedMPL: Refined Monocular PseudoLiDAR for 3D Object Detection in Autonomous Driving](https://arxiv.org/abs/1911.09712)
2 |
3 | _March 2020_
4 |
5 | tl;dr: Sparsify pseudo-lidar points for monocular 3d object detection.
6 |
7 | #### Overall impression
8 | The paper is based on the work of [Pseudo-lidar](pseudo_lidar.md). The main contribution seems to be the faster processing time, and the performance gain is not huge.
9 |
10 | Both the unsupervised and supervised method identify foreground regions using 2D image, then perform a distance stratified sampler to downsample the point cloud.
11 |
12 | #### Key ideas
13 | - Identification of foreground
14 | - Unsupervised: keypoint detection with laplacian of gaussian (LoG), then keep second nearest neighbors.
15 | - Supervised: train a 2D object detector and use union of bbox masks.
16 | - Downsampler: downsample uniformly within different distance bins.
17 |
18 | #### Technical details
19 | - Distance stratified sampler can maintain the 3d detection performance even with down to 10% samples.
20 | - The performance drop is mainly caused by the distance estimation.
21 |
22 | #### Notes
23 | - Questions and notes on how to improve/revise the current work
24 |
25 |
--------------------------------------------------------------------------------
/paper_notes/reid_surround_fisheye.md:
--------------------------------------------------------------------------------
1 | # [Vehicle Re-ID for Surround-view Camera System](https://drive.google.com/file/d/1e6y8wtHAricaEHS9CpasSGOx0aAxCGib/view)
2 |
3 | _June 2020_
4 |
5 | tl;dr: Vehicle reID with fisheye surround cameras.
6 |
7 | #### Overall impression
8 | Another practical work from Zongmu. The tracking
9 |
10 | #### Key ideas
11 | - single camera reID
12 | - This should be largely tracking. --> why this is called ReID?
13 | - SiamRPN++ model for single camera tracking
14 | - multi camera reID
15 | - BDBnet model (batch dropblock, [ICCV 2019](https://arxiv.org/abs/1811.07130), SOTA for pedestrian ReID)
16 | 
17 | - association rule based on physics and geometry to only perform vehicle ReID in overlapping FoV
18 | - feature distance and geometry constraint distance
19 | 
20 |
21 | #### Technical details
22 |
23 | #### Notes
24 | - [Talk at CVPR 2020](https://youtu.be/WRH7N_GxgjE?t=2570)
25 | - I feel that only the physical constraint will already do very good cross camera reID of the same vehicle. Do we really need reID module?
26 |
27 |
--------------------------------------------------------------------------------
/paper_notes/resnest.md:
--------------------------------------------------------------------------------
1 | # [ResNeSt: Split-Attention Networks](https://arxiv.org/abs/2004.08955)
2 |
3 | _May 2020_
4 |
5 | tl;dr: A new drop-in replacement for ResNet for object detection and segmentation task.
6 |
7 | #### Overall impression
8 | It is almost a combination of [ResNeXt](resnext.md) and [SKNet](sknet.md), with improvement in implementation (cardinality-major to radix major).
9 |
10 | I do feel that the paper uses too much tricks ([MixUp](mixup.md), [AutoAugment](autoaugment.md), distributed training, etc) and is too similar to [SKNet](sknet.md), especially that the hyperparameter selection reduces this work. Engineering contribution > innovation.
11 |
12 | #### Key ideas
13 | - Cardinality concept is the same as [ResNeXt](resnext.md).
14 | - The split attention module is very similar to [SKNet](sknet.md) but with the same kernel size.
15 | 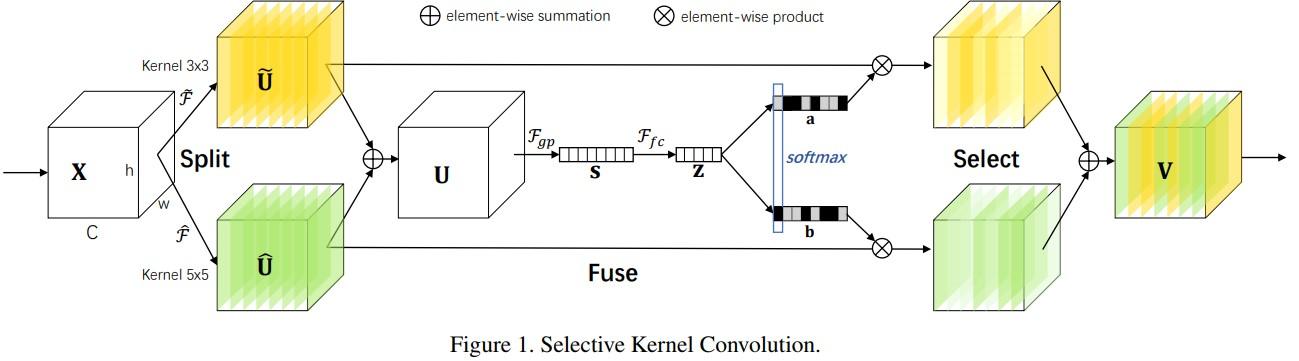
16 | 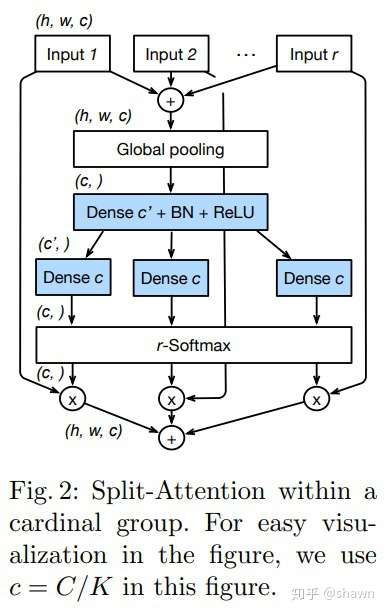
17 | - The change from cardinality-major to radix-major was implemented for better efficiency (how much?).
18 |
19 | #### Technical details
20 | - The final selected hyperparameters are K=1 and R=2. This is very similar to SKNet.
21 |
22 | #### Notes
23 | - Analysis of radix-major in [知乎](https://zhuanlan.zhihu.com/p/133805433)
24 | - This work proves that, with tricks, ResNet can also be SOTA. This is better than works reinventing the wheel such as EfficientDet.
25 | - MobileNet and DepthWise convolution can only accelerate on CPU and are better suited for edge devices.
26 |
--------------------------------------------------------------------------------
/paper_notes/rethinking_pretraining.md:
--------------------------------------------------------------------------------
1 | # [Rethinking ImageNet Pre-training](https://arxiv.org/abs/1811.08883)
2 |
3 | _March 2020_
4 |
5 | tl;dr: ImageNet pretraining speeds up training but not necessarily increases accuracy.
6 |
7 | #### Overall impression
8 | Tons of ablation study. Another solid work from FAIR.
9 |
10 | We should start exploring group normalization
11 |
12 | #### Key ideas
13 | - ImageNet pretraining does not necessarily improve performance, unless it is below **10k COCO images (7 objects per image. For PASCAL images where 2 objects per iamge, we see overfitting even for 15k)**. ImageNet pretraining does not gives better regularization and not help reducing overfitting.
14 | - ImageNet pretraining is still useful in reducing research cycles.
15 |
16 | #### Technical details
17 | - GroupNorm with batch size of 2 x 8 GPUs.
18 |
19 | #### Notes
20 | - Questions and notes on how to improve/revise the current work
21 |
22 |
--------------------------------------------------------------------------------
/paper_notes/rfcn.md:
--------------------------------------------------------------------------------
1 | # [R-FCN: Object Detection via Region-based Fully Convolutional Networks](https://arxiv.org/abs/1605.06409)
2 |
3 | _September 2019_
4 |
5 | tl;dr: Seminal paper from MSRA that improves upon faster R-CNN.
6 |
7 | #### Overall impression
8 | Faster RCNN computation increases as ROI number grows, as each ROI has a fully connected layer. R-FCN improves the computation efficiency by moving the FCN to before ROI pooling by generating position sensitive score maps (feat maps). **Each PS score map is responsible to fire at a particular region (top-left corner) of a particular class.**
9 |
10 | Note that usually R-FCN has slightly lower performance, especially compared to FPN-powered Faster RCNN.
11 |
12 | R-FCN cannot leverage FPN directly as the number of channels are too large for large dataset such as COCO. This is improved in [Light-head RCNN](lighthead_rcnn.md) to reduce the number of score maps from #class x p x p to 10. Instead, the simple voting mechanism is replaced by a fully connected layer.
13 |
14 | #### Key ideas
15 | - Summaries of the key ideas
16 |
17 | #### Technical details
18 | - Summary of technical details
19 |
20 | #### Notes
21 | - [This medium blog post from Jonathan Hui](https://medium.com/@jonathan_hui/understanding-region-based-fully-convolutional-networks-r-fcn-for-object-detection-828316f07c99) explains the intuition very well.
--------------------------------------------------------------------------------
/paper_notes/road_tracer.md:
--------------------------------------------------------------------------------
1 | # [RoadTracer: Automatic Extraction of Road Networks from Aerial Images](https://openaccess.thecvf.com/content_cvpr_2018/papers/Bastani_RoadTracer_Automatic_Extraction_CVPR_2018_paper.pdf)
2 |
3 | _August 2020_
4 |
5 | tl;dr: Dynamic training of a CNN as an DRL agent to draw maps.
6 |
7 | #### Overall impression
8 | The following work are focused on road network discovery and are NOT focused on HD maps.
9 |
10 | - [DeepRoadMapper](deep_road_mapper.md): semantic segmentation
11 | - [RoadTracer](road_tracer.md): like an DRL agent
12 | - [PolyMapper](polymapper): iterate every vertices of a closed polygon
13 |
14 | RoadTracer noted the semantic segmentation results are not a reliable foundation to extract road networks. Instead, it uses an iterative graph construction to get the topology of the road directly, avoiding unreliable intermediate representations.
15 |
16 | The network needs to make a decision to step a certain distance toward a certain direction, resembling an agent in a reinforcement learning setting. This is somehow similar to the cSnake idea in [Deep Boundary Extractor](deep_boundary_extractor.md).
17 |
18 | #### Key ideas
19 |
20 | #### Technical details
21 | - Summary of technical details
22 |
23 | #### Notes
24 | - Questions and notes on how to improve/revise the current work
25 |
26 |
--------------------------------------------------------------------------------
/paper_notes/sc_sfm_learner.md:
--------------------------------------------------------------------------------
1 | # [Unsupervised Scale-consistent Depth and Ego-motion Learning from Monocular Video](https://arxiv.org/abs/1908.10553)
2 |
3 | _September 2019_
4 |
5 | tl;dr: First paper that demonstrate scale consistency in long video and can achieve better performance than stereo.
6 |
7 | The next step paper is [DF-VO](df_vo.md) which predicts dense optical flow and uses 2D-2D matching to regress ego-motion, achieving even more accurate VO.
8 |
9 | #### Overall impression
10 | The introduction of depth scale consistency is the key to the good performance on relative pose estimation, and thus enables the VO use.
11 |
12 | The performance of [sfm-learner](sfm_learner.md) is actually not that good on VO. Scale and rotation drift is large. See [scale consistent sfm-learner](sc_sfm_learner.md) for better VO performance.
13 | 
14 |
15 | #### Key ideas
16 | - The main idea is simple: to ensure that the depth is consistent across frames. The consistency in depth will lead to scale consistency.
17 |
18 | #### Technical details
19 | - Summary of technical details
20 |
21 | #### Notes
22 | - code on [github](https://github.com/JiawangBian/SC-SfMLearner-Release).
23 | - Review on [知乎](https://zhuanlan.zhihu.com/p/83901104)
--------------------------------------------------------------------------------
/paper_notes/scaled_yolov4.md:
--------------------------------------------------------------------------------
1 | # [Scaled-YOLOv4: Scaling Cross Stage Partial Network](https://arxiv.org/abs/2011.08036)
2 |
3 | _November 2020_
4 |
5 | tl;dr: Best practice to scale single-stage object detector. [EfficientNet](efficientnet.md) for [Yolov4](yolov4.md).
6 |
7 | #### Overall impression
8 | The paper is not as well written as the original [Yolov4](yolov4.md) paper. This paper follows the methodology of [EfficientNet](efficientnet.md).
9 |
10 | From this [review on Zhihu](https://www.zhihu.com/question/430668054/answer/1580560177) it looks like Scaled-YOLOv4 is heavily based on [YOLOv5](yolov5.md).
11 |
12 | #### Key ideas
13 | - When input image size is increased, we must increase depth or stages of the network. Best practice is to follows the steps:
14 | - scale up the "size of image + #stages"
15 | - scale up depth and width according to required inference time
16 | - Once-for-all network
17 | - Train one Yolov4-Large network, and drop the later stages for efficiency during inference.
18 |
19 | 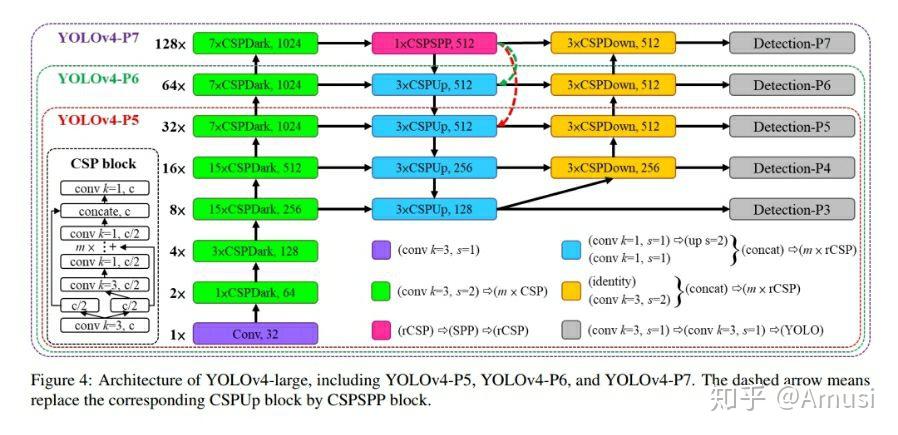
20 |
21 | #### Technical details
22 | - It uses OSA (one shot aggregation) idea from VoVNet. Basically instead of aggregating/recycling features at every stage, OSA proposes to aggregate the features only once at the end. [source](https://paperswithcode.com/method/vovnet)
23 | 
24 |
25 | #### Notes
26 | - Code on [github](https://github.com/WongKinYiu/ScaledYOLOv4/tree/yolov4-large)
27 |
28 |
--------------------------------------------------------------------------------
/paper_notes/simmim.md:
--------------------------------------------------------------------------------
1 | # [SimMIM: A Simple Framework for Masked Image Modeling](https://arxiv.org/abs/2111.09886)
2 |
3 | _November 2021_
4 |
5 | tl;dr: Large scale pretraining based on Masked Image Modeling. Similar to MAE.
6 |
7 | #### Overall impression
8 | This paper is published a week after [MAE](mae.md), obviously rushed by the publication of the latter. The ideas are very similar, but execution (hyperparameter tuning, paper writing) is considerably inferior to MAE.
9 |
10 |
11 | Difference between [MAE](mae.md) and [SimMIM](simmim.md):
12 |
13 | - MAE uses asymmetric design of encoder and decoder, where encoder does not see masked patches. SimMIM uses symmetric design.
14 | - SimMIM stressed the difference between prediction (of only masked patches) and reconstruction (of all patches), and mentioned that the former yields better performance. MAE also observes the trend (in footnote). However MAE also demonstrates the mid-ground: training without losses on visible patches but prediction on all the patches.
15 | - SimMIM was not validated on more fine-grained downstream tasks such as object detection and segmentation.
16 |
17 | Similarities between [MAE](mae.md) and [SimMIM](simmim.md):
18 |
19 | - directly regress the pixels
20 | - light decoder design
21 |
22 | #### Key ideas
23 | - Summaries of the key ideas
24 |
25 | #### Technical details
26 | - Summary of technical details
27 |
28 | #### Notes
29 | - Questions and notes on how to improve/revise the current work
30 |
--------------------------------------------------------------------------------
/paper_notes/sknet.md:
--------------------------------------------------------------------------------
1 | # [SKNet: Selective Kernel Networks](https://arxiv.org/abs/1903.06586)
2 |
3 | _May 2020_
4 |
5 | tl;dr: A new plug-and-play module of SKNet. Two-stream SENet.
6 |
7 | #### Overall impression
8 | This is a solid work to extend SENet (squeeze and excitation). It chooses adaptive receptive field. Either 3x3 or 5x5.
9 |
10 | Compared to inception network, which has multiple parallel path of diff RF, SKNet adaptively chooses which path to focus more.
11 |
12 | This inspired [ResNeSt](resnest.md) and is actually almost exactly the same.
13 |
14 | #### Key ideas
15 | - Split, Fuse and Select.
16 | 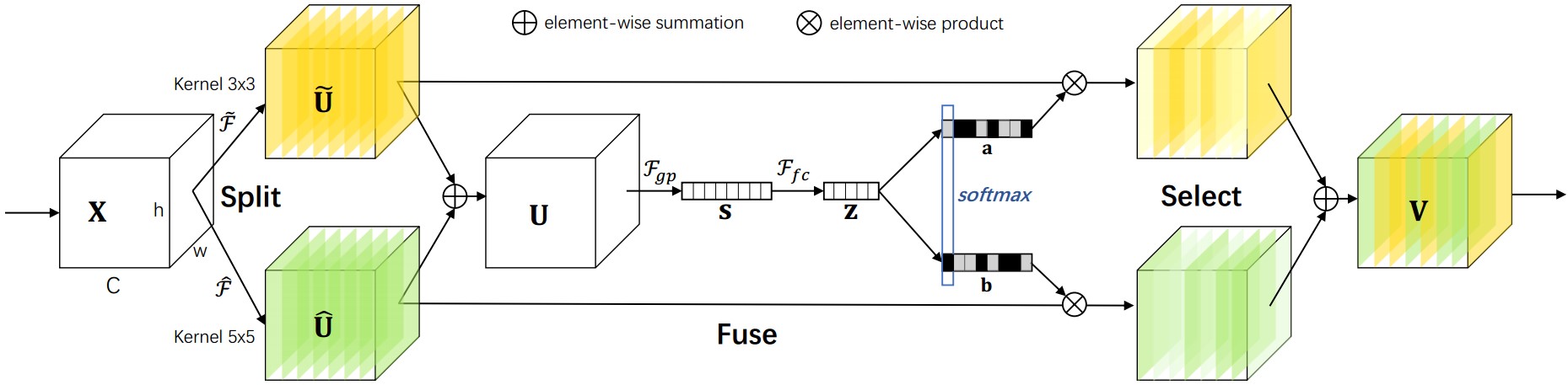
17 | - SK Unit is a plug-and-play module and used to replace a normal 3x3 conv.
18 |
19 | #### Technical details
20 | - 5x5 --> 3x3 with dilation = 2.
21 |
22 | #### Notes
23 | - Questions and notes on how to improve/revise the current work
24 |
25 |
--------------------------------------------------------------------------------
/paper_notes/social_lstm.md:
--------------------------------------------------------------------------------
1 | # [Social LSTM: Human Trajectory Prediction in Crowded Spaces](http://cvgl.stanford.edu/papers/CVPR16_Social_LSTM.pdf)
2 |
3 | _January 2020_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 | Adds a social pooling layer that pools the hidden stages of the neighbors within a spatial radius.
9 |
10 | #### Key ideas
11 | - Instead of a spatial occupancy grid, replace the occupancy with LSTM embedding.
12 |
13 | #### Technical details
14 | - [Social LSTM](social_lstm.md) is actually done from a surveillance view point (between perspective onboard cameras and BEV).
15 |
16 | #### Notes
17 | - [talk at CVPR](https://www.youtube.com/watch?v=q7LjIcKluK4): the animation of predicting a person passing through the gap of a crowd is cool.
18 |
19 |
--------------------------------------------------------------------------------
/paper_notes/spatial_embedding.md:
--------------------------------------------------------------------------------
1 | # [SpatialEmbedding: Instance Segmentation by Jointly Optimizing Spatial Embeddings and Clustering Bandwidth](https://arxiv.org/abs/1906.11109)
2 |
3 | _July 2020_
4 |
5 | tl;dr: Single stage instance segmentation with bottom-up approach.
6 |
7 | #### Overall impression
8 | Overall performance is not that great compared to other approaches. This forms the foundation of [PointTrack](pointtrack.md).
9 |
10 | [PointTrack](pointtrack.md) uses a single stage instance segmentation method with a seeding location. This makes it compatible with many instance segmentation method, such as [CenterMask](centermask.md) or [BlendMask](blendmask.md).
11 |
12 | The visualization of instance distance map looks great.
13 | - 
14 |
15 | #### Key ideas
16 | - SpatialEmbedding predicts
17 | - a seed map (similar to the heatmap in [CenterNet](centernet.md) or [FCOS](fcos.md)
18 | - a sigma map to predict clustering bandwith (learned, largely proportional to bbox size)
19 | - offset map for each pixel pointing to the instance center
20 |
21 | #### Technical details
22 | - Summary of technical details
23 |
24 | #### Notes
25 | - Questions and notes on how to improve/revise the current work
26 |
27 |
--------------------------------------------------------------------------------
/paper_notes/specialized_cyclists.md:
--------------------------------------------------------------------------------
1 | # [Specialized Cyclist Detection Dataset: Challenging Real-World Computer Vision Dataset for Cyclist Detection Using a Monocular RGB Camera](https://drive.google.com/drive/u/0/folders/1inawrX9NVcchDQZepnBeJY4i9aAI5mg9)
2 |
3 | _July 2020_
4 |
5 | tl;dr: Cyclist dataset.
6 |
7 | #### Overall impression
8 | Very close to [Tsinghua Daimler Cyclists](tsinghua_daimler_cyclists.md), with more images, but fewer cyclist instances. But the part about pedestrians wearing special patterns make this paper almost like an informercial.
9 |
10 | #### Key ideas
11 | - 60k images, 18k cyclist instances.
12 | - Difficulty levels:
13 | - Easy: height > 40 pixel, fully visible
14 | - Medium: height > 25 pixel, less than 35% occluded
15 | - Hard: height > 25 pixel, and less than 60% occluded
16 |
17 |
18 | #### Technical details
19 | - BBD100k, cityscape and AutoNUE (IDD) datasets have separate bbox for bicycle and person, and no association information.
20 |
21 | #### Notes
22 | - Questions and notes on how to improve/revise the current work
23 |
24 |
--------------------------------------------------------------------------------
/paper_notes/speednet.md:
--------------------------------------------------------------------------------
1 | # [SpeedNet: Learning the Speediness in Videos](https://arxiv.org/abs/2004.06130)
2 |
3 | _June 2020_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Only classify normal speed or speed up
12 | - adaptive speedup of video: looks more natural, less jittering
13 | - self-supervised learning for video understanding
14 | - video retrieval: similar motion pattern (skydiving similar to surfing)
15 | - spatial temporal visualization
16 |
17 | #### Technical details
18 | - Summary of technical details
19 |
20 | #### Notes
21 | - Questions and notes on how to improve/revise the current work
22 |
23 |
--------------------------------------------------------------------------------
/paper_notes/subpixel_conv.md:
--------------------------------------------------------------------------------
1 | # [Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network](https://arxiv.org/abs/1609.05158)
2 |
3 | _June 2020_
4 |
5 | tl;dr: Channel to spatial subpixel convolution.
6 |
7 | #### Overall impression
8 | This is integrated in Pytorch as pixel shuffle layer.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - Questions and notes on how to improve/revise the current work
18 |
19 |
--------------------------------------------------------------------------------
/paper_notes/super.md:
--------------------------------------------------------------------------------
1 | # [SUPER: A Novel Lane Detection System](https://arxiv.org/abs/2005.07277)
2 |
3 | _June 2020_
4 |
5 | tl;dr: Slope compensated lane line detection.
6 |
7 | #### Overall impression
8 | Nothing too impressive about this approach. The approach is not even end to end differentiable and uses a nonlinear optimizer for solution. This is not quite transferrable.
9 |
10 | It only targets to solve 90% of the problem ("parallel polynomials") and still does not solve split or merge issues. --> See [Semilocal 3D LaneNet](semilocal_3d_lanenet.md) for a method to solve more complex topologies.
11 |
12 | #### Key ideas
13 | - A novel loss that involves entropy and histogram. The main idea is that in BEV space the lane line points collapsed to the x dimension should have multiple equally spaced peaks. But this loss is not differentiable.
14 | - Approximate a road slope. This is essentially the pitch estimation of the road in [LaneNet](lanenet.md).
15 |
16 | #### Technical details
17 | - Summary of technical details
18 |
19 | #### Notes
20 | - Questions and notes on how to improve/revise the current work
21 |
22 |
--------------------------------------------------------------------------------
/paper_notes/surfel_gan.md:
--------------------------------------------------------------------------------
1 | # [SurfelGAN: Synthesizing Realistic Sensor Data for Autonomous Driving](https://arxiv.org/abs/2005.03844)
2 |
3 | _June 2020_
4 |
5 | tl;dr: Drive once, build, and traverse multiple times to generate new data.
6 |
7 | #### Overall impression
8 | Use GAN to bridge the gap of surfel baseline, which is usually with gaps and edges.
9 |
10 | **Surfel** is "surface element," analogous to a "voxel" (volume element) or a "pixel" (picture element).
11 |
12 | - [surfel GAN](surfel_gan.md) generates a photorealistic model
13 | - [lidar sim](lidar_sim.md) focuses on lidar data simulation, which is somewhat easier.
14 |
15 | It can allow closed-loop evaluation of the whole AD stack.
16 |
17 | #### Key ideas
18 | - Build environment from a single run through a scene of interests.
19 | - Simulate other transversals through the scene for virtual replay.
20 | - Use a GAN model to close the domain gap between synthetic data and real data
21 |
22 |
23 | #### Technical details
24 | - Uses lidar data
25 |
26 | #### Notes
27 | - Questions and notes on how to improve/revise the current work
28 |
29 |
--------------------------------------------------------------------------------
/paper_notes/tfl_exploting_map_korea.md:
--------------------------------------------------------------------------------
1 | # [Traffic light recognition exploiting map and localization at every stage](https://web.yonsei.ac.kr/jksuhr/papers/Traffic%20light%20recognition%20exploiting%20map%20and%20localization%20at%20every%20stage.pdf)
2 |
3 | _November 2020_
4 |
5 | tl;dr: Very thorough description of using HD map for TFL recognition.
6 |
7 | #### Overall impression
8 | Although the perception models the paper uses is quite outdated, it has a very clear discussion regarding how to use HD maps online.
9 |
10 | Also refer to [TFL map building with lidar](tfl_lidar_map_building.md) for a similar discussion.
11 |
12 | #### Key ideas
13 | - Prior maps (with lat/long/height of TFLs) improves accuracy of recognition and reduces algorithm complexity.
14 | - **Task trigger**: Recognition algorithms do not have to operate continuously as perception begins only when the distance tot he facing TLF is within a certain threshold
15 | - **ROI extraction**: this limits the search area in an image
16 | - Estimate the size of a TL
17 | - Procedure
18 | - RoI extraction with safety margin. Slanted slope compensation. Road pitch needs to be stored in the HD map as well.
19 | - Detection locates TFL in image
20 | - Classify state of TFL
21 | - Tracking estimate position of TFL. Threshold for association should adjust based on distance.
22 |
23 | #### Technical details
24 | - The effect of pitch (on a bumpy road) is bigger for TFL at long distances. On average the pitch change could be up to +/- 2 deg.
25 |
26 | #### Notes
27 | - Questions and notes on how to improve/revise the current work
28 |
29 |
--------------------------------------------------------------------------------
/paper_notes/tfl_stanford.md:
--------------------------------------------------------------------------------
1 | # [Traffic Light Mapping, Localization, and State Detection for Autonomous Vehicles](http://driving.stanford.edu/papers/ICRA2011.pdf)
2 |
3 | _December 2020_
4 |
5 | tl;dr: Mapping and online detection of TFL.
6 |
7 | #### Overall impression
8 | Traffic light state perception is the key.
9 |
10 | Even in non-autonomous vehicles, traffic light state detection would be beneficial alerting inattentive drivers to changing light status and making intersections safer. --> TLA
11 |
12 | The key to safe operation is the ability to handle common failure cases, such as FP or transient occlusion for camera based TFL perception.
13 |
14 | #### Key ideas
15 | - TFL tracking and triangulation according to [Optimal Ray Intersection For Computing 3D Points From N-View Correspondences](http://gregslabaugh.net/publications/opray.pdf).
16 | - Temporal filtering with **hysterisis**: only change light state when several frames of identical color detection have occurred sequentially. This adds a fraction of a second latency but the response time still matches or is better than that of a human.
17 |
18 | #### Technical details
19 | - Camera with fixed camera
20 | - Coordinate transformation: world, vehicle, camera and object
21 | 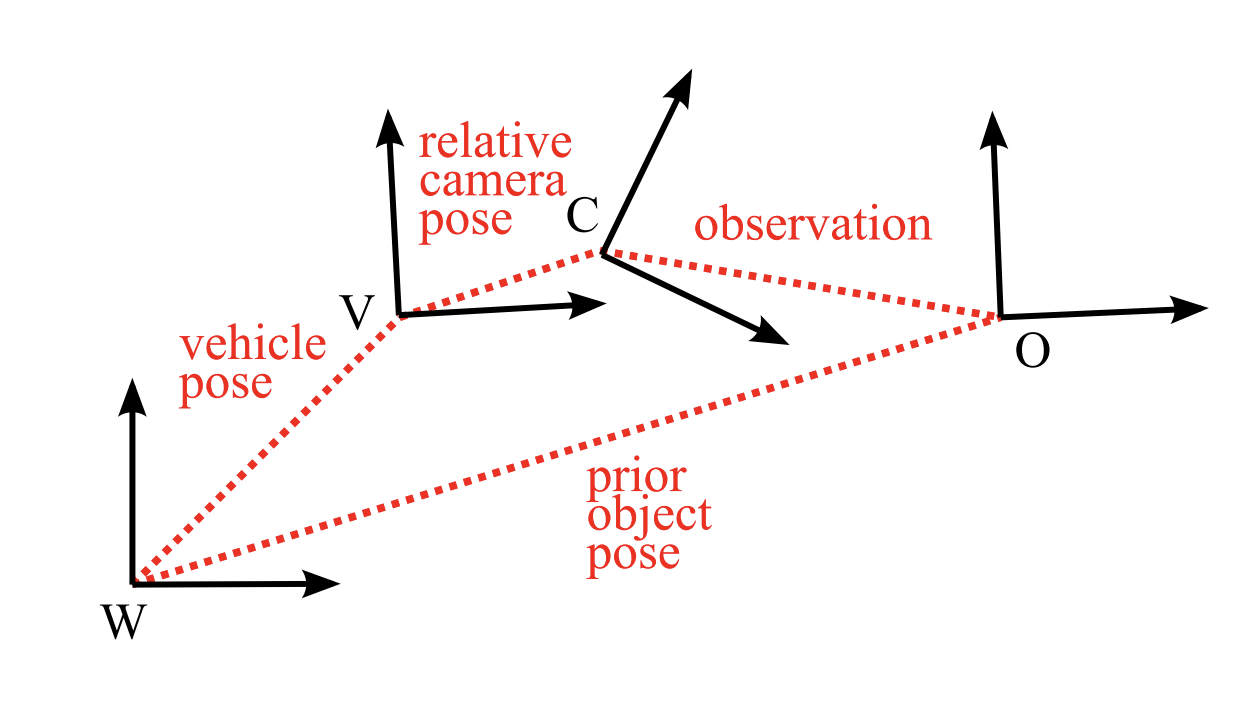
22 | - Traffic light color hue histogram
23 | 
24 |
25 | #### Notes
26 | - Questions and notes on how to improve/revise the current work
27 |
28 |
--------------------------------------------------------------------------------
/paper_notes/tnt.md:
--------------------------------------------------------------------------------
1 | # [TNT: Target-driveN Trajectory Prediction](https://arxiv.org/abs/2008.08294)
2 |
3 | _February 2022_
4 |
5 | tl;dr: Predict diverse set of future targets and then use target to drive trajectory prediction.
6 |
7 | #### Overall impression
8 | The paper described the core drawbacks of previous methods, involving sampling latent states (VAE, GAN), or fixed anchors ([coverNet](covernet.md), [MultiPath](multipath.md)).
9 |
10 | TNT has the following advantages
11 |
12 | - supervised training
13 | - deterministic inference
14 | - interpretable
15 | - adaptive anchors
16 | - likelihood estimation
17 |
18 | The target, or final state capture most uncertainty of a trajectory. TNT decompose the distribution of futures by conditioning on targets, and then marginalizing over them.
19 |
20 | The anchor-based method is improved by [DenseTNT](dense_tnt.md) to be anchor-free, which also eliminated the NMS process by learning.
21 |
22 | #### Key ideas
23 | - Step 1: target prediction, based on manually chosen anchors
24 | - Step 2: Motion estimation, conditioned on targets
25 | - Step 3: Trajectory scoring/selection, with scoring and NMS
26 |
27 | #### Technical details
28 | - Vectorized (sparse) encoding with [VectorNet](vectornet.md).
29 |
30 | #### Notes
31 | - [CoRL talk on Youtube](https://www.youtube.com/watch?v=iaaCbKncY-8)
32 |
--------------------------------------------------------------------------------
/paper_notes/tot.md:
--------------------------------------------------------------------------------
1 | # [ToT: Tree of Thoughts: Deliberate Problem Solving with Large Language Models](https://arxiv.org/abs/2305.10601)
2 |
3 | _June 2023_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - High level review from [Wandb](https://wandb.ai/byyoung3/ml-news/reports/One-Step-Closer-to-AGI-The-Tree-of-Thoughts---Vmlldzo0NTA2NzU4?galleryTag=ml-news)
18 |
--------------------------------------------------------------------------------
/paper_notes/trafficpredict.md:
--------------------------------------------------------------------------------
1 | # [TrafficPredict: Trajectory Prediction for Heterogeneous Traffic-Agents](https://arxiv.org/pdf/1811.02146.pdf)
2 |
3 | _June 2019_
4 |
5 | tl;dr: Propose a 4D graph representation of trajectory prediction problem. The paper also introduced a new dataset in ApolloScape.
6 |
7 | #### Overall impression
8 | The prediction seems not that good? Admittedly the dataset is focused on urban driving scenario and the problem is much harder than highway driving scenarios. The predicted trajectories projected on the single camera frame do not quite make sense either (some agents goes above the horizon and goes to the sky?)..
9 |
10 | #### Key ideas
11 | - In the 4D graph (2D for spatial location and interaction of agents, one dim for time, and one dim for category), each instance is a node, and the relationships in spatial and temporal are represented by edges. Then each node and edge are modeled by a LSTM.
12 | - Two types of layers, instance layer and category layer. The main idea is to aggregate the average behavior of agents of a particular type, and then use it to finetune each individual agent's behavior.
13 | - Three types of agents, bicyles, pedestrians and vehicles.
14 |
15 | #### Technical details
16 | - Used LSTM with Self-attention from the tansformer paper.
17 |
18 | #### Notes
19 | - The simulation(NGSIM) dataset has trajectory data for cards but limited to highway with simlar simple road conditions. This could be useful for behavioral prediction and motion planning.
20 |
21 |
--------------------------------------------------------------------------------
/paper_notes/translating_images_to_maps.md:
--------------------------------------------------------------------------------
1 | # [Translating Images into Maps](https://arxiv.org/abs/2110.00966)
2 |
3 | _December 2021_
4 |
5 | tl;dr: Axial transformers to lift images to BEV.
6 |
7 | #### Overall impression
8 | The paper assumes a 1-1 correspondence between a vertical scanline in the image, and rays passing through the camera location in an overhead map. This relationship holds true regardless of the depth of the pixels to be lifted to 3D.
9 |
10 | This paper is written with unnecessarily cumbersome mathematical notation, and many concepts can be explained in plain language with transformers terminology.
11 |
12 | #### Key ideas
13 | - Ablation studies
14 | - Looking both up and down the same column of image is superior to looking only one way (constructed with MAIL -- monotonic attention with infinite look-back).
15 | - Long range horizontal context does not benefit the model.
16 |
17 | #### Technical details
18 | - The optional dynamic module in BEV space uses axial-attention across the temporal dimension (stack of spatial features along temporal dimension). This seems to be less useful without spatial alignment as seen in [FIERY](fiery.md).
19 |
20 | #### Notes
21 | - [Code on Github](https://github.com/avishkarsaha/translating-images-into-maps) to be released.
22 |
--------------------------------------------------------------------------------
/paper_notes/tsinghua_daimler_cyclists.md:
--------------------------------------------------------------------------------
1 | # [TDC (Tsinghua-Daimler Cyclists): A New Benchmark for Vison-Based Cyclist Detection](http://www.gavrila.net/Publications/iv16_cyclist_benchmark.pdf)
2 |
3 | _July 2020_
4 |
5 | tl;dr: Cyclist dataset collected in Beijing (朝阳区+海淀区).
6 |
7 | #### Overall impression
8 | Related to [Specialized Cyclists](specialized_cyclists.md).
9 |
10 | KITTI only has 1400 cyclists in the entire datasets.
11 |
12 | Why cyclists are important?
13 |
14 | - In some small and mid cities in China where cyclists appear often, even more road accidents involve cyclist.
15 | - Different appearances and sizes at different viewpoints.
16 | - They can move 25 mph, 5 times faster than a pedestrian (pedestrian [preferred moving speed](https://en.wikipedia.org/wiki/Preferred_walking_speed) is 1.4 m/s, or 3 mph)
17 |
18 | #### Key ideas
19 | - 30k images, 22k cyclist instances.
20 | - In many pedestrian datasets, cyclists are ignored as they look like pedestrians.
21 | - Difficulty levels:
22 | - Easy: height > 60 pixel, fully visible
23 | - Medium: height > 45 pixel, less than 40% occluded
24 | - Hard: height > 30 pixel, and less than 80% occluded
25 | - One bbox for the bicycle and person as a whole, and one bbox for the person alone. --> maybe this is an overkill?
26 |
27 | #### Technical details
28 | - Annotate orientation
29 | 
30 | 
31 | 
32 |
33 | #### Notes
34 | - Questions and notes on how to improve/revise the current work
35 |
36 |
--------------------------------------------------------------------------------
/paper_notes/umap.md:
--------------------------------------------------------------------------------
1 | # [UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction](https://arxiv.org/abs/1802.03426)
2 |
3 | _January 2020_
4 |
5 | tl;dr: A better non-linear dimension reduction technique than t-SNE. Can be used for data preprocessing as well, like PCA.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - [video](https://www.youtube.com/watch?time_continue=1557&v=YPJQydzTLwQ&feature=emb_title)
18 | - [UMAP vs t-SNE](https://jlmelville.github.io/uwot/umap-for-tsne.html)
19 | - [How UMAP works](https://towardsdatascience.com/how-exactly-umap-works-13e3040e1668)
20 | - [3D animation: Understanding UMAP](https://pair-code.github.io/understanding-umap/)
--------------------------------------------------------------------------------
/paper_notes/uniad.md:
--------------------------------------------------------------------------------
1 | # [UniAD: Planning-oriented Autonomous Driving](https://arxiv.org/abs/2212.10156)
2 |
3 | _April 2023_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - Questions and notes on how to improve/revise the current work
18 |
--------------------------------------------------------------------------------
/paper_notes/virtual_normal.md:
--------------------------------------------------------------------------------
1 | # [Paper Title](link_to_paper)
2 |
3 | _October 2019_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 | Describe the overall impression of the paper.
9 |
10 | #### Key ideas
11 | - Summaries of the key ideas
12 |
13 | #### Technical details
14 | - Summary of technical details
15 |
16 | #### Notes
17 | - Questions and notes on how to improve/revise the current work
18 |
19 |
--------------------------------------------------------------------------------
/paper_notes/vo_monodepth.md:
--------------------------------------------------------------------------------
1 | # [VO-Monodepth: Enhancing self-supervised monocular depth estimation with traditional visual odometry](https://arxiv.org/abs/1908.03127)
2 |
3 | _December 2019_
4 |
5 | tl;dr: Use sparse density measurement from VO algorithm to enhance depth estimation.
6 |
7 | #### Overall impression
8 | This paper combines the idea of depth estimation with depth completion.
9 |
10 | #### Key ideas
11 | - The paper used a sparsity invariant autoencoder to densify the sparse measurement before concatenating the sparse data with RGB input.
12 | - Inner Loss: between SD (sparse depth) and DD (denser depth after sparse conv)
13 | - Outer loss: between SD and d (dense estimation) on where the SD is defined.
14 |
15 | #### Technical details
16 | - VO pipeline only provides ~0.06% of sparse depth measurement.
17 | - [Sparcity invariant CNNs](https://arxiv.org/abs/1708.06500) performs weighted average only on valid inputs. This makes the network invariant to input sparsity.
18 |
19 | #### Notes
20 | - Best supervised mono depth estimation: DORN
21 | - Scale recovery method is needed for monodepth estimation and any mono VO methods.
22 | - Both ORB-SLAM v1 and v2 supports mono and stereo.
--------------------------------------------------------------------------------
/paper_notes/vpn.md:
--------------------------------------------------------------------------------
1 | # [VPN: Cross-view Semantic Segmentation for Sensing Surroundings](https://arxiv.org/abs/1906.03560)
2 |
3 | _September 2020_
4 |
5 | tl;dr: Generate cross-view segmentation with view parsing network.
6 |
7 | #### Overall impression
8 | The paper could have been written more clearly. Terminology is not well defined and the figure is not clear.
9 |
10 | The idea of using semantic segmentation to bridge the sim2real gap is explored in many BEV semantic segmentation tasks such as [BEV-Seg](bev_seg.md), [CAM2BEV](cam2bev.md), [VPN](vpn.md).
11 |
12 |
13 | #### Key ideas
14 | - **View transformation**: MLP
15 | - View Relation Module (VRM) to model the transformation from perspective to BEV. The view transformation is learned with a MLP with flattened image input HW x C.
16 | - Using synthetic data to train. Use adversarial loss for domain adaptation. **Semantic mask** as intermediate representation without texture gap.
17 | - Each perspective (first-view) sensor data is transformed with its own View Transformer Module. The Feature map is then aggregated into one BEV feature map. The BEV feature map is then decoded into a BEV semantic map.
18 |
19 | #### Technical details
20 |
21 |
22 | #### Notes
23 | - The BEV feature map has the same shape as the input feature map. --> Why is this necessary?
24 | - How was the fusion of feature map done?
25 | - [Review from 1st author on Zhihu](https://mp.weixin.qq.com/s/8jltlOnAxK1EqxYCsJHErA)
--------------------------------------------------------------------------------
/paper_notes/widerperson.md:
--------------------------------------------------------------------------------
1 | # [WiderPerson: A Diverse Dataset for Dense Pedestrian Detection in the Wild](https://arxiv.org/abs/1909.12118)
2 |
3 | _July 2020_
4 |
5 | tl;dr: A relatively scale (8k training images) dataset for crowded/dense human detection.
6 |
7 | #### Overall impression
8 | Overall not quite impressive. It fails to cite a closely related dataset [CrowdHuman](crowdhuman.md), and ablation study of the issue is not as extensive as well.
9 |
10 | #### Key ideas
11 | - 30 persons per image.
12 | - Annotate top of the head and middle of the feet (similar to CityPerson). The bbox is automatically generated with aspect ratio of 0.41. This is
13 | - Difficulty: > 100 pixel (easy), > 50 pixel (medium), > 20 pixel (hard). Similar to WiderFace.
14 | - NMS is a problem in crowded scenes, but it is not handled in this paper. Maybe try [Visibility Guided NMS](vg_nms.md).
15 |
16 | #### Technical details
17 | - Use pHash to avoid duplication of images.
18 | - Annotation tool with examples in the GUI.
19 | - 
20 | - Evaluation metric: MR
21 |
22 | #### Notes
23 | - [Tsinghua-Daimler datasets for cyclists](http://www.gavrila.net/Datasets/Daimler_Pedestrian_Benchmark_D/Tsinghua-Daimler_Cyclist_Detec/tsinghua-daimler_cyclist_detec.html)
24 | - Bounding Box based labels are provided for the classes: ("pedestrian", "cyclist", "motorcyclist", "tricyclist", "wheelchairuser", "mopedrider").
25 | - [The EuroCity Persons Dataset: A Novel Benchmark for Object Detection](https://arxiv.org/abs/1805.07193) T-PAMI 2019
--------------------------------------------------------------------------------
/paper_notes/yolov3.md:
--------------------------------------------------------------------------------
1 | # [YOLOv3: An Incremental Improvement](https://pjreddie.com/media/files/papers/YOLOv3.pdf)
2 |
3 | _May 2020_
4 |
5 | tl;dr: Summary of the main idea.
6 |
7 | #### Overall impression
8 |
9 | #### Key ideas
10 | - Scaling factor s to eliminate grid sensitivity.
11 |
12 | #### Technical details
13 | - Summary of technical details
14 |
15 | #### Notes
16 | - Questions and notes on how to improve/revise the current work
17 |
18 |
--------------------------------------------------------------------------------
/paper_notes/yolov5.md:
--------------------------------------------------------------------------------
1 | # [YOLOv5 by Ultralytics](https://github.com/ultralytics/yolov5)
2 |
3 | _December 2020_
4 |
5 | tl;dr: Pytorch-native improved version of Yolov4.
6 |
7 | #### Overall impression
8 | The author of the repo has not released a paper yet, but the repo is highly useful. Many Kaggler commented that its performance is better than [yolov4](yolov4.md). The training speed of Yolov5 is also much faster than Yolov4.
9 |
10 | #### Key ideas
11 | - Two great reviews on Zhihu
12 | - [使用YOLO V5训练自动驾驶目标检测网络](https://zhuanlan.zhihu.com/p/164627427)
13 | - [深入浅出Yolo系列之Yolov5核心基础知识完整讲解](https://zhuanlan.zhihu.com/p/172121380)
14 | - Focus layer
15 | - This is a spatial to channel layer that warps H x W x 3 into H/2 x W/2 x12.
16 | - See [issue in yolov5 github](https://github.com/ultralytics/yolov5/issues/413)
17 | - Papers such as [TResNet](https://arxiv.org/abs/2003.13630) WACV 2021 and [Isometric Neural Networks](https://arxiv.org/abs/1909.03205) ICCV 2019 workshop
18 | - Adaptive anchor learning with genetic algorithm
19 |
20 | #### Technical details
21 | - Mosaic data aug was first invented in ultralytics's yolov3 and borrowed into [Yolov4](yolov4.md).
22 |
23 |
24 | #### Notes
25 | - Questions and notes on how to improve/revise the current work
26 |
27 |
--------------------------------------------------------------------------------
/talk_notes/andrej.md:
--------------------------------------------------------------------------------
1 | # Andrej Karpathy's Talk
2 |
3 | ## ICML 2019 (CVPR 2019)
4 | * [Video](https://www.youtube.com/watch?v=IHH47nZ7FZU)
5 |
6 | ## [ScaledML 2020](scaledml_2020/scaledml_2020.md)
7 | * [Video](https://www.youtube.com/watch?v=hx7BXih7zx8)
8 |
9 |
10 | ## [CVPR 2020](https://github.com/patrick-llgc/MeetingNotes/blob/master/CVPR2020/workshops.md#scalability-in-autonomous-driving-video-on-youtube)
11 | - [Video](https://www.youtube.com/watch?v=g2R2T631x7k)
12 |
13 |
14 | ## Pytorch Conf
15 | - [video](https://www.youtube.com/watch?v=hx7BXih7zx8)
16 | - [A very good review blog here](https://phucnsp.github.io/blog/self-taught/2020/04/30/tesla-nn-in-production.html)
17 |
18 | ## [CVPR 2021](cvpr_2021/cvpr_2021.md)
19 | - [video](https://www.youtube.com/watch?v=g6bOwQdCJrc)
20 |
21 | ## [2023-05 Microsoft Build](state_of_gpt_2023/state_of_gpt_2023.md)
22 |
23 | ## Misc
24 | ### Tesla Patents
25 | - [link](https://patents.google.com/?q=(machine+learning)&assignee=Tesla%2c+Inc.&after=priority:20180101&oq=(machine+learning)+assignee:(Tesla%2c+Inc.)+after:priority:20180101)
26 |
27 | ### Tweets On FSD
28 | - [Tweets from @phlhr](https://twitter.com/phlhr/status/1318335219586326529) and [another one](https://twitter.com/phlhr/status/1357924763214049285)
--------------------------------------------------------------------------------
/talk_notes/cvpr_2021/assets/8cam_setup.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/cvpr_2021/assets/8cam_setup.jpg
--------------------------------------------------------------------------------
/talk_notes/cvpr_2021/assets/cover.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/cvpr_2021/assets/cover.jpg
--------------------------------------------------------------------------------
/talk_notes/cvpr_2021/assets/data_auto_labeling.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/cvpr_2021/assets/data_auto_labeling.jpg
--------------------------------------------------------------------------------
/talk_notes/cvpr_2021/assets/depth_velocity_with_vision_1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/cvpr_2021/assets/depth_velocity_with_vision_1.jpg
--------------------------------------------------------------------------------
/talk_notes/cvpr_2021/assets/depth_velocity_with_vision_2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/cvpr_2021/assets/depth_velocity_with_vision_2.jpg
--------------------------------------------------------------------------------
/talk_notes/cvpr_2021/assets/depth_velocity_with_vision_3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/cvpr_2021/assets/depth_velocity_with_vision_3.jpg
--------------------------------------------------------------------------------
/talk_notes/cvpr_2021/assets/large_clean_diverse_data.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/cvpr_2021/assets/large_clean_diverse_data.jpg
--------------------------------------------------------------------------------
/talk_notes/cvpr_2021/assets/release_and_validation.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/cvpr_2021/assets/release_and_validation.jpg
--------------------------------------------------------------------------------
/talk_notes/cvpr_2021/assets/tesla_dataset.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/cvpr_2021/assets/tesla_dataset.jpg
--------------------------------------------------------------------------------
/talk_notes/cvpr_2021/assets/tesla_no_radar.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/cvpr_2021/assets/tesla_no_radar.jpg
--------------------------------------------------------------------------------
/talk_notes/cvpr_2021/assets/traffic_control_warning_pmm.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/cvpr_2021/assets/traffic_control_warning_pmm.jpg
--------------------------------------------------------------------------------
/talk_notes/cvpr_2021/assets/trainig_cluster.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/cvpr_2021/assets/trainig_cluster.jpg
--------------------------------------------------------------------------------
/talk_notes/cvpr_2021/cvpr_2021.md:
--------------------------------------------------------------------------------
1 | ## [2021.06.20 CVPR 2021](https://www.youtube.com/watch?v=g6bOwQdCJrc)
2 | - The grand mission: Tesla is ditching radars. They are using neural network and vision to do radar depth + velocity sensing.
3 | - In order to do that, they need a large AND diverse 4D (3D+time) dataset. This is also used to train FSD.
4 | - Tesla has a whole team spending about 4 months focusing on autolabeling
5 | - Tesla uses MANY (221 as of mid-2021) triggers to collect the diverse dataset. They ended up with 1 million 10-second clips.
6 | - Dedicated HPC team. Now Tesla training with 720 8-GPU nodes!
7 | - Tesla argues that vision alone is perfectly capable of depth sensing. It is hard and it requires the fleet.
8 | 
9 |
10 |
11 |
12 |
13 | PMM: pedal misuse mitigation
14 | 
15 |
16 | Tesla's data set-up.
17 | 
18 | 
19 | 
20 |
21 | Have to figure out the road layout the first time the car goes there (drive on perception). Fundamental problem: Depth estimation of monocular
22 | 
23 | 
24 | 
25 |
26 | Once in a while radar gives you a FP that is hard to handle
27 | 
28 | 
29 | 
30 |
31 | Validation process
32 | 
33 |
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/bevnet.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/bevnet.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/env.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/env.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/evaluation.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/evaluation.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/operation_vacation.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/operation_vacation.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/pedestrian_aeb.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/pedestrian_aeb.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/stop1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/stop1.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/stop10.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/stop10.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/stop11.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/stop11.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/stop12.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/stop12.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/stop13.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/stop13.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/stop2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/stop2.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/stop3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/stop3.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/stop4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/stop4.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/stop5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/stop5.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/stop6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/stop6.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/stop7.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/stop7.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/stop8.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/stop8.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/stop9.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/stop9.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/stop_overview.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/stop_overview.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/assets/vidar.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/scaledml_2020/assets/vidar.jpg
--------------------------------------------------------------------------------
/talk_notes/scaledml_2020/scaledml_2020.md:
--------------------------------------------------------------------------------
1 | ## [ScaledML 2020]()
2 | - [Video](https://www.youtube.com/watch?v=hx7BXih7zx8)
3 | - [Review by 黄浴](https://zhuanlan.zhihu.com/p/136179627)
4 |
5 | Stuff that caught my eye:
6 |
7 | - Even state-less SOD such as stop signs can be complex
8 | - active states and modifiers
9 | 
10 | - temporal flickering in shadow mode indicates corner case
11 | - Test driven feature development
12 | 
13 | - BEVNet to learn local map from camera images
14 | 
15 | - Pseudo-lidar (Vidar) approach is promising in urban driving (40mx40m range)
16 | 
17 | - infrastructure: operational vacation
18 | 
19 | - Other pics
20 | 
21 | 
22 | 
23 | 
24 | 
25 | 
26 | 
27 | 
28 | 
29 | 
30 | 
31 | 
32 | 
33 | 
34 | 
35 |
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image001.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image001.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image002.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image002.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image003.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image003.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image004.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image004.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image005.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image005.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image006.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image006.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image007.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image007.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image008.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image008.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image009.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image009.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image010.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image010.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image011.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image011.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image012.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image012.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image013.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image013.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image014.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image014.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image015.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image015.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image016.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image016.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image017.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image017.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image018.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image018.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image019.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image019.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image020.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image020.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image021.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image021.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image022.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image022.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image023.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image023.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image024.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image024.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image025.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image025.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image026.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image026.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image027.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image027.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image028.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image028.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image029.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image029.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image030.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image030.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image031.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image031.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image032.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image032.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image033.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image033.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image034.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image034.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image035.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image035.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image036.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image036.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image037.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image037.jpg
--------------------------------------------------------------------------------
/talk_notes/state_of_gpt_2023/media/image038.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/patrick-llgc/Learning-Deep-Learning/76920bd450ab0e07d5163374ff93537bb4327b0e/talk_notes/state_of_gpt_2023/media/image038.jpg
--------------------------------------------------------------------------------
/topics/topic_3d_lld.md:
--------------------------------------------------------------------------------
1 | # 3d Lane Line Detection
2 |
3 | - [LaneNet: Towards End-to-End Lane Detection: an Instance Segmentation Approach](https://arxiv.org/abs/1802.05591) [[Notes](paper_notes/lanenet.md)] IV 2018 (LaneNet)
4 | - [3D-LaneNet: End-to-End 3D Multiple Lane Detection](http://openaccess.thecvf.com/content_ICCV_2019/papers/Garnett_3D-LaneNet_End-to-End_3D_Multiple_Lane_Detection_ICCV_2019_paper.pdf) [[Notes](paper_notes/3d_lanenet.md)] ICCV 2019
5 | - [Semi-Local 3D Lane Detection and Uncertainty Estimation](https://arxiv.org/abs/2003.05257) [[Notes](paper_notes/semilocal_3d_lanenet.md)] [GM Israel, 3D LLD]
6 | - [Gen-LaneNet: A Generalized and Scalable Approach for 3D Lane Detection](https://arxiv.org/abs/2003.10656) [[Notes](paper_notes/gen_lanenet.md)] ECCV 2020 [Apollo, 3D LLD]
7 | - [3D-LaneNet+: Anchor Free Lane Detection using a Semi-Local Representation](https://arxiv.org/abs/2011.01535) [[Notes](paper_notes/3d_lanenet+.md)] NeurIPS 2020 workshop [GM Israel, 3D LLD]
8 |
--------------------------------------------------------------------------------
/topics/topic_cls_reg.md:
--------------------------------------------------------------------------------
1 | # Classification and Regression
2 |
3 | - [Revisiting Feature Alignment for One-stage Object Detection](https://arxiv.org/abs/1908.01570) [cls+reg]
4 | - [TSD: Revisiting the Sibling Head in Object Detector](https://arxiv.org/abs/2003.07540) CVPR 2020 [sensetime, cls+reg]
5 | - [1st Place Solutions for OpenImage2019 -- Object Detection and Instance Segmentation](https://arxiv.org/abs/2003.07557) [sensetime, cls+reg, 1st place OpenImage2019]
6 | - [CenterNet2: Probabilistic two-stage detection](https://arxiv.org/abs/2103.07461) [[Notes](paper_notes/centernet2.md)] [CenterNet, two-stage]
--------------------------------------------------------------------------------
/topics/topic_crowd_detection.md:
--------------------------------------------------------------------------------
1 | # Detection in Crowded Scenes
2 |
3 | - [RepLoss: Repulsion Loss: Detecting Pedestrians in a Crowd](https://arxiv.org/abs/1711.07752) [[Notes](paper_notes/rep_loss.md)] CVPR 2018 [crowd detection, Megvii]
4 | - [AggLoss: Occlusion-aware R-CNN: Detecting Pedestrians in a Crowd](https://arxiv.org/abs/1807.08407) [[Notes](paper_notes/agg_loss.md)] ECCV 2018 [crowd detection]
5 | - [Adaptive NMS: Refining Pedestrian Detection in a Crowd](https://arxiv.org/abs/1904.03629) [[Notes](paper_notes/adaptive_nms.md)] CVPR 2019 oral [crowd detection, NMS]
6 | - [Double Anchor R-CNN for Human Detection in a Crowd](https://arxiv.org/abs/1909.09998) [[Notes](paper_notes/double_anchor.md)] [head-body bundle]
7 | - [R2-NMS: NMS by Representative Region: Towards Crowded Pedestrian Detection by Proposal Pairing](https://arxiv.org/abs/2003.12729) [[Notes](paper_notes/r2_nms.md)] CVPR 2020
8 | - [VG-NMS: Visibility Guided NMS: Efficient Boosting of Amodal Object Detection in Crowded Traffic Scenes](https://arxiv.org/abs/2006.08547) [[Notes](paper_notes/vg_nms.md)] NeurIPS 2019 workshop [Crowded scene, NMS, Daimler]
9 | - [CrowdDet: Detection in Crowded Scenes: One Proposal, Multiple Predictions](https://arxiv.org/abs/2003.09163) [[Notes](paper_notes/crowd_det.md)] CVPR 2020 oral [crowd detection, Megvii]
10 | - [CSP: High-level Semantic Feature Detection: A New Perspective for Pedestrian Detection](https://arxiv.org/abs/1904.02948) [[Notes](paper_notes/csp_pedestrian.md)] CVPR 2019 [center and scale prediction, anchor-free, near SOTA pedestrian]
11 |
--------------------------------------------------------------------------------
/topics/topic_detr.md:
--------------------------------------------------------------------------------
1 | # Detection with Transformers
2 |
3 | - [Transformer: Attention Is All You Need](https://arxiv.org/abs/1706.03762) [[Notes](paper_notes/transformer.md)] NIPS 2017
4 | - [DETR: End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) [[Notes](paper_notes/detr.md)] ECCV 2020 oral [FAIR]
5 | - [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) [[Notes](paper_notes/deformable_detr.md)] ICLR 2021 [Jifeng Dai, DETR]
6 | - [LSTR: End-to-end Lane Shape Prediction with Transformers](https://arxiv.org/abs/2011.04233) [[Notes](paper_notes/lstr.md)] WACV 2011 [LLD, transformers]
7 | - [ViT: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) [[Notes](paper_notes/vit.md)] ICLR 2021
8 | - [TSP: Rethinking Transformer-based Set Prediction for Object Detection](https://arxiv.org/abs/2011.10881) [[Notes](paper_notes/tsp.md)] [DETR, transformers, Kris Kitani]
9 | - [Sparse R-CNN: End-to-End Object Detection with Learnable Proposals](https://arxiv.org/abs/2011.12450) [[Notes](paper_notes/sparse_rcnn.md)] [DETR, Transformer]
10 | - [DeFCN: End-to-End Object Detection with Fully Convolutional Network](https://arxiv.org/abs/2012.03544) [[Notes](paper_notes/defcn.md)] [Transformer, DETR]
11 | - [OneNet: End-to-End One-Stage Object Detection by Classification Cost](https://arxiv.org/abs/2012.05780) [[Notes](paper_notes/onenet.md)] [Transformer, DETR]
12 | - [PSS: Object Detection Made Simpler by Eliminating Heuristic NMS](https://arxiv.org/abs/2101.11782) [[Notes](paper_notes/pss.md)] [Transformer, DETR]
13 |
--------------------------------------------------------------------------------
/topics/topic_transformers_bev.md:
--------------------------------------------------------------------------------
1 | # BEV perception with Transformers
2 |
3 | - [Transformer: Attention Is All You Need](https://arxiv.org/abs/1706.03762) [[Notes](paper_notes/transformer.md)] NIPS 2017
4 | - [DETR: End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) [[Notes](paper_notes/detr.md)] ECCV 2020 oral [FAIR]
5 | - [STSU: Structured Bird's-Eye-View Traffic Scene Understanding from Onboard Images](https://arxiv.org/abs/2110.01997) [[Notes](paper_notes/stsu.md)] ICCV 2021 [BEV feat stitching, Luc Van Gool]
6 | - [DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries](https://arxiv.org/abs/2110.06922) ICCV 2021 [BEVNet, transformers]
7 | - [Translating Images into Maps](https://arxiv.org/abs/2110.00966) [BEVNet, transformers]
8 | - [PYVA: Projecting Your View Attentively: Monocular Road Scene Layout Estimation via Cross-view Transformation](https://openaccess.thecvf.com/content/CVPR2021/html/Yang_Projecting_Your_View_Attentively_Monocular_Road_Scene_Layout_Estimation_via_CVPR_2021_paper.html) [[Notes](paper_notes/pyva.md)] CVPR 2021 [[Supplementary](https://openaccess.thecvf.com/content/CVPR2021/supplemental/Yang_Projecting_Your_View_CVPR_2021_supplemental.zip)] [BEVNet]
9 | - [NEAT: Neural Attention Fields for End-to-End Autonomous Driving](https://arxiv.org/abs/2109.04456) [[Notes](paper_notes/neat.md)] ICCV 2021 [[supplementary](http://www.cvlibs.net/publications/Chitta2021ICCV_supplementary.pdf)] [BEVNet]
10 |
--------------------------------------------------------------------------------
/topics/topic_vlm.md:
--------------------------------------------------------------------------------
1 | # Vision Language Models
2 |
3 | ## List from RT-2
4 | - Flamingo
5 | - Pali, Pali-x
6 | - Palm-e
7 | - Language models are general purpose interfaces
8 | - Blip-2
9 | - Vil-bert
10 | - VisualBert
11 |
12 | ## LLM deployment
13 | - AFT
14 | - Linformer
--------------------------------------------------------------------------------