├── config.ini
├── LICENSE
├── README.md
├── pdfba_frontend.py
└── pdfba_backend_mk.py
/config.ini:
--------------------------------------------------------------------------------
1 | [default]
2 | ak = change-to-your-deepseek-api-ak
3 | working_dir = /home/pdfba
4 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2025 pdfba
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 背景
2 | 当前大模型的技术还在快速迭代和发展,大模型领域很多先进的技术和工程经验会以科技论文的形式呈现。
3 | 阅读科技论文是快速跟进大模型技术浪潮的,了解大模型领域技术动态的一个重要方式。
4 | 当前大模型领域的科技论文还是以英文为主。
5 | 对于中国的科技从业者,如果将英文论文翻译为中文论文来阅读,获取信息的效率会更高一些。
6 |
7 | 当前的大模型如gtp,deepseek的官网应用还不具备直接将PDF文件全文翻译成中文的能力。
8 | 业界也有一些基于大模型做商业化的PDF文档翻译软件,如基于GPT的simplifyai,和基于文心大模型的百度AI论文精翻。
9 | 这些商业化的软件翻译效果很好,缺点就是费用有点贵。
10 |
11 | 当前也有不错的开源的PDF翻译软件,如PDFMathTranslate。
12 | 但开源软件的问题是安装较复杂,翻译速度较慢,一些较大的文件无法翻译。
13 |
14 | 事实上该项目的起因就是因为有一个超长的单页PDF文件,"The Ultra Scale Playbook Training LLMs on GPU Clusters",想用PDFMathTranslate翻译却翻译不出来。
15 | 我想看看它的后端代码哪里出来问题。
16 | 但他的后端代码写的我实在看不懂。
17 | 我就想是不是可以通过大模型编码的方式来解决?
18 | 然后一发不可收拾,整体上这个项目是通过DeepSeek大模型辅助编码的方式构建的。
19 | 项目核心代码不到5百行,整体上运行的也还不错。
20 | 整个项目架构上参考PDFMathTranslate的前端和后端的架构设计。
21 | 基于当前的项目代码,我们上线了第一版PDF翻译服务: http://pdfba.com/
22 | pdfba当前是基于DeepSeek V3来翻译科技论文的,当前用户可以免费翻译,后续也计划作为一个免费的公益项目运作下去。
23 |
24 | # 软件架构
25 | 前端通过Gradio实现了一个简单的webui。
26 | 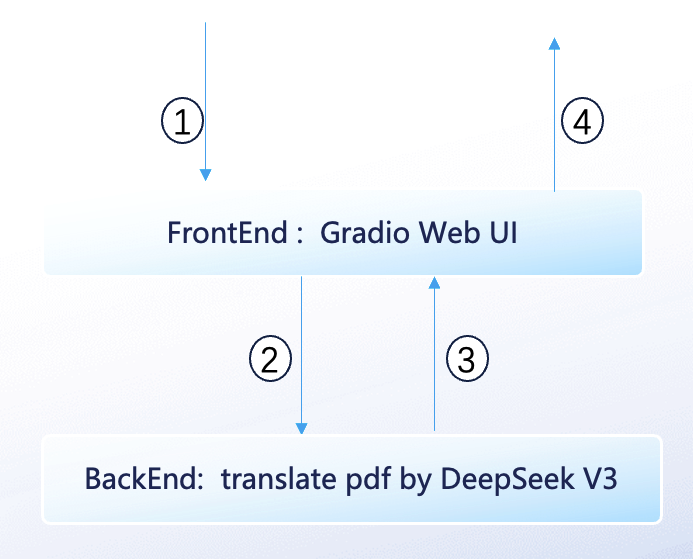
27 | webui中仅包含一个上传文件和翻译的按钮。
28 | 翻译完成后,会生成一个html链接,点击html链接可以查看翻译成中文的文档。
29 |
30 | 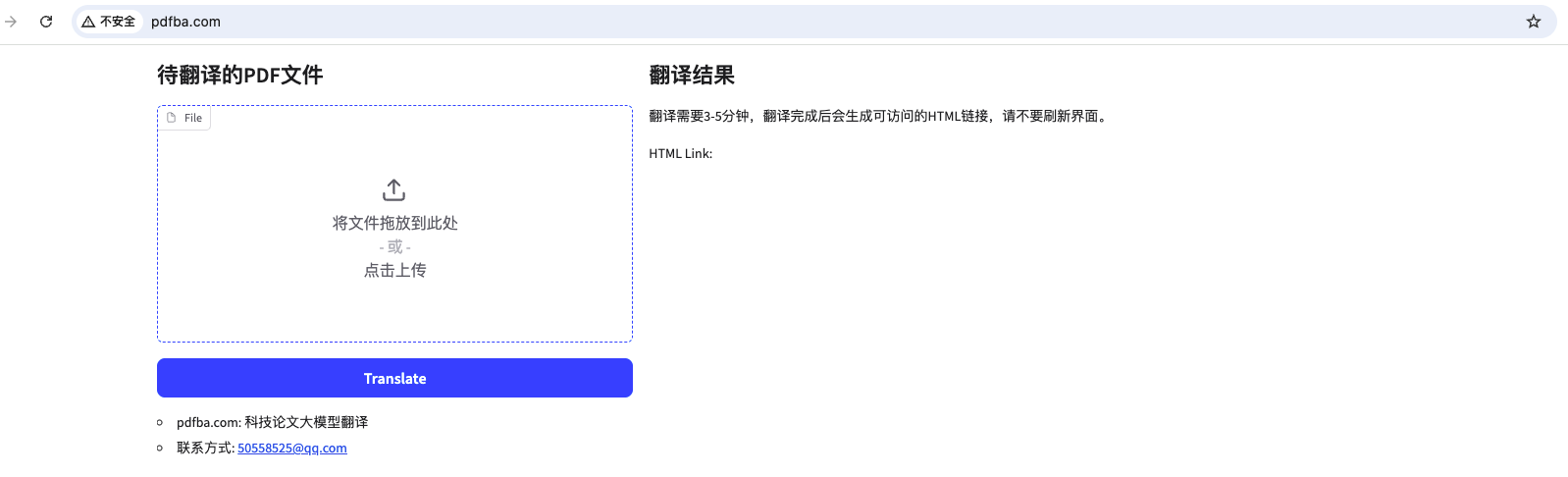
31 |
32 |
33 |
34 |
35 | # 关键实现流程
36 | 整体是一个比较简单的前后端架构。
37 |
38 | 
39 |
40 |
41 |
42 |
43 |
44 |
45 | # 当前的不足和后续的规划
46 | 当前线上的版本还远远达不到成熟和好用的标准,只能说刚刚能用。
47 | 也希望更多的人能加入一起来完善这个公益项目。
48 | ## 一些不足或bug
49 | ### 1. 界面不美观
50 | 基本没做啥前端设计,界面布局,字体等不够美观。
51 | 翻译没有进度条。
52 | 点击翻译按钮后,在翻译完成前,翻译按钮没有置为不可用。
53 | ### 2. 翻译后的文字排版部分文档不美观
54 | 有的论文翻译完成后文字部分缺少换行。
55 | 无法提取论文的全部一级标题作为html的锚点。
56 | ### 3. 翻译后的表格无法排版
57 | 有的论文翻译完成后的表格内容无法正确展示。
58 | ### 4. 翻译后的公式无法友好展示
59 | 当前还没在html里面支持letex公式的展示,所以公式展示的效果不好。
60 | ### 5. 存在无法提取一些图片的问题
61 | 一些论文中的图片无法提取出来。
62 | 一些论文的中的图片能提取,但裁剪的范围有的偏大。
63 | ### 6. 支持的并发不算多
64 | 当前支持50个并发
65 | 总的token生成速度约300 tokens/s
66 | 一篇1万字的科技论文,需要翻译时间在2分钟以内。
67 | ### 7. 有可能存在少翻译的问题
68 | 基于并发api调用翻译,但没做返回值校验。如果部分api没返回数据,会导致内容少翻译的问题
69 |
70 |
71 | ## 规划
72 | ### 1.排版优化:支持公式的显示
73 | 当前版本基本没有处理公式,对于公式较多的论文翻译效果不好,后面计划优化
74 | ### 2.系统优化:API返回结果校验
75 | 当前调用大模型API没有校验返回结果,有可能返回结果为空或不全,针对这种场景后续需要增加返回结果校验和重试机制。
76 | ### 3.系统优化:cache机制
77 | 对于重复翻译的论文,直接返回cache
78 | ### 4.系统优化:提升性能
79 | 当前的总token生成速度约300 tokens/s,后续的目标是探索优化到1000 tokens/s的方案。
80 | 这个优先级略低,因为目前看300 tokens/s的性能也暂时够用
81 | ### 5.功能:增加用户历史翻译记录
82 | 增加可选的用户登录机制,对于登录的用户展示其历史翻译记录
83 | ### 6.功能:增加打赏功能
84 | 系统运行有一定的费用,一篇1万字的论文翻译需要0.5元。
85 | 如果长期运行,假设翻译10万篇论文,需花费5万元。
86 | 有一定的运营成本,如果要长期运营,需考虑增加赞助和捐款功能。
87 |
--------------------------------------------------------------------------------
/pdfba_frontend.py:
--------------------------------------------------------------------------------
1 |
2 | import os
3 | import gradio as gr
4 | from scanf import scanf
5 | import shutil
6 | import subprocess
7 | import yaml
8 | import uuid
9 | import re
10 |
11 |
12 | from pdfba_backend_mk import translate
13 |
14 | from concurrent.futures import ThreadPoolExecutor
15 | # 创建线程池(最大50线程)
16 | executor = ThreadPoolExecutor(max_workers=50)
17 |
18 |
19 |
20 | def immediate_response(file_type, file_input):
21 | """立即返回空响应"""
22 | return "正在处理中,请稍后"
23 |
24 | def process_result(future):
25 | """处理Future对象获取结果"""
26 | try:
27 | return future.result()
28 | except Exception as e:
29 | return f"错误: {str(e)}"
30 |
31 | def read_config(config_path, key_name):
32 | """
33 | 通过正则表达式从配置文件提取 working_dir,ak等信息
34 | """
35 | #config_path_dir = f"/Users/liwei135/pdfba/{config_path}"
36 | config_path_dir = f"/home/pdfba/{config_path}"
37 |
38 |
39 |
40 | with open(config_path_dir, 'r') as f:
41 | config_text = f.read()
42 |
43 | # 匹配 working_dir 的值(支持等号或冒号分隔)
44 | match = re.search(
45 | rf'^{key_name}\s*[=:]\s*(.*?)\s*$',
46 | config_text,
47 | re.MULTILINE
48 | )
49 |
50 | if not match:
51 | raise ValueError(f"{key_name} not found in config file")
52 |
53 | # 去除可能的引号并处理路径
54 | result = match.group(1).strip('\'"')
55 |
56 | return result
57 |
58 | # The following variables associate strings with specific languages
59 | lang_map = {
60 | "Simplified Chinese": "zh",
61 | "English": "en",
62 | }
63 |
64 | def submit_task(file_type,file_input):
65 | """提交任务到线程池"""
66 | #print("提交任务到线程池")
67 | future = executor.submit(translate_file, file_type, file_input)
68 |
69 | return future
70 | #return future.result()
71 |
72 | def run_mkdoc_server(html_link):
73 | # get port from html_link
74 | # 提取 session_id 和 PORT
75 | # html_link的格式"[6049b15f-e9a7-43b0-b3cf-7b4834230df7/MapReduce.html](http://127.0.0.1:13988/translated_html/MapReduce.html)"
76 |
77 | #print("run_mkdoc_server html_link:", html_link)
78 |
79 | result = scanf("[%s/", html_link)
80 |
81 | if result:
82 | session_id = result[0]
83 | port = result[3]
84 | else:
85 | print("未匹配到session_id,port")
86 | return
87 | WORKING_FOLDER_NAME=read_config('config.ini','working_dir')
88 |
89 | print(WORKING_FOLDER_NAME)
90 |
91 | dir_name = f"{WORKING_FOLDER_NAME}/{session_id}"
92 | # 切换到工作 目录
93 | os.chdir(dir_name)
94 |
95 | # 定义配置内容(Python 字典格式)
96 | config = {
97 | "site_name": " ",
98 | "nav": [
99 | {"首页": "index.md"}
100 | ]
101 | }
102 |
103 | # 写入 YAML 文件
104 | with open("mkdocs.yml", "w", encoding="utf-8") as f:
105 | yaml.dump(config, f, allow_unicode=True, sort_keys=False) # allow_unicode 支持中文
106 |
107 | print("mkdocs.yml 已生成!")
108 |
109 | try:
110 |
111 | output_dir = f"{WORKING_FOLDER_NAME}/{session_id}_h"
112 | process = subprocess.Popen(
113 | ["mkdocs", "build", "--site-dir", output_dir],
114 | cwd=dir_name, # 在指定目录执行
115 | text=True
116 | )
117 | print(f"{process}MkDocs 已经完成index.html的生成")
118 |
119 | except FileNotFoundError:
120 | print("错误:未找到 mkdocs 命令,请确保 MkDocs 已安装。")
121 |
122 |
123 |
124 |
125 |
126 | def translate_file(
127 | file_type,
128 | file_input
129 |
130 | ):
131 | """
132 | This function translates a PDF file from one language to another.
133 |
134 | Inputs:
135 | - file_type: The type of file to translate
136 | - file_input: The file to translate
137 | - link_input: The link to the file to translate
138 |
139 | Returns:
140 | - output_html_link: html linkThe translated file
141 | """
142 |
143 | session_id = uuid.uuid4()
144 | #session_id="d3c788fd-87a8-4a96-b4b3-6fd5e1a2e095"
145 |
146 | WORKING_FOLDER_NAME = read_config('config.ini', 'working_dir')
147 | print(WORKING_FOLDER_NAME)
148 |
149 | # 基于session_id生成一个本地文件夹,这块不太合理,后续应该基于user id生成一个文件夹
150 | os.chdir(WORKING_FOLDER_NAME)
151 |
152 | working_dir = f"{WORKING_FOLDER_NAME}"
153 | output = f"{session_id}"
154 |
155 | if not os.path.exists(working_dir):
156 | os.makedirs(working_dir)
157 | print(f"文件夹 '{working_dir}' 已创建。")
158 |
159 | if not os.path.exists(output):
160 | os.makedirs(output)
161 | print(f"文件夹 '{output}' 已创建。")
162 |
163 | output_dir = f"{WORKING_FOLDER_NAME}/{session_id}"
164 |
165 | os.chdir(output_dir)
166 |
167 | if file_type == "File":
168 | if not file_input:
169 | raise gr.Error("No input")
170 | file_path = shutil.copy(file_input, output_dir)
171 |
172 | filename = os.path.basename(str(file_input))
173 | print("filename:", filename)
174 |
175 | file_raw = f"{output}/{filename}"
176 |
177 | lang_from = "English"
178 | lang_to = "Chinese"
179 |
180 | #print(f"Files before translation: {file_raw}")
181 |
182 | output_html_link = translate(str(filename), session_id)
183 |
184 | #print(f"Files after translation: {output_html_link}")
185 | run_mkdoc_server(output_html_link)
186 |
187 | return output_html_link
188 |
189 |
190 | # Global setup
191 | custom_blue = gr.themes.Color(
192 | c50="#E8F3FF",
193 | c100="#BEDAFF",
194 | c200="#94BFFF",
195 | c300="#6AA1FF",
196 | c400="#4080FF",
197 | c500="#165DFF", # Primary color
198 | c600="#0E42D2",
199 | c700="#0A2BA6",
200 | c800="#061D79",
201 | c900="#03114D",
202 | c950="#020B33",
203 | )
204 |
205 | custom_css = """
206 | .secondary-text {color: #999 !important;}
207 | footer {visibility: hidden}
208 | .env-warning {color: #dd5500 !important;}
209 | .env-success {color: #559900 !important;}
210 |
211 | /* Add dashed border to input-file class */
212 | .input-file {
213 | border: 1.2px dashed #165DFF !important;
214 | border-radius: 6px !important;
215 | }
216 |
217 | .progress-bar-wrap {
218 | border-radius: 8px !important;
219 | }
220 |
221 | .progress-bar {
222 | border-radius: 8px !important;
223 | }
224 |
225 | .pdf-canvas canvas {
226 | width: 100%;
227 | }
228 | """
229 |
230 | tech_details_string = f"""
231 | - pdfba.com: 科技论文大模型翻译
232 | - 联系方式: 50558525@qq.com
233 | """
234 |
235 | # The following code creates the GUI
236 | with gr.Blocks(
237 | title="PDFBA.COM",
238 | theme=gr.themes.Default(
239 | primary_hue=custom_blue, spacing_size="md", radius_size="lg"
240 | ),
241 | css=custom_css,
242 |
243 | ) as pdfba_ui:
244 | with gr.Row():
245 | with gr.Column(scale=1):
246 | gr.Markdown("## 待翻译的PDF文件")
247 | file_type = gr.Radio(
248 | choices=["File"],
249 | label="Type",
250 | value="File",
251 | visible=False,
252 | )
253 | file_input = gr.File(
254 | label="File",
255 | file_count="single",
256 | file_types=[".pdf"],
257 | type="filepath",
258 | elem_classes=["input-file"],
259 | )
260 |
261 |
262 | def on_select_filetype(file_type):
263 | return (
264 | gr.update(visible=file_type == "File"),
265 |
266 | )
267 |
268 |
269 | translate_btn = gr.Button("Translate", variant="primary")
270 |
271 | tech_details_tog = gr.Markdown(
272 | tech_details_string
273 | )
274 |
275 | file_type.select(
276 | on_select_filetype,
277 | file_type,
278 | [file_input],
279 |
280 | )
281 |
282 | with gr.Column(scale=2):
283 | gr.Markdown("## 翻译结果")
284 |
285 | gr.Markdown("翻译需要3-5分钟,翻译完成后会生成可访问的HTML链接,请不要刷新界面。")
286 | FE_OUTPUT_HTML_LINK = gr.Markdown("HTML Link:")
287 |
288 | # Event handlers
289 | file_input.upload(
290 | lambda x: x,
291 | inputs=file_input,
292 |
293 | )
294 |
295 | future_state = gr.State() # 用于存储Future对象
296 |
297 | translate_btn.click(
298 | fn=immediate_response,
299 | inputs=[
300 | file_type,
301 | file_input
302 | ],
303 | outputs=FE_OUTPUT_HTML_LINK
304 | ).then(
305 | fn=submit_task,
306 | inputs=[file_type, file_input],
307 | outputs=future_state
308 | ).then(
309 | fn=process_result,
310 | inputs=[future_state], # 接收上一步的输出
311 | outputs=FE_OUTPUT_HTML_LINK
312 | )
313 |
314 |
315 | def setup_gui(
316 | share: bool = False, server_port=80
317 | ) -> None:
318 | """
319 | Setup the GUI with the given parameters.
320 |
321 | Inputs:
322 | - share: Whether to share the GUI.
323 | - auth_file: The file path to read the user name and password.
324 |
325 | Outputs:
326 | - None
327 | """
328 |
329 | try:
330 | pdfba_ui.queue(default_concurrency_limit=50)
331 | pdfba_ui.launch(
332 | server_name="0.0.0.0",
333 | debug=False,
334 | inbrowser=True,
335 | share=share,
336 | server_port=server_port,
337 | )
338 | except Exception:
339 | print(
340 | "Error launching GUI using 0.0.0.0.\nThis may be caused by global mode of proxy software."
341 | )
342 | print(f"启动失败: {str(Exception)}")
343 |
344 |
345 | # For auto-reloading while developing
346 | if __name__ == "__main__":
347 | setup_gui()
348 |
--------------------------------------------------------------------------------
/pdfba_backend_mk.py:
--------------------------------------------------------------------------------
1 |
2 |
3 | import os
4 | import shutil
5 | import random
6 | import time
7 | import re
8 | import fitz
9 | import pymupdf
10 | import configparser
11 |
12 |
13 |
14 | # -*- coding: utf-8 -*-
15 | from pdfminer.pdfparser import PDFParser
16 | from pdfminer.pdfdocument import PDFDocument
17 | from pdfminer.pdfpage import PDFPage
18 | from pdfminer.pdfpage import PDFTextExtractionNotAllowed
19 | from pdfminer.pdfinterp import PDFResourceManager
20 | from pdfminer.pdfinterp import PDFPageInterpreter
21 | from pdfminer.layout import *
22 | from pdfminer.converter import PDFPageAggregator
23 |
24 |
25 | from PIL import Image
26 |
27 | from bs4 import BeautifulSoup
28 |
29 | from openai import OpenAI
30 | import concurrent.futures
31 | import threading
32 |
33 |
34 |
35 |
36 |
37 | # 定义最小尺寸阈值
38 | MIN_WIDTH = 1
39 | MIN_HEIGHT = 1
40 | MAX_PAGE_PIC_NUM = 500
41 | WORD_NUM = 5000
42 |
43 | FILE_LOCK = threading.Lock()
44 |
45 |
46 | # 工作目录
47 | #WORKING_FOLDER_NAME = '/Users/liwei135/pdfba'
48 | # 工作目录
49 | #WORKING_FOLDER_NAME = '/home/pdfba'
50 | # 文件夹名称
51 | PIC_FOLDER_NAME = "docs/pdf_fig_output"
52 | PIC_FOLDER_NAME_SHORT = "pdf_fig_output"
53 | TXT_FOLDER_NAME = "pdf_txt_output"
54 |
55 |
56 | def read_config(config_path, key_name):
57 | """
58 | 通过正则表达式从配置文件提取 working_dir,ak等信息
59 | """
60 |
61 | #config_path_dir = f"/Users/liwei135/PycharmProjects/pdfba/{config_path}"
62 | config_path_dir = f"/home/pdfba/{config_path}"
63 |
64 | with open(config_path_dir, 'r') as f:
65 | config_text = f.read()
66 |
67 | # 匹配 working_dir 的值(支持等号或冒号分隔)
68 | match = re.search(
69 | rf'^{key_name}\s*[=:]\s*(.*?)\s*$',
70 | config_text,
71 | re.MULTILINE
72 | )
73 |
74 | if not match:
75 | raise ValueError(f"{key_name} not found in config file")
76 |
77 | # 去除可能的引号并处理路径
78 | result = match.group(1).strip('\'"')
79 | return result
80 |
81 |
82 |
83 | def translate(
84 | pdf_filename,
85 | session_id,
86 |
87 | ):
88 | #函数维度的全局变量
89 | ALL_PIC_X0_Y0_COORDINATE = []
90 | ALL_TXT_X0_Y0_COORDINATE = []
91 | ALL_TXT_WORDCNT = []
92 | ALL_INSERT_PIC_X0_Y0_COORDINATE = []
93 | ALL_INSERT_IMG_LOCATION = []
94 |
95 |
96 | # 要显示的图片列表
97 | show_pic_list = []
98 | #session_id="d3c788fd-87a8-4a96-b4b3-6fd5e1a2e095"
99 |
100 | WORKING_FOLDER_NAME = read_config('config.ini', 'working_dir')
101 |
102 | pdf_path = f"{WORKING_FOLDER_NAME}/{session_id}/{pdf_filename}"
103 |
104 |
105 | # 检查文件夹是否存在,如果不存在则创建
106 | filename = f"{WORKING_FOLDER_NAME}/{session_id}/{PIC_FOLDER_NAME}"
107 | if not os.path.exists(filename):
108 | os.makedirs(filename)
109 | # print(f"文件夹 '{folder_name}' 已创建。")
110 |
111 | # 检查文件夹是否存在,如果不存在则创建
112 | filename = f"{WORKING_FOLDER_NAME}/{session_id}/{TXT_FOLDER_NAME}"
113 | if not os.path.exists(filename):
114 | os.makedirs(filename)
115 | # print(f"文件夹 '{folder_name}' 已创建。")
116 |
117 | total_page_num = pdf_page_interpret(pdf_path, session_id)
118 |
119 |
120 | for page_num in range(total_page_num):
121 | input_file_name = f"{WORKING_FOLDER_NAME}/{session_id}/{TXT_FOLDER_NAME}/all_element_{page_num}.txt"
122 | out_file_name = f"{WORKING_FOLDER_NAME}/{session_id}/{TXT_FOLDER_NAME}/fig_only_{page_num}.txt"
123 | pdf_extract_fig_element(input_file_name, out_file_name)
124 |
125 | for page_num in range(total_page_num):
126 | input_file_name = f"{WORKING_FOLDER_NAME}/{session_id}/{TXT_FOLDER_NAME}/all_element_{page_num}.txt"
127 | out_file_name = f"{WORKING_FOLDER_NAME}/{session_id}/{TXT_FOLDER_NAME}/txt_only_{page_num}.txt"
128 | pdf_extract_txt_element(input_file_name, out_file_name)
129 |
130 | for page_num in range(total_page_num):
131 | fig_element_file_name = f"{WORKING_FOLDER_NAME}/{session_id}/{TXT_FOLDER_NAME}/fig_only_{page_num}.txt"
132 | pic_x0_y0_coord = save_img_from_pdf_page(pdf_path, page_num, fig_element_file_name, session_id)
133 | ALL_PIC_X0_Y0_COORDINATE.append(pic_x0_y0_coord)
134 |
135 | # 调用函数过滤图片
136 | image_folder = f"{WORKING_FOLDER_NAME}/{session_id}/{PIC_FOLDER_NAME}"
137 | show_pic_list = delete_small_images_return_bigpic_index(image_folder, MIN_WIDTH, MIN_HEIGHT)
138 |
139 |
140 | for page_num in range(total_page_num):
141 | txt_element_file_name = f"{WORKING_FOLDER_NAME}/{session_id}/{TXT_FOLDER_NAME}/txt_only_{page_num}.txt"
142 | txt_coord, txt_cnt = get_page_txtblock_wordcnt(txt_element_file_name)
143 | ALL_TXT_X0_Y0_COORDINATE.append(txt_coord)
144 | ALL_TXT_WORDCNT.append(txt_cnt)
145 |
146 | # 初始化二维数组
147 | for page_num in range(total_page_num):
148 | sublist = [[0, 0] for _ in range(MAX_PAGE_PIC_NUM)]
149 | ALL_INSERT_PIC_X0_Y0_COORDINATE.append(sublist)
150 |
151 | for page_pic_num in show_pic_list:
152 | match = re.search(r"(\d+)_(\d+)", page_pic_num)
153 | if match:
154 | page_num = int(match.group(1))
155 | pic_num = int(match.group(2))
156 | #print("page,pic:",page_num,pic_num)
157 |
158 | #insert_pic_x0_y0_coord = get_insert_pic_y_coordinate(pic_num, page_num)
159 | insert_pic_x0_y0_coord = ALL_PIC_X0_Y0_COORDINATE[page_num][pic_num]
160 | ALL_INSERT_PIC_X0_Y0_COORDINATE[page_num][pic_num] = insert_pic_x0_y0_coord
161 | else:
162 | print("未找到匹配的数字")
163 |
164 | # 初始化二维数组
165 | for page_num in range(total_page_num):
166 | location = []
167 | ALL_INSERT_IMG_LOCATION.append(location)
168 |
169 | #save_txt_with_img_tag(total_page_num, session_id)
170 | for page_num in range(total_page_num):
171 | for coord in ALL_INSERT_PIC_X0_Y0_COORDINATE[page_num]:
172 | if coord[1] > 0:
173 | # only have img, no txt
174 | if len(ALL_TXT_X0_Y0_COORDINATE[page_num]) == 0:
175 | index = 0
176 | else:
177 | index = find_closest_number(ALL_TXT_X0_Y0_COORDINATE[page_num], coord)
178 |
179 | ALL_INSERT_IMG_LOCATION[page_num].append(index)
180 |
181 | for page_num in range(total_page_num):
182 | in_file_path = f"{WORKING_FOLDER_NAME}/{session_id}/{TXT_FOLDER_NAME}/txt_only_{page_num}.txt"
183 | if len(ALL_INSERT_IMG_LOCATION[page_num]) > 0:
184 | with open(in_file_path, "r", encoding="utf-8") as file:
185 | lines = file.readlines() # 读取所有行
186 | else:
187 | continue
188 |
189 | pic_num = 0
190 | for row_num in ALL_INSERT_IMG_LOCATION[page_num]:
191 | line = lines[row_num].rstrip("\n")
192 | # print("line:",line)
193 | modified_line = add_http_img_tag(line, page_num, pic_num)
194 | # print("modified_line:",modified_line)
195 | lines[row_num] = modified_line
196 | pic_num += 1
197 |
198 | # 将修改后的内容写回文件
199 | out_file_path = f"{WORKING_FOLDER_NAME}/{session_id}/{TXT_FOLDER_NAME}/txt_only_{page_num}_img.txt"
200 | with open(out_file_path, "w", encoding="utf-8") as file:
201 | file.writelines(lines)
202 |
203 |
204 |
205 |
206 |
207 |
208 | # 文件路径
209 | en_txt_file_path = f"{WORKING_FOLDER_NAME}/{session_id}/en_txt_only_add_img_final.txt"
210 |
211 | # read all txt file,remove LT content, and save to one txt file
212 | save_to_one_txt(total_page_num, en_txt_file_path, session_id)
213 |
214 | # 将英文中的#替换为空格,去掉页码
215 | en_txt_file_path_2 = f"{WORKING_FOLDER_NAME}/{session_id}/en_txt_only_add_img_final_2.txt"
216 | modify_en_txt_format(en_txt_file_path, en_txt_file_path_2)
217 |
218 | output_txt_file_1 = f"{WORKING_FOLDER_NAME}/{session_id}/docs/index_0.md"
219 | translate_by_ai_agent_save_file(en_txt_file_path_2, output_txt_file_1)
220 |
221 | # 读取文件,解决一下#前面无换行的问题
222 | output_txt_file_2 = f"{WORKING_FOLDER_NAME}/{session_id}/docs/index.md"
223 | modify_txt_format(output_txt_file_1, output_txt_file_2)
224 |
225 |
226 |
227 | # 要删除的文件列表
228 | files_to_delete = [f"{WORKING_FOLDER_NAME}/{session_id}/translate_to_cn_2.txt",
229 | f"{WORKING_FOLDER_NAME}/{session_id}/en_txt_only_add_img_final_2.txt",
230 | f"{WORKING_FOLDER_NAME}/{session_id}/en_txt_only_add_img_final.txt",
231 | f"{WORKING_FOLDER_NAME}/{session_id}/translate_to_cn_1.txt",
232 | f"{WORKING_FOLDER_NAME}/{session_id}/translate_1.html",
233 | f"{WORKING_FOLDER_NAME}/{session_id}/translate_2.html",
234 | f"{WORKING_FOLDER_NAME}/{session_id}/translate_3.html",
235 | f"{WORKING_FOLDER_NAME}/{session_id}/translate_4.html",
236 | f"{WORKING_FOLDER_NAME}/{session_id}/translate_5.html"]
237 |
238 | # 遍历文件列表并删除
239 | for file_name in files_to_delete:
240 | if os.path.exists(file_name): # 检查文件是否存在
241 | os.remove(file_name) # 删除文件
242 | #print(f"文件 {file_name} 已删除")
243 | else:
244 | print(f"文件 {file_name} 不存在")
245 |
246 | # 要删除的目录
247 | dir_txt_path = f"{WORKING_FOLDER_NAME}/{session_id}/{TXT_FOLDER_NAME}"
248 | try:
249 | shutil.rmtree(dir_txt_path)
250 | #print(f"目录 {dir_txt_path} 及其所有内容已删除")
251 | except OSError as e:
252 | print(f"删除失败: {e}")
253 |
254 | # 配置端口,这块代码有问题,临时这么用一下。后续应保障端口不重复
255 | PORT = random.randint(9000, 65000)
256 |
257 | pdf_name = pdf_filename.rsplit(".", 1)[0]
258 |
259 | html_link = f"[{session_id}/{pdf_name}.html](http://pdfba.com:8080/{session_id}_h/)"
260 | #print("html_str:", html_link)
261 |
262 | return html_link
263 |
264 |
265 | def pdf_page_interpret(pdf_path, session_id):
266 | # 逐页解析pdf所有元素,并保存到txt文件,返回总页数
267 |
268 | file_name_all_txt = ""
269 | page_num = 0
270 |
271 | WORKING_FOLDER_NAME = read_config('config.ini', 'working_dir')
272 |
273 | # os.chdir(r'F:\test')
274 | fp = open(pdf_path, 'rb')
275 |
276 | # 来创建一个pdf文档分析器
277 | parser = PDFParser(fp)
278 | # 创建一个PDF文档对象存储文档结构
279 | document = PDFDocument(parser)
280 | # 检查文件是否允许文本提取
281 | if not document.is_extractable:
282 | # print("123")
283 | raise PDFTextExtractionNotAllowed
284 | else:
285 | # 创建一个PDF资源管理器对象来存储资源
286 | rsrcmgr = PDFResourceManager()
287 |
288 | # 创建 LAParams 对象并调整参数
289 | laparams = LAParams(
290 | line_overlap=0.5,
291 | char_margin=2.0,
292 | line_margin=0.5,
293 | word_margin=0.1,
294 | boxes_flow=0.5,
295 | detect_vertical=False, # 禁用垂直文本检测
296 | all_texts=False, # 仅解析可见文本
297 | )
298 |
299 | device = PDFPageAggregator(rsrcmgr, laparams=laparams)
300 | # 创建一个PDF解释器对象
301 | interpreter = PDFPageInterpreter(rsrcmgr, device)
302 | # 处理每一页
303 |
304 | for page in PDFPage.create_pages(document):
305 | # print("page:",page_num)
306 | # #start_time = time.time()
307 |
308 | interpreter.process_page(page)
309 |
310 | # 记录结束时间
311 | #end_time = time.time()
312 | # 计算并打印执行时间
313 | #execution_time = end_time - start_time
314 | #print(f"函数执行时间1: {execution_time:.4f} 秒")
315 |
316 | #start_time = time.time()
317 |
318 | file_name_all_txt = f"{WORKING_FOLDER_NAME}/{session_id}/{TXT_FOLDER_NAME}/all_element_{page_num}.txt"
319 |
320 | # 接受该页面的LTPage对象
321 | layout = device.get_result()
322 | for x in layout:
323 | # 记录开始时间
324 | with open(file_name_all_txt, 'a') as file_all:
325 | print(x, file=file_all)
326 |
327 | # 记录结束时间
328 | #end_time = time.time()
329 | # 计算并打印执行时间
330 | #execution_time = end_time - start_time
331 | # print(f"函数执行时间2: {execution_time:.4f} 秒")
332 |
333 | page_num = page_num + 1
334 |
335 | # print("total page: ",page_num)
336 | return page_num
337 |
338 |
339 | def pdf_extract_fig_element(input_file, output_file):
340 | # 正则表达式匹配 行
341 | pattern = r"]+>"
342 |
343 | # 打开输入文件并读取内容
344 | with open(input_file, "r", encoding="utf-8") as file:
345 | content = file.readlines()
346 |
347 | # 提取所有 行
348 | ltfigure_lines = [line.strip() for line in content if re.match(pattern, line)]
349 |
350 | # 将提取的内容写入输出文件
351 | with open(output_file, "w", encoding="utf-8") as file:
352 | for line in ltfigure_lines:
353 | file.write(line + "\n")
354 |
355 | # print(f"已提取 {len(ltfigure_lines)} 行 内容到 {output_file}")
356 |
357 |
358 | def pdf_extract_txt_element(input_file, output_file):
359 | # 正则表达式匹配 行
360 | pattern = r"]+>"
361 |
362 | # 打开输入文件并读取内容
363 | with open(input_file, "r", encoding="utf-8") as file:
364 | content = file.readlines()
365 |
366 | # 提取所有 行
367 | lttxtbox_lines = [line.strip() for line in content if re.match(pattern, line)]
368 |
369 | # 将提取的内容写入输出文件
370 | with open(output_file, "w", encoding="utf-8") as file:
371 | for line in lttxtbox_lines:
372 | file.write(line + "\n")
373 |
374 | # print(f"已提取 {len(lttxtbox_lines)} 行 内容到 {output_file}")
375 |
376 |
377 | def save_img_from_pdf_page(pdf_file_path, page_num, fig_element_file_name, session_id):
378 | # 文件路径
379 | file_path = fig_element_file_name
380 |
381 | WORKING_FOLDER_NAME = read_config('config.ini', 'working_dir')
382 |
383 | # 打开文件并读取所有行
384 | with open(file_path, "r", encoding="utf-8") as file:
385 | lines = file.readlines()
386 |
387 | # 去除每行的换行符,并将结果存储到列表中
388 | data_list = [line.strip() for line in lines]
389 |
390 | pattern = r"(\d+\.\d+,\d+\.\d+,\d+\.\d+,\d+\.\d+)\s+matrix="
391 |
392 | fig_coord = []
393 |
394 | for line_data in data_list:
395 | match = re.search(pattern, line_data)
396 | # 检查是否匹配成功
397 | if match:
398 | fig_coord.append(match.group(1))
399 | # print("提取的内容:", match.group(1))
400 |
401 | # 用于存储图片坐标
402 | fig_x0_y0_coord = []
403 |
404 | # 遍历 fig_coord 列表中的每个字符串
405 | for coord in fig_coord:
406 | # 按逗号分割字符串
407 | parts = coord.split(',')
408 | # 提取最后一个数字并转换为浮点数(或整数,根据需要)
409 | x0_y0 = [float(parts[0]), float(parts[1])]
410 | # 将最后一个数字添加到 last_numbers 列表中
411 | fig_x0_y0_coord.append(x0_y0)
412 |
413 | # print("fig_y_coord:",fig_y_coord)
414 |
415 | # 打开 PDF 文件
416 | pdf_path = pdf_file_path
417 | doc = fitz.open(pdf_path)
418 |
419 | page = doc.load_page(page_num)
420 | ptm = page.transformation_matrix
421 | # print(ptm)
422 | ind = 0
423 | for coord_data in fig_coord:
424 | # PDF 坐标系统中的边界框
425 | x0_pdf, y0_pdf, x1_pdf, y1_pdf = map(float, coord_data.split(","))
426 | rect = pymupdf.Rect(x0_pdf, y0_pdf, x1_pdf, y1_pdf) * ~ptm
427 | # print(rect)
428 | # 渲染指定区域为图片
429 | pix = page.get_pixmap(clip=rect, dpi=300)
430 | fig_file_name = f"{WORKING_FOLDER_NAME}/{session_id}/{PIC_FOLDER_NAME}/fig_{page_num}_{ind}.png"
431 | # print(fig_file_name)
432 | pix.save(fig_file_name)
433 | # print("Saved figure as ",fig_file_name)
434 | ind = ind + 1
435 |
436 | return fig_x0_y0_coord
437 |
438 |
439 | # 过滤小图片的函数
440 | def delete_small_images_return_bigpic_index(folder_path, min_width, min_height):
441 | filtered_images = []
442 | big_pic_list = []
443 |
444 | for filename in os.listdir(folder_path):
445 | if filename.lower().endswith(".png"): # 只处理 PNG 文件
446 | file_path = os.path.join(folder_path, filename)
447 | # print(file_path)
448 | try:
449 | with Image.open(file_path) as img:
450 | width, height = img.size
451 | if width >= min_width or height >= min_height:
452 | # print(f"大图片: {filename} ({width}x{height})")
453 | # 使用正则表达式提取 _ 和 . 之间的数字
454 | match = re.search(r"fig_(\d+_\d+)\.", filename)
455 | if match:
456 | number = match.group(1) # 提取匹配的数字部分
457 | big_pic_list.append(number)
458 | # print("提取的数字:", number)
459 |
460 | else:
461 | print("未找到匹配的数字")
462 | else:
463 | filtered_images.append(file_path)
464 |
465 | except Exception as e:
466 | print(f"无法读取图片 {filename}: {e}")
467 |
468 | # 遍历列表并删除文件或文件夹
469 | for path in filtered_images:
470 | try:
471 | os.remove(path)
472 | print(f"已删除文件: {path}")
473 | except OSError as e:
474 | print(f"删除 {path} 失败: {e}")
475 |
476 | return big_pic_list
477 |
478 |
479 | # 获取文本字数
480 | def get_page_txtblock_wordcnt(page_file_path):
481 | # 文件路径
482 | file_path = page_file_path
483 |
484 | # 用于保存提取的数字部分
485 | txt_coord_x0_y0_list = []
486 | word_count_list = []
487 | total_txt_len = 0
488 |
489 | # 逐行读取文件
490 | with open(file_path, "r", encoding="utf-8") as file:
491 | for line in file:
492 | # 使用正则表达式提取数字部分
493 | match = re.search(r"(\d+\.\d+),(\d+\.\d+),(\d+\.\d+),(\d+\.\d+)", line)
494 | if match:
495 | # 将提取的数字部分保存到列表
496 | x0_y0_list = [match.group(1), match.group(2)]
497 | txt_coord_x0_y0_list.append(x0_y0_list)
498 |
499 | # 使用正则表达式提取单引号内的字符串
500 | match = re.search(r",(\d+\.\d+)\s+(.*?)>", line)
501 | if match:
502 | # 将提取的字符串保存到列表
503 | text = match.group(2)
504 | # print(text)
505 | text_len = len(text.split())
506 | total_txt_len = total_txt_len + text_len
507 | word_count_list.append(total_txt_len)
508 |
509 | # 打印结果
510 | return txt_coord_x0_y0_list, word_count_list
511 |
512 |
513 | # 获取每页待插入img的y坐标,较全量的是过滤掉了小img
514 | #def get_insert_pic_y_coordinate(pic_num, pageno):
515 | # x0_y0_coord = ALL_PIC_X0_Y0_COORDINATE[pageno][pic_num]
516 | # return x0_y0_coord
517 |
518 |
519 | def find_closest_number(lst, target):
520 | # 初始化最小差异为一个较大的值
521 | min_diff = float('inf')
522 | # 初始化最接近的数字和下标
523 | closest_number = None
524 | closest_index = -1
525 |
526 | target_x0 = float(target[0])
527 | target_y0 = float(target[1])
528 |
529 | # 遍历列表
530 | for index, x0_y0 in enumerate(lst):
531 | # 计算当前数字与目标数字的差异
532 | number_x0 = float(x0_y0[0])
533 | number_y0 = float(x0_y0[1])
534 | # 对于双列PDF, 只比较同一列情况
535 | if 150 > abs(number_x0 - target_x0):
536 | diff = abs(number_y0 - target_y0)
537 | # 如果当前差异小于最小差异,则更新最小差异、最接近的数字和下标
538 | if diff < min_diff:
539 | min_diff = diff
540 | closest_number = number_y0
541 | closest_index = index
542 |
543 | return closest_index
544 |
545 |
546 | def add_http_img_tag(text, page_num, img_num):
547 | # 构造图片路径
548 | img_path = f" 
"
549 |
550 | if text.endswith("\">"):
551 | return text.replace("\\n\">", f"{img_path}\\n\">\n")
552 | elif text.endswith("\'>"):
553 | return text.replace("\\n\'>", f"{img_path}\\n\'>\n")
554 | else:
555 | return "wrong" # 如果没有匹配的结尾,返回原字符串
556 |
557 |
558 | def save_to_one_txt(total_page_num, txt_file_path, session_id):
559 | # 用于保存提取的内容
560 | extracted_texts = []
561 | WORKING_FOLDER_NAME = read_config('config.ini', 'working_dir')
562 |
563 | for page_num in range(total_page_num):
564 | in_file_path = f"{WORKING_FOLDER_NAME}/{session_id}/{TXT_FOLDER_NAME}/txt_only_{page_num}_img.txt"
565 |
566 | # 判断文件是否存在
567 | if not os.path.exists(in_file_path):
568 | in_file_path = f"{WORKING_FOLDER_NAME}/{session_id}/{TXT_FOLDER_NAME}/txt_only_{page_num}.txt"
569 |
570 | with open(in_file_path, "r", encoding="utf-8") as file:
571 | lines = file.readlines() # 读取所有行
572 |
573 | # 分离左侧和右侧页面数据
574 | left_pages = []
575 | right_pages = []
576 |
577 | for line in lines:
578 | # 使用正则表达式提取第一个坐标数字
579 | match = re.search(r' 标签
707 | for img_tag in soup.find_all("img"):
708 | # 添加自适应样式
709 | img_tag["style"] = "max-width: 100%; height: auto;"
710 |
711 | # 将修改后的内容写回文件
712 | with open(output_html_file, "w", encoding="utf-8") as file:
713 | file.write(str(soup))
714 |
715 | print("HTML 文件已修改并保存为", output_html_file)
716 |
717 |
718 |
719 |
720 | def modify_en_txt_format(input_txt_file, output_txt_file):
721 | with open(input_txt_file, "r", encoding="utf-8") as infile, open(output_txt_file, "w", encoding="utf-8") as outfile:
722 | for line in infile:
723 | new_line = line.replace("#", " ")
724 | stripped_line = new_line.strip()
725 | if stripped_line.isdigit() and len(stripped_line) > 0:
726 | outfile.write(" \n")
727 | else:
728 | outfile.write(new_line)
729 |
730 | #print(f"TXT 文件已修改并保存为: {output_txt_file}")
731 |
732 |
733 | def modify_txt_format(input_txt_file, output_txt_file):
734 |
735 | with open(input_txt_file, "r", encoding="utf-8") as file:
736 | content = file.read()
737 |
738 |
739 | # 把句号换成句号加换行,句号后已经有换行的除外
740 | modified_content_1 = re.sub(r'([。;])(?!\n)', r'\1 \n', content)
741 |
742 | # 给换行前面加两个空格
743 | modified_content_2 = re.sub(r'(\n)', r' \n', modified_content_1)
744 |
745 | # 让mkdocs能正常显示表格
746 | modified_content_3 = re.sub(r'(^表.+?\n)', r'\1\n', modified_content_2, flags=re.MULTILINE)
747 |
748 | # 将修改后的内容保存到新文件
749 | with open(output_txt_file, "w", encoding="utf-8") as file:
750 | file.write(modified_content_3)
751 |
752 | print(f"TXT 文件已修改并保存为: {output_txt_file}")
753 |
754 |
755 |
756 |
--------------------------------------------------------------------------------
标签
707 | for img_tag in soup.find_all("img"):
708 | # 添加自适应样式
709 | img_tag["style"] = "max-width: 100%; height: auto;"
710 |
711 | # 将修改后的内容写回文件
712 | with open(output_html_file, "w", encoding="utf-8") as file:
713 | file.write(str(soup))
714 |
715 | print("HTML 文件已修改并保存为", output_html_file)
716 |
717 |
718 |
719 |
720 | def modify_en_txt_format(input_txt_file, output_txt_file):
721 | with open(input_txt_file, "r", encoding="utf-8") as infile, open(output_txt_file, "w", encoding="utf-8") as outfile:
722 | for line in infile:
723 | new_line = line.replace("#", " ")
724 | stripped_line = new_line.strip()
725 | if stripped_line.isdigit() and len(stripped_line) > 0:
726 | outfile.write(" \n")
727 | else:
728 | outfile.write(new_line)
729 |
730 | #print(f"TXT 文件已修改并保存为: {output_txt_file}")
731 |
732 |
733 | def modify_txt_format(input_txt_file, output_txt_file):
734 |
735 | with open(input_txt_file, "r", encoding="utf-8") as file:
736 | content = file.read()
737 |
738 |
739 | # 把句号换成句号加换行,句号后已经有换行的除外
740 | modified_content_1 = re.sub(r'([。;])(?!\n)', r'\1 \n', content)
741 |
742 | # 给换行前面加两个空格
743 | modified_content_2 = re.sub(r'(\n)', r' \n', modified_content_1)
744 |
745 | # 让mkdocs能正常显示表格
746 | modified_content_3 = re.sub(r'(^表.+?\n)', r'\1\n', modified_content_2, flags=re.MULTILINE)
747 |
748 | # 将修改后的内容保存到新文件
749 | with open(output_txt_file, "w", encoding="utf-8") as file:
750 | file.write(modified_content_3)
751 |
752 | print(f"TXT 文件已修改并保存为: {output_txt_file}")
753 |
754 |
755 |
756 |
--------------------------------------------------------------------------------