├── .gitignore
├── README.md
├── custom_retriever
├── __init__.py
├── bm25_retriever.py
├── build_embedding_cache.py
├── ensemble_rerank_retriever.py
├── ensemble_retriever.py
├── query_rewrite_ensemble_retriever.py
└── vector_store_retriever.py
├── data
├── corpus_openai_embedding.npy
├── demo.py
├── doc_qa_dataset.csv
├── doc_qa_dataset.json
├── doc_qa_test.json
├── doc_qa_test_demo.json
├── paul_graham_essay.txt
├── pg_eval_dataset.json
├── queries_openai_embedding.npy
├── query_rewrite.json
└── query_rewrite_openai_embedding.npy
├── docs
├── RAG框架中的Rerank算法评估.md
├── RAG框架中的Retrieve算法评估.md
└── RAG框架中的召回算法可视化分析及提升方法.md
├── embedding_finetune
├── embedding_fine_tuning.ipynb
├── test.txt
└── train.txt
├── evaluation
├── __init__.py
├── evaluation_bge-base-embedding_2024-01-05 12:30:06.csv
├── evaluation_bge-base-sft-embedding_2024-01-05 17:30:54.csv
├── evaluation_bge-large-embedding_2024-01-05 12:14:56.csv
├── evaluation_bge-large-sft-embedding_2024-01-05 17:10:41.csv
├── evaluation_bge-m3-embedding_2024-02-02 23:33:19.csv
├── evaluation_bm25_2023-12-26 12:55:48.csv
├── evaluation_ensemble_2023-12-26 22:20:24.csv
├── evaluation_exp.py
├── evaluation_jina-base-zh-embedding_2024-02-02 23:09:30.csv
├── evaluation_openai-embedding_2023-12-26 17:14:02.csv
├── evaluation_rerank-bge-base_2023-12-29 19:16:40.csv
├── evaluation_rerank-bge-large_2023-12-29 15:35:11.csv
├── evaluation_rerank-cohere_2023-12-26 23:01:01.csv
└── metric_statistics.py
├── late_chunking
├── jina_late_chunking.ipynb
├── jina_zh_late_chunking.ipynb
├── late_chunk_embeddings.py
├── late_chunking_exp.py
├── late_chunking_gradio_server.py
└── my_late_chunking_exp.ipynb
├── preprocess
├── __init__.py
├── add_corpus.py
├── data_transfer.py
├── get_text_id_mapping.py
└── query_rewrite.py
├── requirements.txt
├── services
├── __init__.py
├── data_analysis.py
├── embedding_server.py
├── llama_index_demo.ipynb
├── search_result_analysis.xlsx
└── server_gradio.py
└── utils
├── __init__.py
└── rerank.py
/.gitignore:
--------------------------------------------------------------------------------
1 | .ipynb_checkpoints
2 | .idea
3 | evaluation/*.html
4 | */__pycache__
5 | evaluation/tmp*
6 | late_chunking/.env
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | 本项目是针对RAG中的Retrieve阶段的召回技术及算法效果所做评估实验。使用主体框架为`LlamaIndex`,版本为0.9.21.
2 |
3 | Retrieve Method:
4 |
5 | - BM25 Retriever
6 | - Embedding Retriever(OpenAI, BGE, BGE-Finetune)
7 | - Ensemble Retriever
8 | - Ensemble Retriever + Cohere Rerank
9 | - Ensemble Retriever + BGE-BASE Rerank
10 | - Ensemble Retriever + BGE-LARGE Rerank
11 |
12 | 参考文章(也可查看`docs`文件夹):
13 |
14 | 1. [NLP(八十二)RAG框架中的Retrieve算法评估](https://mp.weixin.qq.com/s?__biz=MzU2NTYyMDk5MQ==&mid=2247486199&idx=1&sn=f24175b05bdf5bc6dd42efed4d5acae8&chksm=fcb9b367cbce3a711fabd1a56bb5b9d803aba2f42964b4e1f9a4dc6e2174f0952ddb9e1d4c55&token=1977141018&lang=zh_CN#rd)
15 | 2. [NLP(八十三)RAG框架中的Rerank算法评估](https://mp.weixin.qq.com/s?__biz=MzU2NTYyMDk5MQ==&mid=2247486225&idx=1&sn=235eb787e2034f24554d8e997dbb4718&chksm=fcb9b281cbce3b9761342ebadbe001747ce2e74d84340f78b0e12c4d4c6aed7a7817f246c845&token=1977141018&lang=zh_CN#rd)
16 | 3. [NLP(八十四)RAG框架中的召回算法可视化分析及提升方法](https://mp.weixin.qq.com/s?__biz=MzU2NTYyMDk5MQ==&mid=2247486264&idx=1&sn=afa31ecc8b23724154a08090ccfab213&chksm=fcb9b2a8cbce3bbeb6daaee6308c10f097c32d304f076c3061718e669fd366c8aec9e6cf379d&token=823710334&lang=zh_CN#rd)
17 | 4. [NLP(八十六)RAG框架Retrieve阶段的Embedding模型微调](https://mp.weixin.qq.com/s?__biz=MzU2NTYyMDk5MQ==&mid=2247486333&idx=1&sn=29d00d472647bc5d6e336bec22c88139&chksm=fcb9b2edcbce3bfb42ea149d96fb1296b10a79a60db7ad2da01b85ab223394191205426bc025&token=1376257911&lang=zh_CN#rd)
18 | 5. [NLP(一百零一)Embedding模型微调实践](https://mp.weixin.qq.com/s/lJ3Mycjw1G99T08r8c7dSQ)
19 | 6. [NLP(一百零二)ReRank模型微调实践](https://mp.weixin.qq.com/s/RiPYANTyEgFtIIFHaKq3Rg)
20 |
21 | ## 数据
22 |
23 | 参考`data/doc_qa_test.json`文件,格式以LlamaIndex框架为标准。
24 |
25 | ## 评估结果
26 |
27 | BM25 Retriever Evaluation:
28 |
29 | | retrievers | hit_rate | mrr | cost_time |
30 | |-----------------|--------------------|--------------------|--------------------|
31 | | bm25_top_1_eval | 0.7975077881619937 | 0.7975077881619937 | 461.2770080566406 |
32 | | bm25_top_2_eval | 0.8535825545171339 | 0.8255451713395638 | 510.3020668029785 |
33 | | bm25_top_3_eval | 0.9003115264797508 | 0.8411214953271028 | 570.6708431243896 |
34 | | bm25_top_4_eval | 0.9158878504672897 | 0.8450155763239875 | 420.72606086730957 |
35 | | bm25_top_5_eval | 0.940809968847352 | 0.8500000000000001 | 388.5960578918457 |
36 |
37 | Embedding Retriever Evaluation:
38 |
39 | | retrievers | hit_rate | mrr | cost_time |
40 | |----------------------|--------------------|--------------------|--------------------|
41 | | embedding_top_1_eval | 0.6074766355140186 | 0.6074766355140186 | 67.68369674682617 |
42 | | embedding_top_2_eval | 0.6978193146417445 | 0.6526479750778816 | 60.84489822387695 |
43 | | embedding_top_3_eval | 0.7320872274143302 | 0.6640706126687436 | 59.905052185058594 |
44 | | embedding_top_4_eval | 0.778816199376947 | 0.6757528556593978 | 63.54880332946777 |
45 | | embedding_top_5_eval | 0.794392523364486 | 0.6788681204569056 | 67.79217720031738 |
46 |
47 | Ensemble Retriever Evaluation:
48 |
49 | | retrievers | hit_rate | mrr | cost_time |
50 | |---------------------|--------------------|--------------------|--------------------|
51 | | ensemble_top_1_eval | 0.7009345794392523 | 0.7009345794392523 | 1072.7379322052002 |
52 | | ensemble_top_2_eval | 0.8535825545171339 | 0.7741433021806854 | 1088.8781547546387 |
53 | | ensemble_top_3_eval | 0.8940809968847352 | 0.7928348909657321 | 980.7949066162109 |
54 | | ensemble_top_4_eval | 0.9190031152647975 | 0.8016614745586708 | 935.1701736450195 |
55 | | ensemble_top_5_eval | 0.9376947040498442 | 0.8078920041536861 | 868.2990074157715 |
56 |
57 | Ensemble Retriever + Rerank Evaluation:
58 |
59 | | retrievers | hit_rate | mrr | cost_time |
60 | |----------------------------|--------------------|--------------------|-------------------|
61 | | ensemble_rerank_top_1_eval | 0.8348909657320872 | 0.8348909657320872 | 2140632.404088974 |
62 | | ensemble_rerank_top_2_eval | 0.9034267912772586 | 0.8785046728971962 | 2157657.287120819 |
63 | | ensemble_rerank_top_3_eval | 0.9345794392523364 | 0.9008307372793353 | 2200800.935983658 |
64 | | ensemble_rerank_top_4_eval | 0.9470404984423676 | 0.9078400830737278 | 2150398.734807968 |
65 | | ensemble_rerank_top_5_eval | 0.9657320872274143 | 0.9098650051921081 | 2149122.938156128 |
66 |
67 | 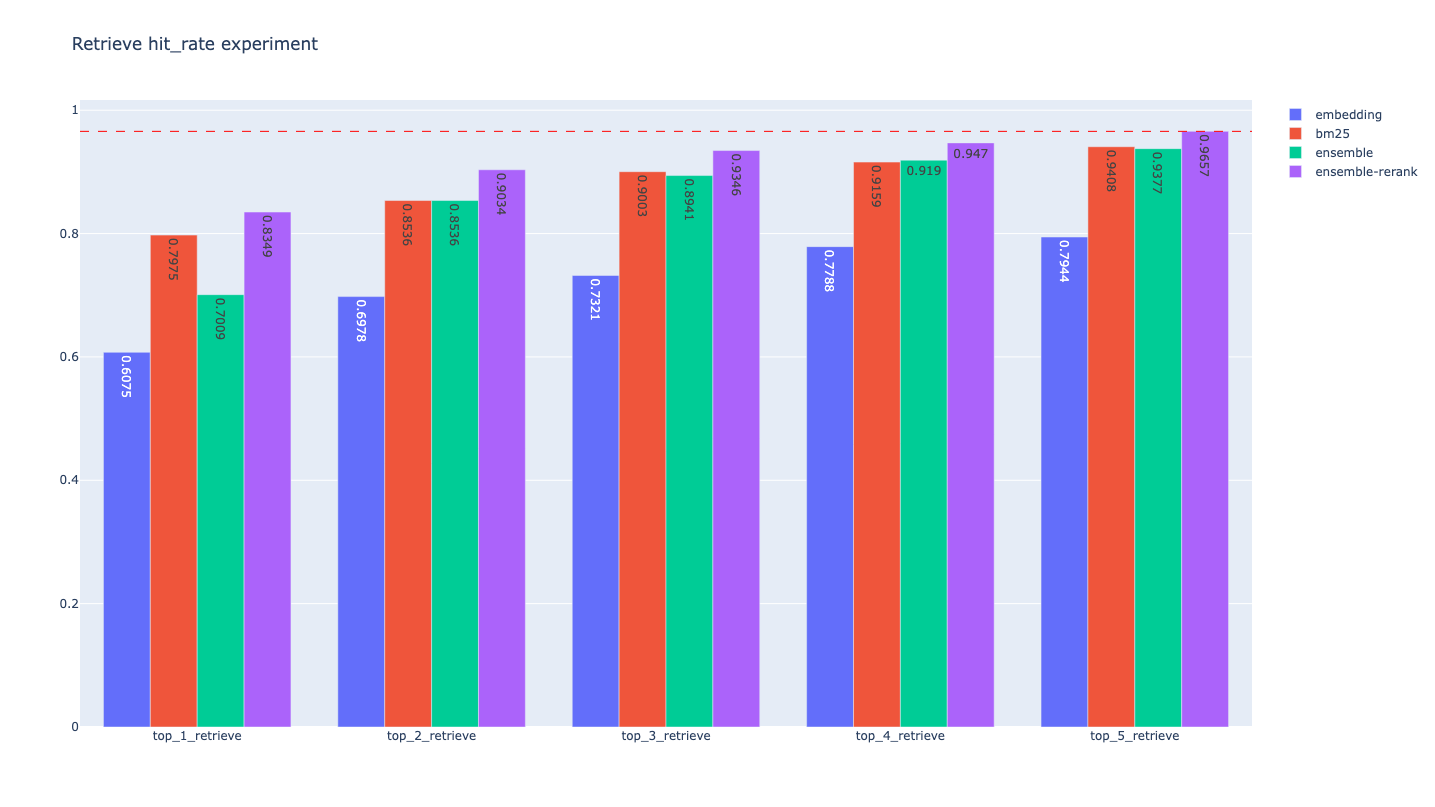
68 |
69 | 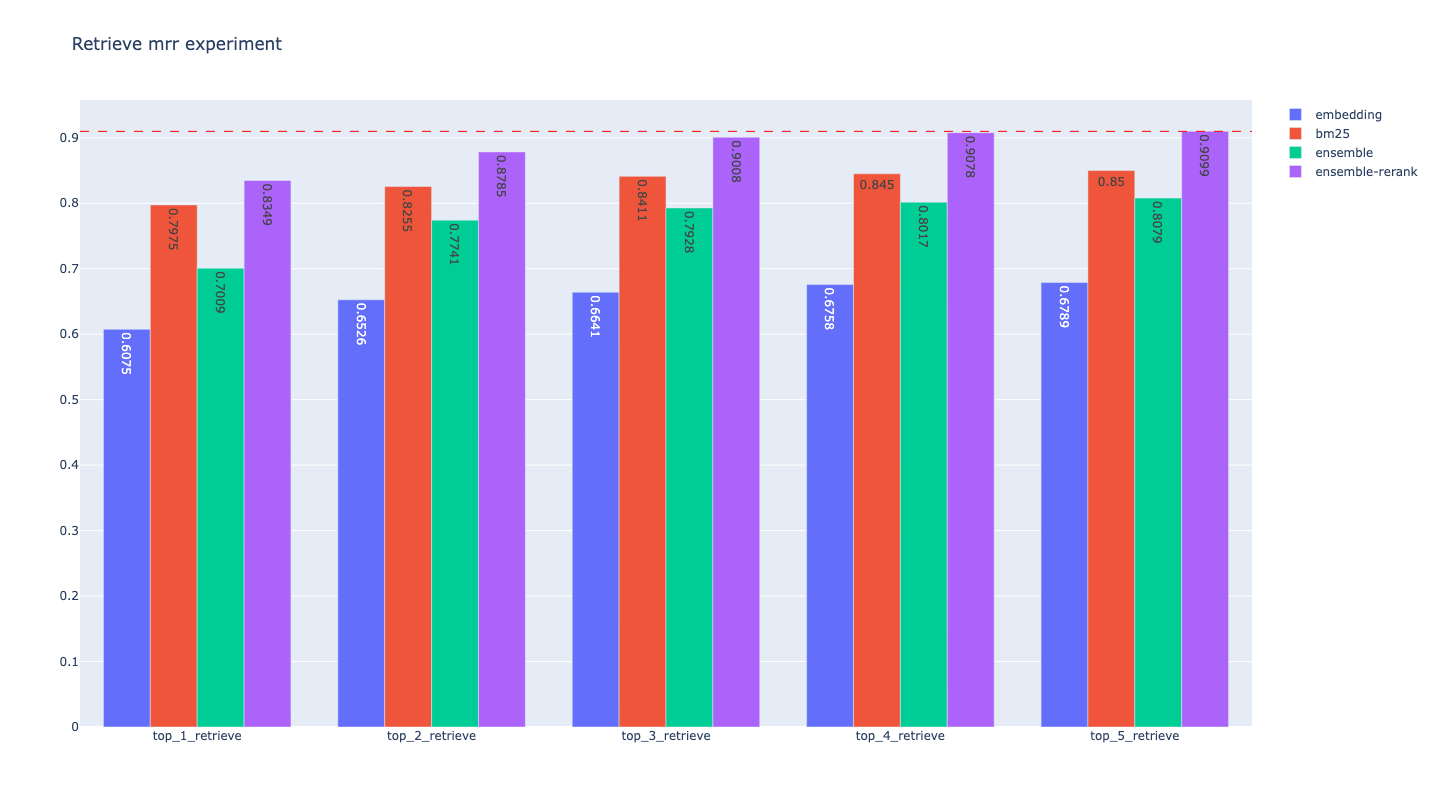
70 |
71 | ## 不同Rerank算法之间的比较
72 |
73 | bge-rerank-base:
74 |
75 | | retrievers | hit_rate | mrr |
76 | |-------------------------------------|----------|--------|
77 | | ensemble_bge_base_rerank_top_1_eval | 0.8255 | 0.8255 |
78 | | ensemble_bge_base_rerank_top_2_eval | 0.8785 | 0.8489 |
79 | | ensemble_bge_base_rerank_top_3_eval | 0.9346 | 0.8686 |
80 | | ensemble_bge_base_rerank_top_4_eval | 0.947 | 0.872 |
81 | | ensemble_bge_base_rerank_top_5_eval | 0.9564 | 0.8693 |
82 |
83 | bge-rerank-large:
84 |
85 | | retrievers | hit_rate | mrr |
86 | |--------------------------------------|----------|--------|
87 | | ensemble_bge_large_rerank_top_1_eval | 0.8224 | 0.8224 |
88 | | ensemble_bge_large_rerank_top_2_eval | 0.8847 | 0.8364 |
89 | | ensemble_bge_large_rerank_top_3_eval | 0.9377 | 0.8572 |
90 | | ensemble_bge_large_rerank_top_4_eval | 0.9502 | 0.8564 |
91 | | ensemble_bge_large_rerank_top_5_eval | 0.9626 | 0.8537 |
92 |
93 | ft-bge-rerank-base:
94 |
95 | | retrievers | hit_rate | mrr |
96 | |----------------------------------------|----------|----------|
97 | | ensemble_ft_bge_base_rerank_top_1_eval | 0.8474 | 0.8474 |
98 | | ensemble_ft_bge_base_rerank_top_2_eval | 0.9003 | 0.8816 |
99 | | ensemble_ft_bge_base_rerank_top_3_eval | 0.9408 | 0.9102 |
100 | | ensemble_ft_bge_base_rerank_top_4_eval | 0.9533 | 0.9180 |
101 | | ensemble_ft_bge_base_rerank_top_5_eval | 0.9657 | 0.9240 |
102 |
103 |
104 | ft-bge-rerank-large:
105 |
106 | | retrievers | hit_rate | mrr |
107 | |-----------------------------------------|----------|---------|
108 | | ensemble_ft_bge_large_rerank_top_1_eval | 0.8474 | 0.8474 |
109 | | ensemble_ft_bge_large_rerank_top_2_eval | 0.9003 | 0.8769 |
110 | | ensemble_ft_bge_large_rerank_top_3_eval | 0.9439 | 0.9024 |
111 | | ensemble_ft_bge_large_rerank_top_4_eval | 0.9564 | 0.9029 |
112 | | ensemble_ft_bge_large_rerank_top_5_eval | 0.9688 | 0.9028 |
113 |
114 |
115 | 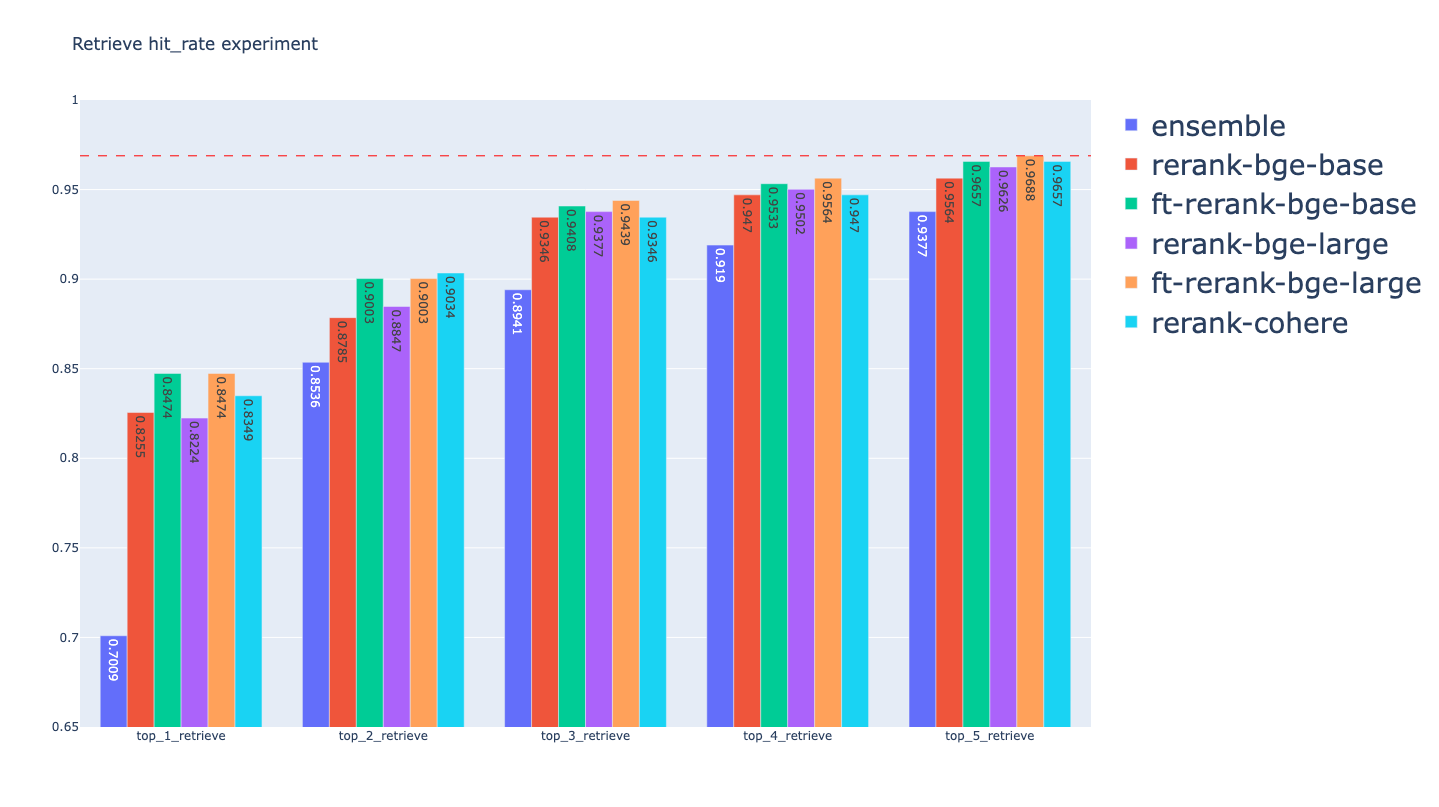
116 |
117 | ## 不同Embedding模型之间的比较
118 |
119 | jina-base-zh-embedding:
120 |
121 | | retrievers | hit_rate | mrr | cost_time |
122 | |----------------------|--------------------|--------------------|--------------------|
123 | | embedding_top_1_eval | 0.5389408099688473 | 0.5389408099688473 | 34.9421501159668 |
124 | | embedding_top_2_eval | 0.6448598130841121 | 0.5919003115264797 | 35.04490852355957 |
125 | | embedding_top_3_eval | 0.7165109034267912 | 0.6157840083073729 | 40.548086166381836 |
126 | | embedding_top_4_eval | 0.7476635514018691 | 0.6235721703011423 | 41.40806198120117 |
127 | | embedding_top_5_eval | 0.7694704049844237 | 0.6279335410176532 | 43.450117111206055 |
128 |
129 | bge-base-embedding:
130 |
131 | | retrievers | hit_rate | mrr | cost_time |
132 | |----------------------|--------------------|--------------------|--------------------|
133 | | embedding_top_1_eval | 0.6043613707165109 | 0.6043613707165109 | 40.014028549194336 |
134 | | embedding_top_2_eval | 0.7071651090342679 | 0.6557632398753894 | 38.26403617858887 |
135 | | embedding_top_3_eval | 0.7538940809968847 | 0.6713395638629284 | 39.404869079589844 |
136 | | embedding_top_4_eval | 0.7912772585669782 | 0.6806853582554517 | 43.24913024902344 |
137 | | embedding_top_5_eval | 0.8099688473520249 | 0.684423676012461 | 53.58481407165527 |
138 |
139 | bge-large-embedding:
140 |
141 | | retrievers | hit_rate | mrr | cost_time |
142 | |----------------------|--------------------|--------------------|--------------------|
143 | | embedding_top_1_eval | 0.5919003115264797 | 0.5919003115264797 | 50.39501190185547 |
144 | | embedding_top_2_eval | 0.7133956386292835 | 0.6526479750778816 | 52.02889442443848 |
145 | | embedding_top_3_eval | 0.7725856697819314 | 0.6723779854620976 | 51.7120361328125 |
146 | | embedding_top_4_eval | 0.794392523364486 | 0.6778296988577361 | 51.872968673706055 |
147 | | embedding_top_5_eval | 0.822429906542056 | 0.6834371754932502 | 56.67304992675781 |
148 |
149 | bge-m3-embedding:
150 |
151 | | retrievers | hit_rate | mrr | cost_time |
152 | |----------------------|--------------------|--------------------|--------------------|
153 | | embedding_top_1_eval | 0.6822429906542056 | 0.6822429906542056 | 43.41626167297363 |
154 | | embedding_top_2_eval | 0.778816199376947 | 0.7305295950155763 | 44.278860092163086 |
155 | | embedding_top_3_eval | 0.8193146417445483 | 0.7440290758047767 | 45.64094543457031 |
156 | | embedding_top_4_eval | 0.8504672897196262 | 0.7518172377985461 | 46.158790588378906 |
157 | | embedding_top_5_eval | 0.8722741433021807 | 0.7561786085150571 | 50.23527145385742 |
158 |
159 | bce-embedding:
160 |
161 | | retrievers | hit_rate | mrr | cost_time |
162 | |----------------------|--------------------|--------------------|--------------------|
163 | | embedding_top_1_eval | 0.5794392523364486 | 0.5794392523364486 | 42.510032653808594 |
164 | | embedding_top_2_eval | 0.6853582554517134 | 0.632398753894081 | 42.72007942199707 |
165 | | embedding_top_3_eval | 0.7227414330218068 | 0.6448598130841121 | 41.066884994506836 |
166 | | embedding_top_4_eval | 0.7507788161993769 | 0.6518691588785047 | 43.18714141845703 |
167 | | embedding_top_5_eval | 0.7663551401869159 | 0.6549844236760125 | 44.08693313598633 |
168 |
169 | bge-base-embedding-finetune:
170 |
171 | | retrievers | hit_rate | mrr | cost_time |
172 | |----------------------|--------------------|--------------------|--------------------|
173 | | embedding_top_1_eval | 0.7289719626168224 | 0.7289719626168224 | 48.82097244262695 |
174 | | embedding_top_2_eval | 0.8598130841121495 | 0.794392523364486 | 42.237043380737305 |
175 | | embedding_top_3_eval | 0.9003115264797508 | 0.8078920041536863 | 42.33193397521973 |
176 | | embedding_top_4_eval | 0.9065420560747663 | 0.8094496365524404 | 45.35722732543945 |
177 | | embedding_top_5_eval | 0.9158878504672897 | 0.811318795430945 | 50.804853439331055 |
178 |
179 | bge-large-embedding-finetune:
180 |
181 | | retrievers | hit_rate | mrr | cost_time |
182 | |----------------------|--------------------|--------------------|--------------------|
183 | | embedding_top_1_eval | 0.7570093457943925 | 0.7570093457943925 | 47.14798927307129 |
184 | | embedding_top_2_eval | 0.881619937694704 | 0.8193146417445483 | 44.70491409301758 |
185 | | embedding_top_3_eval | 0.9190031152647975 | 0.8317757009345794 | 46.12398147583008 |
186 | | embedding_top_4_eval | 0.9376947040498442 | 0.8364485981308412 | 49.448251724243164 |
187 | | embedding_top_5_eval | 0.9376947040498442 | 0.8364485981308412 | 57.805776596069336 |
188 |
189 | 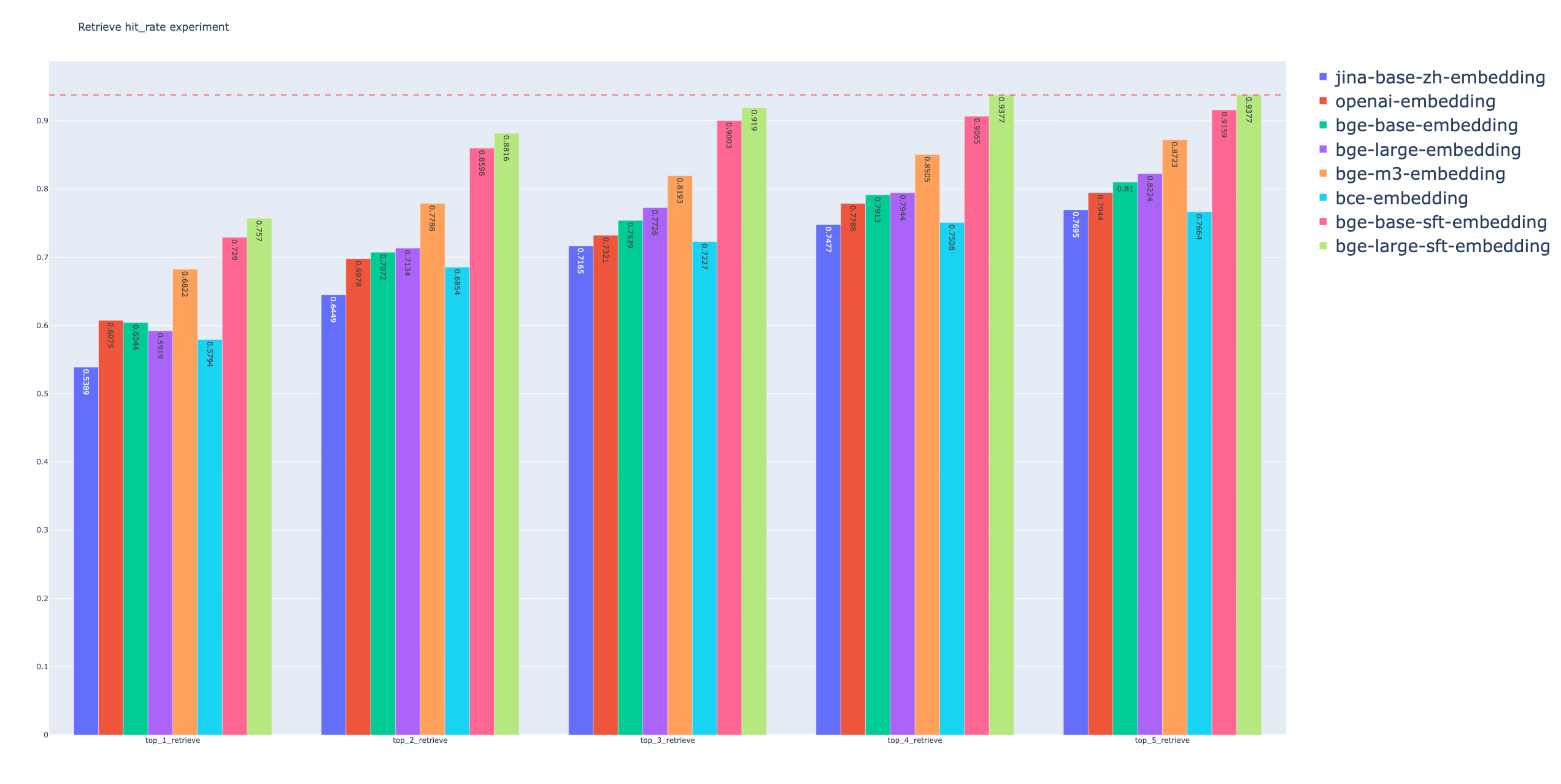
190 |
191 | 
192 |
193 | ## 可视化分析
194 |
195 | 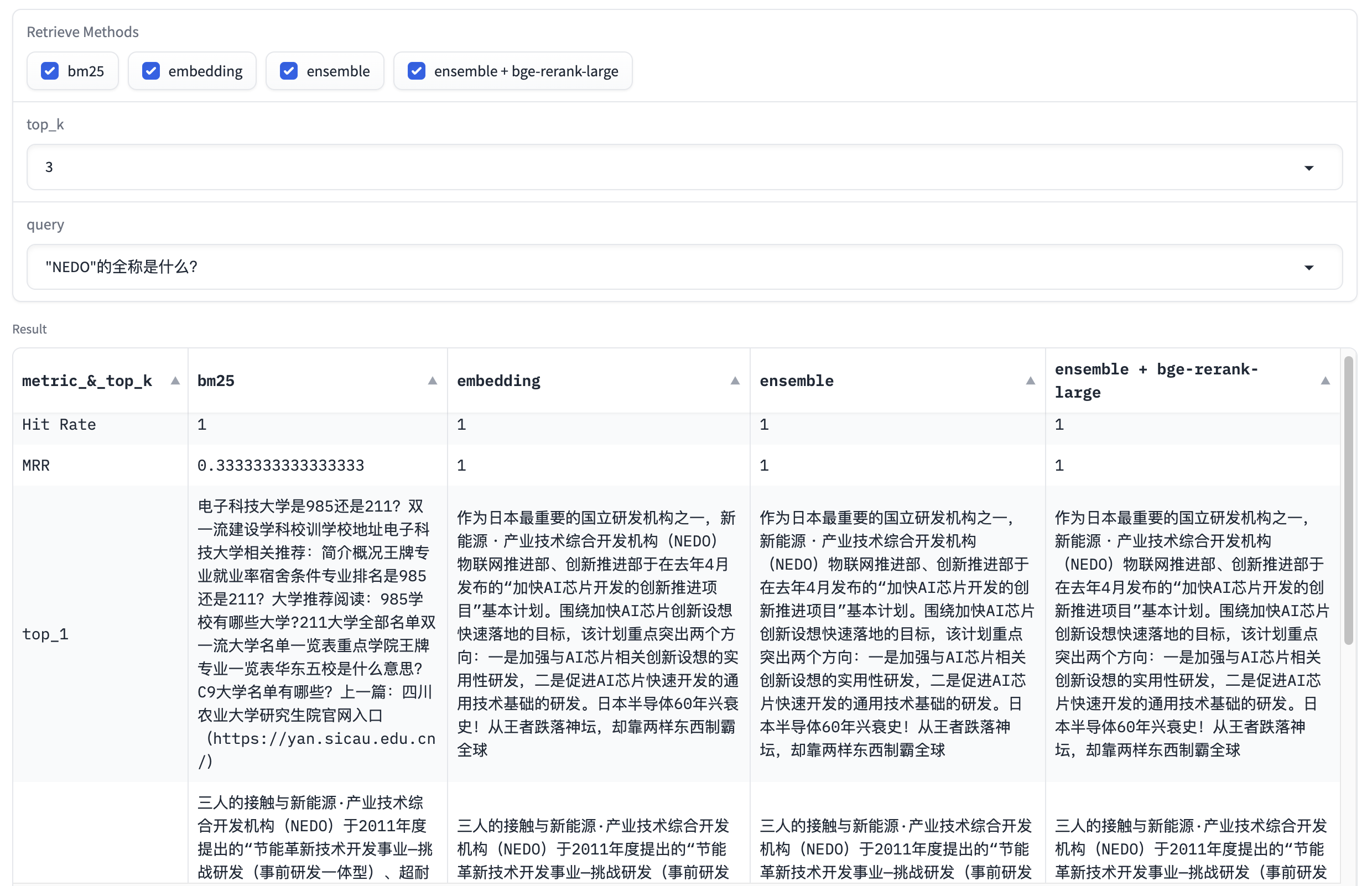
196 |
197 | | 检索类型 | 优点 | 缺点 |
198 | |----------|------|------|
199 | | 向量检索 (Embedding) | 1. 语义理解更强。
2. 能有效处理模糊或间接的查询。
3. 对自然语言的多样性适应性强。
4. 能识别不同词汇的相同意义。 | 1. 计算和存储成本高。
2. 索引时间较长。
3. 高度依赖训练数据的质量和数量。
4. 结果解释性较差。 |
200 | | 关键词检索 (BM25) | 1. 检索速度快。
2. 实现简单,资源需求低。
3. 结果易于理解,可解释性强。
4. 对精确查询表现良好。 | 1. 对复杂语义理解有限。
2. 对查询变化敏感,灵活性差。
3. 难以处理同义词和多义词。
4. 需要用户准确使用关键词。 |
201 |
202 | - `query`: "NEDO"的全称是什么?
203 |
204 | 
205 |
206 | 在这个例子中,Embedding召回结果优于BM25,BM25召回结果虽然在top_3结果中存在,但排名第三,排在首位的是不相关的文本,而Embedding由于文本相似度的优势,将正确结果放在了首位。
207 |
208 | - `query`: 日本半导体产品的主要应用领域是什么?
209 |
210 | 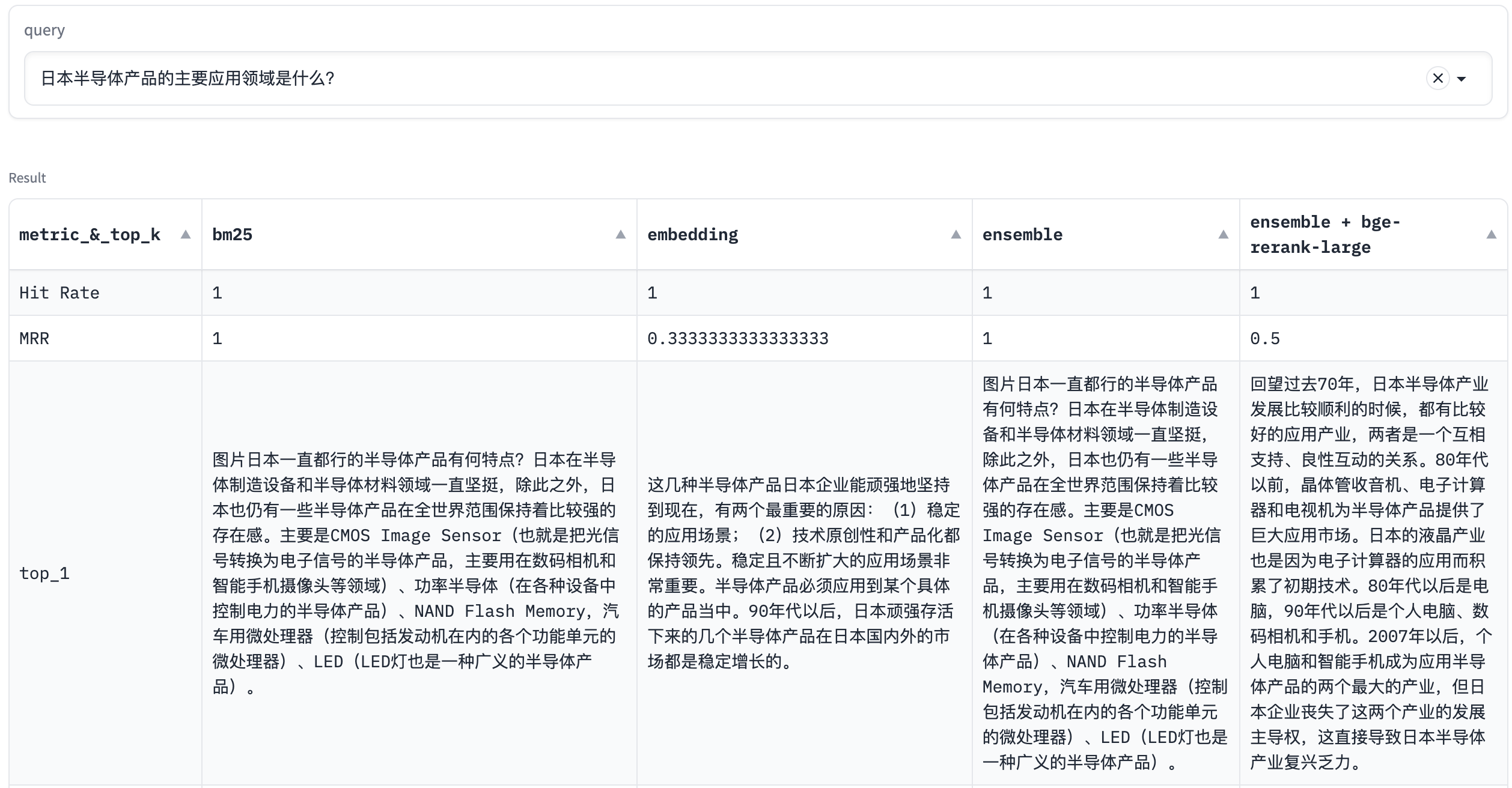
211 |
212 | 在这个例子中,BM25召回结果优于Embedding。
213 |
214 | - `query`: 《美日半导体协议》对日本半导体市场有何影响?
215 |
216 | 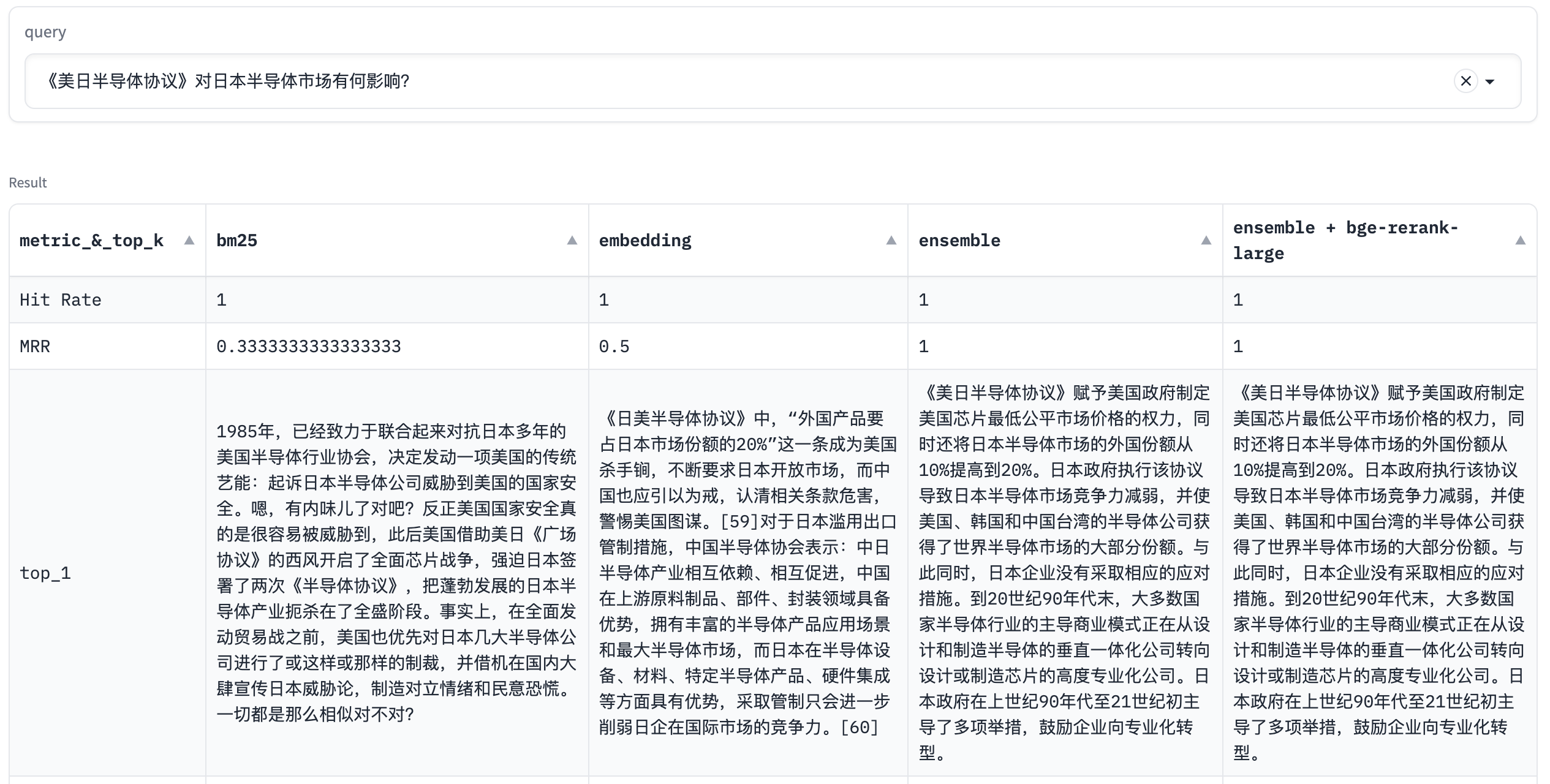
217 |
218 | 在这个例子中,正确文本在BM25算法召回结果中排名第二,在Embedding算法中排第三,混合搜索排名第一,这里体现了混合搜索的优越性。
219 |
220 | - `query`: 80年代日本电子产业的辉煌表现在哪些方面?
221 |
222 | 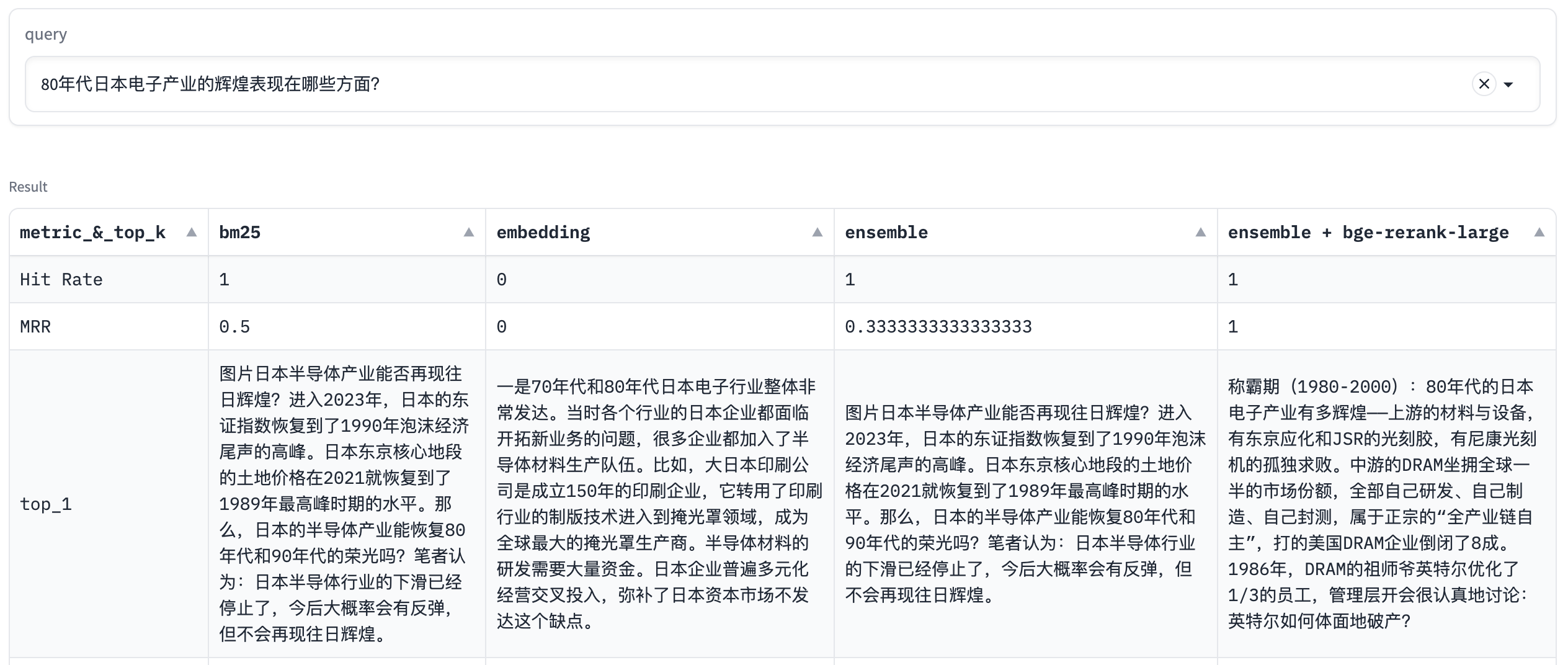
223 |
224 | 在这个例子中,不管是BM25, Embedding,还是Ensemble,都没能将正确文本排在第一位,而经过Rerank以后,正确文本排在第一位,这里体现了Rerank算法的优势。
225 |
226 | ## 改进方案
227 |
228 | 1. Query Rewrite
229 |
230 | - 原始query: 半导体制造设备市场美、日、荷各占多少份额?
231 | - 改写后query:美国、日本和荷兰在半导体制造设备市场的份额分别是多少?
232 |
233 | 改写后的query在BM25和Embedding的top 3召回结果中都能找到。该query对应的正确文本为:
234 |
235 | > 全球半导体设备制造领域,美国、日本和荷兰控制着全球370亿美元半导体制造设备市场的90%以上。其中,美国的半导体制造设备(SME)产业占全球产量的近50%,日本约占30%,荷兰约占17%%。更具体地,以光刻机为例,EUV光刻工序其实有众多日本厂商的参与,如东京电子生产的EUV涂覆显影设备,占据100%的市场份额,Lasertec Corp.也是全球唯一的测试机制造商。另外还有EUV光刻胶,据南大光电在3月发布的相关报告中披露,全球仅有日本厂商研发出了EUV光刻胶。
236 |
237 | 从中我们可以看到,在改写后的query中,美国、日本、荷兰这三个词发挥了重要作用,因此,**query改写对于含有缩写的query有一定的召回效果改善**。
238 |
239 | 2. HyDE
240 |
241 | HyDE(全称Hypothetical Document Embeddings)是RAG中的一种技术,它基于一个假设:相较于直接查询,通过大语言模型 (LLM) 生成的答案在嵌入空间中可能更为接近。HyDE 首先响应查询生成一个假设性文档(答案),然后将其嵌入,从而提高搜索的效果。
242 |
243 | 比如:
244 |
245 | - 原始query: 美日半导体协议是由哪两部门签署的?
246 | - 加上回答后的query: 美日半导体协议是由哪两部门签署的?美日半导体协议是由美国商务部和日本经济产业省签署的。
247 |
248 | 加上回答后的query使用BM25算法可以找回正确文本,且排名第一位,而Embedding算法仍无法召回。
249 |
250 | 正确文本为:
251 |
252 | > 1985年6月,美国半导体产业贸易保护的调子开始升高。美国半导体工业协会向国会递交一份正式的“301条款”文本,要求美国政府制止日本公司的倾销行为。民意调查显示,68%的美国人认为日本是美国最大的威胁。在舆论的引导和半导体工业协会的推动下,美国政府将信息产业定为可以动用国家安全借口进行保护的新兴战略产业,半导体产业成为美日贸易战的焦点。1985年10月,美国商务部出面指控日本公司倾销256K和1M内存。一年后,日本通产省被迫与美国商务部签署第一次《美日半导体协议》。
253 |
254 | 从中可以看出,大模型的回答是正确的,美国商务部这个关键词发挥了重要作用,因此,HyDE对于特定的query有召回效果提升。
255 |
256 |
257 | ## Late Chunking探索
258 |
259 | 1. 中文Late-Chunking例子: late_chunking/jina_zh_late_chunking.ipynb
260 | 2. 使用Gradio实现中文Late-Chunking服务: late_chunking/late_chunking_gradio_server.py
261 | 3. 在RAG过程中,使用Late-Chunking提升召回效果,保证回复质量: late_chunking/my_late_chunking_exp.ipynb
--------------------------------------------------------------------------------
/custom_retriever/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: __init__.py.py
4 | # @time: 2023/12/25 17:42
5 |
--------------------------------------------------------------------------------
/custom_retriever/bm25_retriever.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: bm25_retriever.py
4 | # @time: 2023/12/25 17:42
5 | from typing import List
6 |
7 | from elasticsearch import Elasticsearch
8 | from llama_index.schema import TextNode
9 | from llama_index import QueryBundle
10 | from llama_index.schema import NodeWithScore
11 | from llama_index.retrievers import BaseRetriever
12 | from llama_index.indices.query.schema import QueryType
13 |
14 | from preprocess.get_text_id_mapping import text_node_id_mapping
15 |
16 |
17 | class CustomBM25Retriever(BaseRetriever):
18 | """Custom retriever for elasticsearch with bm25"""
19 | def __init__(self, top_k) -> None:
20 | """Init params."""
21 | super().__init__()
22 | self.es_client = Elasticsearch("http://localhost:9200")
23 | self.top_k = top_k
24 |
25 | def _retrieve(self, query: QueryType) -> List[NodeWithScore]:
26 | if isinstance(query, str):
27 | query = QueryBundle(query)
28 | else:
29 | query = query
30 |
31 | result = []
32 | # 查询数据(全文搜索)
33 | dsl = {
34 | 'query': {
35 | 'match': {
36 | 'content': query.query_str
37 | }
38 | },
39 | "size": self.top_k
40 | }
41 | search_result = self.es_client.search(index='docs', body=dsl)
42 | if search_result['hits']['hits']:
43 | for record in search_result['hits']['hits']:
44 | text = record['_source']['content']
45 | node_with_score = NodeWithScore(node=TextNode(text=text,
46 | id_=text_node_id_mapping[text]),
47 | score=record['_score'])
48 | result.append(node_with_score)
49 |
50 | return result
51 |
52 |
53 | if __name__ == '__main__':
54 | from pprint import pprint
55 | custom_bm25_retriever = CustomBM25Retriever(top_k=3)
56 | query = "美日半导体协议是由哪两部门签署的?美日半导体协议是由美国商务部和日本经济产业省签署的。"
57 | t_result = custom_bm25_retriever.retrieve(str_or_query_bundle=query)
58 | pprint(t_result)
59 |
--------------------------------------------------------------------------------
/custom_retriever/build_embedding_cache.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: build_embedding_cache.py
4 | # @time: 2023/12/26 12:57
5 | import os
6 | import time
7 | import math
8 | import json
9 | import random
10 | import requests
11 | import numpy as np
12 | from retry import retry
13 | from tqdm import tqdm
14 |
15 |
16 | class EmbeddingCache(object):
17 | def __init__(self):
18 | pass
19 |
20 | @staticmethod
21 | @retry(exceptions=Exception, tries=3, max_delay=20)
22 | def get_openai_embedding(req_text: str):
23 | time.sleep(random.random() / 2)
24 | url = "https://api.openai.com/v1/embeddings"
25 | headers = {'Content-Type': 'application/json', "Authorization": f"Bearer {os.getenv('OPENAI_API_KEY')}"}
26 | payload = json.dumps({"model": "text-embedding-ada-002", "input": req_text})
27 | new_req = requests.request("POST", url, headers=headers, data=payload)
28 | return new_req.json()['data'][0]['embedding']
29 |
30 | @staticmethod
31 | @retry(exceptions=Exception, tries=3, max_delay=20)
32 | def get_bge_embedding(req_text: str):
33 | url = "http://localhost:50073/embedding"
34 | headers = {'Content-Type': 'application/json'}
35 | payload = json.dumps({"text": req_text})
36 | new_req = requests.request("POST", url, headers=headers, data=payload)
37 | return new_req.json()['embedding']
38 |
39 | @staticmethod
40 | @retry(exceptions=Exception, tries=3, max_delay=20)
41 | def get_jina_embedding(req_text: str):
42 | time.sleep(random.random() / 2)
43 | url = 'https://api.jina.ai/v1/embeddings'
44 | headers = {
45 | 'Content-Type': 'application/json',
46 | 'Authorization': f'Bearer {os.getenv("JINA_API_KEY")}'
47 | }
48 | data = {
49 | 'input': [req_text],
50 | 'model': 'jina-embeddings-v2-base-zh'
51 | }
52 | response = requests.post(url, headers=headers, json=data)
53 | embedding = response.json()["data"][0]["embedding"]
54 | embedding_norm = math.sqrt(sum([i**2 for i in embedding]))
55 | return [i/embedding_norm for i in embedding]
56 |
57 | def build_with_context(self, context_type: str):
58 | with open("../data/doc_qa_test.json", "r", encoding="utf-8") as f:
59 | content = json.loads(f.read())
60 | queries = list(content[context_type].values())
61 | query_num = len(queries)
62 | embedding_data = np.empty(shape=[query_num, 768])
63 | for i in tqdm(range(query_num), desc="generate embedding"):
64 | embedding_data[i] = self.get_bge_embedding(queries[i])
65 | np.save(f"../data/{context_type}_bce_embedding.npy", embedding_data)
66 |
67 | def build(self):
68 | self.build_with_context("queries")
69 | self.build_with_context("corpus")
70 |
71 | @staticmethod
72 | def load(query_write=False):
73 | current_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
74 | queries_embedding_data = np.load(os.path.join(current_dir, "data/queries_jina_base_zh_embedding.npy"))
75 | corpus_embedding_data = np.load(os.path.join(current_dir, "data/corpus_jina_base_zh_late_chunking_embedding.npy"))
76 | query_embedding_dict = {}
77 | with open(os.path.join(current_dir, "data/doc_qa_test.json"), "r", encoding="utf-8") as f:
78 | content = json.loads(f.read())
79 | queries = list(content["queries"].values())
80 | corpus = list(content["corpus"].values())
81 | for i in range(len(queries)):
82 | query_embedding_dict[queries[i]] = queries_embedding_data[i].tolist()
83 | if query_write:
84 | rewrite_queries_embedding_data = np.load(os.path.join(current_dir, "data/query_rewrite_openai_embedding.npy"))
85 | with open("../data/query_rewrite.json", "r", encoding="utf-8") as f:
86 | rewrite_content = json.loads(f.read())
87 |
88 | rewrite_queries_list = []
89 | for original_query, rewrite_queries in rewrite_content.items():
90 | rewrite_queries_list.extend(rewrite_queries)
91 | for i in range(len(rewrite_queries_list)):
92 | query_embedding_dict[rewrite_queries_list[i]] = rewrite_queries_embedding_data[i].tolist()
93 | return query_embedding_dict, corpus_embedding_data, corpus
94 |
95 |
96 | if __name__ == '__main__':
97 | EmbeddingCache().build()
98 |
--------------------------------------------------------------------------------
/custom_retriever/ensemble_rerank_retriever.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: ensemble_rerank_retriever.py
4 | # @time: 2023/12/26 19:18
5 | from typing import List
6 |
7 | from llama_index.schema import TextNode
8 | from llama_index.schema import NodeWithScore
9 | from llama_index.retrievers import BaseRetriever
10 | from llama_index.indices.query.schema import QueryBundle, QueryType
11 |
12 | from preprocess.get_text_id_mapping import text_node_id_mapping
13 | from custom_retriever.bm25_retriever import CustomBM25Retriever
14 | from custom_retriever.vector_store_retriever import VectorSearchRetriever
15 | from utils.rerank import bge_rerank_result
16 |
17 |
18 | class EnsembleRerankRetriever(BaseRetriever):
19 | def __init__(self, top_k, faiss_index):
20 | super().__init__()
21 | self.faiss_index = faiss_index
22 | self.top_k = top_k
23 | self.embedding_retriever = VectorSearchRetriever(top_k=self.top_k, faiss_index=faiss_index)
24 |
25 | def _retrieve(self, query: QueryType) -> List[NodeWithScore]:
26 | if isinstance(query, str):
27 | query = QueryBundle(query)
28 | else:
29 | query = query
30 | # print(query.query_str)
31 | bm25_search_nodes = CustomBM25Retriever(top_k=self.top_k).retrieve(query)
32 | embedding_search_nodes = self.embedding_retriever.retrieve(query)
33 | bm25_docs = [node.text for node in bm25_search_nodes]
34 | embedding_docs = [node.text for node in embedding_search_nodes]
35 | # remove duplicate document
36 | all_documents = set()
37 | for doc_list in [bm25_docs, embedding_docs]:
38 | for doc in doc_list:
39 | all_documents.add(doc)
40 | doc_lists = list(all_documents)
41 | rerank_doc_lists = bge_rerank_result(query.query_str, doc_lists, top_n=self.top_k)
42 | result = []
43 | for sorted_doc in rerank_doc_lists:
44 | text, score = sorted_doc
45 | node_with_score = NodeWithScore(node=TextNode(text=text,
46 | id_=text_node_id_mapping[text]),
47 | score=score)
48 | result.append(node_with_score)
49 |
50 | return result
51 |
52 |
53 | if __name__ == '__main__':
54 | from faiss import IndexFlatIP
55 |
56 | faiss_index = IndexFlatIP(1536)
57 | ensemble_retriever = EnsembleRerankRetriever(top_k=2, faiss_index=faiss_index)
58 | t_result = ensemble_retriever.retrieve(str_or_query_bundle="索尼1953年引入的技术专利是什么?")
59 | print(t_result)
60 | faiss_index.reset()
61 |
--------------------------------------------------------------------------------
/custom_retriever/ensemble_retriever.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: ensemble_retriever.py
4 | # @time: 2023/12/26 18:50
5 | from typing import List
6 | from operator import itemgetter
7 |
8 | from llama_index.schema import TextNode
9 | from llama_index.schema import NodeWithScore
10 | from llama_index.retrievers import BaseRetriever
11 | from llama_index.indices.query.schema import QueryType
12 |
13 | from preprocess.get_text_id_mapping import text_node_id_mapping
14 | from custom_retriever.bm25_retriever import CustomBM25Retriever
15 | from custom_retriever.vector_store_retriever import VectorSearchRetriever
16 |
17 |
18 | class EnsembleRetriever(BaseRetriever):
19 | def __init__(self, top_k, faiss_index, weights):
20 | super().__init__()
21 | self.weights = weights
22 | self.c: int = 60
23 | self.faiss_index = faiss_index
24 | self.top_k = top_k
25 | self.embedding_retriever = VectorSearchRetriever(top_k=self.top_k, faiss_index=faiss_index)
26 |
27 | def _retrieve(self, query: QueryType) -> List[NodeWithScore]:
28 | bm25_search_nodes = CustomBM25Retriever(top_k=self.top_k).retrieve(query)
29 | embedding_search_nodes = self.embedding_retriever.retrieve(query)
30 | bm25_docs = [node.text for node in bm25_search_nodes]
31 | embedding_docs = [node.text for node in embedding_search_nodes]
32 | doc_lists = [bm25_docs, embedding_docs]
33 |
34 | # Create a union of all unique documents in the input doc_lists
35 | all_documents = set()
36 | for doc_list in doc_lists:
37 | for doc in doc_list:
38 | all_documents.add(doc)
39 |
40 | # Initialize the RRF score dictionary for each document
41 | rrf_score_dic = {doc: 0.0 for doc in all_documents}
42 |
43 | # Calculate RRF scores for each document
44 | for doc_list, weight in zip(doc_lists, self.weights):
45 | for rank, doc in enumerate(doc_list, start=1):
46 | rrf_score = weight * (1 / (rank + self.c))
47 | rrf_score_dic[doc] += rrf_score
48 |
49 | # Sort documents by their RRF scores in descending order
50 | sorted_documents = sorted(rrf_score_dic.items(), key=itemgetter(1), reverse=True)
51 | result = []
52 | for sorted_doc in sorted_documents[:self.top_k]:
53 | text, score = sorted_doc
54 | node_with_score = NodeWithScore(node=TextNode(text=text,
55 | id_=text_node_id_mapping[text]),
56 | score=score)
57 | result.append(node_with_score)
58 |
59 | return result
60 |
61 |
62 | if __name__ == '__main__':
63 | from faiss import IndexFlatIP
64 |
65 | faiss_index = IndexFlatIP(1536)
66 | query = "日本半导体发展史的三个时期是什么?日本半导体发展史可以分为以下三个时期:1. 初期发展(1950年代至1970年代):在这一时期,日本半导体行业主要依赖于进口技术和设备。日本政府积极推动半导体产业的发展,设立了研究机构和实验室,并提供财政支持。日本企业开始生产晶体管和集成电路,逐渐取得了技术突破和市场份额的增长。2. 高速增长(1980年代至1990年代):在这一时期,日本半导体行业迅速崛起,成为全球"
67 | query = "美日半导体协议是由哪两部门签署的?美日半导体协议是由美国商务部和日本经济产业省签署的。"
68 | query = "日美半导体协议要求美国芯片在日本市场份额是多少?根据日美半导体协议,要求美国芯片在日本市场的份额为20%。"
69 | query = "尼康和佳能的光刻机在哪个市场占优势?尼康和佳能都是知名的相机制造商,但在光刻机市场上,尼康占据着主导地位。尼康是全球最大的光刻机制造商之一,其光刻机产品广泛应用于半导体行业,尤其在高端光刻机市场上"
70 | ensemble_retriever = EnsembleRetriever(top_k=3, faiss_index=faiss_index, weights=[0.5, 0.5])
71 | t_result = ensemble_retriever.retrieve(str_or_query_bundle=query)
72 | print(t_result)
73 | faiss_index.reset()
74 |
--------------------------------------------------------------------------------
/custom_retriever/query_rewrite_ensemble_retriever.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: query_rewrite_ensemble_retriever.py
4 | # @time: 2023/12/28 13:49
5 | # -*- coding: utf-8 -*-
6 | # @place: Pudong, Shanghai
7 | # @file: ensemble_retriever.py
8 | # @time: 2023/12/26 18:50
9 | import json
10 | from typing import List
11 | from operator import itemgetter
12 |
13 | from llama_index.schema import TextNode
14 | from llama_index.schema import NodeWithScore
15 | from llama_index.retrievers import BaseRetriever
16 | from llama_index.indices.query.schema import QueryType
17 |
18 | from preprocess.get_text_id_mapping import text_node_id_mapping
19 | from custom_retriever.bm25_retriever import CustomBM25Retriever
20 | from custom_retriever.vector_store_retriever import VectorSearchRetriever
21 |
22 |
23 | class QueryRewriteEnsembleRetriever(BaseRetriever):
24 | def __init__(self, top_k, faiss_index):
25 | super().__init__()
26 | self.c: int = 60
27 | self.faiss_index = faiss_index
28 | self.top_k = top_k
29 | self.embedding_retriever = VectorSearchRetriever(top_k=self.top_k, faiss_index=faiss_index, query_rewrite=True)
30 | with open('../data/query_rewrite.json', 'r') as f:
31 | self.query_write_dict = json.loads(f.read())
32 |
33 | def _retrieve(self, query: QueryType) -> List[NodeWithScore]:
34 | doc_lists = []
35 | bm25_search_nodes = CustomBM25Retriever(top_k=self.top_k).retrieve(query.query_str)
36 | doc_lists.append([node.text for node in bm25_search_nodes])
37 | embedding_search_nodes = self.embedding_retriever.retrieve(query.query_str)
38 | doc_lists.append([node.text for node in embedding_search_nodes])
39 | # check: need query rewrite
40 | if len(set([_.id_ for _ in bm25_search_nodes]) & set([_.id_ for _ in embedding_search_nodes])) == 0:
41 | print(query.query_str)
42 | for search_query in self.query_write_dict[query.query_str]:
43 | bm25_search_nodes = CustomBM25Retriever(top_k=self.top_k).retrieve(search_query)
44 | doc_lists.append([node.text for node in bm25_search_nodes])
45 | embedding_search_nodes = self.embedding_retriever.retrieve(search_query)
46 | doc_lists.append([node.text for node in embedding_search_nodes])
47 |
48 | # Create a union of all unique documents in the input doc_lists
49 | all_documents = set()
50 | for doc_list in doc_lists:
51 | for doc in doc_list:
52 | all_documents.add(doc)
53 | # print(all_documents)
54 |
55 | # Initialize the RRF score dictionary for each document
56 | rrf_score_dic = {doc: 0.0 for doc in all_documents}
57 |
58 | # Calculate RRF scores for each document
59 | for doc_list, weight in zip(doc_lists, [1/len(doc_lists)] * len(doc_lists)):
60 | for rank, doc in enumerate(doc_list, start=1):
61 | rrf_score = weight * (1 / (rank + self.c))
62 | rrf_score_dic[doc] += rrf_score
63 |
64 | # Sort documents by their RRF scores in descending order
65 | sorted_documents = sorted(rrf_score_dic.items(), key=itemgetter(1), reverse=True)
66 | result = []
67 | for sorted_doc in sorted_documents[:self.top_k]:
68 | text, score = sorted_doc
69 | node_with_score = NodeWithScore(node=TextNode(text=text,
70 | id_=text_node_id_mapping[text]),
71 | score=score)
72 | result.append(node_with_score)
73 |
74 | return result
75 |
76 |
77 | if __name__ == '__main__':
78 | from faiss import IndexFlatIP
79 | from pprint import pprint
80 | faiss_index = IndexFlatIP(1536)
81 | ensemble_retriever = QueryRewriteEnsembleRetriever(top_k=3, faiss_index=faiss_index)
82 | query = "半导体制造设备市场美、日、荷各占多少份额?"
83 | t_result = ensemble_retriever.retrieve(str_or_query_bundle=query)
84 | pprint(t_result)
85 | faiss_index.reset()
86 |
--------------------------------------------------------------------------------
/custom_retriever/vector_store_retriever.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: vector_store_retriever.py
4 | # @time: 2023/12/25 17:43
5 | from typing import List
6 |
7 | import numpy as np
8 | from llama_index.schema import TextNode
9 | from llama_index import QueryBundle
10 | from llama_index.schema import NodeWithScore
11 | from llama_index.retrievers import BaseRetriever
12 | from llama_index.indices.query.schema import QueryType
13 |
14 | from preprocess.get_text_id_mapping import text_node_id_mapping
15 | from custom_retriever.build_embedding_cache import EmbeddingCache
16 |
17 |
18 | class VectorSearchRetriever(BaseRetriever):
19 | def __init__(self, top_k, faiss_index, query_rewrite=False) -> None:
20 | super().__init__()
21 | self.top_k = top_k
22 | self.faiss_index = faiss_index
23 | self.queries_embedding_dict, self.corpus_embedding, self.corpus = EmbeddingCache().load(query_write=query_rewrite)
24 | # add vector
25 | self.faiss_index.add(self.corpus_embedding)
26 |
27 | def _retrieve(self, query: QueryType) -> List[NodeWithScore]:
28 | if isinstance(query, str):
29 | query = QueryBundle(query)
30 | else:
31 | query = query
32 |
33 | result = []
34 | # vector search
35 | if query.query_str in self.queries_embedding_dict:
36 | query_embedding = self.queries_embedding_dict[query.query_str]
37 | else:
38 | query_embedding = EmbeddingCache().get_openai_embedding(req_text=query.query_str)
39 | distances, doc_indices = self.faiss_index.search(np.array([query_embedding]), self.top_k)
40 |
41 | for i, sent_index in enumerate(doc_indices.tolist()[0]):
42 | text = self.corpus[sent_index]
43 | node_with_score = NodeWithScore(node=TextNode(text=text, id_=text_node_id_mapping[text]),
44 | score=distances.tolist()[0][i])
45 | result.append(node_with_score)
46 |
47 | return result
48 |
49 |
50 | if __name__ == '__main__':
51 | from pprint import pprint
52 | from faiss import IndexFlatIP
53 | faiss_index = IndexFlatIP(1536)
54 | vector_search_retriever = VectorSearchRetriever(top_k=3, faiss_index=faiss_index)
55 | query = "美日半导体协议是由哪两部门签署的?美日半导体协议是由美国商务部和日本经济产业省签署的。"
56 | t_result = vector_search_retriever.retrieve(str_or_query_bundle=query)
57 | pprint(t_result)
58 | faiss_index.reset()
59 |
--------------------------------------------------------------------------------
/data/corpus_openai_embedding.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/percent4/embedding_rerank_retrieval/f6a0ee5d388b20807e9f07c81c69cf963ea2d463/data/corpus_openai_embedding.npy
--------------------------------------------------------------------------------
/data/demo.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @contact: lianmingjie@shanda.com
4 | # @file: demo.py
5 | # @time: 2023/12/26 11:15
6 | import json
7 | with open("doc_qa_test.json", "r") as f:
8 | content = json.loads(f.read())
9 |
10 | new_content = {}
11 | n = 5
12 | for k, v in content.items():
13 | if k in ["queries", "relevant_docs"]:
14 | new_content[k] = {}
15 | for key in list(v.keys())[:n]:
16 | new_content[k][key] = v[key]
17 | else:
18 | new_content[k] = v
19 |
20 | with open("doc_qa_test_demo.json", "w") as f:
21 | f.write(json.dumps(new_content, indent=4, ensure_ascii=False))
22 |
--------------------------------------------------------------------------------
/data/queries_openai_embedding.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/percent4/embedding_rerank_retrieval/f6a0ee5d388b20807e9f07c81c69cf963ea2d463/data/queries_openai_embedding.npy
--------------------------------------------------------------------------------
/data/query_rewrite_openai_embedding.npy:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/percent4/embedding_rerank_retrieval/f6a0ee5d388b20807e9f07c81c69cf963ea2d463/data/query_rewrite_openai_embedding.npy
--------------------------------------------------------------------------------
/docs/RAG框架中的Rerank算法评估.md:
--------------------------------------------------------------------------------
1 | > 本文将详细介绍RAG框架中的两种Rerank模型的评估实验:bge-reranker和Cohere Rerank。
2 |
3 | 在文章[NLP(八十二)RAG框架中的Retrieve算法评估](https://mp.weixin.qq.com/s?__biz=MzU2NTYyMDk5MQ==&mid=2247486199&idx=1&sn=f24175b05bdf5bc6dd42efed4d5acae8&chksm=fcb9b367cbce3a711fabd1a56bb5b9d803aba2f42964b4e1f9a4dc6e2174f0952ddb9e1d4c55&token=1977141018&lang=zh_CN#rd)中,我们在评估Retrieve算法的时候,发现在Ensemble Search阶段之后加入Rerank算法能有效提升检索效果,其中top_3的Hit Rate指标增加约4%。
4 |
5 | 因此,本文将深入Rerank算法对比,主要对比bge-reranker和Cohere Rerank两种算法,分析它们对于提升检索效果的作用。
6 |
7 | ## 为什么需要重排序?
8 |
9 | **混合检索**通过融合多种检索技术的优势,能够提升检索的召回效果。然而,这种方法在应用不同的检索模式时,必须对结果进行整合和标准化处理。标准化是指将数据调整到一致的标准范围或格式,以便于更有效地进行比较、分析和处理。在完成这些步骤后,这些数据将整合并提供给大型模型进行处理。为了实现这一过程,我们需要引入一个评分系统,即`重排序模型(Rerank Model)`,它有助于进一步优化和精炼检索结果。
10 |
11 | `Rerank模型`通过对候选文档列表进行重新排序,以提高其与用户查询语义的匹配度,从而优化排序结果。该模型的核心在于评估用户问题与每个候选文档之间的关联程度,并基于这种相关性给文档排序,使得与用户问题更为相关的文档排在更前的位置。这种模型的实现通常涉及计算相关性分数,然后按照这些分数从高到低排列文档。市场上已有一些流行的重排序模型,例如 **Cohere rerank**、**bge-reranker** 等,它们在不同的应用场景中表现出了优异的性能。
12 |
13 | 
14 |
15 | ## BGE-Reranker模型
16 |
17 | **Cohere Rerank**模型目前闭源,对外提供API,普通账号提供免费使用额度,生产环境最好使用付费服务,因此,本文不再过多介绍,关于这块的文章可参考其官网博客:[https://txt.cohere.com/rerank/](https://txt.cohere.com/rerank/) .
18 |
19 | **bge-reranker**是`BAAI`(北京智源人工智能研究院)发布的系列模型之一,包括Embedding、Rerank系列模型等。`bge-reranker`模型在HuggingFace上开源,有`base`、`large`两个版本模型。
20 |
21 | 借助`FlagEmbedding`,我们以BAAI/bge-reranker-base模型为例,使用FastAPI封装成HTTP服务,Python代码如下:
22 |
23 | ```python
24 | # !/usr/bin/env python
25 | # encoding: utf-8
26 | import uvicorn
27 | from fastapi import FastAPI
28 | from pydantic import BaseModel
29 | from operator import itemgetter
30 | from FlagEmbedding import FlagReranker
31 |
32 |
33 | app = FastAPI()
34 |
35 | reranker = FlagReranker('/data_2/models/bge-reranker-base/models--BAAI--bge-reranker-base/blobs', use_fp16=True)
36 |
37 |
38 | class QuerySuite(BaseModel):
39 | query: str
40 | passages: list[str]
41 | top_k: int = 1
42 |
43 |
44 | @app.post('/bge_base_rerank')
45 | def rerank(query_suite: QuerySuite):
46 | scores = reranker.compute_score([[query_suite.query, passage] for passage in query_suite.passages])
47 | if isinstance(scores, list):
48 | similarity_dict = {passage: scores[i] for i, passage in enumerate(query_suite.passages)}
49 | else:
50 | similarity_dict = {passage: scores for i, passage in enumerate(query_suite.passages)}
51 | sorted_similarity_dict = sorted(similarity_dict.items(), key=itemgetter(1), reverse=True)
52 | result = {}
53 | for j in range(query_suite.top_k):
54 | result[sorted_similarity_dict[j][0]] = sorted_similarity_dict[j][1]
55 | return result
56 |
57 |
58 | if __name__ == '__main__':
59 | uvicorn.run(app, host='0.0.0.0', port=50072)
60 | ```
61 |
62 | 计算"上海天气"与"北京美食"、"上海气候"的Rerank相关性分数,请求如下:
63 |
64 | ```bash
65 | curl --location 'http://localhost:50072/bge_base_rerank' \
66 | --header 'Content-Type: application/json' \
67 | --data '{
68 | "query": "上海天气",
69 | "passages": ["北京美食", "上海气候"],
70 | "top_k": 2
71 | }'
72 | ```
73 |
74 | 输出如下:
75 |
76 | ```json
77 | {
78 | "上海气候": 6.24609375,
79 | "北京美食": -7.29296875
80 | }
81 | ```
82 |
83 | ## 评估实验
84 |
85 | 我们使用[NLP(八十二)RAG框架中的Retrieve算法评估](https://mp.weixin.qq.com/s?__biz=MzU2NTYyMDk5MQ==&mid=2247486199&idx=1&sn=f24175b05bdf5bc6dd42efed4d5acae8&chksm=fcb9b367cbce3a711fabd1a56bb5b9d803aba2f42964b4e1f9a4dc6e2174f0952ddb9e1d4c55&token=1977141018&lang=zh_CN#rd)中的数据集和评估代码,在ensemble search阶段之后加入BGE-Reranker服务API调用。
86 |
87 | 其中,`bge-reranker-base`的评估结果如下:
88 |
89 | | retrievers | hit_rate | mrr |
90 | |-------------------------------------|----------|--------|
91 | | ensemble_bge_base_rerank_top_1_eval | 0.8255 | 0.8255 |
92 | | ensemble_bge_base_rerank_top_2_eval | 0.8785 | 0.8489 |
93 | | ensemble_bge_base_rerank_top_3_eval | 0.9346 | 0.8686 |
94 | | ensemble_bge_base_rerank_top_4_eval | 0.947 | 0.872 |
95 | | ensemble_bge_base_rerank_top_5_eval | 0.9564 | 0.8693 |
96 |
97 | `bge-reranker-large`的评估结果如下:
98 |
99 | | retrievers | hit_rate | mrr |
100 | |--------------------------------------|----------|--------|
101 | | ensemble_bge_large_rerank_top_1_eval | 0.8224 | 0.8224 |
102 | | ensemble_bge_large_rerank_top_2_eval | 0.8847 | 0.8364 |
103 | | ensemble_bge_large_rerank_top_3_eval | 0.9377 | 0.8572 |
104 | | ensemble_bge_large_rerank_top_4_eval | 0.9502 | 0.8564 |
105 | | ensemble_bge_large_rerank_top_5_eval | 0.9626 | 0.8537 |
106 |
107 | 以Ensemble Search为baseline,分别对三种Rerank模型进行Hit Rate指标统计,柱状图如下:
108 |
109 | 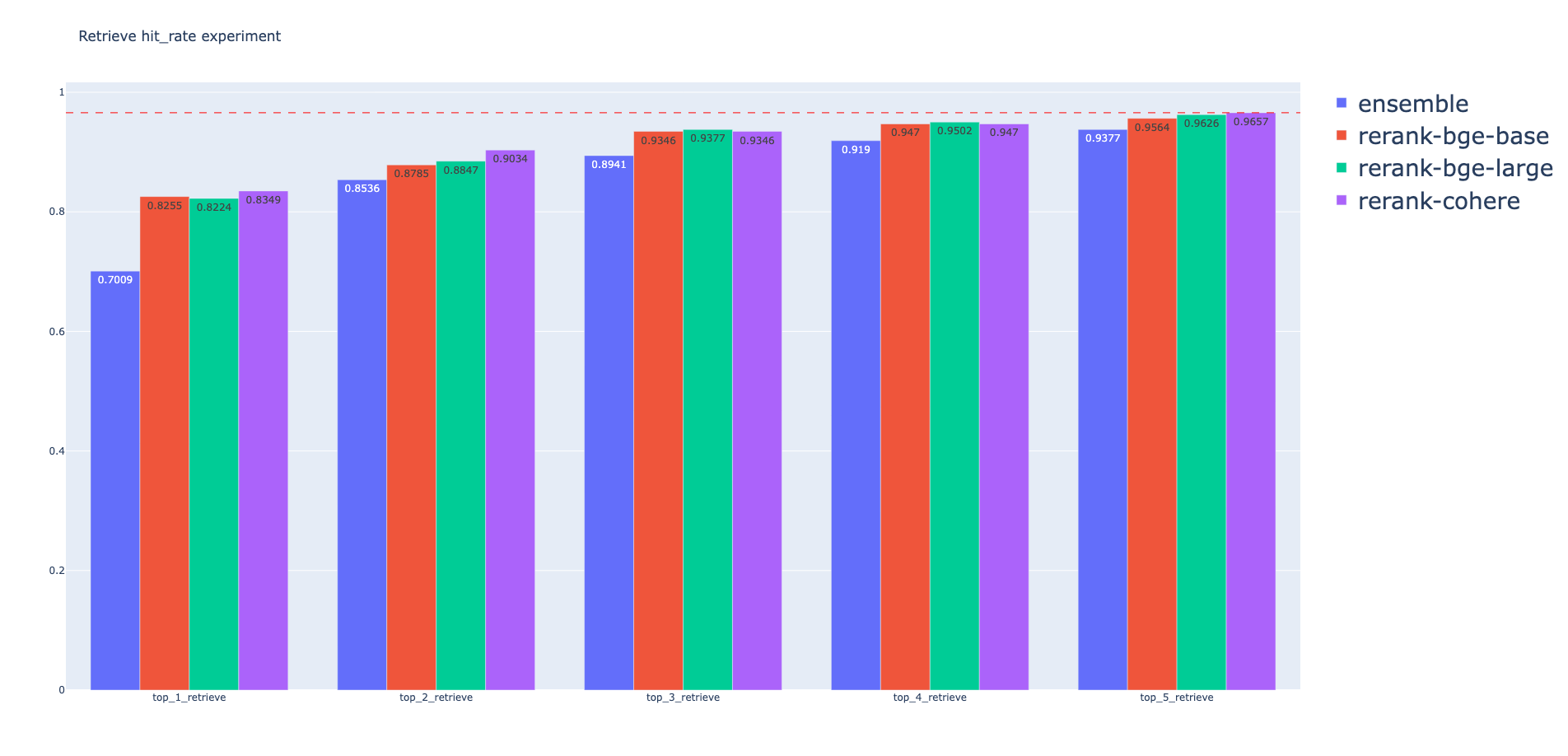
110 |
111 | 从上述的统计图中可以得到如下结论:
112 |
113 | - 在Ensemble Search阶段后加入Rerank模型会有检索效果提升
114 | - 就检索效果而言,Rerank模型的结果为:Cohere > bge-rerank-large > bge-rerank-base,但效果相差不大
115 |
116 |
117 | ## 总结
118 |
119 | 本文详细介绍了RAG框架中的两种Rerank模型的评估实验:bge-reranker和Cohere Rerank,算是在之前Retrieve算法评估实验上的延续工作,后续将会有更多工作持续更新。
120 |
121 | 本文的所有过程及指标结果已开源至Github,网址为:[https://github.com/percent4/embedding_rerank_retrieval](https://github.com/percent4/embedding_rerank_retrieval) .
122 |
--------------------------------------------------------------------------------
/docs/RAG框架中的Retrieve算法评估.md:
--------------------------------------------------------------------------------
1 | > 本文将详细介绍RAG框架中的各种Retrieve算法,比如BM25, Embedding Search, Ensemble Search, Rerank等的评估实验过程与结果。本文是目前除了LlamaIndex官方网站例子之外为数不多的介绍Retrieve算法评估实验的文章。
2 |
3 | ## 什么是RAG中的Retrieve?
4 |
5 | `RAG`即Retrieval Augmented Generation的简称,是现阶段增强使用LLM的常见方式之一,其一般步骤为:
6 |
7 | 1. 文档划分(Document Split)
8 | 2. 向量嵌入(Embedding)
9 | 3. 文档获取(Retrieve)
10 | 4. Prompt工程(Prompt Engineering)
11 | 5. 大模型问答(LLM)
12 |
13 | 大致的流程图参考如下:
14 |
15 | 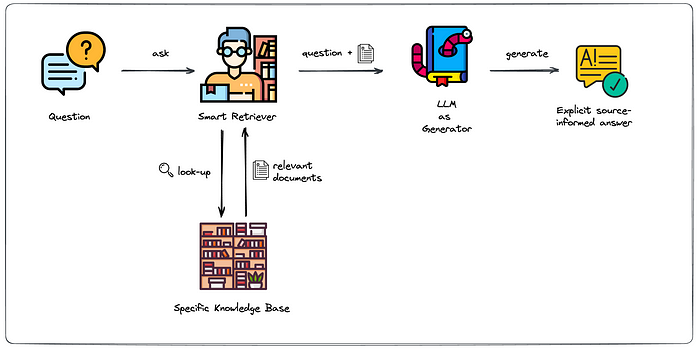
16 |
17 | 通常来说,可将`RAG`划分为召回(**Retrieve**)阶段和答案生成(**Answer Generate**)阶段,而效果优化也从这方面入手。针对召回阶段,文档获取是其中重要的步骤,决定了注入大模型的知识背景,常见的召回算法如下:
18 |
19 | - **BM25(又称Keyword Search)**: 使用BM24算法找回相关文档,一般对于特定领域关键词效果较好,比如人名,结构名等;
20 | - **Embedding Search**: 使用Embedding模型将query和corpus进行文本嵌入,使用向量相似度进行文本匹配,可解决BM25算法的相似关键词召回效果差的问题,该过程一般会使用向量数据库(Vector Database);
21 | - **Ensemble Search**: 融合BM25算法和Embedding Search的结果,使用RFF算法进行重排序,一般会比单独的召回算法效果好;
22 | - **Rerank**: 上述的召回算法一般属于粗召回阶段,更看重性能;Rerank是对粗召回阶段的结果,再与query进行文本匹配,属于Rerank(又称为重排、精排)阶段,更看重效果;
23 |
24 | 综合上述Retrieve算法的框架示意图如下:
25 |
26 | 
27 |
28 | 上述的Retrieve算法更有优劣,一般会选择合适的场景进行使用或考虑综合几种算法进行使用。那么,它们的效果具体如何呢?
29 |
30 |
31 | ## Retrieve算法评估
32 |
33 | 那么,如何对Retrieve算法进行具体效果评估呢?
34 |
35 | 本文将通过构造自有数据集进行测试,分别对上述四种Retrieve算法进行实验,采用`Hit Rate`和`MRR`指标进行评估。
36 |
37 | 在**LlamaIndex**官方Retrieve Evaluation中,提供了对Retrieve算法的评估示例,具体细节可参考如下:
38 |
39 | [https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83](https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83)
40 |
41 | 这是现在网上较为权威的Retrieve Evaluation实验,本文将参考LlamaIndex的做法,给出更为详细的评估实验过程与结果。
42 |
43 | Retrieve Evaluation实验的步骤如下:
44 |
45 | 1. `文档划分`:寻找合适数据集,进行文档划分;
46 | 2. `问题生成`:对划分后的文档,使用LLM对文档内容生成问题;
47 | 3. `召回文本`:对生成的每个问题,采用不同的Retrieve算法,得到召回结果;
48 | 4. `指标评估`:使用`Hit Rate`和`MRR`指标进行评估
49 |
50 | 步骤是清晰的,那么,我们来看下评估指标:`Hit Rate`和`MRR`。
51 |
52 | `Hit Rate`即命中率,一般指的是我们预期的召回文本(真实值)在召回结果的前k个文本中会出现,也就是Recall@k时,能得到预期文本。一般,`Hit Rate`越高,就说明召回算法效果越好。
53 |
54 | `MRR`即Mean Reciprocal Rank,是一种常见的评估检索效果的指标。MRR 是衡量系统在一系列查询中返回相关文档或信息的平均排名的逆数的平均值。例如,如果一个系统对第一个查询的正确答案排在第二位,对第二个查询的正确答案排在第一位,则 MRR 为 (1/2 + 1/1) / 2。
55 |
56 | 在LlamaIndex中,这两个指标的对应类分别为`HitRate`和`MRR`,源代码如下:
57 |
58 | ```python
59 | class HitRate(BaseRetrievalMetric):
60 | """Hit rate metric."""
61 |
62 | metric_name: str = "hit_rate"
63 |
64 | def compute(
65 | self,
66 | query: Optional[str] = None,
67 | expected_ids: Optional[List[str]] = None,
68 | retrieved_ids: Optional[List[str]] = None,
69 | expected_texts: Optional[List[str]] = None,
70 | retrieved_texts: Optional[List[str]] = None,
71 | **kwargs: Any,
72 | ) -> RetrievalMetricResult:
73 | """Compute metric."""
74 | if retrieved_ids is None or expected_ids is None:
75 | raise ValueError("Retrieved ids and expected ids must be provided")
76 | is_hit = any(id in expected_ids for id in retrieved_ids)
77 | return RetrievalMetricResult(
78 | score=1.0 if is_hit else 0.0,
79 | )
80 |
81 |
82 | class MRR(BaseRetrievalMetric):
83 | """MRR metric."""
84 |
85 | metric_name: str = "mrr"
86 |
87 | def compute(
88 | self,
89 | query: Optional[str] = None,
90 | expected_ids: Optional[List[str]] = None,
91 | retrieved_ids: Optional[List[str]] = None,
92 | expected_texts: Optional[List[str]] = None,
93 | retrieved_texts: Optional[List[str]] = None,
94 | **kwargs: Any,
95 | ) -> RetrievalMetricResult:
96 | """Compute metric."""
97 | if retrieved_ids is None or expected_ids is None:
98 | raise ValueError("Retrieved ids and expected ids must be provided")
99 | for i, id in enumerate(retrieved_ids):
100 | if id in expected_ids:
101 | return RetrievalMetricResult(
102 | score=1.0 / (i + 1),
103 | )
104 | return RetrievalMetricResult(
105 | score=0.0,
106 | )
107 | ```
108 |
109 | ## 数据集构造
110 |
111 | 在文章[NLP(六十一)使用Baichuan-13B-Chat模型构建智能文档](https://mp.weixin.qq.com/s?__biz=MzU2NTYyMDk5MQ==&mid=2247485425&idx=1&sn=bd85ddfce82d77ceec5a66cb96835400&chksm=fcb9be61cbce37773109f9703c2b6c4256d5037c8bf4497dfb9ad0f296ce0ee4065255954c1c&token=1977141018&lang=zh_CN#rd)笔者介绍了如何使用RAG框架来实现智能文档问答。
112 |
113 | 以这个项目为基础,笔者采集了日本半导体行业相关的网络文章及其他文档,进行文档划分,导入至ElastricSearch,并使用OpenAI Embedding获取文本嵌入向量。语料库一共为433个文档片段(Chunk),其中321个与日本半导体行业相关(不妨称之为`领域文档`)。
114 |
115 | 还差query数据集。这点是从LlamaIndex官方示例中获取的灵感:**使用大模型生成query**!
116 |
117 | 针对上述321个领域文档,使用GPT-4模型生成一个与文本内容相关的问题,即query,Python代码如下:
118 |
119 | ```python
120 | # -*- coding: utf-8 -*-
121 | # @place: Pudong, Shanghai
122 | # @file: data_transfer.py
123 | # @time: 2023/12/25 17:51
124 | import pandas as pd
125 | from llama_index.llms import OpenAI
126 | from llama_index.schema import TextNode
127 | from llama_index.evaluation import generate_question_context_pairs
128 | import random
129 | random.seed(42)
130 |
131 | llm = OpenAI(model="gpt-4", max_retries=5)
132 |
133 | # Prompt to generate questions
134 | qa_generate_prompt_tmpl = """\
135 | Context information is below.
136 |
137 | ---------------------
138 | {context_str}
139 | ---------------------
140 |
141 | Given the context information and not prior knowledge.
142 | generate only questions based on the below query.
143 |
144 | You are a university professor. Your task is to set {num_questions_per_chunk} questions for the upcoming Chinese quiz.
145 | Questions throughout the test should be diverse. Questions should not contain options or start with Q1/Q2.
146 | Questions must be written in Chinese. The expression must be concise and clear.
147 | It should not exceed 15 Chinese characters. Words such as "这", "那", "根据", "依据" and other punctuation marks
148 | should not be used. Abbreviations may be used for titles and professional terms.
149 | """
150 |
151 | nodes = []
152 | data_df = pd.read_csv("../data/doc_qa_dataset.csv", encoding="utf-8")
153 | for i, row in data_df.iterrows():
154 | if len(row["content"]) > 80 and i > 96:
155 | node = TextNode(text=row["content"])
156 | node.id_ = f"node_{i + 1}"
157 | nodes.append(node)
158 |
159 |
160 | doc_qa_dataset = generate_question_context_pairs(
161 | nodes, llm=llm, num_questions_per_chunk=1, qa_generate_prompt_tmpl=qa_generate_prompt_tmpl
162 | )
163 |
164 | doc_qa_dataset.save_json("../data/doc_qa_dataset.json")
165 | ```
166 |
167 | 原始数据`doc_qa_dataset.csv`是笔者从Kibana中的Discover中导出的,使用llama-index模块和GPT-4模型,以合适的Prompt,对每个领域文档生成一个问题,并保存为doc_qa_dataset.json,这就是我们进行Retrieve Evaluation的数据格式,其中包括queries, corpus, relevant_docs, mode四个字段。
168 |
169 | 我们来查看第一个文档及生成的答案,如下:
170 |
171 | ```json
172 | {
173 | "queries": {
174 | "7813f025-333d-494f-bc14-a51b2d57721b": "日本半导体产业的现状和影响因素是什么?",
175 | ...
176 | },
177 | "corpus": {
178 | "node_98": "日本半导体产业在上世纪80年代到达顶峰后就在缓慢退步,但若简单认为日本半导体产业失败了,就是严重误解,今天日本半导体产业仍有非常有竞争力的企业和产品。客观认识日本半导体产业的成败及其背后的原因,对正在大力发展半导体产业的中国,有非常强的参考价值。",
179 | ...
180 | },
181 | "relevant_docs": {
182 | "7813f025-333d-494f-bc14-a51b2d57721b": [
183 | "node_98"
184 | ],
185 | ...
186 | },
187 | "mode": "text"
188 | }
189 | ```
190 |
191 |
192 | ## Retrieve算法评估
193 |
194 | 我们需要评估的Retrieve算法为BM25, Embedding Search, Ensemble Search, Ensemble + Rerank,下面将分别就Retriever实现方式、指标评估实验对每种Retrieve算法进行详细介绍。
195 |
196 | ### BM25
197 |
198 | BM25的储存采用ElasticSearch,即直接使用ES内置的BM25算法。笔者在llama-index对BaseRetriever进行定制化开发(这也是我们实现自己想法的一种常规方法),对其简单封装,Python代码如下:
199 |
200 | ```python
201 | # -*- coding: utf-8 -*-
202 | # @place: Pudong, Shanghai
203 | # @file: bm25_retriever.py
204 | # @time: 2023/12/25 17:42
205 | from typing import List
206 |
207 | from elasticsearch import Elasticsearch
208 | from llama_index.schema import TextNode
209 | from llama_index import QueryBundle
210 | from llama_index.schema import NodeWithScore
211 | from llama_index.retrievers import BaseRetriever
212 | from llama_index.indices.query.schema import QueryType
213 |
214 | from preprocess.get_text_id_mapping import text_node_id_mapping
215 |
216 |
217 | class CustomBM25Retriever(BaseRetriever):
218 | """Custom retriever for elasticsearch with bm25"""
219 | def __init__(self, top_k) -> None:
220 | """Init params."""
221 | super().__init__()
222 | self.es_client = Elasticsearch([{'host': 'localhost', 'port': 9200}])
223 | self.top_k = top_k
224 |
225 | def _retrieve(self, query: QueryType) -> List[NodeWithScore]:
226 | if isinstance(query, str):
227 | query = QueryBundle(query)
228 | else:
229 | query = query
230 |
231 | result = []
232 | # 查询数据(全文搜索)
233 | dsl = {
234 | 'query': {
235 | 'match': {
236 | 'content': query.query_str
237 | }
238 | },
239 | "size": self.top_k
240 | }
241 | search_result = self.es_client.search(index='docs', body=dsl)
242 | if search_result['hits']['hits']:
243 | for record in search_result['hits']['hits']:
244 | text = record['_source']['content']
245 | node_with_score = NodeWithScore(node=TextNode(text=text,
246 | id_=text_node_id_mapping[text]),
247 | score=record['_score'])
248 | result.append(node_with_score)
249 |
250 | return result
251 | ```
252 |
253 | 之后,对top_k结果进行指标评估,Python代码如下:
254 |
255 | ```python
256 | # -*- coding: utf-8 -*-
257 | # @place: Pudong, Shanghai
258 | # @file: evaluation_exp.py
259 | # @time: 2023/12/25 20:01
260 | import asyncio
261 | import time
262 |
263 | import pandas as pd
264 | from datetime import datetime
265 | from faiss import IndexFlatIP
266 | from llama_index.evaluation import RetrieverEvaluator
267 | from llama_index.finetuning.embeddings.common import EmbeddingQAFinetuneDataset
268 |
269 | from custom_retriever.bm25_retriever import CustomBM25Retriever
270 | from custom_retriever.vector_store_retriever import VectorSearchRetriever
271 | from custom_retriever.ensemble_retriever import EnsembleRetriever
272 | from custom_retriever.ensemble_rerank_retriever import EnsembleRerankRetriever
273 | from custom_retriever.query_rewrite_ensemble_retriever import QueryRewriteEnsembleRetriever
274 |
275 |
276 | # Display results from evaluate.
277 | def display_results(name_list, eval_results_list):
278 | pd.set_option('display.precision', 4)
279 | columns = {"retrievers": [], "hit_rate": [], "mrr": []}
280 | for name, eval_results in zip(name_list, eval_results_list):
281 | metric_dicts = []
282 | for eval_result in eval_results:
283 | metric_dict = eval_result.metric_vals_dict
284 | metric_dicts.append(metric_dict)
285 |
286 | full_df = pd.DataFrame(metric_dicts)
287 |
288 | hit_rate = full_df["hit_rate"].mean()
289 | mrr = full_df["mrr"].mean()
290 |
291 | columns["retrievers"].append(name)
292 | columns["hit_rate"].append(hit_rate)
293 | columns["mrr"].append(mrr)
294 |
295 | metric_df = pd.DataFrame(columns)
296 |
297 | return metric_df
298 |
299 |
300 | doc_qa_dataset = EmbeddingQAFinetuneDataset.from_json("../data/doc_qa_test.json")
301 | metrics = ["mrr", "hit_rate"]
302 | # bm25 retrieve
303 | evaluation_name_list = []
304 | evaluation_result_list = []
305 | cost_time_list = []
306 | for top_k in [1, 2, 3, 4, 5]:
307 | start_time = time.time()
308 | bm25_retriever = CustomBM25Retriever(top_k=top_k)
309 | bm25_retriever_evaluator = RetrieverEvaluator.from_metric_names(metrics, retriever=bm25_retriever)
310 | bm25_eval_results = asyncio.run(bm25_retriever_evaluator.aevaluate_dataset(doc_qa_dataset))
311 | evaluation_name_list.append(f"bm25_top_{top_k}_eval")
312 | evaluation_result_list.append(bm25_eval_results)
313 | cost_time_list.append((time.time() - start_time) * 1000)
314 |
315 | print("done for bm25 evaluation!")
316 | df = display_results(evaluation_name_list, evaluation_result_list)
317 | df['cost_time'] = cost_time_list
318 | print(df.head())
319 | df.to_csv(f"evaluation_bm25_{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}.csv", encoding="utf-8", index=False)
320 | ```
321 |
322 | BM25算法的实验结果如下:
323 |
324 | | retrievers | hit_rate | mrr | cost_time |
325 | |-----------------|----------|--------|-----------|
326 | | bm25_top_1_eval | 0.7975 | 0.7975 | 461.277 |
327 | | bm25_top_2_eval | 0.8536 | 0.8255 | 510.3021 |
328 | | bm25_top_3_eval | 0.9003 | 0.8411 | 570.6708 |
329 | | bm25_top_4_eval | 0.9159 | 0.845 | 420.7261 |
330 | | bm25_top_5_eval | 0.9408 | 0.85 | 388.5961 |
331 |
332 | ### Embedding Search
333 |
334 | BM25算法的实现是简单的。Embedding Search的较为复杂些,首先需要对queries和corpus进行文本嵌入,这里的Embedding模型使用Openai的text-embedding-ada-002,向量维度为1536,并将结果存入numpy数据结构中,保存为npy文件,方便后续加载和重复使用。
335 |
336 | 为了避免使用过重的向量数据集,本实验采用内存向量数据集: **faiss**。使用faiss加载向量,index类型选用IndexFlatIP,并进行向量相似度搜索。
337 |
338 | Embedding Search也需要定制化开发Retriever及指标评估,这里不再赘述,具体实验可参考文章末尾的Github项目地址。
339 |
340 | Embedding Search的实验结果如下:
341 |
342 | | retrievers | hit_rate | mrr | cost_time |
343 | |----------------------|----------|--------|-----------|
344 | | embedding_top_1_eval | 0.6075 | 0.6075 | 67.6837 |
345 | | embedding_top_2_eval | 0.6978 | 0.6526 | 60.8449 |
346 | | embedding_top_3_eval | 0.7321 | 0.6641 | 59.9051 |
347 | | embedding_top_4_eval | 0.7788 | 0.6758 | 63.5488 |
348 | | embedding_top_5_eval | 0.7944 | 0.6789 | 67.7922 |
349 |
350 | > 注意: 这里的召回时间花费比BM25还要少,完全得益于我们已经存储好了文本向量,并使用faiss进行加载、查询。
351 |
352 | ### Ensemble Search
353 |
354 | Ensemble Search融合BM25算法和Embedding Search算法,针对两种算法召回的top_k个文档,使用RRF算法进行重新排序,再获取top_k个文档。RRF算法是经典且优秀的集成排序算法,这里不再展开介绍,后续专门写文章介绍。
355 |
356 | Ensemble Search的实验结果如下:
357 |
358 | | retrievers | hit_rate | mrr | cost_time |
359 | |---------------------|----------|--------|-----------|
360 | | ensemble_top_1_eval | 0.7009 | 0.7009 | 1072.7379 |
361 | | ensemble_top_2_eval | 0.8536 | 0.7741 | 1088.8782 |
362 | | ensemble_top_3_eval | 0.8941 | 0.7928 | 980.7949 |
363 | | ensemble_top_4_eval | 0.919 | 0.8017 | 935.1702 |
364 | | ensemble_top_5_eval | 0.9377 | 0.8079 | 868.299 |
365 |
366 | ### Ensemble + Rerank
367 |
368 | 如果还想在Ensemble Search的基础上再进行效果优化,可考虑加入Rerank算法。常见的Rerank模型有Cohere(API调用),BGE-Rerank(开源模型)等。本文使用Cohere Rerank API.
369 |
370 | Ensemble + Rerank的实验结果如下:
371 |
372 | | retrievers | hit_rate | mrr | cost_time |
373 | |----------------------------|----------|--------|--------------|
374 | | ensemble_rerank_top_1_eval | 0.8349 | 0.8349 | 2140632.4041 |
375 | | ensemble_rerank_top_2_eval | 0.9034 | 0.8785 | 2157657.2871 |
376 | | ensemble_rerank_top_3_eval | 0.9346 | 0.9008 | 2200800.936 |
377 | | ensemble_rerank_top_4_eval | 0.947 | 0.9078 | 2150398.7348 |
378 | | ensemble_rerank_top_5_eval | 0.9657 | 0.9099 | 2149122.9382 |
379 |
380 | ## 指标可视化及分析
381 |
382 | ### 指标可视化
383 |
384 | 上述的评估结果不够直观,我们使用Plotly模块绘制指标的条形图,结果如下:
385 |
386 | 
387 |
388 | 
389 |
390 | ### 指标分析
391 |
392 | 我们对上述统计图进行指标分析,可得到结论如下:
393 |
394 | - 对于每种Retrieve算法,随着k的增加,top_k的Hit Rate指标和MRR指标都有所增加,即检索效果变好,这是显而易见的结论;
395 | - 就总体检索效果而言,Ensemble + Rerank > Ensemble > 单独的Retrieve
396 | - 本项目中就单独的Retrieve算法而言,BM25的检索效果比Embedding Search好(可能与生成的问答来源于文档有关),但这不是普遍结论,两种算法更有合适的场景
397 | - 加入Rerank后,检索效果可获得一定的提升,以top_3评估结果来说,ensemble的Hit Rate为0.8941,加入Rerank后为0.9346,提升约4%
398 |
399 | ## 总结
400 |
401 | 本文详细介绍了RAG框架,并结合自有数据集对各种Retrieve算法进行评估。笔者通过亲身实验和编写Retriever代码,深入了解了RAG框架中的经典之作LlamaIndex,同时,本文也是难得的介绍RAG框架Retrieve阶段评估实验的文章。
402 |
403 | 本文的所有过程及指标结果已开源至Github,网址为:[https://github.com/percent4/embedding_rerank_retrieval](https://github.com/percent4/embedding_rerank_retrieval) .
404 |
405 | 后续,笔者将在此项目基础上,验证各种优化RAG框架Retrieve效果的手段,比如Query Rewrite, Query Transform, HyDE等,这将是一个获益无穷的项目啊!
406 |
407 | ## 参考文献
408 |
409 | 1. Retrieve Evaluation官网文章:https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83
410 | 2. Retrieve Evaluation Colab上的代码:https://colab.research.google.com/drive/1TxDVA__uimVPOJiMEQgP5fwHiqgKqm4-?usp=sharing
411 | 3. LlamaIndex官网:https://docs.llamaindex.ai/en/stable/index.html
412 | 4. RetrieverEvaluator in LlamaIndex: https://docs.llamaindex.ai/en/stable/module_guides/evaluating/usage_pattern_retrieval.html
413 | 5. NLP(六十一)使用Baichuan-13B-Chat模型构建智能文档: https://mp.weixin.qq.com/s?__biz=MzU2NTYyMDk5MQ==&mid=2247485425&idx=1&sn=bd85ddfce82d77ceec5a66cb96835400&chksm=fcb9be61cbce37773109f9703c2b6c4256d5037c8bf4497dfb9ad0f296ce0ee4065255954c1c&token=1977141018&lang=zh_CN#rd
414 | 6. NLP(六十九)智能文档助手升级: https://mp.weixin.qq.com/s?__biz=MzU2NTYyMDk5MQ==&mid=2247485609&idx=1&sn=f8337b4822b1cdf95a586af6097ef288&chksm=fcb9b139cbce382f735e4c119ade8084067cde0482910c72767f36a29e7291385cbe6dfbd6a9&payreadticket=HBB91zkl4I6dXpw0Q4OcOF8ECZz0pS9kOGHJqycwrN7jFWHyUOCBe7sWFWytD7_9wo_NzcM#rd
415 | 7. NLP(八十一)智能文档问答助手项目改进: https://mp.weixin.qq.com/s?__biz=MzU2NTYyMDk5MQ==&mid=2247486103&idx=1&sn=caa204eda0760bab69b7e40abff8e696&chksm=fcb9b307cbce3a1108d305ec44281e3446241e90e9c17d62dd0b6eaa48cba5e20d31f0129584&token=1977141018&lang=zh_CN#rd
416 |
--------------------------------------------------------------------------------
/docs/RAG框架中的召回算法可视化分析及提升方法.md:
--------------------------------------------------------------------------------
1 | > 本文将会对笔者之前在RAG框架中的Retrieve算法的不同召回手段进行可视化分析,并介绍RAG框架中的优化方法。
2 |
3 | 在文章[NLP(八十二)RAG框架中的Retrieve算法评估](https://mp.weixin.qq.com/s?__biz=MzU2NTYyMDk5MQ==&mid=2247486199&idx=1&sn=f24175b05bdf5bc6dd42efed4d5acae8&chksm=fcb9b367cbce3a711fabd1a56bb5b9d803aba2f42964b4e1f9a4dc6e2174f0952ddb9e1d4c55&token=823710334&lang=zh_CN#rd)中笔者介绍了RAG框架中不同的Retrieve算法(包括BM25, Embedding, Ensemble, Ensemble+Rerank)的评估实验,并给出了详细的数据集与评测过程、评估结果。
4 |
5 | 在文章[NLP(八十三)RAG框架中的Rerank算法评估](https://mp.weixin.qq.com/s?__biz=MzU2NTYyMDk5MQ==&mid=2247486225&idx=1&sn=235eb787e2034f24554d8e997dbb4718&chksm=fcb9b281cbce3b9761342ebadbe001747ce2e74d84340f78b0e12c4d4c6aed7a7817f246c845&token=823710334&lang=zh_CN#rd)中笔者进一步介绍了Rerank算法在RAG框架中的作用,并对不同的Rerank算法进行了评估。
6 |
7 | **以上两篇文章是笔者对RAG框架的深入探索,文章获得了读者的一致好评。**
8 |
9 | 本文将会继续深入RAG框架的探索,内容如下:
10 |
11 | - Retrieve算法的可视化分析:使用Gradio模块搭建可视化页面用于展示不同召回算法的结果。
12 | - BM25, Embedding, Ensemble, Ensemble + Rerank召回分析:结合具体事例,给出不同召回手段的结果,比较它们的优劣。
13 | - RAG框架中的提升方法:主要介绍Query Rewirte, HyDE.
14 |
15 | ## Retrieve算法的可视化分析
16 |
17 | 为了对Retrieve算法的召回结果进行分析,笔者使用Gradio模块来开发前端页面以支持召回结果的可视化分析。
18 |
19 | Python代码如下:
20 |
21 | ```python
22 | # -*- coding: utf-8 -*-
23 | from random import shuffle
24 | import gradio as gr
25 | import pandas as pd
26 |
27 | from faiss import IndexFlatIP
28 | from llama_index.evaluation.retrieval.metrics import HitRate, MRR
29 |
30 | from custom_retriever.bm25_retriever import CustomBM25Retriever
31 | from custom_retriever.vector_store_retriever import VectorSearchRetriever
32 | from custom_retriever.ensemble_retriever import EnsembleRetriever
33 | from custom_retriever.ensemble_rerank_retriever import EnsembleRerankRetriever
34 | from preprocess.get_text_id_mapping import queries, query_relevant_docs
35 | from preprocess.query_rewrite import generate_queries, llm
36 |
37 | retrieve_methods = ["bm25", "embedding", "ensemble", "ensemble + bge-rerank-large", "query_rewrite + ensemble"]
38 |
39 |
40 | def get_metric(search_query, search_result):
41 | hit_rate = HitRate().compute(query=search_query,
42 | expected_ids=query_relevant_docs[search_query],
43 | retrieved_ids=[_.id_ for _ in search_result])
44 | mrr = MRR().compute(query=search_query,
45 | expected_ids=query_relevant_docs[search_query],
46 | retrieved_ids=[_.id_ for _ in search_result])
47 | return [hit_rate.score, mrr.score]
48 |
49 |
50 | def get_retrieve_result(retriever_list, retrieve_top_k, retrieve_query):
51 | columns = {"metric_&_top_k": ["Hit Rate", "MRR"] + [f"top_{k + 1}" for k in range(retrieve_top_k)]}
52 | if "bm25" in retriever_list:
53 | bm25_retriever = CustomBM25Retriever(top_k=retrieve_top_k)
54 | search_result = bm25_retriever.retrieve(retrieve_query)
55 | columns["bm25"] = []
56 | columns["bm25"].extend(get_metric(retrieve_query, search_result))
57 | for i, node in enumerate(search_result, start=1):
58 | columns["bm25"].append(node.text)
59 | if "embedding" in retriever_list:
60 | faiss_index = IndexFlatIP(1536)
61 | vector_search_retriever = VectorSearchRetriever(top_k=retrieve_top_k, faiss_index=faiss_index)
62 | search_result = vector_search_retriever.retrieve(str_or_query_bundle=retrieve_query)
63 | columns["embedding"] = []
64 | columns["embedding"].extend(get_metric(retrieve_query, search_result))
65 | for i in range(retrieve_top_k):
66 | columns["embedding"].append(search_result[i].text)
67 | faiss_index.reset()
68 | if "ensemble" in retriever_list:
69 | faiss_index = IndexFlatIP(1536)
70 | ensemble_retriever = EnsembleRetriever(top_k=retrieve_top_k, faiss_index=faiss_index, weights=[0.5, 0.5])
71 | search_result = ensemble_retriever.retrieve(str_or_query_bundle=retrieve_query)
72 | columns["ensemble"] = []
73 | columns["ensemble"].extend(get_metric(retrieve_query, search_result))
74 | for i in range(retrieve_top_k):
75 | columns["ensemble"].append(search_result[i].text)
76 | faiss_index.reset()
77 | if "ensemble + bge-rerank-large" in retriever_list:
78 | faiss_index = IndexFlatIP(1536)
79 | ensemble_retriever = EnsembleRerankRetriever(top_k=retrieve_top_k, faiss_index=faiss_index)
80 | search_result = ensemble_retriever.retrieve(str_or_query_bundle=retrieve_query)
81 | columns["ensemble + bge-rerank-large"] = []
82 | columns["ensemble + bge-rerank-large"].extend(get_metric(retrieve_query, search_result))
83 | for i in range(retrieve_top_k):
84 | columns["ensemble + bge-rerank-large"].append(search_result[i].text)
85 | faiss_index.reset()
86 | if "query_rewrite + ensemble" in retriever_list:
87 | queries = generate_queries(llm, retrieve_query, num_queries=1)
88 | print(f"original query: {retrieve_query}\n"
89 | f"rewrite query: {queries}")
90 | faiss_index = IndexFlatIP(1536)
91 | ensemble_retriever = EnsembleRetriever(top_k=retrieve_top_k, faiss_index=faiss_index, weights=[0.5, 0.5])
92 | search_result = ensemble_retriever.retrieve(str_or_query_bundle=queries[0])
93 | columns["query_rewrite + ensemble"] = []
94 | columns["query_rewrite + ensemble"].extend(get_metric(retrieve_query, search_result))
95 | for i in range(retrieve_top_k):
96 | columns["query_rewrite + ensemble"].append(search_result[i].text)
97 | faiss_index.reset()
98 | retrieve_df = pd.DataFrame(columns)
99 | return retrieve_df
100 |
101 |
102 | with gr.Blocks() as demo:
103 | retrievers = gr.CheckboxGroup(choices=retrieve_methods,
104 | type="value",
105 | label="Retrieve Methods")
106 | top_k = gr.Dropdown(list(range(1, 6)), label="top_k", value=3)
107 | shuffle(queries)
108 | query = gr.Dropdown(queries, label="query", value=queries[0])
109 | # 设置输出组件
110 | result_table = gr.DataFrame(label='Result', wrap=True)
111 | theme = gr.themes.Base()
112 | # 设置按钮
113 | submit = gr.Button("Submit")
114 | submit.click(fn=get_retrieve_result, inputs=[retrievers, top_k, query], outputs=result_table)
115 |
116 |
117 | demo.launch()
118 | ```
119 |
120 | 该页面可以选择召回算法,top_k参数,以及query,返回召回算法的指标及top_k召回文本,如下图:
121 |
122 | 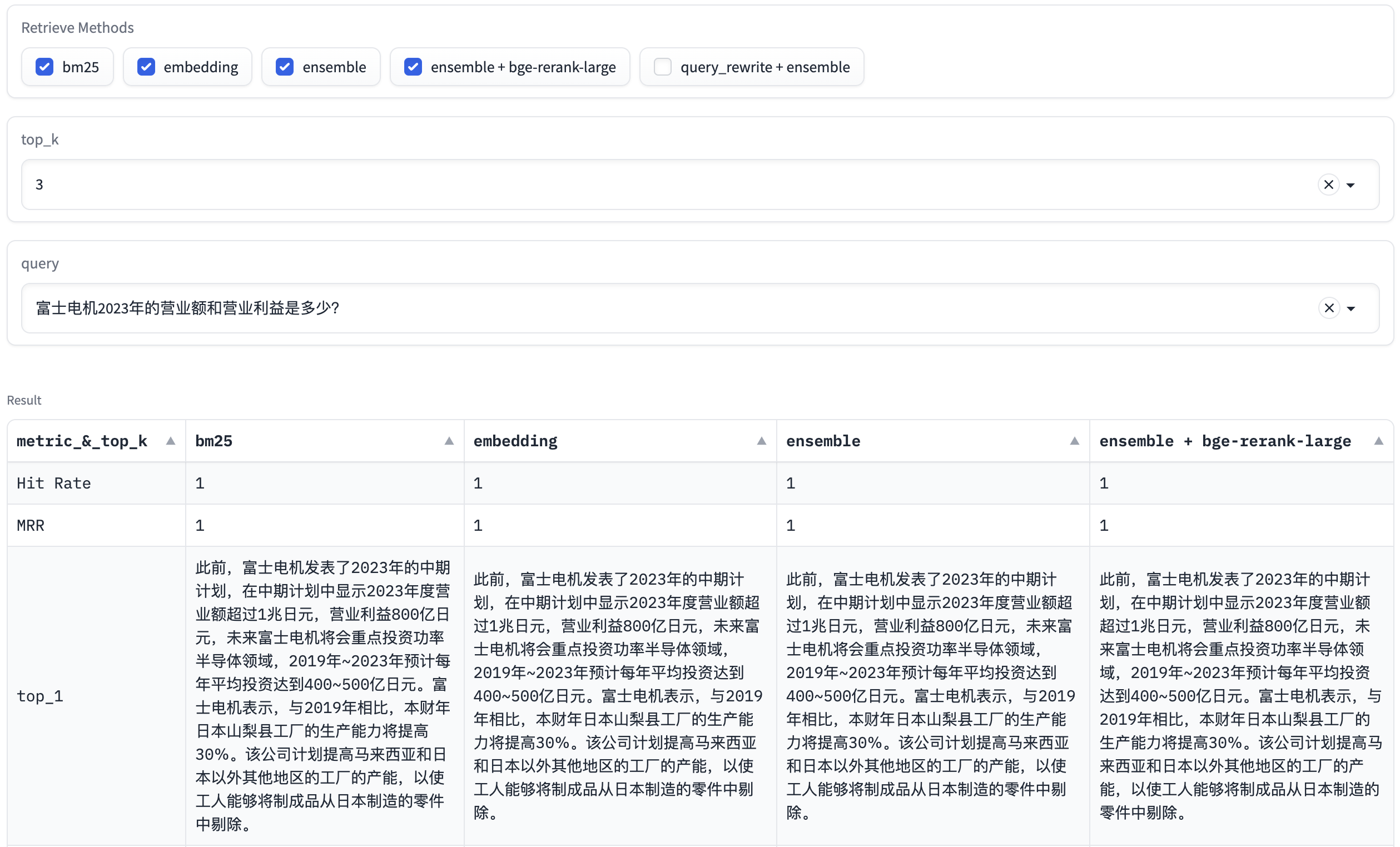
123 |
124 | 有了这个页面,我们可以很方便地对召回结果进行分析。为了有更全面的分析,我们再使用Python脚本,对测试query不同召回算法(BM25, Embedding, Ensemble)的top_3召回结果及指标进行记录。
125 |
126 | 当然,我们还筛选出badcase,用来帮助我们更好地对召回算法进行分析。所谓badcase,指的是query的top_3召回指标在BM25, Embedding, Ensemble算法上都为0。badcase如下:
127 |
128 | |query|
129 | |---|
130 | |日美半导体协议对日本半导体产业有何影响?|
131 | |请列举三个美国的科技公司。|
132 | |日本半导体发展史的三个时期是什么?|
133 | |日美半导体协议要求美国芯片在日本市场份额是多少?|
134 | |日本在全球半导体市场的份额是多少?|
135 | |日本半导体设备在国内市场的占比是多少?|
136 | |日本企业在全球半导体产业的地位如何?|
137 | |美日半导体协议的主要内容是什么?|
138 | |尼康和佳能的光刻机在哪个市场占优势?|
139 | |美日半导体协议是由哪两部门签署的?|
140 | |日本在全球半导体材料行业的地位如何?|
141 | |日本半导体业的衰落原因是什么?|
142 | |日本半导体业的兴衰原因是什么?|
143 | |日本半导体企业如何保持竞争力?|
144 | |日本半导体产业在哪些方面仍有影响力?|
145 | |半导体制造设备市场美、日、荷各占多少份额?|
146 | |80年代日本半导体企业的问题是什么?|
147 | |尼康在哪种技术上失去了优势?|
148 |
149 | ## 不同召回算法实例分析
150 |
151 | 在文章[NLP(八十二)RAG框架中的Retrieve算法评估](https://mp.weixin.qq.com/s?__biz=MzU2NTYyMDk5MQ==&mid=2247486199&idx=1&sn=f24175b05bdf5bc6dd42efed4d5acae8&chksm=fcb9b367cbce3a711fabd1a56bb5b9d803aba2f42964b4e1f9a4dc6e2174f0952ddb9e1d4c55&token=823710334&lang=zh_CN#rd)中,在评估实验中,对于单个的Retrieve算法,BM25表现要优于Embedding。但事实上,两者各有优劣。
152 |
153 | | 检索类型 | 优点 | 缺点 |
154 | |----------|------|------|
155 | | 向量检索 (Embedding) | 1. 语义理解更强。
2. 能有效处理模糊或间接的查询。
3. 对自然语言的多样性适应性强。
4. 能识别不同词汇的相同意义。 | 1. 计算和存储成本高。
2. 索引时间较长。
3. 高度依赖训练数据的质量和数量。
4. 结果解释性较差。 |
156 | | 关键词检索 (BM25) | 1. 检索速度快。
2. 实现简单,资源需求低。
3. 结果易于理解,可解释性强。
4. 对精确查询表现良好。 | 1. 对复杂语义理解有限。
2. 对查询变化敏感,灵活性差。
3. 难以处理同义词和多义词。
4. 需要用户准确使用关键词。 |
157 |
158 |
159 | `向量检索`(Embedding)的优势:
160 |
161 | - 复杂语义的文本查找(基于文本相似度)
162 | - 相近语义理解(如老鼠/捕鼠器/奶酪,谷歌/必应/搜索引擎)
163 | - 多语言理解(跨语言理解,如输入中文匹配英文)
164 | - 多模态理解(支持文本、图像、音视频等的相似匹配)
165 | - 容错性(处理拼写错误、模糊的描述)
166 |
167 | 虽然向量检索在以上情景中具有明显优势,但有某些情况效果不佳。比如:
168 |
169 | - 搜索一个人或物体的名字(例如,伊隆·马斯克,iPhone 15)
170 | - 搜索缩写词或短语(例如,RAG,RLHF)
171 | - 搜索 ID(例如,gpt-3.5-turbo,titan-xlarge-v1.01)
172 |
173 | 而上面这些的缺点恰恰都是传统关键词搜索的优势所在,传统`关键词搜索`(BM25)擅长:
174 |
175 | - 精确匹配(如产品名称、姓名、产品编号)
176 |
177 | - 少量字符的匹配(通过少量字符进行向量检索时效果非常不好,但很多用户恰恰习惯只输入几个关键词)
178 | - 倾向低频词汇的匹配(低频词汇往往承载了语言中的重要意义,比如“你想跟我去喝咖啡吗?”这句话中的分词,“喝”“咖啡”会比“你”“吗”在句子中承载更重要的含义)
179 |
180 | 基于`向量检索`和`关键词搜索`更有优劣,因此才需要`混合搜索`(Ensemble)。而在`混合搜索`的基础上,需要对多路召回结果进行`精排`(即`Rerank`),重新调整召回文本的顺序。
181 |
182 | 为了更好地理解上述召回算法的优缺点,下面结合具体的实例来进行阐述。
183 |
184 | - `query`: "NEDO"的全称是什么?
185 |
186 | 
187 |
188 | 在这个例子中,Embedding召回结果优于BM25,BM25召回结果虽然在top_3结果中存在,但排名第三,排在首位的是不相关的文本,而Embedding由于文本相似度的优势,将正确结果放在了首位。
189 |
190 | - `query`: 日本半导体产品的主要应用领域是什么?
191 |
192 | 
193 |
194 | 在这个例子中,BM25召回结果优于Embedding。
195 |
196 | - `query`: 《美日半导体协议》对日本半导体市场有何影响?
197 |
198 | 
199 |
200 | 在这个例子中,正确文本在BM25算法召回结果中排名第二,在Embedding算法中排第三,混合搜索排名第一,这里体现了混合搜索的优越性。
201 |
202 | - `query`: 80年代日本电子产业的辉煌表现在哪些方面?
203 |
204 | 
205 |
206 | 在这个例子中,不管是BM25, Embedding,还是Ensemble,都没能将正确文本排在第一位,而经过Rerank以后,正确文本排在第一位,这里体现了Rerank算法的优势。
207 |
208 | ## RAG中的提升方法
209 |
210 | 经过上述Retrieve算法的对比,我们对不同的Retrieve算法有了深入的了解。然而,Retrieve算法并不能帮助我们解决所有问题,比如上述的badcase,就是用各种Retrieve算法都无法找回的。
211 |
212 | 那么,还有其它优化手段吗?在RAG框架中,还存在一系列的优化手段,这在`Langchain`和`Llmma-Index`中都给出了各种优化手段。本文将尝试两种优化手段:Query Rewrite和HyDE.
213 |
214 | ### Query Rewrite
215 |
216 | 业界对于Query Rewrite,有着相当完善且复杂的流程,因为它对于后续的召回结果有直接影响。本文借助大模型对query进行直接改写,看看是否有召回效果提升。
217 |
218 | 比如:
219 |
220 | - 原始query: 半导体制造设备市场美、日、荷各占多少份额?
221 | - 改写后query:美国、日本和荷兰在半导体制造设备市场的份额分别是多少?
222 |
223 | 改写后的query在BM25和Embedding的top 3召回结果中都能找到。该query对应的正确文本为:
224 |
225 | > 全球半导体设备制造领域,美国、日本和荷兰控制着全球370亿美元半导体制造设备市场的90%以上。其中,美国的半导体制造设备(SME)产业占全球产量的近50%,日本约占30%,荷兰约占17%%。更具体地,以光刻机为例,EUV光刻工序其实有众多日本厂商的参与,如东京电子生产的EUV涂覆显影设备,占据100%的市场份额,Lasertec Corp.也是全球唯一的测试机制造商。另外还有EUV光刻胶,据南大光电在3月发布的相关报告中披露,全球仅有日本厂商研发出了EUV光刻胶。
226 |
227 | 从中我们可以看到,在改写后的query中,美国、日本、荷兰这三个词发挥了重要作用,因此,**query改写对于含有缩写的query有一定的召回效果改善**。
228 |
229 | ### HyDE
230 |
231 | HyDE(全称Hypothetical Document Embeddings)是RAG中的一种技术,它基于一个假设:相较于直接查询,通过大语言模型 (LLM) 生成的答案在嵌入空间中可能更为接近。HyDE 首先响应查询生成一个假设性文档(答案),然后将其嵌入,从而提高搜索的效果。
232 |
233 | 比如:
234 |
235 | - 原始query: 美日半导体协议是由哪两部门签署的?
236 | - 加上回答后的query: 美日半导体协议是由哪两部门签署的?美日半导体协议是由美国商务部和日本经济产业省签署的。
237 |
238 | 加上回答后的query使用BM25算法可以找回正确文本,且排名第一位,而Embedding算法仍无法召回。
239 |
240 | 正确文本为:
241 |
242 | > 1985年6月,美国半导体产业贸易保护的调子开始升高。美国半导体工业协会向国会递交一份正式的“301条款”文本,要求美国政府制止日本公司的倾销行为。民意调查显示,68%的美国人认为日本是美国最大的威胁。在舆论的引导和半导体工业协会的推动下,美国政府将信息产业定为可以动用国家安全借口进行保护的新兴战略产业,半导体产业成为美日贸易战的焦点。1985年10月,美国商务部出面指控日本公司倾销256K和1M内存。一年后,日本通产省被迫与美国商务部签署第一次《美日半导体协议》。
243 |
244 | 从中可以看出,大模型的回答是正确的,美国商务部这个关键词发挥了重要作用,因此,HyDE对于特定的query有召回效果提升。
245 |
246 | ## 总结
247 |
248 | 本文结合具体的例子,对于不同的Retrieve算法的效果优劣有了比较清晰的认识,事实上,这也是笔者一直在NLP领域努力的一个方向:简单而深刻。
249 |
250 | 同时,还介绍了两种RAG框架中的优化方法,或许可以在工作中有应用价值。后续笔者将继续关注RAG框架,欢迎大家关注。
251 |
252 | 本文代码及数据已开源至Github: [https://github.com/percent4/embedding_rerank_retrieval](https://github.com/percent4/embedding_rerank_retrieval)。
253 |
254 | ## 参考文献
255 |
256 | 1. [NLP(八十二)RAG框架中的Retrieve算法评估](https://mp.weixin.qq.com/s?__biz=MzU2NTYyMDk5MQ==&mid=2247486199&idx=1&sn=f24175b05bdf5bc6dd42efed4d5acae8&chksm=fcb9b367cbce3a711fabd1a56bb5b9d803aba2f42964b4e1f9a4dc6e2174f0952ddb9e1d4c55&token=823710334&lang=zh_CN#rd)
257 | 2. [NLP(八十三)RAG框架中的Rerank算法评估](https://mp.weixin.qq.com/s?__biz=MzU2NTYyMDk5MQ==&mid=2247486225&idx=1&sn=235eb787e2034f24554d8e997dbb4718&chksm=fcb9b281cbce3b9761342ebadbe001747ce2e74d84340f78b0e12c4d4c6aed7a7817f246c845&token=823710334&lang=zh_CN#rd)
258 | 3. 引入混合检索(Hybrid Search)和重排序(Rerank)改进 RAG 系统召回效果: [https://mp.weixin.qq.com/s/_Rmafm7tI3JWMNqoqFX_FQ](https://mp.weixin.qq.com/s/_Rmafm7tI3JWMNqoqFX_FQ)
--------------------------------------------------------------------------------
/embedding_finetune/embedding_fine_tuning.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "id": "c52f65c6-fa88-4490-9b7f-841c564db2b1",
7 | "metadata": {
8 | "execution": {
9 | "iopub.execute_input": "2024-01-09T05:52:04.229194Z",
10 | "iopub.status.busy": "2024-01-09T05:52:04.228352Z",
11 | "iopub.status.idle": "2024-01-09T05:52:04.233790Z",
12 | "shell.execute_reply": "2024-01-09T05:52:04.233085Z",
13 | "shell.execute_reply.started": "2024-01-09T05:52:04.229159Z"
14 | }
15 | },
16 | "outputs": [],
17 | "source": [
18 | "import json\n",
19 | "\n",
20 | "from llama_index import SimpleDirectoryReader\n",
21 | "from llama_index.node_parser import SentenceSplitter\n",
22 | "from llama_index.schema import MetadataMode"
23 | ]
24 | },
25 | {
26 | "cell_type": "code",
27 | "execution_count": 3,
28 | "id": "ca4963ea-966b-49ac-b8b5-17689b4ec0a3",
29 | "metadata": {
30 | "execution": {
31 | "iopub.execute_input": "2024-01-09T05:52:07.163714Z",
32 | "iopub.status.busy": "2024-01-09T05:52:07.163210Z",
33 | "iopub.status.idle": "2024-01-09T05:52:07.167490Z",
34 | "shell.execute_reply": "2024-01-09T05:52:07.166800Z",
35 | "shell.execute_reply.started": "2024-01-09T05:52:07.163683Z"
36 | }
37 | },
38 | "outputs": [],
39 | "source": [
40 | "TRAIN_FILES = [\"train.txt\"]\n",
41 | "VAL_FILES = [\"test.txt\"]\n",
42 | "\n",
43 | "TRAIN_CORPUS_FPATH = \"train_corpus.json\"\n",
44 | "VAL_CORPUS_FPATH = \"val_corpus.json\""
45 | ]
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": 4,
50 | "id": "be5d9621-2e82-496c-b3e6-64c403c51f60",
51 | "metadata": {
52 | "execution": {
53 | "iopub.execute_input": "2024-01-09T05:52:07.862139Z",
54 | "iopub.status.busy": "2024-01-09T05:52:07.860880Z",
55 | "iopub.status.idle": "2024-01-09T05:52:07.869680Z",
56 | "shell.execute_reply": "2024-01-09T05:52:07.868223Z",
57 | "shell.execute_reply.started": "2024-01-09T05:52:07.862096Z"
58 | }
59 | },
60 | "outputs": [],
61 | "source": [
62 | "def load_corpus(files, verbose=False):\n",
63 | " if verbose:\n",
64 | " print(f\"Loading files {files}\")\n",
65 | "\n",
66 | " reader = SimpleDirectoryReader(input_files=files)\n",
67 | " docs = reader.load_data()\n",
68 | " if verbose:\n",
69 | " print(f\"Loaded {len(docs)} docs\")\n",
70 | "\n",
71 | " parser = SentenceSplitter(chunk_size=250, chunk_overlap=0)\n",
72 | " nodes = parser.get_nodes_from_documents(docs, show_progress=verbose)\n",
73 | "\n",
74 | " if verbose:\n",
75 | " print(f\"Parsed {len(nodes)} nodes\")\n",
76 | "\n",
77 | " return nodes"
78 | ]
79 | },
80 | {
81 | "cell_type": "code",
82 | "execution_count": 5,
83 | "id": "dea8767a-69f2-4c06-847b-464127872237",
84 | "metadata": {
85 | "execution": {
86 | "iopub.execute_input": "2024-01-09T05:52:11.452101Z",
87 | "iopub.status.busy": "2024-01-09T05:52:11.451493Z",
88 | "iopub.status.idle": "2024-01-09T05:52:11.862828Z",
89 | "shell.execute_reply": "2024-01-09T05:52:11.862441Z",
90 | "shell.execute_reply.started": "2024-01-09T05:52:11.452067Z"
91 | }
92 | },
93 | "outputs": [
94 | {
95 | "name": "stdout",
96 | "output_type": "stream",
97 | "text": [
98 | "Loading files ['train.txt']\n",
99 | "Loaded 1 docs\n"
100 | ]
101 | },
102 | {
103 | "data": {
104 | "application/vnd.jupyter.widget-view+json": {
105 | "model_id": "d49144fa9bdd4586957406e8a4c8633b",
106 | "version_major": 2,
107 | "version_minor": 0
108 | },
109 | "text/plain": [
110 | "Parsing nodes: 0%| | 0/1 [00:00: RelatedNodeInfo(node_id='008c3477-fbe1-4da1-86a9-91d83316333d', node_type=, metadata={'file_path': 'train.txt', 'file_name': 'train.txt', 'file_type': 'text/plain', 'file_size': 66966, 'creation_date': '2024-01-09', 'last_modified_date': '2024-01-09', 'last_accessed_date': '2024-01-09'}, hash='77b3142f61c86cad975ca9bc682650512f3a0498a97fb38e6a5b3721324a80c7'), : RelatedNodeInfo(node_id='ff466b80-aee4-4e14-9aa3-8becdbaa3a88', node_type=, metadata={}, hash='c2950b491d0515bb6385ef1831baaa2bd4e848f9e12a831e31bdccf00200172f')}, hash='5568080c7f77966aa8e31768c5ef75d877168f8501d8adf530b6db5d72886096', text='受半导体行业周期“磨底”、消费电子市场需求恢复缓慢等影响,今年A股半导体行业上市公司半年度业绩预告显示,归母净利润普遍同比下滑,IC设计、封测等环节成为“重灾区”, 。环比来看,部分头部企业第二季度业绩已经企稳复苏,盈利环比增长,人工智能、汽车电子、电网等板块贡献业绩,有公司表示下半年将企稳增长。', start_char_idx=0, end_char_idx=149, text_template='{metadata_str}\\n\\n{content}', metadata_template='{key}: {value}', metadata_seperator='\\n'),\n",
170 | " TextNode(id_='ff466b80-aee4-4e14-9aa3-8becdbaa3a88', embedding=None, metadata={'file_path': 'train.txt', 'file_name': 'train.txt', 'file_type': 'text/plain', 'file_size': 66966, 'creation_date': '2024-01-09', 'last_modified_date': '2024-01-09', 'last_accessed_date': '2024-01-09'}, excluded_embed_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date'], excluded_llm_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date'], relationships={: RelatedNodeInfo(node_id='008c3477-fbe1-4da1-86a9-91d83316333d', node_type=, metadata={'file_path': 'train.txt', 'file_name': 'train.txt', 'file_type': 'text/plain', 'file_size': 66966, 'creation_date': '2024-01-09', 'last_modified_date': '2024-01-09', 'last_accessed_date': '2024-01-09'}, hash='77b3142f61c86cad975ca9bc682650512f3a0498a97fb38e6a5b3721324a80c7'), : RelatedNodeInfo(node_id='065c7c68-64f1-41e9-9b5f-6d8141aae864', node_type=, metadata={'file_path': 'train.txt', 'file_name': 'train.txt', 'file_type': 'text/plain', 'file_size': 66966, 'creation_date': '2024-01-09', 'last_modified_date': '2024-01-09', 'last_accessed_date': '2024-01-09'}, hash='5568080c7f77966aa8e31768c5ef75d877168f8501d8adf530b6db5d72886096'), : RelatedNodeInfo(node_id='9b42373d-7002-4cbe-b7ea-ea855696124e', node_type=, metadata={}, hash='136ce81b42b41669ca89fa26ec3d4adb9158e83b6c80cc61ab7cec118a83007d')}, hash='c2950b491d0515bb6385ef1831baaa2bd4e848f9e12a831e31bdccf00200172f', text='据Choice金融终端统计,目前超过30家半导体上市公司披露业绩预告,其中,通富微电、汇顶科技、士兰微、上海贝岭、中晶科技、大为股份等公司业绩预计首亏,博通集成预亏增加,韦尔股份、瑞芯微、华天科技等公司最大降幅超过90%。相比之下,北方华创、中微公司等头部企业翻倍增长。\\n\\n\\u3000\\u3000设计企业:', start_char_idx=153, end_char_idx=297, text_template='{metadata_str}\\n\\n{content}', metadata_template='{key}: {value}', metadata_seperator='\\n'),\n",
171 | " TextNode(id_='9b42373d-7002-4cbe-b7ea-ea855696124e', embedding=None, metadata={'file_path': 'train.txt', 'file_name': 'train.txt', 'file_type': 'text/plain', 'file_size': 66966, 'creation_date': '2024-01-09', 'last_modified_date': '2024-01-09', 'last_accessed_date': '2024-01-09'}, excluded_embed_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date'], excluded_llm_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date'], relationships={: RelatedNodeInfo(node_id='008c3477-fbe1-4da1-86a9-91d83316333d', node_type=, metadata={'file_path': 'train.txt', 'file_name': 'train.txt', 'file_type': 'text/plain', 'file_size': 66966, 'creation_date': '2024-01-09', 'last_modified_date': '2024-01-09', 'last_accessed_date': '2024-01-09'}, hash='77b3142f61c86cad975ca9bc682650512f3a0498a97fb38e6a5b3721324a80c7'), : RelatedNodeInfo(node_id='ff466b80-aee4-4e14-9aa3-8becdbaa3a88', node_type=, metadata={'file_path': 'train.txt', 'file_name': 'train.txt', 'file_type': 'text/plain', 'file_size': 66966, 'creation_date': '2024-01-09', 'last_modified_date': '2024-01-09', 'last_accessed_date': '2024-01-09'}, hash='c2950b491d0515bb6385ef1831baaa2bd4e848f9e12a831e31bdccf00200172f'), : RelatedNodeInfo(node_id='e7dbb434-48ba-4289-a3c6-d0369515dd23', node_type=, metadata={}, hash='d853cc49bf966d5bf25eae4174a6910b48855e7c516134121075537cbb9f8db9')}, hash='136ce81b42b41669ca89fa26ec3d4adb9158e83b6c80cc61ab7cec118a83007d', text='加速去库存\\n\\n\\u3000\\u3000由于终端消费电子市场低迷,芯片设计企业上半年业绩同比普遍预降,但随着去库存推进,部分企业业绩触底企稳,并在二季度环比增长。\\n\\n\\u3000\\u3000作为AIot(人工智能与物联网)芯片龙头,瑞芯微预计今年上半年实现营业收入约8.58亿元,同比减少约31%,归母净利润2000万元到3000万元,同比减少93%到89%。环比来看,第二季度公司营收增长约六成,归母净利润环比实现扭亏。', start_char_idx=302, end_char_idx=492, text_template='{metadata_str}\\n\\n{content}', metadata_template='{key}: {value}', metadata_seperator='\\n')]"
172 | ]
173 | },
174 | "execution_count": 6,
175 | "metadata": {},
176 | "output_type": "execute_result"
177 | }
178 | ],
179 | "source": [
180 | "train_nodes[:3]"
181 | ]
182 | },
183 | {
184 | "cell_type": "code",
185 | "execution_count": 1,
186 | "id": "70f02876-0e48-49dc-bfa8-8853b6e6651f",
187 | "metadata": {
188 | "execution": {
189 | "iopub.execute_input": "2024-01-09T05:51:46.252811Z",
190 | "iopub.status.busy": "2024-01-09T05:51:46.252196Z",
191 | "iopub.status.idle": "2024-01-09T05:51:49.289481Z",
192 | "shell.execute_reply": "2024-01-09T05:51:49.289154Z",
193 | "shell.execute_reply.started": "2024-01-09T05:51:46.252775Z"
194 | }
195 | },
196 | "outputs": [],
197 | "source": [
198 | "from llama_index.finetuning import (\n",
199 | " generate_qa_embedding_pairs,\n",
200 | " EmbeddingQAFinetuneDataset,\n",
201 | ")\n",
202 | "from llama_index.llms import OpenAI\n",
203 | "import os\n",
204 | "os.environ[\"OPENAI_API_KEY\"] = \"sk-xxx\"\n",
205 | "llm = OpenAI(model=\"gpt-3.5-turbo\")"
206 | ]
207 | },
208 | {
209 | "cell_type": "code",
210 | "execution_count": 24,
211 | "id": "160e44d2-29e0-4303-85a0-3fb1102b5074",
212 | "metadata": {},
213 | "outputs": [
214 | {
215 | "name": "stderr",
216 | "output_type": "stream",
217 | "text": [
218 | "100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 129/129 [08:03<00:00, 3.75s/it]\n",
219 | "100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 107/107 [06:49<00:00, 3.83s/it]\n"
220 | ]
221 | }
222 | ],
223 | "source": [
224 | "qa_generate_prompt_tmpl = \"\"\"\\\n",
225 | "Context information is below.\n",
226 | "\n",
227 | "---------------------\n",
228 | "{context_str}\n",
229 | "---------------------\n",
230 | "\n",
231 | "Given the context information and not prior knowledge.\n",
232 | "generate only questions based on the below query.\n",
233 | "\n",
234 | "You are a Professor. Your task is to setup \\\n",
235 | "{num_questions_per_chunk} questions for an upcoming \\\n",
236 | "quiz/examination in Chinese. The questions should be diverse in nature \\\n",
237 | "across the document in Chinese. The questions should not contain options, not start with Q1/ Q2. \\\n",
238 | "Restrict the questions to the context information provided.\n",
239 | "\"\"\"\n",
240 | "\n",
241 | "train_dataset = generate_qa_embedding_pairs(nodes=train_nodes, llm=llm, num_questions_per_chunk=1, qa_generate_prompt_tmpl=qa_generate_prompt_tmpl)\n",
242 | "val_dataset = generate_qa_embedding_pairs(nodes=val_nodes, llm=llm, num_questions_per_chunk=1, qa_generate_prompt_tmpl=qa_generate_prompt_tmpl)\n",
243 | "\n",
244 | "train_dataset.save_json(\"train_dataset.json\")\n",
245 | "val_dataset.save_json(\"val_dataset.json\")"
246 | ]
247 | },
248 | {
249 | "cell_type": "code",
250 | "execution_count": 28,
251 | "id": "b0e1401d-6a5d-45d9-a980-0c129ba122a7",
252 | "metadata": {},
253 | "outputs": [],
254 | "source": [
255 | "from llama_index.finetuning import SentenceTransformersFinetuneEngine\n",
256 | "\n",
257 | "finetune_engine = SentenceTransformersFinetuneEngine(\n",
258 | " train_dataset,\n",
259 | " model_id=\"/data-xgb1/lmj/models/bge-base-zh-v1.5\",\n",
260 | " model_output_path=\"/data-xgb1/lmj/models/bge-base-ft-001\",\n",
261 | " val_dataset=val_dataset,\n",
262 | ")"
263 | ]
264 | },
265 | {
266 | "cell_type": "code",
267 | "execution_count": 29,
268 | "id": "b50495a7-50a8-4adf-93e2-854f07098e04",
269 | "metadata": {},
270 | "outputs": [
271 | {
272 | "data": {
273 | "application/vnd.jupyter.widget-view+json": {
274 | "model_id": "1e8718afd38b4b7d8a0c0837f6a999f0",
275 | "version_major": 2,
276 | "version_minor": 0
277 | },
278 | "text/plain": [
279 | "Epoch: 0%| | 0/2 [00:00 max_metric_value:
30 | max_metric_value = metric_value
31 |
32 | trace = []
33 | for model, metric_list in model_hit_rate_dict.items():
34 | trace.append(go.Bar(x=x_list,
35 | y=metric_list,
36 | text=[str(round(_, 4)) for _ in metric_list],
37 | textposition='auto', # 标注位置自动调整
38 | name=model))
39 |
40 | # Layout
41 | layout = go.Layout(title=f'Retrieve {metric} experiment')
42 | # Figure
43 | figure = go.Figure(data=trace, layout=layout)
44 | figure.add_hline(y=max_metric_value, line_width=1, line_dash="dash", line_color="red")
45 | # 设置图例文字大小
46 | figure.update_layout(
47 | legend=dict(
48 | font=dict(
49 | size=28 # 设置图例文字大小
50 | )
51 | ),
52 | yaxis_range=[0.65, 1]
53 | )
54 | # Plot
55 | py.offline.plot(figure, filename=f'{metric}.html')
56 |
--------------------------------------------------------------------------------
/late_chunking/jina_late_chunking.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "id": "54c0d766-85a6-454f-9ab2-90e5547d3f6a",
7 | "metadata": {
8 | "execution": {
9 | "iopub.execute_input": "2024-12-20T07:49:51.533986Z",
10 | "iopub.status.busy": "2024-12-20T07:49:51.533309Z",
11 | "iopub.status.idle": "2024-12-20T07:49:59.146056Z",
12 | "shell.execute_reply": "2024-12-20T07:49:59.145190Z",
13 | "shell.execute_reply.started": "2024-12-20T07:49:51.533947Z"
14 | }
15 | },
16 | "outputs": [
17 | {
18 | "name": "stderr",
19 | "output_type": "stream",
20 | "text": [
21 | "/Users/admin/anaconda3/envs/myenv/lib/python3.10/site-packages/huggingface_hub/file_download.py:797: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`.\n",
22 | " warnings.warn(\n",
23 | "/Users/admin/anaconda3/envs/myenv/lib/python3.10/site-packages/huggingface_hub/file_download.py:797: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`.\n",
24 | " warnings.warn(\n"
25 | ]
26 | }
27 | ],
28 | "source": [
29 | "from transformers import AutoModel\n",
30 | "from transformers import AutoTokenizer\n",
31 | "\n",
32 | "# load model and tokenizer\n",
33 | "tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)\n",
34 | "model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)"
35 | ]
36 | },
37 | {
38 | "cell_type": "code",
39 | "execution_count": 2,
40 | "id": "169bf5d1-be7e-469f-bafc-1ec4798b9f7b",
41 | "metadata": {
42 | "execution": {
43 | "iopub.execute_input": "2024-12-20T07:50:02.398716Z",
44 | "iopub.status.busy": "2024-12-20T07:50:02.396824Z",
45 | "iopub.status.idle": "2024-12-20T07:50:02.410548Z",
46 | "shell.execute_reply": "2024-12-20T07:50:02.409485Z",
47 | "shell.execute_reply.started": "2024-12-20T07:50:02.398658Z"
48 | }
49 | },
50 | "outputs": [],
51 | "source": [
52 | "def chunk_by_sentences(input_text: str, tokenizer: callable):\n",
53 | " \"\"\"\n",
54 | " Split the input text into sentences using the tokenizer\n",
55 | " :param input_text: The text snippet to split into sentences\n",
56 | " :param tokenizer: The tokenizer to use\n",
57 | " :return: A tuple containing the list of text chunks and their corresponding token spans\n",
58 | " \"\"\"\n",
59 | " inputs = tokenizer(input_text, return_tensors='pt', return_offsets_mapping=True)\n",
60 | " punctuation_mark_id = tokenizer.convert_tokens_to_ids('.')\n",
61 | " sep_id = tokenizer.convert_tokens_to_ids('[SEP]')\n",
62 | " token_offsets = inputs['offset_mapping'][0]\n",
63 | " token_ids = inputs['input_ids'][0]\n",
64 | " chunk_positions = [\n",
65 | " (i, int(start + 1))\n",
66 | " for i, (token_id, (start, end)) in enumerate(zip(token_ids, token_offsets))\n",
67 | " if token_id == punctuation_mark_id\n",
68 | " and (\n",
69 | " token_offsets[i + 1][0] - token_offsets[i][1] > 0\n",
70 | " or token_ids[i + 1] == sep_id\n",
71 | " )\n",
72 | " ]\n",
73 | " chunks = [\n",
74 | " input_text[x[1] : y[1]]\n",
75 | " for x, y in zip([(1, 0)] + chunk_positions[:-1], chunk_positions)\n",
76 | " ]\n",
77 | " span_annotations = [\n",
78 | " (x[0], y[0]) for (x, y) in zip([(1, 0)] + chunk_positions[:-1], chunk_positions)\n",
79 | " ]\n",
80 | " return chunks, span_annotations"
81 | ]
82 | },
83 | {
84 | "cell_type": "code",
85 | "execution_count": 3,
86 | "id": "fe8df4a0-fdf2-440d-85a8-36ae8baa2332",
87 | "metadata": {
88 | "execution": {
89 | "iopub.execute_input": "2024-12-20T07:50:04.159084Z",
90 | "iopub.status.busy": "2024-12-20T07:50:04.158659Z",
91 | "iopub.status.idle": "2024-12-20T07:50:04.178358Z",
92 | "shell.execute_reply": "2024-12-20T07:50:04.177899Z",
93 | "shell.execute_reply.started": "2024-12-20T07:50:04.159056Z"
94 | }
95 | },
96 | "outputs": [
97 | {
98 | "name": "stdout",
99 | "output_type": "stream",
100 | "text": [
101 | "Chunks:\n",
102 | "- \"Berlin is the capital and largest city of Germany, both by area and by population.\"\n",
103 | "- \" Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits.\"\n",
104 | "- \" The city is also one of the states of Germany, and is the third smallest state in the country in terms of area.\"\n"
105 | ]
106 | }
107 | ],
108 | "source": [
109 | "input_text = \"Berlin is the capital and largest city of Germany, both by area and by population. Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits. The city is also one of the states of Germany, and is the third smallest state in the country in terms of area.\"\n",
110 | "\n",
111 | "# determine chunks\n",
112 | "chunks, span_annotations = chunk_by_sentences(input_text, tokenizer)\n",
113 | "print('Chunks:\\n- \"' + '\"\\n- \"'.join(chunks) + '\"')"
114 | ]
115 | },
116 | {
117 | "cell_type": "code",
118 | "execution_count": 4,
119 | "id": "4a9fd8be-c56d-4899-a151-c04ae7465b97",
120 | "metadata": {
121 | "execution": {
122 | "iopub.execute_input": "2024-12-20T07:50:05.531642Z",
123 | "iopub.status.busy": "2024-12-20T07:50:05.531191Z",
124 | "iopub.status.idle": "2024-12-20T07:50:05.539772Z",
125 | "shell.execute_reply": "2024-12-20T07:50:05.539244Z",
126 | "shell.execute_reply.started": "2024-12-20T07:50:05.531617Z"
127 | }
128 | },
129 | "outputs": [
130 | {
131 | "data": {
132 | "text/plain": [
133 | "[(1, 17), (17, 44), (44, 69)]"
134 | ]
135 | },
136 | "execution_count": 4,
137 | "metadata": {},
138 | "output_type": "execute_result"
139 | }
140 | ],
141 | "source": [
142 | "span_annotations"
143 | ]
144 | },
145 | {
146 | "cell_type": "code",
147 | "execution_count": 5,
148 | "id": "d504a44f-f37a-4320-9b33-80f51a37af12",
149 | "metadata": {
150 | "execution": {
151 | "iopub.execute_input": "2024-12-20T07:50:10.826082Z",
152 | "iopub.status.busy": "2024-12-20T07:50:10.825511Z",
153 | "iopub.status.idle": "2024-12-20T07:50:10.833907Z",
154 | "shell.execute_reply": "2024-12-20T07:50:10.832825Z",
155 | "shell.execute_reply.started": "2024-12-20T07:50:10.826047Z"
156 | }
157 | },
158 | "outputs": [],
159 | "source": [
160 | "def late_chunking(\n",
161 | " model_output: 'BatchEncoding', span_annotation: list, max_length=None\n",
162 | "):\n",
163 | " token_embeddings = model_output[0]\n",
164 | " outputs = []\n",
165 | " for embeddings, annotations in zip(token_embeddings, span_annotation):\n",
166 | " if (\n",
167 | " max_length is not None\n",
168 | " ): # remove annotations which go bejond the max-length of the model\n",
169 | " annotations = [\n",
170 | " (start, min(end, max_length - 1))\n",
171 | " for (start, end) in annotations\n",
172 | " if start < (max_length - 1)\n",
173 | " ]\n",
174 | " pooled_embeddings = [\n",
175 | " embeddings[start:end].sum(dim=0) / (end - start)\n",
176 | " for start, end in annotations\n",
177 | " if (end - start) >= 1\n",
178 | " ]\n",
179 | " pooled_embeddings = [\n",
180 | " embedding.detach().cpu().numpy() for embedding in pooled_embeddings\n",
181 | " ]\n",
182 | " outputs.append(pooled_embeddings)\n",
183 | "\n",
184 | " return outputs"
185 | ]
186 | },
187 | {
188 | "cell_type": "code",
189 | "execution_count": 8,
190 | "id": "49ab34fe-f9b5-4008-bd45-de955a6ef091",
191 | "metadata": {
192 | "execution": {
193 | "iopub.execute_input": "2024-12-20T07:51:21.313752Z",
194 | "iopub.status.busy": "2024-12-20T07:51:21.313378Z",
195 | "iopub.status.idle": "2024-12-20T07:51:21.325033Z",
196 | "shell.execute_reply": "2024-12-20T07:51:21.324582Z",
197 | "shell.execute_reply.started": "2024-12-20T07:51:21.313733Z"
198 | }
199 | },
200 | "outputs": [
201 | {
202 | "name": "stdout",
203 | "output_type": "stream",
204 | "text": [
205 | "torch.Size([1, 19])\n",
206 | "torch.Size([1, 29])\n",
207 | "torch.Size([1, 27])\n"
208 | ]
209 | }
210 | ],
211 | "source": [
212 | "for chunk in chunks:\n",
213 | " chunk_inputs = tokenizer(chunk, return_tensors='pt')\n",
214 | " print(chunk_inputs['input_ids'].shape)"
215 | ]
216 | },
217 | {
218 | "cell_type": "code",
219 | "execution_count": 6,
220 | "id": "4f9e6383-d405-433c-bcde-4b3284bdda1a",
221 | "metadata": {
222 | "execution": {
223 | "iopub.execute_input": "2024-12-20T07:06:43.534430Z",
224 | "iopub.status.busy": "2024-12-20T07:06:43.532929Z",
225 | "iopub.status.idle": "2024-12-20T07:06:43.827910Z",
226 | "shell.execute_reply": "2024-12-20T07:06:43.827462Z",
227 | "shell.execute_reply.started": "2024-12-20T07:06:43.534359Z"
228 | }
229 | },
230 | "outputs": [],
231 | "source": [
232 | "# chunk before\n",
233 | "embeddings_traditional_chunking = model.encode(chunks)\n",
234 | "\n",
235 | "# chunk afterwards (context-sensitive chunked pooling)\n",
236 | "inputs = tokenizer(input_text, return_tensors='pt')\n",
237 | "model_output = model(**inputs)\n",
238 | "embeddings = late_chunking(model_output, [span_annotations])[0]"
239 | ]
240 | },
241 | {
242 | "cell_type": "code",
243 | "execution_count": 14,
244 | "id": "afc36542-d4a2-4a65-9e24-c94bb8bf34a6",
245 | "metadata": {
246 | "execution": {
247 | "iopub.execute_input": "2024-12-20T07:12:29.021556Z",
248 | "iopub.status.busy": "2024-12-20T07:12:29.021219Z",
249 | "iopub.status.idle": "2024-12-20T07:12:29.026161Z",
250 | "shell.execute_reply": "2024-12-20T07:12:29.025549Z",
251 | "shell.execute_reply.started": "2024-12-20T07:12:29.021534Z"
252 | }
253 | },
254 | "outputs": [
255 | {
256 | "data": {
257 | "text/plain": [
258 | "(3, 768)"
259 | ]
260 | },
261 | "execution_count": 14,
262 | "metadata": {},
263 | "output_type": "execute_result"
264 | }
265 | ],
266 | "source": [
267 | "embeddings_traditional_chunking.shape"
268 | ]
269 | },
270 | {
271 | "cell_type": "code",
272 | "execution_count": 7,
273 | "id": "46585814-afdf-4c0c-8dc0-6717b1b01ac7",
274 | "metadata": {
275 | "execution": {
276 | "iopub.execute_input": "2024-12-20T07:07:00.802624Z",
277 | "iopub.status.busy": "2024-12-20T07:07:00.802016Z",
278 | "iopub.status.idle": "2024-12-20T07:07:00.876205Z",
279 | "shell.execute_reply": "2024-12-20T07:07:00.875734Z",
280 | "shell.execute_reply.started": "2024-12-20T07:07:00.802587Z"
281 | }
282 | },
283 | "outputs": [
284 | {
285 | "name": "stdout",
286 | "output_type": "stream",
287 | "text": [
288 | "similarity_new(\"Berlin\", \"Berlin is the capital and largest city of Germany, both by area and by population.\"): 0.849546\n",
289 | "similarity_trad(\"Berlin\", \"Berlin is the capital and largest city of Germany, both by area and by population.\"): 0.8486218\n",
290 | "similarity_new(\"Berlin\", \" Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits.\"): 0.82489026\n",
291 | "similarity_trad(\"Berlin\", \" Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits.\"): 0.7084338\n",
292 | "similarity_new(\"Berlin\", \" The city is also one of the states of Germany, and is the third smallest state in the country in terms of area.\"): 0.84980094\n",
293 | "similarity_trad(\"Berlin\", \" The city is also one of the states of Germany, and is the third smallest state in the country in terms of area.\"): 0.75345534\n"
294 | ]
295 | }
296 | ],
297 | "source": [
298 | "import numpy as np\n",
299 | "\n",
300 | "cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))\n",
301 | "\n",
302 | "berlin_embedding = model.encode('Berlin')\n",
303 | "\n",
304 | "for chunk, new_embedding, trad_embeddings in zip(chunks, embeddings, embeddings_traditional_chunking):\n",
305 | " print(f'similarity_new(\"Berlin\", \"{chunk}\"):', cos_sim(berlin_embedding, new_embedding))\n",
306 | " print(f'similarity_trad(\"Berlin\", \"{chunk}\"):', cos_sim(berlin_embedding, trad_embeddings))"
307 | ]
308 | },
309 | {
310 | "cell_type": "code",
311 | "execution_count": null,
312 | "id": "83a56afa-0c6f-4f4c-a294-bbfa0a79ccb1",
313 | "metadata": {},
314 | "outputs": [],
315 | "source": []
316 | }
317 | ],
318 | "metadata": {
319 | "kernelspec": {
320 | "display_name": "Python 3 (ipykernel)",
321 | "language": "python",
322 | "name": "python3"
323 | },
324 | "language_info": {
325 | "codemirror_mode": {
326 | "name": "ipython",
327 | "version": 3
328 | },
329 | "file_extension": ".py",
330 | "mimetype": "text/x-python",
331 | "name": "python",
332 | "nbconvert_exporter": "python",
333 | "pygments_lexer": "ipython3",
334 | "version": "3.10.12"
335 | }
336 | },
337 | "nbformat": 4,
338 | "nbformat_minor": 5
339 | }
340 |
--------------------------------------------------------------------------------
/late_chunking/jina_zh_late_chunking.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 2,
6 | "id": "735b9f1d-aa29-4a6b-a0d7-bb1e4a56bdd5",
7 | "metadata": {
8 | "execution": {
9 | "iopub.execute_input": "2024-12-20T09:27:19.547275Z",
10 | "iopub.status.busy": "2024-12-20T09:27:19.546732Z",
11 | "iopub.status.idle": "2024-12-20T09:27:26.642849Z",
12 | "shell.execute_reply": "2024-12-20T09:27:26.642158Z",
13 | "shell.execute_reply.started": "2024-12-20T09:27:19.547243Z"
14 | }
15 | },
16 | "outputs": [
17 | {
18 | "name": "stderr",
19 | "output_type": "stream",
20 | "text": [
21 | "/Users/admin/anaconda3/envs/myenv/lib/python3.10/site-packages/huggingface_hub/file_download.py:797: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`.\n",
22 | " warnings.warn(\n",
23 | "/Users/admin/anaconda3/envs/myenv/lib/python3.10/site-packages/huggingface_hub/file_download.py:797: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`.\n",
24 | " warnings.warn(\n"
25 | ]
26 | }
27 | ],
28 | "source": [
29 | "from transformers import AutoModel\n",
30 | "from transformers import AutoTokenizer\n",
31 | "\n",
32 | "# load model and tokenizer\n",
33 | "tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)\n",
34 | "model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)"
35 | ]
36 | },
37 | {
38 | "cell_type": "code",
39 | "execution_count": 3,
40 | "id": "4841a955-1d88-4b39-be72-7a9183007bbb",
41 | "metadata": {
42 | "execution": {
43 | "iopub.execute_input": "2024-12-20T09:27:28.688076Z",
44 | "iopub.status.busy": "2024-12-20T09:27:28.686259Z",
45 | "iopub.status.idle": "2024-12-20T09:27:28.697457Z",
46 | "shell.execute_reply": "2024-12-20T09:27:28.696836Z",
47 | "shell.execute_reply.started": "2024-12-20T09:27:28.688028Z"
48 | }
49 | },
50 | "outputs": [],
51 | "source": [
52 | "def chunk_by_sentences(input_text: str, tokenizer: callable):\n",
53 | " \"\"\"\n",
54 | " Split the input text into sentences using the tokenizer\n",
55 | " :param input_text: The text snippet to split into sentences\n",
56 | " :param tokenizer: The tokenizer to use\n",
57 | " :return: A tuple containing the list of text chunks and their corresponding token spans\n",
58 | " \"\"\"\n",
59 | " inputs = tokenizer(input_text, return_tensors='pt', return_offsets_mapping=True)\n",
60 | " punctuation_mark_id = tokenizer.convert_tokens_to_ids('。')\n",
61 | " sep_id = tokenizer.eos_token_id\n",
62 | " token_offsets = inputs['offset_mapping'][0]\n",
63 | " token_ids = inputs['input_ids'][0]\n",
64 | " chunk_positions = [\n",
65 | " (i, int(start + 1))\n",
66 | " for i, (token_id, (start, end)) in enumerate(zip(token_ids, token_offsets))\n",
67 | " if token_id == punctuation_mark_id\n",
68 | " and (\n",
69 | " token_offsets[i + 1][0] - token_offsets[i][1] >= 0\n",
70 | " or token_ids[i + 1] == sep_id\n",
71 | " )\n",
72 | " ]\n",
73 | " chunks = [\n",
74 | " input_text[x[1] : y[1]]\n",
75 | " for x, y in zip([(1, 0)] + chunk_positions[:-1], chunk_positions)\n",
76 | " ]\n",
77 | " span_annotations = [\n",
78 | " (x[0], y[0]) for (x, y) in zip([(1, 0)] + chunk_positions[:-1], chunk_positions)\n",
79 | " ]\n",
80 | " return chunks, span_annotations"
81 | ]
82 | },
83 | {
84 | "cell_type": "code",
85 | "execution_count": 4,
86 | "id": "37d4d597-86ce-4419-bb97-c34263ca7241",
87 | "metadata": {
88 | "execution": {
89 | "iopub.execute_input": "2024-12-20T09:27:29.941603Z",
90 | "iopub.status.busy": "2024-12-20T09:27:29.941152Z",
91 | "iopub.status.idle": "2024-12-20T09:27:29.966738Z",
92 | "shell.execute_reply": "2024-12-20T09:27:29.966260Z",
93 | "shell.execute_reply.started": "2024-12-20T09:27:29.941575Z"
94 | }
95 | },
96 | "outputs": [
97 | {
98 | "name": "stdout",
99 | "output_type": "stream",
100 | "text": [
101 | "Chunks:\n",
102 | "- \"王安石(1021年12月19日-1086年5月21日),字介甫,号半山。\"\n",
103 | "- \"抚州临川县(今属江西省抚州市)人。\"\n",
104 | "- \"中国北宋时期政治家、文学家、思想家、改革家。\"\n",
105 | "- \"庆历二年(1042年),王安石中进士,历任扬州签判、鄞县知县、舒州通判等职,政绩显著。\"\n",
106 | "- \"宋仁宗末年,曾作《上仁宗皇帝言事书》,要求对宋初以来的法度进行全盘改革,但未被采纳。\"\n"
107 | ]
108 | }
109 | ],
110 | "source": [
111 | "input_text = \"王安石(1021年12月19日-1086年5月21日),字介甫,号半山。抚州临川县(今属江西省抚州市)人。中国北宋时期政治家、文学家、思想家、改革家。庆历二年(1042年),王安石中进士,历任扬州签判、鄞县知县、舒州通判等职,政绩显著。宋仁宗末年,曾作《上仁宗皇帝言事书》,要求对宋初以来的法度进行全盘改革,但未被采纳。\"\n",
112 | "\n",
113 | "# determine chunks\n",
114 | "chunks, span_annotations = chunk_by_sentences(input_text, tokenizer)\n",
115 | "print('Chunks:\\n- \"' + '\"\\n- \"'.join(chunks) + '\"')"
116 | ]
117 | },
118 | {
119 | "cell_type": "code",
120 | "execution_count": 13,
121 | "id": "1e069617-368c-4b58-8717-bb371841ae23",
122 | "metadata": {
123 | "execution": {
124 | "iopub.execute_input": "2024-12-20T09:30:46.441030Z",
125 | "iopub.status.busy": "2024-12-20T09:30:46.440427Z",
126 | "iopub.status.idle": "2024-12-20T09:30:46.451217Z",
127 | "shell.execute_reply": "2024-12-20T09:30:46.450339Z",
128 | "shell.execute_reply.started": "2024-12-20T09:30:46.440997Z"
129 | }
130 | },
131 | "outputs": [
132 | {
133 | "name": "stdout",
134 | "output_type": "stream",
135 | "text": [
136 | "22\n",
137 | "14\n",
138 | "14\n",
139 | "34\n",
140 | "34\n"
141 | ]
142 | }
143 | ],
144 | "source": [
145 | "for chunk in chunks:\n",
146 | " chunk_inputs = tokenizer(chunk, return_tensors='pt')\n",
147 | " length = chunk_inputs['input_ids'].shape[1]\n",
148 | " print(length - 2)"
149 | ]
150 | },
151 | {
152 | "cell_type": "code",
153 | "execution_count": 5,
154 | "id": "77bab847-582a-4694-a560-995c13f2ba8a",
155 | "metadata": {
156 | "execution": {
157 | "iopub.execute_input": "2024-12-20T09:27:31.052797Z",
158 | "iopub.status.busy": "2024-12-20T09:27:31.052231Z",
159 | "iopub.status.idle": "2024-12-20T09:27:31.062700Z",
160 | "shell.execute_reply": "2024-12-20T09:27:31.062065Z",
161 | "shell.execute_reply.started": "2024-12-20T09:27:31.052765Z"
162 | }
163 | },
164 | "outputs": [
165 | {
166 | "data": {
167 | "text/plain": [
168 | "[(1, 22), (22, 36), (36, 50), (50, 84), (84, 118)]"
169 | ]
170 | },
171 | "execution_count": 5,
172 | "metadata": {},
173 | "output_type": "execute_result"
174 | }
175 | ],
176 | "source": [
177 | "span_annotations"
178 | ]
179 | },
180 | {
181 | "cell_type": "code",
182 | "execution_count": 6,
183 | "id": "8c65f230-ac2c-4c65-8e87-ea99f89951fc",
184 | "metadata": {
185 | "execution": {
186 | "iopub.execute_input": "2024-12-20T09:27:32.564695Z",
187 | "iopub.status.busy": "2024-12-20T09:27:32.564295Z",
188 | "iopub.status.idle": "2024-12-20T09:27:32.570489Z",
189 | "shell.execute_reply": "2024-12-20T09:27:32.569717Z",
190 | "shell.execute_reply.started": "2024-12-20T09:27:32.564674Z"
191 | }
192 | },
193 | "outputs": [],
194 | "source": [
195 | "def late_chunking(\n",
196 | " model_output: 'BatchEncoding', span_annotation: list, max_length=None\n",
197 | "):\n",
198 | " token_embeddings = model_output[0]\n",
199 | " outputs = []\n",
200 | " for embeddings, annotations in zip(token_embeddings, span_annotation):\n",
201 | " if (\n",
202 | " max_length is not None\n",
203 | " ): # remove annotations which go bejond the max-length of the model\n",
204 | " annotations = [\n",
205 | " (start, min(end, max_length - 1))\n",
206 | " for (start, end) in annotations\n",
207 | " if start < (max_length - 1)\n",
208 | " ]\n",
209 | " pooled_embeddings = [\n",
210 | " embeddings[start:end].sum(dim=0) / (end - start)\n",
211 | " for start, end in annotations\n",
212 | " if (end - start) >= 1\n",
213 | " ]\n",
214 | " pooled_embeddings = [\n",
215 | " embedding.detach().cpu().numpy() for embedding in pooled_embeddings\n",
216 | " ]\n",
217 | " outputs.append(pooled_embeddings)\n",
218 | "\n",
219 | " return outputs"
220 | ]
221 | },
222 | {
223 | "cell_type": "code",
224 | "execution_count": 7,
225 | "id": "dffb465d-c525-4d88-9a34-9723a64655ce",
226 | "metadata": {
227 | "execution": {
228 | "iopub.execute_input": "2024-12-20T09:27:34.903337Z",
229 | "iopub.status.busy": "2024-12-20T09:27:34.902946Z",
230 | "iopub.status.idle": "2024-12-20T09:27:35.105692Z",
231 | "shell.execute_reply": "2024-12-20T09:27:35.105332Z",
232 | "shell.execute_reply.started": "2024-12-20T09:27:34.903322Z"
233 | }
234 | },
235 | "outputs": [
236 | {
237 | "name": "stderr",
238 | "output_type": "stream",
239 | "text": [
240 | "huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\n",
241 | "To disable this warning, you can either:\n",
242 | "\t- Avoid using `tokenizers` before the fork if possible\n",
243 | "\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\n"
244 | ]
245 | }
246 | ],
247 | "source": [
248 | "# chunk before\n",
249 | "embeddings_traditional_chunking = model.encode(chunks)\n",
250 | "\n",
251 | "# chunk afterwards (context-sensitive chunked pooling)\n",
252 | "inputs = tokenizer(input_text, return_tensors='pt')\n",
253 | "model_output = model(**inputs)\n",
254 | "embeddings = late_chunking(model_output, [span_annotations])[0]"
255 | ]
256 | },
257 | {
258 | "cell_type": "code",
259 | "execution_count": 9,
260 | "id": "2974f348-deb7-4c28-9c14-940593f06745",
261 | "metadata": {
262 | "execution": {
263 | "iopub.execute_input": "2024-12-20T09:28:15.043015Z",
264 | "iopub.status.busy": "2024-12-20T09:28:15.042216Z",
265 | "iopub.status.idle": "2024-12-20T09:28:15.051071Z",
266 | "shell.execute_reply": "2024-12-20T09:28:15.050337Z",
267 | "shell.execute_reply.started": "2024-12-20T09:28:15.042965Z"
268 | }
269 | },
270 | "outputs": [
271 | {
272 | "data": {
273 | "text/plain": [
274 | "torch.Size([1, 120])"
275 | ]
276 | },
277 | "execution_count": 9,
278 | "metadata": {},
279 | "output_type": "execute_result"
280 | }
281 | ],
282 | "source": [
283 | "inputs['input_ids'].shape"
284 | ]
285 | },
286 | {
287 | "cell_type": "code",
288 | "execution_count": 42,
289 | "id": "a448ac6b-e15f-4303-a6d0-c6556f58ef15",
290 | "metadata": {
291 | "execution": {
292 | "iopub.execute_input": "2024-12-20T08:51:54.744209Z",
293 | "iopub.status.busy": "2024-12-20T08:51:54.743553Z",
294 | "iopub.status.idle": "2024-12-20T08:51:54.805936Z",
295 | "shell.execute_reply": "2024-12-20T08:51:54.805458Z",
296 | "shell.execute_reply.started": "2024-12-20T08:51:54.744172Z"
297 | }
298 | },
299 | "outputs": [
300 | {
301 | "name": "stdout",
302 | "output_type": "stream",
303 | "text": [
304 | "similarity_new(\"王安石是哪个朝代的\", \"王安石(1021年12月19日-1086年5月21日),字介甫,号半山。\"): 0.6774667\n",
305 | "similarity_trad(\"王安石是哪个朝代的\", \"王安石(1021年12月19日-1086年5月21日),字介甫,号半山。\"): 0.7342801\n",
306 | "similarity_new(\"王安石是哪个朝代的\", \"抚州临川县(今属江西省抚州市)人。\"): 0.61272216\n",
307 | "similarity_trad(\"王安石是哪个朝代的\", \"抚州临川县(今属江西省抚州市)人。\"): 0.27474773\n",
308 | "similarity_new(\"王安石是哪个朝代的\", \"中国北宋时期政治家、文学家、思想家、改革家。\"): 0.63981277\n",
309 | "similarity_trad(\"王安石是哪个朝代的\", \"中国北宋时期政治家、文学家、思想家、改革家。\"): 0.49549717\n",
310 | "similarity_new(\"王安石是哪个朝代的\", \"庆历二年(1042年),王安石中进士,历任扬州签判、鄞县知县、舒州通判等职,政绩显著。\"): 0.61709845\n",
311 | "similarity_trad(\"王安石是哪个朝代的\", \"庆历二年(1042年),王安石中进士,历任扬州签判、鄞县知县、舒州通判等职,政绩显著。\"): 0.57014936\n",
312 | "similarity_new(\"王安石是哪个朝代的\", \"宋仁宗末年,曾作《上仁宗皇帝言事书》,要求对宋初以来的法度进行全盘改革,但未被采纳。\"): 0.5486519\n",
313 | "similarity_trad(\"王安石是哪个朝代的\", \"宋仁宗末年,曾作《上仁宗皇帝言事书》,要求对宋初以来的法度进行全盘改革,但未被采纳。\"): 0.36279958\n"
314 | ]
315 | }
316 | ],
317 | "source": [
318 | "import numpy as np\n",
319 | "\n",
320 | "cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))\n",
321 | "\n",
322 | "query = \"王安石是哪个朝代的\"\n",
323 | "# query = \"王安石是哪里人\"\n",
324 | "query_embedding = model.encode(query)\n",
325 | "\n",
326 | "for chunk, new_embedding, trad_embeddings in zip(chunks, embeddings, embeddings_traditional_chunking):\n",
327 | " print(f'similarity_new(\"{query}\", \"{chunk}\"):', cos_sim(query_embedding, new_embedding))\n",
328 | " print(f'similarity_trad(\"{query}\", \"{chunk}\"):', cos_sim(query_embedding, trad_embeddings))"
329 | ]
330 | },
331 | {
332 | "cell_type": "code",
333 | "execution_count": null,
334 | "id": "6ca89072-045f-4513-88d2-92a8de4a8bcf",
335 | "metadata": {},
336 | "outputs": [],
337 | "source": []
338 | },
339 | {
340 | "cell_type": "code",
341 | "execution_count": null,
342 | "id": "893270b9-bab6-4007-a791-6b94682f9898",
343 | "metadata": {},
344 | "outputs": [],
345 | "source": []
346 | }
347 | ],
348 | "metadata": {
349 | "kernelspec": {
350 | "display_name": "Python 3 (ipykernel)",
351 | "language": "python",
352 | "name": "python3"
353 | },
354 | "language_info": {
355 | "codemirror_mode": {
356 | "name": "ipython",
357 | "version": 3
358 | },
359 | "file_extension": ".py",
360 | "mimetype": "text/x-python",
361 | "name": "python",
362 | "nbconvert_exporter": "python",
363 | "pygments_lexer": "ipython3",
364 | "version": "3.10.12"
365 | }
366 | },
367 | "nbformat": 4,
368 | "nbformat_minor": 5
369 | }
370 |
--------------------------------------------------------------------------------
/late_chunking/late_chunk_embeddings.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: late_chunk_embeddings.py
4 | # @time: 2024/12/20 15:31
5 | import json
6 | from transformers import AutoModel
7 | from transformers import AutoTokenizer
8 | from tqdm import tqdm
9 | import numpy as np
10 |
11 | import warnings
12 | warnings.filterwarnings('ignore')
13 |
14 | file_path = '../data/doc_qa_test.json'
15 | with open(file_path, 'r') as f:
16 | data = json.load(f)
17 |
18 | corpus = []
19 |
20 | for i in range(len(data['corpus'])):
21 | corpus.append(data['corpus'][f'node_{i+1}'])
22 |
23 |
24 | # for i, _ in enumerate(corpus):
25 | # print(f'node_{i+1}: {_}')
26 |
27 | node_id_dict = {}
28 | _id = 0
29 | for node_id, node_text in data['corpus'].items():
30 | node_id_dict[_id] = int(node_id.split('_')[-1]) - 1
31 | _id += 1
32 | id_node_dict = {v: k for k, v in node_id_dict.items()}
33 |
34 | print(node_id_dict)
35 | print(id_node_dict)
36 |
37 |
38 | total_text = ''.join(corpus) # 全部文本
39 | print(f"测试数据的全量字符数: {len(total_text)}")
40 |
41 | # 加载模型和分词器
42 | tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)
43 | model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)
44 |
45 | # 获取每个text的token数量
46 | corpus_token_num_list = [tokenizer(text, return_tensors='pt')['input_ids'].shape[1] - 2 for text in corpus]
47 | print(corpus_token_num_list)
48 | CLUSTER_MAX_TOKEN_NUM = 4000
49 |
50 |
51 | # 对corpus_token_num_list按token_num进行聚合,每组的text长度不超过CLUSTER_MAX_TOKEN_NUM,但接可能接近CLUSTER_MAX_TOKEN_NUM
52 | def merge_closest_to_n(arr, n):
53 | """
54 | 合并连续的整数项,使得总和小于n且尽可能接近n。
55 |
56 | :param arr: List[int],整数数组
57 | :param n: int,固定值
58 | :return: List[List[int]],合并后的连续项目分组
59 | """
60 | result = []
61 | i = 0
62 |
63 | while i < len(arr):
64 | current_sum = 0
65 | temp_group = []
66 |
67 | for j in range(i, len(arr)):
68 | if current_sum + arr[j] < n:
69 | current_sum += arr[j]
70 | temp_group.append(arr[j])
71 | else:
72 | break
73 |
74 | if temp_group:
75 | result.append(temp_group)
76 | i += len(temp_group) # 跳过合并的部分
77 | else:
78 | result.append([arr[i]]) # 无法合并的单独项
79 | i += 1
80 |
81 | return result
82 |
83 |
84 | cluster_token_num_list = merge_closest_to_n(corpus_token_num_list, CLUSTER_MAX_TOKEN_NUM)
85 | print(cluster_token_num_list)
86 | print(len(cluster_token_num_list))
87 |
88 | # 对聚合后的cluster_token_num_list进行分组,获取拼接后的text和span_list
89 | cluster_text_list = []
90 | span_list_list = []
91 | cnt = 0
92 | for token_num_list in cluster_token_num_list:
93 | cluster_text = ''
94 | span_list = []
95 | start, end = 0, 0
96 | for i, token_num in enumerate(token_num_list):
97 | cluster_text += corpus[cnt]
98 | start = end if i else end + 1
99 | end = start + token_num if i else start + token_num - 1
100 | span_list.append((start, end))
101 | cnt += 1
102 | cluster_text_list.append(cluster_text)
103 | span_list_list.append(span_list)
104 |
105 | print(cluster_text_list)
106 | print(span_list_list)
107 | # 统计span_list_list中的span数量
108 | span_num = sum([len(_) for _ in span_list_list])
109 | print(span_num)
110 |
111 |
112 | # late chunking
113 | def late_chunking(
114 | model_output: 'BatchEncoding', span_annotation: list, max_length=None
115 | ):
116 | token_embeddings = model_output[0]
117 | outputs = []
118 | for embeddings, annotations in zip(token_embeddings, span_annotation):
119 | if (
120 | max_length is not None
121 | ): # remove annotations which go bejond the max-length of the model
122 | annotations = [
123 | (start, min(end, max_length - 1))
124 | for (start, end) in annotations
125 | if start < (max_length - 1)
126 | ]
127 | pooled_embeddings = [
128 | embeddings[start:end].sum(dim=0) / (end - start)
129 | for start, end in annotations
130 | if (end - start) >= 1
131 | ]
132 | pooled_embeddings = [
133 | embedding.detach().cpu().numpy() for embedding in pooled_embeddings
134 | ]
135 | outputs.append(pooled_embeddings)
136 |
137 | return outputs
138 |
139 |
140 | embedding_sum = 0
141 | embedding_data = np.empty(shape=[span_num, 768])
142 | cnt = 0
143 | for input_text, spans in tqdm(zip(cluster_text_list, span_list_list), desc="generate embedding"):
144 | inputs = tokenizer(input_text, return_tensors='pt', max_length=CLUSTER_MAX_TOKEN_NUM, truncation=True)
145 | model_output = model(**inputs)
146 | embeddings = late_chunking(model_output, [spans])[0]
147 | # print(embeddings)
148 | print(len(embeddings))
149 | embedding_sum += len(embeddings)
150 | for embedding in embeddings:
151 | # 对embedding进行归一化, 使其范数为1
152 | embedding_norm = embedding / np.linalg.norm(embedding)
153 | embedding_data[id_node_dict[cnt]] = embedding_norm
154 | cnt += 1
155 | print(f"cnt: {cnt}")
156 |
157 |
158 | np.save(f"../data/corpus_jina_base_zh_late_chunking_embedding.npy", embedding_data)
159 |
160 | print("总共的embedding数量: ", embedding_sum)
161 |
--------------------------------------------------------------------------------
/late_chunking/late_chunking_exp.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: late_chunking_exp.py
4 | # @time: 2024/12/22 22:48
5 | from transformers import AutoModel
6 | from transformers import AutoTokenizer
7 | import os
8 | import numpy as np
9 | from dotenv import load_dotenv
10 | from openai import OpenAI
11 |
12 | load_dotenv()
13 | # load model and tokenizer
14 | tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)
15 | model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)
16 |
17 | chunks = [
18 | "蔚来ET9正式上市 售78.8万元起",
19 | "易车讯 12月21日,蔚来ET9正式上市,售价区间78.8-81.8万元。蔚来ET9定位蔚来品牌科技行政旗舰轿车,新车搭载众多顶尖的黑科技,是中国首款搭载线控转向技术的量产车型,并搭载先进数字架构。",
20 | "蔚来ET9保留了蔚来家族式设计,标志性的一体式X-Bar和Double Dash日间行车灯,让新车看起来富有力量感。“Design for AD”的设计理念得以延续,前瞭望塔式传感器布局,将3颗激光雷达、摄像头等感应硬件巧妙融入外观造型设计中。",
21 | "车头大灯组采用了行业首发MicroLED智能高像素大灯,结合Aqulia2.0超感系统可以实现“广、亮、准、远”的精细化照明。新车整体造型非常流畅,车顶流线从车头一直延伸到车尾,像一张巨大的弓箭,在保持了经典轿车造型商务感的同时,又带来强大的气场和未来气息。",
22 | "超感系统天鹰座Aquila 2.0新增双侧广角激光雷达,通过两侧金属翼子板集成,即提升了安全性,又提升了辅助驾驶能力。超远距激光雷达,搭载蔚来自研杨戬主控芯片,成像效果更佳清晰。新车首次搭载4D毫米波成像雷达,大大增加前向感知能力。",
23 | "车身尺寸方面,蔚来ET9长宽高分别为5325*2017*1621mm,轴距达到了3250mm。此外,新车还配备了23寸的铝合金锻造轮毂,且搭配同级最大的790mm轮胎直径,极具视觉冲击力。来到车尾,新车延续了家族式设计,贯穿式的尾灯组极具辨识度。值得一提的是,新车搭配了同级唯一的鹅颈式全主动尾翼,运动感十足。蔚来ET9首发感应式电动前备箱,支持脚踢感应和车外语音开启,前备箱容积达到105L。",
24 | "内饰方面,蔚来ET9首次采用了矩形方向盘,同时,新车还首发搭载蓝宝石全焦段 AR HUD,能够实现远焦面15米处等效120寸AR-HUD效果。",
25 | "作为行政旗舰轿车,蔚来ET9采用四座布局,创造性的采用了“天空岛”和“行政桥”的设计,配合拱式车身设计,后排的乘坐体验堪比商务舱。在'行政桥'内部,蔚来为二排乘客精心设计了飞机头等舱座椅,拥有582mm超宽坐垫,拥有前排22向,后排20向电动调节。此外,二排座椅还拥有135°超大躺角,可一键尊享11项功能联动。后排还配备了一张360°无级调节的行政桌案,能在任意角度随心调节。“行政桥”下方集成智能冰箱,最大容积达到10L,温度调节范围在-2°C到55°C,此外还首发了常温模式,总计拥有6种预设模式。",
26 | "此外,全车配备七扇电动遮阳帘,支持一键开启。专为后排商务场景开发的全景互联行政屏,应用14.5英寸OLED高清显示屏,屏幕角度可随座椅位置调节,任意姿态下都能拥有舒适的视角。",
27 | "蔚来ET9还首发九霄天琴蔚来8.2.4.8旗舰沉浸声系统。配备了35个扬声器,采用8.2.4.8声学布局,功率可达2800W。在ET9后排的行政桥内,还设置了中置环绕单元,配备了2个高音扬声器+1个中音扬声器。",
28 | "蔚来ET9还首发搭载cedar 雪松全新智能系统,包含全新一代感知硬件、全新一代中央计算器、SkyOS 天枢整车操作系统等。ET9搭载了蔚来首款5nm车规级智能驾驶芯片——神玑NX9031,与全球首个以车为中心的智能电动汽车整车全域操作系统SkyOS·天枢相结合,实现算力与自身算法的紧密结合,智驾、座舱跨域计算资源的共享,带来极致安全和极致效率。",
29 | "蔚来ET9搭载先进数字架构,定义了一层解耦的计算与通信框架,能够支持智能硬件、操作系统、算法和应用等各层次独立迭代。具体来看,蔚来ET9的先进数字架构由大脑——中央计算平台、小脑与脊髓——高效区域控制器、神经网络——高速冗余的通信网络、血液循环——双冗余低压电源、感知器官——超感系统、灵魂和思想——整车全域操作系统六大部分组成,具备强大的算力、超高带宽与极低时延、极致可靠、精准到点的能源管理等特点。在先进数字架构的支撑下,蔚来ET9实现了多项全球首发与同级领先的技术。",
30 | "SkyOS是蔚来整车底层操作系统,包含了整车系统、智驾系统、智能座舱系统、联通服务补能和移动互联,解决整车各个系统不同域之间的安全性、实时性和应用的复杂性问题,以及将软件定义汽车有效落实到造车的各个环节,建立全方位的、立体的技术体系,使得各种设备能够有机地融合在一起,实现高效的协同工作。",
31 | "蔚来ET9搭载国内首个“全域900V高压架构”,包含电池、电机、线束、空调、DC-DC、车载充电机等核心电子电器元件,拥有最高电压925V、充电峰值功率600kW、充电峰值电流765A的三项全球第一。",
32 | "具体来看,蔚来ET9搭载了前180千瓦感应异步电机,后340千瓦永磁同步电机,综合功率520千瓦,综合扭矩达700牛·米,百公里加速4.3秒。电池方面,蔚来ET9搭载自研46105大圆柱电芯。补能方面,新车的闪电充峰值功率高达600kW,充电峰值电流765A,900V支持充电5分钟补能255公里。",
33 | "蔚来ET9搭载“SkyRide·天行智能底盘系统”,首次将线控转向、后轮转向和全主动悬架三大核心硬件系统集成在一起,是目前全球唯一的全线控智能底盘。全球首创智能化、高集成度的主动悬架系统,每个减振器高度集成独立电动液压泵,无刷直流电机响应迅速,可以在1毫秒内完成信息处理、计算和响应。同时,悬架支持大幅度高度调节,每秒可进行1000次扭矩调整,且四轮独立控制,满足多场景驾驶需求。",
34 | "蔚来ET9首次应用的航空工业级“线控转向”技术,方向盘与转向电机之间采用电讯号传输,不仅结构重量轻,传递效率也能提升40%,并支持OTA迭代升级。在低速泊车、掉头等场景中,“线控转向”技术提供灵敏便捷的转向,无需交叉手打方向盘,配合标配最大后轮转角8.3°的后轮转向系统,实现最小10.9米的转弯直径。",
35 | "天行全主动悬架的每个减振器高度集成独立电动液压泵,无刷直流电机响应迅速,可以在1毫秒内完成信息处理、计算和响应。同时,悬架支持大幅度高度调节,每秒可进行1000次扭矩调整,且四轮独立控制,满足多场景驾驶需求。",
36 | "车身强度方面,新车采用高强度钢铝镁合金车身与空间力学设计,扭转刚度达52600Nm/Deg。车身强度达2000MPa,全面提升乘员舱保护。侧气帘长2.3m,高0.67m,可100%覆盖前后排乘客保护区域。同时,新车搭载了行业首创“V腔”设计的二排专属侧气囊。"
37 | ]
38 |
39 | input_text = ''.join(chunks)
40 |
41 | chunk_inputs = tokenizer(chunks[0], return_tensors='pt')
42 | first_length = chunk_inputs['input_ids'].shape[1]
43 | span_annotations = [(1, first_length)]
44 |
45 | for i in range(1, len(chunks)):
46 | chunk_inputs = tokenizer(chunks[i], return_tensors='pt')
47 | length = chunk_inputs['input_ids'].shape[1]
48 | start = span_annotations[i-1][1]
49 | end = start + length
50 | span_annotations.append((start, end))
51 |
52 | print(span_annotations)
53 |
54 | def late_chunking(
55 | model_output: 'BatchEncoding', span_annotation: list, max_length=None
56 | ):
57 | token_embeddings = model_output[0]
58 | outputs = []
59 | for embeddings, annotations in zip(token_embeddings, span_annotation):
60 | if (
61 | max_length is not None
62 | ): # remove annotations which go bejond the max-length of the model
63 | annotations = [
64 | (start, min(end, max_length - 1))
65 | for (start, end) in annotations
66 | if start < (max_length - 1)
67 | ]
68 | pooled_embeddings = [
69 | embeddings[start:end].sum(dim=0) / (end - start)
70 | for start, end in annotations
71 | if (end - start) >= 1
72 | ]
73 | pooled_embeddings = [
74 | embedding.detach().cpu().numpy() for embedding in pooled_embeddings
75 | ]
76 | outputs.append(pooled_embeddings)
77 |
78 | return outputs
79 |
80 | # chunk before
81 | embeddings_traditional_chunking = model.encode(chunks)
82 |
83 | # chunk after wards (context-sensitive chunked pooling)
84 | inputs = tokenizer(input_text, return_tensors='pt', max_length=4096, truncation=True)
85 | model_output = model(**inputs)
86 | embeddings = late_chunking(model_output, [span_annotations])[0]
87 |
88 | cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
89 |
90 | query = "蔚来ET9中的冰箱的最大容积是多少?"
91 | query_embedding = model.encode(query)
92 |
93 | naive_embedding_score_dict = {}
94 | late_chunking_embedding_score_dict = {}
95 | for chunk, trad_embed, new_embed in zip(chunks, embeddings_traditional_chunking, embeddings):
96 | # 计算query和每个chunk的embedding的cosine similarity,相似度分数转化为float类型
97 | naive_embedding_score_dict[chunk] = cos_sim(query_embedding, trad_embed)
98 | late_chunking_embedding_score_dict[chunk] = cos_sim(query_embedding, new_embed)
99 |
100 | naive_embedding_order = sorted(
101 | naive_embedding_score_dict.items(), key=lambda x: x[1], reverse=True
102 | )
103 | late_chunking_order = sorted(
104 | late_chunking_embedding_score_dict.items(), key=lambda x: x[1], reverse=True
105 | )
106 |
107 |
108 | def get_answer(query, retrieve_result):
109 | top_k = 4
110 | text = ''.join([_[0] for _ in retrieve_result[:top_k]])
111 | prompt = f"给定下面的文本,请问答用户的问题。\n\n{text}\n\n问题:{query}"
112 |
113 | client = OpenAI(
114 | api_key=os.environ.get("OPENAI_API_KEY"), # This is the default and can be omitted
115 | )
116 |
117 | chat_completion = client.chat.completions.create(
118 | messages=[
119 | {
120 | "role": "user",
121 | "content": prompt,
122 | }
123 | ],
124 | model="gpt-4o-mini",
125 | )
126 | return chat_completion.choices[0].message.content
127 |
128 |
129 | naive_embedding_answer = get_answer(query=query, retrieve_result=naive_embedding_order)
130 | print(f"query: {query}, 朴素嵌入时RAG过程中LLM的回复:{naive_embedding_answer}")
131 | late_chunking_answer = get_answer(query=query, retrieve_result=late_chunking_order)
132 | print(f"query: {query}, 迟分嵌入时RAG过程中LLM的回复:{late_chunking_answer}")
133 |
--------------------------------------------------------------------------------
/late_chunking/late_chunking_gradio_server.py:
--------------------------------------------------------------------------------
1 | import gradio as gr
2 | import numpy as np
3 | from transformers import AutoModel, AutoTokenizer
4 |
5 | # load model and tokenizer
6 | tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)
7 | model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)
8 |
9 |
10 | def chunk_by_sentences(input_text: str, tokenizer: callable, separator: str):
11 | inputs = tokenizer(input_text, return_tensors='pt', return_offsets_mapping=True)
12 | punctuation_mark_id = tokenizer.convert_tokens_to_ids(separator)
13 | print(f"separator: {separator}, punctuation_mark_id: {punctuation_mark_id}")
14 | sep_id = tokenizer.eos_token_id
15 | token_offsets = inputs['offset_mapping'][0]
16 | token_ids = inputs['input_ids'][0]
17 | chunk_positions = [
18 | (i, int(start + 1))
19 | for i, (token_id, (start, end)) in enumerate(zip(token_ids, token_offsets))
20 | if token_id == punctuation_mark_id
21 | and (
22 | token_offsets[i + 1][0] - token_offsets[i][1] >= 0
23 | or token_ids[i + 1] == sep_id
24 | )
25 | ]
26 | chunks = [
27 | input_text[x[1]: y[1]]
28 | for x, y in zip([(1, 0)] + chunk_positions[:-1], chunk_positions)
29 | ]
30 | span_annotations = [
31 | (x[0], y[0]) for (x, y) in zip([(1, 0)] + chunk_positions[:-1], chunk_positions)
32 | ]
33 | return chunks, span_annotations
34 |
35 |
36 | def late_chunking(model_output, span_annotation, max_length=None):
37 | token_embeddings = model_output[0]
38 | outputs = []
39 | for embeddings, annotations in zip(token_embeddings, span_annotation):
40 | if max_length is not None:
41 | annotations = [
42 | (start, min(end, max_length - 1))
43 | for (start, end) in annotations
44 | if start < (max_length - 1)
45 | ]
46 | pooled_embeddings = [
47 | embeddings[start:end].sum(dim=0) / (end - start)
48 | for start, end in annotations
49 | if (end - start) >= 1
50 | ]
51 | pooled_embeddings = [
52 | embedding.detach().cpu().numpy() for embedding in pooled_embeddings
53 | ]
54 | outputs.append(pooled_embeddings)
55 |
56 | return outputs
57 |
58 |
59 | def embedding_retriever(query_input, text_input, separator):
60 | chunks, span_annotations = chunk_by_sentences(text_input, tokenizer, separator)
61 | print(f"chunks: ", chunks)
62 | inputs = tokenizer(text_input, return_tensors='pt', max_length=4096, truncation=True)
63 | model_output = model(**inputs)
64 | late_chunking_embeddings = late_chunking(model_output, [span_annotations])[0]
65 |
66 | query_inputs = tokenizer(query_input, return_tensors='pt')
67 | query_embedding = model(**query_inputs)[0].detach().cpu().numpy().mean(axis=1)
68 |
69 | traditional_chunking_embeddings = model.encode(chunks)
70 |
71 | cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
72 |
73 | naive_embedding_score_dict = {}
74 | late_chunking_embedding_score_dict = {}
75 | for chunk, trad_embed, new_embed in zip(chunks, traditional_chunking_embeddings, late_chunking_embeddings):
76 | # 计算query和每个chunk的embedding的cosine similarity,相似度分数转化为float类型
77 | naive_embedding_score_dict[chunk] = round(cos_sim(query_embedding, trad_embed).tolist()[0], 4)
78 | late_chunking_embedding_score_dict[chunk] = round(cos_sim(query_embedding, new_embed).tolist()[0], 4)
79 |
80 | naive_embedding_order = sorted(
81 | naive_embedding_score_dict.items(), key=lambda x: x[1], reverse=True
82 | )
83 | late_chunking_order = sorted(
84 | late_chunking_embedding_score_dict.items(), key=lambda x: x[1], reverse=True
85 | )
86 |
87 | df_data = []
88 | for i in range(len(naive_embedding_order)):
89 | df_data.append([i+1, naive_embedding_order[i][0], naive_embedding_order[i][1],
90 | late_chunking_order[i][0], late_chunking_order[i][1]])
91 | return df_data
92 |
93 |
94 | if __name__ == '__main__':
95 | with gr.Blocks() as demo:
96 | query = gr.TextArea(lines=1, placeholder="your query", label="Query")
97 | text = gr.TextArea(lines=3, placeholder="your text", label="Text")
98 | sep = gr.TextArea(lines=1, placeholder="your separator", label="Separator")
99 | submit = gr.Button("Submit")
100 | result = gr.DataFrame(headers=["order", "naive_embedding_text", "naive_embedding_score",
101 | "late_chunking_text", "late_chunking_score"],
102 | label="Retrieve Result",
103 | wrap=True)
104 |
105 | submit.click(fn=embedding_retriever,
106 | inputs=[query, text, sep],
107 | outputs=[result])
108 | demo.launch()
109 |
--------------------------------------------------------------------------------
/late_chunking/my_late_chunking_exp.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "id": "68b268d8-a849-41b0-b126-7b6bb4292419",
7 | "metadata": {
8 | "execution": {
9 | "iopub.execute_input": "2024-12-22T14:21:36.428981Z",
10 | "iopub.status.busy": "2024-12-22T14:21:36.428520Z",
11 | "iopub.status.idle": "2024-12-22T14:21:43.004824Z",
12 | "shell.execute_reply": "2024-12-22T14:21:43.004042Z",
13 | "shell.execute_reply.started": "2024-12-22T14:21:36.428954Z"
14 | }
15 | },
16 | "outputs": [
17 | {
18 | "name": "stderr",
19 | "output_type": "stream",
20 | "text": [
21 | "/Users/admin/anaconda3/envs/myenv/lib/python3.10/site-packages/huggingface_hub/file_download.py:797: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`.\n",
22 | " warnings.warn(\n",
23 | "/Users/admin/anaconda3/envs/myenv/lib/python3.10/site-packages/huggingface_hub/file_download.py:797: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`.\n",
24 | " warnings.warn(\n"
25 | ]
26 | }
27 | ],
28 | "source": [
29 | "from transformers import AutoModel\n",
30 | "from transformers import AutoTokenizer\n",
31 | "\n",
32 | "# load model and tokenizer\n",
33 | "tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)\n",
34 | "model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)"
35 | ]
36 | },
37 | {
38 | "cell_type": "code",
39 | "execution_count": 2,
40 | "id": "41c34067-e605-4489-b2a0-c06c12e6618e",
41 | "metadata": {
42 | "execution": {
43 | "iopub.execute_input": "2024-12-22T14:21:56.714676Z",
44 | "iopub.status.busy": "2024-12-22T14:21:56.713593Z",
45 | "iopub.status.idle": "2024-12-22T14:21:56.723443Z",
46 | "shell.execute_reply": "2024-12-22T14:21:56.722033Z",
47 | "shell.execute_reply.started": "2024-12-22T14:21:56.714647Z"
48 | }
49 | },
50 | "outputs": [],
51 | "source": [
52 | "chunks = [\n",
53 | " \"蔚来ET9正式上市 售78.8万元起\",\n",
54 | " \"易车讯 12月21日,蔚来ET9正式上市,售价区间78.8-81.8万元。蔚来ET9定位蔚来品牌科技行政旗舰轿车,新车搭载众多顶尖的黑科技,是中国首款搭载线控转向技术的量产车型,并搭载先进数字架构。\",\n",
55 | " \"蔚来ET9保留了蔚来家族式设计,标志性的一体式X-Bar和Double Dash日间行车灯,让新车看起来富有力量感。“Design for AD”的设计理念得以延续,前瞭望塔式传感器布局,将3颗激光雷达、摄像头等感应硬件巧妙融入外观造型设计中。\",\n",
56 | " \"车头大灯组采用了行业首发MicroLED智能高像素大灯,结合Aqulia2.0超感系统可以实现“广、亮、准、远”的精细化照明。新车整体造型非常流畅,车顶流线从车头一直延伸到车尾,像一张巨大的弓箭,在保持了经典轿车造型商务感的同时,又带来强大的气场和未来气息。\",\n",
57 | " \"超感系统天鹰座Aquila 2.0新增双侧广角激光雷达,通过两侧金属翼子板集成,即提升了安全性,又提升了辅助驾驶能力。超远距激光雷达,搭载蔚来自研杨戬主控芯片,成像效果更佳清晰。新车首次搭载4D毫米波成像雷达,大大增加前向感知能力。\",\n",
58 | " \"车身尺寸方面,蔚来ET9长宽高分别为5325*2017*1621mm,轴距达到了3250mm。此外,新车还配备了23寸的铝合金锻造轮毂,且搭配同级最大的790mm轮胎直径,极具视觉冲击力。来到车尾,新车延续了家族式设计,贯穿式的尾灯组极具辨识度。值得一提的是,新车搭配了同级唯一的鹅颈式全主动尾翼,运动感十足。蔚来ET9首发感应式电动前备箱,支持脚踢感应和车外语音开启,前备箱容积达到105L。\",\n",
59 | " \"内饰方面,蔚来ET9首次采用了矩形方向盘,同时,新车还首发搭载蓝宝石全焦段 AR HUD,能够实现远焦面15米处等效120寸AR-HUD效果。\",\n",
60 | " \"作为行政旗舰轿车,蔚来ET9采用四座布局,创造性的采用了“天空岛”和“行政桥”的设计,配合拱式车身设计,后排的乘坐体验堪比商务舱。在'行政桥'内部,蔚来为二排乘客精心设计了飞机头等舱座椅,拥有582mm超宽坐垫,拥有前排22向,后排20向电动调节。此外,二排座椅还拥有135°超大躺角,可一键尊享11项功能联动。后排还配备了一张360°无级调节的行政桌案,能在任意角度随心调节。“行政桥”下方集成智能冰箱,最大容积达到10L,温度调节范围在-2°C到55°C,此外还首发了常温模式,总计拥有6种预设模式。\",\n",
61 | " \"此外,全车配备七扇电动遮阳帘,支持一键开启。专为后排商务场景开发的全景互联行政屏,应用14.5英寸OLED高清显示屏,屏幕角度可随座椅位置调节,任意姿态下都能拥有舒适的视角。\",\n",
62 | " \"蔚来ET9还首发九霄天琴蔚来8.2.4.8旗舰沉浸声系统。配备了35个扬声器,采用8.2.4.8声学布局,功率可达2800W。在ET9后排的行政桥内,还设置了中置环绕单元,配备了2个高音扬声器+1个中音扬声器。\",\n",
63 | " \"蔚来ET9还首发搭载cedar 雪松全新智能系统,包含全新一代感知硬件、全新一代中央计算器、SkyOS 天枢整车操作系统等。ET9搭载了蔚来首款5nm车规级智能驾驶芯片——神玑NX9031,与全球首个以车为中心的智能电动汽车整车全域操作系统SkyOS·天枢相结合,实现算力与自身算法的紧密结合,智驾、座舱跨域计算资源的共享,带来极致安全和极致效率。\",\n",
64 | " \"蔚来ET9搭载先进数字架构,定义了一层解耦的计算与通信框架,能够支持智能硬件、操作系统、算法和应用等各层次独立迭代。具体来看,蔚来ET9的先进数字架构由大脑——中央计算平台、小脑与脊髓——高效区域控制器、神经网络——高速冗余的通信网络、血液循环——双冗余低压电源、感知器官——超感系统、灵魂和思想——整车全域操作系统六大部分组成,具备强大的算力、超高带宽与极低时延、极致可靠、精准到点的能源管理等特点。在先进数字架构的支撑下,蔚来ET9实现了多项全球首发与同级领先的技术。\",\n",
65 | " \"SkyOS是蔚来整车底层操作系统,包含了整车系统、智驾系统、智能座舱系统、联通服务补能和移动互联,解决整车各个系统不同域之间的安全性、实时性和应用的复杂性问题,以及将软件定义汽车有效落实到造车的各个环节,建立全方位的、立体的技术体系,使得各种设备能够有机地融合在一起,实现高效的协同工作。\",\n",
66 | " \"蔚来ET9搭载国内首个“全域900V高压架构”,包含电池、电机、线束、空调、DC-DC、车载充电机等核心电子电器元件,拥有最高电压925V、充电峰值功率600kW、充电峰值电流765A的三项全球第一。\",\n",
67 | " \"具体来看,蔚来ET9搭载了前180千瓦感应异步电机,后340千瓦永磁同步电机,综合功率520千瓦,综合扭矩达700牛·米,百公里加速4.3秒。电池方面,蔚来ET9搭载自研46105大圆柱电芯。补能方面,新车的闪电充峰值功率高达600kW,充电峰值电流765A,900V支持充电5分钟补能255公里。\",\n",
68 | " \"蔚来ET9搭载“SkyRide·天行智能底盘系统”,首次将线控转向、后轮转向和全主动悬架三大核心硬件系统集成在一起,是目前全球唯一的全线控智能底盘。全球首创智能化、高集成度的主动悬架系统,每个减振器高度集成独立电动液压泵,无刷直流电机响应迅速,可以在1毫秒内完成信息处理、计算和响应。同时,悬架支持大幅度高度调节,每秒可进行1000次扭矩调整,且四轮独立控制,满足多场景驾驶需求。\",\n",
69 | " \"蔚来ET9首次应用的航空工业级“线控转向”技术,方向盘与转向电机之间采用电讯号传输,不仅结构重量轻,传递效率也能提升40%,并支持OTA迭代升级。在低速泊车、掉头等场景中,“线控转向”技术提供灵敏便捷的转向,无需交叉手打方向盘,配合标配最大后轮转角8.3°的后轮转向系统,实现最小10.9米的转弯直径。\",\n",
70 | " \"天行全主动悬架的每个减振器高度集成独立电动液压泵,无刷直流电机响应迅速,可以在1毫秒内完成信息处理、计算和响应。同时,悬架支持大幅度高度调节,每秒可进行1000次扭矩调整,且四轮独立控制,满足多场景驾驶需求。\",\n",
71 | " \"车身强度方面,新车采用高强度钢铝镁合金车身与空间力学设计,扭转刚度达52600Nm/Deg。车身强度达2000MPa,全面提升乘员舱保护。侧气帘长2.3m,高0.67m,可100%覆盖前后排乘客保护区域。同时,新车搭载了行业首创“V腔”设计的二排专属侧气囊。\"\n",
72 | "]\n",
73 | "\n",
74 | "input_text = ''.join(chunks)"
75 | ]
76 | },
77 | {
78 | "cell_type": "code",
79 | "execution_count": 3,
80 | "id": "59406dc0-36f9-42cd-a598-012373f8fc8e",
81 | "metadata": {
82 | "execution": {
83 | "iopub.execute_input": "2024-12-22T14:21:57.795793Z",
84 | "iopub.status.busy": "2024-12-22T14:21:57.795375Z",
85 | "iopub.status.idle": "2024-12-22T14:21:57.804897Z",
86 | "shell.execute_reply": "2024-12-22T14:21:57.804218Z",
87 | "shell.execute_reply.started": "2024-12-22T14:21:57.795761Z"
88 | }
89 | },
90 | "outputs": [
91 | {
92 | "data": {
93 | "text/plain": [
94 | "19"
95 | ]
96 | },
97 | "execution_count": 3,
98 | "metadata": {},
99 | "output_type": "execute_result"
100 | }
101 | ],
102 | "source": [
103 | "len(chunks)"
104 | ]
105 | },
106 | {
107 | "cell_type": "code",
108 | "execution_count": 4,
109 | "id": "2dd8c969-ade2-4bc3-a167-b79297e30caa",
110 | "metadata": {
111 | "execution": {
112 | "iopub.execute_input": "2024-12-22T14:22:01.173621Z",
113 | "iopub.status.busy": "2024-12-22T14:22:01.172975Z",
114 | "iopub.status.idle": "2024-12-22T14:22:01.196806Z",
115 | "shell.execute_reply": "2024-12-22T14:22:01.196133Z",
116 | "shell.execute_reply.started": "2024-12-22T14:22:01.173592Z"
117 | }
118 | },
119 | "outputs": [
120 | {
121 | "name": "stdout",
122 | "output_type": "stream",
123 | "text": [
124 | "[(1, 13), (13, 75), (75, 146), (146, 232), (232, 309), (309, 439), (439, 487), (487, 663), (663, 718), (718, 800), (800, 905), (905, 1053), (1053, 1136), (1136, 1199), (1199, 1296), (1296, 1416), (1416, 1520), (1520, 1590), (1590, 1676)]\n"
125 | ]
126 | }
127 | ],
128 | "source": [
129 | "chunk_inputs = tokenizer(chunks[0], return_tensors='pt')\n",
130 | "first_length = chunk_inputs['input_ids'].shape[1]\n",
131 | "span_annotations = [(1, first_length)]\n",
132 | "\n",
133 | "for i in range(1, len(chunks)):\n",
134 | " chunk_inputs = tokenizer(chunks[i], return_tensors='pt')\n",
135 | " length = chunk_inputs['input_ids'].shape[1]\n",
136 | " start = span_annotations[i-1][1]\n",
137 | " end = start + length\n",
138 | " span_annotations.append((start, end))\n",
139 | "\n",
140 | "print(span_annotations)"
141 | ]
142 | },
143 | {
144 | "cell_type": "code",
145 | "execution_count": 5,
146 | "id": "3bdf28a9-2852-4a45-b11f-b38755635b99",
147 | "metadata": {
148 | "execution": {
149 | "iopub.execute_input": "2024-12-22T14:22:03.339150Z",
150 | "iopub.status.busy": "2024-12-22T14:22:03.338775Z",
151 | "iopub.status.idle": "2024-12-22T14:22:03.342675Z",
152 | "shell.execute_reply": "2024-12-22T14:22:03.342050Z",
153 | "shell.execute_reply.started": "2024-12-22T14:22:03.339129Z"
154 | }
155 | },
156 | "outputs": [
157 | {
158 | "name": "stdout",
159 | "output_type": "stream",
160 | "text": [
161 | "Chunks:\n",
162 | "- \"蔚来ET9正式上市 售78.8万元起\"\n",
163 | "- \"易车讯 12月21日,蔚来ET9正式上市,售价区间78.8-81.8万元。蔚来ET9定位蔚来品牌科技行政旗舰轿车,新车搭载众多顶尖的黑科技,是中国首款搭载线控转向技术的量产车型,并搭载先进数字架构。\"\n",
164 | "- \"蔚来ET9保留了蔚来家族式设计,标志性的一体式X-Bar和Double Dash日间行车灯,让新车看起来富有力量感。“Design for AD”的设计理念得以延续,前瞭望塔式传感器布局,将3颗激光雷达、摄像头等感应硬件巧妙融入外观造型设计中。\"\n",
165 | "- \"车头大灯组采用了行业首发MicroLED智能高像素大灯,结合Aqulia2.0超感系统可以实现“广、亮、准、远”的精细化照明。新车整体造型非常流畅,车顶流线从车头一直延伸到车尾,像一张巨大的弓箭,在保持了经典轿车造型商务感的同时,又带来强大的气场和未来气息。\"\n",
166 | "- \"超感系统天鹰座Aquila 2.0新增双侧广角激光雷达,通过两侧金属翼子板集成,即提升了安全性,又提升了辅助驾驶能力。超远距激光雷达,搭载蔚来自研杨戬主控芯片,成像效果更佳清晰。新车首次搭载4D毫米波成像雷达,大大增加前向感知能力。\"\n",
167 | "- \"车身尺寸方面,蔚来ET9长宽高分别为5325*2017*1621mm,轴距达到了3250mm。此外,新车还配备了23寸的铝合金锻造轮毂,且搭配同级最大的790mm轮胎直径,极具视觉冲击力。来到车尾,新车延续了家族式设计,贯穿式的尾灯组极具辨识度。值得一提的是,新车搭配了同级唯一的鹅颈式全主动尾翼,运动感十足。蔚来ET9首发感应式电动前备箱,支持脚踢感应和车外语音开启,前备箱容积达到105L。\"\n",
168 | "- \"内饰方面,蔚来ET9首次采用了矩形方向盘,同时,新车还首发搭载蓝宝石全焦段 AR HUD,能够实现远焦面15米处等效120寸AR-HUD效果。\"\n",
169 | "- \"作为行政旗舰轿车,蔚来ET9采用四座布局,创造性的采用了“天空岛”和“行政桥”的设计,配合拱式车身设计,后排的乘坐体验堪比商务舱。在'行政桥'内部,蔚来为二排乘客精心设计了飞机头等舱座椅,拥有582mm超宽坐垫,拥有前排22向,后排20向电动调节。此外,二排座椅还拥有135°超大躺角,可一键尊享11项功能联动。后排还配备了一张360°无级调节的行政桌案,能在任意角度随心调节。“行政桥”下方集成智能冰箱,最大容积达到10L,温度调节范围在-2°C到55°C,此外还首发了常温模式,总计拥有6种预设模式。\"\n",
170 | "- \"此外,全车配备七扇电动遮阳帘,支持一键开启。专为后排商务场景开发的全景互联行政屏,应用14.5英寸OLED高清显示屏,屏幕角度可随座椅位置调节,任意姿态下都能拥有舒适的视角。\"\n",
171 | "- \"蔚来ET9还首发九霄天琴蔚来8.2.4.8旗舰沉浸声系统。配备了35个扬声器,采用8.2.4.8声学布局,功率可达2800W。在ET9后排的行政桥内,还设置了中置环绕单元,配备了2个高音扬声器+1个中音扬声器。\"\n",
172 | "- \"蔚来ET9还首发搭载cedar 雪松全新智能系统,包含全新一代感知硬件、全新一代中央计算器、SkyOS 天枢整车操作系统等。ET9搭载了蔚来首款5nm车规级智能驾驶芯片——神玑NX9031,与全球首个以车为中心的智能电动汽车整车全域操作系统SkyOS·天枢相结合,实现算力与自身算法的紧密结合,智驾、座舱跨域计算资源的共享,带来极致安全和极致效率。\"\n",
173 | "- \"蔚来ET9搭载先进数字架构,定义了一层解耦的计算与通信框架,能够支持智能硬件、操作系统、算法和应用等各层次独立迭代。具体来看,蔚来ET9的先进数字架构由大脑——中央计算平台、小脑与脊髓——高效区域控制器、神经网络——高速冗余的通信网络、血液循环——双冗余低压电源、感知器官——超感系统、灵魂和思想——整车全域操作系统六大部分组成,具备强大的算力、超高带宽与极低时延、极致可靠、精准到点的能源管理等特点。在先进数字架构的支撑下,蔚来ET9实现了多项全球首发与同级领先的技术。\"\n",
174 | "- \"SkyOS是蔚来整车底层操作系统,包含了整车系统、智驾系统、智能座舱系统、联通服务补能和移动互联,解决整车各个系统不同域之间的安全性、实时性和应用的复杂性问题,以及将软件定义汽车有效落实到造车的各个环节,建立全方位的、立体的技术体系,使得各种设备能够有机地融合在一起,实现高效的协同工作。\"\n",
175 | "- \"蔚来ET9搭载国内首个“全域900V高压架构”,包含电池、电机、线束、空调、DC-DC、车载充电机等核心电子电器元件,拥有最高电压925V、充电峰值功率600kW、充电峰值电流765A的三项全球第一。\"\n",
176 | "- \"具体来看,蔚来ET9搭载了前180千瓦感应异步电机,后340千瓦永磁同步电机,综合功率520千瓦,综合扭矩达700牛·米,百公里加速4.3秒。电池方面,蔚来ET9搭载自研46105大圆柱电芯。补能方面,新车的闪电充峰值功率高达600kW,充电峰值电流765A,900V支持充电5分钟补能255公里。\"\n",
177 | "- \"蔚来ET9搭载“SkyRide·天行智能底盘系统”,首次将线控转向、后轮转向和全主动悬架三大核心硬件系统集成在一起,是目前全球唯一的全线控智能底盘。全球首创智能化、高集成度的主动悬架系统,每个减振器高度集成独立电动液压泵,无刷直流电机响应迅速,可以在1毫秒内完成信息处理、计算和响应。同时,悬架支持大幅度高度调节,每秒可进行1000次扭矩调整,且四轮独立控制,满足多场景驾驶需求。\"\n",
178 | "- \"蔚来ET9首次应用的航空工业级“线控转向”技术,方向盘与转向电机之间采用电讯号传输,不仅结构重量轻,传递效率也能提升40%,并支持OTA迭代升级。在低速泊车、掉头等场景中,“线控转向”技术提供灵敏便捷的转向,无需交叉手打方向盘,配合标配最大后轮转角8.3°的后轮转向系统,实现最小10.9米的转弯直径。\"\n",
179 | "- \"天行全主动悬架的每个减振器高度集成独立电动液压泵,无刷直流电机响应迅速,可以在1毫秒内完成信息处理、计算和响应。同时,悬架支持大幅度高度调节,每秒可进行1000次扭矩调整,且四轮独立控制,满足多场景驾驶需求。\"\n",
180 | "- \"车身强度方面,新车采用高强度钢铝镁合金车身与空间力学设计,扭转刚度达52600Nm/Deg。车身强度达2000MPa,全面提升乘员舱保护。侧气帘长2.3m,高0.67m,可100%覆盖前后排乘客保护区域。同时,新车搭载了行业首创“V腔”设计的二排专属侧气囊。\"\n"
181 | ]
182 | }
183 | ],
184 | "source": [
185 | "print('Chunks:\\n- \"' + '\"\\n- \"'.join(chunks) + '\"')"
186 | ]
187 | },
188 | {
189 | "cell_type": "code",
190 | "execution_count": 6,
191 | "id": "d63e334d-1fda-473e-b51e-97aa41fc3e7d",
192 | "metadata": {
193 | "execution": {
194 | "iopub.execute_input": "2024-12-22T14:22:06.189014Z",
195 | "iopub.status.busy": "2024-12-22T14:22:06.188568Z",
196 | "iopub.status.idle": "2024-12-22T14:22:06.197033Z",
197 | "shell.execute_reply": "2024-12-22T14:22:06.195219Z",
198 | "shell.execute_reply.started": "2024-12-22T14:22:06.188987Z"
199 | }
200 | },
201 | "outputs": [],
202 | "source": [
203 | "def late_chunking(\n",
204 | " model_output: 'BatchEncoding', span_annotation: list, max_length=None\n",
205 | "):\n",
206 | " token_embeddings = model_output[0]\n",
207 | " outputs = []\n",
208 | " for embeddings, annotations in zip(token_embeddings, span_annotation):\n",
209 | " if (\n",
210 | " max_length is not None\n",
211 | " ): # remove annotations which go bejond the max-length of the model\n",
212 | " annotations = [\n",
213 | " (start, min(end, max_length - 1))\n",
214 | " for (start, end) in annotations\n",
215 | " if start < (max_length - 1)\n",
216 | " ]\n",
217 | " pooled_embeddings = [\n",
218 | " embeddings[start:end].sum(dim=0) / (end - start)\n",
219 | " for start, end in annotations\n",
220 | " if (end - start) >= 1\n",
221 | " ]\n",
222 | " pooled_embeddings = [\n",
223 | " embedding.detach().cpu().numpy() for embedding in pooled_embeddings\n",
224 | " ]\n",
225 | " outputs.append(pooled_embeddings)\n",
226 | "\n",
227 | " return outputs"
228 | ]
229 | },
230 | {
231 | "cell_type": "code",
232 | "execution_count": 27,
233 | "id": "3e2e417d-25c9-4d0e-8281-b1cdcaacb6c5",
234 | "metadata": {
235 | "execution": {
236 | "iopub.execute_input": "2024-12-22T14:29:17.568707Z",
237 | "iopub.status.busy": "2024-12-22T14:29:17.567508Z",
238 | "iopub.status.idle": "2024-12-22T14:29:20.825127Z",
239 | "shell.execute_reply": "2024-12-22T14:29:20.824340Z",
240 | "shell.execute_reply.started": "2024-12-22T14:29:17.568627Z"
241 | }
242 | },
243 | "outputs": [],
244 | "source": [
245 | "# chunk before\n",
246 | "embeddings_traditional_chunking = model.encode(chunks)\n",
247 | "\n",
248 | "# chunk afterwards (context-sensitive chunked pooling)\n",
249 | "inputs = tokenizer(input_text, return_tensors='pt', max_length=4096, truncation=True)\n",
250 | "model_output = model(**inputs)\n",
251 | "embeddings = late_chunking(model_output, [span_annotations])[0]"
252 | ]
253 | },
254 | {
255 | "cell_type": "code",
256 | "execution_count": 97,
257 | "id": "63d4e90c-2ea3-40e1-878d-adb59765890e",
258 | "metadata": {
259 | "execution": {
260 | "iopub.execute_input": "2024-12-22T14:46:42.349623Z",
261 | "iopub.status.busy": "2024-12-22T14:46:42.348982Z",
262 | "iopub.status.idle": "2024-12-22T14:46:42.474827Z",
263 | "shell.execute_reply": "2024-12-22T14:46:42.474308Z",
264 | "shell.execute_reply.started": "2024-12-22T14:46:42.349584Z"
265 | }
266 | },
267 | "outputs": [],
268 | "source": [
269 | "import numpy as np\n",
270 | "\n",
271 | "cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))\n",
272 | "\n",
273 | "query = \"蔚来ET9中的冰箱的最大容积是多少?\"\n",
274 | "query_embedding = model.encode(query)\n",
275 | "\n",
276 | "naive_embedding_score_dict = {}\n",
277 | "late_chunking_embedding_score_dict = {}\n",
278 | "for chunk, trad_embed, new_embed in zip(chunks, embeddings_traditional_chunking, embeddings):\n",
279 | " # 计算query和每个chunk的embedding的cosine similarity,相似度分数转化为float类型\n",
280 | " naive_embedding_score_dict[chunk] = cos_sim(query_embedding, trad_embed)\n",
281 | " late_chunking_embedding_score_dict[chunk] = cos_sim(query_embedding, new_embed)\n",
282 | "\n",
283 | "naive_embedding_order = sorted(\n",
284 | " naive_embedding_score_dict.items(), key=lambda x: x[1], reverse=True\n",
285 | ")\n",
286 | "late_chunking_order = sorted(\n",
287 | " late_chunking_embedding_score_dict.items(), key=lambda x: x[1], reverse=True\n",
288 | ")"
289 | ]
290 | },
291 | {
292 | "cell_type": "code",
293 | "execution_count": 98,
294 | "id": "cd5b4145-e8b2-47f2-9a8d-d6af6facfcc5",
295 | "metadata": {
296 | "execution": {
297 | "iopub.execute_input": "2024-12-22T14:46:42.977904Z",
298 | "iopub.status.busy": "2024-12-22T14:46:42.977285Z",
299 | "iopub.status.idle": "2024-12-22T14:46:42.983922Z",
300 | "shell.execute_reply": "2024-12-22T14:46:42.983045Z",
301 | "shell.execute_reply.started": "2024-12-22T14:46:42.977873Z"
302 | }
303 | },
304 | "outputs": [
305 | {
306 | "name": "stdout",
307 | "output_type": "stream",
308 | "text": [
309 | "[('蔚来ET9正式上市 售78.8万元起', 0.6766535), ('内饰方面,蔚来ET9首次采用了矩形方向盘,同时,新车还首发搭载蓝宝石全焦段 AR HUD,能够实现远焦面15米处等效120寸AR-HUD效果。', 0.625085), ('蔚来ET9搭载国内首个“全域900V高压架构”,包含电池、电机、线束、空调、DC-DC、车载充电机等核心电子电器元件,拥有最高电压925V、充电峰值功率600kW、充电峰值电流765A的三项全球第一。', 0.5982587), ('车身尺寸方面,蔚来ET9长宽高分别为5325*2017*1621mm,轴距达到了3250mm。此外,新车还配备了23寸的铝合金锻造轮毂,且搭配同级最大的790mm轮胎直径,极具视觉冲击力。来到车尾,新车延续了家族式设计,贯穿式的尾灯组极具辨识度。值得一提的是,新车搭配了同级唯一的鹅颈式全主动尾翼,运动感十足。蔚来ET9首发感应式电动前备箱,支持脚踢感应和车外语音开启,前备箱容积达到105L。', 0.59242946)]\n"
310 | ]
311 | }
312 | ],
313 | "source": [
314 | "print(naive_embedding_order[:4])"
315 | ]
316 | },
317 | {
318 | "cell_type": "code",
319 | "execution_count": 99,
320 | "id": "7425502b-0781-4ea8-b3f8-1f71cf0f518e",
321 | "metadata": {
322 | "execution": {
323 | "iopub.execute_input": "2024-12-22T14:46:50.671586Z",
324 | "iopub.status.busy": "2024-12-22T14:46:50.670571Z",
325 | "iopub.status.idle": "2024-12-22T14:46:50.676966Z",
326 | "shell.execute_reply": "2024-12-22T14:46:50.676304Z",
327 | "shell.execute_reply.started": "2024-12-22T14:46:50.671525Z"
328 | }
329 | },
330 | "outputs": [
331 | {
332 | "name": "stdout",
333 | "output_type": "stream",
334 | "text": [
335 | "[('此外,全车配备七扇电动遮阳帘,支持一键开启。专为后排商务场景开发的全景互联行政屏,应用14.5英寸OLED高清显示屏,屏幕角度可随座椅位置调节,任意姿态下都能拥有舒适的视角。', 0.59399706), ('内饰方面,蔚来ET9首次采用了矩形方向盘,同时,新车还首发搭载蓝宝石全焦段 AR HUD,能够实现远焦面15米处等效120寸AR-HUD效果。', 0.57931596), (\"作为行政旗舰轿车,蔚来ET9采用四座布局,创造性的采用了“天空岛”和“行政桥”的设计,配合拱式车身设计,后排的乘坐体验堪比商务舱。在'行政桥'内部,蔚来为二排乘客精心设计了飞机头等舱座椅,拥有582mm超宽坐垫,拥有前排22向,后排20向电动调节。此外,二排座椅还拥有135°超大躺角,可一键尊享11项功能联动。后排还配备了一张360°无级调节的行政桌案,能在任意角度随心调节。“行政桥”下方集成智能冰箱,最大容积达到10L,温度调节范围在-2°C到55°C,此外还首发了常温模式,总计拥有6种预设模式。\", 0.57819366), ('具体来看,蔚来ET9搭载了前180千瓦感应异步电机,后340千瓦永磁同步电机,综合功率520千瓦,综合扭矩达700牛·米,百公里加速4.3秒。电池方面,蔚来ET9搭载自研46105大圆柱电芯。补能方面,新车的闪电充峰值功率高达600kW,充电峰值电流765A,900V支持充电5分钟补能255公里。', 0.5769798)]\n"
336 | ]
337 | }
338 | ],
339 | "source": [
340 | "print(late_chunking_order[:4])"
341 | ]
342 | },
343 | {
344 | "cell_type": "code",
345 | "execution_count": 100,
346 | "id": "7b967e79-a27f-4386-bbb9-48c73555627b",
347 | "metadata": {
348 | "execution": {
349 | "iopub.execute_input": "2024-12-22T14:46:52.072701Z",
350 | "iopub.status.busy": "2024-12-22T14:46:52.072137Z",
351 | "iopub.status.idle": "2024-12-22T14:46:52.081058Z",
352 | "shell.execute_reply": "2024-12-22T14:46:52.080467Z",
353 | "shell.execute_reply.started": "2024-12-22T14:46:52.072672Z"
354 | }
355 | },
356 | "outputs": [],
357 | "source": [
358 | "import os\n",
359 | "from dotenv import load_dotenv\n",
360 | "from openai import OpenAI\n",
361 | "\n",
362 | "load_dotenv()\n",
363 | "\n",
364 | "def get_answer(query, retrieve_result):\n",
365 | " top_k = 4\n",
366 | " text = ''.join([_[0] for _ in retrieve_result[:top_k]])\n",
367 | " prompt = f\"给定下面的文本,请问答用户的问题。\\n\\n{text}\\n\\n问题:{query}\"\n",
368 | " \n",
369 | " client = OpenAI(\n",
370 | " api_key=os.environ.get(\"OPENAI_API_KEY\"), # This is the default and can be omitted\n",
371 | " )\n",
372 | " \n",
373 | " chat_completion = client.chat.completions.create(\n",
374 | " messages=[\n",
375 | " {\n",
376 | " \"role\": \"user\",\n",
377 | " \"content\": prompt,\n",
378 | " }\n",
379 | " ],\n",
380 | " model=\"gpt-4o-mini\",\n",
381 | " )\n",
382 | " return chat_completion.choices[0].message.content"
383 | ]
384 | },
385 | {
386 | "cell_type": "code",
387 | "execution_count": 101,
388 | "id": "812852fb-0aed-4be6-9280-936341e2ea3d",
389 | "metadata": {
390 | "execution": {
391 | "iopub.execute_input": "2024-12-22T14:46:53.257073Z",
392 | "iopub.status.busy": "2024-12-22T14:46:53.256504Z",
393 | "iopub.status.idle": "2024-12-22T14:46:55.507917Z",
394 | "shell.execute_reply": "2024-12-22T14:46:55.506405Z",
395 | "shell.execute_reply.started": "2024-12-22T14:46:53.257044Z"
396 | }
397 | },
398 | "outputs": [
399 | {
400 | "name": "stdout",
401 | "output_type": "stream",
402 | "text": [
403 | "query: 蔚来ET9中的冰箱的最大容积是多少?, 朴素嵌入时RAG过程中LLM的回复:根据提供的文本,蔚来ET9并没有提到冰箱的相关信息,因此无法回答关于冰箱最大容积的问题。在文本中提到的是前备箱的容积,前备箱容积达到105L。\n",
404 | "query: 蔚来ET9中的冰箱的最大容积是多少?, 迟分嵌入时RAG过程中LLM的回复:蔚来ET9中的冰箱的最大容积达到10L。\n"
405 | ]
406 | }
407 | ],
408 | "source": [
409 | "naive_embedding_answer = get_answer(query=query, retrieve_result=naive_embedding_order)\n",
410 | "print(f\"query: {query}, 朴素嵌入时RAG过程中LLM的回复:{naive_embedding_answer}\")\n",
411 | "late_chunking_answer = get_answer(query=query, retrieve_result=late_chunking_order)\n",
412 | "print(f\"query: {query}, 迟分嵌入时RAG过程中LLM的回复:{late_chunking_answer}\")"
413 | ]
414 | },
415 | {
416 | "cell_type": "code",
417 | "execution_count": null,
418 | "id": "3deef816-b607-488b-9ad0-631255993eee",
419 | "metadata": {},
420 | "outputs": [],
421 | "source": []
422 | }
423 | ],
424 | "metadata": {
425 | "kernelspec": {
426 | "display_name": "Python 3 (ipykernel)",
427 | "language": "python",
428 | "name": "python3"
429 | },
430 | "language_info": {
431 | "codemirror_mode": {
432 | "name": "ipython",
433 | "version": 3
434 | },
435 | "file_extension": ".py",
436 | "mimetype": "text/x-python",
437 | "name": "python",
438 | "nbconvert_exporter": "python",
439 | "pygments_lexer": "ipython3",
440 | "version": "3.10.12"
441 | }
442 | },
443 | "nbformat": 4,
444 | "nbformat_minor": 5
445 | }
446 |
--------------------------------------------------------------------------------
/preprocess/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: __init__.py.py
4 | # @time: 2023/12/25 17:50
5 |
--------------------------------------------------------------------------------
/preprocess/add_corpus.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: add_corpus.py
4 | # @time: 2023/12/25 19:46
5 | import json
6 | import pandas as pd
7 |
8 | with open('../data/doc_qa_dataset.json', 'r', encoding="utf-8") as f:
9 | content = json.loads(f.read())
10 |
11 | corpus = content['corpus']
12 | texts = [text for node_id, text in content['corpus'].items()]
13 |
14 | data_df = pd.read_csv("../data/doc_qa_dataset.csv", encoding="utf-8")
15 | for i, row in data_df.iterrows():
16 | node_id = f"node_{i + 1}"
17 | if node_id not in corpus:
18 | corpus[f"node_{i + 1}"] = row["content"]
19 |
20 | content["corpus"] = corpus
21 |
22 | with open("../data/doc_qa_test.json", "w", encoding="utf-8") as f:
23 | f.write(json.dumps(content, ensure_ascii=False, indent=4))
24 |
--------------------------------------------------------------------------------
/preprocess/data_transfer.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: data_transfer.py
4 | # @time: 2023/12/25 17:51
5 | import pandas as pd
6 | from llama_index.llms import OpenAI
7 | from llama_index.schema import TextNode
8 | from llama_index.evaluation import generate_question_context_pairs
9 | import random
10 | random.seed(42)
11 |
12 | llm = OpenAI(model="gpt-4", max_retries=5)
13 |
14 | # Prompt to generate questions
15 | qa_generate_prompt_tmpl = """\
16 | Context information is below.
17 |
18 | ---------------------
19 | {context_str}
20 | ---------------------
21 |
22 | Given the context information and not prior knowledge.
23 | generate only questions based on the below query.
24 |
25 | You are a university professor. Your task is to set {num_questions_per_chunk} questions for the upcoming Chinese quiz.
26 | Questions throughout the test should be diverse. Questions should not contain options or start with Q1/Q2.
27 | Questions must be written in Chinese. The expression must be concise and clear.
28 | It should not exceed 15 Chinese characters. Words such as "这", "那", "根据", "依据" and other punctuation marks
29 | should not be used. Abbreviations may be used for titles and professional terms.
30 | """
31 |
32 | nodes = []
33 | data_df = pd.read_csv("../data/doc_qa_dataset.csv", encoding="utf-8")
34 | for i, row in data_df.iterrows():
35 | if len(row["content"]) > 80 and i > 96:
36 | node = TextNode(text=row["content"])
37 | node.id_ = f"node_{i + 1}"
38 | nodes.append(node)
39 |
40 |
41 | doc_qa_dataset = generate_question_context_pairs(
42 | nodes, llm=llm, num_questions_per_chunk=1, qa_generate_prompt_tmpl=qa_generate_prompt_tmpl
43 | )
44 |
45 | doc_qa_dataset.save_json("../data/doc_qa_dataset.json")
46 |
--------------------------------------------------------------------------------
/preprocess/get_text_id_mapping.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: get_text_id_mapping.py
4 | # @time: 2023/12/25 20:18
5 | import os
6 | import json
7 |
8 | current_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
9 |
10 | with open(os.path.join(current_dir, 'data/doc_qa_test.json'), 'r', encoding="utf-8") as f:
11 | content = json.loads(f.read())
12 |
13 | queries = list(content['queries'].values())
14 | query_relevant_docs = {content['queries'][k]: v for k, v in content['relevant_docs'].items()}
15 | node_id_text_mapping = content['corpus']
16 | text_node_id_mapping = {v: k for k, v in node_id_text_mapping.items()}
17 |
--------------------------------------------------------------------------------
/preprocess/query_rewrite.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: query_rewrite.py
4 | # @time: 2023/12/28 12:55
5 | import os
6 | import time
7 | import random
8 | import json
9 | import requests
10 | import numpy as np
11 | from tqdm import tqdm
12 | from retry import retry
13 |
14 | from llama_index.llms import OpenAI, ChatMessage
15 | from llama_index import PromptTemplate
16 |
17 | llm = OpenAI(model="gpt-3.5-turbo")
18 |
19 | query_gen_prompt_str = (
20 | "为下面的问题提供{num_queries}个查询改写,使之能更好地适应搜索引擎。每行一个改写结果,以-开头,当涉及到缩写时,要提供全称。\n"
21 | "问题:{query} \n"
22 | "答案:"
23 | )
24 | query_gen_prompt = PromptTemplate(query_gen_prompt_str)
25 |
26 |
27 | def generate_queries(llm, query_str: str, num_queries: int = 3):
28 | fmt_prompt = query_gen_prompt.format(
29 | num_queries=num_queries, query=query_str
30 | )
31 | response = llm.complete(fmt_prompt)
32 | queries = [_.replace("- ", "").strip() for _ in response.text.split("\n") if _.strip()]
33 | return queries[:num_queries]
34 |
35 |
36 | @retry(exceptions=Exception, tries=3, max_delay=20)
37 | def get_openai_embedding(req_text: str) -> list[float]:
38 | time.sleep(random.random() / 2)
39 | url = "https://api.openai.com/v1/embeddings"
40 | headers = {'Content-Type': 'application/json', "Authorization": f"Bearer {os.getenv('OPENAI_API_KEY')}"}
41 | payload = json.dumps({"model": "text-embedding-ada-002", "input": req_text})
42 | new_req = requests.request("POST", url, headers=headers, data=payload)
43 | return new_req.json()['data'][0]['embedding']
44 |
45 |
46 | if __name__ == '__main__':
47 | # query = "日美半导体协议要求美国芯片在日本市场份额是多少?"
48 | # query = "半导体制造设备市场美、日、荷各占多少份额?"
49 | # query = "尼康和佳能的光刻机在哪个市场占优势?"
50 | # print(generate_queries(llm, query, num_queries=2))
51 | num_queries = 2
52 | with open("../data/doc_qa_test.json", "r", encoding="utf-8") as f:
53 | content = json.loads(f.read())
54 | queries = list(content["queries"].values())
55 | query_num = len(queries)
56 |
57 | rewrite_dict = {}
58 | embedding_data = np.empty(shape=[query_num * num_queries, 1536])
59 | for i in tqdm(range(query_num), desc="generate embedding"):
60 | query = queries[i]
61 | rewrite_queries = generate_queries(llm, query, num_queries=num_queries)
62 | rewrite_dict[query] = rewrite_queries
63 | print(rewrite_queries)
64 | for j, rewrite_query in enumerate(rewrite_queries):
65 | embedding_data[2 * i + j] = get_openai_embedding(rewrite_query)
66 |
67 | with open('../data/query_rewrite.json', "w") as f:
68 | f.write(json.dumps(rewrite_dict, ensure_ascii=False, indent=4))
69 | np.save("../data/query_rewrite_openai_embedding.npy", embedding_data)
70 |
71 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | cohere==4.39
2 | elasticsearch==7.17.0
3 | faiss-cpu==1.7.4
4 | llama-index==0.9.21
5 | numpy==1.26.2
6 | pandas==2.1.4
7 | plotly==5.18.0
8 | Requests==2.31.0
9 | retry==0.9.2
10 | tqdm==4.66.1
11 | gradio==4.12.0
12 | openpyxl==3.1.2
--------------------------------------------------------------------------------
/services/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: __init__.py.py
4 | # @time: 2023/12/30 11:50
5 |
--------------------------------------------------------------------------------
/services/data_analysis.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: data_analysis.py
4 | # @time: 2023/12/30 11:52
5 | import pandas as pd
6 | from faiss import IndexFlatIP
7 | from llama_index.evaluation.retrieval.metrics import HitRate, MRR
8 |
9 | from custom_retriever.bm25_retriever import CustomBM25Retriever
10 | from custom_retriever.vector_store_retriever import VectorSearchRetriever
11 | from custom_retriever.ensemble_retriever import EnsembleRetriever
12 | from custom_retriever.ensemble_rerank_retriever import EnsembleRerankRetriever
13 | from preprocess.get_text_id_mapping import queries, query_relevant_docs, node_id_text_mapping
14 |
15 |
16 | def get_metric(search_query, search_result):
17 | hit_rate = HitRate().compute(query=search_query,
18 | expected_ids=query_relevant_docs[search_query],
19 | retrieved_ids=[_.id_ for _ in search_result])
20 | mrr = MRR().compute(query=search_query,
21 | expected_ids=query_relevant_docs[search_query],
22 | retrieved_ids=[_.id_ for _ in search_result])
23 | return [hit_rate.score, mrr.score]
24 |
25 |
26 | top_k = 3
27 | faiss_index = IndexFlatIP(1536)
28 | data_columns = []
29 | for i, query in enumerate(queries, start=1):
30 | print(i, query)
31 | expect_text = node_id_text_mapping[query_relevant_docs[query][0]]
32 | record = [query]
33 | # bm25
34 | bm25_retriever = CustomBM25Retriever(top_k=top_k)
35 | bm25_search_result = bm25_retriever.retrieve(query)
36 | bm25_metric = get_metric(query, bm25_search_result)
37 | record.extend(bm25_metric)
38 | # embedding search
39 | vector_search_retriever = VectorSearchRetriever(top_k=top_k, faiss_index=faiss_index)
40 | embedding_search_result = vector_search_retriever.retrieve(str_or_query_bundle=query)
41 | embedding_metric = get_metric(query, embedding_search_result)
42 | faiss_index.reset()
43 | record.extend(embedding_metric)
44 | # ensemble search
45 | ensemble_retriever = EnsembleRetriever(top_k=top_k, faiss_index=faiss_index, weights=[0.5, 0.5])
46 | ensemble_search_result = ensemble_retriever.retrieve(str_or_query_bundle=query)
47 | ensemble_metric = get_metric(query, ensemble_search_result)
48 | faiss_index.reset()
49 | record.extend(ensemble_metric)
50 | # ensemble rerank search
51 | ensemble_retriever = EnsembleRerankRetriever(top_k=top_k, faiss_index=faiss_index)
52 | ensemble_rerank_search_result = ensemble_retriever.retrieve(str_or_query_bundle=query)
53 | ensemble_rerank_metric = get_metric(query, ensemble_rerank_search_result)
54 | faiss_index.reset()
55 | record.extend(ensemble_rerank_metric)
56 | record.append(expect_text)
57 | data_columns.append(record)
58 |
59 |
60 | df = pd.DataFrame(data_columns,
61 | columns=["query", "bm25_hit_rate", "bm25_mrr", "embedding_hit_rate", "embedding_mrr",
62 | "ensemble_hit_rate", "ensemble_mrr", "ensemble_rerank_hit_rate",
63 | "ensemble_rerank_mrr", "expect text"])
64 | df.to_excel("search_result_analysis.xlsx", index=False)
65 |
--------------------------------------------------------------------------------
/services/embedding_server.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: embedding_server.py
4 | # @time: 2024/1/5 11:03
5 | import uvicorn
6 | from fastapi import FastAPI
7 | from pydantic import BaseModel
8 | from sentence_transformers import SentenceTransformer
9 |
10 | app = FastAPI()
11 | model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
12 |
13 |
14 | class Sentence(BaseModel):
15 | text: str
16 |
17 |
18 | @app.get('/')
19 | def home():
20 | return 'hello world'
21 |
22 |
23 | @app.post('/embedding')
24 | def get_embedding(sentence: Sentence):
25 | embedding = model.encode(sentence.text, normalize_embeddings=True).tolist()
26 | return {"text": sentence.text, "embedding": embedding}
27 |
28 |
29 | if __name__ == '__main__':
30 | uvicorn.run(app, host='0.0.0.0', port=50072)
31 |
--------------------------------------------------------------------------------
/services/search_result_analysis.xlsx:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/percent4/embedding_rerank_retrieval/f6a0ee5d388b20807e9f07c81c69cf963ea2d463/services/search_result_analysis.xlsx
--------------------------------------------------------------------------------
/services/server_gradio.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: server_gradio.py
4 | # @time: 2023/12/29 22:25
5 | from random import shuffle
6 | import gradio as gr
7 | import pandas as pd
8 |
9 | from faiss import IndexFlatIP
10 | from llama_index.evaluation.retrieval.metrics import HitRate, MRR
11 |
12 | from custom_retriever.bm25_retriever import CustomBM25Retriever
13 | from custom_retriever.vector_store_retriever import VectorSearchRetriever
14 | from custom_retriever.ensemble_retriever import EnsembleRetriever
15 | from custom_retriever.ensemble_rerank_retriever import EnsembleRerankRetriever
16 | from preprocess.get_text_id_mapping import queries, query_relevant_docs
17 | from preprocess.query_rewrite import generate_queries, llm
18 |
19 | retrieve_methods = ["bm25", "embedding", "ensemble", "ensemble + bge-rerank-large", "query_rewrite + ensemble"]
20 |
21 |
22 | def get_metric(search_query, search_result):
23 | hit_rate = HitRate().compute(query=search_query,
24 | expected_ids=query_relevant_docs[search_query],
25 | retrieved_ids=[_.id_ for _ in search_result])
26 | mrr = MRR().compute(query=search_query,
27 | expected_ids=query_relevant_docs[search_query],
28 | retrieved_ids=[_.id_ for _ in search_result])
29 | return [hit_rate.score, mrr.score]
30 |
31 |
32 | def get_retrieve_result(retriever_list, retrieve_top_k, retrieve_query):
33 | columns = {"metric_&_top_k": ["Hit Rate", "MRR"] + [f"top_{k + 1}" for k in range(retrieve_top_k)]}
34 | if "bm25" in retriever_list:
35 | bm25_retriever = CustomBM25Retriever(top_k=retrieve_top_k)
36 | search_result = bm25_retriever.retrieve(retrieve_query)
37 | columns["bm25"] = []
38 | columns["bm25"].extend(get_metric(retrieve_query, search_result))
39 | for i, node in enumerate(search_result, start=1):
40 | columns["bm25"].append(node.text)
41 | if "embedding" in retriever_list:
42 | faiss_index = IndexFlatIP(1536)
43 | vector_search_retriever = VectorSearchRetriever(top_k=retrieve_top_k, faiss_index=faiss_index)
44 | search_result = vector_search_retriever.retrieve(str_or_query_bundle=retrieve_query)
45 | columns["embedding"] = []
46 | columns["embedding"].extend(get_metric(retrieve_query, search_result))
47 | for i in range(retrieve_top_k):
48 | columns["embedding"].append(search_result[i].text)
49 | faiss_index.reset()
50 | if "ensemble" in retriever_list:
51 | faiss_index = IndexFlatIP(1536)
52 | ensemble_retriever = EnsembleRetriever(top_k=retrieve_top_k, faiss_index=faiss_index, weights=[0.5, 0.5])
53 | search_result = ensemble_retriever.retrieve(str_or_query_bundle=retrieve_query)
54 | columns["ensemble"] = []
55 | columns["ensemble"].extend(get_metric(retrieve_query, search_result))
56 | for i in range(retrieve_top_k):
57 | columns["ensemble"].append(search_result[i].text)
58 | faiss_index.reset()
59 | if "ensemble + bge-rerank-large" in retriever_list:
60 | faiss_index = IndexFlatIP(1536)
61 | ensemble_retriever = EnsembleRerankRetriever(top_k=retrieve_top_k, faiss_index=faiss_index)
62 | search_result = ensemble_retriever.retrieve(str_or_query_bundle=retrieve_query)
63 | columns["ensemble + bge-rerank-large"] = []
64 | columns["ensemble + bge-rerank-large"].extend(get_metric(retrieve_query, search_result))
65 | for i in range(retrieve_top_k):
66 | columns["ensemble + bge-rerank-large"].append(search_result[i].text)
67 | faiss_index.reset()
68 | if "query_rewrite + ensemble" in retriever_list:
69 | queries = generate_queries(llm, retrieve_query, num_queries=1)
70 | print(f"original query: {retrieve_query}\n"
71 | f"rewrite query: {queries}")
72 | faiss_index = IndexFlatIP(1536)
73 | ensemble_retriever = EnsembleRetriever(top_k=retrieve_top_k, faiss_index=faiss_index, weights=[0.5, 0.5])
74 | search_result = ensemble_retriever.retrieve(str_or_query_bundle=queries[0])
75 | columns["query_rewrite + ensemble"] = []
76 | columns["query_rewrite + ensemble"].extend(get_metric(retrieve_query, search_result))
77 | for i in range(retrieve_top_k):
78 | columns["query_rewrite + ensemble"].append(search_result[i].text)
79 | faiss_index.reset()
80 | retrieve_df = pd.DataFrame(columns)
81 | return retrieve_df
82 |
83 |
84 | with gr.Blocks() as demo:
85 | retrievers = gr.CheckboxGroup(choices=retrieve_methods,
86 | type="value",
87 | label="Retrieve Methods")
88 | top_k = gr.Dropdown(list(range(1, 6)), label="top_k", value=3)
89 | shuffle(queries)
90 | query = gr.Dropdown(queries, label="query", value=queries[0])
91 | # 设置输出组件
92 | result_table = gr.DataFrame(label='Result', wrap=True)
93 | theme = gr.themes.Base()
94 | # 设置按钮
95 | submit = gr.Button("Submit")
96 | submit.click(fn=get_retrieve_result, inputs=[retrievers, top_k, query], outputs=result_table)
97 |
98 |
99 | demo.launch()
100 |
--------------------------------------------------------------------------------
/utils/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: __init__.py.py
4 | # @time: 2023/12/26 19:21
5 |
--------------------------------------------------------------------------------
/utils/rerank.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @place: Pudong, Shanghai
3 | # @file: rerank.py
4 | # @time: 2023/12/26 19:21
5 | import os
6 | import time
7 | import requests
8 | import json
9 | from random import randint
10 | import cohere
11 | from typing import List, Tuple
12 | from retry import retry
13 |
14 | # cohere_client = cohere.Client(os.getenv("COHERE_API_KEY"))
15 | #
16 | #
17 | # @retry(exceptions=Exception, tries=5, max_delay=60)
18 | # def cohere_rerank_result(query: str, docs: List[str], top_n) -> List[Tuple]:
19 | # time.sleep(randint(1, 10))
20 | # results = cohere_client.rerank(model="rerank-multilingual-v2.0",
21 | # query=query,
22 | # documents=docs,
23 | # top_n=top_n)
24 | # return [(hit.document['text'], hit.relevance_score) for hit in results]
25 |
26 |
27 | @retry(exceptions=Exception, tries=5, max_delay=60)
28 | def bge_rerank_result(query: str, docs: List[str], top_n) -> List[Tuple]:
29 | url = "http://localhost:9000/bge_rerank"
30 | payload = json.dumps({
31 | "query": query,
32 | "passages": docs,
33 | "top_k": top_n
34 | })
35 | headers = {'Content-Type': 'application/json'}
36 |
37 | response = requests.request("POST", url, headers=headers, data=payload)
38 | return [(passage, score) for passage, score in response.json().items()]
39 |
--------------------------------------------------------------------------------