)[\s\S]*?(?=)" 31 | THEBE_PATTERN_WITH_TAGS = r"
[\s\S]*?" 32 | -------------------------------------------------------------------------------- /tests/core/representation/conftest.py: -------------------------------------------------------------------------------- 1 | import pytest 2 | import numpy as np 3 | import random 4 | 5 | 6 | @pytest.fixture(scope="module") 7 | def one_to_two_and_square(): 8 | x = np.linspace(1.0, 2.0, 11) 9 | y = x * x 10 | return [x, y] 11 | 12 | 13 | @pytest.fixture(scope="module") 14 | def example_array(n_vecs=1000, dim=30): 15 | return np.random.rand(n_vecs, dim) 16 | 17 | 18 | @pytest.fixture(scope="module") 19 | def distance_preserving_array_sequence(example_array): 20 | A = example_array 21 | # translation 22 | B = A + 1.0 23 | # dilation 24 | C = 3.0 * B 25 | # rotation of axes 26 | D = np.concatenate((C[:, 1:], C[:, :1]), axis=1) 27 | # reflection of random axes 28 | E = np.array([random.choice([-1, 1]) for i in range(D.shape[1])])[np.newaxis, :] * D 29 | 30 | return [A, B, C, D, E] 31 | 32 | 33 | @pytest.fixture(scope="module") 34 | def diagonal_multiplication_array_sequence(example_array): 35 | A = example_array 36 | M = np.diag(np.random.rand(A.shape[-1])) 37 | B = A @ M 38 | 39 | return [A, B] 40 | 41 | 42 | @pytest.fixture(scope="module") 43 | def random_multiplication_array_sequence(example_array): 44 | A = example_array 45 | ref_dim = A.shape[-1] 46 | M = np.random.rand(ref_dim, np.random.randint(ref_dim // 2, ref_dim)) 47 | B = A @ M 48 | 49 | return [A, B] 50 | -------------------------------------------------------------------------------- /.github/workflows/assemble-readme.yml: -------------------------------------------------------------------------------- 1 | # This workflow will generate README files based on the doc snippets. 2 | 3 | name: Assemble Multilingual README 4 | 5 | on: 6 | push: 7 | branches: 8 | - main 9 | paths: 10 | - 'docs/snippets/markdown/readme/' 11 | - 'docs/pipelines/README.md.template' 12 | - 'docs/pipelines/generate_readme.py' 13 | workflow_dispatch: 14 | 15 | jobs: 16 | assemble-readme: 17 | runs-on: ubuntu-latest 18 | steps: 19 | - uses: actions/checkout@v3 20 | with: 21 | fetch-depth: 0 22 | 23 | - name: Prepare Git 24 | run: | 25 | git config user.name ${{ secrets.ACTIONS_GIT_USERNAME }} 26 | git config user.email ${{ secrets.ACTIONS_GIT_EMAIL }} 27 | 28 | - name: Run script and get output files 29 | run: | 30 | pip install -r requirements-dev.txt 31 | python docs/pipelines/generate_readme.py 32 | mv docs/pipelines/README*.md ./ 33 | git add ./README*.md 34 | git commit -m "Assemble README files from snippets" 35 | 36 | - name: Create Pull Request 37 | uses: peter-evans/create-pull-request@v5 38 | with: 39 | commit-message: Assemble README files from snippets 40 | title: Automatic README update 41 | body: Assemble README files from snippets 42 | branch: assemble-readme 43 | -------------------------------------------------------------------------------- /conda-recipe/meta.yaml: -------------------------------------------------------------------------------- 1 | {% set name = "hover" %} 2 | {% set version = "0.8.1" %} 3 | 4 | 5 | package: 6 | name: {{ name }} 7 | version: {{ version }} 8 | 9 | source: 10 | git_url: https://github.com/phurwicz/hover.git 11 | 12 | build: 13 | number: 0 14 | noarch: python 15 | script: python -m pip install . -vv 16 | 17 | requirements: 18 | host: 19 | - python >=3.7 20 | - pip 21 | run: 22 | - python >=3.7 23 | - bokeh >=3.0.3 24 | - scikit-learn >=0.20.0 25 | - pytorch >=1.10.0 26 | - pandas >=1.3.0 27 | - numpy >=1.14 28 | - scipy >=1.3.2 29 | - tqdm >=4.0 30 | - rich >=11.0.0 31 | - deprecated >=1.1.0 32 | - umap-learn >=0.3.10 33 | - flexmod >=0.1.0 34 | 35 | test: 36 | imports: 37 | - hover 38 | commands: 39 | - python -m spacy download en_core_web_md 40 | - pytest -m lite 41 | requires: 42 | - pip 43 | - pytest 44 | - spacy 45 | - faker 46 | - snorkel>=0.9.8 47 | - openpyxl 48 | - wrappy 49 | - shaffle 50 | source_files: 51 | - fixture_module 52 | - tests 53 | - pytest.ini 54 | 55 | about: 56 | home: https://phurwicz.github.io/hover 57 | license: MIT 58 | license_file: LICENSE 59 | summary: Label data at scale. Fun and precision included. 60 | dev_url: https://github.com/phurwicz/hover 61 | 62 | extra: 63 | recipe-maintainers: 64 | - phurwicz 65 | - haochuanwei 66 | -------------------------------------------------------------------------------- /docs/pipelines/check_scripts.py: -------------------------------------------------------------------------------- 1 | """ 2 | Tests the scripts in the docs. 3 | Intended for a Binder environment, and should be used in conjunction with a local libary in phurwicz/hover-binder. 4 | """ 5 | import re 6 | import uuid 7 | import markdown 8 | import subprocess 9 | from local_helper import batch_routine 10 | from local_config import NAME_TO_SCRIPT_ABS, MARKDOWN_INCLUDE, THEBE_PATTERN_CODE_ONLY 11 | 12 | 13 | def main(): 14 | """ 15 | Test all code blocks in the scripts listed in this file. 16 | Collect all exceptions along the way. 17 | """ 18 | batch_routine(parse_script_and_run, NAME_TO_SCRIPT_ABS) 19 | 20 | 21 | def parse_script_and_run(script_name, source_abs_path): 22 | """ 23 | Retrieve and run code blocks from documentation file. 24 | Note that the doc file can be using markdown-include. 25 | """ 26 | script_tmp_path = f"{script_name}-{uuid.uuid1()}.py" 27 | 28 | with open(source_abs_path, "r") as f_source: 29 | source = f_source.read() 30 | html = markdown.markdown(source, extensions=[MARKDOWN_INCLUDE]) 31 | script = "\n".join(re.findall(THEBE_PATTERN_CODE_ONLY, html)) 32 | 33 | with open(script_tmp_path, "w") as f_script: 34 | f_script.write(script) 35 | 36 | process = subprocess.run( 37 | ["python", script_tmp_path], capture_output=True, timeout=1200 38 | ) 39 | return script, process 40 | 41 | 42 | if __name__ == "__main__": 43 | main() 44 | -------------------------------------------------------------------------------- /docs/snippets/py/t7-0-lf-list.txt: -------------------------------------------------------------------------------- 1 | from hover.utils.snorkel_helper import labeling_function 2 | from hover.module_config import ABSTAIN_DECODED as ABSTAIN 3 | import re 4 | 5 | 6 | @labeling_function(targets=["rec.autos"]) 7 | def auto_keywords(row): 8 | flag = re.search( 9 | r"(?i)(diesel|gasoline|automobile|vehicle|drive|driving)", row.text 10 | ) 11 | return "rec.autos" if flag else ABSTAIN 12 | 13 | 14 | @labeling_function(targets=["rec.sport.baseball"]) 15 | def baseball_keywords(row): 16 | flag = re.search(r"(?i)(baseball|stadium|\ bat\ |\ base\ )", row.text) 17 | return "rec.sport.baseball" if flag else ABSTAIN 18 | 19 | 20 | @labeling_function(targets=["sci.crypt"]) 21 | def crypt_keywords(row): 22 | flag = re.search(r"(?i)(crypt|math|encode|decode|key)", row.text) 23 | return "sci.crypt" if flag else ABSTAIN 24 | 25 | 26 | @labeling_function(targets=["talk.politics.guns"]) 27 | def guns_keywords(row): 28 | flag = re.search(r"(?i)(gun|rifle|ammunition|violence|shoot)", row.text) 29 | return "talk.politics.guns" if flag else ABSTAIN 30 | 31 | 32 | @labeling_function(targets=["misc.forsale"]) 33 | def forsale_keywords(row): 34 | flag = re.search(r"(?i)(sale|deal|price|discount)", row.text) 35 | return "misc.forsale" if flag else ABSTAIN 36 | 37 | 38 | LABELING_FUNCTIONS = [ 39 | auto_keywords, 40 | baseball_keywords, 41 | crypt_keywords, 42 | guns_keywords, 43 | forsale_keywords, 44 | ] 45 | -------------------------------------------------------------------------------- /docs/styles/monokai.css: -------------------------------------------------------------------------------- 1 | .cm-s-monokai { 2 | padding: 2em 2em 2em; 3 | height: auto; 4 | font-size: 0.8em; 5 | line-height: 1.5em; 6 | font-family: inconsolata, monospace; 7 | letter-spacing: 0.3px; 8 | word-spacing: 1px; 9 | background: #272822; 10 | color: #F8F8F2; 11 | } 12 | .cm-s-monokai .CodeMirror-lines { 13 | padding: 8px 0; 14 | } 15 | .cm-s-monokai .CodeMirror-gutters { 16 | box-shadow: 1px 0 2px 0 rgba(0, 0, 0, 0.5); 17 | -webkit-box-shadow: 1px 0 2px 0 rgba(0, 0, 0, 0.5); 18 | background-color: #272822; 19 | padding-right: 10px; 20 | z-index: 3; 21 | border: none; 22 | } 23 | .cm-s-monokai div.CodeMirror-cursor { 24 | border-left: 3px solid #F8F8F2; 25 | } 26 | .cm-s-monokai .CodeMirror-activeline-background { 27 | background: #49483E; 28 | } 29 | .cm-s-monokai .CodeMirror-selected { 30 | background: #49483E; 31 | } 32 | .cm-s-monokai .cm-comment { 33 | color: #75715E; 34 | } 35 | .cm-s-monokai .cm-string { 36 | color: #E6DB74; 37 | } 38 | .cm-s-monokai .cm-number { 39 | color: #66D9EF; 40 | } 41 | .cm-s-monokai .cm-atom { 42 | color: #66D9EF; 43 | } 44 | .cm-s-monokai .cm-keyword { 45 | color: #F92672; 46 | } 47 | .cm-s-monokai .cm-variable { 48 | color: #A6E22E; 49 | } 50 | .cm-s-monokai .cm-def { 51 | color: #FD971F; 52 | } 53 | .cm-s-monokai .cm-variable-2 { 54 | color: #F92672; 55 | } 56 | .cm-s-monokai .cm-property { 57 | color: #66D9EF; 58 | } 59 | .cm-s-monokai .cm-operator { 60 | color: #F92672; 61 | } 62 | .cm-s-monokai .CodeMirror-linenumber { 63 | color: #75715E; 64 | } 65 | -------------------------------------------------------------------------------- /fixture_module/text_vector_net/__init__.py: -------------------------------------------------------------------------------- 1 | """ 2 | Example importable module holding customized ingredients of a workflow with hover. 3 | Specifically for text data. 4 | """ 5 | 6 | import os 7 | import re 8 | import numpy as np 9 | import wrappy 10 | 11 | CACHE_PATH = os.path.join(os.path.dirname(__file__), "vecs.pkl") 12 | 13 | 14 | def get_vectorizer(): 15 | """ 16 | :returns: a text vectorizer. 17 | """ 18 | import spacy 19 | 20 | # SpaCy 'vector' models are perfect for this 21 | # nlp = spacy.load('en_vectors_web_lg') 22 | 23 | # 'core' models are slower due to linguistic features 24 | nlp = spacy.load("en_core_web_md") 25 | 26 | # could use a transformer if speed is ok 27 | # nlp = spacy.load('en_trf_bertbaseuncased_lg') 28 | 29 | # memoization can be useful if the function takes a while to run, e.g. transformer models 30 | @wrappy.memoize( 31 | cache_limit=50000, 32 | return_copy=False, 33 | persist_path=CACHE_PATH, 34 | persist_batch_size=1000, 35 | ) 36 | def vectorizer(text): 37 | """ 38 | A more serious example of a text vectorizer. 39 | """ 40 | clean_text = re.sub(r"[\t\n]", r" ", text) 41 | return nlp(clean_text, disable=nlp.pipe_names).vector 42 | 43 | return vectorizer 44 | 45 | 46 | def get_architecture(): 47 | from hover.utils.common_nn import MLP 48 | 49 | return MLP 50 | 51 | 52 | def get_state_dict_path(): 53 | dir_path = os.path.dirname(__file__) 54 | return os.path.join(dir_path, "model.pt") 55 | -------------------------------------------------------------------------------- /tests/core/representation/test_reduction.py: -------------------------------------------------------------------------------- 1 | from hover.core.representation.reduction import DimensionalityReducer 2 | import numpy as np 3 | import pytest 4 | 5 | 6 | @pytest.mark.lite 7 | def test_create_reducer(n_points=1000): 8 | # if marked as lite, only test the default reducer library 9 | from umap import UMAP 10 | 11 | reducer = DimensionalityReducer.create_reducer( 12 | "umap", 13 | dimension=4, 14 | n_neighbors=10, 15 | ) 16 | assert isinstance(reducer, UMAP) 17 | # dimension is expected to override n_components (default 2) 18 | assert reducer.n_components == 4 19 | # other kwargs are expected to simply get forwarded 20 | assert reducer.n_neighbors == 10 21 | 22 | 23 | def test_dimensionality_reduction(n_points=1000): 24 | 25 | arr = np.random.rand(n_points, 20) 26 | reducer = DimensionalityReducer(arr) 27 | 28 | reducer.fit_transform( 29 | "umap", n_neighbors=3, min_dist=0.01, dimension=3, metric="euclidean" 30 | ) 31 | embedding = reducer.transform(arr, "umap") 32 | assert embedding.shape == (n_points, 3) 33 | embedding = reducer.transform(np.array([])) 34 | assert embedding.shape == (0,) 35 | 36 | reducer.fit_transform( 37 | "ivis", dimension=4, k=3, distance="pn", batch_size=16, epochs=20 38 | ) 39 | embedding = reducer.transform(arr, "ivis") 40 | assert embedding.shape == (n_points, 4) 41 | 42 | try: 43 | reducer.fit_transform("invalid_method") 44 | pytest.fail("Expected exception from invalid reduction method.") 45 | except ValueError: 46 | pass 47 | -------------------------------------------------------------------------------- /hover/core/__init__.py: -------------------------------------------------------------------------------- 1 | """ 2 | Core module: contains classes which are centerpieces of the vast majority of use cases. 3 | 4 | - dataset: defines the primary data structure to work with. 5 | - explorer: defines high-level building blocks of the interactive UI. 6 | - neural: defines sub-applications that involve neural networks. 7 | """ 8 | from rich.console import Console 9 | from hover.utils.meta.traceback import RichTracebackMeta 10 | 11 | 12 | class Loggable(metaclass=RichTracebackMeta): 13 | """ 14 | Base class that provides consistently templated logging. 15 | 16 | Inspired by `wasabi`'s `good`/`info`/`warn`/`fail` methods. 17 | 18 | [`Rich` style guide](https://rich.readthedocs.io/en/latest/style.html) 19 | """ 20 | 21 | CONSOLE = Console() 22 | 23 | def _print(self, *args, **kwargs): 24 | self.__class__.CONSOLE.print(*args, **kwargs) 25 | 26 | def _good(self, message): 27 | self.__class__.CONSOLE.print( 28 | f":green_circle: {self.__class__.__name__}: {message}", 29 | style="green", 30 | ) 31 | 32 | def _info(self, message): 33 | self.__class__.CONSOLE.print( 34 | f":blue_circle: {self.__class__.__name__}: {message}", style="blue" 35 | ) 36 | 37 | def _warn(self, message): 38 | self.__class__.CONSOLE.print( 39 | f":yellow_circle: {self.__class__.__name__}: {message}", 40 | style="yellow", 41 | ) 42 | 43 | def _fail(self, message): 44 | self.__class__.CONSOLE.print( 45 | f":red_circle: {self.__class__.__name__}: {message}", style="red" 46 | ) 47 | -------------------------------------------------------------------------------- /tests/core/test_local_config.py: -------------------------------------------------------------------------------- 1 | from bokeh.models import ( 2 | TableColumn, 3 | ) 4 | from hover.core.local_config import ( 5 | embedding_field, 6 | is_embedding_field, 7 | blank_callback_on_change, 8 | dataset_default_sel_table_columns, 9 | dataset_default_sel_table_kwargs, 10 | ) 11 | import pytest 12 | 13 | 14 | @pytest.mark.lite 15 | def test_embedding_field(): 16 | for i in range(2, 10): 17 | for j in range(i): 18 | assert is_embedding_field(embedding_field(i, j)) 19 | 20 | 21 | @pytest.mark.lite 22 | def test_blank_callback_on_change(): 23 | blank_callback_on_change("value", 0, 1) 24 | 25 | 26 | @pytest.mark.lite 27 | def test_dataset_default_sel_table_columns(): 28 | for feature in ["text", "image", "audio"]: 29 | columns = dataset_default_sel_table_columns(feature) 30 | assert isinstance(columns, list) 31 | assert isinstance(columns[0], TableColumn) 32 | 33 | try: 34 | dataset_default_sel_table_columns("invalid_feature") 35 | pytest.fail("Expected an exception from creating columns on invalid feature.") 36 | except ValueError: 37 | pass 38 | 39 | 40 | @pytest.mark.lite 41 | def test_dataset_default_sel_table_kwargs(): 42 | for feature in ["text", "image", "audio"]: 43 | kwargs = dataset_default_sel_table_kwargs(feature) 44 | assert isinstance(kwargs, dict) 45 | assert kwargs 46 | 47 | try: 48 | dataset_default_sel_table_kwargs("invalid_feature") 49 | pytest.fail("Expected an exception from creating kwargs on invalid feature.") 50 | except ValueError: 51 | pass 52 | -------------------------------------------------------------------------------- /.github/workflows/doc-script-test.yml: -------------------------------------------------------------------------------- 1 | # This workflow will install Python dependencies and run tests on the code snippets included in the documentation. 2 | # For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions 3 | 4 | name: Documentation Script Test 5 | 6 | on: 7 | schedule: 8 | - cron: "0 0 * * 1" 9 | push: 10 | branches: [ main ] 11 | paths: 12 | - 'hover/**.py' 13 | - 'docs/pages/**.md' 14 | - 'docs/pipelines/*.py' 15 | - 'docs/snippets/markdown/dataset-prep.md' 16 | - 'docs/snippets/py/*.*' 17 | pull_request: 18 | branches: [ main ] 19 | paths: 20 | - 'hover/**.py' 21 | - 'docs/pages/**.md' 22 | - 'docs/pipelines/*.py' 23 | - 'docs/snippets/markdown/dataset-prep.md' 24 | - 'docs/snippets/py/*.*' 25 | workflow_dispatch: 26 | 27 | jobs: 28 | doc-script: 29 | 30 | runs-on: ${{ matrix.os }} 31 | strategy: 32 | fail-fast: false 33 | matrix: 34 | python-version: ['3.9'] 35 | os: [ubuntu-latest] 36 | 37 | steps: 38 | - name: Clone hover 39 | uses: actions/checkout@v3 40 | 41 | - name: Set up Python ${{ matrix.python-version }} 42 | uses: actions/setup-python@v3 43 | with: 44 | python-version: ${{ matrix.python-version }} 45 | 46 | - name: Install Non-Python Dependencies 47 | run: | 48 | sudo apt-get update 49 | sudo apt-get install libsndfile1 50 | 51 | - name: Test with Tox 52 | run: | 53 | pip install --upgrade pip 54 | pip install --upgrade tox tox-gh-actions 55 | tox -e test_doc_scripts 56 | -------------------------------------------------------------------------------- /tests/utils/test_torch_helper.py: -------------------------------------------------------------------------------- 1 | from torch.utils.data import Dataset, DataLoader 2 | from hover.utils.torch_helper import ( 3 | VectorDataset, 4 | MultiVectorDataset, 5 | one_hot, 6 | label_smoothing, 7 | ) 8 | import numpy as np 9 | import pytest 10 | 11 | 12 | @pytest.mark.lite 13 | def test_vector_dataset(num_entries=100, dim_inp=128, dim_out=3): 14 | vec_inp = np.random.rand(num_entries, dim_inp) 15 | vec_out = np.random.rand(num_entries, dim_out) 16 | 17 | for dataset in [ 18 | VectorDataset(vec_inp, vec_out), 19 | MultiVectorDataset([vec_inp] * 2, vec_out), 20 | ]: 21 | loader = dataset.loader(batch_size=min(num_entries, 16)) 22 | assert isinstance(dataset, Dataset) 23 | assert isinstance(loader, DataLoader) 24 | assert len(dataset) == num_entries 25 | inp, out, idx = dataset[0] 26 | 27 | 28 | @pytest.mark.lite 29 | def test_one_hot(): 30 | categorical_labels = [0, 1, 2, 1] 31 | one_hot_labels = one_hot(categorical_labels, 3) 32 | assert one_hot_labels.shape == (4, 3) 33 | 34 | 35 | @pytest.mark.lite 36 | def test_label_smoothing(num_entries=100, num_classes=3, coeff=0.1): 37 | assert num_classes >= 2 38 | assert coeff >= 0.0 39 | 40 | categorical_labels = [0] * num_entries 41 | prob_labels = one_hot(categorical_labels, num_classes) 42 | 43 | assert np.allclose(label_smoothing(prob_labels, coefficient=0.0), prob_labels) 44 | smoothed = label_smoothing(prob_labels, coefficient=coeff) 45 | np.testing.assert_almost_equal( 46 | smoothed[0][0], 1.0 - coeff * (1.0 - 1.0 / num_classes) 47 | ) 48 | np.testing.assert_almost_equal(smoothed[0][1], coeff / num_classes) 49 | -------------------------------------------------------------------------------- /hover/utils/bokeh_helper/local_config.py: -------------------------------------------------------------------------------- 1 | import hover 2 | from hover.config_constants import ( 3 | ConfigSection as Section, 4 | ConfigKey as Key, 5 | ) 6 | 7 | 8 | BOKEH_PALETTE = hover.config[Section.VISUAL][Key.BOKEH_PALETTE] 9 | BOKEH_PALETTE_USAGE = hover.config[Section.VISUAL][Key.BOKEH_PALETTE_USAGE] 10 | 11 | TOOLTIP_TEXT_TEMPLATE = """ 12 |
13 |
14 | {key}: @{field}
15 |
16 |
17 | """
18 |
19 | TOOLTIP_IMAGE_TEMPLATE = """
20 |
21 |  25 |
25 |
26 | """
27 |
28 | TOOLTIP_AUDIO_TEMPLATE = """
29 |
30 |
36 |
37 | """
38 |
39 | TOOLTIP_CUSTOM_TEMPLATE = """
40 |
41 |
42 | {key}: @{field}
43 |
44 |
45 | """
46 |
47 | TOOLTIP_LABEL_TEMPLATE = """
48 |
49 |
50 | {key}: @{field}
51 |
52 |
53 | """
54 |
55 | TOOLTIP_COORDS_DIV = """
56 |
57 |
58 | Coordinates: ($x, $y)
59 |
60 |
61 | """
62 |
63 | TOOLTIP_INDEX_DIV = """
64 |
65 |
66 | Index: [$index]
67 |
68 |
69 | """
70 |
--------------------------------------------------------------------------------
/.github/workflows/doc-auto-notebook.yml:
--------------------------------------------------------------------------------
1 | # This workflow will generate Jupyter notebooks based on the code scripts in the documentation.
2 | # For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
3 |
4 | name: Automatic Notebook Generation
5 |
6 | on:
7 | schedule:
8 | - cron: "0 0 * * 2"
9 | workflow_dispatch:
10 |
11 | jobs:
12 | auto-notebook:
13 |
14 | runs-on: ${{ matrix.os }}
15 | strategy:
16 | matrix:
17 | python-version: ['3.9']
18 | os: [ubuntu-latest]
19 |
20 | steps:
21 | - name: Clone hover all branches
22 | uses: actions/checkout@v3
23 | with:
24 | fetch-depth: 0
25 |
26 | - name: Set up Python ${{ matrix.python-version }}
27 | uses: actions/setup-python@v3
28 | with:
29 | python-version: ${{ matrix.python-version }}
30 |
31 | - name: Install Non-Python Dependencies
32 | run: |
33 | sudo apt-get update
34 | sudo apt-get install libsndfile1
35 |
36 | - name: Prepare Git
37 | run: |
38 | git config user.name ${{ secrets.ACTIONS_GIT_USERNAME }}
39 | git config user.email ${{ secrets.ACTIONS_GIT_EMAIL }}
40 | git checkout pipeline/notebook-generation
41 | git merge origin/main --no-edit
42 | git push
43 |
44 | - name: Test with Tox
45 | run: |
46 | pip install --upgrade pip
47 | pip install --upgrade tox tox-gh-actions
48 | tox -e test_notebook_generation
49 |
50 | - name: Update Generated Notebooks
51 | run: |
52 | git add docs/pipelines/generated/*.ipynb
53 | git commit -m "Automatic update of notebooks generated from documentation scripts"
54 | git push
55 |
--------------------------------------------------------------------------------
/hover/utils/meta/traceback.py:
--------------------------------------------------------------------------------
1 | from abc import ABCMeta
2 | from functools import wraps
3 | from types import FunctionType
4 | from rich.console import Console
5 |
6 |
7 | class RichTracebackMeta(type):
8 | """
9 | ???+ note "Metaclass to mass-add traceback override to class methods."
10 |
11 | [`Rich` traceback guide](https://rich.readthedocs.io/en/stable/traceback.html)
12 | """
13 |
14 | def __new__(meta, class_name, bases, class_dict):
15 | # prefers the class's CONSOLE attribute; create one otherwise
16 | console = class_dict.get("CONSOLE", Console())
17 |
18 | def wrapper(func):
19 | @wraps(func)
20 | def wrapped(*args, **kwargs):
21 | try:
22 | return func(*args, **kwargs)
23 | except Exception as e_original:
24 | func_name = f"{func.__module__}.{func.__qualname__}"
25 | console.print(
26 | f":red_circle: {func_name} failed: {e_original}",
27 | style="red bold",
28 | )
29 | console.print_exception(show_locals=False)
30 | raise e_original
31 |
32 | return wrapped
33 |
34 | new_class_dict = {}
35 | for attr_name, attr_value in class_dict.items():
36 | # replace each method with a wrapped version
37 | if isinstance(attr_value, FunctionType):
38 | attr_value = wrapper(attr_value)
39 | new_class_dict[attr_name] = attr_value
40 | return type.__new__(meta, class_name, bases, new_class_dict)
41 |
42 |
43 | class RichTracebackABCMeta(RichTracebackMeta, ABCMeta):
44 | """
45 | ???+ note "Metaclass for rich-traceback abstract base classes."
46 |
47 | To resolve the metaclass conflict between RichTracebackMeta and ABCMeta.
48 | """
49 |
50 | pass
51 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | import setuptools
2 | import os
3 |
4 |
5 | def get_description():
6 | if os.path.isfile("README.md"):
7 | with open("README.md", "r") as fh:
8 | desc = fh.read()
9 | else:
10 | desc = ""
11 | return desc
12 |
13 |
14 | setuptools.setup(
15 | name="hover",
16 | version="0.9.0",
17 | description="Label data at scale. Fun and precision included.",
18 | long_description=get_description(),
19 | long_description_content_type="text/markdown",
20 | author="Pavel",
21 | author_email="pavelhurwicz@gmail.com",
22 | url="https://github.com/phurwicz/hover",
23 | packages=setuptools.find_packages(include=["hover*"]),
24 | install_requires=[
25 | # python-version-specific example: "numpy>=1.14,<=1.21.5;python_version<'3.8.0'",
26 | # interactive/static visualization
27 | "bokeh>=3.0.3",
28 | # preprocessors
29 | "scikit-learn>=0.20.0",
30 | # neural stuff
31 | "torch>=1.10.0",
32 | # data handling
33 | "pandas>=1.3.0",
34 | "polars>=0.17.0",
35 | "pyarrow>=11.0.0",
36 | "numpy>=1.22",
37 | # computations
38 | "scipy>=1.3.2",
39 | # utilities
40 | "tqdm>=4.0",
41 | "rich>=11.0.0",
42 | "deprecated>=1.1.0",
43 | # dimensionality reduction: UMAP is included
44 | "umap-learn>=0.3.10",
45 | # module config customization
46 | "flexmod>=0.1.2",
47 | # optional: more dimensionality reduction methods
48 | # "ivis[cpu]>=1.7",
49 | # optional: distant supervision
50 | # "snorkel>=0.9.8",
51 | ],
52 | python_requires=">=3.8",
53 | classifiers=[
54 | "Programming Language :: Python :: 3",
55 | "Development Status :: 4 - Beta",
56 | "License :: OSI Approved :: MIT License",
57 | "Operating System :: OS Independent",
58 | ],
59 | )
60 |
--------------------------------------------------------------------------------
/fixture_module/audio_vector_net/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Example importable module holding customized ingredients of a workflow with hover.
3 | Specifically for audio data in URLs.
4 | """
5 |
6 | import os
7 | import re
8 | import numpy as np
9 | import wrappy
10 | import requests
11 | import librosa
12 | from io import BytesIO
13 |
14 |
15 | DIR_PATH = os.path.dirname(__file__)
16 | RAW_CACHE_PATH = os.path.join(DIR_PATH, "raws.pkl")
17 | AUD_CACHE_PATH = os.path.join(DIR_PATH, "auds.pkl")
18 | VEC_CACHE_PATH = os.path.join(DIR_PATH, "vecs.pkl")
19 |
20 |
21 | @wrappy.memoize(
22 | cache_limit=50000,
23 | return_copy=False,
24 | persist_path=RAW_CACHE_PATH,
25 | persist_batch_size=100,
26 | )
27 | def url_to_content(url):
28 | """
29 | Turn a URL to response content.
30 | """
31 | response = requests.get(url)
32 | return response.content
33 |
34 |
35 | @wrappy.memoize(
36 | cache_limit=50000,
37 | return_copy=False,
38 | persist_path=AUD_CACHE_PATH,
39 | persist_batch_size=100,
40 | )
41 | def url_to_audio(url):
42 | """
43 | Turn a URL to audio data.
44 | """
45 | data, sampling_rate = librosa.load(BytesIO(url_to_content(url)))
46 | return data, sampling_rate
47 |
48 |
49 | def get_vectorizer():
50 | @wrappy.memoize(
51 | cache_limit=50000,
52 | return_copy=False,
53 | persist_path=VEC_CACHE_PATH,
54 | persist_batch_size=100,
55 | )
56 | def vectorizer(url):
57 | """
58 | Averaged MFCC over time.
59 | Resembles word-embedding-average-as-doc-embedding for texts.
60 | """
61 | y, sr = url_to_audio(url)
62 | mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=32)
63 | return mfcc.mean(axis=1)
64 |
65 | return vectorizer
66 |
67 |
68 | def get_architecture():
69 | from hover.utils.common_nn import LogisticRegression
70 |
71 | return LogisticRegression
72 |
73 |
74 | def get_state_dict_path():
75 | return os.path.join(DIR_PATH, "model.pt")
76 |
--------------------------------------------------------------------------------
/hover/utils/common_nn.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 |
3 |
4 | class BaseSequential(nn.Module):
5 | """
6 | Sequential neural net with no specified architecture.
7 | """
8 |
9 | def __init__(self):
10 | """
11 | Inheriting the parent constructor.
12 | """
13 | super().__init__()
14 |
15 | def init_weights(self):
16 | for _layer in self.model:
17 | if isinstance(_layer, nn.Linear):
18 | nn.init.kaiming_normal_(_layer.weight, a=0.01)
19 | nn.init.constant_(_layer.bias, 0.0)
20 |
21 | def forward(self, input_tensor):
22 | return self.model(input_tensor)
23 |
24 | def eval_per_layer(self, input_tensor):
25 | """
26 | Return the input, all intermediates, and the output.
27 | """
28 | tensors = [input_tensor]
29 | current = input_tensor
30 | self.model.eval()
31 |
32 | for _layer in self.model.children():
33 | current = _layer(current)
34 | tensors.append(current)
35 |
36 | return tensors
37 |
38 |
39 | class MLP(BaseSequential):
40 | def __init__(self, embed_dim, num_classes, dropout=0.25, n_hid=128):
41 | """
42 | Set up a proportionally fixed architecture.
43 | """
44 | super().__init__()
45 | self.model = nn.Sequential(
46 | nn.Dropout(dropout),
47 | nn.Linear(embed_dim, n_hid),
48 | nn.ReLU(),
49 | nn.BatchNorm1d(n_hid),
50 | nn.Dropout(dropout),
51 | nn.Linear(n_hid, n_hid // 4),
52 | nn.ReLU(),
53 | nn.BatchNorm1d(n_hid // 4),
54 | nn.Dropout(dropout),
55 | nn.Linear(n_hid // 4, num_classes),
56 | )
57 | self.init_weights()
58 |
59 |
60 | class LogisticRegression(BaseSequential):
61 | def __init__(self, embed_dim, num_classes):
62 | """
63 | Set up a minimal architecture.
64 | """
65 | super().__init__()
66 | self.model = nn.Sequential(nn.Linear(embed_dim, num_classes))
67 | self.init_weights()
68 |
--------------------------------------------------------------------------------
/docs/snippets/markdown/readme/2-features.zh.md:
--------------------------------------------------------------------------------
1 | ## :sparkles: 具体功能
2 |
3 | :telescope: 将向量降维得到二维数据散点图, 并配有
4 |
5 |
6 |  8 |
8 |
9 |
10 | 提示框 来显示具体数据内容
7 |
8 |
11 |  13 |
13 |
14 |
15 | 表格来 批量检视 选中的数据
12 |
13 |
16 |  18 |
18 |
19 |
20 | 切换按钮来 区分数据子集
17 |
18 |
21 |  23 |
23 |
24 |
25 | :microscope: 与标注界面同步的辅助模式
26 |
27 | 文本/正则匹配 来定向搜寻数据
22 |
23 |
28 |  30 |
30 |
31 |
32 | `Finder`: 以匹配条件来 过滤 选中的数据
29 |
30 |
33 | 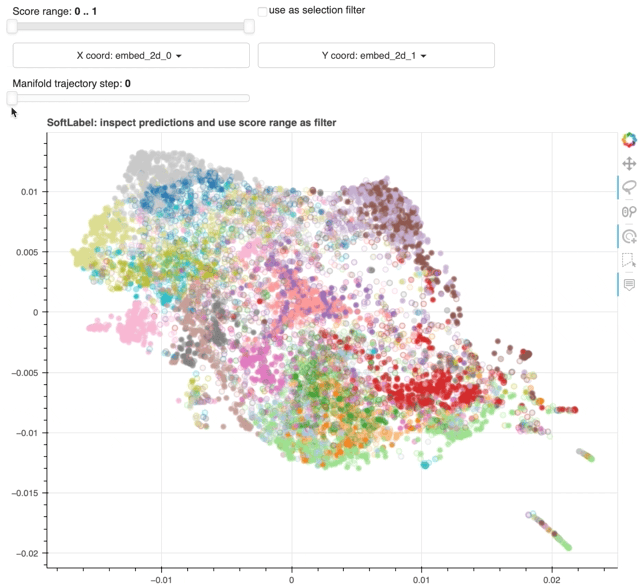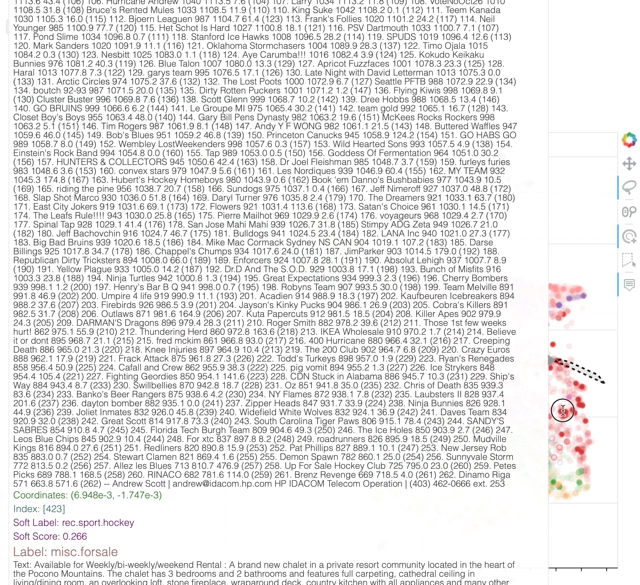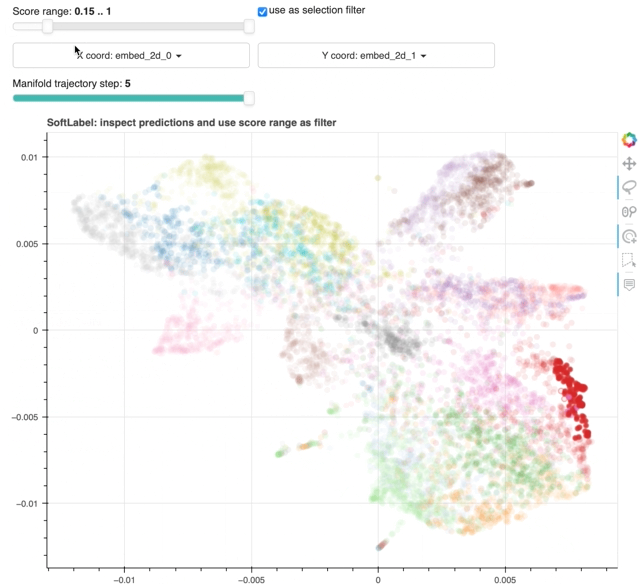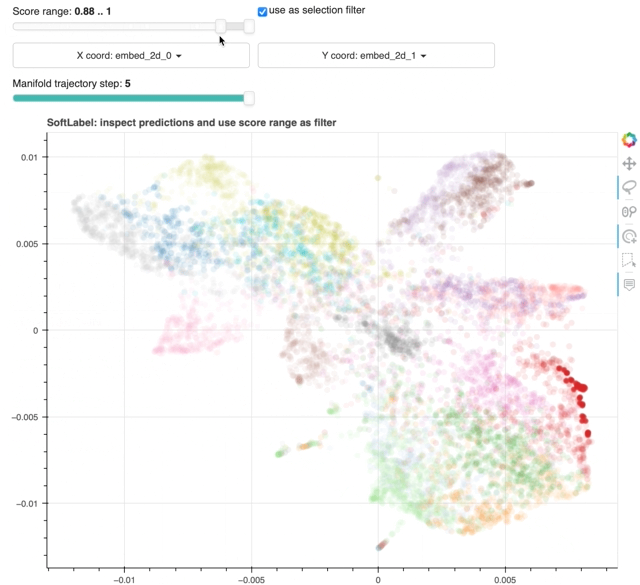 35 |
35 |
36 |
37 | `SoftLabel`: 主动学习 用模型打分过滤选中的数据
34 |
35 |
38 | 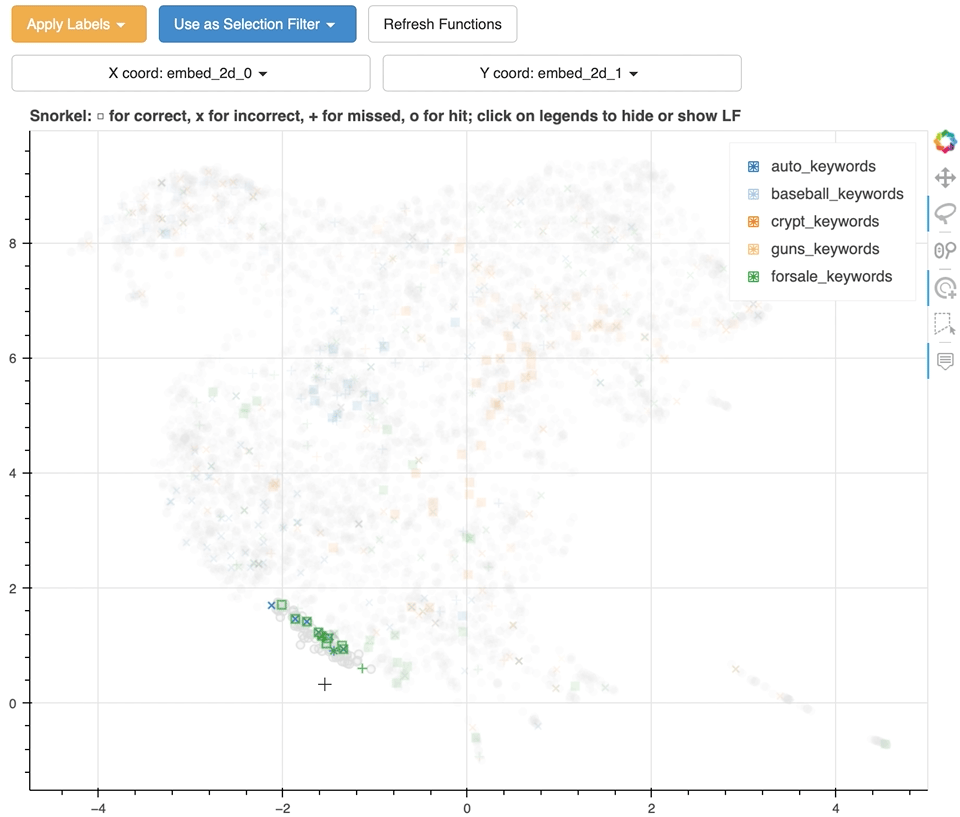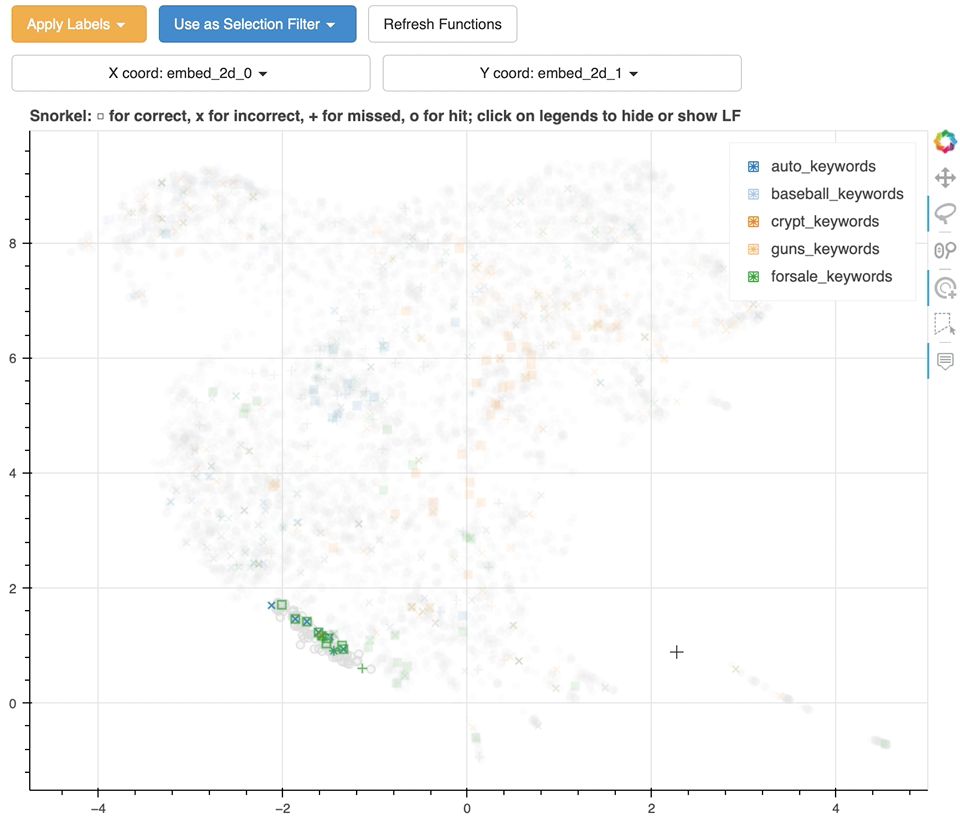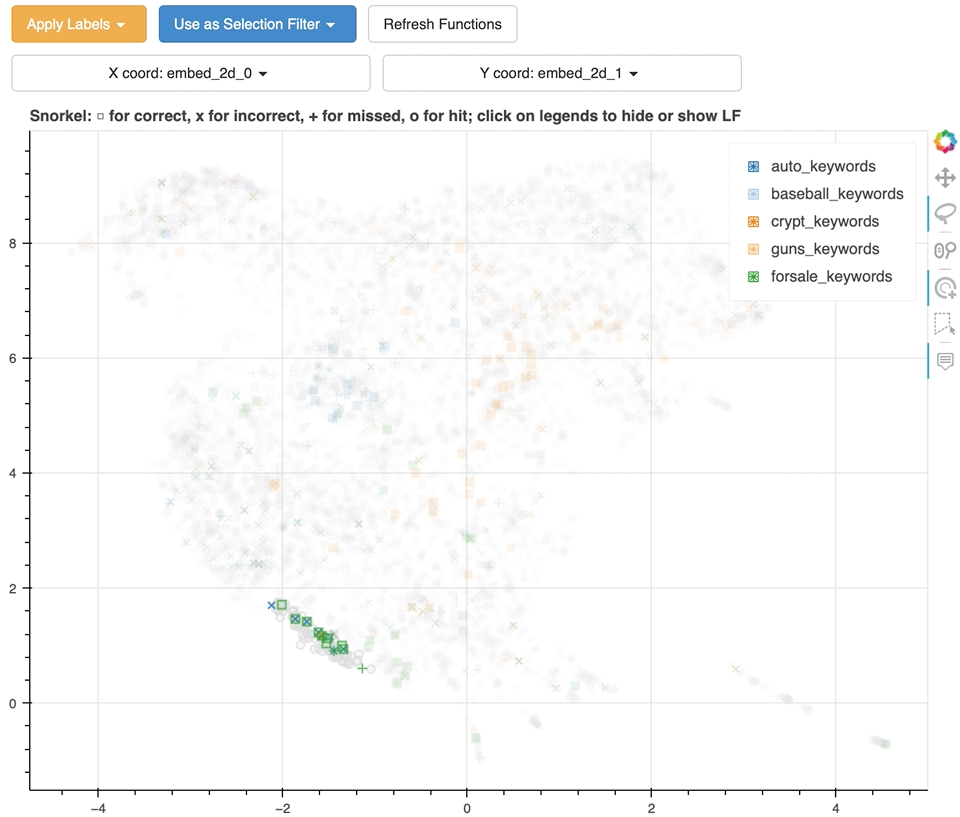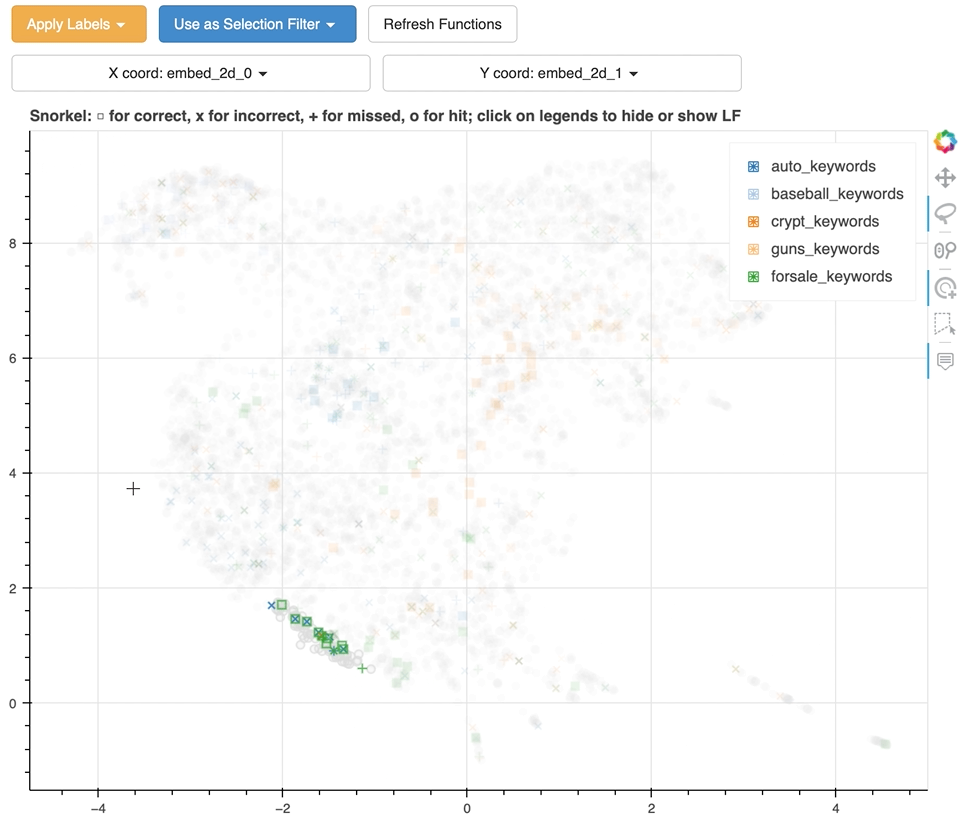 40 |
40 |
41 |
42 | :toolbox: 更多的补充工具
43 |
44 | `Snorkel`: 自定义函数 来过滤数据或直接打标
39 |
40 |
45 |  47 |
47 |
48 |
49 | 降维时保留 更多维度 (3D? 4D?) 并动态选择观察的平面
46 |
47 |
50 |  52 |
52 |
53 |
54 | 跨界面/跨维度地进行 持续选取/反选 以达到更高精度
51 |
52 |
55 | 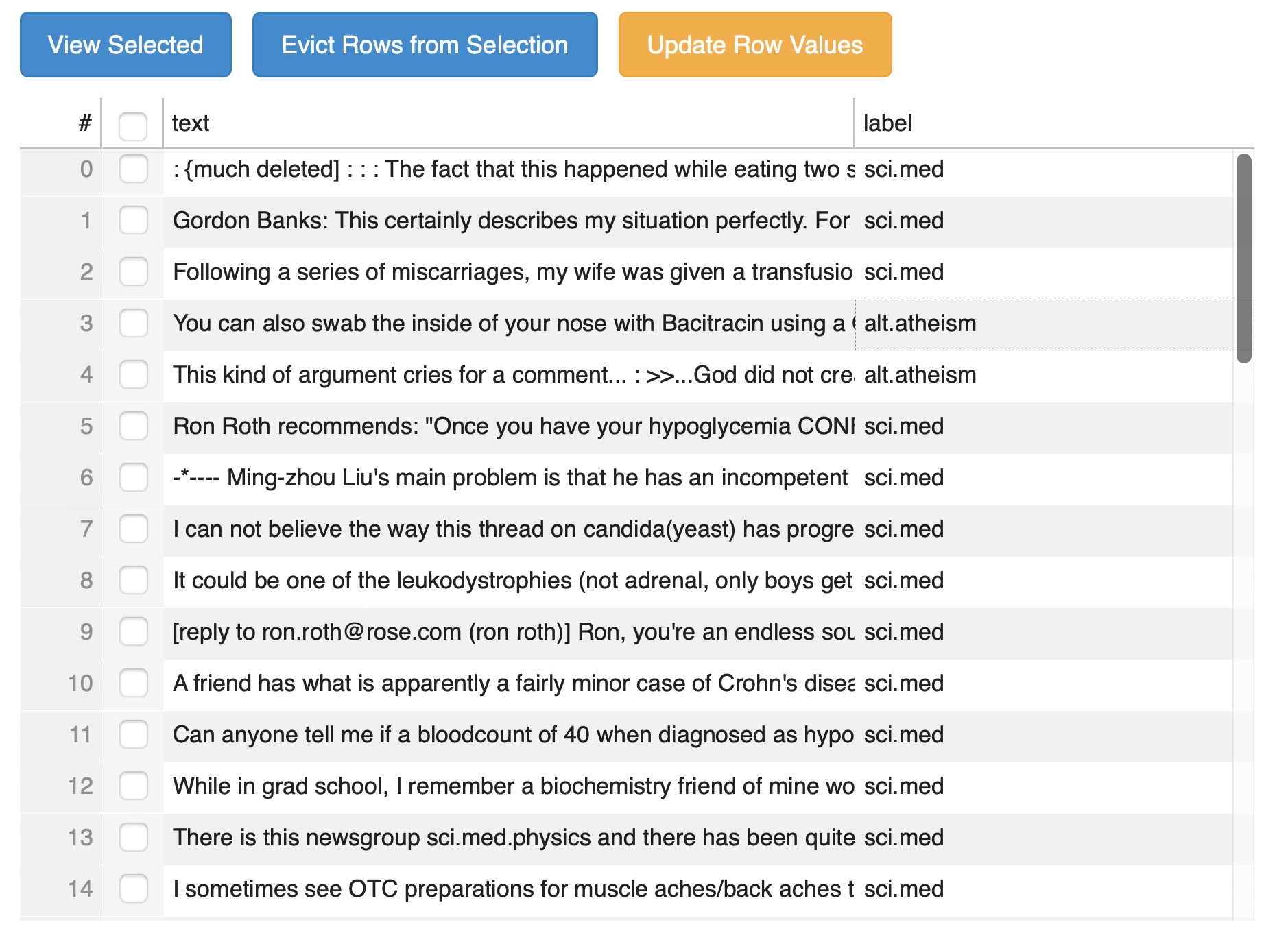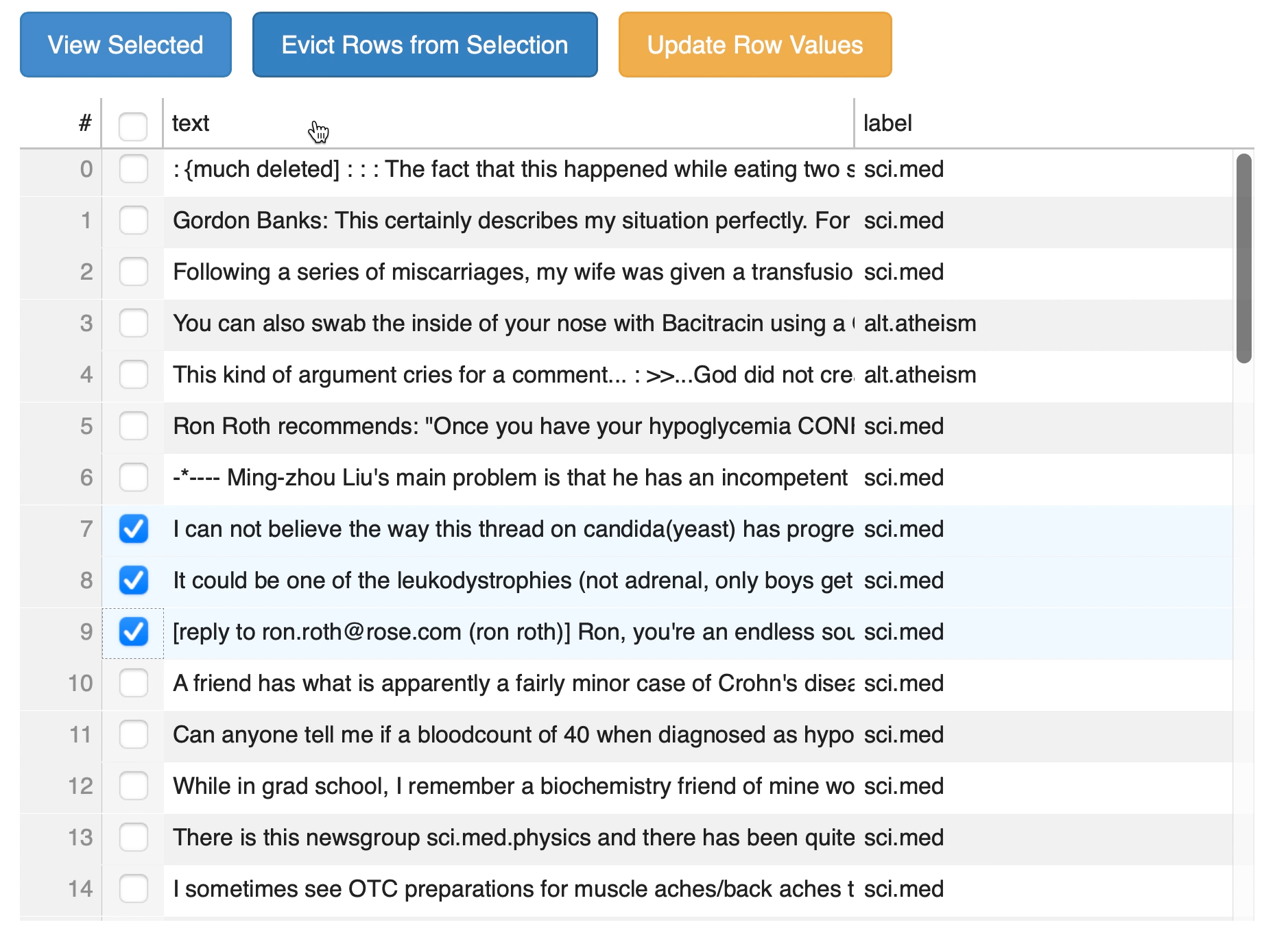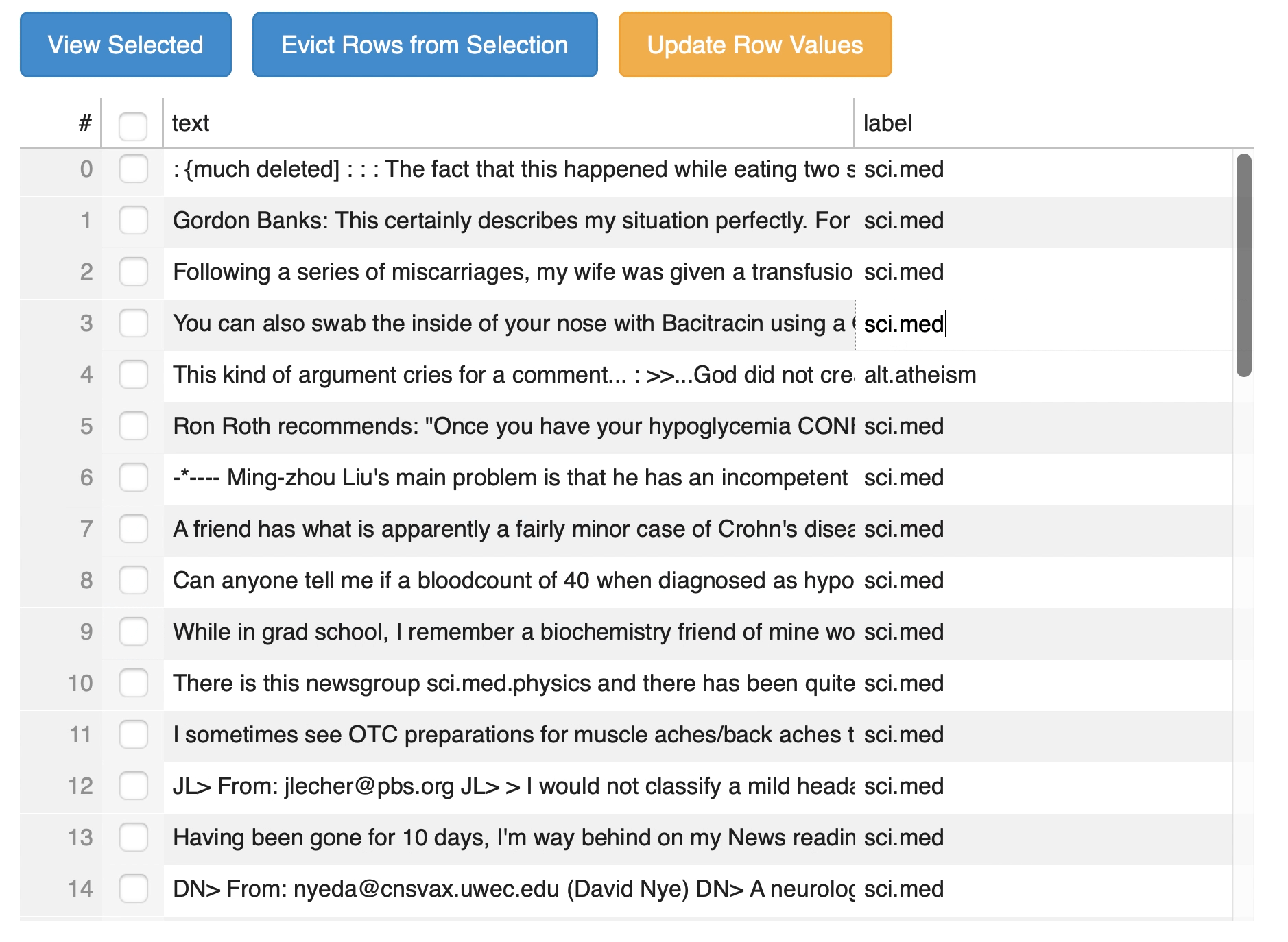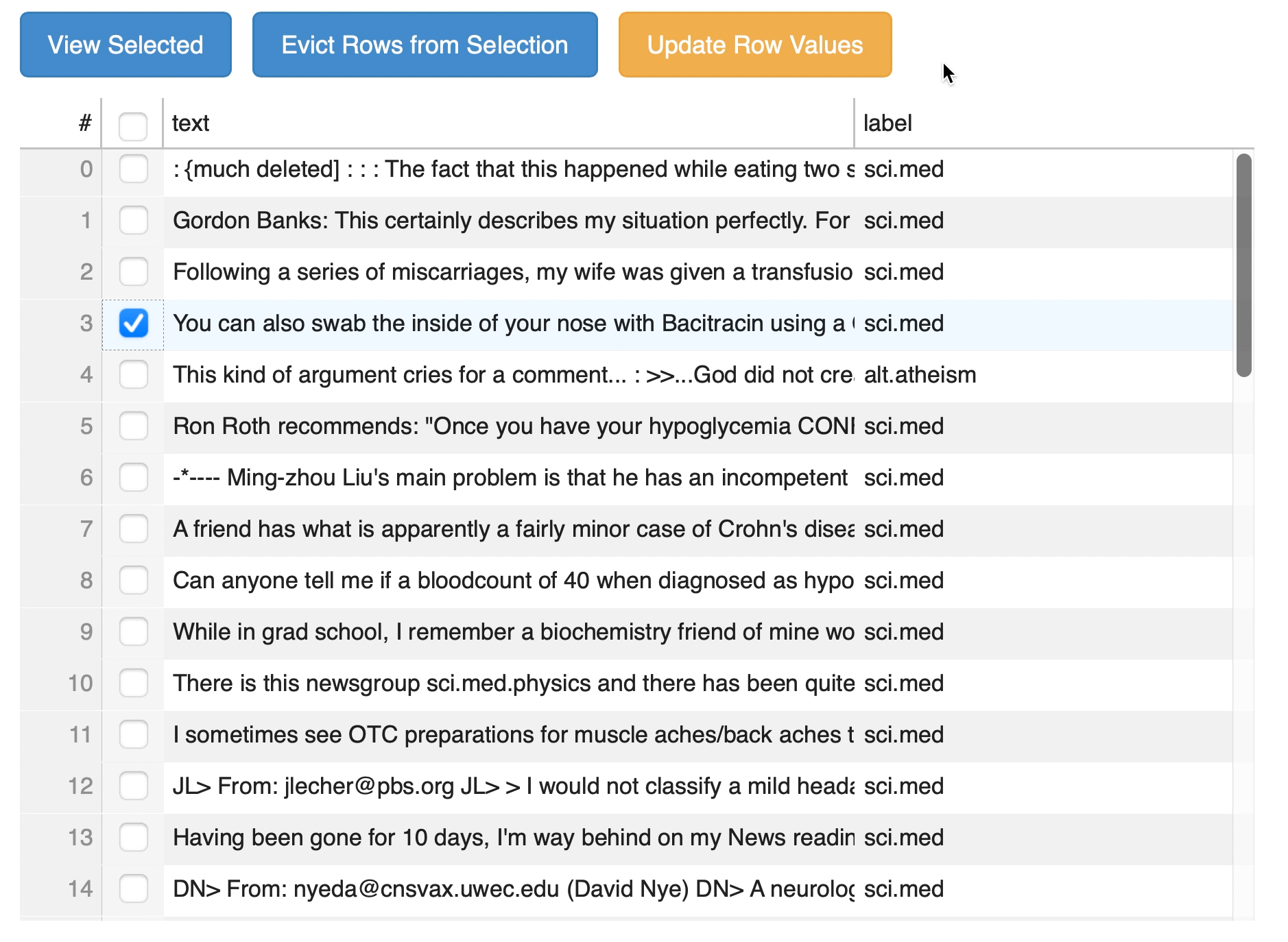 57 |
57 |
58 |
--------------------------------------------------------------------------------
/tests/recipes/local_helper.py:
--------------------------------------------------------------------------------
1 | import time
2 | import operator
3 | from bokeh.document import Document
4 | from bokeh.events import ButtonClick, MenuItemClick
5 | from hover import module_config
6 |
7 |
8 | def action_view_selection(dataset):
9 | view_event = ButtonClick(dataset.selection_viewer)
10 | dataset.selection_viewer._trigger_event(view_event)
11 | # dataset.sel_table.source.data is a {"field": []}-like dict
12 | view_data = dataset.sel_table.source.data.copy()
13 | return view_data
14 |
15 |
16 | def action_evict_selection(dataset):
17 | old_view_data = dataset.sel_table.source.data.copy()
18 | evict_event = ButtonClick(dataset.selection_evictor)
19 | dataset.selection_evictor._trigger_event(evict_event)
20 | new_view_data = dataset.sel_table.source.data.copy()
21 | return old_view_data, new_view_data
22 |
23 |
24 | def action_patch_selection(dataset):
25 | patch_event = ButtonClick(dataset.selection_patcher)
26 | dataset.selection_patcher._trigger_event(patch_event)
27 |
28 |
29 | def action_apply_labels(annotator):
30 | apply_event = ButtonClick(annotator.annotator_apply)
31 | annotator.annotator_apply._trigger_event(apply_event)
32 | labeled_slice = annotator.dfs["raw"].filter_rows_by_operator(
33 | "label", operator.ne, module_config.ABSTAIN_DECODED
34 | )()
35 | return labeled_slice
36 |
37 |
38 | def action_commit_selection(dataset, subset="train"):
39 | commit_event = MenuItemClick(dataset.data_committer, item=subset)
40 | dataset.data_committer._trigger_event(commit_event)
41 |
42 |
43 | def action_deduplicate(dataset):
44 | dedup_event = ButtonClick(dataset.dedup_trigger)
45 | dataset.dedup_trigger._trigger_event(dedup_event)
46 |
47 |
48 | def action_push_data(dataset):
49 | push_event = ButtonClick(dataset.update_pusher)
50 | dataset.update_pusher._trigger_event(push_event)
51 |
52 |
53 | def execute_handle_function(handle):
54 | doc = Document()
55 | handle(doc)
56 | # a few seconds to activate timed callcacks
57 | time.sleep(10)
58 | for wrapped_callback in doc.session_callbacks:
59 | wrapped_callback.callback()
60 |
--------------------------------------------------------------------------------
/.github/workflows/quick-source-test.yml:
--------------------------------------------------------------------------------
1 | # This workflow will install Python dependencies and run tests on the source code.
2 | # For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
3 |
4 | name: Quick Source Test
5 |
6 | on:
7 | push:
8 | branches: [ main, nightly ]
9 | paths:
10 | - 'hover/**.py'
11 | - 'tests/**.py'
12 | - 'pytest.ini'
13 | - 'fixture_module/**.py'
14 | pull_request:
15 | branches: [ main, nightly ]
16 | paths:
17 | - 'hover/**.py'
18 | - 'tests/**.py'
19 | - 'pytest.ini'
20 | - 'fixture_module/**.py'
21 | workflow_dispatch:
22 |
23 | jobs:
24 | test-api:
25 |
26 | runs-on: ${{ matrix.os }}
27 | strategy:
28 | fail-fast: false
29 | matrix:
30 | # test oldest and newest supported Python version
31 | python-version: ['3.8', '3.10']
32 | os: [ubuntu-latest]
33 |
34 | steps:
35 | - uses: actions/checkout@v3
36 | - name: Set up Python ${{ matrix.python-version }}
37 | uses: actions/setup-python@v3
38 | with:
39 | python-version: ${{ matrix.python-version }}
40 |
41 | - name: Find cached tox env
42 | id: find-venv
43 | uses: actions/cache@v3
44 | with:
45 | path: .tox
46 | key: ${{ runner.os }}-${{ runner.python-version }}-tox-env-${{ hashFiles('**/setup.py') }}
47 | restore-keys: |
48 | ${{ runner.os }}-${{ runner.python-version }}-tox-env-
49 |
50 | - name: Get dependencies
51 | run: |
52 | pip install --upgrade pip
53 | pip install --upgrade tox tox-gh-actions
54 |
55 | - name: Test - default config
56 | run: |
57 | tox -e test_api
58 |
59 | - name: Test - alt config 1
60 | run: |
61 | tox -e test_api -- --hover-ini tests/module_config/hover_alt_config_1.ini
62 |
63 | - name: Codacy Coverage Reporter
64 | uses: codacy/codacy-coverage-reporter-action@master
65 | if: ${{ github.event_name == 'workflow_dispatch' || github.event_name == 'push' }}
66 | with:
67 | project-token: ${{ secrets.CODACY_PROJECT_TOKEN }}
68 | coverage-reports: cobertura.xml
69 |
--------------------------------------------------------------------------------
/docs/pages/tutorial/t6-softlabel-joint-filter.md:
--------------------------------------------------------------------------------
1 | > `hover` filters can stack together.
2 | >
3 | > :speedboat: This makes selections incredibly powerful.
4 |
5 | {!docs/snippets/html/thebe.html!}
6 | {!docs/snippets/markdown/binder-kernel.md!}
7 | {!docs/snippets/markdown/component-tutorial.md!}
8 | {!docs/snippets/markdown/local-dependency.md!}
9 | {!docs/snippets/markdown/local-dep-text.md!}
10 | {!docs/snippets/markdown/local-dep-jupyter-bokeh.md!}
11 |
12 | ## **Preparation**
13 |
14 | {!docs/snippets/markdown/dataset-prep.md!}
15 |
16 | ## **Soft-Label Explorer**
17 |
18 | Active learning works by predicting labels and scores (i.e. soft labels) and utilizing that prediction. An intuitive way to plot soft labels is to color-code labels and use opacity ("alpha" by `bokeh` terminology) to represent scores.
19 |
20 | `SoftLabelExplorer` delivers this functionality:
21 |
22 | 剔除选中数据中的异类 以及 修订发现的误标
56 |
57 |
23 | {!docs/snippets/py/tz-bokeh-notebook-common.txt!}
24 |
25 | {!docs/snippets/py/tz-bokeh-notebook-remote.txt!}
26 |
27 | {!docs/snippets/py/t6-0-softlabel-figure.txt!}
28 | 29 | 30 | ## **Filter Selection by Score Range** 31 | 32 | Similarly to `finder`, a `softlabel` plot has its own selection filter. The difference lies in the filter condition: 33 | 34 | {!docs/snippets/markdown/jupyterlab-js-issue.md!} 35 | 36 |
37 | {!docs/snippets/py/t6-1-softlabel-filter.txt!}
38 | 39 | 40 | ## **Linked Selections & Joint Filters** 41 | 42 | When we plot multiple `explorer`s for the same `dataset`, it makes sense to synchronize selections between those plots. `hover` recipes take care of this synchronization. 43 | 44 | - :tada: This also works with cumulative selections. Consequently, the cumulative toggle is synchronized too. 45 | 46 | Since each filter is narrowing down the selections we make, joint filters is just set intersection, extended 47 | 48 | - from two sets (original selection + filter) 49 | - to N sets (original selection + filter A + filter B + ...) 50 | 51 | The [`active_learning` recipe]((../t1-active-learning/)) is built of `softlabel + annotator + finder`, plus a few widgets for iterating the model-in-loop. 52 | 53 | In the next tutorial(s), we will see more recipes taking advantage of linked selections and joint filters. Powerful indeed! 54 | 55 | {!docs/snippets/html/stylesheet.html!} 56 | -------------------------------------------------------------------------------- /docs/pages/guides/g2-hover-config.md: -------------------------------------------------------------------------------- 1 | > `hover` can be customized through its module config. 2 | > 3 | > :bulb: Let's explore a few use cases. 4 | 5 | {!docs/snippets/markdown/tutorial-required.md!} 6 | {!docs/snippets/html/thebe.html!} 7 | {!docs/snippets/markdown/binder-kernel.md!} 8 | 9 | ## **Color Palette for Labeled Data Points** 10 | 11 | You may want to customize the color palette for better contrast or accessibility, which can depend on specific scenarios. 12 | 13 | The snippet below shows an example of default colors assigned to 6 classes. `hover` by default samples [`Turbo256`](https://docs.bokeh.org/en/latest/docs/reference/palettes.html#large-palettes) to accommodate a large number of classes while keeping good contrast. 14 | 15 |
16 | {!docs/snippets/py/g2-0-color-palette.txt!}
17 |
18 |
19 | You can change the palette using any `bokeh` palette, or any iterable of hex colors like `"#000000"`.
20 |
21 | {!docs/snippets/py/g2-1-configure-palette.txt!}
22 |
23 |
24 | ???+ note "Config changes should happen early"
25 | `hover.config` assignments need to happen before plotting your data.
26 |
27 | - This is because `hover` locks config values for consistency as soon as each config value is read by other code.
28 | - Ideally you should change config immediately after `import hover`.
29 |
30 | ## **Color of Unlabeled Data Points**
31 |
32 | For unlabeled data points, `hover` uses a light gray color `"#dcdcdc"`. This is not configured in the color palette above, but here:
33 |
34 |
35 | {!docs/snippets/py/g2-2-configure-abstain-color.txt!}
36 |
37 |
38 | ## **Dimensionality Reduction Method**
39 |
40 | `hover` uses dimensionality reduction in a lot of places. It can be cumbersome to find these places and use your preferred method. In such cases a module-level override can be handy:
41 |
42 |
43 | {!docs/snippets/py/g2-3-configure-reduction-method.txt!}
44 |
45 |
46 | ## **Browse more configs**
47 |
48 | There are more configurations that are more niche which we will skip here. You can find a full list of configurations, default values, and hints here:
49 |
50 |
51 | {!docs/snippets/py/g2-4-config-hint.txt!}
52 |
53 |
54 | Happy customizing!
55 |
56 | {!docs/snippets/html/stylesheet.html!}
57 |
--------------------------------------------------------------------------------
/hover/utils/snorkel_helper.py:
--------------------------------------------------------------------------------
1 | import uuid
2 |
3 |
4 | def labeling_function(targets, label_encoder=None, **kwargs):
5 | """
6 | ???+ note "Hover's flavor of the Snorkel labeling_function decorator."
7 | However, due to the dynamic label encoding nature of hover,
8 | the decorated function should return the original string label, not its encoding integer.
9 |
10 | - assigns a UUID for easy identification
11 | - keeps track of LF targets
12 |
13 | | Param | Type | Description |
14 | | :-------------- | :----- | :----------------------------------- |
15 | | `targets` | `list` of `str` | labels that the labeling function is intended to create |
16 | | `label_encoder` | `dict` | {decoded_label -> encoded_label} mapping, if you also want an original snorkel-style labeling function linked as a `.snorkel` attribute |
17 | | `**kwargs` | | forwarded to `snorkel`'s `labeling_function()` |
18 | """
19 | # lazy import so that the package does not require snorkel
20 | # Feb 3, 2022: snorkel's dependency handling is too strict
21 | # for other dependencies like NumPy, SciPy, SpaCy, etc.
22 | # Let's cite Snorkel and lazy import or copy functions.
23 | # DO NOT explicitly depend on Snorkel without confirming
24 | # that all builds/tests pass by Anaconda standards, else
25 | # we risk having to drop conda support.
26 | from snorkel.labeling import (
27 | labeling_function as snorkel_lf,
28 | LabelingFunction as SnorkelLF,
29 | )
30 |
31 | def wrapper(func):
32 | # set up kwargs for Snorkel's LF
33 | # a default name that can be overridden
34 | snorkel_kwargs = {"name": func.__name__}
35 | snorkel_kwargs.update(kwargs)
36 |
37 | # return value of hover's decorator
38 | lf = SnorkelLF(f=func, **snorkel_kwargs)
39 |
40 | # additional attributes
41 | lf.uuid = uuid.uuid1()
42 | lf.targets = targets[:]
43 |
44 | # link a snorkel-style labeling function if applicable
45 | if label_encoder:
46 | lf.label_encoder = label_encoder
47 |
48 | def snorkel_style_func(x):
49 | return lf.label_encoder[func(x)]
50 |
51 | lf.snorkel = snorkel_lf(**kwargs)(snorkel_style_func)
52 | else:
53 | lf.label_encoder = None
54 | lf.snorkel = None
55 |
56 | return lf
57 |
58 | return wrapper
59 |
--------------------------------------------------------------------------------
/hover/config_constants.py:
--------------------------------------------------------------------------------
1 | import re
2 |
3 |
4 | class ConfigSection:
5 | IO = "io"
6 | BACKEND = "backend"
7 | VISUAL = "visual"
8 | DATA_EMBEDDING = "data.embedding"
9 | DATA_COLUMNS = "data.columns"
10 | DATA_VALUES = "data.values"
11 |
12 |
13 | class ConfigKey:
14 | DATA_SAVE_DIR = "data_save_dir"
15 | DATAFRAME_LIBRARY = "dataframe_library"
16 | ABSTAIN_HEXCOLOR = "abstain_hexcolor"
17 | BOKEH_PALETTE = "bokeh_palette"
18 | BOKEH_PALETTE_USAGE = "bokeh_palette_usage"
19 | TABLE_IMG_STYLE = "table_img_style"
20 | TOOLTIP_IMG_STYLE = "tooltip_img_style"
21 | SEARCH_MATCH_HEXCOLOR = "search_match_hexcolor"
22 | DATAPOINT_BASE_SIZE = "datapoint_base_size"
23 | DEFAULT_REDUCTION_METHOD = "default_reduction_method"
24 | ENCODED_LABEL_KEY = "encoded_label_key"
25 | DATASET_SUBSET_FIELD = "dataset_subset_field"
26 | EMBEDDING_FIELD_PREFIX = "embedding_field_prefix"
27 | SOURCE_COLOR_FIELD = "source_color_field"
28 | SOURCE_ALPHA_FIELD = "source_alpha_field"
29 | SEARCH_SCORE_FIELD = "search_score_field"
30 | ABSTAIN_DECODED = "abstain_decoded"
31 | ABSTAIN_ENCODED = "abstain_encoded"
32 |
33 |
34 | class Validator:
35 | @staticmethod
36 | def is_hex_color(x):
37 | return bool(re.match(r"^\#[0-9a-fA-F]{6}$", x))
38 |
39 | @staticmethod
40 | def is_iterable(x):
41 | return hasattr(x, "__iter__")
42 |
43 | @staticmethod
44 | def is_iterable_of_hex_color(x):
45 | if not Validator.is_iterable(x):
46 | return False
47 | for i in x:
48 | if not Validator.is_hex_color(i):
49 | return False
50 | return True
51 |
52 | @staticmethod
53 | def is_supported_dataframe_library(x):
54 | return x in ["pandas", "polars"]
55 |
56 | @staticmethod
57 | def is_supported_dimensionality_reduction(x):
58 | return x in ["umap", "ivis"]
59 |
60 | @staticmethod
61 | def is_supported_traversal_mode(x):
62 | return x in ["iterate", "linspace"]
63 |
64 | @staticmethod
65 | def is_str(x):
66 | return isinstance(x, str)
67 |
68 | @staticmethod
69 | def is_int_and_compare(op, value):
70 | def func(x):
71 | return isinstance(x, int) and op(x, value)
72 |
73 | return func
74 |
75 |
76 | class Preprocessor:
77 | @staticmethod
78 | def remove_quote_at_ends(x):
79 | return re.sub(r"(^[\'\"]|[\'\"]$)", "", x)
80 |
81 | @staticmethod
82 | def lower(x):
83 | return x.lower()
84 |
--------------------------------------------------------------------------------
/docs/pages/guides/g0-datatype-image.md:
--------------------------------------------------------------------------------
1 | > `hover` supports bulk-labeling images through their URLs (which can be local).
2 | >
3 | > :bulb: Let's do a quickstart for images and note what's different from texts.
4 |
5 | {!docs/snippets/markdown/tutorial-required.md!}
6 | {!docs/snippets/html/thebe.html!}
7 | {!docs/snippets/markdown/binder-kernel.md!}
8 |
9 | ## **Dataset for Images**
10 |
11 | `hover` handles images through their URL addresses. URLs are strings which can be easily stored, hashed, and looked up against. They are also convenient for rendering tooltips in the annotation interface.
12 |
13 | Similarly to `SupervisableTextDataset`, we can build one for images:
14 |
15 |
16 | {!docs/snippets/py/g0-0-dataset-image.txt!}
17 |
18 | {!docs/snippets/py/t0-0a-dataset-text-print.txt!}
19 |
20 |
21 | ## **Vectorizer for Images**
22 |
23 | We can follow a `URL -> content -> image object -> vector` path.
24 |
25 |
26 | {!docs/snippets/py/g0-1-url-to-content.txt!}
27 |
28 |
29 |
30 | {!docs/snippets/py/g0-2-url-to-image.txt!}
31 |
32 |
33 | {!docs/snippets/markdown/wrappy-cache.md!}
34 |
35 |
36 | {!docs/snippets/py/g0-3-image-vectorizer.txt!}
37 |
38 |
39 | ## **Embedding and Plot**
40 |
41 | This is exactly the same as in the quickstart, just switching to image data:
42 |
43 |
44 | {!docs/snippets/py/t0-2-reduction.txt!}
45 |
46 |
47 |
48 | {!docs/snippets/py/t0-3-simple-annotator.txt!}
49 |
50 | {!docs/snippets/py/tz-bokeh-show-server.txt!}
51 |
52 | {!docs/snippets/py/tz-bokeh-show-notebook.txt!}
53 |
54 |
55 | ???+ note "What's special for images?"
56 | **Tooltips**
57 |
58 | For text, the tooltip shows the original value.
59 |
60 | For images, the tooltip embeds the image based on URL.
61 |
62 | - images in the local file system shall be served through [`python -m http.server`](https://docs.python.org/3/library/http.server.html).
63 | - they can then be accessed through `https://localhost:
8 |
10 |
11 |
12 | Tooltip for each point on mouse hover
9 |
10 |
13 |
15 |
16 |
17 | Table view for inspecting selected points
14 |
15 |
18 |
20 |
21 |
22 | Toggle buttons that clearly distinguish data subsets
19 |
20 |
23 |
25 |
26 |
27 | > **It's accurate because multiple components work together.**
28 |
29 | :microscope: Supplementary views to use in conjunction with the annotator, including
30 |
31 | Search widgets for ad-hoc data highlight
24 |
25 |
32 |
34 |
35 |
36 | `Finder`: filter data by search criteria
33 |
34 |
37 |
39 |
40 |
41 | `SoftLabel`: active learning by in-the-loop model prediction score
38 |
39 |
42 |
44 |
45 |
46 | > **It's flexible (and fun!) because the process never gets old.**
47 |
48 | :toolbox: Additional tools and options that allow you to
49 |
50 | `Snorkel`: custom functions for labeling and filtering
43 |
44 |
51 |
53 |
54 |
55 | Go to higher dimensions (3D? 4D?) and choose your xy-axes
52 |
53 |
56 |
58 |
59 |
60 | Consecutively select across areas, dimensions, and views
57 |
58 |
61 |
63 |
64 |
--------------------------------------------------------------------------------
/notebooks/archive-prototype/Dynamic-Widget.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": [
9 | "%load_ext autoreload\n",
10 | "\n",
11 | "%autoreload 2"
12 | ]
13 | },
14 | {
15 | "cell_type": "code",
16 | "execution_count": null,
17 | "metadata": {},
18 | "outputs": [],
19 | "source": [
20 | "import sys\n",
21 | "sys.path.append('../../')"
22 | ]
23 | },
24 | {
25 | "cell_type": "markdown",
26 | "metadata": {},
27 | "source": [
28 | "### Dynamically Change Widget Behavior"
29 | ]
30 | },
31 | {
32 | "cell_type": "code",
33 | "execution_count": null,
34 | "metadata": {},
35 | "outputs": [],
36 | "source": [
37 | "from bokeh.models import Selection, RangeSlider, Button, Dropdown\n",
38 | "from bokeh.layouts import row, column\n",
39 | "from bokeh.io import output_notebook, show\n",
40 | "from hover.utils.bokeh_helper import servable\n",
41 | "\n",
42 | "output_notebook()\n",
43 | "\n",
44 | "slider = RangeSlider(start=-1.0, end=1.0, value=(-0.5, 0.5), step=0.01)\n",
45 | "slider.on_change(\"value\", lambda attr, old, new: print(f\"Range changed to {slider.value}\"))\n",
46 | "\n",
47 | "@servable()\n",
48 | "def burner():\n",
49 | " arr = ['1', '2', '3']\n",
50 | " dropdown = Dropdown(\n",
51 | " label=\"Select Element\",\n",
52 | " button_type=\"primary\",\n",
53 | " menu=arr,\n",
54 | " )\n",
55 | " \n",
56 | " button = Button(label=\"Click Me\", height=100)\n",
57 | " def button_callcack(event):\n",
58 | " dropdown.menu.append(str(int(dropdown.menu[-1]) + 1))\n",
59 | " print(f\"Button Clicked! Got menu: {dropdown.menu}\")\n",
60 | " button.on_click(button_callcack)\n",
61 | "\n",
62 | " return column(dropdown, button)\n",
63 | "\n",
64 | "handle = burner()\n",
65 | "show(handle)"
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": null,
71 | "metadata": {},
72 | "outputs": [],
73 | "source": []
74 | }
75 | ],
76 | "metadata": {
77 | "kernelspec": {
78 | "display_name": "Python 3 (ipykernel)",
79 | "language": "python",
80 | "name": "python3"
81 | },
82 | "language_info": {
83 | "codemirror_mode": {
84 | "name": "ipython",
85 | "version": 3
86 | },
87 | "file_extension": ".py",
88 | "mimetype": "text/x-python",
89 | "name": "python",
90 | "nbconvert_exporter": "python",
91 | "pygments_lexer": "ipython3",
92 | "version": "3.9.7"
93 | }
94 | },
95 | "nbformat": 4,
96 | "nbformat_minor": 4
97 | }
98 |
--------------------------------------------------------------------------------
/fixture_module/image_vector_net/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Example importable module holding customized ingredients of a workflow with hover.
3 | Specifically for 3-channel image data in URLs.
4 | """
5 |
6 | import os
7 | import re
8 | import numpy as np
9 | import wrappy
10 | import requests
11 | from PIL import Image
12 | from io import BytesIO
13 |
14 |
15 | DIR_PATH = os.path.dirname(__file__)
16 | RAW_CACHE_PATH = os.path.join(DIR_PATH, "raws.pkl")
17 | IMG_CACHE_PATH = os.path.join(DIR_PATH, "imgs.pkl")
18 | VEC_CACHE_PATH = os.path.join(DIR_PATH, "vecs.pkl")
19 |
20 |
21 | @wrappy.memoize(
22 | cache_limit=50000,
23 | return_copy=False,
24 | persist_path=RAW_CACHE_PATH,
25 | persist_batch_size=100,
26 | )
27 | def url_to_content(url):
28 | """
29 | Turn a URL to response content.
30 | """
31 | response = requests.get(url)
32 | return response.content
33 |
34 |
35 | @wrappy.memoize(
36 | cache_limit=50000,
37 | return_copy=False,
38 | persist_path=IMG_CACHE_PATH,
39 | persist_batch_size=100,
40 | )
41 | def url_to_image(url):
42 | """
43 | Turn a URL to a PIL Image.
44 | """
45 | img = Image.open(BytesIO(url_to_content(url))).convert("RGB")
46 | return img
47 |
48 |
49 | def get_vectorizer():
50 | import torch
51 | from efficientnet_pytorch import EfficientNet
52 | from torchvision import transforms
53 |
54 | # EfficientNet is a series of pre-trained models
55 | # https://github.com/lukemelas/EfficientNet-PyTorch
56 | model = EfficientNet.from_pretrained("efficientnet-b0")
57 | model.eval()
58 |
59 | # standard transformations for ImageNet-trained models
60 | tfms = transforms.Compose(
61 | [
62 | transforms.Resize(224),
63 | transforms.ToTensor(),
64 | transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
65 | ]
66 | )
67 |
68 | # memoization can be useful if the function takes a while to run, which is common for images
69 | @wrappy.memoize(
70 | cache_limit=50000,
71 | return_copy=False,
72 | persist_path=VEC_CACHE_PATH,
73 | persist_batch_size=100,
74 | )
75 | def vectorizer(url):
76 | """
77 | Using logits on ImageNet-1000 classes.
78 | """
79 | img = tfms(url_to_image(url)).unsqueeze(0)
80 |
81 | with torch.no_grad():
82 | outputs = model(img)
83 |
84 | return outputs.detach().numpy().flatten()
85 |
86 | return vectorizer
87 |
88 |
89 | def get_architecture():
90 | from hover.utils.common_nn import LogisticRegression
91 |
92 | return LogisticRegression
93 |
94 |
95 | def get_state_dict_path():
96 | return os.path.join(DIR_PATH, "model.pt")
97 |
--------------------------------------------------------------------------------
/docs/pages/guides/g1-datatype-audio.md:
--------------------------------------------------------------------------------
1 | > `hover` supports bulk-labeling audios through their URLs (which can be local).
2 | >
3 | > :bulb: Let's do a quickstart for audios and note what's different from texts.
4 |
5 | {!docs/snippets/markdown/tutorial-required.md!}
6 | {!docs/snippets/html/thebe.html!}
7 | {!docs/snippets/markdown/binder-kernel.md!}
8 |
9 | ## **Dataset for audios**
10 |
11 | `hover` handles audios through their URL addresses. URLs are strings which can be easily stored, hashed, and looked up against. They are also convenient for rendering tooltips in the annotation interface.
12 |
13 | Similarly to `SupervisableTextDataset`, we can build one for audios:
14 |
15 | Kick outliers and fix mistakes
62 |
63 |
16 | {!docs/snippets/py/g1-0-dataset-audio.txt!}
17 |
18 | {!docs/snippets/py/t0-0a-dataset-text-print.txt!}
19 |
20 |
21 | ## **Vectorizer for audios**
22 |
23 | We can follow a `URL -> content -> audio array -> vector` path.
24 |
25 |
26 | {!docs/snippets/py/g0-1-url-to-content.txt!}
27 |
28 |
29 |
30 | {!docs/snippets/py/g1-1-url-to-audio.txt!}
31 |
32 |
33 | {!docs/snippets/markdown/wrappy-cache.md!}
34 |
35 |
36 | {!docs/snippets/py/g1-2-audio-vectorizer.txt!}
37 |
38 |
39 | ## **Embedding and Plot**
40 |
41 | This is exactly the same as in the quickstart, just switching to audio data:
42 |
43 |
44 | {!docs/snippets/py/t0-2-reduction.txt!}
45 |
46 |
47 |
48 | {!docs/snippets/py/t0-3-simple-annotator.txt!}
49 |
50 | {!docs/snippets/py/tz-bokeh-show-server.txt!}
51 |
52 | {!docs/snippets/py/tz-bokeh-show-notebook.txt!}
53 |
54 |
55 | ???+ note "What's special for audios?"
56 | **Tooltips**
57 |
58 | For text, the tooltip shows the original value.
59 |
60 | For audios, the tooltip embeds the audio based on URL.
61 |
62 | - audios in the local file system shall be served through [`python -m http.server`](https://docs.python.org/3/library/http.server.html).
63 | - they can then be accessed through `https://localhost:
29 | {!docs/snippets/py/tz-bokeh-notebook-common.txt!}
30 |
31 | {!docs/snippets/py/tz-bokeh-notebook-remote.txt!}
32 |
33 | {!docs/snippets/py/t5-0-finder-filter.txt!}
34 | 35 | 36 | Next to the search widgets is a checkbox. The filter will stay active as long as the checkbox is. 37 | 38 | ???+ info "How the filter interacts with selection options" 39 | Selection options apply before filters. 40 | 41 | `hover` memorizes your pre-filter selections, so you can keep selecting without having to tweaking the filter toggle. 42 | 43 | - Example: 44 | - suppose you have previously selected a set of points called `A`. 45 | - then you toggled a filter `f`, giving you `A∩F` where `F` is the set satisfying `f`. 46 | - now, with selection option "union", you select a set of points called `B`. 47 | - your current selection will be `(A ∪ B) ∩ F`, i.e. `(A ∩ F) ∪ (B ∩ F)`. 48 | - similarly, you would get `(A ∩ B) ∩ F` for "intersection" and `(A ∖ B) ∩ F` for "difference". 49 | - if you untoggle the filter now, you selection would be `A ∪ B`. 50 | 51 | - In the later tutorials, we shall see multiple filters in action together. 52 | - spoiler: `F = F1 ∩ F2 ∩ ...` and that's it! 53 | 54 | ## **Stronger Highlight for Search** 55 | 56 | `finder` also colors data points based on search criteria, making them easier to find. 57 | 58 | {!docs/snippets/markdown/jupyterlab-js-issue.md!} 59 | 60 |
61 | {!docs/snippets/py/t5-1-finder-figure.txt!}
62 | 63 | 64 | {!docs/snippets/html/stylesheet.html!} 65 | -------------------------------------------------------------------------------- /hover/utils/misc.py: -------------------------------------------------------------------------------- 1 | """Mini-functions that do not belong elsewhere.""" 2 | from datetime import datetime 3 | from abc import ABC, abstractmethod 4 | 5 | 6 | def current_time(template="%Y%m%d %H:%M:%S"): 7 | return datetime.now().strftime(template) 8 | 9 | 10 | class BaseUnionFind(ABC): 11 | """ 12 | ???+ note "Data attached to union-find." 13 | """ 14 | 15 | def __init__(self, data): 16 | self._data = data 17 | self._parent = None 18 | self._count = 1 19 | 20 | def __repr__(self): 21 | return self.data.__repr__() 22 | 23 | @property 24 | def count(self): 25 | if self.parent is None: 26 | return self._count 27 | return self.find().count 28 | 29 | @count.setter 30 | def count(self, count): 31 | self._count = count 32 | 33 | @property 34 | def parent(self): 35 | return self._parent 36 | 37 | @parent.setter 38 | def parent(self, other): 39 | assert isinstance(other, BaseUnionFind) 40 | self._parent = other 41 | 42 | def find(self): 43 | if self.parent: 44 | self.parent = self.parent.find() 45 | return self.parent 46 | return self 47 | 48 | @abstractmethod 49 | def union(self, other): 50 | pass 51 | 52 | 53 | class NodeUnionFind(BaseUnionFind): 54 | """ 55 | ???+ note "Each node keeps its own data." 56 | """ 57 | 58 | @property 59 | def data(self): 60 | return self._data 61 | 62 | @data.setter 63 | def data(self, data): 64 | self._data = data 65 | 66 | def union(self, other): 67 | root = self.find() 68 | other_root = other.find() 69 | if root is other_root: 70 | return 71 | 72 | # merge the smaller trees into the larger 73 | if root.count < other_root.count: 74 | other_root.count += root.count 75 | root.parent = other_root 76 | else: 77 | root.count += other_root.count 78 | other_root.parent = root 79 | 80 | 81 | class RootUnionFind(BaseUnionFind): 82 | """ 83 | ???+ note "Union always uses left as root. Each node looks up its root for data." 84 | """ 85 | 86 | @property 87 | def data(self): 88 | root = self.find() 89 | if self is root: 90 | return self._data 91 | return root.data 92 | 93 | @data.setter 94 | def data(self, data): 95 | root = self.find() 96 | if self is root: 97 | self._data = data 98 | root._data = data 99 | 100 | def union(self, other): 101 | root = self.find() 102 | other_root = other.find() 103 | 104 | # clear the data on the other root 105 | other_root.data = None 106 | root.count += other_root.count 107 | other_root.parent = root 108 | -------------------------------------------------------------------------------- /notebooks/archive-prototype/Editing-Datatable.ipynb: -------------------------------------------------------------------------------- 1 | { 2 | "cells": [ 3 | { 4 | "cell_type": "code", 5 | "execution_count": null, 6 | "id": "2bf553ea-eb52-49f8-ae88-da179ca9e793", 7 | "metadata": {}, 8 | "outputs": [], 9 | "source": [ 10 | "from bokeh.models import (\n", 11 | " Button,\n", 12 | " ColumnDataSource,\n", 13 | " DataTable,\n", 14 | " TableColumn\n", 15 | ")\n", 16 | "from bokeh.layouts import column\n", 17 | "from hover.utils.bokeh_helper import servable\n", 18 | "\n", 19 | "@servable()\n", 20 | "def burner():\n", 21 | " df = pd.DataFrame({\n", 22 | " 'f0': np.random.uniform(-1.0, 1.0, size=(100,)).tolist(),\n", 23 | " 'f1': np.random.uniform(-1.0, 1.0, size=(100,)).tolist(),\n", 24 | " 'f2': np.random.uniform(-1.0, 1.0, size=(100,)).tolist(),\n", 25 | " 'f3': np.random.uniform(-1.0, 1.0, size=(100,)).tolist(),\n", 26 | " })\n", 27 | " forward_button = Button(label=\"df-to-table\")\n", 28 | " backward_button = Button(label=\"table-to-df\")\n", 29 | " \n", 30 | " sel_source = ColumnDataSource(dict())\n", 31 | " show_columns = ['f0', 'f2']\n", 32 | " sel_columns = [TableColumn(field=_col, title=_col) for _col in show_columns]\n", 33 | " sel_table = DataTable(source=sel_source, columns=sel_columns, selectable=\"checkbox\", editable=True)\n", 34 | " \n", 35 | " def df_to_table(event):\n", 36 | " sel_source.data = df.to_dict(orient=\"list\")\n", 37 | " \n", 38 | " def table_to_df(event):\n", 39 | " indices = sel_source.selected.indices\n", 40 | " for _col in show_columns:\n", 41 | " _values = sel_source.data[_col]\n", 42 | " _patches = [_values[i] for i in indices]\n", 43 | " df.loc[indices, _col] = _patches\n", 44 | " print(_col, indices, len(_patches))\n", 45 | " \n", 46 | " forward_button.on_click(df_to_table)\n", 47 | " backward_button.on_click(table_to_df)\n", 48 | " return column(forward_button, backward_button, sel_table)" 49 | ] 50 | }, 51 | { 52 | "cell_type": "code", 53 | "execution_count": null, 54 | "id": "1446d4c0-8da7-4101-9816-9b30297036aa", 55 | "metadata": {}, 56 | "outputs": [], 57 | "source": [ 58 | "handle = burner()\n", 59 | "show(handle)" 60 | ] 61 | } 62 | ], 63 | "metadata": { 64 | "kernelspec": { 65 | "display_name": "Python 3 (ipykernel)", 66 | "language": "python", 67 | "name": "python3" 68 | }, 69 | "language_info": { 70 | "codemirror_mode": { 71 | "name": "ipython", 72 | "version": 3 73 | }, 74 | "file_extension": ".py", 75 | "mimetype": "text/x-python", 76 | "name": "python", 77 | "nbconvert_exporter": "python", 78 | "pygments_lexer": "ipython3", 79 | "version": "3.9.7" 80 | } 81 | }, 82 | "nbformat": 4, 83 | "nbformat_minor": 5 84 | } 85 | -------------------------------------------------------------------------------- /hover/core/representation/trajectory.py: -------------------------------------------------------------------------------- 1 | """ 2 | Trajectory interpolation for sequences of vectors. 3 | """ 4 | from scipy import interpolate 5 | import numpy as np 6 | 7 | 8 | def spline(arr_per_dim, points_per_step=1, splprep_kwargs=None): 9 | """ 10 | Fit a spline and evaluate it at a specified density of points. 11 | 12 | - param arr_per_dim(numpy.ndarray): dim-by-points array representing the part of the curve in each dimension. 13 | 14 | - param points_per_step(int): number of points interpolated in between each given point on the curve. 15 | 16 | - param splprep_kwargs(dict): keyword arguments to the splprep() function for fitting the spline in SciPy. 17 | """ 18 | 19 | # cast to array if appropriate 20 | if isinstance(arr_per_dim, list): 21 | arr_per_dim = np.array(arr_per_dim) 22 | 23 | assert points_per_step >= 1, "Need at least one point per step" 24 | splprep_kwargs = splprep_kwargs or dict() 25 | 26 | # check the number of given points in the curve 27 | num_given_points = arr_per_dim[0].shape[0] 28 | assert num_given_points > 1, "Need at least two points to fit a line" 29 | 30 | # check if two vectors are almost identical, and apply a noise in that case 31 | # note that we did not modify arr_per_dim in place 32 | # and that the noise only goes up in a greedy random-walk manner 33 | noise_arr = np.zeros((len(arr_per_dim), num_given_points)) 34 | for i in range(1, num_given_points): 35 | prev_vec, vec = arr_per_dim[:, i - 1] + noise_arr[:, i - 1], arr_per_dim[:, i] 36 | while np.allclose(vec + noise_arr[:, i], prev_vec): 37 | noise_arr[:, i] += np.random.normal(loc=0.0, scale=1e-6, size=vec.shape) 38 | 39 | # reduce spline order if necessary, then fit the spline parameters 40 | splprep_kwargs["k"] = min(3, num_given_points - 1) 41 | tck, u = interpolate.splprep(arr_per_dim + noise_arr, **splprep_kwargs) 42 | 43 | # determine points at which the spline should be evaluated 44 | points_to_eval = [] 45 | for i in range(0, u.shape[0] - 1): 46 | _pts = np.linspace(u[i], u[i + 1], points_per_step, endpoint=False) 47 | points_to_eval.append(_pts) 48 | points_to_eval.append([u[-1]]) 49 | points_to_eval = np.concatenate(points_to_eval) 50 | 51 | traj_per_dim = interpolate.splev(points_to_eval, tck) 52 | return traj_per_dim 53 | 54 | 55 | def manifold_spline(seq_arr, **kwargs): 56 | """ 57 | Fit a spline to every sequence of points in a manifold. 58 | - param seq_arr: L-sequence of M-by-N arrays each containing vectors matched by index. 59 | :type seq_arr: numpy.ndarray 60 | """ 61 | # L is unused 62 | _L, M, N = seq_arr.shape 63 | 64 | # this gives M-by-N-by-f(L, args) 65 | traj_arr = np.array( 66 | [ 67 | spline(np.array([seq_arr[:, _m, _n] for _n in range(N)]), **kwargs) 68 | for _m in range(M) 69 | ] 70 | ) 71 | 72 | # return f(L, args)-by-M-by-N 73 | traj_arr = np.swapaxes(traj_arr, 1, 2) 74 | traj_arr = np.swapaxes(traj_arr, 0, 1) 75 | return traj_arr 76 | -------------------------------------------------------------------------------- /hover/utils/datasets.py: -------------------------------------------------------------------------------- 1 | """ 2 | Submodule that loads and preprocesses public datasets into formats that work smoothly. 3 | """ 4 | 5 | from sklearn.datasets import fetch_20newsgroups 6 | from hover import module_config 7 | import re 8 | 9 | 10 | def clean_string(text, sub_from=r"[^a-zA-Z0-9\ ]", sub_to=r" "): 11 | cleaned = re.sub(sub_from, sub_to, text) 12 | cleaned = re.sub(r" +", r" ", cleaned) 13 | return cleaned 14 | 15 | 16 | def newsgroups_dictl( 17 | data_home="~/scikit_learn_data", 18 | to_remove=("headers", "footers", "quotes"), 19 | text_key="text", 20 | label_key="label", 21 | label_mapping=None, 22 | ): 23 | """ 24 | Load the 20 Newsgroups dataset into a list of dicts, deterministically. 25 | """ 26 | label_mapping = label_mapping or dict() 27 | dataset = dict() 28 | label_set = set() 29 | for _key in ["train", "test"]: 30 | _dictl = [] 31 | 32 | # load subset and transform into a list of dicts 33 | _bunch = fetch_20newsgroups( 34 | data_home=data_home, subset=_key, random_state=42, remove=to_remove 35 | ) 36 | for i, text in enumerate(_bunch.data): 37 | _text = clean_string(text) 38 | _label = _bunch.target_names[_bunch.target[i]] 39 | _label = label_mapping.get(_label, _label) 40 | 41 | _text_actual_characters = re.sub(r"[^a-zA-Z0-9]", r"", _text) 42 | if len(_text_actual_characters) > 5: 43 | label_set.add(_label) 44 | _entry = {text_key: _text, label_key: _label} 45 | _dictl.append(_entry) 46 | 47 | # add to dataset 48 | dataset[_key] = _dictl 49 | 50 | label_list = sorted(list(label_set)) 51 | label_decoder = {idx: value for idx, value in enumerate(label_list)} 52 | label_decoder[module_config.ABSTAIN_ENCODED] = module_config.ABSTAIN_DECODED 53 | label_encoder = {value: idx for idx, value in label_decoder.items()} 54 | return dataset, label_encoder, label_decoder 55 | 56 | 57 | def newsgroups_reduced_dictl(**kwargs): 58 | """ 59 | Load the 20 Newsgroups dataset but reduce categories using a custom mapping. 60 | """ 61 | label_mapping = { 62 | "alt.atheism": "religion", 63 | "comp.graphics": "computer", 64 | "comp.os.ms-windows.misc": "computer", 65 | "comp.sys.ibm.pc.hardware": "computer", 66 | "comp.sys.mac.hardware": "computer", 67 | "comp.windows.x": "computer", 68 | "misc.forsale": "forsale", 69 | "rec.autos": "recreation", 70 | "rec.motorcycles": "recreation", 71 | "rec.sport.baseball": "recreation", 72 | "rec.sport.hockey": "recreation", 73 | "sci.crypt": "computer", 74 | "sci.electronics": "computer", 75 | "sci.med": "med", 76 | "sci.space": "space", 77 | "soc.religion.christian": "religion", 78 | "talk.politics.guns": "politics", 79 | "talk.politics.mideast": "politics", 80 | "talk.politics.misc": "politics", 81 | "talk.religion.misc": "religion", 82 | } 83 | kwargs["label_mapping"] = label_mapping 84 | return newsgroups_dictl(**kwargs) 85 | -------------------------------------------------------------------------------- /docs/pages/tutorial/t2-bokeh-app.md: -------------------------------------------------------------------------------- 1 | > `hover` creates a [`bokeh` server app](https://docs.bokeh.org/en/latest/docs/user_guide/server.html) to deliver its annotation interface. 2 | > 3 | > :rocket: This app can be served flexibly based on your needs. 4 | 5 | {!docs/snippets/html/stylesheet.html!} 6 | 7 | ## **Prerequisites** 8 | 9 | Suppose that we've already used a `recipe` to create a `handle` function like in the [quickstart](../t0-quickstart/#apply-labels). 10 | 11 | ??? info "Recap from the tutorials before" 12 | - the `handle` is a function which renders plot elements on a [`bokeh` document](https://docs.bokeh.org/en/latest/docs/reference/document.html). 13 | 14 | ## **Option 1: Jupyter** 15 | 16 | We are probably familiar with this now: 17 | 18 | ```Python 19 | from bokeh.io import show, output_notebook 20 | output_notebook() 21 | show(handle) # notebook_url='http://localhost:8888' 22 | ``` 23 | 24 | ???+ tip "Pros & Cons" 25 | This inline Jupyter mode can integrate particularly well with your notebook workflow. For example, when your are (tentatively) done with annotation, the `SupervisableDataset` can be accessed directly in the notebook, rather than exported to a file and loaded back. 26 | 27 | The inline mode is highly recommended for local usage. 28 | 29 | - On the contrary, with a remote Jupyter server, it may have trouble displaying the plots. 30 | 31 | - this can be due to failure of loading JavaScript libraries or accessing implicit bokeh server ports. 32 | 33 | ## **Option 2: Command Line** 34 | 35 | [`bokeh serve`](https://docs.bokeh.org/en/latest/docs/user_guide/server.html) starts an explicit `tornado` server from the command line: 36 | 37 | ```bash 38 | bokeh serve my-app.py 39 | ``` 40 | 41 | ```Python 42 | # my-app.py 43 | 44 | # handle = ... 45 | 46 | from bokeh.io import curdoc 47 | doc = curdoc() 48 | handle(doc) 49 | ``` 50 | 51 | ???+ tip "Pros & Cons" 52 | This is the "classic" approach to run a `bokeh` server. Remote access is simple through parameters [**specified here**](https://docs.bokeh.org/en/latest/docs/reference/command/subcommands/serve.html). The bokeh plot tools are mobile-friendly too -- this means you can host a server, e.g. an http-enabled cloud virtual machine, and annotate from a tablet. 53 | 54 | The command line mode is less interactive, since Python objects in the script cannot be accessed on the fly. 55 | 56 | ## **Option 3: Anywhere in Python** 57 | 58 | It is possible to [embed the app](https://docs.bokeh.org/en/latest/docs/user_guide/server.html#embedding-bokeh-server-as-a-library) in regular Python: 59 | 60 | ```Python 61 | from bokeh.server.server import Server 62 | server = Server({'/my-app': handle}) 63 | server.start() 64 | ``` 65 | 66 | ???+ tip "Pros & Cons" 67 | This embedded mode is a go-to for serving within a greater application. 68 | 69 | Also note that each command line argument for `bokeh serve` has a corresponding keyword argument to `Server()`. 70 | 71 | For instance, `bokeh serve
27 | {!docs/snippets/py/t7-0-lf-list.txt!}
28 | 29 | 30 |
31 | {!docs/snippets/py/t7-0a-lf-list-edit.txt!}
32 | 33 | 34 | ### **Using a Function to Apply Labels** 35 | 36 | Hover's `SnorkelExplorer` (short as `snorkel`) can take the labeling functions above and apply them on areas of data that you choose. The widget below is responsible for labeling: 37 | 38 | {!docs/snippets/markdown/jupyterlab-js-issue.md!} 39 | 40 |
41 | {!docs/snippets/py/tz-bokeh-notebook-common.txt!}
42 |
43 | {!docs/snippets/py/tz-bokeh-notebook-remote.txt!}
44 |
45 | {!docs/snippets/py/t7-1-snorkel-apply-button.txt!}
46 | 47 | 48 | ### **Using a Function to Apply Filters** 49 | 50 | Any function that labels is also a function that filters. The filter condition is `"keep if did not abstain"`. The widget below handles filtering: 51 | 52 | {!docs/snippets/markdown/jupyterlab-js-issue.md!} 53 | 54 |
55 | {!docs/snippets/py/t7-2-snorkel-filter-button.txt!}
56 | 57 | 58 | Unlike the toggled filters for `finder` and `softlabel`, filtering with functions is on a per-click basis. In other words, this particular filtration doesn't persist when you select another area. 59 | 60 | ## **Dynamic List of Functions** 61 | 62 | Python lists are mutable, and we are going to take advantage of that for improvising and editing labeling functions on the fly. 63 | 64 | Run the block below and open the resulting URL to launch a recipe. 65 | 66 | - labeling functions are evaluated against the `dev` set. 67 | - hence you are advised to send the labels produced by these functions to the `train` set, not the `dev` set. 68 | - come back and edit the list of labeling functions **in-place** in one of the code cells above. 69 | - then go to the launched app and refresh the functions! 70 | 71 |
72 | {!docs/snippets/py/t7-3-snorkel-crosscheck.txt!}
73 |
74 | {!docs/snippets/py/tz-bokeh-show-server.txt!}
75 |
76 | {!docs/snippets/py/tz-bokeh-show-notebook.txt!}
77 |
78 |
79 | What's really cool is that in your local environment, this update-and-refresh operation can be done all in a notebook. So now you can
80 |
81 | - interactively evaluate and revise labeling functions
82 | - visually assign specific data regions to apply those functions
83 |
84 | which makes labeling functions significantly more accurate and applicable.
85 |
86 | {!docs/snippets/html/stylesheet.html!}
87 |
--------------------------------------------------------------------------------
/hover/utils/torch_helper.py:
--------------------------------------------------------------------------------
1 | """
2 | Submodule that handles interaction with PyTorch.
3 | """
4 | import numpy as np
5 | import torch
6 | import torch.nn.functional as F
7 | from torch.utils.data import Dataset, DataLoader
8 |
9 |
10 | class VectorDataset(Dataset):
11 | """
12 | PyTorch Dataset of vectors and probabilistic classification targets.
13 | """
14 |
15 | DEFAULT_LOADER_KWARGS = dict(batch_size=64, shuffle=True, drop_last=False)
16 |
17 | def __init__(self, input_vectors, output_vectors):
18 | """Overrides the parent constructor."""
19 | assert len(input_vectors) == len(output_vectors)
20 | self.input_tensor = torch.FloatTensor(np.asarray(input_vectors))
21 | self.output_tensor = torch.FloatTensor(np.asarray(output_vectors))
22 |
23 | def __getitem__(self, index):
24 | """Makes the dataset an iterable."""
25 | return self.input_tensor[index], self.output_tensor[index], index
26 |
27 | def __len__(self):
28 | """Defines the length measure."""
29 | return len(self.input_tensor)
30 |
31 | def loader(self, **kwargs):
32 | keyword_args = self.__class__.DEFAULT_LOADER_KWARGS.copy()
33 | keyword_args.update(kwargs)
34 | return DataLoader(dataset=self, **keyword_args)
35 |
36 |
37 | class MultiVectorDataset(Dataset):
38 | """
39 | PyTorch Dataset of multi-vectors and probabilistic classification targets.
40 | """
41 |
42 | DEFAULT_LOADER_KWARGS = dict(batch_size=64, shuffle=True, drop_last=False)
43 |
44 | def __init__(self, input_vector_lists, output_vectors):
45 | """Overrides the parent constructor."""
46 | for _list in input_vector_lists:
47 | assert len(_list) == len(output_vectors)
48 | self.input_tensors = [
49 | torch.FloatTensor(np.asarray(_list)) for _list in input_vector_lists
50 | ]
51 | self.output_tensor = torch.FloatTensor(np.asarray(output_vectors))
52 |
53 | def __getitem__(self, index):
54 | """Makes the dataset an iterable."""
55 | input_vectors = [_tensor[index] for _tensor in self.input_tensors]
56 | return input_vectors, self.output_tensor[index], index
57 |
58 | def __len__(self):
59 | """Defines the length measure."""
60 | return len(self.output_tensor)
61 |
62 | def loader(self, **kwargs):
63 | keyword_args = self.__class__.DEFAULT_LOADER_KWARGS.copy()
64 | keyword_args.update(kwargs)
65 | return DataLoader(dataset=self, **keyword_args)
66 |
67 |
68 | def one_hot(encoded_labels, num_classes):
69 | """
70 | One-hot encoding into a float form.
71 |
72 | :param encoded_labels: integer-encoded labels.
73 | :type encoded_labels: list of int
74 | :param num_classes: the number of classes to encode.
75 | :type num_classes: int
76 | """
77 | return F.one_hot(torch.LongTensor(encoded_labels), num_classes=num_classes).float()
78 |
79 |
80 | def label_smoothing(probabilistic_labels, coefficient=0.1):
81 | """
82 | Smooth probabilistic labels, auto-detecting the number of classes.
83 |
84 | :param probabilistic_labels: N by num_classes tensor
85 | :type probabilistic_labels: torch.Tensor or numpy.ndarray
86 | :param coefficient: the smoothing coeffient for soft labels.
87 | :type coefficient: float
88 | """
89 | assert (
90 | len(probabilistic_labels.shape) == 2
91 | ), f"Expected 2 dimensions, got shape {probabilistic_labels.shape}"
92 | assert coefficient >= 0.0, f"Expected non-negative smoothing, got {coefficient}"
93 | num_classes = probabilistic_labels.shape[-1]
94 | return (1.0 - coefficient) * probabilistic_labels + coefficient / num_classes
95 |
--------------------------------------------------------------------------------
/hover/core/local_config.py:
--------------------------------------------------------------------------------
1 | import re
2 | import hover
3 | from hover.config_constants import (
4 | ConfigSection as Section,
5 | ConfigKey as Key,
6 | )
7 | from bokeh.models import (
8 | Div,
9 | TableColumn,
10 | CellEditor,
11 | HTMLTemplateFormatter,
12 | )
13 |
14 |
15 | DEFAULT_REDUCTION_METHOD = hover.config[Section.DATA_EMBEDDING][
16 | Key.DEFAULT_REDUCTION_METHOD
17 | ]
18 | DATASET_SUBSET_FIELD = hover.config[Section.DATA_COLUMNS][Key.DATASET_SUBSET_FIELD]
19 |
20 | COLOR_GLYPH_TEMPLATE = """
21 | 22 | <%= "███" %> 23 |
24 | """ 25 | 26 | EMBEDDING_FIELD_PREFIX = hover.config[Section.DATA_COLUMNS][Key.EMBEDDING_FIELD_PREFIX] 27 | EMBEDDING_FIELD_REGEX = r"\d+d_\d+$" 28 | 29 | 30 | def embedding_field(total_dim, specific_dim): 31 | return f"{EMBEDDING_FIELD_PREFIX}{total_dim}d_{specific_dim}" 32 | 33 | 34 | def is_embedding_field(column_name): 35 | if not column_name.startswith(EMBEDDING_FIELD_PREFIX): 36 | return False 37 | return bool(re.search(EMBEDDING_FIELD_REGEX, column_name)) 38 | 39 | 40 | def blank_callback_on_change(attr, old, new): 41 | return None 42 | 43 | 44 | def dataset_help_widget(): 45 | text = 'Dataset Widgets Help' 46 | return Div(text=text) 47 | 48 | 49 | def dataset_default_sel_table_columns(feature_key): 50 | """ 51 | ???+ note "Default `SupervisableDataset` selection table columns based on feature type." 52 | 53 | Always allow multi-selection and editing. Based on feature type: 54 | - increases row height for viewing images. 55 | """ 56 | # disable editing the feature through a blank editor 57 | feature_col_kwargs = dict(editor=CellEditor()) 58 | if feature_key == "text": 59 | feature_col_kwargs["formatter"] = HTMLTemplateFormatter( 60 | template="""<%= value %>""" 61 | ) 62 | elif feature_key == "image": 63 | style = hover.config[Section.VISUAL][Key.TABLE_IMG_STYLE] 64 | # width is easily adjustable on the UI, no need to make configurable here 65 | feature_col_kwargs["width"] = 200 66 | feature_col_kwargs["formatter"] = HTMLTemplateFormatter( 67 | template=f"""
18 | {!docs/snippets/py/tz-dataset-text-full.txt!}
19 | 20 | 21 |
22 | {!docs/snippets/py/tz-bokeh-notebook-common.txt!}
23 |
24 | {!docs/snippets/py/tz-bokeh-notebook-remote.txt!}
25 |
26 | {!docs/snippets/py/t3-0-dataset-population-table.txt!}
27 | 28 | 29 | ### **Transfer Data Between Subsets** 30 | 31 | `COMMIT` and `DEDUP` are the mechanisms that `hover` uses to transfer data between subsets. 32 | 33 | - `COMMIT` copies selected points (to be discussed later) to a destination subset 34 | - labeled-raw-only: `COMMIT` automatically detects which points are in the raw set with a valid label. Other points will not get copied. 35 | - keep-last: you can commit the same point to the same subset multiple times and the last copy will be kept. This can be useful for revising labels before `DEDUP`. 36 | - `DEDUP` removes duplicates (identified by feature value) across subsets 37 | - priority rule: test > dev > train > raw, i.e. test set data always gets kept during deduplication 38 | 39 | ???+ info "FAQ" 40 | ??? help "Why does COMMIT only work on the raw subset?" 41 | Most selections will happen through plots, where different subsets are on top of each other. This means selections can contain both unlabeled and labeled points. 42 | 43 | Way too often we find ourselves trying to view both the labeled and the unlabeled, but only moving the unlabeled "raw" points. So it's handy that COMMIT picks those points only. 44 | 45 | These mechanisms correspond to buttons in `hover`'s annotation interface, which you have encountered in the quickstart: 46 | 47 | {!docs/snippets/markdown/jupyterlab-js-issue.md!} 48 | 49 |
50 | {!docs/snippets/py/t3-1-dataset-commit-dedup.txt!}
51 | 52 | 53 | Of course, so far we have nothing to move, because there's no data selected. We shall now discuss selections. 54 | 55 | ## **Selection** 56 | 57 | `hover` labels data points in bulk, which requires selecting groups of homogeneous data, i.e. semantically similar or going to have the same label. Being able to skim through what you selected gives you confidence about homogeneity. 58 | 59 | Normally, selection happens through a plot (`explorer`), as we have seen in the quickstart. For the purpose here, we will "cheat" and assign the selection programmatically: 60 | 61 |
62 | {!docs/snippets/py/t3-2-dataset-selection-table.txt!}
63 | 64 | 65 | ### **Edit Data Within a Selection** 66 | 67 | Often the points selected are not perfectly homogeneous, i.e. some outliers belong to a different label from the selected group overall. It would be helpful to `EVICT` them, and `SupervisableDataset` has a button for it. 68 | 69 | Sometimes you may also wish to edit data values on the fly. In hover this is called `PATCH`, and there also is a button for it. 70 | 71 | - by default, labels can be edited but feature values cannot. 72 | 73 | Let's plot the forementioned buttons along with the selection table. Toggle any number of rows in the table, then click the button to `EVICT` or `PATCH` those rows: 74 | 75 | {!docs/snippets/markdown/jupyterlab-js-issue.md!} 76 | 77 |
78 | {!docs/snippets/py/t3-3-dataset-evict-patch.txt!}
79 | 80 | 81 | 82 | {!docs/snippets/html/stylesheet.html!} 83 | -------------------------------------------------------------------------------- /notebooks/Image-Experiment.ipynb: -------------------------------------------------------------------------------- 1 | { 2 | "cells": [ 3 | { 4 | "cell_type": "code", 5 | "execution_count": null, 6 | "id": "4e78f829-57e4-4bb8-b696-9173057943fe", 7 | "metadata": {}, 8 | "outputs": [], 9 | "source": [ 10 | "import sys\n", 11 | "sys.path.append('../')" 12 | ] 13 | }, 14 | { 15 | "cell_type": "code", 16 | "execution_count": null, 17 | "id": "dba2348a-bb21-4896-a7be-e2cf4d4daff5", 18 | "metadata": {}, 19 | "outputs": [], 20 | "source": [] 21 | }, 22 | { 23 | "cell_type": "code", 24 | "execution_count": null, 25 | "id": "ced47d3d-e030-4136-87b8-377b302a84d6", 26 | "metadata": {}, 27 | "outputs": [], 28 | "source": [ 29 | "import pandas as pd\n", 30 | "\n", 31 | "df = pd.read_csv('imagenet_custom.csv').sample(frac=1.0).reset_index(drop=True)\n", 32 | "df.head()" 33 | ] 34 | }, 35 | { 36 | "cell_type": "code", 37 | "execution_count": null, 38 | "id": "1e1b71ea-b811-4810-9915-9f542829fe13", 39 | "metadata": {}, 40 | "outputs": [], 41 | "source": [ 42 | "df['SUBSET'] = 'raw'\n", 43 | "df['image1'] = df['image']\n", 44 | "df.loc[500:800, 'SUBSET'] = 'train'\n", 45 | "df.loc[800:900, 'SUBSET'] = 'dev'\n", 46 | "df.loc[900:, 'SUBSET'] = 'test'" 47 | ] 48 | }, 49 | { 50 | "cell_type": "code", 51 | "execution_count": null, 52 | "id": "b2f81c8a-66ba-400a-9d2d-54abb1a852ab", 53 | "metadata": {}, 54 | "outputs": [], 55 | "source": [ 56 | "import pandas as pd\n", 57 | "from hover.core.dataset import SupervisableImageDataset\n", 58 | "\n", 59 | "# skip this block if EXPORT_PATH does not have a corresponding file\n", 60 | "dataset = SupervisableImageDataset.from_pandas(df)" 61 | ] 62 | }, 63 | { 64 | "cell_type": "code", 65 | "execution_count": null, 66 | "id": "8ee2b295-343c-4e32-a651-c2a0fe2c9a45", 67 | "metadata": {}, 68 | "outputs": [], 69 | "source": [ 70 | "from fixture_module import image_vector_net\n", 71 | "\n", 72 | "vectorizer = image_vector_net.get_vectorizer()" 73 | ] 74 | }, 75 | { 76 | "cell_type": "code", 77 | "execution_count": null, 78 | "id": "727fab83-57b7-4267-a1ca-2f76fa863ad7", 79 | "metadata": {}, 80 | "outputs": [], 81 | "source": [ 82 | "dataset.compute_nd_embedding(vectorizer, \"umap\", dimension=2)\n", 83 | "dataset.dfs[\"raw\"].head(5)" 84 | ] 85 | }, 86 | { 87 | "cell_type": "code", 88 | "execution_count": null, 89 | "id": "e2877436-e5c3-483c-85ae-84b66da59977", 90 | "metadata": {}, 91 | "outputs": [], 92 | "source": [ 93 | "from hover.recipes import simple_annotator\n", 94 | "from hover.utils.bokeh_helper import bokeh_hover_tooltip\n", 95 | "from bokeh.io import show, output_notebook\n", 96 | "\n", 97 | "handle = simple_annotator(\n", 98 | " dataset.copy(), width=800, height=600,\n", 99 | " #tooltips=bokeh_hover_tooltip(label={\"label\": \"Label\"}, image={\"image\": 60, \"image1\": 80}),\n", 100 | ")\n", 101 | "\n", 102 | "output_notebook()\n", 103 | "show(handle)" 104 | ] 105 | }, 106 | { 107 | "cell_type": "code", 108 | "execution_count": null, 109 | "id": "6264287b-0e98-4785-9ee1-d5e22cd54256", 110 | "metadata": {}, 111 | "outputs": [], 112 | "source": [] 113 | }, 114 | { 115 | "cell_type": "code", 116 | "execution_count": null, 117 | "id": "2c2535ed-de5a-49e5-ab52-6b9ac6852ab8", 118 | "metadata": {}, 119 | "outputs": [], 120 | "source": [] 121 | } 122 | ], 123 | "metadata": { 124 | "kernelspec": { 125 | "display_name": "Python 3 (ipykernel)", 126 | "language": "python", 127 | "name": "python3" 128 | }, 129 | "language_info": { 130 | "codemirror_mode": { 131 | "name": "ipython", 132 | "version": 3 133 | }, 134 | "file_extension": ".py", 135 | "mimetype": "text/x-python", 136 | "name": "python", 137 | "nbconvert_exporter": "python", 138 | "pygments_lexer": "ipython3", 139 | "version": "3.9.7" 140 | } 141 | }, 142 | "nbformat": 4, 143 | "nbformat_minor": 5 144 | } 145 | -------------------------------------------------------------------------------- /tests/core/test_neural.py: -------------------------------------------------------------------------------- 1 | import pytest 2 | import numpy as np 3 | from copy import deepcopy 4 | from hover.core.neural import VectorNet 5 | from hover.module_config import DataFrame 6 | 7 | 8 | @pytest.fixture 9 | def example_vecnet_args(example_text_dataset): 10 | module_name = "fixture_module.text_vector_net" 11 | target_labels = example_text_dataset.classes[:] 12 | return (module_name, target_labels) 13 | 14 | 15 | @pytest.fixture 16 | def blank_vecnet(): 17 | model = VectorNet.from_module("fixture_module.text_vector_net", [], verbose=10) 18 | return model 19 | 20 | 21 | @pytest.fixture 22 | def example_vecnet(example_vecnet_args): 23 | model = VectorNet.from_module(*example_vecnet_args, verbose=10) 24 | return model 25 | 26 | 27 | def subroutine_predict_proba(net, dataset): 28 | num_classes = len(dataset.classes) 29 | proba_single = net.predict_proba("hello") 30 | assert proba_single.shape[0] == num_classes 31 | proba_multi = net.predict_proba(["hello", "bye", "ciao"]) 32 | assert proba_multi.shape[0] == 3 33 | assert proba_multi.shape[1] == num_classes 34 | 35 | 36 | @pytest.mark.core 37 | class TestVectorNet(object): 38 | """ 39 | For the VectorNet base class. 40 | """ 41 | 42 | @staticmethod 43 | @pytest.mark.lite 44 | def test_save_and_load(example_vecnet, example_vecnet_args): 45 | default_path = example_vecnet.nn_update_path 46 | example_vecnet.save(f"{default_path}.test") 47 | loaded_vecnet = VectorNet.from_module(*example_vecnet_args) 48 | loaded_vecnet.save() 49 | 50 | @staticmethod 51 | @pytest.mark.lite 52 | def test_auto_adjust_setup(blank_vecnet, example_text_dataset): 53 | vecnet = deepcopy(blank_vecnet) 54 | targets = example_text_dataset.classes 55 | old_classes = sorted( 56 | vecnet.label_encoder.keys(), 57 | key=lambda k: vecnet.label_encoder[k], 58 | ) 59 | old_nn = vecnet.nn 60 | # normal change of classes should create a new NN 61 | vecnet.auto_adjust_setup(targets) 62 | first_nn = vecnet.nn 63 | assert first_nn is not old_nn 64 | # identical classes should trigger autoskip 65 | vecnet.auto_adjust_setup(targets) 66 | second_nn = vecnet.nn 67 | assert second_nn is first_nn 68 | # change of class order should create a new NN 69 | vecnet.auto_adjust_setup(targets[1:] + targets[:1]) 70 | third_nn = vecnet.nn 71 | assert third_nn is not second_nn 72 | vecnet.auto_adjust_setup(old_classes) 73 | 74 | @staticmethod 75 | @pytest.mark.lite 76 | def test_adjust_optimier_params(example_vecnet): 77 | example_vecnet.adjust_optimizer_params() 78 | 79 | @staticmethod 80 | @pytest.mark.lite 81 | def test_predict_proba(example_vecnet, example_text_dataset): 82 | subroutine_predict_proba(example_vecnet, example_text_dataset) 83 | 84 | @staticmethod 85 | def test_manifold_trajectory(example_vecnet, example_raw_df): 86 | for _method in ["umap", "ivis"]: 87 | traj_arr, seq_arr, disparities = example_vecnet.manifold_trajectory( 88 | DataFrame.series_tolist(example_raw_df["text"]) 89 | ) 90 | assert isinstance(traj_arr, np.ndarray) 91 | assert isinstance(seq_arr, np.ndarray) 92 | assert isinstance(disparities, list) 93 | assert isinstance(disparities[0], float) 94 | 95 | @staticmethod 96 | def test_train_and_evaluate(example_vecnet, example_text_dataset): 97 | vecnet = deepcopy(example_vecnet) 98 | dataset = example_text_dataset 99 | dev_loader = dataset.loader("dev", example_vecnet.vectorizer) 100 | test_loader = dataset.loader("test", example_vecnet.vectorizer) 101 | 102 | train_info = vecnet.train(dev_loader, dev_loader, epochs=5) 103 | accuracy, conf_mat = vecnet.evaluate(test_loader) 104 | 105 | assert isinstance(train_info, list) 106 | assert isinstance(train_info[0], dict) 107 | assert isinstance(accuracy, float) 108 | assert isinstance(conf_mat, np.ndarray) 109 | -------------------------------------------------------------------------------- /mkdocs.yml: -------------------------------------------------------------------------------- 1 | site_name: Hover 2 | site_description: "Hover and label data rapidly." 3 | site_url: "https://phurwicz.github.io/hover" 4 | repo_url: "https://github.com/phurwicz/hover.git" 5 | repo_name: "phurwicz/hover" 6 | 7 | theme: 8 | name: material 9 | icon: 10 | logo: material/alpha-h-box 11 | favicon: images/favicon.png 12 | font: 13 | text: Roboto 14 | code: Roboto Mono 15 | features: 16 | - navigation.expand 17 | - navigation.tabs 18 | - search.suggest 19 | - toc.integrate 20 | palette: 21 | # Palette toggle for light mode 22 | - scheme: default 23 | toggle: 24 | icon: material/weather-night 25 | name: Switch to dark mode 26 | 27 | # Palette toggle for dark mode 28 | - scheme: slate 29 | toggle: 30 | icon: material/weather-sunny 31 | name: Switch to light mode 32 | 33 | nav: 34 | - Home: 'index.md' 35 | - 'Basics': 36 | - 'Quickstart': 'pages/tutorial/t0-quickstart.md' 37 | - 'Using Recipes': 'pages/tutorial/t1-active-learning.md' 38 | - 'Handling Images': 'pages/guides/g0-datatype-image.md' 39 | - 'Handling Audio': 'pages/guides/g1-datatype-audio.md' 40 | - 'Mechanisms': 41 | - 'Managing Data': 'pages/tutorial/t3-dataset-population-selection.md' 42 | - 'Applying Labels': 'pages/tutorial/t4-annotator-dataset-interaction.md' 43 | - 'Options': 44 | - 'Host Options': 'pages/tutorial/t2-bokeh-app.md' 45 | - 'Custom Config': 'pages/guides/g2-hover-config.md' 46 | - 'Powerful Tricks': 47 | - 'Finder & Selection Filter': 'pages/tutorial/t5-finder-filter.md' 48 | - 'Soft Label & Joint Filters': 'pages/tutorial/t6-softlabel-joint-filter.md' 49 | - 'Custom Labeling Functions': 'pages/tutorial/t7-snorkel-improvise-rules.md' 50 | # - 'Data Type: Multimodal': 'pages/topics/datatype-multimodal.md' 51 | #- 'Why Hover': 'pages/topics/what-hover-is.md' 52 | #- 'Customized Usage': 53 | # - 'API Levels': 'pages/topics/api-levels.md' # discuss the interaction between recipe / dataset / explorer 54 | # - 'Custom Recipe': 'pages/topics/custom-recipe.md' # discuss the caveats when making a recipe 55 | # - 'Subclassing Dataset': 'pages/topics/custom-dataset.md' # discuss the caveats when subclassing a SupervisableDataset 56 | # - 'Subclassing Explorer': 'pages/topics/custom-explorer.md' # discuss the caveats when subclassing a BokehBaseExplorer 57 | - 'API Reference': 58 | - 'hover.recipes': 'pages/reference/recipes.md' 59 | - 'hover.core': 60 | - '.dataset': 'pages/reference/core-dataset.md' 61 | - '.explorer': 62 | - '.base': 'pages/reference/core-explorer-base.md' 63 | - '.feature': 'pages/reference/core-explorer-feature.md' 64 | - '.functionality': 'pages/reference/core-explorer-functionality.md' 65 | - '.specialization': 'pages/reference/core-explorer-specialization.md' 66 | - '.neural': 'pages/reference/core-neural.md' 67 | - '.representation': 'pages/reference/core-representation.md' 68 | - 'hover.utils': 69 | - '.bokeh_helper': 'pages/reference/utils-bokeh_helper.md' 70 | - '.snorkel_helper': 'pages/reference/utils-snorkel_helper.md' 71 | 72 | markdown_extensions: 73 | - admonition 74 | - def_list 75 | - markdown_include.include 76 | - pymdownx.critic 77 | - pymdownx.details 78 | - pymdownx.emoji 79 | - pymdownx.superfences 80 | - pymdownx.tabbed: 81 | alternate_style: true 82 | 83 | plugins: 84 | - macros 85 | - search: 86 | - mkdocstrings: 87 | default_handler: python 88 | handlers: 89 | python: 90 | rendering: 91 | show_root_heading: true 92 | show_source: true 93 | watch: 94 | - hover 95 | - i18n: 96 | default_language: en 97 | languages: 98 | en: English 99 | # fr: français 100 | zh: 简体中文 101 | nav_translations: 102 | zh: 103 | Home: 主页 104 | Basics: 基础使用 105 | Mechanisms: 理解机制 106 | Options: 自定配置 107 | Powerful Tricks: 高级技巧 108 | API Reference: API 指南 109 | 110 | extra: 111 | version: 112 | provider: mike 113 | analytics: 114 | provider: google 115 | property: G-M3WR5YEJ33 116 | -------------------------------------------------------------------------------- /tests/recipes/test_experimental.py: -------------------------------------------------------------------------------- 1 | import pytest 2 | import numpy as np 3 | from hover.recipes.experimental import ( 4 | _active_learning, 5 | _snorkel_crosscheck, 6 | active_learning, 7 | snorkel_crosscheck, 8 | ) 9 | from hover.module_config import DataFrame as DF 10 | from bokeh.events import ButtonClick, SelectionGeometry 11 | from .local_helper import execute_handle_function 12 | 13 | 14 | def test_active_learning(example_text_dataset, dummy_vecnet_callback): 15 | def read_scores(dataset, subset): 16 | return DF.series_values(dataset.dfs[subset]["pred_score"]).copy() 17 | 18 | dataset = example_text_dataset.copy() 19 | vecnet = dummy_vecnet_callback(dataset) 20 | layout, objects = _active_learning(dataset, vecnet) 21 | assert layout.visible 22 | 23 | initial_scores = read_scores(dataset, "raw") 24 | 25 | finder, annotator = objects["finder"], objects["annotator"] 26 | softlabel = objects["softlabel"] 27 | coords_slider = softlabel._dynamic_widgets["patch_slider"] 28 | model_trainer = objects["model_trainer"] 29 | train_event = ButtonClick(model_trainer) 30 | 31 | # train for default number of epochs 32 | model_trainer._trigger_event(train_event) 33 | first_scores = read_scores(dataset, "raw") 34 | assert not np.allclose(first_scores, initial_scores) 35 | 36 | # emulating user interaction: slide coords to view manifold trajectory 37 | for _value in range(1, min(coords_slider.end + 1, 4)): 38 | coords_slider.value = _value 39 | 40 | # train for 1 more epoch 41 | model_trainer._trigger_event(train_event) 42 | second_scores = read_scores(dataset, "raw") 43 | assert not np.allclose(second_scores, first_scores) 44 | # take 25 and 75 percentiles of scores for later use 45 | range_low, range_high = np.percentile(second_scores, [25, 75]).tolist() 46 | 47 | # emulate user interface: select everything through a SelectionGeometry event 48 | total_raw = softlabel.dfs["raw"].shape[0] 49 | initial_select = list(range(total_raw)) 50 | # check linked selection 51 | assert annotator.sources["raw"].selected.indices == [] 52 | softlabel.sources["raw"].selected.indices = initial_select 53 | box_select = SelectionGeometry( 54 | softlabel.figure, 55 | geometry={ 56 | "type": "poly", 57 | "sx": [-1e4, -1e4, 1e4, 1e4], 58 | "sy": [-1e4, 1e4, 1e4, -1e4], 59 | "x": [None, None, None, None], 60 | "y": [None, None, None, None], 61 | }, 62 | ) 63 | softlabel.figure._trigger_event(box_select) 64 | assert annotator.sources["raw"].selected.indices == initial_select 65 | 66 | # check score filtering 67 | # nothing happens when filter is inactive 68 | softlabel.score_range.value = (range_low, range_high) 69 | assert softlabel.sources["raw"].selected.indices == initial_select 70 | # activate score filter 71 | softlabel.score_filter_box.active = [0] 72 | first_select = softlabel.sources["raw"].selected.indices[:] 73 | assert first_select != initial_select 74 | assert set(first_select).issubset(set(initial_select)) 75 | assert first_select == annotator.sources["raw"].selected.indices 76 | 77 | # check regex co-filtering 78 | finder.search_filter_box.active = [0] 79 | finder.search_pos.value = r"(?i)s[aeiou]\ " 80 | second_select = softlabel.sources["raw"].selected.indices[:] 81 | assert second_select != first_select 82 | assert set(second_select).issubset(set(first_select)) 83 | 84 | # check filter interaction: untoggle score filter 85 | softlabel.score_filter_box.active = [] 86 | third_select = softlabel.sources["raw"].selected.indices[:] 87 | assert third_select != second_select 88 | assert set(second_select).issubset(set(third_select)) 89 | 90 | # deactivate regex filter too 91 | finder.search_filter_box.active = [] 92 | unfilter_select = softlabel.sources["raw"].selected.indices[:] 93 | assert unfilter_select == initial_select 94 | 95 | 96 | def test_snorkel_crosscheck(example_audio_dataset, dummy_labeling_function_list): 97 | dataset = example_audio_dataset.copy() 98 | layout, objects = _snorkel_crosscheck(dataset, dummy_labeling_function_list) 99 | assert layout.visible 100 | 101 | # TODO: add emulations of user activity 102 | assert objects 103 | 104 | 105 | @pytest.mark.lite 106 | def test_servable_experimental( 107 | example_text_dataset, 108 | dummy_vecnet_callback, 109 | dummy_labeling_function_list, 110 | ): 111 | # one dataset for each recipe 112 | dataset = example_text_dataset.copy() 113 | vecnet = dummy_vecnet_callback(dataset) 114 | active = active_learning(dataset, vecnet) 115 | 116 | dataset = example_text_dataset.copy() 117 | snorkel = snorkel_crosscheck(dataset, dummy_labeling_function_list) 118 | 119 | for handle in [active, snorkel]: 120 | execute_handle_function(handle) 121 | -------------------------------------------------------------------------------- /docs/pages/tutorial/t1-active-learning.md: -------------------------------------------------------------------------------- 1 | > The most common usage of `hover` is through built-in `recipe`s like in the quickstart. 2 | > 3 | > :ferris_wheel: Let's explore another `recipe` -- an active learning example. 4 | 5 | {!docs/snippets/html/thebe.html!} 6 | {!docs/snippets/markdown/binder-kernel.md!} 7 | {!docs/snippets/markdown/local-dependency.md!} 8 | {!docs/snippets/markdown/local-dep-text.md!} 9 | {!docs/snippets/markdown/local-dep-jupyter-bokeh.md!} 10 | 11 | ## **Fundamentals** 12 | 13 | Hover `recipe`s are functions that take a `SupervisableDataset` and return an annotation interface. 14 | 15 | The `SupervisableDataset` is assumed to have some data and embeddings. 16 | 17 | ## **Recap: Data & Embeddings** 18 | 19 | Let's preprare a dataset with embeddings. This is almost the same as in the [quickstart](../t0-quickstart/): 20 | 21 |
22 | {!docs/snippets/py/tz-dataset-text-full.txt!}
23 | 24 | 25 |
26 | {!docs/snippets/py/t0-1-vectorizer.txt!}
27 |
28 | {!docs/snippets/py/t0-1a-vectorizer-print.txt!}
29 | 30 | 31 |
32 | {!docs/snippets/py/t0-2-reduction.txt!}
33 | 34 | 35 | ## **Recipe-Specific Ingredient** 36 | 37 | Each recipe has different functionalities and potentially different signature. 38 | 39 | To utilize active learning, we need to specify how to get a model in the loop. 40 | 41 | `hover` considers the `vectorizer` as a "frozen" embedding and follows up with a neural network, which infers its own dimensionality from the vectorizer and the output classes. 42 | 43 | - This architecture named [`VectorNet`](../../reference/core-neural/#hover.core.neural.VectorNet) is the (default) basis of active learning in `hover`. 44 | 45 | ??? info "Custom models" 46 | It is possible to use a model other than `VectorNet` or its subclass. 47 | 48 | You will need to implement the following methods with the same signatures as `VectorNet`: 49 | 50 | - [`train`](../../reference/core-neural/#hover.core.neural.VectorNet.train) 51 | - [`save`](../../reference/core-neural/#hover.core.neural.VectorNet.save) 52 | - [`predict_proba`](../../reference/core-neural/#hover.core.neural.VectorNet.predict_proba) 53 | - [`prepare_loader`](../../reference/core-neural/#hover.core.neural.VectorNet.prepare_loader) 54 | - [`manifold_trajectory`](../../reference/core-neural/#hover.core.neural.VectorNet.manifold_trajectory) 55 | 56 |
57 | {!docs/snippets/py/t1-0-vecnet-callback.txt!}
58 |
59 | {!docs/snippets/py/t1-0a-vecnet-callback-print.txt!}
60 |
61 |
62 | Note how the callback dynamically takes `dataset.classes`, which means the model architecture will adapt when we add classes during annotation.
63 |
64 |
65 | ## :sparkles: **Apply Labels**
66 |
67 | Now we invoke the `active_learning` recipe.
68 |
69 | ??? tip "Tips: how recipes work programmatically"
70 | In general, a `recipe` is a function taking a `SupervisableDataset` and other arguments based on its functionality.
71 |
72 | Here are a few common recipes:
73 |
74 | === "active_learning"
75 |
76 | ::: hover.recipes.experimental.active_learning
77 | rendering:
78 | show_root_heading: false
79 | show_root_toc_entry: false
80 |
81 | === "simple_annotator"
82 |
83 | ::: hover.recipes.stable.simple_annotator
84 | rendering:
85 | show_root_heading: false
86 | show_root_toc_entry: false
87 |
88 | === "linked_annotator"
89 |
90 | ::: hover.recipes.stable.linked_annotator
91 | rendering:
92 | show_root_heading: false
93 | show_root_toc_entry: false
94 |
95 | The recipe returns a `handle` function which `bokeh` can use to visualize an annotation interface in multiple settings.
96 |
97 |
98 | {!docs/snippets/py/t1-1-active-learning.txt!}
99 |
100 | {!docs/snippets/py/tz-bokeh-show-server.txt!}
101 |
102 | {!docs/snippets/py/tz-bokeh-show-notebook.txt!}
103 |
104 |
105 | ???+ tip "Tips: annotation interface with multiple plots"
106 | ??? example "Video guide: leveraging linked selection"
107 |
108 |
109 | ???+ example "Video guide: active learning"
110 |
111 |
112 | ??? info "Text guide: active learning"
113 | Inspecting model predictions allows us to
114 |
115 | - get an idea of how the current set of annotations will likely teach the model.
116 | - locate the most valuable samples for further annotation.
117 |
118 | {!docs/snippets/html/stylesheet.html!}
119 |
--------------------------------------------------------------------------------
/notebooks/archive-prototype/Programmatic-Polyselect.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": [
9 | "%load_ext autoreload\n",
10 | "\n",
11 | "%autoreload 2"
12 | ]
13 | },
14 | {
15 | "cell_type": "code",
16 | "execution_count": null,
17 | "metadata": {},
18 | "outputs": [],
19 | "source": [
20 | "import sys\n",
21 | "sys.path.append('../../')"
22 | ]
23 | },
24 | {
25 | "cell_type": "markdown",
26 | "metadata": {},
27 | "source": [
28 | "### Use a Event Trigger to Make Selections: **Seems not working**"
29 | ]
30 | },
31 | {
32 | "cell_type": "code",
33 | "execution_count": null,
34 | "metadata": {},
35 | "outputs": [],
36 | "source": [
37 | "import pandas as pd\n",
38 | "import numpy as np\n",
39 | "import random"
40 | ]
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": null,
45 | "metadata": {},
46 | "outputs": [],
47 | "source": [
48 | "from bokeh.io import output_notebook, show\n",
49 | "from bokeh.plotting import figure\n",
50 | "from bokeh.models import ColumnDataSource\n",
51 | "\n",
52 | "output_notebook()"
53 | ]
54 | },
55 | {
56 | "cell_type": "code",
57 | "execution_count": null,
58 | "metadata": {},
59 | "outputs": [],
60 | "source": [
61 | "from bokeh.models import RangeSlider\n",
62 | "from bokeh.layouts import column\n",
63 | "from bokeh.events import SelectionGeometry\n",
64 | "from hover.utils.bokeh_helper import servable\n",
65 | "\n",
66 | "def almost_global_select(figure):\n",
67 | " select_event = SelectionGeometry(\n",
68 | " figure,\n",
69 | " geometry={\n",
70 | " \"type\": \"poly\",\n",
71 | " \"x\": [-1e4, -1e4, 1e4, 1e4],\n",
72 | " \"y\": [-1e4, 1e4, 1e4, -1e4],\n",
73 | " \"sx\": [None, None, None, None],\n",
74 | " \"sy\": [None, None, None, None],\n",
75 | " },\n",
76 | " )\n",
77 | " return select_event\n",
78 | "\n",
79 | "@servable()\n",
80 | "def burner():\n",
81 | " \"\"\"\n",
82 | " Trying to simulate ploygon-based selections.\n",
83 | " \"\"\"\n",
84 | " df = pd.DataFrame({\n",
85 | " 'x': np.random.uniform(-1.0, 1.0, size=(100,)).tolist(),\n",
86 | " 'y': np.random.uniform(-1.0, 1.0, size=(100,)).tolist(),\n",
87 | " 'flag': [random.choice([True, False]) for i in range(100)],\n",
88 | " })\n",
89 | " \n",
90 | " source = ColumnDataSource(df)\n",
91 | " plot = figure(tools=['poly_select', 'lasso_select'])\n",
92 | " plot.circle(source=source)\n",
93 | " x_slider = RangeSlider(start=-1.0, end=1.0, value=(-0.5, 0.5), step=0.01)\n",
94 | " y_slider = RangeSlider(start=-1.0, end=1.0, value=(-0.5, 0.5), step=0.01)\n",
95 | " \n",
96 | " def slider_callback(attr, old, new):\n",
97 | " x_l, x_r = x_slider.value\n",
98 | " y_d, y_u = y_slider.value\n",
99 | " select_event = SelectionGeometry(\n",
100 | " plot,\n",
101 | " geometry={\n",
102 | " \"type\": \"poly\",\n",
103 | " \"x\": [x_l, x_l, x_r, x_r],\n",
104 | " \"y\": [y_d, y_u, y_u, y_d],\n",
105 | " #\"sx\": [None, None, None, None],\n",
106 | " #\"sy\": [None, None, None, None],\n",
107 | " },\n",
108 | " )\n",
109 | " plot._trigger_event(select_event)\n",
110 | " # use a patch to verify the polygon\n",
111 | " plot.patch([x_l, x_l, x_r, x_r], [y_d, y_u, y_u, y_d], alpha=0.2, line_width=1)\n",
112 | " # check the number of selected points\n",
113 | " print(len(source.selected.indices), end=\"\\r\")\n",
114 | " \n",
115 | " x_slider.on_change('value', slider_callback)\n",
116 | " y_slider.on_change('value', slider_callback)\n",
117 | " \n",
118 | " return column(x_slider, y_slider, plot)"
119 | ]
120 | },
121 | {
122 | "cell_type": "code",
123 | "execution_count": null,
124 | "metadata": {},
125 | "outputs": [],
126 | "source": [
127 | "handle = burner()\n",
128 | "show(handle)"
129 | ]
130 | },
131 | {
132 | "cell_type": "code",
133 | "execution_count": null,
134 | "metadata": {},
135 | "outputs": [],
136 | "source": []
137 | }
138 | ],
139 | "metadata": {
140 | "kernelspec": {
141 | "display_name": "Python 3 (ipykernel)",
142 | "language": "python",
143 | "name": "python3"
144 | },
145 | "language_info": {
146 | "codemirror_mode": {
147 | "name": "ipython",
148 | "version": 3
149 | },
150 | "file_extension": ".py",
151 | "mimetype": "text/x-python",
152 | "name": "python",
153 | "nbconvert_exporter": "python",
154 | "pygments_lexer": "ipython3",
155 | "version": "3.9.7"
156 | }
157 | },
158 | "nbformat": 4,
159 | "nbformat_minor": 4
160 | }
161 |
--------------------------------------------------------------------------------
/notebooks/archive-prototype/Slider-Filter.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": [
9 | "%load_ext autoreload\n",
10 | "\n",
11 | "%autoreload 2"
12 | ]
13 | },
14 | {
15 | "cell_type": "code",
16 | "execution_count": null,
17 | "metadata": {},
18 | "outputs": [],
19 | "source": [
20 | "import sys\n",
21 | "sys.path.append('../../')"
22 | ]
23 | },
24 | {
25 | "cell_type": "markdown",
26 | "metadata": {},
27 | "source": [
28 | "### Use a Slider for Filtering Data Points"
29 | ]
30 | },
31 | {
32 | "cell_type": "code",
33 | "execution_count": null,
34 | "metadata": {},
35 | "outputs": [],
36 | "source": [
37 | "import pandas as pd\n",
38 | "import numpy as np\n",
39 | "import random"
40 | ]
41 | },
42 | {
43 | "cell_type": "code",
44 | "execution_count": null,
45 | "metadata": {},
46 | "outputs": [],
47 | "source": [
48 | "df = pd.DataFrame({\n",
49 | " 'x': np.random.uniform(-1.0, 1.0, size=(100,)).tolist(),\n",
50 | " 'y': np.random.uniform(-1.0, 1.0, size=(100,)).tolist(),\n",
51 | " 'flag': [random.choice([True, False]) for i in range(100)],\n",
52 | "})\n",
53 | "df.head()"
54 | ]
55 | },
56 | {
57 | "cell_type": "code",
58 | "execution_count": null,
59 | "metadata": {},
60 | "outputs": [],
61 | "source": [
62 | "from bokeh.io import output_notebook, show\n",
63 | "from bokeh.plotting import figure\n",
64 | "from bokeh.models import ColumnDataSource\n",
65 | "\n",
66 | "output_notebook()"
67 | ]
68 | },
69 | {
70 | "cell_type": "code",
71 | "execution_count": null,
72 | "metadata": {},
73 | "outputs": [],
74 | "source": [
75 | "from bokeh.models import RangeSlider\n",
76 | "from bokeh.layouts import column\n",
77 | "from bokeh.events import SelectionGeometry\n",
78 | "from hover.utils.bokeh_helper import servable\n",
79 | "\n",
80 | "@servable()\n",
81 | "def burner():\n",
82 | " \"\"\"\n",
83 | " Trying to intersect the last manually specified selection with a slider coords/attribute range.\n",
84 | " \"\"\"\n",
85 | " slider = RangeSlider(start=-1.0, end=1.0, value=(-0.5, 0.5), step=0.01)\n",
86 | " source = ColumnDataSource(df)\n",
87 | " plot = figure(tools=['poly_select', 'lasso_select', 'pan', 'wheel_zoom'])\n",
88 | " plot.circle(source=source)\n",
89 | " \n",
90 | " last_manual_selection = set()\n",
91 | " \n",
92 | " def subroutine(lower, upper):\n",
93 | " filter_l = set(np.where(df['y'] > lower)[0])\n",
94 | " filter_u = set(np.where(df['y'] < upper)[0])\n",
95 | " filtered = filter_l.intersection(filter_u)\n",
96 | " return filtered\n",
97 | " \n",
98 | " def selection_callback(event):\n",
99 | " \"\"\"\n",
100 | " CAUTION: this has to overwrite the last manual selection.\n",
101 | " Hence only manual selections should trigger this callback.\n",
102 | " \"\"\"\n",
103 | " last_manual_selection.clear()\n",
104 | " last_manual_selection.update(source.selected.indices.copy())\n",
105 | " filtered = subroutine(*slider.value)\n",
106 | " print('A')\n",
107 | " source.selected.indices = list(filtered.intersection(last_manual_selection))\n",
108 | " \n",
109 | " def foo(event):\n",
110 | " print('B')\n",
111 | " \n",
112 | " def slider_callback(attr, old, new):\n",
113 | " to_select = subroutine(*new)\n",
114 | " if last_manual_selection:\n",
115 | " to_select = to_select.intersection(last_manual_selection)\n",
116 | " source.selected.indices = list(to_select)\n",
117 | " \n",
118 | " plot.on_event(SelectionGeometry, selection_callback)\n",
119 | " plot.on_event(SelectionGeometry, foo)\n",
120 | " slider.on_change('value', slider_callback)\n",
121 | " \n",
122 | " return column(slider, plot)"
123 | ]
124 | },
125 | {
126 | "cell_type": "code",
127 | "execution_count": null,
128 | "metadata": {},
129 | "outputs": [],
130 | "source": [
131 | "handle = burner()\n",
132 | "show(handle)"
133 | ]
134 | },
135 | {
136 | "cell_type": "code",
137 | "execution_count": null,
138 | "metadata": {},
139 | "outputs": [],
140 | "source": []
141 | }
142 | ],
143 | "metadata": {
144 | "kernelspec": {
145 | "display_name": "Python 3 (ipykernel)",
146 | "language": "python",
147 | "name": "python3"
148 | },
149 | "language_info": {
150 | "codemirror_mode": {
151 | "name": "ipython",
152 | "version": 3
153 | },
154 | "file_extension": ".py",
155 | "mimetype": "text/x-python",
156 | "name": "python",
157 | "nbconvert_exporter": "python",
158 | "pygments_lexer": "ipython3",
159 | "version": "3.9.7"
160 | }
161 | },
162 | "nbformat": 4,
163 | "nbformat_minor": 4
164 | }
165 |
--------------------------------------------------------------------------------