 9 |
9 |  48 |
49 | 所有文章禁止转载,如需转载请通过微信公众号联系我。
50 |
51 | ## 详细内容
52 |
53 | ### 1. [善用变量改善代码质量](zh_CN/1-using-variables-well.md)
54 |
55 | - 如何为变量起名
56 | - 1 - 变量名要有描述性,不能太宽泛
57 | - 2 - 变量名最好让人能猜出类型
58 | - 『什么样的名字会被当成 bool 类型?』
59 | - 『什么样的名字会被当成 int/float 类型?』
60 | - 其他类型
61 | - 3 - 适当使用『匈牙利命名法』
62 | - 4 - 变量名尽量短,但是绝对不要太短
63 | - 使用短名字的例外情况
64 | - 5 - 其他注意事项
65 | - 更好的使用变量
66 | - 1 - 保持一致性
67 | - 2 - 尽量不要用 globals()/locals()
68 | - 3 - 变量定义尽量靠近使用
69 | - 4 - 合理使用 namedtuple/dict 来让函数返回多个值
70 | - 5 - 控制单个函数内的变量数量
71 | - 6 - 及时删掉那些没用的变量
72 | - 7 - 能不定义变量就不定义
73 | - 结语
74 |
75 | ### 2. [编写条件分支代码的技巧](zh_CN/2-if-else-block-secrets.md)
76 |
77 | - 最佳实践
78 | - 1 - 避免多层分支嵌套
79 | - 2 - 封装那些过于复杂的逻辑判断
80 | - 3 - 留意不同分支下的重复代码
81 | - 4 - 谨慎使用三元表达式
82 | - 常见技巧
83 | - 1 - 使用“德摩根定律”
84 | - 2 - 自定义对象的“布尔真假”
85 | - 3 - 在条件判断中使用 all() / any()
86 | - 4 - 使用 try/while/for 中 else 分支
87 | - 常见陷阱
88 | - 1 - 与 None 值的比较
89 | - 2 - 留意 and 和 or 的运算优先级
90 | - 结语
91 | - 注解
92 |
93 | ### 3. [使用数字与字符串的技巧](zh_CN/3-tips-on-numbers-and-strings.md)
94 |
95 | - 最佳实践
96 | - 1 - 少写数字字面量
97 | - 使用 enum 枚举类型改善代码
98 | - 2 - 别在裸字符串处理上走太远
99 | - 3 - 不必预计算字面量表达式
100 | - 实用技巧
101 | - 1 - 布尔值其实也是“数字”
102 | - 2 - 改善超长字符串的可读性
103 | - 当多级缩进里出现多行字符串时
104 | - 3 - 别忘了那些 “r” 开头的内建字符串函数
105 | - 4 - 使用“无穷大” float("inf")
106 | - 常见误区
107 | - 1 - “value += 1” 并非线程安全
108 | - 2 - 字符串拼接并不慢
109 | - 结语
110 |
111 | ### 4. [容器的门道](zh_CN/4-mastering-container-types.md)
112 |
113 | - 底层看容器
114 | - 写更快的代码
115 | - 1 - 避免频繁扩充列表/创建新列表
116 | - 2 - 在列表头部操作多的场景使用 deque 模块
117 | - 3 - 使用集合/字典来判断成员是否存在
118 | - 高层看容器
119 | - 写扩展性更好的代码
120 | - 面向容器接口编程
121 | - 常用技巧
122 | - 1 - 使用元组改善分支代码
123 | - 2 - 在更多地方使用动态解包
124 | - 3 - 使用 next() 函数
125 | - 4 - 使用有序字典来去重
126 | - 常见误区
127 | - 1 - 当心那些已经枯竭的迭代器
128 | - 2 - 别在循环体内修改被迭代对象
129 | - 总结
130 | - 系列其他文章
131 | - 注解
132 |
133 | ### 5. [让函数返回结果的技巧](zh_CN/5-function-returning-tips.md)
134 |
135 | - 编程建议
136 | - 1 - 单个函数不要返回多种类型
137 | - 2 - 使用 partial 构造新函数
138 | - 3 - 抛出异常,而不是返回结果与错误
139 | - 4 - 谨慎使用 None 返回值
140 | - 1 - 作为操作类函数的默认返回值
141 | - 2 - 作为某些“意料之中”的可能没有的值
142 | - 3 - 作为调用失败时代表“错误结果”的值
143 | - 5 - 合理使用“空对象模式”
144 | - 6 - 使用生成器函数代替返回列表
145 | - 7 - 限制递归的使用
146 | - 总结
147 | - 附录
148 |
149 | ### 6. [异常处理的三个好习惯](zh_CN/6-three-rituals-of-exceptions-handling.md)
150 |
151 | - 前言
152 | - 三个好习惯
153 | - 1 - 只做最精确的异常捕获
154 | - 2 - 别让异常破坏抽象一致性
155 | - 3 - 异常处理不应该喧宾夺主
156 | - 总结
157 | - 附录
158 |
159 | ### 7. [编写地道循环的两个建议](zh_CN/7-two-tips-on-loop-writing.md)
160 |
161 | - 前言
162 | - 什么是“地道”的循环?
163 | - enumerate() 所代表的编程思路
164 | - 建议1:使用函数修饰被迭代对象来优化循环
165 | - 1 - 使用 product 扁平化多层嵌套循环
166 | - 2 - 使用 islice 实现循环内隔行处理
167 | - 3 - 使用 takewhile 替代 break 语句
168 | - 4 - 使用生成器编写自己的修饰函数
169 | - 建议2:按职责拆解循环体内复杂代码块
170 | - 复杂循环体如何应对新需求
171 | - 使用生成器函数解耦循环体
172 | - 总结
173 | - 附录
174 |
175 | ### 8. [使用装饰器的技巧](zh_CN/8-tips-on-decorators.md)
176 |
177 | - 前言
178 | - 最佳实践
179 | - 1 - 尝试用类来实现装饰器
180 | - 2 - 使用 wrapt 模块编写更扁平的装饰器
181 | - 常见错误
182 | - 1 - “装饰器”并不是“装饰器模式”
183 | - 2 - 记得用 functools.wraps() 装饰内层函数
184 | - 3 - 修改外层变量时记得使用 nonlocal
185 | - 总结
186 | - 附录
187 |
188 | ### 9. [一个关于模块的小故事](zh_CN/9-a-story-on-cyclic-imports.md)
189 |
190 | - 前言
191 | - 一个关于模块的小故事
192 | - 需求变更
193 | - 解决环形依赖问题
194 | - 小 C 的疑问
195 | - 总结
196 | - 附录
197 |
198 | ### 10. [做一个精通规则的玩家](zh_CN/10-a-good-player-know-the-rules.md)
199 |
200 | - 前言
201 | - Python 里的规则
202 | - 案例:从两份旅游数据中获取人员名单
203 | - 第一次蛮力尝试
204 | - 尝试使用集合优化函数
205 | - 对问题的重新思考
206 | - 利用集合的游戏规则
207 | - 使用 dataclass 简化代码
208 | - 案例总结
209 | - 其他规则如何影响我们
210 | - 使用 `__format__` 做对象字符串格式化
211 | - 使用 `__getitem__` 定义对象切片操作
212 | - 总结
213 | - 附录
214 |
215 | ### 11. [高效操作文件的三个建议](zh_CN/11-three-tips-on-writing-file-related-codes.md)
216 |
217 | - 前言
218 | - 建议一:使用 pathlib 模块
219 | - 使用 pathlib 模块改写代码
220 | - 其他用法
221 | - 建议二:掌握如何流式读取大文件
222 | - 标准做法的缺点
223 | - 使用 read 方法分块读取
224 | - 利用生成器解耦代码
225 | - 建议三:设计接受文件对象的函数
226 | - 如何编写兼容二者的函数
227 | - 总结
228 | - 附录
229 | - 注解
230 |
231 | ### 12. [写好面向对象代码的原则(上)](zh_CN/12-write-solid-python-codes-part-1.md)
232 |
233 | - 前言
234 | - Python 对 OOP 的支持
235 | - SOLID 设计原则
236 | - SOLID 原则与 Python
237 | - S:单一职责原则
238 | - 违反“单一职责原则”的坏处
239 | - 拆分大类为多个小类
240 | - 另一种方案:使用函数
241 | - O:开放-关闭原则
242 | - 如何违反“开放-关闭原则”
243 | - 使用类继承来改造代码
244 | - 使用组合与依赖注入来改造代码
245 | - 使用数据驱动思想来改造代码
246 | - 总结
247 | - 附录
248 |
249 | ### 13. [写好面向对象代码的原则(中)](zh_CN/13-write-solid-python-codes-part-2.md)
250 |
251 | - 前言
252 | - 里氏替换原则与继承
253 | - L:里氏替换原则
254 | - 一个违反 L 原则的样例
255 | - 不当继承关系如何违反 L 原则
256 | - 一个简单但错误的解决办法
257 | - 正确的修改办法
258 | - 另一种违反方式:子类修改方法返回值法返回值)
259 | - 分析类方法返回结果
260 | - 如何修改代码
261 | - 方法参数与 L 原则
262 | - 总结
263 | - 附录
264 |
265 | ### 14. [写好面向对象代码的原则(下)](zh_CN/14-write-solid-python-codes-part-3.md)
266 |
267 | - 前言
268 | - D:依赖倒置原则
269 | - 需求:按域名分组统计 HN 新闻数量
270 | - 为 SiteSourceGrouper 编写单元测试
271 | - 使用 mock 模块
272 | - 实现依赖倒置原则
273 | - 依赖倒置后的单元测试
274 | - 问题:一定要使用抽象类 abc 吗?
275 | - 问题:抽象一定是好东西吗?
276 | - I:接口隔离原则
277 | - 例子:开发页面归档功能
278 | - 问题:实体类不符合 HNWebPage 接口规范
279 | - 成功违反 I 协议
280 | - 如何分拆接口
281 | - 一些不容易发现的违反情况
282 | - 现实世界中的接口隔离
283 | - 总结
284 | - 附录
285 |
286 | ### 15. [在边界处思考](zh_CN/15-thinking-in-edge-cases.md)
287 |
288 | - 前言
289 | - 第一课:使用分支还是异常?
290 | - 获取原谅比许可简单(EAFP)
291 | - 当容器内容不存在时
292 | - 使用 defaultdict 改写示例
293 | - 使用 setdefault 取值并修改
294 | - 使用 dict.pop 删除不存在的键
295 | - 当列表切片越界时
296 | - 好用又危险的 “or” 操作符
297 | - 不要手动去做数据校验
298 | - 不要忘记做数学计算
299 | - 总结
300 | - 附录
301 |
302 | ### 16. [语句、表达式和海象操作符](zh_CN/16-stmt-expr-and-walrus-operator.md)
303 |
304 | - 表达式的特点
305 | - 海象操作符
306 | - 1. 用于分支语句
307 | - 2. 消除推导式中的重复
308 | - 3. 捕获推导式的中间结果
309 | - 4. 赋值表达式的限制
310 | - 其他建议
311 | - 1. “更紧凑”不等于“更好”
312 | - 2. 宜少不宜多
313 |
--------------------------------------------------------------------------------
/zh_CN/1-using-variables-well.md:
--------------------------------------------------------------------------------
1 | # Python 工匠:善用变量来改善代码质量
2 |
3 | ## 『Python 工匠』是什么?
4 |
5 | 我一直觉得编程某种意义上是一门『手艺』,因为优雅而高效的代码,就如同完美的手工艺品一样让人赏心悦目。
6 |
7 | 在雕琢代码的过程中,有大工程:比如应该用什么架构、哪种设计模式。也有更多的小细节,比如何时使用异常(Exceptions)、或怎么给变量起名。那些真正优秀的代码,正是由无数优秀的细节造就的。
8 |
9 | 『Python 工匠』这个系列文章,是我的一次小小尝试。它专注于分享 Python 编程中的一些偏 **『小』** 的东西。希望能够帮到每一位编程路上的匠人。
10 |
11 | > 这是 “Python 工匠”系列的第 1 篇文章。[[查看系列所有文章]](https://github.com/piglei/one-python-craftsman)
12 |
13 | ## 变量和代码质量
14 |
15 | 作为『Python 工匠』系列文章的第一篇,我想先谈谈 『变量(Variables)』。因为如何定义和使用变量,一直都是学习任何一门编程语言最先要掌握的技能之一。
16 |
17 | 变量用的好或不好,和代码质量有着非常重要的联系。在关于变量的诸多问题中,为变量起一个好名字尤其重要。
18 |
19 | ### 内容目录
20 |
21 | - [Python 工匠:善用变量来改善代码质量](#python-工匠善用变量来改善代码质量)
22 | - [『Python 工匠』是什么?](#python-工匠是什么)
23 | - [变量和代码质量](#变量和代码质量)
24 | - [内容目录](#内容目录)
25 | - [如何为变量起名](#如何为变量起名)
26 | - [1. 变量名要有描述性,不能太宽泛](#1-变量名要有描述性不能太宽泛)
27 | - [2. 变量名最好让人能猜出类型](#2-变量名最好让人能猜出类型)
28 | - [『什么样的名字会被当成 bool 类型?』](#什么样的名字会被当成-bool-类型)
29 | - [『什么样的名字会被当成 int/float 类型?』](#什么样的名字会被当成-intfloat-类型)
30 | - [其他类型](#其他类型)
31 | - [3. 适当使用『匈牙利命名法』](#3-适当使用匈牙利命名法)
32 | - [4. 变量名尽量短,但是绝对不要太短](#4-变量名尽量短但是绝对不要太短)
33 | - [使用短名字的例外情况](#使用短名字的例外情况)
34 | - [5. 其他注意事项](#5-其他注意事项)
35 | - [更好的使用变量](#更好的使用变量)
36 | - [1. 保持一致性](#1-保持一致性)
37 | - [2. 尽量不要用 globals()/locals()](#2-尽量不要用-globalslocals)
38 | - [3. 变量定义尽量靠近使用](#3-变量定义尽量靠近使用)
39 | - [4. 合理使用 namedtuple/dict 来让函数返回多个值](#4-合理使用-namedtupledict-来让函数返回多个值)
40 | - [5. 控制单个函数内的变量数量](#5-控制单个函数内的变量数量)
41 | - [6. 及时删掉那些没用的变量](#6-及时删掉那些没用的变量)
42 | - [7. 定义临时变量提升可读性](#7-定义临时变量提升可读性)
43 | - [结语](#结语)
44 |
45 | ## 如何为变量起名
46 |
47 | 在计算机科学领域,有一句著名的格言(俏皮话):
48 |
49 | > There are only two hard things in Computer Science: cache invalidation and naming things.
50 | > 在计算机科学领域只有两件难事:缓存失效 和 给东西起名字
51 | >
52 | > -- Phil Karlton
53 |
54 | 第一个『缓存过期问题』的难度不用多说,任何用过缓存的人都会懂。至于第二个『给东西起名字』这事的难度,我也是深有体会。在我的职业生涯里,度过的最为黑暗的下午之一,就是坐在显示器前抓耳挠腮为一个新项目起一个合适的名字。
55 |
56 | 编程时起的最多的名字,还数各种变量。给变量起一个好名字很重要,**因为好的变量命名可以极大提高代码的整体可读性。**
57 |
58 | 下面几点,是我总结的为变量起名时,最好遵守的基本原则。
59 |
60 | ### 1. 变量名要有描述性,不能太宽泛
61 |
62 | 在**可接受的长度范围内**,变量名能把它所指向的内容描述的越精确越好。所以,尽量不要用那些过于宽泛的词来作为你的变量名:
63 |
64 | - **BAD**: `day`, `host`, `cards`, `temp`
65 | - **GOOD**: `day_of_week`, `hosts_to_reboot`, `expired_cards`
66 |
67 | ### 2. 变量名最好让人能猜出类型
68 |
69 | 所有学习 Python 的人都知道,Python 是一门动态类型语言,它(至少在 [PEP 484](https://www.python.org/dev/peps/pep-0484/) 出现前)没有变量类型声明。所以当你看到一个变量时,除了通过上下文猜测,没法轻易知道它是什么类型。
70 |
71 | 不过,人们对于变量名和变量类型的关系,通常会有一些直觉上的约定,我把它们总结在了下面。
72 |
73 | #### 『什么样的名字会被当成 bool 类型?』
74 |
75 | 布尔类型变量的最大特点是:它只存在两个可能的值 **『是』** 或 **『不是』**。所以,用 `is`、`has` 等非黑即白的词修饰的变量名,会是个不错的选择。原则就是:**让读到变量名的人觉得这个变量只会有『是』或『不是』两种值**。
76 |
77 | 下面是几个不错的示例:
78 |
79 | - `is_superuser`:『是否超级用户』,只会有两种值:是/不是
80 | - `has_error`:『有没有错误』,只会有两种值:有/没有
81 | - `allow_vip`:『是否允许 VIP』,只会有两种值:允许/不允许
82 | - `use_msgpack`:『是否使用 msgpack』,只会有两种值:使用/不使用
83 | - `debug`:『是否开启调试模式』,被当做 bool 主要是因为约定俗成
84 |
85 | #### 『什么样的名字会被当成 int/float 类型?』
86 |
87 | 人们看到和数字相关的名字,都会默认他们是 int/float 类型,下面这些是比较常见的:
88 |
89 | - 释义为数字的所有单词,比如:`port(端口号)`、`age(年龄)`、`radius(半径)` 等等
90 | - 使用 _id 结尾的单词,比如:`user_id`、`host_id`
91 | - 使用 length/count 开头或者结尾的单词,比如: `length_of_username`、`max_length`、`users_count`
92 |
93 | **注意:** 不要使用普通的复数来表示一个 int 类型变量,比如 `apples`、`trips`,最好用 `number_of_apples`、`trips_count` 来替代。
94 |
95 | #### 其他类型
96 |
97 | 对于 str、list、tuple、dict 这些复杂类型,很难有一个统一的规则让我们可以通过名字去猜测变量类型。比如 `headers`,既可能是一个头信息列表,也可能是包含头信息的 dict。
98 |
99 | 对于这些类型的变量名,最推荐的方式,就是编写规范的文档,在函数和方法的 document string 中,使用 sphinx 格式([Python 官方文档使用的文档工具](http://www.sphinx-doc.org/en/stable/))来标注所有变量的类型。
100 |
101 | ### 3. 适当使用『匈牙利命名法』
102 |
103 | 第一次知道『[匈牙利命名法](https://en.wikipedia.org/wiki/Hungarian_notation)』,是在 [Joel on Software 的一篇博文](http://www.joelonsoftware.com/articles/Wrong.html)中。简而言之,匈牙利命名法就是把变量的『类型』缩写,放到变量名的最前面。
104 |
105 | 关键在于,这里说的变量『类型』,并非指传统意义上的 int/str/list 这种类型,而是指那些和你的代码业务逻辑相关的类型。
106 |
107 | 比如,在你的代码中有两个变量:`students` 和 `teachers`,他们指向的内容都是一个包含 Person 对象的 list 。使用『匈牙利命名法』后,可以把这两个名字改写成这样:
108 |
109 | students -> `pl_students`
110 | teachers -> `pl_teachers`
111 |
112 | 其中 pl 是 **person list** 的首字母缩写。当变量名被加上前缀后,如果你看到以 `pl_` 打头的变量,就能知道它所指向的值类型了。
113 |
114 | 很多情况下,使用『匈牙利命名法』是个不错的主意,因为它可以改善你的代码可读性,尤其在那些变量众多、同一类型多次出现时。注意不要滥用就好。
115 |
116 | ### 4. 变量名尽量短,但是绝对不要太短
117 |
118 | 在前面,我们提到要让变量名有描述性。如果不给这条原则加上任何限制,那么你很有可能写出这种描述性极强的变量名:`how_much_points_need_for_level2`。如果代码中充斥着这种过长的变量名,对于代码可读性来说是个灾难。
119 |
120 | 一个好的变量名,长度应该控制在 **两到三个单词左右**。比如上面的名字,可以缩写为 `points_level2`。
121 |
122 | **绝大多数情况下,都应该避免使用那些只有一两个字母的短名字**,比如数组索引三剑客 `i`、`j`、`k`,用有明确含义的名字,比如 person_index 来代替它们总是会更好一些。
123 |
124 | #### 使用短名字的例外情况
125 |
126 | 有时,上面的原则也存在一些例外。当一些意义明确但是较长的变量名重复出现时,为了让代码更简洁,使用短名字缩写是完全可以的。但是为了降低理解成本,同一段代码内最好不要使用太多这种短名字。
127 |
128 | 比如在 Python 中导入模块时,就会经常用到短名字作为别名,像 Django i18n 翻译时常用的 `gettext` 方法通常会被缩写成 `_` 来使用*(from django.utils.translation import ugettext as _)*
129 |
130 | ### 5. 其他注意事项
131 |
132 | 其他一些给变量命名的注意事项:
133 |
134 | - 同一段代码内不要使用过于相似的变量名,比如同时出现 `users`、`users1`、 `user3` 这种序列
135 | - 不要使用带否定含义的变量名,用 `is_special` 代替 `is_not_normal`
136 |
137 | ## 更好的使用变量
138 |
139 | 前面讲了如何为变量取一个好名字,下面我们谈谈在日常使用变量时,应该注意的一些小细节。
140 |
141 | ### 1. 保持一致性
142 |
143 | 如果你在一个方法内里面把图片变量叫做 `photo`,在其他的地方就不要把它改成 `image`,这样只会让代码的阅读者困惑:『`image` 和 `photo` 到底是不是同一个东西?』
144 |
145 | 另外,虽然 Python 是动态类型语言,但那也不意味着你可以用同一个变量名一会表示 str 类型,过会又换成 list。**同一个变量名指代的变量类型,也需要保持一致性。**
146 |
147 | ### 2. 尽量不要用 globals()/locals()
148 |
149 | 也许你第一次发现 globals()/locals() 这对内建函数时很兴奋,迫不及待的写下下面这种极端『简洁』的代码:
150 |
151 | ```python
152 | def render_trip_page(request, user_id, trip_id):
153 | user = User.objects.get(id=user_id)
154 | trip = get_object_or_404(Trip, pk=trip_id)
155 | is_suggested = is_suggested(user, trip)
156 | # 利用 locals() 节约了三行代码,我是个天才!
157 | return render(request, 'trip.html', locals())
158 | ```
159 |
160 | 千万不要这么做,这样只会让读到这段代码的人(包括三个月后的你自己)痛恨你,因为他需要记住这个函数内定义的所有变量(想想这个函数增长到两百行会怎么样?),更别提 locals() 还会把一些不必要的变量传递出去。
161 |
162 | 更何况, [The Zen of Python(Python 之禅)](https://www.python.org/dev/peps/pep-0020/) 说的清清楚楚:**Explicit is better than implicit.(显式优于隐式)**。所以,还是老老实实把代码写成这样吧:
163 |
164 | ```python
165 | return render(request, 'trip.html', {
166 | 'user': user,
167 | 'trip': trip,
168 | 'is_suggested': is_suggested
169 | })
170 | ```
171 |
172 | ### 3. 变量定义尽量靠近使用
173 |
174 | 这个原则属于老生常谈了。很多人(包括我)在刚开始学习编程时,会有一个习惯。就是把所有的变量定义写在一起,放在函数或方法的最前面。
175 |
176 | ```python
177 | def generate_trip_png(trip):
178 | path = []
179 | markers = []
180 | photo_markers = []
181 | text_markers = []
182 | marker_count = 0
183 | point_count = 0
184 | ... ...
185 | ```
186 |
187 | 这样做只会让你的代码『看上去很整洁』,但是对提高代码可读性没有任何帮助。
188 |
189 | 更好的做法是,**让变量定义尽量靠近使用**。那样当你阅读代码时,可以更好的理解代码的逻辑,而不是费劲的去想这个变量到底是什么、哪里定义的?
190 |
191 | ### 4. 合理使用 namedtuple/dict 来让函数返回多个值
192 |
193 | Python 的函数可以返回多个值:
194 |
195 | ```python
196 | def latlon_to_address(lat, lon):
197 | return country, province, city
198 |
199 | # 利用多返回值一次解包定义多个变量
200 | country, province, city = latlon_to_address(lat, lon)
201 | ```
202 |
203 | 但是,这样的用法会产生一个小问题:如果某一天, `latlon_to_address` 函数需要返回『城区(District)』时怎么办?
204 |
205 | 如果是上面这种写法,你需要找到所有调用 `latlon_to_address` 的地方,补上多出来的这个变量,否则 *ValueError: too many values to unpack* 就会找上你:
206 |
207 | ```python
208 | country, province, city, district = latlon_to_address(lat, lon)
209 | # 或者使用 _ 忽略多出来的返回值
210 | country, province, city, _ = latlon_to_address(lat, lon)
211 | ```
212 |
213 | 对于这种可能变动的多返回值函数,使用 namedtuple/dict 会更方便一些。当你新增返回值时,不会对之前的函数调用产生任何破坏性的影响:
214 |
215 | ```python
216 | # 1. 使用 dict
217 | def latlon_to_address(lat, lon):
218 | return {
219 | 'country': country,
220 | 'province': province,
221 | 'city': city
222 | }
223 |
224 | addr_dict = latlon_to_address(lat, lon)
225 |
226 | # 2. 使用 namedtuple
227 | from collections import namedtuple
228 |
229 | Address = namedtuple("Address", ['country', 'province', 'city'])
230 |
231 | def latlon_to_address(lat, lon):
232 | return Address(
233 | country=country,
234 | province=province,
235 | city=city
236 | )
237 |
238 | addr = latlon_to_address(lat, lon)
239 | ```
240 |
241 | 不过这样做也有坏处,因为代码对变更的兼容性虽然变好了,但是你不能继续用之前 `x, y = f()` 的方式一次解包定义多个变量了。取舍在于你自己。
242 |
243 | ### 5. 控制单个函数内的变量数量
244 |
245 | 人脑的能力是有限的,研究表明,人类的短期记忆只能同时记住不超过十个名字。所以,当你的某个函数过长(一般来说,超过一屏的的函数就会被认为有点过长了),包含了太多变量时。请及时把它拆分为多个小函数吧。
246 |
247 | ### 6. 及时删掉那些没用的变量
248 |
249 | 这条原则非常简单,也很容易做到。但是如果没有遵守,那它对你的代码质量的打击是毁灭级的。会让阅读你代码的人有一种被愚弄的感觉。
250 |
251 | ```python
252 | def fancy_func():
253 | # 读者心理:嗯,这里定义了一个 fancy_vars
254 | fancy_vars = get_fancy()
255 | ... ...(一大堆代码过后)
256 |
257 | # 读者心理:这里就结束了?之前的 fancy_vars 去哪了?被猫吃了吗?
258 | return result
259 | ```
260 |
261 | 所以,请打开 IDE 的智能提示,及时清理掉那些定义了但是没有使用的变量吧。
262 |
263 | ### 7. 定义临时变量提升可读性
264 |
265 | 有时,我们的代码里会出现一些复杂的表达式,像下面这样:
266 |
267 | ```python
268 | # 为所有性别为女性,或者级别大于 3 的活跃用户发放 10000 个金币
269 | if user.is_active and (user.sex == 'female' or user.level > 3):
270 | user.add_coins(10000)
271 | return
272 | ```
273 |
274 | 看见 `if` 后面那一长串了吗?有点难读对不对?但是如果我们把它赋值成一个临时变量,
275 | 就能给读者一个心理缓冲,提高可读性:
276 |
277 | ```
278 | # 为所有性别为女性,或者级别大于 3 的活跃用户发放 10000 个金币
279 | user_is_eligible = user.is_active and (user.sex == 'female' or user.level > 3):
280 |
281 | if user_is_eligible:
282 | user.add_coins(10000)
283 | return
284 | ```
285 |
286 | 定义临时变量可以提高可读性。但有时,把不必要的东西赋值成临时变量反而会让代码显得啰嗦:
287 |
288 | ```python
289 | def get_best_trip_by_user_id(user_id):
290 |
291 | # 心理活动:『嗯,这个值未来说不定会修改/二次使用』,让我们先把它定义成变量吧!
292 | user = get_user(user_id)
293 | trip = get_best_trip(user_id)
294 | result = {
295 | 'user': user,
296 | 'trip': trip
297 | }
298 | return result
299 | ```
300 |
301 | 其实,你所想的『未来』永远不会来,这段代码里的三个临时变量完全可以去掉,变成这样:
302 |
303 | ```python
304 | def get_best_trip_by_user_id(user_id):
305 | return {
306 | 'user': get_user(user_id),
307 | 'trip': get_best_trip(user_id)
308 | }
309 | ```
310 |
311 | 没必要为了那些可能出现的变动,牺牲代码当前的可读性。如果以后有定义变量的需求,那就以后再加吧。
312 |
313 | ## 结语
314 |
315 | 碎碎念了一大堆,不知道有多少人能够坚持到最后。变量作为程序语言的重要组成部分,值得我们在定义和使用它时,多花一丁点时间思考一下,那样会让你的代码变得更优秀。
316 |
317 | 这是『Python 工匠』系列文章的第一篇,不知道看完文章的你,有没有什么想吐槽的?请留言告诉我吧。
318 |
319 | [>>>下一篇【2.编写条件分支代码的技巧】](2-if-else-block-secrets.md)
320 |
321 | > 文章更新记录:
322 | >
323 | > - 2018.04.09:根据 @onlyice 的建议,添加了 namedtuple 部分
324 |
325 |
--------------------------------------------------------------------------------
/zh_CN/10-a-good-player-know-the-rules.md:
--------------------------------------------------------------------------------
1 | # Python 工匠:做一个精通规则的玩家
2 |
3 | ## 前言
4 |
5 | > 这是 “Python 工匠”系列的第 10 篇文章。[[查看系列所有文章]](https://github.com/piglei/one-python-craftsman)
6 |
7 |
9 |
48 |
49 | 所有文章禁止转载,如需转载请通过微信公众号联系我。
50 |
51 | ## 详细内容
52 |
53 | ### 1. [善用变量改善代码质量](zh_CN/1-using-variables-well.md)
54 |
55 | - 如何为变量起名
56 | - 1 - 变量名要有描述性,不能太宽泛
57 | - 2 - 变量名最好让人能猜出类型
58 | - 『什么样的名字会被当成 bool 类型?』
59 | - 『什么样的名字会被当成 int/float 类型?』
60 | - 其他类型
61 | - 3 - 适当使用『匈牙利命名法』
62 | - 4 - 变量名尽量短,但是绝对不要太短
63 | - 使用短名字的例外情况
64 | - 5 - 其他注意事项
65 | - 更好的使用变量
66 | - 1 - 保持一致性
67 | - 2 - 尽量不要用 globals()/locals()
68 | - 3 - 变量定义尽量靠近使用
69 | - 4 - 合理使用 namedtuple/dict 来让函数返回多个值
70 | - 5 - 控制单个函数内的变量数量
71 | - 6 - 及时删掉那些没用的变量
72 | - 7 - 能不定义变量就不定义
73 | - 结语
74 |
75 | ### 2. [编写条件分支代码的技巧](zh_CN/2-if-else-block-secrets.md)
76 |
77 | - 最佳实践
78 | - 1 - 避免多层分支嵌套
79 | - 2 - 封装那些过于复杂的逻辑判断
80 | - 3 - 留意不同分支下的重复代码
81 | - 4 - 谨慎使用三元表达式
82 | - 常见技巧
83 | - 1 - 使用“德摩根定律”
84 | - 2 - 自定义对象的“布尔真假”
85 | - 3 - 在条件判断中使用 all() / any()
86 | - 4 - 使用 try/while/for 中 else 分支
87 | - 常见陷阱
88 | - 1 - 与 None 值的比较
89 | - 2 - 留意 and 和 or 的运算优先级
90 | - 结语
91 | - 注解
92 |
93 | ### 3. [使用数字与字符串的技巧](zh_CN/3-tips-on-numbers-and-strings.md)
94 |
95 | - 最佳实践
96 | - 1 - 少写数字字面量
97 | - 使用 enum 枚举类型改善代码
98 | - 2 - 别在裸字符串处理上走太远
99 | - 3 - 不必预计算字面量表达式
100 | - 实用技巧
101 | - 1 - 布尔值其实也是“数字”
102 | - 2 - 改善超长字符串的可读性
103 | - 当多级缩进里出现多行字符串时
104 | - 3 - 别忘了那些 “r” 开头的内建字符串函数
105 | - 4 - 使用“无穷大” float("inf")
106 | - 常见误区
107 | - 1 - “value += 1” 并非线程安全
108 | - 2 - 字符串拼接并不慢
109 | - 结语
110 |
111 | ### 4. [容器的门道](zh_CN/4-mastering-container-types.md)
112 |
113 | - 底层看容器
114 | - 写更快的代码
115 | - 1 - 避免频繁扩充列表/创建新列表
116 | - 2 - 在列表头部操作多的场景使用 deque 模块
117 | - 3 - 使用集合/字典来判断成员是否存在
118 | - 高层看容器
119 | - 写扩展性更好的代码
120 | - 面向容器接口编程
121 | - 常用技巧
122 | - 1 - 使用元组改善分支代码
123 | - 2 - 在更多地方使用动态解包
124 | - 3 - 使用 next() 函数
125 | - 4 - 使用有序字典来去重
126 | - 常见误区
127 | - 1 - 当心那些已经枯竭的迭代器
128 | - 2 - 别在循环体内修改被迭代对象
129 | - 总结
130 | - 系列其他文章
131 | - 注解
132 |
133 | ### 5. [让函数返回结果的技巧](zh_CN/5-function-returning-tips.md)
134 |
135 | - 编程建议
136 | - 1 - 单个函数不要返回多种类型
137 | - 2 - 使用 partial 构造新函数
138 | - 3 - 抛出异常,而不是返回结果与错误
139 | - 4 - 谨慎使用 None 返回值
140 | - 1 - 作为操作类函数的默认返回值
141 | - 2 - 作为某些“意料之中”的可能没有的值
142 | - 3 - 作为调用失败时代表“错误结果”的值
143 | - 5 - 合理使用“空对象模式”
144 | - 6 - 使用生成器函数代替返回列表
145 | - 7 - 限制递归的使用
146 | - 总结
147 | - 附录
148 |
149 | ### 6. [异常处理的三个好习惯](zh_CN/6-three-rituals-of-exceptions-handling.md)
150 |
151 | - 前言
152 | - 三个好习惯
153 | - 1 - 只做最精确的异常捕获
154 | - 2 - 别让异常破坏抽象一致性
155 | - 3 - 异常处理不应该喧宾夺主
156 | - 总结
157 | - 附录
158 |
159 | ### 7. [编写地道循环的两个建议](zh_CN/7-two-tips-on-loop-writing.md)
160 |
161 | - 前言
162 | - 什么是“地道”的循环?
163 | - enumerate() 所代表的编程思路
164 | - 建议1:使用函数修饰被迭代对象来优化循环
165 | - 1 - 使用 product 扁平化多层嵌套循环
166 | - 2 - 使用 islice 实现循环内隔行处理
167 | - 3 - 使用 takewhile 替代 break 语句
168 | - 4 - 使用生成器编写自己的修饰函数
169 | - 建议2:按职责拆解循环体内复杂代码块
170 | - 复杂循环体如何应对新需求
171 | - 使用生成器函数解耦循环体
172 | - 总结
173 | - 附录
174 |
175 | ### 8. [使用装饰器的技巧](zh_CN/8-tips-on-decorators.md)
176 |
177 | - 前言
178 | - 最佳实践
179 | - 1 - 尝试用类来实现装饰器
180 | - 2 - 使用 wrapt 模块编写更扁平的装饰器
181 | - 常见错误
182 | - 1 - “装饰器”并不是“装饰器模式”
183 | - 2 - 记得用 functools.wraps() 装饰内层函数
184 | - 3 - 修改外层变量时记得使用 nonlocal
185 | - 总结
186 | - 附录
187 |
188 | ### 9. [一个关于模块的小故事](zh_CN/9-a-story-on-cyclic-imports.md)
189 |
190 | - 前言
191 | - 一个关于模块的小故事
192 | - 需求变更
193 | - 解决环形依赖问题
194 | - 小 C 的疑问
195 | - 总结
196 | - 附录
197 |
198 | ### 10. [做一个精通规则的玩家](zh_CN/10-a-good-player-know-the-rules.md)
199 |
200 | - 前言
201 | - Python 里的规则
202 | - 案例:从两份旅游数据中获取人员名单
203 | - 第一次蛮力尝试
204 | - 尝试使用集合优化函数
205 | - 对问题的重新思考
206 | - 利用集合的游戏规则
207 | - 使用 dataclass 简化代码
208 | - 案例总结
209 | - 其他规则如何影响我们
210 | - 使用 `__format__` 做对象字符串格式化
211 | - 使用 `__getitem__` 定义对象切片操作
212 | - 总结
213 | - 附录
214 |
215 | ### 11. [高效操作文件的三个建议](zh_CN/11-three-tips-on-writing-file-related-codes.md)
216 |
217 | - 前言
218 | - 建议一:使用 pathlib 模块
219 | - 使用 pathlib 模块改写代码
220 | - 其他用法
221 | - 建议二:掌握如何流式读取大文件
222 | - 标准做法的缺点
223 | - 使用 read 方法分块读取
224 | - 利用生成器解耦代码
225 | - 建议三:设计接受文件对象的函数
226 | - 如何编写兼容二者的函数
227 | - 总结
228 | - 附录
229 | - 注解
230 |
231 | ### 12. [写好面向对象代码的原则(上)](zh_CN/12-write-solid-python-codes-part-1.md)
232 |
233 | - 前言
234 | - Python 对 OOP 的支持
235 | - SOLID 设计原则
236 | - SOLID 原则与 Python
237 | - S:单一职责原则
238 | - 违反“单一职责原则”的坏处
239 | - 拆分大类为多个小类
240 | - 另一种方案:使用函数
241 | - O:开放-关闭原则
242 | - 如何违反“开放-关闭原则”
243 | - 使用类继承来改造代码
244 | - 使用组合与依赖注入来改造代码
245 | - 使用数据驱动思想来改造代码
246 | - 总结
247 | - 附录
248 |
249 | ### 13. [写好面向对象代码的原则(中)](zh_CN/13-write-solid-python-codes-part-2.md)
250 |
251 | - 前言
252 | - 里氏替换原则与继承
253 | - L:里氏替换原则
254 | - 一个违反 L 原则的样例
255 | - 不当继承关系如何违反 L 原则
256 | - 一个简单但错误的解决办法
257 | - 正确的修改办法
258 | - 另一种违反方式:子类修改方法返回值法返回值)
259 | - 分析类方法返回结果
260 | - 如何修改代码
261 | - 方法参数与 L 原则
262 | - 总结
263 | - 附录
264 |
265 | ### 14. [写好面向对象代码的原则(下)](zh_CN/14-write-solid-python-codes-part-3.md)
266 |
267 | - 前言
268 | - D:依赖倒置原则
269 | - 需求:按域名分组统计 HN 新闻数量
270 | - 为 SiteSourceGrouper 编写单元测试
271 | - 使用 mock 模块
272 | - 实现依赖倒置原则
273 | - 依赖倒置后的单元测试
274 | - 问题:一定要使用抽象类 abc 吗?
275 | - 问题:抽象一定是好东西吗?
276 | - I:接口隔离原则
277 | - 例子:开发页面归档功能
278 | - 问题:实体类不符合 HNWebPage 接口规范
279 | - 成功违反 I 协议
280 | - 如何分拆接口
281 | - 一些不容易发现的违反情况
282 | - 现实世界中的接口隔离
283 | - 总结
284 | - 附录
285 |
286 | ### 15. [在边界处思考](zh_CN/15-thinking-in-edge-cases.md)
287 |
288 | - 前言
289 | - 第一课:使用分支还是异常?
290 | - 获取原谅比许可简单(EAFP)
291 | - 当容器内容不存在时
292 | - 使用 defaultdict 改写示例
293 | - 使用 setdefault 取值并修改
294 | - 使用 dict.pop 删除不存在的键
295 | - 当列表切片越界时
296 | - 好用又危险的 “or” 操作符
297 | - 不要手动去做数据校验
298 | - 不要忘记做数学计算
299 | - 总结
300 | - 附录
301 |
302 | ### 16. [语句、表达式和海象操作符](zh_CN/16-stmt-expr-and-walrus-operator.md)
303 |
304 | - 表达式的特点
305 | - 海象操作符
306 | - 1. 用于分支语句
307 | - 2. 消除推导式中的重复
308 | - 3. 捕获推导式的中间结果
309 | - 4. 赋值表达式的限制
310 | - 其他建议
311 | - 1. “更紧凑”不等于“更好”
312 | - 2. 宜少不宜多
313 |
--------------------------------------------------------------------------------
/zh_CN/1-using-variables-well.md:
--------------------------------------------------------------------------------
1 | # Python 工匠:善用变量来改善代码质量
2 |
3 | ## 『Python 工匠』是什么?
4 |
5 | 我一直觉得编程某种意义上是一门『手艺』,因为优雅而高效的代码,就如同完美的手工艺品一样让人赏心悦目。
6 |
7 | 在雕琢代码的过程中,有大工程:比如应该用什么架构、哪种设计模式。也有更多的小细节,比如何时使用异常(Exceptions)、或怎么给变量起名。那些真正优秀的代码,正是由无数优秀的细节造就的。
8 |
9 | 『Python 工匠』这个系列文章,是我的一次小小尝试。它专注于分享 Python 编程中的一些偏 **『小』** 的东西。希望能够帮到每一位编程路上的匠人。
10 |
11 | > 这是 “Python 工匠”系列的第 1 篇文章。[[查看系列所有文章]](https://github.com/piglei/one-python-craftsman)
12 |
13 | ## 变量和代码质量
14 |
15 | 作为『Python 工匠』系列文章的第一篇,我想先谈谈 『变量(Variables)』。因为如何定义和使用变量,一直都是学习任何一门编程语言最先要掌握的技能之一。
16 |
17 | 变量用的好或不好,和代码质量有着非常重要的联系。在关于变量的诸多问题中,为变量起一个好名字尤其重要。
18 |
19 | ### 内容目录
20 |
21 | - [Python 工匠:善用变量来改善代码质量](#python-工匠善用变量来改善代码质量)
22 | - [『Python 工匠』是什么?](#python-工匠是什么)
23 | - [变量和代码质量](#变量和代码质量)
24 | - [内容目录](#内容目录)
25 | - [如何为变量起名](#如何为变量起名)
26 | - [1. 变量名要有描述性,不能太宽泛](#1-变量名要有描述性不能太宽泛)
27 | - [2. 变量名最好让人能猜出类型](#2-变量名最好让人能猜出类型)
28 | - [『什么样的名字会被当成 bool 类型?』](#什么样的名字会被当成-bool-类型)
29 | - [『什么样的名字会被当成 int/float 类型?』](#什么样的名字会被当成-intfloat-类型)
30 | - [其他类型](#其他类型)
31 | - [3. 适当使用『匈牙利命名法』](#3-适当使用匈牙利命名法)
32 | - [4. 变量名尽量短,但是绝对不要太短](#4-变量名尽量短但是绝对不要太短)
33 | - [使用短名字的例外情况](#使用短名字的例外情况)
34 | - [5. 其他注意事项](#5-其他注意事项)
35 | - [更好的使用变量](#更好的使用变量)
36 | - [1. 保持一致性](#1-保持一致性)
37 | - [2. 尽量不要用 globals()/locals()](#2-尽量不要用-globalslocals)
38 | - [3. 变量定义尽量靠近使用](#3-变量定义尽量靠近使用)
39 | - [4. 合理使用 namedtuple/dict 来让函数返回多个值](#4-合理使用-namedtupledict-来让函数返回多个值)
40 | - [5. 控制单个函数内的变量数量](#5-控制单个函数内的变量数量)
41 | - [6. 及时删掉那些没用的变量](#6-及时删掉那些没用的变量)
42 | - [7. 定义临时变量提升可读性](#7-定义临时变量提升可读性)
43 | - [结语](#结语)
44 |
45 | ## 如何为变量起名
46 |
47 | 在计算机科学领域,有一句著名的格言(俏皮话):
48 |
49 | > There are only two hard things in Computer Science: cache invalidation and naming things.
50 | > 在计算机科学领域只有两件难事:缓存失效 和 给东西起名字
51 | >
52 | > -- Phil Karlton
53 |
54 | 第一个『缓存过期问题』的难度不用多说,任何用过缓存的人都会懂。至于第二个『给东西起名字』这事的难度,我也是深有体会。在我的职业生涯里,度过的最为黑暗的下午之一,就是坐在显示器前抓耳挠腮为一个新项目起一个合适的名字。
55 |
56 | 编程时起的最多的名字,还数各种变量。给变量起一个好名字很重要,**因为好的变量命名可以极大提高代码的整体可读性。**
57 |
58 | 下面几点,是我总结的为变量起名时,最好遵守的基本原则。
59 |
60 | ### 1. 变量名要有描述性,不能太宽泛
61 |
62 | 在**可接受的长度范围内**,变量名能把它所指向的内容描述的越精确越好。所以,尽量不要用那些过于宽泛的词来作为你的变量名:
63 |
64 | - **BAD**: `day`, `host`, `cards`, `temp`
65 | - **GOOD**: `day_of_week`, `hosts_to_reboot`, `expired_cards`
66 |
67 | ### 2. 变量名最好让人能猜出类型
68 |
69 | 所有学习 Python 的人都知道,Python 是一门动态类型语言,它(至少在 [PEP 484](https://www.python.org/dev/peps/pep-0484/) 出现前)没有变量类型声明。所以当你看到一个变量时,除了通过上下文猜测,没法轻易知道它是什么类型。
70 |
71 | 不过,人们对于变量名和变量类型的关系,通常会有一些直觉上的约定,我把它们总结在了下面。
72 |
73 | #### 『什么样的名字会被当成 bool 类型?』
74 |
75 | 布尔类型变量的最大特点是:它只存在两个可能的值 **『是』** 或 **『不是』**。所以,用 `is`、`has` 等非黑即白的词修饰的变量名,会是个不错的选择。原则就是:**让读到变量名的人觉得这个变量只会有『是』或『不是』两种值**。
76 |
77 | 下面是几个不错的示例:
78 |
79 | - `is_superuser`:『是否超级用户』,只会有两种值:是/不是
80 | - `has_error`:『有没有错误』,只会有两种值:有/没有
81 | - `allow_vip`:『是否允许 VIP』,只会有两种值:允许/不允许
82 | - `use_msgpack`:『是否使用 msgpack』,只会有两种值:使用/不使用
83 | - `debug`:『是否开启调试模式』,被当做 bool 主要是因为约定俗成
84 |
85 | #### 『什么样的名字会被当成 int/float 类型?』
86 |
87 | 人们看到和数字相关的名字,都会默认他们是 int/float 类型,下面这些是比较常见的:
88 |
89 | - 释义为数字的所有单词,比如:`port(端口号)`、`age(年龄)`、`radius(半径)` 等等
90 | - 使用 _id 结尾的单词,比如:`user_id`、`host_id`
91 | - 使用 length/count 开头或者结尾的单词,比如: `length_of_username`、`max_length`、`users_count`
92 |
93 | **注意:** 不要使用普通的复数来表示一个 int 类型变量,比如 `apples`、`trips`,最好用 `number_of_apples`、`trips_count` 来替代。
94 |
95 | #### 其他类型
96 |
97 | 对于 str、list、tuple、dict 这些复杂类型,很难有一个统一的规则让我们可以通过名字去猜测变量类型。比如 `headers`,既可能是一个头信息列表,也可能是包含头信息的 dict。
98 |
99 | 对于这些类型的变量名,最推荐的方式,就是编写规范的文档,在函数和方法的 document string 中,使用 sphinx 格式([Python 官方文档使用的文档工具](http://www.sphinx-doc.org/en/stable/))来标注所有变量的类型。
100 |
101 | ### 3. 适当使用『匈牙利命名法』
102 |
103 | 第一次知道『[匈牙利命名法](https://en.wikipedia.org/wiki/Hungarian_notation)』,是在 [Joel on Software 的一篇博文](http://www.joelonsoftware.com/articles/Wrong.html)中。简而言之,匈牙利命名法就是把变量的『类型』缩写,放到变量名的最前面。
104 |
105 | 关键在于,这里说的变量『类型』,并非指传统意义上的 int/str/list 这种类型,而是指那些和你的代码业务逻辑相关的类型。
106 |
107 | 比如,在你的代码中有两个变量:`students` 和 `teachers`,他们指向的内容都是一个包含 Person 对象的 list 。使用『匈牙利命名法』后,可以把这两个名字改写成这样:
108 |
109 | students -> `pl_students`
110 | teachers -> `pl_teachers`
111 |
112 | 其中 pl 是 **person list** 的首字母缩写。当变量名被加上前缀后,如果你看到以 `pl_` 打头的变量,就能知道它所指向的值类型了。
113 |
114 | 很多情况下,使用『匈牙利命名法』是个不错的主意,因为它可以改善你的代码可读性,尤其在那些变量众多、同一类型多次出现时。注意不要滥用就好。
115 |
116 | ### 4. 变量名尽量短,但是绝对不要太短
117 |
118 | 在前面,我们提到要让变量名有描述性。如果不给这条原则加上任何限制,那么你很有可能写出这种描述性极强的变量名:`how_much_points_need_for_level2`。如果代码中充斥着这种过长的变量名,对于代码可读性来说是个灾难。
119 |
120 | 一个好的变量名,长度应该控制在 **两到三个单词左右**。比如上面的名字,可以缩写为 `points_level2`。
121 |
122 | **绝大多数情况下,都应该避免使用那些只有一两个字母的短名字**,比如数组索引三剑客 `i`、`j`、`k`,用有明确含义的名字,比如 person_index 来代替它们总是会更好一些。
123 |
124 | #### 使用短名字的例外情况
125 |
126 | 有时,上面的原则也存在一些例外。当一些意义明确但是较长的变量名重复出现时,为了让代码更简洁,使用短名字缩写是完全可以的。但是为了降低理解成本,同一段代码内最好不要使用太多这种短名字。
127 |
128 | 比如在 Python 中导入模块时,就会经常用到短名字作为别名,像 Django i18n 翻译时常用的 `gettext` 方法通常会被缩写成 `_` 来使用*(from django.utils.translation import ugettext as _)*
129 |
130 | ### 5. 其他注意事项
131 |
132 | 其他一些给变量命名的注意事项:
133 |
134 | - 同一段代码内不要使用过于相似的变量名,比如同时出现 `users`、`users1`、 `user3` 这种序列
135 | - 不要使用带否定含义的变量名,用 `is_special` 代替 `is_not_normal`
136 |
137 | ## 更好的使用变量
138 |
139 | 前面讲了如何为变量取一个好名字,下面我们谈谈在日常使用变量时,应该注意的一些小细节。
140 |
141 | ### 1. 保持一致性
142 |
143 | 如果你在一个方法内里面把图片变量叫做 `photo`,在其他的地方就不要把它改成 `image`,这样只会让代码的阅读者困惑:『`image` 和 `photo` 到底是不是同一个东西?』
144 |
145 | 另外,虽然 Python 是动态类型语言,但那也不意味着你可以用同一个变量名一会表示 str 类型,过会又换成 list。**同一个变量名指代的变量类型,也需要保持一致性。**
146 |
147 | ### 2. 尽量不要用 globals()/locals()
148 |
149 | 也许你第一次发现 globals()/locals() 这对内建函数时很兴奋,迫不及待的写下下面这种极端『简洁』的代码:
150 |
151 | ```python
152 | def render_trip_page(request, user_id, trip_id):
153 | user = User.objects.get(id=user_id)
154 | trip = get_object_or_404(Trip, pk=trip_id)
155 | is_suggested = is_suggested(user, trip)
156 | # 利用 locals() 节约了三行代码,我是个天才!
157 | return render(request, 'trip.html', locals())
158 | ```
159 |
160 | 千万不要这么做,这样只会让读到这段代码的人(包括三个月后的你自己)痛恨你,因为他需要记住这个函数内定义的所有变量(想想这个函数增长到两百行会怎么样?),更别提 locals() 还会把一些不必要的变量传递出去。
161 |
162 | 更何况, [The Zen of Python(Python 之禅)](https://www.python.org/dev/peps/pep-0020/) 说的清清楚楚:**Explicit is better than implicit.(显式优于隐式)**。所以,还是老老实实把代码写成这样吧:
163 |
164 | ```python
165 | return render(request, 'trip.html', {
166 | 'user': user,
167 | 'trip': trip,
168 | 'is_suggested': is_suggested
169 | })
170 | ```
171 |
172 | ### 3. 变量定义尽量靠近使用
173 |
174 | 这个原则属于老生常谈了。很多人(包括我)在刚开始学习编程时,会有一个习惯。就是把所有的变量定义写在一起,放在函数或方法的最前面。
175 |
176 | ```python
177 | def generate_trip_png(trip):
178 | path = []
179 | markers = []
180 | photo_markers = []
181 | text_markers = []
182 | marker_count = 0
183 | point_count = 0
184 | ... ...
185 | ```
186 |
187 | 这样做只会让你的代码『看上去很整洁』,但是对提高代码可读性没有任何帮助。
188 |
189 | 更好的做法是,**让变量定义尽量靠近使用**。那样当你阅读代码时,可以更好的理解代码的逻辑,而不是费劲的去想这个变量到底是什么、哪里定义的?
190 |
191 | ### 4. 合理使用 namedtuple/dict 来让函数返回多个值
192 |
193 | Python 的函数可以返回多个值:
194 |
195 | ```python
196 | def latlon_to_address(lat, lon):
197 | return country, province, city
198 |
199 | # 利用多返回值一次解包定义多个变量
200 | country, province, city = latlon_to_address(lat, lon)
201 | ```
202 |
203 | 但是,这样的用法会产生一个小问题:如果某一天, `latlon_to_address` 函数需要返回『城区(District)』时怎么办?
204 |
205 | 如果是上面这种写法,你需要找到所有调用 `latlon_to_address` 的地方,补上多出来的这个变量,否则 *ValueError: too many values to unpack* 就会找上你:
206 |
207 | ```python
208 | country, province, city, district = latlon_to_address(lat, lon)
209 | # 或者使用 _ 忽略多出来的返回值
210 | country, province, city, _ = latlon_to_address(lat, lon)
211 | ```
212 |
213 | 对于这种可能变动的多返回值函数,使用 namedtuple/dict 会更方便一些。当你新增返回值时,不会对之前的函数调用产生任何破坏性的影响:
214 |
215 | ```python
216 | # 1. 使用 dict
217 | def latlon_to_address(lat, lon):
218 | return {
219 | 'country': country,
220 | 'province': province,
221 | 'city': city
222 | }
223 |
224 | addr_dict = latlon_to_address(lat, lon)
225 |
226 | # 2. 使用 namedtuple
227 | from collections import namedtuple
228 |
229 | Address = namedtuple("Address", ['country', 'province', 'city'])
230 |
231 | def latlon_to_address(lat, lon):
232 | return Address(
233 | country=country,
234 | province=province,
235 | city=city
236 | )
237 |
238 | addr = latlon_to_address(lat, lon)
239 | ```
240 |
241 | 不过这样做也有坏处,因为代码对变更的兼容性虽然变好了,但是你不能继续用之前 `x, y = f()` 的方式一次解包定义多个变量了。取舍在于你自己。
242 |
243 | ### 5. 控制单个函数内的变量数量
244 |
245 | 人脑的能力是有限的,研究表明,人类的短期记忆只能同时记住不超过十个名字。所以,当你的某个函数过长(一般来说,超过一屏的的函数就会被认为有点过长了),包含了太多变量时。请及时把它拆分为多个小函数吧。
246 |
247 | ### 6. 及时删掉那些没用的变量
248 |
249 | 这条原则非常简单,也很容易做到。但是如果没有遵守,那它对你的代码质量的打击是毁灭级的。会让阅读你代码的人有一种被愚弄的感觉。
250 |
251 | ```python
252 | def fancy_func():
253 | # 读者心理:嗯,这里定义了一个 fancy_vars
254 | fancy_vars = get_fancy()
255 | ... ...(一大堆代码过后)
256 |
257 | # 读者心理:这里就结束了?之前的 fancy_vars 去哪了?被猫吃了吗?
258 | return result
259 | ```
260 |
261 | 所以,请打开 IDE 的智能提示,及时清理掉那些定义了但是没有使用的变量吧。
262 |
263 | ### 7. 定义临时变量提升可读性
264 |
265 | 有时,我们的代码里会出现一些复杂的表达式,像下面这样:
266 |
267 | ```python
268 | # 为所有性别为女性,或者级别大于 3 的活跃用户发放 10000 个金币
269 | if user.is_active and (user.sex == 'female' or user.level > 3):
270 | user.add_coins(10000)
271 | return
272 | ```
273 |
274 | 看见 `if` 后面那一长串了吗?有点难读对不对?但是如果我们把它赋值成一个临时变量,
275 | 就能给读者一个心理缓冲,提高可读性:
276 |
277 | ```
278 | # 为所有性别为女性,或者级别大于 3 的活跃用户发放 10000 个金币
279 | user_is_eligible = user.is_active and (user.sex == 'female' or user.level > 3):
280 |
281 | if user_is_eligible:
282 | user.add_coins(10000)
283 | return
284 | ```
285 |
286 | 定义临时变量可以提高可读性。但有时,把不必要的东西赋值成临时变量反而会让代码显得啰嗦:
287 |
288 | ```python
289 | def get_best_trip_by_user_id(user_id):
290 |
291 | # 心理活动:『嗯,这个值未来说不定会修改/二次使用』,让我们先把它定义成变量吧!
292 | user = get_user(user_id)
293 | trip = get_best_trip(user_id)
294 | result = {
295 | 'user': user,
296 | 'trip': trip
297 | }
298 | return result
299 | ```
300 |
301 | 其实,你所想的『未来』永远不会来,这段代码里的三个临时变量完全可以去掉,变成这样:
302 |
303 | ```python
304 | def get_best_trip_by_user_id(user_id):
305 | return {
306 | 'user': get_user(user_id),
307 | 'trip': get_best_trip(user_id)
308 | }
309 | ```
310 |
311 | 没必要为了那些可能出现的变动,牺牲代码当前的可读性。如果以后有定义变量的需求,那就以后再加吧。
312 |
313 | ## 结语
314 |
315 | 碎碎念了一大堆,不知道有多少人能够坚持到最后。变量作为程序语言的重要组成部分,值得我们在定义和使用它时,多花一丁点时间思考一下,那样会让你的代码变得更优秀。
316 |
317 | 这是『Python 工匠』系列文章的第一篇,不知道看完文章的你,有没有什么想吐槽的?请留言告诉我吧。
318 |
319 | [>>>下一篇【2.编写条件分支代码的技巧】](2-if-else-block-secrets.md)
320 |
321 | > 文章更新记录:
322 | >
323 | > - 2018.04.09:根据 @onlyice 的建议,添加了 namedtuple 部分
324 |
325 |
--------------------------------------------------------------------------------
/zh_CN/10-a-good-player-know-the-rules.md:
--------------------------------------------------------------------------------
1 | # Python 工匠:做一个精通规则的玩家
2 |
3 | ## 前言
4 |
5 | > 这是 “Python 工匠”系列的第 10 篇文章。[[查看系列所有文章]](https://github.com/piglei/one-python-craftsman)
6 |
7 |
9 |  9 |
9 |  9 |
9 | 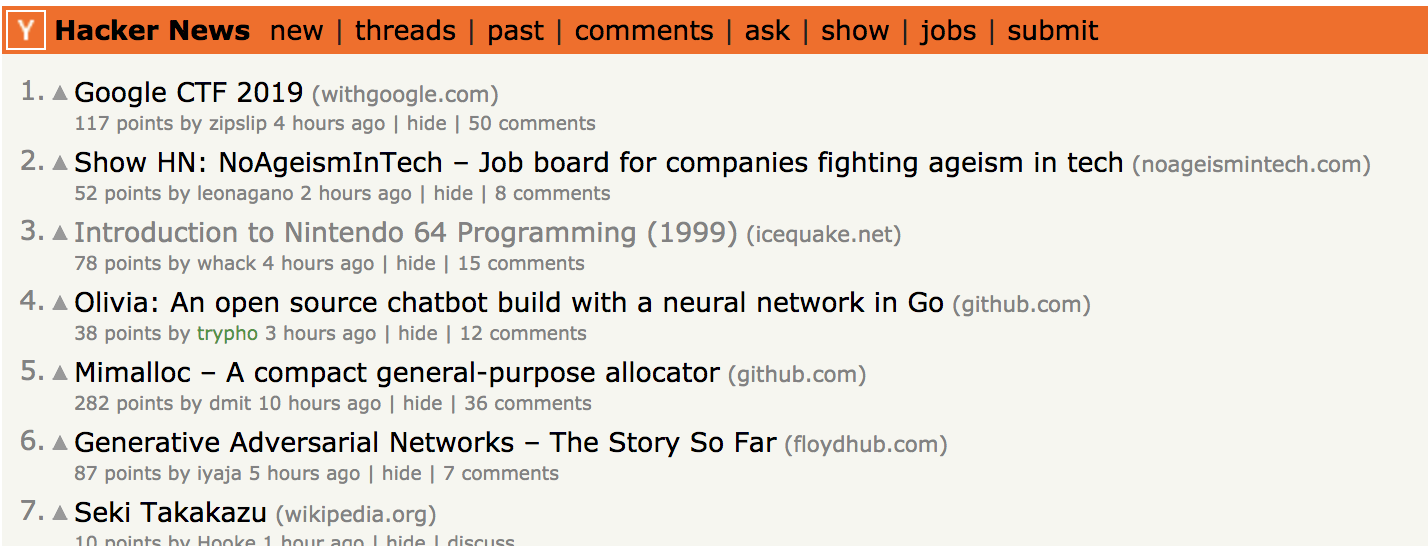 52 | 图:Hacker News 首页截图
53 |
52 | 图:Hacker News 首页截图
53 |  9 |
9 |  9 |
9 | 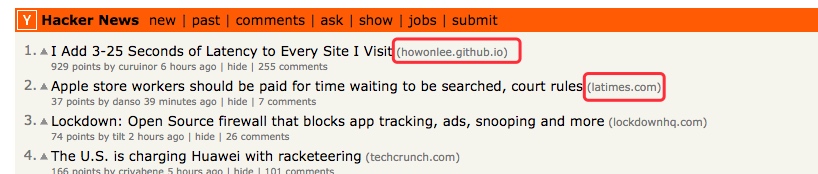 35 | 图:Hacker News 条目来源截图
36 |
35 | 图:Hacker News 条目来源截图
36 | 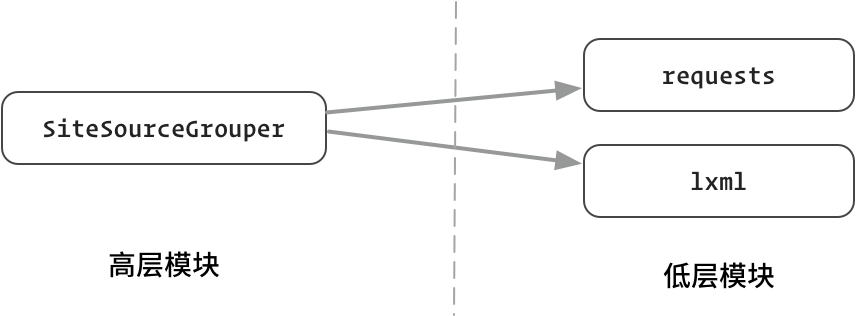 94 | 图:SiteSourceGrouper 依赖 requests、lxml
95 |
94 | 图:SiteSourceGrouper 依赖 requests、lxml
95 | 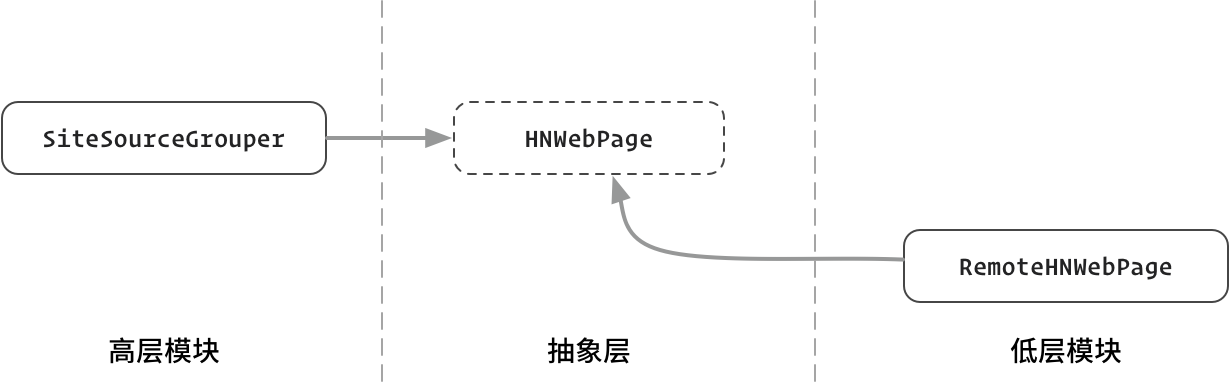 259 | 图:SiteSourceGrouper 和 RemoteHNWebPage 都依赖抽象层 HNWebPage
260 |
259 | 图:SiteSourceGrouper 和 RemoteHNWebPage 都依赖抽象层 HNWebPage
260 | 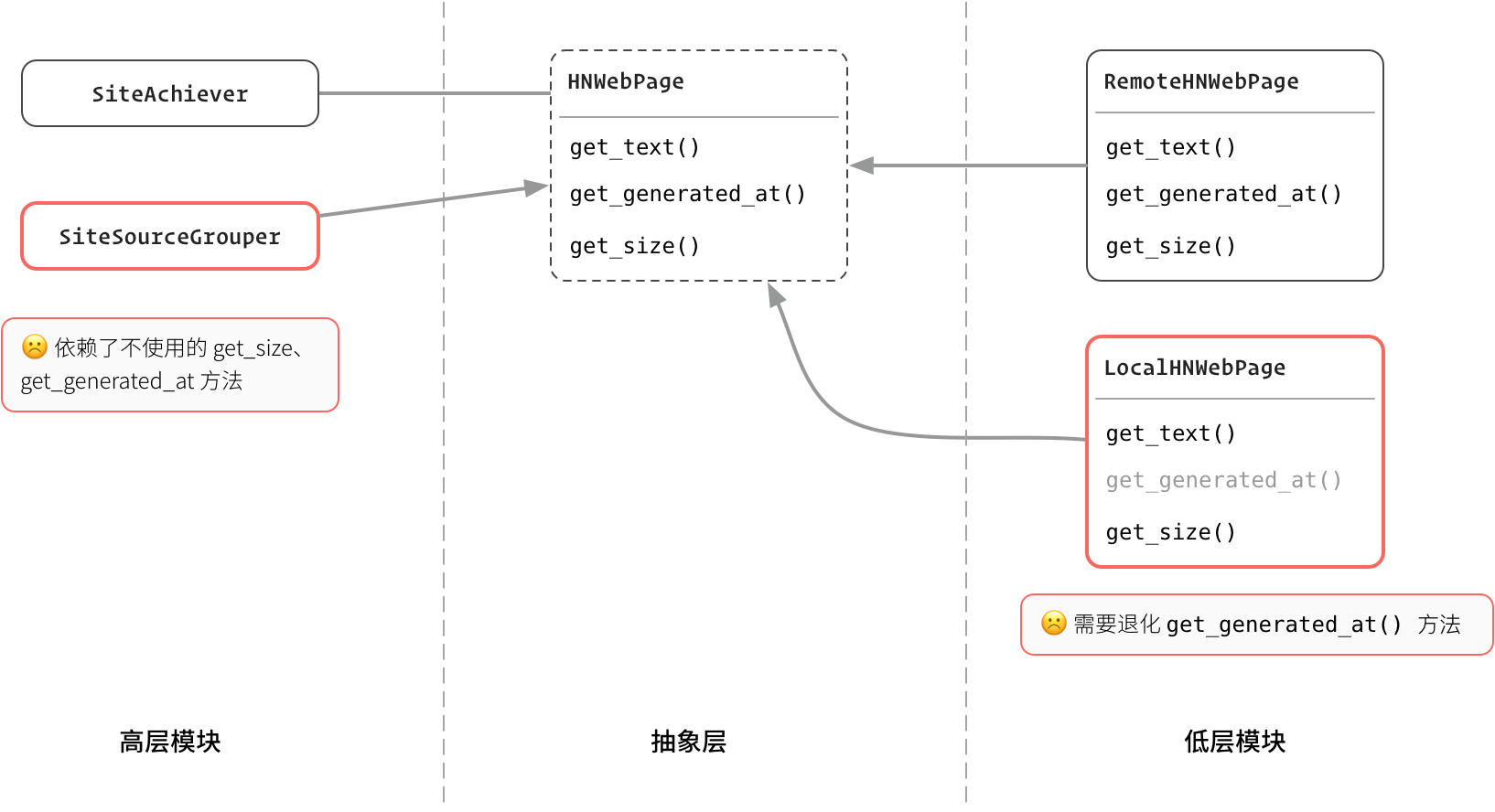 432 | 图:成功违反了 I 协议
433 |
432 | 图:成功违反了 I 协议
433 | 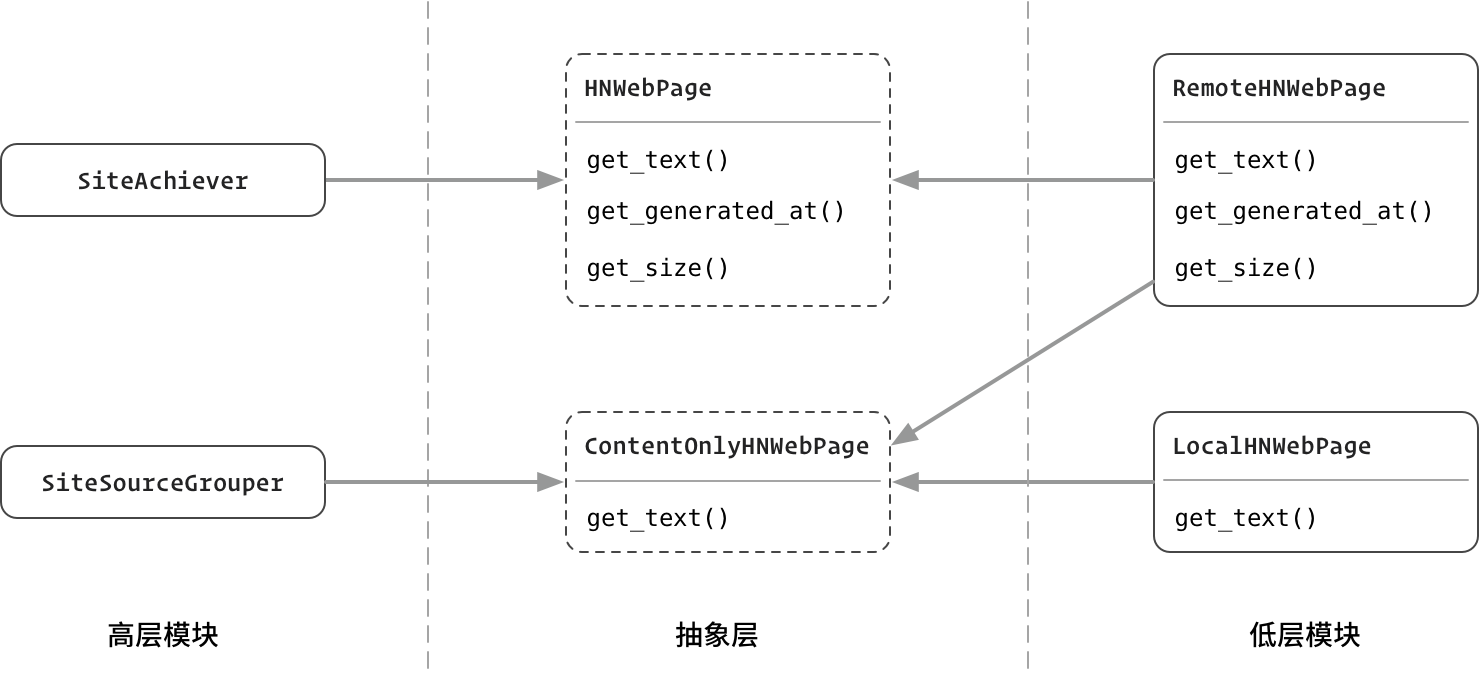 477 | 图:实施接口隔离后的结果
478 |
477 | 图:实施接口隔离后的结果
478 |  9 |
9 | 
 9 |
9 |  9 |
9 |  9 |
9 |  9 |
9 |  9 |
9 |