├── README.md
├── model.py
└── sample_images
├── 0_wrong.png
├── 3.png
├── 4.png
├── 9.png
├── all_layers.png
├── all_layers_fashion.png
├── ankle_boot.png
├── bag_wrong.png
├── dress.png
├── shirt.png
├── trouser.png
└── tshirt_wrong.png
/README.md:
--------------------------------------------------------------------------------
1 | # MNIST Neural Network classifier
2 |
3 | ## The model
4 |
5 | This is a trained neural network built from scratch to classify handwritten digits or fashions from the MNIST dataset.
6 |
7 | By default, the neural network has an architecture:
8 |
9 | *L* = number of layers = 8
10 |
11 | | Layer index (*l*) | Number of Activation units (*n[l]*) | Activation function |
12 | | ----------------- | ----------------------------------- | ------------------- |
13 | | 0 | 784 | N/A |
14 | | 1 | 3000 | ReLU |
15 | | 2 | 2500 | ReLU |
16 | | 3 | 2000 | ReLU |
17 | | 4 | 1500 | ReLU |
18 | | 5 | 1000 | ReLU |
19 | | 6 | 500 | ReLU |
20 | | 7 | 10 | Softmax |
21 |
22 | Trained using Adam optimizer and initialized parameters with He-et-al initialization.
23 |
24 | Default hyperparameters settings:
25 |
26 | | Hyperparameter name | Value |
27 | | ----------------------------------------------------- | ----- |
28 | | Learning rate (alpha) | 0.001 |
29 | | Number of epochs (n_epochs) | 2000 |
30 | | Batch size (batch_size) | 256 |
31 | | Dropout keep activation units probability (keep_prob) | 0.7 |
32 | | L2 regularization parameter (lbd) | 0.05 |
33 | | Adam's parameter β1 (beta1) | 0.9 |
34 | | Adam's parameter β2 (beta2) | 0.999 |
35 | | Learning rate decay (decay_rate) | 1.0 |
36 |
37 |
38 |
39 | ## Installation, demo, and training
40 |
41 | **Prerequisites**: Make sure you've installed the required libraries/packages: Numpy, Tensorflow (only used to get the dataset), and Matplotlib
42 |
43 | 1. Clone this repository
44 |
45 | ```shell
46 | git clone https://github.com/pkien01/MNIST-neural-network-classifier
47 | ```
48 |
49 | 2. Download the pretrained weights for the MNIST digits and fashions dataset [here](https://drive.google.com/drive/folders/1CmQRokKnQ75ukEU_Y5Lq9DsjYVWxP6MM?usp=sharing) and move it to the `MNIST-neural-network-classifier` folder.
50 |
51 | 3. After that, the `MNIST-neural-network-classifier` folder should have the following structure
52 |
53 | ```bash
54 | MNIST-neural-network-classifier/
55 | MNIST-neural-network-classifier/model.py #the model source code
56 | MNIST-neural-network-classifier/mnist_trained_weights_deep.dat #the pretrained MNIST digits weights
57 | MNIST-neural-network-classifier/fashion_mnist_trained_weights_deep.dat #the pretrained MNIST fashion weights
58 | ```
59 |
60 | 4. Open the `model.py` source code file and at the end, it should be similar to the following
61 |
62 | ```python
63 | ...
64 | W, b = load_cache()
65 |
66 | #gradient_descent(W, b, keep_prob=.7, lbd =.03, learning_rate=0.001)
67 | #print(set_performance(X_train, Y_train, W, b))
68 | #print(set_performance(X_test, Y_test, W, b))
69 | demo(W, b, fashion=False)
70 | #demo_wrong(W, b, fashion=False)
71 | #demo_all_layers(W, b)
72 | ```
73 |
74 | 5. Run the source code file
75 |
76 | ```bash
77 | cd MNIST-neural-network-classifier
78 | python3 model.py
79 | ```
80 |
81 | Congrats! You've just ran the demo on the MNIST handwritten digits dataset
82 |
83 | 6. To run it on the MNIST fashion dataset:
84 |
85 | - Open the `model.py` in a text/code editor
86 |
87 | - Change the following line (line 8 in the default source code)
88 |
89 | ```python
90 | (X_train, label_train), (X_test, label_test) = tf.keras.datasets.mnist.load_data()
91 | ```
92 |
93 | to this
94 |
95 | ```
96 | (X_train, label_train), (X_test, label_test) = tf.keras.datasets.fashion_mnist.load_data()
97 | ```
98 |
99 | - Next, change the following line (line 24 in the default source code)
100 |
101 | ```python
102 | weights_file = './mnist_trained_weights_deep.dat'
103 | ```
104 |
105 | to this
106 |
107 | ```python
108 | weights_file = './fashion_mnist_trained_weights_deep.dat'
109 | ```
110 |
111 | * Next, set the `fashion` variable to `True` in the `demo` function
112 |
113 | ```python
114 | demo(W, b, fashion=False)
115 | #demo_wrong(W, b, fashion=False)
116 | ```
117 |
118 | to this
119 |
120 | ```python
121 | demo(W, b, fashion=True)
122 | #demo_wrong(W, b, fashion=True)
123 | ```
124 | * Repeat step 5 to run the source code file
125 |
126 | 7. To demo on incorrectly labeled images, uncomment the line `demo_wrong(W, b, fashion=False)` and comment all the other function calls (of course, the `fashion`variable can be set `True` or `False` depending if you want to demo on the fashion or the handwritten digits images). Then, repeat step 5 to run the source code.
127 |
128 | 8. To verify the model performance on train and test set, respectively, uncomment the following lines (and comment all the other function calls).
129 |
130 | ```python
131 | print(set_performance(X_train, Y_train, W, b))
132 | print(set_performance(X_test, Y_test, W, b))
133 | ```
134 |
135 | Repeat step 5 to run the source code
136 |
137 | 9. To visualize each of the individual layers' activations, uncomment the function `demo_all_layers(W, b)` and comment the rest function calls. Repeat step 5 to run the source code.
138 |
139 | 10. To re-train it from the trained weights, uncomment the function `gradient_descent(W, b, keep_prob=.7, lbd =.03, learning_rate=0.001)` and comment the rest function calls. You can use your own set of hyperparameters to train the neural network or tune it yourself if you want.
140 |
141 | If you want to train from scratch, delete the weights file first before training (though it may take quite a long time to train): `mnist_trained_weights_deep.dat` for the MNIST handwritten digits dataset or `fashion_mnist_trained_weights_deep.dat` for the MNIST fashion dataset.
142 |
143 | You can also train it using a different algorithm like standard gradient descent or gradient descent with momentum, instead of Adam, by modifying the initialization and parameters update function calls in the `gradient descent()` function. For example, the update function of standard gradient descent is `update_para(W, b, dW, db, learning_rate)` and gradient descent with momentum is `update_para_momentum(W, b, dW, db, VdW, Vdb, epoch_num, learning_rate, beta1)`.
144 |
145 |
146 |
147 | ## Results of pretrained weights
148 |
149 | * On the MNIST handwritten digits dataset
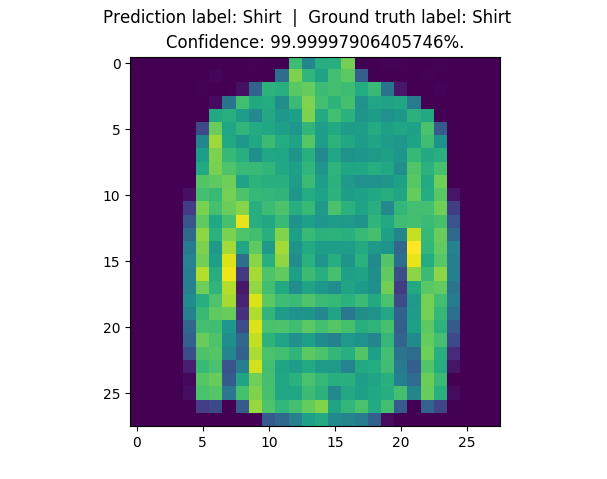
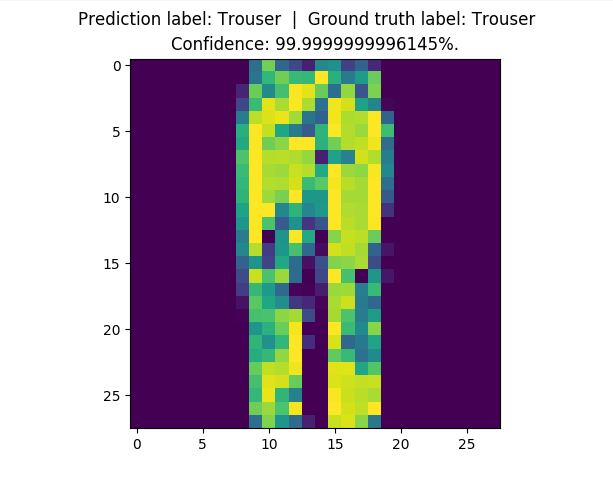
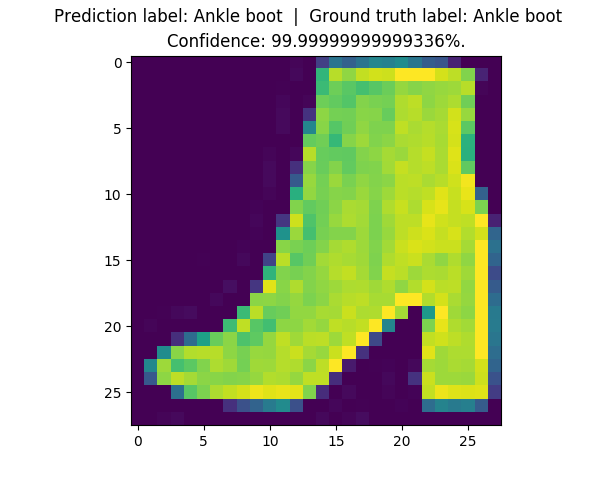
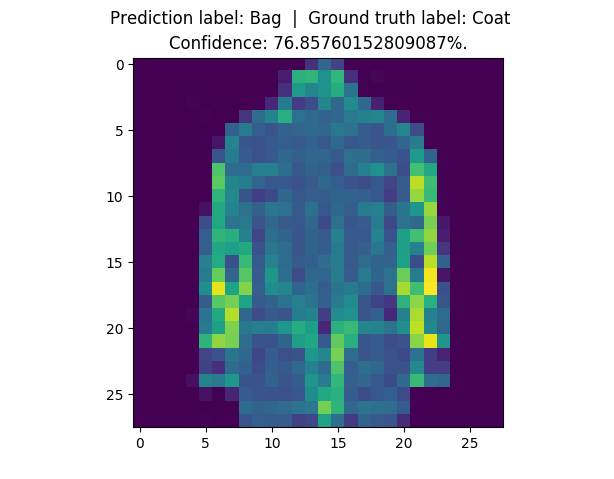
150 |
151 | Training set accuracy: 99.99833%.
152 |
153 | Test set accuracy: 98.09%.
154 |
155 | * On the MNIST fashion dataset
156 |
157 | Training set accuracy: 99.39%.
158 |
159 | Test set accuracy: 89.24%.
160 |
161 |
162 | You can train it for a longer period, and/or adjust the hyperparameters, to get better performance.
163 |
164 |
165 |
166 | Here are the results on some example images on the handwritten digits dataset:
167 |
168 |
169 | 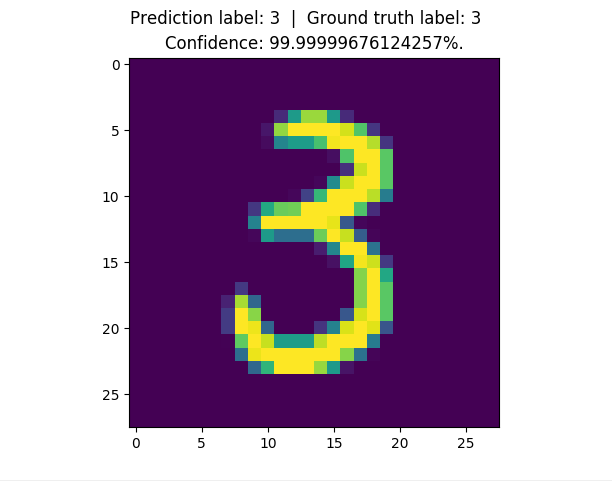 170 |
170 | 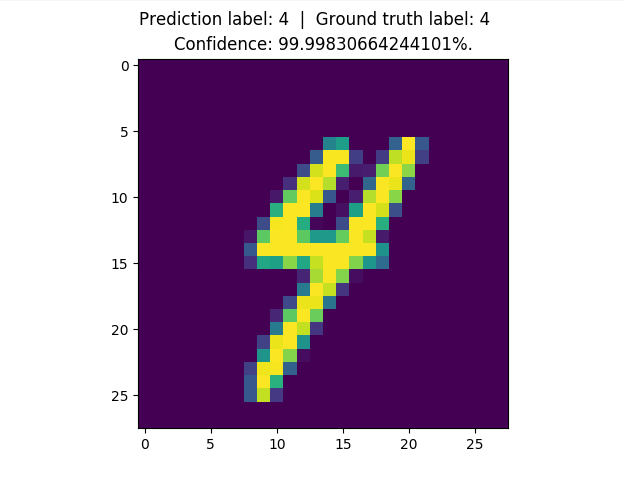 171 |
171 |
172 |
173 | 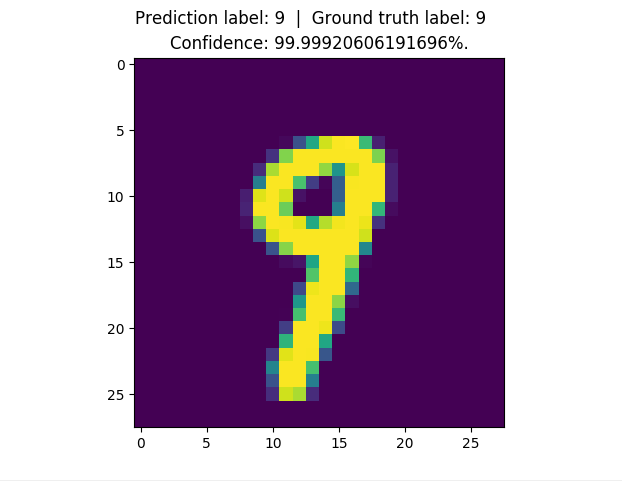 174 |
174 | 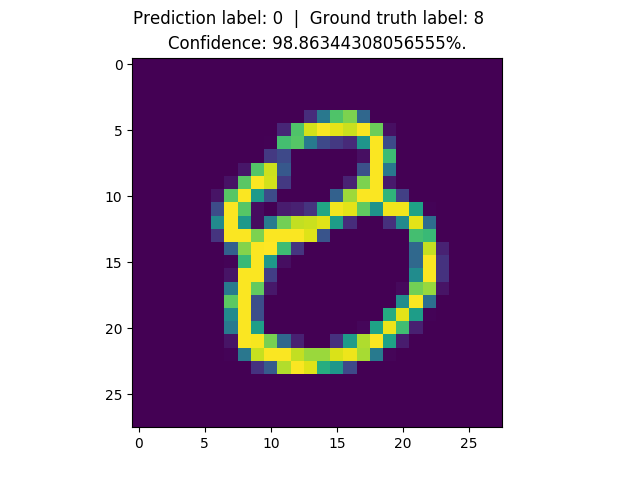 175 |
175 |
176 |
177 | And here are some on the fashion dataset:
178 |
179 |
180 |
181 |
182 |
183 |
184 |
185 |
186 |
187 |
188 |