├── .havenignore
├── src
├── __init__.py
├── datasets
│ ├── utils.py
│ ├── color_matching.py
│ ├── extract_baselines.py
│ ├── preprocess_Waymo.py
│ ├── __init__.py
│ └── waymo_od.py
├── renderer
│ ├── metrics.py
│ └── losses.py
├── pointLF
│ ├── feature_mapping.py
│ ├── pointLF_helper.py
│ ├── ptlf_vis.py
│ ├── light_field_renderer.py
│ ├── layer.py
│ ├── pointcloud_encoding
│ │ ├── simpleview.py
│ │ └── pointnet_features.py
│ ├── scene_point_lightfield.py
│ ├── attention_modules.py
│ └── icp
│ │ └── pts_registration.py
├── scenes
│ ├── nodes.py
│ ├── raysampler
│ │ ├── frustum_helpers.py
│ │ └── rayintersection.py
│ └── init_detection.py
├── utils_dist.py
└── utils.py
├── scripts
├── vis.gif
└── tst_waymo.py
├── exp_configs
├── __init__.py
└── pointLF_exps.py
├── LICENSE
├── .gitignore
├── README.md
└── trainval.py
/.havenignore:
--------------------------------------------------------------------------------
1 | .tmp
--------------------------------------------------------------------------------
/src/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/scripts/vis.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/princeton-computational-imaging/neural-point-light-fields/HEAD/scripts/vis.gif
--------------------------------------------------------------------------------
/exp_configs/__init__.py:
--------------------------------------------------------------------------------
1 | from . import pointLF_exps
2 |
3 | EXP_GROUPS = {}
4 | EXP_GROUPS.update(pointLF_exps.EXP_GROUPS)
5 |
--------------------------------------------------------------------------------
/src/datasets/utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | def invert_transformation(rot, t):
4 | t = np.matmul(-rot.T, t)
5 | inv_translation = np.concatenate([rot.T, t[:, None]], axis=1)
6 | return np.concatenate([inv_translation, np.array([[0., 0., 0., 1.]])])
7 |
8 | def roty_matrix(roty):
9 | c = np.cos(roty)
10 | s = np.sin(roty)
11 | return np.array([[c, 0, s], [0, 1, 0], [-s, 0, c]])
12 |
13 |
14 | def rotz_matrix(roty):
15 | c = np.cos(roty)
16 | s = np.sin(roty)
17 | return np.array([[c, -s, 0], [s, c, 0], [0, 0, 1]])
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2022 princeton-computational-imaging
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/src/renderer/metrics.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | import torch.nn as nn
4 | from ..scenes import NeuralScene
5 | from pytorch3d.renderer.implicit.utils import RayBundle
6 |
7 |
8 | def calc_mse(x: torch.Tensor, y: torch.Tensor, **kwargs):
9 | return torch.mean((x - y) ** 2)
10 |
11 |
12 | def calc_psnr(x: torch.Tensor, y: torch.Tensor, **kwargs):
13 | mse = calc_mse(x, y)
14 | psnr = -10.0 * torch.log10(mse)
15 | return psnr
16 |
17 |
18 | def calc_latent_dist(xycfn, scene, reg, **kwargs):
19 | trainable_latent_nodes_id = scene.getSceneIdByTypeId(list(scene.nodes['scene_object'].keys()))
20 |
21 | # Remove "non"-nodes from the rays
22 | latent_nodess_id = xycfn[..., 4].unique().tolist()
23 | try:
24 | latent_nodess_id.remove(-1)
25 | except:
26 | pass
27 |
28 | # Just include nodes that have latent arrays
29 | # TODO: Do that for each class separatly
30 | latent_nodess_id = set(trainable_latent_nodes_id) & set(latent_nodess_id)
31 |
32 | if len(latent_nodess_id) != 0:
33 | latent_codes = torch.stack([scene.getNodeBySceneId(i).latent for i in latent_nodess_id])
34 | latent_dist = torch.sum(reg * torch.norm(latent_codes, dim=-1))
35 | else:
36 | latent_dist = torch.tensor(0.)
37 |
38 | return latent_dist
39 |
40 |
41 | def get_rgb_gt(rgb: torch.Tensor, scene: NeuralScene, xycfn: torch.Tensor):
42 | xycf = xycfn[..., -1, :4].reshape(len(rgb), -1)
43 | rgb_gt = torch.zeros_like(rgb)
44 |
45 | # TODO: Make more efficient by not retriving image for each pixel,
46 | # but storing all gt_images in a single tensor on the cpu
47 | # TODO: During test time just get all images avilable
48 | for f in xycf[:, 3].unique():
49 | if f == -1:
50 | continue
51 | frame = scene.frames[int(f)]
52 | for c in xycf[:, 2].unique():
53 | cf_mask = torch.all(xycf[:, 2:] == torch.tensor([c, f], device=xycf.device), dim=1)
54 | xy = xycf[cf_mask, :2].cpu()
55 |
56 | c_id = scene.getNodeBySceneId(int(c)).type_idx
57 | gt_img = frame.images[c_id]
58 | gt_px = torch.from_numpy(gt_img[xy[:, 1], xy[:, 0]]).to(device=rgb.device, dtype=rgb.dtype)
59 | rgb_gt[cf_mask] = gt_px
60 |
61 | return rgb_gt
--------------------------------------------------------------------------------
/src/datasets/color_matching.py:
--------------------------------------------------------------------------------
1 | # https://stackoverflow.com/questions/56918877/color-match-in-images
2 | import numpy as np
3 | import cv2
4 | from skimage.io import imread, imsave
5 | from skimage import exposure
6 | from skimage.exposure import match_histograms
7 |
8 | import matplotlib.pyplot as plt
9 |
10 |
11 | # https://www.pyimagesearch.com/2014/06/30/super-fast-color-transfer-images/
12 | def color_transfer(source, target):
13 | source = cv2.normalize(source, None, 0, 255, cv2.NORM_MINMAX, cv2.CV_8U)
14 | target = cv2.normalize(target, None, 0, 255, cv2.NORM_MINMAX, cv2.CV_8U)
15 | source = cv2.cvtColor(source, cv2.COLOR_RGB2BGR)
16 | target = cv2.cvtColor(target, cv2.COLOR_RGB2BGR)
17 |
18 | # convert the images from the RGB to L*ab* color space, being
19 | # sure to utilizing the floating point data type (note: OpenCV
20 | # expects floats to be 32-bit, so use that instead of 64-bit)
21 | source = cv2.cvtColor(source, cv2.COLOR_BGR2LAB).astype("float32")
22 | target = cv2.cvtColor(target, cv2.COLOR_BGR2LAB).astype("float32")
23 |
24 | # compute color statistics for the source and target images
25 | (lMeanSrc, lStdSrc, aMeanSrc, aStdSrc, bMeanSrc, bStdSrc) = image_stats(source)
26 | (lMeanTar, lStdTar, aMeanTar, aStdTar, bMeanTar, bStdTar) = image_stats(target)
27 | # subtract the means from the target image
28 | (l, a, b) = cv2.split(target)
29 | l -= lMeanTar
30 | # a -= aMeanTar
31 | # b -= bMeanTar
32 | # scale by the standard deviations
33 | l = (lStdTar / lStdSrc) * l
34 | # a = (aStdTar / aStdSrc) * a
35 | # b = (bStdTar / bStdSrc) * b
36 | # add in the source mean
37 | l += lMeanSrc
38 | # a += aMeanSrc
39 | # b += bMeanSrc
40 | # clip the pixel intensities to [0, 255] if they fall outside
41 | # this range
42 | l = np.clip(l, 0, 255)
43 | a = np.clip(a, 0, 255)
44 | b = np.clip(b, 0, 255)
45 | # merge the channels together and convert back to the RGB color
46 | # space, being sure to utilize the 8-bit unsigned integer data
47 | # type
48 | transfer = cv2.merge([l, a, b])
49 | transfer = cv2.cvtColor(transfer.astype("uint8"), cv2.COLOR_LAB2BGR)
50 |
51 | # return the color transferred image
52 | transfer = cv2.cvtColor(transfer, cv2.COLOR_BGR2RGB).astype("float32") / 255.
53 | return transfer
54 |
55 |
56 | def image_stats(image):
57 | # compute the mean and standard deviation of each channel
58 | (l, a, b) = cv2.split(image)
59 | (lMean, lStd) = (l.mean(), l.std())
60 | (aMean, aStd) = (a.mean(), a.std())
61 | (bMean, bStd) = (b.mean(), b.std())
62 | # return the color statistics
63 | return (lMean, lStd, aMean, aStd, bMean, bStd)
64 |
65 |
66 | def histogram_matching(source, target):
67 | matched = match_histograms(target, source, multichannel=False)
68 | return matched
--------------------------------------------------------------------------------
/src/pointLF/feature_mapping.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 | import numpy as np
5 |
6 |
7 | # Positional Encoding
8 | class PositionalEncoding(nn.Module):
9 | def __init__(self, multires, input_dims=3, include_input=True, log_sampling=True):
10 |
11 | super().__init__()
12 | self.embed_fns = []
13 | self.out_dims = 0
14 |
15 | if include_input:
16 | self.embed_fns.append(lambda x: x)
17 | self.out_dims += input_dims
18 |
19 | max_freq = multires - 1
20 | N_freqs = multires
21 |
22 | if log_sampling:
23 | freq_bands = 2.0 ** torch.linspace(0.0, max_freq, steps=N_freqs)
24 | else:
25 | freq_bands = torch.linspace(2.0 ** 0.0, 2.0 ** max_freq, steps=N_freqs)
26 |
27 | for freq in freq_bands:
28 | for periodic_fn in [torch.sin, torch.cos]:
29 | self.embed_fns.append(
30 | lambda x, periodic_fn=periodic_fn, freq=freq: periodic_fn(x * freq)
31 | )
32 | self.out_dims += input_dims
33 |
34 | def forward(self, x: torch.Tensor):
35 | return torch.cat([fn(x) for fn in self.embed_fns], -1)
36 |
37 |
38 | # Positional Encoding Old (section 5.1)
39 | class Embedder:
40 | def __init__(self, **kwargs):
41 | self.kwargs = kwargs
42 | self.create_embedding_fn()
43 |
44 | def create_embedding_fn(self):
45 | embed_fns = []
46 | d = self.kwargs["input_dims"]
47 | out_dim = 0
48 | if self.kwargs["include_input"]:
49 | embed_fns.append(lambda x: x)
50 | out_dim += d
51 |
52 | max_freq = self.kwargs["max_freq_log2"]
53 | N_freqs = self.kwargs["num_freqs"]
54 |
55 | if self.kwargs["log_sampling"]:
56 | freq_bands = 2.0 ** torch.linspace(0.0, max_freq, steps=N_freqs)
57 | else:
58 | freq_bands = torch.linspace(2.0 ** 0.0, 2.0 ** max_freq, steps=N_freqs)
59 |
60 | for freq in freq_bands:
61 | for p_fn in self.kwargs["periodic_fns"]:
62 | embed_fns.append(lambda x, p_fn=p_fn, freq=freq: p_fn(x * freq))
63 | out_dim += d
64 |
65 | self.embed_fns = embed_fns
66 | self.out_dim = out_dim
67 |
68 | def embed(self, inputs):
69 | return torch.cat([fn(inputs) for fn in self.embed_fns], -1)
70 |
71 |
72 | def get_embedder(multires, i=0, input_dims=3):
73 | if i == -1:
74 | return nn.Identity(), input_dims
75 |
76 | embed_kwargs = {
77 | "include_input": True,
78 | "input_dims": input_dims,
79 | "max_freq_log2": multires - 1,
80 | "num_freqs": multires,
81 | "log_sampling": True,
82 | "periodic_fns": [torch.sin, torch.cos],
83 | }
84 |
85 | embedder_obj = Embedder(**embed_kwargs)
86 | embed = lambda x, eo=embedder_obj: eo.embed(x)
87 | return embed, embedder_obj.out_dim
88 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | '# Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 | .tmp/*
6 | .tmp
7 | data/*
8 | job_config.py
9 | *.png
10 | /pretrained_models/
11 | conda-spec-file-julian.txt
12 | example_weights/*
13 | # C extensions
14 | *.so
15 | results/*
16 | .results/
17 | # Distribution / packaging
18 | .Python
19 | build/
20 | develop-eggs/
21 | dist/
22 | downloads/
23 | eggs/
24 | .eggs/
25 | lib/
26 | lib64/
27 | parts/
28 | sdist/
29 | var/
30 | wheels/
31 | pip-wheel-metadata/
32 | share/python-wheels/
33 | *.egg-info/
34 | .installed.cfg
35 | *.egg
36 | MANIFEST
37 |
38 | # PyInstaller
39 | # Usually these files are written by a python script from a template
40 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
41 | *.manifest
42 | *.spec
43 |
44 | # Installer logs
45 | pip-log.txt
46 | pip-delete-this-directory.txt
47 |
48 | # Unit test / coverage reports
49 | htmlcov/
50 | .tox/
51 | .nox/
52 | .coverage
53 | .coverage.*
54 | .cache
55 | nosetests.xml
56 | coverage.xml
57 | *.cover
58 | *.py,cover
59 | .hypothesis/
60 | .pytest_cache/
61 |
62 | # Translations
63 | *.mo
64 | *.pot
65 |
66 | # Django stuff:
67 | *.log
68 | local_settings.py
69 | db.sqlite3
70 | db.sqlite3-journal
71 |
72 | # Flask stuff:
73 | instance/
74 | .webassets-cache
75 |
76 | # Scrapy stuff:
77 | .scrapy
78 |
79 | # Sphinx documentation
80 | docs/_build/
81 |
82 | # PyBuilder
83 | target/
84 |
85 | # Jupyter Notebook
86 | .ipynb_checkpoints
87 |
88 | # IPython
89 | profile_default/
90 | ipython_config.py
91 |
92 | # pyenv
93 | .python-version
94 |
95 | # pipenv
96 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
97 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
98 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
99 | # install all needed dependencies.
100 | #Pipfile.lock
101 |
102 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
103 | __pypackages__/
104 |
105 | # Celery stuff
106 | celerybeat-schedule
107 | celerybeat.pid
108 |
109 | # SageMath parsed files
110 | *.sage.py
111 |
112 | # Environments
113 | .env
114 | .venv
115 | env/
116 | venv/
117 | ENV/
118 | env.bak/
119 | venv.bak/
120 |
121 | # Spyder project settings
122 | .spyderproject
123 | .spyproject
124 |
125 | # Rope project settings
126 | .ropeproject
127 |
128 | # mkdocs documentation
129 | /site
130 |
131 | # mypy
132 | .mypy_cache/
133 | .dmypy.json
134 | dmypy.json
135 |
136 | # Pyre type checker
137 | .pyre/
138 |
139 | *.pyc
140 | *#*
141 | *.pyx
142 | *.record
143 | *.tar.gz
144 | *.tar
145 | *.swp
146 | *.npy
147 | *.ckpt*
148 | *.idea*
149 | axcana.egg-info
150 | .vscode
151 | .idea
152 | *.blg
153 | *.gz
154 | *.avi
155 | main.log
156 | main.aux
157 | main.bbl
158 | main.brf
159 | main.pdf
160 | *.log
161 | *.aux
162 | *.bbl
163 | *.brf
164 | mainSup.pdf
165 | egrebuttal.pdf
166 | .tmp/*
167 | /results/
168 | /results/
169 |
170 | /model_library/
171 | old_model/
172 | /.tmp/
173 | /src/datasets/eos_dataset_src/
174 |
--------------------------------------------------------------------------------
/src/pointLF/pointLF_helper.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 |
5 | def pre_scale_MV(x, translation=-1.4):
6 | batchsize = x.size()[0]
7 | scaled_x = x
8 |
9 | for k in range(batchsize):
10 | for i in range(3):
11 | max = scaled_x[k, ..., i].max()
12 | min = scaled_x[k, ..., i].sort()[0][10]
13 | ax_size = max - min
14 | scaled_x[k, ..., i] -= min
15 | scaled_x[k, ..., i] *= 2 / ax_size
16 | scaled_x[k, ..., i] -= 1.
17 |
18 | scaled_x = torch.minimum(scaled_x, torch.tensor([1.], device='cuda'))
19 | scaled_x = torch.maximum(scaled_x, torch.tensor([-1.], device='cuda'))
20 |
21 | # scaled_x[:, 0] = torch.tensor([-1.0, -1.0, -1.0], device=scaled_x.device)
22 | # scaled_x[:, 1] = torch.tensor([1.0, -1.0, -1.0], device=scaled_x.device)
23 | # scaled_x[:, 2] = torch.tensor([-1.0, 1.0, -1.0], device=scaled_x.device)
24 | # scaled_x[:, 3] = torch.tensor([1.0, 1.0, -1.0], device=scaled_x.device)
25 | # scaled_x[:, 4] = torch.tensor([-1.0, -1.0, 1.0], device=scaled_x.device)
26 | # scaled_x[:, 5] = torch.tensor([-1.0, 1.0, 1.0], device=scaled_x.device)
27 | # scaled_x[:, 6] = torch.tensor([1.0, -1.0, 1.0], device=scaled_x.device)
28 | # scaled_x[:, 7] = torch.tensor([1.0, 1.0, 1.0], device=scaled_x.device)
29 |
30 | scaled_x *= 1 / -translation
31 |
32 | # scaled_plt = scaled_x[0].cpu().detach().numpy()
33 | # fig3d = plt.figure()
34 | # ax3d = fig3d.gca(projection='3d')
35 | # ax3d.scatter(scaled_plt[:, 0], scaled_plt[:, 1], scaled_plt[:, 2], c='blue')
36 |
37 | return scaled_x
38 |
39 |
40 | def select_Mv_feat(feature_maps, scaled_pts, closest_mask, batchsize, k_closest, feature_extractor, img_resolution=128,
41 | feature_resolution=16):
42 | feat2img_f = img_resolution // feature_resolution
43 |
44 | # n_feat_maps, batchsize, n_features, feat_heigth, feat_width = feature_maps.shape
45 | n_batch, maps_per_batch, n_features, feat_heigth, feat_width = feature_maps.shape
46 | n_feat_maps = maps_per_batch * n_batch
47 | feature_maps = feature_maps.reshape(n_feat_maps, n_features, feat_heigth, feat_width)
48 |
49 | # Only retrive pts_feat for relevant points
50 | masked_scaled_pts = [sc_x[mask] for (sc_x, mask) in zip(scaled_pts, closest_mask)]
51 | masked_scaled_pts = torch.stack(masked_scaled_pts).view(n_batch, -1, 3)
52 |
53 | # Get coordinates in the feautre maps for each point
54 | coordinates, coord_x, coord_y, depth = feature_extractor._get_img_coord(masked_scaled_pts, resolution=img_resolution)
55 |
56 | # Adjust for downscaled feature maps
57 | coord_x = torch.round(coord_x.view(n_feat_maps, -1, k_closest) / feat2img_f).to(torch.long)
58 | coord_x = torch.minimum(coord_x, torch.tensor([feat_heigth - 1], device=coord_x.device))
59 | coord_y = torch.round(coord_y.view(n_feat_maps, -1, k_closest) / feat2img_f).to(torch.long)
60 | coord_y = torch.minimum(coord_y, torch.tensor([feat_width - 1], device=coord_x.device))
61 |
62 | # depth = depth.view(n_batch, maps_per_batch, -1, k_closest)
63 |
64 | # Extract features for each ray and k closest points
65 | feature_maps = feature_maps.permute(0, 2, 3, 1)
66 | pts_feat = torch.stack([feature_maps[i][tuple([coord_x[i], coord_y[i]])] for i in range(n_feat_maps)])
67 | pts_feat = pts_feat.reshape(n_batch, maps_per_batch, -1, k_closest, n_features)
68 | pts_feat = pts_feat.permute(0, 2, 3, 1, 4)
69 | # Sum all pts_feat from all feature maps
70 | # pts_feat = pts_feat.sum(dim=1)
71 | # pts_feat = torch.max(pts_feat, dim=1)[0]
72 |
73 | return pts_feat
74 |
75 |
76 | def lin_weighting(z, distance, projected, my=0.9):
77 |
78 |
79 | inv_pt_ray_dist = torch.div(1, distance)
80 | pt_ray_dist_weights = inv_pt_ray_dist / torch.norm(inv_pt_ray_dist, dim=-1)[..., None]
81 |
82 | inv_proj_dist = torch.div(1, projected)
83 | pt_proj_dist_weights = inv_proj_dist / torch.norm(inv_proj_dist, dim=-1)[..., None]
84 |
85 | z = z * (my * pt_ray_dist_weights + (1-my) * pt_proj_dist_weights)[..., None, None]
86 |
87 | return torch.sum(z, dim=2)
--------------------------------------------------------------------------------
/scripts/tst_waymo.py:
--------------------------------------------------------------------------------
1 | import os
2 | import numpy as np
3 |
4 | import matplotlib.pyplot as plt
5 | import matplotlib.patches as patches
6 | from PIL import Image
7 | import tensorflow as tf
8 | from waymo_open_dataset.utils import frame_utils
9 | from waymo_open_dataset import dataset_pb2 as open_dataset
10 | from NeuralSceneGraph.data_loader.load_waymo_od import load_waymo_od_data
11 |
12 |
13 | tf.compat.v1.enable_eager_execution()
14 |
15 | # Plot every i_plt image
16 | i_plt = 1
17 |
18 | start = 50
19 | end = 60
20 |
21 | frames_path = '/home/julian/Desktop/waymo_open/segment-9985243312780923024_3049_720_3069_720_with_camera_labels.tfrecord'
22 | basedir = '/home/julian/Desktop/waymo_open'
23 | img_dir = '/home/julian/Desktop/waymo_open/tst_01'
24 |
25 | cam_ls = ['front', 'front_left', 'front_right']
26 |
27 | records = []
28 | dir_list = os.listdir(basedir)
29 | dir_list.sort()
30 | for f in dir_list:
31 | if 'record' in f:
32 | records.append(os.path.join(basedir, f))
33 |
34 |
35 |
36 | images = load_waymo_od_data(frames_path, selected_frames=[start, end])[0]
37 | for i_record, tf_record in enumerate(records):
38 | dataset = tf.data.TFRecordDataset(tf_record, compression_type='')
39 | print(tf_record)
40 |
41 | for i, data in enumerate(dataset):
42 | if not i % i_plt:
43 | frame = open_dataset.Frame()
44 | frame.ParseFromString(bytearray(data.numpy()))
45 |
46 | for index, camera_image in enumerate(frame.images):
47 | if camera_image.name in [1, 2, 3]:
48 | img_arr = np.array(tf.image.decode_jpeg(camera_image.image))
49 | # plt.imshow(img_arr, cmap=None)
50 |
51 | cam_dir = os.path.join(img_dir, cam_ls[camera_image.name-1])
52 | im_name = 'img_' + str(i_record) + '_' + str(i) + '.jpg'
53 | im = Image.fromarray(img_arr)
54 | im.save(os.path.join(cam_dir, im_name))
55 |
56 | # frames = []
57 | # max_frames=10
58 | # i_plt = 100
59 | #
60 | # for i, data in enumerate(dataset):
61 | # if not i % i_plt:
62 | # frame = open_dataset.Frame()
63 | # frame.ParseFromString(bytearray(data.numpy()))
64 | #
65 | # for index, camera_image in enumerate(frame.images):
66 | # if camera_image.name in [1, 2, 3]:
67 | # plt.imshow(tf.image.decode_jpeg(camera_image.image), cmap=None)
68 |
69 | # layout = [3, 3, index+1]
70 | # ax = plt.subplot(*layout)
71 | #
72 | # plt.imshow(tf.image.decode_jpeg(camera_image.image), cmap=None)
73 | # plt.title(open_dataset.CameraName.Name.Name(camera_image.name))
74 | # plt.grid(False)
75 | # plt.axis('off')
76 |
77 | # frames.append(frame)
78 | # if i >= max_frames-1:
79 | # break
80 |
81 | # frame = frames[0]
82 |
83 | (range_images, camera_projections, range_image_top_pose) = (
84 | frame_utils.parse_range_image_and_camera_projection(frame))
85 |
86 | print(frame.context)
87 |
88 | def show_camera_image(camera_image, camera_labels, layout, cmap=None):
89 | """Show a camera image and the given camera labels."""
90 |
91 | ax = plt.subplot(*layout)
92 |
93 | # Draw the camera labels.
94 | for camera_labels in frame.camera_labels:
95 | # Ignore camera labels that do not correspond to this camera.
96 | if camera_labels.name != camera_image.name:
97 | continue
98 |
99 | # Iterate over the individual labels.
100 | for label in camera_labels.labels:
101 | # Draw the object bounding box.
102 | ax.add_patch(patches.Rectangle(
103 | xy=(label.box.center_x - 0.5 * label.box.length,
104 | label.box.center_y - 0.5 * label.box.width),
105 | width=label.box.length,
106 | height=label.box.width,
107 | linewidth=1,
108 | edgecolor='red',
109 | facecolor='none'))
110 |
111 | # Show the camera image.
112 | plt.imshow(tf.image.decode_jpeg(camera_image.image), cmap=cmap)
113 | plt.title(open_dataset.CameraName.Name.Name(camera_image.name))
114 | plt.grid(False)
115 | plt.axis('off')
116 |
117 | plt.figure(figsize=(25, 20))
118 |
119 | for index, image in enumerate(frame.images):
120 | show_camera_image(image, frame.camera_labels, [3, 3, index+1])
121 |
122 |
123 | a = 0
--------------------------------------------------------------------------------
/src/pointLF/ptlf_vis.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | import matplotlib.pyplot as plt
4 | import open3d as o3d
5 | from sklearn.manifold import TSNE
6 |
7 |
8 | def plt_pts_selected_2D(output_dict, axis):
9 | selected_points = [pts[mask] for pts, mask in
10 | zip(output_dict['points_in'], output_dict['closest_mask_in'])]
11 |
12 | for l, cf in enumerate(output_dict['samples']):
13 | plt_pts = selected_points[l].reshape(-1, 3)
14 | all_pts = output_dict['points_in'][l]
15 |
16 | plt.figure()
17 | plt.scatter(all_pts[:, axis[0]], all_pts[:, axis[1]])
18 | plt.scatter(plt_pts[:, axis[0]], plt_pts[:, axis[1]])
19 |
20 | if 'points_scaled' in output_dict:
21 | selected_points = [pts[mask] for pts, mask in
22 | zip(output_dict['points_scaled'], output_dict['closest_mask_in'])]
23 | for l, cf in enumerate(output_dict['samples']):
24 | plt_pts = selected_points[l].reshape(-1, 3)
25 | all_pts = output_dict['points_scaled'][l]
26 |
27 | plt.figure()
28 | plt.scatter(all_pts[:, axis[0]], all_pts[:, axis[1]])
29 | plt.scatter(plt_pts[:, axis[0]], plt_pts[:, axis[1]])
30 |
31 | def plt_BEV_pts_selected(output_dict):
32 | plt_pts_selected_2D(output_dict, (0,1))
33 |
34 | def plt_SIDE_pts_selected(output_dict):
35 | plt_pts_selected_2D(output_dict, (0, 2))
36 |
37 | def plt_FRONT_pts_selected(output_dict):
38 | plt_pts_selected_2D(output_dict, (1, 2))
39 |
40 | def visualize_output(output_dict, selected_only=False, scaled=False, n_plt_rays=None):
41 | if scaled:
42 | pts_in = output_dict['points_scaled']
43 | else:
44 | pts_in = output_dict['points_in']
45 |
46 | masks_in = output_dict['closest_mask_in']
47 |
48 | if 'sum_mv_point_features' in output_dict:
49 | feat_per_point = output_dict['sum_mv_point_features'].squeeze()
50 | if len(feat_per_point.shape) == 4:
51 | n_batch, n_rays, n_closest_pts, feat_dim = feat_per_point.shape
52 | else:
53 | n_batch = 1
54 | n_rays, n_closest_pts, feat_dim = feat_per_point.shape
55 |
56 | for i, (pts, mask, feat) in enumerate(zip(pts_in, masks_in, feat_per_point)):
57 |
58 | # Get feature embedding for visualization
59 | feat = feat.reshape(-1, feat_dim)
60 | feat_embedded = TSNE(n_components=3).fit_transform(feat)
61 |
62 | # Transform embedded space to RGB
63 | feat_embedded = feat_embedded - feat_embedded.min(axis=0)
64 | color = feat_embedded / feat_embedded.max(axis=0)
65 |
66 | if n_plt_rays is not None:
67 | ray_ids = np.random.choice(len(mask), n_plt_rays)
68 | mask = mask[ray_ids]
69 | color = color.reshape(n_rays, n_closest_pts, 3)
70 | color = color[ray_ids].reshape(-1, 3)
71 |
72 | pts_close = pts[mask]
73 | pcd_close = get_pcd_vis(pts_close, color_vector=color)
74 | if selected_only:
75 | o3d.visualization.draw_geometries([pcd_close])
76 | else:
77 | pcd = get_pcd_vis(pts)
78 | o3d.visualization.draw_geometries([pcd, pcd_close])
79 | else:
80 | for i, (pts, mask) in enumerate(zip(pts_in, masks_in)):
81 | pts_close = pts[mask]
82 | pcd_close = get_pcd_vis(pts, uniform_color=[1., 0.7, 0.])
83 |
84 | if selected_only:
85 | o3d.visualization.draw_geometries([pcd_close])
86 | else:
87 | pcd = get_pcd_vis(pts)
88 | o3d.visualization.draw_geometries([pcd, pcd_close])
89 |
90 | def get_pcd_vis(pts, uniform_color=None, color_vector=None):
91 | pts = pts.reshape(-1,3)
92 | pcd = o3d.geometry.PointCloud()
93 | pcd.points = o3d.utility.Vector3dVector(pts)
94 | if uniform_color is not None:
95 | # pcd.paint_uniform_color([1., 0.7, 0.])
96 | pcd.paint_uniform_color(uniform_color)
97 | if color_vector is not None:
98 | assert len(pts) == len(color_vector)
99 | pcd.colors = o3d.utility.Vector3dVector(color_vector)
100 |
101 | return pcd
102 |
103 |
104 |
105 | # pts_in_name = ".tmp/points_in_{}.ply".format(i)
106 | # o3d.io.write_point_cloud(pts_in_name, pcd)
107 | # pcd = o3d.io.read_point_cloud(pts_in_name)
--------------------------------------------------------------------------------
/src/scenes/nodes.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | import torch.nn as nn
4 | from pytorch3d.renderer import PerspectiveCameras
5 | from src.pointLF.point_light_field import PointLightField
6 | from pytorch3d.transforms.rotation_conversions import euler_angles_to_matrix
7 |
8 | DEVICE = "cpu"
9 | TRAINCAM = False
10 | TRAINOBJSZ = False
11 | TRAINOBJ = False
12 |
13 |
14 | class Intrinsics:
15 | def __init__(
16 | self,
17 | H,
18 | W,
19 | focal,
20 | P=None
21 | ):
22 | self.H = int(H)
23 | self.W = int(W)
24 | if np.size(focal) == 1:
25 | self.f_x = nn.Parameter(
26 | torch.tensor(focal, device=DEVICE, requires_grad=TRAINCAM)
27 | )
28 | self.f_y = nn.Parameter(
29 | torch.tensor(focal, device=DEVICE, requires_grad=TRAINCAM)
30 | )
31 | else:
32 | self.f_x = nn.Parameter(
33 | torch.tensor(focal[0], device=DEVICE, requires_grad=TRAINCAM)
34 | )
35 | self.f_y = nn.Parameter(
36 | torch.tensor(focal[1], device=DEVICE, requires_grad=TRAINCAM)
37 | )
38 |
39 | self.P = P
40 |
41 |
42 | class NeuralCamera(PerspectiveCameras):
43 | def __init__(self, h, w, f, intrinsics=None, name=None, type=None, P=None):
44 | # TODO: Cleanup intrinsics and h, w, f
45 | # TODO: Add P matrix for projection
46 | self.H = h
47 | self.W = w
48 | if intrinsics is None:
49 | self.intrinsics = Intrinsics(h, w, f, P)
50 | else:
51 | self.intrinsics = intrinsics
52 |
53 | # Add opengl2cam rotation
54 | opengl2cam = euler_angles_to_matrix(
55 | torch.tensor([np.pi, np.pi, 0.0], device=DEVICE), "ZYX"
56 | )
57 | if type == 'waymo':
58 | waymo_rot = euler_angles_to_matrix(torch.tensor([np.pi, 0., 0.],
59 | device=DEVICE), 'ZYX')
60 |
61 | opengl2cam = torch.matmul(waymo_rot, opengl2cam)
62 |
63 | # Simplified version under the assumption of square pixels
64 | # [self.intrinsics.f_x, self.intrinsics.f_y]
65 | PerspectiveCameras.__init__(
66 | self,
67 | focal_length=torch.tensor([[self.intrinsics.f_x, self.intrinsics.f_y]]),
68 | principal_point=torch.tensor(
69 | [[self.intrinsics.W / 2, self.intrinsics.H / 2]]
70 | ),
71 | R=opengl2cam,
72 | image_size=torch.tensor([[self.intrinsics.W, self.intrinsics.H]]),
73 | )
74 | self.name = name
75 |
76 |
77 | class Lidar:
78 | def __init__(self, Tr_li2cam=None, name=None):
79 | # TODO: Add all relevant params to scene init
80 | self.sensor_type = 'lidar'
81 | self.li2cam = Tr_li2cam
82 |
83 | self.name = name
84 |
85 |
86 | class ObjectClass:
87 | def __init__(self, name):
88 | self.static = False
89 | self.name = name
90 |
91 |
92 | class SceneObject:
93 | def __init__(self, length, height, width, object_class_node):
94 | self.static = False
95 | self.object_class_type_idx = object_class_node.type_idx
96 | self.object_class_name = object_class_node.name
97 | self.length = length
98 | self.height = height
99 | self.width = width
100 | self.box_size = torch.tensor([self.length, self.height, self.width])
101 |
102 |
103 | class Background:
104 | def __init__(self, transformation=None, near=0.5, far=100.0, lightfield_config={}):
105 | self.static = True
106 | global_transformation = np.eye(4)
107 |
108 | if transformation is not None:
109 | transformation = np.squeeze(transformation)
110 | if transformation.shape == (3, 3):
111 | global_transformation[:3, :3] = transformation
112 | elif transformation.shape == (3):
113 | global_transformation[:3, 3] = transformation
114 | elif transformation.shape == (3, 4):
115 | global_transformation[:3, :] = transformation
116 | elif transformation.shape == (4, 4):
117 | global_transformation = transformation
118 | else:
119 | print(
120 | "Ignoring wolrd transformation, not of shape [3, 3], [3, 4], [3, 1] or [4, 4], but",
121 | transformation.shape,
122 | )
123 |
124 | self.transformation = torch.from_numpy(global_transformation)
125 | self.near = torch.tensor(near)
126 | self.far = torch.tensor(far)
--------------------------------------------------------------------------------
/src/utils_dist.py:
--------------------------------------------------------------------------------
1 | import torch.distributed as dist
2 | import torch
3 | from torch.utils.data import DataLoader, DistributedSampler
4 | from operator import itemgetter
5 |
6 |
7 | class DatasetFromSampler(torch.utils.data.Dataset):
8 | """Dataset to create indexes from `Sampler`.
9 | Args:
10 | sampler: PyTorch sampler
11 | """
12 |
13 | def __init__(self, sampler):
14 | """Initialisation for DatasetFromSampler."""
15 | self.sampler = sampler
16 | self.sampler_list = None
17 |
18 | def __getitem__(self, index: int):
19 | """Gets element of the dataset.
20 | Args:
21 | index: index of the element in the dataset
22 | Returns:
23 | Single element by index
24 | """
25 | if self.sampler_list is None:
26 | self.sampler_list = list(self.sampler)
27 | return self.sampler_list[index]
28 |
29 | def __len__(self) -> int:
30 | """
31 | Returns:
32 | int: length of the dataset
33 | """
34 | return len(self.sampler)
35 |
36 |
37 | class DistributedSamplerWrapper(DistributedSampler):
38 | """
39 | Wrapper over `Sampler` for distributed training.
40 | Allows you to use any sampler in distributed mode.
41 | It is especially useful in conjunction with
42 | `torch.nn.parallel.DistributedDataParallel`. In such case, each
43 | process can pass a DistributedSamplerWrapper instance as a DataLoader
44 | sampler, and load a subset of subsampled data of the original dataset
45 | that is exclusive to it.
46 | .. note::
47 | Sampler is assumed to be of constant size.
48 | """
49 |
50 | def __init__(
51 | self,
52 | sampler,
53 | num_replicas=None,
54 | rank=None,
55 | shuffle: bool = True,
56 | ):
57 | """
58 | Args:
59 | sampler: Sampler used for subsampling
60 | num_replicas (int, optional): Number of processes participating in
61 | distributed training
62 | rank (int, optional): Rank of the current process
63 | within ``num_replicas``
64 | shuffle (bool, optional): If true (default),
65 | sampler will shuffle the indices
66 | """
67 | super(DistributedSamplerWrapper, self).__init__(
68 | DatasetFromSampler(sampler),
69 | num_replicas=num_replicas,
70 | rank=rank,
71 | shuffle=shuffle,
72 | )
73 | self.sampler = sampler
74 |
75 | def __iter__(self):
76 | """@TODO: Docs. Contribution is welcome."""
77 | self.dataset = DatasetFromSampler(self.sampler)
78 | indexes_of_indexes = super().__iter__()
79 | subsampler_indexes = self.dataset
80 | return iter(itemgetter(*indexes_of_indexes)(subsampler_indexes))
81 |
82 |
83 | def setup_for_distributed(is_master):
84 | """
85 | This function disables printing when not in master process
86 | """
87 | import builtins as __builtin__
88 |
89 | builtin_print = __builtin__.print
90 |
91 | def print(*args, **kwargs):
92 | force = kwargs.pop("force", False)
93 | if is_master or force:
94 | builtin_print(*args, **kwargs)
95 |
96 | __builtin__.print = print
97 |
98 |
99 | def is_dist_avail_and_initialized():
100 | if not dist.is_available():
101 | return False
102 | if not dist.is_initialized():
103 | return False
104 | return True
105 |
106 |
107 | def get_world_size():
108 | if not is_dist_avail_and_initialized():
109 | return 1
110 | return dist.get_world_size()
111 |
112 |
113 | def get_rank():
114 | if not is_dist_avail_and_initialized():
115 | return 0
116 | return dist.get_rank()
117 |
118 |
119 | def is_main_process():
120 | return get_rank() == 0
121 |
122 |
123 | def save_on_master(*args, **kwargs):
124 | if is_main_process():
125 | torch.save(*args, **kwargs)
126 |
127 |
128 | import os, torch
129 |
130 |
131 | def init_distributed_mode(args):
132 | if "RANK" in os.environ and "WORLD_SIZE" in os.environ:
133 | args.rank = int(os.environ["RANK"])
134 | args.world_size = int(os.environ["WORLD_SIZE"])
135 | args.gpu = int(os.environ["LOCAL_RANK"])
136 | elif "SLURM_PROCID" in os.environ:
137 | args.rank = int(os.environ["SLURM_PROCID"])
138 | args.gpu = args.rank % torch.cuda.device_count()
139 | else:
140 | print("Not using distributed mode")
141 | args.distributed = False
142 | return
143 |
144 | args.distributed = True
145 |
146 | torch.cuda.set_device(args.gpu)
147 | args.dist_backend = "nccl"
148 | print(
149 | "| distributed init (rank {}): {}".format(args.rank, args.dist_url), flush=True
150 | )
151 | torch.distributed.init_process_group(
152 | backend=args.dist_backend,
153 | init_method=args.dist_url,
154 | world_size=args.world_size,
155 | rank=args.rank,
156 | )
157 | torch.distributed.barrier()
158 | setup_for_distributed(args.rank == 0)
159 |
--------------------------------------------------------------------------------
/src/pointLF/light_field_renderer.py:
--------------------------------------------------------------------------------
1 | from typing import Callable, Tuple, List
2 |
3 | import torch
4 | import torch.nn as nn
5 | import torch.nn.functional as F
6 | import numpy
7 | from pytorch3d.renderer import RayBundle
8 | from ..scenes import NeuralScene
9 |
10 |
11 | class LightFieldRenderer(nn.Module):
12 |
13 | def __init__(self, light_field_module, chunksize: int, cam_centered: bool = False):
14 | super(LightFieldRenderer, self).__init__()
15 |
16 | self.light_field_module = light_field_module
17 | self.chunksize = chunksize
18 | if cam_centered:
19 | self.rotate2cam = True
20 | else:
21 | self.rotate2cam = False
22 |
23 | # def forward(self, frame_idx: int, camera_idx: int, scene: NeuralScene, volumetric_function: Callable, chunk_idx: int, **kwargs):
24 | def forward(self, input_dict, scene, **kwargs):
25 |
26 | ##############
27 | # TODO: Clean Up and move somewhere else
28 | ray_bundle = input_dict['ray_bundle']
29 | device = ray_bundle.origins.device
30 | pts = input_dict['pts']
31 | ray_dirs_select = input_dict['ray_dirs_select']
32 | closest_point_mask = input_dict['closest_point_mask']
33 |
34 | cf_ls = [list(pts_k[0].keys()) for pts_k in pts]
35 | import numpy as np
36 | unique_cf = np.unique(np.concatenate([np.array(cf) for cf in cf_ls]), axis=0)
37 |
38 | pts_to_unpack = {
39 | 0: 'pt_cloud_select',
40 | 1: 'closest_point_dist',
41 | 2: 'closest_point_azimuth',
42 | 3: 'closest_point_pitch',
43 |
44 | }
45 |
46 | if len(unique_cf) != len(cf_ls):
47 | new_cf = [tuple(list(cf[0]) + [j]) for j, cf in enumerate(cf_ls)]
48 |
49 | output_dict = {
50 | new_cf[j]:
51 | v
52 | for j, pt in enumerate(pts) for k, v in pt[4].items()
53 | }
54 |
55 | closest_point_mask = {new_cf[j]: v for j, pt in enumerate(closest_point_mask) for k, v in pt.items()}
56 | ray_dirs_select = {new_cf[j]: v.to(device) for j, pt in enumerate(ray_dirs_select) for k, v in pt.items()}
57 | pts = {
58 | n: {
59 | new_cf[j]:
60 | v.to(device)
61 | for j, pt in enumerate(pts) for k, v in pt[i].items()
62 | }
63 | for i, n in pts_to_unpack.items()
64 | }
65 | pts.update({'output_dict': output_dict})
66 |
67 | a = 0
68 |
69 | else:
70 | output_dict = {
71 | k:
72 | v
73 | for pt in pts for k, v in pt[4].items()
74 | }
75 |
76 | closest_point_mask = {k: v for pt in closest_point_mask for k, v in pt.items()}
77 | ray_dirs_select = {k: v.to(device) for pt in ray_dirs_select for k, v in pt.items()}
78 | pts = {
79 | n: {
80 | k:
81 | v.to(device)
82 | for pt in pts for k, v in pt[i].items()
83 | }
84 | for i, n in pts_to_unpack.items()
85 | }
86 | pts.update({'output_dict': output_dict})
87 | ##################
88 |
89 | images, output_dict = self.light_field_module(
90 | ray_bundle=input_dict['ray_bundle'],
91 | scene=scene,
92 | closest_point_mask=closest_point_mask,
93 | pt_cloud_select=pts['pt_cloud_select'],
94 | closest_point_dist=pts['closest_point_dist'],
95 | closest_point_azimuth=pts['closest_point_azimuth'],
96 | closest_point_pitch=pts['closest_point_pitch'],
97 | output_dict=pts['output_dict'],
98 | ray_dirs_select=ray_dirs_select,
99 | rotate2cam=self.rotate2cam,
100 | **kwargs
101 | )
102 |
103 | if scene.tonemapping:
104 | rgb = torch.zeros_like(images)
105 | tone_mapping_ls = [scene.frames[cf[0][1]].load_tone_mapping(cf[0][0]) for cf in cf_ls]
106 | for i in range(len(images)):
107 | rgb[i] = self.tone_map(images[i], tone_mapping_ls[i])
108 |
109 | else:
110 | rgb = images
111 |
112 | output_dict.update(
113 | {
114 | 'rgb': rgb.view(-1, 3),
115 | 'ray_bundle': ray_bundle._replace(xys=ray_bundle.xys[..., None, :])
116 | }
117 | )
118 |
119 | return output_dict
120 |
121 | def tone_map(self, x, tone_mapping_params):
122 |
123 | x = (tone_mapping_params['contrast'] * (x - 0.5) + \
124 | 0.5 + \
125 | tone_mapping_params['brightness']) * \
126 | torch.cat(list(tone_mapping_params['wht_pt'].values()))
127 | x = self.leaky_clamping(x, gamma=tone_mapping_params['gamma'])
128 |
129 | return x
130 |
131 | def leaky_clamping(self, x, gamma, alpha=0.01):
132 | x[x < 0] = x[x < 0] * alpha
133 | x[x > 1] = (-alpha / x[x > 1]) + alpha + 1.
134 | x[(x > 0.) & (x < 1.)] = x[(x > 0.) & (x < 1.)] ** gamma
135 | return x
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Neural Point Light Fields (CVPR 2022)
2 |
3 | 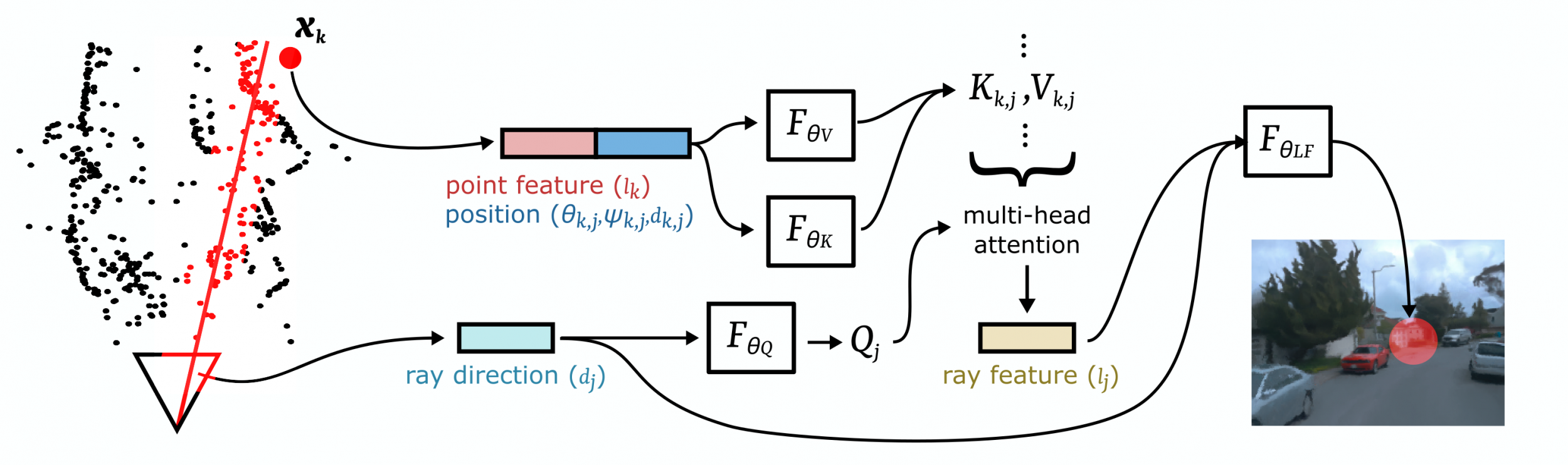 4 |
5 | ### [Project Page](https://light.princeton.edu/publication/neural-point-light-fields)
6 | #### Julian Ost, Issam Laradji, Alejandro Newell, Yuval Bahat, Felix Heide
7 |
8 |
9 | Neural Point Light Fields represent scenes with a light field living on a sparse point cloud. As neural volumetric
10 | rendering methods require dense sampling of the underlying functional scene representation, at hundreds of samples
11 | along with a ray cast through the volume, they are fundamentally limited to small scenes with the same objects
12 | projected to hundreds of training views. Promoting sparse point clouds to neural implicit light fields allows us to
13 | represent large scenes effectively with only a single implicit sampling operation per ray.
14 |
15 | These point light fields are a function of the ray direction, and local point feature neighborhood, allowing us to
16 | interpolate the light field conditioned training images without dense object coverage and parallax. We assess the
17 | proposed method for novel view synthesis on large driving scenarios, where we synthesize realistic unseen views that
18 | existing implicit approaches fail to represent. We validate that Neural Point Light Fields make it possible to predict
19 | videos along unseen trajectories previously only feasible to generate by explicitly modeling the scene.
20 |
21 | ---
22 |
23 | ### Data Preparation
24 | #### Waymo
25 |
26 | 1. Download the compressed data of the Waymo Open Dataset:
27 | [Waymo Validation Tar Files](https://console.cloud.google.com/storage/browser/waymo_open_dataset_v_1_3_1/validation?pageState=(%22StorageObjectListTable%22:(%22f%22:%22%255B%255D%22))&prefix=&forceOnObjectsSortingFiltering=false)
28 |
29 | 2. To run the code as used in the paper, store as follows: `./data/validation/validation_xxxx/segment-xxxxxx`
30 |
31 | 3. Neural Point Light Fields is well tested on the segments mentioned in the [Supplementary](https://light.princeton.edu/wp-content/uploads/2022/04/NeuralPointLightFields-Supplementary.pdf) and shown in the experiment group `pointLF_waymo_server`.
32 |
33 |
34 | 4. Preprocess the data running: `./src/datasets/preprocess_Waymo.py -d "./data/validation/validation_xxxx/segment-xxxxxx" --no_data`
35 |
36 | ---
37 |
38 | ### Requirements
39 |
40 | Environment setup
41 | ```
42 | conda create -n NeuralPointLF python=3.7
43 | conda activate NeuralPointLF
44 | ```
45 | Install required packages
46 | ```
47 | conda install -c pytorch -c conda-forge pytorch=1.7.1 torchvision=0.8.2 cudatoolkit=11.0
48 | conda install -c fvcore -c iopath -c conda-forge fvcore iopath
49 | conda install -c bottler nvidiacub
50 | conda install jupyterlab
51 | pip install scikit-image matplotlib imageio plotly opencv-python
52 | conda install pytorch3d -c pytorch3d
53 | conda install -c open3d-admin -c conda-forge open3d
54 | ```
55 | Add large-scale ML toolkit
56 | ```
57 | pip install --upgrade git+https://github.com/haven-ai/haven-ai
58 | ```
59 |
60 | ---
61 | ### Training and Validation
62 | In the first iteration of a scene, the point clouds will be preprocessed and stored, which might take some time.
63 | If you want to train on unmerged point cloud data set `merge_pcd=False` in the config file.
64 |
65 | Train one specific scene from the Waymo Open data set:
66 | ```
67 | python trainval.py -e pointLF_waymo_server -sb -d ./data/waymo/validation --epoch_size
68 | 100 --num_workers=
69 | ```
70 |
71 | Reconstruct the training path (`--render_only=True`)
72 | ```
73 | python trainval.py -e pointLF_waymo_server -sb -d ./data/waymo/validation --epoch_size
74 | 100 --num_workers= --render_only=True
75 | ```
76 |
77 | Argument Descriptions:
78 | ```
79 | -e [Experiment group to run like 'mushrooms' (the rest of the experiment groups are in exp_configs/sps_exps.py)]
80 | -sb [Directory where the experiments are saved]
81 | -r [Flag for whether to reset the experiments]
82 | -d [Directory where the datasets are aved]
83 | ```
84 |
85 | **_Disclaimer_**: The codebase is optimized to run on larger GPU servers with a lot of free CPU memory.
86 | To test on local and low memory, choose `pointLF_waymo_local` instead of `pointLF_waymo_server`.
87 | Adjustments of batch size, chunk size and number of rays will have an effect on necessary resources.
88 |
89 | ---
90 | ### Visualization of Results
91 |
92 | Follow these steps to visualize plots. Open `results.ipynb`, run the first cell to get a dashboard like in the gif below, click on the "plots" tab, then click on "Display plots". Parameters of the plots can be adjusted in the dashboard for custom visualizations.
93 |
94 |
4 |
5 | ### [Project Page](https://light.princeton.edu/publication/neural-point-light-fields)
6 | #### Julian Ost, Issam Laradji, Alejandro Newell, Yuval Bahat, Felix Heide
7 |
8 |
9 | Neural Point Light Fields represent scenes with a light field living on a sparse point cloud. As neural volumetric
10 | rendering methods require dense sampling of the underlying functional scene representation, at hundreds of samples
11 | along with a ray cast through the volume, they are fundamentally limited to small scenes with the same objects
12 | projected to hundreds of training views. Promoting sparse point clouds to neural implicit light fields allows us to
13 | represent large scenes effectively with only a single implicit sampling operation per ray.
14 |
15 | These point light fields are a function of the ray direction, and local point feature neighborhood, allowing us to
16 | interpolate the light field conditioned training images without dense object coverage and parallax. We assess the
17 | proposed method for novel view synthesis on large driving scenarios, where we synthesize realistic unseen views that
18 | existing implicit approaches fail to represent. We validate that Neural Point Light Fields make it possible to predict
19 | videos along unseen trajectories previously only feasible to generate by explicitly modeling the scene.
20 |
21 | ---
22 |
23 | ### Data Preparation
24 | #### Waymo
25 |
26 | 1. Download the compressed data of the Waymo Open Dataset:
27 | [Waymo Validation Tar Files](https://console.cloud.google.com/storage/browser/waymo_open_dataset_v_1_3_1/validation?pageState=(%22StorageObjectListTable%22:(%22f%22:%22%255B%255D%22))&prefix=&forceOnObjectsSortingFiltering=false)
28 |
29 | 2. To run the code as used in the paper, store as follows: `./data/validation/validation_xxxx/segment-xxxxxx`
30 |
31 | 3. Neural Point Light Fields is well tested on the segments mentioned in the [Supplementary](https://light.princeton.edu/wp-content/uploads/2022/04/NeuralPointLightFields-Supplementary.pdf) and shown in the experiment group `pointLF_waymo_server`.
32 |
33 |
34 | 4. Preprocess the data running: `./src/datasets/preprocess_Waymo.py -d "./data/validation/validation_xxxx/segment-xxxxxx" --no_data`
35 |
36 | ---
37 |
38 | ### Requirements
39 |
40 | Environment setup
41 | ```
42 | conda create -n NeuralPointLF python=3.7
43 | conda activate NeuralPointLF
44 | ```
45 | Install required packages
46 | ```
47 | conda install -c pytorch -c conda-forge pytorch=1.7.1 torchvision=0.8.2 cudatoolkit=11.0
48 | conda install -c fvcore -c iopath -c conda-forge fvcore iopath
49 | conda install -c bottler nvidiacub
50 | conda install jupyterlab
51 | pip install scikit-image matplotlib imageio plotly opencv-python
52 | conda install pytorch3d -c pytorch3d
53 | conda install -c open3d-admin -c conda-forge open3d
54 | ```
55 | Add large-scale ML toolkit
56 | ```
57 | pip install --upgrade git+https://github.com/haven-ai/haven-ai
58 | ```
59 |
60 | ---
61 | ### Training and Validation
62 | In the first iteration of a scene, the point clouds will be preprocessed and stored, which might take some time.
63 | If you want to train on unmerged point cloud data set `merge_pcd=False` in the config file.
64 |
65 | Train one specific scene from the Waymo Open data set:
66 | ```
67 | python trainval.py -e pointLF_waymo_server -sb -d ./data/waymo/validation --epoch_size
68 | 100 --num_workers=
69 | ```
70 |
71 | Reconstruct the training path (`--render_only=True`)
72 | ```
73 | python trainval.py -e pointLF_waymo_server -sb -d ./data/waymo/validation --epoch_size
74 | 100 --num_workers= --render_only=True
75 | ```
76 |
77 | Argument Descriptions:
78 | ```
79 | -e [Experiment group to run like 'mushrooms' (the rest of the experiment groups are in exp_configs/sps_exps.py)]
80 | -sb [Directory where the experiments are saved]
81 | -r [Flag for whether to reset the experiments]
82 | -d [Directory where the datasets are aved]
83 | ```
84 |
85 | **_Disclaimer_**: The codebase is optimized to run on larger GPU servers with a lot of free CPU memory.
86 | To test on local and low memory, choose `pointLF_waymo_local` instead of `pointLF_waymo_server`.
87 | Adjustments of batch size, chunk size and number of rays will have an effect on necessary resources.
88 |
89 | ---
90 | ### Visualization of Results
91 |
92 | Follow these steps to visualize plots. Open `results.ipynb`, run the first cell to get a dashboard like in the gif below, click on the "plots" tab, then click on "Display plots". Parameters of the plots can be adjusted in the dashboard for custom visualizations.
93 |
94 |
95 |  96 |
96 |
97 |
98 | ---
99 | #### Citation
100 | ```
101 | @InProceedings{ost2022pointlightfields,
102 | title = {Neural Point Light Fields},
103 | author = {Ost, Julian and Laradji, Issam and Newell, Alejandro and Bahat, Yuval and Heide, Felix},
104 | journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
105 | year = {2022}
106 | }
107 | ```
108 |
109 |
110 |
--------------------------------------------------------------------------------
/src/datasets/extract_baselines.py:
--------------------------------------------------------------------------------
1 | import os
2 | import numpy as np
3 | import open3d as o3d
4 | import matplotlib.pyplot as plt
5 | from PIL import Image
6 |
7 |
8 | def extract_waymo_poses(dataset, scene_list, i_train, i_test, i_all):
9 | cam_names = ['FRONT', 'FRONT_LEFT', 'FRONT_RIGHT', 'SIDE_LEFT', 'SIDE_RIGHT']
10 | assert len(scene_list) == 1
11 | first_fr = scene_list[0]['first_frame']
12 | last_fr = scene_list[0]['last_frame']
13 |
14 | pose_file_n = "poses_{}_{}.npy".format(str(first_fr).zfill(4), str(last_fr).zfill(4))
15 | img_file_n = "imgs_{}_{}.npy".format(str(first_fr).zfill(4), str(last_fr).zfill(4))
16 | index_test_n= "index_test_{}_{}.npy".format(str(first_fr).zfill(4), str(last_fr).zfill(4))
17 | index_train_n = "index_train_{}_{}.npy".format(str(first_fr).zfill(4), str(last_fr).zfill(4))
18 | pt_depth_file_n = "pt_depth_{}_{}.npy".format(str(first_fr).zfill(4), str(last_fr).zfill(4))
19 | depth_img_file_n = "pt_depth_{}_{}.npy".format(str(first_fr).zfill(4), str(last_fr).zfill(4))
20 |
21 | segmemt_pth = ''
22 | for s in dataset.images[0].split('/')[1:-2]:
23 | segmemt_pth += '/' + s
24 |
25 | remove_side_views = True
26 |
27 | n_frames = len(dataset.poses_world) // 5
28 |
29 | if remove_side_views:
30 | n_imgs = n_frames * 3
31 | cam_names = cam_names[:3]
32 |
33 | else:
34 | n_imgs = n_frames * 5
35 |
36 | cam_pose = dataset.poses_world[:n_imgs]
37 | img_path = dataset.images[:n_imgs]
38 |
39 | cam_pose_openGL = cam_pose.dot(np.array([[-1., 0., 0., 0., ], [0., 1., 0., 0., ], [0., 0., -1., 0., ], [0., 0., 0., 1., ], ]))
40 |
41 | # Add H, W, focal
42 | hwf1 = [np.array([[dataset.H[c_name], dataset.W[c_name], dataset.focal[c_name], 1.]]).repeat(n_frames, axis=0) for c_name in cam_names]
43 | hwf1 = np.concatenate(hwf1)[:, :, None]
44 | cam_pose_openGL = np.concatenate([cam_pose_openGL, hwf1], axis=2)
45 |
46 | np.save(os.path.join(segmemt_pth, pose_file_n), cam_pose_openGL)
47 | np.save(os.path.join(segmemt_pth, img_file_n), img_path)
48 | np.save(os.path.join(segmemt_pth, index_test_n), i_test)
49 | np.save(os.path.join(segmemt_pth, index_train_n), i_train)
50 |
51 | xyz_pts = []
52 |
53 | # Extract depth points (and images)
54 | for i in range(n_imgs):
55 | fr = i % n_frames
56 | pts_i_veh = np.asarray(o3d.io.read_point_cloud(dataset.point_cloud_pth[fr]).points)
57 | pts_i_veh = np.concatenate([pts_i_veh, np.ones([len(pts_i_veh), 1])], axis=-1)
58 |
59 | cam2veh_i = dataset.poses[i]
60 | veh2cam_i = np.concatenate([cam2veh_i[:3, :3].T, np.matmul(cam2veh_i[:3, :3].T, -cam2veh_i[:3, 3])[:, None]], axis=-1)
61 |
62 | pts_i_cam = np.matmul(veh2cam_i, pts_i_veh.T).T
63 |
64 | focal_i = hwf1[i, 2]
65 | h_i = hwf1[i, 0]
66 | w_i = hwf1[i, 1]
67 |
68 | # x - W
69 | x = -focal_i * (pts_i_cam[:, 0] / pts_i_cam[:, 2])
70 | # y - H
71 | y = -focal_i * (pts_i_cam[:, 1] / pts_i_cam[:, 2])
72 |
73 | xyz = np.stack([x, y, pts_i_cam[:, 2]]).T
74 |
75 | visible_pts_map = (xyz[:, 2] > 0) & (np.abs(xyz[:, 0]) < w_i // 2) & (np.abs(xyz[:, 1]) < h_i // 2)
76 |
77 | xyz_visible = xyz[visible_pts_map]
78 |
79 | # xxx['coord'][:, 0] == W
80 | # xxx['coord'][:, 1] == H
81 | xyz_visible[:, 0] = np.maximum(np.minimum(xyz_visible[:, 0] + w_i // 2, w_i), 0)
82 | xyz_visible[:, 1] = np.maximum(np.minimum(xyz_visible[:, 1] + h_i // 2, h_i), 0)
83 |
84 | xyz_pts.append(
85 | {
86 | 'depth': xyz_visible[:, 2],
87 | 'coord': xyz_visible[:, :2],
88 | 'weight': np.ones_like(xyz_visible[:, 2])
89 | }
90 | )
91 |
92 | # ######### Debug Depth Outputs
93 | # if i == 102:
94 | # scale = 8
95 | #
96 | # h_scaled = h_i // scale
97 | # w_scaled = w_i // scale
98 | #
99 | # xyz_vis_scaled = xyz_visible / 8
100 | #
101 | # depth_img = np.zeros([int(h_scaled), int(w_scaled), 1])
102 | # depth_img[np.floor(xyz_vis_scaled[:, 1]).astype("int"), np.floor(xyz_vis_scaled[:, 0]).astype("int")] = xyz_visible[:, 2][:, None]
103 | # plt.figure()
104 | # plt.imshow(depth_img[..., 0], cmap="plasma")
105 | #
106 | # plt.figure()
107 | # img_i = Image.open(img_path[i])
108 | # img_i = img_i.resize((w_scaled, h_scaled))
109 | # plt.imshow(np.asarray(img_i))
110 | #
111 | # # pcd = o3d.geometry.PointCloud()
112 | # # pcd.points = o3d.utility.Vector3dVector(pts_i_cam)
113 |
114 | np.save(os.path.join(segmemt_pth, pt_depth_file_n), xyz_pts)
115 |
116 |
117 | # plt.scatter(cam_pose_openGL[:, 0, 3], cam_pose_openGL[:, 1, 3])
118 | # plt.axis('equal')
119 | #
120 | # for i in range(len(pos)):
121 | # p = cam_pose_openGL[i]
122 | # # p = pos[i].dot(np.array([[-1., 0., 0., 0., ],
123 | # # [0., 1., 0., 0., ],
124 | # # [0., 0., -1., 0., ],
125 | # # [0., 0., 0., 1., ], ]))
126 | # plt.arrow(p[0, 3], p[1, 3], p[0, 0], p[1, 0], color="red")
127 | # plt.arrow(p[0, 3], p[1, 3], p[0, 2], p[1, 2], color="black")
128 |
129 |
130 |
131 | def extract_depth_information(dataset, exp_dict):
132 | pass
133 |
134 |
135 | def extract_depth_image(dataset, exp_dict):
136 | pass
--------------------------------------------------------------------------------
/src/pointLF/layer.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 | from torch import Tensor
5 | import math
6 |
7 | class DenseLayer(nn.Linear):
8 | def __init__(self, in_dim: int, out_dim: int, activate: str = "relu", *args, **kwargs) -> None:
9 | if activate:
10 | self.activation = activate
11 | else:
12 | self.activation = 'linear'
13 | super().__init__(in_dim, out_dim, *args,)
14 |
15 | def reset_parameters(self) -> None:
16 | torch.nn.init.xavier_uniform_(self.weight, gain=torch.nn.init.calculate_gain(self.activation))
17 | if self.bias is not None:
18 | torch.nn.init.zeros_(self.bias)
19 |
20 | def forward(self, input: Tensor, **kwargs) -> Tensor:
21 | out = super(DenseLayer, self).forward(input)
22 | if self.activation == 'relu':
23 | out = F.relu(out)
24 |
25 | return out
26 |
27 |
28 | class EqualLinear(nn.Module):
29 | """Linear layer with equalized learning rate.
30 |
31 | During the forward pass the weights are scaled by the inverse of the He constant (i.e. sqrt(in_dim)) to
32 | prevent vanishing gradients and accelerate training. This constant only works for ReLU or LeakyReLU
33 | activation functions.
34 |
35 | Args:
36 | ----
37 | in_channel: int
38 | Input channels.
39 | out_channel: int
40 | Output channels.
41 | bias: bool
42 | Use bias term.
43 | bias_init: float
44 | Initial value for the bias.
45 | lr_mul: float
46 | Learning rate multiplier. By scaling weights and the bias we can proportionally scale the magnitude of
47 | the gradients, effectively increasing/decreasing the learning rate for this layer.
48 | activate: bool
49 | Apply leakyReLU activation.
50 |
51 | """
52 |
53 | def __init__(self, in_channel, out_channel, bias=True, bias_init=0, lr_mul=1, activate=False):
54 | super().__init__()
55 |
56 | self.weight = nn.Parameter(torch.randn(out_channel, in_channel).div_(lr_mul))
57 |
58 | if bias:
59 | self.bias = nn.Parameter(torch.zeros(out_channel).fill_(bias_init))
60 | else:
61 | self.bias = None
62 |
63 | self.activate = activate
64 | self.scale = (1 / math.sqrt(in_channel)) * lr_mul
65 | self.lr_mul = lr_mul
66 |
67 | def forward(self, input):
68 | if self.activate:
69 | out = F.linear(input, self.weight * self.scale)
70 | out = fused_leaky_relu(out, self.bias * self.lr_mul)
71 | else:
72 | out = F.linear(input, self.weight * self.scale, bias=self.bias * self.lr_mul)
73 | return out
74 |
75 | def __repr__(self):
76 | return f"{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]})"
77 |
78 |
79 | class FusedLeakyReLU(nn.Module):
80 | def __init__(self, channel, bias=True, negative_slope=0.2, scale=2 ** 0.5):
81 | super().__init__()
82 |
83 | if bias:
84 | self.bias = nn.Parameter(torch.zeros(channel))
85 |
86 | else:
87 | self.bias = None
88 |
89 | self.negative_slope = negative_slope
90 | self.scale = scale
91 |
92 | def forward(self, input):
93 | return fused_leaky_relu(input, self.bias, self.negative_slope, self.scale)
94 |
95 |
96 | def fused_leaky_relu(input, bias=None, negative_slope=0.2, scale=2 ** 0.5):
97 | if input.dtype == torch.float16:
98 | bias = bias.half()
99 |
100 | if bias is not None:
101 | rest_dim = [1] * (input.ndim - bias.ndim - 1)
102 | return F.leaky_relu(input + bias.view(1, bias.shape[0], *rest_dim), negative_slope=0.2) * scale
103 |
104 | else:
105 | return F.leaky_relu(input, negative_slope=0.2) * scale
106 |
107 |
108 | class ModulationLayer(nn.Module):
109 | def __init__(self, in_ch, out_ch, z_dim, demodulate=True, activate=True, bias=True, **kwargs):
110 | super(ModulationLayer, self).__init__()
111 | self.eps = 1e-8
112 |
113 | self.in_ch = in_ch
114 | self.out_ch = out_ch
115 | self.z_dim = z_dim
116 | self.demodulate = demodulate
117 |
118 | self.scale = 1 / math.sqrt(in_ch)
119 | self.weight = nn.Parameter(torch.randn(out_ch, in_ch))
120 | self.modulation = EqualLinear(z_dim, in_ch, bias_init=1, activate=False)
121 |
122 | if activate:
123 | # FusedLeakyReLU includes a bias term
124 | self.activate = FusedLeakyReLU(out_ch, bias=bias)
125 | elif bias:
126 | self.bias = nn.Parameter(torch.zeros(1, out_ch))
127 |
128 | def __repr__(self):
129 | return f'{self.__class__.__name__}({self.in_channel}, {self.out_channel}, z_dim={self.z_dim})'
130 |
131 |
132 | def forward(self, input, z):
133 | # feature modulation
134 | gamma = self.modulation(z) # B, in_ch
135 | input = input * gamma
136 |
137 | weight = self.weight * self.scale
138 |
139 | if self.demodulate:
140 | # weight is out_ch x in_ch
141 | # here we calculate the standard deviation per input channel
142 | demod = torch.rsqrt(weight.pow(2).sum([1]) + self.eps)
143 | weight = weight * demod.view(-1, 1)
144 |
145 | # also normalize inputs
146 | input_demod = torch.rsqrt(input.pow(2).sum([1]) + self.eps)
147 | input = input * input_demod.view(-1, 1)
148 |
149 | out = F.linear(input, weight)
150 |
151 | if hasattr(self, 'activate'):
152 | out = self.activate(out)
153 |
154 | if hasattr(self, 'bias'):
155 | out = out + self.bias
156 |
157 | return out
--------------------------------------------------------------------------------
/src/scenes/raysampler/frustum_helpers.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | from pytorch3d.transforms import Rotate, Transform3d
4 | from src.scenes.frames import GraphEdge
5 |
6 |
7 | def get_frustum_world(camera, edge2camera, device='cpu'):
8 | cam_trafo = edge2camera.get_transformation_c2p().to(device=device)
9 | H = camera.intrinsics.H
10 | W = camera.intrinsics.W
11 | focal = camera.intrinsics.f_x
12 | sensor_corner = torch.tensor([[0., 0.], [0., H - 1], [W - 1, H - 1], [W - 1, 0.]], device=device)
13 | frustum_edges = torch.stack([(sensor_corner[:, 0] - W * .5) / focal, -(sensor_corner[:, 1] - H * .5) / focal,
14 | -torch.ones(size=(4,), device=device)], -1)
15 | frustum_edges /= torch.norm(frustum_edges, dim=-1)[:, None]
16 | frustum_edges = \
17 | Rotate(camera.R, device=device).compose(cam_trafo.translate(-edge2camera.translation)).transform_points(
18 | frustum_edges.reshape(1, -1, 3))[0]
19 | frustum_edges /= torch.norm(frustum_edges, dim=-1)[:, None]
20 |
21 | frustum_normals = torch.cross(frustum_edges, frustum_edges[[1, 2, 3, 0], :])
22 |
23 | frustum_normals /= torch.norm(frustum_normals, dim=-1)[:, None]
24 |
25 | return frustum_edges, frustum_normals
26 |
27 |
28 | def get_frustum(camera, edge2camera, edge2reference, device='cpu'):
29 | # Gets the edges and normals of a cameras frustum with respect to a reference system
30 | openGL2dataset = Rotate(camera.R, device=device)
31 |
32 | if type(edge2reference) == GraphEdge:
33 | ref2cam = torch.eye(4, device=device)[None]
34 |
35 | ref2cam[0, 3, :3] = edge2reference.translation - edge2camera.translation
36 | ref2cam[0, :3, :3] = edge2camera.getRotation_c2p().compose(edge2reference.getRotation_p2c()).get_matrix()[:, :3, :3]
37 | cam_trafo = Transform3d(matrix=ref2cam)
38 |
39 | else:
40 | wo2veh = edge2reference
41 | cam2wo = edge2camera.get_transformation_c2p().cpu().get_matrix()[0].T.detach().numpy()
42 |
43 | cam2veh = wo2veh.dot(cam2wo)
44 | cam2veh = Transform3d(matrix=torch.tensor(cam2veh.T, device=device, dtype=torch.float32))
45 | cam_trafo = cam2veh
46 | ref2cam = cam2veh.get_matrix()
47 |
48 | H = camera.intrinsics.H
49 | W = camera.intrinsics.W
50 | focal = camera.intrinsics.f_x.detach()
51 | sensor_corner = torch.tensor([[0., 0.], [0., H - 1], [W - 1, H - 1], [W - 1, 0.]], device=device)
52 | frustum_edges = torch.stack([(sensor_corner[:, 0] - W * .5) / focal, -(sensor_corner[:, 1] - H * .5) / focal,
53 | -torch.ones(size=(4,), device=device)], -1)
54 | frustum_edges /= torch.norm(frustum_edges, dim=-1)[:, None]
55 | frustum_edges = openGL2dataset.compose(cam_trafo.translate(-ref2cam[:, 3, :3])).transform_points(
56 | frustum_edges.reshape(1, -1, 3))[0]
57 | frustum_edges /= torch.norm(frustum_edges, dim=-1)[:, None]
58 | frustum_normals = torch.cross(frustum_edges, frustum_edges[[1, 2, 3, 0], :])
59 | frustum_normals /= torch.norm(frustum_normals, dim=-1)[:, None]
60 | return frustum_edges, frustum_normals
61 |
62 |
63 | def get_frustum_torch(camera, edge2camera, edge2reference, device='cpu'):
64 | # Gets the edges and normals of a cameras frustum with respect to a reference system
65 | openGL2dataset = Rotate(camera.R, device=device)
66 |
67 | if type(edge2reference) == GraphEdge:
68 | ref2cam = torch.eye(4, device=device)[None]
69 |
70 | ref2cam[0, 3, :3] = edge2reference.translation - edge2camera.translation
71 | ref2cam[0, :3, :3] = edge2camera.getRotation_c2p().compose(edge2reference.getRotation_p2c()).get_matrix()[:, :3,
72 | :3]
73 | cam_trafo = Transform3d(matrix=ref2cam)
74 |
75 | else:
76 | wo2veh = edge2reference
77 | cam2wo = edge2camera.get_transformation_c2p(device='cpu', requires_grad=False).get_matrix()[0].T
78 |
79 | cam2veh = torch.matmul(wo2veh, cam2wo)
80 | cam2veh = Transform3d(matrix=cam2veh.T)
81 | cam_trafo = cam2veh
82 | ref2cam = cam2veh.get_matrix()
83 |
84 | H = camera.intrinsics.H
85 | W = camera.intrinsics.W
86 | focal = camera.intrinsics.f_x.detach()
87 | sensor_corner = torch.tensor([[0., 0.], [0., H - 1], [W - 1, H - 1], [W - 1, 0.]], device=device)
88 | frustum_edges = torch.stack([(sensor_corner[:, 0] - W * .5) / focal, -(sensor_corner[:, 1] - H * .5) / focal,
89 | -torch.ones(size=(4,), device=device)], -1)
90 | frustum_edges /= torch.norm(frustum_edges, dim=-1)[:, None]
91 | frustum_edges = openGL2dataset.compose(cam_trafo.translate(-ref2cam[:, 3, :3])).transform_points(
92 | frustum_edges.reshape(1, -1, 3))[0]
93 | frustum_edges /= torch.norm(frustum_edges, dim=-1)[:, None]
94 | frustum_normals = torch.cross(frustum_edges, frustum_edges[[1, 2, 3, 0], :])
95 | frustum_normals /= torch.norm(frustum_normals, dim=-1)[:, None]
96 | return frustum_edges, frustum_normals
97 |
98 |
99 | # TODO: Convert to full numpy version
100 | def get_frustum_np(camera, edge2camera, edge2reference, device='cpu'):
101 | # Gets the edges and normals of a cameras frustum with respect to a reference system
102 |
103 | openGL2dataset = Rotate(camera.R, device=device)
104 |
105 | ref2cam = torch.eye(4, device=device)[None]
106 |
107 | ref2cam[0, 3, :3] = edge2reference.translation - edge2camera.translation
108 | ref2cam[0, :3, :3] = edge2camera.getRotation_c2p().compose(edge2reference.getRotation_p2c()).get_matrix()[:, :3, :3]
109 | cam_trafo = Transform3d(matrix=ref2cam)
110 |
111 | H = camera.intrinsics.H
112 | W = camera.intrinsics.W
113 | focal = camera.intrinsics.f_x
114 | sensor_corner = torch.tensor([[0., 0.], [0., H - 1], [W - 1, H - 1], [W - 1, 0.]], device=device)
115 | frustum_edges = torch.stack([(sensor_corner[:, 0] - W * .5) / focal, -(sensor_corner[:, 1] - H * .5) / focal,
116 | -torch.ones(size=(4,), device=device)], -1)
117 | frustum_edges /= torch.norm(frustum_edges, dim=-1)[:, None]
118 | frustum_edges = openGL2dataset.compose(cam_trafo.translate(-ref2cam[:, 3, :3])).transform_points(
119 | frustum_edges.reshape(1, -1, 3))[0]
120 | frustum_edges /= torch.norm(frustum_edges, dim=-1)[:, None]
121 | frustum_normals = torch.cross(frustum_edges, frustum_edges[[1, 2, 3, 0], :])
122 | frustum_normals /= torch.norm(frustum_normals, dim=-1)[:, None]
123 | return frustum_edges, frustum_normals
--------------------------------------------------------------------------------
/src/pointLF/pointcloud_encoding/simpleview.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | # from all_utils import DATASET_NUM_CLASS
4 | from .simpleview_utils import PCViews, Squeeze, BatchNormPoint
5 | import matplotlib.pyplot as plt
6 |
7 | from .resnet import _resnet, BasicBlock
8 |
9 |
10 | class MVModel(nn.Module):
11 | def __init__(self, task,
12 | # dataset,
13 | backbone,
14 | feat_size,
15 | resolution=128,
16 | upscale_feats = True,
17 | ):
18 | super().__init__()
19 | assert task == 'cls'
20 | self.task = task
21 | self.num_class = 10 # DATASET_NUM_CLASS[dataset]
22 | self.dropout_p = 0.5
23 | self.feat_size = feat_size
24 |
25 | self.resolution = resolution
26 | self.upscale_feats = False
27 |
28 | pc_views = PCViews()
29 | self.num_views = pc_views.num_views
30 | self._get_img = pc_views.get_img
31 | self._get_img_coord = pc_views.get_img_coord
32 |
33 | img_layers, in_features = self.get_img_layers(
34 | backbone, feat_size=feat_size)
35 | self.img_model = nn.Sequential(*img_layers)
36 |
37 | # self.final_fc = MVFC(
38 | # num_views=self.num_views,
39 | # in_features=in_features,
40 | # out_features=self.num_class,
41 | # dropout_p=self.dropout_p)
42 |
43 | # Upscale resnet outputs to img resolution
44 | if upscale_feats:
45 | self.upscale_feats = True
46 |
47 | self.upscaleLin = nn.ModuleList(
48 | [
49 | nn.Sequential(
50 | nn.Linear(in_features=self.feat_size * (2 ** i), out_features=self.resolution), nn.ReLU()
51 | ) for i in range(4)
52 | ]
53 | )
54 | self.upsampleLayer = nn.Upsample(size=(resolution, resolution), mode='nearest')
55 |
56 | self.out_idx = [3, 4, 5, 7]
57 |
58 | def forward(self, pc, **kwargs):
59 | """
60 | :param pc:
61 | :return:
62 | """
63 |
64 | # Does not give the same results if trained on a single or more images, because of batch norm
65 | pc = pc.cuda()
66 | img = self.get_img(pc)
67 |
68 | # feat = self.img_model(img)
69 | outs = []
70 | h = img
71 | for layer in self.img_model:
72 | h = layer(h)
73 | outs.append(h)
74 |
75 | if self.upscale_feats:
76 | feat_ls = []
77 | for i, upLayer in zip(self.out_idx, self.upscaleLin):
78 | h = outs[i].transpose(1,-1)
79 | h = upLayer(h).transpose(-1,1)
80 | feat_ls.append(self.upsampleLayer(h))
81 | feat = torch.sum(torch.stack(feat_ls), dim=0) / len(self.upscaleLin)
82 |
83 | # plt.imshow(torch.sum(outs[7].transpose(1,-1), dim=-1).cpu().detach().numpy()[0])
84 | # plt.imshow(torch.sum(feat.transpose(1, -1), dim=-1).cpu().detach().numpy()[0])
85 | else:
86 | feat = outs[-1]
87 |
88 | # if len(pc) >= 1:
89 | # i_sh = [6, len(pc)] + list(img.shape[1:])
90 | # f_sh = [6, len(pc)] + list(feat.shape[1:])
91 | # img = img.reshape(i_sh)
92 | # feat = feat.reshape(f_sh)
93 | #
94 | # else:
95 | # img = img.unsqueeze(1)
96 | # feat = feat.unsqueeze(1)
97 |
98 | n_img, in_ch, w_in, h_in = img.shape
99 | n_feat_maps, out_ch, w_out, h_out = feat.shape
100 | n_batch = len(pc)
101 | feat = feat.reshape(n_batch, n_feat_maps//n_batch, out_ch, w_out, h_out)
102 | img = img.reshape(n_batch, n_img // n_batch, in_ch, w_in, h_in)
103 |
104 | return feat, img, None
105 |
106 |
107 | def get_img(self, pc):
108 | img = self._get_img(pc, self.resolution)
109 | img = torch.tensor(img).float()
110 | img = img.to(next(self.parameters()).device)
111 | assert len(img.shape) == 3
112 | img = img.unsqueeze(3)
113 | # [num_pc * num_views, 1, RESOLUTION, RESOLUTION]
114 | img = img.permute(0, 3, 1, 2)
115 |
116 | return img
117 |
118 | @staticmethod
119 | def get_img_layers(backbone, feat_size):
120 | """
121 | Return layers for the image model
122 | """
123 | assert backbone == 'resnet18'
124 | layers = [2, 2, 2, 2]
125 | block = BasicBlock
126 | backbone_mod = _resnet(
127 | arch=None,
128 | block=block,
129 | layers=layers,
130 | pretrained=False,
131 | progress=False,
132 | feature_size=feat_size,
133 | zero_init_residual=True)
134 |
135 | all_layers = [x for x in backbone_mod.children()]
136 | in_features = all_layers[-1].in_features
137 |
138 | # all layers except the final fc layer.py and the initial conv layers
139 | # WARNING: this is checked only for resnet models
140 |
141 | # main_layers = all_layers[4:-1]
142 | main_layers = all_layers[4:-2]
143 | img_layers = [
144 | nn.Conv2d(1, feat_size, kernel_size=(3, 3), stride=(1, 1),
145 | padding=(1, 1), bias=False),
146 | nn.BatchNorm2d(feat_size, eps=1e-05, momentum=0.1,
147 | affine=True, track_running_stats=True),
148 | nn.ReLU(inplace=True),
149 | *main_layers,
150 | Squeeze()
151 | ]
152 |
153 | return img_layers, in_features
154 |
155 |
156 | class MVFC(nn.Module):
157 | """
158 | Final FC layers for the MV model
159 | """
160 |
161 | def __init__(self, num_views, in_features, out_features, dropout_p):
162 | super().__init__()
163 | self.num_views = num_views
164 | self.in_features = in_features
165 | self.model = nn.Sequential(
166 | BatchNormPoint(in_features),
167 | # dropout before concatenation so that each view drops features independently
168 | nn.Dropout(dropout_p),
169 | nn.Flatten(),
170 | nn.Linear(in_features=in_features * self.num_views,
171 | out_features=in_features),
172 | nn.BatchNorm1d(in_features),
173 | nn.ReLU(),
174 | nn.Dropout(dropout_p),
175 | nn.Linear(in_features=in_features, out_features=out_features,
176 | bias=True))
177 |
178 | def forward(self, feat):
179 | feat = feat.view((-1, self.num_views, self.in_features))
180 | out = self.model(feat)
181 | return out
182 |
--------------------------------------------------------------------------------
/src/scenes/init_detection.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | from . import createSceneObject
4 | import random
5 |
6 |
7 | def init_frames_on_BEV_anchors(scene,
8 | image_ls,
9 | exp_dict_pretrained,
10 | tgt_frames,
11 | n_anchors_depth=3,
12 | n_anchors_angle=3,
13 | ):
14 | # Get camera
15 | cam = list(scene.nodes['camera'].values())[0]
16 | far = exp_dict_pretrained['scenes'][0]['far_plane']
17 | near = exp_dict_pretrained['scenes'][0]['near_plane']
18 | box_scale= exp_dict_pretrained['scenes'][0]['box_scale']
19 | cam_above_ground_kitti = 1.5
20 |
21 | param_dict = {}
22 |
23 | # Initialize frame with camera and background objects
24 | frame_idx = scene.init_blank_frames(image_ls,
25 | camera_node=cam,
26 | far=far,
27 | near=near,
28 | box_scale=box_scale,)
29 |
30 | # Create anchors at the midpoints of each cell in an BEV grid inside the viewing frustum
31 | anchor_angle, anchor_depth, anchor_height = _create_cyl_mid_point_anchors(cam,
32 | cam_above_ground_kitti,
33 | n_anchors_angle,
34 | n_anchors_depth,
35 | near,
36 | far)
37 |
38 | # Get known object paramteres to sample from
39 | known_objs = list(scene.nodes['scene_object'].keys())
40 |
41 | # Get Car object
42 | for v in scene.nodes['object_class'].values():
43 | if v.name == 'Car':
44 | obj_class = v
45 |
46 | for fr_id in frame_idx:
47 | # Add random deviations
48 | anchor_angle_fr, anchor_depth_fr = _add_random_offset_anchors(cam, anchor_angle, anchor_depth, n_anchors_angle,
49 | n_anchors_depth, near, far)
50 |
51 | # Combine angle and depth values to xyz
52 | anchor_x = anchor_depth * torch.tan(anchor_angle_fr)
53 | anchors = torch.cat([anchor_x[..., None], anchor_height, anchor_depth_fr[..., None]], dim=2)
54 |
55 | # Loop over all anchors
56 | for i, anchor in enumerate(anchors.view(-1, 3)):
57 | # Get params and add a new obj at this anchor
58 | size, latent = _get_anchor_obj_params(scene, known_objs)
59 |
60 | new_obj_dict = createSceneObject(length=size[0],
61 | height=size[1],
62 | width=size[2],
63 | object_class_node=obj_class,
64 | latent=latent,
65 | type_idx=i)
66 |
67 | nodes = scene.updateNodes(new_obj_dict)
68 | new_obj = list(nodes['scene_object'].values())[0]
69 |
70 | # Get rotation
71 | rotation = _get_anchor_box_rotation(anchor)
72 |
73 | # Add new edge for the anchor and new object to the scene
74 | scene.add_new_obj_edges(frame_id=fr_id,
75 | object_node=new_obj,
76 | translation=anchor,
77 | rotation=rotation,
78 | box_size_scaling=box_scale,)
79 |
80 | frame = scene.frames[fr_id]
81 | for obj_id in frame.get_objects_ids():
82 | for v_name, v in frame.get_object_parameters(obj_id).items():
83 | if v_name != 'scaling':
84 | param_dict['{}_{}'.format(v_name, obj_id)] = v
85 |
86 | tgt_dict = {}
87 | for tgt_id in tgt_frames:
88 | tgt_frame = scene.frames[tgt_id]
89 | for obj_id in tgt_frame.get_objects_ids():
90 | for v_name, v in tgt_frame.get_object_parameters(obj_id).items():
91 | if v_name != 'scaling':
92 | tgt_dict['{}_{}'.format(v_name, obj_id)] = v
93 |
94 |
95 | camera_idx = [cam.scene_idx] * len(frame_idx)
96 | return param_dict, frame_idx, camera_idx, tgt_dict
97 |
98 |
99 | def _create_cyl_mid_point_anchors(camera,
100 | cam_above_ground,
101 | n_anchors_angle,
102 | n_anchors_depth,
103 | near,
104 | far):
105 | # Basic BEV Anchors
106 | cam_param = camera.intrinsics
107 | fov_y = 2 * torch.arctan(cam_param.H / (2 * cam_param.f_y))
108 | fov_x = 2 * torch.arctan(cam_param.W / (2 * cam_param.f_x))
109 |
110 | device = fov_y.device
111 |
112 | # Sample anchors on BEV Plane inside camera viewing frustum
113 | # Sample anchors from left to right along the angle inside the FOV
114 | percent_fov_x = torch.linspace(0, n_anchors_angle - 1, n_anchors_angle, device=device) / n_anchors_angle
115 | angle_mid_point = 1 / (2 * n_anchors_angle)
116 | anchor_angle = fov_x * (percent_fov_x + angle_mid_point) - fov_x / 2
117 | anchor_angle = anchor_angle[None, :].repeat(n_anchors_depth, 1)
118 |
119 | # Sample along depth from near to far
120 | depth_mid_point = (far - near) / (2 * n_anchors_depth)
121 | anchor_depth = (far - near) * (
122 | torch.linspace(0, n_anchors_depth - 1, n_anchors_depth, device=device) / n_anchors_depth)
123 | anchor_depth += near + depth_mid_point
124 | anchor_depth = anchor_depth[:, None].repeat(1, n_anchors_angle)
125 |
126 | anchor_height = torch.ones(size=(n_anchors_depth, n_anchors_angle, 1), device=device) * cam_above_ground
127 |
128 | return anchor_angle, anchor_depth, anchor_height
129 |
130 |
131 | def _add_random_offset_anchors(camera, anchor_angle, anchor_depth, n_anchors_angle, n_anchors_depth, near, far):
132 | # Basic BEV Anchors
133 | cam_param = camera.intrinsics
134 | fov_y = 2 * torch.arctan(cam_param.H / (2 * cam_param.f_y))
135 | fov_x = 2 * torch.arctan(cam_param.W / (2 * cam_param.f_x))
136 |
137 | device = anchor_angle.device
138 |
139 | # Add random deviations
140 | rand_angle = (2 * torch.rand(size=anchor_angle.shape, device=device) - 1) * (
141 | fov_x / n_anchors_angle)
142 | rand_depth = (2 * torch.rand(size=anchor_angle.shape, device=device) - 1) * (
143 | (far - near) / n_anchors_depth)
144 |
145 | anchor_angle_fr = anchor_angle + rand_angle
146 | anchor_depth_fr = anchor_depth + rand_depth
147 | return anchor_angle_fr, anchor_depth_fr
148 |
149 |
150 | def _get_anchor_obj_params(scene, known_objs):
151 | random.shuffle(known_objs)
152 | known_obj_id = known_objs[0]
153 | known_obj = scene.nodes['scene_object'][known_obj_id]
154 | size = known_obj.box_size
155 | latent = known_obj.latent
156 |
157 | return size, latent
158 |
159 |
160 | def _get_anchor_box_rotation(anchor):
161 | yaw = torch.rand((1,), device=anchor.device) * - np.pi / 2
162 | if yaw < 1e-4:
163 | yaw += 1e-4
164 | rotation = torch.tensor([0., yaw, 0.])
165 | return rotation
--------------------------------------------------------------------------------
/exp_configs/pointLF_exps.py:
--------------------------------------------------------------------------------
1 | from haven import haven_utils as hu
2 |
3 | EXP_GROUPS = {}
4 |
5 |
6 | def get_scenes(scene_ids, selected_frames='default', dataset='waymo', object_types=None):
7 | scene_list = []
8 | for scene_id in scene_ids:
9 | first_frame = None
10 | last_frame = None
11 | if isinstance(selected_frames, list):
12 | first_frame = selected_frames[0]
13 | last_frame = selected_frames[1]
14 |
15 | if type(scene_id) != list and dataset == 'waymo':
16 | for record_id in range(25):
17 | scene_list += [{'scene_id': [scene_id, record_id],
18 | 'type': dataset,
19 | 'first_frame': None,
20 | 'last_frame': None,
21 | 'far_plane': 150,
22 | 'near_plane': .5,
23 | "new_world": True,
24 | 'box_scale': 1.5,
25 | 'object_types': object_types,
26 | 'fix': True,
27 | 'pt_cloud_fix': True}]
28 |
29 | else:
30 | scene_dict = {'scene_id': scene_id,
31 | 'type': dataset,
32 | 'first_frame': first_frame,
33 | 'last_frame': last_frame,
34 | 'far_plane': 150,
35 | 'near_plane': .5,
36 | "new_world": True,
37 | 'box_scale': 1.5,
38 | 'object_types': object_types,
39 | 'fix': True,
40 | 'pt_cloud_fix': True}
41 | if object_types is not None:
42 | scene_dict['object_types'] = object_types
43 | scene_list += [scene_dict]
44 | return scene_list
45 |
46 |
47 | EXP_GROUPS['pointLF_waymo_local'] = hu.cartesian_exp_group({
48 | "n_rays": [512],
49 | 'image_batch_size': [2, ],
50 | "chunk": [512],
51 | "scenes": [
52 | # get_scenes(scene_ids=[[0, 8]], dataset='waymo', selected_frames=[135, 197], object_types=['TYPE_VEHICLE']),
53 | # get_scenes(scene_ids=[[0, 11]], dataset='waymo', selected_frames=[0, 20], object_types=['TYPE_VEHICLE']),
54 | get_scenes(scene_ids=[[0, 2]], dataset='waymo', selected_frames=[0, 80], object_types=['TYPE_VEHICLE']),
55 | # get_scenes(scene_ids=[[0, 2]], dataset='waymo', selected_frames=[0, 197], object_types=['TYPE_VEHICLE']),
56 | # get_scenes(scene_ids=[[2, 0]], dataset='waymo', selected_frames=[0, 10], object_types=['TYPE_VEHICLE']),
57 | # get_scenes(scene_ids=[[0, 19]], dataset='waymo', selected_frames=[0, 198], object_types=['TYPE_VEHICLE']),
58 | # get_scenes(scene_ids=[[0, 19]], dataset='waymo', selected_frames=[96, 198], object_types=['TYPE_VEHICLE']),
59 | # get_scenes(scene_ids=[[1, 15]], dataset='waymo', selected_frames=[0, 197], object_types=['TYPE_VEHICLE']),
60 | # get_scenes(scene_ids=[[2, 0]], dataset='waymo', selected_frames=[0, 40], object_types=['TYPE_VEHICLE']),
61 | ],
62 | "precache": [False],
63 | "lrate": [0.001, ],
64 | "lrate_decay": 250,
65 | "netchunk": 65536,
66 | 'lightfield': {'k_closest': 4,
67 | 'n_features': 128,
68 | # 'n_sample_pts': 20000,
69 | 'n_sample_pts': 5000,
70 | # 'pointfeat_encoder': 'pointnet_lf_global_weighted',
71 | # 'pointfeat_encoder': 'multiview_attention_modulation',
72 | 'pointfeat_encoder': 'multiview_attention',
73 | # 'pointfeat_encoder': 'multiview_attention_up',
74 | # 'pointfeat_encoder': 'naive_ablation',
75 | # 'pointfeat_encoder': 'one_point_ablation',
76 | # 'pointfeat_encoder': 'pointnet_ablation',
77 | # 'pointfeat_encoder': 'encoding_attention_only',
78 | # 'pointfeat_encoder': 'multiview_attention_big',
79 | # 'pointfeat_encoder': 'multiview_encoded',
80 | # 'pointfeat_encoder': 'multiview_distance_attention',
81 | # 'pointfeat_encoder': 'multiview_encoded_modulation',
82 | # 'pointfeat_encoder': 'multiview_encoded_weighted_modulation',
83 | 'merge_pcd': False,
84 | 'all_cams': True,
85 | 'D_lf': 8,
86 | 'skips_lf': [4],
87 | 'camera_centered': False,
88 | 'augment_frame_order': True,
89 | 'new_enc': False,
90 | 'torch_sampler': True,
91 | 'sky_dome': True,
92 | 'num_merged_frames': 1,
93 | },
94 | # "overfit": "frame",
95 | "scale": 0.0625, # 0.125,
96 | "point_chunk": 1e7,
97 | 'version': [0],
98 | 'tonemapping': False,
99 | 'pose_refinement': False,
100 | 'pt_cache': True,
101 | },
102 | remove_none=True
103 | )
104 |
105 |
106 | EXP_GROUPS['pointLF_waymo_server'] = hu.cartesian_exp_group({
107 | "n_rays": [8192],
108 | 'image_batch_size': [2, ],
109 | "chunk": [64000],
110 | "scenes": [
111 | # get_scenes(scene_ids=[[0, 2]], dataset='waymo', selected_frames=[0, 20], object_types=['TYPE_VEHICLE']),
112 | # get_scenes(scene_ids=[[0, 2]], dataset='waymo', selected_frames=[0, 40], object_types=['TYPE_VEHICLE']),
113 | get_scenes(scene_ids=[[0, 2]], dataset='waymo', selected_frames=[0, 80], object_types=['TYPE_VEHICLE']),
114 | # get_scenes(scene_ids=[[0, 2]], dataset='waymo', selected_frames=[0, 120], object_types=['TYPE_VEHICLE']),
115 | # get_scenes(scene_ids=[[0, 2]], dataset='waymo', selected_frames=[0, 197], object_types=['TYPE_VEHICLE']),
116 | # get_scenes(scene_ids=[[0, 8]], dataset='waymo', selected_frames=[171, 190], object_types=['TYPE_VEHICLE']),
117 | # get_scenes(scene_ids=[[0, 8]], dataset='waymo', selected_frames=[135, 197], object_types=['TYPE_VEHICLE']),
118 | # get_scenes(scene_ids=[[0, 11]], dataset='waymo', selected_frames=[0, 164], object_types=['TYPE_VEHICLE']),
119 | # get_scenes(scene_ids=[[1, 15]], dataset='waymo', selected_frames=[0, 197], object_types=['TYPE_VEHICLE']),
120 | # get_scenes(scene_ids=[[2, 3]], dataset='waymo', selected_frames=[0, 198], object_types=['TYPE_VEHICLE']),
121 | # get_scenes(scene_ids=[[2, 9]], dataset='waymo', selected_frames=[0, 197], object_types=['TYPE_VEHICLE']),
122 | ],
123 | "precache": [False],
124 | "latent_balance": 0.0001,
125 | "lrate_decay": 250,
126 | "netchunk": 65536,
127 | 'lightfield': {'k_closest': 8,
128 | 'n_features': 128,
129 | 'n_sample_pts': 500,
130 | 'pointfeat_encoder': 'multiview_attention',
131 | 'merge_pcd': True,
132 | 'all_cams': False,
133 | 'D_lf': 8,
134 | 'W_lf': 256,
135 | 'skips_lf': [4],
136 | 'layer_modulation': False,
137 | 'camera_centered': False,
138 | 'augment_frame_order': True,
139 | 'new_enc': False,
140 | 'torch_sampler': True,
141 | 'sky_dome': True,
142 | 'num_merged_frames': 20,
143 | },
144 | # "overfit": "frame",
145 | "scale": .125,
146 | 'version': 0,
147 | "point_chunk": 1e7,
148 | 'tonemapping': False,
149 | 'pose_refinement': False,
150 | 'pt_cache': True,
151 | },
152 | remove_none=True
153 | )
154 |
--------------------------------------------------------------------------------
/src/datasets/preprocess_Waymo.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | import glob
4 | import numpy as np
5 | from tqdm import tqdm
6 | from waymo_open_dataset import dataset_pb2 as open_dataset
7 | from waymo_open_dataset.utils import frame_utils
8 | # from waymo_open_dataset import label_pb2 as open_label
9 | import imageio
10 | import tensorflow.compat.v1 as tf
11 | tf.enable_eager_execution()
12 | import pickle
13 | from collections import defaultdict
14 | from copy import deepcopy
15 | # import waymo
16 | import cv2
17 | import open3d as o3d
18 |
19 |
20 | SAVE_INTRINSIC = True
21 | SINGLE_TRACK_INFO_FILE = True
22 | DEBUG = False # If True, processing only the first tfrecord file, and saving with a "_debug" suffix.
23 | MULTIPLE_DIRS = False
24 | # DATADIRS = '/media/ybahat/data/Datasets/Waymo/val/0001'
25 |
26 | parser = argparse.ArgumentParser()
27 | parser.add_argument('-d', '--datadir')
28 | parser.add_argument('-nd', '--no_data', default=False)
29 | args,_ = parser.parse_known_args()
30 | datadirs = args.datadir
31 | export_data = not args.no_data
32 | # datadirs = DATADIRS
33 | saving_dir = '/'.join(datadirs.split('/')[:-1])
34 | if '.tfrecord' not in datadirs:
35 | saving_dir = 1*datadirs
36 | datadirs = glob.glob(datadirs+'/*.tfrecord',recursive=True)
37 | datadirs = sorted([f for f in datadirs if '.tfrecord' in f])
38 | MULTIPLE_DIRS = True
39 |
40 | if not isinstance(datadirs,list): datadirs = [datadirs]
41 | if not os.path.isdir(saving_dir): os.mkdir(saving_dir)
42 |
43 | def extract_label_fields(l,dims):
44 | assert dims in [2,3]
45 | label_dict = {'c_x':l.box.center_x,'c_y':l.box.center_y,'width':l.box.width,'length':l.box.length,'type':l.type}
46 | if dims==3:
47 | label_dict['c_z'] = l.box.center_z
48 | label_dict['height'] = l.box.height
49 | label_dict['heading'] = l.box.heading
50 | return label_dict
51 |
52 | def read_intrinsic(intrinsic_params_vector):
53 | return dict(zip(['f_u', 'f_v', 'c_u', 'c_v', 'k_1', 'k_2', 'p_1', 'p_2', 'k_3'], intrinsic_params_vector))
54 |
55 | isotropic_focal = lambda intrinsic_dict: intrinsic_dict['f_u']==intrinsic_dict['f_v']
56 |
57 | # datadirs = [os.path.join(args.datadir,
58 | # 'segment-10203656353524179475_7625_000_7645_000_with_camera_labels.tfrecord')]
59 | for file_num,file in enumerate(datadirs):
60 | if SINGLE_TRACK_INFO_FILE:
61 | tracking_info = {}
62 | if file_num > 0 and DEBUG: break
63 | file_name = file.split('/')[-1].split('.')[0]
64 | print('Processing file ',file_name)
65 | if not os.path.isdir(os.path.join(saving_dir, file_name)): os.mkdir(os.path.join(saving_dir, file_name))
66 | if not os.path.isdir(os.path.join(saving_dir,file_name, 'images')): os.mkdir(os.path.join(saving_dir,file_name, 'images'))
67 | if not os.path.isdir(os.path.join(saving_dir, file_name, 'point_cloud')): os.mkdir(os.path.join(saving_dir, file_name, 'point_cloud'))
68 | if not SINGLE_TRACK_INFO_FILE:
69 | if not os.path.isdir(os.path.join(saving_dir,file_name, 'tracking')): os.mkdir(os.path.join(saving_dir,file_name, 'tracking'))
70 | dataset = tf.data.TFRecordDataset(file, compression_type='')
71 | for f_num, data in enumerate(tqdm(dataset)):
72 | frame = open_dataset.Frame()
73 | frame.ParseFromString(bytearray(data.numpy()))
74 | pose = np.zeros([len(frame.images), 4, 4])
75 | im_paths = {}
76 | pcd_paths = {}
77 | if SAVE_INTRINSIC:
78 | intrinsic = np.zeros([len(frame.images),9])
79 | extrinsic = np.zeros_like(pose)
80 | width,height,camera_labels = np.zeros([len(frame.images)]),np.zeros([len(frame.images)]),defaultdict(dict)
81 | for im in frame.images:
82 | saving_name = os.path.join(saving_dir,file_name, 'images','%03d_%s.png'%(f_num,open_dataset.CameraName.Name.Name(im.name)))
83 | if not DEBUG and export_data:
84 | im_array = tf.image.decode_jpeg(im.image).numpy()
85 | # No compression imageio
86 | # imageio.imwrite(saving_name, im_array, compress_level=0)
87 | # Less compression imageio
88 | imageio.imwrite(saving_name, im_array, compress_level=3)
89 | # Original:
90 | # imageio.imwrite(saving_name, im_array,)
91 | # OpenCV Alternative (needs debugging for right colors):
92 | # cv2.imwrite(saving_name, im_array)
93 | pose[im.name-1, :, :] = np.reshape(im.pose.transform, [4, 4])
94 | im_paths[im.name] = saving_name
95 | extrinsic[im.name-1, :, :] = np.reshape(frame.context.camera_calibrations[im.name-1].extrinsic.transform, [4, 4])
96 | if SAVE_INTRINSIC:
97 | intrinsic[im.name-1, :] = frame.context.camera_calibrations[im.name-1].intrinsic
98 | assert isotropic_focal(read_intrinsic(intrinsic[im.name-1, :])),'Unexpected difference between f_u and f_v.'
99 | width[im.name-1] = frame.context.camera_calibrations[im.name-1].width
100 | height[im.name-1] = frame.context.camera_calibrations[im.name-1].height
101 | for obj_label in frame.projected_lidar_labels[im.name-1].labels:
102 | camera_labels[im.name][obj_label.id.replace('_'+open_dataset.CameraName.Name.Name(im.name),'')] = extract_label_fields(obj_label,2)
103 | # Extract point cloud data from stored range images
104 | laser_calib = np.zeros([len(frame.lasers), 4,4])
105 | if export_data:
106 | (range_images, camera_projections, range_image_top_pose) = \
107 | frame_utils.parse_range_image_and_camera_projection(frame)
108 | points, cp_points = frame_utils.convert_range_image_to_point_cloud(frame,
109 | range_images,
110 | camera_projections,
111 | range_image_top_pose)
112 | else:
113 | points =np.empty([len(frame.lasers), 1])
114 |
115 | laser_mapping = {}
116 | for (laser, pts) in zip(frame.lasers, points):
117 | saving_name = os.path.join(saving_dir, file_name, 'point_cloud', '%03d_%s.ply' % (f_num, open_dataset.LaserName.Name.Name(laser.name)))
118 | if export_data:
119 | pcd = o3d.geometry.PointCloud()
120 | pcd.points = o3d.utility.Vector3dVector(pts)
121 | o3d.io.write_point_cloud(saving_name, pcd)
122 | calib_id = int(np.where(np.array([cali.name for cali in frame.context.laser_calibrations[:5]]) == laser.name)[0])
123 | laser_calib[laser.name-1, :, :] = np.reshape(frame.context.laser_calibrations[calib_id].extrinsic.transform, [4, 4])
124 | pcd_paths[laser.name] = saving_name
125 | laser_mapping.update({open_dataset.LaserName.Name.Name(laser.name): calib_id})
126 |
127 | if 'intrinsic' in tracking_info:
128 | assert np.all(tracking_info['intrinsic']==intrinsic) and np.all(tracking_info['width']==width) and np.all(tracking_info['height']==height)
129 | else:
130 | tracking_info['intrinsic'],tracking_info['width'],tracking_info['height'] = intrinsic,width,height
131 | dict_2_save = {'per_cam_veh_pose':pose,'cam2veh':extrinsic,'im_paths':im_paths,'width':width,'height':height,
132 | 'veh2laser':laser_calib, 'pcd_paths': pcd_paths}
133 | if SAVE_INTRINSIC and not SINGLE_TRACK_INFO_FILE:
134 | dict_2_save['intrinsic'] = intrinsic
135 | lidar_labels = {}
136 | for obj_label in frame.laser_labels:
137 | lidar_labels[obj_label.id] = extract_label_fields(obj_label,3)
138 | dict_2_save['lidar_labels'] = lidar_labels
139 | dict_2_save['camera_labels'] = camera_labels
140 | dict_2_save['veh_pose'] = np.reshape(frame.pose.transform,[4,4])
141 | # dict_2_save['lidar2veh'] = np.reshape(frame.context.laser_calibrations['extrinsic'].transform,[4,4])
142 | dict_2_save['timestamp'] = frame.timestamp_micros
143 | if SINGLE_TRACK_INFO_FILE:
144 | tracking_info[(file_num,f_num)] = deepcopy(dict_2_save)
145 | else:
146 | with open(os.path.join(saving_dir,file_name, 'tracking','%03d.pkl'%(f_num)),'wb') as f:
147 | pickle.dump(dict_2_save,f)
148 | if SINGLE_TRACK_INFO_FILE:
149 | with open(os.path.join(saving_dir, file_name, 'tracking_info%s.pkl'%('_debug' if DEBUG else '')), 'wb') as f:
150 | pickle.dump(tracking_info, f)
--------------------------------------------------------------------------------
/src/pointLF/pointcloud_encoding/pointnet_features.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 | from torch.autograd import Variable
6 |
7 | # https://github.com/fxia22/pointnet.pytorch
8 | class STN3d(nn.Module):
9 | def __init__(self):
10 | super(STN3d, self).__init__()
11 | self.conv1 = torch.nn.Conv1d(3, 64, 1)
12 | self.conv2 = torch.nn.Conv1d(64, 128, 1)
13 | self.conv3 = torch.nn.Conv1d(128, 1024, 1)
14 | self.fc1 = nn.Linear(1024, 512)
15 | self.fc2 = nn.Linear(512, 256)
16 | self.fc3 = nn.Linear(256, 9)
17 | self.relu = nn.ReLU()
18 |
19 | self.bn1 = nn.BatchNorm1d(64)
20 | self.bn2 = nn.BatchNorm1d(128)
21 | self.bn3 = nn.BatchNorm1d(1024)
22 | self.bn4 = nn.BatchNorm1d(512)
23 | self.bn5 = nn.BatchNorm1d(256)
24 |
25 | def forward(self, x):
26 | batchsize = x.size()[0]
27 | x = F.relu(self.bn1(self.conv1(x)))
28 | x = F.relu(self.bn2(self.conv2(x)))
29 | x = F.relu(self.bn3(self.conv3(x)))
30 | x = torch.max(x, 2, keepdim=True)[0]
31 | x = x.view(-1, 1024)
32 |
33 | if batchsize == 1:
34 | x = F.relu(self.fc1(x))
35 | x = F.relu(self.fc2(x))
36 | else:
37 | x = F.relu(self.bn4(self.fc1(x)))
38 | x = F.relu(self.bn5(self.fc2(x)))
39 | x = self.fc3(x)
40 |
41 | iden = Variable(torch.from_numpy(np.array([1, 0, 0, 0, 1, 0, 0, 0, 1]).astype(np.float32))).view(1, 9).repeat(
42 | batchsize, 1)
43 | if x.is_cuda:
44 | iden = iden.cuda()
45 | x = x + iden
46 | x = x.view(-1, 3, 3)
47 | return x
48 |
49 |
50 | class STNkd(nn.Module):
51 | def __init__(self, k=64):
52 | super(STNkd, self).__init__()
53 | self.conv1 = torch.nn.Conv1d(k, 64, 1)
54 | self.conv2 = torch.nn.Conv1d(64, 128, 1)
55 | self.conv3 = torch.nn.Conv1d(128, 1024, 1)
56 | self.fc1 = nn.Linear(1024, 512)
57 | self.fc2 = nn.Linear(512, 256)
58 | self.fc3 = nn.Linear(256, k * k)
59 | self.relu = nn.ReLU()
60 |
61 | self.bn1 = nn.BatchNorm1d(64)
62 | self.bn2 = nn.BatchNorm1d(128)
63 | self.bn3 = nn.BatchNorm1d(1024)
64 | self.bn4 = nn.BatchNorm1d(512)
65 | self.bn5 = nn.BatchNorm1d(256)
66 |
67 | self.k = k
68 |
69 | def forward(self, x):
70 | batchsize = x.size()[0]
71 | x = F.relu(self.bn1(self.conv1(x)))
72 | x = F.relu(self.bn2(self.conv2(x)))
73 | x = F.relu(self.bn3(self.conv3(x)))
74 | x = torch.max(x, 2, keepdim=True)[0]
75 | x = x.view(-1, 1024)
76 |
77 | if batchsize == 1:
78 | x = F.relu(self.fc1(x))
79 | x = F.relu(self.fc2(x))
80 | else:
81 | x = F.relu(self.bn4(self.fc1(x)))
82 | x = F.relu(self.bn5(self.fc2(x)))
83 | x = self.fc3(x)
84 |
85 | iden = Variable(torch.from_numpy(np.eye(self.k).flatten().astype(np.float32))).view(1, self.k * self.k).repeat(
86 | batchsize, 1)
87 | if x.is_cuda:
88 | iden = iden.cuda()
89 | x = x + iden
90 | x = x.view(-1, self.k, self.k)
91 | return x
92 |
93 |
94 | class PointNetfeat(nn.Module):
95 | def __init__(self, global_feat=True, feature_transform=False):
96 | super(PointNetfeat, self).__init__()
97 | self.stn = STN3d()
98 | self.conv1 = torch.nn.Conv1d(3, 64, 1)
99 | self.conv2 = torch.nn.Conv1d(64, 128, 1)
100 | self.conv3 = torch.nn.Conv1d(128, 1024, 1)
101 | self.bn1 = nn.BatchNorm1d(64)
102 | self.bn2 = nn.BatchNorm1d(128)
103 | self.bn3 = nn.BatchNorm1d(1024)
104 | self.global_feat = global_feat
105 | self.feature_transform = feature_transform
106 | if self.feature_transform:
107 | self.fstn = STNkd(k=64)
108 |
109 | def forward(self, x):
110 | n_pts = x.size()[2]
111 | # input transform
112 | trans = self.stn(x)
113 | x = x.transpose(2, 1)
114 | x = torch.bmm(x, trans)
115 | x = x.transpose(2, 1)
116 | # (64,64)
117 | x = F.relu(self.bn1(self.conv1(x)))
118 |
119 | if self.feature_transform:
120 | # feature transform
121 | trans_feat = self.fstn(x)
122 | x = x.transpose(2, 1)
123 | x = torch.bmm(x, trans_feat)
124 | x = x.transpose(2, 1)
125 | else:
126 | trans_feat = None
127 |
128 | # (64, 128, 1024)
129 | pointfeat = x
130 | x = F.relu(self.bn2(self.conv2(x)))
131 | x = self.bn3(self.conv3(x))
132 |
133 | # Max pool -> global feature
134 | x = torch.max(x, 2, keepdim=True)[0]
135 | x = x.view(-1, 1024)
136 | if self.global_feat:
137 | # Returns only the global features
138 | return x, trans, trans_feat
139 | else:
140 | # Concatenates local and global features
141 | x = x.view(-1, 1024, 1).repeat(1, 1, n_pts)
142 | return torch.cat([x, pointfeat], 1), trans, trans_feat
143 |
144 |
145 | class PointNetDenseCls(nn.Module):
146 | def __init__(self, k=2, feature_transform=False):
147 | super(PointNetDenseCls, self).__init__()
148 | self.k = k
149 | self.feature_transform = feature_transform
150 | self.feat = PointNetfeat(global_feat=False, feature_transform=feature_transform)
151 | self.conv1 = torch.nn.Conv1d(1088, 512, 1)
152 | self.conv2 = torch.nn.Conv1d(512, 256, 1)
153 | self.conv3 = torch.nn.Conv1d(256, 128, 1)
154 | self.conv4 = torch.nn.Conv1d(128, self.k, 1)
155 | self.bn1 = nn.BatchNorm1d(512)
156 | self.bn2 = nn.BatchNorm1d(256)
157 | self.bn3 = nn.BatchNorm1d(128)
158 |
159 | def forward(self, x, **kwargs):
160 | """
161 | x: [batch_size, 3, n_points]
162 | """
163 | batchsize = x.size()[0]
164 | n_pts = x.size()[2]
165 | x, trans, trans_feat = self.feat(x)
166 | x = F.relu(self.bn1(self.conv1(x)))
167 | x = F.relu(self.bn2(self.conv2(x)))
168 | x = F.relu(self.bn3(self.conv3(x)))
169 | x = self.conv4(x)
170 | x = x.transpose(2, 1).contiguous()
171 | x = F.log_softmax(x.view(-1, self.k), dim=-1)
172 | x = x.view(batchsize, n_pts, self.k)
173 | return x, trans, trans_feat
174 |
175 |
176 | class PointNetLightFieldEncoder(nn.Module):
177 | def __init__(self, k=2, feature_transform=False, points_only=False, original=False):
178 | super(PointNetLightFieldEncoder, self).__init__()
179 | self.k = k
180 | self.feature_transform = feature_transform
181 | self.points_only = points_only
182 | self.original = original
183 | self.feat = PointNetfeat(global_feat=False, feature_transform=feature_transform)
184 | if not points_only and not original:
185 | self.conv1 = torch.nn.Conv1d(1024, 256, 1)
186 | self.conv2 = torch.nn.Conv1d(256, 64, 1)
187 | self.conv3 = torch.nn.Conv1d(128, self.k, 1)
188 |
189 | self.bn1 = nn.BatchNorm1d(256)
190 | self.bn2 = nn.BatchNorm1d(64)
191 | self.bn3 = nn.BatchNorm1d(self.k)
192 | elif original:
193 | self.conv1 = torch.nn.Conv1d(1088, 512, 1)
194 | self.conv2 = torch.nn.Conv1d(512, 256, 1)
195 | self.conv3 = torch.nn.Conv1d(256, 128, 1)
196 | self.conv4 = torch.nn.Conv1d(128, self.k, 1)
197 | self.bn1 = nn.BatchNorm1d(512)
198 | self.bn2 = nn.BatchNorm1d(256)
199 | self.bn3 = nn.BatchNorm1d(128)
200 | else:
201 | self.conv4 = torch.nn.Conv1d(64, self.k, 1)
202 | self.bn4 = nn.BatchNorm1d(self.k)
203 |
204 | def forward(self, x, **kwargs):
205 | """
206 | x: [batch_size, 3, n_points]
207 | """
208 | batchsize = x.size()[0]
209 | n_pts = x.size()[2]
210 | x, trans, trans_feat = self.feat(x)
211 | point_feat = x[:, 1024:, :]
212 | glob_feat = x[:, :1024, :]
213 |
214 | if not self.points_only and not self.original:
215 | x = F.relu(self.bn1(self.conv1(glob_feat)))
216 | x = F.relu(self.bn2(self.conv2(x)))
217 | x = torch.cat([x, point_feat], dim=1)
218 | x = F.relu(self.bn3(self.conv3(x)))
219 | elif self.original:
220 | x = F.relu(self.bn1(self.conv1(x)))
221 | x = F.relu(self.bn2(self.conv2(x)))
222 | x = F.relu(self.bn3(self.conv3(x)))
223 | x = self.conv4(x)
224 | else:
225 | x = F.relu(self.bn4(self.conv4(point_feat)))
226 |
227 | x = x.transpose(2, 1).contiguous()
228 | # x = F.log_softmax(x.view(-1, self.k), dim=-1)
229 | x = x.view(batchsize, n_pts, self.k)
230 | return x, trans, trans_feat
--------------------------------------------------------------------------------
/trainval.py:
--------------------------------------------------------------------------------
1 | import importlib; importlib.util.find_spec("waymo_open_dataset")
2 | # assert importlib.util.find_spec("waymo_open_dataset") is not None, "no waymo"
3 |
4 | import argparse
5 | import os
6 | import exp_configs
7 | import pandas as pd
8 | import numpy as np
9 | import torch
10 | import time
11 |
12 | from torch.utils.data import DataLoader
13 | from haven import haven_utils as hu
14 | from haven import haven_wizard as hw
15 | from src import models
16 | from src.scenes import NeuralScene
17 | from src import utils as ut
18 | from src import utils_dist as utd
19 |
20 | torch.backends.cudnn.benchmark = True
21 |
22 | ONLY_PRESENT_SCORES = True
23 |
24 | # 1. define the training and validation function
25 | def trainval(exp_dict, savedir, args):
26 | """
27 | exp_dict: dictionary defining the hyperparameters of the experiment
28 | savedir: the directory where the experiment will be saved
29 | args: arguments passed through the command line
30 | """
31 | # set seed
32 | seed = 42 + exp_dict.get("runs", 0)
33 | np.random.seed(seed)
34 | torch.manual_seed(seed)
35 | torch.cuda.manual_seed_all(seed)
36 |
37 | model_state_dict = None
38 |
39 | render_epi = False
40 | if render_epi:
41 | exp_dict_pth = '/home/julian/workspace/NeuralSceneGraphs/model_library/scene_0_2/exp_dict.json'
42 | model_pth = '/home/julian/workspace/NeuralSceneGraphs/model_library/scene_0_2/model.pth'
43 | epi_frame_idx = 6
44 | epi_row = 96
45 |
46 | # exp_dict_pth = '/home/julian/workspace/NeuralSceneGraphs/model_library/scene_2_3/exp_dict.json'
47 | # model_pth = '/home/julian/workspace/NeuralSceneGraphs/model_library/scene_2_3/model.pth'
48 | # epi_frame_idx = 79
49 | # epi_row = 118
50 | # epi_row = 101
51 |
52 | if args.render_only and os.path.exists(exp_dict_pth):
53 | exp_dict = hu.load_json(exp_dict_pth)
54 | model_state_dict = hu.torch_load(model_pth)
55 |
56 | exp_dict["scale"] = 0.0625
57 | exp_dict["scale"] = 0.125
58 |
59 | scene = NeuralScene(
60 | scene_list=exp_dict["scenes"],
61 | datadir=args.datadir,
62 | args=args,
63 | exp_dict=exp_dict,
64 | )
65 |
66 | batch_size = min(len(scene), exp_dict.get("image_batch_size", 1))
67 | rand_sampler = torch.utils.data.RandomSampler(
68 | scene, num_samples=args.epoch_size * batch_size, replacement=True
69 | )
70 |
71 | scene_loader = torch.utils.data.DataLoader(
72 | scene,
73 | sampler=rand_sampler,
74 | collate_fn=ut.collate_fn_dict_of_lists,
75 | batch_size=batch_size,
76 | num_workers=args.num_workers,
77 | drop_last=True,
78 | )
79 |
80 | if scene.refine_camera_pose:
81 | calib_sampler = torch.utils.data.RandomSampler(
82 | scene, num_samples=len(scene), replacement=True
83 | )
84 | scene_calib_loader = torch.utils.data.DataLoader(
85 | scene,
86 | sampler=calib_sampler,
87 | collate_fn=ut.collate_fn_dict_of_lists,
88 | batch_size=1,
89 | num_workers=0,
90 | drop_last=True,
91 | )
92 | # TODO: Find permanent fix https://discuss.pytorch.org/t/runtimeerror-received-0-items-of-ancdata/4999
93 | # torch.multiprocessing.set_sharing_strategy('file_system')
94 |
95 | model = models.Model(scene, exp_dict, precache=exp_dict.get("precache"), args=args)
96 |
97 | # 3. load checkpoint
98 | chk_dict = hw.get_checkpoint(savedir, return_model_state_dict=True)
99 |
100 | if len(chk_dict["model_state_dict"]):
101 | model.set_state_dict(chk_dict["model_state_dict"])
102 |
103 | if model_state_dict is not None:
104 | model.set_state_dict(model_state_dict)
105 |
106 | # val_dict = model.val_on_scene(scene, savedir_images=os.path.join(savedir, "images"), all_frames=True)
107 |
108 | if not args.render_only:
109 | for e in range(chk_dict["epoch"], 5000):
110 | # 0. init score dict
111 | score_dict = {"epoch": e, "n_objects": len(scene.nodes["scene_object"])}
112 |
113 | # (3. Optional Camera Calibration)
114 | if e % 25 == 0 and scene.refine_camera_pose and e > 0:
115 | for e_calib in range(5):
116 | s_time = time.time()
117 | scene.recalibrate = True
118 | calib_dict = model.train_on_scene(scene_calib_loader)
119 | scene.recalibrate = False
120 | score_dict["calib_time"] = time.time() - s_time
121 | score_dict.update(calib_dict)
122 |
123 | # 1. train on batch
124 | s_time = time.time()
125 | train_dict = model.train_on_scene(scene_loader)
126 | score_dict["train_time"] = time.time() - s_time
127 | score_dict.update(train_dict)
128 |
129 | s_time = time.time()
130 | val_dict = model.val_on_scene(
131 | scene,
132 | savedir_images=os.path.join(savedir, "images"),
133 | )
134 |
135 | # 2. val on batch
136 | if e % 100 == 0 and e > 0:
137 | val_dict = model.val_on_scene(
138 | scene,
139 | savedir_images=os.path.join(savedir, "images_all_frames_{}".format(e)),
140 | all_frames=True,
141 | )
142 |
143 | score_dict["val_time"] = time.time() - s_time
144 | score_dict.update(val_dict)
145 | # ONLY MASTER PROCESS?
146 | if utd.is_main_process():
147 | # 3. save checkpoint
148 | chk_dict["score_list"] += [score_dict]
149 | hw.save_checkpoint(
150 | savedir,
151 | model_state_dict=model.get_state_dict(),
152 | score_list=chk_dict["score_list"],
153 | verbose=not ONLY_PRESENT_SCORES,
154 | )
155 | if ONLY_PRESENT_SCORES:
156 | score_df = pd.DataFrame(chk_dict["score_list"])
157 | print("Save directory: %s" % savedir)
158 | print(score_df.tail(1).to_string(index=False), "\n")
159 | elif render_epi:
160 | val_dict = model.val_on_scene(scene, savedir_images=os.path.join(savedir, "images"), all_frames=False, EPI=True,
161 | epi_row=epi_row, epi_frame_idx=epi_frame_idx)
162 | else:
163 | val_dict = model.val_on_scene(scene, savedir_images=os.path.join(savedir, "images"), all_frames=True)
164 |
165 |
166 | # 7. create main
167 | if __name__ == "__main__":
168 | # 9. Launch experiments using magic command
169 | parser = argparse.ArgumentParser()
170 | parser.add_argument(
171 | "-e", "--exp_group_list", nargs="+", help="Define which exp groups to run."
172 | )
173 | parser.add_argument(
174 | "-sb",
175 | "--savedir_base",
176 | default=None,
177 | help="Define the base directory where the experiments will be saved.",
178 | )
179 | parser.add_argument("-d", "--datadir")
180 | parser.add_argument(
181 | "-r", "--reset", default=0, type=int, help="Reset or resume the experiment."
182 | )
183 | parser.add_argument(
184 | "-j", "--job_scheduler", default=None, help="Run jobs in cluster."
185 | )
186 | parser.add_argument(
187 | "-v",
188 | "--visualize",
189 | default="results/neural_scenes.ipynb",
190 | help="Run jobs in cluster.",
191 | )
192 | parser.add_argument("-p", "--python_binary_path", default="python")
193 | parser.add_argument("-db", "--debug", type=int, default=0)
194 | parser.add_argument("--epoch_size", type=int, default=100)
195 | parser.add_argument("--num_workers", type=int, default=0)
196 | parser.add_argument("--render_only", type=bool, default=False)
197 | # parser.add_argument(
198 | # "--dist_url", default="env://", help="url used to set up distributed training"
199 | # )
200 | parser.add_argument("--ngpus", type=int, default=1)
201 |
202 | args, others = parser.parse_known_args()
203 |
204 | # Load job config to run things on cluster
205 | python_binary_path = args.python_binary_path
206 | jc = None
207 | if os.path.exists("job_config.py"):
208 | import job_config
209 |
210 | jc = job_config.JOB_CONFIG
211 | if args.ngpus > 1:
212 | jc["resources"]["gpu"] = args.ngpus
213 | python_binary_path += (
214 | f" -m torch.distributed.launch --nproc_per_node={args.ngpus} --use_env "
215 | )
216 |
217 | # utd.init_distributed_mode(args)
218 | # if args.distributed and not utd.is_main_process():
219 | # args.reset = 0
220 |
221 | hw.run_wizard(
222 | func=trainval,
223 | exp_groups=exp_configs.EXP_GROUPS,
224 | savedir_base=args.savedir_base,
225 | reset=args.reset,
226 | python_binary_path=python_binary_path,
227 | job_config=jc,
228 | args=args,
229 | use_threads=True,
230 | results_fname="results/neural_scenes.ipynb",
231 | )
232 |
--------------------------------------------------------------------------------
/src/datasets/__init__.py:
--------------------------------------------------------------------------------
1 | import pylab as plt
2 |
3 | # import tensorflow as tf
4 | # from ..nerf_tf.prepare_input_helper import extract_object_information
5 | import numpy as np
6 | import torch, os, copy, glob
7 |
8 | DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
9 |
10 |
11 | def get_dataset(datadir, scene_dict, args):
12 | scene_dict = copy.deepcopy(scene_dict)
13 | selected_frames = None
14 | if scene_dict["last_frame"] is not None:
15 | selected_frames = [scene_dict["first_frame"], scene_dict["last_frame"]]
16 |
17 | if scene_dict['type'] == 'waymo':
18 | from .waymo import Waymo
19 | # Scene Id in Waymo is a combination of dataset number (e.g. 4 for 0004)
20 | # and the rank of the tfrecord sorted alphabetical (e.g. 0 for segment-18446264979321894359_3700_000_3720_000_with_camera_labels.tfrecord)
21 | datadir_full = datadir + ''
22 | scene_id = scene_dict['scene_id']
23 | record_id = scene_id[1]
24 | subdirs_list = [d.name for d in os.scandir(datadir) if d.is_dir() if d.name[-4:].isnumeric()]
25 | assert scene_id[0] -z, y --> x, z --> y
164 | x_c_0 = np.matmul(poses[0, :, :], np.array([5.0, 0.0, 0.0, 1.0]))[:3]
165 | y_c_0 = np.matmul(poses[0, :, :], np.array([0.0, 5.0, 0.0, 1.0]))[:3]
166 | z_c_0 = np.matmul(poses[0, :, :], np.array([0.0, 0.0, 5.0, 1.0]))[:3]
167 | coord_cam_0 = [x_c_0, y_c_0, z_c_0]
168 | c_origin_0 = poses[0, :3, 3]
169 |
170 | plt.sca(ax_lst[0, 0])
171 | plt.arrow(
172 | c_origin_0[ax_birdseye[0]],
173 | c_origin_0[ax_birdseye[1]],
174 | coord_cam_0[ax_birdseye[0]][ax_birdseye[0]] - c_origin_0[ax_birdseye[0]],
175 | coord_cam_0[ax_birdseye[0]][ax_birdseye[1]] - c_origin_0[ax_birdseye[1]],
176 | color="red",
177 | width=0.1,
178 | )
179 | plt.arrow(
180 | c_origin_0[ax_birdseye[0]],
181 | c_origin_0[ax_birdseye[1]],
182 | coord_cam_0[ax_birdseye[1]][ax_birdseye[0]] - c_origin_0[ax_birdseye[0]],
183 | coord_cam_0[ax_birdseye[1]][ax_birdseye[1]] - c_origin_0[ax_birdseye[1]],
184 | color="green",
185 | width=0.1,
186 | )
187 | plt.axis("equal")
188 | plt.sca(ax_lst[1, 0])
189 | plt.arrow(
190 | c_origin_0[ax_xy[0]],
191 | c_origin_0[ax_xy[1]],
192 | coord_cam_0[ax_xy[0]][ax_xy[0]] - c_origin_0[ax_xy[0]],
193 | coord_cam_0[ax_xy[0]][ax_xy[1]] - c_origin_0[ax_xy[1]],
194 | color="red",
195 | width=0.1,
196 | )
197 | plt.arrow(
198 | c_origin_0[ax_xy[0]],
199 | c_origin_0[ax_xy[1]],
200 | coord_cam_0[ax_xy[1]][ax_xy[0]] - c_origin_0[ax_xy[0]],
201 | coord_cam_0[ax_xy[1]][ax_xy[1]] - c_origin_0[ax_xy[1]],
202 | color="green",
203 | width=0.1,
204 | )
205 | plt.axis("equal")
206 | plt.sca(ax_lst[0, 1])
207 | plt.arrow(
208 | c_origin_0[ax_zy[0]],
209 | c_origin_0[ax_zy[1]],
210 | coord_cam_0[ax_zy[0]][ax_zy[0]] - c_origin_0[ax_zy[0]],
211 | coord_cam_0[ax_zy[0]][ax_zy[1]] - c_origin_0[ax_zy[1]],
212 | color="red",
213 | width=0.1,
214 | )
215 | plt.arrow(
216 | c_origin_0[ax_zy[0]],
217 | c_origin_0[ax_zy[1]],
218 | coord_cam_0[ax_zy[1]][ax_zy[0]] - c_origin_0[ax_zy[0]],
219 | coord_cam_0[ax_zy[1]][ax_zy[1]] - c_origin_0[ax_zy[1]],
220 | color="green",
221 | width=0.1,
222 | )
223 | plt.axis("equal")
224 |
225 | # Plot global coord axis
226 | plt.sca(ax_lst[0, 0])
227 | plt.arrow(0, 0, 5, 0, color="cyan", width=0.1)
228 | plt.arrow(0, 0, 0, 5, color="cyan", width=0.1)
229 | plt.savefig(fname)
230 |
--------------------------------------------------------------------------------
/src/pointLF/scene_point_lightfield.py:
--------------------------------------------------------------------------------
1 | from typing import List
2 |
3 | import numpy as np
4 | import torch
5 | import torch.nn as nn
6 | from ..scenes import NeuralScene
7 | from pytorch3d.renderer import RayBundle, ray_bundle_to_ray_points
8 | from pytorch3d.transforms import Transform3d, Translate, Rotate, Scale
9 |
10 |
11 | class PointLightFieldComposition(nn.Module):
12 | def __init__(self,
13 | scene: NeuralScene):
14 |
15 | super(PointLightFieldComposition, self).__init__()
16 |
17 | self._models = {}
18 | self._static_models = {}
19 | self._static_trafos = {}
20 |
21 | for node_types_dict in scene.nodes.values():
22 | for node in node_types_dict.values():
23 | if hasattr(node, 'lightfield'):
24 | if not node.static:
25 | self._models[node.scene_idx] = getattr(node, 'lightfield')
26 | else:
27 | self._static_models[node.scene_idx] = getattr(node, 'lightfield')
28 | self._static_trafos[node.scene_idx] = node.transformation[:3, -1]
29 |
30 | def forward(self,
31 | ray_bundle: RayBundle,
32 | scene: NeuralScene,
33 | closest_point_mask,
34 | pt_cloud_select,
35 | closest_point_dist,
36 | closest_point_azimuth,
37 | closest_point_pitch,
38 | output_dict,
39 | ray_dirs_select,
40 | rotate2cam=False,
41 | **kwargs,
42 | ):
43 | device = ray_bundle.origins.device
44 |
45 | ray_bundle = ray_bundle._replace(
46 | lengths=ray_bundle.lengths.detach(),
47 | directions=ray_bundle.directions.detach(),
48 | origins=ray_bundle.origins.detach(),
49 | )
50 |
51 | # closest_point_mask, [pt_cloud_select, closest_point_dist, closest_point_azimuth, closest_point_pitch, output_dict], ray_dirs_select = pts
52 |
53 | xycfn = ray_bundle.xys
54 |
55 | c = torch.zeros_like(ray_bundle.origins)
56 |
57 | n_batch_rays = min([v.shape[0] for v in closest_point_dist.values()])
58 | # sample_mask = {
59 | # cf_id :
60 | # torch.stack(torch.where(torch.all(xycfn[..., 2:4] == torch.tensor(cf_id, device=device), dim=-1)))
61 | # for cf_id in list(closest_point_dist.keys())
62 | # }
63 | sample_mask = {
64 | cf_id:
65 | torch.stack([
66 | torch.ones(xycfn.shape[-2], dtype=torch.int64, device=device) * j,
67 | torch.linspace(0, xycfn.shape[-2] - 1, xycfn.shape[-2], dtype=torch.int64, device=device)
68 | ])
69 | for j, cf_id in enumerate(list(closest_point_dist.keys()))
70 | }
71 |
72 | pt_cloud_select, closest_point_dist, closest_point_azimuth, closest_point_pitch, ray_dirs_select, closest_point_mask, sample_mask = \
73 | self.split_for_uneven_batch_sz(pt_cloud_select, closest_point_dist, closest_point_azimuth, closest_point_pitch, ray_dirs_select, closest_point_mask, sample_mask, n_batch_rays,
74 | device)
75 |
76 | for node_idx, model in self._static_models.items():
77 | x = None
78 | # TODO: Only get frame specific here
79 | for cf_id, mask in closest_point_mask.items():
80 |
81 | # Check if respective background and frame match
82 | frame = scene.frames[int(cf_id[1])]
83 | if any(node_idx == scene.frames[int(cf_id[1])].scene_matrix[:, 0]):
84 | # TODO: Multiple frames at once
85 | # Get projected rgb
86 | # closest_rgb_fr = self._get_closest_rgb(scene, ray_bundle, point_cloud=pt_cloud_select[cf_id], c=int(cf_id[0]), f=int(cf_id[1]), device=device)
87 | closest_rgb_fr = torch.zeros_like(pt_cloud_select[cf_id])
88 |
89 | # TODO: rotation of the point cloud as part of the sampler or optional
90 | if rotate2cam:
91 | li_idx, li_node = list(scene.nodes['lidar'].items())[0]
92 | assert li_node.name == "TOP"
93 | cam_ed = frame.get_edge_by_child_idx([cf_id[0]])[0][0]
94 | li_ed = frame.get_edge_by_child_idx([li_idx])[0][0]
95 | # Transform x from li2world2cam
96 | # li2world
97 | li2wo = li_ed.get_transformation_c2p().to(device)
98 | # world2cam
99 | wo2cam = cam_ed.get_transformation_p2c().to(device)
100 |
101 | pt_cloud_select[cf_id] = wo2cam.transform_points(li2wo.transform_points(pt_cloud_select[cf_id]))
102 |
103 | # Check if intersections could be found inside frustum
104 | if mask is not None:
105 | if x is None:
106 | x = pt_cloud_select[cf_id][None]
107 | x_dist = closest_point_dist[cf_id][None]
108 | azimuth = closest_point_azimuth[cf_id][None]
109 | pitch = closest_point_pitch[cf_id][None]
110 | ray_dirs = ray_dirs_select[cf_id][None]
111 | closest_mask = closest_point_mask[cf_id][None]
112 | # sample_mask = torch.stack(torch.where(torch.all(xycfn[..., 2:4] == cf_id, dim=-1)))[None]
113 | closest_rgb = closest_rgb_fr[None]
114 | projected_dist = ray_bundle.lengths[tuple(sample_mask[cf_id])][None]
115 | else:
116 | # print(cf_id)
117 | # print(pt_cloud_select[cf_id][None].shape)
118 | # print(x.shape)
119 | x = torch.cat([x, pt_cloud_select[cf_id][None]])
120 | x_dist = torch.cat([x_dist, closest_point_dist[cf_id][None]])
121 | azimuth = torch.cat([azimuth, closest_point_azimuth[cf_id][None]])
122 | pitch = torch.cat([pitch, closest_point_pitch[cf_id][None]])
123 | ray_dirs = torch.cat([ray_dirs, ray_dirs_select[cf_id][None]])
124 | closest_mask = torch.cat([closest_mask, closest_point_mask[cf_id][None]])
125 | # new_fr_mask = torch.stack(torch.where(torch.all(xycfn[..., 2:4] == cf_id, dim=-1)))[None]
126 | # sample_mask = torch.cat([sample_mask, new_fr_mask])
127 | closest_rgb = torch.cat([closest_rgb, closest_rgb_fr[None]])
128 |
129 | projected_dist = torch.cat([projected_dist, ray_bundle.lengths[tuple(sample_mask[cf_id])][None]])
130 |
131 | sample_idx = list(closest_point_mask.keys())
132 | if x is not None:
133 | if self.training:
134 | # start = torch.cuda.Event(enable_timing=True)
135 | # end = torch.cuda.Event(enable_timing=True)
136 | # start.record()
137 | color, output_dict = model(x, ray_dirs, closest_mask, x_dist, x_proj=projected_dist, x_pitch=pitch,
138 | x_azimuth=azimuth, rgb=closest_rgb, sample_idx=sample_idx)
139 | # end.record()
140 | # torch.cuda.synchronize()
141 | # print('CUDA Time: {}'.format(start.elapsed_time(end)))
142 | else:
143 | color, output_dict = model(x, ray_dirs, closest_mask, x_dist, x_proj=projected_dist, x_pitch=pitch,
144 | x_azimuth=azimuth, rgb=closest_rgb, sample_idx=sample_idx)
145 | for (sample_color, mask) in zip(color, list(sample_mask.values())):
146 | c[tuple(mask)] = sample_color
147 |
148 | return c, output_dict
149 |
150 |
151 | def split_for_uneven_batch_sz(self, pt_cloud_select, closest_point_dist, closest_point_azimuth, closest_point_pitch, ray_dirs_select, closest_point_mask, sample_mask, n_batch_rays,
152 | device):
153 | for cf_id in list(closest_point_dist.keys()):
154 | v = closest_point_dist[cf_id]
155 | if v.shape[0] > n_batch_rays:
156 | factor = v.shape[0] // n_batch_rays
157 | for i in range(factor):
158 | cf_id_new = cf_id + tuple([i * 1])
159 | pt_cloud_select[cf_id_new] = pt_cloud_select[cf_id]
160 | closest_point_dist[cf_id_new] = closest_point_dist[cf_id][i * n_batch_rays: (i + 1) * n_batch_rays]
161 | closest_point_azimuth[cf_id_new] = closest_point_azimuth[cf_id][i * n_batch_rays: (i + 1) * n_batch_rays]
162 | closest_point_pitch[cf_id_new] = closest_point_pitch[cf_id][i * n_batch_rays: (i + 1) * n_batch_rays]
163 | ray_dirs_select[cf_id_new] = ray_dirs_select[cf_id][i * n_batch_rays: (i + 1) * n_batch_rays]
164 | closest_point_mask[cf_id_new] = closest_point_mask[cf_id][i * n_batch_rays: (i + 1) * n_batch_rays]
165 | sample_mask[cf_id_new] = sample_mask[cf_id][:, i * n_batch_rays: (i + 1) * n_batch_rays]
166 |
167 | del pt_cloud_select[cf_id]
168 | del closest_point_dist[cf_id]
169 | del closest_point_azimuth[cf_id]
170 | del closest_point_pitch[cf_id]
171 | del ray_dirs_select[cf_id]
172 | del closest_point_mask[cf_id]
173 | del sample_mask[cf_id]
174 |
175 | return pt_cloud_select, closest_point_dist, closest_point_azimuth, closest_point_pitch, ray_dirs_select, closest_point_mask, sample_mask
176 |
177 |
178 | def _get_closest_rgb(self, scene, ray_bundle, point_cloud, c, f, device):
179 | rgb = None
180 | img = torch.tensor(scene.frames[f].load_image(c), device=device)
181 |
182 | cam = scene.nodes['camera'][c]
183 | cam_ed = scene.frames[f].get_edge_by_child_idx([c])[0][0]
184 | # Get Camera Intrinsics and Extrensics
185 | cam_focal = cam.intrinsics.f_x
186 | cam_H = cam.intrinsics.H
187 | cam_W = cam.intrinsics.W
188 | cam_rot = Rotate(cam.R[None, ...].to(device), device=device)
189 | cam_transform = cam_ed.getTransformation()
190 |
191 | cam_w_xyz = point_cloud[:, [1, 2, 0]]
192 | cam_xy = cam_focal * (cam_w_xyz[:, [0, 1]] / cam_w_xyz[:, 2, None])
193 | cam_uv = -cam_xy + torch.tensor([[cam_W / 2, cam_H / 2]], device=device)
194 | cam_uv = cam_uv[:, [1, 0]].to(dtype=torch.int64)
195 | cam_uv = torch.maximum(cam_uv, torch.tensor(0, device=device))
196 | cam_uv[:, 0] = torch.minimum(cam_uv[:, 0], torch.tensor(cam_H - 1, device=device))
197 | cam_uv[:, 1] = torch.minimum(cam_uv[:, 1], torch.tensor(cam_W - 1, device=device))
198 | rgb = img[tuple(cam_uv.T)].detach()
199 |
200 | # img[tuple(cam_uv.T)] = np.array([1.0, 0., 0.])
201 | # f3 = plt.figure()
202 | # plt.imshow(img)
203 |
204 | return rgb
--------------------------------------------------------------------------------
/src/renderer/losses.py:
--------------------------------------------------------------------------------
1 | import time
2 |
3 | import numpy as np
4 | import torch
5 | import torch.nn as nn
6 | from ..scenes import NeuralScene
7 | from pytorch3d.renderer.implicit.utils import RayBundle
8 | import imageio
9 |
10 |
11 | def mse_loss(x, y, colorspace="RGB"):
12 | if "HS" in colorspace:
13 | # x,y = rgb2hsv(x),rgb2hsv(y)
14 | x, y = rgb2NonModuloHSV(x), rgb2NonModuloHSV(y)
15 | if colorspace == "HS":
16 | x, y = x[:, :-1], y[:, :-1]
17 | return torch.nn.functional.mse_loss(x, y)
18 |
19 |
20 | def calc_uncertainty_weighted_loss(
21 | x: torch.Tensor, y: torch.Tensor, uncertainty: torch.Tensor, **kwargs
22 | ):
23 | uncertainty = uncertainty + 0.1
24 | uncertainty_variance = uncertainty ** 2
25 | # TODO: Check if mean or sum in loss function
26 | uncert_weighted_mse = torch.mean((x - y) ** 2 / (2 * uncertainty_variance))
27 | uncert_loss = (
28 | torch.mean(torch.log(uncertainty_variance) / 2) + 3
29 | ) # +3 to make it positive
30 | return uncert_weighted_mse + uncert_loss
31 |
32 |
33 | def calc_density_regularizer(densities: torch.Tensor, reg: torch.int, **kwargs):
34 | return reg * torch.mean(densities)
35 |
36 |
37 | def calc_weight_regularizer(
38 | weights: torch.Tensor,
39 | reg: torch.int,
40 | xycfn: torch.Tensor,
41 | scene: NeuralScene,
42 | **kwargs,
43 | ):
44 | background_weights = []
45 |
46 | n_rays, n_sampling_pts = weights.shape
47 | short_xycfn = xycfn[..., -n_sampling_pts:, :]
48 | short_xycfn = short_xycfn.reshape(n_rays, n_sampling_pts, -1)
49 |
50 | camera_ids_sampled = short_xycfn[:, 0, 2].unique()
51 | for cf in short_xycfn[:, 0, 2:4].unique(dim=0):
52 | c = int(cf[0])
53 | f = int(cf[1])
54 | frame = scene.frames[int(f)]
55 |
56 | cf_mask = torch.all(short_xycfn[..., 2:4] == cf, dim=-1)
57 | cf_mask = torch.where(cf_mask[:, 0])[0]
58 |
59 | relevant_xy = short_xycfn[cf_mask, 0, :2]
60 | xy_mask = tuple(relevant_xy[:, [1, 0]].T)
61 | segmentation_mask = frame.load_mask(c, return_xycfn=False)[xy_mask] == 0
62 | if xy_mask[0].shape[0] == 1:
63 | continue
64 | background_weights.append(weights[cf_mask[segmentation_mask]])
65 |
66 | background_weights = torch.cat(background_weights)
67 |
68 | return reg * torch.mean(background_weights)
69 |
70 |
71 | def xycfn2list(xycfn):
72 | xycfn_list = []
73 | xycfn = xycfn.squeeze(0)
74 | for cf in xycfn[:, 0, 2:4].unique(dim=0):
75 | c = int(cf[0])
76 | f = int(cf[1])
77 |
78 | cf_mask = torch.all(xycfn[..., 2:4] == cf, dim=-1)
79 | cf_mask = torch.where(cf_mask[:, 0])[0]
80 |
81 | yx = xycfn[cf_mask, 0, :2]
82 | xycfn_list += [{"f": f, "c": c, "yx": yx}]
83 |
84 | return xycfn_list
85 |
86 |
87 | def calc_psnr(x: torch.Tensor, y: torch.Tensor):
88 | mse = torch.nn.functional.mse_loss(x, y)
89 | psnr = -10.0 * torch.log10(mse)
90 | return psnr
91 |
92 |
93 | # def calc_latent_dist(
94 | # xycfn, scene, reg, transient_frame_embbeding_reg=0, scene_function=None
95 | # ):
96 | # loss = 0
97 |
98 | # trainable_latent_nodes_id = list(scene.nodes["scene_object"].keys())
99 |
100 | # # Remove "non"-nodes from the rays
101 | # latent_nodess_id = xycfn[..., 4].unique().tolist()
102 | # try:
103 | # latent_nodess_id.remove(-1)
104 | # except:
105 | # pass
106 |
107 | # # Just include nodes that have latent arrays
108 | # latent_nodess_id = set(trainable_latent_nodes_id) & set(latent_nodess_id)
109 |
110 | # if len(latent_nodess_id) != 0:
111 | # latent_codes = torch.stack(
112 | # [
113 | # torch.cat(list(scene.nodes[i]["node"].latent.values()))
114 | # for i in latent_nodess_id
115 | # ]
116 | # )
117 | # latent_dist = torch.sum(reg * torch.norm(latent_codes, dim=-1))
118 | # else:
119 | # latent_dist = torch.tensor(0.0)
120 |
121 | # loss += latent_dist
122 |
123 | # if transient_frame_embbeding_reg:
124 | # image_latent = []
125 | # fn = xycfn[..., 3:5].view(-1, 2).unique(dim=0)
126 |
127 | # tranient_latents = []
128 | # for (f, n) in fn:
129 | # # Get Transient embeddings for each node and frame combination
130 | # key = f"{f}_{n}"
131 | # if key in scene_function.transient_object_embeddings:
132 | # fn_idx = torch.where(
133 | # torch.all(fn == torch.tensor([f, n], device=fn.device), dim=1)
134 | # )
135 | # transient_embedding_object_frame = (
136 | # scene_function.transient_object_embeddings[key]
137 | # )
138 | # tranient_latents.append(transient_embedding_object_frame)
139 |
140 | # # Find a loss on all those to be similar
141 | # image_latent = torch.stack(tranient_latents)
142 | # loss += transient_frame_embbeding_reg * torch.sum(
143 | # torch.std(image_latent, dim=0)
144 | # )
145 |
146 | # return loss
147 |
148 |
149 | def extract_objects_HS_stats(unique_obj_IDs, RGB, per_pix_obj_ID, Hue2Cartesian=True):
150 | # It is actually not neccesary to do this in PyTorch. Currently we are using GT colors, so we might as well work in Numpy since we don't need to backpropagate through it.
151 | if Hue2Cartesian:
152 | color_vals = rgb2NonModuloHSV(RGB)[:, :-1]
153 | else:
154 | color_vals = rgb2hsv(RGB)[:, :-1]
155 | per_obj_vals = dict(
156 | zip(
157 | unique_obj_IDs, [color_vals[per_pix_obj_ID == i, :] for i in unique_obj_IDs]
158 | )
159 | )
160 | # per_obj_color_stats = dict([(k,(np.mean(v.cpu().numpy(),0),np.cov(v.cpu().numpy().transpose()))) for k,v in per_obj_vals.items()])
161 | # color_means,color_covs = np.stack([per_obj_color_stats[k][0] for k in unique_obj_IDs]),np.stack([per_obj_color_stats[k][1] for k in unique_obj_IDs])
162 | per_obj_color_stats = dict(
163 | [(k, (torch.mean(v, 0), cov(v))) for k, v in per_obj_vals.items()]
164 | )
165 | color_means, color_covs = torch.stack(
166 | [per_obj_color_stats[k][0] for k in unique_obj_IDs]
167 | ), torch.stack([per_obj_color_stats[k][1] for k in unique_obj_IDs])
168 | return color_means, color_covs
169 |
170 |
171 | def calc_latent_color_loss(unique_obj_IDs, RGB, per_pix_obj_ID, extract_latent_fn):
172 | color_means, color_covs = extract_objects_HS_stats(
173 | unique_obj_IDs, RGB, per_pix_obj_ID
174 | )
175 | MEANS_WEIGHT = 0.5
176 | latent_dists, color_dists = [], []
177 | for ind1 in range(len(unique_obj_IDs)):
178 | for ind2 in range(ind1 + 1, len(unique_obj_IDs)):
179 | latent_dist = torch.norm(
180 | extract_latent_fn(ind1) - extract_latent_fn(ind2), p=2, dim=0
181 | ) # /np.sqrt(latent_size)
182 | latent_dists.append(latent_dist)
183 | # color_dist = MEANS_WEIGHT*np.linalg.norm(color_means[ind1,:]-color_means[ind2,:],ord=2)/np.sqrt(color_means.shape[1])
184 | # color_dist += (1-MEANS_WEIGHT)*np.linalg.norm(color_covs[ind1,...]-color_covs[ind2,...],ord='fro')/color_means.shape[1]
185 | color_dist = MEANS_WEIGHT * torch.norm(
186 | color_means[ind1, :] - color_means[ind2, :], p=2, dim=0
187 | ) # /np.sqrt(color_means.shape[1])
188 | color_dist += (1 - MEANS_WEIGHT) * torch.norm(
189 | color_covs[ind1, ...] - color_covs[ind2, ...], p="fro"
190 | ) # /color_means.shape[1]
191 | color_dists.append(color_dist)
192 | latent_dists = torch.stack(latent_dists)
193 | color_dists = torch.stack(color_dists)
194 | # color_dists = np.array(color_dists)/np.mean(color_dists)*torch.mean(latent_dists).item()
195 | # return torch.mean((torch.tensor(color_dists).type(latent_dists.type())-latent_dists)**2)
196 | color_dists = color_dists / torch.mean(color_dists) * torch.mean(latent_dists)
197 | return torch.mean((color_dists - latent_dists) ** 2)
198 |
199 |
200 | def prod_density_distribution(
201 | obj_weights: torch.Tensor, transient_weights: torch.Tensor
202 | ):
203 | obj_weights = obj_weights + 1e-5
204 | obj_sample_pdf = obj_weights / torch.sum(obj_weights, -1, keepdim=True)
205 |
206 | transient_weights = transient_weights + 1e-5
207 | transient_sample_pdf = transient_weights / torch.sum(
208 | transient_weights, -1, keepdim=True
209 | )
210 |
211 | return torch.mean(100 * obj_sample_pdf * transient_sample_pdf)
212 |
213 |
214 | def get_rgb_gt(
215 | rgb: torch.Tensor, scene: NeuralScene, xycfn: torch.Tensor, use_gt_mask=False
216 | ):
217 | xycf = xycfn[..., 0, :4].reshape(len(rgb), -1)
218 | rgb_gt = torch.ones_like(rgb) * -1
219 |
220 | # TODO: Make more efficient by not retriving image for each pixel,
221 | # but storing all gt_images in a single tensor on the cpu
222 | # TODO: During test time just get all images avilable
223 | camera_ids_sampled = xycf[:, 2].unique()
224 | for f in xycf[:, 3].unique():
225 | frame = scene.frames[int(f)]
226 | for c in frame.camera_ids:
227 | if c not in camera_ids_sampled:
228 | continue
229 | cf_mask = torch.all(
230 | xycf[:, 2:] == torch.tensor([c, f], device=xycf.device), dim=1
231 | )
232 | xy = xycf[cf_mask, :2].cpu()
233 |
234 | gt_img = frame.load_image(int(c))
235 | if use_gt_mask == 2:
236 | gt_img[frame.load_mask(c, return_xycfn=False) == 0] = 0
237 | if use_gt_mask == 3:
238 | gt_img[frame.load_mask(c, return_xycfn=False) == 0] = 1
239 | gt_px = torch.from_numpy(gt_img[xy[:, 1], xy[:, 0]]).to(
240 | device=rgb.device, dtype=rgb.dtype
241 | )
242 | rgb_gt[cf_mask] = gt_px
243 |
244 | assert (rgb_gt == -1).sum() == 0
245 | return rgb_gt
246 |
247 |
248 | def rgb2hsv(rgb_vect):
249 | img = rgb_vect # * 0.5 + 0.5
250 | per_pix_max, per_pix_min = img.max(1)[0], img.min(1)[0]
251 | delta = per_pix_max - per_pix_min
252 | delta_is_0 = delta == 0
253 | hue = torch.zeros([img.shape[0]]).to(img.device)
254 | max_is_R = torch.logical_and(
255 | img[:, 0] == per_pix_max, torch.logical_not(delta_is_0)
256 | )
257 | max_is_G = torch.logical_and(
258 | img[:, 1] == per_pix_max, torch.logical_not(delta_is_0)
259 | )
260 | max_is_B = torch.logical_and(
261 | img[:, 2] == per_pix_max, torch.logical_not(delta_is_0)
262 | )
263 | hue[max_is_B] = 4.0 + ((img[max_is_B, 0] - img[max_is_B, 1]) / delta[max_is_B])
264 | hue[max_is_G] = 2.0 + ((img[max_is_G, 2] - img[max_is_G, 0]) / delta[max_is_G])
265 | hue[max_is_R] = (
266 | 0.0 + ((img[max_is_R, 1] - img[max_is_R, 2]) / delta[max_is_R])
267 | ) % 6
268 |
269 | hue[delta_is_0] = 0.0
270 | hue = hue / 6
271 |
272 | saturation = torch.zeros_like(hue)
273 | max_is_0 = per_pix_max == 0
274 | saturation[torch.logical_not(max_is_0)] = (
275 | delta[torch.logical_not(max_is_0)] / per_pix_max[torch.logical_not(max_is_0)]
276 | )
277 | saturation[max_is_0] = 0.0
278 |
279 | value = per_pix_max
280 | return torch.stack([hue, saturation, value], 1)
281 |
282 |
283 | def hue2cartesian(hue):
284 | return 0.5 * torch.stack(
285 | [torch.cos(2 * np.pi * hue), torch.sin(2 * np.pi * hue)], 1
286 | )
287 |
288 |
289 | def rgb2NonModuloHSV(rgb_vect):
290 | HSV = rgb2hsv(rgb_vect)
291 | return torch.cat([hue2cartesian(HSV[:, 0]), HSV[:, 1:]], 1)
292 |
293 |
294 | def cov(x, rowvar=False, bias=False, ddof=None, aweights=None):
295 | # From https://github.com/pytorch/pytorch/issues/19037
296 | """Estimates covariance matrix like numpy.cov"""
297 | # ensure at least 2D
298 | if x.dim() == 1:
299 | x = x.view(-1, 1)
300 |
301 | # treat each column as a data point, each row as a variable
302 | if rowvar and x.shape[0] != 1:
303 | x = x.t()
304 |
305 | if ddof is None:
306 | if bias == 0:
307 | ddof = 1
308 | else:
309 | ddof = 0
310 |
311 | w = aweights
312 | if w is not None:
313 | if not torch.is_tensor(w):
314 | w = torch.tensor(w, dtype=torch.float)
315 | w_sum = torch.sum(w)
316 | avg = torch.sum(x * (w / w_sum)[:, None], 0)
317 | else:
318 | avg = torch.mean(x, 0)
319 |
320 | # Determine the normalization
321 | if w is None:
322 | fact = x.shape[0] - ddof
323 | elif ddof == 0:
324 | fact = w_sum
325 | elif aweights is None:
326 | fact = w_sum - ddof
327 | else:
328 | fact = w_sum - ddof * torch.sum(w * w) / w_sum
329 |
330 | xm = x.sub(avg.expand_as(x))
331 |
332 | if w is None:
333 | X_T = xm.t()
334 | else:
335 | X_T = torch.mm(torch.diag(w), xm).t()
336 |
337 | c = torch.mm(X_T, xm)
338 | c = c / fact
339 |
340 | return c.squeeze()
341 |
--------------------------------------------------------------------------------
/src/utils.py:
--------------------------------------------------------------------------------
1 | import tqdm, argparse
2 | import os, exp_configs
3 | import copy
4 | import pandas as pd
5 | import numpy as np
6 | import torch
7 | from PIL import Image
8 | from haven import haven_utils as hu
9 | from haven import haven_examples as he
10 | from haven import haven_wizard as hw
11 | from haven import haven_results as hr
12 | from src import models
13 | from src.scenes import NeuralScene
14 | from .scenes import createCamera, createStereoCamera
15 | # from src.renderer import NeuralSceneRenderer
16 | from pytorch3d.transforms.rotation_conversions import axis_angle_to_quaternion, quaternion_to_axis_angle
17 | import time
18 | from pytorch3d.transforms.so3 import so3_exponential_map, so3_log_map
19 | from pytorch3d.transforms.rotation_conversions import (
20 | euler_angles_to_matrix,
21 | matrix_to_euler_angles,
22 | )
23 |
24 |
25 | def mask_to_xycfn(frame_idx, camera_idx, mask):
26 | xycfn_list = []
27 | for node_id in np.unique(mask):
28 | if node_id == 0:
29 | continue
30 | y, x = np.where(mask == node_id)
31 | xycfn_i = np.zeros((y.shape[0], 5))
32 | xycfn_i[:, 4] = node_id
33 | xycfn_i[:, 3] = frame_idx
34 | xycfn_i[:, 2] = camera_idx
35 | xycfn_i[:, 1] = y
36 | xycfn_i[:, 0] = x
37 | xycfn_list += [xycfn_i]
38 | xycfn = np.vstack(xycfn_list)
39 | return xycfn
40 |
41 |
42 | class to_args(object):
43 | def __init__(self, adict):
44 | self.__dict__.update(adict)
45 |
46 |
47 | def collate_fn_lists_of_dicts(batch):
48 | return batch
49 |
50 |
51 | def collate_fn_dict_of_lists(batch):
52 | import functools
53 |
54 | return {
55 | key: [item[key] for item in batch]
56 | for key in list(
57 | functools.reduce(
58 | lambda x, y: x.union(y), (set(dicts.keys()) for dicts in batch)
59 | )
60 | )
61 | }
62 |
63 |
64 | def display_points(gt_image, out, color):
65 | obj_mask = torch.where(out["xycfn"][..., -1].ge(1))
66 | xycf_relevant = out["xycfn"][obj_mask][..., :4]
67 | for f in xycf_relevant[..., 3].unique():
68 | # frame = scene.frames[int(f)]
69 | for c in xycf_relevant[:, 2].unique():
70 | cf_mask = torch.all(
71 | xycf_relevant[:, 2:]
72 | == torch.tensor([c, f], device=xycf_relevant.device),
73 | dim=1,
74 | )
75 | xy = xycf_relevant[cf_mask, :2].cpu()
76 | # c_id = scene.getNodeBySceneId(int(c)).type_idx
77 | gt_img = gt_image.copy()
78 | gt_img[xy[:, 1], xy[:, 0]] = np.array(color)
79 | return gt_img
80 |
81 |
82 | def add_camera_path_frame(scene, frame_idx=[0], cam_idx=None, n_steps=9, remove_old_cameras=True, offset=0.):
83 | edges_to_cameras_ls = []
84 | imgs = []
85 | frames = []
86 | cams = []
87 |
88 | if cam_idx is None:
89 | cam_idx = [None] * len(frame_idx)
90 |
91 | max_ind_list = len(scene.frames_cameras)
92 |
93 | for frame_id, c_id in zip(frame_idx, cam_idx):
94 | # Extract all information from the frame for which cameras should be interpolated
95 | selected_frame = scene.frames[frame_id]
96 | frames += [selected_frame]
97 | cam_nodes = scene.nodes['camera']
98 | if c_id is None:
99 | # KITIT
100 | cams += [list(cam_nodes.values())[0]]
101 |
102 | edges_to_cameras = selected_frame.get_edge_by_child_idx(list(cam_nodes.keys()))
103 | edges_to_cameras_ls += [ed[0] for ed in edges_to_cameras]
104 |
105 | # edge_ids_to_cameras_ls = selected_frame.get_edge_idx_by_child_idx(list(cam_nodes.keys()))
106 | # edge_ids_to_cameras_ls = [ed_id[0] for ed_id in edge_ids_to_cameras_ls]
107 |
108 | imgs += [list(selected_frame.images.values())[0]]
109 | else:
110 | cams += [cam_nodes[c_id]]
111 |
112 | edges_to_cameras = selected_frame.get_edge_by_child_idx([c_id])
113 | edges_to_cameras_ls += [ed[0] for ed in edges_to_cameras]
114 |
115 | # edge_ids_to_cameras_ls = selected_frame.get_edge_idx_by_child_idx([c_id])
116 | # edge_ids_to_cameras_ls = [ed_id[0] for ed_id in edge_ids_to_cameras_ls]
117 |
118 | imgs += [selected_frame.images[c_id]]
119 |
120 | scene_dict = {}
121 | for fr_c in scene.frames_cameras:
122 | if fr_c[0] == frame_id:
123 | scene_dict = fr_c[2]
124 | scene_id = scene_dict['scene_id']
125 | break
126 |
127 | add_new_val_render_path(frames, cams, edges_to_cameras_ls, imgs, scene, scene_dict, n_steps,
128 | remove_old_cameras, offset)
129 |
130 | new_max_ind_list = len(scene.frames_cameras)
131 | ind_list = np.linspace(max_ind_list, new_max_ind_list - 1, new_max_ind_list - max_ind_list, dtype=int)
132 |
133 | return scene, ind_list
134 |
135 |
136 | def add_new_val_render_path(frames, cams, edges_to_cameras_ls, img_path, scene, scene_dict, n_steps=3, remove_old_cameras=False,
137 | offset=0.):
138 | selected_frame = frames[0]
139 | copied_cam = cams[0]
140 | cam_ids = scene.nodes['camera'].keys()
141 |
142 | fr_edge_ids_to_cameras_ls = [[fr.frame_idx, ed.index] for fr, ed in zip(frames, edges_to_cameras_ls)]
143 | # Create a new frame as a copy of the selected frame
144 | new_frame = copy.deepcopy(selected_frame)
145 |
146 | # Remove image paths from unused cameras
147 | if remove_old_cameras:
148 | for c_id in cam_ids:
149 | if c_id in new_frame.images:
150 | del new_frame.images[c_id]
151 | if len(new_frame.get_edge_by_child_idx([c_id])[0]) > 0:
152 | new_frame.camera_ids.remove(c_id)
153 |
154 | # Get Camera poses
155 | new_rotations, new_translations = interpolate_between_camera_edges(edges_to_cameras_ls, n_steps=n_steps, offset=offset)
156 | new_rotations_no, new_translations_no = interpolate_between_camera_edges(edges_to_cameras_ls, n_steps=n_steps,
157 | offset=0.)
158 |
159 | # Create edges and nodes from new cameras
160 | new_edges_ls = []
161 | for k, (rotation, translation) in enumerate(zip(new_rotations, new_translations)):
162 | # Create new virtual camera
163 | new_cam = createCamera(copied_cam.H, copied_cam.W, copied_cam.intrinsics.f_x.cpu().numpy(), type=scene_dict['type'])
164 | new_nodes = scene.updateNodes(new_cam)
165 | new_cam_id = list(new_nodes['camera'].keys())[0]
166 | new_frame.images[new_cam_id] = img_path[k // n_steps]
167 | new_frame.camera_ids.append(new_cam_id)
168 |
169 | # Create new edge to the camera
170 | new_edge = copy.deepcopy(edges_to_cameras_ls[0])
171 | new_edge.translation = translation
172 | new_edge.rotation = rotation
173 | new_edge.child = new_cam_id
174 |
175 | new_edges_ls.append(new_edge)
176 |
177 | # Remove old cameras if requested
178 | # if remove_old_cameras:
179 | # for fr_id, ed_id in fr_edge_ids_to_cameras_ls:
180 | # new_frame.removeEdge(ed_id)
181 |
182 | # Add edges to the new camera poses to the graph
183 | new_frame.add_edges(new_edges_ls)
184 |
185 | # Add frame to the scene
186 | frame_list = [new_frame]
187 |
188 | scene_id = 1e4
189 | if not len(scene_dict) == 0:
190 | scene_id = scene_dict['scene_id']
191 |
192 | scene.updateFrames(frame_list, scene_id, scene_dict)
193 |
194 |
195 | def add_new_val_render_poses(frame_to_copy_from, camera_to_copy_from, edges_to_cameras_ls, img_path, scene, scene_dict, n_steps=3, remove_old_cameras=True):
196 | selected_frame = frame_to_copy_from
197 | copied_cam = camera_to_copy_from
198 | cam_ids = scene.nodes['camera'].keys()
199 |
200 | edge_ids_to_cameras_ls = selected_frame.get_edge_idx_by_child_idx(list(cam_ids))
201 | edge_ids_to_cameras_ls = [ed_id[0] for ed_id in edge_ids_to_cameras_ls]
202 | # Create a new frame as a copy of the selected frame
203 | new_frame = copy.deepcopy(selected_frame)
204 |
205 | # Remove image paths from unused cameras
206 | if remove_old_cameras:
207 | for c_id in cam_ids:
208 | del new_frame.images[c_id]
209 | new_frame.camera_ids.remove(c_id)
210 |
211 | # Get Camera poses
212 | new_rotations, new_translations = interpolate_between_camera_edges(edges_to_cameras_ls, n_steps=n_steps, )
213 |
214 | # Create edges and nodes from new cameras
215 | new_edges_ls = []
216 | for k, (rotation, translation) in enumerate(zip(new_rotations, new_translations)):
217 | # Create new virtual camera
218 | new_cam = createCamera(copied_cam.H, copied_cam.W, copied_cam.intrinsics.f_x.cpu().numpy(), )
219 | new_nodes = scene.updateNodes(new_cam)
220 | new_cam_id = list(new_nodes['camera'].keys())[0]
221 | new_frame.images[new_cam_id] = img_path
222 | new_frame.camera_ids.append(new_cam_id)
223 |
224 | # Create new edge to the camera
225 | new_edge = copy.deepcopy(edges_to_cameras_ls[0])
226 | new_edge.translation = translation
227 | new_edge.rotation = rotation
228 | new_edge.child = new_cam_id
229 |
230 | new_edges_ls.append(new_edge)
231 |
232 | # Remove old cameras if requested
233 | if remove_old_cameras:
234 | for ed_id in edge_ids_to_cameras_ls:
235 | new_frame.removeEdge(ed_id)
236 |
237 | # Add edges to the new camera poses to the graph
238 | new_frame.add_edges(new_edges_ls)
239 |
240 | # Add frame to the scene
241 | frame_list = [new_frame]
242 |
243 | scene_id = 1e4
244 | if not len(scene_dict) == 0:
245 | scene_id = scene_dict['scene_id']
246 |
247 | scene.updateFrames(frame_list, scene_id, scene_dict)
248 |
249 |
250 | def interpolate_between_camera_edges(edges_to_cameras_ls, n_steps=5, offset=0.):
251 | rots = [ed.rotation for ed in edges_to_cameras_ls]
252 | translations = [ed.translation for ed in edges_to_cameras_ls]
253 |
254 | steps = torch.linspace(0, 1, n_steps, device=rots[0].device)
255 |
256 | new_quat_rots = []
257 | new_translations = []
258 | for cam_pair_i in range(len(rots) - 1):
259 | # Interpolation between translations
260 | translation_0 = translations[cam_pair_i] + torch.matmul(so3_exponential_map(rots[cam_pair_i]),
261 | torch.tensor([1., 0., 0.]) * offset)
262 | translation_1 = translations[cam_pair_i + 1] + torch.matmul(so3_exponential_map(rots[cam_pair_i + 1]),
263 | torch.tensor([1., 0., 0.]) * offset)
264 | mid_translations = translation_0 * (1 - steps[:, None]) + \
265 | translation_1 * (steps[:, None])
266 |
267 | for i in range(n_steps - 1):
268 | new_translations.append(mid_translations[i, None])
269 |
270 | # Implementation between rotations with Quaternion SLERP
271 | quat_rot_0 = axis_angle_to_quaternion(rots[cam_pair_i])
272 | quat_rot_1 = axis_angle_to_quaternion(rots[cam_pair_i + 1])
273 | cosHalfTheta = torch.sum(quat_rot_0 * quat_rot_1)
274 | halfTheta = torch.acos(cosHalfTheta)
275 | sinHalfTheta = torch.sqrt(1.0 - cosHalfTheta * cosHalfTheta)
276 |
277 | if (torch.abs(sinHalfTheta) < 0.001):
278 | # theta is 180 degree --> Rotation around different axis is possible
279 | for i in range(n_steps - 1):
280 | new_quat_rots.append(quat_rot_0)
281 | elif (torch.abs(cosHalfTheta) >= 1.0):
282 | # 0 degree difference --> No new rotation necessary
283 | mid_quat = quat_rot_0 * (1. - steps)[:, None] + quat_rot_1 * (steps)[:, None]
284 | for i in range(n_steps - 1):
285 | new_quat_rots.append(mid_quat[i, None])
286 | else:
287 | ratioA = torch.sin((1 - steps) * halfTheta) / sinHalfTheta
288 | ratioB = torch.sin(steps * halfTheta) / sinHalfTheta
289 | mid_quat = quat_rot_0 * ratioA[:, None] + quat_rot_1 * ratioB[:, None]
290 | for i in range(n_steps - 1):
291 | new_quat_rots.append(mid_quat[i, None])
292 |
293 | new_quat_rots.append(quat_rot_1)
294 | new_translations.append(translation_1)
295 |
296 | new_rotations = [quaternion_to_axis_angle(quaterion) for quaterion in new_quat_rots]
297 |
298 | return new_rotations, new_translations
299 |
300 |
301 | def output_gif(scene, ind_list, savedir_images, tgt_fname):
302 | tgt_path = os.path.join(savedir_images, (tgt_fname + '.gif'))
303 |
304 | iname_ls = [f'frame_{scene.frames_cameras[i][0]}_camera_{scene.frames_cameras[i][1]}' for i in ind_list]
305 |
306 | image_path_ls = [os.path.join(savedir_images, f"{iname}.png") for iname in iname_ls]
307 |
308 | img, *imgs = [Image.open(f) for f in image_path_ls]
309 | img.save(
310 | fp=tgt_path,
311 | format="GIF",
312 | append_images=imgs,
313 | save_all=True,
314 | duration=3000 // len(image_path_ls),
315 | loop=0,
316 | )
--------------------------------------------------------------------------------
/src/scenes/raysampler/rayintersection.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | import torch.nn as nn
4 | from pytorch3d.renderer.implicit.utils import RayBundle
5 | from pytorch3d.transforms import Transform3d
6 | from pytorch3d.transforms.so3 import so3_log_map, so3_exponential_map
7 |
8 |
9 | def join_list(x):
10 | return [inner for outer in x for inner in outer]
11 |
12 |
13 | class RayIntersection(nn.Module):
14 | """
15 | Module to compute Ray intersections
16 | """
17 |
18 | def __init__(self,
19 | n_samples: int,
20 | chunk_size: int):
21 | super().__init__()
22 | self._n_samples = n_samples
23 | self._chunk_size = int(chunk_size)
24 |
25 | def forward(self,
26 | ray_bundle: RayBundle,
27 | scene,
28 | intersections: torch.Tensor = None,
29 | **kwargs
30 | ):
31 | """
32 | Takes rays [ray_origin, ray_direction, frame_id], nodes to intersect and a scene as an Input.
33 | Outputs intersection points in ray coordinates, [z_val, node_scene_id, frame_id]
34 | """
35 | # TODO: Only compute required intersection with plane/boxes/etc. in test time
36 |
37 | # return intersection_pts
38 | pass
39 |
40 |
41 | class RayBoxIntersection(RayIntersection):
42 | def __init__(self,
43 | box_nodes: dict,
44 | chunk_size: int,
45 | n_intersections_box: int=2):
46 |
47 | super().__init__(n_samples=n_intersections_box,
48 | chunk_size=chunk_size)
49 |
50 | self._box_nodes = [node.scene_idx for node in box_nodes.values()]
51 |
52 | def forward(self,
53 | origins: torch.Tensor,
54 | directions: torch.Tensor,
55 | box_bounds: torch.Tensor = torch.tensor([[-1, -1, -1], [1, 1, 1]]),
56 | transformation: Transform3d = None,
57 | output_points: bool = False,
58 | **kwargs,
59 | ):
60 |
61 | if transformation is not None:
62 | origins = transformation.transform_points(origins)
63 | directions = transformation.transform_points(directions)
64 |
65 | if directions.dim() == 2:
66 | n_batch = 1
67 | n_rays_batch = directions.shape[0]
68 | elif directions.dim() == 3:
69 | ray_d_sh = directions.shape
70 | n_batch = ray_d_sh[0]
71 | n_rays_batch = ray_d_sh[1]
72 | directions = directions.flatten(0, -2)
73 | origins = origins.flatten(0, -2)
74 | else:
75 | ValueError("Ray directions are of dimesion {}, but must be of dimension 2 or 3.".format(directions.dim()))
76 |
77 | if origins.dim() < directions.dim():
78 | origins = origins.expand(n_batch, n_rays_batch, 3)
79 | origins = origins.flatten(0, -2)
80 | else:
81 | if origins.shape != directions.shape:
82 | ValueError()
83 |
84 | box_bounds = box_bounds.to(origins.device)
85 | # Perform ray-aabb intersection and return in and out without chunks
86 | inv_d = torch.reciprocal(directions)
87 |
88 | t_min = (box_bounds[0] - origins) * inv_d
89 | t_max = (box_bounds[1] - origins) * inv_d
90 |
91 | t0 = torch.minimum(t_min, t_max)
92 | t1 = torch.maximum(t_min, t_max)
93 | t_near = torch.maximum(torch.maximum(t0[..., 0], t0[..., 1]), t0[..., 2])
94 | t_far = torch.minimum(torch.minimum(t1[..., 0], t1[..., 1]), t1[..., 2])
95 | # Check if rays are inside boxes
96 | intersection_idx = torch.where(t_far > t_near)
97 | # Check that boxes are in front of the ray origin
98 | intersection_idx = intersection_idx[0][t_far[intersection_idx] > 0]
99 | if not len(intersection_idx) == 0:
100 | z_in = t_near[intersection_idx]
101 | z_out = t_far[intersection_idx]
102 |
103 | # Reindex for [n_batches, ....] and sort again
104 | batch_idx = torch.floor(intersection_idx / n_rays_batch).to(torch.int64)
105 | intersection_idx = intersection_idx % n_rays_batch
106 | # intersection_idx, new_sort = torch.sort(intersection_idx)
107 | intersection_mask = tuple([batch_idx, intersection_idx])
108 |
109 | if not output_points:
110 | return [z_in, z_out], intersection_mask
111 | else:
112 | pts_in = origins.view(-1, n_rays_batch, 3)[intersection_idx] + \
113 | directions.view(-1, n_rays_batch, 3)[intersection_idx] * z_in[:, None]
114 | pts_out = origins.view(-1, n_rays_batch, 3)[intersection_idx] + \
115 | directions.view(-1, n_rays_batch, 3)[intersection_idx] * z_out[:, None]
116 |
117 | return [z_in, z_out, pts_in, pts_out], intersection_mask
118 |
119 | else:
120 | if output_points:
121 | return [None, None, None, None], None
122 | else:
123 | return [None, None], None
124 |
125 |
126 | class RaySphereIntersection(RayIntersection):
127 | def __init__(self,
128 | n_samples_box: int,
129 | chunk_size: int,):
130 | super().__init__(n_samples=n_samples_box)
131 |
132 | def forward(self,
133 | ray_bundle: RayBundle,
134 | scene,
135 | intersections: torch.Tensor = None,
136 | **kwargs):
137 | intersection_pts = []
138 | return intersection_pts
139 |
140 |
141 | class RayPlaneIntersection(RayIntersection):
142 | def __init__(self,
143 | n_planes: int,
144 | near: float,
145 | far: float,
146 | chunk_size: int,
147 | camera_poses: list,
148 | background_trafos: torch.Tensor,
149 | transient_background: bool=False):
150 | super().__init__(n_samples=n_planes,
151 | chunk_size=chunk_size)
152 |
153 | self._planes_n = {}
154 | self._planes_p = {}
155 | self._plane_delta = {}
156 | self._near = {}
157 | self._far = {}
158 | self._transient_background = False
159 |
160 | for key, val in background_trafos.items():
161 | if self._transient_background:
162 | self._near[key] = torch.as_tensor(near[key])
163 | self._far[key] = torch.as_tensor(far[key])
164 |
165 | else:
166 | global_trafo = val
167 | near_k = torch.as_tensor(near[key])
168 | far_k = torch.as_tensor(far[key])
169 |
170 | self._planes_n[key] = global_trafo[:3, 2]
171 |
172 | all_camera_poses = []
173 | for edge_dict in camera_poses.values():
174 | for edge in edge_dict.values():
175 | if len(edge) == 0:
176 | continue
177 | if edge[0].parent == key:
178 | all_camera_poses.append(edge[0].translation)
179 |
180 | all_camera_poses = torch.cat(all_camera_poses)
181 | n_cameras = 2
182 | # len(camera_poses)
183 | # assert n_cameras == 2
184 | n_cam_poses = len(all_camera_poses)
185 |
186 | max_pose_dist = torch.norm(all_camera_poses[-1] - all_camera_poses[0])
187 |
188 | # TODO: shouldn't this be int(n_cam_poses / n_cameras) +1
189 | end = int(n_cam_poses / n_cameras) + 1
190 | pose_dist = (all_camera_poses[1:end] - all_camera_poses[:end-1])
191 | pose_dist = torch.norm(pose_dist, dim=1).max()
192 | planes_p = global_trafo[:3, -1] + near_k * self._planes_n[key]
193 |
194 | self._plane_delta[key] = (far_k - near_k) / (self._n_samples - 1)
195 |
196 | poses_per_plane = int(((far_k - near_k) / self._n_samples) / pose_dist)
197 | if poses_per_plane != 0:
198 | add_planes = int(np.ceil((n_cam_poses/n_cameras) / poses_per_plane))
199 | else:
200 | add_planes = 1
201 | id_planes = torch.linspace(0, self._n_samples + add_planes - 1, self._n_samples+ add_planes, dtype=int)
202 |
203 | self._planes_p[key] = planes_p + (id_planes * self._plane_delta[key])[:, None] * self._planes_n[key]
204 | far_k = near_k + self._plane_delta[key] * (id_planes[-1] + add_planes)
205 |
206 | self._near[key] = torch.as_tensor(near_k)
207 | self._far[key] = torch.as_tensor(far_k)
208 |
209 | def forward(self,
210 | ray_bundle: RayBundle,
211 | scene,
212 | intersections: torch.Tensor = None,
213 | obj_obly: bool=False,
214 | **kwargs):
215 | """ Ray-Plane intersection for given planes in the scenes
216 |
217 | Args:
218 | rays: ray origin and directions
219 | planes: first plane position, plane normal and distance between planes
220 | id_planes: ids of used planes
221 | near: distance between camera pose and first intersecting plane
222 |
223 | Returns:
224 | pts: [N_rays, N_samples+N_importance] - intersection points of rays and selected planes
225 | z_vals: integration step along each ray for the respective points
226 | """
227 | if not obj_obly and not self._transient_background:
228 | node_id = 0
229 |
230 | # TODO: Compare with outputs from old method
231 | # Extract ray and plane definitions
232 | device = ray_bundle.origins.device
233 | N_rays = np.prod(ray_bundle.origins.shape[:-1])
234 |
235 | # Get amount of all planes
236 | rays_sh = list(ray_bundle.origins.shape)
237 | xys_sh = list(ray_bundle.xys.shape)
238 |
239 | # Flatten ray origins and directions
240 | all_origs = ray_bundle.origins.flatten(0, -2)
241 | all_dirs = ray_bundle.directions.flatten(0, -2)
242 | xycfn = ray_bundle.xys.flatten(0,-2)
243 |
244 | if len(xycfn) != len(all_origs):
245 | Warning("Please check that global sampler is executed before the local sampler!")
246 |
247 | # TODO: Initilaize planes with right dtype float32
248 | # TODO: Check run time for multiple scene implementation
249 | d_origin_planes = torch.zeros([self._n_samples, len(xycfn)], device=device)
250 |
251 | for n_idx in xycfn[:,-1].unique():
252 | n_i_mask = torch.where(xycfn[:, -1] == n_idx)
253 | background_mask = [
254 | torch.linspace(0, self._n_samples - 1, self._n_samples, dtype=torch.int64)[:, None].repeat(1,len(n_i_mask[0])),
255 | n_i_mask[0][None].repeat(self._n_samples, 1)]
256 |
257 | n_idx = int(n_idx)
258 | origs = all_origs[n_i_mask]
259 | dirs = all_dirs[n_i_mask]
260 |
261 | p = self._planes_p[n_idx].to(device=origs.device, dtype=origs.dtype)
262 | n = self._planes_n[n_idx].to(device=origs.device, dtype=origs.dtype)
263 | near = self._near[n_idx].to(device=origs.device, dtype=origs.dtype)
264 | delta = self._plane_delta[n_idx]
265 |
266 | if len(p) > self._n_samples:
267 | # import matplotlib.pyplot as plt
268 | #
269 | # plt.scatter(origs[:, 0], origs[:, 2])
270 | # plt.scatter(p[:, 0], p[:, 2])
271 | # plt.axis('equal')
272 | # Just get the intersections with self._n_planes - 1 planes in front of the camera and the last plane
273 | d_p0_orig = torch.matmul(p[0] - origs - 1e-3, n)
274 | d_p0_orig = torch.maximum(-d_p0_orig, -near)
275 | start_idx = torch.ceil((d_p0_orig + near) / delta).to(dtype=torch.int64)
276 | plane_idx = start_idx + torch.linspace(0, self._n_samples - 2, self._n_samples - 1, dtype=int, device=near.device)[:, None]
277 | plane_idx = torch.cat([plane_idx, torch.full([1, len(origs)], len(p) - 1, device=near.device)])
278 | p = p[plane_idx]
279 | else:
280 | p = p[:, None, :]
281 |
282 | d_origin_planes_i = p - origs
283 | d_origin_planes_i = torch.matmul(d_origin_planes_i, n)
284 | d_origin_planes_i = d_origin_planes_i / torch.matmul(dirs, n)
285 | # TODO: Include check that validity here (if everything is positive)
286 | d_origin_planes[background_mask] = d_origin_planes_i
287 |
288 | rays_sh.insert(-1, self._n_samples)
289 | lengths = d_origin_planes.transpose(1, 0).reshape(rays_sh[:-1])
290 | else:
291 | if not self._transient_background:
292 | device = ray_bundle.lengths.device
293 | near = min(list(self._near.values()))
294 | far = max(list(self._far.values()))
295 | z = torch.linspace(near, far, self._n_samples)
296 | lengths = torch.ones(ray_bundle.lengths.shape[:-1])[..., None].repeat(1, 1, self._n_samples).to(device)
297 | lengths *= z.to(device)
298 | else:
299 | device = ray_bundle.lengths.device
300 | far = max(list(self._far.values()))
301 | lengths = torch.ones(ray_bundle.lengths.shape[:-1])[..., None].repeat(1, 1, self._n_samples).to(
302 | device)
303 | lengths *= torch.tensor([far]).to(device)
304 |
305 | return lengths
--------------------------------------------------------------------------------
/src/datasets/waymo_od.py:
--------------------------------------------------------------------------------
1 | import os
2 | import time
3 | import imageio
4 | import numpy as np
5 | import random
6 | from matplotlib import pyplot as plt
7 | from PIL import Image
8 | import tensorflow as tf
9 |
10 | # TODO: Make waymo data import and work with neural scenes graphs
11 | # from waymo_open_dataset.utils import frame_utils
12 | # from waymo_open_dataset import dataset_pb2 as open_dataset
13 | # from waymo_open_dataset.utils.transform_utils import *
14 | camera_names = {1: 'FRONT',
15 | 2: 'FRONT LEFT',
16 | 3: 'FRONT RIGHT',
17 | 4: 'SIDE LEFT',
18 | 5: 'SIDE RIGHT',}
19 |
20 | cameras = [1,2,3] # [1, 2, 3]
21 |
22 |
23 | def get_scene_objects(dataset, speed_thresh):
24 | waymo_obj_meta = {}
25 | max_n_obj = 0
26 |
27 | for i, data in enumerate(dataset):
28 | frame = open_dataset.Frame()
29 | frame.ParseFromString(bytearray(data.numpy()))
30 | types = [frame.laser_labels[0].TYPE_PEDESTRIAN,
31 | frame.laser_labels[0].TYPE_VEHICLE,
32 | frame.laser_labels[0].TYPE_CYCLIST]
33 |
34 | n_obj_frame = 0
35 | for laser_label in frame.laser_labels:
36 | if laser_label.type in types:
37 | id = laser_label.id
38 | # length, height, width
39 | dim = np.array([laser_label.box.length, laser_label.box.height, laser_label.box.width])
40 | speed = np.sqrt(np.sum([laser_label.metadata.speed_x ** 2, laser_label.metadata.speed_y ** 2]))
41 | acc_x = laser_label.metadata.accel_x
42 |
43 | if speed > speed_thresh:
44 | n_obj_frame += 1
45 | if id not in waymo_obj_meta:
46 | internal_track_id = len(waymo_obj_meta) + 1
47 | meta_obj = [id, internal_track_id, laser_label.type, dim]
48 | waymo_obj_meta[id] = meta_obj
49 | else:
50 | if np.sum(waymo_obj_meta[id][3] - dim) > 1e-10:
51 | print('Dimension mismatch for same object!')
52 | print(id)
53 | print(np.sum(waymo_obj_meta[id][2] - dim))
54 |
55 | if n_obj_frame > max_n_obj:
56 | max_n_obj = n_obj_frame
57 |
58 | return waymo_obj_meta, max_n_obj
59 |
60 |
61 | def get_frame_objects(laser_labels, v2w_frame_i, waymo_obj_meta, speed_thresh):
62 | # Get all objects from a frame
63 | frame_obj_dict = {}
64 |
65 | # TODO: Add Cyclists and pedestrians (like for metadata)
66 | types = [laser_labels[0].TYPE_VEHICLE]
67 |
68 | for label in laser_labels:
69 | if label.type in types:
70 | id = label.id
71 |
72 | if id in waymo_obj_meta:
73 | # TODO: CHECK vkitti/nerf x, y, z
74 | waymo2vkitti_vehicle = np.array([[1., 0., 0., 0.],
75 | [0., 0., -1., 0.],
76 | [0., 1., 0., 0.],
77 | [0., 0., 0., 1.]])
78 |
79 | x_v = label.box.center_x
80 | y_v = label.box.center_y
81 | z_v = label.box.center_z
82 | yaw_obj = np.array(label.box.heading)
83 |
84 | R_obj2v = get_yaw_rotation(yaw_obj)
85 | t_obj_v = tf.constant([x_v, y_v, z_v])
86 | transform_obj2v = get_transform(tf.cast(R_obj2v, tf.double), tf.cast(t_obj_v, tf.double))
87 | transform_obj2w = np.matmul(v2w_frame_i, transform_obj2v)
88 | R = transform_obj2w[:3, :3]
89 |
90 | yaw_aprox = np.arctan2(-R[2, 0], R[0, 0]) # np.arctan2(R[2, 0], R[0, 0]) - np.arctan2(0, 1)
91 | if yaw_aprox > np.pi:
92 | yaw_aprox -= 2*np.pi
93 | elif yaw_aprox > np.pi:
94 | yaw_aprox += 2*np.pi
95 |
96 | yaw_aprox_o = np.arccos(transform_obj2w[0, 0])
97 | if np.absolute(np.rad2deg(yaw_aprox - yaw_aprox_o)) > 1e-2:
98 | a = 0
99 |
100 | # yaw_aprox = yaw_aprox_o
101 |
102 | speed = np.sqrt(np.sum([label.metadata.speed_x ** 2, label.metadata.speed_y ** 2]))
103 | is_moving = 1. if speed > speed_thresh else 0.
104 |
105 | obj_prop = np.array(
106 | [transform_obj2w[0, 3], transform_obj2w[1, 3], transform_obj2w[2, 3], yaw_aprox, 0, 0, is_moving])
107 | frame_obj_dict[id] = obj_prop
108 |
109 | return frame_obj_dict
110 |
111 |
112 | def get_camera_pose(v2w_frame_i, calibration):
113 | # FROM Waymo OD documentation:
114 | # "Each sensor comes with an extrinsic transform that defines the transform from the
115 | # sensor frame to the vehicle frame.
116 | #
117 | # The camera frame is placed in the center of the camera lens.
118 | # The x-axis points down the lens barrel out of the lens.
119 | # The z-axis points up. The y/z plane is parallel to the camera plane.
120 | # The coordinate system is right handed."
121 |
122 | # Match opengl z --> -x, x --> y, y --> z
123 | opengl2camera = np.array([[0., 0., -1., 0.],
124 | [-1., 0., 0., 0.],
125 | [0., 1., 0., 0.],
126 | [0., 0., 0., 1.]])
127 | extrinsic_transform_c2v = np.reshape(calibration.extrinsic.transform, [4, 4])
128 | extrinsic_transform_c2v = np.matmul(extrinsic_transform_c2v, opengl2camera)
129 | c2w_frame_i_cam_c = np.matmul(v2w_frame_i, extrinsic_transform_c2v)
130 |
131 |
132 | return c2w_frame_i_cam_c
133 |
134 | def get_bbox_2d(label_2d):
135 | center = [label_2d.box.center_x, label_2d.box.center_y]
136 | dim_box = [label_2d.box.length, label_2d.box.width]
137 |
138 | left = np.ceil(center[0] - dim_box[0] * 0.5)
139 | right = np.ceil(center[0] + dim_box[0] * 0.5)
140 | top = np.ceil(center[1] + dim_box[1] * 0.5)
141 | bottom = np.ceil(center[1] - dim_box[1] * 0.5)
142 |
143 | return np.array([left, right, bottom, top])[None, :]
144 |
145 |
146 | def load_waymo_od_data(basedir, selected_frames, max_frames=5, use_obj=True, row_id=False):
147 | """
148 | :param basedir: Path to segment tfrecord
149 | :param max_frames:
150 | :param use_obj:
151 | :param row_id:
152 | :return:
153 | """
154 | if selected_frames == -1:
155 | start_frame = 0
156 | end_frame = 0
157 | else:
158 | start_frame = selected_frames[0]
159 | end_frame = selected_frames[1]
160 |
161 | print('Scene Representation from cameras:')
162 | for cam in cameras:
163 | print(camera_names[cam], ',')
164 |
165 | speed_thresh = 5.1
166 |
167 |
168 | dataset = tf.data.TFRecordDataset(basedir, compression_type='')
169 |
170 | frames = []
171 |
172 | print('Extracting all moving objects!')
173 | # Extract all moving objects
174 | # waymo_obj_meta: object_id, object_type, object_label, color, lenght, height, width
175 | # max_n_obj: maximum number of objects in a single frame
176 | waymo_obj_meta, max_n_obj = get_scene_objects(dataset, speed_thresh)
177 |
178 | # All images from cameras specified at the beginning
179 | images = []
180 |
181 | # Pose of each images camera
182 | poses = []
183 |
184 | # 2D bounding boxes
185 | bboxes = []
186 |
187 | # Frame Number, Camera Name, object_id, xyz, angle, ismoving
188 | visible_objects = []
189 | max_frame_obj = 0
190 |
191 | count = []
192 | # Extract all frames from a single tf_record
193 | for i, data in enumerate(dataset):
194 | if start_frame <= i <= end_frame:
195 | frame = open_dataset.Frame()
196 | frame.ParseFromString(bytearray(data.numpy()))
197 |
198 | # FROM Waymo OD documentation:
199 | # Global Frame/ World Frame
200 | # The origin of this frame is set to the vehicle position when the vehicle starts.
201 | # It is an ‘East-North-Up’ coordinate frame. ‘Up(z)’ is aligned with the gravity vector,
202 | # positive upwards. ‘East(x)’ points directly east along the line of latitude. ‘North(y)’
203 | # points towards the north pole.
204 |
205 | # Match vkitti: waymo global to vkitti global z --> -y, z --> y
206 | waymo2vkitti_world = np.array([[1., 0., 0., 0.],
207 | [0., 0., -1., 0.],
208 | [0., 1., 0., 0.],
209 | [0., 0., 0., 1.]])
210 |
211 | # Vehicle Frame
212 | # The x-axis is positive forwards, y-axis is positive to the left, z-axis is positive upwards.
213 | # A vehicle pose defines the transform from the vehicle frame to the global frame.
214 |
215 |
216 | # Vehicle to global frame transformation for this frame
217 | v2w_frame_i = np.reshape(frame.pose.transform, [4, 4])
218 | v2w_frame_i = np.matmul(waymo2vkitti_world, v2w_frame_i)
219 |
220 | # Get all objects in this frames
221 | frame_obj_dict = get_frame_objects(frame.laser_labels, v2w_frame_i, waymo_obj_meta, speed_thresh)
222 |
223 | # Loop over all camera images and visible objects per camera
224 | for camera_image in frame.images:
225 | for projected_lidar_labels in frame.projected_lidar_labels:
226 | if projected_lidar_labels.name != camera_image.name or projected_lidar_labels.name not in cameras:
227 | continue
228 |
229 | for calibration in frame.context.camera_calibrations:
230 | if calibration.name != camera_image.name:
231 | continue
232 |
233 | cam_no = np.array(camera_image.name).astype(np.float32)[None]
234 | frame_no = np.array(i).astype(np.float32)[None]
235 | count.append(len(images))
236 |
237 | # Extract images and camera pose
238 | images.append(np.array(tf.image.decode_jpeg(camera_image.image)))
239 | extrinsic_transform_c2w = get_camera_pose(v2w_frame_i, calibration)
240 | poses.append(extrinsic_transform_c2w)
241 |
242 | # Extract dynamic objects for image
243 | image_objects = np.ones([max_n_obj, 14]) * -1.
244 | images_boxes = []
245 | i_obj = 0
246 | for label_2d in projected_lidar_labels.labels:
247 | track_id = label_2d.id[:22]
248 |
249 | # Only add objects with 3D information/dynamic objects
250 | if track_id in frame_obj_dict:
251 | pose_3d = frame_obj_dict[track_id]
252 | dim = np.array(waymo_obj_meta[track_id][3]).astype(np.float32)
253 | # Move vehicle reference point to bottom of the box like vkitti
254 | pose_3d[1] = pose_3d[1] + (dim[1] / 2)
255 |
256 | internal_track_id = np.array(waymo_obj_meta[track_id][1]).astype(np.float32)[None]
257 | obj_type = np.array(waymo_obj_meta[track_id][2]).astype(np.float32)[None]
258 |
259 | obj = np.concatenate([frame_no, cam_no, internal_track_id, obj_type, dim, pose_3d])
260 |
261 | image_objects[i_obj, :] = obj
262 | i_obj += 1
263 |
264 | # Extract 2D bounding box for training
265 | bbox_2d = get_bbox_2d(label_2d)
266 | images_boxes.append(bbox_2d)
267 |
268 | if i_obj > max_frame_obj:
269 | max_frame_obj = i_obj
270 |
271 | bboxes.append(images_boxes)
272 | visible_objects.append(np.array(image_objects))
273 |
274 | if len(frames) >= max_frames:
275 | break
276 |
277 | if max_frame_obj > 0:
278 | visible_objects = np.array(visible_objects)[:, :max_frame_obj, :]
279 | else:
280 | print(max_frame_obj)
281 | print(visible_objects)
282 | visible_objects = np.array(visible_objects)[:, None, :]
283 | poses = np.array(poses)
284 | bboxes = np.array(bboxes)
285 | images = (np.maximum(np.minimum(np.array(images), 255), 0) / 255.).astype(np.float32)
286 |
287 |
288 | focal = np.reshape(frame.context.camera_calibrations[0].intrinsic, [9])[0]
289 | H = frame.context.camera_calibrations[0].height
290 | W = frame.context.camera_calibrations[0].width
291 |
292 |
293 | i_split = [np.sort(count[:]),
294 | count[int(0.8 * len(count)):],
295 | count[int(0.8 * len(count)):]]
296 |
297 | novel_view = 'left'
298 | n_oneside = int(poses.shape[0]/2)
299 |
300 | render_poses = poses[:1]
301 | # Novel view middle between both cameras:
302 | if novel_view == 'mid':
303 | new_poses_o = ((poses[n_oneside:, :, -1] - poses[:n_oneside, :, -1]) / 2) + poses[:n_oneside, :, -1]
304 | new_poses = np.concatenate([poses[:n_oneside, :, :-1], new_poses_o[...,None]], axis=2)
305 | render_poses = new_poses
306 |
307 | elif novel_view == 'left':
308 | # Render at trained left camera pose
309 | render_poses = poses[:n_oneside, ...]
310 | elif novel_view == 'right':
311 | # Render at trained left camera pose
312 | render_poses = poses[n_oneside:, ...]
313 |
314 | if use_obj:
315 | render_objects = visible_objects[:n_oneside, ...]
316 | else:
317 | render_objects = None
318 |
319 | # Create meta file matching vkitti2 meta data
320 | objects_meta = {}
321 | for meta_value in waymo_obj_meta.values():
322 | objects_meta[meta_value[1]] = np.concatenate([np.array(meta_value[1])[None],
323 | meta_value[3],
324 | np.array([meta_value[2]]) ])
325 |
326 | half_res = True
327 | if half_res:
328 | print('Using half resolution!!!')
329 | H = H // 2
330 | W = W // 2
331 | focal = focal / 2.
332 | images = tf.image.resize_area(images, [H, W]).numpy()
333 |
334 | for frame_boxes in bboxes:
335 | for i_box, box in enumerate(frame_boxes):
336 | frame_boxes[i_box] = box // 2
337 |
338 |
339 | return images, poses, render_poses, [H, W, focal], i_split, visible_objects, objects_meta, render_objects, bboxes, waymo_obj_meta
--------------------------------------------------------------------------------
/src/pointLF/attention_modules.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 | from src.pointLF.feature_mapping import PositionalEncoding
5 | from src.pointLF.layer import DenseLayer
6 |
7 |
8 | class FeatureDistanceEncoder(nn.Module):
9 | def __init__(self, feat_dim_in=128, W=256, D=1, n_frequ_pos_encoding=4, key_len=16, val_len=None, use_distance=True, use_projected=False, use_pitch=True, use_azimuth=True, azimuth_2d=False, no_feat=False):
10 | '''
11 | feat_dim_in:
12 | W:
13 | D:
14 | n_frequ_pos_encoding:
15 | key_len:
16 | use_distance:
17 | use_projected:
18 | '''
19 | super(FeatureDistanceEncoder, self).__init__()
20 | use_feat = not no_feat
21 |
22 | self.poseEncodingLen = PositionalEncoding(n_frequ_pos_encoding, 1)
23 | self.poseEncodingAng = PositionalEncoding(n_frequ_pos_encoding, 1, include_input=False)
24 |
25 | self.use_distance = use_distance
26 | self.use_projected = use_projected
27 | self.use_pitch = use_pitch
28 | self.use_azimuth = use_azimuth
29 | self.az_2d = azimuth_2d
30 | self.use_feat = use_feat
31 |
32 | self.used_distances = {
33 | 'distance': use_distance,
34 | 'projected_distance': use_projected,
35 | 'pitch': use_pitch,
36 | 'azimuth': use_azimuth,
37 | }
38 |
39 | self.enc_dist_dim = (n_frequ_pos_encoding * 2) * (use_distance + use_projected + use_pitch + use_azimuth + azimuth_2d) \
40 | + 1 * (use_distance + use_projected + 2 * azimuth_2d)
41 |
42 | self.input_ch = feat_dim_in * use_feat + self.enc_dist_dim
43 |
44 | self.dim_feat = feat_dim_in * use_feat
45 |
46 | self.linear = nn.ModuleList(
47 | [DenseLayer(self.input_ch, W)] +
48 | [DenseLayer(W, W,) for i in range(D - 1)])
49 |
50 |
51 | if val_len is None:
52 | self.val_out_ch = W - key_len
53 | else:
54 | self.val_out_ch = val_len
55 |
56 | self.value_linear = DenseLayer(W, self.val_out_ch)
57 | self.key_linear = DenseLayer(W, key_len)
58 |
59 | def forward(self, features, distance, projected_distance, pitch, azimuth):
60 | '''
61 |
62 | directions: [Batch_sz, N_rays, 3]
63 | features: [Batch_sz, N_rays, N_k_closest, N_feat_maps, dim_feat]
64 | distance: [Batch_sz, N_rays, N_k_closest]
65 | projected_distance: [Batch_sz, N_rays, N_k_closest]
66 | :return:
67 | :rtype:
68 | '''
69 | n_batch, n_rays, k_closest, n_feat_maps, feat_len = features.shape
70 |
71 | x = torch.empty(n_batch, n_rays, k_closest, 0, device=distance.device)
72 |
73 | # Normalize feature distances
74 | if self.used_distances['distance']:
75 | enc_dist = self.poseEncodingLen(distance[..., None])
76 | x = torch.cat([x, enc_dist], dim=-1)
77 |
78 | if self.used_distances['projected_distance']:
79 | x_proj_normalized = projected_distance / projected_distance.max(dim=-1).values[..., None]
80 | enc_proj = self.poseEncodingLen(x_proj_normalized[..., None])
81 | x = torch.cat([x, enc_proj], dim=-1)
82 |
83 | if self.used_distances['pitch']:
84 | enc_pitch = self.poseEncodingAng(pitch[..., None])
85 | x = torch.cat([x, enc_pitch], dim=-1)
86 |
87 | if self.used_distances['azimuth']:
88 | if not self.az_2d:
89 | enc_azimuth = self.poseEncodingAng(azimuth[..., None])
90 | else:
91 | enc_azimuth = torch.cat([
92 | self.poseEncodingLen(torch.sin(azimuth)[..., None]),
93 | self.poseEncodingLen(torch.cos(azimuth)[..., None])
94 | ], dim=-1)
95 |
96 | x = torch.cat([x, enc_azimuth], dim=-1)
97 |
98 | x = x[..., None, :].expand(n_batch, n_rays, k_closest, n_feat_maps, self.enc_dist_dim)
99 |
100 | if self.use_feat:
101 | x = torch.cat([features, x], dim=-1)
102 |
103 | x = x.reshape(n_batch*n_rays, k_closest * n_feat_maps, self.input_ch)
104 |
105 | for i, layer in enumerate(self.linear):
106 | x = layer(x)
107 | x = F.relu(x)
108 |
109 | values = self.value_linear(x)
110 | keys = self.key_linear(x)
111 |
112 | return values, keys
113 |
114 |
115 | class RayPointPoseEncoder(nn.Module):
116 | def __init__(self, W=64, D=1, n_frequ_pos_encoding=4, key_len=16, use_distance=True,
117 | use_projected=True, use_angle=True, feat_map_encoding=True):
118 | '''
119 | feat_len:
120 | W:
121 | D:
122 | n_frequ_pos_encoding:
123 | key_len:
124 | use_distance:
125 | use_projected:
126 | '''
127 | super(RayPointPoseEncoder, self).__init__()
128 | self.poseEncoding = PositionalEncoding(n_frequ_pos_encoding, 1)
129 |
130 | self.use_distance = use_distance
131 | self.use_projected = use_projected
132 | self.use_angle = use_angle
133 | self.use_feat_map_enc = feat_map_encoding
134 |
135 | self.input_ch = (n_frequ_pos_encoding * 2 + 1) * (use_distance + use_projected + use_angle) + (n_frequ_pos_encoding * 2) * feat_map_encoding * 3
136 |
137 | self.linear = nn.ModuleList(
138 | [DenseLayer(self.input_ch, W)] +
139 | [DenseLayer(W, W, ) for i in range(D - 1)])
140 |
141 | self.key_linear = DenseLayer(W, key_len)
142 |
143 | self.feat_map_enc = torch.tensor([[-1., 0., 0.], [1., 0., 0.],
144 | [0., -1., 0.], [0., 1., 0.],
145 | [0., 0., -1.], [0., 0., 1.], ])
146 | self.feat_map_enc = PositionalEncoding(n_frequ_pos_encoding, 3, include_input=False,)(self.feat_map_enc)
147 |
148 | def forward(self, distance, projected_distance, angle, n_feat_maps=1):
149 | '''
150 | distance: [Batch_sz, N_rays, N_k_closest]
151 | projected_distance: [Batch_sz, N_rays, N_k_closest]
152 | angle: [Batch_sz, N_rays, N_k_closest]
153 | :return:
154 | :rtype:
155 | '''
156 | n_batch, n_rays, k_closest = distance.shape
157 |
158 | # Normalize feature distances
159 | x_proj_normalized = projected_distance / projected_distance.max(dim=-1).values[..., None]
160 | x_dist_normalized = distance / distance.max(dim=-1).values[..., None]
161 |
162 | # Positional encoding of ray distances and projected distance
163 | # TODO: Debug from here
164 | enc_proj = self.poseEncoding(x_proj_normalized[..., None])
165 | enc_dist = self.poseEncoding(x_dist_normalized[..., None])
166 | enc_angle = self.poseEncoding(angle[..., None])
167 |
168 | if self.use_feat_map_enc:
169 | if n_feat_maps == 6:
170 | feat_map_enc = self.feat_map_enc.to(enc_proj.device)
171 |
172 |
173 | x = torch.cat([enc_dist, enc_proj, enc_angle], dim=-1)
174 | x = x[..., None, :].repeat(1, 1, 1, n_feat_maps, 1)
175 |
176 | feat_map_enc = feat_map_enc[None, None, None].repeat(n_batch, n_rays, k_closest, 1, 1)
177 |
178 | x = torch.cat([x, feat_map_enc], dim=-1)
179 | x = x.reshape(n_batch * n_rays, k_closest * n_feat_maps, self.input_ch)
180 |
181 | else:
182 | Warning('Not implemented yet.')
183 | else:
184 | x = torch.cat([enc_dist, enc_proj, enc_angle], dim=-1)
185 | x = x.reshape(n_batch * n_rays, k_closest, self.input_ch)
186 |
187 | # enc_proj = enc_proj.unsqueeze(3).repeat(1, 1, 1, n_feat_maps, 1)
188 | # enc_dist = enc_dist.unsqueeze(3).repeat(1, 1, 1, n_feat_maps, 1)
189 | # enc_angle = enc_angle.unsqueeze(3).repeat(1, 1, 1, n_feat_maps, 1)
190 |
191 |
192 |
193 | for i, layer in enumerate(self.linear):
194 | x = layer(x)
195 | x = F.relu(x)
196 |
197 | keys = self.key_linear(x)
198 |
199 | return keys
200 |
201 |
202 | class RayEncoder(nn.Module):
203 | def __init__(self, W=64, D=1, q_len=16, n_frequ_pos_encoding=4,):
204 | super(RayEncoder, self).__init__()
205 | self.poseEncoding = PositionalEncoding(n_frequ_pos_encoding, 3)
206 |
207 | self.input_ch = (n_frequ_pos_encoding * 2 + 1) * 3
208 |
209 | self.linear = nn.ModuleList(
210 | [DenseLayer(self.input_ch, W)] +
211 | [DenseLayer(W, W, ) for i in range(D - 2)])
212 |
213 | self.query_linear = DenseLayer(W, q_len,)
214 |
215 |
216 | def forward(self, ray_direction):
217 | x = self.poseEncoding(ray_direction)
218 |
219 | for i, layer in enumerate(self.linear):
220 | x = layer(x)
221 |
222 | x = self.query_linear(x)
223 |
224 | return x
225 |
226 | class ScaledDotProductAttention(nn.Module):
227 | def __init__(self, temperature, attn_dropout=0.1):
228 | super(ScaledDotProductAttention, self).__init__()
229 | self.temperature = temperature
230 | self.dropout = nn.Dropout(attn_dropout)
231 |
232 | def forward(self, q, k, v, mask=None):
233 | attn = torch.matmul(q / self.temperature, k.transpose(1, 2))
234 |
235 | if mask is not None:
236 | attn = attn.masked_fill(mask == 0, -1e9)
237 |
238 |
239 | attn = self.dropout(F.softmax(attn, dim=-1))
240 | output = torch.matmul(attn, v)
241 |
242 | return output, attn
243 |
244 |
245 |
246 | class PointFeatureAttention(nn.Module):
247 | def __init__(self, feat_dim_in, feat_dim_out, embeded_dim=128, n_att_heads=8, kdim=128, vdim=128, Feat_D=2, Feat_W=256, Ray_D=2, Ray_W=64,
248 | new_encoding=False, no_feat=False):
249 | super(PointFeatureAttention, self).__init__()
250 |
251 | if new_encoding:
252 | n_frequ = 8
253 | else:
254 | n_frequ = 4
255 |
256 | self.dim_out = feat_dim_out
257 | self.FeatureEncoder = FeatureDistanceEncoder(feat_dim_in=feat_dim_in,
258 | W=Feat_W,
259 | D=Feat_D,
260 | n_frequ_pos_encoding=n_frequ,
261 | key_len=kdim,
262 | val_len=vdim,
263 | use_distance=True,
264 | use_projected=False,
265 | use_pitch=True,
266 | use_azimuth=True,
267 | azimuth_2d=new_encoding,
268 | no_feat=no_feat)
269 |
270 | self.RayEncoder = RayEncoder(W=Ray_W,
271 | D=Ray_D,
272 | q_len=embeded_dim,
273 | n_frequ_pos_encoding=4,)
274 |
275 | self.n_att_heads = n_att_heads
276 |
277 | if self.n_att_heads > 0:
278 | self.attention = nn.MultiheadAttention(embed_dim=embeded_dim, num_heads=n_att_heads, kdim=kdim, vdim=vdim)
279 | else:
280 | self.attention = ScaledDotProductAttention(1.)
281 |
282 | self.dim_reduction_out = nn.Linear(embeded_dim, feat_dim_out)
283 |
284 | def forward(self, directions, features, distance=None, projected_distance=None, pitch=None, azimuth=None, **kwargs):
285 | feat_dim = features.shape[-1]
286 | n_batch, n_rays, _ = directions.shape
287 | # Generate Key and values from projected point cloud features and positional encoded ray-point distance with an MLP
288 | val, key = self.FeatureEncoder(features, distance, projected_distance, pitch, azimuth)
289 |
290 | # Use encoded ray-dirs in MLP to get query vector
291 | query = self.RayEncoder(directions.reshape(-1, 3))
292 | query = query[:, None]
293 |
294 | # Attention
295 | # Query Vector + per point Key + per-point value vector in transformer-style attention + pooling to create conditioning vector
296 | # Transpose for torch attention module
297 | if self.n_att_heads > 0:
298 | query = query.transpose(1,0)
299 | key = key.transpose(1, 0)
300 | val = val.transpose(1, 0)
301 | out, attn_weights = self.attention(query, key, val)
302 | out = self.dim_reduction_out(out)
303 | out = out.transpose(0, 1)
304 | else:
305 | out, attn_weights = self.attention(query, key, val)
306 | out = self.dim_reduction_out(out)
307 |
308 | out = out.reshape(n_batch, n_rays, self.dim_out)
309 | return out, attn_weights
310 |
311 |
312 | class PointDistanceAttention(nn.Module):
313 | def __init__(self, v_len=128, kq_len=16):
314 | super(PointDistanceAttention, self).__init__()
315 |
316 | self.RayPointPoseEncoder = RayPointPoseEncoder(W=256,
317 | D=2,
318 | n_frequ_pos_encoding=4,
319 | key_len=kq_len,
320 | use_distance=True,
321 | use_projected=True,
322 | use_angle=True,)
323 |
324 | self.RayEncoder = RayEncoder(W=64,
325 | D=1,
326 | q_len=kq_len,
327 | n_frequ_pos_encoding=4, )
328 |
329 | self.kq_len = kq_len
330 | self.val_len = v_len
331 |
332 | # TODO: Integrate and Decide between multi head and single attention module
333 | self.attention = ScaledDotProductAttention(1.)
334 |
335 | def forward(self, directions, features, distance, projected_distance, angle, **kwargs):
336 | n_feat_maps, feat_dim = features.shape[-2:]
337 | n_batch, n_rays, _ = directions.shape
338 |
339 | # b) Take features from feature pints directly and encode with distance, projection and angles
340 | key = self.RayPointPoseEncoder(distance, projected_distance, angle, n_feat_maps)
341 | val = features.reshape(n_batch * n_rays, -1, feat_dim)
342 |
343 | # Use encoded ray-dirs in MLP to get query vector
344 | query = self.RayEncoder(directions.reshape(-1, 3))
345 |
346 | # Attention
347 | # Query Vector + per point Key + per-point value vector in transformer-style attention + pooling to create conditioning vector
348 | out, attn = self.attention(query[:, None], key, val)
349 |
350 | out = out.reshape(n_batch, n_rays, self.val_len)
351 | return out
--------------------------------------------------------------------------------
/src/pointLF/icp/pts_registration.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | import open3d as o3d
4 | import numpy as np
5 | import torch
6 | import torch.nn as nn
7 |
8 | class ICP(nn.Module):
9 | def __init__(self, n_frames=5, step_width=2):
10 | super(ICP, self).__init__()
11 | self.n_frames = n_frames
12 | self.step_width = step_width
13 |
14 | self._merged_pcd_cache = {}
15 | # nppcd = np.load('./src/pointLF/icp/all_pts.npy') #id: 8,0,4,6,10,8,6,6
16 | # poses = np.load('./src/pointLF/icp/lidar_poses.npy') #id: 0,1,2,3,4,5,6,7,8,9,10
17 | #
18 | #
19 | # pts_4 = self.array2pcd(self.transformpts(nppcd[2], poses[4]))
20 | # pts_6 = self.array2pcd(self.transformpts(nppcd[3], poses[6]))
21 | # pts_10 = self.array2pcd(self.transformpts(nppcd[4], poses[10]))
22 | #
23 | # pts_4.paint_uniform_color([1, 0.706, 0])
24 | # pts_6.paint_uniform_color([0, 0.651, 0.929])
25 | # pts_10.paint_uniform_color([0.0, 1.0, 0.0])
26 | #
27 | # pts_4 = self.icp_core(pts_4,pts_10)
28 | # pts_6 = self.icp_core(pts_6,pts_10)
29 | # o3d.visualization.draw_geometries([pts_4,pts_6,pts_10])
30 |
31 | def forward(self, scene, cam_frame_id, caching=False, augment=False, pc_frame_id=None):
32 | '''
33 |
34 | :param scene:
35 | :type scene:
36 | :param cam_frame_id:
37 | :type cam_frame_id:
38 | :param caching:
39 | :type caching:
40 | :param augment: Do not choose the pcd from the current frame but a frame in front or after
41 | :type augment:
42 | :return:
43 | :rtype:
44 | '''
45 | li_sel_idx = np.array([v.scene_idx if v.name == 'TOP' else -1 for k, v in scene.nodes['lidar'].items()])
46 | top_lidar_id = li_sel_idx[np.where(li_sel_idx > 0)][0]
47 |
48 | if pc_frame_id is None:
49 | if augment:
50 | max_augment_distance = 5
51 | augment_distance = np.random.randint(0, max_augment_distance * 2 + 1) - max_augment_distance
52 | pc_frame_id = np.minimum(np.maximum(cam_frame_id + augment_distance, 0), len(scene.frames) - 1)
53 | else:
54 | pc_frame_id = cam_frame_id
55 |
56 | current_points_frame = scene.frames[pc_frame_id]
57 | current_camera_frame = scene.frames[cam_frame_id]
58 |
59 | pcd_path = scene.frames[pc_frame_id].point_cloud_pth[top_lidar_id]
60 |
61 | if not scene.scene_descriptor["type"] == "kitti":
62 | if scene.scene_descriptor.get('pt_cloud_fix', False):
63 | merged_pcd_dir = os.path.join(
64 | *(
65 | ["/"] +
66 | pcd_path.split("/")[1:-1] +
67 | ['merged_pcd_full_{}_scene_{}_{}_frames_{}_{}_n_fr_{}'.format(
68 | scene.scene_descriptor['type'],
69 | # str(scene.scene_descriptor['scene_id']).zfill(4),
70 | str(scene.scene_descriptor['scene_id'][0]).zfill(4),
71 | str(scene.scene_descriptor['scene_id'][1]).zfill(4),
72 | str(scene.scene_descriptor['first_frame']).zfill(4),
73 | str(scene.scene_descriptor['last_frame']).zfill(4),
74 | str(self.n_frames).zfill(4) if self.n_frames is not None else str('all'),)
75 | ]
76 | )
77 | )
78 | else:
79 | merged_pcd_dir = os.path.join(
80 | *(
81 | ["/"] +
82 | pcd_path.split("/")[1:-1] +
83 | ['merged_pcd_{}_scene_{}_{}_frames_{}_{}_n_fr_{}'.format(
84 | scene.scene_descriptor['type'],
85 | # str(scene.scene_descriptor['scene_id']).zfill(4),
86 | str(scene.scene_descriptor['scene_id'][0]).zfill(4),
87 | str(scene.scene_descriptor['scene_id'][1]).zfill(4),
88 | str(scene.scene_descriptor['first_frame']).zfill(4),
89 | str(scene.scene_descriptor['last_frame']).zfill(4),
90 | str(self.n_frames).zfill(4) if self.n_frames is not None else str('all'), )
91 | ]
92 | )
93 | )
94 | else:
95 | merged_pcd_dir = os.path.join(
96 | *(
97 | ["/"] +
98 | pcd_path.split("/")[1:-1] +
99 | ['merged_pcd_full_{}_scene_{}_frames_{}_{}_n_fr_{}'.format(
100 | scene.scene_descriptor['type'],
101 | str(scene.scene_descriptor['scene_id']).zfill(4),
102 | str(scene.scene_descriptor['first_frame']).zfill(4),
103 | str(scene.scene_descriptor['last_frame']).zfill(4),
104 | str(self.n_frames).zfill(4) if self.n_frames is not None else str('all'), )
105 | ]
106 | )
107 | )
108 |
109 | merged_pcd_path = os.path.join(
110 | merged_pcd_dir, '{}.pcd'.format(str(pc_frame_id).zfill(6))
111 | )
112 |
113 | os.umask(0)
114 | if not os.path.isdir(merged_pcd_dir):
115 | os.mkdir(merged_pcd_dir)
116 | else:
117 | # TODO: Add version check here
118 | if os.path.isfile(merged_pcd_path):
119 | current_points_frame.merged_pcd_pth = merged_pcd_path
120 |
121 | # Get the transformation from world coordinates to the vehicle coordinates of the requested frame
122 | veh2wo_0 = current_points_frame.global_transformation
123 | wo2veh_0 = np.concatenate(
124 | [veh2wo_0[:3, :3].T,
125 | veh2wo_0[:3, :3].T.dot(-veh2wo_0[:3, 3])[:, None]],
126 | axis=1
127 | )
128 | wo2veh_0 = np.concatenate([wo2veh_0, np.array([[0., 0., 0., 1.]])])
129 | pose_0 = np.eye(4)
130 |
131 | # Get the transformation from the vehicle pose of the camera to the vehivle pose of the point cloud
132 | veh2wo_cam = current_camera_frame.global_transformation
133 | camera_trafo = wo2veh_0.dot(veh2wo_cam)
134 |
135 | if current_points_frame.merged_pcd_pth is None or (current_points_frame.merged_pcd is None and caching):
136 | all_points_post = None
137 | all_points_pre = None
138 |
139 | # Get points
140 | pts_0 = current_points_frame.load_point_cloud(top_lidar_id)
141 | pts_0 = self.array2pcd(self.transformpts(pts_0[:, :3], pose_0))
142 |
143 | all_points = pts_0
144 | all_points, _ = all_points.remove_statistical_outlier(nb_neighbors=30, std_ratio=2.0)
145 |
146 | first_fr_id = min(scene.frames.keys())
147 | if self.n_frames is not None:
148 | pre_current = np.linspace(cam_frame_id - 1, first_fr_id, cam_frame_id, dtype=int)[:self.n_frames]
149 | else:
150 | pre_current = np.linspace(cam_frame_id - 1, first_fr_id, cam_frame_id, dtype=int)
151 |
152 | last_fr_id = max(scene.frames.keys())
153 | if self.n_frames is not None:
154 | post_current = np.linspace(cam_frame_id + 1, last_fr_id, last_fr_id - cam_frame_id, dtype=int)[:self.n_frames]
155 | else:
156 | post_current = np.linspace(cam_frame_id + 1, last_fr_id, last_fr_id - cam_frame_id, dtype=int)
157 |
158 | # Loop over adjacent frames in the future
159 | # all_points_post = self.merge_adajcent_points(post_current, scene, wo2veh_0, pts_0, top_lidar_id)
160 |
161 | for fr_id in np.concatenate([post_current]):
162 | frame_i = scene.frames[fr_id]
163 | # Load point cloud
164 | pts_i = frame_i.load_point_cloud(top_lidar_id)
165 |
166 | # Do not keep dynamic scene parts behind the geo vehicle from future frames
167 | pts_front_idx = np.where(pts_i[:, 0] > 0.)
168 | pts_back_idx = np.where(np.all(np.stack([pts_i[:, 0] < 0., np.abs(pts_i[:, 1]) > 1.5]), axis=0))
169 | pts_idx = np.concatenate([pts_front_idx[0], pts_back_idx[0]])
170 | pts_i = pts_i[pts_idx]
171 |
172 | # Get Transformation from veh frame to world
173 | veh2wo_i = frame_i.global_transformation
174 |
175 | # Center all point clouds at the requested frame
176 | # Waymo
177 | pose_i = wo2veh_0.dot(veh2wo_i)
178 |
179 | # Transform point cloud into the vehicle frame of the current frame
180 | pts_i = self.array2pcd(self.transformpts(pts_i[:, :3], pose_i))
181 | # Remove noise from point cloud
182 | pts_i, _ = pts_i.remove_statistical_outlier(nb_neighbors=30, std_ratio=2.0)
183 |
184 | if all_points_post is None:
185 | # Match first pointcloud close to the selected frames lidar pose
186 | pts_i = self.icp_core(pts_i, pts_0)
187 | all_points_post = pts_i
188 | else:
189 | pts_i = self.icp_core(pts_i, all_points_post)
190 | all_points_post = all_points_post + pts_i
191 |
192 | if all_points_post is not None:
193 | all_points_post = self.icp_core(all_points_post, pts_0)
194 | all_points += all_points_post
195 |
196 | # Loop over adjacent frames in the past
197 | # all_points_pre = self.merge_adajcent_points(pre_current, scene, wo2veh_0, pts_0, top_lidar_id)
198 |
199 | for fr_id in np.concatenate([pre_current]):
200 | frame_i = scene.frames[fr_id]
201 | # Load point cloud
202 | pts_i = frame_i.load_point_cloud(top_lidar_id)
203 |
204 | # Get Transformation from veh frame to world
205 | veh2wo_i = frame_i.global_transformation
206 |
207 | # Center all point clouds at the requested frame
208 | # Waymo
209 | pose_i = wo2veh_0.dot(veh2wo_i)
210 |
211 | # Transform point cloud into the vehicle frame of the current frame
212 | pts_i = self.array2pcd(self.transformpts(pts_i[:, :3], pose_i))
213 | # Remove noise from point cloud
214 | pts_i, _ = pts_i.remove_statistical_outlier(nb_neighbors=30, std_ratio=2.0)
215 |
216 | if all_points_pre is None:
217 | # Match first pointcloud close to the selected frames lidar pose
218 | pts_i = self.icp_core(pts_i, pts_0)
219 | all_points_pre = pts_i
220 | else:
221 | pts_i = self.icp_core(pts_i, all_points_pre)
222 | all_points_pre = all_points_pre + pts_i
223 |
224 | if all_points_pre is not None:
225 | all_points_pre = self.icp_core(all_points_pre, pts_0)
226 | all_points += all_points_pre
227 |
228 | # Outlier and noise removal
229 | all_points, ind = all_points.remove_statistical_outlier(nb_neighbors=30, std_ratio=2.0)
230 |
231 | if caching:
232 | print("Caching pcd")
233 | current_points_frame.merged_pcd = all_points
234 | else:
235 | # Store merged point cloud for future readings
236 | o3d.io.write_point_cloud(merged_pcd_path, all_points)
237 | else:
238 | if caching:
239 | print("Retriving pcd from cache")
240 | all_points = current_points_frame.merged_pcd
241 | else:
242 | # t0 = time.time()
243 | all_points = o3d.io.read_point_cloud(current_points_frame.merged_pcd_pth, format='pcd')
244 | # print("Read points {}".format(time.time()- t0))
245 |
246 | pts = np.asarray(all_points.points)
247 |
248 | return pts, merged_pcd_path, camera_trafo, pc_frame_id
249 |
250 |
251 | def merge_adajcent_points(self, fr_id_ls, scene, wo2veh_0, pts_0, top_lidar_id):
252 |
253 | # Loop over adjacent frames in the future
254 | for fr_id in np.concatenate([fr_id_ls]):
255 | frame_i = scene.frames[fr_id]
256 | # Load point cloud
257 | pts_i = frame_i.load_point_cloud(top_lidar_id)
258 |
259 | # Do not keep dynamic scene parts hiding behind the ego vehicle from adjacent frames
260 | pts_front_idx = np.where(pts_i[:, 0] > 0.)
261 | pts_back_idx = np.where(np.all(np.stack([pts_i[:, 0] < 0., np.abs(pts_i[:, 1]) > 1.5]), axis=0))
262 | pts_idx = np.concatenate([pts_front_idx[0], pts_back_idx[0]])
263 | pts_i = pts_i[pts_idx]
264 |
265 | # Get Transformation from veh frame to world
266 | veh2wo_i = frame_i.global_transformation
267 |
268 | # Center all point clouds at the requested frame
269 | # Waymo
270 | pose_i = wo2veh_0.dot(veh2wo_i)
271 |
272 | # Transform point cloud into the vehicle frame of the current frame
273 | pts_i = self.array2pcd(self.transformpts(pts_i[:, :3], pose_i))
274 | # Remove noise from point cloud
275 | pts_i, _ = pts_i.remove_statistical_outlier(nb_neighbors=30, std_ratio=2.0)
276 |
277 | if all_points_adj is None:
278 | # Match first pointcloud close to the selected frames lidar pose
279 | pts_i = self.icp_core(pts_i, pts_0)
280 | all_points_adj = pts_i
281 | else:
282 | pts_i = self.icp_core(pts_i, all_points_adj)
283 | all_points_adj = all_points_adj + pts_i
284 |
285 | return all_points_adj
286 |
287 |
288 | def transformpts(self,pts,pose):
289 | pts = np.concatenate((pts,np.ones((pts.shape[0],1))),1)
290 | pts = (pose.dot(pts.T)).T
291 | return pts[:,:3]
292 |
293 | def array2pcd(self, all_pts, color=None):
294 | pcd = o3d.geometry.PointCloud()
295 | pcd.points = o3d.utility.Vector3dVector(all_pts)
296 | if color is not None:
297 | pcd.paint_uniform_color(color)
298 | return pcd
299 |
300 | def icp_core(self,processed_source,processed_target):
301 | threshold = 1.0
302 | trans_init = np.eye(4).astype(np.int)
303 |
304 | reg_p2p = o3d.pipelines.registration.registration_icp(
305 | source=processed_source,
306 | target=processed_target,
307 | max_correspondence_distance=threshold,
308 | init=trans_init,
309 | estimation_method=o3d.pipelines.registration.TransformationEstimationPointToPoint()
310 | )
311 |
312 | # print(reg_p2p.transformation)
313 | processed_source.transform(reg_p2p.transformation)
314 | return processed_source
315 |
--------------------------------------------------------------------------------