├── .gitignore
├── LICENSE
├── README.md
├── _init_paths.py
├── cfgs
├── res101.yml
├── res101_ls.yml
├── res50.yml
└── vgg16.yml
├── demo.py
├── images
├── img1.jpg
├── img1_det.jpg
├── img1_det_res101.jpg
├── img2.jpg
├── img2_det.jpg
├── img2_det_res101.jpg
├── img3.jpg
├── img3_det.jpg
├── img3_det_res101.jpg
├── img4.jpg
├── img4_det.jpg
└── img4_det_res101.jpg
├── lib
├── Makefile
├── datasets
│ ├── VOCdevkit-matlab-wrapper
│ │ ├── get_voc_opts.m
│ │ ├── voc_eval.m
│ │ └── xVOCap.m
│ ├── __init__.py
│ ├── coco.py
│ ├── ds_utils.py
│ ├── factory.py
│ ├── imagenet.py
│ ├── imdb.py
│ ├── pascal_voc.py
│ ├── pascal_voc_rbg.py
│ ├── tools
│ │ └── mcg_munge.py
│ ├── vg.py
│ ├── vg_eval.py
│ └── voc_eval.py
├── make.sh
├── model
│ ├── __init__.py
│ ├── couplenet
│ │ ├── __init__.py
│ │ ├── couplenet.py
│ │ └── resnet_atrous.py
│ ├── faster_rcnn
│ │ ├── __init__.py
│ │ ├── faster_rcnn.py
│ │ ├── resnet.py
│ │ └── vgg16.py
│ ├── nms
│ │ ├── .gitignore
│ │ ├── __init__.py
│ │ ├── _ext
│ │ │ ├── __init__.py
│ │ │ └── nms
│ │ │ │ └── __init__.py
│ │ ├── build.py
│ │ ├── make.sh
│ │ ├── nms_cpu.py
│ │ ├── nms_gpu.py
│ │ ├── nms_kernel.cu
│ │ ├── nms_wrapper.py
│ │ └── src
│ │ │ ├── nms_cuda.c
│ │ │ ├── nms_cuda.h
│ │ │ ├── nms_cuda_kernel.cu
│ │ │ └── nms_cuda_kernel.h
│ ├── psroi_pooling
│ │ ├── __init__.py
│ │ ├── _ext
│ │ │ ├── __init__.py
│ │ │ └── psroi_pooling
│ │ │ │ └── __init__.py
│ │ ├── build.py
│ │ ├── functions
│ │ │ ├── __init__.py
│ │ │ └── psroi_pooling.py
│ │ ├── modules
│ │ │ ├── __init__.py
│ │ │ └── psroi_pool.py
│ │ └── src
│ │ │ ├── cuda
│ │ │ ├── psroi_pooling_kernel.cu
│ │ │ └── psroi_pooling_kernel.h
│ │ │ ├── psroi_pooling_cuda.c
│ │ │ └── psroi_pooling_cuda.h
│ ├── rfcn
│ │ ├── __init__.py
│ │ ├── resnet_atrous.py
│ │ └── rfcn.py
│ ├── roi_align
│ │ ├── __init__.py
│ │ ├── _ext
│ │ │ ├── __init__.py
│ │ │ └── roi_align
│ │ │ │ └── __init__.py
│ │ ├── build.py
│ │ ├── functions
│ │ │ ├── __init__.py
│ │ │ └── roi_align.py
│ │ ├── make.sh
│ │ ├── modules
│ │ │ ├── __init__.py
│ │ │ └── roi_align.py
│ │ └── src
│ │ │ ├── roi_align.c
│ │ │ ├── roi_align.h
│ │ │ ├── roi_align_cuda.c
│ │ │ ├── roi_align_cuda.h
│ │ │ ├── roi_align_kernel.cu
│ │ │ └── roi_align_kernel.h
│ ├── roi_crop
│ │ ├── __init__.py
│ │ ├── _ext
│ │ │ ├── __init__.py
│ │ │ ├── crop_resize
│ │ │ │ └── __init__.py
│ │ │ └── roi_crop
│ │ │ │ └── __init__.py
│ │ ├── build.py
│ │ ├── functions
│ │ │ ├── __init__.py
│ │ │ ├── crop_resize.py
│ │ │ ├── gridgen.py
│ │ │ └── roi_crop.py
│ │ ├── make.sh
│ │ ├── modules
│ │ │ ├── __init__.py
│ │ │ ├── gridgen.py
│ │ │ └── roi_crop.py
│ │ └── src
│ │ │ ├── roi_crop.c
│ │ │ ├── roi_crop.h
│ │ │ ├── roi_crop_cuda.c
│ │ │ ├── roi_crop_cuda.h
│ │ │ ├── roi_crop_cuda_kernel.cu
│ │ │ └── roi_crop_cuda_kernel.h
│ ├── roi_pooling
│ │ ├── __init__.py
│ │ ├── _ext
│ │ │ ├── __init__.py
│ │ │ └── roi_pooling
│ │ │ │ └── __init__.py
│ │ ├── build.py
│ │ ├── functions
│ │ │ ├── __init__.py
│ │ │ └── roi_pool.py
│ │ ├── modules
│ │ │ ├── __init__.py
│ │ │ └── roi_pool.py
│ │ └── src
│ │ │ ├── roi_pooling.c
│ │ │ ├── roi_pooling.h
│ │ │ ├── roi_pooling_cuda.c
│ │ │ ├── roi_pooling_cuda.h
│ │ │ ├── roi_pooling_kernel.cu
│ │ │ └── roi_pooling_kernel.h
│ ├── rpn
│ │ ├── __init__.py
│ │ ├── anchor_target_layer.py
│ │ ├── bbox_transform.py
│ │ ├── generate_anchors.py
│ │ ├── proposal_layer.py
│ │ ├── proposal_target_layer_cascade.py
│ │ └── rpn.py
│ └── utils
│ │ ├── .gitignore
│ │ ├── __init__.py
│ │ ├── bbox.c
│ │ ├── bbox.pyx
│ │ ├── blob.py
│ │ ├── config.py
│ │ ├── logger.py
│ │ └── net_utils.py
├── pycocotools
│ ├── UPSTREAM_REV
│ ├── __init__.py
│ ├── _mask.c
│ ├── _mask.pyx
│ ├── coco.py
│ ├── cocoeval.py
│ ├── license.txt
│ ├── mask.py
│ ├── maskApi.c
│ └── maskApi.h
├── roi_data_layer
│ ├── __init__.py
│ ├── minibatch.py
│ ├── roibatchLoader.py
│ └── roidb.py
└── setup.py
├── requirements.txt
├── test_net.py
└── trainval_net.py
/.gitignore:
--------------------------------------------------------------------------------
1 | data/*
2 | .idea/
3 | *.pyc
4 | *~
5 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2017 Jianwei Yang
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # A Pytorch Implementation of R-FCN/CoupleNet
2 |
3 | This repo has moved to [princewang1994/RFCN_CoupleNet.pytorch](https://github.com/princewang1994/RFCN_CoupleNet.pytorch), it will stop updating here.
4 |
5 | ## Introduction
6 |
7 | This project is an pytorch implement R-FCN and CoupleNet, large part code is reference from [jwyang/faster-rcnn.pytorch](https://github.com/jwyang/faster-rcnn.pytorch). The R-FCN structure is refer to [Caffe R-FCN](https://github.com/daijifeng001/R-FCN) and [Py-R-FCN](https://github.com/YuwenXiong/py-R-FCN)
8 |
9 | - For R-FCN, mAP@0.5 reached 73.2 in VOC2007 trainval dataset
10 | - For CoupleNet, mAP@0.5 reached 75.2 in VOC2007 trainval dataset
11 |
12 | ## R-FCN
13 |
14 | arXiv:1605.06409: [R-FCN: Object Detection via Region-based Fully Convolutional Networks](https://arxiv.org/abs/1605.06409)
15 |
16 | 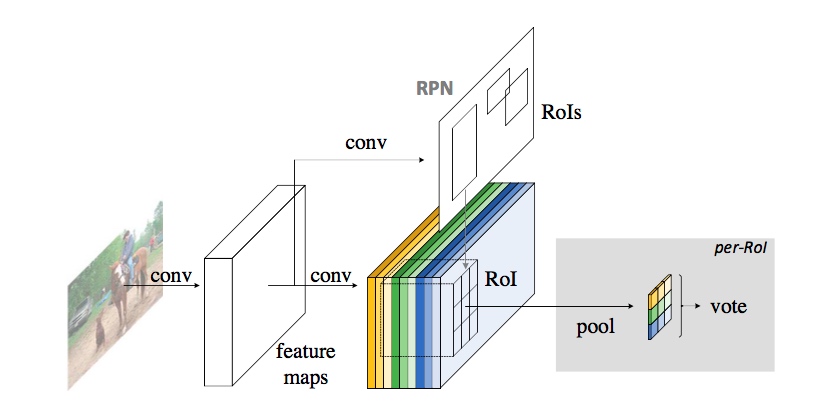
17 |
18 | This repo has following modification compare to [jwyang/faster-rcnn.pytorch](https://github.com/jwyang/faster-rcnn.pytorch):
19 |
20 | - **R-FCN architecture**: We refered to the origin [Caffe version] of R-FCN, the main structure of R-FCN is show in following figure.
21 | - **PS-RoIPooling with CUDA** :(refer to the other pytorch implement R-FCN, pytorch_RFCN). I have modified it to fit multi-image training (not only batch-size=1 is supported)
22 | - **Implement multi-scale training:** As the original paper says, each image is randomly reized to differenct resolutions (400, 500, 600, 700, 800) when training, and during test time, we use fix input size(600). These make 1.2 mAP gain in our experiments.
23 | - **Implement OHEM:** in this repo, we implement Online Hard Example Mining(OHEM) method in the paper, set `OHEM: False` in `cfgs/res101.yml` for using OHEM. Unluckly, it cause a bit performance degration in my experiments
24 |
25 | 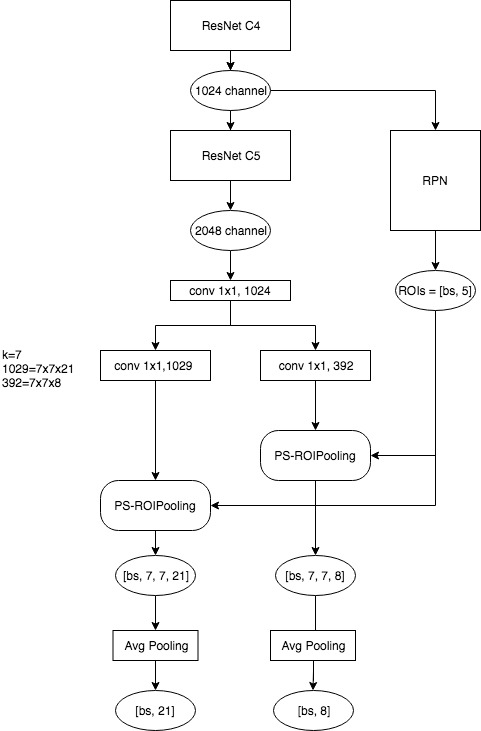
26 |
27 | ## CoupleNet
28 |
29 | arXiv:1708.02863:[CoupleNet: Coupling Global Structure with Local Parts for Object Detection](https://arxiv.org/abs/1708.02863)
30 |
31 | 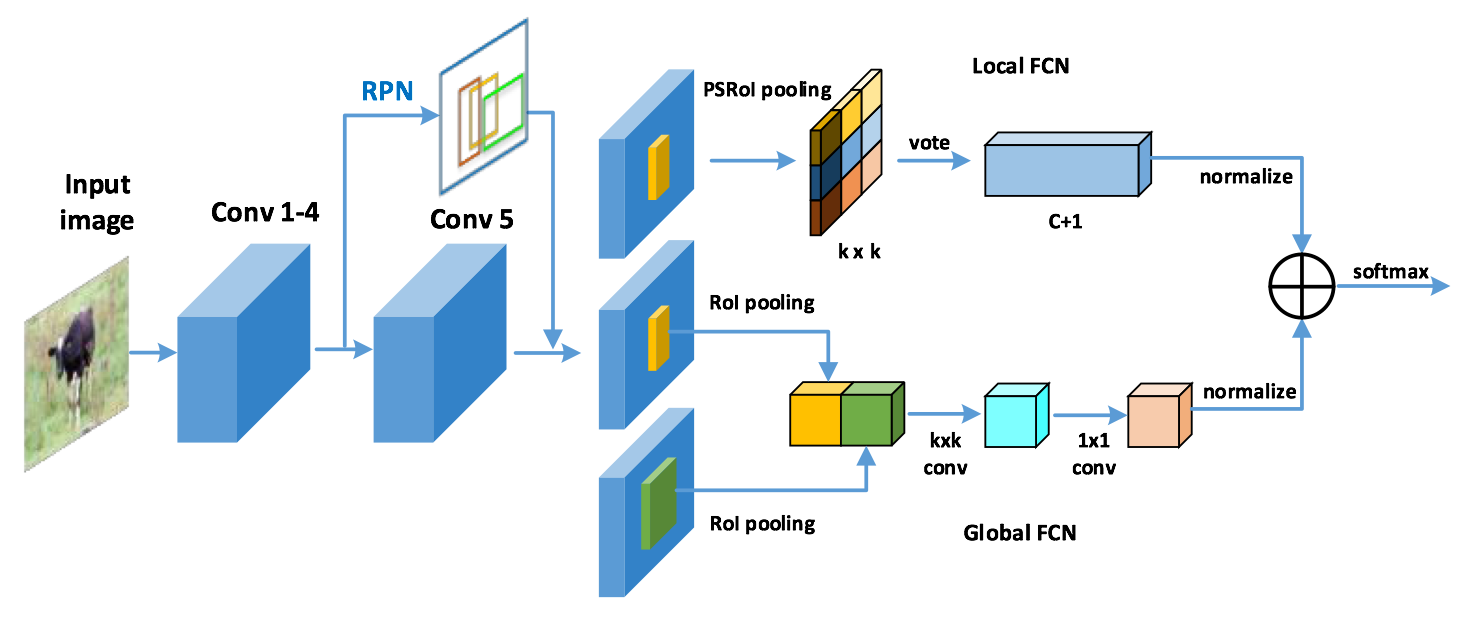
32 |
33 | - Making changes based on R-FCN
34 | - Implement local/global FCN in CoupleNet
35 |
36 | ## Tutorial
37 |
38 | * [R-FCN blog](http://blog.prince2015.club/2018/07/13/R-FCN/)
39 |
40 | ## Benchmarking
41 |
42 | We benchmark our code thoroughly on three datasets: pascal voc using two different architecture: R-FCN and CoupleNet. Results shows following:
43 |
44 | 1). PASCAL VOC 2007 (Train: 07_trainval - Test: 07_test, scale=400, 500, 600, 700, 800)
45 |
46 | model | #GPUs | batch size | lr | lr_decay | max_epoch | time/epoch | mem/GPU | mAP
47 | ---------|--------|-----|--------|-----|-----|-------|--------|-----
48 | [R-FCN](https://drive.google.com/file/d/1JMh0gguOozEEIRijQxkQnMKLTAp2_iu5/view?usp=sharing) | 1 | 2 | 4e-3 | 8 | 20 | 0.88 hr | 3000 MB | 73.8
49 | CouleNet | 1 | 2 | 4e-3 | 8 | 20 | 0.60 hr | 8900 MB | 75.2
50 |
51 | - Pretrained model for R-FCN(VOC2007) has released~, See `Test` part following
52 |
53 |
54 | ## Preparation
55 |
56 |
57 | First of all, clone the code
58 | ```
59 | $ git clone https://github.com/princewang1994/R-FCN.pytorch.git
60 | ```
61 |
62 | Then, create a folder:
63 | ```
64 | $ cd R-FCN.pytorch && mkdir data
65 | $ cd data
66 | $ ln -s $VOC_DEVKIT_ROOT .
67 | ```
68 |
69 | ### prerequisites
70 |
71 | * Python 3.6
72 | * Pytorch 0.3.0, **NOT suport 0.4.0 because of some errors**
73 | * CUDA 8.0 or higher
74 |
75 | ### Data Preparation
76 |
77 | * **PASCAL_VOC 07+12**: Please follow the instructions in [py-faster-rcnn](https://github.com/rbgirshick/py-faster-rcnn#beyond-the-demo-installation-for-training-and-testing-models) to prepare VOC datasets. Actually, you can refer to any others. After downloading the data, creat softlinks in the folder data/.
78 | * **Pretrained ResNet**: download from [here](https://drive.google.com/file/d/1I4Jmh2bU6BJVnwqfg5EDe8KGGdec2UE8/view?usp=sharing) and put it to `$RFCN_ROOT/data/pretrained_model/resnet101_caffe.pth`.
79 |
80 |
81 | ### Compilation
82 |
83 | As pointed out by [ruotianluo/pytorch-faster-rcnn](https://github.com/ruotianluo/pytorch-faster-rcnn), choose the right `-arch` in `make.sh` file, to compile the cuda code:
84 |
85 | | GPU model | Architecture |
86 | | ------------- | ------------- |
87 | | TitanX (Maxwell/Pascal) | sm_52 |
88 | | GTX 960M | sm_50 |
89 | | GTX 1080 (Ti) | sm_61 |
90 | | Grid K520 (AWS g2.2xlarge) | sm_30 |
91 | | Tesla K80 (AWS p2.xlarge) | sm_37 |
92 |
93 | More details about setting the architecture can be found [here](https://developer.nvidia.com/cuda-gpus) or [here](http://arnon.dk/matching-sm-architectures-arch-and-gencode-for-various-nvidia-cards/)
94 |
95 | Install all the python dependencies using pip:
96 | ```
97 | $ pip install -r requirements.txt
98 | ```
99 |
100 | Compile the cuda dependencies using following simple commands:
101 |
102 | ```
103 | $ cd lib
104 | $ sh make.sh
105 | ```
106 |
107 | It will compile all the modules you need, including NMS, ROI_Pooing, ROI_Align and ROI_Crop. The default version is compiled with Python 2.7, please compile by yourself if you are using a different python version.
108 |
109 | ## Train
110 |
111 | To train a R-FCN model with ResNet101 on pascal_voc, simply run:
112 | ```
113 | $ CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py \
114 | --arch rfcn \
115 | --dataset pascal_voc --net res101 \
116 | --bs $BATCH_SIZE --nw $WORKER_NUMBER \
117 | --lr $LEARNING_RATE --lr_decay_step $DECAY_STEP \
118 | --cuda
119 | ```
120 |
121 | - Set `--s` to identified differenct experiments.
122 | - For CoupleNet training, replace `--arch rfcn` with `--arch couplenet`, other arguments should be modified according to your machine. (e.g. larger learning rate for bigger batch-size)
123 | - Model are saved to `$RFCN_ROOT/save`
124 |
125 | ## Test
126 |
127 | If you want to evlauate the detection performance of a pre-trained model on pascal_voc test set, simply run
128 | ```
129 | $ python test_net.py --dataset pascal_voc --arch rfcn \
130 | --net res101 \
131 | --checksession $SESSION \
132 | --checkepoch $EPOCH \
133 | --checkpoint $CHECKPOINT \
134 | --cuda
135 | ```
136 | - Specify the specific model session(`--s` in training phase), chechepoch and checkpoint, e.g., SESSION=1, EPOCH=6, CHECKPOINT=5010.
137 |
138 | ### Pretrained Model
139 |
140 | - R-FCN VOC2007: [faster_rcnn_2_12_5010.pth](https://drive.google.com/file/d/1JMh0gguOozEEIRijQxkQnMKLTAp2_iu5/view?usp=sharing)
141 |
142 | Download from link above and put it to `save/rfcn/res101/pascal_voc/faster_rcnn_2_12_5010.pth`. Then you can set `$SESSiON=2, $EPOCH=12, $CHECKPOINT=5010` in test command. It'll got 73.2 mAP.
143 |
144 | ## Demo
145 |
146 | Below are some detection results:
147 |
148 |
149 |


150 |
2 | #include
3 | #include
4 |
5 |
6 | void ROIAlignForwardCpu(const float* bottom_data, const float spatial_scale, const int num_rois,
7 | const int height, const int width, const int channels,
8 | const int aligned_height, const int aligned_width, const float * bottom_rois,
9 | float* top_data);
10 |
11 | void ROIAlignBackwardCpu(const float* top_diff, const float spatial_scale, const int num_rois,
12 | const int height, const int width, const int channels,
13 | const int aligned_height, const int aligned_width, const float * bottom_rois,
14 | float* top_data);
15 |
16 | int roi_align_forward(int aligned_height, int aligned_width, float spatial_scale,
17 | THFloatTensor * features, THFloatTensor * rois, THFloatTensor * output)
18 | {
19 | //Grab the input tensor
20 | float * data_flat = THFloatTensor_data(features);
21 | float * rois_flat = THFloatTensor_data(rois);
22 |
23 | float * output_flat = THFloatTensor_data(output);
24 |
25 | // Number of ROIs
26 | int num_rois = THFloatTensor_size(rois, 0);
27 | int size_rois = THFloatTensor_size(rois, 1);
28 | if (size_rois != 5)
29 | {
30 | return 0;
31 | }
32 |
33 | // data height
34 | int data_height = THFloatTensor_size(features, 2);
35 | // data width
36 | int data_width = THFloatTensor_size(features, 3);
37 | // Number of channels
38 | int num_channels = THFloatTensor_size(features, 1);
39 |
40 | // do ROIAlignForward
41 | ROIAlignForwardCpu(data_flat, spatial_scale, num_rois, data_height, data_width, num_channels,
42 | aligned_height, aligned_width, rois_flat, output_flat);
43 |
44 | return 1;
45 | }
46 |
47 | int roi_align_backward(int aligned_height, int aligned_width, float spatial_scale,
48 | THFloatTensor * top_grad, THFloatTensor * rois, THFloatTensor * bottom_grad)
49 | {
50 | //Grab the input tensor
51 | float * top_grad_flat = THFloatTensor_data(top_grad);
52 | float * rois_flat = THFloatTensor_data(rois);
53 |
54 | float * bottom_grad_flat = THFloatTensor_data(bottom_grad);
55 |
56 | // Number of ROIs
57 | int num_rois = THFloatTensor_size(rois, 0);
58 | int size_rois = THFloatTensor_size(rois, 1);
59 | if (size_rois != 5)
60 | {
61 | return 0;
62 | }
63 |
64 | // batch size
65 | int batch_size = THFloatTensor_size(bottom_grad, 0);
66 | // data height
67 | int data_height = THFloatTensor_size(bottom_grad, 2);
68 | // data width
69 | int data_width = THFloatTensor_size(bottom_grad, 3);
70 | // Number of channels
71 | int num_channels = THFloatTensor_size(bottom_grad, 1);
72 |
73 | // do ROIAlignBackward
74 | ROIAlignBackwardCpu(top_grad_flat, spatial_scale, num_rois, data_height,
75 | data_width, num_channels, aligned_height, aligned_width, rois_flat, bottom_grad_flat);
76 |
77 | return 1;
78 | }
79 |
80 | void ROIAlignForwardCpu(const float* bottom_data, const float spatial_scale, const int num_rois,
81 | const int height, const int width, const int channels,
82 | const int aligned_height, const int aligned_width, const float * bottom_rois,
83 | float* top_data)
84 | {
85 | const int output_size = num_rois * aligned_height * aligned_width * channels;
86 |
87 | #pragma omp parallel for
88 | for (int idx = 0; idx < output_size; ++idx)
89 | {
90 | // (n, c, ph, pw) is an element in the aligned output
91 | int pw = idx % aligned_width;
92 | int ph = (idx / aligned_width) % aligned_height;
93 | int c = (idx / aligned_width / aligned_height) % channels;
94 | int n = idx / aligned_width / aligned_height / channels;
95 |
96 | float roi_batch_ind = bottom_rois[n * 5 + 0];
97 | float roi_start_w = bottom_rois[n * 5 + 1] * spatial_scale;
98 | float roi_start_h = bottom_rois[n * 5 + 2] * spatial_scale;
99 | float roi_end_w = bottom_rois[n * 5 + 3] * spatial_scale;
100 | float roi_end_h = bottom_rois[n * 5 + 4] * spatial_scale;
101 |
102 | // Force malformed ROI to be 1x1
103 | float roi_width = fmaxf(roi_end_w - roi_start_w + 1., 0.);
104 | float roi_height = fmaxf(roi_end_h - roi_start_h + 1., 0.);
105 | float bin_size_h = roi_height / (aligned_height - 1.);
106 | float bin_size_w = roi_width / (aligned_width - 1.);
107 |
108 | float h = (float)(ph) * bin_size_h + roi_start_h;
109 | float w = (float)(pw) * bin_size_w + roi_start_w;
110 |
111 | int hstart = fminf(floor(h), height - 2);
112 | int wstart = fminf(floor(w), width - 2);
113 |
114 | int img_start = roi_batch_ind * channels * height * width;
115 |
116 | // bilinear interpolation
117 | if (h < 0 || h >= height || w < 0 || w >= width)
118 | {
119 | top_data[idx] = 0.;
120 | }
121 | else
122 | {
123 | float h_ratio = h - (float)(hstart);
124 | float w_ratio = w - (float)(wstart);
125 | int upleft = img_start + (c * height + hstart) * width + wstart;
126 | int upright = upleft + 1;
127 | int downleft = upleft + width;
128 | int downright = downleft + 1;
129 |
130 | top_data[idx] = bottom_data[upleft] * (1. - h_ratio) * (1. - w_ratio)
131 | + bottom_data[upright] * (1. - h_ratio) * w_ratio
132 | + bottom_data[downleft] * h_ratio * (1. - w_ratio)
133 | + bottom_data[downright] * h_ratio * w_ratio;
134 | }
135 | }
136 | }
137 |
138 | void ROIAlignBackwardCpu(const float* top_diff, const float spatial_scale, const int num_rois,
139 | const int height, const int width, const int channels,
140 | const int aligned_height, const int aligned_width, const float * bottom_rois,
141 | float* bottom_diff)
142 | {
143 | const int output_size = num_rois * aligned_height * aligned_width * channels;
144 |
145 | #pragma omp parallel for
146 | for (int idx = 0; idx < output_size; ++idx)
147 | {
148 | // (n, c, ph, pw) is an element in the aligned output
149 | int pw = idx % aligned_width;
150 | int ph = (idx / aligned_width) % aligned_height;
151 | int c = (idx / aligned_width / aligned_height) % channels;
152 | int n = idx / aligned_width / aligned_height / channels;
153 |
154 | float roi_batch_ind = bottom_rois[n * 5 + 0];
155 | float roi_start_w = bottom_rois[n * 5 + 1] * spatial_scale;
156 | float roi_start_h = bottom_rois[n * 5 + 2] * spatial_scale;
157 | float roi_end_w = bottom_rois[n * 5 + 3] * spatial_scale;
158 | float roi_end_h = bottom_rois[n * 5 + 4] * spatial_scale;
159 |
160 | // Force malformed ROI to be 1x1
161 | float roi_width = fmaxf(roi_end_w - roi_start_w + 1., 0.);
162 | float roi_height = fmaxf(roi_end_h - roi_start_h + 1., 0.);
163 | float bin_size_h = roi_height / (aligned_height - 1.);
164 | float bin_size_w = roi_width / (aligned_width - 1.);
165 |
166 | float h = (float)(ph) * bin_size_h + roi_start_h;
167 | float w = (float)(pw) * bin_size_w + roi_start_w;
168 |
169 | int hstart = fminf(floor(h), height - 2);
170 | int wstart = fminf(floor(w), width - 2);
171 |
172 | int img_start = roi_batch_ind * channels * height * width;
173 |
174 | // bilinear interpolation
175 | if (h < 0 || h >= height || w < 0 || w >= width)
176 | {
177 | float h_ratio = h - (float)(hstart);
178 | float w_ratio = w - (float)(wstart);
179 | int upleft = img_start + (c * height + hstart) * width + wstart;
180 | int upright = upleft + 1;
181 | int downleft = upleft + width;
182 | int downright = downleft + 1;
183 |
184 | bottom_diff[upleft] += top_diff[idx] * (1. - h_ratio) * (1. - w_ratio);
185 | bottom_diff[upright] += top_diff[idx] * (1. - h_ratio) * w_ratio;
186 | bottom_diff[downleft] += top_diff[idx] * h_ratio * (1. - w_ratio);
187 | bottom_diff[downright] += top_diff[idx] * h_ratio * w_ratio;
188 | }
189 | }
190 | }
191 |
--------------------------------------------------------------------------------
/lib/model/roi_align/src/roi_align.h:
--------------------------------------------------------------------------------
1 | int roi_align_forward(int aligned_height, int aligned_width, float spatial_scale,
2 | THFloatTensor * features, THFloatTensor * rois, THFloatTensor * output);
3 |
4 | int roi_align_backward(int aligned_height, int aligned_width, float spatial_scale,
5 | THFloatTensor * top_grad, THFloatTensor * rois, THFloatTensor * bottom_grad);
6 |
--------------------------------------------------------------------------------
/lib/model/roi_align/src/roi_align_cuda.c:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | #include "roi_align_kernel.h"
4 |
5 | extern THCState *state;
6 |
7 | int roi_align_forward_cuda(int aligned_height, int aligned_width, float spatial_scale,
8 | THCudaTensor * features, THCudaTensor * rois, THCudaTensor * output)
9 | {
10 | // Grab the input tensor
11 | float * data_flat = THCudaTensor_data(state, features);
12 | float * rois_flat = THCudaTensor_data(state, rois);
13 |
14 | float * output_flat = THCudaTensor_data(state, output);
15 |
16 | // Number of ROIs
17 | int num_rois = THCudaTensor_size(state, rois, 0);
18 | int size_rois = THCudaTensor_size(state, rois, 1);
19 | if (size_rois != 5)
20 | {
21 | return 0;
22 | }
23 |
24 | // data height
25 | int data_height = THCudaTensor_size(state, features, 2);
26 | // data width
27 | int data_width = THCudaTensor_size(state, features, 3);
28 | // Number of channels
29 | int num_channels = THCudaTensor_size(state, features, 1);
30 |
31 | cudaStream_t stream = THCState_getCurrentStream(state);
32 |
33 | ROIAlignForwardLaucher(
34 | data_flat, spatial_scale, num_rois, data_height,
35 | data_width, num_channels, aligned_height,
36 | aligned_width, rois_flat,
37 | output_flat, stream);
38 |
39 | return 1;
40 | }
41 |
42 | int roi_align_backward_cuda(int aligned_height, int aligned_width, float spatial_scale,
43 | THCudaTensor * top_grad, THCudaTensor * rois, THCudaTensor * bottom_grad)
44 | {
45 | // Grab the input tensor
46 | float * top_grad_flat = THCudaTensor_data(state, top_grad);
47 | float * rois_flat = THCudaTensor_data(state, rois);
48 |
49 | float * bottom_grad_flat = THCudaTensor_data(state, bottom_grad);
50 |
51 | // Number of ROIs
52 | int num_rois = THCudaTensor_size(state, rois, 0);
53 | int size_rois = THCudaTensor_size(state, rois, 1);
54 | if (size_rois != 5)
55 | {
56 | return 0;
57 | }
58 |
59 | // batch size
60 | int batch_size = THCudaTensor_size(state, bottom_grad, 0);
61 | // data height
62 | int data_height = THCudaTensor_size(state, bottom_grad, 2);
63 | // data width
64 | int data_width = THCudaTensor_size(state, bottom_grad, 3);
65 | // Number of channels
66 | int num_channels = THCudaTensor_size(state, bottom_grad, 1);
67 |
68 | cudaStream_t stream = THCState_getCurrentStream(state);
69 | ROIAlignBackwardLaucher(
70 | top_grad_flat, spatial_scale, batch_size, num_rois, data_height,
71 | data_width, num_channels, aligned_height,
72 | aligned_width, rois_flat,
73 | bottom_grad_flat, stream);
74 |
75 | return 1;
76 | }
77 |
--------------------------------------------------------------------------------
/lib/model/roi_align/src/roi_align_cuda.h:
--------------------------------------------------------------------------------
1 | int roi_align_forward_cuda(int aligned_height, int aligned_width, float spatial_scale,
2 | THCudaTensor * features, THCudaTensor * rois, THCudaTensor * output);
3 |
4 | int roi_align_backward_cuda(int aligned_height, int aligned_width, float spatial_scale,
5 | THCudaTensor * top_grad, THCudaTensor * rois, THCudaTensor * bottom_grad);
6 |
--------------------------------------------------------------------------------
/lib/model/roi_align/src/roi_align_kernel.cu:
--------------------------------------------------------------------------------
1 | #ifdef __cplusplus
2 | extern "C" {
3 | #endif
4 |
5 | #include
6 | #include
7 | #include
8 | #include "roi_align_kernel.h"
9 |
10 | #define CUDA_1D_KERNEL_LOOP(i, n) \
11 | for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < n; \
12 | i += blockDim.x * gridDim.x)
13 |
14 |
15 | __global__ void ROIAlignForward(const int nthreads, const float* bottom_data, const float spatial_scale, const int height, const int width,
16 | const int channels, const int aligned_height, const int aligned_width, const float* bottom_rois, float* top_data) {
17 | CUDA_1D_KERNEL_LOOP(index, nthreads) {
18 | // (n, c, ph, pw) is an element in the aligned output
19 | // int n = index;
20 | // int pw = n % aligned_width;
21 | // n /= aligned_width;
22 | // int ph = n % aligned_height;
23 | // n /= aligned_height;
24 | // int c = n % channels;
25 | // n /= channels;
26 |
27 | int pw = index % aligned_width;
28 | int ph = (index / aligned_width) % aligned_height;
29 | int c = (index / aligned_width / aligned_height) % channels;
30 | int n = index / aligned_width / aligned_height / channels;
31 |
32 | // bottom_rois += n * 5;
33 | float roi_batch_ind = bottom_rois[n * 5 + 0];
34 | float roi_start_w = bottom_rois[n * 5 + 1] * spatial_scale;
35 | float roi_start_h = bottom_rois[n * 5 + 2] * spatial_scale;
36 | float roi_end_w = bottom_rois[n * 5 + 3] * spatial_scale;
37 | float roi_end_h = bottom_rois[n * 5 + 4] * spatial_scale;
38 |
39 | // Force malformed ROIs to be 1x1
40 | float roi_width = fmaxf(roi_end_w - roi_start_w + 1., 0.);
41 | float roi_height = fmaxf(roi_end_h - roi_start_h + 1., 0.);
42 | float bin_size_h = roi_height / (aligned_height - 1.);
43 | float bin_size_w = roi_width / (aligned_width - 1.);
44 |
45 | float h = (float)(ph) * bin_size_h + roi_start_h;
46 | float w = (float)(pw) * bin_size_w + roi_start_w;
47 |
48 | int hstart = fminf(floor(h), height - 2);
49 | int wstart = fminf(floor(w), width - 2);
50 |
51 | int img_start = roi_batch_ind * channels * height * width;
52 |
53 | // bilinear interpolation
54 | if (h < 0 || h >= height || w < 0 || w >= width) {
55 | top_data[index] = 0.;
56 | } else {
57 | float h_ratio = h - (float)(hstart);
58 | float w_ratio = w - (float)(wstart);
59 | int upleft = img_start + (c * height + hstart) * width + wstart;
60 | int upright = upleft + 1;
61 | int downleft = upleft + width;
62 | int downright = downleft + 1;
63 |
64 | top_data[index] = bottom_data[upleft] * (1. - h_ratio) * (1. - w_ratio)
65 | + bottom_data[upright] * (1. - h_ratio) * w_ratio
66 | + bottom_data[downleft] * h_ratio * (1. - w_ratio)
67 | + bottom_data[downright] * h_ratio * w_ratio;
68 | }
69 | }
70 | }
71 |
72 |
73 | int ROIAlignForwardLaucher(const float* bottom_data, const float spatial_scale, const int num_rois, const int height, const int width,
74 | const int channels, const int aligned_height, const int aligned_width, const float* bottom_rois, float* top_data, cudaStream_t stream) {
75 | const int kThreadsPerBlock = 1024;
76 | const int output_size = num_rois * aligned_height * aligned_width * channels;
77 | cudaError_t err;
78 |
79 |
80 | ROIAlignForward<<<(output_size + kThreadsPerBlock - 1) / kThreadsPerBlock, kThreadsPerBlock, 0, stream>>>(
81 | output_size, bottom_data, spatial_scale, height, width, channels,
82 | aligned_height, aligned_width, bottom_rois, top_data);
83 |
84 | err = cudaGetLastError();
85 | if(cudaSuccess != err) {
86 | fprintf( stderr, "cudaCheckError() failed : %s\n", cudaGetErrorString( err ) );
87 | exit( -1 );
88 | }
89 |
90 | return 1;
91 | }
92 |
93 |
94 | __global__ void ROIAlignBackward(const int nthreads, const float* top_diff, const float spatial_scale, const int height, const int width,
95 | const int channels, const int aligned_height, const int aligned_width, float* bottom_diff, const float* bottom_rois) {
96 | CUDA_1D_KERNEL_LOOP(index, nthreads) {
97 |
98 | // (n, c, ph, pw) is an element in the aligned output
99 | int pw = index % aligned_width;
100 | int ph = (index / aligned_width) % aligned_height;
101 | int c = (index / aligned_width / aligned_height) % channels;
102 | int n = index / aligned_width / aligned_height / channels;
103 |
104 | float roi_batch_ind = bottom_rois[n * 5 + 0];
105 | float roi_start_w = bottom_rois[n * 5 + 1] * spatial_scale;
106 | float roi_start_h = bottom_rois[n * 5 + 2] * spatial_scale;
107 | float roi_end_w = bottom_rois[n * 5 + 3] * spatial_scale;
108 | float roi_end_h = bottom_rois[n * 5 + 4] * spatial_scale;
109 | /* int roi_start_w = round(bottom_rois[1] * spatial_scale); */
110 | /* int roi_start_h = round(bottom_rois[2] * spatial_scale); */
111 | /* int roi_end_w = round(bottom_rois[3] * spatial_scale); */
112 | /* int roi_end_h = round(bottom_rois[4] * spatial_scale); */
113 |
114 | // Force malformed ROIs to be 1x1
115 | float roi_width = fmaxf(roi_end_w - roi_start_w + 1., 0.);
116 | float roi_height = fmaxf(roi_end_h - roi_start_h + 1., 0.);
117 | float bin_size_h = roi_height / (aligned_height - 1.);
118 | float bin_size_w = roi_width / (aligned_width - 1.);
119 |
120 | float h = (float)(ph) * bin_size_h + roi_start_h;
121 | float w = (float)(pw) * bin_size_w + roi_start_w;
122 |
123 | int hstart = fminf(floor(h), height - 2);
124 | int wstart = fminf(floor(w), width - 2);
125 |
126 | int img_start = roi_batch_ind * channels * height * width;
127 |
128 | // bilinear interpolation
129 | if (!(h < 0 || h >= height || w < 0 || w >= width)) {
130 | float h_ratio = h - (float)(hstart);
131 | float w_ratio = w - (float)(wstart);
132 | int upleft = img_start + (c * height + hstart) * width + wstart;
133 | int upright = upleft + 1;
134 | int downleft = upleft + width;
135 | int downright = downleft + 1;
136 |
137 | atomicAdd(bottom_diff + upleft, top_diff[index] * (1. - h_ratio) * (1 - w_ratio));
138 | atomicAdd(bottom_diff + upright, top_diff[index] * (1. - h_ratio) * w_ratio);
139 | atomicAdd(bottom_diff + downleft, top_diff[index] * h_ratio * (1 - w_ratio));
140 | atomicAdd(bottom_diff + downright, top_diff[index] * h_ratio * w_ratio);
141 | }
142 | }
143 | }
144 |
145 | int ROIAlignBackwardLaucher(const float* top_diff, const float spatial_scale, const int batch_size, const int num_rois, const int height, const int width,
146 | const int channels, const int aligned_height, const int aligned_width, const float* bottom_rois, float* bottom_diff, cudaStream_t stream) {
147 | const int kThreadsPerBlock = 1024;
148 | const int output_size = num_rois * aligned_height * aligned_width * channels;
149 | cudaError_t err;
150 |
151 | ROIAlignBackward<<<(output_size + kThreadsPerBlock - 1) / kThreadsPerBlock, kThreadsPerBlock, 0, stream>>>(
152 | output_size, top_diff, spatial_scale, height, width, channels,
153 | aligned_height, aligned_width, bottom_diff, bottom_rois);
154 |
155 | err = cudaGetLastError();
156 | if(cudaSuccess != err) {
157 | fprintf( stderr, "cudaCheckError() failed : %s\n", cudaGetErrorString( err ) );
158 | exit( -1 );
159 | }
160 |
161 | return 1;
162 | }
163 |
164 |
165 | #ifdef __cplusplus
166 | }
167 | #endif
168 |
--------------------------------------------------------------------------------
/lib/model/roi_align/src/roi_align_kernel.h:
--------------------------------------------------------------------------------
1 | #ifndef _ROI_ALIGN_KERNEL
2 | #define _ROI_ALIGN_KERNEL
3 |
4 | #ifdef __cplusplus
5 | extern "C" {
6 | #endif
7 |
8 | __global__ void ROIAlignForward(const int nthreads, const float* bottom_data,
9 | const float spatial_scale, const int height, const int width,
10 | const int channels, const int aligned_height, const int aligned_width,
11 | const float* bottom_rois, float* top_data);
12 |
13 | int ROIAlignForwardLaucher(
14 | const float* bottom_data, const float spatial_scale, const int num_rois, const int height,
15 | const int width, const int channels, const int aligned_height,
16 | const int aligned_width, const float* bottom_rois,
17 | float* top_data, cudaStream_t stream);
18 |
19 | __global__ void ROIAlignBackward(const int nthreads, const float* top_diff,
20 | const float spatial_scale, const int height, const int width,
21 | const int channels, const int aligned_height, const int aligned_width,
22 | float* bottom_diff, const float* bottom_rois);
23 |
24 | int ROIAlignBackwardLaucher(const float* top_diff, const float spatial_scale, const int batch_size, const int num_rois,
25 | const int height, const int width, const int channels, const int aligned_height,
26 | const int aligned_width, const float* bottom_rois,
27 | float* bottom_diff, cudaStream_t stream);
28 |
29 | #ifdef __cplusplus
30 | }
31 | #endif
32 |
33 | #endif
34 |
35 |
--------------------------------------------------------------------------------
/lib/model/roi_crop/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/princewang1994/R-FCN.pytorch/0c8da30bfd23e61f4c7fd1299626b9d82cf8a164/lib/model/roi_crop/__init__.py
--------------------------------------------------------------------------------
/lib/model/roi_crop/_ext/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/princewang1994/R-FCN.pytorch/0c8da30bfd23e61f4c7fd1299626b9d82cf8a164/lib/model/roi_crop/_ext/__init__.py
--------------------------------------------------------------------------------
/lib/model/roi_crop/_ext/crop_resize/__init__.py:
--------------------------------------------------------------------------------
1 |
2 | from torch.utils.ffi import _wrap_function
3 | from ._crop_resize import lib as _lib, ffi as _ffi
4 |
5 | __all__ = []
6 | def _import_symbols(locals):
7 | for symbol in dir(_lib):
8 | fn = getattr(_lib, symbol)
9 | locals[symbol] = _wrap_function(fn, _ffi)
10 | __all__.append(symbol)
11 |
12 | _import_symbols(locals())
13 |
--------------------------------------------------------------------------------
/lib/model/roi_crop/_ext/roi_crop/__init__.py:
--------------------------------------------------------------------------------
1 |
2 | from torch.utils.ffi import _wrap_function
3 | from ._roi_crop import lib as _lib, ffi as _ffi
4 |
5 | __all__ = []
6 | def _import_symbols(locals):
7 | for symbol in dir(_lib):
8 | fn = getattr(_lib, symbol)
9 | if callable(fn):
10 | locals[symbol] = _wrap_function(fn, _ffi)
11 | else:
12 | locals[symbol] = fn
13 | __all__.append(symbol)
14 |
15 | _import_symbols(locals())
16 |
--------------------------------------------------------------------------------
/lib/model/roi_crop/build.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 | import os
3 | import torch
4 | from torch.utils.ffi import create_extension
5 |
6 | #this_file = os.path.dirname(__file__)
7 |
8 | sources = ['src/roi_crop.c']
9 | headers = ['src/roi_crop.h']
10 | defines = []
11 | with_cuda = False
12 |
13 | if torch.cuda.is_available():
14 | print('Including CUDA code.')
15 | sources += ['src/roi_crop_cuda.c']
16 | headers += ['src/roi_crop_cuda.h']
17 | defines += [('WITH_CUDA', None)]
18 | with_cuda = True
19 |
20 | this_file = os.path.dirname(os.path.realpath(__file__))
21 | print(this_file)
22 | extra_objects = ['src/roi_crop_cuda_kernel.cu.o']
23 | extra_objects = [os.path.join(this_file, fname) for fname in extra_objects]
24 |
25 | ffi = create_extension(
26 | '_ext.roi_crop',
27 | headers=headers,
28 | sources=sources,
29 | define_macros=defines,
30 | relative_to=__file__,
31 | with_cuda=with_cuda,
32 | extra_objects=extra_objects
33 | )
34 |
35 | if __name__ == '__main__':
36 | ffi.build()
37 |
--------------------------------------------------------------------------------
/lib/model/roi_crop/functions/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/princewang1994/R-FCN.pytorch/0c8da30bfd23e61f4c7fd1299626b9d82cf8a164/lib/model/roi_crop/functions/__init__.py
--------------------------------------------------------------------------------
/lib/model/roi_crop/functions/crop_resize.py:
--------------------------------------------------------------------------------
1 | # functions/add.py
2 | import torch
3 | from torch.autograd import Function
4 | from .._ext import roi_crop
5 | from cffi import FFI
6 | ffi = FFI()
7 |
8 | class RoICropFunction(Function):
9 | def forward(self, input1, input2):
10 | self.input1 = input1
11 | self.input2 = input2
12 | self.device_c = ffi.new("int *")
13 | output = torch.zeros(input2.size()[0], input1.size()[1], input2.size()[1], input2.size()[2])
14 | #print('decice %d' % torch.cuda.current_device())
15 | if input1.is_cuda:
16 | self.device = torch.cuda.current_device()
17 | else:
18 | self.device = -1
19 | self.device_c[0] = self.device
20 | if not input1.is_cuda:
21 | roi_crop.BilinearSamplerBHWD_updateOutput(input1, input2, output)
22 | else:
23 | output = output.cuda(self.device)
24 | roi_crop.BilinearSamplerBHWD_updateOutput_cuda(input1, input2, output)
25 | return output
26 |
27 | def backward(self, grad_output):
28 | grad_input1 = torch.zeros(self.input1.size())
29 | grad_input2 = torch.zeros(self.input2.size())
30 | #print('backward decice %d' % self.device)
31 | if not grad_output.is_cuda:
32 | roi_crop.BilinearSamplerBHWD_updateGradInput(self.input1, self.input2, grad_input1, grad_input2, grad_output)
33 | else:
34 | grad_input1 = grad_input1.cuda(self.device)
35 | grad_input2 = grad_input2.cuda(self.device)
36 | roi_crop.BilinearSamplerBHWD_updateGradInput_cuda(self.input1, self.input2, grad_input1, grad_input2, grad_output)
37 | return grad_input1, grad_input2
38 |
--------------------------------------------------------------------------------
/lib/model/roi_crop/functions/gridgen.py:
--------------------------------------------------------------------------------
1 | # functions/add.py
2 | import torch
3 | from torch.autograd import Function
4 | import numpy as np
5 |
6 |
7 | class AffineGridGenFunction(Function):
8 | def __init__(self, height, width,lr=1):
9 | super(AffineGridGenFunction, self).__init__()
10 | self.lr = lr
11 | self.height, self.width = height, width
12 | self.grid = np.zeros( [self.height, self.width, 3], dtype=np.float32)
13 | self.grid[:,:,0] = np.expand_dims(np.repeat(np.expand_dims(np.arange(-1, 1, 2.0/(self.height)), 0), repeats = self.width, axis = 0).T, 0)
14 | self.grid[:,:,1] = np.expand_dims(np.repeat(np.expand_dims(np.arange(-1, 1, 2.0/(self.width)), 0), repeats = self.height, axis = 0), 0)
15 | # self.grid[:,:,0] = np.expand_dims(np.repeat(np.expand_dims(np.arange(-1, 1, 2.0/(self.height - 1)), 0), repeats = self.width, axis = 0).T, 0)
16 | # self.grid[:,:,1] = np.expand_dims(np.repeat(np.expand_dims(np.arange(-1, 1, 2.0/(self.width - 1)), 0), repeats = self.height, axis = 0), 0)
17 | self.grid[:,:,2] = np.ones([self.height, width])
18 | self.grid = torch.from_numpy(self.grid.astype(np.float32))
19 | #print(self.grid)
20 |
21 | def forward(self, input1):
22 | self.input1 = input1
23 | output = input1.new(torch.Size([input1.size(0)]) + self.grid.size()).zero_()
24 | self.batchgrid = input1.new(torch.Size([input1.size(0)]) + self.grid.size()).zero_()
25 | for i in range(input1.size(0)):
26 | self.batchgrid[i] = self.grid.astype(self.batchgrid[i])
27 |
28 | # if input1.is_cuda:
29 | # self.batchgrid = self.batchgrid.cuda()
30 | # output = output.cuda()
31 |
32 | for i in range(input1.size(0)):
33 | output = torch.bmm(self.batchgrid.view(-1, self.height*self.width, 3), torch.transpose(input1, 1, 2)).view(-1, self.height, self.width, 2)
34 |
35 | return output
36 |
37 | def backward(self, grad_output):
38 |
39 | grad_input1 = self.input1.new(self.input1.size()).zero_()
40 |
41 | # if grad_output.is_cuda:
42 | # self.batchgrid = self.batchgrid.cuda()
43 | # grad_input1 = grad_input1.cuda()
44 |
45 | grad_input1 = torch.baddbmm(grad_input1, torch.transpose(grad_output.view(-1, self.height*self.width, 2), 1,2), self.batchgrid.view(-1, self.height*self.width, 3))
46 | return grad_input1
47 |
--------------------------------------------------------------------------------
/lib/model/roi_crop/functions/roi_crop.py:
--------------------------------------------------------------------------------
1 | # functions/add.py
2 | import torch
3 | from torch.autograd import Function
4 | from .._ext import roi_crop
5 | import pdb
6 |
7 | class RoICropFunction(Function):
8 | def forward(self, input1, input2):
9 | self.input1 = input1.clone()
10 | self.input2 = input2.clone()
11 | output = input2.new(input2.size()[0], input1.size()[1], input2.size()[1], input2.size()[2]).zero_()
12 | assert output.get_device() == input1.get_device(), "output and input1 must on the same device"
13 | assert output.get_device() == input2.get_device(), "output and input2 must on the same device"
14 | roi_crop.BilinearSamplerBHWD_updateOutput_cuda(input1, input2, output)
15 | return output
16 |
17 | def backward(self, grad_output):
18 | grad_input1 = self.input1.new(self.input1.size()).zero_()
19 | grad_input2 = self.input2.new(self.input2.size()).zero_()
20 | roi_crop.BilinearSamplerBHWD_updateGradInput_cuda(self.input1, self.input2, grad_input1, grad_input2, grad_output)
21 | return grad_input1, grad_input2
22 |
--------------------------------------------------------------------------------
/lib/model/roi_crop/make.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env bash
2 |
3 | CUDA_PATH=/usr/local/cuda/
4 |
5 | cd src
6 | echo "Compiling my_lib kernels by nvcc..."
7 | nvcc -c -o roi_crop_cuda_kernel.cu.o roi_crop_cuda_kernel.cu -x cu -Xcompiler -fPIC -arch=sm_52
8 |
9 | cd ../
10 | python build.py
11 |
--------------------------------------------------------------------------------
/lib/model/roi_crop/modules/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/princewang1994/R-FCN.pytorch/0c8da30bfd23e61f4c7fd1299626b9d82cf8a164/lib/model/roi_crop/modules/__init__.py
--------------------------------------------------------------------------------
/lib/model/roi_crop/modules/roi_crop.py:
--------------------------------------------------------------------------------
1 | from torch.nn.modules.module import Module
2 | from ..functions.roi_crop import RoICropFunction
3 |
4 | class _RoICrop(Module):
5 | def __init__(self, layout = 'BHWD'):
6 | super(_RoICrop, self).__init__()
7 | def forward(self, input1, input2):
8 | return RoICropFunction()(input1, input2)
9 |
--------------------------------------------------------------------------------
/lib/model/roi_crop/src/roi_crop.h:
--------------------------------------------------------------------------------
1 | int BilinearSamplerBHWD_updateOutput(THFloatTensor *inputImages, THFloatTensor *grids, THFloatTensor *output);
2 |
3 | int BilinearSamplerBHWD_updateGradInput(THFloatTensor *inputImages, THFloatTensor *grids, THFloatTensor *gradInputImages,
4 | THFloatTensor *gradGrids, THFloatTensor *gradOutput);
5 |
6 |
7 |
8 | int BilinearSamplerBCHW_updateOutput(THFloatTensor *inputImages, THFloatTensor *grids, THFloatTensor *output);
9 |
10 | int BilinearSamplerBCHW_updateGradInput(THFloatTensor *inputImages, THFloatTensor *grids, THFloatTensor *gradInputImages,
11 | THFloatTensor *gradGrids, THFloatTensor *gradOutput);
12 |
--------------------------------------------------------------------------------
/lib/model/roi_crop/src/roi_crop_cuda.c:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | #include
4 | #include "roi_crop_cuda_kernel.h"
5 |
6 | #define real float
7 |
8 | // this symbol will be resolved automatically from PyTorch libs
9 | extern THCState *state;
10 |
11 | // Bilinear sampling is done in BHWD (coalescing is not obvious in BDHW)
12 | // we assume BHWD format in inputImages
13 | // we assume BHW(YX) format on grids
14 |
15 | int BilinearSamplerBHWD_updateOutput_cuda(THCudaTensor *inputImages, THCudaTensor *grids, THCudaTensor *output){
16 | // THCState *state = getCutorchState(L);
17 | // THCudaTensor *inputImages = (THCudaTensor *)luaT_checkudata(L, 2, "torch.CudaTensor");
18 | // THCudaTensor *grids = (THCudaTensor *)luaT_checkudata(L, 3, "torch.CudaTensor");
19 | // THCudaTensor *output = (THCudaTensor *)luaT_checkudata(L, 4, "torch.CudaTensor");
20 |
21 | int success = 0;
22 | success = BilinearSamplerBHWD_updateOutput_cuda_kernel(output->size[1],
23 | output->size[3],
24 | output->size[2],
25 | output->size[0],
26 | THCudaTensor_size(state, inputImages, 1),
27 | THCudaTensor_size(state, inputImages, 2),
28 | THCudaTensor_size(state, inputImages, 3),
29 | THCudaTensor_size(state, inputImages, 0),
30 | THCudaTensor_data(state, inputImages),
31 | THCudaTensor_stride(state, inputImages, 0),
32 | THCudaTensor_stride(state, inputImages, 1),
33 | THCudaTensor_stride(state, inputImages, 2),
34 | THCudaTensor_stride(state, inputImages, 3),
35 | THCudaTensor_data(state, grids),
36 | THCudaTensor_stride(state, grids, 0),
37 | THCudaTensor_stride(state, grids, 3),
38 | THCudaTensor_stride(state, grids, 1),
39 | THCudaTensor_stride(state, grids, 2),
40 | THCudaTensor_data(state, output),
41 | THCudaTensor_stride(state, output, 0),
42 | THCudaTensor_stride(state, output, 1),
43 | THCudaTensor_stride(state, output, 2),
44 | THCudaTensor_stride(state, output, 3),
45 | THCState_getCurrentStream(state));
46 |
47 | //check for errors
48 | if (!success) {
49 | THError("aborting");
50 | }
51 | return 1;
52 | }
53 |
54 | int BilinearSamplerBHWD_updateGradInput_cuda(THCudaTensor *inputImages, THCudaTensor *grids, THCudaTensor *gradInputImages,
55 | THCudaTensor *gradGrids, THCudaTensor *gradOutput)
56 | {
57 | // THCState *state = getCutorchState(L);
58 | // THCudaTensor *inputImages = (THCudaTensor *)luaT_checkudata(L, 2, "torch.CudaTensor");
59 | // THCudaTensor *grids = (THCudaTensor *)luaT_checkudata(L, 3, "torch.CudaTensor");
60 | // THCudaTensor *gradInputImages = (THCudaTensor *)luaT_checkudata(L, 4, "torch.CudaTensor");
61 | // THCudaTensor *gradGrids = (THCudaTensor *)luaT_checkudata(L, 5, "torch.CudaTensor");
62 | // THCudaTensor *gradOutput = (THCudaTensor *)luaT_checkudata(L, 6, "torch.CudaTensor");
63 |
64 | int success = 0;
65 | success = BilinearSamplerBHWD_updateGradInput_cuda_kernel(gradOutput->size[1],
66 | gradOutput->size[3],
67 | gradOutput->size[2],
68 | gradOutput->size[0],
69 | THCudaTensor_size(state, inputImages, 1),
70 | THCudaTensor_size(state, inputImages, 2),
71 | THCudaTensor_size(state, inputImages, 3),
72 | THCudaTensor_size(state, inputImages, 0),
73 | THCudaTensor_data(state, inputImages),
74 | THCudaTensor_stride(state, inputImages, 0),
75 | THCudaTensor_stride(state, inputImages, 1),
76 | THCudaTensor_stride(state, inputImages, 2),
77 | THCudaTensor_stride(state, inputImages, 3),
78 | THCudaTensor_data(state, grids),
79 | THCudaTensor_stride(state, grids, 0),
80 | THCudaTensor_stride(state, grids, 3),
81 | THCudaTensor_stride(state, grids, 1),
82 | THCudaTensor_stride(state, grids, 2),
83 | THCudaTensor_data(state, gradInputImages),
84 | THCudaTensor_stride(state, gradInputImages, 0),
85 | THCudaTensor_stride(state, gradInputImages, 1),
86 | THCudaTensor_stride(state, gradInputImages, 2),
87 | THCudaTensor_stride(state, gradInputImages, 3),
88 | THCudaTensor_data(state, gradGrids),
89 | THCudaTensor_stride(state, gradGrids, 0),
90 | THCudaTensor_stride(state, gradGrids, 3),
91 | THCudaTensor_stride(state, gradGrids, 1),
92 | THCudaTensor_stride(state, gradGrids, 2),
93 | THCudaTensor_data(state, gradOutput),
94 | THCudaTensor_stride(state, gradOutput, 0),
95 | THCudaTensor_stride(state, gradOutput, 1),
96 | THCudaTensor_stride(state, gradOutput, 2),
97 | THCudaTensor_stride(state, gradOutput, 3),
98 | THCState_getCurrentStream(state));
99 |
100 | //check for errors
101 | if (!success) {
102 | THError("aborting");
103 | }
104 | return 1;
105 | }
106 |
--------------------------------------------------------------------------------
/lib/model/roi_crop/src/roi_crop_cuda.h:
--------------------------------------------------------------------------------
1 | // Bilinear sampling is done in BHWD (coalescing is not obvious in BDHW)
2 | // we assume BHWD format in inputImages
3 | // we assume BHW(YX) format on grids
4 |
5 | int BilinearSamplerBHWD_updateOutput_cuda(THCudaTensor *inputImages, THCudaTensor *grids, THCudaTensor *output);
6 |
7 | int BilinearSamplerBHWD_updateGradInput_cuda(THCudaTensor *inputImages, THCudaTensor *grids, THCudaTensor *gradInputImages,
8 | THCudaTensor *gradGrids, THCudaTensor *gradOutput);
9 |
--------------------------------------------------------------------------------
/lib/model/roi_crop/src/roi_crop_cuda_kernel.h:
--------------------------------------------------------------------------------
1 | #ifdef __cplusplus
2 | extern "C" {
3 | #endif
4 |
5 |
6 | int BilinearSamplerBHWD_updateOutput_cuda_kernel(/*output->size[3]*/int oc,
7 | /*output->size[2]*/int ow,
8 | /*output->size[1]*/int oh,
9 | /*output->size[0]*/int ob,
10 | /*THCudaTensor_size(state, inputImages, 3)*/int ic,
11 | /*THCudaTensor_size(state, inputImages, 1)*/int ih,
12 | /*THCudaTensor_size(state, inputImages, 2)*/int iw,
13 | /*THCudaTensor_size(state, inputImages, 0)*/int ib,
14 | /*THCudaTensor *inputImages*/float *inputImages, int isb, int isc, int ish, int isw,
15 | /*THCudaTensor *grids*/float *grids, int gsb, int gsc, int gsh, int gsw,
16 | /*THCudaTensor *output*/float *output, int osb, int osc, int osh, int osw,
17 | /*THCState_getCurrentStream(state)*/cudaStream_t stream);
18 |
19 | int BilinearSamplerBHWD_updateGradInput_cuda_kernel(/*gradOutput->size[3]*/int goc,
20 | /*gradOutput->size[2]*/int gow,
21 | /*gradOutput->size[1]*/int goh,
22 | /*gradOutput->size[0]*/int gob,
23 | /*THCudaTensor_size(state, inputImages, 3)*/int ic,
24 | /*THCudaTensor_size(state, inputImages, 1)*/int ih,
25 | /*THCudaTensor_size(state, inputImages, 2)*/int iw,
26 | /*THCudaTensor_size(state, inputImages, 0)*/int ib,
27 | /*THCudaTensor *inputImages*/float *inputImages, int isb, int isc, int ish, int isw,
28 | /*THCudaTensor *grids*/float *grids, int gsb, int gsc, int gsh, int gsw,
29 | /*THCudaTensor *gradInputImages*/float *gradInputImages, int gisb, int gisc, int gish, int gisw,
30 | /*THCudaTensor *gradGrids*/float *gradGrids, int ggsb, int ggsc, int ggsh, int ggsw,
31 | /*THCudaTensor *gradOutput*/float *gradOutput, int gosb, int gosc, int gosh, int gosw,
32 | /*THCState_getCurrentStream(state)*/cudaStream_t stream);
33 |
34 |
35 | #ifdef __cplusplus
36 | }
37 | #endif
38 |
--------------------------------------------------------------------------------
/lib/model/roi_pooling/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/princewang1994/R-FCN.pytorch/0c8da30bfd23e61f4c7fd1299626b9d82cf8a164/lib/model/roi_pooling/__init__.py
--------------------------------------------------------------------------------
/lib/model/roi_pooling/_ext/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/princewang1994/R-FCN.pytorch/0c8da30bfd23e61f4c7fd1299626b9d82cf8a164/lib/model/roi_pooling/_ext/__init__.py
--------------------------------------------------------------------------------
/lib/model/roi_pooling/_ext/roi_pooling/__init__.py:
--------------------------------------------------------------------------------
1 |
2 | from torch.utils.ffi import _wrap_function
3 | from ._roi_pooling import lib as _lib, ffi as _ffi
4 |
5 | __all__ = []
6 | def _import_symbols(locals):
7 | for symbol in dir(_lib):
8 | fn = getattr(_lib, symbol)
9 | if callable(fn):
10 | locals[symbol] = _wrap_function(fn, _ffi)
11 | else:
12 | locals[symbol] = fn
13 | __all__.append(symbol)
14 |
15 | _import_symbols(locals())
16 |
--------------------------------------------------------------------------------
/lib/model/roi_pooling/build.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 | import os
3 | import torch
4 | from torch.utils.ffi import create_extension
5 |
6 |
7 | sources = ['src/roi_pooling.c']
8 | headers = ['src/roi_pooling.h']
9 | extra_objects = []
10 | defines = []
11 | with_cuda = False
12 |
13 | this_file = os.path.dirname(os.path.realpath(__file__))
14 | print(this_file)
15 |
16 | if torch.cuda.is_available():
17 | print('Including CUDA code.')
18 | sources += ['src/roi_pooling_cuda.c']
19 | headers += ['src/roi_pooling_cuda.h']
20 | defines += [('WITH_CUDA', None)]
21 | with_cuda = True
22 | extra_objects = ['src/roi_pooling.cu.o']
23 | extra_objects = [os.path.join(this_file, fname) for fname in extra_objects]
24 |
25 | ffi = create_extension(
26 | '_ext.roi_pooling',
27 | headers=headers,
28 | sources=sources,
29 | define_macros=defines,
30 | relative_to=__file__,
31 | with_cuda=with_cuda,
32 | extra_objects=extra_objects
33 | )
34 |
35 | if __name__ == '__main__':
36 | ffi.build()
37 |
--------------------------------------------------------------------------------
/lib/model/roi_pooling/functions/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/princewang1994/R-FCN.pytorch/0c8da30bfd23e61f4c7fd1299626b9d82cf8a164/lib/model/roi_pooling/functions/__init__.py
--------------------------------------------------------------------------------
/lib/model/roi_pooling/functions/roi_pool.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch.autograd import Function
3 | from .._ext import roi_pooling
4 | import pdb
5 |
6 | class RoIPoolFunction(Function):
7 | def __init__(ctx, pooled_height, pooled_width, spatial_scale):
8 | ctx.pooled_width = pooled_width
9 | ctx.pooled_height = pooled_height
10 | ctx.spatial_scale = spatial_scale
11 | ctx.feature_size = None
12 |
13 | def forward(ctx, features, rois):
14 | ctx.feature_size = features.size()
15 | batch_size, num_channels, data_height, data_width = ctx.feature_size
16 | num_rois = rois.size(0)
17 | output = features.new(num_rois, num_channels, ctx.pooled_height, ctx.pooled_width).zero_()
18 | ctx.argmax = features.new(num_rois, num_channels, ctx.pooled_height, ctx.pooled_width).zero_().int()
19 | ctx.rois = rois
20 | if not features.is_cuda:
21 | _features = features.permute(0, 2, 3, 1)
22 | roi_pooling.roi_pooling_forward(ctx.pooled_height, ctx.pooled_width, ctx.spatial_scale,
23 | _features, rois, output)
24 | else:
25 | roi_pooling.roi_pooling_forward_cuda(ctx.pooled_height, ctx.pooled_width, ctx.spatial_scale,
26 | features, rois, output, ctx.argmax)
27 |
28 | return output
29 |
30 | def backward(ctx, grad_output):
31 | assert(ctx.feature_size is not None and grad_output.is_cuda)
32 | batch_size, num_channels, data_height, data_width = ctx.feature_size
33 | grad_input = grad_output.new(batch_size, num_channels, data_height, data_width).zero_()
34 |
35 | roi_pooling.roi_pooling_backward_cuda(ctx.pooled_height, ctx.pooled_width, ctx.spatial_scale,
36 | grad_output, ctx.rois, grad_input, ctx.argmax)
37 |
38 | return grad_input, None
39 |
--------------------------------------------------------------------------------
/lib/model/roi_pooling/modules/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/princewang1994/R-FCN.pytorch/0c8da30bfd23e61f4c7fd1299626b9d82cf8a164/lib/model/roi_pooling/modules/__init__.py
--------------------------------------------------------------------------------
/lib/model/roi_pooling/modules/roi_pool.py:
--------------------------------------------------------------------------------
1 | from torch.nn.modules.module import Module
2 | from ..functions.roi_pool import RoIPoolFunction
3 |
4 |
5 | class _RoIPooling(Module):
6 | def __init__(self, pooled_height, pooled_width, spatial_scale):
7 | super(_RoIPooling, self).__init__()
8 |
9 | self.pooled_width = int(pooled_width)
10 | self.pooled_height = int(pooled_height)
11 | self.spatial_scale = float(spatial_scale)
12 |
13 | def forward(self, features, rois):
14 | return RoIPoolFunction(self.pooled_height, self.pooled_width, self.spatial_scale)(features, rois)
15 |
--------------------------------------------------------------------------------
/lib/model/roi_pooling/src/roi_pooling.c:
--------------------------------------------------------------------------------
1 | #include |
2 | #include
3 |
4 | int roi_pooling_forward(int pooled_height, int pooled_width, float spatial_scale,
5 | THFloatTensor * features, THFloatTensor * rois, THFloatTensor * output)
6 | {
7 | // Grab the input tensor
8 | float * data_flat = THFloatTensor_data(features);
9 | float * rois_flat = THFloatTensor_data(rois);
10 |
11 | float * output_flat = THFloatTensor_data(output);
12 |
13 | // Number of ROIs
14 | int num_rois = THFloatTensor_size(rois, 0);
15 | int size_rois = THFloatTensor_size(rois, 1);
16 | // batch size
17 | int batch_size = THFloatTensor_size(features, 0);
18 | if(batch_size != 1)
19 | {
20 | return 0;
21 | }
22 | // data height
23 | int data_height = THFloatTensor_size(features, 1);
24 | // data width
25 | int data_width = THFloatTensor_size(features, 2);
26 | // Number of channels
27 | int num_channels = THFloatTensor_size(features, 3);
28 |
29 | // Set all element of the output tensor to -inf.
30 | THFloatStorage_fill(THFloatTensor_storage(output), -1);
31 |
32 | // For each ROI R = [batch_index x1 y1 x2 y2]: max pool over R
33 | int index_roi = 0;
34 | int index_output = 0;
35 | int n;
36 | for (n = 0; n < num_rois; ++n)
37 | {
38 | int roi_batch_ind = rois_flat[index_roi + 0];
39 | int roi_start_w = round(rois_flat[index_roi + 1] * spatial_scale);
40 | int roi_start_h = round(rois_flat[index_roi + 2] * spatial_scale);
41 | int roi_end_w = round(rois_flat[index_roi + 3] * spatial_scale);
42 | int roi_end_h = round(rois_flat[index_roi + 4] * spatial_scale);
43 | // CHECK_GE(roi_batch_ind, 0);
44 | // CHECK_LT(roi_batch_ind, batch_size);
45 |
46 | int roi_height = fmaxf(roi_end_h - roi_start_h + 1, 1);
47 | int roi_width = fmaxf(roi_end_w - roi_start_w + 1, 1);
48 | float bin_size_h = (float)(roi_height) / (float)(pooled_height);
49 | float bin_size_w = (float)(roi_width) / (float)(pooled_width);
50 |
51 | int index_data = roi_batch_ind * data_height * data_width * num_channels;
52 | const int output_area = pooled_width * pooled_height;
53 |
54 | int c, ph, pw;
55 | for (ph = 0; ph < pooled_height; ++ph)
56 | {
57 | for (pw = 0; pw < pooled_width; ++pw)
58 | {
59 | int hstart = (floor((float)(ph) * bin_size_h));
60 | int wstart = (floor((float)(pw) * bin_size_w));
61 | int hend = (ceil((float)(ph + 1) * bin_size_h));
62 | int wend = (ceil((float)(pw + 1) * bin_size_w));
63 |
64 | hstart = fminf(fmaxf(hstart + roi_start_h, 0), data_height);
65 | hend = fminf(fmaxf(hend + roi_start_h, 0), data_height);
66 | wstart = fminf(fmaxf(wstart + roi_start_w, 0), data_width);
67 | wend = fminf(fmaxf(wend + roi_start_w, 0), data_width);
68 |
69 | const int pool_index = index_output + (ph * pooled_width + pw);
70 | int is_empty = (hend <= hstart) || (wend <= wstart);
71 | if (is_empty)
72 | {
73 | for (c = 0; c < num_channels * output_area; c += output_area)
74 | {
75 | output_flat[pool_index + c] = 0;
76 | }
77 | }
78 | else
79 | {
80 | int h, w, c;
81 | for (h = hstart; h < hend; ++h)
82 | {
83 | for (w = wstart; w < wend; ++w)
84 | {
85 | for (c = 0; c < num_channels; ++c)
86 | {
87 | const int index = (h * data_width + w) * num_channels + c;
88 | if (data_flat[index_data + index] > output_flat[pool_index + c * output_area])
89 | {
90 | output_flat[pool_index + c * output_area] = data_flat[index_data + index];
91 | }
92 | }
93 | }
94 | }
95 | }
96 | }
97 | }
98 |
99 | // Increment ROI index
100 | index_roi += size_rois;
101 | index_output += pooled_height * pooled_width * num_channels;
102 | }
103 | return 1;
104 | }
--------------------------------------------------------------------------------
/lib/model/roi_pooling/src/roi_pooling.h:
--------------------------------------------------------------------------------
1 | int roi_pooling_forward(int pooled_height, int pooled_width, float spatial_scale,
2 | THFloatTensor * features, THFloatTensor * rois, THFloatTensor * output);
--------------------------------------------------------------------------------
/lib/model/roi_pooling/src/roi_pooling_cuda.c:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | #include "roi_pooling_kernel.h"
4 |
5 | extern THCState *state;
6 |
7 | int roi_pooling_forward_cuda(int pooled_height, int pooled_width, float spatial_scale,
8 | THCudaTensor * features, THCudaTensor * rois, THCudaTensor * output, THCudaIntTensor * argmax)
9 | {
10 | // Grab the input tensor
11 | float * data_flat = THCudaTensor_data(state, features);
12 | float * rois_flat = THCudaTensor_data(state, rois);
13 |
14 | float * output_flat = THCudaTensor_data(state, output);
15 | int * argmax_flat = THCudaIntTensor_data(state, argmax);
16 |
17 | // Number of ROIs
18 | int num_rois = THCudaTensor_size(state, rois, 0);
19 | int size_rois = THCudaTensor_size(state, rois, 1);
20 | if (size_rois != 5)
21 | {
22 | return 0;
23 | }
24 |
25 | // batch size
26 | // int batch_size = THCudaTensor_size(state, features, 0);
27 | // if (batch_size != 1)
28 | // {
29 | // return 0;
30 | // }
31 | // data height
32 | int data_height = THCudaTensor_size(state, features, 2);
33 | // data width
34 | int data_width = THCudaTensor_size(state, features, 3);
35 | // Number of channels
36 | int num_channels = THCudaTensor_size(state, features, 1);
37 |
38 | cudaStream_t stream = THCState_getCurrentStream(state);
39 |
40 | ROIPoolForwardLaucher(
41 | data_flat, spatial_scale, num_rois, data_height,
42 | data_width, num_channels, pooled_height,
43 | pooled_width, rois_flat,
44 | output_flat, argmax_flat, stream);
45 |
46 | return 1;
47 | }
48 |
49 | int roi_pooling_backward_cuda(int pooled_height, int pooled_width, float spatial_scale,
50 | THCudaTensor * top_grad, THCudaTensor * rois, THCudaTensor * bottom_grad, THCudaIntTensor * argmax)
51 | {
52 | // Grab the input tensor
53 | float * top_grad_flat = THCudaTensor_data(state, top_grad);
54 | float * rois_flat = THCudaTensor_data(state, rois);
55 |
56 | float * bottom_grad_flat = THCudaTensor_data(state, bottom_grad);
57 | int * argmax_flat = THCudaIntTensor_data(state, argmax);
58 |
59 | // Number of ROIs
60 | int num_rois = THCudaTensor_size(state, rois, 0);
61 | int size_rois = THCudaTensor_size(state, rois, 1);
62 | if (size_rois != 5)
63 | {
64 | return 0;
65 | }
66 |
67 | // batch size
68 | int batch_size = THCudaTensor_size(state, bottom_grad, 0);
69 | // if (batch_size != 1)
70 | // {
71 | // return 0;
72 | // }
73 | // data height
74 | int data_height = THCudaTensor_size(state, bottom_grad, 2);
75 | // data width
76 | int data_width = THCudaTensor_size(state, bottom_grad, 3);
77 | // Number of channels
78 | int num_channels = THCudaTensor_size(state, bottom_grad, 1);
79 |
80 | cudaStream_t stream = THCState_getCurrentStream(state);
81 | ROIPoolBackwardLaucher(
82 | top_grad_flat, spatial_scale, batch_size, num_rois, data_height,
83 | data_width, num_channels, pooled_height,
84 | pooled_width, rois_flat,
85 | bottom_grad_flat, argmax_flat, stream);
86 |
87 | return 1;
88 | }
89 |
--------------------------------------------------------------------------------
/lib/model/roi_pooling/src/roi_pooling_cuda.h:
--------------------------------------------------------------------------------
1 | int roi_pooling_forward_cuda(int pooled_height, int pooled_width, float spatial_scale,
2 | THCudaTensor * features, THCudaTensor * rois, THCudaTensor * output, THCudaIntTensor * argmax);
3 |
4 | int roi_pooling_backward_cuda(int pooled_height, int pooled_width, float spatial_scale,
5 | THCudaTensor * top_grad, THCudaTensor * rois, THCudaTensor * bottom_grad, THCudaIntTensor * argmax);
--------------------------------------------------------------------------------
/lib/model/roi_pooling/src/roi_pooling_kernel.h:
--------------------------------------------------------------------------------
1 | #ifndef _ROI_POOLING_KERNEL
2 | #define _ROI_POOLING_KERNEL
3 |
4 | #ifdef __cplusplus
5 | extern "C" {
6 | #endif
7 |
8 | int ROIPoolForwardLaucher(
9 | const float* bottom_data, const float spatial_scale, const int num_rois, const int height,
10 | const int width, const int channels, const int pooled_height,
11 | const int pooled_width, const float* bottom_rois,
12 | float* top_data, int* argmax_data, cudaStream_t stream);
13 |
14 |
15 | int ROIPoolBackwardLaucher(const float* top_diff, const float spatial_scale, const int batch_size, const int num_rois,
16 | const int height, const int width, const int channels, const int pooled_height,
17 | const int pooled_width, const float* bottom_rois,
18 | float* bottom_diff, const int* argmax_data, cudaStream_t stream);
19 |
20 | #ifdef __cplusplus
21 | }
22 | #endif
23 |
24 | #endif
25 |
26 |
--------------------------------------------------------------------------------
/lib/model/rpn/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/princewang1994/R-FCN.pytorch/0c8da30bfd23e61f4c7fd1299626b9d82cf8a164/lib/model/rpn/__init__.py
--------------------------------------------------------------------------------
/lib/model/rpn/generate_anchors.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 | # --------------------------------------------------------
3 | # Faster R-CNN
4 | # Copyright (c) 2015 Microsoft
5 | # Licensed under The MIT License [see LICENSE for details]
6 | # Written by Ross Girshick and Sean Bell
7 | # --------------------------------------------------------
8 |
9 | import numpy as np
10 | import pdb
11 |
12 | # Verify that we compute the same anchors as Shaoqing's matlab implementation:
13 | #
14 | # >> load output/rpn_cachedir/faster_rcnn_VOC2007_ZF_stage1_rpn/anchors.mat
15 | # >> anchors
16 | #
17 | # anchors =
18 | #
19 | # -83 -39 100 56
20 | # -175 -87 192 104
21 | # -359 -183 376 200
22 | # -55 -55 72 72
23 | # -119 -119 136 136
24 | # -247 -247 264 264
25 | # -35 -79 52 96
26 | # -79 -167 96 184
27 | # -167 -343 184 360
28 |
29 | #array([[ -83., -39., 100., 56.],
30 | # [-175., -87., 192., 104.],
31 | # [-359., -183., 376., 200.],
32 | # [ -55., -55., 72., 72.],
33 | # [-119., -119., 136., 136.],
34 | # [-247., -247., 264., 264.],
35 | # [ -35., -79., 52., 96.],
36 | # [ -79., -167., 96., 184.],
37 | # [-167., -343., 184., 360.]])
38 |
39 | try:
40 | xrange # Python 2
41 | except NameError:
42 | xrange = range # Python 3
43 |
44 |
45 | def generate_anchors(base_size=16, ratios=[0.5, 1, 2],
46 | scales=2**np.arange(3, 6)):
47 | """
48 | Generate anchor (reference) windows by enumerating aspect ratios X
49 | scales wrt a reference (0, 0, 15, 15) window.
50 | """
51 |
52 | base_anchor = np.array([1, 1, base_size, base_size]) - 1
53 | ratio_anchors = _ratio_enum(base_anchor, ratios)
54 | anchors = np.vstack([_scale_enum(ratio_anchors[i, :], scales)
55 | for i in xrange(ratio_anchors.shape[0])])
56 | return anchors
57 |
58 | def _whctrs(anchor):
59 | """
60 | Return width, height, x center, and y center for an anchor (window).
61 | """
62 |
63 | w = anchor[2] - anchor[0] + 1
64 | h = anchor[3] - anchor[1] + 1
65 | x_ctr = anchor[0] + 0.5 * (w - 1)
66 | y_ctr = anchor[1] + 0.5 * (h - 1)
67 | return w, h, x_ctr, y_ctr
68 |
69 | def _mkanchors(ws, hs, x_ctr, y_ctr):
70 | """
71 | Given a vector of widths (ws) and heights (hs) around a center
72 | (x_ctr, y_ctr), output a set of anchors (windows).
73 | """
74 |
75 | ws = ws[:, np.newaxis]
76 | hs = hs[:, np.newaxis]
77 | anchors = np.hstack((x_ctr - 0.5 * (ws - 1),
78 | y_ctr - 0.5 * (hs - 1),
79 | x_ctr + 0.5 * (ws - 1),
80 | y_ctr + 0.5 * (hs - 1)))
81 | return anchors
82 |
83 | def _ratio_enum(anchor, ratios):
84 | """
85 | Enumerate a set of anchors for each aspect ratio wrt an anchor.
86 | """
87 |
88 | w, h, x_ctr, y_ctr = _whctrs(anchor)
89 | size = w * h
90 | size_ratios = size / ratios
91 | ws = np.round(np.sqrt(size_ratios))
92 | hs = np.round(ws * ratios)
93 | anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
94 | return anchors
95 |
96 | def _scale_enum(anchor, scales):
97 | """
98 | Enumerate a set of anchors for each scale wrt an anchor.
99 | """
100 |
101 | w, h, x_ctr, y_ctr = _whctrs(anchor)
102 | ws = w * scales
103 | hs = h * scales
104 | anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
105 | return anchors
106 |
107 | if __name__ == '__main__':
108 | import time
109 | t = time.time()
110 | a = generate_anchors()
111 | print(time.time() - t)
112 | print(a)
113 | from IPython import embed; embed()
114 |
--------------------------------------------------------------------------------
/lib/model/rpn/proposal_layer.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | # --------------------------------------------------------
3 | # Faster R-CNN
4 | # Copyright (c) 2015 Microsoft
5 | # Licensed under The MIT License [see LICENSE for details]
6 | # Written by Ross Girshick and Sean Bell
7 | # --------------------------------------------------------
8 | # --------------------------------------------------------
9 | # Reorganized and modified by Jianwei Yang and Jiasen Lu
10 | # --------------------------------------------------------
11 |
12 | import torch
13 | import torch.nn as nn
14 | import numpy as np
15 | import math
16 | import yaml
17 | from model.utils.config import cfg
18 | from .generate_anchors import generate_anchors
19 | from .bbox_transform import bbox_transform_inv, clip_boxes, clip_boxes_batch
20 | from model.nms.nms_wrapper import nms
21 |
22 | import pdb
23 |
24 | DEBUG = False
25 |
26 | class _ProposalLayer(nn.Module):
27 | """
28 | Outputs object detection proposals by applying estimated bounding-box
29 | transformations to a set of regular boxes (called "anchors").
30 | """
31 |
32 | def __init__(self, feat_stride, scales, ratios):
33 | super(_ProposalLayer, self).__init__()
34 |
35 | self._feat_stride = feat_stride
36 | self._anchors = torch.from_numpy(generate_anchors(scales=np.array(scales),
37 | ratios=np.array(ratios))).float()
38 | self._num_anchors = self._anchors.size(0)
39 |
40 | # rois blob: holds R regions of interest, each is a 5-tuple
41 | # (n, x1, y1, x2, y2) specifying an image batch index n and a
42 | # rectangle (x1, y1, x2, y2)
43 | # top[0].reshape(1, 5)
44 | #
45 | # # scores blob: holds scores for R regions of interest
46 | # if len(top) > 1:
47 | # top[1].reshape(1, 1, 1, 1)
48 |
49 | def forward(self, input):
50 |
51 | # Algorithm:
52 | #
53 | # for each (H, W) location i
54 | # generate A anchor boxes centered on cell i
55 | # apply predicted bbox deltas at cell i to each of the A anchors
56 | # clip predicted boxes to image
57 | # remove predicted boxes with either height or width < threshold
58 | # sort all (proposal, score) pairs by score from highest to lowest
59 | # take top pre_nms_topN proposals before NMS
60 | # apply NMS with threshold 0.7 to remaining proposals
61 | # take after_nms_topN proposals after NMS
62 | # return the top proposals (-> RoIs top, scores top)
63 |
64 |
65 | # the first set of _num_anchors channels are bg probs
66 | # the second set are the fg probs
67 | scores = input[0][:, self._num_anchors:, :, :]
68 | bbox_deltas = input[1]
69 | im_info = input[2]
70 | cfg_key = input[3]
71 |
72 | pre_nms_topN = cfg[cfg_key].RPN_PRE_NMS_TOP_N
73 | post_nms_topN = cfg[cfg_key].RPN_POST_NMS_TOP_N
74 | nms_thresh = cfg[cfg_key].RPN_NMS_THRESH
75 | min_size = cfg[cfg_key].RPN_MIN_SIZE
76 |
77 | batch_size = bbox_deltas.size(0)
78 |
79 | feat_height, feat_width = scores.size(2), scores.size(3)
80 | shift_x = np.arange(0, feat_width) * self._feat_stride
81 | shift_y = np.arange(0, feat_height) * self._feat_stride
82 | shift_x, shift_y = np.meshgrid(shift_x, shift_y)
83 | shifts = torch.from_numpy(np.vstack((shift_x.ravel(), shift_y.ravel(),
84 | shift_x.ravel(), shift_y.ravel())).transpose())
85 | shifts = shifts.contiguous().type_as(scores).float()
86 |
87 | A = self._num_anchors
88 | K = shifts.size(0)
89 |
90 | self._anchors = self._anchors.type_as(scores)
91 | # anchors = self._anchors.view(1, A, 4) + shifts.view(1, K, 4).permute(1, 0, 2).contiguous()
92 | anchors = self._anchors.view(1, A, 4) + shifts.view(K, 1, 4)
93 | anchors = anchors.view(1, K * A, 4).expand(batch_size, K * A, 4)
94 |
95 | # Transpose and reshape predicted bbox transformations to get them
96 | # into the same order as the anchors:
97 |
98 | bbox_deltas = bbox_deltas.permute(0, 2, 3, 1).contiguous()
99 | bbox_deltas = bbox_deltas.view(batch_size, -1, 4)
100 |
101 | # Same story for the scores:
102 | scores = scores.permute(0, 2, 3, 1).contiguous()
103 | scores = scores.view(batch_size, -1)
104 |
105 | # Convert anchors into proposals via bbox transformations
106 | proposals = bbox_transform_inv(anchors, bbox_deltas, batch_size)
107 |
108 | # 2. clip predicted boxes to image
109 | proposals = clip_boxes(proposals, im_info, batch_size)
110 | # proposals = clip_boxes_batch(proposals, im_info, batch_size)
111 |
112 | # assign the score to 0 if it's non keep.
113 | # keep = self._filter_boxes(proposals, min_size * im_info[:, 2])
114 |
115 | # trim keep index to make it euqal over batch
116 | # keep_idx = torch.cat(tuple(keep_idx), 0)
117 |
118 | # scores_keep = scores.view(-1)[keep_idx].view(batch_size, trim_size)
119 | # proposals_keep = proposals.view(-1, 4)[keep_idx, :].contiguous().view(batch_size, trim_size, 4)
120 |
121 | # _, order = torch.sort(scores_keep, 1, True)
122 |
123 | scores_keep = scores
124 | proposals_keep = proposals
125 | _, order = torch.sort(scores_keep, 1, True)
126 |
127 | output = scores.new(batch_size, post_nms_topN, 5).zero_()
128 | for i in range(batch_size):
129 | # # 3. remove predicted boxes with either height or width < threshold
130 | # # (NOTE: convert min_size to input image scale stored in im_info[2])
131 | proposals_single = proposals_keep[i]
132 | scores_single = scores_keep[i]
133 |
134 | # # 4. sort all (proposal, score) pairs by score from highest to lowest
135 | # # 5. take top pre_nms_topN (e.g. 6000)
136 | order_single = order[i]
137 |
138 | if pre_nms_topN > 0 and pre_nms_topN < scores_keep.numel():
139 | order_single = order_single[:pre_nms_topN]
140 |
141 | proposals_single = proposals_single[order_single, :]
142 | scores_single = scores_single[order_single].view(-1,1)
143 |
144 | # 6. apply nms (e.g. threshold = 0.7)
145 | # 7. take after_nms_topN (e.g. 300)
146 | # 8. return the top proposals (-> RoIs top)
147 |
148 | keep_idx_i = nms(torch.cat((proposals_single, scores_single), 1), nms_thresh, force_cpu=not cfg.USE_GPU_NMS)
149 | keep_idx_i = keep_idx_i.long().view(-1)
150 |
151 | if post_nms_topN > 0:
152 | keep_idx_i = keep_idx_i[:post_nms_topN]
153 | proposals_single = proposals_single[keep_idx_i, :]
154 | scores_single = scores_single[keep_idx_i, :]
155 |
156 | # padding 0 at the end.
157 | num_proposal = proposals_single.size(0)
158 | output[i,:,0] = i
159 | output[i,:num_proposal,1:] = proposals_single
160 |
161 | return output
162 |
163 | def backward(self, top, propagate_down, bottom):
164 | """This layer does not propagate gradients."""
165 | pass
166 |
167 | def reshape(self, bottom, top):
168 | """Reshaping happens during the call to forward."""
169 | pass
170 |
171 | def _filter_boxes(self, boxes, min_size):
172 | """Remove all boxes with any side smaller than min_size."""
173 | ws = boxes[:, :, 2] - boxes[:, :, 0] + 1
174 | hs = boxes[:, :, 3] - boxes[:, :, 1] + 1
175 | keep = ((ws >= min_size.view(-1,1).expand_as(ws)) & (hs >= min_size.view(-1,1).expand_as(hs)))
176 | return keep
177 |
--------------------------------------------------------------------------------
/lib/model/rpn/rpn.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | import torch
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 | from torch.autograd import Variable
6 |
7 | from model.utils.config import cfg
8 | from .proposal_layer import _ProposalLayer
9 | from .anchor_target_layer import _AnchorTargetLayer
10 | from model.utils.net_utils import _smooth_l1_loss
11 |
12 | import numpy as np
13 | import math
14 | import pdb
15 | import time
16 |
17 | class _RPN(nn.Module):
18 | """ region proposal network """
19 | def __init__(self, din):
20 | super(_RPN, self).__init__()
21 |
22 | self.din = din # get depth of input feature map, e.g., 512
23 | self.anchor_scales = cfg.ANCHOR_SCALES
24 | self.anchor_ratios = cfg.ANCHOR_RATIOS
25 | self.feat_stride = cfg.FEAT_STRIDE[0]
26 |
27 | # define the convrelu layers processing input feature map
28 | self.RPN_Conv = nn.Conv2d(self.din, 512, 3, 1, 1, bias=True)
29 |
30 | # define bg/fg classifcation score layer
31 | self.nc_score_out = len(self.anchor_scales) * len(self.anchor_ratios) * 2 # 2(bg/fg) * 9 (anchors)
32 | self.RPN_cls_score = nn.Conv2d(512, self.nc_score_out, 1, 1, 0)
33 |
34 | # define anchor box offset prediction layer
35 | self.nc_bbox_out = len(self.anchor_scales) * len(self.anchor_ratios) * 4 # 4(coords) * 9 (anchors)
36 | self.RPN_bbox_pred = nn.Conv2d(512, self.nc_bbox_out, 1, 1, 0)
37 |
38 | # define proposal layer
39 | self.RPN_proposal = _ProposalLayer(self.feat_stride, self.anchor_scales, self.anchor_ratios)
40 |
41 | # define anchor target layer
42 | self.RPN_anchor_target = _AnchorTargetLayer(self.feat_stride, self.anchor_scales, self.anchor_ratios)
43 |
44 | self.rpn_loss_cls = 0
45 | self.rpn_loss_box = 0
46 |
47 | @staticmethod
48 | def reshape(x, d):
49 | input_shape = x.size()
50 | x = x.view(
51 | input_shape[0],
52 | int(d),
53 | int(float(input_shape[1] * input_shape[2]) / float(d)),
54 | input_shape[3]
55 | )
56 | return x
57 |
58 | def forward(self, base_feat, im_info, gt_boxes, num_boxes):
59 |
60 | batch_size = base_feat.size(0)
61 |
62 | # return feature map after convrelu layer
63 | rpn_conv1 = F.relu(self.RPN_Conv(base_feat), inplace=True)
64 | # get rpn classification score
65 | rpn_cls_score = self.RPN_cls_score(rpn_conv1)
66 |
67 | rpn_cls_score_reshape = self.reshape(rpn_cls_score, 2)
68 | rpn_cls_prob_reshape = F.softmax(rpn_cls_score_reshape, dim=1)
69 | rpn_cls_prob = self.reshape(rpn_cls_prob_reshape, self.nc_score_out)
70 |
71 | # get rpn offsets to the anchor boxes
72 | rpn_bbox_pred = self.RPN_bbox_pred(rpn_conv1)
73 |
74 | # proposal layer
75 | cfg_key = 'TRAIN' if self.training else 'TEST'
76 |
77 | rois = self.RPN_proposal((rpn_cls_prob.data, rpn_bbox_pred.data,
78 | im_info, cfg_key))
79 |
80 | self.rpn_loss_cls = 0
81 | self.rpn_loss_box = 0
82 |
83 | # generating training labels and build the rpn loss
84 | if self.training:
85 | assert gt_boxes is not None
86 |
87 | rpn_data = self.RPN_anchor_target((rpn_cls_score.data, gt_boxes, im_info, num_boxes))
88 |
89 | # compute classification loss
90 | rpn_cls_score = rpn_cls_score_reshape.permute(0, 2, 3, 1).contiguous().view(batch_size, -1, 2)
91 | rpn_label = rpn_data[0].view(batch_size, -1)
92 |
93 | rpn_keep = Variable(rpn_label.view(-1).ne(-1).nonzero().view(-1))
94 | rpn_cls_score = torch.index_select(rpn_cls_score.view(-1,2), 0, rpn_keep)
95 | rpn_label = torch.index_select(rpn_label.view(-1), 0, rpn_keep.data)
96 | rpn_label = Variable(rpn_label.long())
97 | self.rpn_loss_cls = F.cross_entropy(rpn_cls_score, rpn_label)
98 | fg_cnt = torch.sum(rpn_label.data.ne(0))
99 |
100 | rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights = rpn_data[1:]
101 |
102 | # compute bbox regression loss
103 | rpn_bbox_inside_weights = Variable(rpn_bbox_inside_weights)
104 | rpn_bbox_outside_weights = Variable(rpn_bbox_outside_weights)
105 | rpn_bbox_targets = Variable(rpn_bbox_targets)
106 |
107 | self.rpn_loss_box = _smooth_l1_loss(rpn_bbox_pred, rpn_bbox_targets, rpn_bbox_inside_weights,
108 | rpn_bbox_outside_weights, sigma=3, dim=[1,2,3])
109 |
110 | return rois, self.rpn_loss_cls, self.rpn_loss_box
111 |
--------------------------------------------------------------------------------
/lib/model/utils/.gitignore:
--------------------------------------------------------------------------------
1 | *.c
2 | *.cpp
3 | *.so
4 |
--------------------------------------------------------------------------------
/lib/model/utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/princewang1994/R-FCN.pytorch/0c8da30bfd23e61f4c7fd1299626b9d82cf8a164/lib/model/utils/__init__.py
--------------------------------------------------------------------------------
/lib/model/utils/bbox.pyx:
--------------------------------------------------------------------------------
1 | # --------------------------------------------------------
2 | # Fast R-CNN
3 | # Copyright (c) 2015 Microsoft
4 | # Licensed under The MIT License [see LICENSE for details]
5 | # Written by Sergey Karayev
6 | # --------------------------------------------------------
7 |
8 | cimport cython
9 | import numpy as np
10 | cimport numpy as np
11 |
12 | DTYPE = np.float
13 | ctypedef np.float_t DTYPE_t
14 |
15 | def bbox_overlaps(np.ndarray[DTYPE_t, ndim=2] boxes,
16 | np.ndarray[DTYPE_t, ndim=2] query_boxes):
17 | return bbox_overlaps_c(boxes, query_boxes)
18 |
19 | cdef np.ndarray[DTYPE_t, ndim=2] bbox_overlaps_c(
20 | np.ndarray[DTYPE_t, ndim=2] boxes,
21 | np.ndarray[DTYPE_t, ndim=2] query_boxes):
22 | """
23 | Parameters
24 | ----------
25 | boxes: (N, 4) ndarray of float
26 | query_boxes: (K, 4) ndarray of float
27 | Returns
28 | -------
29 | overlaps: (N, K) ndarray of overlap between boxes and query_boxes
30 | """
31 | cdef unsigned int N = boxes.shape[0]
32 | cdef unsigned int K = query_boxes.shape[0]
33 | cdef np.ndarray[DTYPE_t, ndim=2] overlaps = np.zeros((N, K), dtype=DTYPE)
34 | cdef DTYPE_t iw, ih, box_area
35 | cdef DTYPE_t ua
36 | cdef unsigned int k, n
37 | for k in range(K):
38 | box_area = (
39 | (query_boxes[k, 2] - query_boxes[k, 0] + 1) *
40 | (query_boxes[k, 3] - query_boxes[k, 1] + 1)
41 | )
42 | for n in range(N):
43 | iw = (
44 | min(boxes[n, 2], query_boxes[k, 2]) -
45 | max(boxes[n, 0], query_boxes[k, 0]) + 1
46 | )
47 | if iw > 0:
48 | ih = (
49 | min(boxes[n, 3], query_boxes[k, 3]) -
50 | max(boxes[n, 1], query_boxes[k, 1]) + 1
51 | )
52 | if ih > 0:
53 | ua = float(
54 | (boxes[n, 2] - boxes[n, 0] + 1) *
55 | (boxes[n, 3] - boxes[n, 1] + 1) +
56 | box_area - iw * ih
57 | )
58 | overlaps[n, k] = iw * ih / ua
59 | return overlaps
60 |
61 |
62 | def bbox_intersections(
63 | np.ndarray[DTYPE_t, ndim=2] boxes,
64 | np.ndarray[DTYPE_t, ndim=2] query_boxes):
65 | return bbox_intersections_c(boxes, query_boxes)
66 |
67 |
68 | cdef np.ndarray[DTYPE_t, ndim=2] bbox_intersections_c(
69 | np.ndarray[DTYPE_t, ndim=2] boxes,
70 | np.ndarray[DTYPE_t, ndim=2] query_boxes):
71 | """
72 | For each query box compute the intersection ratio covered by boxes
73 | ----------
74 | Parameters
75 | ----------
76 | boxes: (N, 4) ndarray of float
77 | query_boxes: (K, 4) ndarray of float
78 | Returns
79 | -------
80 | overlaps: (N, K) ndarray of intersec between boxes and query_boxes
81 | """
82 | cdef unsigned int N = boxes.shape[0]
83 | cdef unsigned int K = query_boxes.shape[0]
84 | cdef np.ndarray[DTYPE_t, ndim=2] intersec = np.zeros((N, K), dtype=DTYPE)
85 | cdef DTYPE_t iw, ih, box_area
86 | cdef DTYPE_t ua
87 | cdef unsigned int k, n
88 | for k in range(K):
89 | box_area = (
90 | (query_boxes[k, 2] - query_boxes[k, 0] + 1) *
91 | (query_boxes[k, 3] - query_boxes[k, 1] + 1)
92 | )
93 | for n in range(N):
94 | iw = (
95 | min(boxes[n, 2], query_boxes[k, 2]) -
96 | max(boxes[n, 0], query_boxes[k, 0]) + 1
97 | )
98 | if iw > 0:
99 | ih = (
100 | min(boxes[n, 3], query_boxes[k, 3]) -
101 | max(boxes[n, 1], query_boxes[k, 1]) + 1
102 | )
103 | if ih > 0:
104 | intersec[n, k] = iw * ih / box_area
105 | return intersec
--------------------------------------------------------------------------------
/lib/model/utils/blob.py:
--------------------------------------------------------------------------------
1 | # --------------------------------------------------------
2 | # Fast R-CNN
3 | # Copyright (c) 2015 Microsoft
4 | # Licensed under The MIT License [see LICENSE for details]
5 | # Written by Ross Girshick
6 | # --------------------------------------------------------
7 |
8 | """Blob helper functions."""
9 |
10 | import numpy as np
11 | # from scipy.misc import imread, imresize
12 | import cv2
13 |
14 | try:
15 | xrange # Python 2
16 | except NameError:
17 | xrange = range # Python 3
18 |
19 |
20 | def im_list_to_blob(ims):
21 | """Convert a list of images into a network input.
22 |
23 | Assumes images are already prepared (means subtracted, BGR order, ...).
24 | """
25 | max_shape = np.array([im.shape for im in ims]).max(axis=0)
26 | num_images = len(ims)
27 | blob = np.zeros((num_images, max_shape[0], max_shape[1], 3),
28 | dtype=np.float32)
29 | for i in xrange(num_images):
30 | im = ims[i]
31 | blob[i, 0:im.shape[0], 0:im.shape[1], :] = im
32 |
33 | return blob
34 |
35 | def prep_im_for_blob(im, pixel_means, target_size, max_size):
36 | """Mean subtract and scale an image for use in a blob."""
37 |
38 | im = im.astype(np.float32, copy=False)
39 | im -= pixel_means
40 | # im = im[:, :, ::-1]
41 | im_shape = im.shape
42 | im_size_min = np.min(im_shape[0:2])
43 | im_size_max = np.max(im_shape[0:2])
44 | im_scale = float(target_size) / float(im_size_min)
45 | # Prevent the biggest axis from being more than MAX_SIZE
46 | # if np.round(im_scale * im_size_max) > max_size:
47 | # im_scale = float(max_size) / float(im_size_max)
48 | # im = imresize(im, im_scale)
49 | im = cv2.resize(im, None, None, fx=im_scale, fy=im_scale,
50 | interpolation=cv2.INTER_LINEAR)
51 |
52 | return im, im_scale
53 |
--------------------------------------------------------------------------------
/lib/model/utils/logger.py:
--------------------------------------------------------------------------------
1 | # Code referenced from https://gist.github.com/gyglim/1f8dfb1b5c82627ae3efcfbbadb9f514
2 | import tensorflow as tf
3 | import numpy as np
4 | import scipy.misc
5 | try:
6 | from StringIO import StringIO # Python 2.7
7 | except ImportError:
8 | from io import BytesIO # Python 3.x
9 |
10 |
11 | class Logger(object):
12 |
13 | def __init__(self, log_dir):
14 | """Create a summary writer logging to log_dir."""
15 | self.writer = tf.summary.FileWriter(log_dir)
16 |
17 | def scalar_summary(self, tag, value, step):
18 | """Log a scalar variable."""
19 | summary = tf.Summary(value=[tf.Summary.Value(tag=tag, simple_value=value)])
20 | self.writer.add_summary(summary, step)
21 |
22 | def image_summary(self, tag, images, step):
23 | """Log a list of images."""
24 |
25 | img_summaries = []
26 | for i, img in enumerate(images):
27 | # Write the image to a string
28 | try:
29 | s = StringIO()
30 | except:
31 | s = BytesIO()
32 | scipy.misc.toimage(img).save(s, format="png")
33 |
34 | # Create an Image object
35 | img_sum = tf.Summary.Image(encoded_image_string=s.getvalue(),
36 | height=img.shape[0],
37 | width=img.shape[1])
38 | # Create a Summary value
39 | img_summaries.append(tf.Summary.Value(tag='%s/%d' % (tag, i), image=img_sum))
40 |
41 | # Create and write Summary
42 | summary = tf.Summary(value=img_summaries)
43 | self.writer.add_summary(summary, step)
44 |
45 | def histo_summary(self, tag, values, step, bins=1000):
46 | """Log a histogram of the tensor of values."""
47 |
48 | # Create a histogram using numpy
49 | counts, bin_edges = np.histogram(values, bins=bins)
50 |
51 | # Fill the fields of the histogram proto
52 | hist = tf.HistogramProto()
53 | hist.min = float(np.min(values))
54 | hist.max = float(np.max(values))
55 | hist.num = int(np.prod(values.shape))
56 | hist.sum = float(np.sum(values))
57 | hist.sum_squares = float(np.sum(values**2))
58 |
59 | # Drop the start of the first bin
60 | bin_edges = bin_edges[1:]
61 |
62 | # Add bin edges and counts
63 | for edge in bin_edges:
64 | hist.bucket_limit.append(edge)
65 | for c in counts:
66 | hist.bucket.append(c)
67 |
68 | # Create and write Summary
69 | summary = tf.Summary(value=[tf.Summary.Value(tag=tag, histo=hist)])
70 | self.writer.add_summary(summary, step)
71 | self.writer.flush()
72 |
--------------------------------------------------------------------------------
/lib/model/utils/net_utils.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 | from torch.autograd import Variable
5 | import numpy as np
6 | import torchvision.models as models
7 | from model.utils.config import cfg
8 | from model.roi_crop.functions.roi_crop import RoICropFunction
9 | import cv2
10 | import pdb
11 | import random
12 |
13 | def save_net(fname, net):
14 | import h5py
15 | h5f = h5py.File(fname, mode='w')
16 | for k, v in net.state_dict().items():
17 | h5f.create_dataset(k, data=v.cpu().numpy())
18 |
19 | def load_net(fname, net):
20 | import h5py
21 | h5f = h5py.File(fname, mode='r')
22 | for k, v in net.state_dict().items():
23 | param = torch.from_numpy(np.asarray(h5f[k]))
24 | v.copy_(param)
25 |
26 | def weights_normal_init(model, dev=0.01):
27 | if isinstance(model, list):
28 | for m in model:
29 | weights_normal_init(m, dev)
30 | else:
31 | for m in model.modules():
32 | if isinstance(m, nn.Conv2d):
33 | m.weight.data.normal_(0.0, dev)
34 | elif isinstance(m, nn.Linear):
35 | m.weight.data.normal_(0.0, dev)
36 |
37 |
38 | def clip_gradient(model, clip_norm):
39 | """Computes a gradient clipping coefficient based on gradient norm."""
40 | totalnorm = 0
41 | for p in model.parameters():
42 | if p.requires_grad:
43 | modulenorm = p.grad.data.norm()
44 | totalnorm += modulenorm ** 2
45 | totalnorm = np.sqrt(totalnorm)
46 |
47 | norm = clip_norm / max(totalnorm, clip_norm)
48 | for p in model.parameters():
49 | if p.requires_grad:
50 | p.grad.mul_(norm)
51 |
52 | def vis_detections(im, class_name, dets, thresh=0.8):
53 | """Visual debugging of detections."""
54 | for i in range(np.minimum(10, dets.shape[0])):
55 | bbox = tuple(int(np.round(x)) for x in dets[i, :4])
56 | score = dets[i, -1]
57 | if score > thresh:
58 | cv2.rectangle(im, bbox[0:2], bbox[2:4], (0, 204, 0), 2)
59 | cv2.putText(im, '%s: %.3f' % (class_name, score), (bbox[0], bbox[1] + 15), cv2.FONT_HERSHEY_PLAIN,
60 | 1.0, (0, 0, 255), thickness=1)
61 | return im
62 |
63 |
64 | def adjust_learning_rate(optimizer, decay=0.1):
65 | """Sets the learning rate to the initial LR decayed by 0.5 every 20 epochs"""
66 | for param_group in optimizer.param_groups:
67 | param_group['lr'] = decay * param_group['lr']
68 |
69 |
70 | def save_checkpoint(state, filename):
71 | torch.save(state, filename)
72 |
73 | def _smooth_l1_loss(bbox_pred, bbox_targets, bbox_inside_weights, bbox_outside_weights, sigma=1.0, dim=[1]):
74 |
75 | sigma_2 = sigma ** 2
76 | box_diff = bbox_pred - bbox_targets
77 | in_box_diff = bbox_inside_weights * box_diff
78 | abs_in_box_diff = torch.abs(in_box_diff)
79 | smoothL1_sign = (abs_in_box_diff < 1. / sigma_2).detach().float()
80 | in_loss_box = torch.pow(in_box_diff, 2) * (sigma_2 / 2.) * smoothL1_sign \
81 | + (abs_in_box_diff - (0.5 / sigma_2)) * (1. - smoothL1_sign)
82 | out_loss_box = bbox_outside_weights * in_loss_box
83 | loss_box = out_loss_box
84 | for i in sorted(dim, reverse=True):
85 | loss_box = loss_box.sum(i)
86 | loss_box = loss_box.mean()
87 | return loss_box
88 |
89 | def _crop_pool_layer(bottom, rois, max_pool=True):
90 | # code modified from
91 | # https://github.com/ruotianluo/pytorch-faster-rcnn
92 | # implement it using stn
93 | # box to affine
94 | # input (x1,y1,x2,y2)
95 | """
96 | [ x2-x1 x1 + x2 - W + 1 ]
97 | [ ----- 0 --------------- ]
98 | [ W - 1 W - 1 ]
99 | [ ]
100 | [ y2-y1 y1 + y2 - H + 1 ]
101 | [ 0 ----- --------------- ]
102 | [ H - 1 H - 1 ]
103 | """
104 | rois = rois.detach()
105 | batch_size = bottom.size(0)
106 | D = bottom.size(1)
107 | H = bottom.size(2)
108 | W = bottom.size(3)
109 | roi_per_batch = rois.size(0) / batch_size
110 | x1 = rois[:, 1::4] / 16.0
111 | y1 = rois[:, 2::4] / 16.0
112 | x2 = rois[:, 3::4] / 16.0
113 | y2 = rois[:, 4::4] / 16.0
114 |
115 | height = bottom.size(2)
116 | width = bottom.size(3)
117 |
118 | # affine theta
119 | zero = Variable(rois.data.new(rois.size(0), 1).zero_())
120 | theta = torch.cat([\
121 | (x2 - x1) / (width - 1),
122 | zero,
123 | (x1 + x2 - width + 1) / (width - 1),
124 | zero,
125 | (y2 - y1) / (height - 1),
126 | (y1 + y2 - height + 1) / (height - 1)], 1).view(-1, 2, 3)
127 |
128 | if max_pool:
129 | pre_pool_size = cfg.POOLING_SIZE * 2
130 | grid = F.affine_grid(theta, torch.Size((rois.size(0), 1, pre_pool_size, pre_pool_size)))
131 | bottom = bottom.view(1, batch_size, D, H, W).contiguous().expand(roi_per_batch, batch_size, D, H, W)\
132 | .contiguous().view(-1, D, H, W)
133 | crops = F.grid_sample(bottom, grid)
134 | crops = F.max_pool2d(crops, 2, 2)
135 | else:
136 | grid = F.affine_grid(theta, torch.Size((rois.size(0), 1, cfg.POOLING_SIZE, cfg.POOLING_SIZE)))
137 | bottom = bottom.view(1, batch_size, D, H, W).contiguous().expand(roi_per_batch, batch_size, D, H, W)\
138 | .contiguous().view(-1, D, H, W)
139 | crops = F.grid_sample(bottom, grid)
140 |
141 | return crops, grid
142 |
143 | def _affine_grid_gen(rois, input_size, grid_size):
144 |
145 | rois = rois.detach()
146 | x1 = rois[:, 1::4] / 16.0
147 | y1 = rois[:, 2::4] / 16.0
148 | x2 = rois[:, 3::4] / 16.0
149 | y2 = rois[:, 4::4] / 16.0
150 |
151 | height = input_size[0]
152 | width = input_size[1]
153 |
154 | zero = Variable(rois.data.new(rois.size(0), 1).zero_())
155 | theta = torch.cat([\
156 | (x2 - x1) / (width - 1),
157 | zero,
158 | (x1 + x2 - width + 1) / (width - 1),
159 | zero,
160 | (y2 - y1) / (height - 1),
161 | (y1 + y2 - height + 1) / (height - 1)], 1).view(-1, 2, 3)
162 |
163 | grid = F.affine_grid(theta, torch.Size((rois.size(0), 1, grid_size, grid_size)))
164 |
165 | return grid
166 |
167 | def _affine_theta(rois, input_size):
168 |
169 | rois = rois.detach()
170 | x1 = rois[:, 1::4] / 16.0
171 | y1 = rois[:, 2::4] / 16.0
172 | x2 = rois[:, 3::4] / 16.0
173 | y2 = rois[:, 4::4] / 16.0
174 |
175 | height = input_size[0]
176 | width = input_size[1]
177 |
178 | zero = Variable(rois.data.new(rois.size(0), 1).zero_())
179 |
180 | # theta = torch.cat([\
181 | # (x2 - x1) / (width - 1),
182 | # zero,
183 | # (x1 + x2 - width + 1) / (width - 1),
184 | # zero,
185 | # (y2 - y1) / (height - 1),
186 | # (y1 + y2 - height + 1) / (height - 1)], 1).view(-1, 2, 3)
187 |
188 | theta = torch.cat([\
189 | (y2 - y1) / (height - 1),
190 | zero,
191 | (y1 + y2 - height + 1) / (height - 1),
192 | zero,
193 | (x2 - x1) / (width - 1),
194 | (x1 + x2 - width + 1) / (width - 1)], 1).view(-1, 2, 3)
195 |
196 | return theta
197 |
198 | def compare_grid_sample():
199 | # do gradcheck
200 | N = random.randint(1, 8)
201 | C = 2 # random.randint(1, 8)
202 | H = 5 # random.randint(1, 8)
203 | W = 4 # random.randint(1, 8)
204 | input = Variable(torch.randn(N, C, H, W).cuda(), requires_grad=True)
205 | input_p = input.clone().data.contiguous()
206 |
207 | grid = Variable(torch.randn(N, H, W, 2).cuda(), requires_grad=True)
208 | grid_clone = grid.clone().contiguous()
209 |
210 | out_offcial = F.grid_sample(input, grid)
211 | grad_outputs = Variable(torch.rand(out_offcial.size()).cuda())
212 | grad_outputs_clone = grad_outputs.clone().contiguous()
213 | grad_inputs = torch.autograd.grad(out_offcial, (input, grid), grad_outputs.contiguous())
214 | grad_input_off = grad_inputs[0]
215 |
216 |
217 | crf = RoICropFunction()
218 | grid_yx = torch.stack([grid_clone.data[:,:,:,1], grid_clone.data[:,:,:,0]], 3).contiguous().cuda()
219 | out_stn = crf.forward(input_p, grid_yx)
220 | grad_inputs = crf.backward(grad_outputs_clone.data)
221 | grad_input_stn = grad_inputs[0]
222 | pdb.set_trace()
223 |
224 | delta = (grad_input_off.data - grad_input_stn).sum()
225 |
--------------------------------------------------------------------------------
/lib/pycocotools/UPSTREAM_REV:
--------------------------------------------------------------------------------
1 | https://github.com/pdollar/coco/commit/3ac47c77ebd5a1ed4254a98b7fbf2ef4765a3574
2 |
--------------------------------------------------------------------------------
/lib/pycocotools/__init__.py:
--------------------------------------------------------------------------------
1 | __author__ = 'tylin'
2 |
--------------------------------------------------------------------------------
/lib/pycocotools/license.txt:
--------------------------------------------------------------------------------
1 | Copyright (c) 2014, Piotr Dollar and Tsung-Yi Lin
2 | All rights reserved.
3 |
4 | Redistribution and use in source and binary forms, with or without
5 | modification, are permitted provided that the following conditions are met:
6 |
7 | 1. Redistributions of source code must retain the above copyright notice, this
8 | list of conditions and the following disclaimer.
9 | 2. Redistributions in binary form must reproduce the above copyright notice,
10 | this list of conditions and the following disclaimer in the documentation
11 | and/or other materials provided with the distribution.
12 |
13 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
14 | ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
15 | WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
16 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR
17 | ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
18 | (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
19 | LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
20 | ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
21 | (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
22 | SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
23 |
24 | The views and conclusions contained in the software and documentation are those
25 | of the authors and should not be interpreted as representing official policies,
26 | either expressed or implied, of the FreeBSD Project.
27 |
--------------------------------------------------------------------------------
/lib/pycocotools/mask.py:
--------------------------------------------------------------------------------
1 | __author__ = 'tsungyi'
2 |
3 | from . import _mask
4 |
5 | # Interface for manipulating masks stored in RLE format.
6 | #
7 | # RLE is a simple yet efficient format for storing binary masks. RLE
8 | # first divides a vector (or vectorized image) into a series of piecewise
9 | # constant regions and then for each piece simply stores the length of
10 | # that piece. For example, given M=[0 0 1 1 1 0 1] the RLE counts would
11 | # be [2 3 1 1], or for M=[1 1 1 1 1 1 0] the counts would be [0 6 1]
12 | # (note that the odd counts are always the numbers of zeros). Instead of
13 | # storing the counts directly, additional compression is achieved with a
14 | # variable bitrate representation based on a common scheme called LEB128.
15 | #
16 | # Compression is greatest given large piecewise constant regions.
17 | # Specifically, the size of the RLE is proportional to the number of
18 | # *boundaries* in M (or for an image the number of boundaries in the y
19 | # direction). Assuming fairly simple shapes, the RLE representation is
20 | # O(sqrt(n)) where n is number of pixels in the object. Hence space usage
21 | # is substantially lower, especially for large simple objects (large n).
22 | #
23 | # Many common operations on masks can be computed directly using the RLE
24 | # (without need for decoding). This includes computations such as area,
25 | # union, intersection, etc. All of these operations are linear in the
26 | # size of the RLE, in other words they are O(sqrt(n)) where n is the area
27 | # of the object. Computing these operations on the original mask is O(n).
28 | # Thus, using the RLE can result in substantial computational savings.
29 | #
30 | # The following API functions are defined:
31 | # encode - Encode binary masks using RLE.
32 | # decode - Decode binary masks encoded via RLE.
33 | # merge - Compute union or intersection of encoded masks.
34 | # iou - Compute intersection over union between masks.
35 | # area - Compute area of encoded masks.
36 | # toBbox - Get bounding boxes surrounding encoded masks.
37 | # frPyObjects - Convert polygon, bbox, and uncompressed RLE to encoded RLE mask.
38 | #
39 | # Usage:
40 | # Rs = encode( masks )
41 | # masks = decode( Rs )
42 | # R = merge( Rs, intersect=false )
43 | # o = iou( dt, gt, iscrowd )
44 | # a = area( Rs )
45 | # bbs = toBbox( Rs )
46 | # Rs = frPyObjects( [pyObjects], h, w )
47 | #
48 | # In the API the following formats are used:
49 | # Rs - [dict] Run-length encoding of binary masks
50 | # R - dict Run-length encoding of binary mask
51 | # masks - [hxwxn] Binary mask(s) (must have type np.ndarray(dtype=uint8) in column-major order)
52 | # iscrowd - [nx1] list of np.ndarray. 1 indicates corresponding gt image has crowd region to ignore
53 | # bbs - [nx4] Bounding box(es) stored as [x y w h]
54 | # poly - Polygon stored as [[x1 y1 x2 y2...],[x1 y1 ...],...] (2D list)
55 | # dt,gt - May be either bounding boxes or encoded masks
56 | # Both poly and bbs are 0-indexed (bbox=[0 0 1 1] encloses first pixel).
57 | #
58 | # Finally, a note about the intersection over union (iou) computation.
59 | # The standard iou of a ground truth (gt) and detected (dt) object is
60 | # iou(gt,dt) = area(intersect(gt,dt)) / area(union(gt,dt))
61 | # For "crowd" regions, we use a modified criteria. If a gt object is
62 | # marked as "iscrowd", we allow a dt to match any subregion of the gt.
63 | # Choosing gt' in the crowd gt that best matches the dt can be done using
64 | # gt'=intersect(dt,gt). Since by definition union(gt',dt)=dt, computing
65 | # iou(gt,dt,iscrowd) = iou(gt',dt) = area(intersect(gt,dt)) / area(dt)
66 | # For crowd gt regions we use this modified criteria above for the iou.
67 | #
68 | # To compile run "python setup.py build_ext --inplace"
69 | # Please do not contact us for help with compiling.
70 | #
71 | # Microsoft COCO Toolbox. version 2.0
72 | # Data, paper, and tutorials available at: http://mscoco.org/
73 | # Code written by Piotr Dollar and Tsung-Yi Lin, 2015.
74 | # Licensed under the Simplified BSD License [see coco/license.txt]
75 |
76 | encode = _mask.encode
77 | decode = _mask.decode
78 | iou = _mask.iou
79 | merge = _mask.merge
80 | area = _mask.area
81 | toBbox = _mask.toBbox
82 | frPyObjects = _mask.frPyObjects
--------------------------------------------------------------------------------
/lib/pycocotools/maskApi.c:
--------------------------------------------------------------------------------
1 | /**************************************************************************
2 | * Microsoft COCO Toolbox. version 2.0
3 | * Data, paper, and tutorials available at: http://mscoco.org/
4 | * Code written by Piotr Dollar and Tsung-Yi Lin, 2015.
5 | * Licensed under the Simplified BSD License [see coco/license.txt]
6 | **************************************************************************/
7 | #include "maskApi.h"
8 | #include
9 | #include
10 |
11 | uint umin( uint a, uint b ) { return (ab) ? a : b; }
13 |
14 | void rleInit( RLE *R, siz h, siz w, siz m, uint *cnts ) {
15 | R->h=h; R->w=w; R->m=m; R->cnts=(m==0)?0:malloc(sizeof(uint)*m);
16 | if(cnts) for(siz j=0; jcnts[j]=cnts[j];
17 | }
18 |
19 | void rleFree( RLE *R ) {
20 | free(R->cnts); R->cnts=0;
21 | }
22 |
23 | void rlesInit( RLE **R, siz n ) {
24 | *R = (RLE*) malloc(sizeof(RLE)*n);
25 | for(siz i=0; i0 ) {
61 | c=umin(ca,cb); cc+=c; ct=0;
62 | ca-=c; if(!ca && a0) {
83 | crowd=iscrowd!=NULL && iscrowd[g];
84 | if(dt[d].h!=gt[g].h || dt[d].w!=gt[g].w) { o[g*m+d]=-1; continue; }
85 | siz ka, kb, a, b; uint c, ca, cb, ct, i, u; bool va, vb;
86 | ca=dt[d].cnts[0]; ka=dt[d].m; va=vb=0;
87 | cb=gt[g].cnts[0]; kb=gt[g].m; a=b=1; i=u=0; ct=1;
88 | while( ct>0 ) {
89 | c=umin(ca,cb); if(va||vb) { u+=c; if(va&&vb) i+=c; } ct=0;
90 | ca-=c; if(!ca && ad?1:c=dy && xs>xe) || (dxye);
151 | if(flip) { t=xs; xs=xe; xe=t; t=ys; ys=ye; ye=t; }
152 | s = dx>=dy ? (double)(ye-ys)/dx : (double)(xe-xs)/dy;
153 | if(dx>=dy) for( int d=0; d<=dx; d++ ) {
154 | t=flip?dx-d:d; u[m]=t+xs; v[m]=(int)(ys+s*t+.5); m++;
155 | } else for( int d=0; d<=dy; d++ ) {
156 | t=flip?dy-d:d; v[m]=t+ys; u[m]=(int)(xs+s*t+.5); m++;
157 | }
158 | }
159 | // get points along y-boundary and downsample
160 | free(x); free(y); k=m; m=0; double xd, yd;
161 | x=malloc(sizeof(int)*k); y=malloc(sizeof(int)*k);
162 | for( j=1; jw-1 ) continue;
165 | yd=(double)(v[j]h) yd=h; yd=ceil(yd);
167 | x[m]=(int) xd; y[m]=(int) yd; m++;
168 | }
169 | // compute rle encoding given y-boundary points
170 | k=m; a=malloc(sizeof(uint)*(k+1));
171 | for( j=0; j0) b[m++]=a[j++]; else {
177 | j++; if(jm, p=0; long x; bool more;
184 | char *s=malloc(sizeof(char)*m*6);
185 | for( i=0; icnts[i]; if(i>2) x-=(long) R->cnts[i-2]; more=1;
187 | while( more ) {
188 | char c=x & 0x1f; x >>= 5; more=(c & 0x10) ? x!=-1 : x!=0;
189 | if(more) c |= 0x20; c+=48; s[p++]=c;
190 | }
191 | }
192 | s[p]=0; return s;
193 | }
194 |
195 | void rleFrString( RLE *R, char *s, siz h, siz w ) {
196 | siz m=0, p=0, k; long x; bool more; uint *cnts;
197 | while( s[m] ) m++; cnts=malloc(sizeof(uint)*m); m=0;
198 | while( s[p] ) {
199 | x=0; k=0; more=1;
200 | while( more ) {
201 | char c=s[p]-48; x |= (c & 0x1f) << 5*k;
202 | more = c & 0x20; p++; k++;
203 | if(!more && (c & 0x10)) x |= -1 << 5*k;
204 | }
205 | if(m>2) x+=(long) cnts[m-2]; cnts[m++]=(uint) x;
206 | }
207 | rleInit(R,h,w,m,cnts); free(cnts);
208 | }
209 |
--------------------------------------------------------------------------------
/lib/pycocotools/maskApi.h:
--------------------------------------------------------------------------------
1 | /**************************************************************************
2 | * Microsoft COCO Toolbox. version 2.0
3 | * Data, paper, and tutorials available at: http://mscoco.org/
4 | * Code written by Piotr Dollar and Tsung-Yi Lin, 2015.
5 | * Licensed under the Simplified BSD License [see coco/license.txt]
6 | **************************************************************************/
7 | #pragma once
8 | #include
9 |
10 | typedef unsigned int uint;
11 | typedef unsigned long siz;
12 | typedef unsigned char byte;
13 | typedef double* BB;
14 | typedef struct { siz h, w, m; uint *cnts; } RLE;
15 |
16 | // Initialize/destroy RLE.
17 | void rleInit( RLE *R, siz h, siz w, siz m, uint *cnts );
18 | void rleFree( RLE *R );
19 |
20 | // Initialize/destroy RLE array.
21 | void rlesInit( RLE **R, siz n );
22 | void rlesFree( RLE **R, siz n );
23 |
24 | // Encode binary masks using RLE.
25 | void rleEncode( RLE *R, const byte *mask, siz h, siz w, siz n );
26 |
27 | // Decode binary masks encoded via RLE.
28 | void rleDecode( const RLE *R, byte *mask, siz n );
29 |
30 | // Compute union or intersection of encoded masks.
31 | void rleMerge( const RLE *R, RLE *M, siz n, bool intersect );
32 |
33 | // Compute area of encoded masks.
34 | void rleArea( const RLE *R, siz n, uint *a );
35 |
36 | // Compute intersection over union between masks.
37 | void rleIou( RLE *dt, RLE *gt, siz m, siz n, byte *iscrowd, double *o );
38 |
39 | // Compute intersection over union between bounding boxes.
40 | void bbIou( BB dt, BB gt, siz m, siz n, byte *iscrowd, double *o );
41 |
42 | // Get bounding boxes surrounding encoded masks.
43 | void rleToBbox( const RLE *R, BB bb, siz n );
44 |
45 | // Convert bounding boxes to encoded masks.
46 | void rleFrBbox( RLE *R, const BB bb, siz h, siz w, siz n );
47 |
48 | // Convert polygon to encoded mask.
49 | void rleFrPoly( RLE *R, const double *xy, siz k, siz h, siz w );
50 |
51 | // Get compressed string representation of encoded mask.
52 | char* rleToString( const RLE *R );
53 |
54 | // Convert from compressed string representation of encoded mask.
55 | void rleFrString( RLE *R, char *s, siz h, siz w );
56 |
--------------------------------------------------------------------------------
/lib/roi_data_layer/__init__.py:
--------------------------------------------------------------------------------
1 | # --------------------------------------------------------
2 | # Fast R-CNN
3 | # Copyright (c) 2015 Microsoft
4 | # Licensed under The MIT License [see LICENSE for details]
5 | # Written by Ross Girshick
6 | # --------------------------------------------------------
7 |
--------------------------------------------------------------------------------
/lib/roi_data_layer/minibatch.py:
--------------------------------------------------------------------------------
1 | # --------------------------------------------------------
2 | # Fast R-CNN
3 | # Copyright (c) 2015 Microsoft
4 | # Licensed under The MIT License [see LICENSE for details]
5 | # Written by Ross Girshick and Xinlei Chen
6 | # --------------------------------------------------------
7 |
8 | """Compute minibatch blobs for training a Fast R-CNN network."""
9 | from __future__ import absolute_import
10 | from __future__ import division
11 | from __future__ import print_function
12 |
13 | import numpy as np
14 | import numpy.random as npr
15 | from scipy.misc import imread
16 | from model.utils.config import cfg
17 | from model.utils.blob import prep_im_for_blob, im_list_to_blob
18 | import pdb
19 |
20 | def get_minibatch(roidb, num_classes, target_size):
21 | """Given a roidb, construct a minibatch sampled from it."""
22 | num_images = len(roidb)
23 | # Sample random scales to use for each image in this batch
24 | assert(cfg.TRAIN.BATCH_SIZE % num_images == 0), \
25 | 'num_images ({}) must divide BATCH_SIZE ({})'. \
26 | format(num_images, cfg.TRAIN.BATCH_SIZE)
27 |
28 | # Get the input image blob, formatted for caffe
29 | im_blob, im_scales = _get_image_blob(roidb, target_size)
30 |
31 | blobs = {'data': im_blob}
32 |
33 | assert len(im_scales) == 1, "Single batch only"
34 | assert len(roidb) == 1, "Single batch only"
35 |
36 | # gt boxes: (x1, y1, x2, y2, cls)
37 | if cfg.TRAIN.USE_ALL_GT:
38 | # Include all ground truth boxes
39 | gt_inds = np.where(roidb[0]['gt_classes'] != 0)[0]
40 | else:
41 | # For the COCO ground truth boxes, exclude the ones that are ''iscrowd''
42 | gt_inds = np.where((roidb[0]['gt_classes'] != 0) & np.all(roidb[0]['gt_overlaps'].toarray() > -1.0, axis=1))[0]
43 | gt_boxes = np.empty((len(gt_inds), 5), dtype=np.float32)
44 | gt_boxes[:, 0:4] = roidb[0]['boxes'][gt_inds, :] * im_scales[0]
45 | gt_boxes[:, 4] = roidb[0]['gt_classes'][gt_inds]
46 | blobs['gt_boxes'] = gt_boxes
47 | blobs['im_info'] = np.array(
48 | [[im_blob.shape[1], im_blob.shape[2], im_scales[0]]],
49 | dtype=np.float32)
50 |
51 | blobs['img_id'] = roidb[0]['img_id']
52 |
53 | return blobs
54 |
55 | def _get_image_blob(roidb, target_size):
56 | """Builds an input blob from the images in the roidb at the specified
57 | scales.
58 | """
59 | num_images = len(roidb)
60 |
61 | processed_ims = []
62 | im_scales = []
63 | for i in range(num_images):
64 | #im = cv2.imread(roidb[i]['image'])
65 | im = imread(roidb[i]['image'])
66 |
67 | if len(im.shape) == 2:
68 | im = im[:,:,np.newaxis]
69 | im = np.concatenate((im,im,im), axis=2)
70 | # flip the channel, since the original one using cv2
71 | # rgb -> bgr
72 | im = im[:,:,::-1]
73 |
74 | if roidb[i]['flipped']:
75 | im = im[:, ::-1, :]
76 | im, im_scale = prep_im_for_blob(im, cfg.PIXEL_MEANS, target_size[i],
77 | cfg.TRAIN.MAX_SIZE)
78 | im_scales.append(im_scale)
79 | processed_ims.append(im)
80 |
81 | # Create a blob to hold the input images
82 | blob = im_list_to_blob(processed_ims)
83 |
84 | return blob, im_scales
85 |
--------------------------------------------------------------------------------
/lib/roi_data_layer/roidb.py:
--------------------------------------------------------------------------------
1 | """Transform a roidb into a trainable roidb by adding a bunch of metadata."""
2 | from __future__ import absolute_import
3 | from __future__ import division
4 | from __future__ import print_function
5 |
6 | import datasets
7 | import numpy as np
8 | from model.utils.config import cfg
9 | from datasets.factory import get_imdb
10 | import PIL
11 | import pdb
12 |
13 | def prepare_roidb(imdb):
14 | """Enrich the imdb's roidb by adding some derived quantities that
15 | are useful for training. This function precomputes the maximum
16 | overlap, taken over ground-truth boxes, between each ROI and
17 | each ground-truth box. The class with maximum overlap is also
18 | recorded.
19 | """
20 |
21 | roidb = imdb.roidb
22 | if not (imdb.name.startswith('coco')):
23 | sizes = [PIL.Image.open(imdb.image_path_at(i)).size
24 | for i in range(imdb.num_images)]
25 |
26 | for i in range(len(imdb.image_index)):
27 | roidb[i]['img_id'] = imdb.image_id_at(i)
28 | roidb[i]['image'] = imdb.image_path_at(i)
29 | if not (imdb.name.startswith('coco')):
30 | roidb[i]['width'] = sizes[i][0]
31 | roidb[i]['height'] = sizes[i][1]
32 | # need gt_overlaps as a dense array for argmax
33 | gt_overlaps = roidb[i]['gt_overlaps'].toarray()
34 | # max overlap with gt over classes (columns)
35 | max_overlaps = gt_overlaps.max(axis=1)
36 | # gt class that had the max overlap
37 | max_classes = gt_overlaps.argmax(axis=1)
38 | roidb[i]['max_classes'] = max_classes
39 | roidb[i]['max_overlaps'] = max_overlaps
40 | # sanity checks
41 | # max overlap of 0 => class should be zero (background)
42 | zero_inds = np.where(max_overlaps == 0)[0]
43 | assert all(max_classes[zero_inds] == 0)
44 | # max overlap > 0 => class should not be zero (must be a fg class)
45 | nonzero_inds = np.where(max_overlaps > 0)[0]
46 | assert all(max_classes[nonzero_inds] != 0)
47 |
48 |
49 | def rank_roidb_ratio(roidb):
50 | # rank roidb based on the ratio between width and height.
51 | ratio_large = 2 # largest ratio to preserve.
52 | ratio_small = 0.5 # smallest ratio to preserve.
53 |
54 | ratio_list = []
55 | for i in range(len(roidb)):
56 | width = roidb[i]['width']
57 | height = roidb[i]['height']
58 | ratio = width / float(height)
59 |
60 | if ratio > ratio_large:
61 | roidb[i]['need_crop'] = 1
62 | ratio = ratio_large
63 | elif ratio < ratio_small:
64 | roidb[i]['need_crop'] = 1
65 | ratio = ratio_small
66 | else:
67 | roidb[i]['need_crop'] = 0
68 |
69 | ratio_list.append(ratio)
70 |
71 | ratio_list = np.array(ratio_list)
72 | ratio_index = np.argsort(ratio_list)
73 | return ratio_list[ratio_index], ratio_index
74 |
75 | def filter_roidb(roidb):
76 | # filter the image without bounding box.
77 | print('before filtering, there are %d images...' % (len(roidb)))
78 | i = 0
79 | while i < len(roidb):
80 | if len(roidb[i]['boxes']) == 0:
81 | del roidb[i]
82 | i -= 1
83 | i += 1
84 |
85 | print('after filtering, there are %d images...' % (len(roidb)))
86 | return roidb
87 |
88 | def combined_roidb(imdb_names, training=True):
89 | """
90 | Combine multiple roidbs
91 | """
92 |
93 | def get_training_roidb(imdb):
94 | """Returns a roidb (Region of Interest database) for use in training."""
95 | if cfg.TRAIN.USE_FLIPPED:
96 | print('Appending horizontally-flipped training examples...')
97 | imdb.append_flipped_images()
98 | print('done')
99 |
100 | print('Preparing training data...')
101 |
102 | prepare_roidb(imdb)
103 | #ratio_index = rank_roidb_ratio(imdb)
104 | print('done')
105 |
106 | return imdb.roidb
107 |
108 | def get_roidb(imdb_name):
109 | imdb = get_imdb(imdb_name)
110 | print('Loaded dataset `{:s}` for training'.format(imdb.name))
111 | imdb.set_proposal_method(cfg.TRAIN.PROPOSAL_METHOD)
112 | print('Set proposal method: {:s}'.format(cfg.TRAIN.PROPOSAL_METHOD))
113 | roidb = get_training_roidb(imdb)
114 | return roidb
115 |
116 | roidbs = [get_roidb(s) for s in imdb_names.split('+')]
117 | roidb = roidbs[0]
118 |
119 | if len(roidbs) > 1:
120 | for r in roidbs[1:]:
121 | roidb.extend(r)
122 | tmp = get_imdb(imdb_names.split('+')[1])
123 | imdb = datasets.imdb.imdb(imdb_names, tmp.classes)
124 | else:
125 | imdb = get_imdb(imdb_names)
126 |
127 | if training:
128 | roidb = filter_roidb(roidb)
129 |
130 | ratio_list, ratio_index = rank_roidb_ratio(roidb)
131 |
132 | return imdb, roidb, ratio_list, ratio_index
133 |
--------------------------------------------------------------------------------
/lib/setup.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 | # --------------------------------------------------------
3 | # Fast R-CNN
4 | # Copyright (c) 2015 Microsoft
5 | # Licensed under The MIT License [see LICENSE for details]
6 | # Written by Ross Girshick
7 | # --------------------------------------------------------
8 |
9 | import os
10 | from os.path import join as pjoin
11 | import numpy as np
12 | from distutils.core import setup
13 | from distutils.extension import Extension
14 | from Cython.Distutils import build_ext
15 |
16 |
17 | def find_in_path(name, path):
18 | "Find a file in a search path"
19 | # adapted fom http://code.activestate.com/recipes/52224-find-a-file-given-a-search-path/
20 | for dir in path.split(os.pathsep):
21 | binpath = pjoin(dir, name)
22 | if os.path.exists(binpath):
23 | return os.path.abspath(binpath)
24 | return None
25 |
26 |
27 | # def locate_cuda():
28 | # """Locate the CUDA environment on the system
29 | #
30 | # Returns a dict with keys 'home', 'nvcc', 'include', and 'lib64'
31 | # and values giving the absolute path to each directory.
32 | #
33 | # Starts by looking for the CUDAHOME env variable. If not found, everything
34 | # is based on finding 'nvcc' in the PATH.
35 | # """
36 | #
37 | # # first check if the CUDAHOME env variable is in use
38 | # if 'CUDAHOME' in os.environ:
39 | # home = os.environ['CUDAHOME']
40 | # nvcc = pjoin(home, 'bin', 'nvcc')
41 | # else:
42 | # # otherwise, search the PATH for NVCC
43 | # default_path = pjoin(os.sep, 'usr', 'local', 'cuda', 'bin')
44 | # nvcc = find_in_path('nvcc', os.environ['PATH'] + os.pathsep + default_path)
45 | # if nvcc is None:
46 | # raise EnvironmentError('The nvcc binary could not be '
47 | # 'located in your $PATH. Either add it to your path, or set $CUDAHOME')
48 | # home = os.path.dirname(os.path.dirname(nvcc))
49 | #
50 | # cudaconfig = {'home': home, 'nvcc': nvcc,
51 | # 'include': pjoin(home, 'include'),
52 | # 'lib64': pjoin(home, 'lib64')}
53 | # for k, v in cudaconfig.iteritems():
54 | # if not os.path.exists(v):
55 | # raise EnvironmentError('The CUDA %s path could not be located in %s' % (k, v))
56 | #
57 | # return cudaconfig
58 |
59 |
60 | # CUDA = locate_cuda()
61 |
62 | # Obtain the numpy include directory. This logic works across numpy versions.
63 | try:
64 | numpy_include = np.get_include()
65 | except AttributeError:
66 | numpy_include = np.get_numpy_include()
67 |
68 |
69 | def customize_compiler_for_nvcc(self):
70 | """inject deep into distutils to customize how the dispatch
71 | to gcc/nvcc works.
72 |
73 | If you subclass UnixCCompiler, it's not trivial to get your subclass
74 | injected in, and still have the right customizations (i.e.
75 | distutils.sysconfig.customize_compiler) run on it. So instead of going
76 | the OO route, I have this. Note, it's kindof like a wierd functional
77 | subclassing going on."""
78 |
79 | # tell the compiler it can processes .cu
80 | self.src_extensions.append('.cu')
81 |
82 | # save references to the default compiler_so and _comple methods
83 | default_compiler_so = self.compiler_so
84 | super = self._compile
85 |
86 | # now redefine the _compile method. This gets executed for each
87 | # object but distutils doesn't have the ability to change compilers
88 | # based on source extension: we add it.
89 | def _compile(obj, src, ext, cc_args, extra_postargs, pp_opts):
90 | print(extra_postargs)
91 | if os.path.splitext(src)[1] == '.cu':
92 | # use the cuda for .cu files
93 | self.set_executable('compiler_so', CUDA['nvcc'])
94 | # use only a subset of the extra_postargs, which are 1-1 translated
95 | # from the extra_compile_args in the Extension class
96 | postargs = extra_postargs['nvcc']
97 | else:
98 | postargs = extra_postargs['gcc']
99 |
100 | super(obj, src, ext, cc_args, postargs, pp_opts)
101 | # reset the default compiler_so, which we might have changed for cuda
102 | self.compiler_so = default_compiler_so
103 |
104 | # inject our redefined _compile method into the class
105 | self._compile = _compile
106 |
107 |
108 | # run the customize_compiler
109 | class custom_build_ext(build_ext):
110 | def build_extensions(self):
111 | customize_compiler_for_nvcc(self.compiler)
112 | build_ext.build_extensions(self)
113 |
114 |
115 | ext_modules = [
116 | Extension(
117 | "model.utils.cython_bbox",
118 | ["model/utils/bbox.pyx"],
119 | extra_compile_args={'gcc': ["-Wno-cpp", "-Wno-unused-function"]},
120 | include_dirs=[numpy_include]
121 | ),
122 | Extension(
123 | 'pycocotools._mask',
124 | sources=['pycocotools/maskApi.c', 'pycocotools/_mask.pyx'],
125 | include_dirs=[numpy_include, 'pycocotools'],
126 | extra_compile_args={
127 | 'gcc': ['-Wno-cpp', '-Wno-unused-function', '-std=c99']},
128 | ),
129 | ]
130 |
131 | setup(
132 | name='faster_rcnn',
133 | ext_modules=ext_modules,
134 | # inject our custom trigger
135 | cmdclass={'build_ext': custom_build_ext},
136 | )
137 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | cython
2 | cffi
3 | opencv-python
4 | scipy
5 | easydict
6 | matplotlib
7 | pyyaml
8 |
--------------------------------------------------------------------------------
| |