├── .gitignore
├── Makefile
├── README.md
├── SUMMARY.md
├── awesome-system-design.md
├── drafts
├── fintech-sd-work-in-progress.md
├── ideas.md
└── three-basic-topics.md
├── en
├── 11-three-programming-paradigms.md
├── 12-solid-design-principles.md
├── 120-designing-uber.md
├── 121-designing-facebook-photo-storage.md
├── 122-key-value-cache.md
├── 123-ios-architecture-patterns-revisited.md
├── 136-fraud-detection-with-semi-supervised-learning.md
├── 137-stream-and-batch-processing.md
├── 140-designing-a-recommendation-system.md
├── 145-introduction-to-architecture.md
├── 161-designing-stock-exchange.md
├── 162-designing-smart-notification-of-stock-price-changes.md
├── 166-designing-payment-webhook.md
├── 167-designing-paypal-money-transfer.md
├── 168-designing-a-metric-system.md
├── 169-how-to-write-solid-code.md
├── 174-designing-memcached.md
├── 177-designing-Airbnb-or-a-hotel-booking-system.md
├── 178-lyft-marketing-automation-symphony.md
├── 179-designing-typeahead-search-or-autocomplete.md
├── 181-concurrency-models.md
├── 182-designing-l7-load-balancer.md
├── 2016-02-13-crack-the-system-design-interview.md
├── 2018-07-10-cloud-design-patterns.md
├── 2018-07-20-experience-deep-dive.md
├── 2018-07-21-data-partition-and-routing.md
├── 2018-07-22-b-tree-vs-b-plus-tree.md
├── 2018-07-23-load-balancer-types.md
├── 2018-07-24-replica-and-consistency.md
├── 2018-07-26-acid-vs-base.md
├── 38-how-to-stream-video-over-http.md
├── 41-how-to-scale-a-web-service.md
├── 43-how-to-design-robust-and-predictable-apis-with-idempotency.md
├── 45-how-to-design-netflix-view-state-service.md
├── 49-facebook-tao.md
├── 61-what-is-apache-kafka.md
├── 63-soft-skills-interview.md
├── 66-public-api-choices.md
├── 68-bloom-filter.md
├── 69-skiplist.md
├── 78-four-kinds-of-no-sql.md
├── 80-relational-database.md
├── 83-lambda-architecture.md
├── 84-designing-a-url-shortener.md
├── 85-improving-availability-with-failover.md
└── 97-designing-a-kv-store-with-external-storage.md
└── zh-CN
├── 11-three-programming-paradigms.md
├── 12-solid-design-principles.md
├── 120-designing-uber.md
├── 121-designing-facebook-photo-storage.md
├── 122-key-value-cache.md
├── 123-ios-architecture-patterns-revisited.md
├── 136-fraud-detection-with-semi-supervised-learning.md
├── 137-stream-and-batch-processing.md
├── 140-designing-a-recommendation-system.md
├── 145-introduction-to-architecture.md
├── 161-designing-stock-exchange.md
├── 162-designing-smart-notification-of-stock-price-changes.md
├── 166-designing-payment-webhook.md
├── 167-designing-paypal-money-transfer.md
├── 168-designing-a-metric-system.md
├── 169-how-to-write-solid-code.md
├── 174-designing-memcached.md
├── 177-designing-Airbnb-or-a-hotel-booking-system.md
├── 178-lyft-marketing-automation-symphony.md
├── 179-designing-typeahead-search-or-autocomplete.md
├── 181-concurrency-models.md
├── 182-designing-l7-load-balancer.md
├── 2016-02-13-crack-the-system-design-interview.md
├── 2018-07-10-cloud-design-patterns.md
├── 2018-07-20-experience-deep-dive.md
├── 2018-07-21-data-partition-and-routing.md
├── 2018-07-22-b-tree-vs-b-plus-tree.md
├── 2018-07-23-load-balancer-types.md
├── 2018-07-24-replica-and-consistency.md
├── 2018-07-26-acid-vs-base.md
├── 38-how-to-stream-video-over-http.md
├── 41-how-to-scale-a-web-service.md
├── 43-how-to-design-robust-and-predictable-apis-with-idempotency.md
├── 45-how-to-design-netflix-view-state-service.md
├── 49-facebook-tao.md
├── 61-what-is-apache-kafka.md
├── 63-soft-skills-interview.md
├── 66-public-api-choices.md
├── 68-bloom-filter.md
├── 69-skiplist.md
├── 78-four-kinds-of-no-sql.md
├── 80-relational-database.md
├── 83-lambda-architecture.md
├── 84-designing-a-url-shortener.md
├── 85-improving-availability-with-failover.md
├── 97-designing-a-kv-store-with-external-storage.md
└── README.md
/.gitignore:
--------------------------------------------------------------------------------
1 | .idea/
2 | *.pdf
3 | _book/**
4 |
--------------------------------------------------------------------------------
/Makefile:
--------------------------------------------------------------------------------
1 | .PHONY: install
2 | install:
3 | nvm use v10 && npm install gitbook-cli -g
4 |
5 | .PHONY: dev
6 | dev:
7 | gitbook serve
8 |
9 | .PHONY: build
10 | build:
11 | gitbook pdf ./ ./_book/system-design-and-architecture-2nd-edition.pdf
12 | gitbook epub ./ ./_book/system-design-and-architecture-2nd-edition.epub
13 | gitbook mobi ./ ./_book/system-design-and-architecture-2nd-edition.mobi
14 |
--------------------------------------------------------------------------------
/SUMMARY.md:
--------------------------------------------------------------------------------
1 | # Summary
2 |
3 | * [Introduction](README.md)
4 |
5 | ### System Design in Practice
6 |
7 | * [Design Pinterest](./en/2016-02-13-crack-the-system-design-interview.md)
8 | * [Design Uber](./en/120-designing-uber.md)
9 | * [Design Facebook Social Graph Store](./en/49-facebook-tao.md)
10 | * [Design Netflix Viewing Data](./en/45-how-to-design-netflix-view-state-service.md)
11 | * [Design idempotent APIs](./en/43-how-to-design-robust-and-predictable-apis-with-idempotency.md)
12 | * [Design video streaming over HTTP](./en/38-how-to-stream-video-over-http.md)
13 | * [What is Apache Kafka?](./en/61-what-is-apache-kafka.md)
14 | * [Design a URL shortener](./en/84-designing-a-url-shortener.md)
15 | * [Design a KV store with external storage](./en/97-designing-a-kv-store-with-external-storage.md)
16 | * [Design a distributed in-memory KV store or Memcached](./en/174-designing-memcached.md)
17 | * [Design Facebook photo storage](./en/121-designing-facebook-photo-storage.md)
18 | * [Design Stock Exchange](./en/161-designing-stock-exchange.md)
19 | * [Design Smart Notification of Stock Price Changes](./en/162-designing-smart-notification-of-stock-price-changes.md)
20 | * [Design Square Cash or PayPal Money Transfer System](./en/167-designing-paypal-money-transfer.md)
21 | * [Design payment webhook](./en/166-designing-payment-webhook.md)
22 | * [Design a metric system](./en/168-designing-a-metric-system.md)
23 | * [Design a recommendation system](./en/140-designing-a-recommendation-system.md)
24 | * [Design Airbnb or a hotel booking system](./en/177-designing-Airbnb-or-a-hotel-booking-system.md)
25 | * [Lyft's Marketing Automation Platform -- Symphony](./en/178-lyft-marketing-automation-symphony.md)
26 | * [Design typeahead search or autocomplete](./en/179-designing-typeahead-search-or-autocomplete.md)
27 | * [Design a Load Balancer or Dropbox Bandaid](./en/182-designing-l7-load-balancer.md)
28 | * [Fraud Detection with Semi-supervised Learning](./en/136-fraud-detection-with-semi-supervised-learning.md)
29 | * [Credit Card Processing System](./en/236-credit-card-processing-system.md)
30 | * [Design Online Judge or Leetcode](./en/243-designing-online-judge-or-leetcode.md)
31 | * [AuthN and AuthZ](./en/253-authn-authz-micro-services.md)
32 | * [AuthZ 2022](./en/277-enterprise-authorization-2022.md)
33 |
34 |
35 | ## System Design Theories
36 |
37 | * [Introduction to Architecture](./en/145-introduction-to-architecture.md)
38 | * [How to scale a web service?](./en/41-how-to-scale-a-web-service.md)
39 | * [ACID vs BASE](./en/2018-07-26-acid-vs-base.md)
40 | * [Data Partition and Routing](./en/2018-07-21-data-partition-and-routing.md)
41 | * [Replica, Consistency, and CAP theorem](./en/2018-07-24-replica-and-consistency.md)
42 | * [Load Balancer Types](./en/2018-07-23-load-balancer-types.md)
43 | * [Concurrency Model](./en/181-concurrency-models.md)
44 | * [Improving availability with failover](./en/85-improving-availability-with-failover.md)
45 | * [Bloom Filter](./en/68-bloom-filter.md)
46 | * [Skiplist](./en/69-skiplist.md)
47 | * [B tree vs. B+ tree](./en/2018-07-22-b-tree-vs-b-plus-tree.md)
48 | * [Intro to Relational Database](./en/80-relational-database.md)
49 | * [4 Kinds of No-SQL](./en/78-four-kinds-of-no-sql.md)
50 | * [Key value cache](./en/122-key-value-cache.md)
51 | * [Stream and Batch Processing Frameworks](./en/137-stream-and-batch-processing.md)
52 | * [Cloud Design Patterns](./en/2018-07-10-cloud-design-patterns.md)
53 | * [Public API Choices](./en/66-public-api-choices.md)
54 | * [Lambda Architecture](./en/83-lambda-architecture.md)
55 | * [iOS Architecture Patterns Revisited](./en/123-ios-architecture-patterns-revisited.md)
56 | * [What can we communicate in soft skills interview?](./en/63-soft-skills-interview.md)
57 | * [Experience Deep Dive](./en/2018-07-20-experience-deep-dive.md)
58 | * [3 Programming Paradigms](./en/11-three-programming-paradigms.md)
59 | * [SOLID Design Principles](./en/12-solid-design-principles.md)
60 |
61 | ## Effective Interview Prep
62 |
63 | * Introduction to software engineer interview
64 | * How to crack the coding interview, for real?
65 | * How to communicate in the interview?
66 | * Experience deep dive
67 | * Culture fit
68 | * Be a software engineer - a hero's journey
69 |
--------------------------------------------------------------------------------
/awesome-system-design.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: "Awesome System Design Resources"
4 | date: 2020-09-11 22:10
5 | language: en
6 | ---
7 |
8 | ## Tutorials and Blogs
9 |
10 | * https://github.com/puncsky/system-design-and-architecture
11 | * https://github.com/donnemartin/system-design-primer
12 | * http://highscalability.com/
13 | * https://www.educative.io/courses/grokking-the-system-design-interview
14 | * https://medium.com/netflix-techblog
15 | * https://engineering.fb.com/
16 | * https://medium.com/airbnb-engineering
17 | * https://medium.com/paypal-engineering
18 | * https://medium.com/imgur-engineering
19 |
20 | ## Books
21 |
22 | * The Practice of Cloud System Administration (Thomas A. Limoncelli)
23 | * Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems (Martin Kleppmann)
24 | * Database Internals (Alex Petrov)
25 | * Clean Architecture (Robert C. Martin)
26 | * Patterns of Enterprise Application Architecure (Martin Fowler)
27 | * NoSQL Distilled (Pramod J. Sadalage)
28 |
29 | Candidate List: https://docs.google.com/spreadsheets/d/11Rjv-SVXj4DN9l2qTZzM-oirMMK9wXTjbS8GFzBmR0s/edit#gid=2041570299
30 |
--------------------------------------------------------------------------------
/drafts/fintech-sd-work-in-progress.md:
--------------------------------------------------------------------------------
1 | ---
2 | layout: post
3 | title: "FinTech System Design"
4 | date: 2021-05-21 16:40
5 | comments: true
6 | categories: System Design
7 | language: en
8 | abstract: abstract
9 | references:
10 | - references
11 | ---
12 |
13 | @[toc]
14 |
15 | We will go through a series of building blocks of modern financial systems.
16 |
17 | * Centralized Finance
18 | * Deposit Account
19 | * ACH
20 | * Wire
21 | * Check
22 | * Credit Card
23 | * PCI DSS
24 | * Electronic Payment Methods
25 | * NFC
26 | * QR Codes (https://www.w3.org/Payments/WG/)
27 | * https://www.w3.org/2020/10/21-wpwg-minutes.html#emvco
28 | * EMVCo QR code specifications and use cases https://www.w3.org/2020/Talks/emvco-qr-20201021.pdf
29 | * China Union Pay QR code use cases http://www.w3.org/2020/Talks/unionpay-qr-20201021.pptx
30 | * Open Banking
31 | * Web Monetization
32 | * Real-time Payments (RTP) and bill pay
33 | * Web https://www.w3.org/Payments/WG/
34 | * Digital Wallet
35 | * Loan
36 | * Fraud & Risk
37 | * Stock Exchange
38 | * Bookkeeping
39 | * Security & Compliance
40 | * Decentralized Finance
41 | * Blockchain
42 | * Smart Contract
43 | * DApp
44 | * Digital Wallet
45 | * Cross-chain
46 | * Decentralized crypto exchanges
47 | * Case study
48 | * Chinese DC/EP
49 | * Facebook Novi and Intermittence
50 | * Stripe and Aggregators
51 | * Plaid
52 | * Fact.co One-click
53 | * Transaction Fee and Bargaining Power
54 | * Apple Pay
55 | * https://whimsical.com/apple-pay-SZBkbYi4YvzpiTLgJPPRSt
56 |
57 |
58 | # Centralized Finance
59 |
60 | # Decentralized Finance
61 |
62 | # Case Study
63 |
64 | ## Apple Pay
65 |
66 | ### Customer's Perspective
67 |
68 | Goal
69 |
70 | * faster and easier than cards and cash
71 | * retailing-first
72 | * privacy and security by design
73 |
74 |
75 |
76 | ### Developer's Perspective
77 |
--------------------------------------------------------------------------------
/drafts/ideas.md:
--------------------------------------------------------------------------------
1 | #### TODO
2 |
3 | * Designing instagram or newsfeed APIs
4 | * Designing Yelp / Finding nearest K POIs
5 | * Designing trending topics / top K exceptions in the system
6 | * Designing distributed web crawler
7 | * Designing i18n service
8 | * Designing ads bidding system
9 | * Designing a dropbox or a file-sharing system
10 | * Designing a calendar system
11 | * Designing an instant chat system / Facebook Messenger / WeChat
12 | * Designing a ticketing system or Ticketmaster
13 | * Designing a voice assistant or Siri
14 |
15 |
--------------------------------------------------------------------------------
/drafts/three-basic-topics.md:
--------------------------------------------------------------------------------
1 | ## Appendix: Three Basic Topics
2 |
3 | > Here are three basic topics that could be discussed during the interview.
4 |
5 | ### Communication
6 |
7 | How do different microservices interact with each other? -- communication protocols.
8 |
9 | Here is a simple comparison of those protocols.
10 |
11 | - UDP and TCP are both transport layer protocols. TCP is reliable and connection-based. UDP is connectionless and unreliable.
12 | - HTTP is in the application layer and is TCP-based since HTTP assumes a reliable transport.
13 | - RPC, a session layer (or application layer in TCP/IP layer model) protocol, is an inter-process communication that allows a computer program to cause a subroutine or procedure to execute in another machine, like a function call.
14 |
15 | ##### Further discussions
16 |
17 | Since RPC is super useful, some interviewers may ask how RPC works. The following picture is a brief answer.
18 |
19 |
20 | 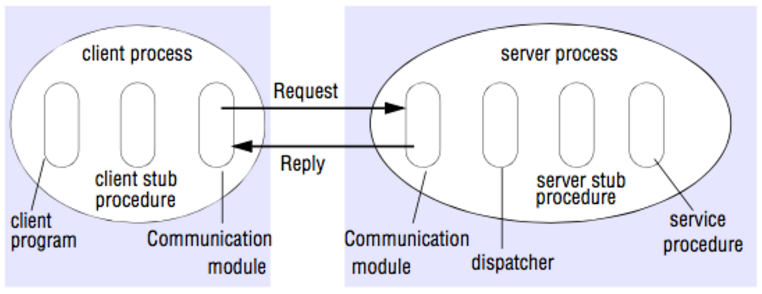
21 |
22 | * Stub procedure: a local procedure that marshals the procedure identifier and the arguments into a request message, and then to send via its communication module to the server. When the reply message arrives, it unmarshals the results.
23 |
24 | We do not have to implement our own RPC protocols. There are off-the-shelf frameworks, like gRPC, Apache Thrift, and Apache Avro.
25 |
26 | - gRPC: a cross-platform open source high performance RPC framework developed by Google.
27 | - Apache Thrift: supports more languages, richer data structures: list, set, map, etc. that Protobuf does not support) Incomplete documentation and hard to find good examples.
28 | - User case: Hbase/Cassandra/Hypertable/Scrib/..
29 | - Apache Avro: Avro is heavily used in the hadoop ecosystem and based on dynamic schemas in Json. It features dynamic typing, untagged data, and no manually-assigned field IDs.
30 |
31 | Generally speaking, RPC is internally used by many tech companies for its great performance; however, it is rather hard to debug or may have compatibility issues in different environments. So for public APIs, we tend to use HTTP APIs, and are usually following the RESTful style.
32 |
33 | - REST (Representational state transfer of resources)
34 | - Best practice of HTTP API to interact with resources.
35 | - URL only decides the location. Headers (Accept and Content-Type, etc.) decide the representation. HTTP methods(GET/POST/PUT/DELETE) decide the state transfer.
36 | - minimize the coupling between client and server (a huge number of HTTP infras on various clients, data-marshalling).
37 | - stateless and scaling out.
38 | - service partitioning feasible.
39 | - used for public API.
40 |
41 | Learn more in [public API choices](66-public-api-choices.md).
42 |
43 | ### Storage
44 |
45 | #### Relational Database
46 |
47 | The relational database is the default choice for most use cases because of ACID (atomicity, consistency, isolation, and durability). One tricky thing is **consistency -- it means that any transaction will bring the database from one valid state to another, (different from the consistency in CAP** in the distributed system.
48 |
49 | ##### Schema Design and 3rd Normal Form (3NF)
50 |
51 | To reduce redundancy and improve consistency, people follow 3NF when designing database schemas:
52 |
53 | - 1NF: tabular, each row-column intersection contains only one value
54 | - 2NF: only the primary key determines all the attributes
55 | - 3NF: only the candidate keys determine all the attributes (and non-prime attributes do not depend on each other)
56 |
57 | ##### Db Proxy
58 |
59 | What if we want to eliminate single point of failure? What if the dataset is too large for one single machine to hold? For MySQL, the answer is to use a DB proxy to distribute data, [either by clustering or by sharding](http://dba.stackexchange.com/questions/8889/mysql-sharding-vs-mysql-cluster ).
60 |
61 | Clustering is a decentralized solution. Everything is automatic. Data is distributed, moved, rebalanced automatically. Nodes gossip with each other, (though it may cause group isolation).
62 |
63 | Sharding is a centralized solution. If we get rid of properties of clustering that we don't like, sharding is what we get. Data is distributed manually and does not move. Nodes are not aware of each other.
64 |
65 | #### NoSQL
66 |
67 | In a regular Internet service, the read write ratio is about 100:1 to 1000:1. However, when reading from a hard disk, a database join operation is time consuming, and 99% of the time is spent on disk seek. Not to mention a distributed join operation across networks.
68 |
69 | To optimize the read performance, **denormalization** is introduced by adding redundant data or by grouping data. These four categories of NoSQL are here to help.
70 |
71 | ##### Key-value Store
72 |
73 | The abstraction of a KV store is a giant hashtable/hashmap/dictionary.
74 |
75 | The main reason we want to use a key-value cache is to reduce latency for accessing active data. Achieve an O(1) read/write performance on a fast and expensive media (like memory or SSD), instead of a traditional O(logn) read/write on a slow and cheap media (typically hard drive).
76 |
77 | There are three major factors to consider when we design the cache.
78 |
79 | 1. Pattern: How to cache? is it read-through/write-through/write-around/write-back/cache-aside?
80 | 2. Placement: Where to place the cache? client side/distinct layer/server side?
81 | 3. Replacement: When to expire/replace the data? LRU/LFU/ARC?
82 |
83 | Out-of-box choices: Redis/Memcache? Redis supports data persistence while memcache does not. Riak, Berkeley DB, HamsterDB, Amazon Dynamo, Project Voldemort, etc.
84 |
85 | ##### Document Store
86 |
87 | The abstraction of a document store is like a KV store, but documents, like XML, JSON, BSON, and so on, are stored in the value part of the pair.
88 |
89 | The main reason we want to use a document store is for flexibility and performance. Flexibility is obtained by schemaless document, and performance is improved by breaking 3NF. Startup's business requirements are changing from time to time. Flexible schema empowers them to move fast.
90 |
91 | Out-of-box choices: MongoDB, CouchDB, Terrastore, OrientDB, RavenDB, etc.
92 |
93 | ##### Column-oriented Store
94 |
95 | The abstraction of a column-oriented store is like a giant nested map: ColumnFamily>.
96 |
97 | The main reason we want to use a column-oriented store is that it is distributed, highly-available, and optimized for write.
98 |
99 | Out-of-box choices: Cassandra, HBase, Hypertable, Amazon SimpleDB, etc.
100 |
101 | ##### Graph Database
102 |
103 | As the name indicates, this database's abstraction is a graph. It allows us to store entities and the relationships between them.
104 |
105 | If we use a relational database to store the graph, adding/removing relationships may involve schema changes and data movement, which is not the case when using a graph database. On the other hand, when we create tables in a relational database for the graph, we model based on the traversal we want; if the traversal changes, the data will have to change.
106 |
107 | Out-of-box choices: Neo4J, Infinitegraph, OrientDB, FlockDB, etc.
108 |
109 | ### CAP Theorem
110 |
111 | When we design a distributed system, **trading off among CAP (consistency, availability, and partition tolerance)** is almost the first thing we want to consider.
112 |
113 | - Consistency: all nodes see the same data at the same time
114 | - Availability: a guarantee that every request receives a response about whether it succeeded or failed
115 | - Partition tolerance: system continues to operate despite arbitrary message loss or failure of part of the system
116 |
117 | In a distributed context, the choice is between CP and AP. Unfortunately, CA is just a joke because a single point of failure is never a choice in the real distributed systems world.
118 |
119 | To ensure consistency, there are some popular protocols to consider: 2PC, eventual consistency (vector clock + RWN), Paxos, [In-Sync Replica](http://www.confluent.io/blog/hands-free-kafka-replication-a-lesson-in-operational-simplicity/), etc.
120 |
121 | To ensure availability, we can add replicas for the data. As to components of the whole system, people usually do [cold standby, warm standby, hot standby, and active-active](https://www.ibm.com/developerworks/community/blogs/RohitShetty/entry/high_availability_cold_warm_hot?lang=en) to handle the failover.
122 |
--------------------------------------------------------------------------------
/en/11-three-programming-paradigms.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 11-three-programming-paradigms
3 | id: 11-three-programming-paradigms
4 | title: "3 Programming Paradigms"
5 | date: 2018-08-12 02:31
6 | comments: true
7 | tags: [system design]
8 | description: "Structured programming is a discipline imposed upon the direct transfer of control. OO programming is a discipline imposed upon the indirect transfer of control. Functional programming is discipline imposed upon variable assignment."
9 | references:
10 | - https://www.amazon.com/Clean-Architecture-Craftsmans-Software-Structure/dp/0134494164
11 | ---
12 |
13 | Structured programming vs. OO programming vs. Functional programming
14 |
15 |
16 |
17 | 1. Structured programming is discipline imposed upon direct transfer of control.
18 | 1. Testability: software is like science: Science does not work by proving statements true, but rather by proving statements false. Structured programming forces us to recursively decompose a program into a set of small provable functions.
19 |
20 |
21 |
22 | 2. OO programming is discipline imposed upon indirect transfer of control.
23 | 1. Capsulation, inheritance, polymorphism(pointers to functions) are not unique to OO.
24 | 2. But OO makes polymorphism safe and convenient to use. And then enable the powerful ==plugin architecture== with dependency inversion
25 | 1. Source code dependencies and flow of control are typically the same. However, if we make them both depend on interfaces, dependency is inverted.
26 | 2. Interfaces empower independent deployability. e.g. when deploying Solidity smart contracts, importing and using interfaces consume much less gases than doing so for the entire implementation.
27 |
28 |
29 |
30 | 3. Functional programming: Immutability. is discipline imposed upon variable assignment.
31 | 1. Why important? All race conditions, deadlock conditions, and concurrent update problems are due to mutable variables.
32 | 2. ==Event sourcing== is a strategy wherein we store the transactions, but not the state. When state is required, we simply apply all the transactions from the beginning of time.
33 |
--------------------------------------------------------------------------------
/en/12-solid-design-principles.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 12-solid-design-principles
3 | id: 12-solid-design-principles
4 | title: "SOLID Design Principles"
5 | date: 2018-08-13 18:07
6 | comments: true
7 | tags: [system design]
8 | description: SOLID is an acronym of design principles that help software engineers write solid code. S is for single responsibility principle, O for open/closed principle, L for Liskov’s substitution principle, I for interface segregation principle and D for dependency inversion principle.
9 | references:
10 | - https://www.amazon.com/Clean-Architecture-Craftsmans-Software-Structure/dp/0134494164
11 | ---
12 |
13 | SOLID is an acronym of design principles that help software engineers write solid code within a project.
14 |
15 | 1. S - **Single Responsibility Principle**. A module should be responsible to one, and only one, actor. a module is just a cohesive set of functions and data structures.
16 |
17 |
18 | 2. O - **Open/Closed Principle**. A software artifact should be open for extension but closed for modification.
19 |
20 |
21 | 3. L - **Liskov’s Substitution Principle**. Simplify code with interface and implementation, generics, sub-classing, and duck-typing for inheritance.
22 |
23 |
24 | 4. I - **Interface Segregation Principle**. Segregate the monolithic interface into smaller ones to decouple modules.
25 |
26 |
27 | 5. D - **Dependency Inversion Principle**. The source code dependencies are inverted against the flow of control. most visible organizing principle in our architecture diagrams.
28 | 1. Things should be stable concrete, Or stale abstract, not ==concrete and volatile.==
29 | 2. So use ==abstract factory== to create volatile concrete objects (manage undesirable dependency.) 产生 interface 的 interface
30 | 3. DIP violations cannot be entirely removed. Most systems will contain at least one such concrete component — this component is often called main.
31 |
--------------------------------------------------------------------------------
/en/120-designing-uber.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 120-designing-uber
3 | id: 120-designing-uber
4 | title: "Designing Uber"
5 | date: 2019-01-03 18:39
6 | comments: true
7 | tags: [system design]
8 | references:
9 | - https://medium.com/yalantis-mobile/uber-underlying-technologies-and-how-it-actually-works-526f55b37c6f
10 | - https://www.youtube.com/watch?t=116&v=vujVmugFsKc
11 | - http://www.infoq.com/news/2015/03/uber-realtime-market-platform
12 | - https://www.youtube.com/watch?v=kb-m2fasdDY&vl=en
13 | ---
14 |
15 | Disclaimer: All things below are collected from public sources or purely original. No Uber-confidential stuff here.
16 |
17 | ## Requirements
18 |
19 | * ride hailing service targeting the transportation markets around the world
20 | * realtime dispatch in massive scale
21 | * backend design
22 |
23 |
24 |
25 | ## Architecture
26 |
27 | 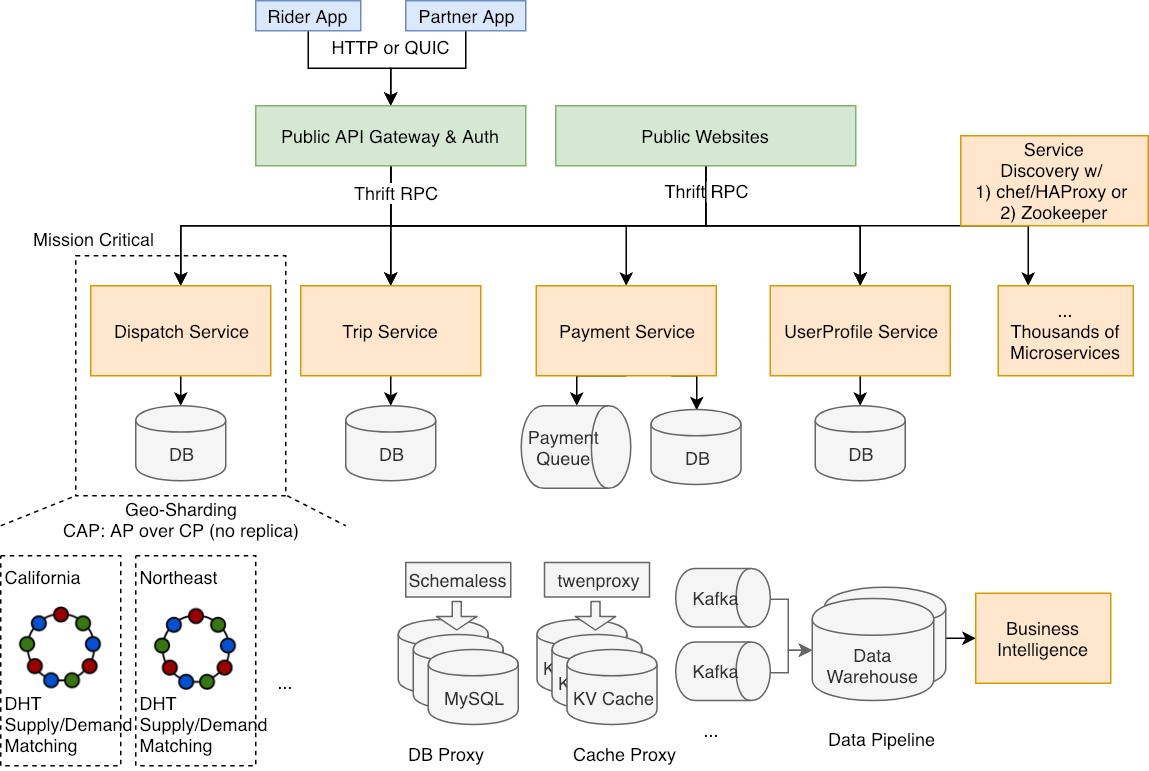
28 |
29 |
30 |
31 | ## Why micro services?
32 | ==Conway's law== says structures of software systems are copies of the organization structures.
33 |
34 | | | Monolithic ==Service== | Micro Services |
35 | |--- |--- |--- |
36 | | Productivity, when teams and codebases are small | ✅ High | ❌ Low |
37 | | ==Productivity, when teams and codebases are large== | ❌ Low | ✅ High (Conway's law) |
38 | | ==Requirements on Engineering Quality== | ❌ High (under-qualified devs break down the system easily) | ✅ Low (runtimes are segregated) |
39 | | Dependency Bump | ✅ Fast (centrally managed) | ❌ Slow |
40 | | Multi-tenancy support / Production-staging Segregation | ✅ Easy | ❌ Hard (each individual service has to either 1) build staging env connected to others in staging 2) Multi-tenancy support across the request contexts and data storage) |
41 | | Debuggability, assuming same modules, metrics, logs | ❌ Low | ✅ High (w/ distributed tracing) |
42 | | Latency | ✅ Low (local) | ❌ High (remote) |
43 | | DevOps Costs | ✅ Low (High on building tools) | ❌ High (capacity planning is hard) |
44 |
45 | Combining monolithic ==codebase== and micro services can bring benefits from both sides.
46 |
47 | ## Dispatch Service
48 |
49 | * consistent hashing sharded by geohash
50 | * data is transient, in memory, and thus there is no need to replicate. (CAP: AP over CP)
51 | * single-threaded or locked matching in a shard to prevent double dispatching
52 |
53 |
54 |
55 | ## Payment Service
56 |
57 | ==The key is to have an async design==, because payment systems usually have a very long latency for ACID transactions across multiple systems.
58 |
59 | * leverage event queues
60 | * payment gateway w/ Braintree, PayPal, Card.io, Alipay, etc.
61 | * logging intensively to track everything
62 | * [APIs with idempotency, exponential backoff, and random jitter](https://puncsky.com/notes/43-how-to-design-robust-and-predictable-apis-with-idempotency)
63 |
64 |
65 | ## UserProfile Service and Trip Service
66 |
67 | * low latency with caching
68 | * UserProfile Service has the challenge to serve users in increasing types (driver, rider, restaurant owner, eater, etc) and user schemas in different regions and countries.
69 |
70 | ## Push Notification Service
71 |
72 | * Apple Push Notifications Service (not quite reliable)
73 | * Google Cloud Messaging Service GCM (it can detect the deliverability) or
74 | * SMS service is usually more reliable
75 |
--------------------------------------------------------------------------------
/en/121-designing-facebook-photo-storage.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 121-designing-facebook-photo-storage
3 | id: 121-designing-facebook-photo-storage
4 | title: "Designing Facebook photo storage"
5 | date: 2019-01-04 12:11
6 | comments: true
7 | tags: [system design]
8 | description: "Traditional NFS based design has metadata bottleneck: large metadata size limits the metadata hit ratio. Facebook photo storage eliminates the metadata by aggregating hundreds of thousands of images in a single haystack store file."
9 | references:
10 | - https://www.usenix.org/conference/osdi10/finding-needle-haystack-facebooks-photo-storage
11 | - https://www.facebook.com/notes/facebook-engineering/needle-in-a-haystack-efficient-storage-of-billions-of-photos/76191543919
12 | ---
13 |
14 | ## Motivation & Assumptions
15 |
16 | * PB-level Blob storage
17 | * Traditional NFS based desgin (Each image stored as a file) has metadata bottleneck: large metadata size severely limits the metadata hit ratio.
18 | * Explain more about the metadata overhead
19 |
20 | > For the Photos application most of this metadata, such as permissions, is unused and thereby wastes storage capacity. Yet the more significant cost is that the file’s metadata must be read from disk into memory in order to find the file itself. While insignificant on a small scale, multiplied over billions of photos and petabytes of data, accessing metadata is the throughput bottleneck.
21 |
22 |
23 |
24 | ## Solution
25 |
26 | Eliminates the metadata overhead by aggregating hundreds of thousands of images in a single haystack store file.
27 |
28 |
29 |
30 | ## Architecture
31 |
32 | 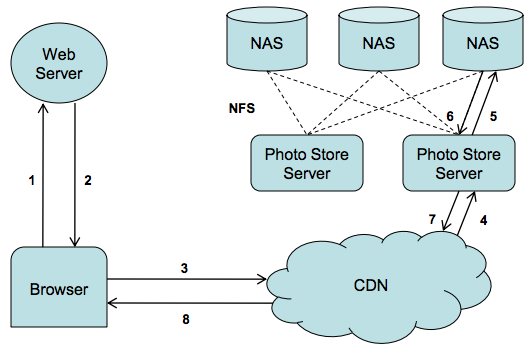
33 |
34 |
35 |
36 | ## Data Layout
37 |
38 | index file (for quick memory load) + haystack store file containing needles.
39 |
40 | index file layout
41 | 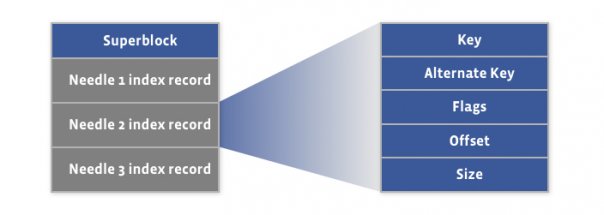
42 |
43 |
44 | 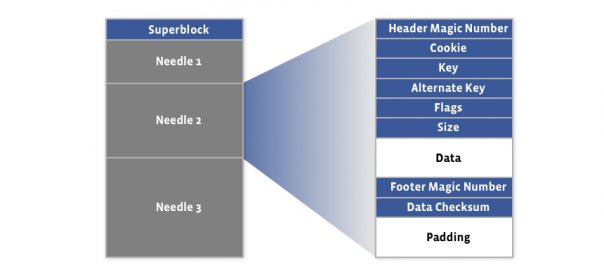
45 |
46 |
47 | haystack store file
48 |
49 | 
50 |
51 |
52 |
53 | ### CRUD Operations
54 |
55 | * Create: write to store file and then ==async== write index file, because index is not critical
56 | * Read: read(offset, key, alternate_key, cookie, data_size)
57 | * Update: Append only. If the app meets duplicate keys, then it can choose one with largest offset to update.
58 | * Delete: soft delete by marking the deleted bit in the flag field. Hard delete is executed by the compact operation.
59 |
60 |
61 |
62 | ## Usecases
63 |
64 | Upload
65 |
66 | 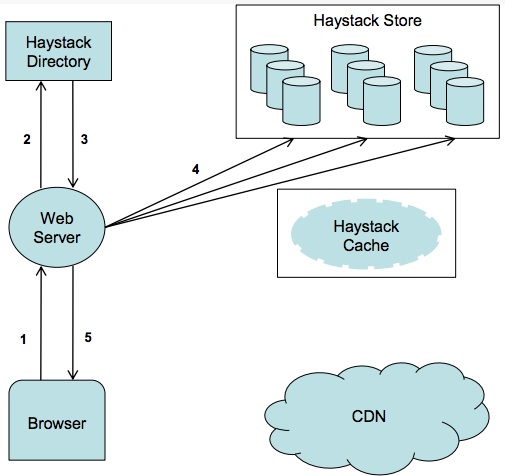
67 |
68 |
69 | Download
70 |
71 | 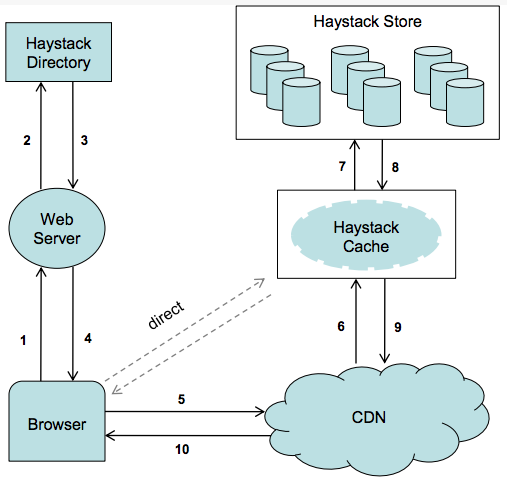
72 |
--------------------------------------------------------------------------------
/en/122-key-value-cache.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 122-key-value-cache
3 | id: 122-key-value-cache
4 | title: "Key value cache"
5 | date: 2019-01-06 23:24
6 | comments: true
7 | description: "The key-value cache is used to reduce the latency of data access. What are read-through, write-through, write-behind, write-back, write-behind, and cache-aside patterns?"
8 | tags: [system design]
9 | ---
10 |
11 | KV cache is like a giant hash map and used to reduce the latency of data access, typically by
12 |
13 | 1. Putting data from slow and cheap media to fast and expensive ones.
14 | 2. Indexing from tree-based data structures of `O(log n)` to hash-based ones of `O(1)` to read and write
15 |
16 |
17 | There are various cache policies like read-through/write-through(or write-back), and cache-aside. By and large, Internet services have a read to write ratio of 100:1 to 1000:1, so we usually optimize for read.
18 |
19 | In distributed systems, we choose those policies according to the business requirements and contexts, under the guidance of [CAP theorem](https://puncsky.com/notes/2018-07-24-replica-and-consistency).
20 |
21 |
22 |
23 | ## Regular Patterns
24 |
25 | * Read
26 | * Read-through: the clients read data from the database via the cache layer. The cache returns when the read hits the cache; otherwise, it fetches data from the database, caches it, and then return the vale.
27 | * Write
28 | * Write-through: clients write to the cache and the cache updates the database. The cache returns when it finishes the database write.
29 | * Write-behind / write-back: clients write to the cache, and the cache returns immediately. Behind the cache write, the cache asynchronously writes to the database.
30 | * Write-around: clients write to the database directly, around the cache.
31 |
32 |
33 |
34 | ## Cache-aside pattern
35 | When a cache does not support native read-through and write-through operations, and the resource demand is unpredictable, we use this cache-aside pattern.
36 |
37 | * Read: try to hit the cache. If not hit, read from the database and then update the cache.
38 | * Write: write to the database first and then ==delete the cache entry==. A common pitfall here is that [people mistakenly update the cache with the value, and double writes in a high concurrency environment will make the cache dirty](https://www.quora.com/Why-does-Facebook-use-delete-to-remove-the-key-value-pair-in-Memcached-instead-of-updating-the-Memcached-during-write-request-to-the-backend).
39 |
40 |
41 | ==There are still chances for dirty cache in this pattern.== It happens when these two cases are met in a racing condition:
42 |
43 | 1. read database and update cache
44 | 2. update database and delete cache
45 |
46 |
47 |
48 | ## Where to put the cache?
49 |
50 | * client-side
51 | * distinct layer
52 | * server-side
53 |
54 |
55 |
56 | ## What if data volume reaches the cache capacity? Use cache replacement policies
57 | * LRU(Least Recently Used): check time, and evict the most recently used entries and keep the most recently used ones.
58 | * LFU(Least Frequently Used): check frequency, and evict the most frequently used entries and keep the most frequently used ones.
59 | * ARC(Adaptive replacement cache): it has a better performance than LRU. It is achieved by keeping both the most frequently and frequently used entries, as well as a history for eviction. (Keeping MRU+MFU+eviction history.)
60 |
61 |
62 |
63 | ## Who are the King of the cache usage?
64 | [Facebook TAO](https://puncsky.com/notes/49-facebook-tao)
65 |
--------------------------------------------------------------------------------
/en/123-ios-architecture-patterns-revisited.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 123-ios-architecture-patterns-revisited
3 | id: 123-ios-architecture-patterns-revisited
4 | title: "iOS Architecture Patterns Revisited"
5 | date: 2019-01-10 02:26
6 | comments: true
7 | tags: [architecture, mobile, system design]
8 | description: "Architecture can directly impact costs per feature. Let's compare Tight-coupling MVC, Cocoa MVC, MVP, MVVM, and VIPER in three dimensions: balanced distribution of responsibility among feature actors, testability and ease of use and maintainability."
9 | references:
10 | - https://medium.com/ios-os-x-development/ios-architecture-patterns-ecba4c38de52
11 | ---
12 |
13 | ## Why bother with architecture?
14 |
15 | Answer: [for reducing human resources costs per feature](https://puncsky.com/notes/10-thinking-software-architecture-as-physical-buildings#ultimate-goal-saving-human-resources-costs-per-feature).
16 |
17 | Mobile developers evaluate the architecture in three dimensions.
18 |
19 | 1. Balanced distribution of responsibilities among feature actors.
20 | 2. Testability
21 | 3. Ease of use and maintainability
22 |
23 |
24 | | | Distribution of Responsibility | Testability | Ease of Use |
25 | | --- | --- | --- | --- |
26 | | Tight-coupling MVC | ❌ | ❌ | ✅ |
27 | | Cocoa MVC | ❌ VC are coupled | ❌ | ✅⭐ |
28 | | MVP | ✅ Separated View Lifecycle | ✅ | Fair: more code |
29 | | MVVM | ✅ | Fair: because of View's UIKit dependant | Fair |
30 | | VIPER | ✅⭐️ | ✅⭐️ | ❌ |
31 |
32 |
33 |
34 | ## Tight-coupling MVC
35 |
36 | 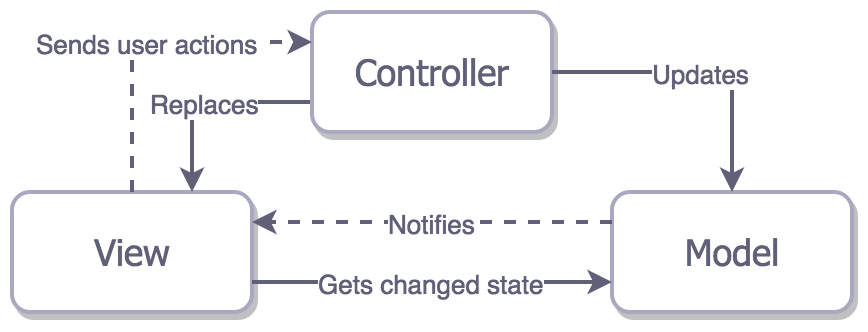
37 |
38 | For example, in a multi-page web application, page completely reloaded once you press on the link to navigate somewhere else. The problem is that the View is tightly coupled with both Controller and Model.
39 |
40 |
41 |
42 | ## Cocoa MVC
43 |
44 | Apple’s MVC, in theory, decouples View from Model via Controller.
45 |
46 | 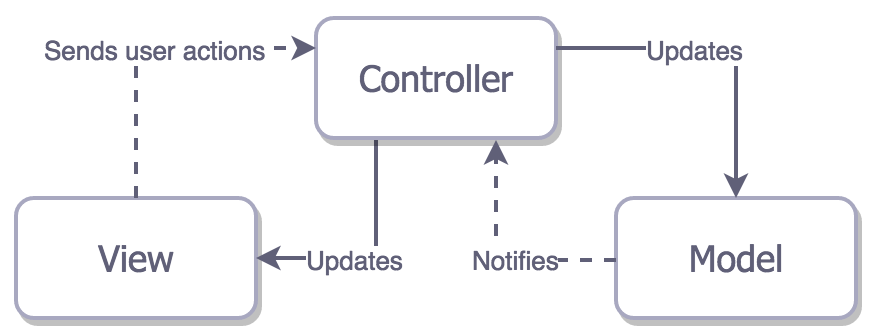
47 |
48 |
49 | Apple’s MVC in reality encourages ==massive view controllers==. And the view controller ends up doing everything.
50 |
51 | 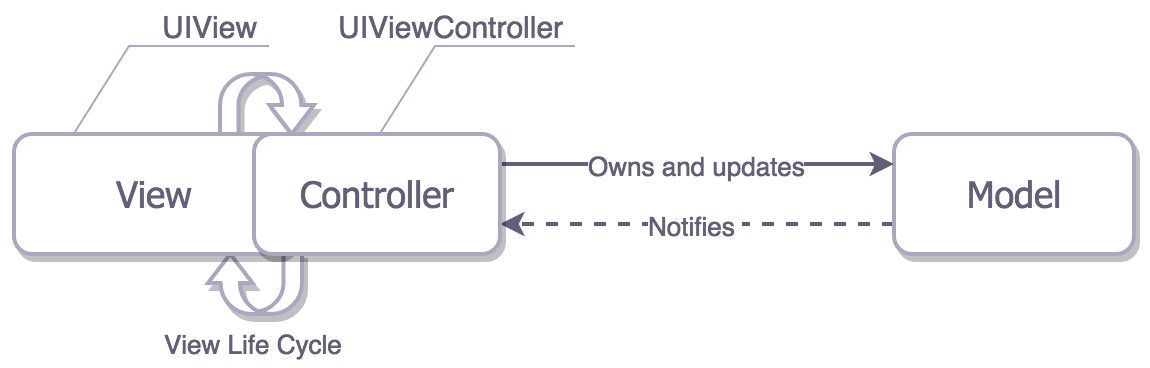
52 |
53 | It is hard to test coupled massive view controllers. However, Cocoa MVC is the best architectural pattern regarding the speed of the development.
54 |
55 |
56 |
57 | ## MVP
58 |
59 | In an MVP, Presenter has nothing to do with the life cycle of the view controller, and the View can be mocked easily. We can say the UIViewController is actually the View.
60 |
61 | 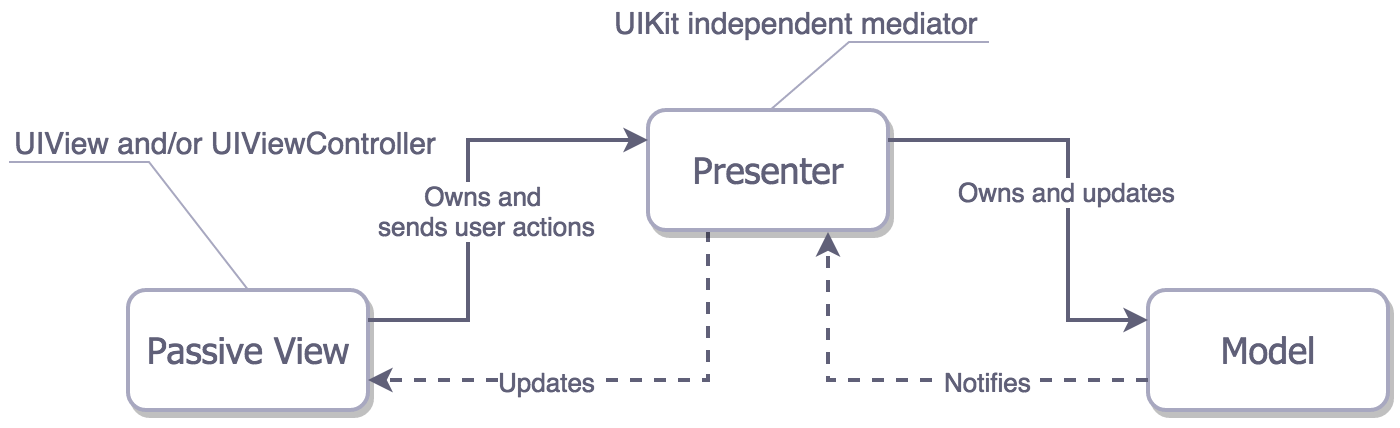
62 |
63 |
64 | There is another kind of MVP: the one with data bindings. And as you can see, there is tight coupling between View and the other two.
65 |
66 | 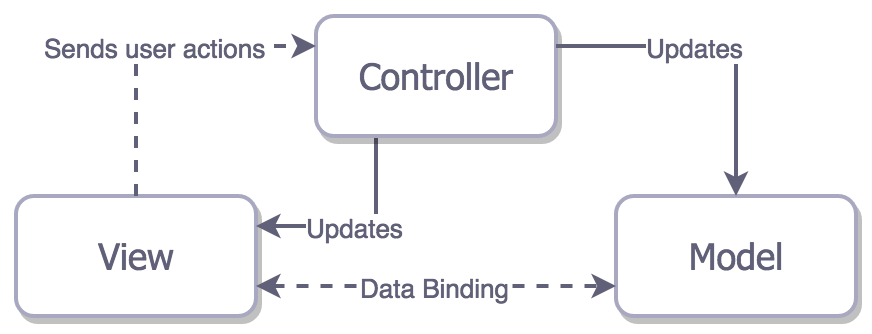
67 |
68 |
69 |
70 | ## MVVM
71 |
72 | It is similar to MVP but binding is between View and View Model.
73 |
74 | 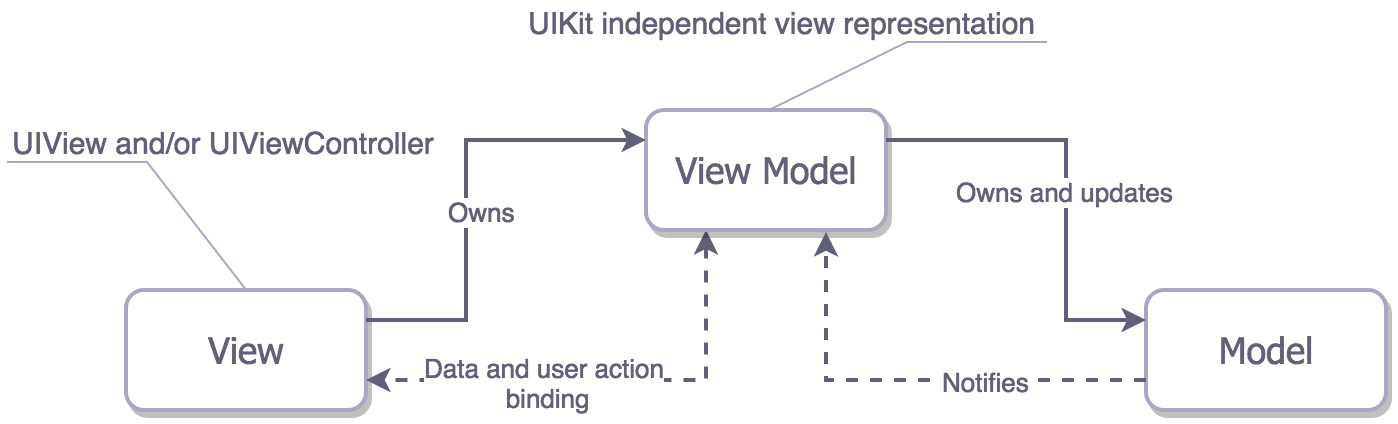
75 |
76 |
77 |
78 | ## VIPER
79 | There are five layers (VIPER View, Interactor, Presenter, Entity, and Routing) instead of three when compared to MV(X). This distributes responsibilities well but the maintainability is bad.
80 |
81 | 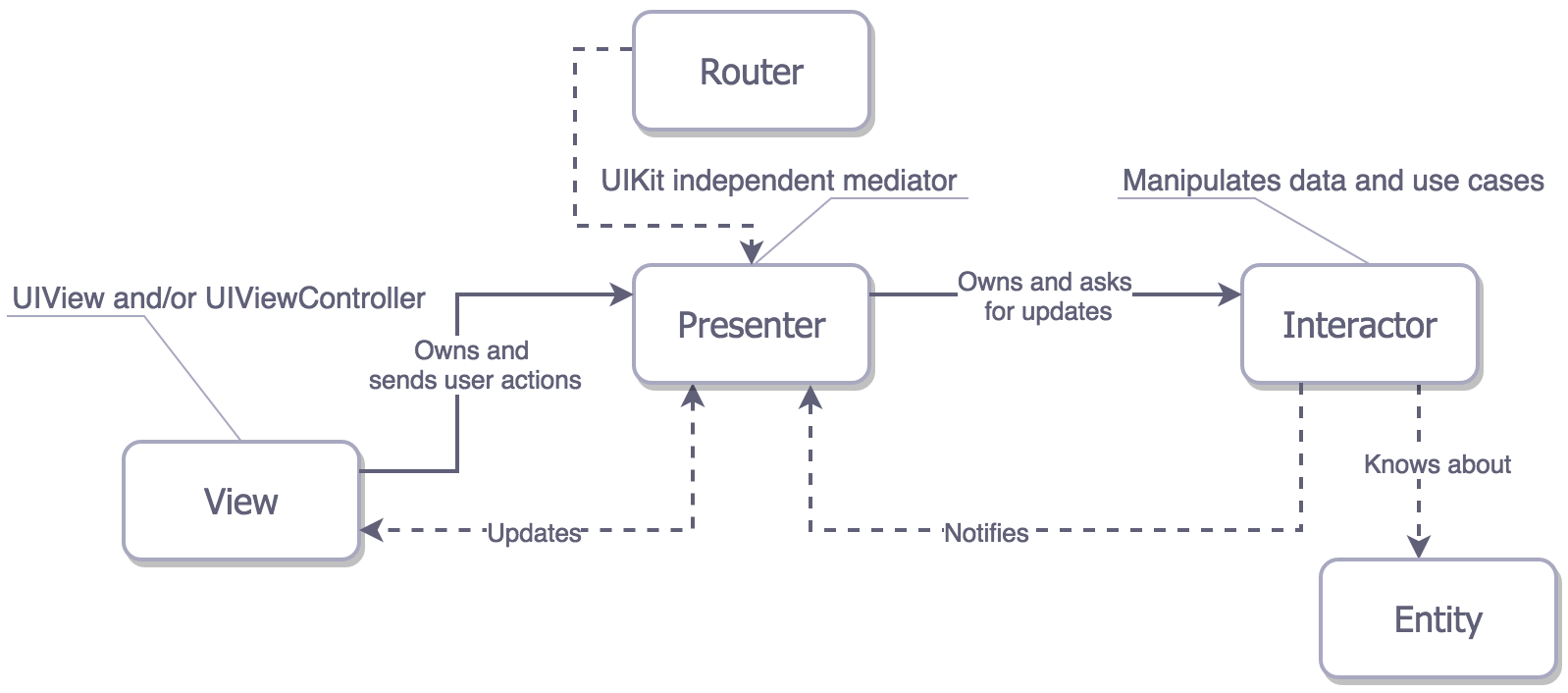
82 |
83 |
84 | When compared to MV(X), VIPER
85 |
86 | 1. Model logic is shifted to Interactor and Entities are left as dumb data structures.
87 | 2. ==UI related business logic is placed into Presenter, while the data altering capabilities are placed into Interactor==.
88 | 3. It introduces Router for the navigation responsibility.
89 |
--------------------------------------------------------------------------------
/en/136-fraud-detection-with-semi-supervised-learning.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 136-fraud-detection-with-semi-supervised-learning
3 | id: 136-fraud-detection-with-semi-supervised-learning
4 | title: "Fraud Detection with Semi-supervised Learning"
5 | date: 2019-02-13 23:57
6 | comments: true
7 | tags: [architecture, system design]
8 | description: Fraud Detection fights against account takeovers and Botnet attacks during login. Semi-supervised learning has better learning accuracy than unsupervised learning and less time and costs than supervised learning.
9 | references:
10 | - https://www.slideshare.net/Hadoop_Summit/semisupervised-learning-in-an-adversarial-environment
11 | image: https://web-dash-v2.onrender.com/api/og-tianpan-co?title=Fraud%20Detection%20with%20Semi-supervised%20Learning
12 |
13 | ---
14 |
15 | ## Clarify Requirements
16 |
17 | Calculate risk probability scores in realtime and make decisions along with a rule engine to prevent ATO (account takeovers) and Botnet attacks.
18 |
19 | Train clustering fatures with online and offline pipelines
20 |
21 | 1. Source from website logs, auth logs, user actions, transactions, high-risk accounts in watch list
22 | 2. track event data in kakfa topics
23 | 3. Process events and prepare clustering features
24 |
25 | Realtime scoring and rule-based decision
26 |
27 | 4. assess a risk score comprehensively for online services
28 |
29 | 5. Maintain flexibility with manually configuration in a rule engine
30 | 6. share, or use the insights in online services
31 |
32 | ATOs ranking from easy to hard to detect
33 |
34 | 1. from single IP
35 | 2. from IPs on the same device
36 | 3. from IPs across the world
37 | 4. from 100k IPs
38 | 5. attacks on specific accounts
39 | 6. phishing and malware
40 |
41 | Challenges
42 |
43 | * Manual feature selection
44 | * Feature evolution in adversarial environment
45 | * Scalability
46 | * No online DBSCAN
47 |
48 | ## **High-level Architecture**
49 |
50 | 
51 |
52 | ## Core Components and Workflows
53 |
54 | Semi-supervised learning = unlabeled data + small amount of labeled data
55 |
56 | Why? better learning accuracy than unsupervised learning + less time and costs than supervised learning
57 |
58 | ### Training: To prepare clustering features in database
59 |
60 | - **Streaming Pipeline on Spark:**
61 | - Runs continuously in real-time.
62 | - Performs feature normalization and categorical transformation on the fly.
63 | - **Feature Normalization**: Scale your numeric features (e.g., age, income) so that they are between 0 and 1.
64 | - **Categorical Feature Transformation**: Apply one-hot encoding or another transformation to convert categorical features into a numeric format suitable for the machine learning model.
65 | - Uses **Spark MLlib’s K-means** to cluster streaming data into groups.
66 | - After running k-means and forming clusters, you might find that certain clusters have more instances of fraud.
67 | - Once you’ve labeled a cluster as fraudulent based on historical data or expert knowledge, you can use that cluster assignment during inference. Any new data point assigned to that fraudulent cluster can be flagged as suspicious.
68 | - **Hourly Cronjob Pipeline:**
69 | - Runs periodically every hour (batch processing).
70 | - Applies **thresholding** to identify anomalies based on results from the clustering model.
71 | - **Tunes parameters** of the **DBSCAN algorithm** to improve clustering and anomaly detection.
72 | - Uses **DBSCAN** from **scikit-learn** to find clusters and detect outliers in batch data.
73 | - DBSCAN, which can detect outliers, might identify clusters of regular transactions and separate them from **noise**, which could be unusual, potentially fraudulent transactions.
74 | - Transactions in the noisy or outlier regions (points that don’t belong to any dense cluster) can be flagged as suspicious.
75 | - After identifying a cluster as fraudulent, DBSCAN helps detect patterns of fraud even in irregularly shaped transaction distributions.
76 |
77 | ## Serving
78 |
79 | The serving layer is where the rubber meets the road - where we turn our machine learning models and business rules into actual fraud prevention decisions. Here's how it works:
80 |
81 | - Fraud Detection Scoring Service:
82 | - Takes real-time features extracted from incoming requests
83 | - Applies both clustering models (K-means from streaming and DBSCAN from batch)
84 | - Combines scores with streaming counters (like login attempts per IP)
85 | - Outputs a unified risk score between 0 and 1
86 | - Rule Engine:
87 | - Acts as the "brain" of the system
88 | - Combines ML scores with configurable business rules
89 | - Examples of rules:
90 | - If risk score > 0.8 AND user is accessing from new IP → require 2FA
91 | - If risk score > 0.9 AND account is high-value → block transaction
92 | - Rules are stored in a database and can be updated without code changes
93 | - Provides an admin portal for security teams to adjust rules
94 | - Integration with Other Services:
95 | - Exposes REST APIs for real-time scoring
96 | - Publishes results to streaming counters for monitoring
97 | - Feeds decisions back to the training pipeline to improve model accuracy
98 | - Observability:
99 | - Tracks key metrics like false positive/negative rates
100 | - Monitors model drift and feature distribution changes
101 | - Provides dashboards for security analysts to investigate patterns
102 | - Logs detailed information for post-incident analysis
103 |
104 |
--------------------------------------------------------------------------------
/en/137-stream-and-batch-processing.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 137-stream-and-batch-processing
3 | id: 137-stream-and-batch-processing
4 | title: "Stream and Batch Processing Frameworks"
5 | date: 2019-02-16 22:13
6 | comments: true
7 | tags: [system design]
8 | description: "Stream and Batch processing frameworks can process high throughput at low latency. Why is Flink gaining popularity? And how to make an architectural choice among Storm, Storm-trident, Spark, and Flink?"
9 | references:
10 | - https://storage.googleapis.com/pub-tools-public-publication-data/pdf/43864.pdf
11 | - https://cs.stanford.edu/~matei/papers/2018/sigmod_structured_streaming.pdf
12 | - https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
13 | - https://stackoverflow.com/questions/28502787/google-dataflow-vs-apache-storm
14 | ---
15 |
16 | ## Why such frameworks?
17 |
18 | * process high-throughput in low latency.
19 | * fault-tolerance in distributed systems.
20 | * generic abstraction to serve volatile business requirements.
21 | * for bounded data set (batch processing) and for unbounded data set (stream processing).
22 |
23 |
24 | ## Brief history of batch/stream processing
25 |
26 | 1. Hadoop and MapReduce. Google made batch processing as simple as MR `result = pairs.map((pair) => (morePairs)).reduce(somePairs => lessPairs)` in a distributed system.
27 | 2. Apache Storm and DAG Topology. MR doesn’t efficiently express iterative algorithms. Thus Nathan Marz abstracted stream processing into a graph of spouts and bolts.
28 | 3. Spark in-memory Computing. Reynold Xin said Spark sorted the same data **3X faster** using **10X fewer machines** compared to Hadoop.
29 | 4. Google Dataflow based on Millwheel and FlumeJava. Google supports both batch and streaming computing with the windowing API.
30 |
31 |
32 | ### Wait... But why is Flink gaining popularity?
33 |
34 | 1. its fast adoption of ==Google Dataflow==/Beam programming model.
35 | 2. its highly efficient implementation of Chandy-Lamport checkpointing.
36 |
37 |
38 |
39 | ## How?
40 |
41 | ### Architectural Choices
42 |
43 | To serve requirements above with commodity machines, the steaming framework use distributed systems in these architectures...
44 |
45 | * master-slave (centralized): apache storm with zookeeper, apache samza with YARN.
46 | * P2P (decentralized): apache s4.
47 |
48 |
49 | ### Features
50 |
51 | 1. DAG Topology for Iterative Processing. e.g. GraphX in Spark, topologies in Apache Storm, DataStream API in Flink.
52 | 2. Delivery Guarantees. How guaranteed to deliver data from nodes to nodes? at-least once / at-most once / exactly once.
53 | 3. Fault-tolerance. Using [cold/warm/hot standby, checkpointing, or active-active](https://tianpan.co/notes/85-improving-availability-with-failover).
54 | 4. Windowing API for unbounded data set. e.g. Stream Windows in Apache Flink. Spark Window Functions. Windowing in Apache Beam.
55 |
56 |
57 | ## Comparison
58 |
59 | | Framework | Storm | Storm-trident | Spark | Flink |
60 | | --------------------------- | ------------- | ------------- | ------------ | ------------ |
61 | | Model | native | micro-batch | micro-batch | native |
62 | | Guarentees | at-least-once | exactly-once | exactly-once | exactly-once |
63 | | Fault-tolerance | Record-Ack | record-ack | checkpoint | checkpoint |
64 | | Overhead of fault-tolerance | high | medium | medium | low |
65 | | latency | very-low | high | high | low |
66 | | throughput | low | medium | high | high |
67 |
--------------------------------------------------------------------------------
/en/145-introduction-to-architecture.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 145-introduction-to-architecture
3 | id: 145-introduction-to-architecture
4 | title: "Introduction to Architecture"
5 | date: 2019-05-11 15:52
6 | comments: true
7 | tags: [system design]
8 | description: Architecture serves the full lifecycle of the software system to make it easy to understand, develop, test, deploy and operate. The O’Reilly book Software Architecture Patterns gives a simple but effective introduction to five fundamental architectures.
9 | references:
10 | - https://puncsky.com/notes/10-thinking-software-architecture-as-physical-buildings
11 | - https://www.oreilly.com/library/view/software-architecture-patterns/9781491971437/ch01.html
12 | - http://www.ruanyifeng.com/blog/2016/09/software-architecture.html
13 | ---
14 |
15 | ## What is architecture?
16 |
17 | Architecture is the shape of the software system. Thinking it as a big picture of physical buildings.
18 |
19 | * paradigms are bricks.
20 | * design principles are rooms.
21 | * components are buildings.
22 |
23 | Together they serve a specific purpose like a hospital is for curing patients and a school is for educating students.
24 |
25 |
26 | ## Why do we need architecture?
27 |
28 | ### Behavior vs. Structure
29 |
30 | Every software system provides two different values to the stakeholders: behavior and structure. Software developers are responsible for ensuring that both those values remain high.
31 |
32 | ==Software architects are, by virtue of their job description, more focused on the structure of the system than on its features and functions.==
33 |
34 |
35 | ### Ultimate Goal - ==saving human resources costs per feature==
36 |
37 | Architecture serves the full lifecycle of the software system to make it easy to understand, develop, test, deploy, and operate.
38 | The goal is to minimize the human resources costs per business use-case.
39 |
40 |
41 |
42 | The O’Reilly book Software Architecture Patterns by Mark Richards is a simple but effective introduction to these five fundamental architectures.
43 |
44 |
45 |
46 | ## 1. Layered Architecture
47 |
48 |
49 |
50 | The layered architecture is the most common in adoption, well-known among developers, and hence the de facto standard for applications. If you do not know what architecture to use, use it.
51 |
52 | [comment]: \<\> (https://www.draw.io/#G1ldM5O9Y62Upqg_t5rcTNHIRseP-7fqQT)
53 |
54 | 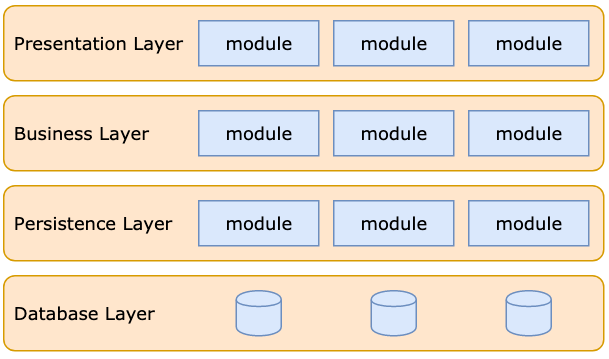
55 |
56 |
57 | Examples
58 |
59 | * TCP / IP Model: Application layer > transport layer > internet layer > network access layer
60 | * [Facebook TAO](https://puncsky.com/notes/49-facebook-tao): web layer > cache layer (follower + leader) > database layer
61 |
62 | Pros and Cons
63 |
64 | * Pros
65 | * ease of use
66 | * separation of responsibility
67 | * testability
68 | * Cons
69 | * monolithic
70 | * hard to adjust, extend or update. You have to make changes to all the layers.
71 |
72 |
73 |
74 | ## 2. Event-Driven Architecture
75 |
76 |
77 |
78 | A state change will emit an event to the system. All the components communicate with each other through events.
79 |
80 | 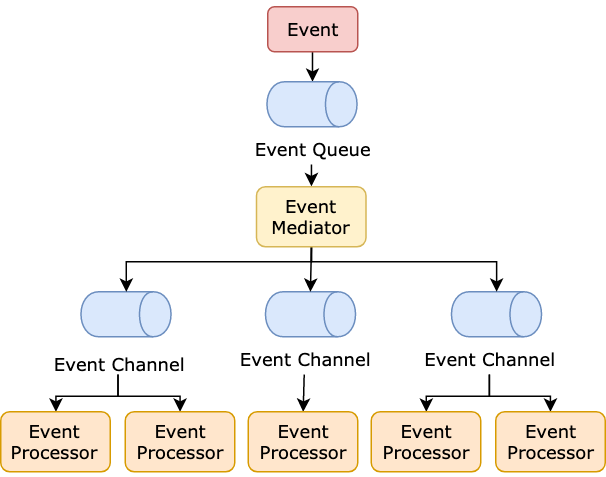
81 |
82 |
83 | A simple project can combine the mediator, event queue, and channel. Then we get a simplified architecture:
84 |
85 | 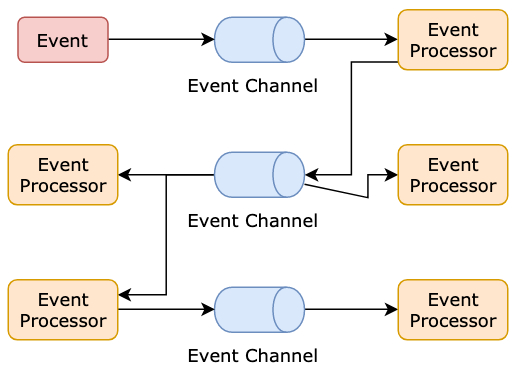
86 |
87 |
88 | Examples
89 |
90 | * QT: Signals and Slots
91 | * Payment Infrastructure: Bank gateways usually have very high latencies, so they adopt async technologies in their architecture design.
92 |
93 |
94 |
95 | ## 3. Micro-kernel Architecture (aka Plug-in Architecture)
96 |
97 |
98 |
99 | The software's responsibilities are divided into one "core" and multiple "plugins". The core contains the bare minimum functionality. Plugins are independent of each other and implement shared interfaces to achieve different goals.
100 |
101 | 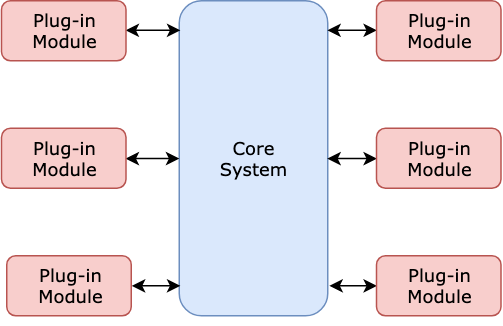
102 |
103 |
104 | Examples
105 |
106 | * Visual Studio Code, Eclipse
107 | * MINIX operating system
108 |
109 |
110 |
111 | ## 4. Microservices Architecture
112 |
113 |
114 |
115 | A massive system is decoupled to multiple micro-services, each of which is a separately deployed unit, and they communicate with each other via [RPCs](/blog/2016-02-13-crack-the-system-design-interview#21-communication).
116 |
117 |
118 | 
119 |
120 |
121 |
122 | Examples
123 |
124 | * Uber: See [designing Uber](https://puncsky.com/notes/120-designing-uber)
125 | * Smartly
126 |
127 |
128 |
129 |
130 | ## 5. Space-based Architecture
131 |
132 |
133 |
134 | This pattern gets its name from "tuple space", which means “distributed shared memory". There is no database or synchronous database access, and thus no database bottleneck. All the processing units share the replicated application data in memory. These processing units can be started up and shut down elastically.
135 |
136 | 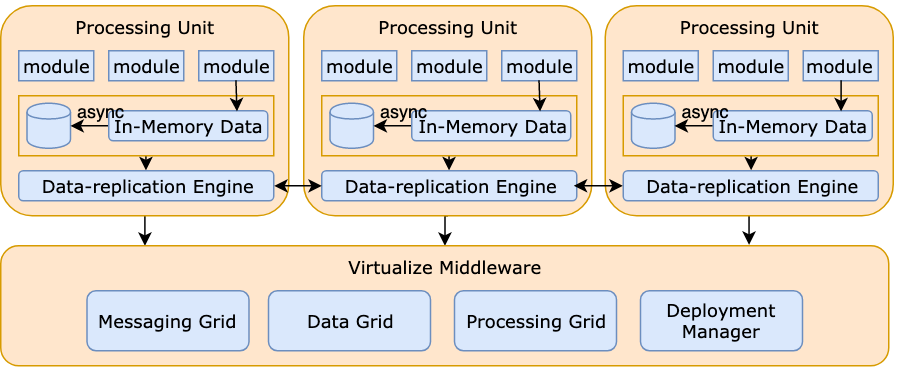
137 |
138 |
139 |
140 | Examples: See [Wikipedia](https://en.wikipedia.org/wiki/Tuple_space#Example_usage)
141 |
142 | - Mostly adopted among Java users: e.g., JavaSpaces
143 |
--------------------------------------------------------------------------------
/en/166-designing-payment-webhook.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 166-designing-payment-webhook
3 | id: 166-designing-payment-webhook
4 | title: "Designing payment webhook"
5 | date: 2019-08-19 21:15
6 | updateDate: 2024-04-06 17:29
7 | comments: true
8 | tags: [system design]
9 | slides: false
10 | description: Design a webhook that notifies the merchant when the payment succeeds. We need to aggregate the metrics (e.g., success vs. failure) and display it on the dashboard.
11 | references:
12 | - https://commerce.coinbase.com/docs/#webhooks
13 | - https://bitworking.org/news/2017/03/prometheus
14 | - https://workos.com/blog/building-webhooks-into-your-application-guidelines-and-best-practices
15 |
16 | ---
17 |
18 | ## 1. Clarifying Requirements
19 |
20 | 1. Webhook will call the merchant back once the payment succeeds.
21 | 1. Merchant developer registers webhook information with us.
22 | 2. Make a POST HTTP request to the webhooks reliably and securely.
23 | 2. High availability, error-handling, and failure-resilience.
24 | 1. Async design. Assuming that the servers of merchants are located across the world, and may have a very high latency like 15s.
25 | 2. At-least-once delivery. Idempotent key.
26 | 3. Order does not matter.
27 | 4. Robust & predictable retry and short-circuit.
28 | 3. Security, observability & scalability
29 | 1. Anti-spoofing.
30 | 2. Notify the merchant when their receivers are broken.
31 | 3. easy to extend and scale.
32 |
33 |
34 |
35 | ## 2. Sketch out the high-level design
36 |
37 | async design + retry + queuing + observability + security
38 |
39 | 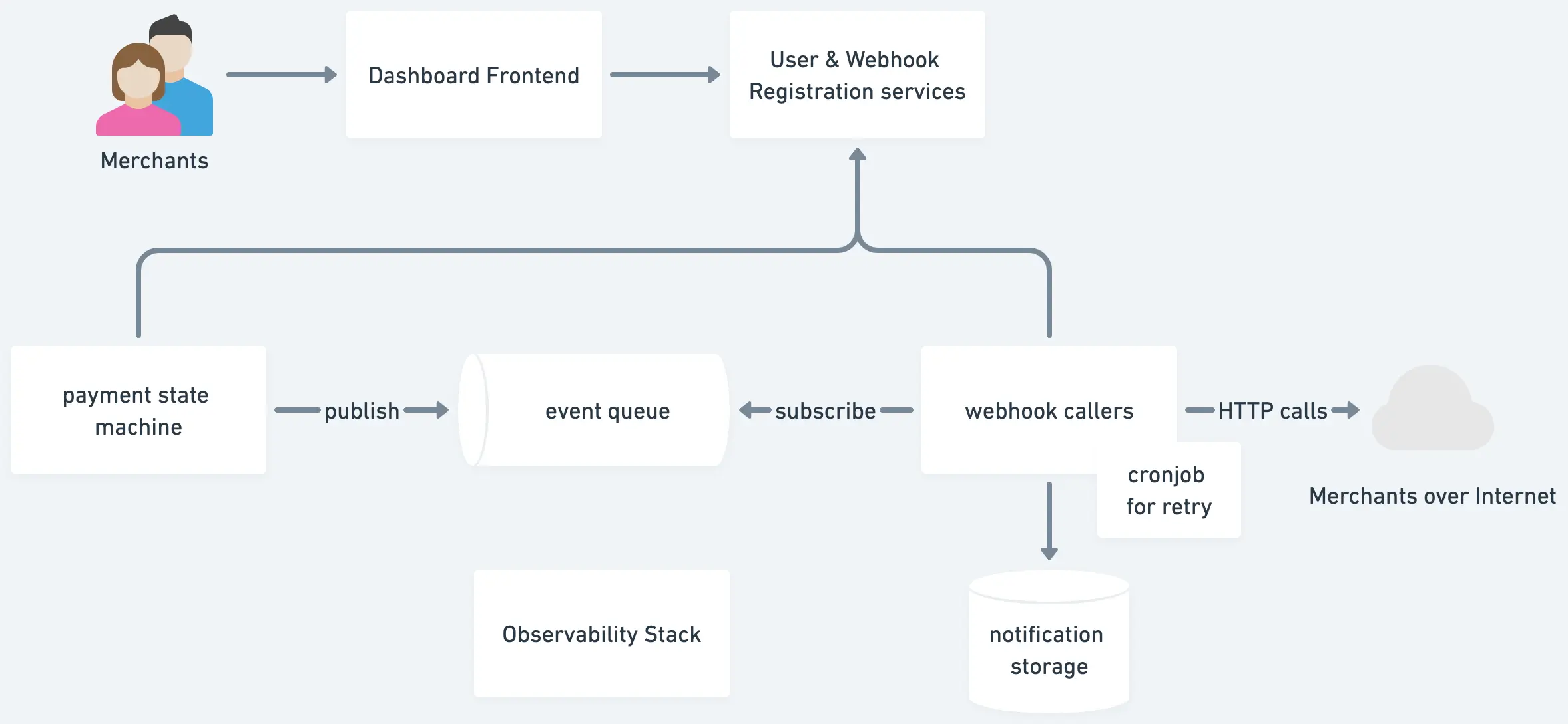
40 |
41 | ## 3. Features and Components
42 |
43 | ### Core Features
44 |
45 | 1. Users go to dashboard frontend to register webhook information with us - like the URL to call, the scope of events they want to subscribe, and then get an API key from us.
46 | 2. When there is a new event, publish it into the queue and then get consumed by callers. Callers get the registration and make the HTTP call to external services.
47 |
48 | ### Webhook callers
49 |
50 | 1. Subscribe to the event queue for payment success events published by a payment state machine or other services.
51 |
52 | 2. Once callers accept an event, fetch webhook URI, secret, and settings from the user settings service. Prepare the request based on those settings. For security...
53 |
54 | * All webhooks from user settings must be in HTTPs
55 |
56 | * If the payload is huge, the prospect latency is high, and we wants to make sure the target reciever is alive, we can verify its existance with a ping carrying a challenge. e.g. [Dropbox verifies webhook endpoints](https://www.dropbox.com/developers/reference/webhooks#documentation) by sending a GET request with a “challenge” param (a random string) encoded in the URL, which your endpoint is required to echo back as a response.
57 | * All callback requests are with header `x-webhook-signature`. So that the receiver can authenticate the request.
58 | * For symetric signature, we can use HMAC/SHA256 signature. Its value is `HMAC(webhook secret, raw request payload);`. Telegram takes this.
59 | * For asymmetric signature, we can use RSA/SHA256 signature. Its value is `RSA(webhook private key, raw request payload);` Stripe takes this.
60 | * If it's sensitive information, we can also consider encryption for the payload instead of just signing.
61 |
62 | 3. Make an HTTP POST request to the external merchant's endpoints with event payload and security headers.
63 |
64 | ### API Definition
65 |
66 | ```json5
67 | // POST https://example.com/webhook/
68 | {
69 | "id": 1,
70 | "scheduled_for": "2017-01-31T20:50:02Z",
71 | "event": {
72 | "id": "24934862-d980-46cb-9402-43c81b0cdba6",
73 | "resource": "event",
74 | "type": "charge:created",
75 | "api_version": "2018-03-22",
76 | "created_at": "2017-01-31T20:49:02Z",
77 | "data": {
78 | "code": "66BEOV2A", // or order ID the user need to fulfill
79 | "name": "The Sovereign Individual",
80 | "description": "Mastering the Transition to the Information Age",
81 | "hosted_url": "https://commerce.coinbase.com/charges/66BEOV2A",
82 | "created_at": "2017-01-31T20:49:02Z",
83 | "expires_at": "2017-01-31T21:49:02Z",
84 | "metadata": {},
85 | "pricing_type": "CNY",
86 | "payments": [
87 | // ...
88 | ],
89 | "addresses": {
90 | // ...
91 | }
92 | }
93 | }
94 | }
95 | ```
96 |
97 | The merchant server should respond with a 200 HTTP status code to acknowledge receipt of a webhook.
98 |
99 | ### Error-handling
100 |
101 | If there is no acknowledgment of receipt, we will [retry with idempotency key and exponential backoff for up to three days. The maximum retry interval is 1 hour.](https://puncsky.com/notes/43-how-to-design-robust-and-predictable-apis-with-idempotency) If it's reaching a certain limit, short-circuit / mark it as broken. Sending out an Email to the merchant.
102 |
103 | ### Metrics
104 |
105 | The Webhook callers service emits statuses into the time-series DB for metrics.
106 |
107 | Using Statsd + Influx DB vs. Prometheus?
108 |
109 | * InfluxDB: Application pushes data to InfluxDB. It has a monolithic DB for metrics and indices.
110 | * Prometheus: Prometheus server pulls the metrics values from the running application periodically. It uses LevelDB for indices, but each metric is stored in its own file.
111 |
112 | Or use the expensive DataDog or other APM services if you have a generous budget.
113 |
--------------------------------------------------------------------------------
/en/169-how-to-write-solid-code.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 169-how-to-write-solid-code
3 | id: 169-how-to-write-solid-code
4 | title: "How to write solid code?"
5 | date: 2019-09-25 02:29
6 | comments: true
7 | tags: [system design]
8 | description: Empathy plays the most important role in writing solid code. Besides, you need to choose a sustainable architecture to decrease human resource costs in total as the project scales. Then, adopt patterns and best practices; avoid anti-patterns. Finally, refactor if necessary.
9 | ---
10 |
11 | 
12 |
13 | 1. empathy / perspective-taking is the most important.
14 | 1. realize that code is written for human to read first and then for machines to execute.
15 | 2. software is so "soft" and there are many ways to achieve one thing. It's all about making the proper trade-offs to fulfill the requirements.
16 | 3. Invent and Simplify: Apple Pay RFID vs. Wechat Scan QR Code.
17 |
18 | 2. choose a sustainable architecture to reduce human resources costs per feature.
19 |
20 |
21 |
22 |
23 | 3. adopt patterns and best practices.
24 |
25 | 4. avoid anti-patterns
26 | * missing error-handling
27 | * callback hell = spaghetti code + unpredictable error handling
28 | * over-long inheritance chain
29 | * circular dependency
30 | * over-complicated code
31 | * nested tertiary operation
32 | * comment out unused code
33 | * missing i18n, especially RTL issues
34 | * don't repeat yourself
35 | * simple copy-and-paste
36 | * unreasonable comments
37 |
38 | 5. effective refactoring
39 | * semantic version
40 | * never introduce breaking change to non major versions
41 | * two legged change
42 |
--------------------------------------------------------------------------------
/en/174-designing-memcached.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 174-designing-memcached
3 | id: 174-designing-memcached
4 | title: "Designing Memcached or an in-memory KV store"
5 | date: 2019-10-03 22:04
6 | comments: true
7 | tags: [system design]
8 | description: Memcached = rich client + distributed servers + hash table + LRU. It features a simple server and pushes complexity to the client) and hence reliable and easy to deploy.
9 | references:
10 | - https://github.com/memcached/memcached/wiki/Overview
11 | - https://people.cs.uchicago.edu/~junchenj/34702/slides/34702-MemCache.pdf
12 | - https://en.wikipedia.org/wiki/Hash_table
13 | ---
14 |
15 | ## Requirements
16 |
17 | 1. High-performance, distributed key-value store
18 | * Why distributed?
19 | * Answer: to hold a larger size of data
20 |  24 | 2. For in-memory storage of small data objects
25 | 3. Simple server (pushing complexity to the client) and hence reliable and easy to deploy
26 |
27 | ## Architecture
28 | Big Picture: Client-server
29 |
30 |
24 | 2. For in-memory storage of small data objects
25 | 3. Simple server (pushing complexity to the client) and hence reliable and easy to deploy
26 |
27 | ## Architecture
28 | Big Picture: Client-server
29 |
30 | 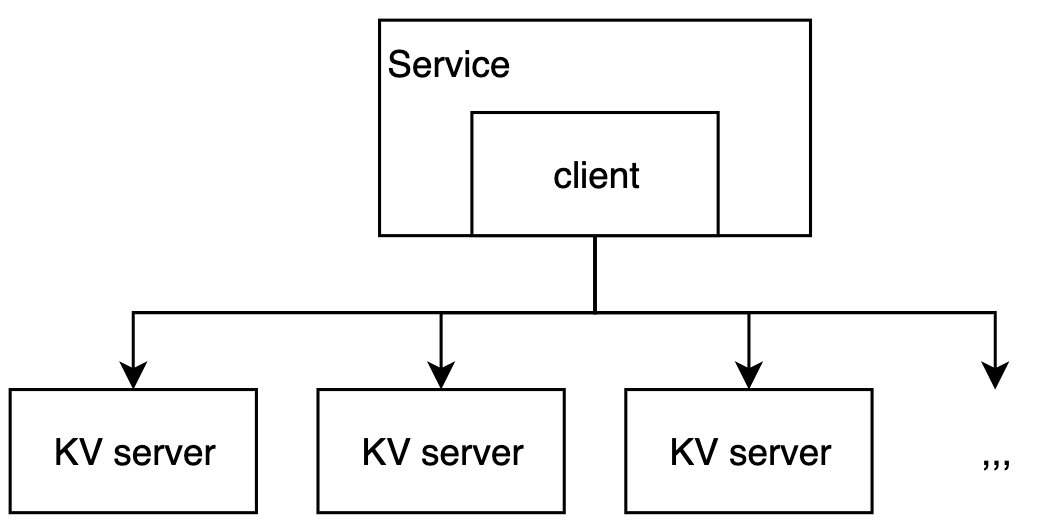 34 |
35 | * client
36 | * given a list of Memcached servers
37 | * chooses a server based on the key
38 | * server
39 | * store KVs into the internal hash table
40 | * LRU eviction
41 |
42 |
43 | The Key-value server consists of a fixed-size hash table + single-threaded handler + coarse locking
44 |
45 | 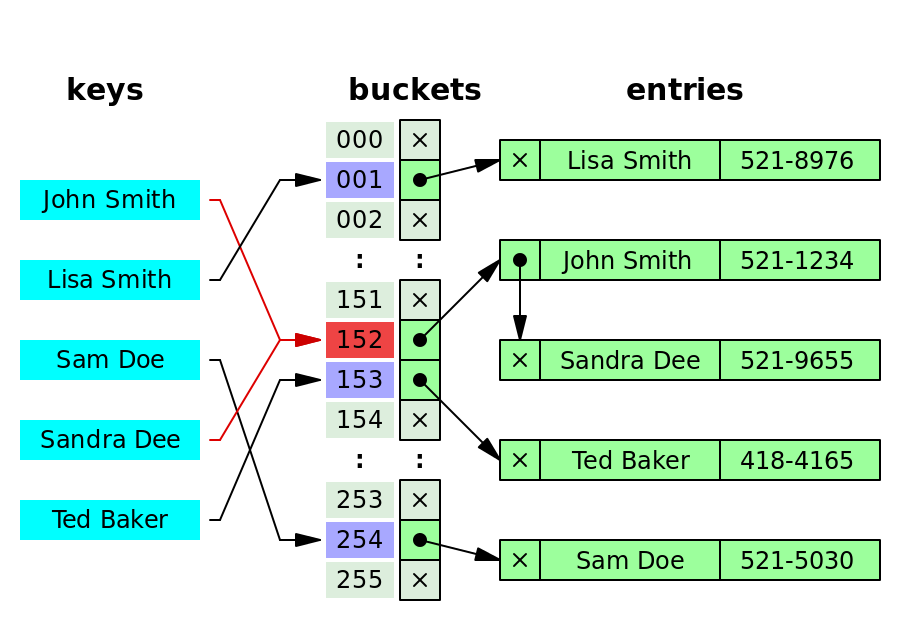
46 |
47 | How to handle collisions? Mostly three ways to resolve:
48 |
49 | 1. Separate chaining: the collided bucket chains a list of entries with the same index, and you can always append the newly collided key-value pair to the list.
50 | 2. open addressing: if there is a collision, go to the next index until finding an available bucket.
51 | 3. dynamic resizing: resize the hash table and allocate more spaces; hence, collisions will happen less frequently.
52 |
53 | ## How does the client determine which server to query?
54 |
55 | See [Data Partition and Routing](https://puncsky.com/notes/2018-07-21-data-partition-and-routing)
56 |
57 | ## How to use cache?
58 |
59 | See [Key value cache](https://puncsky.com/notes/122-key-value-cache)
60 |
61 | ## How to further optimize?
62 |
63 | See [How Facebook Scale its Social Graph Store? TAO](https://puncsky.com/notes/49-facebook-tao)
64 |
--------------------------------------------------------------------------------
/en/177-designing-Airbnb-or-a-hotel-booking-system.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 177-designing-Airbnb-or-a-hotel-booking-system
3 | id: 177-designing-Airbnb-or-a-hotel-booking-system
4 | title: "Designing Airbnb or a hotel booking system"
5 | date: 2019-10-06 01:39
6 | comments: true
7 | slides: false
8 | tags: [system design]
9 | description: For guests and hosts, we store data with a relational database and build indexes to search by location, metadata, and availability. We can use external vendors for payment and remind the reservations with a priority queue.
10 | references:
11 | - https://www.vertabelo.com/blog/designing-a-data-model-for-a-hotel-room-booking-system/
12 | ---
13 |
14 | ## Requirements
15 | * for guests
16 | * search rooms by locations, dates, number of rooms, and number of guests
17 | * get room details (like picture, name, review, address, etc.) and prices
18 | * pay and book room from inventory by date and room id
19 | * checkout as a guest
20 | * user is logged in already
21 | * notification via Email and mobile push notification
22 | * for hotel or rental administrators (suppliers/hosts)
23 | * administrators (receptionist/manager/rental owner): manage room inventory and help the guest to check-in and check out
24 | * housekeeper: clean up rooms routinely
25 |
26 | ## Architecture
27 |
28 | 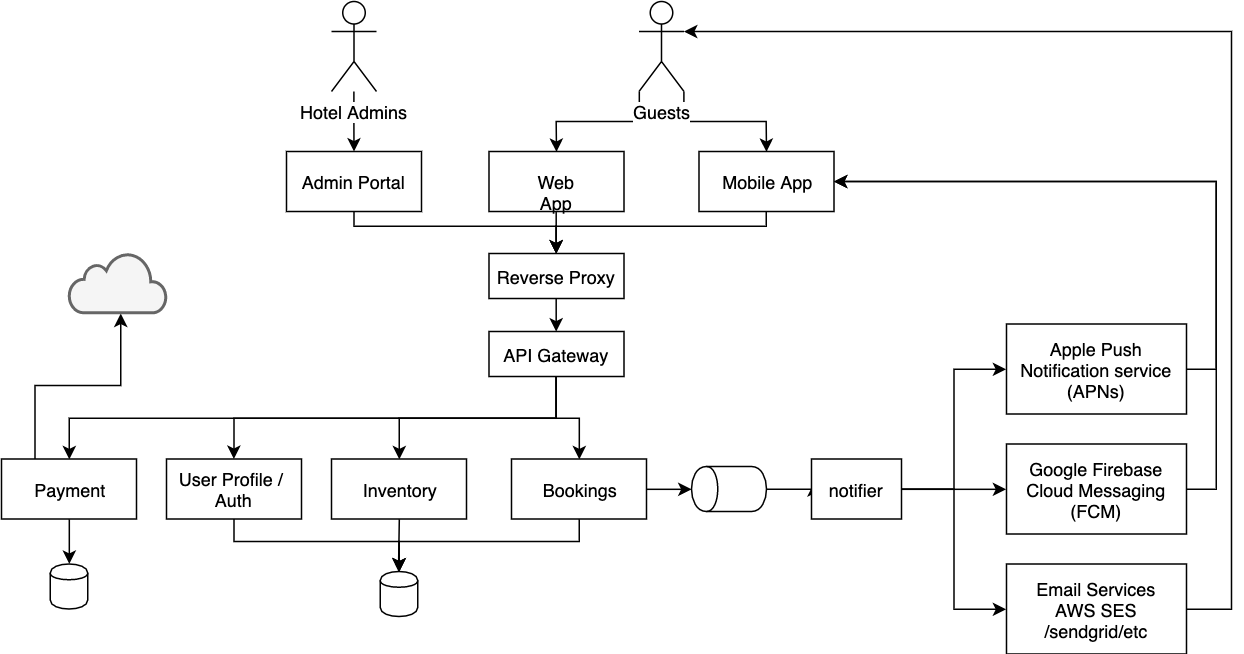
29 |
30 | ## Components
31 |
32 | ### Inventory \<\> Bookings \<\> Users (guests and hosts)
33 |
34 | Suppliers provide their room details in the inventory. And users can search, get, and reserve rooms accordingly. After reserving the room, the user's payment will change the `status` of the `reserved_room` as well. You could check the data model in [this post](https://www.vertabelo.com/blog/designing-a-data-model-for-a-hotel-room-booking-system/).
35 |
36 | ### How to find available rooms?
37 |
38 | * by location: geo-search with [spatial indexing](https://en.wikipedia.org/wiki/Spatial_database), e.g. geo-hash or quad-tree.
39 | * by room metadata: apply filters or search conditions when querying the database.
40 | * by date-in and date-out and availability. Two options:
41 | * option 1: for a given `room_id`, check all `occupied_room` today or later, transform the data structure to an array of occupation by days, and finally find available slots in the array. This process might be time-consuming, so we can build the availability index.
42 | * option 2: for a given `room_id`, always create an entry for an occupied day. Then it will be easier to query unavailable slots by dates.
43 |
44 | ### For hotels, syncing data
45 |
46 | If it is a hotel booking system, then it will probably publish to Booking Channels like GDS, Aggregators, and Wholesalers.
47 |
48 | 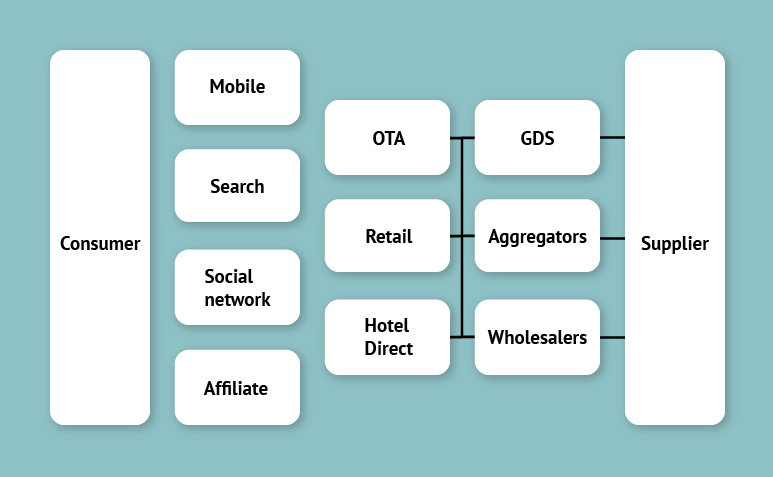
49 |
50 | To sync data across those places. We can
51 |
52 | 1. [retry with idempotency to improve the success rate of the external calls and ensure no duplicate orders](https://puncsky.com/notes/43-how-to-design-robust-and-predictable-apis-with-idempotency).
53 | 2. provide webhook callback APIs to external vendors to update status in the internal system.
54 |
55 | ### Payment & Bookkeeping
56 |
57 | Data model: [double-entry bookkeeping](https://puncsky.com/notes/167-designing-paypal-money-transfer#payment-service)
58 |
59 | To execute the payment, since we are calling the external payment gateway, like bank or Stripe, Braintree, etc. It is crucial to keep data in-sync across different places. [We need to sync data across the transaction table and external banks and vendors.](https://puncsky.com/#how-to-sync-across-the-transaction-table-and-external-banks-and-vendors)
60 |
61 | ### Notifier for reminders / alerts
62 |
63 | The notification system is essentially a delayer scheduler (priority queue + subscriber) plus API integrations.
64 |
65 | For example, a daily cronjob will query the database for notifications to be sent out today and put them into the priority queue by date. The subscriber will get the earliest ones from the priority queue and send out if reaching the expected timestamp. Otherwise, put the task back to the queue and sleep to make the CPU idle for other work, which can be interrupted if there are new alerts added for today.
66 |
--------------------------------------------------------------------------------
/en/178-lyft-marketing-automation-symphony.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 178-lyft-marketing-automation-symphony
3 | id: 178-lyft-marketing-automation-symphony
4 | title: "Lyft's Marketing Automation Platform -- Symphony"
5 | date: 2019-10-09 23:30
6 | comments: true
7 | tags: [marketing, system design]
8 | slides: false
9 | description: "To achieve a higher ROI in advertising, Lyft launched a marketing automation platform, which consists of three main components: lifetime value forecaster, budget allocator, and bidders."
10 | references:
11 | - https://eng.lyft.com/lyft-marketing-automation-b43b7b7537cc
12 | ---
13 |
14 | ## Acquisition Efficiency Problem:How to achieve a better ROI in advertising?
15 |
16 | In details, Lyft's advertisements should meet requirements as below:
17 |
18 | 1. being able to manage region-specific ad campaigns
19 | 2. guided by data-driven growth: The growth must be scalable, measurable, and predictable
20 | 3. supporting Lyft's unique growth model as shown below
21 |
22 | 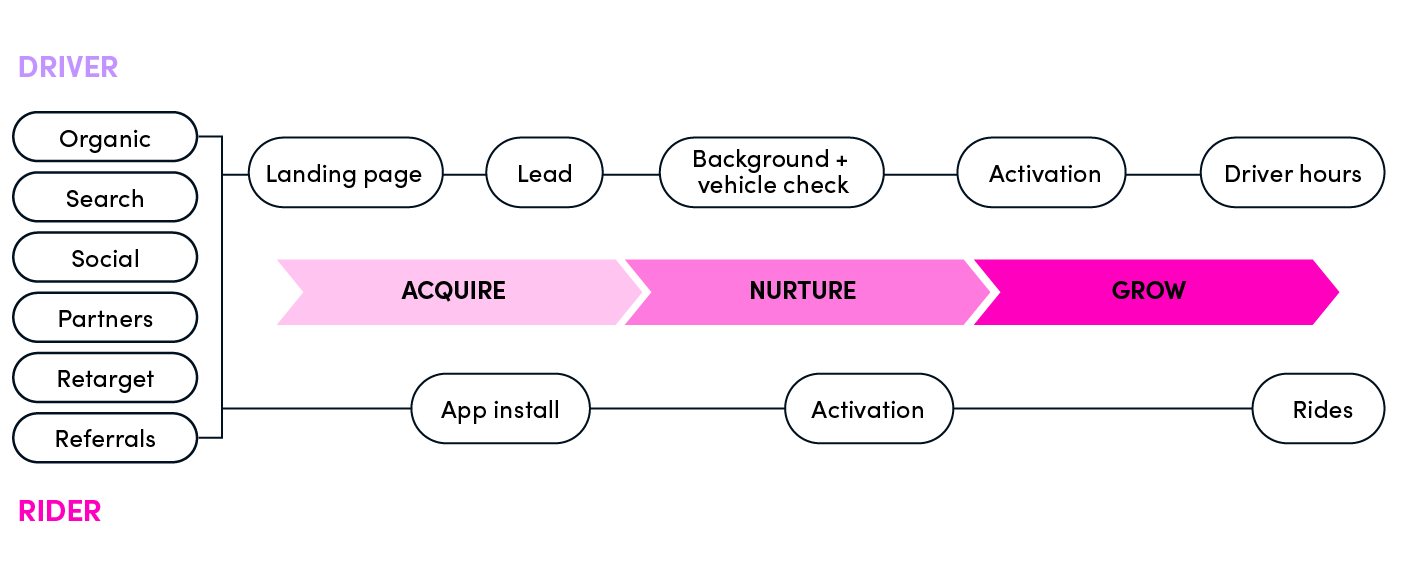
23 |
24 | However, the biggest challenge is to manage all the processes of cross-region marketing at scale, which include choosing bids, budgets, creatives, incentives, and audiences, running A/B tests, and so on. You can see what occupies a day in the life of a digital marketer:
25 |
26 | 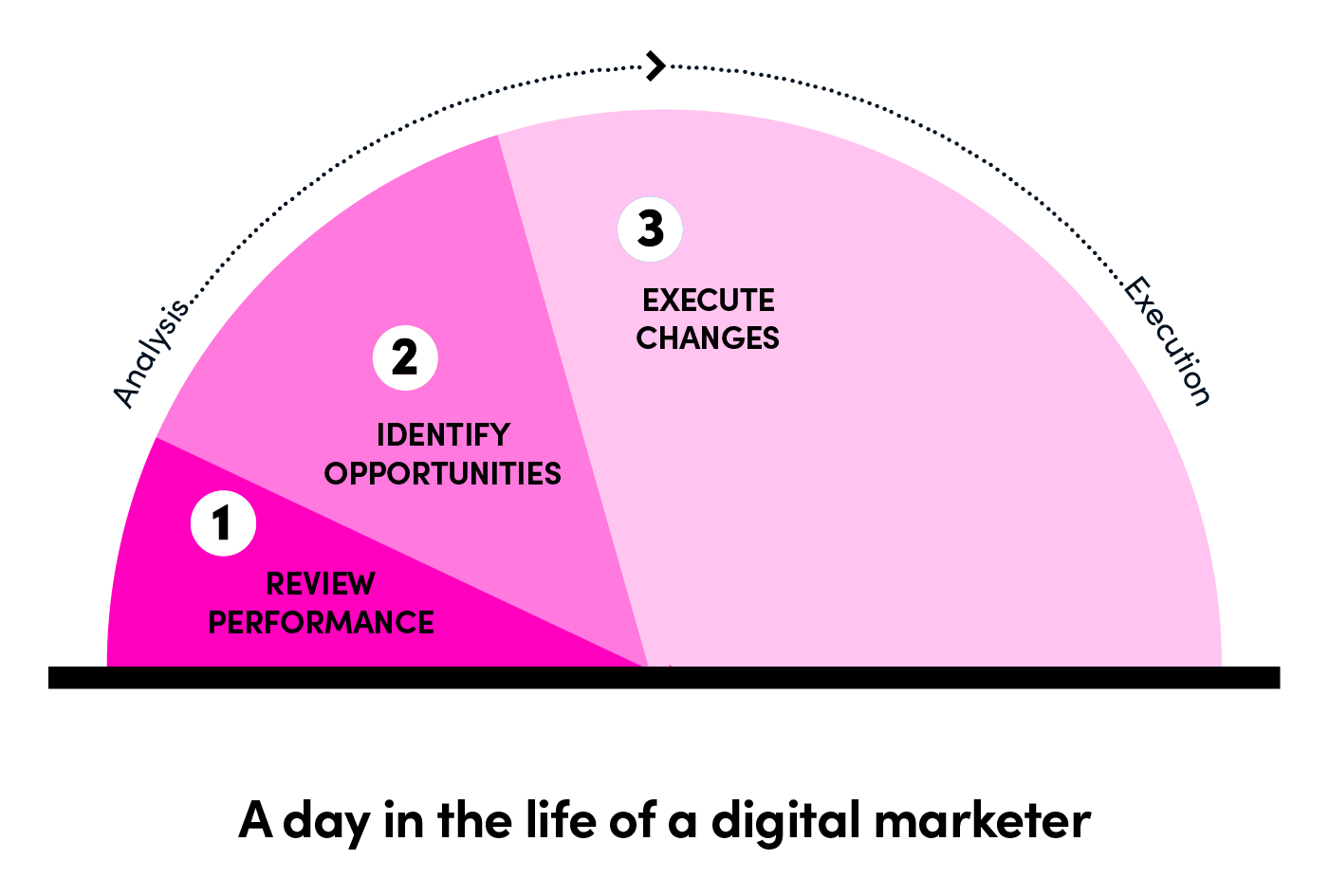
27 |
28 | We can find out that *execution* occupies most of the time while *analysis*, thought as more important, takes much less time. A scaling strategy will enable marketers to concentrate on analysis and decision-making process instead of operational activities.
29 |
30 | ## Solution: Automation
31 |
32 | To reduce costs and improve experimental efficiency, we need to
33 |
34 | 1. predict the likelihood of a new user to be interested in our product
35 | 2. evaluate effectively and allocate marketing budgets across channels
36 | 3. manage thousands of ad campaigns handily
37 |
38 | The marketing performance data flows into the reinforcement-learning system of Lyft: [Amundsen](https://guigu.io/blog/2018-12-03-making-progress-30-kilometers-per-day)
39 |
40 | The problems that need to be automated include:
41 |
42 | 1. updating bids across search keywords
43 | 2. turning off poor-performing creatives
44 | 3. changing referrals values by market
45 | 4. identifying high-value user segments
46 | 5. sharing strategies across campaigns
47 |
48 | ## Architecture
49 |
50 | 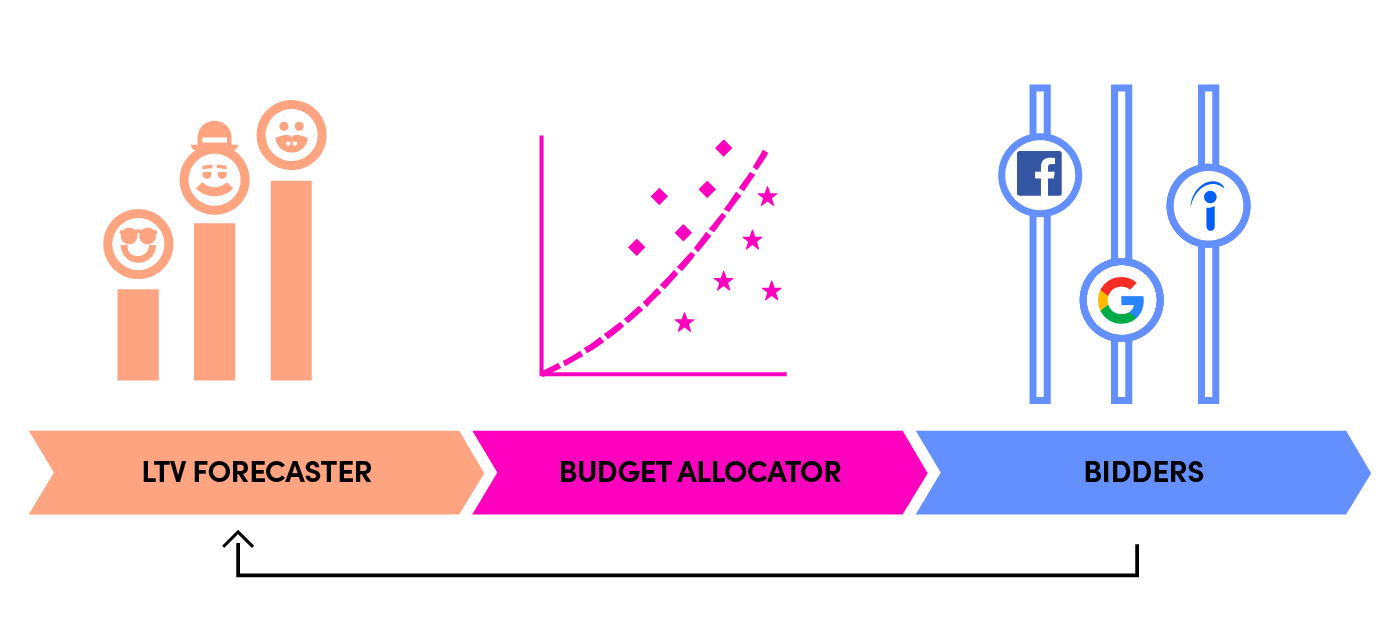
51 |
52 | The tech stack includes - Apache Hive, Presto, ML platform, Airflow, 3rd-party APIs, UI.
53 |
54 | ## Main components
55 |
56 | ### Lifetime Value(LTV) forecaster
57 |
58 | The lifetime value of a user is an important criterion to measure the efficiency of acquisition channels. The budget is determined together by LTV and the price we are willing to pay in that region.
59 |
60 | Our knowledge of a new user is limited. The historical data can help us to predict more accurately as the user interacts with our services.
61 |
62 | Initial eigenvalue:
63 |
64 | 
65 |
66 |
67 | The forecast improves as the historical data of interactivity accumulates:
68 |
69 | 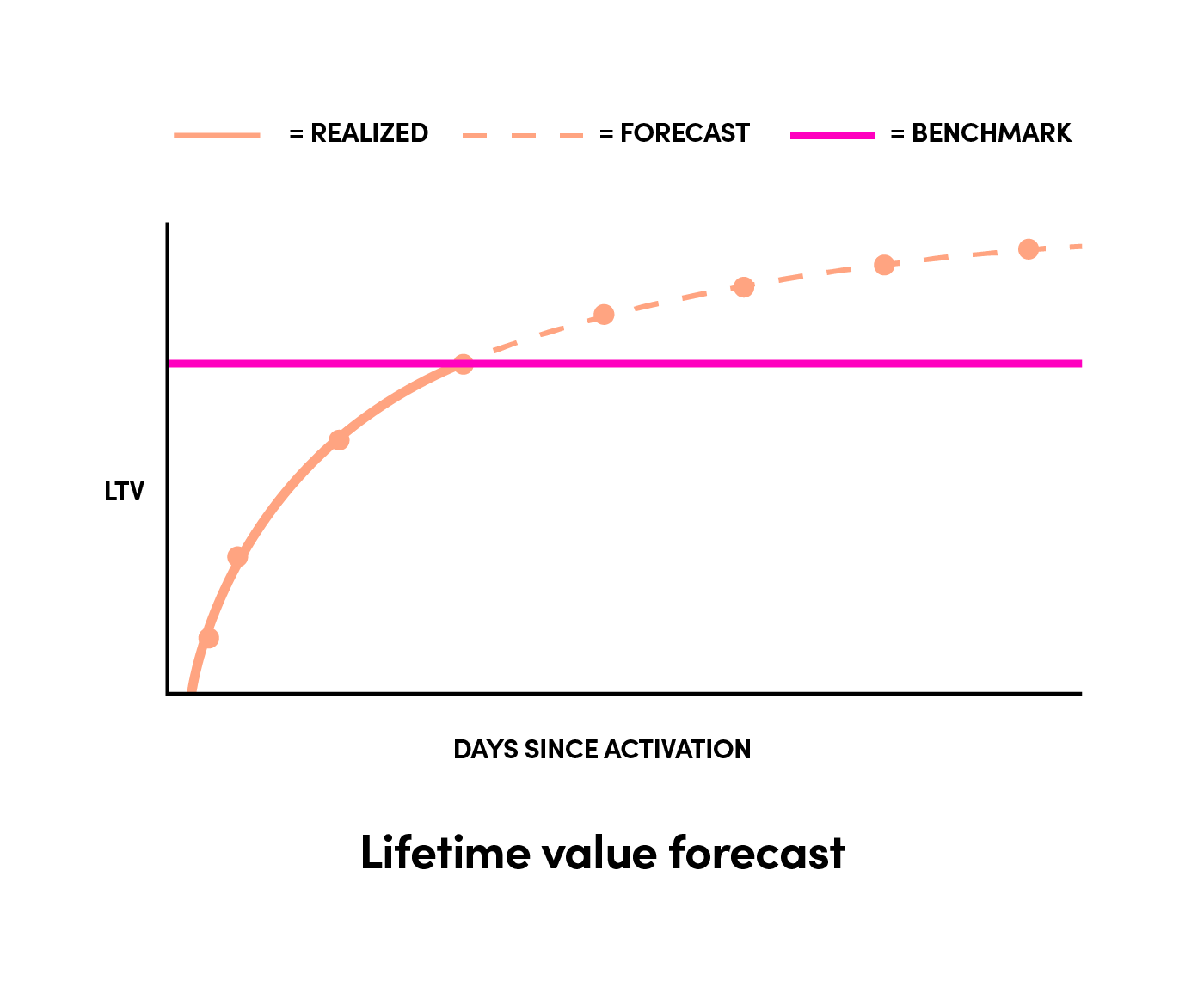
70 |
71 |
72 | ### Budget allocator
73 |
74 | After LTV is predicted, the next is to estimate budgets based on the price. A curve of the form `LTV = a * (spend)^b` is fit to the data. A degree of randomness will be injected into the cost-curve creation process in order to converge a global optimum.
75 |
76 | 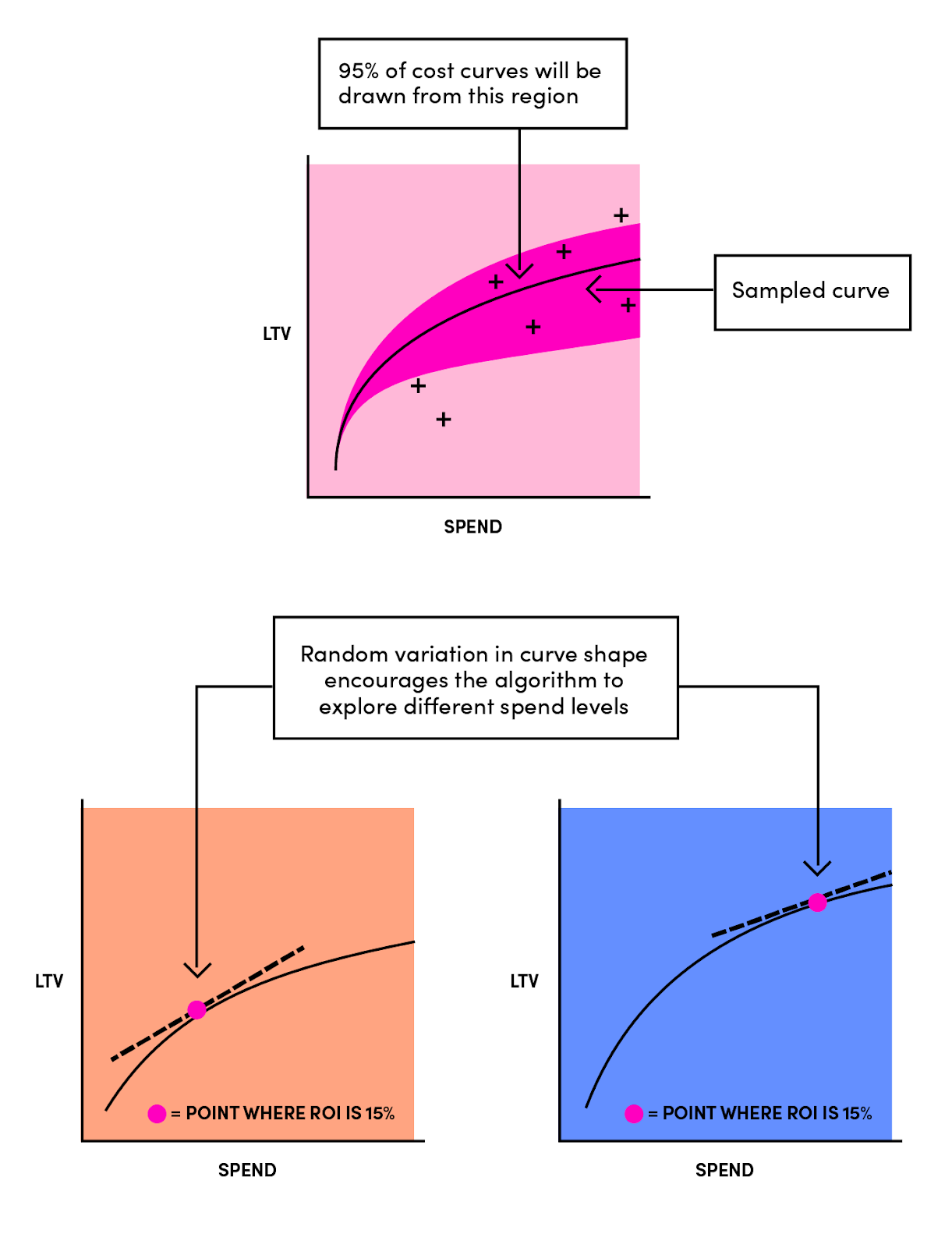
77 |
78 |
79 | ### Bidders
80 |
81 | Bidders are made up of two parts - the tuners and actors. The tuners decide exact channel-specific parameters based on the price. The actors communicate the actual bid to different channels.
82 |
83 | Some popular bidding strategies, applied in different channels, are listed as below:
84 |
85 | 
86 |
87 |
88 | ### Conclusion
89 |
90 | We have to value human experiences in the automation process; otherwise, the quality of the models may be "garbage in, garbage out". Once saved from laboring tasks, marketers can focus more on understanding users, channels, and the messages they want to convey to audiences, and thus obtain better ad impacts. That's how Lyft can achieve a higher ROI with less time and efforts.
91 |
92 |
--------------------------------------------------------------------------------
/en/179-designing-typeahead-search-or-autocomplete.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 179-designing-typeahead-search-or-autocomplete
3 | id: 179-designing-typeahead-search-or-autocomplete
4 | title: "Designing typeahead search or autocomplete"
5 | date: 2019-10-10 18:33
6 | comments: true
7 | tags: [system design]
8 | slides: false
9 | description: How to design a realtime typeahead autocomplete service? Linkedin's Cleo lib answers with a multi-layer architecture (browser cache / web tier / result aggregator / various typeahead backend) and 4 elements (inverted / forward index, bloom filter, scorer).
10 | references:
11 | - https://engineering.linkedin.com/open-source/cleo-open-source-technology-behind-linkedins-typeahead-search
12 | - http://sna-projects.com/cleo/
13 | ---
14 |
15 | ## Requirements
16 |
17 | * realtime / low-latency typeahead and autocomplete service for social networks, like Linkedin or Facebook
18 | * search social profiles with prefixes
19 | * newly added account appear instantly in the scope of the search
20 | * not for “query autocomplete” (like the Google search-box dropdown), but for displaying actual search results, including
21 | * generic typeahead: network-agnostic results from a global ranking scheme like popularity.
22 | * network typeahead: results from user’s 1st and 2nd-degree network connections, and People You May Know scores.
23 |
24 | 
25 |
26 | ## Architecture
27 |
28 | Multi-layer architecture
29 |
30 | * browser cache
31 | * web tier
32 | * result aggregator
33 | * various typeahead backend
34 |
35 | 
36 |
37 | ## Result Aggregator
38 | The abstraction of this problem is to find documents by prefixes and terms in a very large number of elements. The solution leverages these four major data structures:
39 |
40 | 1. `InvertedIndex`: given any prefix, find all the document ids that contain the prefix.
41 | 2. `for each document, prepare a BloomFilter`: with user typing more, we can quickly filter out documents that do not contain the latest prefixes or terms, by check with their bloom filters.
42 | 3. `ForwardIndex`: previous bloom filter may return false positives, and now we query the actual documents to reject them.
43 | 4. `scorer(document):relevance`: Each partition return all of its true hits and scores. And then we aggregate and rank.
44 |
45 | 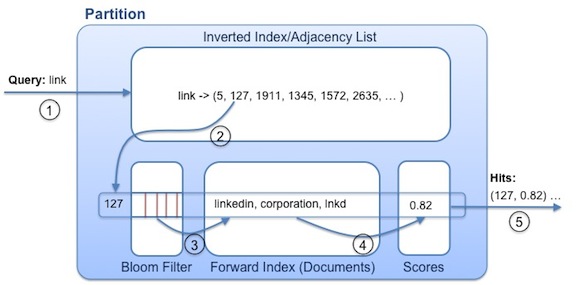
46 |
47 | ## Performance
48 |
49 | * generic typeahead: latency \< \= 1 ms within a cluster
50 | * network typeahead (very-large dataset over 1st and 2nd degree network): latency \< \= 15 ms
51 | * aggregator: latency \< \= 25 ms
52 |
--------------------------------------------------------------------------------
/en/181-concurrency-models.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 181-concurrency-models
3 | id: 181-concurrency-models
4 | title: "Concurrency Models"
5 | date: 2019-10-16 14:04
6 | comments: true
7 | tags: [system design]
8 | description: "Five concurrency models you may want to know: Single-threaded; Multiprocessing and lock-based concurrency; Communicating Sequential Processes (CSP); Actor Model (AM); Software Transactional Memory (STM)."
9 | ---
10 |
11 | 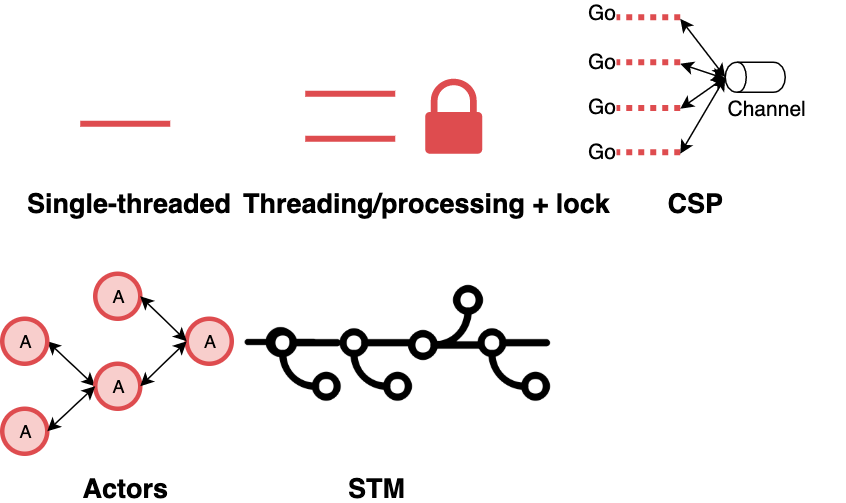
12 |
13 |
14 | * Single-threaded - Callbacks, Promises, Observables and async/await: vanilla JS
15 | * threading/multiprocessing, lock-based concurrency
16 | * protecting critical section vs. performance
17 | * Communicating Sequential Processes (CSP)
18 | * Golang or Clojure’s `core.async`.
19 | * process/thread passes data through channels.
20 | * Actor Model (AM): Elixir, Erlang, Scala
21 | * asynchronous by nature, and have location transparency that spans runtimes and machines - if you have a reference (Akka) or PID (Erlang) of an actor, you can message it via mailboxes.
22 | * powerful fault tolerance by organizing actors into a supervision hierarchy, and you can handle failures at its exact level of hierarchy.
23 | * Software Transactional Memory (STM): Clojure, Haskell
24 | * like MVCC or pure functions: commit / abort / retry
25 |
--------------------------------------------------------------------------------
/en/182-designing-l7-load-balancer.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 182-designing-l7-load-balancer
3 | id: 182-designing-l7-load-balancer
4 | title: "Designing a Load Balancer or Dropbox Bandaid"
5 | date: 2019-10-19 15:21
6 | comments: true
7 | tags: [system design]
8 | slides: false
9 | description: Large-scale web services deal with high-volume traffic, but one host could only serve a limited amount of requests. There is usually a server farm to take the traffic altogether. How to route them so that each host could evenly receive the request?
10 | references:
11 | - https://blogs.dropbox.com/tech/2019/09/enhancing-bandaid-load-balancing-at-dropbox-by-leveraging-real-time-backend-server-load-information/
12 | - https://medium.com/netflix-techblog/netflix-edge-load-balancing-695308b5548c
13 | - https://www.nginx.com/blog/nginx-power-of-two-choices-load-balancing-algorithm/#least_conn
14 | ---
15 |
16 | ## Requirements
17 |
18 |
19 | Internet-scale web services deal with high-volume traffic from the whole world. However, one server could only serve a limited amount of requests at the same time. Consequently, there is usually a server farm or a large cluster of servers to undertake the traffic altogether. Here comes the question: how to route them so that each host could evenly receive and process the request?
20 |
21 | 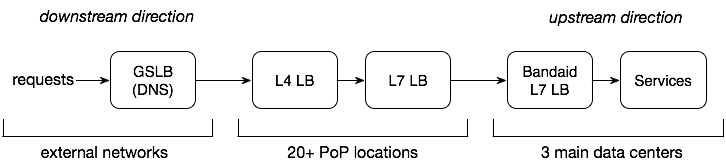
22 |
23 | Since there are many hops and layers of load balancers from the user to the server, specifically speaking, this time our design requirements are
24 |
25 | * [designing an L7 Load Balancer inside a data center](https://tianpan.co/notes/2018-07-23-load-balancer-types)
26 | * leveraging real-time load information from the backend
27 | * serving 10 m RPS, 10 T traffic per sec
28 |
29 | > Note: If Service A depends on (or consumes) Service B, then A is downstream service of B, and B is upstream service of A.
30 |
31 |
32 | ## Challenges
33 | Why is it hard to balance loads? The answer is that it is hard to collect accurate load distribution stats and act accordingly.
34 |
35 | ### Distributing-by-requests ≠ distributing-by-load
36 |
37 | Random and round-robin distribute the traffic by requests. However, the actual load is not per request - some are heavy in CPU or thread utilization, while some are lightweight.
38 |
39 | 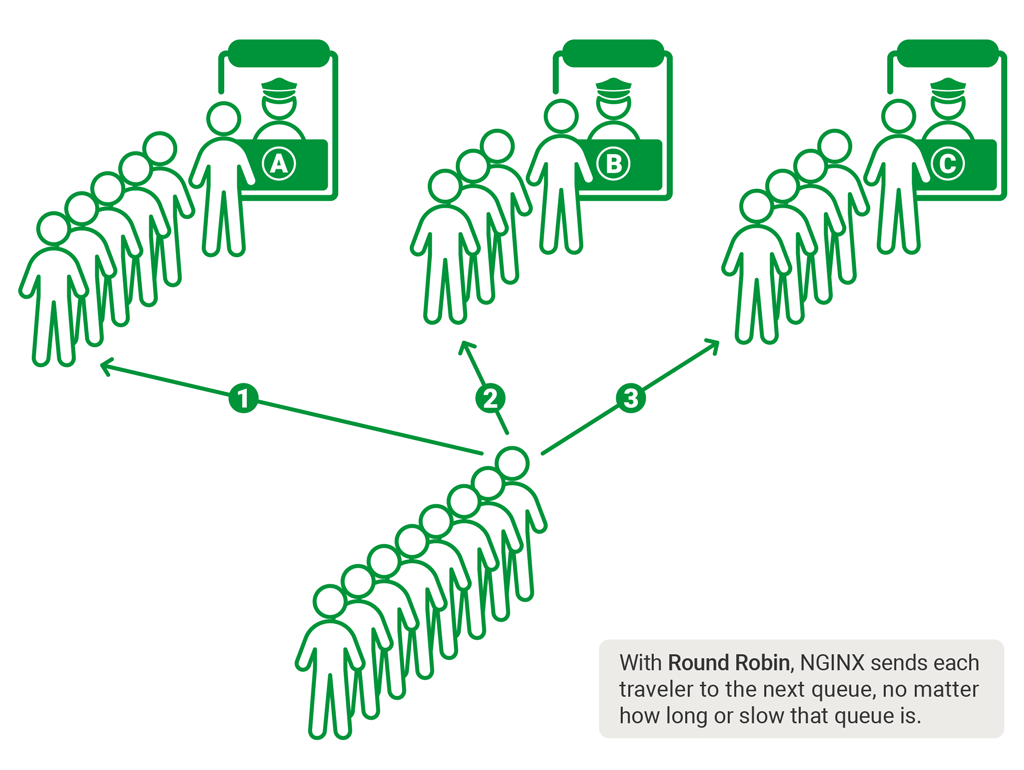
40 |
41 | To be more accurate on the load, load balancers have to maintain local states of observed active request number, connection number, or request process latencies for each backend server. And based on them, we can use distribution algorithms like Least-connections, least-time, and Random N choices:
42 |
43 | **Least-connections**: a request is passed to the server with the least number of active connections.
44 |
45 | 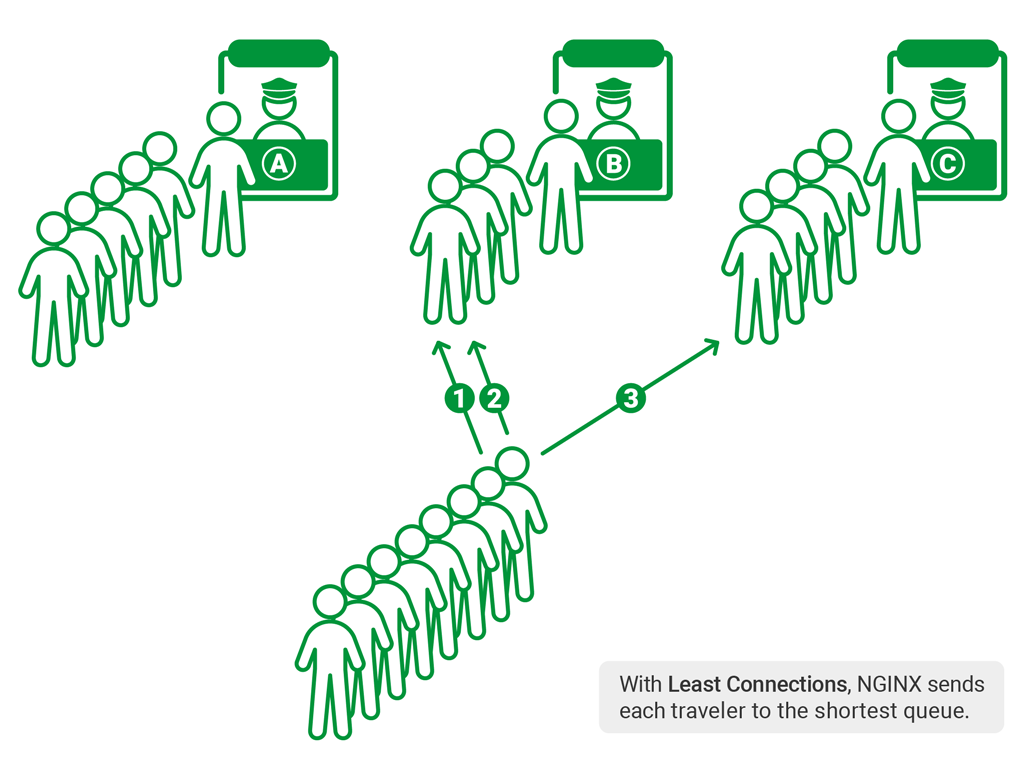
46 |
47 | **latency-based (least-time)**: a request is passed to the server with the least average response time and least number of active connections, taking into account weights of servers.
48 |
49 | 
50 |
51 | However, these two algorithms work well only with only one load balancer. If there are multiple ones, there might have **herd effect**. That is to say; all the load balancers notice that one service is momentarily faster, and then all send requests to that service.
52 |
53 | **Random N choices** (where N=2 in most cases / a.k.a *Power of Two Choices*): pick two at random and chose the better option of the two, *avoiding the worse choice*.
54 |
55 |
56 | ### Distributed environments.
57 |
58 | 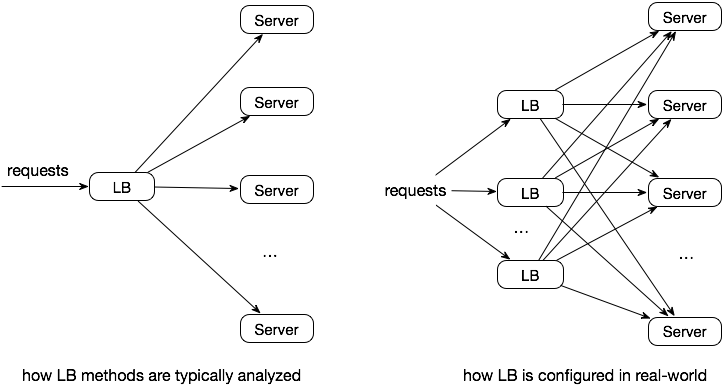
59 |
60 | Local LB is unaware of global downstream and upstream states, including
61 |
62 | * upstream service loads
63 | * upstream service may be super large, and thus it is hard to pick the right subset to cover with the load balancer
64 | * downstream service loads
65 | * the processing time of various requests are hard to predict
66 |
67 | ## Solutions
68 | There are three options to collect load the stats accurately and then act accordingly:
69 |
70 | * centralized & dynamic controller
71 | * distributed but with shared states
72 | * piggybacking server-side information in response messages or active probing
73 |
74 | Dropbox Bandaid team chose the third option because it fits into their existing *random N choices* approach well.
75 |
76 | 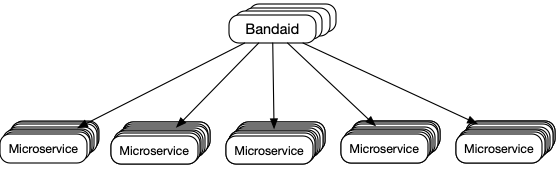
77 |
78 | However, instead of using local states, like the original *random N choices* do, they use real-time global information from the backend servers via the response headers.
79 |
80 | **Server utilization**: Backend servers are configured with a max capacity and count the on-going requests, and then they have utilization percentage calculated ranging from 0.0 to 1.0.
81 |
82 | 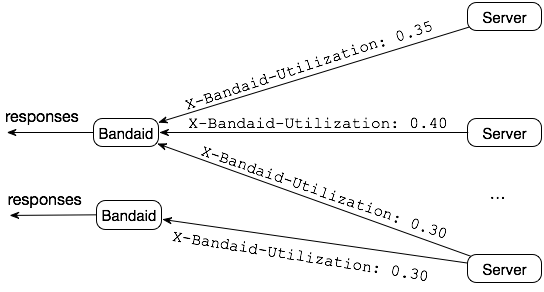
83 |
84 | There are two problems to consider:
85 |
86 | 1. **Handling HTTP errors**: If a server fast fails requests, it attracts more traffic and fails more.
87 | 2. **Stats decay**: If a server’s load is too high, no requests will be distributed there and hence the server gets stuck. They use a decay function of the inverted sigmoid curve to solve the problem.
88 |
89 | ## Results: requests are more balanced
90 |
91 | 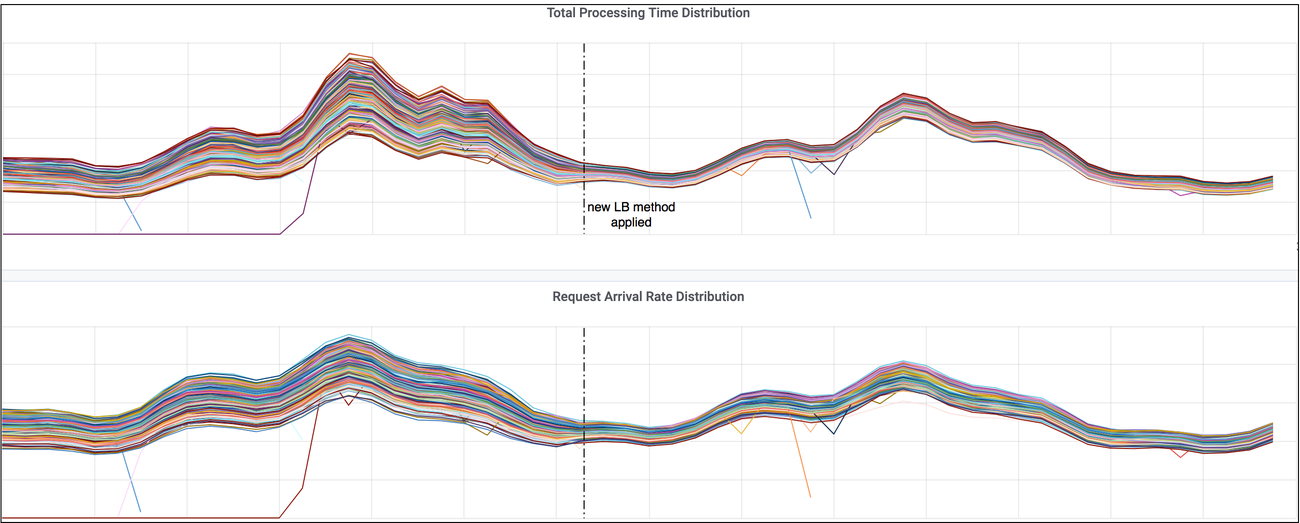
92 |
93 |
--------------------------------------------------------------------------------
/en/2018-07-10-cloud-design-patterns.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-10-cloud-design-patterns
3 | id: 2018-07-10-cloud-design-patterns
4 | title: "Cloud Design Patterns"
5 | date: 2018-07-10 11:16
6 | comments: true
7 | tags: [design patterns, system design]
8 | description: "There are three types of cloud design patterns. Availability patterns have health endpoint monitoring and throttling. Data management patterns have cache-aside and static content hosting. Security patterns have federated identity."
9 | references:
10 | - https://docs.microsoft.com/en-us/azure/architecture/patterns/
11 | ---
12 |
13 | ## Availability patterns
14 | - Health Endpoint Monitoring: Implement functional checks in an application that external tools can access through exposed endpoints at regular intervals.
15 | - Queue-Based Load Leveling: Use a queue that acts as a buffer between a task and a service that it invokes in order to smooth intermittent heavy loads.
16 | - Throttling: Control the consumption of resources used by an instance of an application, an individual tenant, or an entire service.
17 |
18 |
19 |
20 | ## Data Management patterns
21 | - Cache-Aside: Load data on demand into a cache from a data store
22 | - Command and Query Responsibility Segregation: Segregate operations that read data from operations that update data by using separate interfaces.
23 | - Event Sourcing: Use an append-only store to record the full series of events that describe actions taken on data in a domain.
24 | - Index Table: Create indexes over the fields in data stores that are frequently referenced by queries.
25 | - Materialized View: Generate prepopulated views over the data in one or more data stores when the data isn't ideally formatted for required query operations.
26 | - Sharding: Divide a data store into a set of horizontal partitions or shards.
27 | - Static Content Hosting: Deploy static content to a cloud-based storage service that can deliver them directly to the client.
28 |
29 |
30 |
31 | ## Security Patterns
32 | - Federated Identity: Delegate authentication to an external identity provider.
33 | - Gatekeeper: Protect applications and services by using a dedicated host instance that acts as a broker between clients and the application or service, validates and sanitizes requests, and passes requests and data between them.
34 | - Valet Key: Use a token or key that provides clients with restricted direct access to a specific resource or service.
35 |
--------------------------------------------------------------------------------
/en/2018-07-20-experience-deep-dive.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-20-experience-deep-dive
3 | id: 2018-07-20-experience-deep-dive
4 | title: "Experience Deep Dive"
5 | date: 2018-07-20 11:54
6 | comments: true
7 | tags: [system design]
8 | description: "For those who had little experience in leadership positions, we have some tips for interviews. It is necessary to describe your previous projects including challenges or improvements. Also, remember to demonstrate your communication skills."
9 | ---
10 |
11 | ## Intended Audience
12 |
13 | Moderate experience or less, or anyone who was not in a leadership or design position (either formal or informal) in their previous position
14 |
15 |
16 |
17 | ## Question Description
18 |
19 | Describe one of your previous projects that was particularly interesting or memorable to you. Followup questions:
20 |
21 | What about it made it interesting?
22 | What was the most challenging part of the project, and how did you address those challenges?
23 | What did you learn from the project, and what do you wish you had known before you started?
24 | What other designs/implementation methods did you consider? Why did you choose the one that you did? If you were to do the same project over again, what would you do differently?
25 |
26 |
27 |
28 | ## Interviewer tips
29 |
30 | Since the goal here is to assess the technical communication skill and interest level of someone who has not necessarily ever been in a role that they could conduct a crash course in, you should be prepared to keep asking them questions (either for more details, or about other aspects of the project). If they are a recent grad and did a thesis, that's often a good choice to talk about. While this question is in many ways similar to the Resume Questions question from phone screen one, this question is intended to be approximately four times as long, and should get into proportionally more detail about what it is that they have done. As such, the scoring criteria are similar, but should be evaluated with both higher expectations and more data.
31 |
32 |
33 |
34 | ## Scoring
35 |
36 | A great candidate will
37 |
38 | - Be able to talk for the full time about the project, with interaction from the interviewer being conversational rather than directing
39 | - Be knowledgeable about the project as a whole, rather than only their area of focus, and be able to articulate the intent and design of the project
40 |
41 |
42 | - Be passionate about whatever the project was, and able to describe the elements of the project that inspired that passion clearly
43 | - Be able to clearly explain what alternatives were considered, and why they chose the implementation strategy that they did.
44 | - Have reflected on and learned from their experiences
45 |
46 |
47 |
48 | A good candidate will
49 |
50 | - May have some trouble talking for the full time, but will be able to with some help and questions from the interviewer
51 | - May lack some knowledge about the larger scope of the project, but still have strong knowledge of their particular area and pieces that directly interacted with them
52 | - May seem passionate, but be unable to clearly explain what inspired that passion
53 |
54 |
55 | - May be able to discuss alternatives to what they did, but not have considered them in depth
56 | - Have reflected on and learned from their experiences
57 |
58 |
59 |
60 | A bad candidate will
61 | - Have difficulty talking for the full time. The interviewer may feel as if they are interrogating rather than conversing with the candidate
62 | - May lack detailed knowledge of the project, even within the area that they were working. They may not understand why their piece was designed the way it was, or may not understand how it interacted with other systems
63 | - Does not seem very interested in the project - remember that you are asking them about the most interesting project that they have done, they should be very - interested in whatever it was
64 |
65 |
66 | - May not be familiar with potential alternatives to their implementation method
67 | - Does not seem to have learned from or reflected on their experiences with the project. A key sign of this is that the answer to 'what did you learn' and 'what would you do differently' are short and/or nearly identical.
68 |
--------------------------------------------------------------------------------
/en/2018-07-21-data-partition-and-routing.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-21-data-partition-and-routing
3 | id: 2018-07-21-data-partition-and-routing
4 | title: "Data Partition and Routing"
5 | date: 2018-07-20 11:54
6 | comments: true
7 | tags: [system design]
8 | description: "The advantages of implementing data partition and routing are availability and read efficiency while consistency is the weakness. The routing abstract model is essentially two maps: key-partition map and partition-machine map."
9 | ---
10 |
11 | ## Why data partition and routing?
12 |
13 | large dataset ⟶ scale out ⟶ data shard / partition ⟶ 1) routing for data access 2) replica for availability
14 |
15 | - Pros
16 | - availability
17 | - read(parallelization, single read efficiency)
18 | - Cons
19 | - consistency
20 |
21 | ## How to do data partition and routing?
22 |
23 | The routing abstract model is essentially just two maps: 1) key-partition map 2) partition-machine map
24 |
25 |
26 |
27 | ### Hash partition
28 |
29 | 1. hash and mod
30 | - (+) simple
31 | - (-) flexibility (tight coupling two maps: adding and removing nodes (partition-machine map) disrupt existing key-partition map)
32 |
33 | 2. Virtual buckets: key--(hash)-->vBucket, vBucket--(table lookup)-->servers
34 | - Usercase: Membase a.k.a Couchbase, Riak
35 | - (+) flexibility, decoupling two maps
36 | - (-) centralized lookup table
37 |
38 | 3. Consistent hashing and DHT
39 | - [Chord] implementation
40 | - virtual nodes: for load balance in heterogeneous data center
41 | - Usercase: Dynamo, Cassandra
42 | - (+) flexibility, hashing space decouples two maps. two maps use the same hash, but adding and removing nodes ==only impact succeeding nodes==.
43 | - (-) network complexity, hard to maintain
44 |
45 |
46 |
47 | ### Range partition
48 |
49 | sort by primary key, shard by range of primary key
50 |
51 | range-server lookup table (e.g. HBase .META. table) + local tree-based index (e.g. LSM, B+)
52 |
53 | (+) search for a range
54 | (-) log(n)
55 |
56 | Usercase: Yahoo PNUTS, Azure, Bigtable
57 |
--------------------------------------------------------------------------------
/en/2018-07-22-b-tree-vs-b-plus-tree.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-22-b-tree-vs-b-plus-tree
3 | id: 2018-07-22-b-tree-vs-b-plus-tree
4 | title: "B tree vs. B+ tree"
5 | date: 2018-07-22 11:54
6 | comments: true
7 | tags: [system design]
8 | description: "A B+ tree can be seen as B tree in which each node contains only keys. Pros of B+ tree can be summarized as fewer cache misses. In B tree, the data is associated with each key and can be accessed more quickly."
9 | references:
10 | - https://stackoverflow.com/questions/870218/differences-between-b-trees-and-b-trees
11 | ---
12 |
13 | 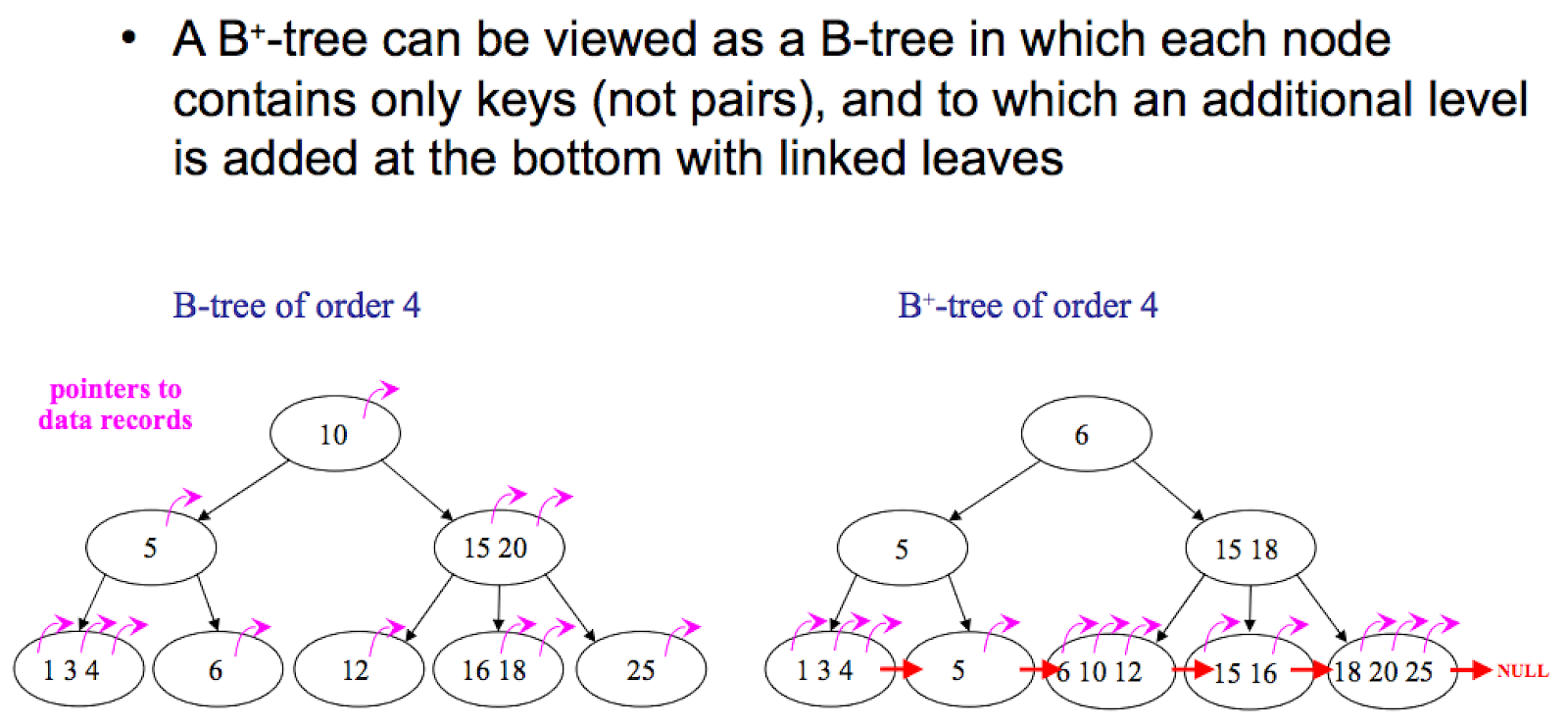
14 |
15 | Pros of B tree
16 |
17 | - Data associated with each key ⟶ frequently accessed nodes can lie closer to the root, and therefore can be accessed more quickly.
18 |
19 | Pros of B+ tree
20 |
21 | - No data associated in the interior nodes ⟶ more keys in memory ⟶ fewer cache misses
22 | - Leaf nodes of B+ trees are linked ⟶ easier to traverse ⟶ fewer cache misses
23 |
--------------------------------------------------------------------------------
/en/2018-07-23-load-balancer-types.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-23-load-balancer-types
3 | id: 2018-07-23-load-balancer-types
4 | title: "Load Balancer Types"
5 | date: 2018-07-23 11:54
6 | comments: true
7 | tags: [system design]
8 | description: "Usually, load balancers have three categories: DNS Round Robin, Network Load balancer and Application Load balancer. DNS Round Robin is rarely used as it is hard to control and not responsive. The network Load balancer has better granularity and is simple and responsive."
9 | references:
10 | - https://www.amazon.com/Practice-Cloud-System-Administration-Practices/dp/032194318X
11 | - https://docs.aws.amazon.com/AmazonECS/latest/developerguide/load-balancer-types.html
12 | ---
13 |
14 | Generally speaking, load balancers fall into three categories:
15 |
16 | - DNS Round Robin (rarely used): clients get a randomly-ordered list of IP addresses.
17 | - pros: easy to implement and free
18 | - cons: hard to control and not responsive, since DNS cache needs time to expire
19 | - Network (L3/L4) Load Balancer: traffic is routed by IP address and ports.L3 is network layer (IP). L4 is session layer (TCP).
20 | - pros: better granularity, simple, responsive
21 | - Application (L7) Load Balancer: traffic is routed by what is inside the HTTP protocol. L7 is application layer (HTTP).
22 |
--------------------------------------------------------------------------------
/en/2018-07-24-replica-and-consistency.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-24-replica-and-consistency
3 | id: 2018-07-24-replica-and-consistency
4 | title: "Replica, Consistency, and CAP theorem"
5 | date: 2018-07-24 11:54
6 | comments: true
7 | tags: [system design]
8 | description: "Any networked system has three desirable properties: consistency, availability and partition tolerance. Systems can have only two of those three. For example, RDBMS prefers consistency and partition tolerance and becomes an ACID system."
9 | references:
10 | - https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed
11 | ---
12 |
13 | ## Why replica and consistency?
14 |
15 | large dataset ⟶ scale out ⟶ data shard / partition ⟶ 1) routing for data access 2) replica for availability ⟶ consistency challenge
16 |
17 |
18 |
19 | ## Consistency trade-offs for CAP theorem
20 |
21 | 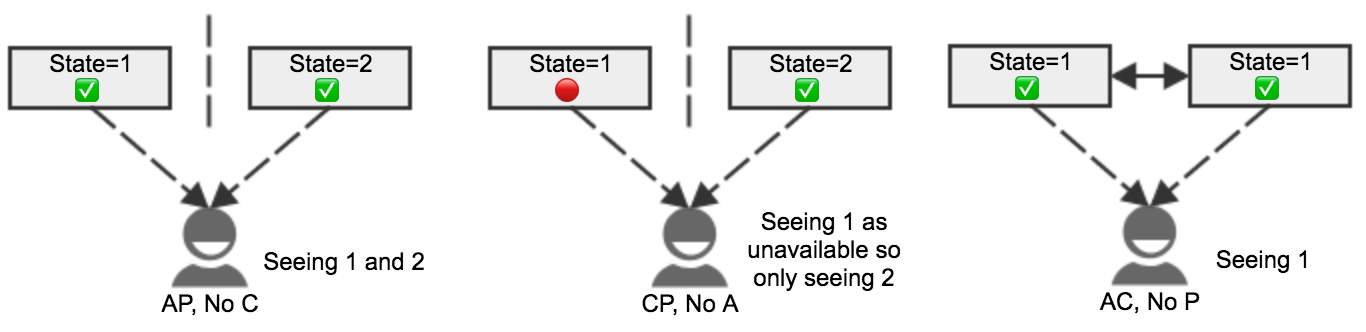
22 |
23 | - Consistency: all nodes see the same data at the same time
24 | - Availability: a guarantee that every request receives a response about whether it succeeded or failed
25 | - Partition tolerance: system continues to operate despite arbitrary message loss or failure of part of the system
26 |
27 |
28 |
29 | Any networked shared-data system can have only two of three desirable properties.
30 |
31 | - rDBMS prefer CP ⟶ ACID
32 | - NoSQL prefer AP ⟶ BASE
33 |
34 |
35 |
36 | ## "2 of 3" is mis-leading
37 |
38 | 12 years later, the author Eric Brewer said "2 of 3" is mis-leading, because
39 |
40 | 1. partitions are rare, there is little reason to forfeit C or A when the system is not partitioned.
41 | 2. choices can be actually applied to multiple places within the same system at very fine granularity.
42 | 3. choices are not binary but with certain degrees.
43 |
44 |
45 |
46 | Consequently, when there is no partition (nodes are connected correctly), which is often the case, we should have both AC. When there are partitions, deal them with 3 steps:
47 |
48 | 1. detect the start of a partition,
49 | 2. enter an explicit partition mode that may limit some operations, and
50 | 3. initiate partition recovery (compensate for mistakes) when communication is restored.
51 |
--------------------------------------------------------------------------------
/en/2018-07-26-acid-vs-base.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-26-acid-vs-base
3 | id: 2018-07-26-acid-vs-base
4 | title: "ACID vs BASE"
5 | date: 2018-07-26 11:54
6 | comments: true
7 | tags: [system design]
8 | description: "ACID and BASE indicate different designing philosophy. ACID focuses on consistency over availability. In ACID, the C means that a transaction pre-serves all the database rules. Meanwhile, BASE focuses more on availability indicating the system is guaranteed to be available."
9 | references:
10 | - https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed
11 | ---
12 |
13 | ACID (Consistency over Availability)
14 |
15 | - Atomicity ensures transaction succeeds completely or fails completely.
16 | - Consistency: In ACID, the C means that a transaction pre-serves all the database rules, such as unique keys, triggers, cascades. In contrast, the C in CAP refers only to single copy consistency, a strict subset of ACID consistency.
17 | - Isolation ensures that concurrent execution of transactions leaves the database in the same state that would have been obtained if the transactions were executed sequentially.
18 | - Durability ensures that once a transaction has been committed, it will remain committed even in the case of a system failure (e.g. power outage or crash).
19 |
20 | BASE (Availability over Consistency)
21 |
22 | - Basically available indicates that the system is guaranteed to be available
23 | - Soft state indicates that the state of the system may change over time, even without input. This is mainly due to the eventually consistent model.
24 | - Eventual consistency indicates that the system will become consistent over time, given that the system doesn't receive input during that time.
25 |
26 | Although most NoSQL takes BASE priciples, they are learning from or moving toward ACID. e.g. Google Spanner provides strong consistency. MongoDB 4.0 adds support for multi-document ACID transactions.
27 |
--------------------------------------------------------------------------------
/en/38-how-to-stream-video-over-http.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 38-how-to-stream-video-over-http
3 | id: 38-how-to-stream-video-over-http
4 | title: "How to stream video over HTTP for mobile devices? HTTP Live Streaming (HLS)"
5 | date: 2018-09-07 21:32
6 | comments: true
7 | tags: [system design]
8 | description: "Video service over Http for mobile devices has two problems: limited memory or storage and unstable network connection and variable bandwidth. HTTP live streaming solve this with separation of concerns, file segmentation, and indexing."
9 | references:
10 | - https://developer.apple.com/library/ios/documentation/NetworkingInternet/Conceptual/StreamingMediaGuide/HTTPStreamingArchitecture/HTTPStreamingArchitecture.html#//apple_ref/doc/uid/TP40008332-CH101-SW2
11 | ---
12 |
13 | ## Motivation
14 |
15 | Video service over Http Live Streaming for mobile devices, which...
16 |
17 | 1. ==has limited memory/storage==
18 | 2. suffers from the unstable network connection and variable bandwidth, and needs ==midstream quality adjustments.==
19 |
20 |
21 |
22 | ## Solution
23 |
24 | 1. Server-side: In a typical configuration, a hardware encoder takes audio-video input, encodes it as H.264 video and AAC audio, and outputs it in an MPEG-2 Transport Stream
25 |
26 | 1. the stream is then broken into a series of short media files (.ts possibly 10s) by a software stream segmenter.
27 | 2. The segmenter also creates and maintains an index(.m3u8) file containing a list of the media files.
28 | 3. Both the media fils and the index files are published on the web server.
29 |
30 | 2. Client-side: client reads the index, then requests the listed media files in order and displays them without any pauses or gaps between segments.
31 |
32 |
33 |
34 | ## Architecture
35 |
36 | 
37 |
--------------------------------------------------------------------------------
/en/41-how-to-scale-a-web-service.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 41-how-to-scale-a-web-service
3 | id: 41-how-to-scale-a-web-service
4 | title: "How to scale a web service?"
5 | date: 2018-09-11 21:32
6 | comments: true
7 | tags: [system design]
8 | references:
9 | - https://akfpartners.com/growth-blog/scale-cube
10 | - https://akfpartners.com/growth-blog/akf-scale-cube-ze-case-for-z-axis
11 | ---
12 |
13 | AKF scale cube visualizes the scaling process into three dimensions…
14 |
15 |
16 | 
17 |
18 |
19 | 1. ==Horizontal Duplication== and Cloning (X-Axis). Having a farm of identical and preferably stateless instances behind a load balancer or reverse proxy. Therefore, every request can be served by any of those hosts and there will be no single point of failure.
20 | 2. ==Functional Decomposition== and Segmentation - Microservices (Y-Axis). e.g. auth service, user profile service, photo service, etc
21 | 3. ==Horizontal Data Partitioning== - Shards (Z-Axis). Replicate the whole stack to different “pods”. Each pod can target a specific large group of users. For example, Uber had China and US data centers. Each datacenter might have different “pods” for different regions.
22 |
23 | Want an example? Go to see [how Facebook scale its social graph data store](https://tianpan.co/notes/49-facebook-tao).
24 |
--------------------------------------------------------------------------------
/en/43-how-to-design-robust-and-predictable-apis-with-idempotency.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 43-how-to-design-robust-and-predictable-apis-with-idempotency
3 | id: 43-how-to-design-robust-and-predictable-apis-with-idempotency
4 | title: "How to design robust and predictable APIs with idempotency?"
5 | date: 2018-09-12 12:55
6 | comments: true
7 | tags: [system design]
8 | description: "APIs can be un-robust and un-predictable. To solve the problem, three principles should be observed. The client retries to ensure consistency. Retry with idempotency, exponential backoff, and random jitter."
9 | references:
10 | - https://stripe.com/blog/idempotency
11 | ---
12 |
13 | How could APIs be un-robust and un-predictable?
14 |
15 | 1. Networks are unreliable.
16 | 2. Servers are more reliable but may still fail.
17 |
18 |
19 | How to solve the problem? 3 Principles:
20 |
21 | 1. Client retries to ensure consistency.
22 |
23 |
24 | 2. Retry with idempotency and idempotency keys to allow clients to pass a unique value.
25 |
26 | 1. In RESTful APIs, the PUT and DELETE verbs are idempotent.
27 | 2. However, POST may cause ==“double-charge” problem in payment==. So we use a ==idempotency key== to identify the request.
28 | 1. If the failure happens before the server, then there is a retry, and the server will see it for the first time, and process it normally.
29 | 2. If the failure happens in the server, then ACID database will guarantee the transaction by the idempotency key.
30 | 3. If the failure happens after the server’s reply, then client retries, and the server simply replies with a cached result of the successful operation.
31 |
32 |
33 | 3. Retry with ==exponential backoff and random jitter==. Be considerate of the ==thundering herd problem== that servers that may be stuck in a degraded state and a burst of retries may further hurt the system.
34 |
35 | For example, Stripe’s client retry calculates the delay like this...
36 |
37 | ```ruby
38 | def self.sleep_time(retry_count)
39 | # Apply exponential backoff with initial_network_retry_delay on the
40 | # number of attempts so far as inputs. Do not allow the number to exceed
41 | # max_network_retry_delay.
42 | sleep_seconds = [Stripe.initial_network_retry_delay * (2 ** (retry_count - 1)), Stripe.max_network_retry_delay].min
43 |
44 | # Apply some jitter by randomizing the value in the range of (sleep_seconds
45 | # / 2) to (sleep_seconds).
46 | sleep_seconds = sleep_seconds * (0.5 * (1 + rand()))
47 |
48 | # But never sleep less than the base sleep seconds.
49 | sleep_seconds = [Stripe.initial_network_retry_delay, sleep_seconds].max
50 |
51 | sleep_seconds
52 | end
53 | ```
54 |
--------------------------------------------------------------------------------
/en/45-how-to-design-netflix-view-state-service.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 45-how-to-design-netflix-view-state-service
3 | id: 45-how-to-design-netflix-view-state-service
4 | title: "How Netflix Serves Viewing Data?"
5 | date: 2018-09-13 20:39
6 | comments: true
7 | tags: [system design]
8 | references:
9 | - http://techblog.netflix.com/2015/01/netflixs-viewing-data-how-we-know-where.html
10 | ---
11 |
12 | ## Motivation
13 |
14 | How to keep users' viewing data in scale (billions of events per day)?
15 |
16 | Here, viewing data means...
17 |
18 | 1. viewing history. What titles have I watched?
19 | 2. viewing progress. Where did I leave off in a given title?
20 | 3. on-going viewers. What else is being watched on my account right now?
21 |
22 |
23 |
24 | ## Architecture
25 |
26 | 
27 |
28 |
29 | The viewing service has two tiers:
30 |
31 | 1. stateful tier = active views stored in memory
32 | - Why? to support the highest volume read/write
33 | - How to scale out?
34 | - partitioned into N stateful nodes by `account_id mod N`
35 | - One problem is that load is not evenly distributed and hence the system is subject to hot spots
36 | - CP over AP in CAP theorem, and there is no replica of active states.
37 | - One failed node will impact `1/nth` of the members. So they use stale data to degrade gracefully.
38 |
39 |
40 | 2. stateless tier = data persistence = Cassandra + Memcached
41 | - Use Cassandra for very high volume, low latency writes.
42 | - Data is evenly distributed. No hot spots because of consistent hashing with virtual nodes to partition the data.
43 | - Use Memcached for very high volume, low latency reads.
44 | - How to update the cache?
45 | - after writing to Cassandra, write the updated data back to Memcached
46 | - eventually consistent to handling multiple writers with a short cache entry TTL and a periodic cache refresh.
47 | - in the future, prefer Redis' appending operation to a time-ordered list over "read-modify-writes" in Memcached.
48 |
--------------------------------------------------------------------------------
/en/49-facebook-tao.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 49-facebook-tao
3 | id: 49-facebook-tao
4 | title: "How Facebook Scale its Social Graph Store? TAO"
5 | date: 2018-09-18 22:50
6 | comments: true
7 | tags: [system design]
8 | description: "Before Tao, Facebook used the cache-aside pattern to scale its social graph store. There were three problems: list update operation is inefficient; clients have to manage cache and hard to offer read-after-write consistency. With Tao, these problems are solved. "
9 | references:
10 | - http://www.cs.cornell.edu/courses/cs6410/2015fa/slides/tao_atc.pptx
11 | - https://cs.stanford.edu/~matei/courses/2015/6.S897/slides/tao.pdf
12 | - https://www.facebook.com/notes/facebook-engineering/tao-the-power-of-the-graph/10151525983993920/
13 | ---
14 |
15 | ## What are the challenges?
16 |
17 | Before TAO, use cache-aside pattern
18 |
19 | 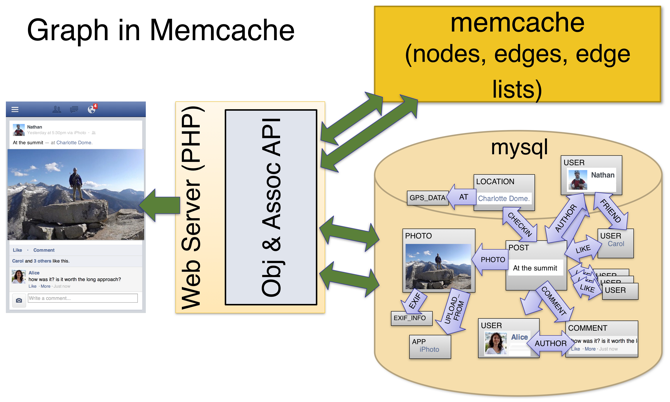
20 |
21 | Social graph data is stored in MySQL and cached in Memcached
22 |
23 |
24 | 3 problems:
25 |
26 | 1. list update operation in Memcached is inefficient. cannot append but update the whole list.
27 | 2. clients have to manage cache
28 | 3. Hard to offer ==read-after-write consistency==
29 |
30 |
31 | To solve those problems, we have 3 goals:
32 |
33 | - online data graph service that is efficiency at scale
34 | - optimize for read (its read-to-write ratio is 500:1)
35 | - low read latency
36 | - high read availability (eventual consistency)
37 | - timeliness of writes (read-after-write)
38 |
39 |
40 |
41 | ## Data Model
42 |
43 | - Objects (e.g. user, location, comment) with unique IDs
44 | - Associations (e.g. tagged, like, author) between two IDs
45 | - Both have key-value data as well as a time field
46 |
47 |
48 |
49 | ## Solutions: TAO
50 |
51 | 1. Efficiency at scale and reduce read latency
52 | - graph-specific caching
53 | - a standalone cache layer between the stateless service layer and the DB layer (aka [Functional Decomposition](https://tianpan.co/notes/41-how-to-scale-a-web-service))
54 | - subdivide data centers (aka [Horizontal Data Partitioning](https://tianpan.co/notes/41-how-to-scale-a-web-service))
55 |
56 |
57 | 2. Write timeliness
58 | - write-through cache
59 | - follower/leader cache to solve thundering herd problem
60 | - async replication
61 |
62 |
63 | 3. Read availability
64 | - Read Failover to alternate data sources
65 |
66 |
67 |
68 | ## TAO's Architecture
69 |
70 | - MySQL databases → durability
71 | - Leader cache → coordinates writes to each object
72 | - Follower caches → serve reads but not writes. forward all writes to leader.
73 |
74 |
75 | 
76 |
77 |
78 | Read failover
79 |
80 | 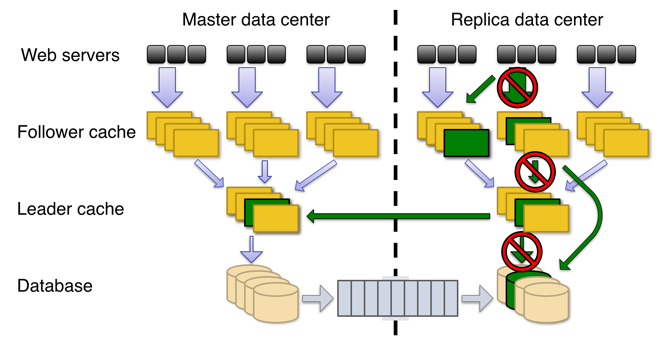
81 |
--------------------------------------------------------------------------------
/en/61-what-is-apache-kafka.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 61-what-is-apache-kafka
3 | id: 61-what-is-apache-kafka
4 | title: "What is Apache Kafka?"
5 | date: 2018-09-27 04:06
6 | comments: true
7 | tags: [system design]
8 | description: "Apache Kafka is a distributed streaming platform, which can be used for logging by topics, messaging system geo-replication or stream processing. It is much faster than other platforms due to its zero-copy technology."
9 | references:
10 | - https://kafka.apache.org/intro
11 | - http://www.michael-noll.com/blog/2014/08/18/apache-kafka-training-deck-and-tutorial/
12 | - https://stackoverflow.com/questions/48271491/where-is-apache-kafka-placed-in-the-pacelc-theorem
13 | - https://engineering.linkedin.com/kafka/intra-cluster-replication-apache-kafka
14 | ---
15 |
16 | Apache Kafka is a distributed streaming platform.
17 |
18 | ## Why use Apache Kafka?
19 |
20 | Its abstraction is a ==queue== and it features
21 |
22 | - a distributed pub-sub messaging system that resolves N^2 relationships to N. Publishers and subscribers can operate at their own rates.
23 | - super fast with zero-copy technology
24 | - support fault-tolerant data persistence
25 |
26 | It can be applied to
27 |
28 | - logging by topics
29 | - messaging system
30 | - geo-replication
31 | - stream processing
32 |
33 | ## Why is Kafka so fast?
34 |
35 | Kafka is using zero copy in which that CPU does not perform the task of copying data from one memory area to another.
36 |
37 | Without zero copy:
38 |
39 |
34 |
35 | * client
36 | * given a list of Memcached servers
37 | * chooses a server based on the key
38 | * server
39 | * store KVs into the internal hash table
40 | * LRU eviction
41 |
42 |
43 | The Key-value server consists of a fixed-size hash table + single-threaded handler + coarse locking
44 |
45 | 
46 |
47 | How to handle collisions? Mostly three ways to resolve:
48 |
49 | 1. Separate chaining: the collided bucket chains a list of entries with the same index, and you can always append the newly collided key-value pair to the list.
50 | 2. open addressing: if there is a collision, go to the next index until finding an available bucket.
51 | 3. dynamic resizing: resize the hash table and allocate more spaces; hence, collisions will happen less frequently.
52 |
53 | ## How does the client determine which server to query?
54 |
55 | See [Data Partition and Routing](https://puncsky.com/notes/2018-07-21-data-partition-and-routing)
56 |
57 | ## How to use cache?
58 |
59 | See [Key value cache](https://puncsky.com/notes/122-key-value-cache)
60 |
61 | ## How to further optimize?
62 |
63 | See [How Facebook Scale its Social Graph Store? TAO](https://puncsky.com/notes/49-facebook-tao)
64 |
--------------------------------------------------------------------------------
/en/177-designing-Airbnb-or-a-hotel-booking-system.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 177-designing-Airbnb-or-a-hotel-booking-system
3 | id: 177-designing-Airbnb-or-a-hotel-booking-system
4 | title: "Designing Airbnb or a hotel booking system"
5 | date: 2019-10-06 01:39
6 | comments: true
7 | slides: false
8 | tags: [system design]
9 | description: For guests and hosts, we store data with a relational database and build indexes to search by location, metadata, and availability. We can use external vendors for payment and remind the reservations with a priority queue.
10 | references:
11 | - https://www.vertabelo.com/blog/designing-a-data-model-for-a-hotel-room-booking-system/
12 | ---
13 |
14 | ## Requirements
15 | * for guests
16 | * search rooms by locations, dates, number of rooms, and number of guests
17 | * get room details (like picture, name, review, address, etc.) and prices
18 | * pay and book room from inventory by date and room id
19 | * checkout as a guest
20 | * user is logged in already
21 | * notification via Email and mobile push notification
22 | * for hotel or rental administrators (suppliers/hosts)
23 | * administrators (receptionist/manager/rental owner): manage room inventory and help the guest to check-in and check out
24 | * housekeeper: clean up rooms routinely
25 |
26 | ## Architecture
27 |
28 | 
29 |
30 | ## Components
31 |
32 | ### Inventory \<\> Bookings \<\> Users (guests and hosts)
33 |
34 | Suppliers provide their room details in the inventory. And users can search, get, and reserve rooms accordingly. After reserving the room, the user's payment will change the `status` of the `reserved_room` as well. You could check the data model in [this post](https://www.vertabelo.com/blog/designing-a-data-model-for-a-hotel-room-booking-system/).
35 |
36 | ### How to find available rooms?
37 |
38 | * by location: geo-search with [spatial indexing](https://en.wikipedia.org/wiki/Spatial_database), e.g. geo-hash or quad-tree.
39 | * by room metadata: apply filters or search conditions when querying the database.
40 | * by date-in and date-out and availability. Two options:
41 | * option 1: for a given `room_id`, check all `occupied_room` today or later, transform the data structure to an array of occupation by days, and finally find available slots in the array. This process might be time-consuming, so we can build the availability index.
42 | * option 2: for a given `room_id`, always create an entry for an occupied day. Then it will be easier to query unavailable slots by dates.
43 |
44 | ### For hotels, syncing data
45 |
46 | If it is a hotel booking system, then it will probably publish to Booking Channels like GDS, Aggregators, and Wholesalers.
47 |
48 | 
49 |
50 | To sync data across those places. We can
51 |
52 | 1. [retry with idempotency to improve the success rate of the external calls and ensure no duplicate orders](https://puncsky.com/notes/43-how-to-design-robust-and-predictable-apis-with-idempotency).
53 | 2. provide webhook callback APIs to external vendors to update status in the internal system.
54 |
55 | ### Payment & Bookkeeping
56 |
57 | Data model: [double-entry bookkeeping](https://puncsky.com/notes/167-designing-paypal-money-transfer#payment-service)
58 |
59 | To execute the payment, since we are calling the external payment gateway, like bank or Stripe, Braintree, etc. It is crucial to keep data in-sync across different places. [We need to sync data across the transaction table and external banks and vendors.](https://puncsky.com/#how-to-sync-across-the-transaction-table-and-external-banks-and-vendors)
60 |
61 | ### Notifier for reminders / alerts
62 |
63 | The notification system is essentially a delayer scheduler (priority queue + subscriber) plus API integrations.
64 |
65 | For example, a daily cronjob will query the database for notifications to be sent out today and put them into the priority queue by date. The subscriber will get the earliest ones from the priority queue and send out if reaching the expected timestamp. Otherwise, put the task back to the queue and sleep to make the CPU idle for other work, which can be interrupted if there are new alerts added for today.
66 |
--------------------------------------------------------------------------------
/en/178-lyft-marketing-automation-symphony.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 178-lyft-marketing-automation-symphony
3 | id: 178-lyft-marketing-automation-symphony
4 | title: "Lyft's Marketing Automation Platform -- Symphony"
5 | date: 2019-10-09 23:30
6 | comments: true
7 | tags: [marketing, system design]
8 | slides: false
9 | description: "To achieve a higher ROI in advertising, Lyft launched a marketing automation platform, which consists of three main components: lifetime value forecaster, budget allocator, and bidders."
10 | references:
11 | - https://eng.lyft.com/lyft-marketing-automation-b43b7b7537cc
12 | ---
13 |
14 | ## Acquisition Efficiency Problem:How to achieve a better ROI in advertising?
15 |
16 | In details, Lyft's advertisements should meet requirements as below:
17 |
18 | 1. being able to manage region-specific ad campaigns
19 | 2. guided by data-driven growth: The growth must be scalable, measurable, and predictable
20 | 3. supporting Lyft's unique growth model as shown below
21 |
22 | 
23 |
24 | However, the biggest challenge is to manage all the processes of cross-region marketing at scale, which include choosing bids, budgets, creatives, incentives, and audiences, running A/B tests, and so on. You can see what occupies a day in the life of a digital marketer:
25 |
26 | 
27 |
28 | We can find out that *execution* occupies most of the time while *analysis*, thought as more important, takes much less time. A scaling strategy will enable marketers to concentrate on analysis and decision-making process instead of operational activities.
29 |
30 | ## Solution: Automation
31 |
32 | To reduce costs and improve experimental efficiency, we need to
33 |
34 | 1. predict the likelihood of a new user to be interested in our product
35 | 2. evaluate effectively and allocate marketing budgets across channels
36 | 3. manage thousands of ad campaigns handily
37 |
38 | The marketing performance data flows into the reinforcement-learning system of Lyft: [Amundsen](https://guigu.io/blog/2018-12-03-making-progress-30-kilometers-per-day)
39 |
40 | The problems that need to be automated include:
41 |
42 | 1. updating bids across search keywords
43 | 2. turning off poor-performing creatives
44 | 3. changing referrals values by market
45 | 4. identifying high-value user segments
46 | 5. sharing strategies across campaigns
47 |
48 | ## Architecture
49 |
50 | 
51 |
52 | The tech stack includes - Apache Hive, Presto, ML platform, Airflow, 3rd-party APIs, UI.
53 |
54 | ## Main components
55 |
56 | ### Lifetime Value(LTV) forecaster
57 |
58 | The lifetime value of a user is an important criterion to measure the efficiency of acquisition channels. The budget is determined together by LTV and the price we are willing to pay in that region.
59 |
60 | Our knowledge of a new user is limited. The historical data can help us to predict more accurately as the user interacts with our services.
61 |
62 | Initial eigenvalue:
63 |
64 | 
65 |
66 |
67 | The forecast improves as the historical data of interactivity accumulates:
68 |
69 | 
70 |
71 |
72 | ### Budget allocator
73 |
74 | After LTV is predicted, the next is to estimate budgets based on the price. A curve of the form `LTV = a * (spend)^b` is fit to the data. A degree of randomness will be injected into the cost-curve creation process in order to converge a global optimum.
75 |
76 | 
77 |
78 |
79 | ### Bidders
80 |
81 | Bidders are made up of two parts - the tuners and actors. The tuners decide exact channel-specific parameters based on the price. The actors communicate the actual bid to different channels.
82 |
83 | Some popular bidding strategies, applied in different channels, are listed as below:
84 |
85 | 
86 |
87 |
88 | ### Conclusion
89 |
90 | We have to value human experiences in the automation process; otherwise, the quality of the models may be "garbage in, garbage out". Once saved from laboring tasks, marketers can focus more on understanding users, channels, and the messages they want to convey to audiences, and thus obtain better ad impacts. That's how Lyft can achieve a higher ROI with less time and efforts.
91 |
92 |
--------------------------------------------------------------------------------
/en/179-designing-typeahead-search-or-autocomplete.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 179-designing-typeahead-search-or-autocomplete
3 | id: 179-designing-typeahead-search-or-autocomplete
4 | title: "Designing typeahead search or autocomplete"
5 | date: 2019-10-10 18:33
6 | comments: true
7 | tags: [system design]
8 | slides: false
9 | description: How to design a realtime typeahead autocomplete service? Linkedin's Cleo lib answers with a multi-layer architecture (browser cache / web tier / result aggregator / various typeahead backend) and 4 elements (inverted / forward index, bloom filter, scorer).
10 | references:
11 | - https://engineering.linkedin.com/open-source/cleo-open-source-technology-behind-linkedins-typeahead-search
12 | - http://sna-projects.com/cleo/
13 | ---
14 |
15 | ## Requirements
16 |
17 | * realtime / low-latency typeahead and autocomplete service for social networks, like Linkedin or Facebook
18 | * search social profiles with prefixes
19 | * newly added account appear instantly in the scope of the search
20 | * not for “query autocomplete” (like the Google search-box dropdown), but for displaying actual search results, including
21 | * generic typeahead: network-agnostic results from a global ranking scheme like popularity.
22 | * network typeahead: results from user’s 1st and 2nd-degree network connections, and People You May Know scores.
23 |
24 | 
25 |
26 | ## Architecture
27 |
28 | Multi-layer architecture
29 |
30 | * browser cache
31 | * web tier
32 | * result aggregator
33 | * various typeahead backend
34 |
35 | 
36 |
37 | ## Result Aggregator
38 | The abstraction of this problem is to find documents by prefixes and terms in a very large number of elements. The solution leverages these four major data structures:
39 |
40 | 1. `InvertedIndex`: given any prefix, find all the document ids that contain the prefix.
41 | 2. `for each document, prepare a BloomFilter`: with user typing more, we can quickly filter out documents that do not contain the latest prefixes or terms, by check with their bloom filters.
42 | 3. `ForwardIndex`: previous bloom filter may return false positives, and now we query the actual documents to reject them.
43 | 4. `scorer(document):relevance`: Each partition return all of its true hits and scores. And then we aggregate and rank.
44 |
45 | 
46 |
47 | ## Performance
48 |
49 | * generic typeahead: latency \< \= 1 ms within a cluster
50 | * network typeahead (very-large dataset over 1st and 2nd degree network): latency \< \= 15 ms
51 | * aggregator: latency \< \= 25 ms
52 |
--------------------------------------------------------------------------------
/en/181-concurrency-models.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 181-concurrency-models
3 | id: 181-concurrency-models
4 | title: "Concurrency Models"
5 | date: 2019-10-16 14:04
6 | comments: true
7 | tags: [system design]
8 | description: "Five concurrency models you may want to know: Single-threaded; Multiprocessing and lock-based concurrency; Communicating Sequential Processes (CSP); Actor Model (AM); Software Transactional Memory (STM)."
9 | ---
10 |
11 | 
12 |
13 |
14 | * Single-threaded - Callbacks, Promises, Observables and async/await: vanilla JS
15 | * threading/multiprocessing, lock-based concurrency
16 | * protecting critical section vs. performance
17 | * Communicating Sequential Processes (CSP)
18 | * Golang or Clojure’s `core.async`.
19 | * process/thread passes data through channels.
20 | * Actor Model (AM): Elixir, Erlang, Scala
21 | * asynchronous by nature, and have location transparency that spans runtimes and machines - if you have a reference (Akka) or PID (Erlang) of an actor, you can message it via mailboxes.
22 | * powerful fault tolerance by organizing actors into a supervision hierarchy, and you can handle failures at its exact level of hierarchy.
23 | * Software Transactional Memory (STM): Clojure, Haskell
24 | * like MVCC or pure functions: commit / abort / retry
25 |
--------------------------------------------------------------------------------
/en/182-designing-l7-load-balancer.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 182-designing-l7-load-balancer
3 | id: 182-designing-l7-load-balancer
4 | title: "Designing a Load Balancer or Dropbox Bandaid"
5 | date: 2019-10-19 15:21
6 | comments: true
7 | tags: [system design]
8 | slides: false
9 | description: Large-scale web services deal with high-volume traffic, but one host could only serve a limited amount of requests. There is usually a server farm to take the traffic altogether. How to route them so that each host could evenly receive the request?
10 | references:
11 | - https://blogs.dropbox.com/tech/2019/09/enhancing-bandaid-load-balancing-at-dropbox-by-leveraging-real-time-backend-server-load-information/
12 | - https://medium.com/netflix-techblog/netflix-edge-load-balancing-695308b5548c
13 | - https://www.nginx.com/blog/nginx-power-of-two-choices-load-balancing-algorithm/#least_conn
14 | ---
15 |
16 | ## Requirements
17 |
18 |
19 | Internet-scale web services deal with high-volume traffic from the whole world. However, one server could only serve a limited amount of requests at the same time. Consequently, there is usually a server farm or a large cluster of servers to undertake the traffic altogether. Here comes the question: how to route them so that each host could evenly receive and process the request?
20 |
21 | 
22 |
23 | Since there are many hops and layers of load balancers from the user to the server, specifically speaking, this time our design requirements are
24 |
25 | * [designing an L7 Load Balancer inside a data center](https://tianpan.co/notes/2018-07-23-load-balancer-types)
26 | * leveraging real-time load information from the backend
27 | * serving 10 m RPS, 10 T traffic per sec
28 |
29 | > Note: If Service A depends on (or consumes) Service B, then A is downstream service of B, and B is upstream service of A.
30 |
31 |
32 | ## Challenges
33 | Why is it hard to balance loads? The answer is that it is hard to collect accurate load distribution stats and act accordingly.
34 |
35 | ### Distributing-by-requests ≠ distributing-by-load
36 |
37 | Random and round-robin distribute the traffic by requests. However, the actual load is not per request - some are heavy in CPU or thread utilization, while some are lightweight.
38 |
39 | 
40 |
41 | To be more accurate on the load, load balancers have to maintain local states of observed active request number, connection number, or request process latencies for each backend server. And based on them, we can use distribution algorithms like Least-connections, least-time, and Random N choices:
42 |
43 | **Least-connections**: a request is passed to the server with the least number of active connections.
44 |
45 | 
46 |
47 | **latency-based (least-time)**: a request is passed to the server with the least average response time and least number of active connections, taking into account weights of servers.
48 |
49 | 
50 |
51 | However, these two algorithms work well only with only one load balancer. If there are multiple ones, there might have **herd effect**. That is to say; all the load balancers notice that one service is momentarily faster, and then all send requests to that service.
52 |
53 | **Random N choices** (where N=2 in most cases / a.k.a *Power of Two Choices*): pick two at random and chose the better option of the two, *avoiding the worse choice*.
54 |
55 |
56 | ### Distributed environments.
57 |
58 | 
59 |
60 | Local LB is unaware of global downstream and upstream states, including
61 |
62 | * upstream service loads
63 | * upstream service may be super large, and thus it is hard to pick the right subset to cover with the load balancer
64 | * downstream service loads
65 | * the processing time of various requests are hard to predict
66 |
67 | ## Solutions
68 | There are three options to collect load the stats accurately and then act accordingly:
69 |
70 | * centralized & dynamic controller
71 | * distributed but with shared states
72 | * piggybacking server-side information in response messages or active probing
73 |
74 | Dropbox Bandaid team chose the third option because it fits into their existing *random N choices* approach well.
75 |
76 | 
77 |
78 | However, instead of using local states, like the original *random N choices* do, they use real-time global information from the backend servers via the response headers.
79 |
80 | **Server utilization**: Backend servers are configured with a max capacity and count the on-going requests, and then they have utilization percentage calculated ranging from 0.0 to 1.0.
81 |
82 | 
83 |
84 | There are two problems to consider:
85 |
86 | 1. **Handling HTTP errors**: If a server fast fails requests, it attracts more traffic and fails more.
87 | 2. **Stats decay**: If a server’s load is too high, no requests will be distributed there and hence the server gets stuck. They use a decay function of the inverted sigmoid curve to solve the problem.
88 |
89 | ## Results: requests are more balanced
90 |
91 | 
92 |
93 |
--------------------------------------------------------------------------------
/en/2018-07-10-cloud-design-patterns.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-10-cloud-design-patterns
3 | id: 2018-07-10-cloud-design-patterns
4 | title: "Cloud Design Patterns"
5 | date: 2018-07-10 11:16
6 | comments: true
7 | tags: [design patterns, system design]
8 | description: "There are three types of cloud design patterns. Availability patterns have health endpoint monitoring and throttling. Data management patterns have cache-aside and static content hosting. Security patterns have federated identity."
9 | references:
10 | - https://docs.microsoft.com/en-us/azure/architecture/patterns/
11 | ---
12 |
13 | ## Availability patterns
14 | - Health Endpoint Monitoring: Implement functional checks in an application that external tools can access through exposed endpoints at regular intervals.
15 | - Queue-Based Load Leveling: Use a queue that acts as a buffer between a task and a service that it invokes in order to smooth intermittent heavy loads.
16 | - Throttling: Control the consumption of resources used by an instance of an application, an individual tenant, or an entire service.
17 |
18 |
19 |
20 | ## Data Management patterns
21 | - Cache-Aside: Load data on demand into a cache from a data store
22 | - Command and Query Responsibility Segregation: Segregate operations that read data from operations that update data by using separate interfaces.
23 | - Event Sourcing: Use an append-only store to record the full series of events that describe actions taken on data in a domain.
24 | - Index Table: Create indexes over the fields in data stores that are frequently referenced by queries.
25 | - Materialized View: Generate prepopulated views over the data in one or more data stores when the data isn't ideally formatted for required query operations.
26 | - Sharding: Divide a data store into a set of horizontal partitions or shards.
27 | - Static Content Hosting: Deploy static content to a cloud-based storage service that can deliver them directly to the client.
28 |
29 |
30 |
31 | ## Security Patterns
32 | - Federated Identity: Delegate authentication to an external identity provider.
33 | - Gatekeeper: Protect applications and services by using a dedicated host instance that acts as a broker between clients and the application or service, validates and sanitizes requests, and passes requests and data between them.
34 | - Valet Key: Use a token or key that provides clients with restricted direct access to a specific resource or service.
35 |
--------------------------------------------------------------------------------
/en/2018-07-20-experience-deep-dive.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-20-experience-deep-dive
3 | id: 2018-07-20-experience-deep-dive
4 | title: "Experience Deep Dive"
5 | date: 2018-07-20 11:54
6 | comments: true
7 | tags: [system design]
8 | description: "For those who had little experience in leadership positions, we have some tips for interviews. It is necessary to describe your previous projects including challenges or improvements. Also, remember to demonstrate your communication skills."
9 | ---
10 |
11 | ## Intended Audience
12 |
13 | Moderate experience or less, or anyone who was not in a leadership or design position (either formal or informal) in their previous position
14 |
15 |
16 |
17 | ## Question Description
18 |
19 | Describe one of your previous projects that was particularly interesting or memorable to you. Followup questions:
20 |
21 | What about it made it interesting?
22 | What was the most challenging part of the project, and how did you address those challenges?
23 | What did you learn from the project, and what do you wish you had known before you started?
24 | What other designs/implementation methods did you consider? Why did you choose the one that you did? If you were to do the same project over again, what would you do differently?
25 |
26 |
27 |
28 | ## Interviewer tips
29 |
30 | Since the goal here is to assess the technical communication skill and interest level of someone who has not necessarily ever been in a role that they could conduct a crash course in, you should be prepared to keep asking them questions (either for more details, or about other aspects of the project). If they are a recent grad and did a thesis, that's often a good choice to talk about. While this question is in many ways similar to the Resume Questions question from phone screen one, this question is intended to be approximately four times as long, and should get into proportionally more detail about what it is that they have done. As such, the scoring criteria are similar, but should be evaluated with both higher expectations and more data.
31 |
32 |
33 |
34 | ## Scoring
35 |
36 | A great candidate will
37 |
38 | - Be able to talk for the full time about the project, with interaction from the interviewer being conversational rather than directing
39 | - Be knowledgeable about the project as a whole, rather than only their area of focus, and be able to articulate the intent and design of the project
40 |
41 |
42 | - Be passionate about whatever the project was, and able to describe the elements of the project that inspired that passion clearly
43 | - Be able to clearly explain what alternatives were considered, and why they chose the implementation strategy that they did.
44 | - Have reflected on and learned from their experiences
45 |
46 |
47 |
48 | A good candidate will
49 |
50 | - May have some trouble talking for the full time, but will be able to with some help and questions from the interviewer
51 | - May lack some knowledge about the larger scope of the project, but still have strong knowledge of their particular area and pieces that directly interacted with them
52 | - May seem passionate, but be unable to clearly explain what inspired that passion
53 |
54 |
55 | - May be able to discuss alternatives to what they did, but not have considered them in depth
56 | - Have reflected on and learned from their experiences
57 |
58 |
59 |
60 | A bad candidate will
61 | - Have difficulty talking for the full time. The interviewer may feel as if they are interrogating rather than conversing with the candidate
62 | - May lack detailed knowledge of the project, even within the area that they were working. They may not understand why their piece was designed the way it was, or may not understand how it interacted with other systems
63 | - Does not seem very interested in the project - remember that you are asking them about the most interesting project that they have done, they should be very - interested in whatever it was
64 |
65 |
66 | - May not be familiar with potential alternatives to their implementation method
67 | - Does not seem to have learned from or reflected on their experiences with the project. A key sign of this is that the answer to 'what did you learn' and 'what would you do differently' are short and/or nearly identical.
68 |
--------------------------------------------------------------------------------
/en/2018-07-21-data-partition-and-routing.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-21-data-partition-and-routing
3 | id: 2018-07-21-data-partition-and-routing
4 | title: "Data Partition and Routing"
5 | date: 2018-07-20 11:54
6 | comments: true
7 | tags: [system design]
8 | description: "The advantages of implementing data partition and routing are availability and read efficiency while consistency is the weakness. The routing abstract model is essentially two maps: key-partition map and partition-machine map."
9 | ---
10 |
11 | ## Why data partition and routing?
12 |
13 | large dataset ⟶ scale out ⟶ data shard / partition ⟶ 1) routing for data access 2) replica for availability
14 |
15 | - Pros
16 | - availability
17 | - read(parallelization, single read efficiency)
18 | - Cons
19 | - consistency
20 |
21 | ## How to do data partition and routing?
22 |
23 | The routing abstract model is essentially just two maps: 1) key-partition map 2) partition-machine map
24 |
25 |
26 |
27 | ### Hash partition
28 |
29 | 1. hash and mod
30 | - (+) simple
31 | - (-) flexibility (tight coupling two maps: adding and removing nodes (partition-machine map) disrupt existing key-partition map)
32 |
33 | 2. Virtual buckets: key--(hash)-->vBucket, vBucket--(table lookup)-->servers
34 | - Usercase: Membase a.k.a Couchbase, Riak
35 | - (+) flexibility, decoupling two maps
36 | - (-) centralized lookup table
37 |
38 | 3. Consistent hashing and DHT
39 | - [Chord] implementation
40 | - virtual nodes: for load balance in heterogeneous data center
41 | - Usercase: Dynamo, Cassandra
42 | - (+) flexibility, hashing space decouples two maps. two maps use the same hash, but adding and removing nodes ==only impact succeeding nodes==.
43 | - (-) network complexity, hard to maintain
44 |
45 |
46 |
47 | ### Range partition
48 |
49 | sort by primary key, shard by range of primary key
50 |
51 | range-server lookup table (e.g. HBase .META. table) + local tree-based index (e.g. LSM, B+)
52 |
53 | (+) search for a range
54 | (-) log(n)
55 |
56 | Usercase: Yahoo PNUTS, Azure, Bigtable
57 |
--------------------------------------------------------------------------------
/en/2018-07-22-b-tree-vs-b-plus-tree.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-22-b-tree-vs-b-plus-tree
3 | id: 2018-07-22-b-tree-vs-b-plus-tree
4 | title: "B tree vs. B+ tree"
5 | date: 2018-07-22 11:54
6 | comments: true
7 | tags: [system design]
8 | description: "A B+ tree can be seen as B tree in which each node contains only keys. Pros of B+ tree can be summarized as fewer cache misses. In B tree, the data is associated with each key and can be accessed more quickly."
9 | references:
10 | - https://stackoverflow.com/questions/870218/differences-between-b-trees-and-b-trees
11 | ---
12 |
13 | 
14 |
15 | Pros of B tree
16 |
17 | - Data associated with each key ⟶ frequently accessed nodes can lie closer to the root, and therefore can be accessed more quickly.
18 |
19 | Pros of B+ tree
20 |
21 | - No data associated in the interior nodes ⟶ more keys in memory ⟶ fewer cache misses
22 | - Leaf nodes of B+ trees are linked ⟶ easier to traverse ⟶ fewer cache misses
23 |
--------------------------------------------------------------------------------
/en/2018-07-23-load-balancer-types.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-23-load-balancer-types
3 | id: 2018-07-23-load-balancer-types
4 | title: "Load Balancer Types"
5 | date: 2018-07-23 11:54
6 | comments: true
7 | tags: [system design]
8 | description: "Usually, load balancers have three categories: DNS Round Robin, Network Load balancer and Application Load balancer. DNS Round Robin is rarely used as it is hard to control and not responsive. The network Load balancer has better granularity and is simple and responsive."
9 | references:
10 | - https://www.amazon.com/Practice-Cloud-System-Administration-Practices/dp/032194318X
11 | - https://docs.aws.amazon.com/AmazonECS/latest/developerguide/load-balancer-types.html
12 | ---
13 |
14 | Generally speaking, load balancers fall into three categories:
15 |
16 | - DNS Round Robin (rarely used): clients get a randomly-ordered list of IP addresses.
17 | - pros: easy to implement and free
18 | - cons: hard to control and not responsive, since DNS cache needs time to expire
19 | - Network (L3/L4) Load Balancer: traffic is routed by IP address and ports.L3 is network layer (IP). L4 is session layer (TCP).
20 | - pros: better granularity, simple, responsive
21 | - Application (L7) Load Balancer: traffic is routed by what is inside the HTTP protocol. L7 is application layer (HTTP).
22 |
--------------------------------------------------------------------------------
/en/2018-07-24-replica-and-consistency.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-24-replica-and-consistency
3 | id: 2018-07-24-replica-and-consistency
4 | title: "Replica, Consistency, and CAP theorem"
5 | date: 2018-07-24 11:54
6 | comments: true
7 | tags: [system design]
8 | description: "Any networked system has three desirable properties: consistency, availability and partition tolerance. Systems can have only two of those three. For example, RDBMS prefers consistency and partition tolerance and becomes an ACID system."
9 | references:
10 | - https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed
11 | ---
12 |
13 | ## Why replica and consistency?
14 |
15 | large dataset ⟶ scale out ⟶ data shard / partition ⟶ 1) routing for data access 2) replica for availability ⟶ consistency challenge
16 |
17 |
18 |
19 | ## Consistency trade-offs for CAP theorem
20 |
21 | 
22 |
23 | - Consistency: all nodes see the same data at the same time
24 | - Availability: a guarantee that every request receives a response about whether it succeeded or failed
25 | - Partition tolerance: system continues to operate despite arbitrary message loss or failure of part of the system
26 |
27 |
28 |
29 | Any networked shared-data system can have only two of three desirable properties.
30 |
31 | - rDBMS prefer CP ⟶ ACID
32 | - NoSQL prefer AP ⟶ BASE
33 |
34 |
35 |
36 | ## "2 of 3" is mis-leading
37 |
38 | 12 years later, the author Eric Brewer said "2 of 3" is mis-leading, because
39 |
40 | 1. partitions are rare, there is little reason to forfeit C or A when the system is not partitioned.
41 | 2. choices can be actually applied to multiple places within the same system at very fine granularity.
42 | 3. choices are not binary but with certain degrees.
43 |
44 |
45 |
46 | Consequently, when there is no partition (nodes are connected correctly), which is often the case, we should have both AC. When there are partitions, deal them with 3 steps:
47 |
48 | 1. detect the start of a partition,
49 | 2. enter an explicit partition mode that may limit some operations, and
50 | 3. initiate partition recovery (compensate for mistakes) when communication is restored.
51 |
--------------------------------------------------------------------------------
/en/2018-07-26-acid-vs-base.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-26-acid-vs-base
3 | id: 2018-07-26-acid-vs-base
4 | title: "ACID vs BASE"
5 | date: 2018-07-26 11:54
6 | comments: true
7 | tags: [system design]
8 | description: "ACID and BASE indicate different designing philosophy. ACID focuses on consistency over availability. In ACID, the C means that a transaction pre-serves all the database rules. Meanwhile, BASE focuses more on availability indicating the system is guaranteed to be available."
9 | references:
10 | - https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed
11 | ---
12 |
13 | ACID (Consistency over Availability)
14 |
15 | - Atomicity ensures transaction succeeds completely or fails completely.
16 | - Consistency: In ACID, the C means that a transaction pre-serves all the database rules, such as unique keys, triggers, cascades. In contrast, the C in CAP refers only to single copy consistency, a strict subset of ACID consistency.
17 | - Isolation ensures that concurrent execution of transactions leaves the database in the same state that would have been obtained if the transactions were executed sequentially.
18 | - Durability ensures that once a transaction has been committed, it will remain committed even in the case of a system failure (e.g. power outage or crash).
19 |
20 | BASE (Availability over Consistency)
21 |
22 | - Basically available indicates that the system is guaranteed to be available
23 | - Soft state indicates that the state of the system may change over time, even without input. This is mainly due to the eventually consistent model.
24 | - Eventual consistency indicates that the system will become consistent over time, given that the system doesn't receive input during that time.
25 |
26 | Although most NoSQL takes BASE priciples, they are learning from or moving toward ACID. e.g. Google Spanner provides strong consistency. MongoDB 4.0 adds support for multi-document ACID transactions.
27 |
--------------------------------------------------------------------------------
/en/38-how-to-stream-video-over-http.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 38-how-to-stream-video-over-http
3 | id: 38-how-to-stream-video-over-http
4 | title: "How to stream video over HTTP for mobile devices? HTTP Live Streaming (HLS)"
5 | date: 2018-09-07 21:32
6 | comments: true
7 | tags: [system design]
8 | description: "Video service over Http for mobile devices has two problems: limited memory or storage and unstable network connection and variable bandwidth. HTTP live streaming solve this with separation of concerns, file segmentation, and indexing."
9 | references:
10 | - https://developer.apple.com/library/ios/documentation/NetworkingInternet/Conceptual/StreamingMediaGuide/HTTPStreamingArchitecture/HTTPStreamingArchitecture.html#//apple_ref/doc/uid/TP40008332-CH101-SW2
11 | ---
12 |
13 | ## Motivation
14 |
15 | Video service over Http Live Streaming for mobile devices, which...
16 |
17 | 1. ==has limited memory/storage==
18 | 2. suffers from the unstable network connection and variable bandwidth, and needs ==midstream quality adjustments.==
19 |
20 |
21 |
22 | ## Solution
23 |
24 | 1. Server-side: In a typical configuration, a hardware encoder takes audio-video input, encodes it as H.264 video and AAC audio, and outputs it in an MPEG-2 Transport Stream
25 |
26 | 1. the stream is then broken into a series of short media files (.ts possibly 10s) by a software stream segmenter.
27 | 2. The segmenter also creates and maintains an index(.m3u8) file containing a list of the media files.
28 | 3. Both the media fils and the index files are published on the web server.
29 |
30 | 2. Client-side: client reads the index, then requests the listed media files in order and displays them without any pauses or gaps between segments.
31 |
32 |
33 |
34 | ## Architecture
35 |
36 | 
37 |
--------------------------------------------------------------------------------
/en/41-how-to-scale-a-web-service.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 41-how-to-scale-a-web-service
3 | id: 41-how-to-scale-a-web-service
4 | title: "How to scale a web service?"
5 | date: 2018-09-11 21:32
6 | comments: true
7 | tags: [system design]
8 | references:
9 | - https://akfpartners.com/growth-blog/scale-cube
10 | - https://akfpartners.com/growth-blog/akf-scale-cube-ze-case-for-z-axis
11 | ---
12 |
13 | AKF scale cube visualizes the scaling process into three dimensions…
14 |
15 |
16 | 
17 |
18 |
19 | 1. ==Horizontal Duplication== and Cloning (X-Axis). Having a farm of identical and preferably stateless instances behind a load balancer or reverse proxy. Therefore, every request can be served by any of those hosts and there will be no single point of failure.
20 | 2. ==Functional Decomposition== and Segmentation - Microservices (Y-Axis). e.g. auth service, user profile service, photo service, etc
21 | 3. ==Horizontal Data Partitioning== - Shards (Z-Axis). Replicate the whole stack to different “pods”. Each pod can target a specific large group of users. For example, Uber had China and US data centers. Each datacenter might have different “pods” for different regions.
22 |
23 | Want an example? Go to see [how Facebook scale its social graph data store](https://tianpan.co/notes/49-facebook-tao).
24 |
--------------------------------------------------------------------------------
/en/43-how-to-design-robust-and-predictable-apis-with-idempotency.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 43-how-to-design-robust-and-predictable-apis-with-idempotency
3 | id: 43-how-to-design-robust-and-predictable-apis-with-idempotency
4 | title: "How to design robust and predictable APIs with idempotency?"
5 | date: 2018-09-12 12:55
6 | comments: true
7 | tags: [system design]
8 | description: "APIs can be un-robust and un-predictable. To solve the problem, three principles should be observed. The client retries to ensure consistency. Retry with idempotency, exponential backoff, and random jitter."
9 | references:
10 | - https://stripe.com/blog/idempotency
11 | ---
12 |
13 | How could APIs be un-robust and un-predictable?
14 |
15 | 1. Networks are unreliable.
16 | 2. Servers are more reliable but may still fail.
17 |
18 |
19 | How to solve the problem? 3 Principles:
20 |
21 | 1. Client retries to ensure consistency.
22 |
23 |
24 | 2. Retry with idempotency and idempotency keys to allow clients to pass a unique value.
25 |
26 | 1. In RESTful APIs, the PUT and DELETE verbs are idempotent.
27 | 2. However, POST may cause ==“double-charge” problem in payment==. So we use a ==idempotency key== to identify the request.
28 | 1. If the failure happens before the server, then there is a retry, and the server will see it for the first time, and process it normally.
29 | 2. If the failure happens in the server, then ACID database will guarantee the transaction by the idempotency key.
30 | 3. If the failure happens after the server’s reply, then client retries, and the server simply replies with a cached result of the successful operation.
31 |
32 |
33 | 3. Retry with ==exponential backoff and random jitter==. Be considerate of the ==thundering herd problem== that servers that may be stuck in a degraded state and a burst of retries may further hurt the system.
34 |
35 | For example, Stripe’s client retry calculates the delay like this...
36 |
37 | ```ruby
38 | def self.sleep_time(retry_count)
39 | # Apply exponential backoff with initial_network_retry_delay on the
40 | # number of attempts so far as inputs. Do not allow the number to exceed
41 | # max_network_retry_delay.
42 | sleep_seconds = [Stripe.initial_network_retry_delay * (2 ** (retry_count - 1)), Stripe.max_network_retry_delay].min
43 |
44 | # Apply some jitter by randomizing the value in the range of (sleep_seconds
45 | # / 2) to (sleep_seconds).
46 | sleep_seconds = sleep_seconds * (0.5 * (1 + rand()))
47 |
48 | # But never sleep less than the base sleep seconds.
49 | sleep_seconds = [Stripe.initial_network_retry_delay, sleep_seconds].max
50 |
51 | sleep_seconds
52 | end
53 | ```
54 |
--------------------------------------------------------------------------------
/en/45-how-to-design-netflix-view-state-service.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 45-how-to-design-netflix-view-state-service
3 | id: 45-how-to-design-netflix-view-state-service
4 | title: "How Netflix Serves Viewing Data?"
5 | date: 2018-09-13 20:39
6 | comments: true
7 | tags: [system design]
8 | references:
9 | - http://techblog.netflix.com/2015/01/netflixs-viewing-data-how-we-know-where.html
10 | ---
11 |
12 | ## Motivation
13 |
14 | How to keep users' viewing data in scale (billions of events per day)?
15 |
16 | Here, viewing data means...
17 |
18 | 1. viewing history. What titles have I watched?
19 | 2. viewing progress. Where did I leave off in a given title?
20 | 3. on-going viewers. What else is being watched on my account right now?
21 |
22 |
23 |
24 | ## Architecture
25 |
26 | 
27 |
28 |
29 | The viewing service has two tiers:
30 |
31 | 1. stateful tier = active views stored in memory
32 | - Why? to support the highest volume read/write
33 | - How to scale out?
34 | - partitioned into N stateful nodes by `account_id mod N`
35 | - One problem is that load is not evenly distributed and hence the system is subject to hot spots
36 | - CP over AP in CAP theorem, and there is no replica of active states.
37 | - One failed node will impact `1/nth` of the members. So they use stale data to degrade gracefully.
38 |
39 |
40 | 2. stateless tier = data persistence = Cassandra + Memcached
41 | - Use Cassandra for very high volume, low latency writes.
42 | - Data is evenly distributed. No hot spots because of consistent hashing with virtual nodes to partition the data.
43 | - Use Memcached for very high volume, low latency reads.
44 | - How to update the cache?
45 | - after writing to Cassandra, write the updated data back to Memcached
46 | - eventually consistent to handling multiple writers with a short cache entry TTL and a periodic cache refresh.
47 | - in the future, prefer Redis' appending operation to a time-ordered list over "read-modify-writes" in Memcached.
48 |
--------------------------------------------------------------------------------
/en/49-facebook-tao.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 49-facebook-tao
3 | id: 49-facebook-tao
4 | title: "How Facebook Scale its Social Graph Store? TAO"
5 | date: 2018-09-18 22:50
6 | comments: true
7 | tags: [system design]
8 | description: "Before Tao, Facebook used the cache-aside pattern to scale its social graph store. There were three problems: list update operation is inefficient; clients have to manage cache and hard to offer read-after-write consistency. With Tao, these problems are solved. "
9 | references:
10 | - http://www.cs.cornell.edu/courses/cs6410/2015fa/slides/tao_atc.pptx
11 | - https://cs.stanford.edu/~matei/courses/2015/6.S897/slides/tao.pdf
12 | - https://www.facebook.com/notes/facebook-engineering/tao-the-power-of-the-graph/10151525983993920/
13 | ---
14 |
15 | ## What are the challenges?
16 |
17 | Before TAO, use cache-aside pattern
18 |
19 | 
20 |
21 | Social graph data is stored in MySQL and cached in Memcached
22 |
23 |
24 | 3 problems:
25 |
26 | 1. list update operation in Memcached is inefficient. cannot append but update the whole list.
27 | 2. clients have to manage cache
28 | 3. Hard to offer ==read-after-write consistency==
29 |
30 |
31 | To solve those problems, we have 3 goals:
32 |
33 | - online data graph service that is efficiency at scale
34 | - optimize for read (its read-to-write ratio is 500:1)
35 | - low read latency
36 | - high read availability (eventual consistency)
37 | - timeliness of writes (read-after-write)
38 |
39 |
40 |
41 | ## Data Model
42 |
43 | - Objects (e.g. user, location, comment) with unique IDs
44 | - Associations (e.g. tagged, like, author) between two IDs
45 | - Both have key-value data as well as a time field
46 |
47 |
48 |
49 | ## Solutions: TAO
50 |
51 | 1. Efficiency at scale and reduce read latency
52 | - graph-specific caching
53 | - a standalone cache layer between the stateless service layer and the DB layer (aka [Functional Decomposition](https://tianpan.co/notes/41-how-to-scale-a-web-service))
54 | - subdivide data centers (aka [Horizontal Data Partitioning](https://tianpan.co/notes/41-how-to-scale-a-web-service))
55 |
56 |
57 | 2. Write timeliness
58 | - write-through cache
59 | - follower/leader cache to solve thundering herd problem
60 | - async replication
61 |
62 |
63 | 3. Read availability
64 | - Read Failover to alternate data sources
65 |
66 |
67 |
68 | ## TAO's Architecture
69 |
70 | - MySQL databases → durability
71 | - Leader cache → coordinates writes to each object
72 | - Follower caches → serve reads but not writes. forward all writes to leader.
73 |
74 |
75 | 
76 |
77 |
78 | Read failover
79 |
80 | 
81 |
--------------------------------------------------------------------------------
/en/61-what-is-apache-kafka.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 61-what-is-apache-kafka
3 | id: 61-what-is-apache-kafka
4 | title: "What is Apache Kafka?"
5 | date: 2018-09-27 04:06
6 | comments: true
7 | tags: [system design]
8 | description: "Apache Kafka is a distributed streaming platform, which can be used for logging by topics, messaging system geo-replication or stream processing. It is much faster than other platforms due to its zero-copy technology."
9 | references:
10 | - https://kafka.apache.org/intro
11 | - http://www.michael-noll.com/blog/2014/08/18/apache-kafka-training-deck-and-tutorial/
12 | - https://stackoverflow.com/questions/48271491/where-is-apache-kafka-placed-in-the-pacelc-theorem
13 | - https://engineering.linkedin.com/kafka/intra-cluster-replication-apache-kafka
14 | ---
15 |
16 | Apache Kafka is a distributed streaming platform.
17 |
18 | ## Why use Apache Kafka?
19 |
20 | Its abstraction is a ==queue== and it features
21 |
22 | - a distributed pub-sub messaging system that resolves N^2 relationships to N. Publishers and subscribers can operate at their own rates.
23 | - super fast with zero-copy technology
24 | - support fault-tolerant data persistence
25 |
26 | It can be applied to
27 |
28 | - logging by topics
29 | - messaging system
30 | - geo-replication
31 | - stream processing
32 |
33 | ## Why is Kafka so fast?
34 |
35 | Kafka is using zero copy in which that CPU does not perform the task of copying data from one memory area to another.
36 |
37 | Without zero copy:
38 |
39 |  43 |
44 | With zero copy:
45 |
46 |
43 |
44 | With zero copy:
45 |
46 |  50 |
51 | ## Architecture
52 |
53 | Looking from outside, producers write to brokers, and consumers read from brokers.
54 |
55 |
50 |
51 | ## Architecture
52 |
53 | Looking from outside, producers write to brokers, and consumers read from brokers.
54 |
55 |  56 |
57 | Data is stored in topics and split into partitions which are replicated.
58 |
59 | 
60 |
61 | 1. Producer publishes messages to a specific topic.
62 | - Write to in-memory buffer first and flush to disk.
63 | - append-only sequence write for fast write.
64 | - Available to read after write to disks.
65 | 2. Consumer pulls messages from a specific topic.
66 | - use an "offset pointer" (offset as seqId) to track/control its only read progress.
67 | 3. A topic consists of partitions, load balance, partition (= ordered + immutable seq of msg that is continually appended to)
68 | - Partitions determine max consumer (group) parallelism. One consumer can read from only one partition at the same time.
69 |
70 | How to serialize data? Avro
71 |
72 | What is its network protocol? TCP
73 |
74 | What is a partition's storage layout? O(1) disk read
75 |
76 |
56 |
57 | Data is stored in topics and split into partitions which are replicated.
58 |
59 | 
60 |
61 | 1. Producer publishes messages to a specific topic.
62 | - Write to in-memory buffer first and flush to disk.
63 | - append-only sequence write for fast write.
64 | - Available to read after write to disks.
65 | 2. Consumer pulls messages from a specific topic.
66 | - use an "offset pointer" (offset as seqId) to track/control its only read progress.
67 | 3. A topic consists of partitions, load balance, partition (= ordered + immutable seq of msg that is continually appended to)
68 | - Partitions determine max consumer (group) parallelism. One consumer can read from only one partition at the same time.
69 |
70 | How to serialize data? Avro
71 |
72 | What is its network protocol? TCP
73 |
74 | What is a partition's storage layout? O(1) disk read
75 |
76 |  80 |
81 | ## How to tolerate fault?
82 |
83 | ==In-sync replica (ISR) protocol==. It tolerates (numReplicas - 1) dead brokers. Every partition has one leader and one or more followers.
84 |
85 | `Total Replicas = ISRs + out-of-sync replicas`
86 |
87 | 1. ISR is the set of replicas that are alive and have fully caught up with the leader (note that the leader is always in ISR).
88 | 2. When a new message is published, the leader waits until it reaches all replicas in the ISR before committing the message.
89 | 3. ==If a follower replica fails, it will be dropped out of the ISR and the leader then continues to commit new messages with fewer replicas in the ISR. Notice that now, the system is running in an under replicated mode.== If a leader fails, an ISR is picked to be a new leader.
90 | 4. Out-of-sync replica keeps pulling message from the leader. Once catches up with the leader, it will be added back to the ISR.
91 |
92 | ## Is Kafka an AP or CP system in [CAP theorem](https://tianpan.co/notes/2018-07-24-replica-and-consistency)?
93 |
94 | Jun Rao says it is CA, because "Our goal was to support replication in a Kafka cluster within a single datacenter, where network partitioning is rare, so our design focuses on maintaining highly available and strongly consistent replicas."
95 |
96 | However, it actually depends on the configuration.
97 |
98 | 1. Out of the box with default config (min.insync.replicas=1, default.replication.factor=1) you are getting AP system (at-most-once).
99 |
100 | 2. If you want to achieve CP, you may set min.insync.replicas=2 and topic replication factor of 3 - then producing a message with acks=all will guarantee CP setup (at-least-once), but (as expected) will block in cases when not enough replicas (\<2) are available for particular topic/partition pair.
101 |
--------------------------------------------------------------------------------
/en/63-soft-skills-interview.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 63-soft-skills-interview
3 | id: 63-soft-skills-interview
4 | title: "What can we communicate in soft skills interview?"
5 | date: 2018-10-01 08:56
6 | comments: true
7 | tags: [system design]
8 | description: "An interview is a process for workers to find future co-workers. The candidate will be evaluated based on answers to three key questions: capability, willingness, and culture-fit.
9 | Any question above can not be answered without good communication."
10 | references:
11 | - https://www.jianshu.com/p/73b1d5682fd3
12 | - https://www.amazon.com/dp/B01NAI5Q6H/
13 | ---
14 |
15 | ## What is an interview?
16 |
17 | An interview is a process for workers to find future co-workers, during which they
18 | are finding signals to answer the following three key questions:
19 |
20 | 1. capability question - can you do the job?
21 | 2. willingness question - will you do the job?
22 | 2. culture-fit question - will you fit in?
23 |
24 |
25 |
26 | ## Why is soft skill so important?
27 |
28 | None of the critical questions above can be answered without good communication.
29 | Your job will be taken away by people who can talk better than you.
30 |
31 |
32 |
33 | ## Generic answers (stories) to prepare
34 |
35 | 1. hard-won triumph. How do you deal with failure? Briefly talk about the harshest moment, and then focus on how you battled back, and then salute the people who helped you. It demonstrates that you have the grit, team-building skills, and relevance to the job.
36 | 2. influence. Can you guide people to yes? `leaders = visionaries who inspire self-sacrifice`. A leader does not exist without the ability to persuade.
37 | 3. technical skills. Do you have a story proving your great technical skills?
38 | 4. culture-fit. The FBI used to ask prospective agents what books they read until an underground network of tipsters figured out the ideal answer: “Tom Clancy spy novels.”
39 | 5. fascination. What's fascinating about you? What makes you different from other people?
40 |
--------------------------------------------------------------------------------
/en/66-public-api-choices.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 66-public-api-choices
3 | id: 66-public-api-choices
4 | title: "Public API Choices"
5 | date: 2018-10-04 01:38
6 | comments: true
7 | tags: [system design]
8 | description: There are several tools for the public API, API gateway or Backend for Frontend gateway. GraphQL distinguishes itself from others for its features like tailing results, batching nested queries, performance tracing, and explicit caching.
9 | ---
10 |
11 | In summary, to choose a tool for the public API, API gateway, or BFF (Backend For Frontend) gateway, I prefer GraphQL for its features like tailing results, batching nested queries, performance tracing, and explicit caching.
12 |
13 | ||JSON RPC|GraphQL|REST|gRPC|
14 | |--- |--- |--- |--- |--- |
15 | |Usecases|Etherum|Github V2, Airbnb, Facebook BFF / API Gateway|Swagger|High performance, Google, internal endpoints|
16 | |Single Endpoint|✅|✅|❌|✅|
17 | |Type System|✅ as weak as JSON
80 |
81 | ## How to tolerate fault?
82 |
83 | ==In-sync replica (ISR) protocol==. It tolerates (numReplicas - 1) dead brokers. Every partition has one leader and one or more followers.
84 |
85 | `Total Replicas = ISRs + out-of-sync replicas`
86 |
87 | 1. ISR is the set of replicas that are alive and have fully caught up with the leader (note that the leader is always in ISR).
88 | 2. When a new message is published, the leader waits until it reaches all replicas in the ISR before committing the message.
89 | 3. ==If a follower replica fails, it will be dropped out of the ISR and the leader then continues to commit new messages with fewer replicas in the ISR. Notice that now, the system is running in an under replicated mode.== If a leader fails, an ISR is picked to be a new leader.
90 | 4. Out-of-sync replica keeps pulling message from the leader. Once catches up with the leader, it will be added back to the ISR.
91 |
92 | ## Is Kafka an AP or CP system in [CAP theorem](https://tianpan.co/notes/2018-07-24-replica-and-consistency)?
93 |
94 | Jun Rao says it is CA, because "Our goal was to support replication in a Kafka cluster within a single datacenter, where network partitioning is rare, so our design focuses on maintaining highly available and strongly consistent replicas."
95 |
96 | However, it actually depends on the configuration.
97 |
98 | 1. Out of the box with default config (min.insync.replicas=1, default.replication.factor=1) you are getting AP system (at-most-once).
99 |
100 | 2. If you want to achieve CP, you may set min.insync.replicas=2 and topic replication factor of 3 - then producing a message with acks=all will guarantee CP setup (at-least-once), but (as expected) will block in cases when not enough replicas (\<2) are available for particular topic/partition pair.
101 |
--------------------------------------------------------------------------------
/en/63-soft-skills-interview.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 63-soft-skills-interview
3 | id: 63-soft-skills-interview
4 | title: "What can we communicate in soft skills interview?"
5 | date: 2018-10-01 08:56
6 | comments: true
7 | tags: [system design]
8 | description: "An interview is a process for workers to find future co-workers. The candidate will be evaluated based on answers to three key questions: capability, willingness, and culture-fit.
9 | Any question above can not be answered without good communication."
10 | references:
11 | - https://www.jianshu.com/p/73b1d5682fd3
12 | - https://www.amazon.com/dp/B01NAI5Q6H/
13 | ---
14 |
15 | ## What is an interview?
16 |
17 | An interview is a process for workers to find future co-workers, during which they
18 | are finding signals to answer the following three key questions:
19 |
20 | 1. capability question - can you do the job?
21 | 2. willingness question - will you do the job?
22 | 2. culture-fit question - will you fit in?
23 |
24 |
25 |
26 | ## Why is soft skill so important?
27 |
28 | None of the critical questions above can be answered without good communication.
29 | Your job will be taken away by people who can talk better than you.
30 |
31 |
32 |
33 | ## Generic answers (stories) to prepare
34 |
35 | 1. hard-won triumph. How do you deal with failure? Briefly talk about the harshest moment, and then focus on how you battled back, and then salute the people who helped you. It demonstrates that you have the grit, team-building skills, and relevance to the job.
36 | 2. influence. Can you guide people to yes? `leaders = visionaries who inspire self-sacrifice`. A leader does not exist without the ability to persuade.
37 | 3. technical skills. Do you have a story proving your great technical skills?
38 | 4. culture-fit. The FBI used to ask prospective agents what books they read until an underground network of tipsters figured out the ideal answer: “Tom Clancy spy novels.”
39 | 5. fascination. What's fascinating about you? What makes you different from other people?
40 |
--------------------------------------------------------------------------------
/en/66-public-api-choices.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 66-public-api-choices
3 | id: 66-public-api-choices
4 | title: "Public API Choices"
5 | date: 2018-10-04 01:38
6 | comments: true
7 | tags: [system design]
8 | description: There are several tools for the public API, API gateway or Backend for Frontend gateway. GraphQL distinguishes itself from others for its features like tailing results, batching nested queries, performance tracing, and explicit caching.
9 | ---
10 |
11 | In summary, to choose a tool for the public API, API gateway, or BFF (Backend For Frontend) gateway, I prefer GraphQL for its features like tailing results, batching nested queries, performance tracing, and explicit caching.
12 |
13 | ||JSON RPC|GraphQL|REST|gRPC|
14 | |--- |--- |--- |--- |--- |
15 | |Usecases|Etherum|Github V2, Airbnb, Facebook BFF / API Gateway|Swagger|High performance, Google, internal endpoints|
16 | |Single Endpoint|✅|✅|❌|✅|
17 | |Type System|✅ as weak as JSON
No uint64|✅
No uint64|✅ w/ Swagger
No uint64|✅
has uint64|
18 | |Tailored Results|❌|✅|❌|❌|
19 | |Batch nested queries|❌|✅|❌|❌|
20 | |Versioning|❌|Schema Extension|Yes, w/ v1/v2 route s|Field Numbers in protobuf|
21 | |Error Handling|Structured|Structured|HTTP Status Code|Structured|
22 | |Cross-platform|✅|✅|✅|✅|
23 | |Playground UI|❌|GraphQL Bin|Swagger|❌|
24 | |Performance tracing|?|Apollo plugin|?|?|
25 | |caching|No or HTTP cache control|Apollo plugin|HTTP cache control|Native support not yet. but still yes w/ HTTP cache control|
26 | |Problem|Lack of community support and toolchainBarrister IDL|42.51 kb client-side bundle size|Unstructured with multiple endpoints. awful portability.|Grpc-web dev in progress140kb JS bundle. Compatibility issues: not all places support HTTP2 and grpc dependencies|
27 |
--------------------------------------------------------------------------------
/en/68-bloom-filter.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 68-bloom-filter
3 | id: 68-bloom-filter
4 | title: "Bloom Filter"
5 | date: 2018-10-09 12:39
6 | comments: true
7 | tags: [system design, data structures]
8 | description: A bloom filter is a data structure used to detect whether an element is in a set in a time and space efficient way. A query returns either "possibly in set" or "definitely not in set".
9 | references:
10 | - https://en.wikipedia.org/wiki/Bloom_filter
11 | ---
12 |
13 | A Bloom filter is a data structure used to detect whether an element is in a set in a time and space efficient way.
14 |
15 | False positive matches are possible, but false negatives are not – in other words, a query returns either "possibly in set" or "definitely not in set". Elements can be added to the set, but not removed (though this can be addressed with a "counting" bloom filter); the more elements that are added to the set, the larger the probability of false positives.
16 |
17 | Usecases
18 |
19 | - Cassandra uses Bloom filters to determine whether an SSTable has data for a particular row.
20 | - An HBase Bloom Filter is an efficient mechanism to test whether a StoreFile contains a specific row or row-col cell.
21 | - A website's anti-fraud system can use bloom filters to reject banned users effectively.
22 | - The Google Chrome web browser used to use a Bloom filter to identify malicious URLs.
23 |
--------------------------------------------------------------------------------
/en/69-skiplist.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 69-skiplist
3 | id: 69-skiplist
4 | title: "Skiplist"
5 | date: 2018-10-09 12:39
6 | comments: true
7 | tags: [system design, data structures]
8 | description: "A skip-list is essentially a linked list that allows you to do a binary search on. The way it accomplishes this is by adding extra nodes that will enable you to ‘skip’ sections of the linked-list. There are LevelDB MemTable, Redis SortedSet and Lucene inverted index using this."
9 | references:
10 | - https://en.wikipedia.org/wiki/Skip_list
11 | ---
12 |
13 | A skip-list is essentially a linked list that allows you to binary search on it. The way it accomplishes this is by adding extra nodes that will enable you to 'skip' sections of the linked-list. Given a random coin toss to create the extra nodes, the skip list should have O(logn) searches, inserts and deletes.
14 |
15 | Usecases
16 |
17 | - LevelDB MemTable
18 | - Redis SortedSet
19 | - Lucene inverted index
20 |
--------------------------------------------------------------------------------
/en/78-four-kinds-of-no-sql.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 78-four-kinds-of-no-sql
3 | id: 78-four-kinds-of-no-sql
4 | title: "4 Kinds of No-SQL"
5 | date: 2018-10-17 00:49
6 | comments: true
7 | tags: ["system design"]
8 | description: "When reading data from a hard disk, a database join operation is time-consuming and 99% of the time is spent on disk seek. To optimize read performance, denormalization is introduced and four categories of NoSQL are here to help."
9 | references:
10 | - https://www.puncsky.com/blog/2016-02-13-crack-the-system-design-interview
11 | ---
12 |
13 | In a regular Internet service, the read:write ratio is about 100:1 to 1000:1. However, when reading from a hard disk, a database join operation is time-consuming, and 99% of the time is spent on disk seek. Not to mention a distributed join operation across networks.
14 |
15 | To optimize the read performance, **denormalization** is introduced by adding redundant data or by grouping data. These four categories of NoSQL are here to help.
16 |
17 |
18 |
19 | ## Key-value Store
20 |
21 | The abstraction of a KV store is a giant hashtable/hashmap/dictionary.
22 |
23 | The main reason we want to use a key-value cache is to reduce latency for accessing active data. Achieve an O(1) read/write performance on a fast and expensive media (like memory or SSD), instead of a traditional O(logn) read/write on a slow and cheap media (typically hard drive).
24 |
25 | There are three major factors to consider when we design the cache.
26 |
27 | 1. Pattern: How to cache? is it read-through/write-through/write-around/write-back/cache-aside?
28 | 2. Placement: Where to place the cache? client-side/distinct layer/server side?
29 | 3. Replacement: When to expire/replace the data? LRU/LFU/ARC?
30 |
31 | Out-of-box choices: Redis/Memcache? Redis supports data persistence while Memcache does not. Riak, Berkeley DB, HamsterDB, Amazon Dynamo, Project Voldemort, etc.
32 |
33 |
34 | ## Document Store
35 |
36 | The abstraction of a document store is like a KV store, but documents, like XML, JSON, BSON, and so on, are stored in the value part of the pair.
37 |
38 | The main reason we want to use a document store is for flexibility and performance. Flexibility is achieved by the schemaless document, and performance is improved by breaking 3NF. Startup's business requirements are changing from time to time. Flexible schema empowers them to move fast.
39 |
40 | Out-of-box choices: MongoDB, CouchDB, Terrastore, OrientDB, RavenDB, etc.
41 |
42 |
43 |
44 | ## Column-oriented Store
45 |
46 | The abstraction of a column-oriented store is like a giant nested map: `ColumnFamily>`.
47 |
48 | The main reason we want to use a column-oriented store is that it is distributed, highly-available, and optimized for write.
49 |
50 | Out-of-box choices: Cassandra, HBase, Hypertable, Amazon SimpleDB, etc.
51 |
52 |
53 |
54 | ## Graph Database
55 |
56 | As the name indicates, this database's abstraction is a graph. It allows us to store entities and the relationships between them.
57 |
58 | If we use a relational database to store the graph, adding/removing relationships may involve schema changes and data movement, which is not the case when using a graph database. On the other hand, when we create tables in a relational database for the graph, we model based on the traversal we want; if the traversal changes, the data will have to change.
59 |
60 | Out-of-box choices: Neo4J, Infinitegraph, OrientDB, FlockDB, etc.
61 |
--------------------------------------------------------------------------------
/en/80-relational-database.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 80-relational-database
3 | id: 80-relational-database
4 | title: "Intro to Relational Database"
5 | date: 2018-10-18 23:19
6 | comments: true
7 | tags: [system design]
8 | description: The relational database is the default choice for most storage use cases, by reason of atomicity, consistency, isolation, and durability. How is consistency here different from the one in CAP theorem? Why do we need 3NF and DB proxy?
9 | references:
10 | - https://www.puncsky.com/blog/2016-02-13-crack-the-system-design-interview
11 | ---
12 |
13 | Relational database is the default choice for most storage use cases, by reason of ACID (atomicity, consistency, isolation, and durability). One tricky thing is "consistency" -- it means that any transaction will bring database from one valid state to another, which is different from Consistency in [CAP theorem](https://tianpan.co/notes/2018-07-24-replica-and-consistency).
14 |
15 | ## Schema Design and 3rd Normal Form (3NF)
16 |
17 | To reduce redundancy and improve consistency, people follow 3NF when designing database schemas:
18 |
19 | - 1NF: tabular, each row-column intersection contains only one value
20 | - 2NF: only the primary key determines all the attributes
21 | - 3NF: only the candidate keys determine all the attributes (and non-prime attributes do not depend on each other)
22 |
23 | ## Db Proxy
24 |
25 | What if we want to eliminate single point of failure? What if the dataset is too large for one single machine to hold? For MySQL, the answer is to use a DB proxy to distribute data, either by clustering or by sharding
26 |
27 | Clustering is a decentralized solution. Everything is automatic. Data is distributed, moved, rebalanced automatically. Nodes gossip with each other, (though it may cause group isolation).
28 |
29 | Sharding is a centralized solution. If we get rid of properties of clustering that we don't like, sharding is what we get. Data is distributed manually and does not move. Nodes are not aware of each other.
30 |
--------------------------------------------------------------------------------
/en/83-lambda-architecture.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 83-lambda-architecture
3 | id: 83-lambda-architecture
4 | title: "Lambda Architecture"
5 | date: 2018-10-23 10:30
6 | comments: true
7 | tags: [system design]
8 | description: Lambda architecture = CQRS (batch layer + serving layer) + speed layer. It solves accuracy, latency, throughput problems of big data.
9 | references:
10 | - https://www.amazon.com/Big-Data-Principles-practices-scalable/dp/1617290343
11 | - https://mapr.com/resources/stream-processing-mapr/
12 | ---
13 |
14 | ## Why lambda architecture?
15 |
16 | To solve three problems introduced by big data
17 |
18 | 1. Accuracy (好)
19 | 2. Latency (快)
20 | 3. Throughput (多)
21 |
22 |
23 | e.g. problems with scaling a pageview service in a traditional way
24 |
25 | 1. You start with a traditional relational database.
26 | 2. Then adding a pub-sub queue.
27 | 3. Then scaling by horizontal partitioning or sharding
28 | 4. Fault-tolerance issues begin
29 | 5. Data corruption happens
30 |
31 | The key point is that ==X-axis dimension alone of the [AKF scale cube](https://tianpan.co/notes/41-how-to-scale-a-web-service) is not good enough. We should introduce Y-axis / functional decomposition as well. Lambda architecture tells us how to do it for a data system.==
32 |
33 |
34 |
35 | ## What is lambda architecture?
36 |
37 | If we define a data system as
38 |
39 | ```txt
40 | Query = function(all data)
41 | ```
42 |
43 |
44 | Then a lambda architecture is
45 |
46 | 
47 |
48 |
49 | ```txt
50 | batch view = function(all data at the batching job's execution time)
51 | realtime view = function(realtime view, new data)
52 |
53 | query = function(batch view. realtime view)
54 | ```
55 |
56 | ==Lambda architecture = CQRS (batch layer + serving layer) + speed layer==
57 |
58 |
59 | 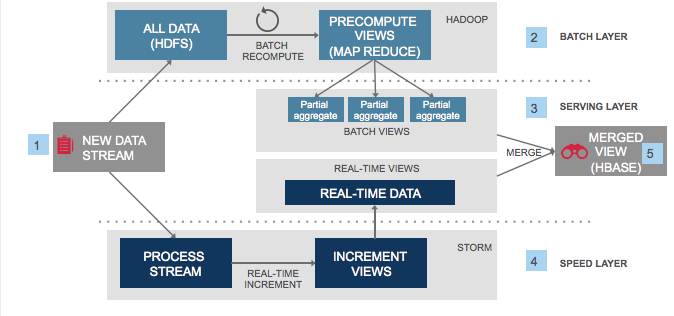
60 |
--------------------------------------------------------------------------------
/en/84-designing-a-url-shortener.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 84-designing-a-url-shortener
3 | id: 84-designing-a-url-shortener
4 | title: "Designing a URL shortener"
5 | date: 2018-10-25 14:32
6 | comments: true
7 | tags: [system design]
8 | description: If you are asked to design a system to take user-provided URLs and transform them to shortened URLs, what would you do? How would you allocate the shorthand URLs? How would you implement the redirect servers? How would you store the click stats?
9 | ---
10 |
11 | Design a system to take user-provided URLs and transform them to a shortened URLs that redirect back to the original. Describe how the system works. How would you allocate the shorthand URLs? How would you store the shorthand to original URL mapping? How would you implement the redirect servers? How would you store the click stats?
12 |
13 | Assumptions: I generally don't include these assumptions in the initial problem presentation. Good candidates will ask about scale when coming up with a design.
14 |
15 | - Total number of unique domains registering redirect URLs is on the order of 10s of thousands
16 | - New URL registrations are on the order of 10,000,000/day (100/sec)
17 | - Redirect requests are on the order of 10B/day (100,000/sec)
18 | - Remind candidates that those are average numbers - during peak traffic (either driven by time, such as 'as people come home from work' or by outside events, such as 'during the Superbowl') they may be much higher.
19 | - Recent stats (within the current day) should be aggregated and available with a 5 minute lag time
20 | - Long look-back stats can be computed daily
21 | - Targeted use cases: The shortened URLs are to be copied-and-pasted only.
22 | - The URLs won't be typed in via a keyboard. Therefore, don't worry about distinguishing between `0` and `o`, `l` and `1`, etc.
23 | - The URLs won't be spelled out verbally. Therefore, there's no need to make the shortened URLs phonetic.
24 |
25 | ## Assumptions
26 |
27 | 1B new URLs per day, 100B entries in total
28 | the shorter, the better
29 | show statics (real-time and daily/monthly/yearly)
30 |
31 | ## Encode Url
32 | http://blog.codinghorror.com/url-shortening-hashes-in-practice/
33 |
34 | Choice 1. md5(128 bit, 16 hex numbers, collision, birthday paradox, 2^(n/2) = 2^64) truncate? (64bit, 8 hex number, collision 2^32), Base64.
35 |
36 | * Pros: hashing is simple and horizontally scalable.
37 | * Cons: too long, how to purify expired URLs?
38 |
39 | Choice 2. Distributed Seq Id Generator. (Base62: a~z, A~Z, 0~9, 62 chars, 62^7), sharding: each node maintains a section of ids.
40 |
41 | * Pros: easy to outdate expired entries, shorter
42 | * Cons: coordination (zookeeper)
43 |
44 | ## KV store
45 |
46 | MySQL(10k qps, slow, no relation), KV (100k qps, Redis, Memcached)
47 |
48 | A great candidate will ask about the lifespan of the aliases and design a system that purges aliases past their expiration.
49 |
50 | ## Followup
51 | Q: How will shortened URLs be generated?
52 |
53 | * A poor candidate will propose a solution that uses a single id generator (single point of failure) or a solution that requires coordination among id generator servers on every request. For example, a single database server using an auto-increment primary key.
54 | * An acceptable candidate will propose a solution using an md5 of the URL, or some form of UUID generator that can be done independently on any node. While this allows distributed generation of non- colliding IDs, it yields large "shortened" URLs
55 | * A good candidate will design a solution that utilizes a cluster of id generators that reserve chunks of the id space from a central coordinator (e.g. ZooKeeper) and independently allocate IDs from their chunk, refreshing as necessary.
56 |
57 | Q: How to store the mappings?
58 |
59 | * A poor candidate will suggest a monolithic database. There are no relational aspects to this store. It is a pure key-value store.
60 | * A good candidate will propose using any light-weight, distributed store. MongoDB/HBase/Voldemort/etc.
61 | * A great candidate will ask about the lifespan of the aliases and design a system that ==purges aliases past their expiration==
62 |
63 | Q: How to implement the redirect servers?
64 |
65 | * A poor candidate will start designing something from scratch to solve an already solved problem
66 | * A good candidate will propose using an off-the-shelf HTTP server with a plug-in that parses the shortened URL key, looks the alias up in the DB, updates click stats and returns a 303 back to the original URL. Apache/Jetty/Netty/tomcat/etc. are all fine.
67 |
68 | Q: How are click stats stored?
69 |
70 | * A poor candidate will suggest write-back to a data store on every click
71 | * A good candidate will suggest some form of ==aggregation tier that accepts clickstream data, aggregates it, and writes back a persistent data store periodically==
72 |
73 | Q: How will the aggregation tier be partitioned?
74 |
75 | * A great candidate will suggest a low-latency messaging system to buffer the click data and transfer it to the aggregation tier.
76 | * A candidate may ask how often the stats need to be updated. If daily, storing in HDFS and running map/reduce jobs to compute stats is a reasonable approach If near real-time, the aggregation logic should compute stats
77 |
78 | Q: How to prevent visiting restricted sites?
79 |
80 | * A good candidate can answer with maintaining a blacklist of hostnames in a KV store.
81 | * A great candidate may propose some advanced scaling techniques like bloom filter.
82 |
--------------------------------------------------------------------------------
/en/85-improving-availability-with-failover.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 85-improving-availability-with-failover
3 | id: 85-improving-availability-with-failover
4 | title: "Improving availability with failover"
5 | date: 2018-10-26 12:02
6 | comments: true
7 | tags: [system design]
8 | description: To improve availability with failover, there are serval ways to achieve the goal such as cold standby, hot standby, warm standby, checkpointing and all active.
9 | references:
10 | - https://www.ibm.com/developerworks/community/blogs/RohitShetty/entry/high_availability_cold_warm_hot
11 | ---
12 |
13 | Cold Standby: Use heartbeat or metrics/alerts to track failure. Provision new standby nodes when a failure occurs. Only suitable for stateless services.
14 |
15 | Hot Standby: Keep two active systems undertaking the same role. Data is mirrored in near real time, and both systems will have identical data.
16 |
17 | Warm Standby: Keep two active systems but the secondary one does not take traffic unless the failure occurs.
18 |
19 | Checkpointing (or like Redis snapshot): Use write-ahead log (WAL) to record requests before processing. Standby node recovers from the log during the failover.
20 |
21 | * cons
22 | * time-consuming for large logs
23 | * lose data since the last checkpoint
24 | * usercase: Storm, WhillWheel, Samza
25 |
26 | Active-active (or all active): Keep two active systems behind a load balancer. Both of them take in parallel. Data replication is bi-directional.
27 |
--------------------------------------------------------------------------------
/en/97-designing-a-kv-store-with-external-storage.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 97-designing-a-kv-store-with-external-storage
3 | id: 97-designing-a-kv-store-with-external-storage
4 | title: "Designing a KV store with external storage"
5 | date: 2018-11-10 12:39
6 | comments: true
7 | tags: [system design]
8 | references:
9 | - http://basho.com/wp-content/uploads/2015/05/bitcask-intro.pdf
10 | ---
11 |
12 | ## Requirements
13 |
14 | 1. Data size: Data size of values is too large to be held in memory, and we should leverage the external storage for them. However, we can still keep the data keys in memory.
15 | 2. Single-host solution. No distributed design.
16 | 3. Optimize for write.
17 |
18 |
19 |
20 | ## Solution
21 | * In-memory hashmap index + index hint file + data files
22 | * Append-only for write optimization. Have only one active data file for write. And compact active data to the older data file(s) for read.
23 |
24 |
25 |
26 | ## Components
27 |
28 | 1. In-memory `HashMap>`
29 |
30 | 2. Data file layout
31 |
32 | ```txt
33 | |crc|timestamp|key_size|value_size|key|value|
34 | ...
35 | ```
36 |
37 | 3. (index) hint file that the in-memory hashmap can recover from
38 |
39 |
40 |
41 | ## Operations
42 |
43 | Delete: get the location by the in-memory hashmap, if it exists, then go to the location on the disk to set the value to a magic number.
44 |
45 | Get: get the location by the in-memory hashmap, and then go to the location on the disk for the value.
46 |
47 | Put: append to the active data file and update the in-memory hash map.
48 |
49 |
50 | Periodical compaction strategies
51 |
52 | * Copy latest entries: In-memory hashmap is always up-to-date. Stop and copy into new files. Time complexity is O(n) n is the number of valid entries.
53 | * Pros: Efficient for lots of entries out-dated or deleted.
54 | * Cons: Consume storage if little entries are out-dated. May double the space. (can be resolved by having a secondary node do the compression work with GET/POST periodically. E.g., Hadoop secondary namenode).
55 |
56 |
57 | * Scan and move: foreach entry, if it is up-to-date, move to the tail of the validated section. Time complexity is O(n) n is the number of all the entries.
58 | * Pros:
59 | * shrink the size
60 | * no extra storage space needed
61 | * Cons:
62 | * Complex and need to sync hashmap and storage with transactions. May hurt performance.
63 |
64 |
65 | Following up questions
66 |
67 | * How to detect records that can be compacted?
68 | * Use timestamp.
69 | * What if one hashmap cannot fit into a single machine’s memory?
70 | * Consistent hashing, chord DHT, query time complexity is O(logn) with the finger table, instead of O(1) here with a hashmap.
71 |
--------------------------------------------------------------------------------
/zh-CN/11-three-programming-paradigms.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 11-three-programming-paradigms
3 | id: 11-three-programming-paradigms
4 | title: "三种编程范式"
5 | date: 2018-08-12 02:31
6 | comments: true
7 | tags: [系统设计]
8 | description: "结构化编程是一种对直接控制转移的约束。面向对象编程是一种对间接控制转移的约束。函数式编程是一种对变量赋值的约束。"
9 | references:
10 | - https://www.amazon.com/Clean-Architecture-Craftsmans-Software-Structure/dp/0134494164
11 | ---
12 |
13 | 结构化编程 vs. 面向对象编程 vs. 函数式编程
14 |
15 |
16 |
17 | 1. 结构化编程是一种对直接控制转移的约束。
18 | 1. 可测试性:软件就像科学:科学不是通过证明陈述为真来工作的,而是通过证明陈述为假来工作的。结构化编程迫使我们递归地将程序分解为一组小的可证明函数。
19 |
20 |
21 |
22 | 2. 面向对象编程是一种对间接控制转移的约束。
23 | 1. 封装、继承、多态(指向函数的指针)并不是面向对象特有的。
24 | 2. 但面向对象使多态的使用变得安全和方便。然后启用强大的==插件架构==与依赖反转
25 | 1. 源代码依赖关系和控制流通常是相同的。然而,如果我们让它们都依赖于接口,依赖关系就会反转。
26 | 2. 接口赋予独立部署的能力。例如,在部署Solidity智能合约时,导入和使用接口消耗的气体远远少于对整个实现进行操作。
27 |
28 |
29 |
30 | 3. 函数式编程:不可变性。是一种对变量赋值的约束。
31 | 1. 为什么重要?所有的竞争条件、死锁条件和并发更新问题都是由于可变变量造成的。
32 | 2. ==事件溯源==是一种策略,我们存储事务,而不是状态。当需要状态时,我们只需从时间的开始应用所有事务。
--------------------------------------------------------------------------------
/zh-CN/12-solid-design-principles.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 12-solid-design-principles
3 | id: 12-solid-design-principles
4 | title: "SOLID 设计原则"
5 | date: 2018-08-13 18:07
6 | comments: true
7 | tags: [系统设计]
8 | description: SOLID 是一组设计原则的首字母缩写,帮助软件工程师编写稳健的代码。S 代表单一职责原则,O 代表开放/封闭原则,L 代表里氏替换原则,I 代表接口隔离原则,D 代表依赖倒置原则。
9 | references:
10 | - https://www.amazon.com/Clean-Architecture-Craftsmans-Software-Structure/dp/0134494164
11 | ---
12 |
13 | SOLID 是一组设计原则的首字母缩写,帮助软件工程师在项目中编写稳健的代码。
14 |
15 | 1. S - **单一职责原则**。一个模块应该只对一个角色负责,一个模块只是一个功能和数据结构的内聚集合。
16 |
17 | 2. O - **开放/封闭原则**。软件工件应该对扩展开放,但对修改封闭。
18 |
19 | 3. L - **里氏替换原则**。通过接口和实现、泛型、子类化和鸭子类型来简化代码的继承。
20 |
21 | 4. I - **接口隔离原则**。将单一的庞大接口分割成更小的接口,以解耦模块。
22 |
23 | 5. D - **依赖倒置原则**。源代码的依赖关系与控制流相反。我们架构图中最明显的组织原则。
24 | 1. 事物应该是稳定的具体,或者是过时的抽象,而不是 ==具体和不稳定==。
25 | 2. 因此使用 ==抽象工厂== 来创建不稳定的具体对象(管理不希望的依赖关系)。产生接口的接口
26 | 3. DIP 违规无法完全消除。大多数系统至少会包含一个这样的具体组件——这个组件通常被称为主组件。
--------------------------------------------------------------------------------
/zh-CN/120-designing-uber.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 120-designing-uber
3 | id: 120-designing-uber
4 | title: "设计 Uber"
5 | date: 2019-01-03 18:39
6 | comments: true
7 | tags: [系统设计]
8 | references:
9 | - https://medium.com/yalantis-mobile/uber-underlying-technologies-and-how-it-actually-works-526f55b37c6f
10 | - https://www.youtube.com/watch?t=116&v=vujVmugFsKc
11 | - http://www.infoq.com/news/2015/03/uber-realtime-market-platform
12 | - https://www.youtube.com/watch?v=kb-m2fasdDY&vl=en
13 | ---
14 |
15 | 免责声明:以下所有内容均来自公共来源或纯原创。这里没有 Uber 机密信息。
16 |
17 | ## 需求
18 |
19 | * 针对全球交通市场的打车服务
20 | * 大规模实时调度
21 | * 后端设计
22 |
23 | ## 架构
24 |
25 | 
26 |
27 | ## 为什么选择微服务?
28 | ==康威定律== 表示软件系统的结构是组织结构的复制。
29 |
30 | | | 单体 ==服务== | 微服务 |
31 | |--- |--- |--- |
32 | | 小团队和代码库时的生产力 | ✅ 高 | ❌ 低 |
33 | | ==大团队和代码库时的生产力== | ❌ 低 | ✅ 高 (康威定律) |
34 | | ==对工程质量的要求== | ❌ 高 (不合格的开发人员容易导致系统崩溃) | ✅ 低 (运行时被隔离) |
35 | | 依赖性提升 | ✅ 快 (集中管理) | ❌ 慢 |
36 | | 多租户支持 / 生产-预发布隔离 | ✅ 简单 | ❌ 难 (每个独立服务必须 1) 构建连接到其他服务的预发布环境 2) 在请求上下文和数据存储中支持多租户) |
37 | | 可调试性,假设相同模块、指标、日志 | ❌ 低 | ✅ 高 (使用分布式追踪) |
38 | | 延迟 | ✅ 低 (本地) | ❌ 高 (远程) |
39 | | DevOps 成本 | ✅ 低 (构建工具成本高) | ❌ 高 (容量规划困难) |
40 |
41 | 结合单体 ==代码库== 和微服务可以带来双方的好处。
42 |
43 | ## 调度服务
44 |
45 | * 一致性哈希按地理哈希分片
46 | * 数据是瞬态的,存在内存中,因此无需复制。(CAP: AP 优于 CP)
47 | * 在分片中使用单线程或锁定匹配以防止双重调度
48 |
49 | ## 支付服务
50 |
51 | ==关键是采用异步设计==,因为支付系统通常在多个系统之间的 ACID 事务中具有非常长的延迟。
52 |
53 | * 利用事件队列
54 | * 支付网关与 Braintree、PayPal、Card.io、支付宝等集成
55 | * 密集记录以跟踪所有内容
56 | * [具有幂等性、指数退避和随机抖动的 API](https://puncsky.com/notes/43-how-to-design-robust-and-predictable-apis-with-idempotency)
57 |
58 | ## 用户资料服务和行程服务
59 |
60 | * 低延迟与缓存
61 | * 用户资料服务面临为越来越多类型的用户(司机、乘客、餐厅老板、吃货等)和不同地区和国家的用户架构提供服务的挑战。
62 |
63 | ## 推送通知服务
64 |
65 | * 苹果推送通知服务(可靠性不高)
66 | * 谷歌云消息服务 GCM (可以检测可送达性)或
67 | * 短信服务通常更可靠
--------------------------------------------------------------------------------
/zh-CN/121-designing-facebook-photo-storage.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 121-designing-facebook-photo-storage
3 | id: 121-designing-facebook-photo-storage
4 | title: "设计 Facebook 照片存储"
5 | date: 2019-01-04 12:11
6 | comments: true
7 | tags: [系统设计]
8 | description: "传统的基于 NFS 的设计存在元数据瓶颈:大的元数据大小限制了元数据命中率。Facebook 照片存储通过将数十万张图像聚合在一个单一的 haystack 存储文件中,消除了元数据。"
9 | references:
10 | - https://www.usenix.org/conference/osdi10/finding-needle-haystack-facebooks-photo-storage
11 | - https://www.facebook.com/notes/facebook-engineering/needle-in-a-haystack-efficient-storage-of-billions-of-photos/76191543919
12 | ---
13 |
14 | ## 动机与假设
15 |
16 | * PB 级 Blob 存储
17 | * 传统的基于 NFS 的设计(每张图像存储为一个文件)存在元数据瓶颈:大的元数据大小严重限制了元数据命中率。
18 | * 进一步解释元数据开销
19 |
20 | > 对于照片应用,大部分元数据(如权限)未被使用,从而浪费了存储容量。然而,更重要的成本在于,文件的元数据必须从磁盘读取到内存中,以便找到文件本身。在小规模上这并不显著,但在数十亿张照片和 PB 级数据的情况下,访问元数据成为了吞吐量瓶颈。
21 |
22 |
23 |
24 | ## 解决方案
25 |
26 | 通过将数十万张图像聚合在一个单一的 haystack 存储文件中,消除了元数据开销。
27 |
28 |
29 |
30 | ## 架构
31 |
32 | 
33 |
34 |
35 |
36 | ## 数据布局
37 |
38 | 索引文件(用于快速内存加载)+ 包含针的 haystack 存储文件。
39 |
40 | 索引文件布局
41 | 
42 |
43 |
44 | 
45 |
46 |
47 | haystack 存储文件
48 |
49 | 
50 |
51 |
52 |
53 | ### CRUD 操作
54 |
55 | * 创建:写入存储文件,然后 ==异步== 写入索引文件,因为索引不是关键的
56 | * 读取:read(offset, key, alternate_key, cookie, data_size)
57 | * 更新:仅追加。如果应用程序遇到重复键,则可以选择具有最大偏移量的一个进行更新。
58 | * 删除:通过在标志字段中标记删除位进行软删除。硬删除通过压缩操作执行。
59 |
60 |
61 |
62 | ## 用例
63 |
64 | 上传
65 |
66 | 
67 |
68 |
69 | 下载
70 |
71 | 
--------------------------------------------------------------------------------
/zh-CN/122-key-value-cache.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 122-key-value-cache
3 | id: 122-key-value-cache
4 | title: "键值缓存"
5 | date: 2019-01-06 23:24
6 | comments: true
7 | description: "键值缓存用于减少数据访问的延迟。什么是读穿、写穿、写后、写回、写后和旁路缓存模式?"
8 | tags: [系统设计]
9 | ---
10 |
11 | KV 缓存就像一个巨大的哈希映射,用于减少数据访问的延迟,通常通过
12 |
13 | 1. 将来自慢速且便宜介质的数据转移到快速且昂贵的介质上。
14 | 2. 从基于树的数据结构的 `O(log n)` 索引转为基于哈希的数据结构的 `O(1)` 进行读写。
15 |
16 | 有各种缓存策略,如读穿/写穿(或写回)和旁路缓存。总体而言,互联网服务的读写比为 100:1 到 1000:1,因此我们通常会优化读取。
17 |
18 | 在分布式系统中,我们根据业务需求和上下文选择这些策略,并在 [CAP 定理](https://puncsky.com/notes/2018-07-24-replica-and-consistency) 的指导下进行选择。
19 |
20 | ## 常规模式
21 |
22 | * 读取
23 | * 读穿:客户端通过缓存层从数据库读取数据。当读取命中缓存时,缓存返回;否则,它从数据库获取数据,缓存后再返回值。
24 | * 写入
25 | * 写穿:客户端写入缓存,缓存更新数据库。缓存在完成数据库写入后返回。
26 | * 写后 / 写回:客户端写入缓存,缓存立即返回。在缓存写入的背后,缓存异步写入数据库。
27 | * 绕过写入:客户端直接写入数据库,绕过缓存。
28 |
29 | ## 旁路缓存模式
30 | 当缓存不支持原生的读穿和写穿操作,并且资源需求不可预测时,我们使用这种旁路缓存模式。
31 |
32 | * 读取:尝试命中缓存。如果未命中,则从数据库读取,然后更新缓存。
33 | * 写入:先写入数据库,然后 ==删除缓存条目==。这里一个常见的陷阱是 [人们错误地用值更新缓存,而在高并发环境中双重写入会使缓存变脏](https://www.quora.com/Why-does-Facebook-use-delete-to-remove-the-key-value-pair-in-Memcached-instead-of-updating-the-Memcached-during-write-request-to-the-backend)。
34 |
35 | ==在这种模式下仍然存在缓存变脏的可能性。== 当满足以下两个条件时,会发生这种情况:
36 |
37 | 1. 读取数据库并更新缓存
38 | 2. 更新数据库并删除缓存
39 |
40 | ## 缓存放在哪里?
41 |
42 | * 客户端
43 | * 独立层
44 | * 服务器端
45 |
46 | ## 如果数据量达到缓存容量怎么办?使用缓存替换策略
47 | * LRU(最近最少使用):检查时间,驱逐最近使用的条目,保留最近使用的条目。
48 | * LFU(最不常用):检查频率,驱逐最常用的条目,保留最常用的条目。
49 | * ARC(自适应替换缓存):其性能优于 LRU。通过同时保留最常用和频繁使用的条目,以及驱逐历史来实现。(保留 MRU + MFU + 驱逐历史。)
50 |
51 | ## 谁是缓存使用的王者?
52 | [Facebook TAO](https://puncsky.com/notes/49-facebook-tao)
--------------------------------------------------------------------------------
/zh-CN/123-ios-architecture-patterns-revisited.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 123-ios-architecture-patterns-revisited
3 | id: 123-ios-architecture-patterns-revisited
4 | title: "iOS 架构模式再探"
5 | date: 2019-01-10 02:26
6 | comments: true
7 | tags: [architecture, mobile, system design]
8 | description: "架构可以直接影响每个功能的成本。让我们在三个维度上比较紧耦合 MVC、Cocoa MVC、MVP、MVVM 和 VIPER:功能参与者之间责任的平衡分配、可测试性以及易用性和可维护性。"
9 | references:
10 | - https://medium.com/ios-os-x-development/ios-architecture-patterns-ecba4c38de52
11 | ---
12 |
13 | ## 为什么要关注架构?
14 |
15 | 答案:[为了降低每个功能的人力资源成本](https://puncsky.com/notes/10-thinking-software-architecture-as-physical-buildings#ultimate-goal-saving-human-resources-costs-per-feature)。
16 |
17 | 移动开发者从三个维度评估架构。
18 |
19 | 1. 功能参与者之间责任的平衡分配。
20 | 2. 可测试性
21 | 3. 易用性和可维护性
22 |
23 |
24 | | | 责任分配 | 可测试性 | 易用性 |
25 | | --- | --- | --- | --- |
26 | | 紧耦合 MVC | ❌ | ❌ | ✅ |
27 | | Cocoa MVC | ❌ VC 耦合 | ❌ | ✅⭐ |
28 | | MVP | ✅ 分离的视图生命周期 | ✅ | 一般:代码较多 |
29 | | MVVM | ✅ | 一般:由于视图依赖 UIKit | 一般 |
30 | | VIPER | ✅⭐️ | ✅⭐️ | ❌ |
31 |
32 |
33 |
34 | ## 紧耦合 MVC
35 |
36 | 
37 |
38 | 例如,在一个多页面的 web 应用中,一旦点击链接导航到其他地方,页面会完全重新加载。问题在于视图与控制器和模型紧密耦合。
39 |
40 |
41 |
42 | ## Cocoa MVC
43 |
44 | 苹果的 MVC 理论上通过控制器将视图与模型解耦。
45 |
46 | 
47 |
48 |
49 | 实际上,苹果的 MVC 鼓励 ==庞大的视图控制器==。而视图控制器最终负责所有事情。
50 |
51 | 
52 |
53 | 测试耦合的庞大视图控制器是困难的。然而,Cocoa MVC 在开发速度方面是最佳的架构模式。
54 |
55 |
56 |
57 | ## MVP
58 |
59 | 在 MVP 中,呈现者与视图控制器的生命周期无关,视图可以轻松模拟。我们可以说 UIViewController 实际上就是视图。
60 |
61 | 
62 |
63 |
64 | 还有另一种 MVP:带有数据绑定的 MVP。正如你所看到的,视图与其他两个之间存在紧密耦合。
65 |
66 | 
67 |
68 |
69 |
70 | ## MVVM
71 |
72 | 它类似于 MVP,但绑定是在视图和视图模型之间。
73 |
74 | 
75 |
76 |
77 |
78 | ## VIPER
79 | 与 MV(X) 相比,VIPER 有五个层次(VIPER 视图、交互器、呈现者、实体和路由)。这很好地分配了责任,但可维护性较差。
80 |
81 | 
82 |
83 |
84 | 与 MV(X) 相比,VIPER
85 |
86 | 1. 模型逻辑转移到交互器,实体作为简单的数据结构保留。
87 | 2. ==与 UI 相关的业务逻辑放入呈现者,而数据修改能力放入交互器==。
88 | 3. 引入路由器负责导航。
--------------------------------------------------------------------------------
/zh-CN/136-fraud-detection-with-semi-supervised-learning.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 136-fraud-detection-with-semi-supervised-learning
3 | id: 136-fraud-detection-with-semi-supervised-learning
4 | title: "使用半监督学习进行欺诈检测"
5 | date: 2019-02-13 23:57
6 | comments: true
7 | tags: [architecture, system design]
8 | description: 欺诈检测在登录过程中对抗账户接管和僵尸网络攻击。半监督学习比无监督学习具有更好的学习准确性,比监督学习花费更少的时间和成本。
9 | references:
10 | - https://www.slideshare.net/Hadoop_Summit/semisupervised-learning-in-an-adversarial-environment
11 | image: https://web-dash-v2.onrender.com/api/og-tianpan-co?title=%E4%BD%BF%E7%94%A8%E5%8D%8A%E7%9B%91%E7%9D%A3%E5%AD%A6%E4%B9%A0%E8%BF%9B%E8%A1%8C%E6%AC%BA%E8%AF%88%E6%A3%80%E6%B5%8B
12 | ---
13 |
14 | ## 明确需求
15 |
16 | 实时计算风险概率分数,并结合规则引擎做出决策,以防止账户接管 (ATO) 和僵尸网络攻击。
17 |
18 | 通过在线和离线管道训练聚类特征
19 |
20 | 1. 来源于网站日志、认证日志、用户行为、交易、监控列表中的高风险账户
21 |
22 | 2. 在 Kafka 主题中跟踪事件数据
23 |
24 | 3. 处理事件并准备聚类特征
25 |
26 | 实时评分和基于规则的决策
27 |
28 | 4. 综合评估在线服务的风险评分
29 |
30 | 5. 在规则引擎中手动配置以保持灵活性
31 |
32 | 6. 在在线服务中共享或使用洞察
33 |
34 | 从易到难检测的账户接管
35 |
36 | 1. 来自单个 IP
37 |
38 | 2. 来自同一设备的 IP
39 |
40 | 3. 来自全球的 IP
41 |
42 | 4. 来自 100k 个 IP
43 |
44 | 5. 针对特定账户的攻击
45 |
46 | 6. 网络钓鱼和恶意软件
47 |
48 | 挑战
49 |
50 | * 手动特征选择
51 |
52 | * 对抗环境中的特征演变
53 |
54 | * 可扩展性
55 |
56 | * 无在线 DBSCAN
57 |
58 | ## **高级架构**
59 |
60 | 
61 |
62 | ## 核心组件和工作流程
63 |
64 | 半监督学习 = 未标记数据 + 少量标记数据
65 |
66 | 为什么?比无监督学习具有更好的学习准确性 + 比监督学习花费更少的时间和成本
67 |
68 | ### 训练:在数据库中准备聚类特征
69 |
70 | - **Spark 上的流处理管道:**
71 |
72 | - 实时连续运行。
73 |
74 | - 动态执行特征归一化和类别转换。
75 |
76 | - **特征归一化**:将数值特征(如年龄、收入)缩放到 0 和 1 之间。
77 |
78 | - **类别特征转换**:应用独热编码或其他转换,将类别特征转换为适合机器学习模型的数值格式。
79 |
80 | - 使用 **Spark MLlib 的 K-means** 将流数据聚类成组。
81 |
82 | - 运行 k-means 并形成聚类后,可能会发现某些聚类中有更多的欺诈实例。
83 |
84 | - 一旦根据历史数据或专家知识将某个聚类标记为欺诈,就可以在推断过程中使用该聚类分配。任何分配到该欺诈聚类的新数据点都可以标记为可疑。
85 |
86 | - **每小时定时任务管道:**
87 |
88 | - 每小时定期运行(批处理)。
89 |
90 | - 应用 **阈值** 来根据聚类模型的结果识别异常。
91 |
92 | - 调整 **DBSCAN 算法** 的参数以改善聚类和异常检测。
93 |
94 | - 使用 **scikit-learn 的 DBSCAN** 在批量数据中寻找聚类并检测异常值。
95 |
96 | - DBSCAN 可以检测异常值,可能会识别出常规交易的聚类,并将其与可能不寻常、潜在欺诈的交易分开。
97 |
98 | - 在噪声或异常区域(不属于任何密集聚类的点)中的交易可以标记为可疑。
99 |
100 | - 在识别出某个聚类为欺诈后,DBSCAN 有助于即使在不规则形状的交易分布中也能检测到欺诈模式。
101 |
102 | ## 服务
103 |
104 | 服务层是将机器学习模型和业务规则转化为实际欺诈预防决策的地方。其工作原理如下:
105 |
106 | - 欺诈检测评分服务:
107 |
108 | - 提取来自传入请求的实时特征
109 |
110 | - 应用两种聚类模型(流处理中的 K-means 和批处理中的 DBSCAN)
111 |
112 | - 将分数与流计数器(如每个 IP 的登录尝试次数)结合
113 |
114 | - 输出 0 到 1 之间的统一风险评分
115 |
116 | - 规则引擎:
117 |
118 | - 作为系统的“头脑”
119 |
120 | - 将 ML 分数与可配置的业务规则结合
121 |
122 | - 规则示例:
123 |
124 | - 如果风险评分 > 0.8 且用户从新 IP 访问 → 需要 2FA
125 |
126 | - 如果风险评分 > 0.9 且账户为高价值 → 阻止交易
127 |
128 | - 规则存储在数据库中,可以无需代码更改进行更新
129 |
130 | - 为安全团队提供调整规则的管理门户
131 |
132 | - 与其他服务的集成:
133 |
134 | - 暴露用于实时评分的 REST API
135 |
136 | - 将结果发布到流计数器以进行监控
137 |
138 | - 将决策反馈到训练管道以提高模型准确性
139 |
140 | - 可观察性:
141 |
142 | - 跟踪关键指标,如误报/漏报率
143 |
144 | - 监控模型漂移和特征分布变化
145 |
146 | - 为安全分析师提供调查模式的仪表板
147 |
148 | - 记录详细信息以进行事后分析
149 |
--------------------------------------------------------------------------------
/zh-CN/137-stream-and-batch-processing.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 137-stream-and-batch-processing
3 | id: 137-stream-and-batch-processing
4 | title: "流处理与批处理框架"
5 | date: 2019-02-16 22:13
6 | comments: true
7 | tags: [系统设计]
8 | description: "流处理和批处理框架可以以低延迟处理高吞吐量。为什么 Flink 正在获得越来越多的关注?如何在 Storm、Storm-trident、Spark 和 Flink 之间做出架构选择?"
9 | references:
10 | - https://storage.googleapis.com/pub-tools-public-publication-data/pdf/43864.pdf
11 | - https://cs.stanford.edu/~matei/papers/2018/sigmod_structured_streaming.pdf
12 | - https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
13 | - https://stackoverflow.com/questions/28502787/google-dataflow-vs-apache-storm
14 | ---
15 |
16 | ## 为什么需要这样的框架?
17 |
18 | * 以低延迟处理高吞吐量。
19 | * 分布式系统中的容错能力。
20 | * 通用抽象以满足多变的业务需求。
21 | * 适用于有界数据集(批处理)和无界数据集(流处理)。
22 |
23 | ## 批处理/流处理的简史
24 |
25 | 1. Hadoop 和 MapReduce。Google 使批处理在分布式系统中变得简单,如 MR `result = pairs.map((pair) => (morePairs)).reduce(somePairs => lessPairs)`。
26 | 2. Apache Storm 和 DAG 拓扑。MR 无法有效表达迭代算法。因此,Nathan Marz 将流处理抽象为喷口和螺栓的图。
27 | 3. Spark 内存计算。Reynold Xin 表示,Spark 使用 **10 倍更少的机器** 以 **3 倍更快** 的速度对相同数据进行排序。
28 | 4. 基于 Millwheel 和 FlumeJava 的 Google Dataflow。Google 支持批处理和流处理计算,使用窗口 API。
29 |
30 | ### 等等……但为什么 Flink 正在获得越来越多的关注?
31 |
32 | 1. 它快速采用了 ==Google Dataflow==/Beam 编程模型。
33 | 2. 它对 Chandy-Lamport 检查点的高效实现。
34 |
35 | ## 如何?
36 |
37 | ### 架构选择
38 |
39 | 为了用商品机器满足上述需求,流处理框架在这些架构中使用分布式系统……
40 |
41 | * 主从(集中式):apache storm 与 zookeeper,apache samza 与 YARN。
42 | * P2P(去中心化):apache s4。
43 |
44 | ### 特性
45 |
46 | 1. DAG 拓扑用于迭代处理。例如,Spark 中的 GraphX,Apache Storm 中的拓扑,Flink 中的数据流 API。
47 | 2. 交付保证。如何保证从节点到节点的数据交付?至少一次 / 至多一次 / 精确一次。
48 | 3. 容错能力。使用 [冷/热备用、检查点或主动-主动](https://tianpan.co/notes/85-improving-availability-with-failover)。
49 | 4. 无界数据集的窗口 API。例如,Apache Flink 中的流窗口。Spark 窗口函数。Apache Beam 中的窗口处理。
50 |
51 | ## 比较
52 |
53 | | 框架 | Storm | Storm-trident | Spark | Flink |
54 | | --------------------------- | ------------- | ------------- | ------------ | ------------ |
55 | | 模型 | 原生 | 微批处理 | 微批处理 | 原生 |
56 | | 保证 | 至少一次 | 精确一次 | 精确一次 | 精确一次 |
57 | | 容错能力 | 记录确认 | 记录确认 | 检查点 | 检查点 |
58 | | 容错开销 | 高 | 中等 | 中等 | 低 |
59 | | 延迟 | 非常低 | 高 | 高 | 低 |
60 | | 吞吐量 | 低 | 中等 | 高 | 高 |
--------------------------------------------------------------------------------
/zh-CN/140-designing-a-recommendation-system.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 140-designing-a-recommendation-system
3 | id: 140-designing-a-recommendation-system
4 | title: "今日头条推荐系统:P1 概述"
5 | date: 2019-02-19 01:33
6 | comments: true
7 | tags: [系统设计]
8 | description: 为了评估用户满意度,实施了机器学习模型。这些模型通过特征工程观察和测量现实,并通过召回策略进一步减少延迟。
9 | references:
10 | - https://medium.com/@impxia/newsfeed-system-behind-toutiao-2c2454a6d23d
11 | - https://36kr.com/p/5114077
12 | ---
13 |
14 | ## 我们优化的目标是什么?用户满意度
15 | 我们正在寻找以下最佳 `function` 以最大化 `用户满意度` 。
16 |
17 | ```txt
18 | 用户满意度 = function(内容, 用户资料, 上下文)
19 | ```
20 |
21 | 1. 内容:文章、视频、用户生成内容短视频、问答等的特征。
22 | 2. 用户资料:兴趣、职业、年龄、性别和行为模式等。
23 | 3. 上下文:在工作空间、通勤、旅行等情况下的移动用户。
24 |
25 |
26 |
27 | ## 如何评估满意度?
28 |
29 | 1. 可测量的目标,例如:
30 | * 点击率
31 | * 会话持续时间
32 | * 点赞
33 | * 评论
34 | * 转发
35 |
36 |
37 | 2. 难以测量的目标:
38 | * 广告和特殊类型内容(问答)的频率控制
39 | * 低俗内容的频率控制
40 | * 减少点击诱饵、低质量、恶心内容
41 | * 强制/置顶/高度权重重要新闻
42 | * 低权重来自低级账户的内容
43 |
44 |
45 |
46 | ## 如何优化这些目标?机器学习模型
47 | 找到上述最佳 `function` 是一个典型的监督机器学习问题。为了实施该系统,我们有以下算法:
48 |
49 | 1. 协同过滤
50 | 2. 逻辑回归
51 | 3. 深度神经网络
52 | 4. 因子分解机
53 | 5. GBDT
54 |
55 |
56 | 一个世界级的推荐系统应该具备 **灵活性**,以进行 A/B 测试并结合上述多种算法。现在结合逻辑回归和深度神经网络变得流行。几年前,Facebook 使用了逻辑回归和 GBDT。
57 |
58 |
59 |
60 | ## 模型如何观察和测量现实?特征工程
61 |
62 | 1. *内容特征与用户兴趣之间的相关性。* 显式相关性包括关键词、类别、来源、类型。隐式相关性可以从 FM 等模型的用户向量或项目向量中提取。
63 | 2. *环境特征,如地理位置、时间。* 可以用作偏见或在其基础上建立相关性。
64 |
65 |
66 | 3. *热门趋势。* 有全球热门趋势、类别热门趋势、主题热门趋势和关键词热门趋势。热门趋势在我们对用户信息较少时非常有助于解决冷启动问题。
67 | 4. *协同特征,帮助避免推荐内容越来越集中。* 协同过滤不是单独分析每个用户的历史,而是根据用户的点击、兴趣、主题、关键词或隐式向量找到用户的相似性。通过找到相似用户,可以扩展推荐内容的多样性。
68 |
69 |
70 |
71 | ## 实时大规模训练
72 |
73 | * 用户喜欢看到根据我们从他们的行为中跟踪到的内容实时更新的新闻源。
74 | * 使用 Apache Storm 实时训练数据(点击、展示、收藏、分享)。
75 | * 收集数据到达阈值后更新推荐模型
76 | * 在高性能计算集群中存储模型参数,如数十亿的原始特征和数十亿的向量特征。
77 |
78 |
79 | 它们的实现步骤如下:
80 |
81 | 1. 在线服务实时记录特征。
82 | 2. 将数据写入 Kafka
83 | 3. 从 Kafka 向 Storm 导入数据
84 | 4. 填充完整的用户资料并准备样本
85 | 5. 根据最新样本更新模型参数
86 | 6. 在线建模获得新知识
87 |
88 |
89 |
90 |
91 | ## 如何进一步减少延迟?召回策略
92 |
93 | 考虑到所有内容的超大规模,无法用模型预测所有事情。因此,我们需要召回策略来关注数据的代表性子集。性能在这里至关重要,超时时间为 50 毫秒。
94 |
95 | 
96 |
97 |
98 | 在所有召回策略中,我们采用 `InvertedIndex> `。
99 |
100 | `Key` 可以是主题、实体、来源等。
101 |
102 | | 兴趣标签 | 相关性 | 文档列表 |
103 | |--- |--- |--- |
104 | | 电子商务 | 0.3| … |
105 | | 娱乐 | 0.2| … |
106 | | 历史 | 0.2| … |
107 | | 军事 | 0.1| … |
108 |
109 |
110 |
111 | ## 数据依赖
112 |
113 | * 特征依赖于用户端和内容端的标签。
114 | * 召回策略依赖于用户端和内容端的标签。
115 | * 用户标签的内容分析和数据挖掘是推荐系统的基石。
116 |
117 |
118 |
119 |
120 | ## 什么是内容分析?
121 |
122 | 内容分析 = 从原始文章和用户行为中推导中间数据。
123 |
124 | 以文章为例。为了建模用户兴趣,我们需要对内容和文章进行标记。为了将用户与“互联网”标签的兴趣关联起来,我们需要知道用户是否阅读了带有“互联网”标签的文章。
125 |
126 |
127 |
128 | ## 我们为什么要分析这些原始数据?
129 |
130 | 我们这样做的原因是 …
131 |
132 | 1. 标记用户(用户资料)
133 | * 标记喜欢带有“互联网”标签的文章的用户。标记喜欢带有“小米”标签的文章的用户。
134 | 2. 通过标签向用户推荐内容
135 | * 向带有“小米”标签的用户推送“小米”内容。向带有“Dota”标签的用户推送“Dota”内容。
136 | 3. 按主题准备内容
137 | * 将“德甲”文章放入“德甲主题”。将“饮食”文章放入“饮食主题”。
138 |
139 |
140 |
141 | ## 案例研究:一篇文章的分析结果
142 |
143 | 这是“文章特征”页面的示例。文章特征包括分类、关键词、主题、实体。
144 |
145 | 
146 |
147 |
148 | 
149 |
150 | 文章特征是什么?
151 |
152 | 1. 语义标签:人类预定义这些标签并赋予明确的含义。
153 | 2. 隐式语义,包括主题和关键词。主题特征描述了单词的统计信息。某些规则生成关键词。
154 |
155 |
156 | 4. 相似性。重复推荐曾是我们客户反馈中最严重的问题。
157 | 5. 时间和地点。
158 | 6. 质量。滥用、色情、广告或“心灵鸡汤”?
159 |
160 |
161 |
162 | ## 文章特征的重要性
163 |
164 | * 推荐系统并非完全无法在没有文章特征的情况下工作。亚马逊、沃尔玛、Netflix 可以通过协同过滤进行推荐。
165 | * **然而,在新闻产品中,用户消费的是同一天的内容。没有文章特征的引导是困难的。协同过滤无法帮助引导。**
166 | * 文章特征的粒度越细,启动的能力越强。
167 |
168 |
169 |
170 | ## 更多关于语义标签
171 |
172 | 我们将语义标签的特征分为三个层次:
173 |
174 | 1. 分类:用于用户资料、过滤主题内容、推荐召回、推荐特征
175 | 2. 概念:用于过滤主题内容、搜索标签、推荐召回(喜欢)
176 | 3. 实体:用于过滤主题内容、搜索标签、推荐召回(喜欢)
177 |
178 |
179 | 为什么要分为不同层次?我们这样做是为了能够以不同的粒度捕捉文章。
180 |
181 | 1. 分类:覆盖全面,准确性低。
182 | 2. 概念:覆盖中等,准确性中等。
183 | 3. 实体:覆盖低,准确性高。它仅覆盖每个领域的热门人物、组织、产品。
184 |
185 |
186 | 分类和概念共享相同的技术基础设施。
187 |
188 |
189 | 我们为什么需要语义标签?
190 |
191 | * 隐式语义
192 | * 一直运作良好。
193 | * 成本远低于语义标签。
194 | * 但是,主题和兴趣需要一个明确的标记系统。
195 | * 语义标签还评估了公司在 NPL 技术方面的能力。
196 |
197 |
198 |
199 | ## 文档分类
200 |
201 | 分类层次结构
202 |
203 | 1. 根
204 | 2. 科学、体育、金融、娱乐
205 | 3. 足球、网球、乒乓球、田径、游泳
206 | 4. 国际、国内
207 | 5. A 队、B 队
208 |
209 |
210 | 分类器:
211 |
212 | * SVM
213 | * SVM + CNN
214 | * SVM + CNN + RNN
215 |
216 |
217 |
218 | ## 计算相关性
219 | 1. 对文章进行词汇分析
220 | 2. 过滤关键词
221 | 3. 消歧义
222 | 4. 计算相关性
--------------------------------------------------------------------------------
/zh-CN/145-introduction-to-architecture.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 145-introduction-to-architecture
3 | id: 145-introduction-to-architecture
4 | title: "架构导论"
5 | date: 2019-05-11 15:52
6 | comments: true
7 | tags: [系统设计]
8 | description: 架构为软件系统的整个生命周期提供服务,使其易于理解、开发、测试、部署和操作。O’Reilly的书《软件架构模式》对五种基本架构进行了简单而有效的介绍。
9 | references:
10 | - https://puncsky.com/notes/10-thinking-software-architecture-as-physical-buildings
11 | - https://www.oreilly.com/library/view/software-architecture-patterns/9781491971437/ch01.html
12 | - http://www.ruanyifeng.com/blog/2016/09/software-architecture.html
13 | ---
14 |
15 | ## 什么是架构?
16 |
17 | 架构是软件系统的形状。就好像是一个物理世界的建筑的全景:
18 |
19 | * 范式是砖块。
20 | * 设计原则是房间。
21 | * 组件是一幢建筑。
22 |
23 | 它们共同服务于特定的目的,例如医院是为治愈病人而设,学校是为教育学生而设。
24 |
25 | ## 我们为什么需要架构?
26 |
27 | ### 行为与结构
28 |
29 | 每个软件系统为利益相关者提供两种不同的价值:行为和结构。软件开发人员负责确保这两种价值都保持高水平。
30 |
31 | ==软件架构师由于其工作描述,更加关注系统的结构,而不是其特性和功能。==
32 |
33 | ### 终极目标 - ==每个功能节省人力资源成本==
34 |
35 | 架构为软件系统的整个生命周期提供服务,使其易于理解、开发、测试、部署和操作。目标是最小化每个业务用例的人力资源成本。
36 |
37 | O’Reilly的书《软件架构模式》由Mark Richards撰写,是对这五种基本架构的简单而有效的介绍。
38 |
39 | ## 1. 分层架构
40 |
41 | 分层架构是最常见的架构,开发人员广泛熟知,因此是应用程序的事实标准。如果您不知道使用什么架构,请使用它。
42 |
43 | [comment]: \<\> (https://www.draw.io/#G1ldM5O9Y62Upqg_t5rcTNHIRseP-7fqQT)
44 |
45 | 
46 |
47 | 示例
48 |
49 | * TCP / IP模型:应用层 > 传输层 > 网络层 > 网络接入层
50 | * [Facebook TAO](https://puncsky.com/notes/49-facebook-tao):网页层 > 缓存层(跟随者 + 领导者) > 数据库层
51 |
52 | 优缺点
53 |
54 | * 优点
55 | * 易于使用
56 | * 职责分离
57 | * 可测试性
58 | * 缺点
59 | * 单体
60 | * 难以调整、扩展或更新。您必须对所有层进行更改。
61 |
62 | ## 2. 事件驱动架构
63 |
64 | 状态变化将向系统发出事件。所有组件通过事件相互通信。
65 |
66 | 
67 |
68 | 一个简单的项目可以结合中介、事件队列和通道。然后我们得到一个简化的架构:
69 |
70 | 
71 |
72 | 示例
73 |
74 | * QT:信号和插槽
75 | * 支付基础设施:银行网关通常具有非常高的延迟,因此在其架构设计中采用异步技术。
76 |
77 | ## 3. 微内核架构(即插件架构)
78 |
79 | 软件的职责被划分为一个“核心”和多个“插件”。核心包含最基本的功能。插件彼此独立,并实现共享接口以实现不同的目标。
80 |
81 | 
82 |
83 | 示例
84 |
85 | * Visual Studio Code,Eclipse
86 | * MINIX操作系统
87 |
88 | ## 4. 微服务架构
89 |
90 | 一个庞大的系统被解耦为多个微服务,每个微服务都是一个单独部署的单元,它们通过[RPCs](/blog/2016-02-13-crack-the-system-design-interview#21-communication)相互通信。
91 |
92 | 
93 |
94 | 示例
95 |
96 | * Uber:见[设计Uber](https://puncsky.com/notes/120-designing-uber)
97 | * Smartly
98 |
99 | ## 5. 基于空间的架构
100 |
101 | 该模式得名于“元组空间”,意为“分布式共享内存”。没有数据库或同步数据库访问,因此没有数据库瓶颈。所有处理单元在内存中共享复制的应用数据。这些处理单元可以弹性启动和关闭。
102 |
103 | 
104 |
105 | 示例:见[维基百科](https://en.wikipedia.org/wiki/Tuple_space#Example_usage)
106 |
107 | - 主要在Java用户中采用:例如,JavaSpaces
108 |
--------------------------------------------------------------------------------
/zh-CN/166-designing-payment-webhook.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 166-designing-payment-webhook
3 | id: 166-designing-payment-webhook
4 | title: "设计支付 webhook"
5 | date: 2019-08-19 21:15
6 | updateDate: 2024-04-06 17:29
7 | comments: true
8 | tags: [系统设计]
9 | slides: false
10 | description: 设计一个 webhook,当支付成功时通知商家。我们需要汇总指标(例如,成功与失败)并在仪表板上显示。
11 | references:
12 | - https://commerce.coinbase.com/docs/#webhooks
13 | - https://bitworking.org/news/2017/03/prometheus
14 | - https://workos.com/blog/building-webhooks-into-your-application-guidelines-and-best-practices
15 |
16 | ---
17 |
18 | ## 1. 澄清需求
19 |
20 | 1. 一旦支付成功,webhook 将回调商家。
21 | 1. 商家开发者向我们注册 webhook 信息。
22 | 2. 可靠且安全地向 webhook 发起 POST HTTP 请求。
23 | 2. 高可用性、错误处理和故障恢复。
24 | 1. 异步设计。假设商家的服务器分布在全球,可能会有高达 15 秒的延迟。
25 | 2. 至少一次交付。幂等密钥。
26 | 3. 顺序无关。
27 | 4. 强大且可预测的重试和短路机制。
28 | 3. 安全性、可观察性和可扩展性。
29 | 1. 防伪造。
30 | 2. 当商家的接收器出现故障时通知商家。
31 | 3. 易于扩展和规模化。
32 |
33 | ## 2. 概述高层设计
34 |
35 | 异步设计 + 重试 + 排队 + 可观察性 + 安全性
36 |
37 | 
38 |
39 | ## 3. 功能和组件
40 |
41 | ### 核心功能
42 |
43 | 1. 用户访问仪表板前端向我们注册 webhook 信息 - 例如要调用的 URL、他们希望订阅的事件范围,然后从我们这里获取 API 密钥。
44 | 2. 当有新事件时,将其发布到队列中,然后被调用者消费。调用者获取注册信息并向外部服务发起 HTTP 调用。
45 |
46 | ### webhook 调用者
47 |
48 | 1. 订阅由支付状态机或其他服务发布的支付成功事件队列。
49 |
50 | 2. 一旦调用者接受事件,从用户设置服务获取 webhook URI、密钥和设置。根据这些设置准备请求。为了安全...
51 |
52 | * 所有来自用户设置的 webhook 必须使用 HTTPS。
53 |
54 | * 如果负载很大,预期延迟很高,并且我们希望确保目标接收器是活跃的,我们可以通过携带挑战的 ping 验证其存在。例如,[Dropbox 通过发送带有“challenge”参数(一个随机字符串)的 GET 请求来验证 webhook 端点](https://www.dropbox.com/developers/reference/webhooks#documentation),您的端点需要将其回显作为响应。
55 | * 所有回调请求都带有头部 `x-webhook-signature`。这样接收者可以验证请求。
56 | * 对于对称签名,我们可以使用 HMAC/SHA256 签名。其值为 `HMAC(webhook secret, raw request payload);` Telegram 使用此方法。
57 | * 对于非对称签名,我们可以使用 RSA/SHA256 签名。其值为 `RSA(webhook private key, raw request payload);` Stripe 使用此方法。
58 | * 如果是敏感信息,我们还可以考虑对负载进行加密,而不仅仅是签名。
59 |
60 | 3. 向外部商家的端点发起带有事件负载和安全头的 HTTP POST 请求。
61 |
62 | ### API 定义
63 |
64 | ```json5
65 | // POST https://example.com/webhook/
66 | {
67 | "id": 1,
68 | "scheduled_for": "2017-01-31T20:50:02Z",
69 | "event": {
70 | "id": "24934862-d980-46cb-9402-43c81b0cdba6",
71 | "resource": "event",
72 | "type": "charge:created",
73 | "api_version": "2018-03-22",
74 | "created_at": "2017-01-31T20:49:02Z",
75 | "data": {
76 | "code": "66BEOV2A", // 或用户需要履行的订单 ID
77 | "name": "主权个体",
78 | "description": "掌握信息时代的过渡",
79 | "hosted_url": "https://commerce.coinbase.com/charges/66BEOV2A",
80 | "created_at": "2017-01-31T20:49:02Z",
81 | "expires_at": "2017-01-31T21:49:02Z",
82 | "metadata": {},
83 | "pricing_type": "CNY",
84 | "payments": [
85 | // ...
86 | ],
87 | "addresses": {
88 | // ...
89 | }
90 | }
91 | }
92 | }
93 | ```
94 |
95 | 商家服务器应以 200 HTTP 状态码响应以确认收到 webhook。
96 |
97 | ### 错误处理
98 |
99 | 如果没有收到确认,我们将[使用幂等性密钥和指数退避重试,最长可达三天。最大重试间隔为 1 小时。](https://puncsky.com/notes/43-how-to-design-robust-and-predictable-apis-with-idempotency) 如果达到某个限制,则短路/标记为损坏。向商家发送电子邮件。
100 |
101 | ### 指标
102 |
103 | Webhook 调用者服务将状态发射到时序数据库以获取指标。
104 |
105 | 使用 Statsd + Influx DB 还是 Prometheus?
106 |
107 | * InfluxDB:应用程序将数据推送到 InfluxDB。它有一个用于指标和索引的单体数据库。
108 | * Prometheus:Prometheus 服务器定期从运行的应用程序中拉取指标值。它使用 LevelDB 进行索引,但每个指标存储在自己的文件中。
109 |
110 | 或者如果您有宽裕的预算,可以使用昂贵的 DataDog 或其他 APM 服务。
--------------------------------------------------------------------------------
/zh-CN/169-how-to-write-solid-code.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 169-how-to-write-solid-code
3 | id: 169-how-to-write-solid-code
4 | title: "如何编写稳健的代码?"
5 | date: 2019-09-25 02:29
6 | comments: true
7 | tags: [系统设计]
8 | description: 同理心在编写稳健代码中扮演着最重要的角色。此外,您需要选择一个可持续的架构,以减少项目扩展时的人力资源成本。然后,采用模式和最佳实践;避免反模式。最后,必要时进行重构。
9 | ---
10 |
11 | 
12 |
13 | 1. 同理心 / 视角转换是最重要的。
14 | 1. 意识到代码首先是为人类阅读而编写的,然后才是为机器执行。
15 | 2. 软件是如此“柔软”,有很多方法可以实现同一目标。关键在于做出适当的权衡,以满足需求。
16 | 3. 发明与简化:Apple Pay RFID 与 微信扫码二维码。
17 |
18 | 2. 选择可持续的架构,以减少每个功能的人力资源成本。
19 |
20 |
21 |
22 |
23 | 3. 采用模式和最佳实践。
24 |
25 | 4. 避免反模式
26 | * 缺少错误处理
27 | * 回调地狱 = 意大利面条代码 + 不可预测的错误处理
28 | * 过长的继承链
29 | * 循环依赖
30 | * 过于复杂的代码
31 | * 嵌套的三元操作
32 | * 注释掉未使用的代码
33 | * 缺少国际化,特别是 RTL 问题
34 | * 不要重复自己
35 | * 简单的复制粘贴
36 | * 不合理的注释
37 |
38 | 5. 有效的重构
39 | * 语义版本
40 | * 永远不要对非主要版本引入破坏性更改
41 | * 两腿变更
--------------------------------------------------------------------------------
/zh-CN/174-designing-memcached.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 174-designing-memcached
3 | id: 174-designing-memcached
4 | title: "设计 Memcached 或内存中的 KV 存储"
5 | date: 2019-10-03 22:04
6 | comments: true
7 | tags: [系统设计]
8 | description: Memcached = 丰富的客户端 + 分布式服务器 + 哈希表 + LRU。它具有简单的服务器,将复杂性推给客户端,因此可靠且易于部署。
9 | references:
10 | - https://github.com/memcached/memcached/wiki/Overview
11 | - https://people.cs.uchicago.edu/~junchenj/34702/slides/34702-MemCache.pdf
12 | - https://en.wikipedia.org/wiki/Hash_table
13 | ---
14 |
15 | ## 需求
16 |
17 | 1. 高性能,分布式键值存储
18 | * 为什么分布式?
19 | * 答:为了存储更大规模的数据
20 |
24 | 2. 用于小数据对象的内存存储
25 | 3. 简单的服务器(将复杂性推给客户端),因此可靠且易于部署
26 |
27 | ## 架构
28 | 大局:客户端-服务器
29 |
30 |
34 |
35 | * 客户端
36 | * 给定一组 Memcached 服务器
37 | * 根据键选择服务器
38 | * 服务器
39 | * 将 KV 存储到内部哈希表中
40 | * LRU 驱逐
41 |
42 |
43 | 键值服务器由固定大小的哈希表 + 单线程处理程序 + 粗粒度锁组成
44 |
45 | 
46 |
47 | 如何处理冲突?主要有三种解决方法:
48 |
49 | 1. 分离链:发生冲突的桶链表中包含相同索引的多个条目,您可以始终将新发生冲突的键值对附加到列表中。
50 | 2. 开放寻址:如果发生冲突,转到下一个索引,直到找到可用的桶。
51 | 3. 动态调整大小:调整哈希表的大小并分配更多空间;因此,冲突发生的频率会降低。
52 |
53 | ## 客户端如何确定查询哪个服务器?
54 |
55 | 请参见 [数据分区与路由](https://puncsky.com/notes/2018-07-21-data-partition-and-routing)
56 |
57 | ## 如何使用缓存?
58 |
59 | 请参见 [键值缓存](https://puncsky.com/notes/122-key-value-cache)
60 |
61 | ## 如何进一步优化?
62 |
63 | 请参见 [Facebook 如何扩展其社交图存储?TAO](https://puncsky.com/notes/49-facebook-tao)
--------------------------------------------------------------------------------
/zh-CN/177-designing-Airbnb-or-a-hotel-booking-system.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 177-designing-Airbnb-or-a-hotel-booking-system
3 | id: 177-designing-Airbnb-or-a-hotel-booking-system
4 | title: "设计 Airbnb 或酒店预订系统"
5 | date: 2019-10-06 01:39
6 | comments: true
7 | slides: false
8 | tags: [系统设计]
9 | description: 对于客人和房东,我们使用关系数据库存储数据,并建立索引以按位置、元数据和可用性进行搜索。我们可以使用外部供应商进行支付,并通过优先队列提醒预订。
10 | references:
11 | - https://www.vertabelo.com/blog/designing-a-data-model-for-a-hotel-room-booking-system/
12 | ---
13 |
14 | ## 需求
15 | * 对于客人
16 | * 按位置、日期、房间数量和客人数量搜索房间
17 | * 获取房间详情(如图片、名称、评论、地址等)和价格
18 | * 按日期和房间 ID 从库存中支付并预订房间
19 | * 作为访客结账
20 | * 用户已登录
21 | * 通过电子邮件和移动推送通知进行通知
22 | * 对于酒店或租赁管理员(供应商/房东)
23 | * 管理员(接待员/经理/租赁所有者):管理房间库存并帮助客人办理入住和退房
24 | * 清洁工:定期清理房间
25 |
26 | ## 架构
27 |
28 | 
29 |
30 | ## 组件
31 |
32 | ### 库存 \<\> 预订 \<\> 用户(客人和房东)
33 |
34 | 供应商在库存中提供他们的房间详情。用户可以相应地搜索、获取和预订房间。在预订房间后,用户的付款也会更改 `reserved_room` 的 `status`。您可以在 [这篇文章](https://www.vertabelo.com/blog/designing-a-data-model-for-a-hotel-room-booking-system/) 中查看数据模型。
35 |
36 | ### 如何查找可用房间?
37 |
38 | * 按位置:使用 [空间索引](https://en.wikipedia.org/wiki/Spatial_database) 进行地理搜索,例如 geo-hash 或四叉树。
39 | * 按房间元数据:在查询数据库时应用过滤器或搜索条件。
40 | * 按入住和退房日期及可用性。两种选择:
41 | * 选项 1:对于给定的 `room_id`,检查今天或更晚的所有 `occupied_room`,将数据结构转换为按天的占用数组,最后在数组中找到可用的时间段。这个过程可能会耗时,因此我们可以建立可用性索引。
42 | * 选项 2:对于给定的 `room_id`,始终为占用的日期创建一个条目。这样更容易按日期查询不可用的时间段。
43 |
44 | ### 对于酒店,同步数据
45 |
46 | 如果这是一个酒店预订系统,那么它可能会发布到 GDS、聚合器和批发商等预订渠道。
47 |
48 | 
49 |
50 | 为了在这些地方同步数据,我们可以
51 |
52 | 1. [使用幂等性重试来提高外部调用的成功率,并确保没有重复订单](https://puncsky.com/notes/43-how-to-design-robust-and-predictable-apis-with-idempotency)。
53 | 2. 向外部供应商提供 webhook 回调 API,以在内部系统中更新状态。
54 |
55 | ### 支付与记账
56 |
57 | 数据模型:[复式记账](https://puncsky.com/notes/167-designing-paypal-money-transfer#payment-service)
58 |
59 | 为了执行支付,由于我们调用外部支付网关,如银行或 Stripe、Braintree 等,保持不同地方的数据同步至关重要。[我们需要在交易表和外部银行及供应商之间同步数据。](https://puncsky.com/#how-to-sync-across-the-transaction-table-and-external-banks-and-vendors)
60 |
61 | ### 提醒/警报的通知者
62 |
63 | 通知系统本质上是一个延迟调度器(优先队列 + 订阅者)加上 API 集成。
64 |
65 | 例如,每日定时任务将查询数据库以获取今天要发送的通知,并按日期将其放入优先队列。订阅者将从优先队列中获取最早的通知,并在达到预期时间戳时发送。如果没有,则将任务放回队列,并让 CPU 空闲以进行其他工作,如果今天有新的警报添加,可以中断此过程。
--------------------------------------------------------------------------------
/zh-CN/178-lyft-marketing-automation-symphony.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 178-lyft-marketing-automation-symphony
3 | id: 178-lyft-marketing-automation-symphony
4 | title: "Lyft 的营销自动化平台 -- Symphony"
5 | date: 2019-10-09 23:30
6 | comments: true
7 | tags: [marketing, system design]
8 | slides: false
9 | description: "为了在广告中实现更高的投资回报率,Lyft推出了一款营销自动化平台,该平台由三个主要组件组成:生命周期价值预测器、预算分配器和竞标者。"
10 | references:
11 | - https://eng.lyft.com/lyft-marketing-automation-b43b7b7537cc
12 | ---
13 |
14 | ## 获取效率问题:如何在广告中实现更好的投资回报率?
15 |
16 | 具体来说,Lyft 的广告应满足以下要求:
17 |
18 | 1. 能够管理区域特定的广告活动
19 | 2. 以数据驱动的增长为指导:增长必须是可扩展的、可衡量的和可预测的
20 | 3. 支持 Lyft 独特的增长模型,如下所示
21 |
22 | 
23 |
24 | 然而,最大挑战是管理跨区域营销的所有流程,包括选择竞标、预算、创意、激励和受众,进行 A/B 测试等。您可以看到数字营销人员一天的工作:
25 |
26 | 
27 |
28 | 我们发现 *执行* 占用了大部分时间,而 *分析*,被认为更重要的,所花的时间要少得多。一个扩展策略将使营销人员能够专注于分析和决策过程,而不是操作活动。
29 |
30 | ## 解决方案:自动化
31 |
32 | 为了降低成本并提高实验效率,我们需要
33 |
34 | 1. 预测新用户对我们产品感兴趣的可能性
35 | 2. 有效评估并在各渠道分配营销预算
36 | 3. 轻松管理成千上万的广告活动
37 |
38 | 营销绩效数据流入 Lyft 的强化学习系统:[Amundsen](https://guigu.io/blog/2018-12-03-making-progress-30-kilometers-per-day)
39 |
40 | 需要自动化的问题包括:
41 |
42 | 1. 更新搜索关键词的竞标
43 | 2. 关闭表现不佳的创意
44 | 3. 按市场更改推荐值
45 | 4. 识别高价值用户细分
46 | 5. 在活动之间共享策略
47 |
48 | ## 架构
49 |
50 | 
51 |
52 | 技术栈包括 - Apache Hive、Presto、ML 平台、Airflow、第三方 API、UI。
53 |
54 | ## 主要组件
55 |
56 | ### 生命周期价值(LTV)预测器
57 |
58 | 用户的生命周期价值是衡量获取渠道效率的重要标准。预算由 LTV 和我们愿意在该地区支付的价格共同决定。
59 |
60 | 我们对新用户的了解有限。历史数据可以帮助我们在用户与我们的服务互动时更准确地进行预测。
61 |
62 | 初始特征值:
63 |
64 | 
65 |
66 | 随着互动历史数据的积累,预测会得到改善:
67 |
68 | 
69 |
70 | ### 预算分配器
71 |
72 | 在预测 LTV 之后,接下来是根据价格估算预算。一个形式为 `LTV = a * (spend)^b` 的曲线拟合数据。在成本曲线创建过程中将注入一定程度的随机性,以便收敛到全局最优解。
73 |
74 | 
75 |
76 | ### 竞标者
77 |
78 | 竞标者由两个部分组成 - 调整器和执行者。调整器根据价格决定特定渠道的确切参数。执行者将实际竞标传达给不同的渠道。
79 |
80 | 一些在不同渠道应用的流行竞标策略如下所示:
81 |
82 | 
83 |
84 | ### 结论
85 |
86 | 我们必须重视自动化过程中的人类经验;否则,模型的质量可能会是“垃圾进,垃圾出”。一旦从繁重的任务中解放出来,营销人员可以更多地专注于理解用户、渠道以及他们想要传达给受众的信息,从而获得更好的广告效果。这就是 Lyft 如何以更少的时间和精力实现更高的投资回报率。
--------------------------------------------------------------------------------
/zh-CN/179-designing-typeahead-search-or-autocomplete.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 179-designing-typeahead-search-or-autocomplete
3 | id: 179-designing-typeahead-search-or-autocomplete
4 | title: "设计实时联想搜索或自动完成功能"
5 | date: 2019-10-10 18:33
6 | comments: true
7 | tags: [系统设计]
8 | slides: false
9 | description: 如何设计一个实时的联想自动完成服务?Linkedin 的 Cleo 库通过多层架构(浏览器缓存 / 网络层 / 结果聚合器 / 各种联想后端)和 4 个元素(倒排索引 / 正向索引,布隆过滤器,评分器)来回答这个问题。
10 | references:
11 | - https://engineering.linkedin.com/open-source/cleo-open-source-technology-behind-linkedins-typeahead-search
12 | - http://sna-projects.com/cleo/
13 | ---
14 |
15 | ## 需求
16 |
17 | * 为社交网络(如 Linkedin 或 Facebook)提供实时 / 低延迟的联想和自动完成功能
18 | * 使用前缀搜索社交资料
19 | * 新添加的账户在搜索范围内即时出现
20 | * 不是用于“查询自动完成”(如 Google 搜索框下拉),而是用于显示实际的搜索结果,包括
21 | * 通用联想:来自全球排名方案(如人气)的网络无关结果。
22 | * 网络联想:来自用户的第一和第二度网络连接的结果,以及“你可能认识的人”评分。
23 |
24 | 
25 |
26 | ## 架构
27 |
28 | 多层架构
29 |
30 | * 浏览器缓存
31 | * 网络层
32 | * 结果聚合器
33 | * 各种联想后端
34 |
35 | 
36 |
37 | ## 结果聚合器
38 | 这个问题的抽象是通过前缀和术语在大量元素中查找文档。解决方案利用这四种主要数据结构:
39 |
40 | 1. `InvertedIndex<前缀或术语, 文档>`:给定任何前缀,找到所有包含该前缀的文档 ID。
41 | 2. `为每个文档准备一个 BloomFilter<前缀或术语>`:随着用户输入的增加,我们可以通过检查它们的布隆过滤器快速过滤掉不包含最新前缀或术语的文档。
42 | 3. `ForwardIndex<文档, 前缀或术语>`:之前的布隆过滤器可能会返回假阳性,现在我们查询实际文档以拒绝它们。
43 | 4. `scorer(文档):相关性`:每个分区返回所有真实命中及其评分。然后我们进行聚合和排名。
44 |
45 | 
46 |
47 | ## 性能
48 |
49 | * 通用联想:延迟 \< \= 1 毫秒在一个集群内
50 | * 网络联想(第一和第二度网络的超大数据集):延迟 \< \= 15 毫秒
51 | * 聚合器:延迟 \< \= 25 毫秒
--------------------------------------------------------------------------------
/zh-CN/181-concurrency-models.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 181-concurrency-models
3 | id: 181-concurrency-models
4 | title: "并发模型"
5 | date: 2019-10-16 14:04
6 | comments: true
7 | tags: [系统设计]
8 | description: "您可能想了解的五种并发模型:单线程;多处理和基于锁的并发;通信顺序进程 (CSP);演员模型 (AM);软件事务内存 (STM)。"
9 | ---
10 |
11 | 
12 |
13 |
14 | * 单线程 - 回调、承诺、可观察对象和 async/await:原生 JS
15 | * 线程/多处理,基于锁的并发
16 | * 保护临界区与性能
17 | * 通信顺序进程 (CSP)
18 | * Golang 或 Clojure 的 `core.async`。
19 | * 进程/线程通过通道传递数据。
20 | * 演员模型 (AM):Elixir、Erlang、Scala
21 | * 本质上是异步的,并且具有跨运行时和机器的位置信息透明性 - 如果您有演员的引用 (Akka) 或 PID (Erlang),您可以通过邮箱向其发送消息。
22 | * 通过将演员组织成监督层次结构来实现强大的容错能力,您可以在其确切的层次结构级别处理故障。
23 | * 软件事务内存 (STM):Clojure、Haskell
24 | * 类似于 MVCC 或纯函数:提交 / 中止 / 重试
--------------------------------------------------------------------------------
/zh-CN/182-designing-l7-load-balancer.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 182-designing-l7-load-balancer
3 | id: 182-designing-l7-load-balancer
4 | title: "设计负载均衡器或 Dropbox 修补程序"
5 | date: 2019-10-19 15:21
6 | comments: true
7 | tags: [系统设计]
8 | slides: false
9 | description: 大规模的网络服务处理来自全球的高流量,但单个主机只能处理有限数量的请求。通常会有一个服务器集群来处理所有流量。如何路由这些请求,以便每个主机能够均匀地接收请求?
10 | references:
11 | - https://blogs.dropbox.com/tech/2019/09/enhancing-bandaid-load-balancing-at-dropbox-by-leveraging-real-time-backend-server-load-information/
12 | - https://medium.com/netflix-techblog/netflix-edge-load-balancing-695308b5548c
13 | - https://www.nginx.com/blog/nginx-power-of-two-choices-load-balancing-algorithm/#least_conn
14 | ---
15 |
16 | ## 需求
17 |
18 | 互联网规模的网络服务处理来自全球的高流量。然而,单个服务器在同一时间只能处理有限数量的请求。因此,通常会有一个服务器集群或大型服务器集群来共同承担流量。问题来了:如何路由这些请求,以便每个主机能够均匀地接收和处理请求?
19 |
20 | 
21 |
22 | 由于从用户到服务器之间有许多跳数和负载均衡器层,因此这次我们的设计要求是
23 |
24 | * [在数据中心设计 L7 负载均衡器](https://tianpan.co/notes/2018-07-23-load-balancer-types)
25 | * 利用来自后端的实时负载信息
26 | * 每秒处理 10 万 RPS,10 TB 流量
27 |
28 | > 注意:如果服务 A 依赖于(或消费)服务 B,则 A 是 B 的下游服务,而 B 是 A 的上游服务。
29 |
30 | ## 挑战
31 | 为什么负载均衡很难?答案是很难收集准确的负载分布统计数据并相应地采取行动。
32 |
33 | ### 按请求分配 ≠ 按负载分配
34 |
35 | 随机和轮询通过请求分配流量。然而,实际负载并不是每个请求 - 有些在 CPU 或线程利用率上很重,而有些则很轻。
36 |
37 | 
38 |
39 | 为了更准确地评估负载,负载均衡器必须维护每个后端服务器的观察到的活动请求数量、连接数量或请求处理延迟的本地状态。基于这些信息,我们可以使用诸如最少连接、最少时间和随机 N 选择等分配算法:
40 |
41 | **最少连接**:请求被传递给活动连接数最少的服务器。
42 |
43 | 
44 |
45 | **基于延迟(最少时间)**:请求被传递给平均响应时间最少和活动连接数最少的服务器,同时考虑服务器的权重。
46 |
47 | 
48 |
49 | 然而,这两种算法仅在只有一个负载均衡器的情况下效果良好。如果有多个负载均衡器,可能会出现 **羊群效应**。也就是说,所有负载均衡器都注意到某个服务瞬时更快,然后都向该服务发送请求。
50 |
51 | **随机 N 选择**(在大多数情况下 N=2 / 也称为 *二选一的力量*):随机选择两个并选择两个中的更好选项,*避免选择更差的选项*。
52 |
53 | ### 分布式环境
54 |
55 | 
56 |
57 | 本地负载均衡器对全局下游和上游状态并不知情,包括
58 |
59 | * 上游服务负载
60 | * 上游服务可能非常庞大,因此很难选择正确的子集来覆盖负载均衡器
61 | * 下游服务负载
62 | * 各种请求的处理时间很难预测
63 |
64 | ## 解决方案
65 | 有三种选项可以准确收集负载统计数据,然后采取相应的行动:
66 |
67 | * 集中式和动态控制器
68 | * 分布式但具有共享状态
69 | * 在响应消息或主动探测中附加服务器端信息
70 |
71 | Dropbox Bandaid 团队选择了第三种选项,因为它很好地适应了他们现有的 *随机 N 选择* 方法。
72 |
73 | 
74 |
75 | 然而,他们并没有像原始的 *随机 N 选择* 那样使用本地状态,而是通过响应头使用来自后端服务器的实时全局信息。
76 |
77 | **服务器利用率**:后端服务器配置了最大容量并计算正在进行的请求,然后计算利用率百分比,范围从 0.0 到 1.0。
78 |
79 | 
80 |
81 | 需要考虑两个问题:
82 |
83 | 1. **处理 HTTP 错误**:如果服务器快速失败请求,它会吸引更多流量并导致更多失败。
84 | 2. **统计衰减**:如果服务器的负载过高,则不会将请求分配到该服务器,因此服务器会被卡住。他们使用反向 sigmoid 曲线的衰减函数来解决此问题。
85 |
86 | ## 结果:请求更加均衡
87 |
88 | 
--------------------------------------------------------------------------------
/zh-CN/2016-02-13-crack-the-system-design-interview.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2016-02-13-crack-the-system-design-interview
3 | id: 2016-02-13-crack-the-system-design-interview
4 | title: "设计 Pinterest"
5 | date: 2016-2-14 01:27
6 | comments: true
7 | tags: [系统设计]
8 | updateDate: 2022-12-25 13:24
9 | description: ""
10 | ---
11 |
12 | 系统设计面试是为了让人们找到能够独立设计和实施互联网服务的团队成员。面试是展示你“工程能力”的绝佳机会——你必须将你的知识与决策能力结合起来,为正确的场景设计合适的系统。
13 |
14 | ### 为你的受众发出正确的信号
15 |
16 | 关于系统设计面试,你需要知道的第一件事是,你必须在整个面试过程中**保持健谈**。当然,你必须咨询面试官,以确定你是否在正确的轨道上,能够满足他们的需求;然而,你仍然需要证明你可以独立完成工作。因此,理想情况下,在面试过程中,你应该不断谈论面试官所期望的内容,甚至在他们提出问题之前。
17 |
18 | 其次,不要仅限于一种解决方案。面对同样的问题,可能有很多种解决方法,成为工程师并不需要许可证。你所做的所有选择都有利弊。与面试官讨论**权衡**,并选择最适合你假设和约束条件的解决方案。这就像在现实世界中,人们不会在沟渠上建造金门大桥,也不会在旧金山湾上建造临时桥。
19 |
20 | 最后,要在面试中表现出色,你最好带来一些新东西。“优秀的工程师编写脚本;伟大的工程师创新”。如果你不能**教会人们一些新东西**,你只是优秀,而不是伟大。优质答案 = 新颖性 x 共鸣。
21 |
22 | ### 4 步模板
23 |
24 | 如果你不确定如何在面试中保持健谈,这里有一个简单的 4 步模板,你可以以分而治之的方式遵循:
25 |
26 | 1. 澄清需求并做出假设。
27 | 2. 勾勒出高层设计。
28 | 3. 深入各个组件及其相互作用。
29 | 4. 总结盲点或瓶颈。
30 |
31 | 本书中的所有设计都将遵循这些步骤。
32 |
33 | > 特别是对于这个“设计 Pinterest”,我将尽可能详细地解释一切,因为这是整本书的第一个案例。然而,为了简单起见,我不会在本书的其他设计中涵盖许多元素。
34 |
35 | # 设计 Pinterest
36 |
37 | ## 第一步:澄清需求并做出假设
38 |
39 | 所有系统存在都是有目的的,软件系统也是如此。同时,软件工程师不是艺术家——我们构建东西是为了满足客户的需求。因此,我们应该始终从客户出发。同时,为了将设计适应 45 分钟的会议,我们必须通过做出假设来设定约束和范围。
40 |
41 | Pinterest 是一个高度可扩展的照片分享服务,拥有数亿月活跃用户。以下是需求:
42 |
43 | - 最重要的功能
44 | - 新闻推送:客户登录后会看到一系列图像。
45 | - 一个客户关注其他客户以订阅他们的推送。
46 | - 上传照片:他们可以上传自己的图像,这些图像会出现在关注者的推送中。
47 | - 扩展性
48 | - 功能和开发产品的团队太多,因此产品被解耦为微服务。
49 | - 大多数服务应具有水平扩展性和无状态性。
50 |
51 | ## 第二步:勾勒出高层设计
52 |
53 | **在勾勒出大局之前,不要深入细节。** 否则,走错方向会浪费时间,并阻止你完成任务。
54 |
55 | 这是高层架构,其中箭头表示依赖关系。(有时,人们会使用箭头来描述数据流的方向。)
56 |
57 | 
58 |
59 | [//]: # (https://whimsical.com/design-instagram-5JeJxJuxbWf3p97DaYttgH)
60 |
61 | ## 第三步:深入各个组件及其相互作用
62 |
63 | 一旦架构确定,我们可以与面试官确认他们是否希望与你一起深入探讨每个组件。有时,面试官可能希望聚焦于一个意想不到的领域问题,比如[设计照片存储](121-designing-facebook-photo-storage.md)(这就是我总是说没有一种适合所有的系统设计解决方案的原因。继续学习...)。然而,在这里,我们仍然假设我们正在构建核心抽象:上传照片,然后发布给关注者。
64 |
65 | > 再次强调,我将尽可能多地以自上而下的顺序进行解释,因为这是我们的第一个设计示例。在现实世界中,你不必逐个组件地详细讨论;相反,你应该首先关注核心抽象。
66 |
67 | 移动和浏览器客户端通过边缘服务器连接到 Pinterest 数据中心。边缘服务器是提供网络入口的边缘设备。在图中,我们看到两种类型的边缘服务器——负载均衡器和反向代理。
68 |
69 | ### 负载均衡器(LB)
70 |
71 | 负载均衡器将传入的网络流量分配给一组后端服务器。它们分为三类:
72 |
73 | - DNS 轮询(很少使用):客户端获得随机顺序的 IP 地址列表。
74 | - 优点:易于实现,通常免费。
75 | - 缺点:难以控制,响应性不强,因为 DNS 缓存需要时间过期。
76 | - L3/L4 网络层负载均衡器:流量通过 IP 地址和端口路由。L3 是网络层(IP)。L4 是传输层(TCP)。
77 | - 优点:更好的粒度,简单,响应迅速。例如,根据端口转发流量。
78 | - 缺点:内容无关:无法根据数据的内容路由流量。
79 | - L7 应用层负载均衡器:流量根据 HTTP 协议内部的内容进行路由。L7 是应用层(HTTP)。如果面试官想要更多,我们可以建议具体的算法,如轮询、加权轮询、最少负载、最少负载与慢启动、利用率限制、延迟、级联等。查看[设计 L7 负载均衡器以了解更多](182-designing-l7-load-balancer.md)。
80 |
81 | 负载均衡器可以存在于许多其他地方,只要有平衡流量的需求。
82 |
83 | ### 反向代理
84 |
85 | 与位于客户端前面的“正向”代理不同,反向代理是一种位于服务器前面的代理,因此称为“反向”。根据这个定义,负载均衡器也是一种反向代理。
86 |
87 | 反向代理根据使用方式带来了许多好处,以下是一些典型的好处:
88 |
89 | 1. 路由:将流量集中到内部服务,并为公众提供统一的接口。例如,www.example.com/index 和 www.example.com/sports 看似来自同一个域,但这些页面来自反向代理后面的不同服务器。
90 | 2. 过滤:过滤掉没有有效凭证的请求,以进行身份验证或授权。
91 | 3. 缓存:某些资源对 HTTP 请求非常受欢迎,因此你可能希望为该路由配置一些缓存,以节省一些服务器资源。
92 |
93 | 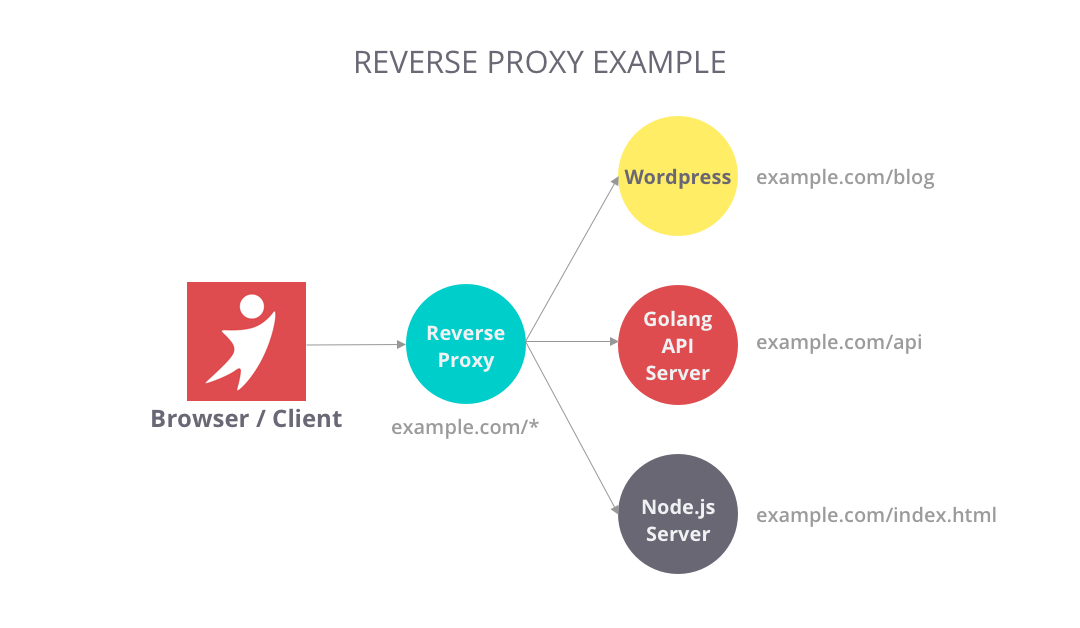
94 |
95 | Nginx、Varnish、HAProxy 和 AWS 弹性负载均衡是市场上流行的产品。我发现编写一个[轻量级反向代理在 Golang 中](https://github.com/puncsky/reverse-proxy-golang-starter)既方便又强大。在 Kubernetes 的上下文中,这基本上就是 Ingress 和 Ingress 控制器所做的。
96 |
97 | ### Web 应用
98 |
99 | 这是我们提供网页的地方。在早期,网络服务通常将后端与页面渲染结合在一起,如 Django 和 Ruby on Rails 框架所做的。后来,随着项目规模的增长,它们通常被解耦为专用的前端和后端项目。前端专注于应用渲染,而后端为前端提供 API 供其使用。
100 |
101 | ### 移动应用
102 |
103 | 大多数后端工程师对移动设计模式不熟悉,可以查看[ iOS 架构模式](123-ios-architecture-patterns-revisited.md)。
104 |
105 | 专用的前端 Web 项目与独立的移动应用非常相似——它们都是服务器的客户端。有些人会称它们为“整体前端”,当工程师能够同时在两个平台上构建用户体验时,比如 Web 的 React 和移动的 React-Native。
106 |
107 | ### API 应用
108 |
109 | 客户端通过公共 API 与服务器通信。如今,人们通常提供 RESTful 或 GraphQL API。了解更多信息,请查看[公共 API 选择](66-public-api-choices.md)。
110 |
111 | ### 无状态 Web 和 API 层
112 |
113 | **整个系统有两个主要瓶颈——负载(每秒请求数)和带宽。** 我们可以通过以下方式改善情况:
114 |
115 | 1. 使用更高效的软件,例如使用具有[异步和非阻塞反应器模式](http://www.puncsky.com/blog/2015/01/13/understanding-reactor-pattern-for-highly-scalable-i-o-bound-web-server/)的框架,或者
116 | 2. 使用更多硬件,例如
117 | 1. 向上扩展,即垂直扩展:使用更强大的机器,如超级计算机或大型机,或
118 | 2. 向外扩展,即水平扩展:使用更多数量的低成本机器。
119 |
120 | 互联网公司更倾向于水平扩展,因为
121 |
122 | 1. 使用大量商品机器更具成本效益。
123 | 2. 这也有利于招聘——每个人都可以用一台 PC 学习编程。
124 |
125 | 为了水平扩展,我们最好保持服务无状态,这意味着它们不在本地内存或存储中保存状态,因此我们可以随时意外终止或重新启动它们。
126 |
127 | 了解更多关于扩展的信息,请查看[如何扩展 Web 服务](41-how-to-scale-a-web-service.md)。
128 |
129 | ### 服务层
130 |
131 | **单一责任原则**提倡小型和自主的服务协同工作,以便每个服务可以“做好一件事并做好”,并独立增长。拥有小型服务的小团队可以更积极地规划超高速增长。了解更多关于微服务与单体服务的信息,请查看[设计 Uber](120-designing-uber.md)。
132 |
133 | ### 服务发现
134 |
135 | 这些服务如何找到彼此?
136 |
137 | [Zookeeper](https://www.slideshare.net/sauravhaloi/introduction-to-apache-zookeeper) 是一个流行的集中式选择。每个服务的实例(名称、地址、端口等)注册到 ZooKeeper 的路径中。如果一个服务不知道如何找到另一个服务,它可以查询 Zookeeper 以获取位置,并在该位置不可用之前记住它。
138 |
139 | Zookeeper 是一个 CP 系统,根据 CAP 定理(有关更多讨论,请参见第 2.3 节),这意味着在发生故障时它保持一致性,但集中共识的领导者将无法注册新服务。
140 |
141 | 与 Zookeeper 相比,Uber 以去中心化的方式做了一些有趣的工作,称为[hyperbahn](https://github.com/uber/hyperbahn),基于[Ringpop 一致性哈希环](https://github.com/uber/ringpop-node),尽管最终被证明是一个巨大的失败。阅读[亚马逊的 Dynamo](http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf)以理解 AP 和最终一致性。
142 |
143 | 在 Kubernetes 的上下文中,我想使用服务对象和 Kube-proxy,因此程序员可以轻松指定目标服务的地址,使用内部 DNS。
144 |
145 | ### 关注者服务
146 |
147 | 关注者和被关注者之间的关系围绕这两个简单的数据结构:
148 |
149 | 1. `Map`
150 | 2. `Map`
151 |
152 | 像 Redis 这样的键值存储非常适合这里,因为数据结构相当简单,并且该服务应该是关键任务,具有高性能和低延迟。
153 |
154 | 关注者服务为关注者和被关注者提供功能。为了使图像出现在推送中,有两种模型可以实现。
155 |
156 | * 推送。一旦图像上传,我们将图像元数据推送到所有关注者的推送中。关注者将直接看到其准备好的推送。
157 | * 如果 `Map ` 的扇出太大,则推送模型将消耗大量时间和数据重复。
158 | * 拉取。我们不提前准备推送;相反,当关注者检查其推送时,它获取关注者列表并获取他们的图像。
159 | * 如果 `Map` 的扇出太大,则拉取模型将花费大量时间遍历庞大的关注者列表。
160 |
161 | ### 推送服务
162 |
163 | 推送服务在数据库中存储图像帖子的元数据,如 URL、名称、描述、位置等,而图像本身通常保存在像 AWS S3 和 Azure Blob 存储这样的 Blob 存储中。以 S3 为例,当客户通过 Web 或移动客户端创建帖子时,可能的解决方案如下:
164 |
165 | 1. 服务器生成一个 S3 预签名 URL,授予写入权限。
166 | 2. 客户端使用生成的预签名 URL 将图像二进制文件上传到 S3。
167 | 3. 客户端将帖子和图像元数据提交给服务器,然后触发数据管道,如果存在推送模型,则将帖子推送到关注者的推送中。
168 |
169 | 客户随着时间的推移向推送中发布,因此 HBase / Cassandra 的时间戳索引非常适合此用例。
170 |
171 | ### 图像 Blob 存储和 CDN
172 |
173 | 传输 Blob 消耗大量带宽。一旦我们上传了 Blob,我们会频繁读取它们,但很少更新或删除它。因此,开发人员通常使用 CDN 来缓存它们,这将把这些 Blob 分发到离客户更近的地方。
174 |
175 | AWS CloudFront CDN + S3 可能是市场上最流行的组合。我个人使用 BunnyCDN 来处理我的在线内容。Web3 开发人员喜欢使用像 IPFS 和 Arware 这样的去中心化存储。
176 |
177 | ### 搜索服务
178 |
179 | 搜索服务连接到所有可能的数据源并对其进行索引,以便人们可以轻松搜索推送。我们通常使用 ElasticSearch 或 Algolia 来完成这项工作。
180 |
181 | ### 垃圾邮件服务
182 |
183 | 垃圾邮件服务使用机器学习技术,如监督学习和无监督学习,来标记和删除不当内容和虚假账户。了解更多信息,请查看[使用半监督学习的欺诈检测](136-fraud-detection-with-semi-supervised-learning.md)。
184 |
185 | ## 第四步:总结盲点或瓶颈。
186 |
187 | 上述设计的盲点或瓶颈是什么?
188 |
189 | * 截至 2022 年,人们发现使用关注者-被关注者的方式组织推送不太可取,因为这对新客户来说很难启动,对现有客户来说也很难找到更有趣的内容。TikTok 和 Toutiao 引领了通过推荐算法组织推送的新一波创新。然而,这个设计并没有涵盖推荐系统的部分。
190 | * 对于一个流行的基于照片的社交网络,扩展是系统面临的最大挑战。因此,为了确保设计能够承受负载,我们需要进行容量规划。
191 |
192 | ### 使用电子表格和简单计算进行容量规划
193 |
194 | 我们可以通过两种方向来接近估算问题:自下而上和自上而下。
195 |
196 | 对于自下而上,你可以对现有系统进行负载测试,并根据公司的当前性能和未来增长率进行未来规划。
197 |
198 | 对于自上而下,你从理论上的客户开始,并进行简单的计算。我强烈建议你使用数字电子表格,在那里你可以轻松列出公式和假设/计算的数字。
199 |
200 | 当我们依赖外部 Blob 存储和 CDN 时,带宽不太可能成为问题。因此,我将以关注者服务为例估算容量:
201 |
202 | | 行 | 描述(“/”表示每) | 估算数量 | 计算结果 |
203 | | ---- | ----------------------------------------------- | -------------------------- | -------- |
204 | | A | 每日活跃用户 | 33,000,000 | |
205 | | B | 每用户每天请求数 | 60 | |
206 | | C | 每台机器的请求数 | 10,000(c10k 问题) | |
207 | | D | 扩展系数
(用户增长的冗余) | 3 倍 | |
208 | | E | 服务实例数量 | = A * B / (24 * 3600) / C * D | ~= 7 |
209 |
210 | 我们可以看到 *行 E* 是公式的计算结果。在对每个微服务和存储应用此估算方法后,我们将更好地理解整个系统。
211 |
212 | 现实世界的容量规划不是一次性的交易。准备过多的机器会浪费资金,而准备过少的机器会导致停机。我们通常会进行几轮估算和实验,以找到正确的答案;或者如果系统支持并且预算不是问题,则使用自动扩展。
213 |
214 | 大型公司的工程师通常享受丰富的计算和存储资源。然而,优秀的工程师会考虑成本和收益。我有时会尝试不同等级的机器,并为它们的月度支出添加行以进行估算。
--------------------------------------------------------------------------------
/zh-CN/2018-07-10-cloud-design-patterns.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-10-cloud-design-patterns
3 | id: 2018-07-10-cloud-design-patterns
4 | title: "Cloud Design Patterns"
5 | date: 2018-07-10 11:16
6 | comments: true
7 | tags: [design patterns, system design]
8 | description: "There are three types of cloud design patterns. Availability patterns have health endpoint monitoring and throttling. Data management patterns have cache-aside and static content hosting. Security patterns have federated identity."
9 | references:
10 | - https://docs.microsoft.com/en-us/azure/architecture/patterns/
11 | ---
12 |
13 | ## Availability patterns
14 | - Health Endpoint Monitoring: Implement functional checks in an application that external tools can access through exposed endpoints at regular intervals.
15 | - Queue-Based Load Leveling: Use a queue that acts as a buffer between a task and a service that it invokes in order to smooth intermittent heavy loads.
16 | - Throttling: Control the consumption of resources used by an instance of an application, an individual tenant, or an entire service.
17 |
18 |
19 |
20 | ## Data Management patterns
21 | - Cache-Aside: Load data on demand into a cache from a data store
22 | - Command and Query Responsibility Segregation: Segregate operations that read data from operations that update data by using separate interfaces.
23 | - Event Sourcing: Use an append-only store to record the full series of events that describe actions taken on data in a domain.
24 | - Index Table: Create indexes over the fields in data stores that are frequently referenced by queries.
25 | - Materialized View: Generate prepopulated views over the data in one or more data stores when the data isn't ideally formatted for required query operations.
26 | - Sharding: Divide a data store into a set of horizontal partitions or shards.
27 | - Static Content Hosting: Deploy static content to a cloud-based storage service that can deliver them directly to the client.
28 |
29 |
30 |
31 | ## Security Patterns
32 | - Federated Identity: Delegate authentication to an external identity provider.
33 | - Gatekeeper: Protect applications and services by using a dedicated host instance that acts as a broker between clients and the application or service, validates and sanitizes requests, and passes requests and data between them.
34 | - Valet Key: Use a token or key that provides clients with restricted direct access to a specific resource or service.
35 |
--------------------------------------------------------------------------------
/zh-CN/2018-07-20-experience-deep-dive.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-20-experience-deep-dive
3 | id: 2018-07-20-experience-deep-dive
4 | title: "深入体验"
5 | date: 2018-07-20 11:54
6 | comments: true
7 | tags: [系统设计]
8 | description: "对于那些在领导职位上经验较少的人,我们提供一些面试建议。需要描述您之前的项目,包括挑战或改进。同时,记得展示您的沟通技巧。"
9 | ---
10 |
11 | ## 目标受众
12 |
13 | 经验中等或更少,或在之前的职位中没有担任领导或设计职位(无论是正式还是非正式)的人
14 |
15 |
16 |
17 | ## 问题描述
18 |
19 | 描述您之前的一个项目,这个项目对您来说特别有趣或令人难忘。后续问题:
20 |
21 | 是什么让这个项目有趣?
22 | 项目中最具挑战性的部分是什么,您是如何应对这些挑战的?
23 | 您从项目中学到了什么,您希望在开始之前知道什么?
24 | 您考虑过其他设计/实施方法吗?您为什么选择了您所选择的那个?如果您要重新做同样的项目,您会有什么不同的做法?
25 |
26 |
27 |
28 | ## 面试官提示
29 |
30 | 由于这里的目标是评估一个可能从未担任过可以进行速成课程角色的人的技术沟通能力和兴趣水平,您应该准备好不断向他们提问(无论是为了获取更多细节,还是关于项目的其他方面)。如果他们是最近毕业的学生并做了论文,通常这是一个很好的谈论选择。虽然这个问题在许多方面与电话筛选中的简历问题相似,但这个问题的预期长度大约是四倍,并且应该更详细地探讨他们所做的事情。因此,评分标准相似,但应以更高的期望和更多的数据进行评估。
31 |
32 |
33 |
34 | ## 评分
35 |
36 | 优秀候选人将会
37 |
38 | - 能够在整个时间内谈论项目,面试官的互动将是对话而非指引
39 | - 对整个项目有深入了解,而不仅仅是他们关注的领域,并能够清晰表达项目的意图和设计
40 |
41 |
42 | - 对项目充满热情,能够清楚描述激发这种热情的项目元素
43 | - 能够清晰解释考虑过的替代方案,以及为什么选择了他们所采用的实施策略
44 | - 对自己的经历进行了反思并从中学习
45 |
46 |
47 |
48 | 良好候选人将会
49 |
50 | - 可能在全程谈话中遇到一些困难,但在面试官的帮助和提问下能够进行交流
51 | - 可能对项目的整体范围缺乏一些了解,但仍对他们的特定领域和直接与他们互动的部分有较强的知识
52 | - 可能表现出热情,但无法清楚解释是什么激发了这种热情
53 |
54 |
55 | - 可能能够讨论他们所做的替代方案,但没有深入考虑
56 | - 对自己的经历进行了反思并从中学习
57 |
58 |
59 |
60 | 差劲候选人将会
61 |
62 | - 在全程谈话中遇到困难。面试官可能会感到他们是在审问而不是与候选人交谈
63 | - 可能对项目缺乏详细了解,即使在他们工作的领域内。他们可能不理解他们的部分是如何设计的,或者可能不理解它如何与其他系统互动
64 | - 对项目似乎不太感兴趣——请记住,您是在询问他们做过的最有趣的项目,他们应该对无论是什么项目都非常感兴趣
65 |
66 |
67 | - 可能对他们的实施方法的潜在替代方案不熟悉
68 | - 似乎没有从项目的经历中学习或反思。一个关键的迹象是对“你学到了什么”和“你会有什么不同的做法”的回答很简短和/或几乎相同。
--------------------------------------------------------------------------------
/zh-CN/2018-07-21-data-partition-and-routing.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-21-data-partition-and-routing
3 | id: 2018-07-21-data-partition-and-routing
4 | title: "数据分区与路由"
5 | date: 2018-07-20 11:54
6 | comments: true
7 | tags: [系统设计]
8 | description: "实施数据分区与路由的优点是可用性和读取效率,而一致性则是其弱点。路由抽象模型本质上是两张地图:键-分区图和分区-机器图。"
9 | ---
10 |
11 | ## 为什么要进行数据分区与路由?
12 |
13 | 大数据集 ⟶ 扩展 ⟶ 数据分片 / 分区 ⟶ 1) 数据访问的路由 2) 可用性的副本
14 |
15 | - 优点
16 | - 可用性
17 | - 读取(并行化,单次读取效率)
18 | - 缺点
19 | - 一致性
20 |
21 | ## 如何进行数据分区与路由?
22 |
23 | 路由抽象模型本质上只有两张地图:1) 键-分区图 2) 分区-机器图
24 |
25 |
26 |
27 | ### 哈希分区
28 |
29 | 1. 哈希和取模
30 | - (+) 简单
31 | - (-) 灵活性(紧耦合两张地图:添加和移除节点(分区-机器图)会破坏现有的键-分区图)
32 |
33 | 2. 虚拟桶:键--(哈希)-->虚拟桶,虚拟桶--(表查找)-->服务器
34 | - 使用案例:Membase 也称为 Couchbase,Riak
35 | - (+) 灵活性,解耦两张地图
36 | - (-) 集中式查找表
37 |
38 | 3. 一致性哈希和 DHT
39 | - [Chord] 实现
40 | - 虚拟节点:用于异构数据中心的负载均衡
41 | - 使用案例:Dynamo,Cassandra
42 | - (+) 灵活性,哈希空间解耦两张地图。两张地图使用相同的哈希,但添加和移除节点==只影响后续节点==。
43 | - (-) 网络复杂性,难以维护
44 |
45 |
46 |
47 | ### 范围分区
48 |
49 | 按主键排序,按主键范围分片
50 |
51 | 范围-服务器查找表(例如 HBase .META. 表)+ 本地基于树的索引(例如 LSM,B+)
52 |
53 | (+) 搜索范围
54 | (-) log(n)
55 |
56 | 使用案例:Yahoo PNUTS,Azure,Bigtable
--------------------------------------------------------------------------------
/zh-CN/2018-07-22-b-tree-vs-b-plus-tree.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-22-b-tree-vs-b-plus-tree
3 | id: 2018-07-22-b-tree-vs-b-plus-tree
4 | title: "B 树与 B+ 树"
5 | date: 2018-07-22 11:54
6 | comments: true
7 | tags: [系统设计]
8 | description: "B+ 树可以被视为 B 树,其中每个节点仅包含键。B+ 树的优点可以总结为更少的缓存未命中。在 B 树中,数据与每个键相关联,可以更快地访问。"
9 | references:
10 | - https://stackoverflow.com/questions/870218/differences-between-b-trees-and-b-trees
11 | ---
12 |
13 | 
14 |
15 | B 树的优点
16 |
17 | - 与每个键相关联的数据 ⟶ 频繁访问的节点可以更靠近根节点,因此可以更快地访问。
18 |
19 | B+ 树的优点
20 |
21 | - 内部节点没有关联数据 ⟶ 内存中更多的键 ⟶ 更少的缓存未命中
22 | - B+ 树的叶子节点是链接的 ⟶ 更容易遍历 ⟶ 更少的缓存未命中
--------------------------------------------------------------------------------
/zh-CN/2018-07-23-load-balancer-types.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-23-load-balancer-types
3 | id: 2018-07-23-load-balancer-types
4 | title: "负载均衡器类型"
5 | date: 2018-07-23 11:54
6 | comments: true
7 | tags: [系统设计]
8 | description: "通常,负载均衡器分为三类:DNS 轮询、网络负载均衡器和应用负载均衡器。DNS 轮询很少使用,因为它难以控制且响应不佳。网络负载均衡器具有更好的粒度,简单且响应迅速。"
9 | references:
10 | - https://www.amazon.com/Practice-Cloud-System-Administration-Practices/dp/032194318X
11 | - https://docs.aws.amazon.com/AmazonECS/latest/developerguide/load-balancer-types.html
12 | ---
13 |
14 | 一般来说,负载均衡器分为三类:
15 |
16 | - DNS 轮询(很少使用):客户端获得一个随机顺序的 IP 地址列表。
17 | - 优点:易于实现且免费
18 | - 缺点:难以控制且响应不佳,因为 DNS 缓存需要时间过期
19 | - 网络(L3/L4)负载均衡器:流量通过 IP 地址和端口进行路由。L3 是网络层(IP)。L4 是会话层(TCP)。
20 | - 优点:更好的粒度,简单,响应迅速
21 | - 应用(L7)负载均衡器:流量根据 HTTP 协议中的内容进行路由。L7 是应用层(HTTP)。
--------------------------------------------------------------------------------
/zh-CN/2018-07-24-replica-and-consistency.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-24-replica-and-consistency
3 | id: 2018-07-24-replica-and-consistency
4 | title: "副本、一致性与CAP定理"
5 | date: 2018-07-24 11:54
6 | comments: true
7 | tags: [系统设计]
8 | description: "任何网络系统都有三种理想属性:一致性、可用性和分区容忍性。系统只能拥有这三者中的两者。例如,关系数据库管理系统(RDBMS)更倾向于一致性和分区容忍性,因此成为ACID系统。"
9 | references:
10 | - https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed
11 | ---
12 |
13 | ## 为什么副本和一致性?
14 |
15 | 大数据集 ⟶ 扩展 ⟶ 数据分片/分区 ⟶ 1) 数据访问路由 2) 可用性副本 ⟶ 一致性挑战
16 |
17 |
18 |
19 | ## CAP定理的一致性权衡
20 |
21 | 
22 |
23 | - 一致性:所有节点在同一时间看到相同的数据
24 | - 可用性:保证每个请求都能收到关于其成功或失败的响应
25 | - 分区容忍性:系统在任意消息丢失或部分系统故障的情况下继续运行
26 |
27 |
28 |
29 | 任何网络共享数据系统只能拥有三种理想属性中的两种。
30 |
31 | - 关系数据库管理系统(rDBMS)倾向于CP ⟶ ACID
32 | - NoSQL倾向于AP ⟶ BASE
33 |
34 |
35 |
36 | ## “2 of 3”是误导性的
37 |
38 | 12年后,作者埃里克·布鲁尔(Eric Brewer)表示“2 of 3”是误导性的,因为
39 |
40 | 1. 分区是罕见的,当系统没有分区时,几乎没有理由放弃C或A。
41 | 2. 选择实际上可以在同一系统内的多个地方以非常细的粒度应用。
42 | 3. 选择不是二元的,而是有一定程度的。
43 |
44 |
45 |
46 | 因此,当没有分区(节点正确连接)时,这种情况经常发生,我们应该同时拥有AC。当出现分区时,处理它们的步骤如下:
47 |
48 | 1. 检测分区的开始,
49 | 2. 进入可能限制某些操作的显式分区模式,并
50 | 3. 当通信恢复时启动分区恢复(补偿错误)。
--------------------------------------------------------------------------------
/zh-CN/2018-07-26-acid-vs-base.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 2018-07-26-acid-vs-base
3 | id: 2018-07-26-acid-vs-base
4 | title: "ACID vs BASE"
5 | date: 2018-07-26 11:54
6 | comments: true
7 | tags: [system design]
8 | description: "ACID 和 BASE 代表了不同的设计理念。ACID 更注重一致性而非可用性。在 ACID 中,C 表示事务保留所有数据库规则。而 BASE 更侧重于可用性,表示系统确保可用。"
9 | references:
10 | - https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed
11 | ---
12 |
13 | ACID(一致性优先于可用性)
14 |
15 | - 原子性确保事务要么完全成功,要么完全失败。
16 | - 一致性:在 ACID 中,C 表示事务保留所有数据库规则,如唯一键、触发器、级联等。相比之下,CAP 中的 C 仅指单一副本一致性,是 ACID 一致性的严格子集。
17 | - 隔离性确保并发执行的事务使数据库保持在与顺序执行事务相同的状态。
18 | - 持久性确保一旦事务提交,即使在系统故障(如断电或崩溃)情况下也会保持提交状态。
19 |
20 | BASE(可用性优先于一致性)
21 |
22 | - 基本可用表示系统确保可用。
23 | - 软状态表示系统的状态可能随时间变化,即使没有输入。这主要是由于最终一致性模型导致的。
24 | - 最终一致性表示只要系统在一定时间内不接收输入,系统最终将达到一致状态。
25 |
26 | 虽然大多数 NoSQL 采用 BASE 原则,但它们正逐渐学习或转向 ACID,例如,Google Spanner 提供强一致性,MongoDB 4.0 增加了对多文档 ACID 事务的支持。
27 |
--------------------------------------------------------------------------------
/zh-CN/38-how-to-stream-video-over-http.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 38-how-to-stream-video-over-http
3 | id: 38-how-to-stream-video-over-http
4 | title: "如何通过 HTTP 为移动设备流式传输视频?HTTP 实时流媒体 (HLS)"
5 | date: 2018-09-07 21:32
6 | comments: true
7 | tags: [系统设计]
8 | description: "移动设备上的 HTTP 视频服务面临两个问题:有限的内存或存储和不稳定的网络连接以及可变的带宽。HTTP 实时流媒体通过关注点分离、文件分段和索引来解决这些问题。"
9 | references:
10 | - https://developer.apple.com/library/ios/documentation/NetworkingInternet/Conceptual/StreamingMediaGuide/HTTPStreamingArchitecture/HTTPStreamingArchitecture.html#//apple_ref/doc/uid/TP40008332-CH101-SW2
11 | ---
12 |
13 | ## 动机
14 |
15 | 移动设备上的 HTTP 实时流媒体视频服务,...
16 |
17 | 1. ==内存/存储有限==
18 | 2. 遭受不稳定的网络连接和可变带宽的影响,并需要 ==中途质量调整。==
19 |
20 |
21 |
22 | ## 解决方案
23 |
24 | 1. 服务器端:在典型配置中,硬件编码器接收音视频输入,将其编码为 H.264 视频和 AAC 音频,并以 MPEG-2 传输流的形式输出。
25 |
26 | 1. 然后,流被软件流分段器分解为一系列短媒体文件(.ts 可能为 10 秒)。
27 | 2. 分段器还创建并维护一个索引(.m3u8)文件,其中包含媒体文件的列表。
28 | 3. 媒体文件和索引文件都发布在网络服务器上。
29 |
30 | 2. 客户端:客户端读取索引,然后按顺序请求列出的媒体文件,并在段之间无任何暂停或间隙地显示它们。
31 |
32 |
33 |
34 | ## 架构
35 |
36 | 
--------------------------------------------------------------------------------
/zh-CN/41-how-to-scale-a-web-service.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 41-how-to-scale-a-web-service
3 | id: 41-how-to-scale-a-web-service
4 | title: "如何扩展网络服务?"
5 | date: 2018-09-11 21:32
6 | comments: true
7 | tags: [系统设计]
8 | references:
9 | - https://akfpartners.com/growth-blog/scale-cube
10 | - https://akfpartners.com/growth-blog/akf-scale-cube-ze-case-for-z-axis
11 | ---
12 |
13 | AKF 规模立方体将扩展过程可视化为三个维度…
14 |
15 | 
16 |
17 | 1. ==水平复制== 和克隆 (X 轴)。在负载均衡器或反向代理后面拥有一组相同且最好是无状态的实例。因此,每个请求都可以由这些主机中的任何一个来处理,并且不会有单点故障。
18 | 2. ==功能分解== 和分段 - 微服务 (Y 轴)。例如,身份验证服务、用户资料服务、照片服务等。
19 | 3. ==水平数据分区== - 分片 (Z 轴)。将整个堆栈复制到不同的“集群”。每个集群可以针对特定的大用户群。例如,Uber 在中国和美国都有数据中心。每个数据中心可能会有不同区域的“集群”。
20 |
21 | 想要一个例子吗?去看看 [Facebook 如何扩展其社交图谱数据存储](https://tianpan.co/notes/49-facebook-tao)。
--------------------------------------------------------------------------------
/zh-CN/43-how-to-design-robust-and-predictable-apis-with-idempotency.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 43-how-to-design-robust-and-predictable-apis-with-idempotency
3 | id: 43-how-to-design-robust-and-predictable-apis-with-idempotency
4 | title: "如何设计健壮且可预测的 API 以实现幂等性?"
5 | date: 2018-09-12 12:55
6 | comments: true
7 | tags: [系统设计]
8 | description: "API 可能不够健壮且不可预测。为了解决这个问题,应遵循三个原则。客户端重试以确保一致性。使用幂等性、指数退避和随机抖动进行重试。"
9 | references:
10 | - https://stripe.com/blog/idempotency
11 | ---
12 |
13 | API 如何可能不够健壮且不可预测?
14 |
15 | 1. 网络不可靠。
16 | 2. 服务器更可靠,但仍可能出现故障。
17 |
18 | 如何解决这个问题?三个原则:
19 |
20 | 1. 客户端重试以确保一致性。
21 |
22 | 2. 使用幂等性和幂等性键进行重试,以允许客户端传递唯一值。
23 |
24 | 1. 在 RESTful API 中,PUT 和 DELETE 动词是幂等的。
25 | 2. 然而,POST 可能导致==“双重收费”问题==。因此,我们使用==幂等性键==来识别请求。
26 | 1. 如果故障发生在服务器之前,则会进行重试,服务器将首次看到该请求,并正常处理。
27 | 2. 如果故障发生在服务器中,则 ACID 数据库将通过幂等性键保证事务。
28 | 3. 如果故障发生在服务器回复之后,则客户端重试,服务器简单地回复成功操作的缓存结果。
29 |
30 | 3. 使用==指数退避和随机抖动==进行重试。要考虑==雷鸣般的群体问题==,即服务器可能处于降级状态,突发的重试可能会进一步损害系统。
31 |
32 | 例如,Stripe 的客户端重试计算延迟如下...
33 |
34 | ```ruby
35 | def self.sleep_time(retry_count)
36 | # 根据到目前为止的尝试次数应用初始网络重试延迟的指数退避。不要让这个数字超过最大网络重试延迟。
37 | sleep_seconds = [Stripe.initial_network_retry_delay * (2 ** (retry_count - 1)), Stripe.max_network_retry_delay].min
38 |
39 | # 通过在 (sleep_seconds / 2) 到 (sleep_seconds) 范围内随机化值来应用一些抖动。
40 | sleep_seconds = sleep_seconds * (0.5 * (1 + rand()))
41 |
42 | # 但永远不要少于基础睡眠秒数。
43 | sleep_seconds = [Stripe.initial_network_retry_delay, sleep_seconds].max
44 |
45 | sleep_seconds
46 | end
47 | ```
--------------------------------------------------------------------------------
/zh-CN/45-how-to-design-netflix-view-state-service.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 45-how-to-design-netflix-view-state-service
3 | id: 45-how-to-design-netflix-view-state-service
4 | title: "Netflix 如何提供观看数据?"
5 | date: 2018-09-13 20:39
6 | comments: true
7 | tags: [system design]
8 | references:
9 | - http://techblog.netflix.com/2015/01/netflixs-viewing-data-how-we-know-where.html
10 | ---
11 |
12 | ## 动机
13 |
14 | 如何在规模上保持用户的观看数据(每天数十亿事件)?
15 |
16 | 在这里,观看数据指的是...
17 |
18 | 1. 观看历史。我看过哪些标题?
19 | 2. 观看进度。我在某个标题中停留在哪里?
20 | 3. 正在观看的内容。我的账户现在还在观看什么?
21 |
22 |
23 |
24 | ## 架构
25 |
26 | 
27 |
28 |
29 | 观看服务有两个层次:
30 |
31 | 1. 有状态层 = 活动视图存储在内存中
32 | - 为什么?为了支持最高的读/写量
33 | - 如何扩展?
34 | - 按照 `account_id mod N` 分区为 N 个有状态节点
35 | - 一个问题是负载分布不均,因此系统容易出现热点
36 | - 在 CAP 定理 下选择 CP 而非 AP,并且没有活动状态的副本。
37 | - 一个失败的节点将影响 `1/n` 的成员。因此,他们使用过时的数据以优雅地降级。
38 |
39 |
40 | 2. 无状态层 = 数据持久性 = Cassandra + Memcached
41 | - 使用 Cassandra 进行非常高的写入量和低延迟。
42 | - 数据均匀分布。由于使用虚拟节点进行一致性哈希来分区数据,因此没有热点。
43 | - 使用 Memcached 进行非常高的读取量和低延迟。
44 | - 如何更新缓存?
45 | - 在写入 Cassandra 后,将更新的数据写回 Memcached
46 | - 最终一致性,以处理多个写入者,具有短的缓存条目 TTL 和定期的缓存刷新。
47 | - 将来,优先考虑 Redis 的追加操作到时间排序列表,而不是 Memcached 中的“读-修改-写”。
--------------------------------------------------------------------------------
/zh-CN/49-facebook-tao.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 49-facebook-tao
3 | id: 49-facebook-tao
4 | title: "Facebook 如何扩展其社交图谱存储?TAO"
5 | date: 2018-09-18 22:50
6 | comments: true
7 | tags: [system design]
8 | description: "在 TAO 之前,Facebook 使用缓存旁路模式来扩展其社交图谱存储。存在三个问题:列表更新操作效率低;客户端必须管理缓存,且很难提供读后写一致性。通过 TAO,这些问题得以解决。"
9 | references:
10 | - http://www.cs.cornell.edu/courses/cs6410/2015fa/slides/tao_atc.pptx
11 | - https://cs.stanford.edu/~matei/courses/2015/6.S897/slides/tao.pdf
12 | - https://www.facebook.com/notes/facebook-engineering/tao-the-power-of-the-graph/10151525983993920/
13 | ---
14 |
15 | ## 面临的挑战是什么?
16 |
17 | 在 TAO 之前,使用缓存旁路模式
18 |
19 | 
20 |
21 | 社交图谱数据存储在 MySQL 中,并缓存于 Memcached 中
22 |
23 |
24 | 三个问题:
25 |
26 | 1. Memcached 中的列表更新操作效率低。无法追加,只能更新整个列表。
27 | 2. 客户端必须管理缓存
28 | 3. 难以提供 ==读后写一致性==
29 |
30 |
31 | 为了解决这些问题,我们有三个目标:
32 |
33 | - 高效扩展的在线数据图服务
34 | - 优化读取(其读写比为 500:1)
35 | - 低读取延迟
36 | - 高读取可用性(最终一致性)
37 | - 写入的及时性(读后写)
38 |
39 |
40 |
41 | ## 数据模型
42 |
43 | - 具有唯一 ID 的对象(例如用户、地点、评论)
44 | - 两个 ID 之间的关联(例如标签、喜欢、作者)
45 | - 两者都有键值数据以及时间字段
46 |
47 |
48 |
49 | ## 解决方案:TAO
50 |
51 | 1. 高效扩展并减少读取延迟
52 | - 图特定缓存
53 | - 在无状态服务层和数据库层之间的独立缓存层(即 [功能分解](https://tianpan.co/notes/41-how-to-scale-a-web-service))
54 | - 数据中心的细分(即 [水平数据分区](https://tianpan.co/notes/41-how-to-scale-a-web-service))
55 |
56 |
57 | 2. 写入及时性
58 | - 写透缓存
59 | - 领导/跟随缓存以解决雷鸣般的拥挤问题
60 | - 异步复制
61 |
62 |
63 | 3. 读取可用性
64 | - 读取故障转移到备用数据源
65 |
66 |
67 |
68 | ## TAO 的架构
69 |
70 | - MySQL 数据库 → 持久性
71 | - 领导缓存 → 协调对每个对象的写入
72 | - 跟随缓存 → 提供读取但不提供写入。将所有写入转发给领导。
73 |
74 |
75 | 
76 |
77 |
78 | 读取故障转移
79 |
80 | 
--------------------------------------------------------------------------------
/zh-CN/61-what-is-apache-kafka.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 61-what-is-apache-kafka
3 | id: 61-what-is-apache-kafka
4 | title: "什么是 Apache Kafka?"
5 | date: 2018-09-27 04:06
6 | comments: true
7 | tags: [系统设计]
8 | description: "Apache Kafka 是一个分布式流处理平台,可用于按主题进行日志记录、消息系统的地理复制或流处理。由于其零拷贝技术,它比其他平台快得多。"
9 | references:
10 | - https://kafka.apache.org/intro
11 | - http://www.michael-noll.com/blog/2014/08/18/apache-kafka-training-deck-and-tutorial/
12 | - https://stackoverflow.com/questions/48271491/where-is-apache-kafka-placed-in-the-pacelc-theorem
13 | - https://engineering.linkedin.com/kafka/intra-cluster-replication-apache-kafka
14 | ---
15 |
16 | Apache Kafka 是一个分布式流处理平台。
17 |
18 | ## 为什么使用 Apache Kafka?
19 |
20 | 它的抽象是一个 ==队列==,并且它具有
21 |
22 | - 一个分布式的发布-订阅消息系统,将 N\^2 关系解决为 N。发布者和订阅者可以以自己的速度操作。
23 | - 采用零拷贝技术,速度极快
24 | - 支持容错的数据持久性
25 |
26 | 它可以应用于
27 |
28 | - 按主题进行日志记录
29 | - 消息系统
30 | - 地理复制
31 | - 流处理
32 |
33 | ## 为什么 Kafka 这么快?
34 |
35 | Kafka 使用零拷贝,CPU 不需要将数据从一个内存区域复制到另一个内存区域。
36 |
37 | 没有零拷贝的情况下:
38 |
39 |
43 |
44 | 使用零拷贝的情况下:
45 |
46 |
50 |
51 | ## 架构
52 |
53 | 从外部看,生产者写入代理,消费者从代理读取。
54 |
55 |
56 |
57 | 数据存储在主题中,并分割成多个分区,这些分区是复制的。
58 |
59 | 
60 |
61 | 1. 生产者将消息发布到特定主题。
62 | - 首先写入内存缓冲区,然后刷新到磁盘。
63 | - 仅追加的顺序写入以实现快速写入。
64 | - 写入磁盘后可供读取。
65 | 2. 消费者从特定主题中拉取消息。
66 | - 使用“偏移指针”(偏移量作为 seqId)来跟踪/控制其唯一的读取进度。
67 | 3. 一个主题由分区组成,负载均衡,分区(= 有序 + 不可变的消息序列,持续追加)
68 | - 分区决定最大消费者(组)并行性。一个消费者在同一时间只能从一个分区读取。
69 |
70 | 如何序列化数据?Avro
71 |
72 | 它的网络协议是什么?TCP
73 |
74 | 分区的存储布局是什么?O(1) 磁盘读取
75 |
76 |
80 |
81 | ## 如何容错?
82 |
83 | ==同步副本 (ISR) 协议==。它容忍 (numReplicas - 1) 个死掉的代理。每个分区有一个领导者和一个或多个跟随者。
84 |
85 | `总副本 = ISRs + 不同步副本`
86 |
87 | 1. ISR 是活着的副本集合,并且已经完全追赶上领导者(注意领导者始终在 ISR 中)。
88 | 2. 当发布新消息时,领导者会等待直到它到达 ISR 中的所有副本,然后才提交消息。
89 | 3. ==如果一个跟随者副本失败,它将被移出 ISR,领导者随后继续以更少的副本在 ISR 中提交新消息。注意,现在系统正在以不足副本模式运行。== 如果领导者失败,将选择一个 ISR 成为新的领导者。
90 | 4. 不同步副本继续从领导者拉取消息。一旦追赶上领导者,它将被重新添加到 ISR 中。
91 |
92 | ## Kafka 是 [CAP 定理](https://tianpan.co/notes/2018-07-24-replica-and-consistency) 中的 AP 还是 CP 系统?
93 |
94 | Jun Rao 说它是 CA,因为“我们的目标是在单个数据中心内支持 Kafka 集群的复制,在那里网络分区是罕见的,因此我们的设计专注于保持高度可用和强一致性的副本。”
95 |
96 | 然而,这实际上取决于配置。
97 |
98 | 1. 默认配置(min.insync.replicas=1,default.replication.factor=1)开箱即用时,您将获得 AP 系统(至多一次)。
99 |
100 | 2. 如果您想实现 CP,您可以将 min.insync.replicas 设置为 2,主题复制因子设置为 3 - 然后使用 acks=all 生产消息将保证 CP 设置(至少一次),但(如预期)在特定主题/分区对可用副本不足(\<2)时将会阻塞。
101 |
--------------------------------------------------------------------------------
/zh-CN/63-soft-skills-interview.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 63-soft-skills-interview
3 | id: 63-soft-skills-interview
4 | title: "在软技能面试中我们可以沟通什么?"
5 | date: 2018-10-01 08:56
6 | comments: true
7 | tags: [系统设计]
8 | description: "面试是员工寻找未来同事的过程。候选人将根据对三个关键问题的回答进行评估:能力、意愿和文化契合。
9 | 以上任何问题都无法在没有良好沟通的情况下回答。"
10 | references:
11 | - https://www.jianshu.com/p/73b1d5682fd3
12 | - https://www.amazon.com/dp/B01NAI5Q6H/
13 | ---
14 |
15 | ## 什么是面试?
16 |
17 | 面试是员工寻找未来同事的过程,在此过程中,他们
18 | 寻找信号来回答以下三个关键问题:
19 |
20 | 1. 能力问题 - 你能胜任这份工作吗?
21 | 2. 意愿问题 - 你愿意做这份工作吗?
22 | 3. 文化契合问题 - 你能融入团队吗?
23 |
24 |
25 |
26 | ## 为什么软技能如此重要?
27 |
28 | 以上任何一个关键问题都无法在没有良好沟通的情况下回答。
29 | 你的工作将被那些沟通能力比你更强的人取代。
30 |
31 |
32 |
33 | ## 准备的通用回答(故事)
34 |
35 | 1. 艰难取得的胜利。你是如何应对失败的?简要谈谈你经历的最艰难时刻,然后专注于你是如何反击的,并感谢那些帮助过你的人。这表明你具备毅力、团队建设能力以及与工作相关的素质。
36 | 2. 影响力。你能引导他人接受你的观点吗?`领导者 = 激励自我牺牲的愿景者`。没有说服能力,领导者就不存在。
37 | 3. 技术技能。你有故事证明你出色的技术技能吗?
38 | 4. 文化契合。联邦调查局曾经询问潜在特工他们读过哪些书,直到一个地下线人的网络找到了理想答案:“汤姆·克兰西的间谍小说。”
39 | 5. 吸引力。你有什么吸引人的地方?是什么让你与其他人不同?
--------------------------------------------------------------------------------
/zh-CN/66-public-api-choices.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 66-public-api-choices
3 | id: 66-public-api-choices
4 | title: "公共 API 选择"
5 | date: 2018-10-04 01:38
6 | comments: true
7 | tags: [系统设计]
8 | description: 有几种工具可用于公共 API、API 网关或前端后端网关。GraphQL 以其诸如尾随结果、批处理嵌套查询、性能追踪和显式缓存等功能而脱颖而出。
9 | ---
10 |
11 | 总之,在选择公共 API、API 网关或 BFF(前端后端)网关的工具时,我更喜欢 GraphQL,因为它具有尾随结果、批处理嵌套查询、性能追踪和显式缓存等功能。
12 |
13 | ||JSON RPC|GraphQL|REST|gRPC|
14 | |--- |--- |--- |--- |--- |
15 | |用例|以太坊|Github V2、Airbnb、Facebook BFF / API 网关|Swagger|高性能、谷歌、内部端点|
16 | |单一端点|✅|✅|❌|✅|
17 | |类型系统|✅,与 JSON 一样弱
无 uint64|✅
无 uint64|✅ w/ Swagger
无 uint64|✅
有 uint64|
18 | |定制结果|❌|✅|❌|❌|
19 | |批处理嵌套查询|❌|✅|❌|❌|
20 | |版本控制|❌|模式扩展|是,使用 v1/v2 路由|protobuf 中的字段编号|
21 | |错误处理|结构化|结构化|HTTP 状态码|结构化|
22 | |跨平台|✅|✅|✅|✅|
23 | |游乐场 UI|❌|GraphQL Bin|Swagger|❌|
24 | |性能追踪|?|Apollo 插件|?|?|
25 | |缓存|无或 HTTP 缓存控制|Apollo 插件|HTTP 缓存控制|尚未原生支持,但仍可使用 HTTP 缓存控制|
26 | |问题|缺乏社区支持和工具链 Barrister IDL|42.51 kb 客户端包大小|多个端点的非结构化,便携性差。|Grpc-web 开发进行中,140kb JS 包。兼容性问题:并非所有地方都支持 HTTP2 和 grpc 依赖|
--------------------------------------------------------------------------------
/zh-CN/68-bloom-filter.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 68-bloom-filter
3 | id: 68-bloom-filter
4 | title: "布隆过滤器"
5 | date: 2018-10-09 12:39
6 | comments: true
7 | tags: [系统设计, 数据结构]
8 | description: 布隆过滤器是一种数据结构,用于以时间和空间高效的方式检测一个元素是否在一个集合中。查询返回“可能在集合中”或“绝对不在集合中”。
9 | references:
10 | - https://zh.wikipedia.org/wiki/%E5%B8%83%E9%9A%86%E8%BF%87%E6%BB%A4%E5%99%A8
11 | ---
12 |
13 | 布隆过滤器是一种数据结构,用于以时间和空间高效的方式检测一个元素是否在一个集合中。
14 |
15 | 可能会出现假阳性匹配,但不会出现假阴性——换句话说,查询返回“可能在集合中”或“绝对不在集合中”。元素可以添加到集合中,但不能移除(尽管可以通过“计数”布隆过滤器来解决这个问题);添加到集合中的元素越多,假阳性的概率就越大。
16 |
17 | 使用案例
18 |
19 | - Cassandra 使用布隆过滤器来确定 SSTable 是否包含特定行的数据。
20 | - HBase 布隆过滤器是一种有效的机制,用于测试 StoreFile 是否包含特定行或行-列单元格。
21 | - 网站的反欺诈系统可以有效地使用布隆过滤器来拒绝被禁止的用户。
22 | - 谷歌 Chrome 浏览器曾经使用布隆过滤器来识别恶意 URL。
--------------------------------------------------------------------------------
/zh-CN/69-skiplist.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 69-skiplist
3 | id: 69-skiplist
4 | title: "跳表"
5 | date: 2018-10-09 12:39
6 | comments: true
7 | tags: [系统设计, 数据结构]
8 | description: "跳表本质上是一种链表,允许您在其上进行二分查找。它通过添加额外的节点来实现这一点,使您能够‘跳过’链表的某些部分。LevelDB MemTable、Redis SortedSet 和 Lucene 倒排索引都使用了这种结构。"
9 | references:
10 | - https://en.wikipedia.org/wiki/Skip_list
11 | ---
12 |
13 | 跳表本质上是一种链表,允许您在其上进行二分查找。它通过添加额外的节点来实现这一点,使您能够‘跳过’链表的某些部分。通过随机投掷硬币来创建额外节点,跳表的搜索、插入和删除操作的时间复杂度应为 O(logn)。
14 |
15 | 用例
16 |
17 | - LevelDB MemTable
18 | - Redis SortedSet
19 | - Lucene 倒排索引
--------------------------------------------------------------------------------
/zh-CN/78-four-kinds-of-no-sql.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 78-four-kinds-of-no-sql
3 | id: 78-four-kinds-of-no-sql
4 | title: "四种 No-SQL"
5 | date: 2018-10-17 00:49
6 | comments: true
7 | tags: ["系统设计"]
8 | description: "从硬盘读取数据时,数据库连接操作耗时,99% 的时间花费在磁盘寻址上。为了优化读取性能,引入了非规范化,并且四种 NoSQL 类型可以帮助解决这个问题。"
9 | references:
10 | - https://www.puncsky.com/blog/2016-02-13-crack-the-system-design-interview
11 | ---
12 |
13 | 在一个常规的互联网服务中,读取与写入的比例大约是 100:1 到 1000:1。然而,从硬盘读取时,数据库连接操作耗时,99% 的时间花费在磁盘寻址上。更不用说跨网络的分布式连接操作了。
14 |
15 | 为了优化读取性能,**非规范化**通过添加冗余数据或分组数据来引入。这四种 NoSQL 类型可以帮助解决这个问题。
16 |
17 |
18 |
19 | ## 键值存储
20 |
21 | 键值存储的抽象是一个巨大的哈希表/哈希映射/字典。
22 |
23 | 我们希望使用键值缓存的主要原因是为了减少访问活跃数据的延迟。在快速且昂贵的介质(如内存或 SSD)上实现 O(1) 的读/写性能,而不是在传统的慢且便宜的介质(通常是硬盘)上实现 O(logn) 的读/写性能。
24 |
25 | 设计缓存时需要考虑三个主要因素。
26 |
27 | 1. 模式:如何缓存?是读透/写透/写旁/写回/缓存旁?
28 | 2. 放置:将缓存放在哪里?客户端/独立层/服务器端?
29 | 3. 替换:何时过期/替换数据?LRU/LFU/ARC?
30 |
31 | 现成的选择:Redis/Memcache?Redis 支持数据持久化,而 Memcache 不支持。Riak、Berkeley DB、HamsterDB、Amazon Dynamo、Project Voldemort 等等。
32 |
33 |
34 |
35 | ## 文档存储
36 |
37 | 文档存储的抽象类似于键值存储,但文档(如 XML、JSON、BSON 等)存储在键值对的值部分。
38 |
39 | 我们希望使用文档存储的主要原因是灵活性和性能。灵活性通过无模式文档实现,性能通过打破 3NF 来提高。初创公司的业务需求时常变化。灵活的模式使他们能够快速行动。
40 |
41 | 现成的选择:MongoDB、CouchDB、Terrastore、OrientDB、RavenDB 等等。
42 |
43 |
44 |
45 | ## 列式存储
46 |
47 | 列式存储的抽象就像一个巨大的嵌套映射:`ColumnFamily>`。
48 |
49 | 我们希望使用列式存储的主要原因是它是分布式的、高可用的,并且针对写入进行了优化。
50 |
51 | 现成的选择:Cassandra、HBase、Hypertable、Amazon SimpleDB 等等。
52 |
53 |
54 |
55 | ## 图数据库
56 |
57 | 顾名思义,这种数据库的抽象是一个图。它允许我们存储实体及其之间的关系。
58 |
59 | 如果我们使用关系数据库来存储图,添加/删除关系可能涉及模式更改和数据移动,而使用图数据库则不需要。另一方面,当我们在关系数据库中为图创建表时,我们是基于我们想要的遍历进行建模;如果遍历发生变化,数据也必须随之变化。
60 |
61 | 现成的选择:Neo4J、Infinitegraph、OrientDB、FlockDB 等等。
--------------------------------------------------------------------------------
/zh-CN/80-relational-database.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 80-relational-database
3 | id: 80-relational-database
4 | title: "关系数据库简介"
5 | date: 2018-10-18 23:19
6 | comments: true
7 | tags: [系统设计]
8 | description: 关系数据库是大多数存储使用案例的默认选择,原因在于原子性、一致性、隔离性和持久性。这里的一致性与 CAP 定理中的一致性有什么不同?我们为什么需要 3NF 和数据库代理?
9 | references:
10 | - https://www.puncsky.com/blog/2016-02-13-crack-the-system-design-interview
11 | ---
12 |
13 | 关系数据库是大多数存储使用案例的默认选择,原因在于 ACID(原子性、一致性、隔离性和持久性)。一个棘手的问题是“一致性”——它意味着任何事务都会将数据库从一个有效状态转变为另一个有效状态,这与 [CAP 定理](https://tianpan.co/notes/2018-07-24-replica-and-consistency) 中的一致性不同。
14 |
15 | ## 模式设计和第三范式 (3NF)
16 |
17 | 为了减少冗余并提高一致性,人们在设计数据库模式时遵循 3NF:
18 |
19 | - 1NF:表格形式,每个行列交集只包含一个值
20 | - 2NF:只有主键决定所有属性
21 | - 3NF:只有候选键决定所有属性(且非主属性之间不相互依赖)
22 |
23 | ## 数据库代理
24 |
25 | 如果我们想消除单点故障怎么办?如果数据集太大,无法由单台机器承载怎么办?对于 MySQL,答案是使用数据库代理来分配数据,可以通过集群或分片。
26 |
27 | 集群是一种去中心化的解决方案。一切都是自动的。数据会自动分配、移动和重新平衡。节点之间互相传递信息(尽管这可能导致组隔离)。
28 |
29 | 分片是一种集中式解决方案。如果我们去掉不喜欢的集群属性,分片就是我们得到的结果。数据是手动分配的,不会移动。节点之间互不知晓。
--------------------------------------------------------------------------------
/zh-CN/83-lambda-architecture.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 83-lambda-architecture
3 | id: 83-lambda-architecture
4 | title: "Lambda 架构"
5 | date: 2018-10-23 10:30
6 | comments: true
7 | tags: [系统设计]
8 | description: Lambda 架构 = CQRS(批处理层 + 服务层) + 快速层。它解决了大数据的准确性、延迟和吞吐量问题。
9 | references:
10 | - https://www.amazon.com/Big-Data-Principles-practices-scalable/dp/1617290343
11 | - https://mapr.com/resources/stream-processing-mapr/
12 | ---
13 |
14 | ## 为什么选择 Lambda 架构?
15 |
16 | 为了解决大数据带来的三个问题
17 |
18 | 1. 准确性(好)
19 | 2. 延迟(快)
20 | 3. 吞吐量(多)
21 |
22 |
23 | 例如,传统方式扩展页面查看服务的问题
24 |
25 | 1. 你从传统关系数据库开始。
26 | 2. 然后添加一个发布-订阅队列。
27 | 3. 然后通过水平分区或分片进行扩展。
28 | 4. 故障容错问题开始出现。
29 | 5. 数据损坏发生。
30 |
31 | 关键点是 ==[AKF 规模立方体](https://tianpan.co/notes/41-how-to-scale-a-web-service) 的 X 轴维度单独并不足够。我们还应该引入 Y 轴 / 功能分解。Lambda 架构告诉我们如何为数据系统做到这一点。==
32 |
33 |
34 |
35 | ## 什么是 Lambda 架构?
36 |
37 | 如果我们将数据系统定义为
38 |
39 | ```txt
40 | 查询 = 函数(所有数据)
41 | ```
42 |
43 |
44 | 那么 Lambda 架构是
45 |
46 | 
47 |
48 |
49 | ```txt
50 | 批处理视图 = 函数(批处理作业执行时的所有数据)
51 | 实时视图 = 函数(实时视图,新数据)
52 |
53 | 查询 = 函数(批处理视图,实时视图)
54 | ```
55 |
56 | ==Lambda 架构 = CQRS(批处理层 + 服务层) + 快速层==
57 |
58 |
59 | 
60 |
61 | ```
--------------------------------------------------------------------------------
/zh-CN/84-designing-a-url-shortener.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 84-designing-a-url-shortener
3 | id: 84-designing-a-url-shortener
4 | title: "设计一个网址缩短器"
5 | date: 2018-10-25 14:32
6 | comments: true
7 | tags: [系统设计]
8 | description: 如果你被要求设计一个系统,将用户提供的网址转换为缩短的网址,你会怎么做?你将如何分配缩短的网址?你将如何实现重定向服务器?你将如何存储点击统计数据?
9 | ---
10 |
11 | 设计一个系统,将用户提供的网址转换为缩短的网址,并重定向回原始网址。描述系统的工作原理。你将如何分配缩短的网址?你将如何存储缩短网址与原始网址的映射?你将如何实现重定向服务器?你将如何存储点击统计数据?
12 |
13 | 假设:我通常不会在初始问题陈述中包含这些假设。优秀的候选人会在提出设计时询问规模。
14 |
15 | - 注册重定向网址的独特域名总数大约在数万左右
16 | - 新网址注册量约为 10,000,000/天(100/秒)
17 | - 重定向请求量约为 10B/天(100,000/秒)
18 | - 提醒候选人这些是平均数字 - 在高峰流量时(例如“人们下班回家时”或“超级碗期间”)可能会高得多。
19 | - 最近的统计数据(在当前日期内)应聚合并在 5 分钟延迟后可用
20 | - 长期回顾统计数据可以每天计算
21 |
22 | ## 假设
23 |
24 | 每天 1B 新网址,总共 100B 条目
25 | 越短越好
26 | 显示统计数据(实时和每日/月度/年度)
27 |
28 | ## 编码网址
29 | http://blog.codinghorror.com/url-shortening-hashes-in-practice/
30 |
31 | 选择 1. md5(128 位,16 个十六进制数字,碰撞,生日悖论,2^(n/2) = 2^64)截断?(64 位,8 个十六进制数字,碰撞 2^32),Base64。
32 |
33 | * 优点:哈希简单且水平可扩展。
34 | * 缺点:太长,如何清理过期网址?
35 |
36 | 选择 2. 分布式序列 ID 生成器。(Base62:a~z,A~Z,0~9,62 个字符,62^7),分片:每个节点维护一部分 ID。
37 |
38 | * 优点:易于淘汰过期条目,更短
39 | * 缺点:协调(zookeeper)
40 |
41 | ## KV 存储
42 |
43 | MySQL(10k qps,慢,无关系),KV(100k qps,Redis,Memcached)
44 |
45 | 优秀的候选人会询问别名的生命周期,并设计一个系统来清理过期的别名。
46 |
47 | ## 后续问题
48 | 问:如何生成缩短的网址?
49 |
50 | * 一个差的候选人会提出一个使用单一 ID 生成器的解决方案(单点故障)或一个在每个请求中需要协调 ID 生成器服务器的解决方案。例如,使用自增主键的单一数据库服务器。
51 | * 一个可接受的候选人会提出使用网址的 md5,或某种形式的 UUID 生成器,可以在任何节点独立完成。虽然这允许分布式生成不冲突的 ID,但会产生较大的“缩短”网址。
52 | * 一个优秀的候选人会设计一个解决方案,利用一组 ID 生成器,从中央协调器(例如 ZooKeeper)保留 ID 空间的块,并独立从其块中分配 ID,必要时刷新。
53 |
54 | 问:如何存储映射?
55 |
56 | * 一个差的候选人会建议使用单体数据库。这个存储没有关系方面。它是一个纯粹的键值存储。
57 | * 一个优秀的候选人会建议使用任何轻量级的分布式存储。MongoDB/HBase/Voldemort 等等。
58 | * 一个优秀的候选人会询问别名的生命周期,并设计一个系统来==清理过期的别名==。
59 |
60 | 问:如何实现重定向服务器?
61 |
62 | * 一个差的候选人会从头开始设计某种东西来解决一个已经解决的问题。
63 | * 一个优秀的候选人会建议使用现成的 HTTP 服务器,配备一个插件,解析缩短的网址键,在数据库中查找别名,更新点击统计并返回 303 到原始网址。Apache/Jetty/Netty/tomcat 等等都可以。
64 |
65 | 问:点击统计数据如何存储?
66 |
67 | * 一个差的候选人会建议在每次点击时写回数据存储。
68 | * 一个优秀的候选人会建议某种形式的==聚合层,接受点击流数据,聚合并定期写回持久数据存储==。
69 |
70 | 问:如何对聚合层进行分区?
71 |
72 | * 一个优秀的候选人会建议使用低延迟消息系统来缓冲点击数据并将其传输到聚合层。
73 | * 一个候选人可能会询问统计数据需要多频繁更新。如果是每日更新,将其存储在 HDFS 中并运行 map/reduce 作业来计算统计数据是一个合理的方法。如果是近实时的,聚合逻辑应计算统计数据。
74 |
75 | 问:如何防止访问受限网站?
76 |
77 | * 一个优秀的候选人可以回答通过在 KV 存储中维护一个主机名黑名单。
78 | * 一个优秀的候选人可能会提出一些高级扩展技术,如布隆过滤器。
79 |
--------------------------------------------------------------------------------
/zh-CN/85-improving-availability-with-failover.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 85-improving-availability-with-failover
3 | id: 85-improving-availability-with-failover
4 | title: "通过故障转移提高可用性"
5 | date: 2018-10-26 12:02
6 | comments: true
7 | tags: [系统设计]
8 | description: 为了通过故障转移提高可用性,有几种方法可以实现这一目标,例如冷备份、热备份、温备份、检查点和全活动。
9 | references:
10 | - https://www.ibm.com/developerworks/community/blogs/RohitShetty/entry/high_availability_cold_warm_hot
11 | ---
12 |
13 | 冷备份:使用心跳或指标/警报来跟踪故障。当发生故障时,配置新的备用节点。仅适用于无状态服务。
14 |
15 | 热备份:保持两个活动系统承担相同的角色。数据几乎实时镜像,两个系统将拥有相同的数据。
16 |
17 | 温备份:保持两个活动系统,但第二个系统在故障发生之前不接收流量。
18 |
19 | 检查点(或类似于 Redis 快照):使用预写日志(WAL)在处理之前记录请求。备用节点在故障转移期间从日志中恢复。
20 |
21 | * 缺点
22 | * 对于大型日志来说耗时较长
23 | * 自上次检查点以来丢失数据
24 | * 使用案例:Storm、WhillWheel、Samza
25 |
26 | 主动-主动(或全活动):在负载均衡器后保持两个活动系统。它们并行处理。数据复制是双向的。
--------------------------------------------------------------------------------
/zh-CN/97-designing-a-kv-store-with-external-storage.md:
--------------------------------------------------------------------------------
1 | ---
2 | slug: 97-designing-a-kv-store-with-external-storage
3 | id: 97-designing-a-kv-store-with-external-storage
4 | title: "设计一个带外部存储的 KV 存储"
5 | date: 2018-11-10 12:39
6 | comments: true
7 | tags: [系统设计]
8 | references:
9 | - http://basho.com/wp-content/uploads/2015/05/bitcask-intro.pdf
10 | ---
11 |
12 | ## 需求
13 |
14 | 1. 数据大小:值的数据大小过大,无法保存在内存中,我们应该利用外部存储来存储它们。然而,我们仍然可以将数据键保存在内存中。
15 | 2. 单主机解决方案。没有分布式设计。
16 | 3. 优化写入。
17 |
18 | ## 解决方案
19 | * 内存哈希表索引 + 索引提示文件 + 数据文件
20 | * 仅追加以优化写入。仅有一个活动数据文件用于写入。并将活动数据压缩到旧的数据文件中以供读取。
21 |
22 | ## 组件
23 |
24 | 1. 内存中的 `HashMap>`
25 |
26 | 2. 数据文件布局
27 |
28 | ```txt
29 | |crc|timestamp|key_size|value_size|key|value|
30 | ...
31 | ```
32 |
33 | 3. (索引)提示文件,内存哈希表可以从中恢复
34 |
35 | ## 操作
36 |
37 | 删除:通过内存哈希表获取位置,如果存在,则前往磁盘上的位置将值设置为一个魔法数字。
38 |
39 | 获取:通过内存哈希表获取位置,然后前往磁盘上的位置获取值。
40 |
41 | 放置:追加到活动数据文件并更新内存哈希表。
42 |
43 | 定期压缩策略
44 |
45 | * 复制最新条目:内存哈希表始终是最新的。停止并复制到新文件中。时间复杂度为 O(n),n 是有效条目的数量。
46 | * 优点:对于过期或删除的条目效率高。
47 | * 缺点:如果过期的条目很少,会消耗存储空间。可能会使空间翻倍。(可以通过让一个辅助节点定期进行压缩工作来解决,例如,Hadoop 辅助名称节点)。
48 |
49 | * 扫描并移动:对于每个条目,如果是最新的,移动到已验证部分的尾部。时间复杂度为 O(n),n 是所有条目的数量。
50 | * 优点:
51 | * 缩小大小
52 | * 不需要额外的存储空间
53 | * 缺点:
54 | * 复杂,需要通过事务同步哈希表和存储。可能会影响性能。
55 |
56 | 后续问题
57 |
58 | * 如何检测可以压缩的记录?
59 | * 使用时间戳。
60 | * 如果一个哈希表无法适应单台机器的内存怎么办?
61 | * 一致性哈希,Chord DHT,查询时间复杂度为 O(logn),使用指针表,而不是这里的 O(1) 使用哈希表。
--------------------------------------------------------------------------------
/zh-CN/README.md:
--------------------------------------------------------------------------------
1 | ## 系统设计与构架 - 中文版
2 |
3 |
4 | ### System Design in Practice
5 |
6 | | Product | Question |
7 | | --- | --- |
8 | |  | [Designing Instagram or Pinterest](2016-02-13-crack-the-system-design-interview.md) |
9 | |
| [Designing Instagram or Pinterest](2016-02-13-crack-the-system-design-interview.md) |
9 | |  | [Designing Uber](120-designing-uber.md) | |
10 | |
| [Designing Uber](120-designing-uber.md) | |
10 | |  | [How Facebook Scale its Social Graph Store? TAO](49-facebook-tao.md) |
11 | |
| [How Facebook Scale its Social Graph Store? TAO](49-facebook-tao.md) |
11 | |  | [How Netflix Serves Viewing Data?](45-how-to-design-netflix-view-state-service.md) |
12 | |
| [How Netflix Serves Viewing Data?](45-how-to-design-netflix-view-state-service.md) |
12 | |  | [How to design robust and predictable APIs with idempotency?](43-how-to-design-robust-and-predictable-apis-with-idempotency.md) |
13 | | | [How to stream video over HTTP for mobile devices? HTTP Live Streaming (HLS)](38-how-to-stream-video-over-http.md) |
14 | |
| [How to design robust and predictable APIs with idempotency?](43-how-to-design-robust-and-predictable-apis-with-idempotency.md) |
13 | | | [How to stream video over HTTP for mobile devices? HTTP Live Streaming (HLS)](38-how-to-stream-video-over-http.md) |
14 | |  | [Designing a distributed logging system](61-what-is-apache-kafka.md) |
15 | |
| [Designing a distributed logging system](61-what-is-apache-kafka.md) |
15 | |  | [Designing a URL shortener](84-designing-a-url-shortener.md) |
16 | |
| [Designing a URL shortener](84-designing-a-url-shortener.md) |
16 | |  | [Designing a KV store with external storage](97-designing-a-kv-store-with-external-storage.md) |
17 | |
| [Designing a KV store with external storage](97-designing-a-kv-store-with-external-storage.md) |
17 | |  | [Designing a distributed in-memory KV store or Memcached](174-designing-memcached.md) |
18 | | | [Designing Facebook photo storage](121-designing-facebook-photo-storage.md) |
19 | |
| [Designing a distributed in-memory KV store or Memcached](174-designing-memcached.md) |
18 | | | [Designing Facebook photo storage](121-designing-facebook-photo-storage.md) |
19 | |  | [Designing Stock Exchange](161-designing-stock-exchange.md) |
20 | | | [Designing Smart Notification of Stock Price Changes](162-designing-smart-notification-of-stock-price-changes.md) |
21 | |
| [Designing Stock Exchange](161-designing-stock-exchange.md) |
20 | | | [Designing Smart Notification of Stock Price Changes](162-designing-smart-notification-of-stock-price-changes.md) |
21 | |  | [Designing Square Cash or PayPal Money Transfer System](167-designing-paypal-money-transfer.md) |
22 | | | [Designing payment webhook](166-designing-payment-webhook.md) |
23 | |
| [Designing Square Cash or PayPal Money Transfer System](167-designing-paypal-money-transfer.md) |
22 | | | [Designing payment webhook](166-designing-payment-webhook.md) |
23 | |  | [Designing a metric system](168-designing-a-metric-system.md) |
24 | |
| [Designing a metric system](168-designing-a-metric-system.md) |
24 | |  | [Designing a recommendation system](140-designing-a-recommendation-system.md) |
25 | |
| [Designing a recommendation system](140-designing-a-recommendation-system.md) |
25 | |  | [Designing Airbnb or a hotel booking system](177-designing-Airbnb-or-a-hotel-booking-system.md) |
26 | |
| [Designing Airbnb or a hotel booking system](177-designing-Airbnb-or-a-hotel-booking-system.md) |
26 | |  | [Lyft's Marketing Automation Platform -- Symphony](178-lyft-marketing-automation-symphony.md) |
27 | | | [Designing typeahead search or autocomplete](179-designing-typeahead-search-or-autocomplete.md) |
28 | |
| [Lyft's Marketing Automation Platform -- Symphony](178-lyft-marketing-automation-symphony.md) |
27 | | | [Designing typeahead search or autocomplete](179-designing-typeahead-search-or-autocomplete.md) |
28 | |  | [Designing a Load Balancer or Dropbox Bandaid](182-designing-l7-load-balancer.md) |
29 | | | [Fraud Detection with Semi-supervised Learning](136-fraud-detection-with-semi-supervised-learning.md) |
30 | |
| [Designing a Load Balancer or Dropbox Bandaid](182-designing-l7-load-balancer.md) |
29 | | | [Fraud Detection with Semi-supervised Learning](136-fraud-detection-with-semi-supervised-learning.md) |
30 | |  | [Designing Online Judge or Leetcode](https://tianpan.co/notes/243-designing-online-judge-or-leetcode) |
31 |
32 | ### System Design Theories
33 |
34 | * [Introduction to Architecture](145-introduction-to-architecture.md)
35 | * [How to scale a web service?](41-how-to-scale-a-web-service.md)
36 | * [ACID vs BASE](2018-07-26-acid-vs-base.md)
37 | * [Data Partition and Routing](2018-07-21-data-partition-and-routing.md)
38 | * [Replica, Consistency, and CAP theorem](2018-07-24-replica-and-consistency.md)
39 | * [Load Balancer Types](2018-07-23-load-balancer-types.md)
40 | * [Concurrency Model](181-concurrency-models.md)
41 | * [Improving availability with failover](85-improving-availability-with-failover.md)
42 | * [Bloom Filter](68-bloom-filter.md)
43 | * [Skiplist](69-skiplist.md)
44 | * [B tree vs. B+ tree](2018-07-22-b-tree-vs-b-plus-tree.md)
45 | * [Intro to Relational Database](80-relational-database.md)
46 | * [4 Kinds of No-SQL](78-four-kinds-of-no-sql.md)
47 | * [Key value cache](122-key-value-cache.md)
48 | * [Stream and Batch Processing Frameworks](137-stream-and-batch-processing.md)
49 | * [Cloud Design Patterns](2018-07-10-cloud-design-patterns.md)
50 | * [Public API Choices](66-public-api-choices.md)
51 | * [Lambda Architecture](83-lambda-architecture.md)
52 | * [iOS Architecture Patterns Revisited](123-ios-architecture-patterns-revisited.md)
53 | * [What can we communicate in soft skills interview?](63-soft-skills-interview.md)
54 | * [Experience Deep Dive](2018-07-20-experience-deep-dive.md)
55 | * [3 Programming Paradigms](11-three-programming-paradigms.md)
56 | * [SOLID Design Principles](12-solid-design-principles.md)
57 |
--------------------------------------------------------------------------------
| [Designing Online Judge or Leetcode](https://tianpan.co/notes/243-designing-online-judge-or-leetcode) |
31 |
32 | ### System Design Theories
33 |
34 | * [Introduction to Architecture](145-introduction-to-architecture.md)
35 | * [How to scale a web service?](41-how-to-scale-a-web-service.md)
36 | * [ACID vs BASE](2018-07-26-acid-vs-base.md)
37 | * [Data Partition and Routing](2018-07-21-data-partition-and-routing.md)
38 | * [Replica, Consistency, and CAP theorem](2018-07-24-replica-and-consistency.md)
39 | * [Load Balancer Types](2018-07-23-load-balancer-types.md)
40 | * [Concurrency Model](181-concurrency-models.md)
41 | * [Improving availability with failover](85-improving-availability-with-failover.md)
42 | * [Bloom Filter](68-bloom-filter.md)
43 | * [Skiplist](69-skiplist.md)
44 | * [B tree vs. B+ tree](2018-07-22-b-tree-vs-b-plus-tree.md)
45 | * [Intro to Relational Database](80-relational-database.md)
46 | * [4 Kinds of No-SQL](78-four-kinds-of-no-sql.md)
47 | * [Key value cache](122-key-value-cache.md)
48 | * [Stream and Batch Processing Frameworks](137-stream-and-batch-processing.md)
49 | * [Cloud Design Patterns](2018-07-10-cloud-design-patterns.md)
50 | * [Public API Choices](66-public-api-choices.md)
51 | * [Lambda Architecture](83-lambda-architecture.md)
52 | * [iOS Architecture Patterns Revisited](123-ios-architecture-patterns-revisited.md)
53 | * [What can we communicate in soft skills interview?](63-soft-skills-interview.md)
54 | * [Experience Deep Dive](2018-07-20-experience-deep-dive.md)
55 | * [3 Programming Paradigms](11-three-programming-paradigms.md)
56 | * [SOLID Design Principles](12-solid-design-principles.md)
57 |
--------------------------------------------------------------------------------