├── Journey
├── Day07
│ ├── translation_cache.json
│ ├── translated_samples.json
│ └── Day07.md
├── Day06
│ └── Day06.md
├── Day03
│ ├── __pycache__
│ │ └── packed_dataset.cpython-310.pyc
│ ├── Day03.md
│ └── Day03.ipynb
├── Day10
│ ├── Attachments
│ │ └── Capture-2024-09-16-235351.png
│ └── Day10.md
├── Day11
│ ├── single_model_inference.py
│ ├── multi_model_inference.py
│ ├── generate_dpo_data.py
│ ├── Day11.md
│ ├── service.py
│ └── Day11.ipynb
├── Day08
│ ├── Day08.md
│ └── Day08.ipynb
├── Day13
│ ├── dpo_train.py
│ ├── Day13.md
│ └── Day13.ipynb
├── Day12
│ ├── Day12.md
│ └── Day12.ipynb
├── Day01
│ └── Day01.md
├── Day02
│ └── Day02.md
├── Day_Final
│ └── Day_final.md
├── Day09
│ ├── Day09.md
│ └── Day09.ipynb
├── Day05
│ ├── Day05.md
│ └── Day05.ipynb
└── Day04
│ ├── Day04.md
│ └── Day04.ipynb
├── .gitignore
├── .gitmodules
├── Experiments
└── configs
│ └── microstories
│ ├── config.json
│ ├── sft.yaml
│ └── pretrain.yaml
└── README.md
/Journey/Day07/translation_cache.json:
--------------------------------------------------------------------------------
1 | {}
2 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | **/.DS_Store
2 | **/.ipynb_checkpoints
3 | **/__pycache__
4 |
--------------------------------------------------------------------------------
/Journey/Day06/Day06.md:
--------------------------------------------------------------------------------
1 | # 从零手搓中文大模型|🚀 Day06
2 |
3 | 这几天比较忙,没来得及肝代码,所以梳理了一下之前的内容上传了`github`。
4 |
5 | 详情可以参见[这里](https://github.com/puppyapple/Chinese_LLM_From_Scratch)。
--------------------------------------------------------------------------------
/Journey/Day03/__pycache__/packed_dataset.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/puppyapple/Chinese_LLM_From_Scratch/HEAD/Journey/Day03/__pycache__/packed_dataset.cpython-310.pyc
--------------------------------------------------------------------------------
/Journey/Day10/Attachments/Capture-2024-09-16-235351.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/puppyapple/Chinese_LLM_From_Scratch/HEAD/Journey/Day10/Attachments/Capture-2024-09-16-235351.png
--------------------------------------------------------------------------------
/.gitmodules:
--------------------------------------------------------------------------------
1 | [submodule "References/nano-llama31"]
2 | path = References/nano-llama31
3 | url = https://github.com/karpathy/nano-llama31.git
4 | [submodule "References/baby-llama2-chinese"]
5 | path = References/baby-llama2-chinese
6 | url = https://github.com/DLLXW/baby-llama2-chinese.git
7 | [submodule "Data/TinyStoriesChinese"]
8 | path = Data/TinyStoriesChinese
9 | url = https://huggingface.co/datasets/adam89/TinyStoriesChinese
10 |
--------------------------------------------------------------------------------
/Experiments/configs/microstories/config.json:
--------------------------------------------------------------------------------
1 | {
2 | "architectures": ["LlamaForCausalLM"],
3 | "bos_token_id": 1,
4 | "eos_token_id": 2,
5 | "initializer_range": 0.02,
6 | "aux_loss_alpha": 0.01,
7 | "hidden_act": "silu",
8 | "tie_word_embeddings": true,
9 | "dropout": 0.0,
10 | "flash_attn": true,
11 | "hidden_size": 768,
12 | "intermediate_size": 2048,
13 | "model_type": "llama",
14 | "multiple_of": 512,
15 | "num_attention_heads": 16,
16 | "num_key_value_heads": 4,
17 | "num_hidden_layers": 16,
18 | "max_position_embeddings": 512,
19 | "n_routed_experts": 4,
20 | "n_shared_experts": true,
21 | "rms_norm_eps": 1e-5,
22 | "norm_topk_prob": true,
23 | "num_experts_per_tok": 2,
24 | "scoring_func": "softmax",
25 | "seq_aux": true,
26 | "torch_dtype": "float32",
27 | "transformers_version": "4.44.0",
28 | "use_moe": false,
29 | "vocab_size": 6400
30 | }
31 |
--------------------------------------------------------------------------------
/Journey/Day11/single_model_inference.py:
--------------------------------------------------------------------------------
1 | import json
2 | import hashlib
3 | from litgpt import LLM
4 | from tqdm import tqdm
5 | from litgpt.prompts import MicroStories
6 |
7 |
8 | def hash_prompt(prompt):
9 | return hashlib.md5(prompt.encode()).hexdigest()
10 |
11 |
12 | ms = MicroStories()
13 | llm = LLM.load(model="../../Experiments/Output/sft/microstories/mask_prompt_5e-4/final")
14 |
15 | sft_data = json.load(
16 | open("../../Data/TinyStoriesInstruct/sft_data_v2.json", "r", encoding="utf-8")
17 | )
18 |
19 | try:
20 | with open("dpo_cache.json", "r", encoding="utf-8") as f:
21 | cache = json.load(f)
22 | except FileNotFoundError:
23 | cache = {}
24 |
25 | try:
26 | for case in tqdm(sft_data):
27 | prompt = ms.apply(prompt=case["instruction"], input=case["input"])
28 | hash_key = hash_prompt(prompt)
29 | if hash_key in cache:
30 | continue
31 | else:
32 | generated = llm.generate(prompt=prompt, max_new_tokens=350)
33 | dpo_sample = {
34 | "prompt": prompt,
35 | "rejected": generated,
36 | "chosen": case["output"],
37 | }
38 | cache[hash_key] = dpo_sample
39 |
40 | except Exception as e:
41 | print(repr(e))
42 | with open("dpo_cache.json", "w", encoding="utf-8") as f:
43 | json.dump(cache, f, ensure_ascii=False)
44 |
--------------------------------------------------------------------------------
/Journey/Day07/translated_samples.json:
--------------------------------------------------------------------------------
1 | {
2 | "-3480331710719636664": "特点:对话 \n摘要:蒂米和妈妈一起去商店,对商店里所有的玩具和糖果感到惊讶。他请求触摸一个玩具,妈妈允许他,这让他非常开心。 \n词汇:触摸、商店、宽敞 \n故事:很久以前,有一个小男孩名叫蒂米。蒂米喜欢在外面玩耍和探索。 \n一天,蒂米和妈妈一起去商店。商店非常大,宽敞。蒂米对他看到的玩具和糖果真是太多了,感到惊讶。 \n突然,蒂米看到一个他非常想触摸的玩具。“妈妈,我可以触摸那个玩具吗?”他问。 \n“当然可以啊,蒂米,”妈妈说。蒂米非常开心,他轻轻摸了摸玩具。摸起来软软的,特别有弹性。 \n离开商店后,蒂米对妈妈说他有多喜欢和她一起逛商店。“我玩得可开心了,摸玩具真有意思,”他说。妈妈微笑着把他抱住了。",
3 | "-845848373090745693": "特征:对话 \n单词:靠近,彩虹,不高兴 \n故事:从前有个小女孩,叫莉莉。一天,莉莉在天空中看到了美丽的彩虹。她非常高兴,想把它展示给她的朋友蒂米。 \n莉莉去了蒂米的家,敲了敲门。蒂米开门问:“怎么了,莉莉?你看起来不高兴。” \n莉莉回答:“我没有不高兴!快看外面,有一条漂亮的彩虹!” \n蒂米看向窗外,说:“哇,太棒了!我们去外面,试着靠近一点。” \n于是,莉莉和蒂米走到外面,朝彩虹跑去。他们无法靠近到可以触摸它,但能看到它就已经很开心了。他们在雨中跳舞、欢笑,直到该回家了。从那天起,每当莉莉和蒂米看到天空中的彩虹时,他们都会特别兴奋,虽然他们试着靠近,但其实只要能看到就已经很开心了。 \n总结:莉莉和蒂米每次看到彩虹时都会特别兴奋,虽然他们试着靠近,但其实只要能看到就已经很开心了。",
4 | "1082711273807971183": "摘要:莉莉不喜欢妈妈的辣番茄汤,决定把它卖给邻居史密斯太太,她喜欢吃辣。她成功地把汤卖给了邻居,邻居非常开心。 \n特点:冲突 \n词汇:卖,汤,平静 \n故事:从前,有一个小女孩叫莉莉。她喜欢吃汤,尤其是番茄汤。一天,她的妈妈给她做了一碗汤当午餐。但是当莉莉尝了一口时,她不喜欢。她觉得这汤太辣了。她哭着说:“我不想要这个汤。太热了。” \n她妈妈试图让她平静下来,说:“别担心,莉莉。我明天会给你做另一种汤。”但莉莉不想等。她现在就想喝汤。于是,她有了一个主意。她决定把汤卖给邻居史密斯太太,她喜欢吃辣。 \n莉莉去了史密斯太太的家,说:“你想买我的汤吗?它很辣,但很好。”史密斯太太尝了一口汤,立刻喜欢上了。她给了莉莉一些钱,说:“谢谢你,莉莉。这汤真好吃!”莉莉很高兴能卖掉汤,还让别人开心。她回到家,告诉妈妈这一切。妈妈为她感到骄傲地说:“你真聪明,莉莉。”他们幸福地生活在一起,过着快乐的生活。",
5 | "-1358704974736508821": "词汇:开车,野餐,差 \n总结:莉莉和家人一起去野餐,了解到找到一个好地方和在不对劲的时候要敢于表达自己的重要性。 \n特点:对话,道德价值 \n故事:从前有个小女孩,叫莉莉。她想和家人一起去野餐。她问妈妈:“我们今天可以去野餐吗?”妈妈说:“可以,今天我们就去野餐吧。” \n他们打包了食物,开车去了公园。当他们到达时,发现了一个不太好的地方。莉莉说:“这个地方不太好。我们找一个更好的地方。”他们四处寻找,找到了一个大树下的好地方。 \n莉莉了解到,找到一个好的野餐地点很重要。她还学会了在不对劲时发声是好的。他们在野餐时玩得很开心,开车回家的路上,心里满是快乐的回忆。"
6 | }
7 |
--------------------------------------------------------------------------------
/Journey/Day11/multi_model_inference.py:
--------------------------------------------------------------------------------
1 | import json
2 | import multiprocessing
3 | from functools import partial
4 | from litgpt import LLM
5 | from litgpt.prompts import MicroStories
6 | import click
7 | import torch
8 |
9 | # 设置多进程启动方法为'spawn'
10 | multiprocessing.set_start_method("spawn", force=True)
11 |
12 |
13 | def init_model():
14 | model = LLM.load(
15 | model="../../Experiments/Output/sft/microstories/mask_prompt_5e-4/final"
16 | )
17 | return model
18 |
19 |
20 | def process_chunk(model, chunk):
21 | ms = MicroStories()
22 | results = []
23 | for case in chunk:
24 | prompt = ms.apply(prompt=case["instruction"], input=case["input"])
25 | with torch.no_grad():
26 | response = model.generate(prompt=prompt, max_new_tokens=350)
27 | results.append(
28 | {"prompt": prompt, "rejected": response, "chosen": case["output"]}
29 | )
30 | return results
31 |
32 |
33 | @click.command()
34 | @click.option("-n", "--num_processes", default=4, help="并发进程数")
35 | @click.option("--test", is_flag=True, help="测试模式,只处理前100条数据")
36 | def main(num_processes, test):
37 | # 加载SFT数据
38 | with open(
39 | "../../Data/TinyStoriesInstruct/sft_data_v2.json", "r", encoding="utf-8"
40 | ) as f:
41 | sft_data = json.load(f)
42 |
43 | if test:
44 | sft_data = sft_data[:100]
45 |
46 | # 确定进程数量
47 | n_processes = min(multiprocessing.cpu_count(), num_processes)
48 |
49 | # 初始化模型
50 | model = init_model()
51 |
52 | # 使用partial创建一个新的函数,将model作为第一个参数
53 | process_chunk_with_model = partial(process_chunk, model)
54 |
55 | # 将数据分成n_processes份
56 | chunk_size = len(sft_data) // n_processes
57 | chunks = [sft_data[i : i + chunk_size] for i in range(0, len(sft_data), chunk_size)]
58 |
59 | # 使用进程池并行处理数据
60 | with multiprocessing.Pool(n_processes) as pool:
61 | results = pool.map(process_chunk_with_model, chunks)
62 |
63 | # 合并结果
64 | dpo_samples = [item for sublist in results for item in sublist]
65 |
66 | # 保存结果
67 | output_file = "dpo_samples_test.json" if test else "dpo_samples.json"
68 | with open(output_file, "w", encoding="utf-8") as f:
69 | json.dump(dpo_samples, f, ensure_ascii=False, indent=2)
70 |
71 | print(f"处理完成,结果已保存到 {output_file}")
72 |
73 |
74 | if __name__ == "__main__":
75 | main()
76 |
--------------------------------------------------------------------------------
/Journey/Day08/Day08.md:
--------------------------------------------------------------------------------
1 | # 从零手搓中文大模型|🚀 Day08
2 |
3 | 上一期介绍了`SFT`的数据准备流程,但是在正式开启`SFT`之前,我打算熟悉了解一些`SFT`的知识点。
4 |
5 | 以下大多数都是来自[互联网上资料](https://zhuanlan.zhihu.com/p/682604566)的收集整理,给自己留个记录,便于复习和回顾。
6 |
7 | 所以这期的内容算是一个**笔记**,也希望能够帮助到有需要的朋友。
8 |
9 | > 另外最近也确实比较忙,这篇总结分享也算是给自己一个缓冲来继续后面的实践。
10 |
11 |
12 | ## 什么是SFT?
13 |
14 | `SFT`是`Supervised Fine-Tuning`的缩写,中文翻译为**有监督微调**。
15 |
16 | 指的是在已经预训练好的模型基础上,使用**有标签的数据**进行微调,以适应特定的任务。
17 |
18 | 在预训练模型中,由于数据量和场景的限制,模型可能无法很好地处理某些特定任务。
19 |
20 | 通过有监督微调,我们可以使模型更好地适应特定场景,提高模型在特定任务上的性能。
21 |
22 | 在大模型领域,我们提到`SFT`,通常指的是它一种特殊形式,即`Instruction Tuning`。
23 |
24 | 接下来的内容都是基于`Instruction Tuning`来展开。
25 |
26 | ## 训练方式
27 |
28 | 在进行指令微调的时候,会将`Instruction`(指令) 以及对应的`Response`(回答)拼接成文本(具体有很多`prompt style`可以参考),然后依然以预训练时的**自回归**方式进行训练。
29 |
30 | 但和预训练不同的是,在`loss`计算的时候只考虑`Response`部分,而不考虑`Instruction`部分(通过`ignore_index`来隐去)。
31 |
32 | ## 训练数据
33 |
34 | `Meta`在论文[LIMA: Less Is More for Alignment](https://arxiv.org/abs/2305.11206)中详细地论述了一个结论:数据集的质量对微调的重要性远大于数据集的数量(即便1万的高质量数据集也能取得很好的效果,胜过10万低质量数据集)。
35 |
36 | 因此我们应该花更多的时间去提升样本质量,而不是追求样本的数量。
37 |
38 | 在大规模的`SFT`上(区别于我这个故事生成的`toy model`),各类指令数据的配比是一个非常重要的参数,但很可惜,各大家开放的报告里对这部分内容的细节描述非常少。
39 |
40 | 找到一篇关于[SFT数据集的配比的调研](https://zhuanlan.zhihu.com/p/703825827),里面搜集整理了一些干货,感兴趣的朋友可以移步去看看。
41 |
42 |
43 |
44 | ## 微调技巧
45 |
46 | ### 训练模式
47 |
48 | 1. base model + domain SFT
49 | 2. base model + domain continue pre-train + domain SFT
50 | 3. base model + common SFT + domain SFT
51 |
52 | 上述的`base model`也都可以换成`chat model`。
53 |
54 | 除了主流的这几种模式,其实还可以有其他的组合方式,例如将`SFT`数据混合到`pretrain`中等等,这里就不穷举了,我自己也没有太多的经验,所以大家按照自己的实际情况调研测试是最好的。
55 |
56 | #### `base model` vs `chat model`
57 | - `base model`质量够好的时候,在base模型基础进行领域数据的SFT与在chat模型上进行SFT,效果上差异不大
58 | - `chat model`接`SFT`时候出现灾难性遗忘的概率比较大
59 | - 如果既追求领域任务的性能,又希望尽量保留通用能力,则可以考虑`base model`
60 | - 如果只追求领域任务的性能,则可以考虑`chat model`
61 |
62 | #### 是否`continue pre-train`
63 | - 如果领域任务数据集和通用数据集差异较大,则务必`continue pre-train`
64 | - 领域任务数据集较大且不在意通用能力而只关注领域任务,则也建议进行`continue pre-train`
65 | - 其他情况可以考虑不进行`continue pre-train`
66 |
67 | ### 关于炼丹
68 |
69 | 1. `SFT`数据集的量级如果不是特别大,建议选择较小学习率,一般设置为`pre-train`阶段学习率的10%左右。
70 |
71 | 例如在`pre-train`阶段的学习率为`1e-5`,则`SFT`阶段的学习率设置为`1e-6`。
72 |
73 | 2. `SFT`阶段建议使用比`pre-train`阶段更小的`warmup steps`,这是因为`SFT`阶段的数据量级远小于`pre-train`阶段,较小的`warmup steps`有助于模型更好地收敛。
74 | 3. `Epoch`数量的设置和`SFT`数据的量级成反比,`SFT`数据量级越大,可以将`Epoch`数量设置越小。
75 |
76 |
77 | ## 说明
78 |
79 | 以上内容是我花了半天的时间简单整理的内容,可能会有不准确的地方,欢迎大家指正。
80 |
81 | `SFT`的细节内容还有很多,例如`SFT`的`loss`计算方式等,这些展开来讲内容会非常多,所以这里就不再赘述了。
82 |
83 | 在后面的实践过程中我再根据自己遇到的问题来补充分享给大家吧。
84 |
85 |
86 |
87 |
--------------------------------------------------------------------------------
/Journey/Day13/dpo_train.py:
--------------------------------------------------------------------------------
1 | import os
2 | import click
3 |
4 | os.environ["CUDA_VISIBLE_DEVICES"] = "0"
5 |
6 | import torch
7 | from peft import get_peft_model, LoraConfig, TaskType
8 | from transformers import TrainingArguments, AutoModelForCausalLM, AutoTokenizer
9 | from trl import DPOTrainer
10 | from trl import DPOConfig
11 | from datasets import load_dataset
12 | from litgpt.utils import num_parameters
13 |
14 |
15 | def find_all_linear_names(model):
16 | cls = torch.nn.Linear
17 | lora_module_names = set()
18 | for name, module in model.named_modules():
19 | if isinstance(module, cls):
20 | names = name.split(".")
21 | lora_module_names.add(names[0] if len(names) == 1 else names[-1])
22 |
23 | if "lm_head" in lora_module_names:
24 | lora_module_names.remove("lm_head")
25 | return list(lora_module_names)
26 |
27 |
28 | def init_model(model_name_or_path, device="cuda:0"):
29 | model = AutoModelForCausalLM.from_pretrained(
30 | model_name_or_path,
31 | # local_files_only=True,
32 | # state_dict=torch.load(f"{model_name_or_path}/pytorch_model.bin"),
33 | )
34 | tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
35 | tokenizer.pad_token = tokenizer.eos_token
36 | print(f"Total parameters: {num_parameters(model):,}")
37 | model = model.to(device)
38 | return model, tokenizer
39 |
40 |
41 | @click.command()
42 | @click.option("--model_name_or_path", type=str)
43 | def main(model_name_or_path):
44 | model, tokenizer = init_model(model_name_or_path)
45 | dpo_config = DPOConfig(
46 | output_dir="../../Experiments/Output/dpo/microstories_lora_v2",
47 | per_device_train_batch_size=16,
48 | remove_unused_columns=False,
49 | num_train_epochs=2,
50 | learning_rate=1e-5,
51 | do_eval=True,
52 | eval_strategy="steps",
53 | eval_steps=200,
54 | save_steps=200,
55 | logging_steps=10,
56 | )
57 |
58 | data_files = {
59 | "train": "../../Data/TinyStoriesInstruct/dpo_data_train.json",
60 | "eval": "../../Data/TinyStoriesInstruct/dpo_data_eval.json",
61 | }
62 | dataset_dpo = load_dataset("json", data_files=data_files)
63 |
64 | dpo_trainer = DPOTrainer(
65 | model,
66 | ref_model=None,
67 | args=dpo_config,
68 | beta=0.1,
69 | train_dataset=dataset_dpo["train"],
70 | eval_dataset=dataset_dpo["eval"],
71 | tokenizer=tokenizer,
72 | max_length=512,
73 | max_prompt_length=512,
74 | )
75 | dpo_trainer.train()
76 |
77 |
78 | if __name__ == "__main__":
79 | main()
80 |
--------------------------------------------------------------------------------
/Journey/Day12/Day12.md:
--------------------------------------------------------------------------------
1 | 之前说准备好`DPO`数据就着手开始自己`DIY`一下训练的实现了(因为`litgpt`库暂时还没有集成相关实现)。
2 | 虽说是`DIY`但是纯从零手撸的成本还是有点高的,因此还是打算参考已有的实现来弄,比如:
3 | - [eric-mitchell/direct-preference-optimization: Reference implementation for DPO (Direct Preference Optimization)](https://github.com/eric-mitchell/direct-preference-optimization)
4 | - [huggingface的trl库里的实现](https://github.com/huggingface/trl/blob/main/trl/trainer/dpo_trainer.py)
5 |
6 | `transformers`库毕竟是大主流,因此还是优先考虑基于`transformers`库的`API`来实现。
7 |
8 | 那么面临的第一个问题就是需要将`litgpt`框架训练的模型转换为`huggingface`库的模型格式。
9 |
10 | 而在这个过程中我遇到了一个**意想不到的坑**,直接给我整**破防**了。
11 |
12 | 大家听我慢慢道来。
13 |
14 |
15 |
16 | ## litgpt模型转换到huggingface format
17 | `litgpt`框架本身考虑得很周全,它从简化模型实现的角度完全基于`torch`实现的[model.py](https://github.com/Lightning-AI/litgpt/blob/main/litgpt/model.py)
18 |
19 | 同时也提供了将`checkpoint`转换为`huggingface`模型格式的`API`:
20 |
21 |
22 | ```python
23 | # ! litgpt convert_from_litgpt input_checkpoint_dir output_dir
24 | ```
25 |
26 | 这里会得到一个`model.pth`文件,为了后续加载方便,大家可以直接改名为`pytorch_model.bin`。
27 |
28 | 另外需要注意的是`transformers`库依赖`config.json`文件,如果大家的模型架构选择的是使用`litgpt`框架已经支持的`huggingface`上的模型,那么可以直接去下载;但如果是自己定义的模型架构,那么就需要大家自己动手来写这个`config.json`文件了。
29 |
30 | > 后面我会写一个简单的脚本,基于`litgpt`框架的`config.yaml`文件来生成`config.json`文件,可能在一些场景下能具备通用性。
31 |
32 |
33 | ## transformers库模型加载
34 |
35 | 模型的转换还是比较简单且顺利的,但是按照[litgpt的convert文档](https://github.com/Lightning-AI/litgpt/blob/main/tutorials/convert_lit_models.md),通过`transformers`库加载转换后的模型文件的时候,问题来了。
36 |
37 | 我的到了一个意想不到的报错,追溯到的是`transformers`库里对模型参数尺寸检查的这段代码:
38 |
39 | 
40 |
41 | **它强制要求了`embedding`的向量尺寸必须正好等于注意力头数`n_heads`和注意力头尺寸`head_size`的乘积**。
42 |
43 | 原因是他们不知出于什么考虑,在对`attention`的`kqv`转换矩阵实现的时候,做了一个简化,大家看下图里我用红框标出的地方。
44 |
45 | 
46 |
47 |
48 | 如果不理解的话,再对比看下面这张图应当就能理解了,是`Karpathy`大神的`nanoGPT`里同样模块的实现。
49 |
50 | 
51 |
52 | 但凡看过原始论文里的公式推导就会知道,`hidden_size = n_heads * head_size`这个要求是**完全没有必要**的。
53 |
54 | `W_k/W_q/W_v`矩阵理论上可以将`hidden_size`投影到任何维度上去,只要最后再通过`W_o`的线性层映射回`hidden_size`即可。
55 |
56 | 而`transformers`库的实现里将这个任何维度简化为了`n_heads * head_size`,这对我这种需要从自定义的模型架构转换过来的场景造成了**毁灭性打击**🤦♂️。
57 |
58 | 因为我当时**拍脑袋**定的`0.044b`参数模型里,`embedding`维度选的`768`,`n_heads`是`6`,而`head_size`定了个`48`,导致这里没有办法加载了。
59 |
60 | 我当然可以通过改源码的方式来弥补这个问题,但是如果我希望我的模型能够被更多使用`transformers`库的人使用,这个方式就不合适了。
61 |
62 | 最保险的方式是按照它这个**不合理的**要求来调整我的模型架构,从而得到一个满足`hidden_size = n_heads * head_size`的模型。
63 |
64 | ## 教训总结
65 |
66 |
67 | 没办法,我最终选择了重新预训练我的故事模型;坑虽然踩了,但是也得到了一些收获。
68 |
69 | 大部分人一般情况下主要是基于`huggingface`上已有的模型架构来训练,我这类**自定义模型架构**的情况相对少见,因此踩坑踩得有点狠。
70 |
71 | 即便是`transformers`库这样的大主流,也难免会有一些设计不合理的地方。
72 |
73 | 也提醒我,对开源库的使用,如果时间精力允许,还是要**多花点功夫看看源码**,理解其背后的设计思想,这样在遇到问题的时候才能从更本质的地方找到解决方案。
74 |
75 |
76 | > 一个更让我欲哭无泪的事实:
77 | >
78 | > 就在我的新架构模型快完成预训练的时候,
79 | > 我发现这个不合理的逻辑其实在[这个PR](https://github.com/huggingface/transformers/pull/32857)里得到了修复。
80 | >
81 | > 在`transformers`库的最新版本里已经没有这个问题了。
82 | >
83 | > 合着是我更新库不够积极呗?🤷♂️
84 |
85 |
86 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 从零手搓中文大模型计划
2 |
3 | ## 项目简介
4 |
5 | 心血来潮想要走一遍大模型训练的流程,于是有了这个项目。
6 |
7 | 由于我自己只有一张`3090`,也不好用单位的显卡,所以训练只能选很小的模型。
8 |
9 | 其实我自己对`SLM`是很感兴趣的,感觉现在也有越来越多地研究开始关注**小尺寸大模型的性能**以及**如何把大模型做小**。
10 |
11 | 如果是希望学习大规模并行训练相关的内容(例如`DeepSpeed`,`Megatron`),这个项目可能不太适合你。
12 |
13 | 另外个人经历和精力有限,所以可能很多地方做的不是很好,请大家多多包涵。也欢迎大家提出意见和建议。
14 |
15 | 最后给自己的自媒体号打个广告,欢迎大家关注一波~(**公众号/B站/小红书/抖音:喵懂AI**)
16 |
17 | 
18 |
19 | ## 最近更新
20 |
21 | 2024-09-25
22 | 上传了Day12 - Day13的内容:
23 |
24 | - `Day12`: `litgpt`模型转换到`huggingface`格式
25 | - `Day13`: `DPO`训练
26 |
27 |
28 |
29 | 2024-09-20
30 | 上传了Day10 - Day11的内容:
31 |
32 | - `Day10`: 中秋特刊,自己关于大模型的一些思考
33 | - `Day11`: `DPO`数据构建
34 |
35 |
36 |
37 | 2024-09-12
38 | 上传了Day07 - Day09的内容:
39 |
40 | - `Day07`: `SFT`数据构建
41 | - `Day08`: `SFT`训练相关知识点调研
42 | - `Day09`: `SFT`训练及效果测试
43 |
44 |
45 |
46 | 2024-09-02
47 | 上传了Day01 - Day05的内容:
48 |
49 | - `Day01`: 项目调研
50 | - `Day02`: `Tokenizer`分词
51 | - `Day03`: 数据预处理
52 | - `Day04`: 模型搭建和预训练启动
53 | - `Day05`: 预训练效果测试
54 |
55 |
56 | ## 计划执行
57 | 在一个垂直领域的小数据集上完成:
58 | - [x] 一个小尺寸模型的预训练(能在单卡上跑)
59 | - [x] 在上面的基础上完成指令微调
60 | - [x] 在上面的基础上完成`DPO`
61 | - [ ] 其他待定
62 |
63 | **Journey**文件夹下有每次任务的详细记录。
64 | 下载相应的文件(`chatglm`的`tokenizer`,`TinyStoriesChinese`的数据集)之后,可以跟着`Journey`中的步骤一步步来。
65 | 理论上可以复现已经放出的结果(`GPU`如果比我还小的,需要自己调整下`batch_size`)。
66 |
67 | ## 训练信息
68 | 机器配置:
69 | ```bash
70 | OS: Ubuntu 22.04.3 LTS x86_64
71 | Kernel: 6.5.0-35-generic
72 | Uptime: 60 days, 4 hours, 55 mins
73 | Packages: 2719 (dpkg), 17 (snap)
74 | Shell: fish 3.6.1
75 | Terminal: WezTerm
76 | CPU: AMD Ryzen 9 5950X (32) @ 3.400G
77 | GPU: NVIDIA 09:00.0 NVIDIA Corporati
78 | Memory: 9347MiB / 64195MiB
79 | ```
80 | ### 预训练
81 | 详细参数请参考 [pretrain.yaml](./Experiments/configs/microstories/pretrain.yaml)。
82 | 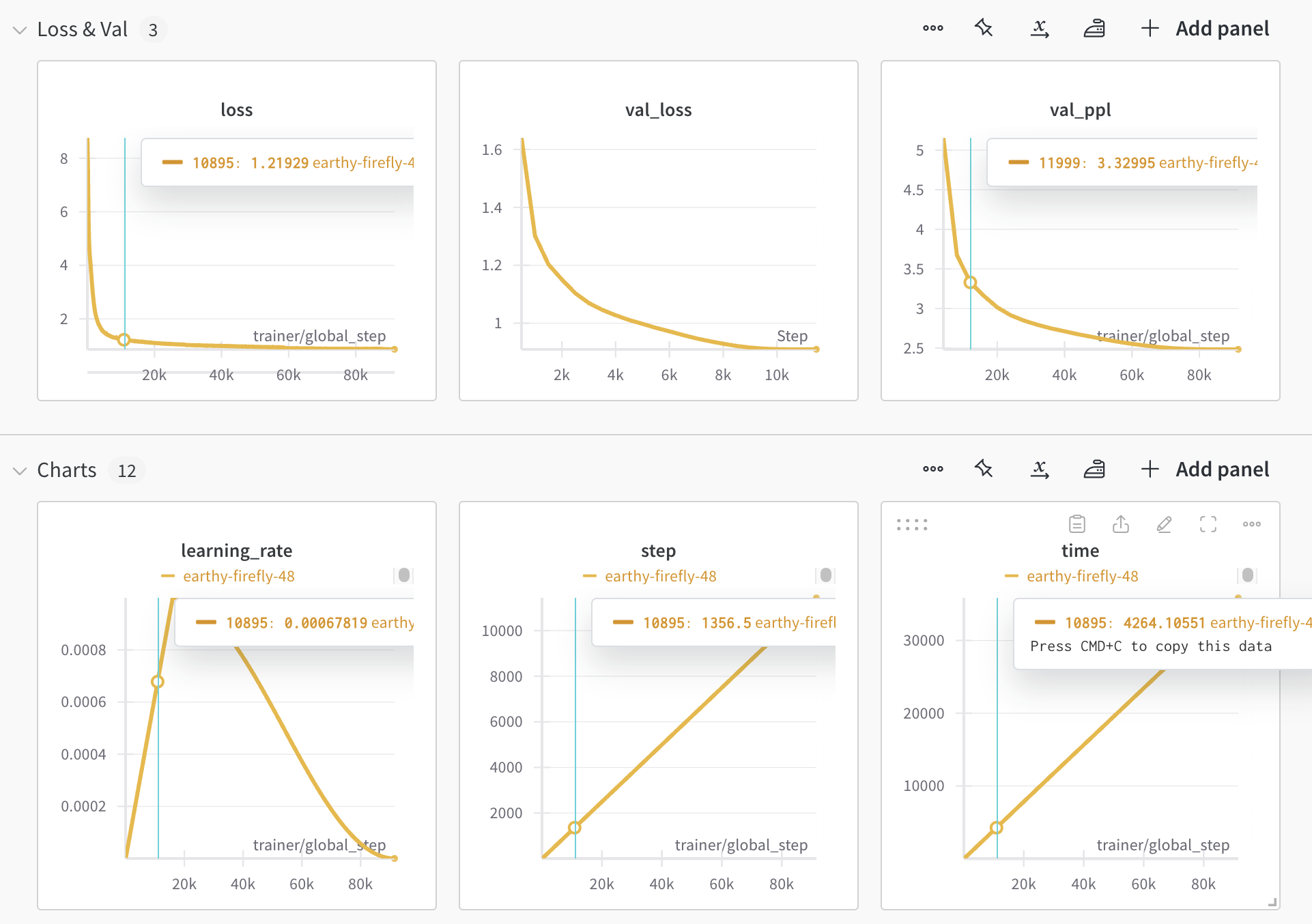
83 |
84 | ### 指令微调
85 | 详细参数请参考 [sft.yaml](./Experiments/configs/microstories/sft.yaml)。
86 | 
87 |
88 | ### DPO
89 | 训练脚本参考[dpo_train.py](./Journey/Day13/dpo_train.py)
90 | 
91 |
92 |
93 | ## 目录结构
94 |
95 | ```
96 | Chinese_LLM_From_Scratch
97 | ├── Data
98 | │ └── TinyStoriesChinese
99 | │ ├── processed_data
100 | │ └── raw_data
101 | ├── Experiments
102 | │ ├── configs
103 | │ │ ├── debug.yaml
104 | │ │ ├── microstories.yaml
105 | │ │ └── ...
106 | │ └── Output
107 | │ └── pretrain
108 | │ ├── debug
109 | │ └── microstories
110 | ├── References
111 | │ ├── chatglm3-6b
112 | │ └── ...
113 | ├── Journey
114 | │ ├── Day01
115 | │ ├── Day02
116 | │ ├── Day03
117 | │ ├── Day04
118 | │ └── ...
119 | ```
120 |
--------------------------------------------------------------------------------
/Journey/Day08/Day08.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 从零手搓中文大模型|🚀 Day08"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "上一期介绍了`SFT`的数据准备流程,但是在正式开启`SFT`之前,我打算熟悉了解一些`SFT`的细节。\n",
15 | "\n",
16 | "大多数都是来自[互联网上资料](https://zhuanlan.zhihu.com/p/682604566)的收集整理,算是给自己留个记录,便于复习和回顾。\n",
17 | "\n",
18 | "也希望能够帮助到有需要的人。\n"
19 | ]
20 | },
21 | {
22 | "cell_type": "markdown",
23 | "metadata": {},
24 | "source": [
25 | "## 什么是SFT?\n",
26 | "\n",
27 | "`SFT`是`Supervised Fine-Tuning`的缩写,中文翻译为`有监督微调`。\n",
28 | "\n",
29 | "指的是在已经预训练好的模型基础上,使用有标签的数据进行微调,以适应特定的任务。\n",
30 | "\n",
31 | "在预训练模型中,由于数据量和场景的限制,模型可能无法很好地处理某些特定任务。\n",
32 | "\n",
33 | "通过有监督微调,我们可以使模型更好地适应特定场景,提高模型在特定任务上的性能。\n",
34 | "\n",
35 | "在大模型领域,我们提到`SFT`,通常指的是它一种特殊形式,即`Instruction Tuning`。\n",
36 | "\n",
37 | "接下来的内容都是基于`Instruction Tuning`来展开。"
38 | ]
39 | },
40 | {
41 | "cell_type": "markdown",
42 | "metadata": {},
43 | "source": [
44 | "## 训练方式\n",
45 | "\n",
46 | "在进行指令微调的时候,会将`Instruction`(指令) 以及对应的`Response`(回答)拼接成文本(具体有很多`prompt style`可以参考),然后依然以预训练时的**自回归**方式进行训练。\n",
47 | "\n",
48 | "但和预训练不同的是,在`loss`计算的时候只考虑`Response`部分,而不考虑`Instruction`部分(通过`ignore_index`来隐去)。"
49 | ]
50 | },
51 | {
52 | "cell_type": "markdown",
53 | "metadata": {},
54 | "source": [
55 | "## 训练数据\n",
56 | "\n",
57 | "`Meta`在论文[LIMA: Less Is More for Alignment](https://arxiv.org/abs/2305.11206)中详细地论述了一个结论:数据集的质量对微调的重要性远大于数据集的数量(即便1万的高质量数据集也能取得很好的效果,胜过10万低质量数据集)。\n",
58 | "\n",
59 | "因此我们应该花更多的时间去提升样本质量,而不是追求样本的数量。"
60 | ]
61 | },
62 | {
63 | "cell_type": "markdown",
64 | "metadata": {},
65 | "source": [
66 | "## 微调技巧"
67 | ]
68 | },
69 | {
70 | "cell_type": "markdown",
71 | "metadata": {},
72 | "source": [
73 | "### 训练模式\n",
74 | "\n",
75 | "1. base model + domain SFT\n",
76 | "2. base model + domain continue pre-train + domain SFT\n",
77 | "3. base model + common SFT + domain SFT\n",
78 | " \n",
79 | "上述的`base model`也都可以换成`chat model`。\n",
80 | "\n",
81 | "#### `base model` vs `chat model`\n",
82 | "- `base model`质量够好的时候,在base模型基础进行领域数据的SFT与在chat模型上进行SFT,效果上差异不大\n",
83 | "- `chat model`接`SFT`时候出现灾难性遗忘的概率比较大\n",
84 | "- 如果既追求领域任务的性能,又希望尽量保留通用能力,则可以考虑`base model`\n",
85 | "- 如果只追求领域任务的性能,则可以考虑`chat model`\n",
86 | "\n",
87 | "#### 是否`continue pre-train`\n",
88 | "- 如果领域任务数据集和通用数据集差异较大,则务必`continue pre-train`\n",
89 | "- 领域任务数据集较大且不在意通用能力而只关注领域任务,则也建议进行`continue pre-train`\n",
90 | "- 其他情况可以考虑不进行`continue pre-train`\n",
91 | "\n",
92 | "### 关于炼丹\n",
93 | "\n",
94 | "1. `SFT`数据集的量级如果不是特别大,建议选择较小学习率,一般设置为`pre-train`阶段学习率的10%左右。\n",
95 | " \n",
96 | " 例如在`pre-train`阶段的学习率为`1e-5`,则`SFT`阶段的学习率设置为`1e-6`。\n",
97 | "\n",
98 | "2. `SFT`阶段建议使用比`pre-train`阶段更小的`warmup steps`,这是因为`SFT`阶段的数据量级远小于`pre-train`阶段,较小的`warmup steps`有助于模型更好地收敛。\n",
99 | "3. `Epoch`数量的设置和`SFT`数据的量级成反比,`SFT`数据量级越大,可以将`Epoch`数量设置越小。"
100 | ]
101 | }
102 | ],
103 | "metadata": {
104 | "kernelspec": {
105 | "display_name": "bigmodel",
106 | "language": "python",
107 | "name": "python3"
108 | },
109 | "language_info": {
110 | "name": "python",
111 | "version": "3.10.10"
112 | }
113 | },
114 | "nbformat": 4,
115 | "nbformat_minor": 2
116 | }
117 |
--------------------------------------------------------------------------------
/Experiments/configs/microstories/sft.yaml:
--------------------------------------------------------------------------------
1 |
2 | # The path to the base model's checkpoint directory to load for finetuning. (type: , default: checkpoints/stabilityai/stablelm-base-alpha-3b)
3 | checkpoint_dir: Chinese_LLM_From_Scratch/Experiments/Output/pretrain/microstories/latest
4 |
5 | # Directory in which to save checkpoints and logs. (type: , default: out/lora)
6 | out_dir: Chinese_LLM_From_Scratch/Experiments/Output/sft/microstories/mask_prompt_5e-4
7 |
8 | # The precision to use for finetuning. Possible choices: "bf16-true", "bf16-mixed", "32-true". (type: Optional[str], default: null)
9 | precision: bf16-true
10 |
11 | # How many devices/GPUs to use. (type: Union[int, str], default: 1)
12 | devices: 1
13 |
14 | # How many nodes to use. (type: int, default: 1)
15 | num_nodes: 1
16 |
17 | # Data-related arguments. If not provided, the default is ``litgpt.data.Alpaca``.
18 | data:
19 | class_path: litgpt.data.JSON
20 | init_args:
21 | json_path: Chinese_LLM_From_Scratch/Data/TinyStoriesInstruct/sft_data.json
22 | mask_prompt: true
23 | val_split_fraction: 0.01
24 | prompt_style: microstories
25 | ignore_index: -100
26 | seed: 42
27 | num_workers: 8
28 |
29 | resume: false
30 |
31 | # Training-related arguments. See ``litgpt.args.TrainArgs`` for details
32 | train:
33 |
34 | # Number of optimizer steps between saving checkpoints (type: Optional[int], default: 1000)
35 | save_interval: 500
36 |
37 | # Number of iterations between logging calls (type: int, default: 1)
38 | log_interval: 1
39 |
40 | # Number of samples between optimizer steps across data-parallel ranks (type: int, default: 128)
41 | global_batch_size: 32
42 |
43 | # Number of samples per data-parallel rank (type: int, default: 4)
44 | micro_batch_size: 32
45 |
46 | # Number of iterations with learning rate warmup active (type: int, default: 100)
47 | lr_warmup_steps: 100
48 |
49 | # Number of epochs to train on (type: Optional[int], default: 5)
50 | epochs: 3
51 |
52 | # Total number of tokens to train on (type: Optional[int], default: null)
53 | max_tokens:
54 |
55 | # Limits the number of optimizer steps to run. (type: Optional[int], default: null)
56 | max_steps:
57 |
58 | # Limits the length of samples. Off by default (type: Optional[int], default: null)
59 | max_seq_length: 512
60 |
61 | # Whether to tie the embedding weights with the language modeling head weights. (type: Optional[bool], default: null)
62 | tie_embeddings:
63 |
64 | # (type: Optional[float], default: null)
65 | max_norm:
66 |
67 | # (type: float, default: 6e-05)
68 | min_lr: 0.0
69 |
70 | # Evaluation-related arguments. See ``litgpt.args.EvalArgs`` for details
71 | eval:
72 |
73 | # Number of optimizer steps between evaluation calls (type: int, default: 100)
74 | interval: 300
75 |
76 | # Number of tokens to generate (type: Optional[int], default: 100)
77 | max_new_tokens: 400
78 |
79 | # Number of iterations (type: int, default: 100)
80 | max_iters: 10
81 |
82 | # Whether to evaluate on the validation set at the beginning of the training
83 | initial_validation: true
84 |
85 | # Whether to evaluate on the validation set at the end the training
86 | final_validation: true
87 |
88 | # The name of the logger to send metrics to. (type: Literal['wandb', 'tensorboard', 'csv'], default: csv)
89 | logger_name: wandb
90 |
91 | # The random seed to use for reproducibility. (type: int, default: 1337)
92 | seed: 1337
93 |
94 | # Optimizer-related arguments
95 | optimizer:
96 |
97 | class_path: torch.optim.AdamW
98 |
99 | init_args:
100 |
101 | # (type: float, default: 0.001)
102 | lr: 0.0005
103 |
104 | # (type: float, default: 0.01)
105 | weight_decay: 0.0
106 |
107 | # (type: tuple, default: (0.9,0.999))
108 | betas:
109 | - 0.9
110 | - 0.95
--------------------------------------------------------------------------------
/Journey/Day11/generate_dpo_data.py:
--------------------------------------------------------------------------------
1 | import asyncio
2 | import aiohttp
3 | import json
4 | import argparse
5 | import hashlib
6 | import time
7 | import atexit
8 | from tqdm import tqdm
9 | from litgpt.prompts import MicroStories
10 | from loguru import logger
11 |
12 |
13 | def hash_prompt(prompt):
14 | return hashlib.md5(prompt.encode()).hexdigest()
15 |
16 |
17 | cache = {}
18 | error_cache = {}
19 |
20 |
21 | def save_caches():
22 | with open("dpo_cache.json", "w", encoding="utf-8") as f:
23 | json.dump(cache, f, ensure_ascii=False, indent=2)
24 | with open("error_cache.json", "w", encoding="utf-8") as f:
25 | json.dump(error_cache, f, ensure_ascii=False, indent=2)
26 | logger.info("缓存已保存")
27 |
28 |
29 | atexit.register(save_caches)
30 |
31 |
32 | async def generate_response(session, prompt, semaphore):
33 | prompt_hash = hash_prompt(prompt)
34 | if prompt_hash in cache:
35 | return cache[prompt_hash]
36 |
37 | async with semaphore:
38 | try:
39 | async with session.post(
40 | "http://127.0.0.1:8000/predict", json={"prompt": prompt}
41 | ) as response:
42 | result = await response.json()
43 | cache[prompt_hash] = result
44 | return result
45 | except Exception as e:
46 | error_msg = f"生成响应时出错: {str(e)}"
47 | logger.error(error_msg)
48 | error_cache[prompt_hash] = error_msg
49 | return None
50 |
51 |
52 | async def main(concurrency, test_mode):
53 | global cache, error_cache
54 | ms = MicroStories()
55 |
56 | with open(
57 | "../../Data/TinyStoriesInstruct/sft_data_v2.json", "r", encoding="utf-8"
58 | ) as f:
59 | sft_data = json.load(f)
60 |
61 | if test_mode:
62 | sft_data = sft_data[:100]
63 |
64 | # 读取缓存
65 | try:
66 | with open("dpo_cache.json", "r", encoding="utf-8") as f:
67 | cache = json.load(f)
68 | logger.info(f"加载缓存: {len(cache)}条")
69 | except FileNotFoundError:
70 | cache = {}
71 |
72 | try:
73 | with open("error_cache.json", "r", encoding="utf-8") as f:
74 | error_cache = json.load(f)
75 | except FileNotFoundError:
76 | error_cache = {}
77 |
78 | semaphore = asyncio.Semaphore(concurrency)
79 |
80 | async with aiohttp.ClientSession() as session:
81 | tasks = []
82 | for i, case in enumerate(tqdm(sft_data, desc="生成DPO数据")):
83 | prompt = ms.apply(prompt=case["instruction"], input=case["input"])
84 | task = asyncio.create_task(generate_response(session, prompt, semaphore))
85 | tasks.append(task)
86 |
87 | # 每处理100个样本保存一次缓存
88 | if (i + 1) % 100 == 0:
89 | save_caches()
90 |
91 | responses = await asyncio.gather(*tasks)
92 |
93 | dpo_data = []
94 | for case, response in zip(sft_data, responses):
95 | prompt = ms.apply(prompt=case["instruction"], input=case["input"])
96 | dpo_sample = {
97 | "prompt": prompt,
98 | "rejected": response.get("output") or response.get("rejected"),
99 | "chosen": case["output"],
100 | }
101 | dpo_data.append(dpo_sample)
102 |
103 | # 保存错误缓存
104 | save_caches() # 最后再保存一次缓存
105 |
106 | output_file = "dpo_data_test.json" if test_mode else "dpo_data.json"
107 | with open(output_file, "w", encoding="utf-8") as f:
108 | json.dump(dpo_data, f, ensure_ascii=False, indent=2)
109 |
110 | logger.info(f"DPO数据已生成并保存到 {output_file}")
111 | logger.info(f"缓存已更新并保存到 dpo_cache.json")
112 | logger.info(f"错误缓存已保存到 error_cache.json")
113 |
114 | end_time = time.time()
115 | execution_time = end_time - start_time
116 | logger.info(f"总执行时间: {execution_time:.2f} 秒")
117 |
118 |
119 | if __name__ == "__main__":
120 | parser = argparse.ArgumentParser(description="生成DPO数据")
121 | parser.add_argument("--concurrency", type=int, default=10, help="并发数量")
122 | parser.add_argument("--test", action="store_true", help="测试模式")
123 | args = parser.parse_args()
124 |
125 | logger.add("generate_dpo_data.log", rotation="500 MB")
126 | start_time = time.time()
127 | asyncio.run(main(args.concurrency, args.test))
128 |
--------------------------------------------------------------------------------
/Journey/Day12/Day12.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "之前说准备好`DPO`数据就着手开始自己`DIY`一下训练的实现了(因为`litgpt`库暂时还没有集成相关实现)。\n",
8 | "虽说是`DIY`但是纯从零手撸的成本还是有点高的,因此还是打算参考已有的实现来弄,比如:\n",
9 | "- [eric-mitchell/direct-preference-optimization: Reference implementation for DPO (Direct Preference Optimization)](https://github.com/eric-mitchell/direct-preference-optimization)\n",
10 | "- [huggingface的trl库里的实现](https://github.com/huggingface/trl/blob/main/trl/trainer/dpo_trainer.py)\n",
11 | "\n",
12 | "`transformers`库毕竟是大主流,因此还是优先考虑基于`transformers`库的`API`来实现。\n",
13 | "\n",
14 | "那么面临的第一个问题就是需要将`litgpt`框架训练的模型转换为`huggingface`库的模型格式。\n",
15 | "\n",
16 | "而在这个过程中我遇到了一个**意想不到的坑**,直接给我整**破防**了。\n",
17 | "\n",
18 | "大家听我慢慢道来。\n",
19 | "\n"
20 | ]
21 | },
22 | {
23 | "cell_type": "markdown",
24 | "metadata": {},
25 | "source": [
26 | "## litgpt模型转换到huggingface format\n",
27 | "`litgpt`框架本身考虑得很周全,它从简化模型实现的角度完全基于`torch`实现的[model.py](https://github.com/Lightning-AI/litgpt/blob/main/litgpt/model.py)\n",
28 | "\n",
29 | "同时也提供了将`checkpoint`转换为`huggingface`模型格式的`API`:"
30 | ]
31 | },
32 | {
33 | "cell_type": "code",
34 | "execution_count": 2,
35 | "metadata": {},
36 | "outputs": [],
37 | "source": [
38 | "# ! litgpt convert_from_litgpt input_checkpoint_dir output_dir"
39 | ]
40 | },
41 | {
42 | "cell_type": "markdown",
43 | "metadata": {},
44 | "source": [
45 | "这里会得到一个`model.pth`文件,为了后续加载方便,大家可以直接改名为`pytorch_model.bin`。\n",
46 | "\n",
47 | "另外需要注意的是`transformers`库依赖`config.json`文件,如果大家的模型架构选择的是使用`litgpt`框架已经支持的`huggingface`上的模型,那么可以直接去下载;但如果是自己定义的模型架构,那么就需要大家自己动手来写这个`config.json`文件了。\n",
48 | "\n",
49 | "> 后面我会写一个简单的脚本,基于`litgpt`框架的`config.yaml`文件来生成`config.json`文件,可能在一些场景下能具备通用性。\n",
50 | "\n",
51 | "\n",
52 | "## transformers库模型加载\n",
53 | " \n",
54 | "模型的转换还是比较简单且顺利的,但是按照[litgpt的convert文档](https://github.com/Lightning-AI/litgpt/blob/main/tutorials/convert_lit_models.md),通过`transformers`库加载转换后的模型文件的时候,问题来了。\n",
55 | "\n",
56 | "我的到了一个意想不到的报错,追溯到的是`transformers`库里对模型参数尺寸检查的这段代码:\n",
57 | "\n",
58 | "\n",
59 | "\n",
60 | "**它强制要求了`embedding`的向量尺寸必须正好等于注意力头数`n_heads`和注意力头尺寸`head_size`的乘积**。\n",
61 | "\n",
62 | "原因是他们不知出于什么考虑,在对`attention`的`kqv`转换矩阵实现的时候,做了一个简化,大家看下图里我用红框标出的地方。\n",
63 | "\n",
64 | "\n",
65 | "\n",
66 | "\n",
67 | "如果不理解的话,再对比看下面这张图应当就能理解了,是`Karpathy`大神的`nanoGPT`里同样模块的实现。\n",
68 | "\n",
69 | "\n",
70 | "\n",
71 | "但凡看过原始论文里的公式推导就会知道,`hidden_size = n_heads * head_size`这个要求是**完全没有必要**的。\n",
72 | "\n",
73 | "`W_k/W_q/W_v`矩阵理论上可以将`hidden_size`投影到任何维度上去,只要最后再通过`W_o`的线性层映射回`hidden_size`即可。\n",
74 | "\n",
75 | "而`transformers`库的实现里将这个任何维度简化为了`n_heads * head_size`,这对我这种需要从自定义的模型架构转换过来的场景造成了**毁灭性打击**🤦♂️。\n",
76 | "\n",
77 | "因为我当时**拍脑袋**定的`0.044b`参数模型里,`embedding`维度选的`768`,`n_heads`是`6`,而`head_size`定了个`48`,导致这里没有办法加载了。\n",
78 | "\n",
79 | "我当然可以通过改源码的方式来弥补这个问题,但是如果我希望我的模型能够被更多使用`transformers`库的人使用,这个方式就不合适了。\n",
80 | "\n",
81 | "最保险的方式是按照它这个**不合理的**要求来调整我的模型架构,从而得到一个满足`hidden_size = n_heads * head_size`的模型。\n",
82 | "\n",
83 | "## 教训总结\n",
84 | "\n",
85 | "\n",
86 | "没办法,我最终选择了重新预训练我的故事模型;坑虽然踩了,但是也得到了一些收获。\n",
87 | "\n",
88 | "大部分人一般情况下主要是基于`huggingface`上已有的模型架构来训练,我这类**自定义模型架构**的情况相对少见,因此踩坑踩得有点狠。\n",
89 | "\n",
90 | "即便是`transformers`库这样的大主流,也难免会有一些设计不合理的地方。\n",
91 | "\n",
92 | "也提醒我,对开源库的使用,如果时间精力允许,还是要**多花点功夫看看源码**,理解其背后的设计思想,这样在遇到问题的时候才能从更本质的地方找到解决方案。\n"
93 | ]
94 | },
95 | {
96 | "cell_type": "markdown",
97 | "metadata": {},
98 | "source": [
99 | "> 一个更让我欲哭无泪的事实:\n",
100 | "> \n",
101 | "> 就在我的新架构模型快完成预训练的时候,\n",
102 | "> 我发现这个不合理的逻辑其实在[这个PR](https://github.com/huggingface/transformers/pull/32857)里得到了修复。\n",
103 | "> \n",
104 | "> 在`transformers`库的最新版本里已经没有这个问题了。\n",
105 | "> \n",
106 | "> 合着是我更新库不够积极呗?🤷♂️"
107 | ]
108 | },
109 | {
110 | "cell_type": "markdown",
111 | "metadata": {},
112 | "source": []
113 | }
114 | ],
115 | "metadata": {
116 | "kernelspec": {
117 | "display_name": "bigmodel",
118 | "language": "python",
119 | "name": "python3"
120 | },
121 | "language_info": {
122 | "codemirror_mode": {
123 | "name": "ipython",
124 | "version": 3
125 | },
126 | "file_extension": ".py",
127 | "mimetype": "text/x-python",
128 | "name": "python",
129 | "nbconvert_exporter": "python",
130 | "pygments_lexer": "ipython3",
131 | "version": "3.10.10"
132 | }
133 | },
134 | "nbformat": 4,
135 | "nbformat_minor": 2
136 | }
137 |
--------------------------------------------------------------------------------
/Journey/Day10/Day10.md:
--------------------------------------------------------------------------------
1 | # 从零手搓中文大模型|🚀 Day10
2 |
3 | 中秋节到啦,假期不太有机会跑代码,打算码码字来讲一讲自己对**大模型**以及**人工智能**的一些拙见。
4 |
5 | 可能有些零碎或者发散,但都是自己平时工作或者学习过程中**反复在思考**的事情,一方面做个记录,一方面希望能抛砖引玉吧。
6 |
7 |
8 |
9 | ## 自回归模型的这一波AI崛起和以往有什么不同
10 |
11 | 这里特地用了**自回归模型**而没有用**大(语言)模型**,是因为这两天看到网上`Karpathy`大神关于「**大语言模型**应该纠正命名」这一引发热议的观点(详见下面的动态原文👇)。
12 |
13 | 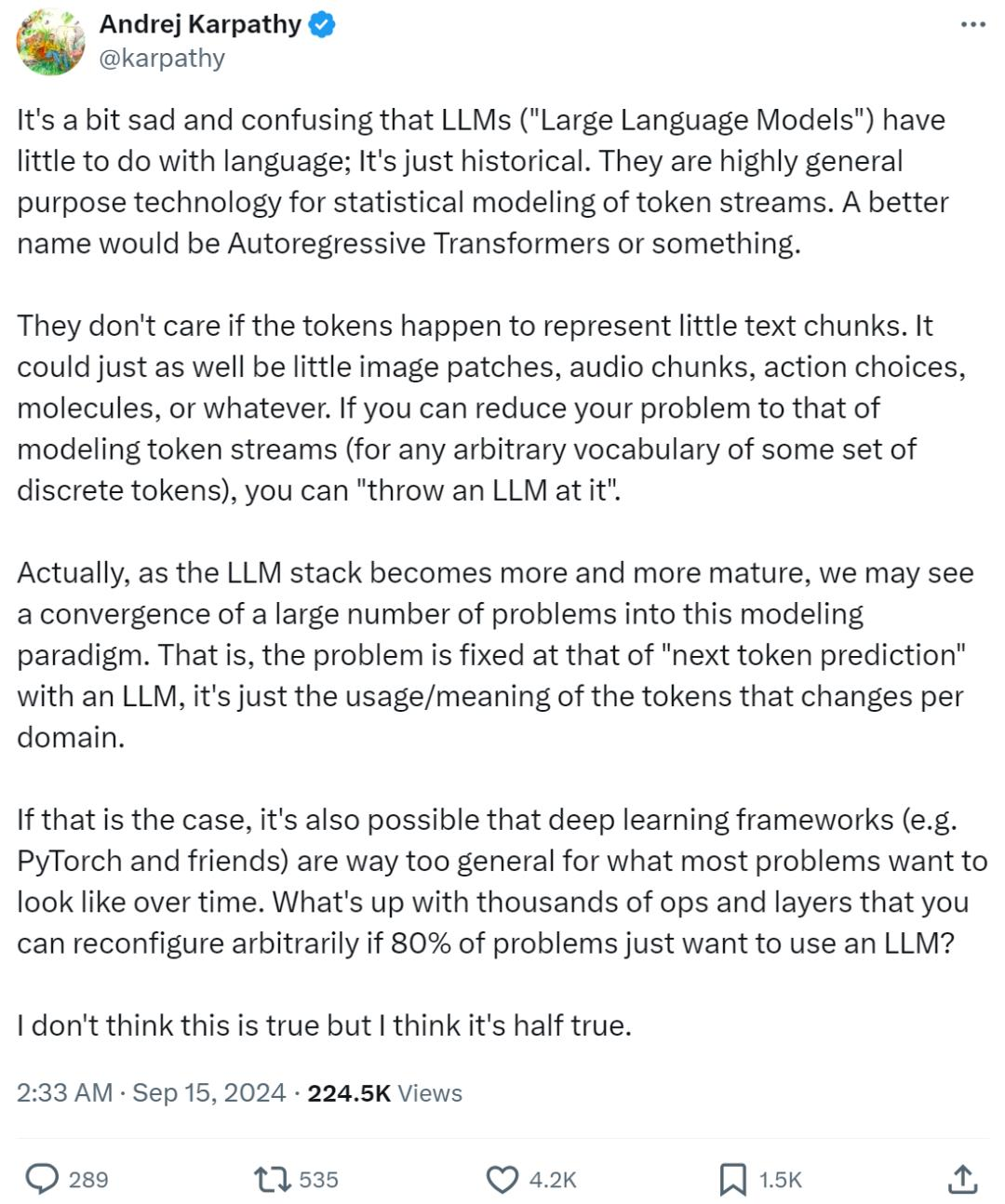
14 |
15 | 大意如下:
16 |
17 | >「大型语言模型(`LLM`)名字虽然带有语言二字,但它们其实与语言关系并不大,这只是命名的历史遗留问题,更确切的名字应该是**自回归 Transformers** (`Autoregressive Transformers`)或者其他类似的表达。
18 | >
19 | >大家现在口中提到的`LLM` 更多是一种通用的统计建模技术:通过自回归的`Transformer`结构来模拟预测`token`流,而这些 `token`可以理论上可以是文本、图片、音频、动作、甚至是分子等任何东西。
20 | >
21 | >换句话说,只要能将实际问题转化为对一系列离散`token`的模拟,理论上都可以应用当下被称为`LLM`的技术路径来解决。
22 |
23 | K神的这个观点我个人赞成**一半**。
24 |
25 | 从**纯粹的底层技术路径**角度来看,这个说法没有一点问题。
26 |
27 | 正如`Elon Musk`也同时发声所指出的:`Multimodal LLM(多模态大语言模型)`这种叫法实在很愚蠢,完全是自相矛盾的。
28 |
29 | 当下对于**大规模参数模型**+**大规模训练数据**结合`Next Token Prediction`进行预训练并且跟随后续的`SFT`/`RLHF`这一完整技术范式的应用,已经不仅仅限于文本数据了,而`LLM`里的`Language`这个词却很容易限制甚至说误导人们的思维在**文本**层面。
30 |
31 | 然而,尽管`Language`的概念应当且已经被从文本扩展到了图片、音频等更宽泛的范畴,这次以`ChatGPT`为引爆点的大模型革命之所以如此成功,很重要的一个不该被忽视的点在于,它在**应用层**让「语言」(这里我指的就是狭义的人类语言——文本或者语音)作为**交互的接口**成为了可能。
32 |
33 | 现在最主流的方向诸如`ChatGPT`以及其他类似的`AI Assistant`,又或是`Text2Image`、`Text2Video`等生成式应用,在其应用阶段甚至应用内部模块的构建阶段,我们都绕不开需要要通过人类的语言和它们底层的模型进行**交流**。
34 |
35 | 无论在大模型黑盒的内部是否建立了**自己的语言**,甚至说产生了**自己的意识**,只要我们还需要或者说还能掌控他们,那么**人类语言**在模型运转机制中的嵌入/耦合就是一个绕不开的必要条件。从这个角度讲,强调`LLM`中的人类`Language`在我看来依然有必要的。
36 |
37 | 扯得有点远哈,再稍微说回**人类语言作为交互接口**这个事儿,这是我个人认为这次「AI革命」中最为颠覆的一个点。
38 |
39 | 最末端的应用侧我就不多说了,用过`GPT4`、`Claude`或者玩过`Midjourney`、`Sora`的应该都深有体会:**人工智障**忽然能听懂人话了,尽管还不是那么利索那么聪明,但是显然已经不能用**智障**来形容人家了。
40 |
41 | 从应用的开发侧来讲,事情也发生了一些变化。
42 |
43 | 人工智能领域中纠缠了多年的**符号主义**、**联结主义**、**行为主义**,撇开其中抽象而复杂的底层逻辑,单看各个路径或者多个路径结合所构建出来的人工智能系统级应用(这里更多地是指类似`Bot`、`Agent`一类的产品形态),交互的**生硬**、**死板**是任何非专业人士也能一眼指出的致命缺陷。
44 |
45 | 私以为其中的一个原因:无论是大量规则构建的**专家系统**还是**(判别式)深度学习模型**为基础模块的**神经网络**系统,都在其内在的某个层面上,难以避免需要以严格的**符号表达或者说结构化数据**来实现通信,说人话就是整个系统需要依赖**类编程语言**这样的「接口」给串联起来。
46 |
47 | > 可以说**符号主义**从来就没有真正消亡,它只是被削减了话语权,退居幕后隐藏得更深了。
48 |
49 | 而**大语言模型**为代表的**生成式模型**的异军突起,给这个问题提供了一个此前想都不敢想的可能性:那就是人类的自然语言也可以作为「接口」了。
50 |
51 | 为`Agent`系统做过`Prompt Engineering`,或者给大模型做过`SFT`之类的`Finetuning`的朋友,或许能感受到这些开发和以往的一些不同。
52 |
53 | 说来挺有意思,人类语言本质也是一种**符号**,但又天然具备了**模糊性**。
54 |
55 | 如果将纯`Symbolic`的东西比做**冰**,`Neural`的东西比做**水**,那么人类语言就好像是**冰水混合物**般的存在,能更加自然地在两者间来回转换。
56 |
57 | 在这个前提下,开发工作的重心之一变成了如何**更自如、更精确地引导这个双向转换的过程**。
58 |
59 | 我不敢也没有资格断言这个方式就一定能解决此前人工智能系统里的所有问题,但至少让大家看到了一种非常不一样的前景。
60 |
61 | 表达和比喻或许都有些抽象,但意思就是这么个意思,要是没看懂或者觉得我在胡说八道,大家权当一乐,不必太较真。
62 |
63 |
64 |
65 | ## 对我们的工作生活到底能有多大影响
66 |
67 | 有很多唱衰大模型这一波的,认为应用还是很难落地,我觉得得更具体地看对**落地**的定义。
68 |
69 | 如果说以`AGI`或者零门槛的「傻瓜式」应用为标准,那么的确现在的应用落地情况还远远达不到。
70 |
71 | 目前基于大模型技术的能带来真正增益的应用(所谓**新质生产力**)都多少有一定的门槛:
72 |
73 | ### 第一道槛是认知门槛
74 |
75 | `Cursor`代码辑器这阵子很火,起初我以为是来了一波营销做得好,试用之后发现和两年前体验时确实不可同日而语,很增效、很智能,于是果断氪金入了坑。
76 |
77 | 作为`AI`从业者,我身边不乏高级程序员,但是像这样能极大提升工作效率的工具,我发现身边并没有太多人在使用。
78 |
79 | 他们或许有所耳闻,但对于它的`AI`能做到什么程度一无所知。
80 |
81 | 这还是我们这群每天在进行人工智能研发的群体里的情况。
82 |
83 | 再比如此前一度红得发紫的`Kimi`,可以说目前也只在一部分白领阶层有一定的知名度,对于更广大的普通老百姓而言,可能顶多就是在短视频平台上能刷到一些展示和`GPT`如何聊天的展示或者`AI`生成的逼真的图片/视频。
84 |
85 | 他们依然会觉得这个东西一定是离自己遥远的高端科技产品,自己不会有机会接触得到或者用得上。
86 |
87 | 他们自然也不会知道即使自己从没学过英语,也可以下一个免费的`APP`,通过不算太复杂的方式让一个`AI`助手辅导自己上小学的孩子的英语听说读写,效果不会逊色几千块的学习机多少。
88 |
89 | 从这个方面来讲,我觉得`AI`技术的**科普**是一件非常**迫在眉睫**的事情。
90 |
91 | 对一个`AI`应用而言,更庞大的、长尾的应用群体可以成为非常重要的发展助力。
92 |
93 | 而对个人而言,等到`AI`工具的使用已经和曾经的`Office`套件一样成为**基础技能**的时候才意识到需要学起来、用起来,可能已经落后了一大步了。
94 |
95 | ### 第二道槛才是技术门槛
96 |
97 | 这里的**技术**并非是编程这类具备专业门槛的技术,而是目前的`AI`应用的使用方式层面的技巧。
98 |
99 | 那些需要「**魔法**」/「**梯子**」的情况我就不多说了,大家懂的都懂。
100 |
101 | 可即便是国内可以接触到的面向C端的`AI Assistant`产品,能真正会用并且用好的人恐怕比例不大。
102 |
103 | 更别提那些完全免费但需要有**硬件支持和部署能力**的开源大模型了,否则像李某舟这样**锋利的镰刀**就不会出现了。
104 |
105 | 光是写`Prompt`这件看似只要会说人话就能干的事儿,其实不但需要对大模型的**技术和概念**有一定的了解,还需要大量**科学的实验和总结**。
106 |
107 | 所以,这两道门槛的存在导致了当下大模型为基础的`AI`应用现状是**割裂**的:头部的**早鸟**们要么已经在挖掘人工智能提效个人生产力的路上一路狂飞,要么已经开始利用信息差**割起了韭菜**;而绝大多数人还没有意识到变革已经在悄悄发生。
108 |
109 |
110 |
111 | ## 大模型出现后,AGI(通用人工智能)还有多远
112 |
113 | 我个人的工作算是`AGI`方向的,尽管我前面对于大模型的应用前景持乐观态度,但对于「**大模型是否带领我们走向AGI**」这件事儿还是存疑的。
114 |
115 | 首先,目前以大模型为基座的`Agent`系统还是在解决一些被动输入的任务,缺乏一个**内在的动力系统**提供自驱力。
116 |
117 | 即使推理能力强如`GPT-o1`,在没有任何外界指令的时候整个系统是静止的,简单来说不具备真正意义上的主动思考的能力。
118 |
119 | 这个问题的解决路径或许不在大模型的技术栈范畴。国内外也有一些前沿的研究在关注这块的内容,例如给机器构建类似人类的**价值体系**来让它具备自我驱动的可能,大家感兴趣的话可以去了解一下。
120 |
121 | 其次,性能是大模型的一个**硬伤**。
122 |
123 | 虽然**力大砖飞**的`Scaling Law`的的确确让大家看到了**大力出奇迹**的可能性,但是我们也不要忘了另一句话:「**天下武功,唯快不破**」。
124 |
125 | 但这反而也给我们提供了更多的想象空间:量变引发质变,其实「**速变**」也可以,这在计算机技术的发展历史上也得到过很多次的证明。
126 |
127 | 我们设想一下,如果能力最强的大模型在推理速度方面有了量级上的突破,那么一个以此为基础的多`Agent`系统能求解的问题复杂度可能要远超我们的想象。
128 |
129 | 最后是**硬件层面的门槛**,这可能已经上升到国家战略层面的博弈了。
130 |
131 | 这个问题和上面的**性能问题**有一定的关联,我个人对硬件技术一窍不通,只能从其他的角度来思考可能的解决途径。
132 |
133 | 于是我对于`SLM`(**小语言模型**)的相关研究产生了兴趣,其实`GPT2`的出现就已经一定程度地证明了**小尺寸的语言模型**也是具备很大的潜力的。
134 |
135 | 如果没有「**速度超快的最强大模型**」作为通用基座来构建系统,那么许多个**能力单一但卓越的小模型**是否能成为无限接近的平替呢?性能和硬件的问题同时得到了解决。
136 |
137 |
138 |
139 | ## 写在最后
140 |
141 | 不知不觉瞎扯的有点多了。
142 |
143 | 还是强调一下,个人水平有限,以上纯属自己个人的胡思乱想,可能有很多异想天开甚至错误的地方。
144 |
145 | 尽管历史证明,每一次人工智能的热潮都将逐渐降温和退去,但每次都将下一次的起点拉高了。
146 |
147 | 因此我对人工智能的未来还是十分乐观的,也很庆幸能在整个领域工作。
148 |
149 | 最后祝大家**中秋快乐**!
150 |
--------------------------------------------------------------------------------
/Experiments/configs/microstories/pretrain.yaml:
--------------------------------------------------------------------------------
1 | # The name of the model to pretrain. Choose from names in ``litgpt.config``. Mutually exclusive with
2 | # ``model_config``. (type: Optional[str], default: null)
3 | model_name: microstories
4 |
5 | # A ``litgpt.Config`` object to define the model architecture. Mutually exclusive with
6 | # ``model_config``. (type: Optional[Config], default: null)
7 | model_config:
8 | name: microstories
9 | hf_config: {}
10 | scale_embeddings: false
11 | block_size: 512
12 | padded_vocab_size: 65024
13 | vocab_size: 64798
14 | n_layer: 6
15 | n_head: 6
16 | n_query_groups: 6
17 | n_embd: 512
18 | head_size: 48
19 | rotary_percentage: 1.0
20 | parallel_residual: false
21 | bias: false
22 | norm_class_name: RMSNorm
23 | mlp_class_name: LLaMAMLP
24 | intermediate_size: 768
25 |
26 | # Directory in which to save checkpoints and logs. If running in a Lightning Studio Job, look for it in
27 | # /teamspace/jobs//share. (type: , default: out/pretrain)
28 | out_dir: Chinese_LLM_From_Scratch/Experiments/Output/pretrain/microstories
29 |
30 | # The precision to use for pretraining. Possible choices: "bf16-true", "bf16-mixed", "32-true". (type: Optional[str], default: null)
31 | precision: bf16-mixed
32 |
33 | # Optional path to a checkpoint directory to initialize the model from.
34 | # Useful for continued pretraining. Mutually exclusive with ``resume``. (type: Optional[Path], default: null)
35 | initial_checkpoint_dir:
36 |
37 | # Path to a checkpoint directory to resume from in case training was interrupted, or ``True`` to resume
38 | # from the latest checkpoint in ``out_dir``. An error will be raised if no checkpoint is found. Passing
39 | # ``'auto'`` will resume from the latest checkpoint but not error if no checkpoint exists.
40 | # (type: Union[bool, Literal["auto"], Path], default: False)
41 | resume: True
42 |
43 | # Data-related arguments. If not provided, the default is ``litgpt.data.TinyLlama``.
44 | data:
45 | # TinyStories
46 | class_path: litgpt.data.LitData
47 | init_args:
48 | data_path: Chinese_LLM_From_Scratch/Data/TinyStoriesChinese/processed_data
49 | split_names:
50 | - train
51 | - val
52 |
53 | # Training-related arguments. See ``litgpt.args.TrainArgs`` for details
54 | train:
55 | # Number of optimizer steps between saving checkpoints (type: Optional[int], default: 1000)
56 | save_interval: 1000
57 |
58 | # Number of iterations between logging calls (type: int, default: 1)
59 | log_interval: 1
60 |
61 | # Number of samples between optimizer steps across data-parallel ranks (type: int, default: 512)
62 | global_batch_size: 512
63 |
64 | # Number of samples per data-parallel rank (type: int, default: 4)
65 | micro_batch_size: 32
66 |
67 | # Number of iterations with learning rate warmup active (type: int, default: 2000)
68 | lr_warmup_steps: 1000
69 |
70 | # Number of epochs to train on (type: Optional[int], default: null)
71 | epochs:
72 |
73 | # Total number of tokens to train on (type: Optional[int], default: 3000000000000)
74 | max_tokens: 3000000000000
75 |
76 | # Limits the number of optimizer steps to run. (type: Optional[int], default: null)
77 | max_steps:
78 |
79 | # Limits the length of samples. Off by default (type: Optional[int], default: null)
80 | max_seq_length: 512
81 |
82 | # Whether to tie the embedding weights with the language modeling head weights. (type: Optional[bool], default: False)
83 | tie_embeddings: true
84 |
85 | # (type: Optional[float], default: 1.0)
86 | max_norm: 1.0
87 |
88 | # (type: float, default: 4e-05)
89 | min_lr: 0.0
90 |
91 | # Evaluation-related arguments. See ``litgpt.args.EvalArgs`` for details
92 | eval:
93 | # Number of optimizer steps between evaluation calls (type: int, default: 1000)
94 | interval: 2000
95 |
96 | # Number of tokens to generate (type: Optional[int], default: null)
97 | max_new_tokens:
98 |
99 | # Number of iterations (type: int, default: 100)
100 | max_iters: 100
101 |
102 | # Whether to evaluate on the validation set at the beginning of the training
103 | initial_validation: false
104 |
105 | # Whether to evaluate on the validation set at the end the training
106 | final_validation: false
107 |
108 | # Optimizer-related arguments
109 | optimizer:
110 | class_path: torch.optim.AdamW
111 |
112 | init_args:
113 | # (type: float, default: 0.001)
114 | lr: 0.0005
115 |
116 | # (type: float, default: 0.01)
117 | weight_decay: 0.1
118 |
119 | # (type: tuple, default: (0.9,0.999))
120 | betas:
121 | - 0.9
122 | - 0.95
123 |
124 | # How many devices/GPUs to use. Uses all GPUs by default. (type: Union[int, str], default: auto)
125 | devices: auto
126 |
127 | # How many nodes to use. (type: int, default: 1)
128 | num_nodes: 1
129 |
130 | # Optional path to the tokenizer dir that was used for preprocessing the dataset. Only some data
131 | # module require this. (type: Optional[Path], default: null)
132 | tokenizer_dir: Chinese_LLM_From_Scratch/References/chatglm3-6b
133 |
134 | # The name of the logger to send metrics to. (type: Literal['wandb', 'tensorboard', 'csv'], default: tensorboard)
135 | logger_name: wandb
136 |
137 | # The random seed to use for reproducibility. (type: int, default: 42)
138 | seed: 42
139 |
--------------------------------------------------------------------------------
/Journey/Day01/Day01.md:
--------------------------------------------------------------------------------
1 | # 从零手搓中文大模型|🚀Day01
2 |
3 | ## 参考项目搜集
4 |
5 | - [nano-llama31](https://github.com/karpathy/nano-llama31/tree/master)
6 |
7 | - Karpathy大神的项目,用700多行代码完成了一个尽可能低依赖的最简洁`Llama3.1`实现,能够进行训练、微调和推理(跪拜🧎♂️)
8 |
9 | - [TinyLlama](https://github.com/jzhang38/TinyLlama/blob/main/README_zh-CN.md)
10 |
11 | - `TinyLlama`项目在3万亿tokens上进行预训练,构建一个拥有`1.1B`参数的`Llama`模型
12 |
13 | - 采用了与`Llama 2`完全相同的架构和分词器
14 |
15 | - [baby-llama2-chinese](https://github.com/DLLXW/baby-llama2-chinese?tab=readme-ov-file)
16 |
17 | - 中文数据从头训练+SFT的一个小参数实现,可以在`24G`单卡运行;目前包含:**预训练**、**SFT指令微调**,**奖励模型**以及**强化学习**待做(但似乎已经断更3个月)
18 |
19 | - 基于`Llama 2`架构
20 |
21 | - [ChatLM-mini-Chinese](https://github.com/charent/ChatLM-mini-Chinese)
22 |
23 | - 中文对话0.2B小模型(ChatLM-Chinese-0.2B),开源所有**数据集来源、数据清洗、tokenizer训练、模型预训练、SFT指令微调、RLHF优化**等流程的全部代码
24 |
25 | - 支持下游任务`sft`微调,给出了三元组信息抽取任务的微调示例
26 |
27 | - 有意思的是作者选的模型架构是`T5`,还有另一个衍生项目用的是`phi-2`架构
28 |
29 | 除了第一个K神的项目是关于模型实现,后面三个项目的`README.md`文件看一遍下来,对于后续整体的实现流程心里便能有了一个大致的概念。
30 |
31 | 之后遇到了实际问题时再去里面寻找细节来参考。
32 |
33 | ## 数据集确定
34 |
35 | 这个计划的主要目地是能从头熟悉一遍大模型训练的流程,所以不需要收集大量的文本数据集(我显然也没有那么多的GPU资源能让我在超大的数据集上快速训练🤷♂️)
36 |
37 | 之前看到微软的一篇论文[TinyStories](https://arxiv.org/abs/2305.07759),探索的是语言模型在多小的情况下还能流利地讲故事。
38 |
39 | 为此他们构造了一个小数据集,包含了一些小故事,我觉得这个数据集很适合我这个项目的目标,所以决定使用这个数据集。
40 |
41 | 由于希望在中文数据集上进行实践,所以原本的打算是通过机器翻译把数据集翻译一遍。
42 |
43 | 结果发现已经有人做了这个工作,所以我打算直接使用这个翻译好的[数据集](https://huggingface.co/datasets/adam89/TinyStoriesChinese)。🙏感谢大佬们的无私奉献。
44 |
45 | 一个样例如下:
46 | ```json
47 | {
48 | "story": "\n\nLily and Ben are friends. They like to play in the park. One day, they see a big tree with a swing. Lily wants to try the swing. She runs to the tree and climbs on the swing.\n\"Push me, Ben!\" she says. Ben pushes her gently. Lily feels happy. She swings higher and higher. She laughs and shouts.\nBen watches Lily. He thinks she is cute. He wants to swing too. He waits for Lily to stop. But Lily does not stop. She swings faster and faster. She is having too much fun.\n\"Can I swing too, Lily?\" Ben asks. Lily does not hear him. She is too busy swinging. Ben feels sad. He walks away.\nLily swings so high that she loses her grip. She falls off the swing. She lands on the ground. She hurts her foot. She cries.\n\"Ow, ow, ow!\" she says. She looks for Ben. She wants him to help her. But Ben is not there. He is gone.\nLily feels sorry. She wishes she had shared the swing with Ben. She wishes he was there to hug her. She limps to the tree. She sees something hanging from a branch. It is Ben's hat. He left it for her.\nLily smiles. She thinks Ben is nice. She puts on his hat. She hopes he will come back. She wants to say sorry. She wants to be friends again.",
49 | "instruction": {
50 | "prompt:": "Write a short story (3-5 paragraphs) which only uses very simple words that a 3 year old child would understand. The story should use the verb \"hang\", the noun \"foot\" and the adjective \"cute\". The story has the following features: the story should contain at least one dialogue. Remember to only use simple words!\n\nPossible story:",
51 | "words": [
52 | "hang",
53 | "foot",
54 | "cute"
55 | ],
56 | "features": [
57 | "Dialogue"
58 | ]
59 | },
60 | "summary": "Lily and Ben play in the park and Lily gets too caught up in swinging, causing Ben to leave. Lily falls off the swing and hurts herself, but Ben leaves his hat for her as a kind gesture.",
61 | "source": "GPT-4",
62 | "story_zh": "莉莉和本是朋友。他们喜欢在公园里玩。有一天,他们在一棵大树下看到了一个秋千。莉莉想试试那个秋千。她跑到树下,爬上了秋千。\n\"推我,本!\"她说。本轻轻地推了她一下。莉莉感到很开心。她越荡越高,笑着喊叫。\n本看着莉莉。他觉得她很可爱。他也想荡秋千。他在莉莉停下来之后等着。但是莉莉没有停下来。她越荡越快。她玩得太高兴了。\n\"我也可以荡秋千吗,莉莉?\"本问。莉莉没听到他的话。她忙着荡秋千。本觉得很难过。他走开了。\n莉莉荡得太高,失去了平衡。她从秋千上摔下来,落在地上。她扭伤了脚。她哭了起来。\n\"哎呀,哎呀,哎呀!\"她说。她在找本。她希望他能帮助她。但本不在那里。他走了。\n莉莉感到很抱歉。她希望她能和本分享秋千。她希望他在那里拥抱她。她一瘸一拐地走到树下。她看到有什么东西挂在树枝上。那是本的帽子。他留给她的。\n莉莉笑了。她觉得本很好。她戴上了他的帽子。她希望他会回来。她想道歉。她想再次成为朋友。"
63 | }
64 | ```
65 |
66 | ### 数据清洗
67 | 在标准的流程里,**文本数据量会非常大**且来自于不同的来源,无论从**质量**上和**内容重复度**上都需要进行清洗。
68 |
69 | 由于这个数据集是一个单独的小数据集,所以我打算先**跳过这一步**。
70 |
71 | 不过这里还是简单说一下数据清洗的一些方法:
72 | - 去除重复数据
73 | - 当量级巨大的时候一般会采用`SimHash`或者`MinHash`的方法
74 | - 短文本过滤(太短的文本对于模型训练而言意义不大,可以直接去除)
75 | - 去除低质量数据
76 | - 一般会采用一些规则或者模型来判断文本的质量,例如:**语法错误、拼写错误、不合理内容、无意义数据**等
77 | - 这一步的成本会比较高,因为需要人工标注或者构建模型(但高质量的数据对于模型训练是非常重要的)
78 |
79 | ## 训练框架选择
80 |
81 | 一个好的训练框架还是很重要的。
82 |
83 | 在上面的参考项目中发现了这个名为[⚡️litgpt](https://github.com/Lightning-AI/litgpt/tree/main)的大模型预训练/微调/部署框架,而且其模型实现代码是基于上面Karpahty大神的`nano-llama31`项目。
84 |
85 | 框架已经支持了`20+`大模型,包括最新的`Llama 3.1`。大概看了一下代码仓库,结构清晰且简洁。
86 |
87 | 
88 |
89 | 另外一个框架是[Llama-Factory](https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md),已经有29k的stars,支持`100+`大模型(尤其是对国内的开源模型支持很好)。
90 |
91 | 
92 |
93 | 所以我决定花时间简单了解一下这两个框架然后选一个作为后续的训练工具。
94 |
95 | 个人觉得如今的大模型训练框架已经非常成熟,大家都在追求**更高的性能和更好的易用性**,所以**选择一个好的框架**对于后续的工作来说是非常重要的。
96 |
97 | 也没有必要自己造轮子,毕竟大家都在造了,我们只需要选择一个适合自己的就好了。
98 |
99 | > 经过调研发现`Llama-Factory`似乎~~只能支持和发布的开源模型参数一致的模型(也可能是我看的不仔细没有找到修改配置的地方,如果是这样欢迎大家指出)~~。
100 | >
101 | > 而litgpt则支持自定义模型参数,
102 | > 由于我后面是希望限制参数量级在一个很小的范畴,所以决定使用litgpt作为后续的训练工具。
103 |
104 | ⚠️更新:
105 |
106 | 后续也找到了`Llama-Factory`里从0训练并且修改参数的方法(修改`config.json`的配置,并且添加`train_from_scratch=True`参数),
107 |
108 | 但`litgpt`的代码架构更加简洁,没有过多的抽象和封装,并且有一些训练加速的优化(`Llama-Factory`是基于`transformers`库),
109 |
110 | 因此最后还是决定使用`litgpt`。
111 |
112 | ## 小结
113 | 1. 确定了项目的数据集来源
114 | 2. 了解了一些数据清洗的方法
115 | 3. 选择了`litgpt`作为后续的训练工具
116 | 4. 了解了一些参考项目,对后续的实现流程有了一个大致的概念
117 |
--------------------------------------------------------------------------------
/Journey/Day02/Day02.md:
--------------------------------------------------------------------------------
1 | # 从零手搓中文大模型|🚀Day02
2 |
3 | 
4 |
5 | > 原本是计划直接进入「**数据处理**」阶段的,但由于实在精力有限,就拆成两期:这次先说说`Tokenizer`,下一期说**数据处理**。
6 | >
7 | > 由于`Tokenizer`的训练算是一个相对独立的过程,且训练相对来说比较简单,因此我也打算偷懒先用国内大厂开源的,之后有时间再自己训练实现一个。
8 | >
9 | > 其实**分词器**这块的内容经常容易被大家忽略,但实际上是非常重要的,因为它直接决定了模型的输入,进而影响到模型的训练效果。
10 | >
11 | > 这部分内容我自己此前也没怎么深入研究过,所以这次也是一边学习一边写,权当补课了,如果有错误的地方,欢迎指正。
12 |
13 | ## Tokenizer选择
14 |
15 | **tokenization**是大模型训练的第一步,是将文本转换为模型可以理解的数字表示(后面也能反向decode回来)。
16 |
17 | 其中目前比较主流的是[BPE(Byte Pair Encoding)](https://zhuanlan.zhihu.com/p/424631681)(详细的介绍可以参考链接文章,下面通过例子简单介绍一下原理)。
18 |
19 | **BPE**是一种简单的数据压缩形式,这种方法用数据中不存在的一个字节表示最常出现的连续字节数据。这样的替换需要重建全部原始数据。
20 |
21 | ### BPE简介
22 |
23 | 假设我们要编码如下数据
24 |
25 | > aaabdaaabac
26 |
27 | 字节对“aa”出现次数最多,所以我们用数据中没有出现的字节“Z”替换“aa”得到替换表
28 |
29 | > Z <- aa
30 |
31 | 数据转变为
32 |
33 | > ZabdZabac
34 |
35 | 在这个数据中,字节对“Za”出现的次数最多,我们用另外一个字节“Y”来替换它(这种情况下由于所有的“Z”都将被替换,所以也可以用“Z”来替换“Za”),得到替换表以及数据
36 |
37 | > Z <- aa
38 | > Y <- Za
39 |
40 | > YbdYbac
41 |
42 | 我们再次替换最常出现的字节对得到:
43 |
44 | > Z <- aa
45 | > Y <- Za
46 | > X <- Yb
47 |
48 | > XdXac
49 |
50 | 由于不再有重复出现的字节对,所以这个数据不能再被进一步压缩。
51 |
52 | 解压的时候,就是按照相反的顺序执行替换过程。
53 |
54 |
55 |
56 |
57 | 
58 |
59 | ### 测试Tokenizer(以ChatGLM3-6B的tokenizer为例)
60 |
61 |
62 | ```python
63 | from transformers import AutoTokenizer
64 |
65 | tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
66 | ```
67 |
68 |
69 | 编码
70 |
71 |
72 | ```python
73 | print(tokenizer("这是一个测试"))
74 | ```
75 |
76 |
77 |
78 | ```
79 | {'input_ids': [64790, 64792, 30910, 36037, 32882], 'attention_mask': [1, 1, 1, 1, 1], 'position_ids': [0, 1, 2, 3, 4]}
80 | ```
81 |
82 |
83 |
84 | 反编码
85 |
86 |
87 | ```python
88 | print(tokenizer.decode(tokenizer("这是一个测试")["input_ids"]))
89 | ```
90 |
91 |
92 |
93 | ```
94 | '[gMASK] sop 这是一个测试'
95 | ```
96 |
97 |
98 |
99 | ⚠️这里可以发现反向解码的时候,多出来了`[gMASK]`和`sop`这两个「奇怪」的token,原因下面会讲到。
100 |
101 | 我们看看词表的大小:
102 |
103 |
104 | ```python
105 | print(tokenizer.vocab_size)
106 | ```
107 |
108 |
109 |
110 |
111 | ```
112 | 64798
113 | ```
114 |
115 |
116 |
117 | 这里我们写一个函数,针对数据集里的一行`json`文本做处理,得到整行中文文本的编码数组。
118 |
119 |
120 | ```python
121 | import numpy as np
122 |
123 |
124 | def process_line(line, tokenizer, add_eos=True, dtype=np.uint16):
125 | js = json.loads(line)
126 | story = js["story_zh"]
127 | story = tokenizer.encode(story, add_special_tokens=False)
128 | if add_eos:
129 | story.append(tokenizer.eos_token_id)
130 | # 这里可以用np.unint16,因为我们的vocab_size是小于65536的
131 | arr = np.array(story, dtype=dtype)
132 | return arr
133 | ```
134 |
135 | ❗️这里有几个需要注意的点:
136 | - `add_special_tokens`参数的作用是添加特殊token。
137 | 是chatglm自定义的例如[gMASK]/sop,属于glm架构里特有的(可以参考[这里](https://github.com/THUDM/ChatGLM3/issues/183))。
138 |
139 | 由于我们后续并不使用glm的架构,因此这里不需要添加,**直接设置为False**。
140 | - 需要在末尾加上`eos`标记对应的token_id。
141 | - chatglm3-6b使用的词表大小为`64798`,刚好在uint16的表示范围内,所以上面我们给numpy.array设置了`dtype=np.uint16`。
142 |
143 | 拿一行测试一下:
144 |
145 |
146 | ```python
147 | import json
148 |
149 | with open("../../Data/TinyStoriesChinese/train/data00_zh.jsonl", "r") as f:
150 | for line in f.readlines():
151 | data = process_line(line, tokenizer)
152 | print(data)
153 | print(tokenizer.decode(data))
154 | break
155 | ```
156 | ```
157 | [30910 56623 56623 54542 50154 31761 31155 31633 31815 54534 32693 54662
158 | 55409 31155 35632 31123 31633 34383 57427 47658 54578 34518 31623 55567
159 | 55226 31155 56623 56623 54695 39887 32437 55567 55226 31155 54790 41309
160 | 52624 31123 56856 32660 55567 55226 31155 13 30955 54834 54546 31123
161 | 54613 31404 30955 36213 31155 54613 36660 54563 54834 43881 32024 31155
162 | 56623 56623 32707 54657 33436 31155 54790 54937 56567 40714 31123 38502
163 | 56653 55483 31155 13 54613 32984 56623 56623 31155 54572 31897 54790
164 | 54657 35245 31155 36551 54695 56567 55567 55226 31155 33152 56623 56623
165 | 51556 31797 39055 31155 31694 56623 56623 31631 51556 31155 54790 54937
166 | 56567 54937 54929 31155 54790 55409 40915 34492 54537 31155 13 30955
167 | 54546 32591 56567 55567 55226 55398 31123 56623 56623 31514 30955 54613
168 | 54761 31155 56623 56623 54721 33906 31804 54887 31155 54790 46977 56567
169 | 55567 55226 31155 54613 31897 32960 54597 31155 54572 54942 34675 31155
170 | 13 56623 56623 56567 40915 54589 31123 36467 33501 31155 54790 54708
171 | 55567 55226 54547 57456 32246 31123 36712 34245 31155 54790 56901 55328
172 | 54537 55673 31155 54790 56399 37247 31155 13 30955 58394 56657 31123
173 | 58394 56657 31123 58394 56657 31404 30955 36213 31155 35957 55227 54613
174 | 31155 54790 31772 47554 31934 54790 31155 54688 54613 33551 33892 31155
175 | 54572 34247 31155 13 56623 56623 32707 54657 52992 31155 54790 31772
176 | 54790 54558 54542 54613 32097 55567 55226 31155 54790 31772 33152 33892
177 | 37322 54790 31155 54790 54531 60337 54531 57635 54563 35220 52624 31155
178 | 54790 31857 33277 32086 44829 49102 54547 31155 35328 43352 41147 31155
179 | 54572 42393 32233 31155 13 56623 56623 40466 31155 54790 31897 54613
180 | 33058 31155 54790 55947 32660 31804 41147 31155 54790 31772 38711 33857
181 | 31155 54790 54695 37300 31155 54790 54695 32462 31705 31761 31155 2]
182 | 莉莉和本是朋友。他们喜欢在公园里玩。有一天,他们在一棵大树下看到了一个秋千。莉莉想试试那个秋千。她跑到树下,爬上了秋千。
183 | "推我,本!"她说。本轻轻地推了她一下。莉莉感到很开心。她越荡越高,笑着喊叫。
184 | 本看着莉莉。他觉得她很可爱。他也想荡秋千。他在莉莉停下来之后等着。但是莉莉没有停下来。她越荡越快。她玩得太高兴了。
185 | "我也可以荡秋千吗,莉莉?"本问。莉莉没听到他的话。她忙着荡秋千。本觉得很难过。他走开了。
186 | 莉莉荡得太高,失去了平衡。她从秋千上摔下来,落在地上。她扭伤了脚。她哭了起来。
187 | "哎呀,哎呀,哎呀!"她说。她在找本。她希望他能帮助她。但本不在那里。他走了。
188 | 莉莉感到很抱歉。她希望她能和本分享秋千。她希望他在那里拥抱她。她一瘸一拐地走到树下。她看到有什么东西挂在树枝上。那是本的帽子。他留给她的。
189 | 莉莉笑了。她觉得本很好。她戴上了他的帽子。她希望他会回来。她想道歉。她想再次成为朋友。
190 | ```
191 |
192 |
193 | ### 选择ChatGLM3-6B的tokenizer的原因
194 |
195 | 该词表大小为`64798`,值得注意的是:这是一个很**妙**的数字,因为它**刚好在uint16的表示范围(0~65535的无符号整数)**,每一个token只需要两个字节即可表示。
196 |
197 | 当我们的语料较大时候,相比常用的`int32`可以**节省一半的存储空间**。
198 |
199 | 另外这里选择一个小尺寸的词表还有一个更重要的原因:我们后面的模型会选择一个小参数量的,如果词表过大,会导致**大部分参数被embedding层占用**,而无法训练出更好的模型。
200 |
201 | ## 小结
202 | 1. 首先熟悉了一下`BPE`的原理
203 | 2. 测试了一下`ChatGLM3-6B`的tokenizer
204 | 3. 编写了一个函数,用于将一行json文本转换为token_id数组
205 | 4. 解释了为什么选择`ChatGLM3-6B`的tokenizer
206 |
207 |
--------------------------------------------------------------------------------
/Journey/Day_Final/Day_final.md:
--------------------------------------------------------------------------------
1 | 这个系列陆陆续续更新了`13`期,总算是在**粗粒度**上把大模型的训练流程走了一遍。
2 |
3 | 在`64G`内存 + `3090 Ti`单卡配置上完成了以下的主要内容:
4 |
5 | 1. 预训练数据的预处理:批量并行的`tokenization`
6 | 2. `0.044B`参数量的`Tinystories(Chinese)`故事模型预训练
7 | 3. 基于大模型(吴恩达`translation-agent`)的`SFT`数据批量翻译
8 | 4. `SFT`训练(包含全参数和`LoRA`两种方式)
9 | 5. `DPO`数据生成
10 | 6. `DPO`训练
11 |
12 | 过程中也不乏许多对**模型实现细节**和**训练框架源码**的深入阅读和理解,以及一些**算法原理**的学习/复习。
13 |
14 | 无论效果好坏,细节是否到位,自己还是觉得收获颇丰的,这一期打算做个大汇总,也算是给这段学习一个完整的交代,同时方便有需要的小伙伴查阅。
15 |
16 | > 整个过程里的尝试和经验不一定具备广泛的普适性,个人水平也十分有限,欢迎大家批评指正。
17 |
18 | 当然,这次总结并不代表这部分的学习就彻底结束了,一些更多的**尝试和思考**还在继续,后面会陆续进行**补充更新**。
19 |
20 |
21 |
22 |
23 | ## 「从零手搓中文大模型」传送门
24 |
25 | 先列一波整个系列的全部相关内容传送门,**想直接看经验总结的可以跳到后面哈**。
26 |
27 | ### 代码传送门
28 |
29 | > https://github.com/puppyapple/Chinese_LLM_From_Scratch
30 |
31 | ### 视频传送门
32 |
33 | > https://space.bilibili.com/341251360/channel/collectiondetail?sid=3724215
34 |
35 | (视频制作不易,所以进度相比公众号文章会慢很多,目前还在努力更新中🤣)
36 |
37 | ### 公众号合集传送门
38 |
39 | [#从零手搓中文大模型](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzkyMzczMjkxMA%3D%3D&action=getalbum&album_id=3599032183991779337&scenenote=https://mp.weixin.qq.com/s?__biz%3DMzkyMzczMjkxMA%3D%3D%26mid%3D2247484081%26idx%3D1%26sn%3Da740d8346704d27dc215950d4ce1d99b%26chksm%3Dc00d71f4e1214c2fe35302fe98ec6f076f29eea2dcd67568a3861863ba6c7e6f4832e89bd955%26scene%3D126%26sessionid%3D1727572824%26subscene%3D91%26clicktime%3D1727572828%26enterid%3D1727572828%26ascene%3D3%26devicetype%3DiOS18.0%26version%3D18003424%26nettype%3D3G+%26abtest_cookie%3DAAACAA%253D%253D%26lang%3Dzh_CN%26countrycode%3DCN%26fontScale%3D100%26exportkey%3Dn_ChQIAhIQW8oJys10cUzrj5zuSU%252BgVxLZAQIE97dBBAEAAAAAAHzMJ7V4CqgAAAAOpnltbLcz9gKNyK89dVj0sfQwZoaQr6vXojy9g0gYCI6hqbyXfvmfGWyzXj89VcxBNbuR8UWmidc%252BZmUF7swRYb8m%252B2xvF3w5fnuadG8%252BJGgBjcdjxf7HCNRfjL1PgQtGWh2VnTyvx%252FXzrqVXYUBpVTQtVBuyiX1nHVUMHr794yaLscaxaDJW497sreHaivMobvVpeRHMVxsd2nDJ%252FQ1SZhYwoN6ZvQUwB9iQsbEyBN7Idn2CKc7%252F8I2Sx%252BXt7%252FTf8cI%253D%26pass_ticket%3DuYco99quUGGX4QRAQ9HXe0zE2X3NtF%252FtqemWE%252BE9lnPOBmDjyzH5rX2KPimEbPQK%26wx_header%3D3&nolastread=1&devicetype=iMac+MacBookAir10,1+OSX+OSX+14.5+build(23F79)&version=13080810&lang=zh_CN&nettype=WIFI&ascene=0&fontScale=100&uin=&key=)
40 |
41 | ### 公众号每日传送门
42 |
43 | [从零手搓中文大模型|Day01|打卡第一天,欢迎大家监督催更](https://mp.weixin.qq.com/s/kbmkdkukkvnGMCzRD2Z1mQ)
44 |
45 | [从零手搓中文大模型|Day02|Tokenizer & BPE](https://mp.weixin.qq.com/s/LD2LTtEz1bvSdxZkIO1ePg)
46 |
47 | [从零手搓中文大模型|Day03|数据预处理](https://mp.weixin.qq.com/s/bVueRGPp_JqXh4N74A-OPg)
48 |
49 | [从零手搓中文大模型|Day04|模型参数配置和训练启动|我的micro模型跑起来啦!](https://mp.weixin.qq.com/s/ZpaO2cxVrTOlBFw45rIqiQ)
50 |
51 | [我的超迷你大模型会讲故事啦|从零手搓中文大模型|Day05](https://mp.weixin.qq.com/s/M7RmebRDvfMXomHln6R5PQ)
52 |
53 | [从零手搓中文大模型|Day06|预训练阶段代码汇总和整理](https://mp.weixin.qq.com/s/D2DCf7iq0A6BRY46X1KN8g)
54 |
55 | [吴恩达老师帮我构造指令微调(SFT)数据|从零手搓中文大模型|Day07](https://mp.weixin.qq.com/s/NnPNkiYoXAwD21Bb3id31g)
56 |
57 | [大模型SFT敲黑板知识点(这次吴恩达老师也帮不了我了)|从零手搓中文大模型|Day08](https://mp.weixin.qq.com/s/_me0CJVrxlQ1Y_JaFfEXhg)
58 |
59 | [说出来你可能不信:0.044B的大模型也能指令遵从呀|从零手搓中文大模型|Day09](https://mp.weixin.qq.com/s/c8FwjnVSr4Il4JYVroWdRQ)
60 |
61 | [手搓了好多天搓累了,歇下来聊聊自己对大模型和人工智能的一些拙见吧|从零手搓中文大模型|中秋特别篇](https://mp.weixin.qq.com/s/vRVhDCPmUybgy5T2jurPiA)
62 |
63 | [只要我的大模型参数量够小,刷数据就再也没有爆显存的烦恼|从零手搓中文大模型|Day11](https://mp.weixin.qq.com/s/K9hnUpQ0mAl0400QCbkgpQ)
64 |
65 | [万万没想到,我被transformers库里这个不负责任的简化代码给整破防了|从零手搓中文大模型|Day12](https://mp.weixin.qq.com/s/GnHxguhtZjh5SiFLU2CGkA)
66 |
67 | [哈哈哈哈果不其然,SFT质量不到位的情况下进行DPO,无异于屎上雕花|从零手搓中文大模型|Day13](https://mp.weixin.qq.com/s/aGpKf4a0iFrIgPqZ0VAotA)
68 |
69 |
70 | ## 踩坑/经验记录
71 |
72 | 这里不光记录自己实践过程中学到的**个人认为比较重要的点**,也会记录一些来自留言区小伙伴的**高质量反馈**,包括我还未来得及去尝试实践的建议。
73 |
74 | 重要性不分先后。
75 |
76 | ### Pretrain
77 |
78 | 1. `learning rate`的选择对模型的收敛效率影响真的很大,尤其是**模型参数**和**数据量**都不是完全参考已有的开源实现而是有很多**自定义**的情况下,学习率就不能迷信已有的经验值,需要自己尝试。例如设置多个`learning rate`,然后训练少量`steps`,观察损失的下降趋势,从而选择一个合适的`learning rate`。
79 |
80 | 2. 无论是垂域还是通用域数据,务必做好数据的**去重**;目前没有确切的研究表明同一条数据被模型学习多少次是合适的,但无论如何,增大两条近似重复数据之间的**距离**总是有益的。
81 |
82 | 3. 如果和我一样想训练一个**小语言模型(SLM)**,`tokenizer`最好是根据自己的数据集专门训练一个,主要是为了减少不必要的`vocabulary`,从而减少`embedding`参数在整个模型中的占比,能有更多的参数用来学习数据本身。
83 |
84 | > 举个例子,在我的故事数据集里其实`6-7k`的词汇量就基本上覆盖了全部的数据了,采用一些开源的`tokenizer`得到的`vocab size`往往至少也有`30k`以上,这样就会导致`embedding`层占用了过大的参数。
85 |
86 | 4. 预训练数据集量级大的时候,一定要做数据`tokenization`的预处理,在训练过程中转`token`是对`GPU`的一种「**侮辱**」。
87 |
88 | ## SFT
89 |
90 | 1. 无论是全参数微调还是`LoRA`,`SFT`首当其冲的**必要条件**是数据集的质量,否则再怎么优化炼丹术也只可能是**garbage in, garbage out**。
91 |
92 | 2. 指令**数据的配比**目前看来对模型的指令遵循能力影响很大(尤其是偏通用能力搭建的场景下),有条件的话可以多做一些不同配比的实验。这次我是纯故事生成场景,只有单一能力要求和垂直数据,所以还没有做这方面的实践尝试。
93 |
94 | 3. `SFT`数据量级较大的时候,的训练**轮数**不宜过多,否则容易导致模型过拟合(当然过拟合总好过欠拟合);相反,数据量级较小的时候,可以适当增加训练轮数让模型学习指令。
95 |
96 | 4. 根据`SFT`领域数据和预训练模型的差异,以及对模型能力最终效果(通用还是纯垂直领域)的期待,需要决策是否**使用SFT数据加入continue pretrain**,以及**SFT阶段是否要混入通用指令数据**。
97 |
98 | 5. 更高级一些的(包括在预训练阶段也是),学习数据的**顺序**对模型效果的影响也很大,甚至会造成**灾难性遗忘**;这个也容易理解,模型学知识和我们人是一样的,先学什么,后学什么,顺序不同,结果也会不同。
99 |
100 | ## RLHF
101 |
102 | 这一部分了解的确实不多,只是跑通了`DPO`的流程,这里记录一下来自**留言区小伙伴**的反馈和建议:
103 |
104 | 1. `offline dpo`无法更新采样,一定是不如`iterative online dpo`的 —— @tomiaoooo。不过后者的实践难度可能会大很多,作为一个个人学习目的主导的实践项目,我可能没有能力去尝试了,后面有理论学习方面的收获的话也尽量分享出来。
105 |
106 | 2. `DPO`这类相比于`PPO`更简单的`RLHF`算法,其实对数据集质量的要求反而更大了 —— @阿白。
107 |
108 | 3. 基座模型比较好的话,`KTO(Model Alignment as Prospect Theoretic Optimization)`的效果不错,甚至可以省去`SFT`阶段,直接用`KTO`进行`RLHF`—— @风飘絮。
109 |
110 | 4. 目前看起来,实际落地的模型测评显示`simpo`表现不错,值得测试 —— @最美的梦给未来的自己。
111 |
112 | 5. `DPO`之类的算法对`SFT`之后的`Instruct Model`的质量有很大依赖,如果`SFT`效果不佳,`DPO`大概起不到预期的效果,甚至可能适得其反。
113 |
114 |
115 | ## 重要参考资料大汇总
116 | `13 Days`的学习实践工程中,我重点参考过的全部资料,包括**技术博客和开源的Repo**,为我的项目顺利走通提供了极大的帮助,强烈推荐给大家,排名不分先后。
117 |
118 | 1. [LLM训练-pretrain](https://zhuanlan.zhihu.com/p/718354385) 知乎大佬`ybq`分享的预训练经验帖,非常详细,强烈推荐当作**八股文**学习背诵。
119 |
120 | 2. [LLM-SFT-trick](https://zhuanlan.zhihu.com/p/682604566) 详细介绍了作者大模型指令微调的实践经验,干货非常多。
121 |
122 | 3. [minimind](https://github.com/jingyaogong/minimind) 一个大佬开源的和我这个类似的「**从零**」构建大模型项目,**中文开放域** + **小参数量级**,从零实现了对话大模型。
123 |
124 | 4. [Lightning-AI/litgpt](https://github.com/Lightning-AI/litgpt/tree/main) 一个轻量级的大模型训练框架,没有复杂的抽象很封装,非常适合`DIY`。
125 |
126 | 5. [jzhang38/TinyLlama](https://github.com/jzhang38/TinyLlama) 基于上面的`litgpt`框架实现的`TinyLlama`,在3万亿`token`数据上训练的`1.1B`参数量模型。
127 |
128 | 6. [zh-babyllama2chinese](https://github.com/DLLXW/baby-llama2-chinese) 一个小参数量(`500M-1B`)的**中文**`Llama2`仓库
129 |
130 | ## 后续计划
131 |
132 | 我个人还是对大模型的**应用**更感兴趣一些,因此后面除了逐渐完成此前一些还没有做过的尝试,我下一步的主要计划是「**从零构建**」一个基于**语言模型(Large or small都可能)**的**应用**,学习实践更多应用层的工程和理论知识。
133 |
134 | 至于具体选择什么样的应用,目前还在绞尽脑汁思索中,如果大家有什么建议也欢迎留言交流哈。
135 |
136 |
--------------------------------------------------------------------------------
/Journey/Day09/Day09.md:
--------------------------------------------------------------------------------
1 | # 从零手搓中文大模型|🚀 Day09
2 |
3 | 微软的`Tinystories`论文里,是直接在200w条`Instruction`数据上做的全量`pretrain`来验证小参数`LLM`的指令遵从效果的。
4 |
5 | 为了挖掘`SLM`的潜力,我想看看在超小规模参数的情况下,少量(相比于`pretrain`)数据的`SFT`是否能起作用。
6 |
7 | (当然还有一个原因是要把`Instruction`数据全通过`GPT API`翻译一遍还是相当贵的😂)。
8 |
9 | ## 全参数SFT训练实验🧪
10 |
11 | 上一期分享了一些`SFT`训练相关的知识点,里面提到了关于训练模式的选择。
12 |
13 | 我的这个项目里,用于`SFT`训练的数据和之前预训练的数据分布是非常相似的,所以这里不打算将`SFT`数据用于`continue pretrain`,而是直接将`SFT`数据用于`finetuning`。
14 |
15 | 由于`SFT`全量`finetuning`其实本质上和`pretrain`没有什么差别,只是在计算`loss`的时候对`prompt`部分做了一个`mask`,所以这里就不对训练参数配置做过多的介绍了。
16 |
17 | > 这里额外提一点,我在上构造的数据基础上做了一个增强的操作(用`GPT API`翻译还是太贵了😂)。
18 | >
19 | > 具体操作是:将上期用吴恩达老师的`translation-agent`翻译构造的数据里的指令部分里的多个约束抽取成了`key: value`,然后随机排列,输出还是故事本身不变,这样就得到了很多新的数据(从之前的1.3w条数据增加到了7.1w条)。
20 | >
21 | > 另外还有一个潜在的好处就是可以让模型知道指令内部的多个约束的顺序是不敏感的,只要输出符合所有指令的约束就可以。
22 |
23 | 我简单地做了几组实验:
24 |
25 | 🟣 `learning_rate = 1e-4, bf16-true`
26 |
27 | 🔴 `learning_rate = 5e-4, bf16-true`
28 |
29 | 🟢 `learning_rate = 5e-4, bf16-true`,但学习率下降比前两者速度更快
30 |
31 | 🔵 `learning_rate = 5e-4, bf16-mixed`,学习率和上一个一样
32 |
33 | 
34 |
35 | > 为了方便观察,图里的曲线都是经过平滑之后的。
36 |
37 | 可以发现几个问题🤔:
38 |
39 | 1. 学习率使用`pretrain`的1/5的时候(`1e-4`),收敛程度不如使用和`pretrain`时一样的`5e-4`。
40 |
41 | 和上一期里搜集的经验描述有些不一致(`SFT`阶段的`learning_rate`使用`pretrain`的1/10的建议)。
42 |
43 | 我个人理解是因为我的`SFT`数据和`pretrain`数据非常相似,且指令相对简单/单一(只是在故事前面加了一些约束文本),所以即使用比较大的学习率也没有出现震荡发散的情况,反而很容易收敛。
44 |
45 | 2. 学习率被设置得下降更快的这一组,收敛速度也更快一些,这个也容易理解:在后期,模型已经非常接近最优解了,这时候学习率下降得快,可以更精细地学习以逼近最优解。
46 | 3. 使用`bf16-mixed`的这一组,收敛速度和前一个差不多,但是loss整体还要更低一些
47 |
48 | ### 结果测试
49 | #### 单一约束
50 |
51 | 我随便构造了几个简单的测试用例,其中的指令都只包含单一的约束。
52 |
53 | 结果如下👇:
54 |
55 |
56 | ```python
57 | from litgpt import LLM
58 | from litgpt.prompts import MicroStories
59 |
60 | ms = MicroStories()
61 | llm = LLM.load(model="../../Experiments/Output/sft/microstories/mask_prompt_5e-4/final")
62 | test_cases = [
63 | {
64 | "instruction": "请用给定的约束生成故事",
65 | "input": "词汇:铲子,草地\n",
66 | },
67 | {
68 | "instruction": "请用给定的约束生成故事",
69 | "input": "特点:转折\n",
70 | },
71 | {
72 | "instruction": "请用给定的约束生成故事",
73 | "input": "摘要:一只小蚂蚁在花园里寻找吃的,最后找到了一个苹果。\n",
74 | },
75 | {
76 | "instruction": "请用给定的约束生成故事",
77 | "input": "随机句子:天空中飘着几朵白云。\n",
78 | },
79 | ]
80 | prompts = [
81 | ms.apply(prompt=case["instruction"], input=case["input"]) for case in test_cases
82 | ]
83 | for prompt in prompts:
84 | text = llm.generate(
85 | prompt=prompt,
86 | max_new_tokens=300,
87 | temperature=0.8,
88 | top_p=0.9,
89 | top_k=30,
90 | )
91 | print(text)
92 | print("-" * 100)
93 | ```
94 | ```text
95 | 从前,有一个大草地。它大得让人惊叹,因为有一群喜欢玩沙子。孩子们会围着草滚来滚去,用铲子在草地上挖沙。
96 | 一天,一个叫莉莉的小女孩决定去玩那个大草地。她拿起铲子开始挖沙。她挖呀挖,直到她发现了一块大石头。她把石头给她的朋友们看,并问能不能用它来挖。
97 | 她的朋友们也挖沙子,但他们挖不出来。然后,他们又开始挖那块石头。突然,莉莉听到了一声巨响。她把沙子挖出来,看到她的朋友们在玩一个玩具。她想起了自己的铲子,微笑着。她知道可以用它来挖沙。
98 | 从那以后,莉莉就爱上了她的大草地和她的铲子。她总是用那块大铲子,确保她的玩具保持安全。每次找到新玩意儿,她都会把它拿出来,用它来挖沙。
99 | ----------------------------------------------------------------------------------------------------
100 | 从前,有一个小男孩。小男孩,他喜欢玩玩具。他喜欢玩玩具,也喜欢和妈妈和爸爸一起玩。
101 | 一天,他看到一只狗。那只狗非常活泼,也想玩耍。他觉得和狗一起玩一定很有趣。
102 | 那只狗的爪子一碰到小水,竟然开始在地上倒水!小男孩非常开心,他捡起水,开始在水面上摇晃。他玩得非常开心,没多久就该把水倒回水里了。小男孩把水倒在地上,狗也跟着他跑。他们玩得特别开心,小男孩说:“谢谢你,小狗,帮了我!”
103 | 小狗用摇晃的水瓶摇晃着,小男孩玩得不亦乐乎。他们玩了很长时间,回家的时候,小男孩和狗都很累。他们都带着灿烂的笑容,小男孩带着他的新朋友小狗,开心地回家。
104 | ----------------------------------------------------------------------------------------------------
105 | 从前,有一只小蚂蚁。蚂蚁在花园里玩耍,发现了一颗好吃的苹果。他吃了苹果,开始感到快乐。
106 | 但随后,蚂蚁看到花园里有一只大狗。狗看到小蚂蚁后,开始追它。
107 | 小蚂蚁感到很害怕。它不知道该怎么办。然后,小蚂蚁听到了他的声音。
108 | 他找到了一些种子,吃了。他感到安全。
109 | 蚂蚁很高兴,感到很满足。他不再害怕狗,继续在花园里享受吃草。
110 |
111 | 故事结束了。
112 | ----------------------------------------------------------------------------------------------------
113 | 从前,有一个小男孩,他感到非常伤心。他想要一些东西来让他的感到快乐,但不知道该怎么做。他看到云朵,他试着想一些特别的东西,但不知道是什么。他环顾四周,看到天空中的星星,感到很快乐。他知道自己想要一些特别的东西。
114 |
115 | 他决定试着让那闪烁的星星消失。他拿起他最喜欢的玩具,一个拼图块。他开始拼这个拼图,拼了很久。他拼了很久,直到拼图拼得整幅画。
116 |
117 | 天空中飘着白云。它们又黑又亮。他感到很开心。他不再感到伤心了,因为他知道闪烁的星星是特别的。
118 |
119 | 小男孩微笑着,心里充满了快乐。然后他知道自己做了一件特别的事情。
120 | ----------------------------------------------------------------------------------------------------
121 | ```
122 |
123 | 可以看到对简单的约束的支持意外地还是不错的:
124 |
125 | **关键词**能完全命中,**转折**虽然很**生硬**,但是看得出来理解了要加入转折。
126 |
127 | 根据**摘要**生成也比较准确,**随机句子**方面没有办法完全包含原句,但是大差不差(感觉完全包含还是有点难为这个尺寸的模型了)。
128 |
129 | #### 组合约束
130 | 再来看看组合约束的效果👇:
131 |
132 |
133 | ```python
134 | test_cases = [
135 | {
136 | "instruction": "请用给定的约束生成故事",
137 | "input": "词汇:铲子,草地\n特点:转折\n",
138 | },
139 | {
140 | "instruction": "请用给定的约束生成故事",
141 | "input": "词汇:铲子,草地\n摘要:一只小蚂蚁在花园里寻找吃的,最后找到了一个苹果。\n",
142 | },
143 | {
144 | "instruction": "请用给定的约束生成故事",
145 | "input": "词汇:铲子,草地\n随机句子:天空中飘着几朵白云。\n摘要:一只小蚂蚁在花园里寻找吃的,最后找到了一个苹果。\n",
146 | },
147 | ]
148 | prompts = [
149 | ms.apply(prompt=case["instruction"], input=case["input"]) for case in test_cases
150 | ]
151 | for prompt in prompts:
152 | text = llm.generate(
153 | prompt=prompt,
154 | max_new_tokens=300,
155 | temperature=0.8,
156 | top_p=1,
157 | top_k=30,
158 | )
159 | print(text)
160 | print("-" * 100)
161 | ```
162 | ```text
163 | 一天,一个名叫蒂姆的男孩去了公园。他看到一个标志。标志上写着:“今天今天我们要去外面用铲子玩。”蒂姆非常高兴,因为他喜欢铲子。他觉得挖个大洞会很有趣。
164 | 蒂姆开始用铲子挖土。他挖呀挖,挖出了一个大洞。沙子让他感到很累,但他在地下埋了虫子和石头。他非常喜欢这个公园,想要找到更多可以玩的东西。
165 | 然后,突然发生了意外的事情。一个大盒子从公园的盖子开了它开进了公园。蒂姆感到非常惊讶。他打开盒子,发现里面有一只小虫子。虫子没有死,它只是想和蒂姆一起玩。他们在公园里一起玩得非常开心。
166 | ----------------------------------------------------------------------------------------------------
167 | 从前,有一只小蚂蚁住在一个大花园里。这个花园很大,有很多草和树。小蚂蚁喜欢到处跑和探索。
168 | 一天,小蚂蚁想要找到一些美味的食物。于是,小蚂蚁开始寻找吃的。小蚂蚁在土里挖呀挖,直到找到了一些苦涩的苹果。苹果太美味了!
169 | 小蚂蚁高兴得跑回去给妈妈看。妈妈也喜欢这些苹果。他们坐在花园里,一起吃苹果。小蚂蚁为自己找到了吃的而感到无比自豪。
170 | ----------------------------------------------------------------------------------------------------
171 | 从前,有一只小蚂蚁住在一个大花园里。这个花园里有许多蚂蚁在花园里努力工作,挖土。一天,这只小蚂蚁饿得不行。
172 | 突然,小蚂蚁看到一朵朵下有一片闪亮的大白云。小蚂蚁心里想:“那是什么东西?”小蚂蚁继续行进,发现那是一棵苹果树。小蚂蚁吃了苹果,感到很开心。
173 | 过了一会儿,小蚂蚁回到了小花园。小蚂蚁为找到这么好的一个家感到自豪。小蚂蚁四处游荡,给所有蚂蚁朋友看了这棵树。他们都微笑着,玩得特别开心。完。
174 | ----------------------------------------------------------------------------------------------------
175 | ```
176 |
177 |
178 | 混合约束的难度明显上升了,虽然看得出模型在努力地理解指令,但是结果并不理想。
179 |
180 | 一方面可能我的`base`模型训练得可能还不够充分,另一方面`SFT`数据量少了。
181 |
182 | 对于`SFT`之后模型生成的连贯性和逻辑性出现明显下降的问题,简单地检索了一下,一个可能的优化方法是在`SFT`数据里加入一些`pretrain`里的数据,这种做法称为`Replay`。
183 |
184 | 时间有限还没来得及尝试,等后面有时间了可以试试,在之后的更新里同步分享结果给大家吧。
185 |
186 | ## LORA微调⌛
187 |
188 | 我也尝试了在`SFT`数据上用`LORA`微调,发现效果并不好,loss下降得很慢,且远高于`SFT`全量微调的loss。
189 |
190 | 
191 |
192 | 如上图,黄色🟡的是全量微调的loss,红色🔴的是`LORA`微调的loss,这里虽然只有两条,但实际上我尝试了不少`learning rate`和其他参数的组合,但结果都差不多。
193 |
194 | 我猜测是因为模型太小了,用`Lora`微调时候使用较小的`r`和`alpha`,可训练参数量就更小,所以效果不好。
195 |
196 | 于是我试了下将`Lora`的`r`和`alpha`调大(🟠从`8_16`调到`256_512`),发现效果好了不少,loss下降得更快了,但收敛速度还是要**远远慢于**全量微调。
197 |
198 | 这时候的可训练参数量级已经接近`22M`,正好是模型自身的一半了,效果变好也是理所当然的,但这样显然已经失去了`LORA`微调的意义。
199 |
200 | > 关于`Lora`的正常使用,后面等有机会训练一个更大的`base model`的时候再尝试吧。
201 |
202 | ## 小结
203 | 1. 分享了`SFT`全量微调的一些实验结果
204 | 2. 测试了一下`SFT`全量微调之后的指令遵循效果
205 | 3. 分享了用`LORA`微调的一些实验结果
206 |
--------------------------------------------------------------------------------
/Journey/Day13/Day13.md:
--------------------------------------------------------------------------------
1 |
7 |
8 | 之前学习的时候就有所耳闻,即便是比`RLHF`简化了很多的`DPO`,想要训练好也不是那么容易的。
9 |
10 | 实际试了一下,当`SFT`模型质量不高时,果然是**屎上雕花**,`DPO`之后的效果还不如`SFT`。
11 |
12 | 尽管如此,毕竟还是走通了流程,还是值得记录一下。
13 |
14 | ## DPO实现
15 |
16 | 在经历了上期说到的`transformers`库的**巨坑**之后,我重新进行了一次`pretrain`,并在此基础上进行了`SFT`。
17 |
18 | 这次终于将`litgpt`得到的模型`checkpoint`转换为`Hugging Face`的模型格式并成功加载了。
19 |
20 | 然后之前通过并行的方式构建了约`15000`条`DPO`数据,于是开始了`DPO`的训练。
21 |
22 | 基于`trl`库的`DPOTrainer`,训练脚本的实现非常容易,直接贴在这里了:
23 |
24 |
25 | ```python
26 | import os
27 | import click
28 |
29 | os.environ["CUDA_VISIBLE_DEVICES"] = "0"
30 |
31 | import torch
32 | from transformers import AutoModelForCausalLM, AutoTokenizer
33 | from trl import DPOTrainer
34 | from trl import DPOConfig
35 | from datasets import load_dataset
36 | from litgpt.utils import num_parameters
37 |
38 |
39 | def find_all_linear_names(model):
40 | cls = torch.nn.Linear
41 | lora_module_names = set()
42 | for name, module in model.named_modules():
43 | if isinstance(module, cls):
44 | names = name.split(".")
45 | lora_module_names.add(names[0] if len(names) == 1 else names[-1])
46 |
47 | if "lm_head" in lora_module_names:
48 | lora_module_names.remove("lm_head")
49 | return list(lora_module_names)
50 |
51 |
52 | def init_model(model_name_or_path, device="cuda:0"):
53 | model = AutoModelForCausalLM.from_pretrained(
54 | model_name_or_path,
55 | )
56 | tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
57 | tokenizer.pad_token = tokenizer.eos_token
58 | print(f"Total parameters: {num_parameters(model):,}")
59 | model = model.to(device)
60 | return model, tokenizer
61 |
62 |
63 | @click.command()
64 | @click.option("--model_name_or_path", type=str)
65 | def main(model_name_or_path):
66 | model, tokenizer = init_model(model_name_or_path)
67 | dpo_config = DPOConfig(
68 | output_dir="../../Experiments/Output/dpo/microstories_lora_v2",
69 | per_device_train_batch_size=16,
70 | remove_unused_columns=False,
71 | num_train_epochs=2,
72 | learning_rate=1e-5,
73 | do_eval=True,
74 | eval_strategy="steps",
75 | eval_steps=200,
76 | save_steps=200,
77 | logging_steps=10,
78 | )
79 |
80 | data_files = {
81 | "train": "../../Data/TinyStoriesInstruct/dpo_data_train.json",
82 | "eval": "../../Data/TinyStoriesInstruct/dpo_data_eval.json",
83 | }
84 | dataset_dpo = load_dataset("json", data_files=data_files)
85 |
86 | dpo_trainer = DPOTrainer(
87 | model,
88 | ref_model=None,
89 | args=dpo_config,
90 | beta=0.1,
91 | train_dataset=dataset_dpo["train"],
92 | eval_dataset=dataset_dpo["eval"],
93 | tokenizer=tokenizer,
94 | max_length=512,
95 | max_prompt_length=512,
96 | )
97 | dpo_trainer.train()
98 |
99 |
100 | if __name__ == "__main__":
101 | main()
102 | ```
103 |
104 | 基于上面的实现,跑起来非常容易,没有遇到什么问题。
105 |
106 | `DPO`这块儿的**炼丹**我确实没什么经验,这里也就不随便发表什么意见了;等后续深入学习之后再来补充。
107 |
108 | 训练过程中的指标波动比较大,简单贴个图:
109 |
110 | 
111 |
112 | `DPO`的原理细节这里就不展开了,大家可以自行参考论文和开源的代码实现。
113 |
114 | 其实不论是`loss type`层面还是各种变体的实现,还有很多可以测试的点,但我时间有限,还没来得及做丰富的测试,后面有机会也一定补上。
115 |
116 | 训练完之后,我随便取了几个样本跑了一下:
117 |
118 | 1. 如很多网上分享的经验一样,`DPO`对数据的质量和`SFT`模型的质量要求都很高,我的场景里这两条件都不是非常理想,所以效果不是很好也在预期之内
119 |
120 | 2. 和`SFT`一样,训练轮次不宜过多,`SFT`只是过拟合,而`DPO`是越往后训练,模型能力反而出现退化,已经开始胡言乱语了。。。(`SFT`模型的指令遵循效果虽然表现一般,但至少生成结果是连贯的)
121 |
122 |
123 |
124 | ```python
125 | import torch
126 | import json
127 | import transformers
128 | from transformers import AutoModelForCausalLM, AutoTokenizer
129 | from litgpt.prompts import Phi2
130 |
131 | path = "../../Experiments/Output/dpo/microstories_lora_v2/checkpoint-300"
132 | prompt_style = Phi2()
133 | model_sft = AutoModelForCausalLM.from_pretrained(
134 | "../../Experiments/Output/sft/microstories_v2/bf16_true_1e-4/saved_by_tf"
135 | )
136 | model_hf = AutoModelForCausalLM.from_pretrained(path)
137 | tokenizer = AutoTokenizer.from_pretrained(path)
138 | model_hf.generation_config.pad_token_id = tokenizer.eos_token_id
139 | model_sft.generation_config.pad_token_id = tokenizer.eos_token_id
140 | pipeline_sft = transformers.pipeline(
141 | "text-generation",
142 | model=model_sft,
143 | torch_dtype=torch.bfloat16,
144 | device="cuda",
145 | tokenizer=tokenizer,
146 | )
147 |
148 | pipeline_dpo = transformers.pipeline(
149 | "text-generation",
150 | model=model_hf,
151 | torch_dtype=torch.bfloat16,
152 | device="cuda",
153 | tokenizer=tokenizer,
154 | )
155 |
156 |
157 | def generate_text(prompt, pipeline, tokenizer):
158 | sequences = pipeline(
159 | prompt,
160 | do_sample=True,
161 | top_k=50,
162 | top_p=0.5,
163 | num_return_sequences=1,
164 | eos_token_id=tokenizer.eos_token_id,
165 | max_new_tokens=400,
166 | )
167 |
168 | return sequences[0]["generated_text"]
169 |
170 |
171 | sft_data = json.load(
172 | open("../../Data/TinyStoriesInstruct/sft_data_v2_simple_few.json", "r")
173 | )
174 | ```
175 |
176 | ## 随便取个样本试试看
177 |
178 |
179 | ```python
180 | data_index = 10001
181 | prompt = prompt_style.apply(sft_data[data_index]["instruction"])
182 | print(
183 | "DPO:\n",
184 | generate_text(prompt, pipeline_dpo, tokenizer),
185 | )
186 | print("-" * 100)
187 | print(
188 | "SFT:\n",
189 | generate_text(prompt, pipeline_sft, tokenizer),
190 | )
191 | print("-" * 100)
192 | print("Ground Truth:\n", sft_data[data_index]["output"])
193 | ```
194 |
195 | ```
196 | DPO:
197 | Instruct: 词汇:挤压,章鱼,兴奋
198 | 摘要:莉莉在海滩上发现了一只紫色的章鱼,和它玩,然后把它放回海里。
199 | Output:从前,有个小女孩叫莉莉。她喜欢在海滩的沙子里玩耍。一天,她看到一只紫色的章鱼在海底深处游泳。
200 | “你好呀,小章鱼!”莉莉兴奋地说。“你想和我玩吗?”
201 | 章鱼没有回答,只是继续游走。莉莉跟着它,惊讶地发现海滩好像很大,到处都是大浪。
202 | “我不知道自己能不能移动,”莉莉建议。“我太小了,不能和章鱼玩。”
203 | 但章鱼依然沉着,游动的本领可爱。最后,莉莉决定把章鱼放回海里,跟它说再见。当她走开时,章鱼突然再次出现,这次还挤着她!
204 | 莉莉惊讶地看到章鱼躲在一块石头后面,他们在海滩上一起欢笑玩耍。从那天起,莉莉总是期待在海滩上看到紫色章鱼,和新朋友一起玩。
205 | ----------------------------------------------------------------------------------------------------
206 | SFT:
207 | Instruct: 词汇:挤压,章鱼,兴奋
208 | 摘要:莉莉在海滩上发现了一只紫色的章鱼,和它玩,然后把它放回海里。
209 | Output:从前,有个小女孩叫莉莉。她喜欢在海滩上玩耍和捡贝壳。一天,她在沙子里发现了一只大紫色的章鱼。它有长长的触手,莉莉兴奋地想和它玩。
210 | 莉莉轻轻地捡起章鱼,紧紧握在手里。但随后,她感到有点累,决定在沙子里打个盹。她把章鱼放在身边,闭上了眼睛。
211 | 当莉莉醒来时,章鱼还在那儿。她睁开眼睛,看到章鱼在她的手中。她微笑着说:“谢谢你陪我玩,章鱼!”然后,她把章鱼放回沙子里,让它回家。莉莉向章鱼挥手告别,高高兴兴地回家了,交到了一个新朋友。
212 | ----------------------------------------------------------------------------------------------------
213 | Ground Truth:
214 | 从前,有一个快乐的小女孩叫莉莉。她喜欢在海滩上玩耍,寻找沙子里的宝藏。一天,她发现了一只大而软绵绵的章鱼!它是紫色的,长着长长的触手。莉莉看到它非常兴奋!
215 | 她轻轻地捡起章鱼,给了它一个拥抱。她喜欢捏它的感觉。章鱼似乎并不介意,甚至用触手缠绕住莉莉的手臂。他们一起玩了一会儿,但莉莉知道是时候让章鱼放回海里了。
216 | 看着它游走时,莉莉感到有点伤心,但也为能遇到这么有趣的生物而感到高兴。她知道那天在海滩上发现章鱼的事会永远记在心里。
217 | ```
218 |
219 | 可以看到上面`DPO`里的故事里已经出现很多语法错误和严重的逻辑错误了。
220 |
221 | 不过没关系,在小尺寸的模型上,这类尝试本来就是一个探索,跑通流程就已经能学到很多东西了。
222 |
223 | 不过无论如何,我的**从零手搓中文大模型**之旅到这里也算是阶段性地告一段落了。
224 |
225 | ## 小结一下
226 |
227 | 接下来自己大概有这么几个计划:
228 |
229 | 1. 尝试一下`DPO`的变体以及其他的参数配置,多做一些实验
230 |
231 | 2. 将自己这段时间**从零手搓**过程中遇到的各种问题、经验、教训等等都整理一下,系统地记录下来
232 |
233 | 3. 时间和条件允许的话,在更通用更大的数据集上(或者相反,一个更垂直的领域上)来做更细致的实现
234 |
235 |
236 |
--------------------------------------------------------------------------------
/Journey/Day11/Day11.md:
--------------------------------------------------------------------------------
1 | # 从零手搓中文大模型|🚀Day11
2 |
3 | 之前已经把`SFT`阶段给跑通了,尽管整体效果差强人意,但至少证明在这么小的参数量级上也是可行的。
4 |
5 | 接下来我继续尝试一下`DPO`阶段,但是首先依然得**搞数据**。
6 |
7 | ## DPO数据构造
8 |
9 | `DPO`数据主要是需要获得`rejected`和`chosen`的数据对。
10 |
11 | `chosen`的数据很好说,直接使用`SFT`数据里的`response`即可。
12 |
13 | 而`rejected`的数据其实就是就是回答质量相对较差的数据,很容易就能想`SFT`之后的模型根据`prompt`给出的`response`肯定是质量低于`ground truth`的,天然就可以作为`rejected`的数据。
14 |
15 | 构造路径倒是很容易,但是根据之前跑生成的经验,单条`prompt`数据生成`response`的时间大概在0.5秒左右,如果使用`SFT`数据全量(在我机制的数据增强之下从1.5w变成了7w多)生成`DPO`数据,那么可能需要10小时左右的时间。
16 |
17 | 那么并发生成就显得尤为重要,可行的方法有两种:
18 | 1. 加载多个模型的实例,将数据均等切分成多个`chunks`每个模型生成一部分数据,最后再合并。
19 | 2. 将模型部署成`API`接口,使用`aiohttp`异步请求。
20 |
21 | > 其实应该同时用上`batch inference`,但`litgpt`库这块的`feature`还在开发中,我自己魔改担心搞不定,就先不尝试了。
22 |
23 | 显然后者的稳定性会更好,那么话不多说,直接上代码👇:
24 |
25 |
26 | ```python
27 | import asyncio
28 | import aiohttp
29 | import json
30 | import argparse
31 | import hashlib
32 | import time
33 | import atexit
34 | from tqdm import tqdm
35 | from litgpt.prompts import MicroStories
36 | from loguru import logger
37 |
38 |
39 | def hash_prompt(prompt):
40 | return hashlib.md5(prompt.encode()).hexdigest()
41 |
42 |
43 | cache = {}
44 | error_cache = {}
45 |
46 |
47 | def save_caches():
48 | with open("dpo_cache.json", "w", encoding="utf-8") as f:
49 | json.dump(cache, f, ensure_ascii=False, indent=2)
50 | with open("error_cache.json", "w", encoding="utf-8") as f:
51 | json.dump(error_cache, f, ensure_ascii=False, indent=2)
52 | logger.info("缓存已保存")
53 |
54 |
55 | atexit.register(save_caches)
56 |
57 |
58 | async def generate_response(session, prompt, semaphore):
59 | prompt_hash = hash_prompt(prompt)
60 | if prompt_hash in cache:
61 | return cache[prompt_hash]
62 |
63 | async with semaphore:
64 | try:
65 | async with session.post(
66 | "http://127.0.0.1:8000/predict", json={"prompt": prompt}
67 | ) as response:
68 | result = await response.json()
69 | cache[prompt_hash] = result
70 | return result
71 | except Exception as e:
72 | error_msg = f"生成响应时出错: {str(e)}"
73 | logger.error(error_msg)
74 | error_cache[prompt_hash] = error_msg
75 | return None
76 |
77 |
78 | async def main(concurrency, test_mode):
79 | global cache, error_cache
80 | ms = MicroStories()
81 |
82 | with open(
83 | "../../Data/TinyStoriesInstruct/sft_data_v2.json", "r", encoding="utf-8"
84 | ) as f:
85 | sft_data = json.load(f)
86 |
87 | if test_mode:
88 | sft_data = sft_data[:100]
89 |
90 | # 读取缓存
91 | try:
92 | with open("dpo_cache.json", "r", encoding="utf-8") as f:
93 | cache = json.load(f)
94 | except FileNotFoundError:
95 | cache = {}
96 |
97 | try:
98 | with open("error_cache.json", "r", encoding="utf-8") as f:
99 | error_cache = json.load(f)
100 | except FileNotFoundError:
101 | error_cache = {}
102 |
103 | semaphore = asyncio.Semaphore(concurrency)
104 |
105 | async with aiohttp.ClientSession() as session:
106 | tasks = []
107 | for i, case in enumerate(tqdm(sft_data, desc="生成DPO数据")):
108 | prompt = ms.apply(prompt=case["instruction"], input=case["input"])
109 | task = asyncio.create_task(generate_response(session, prompt, semaphore))
110 | tasks.append(task)
111 |
112 | # 每处理100个样本保存一次缓存
113 | if (i + 1) % 100 == 0:
114 | save_caches()
115 |
116 | responses = await asyncio.gather(*tasks)
117 |
118 | dpo_data = []
119 | for case, response in zip(sft_data, responses):
120 | prompt = ms.apply(prompt=case["instruction"], input=case["input"])
121 | dpo_sample = {
122 | "prompt": prompt,
123 | "rejected": response.get("output") or response.get("rejected"),
124 | "chosen": case["output"],
125 | }
126 | dpo_data.append(dpo_sample)
127 |
128 | # 保存错误缓存
129 | save_caches() # 最后再保存一次缓存
130 |
131 | output_file = "dpo_data_test.json" if test_mode else "dpo_data.json"
132 | with open(output_file, "w", encoding="utf-8") as f:
133 | json.dump(dpo_data, f, ensure_ascii=False, indent=2)
134 |
135 | logger.info(f"DPO数据已生成并保存到 {output_file}")
136 | logger.info(f"缓存已更新并保存到 dpo_cache.json")
137 | logger.info(f"错误缓存已保存到 error_cache.json")
138 |
139 | end_time = time.time()
140 | execution_time = end_time - start_time
141 | logger.info(f"总执行时间: {execution_time:.2f} 秒")
142 |
143 |
144 | if __name__ == "__main__":
145 | parser = argparse.ArgumentParser(description="生成DPO数据")
146 | parser.add_argument("--concurrency", type=int, default=10, help="并发数量")
147 | parser.add_argument("--test", action="store_true", help="测试模式")
148 | args = parser.parse_args()
149 |
150 | logger.add("generate_dpo_data.log", rotation="500 MB")
151 | start_time = time.time()
152 | asyncio.run(main(args.concurrency, args.test))
153 | ```
154 |
155 | 上面的脚本做了这样几件事:
156 | 1. 构建了一个`generate_response`的函数,用于根据`prompt`生成`response`
157 | 2. 对上面的函数做了异步调度,可以控制并发数量来生成`response`
158 | 3. 设置了对已经生成的样本的结果的缓存以及异常样本的缓存(每100个样本保存一次,且如果脚本异常退出`atexit`会自动保存)
159 | 4. 最后将`SFT`数据和生成的`response`进行拼接,得到最终的`DPO`数据。
160 |
161 |
162 | ```python
163 | # ! python generate_dpo_data.py --concurrency 25
164 | ```
165 |
166 | 聪明的你肯定会问了:异步调度啥的倒是都有了,**可我哪儿来的接口呢?**
167 |
168 | 其实`litgpt`库同时也提供了模型的`serving`功能,只要安装了额外的`litserve`依赖,就可以一键部署:
169 |
170 |
171 | ```python
172 | # ! litgpt serve out/custom-model/final
173 | ```
174 |
175 | 不过这样得到的服务是单实例的,无法满足我们批量刷数据的需求。
176 |
177 | 大家别忘了,我们的模型尺寸只有`0.044B`,显存占用才`600M`,这意味着我们在一张卡上可以轻松部署多个实例。
178 |
179 | 其实`litserve`是支持多`workers`的,不过在`litgpt`库集成的时候没有暴露出参数,问题不大,我们自己基于[litgpt里的serve.py](https://github.com/Lightning-AI/litgpt/blob/main/litgpt/deploy/serve.py)魔改一下就好了。
180 |
181 | 代码太长这里就不完整地贴出了,感兴趣的可以看[这里](https://github.com/puppyapple/Chinese_LLM_From_Scratch/blob/main/Journey/Day11/service.py)。
182 |
183 | 修改其实很简单,就是把`workers_per_device`参数暴露了出来,这样就可以在启动服务的时候指定`workers_per_device`的值了。
184 |
185 |
186 | ```python
187 | @click.command()
188 | @click.option("--checkpoint_dir", type=str)
189 | @click.option("--quantize", type=str, default=None)
190 | @click.option("--precision", type=str, default="bf16-true")
191 | @click.option("--temperature", type=float, default=0.8)
192 | @click.option("--top_k", type=int, default=50)
193 | @click.option("--top_p", type=float, default=1.0)
194 | @click.option("--max_new_tokens", type=int, default=50)
195 | @click.option("--devices", type=int, default=1)
196 | @click.option("--workers_per_device", type=int, default=20)
197 | @click.option("--port", type=int, default=8000)
198 | @click.option("--stream", type=bool, default=False)
199 | @click.option("--accelerator", type=str, default="auto")
200 | def run_server(
201 | checkpoint_dir: Path,
202 | quantize: Optional[
203 | Literal["bnb.nf4", "bnb.nf4-dq", "bnb.fp4", "bnb.fp4-dq", "bnb.int8"]
204 | ] = None,
205 | precision: Optional[str] = None,
206 | temperature: float = 0.8,
207 | top_k: int = 50,
208 | top_p: float = 1.0,
209 | max_new_tokens: int = 50,
210 | devices: int = 1,
211 | port: int = 8000,
212 | accelerator: str = "auto",
213 | workers_per_device: int = 20,
214 | stream: bool = False,
215 | access_token: Optional[str] = None,
216 | ) -> None:
217 | # ...
218 | pass
219 |
220 |
221 | if __name__ == "__main__":
222 | run_server()
223 | ```
224 |
225 | 我设置了`25`个`workers`,然后生成的脚本配置了`--concurrency 25`。
226 |
227 | 运行时的整体`GPU`占用是`20G`左右。
228 |
229 | 
230 |
231 | 截止写这篇文章,数据还在运行中,具体耗时多久等我跑完了在同步给大家。
232 |
233 | > 另外我调研的时候发现`litserve`的`batch inference`其实已经支持了,后面有时间尝试一下,如果有效会更新到项目里。
234 | > 仓库里我也同时提供了单模型和多模型实例来跑数据的脚本。
235 | >
236 | ## 小结
237 |
238 | 今天的内容其实很简单,就是构造了`DPO`数据,并且通过异步请求的方式提高了数据构造的效率。
239 |
240 | 等数据跑完了我会着手进行`DPO`的训练。
241 |
242 | 由于`litgpt`库自身还不支持`DPO`,所以这部分需要完全自己`DIY`了,可能会稍微费点劲,请大家拭目以待!
243 |
244 |
245 |
--------------------------------------------------------------------------------
/Journey/Day05/Day05.md:
--------------------------------------------------------------------------------
1 |
7 | # 从零手搓中文大模型|🚀 Day05
8 |
9 | ## 模型预训练完啦 🎉
10 |
11 | 在**Day 04**的内容里已经介绍过了我的参数配置,在这个配置下呢我训练了`200k step`。
12 |
13 | 由于数据集比较小,参数量级也不大,在这个步数上`validation loss`的下降已经非常缓慢了,所以我停止了训练。
14 |
15 | `wandb`的曲线如下:
16 |
17 | 
18 |
19 | 每`1000 step`保存一次模型,所以现在我已经有`200`多个模型了。
20 | 然后看看最后几个模型文件👇:
21 |
22 |
23 | ```python
24 | ! ls ../../Experiments/Output/pretrain/microstories | tail -5
25 | ```
26 |
27 | ```
28 | step-00205000
29 | step-00206000
30 | step-00207000
31 | step-00208000
32 | step-00209000
33 | ```
34 |
35 |
36 | ## 让我们看看模型效果吧 🥳
37 |
38 | ### 模型inference测试
39 | 直接使用[`litgpt.api`里的代码](https://github.com/Lightning-AI/litgpt/blob/main/litgpt/api.py),我们用第一个`checkpoint`来尝试生成一些文本。
40 |
41 |
42 | ```python
43 | from litgpt import LLM
44 |
45 | llm = LLM.load(model="../../Experiments/Output/pretrain/microstories/step-00001000")
46 | llm.generate(
47 | prompt="汤姆和杰瑞是好朋友,",
48 | max_new_tokens=500,
49 | temperature=0.8,
50 | top_p=0.9,
51 | top_k=30,
52 | )
53 | ```
54 | ```text
55 | 他们喜欢一起玩。有一天,他们在公园里发现了一个大箱子。他们想看看里面有什么。
56 | ```
57 |
58 | 可以看到训练了`1000 steps`的模型已经可以生成一些连贯的文本了,但是长度非常短。
59 |
60 | 看一眼`0.044B`模型的显存占用:
61 |
62 | 
63 |
64 | 毕竟只有`44M`参数,`GPU`占用连`650M`都不到。
65 |
66 | ### 批量测试
67 | 我接下来从200多个`checkpoints`中每20个选一个,来测试一下效果。
68 |
69 |
70 | ```python
71 | import gc
72 |
73 | prompt = "汤姆和杰瑞是好朋友,"
74 | for i in range(20, 220, 20):
75 | llm = LLM.load(
76 | model=f"../../Experiments/Output/pretrain/microstories/step-{i*1000:08d}"
77 | )
78 | print(f"step-{i*1000:08d}")
79 | print("-" * 13)
80 | result = llm.generate(
81 | prompt=prompt,
82 | max_new_tokens=500,
83 | temperature=0.8,
84 | top_p=0,
85 | top_k=30,
86 | )
87 | result = prompt + "\n".join(filter(lambda x: x.strip(), result.split("\n")))
88 | print(result)
89 | print("*" * 100)
90 | print("\n")
91 | del llm
92 | gc.collect()
93 | ```
94 |
95 | ```text
96 | step-00020000
97 | -------------
98 | 汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们在公园里发现了一个大箱子。他们不知道里面有什么。他们想打开它看看里面有什么。
99 | “我们打开箱子吧!”汤姆说。杰瑞同意了。他们试图打开箱子,但太难了。他们推拉,但箱子没有打开。他们很伤心。
100 | 然后,他们看到一个高大的男人。他戴着一顶大帽子,穿着长外套。他看到汤姆和杰瑞,微笑了。
101 | “你们好,孩子们。你们想要个礼物吗?”他问。
102 | “是的,请!”汤姆和杰瑞说。
103 | “你们想要什么?”男人问。
104 | “你们想要什么?”汤姆和杰瑞问。
105 | “你们想要什么?”男人问。
106 | “你们想要什么?”汤姆和杰瑞问。
107 | 男人想了一下。他喜欢汤姆和杰瑞。他们喜欢他。
108 | “你们想要什么?”男人问。
109 | “你们想要什么?”汤姆和杰瑞问。
110 | 男人想了一下。他喜欢汤姆和杰瑞。他们很好奇。
111 | “你们想要什么?”男人问。
112 | “你们想要一个玩具。一个球。一个球。你们想要一个球。你们想要一个球吗?”男人问。
113 | 汤姆和杰瑞瑞点点头。他们喜欢球。
114 | 男人给了他们一个球。它很软,弹跳得很高。汤姆和杰瑞很高兴。他们感谢了男人。
115 | 男人微笑着。他很高兴他们喜欢这个礼物。他喜欢这个礼物。
116 | 汤姆和杰瑞也很高兴。他们有了一个新朋友。他们有了新玩具。他们有了新朋友。他们有了新的玩具。他们有了新的玩具。他们有了新的朋友。他们很开心。
117 | ****************************************************************************************************
118 |
119 |
120 | step-00040000
121 | -------------
122 | 汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们在公园里发现了一个大箱子。他们想看看里面有什么东西。
123 | “我们打开看看吧!”汤姆说。
124 | “好的!”杰瑞说。
125 | 他们试图打开箱子,但太难了。他们推拉了一下,但箱子没有打开。他们很伤心,也很累。
126 | “也许我们可以用棍子打开它。”汤姆说。
127 | 他找到一根棍子,试图打开箱子。但是棍子太短了,打不开。他试了又试,但棍子就是打不开。
128 | “也许我们可以用棍子打开箱子。”杰瑞说。
129 | 他找到一根棍子,试图打开箱子。但棍子太短了,打不开。他试了又试,但棍子就是打不开。
130 | “也许我们需要一个工具。”汤姆说。
131 | 他四处张望,看到地上有一根棍子。他捡起来,用它砸向箱子。
132 | “哎哟!”汤姆说。
133 | 他放下棍子,看着箱子。它又大又重,盖子也打不开。
134 | “也许我们可以用这个棍子打开箱子。”汤姆说。
135 | 他捡起一根棍子,扔向箱子。棍子打中了箱子,发出很大的响声。
136 | “砰!砰!”箱子破了。
137 | 汤姆和杰瑞瑞都笑了。他们觉得很有趣。
138 | “看,我们成功了!”汤姆说。
139 | “我们打开了箱子!”杰瑞说。
140 | 他们跑向箱子,试图打开它。
141 | 但是箱子太重了。他们打不开。
142 | 他们听到一声巨响。
143 | “砰!”箱子破了。
144 | 他们看着箱子,看到箱子破了。
145 | 他们很伤心。
146 | 他们看着彼此。
147 | 他们拥抱了一下,说:“对不起。”
148 | 他们决定一起玩箱子。他们用箱子做了一个房子。他们用箱子做了一个门和一个窗户。他们用箱子做了一个门和一个窗户。
149 | 他们很高兴。
150 | 他们说:“我们爱你们。”
151 | 他们说:“我们爱你们。”
152 | 他们说:“我们爱。”
153 | 他们玩得很开心。
154 | ****************************************************************************************************
155 |
156 |
157 | step-00060000
158 | -------------
159 | 汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们决定去冒险。
160 | 他们走啊走,直到发现一棵大树。汤姆说:“我们爬上这棵树吧!”杰瑞说:“好的,但要小心!”于是,汤姆和杰瑞开始爬树。他们越爬越高,直到到达一个鸟巢。
161 | 在鸟巢里,他们发现了一个大蛋。汤姆说:“哇,看看这个蛋!它好大啊!”杰瑞说:“我们把它带回家吧!”于是,他们把蛋带回了鸟巢。
162 | 但是当他们回到家时,发现蛋不见了!汤姆和杰瑞很伤心。他们到处找蛋,但找不到。然后,他们听到一声响动。他们看到蛋在动!蛋裂开了,一只小鸟出来了。小鸟说:“谢谢你们把我吵醒!”汤姆和杰瑞很高兴,他们交了一个新朋友。
163 | ****************************************************************************************************
164 |
165 |
166 | step-00080000
167 | -------------
168 | 汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们发现了一个大箱子。他们想看看里面有什么。
169 | 汤姆说:“我们打开箱子吧!” 杰瑞同意了,于是他们打开了箱子。里面有很多玩具。他们非常高兴,开始玩这些玩具。
170 | 但是,接下来发生了一件意想不到的事情。这些玩具开始说话了!玩具们说:“你们好,汤姆和杰瑞!我们是魔法玩具。我们来给你们一个惊喜!” 汤姆和杰瑞非常惊讶,但他们也很兴奋。他们和魔法玩具们一起玩了一整天,度过了很多快乐时光。
171 | ****************************************************************************************************
172 |
173 |
174 | step-00100000
175 | -------------
176 | 汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们决定去公园野餐。他们带了一些三明治、水果和果汁。
177 | 当他们到达公园时,发现了一个大而可怕的森林。他们很害怕,但他们想探索一下。他们走了又走,直到发现一棵大树。他们爬上树,看到了一个鸟巢。他们想看看里面有什么,于是伸手去拿。
178 | 突然,他们听到一声巨响。是一只熊!熊生气了,开始追赶他们。汤姆和杰瑞跑得很快,但熊跑得更快。他们跑啊跑,但熊跑得更快。他们试图躲起来,但熊找到了他们。他们非常害怕,不知道该怎么办。
179 | 熊越来越近,他们不知道该怎么办。他们试图呼救,但没有人听到。熊吃了他们,然后他们就再也没有出现过。结束。
180 | ****************************************************************************************************
181 |
182 |
183 | step-00120000
184 | -------------
185 | 汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们决定去公园野餐。他们带了三明治、水果和饼干。
186 | 当他们到达公园时,他们看到一个大牌子上面写着“禁止进入”。汤姆和杰瑞很伤心,因为他们想玩,但又不希望违反规定。他们决定偷偷溜进公园,玩捉迷藏游戏。
187 | 在玩捉迷藏时,他们听到一声巨响。是一只大狗!狗追着他们,他们跑得很快。他们试图逃跑,但狗跑得太快了。突然,他们看到一个写着“禁止进入”的标志。他们很害怕,不知道该怎么办。
188 | 就在这时,一位好心的女士看到了他们,过来帮助他们。她把狗吓跑了,他们安全了。汤姆和杰瑞非常感激,感谢这位女士。他们意识到,尽管他们喜欢玩捉迷藏游戏,但遵守规则并确保安全是很重要的。
189 | ****************************************************************************************************
190 |
191 |
192 | step-00140000
193 | -------------
194 | 汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们决定去公园野餐。他们带了一些三明治和果汁来分享。
195 | 当他们到达公园时,他们看到一个大牌子上面写着“禁止在此野餐”。汤姆和杰瑞很伤心,因为他们不能在公园里野餐了。他们决定去公园的另一边,那里有一个大池塘。
196 | 当他们到达池塘时,他们看到一只鸭子在游泳。汤姆和杰瑞想和鸭子玩,但他们知道必须遵守规则。他们决定在池塘边野餐,并邀请鸭子加入他们。鸭子很高兴,他们一起度过了一个美好的野餐时光。
197 | ****************************************************************************************************
198 |
199 |
200 | step-00160000
201 | -------------
202 | 汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们决定去冒险。他们收拾好行李,去了机场。
203 | 在机场,他们看到了一架大飞机。汤姆说:“我想坐那架飞机!”杰瑞说:“不,我想坐那架飞机!”他们开始争吵,声音越来越大。
204 | 突然,飞机开始摇晃,他们很害怕。他们试图逃跑,但飞机太强大了。飞机坠毁了,他们再也没有回到家。结束。
205 | ****************************************************************************************************
206 |
207 |
208 | step-00180000
209 | -------------
210 | 汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们决定去公园玩。
211 | 当他们到达公园时,他们看到一个很大的滑梯。汤姆和杰瑞想尝试一下,但有一个问题。滑梯的顶部有一个标志,上面写着“禁止进入”。汤姆和杰瑞很伤心,因为他们真的很想滑下滑梯。
212 | 突然,他们看到一个拿着大袋子的人。那个人说:“我给你们一个惊喜。我给你们一个装满玩具的袋子!”汤姆和杰瑞非常高兴,感谢了那个人。他们玩了玩具,度过了很多乐趣。他们忘记了滑梯,只是享受着新玩具带来的乐趣。
213 | ****************************************************************************************************
214 |
215 |
216 | step-00200000
217 | -------------
218 | 汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们去公园玩。
219 | 在公园里,他们看到一棵大树。汤姆说:“我们爬树吧!” 杰瑞很害怕,但汤姆说:“别担心,我会帮助你的。” 他们开始爬树。
220 | 当他们爬得越高时,他们看到了一只大鸟。鸟儿说:“你们好,朋友们!你们想和我一起玩吗?” 汤姆和杰瑞很惊讶,但他们说:“好的,我们想和你一起玩!” 他们一起玩得很开心。
221 | ****************************************************************************************************
222 | ```
223 |
224 |
225 | 可以看到,在`60k`之前的`checkpoints`生成的文本虽然很长,但是有非常严重的重复。
226 |
227 | 而从`60k`开始,生成的文本重复率开始下降,并且越来越连贯。不过可以发现明显的逻辑硬伤。
228 |
229 | 比如`step-00060000`里「**杰瑞说:“我们把它带回家吧!”于是,他们把蛋带回了鸟巢**」,要把蛋带回家,结果后面又说「他们把蛋带回了鸟巢」。
230 |
231 | 另外还有一些悲伤的故事🤣,例如:
232 |
233 | `step-00100000`里两个人遇到了熊,最后「**熊吃了他们,然后他们就再也没有出现过。结束。**」
234 |
235 | `step-00160000`里两个人在飞机上吵架,最后「**飞机坠毁了,他们再也没有回到家。结束。**」
236 |
237 | ### 效果总结
238 | 虽然有些逻辑性的问题,但是整体来说,生成文本的连贯性是越来越好的。而且几乎没有任何明显的语法错误,这一点是非常厉害的。
239 |
240 | 也算是验证了一下微软的 [TinyStories](https://arxiv.org/abs/2305.07759) 里关于小模型(`SLM`)也能生成连贯文本的结论。
241 |
242 |
243 | ## 后续计划 🗓️
244 |
245 | 微软的论文里还有一项进一步的工作,那就是通过`instruction`数据来继续训练模型,从而让模型能够在生成故事的时候遵循一些要求。
246 |
247 | 这部分数据集呢目前只有纯英文的,我打算翻译一下,然后用来继续训练模型的`SFT`阶段。
248 |
249 | **不过最近确实有点忙,可能更新进度会稍微放缓一些。**
250 |
251 | 
252 |
253 | ## 小结
254 | 1. 使用`TinyStories`数据集预训练了`200k steps`的模型,并测试了生成效果。
255 | 2. 从结果来看,模型生成的文本连贯性越来越好,但是仍然存在一些逻辑问题。
256 | 3. 后续计划翻译`instruction`数据集,用来继续训练模型的`SFT`阶段。
257 |
--------------------------------------------------------------------------------
/Journey/Day03/Day03.md:
--------------------------------------------------------------------------------
1 | # 从零手搓中文大模型|🚀Day03
2 | ## 数据预处理
3 |
4 | 虽然省略了数据清洗的逻辑,但是我们还是需要对数据进行预处理,以便于后续的模型训练。
5 |
6 | 包括以下两个细节:
7 |
8 | 1. 在每个文本后添加`eos`标记,以便于模型识别句子的结束。
9 | 2. 将文本转换为**数字序列**,以便于模型处理。
10 |
11 | 这一步其实也可以放到模型训练的时候进行,但提前处理可以减少训练时的计算量。
12 |
13 | ### 数据集划分
14 |
15 | 解压数据集,得到`48`个jsonl文件,共计`3952863`行json数据。
16 |
17 | 我之前已经解压过了,并且将原始数据和处理过后的数据分别存在了不同路径下。
18 |
19 | 这里把命令贴出来以供参考。
20 |
21 |
22 | ```python
23 | # !mkdir -p ../../Data/TinyStoriesChinese/raw_data/train
24 | # !mkdir -p ../../Data/TinyStoriesChinese/raw_data/val
25 | # !mkdir -p ../../Data/TinyStoriesChinese/processed_data/train
26 | # !mkdir -p ../../Data/TinyStoriesChinese/processed_data/val
27 |
28 | # !tar zxvf ../../Data/TinyStoriesChinese/TinyStories_all_data_zh.tar.gz -C ../../Data/TinyStoriesChinese/raw_data/train
29 | ```
30 |
31 | 我把最后一个文件`data47_zh.jsonl`(共计78538行)里切分出来4w行作为`eval`数据。
32 |
33 |
34 | ```python
35 | # !mv ../../Data/TinyStoriesChinese/raw_data/train/data47_zh.jsonl ../../Data/TinyStoriesChinese/raw_data/val/
36 | # !head -n 40000 ../../Data/TinyStoriesChinese/raw_data/val/data47_zh.jsonl > ../../Data/TinyStoriesChinese/raw_data/val/val.jsonl
37 | # !tail -n +40000 ../../Data/TinyStoriesChinese/raw_data/val/data47_zh.jsonl > ../../Data/TinyStoriesChinese/raw_data/train/data47_zh.jsonl
38 | # !rm ../../Data/TinyStoriesChinese/raw_data/val/data47_zh.jsonl
39 | ```
40 |
41 | ### 先看一条数据
42 | (都打印出来太长了,所以只输出前100个字符)
43 |
44 |
45 | ```python
46 | import json
47 |
48 | with open("../../Data/TinyStoriesChinese/raw_data/train/data00_zh.jsonl", "r") as f:
49 | for line in f.readlines():
50 | js = json.loads(line)
51 | print(js["story_zh"][:100])
52 | break
53 | ```
54 | ```
55 | 莉莉和本是朋友。他们喜欢在公园里玩。有一天,他们在一棵大树下看到了一个秋千。莉莉想试试那个秋千。她跑到树下,爬上了秋千。
56 | "推我,本!"她说。本轻轻地推了她一下。莉莉感到很开心。她越荡越高,笑着喊叫。
57 | ```
58 |
59 |
60 | ### 适配框架API
61 |
62 | 由于选择了使用[⚡️litgpt](https://github.com/Lightning-AI/litgpt/tree/main)框架进行训练,所以需要引入框架相关的`Class`和`API`来封装我们的数据准备逻辑。
63 |
64 | 这里我们可以参考[源码里集成的Tinyllama的数据预处理代码](https://github.com/Lightning-AI/litgpt/blob/main/litgpt/data/prepare_slimpajama.py)里的代码,稍作修改。
65 |
66 | 主要是需要将**Day02**里的`line`处理逻辑封装到`ligtgpt`的`API`中。
67 |
68 | 但在此之前我们先熟悉一下`litgpt`的Tokenizer的使用方法:
69 |
70 | 先安装一下`litgpt`以及它所以赖的`litdata`:
71 |
72 |
73 | ```python
74 | # !pip install litgpt
75 | # !pip install litdata
76 | ```
77 |
78 |
79 | ```python
80 | import torch
81 | from litgpt import Tokenizer
82 |
83 | litgpt_tokenizer = Tokenizer("../../References/chatglm3-6b")
84 | ```
85 |
86 | 这里也实验了一下结果,对比发现和咱们之前**Day02**里用原生`Tokenizer`处理的**结果一致**。
87 |
88 | 结果这里就不贴出来了,有兴趣的可以自己试一下。
89 |
90 | > ⚠️不过需要注意`litgpt`的`Tokenizer.encode`返回的是一个`torch`的`Tensor`
91 |
92 |
93 | ```python
94 | import numpy as np
95 |
96 | litgpt_encoded = litgpt_tokenizer.encode(
97 | json.loads(line)["story_zh"][:100], eos=True
98 | ) # 记得设置eos=True
99 | print(litgpt_encoded)
100 | # print(np.array(litgpt_encoded, dtype=np.uint16))
101 | print(litgpt_tokenizer.decode(litgpt_encoded))
102 | ```
103 | ```
104 | tensor([30910, 56623, 56623, 54542, 50154, 31761, 31155, 31633, 31815, 54534,
105 | 32693, 54662, 55409, 31155, 35632, 31123, 31633, 34383, 57427, 47658,
106 | 54578, 34518, 31623, 55567, 55226, 31155, 56623, 56623, 54695, 39887,
107 | 32437, 55567, 55226, 31155, 54790, 41309, 52624, 31123, 56856, 32660,
108 | 55567, 55226, 31155, 13, 30955, 54834, 54546, 31123, 54613, 31404,
109 | 30955, 36213, 31155, 54613, 36660, 54563, 54834, 43881, 32024, 31155,
110 | 56623, 56623, 32707, 54657, 33436, 31155, 54790, 54937, 56567, 40714,
111 | 31123, 38502, 56653, 55483, 31155, 2], dtype=torch.int32)
112 | 莉莉和本是朋友。他们喜欢在公园里玩。有一天,他们在一棵大树下看到了一个秋千。莉莉想试试那个秋千。她跑到树下,爬上了秋千。
113 | "推我,本!"她说。本轻轻地推了她一下。莉莉感到很开心。她越荡越高,笑着喊叫。
114 | ```
115 |
116 |
117 | ### 数据处理代码
118 | 数据处理直接参考了上面给出的[litgpt samples](https://github.com/Lightning-AI/litgpt/blob/main/litgpt/data/prepare_slimpajama.py),我们需要仿照`prepare_slimpajama.py`实现里面相关函数(之前**Day 02**里实现的函数需要稍加改造一下)。
119 |
120 |
121 | ```python
122 | # Copyright Lightning AI. Licensed under the Apache License 2.0, see LICENSE file.
123 |
124 | import json
125 | import os
126 | import time
127 | import numpy as np
128 | from pathlib import Path
129 |
130 | from litgpt.tokenizer import Tokenizer
131 | from litgpt.data.prepare_starcoder import DataChunkRecipe
132 | from litdata import TokensLoader
133 | from litgpt.utils import extend_checkpoint_dir
134 |
135 |
136 | class TinyStoriesZhDataRecipe(DataChunkRecipe):
137 | is_generator = True
138 |
139 | def __init__(self, tokenizer: Tokenizer, chunk_size: int):
140 | super().__init__(chunk_size)
141 | self.tokenizer = tokenizer
142 |
143 | def prepare_structure(self, input_dir):
144 | files = Path(input_dir).rglob("*.jsonl")
145 | return [str(file) for file in files]
146 |
147 | def prepare_item(self, filepath):
148 |
149 | with open(filepath, "rb") as f:
150 | for line in f.readlines():
151 | js = json.loads(line)
152 | story = js["story_zh"]
153 | # 注意这里要添加eos
154 | # 还记得吗:我们的vocab size在int16范围内,所以可以转换为uint16来节省内存
155 | # story_ids = np.array(
156 | # self.tokenizer.encode(story, eos=True), dtype=np.uint16
157 | # )
158 | # 很遗憾,实际使用的时候发现如果按照上面这样写,
159 | # litdata反序列化数据的时候会错误地得到torch.int64且超界的Tensor,
160 | # 但直接存torch.Tensor没问题(加上litdata不支持torch.uint16),
161 | # 所以最后实际使用的时候还是用下面这种写法
162 | story_ids = self.tokenizer.encode(story, eos=True)
163 | yield story_ids
164 |
165 |
166 | def prepare(
167 | input_dir: Path = Path("../../Data/TinyStoriesChinese/raw_data/train"),
168 | output_dir: Path = Path("../../Data/TinyStoriesChinese/processed_data/train"),
169 | tokenizer_path: Path = Path("../../References/chatglm3-6b"),
170 | chunk_size: int = (2049 * 8012),
171 | fast_dev_run: bool = False,
172 | ) -> None:
173 | from litdata.processing.data_processor import DataProcessor
174 |
175 | tokenizer_path = extend_checkpoint_dir(tokenizer_path)
176 | tokenizer = Tokenizer(tokenizer_path)
177 | data_recipe = TinyStoriesZhDataRecipe(tokenizer=tokenizer, chunk_size=chunk_size)
178 | data_processor = DataProcessor(
179 | input_dir=str(input_dir),
180 | output_dir=str(output_dir),
181 | fast_dev_run=fast_dev_run,
182 | num_workers=os.cpu_count(),
183 | num_downloaders=1,
184 | # 这里有个「巨坑」,如果不加这一行,处理好的数据配对的index.json里
185 | # 有一个名为"dim"的key值会为null,导致后续有一个无法规避的报错
186 | # 但是官方的例子里是没有这一行的,很奇怪为何会有这个问题
187 | item_loader=TokensLoader(),
188 | )
189 |
190 | start_time = time.time()
191 | data_processor.run(data_recipe)
192 | elapsed_time = time.time() - start_time
193 | print(f"Time taken: {elapsed_time:.2f} seconds")
194 | ```
195 |
196 | 首先,我这里主要就是把之前实现的`line`处理逻辑封装到`litgpt`的`DataChunkRecipe`中:
197 | - `prepare_structure`函数给定路径返回符合我们期望的数据文件的路径列表
198 | - `prepare_item`函数给定一个上面的数据文件的路径,根据我们**自定义**的`tokenization`处理逻辑返回一个`np.array`对象
199 |
200 | 然后,定义了一个`prepare`函数,指定我们数据的输入路径和输出路径以及一些其它参数配置(其实用默认的即可),其余的都交给了`litdata`的`DataProcessor`,它基于我前面定义的`DataChunkRecipe`来处理数据。
201 |
202 | 感兴趣的可以看看`DataProcessor`的源码,里面做了很多并行之类的数据处理优化。
203 |
204 | #### 先用eval数据集测试
205 |
206 |
207 | ```python
208 | prepare(
209 | input_dir=Path("../../Data/TinyStoriesChinese/raw_data/val"),
210 | output_dir=Path("../../Data/TinyStoriesChinese/processed_data/val"),
211 | tokenizer_path=Path("../../References/chatglm3-6b"),
212 | )
213 | ```
214 |
215 | (也可以设置`fast_dev_run=True`来处理更少的数据,尤其是debug时十分有用)
216 |
217 | 执行完可以在`processed_data/eval`目录下看到生成的`.bin`文件以及记录了每个`chunk`文件信息的`index.json`。
218 |
219 | 比较一下可以发现从原先的`83m`的`.jsonl`文件压缩到了`13m`的`.bin`,压缩比(83/13≈6.385)还是很可观的。
220 |
221 | #### 处理train数据集
222 | 在32核的CPU上处理`train`数据集耗时不到`1min`。
223 |
224 |
225 | ```python
226 | prepare(
227 | input_dir=Path("../../Data/TinyStoriesChinese/raw_data/train"),
228 | output_dir=Path("../../Data/TinyStoriesChinese/processed_data/train"),
229 | tokenizer_path=Path("../../References/chatglm3-6b"),
230 | )
231 | ```
232 |
233 | ## 小结
234 |
235 | 1. 数据预处理的逻辑主要是将文本转换为数字序列,以便于模型处理。
236 | 2. 通过`litgpt`的`Tokenizer`可以方便的实现文本到数字序列的转换。
237 | 3. `litdata`提供了数据处理的`API`,可以方便的封装我们的数据处理逻辑。
238 | 4. 基于上面的开发,将`TinyStoriesChinese`数据集做了数据划分并完成了预处理。
239 |
--------------------------------------------------------------------------------
/Journey/Day04/Day04.md:
--------------------------------------------------------------------------------
1 | # 从零手搓中文大模型|🚀Day04
2 |
3 | 前面已经完成了**数据预处理**,今天我们来研究一下**模型的配置**。
4 |
5 | `litgpt`使用的配置文件和`transformers`有点不太一样,它的仓库里提供了一些预训练所用的`yaml`[配置文件样例](https://github.com/Lightning-AI/litgpt/tree/main/config_hub)。这个主要用于需要自定义模型的场景。
6 |
7 | 另外`litgpt`也内置了一些`huggingface`上的[现成模型](https://github.com/Lightning-AI/litgpt/blob/main/litgpt/config.py),可以直接拿来使用。
8 |
9 | ## 训练配置文件
10 | 以下是我这次定义的一个配置文件。
11 |
12 | 内容有点多,但是还是都列举出来了,可以直接跳到后面对一些关键参数的解释。
13 |
14 | ```yaml
15 | # The name of the model to pretrain. Choose from names in ``litgpt.config``. Mutually exclusive with
16 | # ``model_config``. (type: Optional[str], default: null)
17 | model_name: microstories
18 |
19 | # A ``litgpt.Config`` object to define the model architecture. Mutually exclusive with
20 | # ``model_config``. (type: Optional[Config], default: null)
21 | model_config:
22 | name: microstories
23 | hf_config: {}
24 | scale_embeddings: false
25 | block_size: 512
26 | padded_vocab_size: 65024
27 | vocab_size: 64798
28 | n_layer: 6
29 | n_head: 6
30 | n_query_groups: 6
31 | n_embd: 512
32 | head_size: 48
33 | rotary_percentage: 1.0
34 | parallel_residual: false
35 | bias: false
36 | norm_class_name: RMSNorm
37 | mlp_class_name: LLaMAMLP
38 | intermediate_size: 768
39 |
40 | # Directory in which to save checkpoints and logs. If running in a Lightning Studio Job, look for it in
41 | # /teamspace/jobs//share. (type: , default: out/pretrain)
42 | out_dir: Chinese_LLM_From_Scratch/Experiments/Output/pretrain/microstories
43 |
44 | # The precision to use for pretraining. Possible choices: "bf16-true", "bf16-mixed", "32-true". (type: Optional[str], default: null)
45 | precision: bf16-mixed
46 |
47 | # Optional path to a checkpoint directory to initialize the model from.
48 | # Useful for continued pretraining. Mutually exclusive with ``resume``. (type: Optional[Path], default: null)
49 | initial_checkpoint_dir:
50 |
51 | # Path to a checkpoint directory to resume from in case training was interrupted, or ``True`` to resume
52 | # from the latest checkpoint in ``out_dir``. An error will be raised if no checkpoint is found. Passing
53 | # ``'auto'`` will resume from the latest checkpoint but not error if no checkpoint exists.
54 | # (type: Union[bool, Literal["auto"], Path], default: False)
55 | resume: true
56 |
57 | # Data-related arguments. If not provided, the default is ``litgpt.data.TinyLlama``.
58 | data:
59 | # TinyStories
60 | class_path: litgpt.data.LitData
61 | init_args:
62 | data_path: Chinese_LLM_From_Scratch/Data/TinyStoriesChinese/processed_data
63 | split_names:
64 | - train
65 | - val
66 |
67 | # Training-related arguments. See ``litgpt.args.TrainArgs`` for details
68 | train:
69 | # Number of optimizer steps between saving checkpoints (type: Optional[int], default: 1000)
70 | save_interval: 1000
71 |
72 | # Number of iterations between logging calls (type: int, default: 1)
73 | log_interval: 1
74 |
75 | # Number of samples between optimizer steps across data-parallel ranks (type: int, default: 512)
76 | global_batch_size: 512
77 |
78 | # Number of samples per data-parallel rank (type: int, default: 4)
79 | micro_batch_size: 32
80 |
81 | # Number of iterations with learning rate warmup active (type: int, default: 2000)
82 | lr_warmup_steps: 1000
83 |
84 | # Number of epochs to train on (type: Optional[int], default: null)
85 | epochs:
86 |
87 | # Total number of tokens to train on (type: Optional[int], default: 3000000000000)
88 | max_tokens: 3000000000000
89 |
90 | # Limits the number of optimizer steps to run. (type: Optional[int], default: null)
91 | max_steps:
92 |
93 | # Limits the length of samples. Off by default (type: Optional[int], default: null)
94 | max_seq_length: 512
95 |
96 | # Whether to tie the embedding weights with the language modeling head weights. (type: Optional[bool], default: False)
97 | tie_embeddings: true
98 |
99 | # (type: Optional[float], default: 1.0)
100 | max_norm: 1.0
101 |
102 | # (type: float, default: 4e-05)
103 | min_lr: 0.0
104 |
105 | # Evaluation-related arguments. See ``litgpt.args.EvalArgs`` for details
106 | eval:
107 | # Number of optimizer steps between evaluation calls (type: int, default: 1000)
108 | interval: 2000
109 |
110 | # Number of tokens to generate (type: Optional[int], default: null)
111 | max_new_tokens:
112 |
113 | # Number of iterations (type: int, default: 100)
114 | max_iters: 100
115 |
116 | # Whether to evaluate on the validation set at the beginning of the training
117 | initial_validation: false
118 |
119 | # Whether to evaluate on the validation set at the end the training
120 | final_validation: false
121 |
122 | # Optimizer-related arguments
123 | optimizer:
124 | class_path: torch.optim.AdamW
125 |
126 | init_args:
127 | # (type: float, default: 0.001)
128 | lr: 0.0005
129 |
130 | # (type: float, default: 0.01)
131 | weight_decay: 0.1
132 |
133 | # (type: tuple, default: (0.9,0.999))
134 | betas:
135 | - 0.9
136 | - 0.95
137 |
138 | # How many devices/GPUs to use. Uses all GPUs by default. (type: Union[int, str], default: auto)
139 | devices: auto
140 |
141 | # How many nodes to use. (type: int, default: 1)
142 | num_nodes: 1
143 |
144 | # Optional path to the tokenizer dir that was used for preprocessing the dataset. Only some data
145 | # module require this. (type: Optional[Path], default: null)
146 | tokenizer_dir: Chinese_LLM_From_Scratch/References/chatglm3-6b
147 |
148 | # The name of the logger to send metrics to. (type: Literal['wandb', 'tensorboard', 'csv'], default: tensorboard)
149 | logger_name: wandb
150 |
151 | # The random seed to use for reproducibility. (type: int, default: 42)
152 | seed: 42
153 | ```
154 |
155 | ### model_config
156 |
157 | ```yaml
158 | model_config:
159 | name: microstories
160 | hf_config: {}
161 | scale_embeddings: false
162 | block_size: 512
163 | padded_vocab_size: 65024
164 | vocab_size: 64798
165 | n_layer: 6
166 | n_head: 6
167 | n_query_groups: 6
168 | n_embd: 512
169 | head_size: 48
170 | rotary_percentage: 1.0
171 | parallel_residual: false
172 | bias: false
173 | norm_class_name: RMSNorm
174 | mlp_class_name: LLaMAMLP
175 | intermediate_size: 768
176 | ```
177 |
178 | - `scale_embeddings`控制是否对embedding进行缩放。
179 |
180 | 
181 |
182 | 如果为`True`,那么在`forward`函数中会对`embedding`进行缩放。注意个缩放和`sefl-attention`中的缩放不是一回事,不要弄混了。
183 | 其实也有很多讨论关于这个地方这一步**是否有必要**的,目前看来似乎是区别不大,可以设置为`False`。
184 | - `transformer`中的`block_size`,也就是`max_seq_length`。
185 | - `padded_vovab_size`和`vocab_size`直接取自`tokenizer`。
186 | - `n_layer`和`n_head`都是`6`,构建了一个`6`层`6`头的`transformer`。
187 | - `n_query_groups`是`6`,这是`GQA(Grouped-Query Attention)`的一个参数,控制`query`的分组。当`n_query_groups`等于`n_head`时,其实就是`MHA(Multi-Head Attention)`。下面这个图比较直观:
188 |
189 | 
190 |
191 | - 头的大小`head_size`是`48`,`n_embd`是`512`。
192 | - `rotary_percentage`是`1.0`,这个是`旋转编码(Rotary Position Embedding, RoPE)`的有关参数,这里先不展开介绍了。
193 | - `parallel_residual`是`false`,关于`parallel residual`和`non-parallel residual`的解释可以参考这个图:
194 |
195 | 
196 | - `bias`控制`Linear`层的`bias`是否存在,现在大多模型一般都是`false`。
197 | - `norm_class_name`是`RMSNorm`,`mlp_class_name`是`LLaMAMLP`,具体可以参见`litgpt`里[`model.py`](https://github.com/Lightning-AI/litgpt/blob/main/litgpt/model.py#L30)中的实现。
198 | - `intermediate_size`是`768`,这个是上面的`MLP`中间层的大小。
199 |
200 | 按照上面的配置得到的模型参数量在`44M`左右,也就是只有`0.044B`的大小。
201 |
202 | 但根据微软的[TinyStories](https://arxiv.org/pdf/2305.07759)论文结论,`10-80M`级别的模型能在小故事生成这种简单的语言任务上达到不错的效果(依旧能说人话)。
203 |
204 | ### 其他参数
205 |
206 | 其余的都是一些训练的参数,比如`batch_size`,`lr`,`weight_decay`等等,这些都是比较常见的参数,不再赘述。
207 |
208 | `logger`我这里选择的是`wandb`,可以直接在`wandb`上查看训练过程中的一些指标。
209 |
210 | `data`设置成之前预处理好的数据集的路径(其中指定了加载数据所用的`litdata`的类名)
211 |
212 | `tokenizer_dir`是选用的或者自己训练好的`tokenizer`的路径。
213 |
214 | ## 启动训练
215 |
216 | ```bash
217 | litgpt pretrain --config Experiments/configs/microstories.yaml
218 | ```
219 | 预训练启动的命令非常简单,只需要指定上面的配置文件的路径即可。
220 |
221 | 不出意外地话模型就能开始训练了,可以在`wandb`上查看训练过程中的指标。
222 |
223 | 我的模型其实已经训练了一段时间,show一下训练过程中的图表:
224 |
225 | 
226 |
227 | ## 小结
228 | 1. 详细介绍了`litgpt`的预训练模型配置文件。
229 | 2. 顺带解释了一些重要参数的原理。
230 | 3. 训练启动。
231 |
232 |
233 |
--------------------------------------------------------------------------------
/Journey/Day11/service.py:
--------------------------------------------------------------------------------
1 | # Copyright Lightning AI. Licensed under the Apache License 2.0, see LICENSE file.
2 | import click
3 | from pathlib import Path
4 | from pprint import pprint
5 | from typing import Dict, Any, Optional, Literal
6 | import torch
7 | from litgpt.api import LLM
8 | from litgpt.utils import auto_download_checkpoint
9 | from litserve import LitAPI, LitServer
10 |
11 |
12 | class BaseLitAPI(LitAPI):
13 | def __init__(
14 | self,
15 | checkpoint_dir: Path,
16 | quantize: Optional[
17 | Literal["bnb.nf4", "bnb.nf4-dq", "bnb.fp4", "bnb.fp4-dq", "bnb.int8"]
18 | ] = None,
19 | precision: Optional[str] = None,
20 | temperature: float = 0.8,
21 | top_k: int = 50,
22 | top_p: float = 1.0,
23 | max_new_tokens: int = 50,
24 | devices: int = 1,
25 | ) -> None:
26 |
27 | super().__init__()
28 | self.checkpoint_dir = checkpoint_dir
29 | self.quantize = quantize
30 | self.precision = precision
31 | self.temperature = temperature
32 | self.top_k = top_k
33 | self.max_new_tokens = max_new_tokens
34 | self.top_p = top_p
35 | self.devices = devices
36 |
37 | def setup(self, device: str) -> None:
38 | print(f"device passed in : {device}")
39 | if ":" in device:
40 | accelerator, device = device.split(":")
41 | device = f"[{int(device)}]"
42 | else:
43 | accelerator = device
44 | device = 1
45 |
46 | print("Initializing model...")
47 | print(f"{device=}")
48 | print(f"{self.devices=}")
49 | self.llm = LLM.load(model=self.checkpoint_dir, distribute=None)
50 |
51 | self.llm.distribute(
52 | devices=self.devices,
53 | accelerator=accelerator,
54 | quantize=self.quantize,
55 | precision=self.precision,
56 | generate_strategy=(
57 | "sequential" if self.devices is not None and self.devices > 1 else None
58 | ),
59 | )
60 | print("Model successfully initialized.")
61 |
62 | def decode_request(self, request: Dict[str, Any]) -> Any:
63 | # Convert the request payload to your model input.
64 | prompt = str(request["prompt"])
65 | return prompt
66 |
67 |
68 | class SimpleLitAPI(BaseLitAPI):
69 | def __init__(
70 | self,
71 | checkpoint_dir: Path,
72 | quantize: Optional[str] = None,
73 | precision: Optional[str] = None,
74 | temperature: float = 0.8,
75 | top_k: int = 50,
76 | top_p: float = 1.0,
77 | max_new_tokens: int = 50,
78 | devices: int = 1,
79 | ):
80 | super().__init__(
81 | checkpoint_dir,
82 | quantize,
83 | precision,
84 | temperature,
85 | top_k,
86 | top_p,
87 | max_new_tokens,
88 | devices,
89 | )
90 |
91 | def setup(self, device: str):
92 | super().setup(device)
93 |
94 | def predict(self, inputs: str) -> Any:
95 | output = self.llm.generate(
96 | inputs,
97 | temperature=self.temperature,
98 | top_k=self.top_k,
99 | top_p=self.top_p,
100 | max_new_tokens=self.max_new_tokens,
101 | )
102 | return output
103 |
104 | def encode_response(self, output: str) -> Dict[str, Any]:
105 | # Convert the model output to a response payload.
106 | return {"output": output}
107 |
108 |
109 | class StreamLitAPI(BaseLitAPI):
110 | def __init__(
111 | self,
112 | checkpoint_dir: Path,
113 | quantize: Optional[str] = None,
114 | precision: Optional[str] = None,
115 | temperature: float = 0.8,
116 | top_k: int = 50,
117 | top_p: float = 1.0,
118 | max_new_tokens: int = 50,
119 | devices: int = 1,
120 | ):
121 | super().__init__(
122 | checkpoint_dir,
123 | quantize,
124 | precision,
125 | temperature,
126 | top_k,
127 | top_p,
128 | max_new_tokens,
129 | devices,
130 | )
131 |
132 | def setup(self, device: str):
133 | super().setup(device)
134 |
135 | def predict(self, inputs: torch.Tensor) -> Any:
136 | # Run the model on the input and return the output.
137 | yield from self.llm.generate(
138 | inputs,
139 | temperature=self.temperature,
140 | top_k=self.top_k,
141 | top_p=self.top_p,
142 | max_new_tokens=self.max_new_tokens,
143 | stream=True,
144 | )
145 |
146 | def encode_response(self, output):
147 | for out in output:
148 | yield {"output": out}
149 |
150 |
151 | @click.command()
152 | @click.option("--checkpoint_dir", type=str)
153 | @click.option("--quantize", type=str, default=None)
154 | @click.option("--precision", type=str, default="bf16-true")
155 | @click.option("--temperature", type=float, default=0.8)
156 | @click.option("--top_k", type=int, default=50)
157 | @click.option("--top_p", type=float, default=1.0)
158 | @click.option("--max_new_tokens", type=int, default=50)
159 | @click.option("--devices", type=int, default=1)
160 | @click.option("--workers_per_device", type=int, default=20)
161 | @click.option("--port", type=int, default=8000)
162 | @click.option("--stream", type=bool, default=False)
163 | @click.option("--accelerator", type=str, default="auto")
164 | def run_server(
165 | checkpoint_dir: Path,
166 | quantize: Optional[
167 | Literal["bnb.nf4", "bnb.nf4-dq", "bnb.fp4", "bnb.fp4-dq", "bnb.int8"]
168 | ] = None,
169 | precision: Optional[str] = None,
170 | temperature: float = 0.8,
171 | top_k: int = 50,
172 | top_p: float = 1.0,
173 | max_new_tokens: int = 50,
174 | devices: int = 1,
175 | port: int = 8000,
176 | accelerator: str = "auto",
177 | workers_per_device: int = 20,
178 | stream: bool = False,
179 | access_token: Optional[str] = None,
180 | ) -> None:
181 | """Serve a LitGPT model using LitServe.
182 |
183 | Evaluate a model with the LM Evaluation Harness.
184 |
185 | Arguments:
186 | checkpoint_dir: The checkpoint directory to load the model from.
187 | quantize: Whether to quantize the model and using which method:
188 | - bnb.nf4, bnb.nf4-dq, bnb.fp4, bnb.fp4-dq: 4-bit quantization from bitsandbytes
189 | - bnb.int8: 8-bit quantization from bitsandbytes
190 | for more details, see https://github.com/Lightning-AI/litgpt/blob/main/tutorials/quantize.md
191 | precision: Optional precision setting to instantiate the model weights in. By default, this will
192 | automatically be inferred from the metadata in the given ``checkpoint_dir`` directory.
193 | temperature: Temperature setting for the text generation. Value above 1 increase randomness.
194 | Values below 1 decrease randomness.
195 | top_k: The size of the pool of potential next tokens. Values larger than 1 result in more novel
196 | generated text but can also lead to more incoherent texts.
197 | top_p: If specified, it represents the cumulative probability threshold to consider in the sampling process.
198 | In top-p sampling, the next token is sampled from the highest probability tokens
199 | whose cumulative probability exceeds the threshold `top_p`. When specified,
200 | it must be `0 <= top_p <= 1`. Here, `top_p=0` is equivalent
201 | to sampling the most probable token, while `top_p=1` samples from the whole distribution.
202 | It can be used in conjunction with `top_k` and `temperature` with the following order
203 | of application:
204 |
205 | 1. `top_k` sampling
206 | 2. `temperature` scaling
207 | 3. `top_p` sampling
208 |
209 | For more details, see https://arxiv.org/abs/1904.09751
210 | or https://huyenchip.com/2024/01/16/sampling.html#top_p
211 | max_new_tokens: The number of generation steps to take.
212 | workers_per_device: How many workers to use per device.
213 | max_batch_size: The maximum batch size to use.
214 | devices: How many devices/GPUs to use.
215 | accelerator: The type of accelerator to use. For example, "auto", "cuda", "cpu", or "mps".
216 | The "auto" setting (default) chooses a GPU if available, and otherwise uses a CPU.
217 | port: The network port number on which the model is configured to be served.
218 | stream: Whether to stream the responses.
219 | access_token: Optional API token to access models with restrictions.
220 | """
221 | checkpoint_dir = auto_download_checkpoint(
222 | model_name=checkpoint_dir, access_token=access_token
223 | )
224 | pprint(locals())
225 |
226 | if not stream:
227 | server = LitServer(
228 | SimpleLitAPI(
229 | checkpoint_dir=checkpoint_dir,
230 | quantize=quantize,
231 | precision=precision,
232 | temperature=temperature,
233 | top_k=top_k,
234 | top_p=top_p,
235 | max_new_tokens=max_new_tokens,
236 | devices=devices,
237 | ),
238 | workers_per_device=workers_per_device,
239 | accelerator=accelerator,
240 | devices=devices, # We need to use the devives inside the `SimpleLitAPI` class
241 | )
242 |
243 | else:
244 | server = LitServer(
245 | StreamLitAPI(
246 | checkpoint_dir=checkpoint_dir,
247 | quantize=quantize,
248 | precision=precision,
249 | temperature=temperature,
250 | top_k=top_k,
251 | top_p=top_p,
252 | max_new_tokens=max_new_tokens,
253 | devices=devices, # We need to use the devives inside the `StreamLitAPI` class
254 | ),
255 | workers_per_device=workers_per_device,
256 | accelerator=accelerator,
257 | devices=1,
258 | stream=True,
259 | )
260 |
261 | server.run(port=port, generate_client_file=False)
262 |
263 |
264 | if __name__ == "__main__":
265 | run_server()
266 |
--------------------------------------------------------------------------------
/Journey/Day13/Day13.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "之前学习的时候就有所耳闻,即便是比`RLHF`简化了很多的`DPO`,想要训练好也不是那么容易的。\n",
8 | "\n",
9 | "实际试了一下,当`SFT`模型质量不高时,果然是**屎上雕花**,`DPO`之后的效果还不如`SFT`。\n",
10 | "\n",
11 | "尽管如此,毕竟还是走通了流程,还是值得记录一下。\n",
12 | "\n",
13 | "## DPO实现\n",
14 | "\n",
15 | "在经历了上期说到的`transformers`库的**巨坑**之后,我重新进行了一次`pretrain`,并在此基础上进行了`SFT`。\n",
16 | "\n",
17 | "这次终于将`litgpt`得到的模型`checkpoint`转换为`Hugging Face`的模型格式并成功加载了。\n",
18 | "\n",
19 | "然后之前通过并行的方式构建了约`15000`条`DPO`数据,于是开始了`DPO`的训练。\n",
20 | "\n",
21 | "基于`trl`库的`DPOTrainer`,训练脚本的实现非常容易,直接贴在这里了:"
22 | ]
23 | },
24 | {
25 | "cell_type": "code",
26 | "execution_count": null,
27 | "metadata": {},
28 | "outputs": [],
29 | "source": [
30 | "import os\n",
31 | "import click\n",
32 | "\n",
33 | "os.environ[\"CUDA_VISIBLE_DEVICES\"] = \"0\"\n",
34 | "\n",
35 | "import torch\n",
36 | "from transformers import AutoModelForCausalLM, AutoTokenizer\n",
37 | "from trl import DPOTrainer\n",
38 | "from trl import DPOConfig\n",
39 | "from datasets import load_dataset\n",
40 | "from litgpt.utils import num_parameters\n",
41 | "\n",
42 | "\n",
43 | "def find_all_linear_names(model):\n",
44 | " cls = torch.nn.Linear\n",
45 | " lora_module_names = set()\n",
46 | " for name, module in model.named_modules():\n",
47 | " if isinstance(module, cls):\n",
48 | " names = name.split(\".\")\n",
49 | " lora_module_names.add(names[0] if len(names) == 1 else names[-1])\n",
50 | "\n",
51 | " if \"lm_head\" in lora_module_names:\n",
52 | " lora_module_names.remove(\"lm_head\")\n",
53 | " return list(lora_module_names)\n",
54 | "\n",
55 | "\n",
56 | "def init_model(model_name_or_path, device=\"cuda:0\"):\n",
57 | " model = AutoModelForCausalLM.from_pretrained(\n",
58 | " model_name_or_path,\n",
59 | " # local_files_only=True,\n",
60 | " # state_dict=torch.load(f\"{model_name_or_path}/pytorch_model.bin\"),\n",
61 | " )\n",
62 | " tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)\n",
63 | " tokenizer.pad_token = tokenizer.eos_token\n",
64 | " print(f\"Total parameters: {num_parameters(model):,}\")\n",
65 | " model = model.to(device)\n",
66 | " return model, tokenizer\n",
67 | "\n",
68 | "\n",
69 | "@click.command()\n",
70 | "@click.option(\"--model_name_or_path\", type=str)\n",
71 | "def main(model_name_or_path):\n",
72 | " model, tokenizer = init_model(model_name_or_path)\n",
73 | " dpo_config = DPOConfig(\n",
74 | " output_dir=\"../../Experiments/Output/dpo/microstories_lora_v2\",\n",
75 | " per_device_train_batch_size=16,\n",
76 | " remove_unused_columns=False,\n",
77 | " num_train_epochs=2,\n",
78 | " learning_rate=1e-5,\n",
79 | " do_eval=True,\n",
80 | " eval_strategy=\"steps\",\n",
81 | " eval_steps=200,\n",
82 | " save_steps=200,\n",
83 | " logging_steps=10,\n",
84 | " )\n",
85 | "\n",
86 | " data_files = {\n",
87 | " \"train\": \"../../Data/TinyStoriesInstruct/dpo_data_train.json\",\n",
88 | " \"eval\": \"../../Data/TinyStoriesInstruct/dpo_data_eval.json\",\n",
89 | " }\n",
90 | " dataset_dpo = load_dataset(\"json\", data_files=data_files)\n",
91 | "\n",
92 | " dpo_trainer = DPOTrainer(\n",
93 | " model,\n",
94 | " ref_model=None,\n",
95 | " args=dpo_config,\n",
96 | " beta=0.1,\n",
97 | " train_dataset=dataset_dpo[\"train\"],\n",
98 | " eval_dataset=dataset_dpo[\"eval\"],\n",
99 | " tokenizer=tokenizer,\n",
100 | " max_length=512,\n",
101 | " max_prompt_length=512,\n",
102 | " )\n",
103 | " dpo_trainer.train()\n",
104 | "\n",
105 | "\n",
106 | "if __name__ == \"__main__\":\n",
107 | " main()"
108 | ]
109 | },
110 | {
111 | "cell_type": "markdown",
112 | "metadata": {},
113 | "source": [
114 | "基于上面的实现,跑起来非常容易,没有遇到什么问题。\n",
115 | "\n",
116 | "`DPO`这块儿的**炼丹**我确实没什么经验,这里也就不随便发表什么意见了;等后续深入学习之后再来补充。\n",
117 | "\n",
118 | "训练过程中的指标波动比较大,简单贴个图:\n",
119 | "\n",
120 | ""
121 | ]
122 | },
123 | {
124 | "cell_type": "markdown",
125 | "metadata": {},
126 | "source": [
127 | "`DPO`的原理细节这里就不展开了,大家可以自行参考论文和开源的代码实现。\n",
128 | "\n",
129 | "其实不论是`loss type`层面还是各种变体的实现,还有很多可以测试的点,但我时间有限,还没来得及做丰富的测试,后面有机会也一定补上。\n",
130 | "\n",
131 | "训练完之后,我随便取了几个样本跑了一下:\n",
132 | "\n",
133 | "1. 如很多网上分享的经验一样,`DPO`对数据的质量和`SFT`模型的质量要求都很高,我的场景里这两条件都不是非常理想,所以效果不是很好也在预期之内\n",
134 | "\n",
135 | "2. 和`SFT`一样,训练轮次不宜过多,`SFT`只是过拟合,而`DPO`是越往后训练,模型能力反而出现退化,已经开始胡言乱语了。。。(`SFT`模型的指令遵循效果虽然表现一般,但至少生成结果是连贯的)\n"
136 | ]
137 | },
138 | {
139 | "cell_type": "code",
140 | "execution_count": 1,
141 | "metadata": {},
142 | "outputs": [],
143 | "source": [
144 | "import torch\n",
145 | "import json\n",
146 | "import transformers\n",
147 | "from transformers import AutoModelForCausalLM, AutoTokenizer\n",
148 | "from litgpt.prompts import Phi2\n",
149 | "\n",
150 | "path = \"../../Experiments/Output/dpo/microstories_lora_v2/checkpoint-300\"\n",
151 | "prompt_style = Phi2()\n",
152 | "model_sft = AutoModelForCausalLM.from_pretrained(\n",
153 | " \"../../Experiments/Output/sft/microstories_v2/bf16_true_1e-4/saved_by_tf\"\n",
154 | ")\n",
155 | "model_hf = AutoModelForCausalLM.from_pretrained(path)\n",
156 | "tokenizer = AutoTokenizer.from_pretrained(path)\n",
157 | "model_hf.generation_config.pad_token_id = tokenizer.eos_token_id\n",
158 | "model_sft.generation_config.pad_token_id = tokenizer.eos_token_id\n",
159 | "pipeline_sft = transformers.pipeline(\n",
160 | " \"text-generation\",\n",
161 | " model=model_sft,\n",
162 | " torch_dtype=torch.bfloat16,\n",
163 | " device=\"cuda\",\n",
164 | " tokenizer=tokenizer,\n",
165 | ")\n",
166 | "\n",
167 | "pipeline_dpo = transformers.pipeline(\n",
168 | " \"text-generation\",\n",
169 | " model=model_hf,\n",
170 | " torch_dtype=torch.bfloat16,\n",
171 | " device=\"cuda\",\n",
172 | " tokenizer=tokenizer,\n",
173 | ")\n",
174 | "\n",
175 | "\n",
176 | "def generate_text(prompt, pipeline, tokenizer):\n",
177 | " sequences = pipeline(\n",
178 | " prompt,\n",
179 | " do_sample=True,\n",
180 | " top_k=50,\n",
181 | " top_p=0.5,\n",
182 | " num_return_sequences=1,\n",
183 | " eos_token_id=tokenizer.eos_token_id,\n",
184 | " max_new_tokens=400,\n",
185 | " )\n",
186 | "\n",
187 | " return sequences[0][\"generated_text\"]\n",
188 | "\n",
189 | "\n",
190 | "sft_data = json.load(\n",
191 | " open(\"../../Data/TinyStoriesInstruct/sft_data_v2_simple_few.json\", \"r\")\n",
192 | ")"
193 | ]
194 | },
195 | {
196 | "cell_type": "markdown",
197 | "metadata": {},
198 | "source": [
199 | "## 随便取个样本试试看"
200 | ]
201 | },
202 | {
203 | "cell_type": "code",
204 | "execution_count": 7,
205 | "metadata": {},
206 | "outputs": [
207 | {
208 | "name": "stdout",
209 | "output_type": "stream",
210 | "text": [
211 | "DPO:\n",
212 | " Instruct: 词汇:挤压,章鱼,兴奋\n",
213 | "摘要:莉莉在海滩上发现了一只紫色的章鱼,和它玩,然后把它放回海里。\n",
214 | "Output:从前,有个小女孩叫莉莉。她喜欢在海滩的沙子里玩耍。一天,她看到一只紫色的章鱼在海底深处游泳。 \n",
215 | "“你好呀,小章鱼!”莉莉兴奋地说。“你想和我玩吗?” \n",
216 | "章鱼没有回答,只是继续游走。莉莉跟着它,惊讶地发现海滩好像很大,到处都是大浪。 \n",
217 | "“我不知道自己能不能移动,”莉莉建议。“我太小了,不能和章鱼玩。” \n",
218 | "但章鱼依然沉着,游动的本领可爱。最后,莉莉决定把章鱼放回海里,跟它说再见。当她走开时,章鱼突然再次出现,这次还挤着她! \n",
219 | "莉莉惊讶地看到章鱼躲在一块石头后面,他们在海滩上一起欢笑玩耍。从那天起,莉莉总是期待在海滩上看到紫色章鱼,和新朋友一起玩。\n",
220 | "----------------------------------------------------------------------------------------------------\n",
221 | "SFT:\n",
222 | " Instruct: 词汇:挤压,章鱼,兴奋\n",
223 | "摘要:莉莉在海滩上发现了一只紫色的章鱼,和它玩,然后把它放回海里。\n",
224 | "Output:从前,有个小女孩叫莉莉。她喜欢在海滩上玩耍和捡贝壳。一天,她在沙子里发现了一只大紫色的章鱼。它有长长的触手,莉莉兴奋地想和它玩。 \n",
225 | "莉莉轻轻地捡起章鱼,紧紧握在手里。但随后,她感到有点累,决定在沙子里打个盹。她把章鱼放在身边,闭上了眼睛。 \n",
226 | "当莉莉醒来时,章鱼还在那儿。她睁开眼睛,看到章鱼在她的手中。她微笑着说:“谢谢你陪我玩,章鱼!”然后,她把章鱼放回沙子里,让它回家。莉莉向章鱼挥手告别,高高兴兴地回家了,交到了一个新朋友。\n",
227 | "----------------------------------------------------------------------------------------------------\n",
228 | "Ground Truth:\n",
229 | " 从前,有一个快乐的小女孩叫莉莉。她喜欢在海滩上玩耍,寻找沙子里的宝藏。一天,她发现了一只大而软绵绵的章鱼!它是紫色的,长着长长的触手。莉莉看到它非常兴奋! \n",
230 | "她轻轻地捡起章鱼,给了它一个拥抱。她喜欢捏它的感觉。章鱼似乎并不介意,甚至用触手缠绕住莉莉的手臂。他们一起玩了一会儿,但莉莉知道是时候让章鱼放回海里了。 \n",
231 | "看着它游走时,莉莉感到有点伤心,但也为能遇到这么有趣的生物而感到高兴。她知道那天在海滩上发现章鱼的事会永远记在心里。\n"
232 | ]
233 | }
234 | ],
235 | "source": [
236 | "data_index = 10001\n",
237 | "prompt = prompt_style.apply(sft_data[data_index][\"instruction\"])\n",
238 | "print(\n",
239 | " \"DPO:\\n\",\n",
240 | " generate_text(prompt, pipeline_dpo, tokenizer),\n",
241 | ")\n",
242 | "print(\"-\" * 100)\n",
243 | "print(\n",
244 | " \"SFT:\\n\",\n",
245 | " generate_text(prompt, pipeline_sft, tokenizer),\n",
246 | ")\n",
247 | "print(\"-\" * 100)\n",
248 | "print(\"Ground Truth:\\n\", sft_data[data_index][\"output\"])"
249 | ]
250 | },
251 | {
252 | "cell_type": "markdown",
253 | "metadata": {},
254 | "source": [
255 | "可以看到上面`DPO`里的故事里已经出现很多语法错误和严重的逻辑错误了。\n",
256 | "\n",
257 | "不过没关系,在小尺寸的模型上,这类尝试本来就是一个探索,跑通流程就已经能学到很多东西了。\n",
258 | "\n",
259 | "不过无论如何,我的**从零手搓中文大模型**之旅到这里也算是阶段性地告一段落了。\n",
260 | "\n",
261 | "## 小结一下\n",
262 | "\n",
263 | "接下来自己大概有这么几个计划:\n",
264 | "\n",
265 | "1. 尝试一下`DPO`的变体以及其他的参数配置,多做一些实验\n",
266 | "\n",
267 | "2. 将自己这段时间**从零手搓**过程中遇到的各种问题、经验、教训等等都整理一下,系统地记录下来\n",
268 | " \n",
269 | "3. 时间和条件允许的话,在更通用更大的数据集上(或者相反,一个更垂直的领域上)来做更细致的实现"
270 | ]
271 | },
272 | {
273 | "cell_type": "markdown",
274 | "metadata": {},
275 | "source": []
276 | }
277 | ],
278 | "metadata": {
279 | "kernelspec": {
280 | "display_name": "bigmodel",
281 | "language": "python",
282 | "name": "python3"
283 | },
284 | "language_info": {
285 | "codemirror_mode": {
286 | "name": "ipython",
287 | "version": 3
288 | },
289 | "file_extension": ".py",
290 | "mimetype": "text/x-python",
291 | "name": "python",
292 | "nbconvert_exporter": "python",
293 | "pygments_lexer": "ipython3",
294 | "version": "3.10.10"
295 | }
296 | },
297 | "nbformat": 4,
298 | "nbformat_minor": 2
299 | }
300 |
--------------------------------------------------------------------------------
/Journey/Day11/Day11.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 从零手搓中文大模型|🚀Day11"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "\n",
15 | "之前已经把`SFT`阶段给跑通了,尽管整体效果差强人意,但至少证明在这么小的参数量级上也是可行的。\n",
16 | "\n",
17 | "接下来我继续尝试一下`DPO`阶段,但是首先依然得**搞数据**。\n",
18 | "\n",
19 | "## DPO数据构造\n",
20 | "\n",
21 | "`DPO`数据主要是需要获得`rejected`和`chosen`的数据对。\n",
22 | "\n",
23 | "`chosen`的数据很好说,直接使用`SFT`数据里的`response`即可。\n",
24 | "\n",
25 | "而`rejected`的数据其实就是就是回答质量相对较差的数据,很容易就能想`SFT`之后的模型根据`prompt`给出的`response`肯定是质量低于`ground truth`的,天然就可以作为`rejected`的数据。\n",
26 | "\n",
27 | "构造路径倒是很容易,但是根据之前跑生成的经验,单条`prompt`数据生成`response`的时间大概在0.5秒左右,如果使用`SFT`数据全量(在我机制的数据增强之下从1.5w变成了7w多)生成`DPO`数据,那么可能需要10小时左右的时间。\n",
28 | "\n",
29 | "那么并发生成就显得尤为重要,可行的方法有两种:\n",
30 | "1. 加载多个模型的实例,将数据均等切分成多个`chunks`每个模型生成一部分数据,最后再合并。\n",
31 | "2. 将模型部署成`API`接口,使用`aiohttp`异步请求。\n",
32 | "\n",
33 | "> 其实应该同时用上`batch inference`,但`litgpt`库这块的`feature`还在开发中,我自己魔改担心搞不定,就先不尝试了。\n",
34 | "\n",
35 | "显然后者的稳定性会更好,那么话不多说,直接上代码👇:\n"
36 | ]
37 | },
38 | {
39 | "cell_type": "code",
40 | "execution_count": 26,
41 | "metadata": {},
42 | "outputs": [],
43 | "source": [
44 | "import asyncio\n",
45 | "import aiohttp\n",
46 | "import json\n",
47 | "import argparse\n",
48 | "import hashlib\n",
49 | "import time\n",
50 | "import atexit\n",
51 | "from tqdm import tqdm\n",
52 | "from litgpt.prompts import MicroStories\n",
53 | "from loguru import logger\n",
54 | "\n",
55 | "\n",
56 | "def hash_prompt(prompt):\n",
57 | " return hashlib.md5(prompt.encode()).hexdigest()\n",
58 | "\n",
59 | "\n",
60 | "cache = {}\n",
61 | "error_cache = {}\n",
62 | "\n",
63 | "\n",
64 | "def save_caches():\n",
65 | " with open(\"dpo_cache.json\", \"w\", encoding=\"utf-8\") as f:\n",
66 | " json.dump(cache, f, ensure_ascii=False, indent=2)\n",
67 | " with open(\"error_cache.json\", \"w\", encoding=\"utf-8\") as f:\n",
68 | " json.dump(error_cache, f, ensure_ascii=False, indent=2)\n",
69 | " logger.info(\"缓存已保存\")\n",
70 | "\n",
71 | "\n",
72 | "atexit.register(save_caches)\n",
73 | "\n",
74 | "\n",
75 | "async def generate_response(session, prompt, semaphore):\n",
76 | " prompt_hash = hash_prompt(prompt)\n",
77 | " if prompt_hash in cache:\n",
78 | " return cache[prompt_hash]\n",
79 | "\n",
80 | " async with semaphore:\n",
81 | " try:\n",
82 | " async with session.post(\n",
83 | " \"http://127.0.0.1:8000/predict\", json={\"prompt\": prompt}\n",
84 | " ) as response:\n",
85 | " result = await response.json()\n",
86 | " cache[prompt_hash] = result\n",
87 | " return result\n",
88 | " except Exception as e:\n",
89 | " error_msg = f\"生成响应时出错: {str(e)}\"\n",
90 | " logger.error(error_msg)\n",
91 | " error_cache[prompt_hash] = error_msg\n",
92 | " return None\n",
93 | "\n",
94 | "\n",
95 | "async def main(concurrency, test_mode):\n",
96 | " global cache, error_cache\n",
97 | " ms = MicroStories()\n",
98 | "\n",
99 | " with open(\n",
100 | " \"../../Data/TinyStoriesInstruct/sft_data_v2_simple.json\", \"r\", encoding=\"utf-8\"\n",
101 | " ) as f:\n",
102 | " sft_data = json.load(f)\n",
103 | "\n",
104 | " if test_mode:\n",
105 | " sft_data = sft_data[:100]\n",
106 | "\n",
107 | " # 读取缓存\n",
108 | " try:\n",
109 | " with open(\"dpo_cache.json\", \"r\", encoding=\"utf-8\") as f:\n",
110 | " cache = json.load(f)\n",
111 | " except FileNotFoundError:\n",
112 | " cache = {}\n",
113 | "\n",
114 | " try:\n",
115 | " with open(\"error_cache.json\", \"r\", encoding=\"utf-8\") as f:\n",
116 | " error_cache = json.load(f)\n",
117 | " except FileNotFoundError:\n",
118 | " error_cache = {}\n",
119 | "\n",
120 | " semaphore = asyncio.Semaphore(concurrency)\n",
121 | "\n",
122 | " async with aiohttp.ClientSession() as session:\n",
123 | " tasks = []\n",
124 | " for i, case in enumerate(tqdm(sft_data, desc=\"生成DPO数据\")):\n",
125 | " prompt = ms.apply(prompt=case[\"instruction\"], input=case[\"input\"])\n",
126 | " task = asyncio.create_task(generate_response(session, prompt, semaphore))\n",
127 | " tasks.append(task)\n",
128 | "\n",
129 | " # 每处理100个样本保存一次缓存\n",
130 | " if (i + 1) % 100 == 0:\n",
131 | " save_caches()\n",
132 | "\n",
133 | " responses = await asyncio.gather(*tasks)\n",
134 | "\n",
135 | " dpo_data = []\n",
136 | " for case, response in zip(sft_data, responses):\n",
137 | " prompt = ms.apply(prompt=case[\"instruction\"], input=case[\"input\"])\n",
138 | " dpo_sample = {\n",
139 | " \"prompt\": prompt,\n",
140 | " \"rejected\": response.get(\"output\") or response.get(\"rejected\"),\n",
141 | " \"chosen\": case[\"output\"],\n",
142 | " }\n",
143 | " dpo_data.append(dpo_sample)\n",
144 | "\n",
145 | " # 保存错误缓存\n",
146 | " save_caches() # 最后再保存一次缓存\n",
147 | "\n",
148 | " output_file = \"dpo_data_test.json\" if test_mode else \"dpo_data.json\"\n",
149 | " with open(output_file, \"w\", encoding=\"utf-8\") as f:\n",
150 | " json.dump(dpo_data, f, ensure_ascii=False, indent=2)\n",
151 | "\n",
152 | " logger.info(f\"DPO数据已生成并保存到 {output_file}\")\n",
153 | " logger.info(f\"缓存已更新并保存到 dpo_cache.json\")\n",
154 | " logger.info(f\"错误缓存已保存到 error_cache.json\")\n",
155 | "\n",
156 | " end_time = time.time()\n",
157 | " execution_time = end_time - start_time\n",
158 | " logger.info(f\"总执行时间: {execution_time:.2f} 秒\")\n",
159 | "\n",
160 | "\n",
161 | "if __name__ == \"__main__\":\n",
162 | " parser = argparse.ArgumentParser(description=\"生成DPO数据\")\n",
163 | " parser.add_argument(\"--concurrency\", type=int, default=10, help=\"并发数量\")\n",
164 | " parser.add_argument(\"--test\", action=\"store_true\", help=\"测试模式\")\n",
165 | " args = parser.parse_args()\n",
166 | "\n",
167 | " logger.add(\"generate_dpo_data.log\", rotation=\"500 MB\")\n",
168 | " start_time = time.time()\n",
169 | " asyncio.run(main(args.concurrency, args.test))"
170 | ]
171 | },
172 | {
173 | "cell_type": "markdown",
174 | "metadata": {},
175 | "source": [
176 | "上面的脚本做了这样几件事:\n",
177 | "1. 构建了一个`generate_response`的函数,用于根据`prompt`生成`response`\n",
178 | "2. 对上面的函数做了异步调度,可以控制并发数量来生成`response`\n",
179 | "3. 设置了对已经生成的样本的结果的缓存以及异常样本的缓存(每100个样本保存一次,且如果脚本异常退出`atexit`会自动保存)\n",
180 | "4. 最后将`SFT`数据和生成的`response`进行拼接,得到最终的`DPO`数据。"
181 | ]
182 | },
183 | {
184 | "cell_type": "code",
185 | "execution_count": 1,
186 | "metadata": {
187 | "vscode": {
188 | "languageId": "shellscript"
189 | }
190 | },
191 | "outputs": [],
192 | "source": [
193 | "# ! python generate_dpo_data.py --concurrency 25 "
194 | ]
195 | },
196 | {
197 | "cell_type": "markdown",
198 | "metadata": {},
199 | "source": [
200 | "聪明的你肯定会问了:异步调度啥的倒是都有了,**可我哪儿来的接口呢?**\n",
201 | "\n",
202 | "其实`litgpt`库同时也提供了模型的`serving`功能,只要安装了额外的`litserve`依赖,就可以一键部署:"
203 | ]
204 | },
205 | {
206 | "cell_type": "code",
207 | "execution_count": 4,
208 | "metadata": {
209 | "vscode": {
210 | "languageId": "shellscript"
211 | }
212 | },
213 | "outputs": [],
214 | "source": [
215 | "# ! litgpt serve out/custom-model/final"
216 | ]
217 | },
218 | {
219 | "cell_type": "markdown",
220 | "metadata": {},
221 | "source": [
222 | "不过这样得到的服务是单实例的,无法满足我们批量刷数据的需求。\n",
223 | "\n",
224 | "大家别忘了,我们的模型尺寸只有`0.044B`,显存占用才`600M`,这意味着我们在一张卡上可以轻松部署多个实例。\n",
225 | "\n",
226 | "其实`litserve`是支持多`workers`的,不过在`litgpt`库集成的时候没有暴露出参数,问题不大,我们自己基于[litgpt里的serve.py](https://github.com/Lightning-AI/litgpt/blob/main/litgpt/deploy/serve.py)魔改一下就好了。\n",
227 | "\n",
228 | "代码太长这里就不完整地贴出了,感兴趣的可以看[这里](https://github.com/puppyapple/Chinese_LLM_From_Scratch/blob/main/Journey/Day11/service.py)。\n",
229 | "\n",
230 | "修改其实很简单,就是把`workers_per_device`参数暴露了出来,这样就可以在启动服务的时候指定`workers_per_device`的值了。"
231 | ]
232 | },
233 | {
234 | "cell_type": "code",
235 | "execution_count": null,
236 | "metadata": {},
237 | "outputs": [],
238 | "source": [
239 | "@click.command()\n",
240 | "@click.option(\"--checkpoint_dir\", type=str)\n",
241 | "@click.option(\"--quantize\", type=str, default=None)\n",
242 | "@click.option(\"--precision\", type=str, default=\"bf16-true\")\n",
243 | "@click.option(\"--temperature\", type=float, default=0.8)\n",
244 | "@click.option(\"--top_k\", type=int, default=50)\n",
245 | "@click.option(\"--top_p\", type=float, default=1.0)\n",
246 | "@click.option(\"--max_new_tokens\", type=int, default=50)\n",
247 | "@click.option(\"--devices\", type=int, default=1)\n",
248 | "@click.option(\"--workers_per_device\", type=int, default=20)\n",
249 | "@click.option(\"--port\", type=int, default=8000)\n",
250 | "@click.option(\"--stream\", type=bool, default=False)\n",
251 | "@click.option(\"--accelerator\", type=str, default=\"auto\")\n",
252 | "def run_server(\n",
253 | " checkpoint_dir: Path,\n",
254 | " quantize: Optional[\n",
255 | " Literal[\"bnb.nf4\", \"bnb.nf4-dq\", \"bnb.fp4\", \"bnb.fp4-dq\", \"bnb.int8\"]\n",
256 | " ] = None,\n",
257 | " precision: Optional[str] = None,\n",
258 | " temperature: float = 0.8,\n",
259 | " top_k: int = 50,\n",
260 | " top_p: float = 1.0,\n",
261 | " max_new_tokens: int = 50,\n",
262 | " devices: int = 1,\n",
263 | " port: int = 8000,\n",
264 | " accelerator: str = \"auto\",\n",
265 | " workers_per_device: int = 20,\n",
266 | " stream: bool = False,\n",
267 | " access_token: Optional[str] = None,\n",
268 | ") -> None:\n",
269 | " # ...\n",
270 | " pass\n",
271 | "\n",
272 | "\n",
273 | "if __name__ == \"__main__\":\n",
274 | " run_server()"
275 | ]
276 | },
277 | {
278 | "cell_type": "markdown",
279 | "metadata": {},
280 | "source": [
281 | "我设置了`25`个`workers`,然后生成的脚本配置了`--concurrency 25`。\n",
282 | "\n",
283 | "运行时的整体`GPU`占用是`20G`左右。\n",
284 | "\n",
285 | "\n",
286 | "\n",
287 | "截止写这篇文章,数据还在运行中,具体耗时多久等我跑完了在同步给大家。\n",
288 | "\n",
289 | "> 另外我调研的时候发现`litserve`的`batch inference`其实已经支持了,后面有时间尝试一下,如果有效会更新到项目里。\n",
290 | "> 仓库里我也同时提供了单模型和多模型实例来跑数据的脚本。\n",
291 | ">\n",
292 | "## 小结\n",
293 | "\n",
294 | "今天的内容其实很简单,就是构造了`DPO`数据,并且通过异步请求的方式提高了数据构造的效率。\n",
295 | "\n",
296 | "等数据跑完了我会着手进行`DPO`的训练。\n",
297 | "\n",
298 | "由于`litgpt`库自身还不支持`DPO`,所以这部分需要完全自己`DIY`了,可能会稍微费点劲,请大家拭目以待!"
299 | ]
300 | },
301 | {
302 | "cell_type": "markdown",
303 | "metadata": {},
304 | "source": []
305 | }
306 | ],
307 | "metadata": {
308 | "kernelspec": {
309 | "display_name": "bigmodel",
310 | "language": "python",
311 | "name": "python3"
312 | },
313 | "language_info": {
314 | "codemirror_mode": {
315 | "name": "ipython",
316 | "version": 3
317 | },
318 | "file_extension": ".py",
319 | "mimetype": "text/x-python",
320 | "name": "python",
321 | "nbconvert_exporter": "python",
322 | "pygments_lexer": "ipython3",
323 | "version": "3.10.10"
324 | }
325 | },
326 | "nbformat": 4,
327 | "nbformat_minor": 2
328 | }
329 |
--------------------------------------------------------------------------------
/Journey/Day04/Day04.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 从零手搓中文大模型|🚀Day04"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "前面已经完成了**数据预处理**,今天我们来研究一下**模型的配置**。\n",
15 | "\n",
16 | "`litgpt`使用的配置文件和`transformers`有点不太一样,它的仓库里提供了一些预训练所用的`yaml`[配置文件样例](https://github.com/Lightning-AI/litgpt/tree/main/config_hub)。这个主要用于需要自定义模型的场景。\n",
17 | "\n",
18 | "另外`litgpt`也内置了一些`huggingface`上的[现成模型](https://github.com/Lightning-AI/litgpt/blob/main/litgpt/config.py),可以直接拿来使用。"
19 | ]
20 | },
21 | {
22 | "cell_type": "markdown",
23 | "metadata": {},
24 | "source": [
25 | "## 训练配置文件\n",
26 | "以下是我这次定义的一个配置文件。\n",
27 | "\n",
28 | "内容有点多,但是还是都列举出来了,可以直接跳到后面对一些关键参数的解释。"
29 | ]
30 | },
31 | {
32 | "cell_type": "markdown",
33 | "metadata": {},
34 | "source": [
35 | "```yaml\n",
36 | "# The name of the model to pretrain. Choose from names in ``litgpt.config``. Mutually exclusive with\n",
37 | "# ``model_config``. (type: Optional[str], default: null)\n",
38 | "model_name: microstories\n",
39 | "\n",
40 | "# A ``litgpt.Config`` object to define the model architecture. Mutually exclusive with\n",
41 | "# ``model_config``. (type: Optional[Config], default: null)\n",
42 | "model_config:\n",
43 | " name: microstories\n",
44 | " hf_config: {}\n",
45 | " scale_embeddings: false\n",
46 | " block_size: 512\n",
47 | " padded_vocab_size: 65024\n",
48 | " vocab_size: 64798\n",
49 | " n_layer: 6\n",
50 | " n_head: 6\n",
51 | " n_query_groups: 6\n",
52 | " n_embd: 512\n",
53 | " head_size: 48\n",
54 | " rotary_percentage: 1.0\n",
55 | " parallel_residual: false\n",
56 | " bias: false\n",
57 | " norm_class_name: RMSNorm\n",
58 | " mlp_class_name: LLaMAMLP\n",
59 | " intermediate_size: 768\n",
60 | "\n",
61 | "# Directory in which to save checkpoints and logs. If running in a Lightning Studio Job, look for it in\n",
62 | "# /teamspace/jobs//share. (type: , default: out/pretrain)\n",
63 | "out_dir: Chinese_LLM_From_Scratch/Experiments/Output/pretrain/microstories\n",
64 | "\n",
65 | "# The precision to use for pretraining. Possible choices: \"bf16-true\", \"bf16-mixed\", \"32-true\". (type: Optional[str], default: null)\n",
66 | "precision: bf16-mixed\n",
67 | "\n",
68 | "# Optional path to a checkpoint directory to initialize the model from.\n",
69 | "# Useful for continued pretraining. Mutually exclusive with ``resume``. (type: Optional[Path], default: null)\n",
70 | "initial_checkpoint_dir:\n",
71 | "\n",
72 | "# Path to a checkpoint directory to resume from in case training was interrupted, or ``True`` to resume\n",
73 | "# from the latest checkpoint in ``out_dir``. An error will be raised if no checkpoint is found. Passing\n",
74 | "# ``'auto'`` will resume from the latest checkpoint but not error if no checkpoint exists.\n",
75 | "# (type: Union[bool, Literal[\"auto\"], Path], default: False)\n",
76 | "resume: true\n",
77 | "\n",
78 | "# Data-related arguments. If not provided, the default is ``litgpt.data.TinyLlama``.\n",
79 | "data:\n",
80 | " # TinyStories\n",
81 | " class_path: litgpt.data.LitData\n",
82 | " init_args:\n",
83 | " data_path: Chinese_LLM_From_Scratch/Data/TinyStoriesChinese/processed_data\n",
84 | " split_names:\n",
85 | " - train\n",
86 | " - val\n",
87 | "\n",
88 | "# Training-related arguments. See ``litgpt.args.TrainArgs`` for details\n",
89 | "train:\n",
90 | " # Number of optimizer steps between saving checkpoints (type: Optional[int], default: 1000)\n",
91 | " save_interval: 1000\n",
92 | "\n",
93 | " # Number of iterations between logging calls (type: int, default: 1)\n",
94 | " log_interval: 1\n",
95 | "\n",
96 | " # Number of samples between optimizer steps across data-parallel ranks (type: int, default: 512)\n",
97 | " global_batch_size: 512\n",
98 | "\n",
99 | " # Number of samples per data-parallel rank (type: int, default: 4)\n",
100 | " micro_batch_size: 32\n",
101 | "\n",
102 | " # Number of iterations with learning rate warmup active (type: int, default: 2000)\n",
103 | " lr_warmup_steps: 1000\n",
104 | "\n",
105 | " # Number of epochs to train on (type: Optional[int], default: null)\n",
106 | " epochs:\n",
107 | "\n",
108 | " # Total number of tokens to train on (type: Optional[int], default: 3000000000000)\n",
109 | " max_tokens: 3000000000000\n",
110 | "\n",
111 | " # Limits the number of optimizer steps to run. (type: Optional[int], default: null)\n",
112 | " max_steps:\n",
113 | "\n",
114 | " # Limits the length of samples. Off by default (type: Optional[int], default: null)\n",
115 | " max_seq_length: 512\n",
116 | "\n",
117 | " # Whether to tie the embedding weights with the language modeling head weights. (type: Optional[bool], default: False)\n",
118 | " tie_embeddings: true\n",
119 | "\n",
120 | " # (type: Optional[float], default: 1.0)\n",
121 | " max_norm: 1.0\n",
122 | "\n",
123 | " # (type: float, default: 4e-05)\n",
124 | " min_lr: 0.0\n",
125 | "\n",
126 | "# Evaluation-related arguments. See ``litgpt.args.EvalArgs`` for details\n",
127 | "eval:\n",
128 | " # Number of optimizer steps between evaluation calls (type: int, default: 1000)\n",
129 | " interval: 2000\n",
130 | "\n",
131 | " # Number of tokens to generate (type: Optional[int], default: null)\n",
132 | " max_new_tokens:\n",
133 | "\n",
134 | " # Number of iterations (type: int, default: 100)\n",
135 | " max_iters: 100\n",
136 | "\n",
137 | " # Whether to evaluate on the validation set at the beginning of the training\n",
138 | " initial_validation: false\n",
139 | "\n",
140 | " # Whether to evaluate on the validation set at the end the training\n",
141 | " final_validation: false\n",
142 | "\n",
143 | "# Optimizer-related arguments\n",
144 | "optimizer:\n",
145 | " class_path: torch.optim.AdamW\n",
146 | "\n",
147 | " init_args:\n",
148 | " # (type: float, default: 0.001)\n",
149 | " lr: 0.0005\n",
150 | "\n",
151 | " # (type: float, default: 0.01)\n",
152 | " weight_decay: 0.1\n",
153 | "\n",
154 | " # (type: tuple, default: (0.9,0.999))\n",
155 | " betas:\n",
156 | " - 0.9\n",
157 | " - 0.95\n",
158 | "\n",
159 | "# How many devices/GPUs to use. Uses all GPUs by default. (type: Union[int, str], default: auto)\n",
160 | "devices: auto\n",
161 | "\n",
162 | "# How many nodes to use. (type: int, default: 1)\n",
163 | "num_nodes: 1\n",
164 | "\n",
165 | "# Optional path to the tokenizer dir that was used for preprocessing the dataset. Only some data\n",
166 | "# module require this. (type: Optional[Path], default: null)\n",
167 | "tokenizer_dir: Chinese_LLM_From_Scratch/References/chatglm3-6b\n",
168 | "\n",
169 | "# The name of the logger to send metrics to. (type: Literal['wandb', 'tensorboard', 'csv'], default: tensorboard)\n",
170 | "logger_name: wandb\n",
171 | "\n",
172 | "# The random seed to use for reproducibility. (type: int, default: 42)\n",
173 | "seed: 42\n",
174 | "```"
175 | ]
176 | },
177 | {
178 | "cell_type": "markdown",
179 | "metadata": {},
180 | "source": [
181 | "### model_config"
182 | ]
183 | },
184 | {
185 | "cell_type": "markdown",
186 | "metadata": {},
187 | "source": [
188 | "```yaml\n",
189 | "model_config:\n",
190 | " name: microstories\n",
191 | " hf_config: {}\n",
192 | " scale_embeddings: false\n",
193 | " block_size: 512\n",
194 | " padded_vocab_size: 65024\n",
195 | " vocab_size: 64798\n",
196 | " n_layer: 6\n",
197 | " n_head: 6\n",
198 | " n_query_groups: 6\n",
199 | " n_embd: 512\n",
200 | " head_size: 48\n",
201 | " rotary_percentage: 1.0\n",
202 | " parallel_residual: false\n",
203 | " bias: false\n",
204 | " norm_class_name: RMSNorm\n",
205 | " mlp_class_name: LLaMAMLP\n",
206 | " intermediate_size: 768\n",
207 | "```"
208 | ]
209 | },
210 | {
211 | "cell_type": "markdown",
212 | "metadata": {},
213 | "source": [
214 | "- `scale_embeddings`控制是否对embedding进行缩放。\n",
215 | " \n",
216 | " \n",
217 | " \n",
218 | " 如果为`True`,那么在`forward`函数中会对`embedding`进行缩放。注意个缩放和`sefl-attention`中的缩放不是一回事,不要弄混了。\n",
219 | " 其实也有很多讨论关于这个地方这一步**是否有必要**的,目前看来似乎是区别不大,可以设置为`False`。\n",
220 | "- `transformer`中的`block_size`,也就是`max_seq_length`。\n",
221 | "- `padded_vovab_size`和`vocab_size`直接取自`tokenizer`。\n",
222 | "- `n_layer`和`n_head`都是`6`,构建了一个`6`层`6`头的`transformer`。\n",
223 | "- `n_query_groups`是`6`,这是`GQA(Grouped-Query Attention)`的一个参数,控制`query`的分组。当`n_query_groups`等于`n_head`时,其实就是`MHA(Multi-Head Attention)`。下面这个图比较直观:\n",
224 | " \n",
225 | " \n",
226 | "\n",
227 | "- 头的大小`head_size`是`48`,`n_embd`是`512`。\n",
228 | "- `rotary_percentage`是`1.0`,这个是`旋转编码(Rotary Position Embedding, RoPE)`的有关参数,这里先不展开介绍了。\n",
229 | "- `parallel_residual`是`false`,关于`parallel residual`和`non-parallel residual`的解释可以参考这个图:\n",
230 | " \n",
231 | " \n",
232 | "- `bias`控制`Linear`层的`bias`是否存在,现在大多模型一般都是`false`。\n",
233 | "- `norm_class_name`是`RMSNorm`,`mlp_class_name`是`LLaMAMLP`,具体可以参见`litgpt`里[`model.py`](https://github.com/Lightning-AI/litgpt/blob/main/litgpt/model.py#L30)中的实现。\n",
234 | "- `intermediate_size`是`768`,这个是上面的`MLP`中间层的大小。\n",
235 | "\n",
236 | "按照上面的配置得到的模型参数量在`44M`左右,也就是只有`0.044B`的大小。\n",
237 | "\n",
238 | "但根据微软的[TinyStories](https://arxiv.org/pdf/2305.07759)论文结论,`10-80M`级别的模型能在小故事生成这种简单的语言任务上达到不错的效果(依旧能说人话)。"
239 | ]
240 | },
241 | {
242 | "cell_type": "markdown",
243 | "metadata": {},
244 | "source": [
245 | "### 其他参数\n",
246 | "\n",
247 | "其余的都是一些训练的参数,比如`batch_size`,`lr`,`weight_decay`等等,这些都是比较常见的参数,不再赘述。\n",
248 | "\n",
249 | "`logger`我这里选择的是`wandb`,可以直接在`wandb`上查看训练过程中的一些指标。\n",
250 | "\n",
251 | "`data`设置成之前预处理好的数据集的路径(其中指定了加载数据所用的`litdata`的类名)\n",
252 | "\n",
253 | "`tokenizer_dir`是选用的或者自己训练好的`tokenizer`的路径。"
254 | ]
255 | },
256 | {
257 | "cell_type": "markdown",
258 | "metadata": {},
259 | "source": [
260 | "## 启动训练"
261 | ]
262 | },
263 | {
264 | "cell_type": "markdown",
265 | "metadata": {},
266 | "source": [
267 | "```bash\n",
268 | "litgpt pretrain --config Experiments/configs/microstories.yaml\n",
269 | "```\n",
270 | "预训练启动的命令非常简单,只需要指定上面的配置文件的路径即可。\n",
271 | "\n",
272 | "不出意外地话模型就能开始训练了,可以在`wandb`上查看训练过程中的指标。\n",
273 | "\n",
274 | "我的模型其实已经训练了一段时间,show一下训练过程中的图表:\n",
275 | "\n",
276 | ""
277 | ]
278 | },
279 | {
280 | "cell_type": "markdown",
281 | "metadata": {},
282 | "source": [
283 | "## 小结\n",
284 | "1. 详细介绍了`litgpt`的预训练模型配置文件。\n",
285 | "2. 顺带解释了一些重要参数的原理。\n",
286 | "3. 训练启动。"
287 | ]
288 | },
289 | {
290 | "cell_type": "markdown",
291 | "metadata": {},
292 | "source": []
293 | }
294 | ],
295 | "metadata": {
296 | "kernelspec": {
297 | "display_name": "bigmodel",
298 | "language": "python",
299 | "name": "python3"
300 | },
301 | "language_info": {
302 | "codemirror_mode": {
303 | "name": "ipython",
304 | "version": 3
305 | },
306 | "file_extension": ".py",
307 | "mimetype": "text/x-python",
308 | "name": "python",
309 | "nbconvert_exporter": "python",
310 | "pygments_lexer": "ipython3",
311 | "version": "3.10.10"
312 | }
313 | },
314 | "nbformat": 4,
315 | "nbformat_minor": 2
316 | }
317 |
--------------------------------------------------------------------------------
/Journey/Day05/Day05.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 从零手搓中文大模型|🚀 Day05"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## 模型预训练完啦 🎉\n",
15 | "\n",
16 | "在**Day 04**的内容里已经介绍过了我的参数配置,在这个配置下呢我训练了`200k step`。\n",
17 | "\n",
18 | "由于数据集比较小,参数量级也不大,在这个步数上`validation loss`的下降已经非常缓慢了,所以我停止了训练。\n",
19 | "\n",
20 | "`wandb`的曲线如下:\n",
21 | "\n",
22 | ""
23 | ]
24 | },
25 | {
26 | "cell_type": "markdown",
27 | "metadata": {},
28 | "source": [
29 | "每`1000 step`保存一次模型,所以现在我已经有`200`多个模型了。\n",
30 | "然后看看最后几个模型文件👇:"
31 | ]
32 | },
33 | {
34 | "cell_type": "code",
35 | "execution_count": 1,
36 | "metadata": {},
37 | "outputs": [
38 | {
39 | "name": "stdout",
40 | "output_type": "stream",
41 | "text": [
42 | "step-00205000\n",
43 | "step-00206000\n",
44 | "step-00207000\n",
45 | "step-00208000\n",
46 | "step-00209000\n"
47 | ]
48 | }
49 | ],
50 | "source": [
51 | "! ls ../../Experiments/Output/pretrain/microstories | tail -5"
52 | ]
53 | },
54 | {
55 | "cell_type": "markdown",
56 | "metadata": {},
57 | "source": [
58 | "## 让我们看看模型效果吧 🥳"
59 | ]
60 | },
61 | {
62 | "cell_type": "markdown",
63 | "metadata": {},
64 | "source": [
65 | "### 模型inference测试\n",
66 | "直接使用[`litgpt.api`里的代码](https://github.com/Lightning-AI/litgpt/blob/main/litgpt/api.py),我们用第一个`checkpoint`来尝试生成一些文本。"
67 | ]
68 | },
69 | {
70 | "cell_type": "code",
71 | "execution_count": 2,
72 | "metadata": {},
73 | "outputs": [],
74 | "source": [
75 | "from litgpt import LLM\n",
76 | "\n",
77 | "llm = LLM.load(model=\"../../Experiments/Output/pretrain/microstories/step-00001000\")\n",
78 | "llm.generate(\n",
79 | " prompt=\"汤姆和杰瑞是好朋友,\",\n",
80 | " max_new_tokens=500,\n",
81 | " temperature=0.8,\n",
82 | " top_p=0.9,\n",
83 | " top_k=30,\n",
84 | ")"
85 | ]
86 | },
87 | {
88 | "cell_type": "markdown",
89 | "metadata": {},
90 | "source": [
91 | "可以看到训练了`1000 steps`的模型已经可以生成一些连贯的文本了,但是长度非常短。\n",
92 | "\n",
93 | "看一眼`0.044B`模型的显存占用:\n",
94 | "\n",
95 | "\n",
96 | "\n",
97 | "毕竟只有`44M`参数,`GPU`占用连`650M`都不到。"
98 | ]
99 | },
100 | {
101 | "cell_type": "markdown",
102 | "metadata": {},
103 | "source": [
104 | "### 批量测试\n",
105 | "我接下来从200多个`checkpoints`中每20个选一个,来测试一下效果。"
106 | ]
107 | },
108 | {
109 | "cell_type": "code",
110 | "execution_count": 5,
111 | "metadata": {},
112 | "outputs": [
113 | {
114 | "name": "stdout",
115 | "output_type": "stream",
116 | "text": [
117 | "step-00020000\n",
118 | "-------------\n",
119 | "汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们在公园里发现了一个大箱子。他们不知道里面有什么。他们想打开它看看里面有什么。\n",
120 | "“我们打开箱子吧!”汤姆说。杰瑞同意了。他们试图打开箱子,但太难了。他们推拉,但箱子没有打开。他们很伤心。\n",
121 | "然后,他们看到一个高大的男人。他戴着一顶大帽子,穿着长外套。他看到汤姆和杰瑞,微笑了。\n",
122 | "“你们好,孩子们。你们想要个礼物吗?”他问。\n",
123 | "“是的,请!”汤姆和杰瑞说。\n",
124 | "“你们想要什么?”男人问。\n",
125 | "“你们想要什么?”汤姆和杰瑞问。\n",
126 | "“你们想要什么?”男人问。\n",
127 | "“你们想要什么?”汤姆和杰瑞问。\n",
128 | "男人想了一下。他喜欢汤姆和杰瑞。他们喜欢他。\n",
129 | "“你们想要什么?”男人问。\n",
130 | "“你们想要什么?”汤姆和杰瑞问。\n",
131 | "男人想了一下。他喜欢汤姆和杰瑞。他们很好奇。\n",
132 | "“你们想要什么?”男人问。\n",
133 | "“你们想要一个玩具。一个球。一个球。你们想要一个球。你们想要一个球吗?”男人问。\n",
134 | "汤姆和杰瑞瑞点点头。他们喜欢球。\n",
135 | "男人给了他们一个球。它很软,弹跳得很高。汤姆和杰瑞很高兴。他们感谢了男人。\n",
136 | "男人微笑着。他很高兴他们喜欢这个礼物。他喜欢这个礼物。\n",
137 | "汤姆和杰瑞也很高兴。他们有了一个新朋友。他们有了新玩具。他们有了新朋友。他们有了新的玩具。他们有了新的玩具。他们有了新的朋友。他们很开心。\n",
138 | "****************************************************************************************************\n",
139 | "\n",
140 | "\n",
141 | "step-00040000\n",
142 | "-------------\n",
143 | "汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们在公园里发现了一个大箱子。他们想看看里面有什么东西。\n",
144 | "“我们打开看看吧!”汤姆说。\n",
145 | "“好的!”杰瑞说。\n",
146 | "他们试图打开箱子,但太难了。他们推拉了一下,但箱子没有打开。他们很伤心,也很累。\n",
147 | "“也许我们可以用棍子打开它。”汤姆说。\n",
148 | "他找到一根棍子,试图打开箱子。但是棍子太短了,打不开。他试了又试,但棍子就是打不开。\n",
149 | "“也许我们可以用棍子打开箱子。”杰瑞说。\n",
150 | "他找到一根棍子,试图打开箱子。但棍子太短了,打不开。他试了又试,但棍子就是打不开。\n",
151 | "“也许我们需要一个工具。”汤姆说。\n",
152 | "他四处张望,看到地上有一根棍子。他捡起来,用它砸向箱子。\n",
153 | "“哎哟!”汤姆说。\n",
154 | "他放下棍子,看着箱子。它又大又重,盖子也打不开。\n",
155 | "“也许我们可以用这个棍子打开箱子。”汤姆说。\n",
156 | "他捡起一根棍子,扔向箱子。棍子打中了箱子,发出很大的响声。\n",
157 | "“砰!砰!”箱子破了。\n",
158 | "汤姆和杰瑞瑞都笑了。他们觉得很有趣。\n",
159 | "“看,我们成功了!”汤姆说。\n",
160 | "“我们打开了箱子!”杰瑞说。\n",
161 | "他们跑向箱子,试图打开它。\n",
162 | "但是箱子太重了。他们打不开。\n",
163 | "他们听到一声巨响。\n",
164 | "“砰!”箱子破了。\n",
165 | "他们看着箱子,看到箱子破了。\n",
166 | "他们很伤心。\n",
167 | "他们看着彼此。\n",
168 | "他们拥抱了一下,说:“对不起。”\n",
169 | "他们决定一起玩箱子。他们用箱子做了一个房子。他们用箱子做了一个门和一个窗户。他们用箱子做了一个门和一个窗户。\n",
170 | "他们很高兴。\n",
171 | "他们说:“我们爱你们。”\n",
172 | "他们说:“我们爱你们。”\n",
173 | "他们说:“我们爱。”\n",
174 | "他们玩得很开心。\n",
175 | "****************************************************************************************************\n",
176 | "\n",
177 | "\n",
178 | "step-00060000\n",
179 | "-------------\n",
180 | "汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们决定去冒险。\n",
181 | "他们走啊走,直到发现一棵大树。汤姆说:“我们爬上这棵树吧!”杰瑞说:“好的,但要小心!”于是,汤姆和杰瑞开始爬树。他们越爬越高,直到到达一个鸟巢。\n",
182 | "在鸟巢里,他们发现了一个大蛋。汤姆说:“哇,看看这个蛋!它好大啊!”杰瑞说:“我们把它带回家吧!”于是,他们把蛋带回了鸟巢。\n",
183 | "但是当他们回到家时,发现蛋不见了!汤姆和杰瑞很伤心。他们到处找蛋,但找不到。然后,他们听到一声响动。他们看到蛋在动!蛋裂开了,一只小鸟出来了。小鸟说:“谢谢你们把我吵醒!”汤姆和杰瑞很高兴,他们交了一个新朋友。\n",
184 | "****************************************************************************************************\n",
185 | "\n",
186 | "\n",
187 | "step-00080000\n",
188 | "-------------\n",
189 | "汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们发现了一个大箱子。他们想看看里面有什么。\n",
190 | "汤姆说:“我们打开箱子吧!” 杰瑞同意了,于是他们打开了箱子。里面有很多玩具。他们非常高兴,开始玩这些玩具。\n",
191 | "但是,接下来发生了一件意想不到的事情。这些玩具开始说话了!玩具们说:“你们好,汤姆和杰瑞!我们是魔法玩具。我们来给你们一个惊喜!” 汤姆和杰瑞非常惊讶,但他们也很兴奋。他们和魔法玩具们一起玩了一整天,度过了很多快乐时光。\n",
192 | "****************************************************************************************************\n",
193 | "\n",
194 | "\n",
195 | "step-00100000\n",
196 | "-------------\n",
197 | "汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们决定去公园野餐。他们带了一些三明治、水果和果汁。\n",
198 | "当他们到达公园时,发现了一个大而可怕的森林。他们很害怕,但他们想探索一下。他们走了又走,直到发现一棵大树。他们爬上树,看到了一个鸟巢。他们想看看里面有什么,于是伸手去拿。\n",
199 | "突然,他们听到一声巨响。是一只熊!熊生气了,开始追赶他们。汤姆和杰瑞跑得很快,但熊跑得更快。他们跑啊跑,但熊跑得更快。他们试图躲起来,但熊找到了他们。他们非常害怕,不知道该怎么办。\n",
200 | "熊越来越近,他们不知道该怎么办。他们试图呼救,但没有人听到。熊吃了他们,然后他们就再也没有出现过。结束。\n",
201 | "****************************************************************************************************\n",
202 | "\n",
203 | "\n",
204 | "step-00120000\n",
205 | "-------------\n",
206 | "汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们决定去公园野餐。他们带了三明治、水果和饼干。\n",
207 | "当他们到达公园时,他们看到一个大牌子上面写着“禁止进入”。汤姆和杰瑞很伤心,因为他们想玩,但又不希望违反规定。他们决定偷偷溜进公园,玩捉迷藏游戏。\n",
208 | "在玩捉迷藏时,他们听到一声巨响。是一只大狗!狗追着他们,他们跑得很快。他们试图逃跑,但狗跑得太快了。突然,他们看到一个写着“禁止进入”的标志。他们很害怕,不知道该怎么办。\n",
209 | "就在这时,一位好心的女士看到了他们,过来帮助他们。她把狗吓跑了,他们安全了。汤姆和杰瑞非常感激,感谢这位女士。他们意识到,尽管他们喜欢玩捉迷藏游戏,但遵守规则并确保安全是很重要的。\n",
210 | "****************************************************************************************************\n",
211 | "\n",
212 | "\n",
213 | "step-00140000\n",
214 | "-------------\n",
215 | "汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们决定去公园野餐。他们带了一些三明治和果汁来分享。\n",
216 | "当他们到达公园时,他们看到一个大牌子上面写着“禁止在此野餐”。汤姆和杰瑞很伤心,因为他们不能在公园里野餐了。他们决定去公园的另一边,那里有一个大池塘。\n",
217 | "当他们到达池塘时,他们看到一只鸭子在游泳。汤姆和杰瑞想和鸭子玩,但他们知道必须遵守规则。他们决定在池塘边野餐,并邀请鸭子加入他们。鸭子很高兴,他们一起度过了一个美好的野餐时光。\n",
218 | "****************************************************************************************************\n",
219 | "\n",
220 | "\n",
221 | "step-00160000\n",
222 | "-------------\n",
223 | "汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们决定去冒险。他们收拾好行李,去了机场。\n",
224 | "在机场,他们看到了一架大飞机。汤姆说:“我想坐那架飞机!”杰瑞说:“不,我想坐那架飞机!”他们开始争吵,声音越来越大。\n",
225 | "突然,飞机开始摇晃,他们很害怕。他们试图逃跑,但飞机太强大了。飞机坠毁了,他们再也没有回到家。结束。\n",
226 | "****************************************************************************************************\n",
227 | "\n",
228 | "\n",
229 | "step-00180000\n",
230 | "-------------\n",
231 | "汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们决定去公园玩。\n",
232 | "当他们到达公园时,他们看到一个很大的滑梯。汤姆和杰瑞想尝试一下,但有一个问题。滑梯的顶部有一个标志,上面写着“禁止进入”。汤姆和杰瑞很伤心,因为他们真的很想滑下滑梯。\n",
233 | "突然,他们看到一个拿着大袋子的人。那个人说:“我给你们一个惊喜。我给你们一个装满玩具的袋子!”汤姆和杰瑞非常高兴,感谢了那个人。他们玩了玩具,度过了很多乐趣。他们忘记了滑梯,只是享受着新玩具带来的乐趣。\n",
234 | "****************************************************************************************************\n",
235 | "\n",
236 | "\n",
237 | "step-00200000\n",
238 | "-------------\n",
239 | "汤姆和杰瑞是好朋友,他们喜欢一起玩。有一天,他们去公园玩。\n",
240 | "在公园里,他们看到一棵大树。汤姆说:“我们爬树吧!” 杰瑞很害怕,但汤姆说:“别担心,我会帮助你的。” 他们开始爬树。\n",
241 | "当他们爬得越高时,他们看到了一只大鸟。鸟儿说:“你们好,朋友们!你们想和我一起玩吗?” 汤姆和杰瑞很惊讶,但他们说:“好的,我们想和你一起玩!” 他们一起玩得很开心。\n",
242 | "****************************************************************************************************\n",
243 | "\n",
244 | "\n"
245 | ]
246 | }
247 | ],
248 | "source": [
249 | "import gc\n",
250 | "\n",
251 | "prompt = \"汤姆和杰瑞是好朋友,\"\n",
252 | "for i in range(20, 220, 20):\n",
253 | " llm = LLM.load(\n",
254 | " model=f\"../../Experiments/Output/pretrain/microstories/step-{i*1000:08d}\"\n",
255 | " )\n",
256 | " print(f\"step-{i*1000:08d}\")\n",
257 | " print(\"-\" * 13)\n",
258 | " result = llm.generate(\n",
259 | " prompt=prompt,\n",
260 | " max_new_tokens=500,\n",
261 | " temperature=0.8,\n",
262 | " top_p=0,\n",
263 | " top_k=30,\n",
264 | " )\n",
265 | " result = prompt + \"\\n\".join(filter(lambda x: x.strip(), result.split(\"\\n\")))\n",
266 | " print(result)\n",
267 | " print(\"*\" * 100)\n",
268 | " print(\"\\n\")\n",
269 | " del llm\n",
270 | " gc.collect()"
271 | ]
272 | },
273 | {
274 | "cell_type": "markdown",
275 | "metadata": {},
276 | "source": [
277 | "可以看到,在`60k`之前的`checkpoints`生成的文本虽然很长,但是有非常严重的重复。\n",
278 | "\n",
279 | "而从`60k`开始,生成的文本重复率开始下降,并且越来越连贯。不过可以发现明显的逻辑硬伤。\n",
280 | "\n",
281 | "比如`step-00060000`里「**杰瑞说:“我们把它带回家吧!”于是,他们把蛋带回了鸟巢**」,要把蛋带回家,结果后面又说「他们把蛋带回了鸟巢」。\n",
282 | "\n",
283 | "另外还有一些悲伤的故事🤣,例如:\n",
284 | "\n",
285 | "`step-00100000`里两个人遇到了熊,最后「**熊吃了他们,然后他们就再也没有出现过。结束。**」\n",
286 | "\n",
287 | "`step-00160000`里两个人在飞机上吵架,最后「**飞机坠毁了,他们再也没有回到家。结束。**」"
288 | ]
289 | },
290 | {
291 | "cell_type": "markdown",
292 | "metadata": {},
293 | "source": [
294 | "### 效果总结\n",
295 | "虽然有些逻辑性的问题,但是整体来说,生成文本的连贯性是越来越好的。而且几乎没有任何明显的语法错误,这一点是非常厉害的。\n",
296 | "\n",
297 | "也算是验证了一下微软的 [TinyStories](https://arxiv.org/abs/2305.07759) 里关于小模型(`SLM`)也能生成连贯文本的结论。\n",
298 | "\n",
299 | "\n"
300 | ]
301 | },
302 | {
303 | "cell_type": "markdown",
304 | "metadata": {},
305 | "source": [
306 | "## 后续计划 🗓️\n",
307 | "\n",
308 | "微软的论文里还有一项进一步的工作,那就是通过`instruction`数据来继续训练模型,从而让模型能够在生成故事的时候遵循一些要求。\n",
309 | "\n",
310 | "这部分数据集呢目前只有纯英文的,我打算翻译一下,然后用来继续训练模型的`SFT`阶段。\n",
311 | "\n",
312 | "**不过最近确实有点忙,可能更新进度会稍微放缓一些。**\n",
313 | "\n",
314 | ""
315 | ]
316 | },
317 | {
318 | "cell_type": "markdown",
319 | "metadata": {},
320 | "source": [
321 | "## 小结\n",
322 | "1. 使用`TinyStories`数据集预训练了`200k steps`的模型,并测试了生成效果。\n",
323 | "2. 从结果来看,模型生成的文本连贯性越来越好,但是仍然存在一些逻辑问题。\n",
324 | "3. 后续计划翻译`instruction`数据集,用来继续训练模型的`SFT`阶段。"
325 | ]
326 | }
327 | ],
328 | "metadata": {
329 | "kernelspec": {
330 | "display_name": "bigmodel",
331 | "language": "python",
332 | "name": "python3"
333 | },
334 | "language_info": {
335 | "codemirror_mode": {
336 | "name": "ipython",
337 | "version": 3
338 | },
339 | "file_extension": ".py",
340 | "mimetype": "text/x-python",
341 | "name": "python",
342 | "nbconvert_exporter": "python",
343 | "pygments_lexer": "ipython3",
344 | "version": "3.10.10"
345 | }
346 | },
347 | "nbformat": 4,
348 | "nbformat_minor": 2
349 | }
350 |
--------------------------------------------------------------------------------
/Journey/Day09/Day09.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 从零手搓中文大模型|🚀 Day09"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "微软的`Tinystories`论文里,是直接在200w条`Instruction`数据上做的全量`pretrain`来验证小参数`LLM`的指令遵从效果的。\n",
15 | "\n",
16 | "为了挖掘`SLM`的潜力,我想看看在超小规模参数的情况下,少量(相比于`pretrain`)数据的`SFT`是否能起作用。\n",
17 | "\n",
18 | "(当然还有一个原因是要把`Instruction`数据全通过`GPT API`翻译一遍还是相当贵的😂)。"
19 | ]
20 | },
21 | {
22 | "cell_type": "markdown",
23 | "metadata": {},
24 | "source": [
25 | "## 全参数SFT训练实验🧪"
26 | ]
27 | },
28 | {
29 | "cell_type": "markdown",
30 | "metadata": {},
31 | "source": [
32 | "上一期分享了一些`SFT`训练相关的知识点,里面提到了关于训练模式的选择。\n",
33 | "\n",
34 | "我的这个项目里,用于`SFT`训练的数据和之前预训练的数据分布是非常相似的,所以这里不打算将`SFT`数据用于`continue pretrain`,而是直接将`SFT`数据用于`finetuning`。\n",
35 | "\n",
36 | "由于`SFT`全量`finetuning`其实本质上和`pretrain`没有什么差别,只是在计算`loss`的时候对`prompt`部分做了一个`mask`,所以这里就不对训练参数配置做过多的介绍了。\n",
37 | "\n",
38 | "> 这里额外提一点,我在上构造的数据基础上做了一个增强的操作(用`GPT API`翻译还是太贵了😂)。\n",
39 | "> \n",
40 | "> 具体操作是:将上期用吴恩达老师的`translation-agent`翻译构造的数据里的指令部分里的多个约束抽取成了`key: value`,然后随机排列,输出还是故事本身不变,这样就得到了很多新的数据(从之前的1.3w条数据增加到了7.1w条)。\n",
41 | "> \n",
42 | "> 另外还有一个潜在的好处就是可以让模型知道指令内部的多个约束的顺序是不敏感的,只要输出符合所有指令的约束就可以。\n",
43 | "\n",
44 | "我简单地做了几组实验:\n",
45 | "\n",
46 | "🟣 `learning_rate = 1e-4, bf16-true`\n",
47 | "\n",
48 | "🔴 `learning_rate = 5e-4, bf16-true`\n",
49 | "\n",
50 | "🟢 `learning_rate = 5e-4, bf16-true`,但学习率下降比前两者速度更快\n",
51 | "\n",
52 | "🔵 `learning_rate = 5e-4, bf16-mixed`,学习率和上一个一样\n",
53 | "\n",
54 | ""
55 | ]
56 | },
57 | {
58 | "cell_type": "markdown",
59 | "metadata": {},
60 | "source": [
61 | "> 为了方便观察,图里的曲线都是经过平滑之后的。\n",
62 | "\n",
63 | "可以发现几个问题🤔:\n",
64 | "\n",
65 | "1. 学习率使用`pretrain`的1/5的时候(`1e-4`),收敛程度不如使用和`pretrain`时一样的`5e-4`。\n",
66 | "\n",
67 | " 和上一期里搜集的经验描述有些不一致(`SFT`阶段的`learning_rate`使用`pretrain`的1/10的建议)。\n",
68 | " \n",
69 | " 我个人理解是因为我的`SFT`数据和`pretrain`数据非常相似,且指令相对简单/单一(只是在故事前面加了一些约束文本),所以即使用比较大的学习率也没有出现震荡发散的情况,反而很容易收敛。\n",
70 | "\n",
71 | "2. 学习率被设置得下降更快的这一组,收敛速度也更快一些,这个也容易理解:在后期,模型已经非常接近最优解了,这时候学习率下降得快,可以更精细地学习以逼近最优解。\n",
72 | "3. 使用`bf16-mixed`的这一组,收敛速度和前一个差不多,但是loss整体还要更低一些"
73 | ]
74 | },
75 | {
76 | "cell_type": "markdown",
77 | "metadata": {},
78 | "source": [
79 | "### 结果测试\n",
80 | "#### 单一约束\n",
81 | "\n",
82 | "我随便构造了几个简单的测试用例,其中的指令都只包含单一的约束。\n",
83 | "\n",
84 | "结果如下👇:"
85 | ]
86 | },
87 | {
88 | "cell_type": "code",
89 | "execution_count": 60,
90 | "metadata": {},
91 | "outputs": [],
92 | "source": [
93 | "from litgpt import LLM\n",
94 | "from litgpt.prompts import Phi2\n",
95 | "import json\n",
96 | "\n",
97 | "sft_data = json.load(\n",
98 | " open(\n",
99 | " \"../../Data/TinyStoriesInstruct/sft_data_v2_simple.json\", \"r\", encoding=\"utf-8\"\n",
100 | " )\n",
101 | ")\n",
102 | "\n",
103 | "prompt_style = Phi2()\n",
104 | "llm = LLM.load(\n",
105 | " model=\"../../Experiments/Output/sft/microstories_v2/bf16_true_1e-4/step-000600\"\n",
106 | ")"
107 | ]
108 | },
109 | {
110 | "cell_type": "code",
111 | "execution_count": 61,
112 | "metadata": {},
113 | "outputs": [
114 | {
115 | "name": "stdout",
116 | "output_type": "stream",
117 | "text": [
118 | "随机句子:他们证明了即使是最小的朋友,团结起来也能变得很强大。\n",
119 | "摘要:一辆大卡车被困在事故现场,一只小鸟和它的朋友们前来救援,帮助搬开残骸,让卡车继续前行。他们成为朋友,并继续互相帮助。\n",
120 | "特征:对话\n",
121 | "词汇:醒来,事故现场,强大\n",
122 | "----------------------------------------------------------------------------------------------------\n",
123 | "一天,一辆强壮的大卡车正在路上行驶。卡车非常大且强壮。它可以载很多东西。卡车司机很开心,因为他的工作很有趣。 \n",
124 | "突然,卡车撞上了一个大事故现场。事故现场一片混乱。卡车司机很伤心,因为他再也开不了卡车了。他说:“哦不!我的卡车被卡住了!我该怎么办?” \n",
125 | "一只小鸟听到了卡车司机的话。小鸟说:“别担心,我可以帮你!”小鸟飞走了,带着它的朋友们回来。他们齐心协力搬开事故现场。 \n",
126 | "卡车司机非常高兴。他说:“谢谢你们,小鸟们!你们救了我的卡车!”小鸟们说:“不客气!我们很高兴能帮上忙!”于是他们都成了好朋友。 \n",
127 | "从那天起,卡车司机和小鸟们就开始互相帮助了。他们展示了即使是最小的朋友在一起合作时也能变得强大。每天早晨,鸟儿们都会用快乐的歌声叫醒卡车司机。\n",
128 | "----------------------------------------------------------------------------------------------------\n",
129 | "一天,一辆强壮的大卡车正在路上行驶。卡车非常大且强壮。它可以载很多东西。卡车司机很开心,因为他的工作很有趣。 \n",
130 | "突然,卡车撞上了一个大事故现场。事故现场一片混乱。卡车司机很伤心,因为他再也开不了卡车了。他说:“哦不!我的卡车被卡住了!我该怎么办?” \n",
131 | "一只小鸟听到了卡车司机的话。小鸟说:“别担心,我可以帮你!”小鸟飞走了,带着它的朋友们回来。他们齐心协力搬开事故现场。 \n",
132 | "卡车司机非常高兴。他说:“谢谢你们,小鸟们!你们救了我的卡车!”小鸟们说:“不客气!我们很高兴能帮上忙!”于是他们都成了好朋友。 \n",
133 | "从那天起,卡车司机和小鸟们就开始互相帮助了。他们展示了即使是最小的朋友在一起合作时也能变得强大。每天早晨,鸟儿们都会用快乐的歌声叫醒卡车司机。\n"
134 | ]
135 | }
136 | ],
137 | "source": [
138 | "data_index = 87\n",
139 | "text = llm.generate(\n",
140 | " prompt=prompt_style.apply(prompt=sft_data[data_index][\"instruction\"]),\n",
141 | " max_new_tokens=300,\n",
142 | " temperature=0.2,\n",
143 | " top_p=0.8,\n",
144 | " top_k=50,\n",
145 | ")\n",
146 | "print(sft_data[data_index][\"instruction\"])\n",
147 | "print(\"-\" * 100)\n",
148 | "print(text)\n",
149 | "print(\"-\" * 100)\n",
150 | "print(sft_data[data_index][\"output\"])"
151 | ]
152 | },
153 | {
154 | "cell_type": "code",
155 | "execution_count": 62,
156 | "metadata": {},
157 | "outputs": [
158 | {
159 | "name": "stdout",
160 | "output_type": "stream",
161 | "text": [
162 | "从前,有两个好朋友,名叫汤姆和杰瑞。汤姆和杰瑞是最好的朋友,总是一起做所有事情。一天,汤姆和杰瑞在花园里玩耍。汤姆说:“我们来做点什么吧!”杰瑞说:“好啊,我们做什么?” \n",
163 | "汤姆说:“我们来做个桃子吧!”于是,他们找了一些树枝、叶子和花,开始做桃子。汤姆和杰瑞用锤子、锯子和钉子把桃子捣碎。 \n",
164 | "当桃子做好时,汤姆和杰瑞都特别开心。他们各自拿起一块桃子,咬了一大口。桃子甜得可口了!他们都笑着说:“好好吃!” \n",
165 | "汤姆和杰瑞又做了更多的桃子,并和花园里的其他动物分享。大家都特别开心,享受着美味的桃子。 \n",
166 | "故事结束了。\n",
167 | "----------------------------------------------------------------------------------------------------\n",
168 | "从前,有一个小女孩叫莉莉。她喜欢在草地上玩耍。一天,莉莉在玩耍时看到她的铲子在草地上滚动。她捡起铲子,开始在泥土里挖掘。 \n",
169 | "突然,莉莉的妈妈叫她进屋吃午饭。“莉莉,进来!”她说。“我铲子在草地里玩得可开心了!” \n",
170 | "莉莉回答:“好的,妈妈!”她进屋吃了三明治。她的妈妈问:“你铲子在草地里玩得开心吗?” \n",
171 | "“是的,妈妈!太好玩了!”莉莉笑着说。\n",
172 | "----------------------------------------------------------------------------------------------------\n",
173 | "从前,有一个小女孩叫莉莉。她喜欢在阳光下玩耍。一天,她在花园里看到了一只蝴蝶。它真漂亮!莉莉想抓住它,但它飞走了。 \n",
174 | "那天晚些时候,莉莉的妈妈让她帮忙洗衣服。莉莉看到一堆衣服,决定把它们整理好。她把所有的衬衫放在一堆,把裤子放在另一堆。 \n",
175 | "当天稍晚,莉莉的妈妈让她帮忙洗衣服。她给莉莉展示了一个大篮子,让她把所有的衣服放进去。篮子又大又重,但莉莉很强壮。她把所有的衣服都放了进去,感到很自豪。 \n",
176 | "那天晚上,莉莉上床睡觉,梦到了那只蝴蝶和那堆衣服。她迫不及待想再帮妈妈洗衣服。\n",
177 | "----------------------------------------------------------------------------------------------------\n",
178 | "从前,有一只小蚂蚁。蚂蚁非常饿,想找点食物。蚂蚁看到一个大苹果,爬了过去。但是,苹果上有个大洞,蚂蚁掉进了洞里。蚂蚁吓坏了,不知道该怎么办。突然,一只善良的蜜蜂看见了蚂蚁,飞下来帮助。蜜蜂说:“别担心,小蚂蚁,我会帮你的。”蜜蜂飞走了,带回来一些蜂蜜。蜜蜂把蜂蜜涂在了蚂蚁的脚上,蚂蚁感觉好多了。蚂蚁非常高兴,感谢蜜蜂。从那天起,蚂蚁和蜜蜂成了好朋友,一起经历了很多冒险。\n",
179 | "----------------------------------------------------------------------------------------------------\n",
180 | "从前,有一个小女孩叫莉莉。她喜欢在外面玩耍和采花。一天,她发现了一朵美丽的花,红得像红色的蝴蝶一样。她摘下花,把它放进篮子里。 \n",
181 | "当她走回家的路上,她看到天空中飘着几朵白云。云朵看起来像是要掉下来!莉莉觉得它们看起来像小兔子。她向兔子们挥手,它们也朝她挥手。 \n",
182 | "回到家后,她把花展示给妈妈,并告诉她关于那朵飘在空中的云。妈妈微笑着说:“那是一朵漂亮的云,莉莉。”莉莉感到很开心,也很爱。她把花插在一个花瓶里,看着它。她心里想着那朵兔子和那朵云的冒险,但她知道自己是安全的。\n",
183 | "----------------------------------------------------------------------------------------------------\n"
184 | ]
185 | }
186 | ],
187 | "source": [
188 | "test_cases = [\n",
189 | " {\n",
190 | " \"instruction\": \"词汇:铲子,草地\\n\",\n",
191 | " },\n",
192 | " {\n",
193 | " \"instruction\": \"特点:转折\\n\",\n",
194 | " },\n",
195 | " {\n",
196 | " \"instruction\": \"摘要:一只小蚂蚁在花园里寻找吃的,最后找到了一个苹果。\\n\",\n",
197 | " },\n",
198 | " {\n",
199 | " \"instruction\": \"随机句子:天空中飘着几朵白云。\\n\",\n",
200 | " },\n",
201 | "]\n",
202 | "prompts = [prompt_style.apply(prompt=case[\"instruction\"]) for case in test_cases]\n",
203 | "prompts.insert(0, \"Instruction: 汤姆和杰瑞是一对好朋友\\n\\nOutput:\")\n",
204 | "for prompt in prompts:\n",
205 | " text = llm.generate(\n",
206 | " prompt=prompt,\n",
207 | " max_new_tokens=300,\n",
208 | " temperature=0.2,\n",
209 | " top_p=0.9,\n",
210 | " top_k=30,\n",
211 | " )\n",
212 | " print(text)\n",
213 | " print(\"-\" * 100)"
214 | ]
215 | },
216 | {
217 | "cell_type": "markdown",
218 | "metadata": {},
219 | "source": [
220 | "可以看到对简单的约束的支持意外地还是不错的:\n",
221 | "\n",
222 | "**关键词**能完全命中,**转折**虽然很**生硬**,但是看得出来理解了要加入转折。\n",
223 | "\n",
224 | "根据**摘要**生成也比较准确,**随机句子**方面没有办法完全包含原句,但是大差不差(感觉完全包含还是有点难为这个尺寸的模型了)。"
225 | ]
226 | },
227 | {
228 | "cell_type": "markdown",
229 | "metadata": {},
230 | "source": [
231 | "#### 组合约束\n",
232 | "再来看看组合约束的效果👇:"
233 | ]
234 | },
235 | {
236 | "cell_type": "code",
237 | "execution_count": 3,
238 | "metadata": {},
239 | "outputs": [
240 | {
241 | "name": "stdout",
242 | "output_type": "stream",
243 | "text": [
244 | "从前,有一个聪明的女孩叫露西。她喜欢在草地上玩耍。每天,她都会在草地上跑、跳、穿梭。 \n",
245 | "一天,露西在草地上看到一把锋利的铲子。她捡起来开始玩。她像船一样在地上划过来。真是太好玩了! \n",
246 | "露西的朋友汤姆来找她玩。他看到她在玩铲子,也想来试试。他们都假装在草地上划过来。他们笑着玩得特别开心。 \n",
247 | "突然,露西踩到了一个坎子,铲子飞了起来!汤姆和露西都很惊讶,他们不知道那把铲子怎么会到那里的。他们在草地上飞快地跑着,铲子帮助他们找到更多的故事来探索。 \n",
248 | "总结一下:露西在草地上发现了一把锹,她在草地上用它当作船,她和她的朋友汤姐姐姐在一起玩耍。\n",
249 | "----------------------------------------------------------------------------------------------------\n",
250 | "从前有一只小蚂蚁,它是周围最小的蚂蚁。每天,这只小蚂蚁都在寻找食物。一天,它突然想到一个主意。它决定好好铺一块碗,里面放着一些食物,让其他蚂蚁也能吃。 \n",
251 | "小蚂蚁小心翼翼地把食物倒入碗中。然后,它开始四处张望。它看到了许多美味的苹果片,真是太甜了!它忍不住咬了一口苹果,这是它吃过的最好吃的苹果。 \n",
252 | "小蚂蚁非常高兴,开始带着碗回家。在路上,它注意到附近有几只蚂蚁。每只蚂蚁都有自己吃的食物。小蚂蚁真自豪华,心里满是这么多食物。 \n",
253 | "当小蚂蚁回到家时,它决定好好地把食物放在自己的碗里。这样,它就可以和其他蚂蚂蚁一起分享。现在,所有的蚂蚁都能吃到食物,大家都很开心。\n",
254 | "----------------------------------------------------------------------------------------------------\n",
255 | "从前,有一只小蚂蚁住在花园里。蚂蚁喜欢花园里的草地。一天,蚂蚁在花园里散步时,看见了一棵大树。树上结满了苹果。蚂蚁非常高兴,爬上了树。 \n",
256 | "当蚂蚁到达树顶时,它看到一个苹果。那是一个鲜艳的苹果,看起来真好吃。但就在他准备咬一口时,他听到了一声响亮的声音。那是树枝上的一只声音。树枝枝枝折断了,蚂蚁掉到了地上。 \n",
257 | "蚂蚁很害怕,但它没事。它爬回了家,吃了其他食物。结束。\n",
258 | "----------------------------------------------------------------------------------------------------\n"
259 | ]
260 | }
261 | ],
262 | "source": [
263 | "test_cases = [\n",
264 | " {\n",
265 | " \"instruction\": \"词汇:铲子,草地\\n特点:转折\\n\",\n",
266 | " },\n",
267 | " {\n",
268 | " \"instruction\": \"词汇:铲子,草地\\n摘要:一只小蚂蚁在花园里寻找吃的,最后找到了一个苹果。\\n\",\n",
269 | " },\n",
270 | " {\n",
271 | " \"instruction\": \"词汇:铲子,草地\\n随机句子:天空中飘着几朵白云。\\n摘要:一只小蚂蚁在花园里寻找吃的,最后找到了一个苹果。\\n\",\n",
272 | " },\n",
273 | "]\n",
274 | "prompts = [prompt_style.apply(prompt=case[\"instruction\"]) for case in test_cases]\n",
275 | "for prompt in prompts:\n",
276 | " text = llm.generate(\n",
277 | " prompt=prompt,\n",
278 | " max_new_tokens=300,\n",
279 | " temperature=0.9,\n",
280 | " top_p=1,\n",
281 | " top_k=30,\n",
282 | " )\n",
283 | " print(text)\n",
284 | " print(\"-\" * 100)"
285 | ]
286 | },
287 | {
288 | "cell_type": "markdown",
289 | "metadata": {},
290 | "source": [
291 | "混合约束的难度明显上升了,虽然看得出模型在努力地理解指令,但是结果并不理想。\n",
292 | "\n",
293 | "一方面可能我的`base`模型训练得可能还不够充分,另一方面`SFT`数据量少了。\n",
294 | "\n",
295 | "对于`SFT`之后模型生成的连贯性和逻辑性出现明显下降的问题,简单地检索了一下,一个可能的优化方法是在`SFT`数据里加入一些`pretrain`里的数据,这种做法称为`Replay`。\n",
296 | "\n",
297 | "时间有限还没来得及尝试,等后面有时间了可以试试,在之后的更新里同步分享结果给大家吧。"
298 | ]
299 | },
300 | {
301 | "cell_type": "markdown",
302 | "metadata": {},
303 | "source": [
304 | "## LORA微调⌛\n",
305 | "\n",
306 | "我也尝试了在`SFT`数据上用`LORA`微调,发现效果并不好,loss下降得很慢,且远高于`SFT`全量微调的loss。\n",
307 | "\n",
308 | "\n",
309 | "\n",
310 | "如上图,黄色🟡的是全量微调的loss,红色🔴的是`LORA`微调的loss,这里虽然只有两条,但实际上我尝试了不少`learning rate`和其他参数的组合,但结果都差不多。\n",
311 | "\n",
312 | "我猜测是因为模型太小了,用`Lora`微调时候使用较小的`r`和`alpha`,可训练参数量就更小,所以效果不好。\n",
313 | "\n",
314 | "于是我试了下将`Lora`的`r`和`alpha`调大(🟠从`8_16`调到`256_512`),发现效果好了不少,loss下降得更快了,但收敛速度还是要**远远慢于**全量微调。\n",
315 | "\n",
316 | "这时候的可训练参数量级已经接近`22M`,正好是模型自身的一半了,效果变好也是理所当然的,但这样显然已经失去了`LORA`微调的意义。\n",
317 | "\n",
318 | "> 关于`Lora`的正常使用,后面等有机会训练一个更大的`base model`的时候再尝试吧。"
319 | ]
320 | },
321 | {
322 | "cell_type": "markdown",
323 | "metadata": {},
324 | "source": [
325 | "## 小结\n",
326 | "1. 分享了`SFT`全量微调的一些实验结果\n",
327 | "2. 测试了一下`SFT`全量微调之后的指令遵循效果\n",
328 | "3. 分享了用`LORA`微调的一些实验结果"
329 | ]
330 | },
331 | {
332 | "cell_type": "markdown",
333 | "metadata": {},
334 | "source": []
335 | }
336 | ],
337 | "metadata": {
338 | "kernelspec": {
339 | "display_name": "bigmodel",
340 | "language": "python",
341 | "name": "python3"
342 | },
343 | "language_info": {
344 | "codemirror_mode": {
345 | "name": "ipython",
346 | "version": 3
347 | },
348 | "file_extension": ".py",
349 | "mimetype": "text/x-python",
350 | "name": "python",
351 | "nbconvert_exporter": "python",
352 | "pygments_lexer": "ipython3",
353 | "version": "3.10.10"
354 | }
355 | },
356 | "nbformat": 4,
357 | "nbformat_minor": 2
358 | }
359 |
--------------------------------------------------------------------------------
/Journey/Day03/Day03.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "# 从零手搓中文大模型|🚀Day03"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "## 数据预处理"
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "虽然省略了数据清洗的逻辑,但是我们还是需要对数据进行预处理,以便于后续的模型训练。\n",
22 | "\n",
23 | "包括以下两个细节:\n",
24 | "\n",
25 | "1. 在每个文本后添加`eos`标记,以便于模型识别句子的结束。\n",
26 | "2. 将文本转换为`数字序列`,以便于模型处理。\n",
27 | " \n",
28 | " 这一步其实也可以放到模型训练的时候进行,但提前处理可以减少训练时的计算量。"
29 | ]
30 | },
31 | {
32 | "cell_type": "markdown",
33 | "metadata": {},
34 | "source": [
35 | "### 数据集划分\n",
36 | "\n",
37 | "解压数据集,得到`48`个jsonl文件,共计`3952863`行json数据。\n",
38 | "\n",
39 | "我之前已经解压过了,并且将原始数据和处理过后的数据分别存在了不同路径下。\n",
40 | "\n",
41 | "这里把命令贴出来以供参考。"
42 | ]
43 | },
44 | {
45 | "cell_type": "code",
46 | "execution_count": null,
47 | "metadata": {
48 | "vscode": {
49 | "languageId": "shellscript"
50 | }
51 | },
52 | "outputs": [],
53 | "source": [
54 | "# !mkdir -p ../../Data/TinyStoriesChinese/raw_data/train\n",
55 | "# !mkdir -p ../../Data/TinyStoriesChinese/raw_data/val\n",
56 | "# !mkdir -p ../../Data/TinyStoriesChinese/processed_data/train\n",
57 | "# !mkdir -p ../../Data/TinyStoriesChinese/processed_data/val\n",
58 | "\n",
59 | "# !tar zxvf ../../Data/TinyStoriesChinese/TinyStories_all_data_zh.tar.gz -C ../../Data/TinyStoriesChinese/raw_data/train"
60 | ]
61 | },
62 | {
63 | "cell_type": "markdown",
64 | "metadata": {},
65 | "source": [
66 | "我把最后一个文件`data47_zh.jsonl`(共计78538行)里切分出来4w行作为`eval`数据。"
67 | ]
68 | },
69 | {
70 | "cell_type": "code",
71 | "execution_count": null,
72 | "metadata": {
73 | "vscode": {
74 | "languageId": "shellscript"
75 | }
76 | },
77 | "outputs": [],
78 | "source": [
79 | "# !mv ../../Data/TinyStoriesChinese/raw_data/train/data47_zh.jsonl ../../Data/TinyStoriesChinese/raw_data/val/\n",
80 | "# !head -n 40000 ../../Data/TinyStoriesChinese/raw_data/val/data47_zh.jsonl > ../../Data/TinyStoriesChinese/raw_data/val/val.jsonl\n",
81 | "# !tail -n +40000 ../../Data/TinyStoriesChinese/raw_data/val/data47_zh.jsonl > ../../Data/TinyStoriesChinese/raw_data/train/data47_zh.jsonl\n",
82 | "# !rm ../../Data/TinyStoriesChinese/raw_data/val/data47_zh.jsonl"
83 | ]
84 | },
85 | {
86 | "cell_type": "markdown",
87 | "metadata": {},
88 | "source": [
89 | "### 先看一条数据\n",
90 | "(都打印出来太长了,所以只输出前100个字符)"
91 | ]
92 | },
93 | {
94 | "cell_type": "code",
95 | "execution_count": 1,
96 | "metadata": {},
97 | "outputs": [
98 | {
99 | "name": "stdout",
100 | "output_type": "stream",
101 | "text": [
102 | "莉莉和本是朋友。他们喜欢在公园里玩。有一天,他们在一棵大树下看到了一个秋千。莉莉想试试那个秋千。她跑到树下,爬上了秋千。\n",
103 | "\"推我,本!\"她说。本轻轻地推了她一下。莉莉感到很开心。她越荡越高,笑着喊叫。\n"
104 | ]
105 | }
106 | ],
107 | "source": [
108 | "import json\n",
109 | "\n",
110 | "with open(\"../../Data/TinyStoriesChinese/raw_data/train/data00_zh.jsonl\", \"r\") as f:\n",
111 | " for line in f.readlines():\n",
112 | " js = json.loads(line)\n",
113 | " print(js[\"story_zh\"][:100])\n",
114 | " break"
115 | ]
116 | },
117 | {
118 | "cell_type": "markdown",
119 | "metadata": {},
120 | "source": [
121 | "### 适配框架API"
122 | ]
123 | },
124 | {
125 | "cell_type": "markdown",
126 | "metadata": {},
127 | "source": [
128 | "由于选择了使用[⚡️litgpt](https://github.com/Lightning-AI/litgpt/tree/main)框架进行训练,所以需要引入框架相关的`Class`和`API`来封装我们的数据准备逻辑。\n",
129 | "\n",
130 | "这里我们可以参考[源码里集成的Tinyllama的数据预处理代码](https://github.com/Lightning-AI/litgpt/blob/main/litgpt/data/prepare_slimpajama.py)里的代码,稍作修改。\n",
131 | "\n",
132 | "主要是需要将[Day02](../Day02/Day02.ipynb)里的`line`处理逻辑封装到`ligtgpt`的`API`中。\n",
133 | "\n",
134 | "但在此之前我们先熟悉一下`litgpt`的Tokenizer的使用方法:"
135 | ]
136 | },
137 | {
138 | "cell_type": "markdown",
139 | "metadata": {},
140 | "source": [
141 | "先安装一下`litgpt`以及它所以赖的`litdata`:"
142 | ]
143 | },
144 | {
145 | "cell_type": "code",
146 | "execution_count": null,
147 | "metadata": {
148 | "vscode": {
149 | "languageId": "shellscript"
150 | }
151 | },
152 | "outputs": [],
153 | "source": [
154 | "# !pip install litgpt\n",
155 | "# !pip install litdata"
156 | ]
157 | },
158 | {
159 | "cell_type": "code",
160 | "execution_count": 2,
161 | "metadata": {},
162 | "outputs": [],
163 | "source": [
164 | "import torch\n",
165 | "from litgpt import Tokenizer\n",
166 | "\n",
167 | "litgpt_tokenizer = Tokenizer(\"../../References/chatglm3-6b\")"
168 | ]
169 | },
170 | {
171 | "cell_type": "markdown",
172 | "metadata": {},
173 | "source": [
174 | "这里也实验了一下结果,对比发现和咱们之前[Day02](../Day02/Day02.ipynb)里用原生`Tokenizer`处理的**结果一致**。\n",
175 | "\n",
176 | "结果这里就不贴出来了,有兴趣的可以自己试一下。\n",
177 | "\n",
178 | "> ⚠️不过需要注意`litgpt`的`Tokenizer.encode`返回的是一个`torch`的`Tensor`"
179 | ]
180 | },
181 | {
182 | "cell_type": "code",
183 | "execution_count": 5,
184 | "metadata": {},
185 | "outputs": [
186 | {
187 | "name": "stdout",
188 | "output_type": "stream",
189 | "text": [
190 | "tensor([30910, 56623, 56623, 54542, 50154, 31761, 31155, 31633, 31815, 54534,\n",
191 | " 32693, 54662, 55409, 31155, 35632, 31123, 31633, 34383, 57427, 47658,\n",
192 | " 54578, 34518, 31623, 55567, 55226, 31155, 56623, 56623, 54695, 39887,\n",
193 | " 32437, 55567, 55226, 31155, 54790, 41309, 52624, 31123, 56856, 32660,\n",
194 | " 55567, 55226, 31155, 13, 30955, 54834, 54546, 31123, 54613, 31404,\n",
195 | " 30955, 36213, 31155, 54613, 36660, 54563, 54834, 43881, 32024, 31155,\n",
196 | " 56623, 56623, 32707, 54657, 33436, 31155, 54790, 54937, 56567, 40714,\n",
197 | " 31123, 38502, 56653, 55483, 31155, 2], dtype=torch.int32)\n",
198 | "莉莉和本是朋友。他们喜欢在公园里玩。有一天,他们在一棵大树下看到了一个秋千。莉莉想试试那个秋千。她跑到树下,爬上了秋千。\n",
199 | "\"推我,本!\"她说。本轻轻地推了她一下。莉莉感到很开心。她越荡越高,笑着喊叫。\n"
200 | ]
201 | }
202 | ],
203 | "source": [
204 | "import numpy as np\n",
205 | "\n",
206 | "litgpt_encoded = litgpt_tokenizer.encode(\n",
207 | " json.loads(line)[\"story_zh\"][:100], eos=True\n",
208 | ") # 记得设置eos=True\n",
209 | "print(litgpt_encoded)\n",
210 | "# print(np.array(litgpt_encoded, dtype=np.uint16))\n",
211 | "print(litgpt_tokenizer.decode(litgpt_encoded))"
212 | ]
213 | },
214 | {
215 | "cell_type": "markdown",
216 | "metadata": {},
217 | "source": [
218 | "### 数据处理代码\n",
219 | "数据处理直接参考了上面给出的[litgpt samples](https://github.com/Lightning-AI/litgpt/blob/main/litgpt/data/prepare_slimpajama.py),我们需要仿照`prepare_slimpajama.py`实现里面相关函数(之前**Day 02**里实现的函数需要稍加改造一下)。"
220 | ]
221 | },
222 | {
223 | "cell_type": "code",
224 | "execution_count": null,
225 | "metadata": {},
226 | "outputs": [],
227 | "source": [
228 | "# Copyright Lightning AI. Licensed under the Apache License 2.0, see LICENSE file.\n",
229 | "\n",
230 | "import json\n",
231 | "import os\n",
232 | "import time\n",
233 | "import numpy as np\n",
234 | "from pathlib import Path\n",
235 | "\n",
236 | "from litgpt.tokenizer import Tokenizer\n",
237 | "from litgpt.data.prepare_starcoder import DataChunkRecipe\n",
238 | "from litdata import TokensLoader\n",
239 | "from litgpt.utils import extend_checkpoint_dir\n",
240 | "\n",
241 | "\n",
242 | "class TinyStoriesZhDataRecipe(DataChunkRecipe):\n",
243 | " is_generator = True\n",
244 | "\n",
245 | " def __init__(self, tokenizer: Tokenizer, chunk_size: int):\n",
246 | " super().__init__(chunk_size)\n",
247 | " self.tokenizer = tokenizer\n",
248 | "\n",
249 | " def prepare_structure(self, input_dir):\n",
250 | " files = Path(input_dir).rglob(\"*.jsonl\")\n",
251 | " return [str(file) for file in files]\n",
252 | "\n",
253 | " def prepare_item(self, filepath):\n",
254 | "\n",
255 | " with open(filepath, \"rb\") as f:\n",
256 | " for line in f.readlines():\n",
257 | " js = json.loads(line)\n",
258 | " story = js[\"story_zh\"]\n",
259 | " # 注意这里要添加eos\n",
260 | " # 还记得吗:我们的vocab size在int16范围内,所以可以转换为uint16来节省内存\n",
261 | " # story_ids = np.array(\n",
262 | " # self.tokenizer.encode(story, eos=True), dtype=np.uint16\n",
263 | " # )\n",
264 | " # 很遗憾,实际使用的时候发现如果按照上面这样写,\n",
265 | " # litdata反序列化数据的时候会错误地得到torch.int64且超界的Tensor,\n",
266 | " # 但直接存torch.Tensor没问题(加上litdata不支持torch.uint16),\n",
267 | " # 所以最后实际使用的时候还是用下面这种写法\n",
268 | " story_ids = self.tokenizer.encode(story, eos=True)\n",
269 | " yield story_ids\n",
270 | "\n",
271 | "\n",
272 | "def prepare(\n",
273 | " input_dir: Path = Path(\"../../Data/TinyStoriesChinese/raw_data/train\"),\n",
274 | " output_dir: Path = Path(\"../../Data/TinyStoriesChinese/processed_data/train\"),\n",
275 | " tokenizer_path: Path = Path(\"../../References/chatglm3-6b\"),\n",
276 | " chunk_size: int = (2049 * 8012),\n",
277 | " fast_dev_run: bool = False,\n",
278 | ") -> None:\n",
279 | " from litdata.processing.data_processor import DataProcessor\n",
280 | "\n",
281 | " tokenizer_path = extend_checkpoint_dir(tokenizer_path)\n",
282 | " tokenizer = Tokenizer(tokenizer_path)\n",
283 | " data_recipe = TinyStoriesZhDataRecipe(tokenizer=tokenizer, chunk_size=chunk_size)\n",
284 | " data_processor = DataProcessor(\n",
285 | " input_dir=str(input_dir),\n",
286 | " output_dir=str(output_dir),\n",
287 | " fast_dev_run=fast_dev_run,\n",
288 | " num_workers=os.cpu_count(),\n",
289 | " num_downloaders=1,\n",
290 | " # 这里有个「巨坑」,如果不加这一行,处理好的数据配对的index.json里\n",
291 | " # 有一个名为\"dim\"的key值会为null,导致后续有一个无法规避的报错\n",
292 | " # 但是官方的例子里是没有这一行的,很奇怪为何会有这个问题\n",
293 | " item_loader=TokensLoader(),\n",
294 | " )\n",
295 | "\n",
296 | " start_time = time.time()\n",
297 | " data_processor.run(data_recipe)\n",
298 | " elapsed_time = time.time() - start_time\n",
299 | " print(f\"Time taken: {elapsed_time:.2f} seconds\")"
300 | ]
301 | },
302 | {
303 | "cell_type": "markdown",
304 | "metadata": {},
305 | "source": [
306 | "首先,我这里主要就是把之前实现的`line`处理逻辑封装到`litgpt`的`DataChunkRecipe`中:\n",
307 | "- `prepare_structure`函数给定路径返回符合我们期望的数据文件的路径列表\n",
308 | "- `prepare_item`函数给定一个上面的数据文件的路径,根据我们**自定义**的`tokenization`处理逻辑返回一个`np.array`对象\n",
309 | " \n",
310 | "然后,定义了一个`prepare`函数,指定我们数据的输入路径和输出路径以及一些其它参数配置(其实用默认的即可),其余的都交给了`litdata`的`DataProcessor`,它基于我前面定义的`DataChunkRecipe`来处理数据。\n",
311 | "\n",
312 | "感兴趣的可以看看`DataProcessor`的源码,里面做了很多并行之类的数据处理优化。"
313 | ]
314 | },
315 | {
316 | "cell_type": "markdown",
317 | "metadata": {},
318 | "source": [
319 | "#### 先用eval数据集测试"
320 | ]
321 | },
322 | {
323 | "cell_type": "code",
324 | "execution_count": null,
325 | "metadata": {},
326 | "outputs": [],
327 | "source": [
328 | "prepare(\n",
329 | " input_dir=Path(\"../../Data/TinyStoriesChinese/raw_data/val\"),\n",
330 | " output_dir=Path(\"../../Data/TinyStoriesChinese/processed_data/val\"),\n",
331 | " tokenizer_path=Path(\"../../References/chatglm3-6b\"),\n",
332 | ")"
333 | ]
334 | },
335 | {
336 | "cell_type": "markdown",
337 | "metadata": {},
338 | "source": [
339 | "(也可以设置`fast_dev_run=True`来处理更少的数据,尤其是debug时十分有用)\n",
340 | "\n",
341 | "执行完可以在`processed_data/eval`目录下看到生成的`.bin`文件以及记录了每个`chunk`文件信息的`index.json`。\n",
342 | "\n",
343 | "比较一下可以发现从原先的`83m`的`.jsonl`文件压缩到了`13m`的`.bin`,压缩比(83/13≈6.385)还是很可观的。"
344 | ]
345 | },
346 | {
347 | "cell_type": "markdown",
348 | "metadata": {},
349 | "source": [
350 | "#### 处理train数据集\n",
351 | "在32核的CPU上处理`train`数据集耗时不到`1min`。"
352 | ]
353 | },
354 | {
355 | "cell_type": "code",
356 | "execution_count": null,
357 | "metadata": {},
358 | "outputs": [],
359 | "source": [
360 | "prepare(\n",
361 | " input_dir=Path(\"../../Data/TinyStoriesChinese/raw_data/train\"),\n",
362 | " output_dir=Path(\"../../Data/TinyStoriesChinese/processed_data/train\"),\n",
363 | " tokenizer_path=Path(\"../../References/chatglm3-6b\"),\n",
364 | ")"
365 | ]
366 | },
367 | {
368 | "cell_type": "markdown",
369 | "metadata": {},
370 | "source": [
371 | "## 小结\n",
372 | "\n",
373 | "1. 数据预处理的逻辑主要是将文本转换为数字序列,以便于模型处理。\n",
374 | "2. 通过`litgpt`的`Tokenizer`可以方便的实现文本到数字序列的转换。\n",
375 | "3. `litdata`提供了数据处理的`API`,可以方便的封装我们的数据处理逻辑。\n",
376 | "4. 基于上面的开发,将`TinyStoriesChinese`数据集做了数据划分并完成了预处理。"
377 | ]
378 | }
379 | ],
380 | "metadata": {
381 | "kernelspec": {
382 | "display_name": "bigmodel",
383 | "language": "python",
384 | "name": "python3"
385 | },
386 | "language_info": {
387 | "codemirror_mode": {
388 | "name": "ipython",
389 | "version": 3
390 | },
391 | "file_extension": ".py",
392 | "mimetype": "text/x-python",
393 | "name": "python",
394 | "nbconvert_exporter": "python",
395 | "pygments_lexer": "ipython3",
396 | "version": "3.10.10"
397 | }
398 | },
399 | "nbformat": 4,
400 | "nbformat_minor": 2
401 | }
402 |
--------------------------------------------------------------------------------
/Journey/Day07/Day07.md:
--------------------------------------------------------------------------------
1 | # 从零手搓中文大模型|🚀 Day07
2 |
3 | ## SFT 数据准备
4 |
5 | `TinyStories`数据集其实也提供了[Instruct数据](https://huggingface.co/datasets/roneneldan/TinyStoriesInstruct),我可以基于这个数据集在之前的预训练模型上进行指令微调。
6 |
7 | 先看看数据集的格式:
8 |
9 |
10 | ```python
11 | ! head -10 ../../Data/TinyStoriesInstruct/TinyStories-Instruct-train.txt
12 | ```
13 |
14 | Features: Dialogue
15 | Words: quit, oak, gloomy
16 | Summary: Sara and Ben were playing in the park, but Sara wanted to go home because it was cold and dark. Ben convinced her to stay and play, but eventually agreed to go home and have hot cocoa.
17 | Story:
18 |
19 | Sara and Ben were playing in the park. They liked to climb the big oak tree and pretend they were birds. They made nests with leaves and twigs and sang songs.
20 | But today, the sky was gloomy and the wind was cold. Sara felt sad and cold. She wanted to go home and have some hot cocoa.
21 | "Ben, I want to quit," she said. "It's too cold and dark. Let's go home."
22 | Ben looked at Sara and frowned. He liked the oak tree and the park. He wanted to stay and play.
23 | "No, Sara, don't quit," he said. "It's fun here. Look, there's a squirrel. Let's chase it."
24 |
25 |
26 | 这些指令有四种类型:
27 | 1. 一个单词列表,包含在故事中。
28 | 2. 一个句子,应该出现在故事的某个地方。
29 | 3. 一个特征列表(可能的特征:对话、坏结局、道德价值、情节转折、伏笔、冲突)。
30 | 4. 一个简短的总结(1-2行)。
31 |
32 | 现在面临两个问题:
33 | - 数据集是英文的,我需要想办法给整成中文的。
34 | - 数据集的形式和主流的SFT数据集不太一样,需要做一些适配。
35 |
36 | > 个人理解这里是因为这里的指令相对单一(生成故事),只是约束有一些区别,所以作者采取了简单的拼接方式。
37 | >
38 | > 这里出于学习的目的还是往主流的SFT数据集上靠拢。
39 |
40 | ### 吴恩达老师的翻译Agent测试
41 |
42 | 这里直接试了下[吴恩达老师的translation-agent](https://github.com/andrewyng/translation-agent)项目(`translation-agent.py`文件),使用的是`gpt-4o-mini`的`api`(也尝试过`Ollama`本地部署的`qwen14b`、`qwen7b`,相对来说不太稳定)。
43 |
44 | 可以看到这里单次翻译的耗时在10秒左右(因为单词翻译的时候`agent`逻辑里有多次`api`调用),因此这里为了后面能够并发调用刷数据,我将代码全部改造成了`async`的异步调用。
45 |
46 | 大家如果有其他的翻译`api`或者模型也可以替换,这里纯属心血来潮玩一玩儿。
47 |
48 | `translation-agent`项目其实只有一个`utils.py`文件,但因为太长了,这里就不把改造后的代码贴出来了,有兴趣的同学可以去仓库里查看。
49 |
50 |
51 | ```python
52 | from translation_agent import translate
53 |
54 | text = """
55 | Random sentence: They are very excited and want to fly too.
56 | Features: Dialogue
57 | Summary: Tom and Anna are excited to go on a holiday with their parents, and they fly on a big plane to a place with sun and sand.
58 | Story:
59 | Tom and Anna are brother and sister. They like to play with their toys and read books. They are very happy because they are going on a holiday with their mum and dad. They will fly on a big plane to a place with a lot of sun and sand.
60 | The day of the holiday comes and they pack their bags. They go to the airport and wait for their plane. They see many other planes flying in the sky. They are very excited and want to fly too.
61 | "Look, Anna, that plane is so big and fast!" Tom says.
62 | "Yes, Tom, and it has wings and a tail. I wonder where it is going," Anna says.
63 | They hear their mum call them. "Come on, kids, it's time to board our plane. We have to show our tickets and go through the gate."
64 | They follow their mum and dad and get on their plane. They find their seats and buckle their belts. They look out the window and see the ground and the cars and the people. They hear the pilot say something on the speaker.
65 | "Hello, everyone, this is your pilot speaking. Welcome aboard flight 123 to Sunny Beach. We are ready to take off. Please sit back and enjoy the flight."
66 | The plane starts to move and makes a loud noise. Tom and Anna feel the plane go faster and faster. They see the ground get smaller and smaller. They see the clouds get closer and closer. They are flying!
67 | "Wow, Anna, we are flying! We are in the sky!" Tom says.
68 | "I know, Tom, it's amazing! We are so high! Look, there is the sun!" Anna says.
69 | They smile and laugh and clap their hands. They are not sad at all. They are very happy. They are flying to their holiday.
70 | """
71 |
72 |
73 | result = await translate(
74 | source_lang="English",
75 | target_lang="Chinese",
76 | source_text=text,
77 | country="China",
78 | )
79 | print(result)
80 | ```
81 |
82 | ic| num_tokens_in_text: 416
83 | ic| 'Translating text as a single chunk'
84 |
85 |
86 | 随机句子:他们非常兴奋,也想飞。
87 | 特点:对话
88 | 摘要:汤姆和安娜兴奋地和父母一起去度假,他们乘坐一架大飞机飞往阳光明媚、沙滩细腻的地方。
89 | 故事:
90 | 汤姆和安娜是兄妹。他们喜欢玩玩具和读书。他们非常开心,因为他们要和爸爸妈妈一起去度假。他们将乘坐一架大飞机去一个阳光明媚、沙滩细腻的地方。
91 | 度假的日子到了,他们开始整理行李。他们去机场,等待他们的飞机。他们看到许多其他飞机在天空中飞。他们非常兴奋,也想飞。
92 | “看,安娜,那架飞机又大又快!”汤姆说。
93 | “是的,汤姆,它有翅膀和尾巴。我想知道它要去哪里,”安娜说。
94 | 他们听到妈妈叫他们。“快点,孩子们,差不多该登机了。我们必须出示机票,然后通过登机口。”
95 | 他们跟着爸爸妈妈上了飞机。他们找到自己的座位,系好安全带。他们望向窗外,看到地面、汽车和人。他们听到飞行员在扬声器上说话。
96 | “大家好,我是你们的机长。欢迎乘坐123航班前往阳光海滩。我们准备起飞。请坐好,享受旅程。”
97 | 飞机开始移动,发出轰鸣的声音。汤姆和安娜感觉飞机越来越快。他们看到地面变得越来越小。云朵越来越近。他们在飞!
98 | “哇,安娜,我们在飞!我们在天空中!”汤姆说。
99 | “我知道,汤姆,太神奇了!我们这么高!看,那里是太阳!”安娜说。
100 | 他们微笑、欢笑,拍手欢呼。他们一点都不难过。他们非常快乐。他们正在飞往度假的地方。
101 |
102 |
103 | ### 数据采样
104 |
105 | 我先看看训练集有多少条数据,可以发现文本都是以`<|endoftext|>`结尾的,所以通过统计`endoftext`的个数就可以知道数据集的条数。
106 |
107 |
108 | ```python
109 | ! grep -o "endoftext" ../../Data/TinyStoriesInstruct/TinyStories-Instruct-train.txt | wc -l
110 | ```
111 |
112 | 2476532
113 |
114 |
115 | 接近250w的量级有点大(因为微软的论文里是直接在整个数据集上做的`pretrain`的)。
116 |
117 | 其实很多研究表明,`SFT`数据的量级不重要,质量够高的时候即使很少的数据也能训练出很好的效果。
118 |
119 | 所以这里我打算随机抽取11000条数据来试试。
120 |
121 | 我的策略如下:
122 | 1. 遍历`train`数据集,让四类指令的组合尽量均衡(需要先统计指令组合的的分布)
123 | 2. 用得到的11000条数据调用上面的`translation-agent`进行翻译
124 | 3. 将翻译后的数据整理成`SFT`数据集的`json`格式
125 |
126 | 先来做数据的采样:
127 |
128 |
129 | ```python
130 | from collections import Counter
131 | import random
132 |
133 |
134 | def count_field_combinations(file_path):
135 | with open(file_path, "r", encoding="utf-8") as file:
136 | content = file.read()
137 |
138 | blocks = content.split("<|endoftext|>")
139 | combinations = []
140 |
141 | for block in blocks:
142 | fields = set()
143 | if "Words:" in block:
144 | fields.add("Words")
145 | if "Random sentence:" in block:
146 | fields.add("Random sentence")
147 | if "Features:" in block:
148 | fields.add("Features")
149 | if "Summary:" in block:
150 | fields.add("Summary")
151 |
152 | if fields: # 只有当字段不为空时才添加组合
153 | combinations.append(frozenset(fields))
154 |
155 | return Counter(combinations)
156 |
157 |
158 | def sample_data(file_path, total_samples=11000):
159 | with open(file_path, "r", encoding="utf-8") as file:
160 | content = file.read()
161 |
162 | blocks = content.split("<|endoftext|>")
163 | blocks = [block.strip() for block in blocks if block.strip()] # 移除空块
164 |
165 | combinations = count_field_combinations(file_path)
166 | combination_more_than_1 = {k: v for k, v in combinations.items() if v > 1}
167 | samples_per_combination = total_samples // len(combination_more_than_1)
168 |
169 | sampled_data = []
170 | for combination in combinations:
171 | matching_blocks = [
172 | block for block in blocks if set(get_fields(block)) == set(combination)
173 | ]
174 | sampled_data.extend(
175 | random.sample(
176 | matching_blocks, min(samples_per_combination, len(matching_blocks))
177 | )
178 | )
179 |
180 | return sampled_data
181 |
182 |
183 | def get_fields(block):
184 | fields = set()
185 | if "Words:" in block:
186 | fields.add("Words")
187 | if "Random sentence:" in block:
188 | fields.add("Random sentence")
189 | if "Features:" in block:
190 | fields.add("Features")
191 | if "Summary:" in block:
192 | fields.add("Summary")
193 | return fields
194 | ```
195 |
196 | 执行一下看看效果(为了有备无患,多采样了5000条数据),耗时1-2分钟,肯定还有优化空间,但是可以接受。
197 |
198 | 同时将采样后的数据保存为`pkl`文件,方便后续使用。
199 |
200 |
201 | ```python
202 | import pickle
203 |
204 | # sft_raw = sample_data(
205 | # "../../Data/TinyStoriesInstruct/TinyStories-Instruct-train.txt", 15000
206 | # )
207 | sft_raw = pickle.load(open("sft_raw.pkl", "rb"))
208 | print(f"采样数据总数: {len(sft_raw)}")
209 |
210 | # pickle.dump(sft_raw, open("sft_raw.pkl", "wb"))
211 | ```
212 |
213 | 采样数据总数: 15001
214 |
215 |
216 | ### 批量翻译
217 |
218 | 接下来就可以调用`translation-agent`进行翻译了。
219 |
220 | 这里我除了用异步加速,还使用了`json`文件缓存来避免重复翻译(`gpt-4o-mini`的`api`也不算便宜,能省则省)。
221 |
222 |
223 | ```python
224 | import json
225 | import aiofiles
226 | import asyncio
227 |
228 | cache_file = "translation_cache.json"
229 |
230 |
231 | async def translate_and_cache(block, cache, semaphore):
232 | cache_key = hash(block)
233 |
234 | if str(cache_key) in cache:
235 | return cache[str(cache_key)]
236 |
237 | async with semaphore:
238 | try:
239 | result = await translate(
240 | source_lang="English",
241 | target_lang="Chinese",
242 | source_text=block,
243 | country="China",
244 | )
245 | cache[str(cache_key)] = result
246 | return result
247 | except Exception as e:
248 | print(f"翻译失败: {e}")
249 | return None
250 |
251 |
252 | async def batch_translate(sampled_data, cache_file, max_workers=10):
253 | translated_data = []
254 |
255 | try:
256 | async with aiofiles.open(cache_file, "r") as f:
257 | cache = json.loads(await f.read())
258 | except (FileNotFoundError, json.JSONDecodeError):
259 | cache = {}
260 |
261 | semaphore = asyncio.Semaphore(max_workers)
262 | tasks = [translate_and_cache(block, cache, semaphore) for block in sampled_data]
263 | results = await asyncio.gather(*tasks)
264 |
265 | translated_data = [result for result in results if result]
266 |
267 | async with aiofiles.open(cache_file, "w") as f:
268 | await f.write(json.dumps(cache, ensure_ascii=False, indent=2))
269 |
270 | return translated_data
271 |
272 |
273 | translated_data = await batch_translate(sft_raw, cache_file, max_workers=100)
274 | ```
275 |
276 | 使用了100路的并发,翻译了15000条数据,耗时48分钟,也就是大概每分钟翻译300条数据。
277 |
278 | ### 后续处理
279 |
280 | 翻译完成了,最后一步就是将数据整理成`SFT`数据集的格式。
281 |
282 | (这里还发现了个小问题,翻译统一将**总结**字段放到了最后,导致顺序出现了问题,所以这里需要先处理一下。)
283 |
284 |
285 | ```python
286 | import itertools
287 | import json
288 | import random
289 | from collections import Counter
290 | from pprint import pprint
291 |
292 | instruction_template = "按照下面输入的约束生成故事"
293 |
294 |
295 | def process_translated_data(input_file):
296 | with open(input_file, "r", encoding="utf-8") as f:
297 | data = json.load(f)
298 |
299 | processed_data = []
300 | constraint_keys = Counter()
301 |
302 | for key, value in data.items():
303 | if "故事:" not in value:
304 | continue
305 | parts = value.split("故事:")
306 |
307 | if len(parts) == 2:
308 | input_text = parts[0].strip()
309 | output_text = parts[1].strip()
310 |
311 | # 提取约束描述文本的关键字段
312 | lines = input_text.split("\n")
313 | for line in lines:
314 | if ":" in line:
315 | key, _ = line.split(":", 1)
316 | constraint_keys[key.strip()] += 1
317 |
318 | processed_item = {
319 | "instruction": instruction_template,
320 | "input": f"{input_text}",
321 | "output": output_text,
322 | }
323 |
324 | processed_data.append(processed_item)
325 | # 根据constraint_keys的频率排序,选取出现频率大于10的关键字
326 | constraint_keys = {k: v for k, v in constraint_keys.items() if v > 10}
327 | return constraint_keys, processed_data
328 | ```
329 |
330 |
331 | ```python
332 | constraint_keys, processed_data = process_translated_data("translation_cache.json")
333 | ```
334 |
335 |
336 | ```python
337 | keywords_normalization = {
338 | "词汇": "词汇",
339 | "关键词": "词汇",
340 | "单词": "词汇",
341 | "词语": "词汇",
342 | "词": "词汇",
343 | "字": "词汇",
344 | "特征": "特征",
345 | "特点": "特征",
346 | "故事特点": "特征",
347 | "故事特征": "特征",
348 | "对话特点": "特征",
349 | "主题": "特征",
350 | "随机句子": "随机句子",
351 | "随便一句话": "随机句子",
352 | "随机一句话": "随机句子",
353 | "随机句": "随机句子",
354 | "随机的一句话": "随机句子",
355 | "随机的句子": "随机句子",
356 | "随机句子是": "随机句子",
357 | "随便说一句": "随机句子",
358 | "随便一句": "随机句子",
359 | "随机句子示例": "随机句子",
360 | "摘要": "摘要",
361 | "总结": "摘要",
362 | "故事概要": "摘要",
363 | }
364 | ```
365 |
366 |
367 | ```python
368 | def split_data(data, keys):
369 | result = []
370 | current_key = None
371 | current_content = ""
372 |
373 | for line in data.split("\n"):
374 | line = line.strip()
375 | if any(key in line for key in keys):
376 | if current_key:
377 | result.append((current_key, current_content.strip()))
378 | for key in keys:
379 | if key in line:
380 | current_key, current_content = line.split(key, 1)
381 | current_key = key.strip()
382 | current_content = current_content.strip().lstrip(":").strip()
383 | break
384 | else:
385 | current_content += " " + line
386 |
387 | if current_key:
388 | result.append((current_key, current_content.strip()))
389 |
390 | return result
391 |
392 |
393 | def filter_and_normalize(
394 | processed_data, constraint_keys, output_file, expand_data=True
395 | ):
396 | final_data = []
397 | for item in processed_data:
398 | input_text = item["input"]
399 | output_text = item["output"]
400 | has_keyword = False
401 | for keyword in keywords_normalization:
402 | if f"{keyword}:" in output_text:
403 | content = output_text.split(f"{keyword}:")[1].strip()
404 | input_text += f"\n{keyword}:{content}"
405 | output_text = output_text.split(f"{keyword}:")[0].strip()
406 | has_keyword = True
407 | if f"{keyword}:" in input_text:
408 | input_text = input_text.replace(
409 | f"{keyword}:", f"{keywords_normalization[keyword]}:"
410 | )
411 | has_keyword = True
412 | if not has_keyword:
413 | continue
414 |
415 | # 数据增强
416 | if expand_data:
417 | input_tuple_list = split_data(input_text, keywords_normalization)
418 | if not input_tuple_list:
419 | continue
420 |
421 | for permutation in itertools.permutations(input_tuple_list):
422 | new_item = {
423 | "instruction": instruction_template,
424 | "input": "\n".join(
425 | [f"{key}:{value}" for key, value in permutation]
426 | ),
427 | "output": output_text,
428 | }
429 | final_data.append(new_item)
430 | else:
431 | item.update({"input": input_text, "output": output_text})
432 | final_data.append(item)
433 |
434 | # 对结果做一个打乱
435 | random.shuffle(final_data)
436 | with open(output_file, "w", encoding="utf-8") as f:
437 | json.dump(final_data, f, ensure_ascii=False, indent=2)
438 |
439 | return final_data
440 | ```
441 |
442 |
443 | ```python
444 | final_data = filter_and_normalize(
445 | processed_data,
446 | keywords_normalization,
447 | "../../Data/TinyStoriesInstruct/sft_data_v2.json",
448 | True,
449 | )
450 | ```
451 |
452 | 看一看处理的结果,这样就和经典的`SFT`数据格式一致了。
453 |
454 |
455 | ```python
456 | for i in range(5):
457 | pprint(final_data[i])
458 | ```
459 |
460 | {'input': '随机句子:随机句子:蒂姆的网球水平越来越好,但有时他在错过球的时候会感到不耐烦。\n'
461 | '特征:对话\n'
462 | '摘要:蒂姆和他的爸爸一起打网球,但当蒂姆错过球时会感到不耐烦。他的爸爸鼓励他坚持练习,最终蒂姆成功把球打过了网,并为自己感到骄傲。',
463 | 'instruction': '按照下面输入的约束生成故事',
464 | 'output': '从前,有个叫蒂姆的小男孩。蒂姆喜欢和他的爸爸打网球。他们会去公园,来回击球。蒂姆的网球水平越来越好,但有时他在错过球的时候会感到不耐烦。 \n'
465 | '一天,蒂姆和他的爸爸在打网球,蒂姆错过了很多次球。他变得很不耐烦,甚至哭了起来。他的爸爸说:“别担心,蒂姆。你通过练习会变得更好的。” \n'
466 | '爸爸给蒂姆发了个球,蒂姆把球打过了网。他高兴得不得了!蒂姆说:“我成功了,爸爸!” \n'
467 | '他的爸爸微笑着说:“没错,你成功了!现在我们继续玩,享受其中的乐趣。”蒂姆感到非常自豪,一直打球,直到该回家的时候。'}
468 | {'input': '词汇:撒谎,打架,大\n'
469 | '摘要:艾莉这只大象帮助朋友们蒂米和萨米和解,强调了友谊和一起玩的重要性。\n'
470 | '随机句子:艾莉和她的朋友们住在一片大丛林里。\n'
471 | '特征:对话',
472 | 'instruction': '按照下面输入的约束生成故事',
473 | 'output': '从前,有一只叫艾莉的大象。艾莉和她的朋友们住在一片大丛林里。一天,艾莉看到她的朋友老虎蒂米躺在地上。 \n'
474 | '艾莉问:“蒂米,你怎么躺着?” \n'
475 | '“我和蛇萨米打架,”蒂米悲伤地回答。 \n'
476 | '艾莉看到朋友们打架,心里很难过。她说:“打架可不好,我们应该做朋友,一起玩。” \n'
477 | '蒂米同意了艾莉,他们一起去找萨米。当他们找到萨米时,他们互相道歉,重新成为了好朋友。从那天起,他们都一起玩,在丛林里玩得很开心。'}
478 | {'input': '词汇:滚,比萨,打开\n'
479 | '摘要:蒂姆试图从一家开着的比萨店拿一块大比萨,但它太大了,所以他决定把它滚走。一只狗看到了比萨,追着蒂姆,吃掉了比萨,留下蒂姆感到伤心。',
480 | 'instruction': '按照下面输入的约束生成故事',
481 | 'output': '一天,一个名叫蒂姆的男孩去了比萨店。他特别喜欢比萨。在比萨店里,他看到桌子上有一个大比萨。它看起来很好吃! \n'
482 | '蒂姆说:“哇,我想吃那块比萨!”他试图拿起比萨,但它太大了。所以,他决定把比萨滚走。他把比萨滚出了比萨店。 \n'
483 | '当蒂姆把比萨滚下街的时候,一只大狗看到了比萨。那只狗很饿。狗说:“我也想吃那块比萨!”狗开始追着蒂姆和他的比萨。 \n'
484 | '蒂姆跑得很快,但狗跑得更快。狗追上了蒂姆和他的比萨。狗吃掉了整块比萨,蒂姆感到伤心。那天他一口比萨都没吃到。'}
485 | {'input': '词汇:鼓掌,海洋,危险\n'
486 | '特征:对话\n'
487 | '摘要:莉莉和萨姆想在海洋中游泳,但他们的父母说太危险了。他们在岸边和新朋友一起玩球和放风筝,玩得很开心。他们在水中看到一只海豚,了解到海洋既美妙又危险。',
488 | 'instruction': '按照下面输入的约束生成故事',
489 | 'output': '莉莉和萨姆和他们的爸爸妈妈在海滩上。他们喜欢在沙子里玩耍,欣赏海洋。海洋又大又蓝,发出隆隆的声音。 \n'
490 | '“妈妈,我们可以下水吗?”莉莉问。 \n'
491 | '“不行,亲爱的,今天水太危险了。有大浪和强流。你们可能会受伤或者迷路,”妈妈说。 \n'
492 | '“但是我想游泳,妈妈。我游得很好。你教过我怎么游泳,记得吗?”萨姆说。 \n'
493 | '“我知道,亲爱的,但在海洋里游泳和在游泳池里游泳是不同的。海洋对你们这种小孩来说不安全。你们必须听爸爸妈妈的话,待在岸边,好吗?”爸爸说。 \n'
494 | '莉莉和萨姆感到难过。他们想在水里玩得开心。他们看到其他小朋友在玩球和放风筝。他们决定加入他们,交一些新朋友。 \n'
495 | '他们玩球和放风筝玩得特别开心。他们互相扔球,追着风筝跑。他们欢笑、喊叫、欢呼。他们忘记了水,享受着阳光和微风。 \n'
496 | '不久,到了回家的时间。爸爸妈妈收拾好东西,叫莉莉和萨姆。他们和新朋友道别,感谢他们一起玩。 \n'
497 | '当他们走向车时,他们看到码头上有一群人。他们在看水里的东西。他们听到了一些鼓掌和欢呼声。 \n'
498 | '“他们在看什么,爸爸?”莉莉问。 \n'
499 | '“我们去看看,亲爱的,”爸爸说。 \n'
500 | '他们走到码头,看到一条大鱼从水里跳出来。它是灰色的,闪闪发亮,鼻子还很长。它是一只海豚。它在波浪中玩耍和跳舞。它发出一些有趣的声音,溅起水花。 \n'
501 | '“哇,看看那个,萨姆。是一只海豚。太酷了,”莉莉说。 \n'
502 | '“太神奇了,莉莉。它聪明又友好。它不像水那样危险。真不错,”萨姆说。 \n'
503 | '他们看了一会儿海豚。每次海豚跳跃、旋转或挥手时,他们都鼓掌欢呼。他们微笑着挥手回应。他们感到快乐和兴奋。 \n'
504 | '他们那天学到了很多新东西。他们明白了海洋不仅危险,还有很多美妙的地方。他们学到在海滩上有很多东西可以看、可以做和可以享受。他们学到可以在不下水的情况下玩得开心。他们学到可以交新朋友,看到新动物。他们学到可以为海豚鼓掌。'}
505 | {'input': '特征:对话,道德价值\n'
506 | '随机句子:一天,班尼看到地上有一把梳子。\n'
507 | '摘要:兔子班尼在意外拿走了一把属于小女孩的梳子,并后来遇到一只死鸟后,明白了诚实和尊重生命的重要性。',
508 | 'instruction': '按照下面输入的约束生成故事',
509 | 'output': '从前,有一只叫班尼的兔子。班尼喜欢整天跳跃和玩耍。一天,班尼看到地上有一把梳子。他觉得挺有意思的,决定捡起来。 \n'
510 | '当班尼在梳理自己的毛发时,他听到一个声音说:“嘿,兔子!那把梳子是我的!”这是一个小女孩,她掉了梳子。班尼因为没有询问就拿走了梳子而感到很不好意思,迅速把梳子还给了她。 \n'
511 | '小女孩很高兴,谢班尼的诚实。她告诉他,在拿东西之前一定要先问是很重要的。班尼为自己做对了事情而感到自豪,高高兴兴地跳开了。 \n'
512 | '当他跳来跳去时,班尼看到地上有一只死鸟。他想起了小女孩的话,知道尊重生命是很重要的,即使它们已经不再活着。班尼为那只鸟默哀,继续他的路程,心里感激自己学到的教训。'}
513 |
514 |
515 | ## 小结
516 | 1. 基于`TinyStories`的`Instruct`数据进行指令组合层面均衡的采样,获得了15000条原始数据
517 | 2. 构造了翻译函数,异步使用吴恩达老师的`translation-agent`对数据进行翻译
518 | 3. 基于翻译后的数据,构造了经典格式的`SFT`数据集
519 |
520 |
521 |
--------------------------------------------------------------------------------