├── .gitignore
├── .vscode
├── launch.json
└── settings.json
├── CHANGELOG.md
├── Datasets
└── README.md
├── LICENSE
├── MANIFEST.in
├── Models
└── README.md
├── README.md
├── Tests
├── README.md
├── test_tensorflow_metrics.py
└── test_text_utils.py
├── Tutorials
├── 01_image_to_word
│ ├── README.md
│ ├── configs.py
│ ├── inferenceModel.py
│ ├── model.py
│ ├── requiremenets.txt
│ └── train.py
├── 02_captcha_to_text
│ ├── README.md
│ ├── configs.py
│ ├── inferenceModel.py
│ ├── model.py
│ └── train.py
├── 03_handwriting_recognition
│ ├── README.md
│ ├── configs.py
│ ├── inferenceModel.py
│ ├── model.py
│ └── train.py
├── 04_sentence_recognition
│ ├── README.md
│ ├── configs.py
│ ├── inferenceModel.py
│ ├── model.py
│ └── train.py
├── 05_sound_to_text
│ ├── README.md
│ ├── configs.py
│ ├── inferenceModel.py
│ ├── model.py
│ ├── train.py
│ └── train_no_limit.py
├── 06_pytorch_introduction
│ ├── README.md
│ ├── model.py
│ ├── requirements.txt
│ ├── test.py
│ └── train.py
├── 07_pytorch_wrapper
│ ├── README.md
│ ├── model.py
│ ├── requirements.txt
│ ├── test.py
│ └── train.py
├── 08_handwriting_recognition_torch
│ ├── README.md
│ ├── configs.py
│ ├── inferenceModel.py
│ ├── model.py
│ ├── requirements.txt
│ └── train_torch.py
├── 09_translation_transformer
│ ├── README.md
│ ├── configs.py
│ ├── download.py
│ ├── model.py
│ ├── requirements.txt
│ ├── test.py
│ └── train.py
├── 10_wav2vec2_torch
│ ├── configs.py
│ ├── requirements.txt
│ ├── test.py
│ ├── train.py
│ └── train_tf.py
├── 11_Yolov8
│ ├── README.md
│ ├── convert2onnx.py
│ ├── requirements.txt
│ ├── run_pretrained.py
│ ├── test_yolov8.py
│ └── train_yolov8.py
└── README.md
├── bin
├── read_parquet.py
└── setup.sh
├── mltu
├── __init__.py
├── annotations
│ ├── __init__.py
│ ├── audio.py
│ ├── detections.py
│ └── images.py
├── augmentors.py
├── configs.py
├── dataProvider.py
├── inferenceModel.py
├── preprocessors.py
├── tensorflow
│ ├── README.md
│ ├── __init__.py
│ ├── callbacks.py
│ ├── dataProvider.py
│ ├── layers.py
│ ├── losses.py
│ ├── metrics.py
│ ├── model_utils.py
│ ├── models
│ │ └── u2net.py
│ ├── requirements.txt
│ └── transformer
│ │ ├── __init__.py
│ │ ├── attention.py
│ │ ├── callbacks.py
│ │ ├── layers.py
│ │ └── utils.py
├── tokenizers.py
├── torch
│ ├── README.md
│ ├── __init__.py
│ ├── callbacks.py
│ ├── dataProvider.py
│ ├── handlers.py
│ ├── losses.py
│ ├── metrics.py
│ ├── model.py
│ ├── requirements.txt
│ └── yolo
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── annotation.py
│ │ ├── detectors
│ │ ├── __init__.py
│ │ ├── detector.py
│ │ ├── onnx_detector.py
│ │ └── torch_detector.py
│ │ ├── loss.py
│ │ ├── metrics.py
│ │ ├── optimizer.py
│ │ ├── preprocessors.py
│ │ ├── pruning_utils.py
│ │ └── requirements.txt
├── transformers.py
└── utils
│ ├── __init__.py
│ └── text_utils.py
├── requirements.txt
└── setup.py
/.gitignore:
--------------------------------------------------------------------------------
1 | __pycache__
2 | *.egg-info
3 | *.pyc
4 | venv
5 |
6 | Datasets/*
7 | Models/*
8 | dist
9 |
10 | !*.md
11 |
12 | .idea
13 | .python-version
14 |
15 | test
16 | build
17 | yolov8*
18 | pyrightconfig.json
--------------------------------------------------------------------------------
/.vscode/launch.json:
--------------------------------------------------------------------------------
1 | {
2 | // Use IntelliSense to learn about possible attributes.
3 | // Hover to view descriptions of existing attributes.
4 | // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
5 | "version": "0.2.0",
6 | "configurations": [
7 | {
8 | "name": "Python: Current File",
9 | "type": "python",
10 | "request": "launch",
11 | "program": "${file}",
12 | "console": "integratedTerminal",
13 | "justMyCode": false,
14 | "subProcess": true,
15 | }
16 | ]
17 | }
--------------------------------------------------------------------------------
/.vscode/settings.json:
--------------------------------------------------------------------------------
1 | {
2 | "python.analysis.typeCheckingMode": "off",
3 | "python.testing.unittestArgs": [
4 | "-v",
5 | "-s",
6 | "./Tests",
7 | "-p",
8 | "*test*.py"
9 | ],
10 | "python.testing.pytestEnabled": false,
11 | "python.testing.unittestEnabled": true
12 | }
--------------------------------------------------------------------------------
/Datasets/README.md:
--------------------------------------------------------------------------------
1 | # Empty repository to hold the datasets when running Tutorials
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2022 Rokas
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/MANIFEST.in:
--------------------------------------------------------------------------------
1 | include requirements.txt
--------------------------------------------------------------------------------
/Models/README.md:
--------------------------------------------------------------------------------
1 | # Empty repository to hold the Models when running Tutorials
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # MLTU - Machine Learning Training Utilities
2 | Machine Learning Training Utilities for TensorFlow 2.* and PyTorch with Python 3
3 |
4 |  5 |
5 |
6 |
7 | # Installation:
8 | To use MLTU in your own project, you can install it from PyPI:
9 | ```bash
10 | pip install mltu
11 | ```
12 | When running tutorials, it's necessary to install mltu for a specific tutorial, for example:
13 | ```bash
14 | pip install mltu==0.1.3
15 | ```
16 | Each tutorial has its own requirements.txt file for a specific mltu version. As this project progress, the newest versions may have breaking changes, so it's recommended to use the same version as in the tutorial.
17 |
18 | # Tutorials and Examples can be found on [PyLessons.com](https://pylessons.com/mltu)
19 | 1. [Text Recognition With TensorFlow and CTC network](https://pylessons.com/ctc-text-recognition), code in ```Tutorials\01_image_to_word``` folder;
20 | 2. [TensorFlow OCR model for reading Captchas](https://pylessons.com/tensorflow-ocr-captcha), code in ```Tutorials\02_captcha_to_text``` folder;
21 | 3. [Handwriting words recognition with TensorFlow](https://pylessons.com/handwriting-recognition), code in ```Tutorials\03_handwriting_recognition``` folder;
22 | 4. [Handwritten sentence recognition with TensorFlow](https://pylessons.com/handwritten-sentence-recognition), code in ```Tutorials\04_sentence_recognition``` folder;
23 | 5. [Introduction to speech recognition with TensorFlow](https://pylessons.com/speech-recognition), code in ```Tutorials\05_speech_recognition``` folder;
24 | 6. [Introduction to PyTorch in a practical way](https://pylessons.com/pytorch-introduction), code in ```Tutorials\06_pytorch_introduction``` folder;
25 | 7. [Using custom wrapper to simplify PyTorch models training pipeline](https://pylessons.com/pytorch-introduction), code in ```Tutorials\07_pytorch_wrapper``` folder;
26 | 8. [Handwriting words recognition with PyTorch](https://pylessons.com/handwriting-recognition-pytorch), code in ```Tutorials\08_handwriting_recognition_torch``` folder;
27 | 9. [Transformer training with TensorFlow for Translation task](https://pylessons.com/transformers-training), code in ```Tutorials\09_translation_transformer``` folder;
28 | 10. [Speech Recognition in Python | finetune wav2vec2 model for a custom ASR model](https://youtu.be/h6ooEGzjkj0), code in ```Tutorials\10_wav2vec2_torch``` folder;
29 | 11. [YOLOv8: Real-Time Object Detection Simplified](https://youtu.be/vegL__weCxY), code in ```Tutorials\11_Yolov8``` folder;
30 | 12. [YOLOv8: Customizing Object Detector training](https://youtu.be/ysYiV1CbCyY), code in ```Tutorials\11_Yolov8\train_yolov8.py``` folder;
--------------------------------------------------------------------------------
/Tests/README.md:
--------------------------------------------------------------------------------
1 | # Repository for unit tests
--------------------------------------------------------------------------------
/Tests/test_tensorflow_metrics.py:
--------------------------------------------------------------------------------
1 | import unittest
2 | import numpy as np
3 | from mltu.tensorflow.metrics import CERMetric, WERMetric
4 |
5 | import numpy as np
6 | import tensorflow as tf
7 |
8 | class TestMetrics(unittest.TestCase):
9 |
10 | def to_embeddings(self, sentences, vocab):
11 | embeddings, max_len = [], 0
12 |
13 | for sentence in sentences:
14 | embedding = []
15 | for character in sentence:
16 | embedding.append(vocab.index(character))
17 | embeddings.append(embedding)
18 | max_len = max(max_len, len(embedding))
19 | return embeddings, max_len
20 |
21 | def setUp(self) -> None:
22 | true_words = ["Who are you", "I am a student", "I am a teacher", "Just different sentence length"]
23 | pred_words = ["Who are you", "I am a ztudent", "I am A reacher", "Just different length"]
24 |
25 | vocab = set()
26 | for sen in true_words + pred_words:
27 | for character in sen:
28 | vocab.add(character)
29 | self.vocab = "".join(vocab)
30 |
31 | sentence_true, max_len_true = self.to_embeddings(true_words, self.vocab)
32 | sentence_pred, max_len_pred = self.to_embeddings(pred_words, self.vocab)
33 |
34 | max_len = max(max_len_true, max_len_pred)
35 | padding_length = 64
36 |
37 | self.sen_true = [np.pad(sen, (0, max_len - len(sen)), "constant", constant_values=len(self.vocab)) for sen in sentence_true]
38 | self.sen_pred = [np.pad(sen, (0, padding_length - len(sen)), "constant", constant_values=-1) for sen in sentence_pred]
39 |
40 | def test_CERMetric(self):
41 | vocabulary = tf.constant(list(self.vocab))
42 | cer = CERMetric.get_cer(self.sen_true, self.sen_pred, vocabulary).numpy()
43 |
44 | self.assertTrue(np.array_equal(cer, np.array([0.0, 0.071428575, 0.14285715, 0.42857143], dtype=np.float32)))
45 |
46 | def test_WERMetric(self):
47 | vocabulary = tf.constant(list(self.vocab))
48 | wer = WERMetric.get_wer(self.sen_true, self.sen_pred, vocabulary).numpy()
49 |
50 | self.assertTrue(np.array_equal(wer, np.array([0., 0.25, 0.5, 0.33333334], dtype=np.float32)))
51 |
52 | if __name__ == "__main__":
53 | unittest.main()
--------------------------------------------------------------------------------
/Tests/test_text_utils.py:
--------------------------------------------------------------------------------
1 | import unittest
2 |
3 | from mltu.utils.text_utils import edit_distance, get_cer, get_wer
4 |
5 | class TestTextUtils(unittest.TestCase):
6 |
7 | def test_edit_distance(self):
8 | """ This unit test includes several test cases to cover different scenarios, including no errors,
9 | substitution errors, insertion errors, deletion errors, and a more complex case with multiple
10 | errors. It also includes a test case for empty input.
11 | """
12 | # Test simple case with no errors
13 | prediction_tokens = ["A", "B", "C"]
14 | reference_tokens = ["A", "B", "C"]
15 | self.assertEqual(edit_distance(prediction_tokens, reference_tokens), 0)
16 |
17 | # Test simple case with one substitution error
18 | prediction_tokens = ["A", "B", "D"]
19 | reference_tokens = ["A", "B", "C"]
20 | self.assertEqual(edit_distance(prediction_tokens, reference_tokens), 1)
21 |
22 | # Test simple case with one insertion error
23 | prediction_tokens = ["A", "B", "C"]
24 | reference_tokens = ["A", "B", "C", "D"]
25 | self.assertEqual(edit_distance(prediction_tokens, reference_tokens), 1)
26 |
27 | # Test simple case with one deletion error
28 | prediction_tokens = ["A", "B"]
29 | reference_tokens = ["A", "B", "C"]
30 | self.assertEqual(edit_distance(prediction_tokens, reference_tokens), 1)
31 |
32 | # Test more complex case with multiple errors
33 | prediction_tokens = ["A", "B", "C", "D", "E"]
34 | reference_tokens = ["A", "C", "B", "F", "E"]
35 | self.assertEqual(edit_distance(prediction_tokens, reference_tokens), 3)
36 |
37 | # Test empty input
38 | prediction_tokens = []
39 | reference_tokens = []
40 | self.assertEqual(edit_distance(prediction_tokens, reference_tokens), 0)
41 |
42 | def test_get_cer(self):
43 | # Test simple case with no errors
44 | preds = ["A B C"]
45 | target = ["A B C"]
46 | self.assertEqual(get_cer(preds, target), 0)
47 |
48 | # Test simple case with one character error
49 | preds = ["A B C"]
50 | target = ["A B D"]
51 | self.assertEqual(get_cer(preds, target), 1/5)
52 |
53 | # Test simple case with multiple character errors
54 | preds = ["A B C"]
55 | target = ["D E F"]
56 | self.assertEqual(get_cer(preds, target), 3/5)
57 |
58 | # Test empty input
59 | preds = []
60 | target = []
61 | self.assertEqual(get_cer(preds, target), 0)
62 |
63 | # Test simple case with different word lengths
64 | preds = ["ABC"]
65 | target = ["ABCDEFG"]
66 | self.assertEqual(get_cer(preds, target), 4/7)
67 |
68 | def test_get_wer(self):
69 | # Test simple case with no errors
70 | preds = "A B C"
71 | target = "A B C"
72 | self.assertEqual(get_wer(preds, target), 0)
73 |
74 | # Test simple case with one word error
75 | preds = "A B C"
76 | target = "A B D"
77 | self.assertEqual(get_wer(preds, target), 1/3)
78 |
79 | # Test simple case with multiple word errors
80 | preds = "A B C"
81 | target = "D E F"
82 | self.assertEqual(get_wer(preds, target), 1)
83 |
84 | # Test empty input
85 | preds = ""
86 | target = ""
87 | self.assertEqual(get_wer(preds, target), 0)
88 |
89 | # Test simple case with different sentence lengths
90 | preds = ["ABC"]
91 | target = ["ABC DEF"]
92 | self.assertEqual(get_wer(preds, target), 1)
93 |
94 |
95 | if __name__ == "__main__":
96 | unittest.main()
97 |
--------------------------------------------------------------------------------
/Tutorials/01_image_to_word/configs.py:
--------------------------------------------------------------------------------
1 | import os
2 | from datetime import datetime
3 |
4 | from mltu.configs import BaseModelConfigs
5 |
6 |
7 | class ModelConfigs(BaseModelConfigs):
8 | def __init__(self):
9 | super().__init__()
10 | self.model_path = os.path.join("Models/1_image_to_word", datetime.strftime(datetime.now(), "%Y%m%d%H%M"))
11 | self.vocab = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
12 | self.height = 32
13 | self.width = 128
14 | self.max_text_length = 23
15 | self.batch_size = 1024
16 | self.learning_rate = 1e-4
17 | self.train_epochs = 100
18 | self.train_workers = 20
--------------------------------------------------------------------------------
/Tutorials/01_image_to_word/inferenceModel.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import typing
3 | import numpy as np
4 |
5 | from mltu.inferenceModel import OnnxInferenceModel
6 | from mltu.utils.text_utils import ctc_decoder, get_cer
7 |
8 | class ImageToWordModel(OnnxInferenceModel):
9 | def __init__(self, char_list: typing.Union[str, list], *args, **kwargs):
10 | super().__init__(*args, **kwargs)
11 | self.char_list = char_list
12 |
13 | def predict(self, image: np.ndarray):
14 | image = cv2.resize(image, self.input_shapes[0][1:3][::-1])
15 |
16 | image_pred = np.expand_dims(image, axis=0).astype(np.float32)
17 |
18 | preds = self.model.run(self.output_names, {self.input_names[0]: image_pred})[0]
19 |
20 | text = ctc_decoder(preds, self.char_list)[0]
21 |
22 | return text
23 |
24 |
25 | if __name__ == "__main__":
26 | import pandas as pd
27 | from tqdm import tqdm
28 | from mltu.configs import BaseModelConfigs
29 |
30 | configs = BaseModelConfigs.load("Models/1_image_to_word/202211270035/configs.yaml")
31 |
32 | model = ImageToWordModel(model_path=configs.model_path, char_list=configs.vocab)
33 |
34 | df = pd.read_csv("Models/1_image_to_word/202211270035/val.csv").dropna().values.tolist()
35 |
36 | accum_cer = []
37 | for image_path, label in tqdm(df[:20]):
38 | image = cv2.imread(image_path.replace("\\", "/"))
39 |
40 | try:
41 | prediction_text = model.predict(image)
42 |
43 | cer = get_cer(prediction_text, label)
44 | print(f"Image: {image_path}, Label: {label}, Prediction: {prediction_text}, CER: {cer}")
45 |
46 | # resize image by 3 times for visualization
47 | # image = cv2.resize(image, (image.shape[1] * 3, image.shape[0] * 3))
48 | # cv2.imshow(prediction_text, image)
49 | # cv2.waitKey(0)
50 | # cv2.destroyAllWindows()
51 | except:
52 | continue
53 |
54 | accum_cer.append(cer)
55 |
56 | print(f"Average CER: {np.average(accum_cer)}")
--------------------------------------------------------------------------------
/Tutorials/01_image_to_word/model.py:
--------------------------------------------------------------------------------
1 | from keras import layers
2 | from keras.models import Model
3 |
4 | from mltu.tensorflow.model_utils import residual_block
5 |
6 |
7 | def train_model(input_dim, output_dim, activation="leaky_relu", dropout=0.2):
8 |
9 | inputs = layers.Input(shape=input_dim, name="input")
10 |
11 | input = layers.Lambda(lambda x: x / 255)(inputs)
12 |
13 | x1 = residual_block(input, 16, activation=activation, skip_conv=True, strides=1, dropout=dropout)
14 |
15 | x2 = residual_block(x1, 16, activation=activation, skip_conv=True, strides=2, dropout=dropout)
16 | x3 = residual_block(x2, 16, activation=activation, skip_conv=False, strides=1, dropout=dropout)
17 |
18 | x4 = residual_block(x3, 32, activation=activation, skip_conv=True, strides=2, dropout=dropout)
19 | x5 = residual_block(x4, 32, activation=activation, skip_conv=False, strides=1, dropout=dropout)
20 |
21 | x6 = residual_block(x5, 64, activation=activation, skip_conv=True, strides=1, dropout=dropout)
22 | x7 = residual_block(x6, 64, activation=activation, skip_conv=False, strides=1, dropout=dropout)
23 |
24 | squeezed = layers.Reshape((x7.shape[-3] * x7.shape[-2], x7.shape[-1]))(x7)
25 |
26 | blstm = layers.Bidirectional(layers.LSTM(64, return_sequences=True))(squeezed)
27 |
28 | output = layers.Dense(output_dim + 1, activation="softmax", name="output")(blstm)
29 |
30 | model = Model(inputs=inputs, outputs=output)
31 | return model
--------------------------------------------------------------------------------
/Tutorials/01_image_to_word/requiremenets.txt:
--------------------------------------------------------------------------------
1 | mltu==0.1.3
--------------------------------------------------------------------------------
/Tutorials/01_image_to_word/train.py:
--------------------------------------------------------------------------------
1 | import os
2 | from tqdm import tqdm
3 | import tensorflow as tf
4 |
5 | try: [tf.config.experimental.set_memory_growth(gpu, True) for gpu in tf.config.experimental.list_physical_devices("GPU")]
6 | except: pass
7 |
8 | from keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau, TensorBoard
9 |
10 | from mltu.preprocessors import ImageReader
11 | from mltu.annotations.images import CVImage
12 | from mltu.transformers import ImageResizer, LabelIndexer, LabelPadding
13 | from mltu.tensorflow.dataProvider import DataProvider
14 | from mltu.tensorflow.losses import CTCloss
15 | from mltu.tensorflow.callbacks import Model2onnx, TrainLogger
16 | from mltu.tensorflow.metrics import CWERMetric
17 |
18 |
19 | from model import train_model
20 | from configs import ModelConfigs
21 |
22 | configs = ModelConfigs()
23 |
24 | data_path = "Datasets/90kDICT32px"
25 | val_annotation_path = data_path + "/annotation_val.txt"
26 | train_annotation_path = data_path + "/annotation_train.txt"
27 |
28 | # Read metadata file and parse it
29 | def read_annotation_file(annotation_path):
30 | dataset, vocab, max_len = [], set(), 0
31 | with open(annotation_path, "r") as f:
32 | for line in tqdm(f.readlines()):
33 | line = line.split()
34 | image_path = data_path + line[0][1:]
35 | label = line[0].split("_")[1]
36 | dataset.append([image_path, label])
37 | vocab.update(list(label))
38 | max_len = max(max_len, len(label))
39 | return dataset, sorted(vocab), max_len
40 |
41 | train_dataset, train_vocab, max_train_len = read_annotation_file(train_annotation_path)
42 | val_dataset, val_vocab, max_val_len = read_annotation_file(val_annotation_path)
43 |
44 | # Save vocab and maximum text length to configs
45 | configs.vocab = "".join(train_vocab)
46 | configs.max_text_length = max(max_train_len, max_val_len)
47 | configs.save()
48 |
49 | # Create training data provider
50 | train_data_provider = DataProvider(
51 | dataset=train_dataset,
52 | skip_validation=True,
53 | batch_size=configs.batch_size,
54 | data_preprocessors=[ImageReader(CVImage)],
55 | transformers=[
56 | ImageResizer(configs.width, configs.height),
57 | LabelIndexer(configs.vocab),
58 | LabelPadding(max_word_length=configs.max_text_length, padding_value=len(configs.vocab))
59 | ],
60 | )
61 |
62 | # Create validation data provider
63 | val_data_provider = DataProvider(
64 | dataset=val_dataset,
65 | skip_validation=True,
66 | batch_size=configs.batch_size,
67 | data_preprocessors=[ImageReader(CVImage)],
68 | transformers=[
69 | ImageResizer(configs.width, configs.height),
70 | LabelIndexer(configs.vocab),
71 | LabelPadding(max_word_length=configs.max_text_length, padding_value=len(configs.vocab))
72 | ],
73 | )
74 |
75 | model = train_model(
76 | input_dim = (configs.height, configs.width, 3),
77 | output_dim = len(configs.vocab),
78 | )
79 | # Compile the model and print summary
80 | model.compile(
81 | optimizer=tf.keras.optimizers.Adam(learning_rate=configs.learning_rate),
82 | loss=CTCloss(),
83 | metrics=[CWERMetric()],
84 | run_eagerly=False
85 | )
86 | model.summary(line_length=110)
87 |
88 | # Define path to save the model
89 | os.makedirs(configs.model_path, exist_ok=True)
90 |
91 | # Define callbacks
92 | earlystopper = EarlyStopping(monitor="val_CER", patience=10, verbose=1)
93 | checkpoint = ModelCheckpoint(f"{configs.model_path}/model.h5", monitor="val_CER", verbose=1, save_best_only=True, mode="min")
94 | trainLogger = TrainLogger(configs.model_path)
95 | tb_callback = TensorBoard(f"{configs.model_path}/logs", update_freq=1)
96 | reduceLROnPlat = ReduceLROnPlateau(monitor="val_CER", factor=0.9, min_delta=1e-10, patience=5, verbose=1, mode="auto")
97 | model2onnx = Model2onnx(f"{configs.model_path}/model.h5")
98 |
99 | # Train the model
100 | model.fit(
101 | train_data_provider,
102 | validation_data=val_data_provider,
103 | epochs=configs.train_epochs,
104 | callbacks=[earlystopper, checkpoint, trainLogger, reduceLROnPlat, tb_callback, model2onnx],
105 | workers=configs.train_workers
106 | )
107 |
108 | # Save training and validation datasets as csv files
109 | train_data_provider.to_csv(os.path.join(configs.model_path, "train.csv"))
110 | val_data_provider.to_csv(os.path.join(configs.model_path, "val.csv"))
--------------------------------------------------------------------------------
/Tutorials/02_captcha_to_text/configs.py:
--------------------------------------------------------------------------------
1 | import os
2 | from datetime import datetime
3 |
4 | from mltu.configs import BaseModelConfigs
5 |
6 |
7 | class ModelConfigs(BaseModelConfigs):
8 | def __init__(self):
9 | super().__init__()
10 | self.model_path = os.path.join("Models/02_captcha_to_text", datetime.strftime(datetime.now(), "%Y%m%d%H%M"))
11 | self.vocab = ""
12 | self.height = 50
13 | self.width = 200
14 | self.max_text_length = 0
15 | self.batch_size = 64
16 | self.learning_rate = 1e-3
17 | self.train_epochs = 1000
18 | self.train_workers = 20
--------------------------------------------------------------------------------
/Tutorials/02_captcha_to_text/inferenceModel.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import typing
3 | import numpy as np
4 |
5 | from mltu.inferenceModel import OnnxInferenceModel
6 | from mltu.utils.text_utils import ctc_decoder, get_cer
7 |
8 | class ImageToWordModel(OnnxInferenceModel):
9 | def __init__(self, char_list: typing.Union[str, list], *args, **kwargs):
10 | super().__init__(*args, **kwargs)
11 | self.char_list = char_list
12 |
13 | def predict(self, image: np.ndarray):
14 | image = cv2.resize(image, self.input_shapes[0][1:3][::-1])
15 |
16 | image_pred = np.expand_dims(image, axis=0).astype(np.float32)
17 |
18 | preds = self.model.run(self.output_names, {self.input_names[0]: image_pred})[0]
19 |
20 | text = ctc_decoder(preds, self.char_list)[0]
21 |
22 | return text
23 |
24 | if __name__ == "__main__":
25 | import pandas as pd
26 | from tqdm import tqdm
27 | from mltu.configs import BaseModelConfigs
28 |
29 | configs = BaseModelConfigs.load("Models/02_captcha_to_text/202212211205/configs.yaml")
30 |
31 | model = ImageToWordModel(model_path=configs.model_path, char_list=configs.vocab)
32 |
33 | df = pd.read_csv("Models/02_captcha_to_text/202212211205/val.csv").values.tolist()
34 |
35 | accum_cer = []
36 | for image_path, label in tqdm(df):
37 | image = cv2.imread(image_path.replace("\\", "/"))
38 |
39 | prediction_text = model.predict(image)
40 |
41 | cer = get_cer(prediction_text, label)
42 | print(f"Image: {image_path}, Label: {label}, Prediction: {prediction_text}, CER: {cer}")
43 |
44 | accum_cer.append(cer)
45 |
46 | print(f"Average CER: {np.average(accum_cer)}")
--------------------------------------------------------------------------------
/Tutorials/02_captcha_to_text/model.py:
--------------------------------------------------------------------------------
1 | from keras import layers
2 | from keras.models import Model
3 |
4 | from mltu.tensorflow.model_utils import residual_block
5 |
6 |
7 | def train_model(input_dim, output_dim, activation="leaky_relu", dropout=0.2):
8 |
9 | inputs = layers.Input(shape=input_dim, name="input")
10 |
11 | # normalize images here instead in preprocessing step
12 | input = layers.Lambda(lambda x: x / 255)(inputs)
13 |
14 | x1 = residual_block(input, 16, activation=activation, skip_conv=True, strides=1, dropout=dropout)
15 |
16 | x2 = residual_block(x1, 16, activation=activation, skip_conv=True, strides=2, dropout=dropout)
17 | x3 = residual_block(x2, 16, activation=activation, skip_conv=False, strides=1, dropout=dropout)
18 |
19 | x4 = residual_block(x3, 32, activation=activation, skip_conv=True, strides=2, dropout=dropout)
20 | x5 = residual_block(x4, 32, activation=activation, skip_conv=False, strides=1, dropout=dropout)
21 |
22 | x6 = residual_block(x5, 64, activation=activation, skip_conv=True, strides=2, dropout=dropout)
23 | x7 = residual_block(x6, 32, activation=activation, skip_conv=True, strides=1, dropout=dropout)
24 |
25 | x8 = residual_block(x7, 64, activation=activation, skip_conv=True, strides=2, dropout=dropout)
26 | x9 = residual_block(x8, 64, activation=activation, skip_conv=False, strides=1, dropout=dropout)
27 |
28 | squeezed = layers.Reshape((x9.shape[-3] * x9.shape[-2], x9.shape[-1]))(x9)
29 |
30 | blstm = layers.Bidirectional(layers.LSTM(128, return_sequences=True))(squeezed)
31 | blstm = layers.Dropout(dropout)(blstm)
32 |
33 | output = layers.Dense(output_dim + 1, activation="softmax", name="output")(blstm)
34 |
35 | model = Model(inputs=inputs, outputs=output)
36 | return model
37 |
--------------------------------------------------------------------------------
/Tutorials/02_captcha_to_text/train.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | try: [tf.config.experimental.set_memory_growth(gpu, True) for gpu in tf.config.experimental.list_physical_devices("GPU")]
3 | except: pass
4 |
5 | from keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau, TensorBoard
6 |
7 | from mltu.tensorflow.dataProvider import DataProvider
8 | from mltu.tensorflow.losses import CTCloss
9 | from mltu.tensorflow.callbacks import Model2onnx, TrainLogger
10 | from mltu.tensorflow.metrics import CWERMetric
11 |
12 | from mltu.preprocessors import ImageReader
13 | from mltu.transformers import ImageResizer, LabelIndexer, LabelPadding
14 | from mltu.augmentors import RandomBrightness, RandomRotate, RandomErodeDilate
15 | from mltu.annotations.images import CVImage
16 |
17 | from model import train_model
18 | from configs import ModelConfigs
19 |
20 | import os
21 | from urllib.request import urlopen
22 | from io import BytesIO
23 | from zipfile import ZipFile
24 |
25 |
26 | def download_and_unzip(url, extract_to="Datasets"):
27 | http_response = urlopen(url)
28 | zipfile = ZipFile(BytesIO(http_response.read()))
29 | zipfile.extractall(path=extract_to)
30 |
31 |
32 | if not os.path.exists(os.path.join("Datasets", "captcha_images_v2")):
33 | download_and_unzip("https://github.com/AakashKumarNain/CaptchaCracker/raw/master/captcha_images_v2.zip",
34 | extract_to="Datasets")
35 |
36 | # Create a list of all the images and labels in the dataset
37 | dataset, vocab, max_len = [], set(), 0
38 | captcha_path = os.path.join("Datasets", "captcha_images_v2")
39 | for file in os.listdir(captcha_path):
40 | file_path = os.path.join(captcha_path, file)
41 | label = os.path.splitext(file)[0] # Get the file name without the extension
42 | dataset.append([file_path, label])
43 | vocab.update(list(label))
44 | max_len = max(max_len, len(label))
45 |
46 | configs = ModelConfigs()
47 |
48 | # Save vocab and maximum text length to configs
49 | configs.vocab = "".join(vocab)
50 | configs.max_text_length = max_len
51 | configs.save()
52 |
53 | # Create a data provider for the dataset
54 | data_provider = DataProvider(
55 | dataset=dataset,
56 | skip_validation=True,
57 | batch_size=configs.batch_size,
58 | data_preprocessors=[ImageReader(CVImage)],
59 | transformers=[
60 | ImageResizer(configs.width, configs.height),
61 | LabelIndexer(configs.vocab),
62 | LabelPadding(max_word_length=configs.max_text_length, padding_value=len(configs.vocab))
63 | ],
64 | )
65 | # Split the dataset into training and validation sets
66 | train_data_provider, val_data_provider = data_provider.split(split = 0.9)
67 |
68 | # Augment training data with random brightness, rotation and erode/dilate
69 | train_data_provider.augmentors = [RandomBrightness(), RandomRotate(), RandomErodeDilate()]
70 |
71 | # Creating TensorFlow model architecture
72 | model = train_model(
73 | input_dim = (configs.height, configs.width, 3),
74 | output_dim = len(configs.vocab),
75 | )
76 |
77 | # Compile the model and print summary
78 | model.compile(
79 | optimizer=tf.keras.optimizers.Adam(learning_rate=configs.learning_rate),
80 | loss=CTCloss(),
81 | metrics=[CWERMetric(padding_token=len(configs.vocab))],
82 | run_eagerly=False
83 | )
84 | model.summary(line_length=110)
85 | # Define path to save the model
86 | os.makedirs(configs.model_path, exist_ok=True)
87 |
88 | # Define callbacks
89 | earlystopper = EarlyStopping(monitor="val_CER", patience=50, verbose=1, mode="min")
90 | checkpoint = ModelCheckpoint(f"{configs.model_path}/model.h5", monitor="val_CER", verbose=1, save_best_only=True, mode="min")
91 | trainLogger = TrainLogger(configs.model_path)
92 | tb_callback = TensorBoard(f"{configs.model_path}/logs", update_freq=1)
93 | reduceLROnPlat = ReduceLROnPlateau(monitor="val_CER", factor=0.9, min_delta=1e-10, patience=20, verbose=1, mode="min")
94 | model2onnx = Model2onnx(f"{configs.model_path}/model.h5")
95 |
96 | # Train the model
97 | model.fit(
98 | train_data_provider,
99 | validation_data=val_data_provider,
100 | epochs=configs.train_epochs,
101 | callbacks=[earlystopper, checkpoint, trainLogger, reduceLROnPlat, tb_callback, model2onnx],
102 | workers=configs.train_workers
103 | )
104 |
105 | # Save training and validation datasets as csv files
106 | train_data_provider.to_csv(os.path.join(configs.model_path, "train.csv"))
107 | val_data_provider.to_csv(os.path.join(configs.model_path, "val.csv"))
--------------------------------------------------------------------------------
/Tutorials/03_handwriting_recognition/configs.py:
--------------------------------------------------------------------------------
1 | import os
2 | from datetime import datetime
3 |
4 | from mltu.configs import BaseModelConfigs
5 |
6 | class ModelConfigs(BaseModelConfigs):
7 | def __init__(self):
8 | super().__init__()
9 | self.model_path = os.path.join("Models/03_handwriting_recognition", datetime.strftime(datetime.now(), "%Y%m%d%H%M"))
10 | self.vocab = ""
11 | self.height = 32
12 | self.width = 128
13 | self.max_text_length = 0
14 | self.batch_size = 16
15 | self.learning_rate = 0.0005
16 | self.train_epochs = 1000
17 | self.train_workers = 20
--------------------------------------------------------------------------------
/Tutorials/03_handwriting_recognition/inferenceModel.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import typing
3 | import numpy as np
4 |
5 | from mltu.inferenceModel import OnnxInferenceModel
6 | from mltu.utils.text_utils import ctc_decoder, get_cer
7 |
8 | class ImageToWordModel(OnnxInferenceModel):
9 | def __init__(self, char_list: typing.Union[str, list], *args, **kwargs):
10 | super().__init__(*args, **kwargs)
11 | self.char_list = char_list
12 |
13 | def predict(self, image: np.ndarray):
14 | image = cv2.resize(image, self.input_shapes[0][1:3][::-1])
15 |
16 | image_pred = np.expand_dims(image, axis=0).astype(np.float32)
17 |
18 | preds = self.model.run(self.output_names, {self.input_names[0]: image_pred})[0]
19 |
20 | text = ctc_decoder(preds, self.char_list)[0]
21 |
22 | return text
23 |
24 | if __name__ == "__main__":
25 | import pandas as pd
26 | from tqdm import tqdm
27 | from mltu.configs import BaseModelConfigs
28 |
29 | configs = BaseModelConfigs.load("Models/03_handwriting_recognition/202301111911/configs.yaml")
30 |
31 | model = ImageToWordModel(model_path=configs.model_path, char_list=configs.vocab)
32 |
33 | df = pd.read_csv("Models/03_handwriting_recognition/202301111911/val.csv").values.tolist()
34 |
35 | accum_cer = []
36 | for image_path, label in tqdm(df):
37 | image = cv2.imread(image_path.replace("\\", "/"))
38 |
39 | prediction_text = model.predict(image)
40 |
41 | cer = get_cer(prediction_text, label)
42 | print(f"Image: {image_path}, Label: {label}, Prediction: {prediction_text}, CER: {cer}")
43 |
44 | accum_cer.append(cer)
45 |
46 | # resize by 4x
47 | image = cv2.resize(image, (image.shape[1] * 4, image.shape[0] * 4))
48 | cv2.imshow("Image", image)
49 | cv2.waitKey(0)
50 | cv2.destroyAllWindows()
51 |
52 | print(f"Average CER: {np.average(accum_cer)}")
--------------------------------------------------------------------------------
/Tutorials/03_handwriting_recognition/model.py:
--------------------------------------------------------------------------------
1 | from keras import layers
2 | from keras.models import Model
3 |
4 | from mltu.tensorflow.model_utils import residual_block
5 |
6 |
7 | def train_model(input_dim, output_dim, activation="leaky_relu", dropout=0.2):
8 |
9 | inputs = layers.Input(shape=input_dim, name="input")
10 |
11 | # normalize images here instead in preprocessing step
12 | input = layers.Lambda(lambda x: x / 255)(inputs)
13 |
14 | x1 = residual_block(input, 16, activation=activation, skip_conv=True, strides=1, dropout=dropout)
15 |
16 | x2 = residual_block(x1, 16, activation=activation, skip_conv=True, strides=2, dropout=dropout)
17 | x3 = residual_block(x2, 16, activation=activation, skip_conv=False, strides=1, dropout=dropout)
18 |
19 | x4 = residual_block(x3, 32, activation=activation, skip_conv=True, strides=2, dropout=dropout)
20 | x5 = residual_block(x4, 32, activation=activation, skip_conv=False, strides=1, dropout=dropout)
21 |
22 | x6 = residual_block(x5, 64, activation=activation, skip_conv=True, strides=2, dropout=dropout)
23 | x7 = residual_block(x6, 64, activation=activation, skip_conv=True, strides=1, dropout=dropout)
24 |
25 | x8 = residual_block(x7, 64, activation=activation, skip_conv=False, strides=1, dropout=dropout)
26 | x9 = residual_block(x8, 64, activation=activation, skip_conv=False, strides=1, dropout=dropout)
27 |
28 | squeezed = layers.Reshape((x9.shape[-3] * x9.shape[-2], x9.shape[-1]))(x9)
29 |
30 | blstm = layers.Bidirectional(layers.LSTM(128, return_sequences=True))(squeezed)
31 | blstm = layers.Dropout(dropout)(blstm)
32 |
33 | output = layers.Dense(output_dim + 1, activation="softmax", name="output")(blstm)
34 |
35 | model = Model(inputs=inputs, outputs=output)
36 | return model
37 |
--------------------------------------------------------------------------------
/Tutorials/03_handwriting_recognition/train.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | try: [tf.config.experimental.set_memory_growth(gpu, True) for gpu in tf.config.experimental.list_physical_devices("GPU")]
3 | except: pass
4 |
5 | from keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau, TensorBoard
6 |
7 | from mltu.preprocessors import ImageReader
8 | from mltu.transformers import ImageResizer, LabelIndexer, LabelPadding, ImageShowCV2
9 | from mltu.augmentors import RandomBrightness, RandomRotate, RandomErodeDilate, RandomSharpen
10 | from mltu.annotations.images import CVImage
11 |
12 | from mltu.tensorflow.dataProvider import DataProvider
13 | from mltu.tensorflow.losses import CTCloss
14 | from mltu.tensorflow.callbacks import Model2onnx, TrainLogger
15 | from mltu.tensorflow.metrics import CWERMetric
16 |
17 | from model import train_model
18 | from configs import ModelConfigs
19 |
20 | import os
21 | import tarfile
22 | from tqdm import tqdm
23 | from urllib.request import urlopen
24 | from io import BytesIO
25 | from zipfile import ZipFile
26 |
27 |
28 | def download_and_unzip(url, extract_to="Datasets", chunk_size=1024*1024):
29 | http_response = urlopen(url)
30 |
31 | data = b""
32 | iterations = http_response.length // chunk_size + 1
33 | for _ in tqdm(range(iterations)):
34 | data += http_response.read(chunk_size)
35 |
36 | zipfile = ZipFile(BytesIO(data))
37 | zipfile.extractall(path=extract_to)
38 |
39 | dataset_path = os.path.join("Datasets", "IAM_Words")
40 | if not os.path.exists(dataset_path):
41 | download_and_unzip("https://git.io/J0fjL", extract_to="Datasets")
42 |
43 | file = tarfile.open(os.path.join(dataset_path, "words.tgz"))
44 | file.extractall(os.path.join(dataset_path, "words"))
45 |
46 | dataset, vocab, max_len = [], set(), 0
47 |
48 | # Preprocess the dataset by the specific IAM_Words dataset file structure
49 | words = open(os.path.join(dataset_path, "words.txt"), "r").readlines()
50 | for line in tqdm(words):
51 | if line.startswith("#"):
52 | continue
53 |
54 | line_split = line.split(" ")
55 | if line_split[1] == "err":
56 | continue
57 |
58 | folder1 = line_split[0][:3]
59 | folder2 = "-".join(line_split[0].split("-")[:2])
60 | file_name = line_split[0] + ".png"
61 | label = line_split[-1].rstrip("\n")
62 |
63 | rel_path = os.path.join(dataset_path, "words", folder1, folder2, file_name)
64 | if not os.path.exists(rel_path):
65 | print(f"File not found: {rel_path}")
66 | continue
67 |
68 | dataset.append([rel_path, label])
69 | vocab.update(list(label))
70 | max_len = max(max_len, len(label))
71 |
72 | # Create a ModelConfigs object to store model configurations
73 | configs = ModelConfigs()
74 |
75 | # Save vocab and maximum text length to configs
76 | configs.vocab = "".join(vocab)
77 | configs.max_text_length = max_len
78 | configs.save()
79 |
80 | # Create a data provider for the dataset
81 | data_provider = DataProvider(
82 | dataset=dataset,
83 | skip_validation=True,
84 | batch_size=configs.batch_size,
85 | data_preprocessors=[ImageReader(CVImage)],
86 | transformers=[
87 | ImageResizer(configs.width, configs.height, keep_aspect_ratio=False),
88 | LabelIndexer(configs.vocab),
89 | LabelPadding(max_word_length=configs.max_text_length, padding_value=len(configs.vocab)),
90 | ],
91 | )
92 |
93 | # Split the dataset into training and validation sets
94 | train_data_provider, val_data_provider = data_provider.split(split = 0.9)
95 |
96 | # Augment training data with random brightness, rotation and erode/dilate
97 | train_data_provider.augmentors = [
98 | RandomBrightness(),
99 | RandomErodeDilate(),
100 | RandomSharpen(),
101 | RandomRotate(angle=10),
102 | ]
103 |
104 | # Creating TensorFlow model architecture
105 | model = train_model(
106 | input_dim = (configs.height, configs.width, 3),
107 | output_dim = len(configs.vocab),
108 | )
109 |
110 | # Compile the model and print summary
111 | model.compile(
112 | optimizer=tf.keras.optimizers.Adam(learning_rate=configs.learning_rate),
113 | loss=CTCloss(),
114 | metrics=[CWERMetric(padding_token=len(configs.vocab))],
115 | )
116 | model.summary(line_length=110)
117 |
118 | # Define callbacks
119 | earlystopper = EarlyStopping(monitor="val_CER", patience=20, verbose=1)
120 | checkpoint = ModelCheckpoint(f"{configs.model_path}/model.h5", monitor="val_CER", verbose=1, save_best_only=True, mode="min")
121 | trainLogger = TrainLogger(configs.model_path)
122 | tb_callback = TensorBoard(f"{configs.model_path}/logs", update_freq=1)
123 | reduceLROnPlat = ReduceLROnPlateau(monitor="val_CER", factor=0.9, min_delta=1e-10, patience=10, verbose=1, mode="auto")
124 | model2onnx = Model2onnx(f"{configs.model_path}/model.h5")
125 |
126 | # Train the model
127 | model.fit(
128 | train_data_provider,
129 | validation_data=val_data_provider,
130 | epochs=configs.train_epochs,
131 | callbacks=[earlystopper, checkpoint, trainLogger, reduceLROnPlat, tb_callback, model2onnx],
132 | workers=configs.train_workers
133 | )
134 |
135 | # Save training and validation datasets as csv files
136 | train_data_provider.to_csv(os.path.join(configs.model_path, "train.csv"))
137 | val_data_provider.to_csv(os.path.join(configs.model_path, "val.csv"))
--------------------------------------------------------------------------------
/Tutorials/04_sentence_recognition/README.md:
--------------------------------------------------------------------------------
1 | # Handwritten sentence recognition with TensorFlow
2 | ## Unlock the power of handwritten sentence recognition with TensorFlow and CTC loss. From digitizing notes to transcribing historical documents and automating exam grading
3 |
4 |
5 | ## **Detailed tutorial**:
6 | ## [Handwritten sentence recognition with TensorFlow](https://pylessons.com/handwritten-sentence-recognition)
7 |
8 |
9 |  10 |
10 |
--------------------------------------------------------------------------------
/Tutorials/04_sentence_recognition/configs.py:
--------------------------------------------------------------------------------
1 | import os
2 | from datetime import datetime
3 |
4 | from mltu.configs import BaseModelConfigs
5 |
6 | class ModelConfigs(BaseModelConfigs):
7 | def __init__(self):
8 | super().__init__()
9 | self.model_path = os.path.join("Models/04_sentence_recognition", datetime.strftime(datetime.now(), "%Y%m%d%H%M"))
10 | self.vocab = ""
11 | self.height = 96
12 | self.width = 1408
13 | self.max_text_length = 0
14 | self.batch_size = 32
15 | self.learning_rate = 0.0005
16 | self.train_epochs = 1000
17 | self.train_workers = 20
--------------------------------------------------------------------------------
/Tutorials/04_sentence_recognition/inferenceModel.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import typing
3 | import numpy as np
4 |
5 | from mltu.inferenceModel import OnnxInferenceModel
6 | from mltu.utils.text_utils import ctc_decoder, get_cer, get_wer
7 | from mltu.transformers import ImageResizer
8 |
9 | class ImageToWordModel(OnnxInferenceModel):
10 | def __init__(self, char_list: typing.Union[str, list], *args, **kwargs):
11 | super().__init__(*args, **kwargs)
12 | self.char_list = char_list
13 |
14 | def predict(self, image: np.ndarray):
15 | image = ImageResizer.resize_maintaining_aspect_ratio(image, *self.input_shapes[0][1:3][::-1])
16 |
17 | image_pred = np.expand_dims(image, axis=0).astype(np.float32)
18 |
19 | preds = self.model.run(self.output_names, {self.input_names[0]: image_pred})[0]
20 |
21 | text = ctc_decoder(preds, self.char_list)[0]
22 |
23 | return text
24 |
25 | if __name__ == "__main__":
26 | import pandas as pd
27 | from tqdm import tqdm
28 | from mltu.configs import BaseModelConfigs
29 |
30 | configs = BaseModelConfigs.load("Models/04_sentence_recognition/202301131202/configs.yaml")
31 |
32 | model = ImageToWordModel(model_path=configs.model_path, char_list=configs.vocab)
33 |
34 | df = pd.read_csv("Models/04_sentence_recognition/202301131202/val.csv").values.tolist()
35 |
36 | accum_cer, accum_wer = [], []
37 | for image_path, label in tqdm(df):
38 | image = cv2.imread(image_path.replace("\\", "/"))
39 |
40 | prediction_text = model.predict(image)
41 |
42 | cer = get_cer(prediction_text, label)
43 | wer = get_wer(prediction_text, label)
44 | print("Image: ", image_path)
45 | print("Label:", label)
46 | print("Prediction: ", prediction_text)
47 | print(f"CER: {cer}; WER: {wer}")
48 |
49 | accum_cer.append(cer)
50 | accum_wer.append(wer)
51 |
52 | cv2.imshow(prediction_text, image)
53 | cv2.waitKey(0)
54 | cv2.destroyAllWindows()
55 |
56 | print(f"Average CER: {np.average(accum_cer)}, Average WER: {np.average(accum_wer)}")
--------------------------------------------------------------------------------
/Tutorials/04_sentence_recognition/model.py:
--------------------------------------------------------------------------------
1 | from keras import layers
2 | from keras.models import Model
3 |
4 | from mltu.tensorflow.model_utils import residual_block
5 |
6 |
7 | def train_model(input_dim, output_dim, activation="leaky_relu", dropout=0.2):
8 |
9 | inputs = layers.Input(shape=input_dim, name="input")
10 |
11 | # normalize images here instead in preprocessing step
12 | input = layers.Lambda(lambda x: x / 255)(inputs)
13 |
14 | x1 = residual_block(input, 32, activation=activation, skip_conv=True, strides=1, dropout=dropout)
15 |
16 | x2 = residual_block(x1, 32, activation=activation, skip_conv=True, strides=2, dropout=dropout)
17 | x3 = residual_block(x2, 32, activation=activation, skip_conv=False, strides=1, dropout=dropout)
18 |
19 | x4 = residual_block(x3, 64, activation=activation, skip_conv=True, strides=2, dropout=dropout)
20 | x5 = residual_block(x4, 64, activation=activation, skip_conv=False, strides=1, dropout=dropout)
21 |
22 | x6 = residual_block(x5, 128, activation=activation, skip_conv=True, strides=2, dropout=dropout)
23 | x7 = residual_block(x6, 128, activation=activation, skip_conv=True, strides=1, dropout=dropout)
24 |
25 | x8 = residual_block(x7, 128, activation=activation, skip_conv=True, strides=2, dropout=dropout)
26 | x9 = residual_block(x8, 128, activation=activation, skip_conv=False, strides=1, dropout=dropout)
27 |
28 | squeezed = layers.Reshape((x9.shape[-3] * x9.shape[-2], x9.shape[-1]))(x9)
29 |
30 | blstm = layers.Bidirectional(layers.LSTM(256, return_sequences=True))(squeezed)
31 | blstm = layers.Dropout(dropout)(blstm)
32 |
33 | blstm = layers.Bidirectional(layers.LSTM(64, return_sequences=True))(blstm)
34 | blstm = layers.Dropout(dropout)(blstm)
35 |
36 | output = layers.Dense(output_dim + 1, activation="softmax", name="output")(blstm)
37 |
38 | model = Model(inputs=inputs, outputs=output)
39 | return model
40 |
--------------------------------------------------------------------------------
/Tutorials/04_sentence_recognition/train.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | try: [tf.config.experimental.set_memory_growth(gpu, True) for gpu in tf.config.experimental.list_physical_devices("GPU")]
3 | except: pass
4 |
5 | from keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau, TensorBoard
6 |
7 | from mltu.preprocessors import ImageReader
8 | from mltu.transformers import ImageResizer, LabelIndexer, LabelPadding, ImageShowCV2
9 | from mltu.augmentors import RandomBrightness, RandomRotate, RandomErodeDilate, RandomSharpen
10 | from mltu.annotations.images import CVImage
11 |
12 | from mltu.tensorflow.dataProvider import DataProvider
13 | from mltu.tensorflow.losses import CTCloss
14 | from mltu.tensorflow.callbacks import Model2onnx, TrainLogger
15 | from mltu.tensorflow.metrics import CERMetric, WERMetric
16 |
17 | from model import train_model
18 | from configs import ModelConfigs
19 |
20 | import os
21 | from tqdm import tqdm
22 |
23 | # Must download and extract datasets manually from https://fki.tic.heia-fr.ch/databases/download-the-iam-handwriting-database to Datasets\IAM_Sentences
24 | sentences_txt_path = os.path.join("Datasets", "IAM_Sentences", "ascii", "sentences.txt")
25 | sentences_folder_path = os.path.join("Datasets", "IAM_Sentences", "sentences")
26 |
27 | dataset, vocab, max_len = [], set(), 0
28 | words = open(sentences_txt_path, "r").readlines()
29 | for line in tqdm(words):
30 | if line.startswith("#"):
31 | continue
32 |
33 | line_split = line.split(" ")
34 | if line_split[2] == "err":
35 | continue
36 |
37 | folder1 = line_split[0][:3]
38 | folder2 = "-".join(line_split[0].split("-")[:2])
39 | file_name = line_split[0] + ".png"
40 | label = line_split[-1].rstrip("\n")
41 |
42 | # replace "|" with " " in label
43 | label = label.replace("|", " ")
44 |
45 | rel_path = os.path.join(sentences_folder_path, folder1, folder2, file_name)
46 | if not os.path.exists(rel_path):
47 | print(f"File not found: {rel_path}")
48 | continue
49 |
50 | dataset.append([rel_path, label])
51 | vocab.update(list(label))
52 | max_len = max(max_len, len(label))
53 |
54 | # Create a ModelConfigs object to store model configurations
55 | configs = ModelConfigs()
56 |
57 | # Save vocab and maximum text length to configs
58 | configs.vocab = "".join(vocab)
59 | configs.max_text_length = max_len
60 | configs.save()
61 |
62 | # Create a data provider for the dataset
63 | data_provider = DataProvider(
64 | dataset=dataset,
65 | skip_validation=True,
66 | batch_size=configs.batch_size,
67 | data_preprocessors=[ImageReader(CVImage)],
68 | transformers=[
69 | ImageResizer(configs.width, configs.height, keep_aspect_ratio=True),
70 | LabelIndexer(configs.vocab),
71 | LabelPadding(max_word_length=configs.max_text_length, padding_value=len(configs.vocab)),
72 | ],
73 | )
74 |
75 | # Split the dataset into training and validation sets
76 | train_data_provider, val_data_provider = data_provider.split(split = 0.9)
77 |
78 | # Augment training data with random brightness, rotation and erode/dilate
79 | train_data_provider.augmentors = [
80 | RandomBrightness(),
81 | RandomErodeDilate(),
82 | RandomSharpen(),
83 | ]
84 |
85 | # Creating TensorFlow model architecture
86 | model = train_model(
87 | input_dim = (configs.height, configs.width, 3),
88 | output_dim = len(configs.vocab),
89 | )
90 |
91 | # Compile the model and print summary
92 | model.compile(
93 | optimizer=tf.keras.optimizers.Adam(learning_rate=configs.learning_rate),
94 | loss=CTCloss(),
95 | metrics=[
96 | CERMetric(vocabulary=configs.vocab),
97 | WERMetric(vocabulary=configs.vocab)
98 | ],
99 | run_eagerly=False
100 | )
101 | model.summary(line_length=110)
102 |
103 | # Define callbacks
104 | earlystopper = EarlyStopping(monitor="val_CER", patience=20, verbose=1, mode="min")
105 | checkpoint = ModelCheckpoint(f"{configs.model_path}/model.h5", monitor="val_CER", verbose=1, save_best_only=True, mode="min")
106 | trainLogger = TrainLogger(configs.model_path)
107 | tb_callback = TensorBoard(f"{configs.model_path}/logs", update_freq=1)
108 | reduceLROnPlat = ReduceLROnPlateau(monitor="val_CER", factor=0.9, min_delta=1e-10, patience=5, verbose=1, mode="auto")
109 | model2onnx = Model2onnx(f"{configs.model_path}/model.h5")
110 |
111 | # Train the model
112 | model.fit(
113 | train_data_provider,
114 | validation_data=val_data_provider,
115 | epochs=configs.train_epochs,
116 | callbacks=[earlystopper, checkpoint, trainLogger, reduceLROnPlat, tb_callback, model2onnx],
117 | workers=configs.train_workers
118 | )
119 |
120 | # Save training and validation datasets as csv files
121 | train_data_provider.to_csv(os.path.join(configs.model_path, "train.csv"))
122 | val_data_provider.to_csv(os.path.join(configs.model_path, "val.csv"))
--------------------------------------------------------------------------------
/Tutorials/05_sound_to_text/README.md:
--------------------------------------------------------------------------------
1 | # Introduction to speech recognition with TensorFlow
2 | ## Master the basics of speech recognition with TensorFlow: Learn how to build and train models, implement real-time audio recognition, and develop practical applications
3 |
4 |
5 | ## **Detailed tutorial**:
6 | ## [Introduction to speech recognition with TensorFlow](https://pylessons.com/speech-recognition)
7 |
8 |
9 |  10 |
10 |
--------------------------------------------------------------------------------
/Tutorials/05_sound_to_text/configs.py:
--------------------------------------------------------------------------------
1 | import os
2 | from datetime import datetime
3 |
4 | from mltu.configs import BaseModelConfigs
5 |
6 |
7 | class ModelConfigs(BaseModelConfigs):
8 | def __init__(self):
9 | super().__init__()
10 | self.model_path = os.path.join("Models/05_sound_to_text", datetime.strftime(datetime.now(), "%Y%m%d%H%M"))
11 | self.frame_length = 256
12 | self.frame_step = 160
13 | self.fft_length = 384
14 |
15 | self.vocab = "abcdefghijklmnopqrstuvwxyz'?! "
16 | self.input_shape = None
17 | self.max_text_length = None
18 | self.max_spectrogram_length = None
19 |
20 | self.batch_size = 8
21 | self.learning_rate = 0.0005
22 | self.train_epochs = 1000
23 | self.train_workers = 20
--------------------------------------------------------------------------------
/Tutorials/05_sound_to_text/inferenceModel.py:
--------------------------------------------------------------------------------
1 | import typing
2 | import numpy as np
3 |
4 | from mltu.inferenceModel import OnnxInferenceModel
5 | from mltu.preprocessors import WavReader
6 | from mltu.utils.text_utils import ctc_decoder, get_cer, get_wer
7 |
8 | class WavToTextModel(OnnxInferenceModel):
9 | def __init__(self, char_list: typing.Union[str, list], *args, **kwargs):
10 | super().__init__(*args, **kwargs)
11 | self.char_list = char_list
12 |
13 | def predict(self, data: np.ndarray):
14 | data_pred = np.expand_dims(data, axis=0)
15 |
16 | preds = self.model.run(self.output_names, {self.input_names[0]: data_pred})[0]
17 |
18 | text = ctc_decoder(preds, self.char_list)[0]
19 |
20 | return text
21 |
22 | if __name__ == "__main__":
23 | import pandas as pd
24 | from tqdm import tqdm
25 | from mltu.configs import BaseModelConfigs
26 |
27 | configs = BaseModelConfigs.load("Models/05_sound_to_text/202302051936/configs.yaml")
28 |
29 | model = WavToTextModel(model_path=configs.model_path, char_list=configs.vocab, force_cpu=False)
30 |
31 | df = pd.read_csv("Models/05_sound_to_text/202302051936/val.csv").values.tolist()
32 |
33 | accum_cer, accum_wer = [], []
34 | for wav_path, label in tqdm(df):
35 | wav_path = wav_path.replace("\\", "/")
36 | spectrogram = WavReader.get_spectrogram(wav_path, frame_length=configs.frame_length, frame_step=configs.frame_step, fft_length=configs.fft_length)
37 | WavReader.plot_raw_audio(wav_path, label)
38 |
39 | padded_spectrogram = np.pad(spectrogram, ((0, configs.max_spectrogram_length - spectrogram.shape[0]),(0,0)), mode="constant", constant_values=0)
40 |
41 | WavReader.plot_spectrogram(spectrogram, label)
42 |
43 | text = model.predict(padded_spectrogram)
44 |
45 | true_label = "".join([l for l in label.lower() if l in configs.vocab])
46 |
47 | cer = get_cer(text, true_label)
48 | wer = get_wer(text, true_label)
49 |
50 | accum_cer.append(cer)
51 | accum_wer.append(wer)
52 |
53 | print(f"Average CER: {np.average(accum_cer)}, Average WER: {np.average(accum_wer)}")
--------------------------------------------------------------------------------
/Tutorials/05_sound_to_text/model.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | from keras import layers
3 | from keras.models import Model
4 |
5 | from mltu.tensorflow.model_utils import residual_block, activation_layer
6 |
7 |
8 | def train_model(input_dim, output_dim, activation="leaky_relu", dropout=0.2):
9 |
10 | inputs = layers.Input(shape=input_dim, name="input", dtype=tf.float32)
11 |
12 | # expand dims to add channel dimension
13 | input = layers.Lambda(lambda x: tf.expand_dims(x, axis=-1))(inputs)
14 |
15 | # Convolution layer 1
16 | x = layers.Conv2D(filters=32, kernel_size=[11, 41], strides=[2, 2], padding="same", use_bias=False)(input)
17 | x = layers.BatchNormalization()(x)
18 | x = activation_layer(x, activation="leaky_relu")
19 |
20 | # Convolution layer 2
21 | x = layers.Conv2D(filters=32, kernel_size=[11, 21], strides=[1, 2], padding="same", use_bias=False)(x)
22 | x = layers.BatchNormalization()(x)
23 | x = activation_layer(x, activation="leaky_relu")
24 |
25 | # Reshape the resulted volume to feed the RNNs layers
26 | x = layers.Reshape((-1, x.shape[-2] * x.shape[-1]))(x)
27 |
28 | # RNN layers
29 | x = layers.Bidirectional(layers.LSTM(128, return_sequences=True))(x)
30 | x = layers.Dropout(dropout)(x)
31 |
32 | x = layers.Bidirectional(layers.LSTM(128, return_sequences=True))(x)
33 | x = layers.Dropout(dropout)(x)
34 |
35 | x = layers.Bidirectional(layers.LSTM(128, return_sequences=True))(x)
36 | x = layers.Dropout(dropout)(x)
37 |
38 | x = layers.Bidirectional(layers.LSTM(128, return_sequences=True))(x)
39 | x = layers.Dropout(dropout)(x)
40 |
41 | x = layers.Bidirectional(layers.LSTM(128, return_sequences=True))(x)
42 |
43 | # Dense layer
44 | x = layers.Dense(256)(x)
45 | x = activation_layer(x, activation="leaky_relu")
46 | x = layers.Dropout(dropout)(x)
47 |
48 | # Classification layer
49 | output = layers.Dense(output_dim + 1, activation="softmax", dtype=tf.float32)(x)
50 |
51 | model = Model(inputs=inputs, outputs=output)
52 | return model
--------------------------------------------------------------------------------
/Tutorials/05_sound_to_text/train.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | try: [tf.config.experimental.set_memory_growth(gpu, True) for gpu in tf.config.experimental.list_physical_devices("GPU")]
3 | except: pass
4 |
5 | import os
6 | import tarfile
7 | import pandas as pd
8 | from tqdm import tqdm
9 | from urllib.request import urlopen
10 | from io import BytesIO
11 |
12 | from keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau, TensorBoard
13 | from mltu.preprocessors import WavReader
14 |
15 | from mltu.tensorflow.dataProvider import DataProvider
16 | from mltu.transformers import LabelIndexer, LabelPadding, SpectrogramPadding
17 | from mltu.tensorflow.losses import CTCloss
18 | from mltu.tensorflow.callbacks import Model2onnx, TrainLogger
19 | from mltu.tensorflow.metrics import CERMetric, WERMetric
20 |
21 | from model import train_model
22 | from configs import ModelConfigs
23 |
24 |
25 | def download_and_unzip(url, extract_to="Datasets", chunk_size=1024*1024):
26 | http_response = urlopen(url)
27 |
28 | data = b""
29 | iterations = http_response.length // chunk_size + 1
30 | for _ in tqdm(range(iterations)):
31 | data += http_response.read(chunk_size)
32 |
33 | tarFile = tarfile.open(fileobj=BytesIO(data), mode="r|bz2")
34 | tarFile.extractall(path=extract_to)
35 | tarFile.close()
36 |
37 |
38 | dataset_path = os.path.join("Datasets", "LJSpeech-1.1")
39 | if not os.path.exists(dataset_path):
40 | download_and_unzip("https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2", extract_to="Datasets")
41 |
42 | dataset_path = "Datasets/LJSpeech-1.1"
43 | metadata_path = dataset_path + "/metadata.csv"
44 | wavs_path = dataset_path + "/wavs/"
45 |
46 | # Read metadata file and parse it
47 | metadata_df = pd.read_csv(metadata_path, sep="|", header=None, quoting=3)
48 | metadata_df.columns = ["file_name", "transcription", "normalized_transcription"]
49 | metadata_df = metadata_df[["file_name", "normalized_transcription"]]
50 |
51 | # structure the dataset where each row is a list of [wav_file_path, sound transcription]
52 | dataset = [[f"Datasets/LJSpeech-1.1/wavs/{file}.wav", label.lower()] for file, label in metadata_df.values.tolist()]
53 |
54 | # Create a ModelConfigs object to store model configurations
55 | configs = ModelConfigs()
56 |
57 | max_text_length, max_spectrogram_length = 0, 0
58 | for file_path, label in tqdm(dataset):
59 | spectrogram = WavReader.get_spectrogram(file_path, frame_length=configs.frame_length, frame_step=configs.frame_step, fft_length=configs.fft_length)
60 | valid_label = [c for c in label if c in configs.vocab]
61 | max_text_length = max(max_text_length, len(valid_label))
62 | max_spectrogram_length = max(max_spectrogram_length, spectrogram.shape[0])
63 | configs.input_shape = [max_spectrogram_length, spectrogram.shape[1]]
64 |
65 | configs.max_spectrogram_length = max_spectrogram_length
66 | configs.max_text_length = max_text_length
67 | configs.save()
68 |
69 | # Create a data provider for the dataset
70 | data_provider = DataProvider(
71 | dataset=dataset,
72 | skip_validation=True,
73 | batch_size=configs.batch_size,
74 | data_preprocessors=[
75 | WavReader(frame_length=configs.frame_length, frame_step=configs.frame_step, fft_length=configs.fft_length),
76 | ],
77 | transformers=[
78 | SpectrogramPadding(max_spectrogram_length=configs.max_spectrogram_length, padding_value=0),
79 | LabelIndexer(configs.vocab),
80 | LabelPadding(max_word_length=configs.max_text_length, padding_value=len(configs.vocab)),
81 | ],
82 | )
83 |
84 | # Split the dataset into training and validation sets
85 | train_data_provider, val_data_provider = data_provider.split(split = 0.9)
86 |
87 | # Creating TensorFlow model architecture
88 | model = train_model(
89 | input_dim = configs.input_shape,
90 | output_dim = len(configs.vocab),
91 | dropout=0.5
92 | )
93 |
94 | # Compile the model and print summary
95 | model.compile(
96 | optimizer=tf.keras.optimizers.Adam(learning_rate=configs.learning_rate),
97 | loss=CTCloss(),
98 | metrics=[
99 | CERMetric(vocabulary=configs.vocab),
100 | WERMetric(vocabulary=configs.vocab)
101 | ],
102 | run_eagerly=False
103 | )
104 | model.summary(line_length=110)
105 |
106 | # Define callbacks
107 | earlystopper = EarlyStopping(monitor="val_CER", patience=20, verbose=1, mode="min")
108 | checkpoint = ModelCheckpoint(f"{configs.model_path}/model.h5", monitor="val_CER", verbose=1, save_best_only=True, mode="min")
109 | trainLogger = TrainLogger(configs.model_path)
110 | tb_callback = TensorBoard(f"{configs.model_path}/logs", update_freq=1)
111 | reduceLROnPlat = ReduceLROnPlateau(monitor="val_CER", factor=0.8, min_delta=1e-10, patience=5, verbose=1, mode="auto")
112 | model2onnx = Model2onnx(f"{configs.model_path}/model.h5")
113 |
114 | # Train the model
115 | model.fit(
116 | train_data_provider,
117 | validation_data=val_data_provider,
118 | epochs=configs.train_epochs,
119 | callbacks=[earlystopper, checkpoint, trainLogger, reduceLROnPlat, tb_callback, model2onnx],
120 | workers=configs.train_workers
121 | )
122 |
123 | # Save training and validation datasets as csv files
124 | train_data_provider.to_csv(os.path.join(configs.model_path, "train.csv"))
125 | val_data_provider.to_csv(os.path.join(configs.model_path, "val.csv"))
126 |
--------------------------------------------------------------------------------
/Tutorials/05_sound_to_text/train_no_limit.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | try: [tf.config.experimental.set_memory_growth(gpu, True) for gpu in tf.config.experimental.list_physical_devices("GPU")]
3 | except: pass
4 | tf.keras.mixed_precision.set_global_policy('mixed_float16') # mixed precission training for faster training time
5 |
6 | import os
7 | import tarfile
8 | import pandas as pd
9 | from tqdm import tqdm
10 | from urllib.request import urlopen
11 | from io import BytesIO
12 |
13 | from keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau, TensorBoard
14 | from mltu.preprocessors import WavReader
15 |
16 | from mltu.tensorflow.dataProvider import DataProvider
17 | from mltu.transformers import LabelIndexer, LabelPadding, SpectrogramPadding
18 | from mltu.tensorflow.losses import CTCloss
19 | from mltu.tensorflow.callbacks import Model2onnx, TrainLogger
20 | from mltu.tensorflow.metrics import CERMetric, WERMetric
21 |
22 | from model import train_model
23 | from configs import ModelConfigs
24 |
25 |
26 | def download_and_unzip(url, extract_to="Datasets", chunk_size=1024*1024):
27 | http_response = urlopen(url)
28 |
29 | data = b""
30 | iterations = http_response.length // chunk_size + 1
31 | for _ in tqdm(range(iterations)):
32 | data += http_response.read(chunk_size)
33 |
34 | tarFile = tarfile.open(fileobj=BytesIO(data), mode="r|bz2")
35 | tarFile.extractall(path=extract_to)
36 | tarFile.close()
37 |
38 |
39 | dataset_path = os.path.join("Datasets", "LJSpeech-1.1")
40 | if not os.path.exists(dataset_path):
41 | download_and_unzip("https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2", extract_to="Datasets")
42 |
43 | dataset_path = "Datasets/LJSpeech-1.1"
44 | metadata_path = dataset_path + "/metadata.csv"
45 | wavs_path = dataset_path + "/wavs/"
46 |
47 | # Read metadata file and parse it
48 | metadata_df = pd.read_csv(metadata_path, sep="|", header=None, quoting=3)
49 | metadata_df.columns = ["file_name", "transcription", "normalized_transcription"]
50 | metadata_df = metadata_df[["file_name", "normalized_transcription"]]
51 |
52 | # structure the dataset where each row is a list of [wav_file_path, sound transcription]
53 | dataset = [[f"Datasets/LJSpeech-1.1/wavs/{file}.wav", label.lower()] for file, label in metadata_df.values.tolist()]
54 |
55 | # Create a ModelConfigs object to store model configurations
56 | configs = ModelConfigs()
57 | configs.save()
58 |
59 | # Create a data provider for the dataset
60 | data_provider = DataProvider(
61 | dataset=dataset,
62 | skip_validation=True,
63 | batch_size=configs.batch_size,
64 | data_preprocessors=[
65 | WavReader(frame_length=configs.frame_length, frame_step=configs.frame_step, fft_length=configs.fft_length),
66 | ],
67 | transformers=[
68 | LabelIndexer(configs.vocab),
69 | ],
70 | batch_postprocessors=[
71 | SpectrogramPadding(padding_value=0, use_on_batch=True),
72 | LabelPadding(padding_value=len(configs.vocab), use_on_batch=True),
73 | ],
74 | )
75 |
76 | # Split the dataset into training and validation sets
77 | train_data_provider, val_data_provider = data_provider.split(split = 0.9)
78 |
79 | # Creating TensorFlow model architecture
80 | model = train_model(
81 | input_dim = (None, 193),
82 | output_dim = len(configs.vocab),
83 | dropout=0.5
84 | )
85 |
86 | # Compile the model and print summary
87 | model.compile(
88 | optimizer=tf.keras.optimizers.Adam(learning_rate=configs.learning_rate),
89 | loss=CTCloss(),
90 | metrics=[
91 | CERMetric(vocabulary=configs.vocab),
92 | WERMetric(vocabulary=configs.vocab)
93 | ],
94 | run_eagerly=False
95 | )
96 | model.summary(line_length=110)
97 |
98 | # Define callbacks
99 | earlystopper = EarlyStopping(monitor="val_CER", patience=20, verbose=1, mode="min")
100 | checkpoint = ModelCheckpoint(f"{configs.model_path}/model.h5", monitor="val_CER", verbose=1, save_best_only=True, mode="min")
101 | trainLogger = TrainLogger(configs.model_path)
102 | tb_callback = TensorBoard(f"{configs.model_path}/logs", update_freq=1)
103 | reduceLROnPlat = ReduceLROnPlateau(monitor="val_CER", factor=0.8, min_delta=1e-10, patience=5, verbose=1, mode="auto")
104 | model2onnx = Model2onnx(f"{configs.model_path}/model.h5")
105 |
106 | # Train the model
107 | model.fit(
108 | train_data_provider,
109 | validation_data=val_data_provider,
110 | epochs=configs.train_epochs,
111 | callbacks=[earlystopper, checkpoint, trainLogger, reduceLROnPlat, tb_callback, model2onnx],
112 | workers=configs.train_workers,
113 | )
114 |
115 | # Save training and validation datasets as csv files
116 | train_data_provider.to_csv(os.path.join(configs.model_path, "train.csv"))
117 | val_data_provider.to_csv(os.path.join(configs.model_path, "val.csv"))
--------------------------------------------------------------------------------
/Tutorials/06_pytorch_introduction/README.md:
--------------------------------------------------------------------------------
1 | # Introduction to PyTorch in a practical way
2 | ## In this tutorial, I'll cover the basics of PyTorch, how to prepare a dataset, construct the network, define training and validation loops, save the model and finally test the saved model
3 |
4 | # **Detailed tutorial**:
5 | ## [Introduction to PyTorch in a practical way](https://pylessons.com/pytorch-introduction)
6 |
7 |
8 |  9 |
9 |
--------------------------------------------------------------------------------
/Tutorials/06_pytorch_introduction/model.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 | import torch.nn.functional as F
3 |
4 | # Define the model architecture
5 | class Net(nn.Module):
6 | def __init__(self):
7 | super(Net, self).__init__()
8 | self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
9 | self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
10 | self.conv2_drop = nn.Dropout2d()
11 | self.fc1 = nn.Linear(320, 50)
12 | self.fc2 = nn.Linear(50, 10)
13 |
14 | def forward(self, x):
15 | x = F.relu(F.max_pool2d(self.conv1(x), 2))
16 | x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
17 | x = x.view(-1, 320)
18 | x = F.relu(self.fc1(x))
19 | x = F.dropout(x, training=self.training)
20 | x = self.fc2(x)
21 | x = F.log_softmax(x, dim=1)
22 | return x
--------------------------------------------------------------------------------
/Tutorials/06_pytorch_introduction/requirements.txt:
--------------------------------------------------------------------------------
1 | numpy
2 | opencv-python
3 | tqdm
4 | torch
5 | torchsummary
--------------------------------------------------------------------------------
/Tutorials/06_pytorch_introduction/test.py:
--------------------------------------------------------------------------------
1 | import os
2 | import cv2
3 | import torch
4 | import numpy as np
5 | import requests, gzip, os, hashlib
6 |
7 | from model import Net
8 |
9 | path = "Datasets/mnist" # Path where to save the downloaded mnist dataset
10 |
11 | def fetch(url):
12 | if os.path.exists(path) is False:
13 | os.makedirs(path)
14 |
15 | fp = os.path.join(path, hashlib.md5(url.encode("utf-8")).hexdigest())
16 | if os.path.isfile(fp):
17 | with open(fp, "rb") as f:
18 | data = f.read()
19 | else:
20 | with open(fp, "wb") as f:
21 | data = requests.get(url).content
22 | f.write(data)
23 | return np.frombuffer(gzip.decompress(data), dtype=np.uint8).copy()
24 |
25 | test_data = fetch("http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz")[0x10:].reshape((-1, 28, 28))
26 | test_targets = fetch("http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz")[8:]
27 |
28 | # output path
29 | model_path = "Model/06_pytorch_introduction"
30 |
31 | # construct network and load weights
32 | network = Net()
33 | network.load_state_dict(torch.load("Models/06_pytorch_introduction/model.pt"))
34 | network.eval() # set to evaluation mode
35 |
36 | # loop over test images
37 | for test_image, test_target in zip(test_data, test_targets):
38 |
39 | # normalize image and convert to tensor
40 | inference_image = torch.from_numpy(test_image).float() / 255.0
41 | inference_image = inference_image.unsqueeze(0).unsqueeze(0)
42 |
43 | # predict
44 | output = network(inference_image)
45 | pred = output.argmax(dim=1, keepdim=True)
46 | prediction = str(pred.item())
47 |
48 | test_image = cv2.resize(test_image, (400, 400))
49 | cv2.imshow(prediction, test_image)
50 | key = cv2.waitKey(0)
51 | if key == ord("q"): # break on q key
52 | break
53 |
54 | cv2.destroyAllWindows()
55 |
--------------------------------------------------------------------------------
/Tutorials/06_pytorch_introduction/train.py:
--------------------------------------------------------------------------------
1 | import os
2 | import cv2
3 | import numpy as np
4 | from tqdm import tqdm
5 | import requests, gzip, os, hashlib
6 |
7 | import torch
8 | import torch.nn as nn
9 | import torch.optim as optim
10 | from torchsummary import summary
11 |
12 | from model import Net
13 |
14 | # define path to store dataset
15 | path = "Datasets/mnist"
16 |
17 | def fetch(url):
18 | if os.path.exists(path) is False:
19 | os.makedirs(path)
20 |
21 | fp = os.path.join(path, hashlib.md5(url.encode("utf-8")).hexdigest())
22 | if os.path.isfile(fp):
23 | with open(fp, "rb") as f:
24 | data = f.read()
25 | else:
26 | with open(fp, "wb") as f:
27 | data = requests.get(url).content
28 | f.write(data)
29 | return np.frombuffer(gzip.decompress(data), dtype=np.uint8).copy()
30 |
31 | # load mnist dataset from yann.lecun.com, train data is of shape (60000, 28, 28) and targets are of shape (60000)
32 | train_data = fetch("http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz")[0x10:].reshape((-1, 28, 28))
33 | train_targets = fetch("http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz")[8:]
34 | test_data = fetch("http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz")[0x10:].reshape((-1, 28, 28))
35 | test_targets = fetch("http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz")[8:]
36 |
37 | # uncomment to show images from dataset using OpenCV
38 | # for train_image, train_target in zip(train_data, train_targets):
39 | # train_image = cv2.resize(train_image, (400, 400))
40 | # cv2.imshow("Image", train_image)
41 | # # if Q button break this loop
42 | # if cv2.waitKey(0) & 0xFF == ord("q"):
43 | # break
44 | # cv2.destroyAllWindows()
45 |
46 | # define training hyperparameters
47 | n_epochs = 5
48 | batch_size_train = 64
49 | batch_size_test = 64
50 | learning_rate = 0.001
51 |
52 | # reshape data to (items, channels, height, width) and normalize to [0, 1]
53 | train_data = np.expand_dims(train_data, axis=1) / 255.0
54 | test_data = np.expand_dims(test_data, axis=1) / 255.0
55 |
56 | # split data into batches of size [(batch_size, 1, 28, 28) ...]
57 | train_batches = [np.array(train_data[i:i+batch_size_train]) for i in range(0, len(train_data), batch_size_train)]
58 | # split targets into batches of size [(batch_size) ...]
59 | train_target_batches = [np.array(train_targets[i:i+batch_size_train]) for i in range(0, len(train_targets), batch_size_train)]
60 |
61 | test_batches = [np.array(test_data[i:i+batch_size_test]) for i in range(0, len(test_data), batch_size_test)]
62 | test_target_batches = [np.array(test_targets[i:i+batch_size_test]) for i in range(0, len(test_targets), batch_size_test)]
63 |
64 | # create network
65 | network = Net()
66 |
67 | # uncomment to print network summary
68 | summary(network, (1, 28, 28), device="cpu")
69 |
70 | # define loss function and optimizer
71 | optimizer = optim.Adam(network.parameters(), lr=learning_rate)
72 | loss_function = nn.CrossEntropyLoss()
73 |
74 | # create training loop
75 | def train(epoch):
76 | # set network to training mode
77 | network.train()
78 |
79 | loss_sum = 0
80 | # create a progress bar
81 | train_pbar = tqdm(zip(train_batches, train_target_batches), total=len(train_batches))
82 | for index, (data, target) in enumerate(train_pbar, start=1):
83 |
84 | # convert data to torch.FloatTensor
85 | data = torch.from_numpy(data).float()
86 | target = torch.from_numpy(target).long()
87 |
88 | # zero the parameter gradients
89 | optimizer.zero_grad()
90 |
91 | # forward + backward + optimize
92 | output = network(data)
93 | loss = loss_function(output, target)
94 | loss.backward()
95 | optimizer.step()
96 |
97 | # update progress bar with loss value
98 | loss_sum += loss.item()
99 | train_pbar.set_description(f"Epoch {epoch}, loss: {loss_sum / index:.4f}")
100 |
101 | # create testing loop
102 | def test(epoch):
103 | # set network to evaluation mode
104 | network.eval()
105 |
106 | correct, loss_sum = 0, 0
107 | # create progress bar
108 | val_pbar = tqdm(zip(test_batches, test_target_batches), total=len(test_batches))
109 | with torch.no_grad():
110 | for index, (data, target) in enumerate(val_pbar, start=1):
111 |
112 | # convert data to torch.FloatTensor
113 | data = torch.from_numpy(data).float()
114 | target = torch.from_numpy(target).long()
115 |
116 | # forward pass
117 | output = network(data)
118 |
119 | # update progress bar with loss and accuracy values
120 | loss_sum += loss_function(output, target).item() / target.size(0)
121 | pred = output.data.max(1, keepdim=True)[1]
122 | correct += pred.eq(target.data.view_as(pred)).sum() / target.size(0)
123 |
124 | val_pbar.set_description(f"val_loss: {loss_sum / index:.4f}, val_accuracy: {correct / index:.4f}")
125 |
126 |
127 | # train and test the model
128 | for epoch in range(1, n_epochs + 1):
129 | train(epoch)
130 | test(epoch)
131 |
132 | # define output path and create folder if not exists
133 | output_path = "Models/06_pytorch_introduction"
134 | if not os.path.exists(output_path):
135 | os.makedirs(output_path)
136 |
137 | # save model.pt to defined output path
138 | torch.save(network.state_dict(), os.path.join(output_path, "model.pt"))
--------------------------------------------------------------------------------
/Tutorials/07_pytorch_wrapper/README.md:
--------------------------------------------------------------------------------
1 | # Using custom wrapper to simplify PyTorch models training pipeline
2 | ## I will introduce the PyTorch Wrapper in this tutorial, saving us time when developing the PyTorch models training pipeline. We'll be able to do this in blocks!
3 |
4 | # **Detailed tutorial**:
5 | ## [PyTorch Wrapper to Build and Train Networks](https://pylessons.com/pytorch-introduction)
6 |
7 |
8 | 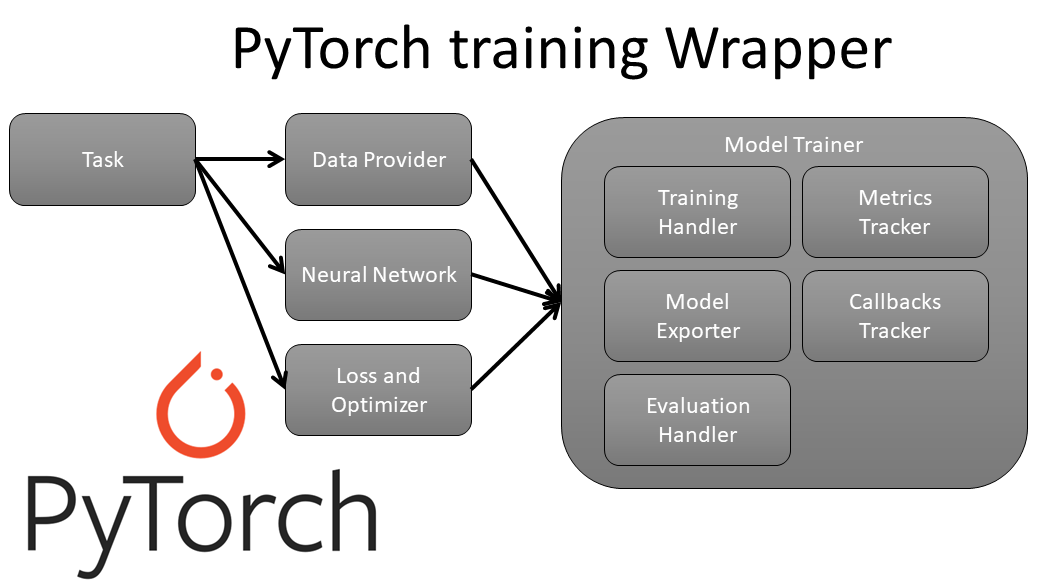 9 |
9 |
--------------------------------------------------------------------------------
/Tutorials/07_pytorch_wrapper/model.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 | import torch.nn.functional as F
3 |
4 | # Define the model architecture
5 | class Net(nn.Module):
6 | def __init__(self):
7 | super(Net, self).__init__()
8 | self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
9 | self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
10 | self.conv2_drop = nn.Dropout2d()
11 | self.fc1 = nn.Linear(320, 50)
12 | self.fc2 = nn.Linear(50, 10)
13 |
14 | def forward(self, x):
15 | x = F.relu(F.max_pool2d(self.conv1(x), 2))
16 | x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
17 | x = x.view(-1, 320)
18 | x = F.relu(self.fc1(x))
19 | x = F.dropout(x, training=self.training)
20 | x = self.fc2(x)
21 | x = F.log_softmax(x, dim=1)
22 | return x
--------------------------------------------------------------------------------
/Tutorials/07_pytorch_wrapper/requirements.txt:
--------------------------------------------------------------------------------
1 | torch
2 | torchsummary
3 | mltu==1.0.1
--------------------------------------------------------------------------------
/Tutorials/07_pytorch_wrapper/test.py:
--------------------------------------------------------------------------------
1 | import os
2 | import cv2
3 | import torch
4 | import numpy as np
5 | import requests, gzip, os, hashlib
6 |
7 | from model import Net
8 |
9 | path = "Datasets/mnist" # Path where to save the downloaded mnist dataset
10 |
11 | def fetch(url):
12 | if os.path.exists(path) is False:
13 | os.makedirs(path)
14 |
15 | fp = os.path.join(path, hashlib.md5(url.encode("utf-8")).hexdigest())
16 | if os.path.isfile(fp):
17 | with open(fp, "rb") as f:
18 | data = f.read()
19 | else:
20 | with open(fp, "wb") as f:
21 | data = requests.get(url).content
22 | f.write(data)
23 | return np.frombuffer(gzip.decompress(data), dtype=np.uint8).copy()
24 |
25 | test_data = fetch("http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz")[0x10:].reshape((-1, 28, 28))
26 | test_targets = fetch("http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz")[8:]
27 |
28 | # output path
29 | model_path = "Model/07_pytorch_wrapper"
30 |
31 | # construct network and load weights
32 | network = Net()
33 | network.load_state_dict(torch.load("Models/07_pytorch_wrapper/model.pt"))
34 | network.eval() # set to evaluation mode
35 |
36 | # loop over test images
37 | for test_image, test_target in zip(test_data, test_targets):
38 |
39 | # normalize image and convert to tensor
40 | inference_image = torch.from_numpy(test_image).float() / 255.0
41 | inference_image = inference_image.unsqueeze(0).unsqueeze(0)
42 |
43 | # predict
44 | output = network(inference_image)
45 | pred = output.argmax(dim=1, keepdim=True)
46 | prediction = str(pred.item())
47 |
48 | test_image = cv2.resize(test_image, (400, 400))
49 | cv2.imshow(prediction, test_image)
50 | key = cv2.waitKey(0)
51 | if key == ord("q"): # break on q key
52 | break
53 |
54 | cv2.destroyAllWindows()
--------------------------------------------------------------------------------
/Tutorials/07_pytorch_wrapper/train.py:
--------------------------------------------------------------------------------
1 | import os
2 | import numpy as np
3 | import requests, gzip, os, hashlib
4 |
5 | import torch
6 | import torch.optim as optim
7 |
8 | from model import Net
9 |
10 | from mltu.torch.dataProvider import DataProvider
11 | from mltu.torch.model import Model
12 | from mltu.torch.metrics import Accuracy
13 | from mltu.torch.callbacks import EarlyStopping, ModelCheckpoint
14 |
15 | # define path to store dataset
16 | path = "Datasets/data"
17 |
18 | def fetch(url):
19 | if os.path.exists(path) is False:
20 | os.makedirs(path)
21 |
22 | fp = os.path.join(path, hashlib.md5(url.encode("utf-8")).hexdigest())
23 | if os.path.isfile(fp):
24 | with open(fp, "rb") as f:
25 | data = f.read()
26 | else:
27 | with open(fp, "wb") as f:
28 | data = requests.get(url).content
29 | f.write(data)
30 | return np.frombuffer(gzip.decompress(data), dtype=np.uint8).copy()
31 |
32 | # load mnist dataset from yann.lecun.com, train data is of shape (60000, 28, 28) and targets are of shape (60000)
33 | train_data = fetch("http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz")[0x10:].reshape((-1, 28, 28))
34 | train_targets = fetch("http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz")[8:]
35 | test_data = fetch("http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz")[0x10:].reshape((-1, 28, 28))
36 | test_targets = fetch("http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz")[8:]
37 |
38 | train_dataset = [[data, target] for data, target in zip(train_data, train_targets)]
39 | test_dataset = [[data, target] for data, target in zip(test_data, test_targets)]
40 |
41 | def preprocessor(data, target):
42 | # original data is shape of (28, 28), expand to (1, 28, 28) and normalize to [0, 1]
43 | data = np.expand_dims(data, axis=0) / 255.0
44 | return data, target
45 |
46 | train_dataProvider = DataProvider(
47 | train_dataset,
48 | data_preprocessors=[preprocessor],
49 | batch_size=64,
50 | )
51 |
52 | test_dataProvider = DataProvider(
53 | test_dataset,
54 | data_preprocessors=[preprocessor],
55 | batch_size=64
56 | )
57 |
58 | # create network, optimizer and define loss function
59 | network = Net()
60 | optimizer = optim.Adam(network.parameters(), lr=0.001)
61 | loss = torch.nn.CrossEntropyLoss()
62 |
63 | # put on cuda device if available
64 | if torch.cuda.is_available():
65 | network = network.cuda()
66 |
67 | # create callbacks
68 | earlyStopping = EarlyStopping(
69 | monitor="val_accuracy",
70 | patience=3,
71 | mode="max",
72 | verbose=1
73 | )
74 | modelCheckpoint = ModelCheckpoint(
75 | "Models/07_pytorch_wrapper/model.pt",
76 | monitor="val_accuracy",
77 | mode="max",
78 | save_best_only=True,
79 | verbose=1
80 | )
81 |
82 | # create model object that will handle training and testing of the network
83 | model = Model(network, optimizer, loss, metrics=[Accuracy()])
84 | model.fit(
85 | train_dataProvider,
86 | test_dataProvider,
87 | epochs=100,
88 | callbacks=[earlyStopping, modelCheckpoint]
89 | )
--------------------------------------------------------------------------------
/Tutorials/08_handwriting_recognition_torch/README.md:
--------------------------------------------------------------------------------
1 | # Using custom wrapper to simplify PyTorch models training pipeline
2 | ### Construct an accurate handwriting recognition model with PyTorch! Understand how to use MLTU package, to simplify the PyTorch models training pipeline, and discover methods to enhance your model's accuracy!
3 |
4 | # **Detailed tutorial**:
5 | ### [Handwriting words recognition with PyTorch](https://pylessons.com/handwriting-recognition-pytorch)
6 |
7 |
8 |  9 |
9 |
--------------------------------------------------------------------------------
/Tutorials/08_handwriting_recognition_torch/configs.py:
--------------------------------------------------------------------------------
1 | import os
2 | from datetime import datetime
3 |
4 | from mltu.configs import BaseModelConfigs
5 |
6 |
7 | class ModelConfigs(BaseModelConfigs):
8 | def __init__(self):
9 | super().__init__()
10 | self.model_path = os.path.join("Models/08_handwriting_recognition_torch", datetime.strftime(datetime.now(), "%Y%m%d%H%M"))
11 | self.vocab = ""
12 | self.height = 32
13 | self.width = 128
14 | self.max_text_length = 0
15 | self.batch_size = 64
16 | self.learning_rate = 0.002
17 | self.train_epochs = 1000
18 |
--------------------------------------------------------------------------------
/Tutorials/08_handwriting_recognition_torch/inferenceModel.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import typing
3 | import numpy as np
4 |
5 | from mltu.inferenceModel import OnnxInferenceModel
6 | from mltu.utils.text_utils import ctc_decoder, get_cer
7 |
8 | class ImageToWordModel(OnnxInferenceModel):
9 | def __init__(self, *args, **kwargs):
10 | super().__init__(*args, **kwargs)
11 |
12 | def predict(self, image: np.ndarray):
13 | image = cv2.resize(image, self.input_shapes[0][1:3][::-1])
14 |
15 | image_pred = np.expand_dims(image, axis=0).astype(np.float32)
16 |
17 | preds = self.model.run(self.output_names, {self.input_names[0]: image_pred})[0]
18 |
19 | text = ctc_decoder(preds, self.metadata["vocab"])[0]
20 |
21 | return text
22 |
23 | if __name__ == "__main__":
24 | import pandas as pd
25 | from tqdm import tqdm
26 |
27 | model = ImageToWordModel(model_path="Models/08_handwriting_recognition_torch/202303142139/model.onnx")
28 |
29 | df = pd.read_csv("Models/08_handwriting_recognition_torch/202303142139/val.csv").values.tolist()
30 |
31 | accum_cer = []
32 | for image_path, label in tqdm(df):
33 | image = cv2.imread(image_path.replace("\\", "/"))
34 |
35 | prediction_text = model.predict(image)
36 |
37 | cer = get_cer(prediction_text, label)
38 | print(f"Image: {image_path}, Label: {label}, Prediction: {prediction_text}, CER: {cer}")
39 |
40 | accum_cer.append(cer)
41 |
42 | print(f"Average CER: {np.average(accum_cer)}")
--------------------------------------------------------------------------------
/Tutorials/08_handwriting_recognition_torch/model.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 |
5 |
6 | def activation_layer(activation: str="relu", alpha: float=0.1, inplace: bool=True):
7 | """ Activation layer wrapper for LeakyReLU and ReLU activation functions
8 |
9 | Args:
10 | activation: str, activation function name (default: 'relu')
11 | alpha: float (LeakyReLU activation function parameter)
12 |
13 | Returns:
14 | torch.Tensor: activation layer
15 | """
16 | if activation == "relu":
17 | return nn.ReLU(inplace=inplace)
18 |
19 | elif activation == "leaky_relu":
20 | return nn.LeakyReLU(negative_slope=alpha, inplace=inplace)
21 |
22 |
23 | class ConvBlock(nn.Module):
24 | """ Convolutional block with batch normalization
25 | """
26 | def __init__(self, in_channels: int, out_channels: int, kernel_size: int, stride: int, padding: int):
27 | super(ConvBlock, self).__init__()
28 | self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding)
29 | self.bn = nn.BatchNorm2d(out_channels)
30 |
31 | def forward(self, x: torch.Tensor):
32 | return self.bn(self.conv(x))
33 |
34 |
35 | class ResidualBlock(nn.Module):
36 | def __init__(self, in_channels, out_channels, skip_conv=True, stride=1, dropout=0.2, activation="leaky_relu"):
37 | super(ResidualBlock, self).__init__()
38 | self.convb1 = ConvBlock(in_channels, out_channels, kernel_size=3, stride=stride, padding=1)
39 | self.act1 = activation_layer(activation)
40 |
41 | self.convb2 = ConvBlock(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
42 |
43 | self.dropout = nn.Dropout(p=dropout)
44 |
45 | self.shortcut = None
46 | if skip_conv:
47 | if stride != 1 or in_channels != out_channels:
48 | self.shortcut = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride)
49 |
50 | self.act2 = activation_layer(activation)
51 |
52 | def forward(self, x):
53 | skip = x
54 |
55 | out = self.act1(self.convb1(x))
56 | out = self.convb2(out)
57 |
58 | if self.shortcut is not None:
59 | out += self.shortcut(skip)
60 |
61 | out = self.act2(out)
62 | out = self.dropout(out)
63 |
64 | return out
65 |
66 | class Network(nn.Module):
67 | """ Handwriting recognition network for CTC loss"""
68 | def __init__(self, num_chars: int, activation: str="leaky_relu", dropout: float=0.2):
69 | super(Network, self).__init__()
70 |
71 | self.rb1 = ResidualBlock(3, 16, skip_conv = True, stride=1, activation=activation, dropout=dropout)
72 | self.rb2 = ResidualBlock(16, 16, skip_conv = True, stride=2, activation=activation, dropout=dropout)
73 | self.rb3 = ResidualBlock(16, 16, skip_conv = False, stride=1, activation=activation, dropout=dropout)
74 |
75 | self.rb4 = ResidualBlock(16, 32, skip_conv = True, stride=2, activation=activation, dropout=dropout)
76 | self.rb5 = ResidualBlock(32, 32, skip_conv = False, stride=1, activation=activation, dropout=dropout)
77 |
78 | self.rb6 = ResidualBlock(32, 64, skip_conv = True, stride=2, activation=activation, dropout=dropout)
79 | self.rb7 = ResidualBlock(64, 64, skip_conv = True, stride=1, activation=activation, dropout=dropout)
80 |
81 | self.rb8 = ResidualBlock(64, 64, skip_conv = False, stride=1, activation=activation, dropout=dropout)
82 | self.rb9 = ResidualBlock(64, 64, skip_conv = False, stride=1, activation=activation, dropout=dropout)
83 |
84 | self.lstm = nn.LSTM(64, 128, bidirectional=True, num_layers=1, batch_first=True)
85 | self.lstm_dropout = nn.Dropout(p=dropout)
86 |
87 | self.output = nn.Linear(256, num_chars + 1)
88 |
89 | def forward(self, images: torch.Tensor) -> torch.Tensor:
90 | # normalize images between 0 and 1
91 | images_flaot = images / 255.0
92 |
93 | # transpose image to channel first
94 | images_flaot = images_flaot.permute(0, 3, 1, 2)
95 |
96 | # apply convolutions
97 | x = self.rb1(images_flaot)
98 | x = self.rb2(x)
99 | x = self.rb3(x)
100 | x = self.rb4(x)
101 | x = self.rb5(x)
102 | x = self.rb6(x)
103 | x = self.rb7(x)
104 | x = self.rb8(x)
105 | x = self.rb9(x)
106 |
107 | x = x.reshape(x.size(0), -1, x.size(1))
108 |
109 | x, _ = self.lstm(x)
110 | x = self.lstm_dropout(x)
111 |
112 | x = self.output(x)
113 | x = F.log_softmax(x, 2)
114 |
115 | return x
--------------------------------------------------------------------------------
/Tutorials/08_handwriting_recognition_torch/requirements.txt:
--------------------------------------------------------------------------------
1 | torch==1.13.1
2 | tensorboard==2.10.1
3 | onnx==1.12.0
4 | torchsummaryX
--------------------------------------------------------------------------------
/Tutorials/08_handwriting_recognition_torch/train_torch.py:
--------------------------------------------------------------------------------
1 | import os
2 | import tarfile
3 | from tqdm import tqdm
4 | from io import BytesIO
5 | from zipfile import ZipFile
6 | from urllib.request import urlopen
7 |
8 | import torch
9 | import torch.optim as optim
10 | from torchsummaryX import summary
11 |
12 | from mltu.torch.model import Model
13 | from mltu.torch.losses import CTCLoss
14 | from mltu.torch.dataProvider import DataProvider
15 | from mltu.torch.metrics import CERMetric, WERMetric
16 | from mltu.torch.callbacks import EarlyStopping, ModelCheckpoint, TensorBoard, Model2onnx, ReduceLROnPlateau
17 |
18 | from mltu.preprocessors import ImageReader
19 | from mltu.transformers import ImageResizer, LabelIndexer, LabelPadding, ImageShowCV2
20 | from mltu.augmentors import RandomBrightness, RandomRotate, RandomErodeDilate, RandomSharpen
21 | from mltu.annotations.images import CVImage
22 |
23 | from model import Network
24 | from configs import ModelConfigs
25 |
26 |
27 | def download_and_unzip(url, extract_to="Datasets", chunk_size=1024*1024):
28 | http_response = urlopen(url)
29 |
30 | data = b""
31 | iterations = http_response.length // chunk_size + 1
32 | for _ in tqdm(range(iterations)):
33 | data += http_response.read(chunk_size)
34 |
35 | zipfile = ZipFile(BytesIO(data))
36 | zipfile.extractall(path=extract_to)
37 |
38 | dataset_path = os.path.join("Datasets", "IAM_Words")
39 | if not os.path.exists(dataset_path):
40 | download_and_unzip("https://git.io/J0fjL", extract_to="Datasets")
41 |
42 | file = tarfile.open(os.path.join(dataset_path, "words.tgz"))
43 | file.extractall(os.path.join(dataset_path, "words"))
44 |
45 | dataset, vocab, max_len = [], set(), 0
46 |
47 | # Preprocess the dataset by the specific IAM_Words dataset file structure
48 | words = open(os.path.join(dataset_path, "words.txt"), "r").readlines()
49 | for line in tqdm(words):
50 | if line.startswith("#"):
51 | continue
52 |
53 | line_split = line.split(" ")
54 | if line_split[1] == "err":
55 | continue
56 |
57 | folder1 = line_split[0][:3]
58 | folder2 = "-".join(line_split[0].split("-")[:2])
59 | file_name = line_split[0] + ".png"
60 | label = line_split[-1].rstrip("\n")
61 |
62 | rel_path = os.path.join(dataset_path, "words", folder1, folder2, file_name)
63 | if not os.path.exists(rel_path):
64 | print(f"File not found: {rel_path}")
65 | continue
66 |
67 | dataset.append([rel_path, label])
68 | vocab.update(list(label))
69 | max_len = max(max_len, len(label))
70 |
71 | configs = ModelConfigs()
72 |
73 | # Save vocab and maximum text length to configs
74 | configs.vocab = "".join(sorted(vocab))
75 | configs.max_text_length = max_len
76 | configs.save()
77 |
78 | # Create a data provider for the dataset
79 | data_provider = DataProvider(
80 | dataset=dataset,
81 | skip_validation=True,
82 | batch_size=configs.batch_size,
83 | data_preprocessors=[ImageReader(CVImage)],
84 | transformers=[
85 | # ImageShowCV2(), # uncomment to show images when iterating over the data provider
86 | ImageResizer(configs.width, configs.height, keep_aspect_ratio=False),
87 | LabelIndexer(configs.vocab),
88 | LabelPadding(max_word_length=configs.max_text_length, padding_value=len(configs.vocab))
89 | ],
90 | use_cache=True,
91 | )
92 |
93 | # Split the dataset into training and validation sets
94 | train_dataProvider, test_dataProvider = data_provider.split(split = 0.9)
95 |
96 | # Augment training data with random brightness, rotation and erode/dilate
97 | train_dataProvider.augmentors = [
98 | RandomBrightness(),
99 | RandomErodeDilate(),
100 | RandomSharpen(),
101 | RandomRotate(angle=10),
102 | ]
103 |
104 | network = Network(len(configs.vocab), activation="leaky_relu", dropout=0.3)
105 | loss = CTCLoss(blank=len(configs.vocab))
106 | optimizer = optim.Adam(network.parameters(), lr=configs.learning_rate)
107 |
108 | # uncomment to print network summary, torchsummaryX package is required
109 | summary(network, torch.zeros((1, configs.height, configs.width, 3)))
110 |
111 | # put on cuda device if available
112 | if torch.cuda.is_available():
113 | network = network.cuda()
114 |
115 | # create callbacks
116 | earlyStopping = EarlyStopping(monitor="val_CER", patience=20, mode="min", verbose=1)
117 | modelCheckpoint = ModelCheckpoint(configs.model_path + "/model.pt", monitor="val_CER", mode="min", save_best_only=True, verbose=1)
118 | tb_callback = TensorBoard(configs.model_path + "/logs")
119 | reduce_lr = ReduceLROnPlateau(monitor="val_CER", factor=0.9, patience=10, verbose=1, mode="min", min_lr=1e-6)
120 | model2onnx = Model2onnx(
121 | saved_model_path=configs.model_path + "/model.pt",
122 | input_shape=(1, configs.height, configs.width, 3),
123 | verbose=1,
124 | metadata={"vocab": configs.vocab}
125 | )
126 |
127 | # create model object that will handle training and testing of the network
128 | model = Model(network, optimizer, loss, metrics=[CERMetric(configs.vocab), WERMetric(configs.vocab)])
129 | model.fit(
130 | train_dataProvider,
131 | test_dataProvider,
132 | epochs=1000,
133 | callbacks=[earlyStopping, modelCheckpoint, tb_callback, reduce_lr, model2onnx]
134 | )
135 |
136 | # Save training and validation datasets as csv files
137 | train_dataProvider.to_csv(os.path.join(configs.model_path, "train.csv"))
138 | test_dataProvider.to_csv(os.path.join(configs.model_path, "val.csv"))
139 |
--------------------------------------------------------------------------------
/Tutorials/09_translation_transformer/README.md:
--------------------------------------------------------------------------------
1 | # Training TensorFlow Transformer model for Spanish to English translation task
2 | ### In this tutorial, I'll walk through a practical example of Transformer Training for Language Translation tasks from Spanish to the English language
3 |
4 |
5 | # **Detailed tutorial**:
6 | ### [Transformer training with TensorFlow for Translation task](https://pylessons.com/transformers-training)
7 |
8 |
9 |  10 |
10 |
--------------------------------------------------------------------------------
/Tutorials/09_translation_transformer/configs.py:
--------------------------------------------------------------------------------
1 | import os
2 | from datetime import datetime
3 |
4 | from mltu.configs import BaseModelConfigs
5 |
6 |
7 | class ModelConfigs(BaseModelConfigs):
8 | def __init__(self):
9 | super().__init__()
10 | self.model_path = os.path.join(
11 | "Models/09_translation_transformer",
12 | datetime.strftime(datetime.now(), "%Y%m%d%H%M"),
13 | )
14 | self.num_layers = 4
15 | self.d_model = 128
16 | self.num_heads = 8
17 | self.dff = 512
18 | self.dropout_rate = 0.1
19 | self.batch_size = 16
20 | self.train_epochs = 50
21 | # CustomSchedule parameters
22 | self.init_lr = 0.00001
23 | self.lr_after_warmup = 0.0005
24 | self.final_lr = 0.0001
25 | self.warmup_epochs = 2
26 | self.decay_epochs = 18
--------------------------------------------------------------------------------
/Tutorials/09_translation_transformer/download.py:
--------------------------------------------------------------------------------
1 |
2 | import os
3 | import requests
4 | from tqdm import tqdm
5 | from bs4 import BeautifulSoup
6 |
7 | # URL to the directory containing the files to be downloaded
8 | language = "en-es"
9 | url = f"https://data.statmt.org/opus-100-corpus/v1.0/supervised/{language}/"
10 | save_directory = f"./Datasets/{language}"
11 |
12 | # Create the save directory if it doesn't exist
13 | os.makedirs(save_directory, exist_ok=True)
14 |
15 | # Send a GET request to the URL
16 | response = requests.get(url)
17 |
18 | # Parse the HTML response
19 | soup = BeautifulSoup(response.content, 'html.parser')
20 |
21 | # Find all the anchor tags in the HTML
22 | links = soup.find_all('a')
23 |
24 | # Extract the href attribute from each anchor tag
25 | file_links = [link['href'] for link in links if '.' in link['href']]
26 |
27 | # Download each file
28 | for file_link in tqdm(file_links):
29 | file_url = url + file_link
30 | save_path = os.path.join(save_directory, file_link)
31 |
32 | print(f"Downloading {file_url}")
33 |
34 | # Send a GET request for the file
35 | file_response = requests.get(file_url)
36 | if file_response.status_code == 404:
37 | print(f"Could not download {file_url}")
38 | continue
39 |
40 | # Save the file to the specified directory
41 | with open(save_path, 'wb') as file:
42 | file.write(file_response.content)
43 |
44 | print(f"Saved {file_link}")
45 |
46 | print("All files have been downloaded.")
--------------------------------------------------------------------------------
/Tutorials/09_translation_transformer/model.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 |
3 | from mltu.tensorflow.transformer.layers import Encoder, Decoder
4 |
5 | def Transformer(
6 | input_vocab_size: int,
7 | target_vocab_size: int,
8 | encoder_input_size: int = None,
9 | decoder_input_size: int = None,
10 | num_layers: int=6,
11 | d_model: int=512,
12 | num_heads: int=8,
13 | dff: int=2048,
14 | dropout_rate: float=0.1,
15 | ) -> tf.keras.Model:
16 | """
17 | A custom TensorFlow model that implements the Transformer architecture.
18 |
19 | Args:
20 | input_vocab_size (int): The size of the input vocabulary.
21 | target_vocab_size (int): The size of the target vocabulary.
22 | encoder_input_size (int): The size of the encoder input sequence.
23 | decoder_input_size (int): The size of the decoder input sequence.
24 | num_layers (int): The number of layers in the encoder and decoder.
25 | d_model (int): The dimensionality of the model.
26 | num_heads (int): The number of heads in the multi-head attention layer.
27 | dff (int): The dimensionality of the feed-forward layer.
28 | dropout_rate (float): The dropout rate.
29 |
30 | Returns:
31 | A TensorFlow Keras model.
32 | """
33 | inputs = [
34 | tf.keras.layers.Input(shape=(encoder_input_size,), dtype=tf.int64),
35 | tf.keras.layers.Input(shape=(decoder_input_size,), dtype=tf.int64)
36 | ]
37 |
38 | encoder_input, decoder_input = inputs
39 |
40 | encoder = Encoder(num_layers=num_layers, d_model=d_model, num_heads=num_heads, dff=dff, vocab_size=input_vocab_size, dropout_rate=dropout_rate)(encoder_input)
41 | decoder = Decoder(num_layers=num_layers, d_model=d_model, num_heads=num_heads, dff=dff, vocab_size=target_vocab_size, dropout_rate=dropout_rate)(decoder_input, encoder)
42 |
43 | output = tf.keras.layers.Dense(target_vocab_size)(decoder)
44 |
45 | return tf.keras.Model(inputs=inputs, outputs=output)
--------------------------------------------------------------------------------
/Tutorials/09_translation_transformer/requirements.txt:
--------------------------------------------------------------------------------
1 | beautifulsoup4
2 | tf2onnx==1.14.0
3 | onnx==1.12.0
--------------------------------------------------------------------------------
/Tutorials/09_translation_transformer/test.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import time
3 |
4 | from mltu.tokenizers import CustomTokenizer
5 | from mltu.inferenceModel import OnnxInferenceModel
6 |
7 | class PtEnTranslator(OnnxInferenceModel):
8 | def __init__(self, *args, **kwargs):
9 | super().__init__(*args, **kwargs)
10 |
11 | self.new_inputs = self.model.get_inputs()
12 | self.tokenizer = CustomTokenizer.load(self.metadata["tokenizer"])
13 | self.detokenizer = CustomTokenizer.load(self.metadata["detokenizer"])
14 |
15 | def predict(self, sentence):
16 | start = time.time()
17 | tokenized_sentence = self.tokenizer.texts_to_sequences([sentence])[0]
18 | encoder_input = np.pad(tokenized_sentence, (0, self.tokenizer.max_length - len(tokenized_sentence)), constant_values=0).astype(np.int64)
19 |
20 | tokenized_results = [self.detokenizer.start_token_index]
21 | for index in range(self.detokenizer.max_length - 1):
22 | decoder_input = np.pad(tokenized_results, (0, self.detokenizer.max_length - len(tokenized_results)), constant_values=0).astype(np.int64)
23 | input_dict = {
24 | self.model._inputs_meta[0].name: np.expand_dims(encoder_input, axis=0),
25 | self.model._inputs_meta[1].name: np.expand_dims(decoder_input, axis=0),
26 | }
27 | preds = self.model.run(None, input_dict)[0] # preds shape (1, 206, 29110)
28 | pred_results = np.argmax(preds, axis=2)
29 | tokenized_results.append(pred_results[0][index])
30 |
31 | if tokenized_results[-1] == self.detokenizer.end_token_index:
32 | break
33 |
34 | results = self.detokenizer.detokenize([tokenized_results])
35 | return results[0], time.time() - start
36 |
37 | def read_files(path):
38 | with open(path, "r", encoding="utf-8") as f:
39 | en_train_dataset = f.read().split("\n")[:-1]
40 | return en_train_dataset
41 |
42 | # Path to dataset
43 | en_validation_data_path = "Datasets/en-es/opus.en-es-dev.en"
44 | es_validation_data_path = "Datasets/en-es/opus.en-es-dev.es"
45 |
46 | en_validation_data = read_files(en_validation_data_path)
47 | es_validation_data = read_files(es_validation_data_path)
48 |
49 | # Consider only sentences with length <= 500
50 | max_lenght = 500
51 | val_examples = [[es_sentence, en_sentence] for es_sentence, en_sentence in zip(es_validation_data, en_validation_data) if len(es_sentence) <= max_lenght and len(en_sentence) <= max_lenght]
52 |
53 | translator = PtEnTranslator("Models/09_translation_transformer/202308241514/model.onnx")
54 |
55 | val_dataset = []
56 | for es, en in val_examples:
57 | results, duration = translator.predict(es)
58 | print("Spanish: ", es.lower())
59 | print("English: ", en.lower())
60 | print("English pred:", results)
61 | print(duration)
62 | print()
--------------------------------------------------------------------------------
/Tutorials/09_translation_transformer/train.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | import tensorflow as tf
4 | try: [tf.config.experimental.set_memory_growth(gpu, True) for gpu in tf.config.experimental.list_physical_devices("GPU")]
5 | except: pass
6 |
7 | from keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau, TensorBoard
8 | from mltu.tensorflow.callbacks import Model2onnx, WarmupCosineDecay
9 |
10 | from mltu.tensorflow.dataProvider import DataProvider
11 | from mltu.tokenizers import CustomTokenizer
12 |
13 | from mltu.tensorflow.transformer.utils import MaskedAccuracy, MaskedLoss
14 | from mltu.tensorflow.transformer.callbacks import EncDecSplitCallback
15 |
16 | from model import Transformer
17 | from configs import ModelConfigs
18 |
19 | configs = ModelConfigs()
20 |
21 | # Path to dataset
22 | en_training_data_path = "Datasets/en-es/opus.en-es-train.en"
23 | en_validation_data_path = "Datasets/en-es/opus.en-es-dev.en"
24 | es_training_data_path = "Datasets/en-es/opus.en-es-train.es"
25 | es_validation_data_path = "Datasets/en-es/opus.en-es-dev.es"
26 |
27 | def read_files(path):
28 | with open(path, "r", encoding="utf-8") as f:
29 | en_train_dataset = f.read().split("\n")[:-1]
30 | return en_train_dataset
31 |
32 | en_training_data = read_files(en_training_data_path)
33 | en_validation_data = read_files(en_validation_data_path)
34 | es_training_data = read_files(es_training_data_path)
35 | es_validation_data = read_files(es_validation_data_path)
36 |
37 | # Consider only sentences with length <= 500
38 | max_lenght = 500
39 | train_dataset = [[es_sentence, en_sentence] for es_sentence, en_sentence in zip(es_training_data, en_training_data) if len(es_sentence) <= max_lenght and len(en_sentence) <= max_lenght]
40 | val_dataset = [[es_sentence, en_sentence] for es_sentence, en_sentence in zip(es_validation_data, en_validation_data) if len(es_sentence) <= max_lenght and len(en_sentence) <= max_lenght]
41 | es_training_data, en_training_data = zip(*train_dataset)
42 | es_validation_data, en_validation_data = zip(*val_dataset)
43 |
44 | # prepare spanish tokenizer, this is the input language
45 | tokenizer = CustomTokenizer(char_level=True)
46 | tokenizer.fit_on_texts(es_training_data)
47 | tokenizer.save(configs.model_path + "/tokenizer.json")
48 |
49 | # prepare english tokenizer, this is the output language
50 | detokenizer = CustomTokenizer(char_level=True)
51 | detokenizer.fit_on_texts(en_training_data)
52 | detokenizer.save(configs.model_path + "/detokenizer.json")
53 |
54 |
55 | def preprocess_inputs(data_batch, label_batch):
56 | encoder_input = np.zeros((len(data_batch), tokenizer.max_length)).astype(np.int64)
57 | decoder_input = np.zeros((len(label_batch), detokenizer.max_length)).astype(np.int64)
58 | decoder_output = np.zeros((len(label_batch), detokenizer.max_length)).astype(np.int64)
59 |
60 | data_batch_tokens = tokenizer.texts_to_sequences(data_batch)
61 | label_batch_tokens = detokenizer.texts_to_sequences(label_batch)
62 |
63 | for index, (data, label) in enumerate(zip(data_batch_tokens, label_batch_tokens)):
64 | encoder_input[index][:len(data)] = data
65 | decoder_input[index][:len(label)-1] = label[:-1] # Drop the [END] tokens
66 | decoder_output[index][:len(label)-1] = label[1:] # Drop the [START] tokens
67 |
68 | return (encoder_input, decoder_input), decoder_output
69 |
70 | # Create Training Data Provider
71 | train_dataProvider = DataProvider(
72 | train_dataset,
73 | batch_size=configs.batch_size,
74 | batch_postprocessors=[preprocess_inputs],
75 | use_cache=True,
76 | )
77 |
78 | # Create Validation Data Provider
79 | val_dataProvider = DataProvider(
80 | val_dataset,
81 | batch_size=configs.batch_size,
82 | batch_postprocessors=[preprocess_inputs],
83 | use_cache=True,
84 | )
85 |
86 | # Create TensorFlow Transformer Model
87 | transformer = Transformer(
88 | num_layers=configs.num_layers,
89 | d_model=configs.d_model,
90 | num_heads=configs.num_heads,
91 | dff=configs.dff,
92 | input_vocab_size=len(tokenizer)+1,
93 | target_vocab_size=len(detokenizer)+1,
94 | dropout_rate=configs.dropout_rate,
95 | encoder_input_size=tokenizer.max_length,
96 | decoder_input_size=detokenizer.max_length
97 | )
98 |
99 | transformer.summary()
100 |
101 | optimizer = tf.keras.optimizers.Adam(learning_rate=configs.init_lr, beta_1=0.9, beta_2=0.98, epsilon=1e-9)
102 |
103 | # Compile the model
104 | transformer.compile(
105 | loss=MaskedLoss(),
106 | optimizer=optimizer,
107 | metrics=[MaskedAccuracy()],
108 | run_eagerly=False
109 | )
110 |
111 | # Define callbacks
112 | warmupCosineDecay = WarmupCosineDecay(
113 | lr_after_warmup=configs.lr_after_warmup,
114 | final_lr=configs.final_lr,
115 | warmup_epochs=configs.warmup_epochs,
116 | decay_epochs=configs.decay_epochs,
117 | initial_lr=configs.init_lr,
118 | )
119 | earlystopper = EarlyStopping(monitor="val_masked_accuracy", patience=5, verbose=1, mode="max")
120 | checkpoint = ModelCheckpoint(f"{configs.model_path}/model.h5", monitor="val_masked_accuracy", verbose=1, save_best_only=True, mode="max", save_weights_only=False)
121 | tb_callback = TensorBoard(f"{configs.model_path}/logs")
122 | reduceLROnPlat = ReduceLROnPlateau(monitor="val_masked_accuracy", factor=0.9, min_delta=1e-10, patience=2, verbose=1, mode="max")
123 | model2onnx = Model2onnx(f"{configs.model_path}/model.h5", metadata={"tokenizer": tokenizer.dict(), "detokenizer": detokenizer.dict()}, save_on_epoch_end=False)
124 | encDecSplitCallback = EncDecSplitCallback(configs.model_path, encoder_metadata={"tokenizer": tokenizer.dict()}, decoder_metadata={"detokenizer": detokenizer.dict()})
125 |
126 | configs.save()
127 |
128 | # Train the model
129 | transformer.fit(
130 | train_dataProvider,
131 | validation_data=val_dataProvider,
132 | epochs=configs.train_epochs,
133 | callbacks=[
134 | earlystopper,
135 | warmupCosineDecay,
136 | checkpoint,
137 | tb_callback,
138 | reduceLROnPlat,
139 | model2onnx,
140 | encDecSplitCallback
141 | ]
142 | )
--------------------------------------------------------------------------------
/Tutorials/10_wav2vec2_torch/configs.py:
--------------------------------------------------------------------------------
1 | import os
2 | from datetime import datetime
3 |
4 | from mltu.configs import BaseModelConfigs
5 |
6 | class ModelConfigs(BaseModelConfigs):
7 | def __init__(self):
8 | super().__init__()
9 | self.model_path = os.path.join(
10 | "Models/10_wav2vec2_torch",
11 | datetime.strftime(datetime.now(), "%Y%m%d%H%M"),
12 | )
13 | self.batch_size = 8
14 | self.train_epochs = 60
15 | self.train_workers = 20
16 |
17 | self.init_lr = 1.0e-8
18 | self.lr_after_warmup = 1e-05
19 | self.final_lr = 5e-06
20 | self.warmup_epochs = 10
21 | self.decay_epochs = 40
22 | self.weight_decay = 0.005
23 | self.mixed_precision = True
24 |
25 | self.max_audio_length = 246000
26 | self.max_label_length = 256
27 |
28 | self.vocab = [' ', "'", 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
--------------------------------------------------------------------------------
/Tutorials/10_wav2vec2_torch/requirements.txt:
--------------------------------------------------------------------------------
1 | torch>=1.13.1+cu117
2 | transformers==4.33.1
3 | mltu==1.1.4
4 | onnx
5 | onnxruntime
--------------------------------------------------------------------------------
/Tutorials/10_wav2vec2_torch/test.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | from mltu.inferenceModel import OnnxInferenceModel
4 | from mltu.utils.text_utils import ctc_decoder, get_cer, get_wer
5 |
6 | class Wav2vec2(OnnxInferenceModel):
7 | def __init__(self, *args, **kwargs):
8 | super().__init__(*args, **kwargs)
9 |
10 | def predict(self, audio: np.ndarray):
11 |
12 | audio = np.expand_dims(audio, axis=0).astype(np.float32)
13 |
14 | preds = self.model.run(None, {self.input_name: audio})[0]
15 |
16 | text = ctc_decoder(preds, self.metadata["vocab"])[0]
17 |
18 | return text
19 |
20 | if __name__ == "__main__":
21 | import librosa
22 | import pandas as pd
23 | from tqdm import tqdm
24 |
25 | model = Wav2vec2(model_path="Models/10_wav2vec2_torch/202309171434/model.onnx")
26 |
27 | # The list of multiple [audio_path, label] for validation
28 | val_dataset = pd.read_csv("Models/10_wav2vec2_torch/202309171434/val.csv").values.tolist()
29 |
30 | accum_cer, accum_wer = [], []
31 | pbar = tqdm(val_dataset)
32 | for vaw_path, label in pbar:
33 | audio, sr = librosa.load(vaw_path, sr=16000)
34 |
35 | prediction_text = model.predict(audio)
36 |
37 | cer = get_cer(prediction_text, label)
38 | wer = get_wer(prediction_text, label)
39 |
40 | accum_cer.append(cer)
41 | accum_wer.append(wer)
42 | print(label)
43 |
44 | pbar.set_description(f"Average CER: {np.average(accum_cer):.4f}, Average WER: {np.average(accum_wer):.4f}")
--------------------------------------------------------------------------------
/Tutorials/10_wav2vec2_torch/train.py:
--------------------------------------------------------------------------------
1 | import os
2 | import tarfile
3 | import pandas as pd
4 | from tqdm import tqdm
5 | from io import BytesIO
6 | from urllib.request import urlopen
7 |
8 | import torch
9 | from torch import nn
10 | from transformers import Wav2Vec2ForCTC
11 | import torch.nn.functional as F
12 |
13 | from mltu.torch.model import Model
14 | from mltu.torch.losses import CTCLoss
15 | from mltu.torch.dataProvider import DataProvider
16 | from mltu.torch.metrics import CERMetric, WERMetric
17 | from mltu.torch.callbacks import EarlyStopping, ModelCheckpoint, TensorBoard, Model2onnx, WarmupCosineDecay
18 | from mltu.augmentors import RandomAudioNoise, RandomAudioPitchShift, RandomAudioTimeStretch
19 |
20 | from mltu.preprocessors import AudioReader
21 | from mltu.transformers import LabelIndexer, LabelPadding, AudioPadding
22 |
23 | from configs import ModelConfigs
24 |
25 | configs = ModelConfigs()
26 |
27 |
28 | def download_and_unzip(url, extract_to="Datasets", chunk_size=1024*1024):
29 | http_response = urlopen(url)
30 |
31 | data = b""
32 | iterations = http_response.length // chunk_size + 1
33 | for _ in tqdm(range(iterations)):
34 | data += http_response.read(chunk_size)
35 |
36 | tarFile = tarfile.open(fileobj=BytesIO(data), mode="r|bz2")
37 | tarFile.extractall(path=extract_to)
38 | tarFile.close()
39 |
40 |
41 | dataset_path = os.path.join("Datasets", "LJSpeech-1.1")
42 | if not os.path.exists(dataset_path):
43 | download_and_unzip("https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2", extract_to="Datasets")
44 |
45 | dataset_path = "Datasets/LJSpeech-1.1"
46 | metadata_path = dataset_path + "/metadata.csv"
47 | wavs_path = dataset_path + "/wavs/"
48 |
49 | # Read metadata file and parse it
50 | metadata_df = pd.read_csv(metadata_path, sep="|", header=None, quoting=3)
51 | dataset = []
52 | vocab = [' ', "'", 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
53 | for file_name, transcription, normalized_transcription in metadata_df.values.tolist():
54 | path = f"Datasets/LJSpeech-1.1/wavs/{file_name}.wav"
55 | new_label = "".join([l for l in normalized_transcription.lower() if l in vocab])
56 | dataset.append([path, new_label])
57 |
58 | # Create a data provider for the dataset
59 | data_provider = DataProvider(
60 | dataset=dataset,
61 | skip_validation=True,
62 | batch_size=configs.batch_size,
63 | data_preprocessors=[
64 | AudioReader(sample_rate=16000),
65 | ],
66 | transformers=[
67 | LabelIndexer(vocab),
68 | ],
69 | use_cache=False,
70 | batch_postprocessors=[
71 | AudioPadding(max_audio_length=configs.max_audio_length, padding_value=0, use_on_batch=True),
72 | LabelPadding(padding_value=len(vocab), use_on_batch=True),
73 | ],
74 | use_multiprocessing=True,
75 | max_queue_size=10,
76 | workers=configs.train_workers,
77 | )
78 | train_dataProvider, test_dataProvider = data_provider.split(split=0.9)
79 |
80 | # train_dataProvider.augmentors = [
81 | # RandomAudioNoise(),
82 | # RandomAudioPitchShift(),
83 | # RandomAudioTimeStretch()
84 | # ]
85 |
86 | vocab = sorted(vocab)
87 | configs.vocab = vocab
88 | configs.save()
89 |
90 |
91 | class CustomWav2Vec2Model(nn.Module):
92 | def __init__(self, hidden_states, dropout_rate=0.2, **kwargs):
93 | super(CustomWav2Vec2Model, self).__init__( **kwargs)
94 | pretrained_name = "facebook/wav2vec2-base-960h"
95 | self.model = Wav2Vec2ForCTC.from_pretrained(pretrained_name, vocab_size=hidden_states, ignore_mismatched_sizes=True)
96 | self.model.freeze_feature_encoder() # this part does not need to be fine-tuned
97 |
98 | def forward(self, inputs):
99 | output = self.model(inputs, attention_mask=None).logits
100 | # Apply softmax
101 | output = F.log_softmax(output, -1)
102 | return output
103 |
104 | custom_model = CustomWav2Vec2Model(hidden_states = len(vocab)+1)
105 |
106 | # put on cuda device if available
107 | if torch.cuda.is_available():
108 | custom_model = custom_model.cuda()
109 |
110 | # create callbacks
111 | warmupCosineDecay = WarmupCosineDecay(
112 | lr_after_warmup=configs.lr_after_warmup,
113 | warmup_epochs=configs.warmup_epochs,
114 | decay_epochs=configs.decay_epochs,
115 | final_lr=configs.final_lr,
116 | initial_lr=configs.init_lr,
117 | verbose=True,
118 | )
119 | tb_callback = TensorBoard(configs.model_path + "/logs")
120 | earlyStopping = EarlyStopping(monitor="val_CER", patience=16, mode="min", verbose=1)
121 | modelCheckpoint = ModelCheckpoint(configs.model_path + "/model.pt", monitor="val_CER", mode="min", save_best_only=True, verbose=1)
122 | model2onnx = Model2onnx(
123 | saved_model_path=configs.model_path + "/model.pt",
124 | input_shape=(1, configs.max_audio_length),
125 | verbose=1,
126 | metadata={"vocab": configs.vocab},
127 | dynamic_axes={"input": {0: "batch_size", 1: "sequence_length"}, "output": {0: "batch_size", 1: "sequence_length"}}
128 | )
129 |
130 | # create model object that will handle training and testing of the network
131 | model = Model(
132 | custom_model,
133 | loss = CTCLoss(blank=len(configs.vocab), zero_infinity=True),
134 | optimizer = torch.optim.AdamW(custom_model.parameters(), lr=configs.init_lr, weight_decay=configs.weight_decay),
135 | metrics=[
136 | CERMetric(configs.vocab),
137 | WERMetric(configs.vocab)
138 | ],
139 | mixed_precision=configs.mixed_precision,
140 | )
141 |
142 | # Save training and validation datasets as csv files
143 | train_dataProvider.to_csv(os.path.join(configs.model_path, "train.csv"))
144 | test_dataProvider.to_csv(os.path.join(configs.model_path, "val.csv"))
145 |
146 | model.fit(
147 | train_dataProvider,
148 | test_dataProvider,
149 | epochs=configs.train_epochs,
150 | callbacks=[
151 | warmupCosineDecay,
152 | tb_callback,
153 | earlyStopping,
154 | modelCheckpoint,
155 | model2onnx
156 | ]
157 | )
--------------------------------------------------------------------------------
/Tutorials/10_wav2vec2_torch/train_tf.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | try:
3 | [
4 | tf.config.experimental.set_memory_growth(gpu, True)
5 | for gpu in tf.config.experimental.list_physical_devices("GPU")
6 | ]
7 | except:
8 | pass
9 |
10 | from keras import layers
11 | from mltu.tensorflow.dataProvider import DataProvider
12 | from mltu.transformers import LabelIndexer, LabelPadding, AudioPadding
13 |
14 | from mltu.tensorflow.losses import CTCloss
15 | from mltu.tensorflow.metrics import CERMetric, WERMetric
16 | from mltu.tensorflow.callbacks import Model2onnx, WarmupCosineDecay
17 |
18 | from mltu.augmentors import RandomAudioNoise, RandomAudioPitchShift, RandomAudioTimeStretch
19 |
20 | from keras.callbacks import EarlyStopping, ModelCheckpoint, TensorBoard
21 |
22 | import pandas as pd
23 |
24 | from configs import ModelConfigs
25 |
26 | configs = ModelConfigs()
27 | from transformers import TFWav2Vec2ForCTC
28 | from mltu.preprocessors import AudioReader
29 |
30 |
31 | train_dataset = pd.read_csv("Models/10_wav2vec2_torch/202309171434/train.csv").values.tolist()
32 | validation_dataset = pd.read_csv("Models/10_wav2vec2_torch/202309171434/val.csv").values.tolist()
33 |
34 | # Create a data provider for the dataset
35 | train_dataProvider = DataProvider(
36 | dataset=train_dataset,
37 | skip_validation=True,
38 | batch_size=configs.batch_size,
39 | data_preprocessors=[
40 | AudioReader(sample_rate=16000),
41 | ],
42 | transformers=[
43 | LabelIndexer(configs.vocab),
44 | LabelPadding(max_word_length=configs.max_label_length, padding_value=len(configs.vocab)),
45 | ],
46 | batch_postprocessors=[
47 | AudioPadding(max_audio_length=configs.max_audio_length, padding_value=0, use_on_batch=True)
48 | ],
49 | augmentors=[
50 | RandomAudioNoise(),
51 | RandomAudioPitchShift(),
52 | RandomAudioTimeStretch()
53 | ],
54 | use_cache=True,
55 | )
56 |
57 | test_dataProvider = DataProvider(
58 | dataset=validation_dataset,
59 | skip_validation=True,
60 | batch_size=configs.batch_size,
61 | data_preprocessors=[
62 | AudioReader(sample_rate=16000),
63 | ],
64 | transformers=[
65 | LabelIndexer(configs.vocab),
66 | LabelPadding(max_word_length=configs.max_label_length, padding_value=len(configs.vocab)),
67 | ],
68 | batch_postprocessors=[
69 | AudioPadding(max_audio_length=configs.max_audio_length, padding_value=0, use_on_batch=True)
70 | ],
71 | use_cache=True,
72 | )
73 |
74 | class CustomWav2Vec2Model(layers.Layer):
75 | def __init__(self, output_dim, **kwargs):
76 | super().__init__(**kwargs)
77 |
78 | pretrained_name = "facebook/wav2vec2-base-960h"
79 | self.model = TFWav2Vec2ForCTC.from_pretrained(pretrained_name, vocab_size=output_dim, ignore_mismatched_sizes=True)
80 | self.model.freeze_feature_encoder() # https://huggingface.co/blog/fine-tune-wav2vec2-english
81 |
82 | def __call__(self, inputs):
83 | outputs = self.model(inputs)
84 |
85 | final_state = tf.nn.softmax(outputs.logits, axis=-1)
86 |
87 | return final_state
88 |
89 | custom_model = tf.keras.Sequential([
90 | layers.Input(shape=(None,), name="input", dtype=tf.float32),
91 | CustomWav2Vec2Model(len(configs.vocab)+1)
92 | ])
93 |
94 | for data in train_dataProvider:
95 | results = custom_model(data[0])
96 | break
97 |
98 | custom_model.summary()
99 | # configs.save()
100 |
101 |
102 | # Compile the model and print summary
103 | custom_model.compile(
104 | optimizer=tf.keras.optimizers.AdamW(learning_rate=configs.init_lr, weight_decay=configs.weight_decay),
105 | loss=CTCloss(),
106 | metrics=[
107 | CERMetric(vocabulary=configs.vocab),
108 | WERMetric(vocabulary=configs.vocab)
109 | ],
110 | )
111 |
112 | # Define callbacks
113 | warmupCosineDecay = WarmupCosineDecay(
114 | lr_after_warmup=configs.lr_after_warmup,
115 | final_lr=configs.final_lr,
116 | warmup_epochs=configs.warmup_epochs,
117 | decay_epochs=configs.decay_epochs,
118 | initial_lr=configs.init_lr,
119 | )
120 | earlystopper = EarlyStopping(
121 | monitor="val_CER", patience=16, verbose=1, mode="min"
122 | )
123 | checkpoint = ModelCheckpoint(
124 | f"{configs.model_path}/model.h5",
125 | monitor="val_CER",
126 | verbose=1,
127 | save_best_only=True,
128 | mode="min",
129 | save_weights_only=False,
130 | )
131 | tb_callback = TensorBoard(f"{configs.model_path}/logs")
132 | model2onnx = Model2onnx(f"{configs.model_path}/model.h5", metadata={"vocab": configs.vocab})
133 |
134 | # Train the model
135 | custom_model.fit(
136 | train_dataProvider,
137 | validation_data=test_dataProvider,
138 | epochs=configs.train_epochs,
139 | callbacks=[warmupCosineDecay, earlystopper, checkpoint, tb_callback, model2onnx],
140 | max_queue_size=configs.train_workers,
141 | workers=configs.train_workers,
142 | use_multiprocessing=True,
143 | )
--------------------------------------------------------------------------------
/Tutorials/11_Yolov8/convert2onnx.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from ultralytics.engine.model import Model as BaseModel
3 |
4 | base_model = BaseModel("yolov8m.pt")
5 |
6 | classes = base_model.names
7 | input_width, input_height = 640, 640
8 | input_shape = (1, 3, input_width, input_height)
9 | model = base_model.model
10 |
11 | # place model on cpu
12 | model.to("cpu")
13 |
14 | # set the model to inference mode
15 | model.eval()
16 |
17 | # convert the model to ONNX format
18 | dummy_input = torch.randn(input_shape).to("cpu")
19 |
20 | # Export the model
21 | torch.onnx.export(
22 | model,
23 | dummy_input,
24 | "yolov8m.onnx",
25 | export_params=True,
26 | input_names = ["input"],
27 | output_names = ["output"],
28 | dynamic_axes = {
29 | "input": {0: "batch_size", 2: "height", 3: "width"},
30 | "output": {0: "batch_size", 2: "anchors"}
31 | }
32 | )
33 |
34 | # Add the class names to the model as metadata
35 | import onnx
36 |
37 | metadata = {"classes": classes}
38 |
39 | # Load the ONNX model
40 | onnx_model = onnx.load("yolov8m.onnx")
41 |
42 | # Add the metadata dictionary to the onnx model's metadata_props attribute
43 | for key, value in metadata.items():
44 | meta = onnx_model.metadata_props.add()
45 | meta.key = key
46 | meta.value = str(value)
47 |
48 | # Save the modified ONNX model
49 | onnx.save(onnx_model, "yolov8m.onnx")
--------------------------------------------------------------------------------
/Tutorials/11_Yolov8/requirements.txt:
--------------------------------------------------------------------------------
1 | mltu==1.2.5
2 | ultralytics==8.1.28
3 | torch==2.0.0
4 | torchvision==0.15.1
5 | onnxruntime==1.15.1
6 | onnx==1.12.0
--------------------------------------------------------------------------------
/Tutorials/11_Yolov8/run_pretrained.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | from ultralytics.engine.model import Model as BaseModel
3 | from mltu.annotations.detections import Detections
4 | from mltu.torch.yolo.detectors.torch_detector import Detector as TorchDetector
5 | from mltu.torch.yolo.detectors.onnx_detector import Detector as OnnxDetector
6 |
7 | input_width, input_height = 640, 640
8 | confidence_threshold = 0.5
9 | iou_threshold = 0.5
10 |
11 | # base_model = BaseModel("yolov8m.pt")
12 | # detector = TorchDetector(base_model.model, input_width, input_height, base_model.names, confidence_threshold, iou_threshold)
13 | detector = OnnxDetector("yolov8m.onnx", input_width, input_height, confidence_threshold, iou_threshold)
14 |
15 | cap = cv2.VideoCapture(0)
16 | while True:
17 | ret, frame = cap.read()
18 | if not ret:
19 | break
20 |
21 | # Perform Yolo object detection
22 | detections: Detections = detector(frame)
23 |
24 | # Apply the detections to the frame
25 | frame = detections.applyToFrame(frame)
26 |
27 | # Print the FPS
28 | print(detector.fps)
29 |
30 | # Display the output image
31 | cv2.imshow("Object Detection", frame)
32 | if cv2.waitKey(1) & 0xFF == ord('q'):
33 | break
34 |
35 | cap.release()
36 | cv2.destroyAllWindows()
--------------------------------------------------------------------------------
/Tutorials/11_Yolov8/test_yolov8.py:
--------------------------------------------------------------------------------
1 | import os
2 | import cv2
3 | from mltu.annotations.detections import Detections
4 | from mltu.torch.yolo.detectors.onnx_detector import Detector as OnnxDetector
5 |
6 | # https://www.kaggle.com/datasets/andrewmvd/car-plate-detection
7 | images_path = "Datasets/car-plate-detection/images"
8 |
9 | input_width, input_height = 416, 416
10 | confidence_threshold = 0.5
11 | iou_threshold = 0.5
12 |
13 | detector = OnnxDetector("Models/11_Yolov8/1714135287/model.onnx", input_width, input_height, confidence_threshold, iou_threshold, force_cpu=False)
14 |
15 | for image_path in os.listdir(images_path):
16 |
17 | frame = cv2.imread(os.path.join(images_path, image_path))
18 |
19 | # Perform Yolo object detection
20 | detections: Detections = detector(frame)
21 |
22 | # Apply the detections to the frame
23 | frame = detections.applyToFrame(frame)
24 |
25 | # Print the FPS
26 | print(detector.fps)
27 |
28 | # Display the output image
29 | cv2.imshow("Object Detection", frame)
30 | if cv2.waitKey(0) & 0xFF == ord('q'):
31 | break
32 |
33 | cv2.destroyAllWindows()
--------------------------------------------------------------------------------
/Tutorials/11_Yolov8/train_yolov8.py:
--------------------------------------------------------------------------------
1 | import os
2 | import time
3 | import torch
4 | from mltu.preprocessors import ImageReader
5 | from mltu.annotations.images import CVImage
6 | from mltu.transformers import ImageResizer, ImageShowCV2, ImageNormalizer
7 | from mltu.augmentors import RandomBrightness, RandomRotate, RandomErodeDilate, RandomSharpen, \
8 | RandomMirror, RandomFlip, RandomGaussianBlur, RandomSaltAndPepper, RandomDropBlock, RandomMosaic, RandomElasticTransform
9 | from mltu.torch.model import Model
10 | from mltu.torch.dataProvider import DataProvider
11 | from mltu.torch.yolo.annotation import VOCAnnotationReader
12 | from mltu.torch.yolo.preprocessors import YoloPreprocessor
13 | from mltu.torch.yolo.loss import v8DetectionLoss
14 | from mltu.torch.yolo.metrics import YoloMetrics
15 | from mltu.torch.yolo.optimizer import build_optimizer, AccumulativeOptimizer
16 | from mltu.torch.callbacks import EarlyStopping, ModelCheckpoint, TensorBoard, Model2onnx, WarmupCosineDecay
17 |
18 | from ultralytics.nn.tasks import DetectionModel
19 | from ultralytics.engine.model import Model as BaseModel
20 |
21 | # https://www.kaggle.com/datasets/andrewmvd/car-plate-detection
22 | annotations_path = "Datasets/car-plate-detection/annotations"
23 |
24 | # Create a dataset from the annotations, the dataset is a list of lists where each list contains the [image path, annotation path]
25 | dataset = [[None, os.path.join(annotations_path, f)] for f in os.listdir(annotations_path)]
26 |
27 | # Make sure torch can see GPU device, it is not recommended to train with CPU
28 | device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
29 |
30 | img_size = 416
31 | labels = {0: "licence"}
32 |
33 | # Create a data provider for the dataset
34 | data_provider = DataProvider(
35 | dataset=dataset,
36 | skip_validation=True,
37 | batch_size=16,
38 | data_preprocessors=[
39 | VOCAnnotationReader(labels=labels),
40 | ImageReader(CVImage),
41 | ],
42 | transformers=[
43 | # ImageShowCV2(),
44 | ImageResizer(img_size, img_size),
45 | ImageNormalizer(transpose_axis=True),
46 | ],
47 | batch_postprocessors=[
48 | YoloPreprocessor(device, img_size)
49 | ],
50 | numpy=False,
51 | )
52 |
53 | # split the dataset into train and test
54 | train_data_provider, val_data_provider = data_provider.split(0.9, shuffle=False)
55 |
56 | # Attaach augmentation to the train data provider
57 | train_data_provider.augmentors = [
58 | RandomBrightness(),
59 | RandomErodeDilate(),
60 | RandomSharpen(),
61 | RandomMirror(),
62 | RandomFlip(),
63 | RandomElasticTransform(),
64 | RandomGaussianBlur(),
65 | RandomSaltAndPepper(),
66 | RandomRotate(angle=10),
67 | RandomDropBlock(),
68 | RandomMosaic(),
69 | ]
70 |
71 | base_model = BaseModel("yolov8n.pt")
72 | # Create a YOLO model
73 | model = DetectionModel('yolov8n.yaml', nc=len(labels))
74 |
75 | # Load the weight from base model
76 | try: model.load_state_dict(base_model.model.state_dict(), strict=False)
77 | except: pass
78 |
79 | model.to(device)
80 |
81 | for k, v in model.named_parameters():
82 | if any(x in k for x in [".dfl"]):
83 | print("freezing", k)
84 | v.requires_grad = False
85 | elif not v.requires_grad:
86 | v.requires_grad = True
87 |
88 | lr = 1e-3
89 | optimizer = build_optimizer(model.model, name="AdamW", lr=lr, weight_decay=0.0, momentum=0.937, decay=0.0005)
90 | optimizer = AccumulativeOptimizer(optimizer, 16, 64)
91 |
92 | # create model object that will handle training and testing of the network
93 | model = Model(
94 | model,
95 | optimizer,
96 | v8DetectionLoss(model),
97 | metrics=[YoloMetrics(nc=len(labels))],
98 | log_errors=False,
99 | output_path=f"Models/11_Yolov8/{int(time.time())}",
100 | clip_grad_norm=10.0,
101 | ema=True,
102 | )
103 |
104 | modelCheckpoint = ModelCheckpoint(monitor="val_fitness", mode="max", save_best_only=True, verbose=True)
105 | tensorBoard = TensorBoard()
106 | earlyStopping = EarlyStopping(monitor="val_fitness", mode="max", patience=31, verbose=True)
107 | model2onnx = Model2onnx(input_shape=(1, 3, img_size, img_size), verbose=True, opset_version=14,
108 | dynamic_axes = {"input": {0: "batch_size", 2: "height", 3: "width"},
109 | "output": {0: "batch_size", 2: "anchors"}},
110 | metadata={"classes": labels})
111 | warmupCosineDecayBias = WarmupCosineDecay(lr_after_warmup=lr, final_lr=lr, initial_lr=0.1,
112 | warmup_steps=len(train_data_provider), warmup_epochs=10, ignore_param_groups=[1, 2]) # lr0
113 | warmupCosineDecay = WarmupCosineDecay(lr_after_warmup=lr, final_lr=lr/10, initial_lr=1e-7,
114 | warmup_steps=len(train_data_provider), warmup_epochs=10, decay_epochs=190, ignore_param_groups=[0]) # lr1 and lr2
115 |
116 | # Train the model
117 | history = model.fit(
118 | train_data_provider,
119 | test_dataProvider=val_data_provider,
120 | epochs=200,
121 | callbacks=[
122 | modelCheckpoint,
123 | tensorBoard,
124 | earlyStopping,
125 | model2onnx,
126 | warmupCosineDecayBias,
127 | warmupCosineDecay
128 | ]
129 | )
--------------------------------------------------------------------------------
/Tutorials/README.md:
--------------------------------------------------------------------------------
1 | # Tutorials and Examples made with MLTU library:
2 | 1. [Text Recognition With TensorFlow and CTC network](https://pylessons.com/ctc-text-recognition), code in ```Tutorials\01_image_to_word``` folder;
3 | 2. [TensorFlow OCR model for reading Captchas](https://pylessons.com/tensorflow-ocr-captcha), code in ```Tutorials\02_captcha_to_text``` folder;
4 | 3. [Handwriting words recognition with TensorFlow](https://pylessons.com/handwriting-recognition), code in ```Tutorials\03_handwriting_recognition``` folder;
5 | 4. [Handwritten sentence recognition with TensorFlow](https://pylessons.com/handwritten-sentence-recognition), code in ```Tutorials\04_sentence_recognition``` folder;
6 | 5. [Introduction to speech recognition with TensorFlow](https://pylessons.com/speech-recognition), code in ```Tutorials\05_speech_recognition``` folder;
7 | 6. [Introduction to PyTorch in a practical way](https://pylessons.com/pytorch-introduction), code in ```Tutorials\06_pytorch_introduction``` folder;
8 | 7. [Using custom wrapper to simplify PyTorch models training pipeline](https://pylessons.com/pytorch-introduction), code in ```Tutorials\07_pytorch_wrapper``` folder;
9 | 8. [Handwriting words recognition with PyTorch](https://pylessons.com/handwriting-recognition-pytorch), code in ```Tutorials\08_handwriting_recognition_torch``` folder;
--------------------------------------------------------------------------------
/bin/read_parquet.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 |
3 | file_path = "/home/rokbal/Downloads/train-00000-of-00001-bfc7b63751c36ab0 (1).parquet"
4 |
5 | df = pd.read_parquet(file_path)
6 |
7 | print(df.head())
--------------------------------------------------------------------------------
/bin/setup.sh:
--------------------------------------------------------------------------------
1 | python3 -m venv venv
2 | activate() {
3 | . venv/bin/activate
4 | echo "installing requirements to virtual environment"
5 | pip install -r requirements.txt
6 | }
7 | activate
--------------------------------------------------------------------------------
/mltu/__init__.py:
--------------------------------------------------------------------------------
1 | __version__ = "1.2.5"
2 |
3 | from .annotations.images import Image
4 | from .annotations.images import CVImage
5 | from .annotations.images import PillowImage
--------------------------------------------------------------------------------
/mltu/annotations/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/pythonlessons/mltu/f3033451f62c3fd2097b990c98b25f97773b640d/mltu/annotations/__init__.py
--------------------------------------------------------------------------------
/mltu/annotations/audio.py:
--------------------------------------------------------------------------------
1 | import os
2 | import numpy as np
3 |
4 | class Audio:
5 | """ Audio object
6 |
7 | Attributes:
8 | audio (np.ndarray): Audio array
9 | sample_rate (int): Sample rate
10 | init_successful (bool): True if audio was successfully read
11 | library (object): Library used to read audio, tested only with librosa
12 | """
13 | init_successful = False
14 | augmented=False
15 |
16 | def __init__(
17 | self,
18 | audioPath: str,
19 | sample_rate: int=22050,
20 | library=None
21 | ) -> None:
22 | if library is None:
23 | raise ValueError("library must be provided. (e.g. librosa object)")
24 |
25 | if isinstance(audioPath, str):
26 | if not os.path.exists(audioPath):
27 | raise FileNotFoundError(f"Image {audioPath} not found.")
28 |
29 | self._audio, self.sample_rate = library.load(audioPath, sr=sample_rate)
30 | self.path = audioPath
31 | self.init_successful = True
32 |
33 | else:
34 | raise TypeError(f"audioPath must be path to audio file, not {type(audioPath)}")
35 |
36 | @property
37 | def audio(self) -> np.ndarray:
38 | return self._audio
39 |
40 | @audio.setter
41 | def audio(self, value: np.ndarray):
42 | self.augmented = True
43 | self._audio = value
44 |
45 | @property
46 | def shape(self) -> tuple:
47 | return self._audio.shape
48 |
49 | def numpy(self) -> np.ndarray:
50 | return self._audio
51 |
52 | def __add__(self, other: np.ndarray) -> np.ndarray:
53 | self._audio = self._audio + other
54 | self.augmented = True
55 | return self
56 |
57 | def __len__(self) -> int:
58 | return len(self._audio)
59 |
60 | def __call__(self) -> np.ndarray:
61 | return self._audio
62 |
63 | def __repr__(self):
64 | return repr(self._audio)
65 |
66 | def __array__(self):
67 | return self._audio
--------------------------------------------------------------------------------
/mltu/configs.py:
--------------------------------------------------------------------------------
1 | import os
2 | import yaml
3 |
4 |
5 | class BaseModelConfigs:
6 | def __init__(self):
7 | self.model_path = None
8 |
9 | def serialize(self):
10 | class_attributes = {key: value
11 | for (key, value)
12 | in type(self).__dict__.items()
13 | if key not in ['__module__', '__init__', '__doc__', '__annotations__']}
14 | instance_attributes = self.__dict__
15 |
16 | # first init with class attributes then apply instance attributes overwriting any existing duplicate attributes
17 | all_attributes = class_attributes.copy()
18 | all_attributes.update(instance_attributes)
19 |
20 | return all_attributes
21 |
22 | def save(self, name: str = "configs.yaml"):
23 | if self.model_path is None:
24 | raise Exception("Model path is not specified")
25 |
26 | # create directory if not exist
27 | if not os.path.exists(self.model_path):
28 | os.makedirs(self.model_path)
29 |
30 | with open(os.path.join(self.model_path, name), "w") as f:
31 | yaml.dump(self.serialize(), f)
32 |
33 | @staticmethod
34 | def load(configs_path: str):
35 | with open(configs_path, "r") as f:
36 | configs = yaml.load(f, Loader=yaml.FullLoader)
37 |
38 | config = BaseModelConfigs()
39 | for key, value in configs.items():
40 | setattr(config, key, value)
41 |
42 | return config
43 |
--------------------------------------------------------------------------------
/mltu/inferenceModel.py:
--------------------------------------------------------------------------------
1 | import os
2 | import time
3 | import typing
4 | import numpy as np
5 | import onnxruntime as ort
6 | from collections import deque
7 |
8 | class FpsWrapper:
9 | """ Decorator to calculate the frames per second of a function
10 | """
11 | def __init__(self, func: typing.Callable):
12 | self.func = func
13 | self.fps_list = deque([], maxlen=100)
14 |
15 | def __call__(self, *args, **kwargs):
16 | start = time.time()
17 | results = self.func(self.instance, *args, **kwargs)
18 | self.fps_list.append(1 / (time.time() - start))
19 | self.instance.fps = np.mean(self.fps_list)
20 | return results
21 |
22 | def __get__(self, instance, owner):
23 | self.instance = instance
24 | return self.__call__.__get__(instance, owner)
25 |
26 |
27 | class OnnxInferenceModel:
28 | """ Base class for all inference models that use onnxruntime
29 |
30 | Attributes:
31 | model_path (str, optional): Path to the model folder. Defaults to "".
32 | force_cpu (bool, optional): Force the model to run on CPU or GPU. Defaults to GPU.
33 | default_model_name (str, optional): Default model name. Defaults to "model.onnx".
34 | """
35 | def __init__(
36 | self,
37 | model_path: str = "",
38 | force_cpu: bool = False,
39 | default_model_name: str = "model.onnx",
40 | *args, **kwargs
41 | ):
42 | self.model_path = model_path.replace("\\", "/")
43 | self.force_cpu = force_cpu
44 | self.default_model_name = default_model_name
45 |
46 | # check if model path is a directory with os path
47 | if os.path.isdir(self.model_path):
48 | self.model_path = os.path.join(self.model_path, self.default_model_name)
49 |
50 | if not os.path.exists(self.model_path):
51 | raise Exception(f"Model path ({self.model_path}) does not exist")
52 |
53 | providers = ["CUDAExecutionProvider", "CPUExecutionProvider"] if ort.get_device() == "GPU" and not force_cpu else ["CPUExecutionProvider"]
54 |
55 | self.model = ort.InferenceSession(self.model_path, providers=providers)
56 |
57 | self.metadata = {}
58 | if self.model.get_modelmeta().custom_metadata_map:
59 | # add metadata to self object
60 | for key, value in self.model.get_modelmeta().custom_metadata_map.items():
61 | try:
62 | new_value = eval(value) # in case the value is a list or dict
63 | except:
64 | new_value = value
65 | self.metadata[key] = new_value
66 |
67 | # Update providers priority to only CPUExecutionProvider
68 | if self.force_cpu:
69 | self.model.set_providers(["CPUExecutionProvider"])
70 |
71 | self.input_shapes = [meta.shape for meta in self.model.get_inputs()]
72 | self.input_names = [meta.name for meta in self.model._inputs_meta]
73 | self.output_names = [meta.name for meta in self.model._outputs_meta]
74 |
75 | def predict(self, data: np.ndarray, *args, **kwargs):
76 | raise NotImplementedError
77 |
78 | @FpsWrapper
79 | def __call__(self, data: np.ndarray):
80 | results = self.predict(data)
81 | return results
--------------------------------------------------------------------------------
/mltu/tensorflow/README.md:
--------------------------------------------------------------------------------
1 | # Functions and objects specific for TensorFlow 2.* and Python 3
--------------------------------------------------------------------------------
/mltu/tensorflow/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/pythonlessons/mltu/f3033451f62c3fd2097b990c98b25f97773b640d/mltu/tensorflow/__init__.py
--------------------------------------------------------------------------------
/mltu/tensorflow/callbacks.py:
--------------------------------------------------------------------------------
1 | import os
2 | import tensorflow as tf
3 | from keras.callbacks import Callback
4 |
5 | import logging
6 |
7 | class Model2onnx(Callback):
8 | """ Converts the model to onnx format after training is finished. """
9 | def __init__(
10 | self,
11 | saved_model_path: str,
12 | metadata: dict=None,
13 | save_on_epoch_end: bool=False,
14 | ) -> None:
15 | """ Converts the model to onnx format after training is finished.
16 | Args:
17 | saved_model_path (str): Path to the saved .h5 model.
18 | metadata (dict, optional): Dictionary containing metadata to be added to the onnx model. Defaults to None.
19 | save_on_epoch_end (bool, optional): Save the onnx model on every epoch end. Defaults to False.
20 | """
21 | super().__init__()
22 | self.saved_model_path = saved_model_path
23 | self.metadata = metadata
24 | self.save_on_epoch_end = save_on_epoch_end
25 |
26 | try:
27 | import tf2onnx
28 | except:
29 | raise ImportError("tf2onnx is not installed. Please install it using 'pip install tf2onnx'")
30 |
31 | try:
32 | import onnx
33 | except:
34 | raise ImportError("onnx is not installed. Please install it using 'pip install onnx'")
35 |
36 | @staticmethod
37 | def model2onnx(model: tf.keras.Model, onnx_model_path: str):
38 | try:
39 | import tf2onnx
40 |
41 | # convert the model to onnx format
42 | tf2onnx.convert.from_keras(model, output_path=onnx_model_path)
43 |
44 | except Exception as e:
45 | print(e)
46 |
47 | @staticmethod
48 | def include_metadata(onnx_model_path: str, metadata: dict=None):
49 | try:
50 | if metadata and isinstance(metadata, dict):
51 |
52 | import onnx
53 | # Load the ONNX model
54 | onnx_model = onnx.load(onnx_model_path)
55 |
56 | # Add the metadata dictionary to the model's metadata_props attribute
57 | for key, value in metadata.items():
58 | meta = onnx_model.metadata_props.add()
59 | meta.key = key
60 | meta.value = str(value)
61 |
62 | # Save the modified ONNX model
63 | onnx.save(onnx_model, onnx_model_path)
64 |
65 | except Exception as e:
66 | print(e)
67 |
68 | def on_epoch_end(self, epoch: int, logs: dict=None):
69 | """ Converts the model to onnx format on every epoch end. """
70 | if self.save_on_epoch_end:
71 | self.on_train_end(logs=logs)
72 |
73 | def on_train_end(self, logs=None):
74 | """ Converts the model to onnx format after training is finished. """
75 | self.model.load_weights(self.saved_model_path)
76 | onnx_model_path = self.saved_model_path.replace(".h5", ".onnx")
77 | self.model2onnx(self.model, onnx_model_path)
78 | self.include_metadata(onnx_model_path, self.metadata)
79 |
80 |
81 | class TrainLogger(Callback):
82 | """Logs training metrics to a file.
83 |
84 | Args:
85 | log_path (str): Path to the directory where the log file will be saved.
86 | log_file (str, optional): Name of the log file. Defaults to 'logs.log'.
87 | logLevel (int, optional): Logging level. Defaults to logging.INFO.
88 | """
89 | def __init__(self, log_path: str, log_file: str="logs.log", logLevel=logging.INFO, console_output=False) -> None:
90 | super().__init__()
91 | self.log_path = log_path
92 | self.log_file = log_file
93 |
94 | if not os.path.exists(log_path):
95 | os.mkdir(log_path)
96 |
97 | self.logger = logging.getLogger()
98 | self.logger.setLevel(logLevel)
99 |
100 | self.formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
101 |
102 | self.file_handler = logging.FileHandler(os.path.join(self.log_path, self.log_file))
103 | self.file_handler.setLevel(logLevel)
104 | self.file_handler.setFormatter(self.formatter)
105 |
106 | if not console_output:
107 | self.logger.handlers[:] = []
108 |
109 | self.logger.addHandler(self.file_handler)
110 |
111 | def on_epoch_end(self, epoch: int, logs: dict=None):
112 | epoch_message = f"Epoch {epoch}; "
113 | logs_message = "; ".join([f"{key}: {value}" for key, value in logs.items()])
114 | self.logger.info(epoch_message + logs_message)
115 |
116 |
117 | class WarmupCosineDecay(Callback):
118 | """ Cosine decay learning rate scheduler with warmup
119 |
120 | Args:
121 | lr_after_warmup (float): Learning rate after warmup
122 | final_lr (float): Final learning rate
123 | warmup_epochs (int): Number of warmup epochs
124 | decay_epochs (int): Number of decay epochs
125 | initial_lr (float, optional): Initial learning rate. Defaults to 0.0.
126 | verbose (bool, optional): Whether to print learning rate. Defaults to False.
127 | """
128 | def __init__(
129 | self,
130 | lr_after_warmup: float,
131 | final_lr: float,
132 | warmup_epochs: int,
133 | decay_epochs: int,
134 | initial_lr: float=0.0,
135 | verbose=False
136 | ) -> None:
137 | super(WarmupCosineDecay, self).__init__()
138 | self.lr_after_warmup = lr_after_warmup
139 | self.final_lr = final_lr
140 | self.warmup_epochs = warmup_epochs
141 | self.decay_epochs = decay_epochs
142 | self.initial_lr = initial_lr
143 | self.verbose = verbose
144 |
145 | def on_epoch_begin(self, epoch: int, logs: dict=None):
146 | """ Adjust learning rate at the beginning of each epoch """
147 |
148 | if epoch >= self.warmup_epochs + self.decay_epochs:
149 | return logs
150 |
151 | if epoch < self.warmup_epochs:
152 | lr = self.initial_lr + (self.lr_after_warmup - self.initial_lr) * (epoch + 1) / self.warmup_epochs
153 | else:
154 | progress = (epoch - self.warmup_epochs) / self.decay_epochs
155 | lr = self.final_lr + 0.5 * (self.lr_after_warmup - self.final_lr) * (1 + tf.cos(tf.constant(progress) * 3.14159))
156 |
157 | tf.keras.backend.set_value(self.model.optimizer.lr, lr)
158 |
159 | if self.verbose:
160 | print(f"Epoch {epoch + 1} - Learning Rate: {lr}")
161 |
162 | def on_epoch_end(self, epoch: int, logs: dict=None):
163 | logs = logs or {}
164 |
165 | # Log the learning rate value
166 | logs["lr"] = self.model.optimizer.lr
167 |
168 | return logs
--------------------------------------------------------------------------------
/mltu/tensorflow/dataProvider.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 |
3 | from ..dataProvider import DataProvider as dataProvider
4 |
5 | class DataProvider(dataProvider, tf.keras.utils.Sequence):
6 | def __init__(self, *args, **kwargs):
7 | super().__init__(*args, **kwargs)
8 |
--------------------------------------------------------------------------------
/mltu/tensorflow/layers.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | from keras import layers
3 | from keras import backend as K
4 |
5 | class SelfAttention(layers.Layer):
6 | """ A self-attention layer for convolutional neural networks.
7 |
8 | This layer takes as input a tensor of shape (batch_size, height, width, channels)
9 | and applies self-attention to the channels dimension.
10 |
11 | Args:
12 | num_heads (int): The number of attention heads to use. Defaults to 8.
13 | wrapper (tf.keras.layers.Wrapper): A wrapper layer to apply to the convolutional layers.
14 |
15 | Raises:
16 | TypeError: If `wrapper` is provided and is not a subclass of `tf.keras.layers.Wrapper`.
17 | """
18 | def __init__(self, num_heads: int = 8, wrapper: tf.keras.layers.Wrapper = None):
19 | super(SelfAttention, self).__init__()
20 | self.num_heads = num_heads
21 | self.wrapper = wrapper
22 |
23 | if wrapper and not issubclass(wrapper, tf.keras.layers.Wrapper):
24 | raise TypeError("wrapper must be a class derived from tf.keras.layers.Wrapper")
25 |
26 | def get_config(self) -> dict:
27 | config = super().get_config()
28 | config.update({
29 | "num_heads": self.num_heads,
30 | })
31 | return config
32 |
33 | def build(self, input_shape):
34 | _, h, w, c = input_shape
35 | self.query_conv = self._conv(filters=c // self.num_heads)
36 | self.key_conv = self._conv(filters=c // self.num_heads)
37 | self.value_conv = self._conv(filters=c)
38 | self.gamma = self.add_weight("gamma", shape=[1], initializer=tf.zeros_initializer(), trainable=True)
39 |
40 | def _conv(self, filters: int) -> tf.keras.layers.Layer:
41 | """ Helper function to create a convolutional layer with the given number of filters.
42 |
43 | Args:
44 | filters (int): The number of filters to use.
45 |
46 | Returns:
47 | tf.keras.layers.Layer: The created convolutional layer.
48 | """
49 | conv = layers.Conv2D(filters=filters, kernel_size=1, strides=1, padding="same")
50 | if self.wrapper:
51 | conv = self.wrapper(conv)
52 |
53 | return conv
54 |
55 | def call(self, inputs: tf.Tensor) -> tf.Tensor:
56 | """ Apply the self-attention mechanism to the input tensor.
57 |
58 | Args:
59 | inputs (tf.Tensor): The input tensor of shape (batch_size, height, width, channels).
60 |
61 | Returns:
62 | tf.Tensor: The output tensor after the self-attention mechanism is applied.
63 | """
64 | _, h, w, c = inputs.shape
65 | q = self.query_conv(inputs)
66 | k = self.key_conv(inputs)
67 | v = self.value_conv(inputs)
68 |
69 | q_reshaped = tf.reshape(q, [-1, h * w, c // self.num_heads])
70 | k_reshaped = tf.reshape(k, [-1, h * w, c // self.num_heads])
71 | v_reshaped = tf.reshape(v, [-1, h * w, c])
72 |
73 | # Compute the attention scores by taking the dot product of the query and key tensors.
74 | attention_scores = tf.matmul(q_reshaped, k_reshaped, transpose_b=True)
75 |
76 | # Scale the attention scores by the square root of the number of channels.
77 | attention_scores = attention_scores / tf.sqrt(tf.cast(c // self.num_heads, dtype=tf.float32))
78 |
79 | # Apply a softmax function to the attention scores to obtain the attention weights.
80 | attention_weights = tf.nn.softmax(attention_scores, axis=-1)
81 |
82 | # Apply the attention weights to the value tensor to obtain the attention output.
83 | attention_output = tf.matmul(attention_weights, v_reshaped)
84 |
85 | # Reshape the attended value tensor to the original input tensor shape.
86 | attention_output = tf.reshape(attention_output, [-1, h, w, c])
87 |
88 | # Apply the gamma parameter to the attended value tensor and add it to the output tensor.
89 | attention_output = self.gamma * attention_output + inputs
90 |
91 | return attention_output
92 |
93 |
94 | class SpectralNormalization(tf.keras.layers.Wrapper):
95 | """Spectral Normalization Wrapper. !!! This is not working yet !!!"""
96 | def __init__(self, layer, power_iterations=1, eps=1e-12, **kwargs):
97 | super(SpectralNormalization, self).__init__(layer, **kwargs)
98 |
99 | if power_iterations <= 0:
100 | raise ValueError(
101 | "`power_iterations` should be greater than zero, got "
102 | "`power_iterations={}`".format(power_iterations)
103 | )
104 | self.power_iterations = power_iterations
105 | self.eps = eps
106 | if not isinstance(layer, tf.keras.layers.Layer):
107 | raise ValueError(
108 | "Please initialize `TimeDistributed` layer with a "
109 | "`Layer` instance. You passed: {input}".format(input=layer))
110 |
111 | def build(self, input_shape):
112 | if not self.layer.built:
113 | self.layer.build(input_shape)
114 |
115 | self.w = self.layer.kernel
116 | self.w_shape = self.w.shape.as_list()
117 |
118 | # self.v = self.add_weight(shape=(1, self.w_shape[0] * self.w_shape[1] * self.w_shape[2]),
119 | # initializer=tf.initializers.TruncatedNormal(stddev=0.02),
120 | # trainable=False,
121 | # name="sn_v",
122 | # dtype=tf.float32)
123 |
124 | self.u = self.add_weight(shape=(1, self.w_shape[-1]),
125 | initializer=tf.initializers.TruncatedNormal(stddev=0.02),
126 | trainable=False,
127 | name="sn_u",
128 | dtype=tf.float32)
129 |
130 | super(SpectralNormalization, self).build()
131 |
132 | def l2normalize(self, v, eps=1e-12):
133 | return v / (tf.reduce_sum(v ** 2) ** 0.5 + eps)
134 |
135 | def power_iteration(self, W, u, rounds=1):
136 | _u = u
137 |
138 | for _ in range(rounds):
139 | # v_ = tf.matmul(_u, tf.transpose(W))
140 | # v_hat = self.l2normalize(v_)
141 | _v = self.l2normalize(K.dot(_u, K.transpose(W)), eps=self.eps)
142 |
143 | # u_ = tf.matmul(v_hat, W)
144 | # u_hat = self.l2normalize(u_)
145 | _u = self.l2normalize(K.dot(_v, W), eps=self.eps)
146 |
147 | return _u, _v
148 |
149 | def call(self, inputs, training=None):
150 | if training is None:
151 | training = tf.keras.backend.learning_phase()
152 |
153 | if training:
154 | self.update_weights()
155 | output = self.layer(inputs)
156 | self.restore_weights() # Restore weights because of this formula "W = W - alpha * W_SN`"
157 | return output
158 |
159 | return self.layer(inputs)
160 |
161 | def update_weights(self):
162 | w_reshaped = tf.reshape(self.w, [-1, self.w_shape[-1]])
163 |
164 | # u_hat = self.u
165 | # v_hat = self.v # init v vector
166 |
167 | u_hat, v_hat = self.power_iteration(w_reshaped, self.u, self.power_iterations)
168 | # v_ = tf.matmul(u_hat, tf.transpose(w_reshaped))
169 | # # v_hat = v_ / (tf.reduce_sum(v_**2)**0.5 + self.eps)
170 | # v_hat = self.l2normalize(v_, self.eps)
171 |
172 | # u_ = tf.matmul(v_hat, w_reshaped)
173 | # # u_hat = u_ / (tf.reduce_sum(u_**2)**0.5 + self.eps)
174 | # u_hat = self.l2normalize(u_, self.eps)
175 |
176 | # sigma = tf.matmul(tf.matmul(v_hat, w_reshaped), tf.transpose(u_hat))
177 | sigma=K.dot(K.dot(v_hat, w_reshaped), K.transpose(u_hat))
178 | self.u.assign(u_hat)
179 | # self.v.assign(v_hat)
180 |
181 | self.layer.kernel.assign(self.w / sigma)
182 |
183 | def restore_weights(self):
184 | self.layer.kernel.assign(self.w)
--------------------------------------------------------------------------------
/mltu/tensorflow/losses.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 |
3 |
4 | class CTCloss(tf.keras.losses.Loss):
5 | """ CTCLoss objec for training the model"""
6 | def __init__(self, name: str = "CTCloss") -> None:
7 | super(CTCloss, self).__init__()
8 | self.name = name
9 | self.loss_fn = tf.keras.backend.ctc_batch_cost
10 |
11 | def __call__(self, y_true: tf.Tensor, y_pred: tf.Tensor, sample_weight=None) -> tf.Tensor:
12 | """ Compute the training batch CTC loss value"""
13 | batch_len = tf.cast(tf.shape(y_true)[0], dtype="int64")
14 | input_length = tf.cast(tf.shape(y_pred)[1], dtype="int64")
15 | label_length = tf.cast(tf.shape(y_true)[1], dtype="int64")
16 |
17 | input_length = input_length * tf.ones(shape=(batch_len, 1), dtype="int64")
18 | label_length = label_length * tf.ones(shape=(batch_len, 1), dtype="int64")
19 |
20 | loss = self.loss_fn(y_true, y_pred, input_length, label_length)
21 |
22 | return loss
--------------------------------------------------------------------------------
/mltu/tensorflow/model_utils.py:
--------------------------------------------------------------------------------
1 | import typing
2 | import tensorflow as tf
3 | from tensorflow import keras
4 | from keras import layers
5 | from keras.models import Model
6 |
7 | class CustomModel(Model):
8 | """ Custom TensorFlow model for debugging training process purposes
9 | """
10 | def train_step(self, train_data):
11 | # Unpack the data. Its structure depends on your model and
12 | # on what you pass to `fit()`.
13 | inputs, targets = train_data
14 | with tf.GradientTape() as tape:
15 | results = self(inputs, training=True)
16 | loss = self.compiled_loss(targets, results, regularization_losses=self.losses)
17 | gradients = tape.gradient(loss, self.trainable_weights)
18 |
19 | # Applying the gradients on the model using the specified optimizer
20 | self.optimizer.apply_gradients(zip(gradients, self.trainable_weights))
21 |
22 | # Update the metrics.
23 | # Metrics are configured in `compile()`.
24 | self.compiled_metrics.update_state(targets, results)
25 |
26 | return {m.name: m.result() for m in self.metrics}
27 |
28 | def test_step(self, test_data):
29 | inputs, targets = test_data
30 | # Get prediction from model
31 | results = self(inputs, training=False)
32 |
33 | # Update the loss
34 | self.compiled_loss(targets, results, regularization_losses=self.losses)
35 |
36 | # Update the metrics
37 | self.compiled_metrics.update_state(targets, results)
38 |
39 | # Return a dict mapping metric names to current value.
40 | # Note that it will include the loss (tracked in self.metrics).
41 | return {m.name: m.result() for m in self.metrics}
42 |
43 |
44 | def activation_layer(layer, activation: str="relu", alpha: float=0.1) -> tf.Tensor:
45 | """ Activation layer wrapper for LeakyReLU and ReLU activation functions
46 | Args:
47 | layer: tf.Tensor
48 | activation: str, activation function name (default: 'relu')
49 | alpha: float (LeakyReLU activation function parameter)
50 | Returns:
51 | tf.Tensor
52 | """
53 | if activation == "relu":
54 | layer = layers.ReLU()(layer)
55 | elif activation == "leaky_relu":
56 | layer = layers.LeakyReLU(alpha=alpha)(layer)
57 |
58 | return layer
59 |
60 |
61 | def residual_block(
62 | x: tf.Tensor,
63 | filter_num: int,
64 | strides: typing.Union[int, list] = 2,
65 | kernel_size: typing.Union[int, list] = 3,
66 | skip_conv: bool = True,
67 | padding: str = "same",
68 | kernel_initializer: str = "he_uniform",
69 | activation: str = "relu",
70 | dropout: float = 0.2):
71 | # Create skip connection tensor
72 | x_skip = x
73 |
74 | # Perform 1-st convolution
75 | x = layers.Conv2D(filter_num, kernel_size, padding = padding, strides = strides, kernel_initializer=kernel_initializer)(x)
76 | x = layers.BatchNormalization()(x)
77 | x = activation_layer(x, activation=activation)
78 |
79 | # Perform 2-nd convoluti
80 | x = layers.Conv2D(filter_num, kernel_size, padding = padding, kernel_initializer=kernel_initializer)(x)
81 | x = layers.BatchNormalization()(x)
82 |
83 | # Perform 3-rd convolution if skip_conv is True, matchin the number of filters and the shape of the skip connection tensor
84 | if skip_conv:
85 | x_skip = layers.Conv2D(filter_num, 1, padding = padding, strides = strides, kernel_initializer=kernel_initializer)(x_skip)
86 |
87 | # Add x and skip connection and apply activation function
88 | x = layers.Add()([x, x_skip])
89 | x = activation_layer(x, activation=activation)
90 |
91 | # Apply dropout
92 | if dropout:
93 | x = layers.Dropout(dropout)(x)
94 |
95 | return x
--------------------------------------------------------------------------------
/mltu/tensorflow/requirements.txt:
--------------------------------------------------------------------------------
1 | tensorflow==2.10.1
2 | tf2onnx
3 | onnx
--------------------------------------------------------------------------------
/mltu/tensorflow/transformer/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/pythonlessons/mltu/f3033451f62c3fd2097b990c98b25f97773b640d/mltu/tensorflow/transformer/__init__.py
--------------------------------------------------------------------------------
/mltu/tensorflow/transformer/attention.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 |
3 | class BaseAttention(tf.keras.layers.Layer):
4 | """
5 | Base class for all attention layers. It contains the common functionality of all attention layers.
6 | This layer contains a MultiHeadAttention layer, a LayerNormalization layer and an Add layer.
7 | It is used as a base class for the GlobalSelfAttention, CausalSelfAttention and CrossAttention layers.
8 | And it is not intended to be used directly.
9 |
10 | Methods:
11 | call: Performs the forward pass of the layer.
12 |
13 | Attributes:
14 | mha (tf.keras.layers.MultiHeadAttention): The MultiHeadAttention layer.
15 | layernorm (tf.keras.layers.LayerNormalization): The LayerNormalization layer.
16 | add (tf.keras.layers.Add): The Add layer.
17 | """
18 | def __init__(self, **kwargs: dict):
19 | """ Constructor of the BaseAttention layer.
20 |
21 | Args:
22 | **kwargs: Additional keyword arguments that are passed to the MultiHeadAttention layer, e. g.
23 | num_heads (number of heads), key_dim (dimensionality of the key space), etc.
24 | """
25 | super().__init__()
26 | self.mha = tf.keras.layers.MultiHeadAttention(**kwargs)
27 | self.layernorm = tf.keras.layers.LayerNormalization()
28 | self.add = tf.keras.layers.Add()
29 |
30 |
31 | class CrossAttention(BaseAttention):
32 | """
33 | A class that implements the cross-attention layer by inheriting from the BaseAttention class.
34 | This layer is used to process two different sequences and attends to the context sequence while processing the query sequence.
35 |
36 | Methods:
37 | call: Performs the forward pass of the layer.
38 |
39 | Attributes:
40 | mha (tf.keras.layers.MultiHeadAttention): The MultiHeadAttention layer.
41 | layernorm (tf.keras.layers.LayerNormalization): The LayerNormalization layer.
42 | add (tf.keras.layers.Add): The Add layer.
43 | """
44 | def call(self, x: tf.Tensor, context: tf.Tensor) -> tf.Tensor:
45 | """
46 | The call function that performs the cross-attention operation.
47 |
48 | Args:
49 | x (tf.Tensor): The query (expected Transformer results) sequence of shape (batch_size, seq_length, d_model).
50 | context (tf.Tensor): The context (inputs to the Transformer) sequence of shape (batch_size, seq_length, d_model).
51 |
52 | Returns:
53 | tf.Tensor: The output sequence of shape (batch_size, seq_length, d_model).
54 | """
55 | attn_output, attn_scores = self.mha(query=x, key=context, value=context, return_attention_scores=True)
56 |
57 | # Cache the attention scores for plotting later.
58 | self.last_attn_scores = attn_scores
59 |
60 | x = self.add([x, attn_output])
61 | x = self.layernorm(x)
62 |
63 | return x
64 |
65 |
66 | class GlobalSelfAttention(BaseAttention):
67 | """
68 | A class that implements the global self-attention layer by inheriting from the BaseAttention class.
69 | This layer is used to process a single sequence and attends to all the tokens in the sequence.
70 |
71 | Methods:
72 | call: Performs the forward pass of the layer.
73 |
74 | Attributes:
75 | mha (tf.keras.layers.MultiHeadAttention): The MultiHeadAttention layer.
76 | layernorm (tf.keras.layers.LayerNormalization): The LayerNormalization layer.
77 | add (tf.keras.layers.Add): The Add layer.
78 | """
79 | def call(self, x: tf.Tensor) -> tf.Tensor:
80 | """
81 | The call function that performs the global self-attention operation.
82 |
83 | Args:
84 | x (tf.Tensor): The input sequence of shape (batch_size, seq_length, d_model).
85 |
86 | Returns:
87 | tf.Tensor: The output sequence of shape (batch_size, seq_length, d_model).
88 | """
89 | attn_output = self.mha(query=x, value=x, key=x)
90 | x = self.add([x, attn_output])
91 | x = self.layernorm(x)
92 | return x
93 |
94 |
95 | class CausalSelfAttention(BaseAttention):
96 | """
97 | Call self attention on the input sequence, ensuring that each position in the
98 | output depends only on previous positions (i.e. a causal model).
99 |
100 | Methods:
101 | call: Performs the forward pass of the layer.
102 |
103 | Attributes:
104 | mha (tf.keras.layers.MultiHeadAttention): The MultiHeadAttention layer.
105 | layernorm (tf.keras.layers.LayerNormalization): The LayerNormalization layer.
106 | add (tf.keras.layers.Add): The Add layer.
107 | """
108 | def call(self, x: tf.Tensor) -> tf.Tensor:
109 | """
110 | The call function that performs the causal self-attention operation.
111 |
112 | Args:
113 | x (tf.Tensor): The input sequence of shape (batch_size, seq_length, d_model).
114 |
115 | Returns:
116 | tf.Tensor: The output sequence of shape (batch_size, seq_length, d_model).
117 | """
118 | attn_output = self.mha(query=x, value=x, key=x, use_causal_mask = True)
119 | x = self.add([x, attn_output])
120 | x = self.layernorm(x)
121 | return x
--------------------------------------------------------------------------------
/mltu/tensorflow/transformer/callbacks.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | from keras.callbacks import Callback
3 | from mltu.tensorflow.callbacks import Model2onnx
4 |
5 |
6 | class EncDecSplitCallback(Callback):
7 | """Callback to extract the encoder and decoder models from Transformer model and save them separately
8 | Also, this callback incorporates Model2onnx callback to convert the encoder and decoder models to ONNX format
9 |
10 | Args:
11 | model_path (str): Path to save the encoder and decoder models
12 | encoder_metadata (dict, optional): Metadata to save with the encoder model. Defaults to None.
13 | decoder_metadata (dict, optional): Metadata to save with the decoder model. Defaults to None.
14 | """
15 |
16 | def __init__(
17 | self,
18 | model_path: str,
19 | encoder_metadata: dict = None,
20 | decoder_metadata: dict = None,
21 | model_name = "model.h5"
22 | ):
23 | """Callback to extract the encoder and decoder models from Transformer model and save them separately"""
24 | super(EncDecSplitCallback, self).__init__()
25 | self.model_path = model_path
26 | self.encoder_metadata = encoder_metadata
27 | self.decoder_metadata = decoder_metadata
28 | self.model_name = model_name
29 |
30 | def on_train_end(self, epoch: int, logs: dict = None):
31 | try:
32 | # load best model weights
33 | self.model.load_weights(self.model_path + "/" + self.model_name)
34 |
35 | # extract encoder and decoder models
36 | encoder_model = tf.keras.Model(
37 | inputs=self.model.inputs[0], outputs=self.model.get_layer("encoder").output
38 | )
39 | decoder_model = tf.keras.Model(
40 | inputs=[self.model.inputs[1], self.model.get_layer("encoder").output],
41 | outputs=self.model.layers[-1].output,
42 | )
43 |
44 | # save encoder and decoder models
45 | encoder_model.save(self.model_path + "/encoder.h5")
46 | decoder_model.save(self.model_path + "/decoder.h5")
47 |
48 | # convert encoder and decoder models to onnx
49 | Model2onnx.model2onnx(encoder_model, self.model_path + "/encoder.onnx")
50 | Model2onnx.model2onnx(decoder_model, self.model_path + "/decoder.onnx")
51 |
52 | # save encoder and decoder metadata
53 | if self.encoder_metadata:
54 | Model2onnx.include_metadata(self.model_path + "/encoder.onnx", self.encoder_metadata)
55 | if self.decoder_metadata:
56 | Model2onnx.include_metadata(self.model_path + "/decoder.onnx", self.decoder_metadata)
57 | except Exception as e:
58 | print(e)
59 | pass
60 |
--------------------------------------------------------------------------------
/mltu/tensorflow/transformer/utils.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 |
3 |
4 | class MaskedLoss(tf.keras.losses.Loss):
5 | """ Masked loss function for Transformer.
6 |
7 | Args:
8 | mask_value (int, optional): Mask value. Defaults to 0.
9 | reduction (str, optional): Reduction method. Defaults to 'none'.
10 | """
11 | def __init__(self, mask_value: int=0, reduction: str='none') -> None:
12 | super(MaskedLoss, self).__init__()
13 | self.mask_value = mask_value
14 | self.reduction = reduction
15 | self.loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction=reduction)
16 |
17 | def __call__(self, y_true: tf.Tensor, y_pred: tf.Tensor, sample_weight=None) -> tf.Tensor:
18 | """ Calculate masked loss.
19 |
20 | Args:
21 | y_true (tf.Tensor): True labels.
22 | y_pred (tf.Tensor): Predicted labels.
23 |
24 | Returns:
25 | tf.Tensor: Masked loss.
26 | """
27 | mask = y_true != self.mask_value
28 | loss = self.loss_object(y_true, y_pred)
29 |
30 | mask = tf.cast(mask, dtype=loss.dtype)
31 | loss *= mask
32 |
33 | loss = tf.reduce_sum(loss) / tf.reduce_sum(mask)
34 | return loss
35 |
36 |
37 | class MaskedAccuracy(tf.keras.metrics.Metric):
38 | """ Masked accuracy metric for Transformer.
39 |
40 | Args:
41 | mask_value (int, optional): Mask value. Defaults to 0.
42 | name (str, optional): Name of the metric. Defaults to 'masked_accuracy'.
43 | """
44 | def __init__(self, mask_value: int=0, name: str='masked_accuracy') -> None:
45 | super(MaskedAccuracy, self).__init__(name=name)
46 | self.mask_value = mask_value
47 | self.total = self.add_weight(name='total', initializer='zeros')
48 | self.count = self.add_weight(name='count', initializer='zeros')
49 |
50 | @tf.function
51 | def update_state(self, y_true: tf.Tensor, y_pred: tf.Tensor, sample_weight=None):
52 | """ Update state of the metric.
53 |
54 | Args:
55 | y_true (tf.Tensor): True labels.
56 | y_pred (tf.Tensor): Predicted labels.
57 | """
58 | pred = tf.argmax(y_pred, axis=2)
59 | label = tf.cast(y_true, pred.dtype)
60 | match = label == pred
61 |
62 | mask = label != self.mask_value
63 |
64 | match = match & mask
65 |
66 | match = tf.cast(match, dtype=tf.float32)
67 | mask = tf.cast(mask, dtype=tf.float32)
68 | match = tf.reduce_sum(match)
69 | mask = tf.reduce_sum(mask)
70 |
71 | self.total.assign_add(match)
72 | self.count.assign_add(mask)
73 |
74 | def result(self) -> tf.Tensor:
75 | """ Calculate masked accuracy.
76 |
77 | Returns:
78 | tf.Tensor: Masked accuracy.
79 | """
80 | return self.total / self.count
81 |
82 |
83 | class CERMetric(tf.keras.metrics.Metric):
84 | """A custom TensorFlow metric to compute the Character Error Rate (CER).
85 |
86 | Args:
87 | vocabulary: A string of the vocabulary used to encode the labels.
88 | name: (Optional) string name of the metric instance.
89 | **kwargs: Additional keyword arguments.
90 | """
91 | def __init__(self, end_token, padding_token: int=0, name="CER", **kwargs):
92 | # Initialize the base Metric class
93 | super(CERMetric, self).__init__(name=name, **kwargs)
94 |
95 | # Initialize variables to keep track of the cumulative character/word error rates and counter
96 | self.cer_accumulator = tf.Variable(0.0, name="cer_accumulator", dtype=tf.float32)
97 | self.batch_counter = tf.Variable(0, name="batch_counter", dtype=tf.int32)
98 |
99 | self.padding_token = padding_token
100 | self.end_token = end_token
101 |
102 | def get_cer(self, pred, y_true, padding=-1):
103 | """ Calculates the character error rate (CER) between the predicted labels and true labels for a batch of input data.
104 |
105 | Args:
106 | pred(tf.Tensor): The predicted labels, with dtype=tf.int32, usually output from tf.keras.backend.ctc_decode
107 | y_true (tf.Tensor): The true labels, with dtype=tf.int32
108 | padding (int, optional): The padding token when converting to sparse tensor. Defaults to -1.
109 |
110 | Returns:
111 | tf.Tensor: The CER between the predicted labels and true labels
112 | """
113 | # find index where end token is
114 | equal = tf.equal(pred, self.end_token)
115 | equal_int = tf.cast(equal, tf.int64)
116 | end_token_index = tf.argmax(equal_int, axis=1)
117 |
118 | # mask out everything after end token
119 | new_range = tf.range(tf.shape(pred)[1], dtype=tf.int64)
120 | range_matrix = tf.tile(new_range[None, :], [tf.shape(pred)[0], 1])
121 |
122 | mask = range_matrix <= tf.expand_dims(end_token_index, axis=1)
123 | masked_pred = tf.where(mask, pred, padding)
124 |
125 | # Convert the valid predicted labels tensor to a sparse tensor
126 | sparse_pred = tf.RaggedTensor.from_tensor(masked_pred, padding=padding).to_sparse()
127 |
128 | # Convert the valid true labels tensor to a sparse tensor
129 | sparse_true = tf.RaggedTensor.from_tensor(y_true, padding=padding).to_sparse()
130 |
131 | # Calculate the normalized edit distance between the sparse predicted labels tensor and sparse true labels tensor
132 | distance = tf.edit_distance(sparse_pred, sparse_true, normalize=True)
133 |
134 | return distance
135 |
136 | # @tf.function
137 | def update_state(self, y_true, y_pred, sample_weight=None):
138 | """Updates the state variables of the metric.
139 |
140 | Args:
141 | y_true: A tensor of true labels with shape (batch_size, sequence_length).
142 | y_pred: A tensor of predicted labels with shape (batch_size, sequence_length, num_classes).
143 | sample_weight: (Optional) a tensor of weights with shape (batch_size, sequence_length).
144 | """
145 | pred = tf.argmax(y_pred, axis=2)
146 |
147 | # Calculate the normalized edit distance between the predicted labels and true labels tensors
148 | distance = self.get_cer(pred, y_true, self.padding_token)
149 |
150 | # Add the sum of the distance tensor to the cer_accumulator variable
151 | self.cer_accumulator.assign_add(tf.reduce_sum(distance))
152 |
153 | # Increment the batch_counter by the batch size
154 | self.batch_counter.assign_add(len(y_true))
155 |
156 | def result(self):
157 | """ Computes and returns the metric result.
158 |
159 | Returns:
160 | A TensorFlow float representing the CER (character error rate).
161 | """
162 | return tf.math.divide_no_nan(self.cer_accumulator, tf.cast(self.batch_counter, tf.float32))
--------------------------------------------------------------------------------
/mltu/torch/README.md:
--------------------------------------------------------------------------------
1 | # Functions and objects specific for PyTorch and Python 3
--------------------------------------------------------------------------------
/mltu/torch/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/pythonlessons/mltu/f3033451f62c3fd2097b990c98b25f97773b640d/mltu/torch/__init__.py
--------------------------------------------------------------------------------
/mltu/torch/handlers.py:
--------------------------------------------------------------------------------
1 | import typing
2 |
3 | from .metrics import Metric
4 | from .callbacks import Callback
5 |
6 | class MetricsHandler:
7 | """ Metrics handler class for training and testing loops"""
8 | def __init__(self, metrics: typing.List[Metric]):
9 | self.metrics = metrics
10 |
11 | # Validate metrics
12 | if not all(isinstance(m, Metric) for m in self.metrics):
13 | raise TypeError("all items in the metrics argument must be of type Metric (Check mltu.metrics.metrics.py for more information)")
14 |
15 | self.train_results_dict = {"loss": None}
16 | self.train_results_dict.update({metric.name: None for metric in self.metrics})
17 |
18 | self.val_results_dict = {"val_loss": None}
19 | self.val_results_dict.update({"val_" + metric.name: None for metric in self.metrics})
20 |
21 | def update(self, target, output, **kwargs):
22 | for metric in self.metrics:
23 | metric.update(output, target, **kwargs)
24 |
25 | def reset(self):
26 | for metric in self.metrics:
27 | metric.reset()
28 |
29 | def results(self, loss, train: bool=True):
30 | suffix = "val_" if not train else ""
31 | results_dict = self.val_results_dict if not train else self.train_results_dict
32 | results_dict[suffix + "loss"] = loss
33 | for metric in self.metrics:
34 | result = metric.result()
35 | if result:
36 | if isinstance(result, dict):
37 | for k, v in result.items():
38 | results_dict[suffix + k] = v
39 | else:
40 | results_dict[suffix + metric.name] = result
41 |
42 | logs = {k: round(v, 4) for k, v in results_dict.items() if v is not None}
43 | return logs
44 |
45 | def description(self, epoch: int=None, train: bool=True):
46 | epoch_desc = f"Epoch {epoch} - " if epoch is not None else " "
47 | dict = self.train_results_dict if train else self.val_results_dict
48 | return epoch_desc + " - ".join([f"{k}: {v:.4f}" for k, v in dict.items() if v])
49 |
50 |
51 | class CallbacksHandler:
52 | """ Callbacks handler class for training and testing loops"""
53 | def __init__(self, model, callbacks: typing.List[Callback]):
54 | self.callbacks = callbacks
55 |
56 | # Validate callbacks
57 | if not all(isinstance(c, Callback) for c in self.callbacks):
58 | raise TypeError("all items in the callbacks argument must be of type Callback (Check mltu.torch.callbacks.py for more information)")
59 |
60 | for callback in self.callbacks:
61 | callback.model = model
62 |
63 | def on_train_begin(self, logs=None):
64 | for callback in self.callbacks:
65 | callback.on_train_begin(logs)
66 |
67 | def on_train_end(self, logs=None):
68 | for callback in self.callbacks:
69 | callback.on_train_end(logs)
70 |
71 | def on_epoch_begin(self, epoch, logs=None):
72 | for callback in self.callbacks:
73 | callback.on_epoch_begin(epoch, logs)
74 |
75 | def on_epoch_end(self, epoch, logs=None):
76 | for callback in self.callbacks:
77 | callback.on_epoch_end(epoch, logs)
78 |
79 | def on_test_begin(self, logs=None):
80 | for callback in self.callbacks:
81 | callback.on_test_begin(logs)
82 |
83 | def on_test_end(self, logs=None):
84 | for callback in self.callbacks:
85 | callback.on_test_end(logs)
86 |
87 | def on_batch_begin(self, batch: int, logs=None, train: bool=True):
88 | for callback in self.callbacks:
89 | callback.on_batch_begin(batch, logs)
90 |
91 | if train:
92 | callback.on_train_batch_begin(batch, logs)
93 | else:
94 | callback.on_test_batch_begin(batch, logs)
95 |
96 | def on_batch_end(self, batch: int, logs=None, train: bool=True):
97 | for callback in self.callbacks:
98 | callback.on_batch_end(batch, logs)
99 |
100 | if train:
101 | callback.on_train_batch_end(batch, logs)
102 | else:
103 | callback.on_test_batch_end(batch, logs)
--------------------------------------------------------------------------------
/mltu/torch/losses.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 |
4 | class CTCLoss(nn.Module):
5 | """ CTC loss for PyTorch
6 | """
7 | def __init__(self, blank: int, reduction: str="mean", zero_infinity: bool=False):
8 | """ CTC loss for PyTorch
9 |
10 | Args:
11 | blank: Index of the blank label
12 | """
13 | super(CTCLoss, self).__init__()
14 | self.ctc_loss = nn.CTCLoss(blank=blank, reduction=reduction, zero_infinity=zero_infinity)
15 | self.blank = blank
16 |
17 | def forward(self, output, target):
18 | """
19 | Args:
20 | output: Tensor of shape (batch_size, num_classes, sequence_length)
21 | target: Tensor of shape (batch_size, sequence_length)
22 |
23 | Returns:
24 | loss: Scalar
25 | """
26 | # Remove padding and blank tokens from target
27 | target_lengths = torch.sum(target != self.blank, dim=1)
28 | using_dtype = torch.int32 if max(target_lengths) <= 256 else torch.int64
29 | device = output.device
30 |
31 | target_unpadded = target[target != self.blank].view(-1).to(using_dtype)
32 |
33 | output = output.permute(1, 0, 2) # (sequence_length, batch_size, num_classes)
34 | output_lengths = torch.full(size=(output.size(1),), fill_value=output.size(0), dtype=using_dtype).to(device)
35 |
36 | loss = self.ctc_loss(output, target_unpadded, output_lengths, target_lengths.to(using_dtype))
37 |
38 | return loss
--------------------------------------------------------------------------------
/mltu/torch/metrics.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import typing
3 | import numpy as np
4 | from itertools import groupby
5 |
6 | from mltu.utils.text_utils import get_cer, get_wer
7 |
8 |
9 | class Metric:
10 | """ Base class for all metrics"""
11 | def __init__(self, name: str) -> None:
12 | """ Initialize metric with name
13 |
14 | Args:
15 | name (str): name of metric
16 | """
17 | self.name = name
18 |
19 | def reset(self):
20 | """ Reset metric state to initial values and return metric value"""
21 | self.__init__()
22 |
23 | def update(self, output: torch.Tensor, target: torch.Tensor, **kwargs):
24 | """ Update metric state with new data
25 |
26 | Args:
27 | output (torch.Tensor): output of model
28 | target (torch.Tensor): target of data
29 | """
30 | pass
31 |
32 | def result(self):
33 | """ Return metric value"""
34 | pass
35 |
36 |
37 | class Accuracy(Metric):
38 | """ Accuracy metric class
39 |
40 | Args:
41 | name (str, optional): name of metric. Defaults to 'accuracy'.
42 | """
43 | def __init__(self, name="accuracy") -> None:
44 | super(Accuracy, self).__init__(name=name)
45 | self.correct = 0
46 | self.total = 0
47 |
48 | def update(self, output: torch.Tensor, target: torch.Tensor, **kwargs):
49 | """ Update metric state with new data
50 |
51 | Args:
52 | output (torch.Tensor): output of model
53 | target (torch.Tensor): target of data
54 | """
55 | _, predicted = torch.max(output.data, 1)
56 | self.total += target.size(0)
57 | self.correct += (predicted == target).sum().item()
58 |
59 | def result(self):
60 | """ Return metric value"""
61 | return self.correct / self.total
62 |
63 |
64 | class CERMetric(Metric):
65 | """A custom PyTorch metric to compute the Character Error Rate (CER).
66 |
67 | Args:
68 | vocabulary: A string of the vocabulary used to encode the labels.
69 | name: (Optional) string name of the metric instance.
70 |
71 | # TODO: implement everything in Torch to avoid converting to numpy
72 | """
73 | def __init__(
74 | self,
75 | vocabulary: typing.Union[str, list],
76 | name: str = "CER"
77 | ) -> None:
78 | super(CERMetric, self).__init__(name=name)
79 | self.vocabulary = vocabulary
80 | self.reset()
81 |
82 | def reset(self):
83 | """ Reset metric state to initial values"""
84 | self.cer = 0
85 | self.counter = 0
86 |
87 | def update(self, output: torch.Tensor, target: torch.Tensor, **kwargs) -> None:
88 | """ Update metric state with new data
89 |
90 | Args:
91 | output (torch.Tensor): output of model
92 | target (torch.Tensor): target of data
93 | """
94 | # convert to numpy
95 | output = output.detach().cpu().numpy()
96 | target = target.detach().cpu().numpy()
97 | # use argmax to find the index of the highest probability
98 | argmax_preds = np.argmax(output, axis=-1)
99 |
100 | # use groupby to find continuous same indexes
101 | grouped_preds = [[k for k,_ in groupby(preds)] for preds in argmax_preds]
102 |
103 | # convert indexes to strings
104 | output_texts = ["".join([self.vocabulary[k] for k in group if k < len(self.vocabulary)]) for group in grouped_preds]
105 | target_texts = ["".join([self.vocabulary[k] for k in group if k < len(self.vocabulary)]) for group in target]
106 |
107 | cer = get_cer(output_texts, target_texts)
108 |
109 | self.cer += cer
110 | self.counter += 1
111 |
112 | def result(self) -> float:
113 | """ Return metric value"""
114 | return self.cer / self.counter
115 |
116 |
117 | class WERMetric(Metric):
118 | """A custom PyTorch metric to compute the Word Error Rate (WER).
119 |
120 | Args:
121 | vocabulary: A string of the vocabulary used to encode the labels.
122 | name: (Optional) string name of the metric instance.
123 |
124 | # TODO: implement everything in Torch to avoid converting to numpy
125 | """
126 | def __init__(
127 | self,
128 | vocabulary: typing.Union[str, list],
129 | name: str = "WER"
130 | ) -> None:
131 | super(WERMetric, self).__init__(name=name)
132 | self.vocabulary = vocabulary
133 | self.reset()
134 |
135 | def reset(self):
136 | """ Reset metric state to initial values"""
137 | self.wer = 0
138 | self.counter = 0
139 |
140 | def update(self, output: torch.Tensor, target: torch.Tensor, **kwargs) -> None:
141 | """ Update metric state with new data
142 |
143 | Args:
144 | output (torch.Tensor): output of model
145 | target (torch.Tensor): target of data
146 | """
147 | # convert to numpy
148 | output = output.detach().cpu().numpy()
149 | target = target.detach().cpu().numpy()
150 | # use argmax to find the index of the highest probability
151 | argmax_preds = np.argmax(output, axis=-1)
152 |
153 | # use groupby to find continuous same indexes
154 | grouped_preds = [[k for k,_ in groupby(preds)] for preds in argmax_preds]
155 |
156 | # convert indexes to strings
157 | output_texts = ["".join([self.vocabulary[k] for k in group if k < len(self.vocabulary)]) for group in grouped_preds]
158 | target_texts = ["".join([self.vocabulary[k] for k in group if k < len(self.vocabulary)]) for group in target]
159 |
160 | wer = get_wer(output_texts, target_texts)
161 |
162 | self.wer += wer
163 | self.counter += 1
164 |
165 | def result(self) -> float:
166 | """ Return metric value"""
167 | return self.wer / self.counter
--------------------------------------------------------------------------------
/mltu/torch/requirements.txt:
--------------------------------------------------------------------------------
1 | torch==1.13.1
2 | tensorboard==2.10.1
3 | onnx==1.12.0
4 | torchsummaryX
--------------------------------------------------------------------------------
/mltu/torch/yolo/README.md:
--------------------------------------------------------------------------------
1 | ## Update Readme
--------------------------------------------------------------------------------
/mltu/torch/yolo/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/pythonlessons/mltu/f3033451f62c3fd2097b990c98b25f97773b640d/mltu/torch/yolo/__init__.py
--------------------------------------------------------------------------------
/mltu/torch/yolo/annotation.py:
--------------------------------------------------------------------------------
1 | import os
2 | import typing
3 | from pathlib import Path
4 | import xml.etree.ElementTree as ET
5 | from mltu.annotations.detections import Detections, Detection, BboxType
6 |
7 | class VOCAnnotationReader:
8 | """Reads annotations from VOC format
9 | """
10 | def __init__(self, labels: dict, images_path: str=None):
11 | self.labels = labels
12 | self.images_path = images_path
13 | self.dataset_found_labels = {}
14 |
15 | @staticmethod
16 | def readFromVOC(voc_annotation_path: str, labels: dict={}, images_path: str=None) -> Detections:
17 | annotation_path = Path(voc_annotation_path)
18 | tree = ET.parse(voc_annotation_path)
19 | root = tree.getroot()
20 |
21 | annotation_dict = {}
22 |
23 | # Iterate through child elements
24 | for child in root:
25 | if child.tag == 'object':
26 | obj_dict = {}
27 | for obj_child in child:
28 | if obj_child.tag == 'bndbox':
29 | bbox_dict = {}
30 | for bbox_child in obj_child:
31 | bbox_dict[bbox_child.tag] = int(bbox_child.text)
32 | obj_dict[obj_child.tag] = bbox_dict
33 | else:
34 | obj_dict[obj_child.tag] = obj_child.text
35 | if 'objects' not in annotation_dict:
36 | annotation_dict['objects'] = []
37 | annotation_dict['objects'].append(obj_dict)
38 | elif child.tag == 'size':
39 | size_dict = {}
40 | for size_child in child:
41 | size_dict[size_child.tag] = int(size_child.text)
42 | annotation_dict['size'] = size_dict
43 | else:
44 | annotation_dict[child.tag] = child.text
45 |
46 | # Get the image path if not provided
47 | if images_path is None:
48 | images_path = annotation_path.parent.parent / annotation_dict["folder"]
49 |
50 | image_path = os.path.join(images_path, annotation_dict['filename'])
51 | dets = []
52 | for obj in annotation_dict['objects']:
53 | if labels and obj['name'] not in labels.values():
54 | print(f"Label {obj['name']} not found in labels")
55 | continue
56 |
57 | dets.append(Detection(
58 | bbox=[obj['bndbox']['xmin'], obj['bndbox']['ymin'], obj['bndbox']['xmax'], obj['bndbox']['ymax']],
59 | label=obj['name'],
60 | bbox_type=BboxType.XYXY,
61 | confidence=1,
62 | image_path=image_path,
63 | width=annotation_dict['size']['width'],
64 | height=annotation_dict['size']['height'],
65 | relative=False
66 | ))
67 |
68 | detections = Detections(
69 | labels=labels,
70 | width=annotation_dict['size']['width'],
71 | height=annotation_dict['size']['height'],
72 | image_path=image_path,
73 | detections=dets
74 | )
75 |
76 | return detections
77 |
78 | def __call__(self, image: typing.Any, annotation: str) -> typing.Tuple[typing.Any, Detections]:
79 | detections = self.readFromVOC(annotation, self.labels, self.images_path)
80 | if image is None:
81 | image = detections.image_path
82 | return image, detections
--------------------------------------------------------------------------------
/mltu/torch/yolo/detectors/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/pythonlessons/mltu/f3033451f62c3fd2097b990c98b25f97773b640d/mltu/torch/yolo/detectors/__init__.py
--------------------------------------------------------------------------------
/mltu/torch/yolo/detectors/detector.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import numpy as np
3 | from mltu.inferenceModel import FpsWrapper
4 |
5 | class BaseDetector:
6 | """Base class for the detectors in the YOLO family"""
7 | @staticmethod
8 | def preprocess(image: np.ndarray, height: int, width: int):
9 | # Convert the image color space from BGR to RGB
10 | img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
11 |
12 | # Resize the image to match the input shape
13 | img = cv2.resize(img, (width, height))
14 |
15 | # Normalize the image data by dividing it by 255.0
16 | image_data = np.array(img) / 255.0
17 |
18 | # Transpose the image to have the channel dimension as the first dimension
19 | image_data = np.transpose(image_data, (2, 0, 1)) # Channel first
20 |
21 | # Expand the dimensions of the image data to match the expected input shape
22 | image_data = np.expand_dims(image_data, axis=0).astype(np.float32)
23 |
24 | return image_data
25 |
26 | @staticmethod
27 | def postprocess(outputs: np.ndarray, x_factor: float, y_factor: float, confidence_threshold: float=0.5, iou_threshold: float=0.5):
28 | # Transpose and squeeze the output to match the expected shape
29 | outputs = np.transpose(np.squeeze(outputs))
30 |
31 | # Extract all classes confidence scores
32 | conf_scores = np.amax(outputs[:, 4:], axis=1)
33 |
34 | # Get the data index of the detections with scores above the confidence threshold
35 | indexes = np.where(conf_scores >= confidence_threshold)[0]
36 |
37 | # Extract the confidence scores of the detections
38 | scores = conf_scores[indexes]
39 |
40 | # Extract the class IDs of the detections
41 | class_ids = np.argmax(outputs[indexes, 4:], axis=1)
42 |
43 | # Extract the bounding box coordinates from the outputs and transform them to the original image space
44 | boxes = outputs[indexes, :4] * np.array([x_factor, y_factor, x_factor, y_factor])
45 |
46 | # Apply non-maximum suppression to filter out overlapping bounding boxes
47 | indices = cv2.dnn.NMSBoxes(boxes, scores, confidence_threshold, iou_threshold)
48 |
49 | # Iterate over the selected indices after non-maximum suppression
50 | return boxes[indices], scores[indices], class_ids[indices]
51 |
52 | def predict(self, image: np.ndarray, **kwargs) -> np.ndarray:
53 | ...
54 |
55 | @FpsWrapper
56 | def __call__(self, image: np.ndarray):
57 | results = self.predict(image)
58 | return results
--------------------------------------------------------------------------------
/mltu/torch/yolo/detectors/onnx_detector.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from mltu.inferenceModel import OnnxInferenceModel
3 | from mltu.torch.yolo.detectors.detector import BaseDetector
4 | from mltu.annotations.detections import BboxType, Detection, Detections
5 |
6 | class Detector(OnnxInferenceModel, BaseDetector):
7 | """ YOLOv8 detector using onnxruntime"""
8 | def __init__(
9 | self,
10 | model_path: str,
11 | input_width: int,
12 | input_height: int,
13 | confidence_threshold: float=0.5,
14 | iou_threshold: float=0.5,
15 | classes: dict = None,
16 | return_raw_output: bool=False,
17 | *args, **kwargs
18 | ):
19 | """
20 | Args:
21 | model_path (str): Path to the model file
22 | input_width (int): Input width to use for the model
23 | input_height (int): Input height to use for the model
24 | confidence_threshold (float, optional): Confidence threshold for filtering the predictions. Defaults to 0.5.
25 | iou_threshold (float, optional): Intersection over union threshold for filtering the predictions. Defaults to 0.5.
26 | classes (dict, optional): Dictionary of class names. Defaults to None.
27 | return_raw_output (bool, optional): Return raw output of the model (return bounding boxes, scores, and class ids). Defaults to False.
28 | """
29 | super().__init__(model_path, *args, **kwargs)
30 | self.input_width = input_width
31 | self.input_height = input_height
32 | self.confidence_threshold = confidence_threshold
33 | self.iou_threshold = iou_threshold
34 | self.return_raw_output = return_raw_output
35 |
36 | self.classes = classes or self.metadata.get("classes", None)
37 | if self.classes is None:
38 | raise ValueError("The classes must be provided")
39 |
40 | # Generate a color palette for the classes
41 | self.color_palette = np.random.uniform(0, 255, size=(len(self.classes), 3))
42 |
43 | def predict(self, image: np.ndarray, **kwargs) -> Detections:
44 | img_height, img_width, _ = image.shape
45 |
46 | # Preprocess the image
47 | preprocessed_image = self.preprocess(image, self.input_height, self.input_width)
48 |
49 | # Perform inference on the preprocessed image
50 | preds = self.model.run(self.output_names, {self.input_names[0]: preprocessed_image})
51 |
52 | # Extract the results from the predictions
53 | results = preds[0][0]
54 |
55 | # Calculate the scaling factors for the bounding box coordinates
56 | x_factor, y_factor = img_width / self.input_width, img_height / self.input_height
57 |
58 | # Perform postprocessing on the predictions
59 | boxes, scores, class_ids = self.postprocess(results, x_factor, y_factor, self.confidence_threshold, self.iou_threshold)
60 |
61 | if self.return_raw_output:
62 | return boxes, scores, class_ids
63 |
64 | detections = []
65 | for bbox, conf, class_id in zip(boxes, scores, class_ids):
66 | detection = Detection(
67 | bbox = bbox,
68 | label = self.classes[class_id],
69 | labels = self.classes,
70 | bbox_type=BboxType.XYWH,
71 | confidence=conf,
72 | relative=False,
73 | width=img_width,
74 | height=img_height
75 | )
76 | detections.append(detection)
77 |
78 | return Detections(
79 | labels=self.classes,
80 | width=img_width,
81 | height=img_height,
82 | detections=detections,
83 | color_palette=self.color_palette,
84 | )
--------------------------------------------------------------------------------
/mltu/torch/yolo/detectors/torch_detector.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | from mltu.torch.yolo.detectors.detector import BaseDetector
4 | from mltu.annotations.detections import BboxType, Detection, Detections
5 |
6 | class Detector(BaseDetector):
7 | def __init__(
8 | self,
9 | model,
10 | input_width: int,
11 | input_height: int,
12 | classes: dict,
13 | confidence_threshold: float=0.5,
14 | iou_threshold: float=0.5,
15 | device: str="cuda"
16 | ):
17 | super().__init__()
18 | self.model = model
19 | self.input_width = input_width
20 | self.input_height = input_height
21 | self.classes = classes
22 | self.confidence_threshold = confidence_threshold
23 | self.iou_threshold = iou_threshold
24 | self.device = torch.device(device if torch.cuda.is_available() else "cpu")
25 | self.model.to(self.device)
26 | self.model.eval()
27 |
28 | # Generate a color palette for the classes
29 | self.color_palette = np.random.uniform(0, 255, size=(len(self.classes), 3))
30 |
31 | def predict(self, image: np.ndarray, **kwargs) -> Detections:
32 | img_height, img_width, _ = image.shape
33 |
34 | # Preprocess the image
35 | preprocessed_image = self.preprocess(image, self.input_height, self.input_width)
36 |
37 | # Perform inference on the preprocessed image
38 | preds = self.model(torch.tensor(preprocessed_image).to(self.device))
39 |
40 | # Convert torch tensor to numpy array
41 | results = preds[0].cpu().detach().numpy()
42 |
43 | # Calculate the scaling factors for the bounding box coordinates
44 | x_factor, y_factor = img_width / self.input_width, img_height / self.input_height
45 |
46 | # Perform postprocessing on the predictions
47 | boxes, scores, class_ids = self.postprocess(results, x_factor, y_factor, self.confidence_threshold, self.iou_threshold)
48 |
49 | detections = []
50 | for bbox, conf, class_id in zip(boxes, scores, class_ids):
51 | detection = Detection(
52 | bbox = bbox,
53 | label = self.classes[class_id],
54 | labels = self.classes,
55 | bbox_type=BboxType.XYWH,
56 | confidence=conf,
57 | relative=False,
58 | width=img_width,
59 | height=img_height
60 | )
61 | detections.append(detection)
62 |
63 | return Detections(
64 | labels=self.classes,
65 | width=img_width,
66 | height=img_height,
67 | detections=detections,
68 | color_palette=self.color_palette,
69 | )
--------------------------------------------------------------------------------
/mltu/torch/yolo/loss.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch import nn
3 |
4 | from ultralytics.utils.loss import BboxLoss, xywh2xyxy
5 | from ultralytics.utils.tal import TaskAlignedAssigner, dist2bbox, make_anchors
6 |
7 | class v8DetectionLoss:
8 | """Criterion class for computing training losses."""
9 |
10 | def __init__(self, model, box: float=7.5, cls: float=0.5, dfl: float=1.5): # model must be de-paralleled
11 | """Initializes v8DetectionLoss with the model, defining model-related properties and BCE loss function."""
12 | self.model = model
13 | device = next(model.parameters()).device # get model device
14 |
15 | self.head = model.model[-1] # Detect() module
16 | self.bce = nn.BCEWithLogitsLoss(reduction="none")
17 | self.stride = self.head.stride # model strides
18 | self.nc = self.head.nc # number of classes
19 | self.no = self.head.no
20 | self.reg_max = self.head.reg_max # max number of regression targets
21 | self.device = device
22 |
23 | self.use_dfl = self.head.reg_max > 1
24 |
25 | self.assigner = TaskAlignedAssigner(topk=10, num_classes=self.nc, alpha=0.5, beta=6.0)
26 | self.bbox_loss = BboxLoss(self.head.reg_max - 1, use_dfl=self.use_dfl).to(device)
27 | self.proj = torch.arange(self.head.reg_max, dtype=torch.float, device=device).to(device)
28 |
29 | self.box = box # box gain
30 | self.cls = cls # cls gain
31 | self.dfl = dfl # dfl gain
32 |
33 | def preprocess(self, targets, batch_size, scale_tensor):
34 | """Preprocesses the target counts and matches with the input batch size to output a tensor."""
35 | if targets.shape[0] == 0:
36 | out = torch.zeros(batch_size, 0, 5, device=self.device)
37 | else:
38 | i = targets[:, 0] # image index
39 | _, counts = i.unique(return_counts=True)
40 | counts = counts.to(dtype=torch.int32)
41 | out = torch.zeros(batch_size, counts.max(), 5, device=self.device)
42 | for j in range(batch_size):
43 | matches = i == j
44 | n = matches.sum()
45 | if n:
46 | out[j, :n] = targets[matches, 1:]
47 | out[..., 1:5] = xywh2xyxy(out[..., 1:5].mul_(scale_tensor))
48 | return out
49 |
50 | def bbox_decode(self, anchor_points, pred_dist):
51 | """Decode predicted object bounding box coordinates from anchor points and distribution."""
52 | if self.use_dfl:
53 | b, a, c = pred_dist.shape # batch, anchors, channels
54 | self.proj = self.proj.to(pred_dist.device)
55 | pred_dist = pred_dist.view(b, a, 4, c // 4).softmax(3).matmul(self.proj.type(pred_dist.dtype))
56 |
57 | return dist2bbox(pred_dist, anchor_points, xywh=False)
58 |
59 | def __call__(self, preds, batch):
60 | """Calculate the sum of the loss for box, cls and dfl multiplied by batch size."""
61 | loss = torch.zeros(3, device=self.device) # box, cls, dfl
62 | feats = preds[1] if isinstance(preds, tuple) else preds
63 | pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
64 | (self.reg_max * 4, self.nc), 1
65 | )
66 |
67 | pred_scores = pred_scores.permute(0, 2, 1).contiguous()
68 | pred_distri = pred_distri.permute(0, 2, 1).contiguous()
69 |
70 | dtype = pred_scores.dtype
71 | batch_size = pred_scores.shape[0]
72 | imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)
73 | anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)
74 |
75 | # Targets
76 | targets = torch.cat((batch["batch_idx"].view(-1, 1), batch["cls"].view(-1, 1), batch["bboxes"]), 1)
77 | targets = self.preprocess(targets.to(self.device), batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])
78 | gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxy
79 | mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0)
80 |
81 | # Pboxes
82 | pred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)
83 |
84 | _, target_bboxes, target_scores, fg_mask, _ = self.assigner(
85 | pred_scores.detach().sigmoid(),
86 | (pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),
87 | anchor_points * stride_tensor,
88 | gt_labels,
89 | gt_bboxes,
90 | mask_gt,
91 | )
92 |
93 | target_scores_sum = max(target_scores.sum(), 1)
94 |
95 | # Cls loss
96 | loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
97 |
98 | # Bbox loss
99 | if fg_mask.sum():
100 | target_bboxes /= stride_tensor
101 | loss[0], loss[2] = self.bbox_loss(
102 | pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask
103 | )
104 |
105 | loss[0] *= self.box # box gain
106 | loss[1] *= self.cls # cls gain
107 | loss[2] *= self.dfl # dfl gain
108 |
109 | detailed_loss = {"box_loss": loss[0].detach(), "cls_loss": loss[1].detach(), "dfl_loss": loss[2].detach()}
110 |
111 | return loss.sum() * batch_size, detailed_loss # loss(box, cls, dfl)
--------------------------------------------------------------------------------
/mltu/torch/yolo/optimizer.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch import nn
3 |
4 | class AccumulativeOptimizer(torch.optim.Optimizer):
5 | def __init__(self, optimizer, batch_size, nbs=64):
6 | super(AccumulativeOptimizer, self).__init__(optimizer.param_groups, optimizer.defaults)
7 | self.optimizer = optimizer
8 | self.accumulation_steps = int(nbs / batch_size)
9 | self.current_step = 0
10 |
11 | def zero_grad(self):
12 | if self.current_step == 0:
13 | self.optimizer.zero_grad()
14 |
15 | def step(self):
16 | self.current_step += 1
17 | if self.current_step >= self.accumulation_steps:
18 | self.optimizer.step()
19 | self.current_step = 0
20 | self.optimizer.zero_grad()
21 |
22 |
23 | def build_optimizer(model, name: str="AdamW", lr: float=1e-3, weight_decay: float=0.0, momentum: float=0.937, decay=0.0005):
24 |
25 | pg0, pg1, pg2 = [], [], [] # optimizer parameter groups
26 | bn = tuple(v for k, v in nn.__dict__.items() if "Norm" in k) # normalization layers, i.e. BatchNorm2d()
27 | for module_name, module in model.named_modules():
28 | for param_name, param in module.named_parameters(recurse=False):
29 | fullname = f"{module_name}.{param_name}" if module_name else param_name
30 | if "bias" in fullname: # bias (no decay)
31 | pg2.append(param)
32 | elif isinstance(module, bn): # weight (no decay)
33 | pg1.append(param)
34 | else: # weight (with decay)
35 | pg0.append(param)
36 |
37 | if name == "AdamW":
38 | optimizer = torch.optim.AdamW(pg2, lr=lr, weight_decay=weight_decay, betas=(momentum, 0.999))
39 | elif name == "Adam":
40 | optimizer = torch.optim.Adam(pg2, lr=lr, weight_decay=weight_decay, betas=(momentum, 0.999))
41 | elif name == "SGD":
42 | optimizer = torch.optim.SGD(pg2, lr=lr, weight_decay=weight_decay, momentum=0.9)
43 | else:
44 | raise ValueError(f"Optimizer {name} not supported!")
45 |
46 | optimizer.add_param_group({'params': pg0, 'weight_decay': decay}) # add pg1 with weight_decay
47 | optimizer.add_param_group({'params': pg1, 'weight_decay': 0.0}) # add pg2 (biases)
48 |
49 | del pg0, pg1, pg2
50 |
51 | return optimizer
--------------------------------------------------------------------------------
/mltu/torch/yolo/preprocessors.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import typing
3 | import numpy as np
4 |
5 | class YoloPreprocessor:
6 | def __init__(self, device: torch.device, imgsz: int=640):
7 | self.device = device
8 | self.imgsz = imgsz
9 |
10 | def __call__(self, images, annotations) -> typing.Tuple[np.ndarray, dict]:
11 | batch = {
12 | "ori_shape": [],
13 | "resized_shape": [],
14 | "cls": [],
15 | "bboxes": [],
16 | "batch_idx": [],
17 | }
18 |
19 | for i, (image, detections) in enumerate(zip(images, annotations)):
20 | batch["ori_shape"].append([detections.height, detections.width])
21 | batch["resized_shape"].append([self.imgsz, self.imgsz])
22 | for detection in detections:
23 | batch["cls"].append([detection.labelId])
24 | batch["bboxes"].append(detection.xywh)
25 | batch["batch_idx"].append(i)
26 |
27 | batch["cls"] = torch.tensor(np.array(batch["cls"])).to(self.device)
28 | batch["bboxes"] = torch.tensor(np.array(batch["bboxes"])).to(self.device)
29 | batch["batch_idx"] = torch.tensor(np.array(batch["batch_idx"])).to(self.device)
30 |
31 | return np.array(images), batch
--------------------------------------------------------------------------------
/mltu/torch/yolo/pruning_utils.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch import nn
3 | from ultralytics.nn.modules import C2f, Conv, Bottleneck
4 |
5 | def infer_shortcut(bottleneck):
6 | c1 = bottleneck.cv1.conv.in_channels
7 | c2 = bottleneck.cv2.conv.out_channels
8 | return c1 == c2 and hasattr(bottleneck, 'add') and bottleneck.add
9 |
10 | class C2f_v2(nn.Module):
11 | # CSP Bottleneck with 2 convolutions
12 | def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
13 | super().__init__()
14 | self.c = int(c2 * e) # hidden channels
15 | self.cv0 = Conv(c1, self.c, 1, 1)
16 | self.cv1 = Conv(c1, self.c, 1, 1)
17 | self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
18 | self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
19 |
20 | def forward(self, x):
21 | # y = list(self.cv1(x).chunk(2, 1))
22 | y = [self.cv0(x), self.cv1(x)]
23 | y.extend(m(y[-1]) for m in self.m)
24 | return self.cv2(torch.cat(y, 1))
25 |
26 | def transfer_weights(c2f, c2f_v2):
27 | c2f_v2.cv2 = c2f.cv2
28 | c2f_v2.m = c2f.m
29 |
30 | state_dict = c2f.state_dict()
31 | state_dict_v2 = c2f_v2.state_dict()
32 |
33 | # Transfer cv1 weights from C2f to cv0 and cv1 in C2f_v2
34 | old_weight = state_dict['cv1.conv.weight']
35 | half_channels = old_weight.shape[0] // 2
36 | state_dict_v2['cv0.conv.weight'] = old_weight[:half_channels]
37 | state_dict_v2['cv1.conv.weight'] = old_weight[half_channels:]
38 |
39 | # Transfer cv1 batchnorm weights and buffers from C2f to cv0 and cv1 in C2f_v2
40 | for bn_key in ['weight', 'bias', 'running_mean', 'running_var']:
41 | old_bn = state_dict[f'cv1.bn.{bn_key}']
42 | state_dict_v2[f'cv0.bn.{bn_key}'] = old_bn[:half_channels]
43 | state_dict_v2[f'cv1.bn.{bn_key}'] = old_bn[half_channels:]
44 |
45 | # Transfer remaining weights and buffers
46 | for key in state_dict:
47 | if not key.startswith('cv1.'):
48 | state_dict_v2[key] = state_dict[key]
49 |
50 | # Transfer all non-method attributes
51 | for attr_name in dir(c2f):
52 | attr_value = getattr(c2f, attr_name)
53 | if not callable(attr_value) and '_' not in attr_name:
54 | setattr(c2f_v2, attr_name, attr_value)
55 |
56 | c2f_v2.load_state_dict(state_dict_v2)
57 |
58 | def replace_c2f_with_c2f_v2(module):
59 | for name, child_module in module.named_children():
60 | if isinstance(child_module, C2f):
61 | # Replace C2f with C2f_v2 while preserving its parameters
62 | shortcut = infer_shortcut(child_module.m[0])
63 | c2f_v2 = C2f_v2(child_module.cv1.conv.in_channels, child_module.cv2.conv.out_channels,
64 | n=len(child_module.m), shortcut=shortcut,
65 | g=child_module.m[0].cv2.conv.groups,
66 | e=child_module.c / child_module.cv2.conv.out_channels)
67 | transfer_weights(child_module, c2f_v2)
68 | setattr(module, name, c2f_v2)
69 | else:
70 | replace_c2f_with_c2f_v2(child_module)
--------------------------------------------------------------------------------
/mltu/torch/yolo/requirements.txt:
--------------------------------------------------------------------------------
1 | ultralytics==8.1.9
2 | torch==2.0.0
3 | torchvision==0.15.1
4 | torch_pruning==1.3.6
--------------------------------------------------------------------------------
/mltu/utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/pythonlessons/mltu/f3033451f62c3fd2097b990c98b25f97773b640d/mltu/utils/__init__.py
--------------------------------------------------------------------------------
/mltu/utils/text_utils.py:
--------------------------------------------------------------------------------
1 | import typing
2 | import numpy as np
3 | from itertools import groupby
4 |
5 |
6 | def ctc_decoder(predictions: np.ndarray, chars: typing.Union[str, list]) -> typing.List[str]:
7 | """ CTC greedy decoder for predictions
8 |
9 | Args:
10 | predictions (np.ndarray): predictions from model
11 | chars (typing.Union[str, list]): list of characters
12 |
13 | Returns:
14 | typing.List[str]: list of words
15 | """
16 | # use argmax to find the index of the highest probability
17 | argmax_preds = np.argmax(predictions, axis=-1)
18 |
19 | # use groupby to find continuous same indexes
20 | grouped_preds = [[k for k,_ in groupby(preds)] for preds in argmax_preds]
21 |
22 | # convert indexes to chars
23 | texts = ["".join([chars[k] for k in group if k < len(chars)]) for group in grouped_preds]
24 |
25 | return texts
26 |
27 |
28 | def edit_distance(prediction_tokens: typing.List[str], reference_tokens: typing.List[str]) -> int:
29 | """ Standard dynamic programming algorithm to compute the Levenshtein Edit Distance Algorithm
30 |
31 | Args:
32 | prediction_tokens: A tokenized predicted sentence
33 | reference_tokens: A tokenized reference sentence
34 | Returns:
35 | Edit distance between the predicted sentence and the reference sentence
36 | """
37 | # Initialize a matrix to store the edit distances
38 | dp = [[0] * (len(reference_tokens) + 1) for _ in range(len(prediction_tokens) + 1)]
39 |
40 | # Fill the first row and column with the number of insertions needed
41 | for i in range(len(prediction_tokens) + 1):
42 | dp[i][0] = i
43 |
44 | for j in range(len(reference_tokens) + 1):
45 | dp[0][j] = j
46 |
47 | # Iterate through the prediction and reference tokens
48 | for i, p_tok in enumerate(prediction_tokens):
49 | for j, r_tok in enumerate(reference_tokens):
50 | # If the tokens are the same, the edit distance is the same as the previous entry
51 | if p_tok == r_tok:
52 | dp[i+1][j+1] = dp[i][j]
53 | # If the tokens are different, the edit distance is the minimum of the previous entries plus 1
54 | else:
55 | dp[i+1][j+1] = min(dp[i][j+1], dp[i+1][j], dp[i][j]) + 1
56 |
57 | # Return the final entry in the matrix as the edit distance
58 | return dp[-1][-1]
59 |
60 | def get_cer(
61 | preds: typing.Union[str, typing.List[str]],
62 | target: typing.Union[str, typing.List[str]],
63 | ) -> float:
64 | """ Update the cer score with the current set of references and predictions.
65 |
66 | Args:
67 | preds (typing.Union[str, typing.List[str]]): list of predicted sentences
68 | target (typing.Union[str, typing.List[str]]): list of target words
69 |
70 | Returns:
71 | Character error rate score
72 | """
73 | if isinstance(preds, str):
74 | preds = [preds]
75 | if isinstance(target, str):
76 | target = [target]
77 |
78 | total, errors = 0, 0
79 | for pred_tokens, tgt_tokens in zip(preds, target):
80 | errors += edit_distance(list(pred_tokens), list(tgt_tokens))
81 | total += len(tgt_tokens)
82 |
83 | if total == 0:
84 | return 0.0
85 |
86 | cer = errors / total
87 |
88 | return cer
89 |
90 | def get_wer(
91 | preds: typing.Union[str, typing.List[str]],
92 | target: typing.Union[str, typing.List[str]],
93 | ) -> float:
94 | """ Update the wer score with the current set of references and predictions.
95 |
96 | Args:
97 | target (typing.Union[str, typing.List[str]]): string of target sentence or list of target words
98 | preds (typing.Union[str, typing.List[str]]): string of predicted sentence or list of predicted words
99 |
100 | Returns:
101 | Word error rate score
102 | """
103 | if isinstance(preds, str) and isinstance(target, str):
104 | preds = [preds]
105 | target = [target]
106 |
107 | if isinstance(preds, list) and isinstance(target, list):
108 | errors, total_words = 0, 0
109 | for _pred, _target in zip(preds, target):
110 | if isinstance(_pred, str) and isinstance(_target, str):
111 | errors += edit_distance(_pred.split(), _target.split())
112 | total_words += len(_target.split())
113 | else:
114 | print("Error: preds and target must be either both strings or both lists of strings.")
115 | return np.inf
116 |
117 | else:
118 | print("Error: preds and target must be either both strings or both lists of strings.")
119 | return np.inf
120 |
121 | wer = errors / total_words
122 |
123 | return wer
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | PyYAML>=6.0
2 | tqdm
3 | qqdm==0.0.7
4 | pandas
5 | numpy
6 | opencv-python
7 | Pillow>=9.4.0
8 | onnxruntime>=1.15.0 # onnxruntime-gpu for GPU support
9 | matplotlib
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | import os
2 | from setuptools import setup, find_packages
3 |
4 |
5 | DIR = os.path.abspath(os.path.dirname(__file__))
6 |
7 | with open(os.path.join(DIR, "README.md")) as fh:
8 | long_description = fh.read()
9 |
10 | with open(os.path.join(DIR, "requirements.txt")) as fh:
11 | requirements = fh.read().splitlines()
12 |
13 |
14 | def get_version(initpath: str) -> str:
15 | """ Get from the init of the source code the version string
16 |
17 | Params:
18 | initpath (str): path to the init file of the python package relative to the setup file
19 |
20 | Returns:
21 | str: The version string in the form 0.0.1
22 | """
23 |
24 | path = os.path.join(os.path.dirname(__file__), initpath)
25 |
26 | with open(path, "r") as handle:
27 | for line in handle.read().splitlines():
28 | if line.startswith("__version__"):
29 | return line.split("=")[1].strip().strip("\"'")
30 | else:
31 | raise RuntimeError("Unable to find version string.")
32 |
33 |
34 | setup(
35 | name="mltu",
36 | version=get_version("mltu/__init__.py"),
37 | long_description=long_description,
38 | long_description_content_type="text/markdown",
39 | url="https://pylessons.com/",
40 | author="PyLessons",
41 | author_email="pythonlessons0@gmail.com",
42 | install_requires=requirements,
43 | extras_require={
44 | "gpu": ["onnxruntime-gpu"],
45 | },
46 | python_requires=">=3",
47 | packages=find_packages(exclude=("*_test.py",)),
48 | include_package_data=True,
49 | project_urls={
50 | "Source": "https://github.com/pythonlessons/mltu/",
51 | "Tracker": "https://github.com/pythonlessons/mltu/issues",
52 | },
53 | description="Machine Learning Training Utilities (MLTU) for TensorFlow and PyTorch",
54 | )
55 |
--------------------------------------------------------------------------------