├── docs
├── 2019
│ ├── 行为型模式.md
│ ├── Netty集成protobuf与多协议消息传递.md
│ ├── 创建型模式.md
│ ├── SpringBoot自定义一个starter.md
│ ├── grpc快速入门.md
│ ├── 结构型模式.md
│ ├── 高性能MySQL.md
│ ├── Thrift安装配置及入门实例.md
│ ├── 分析CountDownLatch源码.md
│ ├── CyclicBarrier.md
│ ├── Semaphore.md
│ ├── Hystrix原理解析.md
│ └── 分布式事务解决方案.md
├── 其它
│ ├── .keep
│ ├── idea调试Spring源码.md
│ ├── Linxu服务命令.md
│ ├── docsify.md
│ └── Zookeeper面试专题.md
├── .nojekyll
├── _media
│ ├── docs.png
│ ├── logo3.jpg
│ ├── storm1.png
│ ├── storm2.png
│ ├── storm6.png
│ ├── storm7.png
│ ├── wxma.jpg
│ ├── hadoop1.png
│ ├── hadoop2.png
│ ├── hadoop3.png
│ ├── hadoop4.png
│ ├── hbase01.png
│ ├── hbase02.png
│ ├── wxma344.jpg
│ ├── wxmalogo.png
│ ├── wxmalogo2.png
│ ├── 搜索框传播样式-标准色版.png
│ └── 扫码_搜索联合传播样式-标准色版.png
├── _navbar.md
├── _coverpage.md
├── _sidebar.md
├── Spring
│ ├── eureka高可用的服务注册中心(Finchley版本).md
│ ├── eureka注册中心访问权限.md
│ ├── SpringMvc生命周期.md
│ ├── Springcloud服务链路追踪.md
│ ├── Spring集成dubbo集群实现服务降级.md
│ ├── SpringBootAdmin.md
│ └── Consul实现服务注册中心.md
├── storm
│ ├── storm07.md
│ ├── storm02.md
│ ├── storm01.md
│ ├── storm04.md
│ └── storm06.md
├── index.html
├── JVM
│ ├── jvm参数的设置和jvm调优.md
│ └── jvm监控命令.md
├── leetcode
│ ├── 约瑟夫环.md
│ └── 排序算法.md
├── distributed
│ ├── Transactional.md
│ ├── Zookeeper.md
│ ├── redis基本操作.md
│ ├── Redis01.md
│ ├── Redis02.md
│ └── nginx.md
├── golang
│ └── 使用goquery爬取影视资源网站.md
├── hadoop
│ ├── hadoop01.md
│ ├── hbase01.md
│ ├── hadoop03.md
│ └── hadoop02.md
└── README.md
├── images
└── nullimg.png
├── .gitattributes
└── README.md
/docs/其它/.keep:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/docs/.nojekyll:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/images/nullimg.png:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/docs/_media/docs.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/qinxuewu/docs/HEAD/docs/_media/docs.png
--------------------------------------------------------------------------------
/docs/_media/logo3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/qinxuewu/docs/HEAD/docs/_media/logo3.jpg
--------------------------------------------------------------------------------
/docs/_media/storm1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/qinxuewu/docs/HEAD/docs/_media/storm1.png
--------------------------------------------------------------------------------
/docs/_media/storm2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/qinxuewu/docs/HEAD/docs/_media/storm2.png
--------------------------------------------------------------------------------
/docs/_media/storm6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/qinxuewu/docs/HEAD/docs/_media/storm6.png
--------------------------------------------------------------------------------
/docs/_media/storm7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/qinxuewu/docs/HEAD/docs/_media/storm7.png
--------------------------------------------------------------------------------
/docs/_media/wxma.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/qinxuewu/docs/HEAD/docs/_media/wxma.jpg
--------------------------------------------------------------------------------
/docs/_media/hadoop1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/qinxuewu/docs/HEAD/docs/_media/hadoop1.png
--------------------------------------------------------------------------------
/docs/_media/hadoop2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/qinxuewu/docs/HEAD/docs/_media/hadoop2.png
--------------------------------------------------------------------------------
/docs/_media/hadoop3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/qinxuewu/docs/HEAD/docs/_media/hadoop3.png
--------------------------------------------------------------------------------
/docs/_media/hadoop4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/qinxuewu/docs/HEAD/docs/_media/hadoop4.png
--------------------------------------------------------------------------------
/docs/_media/hbase01.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/qinxuewu/docs/HEAD/docs/_media/hbase01.png
--------------------------------------------------------------------------------
/docs/_media/hbase02.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/qinxuewu/docs/HEAD/docs/_media/hbase02.png
--------------------------------------------------------------------------------
/docs/_media/wxma344.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/qinxuewu/docs/HEAD/docs/_media/wxma344.jpg
--------------------------------------------------------------------------------
/docs/_media/wxmalogo.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/qinxuewu/docs/HEAD/docs/_media/wxmalogo.png
--------------------------------------------------------------------------------
/docs/_media/wxmalogo2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/qinxuewu/docs/HEAD/docs/_media/wxmalogo2.png
--------------------------------------------------------------------------------
/docs/_media/搜索框传播样式-标准色版.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/qinxuewu/docs/HEAD/docs/_media/搜索框传播样式-标准色版.png
--------------------------------------------------------------------------------
/docs/_media/扫码_搜索联合传播样式-标准色版.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/qinxuewu/docs/HEAD/docs/_media/扫码_搜索联合传播样式-标准色版.png
--------------------------------------------------------------------------------
/.gitattributes:
--------------------------------------------------------------------------------
1 | # Auto detect text files and perform LF normalization
2 | * text=java
3 | *.md linguist-language=java
4 | *.js linguist-language=java
5 | *.css linguist-language=java
6 | *.html linguist-language=java
7 |
--------------------------------------------------------------------------------
/docs/_navbar.md:
--------------------------------------------------------------------------------
1 | * 导航栏
2 | * [快速开始](README.md)
3 | * [简单微信笔记小程序](https://github.com/a870439570/blog-sharon)
4 | * [SpringBoot版Mongodb工具](https://github.com/a870439570/Mongodb-WeAdmin)
5 | * [SpringBoot版本的JVM监控](https://github.com/a870439570/boot-actuator)
--------------------------------------------------------------------------------
/docs/_coverpage.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |  4 |
5 |
6 | > `interview-docs`:个人学习笔记文档
7 |
8 | [](https://jq.qq.com/?_wv=1027&k=5PIRvFq)
9 | [](https://gitee.com/qinxuewu)
10 | [](https://github.com/a870439570)
11 |
12 | [GitHub](https://github.com/a870439570/interview-docs/tree/master)
13 | [Gitee](https://gitee.com/qinxuewu)
14 | [Get Started](#简介)
15 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | # 简介
6 |
7 | Java知识学习总结
8 | [](https://gitee.com/qinxuewu)
9 | [](https://github.com/a870439570)
10 |
11 | ## 关于
12 |
13 | - email: 870439570@qq.com
14 | - CSDN: https://blog.csdn.net/u010391342
15 | - 简书:https://www.jianshu.com/u/65eeb288a0d9
16 | - 掘金: https://juejin.im/user/5a289b556fb9a0450e760117
17 | - 个人博客:https://qinxuewu.github.io
18 |
19 | ## 开源小项目
20 |
21 | - [boot-actuator](https://github.com/qinxuewu/boot-actuator): 基于Spring Boot 实现的监控远程服务器多个Java应用JVM性能图形化工具
22 | - [blog-sharon](https://github.com/qinxuewu/blog-sharon): 一款简单微信小程序个人博客
23 | - [Mongodb-WeAdmin](https://github.com/qinxuewu/Mongodb-WeAdmin): SpringBoot版Mongodb工具
24 |
25 |
26 | # 快速访问地址
27 | https://qinxuewu.github.io/docs
28 |
29 |
30 |
31 |
--------------------------------------------------------------------------------
/docs/_sidebar.md:
--------------------------------------------------------------------------------
1 |
2 | - 分布式
3 | - Storm系列
4 | - [(一)环境搭建安装](storm/storm01.md)
5 | - [(二)常用shell命令](storm/storm02.md)
6 | - [(三)Java编写第一个本地模式demo](storm/storm03.md)
7 | - [(四)并行度和流分组](storm/storm04.md)
8 | - [(五)DRPC远程调用](storm/storm05.md)
9 | - [(六)Trident使用](storm/storm06.md)
10 | - [(七)集成kafka](storm/storm07.md)
11 | - hadoop系列
12 | - [(一)伪分布式搭建](hadoop/hadoop01.md)
13 | - [(二)HDFS shell操作](hadoop/hadoop02.md)
14 | - [(三)HDFS的java api](hadoop/hadoop03.md)
15 | - [(四)MapReduce分布式计算利器](hadoop/hadoop04.md)
16 | - [HBase安装以及基本操作](hadoop/hbase01.md)
17 | - [HBase之Java API 操作](hadoop/hbase02.md)
18 | - [什么是Zookeeper](distributed/Zookeeper.md)
19 | - [基于Zookeeper分布式锁](distributed/Zookeeper_lock.md)
20 | - [为什么分布式一定要有Redis](distributed/Redis01.md)
21 | - [基于Redis分布式锁](distributed/Redis02.md)
22 | - [什么是分布式事物 ](distributed/Transactional.md)
23 | - [nginx实现负载均衡](distributed/nginx.md)
24 | - [RocketMQ安装配置及Api使用](distributed/RocketMQ.md)
25 | - [ElasticSearch安装及Api使用](distributed/ElasticSearch.md)
26 |
27 |
--------------------------------------------------------------------------------
/docs/Spring/eureka高可用的服务注册中心(Finchley版本).md:
--------------------------------------------------------------------------------
1 | 在eureka-server工程中resources文件夹下,创建配置文件application-peer1.yml:
2 |
3 | ```
4 | server:
5 | port: 8761
6 |
7 | spring:
8 | profiles: peer1
9 | eureka:
10 | instance:
11 | hostname: peer1
12 | client:
13 | serviceUrl:
14 | defaultZone: http://peer2:8769/eureka/
15 | ```
16 | 并且创建另外一个配置文件application-peer2.yml:
17 |
18 | ```
19 | server:
20 | port: 8769
21 |
22 | spring:
23 | profiles: peer2
24 | eureka:
25 | instance:
26 | hostname: peer2
27 | client:
28 | serviceUrl:
29 | defaultZone: http://peer1:8761/eureka/
30 | ```
31 | 这时eureka-server就已经改造完毕。
32 |
33 | 按照官方文档的指示,需要改变etc/hosts,linux系统通过vim /etc/hosts ,加上:
34 |
35 | ```
36 | 127.0.0.1 peer1
37 | 127.0.0.1 peer2
38 | ```
39 | 这里时候需要改造服务提供者
40 | 单个注册中心时,服务提供者的配置
41 | ```
42 | spring.application.name=szq-api
43 | server.port=8762
44 | eureka.client.serviceUrl.defaultZone=http://localhost:8761/eureka/
45 | ```
46 |
47 | ```
48 | eureka.client.serviceUrl.defaultZone=http://peer1:8761/eureka/
49 | server.port=8762
50 | spring.application.name=service-api
51 | ```
52 |
53 | 启动多个不同端口号注册中心eureka-server和服务提供者
54 |
55 | eureka.instance.preferIpAddress=true是通过设置ip让eureka让其他服务注册它。也许能通过去改变去通过改变host的方式。
56 |
57 |
--------------------------------------------------------------------------------
/docs/其它/idea调试Spring源码.md:
--------------------------------------------------------------------------------
1 | ### 源码下载地址
2 |
3 | Spring的源码可以从GitHub上下载:https://github.com/spring-projects/spring-framework
4 |
5 | ### 下载配置gradle
6 | https://gradle.org/releases/ 解压。配置环境变量,在cmd中使用命令:gradle -version,出现版本信息则是配置完成。
7 |
8 | ### 使用gradle编译spring
9 | - spring目录中:import-into-eclipse.*是导入Eclipse的脚本,点击运行之后会有提示。
10 | - 因为我用的是idea,因此需要使用import-into-idea.md,最后一个文件是文本文件,打开之后会发现这是一个指导用户怎么编译的说明(这是一个用markdown语法写的文件)。
11 |
12 |
13 | 打开cmd,cd到spring源码目录中,使用命令:gradlew.bat cleanIdea :spring-oxm:compileTestJava。先对 Spring-oxm 模块进行预编译耐心等待。
14 |
15 | 
16 |
17 | 还是在 …/spring-framework 目录 ,执行 ./gradlew build -x test 编译,整个Spring的源码。 后面的 -x test 是编译期间忽略测试用例,需要加上这个,Spring的测试用例,有些是编译不过的。编译过程时间,会随着网络的畅通程度而不同。
18 |
19 | ### 源码导入IDEA
20 | 在IDEA中 File -> New -> Project from Existing Sources -> Navigate to directory ,选择Spring源码目录,导入,然后IDEA会自动的使用Gradle进行构建。构建完成之后,需要做如下设置:
21 |
22 | 排除 spring-aspects 项目,这个是Spring 的AOP体系集成了 aspects ,但在IDEA中无法编译通过,原因可以参见:
23 |
24 | http://youtrack.jetbrains.com/issue/IDEA-64446
25 |
26 | 选中 spring-aspects 项目 右键,选择“Load/Unload Moudules” 在弹出的窗体中进行设置(如下图所示):
27 | 
--------------------------------------------------------------------------------
/docs/2019/行为型模式.md:
--------------------------------------------------------------------------------
1 |
2 | ### 模版方法模式
3 | - 模板方法模式又叫模板模式,在一个抽象类公开定义了执行 它的方法的模板。它的子类可以按需要重写方法实现,但调用将以抽象类中定义的方式进行
4 | - 简单说,模板方法模式定义一个操作中的算法的骨架,而将一些步骤延迟到子类中,使得子类可以不改变一个算法的结构,就可以重定义该算法的某些特定步骤
5 | - SpringIOC容器初始化时运用到的模板方法模式
6 |
7 | 
8 |
9 |
10 |
11 | ### 命令模式
12 | - 命令模式在软件设计中,我们经常需要向某些对象发送请求,但是并不知道请求的接收者是谁,也不知道被请求的操作是哪个
13 | - 通俗易懂的理解:将军发布命令,士兵去执行。其中有几个角色:将军(命令发布者)、士兵(命令的具体执行者)、命令(连接将军和士兵)。
14 | - 优点:降低了系统耦合度。新的命令可以很容易添加到系统中去。
15 | - 缺点:使用命令模式可能会导致某些系统有过多的具体命令类。
16 |
17 |
18 | ### 策略模式
19 | - 是指定义了算法家族、分别封装起来,让它们之间可以互相替换,此模式让算法的变化不会影响到使用算法的用户
20 | - 常见的if else多重判断就可以使用策略模式优化
21 |
22 | 
23 |
24 |
25 | ### 访问者模式
26 | ### 迭代器模式
27 | ### 观察者模式
28 | ### 中介者模式
29 | ### 备忘录模式
30 | ### 解释器模式
31 |
32 | ### 状态模式
33 | - 主要用来解决对象在多种状态转换时,需要对外输出不同的行为的问题。状态和行为是一一对应的,状态之间可以相互转换
34 | - 当一个对象的内在状态改变时,允许改变其行为,这个对象看起来像是改变了其类
35 |
36 | 
37 |
38 |
39 | ### 责任链模式
40 | - 为了避免请求发送者与多个请求处理者耦合在一起,将所有请求的处理者通过前一对象记住其下一个对象的引用而连成一条链;当有请求发生时,可将请求沿着这条链传递,直到有对象处理它为止
41 | - 在责任链模式中,客户只需要将请求发送到责任链上即可,无须关心请求的处理细节和请求的传递过程,所以责任链将请求的发送者和请求的处理者解耦了。
42 |
43 | #### 应用场景
44 | - 学校OA系统的采购审批项目需求:采购员采购教学器材
45 | - 如果金额小于等于5000,由教学主任审批
46 | - 如果金额小于等于10000,由院长审批
47 | - 如果金额小于等于30000,由副校长审批
48 | - 如果金额超过30000以上,有校长审批
49 |
50 | 
51 |
--------------------------------------------------------------------------------
/docs/storm/storm07.md:
--------------------------------------------------------------------------------
1 | ## 使用kafka-client jar进行Storm Apache Kafka集成
2 | 这包括新的Apache Kafka消费者API。兼容性 Apache Kafka版本0.10起
3 | 引入jar包
4 | ```java
5 |
6 | org.apache.storm
7 | storm-kafka-client
8 | 1.2.0
9 |
10 | ```
11 |
12 | ## 从kafka中订阅消息读取
13 | 通过使用KafkaSpoutConfig类来配置spout实现。此类使用Builder模式,可以通过调用其中一个Builders构造函数或通过调用KafkaSpoutConfig类中的静态方法构建器来启动。
14 |
15 | ## 用法示例
16 | 创建一个简单的不kafka数据源
17 | 以下将使用发布到“topic”的所有事件,并将它们发送到MyBolt,其中包含“topic”,“partition”,“offset”,“key”,“value”字段。
18 |
19 | ```java
20 | TopologyBuilder tp = new TopologyBuilder();
21 | tp.setSpout("kafka_spout", new KafkaSpout(KafkaSpoutConfig.builder("localhost:9092" , "qxw").build()), 1);
22 | tp.setBolt("bolt", new MyBolt()).shuffleGrouping("kafka_spout");
23 | Config cfg=new Config();
24 | cfg.setNumWorkers(1);//指定工作进程数 (jvm数量,分布式环境下可用,本地模式设置无意义)
25 | cfg.setDebug(true);
26 | LocalCluster locl=new LocalCluster();
27 | locl.submitTopology("kkafka-topo",cfg,tp.createTopology());
28 | ```
29 |
30 | ```java
31 | public static class MyBolt extends BaseBasicBolt{
32 | public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
33 | System.err.println("接受订阅kafka消息: "+tuple.getStringByField("topic"));
34 | System.err.println("接受订阅kafka消息: "+tuple.getStringByField("value"));
35 | }
36 | public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
37 | }
38 | }
39 | ```
40 |
--------------------------------------------------------------------------------
/docs/2019/Netty集成protobuf与多协议消息传递.md:
--------------------------------------------------------------------------------
1 | # 什么是protobuf
2 | * protobuf全称Google Protocol Buffers,是google开发的的一套用于数据存储,网络通信时用于协议编解码的工具库。它和XML或者JSON差不多,也就是把某种数据结构的信息,以某种格式(XML,JSON)保存起来,protobuf与XML和JSON不同在于,protobuf是基于二进制的。主要用于数据存储、传输协议格式等场合
3 |
4 | # 安装配置
5 | - 下载地址:https://github.com/protocolbuffers/protobuf/releases
6 | - 查看命令帮助:进入下载包的解压目录`F:\protoc-3.9.0-win64\bin` cmd运行 `protoc --help`
7 | - 配置系统环境变量path
8 |
9 | # 编写.proto文件(src/protobuf/Student.porto)
10 | ```
11 | syntax = "proto3";
12 |
13 | package com.github.protobuf;
14 |
15 | option optimize_for = SPEED;
16 | option java_package = "com.github.protobuf";
17 | option java_outer_classname = "DataInfo";
18 |
19 | message Person {
20 | string name = 1;
21 | int32 age = 2;
22 | string address = 3;
23 | }
24 | ```
25 | # 生成.java文件
26 | ```
27 | # 进入项目录
28 | cd nettytest
29 | # 编译命令
30 | protoc --java_out=src/main/java src/protobuf/Student.porto
31 | ```
32 |
33 | # 编写测试类
34 | ```java
35 | package com.github.protobuf;
36 | public class ProtoBufTest {
37 | public static void main(String[] args) throws Exception{
38 | // 构造对象 初始化数据
39 | DataInfo.Person person= DataInfo.Person.newBuilder()
40 | .setName("张三").setAge(20).setAddress("广州").build();
41 | // 转换成字节数组
42 | byte[] personByteArray=person.toByteArray();
43 |
44 | //
45 | DataInfo.Person person1=DataInfo.Person.parseFrom(personByteArray);
46 | System.out.println(person1);
47 | System.out.println(person1.getName());
48 | System.out.println(person1.getAge());
49 | System.out.println(person1.getAddress());
50 | }
51 | }
52 |
53 | ```
54 |
55 | 
56 |
--------------------------------------------------------------------------------
/docs/index.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | interview-docs
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
50 |
51 |
52 |
53 |
54 |
55 |
--------------------------------------------------------------------------------
/docs/storm/storm02.md:
--------------------------------------------------------------------------------
1 | # 官方文档
2 | http://storm.apache.org/releases/1.2.2/Command-line-client.html
3 | ```bash
4 | [root@web1 apache-storm-1.2.2]# bin/storm help
5 | Commands:
6 | activate
7 | blobstore
8 | classpath
9 | deactivate
10 | dev-zookeeper
11 | drpc
12 | get-errors
13 | heartbeats
14 | help
15 | jar
16 | kill
17 | kill_workers
18 | list
19 | localconfvalue
20 | logviewer
21 | monitor
22 | nimbus
23 | node-health-check
24 | pacemaker
25 | rebalance
26 | remoteconfvalue
27 | repl
28 | set_log_level
29 | shell
30 | sql
31 | supervisor
32 | ui
33 | upload-credentials
34 | version
35 |
36 | Help:
37 | help
38 | help
39 |
40 | Documentation for the storm client can be found at http://storm.apache.org/documentation/Command-line-client.html
41 |
42 | Configs can be overridden using one or more -c flags, e.g. "storm list -c nimbus.host=nimbus.mycompany.com"
43 |
44 | ```
45 |
46 | ## activate 激活指定拓扑的spouts
47 | ```bash
48 | 语法:storm activate topology-name
49 | ```
50 | ## classpath 在运行命令时打印storm客户端使用的类路径
51 | ```bash
52 | storm classpath
53 | ```
54 | ## deactivate 停用指定拓扑的spouts
55 | ```
56 | storm deactivate topology-name
57 | ```
58 | ## drpc 启动DRPC守护程序
59 | ```
60 | storm drpc
61 | ```
62 | ## get-errors
63 | 从正在运行的拓扑中获取最新错误。返回的结果包含组件名称的键值对和错误组件的组件错误。结果以json格式返回
64 | ```
65 | storm get-errors topology-name
66 | ```
67 | ## jar
68 | 使用指定的参数运行类的主要方法。提交拓扑使用
69 | ```
70 | storm jar topology-jar-path class ...
71 | ```
72 | ## kill
73 | 使用名称终止拓扑topology-name 您可以使用-w标志覆盖Storm在停用和关闭之间等待的时间长度
74 | ```
75 | storm kill topology-name [-w wait-time-secs]
76 | ```
77 | ## list
78 | 列出正在运行的拓扑及其状态
79 | ```
80 | storm list
81 | ```
82 | ## localconfvalue
83 | 打印出本地Storm配置的conf-name的值
84 | ```
85 | storm localconfvalue conf-name
86 | ```
87 | ## logviewer
88 | 启动Logviewer守护进程
89 | ```
90 | storm logviewe
91 | ```
92 | ## nimbus
93 | 启动Nimbus守护进程
94 | ```
95 | storm nimbus
96 | ```
97 | ## supervisor
98 | ```
99 | storm supervisor
100 | ```
101 | ## version
102 | ```
103 | storm version
104 |
105 | ```
106 |
--------------------------------------------------------------------------------
/docs/其它/Linxu服务命令.md:
--------------------------------------------------------------------------------
1 | ### Linux系统查看公网IP地址
2 | curl members.3322.org/dyndns/getip
3 |
4 | ### 查看tomact日志
5 | tail -f catalina.out
6 |
7 | ### 查看Tomcat是否以关闭
8 | ps -ef|grep java
9 |
10 | ### 杀死Tomcat进程
11 | kill -9 8080
12 |
13 | ### Tomcat关闭命令
14 | ./shutdown.sh
15 | ### 启动Tomcat
16 | ./startup.sh
17 | ### linux中怎么清理catalina.out
18 | echo "">catalina.out
19 |
20 | ### 服务器内存使用情况
21 |
22 | ```
23 | free -m
24 |
25 | total(总) used(使用) free(剩余) shared buffers cached
26 | Mem: 1526 182 1344 0 16 99
27 | -/+ buffers/cache: 65 1460
28 | Swap: 3071 0 3071
29 |
30 | top命令
31 | top命令中的显示结果中有这样两行:
32 | Mem: 1563088k total, 186784k used, 1376304k free, 17444k buffers
33 | Swap: 3145720k total, 0k used, 3145720k free, 101980k cached
34 |
35 | vmstat命令
36 | procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
37 | r b swpd free buff cache si so bi bo in cs us sy id wa st
38 | 0 0 0 1376320 17452 101980 0 0 1 1 4 5 0 0 100 0 0
39 | ```
40 |
41 |
42 | ### Linux grep 命令
43 | ```
44 | 1.作用
45 | Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
46 | 2.格式
47 | grep [options]
48 | 3.主要参数
49 | [options]主要参数:
50 | -c:只输出匹配行的计数。
51 | -I:不区分大 小写(只适用于单字符)。
52 | -h:查询多文件时不显示文件名。
53 | -l:查询多文件时只输出包含匹配字符的文件名。
54 | -n:显示匹配行及 行号。
55 | -s:不显示不存在或无匹配文本的错误信息。
56 | -v:显示不包含匹配文本的所有行。
57 | pattern正则表达式主要参数:
58 | \: 忽略正则表达式中特殊字符的原有含义。
59 | ^:匹配正则表达式的开始行。
60 | $: 匹配正则表达式的结束行。
61 | \<:从匹配正则表达 式的行开始。
62 | \>:到匹配正则表达式的行结束。
63 | [ ]:单个字符,如[A]即A符合要求 。
64 | [ - ]:范围,如[A-Z],即A、B、C一直到Z都符合要求 。
65 | 。:所有的单个字符。
66 | * :有字符,长度可以为0。
67 | ```
68 |
69 | ```
70 | 4.grep命令使用简单实例
71 | $ grep ‘test’ d*
72 | 显示所有以d开头的文件中包含 test的行。
73 | $ grep ‘test’ aa bb cc
74 | 显示在aa,bb,cc文件中匹配test的行。
75 | $ grep ‘[a-z]\{5\}’ aa
76 | 显示所有包含每个字符串至少有5个连续小写字符的字符串的行。
77 | $ grep ‘w\(es\)t.*\1′ aa
78 | 如果west被匹配,则es就被存储到内存中,并标记为1,然后搜索任意个字符(.*),这些字符后面紧跟着 另外一个es(\1),找到就显示该行。如果用egrep或grep -E,就不用”\”号进行转义,直接写成’w(es)t.*\1′就可以了。
79 | ```
80 |
81 | Linux的chmod命令,对一个目录及其子目录所有文件添加权限
82 |
83 | ```
84 | chmod 777 -R ./html
85 | ```
86 |
87 | ### 查看线程的堆栈信息
88 | ```
89 | #使用top命令,查找pid
90 | $ top
91 |
92 | # 通过TOP -H -p 进程ID,找到具体的线程占用情况
93 | $ top -H -p 21564
94 |
95 | #通过命令pstack 进程ID显示线程堆栈\
96 | $ pstack 24714
97 | ```
98 |
--------------------------------------------------------------------------------
/docs/其它/docsify.md:
--------------------------------------------------------------------------------
1 | ### 简介
2 | 在日常开发中 前后端对接时 经常要写很多文档Api。docsify就是一个强大的文档生成工具 界面清新好 支持语法高亮和Markdown 语法,并且docsify 扩展了一些 Markdown 语法可以让文档更易读。像vue.js官网(https://cn.vuejs.org/)就是docsify 其中的一种注意 并且是目前用的的最多的主题
3 |
4 | ### 效果图如下
5 | 预览链接:https://a870439570.github.io/interview-docs
6 | 
7 |
8 | 
9 |
10 |
11 | ### 快速开始
12 | 首先先安装好npm和nodejs,这里就不做过多介绍了 自信安装即可 (https://blog.csdn.net/zimushuang/article/details/79715679)
13 |
14 | 安装docsify 推荐安装 docsify-cli 工具,可以方便创建及本地预览文档网站。
15 |
16 | ```
17 | npm i docsify-cli -g
18 | ```
19 | 初始化项目
20 | ```
21 | # 进入指定文件目录 如下:F:\ideWork\githubWork\test_docs
22 | 运行 docsify init ./docs
23 | ```
24 | 
25 | 初始化成功后,可以看到 ./docs 目录下创建的几个文件
26 |
27 | index.html 入口文件
28 | README.md 会做为主页内容渲染
29 | .nojekyll 用于阻止 GitHub Pages 会忽略掉下划线开头的文件
30 |
31 | 
32 |
33 |
34 | ## 本地预览网站
35 | 运行一个本地服务器通过 docsify serve 可以方便的预览效果,而且提供 LiveReload 功能,可以让实时的预览。默认访问http://localhost:3000/#/。
36 | ```
37 | docsify serve docs
38 | ```
39 | 一个基本的文档网站就搭建好了,docsify还可以自定义导航栏,自定义侧边栏以及背景图和一些开发插件等等
40 | 更多配置请参考官方文档 https://docsify.js.org/#/zh-cn/quickstart
41 |
42 | ### 下面介绍docsify如何部署到Github 使用免费的站点
43 | 和 GitBook 生成的文档一样,我们可以直接把文档网站部署到 GitHub Pages 或者 VPS 上
44 |
45 |
46 | ## GitHub Pages
47 | GitHub Pages 支持从三个地方读取文件
48 |
49 | - docs/ 目录
50 | - master 分支
51 | - gh-pages 分支
52 |
53 | 上传文件至Github仓库 官方推荐直接将文档放在 docs/ 目录下,在设置页面开启 GitHub Pages 功能并选择 master branch /docs folder 选项。
54 |
55 |
56 | 此时等待几秒钟 就可以访问了 我这里使用了自定义域名
57 |
58 | ### Github如何配置自定义域名
59 | 在根目录下创建CNAME文件 并配置你的阿里云或其它网站购买的域名
60 | 
61 |
62 | 设置页面 Custom domain 更改域名
63 | 
64 |
65 |
66 | 进入域名平台 进行解析 添加继续记录 ;类型为CNAME
67 | 
68 |
69 | 解析后 等待十分钟既可开启了
70 |
71 |
72 | 官方文档 https://docsify.js.org/#/zh-cn/quickstart
73 |
74 | 预览链接:https://a870439570.github.io/interview-docs
75 |
--------------------------------------------------------------------------------
/docs/Spring/eureka注册中心访问权限.md:
--------------------------------------------------------------------------------
1 | ## 概述
2 | - SpringCloud组件它主要提供的模块包括:服务发现(Eureka),断路器(Hystrix),智能路有(Zuul),客户端负载均衡(Ribbon),Archaius,Turbine等
3 | - Eureka作用相当于zookeeper,用于微服务项目中的服务注册及发现,在采用springBoot+springCloud开发微服务时,通过一些简单的配置就能够达到基本的目的
4 |
5 |
6 | ### 注册中心访问权限配置
7 | 在注册中心服务pom.xml添加依赖
8 |
9 | ```
10 |
11 |
12 | org.springframework.boot
13 | spring-boot-starter-security
14 |
15 | ```
16 | 在注册中心服务application.properties文件(注意),内容如下
17 |
18 | ```
19 | #新版本开启权限
20 | #注册中心配置
21 | spring.application.name=szq-server
22 | server.port=8761
23 | eureka.instance.hostname=localhost
24 | eureka.client.registerWithEureka=false
25 | eureka.client.fetch-registry=false
26 | eureka.client.serviceUrl.defaultZone=http://admin:123456@${eureka.instance.hostname}:${server.port}/eureka/
27 |
28 | #新版本开启权限
29 | spring.security.user.name=admin
30 | spring.security.user.password=123456
31 | ```
32 | 启动注册中心服务项目,浏览器输入http://localhost:8761/出现eureka控制台页面并要求输入用户名和密码框即为成功
33 |
34 | 
35 |
36 | ## 开启验证后服务无法连接注册中心解决方案
37 | 运行错误提示
38 | ```
39 | com.netflix.discovery.shared.transport.TransportException: Cannot execute request on any known server
40 | ```
41 | Spring Cloud 2.0 以上的security默认启用了csrf检验,要在eurekaServer端配置security的csrf检验为false
42 |
43 | ```
44 | 服务注册中心注册时加上账号密码
45 | eureka.client.serviceUrl.defaultZone=http://admin:123456@localhost:8761/eureka/
46 | ```
47 | - 添加一个继承 WebSecurityConfigurerAdapter 的类
48 | - 在类上添加 @EnableWebSecurity 注解;
49 | - 覆盖父类的 configure(HttpSecurity http) 方法,关闭掉 csrf
50 | ```
51 | package com.pflm;
52 | import org.springframework.security.config.annotation.web.builders.HttpSecurity;
53 | import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
54 | import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;
55 |
56 | /**
57 | * eureka开启验证后无法连接注册中心?
58 | * spring Cloud 2.0 以上)的security默认启用了csrf检验,要在eurekaServer端配置security的csrf检验为false
59 | * @author qxw
60 | * @data 2018年7月24日下午1:58:31
61 | */
62 | @EnableWebSecurity
63 | public class WebSecurityConfig extends WebSecurityConfigurerAdapter{
64 | @Override
65 | protected void configure(HttpSecurity http) throws Exception {
66 | http.csrf().disable();
67 | super.configure(http);
68 | }
69 | }
70 |
71 | ```
72 |
--------------------------------------------------------------------------------
/docs/JVM/jvm参数的设置和jvm调优.md:
--------------------------------------------------------------------------------
1 | ### JVM内存模型及垃圾收集算法
2 | **1.根据Java虚拟机规范,JVM将内存划分为:**
3 | - New(年轻代),Tenured(年老代),永久代(Perm)
4 | - 其中New和Tenured属于堆内存,堆内存会从JVM启动参数(-Xmx:3G)指定的内存中分配,Perm不属于堆内存,有虚拟机直接分配,但可以通过-XX:PermSize -XX:MaxPermSize 等参数调整其大小
5 | - 年轻代(New):年轻代用来存放JVM刚分配的Java对象
6 | - 年老代(Tenured):年轻代中经过垃圾回收没有回收掉的对象将被Copy到年老代
7 | - 永久代(Perm):永久代存放Class、Method元信息,其大小跟项目的规模、类、方法的量有关,一般设置为128M就足够,设置原则是预留30%的空间。
8 |
9 |
10 | **New(年轻代)又分为几个部分:**
11 | - Eden:Eden用来存放JVM刚分配的对象
12 | - Survivor1,Survivro2两个Survivor空间一样大,当Eden中的对象经过垃圾回收没有被回收掉时,会在两个Survivor之间来回Copy,当满足某个条件,比如Copy次数,就会被Copy到Tenured(年老代)。显然,Survivor只是增加了对象在年轻代中的逗留时间,增加了被垃圾回收的可能性。
13 |
14 |
15 | ### 垃圾回收算法
16 | - 垃圾回收算法可以分为三类,都基于标记-清除(复制)算法:
17 | - Serial算法(单线程) 并行算法 并发算法 JVM会根据机器的硬件配置对每个内存代选择适合的回收算法,比如,如果机器多于1个核,会对年轻代选择并行算法
18 | - 并行算法是用多线程进行垃圾回收,回收期间会暂停程序的执行,而并发算法,也是多线程回收,但期间不停止应用执行。所以,并发算法适用于交互性高的一些程序。经过观察,并发算法会减少年轻代的大小,其实就是使用了一个大的年老代,这反过来跟并行算法相比吞吐量相对较低。
19 |
20 | ### 垃圾回收动作何时执行?
21 | - 当年轻代内存满时,会引发一次普通GC,该GC仅回收年轻代。需要强调的时,年轻代满是指Eden代满,Survivor满不会引发GC
22 | - 当年老代满时会引发Full GC,Full GC将会同时回收年轻代、年老代
23 | - 当永久代满时也会引发Full GC,会导致Class、Method元信息的卸载
24 |
25 | ### 何时会抛出OutOfMemoryException
26 | - 并不是内存被耗空的时候才抛出,JVM98%的时间都花费在内存回收 每次回收的内存小于2% 满足这两个条件将触发OutOfMemoryException
27 | - 这将会留给系统一个微小的间隙以做一些Down之前的操作,比如手动打印Heap Dump。
28 |
29 |
30 | ### 内存泄漏及解决方法
31 | **系统崩溃前的一些现象:**
32 | - 每次垃圾回收的时间越来越长,由之前的10ms延长到50ms左右,FullGC的时间也有之前的0.5s延长到4、5s
33 | - FullGC的次数越来越多,最频繁时隔不到1分钟就进行一次FullGC
34 | - 年老代的内存越来越大并且每次FullGC后年老代没有内存被释放
35 | - 之后系统会无法响应新的请求,逐渐到达OutOfMemoryError的临界值。
36 |
37 | **生成堆的dump文件**
38 | - 通过JMX的MBean生成当前的Heap信息,大小为一个3G(整个堆的大小)的hprof文件,如果没有启动JMX可以通过Java的jmap命令来生成该文件。
39 | ```
40 | 列出当前所有运行的 java 进程:jcmd -l
41 | 列出当前运行的 java 进程可以执行的操作:jcmd PID help
42 | #生成dump
43 | jmap -dump:live,format=b,file=e:/heap.hprof 10444
44 | ```
45 |
46 | **分析dump文件**
47 | - 下面要考虑的是如何打开这个3G的堆信息文件,显然一般的Window系统没有这么大的内存,必须借助高配置的Linux。当然我们可以借助X-Window把Linux上的图形导入到Window。我们考虑用下面几种工具打开该文件:
48 |
49 | ```
50 | Visual VM
51 | IBM HeapAnalyzer
52 | JDK 自带的Hprof工具
53 |
54 | 使用这些工具时为了确保加载速度,建议设置最大内存为6G。使用后发现,这些工具都无法直观地观察到内存泄漏,Visual VM虽能观察到对象大小,但看不到调用堆栈;HeapAnalyzer虽然能看到调用堆栈,却无法正确打开一个3G的文件。因此,我们又选用了Eclipse专门的静态内存分析工具:Mat。
55 | ```
56 |
57 | ### 为什么崩溃前垃圾回收的时间越来越长?
58 | 根据内存模型和垃圾回收算法,垃圾回收分两部分:内存标记、清除(复制),标记部分只要内存大小固定时间是不变的,变的是复制部分,因为每次垃圾回收都有一些回收不掉的内存,所以增加了复制量,导致时间延长。所以,垃圾回收的时间也可以作为判断内存泄漏的依据
59 |
60 | ### 为什么Full GC的次数越来越多?
61 | 因此内存的积累,逐渐耗尽了年老代的内存,导致新对象分配没有更多的空间,从而导致频繁的垃圾回收
62 |
63 | ### 为什么年老代占用的内存越来越大?
64 | 因为年轻代的内存无法被回收,越来越多地被Copy到年老代
65 |
66 |
67 |
68 |
69 |
70 |
71 |
--------------------------------------------------------------------------------
/docs/2019/创建型模式.md:
--------------------------------------------------------------------------------
1 | ## 创建型模式
2 |
3 | ### 单例模式
4 | #### 饿汉式(静态常量)
5 |
6 | 
7 |
8 |
9 | #### 双重锁检查懒汉式
10 | 
11 |
12 |
13 | #### 静态内部类
14 | - 这种方式采用了类装载的机制来保证初始化实例时只有一个线程
15 | - 静态内部类方式在Single2类被装载时并不会立即实例化,而是在需要实例化时,调用getInstance方法,才会装载SingleInstance类,从而完成Singleton的实例化
16 | - 类的静态属性只会在第一次加载类的时候初始化,所以在这里, JVM帮助我们保证了线程的安全性,在类进行初始化时,别的线程是无法进入的
17 | - 避免了线程不安全,利用静态内部类特点实现延迟加载,效率高
18 |
19 | 
20 |
21 |
22 | #### 枚举类
23 | - 借助JDK1.5中添加的枚举来实现单例模式。不仅能避免多线程同步问题,而且还能防止反序列化重新创建新的对象
24 |
25 | 
26 |
27 |
28 | ### 简单工厂模式
29 | - 定义一个创建对象的接口,让其子类自己决定实例化哪一个工厂类,工厂模式使其创建过程延迟到子类进行
30 | - 在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象
31 |
32 | ### 优点和缺点
33 | - 一个调用者想创建一个对象,只要知道其名称就可以了。
34 | - 扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以。
35 | - 屏蔽产品的具体实现,调用者只关心产品的接口。
36 | - 每次增加一个产品时,都需要增加一个具体类和对象实现工厂,使得系统中类的个数成倍增加,在一定程度上增加了系统的复杂度,
37 |
38 | #### 使用场景
39 | - 日志记录器:记录可能记录到本地硬盘、系统事件、远程服务器等,用户可以选择记录日志到什么地方。
40 | - 数据库访问,当用户不知道最后系统采用哪一类数据库,以及数据库可能有变化时。
41 |
42 | 
43 |
44 |
45 | ### 工厂方法模式
46 | - 定义了一个创建对象的抽象方法,由子类决定要实例化的类。工厂方法模式将对象的实例化推迟到子类。
47 | - 工厂模式可以说是简单工厂模式的进一步抽象和拓展,在保留了简单工厂的封装优点的同时,让扩展变得简单,让继承变得可行,增加了多态性的体现。
48 |
49 | 
50 |
51 |
52 | ### 抽象工厂模式
53 | - 抽象工厂模式是围绕一个超级工厂创建其他工厂。该超级工厂又称为其他工厂的工厂。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
54 | - 在抽象工厂模式中,接口是负责创建一个相关对象的工厂,不需要显式指定它们的类。每个生成的工厂都能按照工厂模式提供对象。
55 |
56 | 
57 |
58 |
59 | ### 原型模式
60 | - 原型模式是指:用原型实例指定创建对象的种类,并且通过拷贝这些原型, 创建新的对象
61 | - 原型模式是一种创建型设计模式,允许一个对象再创建另外一个可定制的对象,无需知道如何创建的细节
62 | - 工作原理是:通过将一个原型对象传给那个要发动创建的对象,这个要发动创建的对象通过请求原型对象拷贝它们自己来实施创建,即 对象.clone()
63 | - 形象的理解:孙大圣拔出猴毛, 变出其它孙大圣
64 |
65 | #### 浅拷贝和深拷贝
66 | - 对于数据类型是基本数据类型的成员变量,浅拷贝会直接进行值传递,也就是将该属性值复制一份给新的对象。
67 | - 对于数据类型是引用数据类型的成员变量,比如说成员变量是某个数组、某个类的对象等,那么浅拷贝会进行引用传递,也就是只是将该成员变量的引用值(内存地址)复制一份给新的对象。
68 | - 因为实际上两个对象的该成员变量都指向同一个实例。在这种情况下,在一个对象中修改该成员变量会影响到另一个对象的该成员变量值
69 | - 深拷贝实现方式1:重写clone方法来实现深拷贝
70 | - 深拷贝实现方式2:通过对象序列化实现深拷贝(推荐)
71 |
72 | #### 注意事项和细节
73 | - 创建新的对象比较复杂时,可以利用原型模式简化对象的创建过程,同时也能够提高效率
74 | - 不用重新初始化对象,而是动态地获得对象运行时的状态
75 | - 如果原始对象发生变化(增加或者减少属性),其它克隆对象的也会发生相应的变化,无需修改代码
76 | - 缺点:需要为每一个类配备一个克隆方法,这对全新的类来说不是很难,但对已有的类进行改造时,需要修改其源代码,违背了ocp原则
77 |
78 | 
79 |
80 |
81 | ### 建造者模式
82 | - 建造者模式又叫生成器模式,是一种对象构建模式
83 | - 建造者模式是一步一步创建一个复杂的对象,它允许用户只通过指定复杂对象的类型和内容就可以构建它们,用户不需要知道内部的具体构建细节
84 | - java.lang.StringBuilder中的建造者模式即充当了指挥者角色,同时充当了具体的建造者,建造方法的实现是由AbstractStringBuilder完成,而StringBuilder 继承了 AbstractStringBuilder
85 |
86 | 
87 |
--------------------------------------------------------------------------------
/docs/leetcode/约瑟夫环.md:
--------------------------------------------------------------------------------
1 | #### 单向循环链表(约瑟夫环)
2 | - 设编号为`1,2,…n`的n个人围坐一圈,约定编号为`k(1<=k<=n)`的人从`1`开始报数,数到`m`的那个人出列,它的下一位又从1开始报数,数到m的那个人又出列,依次类推,直到所有人出列为止,由此产生一个出队编号的序列
3 |
4 | **解题思路**
5 |
6 | > 1.首先初始化单向循环链表,然后定义一个helper辅助变量,指向链表的尾节点。
7 | 开始报数前,先让helper和first移动k-1次
8 |
9 | 
10 |
11 | > 2.当开始报数数 让helper和first同时移动m-1次
12 | 这时就可以将first指向的节点出圈:`first=first.next helper.next=first`
13 |
14 | 
15 |
16 | > 3. 重复以上步骤,直到helper=first
17 |
18 | 
19 |
20 | ```
21 | public class CycleSingleLinkedList {
22 | private Boy first=null;
23 |
24 | // 构建单向循环链表:让尾节点的next指向首节点
25 | public void addBoy(int num){
26 | if(num<0){ return; }
27 | Boy cur=null; //辅助指针用来记录当前节点
28 | for (int i = 1; i <= num; i++) {
29 | Boy boy=new Boy(i);
30 | if(i==1){
31 | //当为一个时 直接first=cur
32 | first=boy;
33 | first.next=first; //构成环
34 | cur=boy; // 节点移动 指向一个
35 | }else{
36 | cur.next=boy;// 添加到当前节点后面
37 | boy.next=first; //构成环
38 | cur=boy;
39 | }
40 | }
41 | }
42 |
43 | // 遍历
44 | public void showAll(){
45 | // 用一个辅助节点curBoy 遍历链表 当curBoy.next=first 则遍历结束
46 | Boy curBoy=first;
47 | while (true){
48 | System.out.println(curBoy.no);
49 | if(curBoy.next==first){
50 | break;
51 | }
52 | curBoy=curBoy.next;
53 | }
54 | }
55 |
56 | /**
57 | * 约瑟夫环报数问题
58 | *
59 | * 1 先创建一个辅助变量helper,事先指向链表的最后这个节点
60 | * 提醒: 首选i让helper和first移动k-1次
61 | * 2 当开始报数数 让helper和first同时移动m-1次
62 | * 3 这时就可以将first指向的节点出圈 first=first.next,helper.next=first,、
63 | * 直到helper.next=first 则表示链表剩下一个节点
64 | * @param k 从第几个报数
65 | * @param m 数几下
66 | * @param nums 总共多少个人
67 | */
68 | public void counBoy(int k,int m,int nums) {
69 | if(k< 1 | k >nums){ throw new RuntimeException("参数有误"); }
70 | // 先创建一个辅助变量helper,
71 | Boy helper=first;
72 | while (true){
73 | // 链表剩下一个节点
74 | if(helper.next==first){ break; }
75 |
76 | helper=helper.next; //指向链表的最后这个节点
77 | }
78 | // 首选让helper和first移动k-1次
79 | for (int i = 0; i < k-1; i++) {
80 | helper=helper.next;
81 | first=first.next;
82 | }
83 | // 当开始报数数 让helper和first同时移动m-1次
84 | while (true){
85 | // first指向的节点出圈
86 | if(helper==first){ break; }
87 | for (int i = 0; i < m-1; i++) {
88 | helper=helper.next;
89 | first=first.next;
90 | }
91 | // 这时就可以将first指向的节点出圈
92 | System.out.println("出圈:"+first.no);
93 | first=first.next;
94 | helper.next=first;
95 | }
96 | System.out.println("最后出圈:"+first.no);
97 | }
98 |
99 | public static void main(String[] args) {
100 | CycleSingleLinkedList list=new CycleSingleLinkedList();
101 | list.addBoy(6);
102 | list.showAll();
103 | }
104 | }
105 |
106 | class Boy {
107 | public int no;
108 | public Boy next;
109 | public Boy(int no){
110 | this.no=no;
111 | }
112 | }
113 | ```
114 |
--------------------------------------------------------------------------------
/docs/storm/storm01.md:
--------------------------------------------------------------------------------
1 | ## 什么是Apache Storm
2 | Apache Storm是一个分布式实时大数据处理系统。Storm设计用于在容错和水平可扩展方法中处理大量数据。它是一个流数据框架,具有最高的摄取率。虽然Storm是无状态的,它通过Apache ZooKeeper管理分布式环境和集群状态。它很简单,您可以并行地对实时数据执行各种操作。
3 |
4 | ## Apache Storm 和 Hadoop对比
5 |
4 |
5 |
6 | > `interview-docs`:个人学习笔记文档
7 |
8 | [](https://jq.qq.com/?_wv=1027&k=5PIRvFq)
9 | [](https://gitee.com/qinxuewu)
10 | [](https://github.com/a870439570)
11 |
12 | [GitHub](https://github.com/a870439570/interview-docs/tree/master)
13 | [Gitee](https://gitee.com/qinxuewu)
14 | [Get Started](#简介)
15 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | # 简介
6 |
7 | Java知识学习总结
8 | [](https://gitee.com/qinxuewu)
9 | [](https://github.com/a870439570)
10 |
11 | ## 关于
12 |
13 | - email: 870439570@qq.com
14 | - CSDN: https://blog.csdn.net/u010391342
15 | - 简书:https://www.jianshu.com/u/65eeb288a0d9
16 | - 掘金: https://juejin.im/user/5a289b556fb9a0450e760117
17 | - 个人博客:https://qinxuewu.github.io
18 |
19 | ## 开源小项目
20 |
21 | - [boot-actuator](https://github.com/qinxuewu/boot-actuator): 基于Spring Boot 实现的监控远程服务器多个Java应用JVM性能图形化工具
22 | - [blog-sharon](https://github.com/qinxuewu/blog-sharon): 一款简单微信小程序个人博客
23 | - [Mongodb-WeAdmin](https://github.com/qinxuewu/Mongodb-WeAdmin): SpringBoot版Mongodb工具
24 |
25 |
26 | # 快速访问地址
27 | https://qinxuewu.github.io/docs
28 |
29 |
30 |
31 |
--------------------------------------------------------------------------------
/docs/_sidebar.md:
--------------------------------------------------------------------------------
1 |
2 | - 分布式
3 | - Storm系列
4 | - [(一)环境搭建安装](storm/storm01.md)
5 | - [(二)常用shell命令](storm/storm02.md)
6 | - [(三)Java编写第一个本地模式demo](storm/storm03.md)
7 | - [(四)并行度和流分组](storm/storm04.md)
8 | - [(五)DRPC远程调用](storm/storm05.md)
9 | - [(六)Trident使用](storm/storm06.md)
10 | - [(七)集成kafka](storm/storm07.md)
11 | - hadoop系列
12 | - [(一)伪分布式搭建](hadoop/hadoop01.md)
13 | - [(二)HDFS shell操作](hadoop/hadoop02.md)
14 | - [(三)HDFS的java api](hadoop/hadoop03.md)
15 | - [(四)MapReduce分布式计算利器](hadoop/hadoop04.md)
16 | - [HBase安装以及基本操作](hadoop/hbase01.md)
17 | - [HBase之Java API 操作](hadoop/hbase02.md)
18 | - [什么是Zookeeper](distributed/Zookeeper.md)
19 | - [基于Zookeeper分布式锁](distributed/Zookeeper_lock.md)
20 | - [为什么分布式一定要有Redis](distributed/Redis01.md)
21 | - [基于Redis分布式锁](distributed/Redis02.md)
22 | - [什么是分布式事物 ](distributed/Transactional.md)
23 | - [nginx实现负载均衡](distributed/nginx.md)
24 | - [RocketMQ安装配置及Api使用](distributed/RocketMQ.md)
25 | - [ElasticSearch安装及Api使用](distributed/ElasticSearch.md)
26 |
27 |
--------------------------------------------------------------------------------
/docs/Spring/eureka高可用的服务注册中心(Finchley版本).md:
--------------------------------------------------------------------------------
1 | 在eureka-server工程中resources文件夹下,创建配置文件application-peer1.yml:
2 |
3 | ```
4 | server:
5 | port: 8761
6 |
7 | spring:
8 | profiles: peer1
9 | eureka:
10 | instance:
11 | hostname: peer1
12 | client:
13 | serviceUrl:
14 | defaultZone: http://peer2:8769/eureka/
15 | ```
16 | 并且创建另外一个配置文件application-peer2.yml:
17 |
18 | ```
19 | server:
20 | port: 8769
21 |
22 | spring:
23 | profiles: peer2
24 | eureka:
25 | instance:
26 | hostname: peer2
27 | client:
28 | serviceUrl:
29 | defaultZone: http://peer1:8761/eureka/
30 | ```
31 | 这时eureka-server就已经改造完毕。
32 |
33 | 按照官方文档的指示,需要改变etc/hosts,linux系统通过vim /etc/hosts ,加上:
34 |
35 | ```
36 | 127.0.0.1 peer1
37 | 127.0.0.1 peer2
38 | ```
39 | 这里时候需要改造服务提供者
40 | 单个注册中心时,服务提供者的配置
41 | ```
42 | spring.application.name=szq-api
43 | server.port=8762
44 | eureka.client.serviceUrl.defaultZone=http://localhost:8761/eureka/
45 | ```
46 |
47 | ```
48 | eureka.client.serviceUrl.defaultZone=http://peer1:8761/eureka/
49 | server.port=8762
50 | spring.application.name=service-api
51 | ```
52 |
53 | 启动多个不同端口号注册中心eureka-server和服务提供者
54 |
55 | eureka.instance.preferIpAddress=true是通过设置ip让eureka让其他服务注册它。也许能通过去改变去通过改变host的方式。
56 |
57 |
--------------------------------------------------------------------------------
/docs/其它/idea调试Spring源码.md:
--------------------------------------------------------------------------------
1 | ### 源码下载地址
2 |
3 | Spring的源码可以从GitHub上下载:https://github.com/spring-projects/spring-framework
4 |
5 | ### 下载配置gradle
6 | https://gradle.org/releases/ 解压。配置环境变量,在cmd中使用命令:gradle -version,出现版本信息则是配置完成。
7 |
8 | ### 使用gradle编译spring
9 | - spring目录中:import-into-eclipse.*是导入Eclipse的脚本,点击运行之后会有提示。
10 | - 因为我用的是idea,因此需要使用import-into-idea.md,最后一个文件是文本文件,打开之后会发现这是一个指导用户怎么编译的说明(这是一个用markdown语法写的文件)。
11 |
12 |
13 | 打开cmd,cd到spring源码目录中,使用命令:gradlew.bat cleanIdea :spring-oxm:compileTestJava。先对 Spring-oxm 模块进行预编译耐心等待。
14 |
15 | 
16 |
17 | 还是在 …/spring-framework 目录 ,执行 ./gradlew build -x test 编译,整个Spring的源码。 后面的 -x test 是编译期间忽略测试用例,需要加上这个,Spring的测试用例,有些是编译不过的。编译过程时间,会随着网络的畅通程度而不同。
18 |
19 | ### 源码导入IDEA
20 | 在IDEA中 File -> New -> Project from Existing Sources -> Navigate to directory ,选择Spring源码目录,导入,然后IDEA会自动的使用Gradle进行构建。构建完成之后,需要做如下设置:
21 |
22 | 排除 spring-aspects 项目,这个是Spring 的AOP体系集成了 aspects ,但在IDEA中无法编译通过,原因可以参见:
23 |
24 | http://youtrack.jetbrains.com/issue/IDEA-64446
25 |
26 | 选中 spring-aspects 项目 右键,选择“Load/Unload Moudules” 在弹出的窗体中进行设置(如下图所示):
27 | 
--------------------------------------------------------------------------------
/docs/2019/行为型模式.md:
--------------------------------------------------------------------------------
1 |
2 | ### 模版方法模式
3 | - 模板方法模式又叫模板模式,在一个抽象类公开定义了执行 它的方法的模板。它的子类可以按需要重写方法实现,但调用将以抽象类中定义的方式进行
4 | - 简单说,模板方法模式定义一个操作中的算法的骨架,而将一些步骤延迟到子类中,使得子类可以不改变一个算法的结构,就可以重定义该算法的某些特定步骤
5 | - SpringIOC容器初始化时运用到的模板方法模式
6 |
7 | 
8 |
9 |
10 |
11 | ### 命令模式
12 | - 命令模式在软件设计中,我们经常需要向某些对象发送请求,但是并不知道请求的接收者是谁,也不知道被请求的操作是哪个
13 | - 通俗易懂的理解:将军发布命令,士兵去执行。其中有几个角色:将军(命令发布者)、士兵(命令的具体执行者)、命令(连接将军和士兵)。
14 | - 优点:降低了系统耦合度。新的命令可以很容易添加到系统中去。
15 | - 缺点:使用命令模式可能会导致某些系统有过多的具体命令类。
16 |
17 |
18 | ### 策略模式
19 | - 是指定义了算法家族、分别封装起来,让它们之间可以互相替换,此模式让算法的变化不会影响到使用算法的用户
20 | - 常见的if else多重判断就可以使用策略模式优化
21 |
22 | 
23 |
24 |
25 | ### 访问者模式
26 | ### 迭代器模式
27 | ### 观察者模式
28 | ### 中介者模式
29 | ### 备忘录模式
30 | ### 解释器模式
31 |
32 | ### 状态模式
33 | - 主要用来解决对象在多种状态转换时,需要对外输出不同的行为的问题。状态和行为是一一对应的,状态之间可以相互转换
34 | - 当一个对象的内在状态改变时,允许改变其行为,这个对象看起来像是改变了其类
35 |
36 | 
37 |
38 |
39 | ### 责任链模式
40 | - 为了避免请求发送者与多个请求处理者耦合在一起,将所有请求的处理者通过前一对象记住其下一个对象的引用而连成一条链;当有请求发生时,可将请求沿着这条链传递,直到有对象处理它为止
41 | - 在责任链模式中,客户只需要将请求发送到责任链上即可,无须关心请求的处理细节和请求的传递过程,所以责任链将请求的发送者和请求的处理者解耦了。
42 |
43 | #### 应用场景
44 | - 学校OA系统的采购审批项目需求:采购员采购教学器材
45 | - 如果金额小于等于5000,由教学主任审批
46 | - 如果金额小于等于10000,由院长审批
47 | - 如果金额小于等于30000,由副校长审批
48 | - 如果金额超过30000以上,有校长审批
49 |
50 | 
51 |
--------------------------------------------------------------------------------
/docs/storm/storm07.md:
--------------------------------------------------------------------------------
1 | ## 使用kafka-client jar进行Storm Apache Kafka集成
2 | 这包括新的Apache Kafka消费者API。兼容性 Apache Kafka版本0.10起
3 | 引入jar包
4 | ```java
5 |
6 | org.apache.storm
7 | storm-kafka-client
8 | 1.2.0
9 |
10 | ```
11 |
12 | ## 从kafka中订阅消息读取
13 | 通过使用KafkaSpoutConfig类来配置spout实现。此类使用Builder模式,可以通过调用其中一个Builders构造函数或通过调用KafkaSpoutConfig类中的静态方法构建器来启动。
14 |
15 | ## 用法示例
16 | 创建一个简单的不kafka数据源
17 | 以下将使用发布到“topic”的所有事件,并将它们发送到MyBolt,其中包含“topic”,“partition”,“offset”,“key”,“value”字段。
18 |
19 | ```java
20 | TopologyBuilder tp = new TopologyBuilder();
21 | tp.setSpout("kafka_spout", new KafkaSpout(KafkaSpoutConfig.builder("localhost:9092" , "qxw").build()), 1);
22 | tp.setBolt("bolt", new MyBolt()).shuffleGrouping("kafka_spout");
23 | Config cfg=new Config();
24 | cfg.setNumWorkers(1);//指定工作进程数 (jvm数量,分布式环境下可用,本地模式设置无意义)
25 | cfg.setDebug(true);
26 | LocalCluster locl=new LocalCluster();
27 | locl.submitTopology("kkafka-topo",cfg,tp.createTopology());
28 | ```
29 |
30 | ```java
31 | public static class MyBolt extends BaseBasicBolt{
32 | public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
33 | System.err.println("接受订阅kafka消息: "+tuple.getStringByField("topic"));
34 | System.err.println("接受订阅kafka消息: "+tuple.getStringByField("value"));
35 | }
36 | public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
37 | }
38 | }
39 | ```
40 |
--------------------------------------------------------------------------------
/docs/2019/Netty集成protobuf与多协议消息传递.md:
--------------------------------------------------------------------------------
1 | # 什么是protobuf
2 | * protobuf全称Google Protocol Buffers,是google开发的的一套用于数据存储,网络通信时用于协议编解码的工具库。它和XML或者JSON差不多,也就是把某种数据结构的信息,以某种格式(XML,JSON)保存起来,protobuf与XML和JSON不同在于,protobuf是基于二进制的。主要用于数据存储、传输协议格式等场合
3 |
4 | # 安装配置
5 | - 下载地址:https://github.com/protocolbuffers/protobuf/releases
6 | - 查看命令帮助:进入下载包的解压目录`F:\protoc-3.9.0-win64\bin` cmd运行 `protoc --help`
7 | - 配置系统环境变量path
8 |
9 | # 编写.proto文件(src/protobuf/Student.porto)
10 | ```
11 | syntax = "proto3";
12 |
13 | package com.github.protobuf;
14 |
15 | option optimize_for = SPEED;
16 | option java_package = "com.github.protobuf";
17 | option java_outer_classname = "DataInfo";
18 |
19 | message Person {
20 | string name = 1;
21 | int32 age = 2;
22 | string address = 3;
23 | }
24 | ```
25 | # 生成.java文件
26 | ```
27 | # 进入项目录
28 | cd nettytest
29 | # 编译命令
30 | protoc --java_out=src/main/java src/protobuf/Student.porto
31 | ```
32 |
33 | # 编写测试类
34 | ```java
35 | package com.github.protobuf;
36 | public class ProtoBufTest {
37 | public static void main(String[] args) throws Exception{
38 | // 构造对象 初始化数据
39 | DataInfo.Person person= DataInfo.Person.newBuilder()
40 | .setName("张三").setAge(20).setAddress("广州").build();
41 | // 转换成字节数组
42 | byte[] personByteArray=person.toByteArray();
43 |
44 | //
45 | DataInfo.Person person1=DataInfo.Person.parseFrom(personByteArray);
46 | System.out.println(person1);
47 | System.out.println(person1.getName());
48 | System.out.println(person1.getAge());
49 | System.out.println(person1.getAddress());
50 | }
51 | }
52 |
53 | ```
54 |
55 | 
56 |
--------------------------------------------------------------------------------
/docs/index.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 | interview-docs
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
39 |
40 |
41 |
42 |
43 |
44 |
45 |
50 |
51 |
52 |
53 |
54 |
55 |
--------------------------------------------------------------------------------
/docs/storm/storm02.md:
--------------------------------------------------------------------------------
1 | # 官方文档
2 | http://storm.apache.org/releases/1.2.2/Command-line-client.html
3 | ```bash
4 | [root@web1 apache-storm-1.2.2]# bin/storm help
5 | Commands:
6 | activate
7 | blobstore
8 | classpath
9 | deactivate
10 | dev-zookeeper
11 | drpc
12 | get-errors
13 | heartbeats
14 | help
15 | jar
16 | kill
17 | kill_workers
18 | list
19 | localconfvalue
20 | logviewer
21 | monitor
22 | nimbus
23 | node-health-check
24 | pacemaker
25 | rebalance
26 | remoteconfvalue
27 | repl
28 | set_log_level
29 | shell
30 | sql
31 | supervisor
32 | ui
33 | upload-credentials
34 | version
35 |
36 | Help:
37 | help
38 | help
39 |
40 | Documentation for the storm client can be found at http://storm.apache.org/documentation/Command-line-client.html
41 |
42 | Configs can be overridden using one or more -c flags, e.g. "storm list -c nimbus.host=nimbus.mycompany.com"
43 |
44 | ```
45 |
46 | ## activate 激活指定拓扑的spouts
47 | ```bash
48 | 语法:storm activate topology-name
49 | ```
50 | ## classpath 在运行命令时打印storm客户端使用的类路径
51 | ```bash
52 | storm classpath
53 | ```
54 | ## deactivate 停用指定拓扑的spouts
55 | ```
56 | storm deactivate topology-name
57 | ```
58 | ## drpc 启动DRPC守护程序
59 | ```
60 | storm drpc
61 | ```
62 | ## get-errors
63 | 从正在运行的拓扑中获取最新错误。返回的结果包含组件名称的键值对和错误组件的组件错误。结果以json格式返回
64 | ```
65 | storm get-errors topology-name
66 | ```
67 | ## jar
68 | 使用指定的参数运行类的主要方法。提交拓扑使用
69 | ```
70 | storm jar topology-jar-path class ...
71 | ```
72 | ## kill
73 | 使用名称终止拓扑topology-name 您可以使用-w标志覆盖Storm在停用和关闭之间等待的时间长度
74 | ```
75 | storm kill topology-name [-w wait-time-secs]
76 | ```
77 | ## list
78 | 列出正在运行的拓扑及其状态
79 | ```
80 | storm list
81 | ```
82 | ## localconfvalue
83 | 打印出本地Storm配置的conf-name的值
84 | ```
85 | storm localconfvalue conf-name
86 | ```
87 | ## logviewer
88 | 启动Logviewer守护进程
89 | ```
90 | storm logviewe
91 | ```
92 | ## nimbus
93 | 启动Nimbus守护进程
94 | ```
95 | storm nimbus
96 | ```
97 | ## supervisor
98 | ```
99 | storm supervisor
100 | ```
101 | ## version
102 | ```
103 | storm version
104 |
105 | ```
106 |
--------------------------------------------------------------------------------
/docs/其它/Linxu服务命令.md:
--------------------------------------------------------------------------------
1 | ### Linux系统查看公网IP地址
2 | curl members.3322.org/dyndns/getip
3 |
4 | ### 查看tomact日志
5 | tail -f catalina.out
6 |
7 | ### 查看Tomcat是否以关闭
8 | ps -ef|grep java
9 |
10 | ### 杀死Tomcat进程
11 | kill -9 8080
12 |
13 | ### Tomcat关闭命令
14 | ./shutdown.sh
15 | ### 启动Tomcat
16 | ./startup.sh
17 | ### linux中怎么清理catalina.out
18 | echo "">catalina.out
19 |
20 | ### 服务器内存使用情况
21 |
22 | ```
23 | free -m
24 |
25 | total(总) used(使用) free(剩余) shared buffers cached
26 | Mem: 1526 182 1344 0 16 99
27 | -/+ buffers/cache: 65 1460
28 | Swap: 3071 0 3071
29 |
30 | top命令
31 | top命令中的显示结果中有这样两行:
32 | Mem: 1563088k total, 186784k used, 1376304k free, 17444k buffers
33 | Swap: 3145720k total, 0k used, 3145720k free, 101980k cached
34 |
35 | vmstat命令
36 | procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
37 | r b swpd free buff cache si so bi bo in cs us sy id wa st
38 | 0 0 0 1376320 17452 101980 0 0 1 1 4 5 0 0 100 0 0
39 | ```
40 |
41 |
42 | ### Linux grep 命令
43 | ```
44 | 1.作用
45 | Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
46 | 2.格式
47 | grep [options]
48 | 3.主要参数
49 | [options]主要参数:
50 | -c:只输出匹配行的计数。
51 | -I:不区分大 小写(只适用于单字符)。
52 | -h:查询多文件时不显示文件名。
53 | -l:查询多文件时只输出包含匹配字符的文件名。
54 | -n:显示匹配行及 行号。
55 | -s:不显示不存在或无匹配文本的错误信息。
56 | -v:显示不包含匹配文本的所有行。
57 | pattern正则表达式主要参数:
58 | \: 忽略正则表达式中特殊字符的原有含义。
59 | ^:匹配正则表达式的开始行。
60 | $: 匹配正则表达式的结束行。
61 | \<:从匹配正则表达 式的行开始。
62 | \>:到匹配正则表达式的行结束。
63 | [ ]:单个字符,如[A]即A符合要求 。
64 | [ - ]:范围,如[A-Z],即A、B、C一直到Z都符合要求 。
65 | 。:所有的单个字符。
66 | * :有字符,长度可以为0。
67 | ```
68 |
69 | ```
70 | 4.grep命令使用简单实例
71 | $ grep ‘test’ d*
72 | 显示所有以d开头的文件中包含 test的行。
73 | $ grep ‘test’ aa bb cc
74 | 显示在aa,bb,cc文件中匹配test的行。
75 | $ grep ‘[a-z]\{5\}’ aa
76 | 显示所有包含每个字符串至少有5个连续小写字符的字符串的行。
77 | $ grep ‘w\(es\)t.*\1′ aa
78 | 如果west被匹配,则es就被存储到内存中,并标记为1,然后搜索任意个字符(.*),这些字符后面紧跟着 另外一个es(\1),找到就显示该行。如果用egrep或grep -E,就不用”\”号进行转义,直接写成’w(es)t.*\1′就可以了。
79 | ```
80 |
81 | Linux的chmod命令,对一个目录及其子目录所有文件添加权限
82 |
83 | ```
84 | chmod 777 -R ./html
85 | ```
86 |
87 | ### 查看线程的堆栈信息
88 | ```
89 | #使用top命令,查找pid
90 | $ top
91 |
92 | # 通过TOP -H -p 进程ID,找到具体的线程占用情况
93 | $ top -H -p 21564
94 |
95 | #通过命令pstack 进程ID显示线程堆栈\
96 | $ pstack 24714
97 | ```
98 |
--------------------------------------------------------------------------------
/docs/其它/docsify.md:
--------------------------------------------------------------------------------
1 | ### 简介
2 | 在日常开发中 前后端对接时 经常要写很多文档Api。docsify就是一个强大的文档生成工具 界面清新好 支持语法高亮和Markdown 语法,并且docsify 扩展了一些 Markdown 语法可以让文档更易读。像vue.js官网(https://cn.vuejs.org/)就是docsify 其中的一种注意 并且是目前用的的最多的主题
3 |
4 | ### 效果图如下
5 | 预览链接:https://a870439570.github.io/interview-docs
6 | 
7 |
8 | 
9 |
10 |
11 | ### 快速开始
12 | 首先先安装好npm和nodejs,这里就不做过多介绍了 自信安装即可 (https://blog.csdn.net/zimushuang/article/details/79715679)
13 |
14 | 安装docsify 推荐安装 docsify-cli 工具,可以方便创建及本地预览文档网站。
15 |
16 | ```
17 | npm i docsify-cli -g
18 | ```
19 | 初始化项目
20 | ```
21 | # 进入指定文件目录 如下:F:\ideWork\githubWork\test_docs
22 | 运行 docsify init ./docs
23 | ```
24 | 
25 | 初始化成功后,可以看到 ./docs 目录下创建的几个文件
26 |
27 | index.html 入口文件
28 | README.md 会做为主页内容渲染
29 | .nojekyll 用于阻止 GitHub Pages 会忽略掉下划线开头的文件
30 |
31 | 
32 |
33 |
34 | ## 本地预览网站
35 | 运行一个本地服务器通过 docsify serve 可以方便的预览效果,而且提供 LiveReload 功能,可以让实时的预览。默认访问http://localhost:3000/#/。
36 | ```
37 | docsify serve docs
38 | ```
39 | 一个基本的文档网站就搭建好了,docsify还可以自定义导航栏,自定义侧边栏以及背景图和一些开发插件等等
40 | 更多配置请参考官方文档 https://docsify.js.org/#/zh-cn/quickstart
41 |
42 | ### 下面介绍docsify如何部署到Github 使用免费的站点
43 | 和 GitBook 生成的文档一样,我们可以直接把文档网站部署到 GitHub Pages 或者 VPS 上
44 |
45 |
46 | ## GitHub Pages
47 | GitHub Pages 支持从三个地方读取文件
48 |
49 | - docs/ 目录
50 | - master 分支
51 | - gh-pages 分支
52 |
53 | 上传文件至Github仓库 官方推荐直接将文档放在 docs/ 目录下,在设置页面开启 GitHub Pages 功能并选择 master branch /docs folder 选项。
54 |
55 |
56 | 此时等待几秒钟 就可以访问了 我这里使用了自定义域名
57 |
58 | ### Github如何配置自定义域名
59 | 在根目录下创建CNAME文件 并配置你的阿里云或其它网站购买的域名
60 | 
61 |
62 | 设置页面 Custom domain 更改域名
63 | 
64 |
65 |
66 | 进入域名平台 进行解析 添加继续记录 ;类型为CNAME
67 | 
68 |
69 | 解析后 等待十分钟既可开启了
70 |
71 |
72 | 官方文档 https://docsify.js.org/#/zh-cn/quickstart
73 |
74 | 预览链接:https://a870439570.github.io/interview-docs
75 |
--------------------------------------------------------------------------------
/docs/Spring/eureka注册中心访问权限.md:
--------------------------------------------------------------------------------
1 | ## 概述
2 | - SpringCloud组件它主要提供的模块包括:服务发现(Eureka),断路器(Hystrix),智能路有(Zuul),客户端负载均衡(Ribbon),Archaius,Turbine等
3 | - Eureka作用相当于zookeeper,用于微服务项目中的服务注册及发现,在采用springBoot+springCloud开发微服务时,通过一些简单的配置就能够达到基本的目的
4 |
5 |
6 | ### 注册中心访问权限配置
7 | 在注册中心服务pom.xml添加依赖
8 |
9 | ```
10 |
11 |
12 | org.springframework.boot
13 | spring-boot-starter-security
14 |
15 | ```
16 | 在注册中心服务application.properties文件(注意),内容如下
17 |
18 | ```
19 | #新版本开启权限
20 | #注册中心配置
21 | spring.application.name=szq-server
22 | server.port=8761
23 | eureka.instance.hostname=localhost
24 | eureka.client.registerWithEureka=false
25 | eureka.client.fetch-registry=false
26 | eureka.client.serviceUrl.defaultZone=http://admin:123456@${eureka.instance.hostname}:${server.port}/eureka/
27 |
28 | #新版本开启权限
29 | spring.security.user.name=admin
30 | spring.security.user.password=123456
31 | ```
32 | 启动注册中心服务项目,浏览器输入http://localhost:8761/出现eureka控制台页面并要求输入用户名和密码框即为成功
33 |
34 | 
35 |
36 | ## 开启验证后服务无法连接注册中心解决方案
37 | 运行错误提示
38 | ```
39 | com.netflix.discovery.shared.transport.TransportException: Cannot execute request on any known server
40 | ```
41 | Spring Cloud 2.0 以上的security默认启用了csrf检验,要在eurekaServer端配置security的csrf检验为false
42 |
43 | ```
44 | 服务注册中心注册时加上账号密码
45 | eureka.client.serviceUrl.defaultZone=http://admin:123456@localhost:8761/eureka/
46 | ```
47 | - 添加一个继承 WebSecurityConfigurerAdapter 的类
48 | - 在类上添加 @EnableWebSecurity 注解;
49 | - 覆盖父类的 configure(HttpSecurity http) 方法,关闭掉 csrf
50 | ```
51 | package com.pflm;
52 | import org.springframework.security.config.annotation.web.builders.HttpSecurity;
53 | import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
54 | import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;
55 |
56 | /**
57 | * eureka开启验证后无法连接注册中心?
58 | * spring Cloud 2.0 以上)的security默认启用了csrf检验,要在eurekaServer端配置security的csrf检验为false
59 | * @author qxw
60 | * @data 2018年7月24日下午1:58:31
61 | */
62 | @EnableWebSecurity
63 | public class WebSecurityConfig extends WebSecurityConfigurerAdapter{
64 | @Override
65 | protected void configure(HttpSecurity http) throws Exception {
66 | http.csrf().disable();
67 | super.configure(http);
68 | }
69 | }
70 |
71 | ```
72 |
--------------------------------------------------------------------------------
/docs/JVM/jvm参数的设置和jvm调优.md:
--------------------------------------------------------------------------------
1 | ### JVM内存模型及垃圾收集算法
2 | **1.根据Java虚拟机规范,JVM将内存划分为:**
3 | - New(年轻代),Tenured(年老代),永久代(Perm)
4 | - 其中New和Tenured属于堆内存,堆内存会从JVM启动参数(-Xmx:3G)指定的内存中分配,Perm不属于堆内存,有虚拟机直接分配,但可以通过-XX:PermSize -XX:MaxPermSize 等参数调整其大小
5 | - 年轻代(New):年轻代用来存放JVM刚分配的Java对象
6 | - 年老代(Tenured):年轻代中经过垃圾回收没有回收掉的对象将被Copy到年老代
7 | - 永久代(Perm):永久代存放Class、Method元信息,其大小跟项目的规模、类、方法的量有关,一般设置为128M就足够,设置原则是预留30%的空间。
8 |
9 |
10 | **New(年轻代)又分为几个部分:**
11 | - Eden:Eden用来存放JVM刚分配的对象
12 | - Survivor1,Survivro2两个Survivor空间一样大,当Eden中的对象经过垃圾回收没有被回收掉时,会在两个Survivor之间来回Copy,当满足某个条件,比如Copy次数,就会被Copy到Tenured(年老代)。显然,Survivor只是增加了对象在年轻代中的逗留时间,增加了被垃圾回收的可能性。
13 |
14 |
15 | ### 垃圾回收算法
16 | - 垃圾回收算法可以分为三类,都基于标记-清除(复制)算法:
17 | - Serial算法(单线程) 并行算法 并发算法 JVM会根据机器的硬件配置对每个内存代选择适合的回收算法,比如,如果机器多于1个核,会对年轻代选择并行算法
18 | - 并行算法是用多线程进行垃圾回收,回收期间会暂停程序的执行,而并发算法,也是多线程回收,但期间不停止应用执行。所以,并发算法适用于交互性高的一些程序。经过观察,并发算法会减少年轻代的大小,其实就是使用了一个大的年老代,这反过来跟并行算法相比吞吐量相对较低。
19 |
20 | ### 垃圾回收动作何时执行?
21 | - 当年轻代内存满时,会引发一次普通GC,该GC仅回收年轻代。需要强调的时,年轻代满是指Eden代满,Survivor满不会引发GC
22 | - 当年老代满时会引发Full GC,Full GC将会同时回收年轻代、年老代
23 | - 当永久代满时也会引发Full GC,会导致Class、Method元信息的卸载
24 |
25 | ### 何时会抛出OutOfMemoryException
26 | - 并不是内存被耗空的时候才抛出,JVM98%的时间都花费在内存回收 每次回收的内存小于2% 满足这两个条件将触发OutOfMemoryException
27 | - 这将会留给系统一个微小的间隙以做一些Down之前的操作,比如手动打印Heap Dump。
28 |
29 |
30 | ### 内存泄漏及解决方法
31 | **系统崩溃前的一些现象:**
32 | - 每次垃圾回收的时间越来越长,由之前的10ms延长到50ms左右,FullGC的时间也有之前的0.5s延长到4、5s
33 | - FullGC的次数越来越多,最频繁时隔不到1分钟就进行一次FullGC
34 | - 年老代的内存越来越大并且每次FullGC后年老代没有内存被释放
35 | - 之后系统会无法响应新的请求,逐渐到达OutOfMemoryError的临界值。
36 |
37 | **生成堆的dump文件**
38 | - 通过JMX的MBean生成当前的Heap信息,大小为一个3G(整个堆的大小)的hprof文件,如果没有启动JMX可以通过Java的jmap命令来生成该文件。
39 | ```
40 | 列出当前所有运行的 java 进程:jcmd -l
41 | 列出当前运行的 java 进程可以执行的操作:jcmd PID help
42 | #生成dump
43 | jmap -dump:live,format=b,file=e:/heap.hprof 10444
44 | ```
45 |
46 | **分析dump文件**
47 | - 下面要考虑的是如何打开这个3G的堆信息文件,显然一般的Window系统没有这么大的内存,必须借助高配置的Linux。当然我们可以借助X-Window把Linux上的图形导入到Window。我们考虑用下面几种工具打开该文件:
48 |
49 | ```
50 | Visual VM
51 | IBM HeapAnalyzer
52 | JDK 自带的Hprof工具
53 |
54 | 使用这些工具时为了确保加载速度,建议设置最大内存为6G。使用后发现,这些工具都无法直观地观察到内存泄漏,Visual VM虽能观察到对象大小,但看不到调用堆栈;HeapAnalyzer虽然能看到调用堆栈,却无法正确打开一个3G的文件。因此,我们又选用了Eclipse专门的静态内存分析工具:Mat。
55 | ```
56 |
57 | ### 为什么崩溃前垃圾回收的时间越来越长?
58 | 根据内存模型和垃圾回收算法,垃圾回收分两部分:内存标记、清除(复制),标记部分只要内存大小固定时间是不变的,变的是复制部分,因为每次垃圾回收都有一些回收不掉的内存,所以增加了复制量,导致时间延长。所以,垃圾回收的时间也可以作为判断内存泄漏的依据
59 |
60 | ### 为什么Full GC的次数越来越多?
61 | 因此内存的积累,逐渐耗尽了年老代的内存,导致新对象分配没有更多的空间,从而导致频繁的垃圾回收
62 |
63 | ### 为什么年老代占用的内存越来越大?
64 | 因为年轻代的内存无法被回收,越来越多地被Copy到年老代
65 |
66 |
67 |
68 |
69 |
70 |
71 |
--------------------------------------------------------------------------------
/docs/2019/创建型模式.md:
--------------------------------------------------------------------------------
1 | ## 创建型模式
2 |
3 | ### 单例模式
4 | #### 饿汉式(静态常量)
5 |
6 | 
7 |
8 |
9 | #### 双重锁检查懒汉式
10 | 
11 |
12 |
13 | #### 静态内部类
14 | - 这种方式采用了类装载的机制来保证初始化实例时只有一个线程
15 | - 静态内部类方式在Single2类被装载时并不会立即实例化,而是在需要实例化时,调用getInstance方法,才会装载SingleInstance类,从而完成Singleton的实例化
16 | - 类的静态属性只会在第一次加载类的时候初始化,所以在这里, JVM帮助我们保证了线程的安全性,在类进行初始化时,别的线程是无法进入的
17 | - 避免了线程不安全,利用静态内部类特点实现延迟加载,效率高
18 |
19 | 
20 |
21 |
22 | #### 枚举类
23 | - 借助JDK1.5中添加的枚举来实现单例模式。不仅能避免多线程同步问题,而且还能防止反序列化重新创建新的对象
24 |
25 | 
26 |
27 |
28 | ### 简单工厂模式
29 | - 定义一个创建对象的接口,让其子类自己决定实例化哪一个工厂类,工厂模式使其创建过程延迟到子类进行
30 | - 在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象
31 |
32 | ### 优点和缺点
33 | - 一个调用者想创建一个对象,只要知道其名称就可以了。
34 | - 扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以。
35 | - 屏蔽产品的具体实现,调用者只关心产品的接口。
36 | - 每次增加一个产品时,都需要增加一个具体类和对象实现工厂,使得系统中类的个数成倍增加,在一定程度上增加了系统的复杂度,
37 |
38 | #### 使用场景
39 | - 日志记录器:记录可能记录到本地硬盘、系统事件、远程服务器等,用户可以选择记录日志到什么地方。
40 | - 数据库访问,当用户不知道最后系统采用哪一类数据库,以及数据库可能有变化时。
41 |
42 | 
43 |
44 |
45 | ### 工厂方法模式
46 | - 定义了一个创建对象的抽象方法,由子类决定要实例化的类。工厂方法模式将对象的实例化推迟到子类。
47 | - 工厂模式可以说是简单工厂模式的进一步抽象和拓展,在保留了简单工厂的封装优点的同时,让扩展变得简单,让继承变得可行,增加了多态性的体现。
48 |
49 | 
50 |
51 |
52 | ### 抽象工厂模式
53 | - 抽象工厂模式是围绕一个超级工厂创建其他工厂。该超级工厂又称为其他工厂的工厂。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
54 | - 在抽象工厂模式中,接口是负责创建一个相关对象的工厂,不需要显式指定它们的类。每个生成的工厂都能按照工厂模式提供对象。
55 |
56 | 
57 |
58 |
59 | ### 原型模式
60 | - 原型模式是指:用原型实例指定创建对象的种类,并且通过拷贝这些原型, 创建新的对象
61 | - 原型模式是一种创建型设计模式,允许一个对象再创建另外一个可定制的对象,无需知道如何创建的细节
62 | - 工作原理是:通过将一个原型对象传给那个要发动创建的对象,这个要发动创建的对象通过请求原型对象拷贝它们自己来实施创建,即 对象.clone()
63 | - 形象的理解:孙大圣拔出猴毛, 变出其它孙大圣
64 |
65 | #### 浅拷贝和深拷贝
66 | - 对于数据类型是基本数据类型的成员变量,浅拷贝会直接进行值传递,也就是将该属性值复制一份给新的对象。
67 | - 对于数据类型是引用数据类型的成员变量,比如说成员变量是某个数组、某个类的对象等,那么浅拷贝会进行引用传递,也就是只是将该成员变量的引用值(内存地址)复制一份给新的对象。
68 | - 因为实际上两个对象的该成员变量都指向同一个实例。在这种情况下,在一个对象中修改该成员变量会影响到另一个对象的该成员变量值
69 | - 深拷贝实现方式1:重写clone方法来实现深拷贝
70 | - 深拷贝实现方式2:通过对象序列化实现深拷贝(推荐)
71 |
72 | #### 注意事项和细节
73 | - 创建新的对象比较复杂时,可以利用原型模式简化对象的创建过程,同时也能够提高效率
74 | - 不用重新初始化对象,而是动态地获得对象运行时的状态
75 | - 如果原始对象发生变化(增加或者减少属性),其它克隆对象的也会发生相应的变化,无需修改代码
76 | - 缺点:需要为每一个类配备一个克隆方法,这对全新的类来说不是很难,但对已有的类进行改造时,需要修改其源代码,违背了ocp原则
77 |
78 | 
79 |
80 |
81 | ### 建造者模式
82 | - 建造者模式又叫生成器模式,是一种对象构建模式
83 | - 建造者模式是一步一步创建一个复杂的对象,它允许用户只通过指定复杂对象的类型和内容就可以构建它们,用户不需要知道内部的具体构建细节
84 | - java.lang.StringBuilder中的建造者模式即充当了指挥者角色,同时充当了具体的建造者,建造方法的实现是由AbstractStringBuilder完成,而StringBuilder 继承了 AbstractStringBuilder
85 |
86 | 
87 |
--------------------------------------------------------------------------------
/docs/leetcode/约瑟夫环.md:
--------------------------------------------------------------------------------
1 | #### 单向循环链表(约瑟夫环)
2 | - 设编号为`1,2,…n`的n个人围坐一圈,约定编号为`k(1<=k<=n)`的人从`1`开始报数,数到`m`的那个人出列,它的下一位又从1开始报数,数到m的那个人又出列,依次类推,直到所有人出列为止,由此产生一个出队编号的序列
3 |
4 | **解题思路**
5 |
6 | > 1.首先初始化单向循环链表,然后定义一个helper辅助变量,指向链表的尾节点。
7 | 开始报数前,先让helper和first移动k-1次
8 |
9 | 
10 |
11 | > 2.当开始报数数 让helper和first同时移动m-1次
12 | 这时就可以将first指向的节点出圈:`first=first.next helper.next=first`
13 |
14 | 
15 |
16 | > 3. 重复以上步骤,直到helper=first
17 |
18 | 
19 |
20 | ```
21 | public class CycleSingleLinkedList {
22 | private Boy first=null;
23 |
24 | // 构建单向循环链表:让尾节点的next指向首节点
25 | public void addBoy(int num){
26 | if(num<0){ return; }
27 | Boy cur=null; //辅助指针用来记录当前节点
28 | for (int i = 1; i <= num; i++) {
29 | Boy boy=new Boy(i);
30 | if(i==1){
31 | //当为一个时 直接first=cur
32 | first=boy;
33 | first.next=first; //构成环
34 | cur=boy; // 节点移动 指向一个
35 | }else{
36 | cur.next=boy;// 添加到当前节点后面
37 | boy.next=first; //构成环
38 | cur=boy;
39 | }
40 | }
41 | }
42 |
43 | // 遍历
44 | public void showAll(){
45 | // 用一个辅助节点curBoy 遍历链表 当curBoy.next=first 则遍历结束
46 | Boy curBoy=first;
47 | while (true){
48 | System.out.println(curBoy.no);
49 | if(curBoy.next==first){
50 | break;
51 | }
52 | curBoy=curBoy.next;
53 | }
54 | }
55 |
56 | /**
57 | * 约瑟夫环报数问题
58 | *
59 | * 1 先创建一个辅助变量helper,事先指向链表的最后这个节点
60 | * 提醒: 首选i让helper和first移动k-1次
61 | * 2 当开始报数数 让helper和first同时移动m-1次
62 | * 3 这时就可以将first指向的节点出圈 first=first.next,helper.next=first,、
63 | * 直到helper.next=first 则表示链表剩下一个节点
64 | * @param k 从第几个报数
65 | * @param m 数几下
66 | * @param nums 总共多少个人
67 | */
68 | public void counBoy(int k,int m,int nums) {
69 | if(k< 1 | k >nums){ throw new RuntimeException("参数有误"); }
70 | // 先创建一个辅助变量helper,
71 | Boy helper=first;
72 | while (true){
73 | // 链表剩下一个节点
74 | if(helper.next==first){ break; }
75 |
76 | helper=helper.next; //指向链表的最后这个节点
77 | }
78 | // 首选让helper和first移动k-1次
79 | for (int i = 0; i < k-1; i++) {
80 | helper=helper.next;
81 | first=first.next;
82 | }
83 | // 当开始报数数 让helper和first同时移动m-1次
84 | while (true){
85 | // first指向的节点出圈
86 | if(helper==first){ break; }
87 | for (int i = 0; i < m-1; i++) {
88 | helper=helper.next;
89 | first=first.next;
90 | }
91 | // 这时就可以将first指向的节点出圈
92 | System.out.println("出圈:"+first.no);
93 | first=first.next;
94 | helper.next=first;
95 | }
96 | System.out.println("最后出圈:"+first.no);
97 | }
98 |
99 | public static void main(String[] args) {
100 | CycleSingleLinkedList list=new CycleSingleLinkedList();
101 | list.addBoy(6);
102 | list.showAll();
103 | }
104 | }
105 |
106 | class Boy {
107 | public int no;
108 | public Boy next;
109 | public Boy(int no){
110 | this.no=no;
111 | }
112 | }
113 | ```
114 |
--------------------------------------------------------------------------------
/docs/storm/storm01.md:
--------------------------------------------------------------------------------
1 | ## 什么是Apache Storm
2 | Apache Storm是一个分布式实时大数据处理系统。Storm设计用于在容错和水平可扩展方法中处理大量数据。它是一个流数据框架,具有最高的摄取率。虽然Storm是无状态的,它通过Apache ZooKeeper管理分布式环境和集群状态。它很简单,您可以并行地对实时数据执行各种操作。
3 |
4 | ## Apache Storm 和 Hadoop对比
5 |  6 |
7 | ## Apache Storm优势
8 | - storm是开源的,强大的,用户友好的。它可以用于小公司和大公司。
9 | - Storm是容错的,灵活的,可靠的,并且支持任何编程语言。
10 | - 允许实时流处理。
11 | - Storm是令人难以置信的快,因为它具有巨大的处理数据的力量。
12 | - Storm可以通过线性增加资源来保持性能,即使在负载增加的情况下。它是高度可扩展的。
13 | - Storm在几秒钟或几分钟内执行数据刷新和端到端传送响应取决于问题。它具有非常低的延迟。
14 | - Storm有操作智能。
15 | - Storm提供保证的数据处理,即使群集中的任何连接的节点死或消息丢失。
16 |
17 | ## Storm 系统中包含以下几个基本概念:
18 | --------------------
19 | * 拓扑(Topologies)
20 | * 流(Streams)
21 | * 数据源(Spouts)
22 | * 数据流处理组件(Bolts)
23 | * 数据流分组(Stream groupings)
24 | * 可靠性(Reliability)
25 | * 任务(Tasks
26 | * 工作进程(Workers
27 |
28 |
29 | ## Apache Storm的组件
30 | **Tuple**
31 | - Tuple是Storm中的主要数据结构。它是有序元素的列表。默认情况下,Tuple支持所有数据类型。通常,它被建模为一组逗号分隔的值,并传递到Storm集群。
32 |
33 | **Stream**
34 | - 流是元组的无序序列。
35 |
36 | **Spouts**
37 | - 流的源。通常,Storm从原始数据源(如Twitter Streaming API,Apache Kafka队列,Kestrel队列等)接受输入数据。否则,您可以编写spouts以从数据源读取数据。“ISpout”是实现spouts的核心接口,一些特定的接口是IRichSpout,BaseRichSpout,KafkaSpout等。
38 |
39 | **Bolts**
40 | - Bolts是逻辑处理单元。Spouts将数据传递到Bolts和Bolts过程,并产生新的输出流。Bolts可以执行过滤,聚合,加入,与数据源和数据库交互的操作。Bolts接收数据并发射到一个或多个Bolts。 “IBolt”是实现Bolts的核心接口。一些常见的接口是IRichBolt,IBasicBolt等。
41 |
42 | ## Storm工作流程
43 | 一个工作的Storm集群应该有一个Nimbus和一个或多个supervisors。另一个重要的节点是Apache ZooKeeper,它将用于nimbus和supervisors之间的协调。
44 |
45 | **现在让我们仔细看看Apache Storm的工作流程 −**
46 | - 最初,nimbus将等待“Storm拓扑”提交给它。
47 | - 一旦提交拓扑,它将处理拓扑并收集要执行的所有任务和任务将被执行的顺序。
48 | - 然后,nimbus将任务均匀分配给所有可用的supervisors。
49 | - 在特定的时间间隔,所有supervisor将向nimbus发送心跳以通知它们仍然运行着。
50 | - 当supervisor终止并且不向心跳发送心跳时,则nimbus将任务分配给另一个supervisor。
51 | - 当nimbus本身终止时,supervisor将在没有任何问题的情况下对已经分配的任务进行工作。
52 | - 一旦所有的任务都完成后,supervisor将等待新的任务进去。
53 | - 同时,终止nimbus将由服务监控工具自动重新启动。
54 | - 重新启动的网络将从停止的地方继续。同样,终止supervisor也可以自动重新启动。由于网络管理程序和supervisor都可以自动重新启动,并且两者将像以前一样继续,因此Storm保证至少处理所有任务一次。
55 | - 一旦处理了所有拓扑,则网络管理器等待新的拓扑到达,并且类似地,管理器等待新的任务。
56 |
57 | **默认情况下,Storm集群中有两种模式:**
58 | - 本地模式 -此模式用于开发,测试和调试,因为它是查看所有拓扑组件协同工作的最简单方法。在这种模式下,我们可以调整参数,使我们能够看到我们的拓扑如何在不同的Storm配置环境中运行。在本地模式下,storm拓扑在本地机器上在单个JVM中运行。
59 | - 生产模式 -在这种模式下,我们将拓扑提交到工作Storm集群,该集群由许多进程组成,通常运行在不同的机器上。如在storm的工作流中所讨论的,工作集群将无限地运行,直到它被关闭。
60 |
61 | ## Storm安装(首先安装jdk和zookeeper)
62 |
63 | https://www.apache.org/dyn/closer.lua/storm/apache-storm-1.2.2/apache-storm-1.2.2.tar.gz
64 | 下载解压,编辑conf/storm.yaml文件
65 | ```bash
66 | ##填写zookeeper集群的ip地址或者主机名
67 | ########### These MUST be filled in for a storm configuration
68 | storm.zookeeper.servers:
69 | - "192.168.2.149"
70 | - "192.168.2.150"
71 | - "192.168.2.151"
72 |
73 | nimbus.seeds: ["192.168.2.149"]
74 | #配置数据存储路径
75 | storm.local.dir: "/data/ms/storm-1.1.1/data"
76 |
77 | ##配置节点健康检测
78 | storm.health.check.dir: "healthchecks"
79 | storm.health.check.timeout.ms: 5000
80 |
81 | storm.local.hostname: "192.168.2.150"
82 |
83 | #配置supervisor: 开启几个端口插槽,就开启几个对应的worker进程
84 | supervisor.slots.ports:
85 | - 6700
86 | - 6701
87 | - 6702
88 | - 6703
89 | ```
90 | 配置详解 http://xstarcd.github.io/wiki/Cloud/storm_config_detail.html
91 |
92 | ## 启动
93 | 最后一步是启动所有的Storm守护进程。 在监督下运行这些守护进程是非常重要的。 Storm是一个快速失败(fail-fast)系统,意味着只要遇到意外错误,进程就会停止。 Storm的设计可以在任何时候安全停止,并在重新启动过程时正确恢复。 这就是为什么Storm在进程中不保持状态 - 如果Nimbus或Supervisors重新启动,运行的拓扑结构不受影响。 以下是如何运行Storm守护进程:
94 |
95 | ```bash
96 | Nimbus:在Storm主控节点上运行命令bin/storm nimbus &,启动Nimbus后台程序,并放到后台执行。
97 |
98 | Supervisor:在Storm各个工作节点上运行命令bin/storm supervisor &。
99 |
100 | UI: 在Storm主控节点上运行命令bin/storm ui &,启动UI后台程序,并放到后台执行
101 | ```
102 | 访问http://192.168.1.191:8080 成功
103 |
104 | 参考链接:https://github.com/weyo/Storm-Documents/blob/master/Manual/zh/Concepts.md
105 |
--------------------------------------------------------------------------------
/docs/2019/SpringBoot自定义一个starter.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | > SprngBoot之所以现在这吗火热,是因为spring starter模式使我们日常模块化开发独立化, 模块之间依赖关系更加松散,更加的方便集成
4 |
5 | ## 如何实现
6 | 首先建立一个普通maven工程,修改pom配置文件
7 |
8 | ```java
9 |
10 |
11 | org.springframework.boot
12 | spring-boot-autoconfigure
13 |
14 |
15 | org.springframework.boot
16 | spring-boot-configuration-processor
17 | true
18 |
19 |
20 |
21 |
22 |
23 |
24 | org.springframework.boot
25 | spring-boot-starter-parent
26 | 2.0.6.RELEASE
27 | pom
28 | import
29 |
30 |
31 |
32 | ```
33 | 然后定义一个配置文件属性的类,为后续再其它项目中配置属性时使用。以spring.test-starter为开头,后面配置时间添加相应的属性即可
34 |
35 | ```java
36 | @ConfigurationProperties(prefix = "spring.test-starter")
37 | public class TestProperties {
38 | private String name;
39 | private int age;
40 | public String getName() {
41 | return name;
42 | }
43 | public void setName(String name) {
44 | this.name = name;
45 | }
46 | public int getAge() {
47 | return age;
48 | }
49 | public void setAge(int age) {
50 | this.age = age;
51 | }
52 | }
53 | ```
54 | t添加一个测试的service。其它模块集成这个starter时可以直接调用
55 | ```java
56 | public class TestService {
57 |
58 | private TestProperties properties;
59 |
60 | public TestService() {
61 | }
62 |
63 | public TestService(TestProperties properties) {
64 | this.properties = properties;
65 | }
66 |
67 | public String sayHello(){
68 | return "自定义starter->读取配置文件,name="+properties.getName()+"age="+properties.getAge();
69 | }
70 | }
71 | ```
72 | 创建自动配置。用于读取自定义的配置属性和自动注入TestService的 bean。每个starter都至少会有一个自动配置类
73 |
74 | ```java
75 | @Configuration
76 | @EnableConfigurationProperties(TestProperties.class)
77 | @ConditionalOnClass(TestService.class)
78 | @ConditionalOnProperty(prefix = "spring.test-starter", value = "enabled", matchIfMissing = true)
79 | public class TestServiceAutoConfiguration {
80 | @Autowired
81 | private TestProperties properties;
82 | /**
83 | *
84 | * 容器中没有指定Bean时会自动配置PestService
85 | * @return
86 | */
87 | @Bean
88 | @ConditionalOnMissingBean(TestService.class)
89 | public TestService testService(){
90 | TestService testService = new TestService(properties);
91 | return testService;
92 | }
93 | ```
94 | 在resources目录下创建META-INF文件夹并添加spring.factories文件。在该文件中配置自己的自动配置类。如果去debug springboot源码会发现SpringApplication.run中就执行了读取spring.factories文件的操作去进行自动配置
95 | ```java
96 | org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
97 | com.example.TestServiceAutoConfiguration
98 | ```
99 | 这样自定义一个starter 就完成了。接下来就可以到其它模块中使用了。首先在其他模块中引入
100 | ```java
101 |
102 | com.example
103 | test-springboot-starter
104 | 1.0
105 |
106 | ```
107 | application.properties中添加配置属性
108 | ```java
109 | spring.test-starter.name=qxwxww
110 | spring.test-starter.age=25
111 | ```
112 | 测试
113 | ```java
114 | @RunWith(SpringRunner.class)
115 | @SpringBootTest
116 | public class TestSpringbootApplicationTests {
117 | @Autowired
118 | TestService testService;
119 | @Test
120 | public void contextLoads() {
121 | System.err.println(testService.sayHello());
122 | }
123 |
124 | }
125 | ```
126 | 输出如下提示,表示成功
127 | 
128 |
129 |
--------------------------------------------------------------------------------
/docs/storm/storm04.md:
--------------------------------------------------------------------------------
1 | ## 并行度(parallelism)概念
2 | ------------------
3 |
4 | - 一个运行中的拓扑是由什么构成的:工作进程(worker processes),执行器(executors)和任务(tasks)
5 | - 在 Worker 中运行的是拓扑的一个子集。一个 worker 进程是从属于某一个特定的拓扑的,在 worker
6 | 进程中会运行一个或者多个与拓扑中的组件相关联的 executor。一个运行中的拓扑就是由这些运行于 Storm集群中的很多机器上的进程组成的。
7 | - 一个 executor 是由 worker 进程生成的一个线程。在 executor 中可能会有一个或者多个 task,这些 task
8 | 都是为同一个组件(spout 或者 bolt)服务的。
9 | - task 是实际执行数据处理的最小工作单元(注意,task 并不是线程) —— 在你的代码中实现的每个 spout 或者 bolt 都会在集群中运行很多个 task。在拓扑的整个生命周期中每个组件的 task 数量都是保持不变的,不过每个组件的 executor数量却是有可能会随着时间变化。在默认情况下 task 的数量是和 executor 的数量一样的,也就是说,默认情况下 Storm会在每个线程上运行一个 task。
10 |
11 |
12 | ## Storm的流分组策略
13 | -----------
14 | - Storm的分组策略对结果有着直接的影响,不同的分组的结果一定是不一样的。其次,不同的分组策略对资源的利用也是有着非常大的不同
15 | - 拓扑定义的一部分就是为每个Bolt指定输入的数据流,而数据流分组则定义了在Bolt的task之间如何分配数据流。
16 |
17 |
18 | ## 八种流分组定义
19 | -------
20 |
21 | ### Shuffle grouping:
22 | - 随机分组:随机的将tuple分发给bolt的各个task,每个bolt实例接收到相同数量的tuple。
23 |
24 | ### Fields grouping
25 | - 按字段分组:根据指定的字段的值进行分组,举个栗子,流按照“user-id”进行分组,那么具有相同的“user-id”的tuple会发到同一个task,而具有不同“user-id”值的tuple可能会发到不同的task上。这种情况常常用在单词计数,而实际情况是很少用到,因为如果某个字段的某个值太多,就会导致task不均衡的问题。
26 |
27 | ### Partial Key grouping
28 | - 部分字段分组:流由分组中指定的字段分区,如“字段”分组,但是在两个下游Bolt之间进行负载平衡,当输入数据歪斜时,可以更好地利用资源。优点。有了这个分组就完全可以不用Fields grouping了
29 |
30 | ### All grouping
31 | - 广播分组:将所有的tuple都复制之后再分发给Bolt所有的task,每一个订阅数据流的task都会接收到一份相同的完全的tuple的拷贝。
32 |
33 | ### Global grouping
34 | - 全局分组:这种分组会将所有的tuple都发到一个taskid最小的task上。由于所有的tuple都发到唯一一个task上,势必在数据量大的时候会造成资源不够用的情况。
35 |
36 | ### None grouping
37 | - 不分组:不指定分组就表示你不关心数据流如何分组。目前来说不分组和随机分组效果是一样的,但是最终,Storm可能会使用与其订阅的bolt或spout在相同进程的bolt来执行这些tuple
38 |
39 | ### Direct grouping
40 | - 指向分组:这是一种特殊的分组策略。以这种方式分组的流意味着将由元组的生成者决定消费者的哪个task能接收该元组。指向分组只能在已经声明为指向数据流的数据流中声明。tuple的发射必须使用emitDirect种的一种方法。Bolt可以通过使用TopologyContext或通过在OutputCollector(返回元组发送到的taskID)中跟踪emit方法的输出来获取其消费者的taskID。
41 |
42 | ### Local or shuffle grouping:
43 | 本地或随机分组:和随机分组类似,但是如果目标Bolt在同一个工作进程中有一个或多个任务,那么元组将被随机分配到那些进程内task。简而言之就是如果发送者和接受者在同一个worker则会减少网络传输,从而提高整个拓扑的性能。有了此分组就完全可以不用shuffle grouping了。
44 |
45 |
46 | ## 示例
47 | ----
48 | 修改上一章节的Topology
49 | [Storm(三)Java编写第一个本地模式demo](storm/storm03.md)
50 | ```java
51 | package com.qxw.topology;
52 | import org.apache.storm.Config;
53 | import org.apache.storm.LocalCluster;
54 | import org.apache.storm.topology.TopologyBuilder;
55 | import org.apache.storm.tuple.Fields;
56 |
57 | import com.qxw.bolt.OutBolt;
58 | import com.qxw.bolt.OutBolt2;
59 | import com.qxw.spout.DataSource;
60 |
61 | /**
62 | * 拓扑的并行性
63 | * @author qxw
64 | * @data 2018年9月17日下午2:49:09
65 | */
66 | public class TopologyTest2 {
67 |
68 | public static void main(String[] args) throws Exception {
69 | //配置
70 | Config cfg = new Config();
71 | cfg.setNumWorkers(2);//指定工作进程数 (jvm数量,分布式环境下可用,本地模式设置无意义)
72 | cfg.setDebug(false);
73 |
74 | //构造拓扑流程图
75 | TopologyBuilder builder = new TopologyBuilder();
76 | //设置数据源(产生2个执行器和俩个任务)
77 | builder.setSpout("dataSource", new DataSource(),2).setNumTasks(2);
78 | //设置数据建流处理组件(产生2个执行器和4个任务)
79 | builder.setBolt("out-bolt", new OutBolt(),2).shuffleGrouping("dataSource").setNumTasks(4); //随机分组
80 | //设置bolt的并行度和任务数:(产生6个执行器和6个任务)
81 | // builder.setBolt("out-bol2", new OutBolt2(),6).shuffleGrouping("out-bolt").setNumTasks(6); //随机分组
82 |
83 | //设置字段分组(产生8个执行器和8个任务)字段分组
84 | builder.setBolt("out-bol2", new OutBolt2(),8).fieldsGrouping("out-bolt", new Fields("outdata")).setNumTasks(8);
85 | //设置广播分组
86 | //builder.setBolt("write-bolt", new OutBolt2(), 4).allGrouping("print-bolt");
87 | //设置全局分组
88 | //builder.setBolt("write-bolt", new OutBolt2(), 4).globalGrouping("print-bolt");
89 |
90 | //1 本地模式
91 | LocalCluster cluster = new LocalCluster();
92 |
93 | //提交拓扑图 会一直轮询执行
94 | cluster.submitTopology("topo", cfg, builder.createTopology());
95 |
96 |
97 | //2 集群模式
98 | // StormSubmitter.submitTopology("topo", cfg, builder.createTopology());
99 |
100 | }
101 | }
102 |
103 | }
104 |
105 |
106 | ```
--------------------------------------------------------------------------------
/docs/storm/storm06.md:
--------------------------------------------------------------------------------
1 | ## DRPC简介
2 | Storm里面引入DRPC主要是利用storm的实时计算能力来并行化CPU intensive的计算。DRPC的storm topology以函数的参数流作为输入,而把这些函数调用的返回值作为topology的输出流。
3 |
4 | DRPC其实不能算是storm本身的一个特性, 它是通过组合storm的原语spout,bolt, topology而成的一种模式(pattern)。
5 |
6 | ## DRPC服务调用过程
7 | - 接收一个RPC请求。
8 | - 发送请求到storm topology
9 | - 从storm topology接收结果
10 | - 把结果发回给等待的客户端。从客户端的角度来看一个DRPC调用跟一个普通的RPC调用没有任何区别
11 |
12 |
6 |
7 | ## Apache Storm优势
8 | - storm是开源的,强大的,用户友好的。它可以用于小公司和大公司。
9 | - Storm是容错的,灵活的,可靠的,并且支持任何编程语言。
10 | - 允许实时流处理。
11 | - Storm是令人难以置信的快,因为它具有巨大的处理数据的力量。
12 | - Storm可以通过线性增加资源来保持性能,即使在负载增加的情况下。它是高度可扩展的。
13 | - Storm在几秒钟或几分钟内执行数据刷新和端到端传送响应取决于问题。它具有非常低的延迟。
14 | - Storm有操作智能。
15 | - Storm提供保证的数据处理,即使群集中的任何连接的节点死或消息丢失。
16 |
17 | ## Storm 系统中包含以下几个基本概念:
18 | --------------------
19 | * 拓扑(Topologies)
20 | * 流(Streams)
21 | * 数据源(Spouts)
22 | * 数据流处理组件(Bolts)
23 | * 数据流分组(Stream groupings)
24 | * 可靠性(Reliability)
25 | * 任务(Tasks
26 | * 工作进程(Workers
27 |
28 |
29 | ## Apache Storm的组件
30 | **Tuple**
31 | - Tuple是Storm中的主要数据结构。它是有序元素的列表。默认情况下,Tuple支持所有数据类型。通常,它被建模为一组逗号分隔的值,并传递到Storm集群。
32 |
33 | **Stream**
34 | - 流是元组的无序序列。
35 |
36 | **Spouts**
37 | - 流的源。通常,Storm从原始数据源(如Twitter Streaming API,Apache Kafka队列,Kestrel队列等)接受输入数据。否则,您可以编写spouts以从数据源读取数据。“ISpout”是实现spouts的核心接口,一些特定的接口是IRichSpout,BaseRichSpout,KafkaSpout等。
38 |
39 | **Bolts**
40 | - Bolts是逻辑处理单元。Spouts将数据传递到Bolts和Bolts过程,并产生新的输出流。Bolts可以执行过滤,聚合,加入,与数据源和数据库交互的操作。Bolts接收数据并发射到一个或多个Bolts。 “IBolt”是实现Bolts的核心接口。一些常见的接口是IRichBolt,IBasicBolt等。
41 |
42 | ## Storm工作流程
43 | 一个工作的Storm集群应该有一个Nimbus和一个或多个supervisors。另一个重要的节点是Apache ZooKeeper,它将用于nimbus和supervisors之间的协调。
44 |
45 | **现在让我们仔细看看Apache Storm的工作流程 −**
46 | - 最初,nimbus将等待“Storm拓扑”提交给它。
47 | - 一旦提交拓扑,它将处理拓扑并收集要执行的所有任务和任务将被执行的顺序。
48 | - 然后,nimbus将任务均匀分配给所有可用的supervisors。
49 | - 在特定的时间间隔,所有supervisor将向nimbus发送心跳以通知它们仍然运行着。
50 | - 当supervisor终止并且不向心跳发送心跳时,则nimbus将任务分配给另一个supervisor。
51 | - 当nimbus本身终止时,supervisor将在没有任何问题的情况下对已经分配的任务进行工作。
52 | - 一旦所有的任务都完成后,supervisor将等待新的任务进去。
53 | - 同时,终止nimbus将由服务监控工具自动重新启动。
54 | - 重新启动的网络将从停止的地方继续。同样,终止supervisor也可以自动重新启动。由于网络管理程序和supervisor都可以自动重新启动,并且两者将像以前一样继续,因此Storm保证至少处理所有任务一次。
55 | - 一旦处理了所有拓扑,则网络管理器等待新的拓扑到达,并且类似地,管理器等待新的任务。
56 |
57 | **默认情况下,Storm集群中有两种模式:**
58 | - 本地模式 -此模式用于开发,测试和调试,因为它是查看所有拓扑组件协同工作的最简单方法。在这种模式下,我们可以调整参数,使我们能够看到我们的拓扑如何在不同的Storm配置环境中运行。在本地模式下,storm拓扑在本地机器上在单个JVM中运行。
59 | - 生产模式 -在这种模式下,我们将拓扑提交到工作Storm集群,该集群由许多进程组成,通常运行在不同的机器上。如在storm的工作流中所讨论的,工作集群将无限地运行,直到它被关闭。
60 |
61 | ## Storm安装(首先安装jdk和zookeeper)
62 |
63 | https://www.apache.org/dyn/closer.lua/storm/apache-storm-1.2.2/apache-storm-1.2.2.tar.gz
64 | 下载解压,编辑conf/storm.yaml文件
65 | ```bash
66 | ##填写zookeeper集群的ip地址或者主机名
67 | ########### These MUST be filled in for a storm configuration
68 | storm.zookeeper.servers:
69 | - "192.168.2.149"
70 | - "192.168.2.150"
71 | - "192.168.2.151"
72 |
73 | nimbus.seeds: ["192.168.2.149"]
74 | #配置数据存储路径
75 | storm.local.dir: "/data/ms/storm-1.1.1/data"
76 |
77 | ##配置节点健康检测
78 | storm.health.check.dir: "healthchecks"
79 | storm.health.check.timeout.ms: 5000
80 |
81 | storm.local.hostname: "192.168.2.150"
82 |
83 | #配置supervisor: 开启几个端口插槽,就开启几个对应的worker进程
84 | supervisor.slots.ports:
85 | - 6700
86 | - 6701
87 | - 6702
88 | - 6703
89 | ```
90 | 配置详解 http://xstarcd.github.io/wiki/Cloud/storm_config_detail.html
91 |
92 | ## 启动
93 | 最后一步是启动所有的Storm守护进程。 在监督下运行这些守护进程是非常重要的。 Storm是一个快速失败(fail-fast)系统,意味着只要遇到意外错误,进程就会停止。 Storm的设计可以在任何时候安全停止,并在重新启动过程时正确恢复。 这就是为什么Storm在进程中不保持状态 - 如果Nimbus或Supervisors重新启动,运行的拓扑结构不受影响。 以下是如何运行Storm守护进程:
94 |
95 | ```bash
96 | Nimbus:在Storm主控节点上运行命令bin/storm nimbus &,启动Nimbus后台程序,并放到后台执行。
97 |
98 | Supervisor:在Storm各个工作节点上运行命令bin/storm supervisor &。
99 |
100 | UI: 在Storm主控节点上运行命令bin/storm ui &,启动UI后台程序,并放到后台执行
101 | ```
102 | 访问http://192.168.1.191:8080 成功
103 |
104 | 参考链接:https://github.com/weyo/Storm-Documents/blob/master/Manual/zh/Concepts.md
105 |
--------------------------------------------------------------------------------
/docs/2019/SpringBoot自定义一个starter.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | > SprngBoot之所以现在这吗火热,是因为spring starter模式使我们日常模块化开发独立化, 模块之间依赖关系更加松散,更加的方便集成
4 |
5 | ## 如何实现
6 | 首先建立一个普通maven工程,修改pom配置文件
7 |
8 | ```java
9 |
10 |
11 | org.springframework.boot
12 | spring-boot-autoconfigure
13 |
14 |
15 | org.springframework.boot
16 | spring-boot-configuration-processor
17 | true
18 |
19 |
20 |
21 |
22 |
23 |
24 | org.springframework.boot
25 | spring-boot-starter-parent
26 | 2.0.6.RELEASE
27 | pom
28 | import
29 |
30 |
31 |
32 | ```
33 | 然后定义一个配置文件属性的类,为后续再其它项目中配置属性时使用。以spring.test-starter为开头,后面配置时间添加相应的属性即可
34 |
35 | ```java
36 | @ConfigurationProperties(prefix = "spring.test-starter")
37 | public class TestProperties {
38 | private String name;
39 | private int age;
40 | public String getName() {
41 | return name;
42 | }
43 | public void setName(String name) {
44 | this.name = name;
45 | }
46 | public int getAge() {
47 | return age;
48 | }
49 | public void setAge(int age) {
50 | this.age = age;
51 | }
52 | }
53 | ```
54 | t添加一个测试的service。其它模块集成这个starter时可以直接调用
55 | ```java
56 | public class TestService {
57 |
58 | private TestProperties properties;
59 |
60 | public TestService() {
61 | }
62 |
63 | public TestService(TestProperties properties) {
64 | this.properties = properties;
65 | }
66 |
67 | public String sayHello(){
68 | return "自定义starter->读取配置文件,name="+properties.getName()+"age="+properties.getAge();
69 | }
70 | }
71 | ```
72 | 创建自动配置。用于读取自定义的配置属性和自动注入TestService的 bean。每个starter都至少会有一个自动配置类
73 |
74 | ```java
75 | @Configuration
76 | @EnableConfigurationProperties(TestProperties.class)
77 | @ConditionalOnClass(TestService.class)
78 | @ConditionalOnProperty(prefix = "spring.test-starter", value = "enabled", matchIfMissing = true)
79 | public class TestServiceAutoConfiguration {
80 | @Autowired
81 | private TestProperties properties;
82 | /**
83 | *
84 | * 容器中没有指定Bean时会自动配置PestService
85 | * @return
86 | */
87 | @Bean
88 | @ConditionalOnMissingBean(TestService.class)
89 | public TestService testService(){
90 | TestService testService = new TestService(properties);
91 | return testService;
92 | }
93 | ```
94 | 在resources目录下创建META-INF文件夹并添加spring.factories文件。在该文件中配置自己的自动配置类。如果去debug springboot源码会发现SpringApplication.run中就执行了读取spring.factories文件的操作去进行自动配置
95 | ```java
96 | org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
97 | com.example.TestServiceAutoConfiguration
98 | ```
99 | 这样自定义一个starter 就完成了。接下来就可以到其它模块中使用了。首先在其他模块中引入
100 | ```java
101 |
102 | com.example
103 | test-springboot-starter
104 | 1.0
105 |
106 | ```
107 | application.properties中添加配置属性
108 | ```java
109 | spring.test-starter.name=qxwxww
110 | spring.test-starter.age=25
111 | ```
112 | 测试
113 | ```java
114 | @RunWith(SpringRunner.class)
115 | @SpringBootTest
116 | public class TestSpringbootApplicationTests {
117 | @Autowired
118 | TestService testService;
119 | @Test
120 | public void contextLoads() {
121 | System.err.println(testService.sayHello());
122 | }
123 |
124 | }
125 | ```
126 | 输出如下提示,表示成功
127 | 
128 |
129 |
--------------------------------------------------------------------------------
/docs/storm/storm04.md:
--------------------------------------------------------------------------------
1 | ## 并行度(parallelism)概念
2 | ------------------
3 |
4 | - 一个运行中的拓扑是由什么构成的:工作进程(worker processes),执行器(executors)和任务(tasks)
5 | - 在 Worker 中运行的是拓扑的一个子集。一个 worker 进程是从属于某一个特定的拓扑的,在 worker
6 | 进程中会运行一个或者多个与拓扑中的组件相关联的 executor。一个运行中的拓扑就是由这些运行于 Storm集群中的很多机器上的进程组成的。
7 | - 一个 executor 是由 worker 进程生成的一个线程。在 executor 中可能会有一个或者多个 task,这些 task
8 | 都是为同一个组件(spout 或者 bolt)服务的。
9 | - task 是实际执行数据处理的最小工作单元(注意,task 并不是线程) —— 在你的代码中实现的每个 spout 或者 bolt 都会在集群中运行很多个 task。在拓扑的整个生命周期中每个组件的 task 数量都是保持不变的,不过每个组件的 executor数量却是有可能会随着时间变化。在默认情况下 task 的数量是和 executor 的数量一样的,也就是说,默认情况下 Storm会在每个线程上运行一个 task。
10 |
11 |
12 | ## Storm的流分组策略
13 | -----------
14 | - Storm的分组策略对结果有着直接的影响,不同的分组的结果一定是不一样的。其次,不同的分组策略对资源的利用也是有着非常大的不同
15 | - 拓扑定义的一部分就是为每个Bolt指定输入的数据流,而数据流分组则定义了在Bolt的task之间如何分配数据流。
16 |
17 |
18 | ## 八种流分组定义
19 | -------
20 |
21 | ### Shuffle grouping:
22 | - 随机分组:随机的将tuple分发给bolt的各个task,每个bolt实例接收到相同数量的tuple。
23 |
24 | ### Fields grouping
25 | - 按字段分组:根据指定的字段的值进行分组,举个栗子,流按照“user-id”进行分组,那么具有相同的“user-id”的tuple会发到同一个task,而具有不同“user-id”值的tuple可能会发到不同的task上。这种情况常常用在单词计数,而实际情况是很少用到,因为如果某个字段的某个值太多,就会导致task不均衡的问题。
26 |
27 | ### Partial Key grouping
28 | - 部分字段分组:流由分组中指定的字段分区,如“字段”分组,但是在两个下游Bolt之间进行负载平衡,当输入数据歪斜时,可以更好地利用资源。优点。有了这个分组就完全可以不用Fields grouping了
29 |
30 | ### All grouping
31 | - 广播分组:将所有的tuple都复制之后再分发给Bolt所有的task,每一个订阅数据流的task都会接收到一份相同的完全的tuple的拷贝。
32 |
33 | ### Global grouping
34 | - 全局分组:这种分组会将所有的tuple都发到一个taskid最小的task上。由于所有的tuple都发到唯一一个task上,势必在数据量大的时候会造成资源不够用的情况。
35 |
36 | ### None grouping
37 | - 不分组:不指定分组就表示你不关心数据流如何分组。目前来说不分组和随机分组效果是一样的,但是最终,Storm可能会使用与其订阅的bolt或spout在相同进程的bolt来执行这些tuple
38 |
39 | ### Direct grouping
40 | - 指向分组:这是一种特殊的分组策略。以这种方式分组的流意味着将由元组的生成者决定消费者的哪个task能接收该元组。指向分组只能在已经声明为指向数据流的数据流中声明。tuple的发射必须使用emitDirect种的一种方法。Bolt可以通过使用TopologyContext或通过在OutputCollector(返回元组发送到的taskID)中跟踪emit方法的输出来获取其消费者的taskID。
41 |
42 | ### Local or shuffle grouping:
43 | 本地或随机分组:和随机分组类似,但是如果目标Bolt在同一个工作进程中有一个或多个任务,那么元组将被随机分配到那些进程内task。简而言之就是如果发送者和接受者在同一个worker则会减少网络传输,从而提高整个拓扑的性能。有了此分组就完全可以不用shuffle grouping了。
44 |
45 |
46 | ## 示例
47 | ----
48 | 修改上一章节的Topology
49 | [Storm(三)Java编写第一个本地模式demo](storm/storm03.md)
50 | ```java
51 | package com.qxw.topology;
52 | import org.apache.storm.Config;
53 | import org.apache.storm.LocalCluster;
54 | import org.apache.storm.topology.TopologyBuilder;
55 | import org.apache.storm.tuple.Fields;
56 |
57 | import com.qxw.bolt.OutBolt;
58 | import com.qxw.bolt.OutBolt2;
59 | import com.qxw.spout.DataSource;
60 |
61 | /**
62 | * 拓扑的并行性
63 | * @author qxw
64 | * @data 2018年9月17日下午2:49:09
65 | */
66 | public class TopologyTest2 {
67 |
68 | public static void main(String[] args) throws Exception {
69 | //配置
70 | Config cfg = new Config();
71 | cfg.setNumWorkers(2);//指定工作进程数 (jvm数量,分布式环境下可用,本地模式设置无意义)
72 | cfg.setDebug(false);
73 |
74 | //构造拓扑流程图
75 | TopologyBuilder builder = new TopologyBuilder();
76 | //设置数据源(产生2个执行器和俩个任务)
77 | builder.setSpout("dataSource", new DataSource(),2).setNumTasks(2);
78 | //设置数据建流处理组件(产生2个执行器和4个任务)
79 | builder.setBolt("out-bolt", new OutBolt(),2).shuffleGrouping("dataSource").setNumTasks(4); //随机分组
80 | //设置bolt的并行度和任务数:(产生6个执行器和6个任务)
81 | // builder.setBolt("out-bol2", new OutBolt2(),6).shuffleGrouping("out-bolt").setNumTasks(6); //随机分组
82 |
83 | //设置字段分组(产生8个执行器和8个任务)字段分组
84 | builder.setBolt("out-bol2", new OutBolt2(),8).fieldsGrouping("out-bolt", new Fields("outdata")).setNumTasks(8);
85 | //设置广播分组
86 | //builder.setBolt("write-bolt", new OutBolt2(), 4).allGrouping("print-bolt");
87 | //设置全局分组
88 | //builder.setBolt("write-bolt", new OutBolt2(), 4).globalGrouping("print-bolt");
89 |
90 | //1 本地模式
91 | LocalCluster cluster = new LocalCluster();
92 |
93 | //提交拓扑图 会一直轮询执行
94 | cluster.submitTopology("topo", cfg, builder.createTopology());
95 |
96 |
97 | //2 集群模式
98 | // StormSubmitter.submitTopology("topo", cfg, builder.createTopology());
99 |
100 | }
101 | }
102 |
103 | }
104 |
105 |
106 | ```
--------------------------------------------------------------------------------
/docs/storm/storm06.md:
--------------------------------------------------------------------------------
1 | ## DRPC简介
2 | Storm里面引入DRPC主要是利用storm的实时计算能力来并行化CPU intensive的计算。DRPC的storm topology以函数的参数流作为输入,而把这些函数调用的返回值作为topology的输出流。
3 |
4 | DRPC其实不能算是storm本身的一个特性, 它是通过组合storm的原语spout,bolt, topology而成的一种模式(pattern)。
5 |
6 | ## DRPC服务调用过程
7 | - 接收一个RPC请求。
8 | - 发送请求到storm topology
9 | - 从storm topology接收结果
10 | - 把结果发回给等待的客户端。从客户端的角度来看一个DRPC调用跟一个普通的RPC调用没有任何区别
11 |
12 |  13 |
14 | ## 要使用DRPC首先要修改storm配置文件
15 |
16 | apache-storm-1.2.2/conf/storm.yaml
17 | ```bash
18 | storm.zookeeper.servers:
19 | - "192.168.1.191"
20 | storm.zookeeper.port: 2181
21 | storm.local.dir: "/usr/local/apache-storm-1.2.2/data"
22 | nimbus.seeds: ["192.168.1.191"]
23 | supervisor.slots.ports:
24 | - 6700
25 | - 6701
26 | - 6702
27 | - 6703
28 | storm.health.check.dir: "healthchecks"
29 | storm.health.check.timeout.ms: 5000
30 | #配置drpc
31 | drpc.servers:
32 | - "192.168.1.191"
33 | ```
34 | ## 启动drpc服务
35 | ```
36 | bin/storm drpc &
37 | ```
38 | ## 编写drpc服务代码
39 |
40 | ```java
41 | public class DrpcTopology {
42 | public static class ExclaimBolt extends BaseBasicBolt {
43 | public void execute(Tuple tuple, BasicOutputCollector collector) {
44 | String input = tuple.getString(1);
45 | collector.emit(new Values(tuple.getValue(0), input + "1"));
46 | }
47 |
48 | public void declareOutputFields(OutputFieldsDeclarer declarer) {
49 | declarer.declare(new Fields("id", "result"));
50 | }
51 | }
52 |
53 | /**
54 | * Distributed RPC是由一个”DPRC Server”协调的(storm自带了一个实现)。
55 | * DRPC服务调用过程:
56 | * 接收一个RPC请求。
57 | * 发送请求到storm topology
58 | * 从storm topology接收结果
59 | * 把结果发回给等待的客户端。从客户端的角度来看一个DRPC调用跟一个普通的RPC调用没有任何区别
60 | * @param args
61 | * @throws Exception
62 | */
63 | public static void main(String[] args) throws Exception {
64 | LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("exclamation");
65 | builder.addBolt(new ExclaimBolt(), 3);
66 | Config conf = new Config();
67 | conf.setDebug(true);
68 | conf.setNumWorkers(2);
69 | try {
70 | // LocalDRPC drpc = new LocalDRPC();
71 | // LocalCluster cluster = new LocalCluster();
72 | // cluster.submitTopology("drpc-demo", conf, builder.createLocalTopology(drpc));
73 | // System.out.println("DRPC测试 'hello':" + drpc.execute("exclamation", "hello"));
74 | //
75 | // cluster.shutdown();
76 | // drpc.shutdown();
77 | //集群模式
78 | conf.setNumWorkers(3);
79 | StormSubmitter.submitTopology("exclamation", conf,builder.createRemoteTopology());
80 | } catch (Exception e) {
81 | e.printStackTrace();
82 | }
83 | }
84 | ```
85 | ## 打包提交到storm集群
86 | 语法:bin/storm jar (jar包名) | 主函数路径 | Topology名称
87 | ```
88 | bin/storm jar stom-demo-1.0.jar com.qxw.drpc.DrpcTopology exclamation
89 | ```
90 |
91 | ## 访问UI查看是否提交成功
92 | http://192.168.1.191:8080
93 |
13 |
14 | ## 要使用DRPC首先要修改storm配置文件
15 |
16 | apache-storm-1.2.2/conf/storm.yaml
17 | ```bash
18 | storm.zookeeper.servers:
19 | - "192.168.1.191"
20 | storm.zookeeper.port: 2181
21 | storm.local.dir: "/usr/local/apache-storm-1.2.2/data"
22 | nimbus.seeds: ["192.168.1.191"]
23 | supervisor.slots.ports:
24 | - 6700
25 | - 6701
26 | - 6702
27 | - 6703
28 | storm.health.check.dir: "healthchecks"
29 | storm.health.check.timeout.ms: 5000
30 | #配置drpc
31 | drpc.servers:
32 | - "192.168.1.191"
33 | ```
34 | ## 启动drpc服务
35 | ```
36 | bin/storm drpc &
37 | ```
38 | ## 编写drpc服务代码
39 |
40 | ```java
41 | public class DrpcTopology {
42 | public static class ExclaimBolt extends BaseBasicBolt {
43 | public void execute(Tuple tuple, BasicOutputCollector collector) {
44 | String input = tuple.getString(1);
45 | collector.emit(new Values(tuple.getValue(0), input + "1"));
46 | }
47 |
48 | public void declareOutputFields(OutputFieldsDeclarer declarer) {
49 | declarer.declare(new Fields("id", "result"));
50 | }
51 | }
52 |
53 | /**
54 | * Distributed RPC是由一个”DPRC Server”协调的(storm自带了一个实现)。
55 | * DRPC服务调用过程:
56 | * 接收一个RPC请求。
57 | * 发送请求到storm topology
58 | * 从storm topology接收结果
59 | * 把结果发回给等待的客户端。从客户端的角度来看一个DRPC调用跟一个普通的RPC调用没有任何区别
60 | * @param args
61 | * @throws Exception
62 | */
63 | public static void main(String[] args) throws Exception {
64 | LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("exclamation");
65 | builder.addBolt(new ExclaimBolt(), 3);
66 | Config conf = new Config();
67 | conf.setDebug(true);
68 | conf.setNumWorkers(2);
69 | try {
70 | // LocalDRPC drpc = new LocalDRPC();
71 | // LocalCluster cluster = new LocalCluster();
72 | // cluster.submitTopology("drpc-demo", conf, builder.createLocalTopology(drpc));
73 | // System.out.println("DRPC测试 'hello':" + drpc.execute("exclamation", "hello"));
74 | //
75 | // cluster.shutdown();
76 | // drpc.shutdown();
77 | //集群模式
78 | conf.setNumWorkers(3);
79 | StormSubmitter.submitTopology("exclamation", conf,builder.createRemoteTopology());
80 | } catch (Exception e) {
81 | e.printStackTrace();
82 | }
83 | }
84 | ```
85 | ## 打包提交到storm集群
86 | 语法:bin/storm jar (jar包名) | 主函数路径 | Topology名称
87 | ```
88 | bin/storm jar stom-demo-1.0.jar com.qxw.drpc.DrpcTopology exclamation
89 | ```
90 |
91 | ## 访问UI查看是否提交成功
92 | http://192.168.1.191:8080
93 |  94 |
95 | **linux查看正在运行的Topology**
96 | ```bash
97 | [root@web1 apache-storm-1.2.2]# bin/storm list
98 | 3893 [main] INFO o.a.s.u.NimbusClient - Found leader nimbus : web1:6627
99 | Topology_name Status Num_tasks Num_workers Uptime_secs
100 | -------------------------------------------------------------------
101 | exclamation ACTIVE 0 0 1020
102 | ```
103 | ## 调用集群的drpc
104 | ```java
105 | public class DrpcTest {
106 | public static void main(String[] args) {
107 | try {
108 | Config conf = new Config();
109 | conf.setDebug(false);
110 | Map config = Utils.readDefaultConfig();
111 | DRPCClient client = new DRPCClient(config,"192.168.1.191", 3772); //drpc服务
112 | String result = client.execute("exclamation", "hello");/// 调用drpcTest函数,传递参数为hello
113 | System.out.println(result);
114 | } catch (Exception e) {
115 | e.printStackTrace();
116 | }
117 | }
118 | }
119 | ```
120 |
121 |
122 | 参考链接:https://blog.csdn.net/qq403977698/article/details/49025345
--------------------------------------------------------------------------------
/docs/distributed/Transactional.md:
--------------------------------------------------------------------------------
1 | ### 事务的具体定义
2 | - 事务提供一种机制将一个活动涉及的所有操作纳入到一个不可分割的执行单元,组成事务的所有操作只有在所有操作均能正常执行的情况下方能提交,只要其中任一操作执行失败,都将导致整个事务的回滚。简单地说,事务提供一种“要么什么都不做,要么做全套(All or Nothing)”机制。
3 |
4 | ### 数据库本地事务
5 | **ACID**
6 |
7 | 说到数据库事务就不得不说,数据库事务中的四大特性,ACID:
8 |
9 | **A:原子性(Atomicity)**
10 | - 一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
11 |
12 | **C:一致性(Consistency)**
13 | - 事务的一致性指的是在一个事务执行之前和执行之后数据库都必须处于一致性状态。如果事务成功地完成,那么系统中所有变化将正确地应用,系统处于有效状态。如果在事务中出现错误,那么系统中的所有变化将自动地回滚,系统返回到原始状态。
14 |
15 | **I:隔离性(Isolation)**
16 | - 指的是在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。由并发事务所做的修改必须与任何其他并发事务所做的修改隔离。事务查看数据更新时,数据所处的状态要么是另一事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看到中间状态的数据。
17 |
18 | **D:持久性(Durability)**
19 | - 指的是只要事务成功结束,它对数据库所做的更新就必须永久保存下来。即使发生系统崩溃,重新启动数据库系统后,数据库还能恢复到事务成功结束时的状态。
20 |
21 |
22 | ### InnoDB实现原理
23 | - InnoDB是mysql的一个存储引擎,大部分人对mysql都比较熟悉,这里简单介绍一下数据库事务实现的一些基本原理,在本地事务中,服务和资源在事务的包裹下可以看做是一体的,我们的本地事务由资源管理器进行管理,而事务的ACID是通过InnoDB日志和锁来保证。
24 | - 事务的隔离性是通过数据库锁的机制实现的,持久性通过redo log(重做日志)来实现,原子性和一致性通过Undo log来实现
25 | - UndoLog的原理很简单,为了满足事务的原子性,在操作任何数据之前,首先将数据备份到一个地方(这个存储数据备份的地方称为UndoLog)。然后进行数据的修改。如果出现了错误或者用户执行了ROLLBACK语句,系统可以利用Undo Log中的备份将数据恢复到事务开始之前的状态。
26 | - RedoLog记录的是新数据的备份。在事务提交前,只要将RedoLog持久化即可,不需要将数据持久化。当系统崩溃时,虽然数据没有持久化,但是RedoLog已经持久化。系统可以根据RedoLog的内容,将所有数据恢复到最新的状态。
27 |
28 |
29 | ### 什么是分布式事务
30 | - 分布式事务就是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。简单的说,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
31 |
32 | ### CAP定理,又被叫作布鲁尔定理 设计分布式系统 CAP就是入门理论。
33 | - C (一致性):对某个指定的客户端来说,读操作能返回最新的写操作。对于数据分布在不同节点上的数据上来说,如果在某个节点更新了数据,那么在其他节点如果都能读取到这个最新的数据,那么就称为强一致,如果有某个节点没有读取到,那就是分布式不一致。
34 | - A (可用性):非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。可用性的两个关键一个是合理的时间,一个是合理的响应。合理的时间指的是请求不能无限被阻塞,应该在合理的时间给出返回。合理的响应指的是系统应该明确返回结果并且结果是正确的,这里的正确指的是比如应该返回50,而不是返回40。
35 | - P (分区容错性):当出现网络分区后,系统能够继续工作。打个比方,这里个集群有多台机器,有台机器网络出现了问题,但是这个集群仍然可以正常工作。
36 |
37 |
38 | 熟悉CAP的人都知道,三者不能共有,如果感兴趣可以搜索CAP的证明,在分布式系统中,网络无法100%可靠,分区其实是一个必然现象,如果我们选择了CA而放弃了P,那么当发生分区现象时,为了保证一致性,这个时候必须拒绝请求,但是A又不允许,所以分布式系统理论上不可能选择CA架构,只能选择CP或者AP架构。
39 |
40 | 对于CP来说,放弃可用性,追求一致性和分区容错性,我们的zookeeper其实就是追求的强一致。
41 |
42 | 对于AP来说,放弃一致性(这里说的一致性是强一致性),追求分区容错性和可用性,这是很多分布式系统设计时的选择,后面的BASE也是根据AP来扩展。
43 |
44 |
45 | ### BASE
46 | BASE 是 Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent (最终一致性)三个短语的缩写。是对CAP中AP的一个扩展
47 | - 基本可用:分布式系统在出现故障时,允许损失部分可用功能,保证核心功能可用。
48 | - 软状态:允许系统中存在中间状态,这个状态不影响系统可用性,这里指的是CAP中的不一致。
49 | - 最终一致:最终一致是指经过一段时间后,所有节点数据都将会达到一致。
50 |
51 | BASE解决了CAP中理论没有网络延迟,在BASE中用软状态和最终一致,保证了延迟后的一致性。BASE和 ACID 是相反的,它完全不同于ACID的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。
52 |
53 | ### 分布式事务解决方案
54 |
55 | ### TCC
56 |
57 |
58 | 
59 |
60 | **对于TCC的解释:**
61 | - Try阶段:尝试执行,完成所有业务检查(一致性),预留必须业务资源(准隔离性)
62 | - Confirm阶段:确认执行真正执行业务,不作任何业务检查,只使用Try阶段预留的业务资源,Confirm操作满足幂等性。要求具备幂等设计,Confirm失败后需要进行重试。
63 | - Cancel阶段:取消执行,释放Try阶段预留的业务资源 Cancel操作满足幂等性Cancel阶段的异常和Confirm阶段异常处理方案基本上一致。
64 |
65 | **举个简单的例子**
66 | - 如果你用100元买了一瓶水, Try阶段:你需要向你的钱包检查是否够100元并锁住这100元,水也是一样的。
67 | - 如果有一个失败,则进行cancel(释放这100元和这一瓶水),如果cancel失败不论什么失败都进行重试cancel,所以需要保持幂等。
68 | - 如果都成功,则进行confirm,确认这100元扣,和这一瓶水被卖,如果confirm失败无论什么失败则重试(会依靠活动日志进行重试)
69 |
70 | **对于TCC来说适合一些:**
71 | - 强隔离性,严格一致性要求的活动业务。
72 | - 执行时间较短的业务
73 | - 实现参考:ByteTCC:https://github.com/liuyangming/ByteTCC/
74 |
75 | ### MQ事务
76 | - 在RocketMQ中实现了分布式事务,实际上其实是对本地消息表的一个封装,将本地消息表移动到了MQ内部,下面简单介绍一下MQ事务,如果想对其详细了解可以参考: https://www.jianshu.com/p/453c6e7ff81c。
77 | 
78 |
79 | - 程如下: 第一阶段Prepared消息,会拿到消息的地址。
80 | - 第二阶段执行本地事务。
81 | - 第三阶段通过第一阶段拿到的地址去访问消息,并修改状态。消息接受者就能使用这个消息。
82 |
83 |
84 | 如果确认消息失败,在RocketMq Broker中提供了定时扫描没有更新状态的消息,如果有消息没有得到确认,会向消息发送者发送消息,来判断是否提交,在rocketmq中是以listener的形式给发送者,用来处理。
85 | 
86 |
87 | 如果消费超时,则需要一直重试,消息接收端需要保证幂等。如果消息消费失败,这个就需要人工进行处理,因为这个概率较低,如果为了这种小概率时间而设计这个复杂的流程反而得不偿失
--------------------------------------------------------------------------------
/docs/distributed/Zookeeper.md:
--------------------------------------------------------------------------------
1 | ### Zookeeper的数据模型
2 | Zookeeper的数据模型是什么样子呢?它很像数据结构当中的树,也很像文件系统的目录。
3 | 
4 |
5 | 树是由节点所组成,Zookeeper的数据存储也同样是基于节点,这种节点叫做Znode。
6 |
7 | 但是,不同于树的节点,Znode的引用方式是路径引用,类似于文件路径:
8 |
9 | / 动物 / 仓鼠
10 |
11 | / 植物 / 荷花
12 |
13 | 这样的层级结构,让每一个Znode节点拥有唯一的路径,就像命名空间一样对不同信息作出清晰的隔离。
14 |
15 | **Znode包含了数据,子节点引用,访问权限等**
16 |
17 | 
18 |
19 | **data:**
20 |
21 | Znode存储的数据信息。
22 |
23 | **ACL:**
24 |
25 | 记录Znode的访问权限,即哪些人或哪些IP可以访问本节点。
26 |
27 | **stat:**
28 |
29 | 包含Znode的各种元数据,比如事务ID、版本号、时间戳、大小等等。
30 |
31 | **child:**
32 |
33 | 当前节点的子节点引用,类似于二叉树的左孩子右孩子。
34 |
35 | 这里需要注意一点,Zookeeper是为读多写少的场景所设计。Znode并不是用来存储大规模业务数据,而是用于存储少量的状态和配置信息,每个节点的数据最大不能超过1MB。
36 |
37 | ### Zookeeper的基本操作和事件通知
38 | create
39 | 创建节点
40 |
41 | delete
42 | 删除节点
43 |
44 | exists
45 | 判断节点是否存在
46 |
47 | getData
48 | 获得一个节点的数据
49 |
50 | setData
51 | 设置一个节点的数据
52 |
53 | getChildren
54 | 获取节点下的所有子节点
55 |
56 | 这其中,exists,getData,getChildren属于读操作。Zookeeper客户端在请求读操作的时候,可以选择是否设置Watch。
57 |
58 | ### Watch是什么意思呢?
59 | 我们可以理解成是注册在特定Znode上的触发器。当这个Znode发生改变,也就是调用了create,delete,setData方法的时候,将会触发Znode上注册的对应事件,请求Watch的客户端会接收到异步通知。
60 |
61 | ### Zookeeper的一致性
62 | Zookeeper身为分布式系统的协调服务,如果自身挂掉了怎嘛办?为了防止单击挂掉的情况,Zookeeper维护了一个集群
63 |
64 | 
65 |
66 | ### Zookeeper Service集群是一主多从结构
67 |
68 |
69 | 在更新数据时,首先更新到主节点(这里的节点是指服务器,不是Znode),再同步到从节点。
70 |
71 | 在读取数据时,直接读取任意从节点。
72 |
73 | 为了保证主从节点的数据一致性,Zookeeper采用了ZAB协议,这种协议非常类似于一致性算法Paxos和Raft。
74 |
75 | ### ZAB是什么?
76 | ZAB即Zookeeper Atomic Broadcast有效解决了Zookeeper 集群崩溃恢复,以及主从同步数据问题
77 |
78 | ### ZAB协议所定义的三种节点状态:
79 | - Looking :选举状态。
80 | - Following :Follower节点(从节点)所处的状态。
81 | - Leading :Leader节点(主节点)所处状态。
82 |
83 | **最大ZXID的概念:**
84 | - 最大ZXID也就是节点本地的最新事务编号,包含epoch和计数两部分。epoch是纪元的意思,相当于Raft算法选主时候的term。
85 |
86 | **假如Zookeeper当前的主节点挂掉了,集群会进行崩溃恢复。ZAB的崩溃恢复分成三个阶段:**
87 |
88 | 1.Leader election
89 |
90 | 选举阶段,此时集群中的节点处于Looking状态。它们会各自向其他节点发起投票,投票当中包含自己的服务器ID和最新事务ID(ZXID)。
91 |
92 | 
93 |
94 | 接下来,节点会用自身的ZXID和从其他节点接收到的ZXID做比较,如果发现别人家的ZXID比自己大,也就是数据比自己新,那么就重新发起投票,投票给目前已知最大的ZXID所属节点。
95 |
96 | 
97 |
98 | 每次投票后,服务器都会统计投票数量,判断是否有某个节点得到半数以上的投票。如果存在这样的节点,该节点将会成为准Leader,状态变为Leading。其他节点的状态变为Following。
99 |
100 | 
101 |
102 | 2.Discovery
103 |
104 | 发现阶段,用于在从节点中发现最新的ZXID和事务日志。或许有人会问:既然Leader被选为主节点,已经是集群里数据最新的了,为什么还要从节点中寻找最新事务呢?
105 |
106 | 这是为了防止某些意外情况,比如因网络原因在上一阶段产生多个Leader的情况。
107 |
108 | 所以这一阶段,Leader集思广益,接收所有Follower发来各自的最新epoch值。Leader从中选出最大的epoch,基于此值加1,生成新的epoch分发给各个Follower。
109 |
110 | 各个Follower收到全新的epoch后,返回ACK给Leader,带上各自最大的ZXID和历史事务日志。Leader选出最大的ZXID,并更新自身历史日志。
111 |
112 | 3.Synchronization
113 |
114 | 同步阶段,把Leader刚才收集得到的最新历史事务日志,同步给集群中所有的Follower。只有当半数Follower同步成功,这个准Leader才能成为正式的Leader。
115 |
116 | 自此,故障恢复正式完成。
117 |
118 | ### ZAB是怎嘛实现数据写入的(依靠Broadcast阶段)?
119 |
120 | 什么是Broadcast呢?简单来说,就是Zookeeper常规情况下更新数据的时候,由Leader广播到所有的Follower。其过程如下:
121 |
122 | 1.客户端发出写入数据请求给任意Follower。
123 |
124 | 2.Follower把写入数据请求转发给Leader。
125 |
126 | 3.Leader采用二阶段提交方式,先发送Propose广播给Follower。
127 |
128 | 4.Follower接到Propose消息,写入日志成功后,返回ACK消息给Leader。
129 |
130 | 5.Leader接到半数以上ACK消息,返回成功给客户端,并且广播Commit请求给Follower。
131 |
132 | Zab协议既不是强一致性,也不是弱一致性,而是处于两者之间的单调一致性。它依靠事务ID和版本号,保证了数据的更新和读取是有序的。
133 |
134 | ### Zookeeper的应用
135 | 1.分布式锁
136 |
137 | 这是雅虎研究员设计Zookeeper的初衷。利用Zookeeper的临时顺序节点,可以轻松实现分布式锁。
138 |
139 |
140 | 2.服务注册和发现
141 |
142 | 利用Znode和Watcher,可以实现分布式服务的注册和发现。最著名的应用就是阿里的分布式RPC框架Dubbo。
143 |
144 | 3.共享配置和状态信息
145 |
146 | Redis的分布式解决方案Codis,就利用了Zookeeper来存放数据路由表和 codis-proxy 节点的元信息。同时 codis-config 发起的命令都会通过 ZooKeeper 同步到各个存活的 codis-proxy。
147 |
148 | 此外,Kafka、HBase、Hadoop,也都依靠Zookeeper同步节点信息,实现高可用。
149 |
150 |
151 | #### 参考
152 | - https://mp.weixin.qq.com/s/Gs4rrF8wwRzF6EvyrF_o4A
--------------------------------------------------------------------------------
/docs/golang/使用goquery爬取影视资源网站.md:
--------------------------------------------------------------------------------
1 | ### goquery常用方法
2 | 会用jquery的,goquery基本可以1分钟上手
3 |
4 | ```go
5 | Eq(index int) *Selection //根据索引获取某个节点集
6 | First() *Selection //获取第一个子节点集
7 | Last() *Selection //获取最后一个子节点集
8 | Next() *Selection //获取下一个兄弟节点集
9 | NextAll() *Selection //获取后面所有兄弟节点集
10 | Prev() *Selection //前一个兄弟节点集
11 | Get(index int) *html.Node //根据索引获取一个节点
12 | Index() int //返回选择对象中第一个元素的位置
13 | Slice(start, end int) *Selection //根据起始位置获取子节点集
14 | Each(f func(int, *Selection)) *Selection //遍历
15 | EachWithBreak(f func(int, *Selection) bool) *Selection //可中断遍历
16 | Map(f func(int, *Selection) string) (result []string) //返回字符串数组
17 | Attr(), RemoveAttr(), SetAttr() //获取,移除,设置属性的值
18 | AddClass(), HasClass(), RemoveClass(), ToggleClass()
19 | Html() //获取该节点的html
20 | Length() //返回该Selection的元素个数
21 | Text() //获取该节点的文本值
22 | Children() //返回selection中各个节点下的孩子节点
23 | Contents() //获取当前节点下的所有节点
24 | Find() //查找获取当前匹配的元素
25 | Next() //下一个元素
26 | Prev() //上一个元素
27 | ```
28 |
29 | ## 代码
30 |
31 | ```go
32 | package main
33 |
34 | import (
35 | "fmt"
36 | "github.com/PuerkitoBio/goquery"
37 | "log"
38 | "net/http"
39 | "os"
40 | "strconv"
41 | "strings"
42 | )
43 |
44 | // 电影列表地址
45 | var url="http://zuikzy.cc/?m=vod-type-id-PAGE.html";
46 | const YUMING = "http://zuikzy.cc/"
47 |
48 |
49 | // 爬虫电影网站资源 添加到数据库
50 | func SaveVideo(page int){
51 |
52 | // 如果n为-1,则全部替换;如果 old 为空
53 | movieurl:=strings.Replace(url,"PAGE",strconv.Itoa(page),-1)
54 | log.Println(fmt.Sprintf("【开始爬取电影,页码:%d 请求地址为 %s 】",page,movieurl))
55 | res, err := http.Get(movieurl)
56 | checkErr(err,"【爬取网站地址请求异常 】")
57 | if res.StatusCode != 200 {
58 | log.Fatalf("status code error: %d %s", res.StatusCode, res.Status)
59 | }
60 | doc, err := goquery.NewDocumentFromReader(res.Body)
61 | checkErr(err,"爬取成功,解析html异常")
62 |
63 | doc.Find(".DianDian").Each(func(j int, tr *goquery.Selection) {
64 | title:=tr.Find("td").Eq(0).Text() //标题
65 | detailsLink,_:=tr.Find("td").Eq(0).Find("a").Eq(0).Attr("href") //详情页地址
66 |
67 | types:=tr.Find("td").Eq(1).Text() // 电影类型
68 |
69 | // 爬取播放地址和详情链接
70 | res, err= http.Get(YUMING+detailsLink)
71 | checkErr(err,"【爬取电影: %s 异常】")
72 | if res.StatusCode != 200 {
73 | log.Fatalf("status code error: %d %s", res.StatusCode, res.Status)
74 | }
75 | doc,_= goquery.NewDocumentFromReader(res.Body)
76 |
77 | //imgpath,_:=doc.Find(".videoPic img").Eq(0).Attr("src")
78 | //reamrk:=doc.Find(".movievod").Eq(1).Text();
79 | palyLink:=doc.Find(".contentURL li").Eq(1).Text()
80 |
81 | palyLink=strings.Replace(palyLink,"$","-",-1)
82 |
83 | log.Println(fmt.Sprintf("标题:%s 类型 %s 播放地址 %s ",title,types,palyLink))
84 |
85 | tracefile(fmt.Sprintf("标题:%s 类型 %s 播放地址 %s ",title,types,palyLink))
86 |
87 |
88 | })
89 | defer res.Body.Close()
90 | }
91 |
92 | func main() {
93 | for i := 1; i < 10; i++ {
94 | SaveVideo(i)
95 | }
96 | }
97 |
98 | func tracefile(str_content string) {
99 | // // 读写模式打开文件 如果不存在将创建一个新文件 写操作时将数据附加到文件尾部
100 | fd,_:=os.OpenFile("爬取全网VIP电影在线观看.txt",os.O_RDWR|os.O_CREATE|os.O_APPEND,0644)
101 | fd_content:=strings.Join([]string{str_content,"\n"},"")
102 | buf:=[]byte(fd_content)
103 | fd.Write(buf)
104 | fd.Close()
105 | }
106 |
107 |
108 | // 错误检查
109 | func checkErr(err error,msg string) {
110 | if err != nil {
111 | fmt.Println(msg,err)
112 | }
113 | }
114 | ```
115 | ### 爬取结果,复制地址到浏览即可在线播放
116 | ```bash
117 | 标题:神医 [高清]
118 | 类型 剧情片 播放地址 高清-https://zkgn.wb699.com/share/4bUkbVK2CRMgHeUo
119 | 标题:匹诺曹 [高清]
120 | 类型 爱情片 播放地址 高清-https://zkgn.wb699.com/share/v5339kxgH65mjfn8
121 | 标题:等风来 [高清]
122 | 类型 喜剧片 播放地址 高清-https://zkgn.wb699.com/share/7KE8MG7uiDVCbLvg
123 | 标题:相见恨晚 [德语1080P]
124 | 类型 喜剧片 播放地址 德语1080P-https://zkgn.wb699.com/share/dpfgCBaQzS7HPJh1
125 | 标题:都市灰姑娘 [德语1080P]
126 | 类型 剧情片 播放地址 德语1080P-https://zkgn.wb699.com/share/FPucBGxQy30QpzQ7
127 | 标题:米娅和白狮 [BD中英双字]
128 | 类型 剧情片 播放地址 BD中英双字-https://zkgn.wb699.com/share/uLiLFpOTGlfEBz71
129 | ```
130 | ### 源码地址
131 | - [demo源码](https://github.com/a870439570/Go-notes)
132 | ## 参考
133 | - [goquery用法](https://blog.csdn.net/jeffrey11223/article/details/79318856)
134 | - [采集地址](http://zuikzy.cc/?m=vod-type-id-1.html)
135 | - [goquery官方文档地址](https://godoc.org/github.com/PuerkitoBio/goquery)
136 |
137 |
--------------------------------------------------------------------------------
/docs/Spring/SpringMvc生命周期.md:
--------------------------------------------------------------------------------
1 | ## SpringMVC运行流程及九大组件
2 |
3 | 
4 |
5 | ## SpringMVC流程
6 |
7 | 1. 用户发送请求至前端控制器DispatcherServlet。
8 | 1. DispatcherServlet收到请求调用HandlerMapping处理器映射器。
9 | 1. 处理器映射器找到具体的处理器(可以根据xml配置、注解进行查找),生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。
10 | 1. DispatcherServlet调用HandlerAdapter处理器适配器。
11 | 1. HandlerAdapter经过适配调用具体的处理器(Controller,也叫后端控制器)。
12 | 1. Controller执行完成返回ModelAndView。
13 | 1. HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet。
14 | 1. DispatcherServlet将ModelAndView传给ViewReslover视图解析器。
15 | 1. ViewReslover解析后返回具体View。
16 | 1. DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)。
17 | 1. DispatcherServlet响应用户。
18 |
19 | ## 组件说明:
20 | 以下组件通常使用框架提供实现:
21 |
22 | 1. DispatcherServlet:作为前端控制器,整个流程控制的中心,控制其它组件执行,统一调度,降低组件之间的耦合性,提高每个组件的扩展性。
23 | 1. HandlerMapping:通过扩展处理器映射器实现不同的映射方式,例如:配置文件方式,实现接口方式,注解方式等。
24 | 1. HandlAdapter:通过扩展处理器适配器,支持更多类型的处理器。
25 | 1. ViewResolver:通过扩展视图解析器,支持更多类型的视图解析,例如:jsp、freemarker、pdf、excel等。
26 |
27 | **1、前端控制器DispatcherServlet(不需要工程师开发),由框架提供**
28 | - 作用:接收请求,响应结果,相当于转发器,中央处理器。有了dispatcherServlet减少了其它组件之间的耦合度。
29 | - 用户请求到达前端控制器,它就相当于mvc模式中的c,dispatcherServlet是整个流程控制的中心,由它调用其它组件处理用户的请求,dispatcherServlet的存在降低了组件之间的耦合性。
30 |
31 | **2、处理器映射器HandlerMapping(不需要工程师开发),由框架提供**
32 | - 作用:根据请求的url查找Handler
33 | - HandlerMapping负责根据用户请求找到Handler即处理器,springmvc提供了不同的映射器实现不同的映射方式,例如:配置文件方式,实现接口方式,注解方式等。
34 |
35 | **3、处理器适配器HandlerAdapter**
36 | - 作用:按照特定规则(HandlerAdapter要求的规则)去执行Handler
37 | - 通过HandlerAdapter对处理器进行执行,这是适配器模式的应用,通过扩展适配器可以对更多类型的处理器进行执行。
38 |
39 | **4、处理器Handler(需要工程师开发)**
40 | - 注意:编写Handler时按照HandlerAdapter的要求去做,这样适配器才可以去正确执行Handler
41 | - Handler 是继DispatcherServlet前端控制器的后端控制器,在DispatcherServlet的控制下Handler对具体的用户请求进行处理。
42 | - 由于Handler涉及到具体的用户业务请求 所以一般情况需要工程师根据业务需求开发Handler。
43 |
44 |
45 | **5、视图解析器View resolver(不需要工程师开发),由框架提供**
46 | - 作用:进行视图解析,根据逻辑视图名解析成真正的视图(view)
47 | - View Resolver负责将处理结果生成View视图,View Resolver首先根据逻辑视图名解析成物理视图名即具体的页面地址,再生成View视图对象,最后对View进行渲染将处理结果通过页面展示给用户。 springmvc框架提供了很多的View视图类型,包括:jstlView、freemarkerView、pdfView等。
48 | - 一般情况下需要通过页面标签或页面模版技术将模型数据通过页面展示给用户,需要由工程师根据业务需求开发具体的页面。
49 |
50 |
51 | **6、视图View(需要工程师开发jsp...)**
52 | - View是一个接口,实现类支持不同的View类型(jsp、freemarker、pdf...)
53 |
54 |
55 | ## 核心架构的具体流程
56 | - 1、首先用户发送请求——>DispatcherServlet,前端控制器收到请求后自己不进行处理,而是委托给其他的解析器进行处理,作为统一访问点,进行全局的流程控制;
57 |
58 | - 2、DispatcherServlet——>HandlerMapping, HandlerMapping 将会把请求映射为HandlerExecutionChain 对象(包含一个Handler 处理器(页面控制器)对象、多个HandlerInterceptor 拦截器)对象,通过这种策略模式,很容易添加新的映射策略;
59 |
60 | - 3、DispatcherServlet——>HandlerAdapter,HandlerAdapter 将会把处理器包装为适配器,从而支持多种类型的处理器,即适配器设计模式的应用,从而很容易支持很多类型的处理器;
61 |
62 | - 4、HandlerAdapter——>处理器功能处理方法的调用,HandlerAdapter 将会根据适配的结果调用真正的处理器的功能处理方法,完成功能处理;并返回一个ModelAndView 对象(包含模型数据、逻辑视图名);
63 |
64 | - 5、ModelAndView的逻辑视图名——> ViewResolver, ViewResolver 将把逻辑视图名解析为具体的View,通过这种策略模式,很容易更换其他视图技术;
65 |
66 | - 6、View——>渲染,View会根据传进来的Model模型数据进行渲染,此处的Model实际是一个Map数据结构,因此很容易支持其他视图技术;
67 |
68 | - 7、返回控制权给DispatcherServlet,由DispatcherServlet返回响应给用户,到此一个流程结束。
69 |
70 |
71 | **下边两个组件通常情况下需要开发:**
72 | - Handler:处理器,即后端控制器用controller表示。
73 | - View:视图,即展示给用户的界面,视图中通常需要标签语言展示模型数据。
74 |
75 | ## 什么是MVC模式
76 | MVC的原理图:
77 | 
78 |
79 | **分析:**
80 | - M-Model 模型(完成业务逻辑:有javaBean构成,service+dao+entity)
81 | - V-View 视图(做界面的展示 jsp,html……)
82 | - C-Controller 控制器(接收请求—>调用模型—>根据结果派发页面)
83 |
84 | ### SpringMVC的原理
85 | - 第一步:用户发起请求到前端控制器(DispatcherServlet)
86 |
87 | - 第二步:前端控制器请求处理器映射器(HandlerMappering)去查找处理器(Handle):通过xml配置或者注解进行查找
88 |
89 | - 第三步:找到以后处理器映射器(HandlerMappering)像前端控制器返回执行链(HandlerExecutionChain)
90 |
91 | - 第四步:前端控制器(DispatcherServlet)调用处理器适配器(HandlerAdapter)去执行处理器(Handler)
92 | -
93 | - 第五步:处理器适配器去执行Handler
94 |
95 | - 第六步:Handler执行完给处理器适配器返回ModelAndView
96 |
97 | - 第七步:处理器适配器向前端控制器返回ModelAndView
98 |
99 | - 第八步:前端控制器请求视图解析器(ViewResolver)去进行视图解析
100 |
101 | - 第九步:视图解析器像前端控制器返回View
102 |
103 | - 第十步:前端控制器对视图进行渲染
104 |
105 | - 第十一步:前端控制器向用户响应结果
106 |
107 | - 看到这些步骤我相信大家很感觉非常的乱,这是正常的,但是这里主要是要大家理解springMVC中的几个组件:
108 |
109 | - 前端控制器(DispatcherServlet):接收请求,响应结果,相当于电脑的CPU。
110 |
111 | - 处理器映射器(HandlerMapping):根据URL去查找处理器
112 |
113 | - 处理器(Handler):(需要程序员去写代码处理逻辑的)
114 |
115 | - 处理器适配器(HandlerAdapter):会把处理器包装成适配器,这样就可以支持多种类型的处理器,类比笔记本的适配器(适配器模式的应用)
116 |
117 | - 视图解析器(ViewResovler):进行视图解析,多返回的字符串,进行处理,可以解析成对应的页面
118 |
119 |
120 |
--------------------------------------------------------------------------------
/docs/distributed/redis基本操作.md:
--------------------------------------------------------------------------------
1 | ## 简介
2 | * Redis虽然是一个内存数据库,但也可以将数据持久化到硬盘,有两种持久化方式:RDB和AOF。
3 | * RDB持久化方式定时将数据快照写入磁盘。这种方式并不是非常可靠,因为可能丢失数据,但非常快速。
4 | * AOF持久化方式更加可靠,将服务端收到的每个写操作都写入磁盘。在服务器重启时,这些写操作被重新执行来重新构建数据集
5 | * Redis支持五种数据类型:string(字符串),hash(哈希)
6 | * list(列表),set(集合)及zset(sorted set:有序集合)。
7 |
8 |
9 | ## String类型
10 | * string是redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value。
11 | * string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象 。
12 | * string类型是最基本的数据类型,一个键最大能存储512MB。
13 |
14 | ```
15 | set name 1
16 | get name
17 |
18 | #只有在 key 不存在时设置 key 的值。
19 | setnx
20 |
21 | #设置有效期
22 | setex color 10 red
23 |
24 | #从第六个开始字符替换
25 | setrange name 6 qcw.com
26 |
27 | #批量设置 不会覆盖已经存在到key
28 | mset key1 v1 key2 v2
29 |
30 | #获取旧值并设置新值
31 | getset name 123
32 |
33 | #获取0-4之间字符
34 | getrange name 0 4
35 |
36 | #批量获取
37 | mget key1 key2 key3
38 |
39 | #对值递增加1 返回新值
40 | incr key1
41 |
42 | #不存在自动创建,初始值默认为0自增自减少数自定义
43 | incrby key1 5
44 |
45 | #自减少
46 | decr keyy
47 |
48 | #正数自增 负数 自减少
49 | decrby key -3
50 |
51 | #给指定的字符串增加,返回长度
52 | append naem .net
53 |
54 | #取指定字符串的长度, 返回长度
55 | strken name
56 | ```
57 |
58 | ## hashes(哈希)类型
59 | * Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
60 |
61 | ```
62 | # 设置hash field 为指定值 如果key不存在创建
63 | hset user:001 name qxw
64 | hget user:001 name
65 | hsetnx user:002 name lamp (返回1,失败 0)
66 |
67 | # 批量设置值
68 | hmset user:003 name 333 age 20 sex 1
69 |
70 | # 批量获取value
71 | hmget user:003 name age sex
72 |
73 | # 指定自增
74 | hincrby user:003 age 5
75 |
76 | # 测试值是否存在
77 | hexists user:003 age
78 |
79 | # 返回hash的数量
80 | hlen user:003
81 |
82 | # 删除
83 | hdel user:003 age
84 |
85 | # 返回hash 表所有key
86 | hkeys user:003 ()
87 |
88 | # 返回所有 value
89 | hvals user:003
90 |
91 | # 返回所有的key和value
92 | hgetall user:003
93 |
94 | ```
95 |
96 | ## list(列表)
97 | * Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
98 | * 是一个链表结构push pop 获取一个范围的所有值
99 |
100 |
101 | ```
102 | #从头部压入一个元素
103 | lpush list1 “hello”
104 |
105 | #从尾部压入一个元素)
106 | rpush list1 “word”
107 |
108 | #取值
109 | lrange list1 0 -1
110 |
111 | #在特定的元素前或后添加元素
112 | linsert list1 before “word” “hello”
113 |
114 | #删除n个和value相同的元素 n=0全部删粗 n<0 从尾部删除
115 | lrem list 3 “hello”
116 |
117 | #保留指定key的范围内的数据,下表从0开始 -1代表一直到结束
118 | ltrim list1 1 -1
119 |
120 | #从头部删除元素,并返回删除元素
121 | lpop list1
122 |
123 | #从尾部删除元素,并返回删除的元素
124 | rpop list1
125 |
126 | #从第一个list的尾部移除元素并添加到第二个list的头部
127 | rpoplpush list1 list2
128 |
129 | #返回key的list中index位置的元素
130 | lindex list1 0
131 |
132 | #返回key对应list的长度
133 | llen list1
134 |
135 | ```
136 |
137 | ## Set(集合)
138 | * Redis的Set是string类型的无序集合。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)
139 |
140 | ```
141 | #向集合成添加一个或多个成员
142 | sadd myset key hello key2 hollo2
143 |
144 | #获取集合成员的个数
145 | scard myset
146 |
147 | #返回给定所有集合的差集
148 | sdiff myset myset2
149 |
150 | #返回给定集合的所有差集并存储在detis中
151 | sdiff detis myset myset2
152 |
153 | #返回集合的交集
154 | sinter myset myset2
155 |
156 | #返回交集 并存储在detis中
157 | sinterstore detis myset myset2
158 |
159 | #判断元素是否是myset集合中的成员
160 | sismember myset "hello"
161 |
162 | #返回集合中所有的成员
163 | smembers myset
164 |
165 | #将元素移动到detis中
166 | smove myset detis hello
167 |
168 | #移除并返回集合中的一个随机元素
169 | spop myset
170 |
171 | #返回集合中一个或多个随机数
172 | srandmember myset 2
173 |
174 | #移除集合中一个或多个成员
175 | srem myset [member2] [member2]
176 |
177 | #返回集合并集
178 | sunion myset myset2
179 |
180 | #将指定的集合存储在detis中
181 | sunionstore detis myset myset2
182 |
183 | ```
184 |
185 | ## 有序集合(sorted set)
186 | * Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。
187 | * 不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
188 | * 有序集合的成员是唯一的,但分数(score)却可以重复。
189 | * 集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
190 | * 集合中最大的成员数为232-1(4294967295,每个集合可存储40多亿个成员)。
191 |
192 |
193 | ```
194 | #添加一个或多个成员,或者更新已存在成员的分数
195 | zadd myset 1"hello"
196 |
197 | #获取集合中的所有元素和分数
198 | zrange myzset 0-1 WITHSCORES
199 | zrange salary 1 2 WITHSCORE
200 |
201 | #获取有序集合的成员数
202 | zcard myset4
203 |
204 | #返回指定区间分数的成员个数
205 | zcount myset4 1 4
206 |
207 | #将集合中指定的成员的分数加2
208 | zincrby myset4 2 "hello"()
209 |
210 | #取交集,分数相加,存储到 sumpoint
211 | zinterstore sumpoint 2 myset4 myset3
212 |
213 | #计算有序集合中指定字典区间的成员数量
214 | zlexcount myset4 - +
215 |
216 | #Redis Zrangebylex 通过字典区间返回有序集合的成员。
217 | redis 127.0.0.1:6379> ZADD myzset 0 a 0 b 0 c 0 d 0 e 0 f 0 g
218 | (integer)7
219 | redis 127.0.0.1:6379> ZRANGEBYLEX myzset -[c
220 | 1)"a"2)"b"3)"c"
221 | redis 127.0.0.1:6379> ZRANGEBYLEX myzset -(c
222 | 1)"a"2)"b"
223 | redis 127.0.0.1:6379> ZRANGEBYLEX myzset [aaa (g
224 | 1)"b"2)"c"3)"d"4)"e"5)"f"
225 | redis>
226 | ```
227 |
--------------------------------------------------------------------------------
/docs/distributed/Redis01.md:
--------------------------------------------------------------------------------
1 | ### 使用 Redis 有什么缺点
2 | **主要是四个问题:**
3 | - 缓存和数据库双写一致性问题
4 | - 缓存雪崩问题
5 | - 缓存击穿问题
6 | - 缓存的并发竞争问题
7 |
8 | ### 单线程的 Redis 为什么这么快
9 | - Redis 是单线程工作模型,纯内存操作
10 | - 单线程操作,避免了频繁的上下文切换
11 | - 采用了非阻塞 I/O 多路复用机制
12 |
13 | ### 什么是I/O多路复用机制?
14 | 打一个比方:小曲在 S 城开了一家快递店,负责同城快送服务。小曲因为资金限制,雇佣了一批快递员,然后小曲发现资金不够了,只够买一辆车送快递。
15 |
16 |
17 | **经营方式一**
18 | - 客户每送来一份快递,小曲就让一个快递员盯着,然后快递员开车去送快递。慢慢的小曲就发现了这种经营方式存在下述问题:几十个快递员基本上时间都花在了抢车上了,大部分快递员都处在闲置状态,谁抢到了车,谁就能去送快递。随着快递的增多,快递员也越来越多,小曲发现快递店里越来越挤,没办法雇佣新的快递员了。快递员之间的协调很花时间。
19 |
20 | 综合上述缺点,小曲痛定思痛,提出了下面的经营方式。
21 |
22 | **经营方式二**
23 | - 小曲只雇佣一个快递员。然后呢,客户送来的快递,小曲按送达地点标注好,然后依次放在一个地方。最后,那个快递员依次的去取快递,一次拿一个,然后开着车去送快递,送好了就回来拿下一个快递。上述两种经营方式对比,是不是明显觉得第二种,效率更高,更好呢?
24 |
25 | **在上述比喻中:**
26 | - 每个快递员→每个线程
27 | - 每个快递→每个 Socket(I/O 流)
28 | - 快递的送达地点→Socket 的不同状态
29 | - 客户送快递请求→来自客户端的请求
30 | - 小曲的经营方式→服务端运行的代码
31 | - 一辆车→CPU 的核数
32 |
33 | **于是我们有如下结论:**
34 | - 经营方式一就是传统的并发模型,每个 I/O 流(快递)都有一个新的线程(快递员)管理。
35 | - 经营方式二就是 I/O 多路复用。只有单个线程(一个快递员),通过跟踪每个 I/O 流的状态(每个快递的送达地点),来管理多个I/O 流。
36 |
37 | 下面类比到真实的 Redis 线程模型,如图所示:
38 | 
39 |
40 | 简单来说,就是我们的 redis-client 在操作的时候,会产生具有不同事件类型的 Socket。
41 |
42 | 在服务端,有一段 I/O 多路复用程序,将其置入队列之中。然后,文件事件分派器,依次去队列中取,转发到不同的事件处理器中。
43 |
44 | 需要说明的是,这个 I/O 多路复用机制,Redis 还提供了 select、epoll、evport、kqueue 等多路复用函数库,大家可以自行去了解。
45 |
46 |
47 | ### Redis 的数据类型,以及每种数据类型的使用场景
48 | 1. String: 最常规的 set/get 操作,Value 可以是 String 也可以是数字。一般做一些复杂的计数功能的缓存。
49 | 1. Hash:这里 Value 存放的是结构化的对象,比较方便的就是操作其中的某个字段。做单点登录的时候,就是用这种数据结构存储用户信息,以 CookieId 作为 Key,设置 30 分钟为缓存过期时间,能很好的模拟出类似 Session 的效果。
50 | 1. List:使用 List 的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以利用 lrange 命令,做基于 Redis 的分页功能,性能极佳,用户体验好。
51 | 1. Set:因为 Set 堆放的是一堆不重复值的集合。所以可以做全局去重的功能。
52 | 1. Sorted Set:Sorted Set多了一个权重参数 Score,集合中的元素能够按 Score 进行排列。可以做排行榜应用,取 TOP N 操作。Sorted Set 可以用来做延时任务。最后一个应用就是可以做范围查找。
53 |
54 | ### Redis 的过期策略以及内存淘汰机制
55 | Redis 采用的是定期删除+惰性删除策略。
56 |
57 | **为什么不用定时删除策略**
58 | - 定时删除,用一个定时器来负责监视 Key,过期则自动删除。虽然内存及时释放,但是十分消耗 CPU 资源。
59 | - 在大并发请求下,CPU 要将时间应用在处理请求,而不是删除 Key,因此没有采用这一策略。
60 |
61 | **定期删除+惰性删除是如何工作**
62 | - 定期删除,Redis 默认每个 100ms 检查,是否有过期的 Key,有过期 Key 则删除。
63 | - 需要说明的是,Redis 不是每个 100ms 将所有的 Key 检查一次,而是随机抽取进行检查(如果每隔 100ms,全部 Key 进行检查,Redis 岂不是卡死)。
64 | - 因此,如果只采用定期删除策略,会导致很多 Key 到时间没有删除。于是,惰性删除派上用场。
65 | - 也就是说在你获取某个 Key 的时候,Redis 会检查一下,这个 Key 如果设置了过期时间,那么是否过期了?如果过期了此时就会删除。
66 |
67 | **采用定期删除+惰性删除就没其他问题了么?**
68 | - 不是的,如果定期删除没删除 Key。然后你也没即时去请求 Key,也就是说惰性删除也没生效。这样,Redis的内存会越来越高。那么就应该采用内存淘汰机制。在 redis.conf 中有一行配置:
69 |
70 | maxmemory-policy volatile-lru :
71 | 该配置就是配内存淘汰策略的
72 |
73 | noeviction:
74 | 当内存不足以容纳新写入数据时,新写入操作会报错。应该没人用吧。
75 |
76 | allkeys-lru:
77 | 当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 Key。推荐使用,目前项目在用这种。
78 |
79 | allkeys-random:
80 | 当内存不足以容纳新写入数据时,在键空间中,随机移除某个 Key。应该也没人用吧,你不删最少使用 Key,去随机删。
81 |
82 | volatile-lru:
83 | 当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的 Key。这种情况一般是把 Redis 既当缓存,又做持久化存储的时候才用。不推荐。
84 |
85 | volatile-random:
86 | 当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个 Key。依然不推荐。
87 |
88 | volatile-ttl:
89 | 当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的 Key 优先移除。不推荐。
90 | ```
91 | PS:如果没有设置 expire 的 Key,不满足先决条件(prerequisites);那么 volatile-lru,volatile-random 和 volatile-ttl 策略的行为,和 noeviction(不删除) 基本上一致。
92 |
93 |
94 | ### Redis 和数据库双写一致性问题
95 | 一致性问题是分布式常见问题,还可以再分为最终一致性和强一致性。数据库和缓存双写,就必然会存在不一致的问题。
96 | 如果对数据有强一致性要求,不能放缓存。我们所做的一切,只能保证最终一致性。另外,我们所做的方案从根本上来说,只能说降低不一致发生的概率,无法完全避免。因此,有强一致性要求的数据,不能放缓存。
97 |
98 | 首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
99 |
100 | ### 如何应对缓存穿透和缓存雪崩问题
101 |
102 | **缓存穿透**
103 | - 即黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库上,从而数据库连接异常。
104 |
105 | **缓存穿透解决方案:**
106 | - 利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试。
107 | - 采用异步更新策略,无论 Key 是否取到值,都直接返回。Value 值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。
108 | - 提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的 Key。迅速判断出,请求所携带的 Key 是否合法有效。如果不合法,则直接返回。
109 |
110 | **缓存雪崩**
111 | - 即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常
112 |
113 | **缓存雪崩解决方案:**
114 | - 给缓存的失效时间,加上一个随机值,避免集体失效。
115 | - 使用互斥锁,但是该方案吞吐量明显下降了。
116 | - 双缓存。我们有两个缓存,缓存 A 和缓存 B。缓存 A 的失效时间为 20 分钟,缓存 B 不设失效时间。自己做缓存预热操作。然后细分以下几个小点:从缓存 A 读数据库,有则直接返回;A 没有数据,直接从 B 读数据,直接返回,并且异步启动一个更新线程,更新线程同时更新缓存 A 和缓存 B。
117 |
118 | ### 如何解决 Redis 的并发竞争 Key 问题
119 | - 这个问题大致就是,同时有多个子系统去 Set 一个 Key。这个时候大家思考过要注意什么呢?如果对这个 Key 操作,不要求顺序,这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做 set 操作即可,比较简单。
120 | - 如果对这个 Key 操作,要求顺序.假设有一个 key1,系统 A 需要将 key1 设置为 valueA,系统 B 需要将 key1 设置为 valueB,系统 C 需要将 key1 设置为 valueC。期望按照 key1 的 value 值按照 valueA > valueB > valueC 的顺序变化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。
121 |
122 | 假设时间戳如下:
123 |
124 | 系统A key 1 {valueA 3:00}
125 |
126 | 系统B key 1 {valueB 3:05}
127 |
128 | 系统C key 1 {valueC 3:10}
129 |
130 | 那么,假设这会系统 B 先抢到锁,将 key1 设置为{valueB 3:05}。接下来系统 A 抢到锁,发现自己的 valueA 的时间戳早于缓存中的时间戳,那就不做 set 操作了,以此类推。
131 |
132 | 其他方法,比如利用队列,将 set 方法变成串行访问也可以。总之,灵活变通。
133 |
134 |
135 |
--------------------------------------------------------------------------------
/docs/leetcode/排序算法.md:
--------------------------------------------------------------------------------
1 | # 简介
2 |
3 |
94 |
95 | **linux查看正在运行的Topology**
96 | ```bash
97 | [root@web1 apache-storm-1.2.2]# bin/storm list
98 | 3893 [main] INFO o.a.s.u.NimbusClient - Found leader nimbus : web1:6627
99 | Topology_name Status Num_tasks Num_workers Uptime_secs
100 | -------------------------------------------------------------------
101 | exclamation ACTIVE 0 0 1020
102 | ```
103 | ## 调用集群的drpc
104 | ```java
105 | public class DrpcTest {
106 | public static void main(String[] args) {
107 | try {
108 | Config conf = new Config();
109 | conf.setDebug(false);
110 | Map config = Utils.readDefaultConfig();
111 | DRPCClient client = new DRPCClient(config,"192.168.1.191", 3772); //drpc服务
112 | String result = client.execute("exclamation", "hello");/// 调用drpcTest函数,传递参数为hello
113 | System.out.println(result);
114 | } catch (Exception e) {
115 | e.printStackTrace();
116 | }
117 | }
118 | }
119 | ```
120 |
121 |
122 | 参考链接:https://blog.csdn.net/qq403977698/article/details/49025345
--------------------------------------------------------------------------------
/docs/distributed/Transactional.md:
--------------------------------------------------------------------------------
1 | ### 事务的具体定义
2 | - 事务提供一种机制将一个活动涉及的所有操作纳入到一个不可分割的执行单元,组成事务的所有操作只有在所有操作均能正常执行的情况下方能提交,只要其中任一操作执行失败,都将导致整个事务的回滚。简单地说,事务提供一种“要么什么都不做,要么做全套(All or Nothing)”机制。
3 |
4 | ### 数据库本地事务
5 | **ACID**
6 |
7 | 说到数据库事务就不得不说,数据库事务中的四大特性,ACID:
8 |
9 | **A:原子性(Atomicity)**
10 | - 一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
11 |
12 | **C:一致性(Consistency)**
13 | - 事务的一致性指的是在一个事务执行之前和执行之后数据库都必须处于一致性状态。如果事务成功地完成,那么系统中所有变化将正确地应用,系统处于有效状态。如果在事务中出现错误,那么系统中的所有变化将自动地回滚,系统返回到原始状态。
14 |
15 | **I:隔离性(Isolation)**
16 | - 指的是在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。由并发事务所做的修改必须与任何其他并发事务所做的修改隔离。事务查看数据更新时,数据所处的状态要么是另一事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看到中间状态的数据。
17 |
18 | **D:持久性(Durability)**
19 | - 指的是只要事务成功结束,它对数据库所做的更新就必须永久保存下来。即使发生系统崩溃,重新启动数据库系统后,数据库还能恢复到事务成功结束时的状态。
20 |
21 |
22 | ### InnoDB实现原理
23 | - InnoDB是mysql的一个存储引擎,大部分人对mysql都比较熟悉,这里简单介绍一下数据库事务实现的一些基本原理,在本地事务中,服务和资源在事务的包裹下可以看做是一体的,我们的本地事务由资源管理器进行管理,而事务的ACID是通过InnoDB日志和锁来保证。
24 | - 事务的隔离性是通过数据库锁的机制实现的,持久性通过redo log(重做日志)来实现,原子性和一致性通过Undo log来实现
25 | - UndoLog的原理很简单,为了满足事务的原子性,在操作任何数据之前,首先将数据备份到一个地方(这个存储数据备份的地方称为UndoLog)。然后进行数据的修改。如果出现了错误或者用户执行了ROLLBACK语句,系统可以利用Undo Log中的备份将数据恢复到事务开始之前的状态。
26 | - RedoLog记录的是新数据的备份。在事务提交前,只要将RedoLog持久化即可,不需要将数据持久化。当系统崩溃时,虽然数据没有持久化,但是RedoLog已经持久化。系统可以根据RedoLog的内容,将所有数据恢复到最新的状态。
27 |
28 |
29 | ### 什么是分布式事务
30 | - 分布式事务就是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。简单的说,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
31 |
32 | ### CAP定理,又被叫作布鲁尔定理 设计分布式系统 CAP就是入门理论。
33 | - C (一致性):对某个指定的客户端来说,读操作能返回最新的写操作。对于数据分布在不同节点上的数据上来说,如果在某个节点更新了数据,那么在其他节点如果都能读取到这个最新的数据,那么就称为强一致,如果有某个节点没有读取到,那就是分布式不一致。
34 | - A (可用性):非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。可用性的两个关键一个是合理的时间,一个是合理的响应。合理的时间指的是请求不能无限被阻塞,应该在合理的时间给出返回。合理的响应指的是系统应该明确返回结果并且结果是正确的,这里的正确指的是比如应该返回50,而不是返回40。
35 | - P (分区容错性):当出现网络分区后,系统能够继续工作。打个比方,这里个集群有多台机器,有台机器网络出现了问题,但是这个集群仍然可以正常工作。
36 |
37 |
38 | 熟悉CAP的人都知道,三者不能共有,如果感兴趣可以搜索CAP的证明,在分布式系统中,网络无法100%可靠,分区其实是一个必然现象,如果我们选择了CA而放弃了P,那么当发生分区现象时,为了保证一致性,这个时候必须拒绝请求,但是A又不允许,所以分布式系统理论上不可能选择CA架构,只能选择CP或者AP架构。
39 |
40 | 对于CP来说,放弃可用性,追求一致性和分区容错性,我们的zookeeper其实就是追求的强一致。
41 |
42 | 对于AP来说,放弃一致性(这里说的一致性是强一致性),追求分区容错性和可用性,这是很多分布式系统设计时的选择,后面的BASE也是根据AP来扩展。
43 |
44 |
45 | ### BASE
46 | BASE 是 Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent (最终一致性)三个短语的缩写。是对CAP中AP的一个扩展
47 | - 基本可用:分布式系统在出现故障时,允许损失部分可用功能,保证核心功能可用。
48 | - 软状态:允许系统中存在中间状态,这个状态不影响系统可用性,这里指的是CAP中的不一致。
49 | - 最终一致:最终一致是指经过一段时间后,所有节点数据都将会达到一致。
50 |
51 | BASE解决了CAP中理论没有网络延迟,在BASE中用软状态和最终一致,保证了延迟后的一致性。BASE和 ACID 是相反的,它完全不同于ACID的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。
52 |
53 | ### 分布式事务解决方案
54 |
55 | ### TCC
56 |
57 |
58 | 
59 |
60 | **对于TCC的解释:**
61 | - Try阶段:尝试执行,完成所有业务检查(一致性),预留必须业务资源(准隔离性)
62 | - Confirm阶段:确认执行真正执行业务,不作任何业务检查,只使用Try阶段预留的业务资源,Confirm操作满足幂等性。要求具备幂等设计,Confirm失败后需要进行重试。
63 | - Cancel阶段:取消执行,释放Try阶段预留的业务资源 Cancel操作满足幂等性Cancel阶段的异常和Confirm阶段异常处理方案基本上一致。
64 |
65 | **举个简单的例子**
66 | - 如果你用100元买了一瓶水, Try阶段:你需要向你的钱包检查是否够100元并锁住这100元,水也是一样的。
67 | - 如果有一个失败,则进行cancel(释放这100元和这一瓶水),如果cancel失败不论什么失败都进行重试cancel,所以需要保持幂等。
68 | - 如果都成功,则进行confirm,确认这100元扣,和这一瓶水被卖,如果confirm失败无论什么失败则重试(会依靠活动日志进行重试)
69 |
70 | **对于TCC来说适合一些:**
71 | - 强隔离性,严格一致性要求的活动业务。
72 | - 执行时间较短的业务
73 | - 实现参考:ByteTCC:https://github.com/liuyangming/ByteTCC/
74 |
75 | ### MQ事务
76 | - 在RocketMQ中实现了分布式事务,实际上其实是对本地消息表的一个封装,将本地消息表移动到了MQ内部,下面简单介绍一下MQ事务,如果想对其详细了解可以参考: https://www.jianshu.com/p/453c6e7ff81c。
77 | 
78 |
79 | - 程如下: 第一阶段Prepared消息,会拿到消息的地址。
80 | - 第二阶段执行本地事务。
81 | - 第三阶段通过第一阶段拿到的地址去访问消息,并修改状态。消息接受者就能使用这个消息。
82 |
83 |
84 | 如果确认消息失败,在RocketMq Broker中提供了定时扫描没有更新状态的消息,如果有消息没有得到确认,会向消息发送者发送消息,来判断是否提交,在rocketmq中是以listener的形式给发送者,用来处理。
85 | 
86 |
87 | 如果消费超时,则需要一直重试,消息接收端需要保证幂等。如果消息消费失败,这个就需要人工进行处理,因为这个概率较低,如果为了这种小概率时间而设计这个复杂的流程反而得不偿失
--------------------------------------------------------------------------------
/docs/distributed/Zookeeper.md:
--------------------------------------------------------------------------------
1 | ### Zookeeper的数据模型
2 | Zookeeper的数据模型是什么样子呢?它很像数据结构当中的树,也很像文件系统的目录。
3 | 
4 |
5 | 树是由节点所组成,Zookeeper的数据存储也同样是基于节点,这种节点叫做Znode。
6 |
7 | 但是,不同于树的节点,Znode的引用方式是路径引用,类似于文件路径:
8 |
9 | / 动物 / 仓鼠
10 |
11 | / 植物 / 荷花
12 |
13 | 这样的层级结构,让每一个Znode节点拥有唯一的路径,就像命名空间一样对不同信息作出清晰的隔离。
14 |
15 | **Znode包含了数据,子节点引用,访问权限等**
16 |
17 | 
18 |
19 | **data:**
20 |
21 | Znode存储的数据信息。
22 |
23 | **ACL:**
24 |
25 | 记录Znode的访问权限,即哪些人或哪些IP可以访问本节点。
26 |
27 | **stat:**
28 |
29 | 包含Znode的各种元数据,比如事务ID、版本号、时间戳、大小等等。
30 |
31 | **child:**
32 |
33 | 当前节点的子节点引用,类似于二叉树的左孩子右孩子。
34 |
35 | 这里需要注意一点,Zookeeper是为读多写少的场景所设计。Znode并不是用来存储大规模业务数据,而是用于存储少量的状态和配置信息,每个节点的数据最大不能超过1MB。
36 |
37 | ### Zookeeper的基本操作和事件通知
38 | create
39 | 创建节点
40 |
41 | delete
42 | 删除节点
43 |
44 | exists
45 | 判断节点是否存在
46 |
47 | getData
48 | 获得一个节点的数据
49 |
50 | setData
51 | 设置一个节点的数据
52 |
53 | getChildren
54 | 获取节点下的所有子节点
55 |
56 | 这其中,exists,getData,getChildren属于读操作。Zookeeper客户端在请求读操作的时候,可以选择是否设置Watch。
57 |
58 | ### Watch是什么意思呢?
59 | 我们可以理解成是注册在特定Znode上的触发器。当这个Znode发生改变,也就是调用了create,delete,setData方法的时候,将会触发Znode上注册的对应事件,请求Watch的客户端会接收到异步通知。
60 |
61 | ### Zookeeper的一致性
62 | Zookeeper身为分布式系统的协调服务,如果自身挂掉了怎嘛办?为了防止单击挂掉的情况,Zookeeper维护了一个集群
63 |
64 | 
65 |
66 | ### Zookeeper Service集群是一主多从结构
67 |
68 |
69 | 在更新数据时,首先更新到主节点(这里的节点是指服务器,不是Znode),再同步到从节点。
70 |
71 | 在读取数据时,直接读取任意从节点。
72 |
73 | 为了保证主从节点的数据一致性,Zookeeper采用了ZAB协议,这种协议非常类似于一致性算法Paxos和Raft。
74 |
75 | ### ZAB是什么?
76 | ZAB即Zookeeper Atomic Broadcast有效解决了Zookeeper 集群崩溃恢复,以及主从同步数据问题
77 |
78 | ### ZAB协议所定义的三种节点状态:
79 | - Looking :选举状态。
80 | - Following :Follower节点(从节点)所处的状态。
81 | - Leading :Leader节点(主节点)所处状态。
82 |
83 | **最大ZXID的概念:**
84 | - 最大ZXID也就是节点本地的最新事务编号,包含epoch和计数两部分。epoch是纪元的意思,相当于Raft算法选主时候的term。
85 |
86 | **假如Zookeeper当前的主节点挂掉了,集群会进行崩溃恢复。ZAB的崩溃恢复分成三个阶段:**
87 |
88 | 1.Leader election
89 |
90 | 选举阶段,此时集群中的节点处于Looking状态。它们会各自向其他节点发起投票,投票当中包含自己的服务器ID和最新事务ID(ZXID)。
91 |
92 | 
93 |
94 | 接下来,节点会用自身的ZXID和从其他节点接收到的ZXID做比较,如果发现别人家的ZXID比自己大,也就是数据比自己新,那么就重新发起投票,投票给目前已知最大的ZXID所属节点。
95 |
96 | 
97 |
98 | 每次投票后,服务器都会统计投票数量,判断是否有某个节点得到半数以上的投票。如果存在这样的节点,该节点将会成为准Leader,状态变为Leading。其他节点的状态变为Following。
99 |
100 | 
101 |
102 | 2.Discovery
103 |
104 | 发现阶段,用于在从节点中发现最新的ZXID和事务日志。或许有人会问:既然Leader被选为主节点,已经是集群里数据最新的了,为什么还要从节点中寻找最新事务呢?
105 |
106 | 这是为了防止某些意外情况,比如因网络原因在上一阶段产生多个Leader的情况。
107 |
108 | 所以这一阶段,Leader集思广益,接收所有Follower发来各自的最新epoch值。Leader从中选出最大的epoch,基于此值加1,生成新的epoch分发给各个Follower。
109 |
110 | 各个Follower收到全新的epoch后,返回ACK给Leader,带上各自最大的ZXID和历史事务日志。Leader选出最大的ZXID,并更新自身历史日志。
111 |
112 | 3.Synchronization
113 |
114 | 同步阶段,把Leader刚才收集得到的最新历史事务日志,同步给集群中所有的Follower。只有当半数Follower同步成功,这个准Leader才能成为正式的Leader。
115 |
116 | 自此,故障恢复正式完成。
117 |
118 | ### ZAB是怎嘛实现数据写入的(依靠Broadcast阶段)?
119 |
120 | 什么是Broadcast呢?简单来说,就是Zookeeper常规情况下更新数据的时候,由Leader广播到所有的Follower。其过程如下:
121 |
122 | 1.客户端发出写入数据请求给任意Follower。
123 |
124 | 2.Follower把写入数据请求转发给Leader。
125 |
126 | 3.Leader采用二阶段提交方式,先发送Propose广播给Follower。
127 |
128 | 4.Follower接到Propose消息,写入日志成功后,返回ACK消息给Leader。
129 |
130 | 5.Leader接到半数以上ACK消息,返回成功给客户端,并且广播Commit请求给Follower。
131 |
132 | Zab协议既不是强一致性,也不是弱一致性,而是处于两者之间的单调一致性。它依靠事务ID和版本号,保证了数据的更新和读取是有序的。
133 |
134 | ### Zookeeper的应用
135 | 1.分布式锁
136 |
137 | 这是雅虎研究员设计Zookeeper的初衷。利用Zookeeper的临时顺序节点,可以轻松实现分布式锁。
138 |
139 |
140 | 2.服务注册和发现
141 |
142 | 利用Znode和Watcher,可以实现分布式服务的注册和发现。最著名的应用就是阿里的分布式RPC框架Dubbo。
143 |
144 | 3.共享配置和状态信息
145 |
146 | Redis的分布式解决方案Codis,就利用了Zookeeper来存放数据路由表和 codis-proxy 节点的元信息。同时 codis-config 发起的命令都会通过 ZooKeeper 同步到各个存活的 codis-proxy。
147 |
148 | 此外,Kafka、HBase、Hadoop,也都依靠Zookeeper同步节点信息,实现高可用。
149 |
150 |
151 | #### 参考
152 | - https://mp.weixin.qq.com/s/Gs4rrF8wwRzF6EvyrF_o4A
--------------------------------------------------------------------------------
/docs/golang/使用goquery爬取影视资源网站.md:
--------------------------------------------------------------------------------
1 | ### goquery常用方法
2 | 会用jquery的,goquery基本可以1分钟上手
3 |
4 | ```go
5 | Eq(index int) *Selection //根据索引获取某个节点集
6 | First() *Selection //获取第一个子节点集
7 | Last() *Selection //获取最后一个子节点集
8 | Next() *Selection //获取下一个兄弟节点集
9 | NextAll() *Selection //获取后面所有兄弟节点集
10 | Prev() *Selection //前一个兄弟节点集
11 | Get(index int) *html.Node //根据索引获取一个节点
12 | Index() int //返回选择对象中第一个元素的位置
13 | Slice(start, end int) *Selection //根据起始位置获取子节点集
14 | Each(f func(int, *Selection)) *Selection //遍历
15 | EachWithBreak(f func(int, *Selection) bool) *Selection //可中断遍历
16 | Map(f func(int, *Selection) string) (result []string) //返回字符串数组
17 | Attr(), RemoveAttr(), SetAttr() //获取,移除,设置属性的值
18 | AddClass(), HasClass(), RemoveClass(), ToggleClass()
19 | Html() //获取该节点的html
20 | Length() //返回该Selection的元素个数
21 | Text() //获取该节点的文本值
22 | Children() //返回selection中各个节点下的孩子节点
23 | Contents() //获取当前节点下的所有节点
24 | Find() //查找获取当前匹配的元素
25 | Next() //下一个元素
26 | Prev() //上一个元素
27 | ```
28 |
29 | ## 代码
30 |
31 | ```go
32 | package main
33 |
34 | import (
35 | "fmt"
36 | "github.com/PuerkitoBio/goquery"
37 | "log"
38 | "net/http"
39 | "os"
40 | "strconv"
41 | "strings"
42 | )
43 |
44 | // 电影列表地址
45 | var url="http://zuikzy.cc/?m=vod-type-id-PAGE.html";
46 | const YUMING = "http://zuikzy.cc/"
47 |
48 |
49 | // 爬虫电影网站资源 添加到数据库
50 | func SaveVideo(page int){
51 |
52 | // 如果n为-1,则全部替换;如果 old 为空
53 | movieurl:=strings.Replace(url,"PAGE",strconv.Itoa(page),-1)
54 | log.Println(fmt.Sprintf("【开始爬取电影,页码:%d 请求地址为 %s 】",page,movieurl))
55 | res, err := http.Get(movieurl)
56 | checkErr(err,"【爬取网站地址请求异常 】")
57 | if res.StatusCode != 200 {
58 | log.Fatalf("status code error: %d %s", res.StatusCode, res.Status)
59 | }
60 | doc, err := goquery.NewDocumentFromReader(res.Body)
61 | checkErr(err,"爬取成功,解析html异常")
62 |
63 | doc.Find(".DianDian").Each(func(j int, tr *goquery.Selection) {
64 | title:=tr.Find("td").Eq(0).Text() //标题
65 | detailsLink,_:=tr.Find("td").Eq(0).Find("a").Eq(0).Attr("href") //详情页地址
66 |
67 | types:=tr.Find("td").Eq(1).Text() // 电影类型
68 |
69 | // 爬取播放地址和详情链接
70 | res, err= http.Get(YUMING+detailsLink)
71 | checkErr(err,"【爬取电影: %s 异常】")
72 | if res.StatusCode != 200 {
73 | log.Fatalf("status code error: %d %s", res.StatusCode, res.Status)
74 | }
75 | doc,_= goquery.NewDocumentFromReader(res.Body)
76 |
77 | //imgpath,_:=doc.Find(".videoPic img").Eq(0).Attr("src")
78 | //reamrk:=doc.Find(".movievod").Eq(1).Text();
79 | palyLink:=doc.Find(".contentURL li").Eq(1).Text()
80 |
81 | palyLink=strings.Replace(palyLink,"$","-",-1)
82 |
83 | log.Println(fmt.Sprintf("标题:%s 类型 %s 播放地址 %s ",title,types,palyLink))
84 |
85 | tracefile(fmt.Sprintf("标题:%s 类型 %s 播放地址 %s ",title,types,palyLink))
86 |
87 |
88 | })
89 | defer res.Body.Close()
90 | }
91 |
92 | func main() {
93 | for i := 1; i < 10; i++ {
94 | SaveVideo(i)
95 | }
96 | }
97 |
98 | func tracefile(str_content string) {
99 | // // 读写模式打开文件 如果不存在将创建一个新文件 写操作时将数据附加到文件尾部
100 | fd,_:=os.OpenFile("爬取全网VIP电影在线观看.txt",os.O_RDWR|os.O_CREATE|os.O_APPEND,0644)
101 | fd_content:=strings.Join([]string{str_content,"\n"},"")
102 | buf:=[]byte(fd_content)
103 | fd.Write(buf)
104 | fd.Close()
105 | }
106 |
107 |
108 | // 错误检查
109 | func checkErr(err error,msg string) {
110 | if err != nil {
111 | fmt.Println(msg,err)
112 | }
113 | }
114 | ```
115 | ### 爬取结果,复制地址到浏览即可在线播放
116 | ```bash
117 | 标题:神医 [高清]
118 | 类型 剧情片 播放地址 高清-https://zkgn.wb699.com/share/4bUkbVK2CRMgHeUo
119 | 标题:匹诺曹 [高清]
120 | 类型 爱情片 播放地址 高清-https://zkgn.wb699.com/share/v5339kxgH65mjfn8
121 | 标题:等风来 [高清]
122 | 类型 喜剧片 播放地址 高清-https://zkgn.wb699.com/share/7KE8MG7uiDVCbLvg
123 | 标题:相见恨晚 [德语1080P]
124 | 类型 喜剧片 播放地址 德语1080P-https://zkgn.wb699.com/share/dpfgCBaQzS7HPJh1
125 | 标题:都市灰姑娘 [德语1080P]
126 | 类型 剧情片 播放地址 德语1080P-https://zkgn.wb699.com/share/FPucBGxQy30QpzQ7
127 | 标题:米娅和白狮 [BD中英双字]
128 | 类型 剧情片 播放地址 BD中英双字-https://zkgn.wb699.com/share/uLiLFpOTGlfEBz71
129 | ```
130 | ### 源码地址
131 | - [demo源码](https://github.com/a870439570/Go-notes)
132 | ## 参考
133 | - [goquery用法](https://blog.csdn.net/jeffrey11223/article/details/79318856)
134 | - [采集地址](http://zuikzy.cc/?m=vod-type-id-1.html)
135 | - [goquery官方文档地址](https://godoc.org/github.com/PuerkitoBio/goquery)
136 |
137 |
--------------------------------------------------------------------------------
/docs/Spring/SpringMvc生命周期.md:
--------------------------------------------------------------------------------
1 | ## SpringMVC运行流程及九大组件
2 |
3 | 
4 |
5 | ## SpringMVC流程
6 |
7 | 1. 用户发送请求至前端控制器DispatcherServlet。
8 | 1. DispatcherServlet收到请求调用HandlerMapping处理器映射器。
9 | 1. 处理器映射器找到具体的处理器(可以根据xml配置、注解进行查找),生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。
10 | 1. DispatcherServlet调用HandlerAdapter处理器适配器。
11 | 1. HandlerAdapter经过适配调用具体的处理器(Controller,也叫后端控制器)。
12 | 1. Controller执行完成返回ModelAndView。
13 | 1. HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet。
14 | 1. DispatcherServlet将ModelAndView传给ViewReslover视图解析器。
15 | 1. ViewReslover解析后返回具体View。
16 | 1. DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)。
17 | 1. DispatcherServlet响应用户。
18 |
19 | ## 组件说明:
20 | 以下组件通常使用框架提供实现:
21 |
22 | 1. DispatcherServlet:作为前端控制器,整个流程控制的中心,控制其它组件执行,统一调度,降低组件之间的耦合性,提高每个组件的扩展性。
23 | 1. HandlerMapping:通过扩展处理器映射器实现不同的映射方式,例如:配置文件方式,实现接口方式,注解方式等。
24 | 1. HandlAdapter:通过扩展处理器适配器,支持更多类型的处理器。
25 | 1. ViewResolver:通过扩展视图解析器,支持更多类型的视图解析,例如:jsp、freemarker、pdf、excel等。
26 |
27 | **1、前端控制器DispatcherServlet(不需要工程师开发),由框架提供**
28 | - 作用:接收请求,响应结果,相当于转发器,中央处理器。有了dispatcherServlet减少了其它组件之间的耦合度。
29 | - 用户请求到达前端控制器,它就相当于mvc模式中的c,dispatcherServlet是整个流程控制的中心,由它调用其它组件处理用户的请求,dispatcherServlet的存在降低了组件之间的耦合性。
30 |
31 | **2、处理器映射器HandlerMapping(不需要工程师开发),由框架提供**
32 | - 作用:根据请求的url查找Handler
33 | - HandlerMapping负责根据用户请求找到Handler即处理器,springmvc提供了不同的映射器实现不同的映射方式,例如:配置文件方式,实现接口方式,注解方式等。
34 |
35 | **3、处理器适配器HandlerAdapter**
36 | - 作用:按照特定规则(HandlerAdapter要求的规则)去执行Handler
37 | - 通过HandlerAdapter对处理器进行执行,这是适配器模式的应用,通过扩展适配器可以对更多类型的处理器进行执行。
38 |
39 | **4、处理器Handler(需要工程师开发)**
40 | - 注意:编写Handler时按照HandlerAdapter的要求去做,这样适配器才可以去正确执行Handler
41 | - Handler 是继DispatcherServlet前端控制器的后端控制器,在DispatcherServlet的控制下Handler对具体的用户请求进行处理。
42 | - 由于Handler涉及到具体的用户业务请求 所以一般情况需要工程师根据业务需求开发Handler。
43 |
44 |
45 | **5、视图解析器View resolver(不需要工程师开发),由框架提供**
46 | - 作用:进行视图解析,根据逻辑视图名解析成真正的视图(view)
47 | - View Resolver负责将处理结果生成View视图,View Resolver首先根据逻辑视图名解析成物理视图名即具体的页面地址,再生成View视图对象,最后对View进行渲染将处理结果通过页面展示给用户。 springmvc框架提供了很多的View视图类型,包括:jstlView、freemarkerView、pdfView等。
48 | - 一般情况下需要通过页面标签或页面模版技术将模型数据通过页面展示给用户,需要由工程师根据业务需求开发具体的页面。
49 |
50 |
51 | **6、视图View(需要工程师开发jsp...)**
52 | - View是一个接口,实现类支持不同的View类型(jsp、freemarker、pdf...)
53 |
54 |
55 | ## 核心架构的具体流程
56 | - 1、首先用户发送请求——>DispatcherServlet,前端控制器收到请求后自己不进行处理,而是委托给其他的解析器进行处理,作为统一访问点,进行全局的流程控制;
57 |
58 | - 2、DispatcherServlet——>HandlerMapping, HandlerMapping 将会把请求映射为HandlerExecutionChain 对象(包含一个Handler 处理器(页面控制器)对象、多个HandlerInterceptor 拦截器)对象,通过这种策略模式,很容易添加新的映射策略;
59 |
60 | - 3、DispatcherServlet——>HandlerAdapter,HandlerAdapter 将会把处理器包装为适配器,从而支持多种类型的处理器,即适配器设计模式的应用,从而很容易支持很多类型的处理器;
61 |
62 | - 4、HandlerAdapter——>处理器功能处理方法的调用,HandlerAdapter 将会根据适配的结果调用真正的处理器的功能处理方法,完成功能处理;并返回一个ModelAndView 对象(包含模型数据、逻辑视图名);
63 |
64 | - 5、ModelAndView的逻辑视图名——> ViewResolver, ViewResolver 将把逻辑视图名解析为具体的View,通过这种策略模式,很容易更换其他视图技术;
65 |
66 | - 6、View——>渲染,View会根据传进来的Model模型数据进行渲染,此处的Model实际是一个Map数据结构,因此很容易支持其他视图技术;
67 |
68 | - 7、返回控制权给DispatcherServlet,由DispatcherServlet返回响应给用户,到此一个流程结束。
69 |
70 |
71 | **下边两个组件通常情况下需要开发:**
72 | - Handler:处理器,即后端控制器用controller表示。
73 | - View:视图,即展示给用户的界面,视图中通常需要标签语言展示模型数据。
74 |
75 | ## 什么是MVC模式
76 | MVC的原理图:
77 | 
78 |
79 | **分析:**
80 | - M-Model 模型(完成业务逻辑:有javaBean构成,service+dao+entity)
81 | - V-View 视图(做界面的展示 jsp,html……)
82 | - C-Controller 控制器(接收请求—>调用模型—>根据结果派发页面)
83 |
84 | ### SpringMVC的原理
85 | - 第一步:用户发起请求到前端控制器(DispatcherServlet)
86 |
87 | - 第二步:前端控制器请求处理器映射器(HandlerMappering)去查找处理器(Handle):通过xml配置或者注解进行查找
88 |
89 | - 第三步:找到以后处理器映射器(HandlerMappering)像前端控制器返回执行链(HandlerExecutionChain)
90 |
91 | - 第四步:前端控制器(DispatcherServlet)调用处理器适配器(HandlerAdapter)去执行处理器(Handler)
92 | -
93 | - 第五步:处理器适配器去执行Handler
94 |
95 | - 第六步:Handler执行完给处理器适配器返回ModelAndView
96 |
97 | - 第七步:处理器适配器向前端控制器返回ModelAndView
98 |
99 | - 第八步:前端控制器请求视图解析器(ViewResolver)去进行视图解析
100 |
101 | - 第九步:视图解析器像前端控制器返回View
102 |
103 | - 第十步:前端控制器对视图进行渲染
104 |
105 | - 第十一步:前端控制器向用户响应结果
106 |
107 | - 看到这些步骤我相信大家很感觉非常的乱,这是正常的,但是这里主要是要大家理解springMVC中的几个组件:
108 |
109 | - 前端控制器(DispatcherServlet):接收请求,响应结果,相当于电脑的CPU。
110 |
111 | - 处理器映射器(HandlerMapping):根据URL去查找处理器
112 |
113 | - 处理器(Handler):(需要程序员去写代码处理逻辑的)
114 |
115 | - 处理器适配器(HandlerAdapter):会把处理器包装成适配器,这样就可以支持多种类型的处理器,类比笔记本的适配器(适配器模式的应用)
116 |
117 | - 视图解析器(ViewResovler):进行视图解析,多返回的字符串,进行处理,可以解析成对应的页面
118 |
119 |
120 |
--------------------------------------------------------------------------------
/docs/distributed/redis基本操作.md:
--------------------------------------------------------------------------------
1 | ## 简介
2 | * Redis虽然是一个内存数据库,但也可以将数据持久化到硬盘,有两种持久化方式:RDB和AOF。
3 | * RDB持久化方式定时将数据快照写入磁盘。这种方式并不是非常可靠,因为可能丢失数据,但非常快速。
4 | * AOF持久化方式更加可靠,将服务端收到的每个写操作都写入磁盘。在服务器重启时,这些写操作被重新执行来重新构建数据集
5 | * Redis支持五种数据类型:string(字符串),hash(哈希)
6 | * list(列表),set(集合)及zset(sorted set:有序集合)。
7 |
8 |
9 | ## String类型
10 | * string是redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value。
11 | * string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象 。
12 | * string类型是最基本的数据类型,一个键最大能存储512MB。
13 |
14 | ```
15 | set name 1
16 | get name
17 |
18 | #只有在 key 不存在时设置 key 的值。
19 | setnx
20 |
21 | #设置有效期
22 | setex color 10 red
23 |
24 | #从第六个开始字符替换
25 | setrange name 6 qcw.com
26 |
27 | #批量设置 不会覆盖已经存在到key
28 | mset key1 v1 key2 v2
29 |
30 | #获取旧值并设置新值
31 | getset name 123
32 |
33 | #获取0-4之间字符
34 | getrange name 0 4
35 |
36 | #批量获取
37 | mget key1 key2 key3
38 |
39 | #对值递增加1 返回新值
40 | incr key1
41 |
42 | #不存在自动创建,初始值默认为0自增自减少数自定义
43 | incrby key1 5
44 |
45 | #自减少
46 | decr keyy
47 |
48 | #正数自增 负数 自减少
49 | decrby key -3
50 |
51 | #给指定的字符串增加,返回长度
52 | append naem .net
53 |
54 | #取指定字符串的长度, 返回长度
55 | strken name
56 | ```
57 |
58 | ## hashes(哈希)类型
59 | * Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
60 |
61 | ```
62 | # 设置hash field 为指定值 如果key不存在创建
63 | hset user:001 name qxw
64 | hget user:001 name
65 | hsetnx user:002 name lamp (返回1,失败 0)
66 |
67 | # 批量设置值
68 | hmset user:003 name 333 age 20 sex 1
69 |
70 | # 批量获取value
71 | hmget user:003 name age sex
72 |
73 | # 指定自增
74 | hincrby user:003 age 5
75 |
76 | # 测试值是否存在
77 | hexists user:003 age
78 |
79 | # 返回hash的数量
80 | hlen user:003
81 |
82 | # 删除
83 | hdel user:003 age
84 |
85 | # 返回hash 表所有key
86 | hkeys user:003 ()
87 |
88 | # 返回所有 value
89 | hvals user:003
90 |
91 | # 返回所有的key和value
92 | hgetall user:003
93 |
94 | ```
95 |
96 | ## list(列表)
97 | * Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
98 | * 是一个链表结构push pop 获取一个范围的所有值
99 |
100 |
101 | ```
102 | #从头部压入一个元素
103 | lpush list1 “hello”
104 |
105 | #从尾部压入一个元素)
106 | rpush list1 “word”
107 |
108 | #取值
109 | lrange list1 0 -1
110 |
111 | #在特定的元素前或后添加元素
112 | linsert list1 before “word” “hello”
113 |
114 | #删除n个和value相同的元素 n=0全部删粗 n<0 从尾部删除
115 | lrem list 3 “hello”
116 |
117 | #保留指定key的范围内的数据,下表从0开始 -1代表一直到结束
118 | ltrim list1 1 -1
119 |
120 | #从头部删除元素,并返回删除元素
121 | lpop list1
122 |
123 | #从尾部删除元素,并返回删除的元素
124 | rpop list1
125 |
126 | #从第一个list的尾部移除元素并添加到第二个list的头部
127 | rpoplpush list1 list2
128 |
129 | #返回key的list中index位置的元素
130 | lindex list1 0
131 |
132 | #返回key对应list的长度
133 | llen list1
134 |
135 | ```
136 |
137 | ## Set(集合)
138 | * Redis的Set是string类型的无序集合。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)
139 |
140 | ```
141 | #向集合成添加一个或多个成员
142 | sadd myset key hello key2 hollo2
143 |
144 | #获取集合成员的个数
145 | scard myset
146 |
147 | #返回给定所有集合的差集
148 | sdiff myset myset2
149 |
150 | #返回给定集合的所有差集并存储在detis中
151 | sdiff detis myset myset2
152 |
153 | #返回集合的交集
154 | sinter myset myset2
155 |
156 | #返回交集 并存储在detis中
157 | sinterstore detis myset myset2
158 |
159 | #判断元素是否是myset集合中的成员
160 | sismember myset "hello"
161 |
162 | #返回集合中所有的成员
163 | smembers myset
164 |
165 | #将元素移动到detis中
166 | smove myset detis hello
167 |
168 | #移除并返回集合中的一个随机元素
169 | spop myset
170 |
171 | #返回集合中一个或多个随机数
172 | srandmember myset 2
173 |
174 | #移除集合中一个或多个成员
175 | srem myset [member2] [member2]
176 |
177 | #返回集合并集
178 | sunion myset myset2
179 |
180 | #将指定的集合存储在detis中
181 | sunionstore detis myset myset2
182 |
183 | ```
184 |
185 | ## 有序集合(sorted set)
186 | * Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。
187 | * 不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
188 | * 有序集合的成员是唯一的,但分数(score)却可以重复。
189 | * 集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
190 | * 集合中最大的成员数为232-1(4294967295,每个集合可存储40多亿个成员)。
191 |
192 |
193 | ```
194 | #添加一个或多个成员,或者更新已存在成员的分数
195 | zadd myset 1"hello"
196 |
197 | #获取集合中的所有元素和分数
198 | zrange myzset 0-1 WITHSCORES
199 | zrange salary 1 2 WITHSCORE
200 |
201 | #获取有序集合的成员数
202 | zcard myset4
203 |
204 | #返回指定区间分数的成员个数
205 | zcount myset4 1 4
206 |
207 | #将集合中指定的成员的分数加2
208 | zincrby myset4 2 "hello"()
209 |
210 | #取交集,分数相加,存储到 sumpoint
211 | zinterstore sumpoint 2 myset4 myset3
212 |
213 | #计算有序集合中指定字典区间的成员数量
214 | zlexcount myset4 - +
215 |
216 | #Redis Zrangebylex 通过字典区间返回有序集合的成员。
217 | redis 127.0.0.1:6379> ZADD myzset 0 a 0 b 0 c 0 d 0 e 0 f 0 g
218 | (integer)7
219 | redis 127.0.0.1:6379> ZRANGEBYLEX myzset -[c
220 | 1)"a"2)"b"3)"c"
221 | redis 127.0.0.1:6379> ZRANGEBYLEX myzset -(c
222 | 1)"a"2)"b"
223 | redis 127.0.0.1:6379> ZRANGEBYLEX myzset [aaa (g
224 | 1)"b"2)"c"3)"d"4)"e"5)"f"
225 | redis>
226 | ```
227 |
--------------------------------------------------------------------------------
/docs/distributed/Redis01.md:
--------------------------------------------------------------------------------
1 | ### 使用 Redis 有什么缺点
2 | **主要是四个问题:**
3 | - 缓存和数据库双写一致性问题
4 | - 缓存雪崩问题
5 | - 缓存击穿问题
6 | - 缓存的并发竞争问题
7 |
8 | ### 单线程的 Redis 为什么这么快
9 | - Redis 是单线程工作模型,纯内存操作
10 | - 单线程操作,避免了频繁的上下文切换
11 | - 采用了非阻塞 I/O 多路复用机制
12 |
13 | ### 什么是I/O多路复用机制?
14 | 打一个比方:小曲在 S 城开了一家快递店,负责同城快送服务。小曲因为资金限制,雇佣了一批快递员,然后小曲发现资金不够了,只够买一辆车送快递。
15 |
16 |
17 | **经营方式一**
18 | - 客户每送来一份快递,小曲就让一个快递员盯着,然后快递员开车去送快递。慢慢的小曲就发现了这种经营方式存在下述问题:几十个快递员基本上时间都花在了抢车上了,大部分快递员都处在闲置状态,谁抢到了车,谁就能去送快递。随着快递的增多,快递员也越来越多,小曲发现快递店里越来越挤,没办法雇佣新的快递员了。快递员之间的协调很花时间。
19 |
20 | 综合上述缺点,小曲痛定思痛,提出了下面的经营方式。
21 |
22 | **经营方式二**
23 | - 小曲只雇佣一个快递员。然后呢,客户送来的快递,小曲按送达地点标注好,然后依次放在一个地方。最后,那个快递员依次的去取快递,一次拿一个,然后开着车去送快递,送好了就回来拿下一个快递。上述两种经营方式对比,是不是明显觉得第二种,效率更高,更好呢?
24 |
25 | **在上述比喻中:**
26 | - 每个快递员→每个线程
27 | - 每个快递→每个 Socket(I/O 流)
28 | - 快递的送达地点→Socket 的不同状态
29 | - 客户送快递请求→来自客户端的请求
30 | - 小曲的经营方式→服务端运行的代码
31 | - 一辆车→CPU 的核数
32 |
33 | **于是我们有如下结论:**
34 | - 经营方式一就是传统的并发模型,每个 I/O 流(快递)都有一个新的线程(快递员)管理。
35 | - 经营方式二就是 I/O 多路复用。只有单个线程(一个快递员),通过跟踪每个 I/O 流的状态(每个快递的送达地点),来管理多个I/O 流。
36 |
37 | 下面类比到真实的 Redis 线程模型,如图所示:
38 | 
39 |
40 | 简单来说,就是我们的 redis-client 在操作的时候,会产生具有不同事件类型的 Socket。
41 |
42 | 在服务端,有一段 I/O 多路复用程序,将其置入队列之中。然后,文件事件分派器,依次去队列中取,转发到不同的事件处理器中。
43 |
44 | 需要说明的是,这个 I/O 多路复用机制,Redis 还提供了 select、epoll、evport、kqueue 等多路复用函数库,大家可以自行去了解。
45 |
46 |
47 | ### Redis 的数据类型,以及每种数据类型的使用场景
48 | 1. String: 最常规的 set/get 操作,Value 可以是 String 也可以是数字。一般做一些复杂的计数功能的缓存。
49 | 1. Hash:这里 Value 存放的是结构化的对象,比较方便的就是操作其中的某个字段。做单点登录的时候,就是用这种数据结构存储用户信息,以 CookieId 作为 Key,设置 30 分钟为缓存过期时间,能很好的模拟出类似 Session 的效果。
50 | 1. List:使用 List 的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以利用 lrange 命令,做基于 Redis 的分页功能,性能极佳,用户体验好。
51 | 1. Set:因为 Set 堆放的是一堆不重复值的集合。所以可以做全局去重的功能。
52 | 1. Sorted Set:Sorted Set多了一个权重参数 Score,集合中的元素能够按 Score 进行排列。可以做排行榜应用,取 TOP N 操作。Sorted Set 可以用来做延时任务。最后一个应用就是可以做范围查找。
53 |
54 | ### Redis 的过期策略以及内存淘汰机制
55 | Redis 采用的是定期删除+惰性删除策略。
56 |
57 | **为什么不用定时删除策略**
58 | - 定时删除,用一个定时器来负责监视 Key,过期则自动删除。虽然内存及时释放,但是十分消耗 CPU 资源。
59 | - 在大并发请求下,CPU 要将时间应用在处理请求,而不是删除 Key,因此没有采用这一策略。
60 |
61 | **定期删除+惰性删除是如何工作**
62 | - 定期删除,Redis 默认每个 100ms 检查,是否有过期的 Key,有过期 Key 则删除。
63 | - 需要说明的是,Redis 不是每个 100ms 将所有的 Key 检查一次,而是随机抽取进行检查(如果每隔 100ms,全部 Key 进行检查,Redis 岂不是卡死)。
64 | - 因此,如果只采用定期删除策略,会导致很多 Key 到时间没有删除。于是,惰性删除派上用场。
65 | - 也就是说在你获取某个 Key 的时候,Redis 会检查一下,这个 Key 如果设置了过期时间,那么是否过期了?如果过期了此时就会删除。
66 |
67 | **采用定期删除+惰性删除就没其他问题了么?**
68 | - 不是的,如果定期删除没删除 Key。然后你也没即时去请求 Key,也就是说惰性删除也没生效。这样,Redis的内存会越来越高。那么就应该采用内存淘汰机制。在 redis.conf 中有一行配置:
69 |
70 | maxmemory-policy volatile-lru :
71 | 该配置就是配内存淘汰策略的
72 |
73 | noeviction:
74 | 当内存不足以容纳新写入数据时,新写入操作会报错。应该没人用吧。
75 |
76 | allkeys-lru:
77 | 当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 Key。推荐使用,目前项目在用这种。
78 |
79 | allkeys-random:
80 | 当内存不足以容纳新写入数据时,在键空间中,随机移除某个 Key。应该也没人用吧,你不删最少使用 Key,去随机删。
81 |
82 | volatile-lru:
83 | 当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的 Key。这种情况一般是把 Redis 既当缓存,又做持久化存储的时候才用。不推荐。
84 |
85 | volatile-random:
86 | 当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个 Key。依然不推荐。
87 |
88 | volatile-ttl:
89 | 当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的 Key 优先移除。不推荐。
90 | ```
91 | PS:如果没有设置 expire 的 Key,不满足先决条件(prerequisites);那么 volatile-lru,volatile-random 和 volatile-ttl 策略的行为,和 noeviction(不删除) 基本上一致。
92 |
93 |
94 | ### Redis 和数据库双写一致性问题
95 | 一致性问题是分布式常见问题,还可以再分为最终一致性和强一致性。数据库和缓存双写,就必然会存在不一致的问题。
96 | 如果对数据有强一致性要求,不能放缓存。我们所做的一切,只能保证最终一致性。另外,我们所做的方案从根本上来说,只能说降低不一致发生的概率,无法完全避免。因此,有强一致性要求的数据,不能放缓存。
97 |
98 | 首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
99 |
100 | ### 如何应对缓存穿透和缓存雪崩问题
101 |
102 | **缓存穿透**
103 | - 即黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库上,从而数据库连接异常。
104 |
105 | **缓存穿透解决方案:**
106 | - 利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试。
107 | - 采用异步更新策略,无论 Key 是否取到值,都直接返回。Value 值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。
108 | - 提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的 Key。迅速判断出,请求所携带的 Key 是否合法有效。如果不合法,则直接返回。
109 |
110 | **缓存雪崩**
111 | - 即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常
112 |
113 | **缓存雪崩解决方案:**
114 | - 给缓存的失效时间,加上一个随机值,避免集体失效。
115 | - 使用互斥锁,但是该方案吞吐量明显下降了。
116 | - 双缓存。我们有两个缓存,缓存 A 和缓存 B。缓存 A 的失效时间为 20 分钟,缓存 B 不设失效时间。自己做缓存预热操作。然后细分以下几个小点:从缓存 A 读数据库,有则直接返回;A 没有数据,直接从 B 读数据,直接返回,并且异步启动一个更新线程,更新线程同时更新缓存 A 和缓存 B。
117 |
118 | ### 如何解决 Redis 的并发竞争 Key 问题
119 | - 这个问题大致就是,同时有多个子系统去 Set 一个 Key。这个时候大家思考过要注意什么呢?如果对这个 Key 操作,不要求顺序,这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做 set 操作即可,比较简单。
120 | - 如果对这个 Key 操作,要求顺序.假设有一个 key1,系统 A 需要将 key1 设置为 valueA,系统 B 需要将 key1 设置为 valueB,系统 C 需要将 key1 设置为 valueC。期望按照 key1 的 value 值按照 valueA > valueB > valueC 的顺序变化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。
121 |
122 | 假设时间戳如下:
123 |
124 | 系统A key 1 {valueA 3:00}
125 |
126 | 系统B key 1 {valueB 3:05}
127 |
128 | 系统C key 1 {valueC 3:10}
129 |
130 | 那么,假设这会系统 B 先抢到锁,将 key1 设置为{valueB 3:05}。接下来系统 A 抢到锁,发现自己的 valueA 的时间戳早于缓存中的时间戳,那就不做 set 操作了,以此类推。
131 |
132 | 其他方法,比如利用队列,将 set 方法变成串行访问也可以。总之,灵活变通。
133 |
134 |
135 |
--------------------------------------------------------------------------------
/docs/leetcode/排序算法.md:
--------------------------------------------------------------------------------
1 | # 简介
2 |
3 |  4 |
5 |
6 | - 常见的快速排序、归并排序、堆排序、冒泡排序等属于比较排序。在排序的最终结果里,元素之间的次序依赖于它们之间的比较。每个数都必须和其他数进行比较,才能确定自己的位置。
7 | 在冒泡排序之类的排序中,问题规模为n,又因为需要比较n次,所以平均时间复杂度为O(n²)。在归并排序、快速排序之类的排序中,问题规模通过分治法消减为logN次,所以时间复杂度平均O(nlogn)。
8 | - 比较排序的优势是,适用于各种规模的数据,也不在乎数据的分布,都能进行排序。可以说,比较排序适用于一切需要排序的情况。
9 | - 计数排序、基数排序、桶排序则属于非比较排序。非比较排序是通过确定每个元素之前,应该有多少个元素来排序。针对数组arr,计算arr[i]之前有多少个元素,则唯一确定了arr[i]在排序后数组中的位置。
10 | - 非比较排序只要确定每个元素之前的已有的元素个数即可,所有一次遍历即可解决。算法时间复杂度O(n)。
11 | - 非比较排序时间复杂度底,但由于非比较排序需要占用空间来确定唯一位置。所以对数据规模和数据分布有一定的要求。
12 |
13 |
14 |
15 |
16 | ## 术语
17 | * 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面;
18 | * 不稳定:如果a原本在b的前面,而a=b,排序之后a可能会出现在b的后面;
19 | * 内排序:所有排序操作都在内存中完成;
20 | * 外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行;
21 | * 时间复杂度: 一个算法执行所耗费的时间。
22 | * 空间复杂度:运行完一个程序所需内存的大小。
23 | * n: 数据规模
24 | * k: “桶”的个数
25 | * In-place: 占用常数内存,不占用额外内存
26 | * Out-place: 占用额外内存
27 |
28 | ## 冒泡排序
29 | - 冒泡排序的英文Bubble Sort,是一种最基础的交换排序。
30 | - 冒泡排序之所以叫做冒泡排序,正是因为这种排序算法的每一个元素都可以像小气泡一样,根据自身大小,一点一点向着数组的一侧移动。
31 |
32 |
33 | ```
34 | /**
35 | * 冒泡排序思路
36 | * 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
37 | * 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
38 | */
39 | public static void maopao(){
40 | int [] array={1,4,3,2,8,5,9,10};
41 | //临时变量 存储比价后最大的元素
42 | int tmp=0;
43 |
44 |
45 |
46 | for (int i = 0; i < array.length; i++) {
47 | //有序标记,每一轮的初始是true
48 | boolean isSorted = true;
49 | //内部循环代表每一轮的冒泡处理,先进行元素比较,再进行元素交换。
50 | for (int j = 0; j < array.length-i-1; j++) {
51 | if(array[j]>array[j+1]){
52 | tmp=array[j];
53 | array[j]=array[j+1];
54 | array[j+1]=tmp;
55 | isSorted=false; //还有元素交换 所以不是有序
56 | }
57 |
58 | }
59 | //如果没有元素交换 说明后面回合都是有序的 无需排序
60 | if(isSorted){
61 | break;
62 | }
63 | }
64 | System.out.println("排序后的结果:"+Arrays.toString(array));
65 | }
66 |
67 |
68 |
69 | /***
70 | * 冒泡排序优化:
71 | * 比如 数列是: 3 4 2 1 4 5 6 7 8 9
72 | * 这个数列的特点是前半部分(3,4,2,1)无序,后半部分(5,6,7,8)升序,并且后半部分的元素已经是数列最大值。
73 | * 所以只需要排序前半部分即可 所以要判断出数列有序元素的位置。
74 | */
75 | public static void maopao2(){
76 | int [] array={1,4,3,2,8,5,9,10};
77 | //临时变量 存储比价后最大的元素
78 | int tmp=0;
79 |
80 | //记录最后一次交换的位置
81 | int lastExchangeIndex =0;
82 | //无序数列的边界,每次比较只需要比到这里为止
83 | int sortBorder =array.length -1;
84 | for (int i = 0; i < array.length; i++) {
85 | //有序标记,每一轮的初始是true
86 | boolean isSorted = true;
87 | //内部循环代表每一轮的冒泡处理,先进行元素比较,再进行元素交换。
88 | for (int j = 0; j array[j+1]){
90 | tmp=array[j];
91 | array[j]=array[j+1];
92 | array[j+1]=tmp;
93 | //有元素交换,所以不是有序,标记变为false
94 | isSorted =false;
95 | //把无序数列的边界更新为最后一次交换元素的位置
96 | lastExchangeIndex =j;
97 | }
98 |
99 | }
100 | // sortBorder就是无序数列的边界。每一轮排序过程中,sortBorder之后的元素就完全不需要比较了,肯定是有序的。
101 | sortBorder =lastExchangeIndex ;
102 | //如果没有元素交换 说明后面回合都是有序的 无需排序
103 | if(isSorted){
104 | break;
105 | }
106 | }
107 | System.out.println("排序后的结果:"+Arrays.toString(array));
108 | }
109 | ```
110 | ## 选择排序
111 | - 表现最稳定的排序算法之一,因为无论什么数据进去都是O(n2)的时间复杂度
112 | - 选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
113 |
114 |
4 |
5 |
6 | - 常见的快速排序、归并排序、堆排序、冒泡排序等属于比较排序。在排序的最终结果里,元素之间的次序依赖于它们之间的比较。每个数都必须和其他数进行比较,才能确定自己的位置。
7 | 在冒泡排序之类的排序中,问题规模为n,又因为需要比较n次,所以平均时间复杂度为O(n²)。在归并排序、快速排序之类的排序中,问题规模通过分治法消减为logN次,所以时间复杂度平均O(nlogn)。
8 | - 比较排序的优势是,适用于各种规模的数据,也不在乎数据的分布,都能进行排序。可以说,比较排序适用于一切需要排序的情况。
9 | - 计数排序、基数排序、桶排序则属于非比较排序。非比较排序是通过确定每个元素之前,应该有多少个元素来排序。针对数组arr,计算arr[i]之前有多少个元素,则唯一确定了arr[i]在排序后数组中的位置。
10 | - 非比较排序只要确定每个元素之前的已有的元素个数即可,所有一次遍历即可解决。算法时间复杂度O(n)。
11 | - 非比较排序时间复杂度底,但由于非比较排序需要占用空间来确定唯一位置。所以对数据规模和数据分布有一定的要求。
12 |
13 |
14 |
15 |
16 | ## 术语
17 | * 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面;
18 | * 不稳定:如果a原本在b的前面,而a=b,排序之后a可能会出现在b的后面;
19 | * 内排序:所有排序操作都在内存中完成;
20 | * 外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行;
21 | * 时间复杂度: 一个算法执行所耗费的时间。
22 | * 空间复杂度:运行完一个程序所需内存的大小。
23 | * n: 数据规模
24 | * k: “桶”的个数
25 | * In-place: 占用常数内存,不占用额外内存
26 | * Out-place: 占用额外内存
27 |
28 | ## 冒泡排序
29 | - 冒泡排序的英文Bubble Sort,是一种最基础的交换排序。
30 | - 冒泡排序之所以叫做冒泡排序,正是因为这种排序算法的每一个元素都可以像小气泡一样,根据自身大小,一点一点向着数组的一侧移动。
31 |
32 |
33 | ```
34 | /**
35 | * 冒泡排序思路
36 | * 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
37 | * 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
38 | */
39 | public static void maopao(){
40 | int [] array={1,4,3,2,8,5,9,10};
41 | //临时变量 存储比价后最大的元素
42 | int tmp=0;
43 |
44 |
45 |
46 | for (int i = 0; i < array.length; i++) {
47 | //有序标记,每一轮的初始是true
48 | boolean isSorted = true;
49 | //内部循环代表每一轮的冒泡处理,先进行元素比较,再进行元素交换。
50 | for (int j = 0; j < array.length-i-1; j++) {
51 | if(array[j]>array[j+1]){
52 | tmp=array[j];
53 | array[j]=array[j+1];
54 | array[j+1]=tmp;
55 | isSorted=false; //还有元素交换 所以不是有序
56 | }
57 |
58 | }
59 | //如果没有元素交换 说明后面回合都是有序的 无需排序
60 | if(isSorted){
61 | break;
62 | }
63 | }
64 | System.out.println("排序后的结果:"+Arrays.toString(array));
65 | }
66 |
67 |
68 |
69 | /***
70 | * 冒泡排序优化:
71 | * 比如 数列是: 3 4 2 1 4 5 6 7 8 9
72 | * 这个数列的特点是前半部分(3,4,2,1)无序,后半部分(5,6,7,8)升序,并且后半部分的元素已经是数列最大值。
73 | * 所以只需要排序前半部分即可 所以要判断出数列有序元素的位置。
74 | */
75 | public static void maopao2(){
76 | int [] array={1,4,3,2,8,5,9,10};
77 | //临时变量 存储比价后最大的元素
78 | int tmp=0;
79 |
80 | //记录最后一次交换的位置
81 | int lastExchangeIndex =0;
82 | //无序数列的边界,每次比较只需要比到这里为止
83 | int sortBorder =array.length -1;
84 | for (int i = 0; i < array.length; i++) {
85 | //有序标记,每一轮的初始是true
86 | boolean isSorted = true;
87 | //内部循环代表每一轮的冒泡处理,先进行元素比较,再进行元素交换。
88 | for (int j = 0; j array[j+1]){
90 | tmp=array[j];
91 | array[j]=array[j+1];
92 | array[j+1]=tmp;
93 | //有元素交换,所以不是有序,标记变为false
94 | isSorted =false;
95 | //把无序数列的边界更新为最后一次交换元素的位置
96 | lastExchangeIndex =j;
97 | }
98 |
99 | }
100 | // sortBorder就是无序数列的边界。每一轮排序过程中,sortBorder之后的元素就完全不需要比较了,肯定是有序的。
101 | sortBorder =lastExchangeIndex ;
102 | //如果没有元素交换 说明后面回合都是有序的 无需排序
103 | if(isSorted){
104 | break;
105 | }
106 | }
107 | System.out.println("排序后的结果:"+Arrays.toString(array));
108 | }
109 | ```
110 | ## 选择排序
111 | - 表现最稳定的排序算法之一,因为无论什么数据进去都是O(n2)的时间复杂度
112 | - 选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
113 |
114 |  115 |
116 | ```
117 | public static void selectOrder(){
118 | int [] array={1,4,3,2,8,5,9,10};
119 | for (int i = 0; i < array.length; i++){
120 | //最小元素的小标 ,默认是未排序的列的起始元素
121 | int minIndex=i;
122 | for (int j =i; j < array.length; j++) {
123 | if(array[j]= 0 && current < array[preIndex]) {
157 | array[preIndex + 1] = array[preIndex];
158 | preIndex--;
159 | }
160 | array[preIndex + 1] = current;
161 | System.out.println(Arrays.toString(array));
162 | }
163 | System.out.println(Arrays.toString(array));
164 | }
165 | ```
166 | 参考链接 :https://www.cnblogs.com/guoyaohua/p/8600214.html
167 |
--------------------------------------------------------------------------------
/docs/2019/grpc快速入门.md:
--------------------------------------------------------------------------------
1 | # 概述
2 | * 在gRPC中,客户端应用程序可以直接调用不同计算机上的服务器应用程序上的方法,就像它是本地对象一样,使您可以更轻松地创建分布式应用程序和服务
3 | * 与许多RPC系统一样,gRPC基于定义服务的思想,指定可以使用其参数和返回类型远程调用的方法。
4 | * 在服务器端,服务器实现此接口并运行gRPC服务器来处理客户端调用。在客户端,客户端有一个存根(在某些语言中称为客户端),它提供与服务器相同的方法
5 |
6 | # gRPC具有以下特点
7 | * 基于 HTTP/2, 继而提供了连接多路复用、Body 和 Header 压缩等机制。可以节省带宽、降低TCP链接次数、节省CPU使用和延长电池寿命等。
8 | * 支持主流开发语言(C, C++, Python, PHP, Ruby, NodeJS, C#, Objective-C、Golang、Java)
9 | * IDL (Interface Definition Language) 层使用了 Protocol Buffers, 非常适合团队的接口设计
10 |
11 | # 编写GrpcStudend.proto文件
12 | ```
13 | syntax = "proto3";
14 |
15 | package com.github.proto;
16 |
17 |
18 | option java_package = "com.github.proto";
19 | option java_outer_classname = "GrpcStudentProto";
20 | option java_multiple_files = true;
21 |
22 |
23 | message MyRequest {
24 | string name = 1;
25 | }
26 |
27 | message MyResponse {
28 | string realname = 2;
29 | }
30 |
31 | service GrpcStudentProtoService {
32 | rpc GetName(MyRequest) returns (MyResponse) { }
33 | }
34 | ```
35 | # 生成代码
36 | ```
37 | # 进入cmd
38 | F:\ideWork\githubWork\nettytest>
39 |
40 | # 生成生成model相关类
41 | protoc --java_out=src/main/java src/main/proto/GrpcStudend.porto
42 |
43 | # 生成service
44 | 下载插件:protoc-gen-grpc-java-1.10.0-windows-x86_64.exe
45 | http://central.maven.org/maven2/io/grpc/protoc-gen-grpc-java/1.10.0/protoc-gen-grpc-java-1.10.0-windows-x86_64.exe
46 |
47 | 然后配置到系统环境变量
48 |
49 | #生成service
50 | protoc --grpc-java_out=src/main/java src/main/proto/GrpcStudend.porto
51 |
52 | ```
53 | # 编写服务端
54 | ``` java
55 | public class GrpcStudentSrviceImpl extends GrpcStudentProtoServiceGrpc.GrpcStudentProtoServiceImplBase {
56 |
57 | @Override
58 | public void getName(MyRequest request, StreamObserver responseObserver) {
59 | System.out.println("接收客户端的消息:"+request.getName());
60 | // 每次接下来要做的事
61 | responseObserver.onNext(MyResponse.newBuilder().setRealname("张三11111").build());
62 | responseObserver.onCompleted(); //结束时调用 返回客户端 只调用一次
63 | }
64 | }
65 |
66 | public class GrpcService {
67 | private Server server;
68 |
69 | private void start() throws IOException {
70 | this.server= ServerBuilder.forPort(8899).addService(new GrpcStudentSrviceImpl()).build().start();
71 | System.out.println("server startted!..................");
72 |
73 | // 回调钩子
74 | Runtime.getRuntime().addShutdownHook(new Thread(()->{
75 | System.out.println("jvm关闭!");
76 |
77 | GrpcService.this.stop();
78 | }));
79 |
80 | System.out.println("执行这里。。。。。。。。。。。。。。。");
81 | }
82 |
83 | private void stop(){
84 | if (null != this.server){
85 | this.server.shutdown();
86 | }
87 | }
88 |
89 | // 等待被调用
90 | private void awaitTermination() throws InterruptedException{
91 | if (null != this.server){
92 | this.server.awaitTermination();
93 | }
94 | }
95 |
96 | public static void main(String[] args) throws Exception {
97 | GrpcService service=new GrpcService();
98 | service.start();
99 | service.awaitTermination();
100 | }
101 | }
102 |
103 | ```
104 |
105 | 客户端
106 |
107 | ``` java
108 | public class GrpcClinet {
109 |
110 | public static void main(String[] args) throws Exception {
111 | ManagedChannel managedChannel= ManagedChannelBuilder.forAddress("localhost",8899)
112 | .usePlaintext().build();
113 | GrpcStudentProtoServiceGrpc.GrpcStudentProtoServiceBlockingStub blockingStub=GrpcStudentProtoServiceGrpc
114 | .newBlockingStub(managedChannel);
115 |
116 | MyResponse myResponse=blockingStub.getName(MyRequest.newBuilder().setName("zhangsan").build());
117 | myResponse=blockingStub.getName(MyRequest.newBuilder().setName("zhangsan").build());
118 | myResponse=blockingStub.getName(MyRequest.newBuilder().setName("zhangsan").build());myResponse=blockingStub.getName(MyRequest.newBuilder().setName("zhangsan").build());
119 | myResponse=blockingStub.getName(MyRequest.newBuilder().setName("zhangsan").build());
120 |
121 |
122 | System.out.println(myResponse.getRealname());
123 | managedChannel.shutdown().awaitTermination(1, TimeUnit.SECONDS);
124 | }
125 | }
126 |
127 | ```
128 |
129 | # MAC系统安装protobuf和grpc
130 | ```
131 | 下载:https://github.com/protocolbuffers/protobuf/releases
132 | cd protobuf-3.5.0
133 | ./configure --prefix=/usr/local/protobuf /usr/local/protobuf/ # 配置编译安装目录
134 |
135 | # 解压的目录下进行
136 | make
137 | make install
138 |
139 | # 配置环境变量
140 | sudo vim .bash_profile
141 |
142 | # 配置
143 | export PROTOBUF=/usr/local/protobuf
144 | export PATH=$PROTOBUF/bin:$PATH
145 |
146 | # 配置生效
147 | source .bash_profile
148 |
149 | # 测试生效
150 | protoc --version
151 |
152 | # grpc-java 生成插件安装
153 | 下载:https://github.com/grpc/grpc-java/archive/v1.7.1.tar.gz
154 | tar zxvf grpc-java-1.7.1.tar.gz
155 | cd grpc-java/compiler
156 | export CXXFLAGS="-I/usr/local/protobuf/include" LDFLAGS="-L/usr/local/protobuf/lib"
157 | ../gradlew java_pluginExecutable
158 |
159 | # 生成代码
160 | protoc --java_out=src/main/java --plugin=protoc-gen-grpc-java=/Users/mac/Documents/grpc-java/compiler/build/exe/java_plugin/protoc-gen-grpc-java --grpc-java_out=src/main/java src/main/proto/GrpcStudend.porto
161 |
162 | ```
163 |
--------------------------------------------------------------------------------
/docs/2019/结构型模式.md:
--------------------------------------------------------------------------------
1 | ### 适配器模式
2 | 适配器模式把一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口不匹配而无法在一起工作的两个类能够在一起工作。
3 |
4 | **适配器模式的用途**
5 | - 用电器做例子,笔记本电脑的插头一般都是三相的,即除了阳极、阴极外,还有一个地极。而有些地方的电源插座却只有两极,没有地极。电源插座与笔记本电脑的电源插头不匹配使得笔记本电脑无法使用。这时候一个三相到两相的转换器(适配器)就能解决此问题,而这正像是本模式所做的事情。
6 |
7 | **适配器模式的结构**
8 | - 适配器模式有类的适配器模式和对象的适配器模式两种不同的形式
9 |
10 | **类适配器模式**
11 | - 类的适配器模式把适配的类的API转换成为目标类的API
12 | 
13 | 在上图中可以看出,Adaptee类并没有sampleOperation2()方法,而客户端则期待这个方法。为使客户端能够使用Adaptee类,提供一个中间环节,即类Adapter,把Adaptee的API与Target类的API衔接起来。Adapter与Adaptee是继承关系,这决定了这个适配器模式是类的:
14 |
15 | **模式所涉及的角色有:**
16 | - 目标(Target)角色:这就是所期待得到的接口。注意:由于这里讨论的是类适配器模式,因此目标不可以是类。
17 | - 源(Adapee)角色:现在需要适配的接口。
18 | - 配器(Adaper)角色:适配器类是本模式的核心。适配器把源接口转换成目标接口。显然,这一角色不可以是接口,而必须是具体类。
19 |
20 | ```
21 | public interface Target {
22 | /**
23 | * 这是源类Adaptee也有的方法
24 | */
25 | public void sampleOperation1();
26 | /**
27 | * 这是源类Adapteee没有的方法
28 | */
29 | public void sampleOperation2();
30 | }
31 | ```
32 | 上面给出的是目标角色的源代码,这个角色是以一个JAVA接口的形式实现的。可以看出,这个接口声明了两个方法:sampleOperation1()和sampleOperation2()。而源角色Adaptee是一个具体类,它有一个sampleOperation1()方法,但是没有sampleOperation2()方法。
33 | ```
34 | public class Adaptee {
35 | public void sampleOperation1(){
36 | System.out.println("sampleOperation1 方法执行");
37 | }
38 | }
39 | ```
40 | 适配器角色Adapter扩展了Adaptee,同时又实现了目标(Target)接口。由于Adaptee没有提供sampleOperation2()方法,而目标接口又要求这个方法,因此适配器角色Adapter实现了这个方法。
41 |
42 | ```
43 | public class Adapter extends Adaptee implements Target{
44 | /**
45 | * 由于源类Adaptee没有方法sampleOperation2()
46 | * 因此适配器补充上这个方法
47 | */
48 | @Override
49 | public void sampleOperation2() {
50 | System.out.println("适配器角色调用原类没有的方法");
51 | }
52 | }
53 | ```
54 | **对象适配器模式**
55 | - 与类的适配器模式一样,对象的适配器模式把被适配的类的API转换成为目标类的API,与类的适配器模式不同的是,对象的适配器模式不是使用继承关系连接到Adaptee类,而是使用委派关系连接到Adaptee类。
56 |
57 | - Adaptee类并没有sampleOperation2()方法,而客户端则期待这个方法。为使客户端能够使用Adaptee类,需要提供一个包装(Wrapper)类Adapter。这个包装类包装了一个Adaptee的实例,从而此包装类能够把Adaptee的API与Target类的API衔接起来。Adapter与Adaptee是委派关系,这决定了适配器模式是对象的。
58 |
59 | ```
60 | public class Adapter2{
61 | private Adaptee adaptee;
62 | public Adapter2(Adaptee adaptee){
63 | this.adaptee = adaptee;
64 | }
65 | /**
66 | * 源类Adaptee有方法sampleOperation1
67 | * 因此适配器类直接委派即可
68 | */
69 | public void sampleOperation1(){
70 | this.adaptee.sampleOperation1();
71 | }
72 | /**
73 | * 源类Adaptee没有方法sampleOperation2
74 | * 因此由适配器类需要补充此方法
75 | */
76 | public void sampleOperation2(){
77 | //写相关的代码
78 | }
79 | }
80 | ```
81 | **类适配器和对象适配器的权衡**
82 | - 类适配器使用对象继承的方式,是静态的定义方式;而对象适配器使用对象组合的方式,是动态组合的方式。
83 | - 对于类适配器,由于适配器直接继承了Adaptee,使得适配器不能和Adaptee的子类一起工作,因为继承是静态的关系,当适配器继承了Adaptee后,就不可能再去处理 Adaptee的子类了。
84 | - 对于对象适配器,一个适配器可以把多种不同的源适配到同一个目标。换言之,同一个适配器可以把源类和它的子类都适配到目标接口。因为对象适配器采用的是对象组合的关系,只要对象类型正确,是不是子类都无所谓。
85 | - 对于类适配器,适配器可以重定义Adaptee的部分行为,相当于子类覆盖父类的部分实现方法。
86 | - 对于对象适配器,要重定义Adaptee的行为比较困难,这种情况下,需要定义Adaptee的子类来实现重定义,然后让适配器组合子类。虽然重定义Adaptee的行为比较困难,但是想要增加一些新的行为则方便的很,而且新增加的行为可同时适用于所有的源。
87 | - 对于类适配器,仅仅引入了一个对象,并不需要额外的引用来间接得到Adaptee。
88 | - 对于对象适配器,需要额外的引用来间接得到Adaptee。
89 | - 建议尽量使用对象适配器的实现方式,多用合成/聚合、少用继承。当然,具体问题具体分析,根据需要来选用实现方式,最适合的才是最好的。
90 |
91 | **适配器模式的优点**
92 | - 更好的复用性,系统需要使用现有的类,而此类的接口不符合系统的需要。那么通过适配器模式就可以让这些功能得到更好的复用。
93 | - 更好的扩展性,在实现适配器功能的时候,可以调用自己开发的功能,从而自然地扩展系统的功能
94 |
95 | **适配器模式的缺点**
96 | - 过多的使用适配器,会让系统非常零乱,不易整体进行把握。比如,明明看到调用的是A接口,其实内部被适配成了B接口的实现,一个系统如果太多出现这种情况,无异于一场灾难。因此如果不是很有必要,可以不使用适配器,而是直接对系统进行重构。
97 |
98 | **缺省适配模式**
99 | - 缺省适配(Default Adapter)模式为一个接口提供缺省实现,这样子类型可以从这个缺省实现进行扩展,而不必从原有接口进行扩展。
100 | - 很多情况下,必须让一个具体类实现某一个接口,但是这个类又用不到接口所规定的所有的方法。通常的处理方法是,这个具体类要实现所有的方法,那些有用的方法要有实现,那些没有用的方法也要有空的、平庸的实现。
101 | 缺省适配模式可以很好的处理这一情况。可以设计一个抽象的适配器类实现接口,此抽象类要给接口所要求的每一种方法都提供一个空的方法,以使它的具体子类免于被迫实现空的方法。
102 | - 适配器模式的用意是要改变源的接口,以便于目标接口相容。缺省适配的用意稍有不同,它是为了方便建立一个不平庸的适配器类而提供的一种平庸实现。
103 | - 在任何时候,如果不准备实现一个接口的所有方法时,就可以使用“缺省适配模式”制造一个抽象类,给出所有方法的平庸的具体实现。这样,从这个抽象类再继承下去的子类就不必实现所有的方法了。
104 |
105 | ```
106 | public interface AbstractService {
107 | public void serviceOperation1();
108 | public int serviceOperation2();
109 | public String serviceOperation3();
110 | }
111 | ```
112 |
113 | ```
114 | public abstract class ServiceAdapter implements AbstractService{
115 | @Override
116 | public void serviceOperation1() {
117 | }
118 | @Override
119 | public int serviceOperation2() {
120 | return 0;
121 | }
122 | @Override
123 | public String serviceOperation3() {
124 | return null;
125 | }
126 | }
127 | ```
128 | 可以看到,接口AbstractService要求定义三个方法,分别是serviceOperation1()、serviceOperation2()、serviceOperation3();而抽象适配器类ServiceAdapter则为这三种方法都提供了平庸的实现。因此,任何继承自抽象类ServiceAdapter的具体类都可以选择它所需要的方法实现,而不必理会其他的不需要的方法。
129 |
130 | ### [桥梁模式](https://www.cnblogs.com/java-my-life/archive/2012/05/07/2480938.html)
131 | ### [组合模式](https://blog.csdn.net/jason0539/article/details/22642281)
132 | ### [外观模式](https://blog.csdn.net/jason0539/article/details/22775311)
133 | ### [装饰者模式](https://www.cnblogs.com/java-my-life/archive/2012/04/20/2455726.html)
134 | ### [享元模式](https://www.cnblogs.com/java-my-life/archive/2012/04/26/2468499.html)
135 | ### [代理模式](https://www.cnblogs.com/java-my-life/archive/2012/04/23/2466712.html)
136 |
137 |
--------------------------------------------------------------------------------
/docs/hadoop/hadoop01.md:
--------------------------------------------------------------------------------
1 | ### 伪分布模式安装
2 | hadoop 的安装分为本地模式、伪分布模式、集群模式。本地模式是运行在本地,只负
3 | 责存储,没有计算功能,本书不讲述。伪分布模式是在一台机器上模拟分布式部署,方便学
4 | 习和调试。集群模式是在多个机器上配置 hadoop,是真正的“分布式”。
5 |
6 |
7 |
8 | ### 下载
9 | - http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.7.7
10 | - 解压缩文件,并重命名为 hadoop,方便使用。重命名后这时,hadoop 目录的完整路径
11 | - 是“/usr/local/hadoop”。
12 |
13 | ### 配置 hadoop 的环境变量
14 | ```bash
15 | 修改文件 vi /etc/profile
16 |
17 | JAVA_HOME=/usr/local/java/jdk1.8.0_181
18 | CLASSPATH=$JAVA_HOME/lib/
19 | PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
20 | export PATH JAVA_HOME CLASSPATH
21 |
22 | export HADOOP_HOME=/usr/local/hadoop-2.7.7
23 |
24 | 然后输入如下命令保存生效:
25 | source /etc/profile
26 | ```
27 | 在任意目录下,输入 hadoop,出现如下信息即配置成功
28 |
29 | ```bash
30 | [root@web1 hadoop-2.7.7]# hadoop
31 | Usage: hadoop [--config confdir] [COMMAND | CLASSNAME]
32 | CLASSNAME run the class named CLASSNAME
33 | or
34 | where COMMAND is one of:
35 | fs run a generic filesystem user client
36 | version print the version
37 | jar run a jar file
38 | note: please use "yarn jar" to launch
39 | YARN applications, not this command.
40 | checknative [-a|-h] check native hadoop and compression libraries availability
41 | distcp copy file or directories recursively
42 | archive -archiveName NAME -p * create a hadoop archive
43 | classpath prints the class path needed to get the
44 | credential interact with credential providers
45 | Hadoop jar and the required libraries
46 | daemonlog get/set the log level for each daemon
47 | trace view and modify Hadoop tracing settings
48 |
49 | Most commands print help when invoked w/o parameters.
50 | ```
51 |
52 | ### 修改配置文件
53 | hadoop 配置文件默认是本地模式,我们修改四个配置文件,这些文件都位于/usr/local/hadoop-2.7.7/etc/hadoop 目录下。
54 | ```bash
55 | #第一个是 hadoop 环境变量脚本文件 hadoop-env.sh
56 | export JAVA_HOME=/usr/local/java/jdk1.8.0_181
57 |
58 | #第二个是 hadoop 核心配置文件 core-site.xml
59 |
60 |
61 | fs.defaultFS
62 | hdfs://192.168.1.191:9000
63 | HDFS 的访问路径
64 |
65 |
66 | hadoop.tmp.dir
67 | /usr/local/hadoop-2.7.7/tmp
68 | hadoop 的运行临时文件的主目录
69 |
70 |
71 |
72 |
73 | #第三个是 hdfs 配置文件 hdfs-site.xml
74 |
75 |
76 | dfs.replication
77 | 1
78 |
79 | 存储副本数
80 |
81 |
82 | #第四个是 MapReduce 配置文件 mapred-site.xml
83 |
84 |
85 | mapred.job.tracker
86 | 192.168.1.191:9001
87 | JobTracker 的访问路径
88 |
89 |
90 | ```
91 | 这是安装伪分布模式的最小化配置。目前的任务是把 hadoop 跑起来
92 |
93 | ### 格式化文件系统
94 | hdfs 是 文 件 系 统 , 所 以 在 第 一 次 使 用 之 前 需 要 进 行 格 式 化
95 |
96 | ```bash
97 | bin/hdfs namenode -format
98 | ```
99 | ### 启动 hdfs
100 | hadoop 启动的三种方式:
101 |
102 | ```bash
103 | #第一种,一次性全部启动
104 | 执行 start-all.sh 启动 hadoop
105 |
106 | #第二种,分别启动 HDFS 和 MapReduce
107 | 执行命令 start-dfs.sh,是单独启动 hdfs(sbin/start-dfs.sh)
108 | 执行命令 start-mapred.sh,可以单独启动 MapReduce 的两个进程。
109 | #那么我们就可以 通过 http://192.168.1.191:50070 来访问 NameNode
110 |
111 |
112 | #第三种,分别启动各个进程:
113 | [root@book0 bin]# hadoop-daemon.sh start namenode
114 | [root@book0 bin]# hadoop-daemon.sh start datanode
115 | [root@book0 bin]# hadoop-daemon.sh start secondarynamenode
116 | [root@book0 bin]# hadoop-daemon.sh start jobtracker
117 | [root@book0 bin]# hadoop-daemon.sh start tasktracker
118 | [root@book0 bin]# jps
119 | 14855 NameNode
120 | 14946 DataNode
121 | 15043 SecondaryNameNode
122 | 15196 TaskTracker
123 | 15115 JobTracker
124 | 15303 Jps
125 | ```
126 | ### 解决hadoop启动总是提示输入密码
127 |
128 | ```bash
129 | #配置本机的免秘钥登录 第二步一直回车
130 | cd ~/.ssh
131 | ssh-keygen -t rsa
132 | cat id_rsa.pub >> authorized_keys
133 |
134 | #修改hadoop-env.sh,将JAVA_HOME改为绝对路径
135 | export HADOOP_COMMON_LIB_NATIVE_DIR="/usr/local/hadoop-2.7.7/lib/native"
136 | export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=/usr/local/hadoop-2.7.7/lib/native"
137 | export JAVA_HOME=/usr/local/jdk1.7.0_79
138 |
139 | #再次启动
140 | sbin/start-all.sh
141 |
142 | #查看 jps
143 | [root@web1 hadoop-2.7.7]# jps
144 | 4388 DataNode
145 | 4889 Jps
146 | 4748 NodeManager
147 | 4542 SecondaryNameNode
148 | 4270 NameNode
149 | 3871 ResourceManager
150 | ```
151 | - 执行 start-all.sh 启动 hadoop,观察控制台的输出,见图 3-5,可以看到正在启动进程,分
152 | 别是 namenode、datanode、secondarynamenode、jobtracker、tasktracker,一共 5 个,待执行
153 | 完毕后,并不意味着这 5 个进程成功启动,上面仅仅表示系统正在启动进程而已
154 |
155 | **访问 http://192.168.1.191:50070 查看hadoop服务**
156 | **访问集群中的所有应用程序的默认端口号为8088。使用以下URL访问该服务 http://192.168.1.191:8088**
157 |
158 |
115 |
116 | ```
117 | public static void selectOrder(){
118 | int [] array={1,4,3,2,8,5,9,10};
119 | for (int i = 0; i < array.length; i++){
120 | //最小元素的小标 ,默认是未排序的列的起始元素
121 | int minIndex=i;
122 | for (int j =i; j < array.length; j++) {
123 | if(array[j]= 0 && current < array[preIndex]) {
157 | array[preIndex + 1] = array[preIndex];
158 | preIndex--;
159 | }
160 | array[preIndex + 1] = current;
161 | System.out.println(Arrays.toString(array));
162 | }
163 | System.out.println(Arrays.toString(array));
164 | }
165 | ```
166 | 参考链接 :https://www.cnblogs.com/guoyaohua/p/8600214.html
167 |
--------------------------------------------------------------------------------
/docs/2019/grpc快速入门.md:
--------------------------------------------------------------------------------
1 | # 概述
2 | * 在gRPC中,客户端应用程序可以直接调用不同计算机上的服务器应用程序上的方法,就像它是本地对象一样,使您可以更轻松地创建分布式应用程序和服务
3 | * 与许多RPC系统一样,gRPC基于定义服务的思想,指定可以使用其参数和返回类型远程调用的方法。
4 | * 在服务器端,服务器实现此接口并运行gRPC服务器来处理客户端调用。在客户端,客户端有一个存根(在某些语言中称为客户端),它提供与服务器相同的方法
5 |
6 | # gRPC具有以下特点
7 | * 基于 HTTP/2, 继而提供了连接多路复用、Body 和 Header 压缩等机制。可以节省带宽、降低TCP链接次数、节省CPU使用和延长电池寿命等。
8 | * 支持主流开发语言(C, C++, Python, PHP, Ruby, NodeJS, C#, Objective-C、Golang、Java)
9 | * IDL (Interface Definition Language) 层使用了 Protocol Buffers, 非常适合团队的接口设计
10 |
11 | # 编写GrpcStudend.proto文件
12 | ```
13 | syntax = "proto3";
14 |
15 | package com.github.proto;
16 |
17 |
18 | option java_package = "com.github.proto";
19 | option java_outer_classname = "GrpcStudentProto";
20 | option java_multiple_files = true;
21 |
22 |
23 | message MyRequest {
24 | string name = 1;
25 | }
26 |
27 | message MyResponse {
28 | string realname = 2;
29 | }
30 |
31 | service GrpcStudentProtoService {
32 | rpc GetName(MyRequest) returns (MyResponse) { }
33 | }
34 | ```
35 | # 生成代码
36 | ```
37 | # 进入cmd
38 | F:\ideWork\githubWork\nettytest>
39 |
40 | # 生成生成model相关类
41 | protoc --java_out=src/main/java src/main/proto/GrpcStudend.porto
42 |
43 | # 生成service
44 | 下载插件:protoc-gen-grpc-java-1.10.0-windows-x86_64.exe
45 | http://central.maven.org/maven2/io/grpc/protoc-gen-grpc-java/1.10.0/protoc-gen-grpc-java-1.10.0-windows-x86_64.exe
46 |
47 | 然后配置到系统环境变量
48 |
49 | #生成service
50 | protoc --grpc-java_out=src/main/java src/main/proto/GrpcStudend.porto
51 |
52 | ```
53 | # 编写服务端
54 | ``` java
55 | public class GrpcStudentSrviceImpl extends GrpcStudentProtoServiceGrpc.GrpcStudentProtoServiceImplBase {
56 |
57 | @Override
58 | public void getName(MyRequest request, StreamObserver responseObserver) {
59 | System.out.println("接收客户端的消息:"+request.getName());
60 | // 每次接下来要做的事
61 | responseObserver.onNext(MyResponse.newBuilder().setRealname("张三11111").build());
62 | responseObserver.onCompleted(); //结束时调用 返回客户端 只调用一次
63 | }
64 | }
65 |
66 | public class GrpcService {
67 | private Server server;
68 |
69 | private void start() throws IOException {
70 | this.server= ServerBuilder.forPort(8899).addService(new GrpcStudentSrviceImpl()).build().start();
71 | System.out.println("server startted!..................");
72 |
73 | // 回调钩子
74 | Runtime.getRuntime().addShutdownHook(new Thread(()->{
75 | System.out.println("jvm关闭!");
76 |
77 | GrpcService.this.stop();
78 | }));
79 |
80 | System.out.println("执行这里。。。。。。。。。。。。。。。");
81 | }
82 |
83 | private void stop(){
84 | if (null != this.server){
85 | this.server.shutdown();
86 | }
87 | }
88 |
89 | // 等待被调用
90 | private void awaitTermination() throws InterruptedException{
91 | if (null != this.server){
92 | this.server.awaitTermination();
93 | }
94 | }
95 |
96 | public static void main(String[] args) throws Exception {
97 | GrpcService service=new GrpcService();
98 | service.start();
99 | service.awaitTermination();
100 | }
101 | }
102 |
103 | ```
104 |
105 | 客户端
106 |
107 | ``` java
108 | public class GrpcClinet {
109 |
110 | public static void main(String[] args) throws Exception {
111 | ManagedChannel managedChannel= ManagedChannelBuilder.forAddress("localhost",8899)
112 | .usePlaintext().build();
113 | GrpcStudentProtoServiceGrpc.GrpcStudentProtoServiceBlockingStub blockingStub=GrpcStudentProtoServiceGrpc
114 | .newBlockingStub(managedChannel);
115 |
116 | MyResponse myResponse=blockingStub.getName(MyRequest.newBuilder().setName("zhangsan").build());
117 | myResponse=blockingStub.getName(MyRequest.newBuilder().setName("zhangsan").build());
118 | myResponse=blockingStub.getName(MyRequest.newBuilder().setName("zhangsan").build());myResponse=blockingStub.getName(MyRequest.newBuilder().setName("zhangsan").build());
119 | myResponse=blockingStub.getName(MyRequest.newBuilder().setName("zhangsan").build());
120 |
121 |
122 | System.out.println(myResponse.getRealname());
123 | managedChannel.shutdown().awaitTermination(1, TimeUnit.SECONDS);
124 | }
125 | }
126 |
127 | ```
128 |
129 | # MAC系统安装protobuf和grpc
130 | ```
131 | 下载:https://github.com/protocolbuffers/protobuf/releases
132 | cd protobuf-3.5.0
133 | ./configure --prefix=/usr/local/protobuf /usr/local/protobuf/ # 配置编译安装目录
134 |
135 | # 解压的目录下进行
136 | make
137 | make install
138 |
139 | # 配置环境变量
140 | sudo vim .bash_profile
141 |
142 | # 配置
143 | export PROTOBUF=/usr/local/protobuf
144 | export PATH=$PROTOBUF/bin:$PATH
145 |
146 | # 配置生效
147 | source .bash_profile
148 |
149 | # 测试生效
150 | protoc --version
151 |
152 | # grpc-java 生成插件安装
153 | 下载:https://github.com/grpc/grpc-java/archive/v1.7.1.tar.gz
154 | tar zxvf grpc-java-1.7.1.tar.gz
155 | cd grpc-java/compiler
156 | export CXXFLAGS="-I/usr/local/protobuf/include" LDFLAGS="-L/usr/local/protobuf/lib"
157 | ../gradlew java_pluginExecutable
158 |
159 | # 生成代码
160 | protoc --java_out=src/main/java --plugin=protoc-gen-grpc-java=/Users/mac/Documents/grpc-java/compiler/build/exe/java_plugin/protoc-gen-grpc-java --grpc-java_out=src/main/java src/main/proto/GrpcStudend.porto
161 |
162 | ```
163 |
--------------------------------------------------------------------------------
/docs/2019/结构型模式.md:
--------------------------------------------------------------------------------
1 | ### 适配器模式
2 | 适配器模式把一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口不匹配而无法在一起工作的两个类能够在一起工作。
3 |
4 | **适配器模式的用途**
5 | - 用电器做例子,笔记本电脑的插头一般都是三相的,即除了阳极、阴极外,还有一个地极。而有些地方的电源插座却只有两极,没有地极。电源插座与笔记本电脑的电源插头不匹配使得笔记本电脑无法使用。这时候一个三相到两相的转换器(适配器)就能解决此问题,而这正像是本模式所做的事情。
6 |
7 | **适配器模式的结构**
8 | - 适配器模式有类的适配器模式和对象的适配器模式两种不同的形式
9 |
10 | **类适配器模式**
11 | - 类的适配器模式把适配的类的API转换成为目标类的API
12 | 
13 | 在上图中可以看出,Adaptee类并没有sampleOperation2()方法,而客户端则期待这个方法。为使客户端能够使用Adaptee类,提供一个中间环节,即类Adapter,把Adaptee的API与Target类的API衔接起来。Adapter与Adaptee是继承关系,这决定了这个适配器模式是类的:
14 |
15 | **模式所涉及的角色有:**
16 | - 目标(Target)角色:这就是所期待得到的接口。注意:由于这里讨论的是类适配器模式,因此目标不可以是类。
17 | - 源(Adapee)角色:现在需要适配的接口。
18 | - 配器(Adaper)角色:适配器类是本模式的核心。适配器把源接口转换成目标接口。显然,这一角色不可以是接口,而必须是具体类。
19 |
20 | ```
21 | public interface Target {
22 | /**
23 | * 这是源类Adaptee也有的方法
24 | */
25 | public void sampleOperation1();
26 | /**
27 | * 这是源类Adapteee没有的方法
28 | */
29 | public void sampleOperation2();
30 | }
31 | ```
32 | 上面给出的是目标角色的源代码,这个角色是以一个JAVA接口的形式实现的。可以看出,这个接口声明了两个方法:sampleOperation1()和sampleOperation2()。而源角色Adaptee是一个具体类,它有一个sampleOperation1()方法,但是没有sampleOperation2()方法。
33 | ```
34 | public class Adaptee {
35 | public void sampleOperation1(){
36 | System.out.println("sampleOperation1 方法执行");
37 | }
38 | }
39 | ```
40 | 适配器角色Adapter扩展了Adaptee,同时又实现了目标(Target)接口。由于Adaptee没有提供sampleOperation2()方法,而目标接口又要求这个方法,因此适配器角色Adapter实现了这个方法。
41 |
42 | ```
43 | public class Adapter extends Adaptee implements Target{
44 | /**
45 | * 由于源类Adaptee没有方法sampleOperation2()
46 | * 因此适配器补充上这个方法
47 | */
48 | @Override
49 | public void sampleOperation2() {
50 | System.out.println("适配器角色调用原类没有的方法");
51 | }
52 | }
53 | ```
54 | **对象适配器模式**
55 | - 与类的适配器模式一样,对象的适配器模式把被适配的类的API转换成为目标类的API,与类的适配器模式不同的是,对象的适配器模式不是使用继承关系连接到Adaptee类,而是使用委派关系连接到Adaptee类。
56 |
57 | - Adaptee类并没有sampleOperation2()方法,而客户端则期待这个方法。为使客户端能够使用Adaptee类,需要提供一个包装(Wrapper)类Adapter。这个包装类包装了一个Adaptee的实例,从而此包装类能够把Adaptee的API与Target类的API衔接起来。Adapter与Adaptee是委派关系,这决定了适配器模式是对象的。
58 |
59 | ```
60 | public class Adapter2{
61 | private Adaptee adaptee;
62 | public Adapter2(Adaptee adaptee){
63 | this.adaptee = adaptee;
64 | }
65 | /**
66 | * 源类Adaptee有方法sampleOperation1
67 | * 因此适配器类直接委派即可
68 | */
69 | public void sampleOperation1(){
70 | this.adaptee.sampleOperation1();
71 | }
72 | /**
73 | * 源类Adaptee没有方法sampleOperation2
74 | * 因此由适配器类需要补充此方法
75 | */
76 | public void sampleOperation2(){
77 | //写相关的代码
78 | }
79 | }
80 | ```
81 | **类适配器和对象适配器的权衡**
82 | - 类适配器使用对象继承的方式,是静态的定义方式;而对象适配器使用对象组合的方式,是动态组合的方式。
83 | - 对于类适配器,由于适配器直接继承了Adaptee,使得适配器不能和Adaptee的子类一起工作,因为继承是静态的关系,当适配器继承了Adaptee后,就不可能再去处理 Adaptee的子类了。
84 | - 对于对象适配器,一个适配器可以把多种不同的源适配到同一个目标。换言之,同一个适配器可以把源类和它的子类都适配到目标接口。因为对象适配器采用的是对象组合的关系,只要对象类型正确,是不是子类都无所谓。
85 | - 对于类适配器,适配器可以重定义Adaptee的部分行为,相当于子类覆盖父类的部分实现方法。
86 | - 对于对象适配器,要重定义Adaptee的行为比较困难,这种情况下,需要定义Adaptee的子类来实现重定义,然后让适配器组合子类。虽然重定义Adaptee的行为比较困难,但是想要增加一些新的行为则方便的很,而且新增加的行为可同时适用于所有的源。
87 | - 对于类适配器,仅仅引入了一个对象,并不需要额外的引用来间接得到Adaptee。
88 | - 对于对象适配器,需要额外的引用来间接得到Adaptee。
89 | - 建议尽量使用对象适配器的实现方式,多用合成/聚合、少用继承。当然,具体问题具体分析,根据需要来选用实现方式,最适合的才是最好的。
90 |
91 | **适配器模式的优点**
92 | - 更好的复用性,系统需要使用现有的类,而此类的接口不符合系统的需要。那么通过适配器模式就可以让这些功能得到更好的复用。
93 | - 更好的扩展性,在实现适配器功能的时候,可以调用自己开发的功能,从而自然地扩展系统的功能
94 |
95 | **适配器模式的缺点**
96 | - 过多的使用适配器,会让系统非常零乱,不易整体进行把握。比如,明明看到调用的是A接口,其实内部被适配成了B接口的实现,一个系统如果太多出现这种情况,无异于一场灾难。因此如果不是很有必要,可以不使用适配器,而是直接对系统进行重构。
97 |
98 | **缺省适配模式**
99 | - 缺省适配(Default Adapter)模式为一个接口提供缺省实现,这样子类型可以从这个缺省实现进行扩展,而不必从原有接口进行扩展。
100 | - 很多情况下,必须让一个具体类实现某一个接口,但是这个类又用不到接口所规定的所有的方法。通常的处理方法是,这个具体类要实现所有的方法,那些有用的方法要有实现,那些没有用的方法也要有空的、平庸的实现。
101 | 缺省适配模式可以很好的处理这一情况。可以设计一个抽象的适配器类实现接口,此抽象类要给接口所要求的每一种方法都提供一个空的方法,以使它的具体子类免于被迫实现空的方法。
102 | - 适配器模式的用意是要改变源的接口,以便于目标接口相容。缺省适配的用意稍有不同,它是为了方便建立一个不平庸的适配器类而提供的一种平庸实现。
103 | - 在任何时候,如果不准备实现一个接口的所有方法时,就可以使用“缺省适配模式”制造一个抽象类,给出所有方法的平庸的具体实现。这样,从这个抽象类再继承下去的子类就不必实现所有的方法了。
104 |
105 | ```
106 | public interface AbstractService {
107 | public void serviceOperation1();
108 | public int serviceOperation2();
109 | public String serviceOperation3();
110 | }
111 | ```
112 |
113 | ```
114 | public abstract class ServiceAdapter implements AbstractService{
115 | @Override
116 | public void serviceOperation1() {
117 | }
118 | @Override
119 | public int serviceOperation2() {
120 | return 0;
121 | }
122 | @Override
123 | public String serviceOperation3() {
124 | return null;
125 | }
126 | }
127 | ```
128 | 可以看到,接口AbstractService要求定义三个方法,分别是serviceOperation1()、serviceOperation2()、serviceOperation3();而抽象适配器类ServiceAdapter则为这三种方法都提供了平庸的实现。因此,任何继承自抽象类ServiceAdapter的具体类都可以选择它所需要的方法实现,而不必理会其他的不需要的方法。
129 |
130 | ### [桥梁模式](https://www.cnblogs.com/java-my-life/archive/2012/05/07/2480938.html)
131 | ### [组合模式](https://blog.csdn.net/jason0539/article/details/22642281)
132 | ### [外观模式](https://blog.csdn.net/jason0539/article/details/22775311)
133 | ### [装饰者模式](https://www.cnblogs.com/java-my-life/archive/2012/04/20/2455726.html)
134 | ### [享元模式](https://www.cnblogs.com/java-my-life/archive/2012/04/26/2468499.html)
135 | ### [代理模式](https://www.cnblogs.com/java-my-life/archive/2012/04/23/2466712.html)
136 |
137 |
--------------------------------------------------------------------------------
/docs/hadoop/hadoop01.md:
--------------------------------------------------------------------------------
1 | ### 伪分布模式安装
2 | hadoop 的安装分为本地模式、伪分布模式、集群模式。本地模式是运行在本地,只负
3 | 责存储,没有计算功能,本书不讲述。伪分布模式是在一台机器上模拟分布式部署,方便学
4 | 习和调试。集群模式是在多个机器上配置 hadoop,是真正的“分布式”。
5 |
6 |
7 |
8 | ### 下载
9 | - http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.7.7
10 | - 解压缩文件,并重命名为 hadoop,方便使用。重命名后这时,hadoop 目录的完整路径
11 | - 是“/usr/local/hadoop”。
12 |
13 | ### 配置 hadoop 的环境变量
14 | ```bash
15 | 修改文件 vi /etc/profile
16 |
17 | JAVA_HOME=/usr/local/java/jdk1.8.0_181
18 | CLASSPATH=$JAVA_HOME/lib/
19 | PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
20 | export PATH JAVA_HOME CLASSPATH
21 |
22 | export HADOOP_HOME=/usr/local/hadoop-2.7.7
23 |
24 | 然后输入如下命令保存生效:
25 | source /etc/profile
26 | ```
27 | 在任意目录下,输入 hadoop,出现如下信息即配置成功
28 |
29 | ```bash
30 | [root@web1 hadoop-2.7.7]# hadoop
31 | Usage: hadoop [--config confdir] [COMMAND | CLASSNAME]
32 | CLASSNAME run the class named CLASSNAME
33 | or
34 | where COMMAND is one of:
35 | fs run a generic filesystem user client
36 | version print the version
37 | jar run a jar file
38 | note: please use "yarn jar" to launch
39 | YARN applications, not this command.
40 | checknative [-a|-h] check native hadoop and compression libraries availability
41 | distcp copy file or directories recursively
42 | archive -archiveName NAME -p * create a hadoop archive
43 | classpath prints the class path needed to get the
44 | credential interact with credential providers
45 | Hadoop jar and the required libraries
46 | daemonlog get/set the log level for each daemon
47 | trace view and modify Hadoop tracing settings
48 |
49 | Most commands print help when invoked w/o parameters.
50 | ```
51 |
52 | ### 修改配置文件
53 | hadoop 配置文件默认是本地模式,我们修改四个配置文件,这些文件都位于/usr/local/hadoop-2.7.7/etc/hadoop 目录下。
54 | ```bash
55 | #第一个是 hadoop 环境变量脚本文件 hadoop-env.sh
56 | export JAVA_HOME=/usr/local/java/jdk1.8.0_181
57 |
58 | #第二个是 hadoop 核心配置文件 core-site.xml
59 |
60 |
61 | fs.defaultFS
62 | hdfs://192.168.1.191:9000
63 | HDFS 的访问路径
64 |
65 |
66 | hadoop.tmp.dir
67 | /usr/local/hadoop-2.7.7/tmp
68 | hadoop 的运行临时文件的主目录
69 |
70 |
71 |
72 |
73 | #第三个是 hdfs 配置文件 hdfs-site.xml
74 |
75 |
76 | dfs.replication
77 | 1
78 |
79 | 存储副本数
80 |
81 |
82 | #第四个是 MapReduce 配置文件 mapred-site.xml
83 |
84 |
85 | mapred.job.tracker
86 | 192.168.1.191:9001
87 | JobTracker 的访问路径
88 |
89 |
90 | ```
91 | 这是安装伪分布模式的最小化配置。目前的任务是把 hadoop 跑起来
92 |
93 | ### 格式化文件系统
94 | hdfs 是 文 件 系 统 , 所 以 在 第 一 次 使 用 之 前 需 要 进 行 格 式 化
95 |
96 | ```bash
97 | bin/hdfs namenode -format
98 | ```
99 | ### 启动 hdfs
100 | hadoop 启动的三种方式:
101 |
102 | ```bash
103 | #第一种,一次性全部启动
104 | 执行 start-all.sh 启动 hadoop
105 |
106 | #第二种,分别启动 HDFS 和 MapReduce
107 | 执行命令 start-dfs.sh,是单独启动 hdfs(sbin/start-dfs.sh)
108 | 执行命令 start-mapred.sh,可以单独启动 MapReduce 的两个进程。
109 | #那么我们就可以 通过 http://192.168.1.191:50070 来访问 NameNode
110 |
111 |
112 | #第三种,分别启动各个进程:
113 | [root@book0 bin]# hadoop-daemon.sh start namenode
114 | [root@book0 bin]# hadoop-daemon.sh start datanode
115 | [root@book0 bin]# hadoop-daemon.sh start secondarynamenode
116 | [root@book0 bin]# hadoop-daemon.sh start jobtracker
117 | [root@book0 bin]# hadoop-daemon.sh start tasktracker
118 | [root@book0 bin]# jps
119 | 14855 NameNode
120 | 14946 DataNode
121 | 15043 SecondaryNameNode
122 | 15196 TaskTracker
123 | 15115 JobTracker
124 | 15303 Jps
125 | ```
126 | ### 解决hadoop启动总是提示输入密码
127 |
128 | ```bash
129 | #配置本机的免秘钥登录 第二步一直回车
130 | cd ~/.ssh
131 | ssh-keygen -t rsa
132 | cat id_rsa.pub >> authorized_keys
133 |
134 | #修改hadoop-env.sh,将JAVA_HOME改为绝对路径
135 | export HADOOP_COMMON_LIB_NATIVE_DIR="/usr/local/hadoop-2.7.7/lib/native"
136 | export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=/usr/local/hadoop-2.7.7/lib/native"
137 | export JAVA_HOME=/usr/local/jdk1.7.0_79
138 |
139 | #再次启动
140 | sbin/start-all.sh
141 |
142 | #查看 jps
143 | [root@web1 hadoop-2.7.7]# jps
144 | 4388 DataNode
145 | 4889 Jps
146 | 4748 NodeManager
147 | 4542 SecondaryNameNode
148 | 4270 NameNode
149 | 3871 ResourceManager
150 | ```
151 | - 执行 start-all.sh 启动 hadoop,观察控制台的输出,见图 3-5,可以看到正在启动进程,分
152 | 别是 namenode、datanode、secondarynamenode、jobtracker、tasktracker,一共 5 个,待执行
153 | 完毕后,并不意味着这 5 个进程成功启动,上面仅仅表示系统正在启动进程而已
154 |
155 | **访问 http://192.168.1.191:50070 查看hadoop服务**
156 | **访问集群中的所有应用程序的默认端口号为8088。使用以下URL访问该服务 http://192.168.1.191:8088**
157 |
158 |  159 |
160 | 解决hadoop启动时报错
161 | -------------
162 | 当启动hadoop时,出现警告:“util.NativeCodeLoader: Unable to load native-hadoop library for your platform”,这个警告导致hadoop fs -ls /与hadoop fs -mkdir /dir1等都无法成功。下载此文件 覆盖hadoop/lib/native/中的所有文件即可
163 |
164 | hadoop-native-64-2.7.0.tar下载地址
165 | https://gitee.com/qinxuewu/basic_induction_of_java/attach_files
--------------------------------------------------------------------------------
/docs/hadoop/hbase01.md:
--------------------------------------------------------------------------------
1 | ### Apache HBase
2 | - Apache HBase™是Hadoop数据库,是一个分布式,可扩展的大数据存储。
3 | - 当您需要对大数据进行随机,实时读/写访问时,请使用Apache HBase™。该项目的目标是托管非常大的表 - 数十亿行X百万列 - 在商品硬件集群上。Apache HBase是一个开源的,分布式的,版本化的非关系数据库
4 |
5 | ### 特征
6 | - 线性和模块化可扩展性。
7 | - 严格一致的读写操作。
8 | - 表的自动和可配置分片
9 | - RegionServers之间的自动故障转移支持。
10 | - 方便的基类,用于使用Apache HBase表支持Hadoop MapReduce作业。
11 | - 易于使用的Java API,用于客户端访问。
12 | - 阻止缓存和布隆过滤器以进行实时查询。
13 | - 查询谓词通过服务器端过滤器下推
14 | - Thrift网关和REST-ful Web服务,支持XML,Protobuf和二进制数据编码选项
15 | - 可扩展的基于jruby(JIRB)的外壳
16 | - 支持通过Hadoop指标子系统将指标导出到文件或Ganglia; 或通过JMX
17 |
18 | ### 安装 独立HBase
19 | HBase要求安装JDK。有关支持的JDK版本的信息
20 |
159 |
160 | 解决hadoop启动时报错
161 | -------------
162 | 当启动hadoop时,出现警告:“util.NativeCodeLoader: Unable to load native-hadoop library for your platform”,这个警告导致hadoop fs -ls /与hadoop fs -mkdir /dir1等都无法成功。下载此文件 覆盖hadoop/lib/native/中的所有文件即可
163 |
164 | hadoop-native-64-2.7.0.tar下载地址
165 | https://gitee.com/qinxuewu/basic_induction_of_java/attach_files
--------------------------------------------------------------------------------
/docs/hadoop/hbase01.md:
--------------------------------------------------------------------------------
1 | ### Apache HBase
2 | - Apache HBase™是Hadoop数据库,是一个分布式,可扩展的大数据存储。
3 | - 当您需要对大数据进行随机,实时读/写访问时,请使用Apache HBase™。该项目的目标是托管非常大的表 - 数十亿行X百万列 - 在商品硬件集群上。Apache HBase是一个开源的,分布式的,版本化的非关系数据库
4 |
5 | ### 特征
6 | - 线性和模块化可扩展性。
7 | - 严格一致的读写操作。
8 | - 表的自动和可配置分片
9 | - RegionServers之间的自动故障转移支持。
10 | - 方便的基类,用于使用Apache HBase表支持Hadoop MapReduce作业。
11 | - 易于使用的Java API,用于客户端访问。
12 | - 阻止缓存和布隆过滤器以进行实时查询。
13 | - 查询谓词通过服务器端过滤器下推
14 | - Thrift网关和REST-ful Web服务,支持XML,Protobuf和二进制数据编码选项
15 | - 可扩展的基于jruby(JIRB)的外壳
16 | - 支持通过Hadoop指标子系统将指标导出到文件或Ganglia; 或通过JMX
17 |
18 | ### 安装 独立HBase
19 | HBase要求安装JDK。有关支持的JDK版本的信息
20 |  21 |
22 | 从此Apache下载镜像列表中选择一个下载站点。单击建议的顶部链接。这将带您进入HBase版本的镜像。单击名为stable的文件夹,然后将以.tar.gz结尾的二进制文件下载到本地文件系统。暂时不要下载以src.tar.gz结尾的文件。
23 |
24 |
25 | 解压缩下载的文件,然后切换到新创建的目录。
26 |
27 | ```
28 | $ tar -xzvf hbase-1.2.6.1-bin.tar.gz
29 | ```
30 | 为HBase设置Java目录,并从conf文件夹打开hbase-env.sh文件。编辑JAVA_HOME环境变量,改变路径到当前JAVA_HOME变量
31 |
32 | ```
33 | #编辑/home/hbase-1.2.6.1/conf/hbase-env.sh
34 | #配置hbase-env.sh文件:把29行的注释取消,配置虚拟机上面的Java地址
35 | export JAVA_HOME=/usr/local/java/jdk1.7.0_79
36 | ```
37 | 编辑conf/hbase-site.xml,这是主要的HBase配置文件
38 |
39 | ```bash
40 |
41 |
42 |
43 | hbase.rootdir
44 | file:///home/pflm/HBase/HFiles
45 |
46 |
47 |
48 | hbase.zookeeper.property.dataDir
49 | /home/pflm/HBase/zookeeper
50 |
51 |
52 | ```
53 | 到此 HBase 的安装配置已成功完成。可以通过使用 HBase 的 bin 文件夹中提供 start-hbase.sh 脚本启动 HBase
54 |
55 | ```bash
56 | $ ./bin/start-hbase.sh
57 | ```
58 | 运行HBase启动脚本,它会提示一条消息:HBase has started
59 |
60 | ```bash
61 | starting master, logging to /usr/local/HBase/bin/../logs/hbase-tpmaster-localhost.localdomain.out
62 | ```
63 | - 该./start-hbase.sh脚本是作为启动HBase的一种便捷方式。发出命令,如果一切顺利,将在标准输出中记录一条消息,显示HBase已成功启动。您可以使用该jps命令验证是否有一个正在运行的进程HMaster。在独立模式下,HBase运行此单个JVM中的所有守护程序,即HMaster,单个HRegionServer和ZooKeeper守护程序。转到`http:// localhost:16010`以查看HBase Web UI。
64 |
65 | ### HBase Shell
66 | 要访问HBase shell,必须导航进入到HBase的主文件夹。
67 |
68 | ```bash
69 | #进入shell
70 | /bin/hbase shell
71 |
72 | #列出HBase的所有表。
73 | hbase(main):001:0> list
74 | TABLE
75 | ```
76 | **通用命令**
77 |
78 | ```bash
79 | status: 提供HBase的状态,例如,服务器的数量。
80 | version: 提供正在使用HBase版本。
81 | table_help: 表引用命令提供帮助
82 | whoami: 提供有关用户的信息。
83 | ```
84 | **HBase在表中操作的命令。**
85 | ```
86 | create: 创建一个表。
87 | list: 列出HBase的所有表。
88 | disable: 禁用表。
89 | is_disabled: 验证表是否被禁用。
90 | enable: 启用一个表。
91 | is_enabled: 验证表是否已启用。
92 | describe: 提供了一个表的描述。
93 | alter: 改变一个表。
94 | exists: 验证表是否存在。
95 | drop: 从HBase中删除表。
96 | drop_all: 丢弃在命令中给出匹配“regex”的表
97 | ```
98 | **数据操纵语言**
99 |
100 | ```
101 | put: 把指定列在指定的行中单元格的值在一个特定的表。
102 | get: 取行或单元格的内容。
103 | delete: 删除表中的单元格值。
104 | deleteall: 删除给定行的所有单元格。
105 | scan: 扫描并返回表数据。
106 | count: 计数并返回表中的行的数目。
107 | truncate: 禁用,删除和重新创建一个指定的表。
108 | ```
109 |
110 | ### 解决Java API不能远程访问HBase的问题
111 | **1、配置Linux的hostname**
112 |
113 | ```
114 | [root@CentOS124 hbase-1.2.6.1]# vie /etc/sysconfig/network
115 | NETWORKING=yes
116 | HOSTNAME=CentOS124 #名字随便
117 | ```
118 | 这里配置的hostname要Linux重启才生效,为了不重启就生效,我们可以执行:hostname CentOS124命令,暂时设置hostname
119 |
120 | **2、配置Linux的hosts,映射ip的hostname的关系**
121 |
122 | ```
123 | #映射ip的hostname的关系
124 | [root@CentOS124 hbase-1.2.6.1]# vim /etc/host
125 |
126 | #查看hbase ip绑定是否成功
127 | [root@CentOS124 hbase-1.2.6.1]# netstat -anp|grep 16010
128 | ```
129 |
21 |
22 | 从此Apache下载镜像列表中选择一个下载站点。单击建议的顶部链接。这将带您进入HBase版本的镜像。单击名为stable的文件夹,然后将以.tar.gz结尾的二进制文件下载到本地文件系统。暂时不要下载以src.tar.gz结尾的文件。
23 |
24 |
25 | 解压缩下载的文件,然后切换到新创建的目录。
26 |
27 | ```
28 | $ tar -xzvf hbase-1.2.6.1-bin.tar.gz
29 | ```
30 | 为HBase设置Java目录,并从conf文件夹打开hbase-env.sh文件。编辑JAVA_HOME环境变量,改变路径到当前JAVA_HOME变量
31 |
32 | ```
33 | #编辑/home/hbase-1.2.6.1/conf/hbase-env.sh
34 | #配置hbase-env.sh文件:把29行的注释取消,配置虚拟机上面的Java地址
35 | export JAVA_HOME=/usr/local/java/jdk1.7.0_79
36 | ```
37 | 编辑conf/hbase-site.xml,这是主要的HBase配置文件
38 |
39 | ```bash
40 |
41 |
42 |
43 | hbase.rootdir
44 | file:///home/pflm/HBase/HFiles
45 |
46 |
47 |
48 | hbase.zookeeper.property.dataDir
49 | /home/pflm/HBase/zookeeper
50 |
51 |
52 | ```
53 | 到此 HBase 的安装配置已成功完成。可以通过使用 HBase 的 bin 文件夹中提供 start-hbase.sh 脚本启动 HBase
54 |
55 | ```bash
56 | $ ./bin/start-hbase.sh
57 | ```
58 | 运行HBase启动脚本,它会提示一条消息:HBase has started
59 |
60 | ```bash
61 | starting master, logging to /usr/local/HBase/bin/../logs/hbase-tpmaster-localhost.localdomain.out
62 | ```
63 | - 该./start-hbase.sh脚本是作为启动HBase的一种便捷方式。发出命令,如果一切顺利,将在标准输出中记录一条消息,显示HBase已成功启动。您可以使用该jps命令验证是否有一个正在运行的进程HMaster。在独立模式下,HBase运行此单个JVM中的所有守护程序,即HMaster,单个HRegionServer和ZooKeeper守护程序。转到`http:// localhost:16010`以查看HBase Web UI。
64 |
65 | ### HBase Shell
66 | 要访问HBase shell,必须导航进入到HBase的主文件夹。
67 |
68 | ```bash
69 | #进入shell
70 | /bin/hbase shell
71 |
72 | #列出HBase的所有表。
73 | hbase(main):001:0> list
74 | TABLE
75 | ```
76 | **通用命令**
77 |
78 | ```bash
79 | status: 提供HBase的状态,例如,服务器的数量。
80 | version: 提供正在使用HBase版本。
81 | table_help: 表引用命令提供帮助
82 | whoami: 提供有关用户的信息。
83 | ```
84 | **HBase在表中操作的命令。**
85 | ```
86 | create: 创建一个表。
87 | list: 列出HBase的所有表。
88 | disable: 禁用表。
89 | is_disabled: 验证表是否被禁用。
90 | enable: 启用一个表。
91 | is_enabled: 验证表是否已启用。
92 | describe: 提供了一个表的描述。
93 | alter: 改变一个表。
94 | exists: 验证表是否存在。
95 | drop: 从HBase中删除表。
96 | drop_all: 丢弃在命令中给出匹配“regex”的表
97 | ```
98 | **数据操纵语言**
99 |
100 | ```
101 | put: 把指定列在指定的行中单元格的值在一个特定的表。
102 | get: 取行或单元格的内容。
103 | delete: 删除表中的单元格值。
104 | deleteall: 删除给定行的所有单元格。
105 | scan: 扫描并返回表数据。
106 | count: 计数并返回表中的行的数目。
107 | truncate: 禁用,删除和重新创建一个指定的表。
108 | ```
109 |
110 | ### 解决Java API不能远程访问HBase的问题
111 | **1、配置Linux的hostname**
112 |
113 | ```
114 | [root@CentOS124 hbase-1.2.6.1]# vie /etc/sysconfig/network
115 | NETWORKING=yes
116 | HOSTNAME=CentOS124 #名字随便
117 | ```
118 | 这里配置的hostname要Linux重启才生效,为了不重启就生效,我们可以执行:hostname CentOS124命令,暂时设置hostname
119 |
120 | **2、配置Linux的hosts,映射ip的hostname的关系**
121 |
122 | ```
123 | #映射ip的hostname的关系
124 | [root@CentOS124 hbase-1.2.6.1]# vim /etc/host
125 |
126 | #查看hbase ip绑定是否成功
127 | [root@CentOS124 hbase-1.2.6.1]# netstat -anp|grep 16010
128 | ```
129 |  130 |
131 | **3、配置访问windows的hosts**
132 | ```
133 | #hbase
134 | 192.168.10.124 CentOS124
135 | ```
136 |
137 |
138 | # Java 操作远程hbase
139 | ```java
140 | public class HbaseTest {
141 | public static Connection connection;
142 | public static Configuration configuration;
143 | static {
144 |
145 | configuration = HBaseConfiguration.create();
146 | // 设置连接参数:HBase数据库使用的端口
147 | configuration.set("hbase.zookeeper.property.clientPort", "2181");
148 | // 设置连接参数:HBase数据库所在的主机IP
149 | configuration.set("hbase.zookeeper.quorum", "192.168.10.124");
150 | // configuration.addResource("hbase-site.xml");
151 | try {
152 | // 取得一个数据库连接对象
153 | connection = ConnectionFactory.createConnection(configuration);
154 | } catch (IOException e) {
155 | e.printStackTrace();
156 | }
157 |
158 | }
159 | public static void main(String[] args) throws Exception {
160 | createTable("gazw", "id","name");
161 | // deleteTable("gazw");
162 | }
163 |
164 | public static void createTable(String tableName,String... cf1) throws IOException {
165 | Admin admin = connection.getAdmin();
166 | //HTD需要TableName类型的tableName,创建TableName类型的tableName
167 | TableName tbName = TableName.valueOf(tableName);
168 | //判断表述否已存在,不存在则创建表
169 | if(admin.tableExists(tbName)){
170 | System.err.println("表" + tableName + "已存在!");
171 | return;
172 | }
173 | //通过HTableDescriptor创建一个HTableDescriptor将表的描述传到createTable参数中
174 | HTableDescriptor HTD = new HTableDescriptor(tbName);
175 | //为描述器添加表的详细参数
176 | for(String cf : cf1){
177 | // 创建HColumnDescriptor对象添加表的详细的描述
178 | HColumnDescriptor HCD =new HColumnDescriptor(cf);
179 | HTD.addFamily(HCD);
180 | }
181 | //调用createtable方法创建表
182 | admin.createTable(HTD);
183 | System.out.println("创建成功");
184 | }
185 | }
186 | ```
187 |
188 |
--------------------------------------------------------------------------------
/docs/2019/高性能MySQL.md:
--------------------------------------------------------------------------------
1 |
2 | 
3 | >无论何时,只要有多个查询需要在同一个时刻修改数据时,就会有并发问题。MySql主要在`服务器层`与`存储引擎层`进行并发控制。
4 |
5 | 假设数据库中国一张邮箱表,每个邮件都是一条记录。如果某个客户正在读取邮箱,同时其他客户试图在删除邮箱表中的某一条数据。这个时候,读取的结构就是不确定的了。在MySql中会通过锁定防止其它用户读取同一数据。大多数时候,MySQL锁的内部管理都是透明的。
6 |
7 | # MySQL锁的粒度
8 | * 每种MySql引擎都可以实现自己的锁策略和锁粒度,将锁粒度固定在某个级别,可以为某些特定的场景提供更好的性能。
9 |
10 | **表锁(table lock)**
11 | * 表锁是mysql中最基本的锁略,并且是开销最小的策略。它会锁定整个表,一个用户在对表进行写操作(插入、删除、更新等)前,需要先获得写锁,这会阻塞其他用户对该表的所有读写操作。只有没有写锁时,其他读取的用户才能获得读锁,读锁之间是不相互阻塞的。
12 | * 在特定的场景中,表锁也可能有良好的性能。例如,`READ L0CAL` 表锁支持某些类型的并发写操作。另外,写锁也比读锁有更高的优先级,因此-一个写锁请求可能会被插入到读
13 | 锁队列的前面(写锁可以插入到锁队列中读锁的前面,反之读锁则不能插入到写锁的前
14 | 面)。
15 | * 尽管存储引擎可以管理自己的锁,MySQL本身还是会使用各种有效的表锁来实现不同
16 | 的目的。例如,服务器会为诸如`ALTER TABLE` 之类的语句使用表锁,而忽略存储引擎的
17 | 锁机制。
18 |
19 | **行级锁(row lock)**
20 | * 行级锁可以最大程度地支持并发处理(同时也带来了最大的锁开销)。
21 | * 在`InnoDB`和`XtraDB`,以及其他一些存储引擎中实现了行级锁。
22 | * 行级锁只在存储引擎层实现,而MySQL服务器层没有实现。服务器层完全不了解存储引擎中的锁实现。
23 |
24 | # MySQL的事务
25 | **事务特性**
26 | * A(原子性)事务的各步操作是不可分的,保证一系列的操作要么都完成,要么都不完成;
27 | * C(一致性)事务完成,数据必须处于一致的状态;
28 | * I(隔离性)对数据进行修改的所有并发事务彼此之间是相互隔离,这表明事务必须是独立的,不应以任何方式依赖或影响其他事务;
29 | * D(持久性)表示事务对数据处理结束后,对数据更改必须持久化,不管是事务成功还是回滚。事务日志都能够保持事务的永久性。
30 |
31 | **事务的隔离级别**
32 | * SQL标准的事务隔离级别包括:读未提交(read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(serializable )
33 | * 读未提交是指,一个事务还没提交时,它做的变更就能被别的事务看到。
34 | * 读提交是指,一个事务提交之后,它做的变更才会被其他事务看到。
35 | * 可重复读是指,一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。未提交的更改对其他事务是不可见的
36 | * 串行化:对应一个记录会加读写锁,出现冲突的时候,后访问的事务必须等前一个事务执行完成才能继续执行。最高的隔离级别
37 |
38 | **MySQL中的事务**
39 | * MySQL提供了两种事务型的存储引擎: `InnoDB`和`NDB Cluster`。另外还有一些第三方
40 | 存储引擎也支持事
41 | * MySQL默认采用自动提交(AUTOCOMIT) 模式。如果不是显式地开始-一个个事务,则每个查询都被当作一事务执行提交操作。在当前连接中,可以通过设置AUTOCOMMIT变量来启用或者禁用自动提交模式:
42 | * InnoDB采用的是两阶段锁定协议(two-phase locking protocol)。在事务执行过程中,随
43 | 时都可以执行锁定,锁只有在执行`COMMIT`或者`ROLLBACK`的时候才会释放,并且所有的
44 | 锁是在同一时刻被释放。
45 | * InnoDB也支持通过特定的语句进行显式锁定`SELECT ... LOCK IN SHARE MODE`和`SELECT FOR UPDATE` 些语句不属于SQL规范
46 |
47 | # 多版本并发控制MVCC
48 | * `MVCC`是行级锁的一个变种,但是它在很多情况下避免了加锁操作,因此开销更低。虽然实现机制有所不同,但大都实现了非阻塞的读操作,写操作也只锁定必要的行。
49 | * MVCC的实现,是通过保存数据在某个时间点的快照来实现的。也就是说,不管需要执行多长时间,每个事务看到的数据都是一致的。根据事务开始的时间不同,每个事务对同张表,同一时刻看到的数据可能是不一样的。
50 | * `InnoDB`的MVCC,是通过在每行记录后面保存两个隐藏的列来实现的。这两个列,一个保存了行的创建时间,一个保存行的过期时间(或删除时间)。当然存储的并不是实际的时间值,而是系统版本号。每开始一个新的事务,系统版本号都会自动递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行比较。
51 | * MVCC只在可重复读和读提交的隔离级别生效。其它两个级别都不兼容
52 |
53 | > 在可重复读(`REPEATABLE READ`) 隔离级别下,MVCC具体是如何操作的。
54 |
55 | **SELECT查询操作时**
56 |
57 | InnoDB会根据以下两个条件检查每行记录:
58 | * InnoDB只查找版本早于当前事务版本的数据行(也就是,行的系统版本号小于或等于事务的系统版本号),这样可以确保事务读取的行,要么是在事务开始前已经存在的,要么是事务自身插入或者修改过的。
59 | * 行的删除版本要么未定义,要么大于当前事务版本号。这可以确保事务读取到的行,在事务开始之前未被删除。
60 |
61 | **INSERT**
62 | * InnoDB为新播入的每-一行保存当前系统版本号作为行版本号。
63 |
64 | **DELETE**
65 | * InnoDB为删除的每-*行保存当前系统版本号作为行删除标识。
66 |
67 | **UPDATE**
68 | * InnoDB为插入-行新记录,保存当前系统版本号作为行版本号,同时保存当前系统
69 | 版本号到原来的行作为行删除标识。
70 |
71 | # 数据库存储引擎
72 | ## InnDB存储引擎
73 | * InnDB是Mysql默认的事务型存储引擎。它被设计用来处理大量的短期(short-lived) 事务,短期事务大部分情况是正常提交的,很少会被回滚。InnoDB的性能和自动崩溃恢复特性,使得它在非事务型存储的需求中也很流行
74 | * InnoDB的数据存储在表空间(tablespace) 中,表空间是由InnoDB管理的-个黑盒子,由一系列的数据文件组成。
75 | * InnoDB采用`MVCC`来支持高并发,并且实现了四个标准的隔离级别。其默认级别是
76 | REPEATABLE READ (`可重复读`) ,并且通过`间隙锁`(next-key locking)策略防止`幻读`的出现。间隙锁使得InnoDB不仅仅锁定查询涉及的行,还会对索引中的间隙进行锁定,以防止幻影行的插入。
77 | * InnoDB表是基于聚簇索引建立的。聚簇素引对主键查询有很高的性能,不过它的二级索引(secondary index,非主键索引)中必须包含主键列,所以如果主键列很大的话,其他的所有索引都会很大。因此,若表上的索引较多的话,主键应当尽可能的小。
78 | * InnoDB内部做了很多优化,包括从磁盘读取数据时采用的可预测性预读,能够自动在
79 | 内存中创建hash索引以加速读操作的自适应哈希索引(adaptive hash index),以及能够
80 | 加速插入操作的插入缓冲区(insert buffer)等
81 |
82 | ## MyISAM引擎
83 | * `MyISAM不支持事务和行锁`,在MySQL5.1之前的版本是默认的存储引擎,有一个缺陷是崩溃后无法恢复。
84 | * 优点是对于只读的数据,或者表比较小,可以忍受修复操作,可以继续使用
85 | * MyISAM会将表存储在两个文件中:数据文件和索引文件,分别以.MYD和.MYI为扩展名
86 | * MyISAM表可以包含动态或者静态(长度固定)行。MySQL会根据表的定义来决定采用何种行格式。MyISAM表可以存储的行记录数,一般受限于可用的磁盘空间,或者操作系统中单个文件的最大尺寸。
87 | * `MyISAM对整张表加锁,而不是针对行`。读取时会对需要读到的所有表加共享锁,写入时则对表加排他锁。但是在表有读取查询的同时,也可以往表中插入新的记录(这被称为并发插入)
88 |
89 | ## Archive引擎
90 | * Archive引擎会缓存所有的写并利用zlib对插人的行进行压缩,所以比MyISAM表的磁盘I/O更少。但是每次SELECT查询都需要执行全表扫描。所以Archive表适合日志和数据采集类应用,这类应用做数据分析时往往需要全表扫描。或者在一- 些需要更快速的INSERT操作的场合下也可以使用。
91 | * `Archive引擎`支持`行级锁和专用的缓冲区`,所以可以实现高并发的插人。在一个查询开始直到返回表中存在的所有行数之前,Archive引擎会阻止其他的SELECT执行,以实现一致性读。另外,也实现了批量插入在完成之前对读操作是不可见的。这种机制模仿了事务和MVCC的一些特性,但Archive引擎不是一个事务型的引擎,而是-一个针对高速插人和压缩做了优化的简单引擎。
92 |
93 | ## Blackhole引擎
94 | * Blackhole引擎没有实现任何的存储机制,它会丟弃所有插入的数据,不做任何保存。但是服务器会记录Blackhole表的日志,所以可以用于复制数据到备库,或者只是简单地记录到日志。这种特殊的存储引擎可以在--些特殊的复制架构和8志审核时发挥作用。但这种应用方式我们碰到过很多问题,因此并不推荐。
95 |
96 | ## CSV引擎
97 | * CSV引擎可以将普通的CSV文件(逗号分割值的文件)作为MySQL的表来处理,但这种表不支持索引。CSV引擎可以在数据库运行时拷入或者拷出文件。可以将Excel等电子表格软件中的数据存储为CSV文件,然后复制到MySQL数据目录下,就能在MySQL中打开使用。同样,如果将数据写人到一个CSV引擎表,其他的外部程序也能立即从表的数据文件中读取CSV格式的数据。因此CSV引擎可以作为- -种数据交换的机制,非常有用。
98 |
99 | ## Federated引擎
100 | * Federated引擎是访问其他MySQL服务器的-一个代理,它会创建-一个到远程MySQL服务器的客户端连接,并将查询传输到远程服务器执行,然后提取或者发送需要的数据。最初设计该存储引擎是为了和企业级数据库如Microsoft SQL Server和Oracle的类似特性竞争的,可以说更多的是一种市场行为。尽管该引擎看起来提供了一种很好的跨服务器的灵活性,但也经常带来问题,因此默认是禁用的。
101 |
102 | ## Memory引擎
103 | * 如果需要快速地访问数据,并且这些数据不会被修改,重启以后丢失也没有关系,那么使用Memory表(以前也叫做HEAP表)是非常有用的。Memory 表至少比MyISAM表要快一个数量级,因为所有的数据都保存在内存中,不需要进行磁盘I/O。Memory 表的结构在重启以后还会保留,但数据会丢失。
104 |
105 |
106 | # Schema(数据库的组织和结构)与数据类型优化
107 | ## 更小的通常好
108 | * 尽量使用可以正确存储数据的最下数据类型,更小的数据类型通常更快,占用更小的磁盘,内存和cpu缓存,并且处理时需要的cpu周期更少
109 | * 但是要确保没有低估需要存储的值的范围,因为在schema中的多个地方增加数据类型的范围是一个非常耗时和痛苦的操作。如果无法确定哪个数据类型是最好的,就选择你认为不会超过范围的最小类型
110 |
111 | ## 简单就好
112 | * 简单数据类型的操作通常需要更少的CPU周期。例如,整型比字符操作代价更低,
113 | * 整型比字符操作代价更低,因为字符集和校对规则(排序规则)使字符比较比整型比较更复杂
114 | * 使用MySQL内建的类型而不是字符串来存储日期和时间
115 | * 用整型存储IP地址
116 |
117 | ## 尽量避免NUll
118 | * 如果查询中包含null的列,会使得索引,索引统计和值比较更复杂
119 | * 当可以NULL的列被索引时,每个索引记录需要一个额外的字节
120 |
121 | ## datetime和timesamp
122 | * datetime和timesamp都可以存储相同的数据类型,时间和日期,精确到秒。然而timesamp只使用datetime一半的存储空间
123 | * timesamp 会根据时区变化,具有特殊的自动更新能力,允许的时间范围要小很多,有时它的特许能力会成为障碍
124 |
125 |
126 |
--------------------------------------------------------------------------------
/docs/Spring/Springcloud服务链路追踪.md:
--------------------------------------------------------------------------------
1 | # spring-cloud
2 |
3 | [SpringCloud 教程Finchley版本](https://blog.csdn.net/forezp/article/details/81040925)
4 |
5 | ### 服务链路追踪(Spring Cloud Sleuth)(Finchley版本)
6 | 在spring Cloud为F版本的时候,已经不需要自己构建Zipkin Server了,只需要下载jar即可,下载地址:
7 | https://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/
8 |
9 | ```
10 | java -jar zipkin-server-2.10.1-exec.jar
11 |
12 | 访问 localhost:9411
13 | ```
14 | **构建工程**
15 | - 基本知识讲解完毕,下面我们来实战,本文的案例主要有三个工程组成:一个server-zipkin,它的主要作用使用ZipkinServer 的功能,收集调用数据,并展示;一个service-hi,对外暴露hi接口;一个service-miya,对外暴露miya接口;这两个service可以相互调用;并且只有调用了,server-zipkin才会收集数据的,这就是为什么叫服务追踪了。
16 |
17 | **创建service-hi**
18 |
19 | application.properties配制文件
20 | ```
21 | server.port=8988
22 | spring.zipkin.base-url=http://localhost:9411
23 | spring.application.name=service-hi
24 |
25 | ```
26 | 启动类
27 | ```
28 | @SpringBootApplication
29 | @RestController
30 | public class ServiceHiApplication {
31 | public static void main(String[] args) {
32 | SpringApplication.run(ServiceHiApplication.class, args);
33 | }
34 | private static final Logger LOG = Logger.getLogger(ServiceHiApplication.class.getName());
35 | @Autowired
36 | private RestTemplate restTemplate;
37 | @Bean
38 | public RestTemplate getRestTemplate(){
39 | return new RestTemplate();
40 | }
41 | @RequestMapping("/hi")
42 | public String callHome(){
43 | LOG.log(Level.INFO, "calling trace service-hi ");
44 | return restTemplate.getForObject("http://localhost:8989/miya", String.class);
45 | }
46 | @RequestMapping("/info")
47 | public String info(){
48 | LOG.log(Level.INFO, "calling trace service-hi ");
49 | return "i'm service-hi";
50 | }
51 | @Bean
52 | public Sampler defaultSampler() {
53 | return Sampler.ALWAYS_SAMPLE;
54 | }
55 | }
56 |
57 | ```
58 |
59 | **创建service-miya**
60 |
61 | 创建过程痛service-hi,引入相同的依赖,配置下spring.zipkin.base-url。
62 | application.properties配制文件
63 | ```
64 | server.port=8989
65 | spring.zipkin.base-url=http://localhost:9411
66 | spring.application.name=service-miya
67 | ```
68 | 启动类
69 |
70 | ```
71 | @SpringBootApplication
72 | @RestController
73 | public class ServiceMiyaApplication {
74 | public static void main(String[] args) {
75 | SpringApplication.run(ServiceMiyaApplication.class, args);
76 | }
77 | private static final Logger LOG = Logger.getLogger(ServiceMiyaApplication.class.getName());
78 | @RequestMapping("/hi")
79 | public String home(){
80 | LOG.log(Level.INFO, "hi is being called");
81 | return "hi i'm miya!";
82 | }
83 | @RequestMapping("/miya")
84 | public String info(){
85 | LOG.log(Level.INFO, "info is being called");
86 | return restTemplate.getForObject("http://localhost:8988/info",String.class);
87 | }
88 | @Autowired
89 | private RestTemplate restTemplate;
90 | @Bean
91 | public RestTemplate getRestTemplate(){
92 | return new RestTemplate();
93 | }
94 | @Bean
95 | public Sampler defaultSampler() {
96 | return Sampler.ALWAYS_SAMPLE;
97 | }
98 | }
99 | ```
100 | pom.xml
101 | ```
102 |
103 |
105 | 4.0.0
106 |
107 | com.pflm
108 | service-miya
109 | 0.0.1-SNAPSHOT
110 | jar
111 |
112 | service-miya
113 | 服务链路追踪演示
114 |
115 |
116 | org.springframework.boot
117 | spring-boot-starter-parent
118 | 2.0.3.RELEASE
119 |
120 |
121 |
122 |
123 | UTF-8
124 | UTF-8
125 | 1.8
126 | Finchley.RELEASE
127 |
128 |
129 |
130 |
131 | org.springframework.boot
132 | spring-boot-starter-web
133 |
134 |
135 | org.springframework.cloud
136 | spring-cloud-starter-zipkin
137 |
138 |
139 | org.springframework.boot
140 | spring-boot-starter-test
141 | test
142 |
143 |
144 |
145 |
146 |
147 |
148 | org.springframework.cloud
149 | spring-cloud-dependencies
150 | ${spring-cloud.version}
151 | pom
152 | import
153 |
154 |
155 |
156 |
157 |
158 |
159 |
160 | org.springframework.boot
161 | spring-boot-maven-plugin
162 |
163 |
164 |
165 |
166 |
167 | ```
168 | - 依次启动上面的工程,打开浏览器访问:http://localhost:9411/,会出现以下界面:
169 | - 访问:http://localhost:8989/miya,浏览器出现: i’m service-hi
170 | - 再打开http://localhost:9411/的界面,点击Dependencies,可以发现服务的依赖关系:
--------------------------------------------------------------------------------
/docs/README.md:
--------------------------------------------------------------------------------
1 | # 简介
2 |
3 | > Java知识学习总结
4 |
5 |
6 | [](https://gitee.com/qinxuewu)
7 | [](https://github.com/a870439570)
8 |
9 | ## 关于
10 |
11 | - email: 870439570@qq.com
12 | - CSDN: https://blog.csdn.net/u010391342
13 | - 个人博客:https://qinxuewu.github.io/
14 |
15 | ## 开源小项目
16 |
17 | - [boot-actuator](https://github.com/qinxuewu/boot-actuator): 基于Spring Boot 实现的监控远程服务器多个Java应用JVM性能图形化工具
18 | - [blog-sharon](https://github.com/qinxuewu/blog-sharon): 一款简单微信小程序个人博客
19 | - [Mongodb-WeAdmin](https://github.com/qinxuewu/Mongodb-WeAdmin): SpringBoot版Mongodb工具
20 |
21 |
22 |
23 | ## JAVA基础
24 | - [深入理解JVM](2019/深入理解JVM.md)
25 | - [jvm监控命令](JVM/jvm监控命令.md)
26 | - [(深入理解JUC)什么是AQS队列同步器](https://blog.csdn.net/u010391342/article/details/88657920)
27 | - [(深入理解JUC)分析ReentrantLock源码](https://blog.csdn.net/u010391342/article/details/88686965)
28 | - [(深入理解JUC)分析CountDownLatch源码](2019/分析CountDownLatch源码.md)
29 | - [(深入理解JUC)分析CyclicBarrier同步屏障源码](2019/CyclicBarrier.md)
30 | - [(深入理解JUC)分析Semaphore信号量源码](2019/Semaphore.md)
31 | - [(深入理解JUC)ConcurrentLinkedQueue源码](https://blog.csdn.net/u010391342/article/details/88856530)
32 | - [volatile的内存语义](https://blog.csdn.net/u010391342/article/details/89042895)
33 |
34 |
35 |
36 | ## SpringBoot/SpringCloud/Spring
37 | - [SpringBoot集成Sharding-JDBC实现分库分表](2019/SpringBoot2集成Sharding-JDBC实现分库分表.md)
38 | - [SpringBoot自定义一个starter](2019/SpringBoot自定义一个starter.md )
39 | - [SpringBoot集成prometheus+Grafana监控](https://blog.csdn.net/u010391342/article/details/88970133)
40 | - [SpringBoot Admin监控集成](Spring/SpringBootAdmin.md)
41 | - [SpringBoot集成ElasticSearch6.2版本](https://blog.csdn.net/u010391342/article/details/82153709)
42 | - [SpringBoot集成Kafka](https://blog.csdn.net/u010391342/article/details/81430402)
43 | - [SpringBoot集成Zookeeper](2019/SpringBoot集成Zookeeper.md)
44 | - [SpringCloud集成eureka注册中心访问权限](https://blog.csdn.net/u010391342/article/details/83086519)
45 | - [SpringCloud集成Consul实现服务注册中心](https://blog.csdn.net/u010391342/article/details/83082801)
46 | - [SpringCloud服务链路追踪](Spring/Springcloud服务链路追踪.md)
47 | - [SpringCloud Alibaba系列(一)服务注册](https://blog.csdn.net/u010391342/article/details/86655712)
48 | - [SpringCloud Alibaba系列(二)Sentinel应用的限流管理](https://blog.csdn.net/u010391342/article/details/86678637)
49 | - [SpringCloud Alibaba系列(三)Nacos Config配置中心](https://blog.csdn.net/u010391342/article/details/86702084)
50 | - [Spring集成dubbo实现服务降级](Spring/Spring集成dubbo集群实现服务降级.md)
51 | - [SpringMVC生命周期](Spring/SpringMvc生命周期.md)
52 | - [Hystrix原理解析](2019/Hystrix原理解析.md)
53 |
54 | ## 分布式
55 | - [ELK分布式日志平台搭建](https://blog.csdn.net/u010391342/article/details/82895385)
56 | - [Netty入门(一)HelloWorld程序编写](https://blog.csdn.net/u010391342/article/details/83011198)
57 | - [Netty入门(二)TCP粘包与拆包问题处理](https://blog.csdn.net/u010391342/article/details/83011294)
58 | - [Netty入门(三)Netty集成protobuf与多协议消息传递](2019/Netty集成protobuf与多协议消息传递.md)
59 | - [基于Zookeeper实现分布式锁和队列](https://blog.csdn.net/u010391342/article/details/82192933)
60 | - [ElasticSearch本地快速搭建与使用](https://blog.csdn.net/u010391342/article/details/82117389)
61 | - [Apache Thrift安装配置及入门实例](2019/Thrift安装配置及入门实例.md)
62 | - [Grpc快速入门](2019/grpc快速入门.md)
63 | - [Redis基本操作](distributed/redis基本操作.md)
64 | - [分布式事务解决方案](2019/分布式事务解决方案.md)
65 |
66 | ## 设计模式
67 | - [创建型模式](2019/创建型模式.md)
68 | - [结构型模式](2019/结构型模式.md)
69 | - [行为型模式](2019/行为型模式.md)
70 |
71 | ## 数据结构与算法
72 | - [leetcode算法题](leetcode/leetcodeJava.md)
73 | - [leetcode数据库算法题](leetcode/sql算法.md)
74 | - [单向循环链表(约瑟夫环)](leetcode/约瑟夫环.md)
75 | - [(大话数据结构01)顺序表和单链表的比较](https://blog.csdn.net/u010391342/article/details/86760777)
76 | - [(大话数据结构02)循环列表的实现](https://blog.csdn.net/u010391342/article/details/86767093)
77 | - [(大话数据结构03)什么是双向链表](https://blog.csdn.net/u010391342/article/details/86768074)
78 | - [(大话数据结构04)什么是栈](https://blog.csdn.net/u010391342/article/details/86773596)
79 | - [(大话数据结构05)什么是队列](https://blog.csdn.net/u010391342/article/details/86775025)
80 | - [(大话数据结构06)什么是二叉树](https://blog.csdn.net/u010391342/article/details/86990584)
81 | - [(大话数据结构07)查找算法](https://blog.csdn.net/u010391342/article/details/88715233)
82 |
83 | ## Storm系列
84 | - [(一)环境搭建安装](storm/storm01.md)
85 | - [(二)常用shell命令](storm/storm02.md)
86 | - [(三)Java编写第一个本地模式demo](storm/storm03.md)
87 | - [(四)并行度和流分组](storm/storm04.md)
88 | - [(五)DRPC远程调用](storm/storm05.md)
89 | - [(六)Trident使用](storm/storm06.md)
90 | - [(七)集成kafka](storm/storm07.md)
91 |
92 | ## hadoop系列
93 | - [(一)伪分布式搭建](hadoop/hadoop01.md)
94 | - [(二)HDFS shell操作](hadoop/hadoop02.md)
95 | - [(三)HDFS的java api](hadoop/hadoop03.md)
96 | - [(四)MapReduce分布式计算利器](hadoop/hadoop04.md)
97 | - [HBase安装以及基本操作](hadoop/hbase01.md)
98 | - [HBase之Java API 操作](hadoop/hbase02.md)
99 |
100 | ## 知识点总结
101 | - [多线程和JVM知识总结](2019/多线程和JVM知识总结.md)
102 | - [JAVA核心技术36讲笔记](2019/JAVA核心技术36讲.md)
103 | - [MySQL实战45讲笔记](2019/MySQL实战45讲笔记.md)
104 | - [高性能MySQL笔记](2019/高性能MySQL.md)
105 | - [从Paxos到Zookeeper分布式一致性原理与实践](2019/从Paxos到Zookeeper分布式一致性原理与实践.md)
106 | - [Kafka知识点总结](2019/Kafka知识点总结.md)
107 | - [Zookeeper原理解析](其它/Zookeeper面试专题.md)
108 | - [Redis深入原理解析](其它/Redis深入原理解析)
109 | - [Spring面试总结](其它/spring.md)
110 |
111 |
112 |
113 | ## 随笔
114 | - [docsify一个神奇的文档生成工具](其它/docsify.md)
115 | - [Linux服务命令](其它/Linxu服务命令.md)
116 | - [PMP备考练习题](2019/PMP练习题.md)
117 | - [Docker学习笔记](2019/docker笔记.md)
118 | - [Git的奇技淫巧](https://github.com/521xueweihan/git-tips)
119 | - [图解LeetCode](https://github.com/ZXZxin/ZXBlog/blob/master/%E5%88%B7%E9%A2%98/LeetCode/LeetCodeSolutionIndex.md)
120 | - [图解剑指Offer](https://github.com/ZXZxin/ZXBlog/tree/master/%E5%88%B7%E9%A2%98/Other/%E5%89%91%E6%8C%87Offer)
121 | - [互联网Java工程师进阶知识完全扫盲](https://github.com/doocs/advanced-java)
122 | - [pandownload百度网盘不限速下载](http://pandownload.com/index.html)
123 |
124 | ## Golang学习笔记
125 | - [【从零开始学Go】使用goquery爬取影视资源网站](golang/使用goquery爬取影视资源网站.md)
126 |
--------------------------------------------------------------------------------
/docs/distributed/Redis02.md:
--------------------------------------------------------------------------------
1 | ### [分布锁框架Redisson](https://github.com/redisson/redisson/wiki/1.-%E6%A6%82%E8%BF%B0)
2 | - Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务。其中包括(BitSet, Set, Multimap, SortedSet, Map, List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish / Subscribe, Bloom filter, Remote service, Spring cache, Executor service, Live Object service, Scheduler service) Redisson提供了使用Redis的最简单和最便捷的方法。Redisson的宗旨是促进使用者对Redis的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。
3 |
4 |
5 | ### 程序化配置方法
6 | Redisson程序化的配置方法是通过构建Config对象实例来实现的。例如
7 |
8 | ```
9 | Config config = new Config();
10 | config.setTransportMode(TransportMode.EPOLL);
11 | //可以用"rediss://"来启用SSL连接
12 | config.useClusterServers().addNodeAddress("redis://127.0.0.1:7181");
13 | ```
14 |
15 | ### 文件方式配置
16 | Redisson既可以通过用户提供的JSON或YAML格式的文本文件来配置,也可以通过含有Redisson专有命名空间的,Spring框架格式的XML文本文件来配置。
17 |
18 | ```
19 | Config config = Config.fromJSON(new File("config-file.json"));
20 | RedissonClient redisson = Redisson.create(config);
21 | ```
22 | 也通过调用config.fromYAML方法并指定一个File实例来实现读取YAML格式的配置:
23 |
24 | ```
25 | Config config = Config.fromYAML(new File("config-file.yaml"));
26 | RedissonClient redisson = Redisson.create(config);
27 | ```
28 |
29 | ### 集群模式
30 | 集群模式除了适用于Redis集群环境,也适用于任何云计算服务商提供的集群模式,例如AWS ElastiCache集群版、Azure Redis Cache和阿里云(Aliyun)的云数据库Redis版。
31 |
32 | 程序化配置集群的用法:
33 |
34 | ```
35 | Config config = new Config();
36 | config.useClusterServers()
37 | .setScanInterval(2000) // 集群状态扫描间隔时间,单位是毫秒
38 | //可以用"rediss://"来启用SSL连接
39 | .addNodeAddress("redis://127.0.0.1:7000", "redis://127.0.0.1:7001")
40 | .addNodeAddress("redis://127.0.0.1:7002");
41 |
42 | RedissonClient redisson = Redisson.create(config);
43 | ```
44 | ### 主从模式
45 |
46 | ```
47 | Config config = new Config();
48 | config.useMasterSlaveServers()
49 | //可以用"rediss://"来启用SSL连接
50 | .setMasterAddress("redis://127.0.0.1:6379")
51 | .addSlaveAddress("redis://127.0.0.1:6389", "redis://127.0.0.1:6332", "redis://127.0.0.1:6419")
52 | .addSlaveAddress("redis://127.0.0.1:6399");
53 |
54 | RedissonClient redisson = Redisson.create(config);
55 | ```
56 |
57 | ### RedissonLock分布式锁的代码
58 |
59 | ```
60 | public class RedissonLock {
61 | private static RedissonClient redissonClient;
62 | static{
63 | Config config = new Config();
64 | config.useSingleServer().setAddress("redis://127.0.0.1:6379").setPassword(null);
65 | // config.useSingleServer().setAddress("redis://192.168.188.4:6380").setPassword("ty3foGTrNiKi");
66 | redissonClient = Redisson.create(config);
67 | }
68 |
69 | public static RedissonClient getRedisson(){
70 | return redissonClient;
71 | }
72 |
73 |
74 | public static void main(String[] args) throws InterruptedException{
75 |
76 | RLock fairLock = getRedisson().getLock("TEST_KEY");
77 | System.out.println(fairLock.toString());
78 | // fairLock.lock();
79 | // 尝试加锁,最多等待10秒,上锁以后10秒自动解锁
80 | boolean res = fairLock.tryLock(10, 10, TimeUnit.SECONDS);
81 | System.out.println(res);
82 | fairLock.unlock();
83 |
84 | //有界阻塞队列
85 | RBoundedBlockingQueue queue = getRedisson().getBoundedBlockingQueue("anyQueue");
86 | // 如果初始容量(边界)设定成功则返回`真(true)`,
87 | // 如果初始容量(边界)已近存在则返回`假(false)`。
88 | System.out.println(queue.trySetCapacity(10));
89 | JSONObject o=new JSONObject();
90 | o.put("name", 1);
91 | if(!queue.contains(o)){
92 | queue.offer(o);
93 | }
94 |
95 | JSONObject o2=new JSONObject();
96 | o2.put("name", 2);
97 | // 此时容量已满,下面代码将会被阻塞,直到有空闲为止。
98 |
99 | if(!queue.contains(o2)){
100 | queue.offer(o2);
101 | }
102 |
103 | // 获取但不移除此队列的头;如果此队列为空,则返回 null。
104 | JSONObject obj = queue.peek();
105 | //获取并移除此队列的头部,在指定的等待时间前等待可用的元素(如果有必要)。
106 | JSONObject ob = queue.poll(10, TimeUnit.MINUTES);
107 |
108 | //获取并移除此队列的头,如果此队列为空,则返回 null。
109 | Iterator iterator=queue.iterator();
110 | while (iterator.hasNext()){
111 | JSONObject i =iterator.next();
112 | System.out.println(i.toJSONString());
113 | iterator.remove();
114 |
115 | }
116 | while(queue.size()>0){
117 | JSONObject obs = queue.poll();
118 | System.out.println(obs.toJSONString());
119 | }
120 |
121 | JSONObject someObj = queue.poll();
122 | System.out.println(someObj.toJSONString());
123 | }
124 | }
125 |
126 | ```
127 | **[Table of Content](./Table-of-Content)** | [目录](./目录)
128 |
129 | 1. **[Overview](./1.-Overview)**
130 |
131 | **3、配置访问windows的hosts**
132 | ```
133 | #hbase
134 | 192.168.10.124 CentOS124
135 | ```
136 |
137 |
138 | # Java 操作远程hbase
139 | ```java
140 | public class HbaseTest {
141 | public static Connection connection;
142 | public static Configuration configuration;
143 | static {
144 |
145 | configuration = HBaseConfiguration.create();
146 | // 设置连接参数:HBase数据库使用的端口
147 | configuration.set("hbase.zookeeper.property.clientPort", "2181");
148 | // 设置连接参数:HBase数据库所在的主机IP
149 | configuration.set("hbase.zookeeper.quorum", "192.168.10.124");
150 | // configuration.addResource("hbase-site.xml");
151 | try {
152 | // 取得一个数据库连接对象
153 | connection = ConnectionFactory.createConnection(configuration);
154 | } catch (IOException e) {
155 | e.printStackTrace();
156 | }
157 |
158 | }
159 | public static void main(String[] args) throws Exception {
160 | createTable("gazw", "id","name");
161 | // deleteTable("gazw");
162 | }
163 |
164 | public static void createTable(String tableName,String... cf1) throws IOException {
165 | Admin admin = connection.getAdmin();
166 | //HTD需要TableName类型的tableName,创建TableName类型的tableName
167 | TableName tbName = TableName.valueOf(tableName);
168 | //判断表述否已存在,不存在则创建表
169 | if(admin.tableExists(tbName)){
170 | System.err.println("表" + tableName + "已存在!");
171 | return;
172 | }
173 | //通过HTableDescriptor创建一个HTableDescriptor将表的描述传到createTable参数中
174 | HTableDescriptor HTD = new HTableDescriptor(tbName);
175 | //为描述器添加表的详细参数
176 | for(String cf : cf1){
177 | // 创建HColumnDescriptor对象添加表的详细的描述
178 | HColumnDescriptor HCD =new HColumnDescriptor(cf);
179 | HTD.addFamily(HCD);
180 | }
181 | //调用createtable方法创建表
182 | admin.createTable(HTD);
183 | System.out.println("创建成功");
184 | }
185 | }
186 | ```
187 |
188 |
--------------------------------------------------------------------------------
/docs/2019/高性能MySQL.md:
--------------------------------------------------------------------------------
1 |
2 | 
3 | >无论何时,只要有多个查询需要在同一个时刻修改数据时,就会有并发问题。MySql主要在`服务器层`与`存储引擎层`进行并发控制。
4 |
5 | 假设数据库中国一张邮箱表,每个邮件都是一条记录。如果某个客户正在读取邮箱,同时其他客户试图在删除邮箱表中的某一条数据。这个时候,读取的结构就是不确定的了。在MySql中会通过锁定防止其它用户读取同一数据。大多数时候,MySQL锁的内部管理都是透明的。
6 |
7 | # MySQL锁的粒度
8 | * 每种MySql引擎都可以实现自己的锁策略和锁粒度,将锁粒度固定在某个级别,可以为某些特定的场景提供更好的性能。
9 |
10 | **表锁(table lock)**
11 | * 表锁是mysql中最基本的锁略,并且是开销最小的策略。它会锁定整个表,一个用户在对表进行写操作(插入、删除、更新等)前,需要先获得写锁,这会阻塞其他用户对该表的所有读写操作。只有没有写锁时,其他读取的用户才能获得读锁,读锁之间是不相互阻塞的。
12 | * 在特定的场景中,表锁也可能有良好的性能。例如,`READ L0CAL` 表锁支持某些类型的并发写操作。另外,写锁也比读锁有更高的优先级,因此-一个写锁请求可能会被插入到读
13 | 锁队列的前面(写锁可以插入到锁队列中读锁的前面,反之读锁则不能插入到写锁的前
14 | 面)。
15 | * 尽管存储引擎可以管理自己的锁,MySQL本身还是会使用各种有效的表锁来实现不同
16 | 的目的。例如,服务器会为诸如`ALTER TABLE` 之类的语句使用表锁,而忽略存储引擎的
17 | 锁机制。
18 |
19 | **行级锁(row lock)**
20 | * 行级锁可以最大程度地支持并发处理(同时也带来了最大的锁开销)。
21 | * 在`InnoDB`和`XtraDB`,以及其他一些存储引擎中实现了行级锁。
22 | * 行级锁只在存储引擎层实现,而MySQL服务器层没有实现。服务器层完全不了解存储引擎中的锁实现。
23 |
24 | # MySQL的事务
25 | **事务特性**
26 | * A(原子性)事务的各步操作是不可分的,保证一系列的操作要么都完成,要么都不完成;
27 | * C(一致性)事务完成,数据必须处于一致的状态;
28 | * I(隔离性)对数据进行修改的所有并发事务彼此之间是相互隔离,这表明事务必须是独立的,不应以任何方式依赖或影响其他事务;
29 | * D(持久性)表示事务对数据处理结束后,对数据更改必须持久化,不管是事务成功还是回滚。事务日志都能够保持事务的永久性。
30 |
31 | **事务的隔离级别**
32 | * SQL标准的事务隔离级别包括:读未提交(read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(serializable )
33 | * 读未提交是指,一个事务还没提交时,它做的变更就能被别的事务看到。
34 | * 读提交是指,一个事务提交之后,它做的变更才会被其他事务看到。
35 | * 可重复读是指,一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。未提交的更改对其他事务是不可见的
36 | * 串行化:对应一个记录会加读写锁,出现冲突的时候,后访问的事务必须等前一个事务执行完成才能继续执行。最高的隔离级别
37 |
38 | **MySQL中的事务**
39 | * MySQL提供了两种事务型的存储引擎: `InnoDB`和`NDB Cluster`。另外还有一些第三方
40 | 存储引擎也支持事
41 | * MySQL默认采用自动提交(AUTOCOMIT) 模式。如果不是显式地开始-一个个事务,则每个查询都被当作一事务执行提交操作。在当前连接中,可以通过设置AUTOCOMMIT变量来启用或者禁用自动提交模式:
42 | * InnoDB采用的是两阶段锁定协议(two-phase locking protocol)。在事务执行过程中,随
43 | 时都可以执行锁定,锁只有在执行`COMMIT`或者`ROLLBACK`的时候才会释放,并且所有的
44 | 锁是在同一时刻被释放。
45 | * InnoDB也支持通过特定的语句进行显式锁定`SELECT ... LOCK IN SHARE MODE`和`SELECT FOR UPDATE` 些语句不属于SQL规范
46 |
47 | # 多版本并发控制MVCC
48 | * `MVCC`是行级锁的一个变种,但是它在很多情况下避免了加锁操作,因此开销更低。虽然实现机制有所不同,但大都实现了非阻塞的读操作,写操作也只锁定必要的行。
49 | * MVCC的实现,是通过保存数据在某个时间点的快照来实现的。也就是说,不管需要执行多长时间,每个事务看到的数据都是一致的。根据事务开始的时间不同,每个事务对同张表,同一时刻看到的数据可能是不一样的。
50 | * `InnoDB`的MVCC,是通过在每行记录后面保存两个隐藏的列来实现的。这两个列,一个保存了行的创建时间,一个保存行的过期时间(或删除时间)。当然存储的并不是实际的时间值,而是系统版本号。每开始一个新的事务,系统版本号都会自动递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行比较。
51 | * MVCC只在可重复读和读提交的隔离级别生效。其它两个级别都不兼容
52 |
53 | > 在可重复读(`REPEATABLE READ`) 隔离级别下,MVCC具体是如何操作的。
54 |
55 | **SELECT查询操作时**
56 |
57 | InnoDB会根据以下两个条件检查每行记录:
58 | * InnoDB只查找版本早于当前事务版本的数据行(也就是,行的系统版本号小于或等于事务的系统版本号),这样可以确保事务读取的行,要么是在事务开始前已经存在的,要么是事务自身插入或者修改过的。
59 | * 行的删除版本要么未定义,要么大于当前事务版本号。这可以确保事务读取到的行,在事务开始之前未被删除。
60 |
61 | **INSERT**
62 | * InnoDB为新播入的每-一行保存当前系统版本号作为行版本号。
63 |
64 | **DELETE**
65 | * InnoDB为删除的每-*行保存当前系统版本号作为行删除标识。
66 |
67 | **UPDATE**
68 | * InnoDB为插入-行新记录,保存当前系统版本号作为行版本号,同时保存当前系统
69 | 版本号到原来的行作为行删除标识。
70 |
71 | # 数据库存储引擎
72 | ## InnDB存储引擎
73 | * InnDB是Mysql默认的事务型存储引擎。它被设计用来处理大量的短期(short-lived) 事务,短期事务大部分情况是正常提交的,很少会被回滚。InnoDB的性能和自动崩溃恢复特性,使得它在非事务型存储的需求中也很流行
74 | * InnoDB的数据存储在表空间(tablespace) 中,表空间是由InnoDB管理的-个黑盒子,由一系列的数据文件组成。
75 | * InnoDB采用`MVCC`来支持高并发,并且实现了四个标准的隔离级别。其默认级别是
76 | REPEATABLE READ (`可重复读`) ,并且通过`间隙锁`(next-key locking)策略防止`幻读`的出现。间隙锁使得InnoDB不仅仅锁定查询涉及的行,还会对索引中的间隙进行锁定,以防止幻影行的插入。
77 | * InnoDB表是基于聚簇索引建立的。聚簇素引对主键查询有很高的性能,不过它的二级索引(secondary index,非主键索引)中必须包含主键列,所以如果主键列很大的话,其他的所有索引都会很大。因此,若表上的索引较多的话,主键应当尽可能的小。
78 | * InnoDB内部做了很多优化,包括从磁盘读取数据时采用的可预测性预读,能够自动在
79 | 内存中创建hash索引以加速读操作的自适应哈希索引(adaptive hash index),以及能够
80 | 加速插入操作的插入缓冲区(insert buffer)等
81 |
82 | ## MyISAM引擎
83 | * `MyISAM不支持事务和行锁`,在MySQL5.1之前的版本是默认的存储引擎,有一个缺陷是崩溃后无法恢复。
84 | * 优点是对于只读的数据,或者表比较小,可以忍受修复操作,可以继续使用
85 | * MyISAM会将表存储在两个文件中:数据文件和索引文件,分别以.MYD和.MYI为扩展名
86 | * MyISAM表可以包含动态或者静态(长度固定)行。MySQL会根据表的定义来决定采用何种行格式。MyISAM表可以存储的行记录数,一般受限于可用的磁盘空间,或者操作系统中单个文件的最大尺寸。
87 | * `MyISAM对整张表加锁,而不是针对行`。读取时会对需要读到的所有表加共享锁,写入时则对表加排他锁。但是在表有读取查询的同时,也可以往表中插入新的记录(这被称为并发插入)
88 |
89 | ## Archive引擎
90 | * Archive引擎会缓存所有的写并利用zlib对插人的行进行压缩,所以比MyISAM表的磁盘I/O更少。但是每次SELECT查询都需要执行全表扫描。所以Archive表适合日志和数据采集类应用,这类应用做数据分析时往往需要全表扫描。或者在一- 些需要更快速的INSERT操作的场合下也可以使用。
91 | * `Archive引擎`支持`行级锁和专用的缓冲区`,所以可以实现高并发的插人。在一个查询开始直到返回表中存在的所有行数之前,Archive引擎会阻止其他的SELECT执行,以实现一致性读。另外,也实现了批量插入在完成之前对读操作是不可见的。这种机制模仿了事务和MVCC的一些特性,但Archive引擎不是一个事务型的引擎,而是-一个针对高速插人和压缩做了优化的简单引擎。
92 |
93 | ## Blackhole引擎
94 | * Blackhole引擎没有实现任何的存储机制,它会丟弃所有插入的数据,不做任何保存。但是服务器会记录Blackhole表的日志,所以可以用于复制数据到备库,或者只是简单地记录到日志。这种特殊的存储引擎可以在--些特殊的复制架构和8志审核时发挥作用。但这种应用方式我们碰到过很多问题,因此并不推荐。
95 |
96 | ## CSV引擎
97 | * CSV引擎可以将普通的CSV文件(逗号分割值的文件)作为MySQL的表来处理,但这种表不支持索引。CSV引擎可以在数据库运行时拷入或者拷出文件。可以将Excel等电子表格软件中的数据存储为CSV文件,然后复制到MySQL数据目录下,就能在MySQL中打开使用。同样,如果将数据写人到一个CSV引擎表,其他的外部程序也能立即从表的数据文件中读取CSV格式的数据。因此CSV引擎可以作为- -种数据交换的机制,非常有用。
98 |
99 | ## Federated引擎
100 | * Federated引擎是访问其他MySQL服务器的-一个代理,它会创建-一个到远程MySQL服务器的客户端连接,并将查询传输到远程服务器执行,然后提取或者发送需要的数据。最初设计该存储引擎是为了和企业级数据库如Microsoft SQL Server和Oracle的类似特性竞争的,可以说更多的是一种市场行为。尽管该引擎看起来提供了一种很好的跨服务器的灵活性,但也经常带来问题,因此默认是禁用的。
101 |
102 | ## Memory引擎
103 | * 如果需要快速地访问数据,并且这些数据不会被修改,重启以后丢失也没有关系,那么使用Memory表(以前也叫做HEAP表)是非常有用的。Memory 表至少比MyISAM表要快一个数量级,因为所有的数据都保存在内存中,不需要进行磁盘I/O。Memory 表的结构在重启以后还会保留,但数据会丢失。
104 |
105 |
106 | # Schema(数据库的组织和结构)与数据类型优化
107 | ## 更小的通常好
108 | * 尽量使用可以正确存储数据的最下数据类型,更小的数据类型通常更快,占用更小的磁盘,内存和cpu缓存,并且处理时需要的cpu周期更少
109 | * 但是要确保没有低估需要存储的值的范围,因为在schema中的多个地方增加数据类型的范围是一个非常耗时和痛苦的操作。如果无法确定哪个数据类型是最好的,就选择你认为不会超过范围的最小类型
110 |
111 | ## 简单就好
112 | * 简单数据类型的操作通常需要更少的CPU周期。例如,整型比字符操作代价更低,
113 | * 整型比字符操作代价更低,因为字符集和校对规则(排序规则)使字符比较比整型比较更复杂
114 | * 使用MySQL内建的类型而不是字符串来存储日期和时间
115 | * 用整型存储IP地址
116 |
117 | ## 尽量避免NUll
118 | * 如果查询中包含null的列,会使得索引,索引统计和值比较更复杂
119 | * 当可以NULL的列被索引时,每个索引记录需要一个额外的字节
120 |
121 | ## datetime和timesamp
122 | * datetime和timesamp都可以存储相同的数据类型,时间和日期,精确到秒。然而timesamp只使用datetime一半的存储空间
123 | * timesamp 会根据时区变化,具有特殊的自动更新能力,允许的时间范围要小很多,有时它的特许能力会成为障碍
124 |
125 |
126 |
--------------------------------------------------------------------------------
/docs/Spring/Springcloud服务链路追踪.md:
--------------------------------------------------------------------------------
1 | # spring-cloud
2 |
3 | [SpringCloud 教程Finchley版本](https://blog.csdn.net/forezp/article/details/81040925)
4 |
5 | ### 服务链路追踪(Spring Cloud Sleuth)(Finchley版本)
6 | 在spring Cloud为F版本的时候,已经不需要自己构建Zipkin Server了,只需要下载jar即可,下载地址:
7 | https://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/
8 |
9 | ```
10 | java -jar zipkin-server-2.10.1-exec.jar
11 |
12 | 访问 localhost:9411
13 | ```
14 | **构建工程**
15 | - 基本知识讲解完毕,下面我们来实战,本文的案例主要有三个工程组成:一个server-zipkin,它的主要作用使用ZipkinServer 的功能,收集调用数据,并展示;一个service-hi,对外暴露hi接口;一个service-miya,对外暴露miya接口;这两个service可以相互调用;并且只有调用了,server-zipkin才会收集数据的,这就是为什么叫服务追踪了。
16 |
17 | **创建service-hi**
18 |
19 | application.properties配制文件
20 | ```
21 | server.port=8988
22 | spring.zipkin.base-url=http://localhost:9411
23 | spring.application.name=service-hi
24 |
25 | ```
26 | 启动类
27 | ```
28 | @SpringBootApplication
29 | @RestController
30 | public class ServiceHiApplication {
31 | public static void main(String[] args) {
32 | SpringApplication.run(ServiceHiApplication.class, args);
33 | }
34 | private static final Logger LOG = Logger.getLogger(ServiceHiApplication.class.getName());
35 | @Autowired
36 | private RestTemplate restTemplate;
37 | @Bean
38 | public RestTemplate getRestTemplate(){
39 | return new RestTemplate();
40 | }
41 | @RequestMapping("/hi")
42 | public String callHome(){
43 | LOG.log(Level.INFO, "calling trace service-hi ");
44 | return restTemplate.getForObject("http://localhost:8989/miya", String.class);
45 | }
46 | @RequestMapping("/info")
47 | public String info(){
48 | LOG.log(Level.INFO, "calling trace service-hi ");
49 | return "i'm service-hi";
50 | }
51 | @Bean
52 | public Sampler defaultSampler() {
53 | return Sampler.ALWAYS_SAMPLE;
54 | }
55 | }
56 |
57 | ```
58 |
59 | **创建service-miya**
60 |
61 | 创建过程痛service-hi,引入相同的依赖,配置下spring.zipkin.base-url。
62 | application.properties配制文件
63 | ```
64 | server.port=8989
65 | spring.zipkin.base-url=http://localhost:9411
66 | spring.application.name=service-miya
67 | ```
68 | 启动类
69 |
70 | ```
71 | @SpringBootApplication
72 | @RestController
73 | public class ServiceMiyaApplication {
74 | public static void main(String[] args) {
75 | SpringApplication.run(ServiceMiyaApplication.class, args);
76 | }
77 | private static final Logger LOG = Logger.getLogger(ServiceMiyaApplication.class.getName());
78 | @RequestMapping("/hi")
79 | public String home(){
80 | LOG.log(Level.INFO, "hi is being called");
81 | return "hi i'm miya!";
82 | }
83 | @RequestMapping("/miya")
84 | public String info(){
85 | LOG.log(Level.INFO, "info is being called");
86 | return restTemplate.getForObject("http://localhost:8988/info",String.class);
87 | }
88 | @Autowired
89 | private RestTemplate restTemplate;
90 | @Bean
91 | public RestTemplate getRestTemplate(){
92 | return new RestTemplate();
93 | }
94 | @Bean
95 | public Sampler defaultSampler() {
96 | return Sampler.ALWAYS_SAMPLE;
97 | }
98 | }
99 | ```
100 | pom.xml
101 | ```
102 |
103 |
105 | 4.0.0
106 |
107 | com.pflm
108 | service-miya
109 | 0.0.1-SNAPSHOT
110 | jar
111 |
112 | service-miya
113 | 服务链路追踪演示
114 |
115 |
116 | org.springframework.boot
117 | spring-boot-starter-parent
118 | 2.0.3.RELEASE
119 |
120 |
121 |
122 |
123 | UTF-8
124 | UTF-8
125 | 1.8
126 | Finchley.RELEASE
127 |
128 |
129 |
130 |
131 | org.springframework.boot
132 | spring-boot-starter-web
133 |
134 |
135 | org.springframework.cloud
136 | spring-cloud-starter-zipkin
137 |
138 |
139 | org.springframework.boot
140 | spring-boot-starter-test
141 | test
142 |
143 |
144 |
145 |
146 |
147 |
148 | org.springframework.cloud
149 | spring-cloud-dependencies
150 | ${spring-cloud.version}
151 | pom
152 | import
153 |
154 |
155 |
156 |
157 |
158 |
159 |
160 | org.springframework.boot
161 | spring-boot-maven-plugin
162 |
163 |
164 |
165 |
166 |
167 | ```
168 | - 依次启动上面的工程,打开浏览器访问:http://localhost:9411/,会出现以下界面:
169 | - 访问:http://localhost:8989/miya,浏览器出现: i’m service-hi
170 | - 再打开http://localhost:9411/的界面,点击Dependencies,可以发现服务的依赖关系:
--------------------------------------------------------------------------------
/docs/README.md:
--------------------------------------------------------------------------------
1 | # 简介
2 |
3 | > Java知识学习总结
4 |
5 |
6 | [](https://gitee.com/qinxuewu)
7 | [](https://github.com/a870439570)
8 |
9 | ## 关于
10 |
11 | - email: 870439570@qq.com
12 | - CSDN: https://blog.csdn.net/u010391342
13 | - 个人博客:https://qinxuewu.github.io/
14 |
15 | ## 开源小项目
16 |
17 | - [boot-actuator](https://github.com/qinxuewu/boot-actuator): 基于Spring Boot 实现的监控远程服务器多个Java应用JVM性能图形化工具
18 | - [blog-sharon](https://github.com/qinxuewu/blog-sharon): 一款简单微信小程序个人博客
19 | - [Mongodb-WeAdmin](https://github.com/qinxuewu/Mongodb-WeAdmin): SpringBoot版Mongodb工具
20 |
21 |
22 |
23 | ## JAVA基础
24 | - [深入理解JVM](2019/深入理解JVM.md)
25 | - [jvm监控命令](JVM/jvm监控命令.md)
26 | - [(深入理解JUC)什么是AQS队列同步器](https://blog.csdn.net/u010391342/article/details/88657920)
27 | - [(深入理解JUC)分析ReentrantLock源码](https://blog.csdn.net/u010391342/article/details/88686965)
28 | - [(深入理解JUC)分析CountDownLatch源码](2019/分析CountDownLatch源码.md)
29 | - [(深入理解JUC)分析CyclicBarrier同步屏障源码](2019/CyclicBarrier.md)
30 | - [(深入理解JUC)分析Semaphore信号量源码](2019/Semaphore.md)
31 | - [(深入理解JUC)ConcurrentLinkedQueue源码](https://blog.csdn.net/u010391342/article/details/88856530)
32 | - [volatile的内存语义](https://blog.csdn.net/u010391342/article/details/89042895)
33 |
34 |
35 |
36 | ## SpringBoot/SpringCloud/Spring
37 | - [SpringBoot集成Sharding-JDBC实现分库分表](2019/SpringBoot2集成Sharding-JDBC实现分库分表.md)
38 | - [SpringBoot自定义一个starter](2019/SpringBoot自定义一个starter.md )
39 | - [SpringBoot集成prometheus+Grafana监控](https://blog.csdn.net/u010391342/article/details/88970133)
40 | - [SpringBoot Admin监控集成](Spring/SpringBootAdmin.md)
41 | - [SpringBoot集成ElasticSearch6.2版本](https://blog.csdn.net/u010391342/article/details/82153709)
42 | - [SpringBoot集成Kafka](https://blog.csdn.net/u010391342/article/details/81430402)
43 | - [SpringBoot集成Zookeeper](2019/SpringBoot集成Zookeeper.md)
44 | - [SpringCloud集成eureka注册中心访问权限](https://blog.csdn.net/u010391342/article/details/83086519)
45 | - [SpringCloud集成Consul实现服务注册中心](https://blog.csdn.net/u010391342/article/details/83082801)
46 | - [SpringCloud服务链路追踪](Spring/Springcloud服务链路追踪.md)
47 | - [SpringCloud Alibaba系列(一)服务注册](https://blog.csdn.net/u010391342/article/details/86655712)
48 | - [SpringCloud Alibaba系列(二)Sentinel应用的限流管理](https://blog.csdn.net/u010391342/article/details/86678637)
49 | - [SpringCloud Alibaba系列(三)Nacos Config配置中心](https://blog.csdn.net/u010391342/article/details/86702084)
50 | - [Spring集成dubbo实现服务降级](Spring/Spring集成dubbo集群实现服务降级.md)
51 | - [SpringMVC生命周期](Spring/SpringMvc生命周期.md)
52 | - [Hystrix原理解析](2019/Hystrix原理解析.md)
53 |
54 | ## 分布式
55 | - [ELK分布式日志平台搭建](https://blog.csdn.net/u010391342/article/details/82895385)
56 | - [Netty入门(一)HelloWorld程序编写](https://blog.csdn.net/u010391342/article/details/83011198)
57 | - [Netty入门(二)TCP粘包与拆包问题处理](https://blog.csdn.net/u010391342/article/details/83011294)
58 | - [Netty入门(三)Netty集成protobuf与多协议消息传递](2019/Netty集成protobuf与多协议消息传递.md)
59 | - [基于Zookeeper实现分布式锁和队列](https://blog.csdn.net/u010391342/article/details/82192933)
60 | - [ElasticSearch本地快速搭建与使用](https://blog.csdn.net/u010391342/article/details/82117389)
61 | - [Apache Thrift安装配置及入门实例](2019/Thrift安装配置及入门实例.md)
62 | - [Grpc快速入门](2019/grpc快速入门.md)
63 | - [Redis基本操作](distributed/redis基本操作.md)
64 | - [分布式事务解决方案](2019/分布式事务解决方案.md)
65 |
66 | ## 设计模式
67 | - [创建型模式](2019/创建型模式.md)
68 | - [结构型模式](2019/结构型模式.md)
69 | - [行为型模式](2019/行为型模式.md)
70 |
71 | ## 数据结构与算法
72 | - [leetcode算法题](leetcode/leetcodeJava.md)
73 | - [leetcode数据库算法题](leetcode/sql算法.md)
74 | - [单向循环链表(约瑟夫环)](leetcode/约瑟夫环.md)
75 | - [(大话数据结构01)顺序表和单链表的比较](https://blog.csdn.net/u010391342/article/details/86760777)
76 | - [(大话数据结构02)循环列表的实现](https://blog.csdn.net/u010391342/article/details/86767093)
77 | - [(大话数据结构03)什么是双向链表](https://blog.csdn.net/u010391342/article/details/86768074)
78 | - [(大话数据结构04)什么是栈](https://blog.csdn.net/u010391342/article/details/86773596)
79 | - [(大话数据结构05)什么是队列](https://blog.csdn.net/u010391342/article/details/86775025)
80 | - [(大话数据结构06)什么是二叉树](https://blog.csdn.net/u010391342/article/details/86990584)
81 | - [(大话数据结构07)查找算法](https://blog.csdn.net/u010391342/article/details/88715233)
82 |
83 | ## Storm系列
84 | - [(一)环境搭建安装](storm/storm01.md)
85 | - [(二)常用shell命令](storm/storm02.md)
86 | - [(三)Java编写第一个本地模式demo](storm/storm03.md)
87 | - [(四)并行度和流分组](storm/storm04.md)
88 | - [(五)DRPC远程调用](storm/storm05.md)
89 | - [(六)Trident使用](storm/storm06.md)
90 | - [(七)集成kafka](storm/storm07.md)
91 |
92 | ## hadoop系列
93 | - [(一)伪分布式搭建](hadoop/hadoop01.md)
94 | - [(二)HDFS shell操作](hadoop/hadoop02.md)
95 | - [(三)HDFS的java api](hadoop/hadoop03.md)
96 | - [(四)MapReduce分布式计算利器](hadoop/hadoop04.md)
97 | - [HBase安装以及基本操作](hadoop/hbase01.md)
98 | - [HBase之Java API 操作](hadoop/hbase02.md)
99 |
100 | ## 知识点总结
101 | - [多线程和JVM知识总结](2019/多线程和JVM知识总结.md)
102 | - [JAVA核心技术36讲笔记](2019/JAVA核心技术36讲.md)
103 | - [MySQL实战45讲笔记](2019/MySQL实战45讲笔记.md)
104 | - [高性能MySQL笔记](2019/高性能MySQL.md)
105 | - [从Paxos到Zookeeper分布式一致性原理与实践](2019/从Paxos到Zookeeper分布式一致性原理与实践.md)
106 | - [Kafka知识点总结](2019/Kafka知识点总结.md)
107 | - [Zookeeper原理解析](其它/Zookeeper面试专题.md)
108 | - [Redis深入原理解析](其它/Redis深入原理解析)
109 | - [Spring面试总结](其它/spring.md)
110 |
111 |
112 |
113 | ## 随笔
114 | - [docsify一个神奇的文档生成工具](其它/docsify.md)
115 | - [Linux服务命令](其它/Linxu服务命令.md)
116 | - [PMP备考练习题](2019/PMP练习题.md)
117 | - [Docker学习笔记](2019/docker笔记.md)
118 | - [Git的奇技淫巧](https://github.com/521xueweihan/git-tips)
119 | - [图解LeetCode](https://github.com/ZXZxin/ZXBlog/blob/master/%E5%88%B7%E9%A2%98/LeetCode/LeetCodeSolutionIndex.md)
120 | - [图解剑指Offer](https://github.com/ZXZxin/ZXBlog/tree/master/%E5%88%B7%E9%A2%98/Other/%E5%89%91%E6%8C%87Offer)
121 | - [互联网Java工程师进阶知识完全扫盲](https://github.com/doocs/advanced-java)
122 | - [pandownload百度网盘不限速下载](http://pandownload.com/index.html)
123 |
124 | ## Golang学习笔记
125 | - [【从零开始学Go】使用goquery爬取影视资源网站](golang/使用goquery爬取影视资源网站.md)
126 |
--------------------------------------------------------------------------------
/docs/distributed/Redis02.md:
--------------------------------------------------------------------------------
1 | ### [分布锁框架Redisson](https://github.com/redisson/redisson/wiki/1.-%E6%A6%82%E8%BF%B0)
2 | - Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务。其中包括(BitSet, Set, Multimap, SortedSet, Map, List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish / Subscribe, Bloom filter, Remote service, Spring cache, Executor service, Live Object service, Scheduler service) Redisson提供了使用Redis的最简单和最便捷的方法。Redisson的宗旨是促进使用者对Redis的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。
3 |
4 |
5 | ### 程序化配置方法
6 | Redisson程序化的配置方法是通过构建Config对象实例来实现的。例如
7 |
8 | ```
9 | Config config = new Config();
10 | config.setTransportMode(TransportMode.EPOLL);
11 | //可以用"rediss://"来启用SSL连接
12 | config.useClusterServers().addNodeAddress("redis://127.0.0.1:7181");
13 | ```
14 |
15 | ### 文件方式配置
16 | Redisson既可以通过用户提供的JSON或YAML格式的文本文件来配置,也可以通过含有Redisson专有命名空间的,Spring框架格式的XML文本文件来配置。
17 |
18 | ```
19 | Config config = Config.fromJSON(new File("config-file.json"));
20 | RedissonClient redisson = Redisson.create(config);
21 | ```
22 | 也通过调用config.fromYAML方法并指定一个File实例来实现读取YAML格式的配置:
23 |
24 | ```
25 | Config config = Config.fromYAML(new File("config-file.yaml"));
26 | RedissonClient redisson = Redisson.create(config);
27 | ```
28 |
29 | ### 集群模式
30 | 集群模式除了适用于Redis集群环境,也适用于任何云计算服务商提供的集群模式,例如AWS ElastiCache集群版、Azure Redis Cache和阿里云(Aliyun)的云数据库Redis版。
31 |
32 | 程序化配置集群的用法:
33 |
34 | ```
35 | Config config = new Config();
36 | config.useClusterServers()
37 | .setScanInterval(2000) // 集群状态扫描间隔时间,单位是毫秒
38 | //可以用"rediss://"来启用SSL连接
39 | .addNodeAddress("redis://127.0.0.1:7000", "redis://127.0.0.1:7001")
40 | .addNodeAddress("redis://127.0.0.1:7002");
41 |
42 | RedissonClient redisson = Redisson.create(config);
43 | ```
44 | ### 主从模式
45 |
46 | ```
47 | Config config = new Config();
48 | config.useMasterSlaveServers()
49 | //可以用"rediss://"来启用SSL连接
50 | .setMasterAddress("redis://127.0.0.1:6379")
51 | .addSlaveAddress("redis://127.0.0.1:6389", "redis://127.0.0.1:6332", "redis://127.0.0.1:6419")
52 | .addSlaveAddress("redis://127.0.0.1:6399");
53 |
54 | RedissonClient redisson = Redisson.create(config);
55 | ```
56 |
57 | ### RedissonLock分布式锁的代码
58 |
59 | ```
60 | public class RedissonLock {
61 | private static RedissonClient redissonClient;
62 | static{
63 | Config config = new Config();
64 | config.useSingleServer().setAddress("redis://127.0.0.1:6379").setPassword(null);
65 | // config.useSingleServer().setAddress("redis://192.168.188.4:6380").setPassword("ty3foGTrNiKi");
66 | redissonClient = Redisson.create(config);
67 | }
68 |
69 | public static RedissonClient getRedisson(){
70 | return redissonClient;
71 | }
72 |
73 |
74 | public static void main(String[] args) throws InterruptedException{
75 |
76 | RLock fairLock = getRedisson().getLock("TEST_KEY");
77 | System.out.println(fairLock.toString());
78 | // fairLock.lock();
79 | // 尝试加锁,最多等待10秒,上锁以后10秒自动解锁
80 | boolean res = fairLock.tryLock(10, 10, TimeUnit.SECONDS);
81 | System.out.println(res);
82 | fairLock.unlock();
83 |
84 | //有界阻塞队列
85 | RBoundedBlockingQueue queue = getRedisson().getBoundedBlockingQueue("anyQueue");
86 | // 如果初始容量(边界)设定成功则返回`真(true)`,
87 | // 如果初始容量(边界)已近存在则返回`假(false)`。
88 | System.out.println(queue.trySetCapacity(10));
89 | JSONObject o=new JSONObject();
90 | o.put("name", 1);
91 | if(!queue.contains(o)){
92 | queue.offer(o);
93 | }
94 |
95 | JSONObject o2=new JSONObject();
96 | o2.put("name", 2);
97 | // 此时容量已满,下面代码将会被阻塞,直到有空闲为止。
98 |
99 | if(!queue.contains(o2)){
100 | queue.offer(o2);
101 | }
102 |
103 | // 获取但不移除此队列的头;如果此队列为空,则返回 null。
104 | JSONObject obj = queue.peek();
105 | //获取并移除此队列的头部,在指定的等待时间前等待可用的元素(如果有必要)。
106 | JSONObject ob = queue.poll(10, TimeUnit.MINUTES);
107 |
108 | //获取并移除此队列的头,如果此队列为空,则返回 null。
109 | Iterator iterator=queue.iterator();
110 | while (iterator.hasNext()){
111 | JSONObject i =iterator.next();
112 | System.out.println(i.toJSONString());
113 | iterator.remove();
114 |
115 | }
116 | while(queue.size()>0){
117 | JSONObject obs = queue.poll();
118 | System.out.println(obs.toJSONString());
119 | }
120 |
121 | JSONObject someObj = queue.poll();
122 | System.out.println(someObj.toJSONString());
123 | }
124 | }
125 |
126 | ```
127 | **[Table of Content](./Table-of-Content)** | [目录](./目录)
128 |
129 | 1. **[Overview](./1.-Overview)**
130 | [概述](./1.-概述)
131 | 2. **[Configuration](./2.-Configuration)**
132 | [配置方法](./2.-配置方法)
133 | 3. **[Operations execution](./3.-operations-execution)**
134 | [程序接口调用方式](./3.-程序接口调用方式)
135 | 4. **[Data serialization](./4.-data-serialization)**
136 | [数据序列化](./4.-数据序列化)
137 | 5. **[Data partitioning (sharding)](./5.-data-partitioning-(sharding))**
138 | [单个集合数据分片(Sharding)](./5.-单个集合数据分片(Sharding))
139 | 6. **[Distributed objects](./6.-distributed-objects)**
140 | [分布式对象](./6.-分布式对象)
141 | 7. **[Distributed collections](./7.-distributed-collections)**
142 | [分布式集合](./7.-分布式集合)
143 | 8. **[Distributed locks and synchronizers](./8.-distributed-locks-and-synchronizers)**
144 | [分布式锁和同步器](./8.-分布式锁和同步器)
145 | 9. **[Distributed services](./9.-distributed-services)**
146 | [分布式服务](./9.-分布式服务)
147 | 10. **[Additional features](./10.-additional-features)**
148 | [额外功能](./10.-额外功能)
149 | 11. **[Redis commands mapping](./11.-Redis-commands-mapping)**
150 | [Redis命令和Redisson对象匹配列表](./11.-Redis命令和Redisson对象匹配列表)
151 | 12. **[Standalone node](./12.-Standalone-node)**
152 | [独立节点模式](./12.-独立节点模式)
153 | 13. **[Tools](./13.-Tools)**
154 | [工具](./13.-工具)
155 | 14. **[Integration with frameworks](./14.-Integration-with-frameworks)**
156 | [第三方框架整合](./14.-第三方框架整合)
157 | 15. **[Dependency list](./15.-Dependency-list)**
158 | [项目依赖列表](./15.-项目依赖列表)
159 | 16. **[FAQ](./16.-FAQ)**
--------------------------------------------------------------------------------
/docs/Spring/Spring集成dubbo集群实现服务降级.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ## dubbo源码地址
4 | [https://github.com/alibaba/dubbo](https://github.com/alibaba/dubbo)
5 | - 进入下载dubbo-admin管理界面源码,进行maven打包 把打包war包部署到tomcat
6 | - 打包war包,进入dubbo-admin这个文件目录 运行命令:
7 | ```
8 | mvn package -Dmaven.skip.test=true
9 | ```
10 | - zookeeper 安装 windows环境
11 | - 在apache的官方网站提供了好多镜像下载地址,然后找到对应的版本
12 | 下载地址:
13 | [https://mirrors.cnnic.cn/apache/zookeeper/](https://mirrors.cnnic.cn/apache/zookeeper/)
14 | - 把下载的zookeeper的文件解压到指定目录
15 | - 修改conf下增加一个zoo.cfg,可以用zoo_sample.cfg内内容替代
16 | 安装完成进入bin目录启动zkServer.cmd命令
17 | ```
18 | # The number of milliseconds of each tick 心跳间隔 毫秒每次
19 | tickTime=2000
20 | # The number of ticks that the initial
21 | # synchronization phase can take
22 | #多少个心跳时间内,允许其他server连接并初始化数据,如果ZooKeeper管理的数据较大,则应相应增大这个值
23 | initLimit=10
24 | # The number of ticks that can pass between
25 | # sending a request and getting an acknowledgement
26 | #多少个tickTime内,允许follower同步,如果follower落后太多,则会被丢弃
27 | syncLimit=5
28 | # the directory where the snapshot is stored.
29 | #日志位置
30 | dataDir=F:\\zookeeper-3.3.6\\logs
31 | # the port at which the clients will connect 监听客户端连接的端口
32 | clientPort=2181
33 | ```
34 | ## w系统伪集群安装
35 |
36 |
37 | - 在 一台机器上通过伪集群运行时可以修改 zkServer.cmd 文件在里面加入
38 | - set ZOOCFG=..\conf\zoo1.cfg 这行,另存为 zkServer-1.cmd
39 | ](https://gitee.com/uploads/images/2018/0112/110013_3184576d_1478371.png "屏幕截图.png")
40 |
41 | 如果有多个可以以此类推
42 | 
43 | 
44 |
45 | 
46 | 
47 |
48 | 
49 | 还需要 在对应的
50 |
51 | /tmp/zookeeper/1,
52 |
53 | /tmp/zookeeper/2,
54 |
55 | /tmp/zookeeper/3
56 |
57 | 建立一个文本文件命名为myid,内容就为对应的zoo.cfg里server.后数字
58 | ## Linux环境下安装
59 |
60 |
61 | - 安装:
62 |
63 | ```
64 | wget http://www.apache.org/dist//zookeeper/zookeeper-3.3.3/zookeeper-3.3.3.tar.gz
65 | tar zxvf zookeeper-3.3.3.tar.gz
66 | cd zookeeper-3.3.3
67 | cp conf/zoo_sample.cfg conf/zoo.cfg
68 | ```
69 | - 配置:
70 | ```
71 | vi conf/zoo.cfg
72 | ```
73 | 如果不需要集群,zoo.cfg 的内容如下 2:
74 | ```
75 | tickTime=2000
76 | initLimit=10
77 | syncLimit=5
78 | dataDir=/home/dubbo/zookeeper-3.3.3/data
79 | clientPort=2181
80 | ```
81 | 如果需要集群,zoo.cfg 的内容如下
82 | ```
83 | tickTime=2000
84 | initLimit=10
85 | syncLimit=5
86 | dataDir=/home/dubbo/zookeeper-3.3.3/data
87 | clientPort=2181
88 | server.1=10.20.153.10:2555:3555
89 | server.2=10.20.153.11:2555:3555
90 | ```
91 | 并在 data 目录 4 下放置 myid 文件:
92 | ```
93 | mkdir data
94 | vi myid
95 | ```
96 | myid 指明自己的 id,对应上面 zoo.cfg 中 server. 后的数字,第一台的内容为 1,第二台的内容为2
97 | ```
98 | 启动:
99 |
100 | ./bin/zkServer.sh start
101 | 停止:
102 |
103 | ./bin/zkServer.sh stop
104 | 命令行 5:
105 | telnet 127.0.0.1 2181
106 | dump
107 | ```
108 | ## Dubbo架构
109 |
110 |
111 | - Provider: 暴露服务的服务提供方。
112 | - Consumer: 调用远程服务的服务消费方。
113 | - Registry: 服务注册与发现的注册中心。
114 | - Monitor: 统计服务的调用次调和调用时间的监控中心。
115 | - Container: 服务运行容器。
116 | - ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务。
117 |
118 | ## Dubbo提供的注册中心有如下几种类型
119 |
120 |
121 | - * Multicast注册中心
122 | - * Zookeeper注册中心
123 | - * Redis注册中心
124 | - * Simple注册中心
125 |
126 | ## Dubbo优缺点
127 |
128 |
129 | - 优点:
130 | - 透明化的远程方法调用
131 | - 像调用本地方法一样调用远程方法;只需简单配置,没有任何API侵入。
132 | - 软负载均衡及容错机制
133 | - 可在内网替代nginx lvs等硬件负载均衡器。
134 | - 服务注册中心自动注册 & 配置管理
135 | - 不需要写死服务提供者地址,注册中心基于接口名自动查询提供者ip。
136 | - 使用类似zookeeper等分布式协调服务作为服务注册中心,可以将绝大部分项目配置移入zookeeper集群。
137 | - 服务接口监控与治理
138 | - Dubbo-admin与Dubbo-monitor提供了完善的服务接口管理与监控功能,针对不同应用的不同接口,可以进行 多
139 | 版本,多协议,多注册中心管理
140 | - 缺点:只支持JAVA语言
141 | * Dubbo中zookeeper做注册中心,如果注册中心集群都挂掉,发布者和订阅者之间还能通信么?
142 |
143 |
144 | - 可以的,启动dubbo时,消费者会从zk拉取注册的生产者的地址接口等数据,缓存在本地。每次调用时,按照本地存储的地址进行调用
145 | - 可以,消费者本地有一个生产者的列表,他会按照列表继续工作,倒是无法从注册中心去同步最新的服务列表,短期的注册中心挂掉是不要紧的,但一定要尽快修复
146 |
147 | ## Dubbo在安全机制方面是如何解决的
148 | Dubbo通过Token令牌防止用户绕过注册中心直连,然后在注册中心上管理授权。Dubbo还提供服务黑白名单,来控制服务所允许的调用方。
149 |
150 | ## dubbo配置文件详解
151 |
152 |
153 | 1. [Dubbo用户手册](http://dubbo.io/books/dubbo-user-book/)
154 | 1. [Dubbo开发者指南](http://dubbo.io/books/dubbo-dev-book/)
155 | 1. [Dubbo管理员手册](http://dubbo.io/books/dubbo-admin-book/)
156 | ```
157 | 要暴露服务的接口 个服务可以用多个协议暴露,一个服务也可以注册到多个注册中心。
158 |
159 |
160 |
161 | 引用服务配置,用于创建一个远程服务代理,一个引用可以指向多个注册中心。
162 |
163 |
164 |
165 | 协议配置,用于配置提供服务的协议信息,协议由提供方指定,消费方被动接受。
166 |
167 |
168 |
169 |
170 | 应用配置,用于配置当前应用信息,不管该应用是提供者还是消费者。
171 |
172 |
173 |
174 |
175 | 注册中心配置,用于配置连接注册中心相关信息。
176 |
177 |
178 |
179 | 模块配置,用于配置当前模块信息,可选。
180 | 监控中心配置,用于配置连接监控中心相关信息,可选。
181 | 提供方的缺省值,当ProtocolConfig和ServiceConfig某属性没有配置时,采用此缺省值,可选。
182 | 消费方缺省配置,当ReferenceConfig某属性没有配置时,采用此缺省值,可选。
183 | 方法配置,用于ServiceConfig和ReferenceConfig指定方法级的配置信息。
184 | 用于指定方法参数配置。
185 | ```
186 | ## dubbo实现服务降级
187 |
188 |
189 | - 查看dubbo的官方文档,可以发现有个mock的配置,mock只在出现非业务异常(比如超时,网络异常等)时执行。mock的配置支持两种
190 | - 一种为boolean值,默认的为false。如果配置为true,则缺省使用mock类名,即类名+Mock后缀;
191 | - 接口名要注意命名规范:接口名+Mock后缀。此时如果调用失败会调用Mock实现;
192 |
193 | 
194 |
195 |
196 | - 另外一种则是配置"return null",可以很简单的忽略掉异常。
197 |
198 | ```
199 | 在服务消费者放的增加mock就可以实现服务降级
200 |
201 |
202 | ```
203 |
--------------------------------------------------------------------------------
/docs/2019/Thrift安装配置及入门实例.md:
--------------------------------------------------------------------------------
1 | # 概述
2 | * Thrift是一种接口描述语言和二进制通讯协议,[1]它被用来定义和创建跨语言的服务。[2]它被当作一个远程过程调用(RPC)框架来使用,是由Facebook为“大规模跨语言服务开发”而开发的,支持c++, java, .net, python,php,go等
3 | * Thrift是一个典型的CS结构,客户端和服务端可以使用不同的语言开发,这种语言就是IDL
4 |
5 | # Thrift常见几种数据类型
6 | - thrift不支持无符号类型,因为很多编程语言不存在无符号类型,比如java
7 | - byte:有符号字节
8 | - i16:16位有符号整数
9 | - i32:32位有符号整数
10 | - i64:64位有符号整数
11 | - double:64位浮点数
12 | - string: 字符串
13 |
14 | # Thrift容器类型
15 | * 集合中的元素可以是除了service之外的任何类型,包括exception
16 | * list: 一系列由T类型的数据组成的有序列表,元素可以重复
17 | * set: 一系列由T类型的数据的无序集合,不可重复
18 | * map :一个字典结构,相当于java中的HashMap
19 |
20 | # Thrift工作流程
21 | * 定义thrift文件,由thrift文件(IDL)生成双方语言的接口,model,在生成model以及接口中会有解码编码的代码
22 |
23 | # Thrift IDL文件
24 | * struct :结构体 目的是将一些数据聚合在一起,方便传输管理
25 | * enum: 枚举的定义和JAVA类似
26 | * exception:异常
27 |
28 | ```
29 | namespace java thrift.demo
30 | # 相当于java的类
31 | struct News{
32 | 1:i32 id;
33 | 2:string title;
34 | }
35 |
36 | # 枚举
37 | enum Gender{
38 | MALE,
39 | FEMALE
40 | }
41 |
42 | exception RequestException{
43 | 1:i32 code;
44 | 2:string reason;
45 | }
46 |
47 | # 相当于服务结构
48 | service Hello{
49 | string helloString(1:string para)
50 | }
51 | ```
52 | # 类型定义
53 | * 利用typedef关键可以在开始定义类型比如:`typedef i32 int typedef i64 long` 后面可以直接使用int和long
54 |
55 | # 常量
56 | * thrift支持厂里定义 使用const关键字 `const i32 MAX_TIME = 10`,`const string MY_NAME = `
57 |
58 | # 命名空间
59 | * thrift使用namespace 关键字定义,相当于JAVA中的package
60 |
61 | # 文件包含
62 | * thrift使用include支持文件包含 相当于java中的import 定义:`include "global.thrift" `
63 |
64 | # 可选与必选
65 | * thrift支持两个关键字`required,optional` 分别用于表示对应的字段是必填还是可选 比如
66 |
67 | ```bash
68 | struct People{
69 | 1:required string name;
70 | 2:optional i32 age;
71 | }
72 | ```
73 | # Thrift的传输格式
74 | * TBinaryprotocol:二进制格式
75 | * TCompactProtocol:压缩格式
76 | * TJSONNProtocol JSON格式
77 | * TSimpleJSONProtocol: 提供JSON只写协议,生成的文件容易通过脚本语言解析
78 | * TDebugProtocol 使用易懂的可读文本格式 便于debug
79 |
80 | # Thrift的数据传输方式
81 | * TSocket:阻塞式socker
82 | * TFramedTransport:以frame为单位进行传输,并非阻塞式服务中使用
83 | * TFileTransport:以文件形式进行传输
84 | * TMeoryTransport:将内存用于IO java实时内部实际使用了简单的ByteArratOutputStream
85 | * TZlibTransport 使用zlib进行压缩,与其他传输方式联合使用
86 |
87 | # Thrift支持的服务模型
88 | * TSimpleServer : 简单的单线程模型,常用语测试
89 | * TThreadPoolServer : 多线程服务模型 使用标准的阻塞式IO
90 | * TNonblockingServer: 多线程服务模型,使用非阻塞式IO(需要使用TFramedTransport数据传输方式)
91 | * THsHaServer : THsHa引入了线程池去处理 其模型把读写任务放到线程池去处理 Half-sync/Half-async的处理模式,Half-aysnc是在处理IO事件(accept/read/write io) Half-sync用于hander对rpc的同步处理
92 |
93 | # w7 系统安装
94 | - 下载地址: https://thrift.apache.org/download 创建文件夹放入thrift (重新命名 thrift.exe)
95 | - 配置环境变量:系统环境变量Path添加目录: F:\thrift-0.12.0
96 | - 检测安装是否成功:`thrift -version`
97 |
98 | # 编写thrift 文件
99 | ```bash
100 | namespace java thrift.generated
101 |
102 | // 定义类型
103 | typedef i16 short
104 | typedef i32 int
105 | typedef i64 long
106 | typedef bool boolean
107 | typedef string String
108 |
109 | struct Person {
110 | 1:optional String username,
111 | 2:optional int age,
112 | 3:optional boolean married
113 | }
114 |
115 | exception DataException {
116 | 1:optional String meaages,
117 | 2:optional String callStack,
118 | 3:optional String date
119 | }
120 |
121 | service PersonService {
122 | // 根据名称查询 抛出自定义异常
123 | Person getPersonByUsername(1:required String username) throws (1:DataException dataEception),
124 | // 添加
125 | void savePerson(1:required Person person) throws (1:DataException dataEception)
126 | }
127 | ```
128 | # 生成JAVA代码
129 | ```
130 | #cmd执行
131 | thrift --gen java src/thrift/data.thrift
132 | ```
133 |
134 | * 复制到java源码包目录
135 |
136 | 
137 |
138 | # 编写服务调用代码
139 |
140 | ```java
141 | public class PersonServiceImpl implements PersonService.Iface {
142 | @Override
143 | public Person getPersonByUsername(String username) throws DataException, TException {
144 | System.out.println("查询方法调用: "+username);
145 | Person person=new Person();
146 | person.setUsername(username);
147 | person.setAge(20);
148 | person.setMarried(false);
149 | return person;
150 | }
151 |
152 | @Override
153 | public void savePerson(Person person) throws DataException, TException {
154 | System.out.println("添加方法调用: ");
155 | System.out.println(person.getUsername());
156 | System.out.println(person.getAge());
157 | }
158 | }
159 | ```
160 |
161 | 客户度
162 |
163 | ```java
164 | public class ThriftClient {
165 | public static void main(String[] args) {
166 | TTransport transport=new TFramedTransport(new TSocket("localhost",8899),600);
167 | TProtocol protocol=new TCompactProtocol(transport);
168 | PersonService.Client client=new PersonService.Client(protocol);
169 |
170 | try {
171 | transport.open();
172 | Person person=client.getPersonByUsername("qx");
173 | System.out.println(person.getUsername());
174 | System.out.println(person.getAge());
175 |
176 | Person person1=new Person();
177 | person1.setUsername("dddddd");
178 | person1.setAge(111);
179 | person.setMarried(true);
180 | client.savePerson(person1);
181 |
182 | }catch (Exception e){
183 | transport.close();
184 | }
185 | }
186 | }
187 | ```
188 |
189 | 服务端
190 |
191 | ```java
192 | public class ThriftServer {
193 | public static void main(String[] args) throws Exception {
194 | // 异步非阻塞
195 | TNonblockingServerSocket socket=new TNonblockingServerSocket(8899);
196 | THsHaServer.Args arg=new THsHaServer.Args(socket).minWorkerThreads(2).maxWorkerThreads(4);
197 | PersonService.Processor processor=new PersonService.Processor<>(new PersonServiceImpl());
198 | arg.protocolFactory(new TCompactProtocol.Factory());
199 | arg.transportFactory(new TFramedTransport.Factory());
200 | arg.processorFactory(new TProcessorFactory(processor));
201 |
202 | TServer server=new THsHaServer(arg);
203 |
204 | System.out.println("");
205 |
206 | // 启动 死循环 永远不会退出
207 | server.serve();
208 |
209 | }
210 | }
211 | ```
212 |
213 |
--------------------------------------------------------------------------------
/docs/其它/Zookeeper面试专题.md:
--------------------------------------------------------------------------------
1 | #### Zookeeper是什么框架
2 | - 分布式的、开源的分布式应用程序协调服务,原本是Hadoop、HBase的一个重要组件。它为分布式应用提供一致性服务的软件,包括:配置维护、域名服务、分布式同步、组服务等。
3 |
4 | #### 应用场景
5 | - zookeeper的功能很强大,应用场景很多,结合我实际工作中使用Dubbo框架的情况,Zookeeper主要是做注册中心用。基于Dubbo框架开发的提供者、消费者都向Zookeeper注册自己的URL,消费者还能拿到并订阅提供者的注册URL,以便在后续程序的执行中去调用提供者。而提供者发生了变动,也会通过Zookeeper向订阅的消费者发送通知。
6 |
7 | #### Paxos算法& Zookeeper使用协议
8 | - Paxos算法是分布式选举算法,Zookeeper使用的 ZAB协议(Zookeeper原子广播),二者有相同的地方,比如都有一个Leader,用来协调N个Follower的运行;Leader要等待超半数的Follower做出正确反馈之后才进行提案;二者都有一个值来代表Leader的周期。
9 | - 不同的地方在于:
10 | - ZAB用来构建高可用的分布式数据主备系统(Zookeeper),Paxos是用来构建分布式一致性状态机系统。
11 |
12 | Paxos算法、ZAB协议要想讲清楚可不是一时半会的事儿,自1990年莱斯利·兰伯特提出Paxos算法以来,因为晦涩难懂并没有受到重视。后续几年,兰伯特通过好几篇论文对其进行更进一步地解释,也直到06年谷歌发表了三篇论文,选择Paxos作为chubby cell的一致性算法,Paxos才真正流行起来。
13 |
14 | 对于普通开发者来说,尤其是学习使用Zookeeper的开发者明确一点就好:分布式Zookeeper选举Leader服务器的算法与Paxos有很深的关系。
15 |
16 | #### ZooKeeper提供的常见服务
17 | - 命名服务 - 按名称标识集群中的节点。它类似于DNS,但仅对于节点。
18 | - 配置管理 - 加入节点的最近的和最新的系统配置信息。
19 | - 集群管理 - 实时地在集群和节点状态中加入/离开节点。
20 | - 选举算法 - 选举一个节点作为协调目的的leader。
21 | - 高度可靠的数据注册表 - 即使在一个或几个节点关闭时也可以获得数据。
22 | - 锁定和同步服务 - 在修改数据的同时锁定数据。
23 |
24 | #### Zookeeper有哪几种节点类型
25 | - 持久节点:创建之后一直存在,除非有删除操作,创建节点的客户端会话失效也不影响此节点。
26 | - 持久顺序节点 :跟持久一样,就是父节点在创建下一级子节点的时候,记录每个子节点创建的先后顺序,会给每个子节点名加上一个数字后缀。
27 | - 临时节点:创建客户端会话失效(注意是会话失效,不是连接断了),节点也就没了。不能建子节点。
28 | - 临时顺序节点
29 |
30 | #### Zookeeper对节点的watch监听通知是永久的吗?
31 | - 不是。官方声明:一个Watch事件是一个一次性的触发器,当被设置了Watch的数据发生了改变的时候,则服务器将这个改变发送给设置了Watch的客户端,以便通知它们。
32 |
33 | #### 为什么不是watch监听通知不是永久的?
34 | - 如果服务端变动频繁,而监听的客户端很多情况下,每次变动都要通知到所有的客户端,这太消耗性能了。
35 | - 一般是客户端执行getData(“/节点A”,true),如果节点A发生了变更或删除,客户端会得到它的watch事件,但是在之后节点A又发生了变更,而客户端又没有设置watch事件,就不再给客户端发送。
36 |
37 | #### 部署方式?集群中的机器角色都有哪些?集群最少要几台机器
38 | - 单机,集群。Leader、Follower。集群最低3(2N+1)台,保证奇数,主要是为了选举算法。
39 | - 集群如果有3台机器,挂掉一台集群还能工作吗?挂掉两台呢?
40 | - 记住一个原则:过半存活即可用。
41 |
42 | #### 集群支持动态添加机器吗
43 | - 其实就是水平扩容了,Zookeeper在这方面不太好。两种方式:
44 | - 全部重启:关闭所有Zookeeper服务,修改配置之后启动。不影响之前客户端的会话。
45 | - 逐个重启:顾名思义。这是比较常用的方式。
46 |
47 | #### zookeeper是如何保证事务的顺序一致性的
48 | - zookeeper采用了递增的事务Id来标识,所有的proposal都在被提出的时候加上了zxid,zxid实际上是一个64位的数字,高32位是epoch用来标识leader是否发生改变,如果有新的leader产生出来,epoch会自增,低32位用来递增计数。当新产生proposal的时候,会依据数据库的两阶段过程,首先会向其他的server发出事务执行请求,如果超过半数的机器都能执行并且能够成功,那么就会开始执行
49 |
50 | #### zookeeper是如何选取主leader的?
51 | - 所有节点创建具有相同路径 /app/leader_election/guid_ 的顺序、临时节点。
52 | - ZooKeeper集合将附加10位序列号到路径,创建的znode将是 /app/leader_election/guid_0000000001,/app/leader_election/guid_0000000002等。
53 | - 对于给定的实例,在znode中创建最小数字的节点成为leader,而所有其他节点是follower。
54 | - 每个follower节点监视下一个具有最小数字的znode。例如,创建znode/app/leader_election/guid_0000000008的节点将监视znode/app/leader_election/guid_0000000007,创建znode/app/leader_election/guid_0000000007的节点将监视znode/app/leader_election/guid_0000000006。
55 | - 如果leader关闭,则其相应的znode/app/leader_electionN会被删除。
56 | - 下一个在线follower节点将通过监视器获得关于leader移除的通知。
57 | - 下一个在线follower节点将检查是否存在其他具有最小数字的znode。如果没有,那么它将承担leader的角色。否则,它找到的创建具有最小数字的znode的节点将作为leader。
58 | - 类似地,所有其他follower节点选举创建具有最小数字的znode的节点作为leader。
59 |
60 | #### 机器中为什么会有master;
61 | - 在分布式环境中,有些业务逻辑只需要集群中的某一台机器进行执行,其他的机器可以共享这个结果,这样可以大大减少重复计算,提高性能,于是就需要进行master选举。
62 |
63 | #### ZooKeeper集群中服务器之间是怎样通信的?
64 | - Leader服务器会和每一个Follower/Observer服务器都建立TCP连接,同时为每个F/O都创建一个叫做LearnerHandler的实体。LearnerHandler主要负责Leader和F/O之间的网络通讯,包括数据同步,请求转发和Proposal提议的投票等。Leader服务器保存了所有F/O的LearnerHandler。
65 |
66 | #### zookeeper是否会自动进行日志清理?如何进行日志清理?
67 | - zk自己不会进行日志清理,需要运维人员进行日志清理
68 |
69 | #### ZK选举过程
70 | - 当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的Server都恢复到一个正确的状态。Zk的选举算法使用ZAB协议:
71 | - ① 选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;
72 | - ② 选举线程首先向所有Server发起一次询问(包括自己);
73 | - ③ 选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
74 | - ④ 收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
75 | - ⑤ 线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得n/2 + 1的Server票数, 设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。
76 | - 通过流程分析我们可以得出:要使Leader获得多数Server的支持,则Server总数最好是奇数2n+1,且存活的Server的数目不得少于n+1
77 |
78 | #### 客户端对ServerList的轮询机制是什么
79 | - 随机,客户端在初始化( new ZooKeeper(String connectString, int sessionTimeout, Watcher watcher) )的过程中,将所有Server保存在一个List中,然后随机打散,形成一个环。之后从0号位开始一个一个使用。
80 | - 两个注意点:
81 | - ① Server地址能够重复配置,这样能够弥补客户端无法设置Server权重的缺陷,但是也会加大风险。(比如: 192.168.1.1:2181,192.168.1.1:2181,192.168.1.2:2181).
82 | - ② 如果客户端在进行Server切换过程中耗时过长,那么将会收到SESSION_EXPIRED. 这也是上面第1点中的加大风险之处
83 |
84 | ##### 客户端如何正确处理CONNECTIONLOSS(连接断开) 和 SESSIONEXPIRED(Session 过期)两类连接异常**
85 | - 在ZooKeeper中,服务器和客户端之间维持的是一个长连接,在 SESSION_TIMEOUT 时间内,服务器会确定客户端是否正常连接(客户端会定时向服务器发送heart_beat),服务器重置下次SESSION_TIMEOUT时间。因此,在正常情况下,Session一直有效,并且zk集群所有机器上都保存这个Session信息。在出现问题情况下,客户端与服务器之间连接断了(客户端所连接的那台zk机器挂了,或是其它原因的网络闪断),这个时候客户端会主动在地址列表(初始化的时候传入构造方法的那个参数connectString)中选择新的地址进行连接。
86 |
87 | #### 一个客户端修改了某个节点的数据,其它客户端能够马上获取到这个最新数据吗
88 | ZooKeeper不能确保任何客户端能够获取(即Read Request)到一样的数据,除非客户端自己要求:方法是客户端在获取数据之前调用org.apache.zookeeper.AsyncCallback.VoidCallback, java.lang.Object) sync.
89 |
90 | 通常情况下(这里所说的通常情况满足:1. 对获取的数据是否是最新版本不敏感,2. 一个客户端修改了数据,其它客户端是否需要立即能够获取最新),可以不关心这点。
91 |
92 | 在其它情况下,最清晰的场景是这样:ZK客户端A对 /my_test 的内容从 v1->v2, 但是ZK客户端B对 /my_test 的内容获取,依然得到的是 v1. 请注意,这个是实际存在的现象,当然延时很短。解决的方法是客户端B先调用 sync(), 再调用 getData().
93 |
94 | #### ZK为什么不提供一个永久性的Watcher注册机制
95 | 不支持用持久Watcher的原因很简单,ZK无法保证性能。
96 |
97 | 使用watch需要注意的几点
98 |
99 | ① Watches通知是一次性的,必须重复注册.
100 |
101 | ② 发生CONNECTIONLOSS之后,只要在session_timeout之内再次连接上(即不发生SESSIONEXPIRED),那么这个连接注册的watches依然在。
102 |
103 | ③ 节点数据的版本变化会触发NodeDataChanged,注意,这里特意说明了是版本变化。存在这样的情况,只要成功执行了setData()方法,无论内容是否和之前一致,都会触发NodeDataChanged。
104 |
105 | ④ 对某个节点注册了watch,但是节点被删除了,那么注册在这个节点上的watches都会被移除。
106 |
107 | ⑤ 同一个zk客户端对某一个节点注册相同的watch,只会收到一次通知。
108 |
109 | ⑥ Watcher对象只会保存在客户端,不会传递到服务端。
110 |
111 | #### 我能否收到每次节点变化的通知
112 | 如果节点数据的更新频率很高的话,不能。
113 |
114 | 原因在于:当一次数据修改,通知客户端,客户端再次注册watch,在这个过程中,可能数据已经发生了许多次数据修改,因此,千万不要做这样的测试:”数据被修改了n次,一定会收到n次通知”来测试server是否正常工作。(我曾经就做过这样的傻事,发现Server一直工作不正常?其实不是)。即使你使用了GitHub上这个客户端也一样。
115 |
116 |
117 | #### 是否可以拒绝单个IP对ZK的访问,操作
118 | ZK本身不提供这样的功能,它仅仅提供了对单个IP的连接数的限制。你可以通过修改iptables来实现对单个ip的限制,当然,你也可以通过这样的方式来解决。https://issues.apache.org/jira/browse/ZOOKEEPER-1320
119 |
120 | #### 在getChildren(String path, boolean watch)是注册了对节点子节点的变化,那么子节点的子节点变化能通知吗
121 | 不能
122 |
123 | #### 创建的临时节点什么时候会被删除,是连接一断就删除吗?延时是多少?
124 | 连接断了之后,ZK不会马上移除临时数据,只有当SESSIONEXPIRED之后,才会把这个会话建立的临时数据移除。因此,用户需要谨慎设置Session_TimeOut
125 |
--------------------------------------------------------------------------------
/docs/JVM/jvm监控命令.md:
--------------------------------------------------------------------------------
1 | # jps
2 | 输出正字运行的相关进程信息
3 |
4 | * `jps -v` 输出传递给jvm参数
5 | * `jps -l` 输出模块名以及包名,如果是jar 则出输jar文件全名
6 | * `jps -m` 输出传递给jvm参数
7 | * `jps -mlv` 输出进程号,包名,虚拟机参数等所有信息
8 |
9 | ```bash
10 | [root@izadux3fzjykx7z ~]# jps -mlv
11 | 12656 sun.tools.jps.Jps -mlv -Dapplication.home=/usr/java/jdk1.8.0_171 -Xms8m
12 | 16418 halo-latest.jar -Xms256m -Xmx256m
13 | [root@izadux3fzjykx7z ~]#
14 | ```
15 | # jstat
16 | 监控指定Java进程的性能
17 |
18 | * `-class ` 显示类的加载信息的相关信息;
19 | * `-compiler ` 显示类编译相关信息;
20 | * `-gc ` 显示和gc相关的堆信息
21 | * `-gccapacity ` 堆内存统计
22 | * `-gcmetacapacity ` 元空间大小
23 | * `-gcnew ` 新生代信息
24 | * `-gcnewcapacity ` 新生代大小和使用情况
25 | * `-gcold ` 显示老年代和永久代的信息;
26 | * `-gcoldcapacity ` 老年代的大小
27 | * `-gcutil ` 显示垃圾收集信息
28 | * `-gccause ` 显示垃圾回收的相关信息
29 | * `-printcompilation ` 输出JIT编译的方法信息;
30 |
31 |
32 | - 类的加载信息 jstat -class pid
33 | ```bash
34 | [root@izadux3fzjykx7z ~]# jstat -class 16418
35 | Loaded Bytes Unloaded Bytes Time
36 | 13293 23828.4 0 0.0 17.14
37 |
38 | Loaded: class加载的的总数量
39 | Bytes: 占用空间大小
40 | Unloaded 未加载数量
41 | Bytes 未加载占用空间大小
42 | Time: 加载总耗时 秒
43 | ```
44 |
45 | - 类编译的统计 jstat -compiler pid
46 | ```bash
47 | [root@izadux3fzjykx7z ~]# jstat -compiler 16418
48 | Compiled Failed Invalid Time FailedType FailedMethod
49 | 14109 3 0 62.83 1 org/springframework/core/xxxxxx
50 |
51 | Compiled:编译数量。
52 | Failed:编译失败数量
53 | Invalid:不可用数量
54 | Time:编译耗时 秒
55 | FailedType:失败类型
56 | FailedMethod:失败的方法
57 |
58 | ```
59 |
60 | - gc回收统计 jstat -gc pid
61 |
62 | ```bash
63 | [root@izadux3fzjykx7z ~]# jstat -gc 16418
64 | S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
65 | 8704.0 8704.0 0.0 5466.6 69952.0 29822.5 174784.0 73377.5 75008.0 71393.1 9472.0 8916.8 53 1.199 3 0.293 1.492
66 | [root@izadux3fzjykx7z ~]#
67 |
68 | S0C:第一个幸存区的大小
69 | S1C:第二个幸存区的大小
70 | S0U:第一个幸存区的使用大小
71 | S1U:第二个幸存区的使用大小
72 | EC:伊甸园区的大小
73 | EU:伊甸园区的使用大小
74 | OC:老年代大小
75 | OU:老年代使用大小
76 | MC:方法区大小
77 | MU:方法区使用大小
78 | CCSC:压缩类空间大小
79 | CCSU:压缩类空间使用大小
80 | YGC:年轻代垃圾回收次数
81 | YGCT:年轻代垃圾回收消耗时间
82 | FGC:老年代垃圾回收次数
83 | FGCT:老年代垃圾回收消耗时间
84 | GCT:垃圾回收消耗总时间
85 | ```
86 |
87 | - 堆内存统计 jstat -gccapacity pid
88 |
89 | ```bash
90 | [root@izadux3fzjykx7z ~]# jstat -gccapacity 16418
91 | NGCMN NGCMX NGC S0C S1C EC OGCMN OGCMX OGC OC MCMN MCMX MC CCSMN CCSMX CCSC YGC FGC
92 | 87360.0 87360.0 87360.0 8704.0 8704.0 69952.0 174784.0 174784.0 174784.0 174784.0 0.0 1114112.0 75008.0 0.0 1048576.0 9472.0 53 3
93 |
94 | NGCMN:新生代最小容量
95 | NGCMX:新生代最大容量
96 | NGC:当前新生代容量
97 | S0C:第一个幸存区大小
98 | S1C:第二个幸存区的大小
99 | EC:伊甸园区的大小
100 | OGCMN:老年代最小容量
101 | OGCMX:老年代最大容量
102 | OGC:当前老年代大小
103 | OC:当前老年代大小
104 | MCMN:最小元数据容量
105 | MCMX:最大元数据容量
106 | MC:当前元数据空间大小
107 | CCSMN:最小压缩类空间大小
108 | CCSMX:最大压缩类空间大小
109 | CCSC:当前压缩类空间大小
110 | YGC:年轻代gc次数
111 | FGC:老年代GC次数
112 |
113 | ```
114 |
115 |
116 | - 新生代gc统计 jstat -gcnew pid
117 |
118 | ```bash
119 | [root@izadux3fzjykx7z ~]# jstat -gcnew 16418
120 | S0C S1C S0U S1U TT MTT DSS EC EU YGC YGCT
121 | 8704.0 8704.0 0.0 5466.6 6 15 4352.0 69952.0 30899.8 53 1.199
122 |
123 | S0C:第一个幸存区大小
124 | S1C:第二个幸存区的大小
125 | S0U:第一个幸存区的使用大小
126 | S1U:第二个幸存区的使用大小
127 | TT:对象在新生代存活的次数
128 | MTT:对象在新生代存活的最大次数
129 | DSS:期望的幸存区大小
130 | EC:伊甸园区的大小
131 | EU:伊甸园区的使用大小
132 | YGC:年轻代垃圾回收次数
133 | YGCT:年轻代垃圾回收消耗时间
134 |
135 | ```
136 |
137 | # jmap
138 | 以获得运行中的jvm的堆的快照,从而可以离线分析堆,以检查内存泄漏,检查一些严重影响性能的大对象的创建,检查系统中什么对象最多,
139 | 各种对象所占内存的大小等等。可以使用jmap生成Heap Dump
140 |
141 | * `jmap -heap 16418` 打印heap空间的概要
142 |
143 | ```bash
144 | [root@izadux3fzjykx7z ~]# jmap -heap 16418
145 | Attaching to process ID 16418, please wait...
146 | Debugger attached successfully.
147 | Server compiler detected.
148 | JVM version is 25.171-b11
149 |
150 | using thread-local object allocation.
151 | Mark Sweep Compact GC
152 |
153 | Heap Configuration:
154 | MinHeapFreeRatio = 40
155 | MaxHeapFreeRatio = 70
156 | MaxHeapSize = 268435456 (256.0MB)
157 | NewSize = 89456640 (85.3125MB)
158 | MaxNewSize = 89456640 (85.3125MB)
159 | OldSize = 178978816 (170.6875MB)
160 | NewRatio = 2
161 | SurvivorRatio = 8
162 | MetaspaceSize = 21807104 (20.796875MB)
163 | CompressedClassSpaceSize = 1073741824 (1024.0MB)
164 | MaxMetaspaceSize = 17592186044415 MB
165 | G1HeapRegionSize = 0 (0.0MB)
166 |
167 | Heap Usage:
168 | New Generation (Eden + 1 Survivor Space): // 新生代区
169 | capacity = 80543744 (76.8125MB) //分配的大小
170 | used = 44269728 (42.218902587890625MB) //使用
171 | free = 36274016 (34.593597412109375MB) //剩余
172 | 54.96358351556143% used
173 | Eden Space: //伊甸园区
174 | capacity = 71630848 (68.3125MB)
175 | used = 38671896 (36.880393981933594MB)
176 | free = 32958952 (31.432106018066406MB)
177 | 53.98776795159538% used
178 | From Space: //年轻代 幸存者1
179 | capacity = 8912896 (8.5MB)
180 | used = 5597832 (5.338508605957031MB)
181 | free = 3315064 (3.1614913940429688MB)
182 | 62.80598359949448% used
183 | To Space: /年轻代 幸存者2
184 | capacity = 8912896 (8.5MB)
185 | used = 0 (0.0MB)
186 | free = 8912896 (8.5MB)
187 | 0.0% used
188 | tenured generation: //老年代
189 | capacity = 178978816 (170.6875MB)
190 | used = 75138528 (71.65768432617188MB)
191 | free = 103840288 (99.02981567382812MB)
192 | 41.98179967846027% used
193 |
194 | 30511 interned Strings occupying 3634816 bytes.
195 |
196 | ```
197 |
198 | * `jmap -dump:live,format=b,file=/home/tess.dump 16418` 产生一个HeapDump文件
199 | * `jmap -histo 16418` 统计各个类的实例数目以及占用内存,并按照内存使用量从多至少的顺序排列。
200 |
201 | # jinfo
202 | 查看目标 Java 进程的参数,如传递给 Java 虚拟机的参数
203 | * `jinfo 16418`
204 |
205 | # jcmd
206 | 可以用来实现前面除了jstat 之外所有命令的功能。
207 |
208 |
209 |
210 |
211 |
212 |
213 |
214 |
--------------------------------------------------------------------------------
/docs/hadoop/hadoop03.md:
--------------------------------------------------------------------------------
1 | **要使用宿主机中的 java 代码访问客户机中的 hdfs,需要保证以下几点**
2 |
3 | - 确保宿主机与客户机的网络是互通的 确保宿主机和客户机的防火墙都关闭,因为很多端口需要通过,为了减少防火墙配置,直接关闭
4 | - 确保宿主机与客户机使用的 jdk 版本一致。如果客户机使用 jdk6,宿主机使用 jdk7,那么代码运行时会报不支持的版本的错误
5 | - 宿主机的登录用户名必须与客户机的用户名一直。比如我们 linux 使用的是 root 用户,那么 windows 也要使用 root
6 | - 用户,否则会报权限异常 在 eclipse 项目中覆盖 hadoop 的 org.apache.hadoop.fs.FileUtil 类的
7 | checkReturnValue 方 法,目的是为了避免权限错误
8 |
9 | HDFS Api常用类
10 | -----------
11 | - configuration类:此类封装了客户端或服务器的配置,通过配置文件来读取类路径实现(一般是core-site.xml)。
12 | - FileSystem类:一个通用的文件系统api,用该对象的一些方法来对文件进行操作。
13 | - FSDataInputStream:HDFS的文件输入流,FileSystem.open()方法返回的即是此类。
14 | - FSDataOutputStream:HDFS的文件输入出流,FileSystem.create()方法返回的即是此类。
15 |
16 | ```java
17 | package com.example;
18 | import java.io.ByteArrayInputStream;
19 | import java.io.File;
20 | import java.io.IOException;
21 | import java.net.URI;
22 |
23 | import org.apache.hadoop.conf.Configuration;
24 | import org.apache.hadoop.fs.FSDataInputStream;
25 | import org.apache.hadoop.fs.FSDataOutputStream;
26 | import org.apache.hadoop.fs.FileStatus;
27 | import org.apache.hadoop.fs.FileSystem;
28 | import org.apache.hadoop.fs.Path;
29 | import org.apache.hadoop.io.IOUtils;
30 | /**
31 | * http://hadoop.apache.org/docs/r2.7.3/api/index.html(api地址)
32 | *
33 | *
34 | * https://blog.csdn.net/snwdwtm/article/details/78242805
35 | *
36 | * 该类含有操作 HDFS 的各种方法,类似于 jdbc 中操作数据库的直接入口是 Connection 类。
37 | * @author qinxuewu
38 | * @version 1.00
39 | * @time 13/9/2018下午 5:19
40 | */
41 | public class FileSystemApi {
42 | private static FileSystem fs=null;
43 | private static Configuration conf=null;
44 | static{
45 | try {
46 | URI uri = new URI("hdfs://192.168.1.191:9000");
47 | conf = new Configuration();
48 | fs = FileSystem.get(uri,conf,"root"); //指定root用户
49 | } catch (Exception e) {
50 | e.printStackTrace();
51 | }
52 | }
53 |
54 |
55 |
56 | public static void main(String[] args) throws IOException, InterruptedException {
57 | // mkdirs("/usr/local/api2");
58 | // putFile("C:\\Users\\admin\\Desktop\\111.txt", "/usr/local/api2");
59 | // down("/usr/local/api2/111.txt", "C:\\Users\\admin\\Desktop", false);
60 | // delete("/usr/local/apifiledist", true);
61 | // listStatus("/usr/local");
62 | // rename("/usr/local/api2/111.txt", "/usr/local/api2/222.txt");
63 | // write("/usr/local/f1", "DDDDDDDDDDDDDDDDDDDDDDDDDDDDD");
64 | // open("/usr/local/api2/222.txt");
65 | }
66 |
67 | /**
68 | * 创建文件夹
69 | * @param path
70 | */
71 | public static void mkdirs(String path) throws IllegalArgumentException, IOException{
72 | boolean exists = fs.exists(new Path(path));
73 | System.out.println(path+":文件夹是否存在 "+exists);
74 | if(!exists){
75 | boolean result = fs.mkdirs(new Path(path));
76 | System.out.println("创建文件夹:"+result);
77 | }
78 | }
79 |
80 | /**
81 | * 上传文件导HDFS
82 | * @param localFile 本地文件路径
83 | * @param path 远程HDFS服务器路径
84 | */
85 | public static void putFile(String localFile,String dst){
86 | try {
87 | fs.copyFromLocalFile(new Path(localFile), new Path(dst));
88 | File f=new File(localFile);
89 | String fileName=f.getName();
90 | System.out.println("文件名:"+fileName);
91 | boolean ex=fs.exists(new Path(dst+fileName));
92 | if(ex){
93 | System.out.println("上传成功:"+dst+fileName);
94 | }else{
95 | System.out.println("上传失败:"+dst+fileName);
96 | }
97 | } catch (Exception e) {
98 | e.printStackTrace();
99 | }
100 | }
101 |
102 | /**
103 | * 下载文件
104 | * @param dst 远程HDFS服务器文件路径
105 | * @param localPath 本地存储路径
106 | * @param falg 若执行该值为false 则不删除 hdfs上的相应文件
107 | * @param
108 | */
109 | public static void down(String dst,String localPath,boolean falg){
110 | try {
111 | //第4个参数表示使用本地原文件系统
112 | fs.copyToLocalFile(falg,new Path(dst), new Path(localPath),true);
113 | } catch (Exception e) {
114 | e.printStackTrace();
115 | }
116 | }
117 |
118 | /**
119 | * 删除文件夹
120 | * @param dst 远程HDFS服务器文件夹路径
121 | * @param falg 为true时能够将带有内容的文件夹删除,为false时,则只能删除空目录
122 | */
123 | public static void delete(String dst,boolean falg){
124 | try {
125 | boolean b= fs.delete(new Path(dst), falg);
126 | System.out.println("删除文件夹状态:"+b);
127 | } catch (Exception e) {
128 | e.printStackTrace();
129 | }
130 | }
131 |
132 | /**
133 | * 查看文件及文件夹的信息
134 | * @param dst 远程HDFS服务器文件夹路径
135 | */
136 | public static void listStatus(String dst){
137 | try {
138 | FileStatus[ ] fss = fs.listStatus(new Path(dst));
139 | String flag ="";
140 | for(FileStatus f : fss){
141 | if(f.isDirectory()){
142 | flag = "Directory";
143 | }else{
144 | flag ="file";
145 | }
146 | System.out.println(flag + "\t" +f.getPath().getName());
147 | }
148 | } catch (Exception e) {
149 | e.printStackTrace();
150 | }
151 | }
152 |
153 | /**
154 | * 文件重命名
155 | * @param dst
156 | * @param newDst
157 | */
158 | public static void rename(String dst,String newDst){
159 | try {
160 | boolean bs = fs.rename(new Path(dst), new Path(newDst));
161 | System.out.println("文件重命名:"+bs);
162 | } catch (Exception e) {
163 | e.printStackTrace();
164 | }
165 | }
166 |
167 | /**
168 | * 写入文件
169 | * @param dst 文件服务器目录
170 | * @param value 值
171 | */
172 | public static void write(String dst,String value){
173 | try {
174 | FSDataOutputStream fsDataOutputStream = fs.create(new Path(dst));
175 | IOUtils.copyBytes(new ByteArrayInputStream(value.getBytes()), fsDataOutputStream, conf, true);
176 | //读
177 | FSDataInputStream fsDataInputStream = fs.open(new Path(dst));
178 | IOUtils.copyBytes(fsDataInputStream, System.out, conf, true);
179 | } catch (Exception e) {
180 | e.printStackTrace();
181 | }
182 | }
183 | /**
184 | * 读文件
185 | * @param dst
186 | */
187 | public static void open(String dst){
188 | try {
189 | FSDataInputStream fsDataInputStream = fs.open(new Path(dst));
190 | IOUtils.copyBytes(fsDataInputStream, System.out, conf, true);
191 | } catch (Exception e) {
192 | e.printStackTrace();
193 | }
194 | }
195 |
196 |
197 | }
198 |
199 | ```
200 |
201 |
--------------------------------------------------------------------------------
/docs/hadoop/hadoop02.md:
--------------------------------------------------------------------------------
1 | HDFS简介
2 | ------
3 |
4 | - 数据量越来越大,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统
5 | 管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就 是分布式文件管理系统 。
6 | - 分布式文件系统是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间
7 | - 分布式文件管理系统很多,HDFS 只是其中一种。适用于一次写入、多次查询的情
8 | 况,不支持并发写情况,小文件不合适
9 |
10 | HDFS的特点
11 | -------
12 |
13 | - 它适用于在分布式存储和处理。
14 | - Hadoop提供的命令接口与HDFS进行交互。
15 | - 流式访问文件系统数据
16 | - HDFS提供了文件的权限和验证。
17 |
18 | HDFS 的 shell 操作(Hadoop2.7版本)
19 | ---------------
20 | **hadoop fs,hadoop dfs以及hdfs dfs区别**
21 | - hadoop fs: 说该命令可以用于其他文件系统,不止是hdfs文件系统内,也就是说该命令的使用范围更广
22 | - hadoop dfs 专门针对hdfs分布式文件系统
23 | - hdfs dfs 和上面的命令作用相同,相比于上面的命令更为推荐,并且当使用hadoop dfs时内部会被转为hdfs dfs命令
24 |
25 | **查看hdfs帮助命令**
26 | ```bash
27 | [root@web1 bin]# hdfs dfs
28 | Usage: hadoop fs [generic options]
29 | [-appendToFile ... ] #将本地文件或标准输入(stdin)追加到目标文件系统
30 | [-cat [-ignoreCrc] ...] # 用法和linux一致,将源输出到标准输出
31 | [-checksum ...] #返回文件的checksum信息
32 | [-chgrp [-R] GROUP PATH...]#改变文件所属的group,操作者需要是文件的拥有者或者超级用户
33 | [-chmod [-R] PATH...]#用于授权
34 | [-chown [-R] [OWNER][:[GROUP]] PATH...]#改变文件的拥有者,操作者需要是超级用户
35 | [-copyFromLocal [-f] [-p] [-l] ... ]#类似于put命令,源文件必须是本地的
36 | [-copyToLocal [-p] [-ignoreCrc] [-crc] ... ]#类似于get命令,目标必须是本地的
37 | [-count [-q] [-h] ...]# 输出指定路径的目录数,文件数,内容大小,路径名
38 | [-cp [-f] [-p | -p[topax]] ... ]#用于复制
39 | [-createSnapshot []]# 用于创建快照
40 | [-deleteSnapshot ]#用于删除快照
41 | [-df [-h] [ ...]]# 展示剩余空间
42 | [-du [-s] [-h] ...]# 展示文件和目录的大小
43 | [-expunge]#从垃圾目录(trash dir)的检查点中永久删除时间久于阈值(由core-site.xml中的fs.trash.checkpoint.interval指定,这个值需要小于fs.trash.interval)的文件,并创建新的检查点。
44 | [-find ... ...]# 查找文件并对他们执行某操作
45 | [-get [-p] [-ignoreCrc] [-crc] ... ]#将文件复制到本地文件系统。未通过CRC检查的文件将会自带-ignorecrc参数,其他将会自带-crc参数。
46 | [-getfacl [-R] ]#展示所有文件和目录的访问控制列表
47 | [-getfattr [-R] {-n name | -d} [-e en] ]#展示文件或目录的extended attribute name and value
48 | [-getmerge [-nl] ]# 将源目录的文件融合到一个目标文件中
49 | [-help [cmd ...]]# 返回使用方法
50 | [-ls [-d] [-h] [-R] [ ...]]#同linux类似,展示目录或文件的某些信息
51 | [-mkdir [-p] ...]#创建目录
52 | [-moveFromLocal ... ]#put类似,但是源文件会被删除
53 | [-moveToLocal ]
54 | [-mv ... ]#移动文件
55 | [-put [-f] [-p] [-l] ... ]#将文件从本地提交到目标文件系统,也可以从stdin写入到目标文件系统
56 | [-renameSnapshot ]# 重命名快照
57 | [-rm [-f] [-r|-R] [-skipTrash] ...]#删除特定文件
58 | [-rmdir [--ignore-fail-on-non-empty] ...]# 删除特定目录
59 | [-setfacl [-R] [{-b|-k} {-m|-x } ]|[--set ]]# 设置文件或目录的访问控制列表
60 | [-setfattr {-n name [-v value] | -x name} ]
61 | [-setrep [-R] [-w] ...]# 修改文件的复制因子。
62 | [-stat [format] ...]#用自定义的格式打印文件或目录的一些信息,包括文件大小、类型、所属group、文件名、block大小、复制因子、拥有者和修改时间
63 | [-tail [-f] ]#显示文件最后的1000byte
64 | [-test -[defsz] ]#测试路径是否是有效的文件或目录
65 | [-text [-ignoreCrc] ...]#将输入文件以文本格式输出,允许的格式包括zip和TextRecordInputStream
66 | [-touchz ...]# 创建一个长度为0的文件
67 | [-truncate [-w] ...]#将所有匹配的文件截断到指定的长度
68 | [-usage [cmd ...]]#返回某个特定命令的使用方法
69 | ```
70 | **创建一个目录**
71 | 功能:在 hdfs 上创建目录,-p 表示会创建路径中的各级父目录。
72 | ```bash
73 | [root@web1 bin]# hdfs dfs -mkdir -p /usr/local/input
74 | ```
75 | **显示目录结构**
76 | ```bash
77 | [root@web1 bin]# hdfs dfs -ls -help
78 | -ls: Illegal option -help
79 | Usage: hadoop fs [generic options] -ls [-d] [-h] [-R] [ ...]
80 | [root@web1 bin]# hdfs dfs -ls /usr/local/
81 | Found 2 items
82 | drwxr-xr-x - root supergroup 0 2018-09-12 19:45 /usr/local/hduser
83 | drwxr-xr-x - root supergroup 0 2018-09-12 19:42 /usr/local/input
84 | [root@web1 bin]# hdfs dfs -lsr /usr/local/
85 | lsr: DEPRECATED: Please use 'ls -R' instead.
86 | drwxr-xr-x - root supergroup 0 2018-09-12 19:45 /usr/local/hduser
87 | drwxr-xr-x - root supergroup 0 2018-09-12 19:42 /usr/local/input
88 | [root@web1 bin]#
89 | ```
90 | **展示文件和目录的大小**
91 |
92 | ```bash
93 | [root@web1 bin]# hdfs dfs -du /usr/local/
94 | 0 /usr/local/hduser
95 | 0 /usr/local/input
96 | [root@web1 bin]#
97 | ```
98 | **-count 统计文件(夹)数量**
99 | ```bash
100 | hdfs dfs -count /usr/local/
101 | ```
102 | -put 上传文件
103 | 该命令选项表示把 linux 上的文件复制到 hdfs 中
104 | ```bash
105 | [root@web1 bin]# hdfs dfs -put /usr/local/redis-3.2.12.tar.gz /usr/local/hduser
106 | [root@web1 bin]# hdfs dfs -ls /usr/local/hduser
107 | Found 1 items
108 | -rw-r--r-- 3 root supergroup 1551468 2018-09-12 20:41 /usr/local/hduser/redis-3.2.12.tar.gz
109 | [root@web1 bin]#
110 | ```
111 |
112 | -mv 移动
113 | 该命令选项表示移动 hdfs 的文件到指定的 hdfs 目录中。后面跟两个路径,第一个
114 | 表示源文件,第二个表示目的目录
115 | ```bash
116 | [root@web1 bin]# hdfs dfs -mv /usr/local/hduser/redis-3.2.12.tar.gz /usr/local/input
117 | [root@web1 bin]# hdfs dfs -ls /usr/local/input
118 | Found 1 items
119 | -rw-r--r-- 3 root supergroup 1551468 2018-09-12 20:41 /usr/local/input/redis-3.2.12.tar.gz
120 | [root@web1 bin]#
121 | ```
122 | -cp 复制
123 | 该命令选项表示复制 hdfs 指定的文件到指定的 hdfs 目录中。后面跟两个路径,第一个是被复制的文件,第二个是目的地
124 |
125 | ```bash
126 | [root@web1 bin]# hdfs dfs -cp /usr/local/input/redis-3.2.12.tar.gz /usr/local/hduser
127 | [root@web1 bin]# hdfs dfs -ls /usr/local/hduser
128 | Found 1 items
129 | -rw-r--r-- 3 root supergroup 1551468 2018-09-12 20:48 /usr/local/hduser/redis-3.2.12.tar.gz
130 | ```
131 |
132 | -get
133 | 使用方法:hadoop fs -get [-ignorecrc] [-crc] [-p] [-f]
134 | -ignorecrc:跳过对下载文件的 CRC 检查。
135 | -crc:为下载的文件写 CRC 校验和。
136 | 功能:将文件复制到本地文件系统。
137 | ```bash
138 | [root@web1 bin]# hdfs dfs -get hdfs://192.168.1.191:9000/usr/local/hduser/redis-3.2.12.tar.gz /usr
139 | ```
140 |  141 |
142 | 参考:https://blog.csdn.net/qq_35379598/article/details/80925458
143 |
144 | #### HDFS 体系结构与基本概念
145 |
146 | - 我们通过 hadoop shell 上传的文件是存放在 DataNode 的 block 中,通过 linux shell 是看
147 | 不到文件的,只能看到 block。
148 | - 可以一句话描述 HDFS:把客户端的大文件存放在很多节点的数据块中。在这里,出现 了三个关键词:文件、节点、数据块。HDFS就是围绕着这三个关键词设计的
149 |
150 | **NameNode**
151 | - NameNode 的作用是管理文件目录结构,是管理数据节点的。名字节点维护两套数据,
152 | 一套是文件目录与数据块之间的关系,另一套是数据块与节点之间的关系。前一套数据是静 态的,是存放在磁盘上的,通过 fsimage 和edits 文件来维护;后一套数据是动态的,不持 久化到磁盘的,每当集群启动的时候,会自动建立这些信息。
153 |
154 | DataNode
155 | --------
156 | - DataNode 的作用 是 HDFS 中真正存储数据的。 DataNode 在存储数据的时候是按照 block
157 | 为单位读写数据的。block 是 hdfs 读写数据的基本单位。
158 | - 假设文件大小是 100GB,从字节位置 0 开始,每 64MB 字节划分为一个 block,以依此 类推,可以划分出很多的 block。每个 block 就是 64MB 大小。
159 | - block 本质上是一个逻辑概念,意味着 block 里面不会真正的存储数据,只是划分文件的
160 |
161 | SecondaryNameNode
162 | -----------------
163 | SNN 只有一个职责,就是合并 NameNode 中的 edits 到 fsimage 中
164 |
--------------------------------------------------------------------------------
/docs/2019/分析CountDownLatch源码.md:
--------------------------------------------------------------------------------
1 | 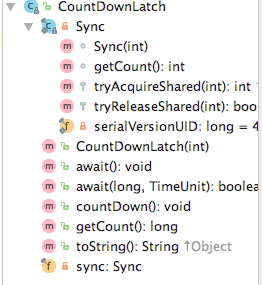
2 | ## 概述
3 | * 允许一个线程的或多个线程等待其他线程完成操作。和join方法类似,初始化对象时通过传入一个固定的计数器总数,线程方法执行时调用countDown给计数器减1,当计数器0时,就会恢复等待的线程继续执行。
4 | * CountDownLatch的计数器不能重用。只能使用一次
5 | *常用的使用场景是提升程序的并行效率,同时处理多个任务后,最后需要提示任务完成。类似的表格的批量解析读取。
6 |
7 | ## 使用方法
8 | ### 一个线程等待
9 | ```java
10 | static CountDownLatch c=new CountDownLatch(2);
11 | public static void main(String[] args) throws InterruptedException {
12 | System.out.println("初始化任务数:"+c.getCount());
13 | new Thread(()->{
14 | System.out.println("任务1执行");
15 | c.countDown();
16 | System.out.println("任务2执行");
17 | c.countDown();
18 | }).start();;
19 | c.await();
20 | System.out.println("任务执行完毕!");
21 | }
22 | ```
23 | 输出结果
24 | ```java
25 | 初始化任务数:2
26 | 任务1执行
27 | 任务2执行
28 | 任务执行完毕!
29 |
30 | ```
31 |
32 | ### 多个线程等待
33 | ```java
34 | static CountDownLatch countDownLatch=new CountDownLatch(3);
35 | //汇总任务
36 | static class T1 extends Thread{
37 | @Override
38 | public void run() {
39 | try {
40 | countDownLatch.await();
41 | } catch (InterruptedException e) {
42 | e.printStackTrace();
43 | }
44 |
45 | System.out.println("所有表格已经读取完了,进行汇总处理");
46 | }
47 | }
48 |
49 | //批量处里表格数据任务
50 | static class task extends Thread{
51 | @Override
52 | public void run() {
53 | System.out.println(Thread.currentThread().getName() + ":开始处理表格数据");
54 | //处理完计数器就减1
55 | countDownLatch.countDown();
56 | }
57 | }
58 | public static void main(String[] args) throws InterruptedException {
59 | new T1().start();
60 | for (int i = 1; i <=3; i++) {
61 | new task().start(); //多线程读取表格
62 | }
63 |
64 | }
65 | ```
66 | 输出结果
67 | ```java
68 | Thread-1:开始处理表格数据
69 | Thread-2:开始处理表格数据
70 | Thread-3:开始处理表格数据
71 | 所有表格已经读取完了,进行汇总处理
72 | ```
73 | ## 源码分析
74 | ### 获取一个countDownLatch时
75 | 
76 | * 源码中可以看出是如果初始传入的j计数器为0时是直接抛出异常的;
77 | * 内部是通过new Sync一个内部返回一个对象的。Sync是一个内部同步器类,继承AQS。
78 |
79 | ### Sync内部类
80 | ```java
81 | private static final class Sync extends AbstractQueuedSynchronizer {
82 | private static final long serialVersionUID = 4982264981922014374L;
83 | //初始化同步状态,count就是传入的计数器
84 | Sync(int count) {
85 | setState(count);
86 | }
87 | //获取同步状态总数,就好像类似锁重入的总次数
88 | int getCount() {
89 | return getState();
90 | }
91 | /**
92 | /共享式获取同步,类似读写锁的读写,,但是这里只是获取,没有做其它操作
93 | state是一个volatile修饰的成员变量
94 | */
95 | protected int tryAcquireShared(int acquires) {
96 | return (getState() == 0) ? 1 : -1;
97 | }
98 | //共享式的释放同步状态,
99 | protected boolean tryReleaseShared(int releases) {
100 | // 自旋
101 | for (;;) {
102 | int c = getState();
103 | //为0 说明计数器已经减完了 直接返回false
104 | if (c == 0)
105 | return false;
106 | //不为0的操作。 获取当前同步状态总数减一
107 | int nextc = c-1;
108 | //CA方式设置state,成功返回true
109 | if (compareAndSetState(c, nextc))
110 | return nextc == 0;
111 | }
112 | }
113 | }
114 | ```
115 | ### await方法
116 |
117 | ```java
118 | public void await() throws InterruptedException {
119 | sync.acquireSharedInterruptibly(1);
120 | }
121 | ```
122 | * await方法是通过sync内部类调用AQS中的`acquireSharedInterruptibly()`方法
123 | * 执行`await`方法的线程会在计数器没有成为0时一直处于等待,除非线程被中断,支持可中断的。
124 |
125 | ```java
126 | public final void acquireSharedInterruptibly(int arg)
127 | throws InterruptedException {
128 | //判断是中断了
129 | if (Thread.interrupted())
130 | throw new InterruptedException();
131 | //这里是执行内部类的tryAcquireShared方法提供了具体实现,
132 | //就是获取同步状态的值,如果获取失败就会返回-1
133 | if (tryAcquireShared(arg) < 0)
134 | //获取同步状态失败 执行如下方法,这个方法以自旋的方式一直获取同步状态
135 | doAcquireSharedInterruptibly(arg);
136 | }
137 | private void doAcquireSharedInterruptibly(int arg)
138 | throws InterruptedException {
139 | final Node node = addWaiter(Node.SHARED);
140 | boolean failed = true;
141 | try {
142 | for (;;) {
143 | final Node p = node.predecessor();
144 | if (p == head) {
145 | int r = tryAcquireShared(arg);
146 | if (r >= 0) {
147 | setHeadAndPropagate(node, r);
148 | p.next = null; // help GC
149 | failed = false;
150 | return;
151 | }
152 | }
153 | if (shouldParkAfterFailedAcquire(p, node) &&
154 | parkAndCheckInterrupt())
155 | throw new InterruptedException();
156 | }
157 | } finally {
158 | if (failed)
159 | cancelAcquire(node);
160 | }
161 | }
162 | ```
163 | ### countDown执行计数器减法操作
164 | * countDownf方法每执行一次,计数器就减1,如果计数到达零,则释放所有等待的线程
165 | ```java
166 | public void countDown() {
167 | //通过内部类sync执行AQS中的共享式释放同步状态
168 | sync.releaseShared(1);
169 | }
170 | //AQS中的方法
171 | public final boolean releaseShared(int arg) {
172 | //tryReleaseShared方法是syncs实现了重写,如果返回true则说明释放同步状态失败
173 | if (tryReleaseShared(arg)) {
174 | //失败AQS doReleaseShared方法,
175 | doReleaseShared();
176 | return true;
177 | }
178 | return false;
179 | }
180 | ```
181 | * doReleaseShared方法会依自旋的方式不断尝试释放同步状态
182 |
183 | ```java
184 | private void doReleaseShared() {
185 | for (;;) {
186 | Node h = head;
187 | if (h != null && h != tail) {
188 | int ws = h.waitStatus;
189 | if (ws == Node.SIGNAL) {
190 | if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
191 | continue;
192 | unparkSuccessor(h);
193 | }
194 | else if (ws == 0 && !compareAndSetWaitStatus(h,0,Node.PROPAGATE))
195 | continue;
196 | }
197 | if (h == head)
198 | break;
199 | }
200 | }
201 | ```
202 | ## 总结
203 | * CountDownLatch是基于AQS实现的一个并发工具类,允许一个线程或多个线程等待其它线程操作,初始化是传入总的计数器,内部都通过`new Sync`一个返回一个对象。当调用countDown()方法 就会吧计数器做递减,当计数器为0时,就会恢复等待的线程继续执行,计数到达零之前,await 方法会一直受阻塞。
204 |
--------------------------------------------------------------------------------
/docs/Spring/SpringBootAdmin.md:
--------------------------------------------------------------------------------
1 | ## 介绍
2 | Spring Boot Admin应用监控
3 |
4 | - Spring Boot Admin 是一个管理和监控Spring Boot 应用程序的开源软件。每个应用都认为是一个客户端,通过HTTP或者使用 Eureka注册到admin server中进行展示,Spring Boot Admin UI部分使用AngularJs将数据展示在前端。
5 | - Spring Boot Admin 是一个针对spring-boot的actuator接口进行UI美化封装的监控工具。他可以:在列表中浏览所有被监控spring-boot项目的基本信息,详细的Health信息、内存信息、JVM信息、垃圾回收信息、各种配置信息(比如数据源、缓存列表和命中率)等,还可以直接修改logger的level。
6 |
7 | ## 设置Spring Boot Admin Server
8 | - 新建一个springBoot2.x工程,将Spring Boot Admin Server启动器添加到pom.xml
9 | - 使用ide新建工程可以直接选择引入Spring Boot Admin
10 |
11 | ```
12 |
13 | de.codecentric
14 | spring-boot-admin-starter-server
15 |
16 |
17 | org.springframework.boot
18 | spring-boot-starter-test
19 | test
20 |
21 |
22 | org.springframework.boot
23 | spring-boot-starter-web
24 |
25 |
26 | de.codecentric
27 | spring-boot-admin-server-ui
28 |
29 |
30 | org.springframework.boot
31 | spring-boot-starter-security
32 |
33 | ```
34 | ## 启动类添加如下注解
35 |
36 | ```
37 | @SpringBootApplication
38 | @EnableAdminServer
39 | public class SpringbootAdminApplication {
40 |
41 | public static void main(String[] args) {
42 | SpringApplication.run(SpringbootAdminApplication.class, args);
43 | }
44 | }
45 | ```
46 | ## 添加身份验证和授权
47 |
48 | ```
49 | @Configuration
50 | public class SecuritySecureConfig extends WebSecurityConfigurerAdapter {
51 |
52 |
53 |
54 | private final String adminContextPath;
55 |
56 | public SecuritySecureConfig(AdminServerProperties adminServerProperties) {
57 | this.adminContextPath = adminServerProperties.getContextPath();
58 | }
59 |
60 | @Override
61 | protected void configure(HttpSecurity http) throws Exception {
62 | // @formatter:off
63 | SavedRequestAwareAuthenticationSuccessHandler successHandler = new SavedRequestAwareAuthenticationSuccessHandler();
64 | successHandler.setTargetUrlParameter("redirectTo");
65 | successHandler.setDefaultTargetUrl(adminContextPath + "/");
66 |
67 | http.authorizeRequests()
68 | //授予对所有静态资产和登录页面的公共访问权限。
69 | .antMatchers(adminContextPath + "/assets/**").permitAll()
70 | .antMatchers(adminContextPath + "/login").permitAll()
71 | //必须对每个其他请求进行身份验证
72 | .anyRequest().authenticated()
73 | .and()
74 | // 配置登录和注销。
75 | .formLogin().loginPage(adminContextPath + "/login").successHandler(successHandler).and()
76 | .logout().logoutUrl(adminContextPath + "/logout").and()
77 | //启用HTTP-Basic支持。这是Spring Boot Admin Client注册所必需的
78 | .httpBasic().and()
79 | .csrf()
80 | //使用Cookie启用CSRF保护
81 | .csrfTokenRepository(CookieCsrfTokenRepository.withHttpOnlyFalse())
82 | .ignoringAntMatchers(
83 | adminContextPath + "/instances", //禁用CRSF-Protection Spring Boot Admin Client用于注册的端点。
84 | adminContextPath + "/actuator/**" //
85 | );
86 | // @formatter:on
87 | }
88 | }
89 |
90 | ```
91 |
92 | ## application.properties配置文件
93 |
94 | ```
95 | server.port=8088
96 | server.tomcat.uri-encoding=UTF-8
97 | server.tomcat.max-threads=1000
98 | server.tomcat.min-spare-threads=30
99 | #账户密码
100 | spring.security.user.name=gzpflm
101 | spring.security.user.password=gzpflm
102 | #项目访问名
103 | spring.boot.admin.context-path=/szq-monitoring
104 | #UI界面标题
105 | spring.boot.admin.ui.title=szq-Monitpring
106 |
107 | ```
108 | 启动运行:http://localhost:8088/szq-monitoring/login 出现登录界面表示成功
109 | 
110 |
111 | ## Spring Boot客户端配置监控
112 | - 客户端需要配置账户密码 不然无法注册到springBoot Admin
113 | - 每个要注册的应用程序都必须包含Spring Boot Admin Client 配置如下
114 | ```
115 |
116 | de.codecentric
117 | spring-boot-admin-starter-client
118 |
119 | ```
120 | **application.properties配置文件**
121 |
122 | ```
123 | server.port=8081
124 | spring.application.name=Spring Boot Client
125 | spring.boot.admin.client.url=http://localhost:8088/szq-monitoring
126 | management.endpoints.web.exposure.include=*
127 | spring.boot.admin.client.username=gzpflm
128 | spring.boot.admin.client.password=gzpflm
129 | spring.boot.admin.client.enabled=true
130 | #启用ip显示
131 | spring.boot.admin.client.instance.prefer-ip=true
132 | #注册的service-url值
133 | spring.boot.admin.client.instance.service-url=http://localhost:8081
134 | ```
135 | 启动后:监控的服务端就会收到通知 刷新页面就可以看到监控的服务
136 | 
137 |
138 | 
139 |
140 |
141 | ## Spring Boot Admin Client配置选项
142 |
143 | ```
144 | spring.boot.admin.client.enabled #启用Spring Boot Admin Client,默认值true
145 | spring.boot.admin.client.url #逗号分隔Spring Boot Admin服务器的有序URL列表以进行注册
146 | spring.boot.admin.client.api-path #管理服务器上的注册端点的Http路径 默认值"instances"
147 | #SBA Server api受HTTP基本身份验证保护时的用户名和密码。
148 | spring.boot.admin.client.username
149 | spring.boot.admin.client.password
150 | spring.boot.admin.client.period #重复注册的间隔(以ms为单位)默认自10,000
151 | spring.boot.admin.client.connect-timeout #连接超时进行注册(以ms为单位 #默认5,000
152 | ```
153 | ## 官方配置
154 | http://codecentric.github.io/spring-boot-admin/current/#register-clients-via-spring-boot-admin
155 |
156 | 打jar包放到linux服务器后台运行模式
157 |
158 | ```
159 | java -jar spring-boot01-1.0-SNAPSHOT.jar > log.file 2>&1 &
160 | ```
161 |
162 | ## 邮件通知配置
163 | ```
164 | spring.mail.host=smtp.qq.com
165 | spring.mail.username=870439570@qq.com
166 | #qq邮箱开通的授权码
167 | spring.mail.password=qq邮箱开通的授权码
168 | spring.mail.properties.mail.smtp.auth=true
169 | spring.mail.properties.mail.smtp.starttls.enable=true
170 | spring.mail.properties.mail.smtp.starttls.required=true
171 | # 发送给谁
172 | spring.boot.admin.notify.mail.to=qinxw@brh99.com
173 | # 是谁发送出去的
174 | spring.boot.admin.notify.mail.from=870439570@qq.com
175 | ```
176 | **QQ邮箱开通邮件客户端方法**
177 | - 登录邮箱 进入设置-》账户-》开启IMAP/SMTP服务获取授权码
178 | 
179 |
180 | 重启项目后 如果注服务下线就会收到邮件通知
181 | 
182 |
--------------------------------------------------------------------------------
/docs/2019/CyclicBarrier.md:
--------------------------------------------------------------------------------
1 | ## 概述
2 | * CyclicBarrie允许让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。
3 | * CyclicBarrier只能唤起一个任务,CountDownLatch可以同时唤起多个任务
4 | * CyclicBarrier可重用,CountDownLatch不可重用,计数值为0该CountDownLatch就不可再用了
5 |
6 | ## 方法摘要
7 | * `CyclicBarrie`有两个构造方法,`CyclicBarrier(int parties) ` 创建一个新的 `CyclicBarrier`,它将在给定数量的参与者(线程)处于等待状态时启动,但它不会在启动 barrier 时执行预定义的操作。
8 | * `CyclicBarrier(int parties, Runnable barrierAction) ` 多了一个传入的屏障被唤醒时指定优先执行的方法,该操作由最后一个进入 barrier 的线程执行。
9 | * `await() ` 在所有参与者都已经在此 barrier 上调用 await 方法之前,将一直等待。
10 | * `await(long timeout, TimeUnit unit) ` 在所有参与者都已经在此屏障上调用 await 方法之前将一直等待,或者超出了指定的等待时间。
11 | * `int getNumberWaiting() ` 返回当前在屏障处等待的参与者数目。
12 | * `int getParties() ` 返回要求启动此 barrier 的参与者数目。
13 | * `boolean isBroken() ` 查询此屏障是否处于损坏状态。
14 | * `void reset() `将屏障重置为其初始状态。
15 | ## 如何使用
16 |
17 | ```java
18 | public class CyclicBarrierTest {
19 | private static CyclicBarrier c;
20 | //批量处里表格数据任务
21 | static class task extends Thread{
22 | @Override
23 | public void run() {
24 | System.out.println(Thread.currentThread().getName() + ":开始处理表格数据");
25 | try {
26 | //处理完计数器就减1
27 | c.await();
28 | }catch (Exception e){
29 |
30 | }
31 | }
32 | }
33 | public static void main(String[] args) throws InterruptedException {
34 | //初始化屏障总数,并指定优先执行的方法,该操作由最后一个进入 barrier 的线程执行。
35 | c=new CyclicBarrier(3, new Runnable() {
36 | @Override
37 | public void run() {
38 | System.out.println("屏障已到达,开始汇总任务执行。。。。");
39 | }
40 | });
41 |
42 | for (int i = 1; i <=3 ; i++) {
43 | new task().start();
44 | }
45 | }
46 | }
47 | ```
48 | 输出
49 |
50 | ```java
51 | Thread-0:开始处理表格数据
52 | Thread-1:开始处理表格数据
53 | Thread-2:开始处理表格数据
54 | 屏障已到达,开始汇总任务执行。。。。
55 | ```
56 |
57 | ## 源码分析
58 | ### 初始化
59 | ```java
60 | /** 重入 */
61 | private final ReentrantLock lock = new ReentrantLock();
62 | private final Condition trip = lock.newCondition();
63 | private final int parties;
64 | private final Runnable barrierCommand;
65 | private Generation generation = new Generation();
66 | private int count;
67 | public CyclicBarrier(int parties, Runnable barrierAction) {
68 | if (parties <= 0) throw new IllegalArgumentException();
69 | this.parties = parties;
70 | this.count = parties;
71 | this.barrierCommand = barrierAction;
72 | }
73 | public CyclicBarrier(int parties) {
74 | this(parties, null);
75 | }
76 | ```
77 | * 可以看出屏障计数器不能为0 。内部是依赖重入锁ReentrantLock和Condition实现的,这点和CountDownLatch不一样。
78 |
79 | ### await()方法
80 | ```java
81 | public int await() throws InterruptedException, BrokenBarrierException {
82 | try {
83 | return dowait(false, 0L);
84 | } catch (TimeoutException toe) {
85 | throw new Error(toe); // cannot happen
86 | }
87 | }
88 | ```
89 | * `await()`方法主要依靠`dowait`方法时u,会让线程会到达屏障点时一直处于等待中
90 |
91 | ```java
92 | private int dowait(boolean timed, long nanos)
93 | throws InterruptedException, BrokenBarrierException, TimeoutException {
94 | final ReentrantLock lock = this.lock;
95 | lock.lock(); //加锁
96 | try {
97 | //屏障的每次使用都表示为生成实例,每当屏障被触发或重置时,生成都会改变
98 | final Generation g = generation;
99 | //broken破碎的意思,检测Generation是否破碎,就抛出异常。
100 | if (g.broken)
101 | throw new BrokenBarrierException();
102 | //检测到线程执行了中断操作,抛异常,终止CyclicBarrie操作
103 | if (Thread.interrupted()) {
104 | //将当前屏障生成设置为已断开(broken置为true),并唤醒所有人。仅在持锁时调用。
105 | breakBarrier();
106 | throw new InterruptedException();
107 | }
108 | //每当有线程执await时,屏障总数就递减1一个
109 | int index = --count;
110 | //屏障数为0时,说明线程都已到达屏障点,开门执行
111 | if (index == 0) { // tripped
112 | boolean ranAction = false;
113 | try {
114 | final Runnable command = barrierCommand;
115 | //触发线构造函数时,传入的优先执行的线程任务,如果有
116 | if (command != null)
117 | command.run();
118 | ranAction = true;
119 | //唤醒所有等待线程,并重新初始化Generation ,broken置为false
120 | nextGeneration();
121 | return 0;
122 | } finally {
123 | // 如果唤醒失败,
124 | if (!ranAction)
125 | //则中断CyclicBarrier,并唤醒所有等待线程
126 | breakBarrier();
127 | }
128 | }
129 | // 屏障未到达时的逻辑,一个死循坏, 自选操作
130 | for (;;) {
131 | try {
132 | //如果未指定超时等待时间,则调用Condition.await()方法使线程处于等待
133 | if (!timed)
134 | trip.await();
135 | //如果指定了超时等待时间大于0,则使用Condition的超时等待方法
136 | else if (nanos > 0L)
137 | nanos = trip.awaitNanos(nanos);
138 | } catch (InterruptedException ie) {
139 | //发生异常处理操作
140 | if (g == generation && ! g.broken) {
141 | breakBarrier();
142 | throw ie;
143 | } else {
144 | //中断当前线程
145 | Thread.currentThread().interrupt();
146 | }
147 | }
148 | // generation 破碎时(中断操作),则抛异常,
149 | if (g.broken)
150 | throw new BrokenBarrierException();
151 | if (g != generation)
152 | return index;
153 | //超时等待了 唤醒所又线程,并抛出异常
154 | if (timed && nanos <= 0L) {
155 | breakBarrier();
156 | throw new TimeoutException();
157 | }
158 | }
159 | } finally {
160 | //释放锁
161 | lock.unlock();
162 | }
163 | }
164 | ```
165 | * 当线程调用`await`方法,首先会拿到`ReentrantLock` 重入锁执行加锁操作,然后判断是否有线程执行了中断操作,如果有则抛出异常,没有就继续向下执行,把屏障计数器做递减操作,然后判断这个屏障计数器是否为0 ,如果递减后的计数器等于0,则表明所有线程都已到达屏障点。
166 | * 然后判断是否有传入指定的优先执行任务,如果有则先启动这个任务,然后唤醒所有等待的线程,重置屏障计数器`count`和`Generation`
167 | * 如果屏障值不为0,则执行一个死循环,也就是自选操作。自选操作中,会先判断是否制定了超时等待时间,如果没有指定就执行`Condition`的`await`方法,让线程一直处于等待中,除非被唤醒或有其它线程执行了中断CyclicBarrier操作。
168 | * 如果制定了超时等待时间,则执行`Condition`的超时等待方法,让线程一直处于等待中,除非被唤醒或到达超时等待时间
169 |
170 | ## 总结
171 | * `CyclicBarrier`的某个线程运行到某个点上之后,该线程即停止运行,直到所有的线程都到达了这个点,所有线程才重新运行;`CountDownLatch`则不是,某线程运行到某个点上之后,只是给某个数值-1而已,该线程继续运行
172 | * `CyclicBarrier`只能唤起一个任务,`CountDownLatch`可以唤起多个任务
173 | * `CyclicBarrier`可重用,`CountDownLatch`不可重用,计数值为`0`该`CountDownLatch`就不可再用了
174 | * `CountDownLatch`内部是基于`AQS`队列同步器实现,`CyclicBarrier`基于ReentrantLock和Condition实现等待机制和唤醒的
175 |
--------------------------------------------------------------------------------
/docs/2019/Semaphore.md:
--------------------------------------------------------------------------------
1 | ## 概述
2 | * `Semaphore` 通常用于限制可以访问某些资源(物理或逻辑的)的线程数目。
3 | * 比如数据库的连接资源是非常有限的,如果同时有上千个线程去数据获取连接,对数据造成的压力是非常的,会造成数据库无法连接而报错,`Semaphore`就可以限制此类问题
4 | * `Semaphore`有非公平和公平模式,默认是非公平的。当`Semaphore`设置为1时,可以排它锁使用,同一个时刻,只能限制一个线程访问。和`CountDownLatch`一样的,内部都有一个Sync内部类,基于AQS实现同步状态的释放和获取。
5 |
6 | ## Semaphore提供的方法
7 | * `Semaphore(int permits) ` 创建非公平的指定许可数的信号量
8 | * `Semaphore(int permits, boolean fair) ` 创建指定的许可数和指定是否是公平模式的信号量
9 | * `void acquire() ` 从此信号量获取一个许可,在提供一个许可前一直将线程阻塞,否则线程被中断
10 | * `void acquire(int permits) ` 从此信号量获取给定数目的许可,在提供这些许可前一直将线程阻塞,或者线程已被中断。
11 | * `int availablePermits() ` 返回此信号量中当前可用的许可数。
12 | * `int getQueueLength() ` 返回正在等待获取的线程的估计数目。
13 | * `boolean hasQueuedThreads() ` 查询是否有线程正在等待获取。
14 | * `Collection getQueuedThreads() ` 返回一个 collection,包含可能等待获取的线程。
15 | * `reducePermits(int reduction) ` 根据指定的缩减量减小可用许可的数目。
16 | * `release() ` 释放一个许可,将其返回给信号量。
17 | * `release(int permits) ` 返回标识此信号量的字符串,以及信号量的状态。
18 | *
19 | ## 使用方法
20 |
21 | ```java
22 | public class SemaphoreTest {
23 | static Semaphore s=new Semaphore(3); //非公平
24 |
25 | static class Task implements Runnable{
26 | @Override
27 | public void run() {
28 |
29 | try {
30 | s.acquire(); //获取一个许可
31 | System.out.println(Thread.currentThread().getName()+" 获取一个许可开始执行...");
32 | Thread.sleep(1000);
33 | System.out.println(Thread.currentThread().getName()+" 退出。");
34 | }catch (Exception e){
35 | }finally {
36 | s.release(); //规划一个许可
37 | }
38 | }
39 | }
40 | public static void main(String[] args) {
41 | for (int i = 0; i <=5 ; i++) {
42 | new Thread(new Task()).start();
43 | }
44 | }
45 | }
46 |
47 | ```
48 | * 输出结果,可以看出同一时刻只能三个线程进入执行,当有一个线程退出归还许可后,立马就会有其余线程去竞争这个多出的许可。
49 |
50 | ```java
51 | Thread-0 获取一个许可开始执行...
52 | Thread-1 获取一个许可开始执行...
53 | Thread-2 获取一个许可开始执行...
54 | Thread-2 退出。
55 | Thread-1 退出。
56 | Thread-3 获取一个许可开始执行...
57 | Thread-0 退出。
58 | Thread-4 获取一个许可开始执行...
59 | Thread-5 获取一个许可开始执行...
60 | Thread-4 退出。
61 | Thread-3 退出。
62 | Thread-5 退出
63 | ```
64 | ## 源码分析
65 | ### 初始化一个信号时
66 | * 当执行`new Semaphore(3)`时,默认是非公平的实现方式。看看内部是如何是实现的
67 |
68 | ```java
69 | public Semaphore(int permits) {
70 | sync = new NonfairSync(permits);
71 | }
72 | ```
73 | * 源码中可以看出是通过`NonfairSync``这个`内部类返回的一个实列,`NonfairSync`是`Sync`子类。
74 | ### acquire 获取一个许可
75 | ```java
76 | public void acquire() throws InterruptedException {
77 | sync.acquireSharedInterruptibly(1);
78 | }
79 | ```
80 | * 获取许可时调用的是AQS中的`acquireSharedInterruptibly`方法,以共享模式获同步状态,如果被中断则中止。
81 |
82 | ```java
83 | public final void acquireSharedInterruptibly(int arg)
84 | throws InterruptedException {
85 | // 判断线程是否中断
86 | if (Thread.interrupted())
87 | throw new InterruptedException();
88 |
89 | if (tryAcquireShared(arg) < 0)
90 | //获取同步状态失败 执行如下方法,这个方法以自旋的方式一直获取同步状态
91 | doAcquireSharedInterruptibly(arg);
92 | }
93 | ```
94 | * `tryAcquireShared`由Sync类提供实现,非公平模式调用`NonfairSync`的,否则调用`FairSync`类的方法
95 |
96 | ### 非公平
97 | ```java
98 | static final class NonfairSync extends Sync {
99 | private static final long serialVersionUID = -2694183684443567898L;
100 |
101 | NonfairSync(int permits) {
102 | super(permits);
103 | }
104 | //获取锁
105 | protected int tryAcquireShared(int acquires) {
106 | // Sync类的非公平获取同步状态方法
107 | return nonfairTryAcquireShared(acquires);
108 | }
109 | }
110 | ```
111 |
112 | ### 公平
113 | ```java
114 | static final class FairSync extends Sync {
115 | private static final long serialVersionUID = 2014338818796000944L;
116 |
117 | FairSync(int permits) {
118 | super(permits);
119 | }
120 | //公平模式获取信号量
121 | protected int tryAcquireShared(int acquires) {
122 | //自旋操作
123 | for (;;) {
124 | //公平模式,先要判断该线程是否位于CLH同步队列的列头
125 | if (hasQueuedPredecessors())
126 | return -1;
127 | //获取同步状态总数(信号量)
128 | int available = getState();
129 | //当前信号量减去获取的acquires个信号。
130 | int remaining = available - acquires;
131 | //CAS方式设置信号量。unsafe类提供实现,返回信号量
132 | if (remaining < 0 ||
133 | compareAndSetState(available, remaining))
134 | return remaining;
135 | }
136 | }
137 | }
138 | ```
139 | * Sync`是继承AQS队列同步器,是自定义同步组件的具体的实现。
140 | ```java
141 | abstract static class Sync extends AbstractQueuedSynchronizer {
142 | private static final long serialVersionUID = 1192457210091910933L;
143 |
144 | Sync(int permits) {
145 | setState(permits);
146 | }
147 |
148 | final int getPermits() {
149 | return getState();
150 | }
151 | //非公平获取信号量
152 | final int nonfairTryAcquireShared(int acquires) {
153 | //自旋
154 | for (;;) {
155 | //获取同步状态总数(信号量)
156 | int available = getState();
157 | //当前信号量减去获取的acquires个信号。
158 | int remaining = available - acquires;
159 | //CAS方式设置信号量。unsafe类提供实现,返回信号量
160 | if (remaining < 0 ||
161 | compareAndSetState(available, remaining))
162 | return remaining;
163 | }
164 | }
165 |
166 |
167 | final void reducePermits(int reductions) {
168 | for (;;) {
169 | int current = getState();
170 | int next = current - reductions;
171 | if (next > current) // underflow
172 | throw new Error("Permit count underflow");
173 | if (compareAndSetState(current, next))
174 | return;
175 | }
176 | }
177 |
178 | final int drainPermits() {
179 | for (;;) {
180 | int current = getState();
181 | if (current == 0 || compareAndSetState(current, 0))
182 | return current;
183 | }
184 | }
185 | }
186 | ```
187 | * 从源码中得出,Semaphore获取信号量许可时,公平和非公平的区别是,公平模式首先判断当前线程是否位于CLH同步队列的队列头中。
188 | * 而非公平模式是的竞争是抢占式,谁竞争到就谁获取。
189 | * 先是获取当前信号总数减去`acquires`个许可信号,然后以CAS方式设置CAS方式设置信号,并返回新的信号总数。CAS内部是依赖于AQS队列同步器中的`unsafel`类提供实现。
190 |
191 | ### release归还许可
192 |
193 | ```java
194 | public void release() {
195 | sync.releaseShared(1);
196 | }
197 | public final boolean releaseShared(int arg) {
198 | if (tryReleaseShared(arg)) {
199 | doReleaseShared();
200 | return true;
201 | }
202 | return false;
203 | }
204 | ```
205 | * 释放信号量 `release` 首先会调用AQS`releaseShared`.
206 | * `tryReleaseShared` 会调用`Sync`的`tryReleaseShared`方法
207 | * 释放操作时以自旋方式执行,首先获取总的信号建去要释放的信号量,然后判断这个信号量是否小于大于总的信号量,如果大于则抛出异常,否则以CAS的方式设置信号量
208 |
209 | ```java
210 | //释放同步状态,也就是归还信号量
211 | protected final boolean tryReleaseShared(int releases) {
212 | // 自旋操作
213 | for (;;) {
214 | int current = getState();
215 | int next = current + releases;
216 | if (next < current) // overflow
217 | throw new Error("Maximum permit count exceeded");
218 | if (compareAndSetState(current, next))
219 | return true;
220 | }
221 | }
222 | ```
223 | ## 总结
224 | * 从源码中可以看出Semaphore的实现方式主要是依靠AQS实现的,以`state`同步状态成变量作为信号量的总数,获取和释放都是以CAS+自旋操作的方式设置`state`成员变量。
225 | * JDK并发包中的工具了哦都是AQS为基石实现的。大多都是使用CAS+自旋的方式去改变state来达到锁的获和释放
226 |
--------------------------------------------------------------------------------
/docs/2019/Hystrix原理解析.md:
--------------------------------------------------------------------------------
1 | ## hystrix与高可用系统架构
2 | - hystrix,框架,提供了高可用相关的各种各样的功能,然后确保说在hystrix的保护下,整个系统可以长期处于高可用的状态,100%,99.99999%
3 | - hystrix的特点:线程资源隔离、限流、熔断、降级、运维监控
4 | - 资源隔离:让你的系统里,某一块东西,在故障的情况下,不会耗尽系统所有的资源,比如线程资源
5 | - 限流:高并发的流量涌入进来,比如说突然间一秒钟100万QPS,废掉了,10万QPS进入系统,其他90万QPS被拒绝了
6 | - 熔断:系统后端的一些依赖,出了一些故障,比如说mysql挂掉了,每次请求都是报错的,熔断了,后续的请求过来直接不接收了,拒绝访问,10分钟之后再尝试去看看mysql恢复没有
7 | - 降级:mysql挂了,系统发现了,自动降级,从内存里存的少量数据中,去提取一些数据出来
8 | - 运维监控:监控+报警+优化,各种异常的情况,有问题就及时报警,优化一些系统的配置和参数,或者代码
9 |
10 | ### Hystrix的设计原则是什么
11 | - 1)对依赖服务调用时出现的调用延迟和调用失败进行控制和容错保护
12 | - 2)在复杂的分布式系统中,阻止某一个依赖服务的故障在整个系统中蔓延
13 | - 3)提供fail-fast(快速失败)和快速恢复的支持
14 | - 4)提供fallback优雅降级的支持
15 | - 5)支持近实时的监控、报警以及运维操作
16 |
17 | ### Hystrix的更加细节的设计原则是什么
18 | - 1)阻止任何一个依赖服务耗尽所有的资源,比如tomcat中的所有线程资源
19 | - 2)避免请求排队和积压,采用限流和fail fast来控制故障
20 | - 3)提供fallback降级机制来应对故障
21 | - 4)使用资源隔离技术,比如bulkhead(舱壁隔离技术),swimlane(泳道技术),circuit breaker(短路技术),来限制任何一个依赖服务的故障的影响
22 | - 5)通过近实时的统计/监控/报警功能,来提高故障发现的速度
23 | - 6)通过近实时的属性和配置热修改功能,来提高故障处理和恢复的速度
24 | - 7)保护依赖服务调用的所有故障情况,而不仅仅只是网络故障情况
25 |
26 | ### Hystrix是如何实现它的目标的
27 | - 1)通过`HystrixCommand`或者`HystrixObservableCommand`来封装对外部依赖的访问请求,这个访问请求一般会运行在独立的线程中,资源隔离
28 | - 2)对于超出我们设定阈值的服务调用,直接进行超时,不允许其耗费过长时间阻塞住。这个超时时间默认是`99.5%`的访问时间,但是一般我们可以自己设置一下
29 | - 3)为每一个依赖服务维护一个`独立的线程池`,或者是`semaphore`,当线程池已满时,直接拒绝对这个服务的调用
30 | - 4)对依赖服务的调用的成功次数,失败次数,拒绝次数,超时次数,进行统计
31 | - 5)如果对一个依赖服务的调用失败次数超过了一定的阈值,自动进行熔断,在一定时间内对该服务的调用直接降级,一段时间后再自动尝试恢复
32 | - 6)当一个服务调用出现失败,被拒绝,超时,短路等异常情况时,自动调用fallback降级机制
33 | - 7)对属性和配置的修改提供近实时的支持
34 | - hystrix进行资源隔离,其实是提供了一个抽象,叫做command,就是说,你如果要把对某一个依赖服务的所有调用请求,全部隔离在同一份资源池内。对这个依赖服务的所有调用请求,全部走这个资源池内的资源,不会去用其他的资源了,这个就叫做资源隔离
35 | - hystrix最最基本的资源隔离的技术,线程池隔离技术,对某一个依赖服务,商品服务,所有的调用请求,全部隔离到一个线程池内,对商品服务的每次调用请求都封装在一个command里面,每个command(每次服务调用请求)都是使用线程池内的一个线程去执行的。所以哪怕是对这个依赖服务,商品服务,现在同时发起的调用量已经到了1000了,但是线程池内就10个线程,最多就只会用这10个线程去执行。不会说,对商品服务的请求,因为接口调用延迟,将tomcat内部所有的线程资源全部耗尽,不会出现了
36 |
37 | ### Hystrix常用方法
38 | - HystrixCommand:是用来获取一条数据的
39 | - HystrixObservableCommand:是设计用来获取多条数据的
40 | - 同步执行:`new CommandHelloWorld("World").execute()`,`new ObservableCommandHelloWorld("World").toBlocking().toFuture().get()`
41 | - 异步执行:`new CommandHelloWorld("World").queue()`,`new ObservableCommandHelloWorld("World").toBlocking().toFuture()`
42 | - 对command调用queue(),仅仅将command放入线程池的一个等待队列,就立即返回,拿到一个Future对象,后面可以做一些其他的事情,然后过一段时间对future调用get()方法获取数据
43 |
44 | ### Hystrix不同的执行方式
45 | - execute(),获取一个 Future.get(),然后拿到单个结果。
46 | - queue(),返回一个 Future。
47 | - observe(),立即订阅 Observable,然后启动 8 大执行步骤,返回一个拷贝的 - Observable,订阅时立即回调给你结果。
48 | - toObservable(),返回一个原始的 Observable,必须手动订阅才会去执行 8 大步骤。
49 |
50 | ### Hystrix常见参数设置
51 | - `withCircuitBreakerEnabled`:控制短路器是否允许工作,包括跟踪依赖服务调用的健康状况,以及对异常情况过多时是否允许触发短路,默认是true
52 | - `withCircuitBreakerRequestVolumeThreshold`:设置滑动窗口中,最少要有多少个请求时,才触发开启短路,举例来说,如果设置为20(默认值),那么在一个10秒的滑动窗口内,如果只有19个请求,即使这19个请求都是异常的,也是不会触发开启短路器的
53 | - `withCircuitBreakerSleepWindowInMilliseconds`:设置在短路之后,需要在多长时间内直接reject请求,然后在这段时间之后,尝试允许请求通过以及自动恢复,默认值是5000毫秒
54 | - `withCircuitBreakerErrorThresholdPercentage`:设置异常请求量的百分比,当异常请求达到这个百分比时,就触发打开短路器,默认是50,也就是50%
55 | - `withCircuitBreakerForceOpen`:如果设置为true的话,直接强迫打开短路器,相当于是手动短路了,手动降级,默认false
56 | - `withCircuitBreakerForceClosed`:如果设置为ture的话,直接强迫关闭短路器,相当于是手动停止短路了,手动升级,默认false
57 | - `execution.isolation.strategy`:strategy,设置为SEMAPHORE,那么hystrix就会用semaphore机制来替代线程池机制,来对依赖服务的访问进行限流,如果通过semaphore调用的时候,底层的网络调用延迟很严重,那么是无法timeout的,只能一直block住,一旦请求数量超过了semephore限定的数量之后,就会立即开启限流
58 | - `withCoreSize`:设置你的线程池的大小
59 | - `withMaxQueueSize:`设置的是你的等待队列,缓冲队列的大小
60 | - `withQueueSizeRejectionThreshol`:如果withMaxQueueSize 请求合并的三种级别:
125 |
126 | - global context,tomcat所有调用线程,对一个依赖服务的任何一个command调用都可以被合并在一起,hystrix就传递一个HystrixRequestContext
127 | - user request context,tomcat内某一个调用线程,将某一个tomcat线程对某个依赖服务的多个command调用合并在一起
128 | - object modeling,基于对象的请求合并,如果有几百个对象,遍历后依次调用每个对象的某个方法,可能导致发起几百次网络请求,基于hystrix可以自动将对多个对象模型的调用合并到一起
129 | - 使用请求合并技术的开销就是导致延迟大幅度增加,因为需要一定的时间将多个请求合并起来
130 |
131 |
132 |
--------------------------------------------------------------------------------
/docs/2019/分布式事务解决方案.md:
--------------------------------------------------------------------------------
1 | [TOC]
2 |
3 | ## 分布式事务
4 | - 分布式事务是指事务的参与者,支持事务的服务器,资源服务器分别位于分布式系统的不同节点之上,通常一个分布式事物中会涉及到对多个数据源或业务系统的操作。
5 | - 典型的分布式事务场景:跨银行转操作就涉及调用两个异地银行服务
6 |
7 | ### CAP理论
8 | - CAP理论:一个分布式系统不可能同时满足一致性,可用性和分区容错性这个三个基本需求,最多只能同时满足其中两项
9 | - 一致性(C):数据在多个副本之间是否能够保持一致的特性。
10 | - 可用性(A):是指系统提供的服务必须一致处于可用状态,对于每一个用户的请求总是在有限的时间内返回结果,超过时间就认为系统是不可用的
11 | - 分区容错性(P):分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非整个网络环境都发生故障。
12 |
13 | ### CAP定理的应用
14 | - 放弃P(CA):如果希望能够避免系统出现分区容错性问题,一种较为简单的做法就是将所有的数据(或者是与事物先相关的数据)都放在一个分布式节点上,这样虽然无法保证100%系统不会出错,但至少不会碰到由于网络分区带来的负面影响
15 | - 放弃A(CP):其做法是一旦系统遇到网络分区或其他故障时,那受到影响的服务需要等待一定的时间,应用等待期间系统无法对外提供正常的服务,即不可用
16 | - 放弃C(AP):这里说的放弃一致性,并不是完全不需要数据一致性,是指放弃数据的强一致性,保留数据的最终一致性。
17 |
18 |
19 | ### BASE理论
20 | - BASE是基本可用,软状态,最终一致性。是对CAP中一致性和可用性权限的结果,是基于CAP定理演化而来的,核心思想是即使无法做到强一致性,但每个应用都可以根据自身的业务特定,采用适当的方式来使系统达到最终一致性
21 |
22 | ### 2PC提交
23 | - 二阶段提交协议是将事务的提交过程分成提交事务请求和执行事务提交两个阶段进行处理。
24 |
25 | #### 阶段1:提交事务请求
26 | - 事务询问:协调者向所有的参与者发送事务内容,询问是否可以执行事务提交操作,并开始等待各参与者的响应
27 | - 执行事务:各参与者节点执行事务操作,并将Undo和Redo信息记入事务日志中
28 | - 如果参与者成功执事务操作,就反馈给协调者Yes响应,表示事物可以执行,如果没有成功执行事务,就反馈给协调者No响应,表示事务不可以执行
29 | - 二阶段提交一些的阶段一夜被称为投票阶段,即各参与者投票票表明是否可以继续执行接下去的事务提交操作
30 |
31 | #### 阶段二:执行事务提交
32 | - 假如协调者从所有的参与者或得反馈都是Yes响应,那么就会执行事务提交。
33 | - 发送提交请求:协调者向所有参与者节点发出Commit请求
34 | - 事务提交:参与者接受到Commit请求后,会正式执行事务提交操作,并在完成提交之后放弃整个事务执行期间占用的事务资源
35 | - 反馈事务提交结果:参与者在完成事物提交之后,向协调者发送ACK消息
36 | - 完成事务:协调者接收到所有参与者反馈的ACK消息后,完成事务
37 |
38 | #### 中断事务
39 | - 假如任何一个参与者向协调者反馈了No响应,或者在等待超市之后,协调者尚无法接收到所有参与者的反馈响应,那么就中断事务。
40 | - 发送回滚请求:协调者向所有参与者节点发出Rollback请求
41 | - 事务回滚:参与者接收到Rollback请求后,会利用其在阶段一种记录的Undo信息执行事物回滚操作,并在完成回滚之后释放事务执行期间占用的资源。
42 | - 反馈事务回滚结果:参与则在完成事务回滚之后,向协调者发送ACK消息
43 | - 中断事务:协调者接收到所有参与者反馈的ACk消息后,完成事务中断、
44 |
45 | > 优缺点
46 |
47 | - 原理简单,实现方便
48 | - 缺点是同步阻塞,单点问题,脑裂,保守
49 |
50 | ### 3PC提交
51 | - 三阶段提,也叫三阶段提交协议,是二阶段提交(2PC)的改进版本。
52 | - 与两阶段提交不同的是,三阶段提交有两个改动点。引入超时机制。同时在协调者和参与者中都引入超时机制。在第一阶段和第二阶段中插入一个准备阶段。保证了在最后提交阶段之前各参与节点的状态是一致的。
53 | - 三阶段提交就有CanCommit、PreCommit、DoCommit三个阶段。
54 |
55 |
56 | ## Seata分布式事务方案
57 | - Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
58 |
59 |
60 | ### Seata术语
61 | - TC:事务协调者。维护全局和分支事务的状态,驱动全局事务提交或回滚。
62 | - TM:事务管理器。定义全局事务的范围:开始全局事务、提交或回滚全局事务
63 | - RM:管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
64 |
65 | ### Seata的2PC方案
66 | - 一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
67 | - 二阶段:提交异步化,非常快速地完成。回滚通过一阶段的回滚日志进行反向补偿。
68 | - 一阶段本地事务提交前,需要确保先拿到 全局锁 。拿不到全局锁 ,不能提交本地事务。
69 | - 拿全局锁的尝试被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁。
70 | - 在数据库本地事务隔离级别读已提交或以上的基础上,Seata(AT 模式)的默认全局隔离级别是 读未提交
71 | - 如果应用在特定场景下,必需要求全局的 读已提交 ,目前 Seata 的方式是通过 SELECT FOR UPDATE 语句的代理。
72 |
73 |
74 | ### Seata执行流程分析
75 |
76 | 
77 |
78 | - 每个`RM`使用`DataSourceProxy`链接数据路,目的是使用`ConnectionProxy`,使用数据源和数据代理的目的是在第一阶段将`undo_log`和业务数据放在一个本地事务提交,这样就保存了只要有业务操作就一定有undo_log
79 | - 在第一阶段undo_log中存放了数据修改前后修改后的值,为事务回滚做好准别,所以第一阶段完成就已经将分支事务提交了,也就释放了锁资源
80 | - TM开启全局事务开始,将XID全局事务ID放在事务上下文中,通过feign调用也将XID传入下游分支事务,每个分支事务将自己的Branch ID 分支事务ID与XID关联
81 | - 第二阶段全局事务提交,TC会通知各分支参与者提交分支事务,在第一阶段就已经提交了分支事务,这里各参与者只需要删除undo_log即可,并且可以异步执行,第二阶段很快可以完成
82 | - 如果某一个分支事务异常,第二阶段就全局事务回滚操作,TC会通知各分支参与者回滚分支事务,通过`XID`和`Branch-ID`找到对应的回滚日志,通过回滚日志生成的反向`SQL`并执行,以完成分支事务回滚到之前
83 |
84 | ### Seata的实战案列
85 | - https://github.com/seata/seata-samples
86 | - https://github.com/seata/seata-samples/blob/master/doc/quick-integration-with-spring-cloud.md
87 | -
88 |
89 |
90 |
91 | ## TCC分布式事务
92 | - TCC是服务化的两阶段编程模型,其Try、Confirm、Cancel,3个方法均由业务编码实现
93 | - TCC要求每个分支事务实现三个操作:预处理Try,确认Confirm,撤销Cancel。
94 | - Try操作做业务检查及资源预留,
95 | - Confirm做业务确认操作
96 | - Cancel实现一个与Try相反的操作即回滚操作。
97 | - TM首先发起所有的分支事务Try操作,任何一个分支事务的Try操作执行失败,TM将会发起所有分支事务的Cancel操作,若Try操作全部成功,TM将会发起所有分支事务的Confirm操作,其中Confirm/Cancel操作若执行失败,TM会进行重试。
98 |
99 | ### TCC的三个阶段
100 | - Try阶段是做业务检查(一致性)及资源预留(隔离),此阶段仅是一个初步操作,它和后续的Confirmy一起才能构成一个完整的业务逻辑
101 | - Confirm阶段是做确认提交,Try阶段所有分支事务执行成功后开始执行Confirm,通常情况下,采用TCC则认为Confirm阶段是不会出错的,即:只要Try成功,Confirm一定成功,若Confirm阶段真的出错,需要引入重试机制或人工处理
102 | - Cancel阶段是在业务执行错误需要回滚到状态下执行分支事务的取消,预留资源的释放,通常情况下,采用TCC则认为Cancel阶段也一定是真功的,若Cance阶段真的出错,需要引入重试机制或人工处理
103 | - TM事务管理器:TM事务管理器可以实现为独立的服务,也可以让`全局事务发起方`充当TM的角色,TM独立出来是为了公用组件,是为了考虑系统结构和软件的复用
104 | - TM在发起全局事务时生成全局事务记录,全局事务ID贯穿整个分布式事务调用链条,用来记录事务上下文,追踪和记录状态,用于Confirm和cacel失败需要进行重试,因此需要实现幂等
105 |
106 | ### TCC的三种异常处理情况
107 | #### 幂等处理
108 | - 因为网络抖动等原因,分布式事务框架可能会重复调用同一个分布式事务中的一个分支事务的二阶段接口。所以分支事务的二阶段接口Confirm/Cancel需要能够保证幂等性。如果二阶段接口不能保证幂等性,则会产生严重的问题,造成资源的重复使用或者重复释放,进而导致业务故障。
109 | - 对于幂等类型的问题,通常的手段是引入幂等字段进行防重放攻击。对于分布式事务框架中的幂等问题,同样可以祭出这一利器。
110 | - 幂等记录的插入时机是参与者的Try方法,此时的分支事务状态会被初始化为INIT。然后当二阶段的Confirm/Cancel执行时会将其状态置为CONFIRMED/ROLLBACKED。
111 | - 当TC重复调用二阶段接口时,参与者会先获取事务状态控制表的对应记录查看其事务状态。如果状态已经为CONFIRMED/ROLLBACKED,那么表示参与者已经处理完其分内之事,不需要再次执行,可以直接返回幂等成功的结果给TC,帮助其推进分布式事务。
112 |
113 | #### 空回滚
114 | - 当没有调用参与方Try方法的情况下,就调用了二阶段的Cancel方法,Cancel方法需要有办法识别出此时Try有没有执行。如果Try还没执行,表示这个Cancel操作是无效的,即本次Cancel属于空回滚;如果Try已经执行,那么执行的是正常的回滚逻辑。
115 | - 要应对空回滚的问题,就需要让参与者在二阶段的Cancel方法中有办法识别到一阶段的Try是否已经执行。很显然,可以继续利用事务状态控制表来实现这个功能。
116 | - 当Try方法被成功执行后,会插入一条记录,标识该分支事务处于INIT状态。所以后续当二阶段的Cancel方法被调用时,可以通过查询控制表的对应记录进行判断。如果记录存在且状态为INIT,就表示一阶段已成功执行,可以正常执行回滚操作,释放预留的资源;如果记录不存在则表示一阶段未执行,本次为空回滚,不释放任何资源。
117 |
118 | #### 资源悬挂
119 | - 问题:TC回滚事务调用二阶段完成空回滚后,一阶段执行成功
120 | - 解决:事务状态控制记录作为控制手段,二阶段发现无记录时插入记录,一阶段执行时检查记录是否存在
121 |
122 | #### TCC和2PC比较
123 | - 2PC通常都是在跨库的DB层面,而TCC则在应用层面处理,需要通过业务逻辑实现,这种分布式事务的实现方式优势在于,可以让应用自己定义数据操作的粒度,使得降低锁冲突,提高吞吐量成为可能
124 | - 而不足之处则在于对应用的侵入性非常强,业务逻辑的每个分支都需要实现Try,confirm,cancel三个操作。此外,其实现难度也比较大,需要按照网络状态,系统故障的不同失败原因实现不同的回滚策略
125 |
126 | #### Hmily框架实现TCC案列
127 |
128 | 
129 |
130 | ```
131 | # 账户A
132 | try:
133 | try的幂等效验
134 | try的悬挂处理
135 | 检查余额是否够30元
136 | 扣减30元
137 |
138 |
139 | confirm:
140 | 空处理即可,通常TCC阶段是认为confirm是不会出错的
141 |
142 | cancel:
143 | cancel幂等效验
144 | cacel空回滚处理
145 | 增加可用余额30元,回滚操作
146 |
147 |
148 | # 账户B
149 |
150 | try:
151 | 空处理即可
152 |
153 | confirm:
154 | confirm的幂等效验
155 | 正式增加30元
156 | cancel:
157 | 空处理即可
158 |
159 | ```
160 |
161 | ## RocketMQ实现可靠消息最终一致性
162 | - 可靠消息最终一致性就是保证消息从生产方经过消息中间件传递到消费方的一致性
163 | - RocketMQ主要解决了两个功能:本地事务与消息发送的原子性问题。事务参与方接收消息的可靠性
164 | - 可靠消息最终一致性事务适合执行周期长且实时性要求不高的场景,引入消息机制后,同步的事务操作变为基于消息执行的异步操作,避免分布式事务中的同步阻塞操作的影响,并实现了两个服务的解耦
165 |
166 | 
167 |
168 |
169 | ## 最大努力通知
170 | ### 最大努力通知与可靠消息一致性有什么不同
171 | - 可靠消息一致性,发起通知方需要保证将消息发出去,并且将消息发送到接收通知方,消息的可靠性由发起通知方保证
172 | - 最大努力通知,发起通知方尽最大的努力将业务处理结果通知为接收通知方,但是消息可能接收不到,此时需要接收通知方主动调用发起通知方的接口查询业务,通知可靠性关键在于接收通知方
173 |
174 | ### 两者的应用场景
175 | - 可靠消息一致性关注的是交易过程的事务一致,以异步的方式完成交易
176 | - 最大努力通知关注的是交易后的通知事务,即将交易结果可靠的通知出去
177 |
178 | ### 基于MQ的ack机制实现最大努力通知
179 |
180 | 
181 |
182 | - 利用MQ的ack机制由MQ向接收通知方发送消息通知,发起方将普通消息发送到MQ
183 | - 接收通知监听MQ,接收消息,业务处理完成回应ACK
184 | - 接收通知方如果没有回应ACK则MQ会重复通知,按照时间间隔的方式,逐步拉大通知间隔
185 | - 此方案适用于内部微服务之间的通知,不适应与通知外部平台
186 |
187 | > 方案二:增加一个通知服务区进行通知,提供外部第三方时适用
188 |
189 | 
190 |
191 |
192 | ## 分布式事务方案对比分析
193 | - `2PC` 最大的一个诟病是一个阻塞协议。RM在执行分支事务后需要等待TM的决定,此时服务会阻塞锁定资源。由于其阻塞机制和最差时间复杂度高,因此,这种设计不能适应随着事务涉及的服务数量增加而扩展的需要,很难用于并发较高以及子事务生命周期较长的分布式服务中
194 | - 如果拿`TCC`事务的处理流程与2PC两阶段提交做比较,2PC通常都是在跨库的DB层面,而TCC则在应用层面处理,需要通过业务逻辑来实现。这种分布式事务的优势在于,可以让`应用自定义数据操作的粒度,使得降低锁冲突,提高吞吐量成为可能`。而不足之处在于对应用的侵入性非常强,业务逻辑的每个分支都需要实现三个操作。此外,其实现难度也比较大,需要按照网络状态,系统故障等不同失败原因实现不同的策略。
195 | - `可靠消息最终一致性`事务适合执行周期长且实时性要求不高的场景。引入消息机制后,同步的事务操作变为基于消息执行的异步操作,避免了分布式事务中的同步阻塞操作的影响,并实现了两个服务的解耦,典型的场景:注册送积分,登陆送优惠券等
196 | - `最大努力通知`是分布式事务中要求最低的一种,适用于一些最终一致性时间敏感度低的业务,允许发起通知方业务处理失败,在接收通知方收到通知后积极进行失败处理,无论发起通知方如何处理结果都不会影响到接收通知方的后续处理,发起通知方需提供查询执行情况接口,用于接收通知方校对结果,典型的应用场景:银行通知,支付结果通知等。
197 |
198 |
199 | | | 2PC | TCC |可靠消息| 最大努力通知|
200 | | -------- | -----: | -----: | -----: | :----: |
201 | | 一致性 | 强一直性 | 最终一致 |最终一致 | 最终一致 |
202 | | 吞吐量 | 低 | 中 |高 | 高 |
203 | | 实现复杂度| 容易 | 难 |中 | 容易 |
204 |
205 |
206 |
207 | ## 案列Demo源码地址
208 | - https://github.com/qinxuewu/boot-cloud
209 |
--------------------------------------------------------------------------------
/docs/Spring/Consul实现服务注册中心.md:
--------------------------------------------------------------------------------
1 | ## 概述
2 | **Spring Cloud 支持很多服务发现的软件,Eureka 只是其中之一,下面是 Spring Cloud 支持的服务发现软件以及特性对比:**
3 | 
4 |
5 | ## Consul介绍
6 | - Consul 是 HashiCorp 公司推出的开源工具,用于实现分布式系统的服务发现与配置。与其他分布式服务注册与发现的方案,Consul 的方案更“一站式”,内置了服务注册与发现框 架、分布一致性协议实现、健康检查、Key/Value 存储、多数据中心方案,不再需要依赖其他工具(比如 ZooKeeper 等)。使用起来也较 为简单。Consul 使用 Go 语言编写,因此具有天然可移植性(支持Linux、windows和Mac OS X);安装包仅包含一个可执行文件,方便部署,与 Docker 等轻量级容器可无缝配合。
7 |
8 | ## Consul的优势:
9 | - 使用 Raft 算法来保证一致性, 比复杂的 Paxos 算法更直接. 相比较而言, zookeeper 采用的是 Paxos, 而 etcd 使用的则是 Raft。
10 | - 支持多数据中心,内外网的服务采用不同的端口进行监听。 多数据中心集群可以避免单数据中心的单点故障,而其部署则需要考虑网络延迟, 分片等情况等。 zookeeper 和 etcd 均不提供多数据中心功能的支持。
11 | - 支持健康检查。 etcd 不提供此功能。
12 | - 支持 http 和 dns 协议接口。 zookeeper 的集成较为复杂, etcd 只支持 http 协议。
13 | - 官方提供 web 管理界面, etcd 无此功能。
14 | - 综合比较, Consul 作为服务注册和配置管理的新星, 比较值得关注和研究。
15 |
16 | ## 特性
17 | - 服务发现
18 | - 健康检查
19 | - Key/Value 存储
20 | - 多数据中心
21 |
22 | ## Consul角色
23 | - client: 客户端, 无状态, 将 HTTP 和 DNS 接口请求转发给局域网内的服务端集群。
24 | - server: 服务端, 保存配置信息, 高可用集群, 在局域网内与本地客户端通讯, 通过广域网与其他数据中心通讯。 每个数据中心的 server 数量推荐为 3 个或是 5 个。
25 |
26 | ## 安装
27 | Consul 不同于 Eureka 需要单独安装,访问Consul 官网下载 Consul 的最新版本,
28 |
29 | 我这里以 Windows 为例,下载下来是一个 consul_1.2.1_windows_amd64.zip 的压缩包,解压是是一个 consul.exe 的执行文件。
30 | 
31 |
32 | cd 到对应的目录下,使用 cmd 启动 Consul
33 |
34 | ```
35 | cd D:\Common Files\consul
36 |
37 | #cmd启动:
38 | consul agent -dev # -dev表示开发模式运行,另外还有-server表示服务模式运行
39 | ```
40 | 为了方便期间,可以在同级目录下创建一个 run.bat 脚本来启动,脚本内容如下
41 |
42 | ```
43 | consul agent -dev
44 | ```
45 |
46 | 启动结果如下:
47 | 
48 |
49 | 启动成功之后访问:http://localhost:8500,可以看到 Consul 的管理界面
50 | 
51 |
52 | 这样就意味着我们的 Consul 服务启动成功了。
53 |
54 | ## Linux环境安装
55 | 把下载的linux下的安装包consul拷贝到linux环境里面,使用unzip进行解压:
56 |
57 | **2,配置环境变量**
58 | ```
59 | vi /etc/profile
60 |
61 | export JAVA_HOME=/usr/local/jdk1.8.0_172
62 | export MAVEN_HOME=/usr/local/apache-maven-3.5.4
63 | export CONSUL_HOME=/usr/local/consul
64 |
65 | export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
66 | export PATH=$JAVA_HOME/bin:$MAVEN_HOME/bin:$CONSUL_HOME:$PATH
67 |
68 | #上面的CONSUL_HOME就是consul的路径,上面的配置仅供参考。
69 | source /etc/profile #命令使配置生效
70 |
71 | #查看安装的consul版本
72 | [root@CentOS124 /]# consul -v
73 | Consul v1.2.2
74 | Protocol 2 spoken by default, understands 2 to 3 (agent will automatically use protocol >2 when speaking to compatible agents)
75 | [root@CentOS124 /]#
76 | ```
77 |
78 |
79 | ## 服务端
80 | 创建一个 spring-cloud-consul-producer 项目 依赖包如下:
81 | ```
82 |
83 |
84 | org.springframework.boot
85 | spring-boot-starter-actuator
86 |
87 |
88 | org.springframework.cloud
89 | spring-cloud-starter-consul-discovery
90 |
91 |
92 | org.springframework.boot
93 | spring-boot-starter-web
94 |
95 |
96 | org.springframework.boot
97 | spring-boot-starter-test
98 | test
99 |
100 |
101 | ```
102 | - spring-boot-starter-actuator 健康检查依赖于此包。
103 | - spring-cloud-starter-consul-discovery Spring Cloud Consul 的支持。
104 |
105 | **配置文件内容如下**
106 |
107 | ```
108 | spring.application.name=spring-cloud-consul-producer
109 | server.port=8501
110 | spring.cloud.consul.host=localhost
111 | spring.cloud.consul.port=8500
112 | #注册到consul的服务名称
113 | spring.cloud.consul.discovery.serviceName=service-producer
114 | ```
115 | - Consul 的地址和端口号默认是 localhost:8500 ,如果不是这个地址可以自行配置。
116 | - spring.cloud.consul.discovery.serviceName 是指注册到 Consul 的服务名称,后期客户端会根据这个名称来进行服务调用。
117 |
118 | **启动类**
119 |
120 | ```
121 | @SpringBootApplication
122 | @EnableDiscoveryClient
123 | public class ConsulProducerApplication {
124 | public static void main(String[] args) {
125 | SpringApplication.run(ConsulProducerApplication.class, args);
126 | }
127 | }
128 | ```
129 | 添加了 @EnableDiscoveryClient 注解表示支持服务发现。
130 |
131 | **创建一个 Controller,推文提供 hello 的服务**
132 |
133 | ```
134 | @RestController
135 | public class HelloController {
136 | @RequestMapping("/hello")
137 | public String hello() {
138 | return "helle consul";
139 | }
140 | }
141 | ```
142 | 为了模拟注册均衡负载复制一份上面的项目重命名为 spring-cloud-consul-producer-2 ,修改对应的端口为 8502,修改 hello 方法的返回值为:"helle consul two",修改完成后依次启动两个项目。
143 |
144 | 这时候我们再次在浏览器访问地址:http://localhost:8500 就会显示出来两个服务提供者
145 |
146 | ## 消费端
147 | 创建一个 spring-cloud-consul-consumer 项目,pom 文件和上面示例保持一致
148 |
149 | **配置文件内容如下**
150 |
151 | ```
152 | spring.application.name=spring-cloud-consul-consumer
153 | server.port=8503
154 | spring.cloud.consul.host=127.0.0.1
155 | spring.cloud.consul.port=8500
156 | #设置不需要注册到 consul 中
157 | spring.cloud.consul.discovery.register=false
158 | ```
159 | 客户端可以设置注册到 Consul 中,也可以不注册到 Consul 注册中心中,根据我们的业务来选择,只需要在使用服务时通过 Consul 对外提供的接口获取服务信息即可。
160 |
161 | **启动类**
162 |
163 | ```
164 | @SpringBootApplication
165 | public class ConsulConsumerApplication {
166 | public static void main(String[] args) {
167 | SpringApplication.run(ConsulConsumerApplication.class, args);
168 | }
169 | }
170 | ```
171 |
172 | **进行测试**
173 |
174 | 创建一个 ServiceController ,试试如果去获取 Consul 中的服务
175 |
176 | ```
177 | @RestController
178 | public class ServiceController {
179 | @Autowired
180 | private LoadBalancerClient loadBalancer;
181 | @Autowired
182 | private DiscoveryClient discoveryClient;
183 | //获取所有服务
184 | @RequestMapping("/services")
185 | public Object services() {
186 | return discoveryClient.getInstances("service-producer");
187 | }
188 | //从所有服务中选择一个服务(轮询)
189 | @RequestMapping("/discover")
190 | public Object discover() {
191 | return loadBalancer.choose("service-producer").getUri().toString();
192 | }
193 | }
194 | ```
195 | Controller 中有俩个方法,一个是获取所有服务名为service-producer的服务信息并返回到页面,一个是随机从服务名为service-producer的服务中获取一个并返回到页面。
196 |
197 | 添加完 ServiceController 之后我们启动项目,访问地址:http://localhost:8503/services,返回jsn数据
198 |
199 | ```
200 | [{"serviceId":"service-producer","host":"windows10.microdone.cn","port":8501,"secure":false,"metadata":{"secure":"false"},"uri":"http://windows10.microdone.cn:8501","scheme":null},{"serviceId":"service-producer","host":"windows10.microdone.cn","port":8502,"secure":false,"metadata":{"secure":"false"},"uri":"http://windows10.microdone.cn:8502","scheme":null}]
201 | ```
202 |
203 | 发现我们刚才创建的端口为 8501 和 8502 的两个服务端都存在
204 |
205 | 多次访问地址:http://localhost:8503/discover,页面会交替返回信息:
206 |
207 | 说明 8501 和 8501 的两个服务会交替出现,从而实现了获取服务端地址的均衡负载。
208 |
209 | 大多数情况下我们希望使用均衡负载的形式去获取服务端提供的服务,因此使用第二种方法来模拟调用服务端提供的 hello 方法。
210 |
211 | **创建 CallHelloController :**
212 |
213 | ```
214 | @RestController
215 | public class CallHelloController {
216 | @Autowired
217 | private LoadBalancerClient loadBalancer;
218 | @RequestMapping("/call")
219 | public String call() {
220 | ServiceInstance serviceInstance = loadBalancer.choose("service-producer");
221 | System.out.println("服务地址:" + serviceInstance.getUri());
222 | System.out.println("服务名称:" + serviceInstance.getServiceId());
223 | String callServiceResult = new RestTemplate().getForObject(serviceInstance.getUri().toString() + "/hello", String.class);
224 | System.out.println(callServiceResult);
225 | return callServiceResult;
226 | }
227 | }
228 | ```
229 | 使用 RestTemplate 进行远程调用。添加完之后重启 spring-cloud-consul-consumer 项目。在浏览器中访问地址:http://localhost:8503/call,依次返回结果如下:
230 |
231 | ```
232 | helle consul
233 |
234 | helle consul two
235 | ```
236 |
237 | 说明我们已经成功的调用了 Consul 服务端提供的服务,并且实现了服务端的均衡负载功能
238 |
239 | 示例代码:https://github.com/ityouknow/spring-cloud-examples
240 |
241 |
242 |
243 |
244 |
245 |
246 |
--------------------------------------------------------------------------------
/docs/distributed/nginx.md:
--------------------------------------------------------------------------------
1 | ### 利用nginx实现负载均衡
2 | 安装了两个tomcat,端口分别是42000和42001。第二个tomcat的首页随便加了些代码区分
3 |
4 | ### nginx配置
5 |
6 | ```
7 | #这里的域名要和下面proxy_pass的一样
8 | #设定负载均衡的服务器列表 weigth参数表示权值,权值越高被分配到的几率越大
9 | upstream fengzp.com {
10 | server 192.168.99.100:42000 weight=1;
11 | server 192.168.99.100:42001 weight=2;
12 | }
13 |
14 | server {
15 | listen 80;
16 | server_name 192.168.99.100;
17 |
18 | location / {
19 | proxy_pass http://fengzp.com;
20 | proxy_redirect default;
21 | }
22 |
23 | error_page 500 502 503 504 /50x.html;
24 | location = /50x.html {
25 | root html;
26 | }
27 | }
28 | ```
29 |
30 | ### 测试
31 | 
32 | 
33 |
34 | 刷新页面发现页面会发生变化,证明负载配置成功。因为我配的权重第二个是第一个的两倍,所以第二个出现的概率会是第一个的两倍。
35 |
36 |
37 |
38 | 如果关了tomcat1,再多次刷新页面,接下来出现的就会都是tomcat2的页面,但是时而快时而慢。这其中原因是当如果nginx将请求转发到tomcat2时,服务器会马上跳转成功,但是如果是转到tomcat1,因为tomcat1已经关闭了,所以会出现一段等待响应过程的过程,要等它失败后才会转到tomcat2。
39 | 而这个等待响应的时间我们是可以配置的。
40 |
41 |
42 | 这个时间由以下3个参数控制:
43 | proxy_connect_timeout:与服务器连接的超时时间,默认60s
44 | fail_timeout:当该时间内服务器没响应,则认为服务器失效,默认10s
45 | max_fails:允许连接失败次数,默认为1
46 |
47 | 等待时间 = proxy_connect_timeout + fail_timeout * max_fails
48 |
49 | 
50 |
51 | 如果我这样配置的话,只需等待6秒就可以了。
52 |
53 |
54 | ### 负载均衡策略
55 | **1、轮询**
56 |
57 | ```
58 | #这种是默认的策略,把每个请求按顺序逐一分配到不同的server,如果server挂掉,能自动剔除
59 |
60 | upstream fengzp.com {
61 | server 192.168.99.100:42000;
62 | server 192.168.99.100:42001;
63 | }
64 | ```
65 | **2、最少连接**
66 |
67 | ```
68 | #把请求分配到连接数最少的server
69 |
70 | upstream fengzp.com {
71 | least_conn;
72 | server 192.168.99.100:42000;
73 | server 192.168.99.100:42001;
74 | }
75 | ```
76 | **3、权重**
77 |
78 | ```
79 | #使用weight来指定server访问比率,weight默认是1。以下配置会是server2访问的比例是server1的两倍
80 |
81 | upstream fengzp.com {
82 | server 192.168.99.100:42000 weight=1;
83 | server 192.168.99.100:42001 weight=2;
84 | }
85 | ```
86 |
87 | **4、ip_hash**
88 | **每个请求会按照访问ip的hash值分配,这样同一客户端连续的Web请求都会被分发到同一server进行处理,可以解决session的问题。如果server挂掉,能自动剔除。**
89 | ```
90 | upstream fengzp.com {
91 | ip_hash;
92 | server 192.168.99.100:42000;
93 | server 192.168.99.100:42001;
94 | }
95 | ```
96 | ip_hash可以和weight结合使用。
97 |
98 | ### nginx实现请求的负载均衡 + keepalived实现nginx的高可用
99 | https://www.cnblogs.com/youzhibing/p/7327342.html
100 |
101 |
102 |
103 | ### 一个域名配置多项目访问
104 |
105 | ```
106 |
107 | #user nobody;
108 | worker_processes 1;
109 |
110 | #error_log logs/error.log;
111 | #error_log logs/error.log notice;
112 | #error_log logs/error.log info;
113 |
114 | pid logs/nginx.pid;
115 |
116 |
117 | events {
118 | worker_connections 1024;
119 | }
120 |
121 |
122 | http {
123 | include mime.types;
124 | default_type application/octet-stream;
125 |
126 | #log_format main '$remote_addr - $remote_user [$time_local] "$request" '
127 | # '$status $body_bytes_sent "$http_referer" '
128 | # '"$http_user_agent" "$http_x_forwarded_for"';
129 |
130 | #access_log logs/access.log main;
131 |
132 | sendfile on;
133 | #tcp_nopush on;
134 |
135 | #keepalive_timeout 0;
136 | keepalive_timeout 65;
137 |
138 | #gzip on;
139 |
140 | upstream rongdaitianxia {
141 | #表示在10s(fail_timeout)之内,有1(max_fails)个请求打到这台挂了的服务器,nginx就会把这台upstream server设为down机的状态,时长是10s,
142 | #在这10s内如果又有请求进来,就不会被转到这台server上,过了10s重新认为这台server又恢复了
143 | server 127.0.0.1:8080 max_fails=2 fail_timeout=10s;
144 | server 127.0.0.1:8082 max_fails=2 fail_timeout=10s;
145 | }
146 |
147 |
148 |
149 |
150 | server {
151 | listen 443;
152 | server_name 填你的域名;
153 | ssl on;
154 | ssl_certificate /home/nginx/certs/1_www.rongdaitianxia.com_bundle.crt;
155 | ssl_certificate_key /home/nginx/certs/2_www.rongdaitianxia.com.key;
156 | ssl_session_timeout 5m;
157 | ssl_protocols TLSv1.2;
158 | ssl_ciphers HIGH:!aNULL:!MD5;
159 | ssl_prefer_server_ciphers on;
160 |
161 | #location / {
162 | #client_max_body_size 16m;
163 | #client_body_buffer_size 128k;
164 | #proxy_pass http://rongdaitianxia/;
165 | #proxy_set_header Upgrade $http_upgrade;
166 | #proxy_set_header Connection "upgrade";
167 | #proxy_set_header Host $host;
168 | #proxy_set_header X-Real-IP $remote_addr;
169 | #proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
170 | #proxy_set_header X-Forwarded-Proto https;
171 | #proxy_next_upstream off;
172 | #proxy_connect_timeout 30;
173 | #proxy_read_timeout 300;
174 | #proxy_send_timeout 300;
175 | #}
176 |
177 |
178 | location /wxloan {
179 | client_max_body_size 16m;
180 | client_body_buffer_size 128k;
181 | proxy_pass http://127.0.0.1:8080/wxloan;
182 | proxy_set_header Upgrade $http_upgrade;
183 | proxy_set_header Connection "upgrade";
184 | proxy_set_header Host $host;
185 | proxy_set_header X-Real-IP $remote_addr;
186 | proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
187 | proxy_set_header X-Forwarded-Proto https;
188 | proxy_next_upstream off;
189 | proxy_connect_timeout 30;
190 | proxy_read_timeout 300;
191 | proxy_send_timeout 300;
192 | }
193 |
194 |
195 | location /loan-master {
196 | client_max_body_size 16m;
197 | client_body_buffer_size 128k;
198 | proxy_pass http://127.0.0.1:8081/loan-master;
199 | proxy_set_header Upgrade $http_upgrade;
200 | proxy_set_header Connection "upgrade";
201 | proxy_set_header Host $host;
202 | proxy_set_header X-Real-IP $remote_addr;
203 | proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
204 | proxy_set_header X-Forwarded-Proto https;
205 | proxy_next_upstream off;
206 | proxy_connect_timeout 30;
207 | proxy_read_timeout 300;
208 | proxy_send_timeout 300;
209 | }
210 |
211 |
212 | location /wxmp {
213 | client_max_body_size 16m;
214 | client_body_buffer_size 128k;
215 | proxy_pass http://127.0.0.1:8081/wxmp;
216 | proxy_set_header Upgrade $http_upgrade;
217 | proxy_set_header Connection "upgrade";
218 | proxy_set_header Host $host;
219 | proxy_set_header X-Real-IP $remote_addr;
220 | proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
221 | proxy_set_header X-Forwarded-Proto https;
222 | proxy_next_upstream off;
223 | proxy_connect_timeout 30;
224 | proxy_read_timeout 300;
225 | proxy_send_timeout 300;
226 | }
227 |
228 | location /wechat {
229 | client_max_body_size 16m;
230 | client_body_buffer_size 128k;
231 | proxy_pass http://127.0.0.1:8084/wechat;
232 | proxy_set_header Upgrade $http_upgrade;
233 | proxy_set_header Connection "upgrade";
234 | proxy_set_header Host $host;
235 | proxy_set_header X-Real-IP $remote_addr;
236 | proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
237 | proxy_set_header X-Forwarded-Proto https;
238 | proxy_next_upstream off;
239 | proxy_connect_timeout 30;
240 | proxy_read_timeout 600;
241 | proxy_send_timeout 300;
242 | }
243 |
244 |
245 |
246 | }
247 |
248 |
249 |
250 |
251 |
252 |
253 |
254 | }
255 |
256 | ```
257 |
258 |
--------------------------------------------------------------------------------
141 |
142 | 参考:https://blog.csdn.net/qq_35379598/article/details/80925458
143 |
144 | #### HDFS 体系结构与基本概念
145 |
146 | - 我们通过 hadoop shell 上传的文件是存放在 DataNode 的 block 中,通过 linux shell 是看
147 | 不到文件的,只能看到 block。
148 | - 可以一句话描述 HDFS:把客户端的大文件存放在很多节点的数据块中。在这里,出现 了三个关键词:文件、节点、数据块。HDFS就是围绕着这三个关键词设计的
149 |
150 | **NameNode**
151 | - NameNode 的作用是管理文件目录结构,是管理数据节点的。名字节点维护两套数据,
152 | 一套是文件目录与数据块之间的关系,另一套是数据块与节点之间的关系。前一套数据是静 态的,是存放在磁盘上的,通过 fsimage 和edits 文件来维护;后一套数据是动态的,不持 久化到磁盘的,每当集群启动的时候,会自动建立这些信息。
153 |
154 | DataNode
155 | --------
156 | - DataNode 的作用 是 HDFS 中真正存储数据的。 DataNode 在存储数据的时候是按照 block
157 | 为单位读写数据的。block 是 hdfs 读写数据的基本单位。
158 | - 假设文件大小是 100GB,从字节位置 0 开始,每 64MB 字节划分为一个 block,以依此 类推,可以划分出很多的 block。每个 block 就是 64MB 大小。
159 | - block 本质上是一个逻辑概念,意味着 block 里面不会真正的存储数据,只是划分文件的
160 |
161 | SecondaryNameNode
162 | -----------------
163 | SNN 只有一个职责,就是合并 NameNode 中的 edits 到 fsimage 中
164 |
--------------------------------------------------------------------------------
/docs/2019/分析CountDownLatch源码.md:
--------------------------------------------------------------------------------
1 | 
2 | ## 概述
3 | * 允许一个线程的或多个线程等待其他线程完成操作。和join方法类似,初始化对象时通过传入一个固定的计数器总数,线程方法执行时调用countDown给计数器减1,当计数器0时,就会恢复等待的线程继续执行。
4 | * CountDownLatch的计数器不能重用。只能使用一次
5 | *常用的使用场景是提升程序的并行效率,同时处理多个任务后,最后需要提示任务完成。类似的表格的批量解析读取。
6 |
7 | ## 使用方法
8 | ### 一个线程等待
9 | ```java
10 | static CountDownLatch c=new CountDownLatch(2);
11 | public static void main(String[] args) throws InterruptedException {
12 | System.out.println("初始化任务数:"+c.getCount());
13 | new Thread(()->{
14 | System.out.println("任务1执行");
15 | c.countDown();
16 | System.out.println("任务2执行");
17 | c.countDown();
18 | }).start();;
19 | c.await();
20 | System.out.println("任务执行完毕!");
21 | }
22 | ```
23 | 输出结果
24 | ```java
25 | 初始化任务数:2
26 | 任务1执行
27 | 任务2执行
28 | 任务执行完毕!
29 |
30 | ```
31 |
32 | ### 多个线程等待
33 | ```java
34 | static CountDownLatch countDownLatch=new CountDownLatch(3);
35 | //汇总任务
36 | static class T1 extends Thread{
37 | @Override
38 | public void run() {
39 | try {
40 | countDownLatch.await();
41 | } catch (InterruptedException e) {
42 | e.printStackTrace();
43 | }
44 |
45 | System.out.println("所有表格已经读取完了,进行汇总处理");
46 | }
47 | }
48 |
49 | //批量处里表格数据任务
50 | static class task extends Thread{
51 | @Override
52 | public void run() {
53 | System.out.println(Thread.currentThread().getName() + ":开始处理表格数据");
54 | //处理完计数器就减1
55 | countDownLatch.countDown();
56 | }
57 | }
58 | public static void main(String[] args) throws InterruptedException {
59 | new T1().start();
60 | for (int i = 1; i <=3; i++) {
61 | new task().start(); //多线程读取表格
62 | }
63 |
64 | }
65 | ```
66 | 输出结果
67 | ```java
68 | Thread-1:开始处理表格数据
69 | Thread-2:开始处理表格数据
70 | Thread-3:开始处理表格数据
71 | 所有表格已经读取完了,进行汇总处理
72 | ```
73 | ## 源码分析
74 | ### 获取一个countDownLatch时
75 | 
76 | * 源码中可以看出是如果初始传入的j计数器为0时是直接抛出异常的;
77 | * 内部是通过new Sync一个内部返回一个对象的。Sync是一个内部同步器类,继承AQS。
78 |
79 | ### Sync内部类
80 | ```java
81 | private static final class Sync extends AbstractQueuedSynchronizer {
82 | private static final long serialVersionUID = 4982264981922014374L;
83 | //初始化同步状态,count就是传入的计数器
84 | Sync(int count) {
85 | setState(count);
86 | }
87 | //获取同步状态总数,就好像类似锁重入的总次数
88 | int getCount() {
89 | return getState();
90 | }
91 | /**
92 | /共享式获取同步,类似读写锁的读写,,但是这里只是获取,没有做其它操作
93 | state是一个volatile修饰的成员变量
94 | */
95 | protected int tryAcquireShared(int acquires) {
96 | return (getState() == 0) ? 1 : -1;
97 | }
98 | //共享式的释放同步状态,
99 | protected boolean tryReleaseShared(int releases) {
100 | // 自旋
101 | for (;;) {
102 | int c = getState();
103 | //为0 说明计数器已经减完了 直接返回false
104 | if (c == 0)
105 | return false;
106 | //不为0的操作。 获取当前同步状态总数减一
107 | int nextc = c-1;
108 | //CA方式设置state,成功返回true
109 | if (compareAndSetState(c, nextc))
110 | return nextc == 0;
111 | }
112 | }
113 | }
114 | ```
115 | ### await方法
116 |
117 | ```java
118 | public void await() throws InterruptedException {
119 | sync.acquireSharedInterruptibly(1);
120 | }
121 | ```
122 | * await方法是通过sync内部类调用AQS中的`acquireSharedInterruptibly()`方法
123 | * 执行`await`方法的线程会在计数器没有成为0时一直处于等待,除非线程被中断,支持可中断的。
124 |
125 | ```java
126 | public final void acquireSharedInterruptibly(int arg)
127 | throws InterruptedException {
128 | //判断是中断了
129 | if (Thread.interrupted())
130 | throw new InterruptedException();
131 | //这里是执行内部类的tryAcquireShared方法提供了具体实现,
132 | //就是获取同步状态的值,如果获取失败就会返回-1
133 | if (tryAcquireShared(arg) < 0)
134 | //获取同步状态失败 执行如下方法,这个方法以自旋的方式一直获取同步状态
135 | doAcquireSharedInterruptibly(arg);
136 | }
137 | private void doAcquireSharedInterruptibly(int arg)
138 | throws InterruptedException {
139 | final Node node = addWaiter(Node.SHARED);
140 | boolean failed = true;
141 | try {
142 | for (;;) {
143 | final Node p = node.predecessor();
144 | if (p == head) {
145 | int r = tryAcquireShared(arg);
146 | if (r >= 0) {
147 | setHeadAndPropagate(node, r);
148 | p.next = null; // help GC
149 | failed = false;
150 | return;
151 | }
152 | }
153 | if (shouldParkAfterFailedAcquire(p, node) &&
154 | parkAndCheckInterrupt())
155 | throw new InterruptedException();
156 | }
157 | } finally {
158 | if (failed)
159 | cancelAcquire(node);
160 | }
161 | }
162 | ```
163 | ### countDown执行计数器减法操作
164 | * countDownf方法每执行一次,计数器就减1,如果计数到达零,则释放所有等待的线程
165 | ```java
166 | public void countDown() {
167 | //通过内部类sync执行AQS中的共享式释放同步状态
168 | sync.releaseShared(1);
169 | }
170 | //AQS中的方法
171 | public final boolean releaseShared(int arg) {
172 | //tryReleaseShared方法是syncs实现了重写,如果返回true则说明释放同步状态失败
173 | if (tryReleaseShared(arg)) {
174 | //失败AQS doReleaseShared方法,
175 | doReleaseShared();
176 | return true;
177 | }
178 | return false;
179 | }
180 | ```
181 | * doReleaseShared方法会依自旋的方式不断尝试释放同步状态
182 |
183 | ```java
184 | private void doReleaseShared() {
185 | for (;;) {
186 | Node h = head;
187 | if (h != null && h != tail) {
188 | int ws = h.waitStatus;
189 | if (ws == Node.SIGNAL) {
190 | if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
191 | continue;
192 | unparkSuccessor(h);
193 | }
194 | else if (ws == 0 && !compareAndSetWaitStatus(h,0,Node.PROPAGATE))
195 | continue;
196 | }
197 | if (h == head)
198 | break;
199 | }
200 | }
201 | ```
202 | ## 总结
203 | * CountDownLatch是基于AQS实现的一个并发工具类,允许一个线程或多个线程等待其它线程操作,初始化是传入总的计数器,内部都通过`new Sync`一个返回一个对象。当调用countDown()方法 就会吧计数器做递减,当计数器为0时,就会恢复等待的线程继续执行,计数到达零之前,await 方法会一直受阻塞。
204 |
--------------------------------------------------------------------------------
/docs/Spring/SpringBootAdmin.md:
--------------------------------------------------------------------------------
1 | ## 介绍
2 | Spring Boot Admin应用监控
3 |
4 | - Spring Boot Admin 是一个管理和监控Spring Boot 应用程序的开源软件。每个应用都认为是一个客户端,通过HTTP或者使用 Eureka注册到admin server中进行展示,Spring Boot Admin UI部分使用AngularJs将数据展示在前端。
5 | - Spring Boot Admin 是一个针对spring-boot的actuator接口进行UI美化封装的监控工具。他可以:在列表中浏览所有被监控spring-boot项目的基本信息,详细的Health信息、内存信息、JVM信息、垃圾回收信息、各种配置信息(比如数据源、缓存列表和命中率)等,还可以直接修改logger的level。
6 |
7 | ## 设置Spring Boot Admin Server
8 | - 新建一个springBoot2.x工程,将Spring Boot Admin Server启动器添加到pom.xml
9 | - 使用ide新建工程可以直接选择引入Spring Boot Admin
10 |
11 | ```
12 |
13 | de.codecentric
14 | spring-boot-admin-starter-server
15 |
16 |
17 | org.springframework.boot
18 | spring-boot-starter-test
19 | test
20 |
21 |
22 | org.springframework.boot
23 | spring-boot-starter-web
24 |
25 |
26 | de.codecentric
27 | spring-boot-admin-server-ui
28 |
29 |
30 | org.springframework.boot
31 | spring-boot-starter-security
32 |
33 | ```
34 | ## 启动类添加如下注解
35 |
36 | ```
37 | @SpringBootApplication
38 | @EnableAdminServer
39 | public class SpringbootAdminApplication {
40 |
41 | public static void main(String[] args) {
42 | SpringApplication.run(SpringbootAdminApplication.class, args);
43 | }
44 | }
45 | ```
46 | ## 添加身份验证和授权
47 |
48 | ```
49 | @Configuration
50 | public class SecuritySecureConfig extends WebSecurityConfigurerAdapter {
51 |
52 |
53 |
54 | private final String adminContextPath;
55 |
56 | public SecuritySecureConfig(AdminServerProperties adminServerProperties) {
57 | this.adminContextPath = adminServerProperties.getContextPath();
58 | }
59 |
60 | @Override
61 | protected void configure(HttpSecurity http) throws Exception {
62 | // @formatter:off
63 | SavedRequestAwareAuthenticationSuccessHandler successHandler = new SavedRequestAwareAuthenticationSuccessHandler();
64 | successHandler.setTargetUrlParameter("redirectTo");
65 | successHandler.setDefaultTargetUrl(adminContextPath + "/");
66 |
67 | http.authorizeRequests()
68 | //授予对所有静态资产和登录页面的公共访问权限。
69 | .antMatchers(adminContextPath + "/assets/**").permitAll()
70 | .antMatchers(adminContextPath + "/login").permitAll()
71 | //必须对每个其他请求进行身份验证
72 | .anyRequest().authenticated()
73 | .and()
74 | // 配置登录和注销。
75 | .formLogin().loginPage(adminContextPath + "/login").successHandler(successHandler).and()
76 | .logout().logoutUrl(adminContextPath + "/logout").and()
77 | //启用HTTP-Basic支持。这是Spring Boot Admin Client注册所必需的
78 | .httpBasic().and()
79 | .csrf()
80 | //使用Cookie启用CSRF保护
81 | .csrfTokenRepository(CookieCsrfTokenRepository.withHttpOnlyFalse())
82 | .ignoringAntMatchers(
83 | adminContextPath + "/instances", //禁用CRSF-Protection Spring Boot Admin Client用于注册的端点。
84 | adminContextPath + "/actuator/**" //
85 | );
86 | // @formatter:on
87 | }
88 | }
89 |
90 | ```
91 |
92 | ## application.properties配置文件
93 |
94 | ```
95 | server.port=8088
96 | server.tomcat.uri-encoding=UTF-8
97 | server.tomcat.max-threads=1000
98 | server.tomcat.min-spare-threads=30
99 | #账户密码
100 | spring.security.user.name=gzpflm
101 | spring.security.user.password=gzpflm
102 | #项目访问名
103 | spring.boot.admin.context-path=/szq-monitoring
104 | #UI界面标题
105 | spring.boot.admin.ui.title=szq-Monitpring
106 |
107 | ```
108 | 启动运行:http://localhost:8088/szq-monitoring/login 出现登录界面表示成功
109 | 
110 |
111 | ## Spring Boot客户端配置监控
112 | - 客户端需要配置账户密码 不然无法注册到springBoot Admin
113 | - 每个要注册的应用程序都必须包含Spring Boot Admin Client 配置如下
114 | ```
115 |
116 | de.codecentric
117 | spring-boot-admin-starter-client
118 |
119 | ```
120 | **application.properties配置文件**
121 |
122 | ```
123 | server.port=8081
124 | spring.application.name=Spring Boot Client
125 | spring.boot.admin.client.url=http://localhost:8088/szq-monitoring
126 | management.endpoints.web.exposure.include=*
127 | spring.boot.admin.client.username=gzpflm
128 | spring.boot.admin.client.password=gzpflm
129 | spring.boot.admin.client.enabled=true
130 | #启用ip显示
131 | spring.boot.admin.client.instance.prefer-ip=true
132 | #注册的service-url值
133 | spring.boot.admin.client.instance.service-url=http://localhost:8081
134 | ```
135 | 启动后:监控的服务端就会收到通知 刷新页面就可以看到监控的服务
136 | 
137 |
138 | 
139 |
140 |
141 | ## Spring Boot Admin Client配置选项
142 |
143 | ```
144 | spring.boot.admin.client.enabled #启用Spring Boot Admin Client,默认值true
145 | spring.boot.admin.client.url #逗号分隔Spring Boot Admin服务器的有序URL列表以进行注册
146 | spring.boot.admin.client.api-path #管理服务器上的注册端点的Http路径 默认值"instances"
147 | #SBA Server api受HTTP基本身份验证保护时的用户名和密码。
148 | spring.boot.admin.client.username
149 | spring.boot.admin.client.password
150 | spring.boot.admin.client.period #重复注册的间隔(以ms为单位)默认自10,000
151 | spring.boot.admin.client.connect-timeout #连接超时进行注册(以ms为单位 #默认5,000
152 | ```
153 | ## 官方配置
154 | http://codecentric.github.io/spring-boot-admin/current/#register-clients-via-spring-boot-admin
155 |
156 | 打jar包放到linux服务器后台运行模式
157 |
158 | ```
159 | java -jar spring-boot01-1.0-SNAPSHOT.jar > log.file 2>&1 &
160 | ```
161 |
162 | ## 邮件通知配置
163 | ```
164 | spring.mail.host=smtp.qq.com
165 | spring.mail.username=870439570@qq.com
166 | #qq邮箱开通的授权码
167 | spring.mail.password=qq邮箱开通的授权码
168 | spring.mail.properties.mail.smtp.auth=true
169 | spring.mail.properties.mail.smtp.starttls.enable=true
170 | spring.mail.properties.mail.smtp.starttls.required=true
171 | # 发送给谁
172 | spring.boot.admin.notify.mail.to=qinxw@brh99.com
173 | # 是谁发送出去的
174 | spring.boot.admin.notify.mail.from=870439570@qq.com
175 | ```
176 | **QQ邮箱开通邮件客户端方法**
177 | - 登录邮箱 进入设置-》账户-》开启IMAP/SMTP服务获取授权码
178 | 
179 |
180 | 重启项目后 如果注服务下线就会收到邮件通知
181 | 
182 |
--------------------------------------------------------------------------------
/docs/2019/CyclicBarrier.md:
--------------------------------------------------------------------------------
1 | ## 概述
2 | * CyclicBarrie允许让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。
3 | * CyclicBarrier只能唤起一个任务,CountDownLatch可以同时唤起多个任务
4 | * CyclicBarrier可重用,CountDownLatch不可重用,计数值为0该CountDownLatch就不可再用了
5 |
6 | ## 方法摘要
7 | * `CyclicBarrie`有两个构造方法,`CyclicBarrier(int parties) ` 创建一个新的 `CyclicBarrier`,它将在给定数量的参与者(线程)处于等待状态时启动,但它不会在启动 barrier 时执行预定义的操作。
8 | * `CyclicBarrier(int parties, Runnable barrierAction) ` 多了一个传入的屏障被唤醒时指定优先执行的方法,该操作由最后一个进入 barrier 的线程执行。
9 | * `await() ` 在所有参与者都已经在此 barrier 上调用 await 方法之前,将一直等待。
10 | * `await(long timeout, TimeUnit unit) ` 在所有参与者都已经在此屏障上调用 await 方法之前将一直等待,或者超出了指定的等待时间。
11 | * `int getNumberWaiting() ` 返回当前在屏障处等待的参与者数目。
12 | * `int getParties() ` 返回要求启动此 barrier 的参与者数目。
13 | * `boolean isBroken() ` 查询此屏障是否处于损坏状态。
14 | * `void reset() `将屏障重置为其初始状态。
15 | ## 如何使用
16 |
17 | ```java
18 | public class CyclicBarrierTest {
19 | private static CyclicBarrier c;
20 | //批量处里表格数据任务
21 | static class task extends Thread{
22 | @Override
23 | public void run() {
24 | System.out.println(Thread.currentThread().getName() + ":开始处理表格数据");
25 | try {
26 | //处理完计数器就减1
27 | c.await();
28 | }catch (Exception e){
29 |
30 | }
31 | }
32 | }
33 | public static void main(String[] args) throws InterruptedException {
34 | //初始化屏障总数,并指定优先执行的方法,该操作由最后一个进入 barrier 的线程执行。
35 | c=new CyclicBarrier(3, new Runnable() {
36 | @Override
37 | public void run() {
38 | System.out.println("屏障已到达,开始汇总任务执行。。。。");
39 | }
40 | });
41 |
42 | for (int i = 1; i <=3 ; i++) {
43 | new task().start();
44 | }
45 | }
46 | }
47 | ```
48 | 输出
49 |
50 | ```java
51 | Thread-0:开始处理表格数据
52 | Thread-1:开始处理表格数据
53 | Thread-2:开始处理表格数据
54 | 屏障已到达,开始汇总任务执行。。。。
55 | ```
56 |
57 | ## 源码分析
58 | ### 初始化
59 | ```java
60 | /** 重入 */
61 | private final ReentrantLock lock = new ReentrantLock();
62 | private final Condition trip = lock.newCondition();
63 | private final int parties;
64 | private final Runnable barrierCommand;
65 | private Generation generation = new Generation();
66 | private int count;
67 | public CyclicBarrier(int parties, Runnable barrierAction) {
68 | if (parties <= 0) throw new IllegalArgumentException();
69 | this.parties = parties;
70 | this.count = parties;
71 | this.barrierCommand = barrierAction;
72 | }
73 | public CyclicBarrier(int parties) {
74 | this(parties, null);
75 | }
76 | ```
77 | * 可以看出屏障计数器不能为0 。内部是依赖重入锁ReentrantLock和Condition实现的,这点和CountDownLatch不一样。
78 |
79 | ### await()方法
80 | ```java
81 | public int await() throws InterruptedException, BrokenBarrierException {
82 | try {
83 | return dowait(false, 0L);
84 | } catch (TimeoutException toe) {
85 | throw new Error(toe); // cannot happen
86 | }
87 | }
88 | ```
89 | * `await()`方法主要依靠`dowait`方法时u,会让线程会到达屏障点时一直处于等待中
90 |
91 | ```java
92 | private int dowait(boolean timed, long nanos)
93 | throws InterruptedException, BrokenBarrierException, TimeoutException {
94 | final ReentrantLock lock = this.lock;
95 | lock.lock(); //加锁
96 | try {
97 | //屏障的每次使用都表示为生成实例,每当屏障被触发或重置时,生成都会改变
98 | final Generation g = generation;
99 | //broken破碎的意思,检测Generation是否破碎,就抛出异常。
100 | if (g.broken)
101 | throw new BrokenBarrierException();
102 | //检测到线程执行了中断操作,抛异常,终止CyclicBarrie操作
103 | if (Thread.interrupted()) {
104 | //将当前屏障生成设置为已断开(broken置为true),并唤醒所有人。仅在持锁时调用。
105 | breakBarrier();
106 | throw new InterruptedException();
107 | }
108 | //每当有线程执await时,屏障总数就递减1一个
109 | int index = --count;
110 | //屏障数为0时,说明线程都已到达屏障点,开门执行
111 | if (index == 0) { // tripped
112 | boolean ranAction = false;
113 | try {
114 | final Runnable command = barrierCommand;
115 | //触发线构造函数时,传入的优先执行的线程任务,如果有
116 | if (command != null)
117 | command.run();
118 | ranAction = true;
119 | //唤醒所有等待线程,并重新初始化Generation ,broken置为false
120 | nextGeneration();
121 | return 0;
122 | } finally {
123 | // 如果唤醒失败,
124 | if (!ranAction)
125 | //则中断CyclicBarrier,并唤醒所有等待线程
126 | breakBarrier();
127 | }
128 | }
129 | // 屏障未到达时的逻辑,一个死循坏, 自选操作
130 | for (;;) {
131 | try {
132 | //如果未指定超时等待时间,则调用Condition.await()方法使线程处于等待
133 | if (!timed)
134 | trip.await();
135 | //如果指定了超时等待时间大于0,则使用Condition的超时等待方法
136 | else if (nanos > 0L)
137 | nanos = trip.awaitNanos(nanos);
138 | } catch (InterruptedException ie) {
139 | //发生异常处理操作
140 | if (g == generation && ! g.broken) {
141 | breakBarrier();
142 | throw ie;
143 | } else {
144 | //中断当前线程
145 | Thread.currentThread().interrupt();
146 | }
147 | }
148 | // generation 破碎时(中断操作),则抛异常,
149 | if (g.broken)
150 | throw new BrokenBarrierException();
151 | if (g != generation)
152 | return index;
153 | //超时等待了 唤醒所又线程,并抛出异常
154 | if (timed && nanos <= 0L) {
155 | breakBarrier();
156 | throw new TimeoutException();
157 | }
158 | }
159 | } finally {
160 | //释放锁
161 | lock.unlock();
162 | }
163 | }
164 | ```
165 | * 当线程调用`await`方法,首先会拿到`ReentrantLock` 重入锁执行加锁操作,然后判断是否有线程执行了中断操作,如果有则抛出异常,没有就继续向下执行,把屏障计数器做递减操作,然后判断这个屏障计数器是否为0 ,如果递减后的计数器等于0,则表明所有线程都已到达屏障点。
166 | * 然后判断是否有传入指定的优先执行任务,如果有则先启动这个任务,然后唤醒所有等待的线程,重置屏障计数器`count`和`Generation`
167 | * 如果屏障值不为0,则执行一个死循环,也就是自选操作。自选操作中,会先判断是否制定了超时等待时间,如果没有指定就执行`Condition`的`await`方法,让线程一直处于等待中,除非被唤醒或有其它线程执行了中断CyclicBarrier操作。
168 | * 如果制定了超时等待时间,则执行`Condition`的超时等待方法,让线程一直处于等待中,除非被唤醒或到达超时等待时间
169 |
170 | ## 总结
171 | * `CyclicBarrier`的某个线程运行到某个点上之后,该线程即停止运行,直到所有的线程都到达了这个点,所有线程才重新运行;`CountDownLatch`则不是,某线程运行到某个点上之后,只是给某个数值-1而已,该线程继续运行
172 | * `CyclicBarrier`只能唤起一个任务,`CountDownLatch`可以唤起多个任务
173 | * `CyclicBarrier`可重用,`CountDownLatch`不可重用,计数值为`0`该`CountDownLatch`就不可再用了
174 | * `CountDownLatch`内部是基于`AQS`队列同步器实现,`CyclicBarrier`基于ReentrantLock和Condition实现等待机制和唤醒的
175 |
--------------------------------------------------------------------------------
/docs/2019/Semaphore.md:
--------------------------------------------------------------------------------
1 | ## 概述
2 | * `Semaphore` 通常用于限制可以访问某些资源(物理或逻辑的)的线程数目。
3 | * 比如数据库的连接资源是非常有限的,如果同时有上千个线程去数据获取连接,对数据造成的压力是非常的,会造成数据库无法连接而报错,`Semaphore`就可以限制此类问题
4 | * `Semaphore`有非公平和公平模式,默认是非公平的。当`Semaphore`设置为1时,可以排它锁使用,同一个时刻,只能限制一个线程访问。和`CountDownLatch`一样的,内部都有一个Sync内部类,基于AQS实现同步状态的释放和获取。
5 |
6 | ## Semaphore提供的方法
7 | * `Semaphore(int permits) ` 创建非公平的指定许可数的信号量
8 | * `Semaphore(int permits, boolean fair) ` 创建指定的许可数和指定是否是公平模式的信号量
9 | * `void acquire() ` 从此信号量获取一个许可,在提供一个许可前一直将线程阻塞,否则线程被中断
10 | * `void acquire(int permits) ` 从此信号量获取给定数目的许可,在提供这些许可前一直将线程阻塞,或者线程已被中断。
11 | * `int availablePermits() ` 返回此信号量中当前可用的许可数。
12 | * `int getQueueLength() ` 返回正在等待获取的线程的估计数目。
13 | * `boolean hasQueuedThreads() ` 查询是否有线程正在等待获取。
14 | * `Collection getQueuedThreads() ` 返回一个 collection,包含可能等待获取的线程。
15 | * `reducePermits(int reduction) ` 根据指定的缩减量减小可用许可的数目。
16 | * `release() ` 释放一个许可,将其返回给信号量。
17 | * `release(int permits) ` 返回标识此信号量的字符串,以及信号量的状态。
18 | *
19 | ## 使用方法
20 |
21 | ```java
22 | public class SemaphoreTest {
23 | static Semaphore s=new Semaphore(3); //非公平
24 |
25 | static class Task implements Runnable{
26 | @Override
27 | public void run() {
28 |
29 | try {
30 | s.acquire(); //获取一个许可
31 | System.out.println(Thread.currentThread().getName()+" 获取一个许可开始执行...");
32 | Thread.sleep(1000);
33 | System.out.println(Thread.currentThread().getName()+" 退出。");
34 | }catch (Exception e){
35 | }finally {
36 | s.release(); //规划一个许可
37 | }
38 | }
39 | }
40 | public static void main(String[] args) {
41 | for (int i = 0; i <=5 ; i++) {
42 | new Thread(new Task()).start();
43 | }
44 | }
45 | }
46 |
47 | ```
48 | * 输出结果,可以看出同一时刻只能三个线程进入执行,当有一个线程退出归还许可后,立马就会有其余线程去竞争这个多出的许可。
49 |
50 | ```java
51 | Thread-0 获取一个许可开始执行...
52 | Thread-1 获取一个许可开始执行...
53 | Thread-2 获取一个许可开始执行...
54 | Thread-2 退出。
55 | Thread-1 退出。
56 | Thread-3 获取一个许可开始执行...
57 | Thread-0 退出。
58 | Thread-4 获取一个许可开始执行...
59 | Thread-5 获取一个许可开始执行...
60 | Thread-4 退出。
61 | Thread-3 退出。
62 | Thread-5 退出
63 | ```
64 | ## 源码分析
65 | ### 初始化一个信号时
66 | * 当执行`new Semaphore(3)`时,默认是非公平的实现方式。看看内部是如何是实现的
67 |
68 | ```java
69 | public Semaphore(int permits) {
70 | sync = new NonfairSync(permits);
71 | }
72 | ```
73 | * 源码中可以看出是通过`NonfairSync``这个`内部类返回的一个实列,`NonfairSync`是`Sync`子类。
74 | ### acquire 获取一个许可
75 | ```java
76 | public void acquire() throws InterruptedException {
77 | sync.acquireSharedInterruptibly(1);
78 | }
79 | ```
80 | * 获取许可时调用的是AQS中的`acquireSharedInterruptibly`方法,以共享模式获同步状态,如果被中断则中止。
81 |
82 | ```java
83 | public final void acquireSharedInterruptibly(int arg)
84 | throws InterruptedException {
85 | // 判断线程是否中断
86 | if (Thread.interrupted())
87 | throw new InterruptedException();
88 |
89 | if (tryAcquireShared(arg) < 0)
90 | //获取同步状态失败 执行如下方法,这个方法以自旋的方式一直获取同步状态
91 | doAcquireSharedInterruptibly(arg);
92 | }
93 | ```
94 | * `tryAcquireShared`由Sync类提供实现,非公平模式调用`NonfairSync`的,否则调用`FairSync`类的方法
95 |
96 | ### 非公平
97 | ```java
98 | static final class NonfairSync extends Sync {
99 | private static final long serialVersionUID = -2694183684443567898L;
100 |
101 | NonfairSync(int permits) {
102 | super(permits);
103 | }
104 | //获取锁
105 | protected int tryAcquireShared(int acquires) {
106 | // Sync类的非公平获取同步状态方法
107 | return nonfairTryAcquireShared(acquires);
108 | }
109 | }
110 | ```
111 |
112 | ### 公平
113 | ```java
114 | static final class FairSync extends Sync {
115 | private static final long serialVersionUID = 2014338818796000944L;
116 |
117 | FairSync(int permits) {
118 | super(permits);
119 | }
120 | //公平模式获取信号量
121 | protected int tryAcquireShared(int acquires) {
122 | //自旋操作
123 | for (;;) {
124 | //公平模式,先要判断该线程是否位于CLH同步队列的列头
125 | if (hasQueuedPredecessors())
126 | return -1;
127 | //获取同步状态总数(信号量)
128 | int available = getState();
129 | //当前信号量减去获取的acquires个信号。
130 | int remaining = available - acquires;
131 | //CAS方式设置信号量。unsafe类提供实现,返回信号量
132 | if (remaining < 0 ||
133 | compareAndSetState(available, remaining))
134 | return remaining;
135 | }
136 | }
137 | }
138 | ```
139 | * Sync`是继承AQS队列同步器,是自定义同步组件的具体的实现。
140 | ```java
141 | abstract static class Sync extends AbstractQueuedSynchronizer {
142 | private static final long serialVersionUID = 1192457210091910933L;
143 |
144 | Sync(int permits) {
145 | setState(permits);
146 | }
147 |
148 | final int getPermits() {
149 | return getState();
150 | }
151 | //非公平获取信号量
152 | final int nonfairTryAcquireShared(int acquires) {
153 | //自旋
154 | for (;;) {
155 | //获取同步状态总数(信号量)
156 | int available = getState();
157 | //当前信号量减去获取的acquires个信号。
158 | int remaining = available - acquires;
159 | //CAS方式设置信号量。unsafe类提供实现,返回信号量
160 | if (remaining < 0 ||
161 | compareAndSetState(available, remaining))
162 | return remaining;
163 | }
164 | }
165 |
166 |
167 | final void reducePermits(int reductions) {
168 | for (;;) {
169 | int current = getState();
170 | int next = current - reductions;
171 | if (next > current) // underflow
172 | throw new Error("Permit count underflow");
173 | if (compareAndSetState(current, next))
174 | return;
175 | }
176 | }
177 |
178 | final int drainPermits() {
179 | for (;;) {
180 | int current = getState();
181 | if (current == 0 || compareAndSetState(current, 0))
182 | return current;
183 | }
184 | }
185 | }
186 | ```
187 | * 从源码中得出,Semaphore获取信号量许可时,公平和非公平的区别是,公平模式首先判断当前线程是否位于CLH同步队列的队列头中。
188 | * 而非公平模式是的竞争是抢占式,谁竞争到就谁获取。
189 | * 先是获取当前信号总数减去`acquires`个许可信号,然后以CAS方式设置CAS方式设置信号,并返回新的信号总数。CAS内部是依赖于AQS队列同步器中的`unsafel`类提供实现。
190 |
191 | ### release归还许可
192 |
193 | ```java
194 | public void release() {
195 | sync.releaseShared(1);
196 | }
197 | public final boolean releaseShared(int arg) {
198 | if (tryReleaseShared(arg)) {
199 | doReleaseShared();
200 | return true;
201 | }
202 | return false;
203 | }
204 | ```
205 | * 释放信号量 `release` 首先会调用AQS`releaseShared`.
206 | * `tryReleaseShared` 会调用`Sync`的`tryReleaseShared`方法
207 | * 释放操作时以自旋方式执行,首先获取总的信号建去要释放的信号量,然后判断这个信号量是否小于大于总的信号量,如果大于则抛出异常,否则以CAS的方式设置信号量
208 |
209 | ```java
210 | //释放同步状态,也就是归还信号量
211 | protected final boolean tryReleaseShared(int releases) {
212 | // 自旋操作
213 | for (;;) {
214 | int current = getState();
215 | int next = current + releases;
216 | if (next < current) // overflow
217 | throw new Error("Maximum permit count exceeded");
218 | if (compareAndSetState(current, next))
219 | return true;
220 | }
221 | }
222 | ```
223 | ## 总结
224 | * 从源码中可以看出Semaphore的实现方式主要是依靠AQS实现的,以`state`同步状态成变量作为信号量的总数,获取和释放都是以CAS+自旋操作的方式设置`state`成员变量。
225 | * JDK并发包中的工具了哦都是AQS为基石实现的。大多都是使用CAS+自旋的方式去改变state来达到锁的获和释放
226 |
--------------------------------------------------------------------------------
/docs/2019/Hystrix原理解析.md:
--------------------------------------------------------------------------------
1 | ## hystrix与高可用系统架构
2 | - hystrix,框架,提供了高可用相关的各种各样的功能,然后确保说在hystrix的保护下,整个系统可以长期处于高可用的状态,100%,99.99999%
3 | - hystrix的特点:线程资源隔离、限流、熔断、降级、运维监控
4 | - 资源隔离:让你的系统里,某一块东西,在故障的情况下,不会耗尽系统所有的资源,比如线程资源
5 | - 限流:高并发的流量涌入进来,比如说突然间一秒钟100万QPS,废掉了,10万QPS进入系统,其他90万QPS被拒绝了
6 | - 熔断:系统后端的一些依赖,出了一些故障,比如说mysql挂掉了,每次请求都是报错的,熔断了,后续的请求过来直接不接收了,拒绝访问,10分钟之后再尝试去看看mysql恢复没有
7 | - 降级:mysql挂了,系统发现了,自动降级,从内存里存的少量数据中,去提取一些数据出来
8 | - 运维监控:监控+报警+优化,各种异常的情况,有问题就及时报警,优化一些系统的配置和参数,或者代码
9 |
10 | ### Hystrix的设计原则是什么
11 | - 1)对依赖服务调用时出现的调用延迟和调用失败进行控制和容错保护
12 | - 2)在复杂的分布式系统中,阻止某一个依赖服务的故障在整个系统中蔓延
13 | - 3)提供fail-fast(快速失败)和快速恢复的支持
14 | - 4)提供fallback优雅降级的支持
15 | - 5)支持近实时的监控、报警以及运维操作
16 |
17 | ### Hystrix的更加细节的设计原则是什么
18 | - 1)阻止任何一个依赖服务耗尽所有的资源,比如tomcat中的所有线程资源
19 | - 2)避免请求排队和积压,采用限流和fail fast来控制故障
20 | - 3)提供fallback降级机制来应对故障
21 | - 4)使用资源隔离技术,比如bulkhead(舱壁隔离技术),swimlane(泳道技术),circuit breaker(短路技术),来限制任何一个依赖服务的故障的影响
22 | - 5)通过近实时的统计/监控/报警功能,来提高故障发现的速度
23 | - 6)通过近实时的属性和配置热修改功能,来提高故障处理和恢复的速度
24 | - 7)保护依赖服务调用的所有故障情况,而不仅仅只是网络故障情况
25 |
26 | ### Hystrix是如何实现它的目标的
27 | - 1)通过`HystrixCommand`或者`HystrixObservableCommand`来封装对外部依赖的访问请求,这个访问请求一般会运行在独立的线程中,资源隔离
28 | - 2)对于超出我们设定阈值的服务调用,直接进行超时,不允许其耗费过长时间阻塞住。这个超时时间默认是`99.5%`的访问时间,但是一般我们可以自己设置一下
29 | - 3)为每一个依赖服务维护一个`独立的线程池`,或者是`semaphore`,当线程池已满时,直接拒绝对这个服务的调用
30 | - 4)对依赖服务的调用的成功次数,失败次数,拒绝次数,超时次数,进行统计
31 | - 5)如果对一个依赖服务的调用失败次数超过了一定的阈值,自动进行熔断,在一定时间内对该服务的调用直接降级,一段时间后再自动尝试恢复
32 | - 6)当一个服务调用出现失败,被拒绝,超时,短路等异常情况时,自动调用fallback降级机制
33 | - 7)对属性和配置的修改提供近实时的支持
34 | - hystrix进行资源隔离,其实是提供了一个抽象,叫做command,就是说,你如果要把对某一个依赖服务的所有调用请求,全部隔离在同一份资源池内。对这个依赖服务的所有调用请求,全部走这个资源池内的资源,不会去用其他的资源了,这个就叫做资源隔离
35 | - hystrix最最基本的资源隔离的技术,线程池隔离技术,对某一个依赖服务,商品服务,所有的调用请求,全部隔离到一个线程池内,对商品服务的每次调用请求都封装在一个command里面,每个command(每次服务调用请求)都是使用线程池内的一个线程去执行的。所以哪怕是对这个依赖服务,商品服务,现在同时发起的调用量已经到了1000了,但是线程池内就10个线程,最多就只会用这10个线程去执行。不会说,对商品服务的请求,因为接口调用延迟,将tomcat内部所有的线程资源全部耗尽,不会出现了
36 |
37 | ### Hystrix常用方法
38 | - HystrixCommand:是用来获取一条数据的
39 | - HystrixObservableCommand:是设计用来获取多条数据的
40 | - 同步执行:`new CommandHelloWorld("World").execute()`,`new ObservableCommandHelloWorld("World").toBlocking().toFuture().get()`
41 | - 异步执行:`new CommandHelloWorld("World").queue()`,`new ObservableCommandHelloWorld("World").toBlocking().toFuture()`
42 | - 对command调用queue(),仅仅将command放入线程池的一个等待队列,就立即返回,拿到一个Future对象,后面可以做一些其他的事情,然后过一段时间对future调用get()方法获取数据
43 |
44 | ### Hystrix不同的执行方式
45 | - execute(),获取一个 Future.get(),然后拿到单个结果。
46 | - queue(),返回一个 Future。
47 | - observe(),立即订阅 Observable,然后启动 8 大执行步骤,返回一个拷贝的 - Observable,订阅时立即回调给你结果。
48 | - toObservable(),返回一个原始的 Observable,必须手动订阅才会去执行 8 大步骤。
49 |
50 | ### Hystrix常见参数设置
51 | - `withCircuitBreakerEnabled`:控制短路器是否允许工作,包括跟踪依赖服务调用的健康状况,以及对异常情况过多时是否允许触发短路,默认是true
52 | - `withCircuitBreakerRequestVolumeThreshold`:设置滑动窗口中,最少要有多少个请求时,才触发开启短路,举例来说,如果设置为20(默认值),那么在一个10秒的滑动窗口内,如果只有19个请求,即使这19个请求都是异常的,也是不会触发开启短路器的
53 | - `withCircuitBreakerSleepWindowInMilliseconds`:设置在短路之后,需要在多长时间内直接reject请求,然后在这段时间之后,尝试允许请求通过以及自动恢复,默认值是5000毫秒
54 | - `withCircuitBreakerErrorThresholdPercentage`:设置异常请求量的百分比,当异常请求达到这个百分比时,就触发打开短路器,默认是50,也就是50%
55 | - `withCircuitBreakerForceOpen`:如果设置为true的话,直接强迫打开短路器,相当于是手动短路了,手动降级,默认false
56 | - `withCircuitBreakerForceClosed`:如果设置为ture的话,直接强迫关闭短路器,相当于是手动停止短路了,手动升级,默认false
57 | - `execution.isolation.strategy`:strategy,设置为SEMAPHORE,那么hystrix就会用semaphore机制来替代线程池机制,来对依赖服务的访问进行限流,如果通过semaphore调用的时候,底层的网络调用延迟很严重,那么是无法timeout的,只能一直block住,一旦请求数量超过了semephore限定的数量之后,就会立即开启限流
58 | - `withCoreSize`:设置你的线程池的大小
59 | - `withMaxQueueSize:`设置的是你的等待队列,缓冲队列的大小
60 | - `withQueueSizeRejectionThreshol`:如果withMaxQueueSize 请求合并的三种级别:
125 |
126 | - global context,tomcat所有调用线程,对一个依赖服务的任何一个command调用都可以被合并在一起,hystrix就传递一个HystrixRequestContext
127 | - user request context,tomcat内某一个调用线程,将某一个tomcat线程对某个依赖服务的多个command调用合并在一起
128 | - object modeling,基于对象的请求合并,如果有几百个对象,遍历后依次调用每个对象的某个方法,可能导致发起几百次网络请求,基于hystrix可以自动将对多个对象模型的调用合并到一起
129 | - 使用请求合并技术的开销就是导致延迟大幅度增加,因为需要一定的时间将多个请求合并起来
130 |
131 |
132 |
--------------------------------------------------------------------------------
/docs/2019/分布式事务解决方案.md:
--------------------------------------------------------------------------------
1 | [TOC]
2 |
3 | ## 分布式事务
4 | - 分布式事务是指事务的参与者,支持事务的服务器,资源服务器分别位于分布式系统的不同节点之上,通常一个分布式事物中会涉及到对多个数据源或业务系统的操作。
5 | - 典型的分布式事务场景:跨银行转操作就涉及调用两个异地银行服务
6 |
7 | ### CAP理论
8 | - CAP理论:一个分布式系统不可能同时满足一致性,可用性和分区容错性这个三个基本需求,最多只能同时满足其中两项
9 | - 一致性(C):数据在多个副本之间是否能够保持一致的特性。
10 | - 可用性(A):是指系统提供的服务必须一致处于可用状态,对于每一个用户的请求总是在有限的时间内返回结果,超过时间就认为系统是不可用的
11 | - 分区容错性(P):分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非整个网络环境都发生故障。
12 |
13 | ### CAP定理的应用
14 | - 放弃P(CA):如果希望能够避免系统出现分区容错性问题,一种较为简单的做法就是将所有的数据(或者是与事物先相关的数据)都放在一个分布式节点上,这样虽然无法保证100%系统不会出错,但至少不会碰到由于网络分区带来的负面影响
15 | - 放弃A(CP):其做法是一旦系统遇到网络分区或其他故障时,那受到影响的服务需要等待一定的时间,应用等待期间系统无法对外提供正常的服务,即不可用
16 | - 放弃C(AP):这里说的放弃一致性,并不是完全不需要数据一致性,是指放弃数据的强一致性,保留数据的最终一致性。
17 |
18 |
19 | ### BASE理论
20 | - BASE是基本可用,软状态,最终一致性。是对CAP中一致性和可用性权限的结果,是基于CAP定理演化而来的,核心思想是即使无法做到强一致性,但每个应用都可以根据自身的业务特定,采用适当的方式来使系统达到最终一致性
21 |
22 | ### 2PC提交
23 | - 二阶段提交协议是将事务的提交过程分成提交事务请求和执行事务提交两个阶段进行处理。
24 |
25 | #### 阶段1:提交事务请求
26 | - 事务询问:协调者向所有的参与者发送事务内容,询问是否可以执行事务提交操作,并开始等待各参与者的响应
27 | - 执行事务:各参与者节点执行事务操作,并将Undo和Redo信息记入事务日志中
28 | - 如果参与者成功执事务操作,就反馈给协调者Yes响应,表示事物可以执行,如果没有成功执行事务,就反馈给协调者No响应,表示事务不可以执行
29 | - 二阶段提交一些的阶段一夜被称为投票阶段,即各参与者投票票表明是否可以继续执行接下去的事务提交操作
30 |
31 | #### 阶段二:执行事务提交
32 | - 假如协调者从所有的参与者或得反馈都是Yes响应,那么就会执行事务提交。
33 | - 发送提交请求:协调者向所有参与者节点发出Commit请求
34 | - 事务提交:参与者接受到Commit请求后,会正式执行事务提交操作,并在完成提交之后放弃整个事务执行期间占用的事务资源
35 | - 反馈事务提交结果:参与者在完成事物提交之后,向协调者发送ACK消息
36 | - 完成事务:协调者接收到所有参与者反馈的ACK消息后,完成事务
37 |
38 | #### 中断事务
39 | - 假如任何一个参与者向协调者反馈了No响应,或者在等待超市之后,协调者尚无法接收到所有参与者的反馈响应,那么就中断事务。
40 | - 发送回滚请求:协调者向所有参与者节点发出Rollback请求
41 | - 事务回滚:参与者接收到Rollback请求后,会利用其在阶段一种记录的Undo信息执行事物回滚操作,并在完成回滚之后释放事务执行期间占用的资源。
42 | - 反馈事务回滚结果:参与则在完成事务回滚之后,向协调者发送ACK消息
43 | - 中断事务:协调者接收到所有参与者反馈的ACk消息后,完成事务中断、
44 |
45 | > 优缺点
46 |
47 | - 原理简单,实现方便
48 | - 缺点是同步阻塞,单点问题,脑裂,保守
49 |
50 | ### 3PC提交
51 | - 三阶段提,也叫三阶段提交协议,是二阶段提交(2PC)的改进版本。
52 | - 与两阶段提交不同的是,三阶段提交有两个改动点。引入超时机制。同时在协调者和参与者中都引入超时机制。在第一阶段和第二阶段中插入一个准备阶段。保证了在最后提交阶段之前各参与节点的状态是一致的。
53 | - 三阶段提交就有CanCommit、PreCommit、DoCommit三个阶段。
54 |
55 |
56 | ## Seata分布式事务方案
57 | - Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
58 |
59 |
60 | ### Seata术语
61 | - TC:事务协调者。维护全局和分支事务的状态,驱动全局事务提交或回滚。
62 | - TM:事务管理器。定义全局事务的范围:开始全局事务、提交或回滚全局事务
63 | - RM:管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
64 |
65 | ### Seata的2PC方案
66 | - 一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
67 | - 二阶段:提交异步化,非常快速地完成。回滚通过一阶段的回滚日志进行反向补偿。
68 | - 一阶段本地事务提交前,需要确保先拿到 全局锁 。拿不到全局锁 ,不能提交本地事务。
69 | - 拿全局锁的尝试被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁。
70 | - 在数据库本地事务隔离级别读已提交或以上的基础上,Seata(AT 模式)的默认全局隔离级别是 读未提交
71 | - 如果应用在特定场景下,必需要求全局的 读已提交 ,目前 Seata 的方式是通过 SELECT FOR UPDATE 语句的代理。
72 |
73 |
74 | ### Seata执行流程分析
75 |
76 | 
77 |
78 | - 每个`RM`使用`DataSourceProxy`链接数据路,目的是使用`ConnectionProxy`,使用数据源和数据代理的目的是在第一阶段将`undo_log`和业务数据放在一个本地事务提交,这样就保存了只要有业务操作就一定有undo_log
79 | - 在第一阶段undo_log中存放了数据修改前后修改后的值,为事务回滚做好准别,所以第一阶段完成就已经将分支事务提交了,也就释放了锁资源
80 | - TM开启全局事务开始,将XID全局事务ID放在事务上下文中,通过feign调用也将XID传入下游分支事务,每个分支事务将自己的Branch ID 分支事务ID与XID关联
81 | - 第二阶段全局事务提交,TC会通知各分支参与者提交分支事务,在第一阶段就已经提交了分支事务,这里各参与者只需要删除undo_log即可,并且可以异步执行,第二阶段很快可以完成
82 | - 如果某一个分支事务异常,第二阶段就全局事务回滚操作,TC会通知各分支参与者回滚分支事务,通过`XID`和`Branch-ID`找到对应的回滚日志,通过回滚日志生成的反向`SQL`并执行,以完成分支事务回滚到之前
83 |
84 | ### Seata的实战案列
85 | - https://github.com/seata/seata-samples
86 | - https://github.com/seata/seata-samples/blob/master/doc/quick-integration-with-spring-cloud.md
87 | -
88 |
89 |
90 |
91 | ## TCC分布式事务
92 | - TCC是服务化的两阶段编程模型,其Try、Confirm、Cancel,3个方法均由业务编码实现
93 | - TCC要求每个分支事务实现三个操作:预处理Try,确认Confirm,撤销Cancel。
94 | - Try操作做业务检查及资源预留,
95 | - Confirm做业务确认操作
96 | - Cancel实现一个与Try相反的操作即回滚操作。
97 | - TM首先发起所有的分支事务Try操作,任何一个分支事务的Try操作执行失败,TM将会发起所有分支事务的Cancel操作,若Try操作全部成功,TM将会发起所有分支事务的Confirm操作,其中Confirm/Cancel操作若执行失败,TM会进行重试。
98 |
99 | ### TCC的三个阶段
100 | - Try阶段是做业务检查(一致性)及资源预留(隔离),此阶段仅是一个初步操作,它和后续的Confirmy一起才能构成一个完整的业务逻辑
101 | - Confirm阶段是做确认提交,Try阶段所有分支事务执行成功后开始执行Confirm,通常情况下,采用TCC则认为Confirm阶段是不会出错的,即:只要Try成功,Confirm一定成功,若Confirm阶段真的出错,需要引入重试机制或人工处理
102 | - Cancel阶段是在业务执行错误需要回滚到状态下执行分支事务的取消,预留资源的释放,通常情况下,采用TCC则认为Cancel阶段也一定是真功的,若Cance阶段真的出错,需要引入重试机制或人工处理
103 | - TM事务管理器:TM事务管理器可以实现为独立的服务,也可以让`全局事务发起方`充当TM的角色,TM独立出来是为了公用组件,是为了考虑系统结构和软件的复用
104 | - TM在发起全局事务时生成全局事务记录,全局事务ID贯穿整个分布式事务调用链条,用来记录事务上下文,追踪和记录状态,用于Confirm和cacel失败需要进行重试,因此需要实现幂等
105 |
106 | ### TCC的三种异常处理情况
107 | #### 幂等处理
108 | - 因为网络抖动等原因,分布式事务框架可能会重复调用同一个分布式事务中的一个分支事务的二阶段接口。所以分支事务的二阶段接口Confirm/Cancel需要能够保证幂等性。如果二阶段接口不能保证幂等性,则会产生严重的问题,造成资源的重复使用或者重复释放,进而导致业务故障。
109 | - 对于幂等类型的问题,通常的手段是引入幂等字段进行防重放攻击。对于分布式事务框架中的幂等问题,同样可以祭出这一利器。
110 | - 幂等记录的插入时机是参与者的Try方法,此时的分支事务状态会被初始化为INIT。然后当二阶段的Confirm/Cancel执行时会将其状态置为CONFIRMED/ROLLBACKED。
111 | - 当TC重复调用二阶段接口时,参与者会先获取事务状态控制表的对应记录查看其事务状态。如果状态已经为CONFIRMED/ROLLBACKED,那么表示参与者已经处理完其分内之事,不需要再次执行,可以直接返回幂等成功的结果给TC,帮助其推进分布式事务。
112 |
113 | #### 空回滚
114 | - 当没有调用参与方Try方法的情况下,就调用了二阶段的Cancel方法,Cancel方法需要有办法识别出此时Try有没有执行。如果Try还没执行,表示这个Cancel操作是无效的,即本次Cancel属于空回滚;如果Try已经执行,那么执行的是正常的回滚逻辑。
115 | - 要应对空回滚的问题,就需要让参与者在二阶段的Cancel方法中有办法识别到一阶段的Try是否已经执行。很显然,可以继续利用事务状态控制表来实现这个功能。
116 | - 当Try方法被成功执行后,会插入一条记录,标识该分支事务处于INIT状态。所以后续当二阶段的Cancel方法被调用时,可以通过查询控制表的对应记录进行判断。如果记录存在且状态为INIT,就表示一阶段已成功执行,可以正常执行回滚操作,释放预留的资源;如果记录不存在则表示一阶段未执行,本次为空回滚,不释放任何资源。
117 |
118 | #### 资源悬挂
119 | - 问题:TC回滚事务调用二阶段完成空回滚后,一阶段执行成功
120 | - 解决:事务状态控制记录作为控制手段,二阶段发现无记录时插入记录,一阶段执行时检查记录是否存在
121 |
122 | #### TCC和2PC比较
123 | - 2PC通常都是在跨库的DB层面,而TCC则在应用层面处理,需要通过业务逻辑实现,这种分布式事务的实现方式优势在于,可以让应用自己定义数据操作的粒度,使得降低锁冲突,提高吞吐量成为可能
124 | - 而不足之处则在于对应用的侵入性非常强,业务逻辑的每个分支都需要实现Try,confirm,cancel三个操作。此外,其实现难度也比较大,需要按照网络状态,系统故障的不同失败原因实现不同的回滚策略
125 |
126 | #### Hmily框架实现TCC案列
127 |
128 | 
129 |
130 | ```
131 | # 账户A
132 | try:
133 | try的幂等效验
134 | try的悬挂处理
135 | 检查余额是否够30元
136 | 扣减30元
137 |
138 |
139 | confirm:
140 | 空处理即可,通常TCC阶段是认为confirm是不会出错的
141 |
142 | cancel:
143 | cancel幂等效验
144 | cacel空回滚处理
145 | 增加可用余额30元,回滚操作
146 |
147 |
148 | # 账户B
149 |
150 | try:
151 | 空处理即可
152 |
153 | confirm:
154 | confirm的幂等效验
155 | 正式增加30元
156 | cancel:
157 | 空处理即可
158 |
159 | ```
160 |
161 | ## RocketMQ实现可靠消息最终一致性
162 | - 可靠消息最终一致性就是保证消息从生产方经过消息中间件传递到消费方的一致性
163 | - RocketMQ主要解决了两个功能:本地事务与消息发送的原子性问题。事务参与方接收消息的可靠性
164 | - 可靠消息最终一致性事务适合执行周期长且实时性要求不高的场景,引入消息机制后,同步的事务操作变为基于消息执行的异步操作,避免分布式事务中的同步阻塞操作的影响,并实现了两个服务的解耦
165 |
166 | 
167 |
168 |
169 | ## 最大努力通知
170 | ### 最大努力通知与可靠消息一致性有什么不同
171 | - 可靠消息一致性,发起通知方需要保证将消息发出去,并且将消息发送到接收通知方,消息的可靠性由发起通知方保证
172 | - 最大努力通知,发起通知方尽最大的努力将业务处理结果通知为接收通知方,但是消息可能接收不到,此时需要接收通知方主动调用发起通知方的接口查询业务,通知可靠性关键在于接收通知方
173 |
174 | ### 两者的应用场景
175 | - 可靠消息一致性关注的是交易过程的事务一致,以异步的方式完成交易
176 | - 最大努力通知关注的是交易后的通知事务,即将交易结果可靠的通知出去
177 |
178 | ### 基于MQ的ack机制实现最大努力通知
179 |
180 | 
181 |
182 | - 利用MQ的ack机制由MQ向接收通知方发送消息通知,发起方将普通消息发送到MQ
183 | - 接收通知监听MQ,接收消息,业务处理完成回应ACK
184 | - 接收通知方如果没有回应ACK则MQ会重复通知,按照时间间隔的方式,逐步拉大通知间隔
185 | - 此方案适用于内部微服务之间的通知,不适应与通知外部平台
186 |
187 | > 方案二:增加一个通知服务区进行通知,提供外部第三方时适用
188 |
189 | 
190 |
191 |
192 | ## 分布式事务方案对比分析
193 | - `2PC` 最大的一个诟病是一个阻塞协议。RM在执行分支事务后需要等待TM的决定,此时服务会阻塞锁定资源。由于其阻塞机制和最差时间复杂度高,因此,这种设计不能适应随着事务涉及的服务数量增加而扩展的需要,很难用于并发较高以及子事务生命周期较长的分布式服务中
194 | - 如果拿`TCC`事务的处理流程与2PC两阶段提交做比较,2PC通常都是在跨库的DB层面,而TCC则在应用层面处理,需要通过业务逻辑来实现。这种分布式事务的优势在于,可以让`应用自定义数据操作的粒度,使得降低锁冲突,提高吞吐量成为可能`。而不足之处在于对应用的侵入性非常强,业务逻辑的每个分支都需要实现三个操作。此外,其实现难度也比较大,需要按照网络状态,系统故障等不同失败原因实现不同的策略。
195 | - `可靠消息最终一致性`事务适合执行周期长且实时性要求不高的场景。引入消息机制后,同步的事务操作变为基于消息执行的异步操作,避免了分布式事务中的同步阻塞操作的影响,并实现了两个服务的解耦,典型的场景:注册送积分,登陆送优惠券等
196 | - `最大努力通知`是分布式事务中要求最低的一种,适用于一些最终一致性时间敏感度低的业务,允许发起通知方业务处理失败,在接收通知方收到通知后积极进行失败处理,无论发起通知方如何处理结果都不会影响到接收通知方的后续处理,发起通知方需提供查询执行情况接口,用于接收通知方校对结果,典型的应用场景:银行通知,支付结果通知等。
197 |
198 |
199 | | | 2PC | TCC |可靠消息| 最大努力通知|
200 | | -------- | -----: | -----: | -----: | :----: |
201 | | 一致性 | 强一直性 | 最终一致 |最终一致 | 最终一致 |
202 | | 吞吐量 | 低 | 中 |高 | 高 |
203 | | 实现复杂度| 容易 | 难 |中 | 容易 |
204 |
205 |
206 |
207 | ## 案列Demo源码地址
208 | - https://github.com/qinxuewu/boot-cloud
209 |
--------------------------------------------------------------------------------
/docs/Spring/Consul实现服务注册中心.md:
--------------------------------------------------------------------------------
1 | ## 概述
2 | **Spring Cloud 支持很多服务发现的软件,Eureka 只是其中之一,下面是 Spring Cloud 支持的服务发现软件以及特性对比:**
3 | 
4 |
5 | ## Consul介绍
6 | - Consul 是 HashiCorp 公司推出的开源工具,用于实现分布式系统的服务发现与配置。与其他分布式服务注册与发现的方案,Consul 的方案更“一站式”,内置了服务注册与发现框 架、分布一致性协议实现、健康检查、Key/Value 存储、多数据中心方案,不再需要依赖其他工具(比如 ZooKeeper 等)。使用起来也较 为简单。Consul 使用 Go 语言编写,因此具有天然可移植性(支持Linux、windows和Mac OS X);安装包仅包含一个可执行文件,方便部署,与 Docker 等轻量级容器可无缝配合。
7 |
8 | ## Consul的优势:
9 | - 使用 Raft 算法来保证一致性, 比复杂的 Paxos 算法更直接. 相比较而言, zookeeper 采用的是 Paxos, 而 etcd 使用的则是 Raft。
10 | - 支持多数据中心,内外网的服务采用不同的端口进行监听。 多数据中心集群可以避免单数据中心的单点故障,而其部署则需要考虑网络延迟, 分片等情况等。 zookeeper 和 etcd 均不提供多数据中心功能的支持。
11 | - 支持健康检查。 etcd 不提供此功能。
12 | - 支持 http 和 dns 协议接口。 zookeeper 的集成较为复杂, etcd 只支持 http 协议。
13 | - 官方提供 web 管理界面, etcd 无此功能。
14 | - 综合比较, Consul 作为服务注册和配置管理的新星, 比较值得关注和研究。
15 |
16 | ## 特性
17 | - 服务发现
18 | - 健康检查
19 | - Key/Value 存储
20 | - 多数据中心
21 |
22 | ## Consul角色
23 | - client: 客户端, 无状态, 将 HTTP 和 DNS 接口请求转发给局域网内的服务端集群。
24 | - server: 服务端, 保存配置信息, 高可用集群, 在局域网内与本地客户端通讯, 通过广域网与其他数据中心通讯。 每个数据中心的 server 数量推荐为 3 个或是 5 个。
25 |
26 | ## 安装
27 | Consul 不同于 Eureka 需要单独安装,访问Consul 官网下载 Consul 的最新版本,
28 |
29 | 我这里以 Windows 为例,下载下来是一个 consul_1.2.1_windows_amd64.zip 的压缩包,解压是是一个 consul.exe 的执行文件。
30 | 
31 |
32 | cd 到对应的目录下,使用 cmd 启动 Consul
33 |
34 | ```
35 | cd D:\Common Files\consul
36 |
37 | #cmd启动:
38 | consul agent -dev # -dev表示开发模式运行,另外还有-server表示服务模式运行
39 | ```
40 | 为了方便期间,可以在同级目录下创建一个 run.bat 脚本来启动,脚本内容如下
41 |
42 | ```
43 | consul agent -dev
44 | ```
45 |
46 | 启动结果如下:
47 | 
48 |
49 | 启动成功之后访问:http://localhost:8500,可以看到 Consul 的管理界面
50 | 
51 |
52 | 这样就意味着我们的 Consul 服务启动成功了。
53 |
54 | ## Linux环境安装
55 | 把下载的linux下的安装包consul拷贝到linux环境里面,使用unzip进行解压:
56 |
57 | **2,配置环境变量**
58 | ```
59 | vi /etc/profile
60 |
61 | export JAVA_HOME=/usr/local/jdk1.8.0_172
62 | export MAVEN_HOME=/usr/local/apache-maven-3.5.4
63 | export CONSUL_HOME=/usr/local/consul
64 |
65 | export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
66 | export PATH=$JAVA_HOME/bin:$MAVEN_HOME/bin:$CONSUL_HOME:$PATH
67 |
68 | #上面的CONSUL_HOME就是consul的路径,上面的配置仅供参考。
69 | source /etc/profile #命令使配置生效
70 |
71 | #查看安装的consul版本
72 | [root@CentOS124 /]# consul -v
73 | Consul v1.2.2
74 | Protocol 2 spoken by default, understands 2 to 3 (agent will automatically use protocol >2 when speaking to compatible agents)
75 | [root@CentOS124 /]#
76 | ```
77 |
78 |
79 | ## 服务端
80 | 创建一个 spring-cloud-consul-producer 项目 依赖包如下:
81 | ```
82 |
83 |
84 | org.springframework.boot
85 | spring-boot-starter-actuator
86 |
87 |
88 | org.springframework.cloud
89 | spring-cloud-starter-consul-discovery
90 |
91 |
92 | org.springframework.boot
93 | spring-boot-starter-web
94 |
95 |
96 | org.springframework.boot
97 | spring-boot-starter-test
98 | test
99 |
100 |
101 | ```
102 | - spring-boot-starter-actuator 健康检查依赖于此包。
103 | - spring-cloud-starter-consul-discovery Spring Cloud Consul 的支持。
104 |
105 | **配置文件内容如下**
106 |
107 | ```
108 | spring.application.name=spring-cloud-consul-producer
109 | server.port=8501
110 | spring.cloud.consul.host=localhost
111 | spring.cloud.consul.port=8500
112 | #注册到consul的服务名称
113 | spring.cloud.consul.discovery.serviceName=service-producer
114 | ```
115 | - Consul 的地址和端口号默认是 localhost:8500 ,如果不是这个地址可以自行配置。
116 | - spring.cloud.consul.discovery.serviceName 是指注册到 Consul 的服务名称,后期客户端会根据这个名称来进行服务调用。
117 |
118 | **启动类**
119 |
120 | ```
121 | @SpringBootApplication
122 | @EnableDiscoveryClient
123 | public class ConsulProducerApplication {
124 | public static void main(String[] args) {
125 | SpringApplication.run(ConsulProducerApplication.class, args);
126 | }
127 | }
128 | ```
129 | 添加了 @EnableDiscoveryClient 注解表示支持服务发现。
130 |
131 | **创建一个 Controller,推文提供 hello 的服务**
132 |
133 | ```
134 | @RestController
135 | public class HelloController {
136 | @RequestMapping("/hello")
137 | public String hello() {
138 | return "helle consul";
139 | }
140 | }
141 | ```
142 | 为了模拟注册均衡负载复制一份上面的项目重命名为 spring-cloud-consul-producer-2 ,修改对应的端口为 8502,修改 hello 方法的返回值为:"helle consul two",修改完成后依次启动两个项目。
143 |
144 | 这时候我们再次在浏览器访问地址:http://localhost:8500 就会显示出来两个服务提供者
145 |
146 | ## 消费端
147 | 创建一个 spring-cloud-consul-consumer 项目,pom 文件和上面示例保持一致
148 |
149 | **配置文件内容如下**
150 |
151 | ```
152 | spring.application.name=spring-cloud-consul-consumer
153 | server.port=8503
154 | spring.cloud.consul.host=127.0.0.1
155 | spring.cloud.consul.port=8500
156 | #设置不需要注册到 consul 中
157 | spring.cloud.consul.discovery.register=false
158 | ```
159 | 客户端可以设置注册到 Consul 中,也可以不注册到 Consul 注册中心中,根据我们的业务来选择,只需要在使用服务时通过 Consul 对外提供的接口获取服务信息即可。
160 |
161 | **启动类**
162 |
163 | ```
164 | @SpringBootApplication
165 | public class ConsulConsumerApplication {
166 | public static void main(String[] args) {
167 | SpringApplication.run(ConsulConsumerApplication.class, args);
168 | }
169 | }
170 | ```
171 |
172 | **进行测试**
173 |
174 | 创建一个 ServiceController ,试试如果去获取 Consul 中的服务
175 |
176 | ```
177 | @RestController
178 | public class ServiceController {
179 | @Autowired
180 | private LoadBalancerClient loadBalancer;
181 | @Autowired
182 | private DiscoveryClient discoveryClient;
183 | //获取所有服务
184 | @RequestMapping("/services")
185 | public Object services() {
186 | return discoveryClient.getInstances("service-producer");
187 | }
188 | //从所有服务中选择一个服务(轮询)
189 | @RequestMapping("/discover")
190 | public Object discover() {
191 | return loadBalancer.choose("service-producer").getUri().toString();
192 | }
193 | }
194 | ```
195 | Controller 中有俩个方法,一个是获取所有服务名为service-producer的服务信息并返回到页面,一个是随机从服务名为service-producer的服务中获取一个并返回到页面。
196 |
197 | 添加完 ServiceController 之后我们启动项目,访问地址:http://localhost:8503/services,返回jsn数据
198 |
199 | ```
200 | [{"serviceId":"service-producer","host":"windows10.microdone.cn","port":8501,"secure":false,"metadata":{"secure":"false"},"uri":"http://windows10.microdone.cn:8501","scheme":null},{"serviceId":"service-producer","host":"windows10.microdone.cn","port":8502,"secure":false,"metadata":{"secure":"false"},"uri":"http://windows10.microdone.cn:8502","scheme":null}]
201 | ```
202 |
203 | 发现我们刚才创建的端口为 8501 和 8502 的两个服务端都存在
204 |
205 | 多次访问地址:http://localhost:8503/discover,页面会交替返回信息:
206 |
207 | 说明 8501 和 8501 的两个服务会交替出现,从而实现了获取服务端地址的均衡负载。
208 |
209 | 大多数情况下我们希望使用均衡负载的形式去获取服务端提供的服务,因此使用第二种方法来模拟调用服务端提供的 hello 方法。
210 |
211 | **创建 CallHelloController :**
212 |
213 | ```
214 | @RestController
215 | public class CallHelloController {
216 | @Autowired
217 | private LoadBalancerClient loadBalancer;
218 | @RequestMapping("/call")
219 | public String call() {
220 | ServiceInstance serviceInstance = loadBalancer.choose("service-producer");
221 | System.out.println("服务地址:" + serviceInstance.getUri());
222 | System.out.println("服务名称:" + serviceInstance.getServiceId());
223 | String callServiceResult = new RestTemplate().getForObject(serviceInstance.getUri().toString() + "/hello", String.class);
224 | System.out.println(callServiceResult);
225 | return callServiceResult;
226 | }
227 | }
228 | ```
229 | 使用 RestTemplate 进行远程调用。添加完之后重启 spring-cloud-consul-consumer 项目。在浏览器中访问地址:http://localhost:8503/call,依次返回结果如下:
230 |
231 | ```
232 | helle consul
233 |
234 | helle consul two
235 | ```
236 |
237 | 说明我们已经成功的调用了 Consul 服务端提供的服务,并且实现了服务端的均衡负载功能
238 |
239 | 示例代码:https://github.com/ityouknow/spring-cloud-examples
240 |
241 |
242 |
243 |
244 |
245 |
246 |
--------------------------------------------------------------------------------
/docs/distributed/nginx.md:
--------------------------------------------------------------------------------
1 | ### 利用nginx实现负载均衡
2 | 安装了两个tomcat,端口分别是42000和42001。第二个tomcat的首页随便加了些代码区分
3 |
4 | ### nginx配置
5 |
6 | ```
7 | #这里的域名要和下面proxy_pass的一样
8 | #设定负载均衡的服务器列表 weigth参数表示权值,权值越高被分配到的几率越大
9 | upstream fengzp.com {
10 | server 192.168.99.100:42000 weight=1;
11 | server 192.168.99.100:42001 weight=2;
12 | }
13 |
14 | server {
15 | listen 80;
16 | server_name 192.168.99.100;
17 |
18 | location / {
19 | proxy_pass http://fengzp.com;
20 | proxy_redirect default;
21 | }
22 |
23 | error_page 500 502 503 504 /50x.html;
24 | location = /50x.html {
25 | root html;
26 | }
27 | }
28 | ```
29 |
30 | ### 测试
31 | 
32 | 
33 |
34 | 刷新页面发现页面会发生变化,证明负载配置成功。因为我配的权重第二个是第一个的两倍,所以第二个出现的概率会是第一个的两倍。
35 |
36 |
37 |
38 | 如果关了tomcat1,再多次刷新页面,接下来出现的就会都是tomcat2的页面,但是时而快时而慢。这其中原因是当如果nginx将请求转发到tomcat2时,服务器会马上跳转成功,但是如果是转到tomcat1,因为tomcat1已经关闭了,所以会出现一段等待响应过程的过程,要等它失败后才会转到tomcat2。
39 | 而这个等待响应的时间我们是可以配置的。
40 |
41 |
42 | 这个时间由以下3个参数控制:
43 | proxy_connect_timeout:与服务器连接的超时时间,默认60s
44 | fail_timeout:当该时间内服务器没响应,则认为服务器失效,默认10s
45 | max_fails:允许连接失败次数,默认为1
46 |
47 | 等待时间 = proxy_connect_timeout + fail_timeout * max_fails
48 |
49 | 
50 |
51 | 如果我这样配置的话,只需等待6秒就可以了。
52 |
53 |
54 | ### 负载均衡策略
55 | **1、轮询**
56 |
57 | ```
58 | #这种是默认的策略,把每个请求按顺序逐一分配到不同的server,如果server挂掉,能自动剔除
59 |
60 | upstream fengzp.com {
61 | server 192.168.99.100:42000;
62 | server 192.168.99.100:42001;
63 | }
64 | ```
65 | **2、最少连接**
66 |
67 | ```
68 | #把请求分配到连接数最少的server
69 |
70 | upstream fengzp.com {
71 | least_conn;
72 | server 192.168.99.100:42000;
73 | server 192.168.99.100:42001;
74 | }
75 | ```
76 | **3、权重**
77 |
78 | ```
79 | #使用weight来指定server访问比率,weight默认是1。以下配置会是server2访问的比例是server1的两倍
80 |
81 | upstream fengzp.com {
82 | server 192.168.99.100:42000 weight=1;
83 | server 192.168.99.100:42001 weight=2;
84 | }
85 | ```
86 |
87 | **4、ip_hash**
88 | **每个请求会按照访问ip的hash值分配,这样同一客户端连续的Web请求都会被分发到同一server进行处理,可以解决session的问题。如果server挂掉,能自动剔除。**
89 | ```
90 | upstream fengzp.com {
91 | ip_hash;
92 | server 192.168.99.100:42000;
93 | server 192.168.99.100:42001;
94 | }
95 | ```
96 | ip_hash可以和weight结合使用。
97 |
98 | ### nginx实现请求的负载均衡 + keepalived实现nginx的高可用
99 | https://www.cnblogs.com/youzhibing/p/7327342.html
100 |
101 |
102 |
103 | ### 一个域名配置多项目访问
104 |
105 | ```
106 |
107 | #user nobody;
108 | worker_processes 1;
109 |
110 | #error_log logs/error.log;
111 | #error_log logs/error.log notice;
112 | #error_log logs/error.log info;
113 |
114 | pid logs/nginx.pid;
115 |
116 |
117 | events {
118 | worker_connections 1024;
119 | }
120 |
121 |
122 | http {
123 | include mime.types;
124 | default_type application/octet-stream;
125 |
126 | #log_format main '$remote_addr - $remote_user [$time_local] "$request" '
127 | # '$status $body_bytes_sent "$http_referer" '
128 | # '"$http_user_agent" "$http_x_forwarded_for"';
129 |
130 | #access_log logs/access.log main;
131 |
132 | sendfile on;
133 | #tcp_nopush on;
134 |
135 | #keepalive_timeout 0;
136 | keepalive_timeout 65;
137 |
138 | #gzip on;
139 |
140 | upstream rongdaitianxia {
141 | #表示在10s(fail_timeout)之内,有1(max_fails)个请求打到这台挂了的服务器,nginx就会把这台upstream server设为down机的状态,时长是10s,
142 | #在这10s内如果又有请求进来,就不会被转到这台server上,过了10s重新认为这台server又恢复了
143 | server 127.0.0.1:8080 max_fails=2 fail_timeout=10s;
144 | server 127.0.0.1:8082 max_fails=2 fail_timeout=10s;
145 | }
146 |
147 |
148 |
149 |
150 | server {
151 | listen 443;
152 | server_name 填你的域名;
153 | ssl on;
154 | ssl_certificate /home/nginx/certs/1_www.rongdaitianxia.com_bundle.crt;
155 | ssl_certificate_key /home/nginx/certs/2_www.rongdaitianxia.com.key;
156 | ssl_session_timeout 5m;
157 | ssl_protocols TLSv1.2;
158 | ssl_ciphers HIGH:!aNULL:!MD5;
159 | ssl_prefer_server_ciphers on;
160 |
161 | #location / {
162 | #client_max_body_size 16m;
163 | #client_body_buffer_size 128k;
164 | #proxy_pass http://rongdaitianxia/;
165 | #proxy_set_header Upgrade $http_upgrade;
166 | #proxy_set_header Connection "upgrade";
167 | #proxy_set_header Host $host;
168 | #proxy_set_header X-Real-IP $remote_addr;
169 | #proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
170 | #proxy_set_header X-Forwarded-Proto https;
171 | #proxy_next_upstream off;
172 | #proxy_connect_timeout 30;
173 | #proxy_read_timeout 300;
174 | #proxy_send_timeout 300;
175 | #}
176 |
177 |
178 | location /wxloan {
179 | client_max_body_size 16m;
180 | client_body_buffer_size 128k;
181 | proxy_pass http://127.0.0.1:8080/wxloan;
182 | proxy_set_header Upgrade $http_upgrade;
183 | proxy_set_header Connection "upgrade";
184 | proxy_set_header Host $host;
185 | proxy_set_header X-Real-IP $remote_addr;
186 | proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
187 | proxy_set_header X-Forwarded-Proto https;
188 | proxy_next_upstream off;
189 | proxy_connect_timeout 30;
190 | proxy_read_timeout 300;
191 | proxy_send_timeout 300;
192 | }
193 |
194 |
195 | location /loan-master {
196 | client_max_body_size 16m;
197 | client_body_buffer_size 128k;
198 | proxy_pass http://127.0.0.1:8081/loan-master;
199 | proxy_set_header Upgrade $http_upgrade;
200 | proxy_set_header Connection "upgrade";
201 | proxy_set_header Host $host;
202 | proxy_set_header X-Real-IP $remote_addr;
203 | proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
204 | proxy_set_header X-Forwarded-Proto https;
205 | proxy_next_upstream off;
206 | proxy_connect_timeout 30;
207 | proxy_read_timeout 300;
208 | proxy_send_timeout 300;
209 | }
210 |
211 |
212 | location /wxmp {
213 | client_max_body_size 16m;
214 | client_body_buffer_size 128k;
215 | proxy_pass http://127.0.0.1:8081/wxmp;
216 | proxy_set_header Upgrade $http_upgrade;
217 | proxy_set_header Connection "upgrade";
218 | proxy_set_header Host $host;
219 | proxy_set_header X-Real-IP $remote_addr;
220 | proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
221 | proxy_set_header X-Forwarded-Proto https;
222 | proxy_next_upstream off;
223 | proxy_connect_timeout 30;
224 | proxy_read_timeout 300;
225 | proxy_send_timeout 300;
226 | }
227 |
228 | location /wechat {
229 | client_max_body_size 16m;
230 | client_body_buffer_size 128k;
231 | proxy_pass http://127.0.0.1:8084/wechat;
232 | proxy_set_header Upgrade $http_upgrade;
233 | proxy_set_header Connection "upgrade";
234 | proxy_set_header Host $host;
235 | proxy_set_header X-Real-IP $remote_addr;
236 | proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
237 | proxy_set_header X-Forwarded-Proto https;
238 | proxy_next_upstream off;
239 | proxy_connect_timeout 30;
240 | proxy_read_timeout 600;
241 | proxy_send_timeout 300;
242 | }
243 |
244 |
245 |
246 | }
247 |
248 |
249 |
250 |
251 |
252 |
253 |
254 | }
255 |
256 | ```
257 |
258 |
--------------------------------------------------------------------------------