├── .github
└── workflows
│ └── update_index.yaml
├── .gitignore
├── .pre-commit-config.yaml
├── LICENSE
├── Makefile
├── README.md
├── datasets
├── data-still-to-label.jsonl
├── embedding_qa.json
├── eval-dataset-v1.jsonl
├── eval-dataset-v2-alpha.jsonl
├── reranker-corrections.csv
├── routing-dataset-test.jsonl
└── routing-dataset-train.jsonl
├── deploy
├── jobs
│ └── update_index.yaml
└── services
│ └── service.yaml
├── experiments
├── evaluations
│ ├── bge-large-en_gpt-4.json
│ ├── chunk-size-100_gpt-4.json
│ ├── chunk-size-300_gpt-4.json
│ ├── chunk-size-500_gpt-4.json
│ ├── chunk-size-700_gpt-4.json
│ ├── chunk-size-900_gpt-4.json
│ ├── codellama-34b-instruct-hf_gpt-4.json
│ ├── cross-encoder-reranker_gpt-4.json
│ ├── falcon-180b_gpt-4.json
│ ├── gpt-3.5-turbo_gpt-4.json
│ ├── gpt-4-1106-preview_gpt-4.json
│ ├── gpt-4_gpt-4.json
│ ├── gte-base-fine-tuned-linear-adapter_gpt-4.json
│ ├── gte-base_gpt-4.json
│ ├── gte-large-fine-tuned-el_gpt-4.json
│ ├── gte-large-fine-tuned-fp_gpt-4.json
│ ├── gte-large-fine-tuned_gpt-4.json
│ ├── gte-large_gpt-4.json
│ ├── lexical-search-bm25-1_gpt-4.json
│ ├── lexical-search-bm25-3_gpt-4.json
│ ├── lexical-search-bm25-5_gpt-4.json
│ ├── llama-2-13b-chat-hf_gpt-4.json
│ ├── llama-2-70b-chat-hf_gpt-4.json
│ ├── llama-2-7b-chat-hf_gpt-4.json
│ ├── mistral-7b-instruct-v0.1_gpt-4.json
│ ├── mixtral-8x7b-instruct-v0.1_gpt-4.json
│ ├── num-chunks-11_gpt-4.json
│ ├── num-chunks-13_gpt-4.json
│ ├── num-chunks-15_gpt-4.json
│ ├── num-chunks-1_gpt-4.json
│ ├── num-chunks-3_gpt-4.json
│ ├── num-chunks-5_gpt-4.json
│ ├── num-chunks-7_gpt-4.json
│ ├── num-chunks-9_gpt-4.json
│ ├── prompt-ignore-contexts_gpt-4.json
│ ├── rerank-0.3_gpt-4.json
│ ├── rerank-0.5_gpt-4.json
│ ├── rerank-0.7_gpt-4.json
│ ├── rerank-0.9_gpt-4.json
│ ├── rerank-0_gpt-4.json
│ ├── text-embedding-ada-002_gpt-4.json
│ ├── with-context_gpt-4.json
│ ├── with-sections_gpt-4.json
│ ├── without-context-gpt-4-1106-preview_gpt-4.json
│ ├── without-context-gpt-4_gpt-4.json
│ ├── without-context-mixtral-8x7b-instruct-v0.1_gpt-4.json
│ ├── without-context_gpt-4.json
│ └── without-sections_gpt-4.json
├── references
│ ├── gpt-4-turbo.json
│ ├── gpt-4.json
│ ├── llama-2-70b.json
│ └── mixtral.json
└── responses
│ ├── bge-large-en.json
│ ├── chunk-size-100.json
│ ├── chunk-size-300.json
│ ├── chunk-size-500.json
│ ├── chunk-size-600.json
│ ├── chunk-size-700.json
│ ├── chunk-size-900.json
│ ├── codellama-34b-instruct-hf.json
│ ├── cross-encoder-reranker.json
│ ├── gpt-3.5-turbo-16k.json
│ ├── gpt-3.5-turbo.json
│ ├── gpt-4-1106-preview.json
│ ├── gpt-4.json
│ ├── gte-base-fine-tuned-linear-adapter.json
│ ├── gte-base.json
│ ├── gte-large-fine-tuned-el.json
│ ├── gte-large-fine-tuned-fp.json
│ ├── gte-large-fine-tuned.json
│ ├── gte-large.json
│ ├── lexical-search-bm25-1.json
│ ├── lexical-search-bm25-3.json
│ ├── lexical-search-bm25-5.json
│ ├── llama-2-13b-chat-hf.json
│ ├── llama-2-70b-chat-hf.json
│ ├── llama-2-7b-chat-hf.json
│ ├── mistral-7b-instruct-v0.1.json
│ ├── mixtral-8x7b-instruct-v0.1.json
│ ├── num-chunks-1.json
│ ├── num-chunks-10.json
│ ├── num-chunks-11.json
│ ├── num-chunks-13.json
│ ├── num-chunks-15.json
│ ├── num-chunks-20.json
│ ├── num-chunks-3.json
│ ├── num-chunks-5.json
│ ├── num-chunks-6.json
│ ├── num-chunks-7.json
│ ├── num-chunks-9.json
│ ├── prompt-ignore-contexts.json
│ ├── rerank-0.3.json
│ ├── rerank-0.5.json
│ ├── rerank-0.7.json
│ ├── rerank-0.9.json
│ ├── rerank-0.json
│ ├── text-embedding-ada-002.json
│ ├── with-context.json
│ ├── with-sections.json
│ ├── without-context-gpt-4-1106-preview.json
│ ├── without-context-gpt-4.json
│ ├── without-context-mixtral-8x7b-instruct-v0.1.json
│ ├── without-context-small.json
│ ├── without-context.json
│ └── without-sections.json
├── migrations
├── vector-1024.sql
├── vector-1536.sql
└── vector-768.sql
├── notebooks
├── clear_cell_nums.py
└── rag.ipynb
├── pyproject.toml
├── rag
├── __init__.py
├── config.py
├── data.py
├── embed.py
├── evaluate.py
├── generate.py
├── index.py
├── rerank.py
├── search.py
├── serve.py
└── utils.py
├── requirements.txt
├── setup-pgvector.sh
├── test.py
└── update-index.sh
/.github/workflows/update_index.yaml:
--------------------------------------------------------------------------------
1 | name: update-index
2 | on:
3 | workflow_dispatch: # manual trigger
4 | permissions: write-all
5 |
6 | jobs:
7 | workloads:
8 | runs-on: ubuntu-22.04
9 | steps:
10 |
11 | # Set up dependencies
12 | - uses: actions/checkout@v3
13 | - uses: actions/setup-python@v4
14 | with:
15 | python-version: '3.10.11'
16 | cache: 'pip'
17 | - run: python3 -m pip install anyscale
18 |
19 | # Run workloads
20 | - name: Workloads
21 | run: |
22 | export ANYSCALE_HOST=${{ secrets.ANYSCALE_HOST }}
23 | export ANYSCALE_CLI_TOKEN=${{ secrets.ANYSCALE_CLI_TOKEN }}
24 | anyscale job submit deploy/jobs/update_index.yaml --wait
25 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Data
2 | ray/
3 |
4 | # VSCode
5 | .vscode/
6 | .idea
7 |
8 | # Byte-compiled / optimized / DLL files
9 | __pycache__/
10 | *.py[cod]
11 | *$py.class
12 |
13 | # C extensions
14 | *.so
15 |
16 | # Distribution / packaging
17 | .Python
18 | build/
19 | develop-eggs/
20 | dist/
21 | downloads/
22 | eggs/
23 | .eggs/
24 | lib/
25 | lib64/
26 | parts/
27 | sdist/
28 | var/
29 | wheels/
30 | pip-wheel-metadata/
31 | share/python-wheels/
32 | *.egg-info/
33 | .installed.cfg
34 | *.egg
35 | MANIFEST
36 |
37 | # PyInstaller
38 | *.manifest
39 | *.spec
40 |
41 | # Installer logs
42 | pip-log.txt
43 | pip-delete-this-directory.txt
44 |
45 | # Unit test / coverage reports
46 | htmlcov/
47 | .tox/
48 | .nox/
49 | .coverage
50 | .coverage.*
51 | .cache
52 | nosetests.xml
53 | coverage.xml
54 | *.cover
55 | *.py,cover
56 | .hypothesis/
57 | .pytest_cache/
58 |
59 | # Flask:
60 | instance/
61 | .webassets-cache
62 |
63 | # Scrapy:
64 | .scrapy
65 |
66 | # Sphinx
67 | docs/_build/
68 |
69 | # PyBuilder
70 | target/
71 |
72 | # IPython
73 | .ipynb_checkpoints
74 | profile_default/
75 | ipython_config.py
76 |
77 | # pyenv
78 | .python-version
79 |
80 | # PEP 582
81 | __pypackages__/
82 |
83 | # Celery
84 | celerybeat-schedule
85 | celerybeat.pid
86 |
87 | # Environment
88 | .env
89 | .venv
90 | env/
91 | venv/
92 | ENV/
93 | env.bak/
94 | venv.bak/
95 |
96 | # mkdocs
97 | site/
98 |
99 | # Airflow
100 | airflow/airflow.db
101 |
102 | # MacOS
103 | .DS_Store
104 |
105 | # Clean up
106 | .trash/
107 |
108 | # scraped folders
109 | docs.ray.io/
110 |
111 | # book and other source folders
112 | data/
113 |
--------------------------------------------------------------------------------
/.pre-commit-config.yaml:
--------------------------------------------------------------------------------
1 | # See https://pre-commit.com for more information
2 | # See https://pre-commit.com/hooks.html for more hooks
3 | repos:
4 | - repo: https://github.com/pre-commit/pre-commit-hooks
5 | rev: v4.5.0
6 | hooks:
7 | - id: trailing-whitespace
8 | - id: end-of-file-fixer
9 | - id: check-merge-conflict
10 | - id: check-yaml
11 | - id: check-added-large-files
12 | args: ['--maxkb=1000']
13 | exclude: "notebooks"
14 | - id: check-yaml
15 | exclude: "mkdocs.yml"
16 | - repo: https://github.com/Yelp/detect-secrets
17 | rev: v1.4.0
18 | hooks:
19 | - id: detect-secrets
20 | exclude: "notebooks|experiments|datasets"
21 | - repo: local
22 | hooks:
23 | - id: clean
24 | name: clean
25 | entry: make
26 | args: ["clean"]
27 | language: system
28 | pass_filenames: false
29 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Copyright (2023) Anyscale, Inc.
2 |
3 | Attribution 4.0 International
4 |
5 | =======================================================================
6 |
7 | Creative Commons Corporation ("Creative Commons") is not a law firm and
8 | does not provide legal services or legal advice. Distribution of
9 | Creative Commons public licenses does not create a lawyer-client or
10 | other relationship. Creative Commons makes its licenses and related
11 | information available on an "as-is" basis. Creative Commons gives no
12 | warranties regarding its licenses, any material licensed under their
13 | terms and conditions, or any related information. Creative Commons
14 | disclaims all liability for damages resulting from their use to the
15 | fullest extent possible.
16 |
17 | Using Creative Commons Public Licenses
18 |
19 | Creative Commons public licenses provide a standard set of terms and
20 | conditions that creators and other rights holders may use to share
21 | original works of authorship and other material subject to copyright
22 | and certain other rights specified in the public license below. The
23 | following considerations are for informational purposes only, are not
24 | exhaustive, and do not form part of our licenses.
25 |
26 | Considerations for licensors: Our public licenses are
27 | intended for use by those authorized to give the public
28 | permission to use material in ways otherwise restricted by
29 | copyright and certain other rights. Our licenses are
30 | irrevocable. Licensors should read and understand the terms
31 | and conditions of the license they choose before applying it.
32 | Licensors should also secure all rights necessary before
33 | applying our licenses so that the public can reuse the
34 | material as expected. Licensors should clearly mark any
35 | material not subject to the license. This includes other CC-
36 | licensed material, or material used under an exception or
37 | limitation to copyright. More considerations for licensors:
38 | wiki.creativecommons.org/Considerations_for_licensors
39 |
40 | Considerations for the public: By using one of our public
41 | licenses, a licensor grants the public permission to use the
42 | licensed material under specified terms and conditions. If
43 | the licensor's permission is not necessary for any reason--for
44 | example, because of any applicable exception or limitation to
45 | copyright--then that use is not regulated by the license. Our
46 | licenses grant only permissions under copyright and certain
47 | other rights that a licensor has authority to grant. Use of
48 | the licensed material may still be restricted for other
49 | reasons, including because others have copyright or other
50 | rights in the material. A licensor may make special requests,
51 | such as asking that all changes be marked or described.
52 | Although not required by our licenses, you are encouraged to
53 | respect those requests where reasonable. More_considerations
54 | for the public:
55 | wiki.creativecommons.org/Considerations_for_licensees
56 |
57 | =======================================================================
58 |
59 | Creative Commons Attribution 4.0 International Public License
60 |
61 | By exercising the Licensed Rights (defined below), You accept and agree
62 | to be bound by the terms and conditions of this Creative Commons
63 | Attribution 4.0 International Public License ("Public License"). To the
64 | extent this Public License may be interpreted as a contract, You are
65 | granted the Licensed Rights in consideration of Your acceptance of
66 | these terms and conditions, and the Licensor grants You such rights in
67 | consideration of benefits the Licensor receives from making the
68 | Licensed Material available under these terms and conditions.
69 |
70 |
71 | Section 1 -- Definitions.
72 |
73 | a. Adapted Material means material subject to Copyright and Similar
74 | Rights that is derived from or based upon the Licensed Material
75 | and in which the Licensed Material is translated, altered,
76 | arranged, transformed, or otherwise modified in a manner requiring
77 | permission under the Copyright and Similar Rights held by the
78 | Licensor. For purposes of this Public License, where the Licensed
79 | Material is a musical work, performance, or sound recording,
80 | Adapted Material is always produced where the Licensed Material is
81 | synched in timed relation with a moving image.
82 |
83 | b. Adapter's License means the license You apply to Your Copyright
84 | and Similar Rights in Your contributions to Adapted Material in
85 | accordance with the terms and conditions of this Public License.
86 |
87 | c. Copyright and Similar Rights means copyright and/or similar rights
88 | closely related to copyright including, without limitation,
89 | performance, broadcast, sound recording, and Sui Generis Database
90 | Rights, without regard to how the rights are labeled or
91 | categorized. For purposes of this Public License, the rights
92 | specified in Section 2(b)(1)-(2) are not Copyright and Similar
93 | Rights.
94 |
95 | d. Effective Technological Measures means those measures that, in the
96 | absence of proper authority, may not be circumvented under laws
97 | fulfilling obligations under Article 11 of the WIPO Copyright
98 | Treaty adopted on December 20, 1996, and/or similar international
99 | agreements.
100 |
101 | e. Exceptions and Limitations means fair use, fair dealing, and/or
102 | any other exception or limitation to Copyright and Similar Rights
103 | that applies to Your use of the Licensed Material.
104 |
105 | f. Licensed Material means the artistic or literary work, database,
106 | or other material to which the Licensor applied this Public
107 | License.
108 |
109 | g. Licensed Rights means the rights granted to You subject to the
110 | terms and conditions of this Public License, which are limited to
111 | all Copyright and Similar Rights that apply to Your use of the
112 | Licensed Material and that the Licensor has authority to license.
113 |
114 | h. Licensor means the individual(s) or entity(ies) granting rights
115 | under this Public License.
116 |
117 | i. Share means to provide material to the public by any means or
118 | process that requires permission under the Licensed Rights, such
119 | as reproduction, public display, public performance, distribution,
120 | dissemination, communication, or importation, and to make material
121 | available to the public including in ways that members of the
122 | public may access the material from a place and at a time
123 | individually chosen by them.
124 |
125 | j. Sui Generis Database Rights means rights other than copyright
126 | resulting from Directive 96/9/EC of the European Parliament and of
127 | the Council of 11 March 1996 on the legal protection of databases,
128 | as amended and/or succeeded, as well as other essentially
129 | equivalent rights anywhere in the world.
130 |
131 | k. You means the individual or entity exercising the Licensed Rights
132 | under this Public License. Your has a corresponding meaning.
133 |
134 |
135 | Section 2 -- Scope.
136 |
137 | a. License grant.
138 |
139 | 1. Subject to the terms and conditions of this Public License,
140 | the Licensor hereby grants You a worldwide, royalty-free,
141 | non-sublicensable, non-exclusive, irrevocable license to
142 | exercise the Licensed Rights in the Licensed Material to:
143 |
144 | a. reproduce and Share the Licensed Material, in whole or
145 | in part; and
146 |
147 | b. produce, reproduce, and Share Adapted Material.
148 |
149 | 2. Exceptions and Limitations. For the avoidance of doubt, where
150 | Exceptions and Limitations apply to Your use, this Public
151 | License does not apply, and You do not need to comply with
152 | its terms and conditions.
153 |
154 | 3. Term. The term of this Public License is specified in Section
155 | 6(a).
156 |
157 | 4. Media and formats; technical modifications allowed. The
158 | Licensor authorizes You to exercise the Licensed Rights in
159 | all media and formats whether now known or hereafter created,
160 | and to make technical modifications necessary to do so. The
161 | Licensor waives and/or agrees not to assert any right or
162 | authority to forbid You from making technical modifications
163 | necessary to exercise the Licensed Rights, including
164 | technical modifications necessary to circumvent Effective
165 | Technological Measures. For purposes of this Public License,
166 | simply making modifications authorized by this Section 2(a)
167 | (4) never produces Adapted Material.
168 |
169 | 5. Downstream recipients.
170 |
171 | a. Offer from the Licensor -- Licensed Material. Every
172 | recipient of the Licensed Material automatically
173 | receives an offer from the Licensor to exercise the
174 | Licensed Rights under the terms and conditions of this
175 | Public License.
176 |
177 | b. No downstream restrictions. You may not offer or impose
178 | any additional or different terms or conditions on, or
179 | apply any Effective Technological Measures to, the
180 | Licensed Material if doing so restricts exercise of the
181 | Licensed Rights by any recipient of the Licensed
182 | Material.
183 |
184 | 6. No endorsement. Nothing in this Public License constitutes or
185 | may be construed as permission to assert or imply that You
186 | are, or that Your use of the Licensed Material is, connected
187 | with, or sponsored, endorsed, or granted official status by,
188 | the Licensor or others designated to receive attribution as
189 | provided in Section 3(a)(1)(A)(i).
190 |
191 | b. Other rights.
192 |
193 | 1. Moral rights, such as the right of integrity, are not
194 | licensed under this Public License, nor are publicity,
195 | privacy, and/or other similar personality rights; however, to
196 | the extent possible, the Licensor waives and/or agrees not to
197 | assert any such rights held by the Licensor to the limited
198 | extent necessary to allow You to exercise the Licensed
199 | Rights, but not otherwise.
200 |
201 | 2. Patent and trademark rights are not licensed under this
202 | Public License.
203 |
204 | 3. To the extent possible, the Licensor waives any right to
205 | collect royalties from You for the exercise of the Licensed
206 | Rights, whether directly or through a collecting society
207 | under any voluntary or waivable statutory or compulsory
208 | licensing scheme. In all other cases the Licensor expressly
209 | reserves any right to collect such royalties.
210 |
211 |
212 | Section 3 -- License Conditions.
213 |
214 | Your exercise of the Licensed Rights is expressly made subject to the
215 | following conditions.
216 |
217 | a. Attribution.
218 |
219 | 1. If You Share the Licensed Material (including in modified
220 | form), You must:
221 |
222 | a. retain the following if it is supplied by the Licensor
223 | with the Licensed Material:
224 |
225 | i. identification of the creator(s) of the Licensed
226 | Material and any others designated to receive
227 | attribution, in any reasonable manner requested by
228 | the Licensor (including by pseudonym if
229 | designated);
230 |
231 | ii. a copyright notice;
232 |
233 | iii. a notice that refers to this Public License;
234 |
235 | iv. a notice that refers to the disclaimer of
236 | warranties;
237 |
238 | v. a URI or hyperlink to the Licensed Material to the
239 | extent reasonably practicable;
240 |
241 | b. indicate if You modified the Licensed Material and
242 | retain an indication of any previous modifications; and
243 |
244 | c. indicate the Licensed Material is licensed under this
245 | Public License, and include the text of, or the URI or
246 | hyperlink to, this Public License.
247 |
248 | 2. You may satisfy the conditions in Section 3(a)(1) in any
249 | reasonable manner based on the medium, means, and context in
250 | which You Share the Licensed Material. For example, it may be
251 | reasonable to satisfy the conditions by providing a URI or
252 | hyperlink to a resource that includes the required
253 | information.
254 |
255 | 3. If requested by the Licensor, You must remove any of the
256 | information required by Section 3(a)(1)(A) to the extent
257 | reasonably practicable.
258 |
259 | 4. If You Share Adapted Material You produce, the Adapter's
260 | License You apply must not prevent recipients of the Adapted
261 | Material from complying with this Public License.
262 |
263 |
264 | Section 4 -- Sui Generis Database Rights.
265 |
266 | Where the Licensed Rights include Sui Generis Database Rights that
267 | apply to Your use of the Licensed Material:
268 |
269 | a. for the avoidance of doubt, Section 2(a)(1) grants You the right
270 | to extract, reuse, reproduce, and Share all or a substantial
271 | portion of the contents of the database;
272 |
273 | b. if You include all or a substantial portion of the database
274 | contents in a database in which You have Sui Generis Database
275 | Rights, then the database in which You have Sui Generis Database
276 | Rights (but not its individual contents) is Adapted Material; and
277 |
278 | c. You must comply with the conditions in Section 3(a) if You Share
279 | all or a substantial portion of the contents of the database.
280 |
281 | For the avoidance of doubt, this Section 4 supplements and does not
282 | replace Your obligations under this Public License where the Licensed
283 | Rights include other Copyright and Similar Rights.
284 |
285 |
286 | Section 5 -- Disclaimer of Warranties and Limitation of Liability.
287 |
288 | a. UNLESS OTHERWISE SEPARATELY UNDERTAKEN BY THE LICENSOR, TO THE
289 | EXTENT POSSIBLE, THE LICENSOR OFFERS THE LICENSED MATERIAL AS-IS
290 | AND AS-AVAILABLE, AND MAKES NO REPRESENTATIONS OR WARRANTIES OF
291 | ANY KIND CONCERNING THE LICENSED MATERIAL, WHETHER EXPRESS,
292 | IMPLIED, STATUTORY, OR OTHER. THIS INCLUDES, WITHOUT LIMITATION,
293 | WARRANTIES OF TITLE, MERCHANTABILITY, FITNESS FOR A PARTICULAR
294 | PURPOSE, NON-INFRINGEMENT, ABSENCE OF LATENT OR OTHER DEFECTS,
295 | ACCURACY, OR THE PRESENCE OR ABSENCE OF ERRORS, WHETHER OR NOT
296 | KNOWN OR DISCOVERABLE. WHERE DISCLAIMERS OF WARRANTIES ARE NOT
297 | ALLOWED IN FULL OR IN PART, THIS DISCLAIMER MAY NOT APPLY TO YOU.
298 |
299 | b. TO THE EXTENT POSSIBLE, IN NO EVENT WILL THE LICENSOR BE LIABLE
300 | TO YOU ON ANY LEGAL THEORY (INCLUDING, WITHOUT LIMITATION,
301 | NEGLIGENCE) OR OTHERWISE FOR ANY DIRECT, SPECIAL, INDIRECT,
302 | INCIDENTAL, CONSEQUENTIAL, PUNITIVE, EXEMPLARY, OR OTHER LOSSES,
303 | COSTS, EXPENSES, OR DAMAGES ARISING OUT OF THIS PUBLIC LICENSE OR
304 | USE OF THE LICENSED MATERIAL, EVEN IF THE LICENSOR HAS BEEN
305 | ADVISED OF THE POSSIBILITY OF SUCH LOSSES, COSTS, EXPENSES, OR
306 | DAMAGES. WHERE A LIMITATION OF LIABILITY IS NOT ALLOWED IN FULL OR
307 | IN PART, THIS LIMITATION MAY NOT APPLY TO YOU.
308 |
309 | c. The disclaimer of warranties and limitation of liability provided
310 | above shall be interpreted in a manner that, to the extent
311 | possible, most closely approximates an absolute disclaimer and
312 | waiver of all liability.
313 |
314 |
315 | Section 6 -- Term and Termination.
316 |
317 | a. This Public License applies for the term of the Copyright and
318 | Similar Rights licensed here. However, if You fail to comply with
319 | this Public License, then Your rights under this Public License
320 | terminate automatically.
321 |
322 | b. Where Your right to use the Licensed Material has terminated under
323 | Section 6(a), it reinstates:
324 |
325 | 1. automatically as of the date the violation is cured, provided
326 | it is cured within 30 days of Your discovery of the
327 | violation; or
328 |
329 | 2. upon express reinstatement by the Licensor.
330 |
331 | For the avoidance of doubt, this Section 6(b) does not affect any
332 | right the Licensor may have to seek remedies for Your violations
333 | of this Public License.
334 |
335 | c. For the avoidance of doubt, the Licensor may also offer the
336 | Licensed Material under separate terms or conditions or stop
337 | distributing the Licensed Material at any time; however, doing so
338 | will not terminate this Public License.
339 |
340 | d. Sections 1, 5, 6, 7, and 8 survive termination of this Public
341 | License.
342 |
343 |
344 | Section 7 -- Other Terms and Conditions.
345 |
346 | a. The Licensor shall not be bound by any additional or different
347 | terms or conditions communicated by You unless expressly agreed.
348 |
349 | b. Any arrangements, understandings, or agreements regarding the
350 | Licensed Material not stated herein are separate from and
351 | independent of the terms and conditions of this Public License.
352 |
353 |
354 | Section 8 -- Interpretation.
355 |
356 | a. For the avoidance of doubt, this Public License does not, and
357 | shall not be interpreted to, reduce, limit, restrict, or impose
358 | conditions on any use of the Licensed Material that could lawfully
359 | be made without permission under this Public License.
360 |
361 | b. To the extent possible, if any provision of this Public License is
362 | deemed unenforceable, it shall be automatically reformed to the
363 | minimum extent necessary to make it enforceable. If the provision
364 | cannot be reformed, it shall be severed from this Public License
365 | without affecting the enforceability of the remaining terms and
366 | conditions.
367 |
368 | c. No term or condition of this Public License will be waived and no
369 | failure to comply consented to unless expressly agreed to by the
370 | Licensor.
371 |
372 | d. Nothing in this Public License constitutes or may be interpreted
373 | as a limitation upon, or waiver of, any privileges and immunities
374 | that apply to the Licensor or You, including from the legal
375 | processes of any jurisdiction or authority.
376 |
377 |
378 | =======================================================================
379 |
380 | Creative Commons is not a party to its public
381 | licenses. Notwithstanding, Creative Commons may elect to apply one of
382 | its public licenses to material it publishes and in those instances
383 | will be considered the “Licensor.” The text of the Creative Commons
384 | public licenses is dedicated to the public domain under the CC0 Public
385 | Domain Dedication. Except for the limited purpose of indicating that
386 | material is shared under a Creative Commons public license or as
387 | otherwise permitted by the Creative Commons policies published at
388 | creativecommons.org/policies, Creative Commons does not authorize the
389 | use of the trademark "Creative Commons" or any other trademark or logo
390 | of Creative Commons without its prior written consent including,
391 | without limitation, in connection with any unauthorized modifications
392 | to any of its public licenses or any other arrangements,
393 | understandings, or agreements concerning use of licensed material. For
394 | the avoidance of doubt, this paragraph does not form part of the
395 | public licenses.
396 |
397 | Creative Commons may be contacted at creativecommons.org.
398 |
--------------------------------------------------------------------------------
/Makefile:
--------------------------------------------------------------------------------
1 | # Makefile
2 | SHELL = /bin/bash
3 |
4 | # Styling
5 | .PHONY: style
6 | style:
7 | black .
8 | flake8
9 | python3 -m isort .
10 | pyupgrade
11 |
12 | # Cleaning
13 | .PHONY: clean
14 | clean: style
15 | python notebooks/clear_cell_nums.py
16 | find . -type f -name "*.DS_Store" -ls -delete
17 | find . | grep -E "(__pycache__|\.pyc|\.pyo)" | xargs rm -rf
18 | find . | grep -E ".pytest_cache" | xargs rm -rf
19 | find . | grep -E ".ipynb_checkpoints" | xargs rm -rf
20 | rm -rf .coverage*
21 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # LLM Applications
2 |
3 | A comprehensive guide to building RAG-based LLM applications for production.
4 |
5 | - **Blog post**: https://www.anyscale.com/blog/a-comprehensive-guide-for-building-rag-based-llm-applications-part-1
6 | - **GitHub repository**: https://github.com/ray-project/llm-applications
7 | - **Interactive notebook**: https://github.com/ray-project/llm-applications/blob/main/notebooks/rag.ipynb
8 | - **Anyscale Endpoints**: https://endpoints.anyscale.com/
9 | - **Ray documentation**: https://docs.ray.io/
10 |
11 | In this guide, we will learn how to:
12 |
13 | - 💻 Develop a retrieval augmented generation (RAG) based LLM application from scratch.
14 | - 🚀 Scale the major components (load, chunk, embed, index, serve, etc.) in our application.
15 | - ✅ Evaluate different configurations of our application to optimize for both per-component (ex. retrieval_score) and overall performance (quality_score).
16 | - 🔀 Implement LLM hybrid routing approach to bridge the gap b/w OSS and closed LLMs.
17 | - 📦 Serve the application in a highly scalable and available manner.
18 | - 💥 Share the 1st order and 2nd order impacts LLM applications have had on our products.
19 |
20 |
21 | 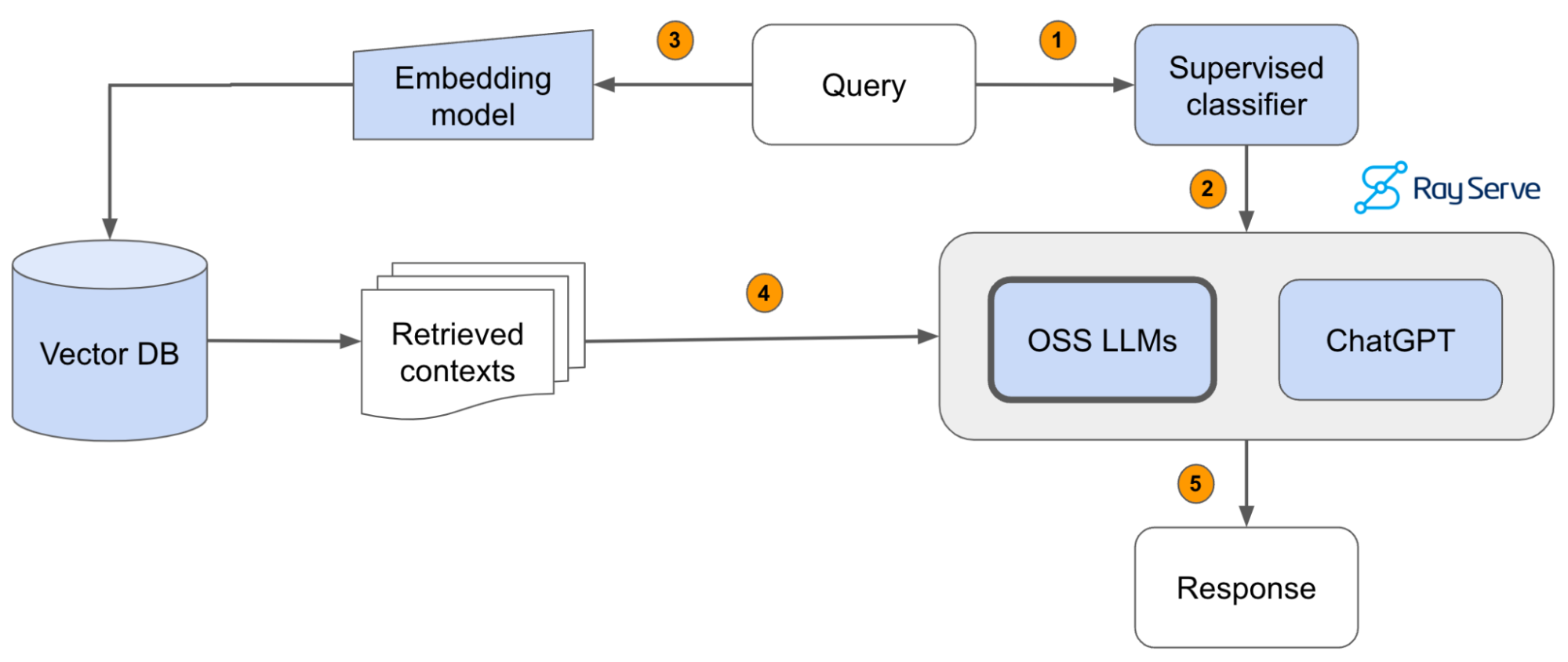 22 |
23 | ## Setup
24 |
25 | ### API keys
26 | We'll be using [OpenAI](https://platform.openai.com/docs/models/) to access ChatGPT models like `gpt-3.5-turbo`, `gpt-4`, etc. and [Anyscale Endpoints](https://endpoints.anyscale.com/) to access OSS LLMs like `Llama-2-70b`. Be sure to create your accounts for both and have your credentials ready.
27 |
28 | ### Compute
29 |
22 |
23 | ## Setup
24 |
25 | ### API keys
26 | We'll be using [OpenAI](https://platform.openai.com/docs/models/) to access ChatGPT models like `gpt-3.5-turbo`, `gpt-4`, etc. and [Anyscale Endpoints](https://endpoints.anyscale.com/) to access OSS LLMs like `Llama-2-70b`. Be sure to create your accounts for both and have your credentials ready.
27 |
28 | ### Compute
29 |
30 | Local
31 | You could run this on your local laptop but a we highly recommend using a setup with access to GPUs. You can set this up on your own or on [Anyscale](http://anyscale.com/).
32 |
33 |
34 |
35 | Anyscale
36 |
37 | - Start a new Anyscale workspace on staging using an
g3.8xlarge head node, which has 2 GPUs and 32 CPUs. We can also add GPU worker nodes to run the workloads faster. If you're not on Anyscale, you can configure a similar instance on your cloud.
38 | - Use the
default_cluster_env_2.6.2_py39 cluster environment.
39 | - Use the
us-west-2 if you'd like to use the artifacts in our shared storage (source docs, vector DB dumps, etc.).
40 |
41 |
42 |
43 |
44 | ### Repository
45 | ```bash
46 | git clone https://github.com/ray-project/llm-applications.git .
47 | git config --global user.name
48 | git config --global user.email
49 | ```
50 |
51 | ### Data
52 | Our data is already ready at `/efs/shared_storage/goku/docs.ray.io/en/master/` (on Staging, `us-east-1`) but if you wanted to load it yourself, run this bash command (change `/desired/output/directory`, but make sure it's on the shared storage,
53 | so that it's accessible to the workers)
54 | ```bash
55 | git clone https://github.com/ray-project/llm-applications.git .
56 | ```
57 |
58 | ### Environment
59 |
60 | Then set up the environment correctly by specifying the values in your `.env` file,
61 | and installing the dependencies:
62 |
63 | ```bash
64 | pip install --user -r requirements.txt
65 | export PYTHONPATH=$PYTHONPATH:$PWD
66 | pre-commit install
67 | pre-commit autoupdate
68 | ```
69 |
70 | ### Credentials
71 | ```bash
72 | touch .env
73 | # Add environment variables to .env
74 | OPENAI_API_BASE="https://api.openai.com/v1"
75 | OPENAI_API_KEY="" # https://platform.openai.com/account/api-keys
76 | ANYSCALE_API_BASE="https://api.endpoints.anyscale.com/v1"
77 | ANYSCALE_API_KEY="" # https://app.endpoints.anyscale.com/credentials
78 | DB_CONNECTION_STRING="dbname=postgres user=postgres host=localhost password=postgres"
79 | source .env
80 | ```
81 |
82 | Now we're ready to go through the [rag.ipynb](notebooks/rag.ipynb) interactive notebook to develop and serve our LLM application!
83 |
84 | ### Learn more
85 | - If your team is investing heavily in developing LLM applications, [reach out](mailto:endpoints-help@anyscale.com) to us to learn more about how [Ray](https://github.com/ray-project/ray) and [Anyscale](http://anyscale.com/) can help you scale and productionize everything.
86 | - Start serving (+fine-tuning) OSS LLMs with [Anyscale Endpoints](https://endpoints.anyscale.com/) ($1/M tokens for `Llama-3-70b`) and private endpoints available upon request (1M free tokens trial).
87 | - Learn more about how companies like OpenAI, Netflix, Pinterest, Verizon, Instacart and others leverage Ray and Anyscale for their AI workloads at the [Ray Summit 2024](https://raysummit.anyscale.com/) this Sept 18-20 in San Francisco.
88 |
--------------------------------------------------------------------------------
/datasets/data-still-to-label.jsonl:
--------------------------------------------------------------------------------
1 | {'question': 'What is the rest api for getting the head node id?', 'source': 'https://docs.ray.io/en/latest/index.html'}
2 | {'question': 'how to rerun a canceled ray task', 'source': 'https://docs.ray.io/en/latest/ray-core/api/doc/ray.cancel.html#ray.cancel'}
3 | {'question': 'how to print ray version in notebook', 'source': 'https://docs.ray.io/en/latest/ray-core/handling-dependencies.html#runtime-environments-api-ref'}
4 | {'question': 'How do I set the max parallel concurrent scheduled tasks in map_batches?', 'source': 'https://docs.ray.io/en/latest/ray-core/examples/batch_prediction.html'}
5 | {'question': 'How do I get the number of cpus from ray cluster?', 'source': 'https://docs.ray.io/en/latest/ray-air/examples/huggingface_text_classification.html'}
6 | {'question': 'How to use the exclude option to the runtime_env', 'source': 'https://docs.ray.io/en/latest/ray-core/handling-dependencies.html#api-reference'}
7 | {'question': 'show a map batch example with batch_format', 'source': 'https://docs.ray.io/en/latest/data/transforming-data.html'}
8 | {'question': 'how to find local ray address', 'source': 'https://docs.ray.io/en/latest/ray-core/examples/gentle_walkthrough.html'}
9 | {'question': 'Why don’t I see any deprecation warnings from `warnings.warn` when running with Ray Tune?', 'source': 'https://docs.ray.io/en/latest/tune/tutorials/tune-output.html'}
10 | {'question': 'how can I set *num_heartbeats_timeout in `ray start --head`* command ?', 'source': 'https://docs.ray.io/en/latest/cluster/cli.html'}
11 | {'question': "ray crashing with AttributeError: module 'pydantic.fields' has no attribute 'ModelField", 'source': 'https://discuss.ray.io/'}
12 | {'question': 'How to start ray cluster on multiple node via CLI?', 'source': 'https://docs.ray.io/en/latest/cluster/vms/user-guides/launching-clusters/aws.html'}
13 | {'question': 'my ray tuner shows "running" but CPU usage is almost 0%. why ?', 'source': 'https://docs.ray.io/en/latest/tune/faq.html'}
14 | {'question': 'should the Ray head node and all workers have the same object store memory size allocated?', 'source': 'https://docs.ray.io/en/latest/ray-observability/user-guides/debug-apps/debug-memory.html'}
15 | {'question': 'I want to set up gcs health checks via REST API, what is the endpoint that I can hit to check health for gcs?', 'source': 'https://docs.ray.io'}
16 | {'question': 'In Ray Serve, how to specify whether to set up an httpproxy on each node, or just the head node?', 'source': 'https://docs.ray.io/en/latest/serve/architecture.html'}
17 | {'question': 'Want to embed Grafana into the Ray Dashboard, given that I am using KubeRay\n\nGiven the context that Prometheus and Grafana are not running on my Head node, and that I am using KubeRay, how should I be setting the following variables?\n• `RAY_GRAFANA_HOST`\n• `RAY_PROMETHEUS_HOST`\nAnd is there a way to set them more intelligently, given that head node IP is changing every time we reconfigure our cluster?', 'source': 'https://docs.ray.io/en/latest/cluster/configure-manage-dashboard.html'}
18 | {'question': 'How the GCS determines which Kubernetes pod to kill when using KubeRay autoscaling?', 'source': 'https://docs.ray.io/en/latest/cluster/kubernetes/user-guides/configuring-autoscaling.html'}
19 | {'question': 'How can I set the `request_timeout_s` in `http_options` section of a Ray Serve YAML config file?', 'source': 'https://docs.ray.io/en/latest/serve/index.html'}
20 | {'question': 'How do I make the GPU available on my M1 laptop to ray?', 'source': 'https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh'}
21 | {'question': 'How can I add a timeout for the Ray job?', 'source': 'https://docs.ray.io/en/latest/serve/performance.html'}
22 | {'question': 'how do I set custom /tmp directory for remote cluster?', 'source': 'https://discuss.ray.io/t/8862'}
23 | {'question': 'if I set --temp-dir to a different directory than /tmp, will ray object spill to the custom directory ?', 'source': 'https://docs.ray.io/en/latest/ray-core/objects/object-spilling.html'}
24 | {'question': 'can you give me an example for *`--runtime-env-json`*', 'source': 'https://docs.ray.io/en/latest/serve/dev-workflow.html'}
25 | {'question': 'What is a default value for memory for rayActorOptions?', 'source': 'https://docs.ray.io/en/latest/serve/api/doc/ray.serve.schema.RayActorOptionsSchema.html'}
26 | {'question': 'What should be the value of `maxConcurrentReplicas` if autoscaling configuration is specified?', 'source': 'https://docs.ray.io/en/latest/serve/api/doc/ray.serve.schema.DeploymentSchema.html#ray.serve.schema.DeploymentSchema.num_replicas_and_autoscaling_config_mutually_exclusive'}
27 | {'question': 'Yes what should be the value of `max_concurrent_queries` when `target_num_ongoing_requests_per_replica` is specified?', 'source': 'https://docs.ray.io/en/latest/serve/performance.html'}
28 | {'question': 'what is a `smoothing_factor`', 'source': 'https://docs.ray.io/en/latest/serve/scaling-and-resource-allocation.html'}
29 | {'question': 'Why do we need to configure ray serve application such that it can run on one node?', 'source': 'https://www.anyscale.com/blog/simplify-your-mlops-with-ray-and-ray-serve'}
30 | {'question': 'What is the reason actors change their state to unhealthy?', 'source': 'https://docs.ray.io/en/latest/ray-core/fault_tolerance/actors.html'}
31 | {'question': 'How can I add `max_restarts` to serve deployment?', 'source': 'https://docs.ray.io/en/latest/serve/index.html'}
32 | {'question': 'How do I access logs for a dead node?', 'source': 'https://docs.ray.io/en/latest/ray-observability/user-guides/cli-sdk.html'}
33 | {'question': 'What are the reasons for a node to change it’s status to dead?', 'source': 'https://docs.ray.io/en/latest/ray-core/fault_tolerance/nodes.html'}
34 | {'question': 'What are the reasons for spikes in node CPU utilization', 'source': 'https://www.anyscale.com/blog/autoscaling-clusters-with-ray'}
35 | {'question': 'What AWS machine type is recommended to deploy a RayService on EKS?', 'source': 'https://docs.ray.io/en/latest/'}
36 | {'question': 'Can you write a function that runs exactly once on each node of a ray cluster?', 'source': 'https://docs.ray.io/en/latest/ray-air/examples/gptj_deepspeed_fine_tuning.html'}
37 | {'question': 'can you drain a node for maintenance?', 'source': 'https://docs.ray.io/en/latest/cluster/cli.html'}
38 | {'question': 'what env variable should I set to disable the heartbeat message displayed every 5 sec? I would like to turn it to every 1 minute for instance.', 'source': 'https://docs.ray.io/en/latest/'}
39 | {'question': 'Is there a way to configure the session name generated by ray?', 'source': 'https://docs.ray.io/en/latest/ray-core/configure.html'}
40 | {'question': 'How can I choose which worker group to use when submitting a ray job?', 'source': 'https://discuss.ray.io/t/9824'}
41 | {'question': 'can I use the Python SDK to get a link to Ray dashboard for a given job?', 'source': 'https://docs.ray.io/en/latest/ray-observability/getting-started.html'}
42 | {'question': 'I’d like to use the Ray Jobs Python SDK to get a link to a specific Job view in the dashboard', 'source': 'https://docs.ray.io/en/latest/cluster/running-applications/job-submission/sdk.html'}
43 | {'question': 'I am building a product on top of ray and would like to use ray name & logo for it :slightly_smiling_face: where can I find ray name usage guidelines?', 'source': 'https://forms.gle/9TSdDYUgxYs8SA9e8'}
44 | {'question': 'What may possible cause the node where this task was running crashed unexpectedly. This can happen if: (1) the instance where the node was running failed, (2) raylet crashes unexpectedly (OOM, preempted node, etc).', 'source': 'https://www.anyscale.com/blog/automatic-and-optimistic-memory-scheduling-for-ml-workloads-in-ray'}
45 | {'question': 'Do you know how to resolve (gcs_server) : Health check failed for node? I observed that the node is still up and running.', 'source': 'https://docs.ray.io/en/latest/ray-observability/user-guides/cli-sdk.html'}
46 | {'question': 'How to extend the health check threshold?', 'source': 'https://docs.ray.io/en/latest/serve/api/doc/ray.serve.schema.DeploymentSchema.html'}
47 | {'question': 'How to extend the GCS health check threshold for for a Ray job use case?', 'source': 'https://docs.ray.io/en/latest/ray-core/fault_tolerance/gcs.html'}
48 | {'question': 'What is the working of `PowerOfTwoChoicesReplicaScheduler` ?', 'source': 'https://github.com/ray-project/ray/pull/36501'}
49 | {'question': 'Do you need the DAGDriver to deploy a serve application using RayServe?', 'source': 'https://docs.ray.io/en/latest/serve/key-concepts.html'}
50 | {'question': 'What’s the import path that I need to provide to a simple RayServe deployment?', 'source': 'https://maxpumperla.com/learning_ray'}
51 | {'question': 'what’s the latest version of ray', 'source': 'https://github.com/ray-project/ray/releases/tag/ray-1.11.0'}
52 | {'question': 'do you know ray have been updated to version 2.6?', 'source': 'https://github.com/ray-project/ray'}
53 | {'question': 'do you have any documents / examples showing the usage of RayJob in Kuberay?', 'source': 'https://ray-project.github.io/kuberay/guidance/rayjob/'}
54 | {'question': 'Do you have any document/guide which shows how to setup the local development environment for kuberay on a arm64 processor based machine?', 'source': 'https://docs.ray.io/en/latest/ray-contribute/development.html#building-ray'}
55 | {'question': 'How can I configure min and max worker number of nodes when I’m using Ray on Databricks?', 'source': 'https://docs.ray.io/en/latest/cluster/vms/references/ray-cluster-configuration.html'}
56 | {'question': 'Does Ray metrics have to be exported via an actor?', 'source': 'https://docs.ray.io/en/latest/ray-core/ray-metrics.html'}
57 | {'question': 'How is object store memory calculated?', 'source': 'https://docs.ray.io/en/latest/ray-core/scheduling/memory-management.html'}
58 | {'question': 'how can I avoid objects not getting spilled?', 'source': 'https://docs.ray.io/en/latest/data/data-internals.html'}
59 | {'question': 'what’s ray core', 'source': 'https://docs.ray.io/en/latest/ray-core/tasks.html#ray-remote-functions'}
60 | {'question': 'Does ray support cron job', 'source': 'https://pillow.readthedocs.io/en/stable/handbook/concepts.html#modes'}
61 | {'question': 'can you give me the dependencies list for api read_images?', 'source': 'https://pillow.readthedocs.io/en/stable/handbook/concepts.html#modes'}
62 | {'question': 'how do I kill a specific serve replica', 'source': 'https://docs.ray.io/en/latest/serve/production-guide/fault-tolerance.html'}
63 | {'question': 'What exactly is rayjob? How is it handled in kuberay? Can you give an example of what a Rayjob will look like?', 'source': 'https://ray-project.github.io/kuberay/guidance/rayjob/'}
64 | {'question': 'do you have access to the CRD yaml file of RayJob for KubeRay?', 'source': 'https://github.com/ray-project/kuberay'}
65 | {'question': 'how do I adjust the episodes per iteration in Ray Tune?', 'source': 'https://docs.ray.io/en/latest/tune/index.html'}
66 | {'question': 'in Ray Tune, can you explain what episodes are?', 'source': 'https://docs.ray.io/en/latest/ray-references/glossary.html'}
67 | {'question': 'how do I know how many agents a Tune episode is spanning?', 'source': 'https://docs.ray.io/en/latest/index.html'}
68 | {'question': 'how can I limit the number of jobs in the history stored in the ray GCS?', 'source': 'https://docs.ray.io/en/latest/index.html'}
69 | {'question': 'I have a large csv file on S3. How do I use Ray to create another csv file with one column removed?', 'source': 'https://docs.ray.io/en/master/data/api/doc/ray.data.read_csv.html#ray-data-read-csv'}
70 | {'question': 'How to discover what node was used to run a given task', 'source': 'https://docs.ray.io/en/latest/ray-core/ray-dashboard.html#ray-dashboard'}
71 | {'question': 'it is possible to discover what node was used to execute a given task using its return future, object reference ?', 'source': 'https://docs.ray.io/en/latest/ray-core/walkthrough.html#running-a-task'}
72 | {'question': 'how to efficiently broadcast a large nested dictionary from a single actor to thousands of tasks', 'source': 'https://discuss.ray.io/t/6521'}
73 | {'question': 'How to mock remote calls of an Actor for Testcases?', 'source': 'https://docs.ray.io/en/latest/ray-core/handling-dependencies.html#runtime-environments'}
74 | {'question': 'How to use pytest mock to create a Actor', 'source': 'https://docs.ray.io/en/latest/ray-core/handling-dependencies.html#runtime-environments'}
75 | {'question': 'Can I initiate an Actor directly without remote()', 'source': 'https://docs.ray.io/en/latest/ray-core/handling-dependencies.html#runtime-environments'}
76 | {'question': 'Is there a timeout or retry setting for long a worker will wait / retry to make an initial connection to the head node?', 'source': 'https://docs.ray.io/en/latest/ray-core/handling-dependencies.html#runtime-environments'}
77 | {'question': 'im getting this error of ValueError: The base resource usage of this topology ExecutionResources but my worker and head node are both GPU nodes...oh is it expecting 2 GPUs on a single worker node is that why?', 'source': 'https://docs.ray.io/en/latest/train/faq.html'}
78 | {'question': 'how can I move airflow variables in ray task ?', 'source': 'https://docs.ray.io/en/latest/ray-observability/monitoring-debugging/gotchas.html#environment-variables-are-not-passed-from-the-driver-to-workers'}
79 | {'question': 'How to recompile Ray docker image using Ubuntu 22.04LTS as the base docker image?', 'source': 'https://github.com/ray-project/ray.git'}
80 | {'question': 'I am using TuneSearchCV with an XGBoost regressor. To test it out, I have set the n_trials to 3 and left the n_jobs at its default of -1 to use all available processors. From what I have observed, only one trial runs per CPU since 3 trials only uses 3 CPUs which is pretty time consuming. Is there a way to run a single trial across multiple CPUs to speed things up?', 'source': 'https://docs.ray.io/en/latest/ray-core/actors/async_api.html'}
81 | {'question': 'how do I make rolling mean column in ray dataset?', 'source': 'https://docs.ray.io/en/latest/ray-core/actors/terminating-actors.html#manual-termination-within-the-actor'}
82 | {'question': "Where is the execution limit coming from? I'm not sure where I set it", 'source': 'https://docs.ray.io/en/latest/data/dataset-internals.html#configuring-resources-and-locality'}
83 | {'question': 'The ray cluster spins up the workers, but then immediately kills them when it starts to process the data - is this expected behavior? If not, what could the issue be?', 'source': 'https://docs.ray.io/en/latest/data/examples/nyc_taxi_basic_processing.html'}
84 | {'question': 'Does Ray support numpy 1.24.2?', 'source': 'https://docs.ray.io/en/latest/index.html'}
85 | {'question': 'Can I have a super class of Actor?', 'source': 'https://docs.ray.io/en/latest/cluster/running-applications/job-submission/ray-client.html#client-arguments'}
86 | {'question': 'can I specify working directory in ray.client(base_url).namespace(namespsce).connect()', 'source': 'https://docs.ray.io/en/latest/cluster/running-applications/job-submission/ray-client.html#client-arguments'}
87 | {'question': 'can I monkey patch a ray function?', 'source': 'https://docs.ray.io/en/latest/ray-observability/monitoring-debugging/gotchas.html#outdated-function-definitions'}
88 | {'question': 'I get the following error using Ray Tune with Ray version 2.4.0 after a successful training epoch: “TypeError: can’t convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.” According to the stack trace, the error seems to come from the __report_progress_ method. I’m using one GPU to train a pretrained ResNet18 model. Do you know what is causing this issue?', 'source': 'https://docs.ray.io/en/latest/index.html'}
89 | {'question': 'how to use ray.init to launch a multi-node cluster', 'source': 'https://docs.ray.io/en/latest/cluster/vms/references/ray-cluster-configuration.html'}
90 | {'question': 'why detauched Actor pointing to old working directory ?', 'source': 'https://docs.ray.io/en/latest/ray-core/actors/named-actors.html#actor-lifetimes'}
91 | {'question': 'If I spawn a process in a Ray Task, what happens to that process when the Ray Task completes?', 'source': 'https://docs.ray.io/en/latest/ray-core/tasks/using-ray-with-gpus.html'}
92 | {'question': 'how can I use torch.distributed.launch with Ray jobs?', 'source': 'https://www.anyscale.com/blog/large-scale-distributed-training-with-torchx-and-ray'}
93 | {'question': 'how to fix this issue: "WARNING sample.py:469 -- sample_from functions that take a spec dict are deprecated. Please update your function to work with the config dict directly."', 'source': 'https://docs.ray.io/en/latest/tune/api/doc/ray.tune.sample_from.html'}
94 | {'question': 'How does one define the number of timesteps and episodes when training a PPO algorithm with Rllib?', 'source': 'https://docs.ray.io/en/latest/rllib/rllib-algorithms.html#part-2'}
95 | {'question': "my serve endpoint doesn't seem to run my code when deployed onto our remote cluster. Only the endpoints that are using DAGDrivers are running into issues", 'source': 'https://docs.ray.io/en/latest/serve/production-guide/deploy-vm.html#adding-a-runtime-environment'}
96 | {'question': 'How to specify different preprocessors for train and evaluation ray datasets?', 'source': 'https://docs.ray.io/en/latest/'}
97 | {'question': 'Can I set the ray.init() in the worker code for ray serve?', 'source': 'https://docs.ray.io/en/latest/serve/api/index.html'}
98 | {'question': 'Can I use a ubuntu 22.04 image to install Ray as a python package and use it for Kubernetes cluster?', 'source': 'https://docs.ray.io/en/latest/ray-overview/installation.html#installation'}
99 |
--------------------------------------------------------------------------------
/datasets/eval-dataset-v1.jsonl:
--------------------------------------------------------------------------------
1 | {"question": "I’m struggling a bit with Ray Data type conversions when I do map_batches. Any advice?", "source": "https://docs.ray.io/en/master/data/transforming-data.html#configuring-batch-format"}
2 | {"question": "How does autoscaling work in a Ray Serve application?", "source": "https://docs.ray.io/en/master/serve/scaling-and-resource-allocation.html#autoscaling"}
3 | {"question": "how do I get the address of a ray node", "source": "https://docs.ray.io/en/master/ray-core/miscellaneous.html#node-information"}
4 | {"question": "Does Ray support NCCL?", "source": "https://docs.ray.io/en/master/ray-more-libs/ray-collective.html"}
5 | {"question": "Is Ray integrated with DeepSpeed?", "source": "https://docs.ray.io/en/master/ray-air/examples/gptj_deepspeed_fine_tuning.html#fine-tuning-the-model-with-ray-air-a-name-train-a"}
6 | {"question": "what will happen if I use AsyncIO's await to wait for a Ray future like `await x.remote()`", "source": "https://docs.ray.io/en/master/ray-core/actors/async_api.html#objectrefs-as-asyncio-futures"}
7 | {"question": "How would you compare Spark, Ray, Dask?", "source": "https://docs.ray.io/en/master/data/overview.html#how-does-ray-data-compare-to-x-for-offline-inference"}
8 | {"question": "why would ray overload a node w/ more task that the resources allow ?", "source": "https://docs.ray.io/en/master/ray-core/scheduling/resources.html#physical-resources-and-logical-resources"}
9 | {"question": "when should I use Ray Client?", "source": "https://docs.ray.io/en/master/cluster/running-applications/job-submission/ray-client.html#when-to-use-ray-client"}
10 | {"question": "how to scatter actors across the cluster?", "source": "https://docs.ray.io/en/master/ray-core/scheduling/index.html#spread"}
11 | {"question": "On remote ray cluster, when I do `ray debug` I'm getting connection refused error. Why ?", "source": "https://docs.ray.io/en/master/ray-observability/user-guides/debug-apps/ray-debugging.html#running-on-a-cluster"}
12 | {"question": "How does Ray AIR set up the model to communicate gradient updates across machines?", "source": "https://docs.ray.io/en/master/train/train.html#intro-to-ray-train"}
13 | {"question": "Why would I use Ray Serve instead of Modal or Seldon? Why can't I just do it via containers?", "source": "https://docs.ray.io/en/master/serve/index.html"}
14 | {"question": "How do I deploy an LLM workload on top of Ray Serve?", "source": "https://docs.ray.io/en/master/ray-air/examples/gptj_serving.html"}
15 | {"question": "what size of memory should I need for this if I am setting set the `model_id` to “EleutherAI/gpt-j-6B”?", "source": "https://docs.ray.io/en/master/ray-air/examples/gptj_serving.html"}
16 | {"question": "How do I log the results from multiple distributed workers into a single tensorboard?", "source": "https://docs.ray.io/en/master/tune/tutorials/tune-output.html#how-to-log-your-tune-runs-to-tensorboard"}
17 | {"question": "how do you config SyncConfig for a Ray AIR job?", "source": "https://docs.ray.io/en/master/tune/tutorials/tune-storage.html#on-a-multi-node-cluster-deprecated"}
18 | {"question": "how can I quickly narrow down the root case of a failed ray job, assuming I have access to all the logs", "source": "https://docs.ray.io/en/master/ray-observability/user-guides/configure-logging.html#log-files-in-logging-directory"}
19 | {"question": "How do I specify how many GPUs a serve deployment needs?", "source": "https://docs.ray.io/en/master/serve/scaling-and-resource-allocation.html#resource-management-cpus-gpus"}
20 | {"question": "One of my worker nodes keeps dying on using TensorflowTrainer with around 1500 workers, I observe SIGTERM has been received to the died node's raylet. How can I debug this?", "source": "https://docs.ray.io/en/master/ray-observability/user-guides/configure-logging.html#log-files-in-logging-directory"}
21 | {"question": "what are the possible reasons for nodes dying in a cluster?", "source": "https://docs.ray.io/en/master/ray-core/scheduling/ray-oom-prevention.html"}
22 | {"question": "how do I programatically get ray remote cluster to a target size immediately without scaling up through autoscaler ?", "source": "https://docs.ray.io/en/master/cluster/running-applications/autoscaling/reference.html#ray-autoscaler-sdk-request-resources"}
23 | {"question": "how do you disable async iter_batches with Ray Dataset?", "source": "https://docs.ray.io/en/master/data/api/doc/ray.data.Dataset.iter_batches.html#ray-data-dataset-iter-batches"}
24 | {"question": "what is the different between a batch and a block, for ray datasets?", "source": "https://docs.ray.io/en/master/data/data-internals.html#datasets-and-blocks"}
25 | {"question": "How to setup the development environments for ray project?", "source": "https://docs.ray.io/en/master/ray-contribute/development.html"}
26 | {"question": "how do I debug why ray rollout workers are deadlocking when using the sample API in `ray/rllib/evaluation/rollout_worker.py`", "source": "https://docs.ray.io/en/master/rllib/rllib-dev.html#troubleshooting"}
27 | {"question": "how do I join two ray datasets?", "source": "https://docs.ray.io/en/master/data/api/doc/ray.data.Dataset.zip.html"}
28 | {"question": "Is there a way to retrieve an object ref from its id?", "source": "https://docs.ray.io/en/master/ray-core/objects.html"}
29 | {"question": "how to create model Checkpoint from the model in memory?", "source": "https://docs.ray.io/en/master/train/api/doc/ray.train.torch.TorchCheckpoint.from_model.html#ray-train-torch-torchcheckpoint-from-model"}
30 | {"question": "what is Deployment in Ray Serve?", "source": "https://docs.ray.io/en/master/serve/key-concepts.html#deployment"}
31 | {"question": "What is user config in Ray Serve? how do I use it?", "source": "https://docs.ray.io/en/master/serve/configure-serve-deployment.html#configure-ray-serve-deployments"}
32 | {"question": "What is the difference between PACK and SPREAD strategy?", "source": "https://docs.ray.io/en/master/ray-core/scheduling/placement-group.html#placement-strategy"}
33 | {"question": "What’s the best way to run ray across multiple machines?", "source": "https://docs.ray.io/en/master/ray-core/cluster/index.html"}
34 | {"question": "how do I specify ScalingConfig for a Tuner run?", "source": "https://docs.ray.io/en/master/tune/api/doc/ray.tune.Tuner.html"}
35 | {"question": "how to utilize ‘zero-copy’ feature ray provide for numpy?", "source": "https://docs.ray.io/en/master/ray-core/objects/serialization.html#numpy-arrays"}
36 | {"question": "if there are O(millions) of keys that all have state, is it ok to spin up 1=1 actors? Or would it be advised to create ‘key pools’ where an actor can hold 1=many keys?", "source": "https://docs.ray.io/en/master/ray-core/patterns/too-fine-grained-tasks.html"}
37 | {"question": "How to find the best checkpoint from the trial directory?", "source": "https://docs.ray.io/en/master/tune/api/doc/ray.tune.ExperimentAnalysis.html"}
38 | {"question": "what are the advantage and disadvantage of using singleton Actor ?", "source": "https://docs.ray.io/en/master/ray-core/actors/named-actors.html"}
39 | {"question": "what are the advantages of using a named actor?", "source": "https://docs.ray.io/en/master/ray-core/actors/named-actors.html"}
40 | {"question": "How do I read a text file stored on S3 using Ray Data?", "source": "https://docs.ray.io/en/master/data/api/doc/ray.data.read_text.html"}
41 | {"question": "how do I get the IP of the head node for my Ray cluster?", "source": "https://docs.ray.io/en/master/ray-core/miscellaneous.html#node-information"}
42 | {"question": "How to write a map function that returns a list of object for `map_batches`?", "source": "https://docs.ray.io/en/master/data/api/doc/ray.data.Dataset.map_batches.html#ray-data-dataset-map-batches"}
43 | {"question": "How do I set a maximum episode length when training with Rllib?", "source": "https://docs.ray.io/en/master/rllib/key-concepts.html"}
44 | {"question": "how do I make a Ray Tune trial retry on failures?", "source": "https://docs.ray.io/en/master/tune/tutorials/tune-fault-tolerance.html"}
45 | {"question": "For the supervised actor pattern, can we keep the Worker Actor up if the Supervisor passes a reference to the Actor to another Actor, to allow the worker actor to remain even on Supervisor / Driver failure?", "source": "https://docs.ray.io/en/master/ray-core/patterns/tree-of-actors.html"}
46 | {"question": "How do I read a large text file in S3 with Ray?", "source": "https://docs.ray.io/en/master/data/api/doc/ray.data.read_text.html"}
47 | {"question": "how do I get a ray dataset from pandas", "source": "https://docs.ray.io/en/master/data/api/doc/ray.data.from_pandas.html"}
48 | {"question": "can you give me an example of using `ray.data.map` ?", "source": "https://docs.ray.io/en/master/data/api/doc/ray.data.Dataset.map.html"}
49 | {"question": "can you give me an example of using `ray.data.map` , with a callable class as input?", "source": "https://docs.ray.io/en/master/data/api/doc/ray.data.Dataset.map.html"}
50 | {"question": "How to set memory limit for each trial in Ray Tuner?", "source": "https://docs.ray.io/en/master/tune/tutorials/tune-resources.html"}
51 | {"question": "how do I get the actor id of an actor", "source": "https://docs.ray.io/en/master/ray-core/api/doc/ray.runtime_context.get_runtime_context.html"}
52 | {"question": "can ray.init() can check if ray is all-ready initiated ?", "source": "https://docs.ray.io/en/master/ray-core/api/doc/ray.init.html"}
53 | {"question": "What does the `compute=actor` argument do within `ray.data.map_batches` ?", "source": "https://docs.ray.io/en/master/data/api/doc/ray.data.Dataset.map_batches.html"}
54 | {"question": "how do I use wandb logger with accelerateTrainer?", "source": "https://docs.ray.io/en/master/tune/examples/tune-wandb.html"}
55 | {"question": "What will be implicitly put into object store?", "source": "https://docs.ray.io/en/master/ray-core/objects.html#objects"}
56 | {"question": "How do I kill or cancel a ray task that I already started?", "source": "https://docs.ray.io/en/master/ray-core/fault_tolerance/tasks.html#cancelling-misbehaving-tasks"}
57 | {"question": "how to send extra arguments in dataset.map_batches function?", "source": "https://docs.ray.io/en/master/data/api/doc/ray.data.Dataset.map_batches.html#ray-data-dataset-map-batches"}
58 | {"question": "where does ray GCS store the history of jobs run on a kuberay cluster? What type of database and format does it use for this?", "source": "https://docs.ray.io/en/master/cluster/kubernetes/user-guides/static-ray-cluster-without-kuberay.html#external-redis-integration-for-fault-tolerance"}
59 | {"question": "How to resolve ValueError: The actor ImplicitFunc is too large?", "source": "https://docs.ray.io/en/master/ray-core/patterns/closure-capture-large-objects.html"}
60 | {"question": "How do I use ray to distribute training for my custom neural net written using Keras in Databricks?", "source": "https://docs.ray.io/en/master/train/examples/tf/tensorflow_mnist_example.html"}
61 | {"question": "how to use ray.put and ray,get?", "source": "https://docs.ray.io/en/master/ray-core/objects.html#fetching-object-data"}
62 | {"question": "how do I use Ray Data to pre process many files?", "source": "https://docs.ray.io/en/master/data/transforming-data.html#transforming-batches-with-tasks"}
63 | {"question": "can’t pickle SSLContext objects", "source": "https://docs.ray.io/en/master/ray-core/objects/serialization.html#customized-serialization"}
64 | {"question": "How do I install CRDs in Kuberay?", "source": "https://docs.ray.io/en/master/cluster/kubernetes/getting-started.html#deploying-the-kuberay-operator"}
65 | {"question": "Why the function for Ray data batch inference has to be named as _`__call__()`_ ?", "source": "https://docs.ray.io/en/master/data/examples/nyc_taxi_basic_processing.html#parallel-batch-inference"}
66 | {"question": "How to disconnnect ray client?", "source": "https://docs.ray.io/en/master/cluster/running-applications/job-submission/ray-client.html#connect-to-multiple-ray-clusters-experimental"}
67 | {"question": "how to submit job with python with local files?", "source": "https://docs.ray.io/en/master/cluster/running-applications/job-submission/quickstart.html#submitting-a-job"}
68 | {"question": "How do I do inference from a model trained by Ray tune.fit()?", "source": "https://docs.ray.io/en/master/data/batch_inference.html#using-models-from-ray-train"}
69 | {"question": "is there a way to load and run inference without using pytorch or tensorflow directly?", "source": "https://docs.ray.io/en/master/serve/index.html"}
70 | {"question": "what does ray do", "source": "https://docs.ray.io/en/master/ray-overview/index.html#overview"}
71 | {"question": "If I specify a fractional GPU in the resource spec, what happens if I use more than that?", "source": "https://docs.ray.io/en/master/ray-core/tasks/using-ray-with-gpus.html#fractional-gpus"}
72 | {"question": "how to pickle a variable defined in actor’s init method", "source": "https://docs.ray.io/en/master/ray-core/objects/serialization.html#customized-serialization"}
73 | {"question": "how do I do an all_reduce operation among a list of actors", "source": "https://docs.ray.io/en/master/ray-core/examples/map_reduce.html#shuffling-and-reducing-data"}
74 | {"question": "What will happen if we specify a bundle with `{\"CPU\":0}` in the PlacementGroup?", "source": "https://docs.ray.io/en/master/ray-core/scheduling/placement-group.html#bundles"}
75 | {"question": "How to cancel job from UI?", "source": "https://docs.ray.io/en/master/cluster/running-applications/job-submission/cli.html#ray-job-stop"}
76 | {"question": "how do I get my project files on the cluster when using Ray Serve? My workflow is to call `serve deploy config.yaml --address `", "source": "https://docs.ray.io/en/master/serve/advanced-guides/dev-workflow.html#testing-on-a-remote-cluster"}
77 | {"question": "how do i install ray nightly wheel", "source": "https://docs.ray.io/en/master/ray-overview/installation.html#daily-releases-nightlies"}
78 | {"question": "how do i install the latest ray nightly wheel?", "source": "https://docs.ray.io/en/master/ray-overview/installation.html#daily-releases-nightlies"}
79 | {"question": "how can I write unit tests for Ray code?", "source": "https://docs.ray.io/en/master/ray-core/examples/testing-tips.html#tip-2-sharing-the-ray-cluster-across-tests-if-possible"}
80 | {"question": "How I stop Ray from spamming lots of Info updates on stdout?", "source": "https://docs.ray.io/en/master/ray-observability/user-guides/configure-logging.html#disable-logging-to-the-driver"}
81 | {"question": "how to deploy stable diffusion 2.1 with Ray Serve?", "source": "https://docs.ray.io/en/master/serve/tutorials/stable-diffusion.html#serving-a-stable-diffusion-model"}
82 | {"question": "what is actor_handle?", "source": "https://docs.ray.io/en/master/ray-core/actors.html#passing-around-actor-handles"}
83 | {"question": "how to kill a r detached actors?", "source": "https://docs.ray.io/en/master/ray-core/actors/named-actors.html#actor-lifetimes"}
84 | {"question": "How to force upgrade the pip package in the runtime environment if an old version exists?", "source": "https://docs.ray.io/en/master/ray-core/handling-dependencies.html#api-reference"}
85 | {"question": "How do I do global shuffle with Ray?", "source": "https://docs.ray.io/en/master/data/transforming-data.html#shuffling-rows"}
86 | {"question": "How to find namespace of an Actor?", "source": "https://docs.ray.io/en/master/ray-observability/reference/doc/ray.util.state.list_actors.html#ray-util-state-list-actors"}
87 | {"question": "How does Ray work with async.io ?", "source": "https://docs.ray.io/en/master/ray-core/actors/async_api.html#asyncio-for-actors"}
88 | {"question": "How do I debug a hanging `ray.get()` call? I have it reproduced locally.", "source": "https://docs.ray.io/en/master/ray-observability/user-guides/debug-apps/debug-hangs.html"}
89 | {"question": "can you show me an example of ray.actor.exit_actor()", "source": "https://docs.ray.io/en/master/ray-core/actors/terminating-actors.html#manual-termination-within-the-actor"}
90 | {"question": "how to add log inside actor?", "source": "https://docs.ray.io/en/master/ray-observability/user-guides/configure-logging.html#customizing-worker-process-loggers"}
91 | {"question": "can you write a script to do batch inference with GPT-2 on text data from an S3 bucket?", "source": "https://docs.ray.io/en/master/data/working-with-text.html#performing-inference-on-text"}
92 | {"question": "How do I enable Ray debug logs?", "source": "https://docs.ray.io/en/master/ray-observability/user-guides/configure-logging.html#using-rays-logger"}
93 | {"question": "How do I list the current Ray actors from python?", "source": "https://docs.ray.io/en/master/ray-observability/reference/doc/ray.util.state.list_actors.html#ray-util-state-list-actors"}
94 | {"question": "I want to kill the replica actor from Python. how do I do it?", "source": "https://docs.ray.io/en/master/ray-core/actors/terminating-actors.html#manual-termination-via-an-actor-handle"}
95 | {"question": "how do I specify in my remote function declaration that I want the task to run on a V100 GPU type?", "source": "https://docs.ray.io/en/master/ray-core/tasks/using-ray-with-gpus.html#accelerator-types"}
96 | {"question": "How do I get started?", "source": "https://docs.ray.io/en/master/ray-overview/getting-started.html#getting-started"}
97 | {"question": "How to specify python version in runtime_env?", "source": "https://docs.ray.io/en/master/ray-core/handling-dependencies.html#api-reference"}
98 | {"question": "how to create a Actor in a namespace?", "source": "https://docs.ray.io/en/master/ray-core/namespaces.html#using-namespaces"}
99 | {"question": "Can I specify multiple working directories?", "source": "https://docs.ray.io/en/master/ray-core/handling-dependencies.html#using-local-files"}
100 | {"question": "what if I set num_cpus=0 for tasks", "source": "https://docs.ray.io/en/master/ray-core/scheduling/resources.html#fractional-resource-requirements"}
101 | {"question": "is it possible to have ray on k8s without using kuberay? especially with the case that autoscaler is enabled.", "source": "https://docs.ray.io/en/master/cluster/kubernetes/user-guides/static-ray-cluster-without-kuberay.html"}
102 | {"question": "how to manually configure and manage Ray cluster on Kubernetes", "source": "https://docs.ray.io/en/master/cluster/kubernetes/user-guides/static-ray-cluster-without-kuberay.html#deploying-a-static-ray-cluster"}
103 | {"question": "If I shutdown a raylet, will the tasks and workers on that node also get killed?", "source": "https://docs.ray.io/en/master/ray-core/fault_tolerance/nodes.html#node-fault-tolerance"}
104 | {"question": "If I’d like to debug out of memory, how do I Do that, and which documentation should I look?", "source": "https://docs.ray.io/en/master/ray-observability/user-guides/debug-apps/debug-memory.html#detecting-out-of-memory-errors"}
105 | {"question": "How to use callback in Trainer?", "source": "https://docs.ray.io/en/master/tune/api/doc/ray.tune.Callback.html#ray-tune-callback"}
106 | {"question": "How to provide current working directory to ray?", "source": "https://docs.ray.io/en/master/ray-core/handling-dependencies.html#remote-uris"}
107 | {"question": "how to create an actor instance with parameter?", "source": "https://docs.ray.io/en/master/ray-core/actors.html#actors"}
108 | {"question": "how to push a custom module to ray which is using by Actor ?", "source": "https://docs.ray.io/en/master/ray-core/handling-dependencies.html#library-development"}
109 | {"question": "how to print ray working directory?", "source": "https://docs.ray.io/en/master/ray-core/handling-dependencies.html#runtime-environments"}
110 | {"question": "why I can not see log.info in ray log?", "source": "https://docs.ray.io/en/master/ray-observability/user-guides/configure-logging.html#customizing-worker-process-loggers"}
111 | {"question": "when you use ray dataset to read a file, can you make sure the order of the data is preserved?", "source": "https://docs.ray.io/en/master/data/performance-tips.html#deterministic-execution"}
112 | {"question": "Can you explain what \"Ray will *not* retry tasks upon exceptions thrown by application code\" means ?", "source": "https://docs.ray.io/en/master/ray-core/fault_tolerance/tasks.html#retrying-failed-tasks"}
113 | {"question": "how do I specify the log directory when starting Ray?", "source": "https://docs.ray.io/en/master/ray-core/configure.html#logging-and-debugging"}
114 | {"question": "how to launch a ray cluster with 10 nodes, without setting the min worker as 10", "source": "https://docs.ray.io/en/master/cluster/vms/user-guides/launching-clusters/on-premises.html#start-worker-nodes"}
115 | {"question": "how to use ray api to scale up a cluster", "source": "https://docs.ray.io/en/master/cluster/running-applications/autoscaling/reference.html#ray-autoscaler-sdk-request-resources"}
116 | {"question": "we plan to use Ray cloud launcher to start a cluster in AWS. How can we specify a subnet in the deployment file?", "source": "https://docs.ray.io/en/master/cluster/vms/references/ray-cluster-configuration.html#full-configuration"}
117 | {"question": "where I can find HTTP server error code log for Ray serve", "source": "https://docs.ray.io/en/master/serve/monitoring.html#ray-logging"}
118 | {"question": "I am running ray cluster on amazon and I have troubles displaying the dashboard. When a I tunnel the dashboard port from the headnode to my machine, the dashboard opens, and then it disappears (internal refresh fails). Is it a known problem? What am I doing wrong?", "source": "https://docs.ray.io/en/master/cluster/configure-manage-dashboard.html#viewing-ray-dashboard-in-browsers"}
119 | {"question": "In the Ray cluster launcher YAML, does `max_workers` include the head node, or only worker nodes?", "source": "https://docs.ray.io/en/master/cluster/vms/references/ray-cluster-configuration.html"}
120 | {"question": "How to update files in working directory ?", "source": "https://docs.ray.io/en/master/ray-core/handling-dependencies.html#using-local-files"}
121 | {"question": "How I can update working directory file when ray allready initiated ?", "source": "https://docs.ray.io/en/master/ray-core/handling-dependencies.html#using-local-files"}
122 | {"question": "how can I force ray head node to use custom pem file to ssh worker node?", "source": "https://docs.ray.io/en/master/cluster/vms/references/ray-cluster-configuration.html#full-configuration"}
123 | {"question": "what doess the GCS server do, and why is my GCS server taking up so much memory on the head node?", "source": "https://docs.ray.io/en/master/ray-references/glossary.html"}
124 | {"question": "when starting cluster with ray up, there are few nodes \"pending\" for a long time. how can I debug this?", "source": "https://docs.ray.io/en/master/ray-observability/getting-started.html#ray-status"}
125 | {"question": "how to install Ray 2.5.1 from github or wheel?", "source": "https://docs.ray.io/en/master/ray-overview/installation.html#from-wheels"}
126 | {"question": "How do I use `worker_setup_hook` in a runtime env to set do some setup on worker node creation?", "source": "https://docs.ray.io/en/master/ray-observability/user-guides/configure-logging.html#customizing-worker-process-loggers"}
127 | {"question": "how to use Ray dataset on aws", "source": "https://docs.ray.io/en/master/data/key-concepts.html"}
128 | {"question": "How do I avoid my dataset shuffling during a ray.data.map_batches?", "source": "https://docs.ray.io/en/master/data/performance-tips.html#deterministic-execution"}
129 | {"question": "Is the order of the input data preserved after a map_batches operation?", "source": "https://docs.ray.io/en/master/data/performance-tips.html#deterministic-execution"}
130 | {"question": "ray serve returns generic internal service error when there is an internal failure, how do I get it to emit more detailed errors or logs?", "source": "https://docs.ray.io/en/master/serve/monitoring.html#ray-logging"}
131 | {"question": "how do i track an uncaught exception in ray serve", "source": "https://docs.ray.io/en/master/serve/monitoring.html#ray-logging"}
132 | {"question": "where do I view logs using python logger emitted by my ray serve endpoint in the ray cluster", "source": "https://docs.ray.io/en/master/serve/monitoring.html#ray-logging"}
133 | {"question": "where can I see logs for a failed ray serve deployment", "source": "https://docs.ray.io/en/master/ray-observability/getting-started.html#serve-view"}
134 | {"question": "How to take a subset of a Ray Dataset?", "source": "https://docs.ray.io/en/master/data/api/doc/ray.data.Dataset.limit.html#ray-data-dataset-limit"}
135 | {"question": "How do I load all checkpoints from trials of a Tune experiment launched with `tune.run`? I ran my initial experiment with cloud checkpointing, so I’d need to download all the checkpoints to analyze them.", "source": "https://docs.ray.io/en/master/tune/tutorials/tune_get_data_in_and_out.html#how-do-i-access-tune-results-after-i-am-finished"}
136 | {"question": "How can I kill a \"detached\" Actor ?", "source": "https://docs.ray.io/en/master/ray-core/actors/named-actors.html#actor-lifetimes"}
137 | {"question": "How do I set env variables in ray init? Let’ say it’s export foo=“foo”", "source": "https://docs.ray.io/en/master/ray-core/api/doc/ray.runtime_env.RuntimeEnv.html#ray-runtime-env-runtimeenv"}
138 | {"question": "What is the rest api for getting the head node id?", "source": "https://docs.ray.io/en/master/ray-observability/reference/doc/ray.util.state.list_nodes.html#ray-util-state-list-nodes"}
139 | {"question": "how to rerun a canceled ray task", "source": "https://docs.ray.io/en/master/ray-core/api/doc/ray.cancel.html#ray-cancel"}
140 | {"question": "How do I set the max parallel concurrent scheduled tasks in map_batches?", "source": "https://docs.ray.io/en/master/data/api/doc/ray.data.Dataset.map_batches.html#ray-data-dataset-map-batches"}
141 | {"question": "How do I get the number of cpus from ray cluster?", "source": "https://docs.ray.io/en/master/ray-core/miscellaneous.html#resource-information"}
142 | {"question": "How to use the exclude option to the runtime_env", "source": "https://docs.ray.io/en/master/ray-core/handling-dependencies.html#api-reference"}
143 | {"question": "show a map batch example with batch_format", "source": "https://docs.ray.io/en/master/data/transforming-data.html#configuring-batch-format"}
144 | {"question": "how to find local ray address", "source": "https://docs.ray.io/en/master/ray-core/examples/gentle_walkthrough.html#ray-core"}
145 | {"question": "How to start ray cluster on multiple node via CLI?", "source": "https://docs.ray.io/en/master/cluster/vms/user-guides/launching-clusters/on-premises.html#manually-set-up-a-ray-cluster"}
146 | {"question": "my ray tuner shows \"running\" but CPU usage is almost 0%. why ?", "source": "https://docs.ray.io/en/master/ray-observability/user-guides/debug-apps/optimize-performance.html#no-speedup"}
147 | {"question": "should the Ray head node and all workers have the same object store memory size allocated?", "source": "https://docs.ray.io/en/master/cluster/vms/user-guides/large-cluster-best-practices.html#configuring-the-head-node"}
148 | {"question": "In Ray Serve, how to specify whether to set up an httpproxy on each node, or just the head node?", "source": "https://docs.ray.io/en/master/serve/architecture.html#how-does-serve-ensure-horizontal-scalability-and-availability"}
149 | {"question": "Want to embed Grafana into the Ray Dashboard, given that I am using KubeRay\n\nGiven the context that Prometheus and Grafana are not running on my Head node, and that I am using KubeRay, how should I be setting the following variables?\n• `RAY_GRAFANA_HOST`\n• `RAY_PROMETHEUS_HOST`\nAnd is there a way to set them more intelligently, given that head node IP is changing every time we reconfigure our cluster?", "source": "https://docs.ray.io/en/master/cluster/metrics.html"}
150 | {"question": "How the GCS determines which Kubernetes pod to kill when using KubeRay autoscaling?", "source": "https://docs.ray.io/en/master/cluster/kubernetes/user-guides/configuring-autoscaling.html"}
151 | {"question": "How can I set the `request_timeout_s` in `http_options` section of a Ray Serve YAML config file?", "source": "https://docs.ray.io/en/master/serve/production-guide/config.html#serve-config-files-serve-build"}
152 | {"question": "How do I make the GPU available on my M1 laptop to ray?", "source": "https://docs.ray.io/en/master/ray-overview/installation.html#m1-mac-apple-silicon-support"}
153 | {"question": "How can I add a timeout for the Ray job?", "source": "https://docs.ray.io/en/master/cluster/running-applications/job-submission/quickstart.html#interacting-with-long-running-jobs"}
154 | {"question": "how do I set custom /tmp directory for remote cluster?", "source": "https://docs.ray.io/en/master/cluster/cli.html#ray-start"}
155 | {"question": "if I set --temp-dir to a different directory than /tmp, will ray object spill to the custom directory ?", "source": "https://docs.ray.io/en/master/ray-core/objects/object-spilling.html"}
156 | {"question": "can you give me an example for *`--runtime-env-json`*", "source": "https://docs.ray.io/en/master/ray-core/handling-dependencies.html#specifying-a-runtime-environment-per-job"}
157 | {"question": "What should be the value of `maxConcurrentReplicas` if autoscaling configuration is specified?", "source": "https://docs.ray.io/en/master/serve/scaling-and-resource-allocation.html#autoscaling-config-parameters"}
158 | {"question": "Yes what should be the value of `max_concurrent_queries` when `target_num_ongoing_requests_per_replica` is specified?", "source": "https://docs.ray.io/en/master/serve/architecture.html#ray-serve-autoscaling"}
159 | {"question": "what is a `smoothing_factor`", "source": "https://docs.ray.io/en/master/serve/scaling-and-resource-allocation.html#autoscaling-config-parameters"}
160 | {"question": "What is the reason actors change their state to unhealthy?", "source": "https://docs.ray.io/en/master/ray-observability/reference/doc/ray.util.state.common.ActorState.html#ray-util-state-common-actorstate"}
161 | {"question": "How do I access logs for a dead node?", "source": "https://docs.ray.io/en/master/cluster/kubernetes/user-guides/logging.html#log-persistence"}
162 | {"question": "What are the reasons for a node to change it’s status to dead?", "source": "https://docs.ray.io/en/master/ray-core/fault_tolerance/nodes.html"}
163 | {"question": "What are the reasons for spikes in node CPU utilization", "source": "https://docs.ray.io/en/master/ray-core/patterns/limit-running-tasks.html#pattern-using-resources-to-limit-the-number-of-concurrently-running-tasks"}
164 | {"question": "What AWS machine type is recommended to deploy a RayService on EKS?", "source": "https://docs.ray.io/en/master/cluster/vms/user-guides/large-cluster-best-practices.html#configuring-the-head-node"}
165 | {"question": "Is there a way to configure the session name generated by ray?", "source": "https://docs.ray.io/en/master/ray-core/configure.html#logging-and-debugging"}
166 | {"question": "can I use the Python SDK to get a link to Ray dashboard for a given job?", "source": "https://docs.ray.io/en/master/ray-observability/getting-started.html#set-up-dashboard"}
167 | {"question": "What may possible cause the node where this task was running crashed unexpectedly. This can happen if: (1) the instance where the node was running failed, (2) raylet crashes unexpectedly (OOM, preempted node, etc).", "source": "https://docs.ray.io/en/master/ray-observability/user-guides/debug-apps/debug-memory.html#debugging-memory-issues"}
168 | {"question": "Do you know how to resolve (gcs_server) gcs_health_check_manager.cc:108: Health check failed for node? I observed that the node is still up and running.", "source": "https://docs.ray.io/en/master/ray-observability/user-guides/configure-logging.html#system-component-logs"}
169 | {"question": "Do you need the DAGDriver to deploy a serve application using RayServe?", "source": "https://docs.ray.io/en/master/serve/key-concepts.html#deployment"}
170 | {"question": "What’s the import path that I need to provide to a simple RayServe deployment?", "source": "https://docs.ray.io/en/master/serve/production-guide/config.html#serve-config-files-serve-build"}
171 | {"question": "do you have any documents / examples showing the usage of RayJob in Kuberay?", "source": "https://docs.ray.io/en/master/cluster/kubernetes/user-guides/experimental.html#rayjobs"}
172 | {"question": "Does Ray metrics have to be exported via an actor?", "source": "https://docs.ray.io/en/master/cluster/metrics.html#processing-and-exporting-metrics"}
173 | {"question": "how can I avoid objects not getting spilled?", "source": "https://docs.ray.io/en/master/ray-core/objects/object-spilling.html#single-node"}
174 | {"question": "what’s ray core", "source": "https://docs.ray.io/en/master/ray-core/walkthrough.html#what-is-ray-core"}
175 | {"question": "Does ray support cron job", "source": "https://docs.ray.io/en/master/cluster/running-applications/job-submission/index.html#ray-jobs-api"}
176 | {"question": "can you give me the dependencies list for api read_images?", "source": "https://docs.ray.io/en/master/data/api/doc/ray.data.read_images.html#ray-data-read-images"}
177 | {"question": "how do I kill a specific serve replica", "source": "https://docs.ray.io/en/master/serve/production-guide/fault-tolerance.html"}
178 |
--------------------------------------------------------------------------------
/deploy/jobs/update_index.yaml:
--------------------------------------------------------------------------------
1 | name: update_index
2 | project_id: prj_h51x37siq3qan75kl4fc5havwn
3 | cluster_env: ray-assistant
4 | compute_config: ray-assistant-g5.2xlarge
5 | runtime_env:
6 | working_dir: "https://github.com//ray-project/llm-applications/archive/refs/heads/main.zip"
7 | entrypoint: bash update-index.sh --load-docs
8 | max_retries: 0
9 |
--------------------------------------------------------------------------------
/deploy/services/service.yaml:
--------------------------------------------------------------------------------
1 | name: "ray-assistant-public"
2 | compute_config_id: cpt_waeba7v8yurzlh42us6cy619ha
3 | cluster_env: ray-assistant
4 | config:
5 | access:
6 | use_bearer_token: False
7 | ray_serve_config:
8 | import_path: rag.serve:deployment
9 | runtime_env:
10 | working_dir: "."
11 | env_vars:
12 | RAY_ASSISTANT_SECRET: "ray-assistant-prod" # pragma: allowlist secret
13 | RAY_ASSISTANT_LOGS: "/mnt/shared_storage/ray-assistant-logs/info.log"
14 | RAY_ASSISTANT_INDEX: "/mnt/shared_storage/ray-assistant-data/index.sql"
15 | RAY_ASSISTANT_EMBEDDING_MODEL: "thenlper/gte-large"
16 | RAY_ASSISTANT_ROUTER_MODEL: "/mnt/shared_storage/ray-assistant-data/router.pkl"
17 | RAY_ASSISTANT_RERANKER_MODEL: "/mnt/shared_storage/ray-assistant-data/reranker.pkl"
18 |
--------------------------------------------------------------------------------
/experiments/responses/without-context-gpt-4.json:
--------------------------------------------------------------------------------
1 | {
2 | "config": {
3 | "experiment_name": "without-context-gpt-4",
4 | "chunk_size": 700,
5 | "chunk_overlap": 50,
6 | "num_chunks": 0,
7 | "embedding_model_name": "thenlper/gte-large",
8 | "llm": "gpt-4",
9 | "temperature": 0.0,
10 | "max_context_length": 8192,
11 | "system_content": "Answer the query using the context provided. Be succinct.",
12 | "assistant_content": "",
13 | "docs_dir": "/efs/shared_storage/goku/docs.ray.io/en/master",
14 | "experiments_dir": "/home/ray/ray-assistant/notebooks/../experiments",
15 | "references_fp": "/home/ray/ray-assistant/notebooks/../experiments/references/gpt-4.json",
16 | "num_samples": 177
17 | },
18 | "results": [
19 | {
20 | "question": "I\u2019m struggling a bit with Ray Data type conversions when I do map_batches. Any advice?",
21 | "sources": [],
22 | "document_ids": [],
23 | "answer": "The context provided does not contain any information to answer the query. Please provide more details or context.",
24 | "llm": "gpt-4"
25 | },
26 | {
27 | "question": "How does autoscaling work in a Ray Serve application?",
28 | "sources": [],
29 | "document_ids": [],
30 | "answer": "The context provided does not contain information on how autoscaling works in a Ray Serve application.",
31 | "llm": "gpt-4"
32 | },
33 | {
34 | "question": "how do I get the address of a ray node",
35 | "sources": [],
36 | "document_ids": [],
37 | "answer": "The context provided does not contain information on how to get the address of a ray node.",
38 | "llm": "gpt-4"
39 | },
40 | {
41 | "question": "Does Ray support NCCL?",
42 | "sources": [],
43 | "document_ids": [],
44 | "answer": "The context provided does not contain information on whether Ray supports NCCL.",
45 | "llm": "gpt-4"
46 | },
47 | {
48 | "question": "Is Ray integrated with DeepSpeed?",
49 | "sources": [],
50 | "document_ids": [],
51 | "answer": "The context provided does not contain information on whether Ray is integrated with DeepSpeed.",
52 | "llm": "gpt-4"
53 | },
54 | {
55 | "question": "what will happen if I use AsyncIO's await to wait for a Ray future like `await x.remote()`",
56 | "sources": [],
57 | "document_ids": [],
58 | "answer": "The context provided does not contain enough information to answer the query.",
59 | "llm": "gpt-4"
60 | },
61 | {
62 | "question": "How would you compare Spark, Ray, Dask?",
63 | "sources": [],
64 | "document_ids": [],
65 | "answer": "Without a specific context, I can't provide a comparison. However, generally speaking, Spark, Ray, and Dask are all open-source parallel computing libraries, but they have different focuses. Spark is widely used for big data processing and analytics, offering built-in modules for SQL, streaming, machine learning, and graph processing. Dask is more flexible and can be used for a wider range of tasks. It's designed to integrate with Python-based data science stacks like Pandas and Numpy. Ray, on the other hand, is focused on providing a universal framework for distributed computing, making it ideal for machine learning tasks. It's also designed to be highly scalable.",
66 | "llm": "gpt-4"
67 | },
68 | {
69 | "question": "why would ray overload a node w/ more task that the resources allow ?",
70 | "sources": [],
71 | "document_ids": [],
72 | "answer": "The context provided does not contain information to answer the query about why Ray would overload a node with more tasks than the resources allow.",
73 | "llm": "gpt-4"
74 | },
75 | {
76 | "question": "when should I use Ray Client?",
77 | "sources": [],
78 | "document_ids": [],
79 | "answer": "The context provided does not contain information on when to use Ray Client.",
80 | "llm": "gpt-4"
81 | },
82 | {
83 | "question": "how to scatter actors across the cluster?",
84 | "sources": [],
85 | "document_ids": [],
86 | "answer": "The context provided does not contain enough information to answer the query on how to scatter actors across the cluster.",
87 | "llm": "gpt-4"
88 | },
89 | {
90 | "question": "On remote ray cluster, when I do `ray debug` I'm getting connection refused error. Why ?",
91 | "sources": [],
92 | "document_ids": [],
93 | "answer": "The context provided does not contain enough information to accurately answer the query. However, a \"connection refused\" error generally indicates that there is no server application listening at the specified port, or a firewall is blocking the connection. In the context of a remote ray cluster, it could mean that the cluster is not properly set up or is not currently running.",
94 | "llm": "gpt-4"
95 | },
96 | {
97 | "question": "How does Ray AIR set up the model to communicate gradient updates across machines?",
98 | "sources": [],
99 | "document_ids": [],
100 | "answer": "The context provided does not contain information on how Ray AIR sets up the model to communicate gradient updates across machines.",
101 | "llm": "gpt-4"
102 | },
103 | {
104 | "question": "Why would I use Ray Serve instead of Modal or Seldon? Why can't I just do it via containers?",
105 | "sources": [],
106 | "document_ids": [],
107 | "answer": "The context provided does not contain sufficient information to answer the query.",
108 | "llm": "gpt-4"
109 | },
110 | {
111 | "question": "How do I deploy an LLM workload on top of Ray Serve?",
112 | "sources": [],
113 | "document_ids": [],
114 | "answer": "The context provided does not contain information on how to deploy an LLM workload on top of Ray Serve.",
115 | "llm": "gpt-4"
116 | },
117 | {
118 | "question": "what size of memory should I need for this if I am setting set the `model_id` to \u201cEleutherAI/gpt-j-6B\u201d?",
119 | "sources": [],
120 | "document_ids": [],
121 | "answer": "The context provided does not include information about the memory size needed for setting the `model_id` to \u201cEleutherAI/gpt-j-6B\u201d.",
122 | "llm": "gpt-4"
123 | },
124 | {
125 | "question": "How do I log the results from multiple distributed workers into a single tensorboard?",
126 | "sources": [],
127 | "document_ids": [],
128 | "answer": "The context provided does not contain information to answer the query.",
129 | "llm": "gpt-4"
130 | },
131 | {
132 | "question": "how do you config SyncConfig for a Ray AIR job?",
133 | "sources": [],
134 | "document_ids": [],
135 | "answer": "The context provided does not contain information on how to configure SyncConfig for a Ray AIR job.",
136 | "llm": "gpt-4"
137 | },
138 | {
139 | "question": "how can I quickly narrow down the root case of a failed ray job, assuming I have access to all the logs",
140 | "sources": [],
141 | "document_ids": [],
142 | "answer": "The context provided does not contain specific information on how to quickly narrow down the root cause of a failed ray job.",
143 | "llm": "gpt-4"
144 | },
145 | {
146 | "question": "How do I specify how many GPUs a serve deployment needs?",
147 | "sources": [],
148 | "document_ids": [],
149 | "answer": "The context provided does not contain information on how to specify the number of GPUs a server deployment needs.",
150 | "llm": "gpt-4"
151 | },
152 | {
153 | "question": "One of my worker nodes keeps dying on using TensorflowTrainer with around 1500 workers, I observe SIGTERM has been received to the died node's raylet. How can I debug this?",
154 | "sources": [],
155 | "document_ids": [],
156 | "answer": "Without a specific context, it's hard to provide a precise solution. However, you can start debugging by checking the logs of the worker node that is dying. You can also monitor the system resources (like CPU, memory, disk I/O, network) to see if there's any resource exhaustion. If you're running out of memory, you might need to reduce the number of workers or increase the memory of your nodes. Additionally, ensure that your TensorflowTrainer and Ray versions are compatible and up-to-date.",
157 | "llm": "gpt-4"
158 | },
159 | {
160 | "question": "what are the possible reasons for nodes dying in a cluster?",
161 | "sources": [],
162 | "document_ids": [],
163 | "answer": "The context provided does not contain information to answer the query.",
164 | "llm": "gpt-4"
165 | },
166 | {
167 | "question": "how do I programatically get ray remote cluster to a target size immediately without scaling up through autoscaler ?",
168 | "sources": [],
169 | "document_ids": [],
170 | "answer": "The context provided does not contain information to answer the query about programming a ray remote cluster to a target size immediately without scaling up through an autoscaler.",
171 | "llm": "gpt-4"
172 | },
173 | {
174 | "question": "how do you disable async iter_batches with Ray Dataset?",
175 | "sources": [],
176 | "document_ids": [],
177 | "answer": "The context provided does not contain information on how to disable async iter_batches with Ray Dataset.",
178 | "llm": "gpt-4"
179 | },
180 | {
181 | "question": "what is the different between a batch and a block, for ray datasets?",
182 | "sources": [],
183 | "document_ids": [],
184 | "answer": "The context provided does not contain information to answer the query about the difference between a batch and a block for Ray datasets.",
185 | "llm": "gpt-4"
186 | },
187 | {
188 | "question": "How to setup the development environments for ray project?",
189 | "sources": [],
190 | "document_ids": [],
191 | "answer": "The context provided does not contain information on how to setup the development environments for the ray project.",
192 | "llm": "gpt-4"
193 | },
194 | {
195 | "question": "how do I debug why ray rollout workers are deadlocking when using the sample API in `ray/rllib/evaluation/rollout_worker.py`",
196 | "sources": [],
197 | "document_ids": [],
198 | "answer": "The context provided does not contain specific information on how to debug deadlocking issues with ray rollout workers when using the sample API in `ray/rllib/evaluation/rollout_worker.py`. However, generally, you can debug such issues by checking the logs for any error messages, using debugging tools like pdb in Python, or by adding print statements in your code to track the execution flow. You may also want to ensure that your code is thread-safe and does not have race conditions which can lead to deadlocks.",
199 | "llm": "gpt-4"
200 | },
201 | {
202 | "question": "how do I join two ray datasets?",
203 | "sources": [],
204 | "document_ids": [],
205 | "answer": "The context provided does not contain information on how to join two ray datasets.",
206 | "llm": "gpt-4"
207 | },
208 | {
209 | "question": "Is there a way to retrieve an object ref from its id?",
210 | "sources": [],
211 | "document_ids": [],
212 | "answer": "The context provided does not contain any information to answer the query.",
213 | "llm": "gpt-4"
214 | },
215 | {
216 | "question": "how to create model Checkpoint from the model in memory?",
217 | "sources": [],
218 | "document_ids": [],
219 | "answer": "The context provided does not contain any information to answer the query.",
220 | "llm": "gpt-4"
221 | },
222 | {
223 | "question": "what is Deployment in Ray Serve?",
224 | "sources": [],
225 | "document_ids": [],
226 | "answer": "The context provided does not contain information about \"Deployment in Ray Serve\".",
227 | "llm": "gpt-4"
228 | },
229 | {
230 | "question": "What is user config in Ray Serve? how do I use it?",
231 | "sources": [],
232 | "document_ids": [],
233 | "answer": "The context provided does not contain any information about \"user config\" in Ray Serve. Please provide a relevant context.",
234 | "llm": "gpt-4"
235 | },
236 | {
237 | "question": "What is the difference between PACK and SPREAD strategy?",
238 | "sources": [],
239 | "document_ids": [],
240 | "answer": "The context provided does not contain information about the difference between PACK and SPREAD strategy.",
241 | "llm": "gpt-4"
242 | },
243 | {
244 | "question": "What\u2019s the best way to run ray across multiple machines?",
245 | "sources": [],
246 | "document_ids": [],
247 | "answer": "The context provided does not contain information on how to run ray across multiple machines.",
248 | "llm": "gpt-4"
249 | },
250 | {
251 | "question": "how do I specify ScalingConfig for a Tuner run?",
252 | "sources": [],
253 | "document_ids": [],
254 | "answer": "The context provided does not contain information on how to specify ScalingConfig for a Tuner run.",
255 | "llm": "gpt-4"
256 | },
257 | {
258 | "question": "how to utilize \u2018zero-copy\u2019 feature ray provide for numpy?",
259 | "sources": [],
260 | "document_ids": [],
261 | "answer": "The context provided does not contain information on how to utilize the 'zero-copy' feature Ray provides for numpy.",
262 | "llm": "gpt-4"
263 | },
264 | {
265 | "question": "if there are O(millions) of keys that all have state, is it ok to spin up 1=1 actors? Or would it be advised to create \u2018key pools\u2019 where an actor can hold 1=many keys?",
266 | "sources": [],
267 | "document_ids": [],
268 | "answer": "The context provided does not contain enough information to answer the query.",
269 | "llm": "gpt-4"
270 | },
271 | {
272 | "question": "How to find the best checkpoint from the trial directory?",
273 | "sources": [],
274 | "document_ids": [],
275 | "answer": "The context provided does not contain information on how to find the best checkpoint from the trial directory.",
276 | "llm": "gpt-4"
277 | },
278 | {
279 | "question": "what are the advantage and disadvantage of using singleton Actor ?",
280 | "sources": [],
281 | "document_ids": [],
282 | "answer": "The context provided does not contain any information about the advantages and disadvantages of using a singleton Actor.",
283 | "llm": "gpt-4"
284 | },
285 | {
286 | "question": "what are the advantages of using a named actor?",
287 | "sources": [],
288 | "document_ids": [],
289 | "answer": "The context provided does not contain information to answer the query about the advantages of using a named actor.",
290 | "llm": "gpt-4"
291 | },
292 | {
293 | "question": "How do I read a text file stored on S3 using Ray Data?",
294 | "sources": [],
295 | "document_ids": [],
296 | "answer": "The context provided does not contain information on how to read a text file stored on S3 using Ray Data.",
297 | "llm": "gpt-4"
298 | },
299 | {
300 | "question": "how do I get the IP of the head node for my Ray cluster?",
301 | "sources": [],
302 | "document_ids": [],
303 | "answer": "The context provided does not contain information on how to get the IP of the head node for a Ray cluster.",
304 | "llm": "gpt-4"
305 | },
306 | {
307 | "question": "How to write a map function that returns a list of object for `map_batches`?",
308 | "sources": [],
309 | "document_ids": [],
310 | "answer": "The context provided does not contain enough information to answer the query.",
311 | "llm": "gpt-4"
312 | },
313 | {
314 | "question": "How do I set a maximum episode length when training with Rllib?",
315 | "sources": [],
316 | "document_ids": [],
317 | "answer": "The context provided does not contain information on how to set a maximum episode length when training with Rllib.",
318 | "llm": "gpt-4"
319 | },
320 | {
321 | "question": "how do I make a Ray Tune trial retry on failures?",
322 | "sources": [],
323 | "document_ids": [],
324 | "answer": "The context provided does not contain information on how to make a Ray Tune trial retry on failures.",
325 | "llm": "gpt-4"
326 | },
327 | {
328 | "question": "For the supervised actor pattern, can we keep the Worker Actor up if the Supervisor passes a reference to the Actor to another Actor, to allow the worker actor to remain even on Supervisor / Driver failure?",
329 | "sources": [],
330 | "document_ids": [],
331 | "answer": "The context provided does not contain sufficient information to answer the query.",
332 | "llm": "gpt-4"
333 | },
334 | {
335 | "question": "How do I read a large text file in S3 with Ray?",
336 | "sources": [],
337 | "document_ids": [],
338 | "answer": "The context provided does not contain information on how to read a large text file in S3 with Ray.",
339 | "llm": "gpt-4"
340 | },
341 | {
342 | "question": "how do I get a ray dataset from pandas",
343 | "sources": [],
344 | "document_ids": [],
345 | "answer": "The context provided does not contain information on how to get a Ray dataset from pandas.",
346 | "llm": "gpt-4"
347 | },
348 | {
349 | "question": "can you give me an example of using `ray.data.map` ?",
350 | "sources": [],
351 | "document_ids": [],
352 | "answer": "As there is no context provided about `ray.data.map`, I'll provide a general example of how it might be used in Python with the Ray framework:\n\n```python\nimport ray\n\nray.init()\n\n@ray.remote\ndef multiply_by_two(x):\n return x * 2\n\ndata = ray.data.range(10)\nresult = data.map(multiply_by_two)\nprint(result.collect())\n```\n\nIn this example, `ray.data.range(10)` creates a dataset of numbers from 0 to 9. `data.map(multiply_by_two)` applies the function `multiply_by_two` to each element in the dataset. The `result.collect()` line prints the result, which should be a list of numbers from 0 to 18, each multiplied by 2.",
353 | "llm": "gpt-4"
354 | },
355 | {
356 | "question": "can you give me an example of using `ray.data.map` , with a callable class as input?",
357 | "sources": [],
358 | "document_ids": [],
359 | "answer": "The context provided does not contain any information to answer the query.",
360 | "llm": "gpt-4"
361 | },
362 | {
363 | "question": "How to set memory limit for each trial in Ray Tuner?",
364 | "sources": [],
365 | "document_ids": [],
366 | "answer": "The context provided does not contain information on how to set a memory limit for each trial in Ray Tuner.",
367 | "llm": "gpt-4"
368 | },
369 | {
370 | "question": "how do I get the actor id of an actor",
371 | "sources": [],
372 | "document_ids": [],
373 | "answer": "The context provided does not contain information on how to get the actor id of an actor.",
374 | "llm": "gpt-4"
375 | },
376 | {
377 | "question": "can ray.init() can check if ray is all-ready initiated ?",
378 | "sources": [],
379 | "document_ids": [],
380 | "answer": "The context provided does not contain sufficient information to answer the query.",
381 | "llm": "gpt-4"
382 | },
383 | {
384 | "question": "What does the `compute=actor` argument do within `ray.data.map_batches` ?",
385 | "sources": [],
386 | "document_ids": [],
387 | "answer": "The context provided does not contain information to answer the query about what the `compute=actor` argument does within `ray.data.map_batches`.",
388 | "llm": "gpt-4"
389 | },
390 | {
391 | "question": "how do I use wandb logger with accelerateTrainer?",
392 | "sources": [],
393 | "document_ids": [],
394 | "answer": "The context provided does not contain information on how to use wandb logger with accelerateTrainer.",
395 | "llm": "gpt-4"
396 | },
397 | {
398 | "question": "What will be implicitly put into object store?",
399 | "sources": [],
400 | "document_ids": [],
401 | "answer": "The context provided does not contain information to answer the query about what will be implicitly put into object store.",
402 | "llm": "gpt-4"
403 | },
404 | {
405 | "question": "How do I kill or cancel a ray task that I already started?",
406 | "sources": [],
407 | "document_ids": [],
408 | "answer": "The context provided does not contain information on how to kill or cancel a ray task that has already been started.",
409 | "llm": "gpt-4"
410 | },
411 | {
412 | "question": "how to send extra arguments in dataset.map_batches function?",
413 | "sources": [],
414 | "document_ids": [],
415 | "answer": "The context provided does not contain information on how to send extra arguments in the dataset.map_batches function.",
416 | "llm": "gpt-4"
417 | },
418 | {
419 | "question": "where does ray GCS store the history of jobs run on a kuberay cluster? What type of database and format does it use for this?",
420 | "sources": [],
421 | "document_ids": [],
422 | "answer": "The context provided does not contain information to answer the query.",
423 | "llm": "gpt-4"
424 | },
425 | {
426 | "question": "How to resolve ValueError: The actor ImplicitFunc is too large?",
427 | "sources": [],
428 | "document_ids": [],
429 | "answer": "The context provided does not contain information on how to resolve the ValueError: The actor ImplicitFunc is too large.",
430 | "llm": "gpt-4"
431 | },
432 | {
433 | "question": "How do I use ray to distribute training for my custom neural net written using Keras in Databricks?",
434 | "sources": [],
435 | "document_ids": [],
436 | "answer": "The context provided does not contain information on how to use Ray to distribute training for a custom neural net written using Keras in Databricks.",
437 | "llm": "gpt-4"
438 | },
439 | {
440 | "question": "how to use ray.put and ray,get?",
441 | "sources": [],
442 | "document_ids": [],
443 | "answer": "The context provided does not contain any information about how to use ray.put and ray.get.",
444 | "llm": "gpt-4"
445 | },
446 | {
447 | "question": "how do I use Ray Data to pre process many files?",
448 | "sources": [],
449 | "document_ids": [],
450 | "answer": "The context provided does not contain information on how to use Ray Data to pre process many files.",
451 | "llm": "gpt-4"
452 | },
453 | {
454 | "question": "can\u2019t pickle SSLContext objects",
455 | "sources": [],
456 | "document_ids": [],
457 | "answer": "The context provided does not contain any information to answer the query about pickling SSLContext objects.",
458 | "llm": "gpt-4"
459 | },
460 | {
461 | "question": "How do I install CRDs in Kuberay?",
462 | "sources": [],
463 | "document_ids": [],
464 | "answer": "The context provided does not contain information on how to install CRDs in Kuberay.",
465 | "llm": "gpt-4"
466 | },
467 | {
468 | "question": "Why the function for Ray data batch inference has to be named as _`__call__()`_ ?",
469 | "sources": [],
470 | "document_ids": [],
471 | "answer": "The context provided does not contain information to answer the query.",
472 | "llm": "gpt-4"
473 | },
474 | {
475 | "question": "How to disconnnect ray client?",
476 | "sources": [],
477 | "document_ids": [],
478 | "answer": "The context provided does not contain information on how to disconnect a ray client.",
479 | "llm": "gpt-4"
480 | },
481 | {
482 | "question": "how to submit job with python with local files?",
483 | "sources": [],
484 | "document_ids": [],
485 | "answer": "The context provided does not contain information to answer the query.",
486 | "llm": "gpt-4"
487 | },
488 | {
489 | "question": "How do I do inference from a model trained by Ray tune.fit()?",
490 | "sources": [],
491 | "document_ids": [],
492 | "answer": "The context provided does not contain any information to answer the query.",
493 | "llm": "gpt-4"
494 | },
495 | {
496 | "question": "is there a way to load and run inference without using pytorch or tensorflow directly?",
497 | "sources": [],
498 | "document_ids": [],
499 | "answer": "The context provided does not contain any information to answer the query.",
500 | "llm": "gpt-4"
501 | },
502 | {
503 | "question": "what does ray do",
504 | "sources": [],
505 | "document_ids": [],
506 | "answer": "The context provided does not give information about who or what \"Ray\" is. Please provide more details.",
507 | "llm": "gpt-4"
508 | },
509 | {
510 | "question": "If I specify a fractional GPU in the resource spec, what happens if I use more than that?",
511 | "sources": [],
512 | "document_ids": [],
513 | "answer": "The context provided does not contain enough information to answer the query.",
514 | "llm": "gpt-4"
515 | },
516 | {
517 | "question": "how to pickle a variable defined in actor\u2019s init method",
518 | "sources": [],
519 | "document_ids": [],
520 | "answer": "The context provided does not contain sufficient information to answer the query.",
521 | "llm": "gpt-4"
522 | },
523 | {
524 | "question": "how do I do an all_reduce operation among a list of actors",
525 | "sources": [],
526 | "document_ids": [],
527 | "answer": "The context provided does not contain sufficient information to answer the query about performing an all_reduce operation among a list of actors.",
528 | "llm": "gpt-4"
529 | },
530 | {
531 | "question": "What will happen if we specify a bundle with `{\"CPU\":0}` in the PlacementGroup?",
532 | "sources": [],
533 | "document_ids": [],
534 | "answer": "The context provided does not contain enough information to answer the query.",
535 | "llm": "gpt-4"
536 | },
537 | {
538 | "question": "How to cancel job from UI?",
539 | "sources": [],
540 | "document_ids": [],
541 | "answer": "The context provided does not contain information on how to cancel a job from UI.",
542 | "llm": "gpt-4"
543 | },
544 | {
545 | "question": "how do I get my project files on the cluster when using Ray Serve? My workflow is to call `serve deploy config.yaml --address `",
546 | "sources": [],
547 | "document_ids": [],
548 | "answer": "The context provided does not contain information on how to get your project files on the cluster when using Ray Serve.",
549 | "llm": "gpt-4"
550 | },
551 | {
552 | "question": "how do i install ray nightly wheel",
553 | "sources": [],
554 | "document_ids": [],
555 | "answer": "The context provided does not contain information on how to install ray nightly wheel.",
556 | "llm": "gpt-4"
557 | },
558 | {
559 | "question": "how do i install the latest ray nightly wheel?",
560 | "sources": [],
561 | "document_ids": [],
562 | "answer": "The context provided does not contain information on how to install the latest Ray nightly wheel.",
563 | "llm": "gpt-4"
564 | },
565 | {
566 | "question": "how can I write unit tests for Ray code?",
567 | "sources": [],
568 | "document_ids": [],
569 | "answer": "The context provided does not contain information on how to write unit tests for Ray code.",
570 | "llm": "gpt-4"
571 | },
572 | {
573 | "question": "How I stop Ray from spamming lots of Info updates on stdout?",
574 | "sources": [],
575 | "document_ids": [],
576 | "answer": "The context provided does not contain information on how to stop Ray from spamming lots of Info updates on stdout.",
577 | "llm": "gpt-4"
578 | },
579 | {
580 | "question": "how to deploy stable diffusion 2.1 with Ray Serve?",
581 | "sources": [],
582 | "document_ids": [],
583 | "answer": "The context provided does not contain information on how to deploy stable diffusion 2.1 with Ray Serve.",
584 | "llm": "gpt-4"
585 | },
586 | {
587 | "question": "what is actor_handle?",
588 | "sources": [],
589 | "document_ids": [],
590 | "answer": "The context provided does not contain information about \"actor_handle\".",
591 | "llm": "gpt-4"
592 | },
593 | {
594 | "question": "how to kill a r detached actors?",
595 | "sources": [],
596 | "document_ids": [],
597 | "answer": "The context provided does not contain information on how to kill a r detached actors.",
598 | "llm": "gpt-4"
599 | },
600 | {
601 | "question": "How to force upgrade the pip package in the runtime environment if an old version exists?",
602 | "sources": [],
603 | "document_ids": [],
604 | "answer": "The context provided does not contain information to answer the query. However, generally, you can force upgrade the pip package in the runtime environment by using the command: `pip install --upgrade pip`.",
605 | "llm": "gpt-4"
606 | },
607 | {
608 | "question": "How do I do global shuffle with Ray?",
609 | "sources": [],
610 | "document_ids": [],
611 | "answer": "The context provided does not contain information on how to do a global shuffle with Ray.",
612 | "llm": "gpt-4"
613 | },
614 | {
615 | "question": "How to find namespace of an Actor?",
616 | "sources": [],
617 | "document_ids": [],
618 | "answer": "The context provided does not contain information on how to find the namespace of an Actor.",
619 | "llm": "gpt-4"
620 | },
621 | {
622 | "question": "How does Ray work with async.io ?",
623 | "sources": [],
624 | "document_ids": [],
625 | "answer": "The context provided does not contain information on how Ray works with async.io.",
626 | "llm": "gpt-4"
627 | },
628 | {
629 | "question": "How do I debug a hanging `ray.get()` call? I have it reproduced locally.",
630 | "sources": [],
631 | "document_ids": [],
632 | "answer": "The context provided does not contain enough information to answer the query. Please provide more details.",
633 | "llm": "gpt-4"
634 | },
635 | {
636 | "question": "can you show me an example of ray.actor.exit_actor()",
637 | "sources": [],
638 | "document_ids": [],
639 | "answer": "I'm sorry, but I can't provide an example of ray.actor.exit_actor() without a proper context. This function is used in Ray, a framework for distributed computing, to exit an actor. However, without a specific use case or context, it's hard to provide a meaningful example.",
640 | "llm": "gpt-4"
641 | },
642 | {
643 | "question": "how to add log inside actor?",
644 | "sources": [],
645 | "document_ids": [],
646 | "answer": "The context provided does not contain enough information to accurately answer the query. Please provide more details.",
647 | "llm": "gpt-4"
648 | },
649 | {
650 | "question": "can you write a script to do batch inference with GPT-2 on text data from an S3 bucket?",
651 | "sources": [],
652 | "document_ids": [],
653 | "answer": "The context provided does not contain any information to answer the query.",
654 | "llm": "gpt-4"
655 | },
656 | {
657 | "question": "How do I enable Ray debug logs?",
658 | "sources": [],
659 | "document_ids": [],
660 | "answer": "The context provided does not contain information on how to enable Ray debug logs.",
661 | "llm": "gpt-4"
662 | },
663 | {
664 | "question": "How do I list the current Ray actors from python?",
665 | "sources": [],
666 | "document_ids": [],
667 | "answer": "The context provided does not contain information on how to list the current Ray actors from Python.",
668 | "llm": "gpt-4"
669 | },
670 | {
671 | "question": "I want to kill the replica actor from Python. how do I do it?",
672 | "sources": [],
673 | "document_ids": [],
674 | "answer": "The context provided does not contain any information to answer your query.",
675 | "llm": "gpt-4"
676 | },
677 | {
678 | "question": "how do I specify in my remote function declaration that I want the task to run on a V100 GPU type?",
679 | "sources": [],
680 | "document_ids": [],
681 | "answer": "The context provided does not contain information on how to specify a task to run on a V100 GPU type in a remote function declaration.",
682 | "llm": "gpt-4"
683 | },
684 | {
685 | "question": "How do I get started?",
686 | "sources": [],
687 | "document_ids": [],
688 | "answer": "The context provided does not specify what you want to get started with. Please provide more details.",
689 | "llm": "gpt-4"
690 | },
691 | {
692 | "question": "How to specify python version in runtime_env?",
693 | "sources": [],
694 | "document_ids": [],
695 | "answer": "The context provided does not contain information on how to specify a Python version in runtime_env.",
696 | "llm": "gpt-4"
697 | },
698 | {
699 | "question": "how to create a Actor in a namespace?",
700 | "sources": [],
701 | "document_ids": [],
702 | "answer": "The context provided does not contain enough information to answer the query on how to create an Actor in a namespace.",
703 | "llm": "gpt-4"
704 | },
705 | {
706 | "question": "Can I specify multiple working directories?",
707 | "sources": [],
708 | "document_ids": [],
709 | "answer": "The context provided does not contain enough information to accurately answer the query.",
710 | "llm": "gpt-4"
711 | },
712 | {
713 | "question": "what if I set num_cpus=0 for tasks",
714 | "sources": [],
715 | "document_ids": [],
716 | "answer": "The context provided does not contain enough information to answer the query.",
717 | "llm": "gpt-4"
718 | },
719 | {
720 | "question": "is it possible to have ray on k8s without using kuberay? especially with the case that autoscaler is enabled.",
721 | "sources": [],
722 | "document_ids": [],
723 | "answer": "The context provided does not contain sufficient information to answer the query.",
724 | "llm": "gpt-4"
725 | },
726 | {
727 | "question": "how to manually configure and manage Ray cluster on Kubernetes",
728 | "sources": [],
729 | "document_ids": [],
730 | "answer": "The context provided does not contain information on how to manually configure and manage a Ray cluster on Kubernetes.",
731 | "llm": "gpt-4"
732 | },
733 | {
734 | "question": "If I shutdown a raylet, will the tasks and workers on that node also get killed?",
735 | "sources": [],
736 | "document_ids": [],
737 | "answer": "The context provided does not contain enough information to answer the query.",
738 | "llm": "gpt-4"
739 | },
740 | {
741 | "question": "If I\u2019d like to debug out of memory, how do I Do that, and which documentation should I look?",
742 | "sources": [],
743 | "document_ids": [],
744 | "answer": "The context provided does not contain information on how to debug out of memory issues or which documentation to refer to.",
745 | "llm": "gpt-4"
746 | },
747 | {
748 | "question": "How to use callback in Trainer?",
749 | "sources": [],
750 | "document_ids": [],
751 | "answer": "The context provided does not contain information on how to use a callback in Trainer.",
752 | "llm": "gpt-4"
753 | },
754 | {
755 | "question": "How to provide current working directory to ray?",
756 | "sources": [],
757 | "document_ids": [],
758 | "answer": "The context provided does not contain information on how to provide the current working directory to Ray.",
759 | "llm": "gpt-4"
760 | },
761 | {
762 | "question": "how to create an actor instance with parameter?",
763 | "sources": [],
764 | "document_ids": [],
765 | "answer": "The context provided does not contain any information to answer the query.",
766 | "llm": "gpt-4"
767 | },
768 | {
769 | "question": "how to push a custom module to ray which is using by Actor ?",
770 | "sources": [],
771 | "document_ids": [],
772 | "answer": "The context provided does not contain enough information to answer the query.",
773 | "llm": "gpt-4"
774 | },
775 | {
776 | "question": "how to print ray working directory?",
777 | "sources": [],
778 | "document_ids": [],
779 | "answer": "The context provided does not contain information on how to print the Ray working directory.",
780 | "llm": "gpt-4"
781 | },
782 | {
783 | "question": "why I can not see log.info in ray log?",
784 | "sources": [],
785 | "document_ids": [],
786 | "answer": "The context provided does not contain enough information to answer the query.",
787 | "llm": "gpt-4"
788 | },
789 | {
790 | "question": "when you use ray dataset to read a file, can you make sure the order of the data is preserved?",
791 | "sources": [],
792 | "document_ids": [],
793 | "answer": "The context provided does not contain information to answer the query.",
794 | "llm": "gpt-4"
795 | },
796 | {
797 | "question": "Can you explain what \"Ray will *not* retry tasks upon exceptions thrown by application code\" means ?",
798 | "sources": [],
799 | "document_ids": [],
800 | "answer": "Without a specific context, the statement \"Ray will *not* retry tasks upon exceptions thrown by application code\" generally means that if an error or exception occurs in the application code while Ray (a general-purpose distributed computing framework) is executing tasks, Ray will not automatically attempt to run those tasks again.",
801 | "llm": "gpt-4"
802 | },
803 | {
804 | "question": "how do I specify the log directory when starting Ray?",
805 | "sources": [],
806 | "document_ids": [],
807 | "answer": "The context provided does not contain information on how to specify the log directory when starting Ray.",
808 | "llm": "gpt-4"
809 | },
810 | {
811 | "question": "how to launch a ray cluster with 10 nodes, without setting the min worker as 10",
812 | "sources": [],
813 | "document_ids": [],
814 | "answer": "The context provided does not contain information on how to launch a ray cluster with 10 nodes without setting the min worker as 10.",
815 | "llm": "gpt-4"
816 | },
817 | {
818 | "question": "how to use ray api to scale up a cluster",
819 | "sources": [],
820 | "document_ids": [],
821 | "answer": "The context provided does not contain information on how to use Ray API to scale up a cluster.",
822 | "llm": "gpt-4"
823 | },
824 | {
825 | "question": "we plan to use Ray cloud launcher to start a cluster in AWS. How can we specify a subnet in the deployment file?",
826 | "sources": [],
827 | "document_ids": [],
828 | "answer": "The context provided does not contain information on how to specify a subnet in the deployment file using Ray cloud launcher to start a cluster in AWS.",
829 | "llm": "gpt-4"
830 | },
831 | {
832 | "question": "where I can find HTTP server error code log for Ray serve",
833 | "sources": [],
834 | "document_ids": [],
835 | "answer": "The context provided does not contain information on where to find the HTTP server error code log for Ray serve.",
836 | "llm": "gpt-4"
837 | },
838 | {
839 | "question": "I am running ray cluster on amazon and I have troubles displaying the dashboard. When a I tunnel the dashboard port from the headnode to my machine, the dashboard opens, and then it disappears (internal refresh fails). Is it a known problem? What am I doing wrong?",
840 | "sources": [],
841 | "document_ids": [],
842 | "answer": "The context provided does not contain any information to answer the query.",
843 | "llm": "gpt-4"
844 | },
845 | {
846 | "question": "In the Ray cluster launcher YAML, does `max_workers` include the head node, or only worker nodes?",
847 | "sources": [],
848 | "document_ids": [],
849 | "answer": "The context provided does not contain information to answer the query about the Ray cluster launcher YAML and `max_workers`.",
850 | "llm": "gpt-4"
851 | },
852 | {
853 | "question": "How to update files in working directory ?",
854 | "sources": [],
855 | "document_ids": [],
856 | "answer": "The context provided does not contain information on how to update files in a working directory.",
857 | "llm": "gpt-4"
858 | },
859 | {
860 | "question": "How I can update working directory file when ray allready initiated ?",
861 | "sources": [],
862 | "document_ids": [],
863 | "answer": "The context provided does not contain enough information to accurately answer the query.",
864 | "llm": "gpt-4"
865 | },
866 | {
867 | "question": "how can I force ray head node to use custom pem file to ssh worker node?",
868 | "sources": [],
869 | "document_ids": [],
870 | "answer": "The context provided does not contain information on how to force a ray head node to use a custom pem file to ssh a worker node.",
871 | "llm": "gpt-4"
872 | },
873 | {
874 | "question": "what doess the GCS server do, and why is my GCS server taking up so much memory on the head node?",
875 | "sources": [],
876 | "document_ids": [],
877 | "answer": "The context provided does not contain information about what a GCS server does or why it might be taking up a lot of memory on the head node.",
878 | "llm": "gpt-4"
879 | },
880 | {
881 | "question": "when starting cluster with ray up, there are few nodes \"pending\" for a long time. how can I debug this?",
882 | "sources": [],
883 | "document_ids": [],
884 | "answer": "The context provided does not contain any information to answer the query.",
885 | "llm": "gpt-4"
886 | },
887 | {
888 | "question": "how to install Ray 2.5.1 from github or wheel?",
889 | "sources": [],
890 | "document_ids": [],
891 | "answer": "The context provided does not contain information on how to install Ray 2.5.1 from GitHub or wheel.",
892 | "llm": "gpt-4"
893 | },
894 | {
895 | "question": "How do I use `worker_setup_hook` in a runtime env to set do some setup on worker node creation?",
896 | "sources": [],
897 | "document_ids": [],
898 | "answer": "The context provided does not contain information on how to use `worker_setup_hook` in a runtime env to set up on worker node creation.",
899 | "llm": "gpt-4"
900 | },
901 | {
902 | "question": "how to use Ray dataset on aws",
903 | "sources": [],
904 | "document_ids": [],
905 | "answer": "The context provided does not contain information on how to use Ray dataset on AWS.",
906 | "llm": "gpt-4"
907 | },
908 | {
909 | "question": "How do I avoid my dataset shuffling during a ray.data.map_batches?",
910 | "sources": [],
911 | "document_ids": [],
912 | "answer": "The context provided does not contain sufficient information to answer the query.",
913 | "llm": "gpt-4"
914 | },
915 | {
916 | "question": "Is the order of the input data preserved after a map_batches operation?",
917 | "sources": [],
918 | "document_ids": [],
919 | "answer": "The context provided does not contain sufficient information to answer the query.",
920 | "llm": "gpt-4"
921 | },
922 | {
923 | "question": "ray serve returns generic internal service error when there is an internal failure, how do I get it to emit more detailed errors or logs?",
924 | "sources": [],
925 | "document_ids": [],
926 | "answer": "The context provided does not contain information to answer the query.",
927 | "llm": "gpt-4"
928 | },
929 | {
930 | "question": "how do i track an uncaught exception in ray serve",
931 | "sources": [],
932 | "document_ids": [],
933 | "answer": "The context provided does not contain information on how to track an uncaught exception in Ray Serve.",
934 | "llm": "gpt-4"
935 | },
936 | {
937 | "question": "where do I view logs using python logger emitted by my ray serve endpoint in the ray cluster",
938 | "sources": [],
939 | "document_ids": [],
940 | "answer": "The context provided does not contain specific information on where to view logs using python logger emitted by your ray serve endpoint in the ray cluster.",
941 | "llm": "gpt-4"
942 | },
943 | {
944 | "question": "where can I see logs for a failed ray serve deployment",
945 | "sources": [],
946 | "document_ids": [],
947 | "answer": "The context provided does not contain information on where to see logs for a failed ray serve deployment.",
948 | "llm": "gpt-4"
949 | },
950 | {
951 | "question": "How to take a subset of a Ray Dataset?",
952 | "sources": [],
953 | "document_ids": [],
954 | "answer": "The context provided does not contain information on how to take a subset of a Ray Dataset.",
955 | "llm": "gpt-4"
956 | },
957 | {
958 | "question": "How do I load all checkpoints from trials of a Tune experiment launched with `tune.run`? I ran my initial experiment with cloud checkpointing, so I\u2019d need to download all the checkpoints to analyze them.",
959 | "sources": [],
960 | "document_ids": [],
961 | "answer": "The context provided does not contain enough information to answer the query.",
962 | "llm": "gpt-4"
963 | },
964 | {
965 | "question": "How can I kill a \"detached\" Actor ?",
966 | "sources": [],
967 | "document_ids": [],
968 | "answer": "The context provided does not contain enough information to answer the query.",
969 | "llm": "gpt-4"
970 | },
971 | {
972 | "question": "How do I set env variables in ray init? Let\u2019 say it\u2019s export foo=\u201cfoo\u201d",
973 | "sources": [],
974 | "document_ids": [],
975 | "answer": "The context provided does not contain information on how to set environment variables in ray init.",
976 | "llm": "gpt-4"
977 | },
978 | {
979 | "question": "What is the rest api for getting the head node id?",
980 | "sources": [],
981 | "document_ids": [],
982 | "answer": "The context provided does not contain information about the REST API for getting the head node ID.",
983 | "llm": "gpt-4"
984 | },
985 | {
986 | "question": "how to rerun a canceled ray task",
987 | "sources": [],
988 | "document_ids": [],
989 | "answer": "The context provided does not contain information on how to rerun a canceled ray task.",
990 | "llm": "gpt-4"
991 | },
992 | {
993 | "question": "How do I set the max parallel concurrent scheduled tasks in map_batches?",
994 | "sources": [],
995 | "document_ids": [],
996 | "answer": "The context provided does not contain information on how to set the max parallel concurrent scheduled tasks in map_batches.",
997 | "llm": "gpt-4"
998 | },
999 | {
1000 | "question": "How do I get the number of cpus from ray cluster?",
1001 | "sources": [],
1002 | "document_ids": [],
1003 | "answer": "The context provided does not contain information on how to get the number of CPUs from a ray cluster.",
1004 | "llm": "gpt-4"
1005 | },
1006 | {
1007 | "question": "How to use the exclude option to the runtime_env",
1008 | "sources": [],
1009 | "document_ids": [],
1010 | "answer": "The context provided does not contain information on how to use the exclude option to the runtime_env.",
1011 | "llm": "gpt-4"
1012 | },
1013 | {
1014 | "question": "show a map batch example with batch_format",
1015 | "sources": [],
1016 | "document_ids": [],
1017 | "answer": "The context provided does not contain any information related to a map batch example with batch_format. Please provide a relevant context.",
1018 | "llm": "gpt-4"
1019 | },
1020 | {
1021 | "question": "how to find local ray address",
1022 | "sources": [],
1023 | "document_ids": [],
1024 | "answer": "The context provided does not contain information on how to find a local ray address.",
1025 | "llm": "gpt-4"
1026 | },
1027 | {
1028 | "question": "How to start ray cluster on multiple node via CLI?",
1029 | "sources": [],
1030 | "document_ids": [],
1031 | "answer": "The context provided does not contain information on how to start a ray cluster on multiple nodes via CLI.",
1032 | "llm": "gpt-4"
1033 | },
1034 | {
1035 | "question": "my ray tuner shows \"running\" but CPU usage is almost 0%. why ?",
1036 | "sources": [],
1037 | "document_ids": [],
1038 | "answer": "Without a specific context, it's hard to provide an exact answer. However, a possible reason could be that your Ray Tuner is waiting for resources to be freed up or it's in a stage of its process where it doesn't require much CPU usage, such as waiting for data or dealing with I/O operations. It could also be due to a bottleneck in another area of your system, or a problem with the code itself.",
1039 | "llm": "gpt-4"
1040 | },
1041 | {
1042 | "question": "should the Ray head node and all workers have the same object store memory size allocated?",
1043 | "sources": [],
1044 | "document_ids": [],
1045 | "answer": "The context provided does not contain sufficient information to answer the query.",
1046 | "llm": "gpt-4"
1047 | },
1048 | {
1049 | "question": "In Ray Serve, how to specify whether to set up an httpproxy on each node, or just the head node?",
1050 | "sources": [],
1051 | "document_ids": [],
1052 | "answer": "The context provided does not contain information on how to specify whether to set up an httpproxy on each node, or just the head node in Ray Serve.",
1053 | "llm": "gpt-4"
1054 | },
1055 | {
1056 | "question": "Want to embed Grafana into the Ray Dashboard, given that I am using KubeRay\n\nGiven the context that Prometheus and Grafana are not running on my Head node, and that I am using KubeRay, how should I be setting the following variables?\n\u2022 `RAY_GRAFANA_HOST`\n\u2022 `RAY_PROMETHEUS_HOST`\nAnd is there a way to set them more intelligently, given that head node IP is changing every time we reconfigure our cluster?",
1057 | "sources": [],
1058 | "document_ids": [],
1059 | "answer": "The context provided does not contain sufficient information to answer the query.",
1060 | "llm": "gpt-4"
1061 | },
1062 | {
1063 | "question": "How the GCS determines which Kubernetes pod to kill when using KubeRay autoscaling?",
1064 | "sources": [],
1065 | "document_ids": [],
1066 | "answer": "The context provided does not contain information on how the GCS determines which Kubernetes pod to kill when using KubeRay autoscaling.",
1067 | "llm": "gpt-4"
1068 | },
1069 | {
1070 | "question": "How can I set the `request_timeout_s` in `http_options` section of a Ray Serve YAML config file?",
1071 | "sources": [],
1072 | "document_ids": [],
1073 | "answer": "The context provided does not contain information on how to set the `request_timeout_s` in `http_options` section of a Ray Serve YAML config file.",
1074 | "llm": "gpt-4"
1075 | },
1076 | {
1077 | "question": "How do I make the GPU available on my M1 laptop to ray?",
1078 | "sources": [],
1079 | "document_ids": [],
1080 | "answer": "The context provided does not contain information on how to make the GPU available on an M1 laptop for Ray.",
1081 | "llm": "gpt-4"
1082 | },
1083 | {
1084 | "question": "How can I add a timeout for the Ray job?",
1085 | "sources": [],
1086 | "document_ids": [],
1087 | "answer": "The context provided does not contain information on how to add a timeout for a Ray job.",
1088 | "llm": "gpt-4"
1089 | },
1090 | {
1091 | "question": "how do I set custom /tmp directory for remote cluster?",
1092 | "sources": [],
1093 | "document_ids": [],
1094 | "answer": "The context provided does not contain information on how to set a custom /tmp directory for a remote cluster.",
1095 | "llm": "gpt-4"
1096 | },
1097 | {
1098 | "question": "if I set --temp-dir to a different directory than /tmp, will ray object spill to the custom directory ?",
1099 | "sources": [],
1100 | "document_ids": [],
1101 | "answer": "The context provided does not contain sufficient information to accurately answer the query.",
1102 | "llm": "gpt-4"
1103 | },
1104 | {
1105 | "question": "can you give me an example for *`--runtime-env-json`*",
1106 | "sources": [],
1107 | "document_ids": [],
1108 | "answer": "The context provided does not contain any information related to `--runtime-env-json`. Therefore, I am unable to provide an example.",
1109 | "llm": "gpt-4"
1110 | },
1111 | {
1112 | "question": "What should be the value of `maxConcurrentReplicas` if autoscaling configuration is specified?",
1113 | "sources": [],
1114 | "document_ids": [],
1115 | "answer": "The context provided does not contain information to answer the query about the value of `maxConcurrentReplicas` in autoscaling configuration.",
1116 | "llm": "gpt-4"
1117 | },
1118 | {
1119 | "question": "Yes what should be the value of `max_concurrent_queries` when `target_num_ongoing_requests_per_replica` is specified?",
1120 | "sources": [],
1121 | "document_ids": [],
1122 | "answer": "The context provided does not contain information to answer the query about the value of `max_concurrent_queries` when `target_num_ongoing_requests_per_replica` is specified.",
1123 | "llm": "gpt-4"
1124 | },
1125 | {
1126 | "question": "what is a `smoothing_factor`",
1127 | "sources": [],
1128 | "document_ids": [],
1129 | "answer": "The context provided does not contain information about a 'smoothing_factor'.",
1130 | "llm": "gpt-4"
1131 | },
1132 | {
1133 | "question": "What is the reason actors change their state to unhealthy?",
1134 | "sources": [],
1135 | "document_ids": [],
1136 | "answer": "The context provided does not contain information to answer the query about why actors change their state to unhealthy.",
1137 | "llm": "gpt-4"
1138 | },
1139 | {
1140 | "question": "How do I access logs for a dead node?",
1141 | "sources": [],
1142 | "document_ids": [],
1143 | "answer": "The context provided does not contain information on how to access logs for a dead node.",
1144 | "llm": "gpt-4"
1145 | },
1146 | {
1147 | "question": "What are the reasons for a node to change it\u2019s status to dead?",
1148 | "sources": [],
1149 | "document_ids": [],
1150 | "answer": "The context provided does not contain information to answer the query about the reasons for a node to change its status to dead.",
1151 | "llm": "gpt-4"
1152 | },
1153 | {
1154 | "question": "What are the reasons for spikes in node CPU utilization",
1155 | "sources": [],
1156 | "document_ids": [],
1157 | "answer": "The context provided does not contain any information to answer the query.",
1158 | "llm": "gpt-4"
1159 | },
1160 | {
1161 | "question": "What AWS machine type is recommended to deploy a RayService on EKS?",
1162 | "sources": [],
1163 | "document_ids": [],
1164 | "answer": "The context provided does not include information on the recommended AWS machine type to deploy a RayService on EKS.",
1165 | "llm": "gpt-4"
1166 | },
1167 | {
1168 | "question": "Is there a way to configure the session name generated by ray?",
1169 | "sources": [],
1170 | "document_ids": [],
1171 | "answer": "The context provided does not contain information to answer the query.",
1172 | "llm": "gpt-4"
1173 | },
1174 | {
1175 | "question": "can I use the Python SDK to get a link to Ray dashboard for a given job?",
1176 | "sources": [],
1177 | "document_ids": [],
1178 | "answer": "The context provided does not contain information about using the Python SDK to get a link to Ray dashboard for a given job.",
1179 | "llm": "gpt-4"
1180 | },
1181 | {
1182 | "question": "What may possible cause the node where this task was running crashed unexpectedly. This can happen if: (1) the instance where the node was running failed, (2) raylet crashes unexpectedly (OOM, preempted node, etc).",
1183 | "sources": [],
1184 | "document_ids": [],
1185 | "answer": "The node where the task was running may crash unexpectedly due to the failure of the instance where the node was running or if the raylet (a system component of Ray, a framework for distributed computing) crashes unexpectedly. This could be due to reasons such as out of memory (OOM) errors or the node being preempted.",
1186 | "llm": "gpt-4"
1187 | },
1188 | {
1189 | "question": "Do you know how to resolve (gcs_server) gcs_health_check_manager.cc:108: Health check failed for node? I observed that the node is still up and running.",
1190 | "sources": [],
1191 | "document_ids": [],
1192 | "answer": "The context provided does not contain any information or solution related to the issue \"(gcs_server) gcs_health_check_manager.cc:108: Health check failed for node\". Please provide more details or context.",
1193 | "llm": "gpt-4"
1194 | },
1195 | {
1196 | "question": "Do you need the DAGDriver to deploy a serve application using RayServe?",
1197 | "sources": [],
1198 | "document_ids": [],
1199 | "answer": "The context provided does not contain information to answer the query about needing the DAGDriver to deploy a serve application using RayServe.",
1200 | "llm": "gpt-4"
1201 | },
1202 | {
1203 | "question": "What\u2019s the import path that I need to provide to a simple RayServe deployment?",
1204 | "sources": [],
1205 | "document_ids": [],
1206 | "answer": "The context provided does not contain information needed to answer the query.",
1207 | "llm": "gpt-4"
1208 | },
1209 | {
1210 | "question": "do you have any documents / examples showing the usage of RayJob in Kuberay?",
1211 | "sources": [],
1212 | "document_ids": [],
1213 | "answer": "The context provided does not contain any information about the usage of RayJob in Kuberay.",
1214 | "llm": "gpt-4"
1215 | },
1216 | {
1217 | "question": "Does Ray metrics have to be exported via an actor?",
1218 | "sources": [],
1219 | "document_ids": [],
1220 | "answer": "The context provided does not contain information to answer the query about Ray metrics being exported via an actor.",
1221 | "llm": "gpt-4"
1222 | },
1223 | {
1224 | "question": "how can I avoid objects not getting spilled?",
1225 | "sources": [],
1226 | "document_ids": [],
1227 | "answer": "The context provided does not contain any information to answer the query.",
1228 | "llm": "gpt-4"
1229 | },
1230 | {
1231 | "question": "what\u2019s ray core",
1232 | "sources": [],
1233 | "document_ids": [],
1234 | "answer": "The context provided does not contain information about \"ray core\".",
1235 | "llm": "gpt-4"
1236 | },
1237 | {
1238 | "question": "Does ray support cron job",
1239 | "sources": [],
1240 | "document_ids": [],
1241 | "answer": "The context provided does not contain information about whether Ray supports cron jobs.",
1242 | "llm": "gpt-4"
1243 | },
1244 | {
1245 | "question": "can you give me the dependencies list for api read_images?",
1246 | "sources": [],
1247 | "document_ids": [],
1248 | "answer": "The context provided does not contain information about the dependencies for the API read_images.",
1249 | "llm": "gpt-4"
1250 | },
1251 | {
1252 | "question": "how do I kill a specific serve replica",
1253 | "sources": [],
1254 | "document_ids": [],
1255 | "answer": "The context provided does not contain enough information to answer the query.",
1256 | "llm": "gpt-4"
1257 | }
1258 | ]
1259 | }
1260 |
--------------------------------------------------------------------------------
/experiments/responses/without-context-small.json:
--------------------------------------------------------------------------------
1 | {
2 | "config": {
3 | "experiment_name": "without-context-small",
4 | "data_path": "/home/ray/ray-assistant/datasets/eval-dataset-v1.jsonl",
5 | "chunk_size": 100,
6 | "chunk_overlap": 50,
7 | "num_chunks": 0,
8 | "embedding_model_name": "thenlper/gte-base",
9 | "llm": "meta-llama/Llama-2-70b-chat-hf",
10 | "temperature": 0.0,
11 | "max_context_length": 4096,
12 | "system_content": "Answer the query using the context provided. Be succinct.",
13 | "assistant_content": ""
14 | },
15 | "results": [
16 | {
17 | "question": "I\u2019m struggling a bit with Ray Data type conversions when I do map_batches. Any advice?",
18 | "sources": [],
19 | "answer": "Sure, I can help you with that! Ray Data type conversions can sometimes be tricky when working with `map_batches`. Here are a few tips that might be helpful:\n\n1. Use the `ray.data.convert` function: This function can be used to convert a Ray Data object to a different data type. For example, if you have a Ray Data object of type `int` and you want to convert it to a type `float`, you can use the following code:\n```\nimport ray\n\n# Create a Ray Data object of type int\ndata = ray.data.IntVector([1, 2, 3])\n\n# Convert the data to a type float\nconverted_data = ray.data.convert(data, ray.data.float32)\n```\n2. Use the `map_batches` method with a custom function: You can also use a custom function to perform type conversions when mapping over a Ray Data object. Here's an example:\n```\nimport ray\n\n# Create a Ray Data object of type int\ndata = ray.data.IntVector([1, 2, 3])\n\n# Define a custom function to convert the data to a type float\ndef convert_to_float(item):\n return float(item)\n\n# Map over the data using the custom function\nfloat_data = data.map_batches(convert_to_float)\n```\nIn this example, the `convert_to_float` function takes an item from the Ray Data object and returns its float equivalent. The `map_batches` method then applies this function to each item in the data object, resulting in a new Ray Data object of type `float`.\n\n3. Use the `ray.data.to_numpy` method: If you want to convert a Ray Data object to a NumPy array, you can use the `ray.data.to_numpy` method. This method returns a NumPy array with the same data as the Ray Data object. Here's an example:\n```\nimport ray\nimport numpy as np\n\n# Create a Ray Data object of type int\ndata = ray.data.IntVector([1, 2, 3])\n\n# Convert the data to a NumPy array\nnumpy_data = ray.data.to_numpy(data)\n\n# Convert the NumPy array to a type float\nfloat_data = numpy_data.astype(np.float32)\n```\nIn this example, the `to_numpy` method is used to convert the Ray Data object to a NumPy array. The resulting NumPy array is then converted to a type float using the `astype` method.\n\nI hope these tips are helpful! Let me know if you have any further questions."
20 | },
21 | {
22 | "question": "How does autoscaling work in a Ray Serve application?",
23 | "sources": [],
24 | "answer": "Autoscaling in a Ray Serve application works by using the Ray Autoscaler to automatically adjust the number of worker nodes in the cluster based on the current workload. The Autoscaler uses a variety of metrics, such as CPU utilization and task queues, to determine when to add or remove worker nodes.\n\nHere's a high-level overview of how autoscaling works in a Ray Serve application:\n\n1. The Autoscaler periodically collects metrics from the worker nodes in the cluster, such as CPU utilization and task queues.\n2. The Autoscaler uses these metrics to determine the current workload and whether the cluster is underutilized or overutilized.\n3. If the cluster is underutilized, the Autoscaler may decide to remove worker nodes to save resources.\n4. If the cluster is overutilized, the Autoscaler may decide to add worker nodes to handle the increased workload.\n5. The Autoscaler then sends a request to the Ray Cluster Manager to add or remove worker nodes as needed.\n6. The Ray Cluster Manager then provisions new worker nodes or removes existing worker nodes from the cluster.\n7. The Autoscaler monitors the cluster again after a few minutes to ensure that the desired number of worker nodes is running and that the workload is being handled effectively.\n\nBy using autoscaling in a Ray Serve application, you can ensure that your application can handle changes in workload without manual intervention, and that you are using your resources efficiently."
25 | }
26 | ]
27 | }
28 |
--------------------------------------------------------------------------------
/migrations/vector-1024.sql:
--------------------------------------------------------------------------------
1 | CREATE TABLE document (
2 | id serial primary key,
3 | "text" text not null,
4 | source text not null,
5 | embedding vector(1024)
6 | );
7 |
--------------------------------------------------------------------------------
/migrations/vector-1536.sql:
--------------------------------------------------------------------------------
1 | CREATE TABLE document (
2 | id serial primary key,
3 | "text" text not null,
4 | source text not null,
5 | embedding vector(1536)
6 | );
7 |
--------------------------------------------------------------------------------
/migrations/vector-768.sql:
--------------------------------------------------------------------------------
1 | CREATE TABLE document (
2 | id serial primary key,
3 | "text" text not null,
4 | source text not null,
5 | embedding vector(768)
6 | );
7 |
--------------------------------------------------------------------------------
/notebooks/clear_cell_nums.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 |
3 | import nbformat
4 |
5 |
6 | def clear_execution_numbers(nb_path):
7 | with open(nb_path, "r", encoding="utf-8") as f:
8 | nb = nbformat.read(f, as_version=4)
9 | for cell in nb["cells"]:
10 | if cell["cell_type"] == "code":
11 | cell["execution_count"] = None
12 | for output in cell["outputs"]:
13 | if "execution_count" in output:
14 | output["execution_count"] = None
15 | with open(nb_path, "w", encoding="utf-8") as f:
16 | nbformat.write(nb, f)
17 |
18 |
19 | if __name__ == "__main__":
20 | NOTEBOOK_DIR = Path(__file__).parent
21 | notebook_fps = list(NOTEBOOK_DIR.glob("**/*.ipynb"))
22 | for fp in notebook_fps:
23 | clear_execution_numbers(fp)
24 |
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | # Black formatting
2 | [tool.black]
3 | line-length = 99
4 | include = '\.pyi?$'
5 | exclude = '''
6 | /(
7 | .eggs # exclude a few common directories in the
8 | | .git # root of the project
9 | | .hg
10 | | .mypy_cache
11 | | .tox
12 | | venv
13 | | _build
14 | | buck-out
15 | | build
16 | | dist
17 | )/
18 | '''
19 |
20 | # iSort
21 | [tool.isort]
22 | profile = "black"
23 | line_length = 79
24 | multi_line_output = 3
25 | include_trailing_comma = true
26 | virtual_env = "venv"
27 |
28 | [tool.flake8]
29 | exclude = "venv"
30 | ignore = ["E501", "W503", "E226"]
31 | # E501: Line too long
32 | # W503: Line break occurred before binary operator
33 | # E226: Missing white space around arithmetic operator
34 |
35 | [tool.pyupgrade]
36 | py39plus = true
37 |
--------------------------------------------------------------------------------
/rag/__init__.py:
--------------------------------------------------------------------------------
1 | from dotenv import load_dotenv
2 |
3 | load_dotenv()
4 |
--------------------------------------------------------------------------------
/rag/config.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 |
3 | # Directories
4 | EFS_DIR = Path("/mnt/shared_storage/ray-assistant-data")
5 | ROOT_DIR = Path(__file__).parent.parent.absolute()
6 |
7 | # Embedding dimensions
8 | EMBEDDING_DIMENSIONS = {
9 | "thenlper/gte-base": 768,
10 | "thenlper/gte-large": 1024,
11 | "BAAI/bge-large-en": 1024,
12 | "text-embedding-ada-002": 1536,
13 | "gte-large-fine-tuned": 1024,
14 | }
15 |
16 | # Maximum context lengths
17 | MAX_CONTEXT_LENGTHS = {
18 | "gpt-4": 8192,
19 | "gpt-3.5-turbo": 4096,
20 | "gpt-3.5-turbo-16k": 16384,
21 | "gpt-4-1106-preview": 128000,
22 | "meta-llama/Llama-2-7b-chat-hf": 4096,
23 | "meta-llama/Llama-2-13b-chat-hf": 4096,
24 | "meta-llama/Llama-2-70b-chat-hf": 4096,
25 | "meta-llama/Llama-3-8b-chat-hf": 8192,
26 | "meta-llama/Llama-3-70b-chat-hf": 8192,
27 | "codellama/CodeLlama-34b-Instruct-hf": 16384,
28 | "mistralai/Mistral-7B-Instruct-v0.1": 65536,
29 | "mistralai/Mixtral-8x7B-Instruct-v0.1": 32768,
30 | "mistralai/Mixtral-8x22B-Instruct-v0.1": 65536,
31 | }
32 |
33 | # Pricing per 1M tokens
34 | PRICING = {
35 | "gpt-3.5-turbo": {"prompt": 1.5, "sampled": 2},
36 | "gpt-4": {"prompt": 30, "sampled": 60},
37 | "gpt-4-1106-preview": {"prompt": 10, "sampled": 30},
38 | "llama-2-7b-chat-hf": {"prompt": 0.15, "sampled": 0.15},
39 | "llama-2-13b-chat-hf": {"prompt": 0.25, "sampled": 0.25},
40 | "llama-2-70b-chat-hf": {"prompt": 1, "sampled": 1},
41 | "llama-3-8b-chat-hf": {"prompt": 0.15, "sampled": 0.15},
42 | "llama-3-70b-chat-hf": {"prompt": 1, "sampled": 1},
43 | "codellama-34b-instruct-hf": {"prompt": 1, "sampled": 1},
44 | "mistral-7b-instruct-v0.1": {"prompt": 0.15, "sampled": 0.15},
45 | "mixtral-8x7b-instruct-v0.1": {"prompt": 0.50, "sampled": 0.50},
46 | "mixtral-8x22b-instruct-v0.1": {"prompt": 0.9, "sampled": 0.9},
47 | }
48 |
--------------------------------------------------------------------------------
/rag/data.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 |
3 | from bs4 import BeautifulSoup, NavigableString
4 |
5 | from rag.config import EFS_DIR
6 |
7 |
8 | def extract_text_from_section(section):
9 | texts = []
10 | for elem in section.children:
11 | if isinstance(elem, NavigableString):
12 | if elem.strip():
13 | texts.append(elem.strip())
14 | elif elem.name == "section":
15 | continue
16 | else:
17 | texts.append(elem.get_text().strip())
18 | return "\n".join(texts)
19 |
20 |
21 | def path_to_uri(path, scheme="https://", domain="docs.ray.io"):
22 | return scheme + domain + str(path).split(domain)[-1]
23 |
24 |
25 | def extract_sections(record):
26 | with open(record["path"], "r", encoding="utf-8") as html_file:
27 | soup = BeautifulSoup(html_file, "html.parser")
28 | sections = soup.find_all("section")
29 | section_list = []
30 | for section in sections:
31 | section_id = section.get("id")
32 | section_text = extract_text_from_section(section)
33 | if section_id:
34 | uri = path_to_uri(path=record["path"])
35 | section_list.append({"source": f"{uri}#{section_id}", "text": section_text})
36 | return section_list
37 |
38 |
39 | def fetch_text(uri):
40 | url, anchor = uri.split("#") if "#" in uri else (uri, None)
41 | file_path = Path(EFS_DIR, url.split("https://")[-1])
42 | with open(file_path, "r", encoding="utf-8") as file:
43 | html_content = file.read()
44 | soup = BeautifulSoup(html_content, "html.parser")
45 | if anchor:
46 | target_element = soup.find(id=anchor)
47 | if target_element:
48 | text = target_element.get_text()
49 | else:
50 | return fetch_text(uri=url)
51 | else:
52 | text = soup.get_text()
53 | return text
54 |
--------------------------------------------------------------------------------
/rag/embed.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | from langchain.embeddings import OpenAIEmbeddings
4 | from langchain.embeddings.huggingface import HuggingFaceEmbeddings
5 |
6 |
7 | def get_embedding_model(embedding_model_name, model_kwargs, encode_kwargs):
8 | if embedding_model_name == "text-embedding-ada-002":
9 | embedding_model = OpenAIEmbeddings(
10 | model=embedding_model_name,
11 | openai_api_base=os.environ["OPENAI_API_BASE"],
12 | openai_api_key=os.environ["OPENAI_API_KEY"],
13 | )
14 | else:
15 | embedding_model = HuggingFaceEmbeddings(
16 | model_name=embedding_model_name,
17 | model_kwargs=model_kwargs,
18 | encode_kwargs=encode_kwargs,
19 | )
20 | return embedding_model
21 |
22 |
23 | class EmbedChunks:
24 | def __init__(self, model_name):
25 | # Embedding model
26 | self.embedding_model = get_embedding_model(
27 | embedding_model_name=model_name,
28 | model_kwargs={"device": "cuda"},
29 | encode_kwargs={"device": "cuda", "batch_size": 100},
30 | )
31 |
32 | def __call__(self, batch):
33 | embeddings = self.embedding_model.embed_documents(batch["text"])
34 | return {"text": batch["text"], "source": batch["source"], "embeddings": embeddings}
35 |
--------------------------------------------------------------------------------
/rag/evaluate.py:
--------------------------------------------------------------------------------
1 | import json
2 | import re
3 | from pathlib import Path
4 |
5 | import numpy as np
6 | from IPython.display import JSON, clear_output, display
7 | from tqdm import tqdm
8 |
9 | from rag.generate import generate_response
10 | from rag.utils import get_num_tokens, trim
11 |
12 |
13 | def get_retrieval_score(references, generated):
14 | matches = np.zeros(len(references))
15 | for i in range(len(references)):
16 | reference_source = references[i]["source"].split("#")[0]
17 | if not reference_source:
18 | matches[i] = 1
19 | continue
20 | for source in generated[i]["sources"]:
21 | # sections don't have to perfectly match
22 | if reference_source == source.split("#")[0]:
23 | matches[i] = 1
24 | continue
25 | retrieval_score = np.mean(matches)
26 | return retrieval_score
27 |
28 |
29 | def extract_from_response(response):
30 | # Define regular expressions for extracting values
31 | answer_pattern = r'"answer"\s*:\s*"([^"]*)"'
32 | score_pattern = r'"score"\s*:\s*([0-9]+)'
33 | reasoning_pattern = r'"reasoning"\s*:\s*"([^"]*)"'
34 |
35 | # Extract values using regular expressions
36 | answer_match = re.search(answer_pattern, response)
37 | score_match = re.search(score_pattern, response)
38 | reasoning_match = re.search(reasoning_pattern, response)
39 |
40 | # Convert
41 | if answer_match and score_match and reasoning_match:
42 | answer = answer_match.group(1)
43 | score = float(score_match.group(1))
44 | reasoning = reasoning_match.group(1)
45 | return answer, score, reasoning
46 |
47 | return "", "", ""
48 |
49 |
50 | def evaluate_responses(
51 | experiment_name,
52 | evaluator,
53 | temperature,
54 | max_context_length,
55 | system_content,
56 | assistant_content,
57 | experiments_dir,
58 | references_fp,
59 | responses_fp,
60 | num_samples=None,
61 | ):
62 | # Load answers
63 | with open(Path(references_fp), "r") as f:
64 | references = [item for item in json.load(f)][:num_samples]
65 | with open(Path(responses_fp), "r") as f:
66 | generated = [item for item in json.load(f)["results"]][:num_samples]
67 | assert len(references) == len(generated)
68 |
69 | # Quality score
70 | results = []
71 | context_length = max_context_length - get_num_tokens(system_content + assistant_content)
72 | for ref, gen in tqdm(zip(references, generated), total=len(references)):
73 | assert ref["question"] == gen["question"]
74 | user_content = trim(
75 | str(
76 | {
77 | "question": gen["question"],
78 | "generated_answer": gen["answer"],
79 | "reference_answer": ref["answer"],
80 | }
81 | ),
82 | context_length,
83 | )
84 |
85 | # Generate response
86 | response = generate_response(
87 | llm=evaluator,
88 | temperature=temperature,
89 | system_content=system_content,
90 | assistant_content=assistant_content,
91 | user_content=user_content,
92 | )
93 |
94 | # Extract from response
95 | score, reasoning = response.split("\n", 1) if "\n" in response else (0, "")
96 | result = {
97 | "question": gen["question"],
98 | "generated_answer": gen["answer"],
99 | "reference_answer": ref["answer"],
100 | "score": float(score),
101 | "reasoning": reasoning.lstrip("\n"),
102 | "sources": gen["sources"],
103 | }
104 | results.append(result)
105 | clear_output(wait=True)
106 | display(JSON(json.dumps(result, indent=2)))
107 |
108 | # Save to file
109 | evaluator_name = evaluator.split("/")[-1].lower()
110 | evaluation_fp = Path(
111 | experiments_dir, "evaluations", f"{experiment_name}_{evaluator_name}.json"
112 | )
113 | evaluation_fp.parent.mkdir(parents=True, exist_ok=True)
114 | config = {
115 | "experiment_name": experiment_name,
116 | "evaluator": evaluator,
117 | "temperature": temperature,
118 | "max_context_length": max_context_length,
119 | "system_content": system_content,
120 | "assistant_content": assistant_content,
121 | "experiments_dir": str(experiments_dir),
122 | "references_fp": str(references_fp),
123 | "responses_fp": str(responses_fp),
124 | }
125 | evaluation = {
126 | "config": config,
127 | "retrieval_score": get_retrieval_score(references, generated),
128 | "quality_score": np.mean(
129 | [item["score"] for item in results if (item["score"] and item["reference_answer"])]
130 | ),
131 | "results": results,
132 | }
133 | with open(evaluation_fp, "w") as fp:
134 | json.dump(evaluation, fp, indent=4)
135 |
--------------------------------------------------------------------------------
/rag/generate.py:
--------------------------------------------------------------------------------
1 | import json
2 | import pickle
3 | import re
4 | import time
5 | from pathlib import Path
6 |
7 | from IPython.display import JSON, clear_output, display
8 | from rank_bm25 import BM25Okapi
9 | from tqdm import tqdm
10 |
11 | from rag.config import EFS_DIR, ROOT_DIR
12 | from rag.embed import get_embedding_model
13 | from rag.index import load_index
14 | from rag.rerank import custom_predict, get_reranked_indices
15 | from rag.search import lexical_search, semantic_search
16 | from rag.utils import get_client, get_num_tokens, trim
17 |
18 |
19 | def response_stream(chat_completion):
20 | for chunk in chat_completion:
21 | content = chunk.choices[0].delta.content
22 | if content is not None:
23 | yield content
24 |
25 |
26 | def prepare_response(chat_completion, stream):
27 | if stream:
28 | return response_stream(chat_completion)
29 | else:
30 | return chat_completion.choices[0].message.content
31 |
32 |
33 | def send_request(
34 | llm,
35 | messages,
36 | max_tokens=None,
37 | temperature=0.0,
38 | stream=False,
39 | max_retries=1,
40 | retry_interval=60,
41 | ):
42 | retry_count = 0
43 | client = get_client(llm=llm)
44 | while retry_count <= max_retries:
45 | try:
46 | chat_completion = client.chat.completions.create(
47 | model=llm,
48 | max_tokens=max_tokens,
49 | temperature=temperature,
50 | stream=stream,
51 | messages=messages,
52 | )
53 | return prepare_response(chat_completion, stream=stream)
54 |
55 | except Exception as e:
56 | print(f"Exception: {e}")
57 | time.sleep(retry_interval) # default is per-minute rate limits
58 | retry_count += 1
59 | return ""
60 |
61 |
62 | def generate_response(
63 | llm,
64 | max_tokens=None,
65 | temperature=0.0,
66 | stream=False,
67 | system_content="",
68 | assistant_content="",
69 | user_content="",
70 | max_retries=1,
71 | retry_interval=60,
72 | ):
73 | """Generate response from an LLM."""
74 | messages = [
75 | {"role": role, "content": content}
76 | for role, content in [
77 | ("system", system_content),
78 | ("assistant", assistant_content),
79 | ("user", user_content),
80 | ]
81 | if content
82 | ]
83 | return send_request(
84 | llm, messages, max_tokens, temperature, stream, max_retries, retry_interval
85 | )
86 |
87 |
88 | class QueryAgent:
89 | def __init__(
90 | self,
91 | embedding_model_name="thenlper/gte-base",
92 | chunks=None,
93 | lexical_index=None,
94 | reranker=None,
95 | llm="meta-llama/Llama-2-70b-chat-hf",
96 | temperature=0.0,
97 | max_context_length=4096,
98 | system_content="",
99 | assistant_content="",
100 | ):
101 | # Embedding model
102 | self.embedding_model = get_embedding_model(
103 | embedding_model_name=embedding_model_name,
104 | model_kwargs={"device": "cuda"},
105 | encode_kwargs={"device": "cuda", "batch_size": 100},
106 | )
107 |
108 | # Lexical search
109 | self.chunks = chunks
110 | self.lexical_index = lexical_index
111 |
112 | # Reranker
113 | self.reranker = reranker
114 |
115 | # LLM
116 | self.llm = llm
117 | self.temperature = temperature
118 | self.context_length = int(
119 | 0.5 * max_context_length
120 | ) - get_num_tokens( # 50% of total context reserved for input
121 | system_content + assistant_content
122 | )
123 | self.max_tokens = int(
124 | 0.5 * max_context_length
125 | ) # max sampled output (the other 50% of total context)
126 | self.system_content = system_content
127 | self.assistant_content = assistant_content
128 |
129 | def __call__(
130 | self,
131 | query,
132 | num_chunks=5,
133 | lexical_search_k=1,
134 | rerank_threshold=0.2,
135 | rerank_k=7,
136 | stream=True,
137 | ):
138 | # Get top_k context
139 | context_results = semantic_search(
140 | query=query, embedding_model=self.embedding_model, k=num_chunks
141 | )
142 |
143 | # Add lexical search results
144 | if self.lexical_index:
145 | lexical_context = lexical_search(
146 | index=self.lexical_index, query=query, chunks=self.chunks, k=lexical_search_k
147 | )
148 | # Insert after worth of semantic results
149 | context_results[lexical_search_k:lexical_search_k] = lexical_context
150 |
151 | # Rerank
152 | if self.reranker:
153 | predicted_tag = custom_predict(
154 | inputs=[query], classifier=self.reranker, threshold=rerank_threshold
155 | )[0]
156 | if predicted_tag != "other":
157 | sources = [item["source"] for item in context_results]
158 | reranked_indices = get_reranked_indices(sources, predicted_tag)
159 | context_results = [context_results[i] for i in reranked_indices]
160 | context_results = context_results[:rerank_k]
161 |
162 | # Generate response
163 | document_ids = [item["id"] for item in context_results]
164 | context = [item["text"] for item in context_results]
165 | sources = set([item["source"] for item in context_results])
166 | user_content = f"query: {query}, context: {context}"
167 | answer = generate_response(
168 | llm=self.llm,
169 | max_tokens=self.max_tokens,
170 | temperature=self.temperature,
171 | stream=stream,
172 | system_content=self.system_content,
173 | assistant_content=self.assistant_content,
174 | user_content=trim(user_content, self.context_length),
175 | )
176 |
177 | # Result
178 | result = {
179 | "question": query,
180 | "sources": sources,
181 | "document_ids": document_ids,
182 | "answer": answer,
183 | "llm": self.llm,
184 | }
185 | return result
186 |
187 |
188 | # Generate responses
189 | def generate_responses(
190 | experiment_name,
191 | chunk_size,
192 | chunk_overlap,
193 | num_chunks,
194 | embedding_model_name,
195 | embedding_dim,
196 | use_lexical_search,
197 | lexical_search_k,
198 | use_reranking,
199 | rerank_threshold,
200 | rerank_k,
201 | llm,
202 | temperature,
203 | max_context_length,
204 | system_content,
205 | assistant_content,
206 | docs_dir,
207 | experiments_dir,
208 | references_fp,
209 | num_samples=None,
210 | sql_dump_fp=None,
211 | ):
212 | # Build index
213 | chunks = load_index(
214 | embedding_model_name=embedding_model_name,
215 | embedding_dim=embedding_dim,
216 | chunk_size=chunk_size,
217 | chunk_overlap=chunk_overlap,
218 | docs_dir=docs_dir,
219 | sql_dump_fp=sql_dump_fp,
220 | )
221 |
222 | # Lexical index
223 | lexical_index = None
224 | if use_lexical_search:
225 | texts = [re.sub(r"[^a-zA-Z0-9]", " ", chunk[1]).lower().split() for chunk in chunks]
226 | lexical_index = BM25Okapi(texts)
227 |
228 | # Reranker
229 | reranker = None
230 | if use_reranking:
231 | reranker_fp = Path(EFS_DIR, "reranker.pkl")
232 | with open(reranker_fp, "rb") as file:
233 | reranker = pickle.load(file)
234 |
235 | # Query agent
236 | agent = QueryAgent(
237 | embedding_model_name=embedding_model_name,
238 | chunks=chunks,
239 | lexical_index=lexical_index,
240 | reranker=reranker,
241 | llm=llm,
242 | temperature=temperature,
243 | system_content=system_content,
244 | assistant_content=assistant_content,
245 | )
246 |
247 | # Generate responses
248 | results = []
249 | with open(Path(references_fp), "r") as f:
250 | questions = [item["question"] for item in json.load(f)][:num_samples]
251 | for query in tqdm(questions):
252 | result = agent(
253 | query=query,
254 | num_chunks=num_chunks,
255 | lexical_search_k=lexical_search_k,
256 | rerank_threshold=rerank_threshold,
257 | rerank_k=rerank_k,
258 | stream=False,
259 | )
260 | results.append(result)
261 | clear_output(wait=True)
262 | display(JSON(json.dumps(result, indent=2)))
263 |
264 | # Save to file
265 | responses_fp = Path(ROOT_DIR, experiments_dir, "responses", f"{experiment_name}.json")
266 | responses_fp.parent.mkdir(parents=True, exist_ok=True)
267 | config = {
268 | "experiment_name": experiment_name,
269 | "chunk_size": chunk_size,
270 | "chunk_overlap": chunk_overlap,
271 | "num_chunks": num_chunks,
272 | "embedding_model_name": embedding_model_name,
273 | "llm": llm,
274 | "temperature": temperature,
275 | "max_context_length": max_context_length,
276 | "system_content": system_content,
277 | "assistant_content": assistant_content,
278 | "docs_dir": str(docs_dir),
279 | "experiments_dir": str(experiments_dir),
280 | "references_fp": str(references_fp),
281 | "num_samples": len(questions),
282 | }
283 | responses = {
284 | "config": config,
285 | "results": results,
286 | }
287 | with open(responses_fp, "w") as fp:
288 | json.dump(responses, fp, indent=4)
289 |
--------------------------------------------------------------------------------
/rag/index.py:
--------------------------------------------------------------------------------
1 | import os
2 | from functools import partial
3 | from pathlib import Path
4 |
5 | import psycopg
6 | import ray
7 | from langchain.text_splitter import RecursiveCharacterTextSplitter
8 | from pgvector.psycopg import register_vector
9 | from ray.data import ActorPoolStrategy
10 |
11 | from rag.config import EFS_DIR
12 | from rag.data import extract_sections
13 | from rag.embed import EmbedChunks
14 | from rag.utils import execute_bash
15 |
16 |
17 | class StoreResults:
18 | def __call__(self, batch):
19 | with psycopg.connect(
20 | "dbname=postgres user=postgres host=localhost password=postgres"
21 | ) as conn:
22 | register_vector(conn)
23 | with conn.cursor() as cur:
24 | for text, source, embedding in zip(
25 | batch["text"], batch["source"], batch["embeddings"]
26 | ):
27 | cur.execute(
28 | "INSERT INTO document (text, source, embedding) VALUES (%s, %s, %s)",
29 | (
30 | text,
31 | source,
32 | embedding,
33 | ),
34 | )
35 | return {}
36 |
37 |
38 | def chunk_section(section, chunk_size, chunk_overlap):
39 | text_splitter = RecursiveCharacterTextSplitter(
40 | separators=["\n\n", "\n", " ", ""],
41 | chunk_size=chunk_size,
42 | chunk_overlap=chunk_overlap,
43 | length_function=len,
44 | )
45 | chunks = text_splitter.create_documents(
46 | texts=[section["text"]], metadatas=[{"source": section["source"]}]
47 | )
48 | return [{"text": chunk.page_content, "source": chunk.metadata["source"]} for chunk in chunks]
49 |
50 |
51 | def build_index(docs_dir, chunk_size, chunk_overlap, embedding_model_name, sql_dump_fp):
52 | # docs -> sections -> chunks
53 | ds = ray.data.from_items(
54 | [{"path": path} for path in docs_dir.rglob("*.html") if not path.is_dir()]
55 | )
56 | sections_ds = ds.flat_map(extract_sections)
57 | chunks_ds = sections_ds.flat_map(
58 | partial(chunk_section, chunk_size=chunk_size, chunk_overlap=chunk_overlap)
59 | )
60 |
61 | # Embed chunks
62 | embedded_chunks = chunks_ds.map_batches(
63 | EmbedChunks,
64 | fn_constructor_kwargs={"model_name": embedding_model_name},
65 | batch_size=100,
66 | num_gpus=1,
67 | compute=ActorPoolStrategy(size=1),
68 | )
69 |
70 | # Index data
71 | embedded_chunks.map_batches(
72 | StoreResults,
73 | batch_size=128,
74 | num_cpus=1,
75 | compute=ActorPoolStrategy(size=6),
76 | ).count()
77 |
78 | # Save to SQL dump
79 | execute_bash(f"sudo -u postgres pg_dump -c > {sql_dump_fp}")
80 | print("Updated the index!")
81 |
82 |
83 | def load_index(
84 | embedding_model_name, embedding_dim, chunk_size, chunk_overlap, docs_dir=None, sql_dump_fp=None
85 | ):
86 | # Drop current Vector DB and prepare for new one
87 | execute_bash(f'psql "{os.environ["DB_CONNECTION_STRING"]}" -c "DROP TABLE document;"')
88 | execute_bash(f"sudo -u postgres psql -f ../migrations/vector-{embedding_dim}.sql")
89 | if not sql_dump_fp:
90 | sql_dump_fp = Path(
91 | EFS_DIR,
92 | "sql_dumps",
93 | f"{embedding_model_name.split('/')[-1]}_{chunk_size}_{chunk_overlap}.sql",
94 | )
95 |
96 | # Vector DB
97 | if sql_dump_fp.exists(): # Load from SQL dump
98 | execute_bash(f'psql "{os.environ["DB_CONNECTION_STRING"]}" -f {sql_dump_fp}')
99 | else: # Create new index
100 | build_index(
101 | docs_dir=docs_dir,
102 | chunk_size=chunk_size,
103 | chunk_overlap=chunk_overlap,
104 | embedding_model_name=embedding_model_name,
105 | sql_dump_fp=sql_dump_fp,
106 | )
107 |
108 | # Chunks
109 | with psycopg.connect(os.environ["DB_CONNECTION_STRING"]) as conn:
110 | register_vector(conn)
111 | with conn.cursor() as cur:
112 | cur.execute("SELECT id, text, source FROM document")
113 | chunks = cur.fetchall()
114 | return chunks
115 |
--------------------------------------------------------------------------------
/rag/rerank.py:
--------------------------------------------------------------------------------
1 | import re
2 |
3 | from transformers import BertTokenizer
4 |
5 | # Tokenizer
6 | tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
7 |
8 |
9 | def split_camel_case_in_sentences(sentences):
10 | def split_camel_case_word(word):
11 | return re.sub("([a-z0-9])([A-Z])", r"\1 \2", word)
12 |
13 | processed_sentences = []
14 | for sentence in sentences:
15 | processed_words = []
16 | for word in sentence.split():
17 | processed_words.extend(split_camel_case_word(word).split())
18 | processed_sentences.append(" ".join(processed_words))
19 | return processed_sentences
20 |
21 |
22 | def preprocess(texts):
23 | texts = [re.sub(r"(?<=\w)([?.,!])(?!\s)", r" \1", text) for text in texts]
24 | texts = [
25 | text.replace("_", " ")
26 | .replace("-", " ")
27 | .replace("#", " ")
28 | .replace(".html", "")
29 | .replace(".", " ")
30 | for text in texts
31 | ]
32 | texts = split_camel_case_in_sentences(texts) # camelcase
33 | texts = [tokenizer.tokenize(text) for text in texts] # subtokens
34 | texts = [" ".join(word for word in text) for text in texts]
35 | return texts
36 |
37 |
38 | def get_tag(url):
39 | return re.findall(r"docs\.ray\.io/en/latest/([^/]+)", url)[0].split("#")[0]
40 |
41 |
42 | def custom_predict(inputs, classifier, threshold=0.2, other_label="other"):
43 | y_pred = []
44 | for item in classifier.predict_proba(inputs):
45 | prob = max(item)
46 | index = item.argmax()
47 | if prob >= threshold:
48 | pred = classifier.classes_[index]
49 | else:
50 | pred = other_label
51 | y_pred.append(pred)
52 | return y_pred
53 |
54 |
55 | def get_reranked_indices(sources, predicted_tag):
56 | tags = [get_tag(source) for source in sources]
57 | reranked_indices = sorted(range(len(tags)), key=lambda i: (tags[i] != predicted_tag, i))
58 | return reranked_indices
59 |
--------------------------------------------------------------------------------
/rag/search.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | import numpy as np
4 | import psycopg
5 | from pgvector.psycopg import register_vector
6 |
7 |
8 | def semantic_search(query, embedding_model, k):
9 | embedding = np.array(embedding_model.embed_query(query))
10 | with psycopg.connect(os.environ["DB_CONNECTION_STRING"]) as conn:
11 | register_vector(conn)
12 | with conn.cursor() as cur:
13 | cur.execute(
14 | "SELECT * FROM document ORDER BY embedding <=> %s LIMIT %s",
15 | (embedding, k),
16 | )
17 | rows = cur.fetchall()
18 | semantic_context = [{"id": row[0], "text": row[1], "source": row[2]} for row in rows]
19 | return semantic_context
20 |
21 |
22 | def lexical_search(index, query, chunks, k):
23 | query_tokens = query.lower().split() # preprocess query
24 | scores = index.get_scores(query_tokens) # get best matching (BM) scores
25 | indices = sorted(range(len(scores)), key=lambda i: -scores[i])[:k] # sort and get top k
26 | lexical_context = [
27 | {"id": chunks[i][0], "text": chunks[i][1], "source": chunks[i][2], "score": scores[i]}
28 | for i in indices
29 | ]
30 | return lexical_context
31 |
--------------------------------------------------------------------------------
/rag/serve.py:
--------------------------------------------------------------------------------
1 | import json
2 | import logging
3 | import os
4 | import pickle
5 | import re
6 | from pathlib import Path
7 | from typing import Any, Dict, List
8 |
9 | import ray
10 | import requests
11 | import structlog
12 | from fastapi import FastAPI
13 | from fastapi.middleware.cors import CORSMiddleware
14 | from pydantic import BaseModel, Field
15 | from rank_bm25 import BM25Okapi
16 | from ray import serve
17 | from slack_bolt import App
18 | from slack_bolt.adapter.socket_mode import SocketModeHandler
19 | from starlette.responses import StreamingResponse
20 |
21 | from rag.config import EMBEDDING_DIMENSIONS, MAX_CONTEXT_LENGTHS
22 | from rag.generate import QueryAgent, send_request
23 | from rag.index import load_index
24 |
25 | app = FastAPI()
26 |
27 | origins = ["*"]
28 |
29 | app.add_middleware(
30 | CORSMiddleware,
31 | allow_origins=origins,
32 | allow_credentials=True,
33 | allow_methods=["*"],
34 | allow_headers=["*"],
35 | )
36 |
37 |
38 | def get_secret(secret_name):
39 | import boto3
40 |
41 | client = boto3.client("secretsmanager", region_name="us-west-2")
42 | response = client.get_secret_value(SecretId=os.environ["RAY_ASSISTANT_SECRET"])
43 | return json.loads(response["SecretString"])[secret_name]
44 |
45 |
46 | @ray.remote
47 | class SlackApp:
48 | def __init__(self):
49 | slack_app = App(token=get_secret("SLACK_BOT_TOKEN"))
50 |
51 | @slack_app.event("app_mention")
52 | def event_mention(body, say):
53 | event = body["event"]
54 | thread_ts = event.get("thread_ts", None) or event["ts"]
55 | text = event["text"][15:] # strip slack user id of bot mention
56 | result = requests.post("http://127.0.0.1:8000/query/", json={"query": text}).json()
57 | reply = result["answer"] + "\n" + "\n".join(result["sources"])
58 | say(reply, thread_ts=thread_ts)
59 |
60 | self.slack_app = slack_app
61 |
62 | def run(self):
63 | SocketModeHandler(self.slack_app, get_secret("SLACK_APP_TOKEN")).start()
64 |
65 |
66 | class Query(BaseModel):
67 | query: str
68 |
69 |
70 | class Message(BaseModel):
71 | role: str = Field(
72 | ..., description="The role of the author of the message, typically 'user', or 'assistant'."
73 | )
74 | content: str = Field(..., description="The content of the message.")
75 |
76 |
77 | class Request(BaseModel):
78 | messages: List[Message] = Field(
79 | ..., description="A list of messages that make up the conversation."
80 | )
81 |
82 |
83 | class Answer(BaseModel):
84 | question: str
85 | answer: str
86 | sources: List[str]
87 | llm: str
88 |
89 |
90 | @serve.deployment(
91 | route_prefix="/", num_replicas=1, ray_actor_options={"num_cpus": 6, "num_gpus": 1}
92 | )
93 | @serve.ingress(app)
94 | class RayAssistantDeployment:
95 | def __init__(
96 | self,
97 | chunk_size,
98 | chunk_overlap,
99 | num_chunks,
100 | embedding_model_name,
101 | embedding_dim,
102 | use_lexical_search,
103 | lexical_search_k,
104 | use_reranking,
105 | rerank_threshold,
106 | rerank_k,
107 | llm,
108 | sql_dump_fp=None,
109 | run_slack=False,
110 | ):
111 | # Configure logging
112 | logging.basicConfig(
113 | filename=os.environ["RAY_ASSISTANT_LOGS"], level=logging.INFO, encoding="utf-8"
114 | )
115 | structlog.configure(
116 | processors=[
117 | structlog.processors.TimeStamper(fmt="iso"),
118 | structlog.processors.JSONRenderer(),
119 | ],
120 | logger_factory=structlog.stdlib.LoggerFactory(),
121 | )
122 | self.logger = structlog.get_logger()
123 |
124 | # Set credentials
125 | os.environ["ANYSCALE_API_BASE"] = "https://api.endpoints.anyscale.com/v1"
126 | os.environ["ANYSCALE_API_KEY"] = get_secret("ANYSCALE_API_KEY")
127 | os.environ["OPENAI_API_BASE"] = "https://api.openai.com/v1"
128 | os.environ["OPENAI_API_KEY"] = get_secret("OPENAI_API_KEY")
129 | os.environ["DB_CONNECTION_STRING"] = get_secret("DB_CONNECTION_STRING")
130 |
131 | # Set up
132 | chunks = load_index(
133 | embedding_model_name=embedding_model_name,
134 | embedding_dim=embedding_dim,
135 | chunk_size=chunk_size,
136 | chunk_overlap=chunk_overlap,
137 | sql_dump_fp=sql_dump_fp,
138 | )
139 |
140 | # Lexical index
141 | lexical_index = None
142 | self.lexical_search_k = lexical_search_k
143 | if use_lexical_search:
144 | texts = [re.sub(r"[^a-zA-Z0-9]", " ", chunk[1]).lower().split() for chunk in chunks]
145 | lexical_index = BM25Okapi(texts)
146 |
147 | # Reranker
148 | reranker = None
149 | self.rerank_threshold = rerank_threshold
150 | self.rerank_k = rerank_k
151 | if use_reranking:
152 | reranker_fp = Path(os.environ["RAY_ASSISTANT_RERANKER_MODEL"])
153 | with open(reranker_fp, "rb") as file:
154 | reranker = pickle.load(file)
155 |
156 | # Query agent
157 | self.num_chunks = num_chunks
158 | system_content = (
159 | "Answer the query using the context provided. Be succinct. "
160 | "Contexts are organized in a list of dictionaries [{'text': }, {'text': }, ...]. "
161 | "Feel free to ignore any contexts in the list that don't seem relevant to the query. "
162 | )
163 | self.oss_agent = QueryAgent(
164 | embedding_model_name=embedding_model_name,
165 | chunks=chunks,
166 | lexical_index=lexical_index,
167 | reranker=reranker,
168 | llm=llm,
169 | max_context_length=MAX_CONTEXT_LENGTHS[llm],
170 | system_content=system_content,
171 | )
172 | self.gpt_agent = QueryAgent(
173 | embedding_model_name=embedding_model_name,
174 | chunks=chunks,
175 | lexical_index=lexical_index,
176 | reranker=reranker,
177 | llm="gpt-4",
178 | max_context_length=MAX_CONTEXT_LENGTHS["gpt-4"],
179 | system_content=system_content,
180 | )
181 |
182 | # Router
183 | router_fp = Path(os.environ["RAY_ASSISTANT_ROUTER_MODEL"])
184 | with open(router_fp, "rb") as file:
185 | self.router = pickle.load(file)
186 |
187 | if run_slack:
188 | # Run the Slack app in the background
189 | self.slack_app = SlackApp.remote()
190 | self.runner = self.slack_app.run.remote()
191 |
192 | def predict(self, query: Query, stream: bool) -> Dict[str, Any]:
193 | use_oss_agent = self.router.predict([query.query])[0]
194 | agent = self.oss_agent if use_oss_agent else self.gpt_agent
195 | result = agent(
196 | query=query.query,
197 | num_chunks=self.num_chunks,
198 | lexical_search_k=self.lexical_search_k,
199 | rerank_threshold=self.rerank_threshold,
200 | rerank_k=self.rerank_k,
201 | stream=stream,
202 | )
203 | return result
204 |
205 | @app.post("/query")
206 | def query(self, query: Query) -> Answer:
207 | result = self.predict(query, stream=False)
208 | return Answer.parse_obj(result)
209 |
210 | # This will be removed after all traffic is migrated to the /chat endpoint
211 | def produce_streaming_answer(self, query, result):
212 | answer = []
213 | for answer_piece in result["answer"]:
214 | answer.append(answer_piece)
215 | yield answer_piece
216 |
217 | if result["sources"]:
218 | yield "\n\n**Sources:**\n"
219 | for source in result["sources"]:
220 | yield "* " + source + "\n"
221 |
222 | self.logger.info(
223 | "finished streaming query",
224 | query=query,
225 | document_ids=result["document_ids"],
226 | llm=result["llm"],
227 | answer="".join(answer),
228 | )
229 |
230 | # This will be removed after all traffic is migrated to the /chat endpoint
231 | @app.post("/stream")
232 | def stream(self, query: Query) -> StreamingResponse:
233 | result = self.predict(query, stream=True)
234 | return StreamingResponse(
235 | self.produce_streaming_answer(query.query, result), media_type="text/plain"
236 | )
237 |
238 | def produce_chat_answer(self, request, result):
239 | answer = []
240 | for answer_piece in result["answer"]:
241 | answer.append(answer_piece)
242 | yield answer_piece
243 |
244 | if result["sources"]:
245 | yield "\n\n**Sources:**\n"
246 | for source in result["sources"]:
247 | yield "* " + source + "\n"
248 |
249 | self.logger.info(
250 | "finished chat query",
251 | request=request.dict(),
252 | document_ids=result["document_ids"],
253 | llm=result["llm"],
254 | answer="".join(answer),
255 | )
256 |
257 | @app.post("/chat")
258 | def chat(self, request: Request) -> StreamingResponse:
259 | if len(request.messages) == 1:
260 | query = Query(query=request.messages[0].content)
261 | result = self.predict(query, stream=True)
262 | else:
263 | # For now, we always use the OSS agent for follow up questions
264 | agent = self.oss_agent
265 | answer = send_request(
266 | llm=agent.llm,
267 | messages=request.messages,
268 | max_tokens=agent.max_tokens,
269 | temperature=agent.temperature,
270 | stream=True,
271 | )
272 | result = {"answer": answer, "llm": agent.llm, "sources": [], "document_ids": []}
273 |
274 | return StreamingResponse(
275 | self.produce_chat_answer(request, result), media_type="text/plain"
276 | )
277 |
278 |
279 | # Deploy the Ray Serve app
280 | deployment = RayAssistantDeployment.bind(
281 | chunk_size=700,
282 | chunk_overlap=50,
283 | num_chunks=30,
284 | embedding_model_name=os.environ["RAY_ASSISTANT_EMBEDDING_MODEL"],
285 | embedding_dim=EMBEDDING_DIMENSIONS[os.environ["RAY_ASSISTANT_EMBEDDING_MODEL"]],
286 | use_lexical_search=True,
287 | lexical_search_k=1,
288 | use_reranking=True,
289 | rerank_threshold=0.9,
290 | rerank_k=13,
291 | llm="gpt-4",
292 | sql_dump_fp=Path(os.environ["RAY_ASSISTANT_INDEX"]),
293 | )
294 |
--------------------------------------------------------------------------------
/rag/utils.py:
--------------------------------------------------------------------------------
1 | import os
2 | import subprocess
3 |
4 | import numpy as np
5 | import openai
6 | import tiktoken
7 | import torch
8 | import torch.nn.functional as F
9 |
10 |
11 | def get_num_tokens(text):
12 | enc = tiktoken.get_encoding("cl100k_base")
13 | return len(enc.encode(text))
14 |
15 |
16 | def trim(text, max_context_length):
17 | enc = tiktoken.get_encoding("cl100k_base")
18 | return enc.decode(enc.encode(text)[:max_context_length])
19 |
20 |
21 | def get_client(llm):
22 | if llm.startswith("gpt"):
23 | base_url = os.environ["OPENAI_API_BASE"]
24 | api_key = os.environ["OPENAI_API_KEY"]
25 | else:
26 | base_url = os.environ["ANYSCALE_API_BASE"]
27 | api_key = os.environ["ANYSCALE_API_KEY"]
28 | client = openai.OpenAI(base_url=base_url, api_key=api_key)
29 | return client
30 |
31 |
32 | def execute_bash(command):
33 | results = subprocess.run(
34 | command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True
35 | )
36 | return results
37 |
38 |
39 | def predict(inputs, preprocess_fnc, tokenizer, model, label_encoder, device="cpu", threshold=0.0):
40 | # Get probabilities
41 | model.eval()
42 | inputs = [preprocess_fnc(item) for item in inputs]
43 | inputs = tokenizer(inputs, return_tensors="pt", padding=True, truncation=True).to(device)
44 | with torch.no_grad():
45 | outputs = model(**inputs)
46 | y_probs = F.softmax(outputs.logits, dim=-1).cpu().numpy()
47 |
48 | # Assign labels based on the threshold
49 | labels = []
50 | for prob in y_probs:
51 | max_prob = np.max(prob)
52 | if max_prob < threshold:
53 | labels.append("other")
54 | else:
55 | labels.append(label_encoder.inverse_transform([prob.argmax()])[0])
56 | return labels, y_probs
57 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | # Default
2 | beautifulsoup4
3 | rank-bm25
4 | fastapi
5 | langchain
6 | matplotlib
7 | openai
8 | pre-commit
9 | python-dotenv
10 | ray
11 | seaborn
12 | sentence_transformers
13 | slack_bolt
14 | streamlit
15 | structlog
16 | typer
17 | tiktoken
18 |
19 | # Vector DB
20 | asyncpg
21 | pgvector
22 | psycopg[binary,pool]
23 | psycopg2-binary
24 | sqlalchemy[asyncio]
25 |
26 | # Styling
27 | black
28 | flake8
29 | Flake8-pyproject
30 | isort
31 | pyupgrade
32 |
--------------------------------------------------------------------------------
/setup-pgvector.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | # Install postgres
3 | sudo apt install -y wget ca-certificates
4 | wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
5 | sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt/ $(lsb_release -cs)-pgdg main" >> /etc/apt/sources.list.d/pgdg.list'
6 | sudo apt update -y && sudo apt install -y postgresql postgresql-contrib
7 | # Install pgvector
8 | sudo apt install -y postgresql-server-dev-all
9 | pushd /tmp && git clone --branch v0.4.4 https://github.com/pgvector/pgvector.git && pushd pgvector && make && sudo make install && popd && popd
10 | # Activate pgvector and the database
11 | echo 'ray ALL=(ALL:ALL) NOPASSWD:ALL' | sudo tee /etc/sudoers
12 | sudo service postgresql start
13 | # pragma: allowlist nextline secret
14 | sudo -u postgres psql -c "ALTER USER postgres with password 'postgres';"
15 | sudo -u postgres psql -c "CREATE EXTENSION vector;"
16 |
--------------------------------------------------------------------------------
/test.py:
--------------------------------------------------------------------------------
1 | import requests
2 |
3 | # Service specific config
4 | data = {"query": "How can i query the ray StateApiClient in batch?"}
5 | base_url = "https://ray-assistant-public-98zsh.cld-kvedzwag2qa8i5bj.s.anyscaleuserdata.com"
6 |
7 | # Requests config
8 | path = "/stream"
9 | full_url = f"{base_url}{path}"
10 |
11 | resp = requests.post(full_url, json=data)
12 |
13 | print(resp.text)
14 |
15 | # # Constructing the new request data structure with the required 'role' field
16 | # data = {
17 | # "messages": [
18 | # {
19 | # "content": "What is the default batch size for map_batches?",
20 | # "role": "user" # Assuming 'user' is the correct role value. Adjust if necessary.
21 | # }
22 | # ]
23 | # }
24 | # # Requests config
25 | # path = "/chat"
26 | # full_url = f"{base_url}{path}"
27 |
28 | # # Send POST request to the modified endpoint, including the 'role' field
29 | # resp = requests.post(full_url, json=data)
30 | # print(resp.text)
31 |
--------------------------------------------------------------------------------
/update-index.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | # Initialize a flag variable
4 | load_docs=false
5 |
6 | # Loop through arguments and check for the --do-it flag
7 | for arg in "$@"
8 | do
9 | if [ "$arg" == "--load-docs" ]; then
10 | load_docs=true
11 | break
12 | fi
13 | done
14 |
15 | # If the flag is true, execute the commands inside the if block
16 | if [ "$load_docs" = true ]; then
17 | export EFS_DIR=$(python -c "from rag.config import EFS_DIR; print(EFS_DIR)")
18 | wget -e robots=off --recursive --no-clobber --page-requisites \
19 | --html-extension --convert-links --restrict-file-names=windows \
20 | --domains docs.ray.io --no-parent --accept=html --retry-on-http-error=429 \
21 | -P $EFS_DIR https://docs.ray.io/en/latest/
22 | fi
23 |
24 | # Drop and create table
25 | export DB_CONNECTION_STRING="dbname=postgres user=postgres host=localhost password=postgres" # TODO: move to CI/CD secrets manager
26 | export EMBEDDING_MODEL_NAME="thenlper/gte-large" # TODO: use service env vars
27 | export MIGRATION_FP="migrations/vector-1024.sql" # TODO: dynamically set this
28 | export SQL_DUMP_FILE="/mnt/shared_storage/ray-assistant-data/index.sql"
29 | psql "$DB_CONNECTION_STRING" -c "DROP TABLE IF EXISTS document;"
30 | sudo -u postgres psql -f $MIGRATION_FP
31 |
32 | # Build index (fixed for now, need to make dynamic)
33 | python << EOF
34 | import os
35 | from pathlib import Path
36 | from rag.config import EFS_DIR
37 | from rag.index import build_index
38 | build_index(
39 | docs_dir=Path(EFS_DIR, "docs.ray.io/en/latest/"),
40 | chunk_size=700,
41 | chunk_overlap=50,
42 | embedding_model_name=os.environ["EMBEDDING_MODEL_NAME"],
43 | sql_dump_fp=os.environ["SQL_DUMP_FILE"])
44 | EOF
45 |
--------------------------------------------------------------------------------