├── .gitignore
├── .vscode
└── tasks.json
├── Algorithm
├── bellman_ford.md
├── bfs.md
├── dfs.md
├── dijkstra.md
├── floyd_warshall.md
├── greedy.md
└── prim.md
├── Back-End
├── Internet
│ ├── 3handshake.md
│ ├── cache.md
│ ├── cache_header.md
│ ├── cdn.md
│ ├── dns.md
│ ├── domain.md
│ ├── etag.md
│ ├── host.md
│ ├── http.md
│ ├── image
│ │ ├── ISP.png
│ │ ├── cdn.png
│ │ ├── dhcp.png
│ │ ├── dnsserver.png
│ │ ├── domain.png
│ │ ├── p2p.jpeg
│ │ ├── webflow.png
│ │ ├── websocket.png
│ │ ├── 브라우저기본구조.png
│ │ ├── 운.png
│ │ ├── 웹캐시.png
│ │ ├── 웹킷동작방식.png
│ │ ├── 웹호스팅.png
│ │ ├── 클라우드호스팅.png
│ │ └── 호스팅차이.png
│ ├── inoutbound.md
│ ├── internet.md
│ ├── ip.md
│ ├── ln.md
│ ├── mq.md
│ ├── ositcp.md
│ ├── p2p.md
│ ├── router_switch.md
│ ├── ssl_tls.md
│ ├── subnetsupernet.md
│ ├── tcppacket.md
│ ├── tomcat.md
│ ├── trace.md
│ ├── webactive.md
│ ├── webcache.md
│ ├── webflow.md
│ └── websocket.md
├── JAVA
│ ├── 4특징.md
│ ├── 5원칙.md
│ ├── JAVA.md
│ ├── StringBuilder.md
│ ├── abstract.md
│ ├── aio.md
│ ├── callable_future.md
│ ├── cleaner.md
│ ├── coi.md
│ ├── collection.md
│ ├── date.md
│ ├── exception.md
│ ├── exception_cost.md
│ ├── executor.md
│ ├── finalize.md
│ ├── functional_interface.md
│ ├── functional_interface2.md
│ ├── g1gc.md
│ ├── gc.md
│ ├── gc_4.md
│ ├── gc_kind.md
│ ├── generic.md
│ ├── graal.md
│ ├── graal_memory.md
│ ├── hashmap.md
│ ├── hot_cold_publisher.md
│ ├── hotspotvm.md
│ ├── image
│ │ ├── disabled.png
│ │ ├── invokeAll-api-docs.png
│ │ ├── jvm메모리구조.png
│ │ ├── jvm실행.png
│ │ ├── newSingleThreadExecutorEx.png
│ │ ├── runtimearea.png
│ │ ├── stackArea.png
│ │ ├── stringbuilder.png
│ │ ├── stringcode.png
│ │ ├── stringin1.png
│ │ ├── stringin2.png
│ │ ├── stringin3.png
│ │ ├── stringrun.png
│ │ ├── 래퍼클래스구조도.png
│ │ ├── 박싱언박싱.png
│ │ ├── 서블릿.png
│ │ ├── 서블릿동작.png
│ │ ├── 서블릿컨테이너.png
│ │ └── 의존.png
│ ├── javanet.md
│ ├── jdkproxy_cglib.md
│ ├── jmm.md
│ ├── jvm.md
│ ├── jvmm.md
│ ├── lifecycle.md
│ ├── lock.md
│ ├── native_image.md
│ ├── object.md
│ ├── oom.md
│ ├── optional.md
│ ├── overding.md
│ ├── reactive_steam.md
│ ├── reactive_stream.md
│ ├── reference.md
│ ├── reflection.md
│ ├── runtime.md
│ ├── servlet.md
│ ├── stringB.md
│ ├── string_pool.md
│ ├── warmup1.md
│ ├── warmup2.md
│ ├── wrapper.md
│ ├── 다형성.md
│ └── 생성자.md
├── Node
│ ├── node.md
│ ├── npm.md
│ ├── npm1.md
│ ├── npm2.md
│ ├── npmjson.md
│ └── server.md
├── backend
│ ├── api.md
│ ├── async.md
│ ├── auth.md
│ ├── cleanspring.md
│ ├── dr.md
│ ├── eviction.md
│ ├── history.md
│ ├── image
│ │ ├── apidocs.png
│ │ ├── cleanarchitecture.jpeg
│ │ ├── msa.png
│ │ ├── msa등장.png
│ │ ├── pub_sub1.png
│ │ ├── pub_sub2.png
│ │ ├── pub_sub3.png
│ │ ├── pub_sub4.png
│ │ └── 모놀리식.png
│ ├── kafka요소.md
│ ├── kafka요소2.md
│ ├── logger.md
│ ├── logicaltime.md
│ ├── mono.md
│ ├── msa.md
│ ├── multi_session.md
│ ├── netty.md
│ ├── partition.md
│ ├── paxos.md
│ ├── protobuf.md
│ ├── pub_sub.md
│ ├── reactive_programming.md
│ ├── solid.md
│ ├── test_cov.md
│ ├── timesync.md
│ └── 당근밋업.md
├── baemin_batch.md
├── ddd
│ ├── boundcontext.md
│ ├── cqrs.md
│ ├── domainservice.md
│ ├── event.md
│ ├── event2.md
│ ├── event3.md
│ ├── presentation.md
│ └── transaction.md
├── encrypt.md
├── git
│ ├── basic.md
│ ├── basic2.md
│ ├── branch.md
│ ├── conflict.md
│ ├── issue.md
│ ├── log.md
│ ├── pull.md
│ ├── pushR.md
│ ├── request.md
│ ├── revert.md
│ ├── version.md
│ └── 용어.md
├── go
│ ├── http_handler.md
│ ├── mux.md
│ ├── pointer.md
│ └── sqlite.md
├── http
│ ├── HTTP기본
│ │ ├── connectionless.md
│ │ ├── everyhttp.md
│ │ ├── message.md
│ │ ├── state.md
│ │ └── structclient.md
│ ├── HTTP메서드
│ │ ├── attrib.md
│ │ ├── exam.md
│ │ ├── getpost.md
│ │ ├── httpapi.md
│ │ ├── putpadel.md
│ │ └── submit.md
│ ├── HTTP상태코드
│ │ ├── 2xx.md
│ │ ├── 3xx.md
│ │ ├── 4xx5xx.md
│ │ └── status.md
│ ├── HTTP헤더
│ │ ├── cookie.md
│ │ ├── info.md
│ │ ├── nego.md
│ │ └── summary.md
│ ├── HTTP헤더2
│ │ ├── cache.md
│ │ ├── cachehead.md
│ │ ├── proxy.md
│ │ └── verify.md
│ ├── URI
│ │ ├── uri.md
│ │ └── web.md
│ ├── image
│ │ ├── adapt.png
│ │ ├── connectionless.png
│ │ ├── httpmessage.png
│ │ └── uri.png
│ └── network
│ │ ├── ip.md
│ │ ├── port.md
│ │ └── tcpudp.md
├── jpa
│ ├── bulk.md
│ ├── embedded.md
│ ├── equals.md
│ ├── fetchjoin.md
│ ├── hibernate.md
│ ├── n+1.md
│ ├── osiv.md
│ ├── persistence
│ │ ├── flush.md
│ │ ├── image
│ │ │ └── entitylife.png
│ │ └── persistcontext.md
│ ├── propagration.md
│ ├── proxy.md
│ ├── queryfk.md
│ ├── table
│ │ ├── entity.md
│ │ └── util.md
│ └── 일반Join은언제.md
├── kafka
│ ├── autocommit.md
│ ├── disk.md
│ ├── isr.md
│ ├── partition.md
│ ├── partition2.md
│ ├── producer.md
│ ├── rebalancing.md
│ └── replica.md
├── kernel
│ ├── blockio.md
│ └── kernel.md
├── kotlin
│ ├── collection.md
│ ├── companion.md
│ ├── companion_and_object.md
│ ├── coroutine.md
│ ├── coroutine
│ │ ├── coroutine.md
│ │ ├── coroutine_context.md
│ │ ├── coroutinedispatcher.md
│ │ ├── launch.md
│ │ ├── lazy.md
│ │ ├── state.md
│ │ ├── state_variable.md
│ │ └── suspend.md
│ ├── datapersist.md
│ ├── delegate.md
│ ├── delegate2.md
│ ├── dsl.md
│ ├── effectivenull.md
│ ├── field_property.md
│ ├── fun.md
│ ├── inline.md
│ ├── inline2.md
│ ├── jvmannotation.md
│ ├── kopring.md
│ ├── kotest.md
│ ├── kotlin.md
│ ├── kotlin_jpa.md
│ ├── kotlinoop.md
│ ├── lombokcant.md
│ ├── runcatching.md
│ ├── sealed.md
│ ├── singleton.md
│ ├── sortedWith.md
│ ├── starpro.md
│ ├── toPair.md
│ ├── top_level.md
│ ├── unit_nothing.md
│ ├── use.md
│ └── 공변성.md
├── kyd.md
├── linux
│ ├── lxc.md
│ └── nmap.md
├── netty_flow.md
├── netty_thread.md
├── socketp.md
├── spring
│ ├── advice_control.md
│ ├── annotation.md
│ ├── aop.md
│ ├── aop_transaction.md
│ ├── args_resolver.md
│ ├── aspectj.md
│ ├── batch.md
│ ├── batch_concurrency.md
│ ├── batch_tradeoff.md
│ ├── bean.md
│ ├── bean_scope.md
│ ├── beans.md
│ ├── beanscope.md
│ ├── builder.md
│ ├── controlleradvice.md
│ ├── cre.md
│ ├── data_binding.md
│ ├── datajpa.md
│ ├── exception.md
│ ├── image-1.png
│ ├── image-2.png
│ ├── image-3.png
│ ├── image-4.png
│ ├── image.png
│ ├── image
│ │ ├── DI.png
│ │ ├── Token.png
│ │ ├── ac.png
│ │ ├── aop.png
│ │ ├── bean.png
│ │ ├── bean2.png
│ │ ├── dao.png
│ │ ├── jdbc.png
│ │ ├── jwt.png
│ │ ├── jwttoken.png
│ │ ├── mvcp.png
│ │ ├── springdto.png
│ │ └── 패키지구조.png
│ ├── indexing.md
│ ├── ioc.md
│ ├── jdbc.md
│ ├── jwt.md
│ ├── lombok.md
│ ├── mapping.md
│ ├── mock_stub.md
│ ├── mockk.md
│ ├── modifying.md
│ ├── mvc.md
│ ├── naturalid.md
│ ├── objmapper.md
│ ├── package.md
│ ├── plugko.md
│ ├── profile.md
│ ├── resource.md
│ ├── resource2.md
│ ├── scheduler.md
│ ├── scuconfig.md
│ ├── security_filter.md
│ ├── security_strategy.md
│ ├── springcp.md
│ ├── swagger.md
│ ├── testsecurity.md
│ ├── token.md
│ ├── tomcat.md
│ ├── transactionaljpa.md
│ ├── valid.md
│ └── webflux
│ │ └── webflux.md
├── state_machine.md
└── test
│ └── tdd.md
├── Data-Structure
├── ast.md
├── image
│ ├── case1.png
│ ├── case23.png
│ ├── deletecase2.png
│ ├── deleteexam.png
│ ├── deleteexam2.png
│ ├── deleteexam3.png
│ ├── deleteexam4.png
│ ├── examplenode.png
│ ├── math.png
│ ├── nilnode.png
│ ├── nodetree.png
│ ├── redblack.png
│ ├── rededge.png
│ ├── rotation.png
│ └── violation.png
├── parsetree.md
├── 비선형
│ ├── graph
│ │ ├── graph.md
│ │ ├── image
│ │ │ ├── bfs2.png
│ │ │ ├── bfsal.png
│ │ │ ├── bfsexam.png
│ │ │ ├── bfsimpl.png
│ │ │ ├── dfs.png
│ │ │ └── differgraph.png
│ │ └── search
│ │ │ ├── bfs.md
│ │ │ └── dfs.md
│ └── tree
│ │ ├── avl.md
│ │ ├── bst.md
│ │ ├── btree.md
│ │ ├── btree_delete.md
│ │ ├── image
│ │ ├── LLcase.png
│ │ ├── avl.png
│ │ ├── bst.png
│ │ ├── bstdelete2.png
│ │ ├── bstdelete3.png
│ │ ├── bstdetail1.png
│ │ ├── bstdetail2.png
│ │ ├── bstinsert2.png
│ │ ├── deletebst1.png
│ │ ├── express.jpeg
│ │ ├── insertbst.png
│ │ ├── linuxtree.png
│ │ ├── lr.png
│ │ ├── rl.png
│ │ ├── rr.png
│ │ ├── tree.png
│ │ └── windowtree.gif
│ │ ├── redblack.md
│ │ └── tree.md
└── 선형
│ ├── linearlist
│ └── linearlist.md
│ ├── linkedlist
│ └── linkedlist.md
│ ├── queue
│ ├── image
│ │ └── queue.png
│ └── queue.md
│ └── stack
│ └── stack.md
├── DataBase
├── ACID.md
├── Image
│ ├── 1정규화적용.png
│ ├── BCNF적용.png
│ ├── BCNF정규화.png
│ ├── btree.png
│ ├── cap.png
│ ├── index.png
│ ├── table.png
│ ├── transaction.png
│ ├── 리플리케이션.png
│ ├── 제1정규화.png
│ ├── 제2정규화.png
│ ├── 제2정규화적용.png
│ ├── 제3정규화.png
│ ├── 제3정규화적용.png
│ └── 클러스터링.png
├── ORMs.md
├── analytic_function.md
├── b+tree.md
├── cap.md
├── cluster.md
├── clustering.md
├── connectionp.md
├── coverindex.md
├── dbload.md
├── dlock.md
├── ear.md
├── index.md
├── join.md
├── key.md
├── load
│ ├── partitioning.md
│ └── partitioning2.md
├── lock.md
├── lsmtree.md
├── mmr.md
├── modeling.md
├── mysql_lock.md
├── normal.md
├── nosql
│ ├── mongodb
│ │ ├── crud.md
│ │ ├── document.md
│ │ ├── mongodb.md
│ │ ├── shard.md
│ │ ├── tradeoff1.md
│ │ └── undo_redo.md
│ ├── redis
│ │ ├── architecture.md
│ │ ├── atomic.md
│ │ ├── cluster.md
│ │ ├── config.md
│ │ ├── distributed.md
│ │ ├── distributed2.md
│ │ ├── fragment.md
│ │ ├── incr.md
│ │ ├── locksync.md
│ │ ├── memory.md
│ │ ├── redis.md
│ │ ├── replica.md
│ │ └── replication.md
│ └── sql_nosql.md
├── optimizer.md
├── optimizer2.md
├── pk.md
├── recoverability.md
├── rep_clu.md
├── serializability.md
├── sharding.md
├── sql
│ ├── date.md
│ ├── dcl.md
│ ├── ddl.md
│ ├── dml.md
│ ├── full_text.md
│ ├── groupby.md
│ ├── innerjoin.md
│ ├── level.md
│ ├── null.md
│ ├── numberfun.md
│ ├── orderby.md
│ ├── replace.md
│ ├── substr.md
│ ├── upperlower.md
│ ├── where.md
│ ├── windowfun.md
│ └── 프로시저_트리거.md
├── varchar_text.md
├── 반정규화.md
├── 전문검색인덱스.md
└── 정규화.md
├── Design-Pattern
├── designp.md
├── image
│ ├── proxy.png
│ └── templete.png
├── 구조
│ ├── adapter.md
│ ├── bridge.md
│ ├── composite.md
│ ├── decorator.md
│ ├── facade.md
│ └── proxyp.md
├── 생성
│ ├── abstract_factory.md
│ ├── builder.md
│ ├── factory_method.md
│ ├── prototype.md
│ └── singleton.md
└── 행동
│ ├── Interpreter.md
│ ├── chain_of_resp.md
│ ├── command.md
│ ├── iterator.md
│ ├── mediator.md
│ ├── observer.md
│ ├── singleton.md
│ ├── state.md
│ ├── strategy.md
│ └── template.md
├── DevOps
├── Docker
│ ├── container.md
│ ├── denied.md
│ ├── docker.md
│ ├── docker_image.md
│ ├── image
│ │ ├── 가상환경.png
│ │ ├── 격리.png
│ │ ├── 격리2.png
│ │ ├── 도커.png
│ │ ├── 도커한계.png
│ │ ├── 성능 비교.png
│ │ ├── 성능비교2.png
│ │ ├── 스웜.png
│ │ └── 컨테이너.png
│ ├── network.md
│ ├── ns.md
│ ├── spring_docker.md
│ ├── swarm.md
│ ├── 도커볼륨.md
│ ├── 도커엔진.md
│ ├── 이미지관련명령어.md
│ ├── 컨테이너관리명령어.md
│ ├── 컨테이너애플리케이션구축.md
│ ├── 컨테이너외부노출.md
│ └── 컨테이너제어명령어.md
├── ELK.md
├── XaaS.md
├── agile.md
├── apm.md
├── aws.md
├── aws
│ ├── EC2Price.md
│ ├── ELK.md
│ ├── SES.md
│ ├── SNS.md
│ ├── SQS.md
│ ├── as.md
│ ├── aurora.md
│ ├── bastion.md
│ ├── cloudfront.md
│ ├── cloudwatch.md
│ ├── ebs.md
│ ├── ecr.md
│ ├── eks
│ │ ├── alb_controller.md
│ │ ├── cni.md
│ │ ├── communicate.md
│ │ ├── eks.md
│ │ └── nlb_alb.md
│ ├── elastic_ip.md
│ ├── elb.md
│ ├── iam.md
│ ├── natgateway.md
│ ├── rds.md
│ ├── securitygroup.md
│ ├── session_manager.md
│ ├── vpc.md
│ ├── 고가용성_장애내구성.md
│ └── 라우팅테이블.md
├── bg.md
├── blue_green.md
├── cicd.md
├── cloud_architecture.md
├── deploy.md
├── devops.md
├── ec2.md
├── exporter.md
├── gitaction.md
├── gitops.md
├── grpc.md
├── hcl
│ ├── condition.md
│ ├── dynamic_block.md
│ ├── hcl.md
│ ├── state.md
│ └── terraform_work.md
├── hybrid.md
├── image
│ ├── XaaS.jpeg
│ ├── ami.webp
│ ├── apm.png
│ ├── aws.png
│ ├── blue_green.png
│ ├── cicd.png
│ ├── containers-101.png
│ ├── ident.webp
│ ├── instance.webp
│ ├── instancestart.webp
│ ├── nameins.webp
│ ├── publicinstance.webp
│ ├── start.webp
│ ├── startinstance.webp
│ └── 가상화.jpeg
├── istio.md
├── k8s
│ ├── api_resource.md
│ ├── cluster.md
│ ├── component.md
│ ├── config_map.md
│ ├── control_plane.md
│ ├── daemonset.md
│ ├── dashboard.md
│ ├── deploy.md
│ ├── deployment.md
│ ├── desired_state.md
│ ├── k8s.md
│ ├── karpenter.md
│ ├── multipod.md
│ ├── namespace.md
│ ├── network.md
│ ├── node.md
│ ├── node_scheduling.md
│ ├── pod.md
│ ├── pod_lifecycle.md
│ ├── podstatus.md
│ ├── probe.md
│ ├── process.md
│ ├── pvpvc.md
│ ├── qos.md
│ ├── replicaset.md
│ ├── scheduler.md
│ ├── security.md
│ ├── service.md
│ ├── service2.md
│ └── volume.md
├── nginx.md
├── prometheus_grafana.md
├── rabbitmq.md
├── service_discovery.md
├── service_mesh.md
├── vircon.md
├── 데몬프로세스.md
├── 이중화.md
├── 컨테이너로깅.md
└── 컨테이너자원제한.md
├── Front-End
├── JS
│ ├── DOM.md
│ ├── DOM2.md
│ ├── Immutability.md
│ ├── JSON.md
│ ├── Lodash.md
│ ├── Number.md
│ ├── Object.md
│ ├── Object2.md
│ ├── Object3.md
│ ├── Storage.md
│ ├── TS_class.md
│ ├── ajax.md
│ ├── array.md
│ ├── array2.md
│ ├── class.md
│ ├── constructor.md
│ ├── destruct.md
│ ├── export.md
│ ├── fetch.md
│ ├── function.md
│ ├── garbage.md
│ ├── import.md
│ ├── promise.md
│ ├── typeString.md
│ └── 정규표현식.md
├── React
│ ├── classcompo.md
│ ├── component.md
│ ├── funcompo.md
│ └── react.md
└── TS
│ ├── TS_Type.md
│ ├── TS_compiler.md
│ ├── TS_function.md
│ ├── TS_generic.md
│ ├── TS_interface.md
│ ├── TS_interface2.md
│ └── TypeScript.md
├── Linux
├── df.md
├── dmesg.md
├── epoll.md
├── free.md
├── netstat.md
├── top.md
└── uptime.md
├── MSA
├── distribution.md
├── ipc
│ ├── async_message.md
│ ├── ipc.md
│ └── rpi.md
├── pattern
│ ├── cqrs.md
│ ├── event_sourcing.md
│ ├── outbox.md
│ ├── saga.md
│ └── two_phase_commit.md
├── recover.md
├── service_discovery.md
├── service_discovery_dns.md
└── 확장큐브.md
├── Network
├── VLAN.md
├── addr.md
├── component.md
├── conn.md
├── dhcp.md
├── et.md
├── qos.md
├── router.md
├── ssl_handshake.md
├── subn.md
├── switch_act.md
├── tcp_flag.md
├── tcp_header.md
├── tcp_keepalive.md
└── vlan2.md
├── Operating-System
├── cache_memory.md
├── compiler_optimize.md
├── computingsystem.md
├── fragmentation.md
├── hypervisor.md
├── image
│ ├── image-1.png
│ └── image.png
├── ipc.md
├── mmu.md
├── mutex_semaphore.md
├── mutual_exclusion.md
├── page.md
├── paritiy.md
├── process_memory.md
├── swapping.md
├── tlb.md
├── uds.md
└── vm.md
├── README.md
├── SRE
└── slo.md
├── v2
└── Infra
│ ├── linux_filesystem.md
│ └── sqs_optimize.md
└── 정보처리
├── Java.md
├── comrun.md
├── cpus.md
├── database.md
├── database2.md
├── ddl.md
├── doker.md
├── httpmethod.md
├── image
├── doker.jpeg
├── http-method.png
├── 데드락.png
├── 상태전이.png
└── 스케쥴링.png
├── network.md
├── os.md
├── osiproto.md
├── processthread.md
├── protocall.md
├── rest.md
├── sql.md
├── test.md
├── 검토.md
├── 동기화.md
├── 스레드.md
├── 응용SW.md
├── 응용SW2.md
└── 자료구조알고리즘.md
/.gitignore:
--------------------------------------------------------------------------------
1 | .DS_STORE
2 | .idea
--------------------------------------------------------------------------------
/.vscode/tasks.json:
--------------------------------------------------------------------------------
1 | {
2 | "tasks": [
3 | {
4 | "type": "cppbuild",
5 | "label": "C/C++: gcc 활성 파일 빌드",
6 | "command": "/usr/bin/gcc",
7 | "args": [
8 | "-fdiagnostics-color=always",
9 | "-g",
10 | "${file}",
11 | "-o",
12 | "${fileDirname}/${fileBasenameNoExtension}"
13 | ],
14 | "options": {
15 | "cwd": "${fileDirname}"
16 | },
17 | "problemMatcher": [
18 | "$gcc"
19 | ],
20 | "group": {
21 | "kind": "build",
22 | "isDefault": true
23 | },
24 | "detail": "디버거에서 생성된 작업입니다."
25 | }
26 | ],
27 | "version": "2.0.0"
28 | }
--------------------------------------------------------------------------------
/Algorithm/dijkstra.md:
--------------------------------------------------------------------------------
1 | # 다익스트라 알고리즘
2 |
3 | 다익스트라 알고리즘은 다이나믹 프로그래밍을 활용한 대표적인 **최단 경로 탐색 알고리즘**이다.
4 |
5 | 흔히 인공위성 GPS 소프트웨어 등에서 가장 많이 사용된다.
6 |
7 | 다익스트라 알고리즘은 특정한 하나의 정점에서 다른 모든 정점으로 가는 최단 경로를 알려줍니다.
8 |
9 | 다만 이 때 음의 간선은 포함할 수 없습니다. 물론 현실 세계에서는 음의 간선이 존재하지 않기 때문에 다익스트라는 현실 세계에서 사용하기 매우 적합한 알고리즘 입니다.
10 |
11 | 다익스트라 알고리즘이 다이나믹 프로그래밍 문제인 이유는 **최단 거리는 여러 개의 최단 거리로 이루어져있기 때문입니다.**
12 |
13 | 작은 문제가 큰 문제의 부분 집합에 속해있다고 볼 수 있습니다.
14 | 기본적으로 다익스트라는 하나의 최단 거리를 구할 때 그 이전까지 구했던 최단 거리 정보를 그대로 사용한다는 특징이 있습니다.
--------------------------------------------------------------------------------
/Algorithm/floyd_warshall.md:
--------------------------------------------------------------------------------
1 | # 플로이드 와샬 알고리즘
2 |
3 | 모든 정점에서 모든 정점으로 최단 경로를 구하고 싶다면 플로이드 와샬 알고리즘을 사용한다.
4 |
5 | 다익스트라 알고리즘은 가장 적은 비용을 하나씩 선택해야 했다면 플로이드 와샬 알고리즘은 기본적으로 거쳐가는 정점을 기준으로 알고리즘을 수행한다는 점에서 그 특징이 있다.
6 |
7 | 플로이드 와샬도 마찬가지로 기본적으로 다이나믹 프로그래밍 기술에 의거한다.
8 |
9 | > 플로이드 와샬 알고리즘의 핵심 아이디어는 거쳐가는 정점을 기준으로 최단 거리를 구하는 것이다.
10 |
11 | - 모든 지점에서 다른 모든 지점까지의 최단 경로를 모두 구해하는 경우에 사용할 수 있는 알고리즘
12 |
13 | - 소스코드가 다익스트라에 비해 매우 짧아 구현이 쉽다.
14 | - 다익스트라의 경우 단계마다 최단 거리를 가지는 노드를 하나씩 반복적으로 선택한다. 이후 해당 노드를 거쳐가는 경로를 확인하여 최단 거리 테이블을 갱신하는 방식으로 동작한다. <-> 플로이드 와샬 알고리즘 또한 단계마다 거쳐 가는 노드를 기준으로 알고리즘을 수행한다. 하지만, 매 단계마다 방문하지 않은 노드 중에서 최단 거리를 갖는 노드를 찾을 필요가 없다
15 | - 플로이드 와샬은 2차원 테이블에 최단 거리 정보를 저장한다. (모든 지점에서 다른 모든 지점까지의 최단 거리를 저장해야 하기 때문이다.) <-> 다익스트라는 한 지점에서 다른 지점까지의 최단 거리이기 때문에 1차원 리스트에 저장한다.
--------------------------------------------------------------------------------
/Back-End/Internet/cdn.md:
--------------------------------------------------------------------------------
1 | # CDN(Content Delivery Networks)
2 |
3 | 
4 |
5 | - 지리적 물리적으로 떨어져 있는 사용자에게 컨텐츠 제공자의 컨텐츠를 더 빠르게 제공하기 위해 Cache Sever를 이용하는 기술
6 | - 엔드유저와 가장 가까운 위치에서 최적으로 배치된 CDN 서버에 엔드유저가 매핑
--------------------------------------------------------------------------------
/Back-End/Internet/dns.md:
--------------------------------------------------------------------------------
1 | # DNS 동작 원리
2 |
3 | ## DNS 란 ?
4 | > 도메인 네임 시스템은 호스트의 도메인 이름을 호스트의 네트워크 주소로 바꾸거나 그 반대의 변환을 수행할 수 있도록 하기 위해 개발되었다.
5 |
6 | 예를 들면 우리가 자주 접하는 naver.com , google.com 모두 DNS 를 가진 DN(Domain Name)이라고 할 수 있다.
7 |
8 | 이들은 사실 문자열의 탈을 쓴 IP라 볼 수 있다.
9 |
10 |
11 |
12 | ## DNS의 작동원리
13 | 
14 |
15 | 1. 웹 브라우저에 www.naver.com을 입력하면 먼저 local DNS에게 www.naver.com 이라는 hostname에 대한 IP 주소를 질의하여 local DNS에 없으면 다른 DNS name 서버 정보를 받는다.
16 |
17 | ### Root DNS
18 | - 인터넷의 도메인 네임 시스템의 루트 존이다.
19 | - 루트 존의 레코드의 요청에 직접 응답하고 적절한 최상위 도메인에 대해 권한이 있는 네임 서버 목록을 반환함으로써 다른 요청에 응답한다.
20 | - 전세계 961개의 루트 DNS가 운영되고 있다.
21 |
22 |
23 | 2. Root DNS 서버에 'www.naver.com' 질의
24 | 3. Root DNS 서버로 부터 "com 도메인" 을 관리하는 `TLD (Top-Level Domain)` 이름 서버 정보 전달 받음
25 |
26 | > 여기는 TLD는 .com을 관리하는 서버를 칭함
27 |
28 | 4. TLD에 'www.naver.com' 질의
29 | 5. TLD에서 'name.com'관리하는 DNS 정보 전달
30 | 6. 'naver.com' 도메인을 관리하는 DNS 서버에서 'www.naver.com' 호스트네임에 대한 ip 주소 질의
31 | 7. Local DNS 서버에게 응! www.naver.com에 대한 IP 주소는 222.122.195.6 응답.
32 | 8. Local DNS 는 www.naver.com에 대한 IP 주소 정보 전달
--------------------------------------------------------------------------------
/Back-End/Internet/domain.md:
--------------------------------------------------------------------------------
1 | # 도메인 네임
2 | 1. 도메인 네임이란 IP 주소를 문자로 알아보기 쉽게 만든 인터넷 상의 주소이다.
3 | 2. 도메인 네임의 구조는 다음과 같다.
4 |
5 |
6 |
7 | 
8 |
9 | 우측에 좌측으로 읽으며 root TLD SLD SUB(도메인 이름) 순이다.
10 |
11 | www 는 도메인 네임에 포함되지 않는 호스트명이다.
12 |
13 | 3. SLD는 생략될 수 있기 때문에, 그 유무에 따라 2단계와 3단계 도메인 구조로 나뉜다.
14 |
15 | ## 도메인 네임 이란
16 | 앞서 정리한 내용처럼 도메인 네임이란
17 |
18 | IP 주소를 문자로 알아보기 쉽게 만든 인터넷상의 주소이다.
19 |
20 | > 도메인 네임은 넓은 의미로는 네트워크상에서 컴퓨터를 식별하는 호스트명을 가리키며, 좁은 의미에서는 도메인 레지스트리에게서 등록된 이름을 의미한다. 이를 통틀어서 `웹 주소` 라고 부르기도 한다.
21 |
--------------------------------------------------------------------------------
/Back-End/Internet/etag.md:
--------------------------------------------------------------------------------
1 | # 캐시 검증 헤더 ETag, If-None-Match
2 |
3 | Last-Modified, If-Modified-Since보다 좀 더 간단한 방식으로 ETag와 If-None-Match 검증 헤더가 있다.
4 |
5 | 서버에서 완전히 캐시를 컨트롤하고 싶은 경우 ETag를 사용할 수 있음
6 |
7 | 
8 |
9 | ### 작동 방식
10 | 서버에서 헤더에 ETag를 작성해 응답한다.
11 |
12 | 클라이언트의 캐시에서 해당 ETag 값을 저장한다.
13 |
14 | 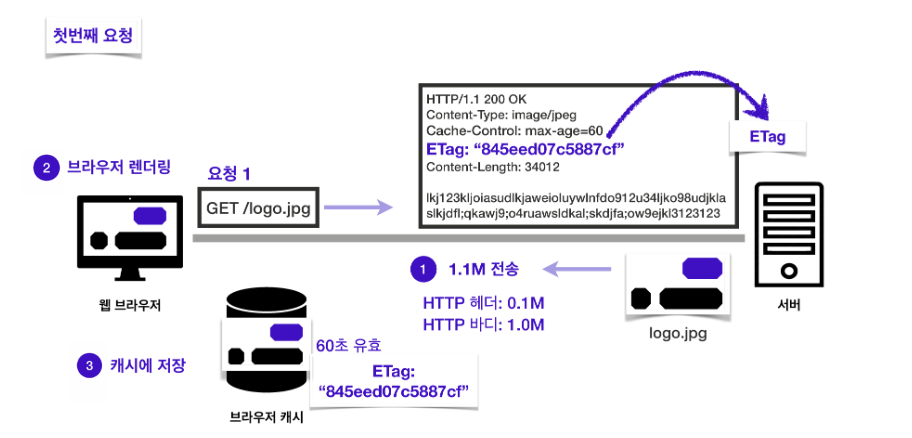
15 |
16 | 만약 캐시 시간이 초과돼서 다시 요청을 해야 하는 경우라면 이때 ETag 값을 검증하는 If-None-Match를 요청 헤더에 작성해서 보낸다.(조건부요청)
17 |
18 | 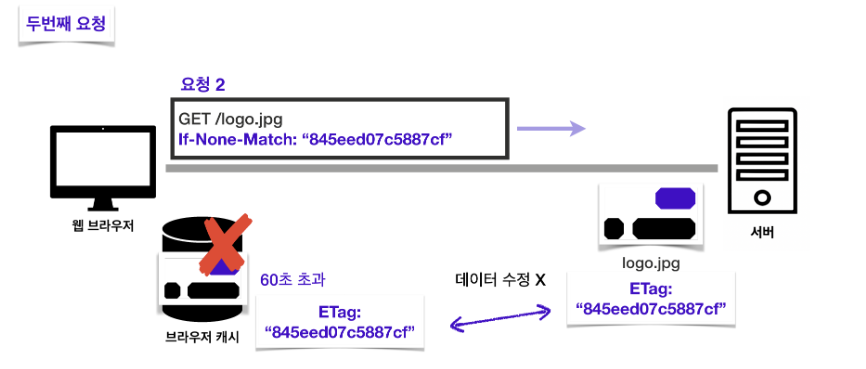
19 |
20 | 서버에서 데이터가 변경되지 않았을 경우 ETag는 동일하기에 그래서 If-None-Match는 거짓이 된다.
21 |
22 | 이 경우에 서버에서 304 Not Modifed를 응답하며 이때 역시 HTTP body는 없다.
23 |
24 | 브라우저 캐시에서는 응답 겨로가를 재사용하고 헤더 데이터를 갱신한다.
25 |
26 | 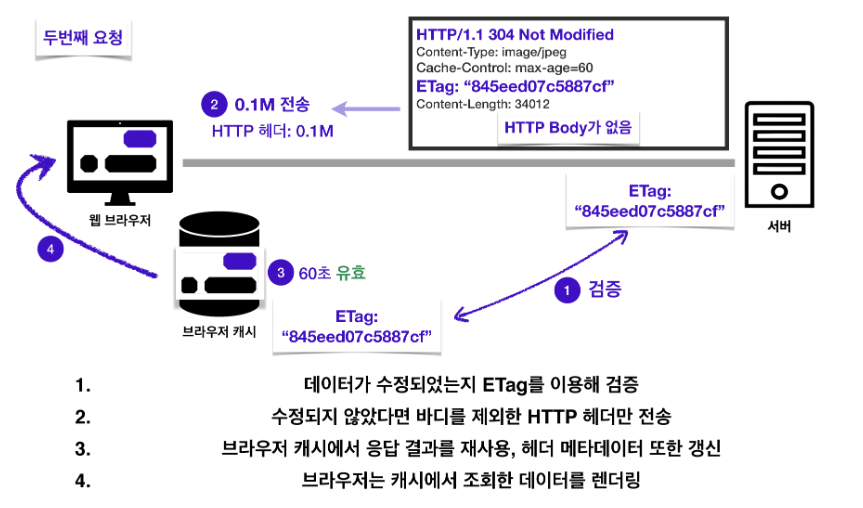
27 |
28 | ### 정리
29 |
30 | 
--------------------------------------------------------------------------------
/Back-End/Internet/host.md:
--------------------------------------------------------------------------------
1 | # 호스팅
2 |
3 | ## 호스팅이란 ?
4 |
5 | - 어떠한 서비스를 빌려서 사용한다는 말이다.
6 | - 그럼 웹 호스팅은? 말그대로 외부의 서버를 빌려서 기능을 사용한다는 말을 의미한다. 호스팅은 웹호스팅, 서버호스팅, 클라우드호스팅과 같은 종류가 있다.
7 |
8 |
9 |
10 | ## 웹 호스팅
11 |
12 | 
13 |
14 | - 예를들어 HTML이나 CSS 와 같은 코드를 이용해서 웹 페이지를 만들었다고 치자. 웹페이지를 하나 제작했다고 해서 누구나 내 사이트에 접속할 수 있는 것이 아니다. 배포과정을 거치고 도메인까지 연결을 해야 비로소 하나의 웹 페이지가 웹 사이트로 거듭나는 것이다.
15 | - 이 배포 과정을 전문 업체에 맡기는 것이다. 물론 이 과정을 직접 할 수도 있지만 개인이 서버를 구매하고 설치하는것은 좀 많이 어렵다.
16 |
17 |
18 |
19 | ## 서버 호스팅
20 |
21 | 서버호스팅과 웹호스팅의 차이는 ?
22 |
23 | 
24 |
25 | - 웹 호스팅 : 서버중 `일부` 만 빌리는 서비스
26 | - 서버 호스팅 : 서버 하나를 통째로 구매할 수 있으며 서버 운영에 필요한 인프라와 기술력까지 제공받을 수 있다.
27 |
28 | > 웹 호스팅은 소규모 웹사이트에 주로 사용되고
29 | > 서버 호스팅은 서버 관리에 대한 직접권한을 갖고 서버를 단독으로 사용하기 떄문에 보안상으로도 유리하지만 초기 구축단계에서 웹 호스팅에 비해 시간과 비용이 많이 든다는 단점이 있다. 보통 회사의 인터라넷, 대형 쇼핑몰등 고정적으로 대용량 트래픽과 DB가 많이 사용되는 곳에 사용됨
30 |
31 |
32 |
33 | ## 클라우드 호스팅
34 |
35 | 클라우드 호스팅은 웹호스팅의 장점과 서버호스팅의 장점을 모두 가지고 있는 호스팅이며 최근 많은 주목을 받는 호스팅 방법이다. 아마존의 EC2와 구글의 클라우드 플랫폼 등 다양한 서비스가 존재하며 장점을 나열해보자면 앉은자리에서 클릭 몇번으로 10분 안에 누구나 서버를 생성하고 관리할 수 있으며 트래픽 변동에도 유연하게 대처할 수 있기 때문에 일시적인 이벤트나 인프라가 유동적인 곳에 사용하기 편리하다는 장점이 있다. 단점도 있지만 점점 클라우드 호스팅의 변화로 단점이 사라지고 있는 추세이다.
36 |
37 | 
38 |
39 |
40 |
41 | ## 비교
42 |
43 | 1. 개인 블로그 , 소규모 트래픽이 필요한 곳 : 웹 호스팅
44 | 2. 트래픽과 DB 사용량이 많아 서버 관리 인프라가 같이 필요한 곳 : 서버 호스팅
45 | 3. 트래픽 변화에 유동적인 대처가 가능하며 빠른 시간안에 서버를 구축할 수 있는 서비스 : 클라우드 호스팅
--------------------------------------------------------------------------------
/Back-End/Internet/image/ISP.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/Internet/image/ISP.png
--------------------------------------------------------------------------------
/Back-End/Internet/image/cdn.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/Internet/image/cdn.png
--------------------------------------------------------------------------------
/Back-End/Internet/image/dhcp.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/Internet/image/dhcp.png
--------------------------------------------------------------------------------
/Back-End/Internet/image/dnsserver.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/Internet/image/dnsserver.png
--------------------------------------------------------------------------------
/Back-End/Internet/image/domain.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/Internet/image/domain.png
--------------------------------------------------------------------------------
/Back-End/Internet/image/p2p.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/Internet/image/p2p.jpeg
--------------------------------------------------------------------------------
/Back-End/Internet/image/webflow.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/Internet/image/webflow.png
--------------------------------------------------------------------------------
/Back-End/Internet/image/websocket.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/Internet/image/websocket.png
--------------------------------------------------------------------------------
/Back-End/Internet/image/브라우저기본구조.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/Internet/image/브라우저기본구조.png
--------------------------------------------------------------------------------
/Back-End/Internet/image/운.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/Internet/image/운.png
--------------------------------------------------------------------------------
/Back-End/Internet/image/웹캐시.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/Internet/image/웹캐시.png
--------------------------------------------------------------------------------
/Back-End/Internet/image/웹킷동작방식.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/Internet/image/웹킷동작방식.png
--------------------------------------------------------------------------------
/Back-End/Internet/image/웹호스팅.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/Internet/image/웹호스팅.png
--------------------------------------------------------------------------------
/Back-End/Internet/image/클라우드호스팅.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/Internet/image/클라우드호스팅.png
--------------------------------------------------------------------------------
/Back-End/Internet/image/호스팅차이.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/Internet/image/호스팅차이.png
--------------------------------------------------------------------------------
/Back-End/Internet/inoutbound.md:
--------------------------------------------------------------------------------
1 | # 인바운드 (Inbound), 아웃 바운드 (Outbound)
2 |
3 | 인바운드와 아웃바운드는 **트래픽에 네트워크 간에 이동하는 방향**을 말한다.
4 |
5 | ### 인바운드
6 | 인바운드 트래픽은 **네트워크에서 들어오는 정보**
7 |
8 | 메시지가 클라이언트에서 서버로 향하는 것
9 | > ex) 첨부파일을 서버에 저장할 때
10 |
11 |
12 | ### 아웃 바운드
13 | 아웃바운드 트래픽은 **네트워크에서 나가는 정보**
14 |
15 | 클라이언트의 요청을 처리하고 메시지가 서버에서 클라이언트로 다시 향하는 것
16 | > ex) 첨부 파일을 다운로드 할 때
17 |
18 | 
--------------------------------------------------------------------------------
/Back-End/Internet/ositcp.md:
--------------------------------------------------------------------------------
1 | # OSI 7계층과 TCP/IP 4계층
2 |
3 | 네트워크 프로토콜 계층은 다음과 같이 OSI 7계층과 TCP/IP 4계층으로 나눌 수 있음
4 |
5 | 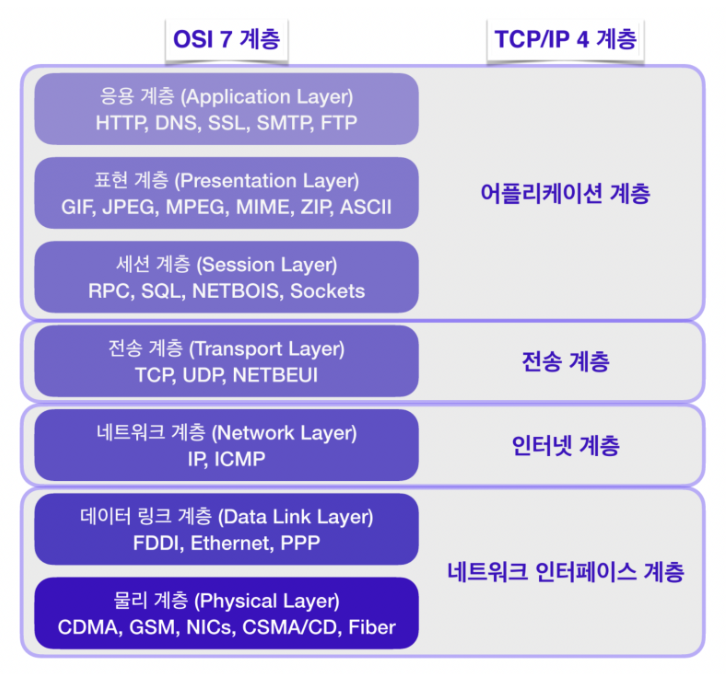
6 |
7 | IP 프로토콜보다 더 높은 계층에 TCP 프로토콜이 존재하기 때문에 앞서 다룬 IP 프로토콜의 한계를 보완할 수 있음
8 |
9 | > TCP/IP 4계층은 OSI 7계층보다 먼저 개발되었으며 TCP/IP 프로토콜의 계층은 OSI 모델의 계층과 정확하게 일치하지는 않는다. 실제 네트워크 표준은 업계표준을 따라는 TCP/IP 4계층에 가깝다.
10 |
11 | ### 예시) 채팅프로그램에서 메시지를 보낼때 일어나는 일
12 |
13 | 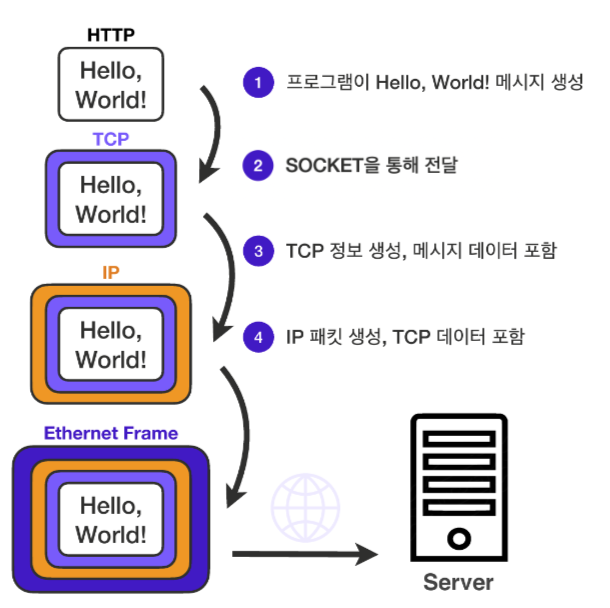
14 |
15 | 1. 채팅창에서 메시지 생성
16 | 2. HTTP 메시지가 생성되면 Socket을 통해 전달된다.
17 |
18 | > 프로그램이 네트워크에서 데이터를 송수신할 수 있도록 네트워크 환경에 연결할 수 있게 만들어진 연결부가 바로 소켓이다. (Socket)
19 |
20 | 3. TCP 세그먼트 생성, 메시지 데이터 포함
21 | 4. IP 패킷 생성, TCP 데이터 포함
22 | 5. 생성된 TCP/IP 패킷은 LAN 카드와 같은 물리적 계층을 지나기 위해 이더넷 프레임워크에 포함되어 서버로 전송된다.
--------------------------------------------------------------------------------
/Back-End/Internet/p2p.md:
--------------------------------------------------------------------------------
1 | # P2P
2 |
3 | 
4 |
5 | - **중앙 서버 없이 대등한 관계**의 컴퓨터 그룹이 직접 서로 통신하는 분산 구조
6 | - 망 구성에 참여하는 Peer들이 Processing power, 저장공간, bandwith등의 자원 공유
7 | - application layer에 네트워크를 build 하는 overlay network
8 | - 빠른 인터넷 연결 속도, end-user들의 높은 성능. peer가 많을 수록 power 상승
9 | - 확장성, 신뢰성(복사본, 지리적 분산, No single point of failure), 저렴함
10 | - **Structured P2P**
11 | - DHT(Distributed Hash Table) : key: hash(filename); value : a node (IP address)
12 | - assign : 가장 가까운 peer에게 key를 주기, find: key에 해당되는 노드들 찾기
13 | - key lookup 방식
14 | - 직속 successor peer의 주소만 아는 경우: 물어보고->물어보고->물어보고.. 쿼리 O(N)유지 O(1)
15 | - 모든 peer의 주소를 아는경우: 쿼리 O(1) 유지 O(N)
16 | - Chord Lookup: 2^i로 뛰며 탐색해서 O(logN)
--------------------------------------------------------------------------------
/Back-End/Internet/tomcat.md:
--------------------------------------------------------------------------------
1 | # 아파치 톰캣 (Apache Tomcat)
2 |
3 | ### What is Apache Tomcat ?
4 |
5 | #### Server, Web Server
6 | 우리가 사용하는 웹페이지는 아파치 톰캣으로 이루어져있다. 리눅스 서버를 만들거나 웹서버를 만들다보면 아파치 톰캣을 설치하라고 한다. 그 아파치와 톰캣의 기능과 차이를 아는 것 또한 중요하다.
7 |
8 | ### 아파치(Apache)
9 | - 소프트웨어 재단의 `오픈소스 프로젝트` 일명 웹서버로 불리며
10 | - 클라이언트 요청이 왔을때만 응답하는 정적 웹페이지에 사용된다.
11 | - 웹서버 80번 포트로 클라이언트 요청(POST,GET,DELETE)이 왔을때만 응답.
12 | - 정적인 데이터만 처리(html, css , image 등)
13 |
14 | ### 톰캣 (Tomcat)
15 | - dynamic(동적)인 웹을 만들기 위한 웹 컨테이너, 서블릿 컨테이너라고 불리며
16 | - 정적으로 처리해야할 데이터를 제외한 JSP ASP PHP 등은 웹 컨테이너(톰캣) 에게 전달한다.
17 |
18 |
19 |
20 | ## WAS(Web Application Server)
21 | - 컨테이너 , 웹 컨테이너, 서블릿 컨테이너라고 부름
22 | - JSP, 서블릿처리 HTTP 요청 수신 및 응답 아파치만 쓰면 정적인 웹페이지만 처리하므로 처리속도가 매우 빠르고 안정적임
23 | - 하지만 톰캣(WAS)을 사용하면 동적인 데이터 처리가 가능하다.
24 | - DB연결, 데이터 조작, 다른 응용프로그램과 상호작용이 가능하다.
25 | - 톰캣은 8080포트로 처리한다.
26 |
27 |
28 |
29 | ### 아파치 톰캣(Apache + Tomcat)
30 | 톰캣이 아파치의 기능 일부를 가져와서 제공해주는 형태이기 때문에 같이 합쳐서 부른다.(WAS Web Application Server)
31 |
32 | 톰캣은 일반적으로 WAS라고 불리며, 톰캣은 아파치와 합쳐서 아파치 톰캣이라 부른다.
33 |
34 | 아파치만 사용하면 정적인 웹페이지만 처리 가능 톰캣만 사용하면 동적인 웹페이지 처리가 가능하지만 아파치에서 필요한 기능을 못가져온다. 또한 여러 사용자가 요청할 시에 톰캣에 과부하가 걸린다. 아파치 톰캣을 같이 쓰면 아파치는 정적인 데이터만 처리하고, JSP처리는 Web Container(톰캣의 일부)로 보내주어 분산처리 할 수 있다.
35 |
36 | 아파치 : 80포트
37 | 톰캣 : 8080 포트
38 |
39 | > 하지만 실제로는 80포트로 다 처리하므로, 8080포트는 아파치가 알아서 보내줌. 8080포트를 다루거나 보려면 리눅스 단에서 처리하거나 수동적으로 포트 처리할때 빼고는 보기 힘듬
40 |
41 |
42 |
--------------------------------------------------------------------------------
/Back-End/Internet/trace.md:
--------------------------------------------------------------------------------
1 | # 회선교환 방식과 패킷교환 방식
2 |
3 | ## 회선 교환 방식
4 | 발신자와 수신자 사이에 데이터를 전송할 전용선을 미리 할당하고 둘을 연결한다.
5 |
6 | 그래서 내가 연결하고 싶은 상대가 다른 상대와 연결중이라면, 상대방은 이미 다른 상대와의 전용선과 연결되어 있기 때문에 그 연결이 끊어지고 나서야 상대방과 연결할 수 있음.
7 |
8 | 특정 회선이 끊어지는 경우에는 처음부터 다시 연결을 성립해야한다.
9 |
10 | > 회선교환 방식은 즉시성이 떨어진다는 비효율이 존재한다.
11 |
12 | ## 패킷 교환 방식
13 | 패킷교환 방식은 기존에 전화에서 사용했던 회선교환 방식의 단점을 보완한 방식으로 `패킷`이라는 단위로 데이터를 잘게 나누어 전송하는 방식이다.
14 |
15 | - 소포를 보내듯 각 패킷에는 출발지와 목적지 정보가 있고 이에 따라 패킷이 목적지를 향해 가장 효율적인 방식으로 이동할 수 있다.
16 | - 이를 이용하면 특정 회선이 전용선으로 할당되지 않기 때문에 효율적으로 데이터를 전송할 수 있다.
17 |
18 | > 정리하면 인터넷 프로토콜, 줄여서 IP는 출발자와 목적지의 정보를 IP 주소라는 특정한 숫자값으로 표기하고 패킷 단위로 데이터를 전송하게 된다.
--------------------------------------------------------------------------------
/Back-End/Internet/webcache.md:
--------------------------------------------------------------------------------
1 | # 웹 캐시(프록시 서버)
2 |
3 | 
4 |
5 | - orogin 서버 없이도 미리 저장해둔 데이터로 중간에서 response
6 | - client의 요청에 대한 응답 시간과 트래픽을 줄여주고 효과적으로 데이터 전달
7 | - cache 서버의 데이터가 up-to-date인지 (origin 서버와 같은 상태인지) 체크해서 받는 Conditional GET 방법도 있음(if-modified-since 헤더)
8 |
9 |
--------------------------------------------------------------------------------
/Back-End/JAVA/4특징.md:
--------------------------------------------------------------------------------
1 | # OOP의 4가지 특징
2 |
3 | - `캡슐화`
4 | - 데이터와 코드의 형태를 외부로부터 알 수 없게 하고, 데이터의 구조와 역할, 기능을 하나의 캡슐 형태로 만드는 방법
5 | - `추상화`
6 | - 클래스들의 공통적인 특성(변수, 메소드)들을 묶어 표현하는 것
7 | - `상속화`
8 | - 부모 클래스에 정의된 변수 및 메서드를 자식 클래스에서 상속받아 사용하는 것
9 | - `다형화`
10 | - 다양한 형태로 표현이 가능한 구조를 말한다.
11 |
12 |
13 |
14 | ### 캡슐화
15 | 데이터와 코드의 형태를 외부로부터 알 수 없게 하고, 데이터의 구조와 역할, 기능을 하나의 캡슐 형태로 만드는 방법(정보 은닉)
16 |
17 | - 캡슐화 방법
18 | 1. 멤버 변수 앞에 접근 제어자 private를 붙인다.(private : 자기 클래스에서만 접근할 수 있는 것)
19 | 2. 멤버 변수에 값을 넣고 꺼내 올 수 있는 메서드를 만든다(getter setter)
20 |
21 | ### 추상화
22 | 클래스들의 공통적인 특성(변수, 메소드)들을 묶어 표현하는 것
23 |
24 | ### 상속화
25 | 부모 클래스에 정의된 변수 및 메서드를 자식 클래스에서 상속받아 사용하는 것
26 |
27 | ex) extends라는 키워드 이용
28 |
29 | ### 다형화
30 | 메시지에 의해 객체가 연산을 수행하게 될 때, 하나의 메시지에 대해 각 객체가 가지고 있는 고유한 방법으로 응답할 수 있는 능력
31 |
32 | - 다영화 지원 방법
33 | - 오버로딩
34 | - 오버 라이딩
35 |
36 | #### 오버로딩
37 | 하나의 클래스 안에서 같은 이름의 메서드를 여러 개 정의하는 것
38 |
39 | #### 오버라이딩
40 | 부모 클래스로부터 상속받은 메서드 내용을 변경하여 사용하는 것
41 | 매개변수와 리턴 타입이 같아야 함
--------------------------------------------------------------------------------
/Back-End/JAVA/aio.md:
--------------------------------------------------------------------------------
1 | # Java AIO
2 |
3 | Java NIO 패키지에서 제공하는 비동기(Asynchronous) I/O API다.
4 |
5 | I/O 작업을 수행할 때 블로킹되지 않으므로 다른 작업을 수행할 수 있다.
6 |
7 | > NIO와 달리 CompletionHandler 인터페이스를 사용해 I/O 작업이 완료될 때 까지 알림을 받는다.
8 |
9 |
10 |
11 |
12 | ### AIO 지원
13 | - AsynchronousChannel 클래스
14 | - AsynchronousSocketChannel 클래스
15 | - AsynchronousServerSocketChannel 클래스
16 | - AsynchronousFileChannle 클래스
17 | - callback, future 지원
18 |
19 |
20 | `Thread pool`, `epoll`, `kqueue` 등의 이벤트 알림 `system call`을 사용한다.
21 |
22 | I/O가 준비되었을 때, Future 혹은 callback으로 비동기적인 로직이 처리가 가능하다.
23 |
24 |
25 | ### AsynchronousSocketChannel
26 |
27 | 클라이언트 소켓을 위한 비동기 채널이다.
28 |
29 | ### AsynchronousServerSocketChannel
30 |
31 | 서버(TCP) 소켓을 위한 비동기 채널이다.
32 |
33 | ### AsynchronousFileChannel
34 |
35 | 파일 읽기 쓰기 조작을 위한 비동기 채널이다.
36 |
37 |
38 |
39 | ## CompletionHandler
40 |
41 |
42 |
43 | Java AIO API에서 비동기 I/O 작업 완료를 처리하는 인터페이스다.
44 |
45 | 이 인터페이스를 구현하여 I/O 작업이 완료될 때 호출되는 콜백 메서드를 정의할 수 있다.
46 |
47 | CompletionHandler는 제네릭 타입들을 가지고 있는데, 그 타입은
48 | 1. I/O 작업의 결과 타입
49 | 2. I/O 작업 결과를 처리할 때 사용할 객체의 타입
50 |
51 | 이렇게 두가지다.
52 |
53 | 이 인터페이스를 구현하면 I/O 작업이 완료될 때 자동으로 호출되는 completed() 메서드와 I/O 작업 중 예외가 발생했을 때 호출되는 failed() 메서드를 정의할 수 있다.
54 |
55 | 이를 통해 비동기 I/O 작업을 처리할 때 **콜백 방식**으로 처리할 수 있습니다.
--------------------------------------------------------------------------------
/Back-End/JAVA/executor.md:
--------------------------------------------------------------------------------
1 | # Java Executors
2 |
3 | 스레드를 만들고 관리하는 작업을 고수준의 api에게 위임하는게 Executors 이다.
4 |
5 | 스레드를 만들고 처리하고 실행하고 종료하는 것을 해주는 역할을 한다.
6 |
7 | ## ExecutorService
8 | 우선 ExecutorService는 Executor를 상속받은 인터페이스로, Callable도 실행할 수 있으며 Executor를 종료시키거나, Callable을 동시에 실행하는 동의 기능을 제공한다.
9 |
10 | ```java
11 | public class ExecutorEx {
12 | public static void main(String[] args) {
13 | ExecutorService executorService = Executors.newSingleThreadExecutor();
14 | executorService.submit(() -> {
15 | System.out.println("Thread " + Thread.currentThread().getName());
16 | });
17 | }
18 | }
19 | ```
20 | 이 코드를 실행해 보면
21 | 
22 |
23 | 이처럼 newSingleThreadExecutor()은 무제한 큐에서 작동하는 단일 스레드를 사용하는 Executor를 만들어 준다.
24 | 그래서 프로세스가 실행되고 계속 유지되고 종료되지 않는 것을 확인할 수 있다.
25 |
26 | 프로세스를 종료하고 싶담녀 종료 메서드를 사용하여 프로세스를 닫아줘야 한다. executorService.shutdown();
27 |
28 | Fork/Join 프레임워크를 사용하여 멀티 프로세스도 활용할 수 있다.
--------------------------------------------------------------------------------
/Back-End/JAVA/finalize.md:
--------------------------------------------------------------------------------
1 | # 자바에서 Finalize 메서드의 역할은 무엇일까요?
2 |
3 | ### finalize()
4 |
5 | `finalize()` 메서드는 자바의 Object 클래스에 정의된 메서드로, 객체가 가비지 컬렉션에 의해 회수되기 직전에 실행되는 코드를 작성하기 위해 사용됩니다.
6 |
7 | ```java
8 | 복사
9 | protected void finalize() throws Throwable {
10 | try {
11 | // 객체 정리 로직
12 | } finally {
13 | super.finalize();
14 | }
15 | }
16 | ```
17 |
18 | 이 메서드는 가비지 컬렉터에 의해 자동으로 호출되며, 해당 객체가 사용되던 리소스를 회수하기 위한 마지막 기회를 제공합니다.
19 |
20 | 예를 들어, 객체가 네트워크 연결이나 파일 핸들과 같은 시스템 리소스를 사용하는 경우, finalize() 메서드에서 이러한 리소스를 명시적으로 해제하는 코드를 작성할 수 있습니다.
21 |
22 | 그러나 실제로 이 메서드를 사용하는 것은 권장하지 않습니다. 이는 가비지 컬렉터의 실행 시점을 정확히 예측할 수 없으므로 finalize() 메서드가 호출되는 시점 역시 예측할 수 없기 때문입니다.
23 |
24 | 이로 인해 리소스 누수가 발생하거나, 성능에 부정적인 영향을 미칠 수 있습니다.
25 |
26 | 따라서, 대신에 try-finally 블록이나 try with resources 구문을 사용하여 필요한 시점에 직접 리소스를 해체하는 것이 좋습니다.
27 |
28 | > Java 9부터는 finalize() 메서드가 deprecated 되었고 java 12에서는 Cleaner, PhantomReference를 사용한 대안이 제시되었습니다.
--------------------------------------------------------------------------------
/Back-End/JAVA/gc_kind.md:
--------------------------------------------------------------------------------
1 | # GC의 종류와 각각의 차이점
2 |
3 | 자바의 가비지 컬렉션 GC는 힙 영역의 더 이상 사용되지 않는 객체를 자동을 정리하는 메모리 관리 기법입니다. 여러 가지 GC 알고리즘이 있으며, 각각은 서로 다른 상황과 요구 사항에 최적화되어 있습니다.
4 |
5 | ## Serial GC
6 | 이 GC는 매우 간단하며, 단일 스레드에서 실행되므로 애플리케이션의 응답 시간이 중요하지 않은 시스템에서 가장 잘 작동합니다. 이 GC는 작은 힙과 CPU가 제한적인 환경에서 주로 사용됩니다.
7 |
8 | ## Parallel GC
9 | 이 GC는 스루풋을 최적화하기 위해 설계되었습니다. 가비지 컬렉션 동안 모든 애플리케이션 스레드를 중지 (stop the world)하므로 GC의 처리 시간을 최소화하기 위해 여러 GC 스레드를 동시에 사용합니다. 이는 CPU 코어가 많은 서버 환경에 적합합니다.
10 |
11 | ## Concurrent Mark Sweep(CMS) GC
12 | 이 GC는 애플리케이션의 응답 시간을 최적화하기 위해 설계되었습니다. CMS GC는 대부분의 가비지 컬렉션 작업을 애플리케이션 스레드가 동작하는 동안 병렬로 실행합니다. 하지만, 이 GC는 CPU 자원을 많이 사용하며, 메모리 단편화 문제가 발생할 수 있습니다.
13 |
14 | ## G1(Garbage First) GC
15 |
16 | 이 GC는 힙을 여러 개의 동일한 크기의 영역으로 나누고, 각 영역을 독립적으로 관리하는 새로운 접근 방식을 제공합니다. 가비지가 가장 많이 쌓인 영역으로부터 처리하여 효율성을 높입니다. 이 GC는 힙 크기가 큰 시스템에서 잘 작동하며, 가비지 컬렉션중에 일어나느 애플리케이션 멈춤 시간을 줄이는 것이 목표입니다.
17 |
18 | > 각 GC는 특정 환경과 요구 사항에 따라 성능이 달라질 수 있으므로, 애플리케이션의 성능 요구 사항과 실행 환경에 따라 적절한 GC를 선택해야 합니다.
--------------------------------------------------------------------------------
/Back-End/JAVA/hot_cold_publisher.md:
--------------------------------------------------------------------------------
1 | # Cold Publisher & Hot Publisher
2 |
3 | ## Cold Publisher
4 |
5 | Publihser는 Subscriber가 구독할 때마다 데이터를 처음부터 새로 토잊한다.
6 |
7 | 데이터를 통지하는 새로운 타임 라인이 생성된다.
8 |
9 | Subscriber는 구독 시점과 상관없이 통지된 데이터를 처음부터 전달 받을 수 있다.
10 |
11 | ```java
12 | void ColdPublisher() {
13 | Flowable flowable = Flowable.just(1, 3, 5, 7);
14 |
15 | flowable.subscribe(data -> System.out.println("구독자1: " + data));
16 | flowable.subscribe(data -> System.out.println("구독자2: " + data));
17 | }
18 | ```
19 |
20 | Result
21 |
22 | ```
23 | 구독자1: 1
24 | 구독자1: 3
25 | 구독자1: 5
26 | 구독자1: 7
27 | 구독자2: 1
28 | 구독자2: 3
29 | 구독자2: 5
30 | 구독자2: 7
31 | ```
32 |
33 |
34 |
35 | ## Hot Publisher
36 |
37 | Publisher는 Subscriber 수와 상관 없이 데이터를 한번만 통지한다.
38 |
39 | 즉, 데이터를 통지하는 타임라인은 하나다.
40 |
41 | Subscriber는 발행된 데이터를 처음부터 전달 받는게 아니라 구독한 시점에 통지된 데이터들만 전달 받을 수 있다.
42 |
43 | ```java
44 | void HotPublisher() {
45 | PublishProcessor processor = PublishProcessor.create();
46 | processor.subscribe(data -> System.out.println("구독자1: " + data));
47 | processor.onNext(1);
48 | processor.onNext(3);
49 |
50 | processor.subscribe(data -> System.out.println("구독자2: " + data));
51 | processor.onNext(5);
52 | processor.onNext(7);
53 |
54 | processor.onComplete();
55 | }
56 | ```
57 |
58 | Result
59 | ```
60 | 구독자1: 1
61 | 구독자1: 3
62 | 구독자1: 5
63 | 구독자2: 5
64 | 구독자1: 7
65 | 구독자2: 7
66 | ```
--------------------------------------------------------------------------------
/Back-End/JAVA/image/disabled.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/JAVA/image/disabled.png
--------------------------------------------------------------------------------
/Back-End/JAVA/image/invokeAll-api-docs.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/JAVA/image/invokeAll-api-docs.png
--------------------------------------------------------------------------------
/Back-End/JAVA/image/jvm메모리구조.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/JAVA/image/jvm메모리구조.png
--------------------------------------------------------------------------------
/Back-End/JAVA/image/jvm실행.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/JAVA/image/jvm실행.png
--------------------------------------------------------------------------------
/Back-End/JAVA/image/newSingleThreadExecutorEx.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/JAVA/image/newSingleThreadExecutorEx.png
--------------------------------------------------------------------------------
/Back-End/JAVA/image/runtimearea.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/JAVA/image/runtimearea.png
--------------------------------------------------------------------------------
/Back-End/JAVA/image/stackArea.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/JAVA/image/stackArea.png
--------------------------------------------------------------------------------
/Back-End/JAVA/image/stringbuilder.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/JAVA/image/stringbuilder.png
--------------------------------------------------------------------------------
/Back-End/JAVA/image/stringcode.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/JAVA/image/stringcode.png
--------------------------------------------------------------------------------
/Back-End/JAVA/image/stringin1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/JAVA/image/stringin1.png
--------------------------------------------------------------------------------
/Back-End/JAVA/image/stringin2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/JAVA/image/stringin2.png
--------------------------------------------------------------------------------
/Back-End/JAVA/image/stringin3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/JAVA/image/stringin3.png
--------------------------------------------------------------------------------
/Back-End/JAVA/image/stringrun.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/JAVA/image/stringrun.png
--------------------------------------------------------------------------------
/Back-End/JAVA/image/래퍼클래스구조도.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/JAVA/image/래퍼클래스구조도.png
--------------------------------------------------------------------------------
/Back-End/JAVA/image/박싱언박싱.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/JAVA/image/박싱언박싱.png
--------------------------------------------------------------------------------
/Back-End/JAVA/image/서블릿.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/JAVA/image/서블릿.png
--------------------------------------------------------------------------------
/Back-End/JAVA/image/서블릿동작.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/JAVA/image/서블릿동작.png
--------------------------------------------------------------------------------
/Back-End/JAVA/image/서블릿컨테이너.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/JAVA/image/서블릿컨테이너.png
--------------------------------------------------------------------------------
/Back-End/JAVA/image/의존.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/JAVA/image/의존.png
--------------------------------------------------------------------------------
/Back-End/JAVA/jmm.md:
--------------------------------------------------------------------------------
1 | # JMM(Java Memory Model)
2 |
3 | ## JMM
4 | 자바 메모리 모델 JMM은 자바 프로그램의 동작을 이해하고 멀티스레드 환경에서 동기화 이슈를 다루기 위한 핵심 개념입니다.
5 |
6 | 이 모델은 필드, 메서드, 객체 등 메모리에서 어떻게 표현되는지, 그리고 이들이 어떻게 스레드에 의해 접근되는지 정의합니다.
7 |
8 | JMM은 기본적으로 두 가지 메모리 영역, 즉 `Heap`, `Stack`을 관리합니다.
9 |
10 | ### Heap
11 | 힙은 모든 스레드가 공유하는 메모리 영역입니다. 객체의 실제 데이터와 그런 객체들의 인스턴스 변수들을 이 곳에 할당됩니다. 가비지 컬렉션이 이 영역의 불필요한 객체를 제거하는 작업을 수행합니다.
12 |
13 | ### Stack
14 |
15 | 스택은 각 스레드가 개별적으로 가지는 메모리 영역입니다. 메서드 호출과 지역 변수에 대한 정보가 이 곳에 저장됩니다. 메서드 호출이 발생할 때마다 메서드 호출에 대한 스택 프레임이 생성되고, 메서드가 종료되면 해당 스택 프레임이 제거됩니다.
16 |
17 | > 또한 JMM은 휘발성, 동기화, 원자적과 같은 개념을 제공하여 멀티스레드 환경에서 동시성 문제를 처리하는 데 도움을 줍니다. 휘발성은 변수의 값을 스레드 간에 공유하도록 하고 동기화는 임계 영역의 동시 접근을 제어하며 원자적은 동시성 문제 없이 단일 연산을 수행할 수 있도록 합니다.
18 |
19 | JMM은 이러한 개념들을 통해서 자바 프로그램의 안정성과 성능을 보장합니다.
--------------------------------------------------------------------------------
/Back-End/JAVA/jvmm.md:
--------------------------------------------------------------------------------
1 | # JVM 메모리 모델
2 |
3 | JVM 메모리 모델은 자바 프로그램이 실행되는 과정에서 메모리가 어떻게 할당되고 관리되는지를 정의합니다.
4 |
5 | ### Method Area(메서드 영역)
6 |
7 | 이 영역은 JVM이 시작될 때 생성되며, 각 클래스와 인터페이스에 대한 런타임 상수 풀, 필드와 메서드 데이터, 생성자 등의 코드를 저장합니다.
8 |
9 | ### Heap Area(힙 영역)
10 | 모든 객체 인스턴스와 배열이 이 영역에 할당됩니다. 이 영역은 JVM의 여러 스레드가 공유하며, 가비지 컬렉터가 활동하는 곳입니다.
11 |
12 | ### Stack Area(스택 영역)
13 | 스택 영역은 각 스레드에 대해 JVM이 별도의 런타임 스택을 생성하며, 메서드 호출과 로컬 변수에 대한 정보를 저장합니다. 각 메서드 호출에 대해 스택 프레임이 생성되고, 그 프레임 내에 로컬 변수, 연산 스택, 메서드 호출 및 반환에 대한 정보 등이 저장됩니다.
14 |
15 | ### PC Register(PC 레지스터)
16 | PC 레지스터는 현재 실행중인 JVM 명령의 주소를 저장합니다. 이 레지스터는 각 스레드에 대해 별도로 생성됩니다.
17 |
18 | ### Native Method Stacks(네이티브 메서드 스택)
19 | 네이티브 메서드 스택은 JVM이 네티이브 메서드를 처리하는데 사용합니다.
20 |
21 | > 네이티브 메서드: C,C++ 등의 네이티브 언어로 작성된 코드를 호출하는 기능
22 |
23 | 이러한 영역들은 자바 프로그램이 실행되는 동안 서로 상호작용하며, JVM의 역할은 이 메모리 모델을 통해 자바 프로그램의 실행을 관리하는 것 입니다. 이 메모리 모델은 자바의 플랫폼 독립성, 메모리 관리, 가비지 컬렉션 등의 특징을 가능하게 합니다.
24 |
25 | 
--------------------------------------------------------------------------------
/Back-End/JAVA/lifecycle.md:
--------------------------------------------------------------------------------
1 | # 객체의 생명주기 (생성, 사용, 소멸)
2 |
3 | 객체의 생명 주기는 크게 생성 사용 그리고 소멸 단계로 나눌 수 있습니다.
4 |
5 | ### 객체 생성
6 | 객체의 생명주기는 먼저 new 키워드를 사용해 객체를 생성하는 것으로 시작합니다.
7 |
8 | 이때 생성자가 호출되며, 해당 객체에 필요한 리소스가 할당됩니다.
9 |
10 | 생성된 객체는 힙 메모리 영역에 저장되며, 참조 변수를 통해 접근할 수 있습니다.
11 |
12 | ### 객체 사용
13 |
14 | 객체가 생성되고 나면, 해당 객체의 메서드를 호출하거나 필드를 이용하여 상태를 변경할 수 있습니다. 객체가 사용되는 동안 가비지 컬렉션의 대상이 되지 않습니다.
15 |
16 | ### 객체 소멸
17 |
18 | 객체가 더 이상 필요하지 않게 되면, 해당 객체를 참조하는 변수가 없게 됩니다. 그러면 가비지 컬렉터에 의해 메모리에서 제거될 수 있게 됩니다.
19 |
20 | 이는 객체의 참조 카운트가 0이 되는 시점입니다. 가비지 컬렉션은 자동으로 수행되며 개발자가 직접 제어할 수는 없습니다.
21 |
22 | Java에서는 finalize() 메서드를 통해 객체가 메모리에서 회수되기 전에 수행할 작업을 정의할 수 없지만, 이 메서드 호출 시점은 정확히 예측할 수 없으므로 안정적인 리소스 해체에는 적합하지 않습니다.
23 |
24 |
25 | > 이렇게 객체는 생성, 사용, 소멸의 생성주기를 거치며, 각 단계에서 적절한 리소스 관리와 가비지 컬렉션 처리가 필요합니다. 이를 통해 메모리 누수나 리소스 누수를 방지하고, 효율적인 시스템 운영이 가능하게 합니다.
26 |
--------------------------------------------------------------------------------
/Back-End/JAVA/oom.md:
--------------------------------------------------------------------------------
1 | # OutOfMemoryError가 발생했을 때 해결하는 방법
2 |
3 | ## OutOfMemoryError
4 | `OutOfMemoryError`는 Java 애플리케이션이 사용 가능한 메모리를 모두 소진하였을 때 발생한다.
5 |
6 | 이 오류는 종종 메모리 누수나 리소스 누스를 방지하고, 효율적인 시스템 운영이 가능하게 한다.
7 |
8 | ## 해결 방법
9 |
10 | ### JVM의 힙 크기 조정
11 |
12 | JVM에 할당된 힙 메모리 크기를 늘리는 것으로 임시적인 해결책이 될 수 있다. `-Xmx`, `-Xms`옵션을 사용해 초기 힙 크기와 최대 힙 크기를 조정할 수 있다.
13 |
14 | 이 방법은 OutOfMemoryError를 일으킨 원인이 데이터 처리량의 일시적인 증가 등으로 인한 것일 경우 유효하다.
15 |
16 | ### 메모리 누수 탐색
17 |
18 | 메모리 누수가 오류의 원인일 경우, 메모리 누수를 찾아 수정해야 합니다.
19 |
20 | 객체 참조를 적절히 제거하지 않으면 가비지 컬렉터가 그 객체를 회수할 수 없으므로 메모리 누수가 발생할 수 있습니다.
21 |
22 | Java 프로파일러를 사용하여 메모리 사용 패턴을 관찰하고 누수를 탐지하는 데 도움이 될 수 있습니다.
23 |
24 | ### 코드 최적화
25 | 데이터 구조를 효율적으로 사용하거나, 불필요한 객체 생성을 피하는 등의 방법으로 메모리 사용량을 줄일 수 있습니다. 또한, 스트림이나 대형 파일을 처리할 때에는 데이터를 한번에 모두 로드하지 않고 필요한 만큼만 로드하여 메모리 사용량을 줄일 수 있습니다.
26 |
27 | ### 리소스 사용 최적화
28 |
29 | 데이터베이스 연결, 파일 핸들링 등 시스템 리소스를 사용할 때는 적절하게 닫아 주어야 합니다. 이러한 리소스가 제대로 닫히지 않으면 메모리 누수가 발생할 수 있습니다.
30 |
31 | > 이런 방법들로 OutOfMemoryError를 해결할 수 있습니다. 하지만 정확한 원인 파악이 중요하므로, 먼저 프로파일러나 메모리 분석 도구를 사용하여 문제를 분석하는 것이 좋습니다.
--------------------------------------------------------------------------------
/Back-End/JAVA/reference.md:
--------------------------------------------------------------------------------
1 | # 자바의 네 가지 참조 유형(Strong, Weak, Soft, Phantom)
2 |
3 | ## 강한 참조 Strong Reference
4 |
5 | 이것은 우리가 가장 일반적으로 사용하는 참조 유형입니다.
6 |
7 | 강한 참조가 객체에 연결되어 있으면, 가비지 컬렉터는 그 객체를 회수하지 않습니다.
8 |
9 | ## 약한 참조 Weak Reference
10 |
11 | WeakReference 클래스를 사용해 객체에 대한 약한 참조를 만들 수 있습니다.
12 |
13 | 가비지 컬렉터가 실행되면, 약한 참조만이 남아있는 객체는 메모리에서 제거됩니다.
14 |
15 | ## 소프트 참조 Soft Reference
16 |
17 | SoftReference 클래스를 사용해 만듭니다.
18 |
19 | 소프트 참조는 메모리가 부족할 때까지 가비지 컬렉션의 대상이 되지 않습니다.
20 |
21 | 즉, 가비지 컬렉터가 실행되더라도 충분한 메모리가 있는 경우에는 소프트 참조가 가리키니는 객체는 회수되지 않습니다.
22 |
23 | ## 팬텀 참조 Phantom Reference
24 |
25 | PhantomRefernce 클래스를 사용하여 만들 수 있습니다.
26 |
27 | 팬텀 참조는 참조된 객체가 가비지 컬렉션에 의해 회수되도록 허용합니다.
28 |
29 | 이 참조 유형은 주로 객체가 메모리에서 제거되기 전에 수행해야 하는 특별한 종료 작업을 처리하는데 사용됩니다.
30 |
31 | > 이들 참조 유형은 모두 java.lang.ref 패키지에 속해있으며, 각각의 사용 방법은 상황에 따라 다르지만 메모리 관리 및 리소스 정리에 있어서 중요한 도구입니다.
32 |
33 |
--------------------------------------------------------------------------------
/Back-End/JAVA/string_pool.md:
--------------------------------------------------------------------------------
1 | # Java String Pool
2 |
3 | 자바의 String Pool은 JVM의 힙 메모리 영역에 위치한 특별한 저장소입니다.
4 |
5 | **이곳은 특히 문자열 리터럴을 저장하고 공유하기 위한 공간입니다.**
6 |
7 | 자바에서 문자열 리터럴 코드에 직접 쓰여진 문자열을 가리키며, 컴파일 시점에 String Pool에 저장되며, 이를 통해 JVM은 문자열에 대한 메모리 사용량을 효율적으로 줄일 수 있습니다.
8 |
9 | ### 예시
10 |
11 | 예를 들어 "Hello" 라는 문자열 리터럴이 여러 곳에서 사용되면, 이 모든 경우에 대해 메모리에 하나의 Hello 라는 문자열 인스턴스만 생성되고, 해당 인스턴스에 대한 참조만이 공유됩니다.
12 |
13 | 즉, 같은 값을 가진 문자열 리터럴은 String Poold에서 한 번만 저장되므로, 같은 값의 문자열을 여러 번 사용하는 경우 메모리 사용량을 크게 줄일 수 있습니다.
14 |
15 | 그러나 이러한 특징은 new 연산자를 사용해 명시적으로 새로운 String 객체를 생성하는 경우에는 적용되지 않습니다. 즉 String s = new String("Hello"); 와 같이 문자열을 생성하면, String Pool을 사용하지 않고 힙 메모리에 새로운 String 객체가 생성됩니다.
--------------------------------------------------------------------------------
/Back-End/Node/node.md:
--------------------------------------------------------------------------------
1 | # Node.js
2 |
3 | ## Node 란?
4 | `JavaScript의 Runtime(실행기)` : 브라우저 없이도 사용할 수 있는 JS 실행기
5 | `활용` : 서버, 데스크탑 웹, 모바일 웹, 게임 , but `속도가 느리므로` 운영체제에서는 사용 안한다.
6 |
7 |
8 |
9 | ### 제작된 과정
10 | 원래 JS는 구글에서 개발한 `V& 엔진` 이라는 웹브라우저 내부에서 실행되는 JS엔진을 통하여 웹브라우저에서만 사용가능했다. 하지만 구글이 오픈소스로 풀어버린 이후 브라우저 바깥으로 JS를 빼버리게 된 것이 `Node.js` 이다.
11 |
12 | > 한계 : 하지만, 브라우저에서 벗어났기 때문에 document / window 객체는 사용불가능
13 |
14 | ### 설치
15 | [Node.js 설치 페이지](https://nodejs.org/ko/) 에서 `LTS` 버전을 사용했다.
16 | `LTS버전`은 Long Term Support의 약자로 안정적인 버전으로 3년간 유지보수 / 업데이트를 지원한다
17 |
18 |
19 |
20 | ## 컴파일 언어 vs 런타임(인터프리터) 언어
21 |
22 | ### 1. 컴파일 언어
23 | - `전체`를 번역하고 실행하고 CPU가 알아들을 수 있는 언어다. 번역이 되면 실행기 없이도 앱 동작이 가능하다 `속도가 빠르다`
24 | - C / C++
25 |
26 |
27 |
28 | ### 2. 런타임(인터프리터) 언어
29 | - 중간중간 실행 가능하고 명령이 오면 `즉각` 실행 가능하다. 실행에 필요한 것들을 모아놓은 `환경`을 뜻하는 런타임에 걸맞게 실행기가 있어야만 프로그램 동작 가능하다. 컴파일에 비해 상대적으로 느리다.
30 | - Python / JS
31 |
32 |
33 |
34 | ### REPL
35 | - Node의 Shell을 뜻하고 사용자가 어떤 값을 입력하면 결과 읽고 해석하고 출력하고 반복하는 `터미널` 이다. Read Eval Print Loop 의 줄임말
36 |
37 |
38 |
39 | ### Express
40 | - Node.js의 대표적인 `웹 프레임워크` 로서 손쉽게 웹서버를 구축할 수 있게 만든 프레임워크다. 웹서버를 구축하기 위해서는 포괄적으로 가능하게 만든 Node.js 보다는 세세하게 조작가능한 Express를 사용하는 것이 좋다.
41 |
42 |
43 |
--------------------------------------------------------------------------------
/Back-End/Node/npm.md:
--------------------------------------------------------------------------------
1 | # Npm(Node.js) - 기초 명령어 사용법 정리
2 |
3 | ## npm(node.js) - 명령어 기본 설명
4 | 1. npm - node.js를 설치하면 자동으로 함께 설치 된다.
5 | 2. 실제 프로젝트에서 npm 기반 모듈 설치 & 제거 및 버전 관리 사용법은 정말 중요하다
6 | 3. 프로젝트 초기에 각 모듈별 버전 관리를 철저학 ㅔ해야 나중에 꼬이지 않는다.
7 |
8 |
9 |
10 | ### npm - 도움말 옵션(-h)
11 | ```bash
12 | # npm 커맨드 확인
13 | npm -h
14 |
15 | # npm 커맨드 세부사항 확인
16 | npm 커맨드 -h
17 | ```
18 |
19 |
20 |
21 | ### npm - list
22 | ```bash
23 | # 현재 프로젝트 설치된 모듈 확인
24 | npm list
25 |
26 | # npm 전역에 설치 모듈 확인
27 | npm list -g
28 |
29 | # depth 옵션
30 | npm list -g --depth=0
31 | ```
32 |
33 |
34 |
35 | ### npm - view
36 |
37 | ```bash
38 | # 모듈의 최신버전 확인
39 | npm view 모듈명 version
40 | ```
41 |
42 |
43 |
--------------------------------------------------------------------------------
/Back-End/Node/npm1.md:
--------------------------------------------------------------------------------
1 | # 패키지 설치 / 삭제 명령어
2 |
3 | - 외부 모듈인 패키지를 설치/삭제하는 명령어이다.
4 |
5 | ## 1. 패키지 설치
6 | - 명령어 : n`pm install 패키지명`
7 | - 패키지를 현재 프로젝트의 node_modules 폴더에 설치한다
8 | - package.json 파일의 dependencies 항목에도 자동으로 추가 된다.
9 | > 과거에는 dependencies에 패키지를 추가하기 위해 npm install --save 패키지명 으로 설치했으나, npm@5 버전 이후부터는 디폴트로 적용되므로 --save를 붙이지 않아도 된다.
10 | - `npm i 패키지명` 으로 축약가능하다
11 | - `npm install 패키지명@버전` 으로 버전을 지정 가능
12 | - `npm install 주소`로 패키지 설치 주소를 지정하여 설치가능
13 |
14 |
15 |
16 | ## 2. 패키지 여러개 설치
17 | - 명령어 : `npm install 패키지1 2 3..`
18 | - 여러개의 패키지를 동시에 설치한다.
19 |
20 |
21 |
22 | ## 3. 전역 설치
23 | - 명령어 : `npm install -global 패키지명`
24 | - npm 자체가 설치되어 있는 폴더에 패키지를 설치하여 어디서나 참조할 수 있게 한다.
25 | > 맥, 리눅스의 경우 , sudo를 붙여서 sudo npm i --global 패키지명 으로 설치해야 할 수 있다.
26 |
27 | > `npm i -g 패키지명` 으로 축약가능
28 |
29 |
30 |
31 | ## 4. 개발용 설치
32 | - 명령어 : `npm install --save-dev 패키지명`
33 | - package.json 파일의 devDependencies 항목에 추가되도록 설치한다
34 | > `npm i -D` 로 축약 가능
35 |
36 |
37 |
38 |
39 | ## 5. package.json 파일을 사용한 설치
40 | - 명령어 `npm install`
41 | - package.json 파일이 저장된 폴더에서 명령어를 실행하면 , dependencies 항목에 기록된 패키지들을 모두 자동으로 설치해 준다.
42 |
43 |
44 |
45 | ## 6. 패키지 삭제
46 | - 명령어 : `npm uninstall 패키지명`
47 | - node_modules 폴더에 설치된 패키지를 삭제한다. package.json의 dependencies 항목에서도 제거 된다.
48 | > npm rm 패키지명 으로 축약가능
49 |
--------------------------------------------------------------------------------
/Back-End/Node/npm2.md:
--------------------------------------------------------------------------------
1 | # 기타 명령어
2 |
3 | ### npm -version
4 | - npm 자체의 버전 체크
5 | > npm -v 로 축약 가능
6 |
7 |
8 |
9 | ### npm install -g npm
10 | - npm 자체의 버전 업그레이드
11 | > 맥 리눅스의 경우에는 sudo를 붙여야 할 수도있다.
12 |
13 |
14 |
15 | ### npm outdated
16 | - 업데이트 가능한 패키지가 있는지 체크
17 |
18 |
19 |
20 | ### npm update 패키지명
21 | - 패키지를 최신 버전으로 업데이트
22 |
23 |
24 |
25 | ### npm info 패키지명
26 | - 패키지의 상세 정보 파악
27 |
28 |
29 |
30 | ### npm search 검색어
31 | - npm 서버의 패키지 검색
32 |
33 |
34 |
35 | ### npm help
36 | - 명령어 목록 확인
37 |
38 |
39 |
40 | ### npm ls
41 | - 설치된 패키지들의 구조를 보여준다.
42 | > npm ls 패키지명 : 패키지와 관련된 구조만 노출
43 | > npm ll : 더 상세한 패키지 구조 정보 노출
44 |
45 |
46 |
47 | ### npx 패키지명 [옵션]
48 | - 설치하지 않은 패키지를 전역처럼 콘솔에서도 사용할 수 있도록 해주는 명령어
49 | - 즉, node_modules/bin 폴도에서 해당 패키지의 바이너리 파일을 찾아서 실행시켜 준다.
50 | - 만약 해당 패키지가 없다면 임시로 다운로드 받아 설치하여 실행시킨다.
51 | > npx에 대한 내용은 길어질 수 있으므로 생략
52 | > 사용예시 : npx pm2 list
53 |
54 |
55 |
56 |
57 | ## Node.js가 패키지를 참조하는 방식
58 | - node.js 에서 외부모듈을 사용하면, 아래와 같은 순서로 패키지를 찾아간다.
59 |
60 | 1. `현재 실행 중인 폴더` 에서 찾는다 (최우선 순위)
61 | 2. `상위 폴더로 이동`해서 찾는다.
62 | 3. `전역 패키지가 설치된 폴더`로 이동해서 찾는다.
--------------------------------------------------------------------------------
/Back-End/Node/npmjson.md:
--------------------------------------------------------------------------------
1 | # package.json 생성
2 | - 수많은 패키지를 다운받다보면 관리가 어려워진다.
3 | - 그래서 프로젝트마다 package.json 파일을 만들어서 패키지 목록 및 버전을 관리한다.
4 | > 프로젝트를 생성하자마자 package.json을 만들어주고 시작하길 권장한다.
5 |
6 | - 명령어 : `npm init`
7 |
8 |
9 |
10 | 1. package name 등의 정보를 입력해준다. 필요 없는 항목은 엔터키로 스킵가능
11 | 2. 마지막에 Is this OK? 항목에서 yes 입력한다.
12 |
13 | - 정상적으로 파일을 생성했다면 아래의 3가지 파일 및 폴더가 생성될 것이다.
14 | > 단 , 외부 패키지를 전혀 설치하지 않은 초기 상태라면 node_modules 폴더, package-lock.json 파일은 생성되지 않을 수 있다.
15 |
16 |
17 |
18 | ## 1. package.json 파일
19 | - 설치된 패키지를 `dependencies` 항목에서 관리한다.
20 |
21 | ```json
22 | {
23 | "name" : "node.package",
24 | "version" : "1.0.0",
25 | "description" : "my node package",
26 | "main" : "index.js",
27 |
28 | "scripts" : {
29 | "test" : "echo / Error: no test specifed\ && exit 1 "
30 | },
31 | "dependencise" : {
32 | "socket.io" : "^4.1.2"
33 | }
34 | }
35 | ```
36 |
37 |
38 |
39 | ## node-modules 폴더
40 | - 설치한 패키지가 실제로 저장되어 있는 폴더이다.
41 | - 설치한 패키지가 의존하는 다른 패키지도 함께 설치되어야 저장된다.
42 |
43 |
44 |
45 | ## package-lock.json 파일
46 | - 설치한 패키지 + 의존하는 패키지 항목을 모두 관리한다.
--------------------------------------------------------------------------------
/Back-End/backend/eviction.md:
--------------------------------------------------------------------------------
1 | # Cache Eviction, Expiration, Passivation
2 |
3 | cache는 속도를 위해 대부분 메모리를 사용한다.
4 |
5 | 메모리는 디스크에 비해 사용 공간이 훨씬 적다.
6 |
7 | ### Eviction
8 | 공간이 필요할 때 어떤 데이터를 지워주는 것이다.
9 |
10 | 메모리가 가득 차면 사용하지 않는 데이터를 지워저야 새로운 데이터가 들어올 수 있다.
11 |
12 | 대부분 LRU(Least Recently Used)라는 **가장 오랜 기간 참조되지 않는 데이터를 교채** 알고리즘 방식을 사용한다.
13 |
14 | ### Expiration
15 |
16 | 데이터의 유통기한이다.
17 |
18 | 일반적으로 TTL(TIme To Live)라는 단어를 사용한다.
19 |
20 | ### Passivation
21 |
22 | 기능을 사용하면 eviction의 대상이 되는 데이터가 **지워지기 전에 우선 디스크등 다른 스토리지에 저장**한다.
23 |
24 | 추후 같은 데이터에 대한 요청이 들어오면 파일에서 찾아 돌려준다.
--------------------------------------------------------------------------------
/Back-End/backend/history.md:
--------------------------------------------------------------------------------
1 | # Java Backend 웹 기술 역사
2 |
3 | ### 과거
4 | - 1997년 `Servlet`
5 | - 자바 코드로 짜야 하므로 HTML을 동적으로 생성하는게 어려웠다.
6 | - 199년 `JSP`
7 | - HTML 생성은 편리하지만 비즈니스 로직까지 너무 많은 역할을 담당하게 된다.
8 | - Selvet,JSP를 조합한 `MVC 패턴`
9 | - 모델 뷰 컨트롤러로 역할을 나누어 개발한다.
10 | - 2000년 초 ~ 2010년 초 `MVC 프레임워크 춘추 전국 시대`
11 | - MVC 패턴을 자동화한다.
12 | - 복잡한 웹 기술을 편리하게 사용할 수 있는 다양한 기능을 지원한다.
13 |
14 |
15 |
16 | ### 현재
17 | - 어노테이션 기반의 스프링 MVC
18 | - @Controller
19 | - MVC 프레임워크의 춘추 전국 시대가 마무리된다.
20 | - Spring boot의 등장
21 | - 서버를 내장한 스프링 부트가 등장한다.
22 | - 과거에는 서버에서 WAS를 직접 설치하고 소스는 WAR파일을 만들어 설치한 WAS에 배포했다
23 | - 스프링 부트는 빌드 결과인 JAR에 WAS 서버가 포함되어 빌드가 단순화 되었다.
24 |
25 |
26 |
27 | ### 최신
28 | 스프링 웹 기술이 분화되고 있다.
29 | - Web Servlet
30 | - Spring MVC
31 | - Web Reactive
32 | - Spring WebFlux
33 |
34 | #### WebFlux
35 | - 비동기로 non blocking을 처리한다.
36 | - 최소의 스레드로 최대 성능을 낸다.
37 | - 스레드 컨텍스트 스위칭 비용을 효울화한다.
38 | - 함수형 스타일로 개발 가능하다.
39 | - 동시 처리 코드의 효율성을 높인다.
40 | - 서블릿 기술을 사용하지 않는다.
41 | - netty를 사용
42 |
43 | 하지만 웹 플럭스는 기술적인 난이도가 매우 높다. 아직 RDB에 대한 지원이 부족하다. 일반 MVC의 스레드 모델도 충분히 빨라서 실무에서 아직 많이 사용하지는 않는다.
44 |
45 |
46 |
47 | ### 자바 뷰 템플릿\
48 | HTML을 편하게 생성하는 뷰 기능이다
49 |
50 | #### JSP
51 | 속도 문제를 해결했으면 다양한 기능이있다.
52 |
53 | #### 타임리프
54 | 내추럴 템플릿으로 HTML의 모양을 유지하면서 뷰 템플릿을 적용할 수 있다. 스프링 MVC와 기능이 통합되어 있어 최선의 선택이다. 단, 성능은 프리마커와 벨로시티가 더 빠르다.
--------------------------------------------------------------------------------
/Back-End/backend/image/apidocs.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/backend/image/apidocs.png
--------------------------------------------------------------------------------
/Back-End/backend/image/cleanarchitecture.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/backend/image/cleanarchitecture.jpeg
--------------------------------------------------------------------------------
/Back-End/backend/image/msa.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/backend/image/msa.png
--------------------------------------------------------------------------------
/Back-End/backend/image/msa등장.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/backend/image/msa등장.png
--------------------------------------------------------------------------------
/Back-End/backend/image/pub_sub1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/backend/image/pub_sub1.png
--------------------------------------------------------------------------------
/Back-End/backend/image/pub_sub2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/backend/image/pub_sub2.png
--------------------------------------------------------------------------------
/Back-End/backend/image/pub_sub3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/backend/image/pub_sub3.png
--------------------------------------------------------------------------------
/Back-End/backend/image/pub_sub4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/backend/image/pub_sub4.png
--------------------------------------------------------------------------------
/Back-End/backend/image/모놀리식.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/backend/image/모놀리식.png
--------------------------------------------------------------------------------
/Back-End/backend/mono.md:
--------------------------------------------------------------------------------
1 | # 모놀리식 아키텍처 (Monolithic Architecture)
2 |
3 | ### 모놀리식 아키텍처
4 | - 전통의 아키텍처를 지칭한다. 소프트웨어의 모든 구성요소가 한 프로젝트에 통합 되어 있는 형태다.
5 | - 모놀리식 아키텍처의 경우 모든 프로세스가 긴밀하게 결합되고 단일 서비스로 실행된다.
6 | - 따라서 애플리케이션의 한 프로세스에 대한 수요가 급증하면 해당 아키텍처 전체를 확장해야한다.
7 | - 코드베이스가 증가하게 되면 모놀리식 애플리케이션의 기능을 추가하거나 개선하기가 더 복잡해진다.
8 |
9 | ### 장점
10 | 1. 소규모 프로젝트에서는 합리적이다.
11 | 2. 개발, 빌드, 배포, 테스트가 용이하다.
12 |
13 | ### 단점
14 | 1. 어플리케이션 구동시간이 늘어나고 빌드, 배포 시간이 길어진다.
15 | 2. 조그마한 수정사항이 있어도 전체를 다시 빌드하고 배포해야한다.
16 | 3. 많은 양의 코드가 몰려있어 유지보수가 힘들다.
17 | 4. 일부부느이 오류가 전체에 영향을 미친다.
18 | 5. 기능별로 알맞는 기술, 언어, 프레임워크를 선택하기가 까다롭다.
19 | 6. scale out이 불가능하다.
20 |
21 |
22 |
23 | ### 마이크로 서비스 아키텍처와 비교
24 |
25 | 
--------------------------------------------------------------------------------
/Back-End/backend/netty.md:
--------------------------------------------------------------------------------
1 | # Netty
2 |
3 | Netty(네티)는 자바 기반의 비동기 이벤트 기반 네트워크 애플리케이션 프레임워크이다.
4 |
5 | ### 네티를 왜 사용하는가?
6 |
7 | 네티를 사용하면 TCP, UDP, HTTP 및 웹소켓과 같은 다양한 프로토콜을 처리할 수 있으며, **고성능, 확장성 및 유연성을 제공**한다.
8 |
9 | 네트워크 애플리케이션을 그냥 자바의 소켓 프로그래밍을 통해 구현하는 것에 비해 네티의 추상화로 인해 얼마나 간결하게 자바 네트워크 프로그래밍을 할 수 있는지를 보여준다.
10 |
11 | ### 네티에서 데이터 이동의 방향성
12 |
13 | 네티는 이벤트를 Inbound 이벤트, Outbound 이벤트로 구분한다.
14 |
15 | 클라이언트로 부터 데이터를 수신할 때 발생하는 이벤트에 관심이 있다면, Inbound 이벤트 중 하나인 데이터 수신 이벤트를 담당하는 메서드에 원하는 로직을 넣으면 된다.
16 |
17 | ## 동작 방식
18 |
19 | 
20 |
21 | 소켓의 동작방식이 다르므로 입출력을 위한 메서드 및 프로그램 호출 구조가 다르다.
22 |
23 | 하지만 네티는 소켓의 모드와 상관없이 개발할 수 있도록 추상화된 전송 API를 제공한다.
24 |
25 | 따라서 소켓 모드를 바꾸기 위해서 데이터 송수신 부분의 로직을 고치지 않아도 된다.
26 |
27 | ## NIO(Non-Blocking I/O)
28 |
29 |
30 | NIO는 자바에서 제공하는 I/O 처리 방식 중 하나로, 기존의 I/O 방식인 스트림 기반에 I/O 처리 방식과 다르게 채널(Channel)과 버퍼(Buffer)를 사용해 작업을 처리합니다.
31 |
32 |
--------------------------------------------------------------------------------
/Back-End/backend/pub_sub.md:
--------------------------------------------------------------------------------
1 | # PUB/SUB (발행/구독) 아키텍처의 이해
2 |
3 | 두명의 사용자 클라이언트가 있다. 사용자는 서버와 웹소켓으로 연결되어 있는데, 구독하는 주소를 동일하게 no01에 구독하도록 설정했다.
4 |
5 | 
6 |
7 | 발행자 메시지의 타겟을 no01로 설정해서 메시지를 보냈는데, 서버에서는 발행자의 메시지를 확인한 후 no01 채널을 구독하는 모든 사용자(클라이언트)에게 메시지를 보내고싶어한다.
8 |
9 | 구독url이 다른 사용자는 어떻게 될까? 아래 그림과 같이, 다른 구독 url로 구독중이라면 메시지를 받지 못하게 된다.
10 |
11 | 
12 |
13 | 구독과 발행 역할을 동시에 수행할 수 있다.
14 |
15 | 
16 |
17 | 구독과 발행을 동시에 하는 대표적인 예시는 채팅 기능이다. 채팅 메시지는 단방향으로만 받기만 하지 않는다. 서로 메시지를 주고 받아야 한다.
18 |
19 | 조금만 더 구체적으로 알아보자. 각 구독자는 각각의 큐를 갖는다. 쉽게 이해하면, 개인 우편함이라 생각해도 된다.
20 |
21 | 아파트에 가면 각각의 호수 번호가 적혀잇는 우편함을 볼 수 있다. 우편함에는 주소가 적혀 있을 것이다.
22 |
23 | 신문을 구독하면 아침마다 집 문앞에 신문이 놓여있던 신문 배달이란 것이 있었다. 사용자 1, 2는 조선일보 신문을 받고, 사용자3은 한겨례 신문을 받기로 했다면, 조선일보 신문이 no01이라는 구독 채널이고, 한겨례 신문이 no02 라는 구독 채널이라고 생각해도 된다. 각자 구독중인 신문만 받아야하고, 각자 우편함이 따로 존재할 것이다.
24 |
25 | 
26 |
27 | 암튼, 발행자는 반드시 채널 id를 지정해서 전달해야한다. 그래야 해당 채널을 구독중인 사용자에게 메시지를 보낼 것이다.
28 |
29 | 채널 아이디에 해당하는 구독자가 전혀 없다면, 메시지는 전송 되지 않을것이다.
--------------------------------------------------------------------------------
/Back-End/backend/test_cov.md:
--------------------------------------------------------------------------------
1 | # IntelliJ 테스트 커버리지 확인하기
2 |
3 | Proejct -> test -> java에서 우클릭 -> Run 'Tests in '...'' with Coverage 선택
4 |
5 | 
6 |
7 | 그러면 이렇게 테스트 커버리지를 확인할 수 있다.
8 |
9 | 왼쪽 Project 탭에는 패키지/클래스별 커버리지 퍼센테이지가 나타난다.
10 |
11 | 중간 소스탭에는 커버된 부분은 초록색으로, 커버되지 않은 부분은 붉은색으로 나타난다.
12 |
13 | 우측 커버리지탭에서는 Element별 커버리지를 볼 수 있고, 클릭하여 하위로 접근할 수도 있다.
14 |
15 | 
16 |
17 | 이를 이용해 테스트를 조금 더 강화시켜보면 좋을 것 같다.
--------------------------------------------------------------------------------
/Back-End/git/conflict.md:
--------------------------------------------------------------------------------
1 | # conflict - 충돌 해결
2 |
3 | - 같은 파일을 부득이 수정하는 경우가 생기고 필연적으로 충돌이 발생하는데, 강제로 상황을 만들고 충돌을 해결하는 방법을 알아보자.
4 |
5 | `update-red` 브랜치에서 수정한 `red`파일을 `main` 브랜치에서도 수정하여 충돌 상황을 만들어보자.
6 |
7 |
8 |
9 | ### 작업
10 | 1. `main` 브랜치에서 `red`파일 수정
11 | 2. 전체 변경사항을 인덱스에 추가
12 | 3. 커밋 작성
13 | 4. `update-red` 브랜치를 `main`으로 머지
14 |
15 | ```bash
16 | echo "빨간색" > red
17 | git add -A # gaa
18 | git commit -m "update red color"
19 | git merge update-red
20 | ```
21 |
22 | `result` : conflict라는 메시지와 함께 실패
23 |
24 | > ### CONFLCIT
25 | > 충돌은 정말 마주치고 싶지 않은 상황입니다. 하지만, 상황이 발생했으면 해결해야 합니다.
26 | > 충돌을 해결하고 커밋을 하거나, 머지 작업을 취소할 수 있습니다.
27 |
28 |
29 |
30 | ```
31 | <<<<<<< HEAD
32 | 빨간색
33 | ======
34 | 붉은색
35 | >>>>>>> update-red
36 | ```
37 | - 충돌이 발생하면 양쪽 브랜치에서 동시에 변경된 사항을 표시해 줍니다.
38 | - `<<<<<<<` , `=======` , `>>>>>>>` 이 내용이 충돌이 발생한 지점을 의미합니다.
39 |
40 |
41 |
42 | 위에 내용은 `main` 브랜치에서 작업한 내용이고 아래 내용은 `update-red` 브랜치에서 작업한 내용이다. 둘중에 어떤 내용이 맞는지는 개발자가 스스로 판단하고 선택해야한다.
43 |
44 | - 여기선 붉은 색만 남기고 다른 줄을 삭제한다.
45 | - 충돌을 해결했다면 기존과 동일한 방식으로 커밋을 진행한다 여기서 차이점은 `commit -m` 메세지를 입력하지 않고 commit 만한다.
46 | - 충돌을 수정한 내용을 자동으로 메시지로 만들기 때문에 입력 안해도 된다.
47 |
48 | ```bash
49 | git add -A
50 | git commit
51 | ```
52 |
53 | > vi 창이 열리고 메시지를 입력하는 화면이 나오면 당황하지 말고 esc 키를 누르고 :x를 차례로 입력한 다음 엔터를 친다.
--------------------------------------------------------------------------------
/Back-End/git/issue.md:
--------------------------------------------------------------------------------
1 | # Issue
2 | - 이슈는 프로젝트의 작업, 개선 사항 및 버그를 추적하는 좋은 방법으로 사용된다.
3 | - 프로젝트 기획, 새롭게 추가될 기능, 버그와 수정사항 모든 것을 이슈라고 할 수 있다.
4 | - 모든 활동 내역에 대해서 이슈를 등록하고 등록한 이슈를 기반으로 작업을 진행할 수 있다.
5 | - 개발자간 idead, work, bug(problem)을 다루기 위히 깃허브는 이슈를 사용합니다.
6 | - 아이더 구현에 관한 논의
7 | - 작업 진행사항 추적
8 | - 기능 제한 수락, 질문, 요청 지원 또은 버그 보고
9 | - 정교한 코드 구현
10 | - 이슈를 등록하기 위해 보통 다음 단계를 거칩니다.
11 | - 이슈 탭을 눌러 엽니다.
12 | - 해당 문제, 상황을 재현할 수 있는 최대한 많은 정보를(context) 제공합니다.
13 | - 해당 환경 정보(버전, os등) 관련이 있다고 생각하는 모든 정보를 제공합니다.
14 | - 이슈를 등록하게 되면 보통 다음 단계를 거칩니다.
15 | - 프로젝트 팀(혹은 매니저)이 라벨과 담당자를 지정합니다.
16 | - 담당자가 최대한 빨리 답변하기 위해 노력합니다.
17 | - 해결이 되거나 오랜 기간 답변이 없다면, 이슈는 답합니다.(closed)
18 |
19 | ### 템플릿
20 | - 프로젝트의 핵심 개발자와 관리자는 이슈의 오남요을 막기 위해 template을 만들었습니다.
21 | - 깃허브에는 .github 폴더 밑에 이슈 템플릿을 작성합니다.
22 | - @mentions: 해당 ID를 가진 사람에게 알림을 보냅니다.
23 | - #reference #9999 처럼 숫자로 사용합니다. 다른 이슈를 참조합니다.
24 | - /cc: Carbon Copy 의 줄임말로 참조를 뜻합니다. 뒤에 멘션을 붙입니다.
25 | - /assign: 뒤에 멘션을 붙여 담당자를 지정합니다.
26 | - /milestone: 애자일 스프린트 시간 설정 기능입니다.
27 | - /label: 다양한 이슈를 관리하기 위해 라벨을 붙입니다.
28 | - /due: 목표일을 지정합니다.
29 |
30 | ### 머지 요청
31 | - 해결한 문제는 merge request하면 프로젝트 관리자가 메인 브랜치와 병합하게 됩니다.
--------------------------------------------------------------------------------
/Back-End/git/log.md:
--------------------------------------------------------------------------------
1 | # git log - 이력확인
2 | - git log는 다양한 옵션을 조합하여 원하는 형태의 로그를 출력할 수 있는 강력한 기능입니다. 이번 실습에선, 추가 옵션 없이 `git log`만 사용합니다.
3 |
4 | ### 작업
5 | 1. 전체 로그 확인
6 |
7 | ```bash
8 | git log
9 | ```
10 |
11 | 결과
12 |
13 | ```bash
14 | commit 306b9474de0af37367ff90e5c1367588413f81bf (HEAD -> main)
15 | Author: subicura
16 | Date: Sat Jul 17 00:55:36 2021 +0900
17 |
18 | v3 commit
19 |
20 | commit 27a00b73cf7ab2e70e8dd5e5235bf7f94e9ddd84
21 | Author: subicura
22 | Date: Sat Jul 17 00:53:50 2021 +0900
23 |
24 | v2 commit
25 |
26 | commit 1ac5146ad27c5277996d54c08ec4ccded0edd4e3
27 | Author: subicura
28 | Date: Sat Jul 17 00:50:30 2021 +0900
29 |
30 | v1 commit
31 | ```
32 | - 전체 커밋 로그 확인.
--------------------------------------------------------------------------------
/Back-End/git/pushR.md:
--------------------------------------------------------------------------------
1 | # 다른사람 Repo 관리
2 |
3 | 1. 먼저 collaborator로 초대를 받는다.
4 | 2. 이메일에서 초대를 승인한다.
5 |
6 |
7 |
8 | ## 다른사람의 Repo를 내 Repo로 가져오기
9 |
10 | 1. 내 깃허브에서 가져올 리포의 이름과 동일한 새 리포를 생성. 이때, README, gitignore, license는 모두 초기화 하지 않는다.
11 |
12 | 2. 가져올 repo를 내 컴퓨터에 다음과 같이 clone 한다.
13 |
14 | ```bash
15 | git clone
16 | ```
17 |
18 | 3. clone 한 local repo를 1번에서 만든 새 repo와 연결
19 | ```bash
20 | git remote add origin
21 | ```
22 |
23 | 4. 다음과 같이 알잘딱
24 |
25 | ```bash
26 | git branch -M main
27 | git push -u origin master
28 | ```
--------------------------------------------------------------------------------
/Back-End/git/revert.md:
--------------------------------------------------------------------------------
1 | # 이전 버전으로 되돌리기 ,
2 |
3 | - 이전 버전 보고 돌아오기
4 |
5 | 이전 커밋의 소스를 확인하고 싶을 경우, 두가지 방법이 있다.
6 |
7 | 1. 커밋 메시지 보고 특정 커밋으로 되돌리기
8 | - `git log`
9 | 1. 명령 입력 후 위 아래 방향키로 원하는 버전 커밋 찾기.
10 | 2. 'commit' 문구 뒤의 해시코드 앞에서 4자리 이상 복사.
11 | - `git checkout 복사한 4자리 이상 해시코드`
12 | - `git checkout 브랜치 이름`
13 |
14 | 2. 단계별로 되돌아가기
15 | - `git checkout head ~ 1`
16 | - 최신 커밋으로 부터 한단계 전으로 되돌린다.
17 | - 1에 해당하는 부분을 바꿔서 원하는 단계만큼 지정할 수 있다.
18 |
19 |
20 |
21 |
22 | ## 이전 버전으로 되돌리기
23 |
24 | > 되돌렸다가 돌아오지 않고 아예 되돌리고 싶은 경우에도 두 가지 방법이 있지만, 웬만하면 revert를 권장한다.
25 |
26 | 1. 되돌리는 버전을 새로 커밋하기
27 | ```bash
28 | git revert head ~ 1 혹은
29 | git revert head 커밋해시코드
30 | ```
31 | - 앞서 설명한 checkout 의 두 가지 방법 모두 똑같이 revert에 적용 가능.
32 | - revert 명령시 해당 커밋 버전으로 새로 커밋하게 되므로, 커밋 메시지 입력창이 나타난다.
33 |
34 | 2. 되돌리는 버전 이후의 커밋을 삭제하기 (권장 X)
35 |
36 | ```bash
37 | git reset --hard head ~ 1 혹은
38 | git reset --hard 커밋해시코드
39 | ```
40 |
41 | - 남아있는 추가 됐던 파일 지우기
42 |
43 | ### head
44 |
45 | - `head ~` 전단계
46 | - `head ~ 2` 두 커밋 전
47 | - `head ~ 3` 세 커밋 전
48 | > 이런식으로 사용 가능
49 |
50 |
51 | ### + Revert와 Reset의 차이 설명 좀 더 상세히
52 |
53 | - git revert는 기록을 유지하면서 상태를 되돌릴 수 있다.
54 | - git reset 은 기록을 삭제한다.
55 |
56 | > 과거가 필요 없다면 reset 혹시 몰라 남겨야겠다면 revert를 사용
57 |
58 | > revert 사용을 더 권장한다.
--------------------------------------------------------------------------------
/Back-End/git/version.md:
--------------------------------------------------------------------------------
1 | # version
2 |
3 | - Git은 무료로 사용할 수 있는 오픈소스 분산 버전 관리 도구입니다. 리눅스 배포판에는 Git이 기본적으로 설치되어있는 경우가 있습니다. 설치가 되어있지 않은 경우 직접 인스톨러나 패키지 관리자로 설치해야합니다. 원래 설치되어있었거나, 예전에 설치해둔 경우 Git 버전인 경우가 있습니다. 이 글에서는 현재 시스템에 설치된 Git의 버전을 확인하는 방법과 최신 버전으로 업그레이드 하는 방법을 소개합니다.
4 |
5 |
6 | ## Git 버전 확인
7 |
8 | ```bash
9 | git --version
10 | ```
11 |
12 | > git --version을 입력하면 현재 버전을 보여줍니다.
13 |
14 | ## Git 최신 버전 확인
15 | - Git 공식 사이트에서 확인이 가능합니다.
16 |
17 | - [Git](https://git-scm.com/downloads)
--------------------------------------------------------------------------------
/Back-End/git/용어.md:
--------------------------------------------------------------------------------
1 | # 깃허브 용어정리
2 |
3 | ### GitHub
4 | - 소프트웨어 개발 프로젝트를 위한 소스코드 관리 서비스
5 |
6 |
7 |
8 | ## Git 필수 용어
9 |
10 |
11 |
12 |
13 | ### 로컬 저장소
14 | - 저장소는 파일이나 디렉토리를 저장하는 장소라고 한다.
15 | - 자신의 컴퓨터에 있는 저장소를 `로컬저장소`라고 한다.
16 |
17 |
18 |
19 |
20 |
21 | ### 원격 저장소
22 | - 서버나 네트워크에 있는 저장소를 `원격저장소`라고 한다.
23 | - 기본적으로 로컬저장소에서 작업을 수행하고 그 결과를 원격 저장소에 저장하는 방식
24 |
25 |
26 |
27 |
28 | ### init , clone
29 | - git init : 소스코드 파일을 git으로 관리하기 위해 git 저장소를 초기화하는 명령어
30 | - git clone : 깃허브 상 오픈소스 혹은 이미 만들어져 있는 프로젝트 개발에 참여할 대, 원격 저장소를 로컬로 복제해와서 사용하는 명령어
31 |
32 |
33 |
34 |
35 |
36 | ### branch , commit
37 | - branch : 깃 리포지토리를 하나 만들면 기본적으로 메인 브렌치가 하나 생성된 후 메인 브렌치의 소스코드를 그대로 둔 상태에서 main 브랜치의 기능을 추가하거나 유지보수 할 대에 사용한다.
38 |
39 | - commit : 소스코드의 업데이트를 확정하는 의미, 확정된 순간의 코드를 상태를 커밋 메시지와 함께 git 리포지토리에 저장된다. 로컬 저장소에 변경에는 반영되지만 원격 저장소에는 아직 반영되지 않는 상태이다.
40 |
41 |
42 |
43 |
44 |
45 | ### pull, push
46 | - pull : 원격 저장소의 내용을 로컬 저장소에 반영하는 것(fetch + merge)
47 | - push : 커밋을 원격 저장소에 올리는 것 즉 로컬 저장소에서 원격 저장소로 업로드.
48 |
49 |
50 |
51 |
52 |
53 | ### Rebase , Pull Request , checkout
54 | - rebase : 2개의 branch를 합칠 때 사용한다. merge와 비슷하나 merge는 두 branch의 최종결과만 합치나 rebase는 브랜치의 변경사항을 순서대로 다른 브랜치에 적용하면서 합친다.
55 |
56 | - Pull Request : 브랜치에서 완료된 작업을 프로젝트 동료들끼리 리뷰하고, 마스터에 합치도록 요청하는 명령어
57 | - Checkout : branch를 변경하는 ㅁ여령어
--------------------------------------------------------------------------------
/Back-End/http/HTTP기본/connectionless.md:
--------------------------------------------------------------------------------
1 | # 비 연결성 (connectionless)
2 |
3 | 클라이언트와 서버는 요청을 주고 받을때만 연결을 유지하여 최소한의 자원을 사용한다.
4 |
5 | - HTTP는 기본이 연결을 유지하지 않는 모델
6 | - 일반적으로 초 단위 이하의 빠른 속도로 응답
7 | - 1시간 동안 수천명이 서비스를 사용해도 실제 서버에서 동시에 처리하는 요청은 수십개 이하로 매우 작음 예) 웹 브라우저에서 계속 연속해서 검색 버튼을 누르지 않는다.
8 | - 서버 자원을 매우 효율적으로 사용 가능함
9 |
10 | #### 한계와 극복
11 | - TCP/IP 연결을 새로 맺어야함 > 3 way handshake 시간 추가
12 | - 웹 브라우저로 사이트를 요청하면 html 뿐만 아니라 js , css ,image 등 수 많은 자원이 함께 다운로드
13 | - 지금은 http 지속 연결로 문제 해결
14 | - http//2 , http/3 에서 더 많은 최적화
15 |
16 | 
17 |
18 | #### Stateless 를 기억하자
19 | 서버 개발자들이 어려워하는 업무
20 |
21 | - 정말 같은 시간에 딱 맞추어 발생하는 대용량 트래픽
22 | - 예 ) 선착순 이벤트, 명절 ktx 예약, 학과 수업 등록
23 | - 예 ) 저녁 6시 선착훈 1000명 치킨 할인 이벤트 > 수만명 동시 요청
24 |
--------------------------------------------------------------------------------
/Back-End/http/HTTP기본/everyhttp.md:
--------------------------------------------------------------------------------
1 | # 모든 것이 HTTP
2 |
3 | **HTTP (Hyper Text Transfer Protocol)**
4 | html을 전송하는 프로토콜로 처음 시작됐는데 지금은 모든 것을 전송할 수 있다.
5 | - HTML , TEXT
6 | - IMAGE , 음성 , 영상 , 파일
7 | - JSON , XML(API)
8 | - 거의 모든 형태의 데이터 전송 가능
9 | - 서버간에 데이터를 주고 받을 때도 대부분 HTTP 사용
10 | - 지금은 HTTP의 시대
11 |
12 |
13 |
14 | ### HTTP 역사
15 | - HTTP/0.9 1991년 : GET 메서드만 지원 HTTP 헤더 X
16 | - HTTP/1.0 1996년 : 메서드 , 헤더 추가
17 | - HTTP/1.1 1997년 : 가장 많이 사용, 우리에게 가장 중요한 버전 RFC2068(1997) > RFC2616 (1999) > RFC7230~7235(2014)
18 | - HTTP/2 2015년 : 성능 대선
19 | - HTTP/3 진행중 : TCP 대신에 UDP, 성능 개선
20 |
21 |
22 |
23 | ### 기반 프로토콜
24 | - TCP : HTTP/1.1 , HTTP/2
25 | - UDP : HTTP/3
26 | - 현재 HTTP/1.1 주로 사용
27 | - HTTP/2 , HTTP/3 도 점점 증가
28 |
29 |
30 |
31 | ### HTTP 특징
32 | - 클라이언트 서버 구조로 동작한다.
33 | - 무상태 프로토콜(Stateless) 지향, 비연결성
34 | - HTTP 메시지를 통해서 통신
35 | - 단순하고 확장 가능하다.
36 |
37 |
--------------------------------------------------------------------------------
/Back-End/http/HTTP기본/state.md:
--------------------------------------------------------------------------------
1 | # Stateful, Stateless
2 |
3 | ### 무상태 프로토콜 (Stateless)
4 | - 서버가 클라이언트의 상태를 보존하지 않는다.
5 |
6 | #### 장점
7 | 서버 확장성이 높다 (스케일 아웃)
8 |
9 | #### 단점
10 | 클라이언트 추가 데이터 전송
11 |
12 | #### ex)
13 |
14 | 상태유지 - Stateful
15 | ```
16 | 고객: 이 노트북 얼마인가요?
17 | 점원: 100만원 입니다. (노트북 상태 유지)
18 | 고객: 2개 구매하겠습니다.
19 | 점원: 200만원 입니다. 신용카드, 현금 중에 어떤 걸로 구매 하시겠어요? (노트북, 2개 상태 유지)
20 | 고객: 신용카드로 구매하겠습니다.
21 | 점원: 200만원 결제 완료되었습니다. (노트북, 2개, 신용카드 상태 유지)
22 | ```
23 |
24 | 무상태 = Stateless
25 | ```
26 | 고객: 이 노트북 얼마인가요?
27 | 점원: 100만원 입니다.
28 | 고객: 노트북 2개 구매하겠습니다.
29 | 점원: 노트북 2개는 200만원 입니다. 신용카드, 현금중에 어떤 걸로 구매 하시겠어요?
30 | 고객: 노트북 2개를 신용카드로 구매하겠습니다.
31 | 점원: 200만원 결제 완료되었습니다.
32 | ```
33 |
34 | #### Stateful, Stateless 차이
35 |
36 | - 상태 유지 : 중간에 다른 점원으로 바뀌면 안된다 >> 중간에 서버장애가 나면 클라이언트일을 처음부터 다시 해야한다.(중간에 다른 점원으로 바뀔 때 상태 정보를 다른 점원에게 미리 알려줘야 한다.)
37 | - 무상태 : 중간에 다른 점원으로 바뀌어도 된다.
38 | - 갑자기 고객이 증가해도 점원을 대거 투입 가능
39 | - 갑자기 클라이언트 요청이 증가해도 서버를 대거 투입할 수 있다.(스케일 아웃)
40 | - 무상태는 응답 서버를 쉽게 바꿀 수 있다. -> 무한한 서버 증설 가능
41 |
42 |
43 |
44 | ### Stateless 실무 한계
45 | - 모든 것을 무상태로 설계할 수 있는 경우도 있고 없는 경우도 있다.
46 | - 무상태 예) 로그인이 필요 없는 단순한 서비스 소개 화면
47 | - 상태 유지 예) 로그인
48 | - 로그인한 사용자의 경우 로그인 했다는 상태를 서버에 유지
49 | - 일반적으로 브라우저 쿠키와 서버 세션 등을 사용해서 상태 유지
50 | - 상태 유지는 최소한만 사용
51 |
--------------------------------------------------------------------------------
/Back-End/http/HTTP기본/structclient.md:
--------------------------------------------------------------------------------
1 | # 클라이언트 서버 구조
2 | - Request Response 구조이다.
3 | - 클라이언트는 서버에 요청을 보내고, 응답을 대기한다.
4 | - 서버가 요청에 대한 결과를 만들어서 응답한다.
5 | - 응답 결과를 열어서 클라이언트가 동작한다.
6 |
7 | 옛날에는 클라이언트와 서버가 통합되어 있었는데, 지금은 분리해서 비즈니스 로직과 데이터등은 서버에 밀어넣고 클라이언트는 ui , 사용성 등에 집중을 한다. 그러면 클라이언트와 서버가 각각 **독립적으로 진화할 수 있다.**
8 |
9 | ### 클라이언트 - 서버 구성 요소
10 |
11 | #### 클라이언트
12 | - 서비스를 요청하는 시스템입니다.
13 | - 데스크톱 , 노트북 , 스마트 폰, 태블릿 등이 있습니다.
14 |
15 | #### 서버
16 | - 서비스를 제공하는 시스템입니다.
17 | - 데이터베이스 서버, 웹 애플리케이션 서버, 파일 서버, DNS 등이 있습니다.
18 |
19 | #### 네트워킹 장치
20 | - 클라이언트와 서버를 연결합니다.
21 | - 스위치, 라우터, 게이트웨이, 모뎀 등이 있습니다.
22 |
23 |
24 |
25 | #### 클라이언트-서버 모델이 작동하는 방식
26 | 1. 클라이언트는 네트워킹 장치에 요청을 제출합니다.
27 | 2. 네트워크 서버는 요청을 수신하고 처리합니다.
28 | 3. 서버는 클라이언트에 응답을 전달하빈다.
29 |
30 | > 클라이언트는 서버 연결을 위해 LAN(Local Area Network) 또는 WAN(Wide Area Network)을 이용합니다.
--------------------------------------------------------------------------------
/Back-End/http/HTTP메서드/attrib.md:
--------------------------------------------------------------------------------
1 | # HTTP 메서드의 속성
2 |
3 | #### HTTP 메서드의 속성
4 | - 안전(Safe Methods)
5 | - 멱등(Idempotent Methods)
6 | - 캐시 가능(Cacheable Methods)
7 |
8 | **안전 Safe**
9 | - 호출해도 리소스를 변경하지 않는다.
10 | - q: 그래도 계속 호출하여 로그 같은게 쌓여 장애가 발생하면?
11 | - a : 안전은 해당 리소스만 고려한다. 그런 부분까지 고려하지 않는다.
12 |
13 | **멱등 Idempotent**
14 | - f(f(x)) = f(x)
15 | - 한 번 호출하든 두 번 호출하든 100번 호출하든 결과가 똑같다.
16 | - 멱등 메서드
17 | - GET : 한 번 조회하든 몇 번을 조회하든 같은 결과가 조회된다.
18 | - PUT: 결과를 대체한다. 따라서 같은 요청을 여러번 해도 최종 결과는 같다.
19 | - DELETE : 결과를 삭제한다. 같은 요청을 여러번 해도 삭제된 결과는 똑같다.
20 | - POST : 멱등이 아니다. 두 번 호출하면 같은 결제가 중복해서 발생할 수 있다.
21 |
22 | - 활용
23 | - 자동 복구 매커니즘
24 | - 서버가 TIMEOUT 등으로 정상 응답을 못주었을 때, 클라이언트가 같은 요청을 다시 해도 되는가? 판단 근거
25 | - q : 재요청 중간에 다른 곳에서 리소스를 변경해버리면?
26 | - 사용자1 : GET > username : A age : 20
27 | - 사용자2 : PUT > username : A age : 30
28 | - 사용자1 : GET > username :A age : 30 -> 사용자2의 영향으로 바뀐 데이터 조회
29 | - A: 멱등은 외부 요인으로 중간에 리소스가 변경되는 것 까지는 고려하지 않는다.
30 |
31 | **캐시 가능 Cacheable**
32 | - 응답 결과 리소스를 캐시해서 사용해도 되는가?
33 | - GET , HEAD , POST, PATCH 캐시 가능
34 | - 실제로는 GET , HEAD 정도만 캐시로 사용
35 | - POST, PATCH는 본문 내용까지 캐시 키로 고려해야 하는데, 구현이 쉽지 않음
--------------------------------------------------------------------------------
/Back-End/http/HTTP메서드/httpapi.md:
--------------------------------------------------------------------------------
1 | # HTTP API를 만들어보자
2 |
3 | 요구사항 : 회원 정보 관리 api 를 만들어라.
4 |
5 | 가장 중요한 것은 `리소스 식별`
6 |
7 | ### 리소스의 의미
8 | - 회원을 등록하고 수정하고 조회하는게 리소스가 아니다.
9 | - 예 ) 미네랄을 캐라 -> 미네랄이 리소스
10 | - 회원이라는 개념 자체가 바로 리소스다
11 | - 리소스를 어떻게 식별하는게 좋을까 ?
12 | - 회원을 등록하고 수정하고 조회하는 것을 모두 배제
13 | - 회원이라는 리소스만 식별하면 된다 -> 회원 리소스를 URI에 매핑
14 |
15 |
16 | ### API URI 설계
17 | URI(Uniform Resource Identifier)
18 | 리소스 식별 , URI 계층 구조 활용
19 |
20 | - `회원` 목록 조회 / members
21 | - `회원` 조회 /members/{id} -> 어떻게 구분?
22 | - `회원` 등록 /members/{id} -> 어떻게 구분?
23 | - `회원` 수정 /members/{id} -> 어떻게 구분?
24 | - `회원` 삭제 /members/{id} -> 어떻게 구분?
25 | - 참고 : 계층 구조상 상위를 컬렉션으로 보고 복수단어 사용을 권장(member >> members)
26 |
27 | ### 리소스와 행위를 분리
28 | 가장 중요한 것은 리소스를 식별하는 것
29 | - URI 는 리소스만 식별!
30 | - 리소스와 해당 리소스를 대상으로 하는 `행위`를 분리
31 | - 리소스는 명사, 행위는 동사
32 | - 행위(메서드)는 어떻게 구분할까?
33 |
34 | > HTTP 메서드편에서 다루겠다.
35 |
36 |
37 |
--------------------------------------------------------------------------------
/Back-End/http/HTTP상태코드/2xx.md:
--------------------------------------------------------------------------------
1 | # 2xx - 성공
2 |
3 | ### 2xx (Successful)
4 | 클라이언트의 요청을 성공적으로 처리
5 |
6 | - 200 OK : 요청 성공
7 | - ex) GET
8 | - 201 Created : 요청 성공해서 새로운 리소스가 생성됨
9 | - ex) POST, 생성된 리소스는 응답의 Location 헤더 필드로 식별
10 | - Location : /members/100
11 | - 202 Accepted
12 | - 배치 처리 같은 곳에서 사용
13 | - 예) 요청 접수 후 1시간 뒤에 배치 프로세스가 요청을 처리함
14 | - 요청이 접수되었으나 처리가 `완료되지 않았음`
15 | - 204 No Content
16 | - 예) 웹 문서 편집기에서 save 버튼
17 | - save 버튼의 결과로 아무 내용이 없어도 된다.
18 | - save 버튼을 눌러도 같은 화면을 유지해야 한다.
19 | - 결과 내용이 없어도 204 메시지(2xx)만으로 성공을 인식할 수 있다.
--------------------------------------------------------------------------------
/Back-End/http/HTTP상태코드/status.md:
--------------------------------------------------------------------------------
1 | # HTTP 상태코드
2 |
3 | ### HTTP 상태코드 소개
4 |
5 | **상태코드**
6 | 클라이언트가 보낸 요청의 처리 상태를 응답해서 알려주는 `기능`
7 |
8 | - 1xx (Information) : 요청이 수신되어 처리중
9 | - 2xx (Successful) : 요청 정상 처리
10 | - 3xx (Redirection) : 요청을 완료하려면 추가 행동이 필요
11 | - 4xx (Client Error) : 클라이언트 오류, 잘못된 문법등으로 서버가 요청을 수행할 수 없음
12 | - 5xx (Server Error) : 서버 오류, 서버가 정상 요청을 처리하지 못함
13 |
14 | **만약 모르는 상태 코드가 나타나면?**
15 | - 클라이언트가 인식할 수 없는 상태코드를 서버가 반환하면?
16 | - 클라이언트는 상위 상태코드로 해석해서 처리
17 | - 미래에 새로운 상태 코드가 추가되어도 클라이언트를 변경하지 않아도 됨
18 | - 예)
19 | - 299 ??? -> 2xx(Successful)
20 | - 451 ??? -> 4xx(Client Error)
21 | - 599 ??? -> 5xx(Server Error)
22 |
23 |
24 |
25 | ### 1xx (Informational)
26 | 요청이 수신되어 처리중
27 | - 거의 사용하지 않으므로 생략
--------------------------------------------------------------------------------
/Back-End/http/HTTP헤더2/cache.md:
--------------------------------------------------------------------------------
1 | # 캐시 기본 동작
2 |
3 | ### 캐시가 없을 때
4 | - 데이터가 변경되지 않아도 계속 네트워크를 통해서 데이터를 다운로드 받아야 한다.
5 | - 인터넷 네트워크는 매우 느리고 비싸다
6 | - 브라우저 로딩 속도가 느리다.
7 | - 느린 사용자 경험
8 |
9 |
10 | ### 캐시 적용
11 |
12 | **첫 번째 요청**
13 | ```
14 | HTTP/1.1 200 OK
15 | Content-Type: image/jpeg
16 | cache-control: max-age=60
17 | Content-Length: 34012
18 |
19 | dafdsfasfsad
20 | ```
21 |
22 | **캐시 적용**
23 | - 캐시 덕분에 캐시 가능 시간동안 네트워크를 사용하지 않아도 된다.
24 | - 비싼 네트워크 사용량을 줄일 수 있다.
25 | - 브라우저 로딩 속도가 매우 빠르다.
26 | - 빠른 사용자 경험
27 |
28 | **세 번째 요청 - 캐시 시간 초과**
29 | 요청할때 브라우저 캐시에서 유효시간을 검증한다.
30 | 시간이 지나있으면 첫번째 요청처럼 다시받아서 캐시에 저장한다.
31 | - 캐시 유효시간이 초과하면, 서버를 통해 데이터를 다시 조회하고, 캐시를 갱신한다.
32 | - 이 때 다시 네트워크 다운로드가 발생한다.
--------------------------------------------------------------------------------
/Back-End/http/HTTP헤더2/cachehead.md:
--------------------------------------------------------------------------------
1 | # 캐시와 조건부 요청 헤더
2 |
3 | - Cache-Control : 캐시 제어
4 | - Pragma : 캐시 제어 (하위 호환)
5 | - Expires : 캐시 유효 기간 (하위 호환)
6 |
7 | ### Cache-Control
8 | **캐시 지시어(directives)**
9 | - Cache-Control: max-age
10 | - 캐시 유효 시간, 초 단위
11 | - Cache-Control: no-cache
12 | - 데이터는 캐시해도 되지만, 항상 원(origin) 서버에 검증하고 사용
13 | - Cache-Control: no-store
14 | - 데이터에 민감한 정보가 있으므로 저장하면 안됨(메모리에서 사용하고 최대한 빨리 삭제)
15 |
16 |
17 | ### Pragma
18 | **캐시 제어(하위호환)**
19 | - Pragma : no-cache
20 | - HTTP/1.0 하위 호환
21 |
22 | ### Expires
23 | **캐시 만료일 지정(하위 호환)**
24 | - expries: Mon, 01 Jan 1990 00:00:00 GMT
25 | - 캐시 만료일을 정확한 날짜로 지정
26 | - HTTP 1.0 부터 사용
27 | - 지금은 더 유연한 Cache-Control: max-age 권장
28 | - Cache-Control: max-age와 함께 사용하면 Expires는 무시
--------------------------------------------------------------------------------
/Back-End/http/HTTP헤더2/proxy.md:
--------------------------------------------------------------------------------
1 | # 프록시 캐시
2 | **Cache-Control**
3 | 캐시 지시어(directives) - 기타
4 | - Cache-Control: public
5 | - 응답이 public 캐시에 저장되오도 됨
6 | - Cache-Control: private
7 | - 응답이 해당 사용자만을 위한 것임, private 캐시에 저장해야 함(기본값)
8 | - Cache-Control: s-maxage
9 | - 프록시 캐시에만 적용되는 max-age
10 | - Age: 60 (HTTP 헤더)
11 | - 오리진 서버에서 응답 후 프록시 캐시 내에 머문 시간(초)
12 |
13 | ## 캐시 무효화
14 |
15 | ### Cache-Control
16 | **확실한 캐시 무효화 응답**
17 | - Cache-Control: no-cache, no-store, must-revalidate
18 | - Pragma: no-cache
19 | - HTTP 1.0 하위호환
20 |
21 | **캐시 지시어(directive) - 확실한 캐시 무효화**
22 |
23 | - Cache-Control: no-cache
24 | - 데이터는 캐시해도 되지만, 항상 원 서버에 검증하고 사용(이름에 주의!)
25 | - Cache-Control: no-store
26 | - 데이터에 민감한 정보가 있으므로 저장하면 안됨
27 | (메모리에서 사용하고 최대한 빨리 삭제)
28 | - Cache-Control: must-revalidate
29 | - 캐시 만료후 최초 조회시 원 서버에 검증해야함
30 | - 원 서버 접근 실패시 반드시 오류가 발생해야함 - 504(Gateway Timeout)
31 | - must-revalidate는 캐시 유효 시간이라면 캐시를 사용함
32 | - Pragma: no-cache
33 | - HTTP 1.0 하위 호환
34 |
35 | no-cache에서 원서버에 접근할 수 없는 경우 캐시 서버 설정에 따라 프록시에서 캐시 데이터를 반환할 수 있음 Error or 200 OK(오류 보다는 오래된 데이터라도 보여주자) must-revalidate의 경우 원 서버에 접근할 수 없는 경우 항상 오류가 발생해야 한다. 504 Gateway Timeout(매우 중요한 돈과 관련된 결과로 생각해보자)
--------------------------------------------------------------------------------
/Back-End/http/URI/web.md:
--------------------------------------------------------------------------------
1 | # 웹 브라우저 요청 흐름
2 | https://www.google.com:443/search?q=hello&hl=ko
3 | DNS조회 , HTTPS PORT 생략, 433
4 | 웹 브라우저에서 HTTP 요청 메시지를 생성
5 | ```
6 | HTTP 요청 메세지
7 | GET/search?q=hello&hl=ko HTTP/1.1
8 | Host: www.google.com
9 | ```
10 | 1. 웹 브라우저가 http 메시지 생성
11 | 2. SOCKET 라이브러리 통해 전달
12 | - A:TCP/IP 연결(IP , PORT)
13 | - B: 데이터 전달
14 | 3. **TCP/IP 패킷 생성** , HTTP 메시지 데이터 포함
15 | 4. LAN카드로 인터넷을 통해 HTTP 메시지를 서버에 전송
16 |
17 | 구글 서버에서는 TCP/IP 패킷은 까서 버리고 HTTP 메시지만 해석을 한다.
18 |
19 | ```
20 | HTTP 응답 메시지
21 |
22 | HTTP/1.1 200 OK
23 | Content-Type : text/html;charset=UTF-8
24 | Content-Length: 3423
25 |
26 |
27 | ...
28 |
29 | ```
30 | 클라이언트의 웹 브라우저가 http 응답 메시지를 렌더링 해서 결과를 볼 수 있다.
--------------------------------------------------------------------------------
/Back-End/http/image/adapt.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/http/image/adapt.png
--------------------------------------------------------------------------------
/Back-End/http/image/connectionless.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/http/image/connectionless.png
--------------------------------------------------------------------------------
/Back-End/http/image/httpmessage.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/http/image/httpmessage.png
--------------------------------------------------------------------------------
/Back-End/http/image/uri.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/http/image/uri.png
--------------------------------------------------------------------------------
/Back-End/http/network/ip.md:
--------------------------------------------------------------------------------
1 | # IP(인터넷 프로토콜)
2 |
3 | ### IP 란 ?
4 | - IP(Internet Protocol) 란 인터넷에 연결되어 있는 모든 장치들(컴퓨터, 서버 장비, 스마트폰 등)을 식별할 수 있도록 각각의 장비에게 부여되는 고유 주소이다.
5 |
6 | ### IP의 역할
7 | - 지정한 IP 주소에 데이터 전달
8 | - 패킷이라는 통신 단위로 데이터 전달
9 |
10 | ### 패킷 전달 과정
11 | - IP 패킷 정보가 필요하다 : 출발지 IP 도착지 IP ,기타 ...
12 | - `클라이언트 패킷 전달` : 클라이언트가 서버에 데이터를 전달하려 하면 여러개의 노드를 거쳐 목적지 IP로 데이터를 전달시킨다.
13 | - `서버 패킷 전달` : 서버가 클라이언트에게 전달할때도 클라이언트 IP로 정보를 전달한다.
14 |
15 |
16 |
17 | ### IP 프로토콜의 한계
18 |
19 | #### 비연결성
20 | - 패킷이 받을 대상이 없거나 서비스 불능 상태여도 패킷 전송
21 |
22 | #### 비신뢰성
23 | - 중간에 패킷이 사라지면?
24 | - 패킷이 순서대로 안오면?
25 |
26 | #### 프로그램 구분
27 | - 같은 IP를 사용하는 서버에 실행중인 애플리케이션이 둘 이상이면 ?
28 |
29 |
30 | #### 발생하는 문제
31 | 대상이 서비스 불능 , 패킷전송 ->
32 | 1. 대상 서버가 패킷을 받을 수 있는 지 모름
33 | 2. 패킷 소실
34 | 3. 패킷 전달 순서 문제 발생
35 |
36 |
37 |
38 |
39 | > 그리하여 나온게 TCP와 UDP이다.
--------------------------------------------------------------------------------
/Back-End/http/network/port.md:
--------------------------------------------------------------------------------
1 | ## PORT
2 | 영어 뜻은 항구
3 | 클라이언트에서 한번에 둘 이상의 서버와 연결 할때 구분하기 위해 사용한다.
4 | TCP/IP 패킷 정보에는 출발지 port 와 목적지 port가 포함되어있다.
5 |
6 | 예) 클라이언트 100.100.100.1 게임(8090) , 화상통화(21000) , 웹브라우저 요청(10010)
7 | 서버 200.200.200.2 게임(11220) , 화상통화 (32202) , 서버 200.200.200.3 웹 브라우저 요청(80)
8 |
9 | 100.100.100.1 게임(8090)- 200.200.200.2 게임(11220)
10 | 100.100.100.1 화상통화(21000)- 200.200.200.2 화상통화(32202)
11 | 100.100.100.1 웹브라우저 요청(10010)- 200.200.200.3 웹브라우저 요청(80)
12 |
13 | - 0~65535 할당 가능
14 | - 0~1023 잘 알려진 포트, 사용하지 않는 것이 좋음
15 |
16 |
17 | FTP - 20,21
18 | TELNET - 23
19 | HTTP - 80
20 | HTTPS - 443
21 |
22 |
23 |
24 | ## DNS
25 | 1. IP는 기억하기 어렵다.
26 | 2. IP는 변경될 수 있다.
27 |
28 | **DNS** : 도메인 네임 시스템
29 | - 전화번호부
30 | - 도메인 명을 IP 주소로 변환
31 |
32 | ### 인터넷 네트워크 정리
33 | IP의 한계를 극복하기 위해 TCP 도입, UDP는 IP와 비슷한데 port가 추가됐고, 필요하면 애플리케이션에서 기능확장 가능
34 | port는 같은 IP 안에서 동작하는 애플리케이션을 구분하기 위해서 사용, IP가 아파트라면 port는 동호수
35 | DNS는 변경될 수 잇고 외우기 힘든 IP를 대신해서 사용
--------------------------------------------------------------------------------
/Back-End/http/network/tcpudp.md:
--------------------------------------------------------------------------------
1 | # TCP & UDP
2 |
3 | 인터넷 프로토콜 스택의 4 계층
4 | 애플리케이션 계층 - HTTP , FTP
5 | 전송 계층 - TCP , UDP
6 | 인터넷 계층 - IP
7 | 네트워크 인터페이스 계층
8 |
9 | > EX ) 채팅 프로그램 사용시
10 |
11 | 1. 프로그램이 hello world 메시지 작성
12 | 2. 소켓 라이브러리를 통해 전달.
13 | 3. `TCP 정보 생성` , 메시지 데이터 포함.
14 | 4. `IP 패킷 생성` , TCP 데이터 포함
15 | 5. LAN 카드로 서버에 보냄(Ethernet frame)
16 |
17 |
18 | TCP/IP 패킷 정보 : IP 패킷 정보 안에 TCP 패킷 정보가 있다.
19 | TCP 세그먼트 :출발지 port , 목적지 port , 전송 제어 , 순서 , 검증 정보
20 |
21 | ### TCP 특징
22 | 전송 제어 프로토콜 (Transmission Control Protocol)
23 | - 연결 지향 - TCP 3way handshake(가상 연결) : 진짜 연결이 된게 아니고 개념적으로만 연결됨
24 | - 데이터 전달 보증 : 클라이언트가 서버로 데이터 전송을 하면 서버는 클라이언트로 데이터 잘 받았다고 보낸다.
25 | - 순서 보장 : 순서 안맞으면 다시보내라고 요총보냄
26 | - 신뢰할 수 있는 프로토콜
27 | - 현재는 대부분 TCP 사용
28 |
29 | ### UDP 특징
30 | 사용자 데이터그램 프로토콜(User Datagram Protocol)
31 | - 하얀 도화지에 비유(기능이 거의 없다.)
32 | - 연결지향 - TCP 3 way handshake X
33 | - 데이터 전달 보증 X
34 | - 순서 보장 X
35 | - 데이터 전달 및 순서가 보장되지 않지만 , 단순하고 빠름
36 | - IP와 거의 같고 PORT 체크섬 정도만 추가 , 애플리케이션에서 추가 작업 필요
37 |
38 |
39 |
40 | port : 하나의 아이피에서 여러 애플리케이션을 사용할때(게임 , 음악 등등) 어떤게 게임용이고 어떤게 음악용 패킷인지 구분하는 역할
41 |
42 | TCP는 좋지만 전송속도를 빠르게할 수 없고 데이터 양도 많아진다. 그리고 TCP는 손을 못대기 때문에 UDP위에 내가 원하는 것을 만들 수 있다. http3 에서 udp protocol 사용.
--------------------------------------------------------------------------------
/Back-End/jpa/persistence/image/entitylife.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/jpa/persistence/image/entitylife.png
--------------------------------------------------------------------------------
/Back-End/jpa/propagration.md:
--------------------------------------------------------------------------------
1 | # JPA Propagation 트랜잭션 전파 단계
2 |
3 | JPA Propagation은 트랜잭션 동작 도중 다른 트랜잭션을 호출하는 상황에 선택할 수 있는 옵션이다.
4 |
5 | @Transactional의 propagation 속성을 통해 피호출 트랜잭션 입장에서는 호출한 쪽의 트랜잭션을 그대로 사용할 수도 있고, 새로운 트랜잭션을 생성할 수도 있다.
6 |
7 | `REQURIED`: default 값이며 부모 트랜잭션 내에서 실행하여 부모 트랜잭션이 없을 경우 새로운 트랜잭션을 수행한다.
8 | `REQUIRED_NEW`: 기존에 트랜잭션이 있으면 그것을 중단하고, 새로운 것을 생성한다.
9 |
10 | 이 외에도 종류가 REQUIRED_NEW, SUPPORTS, MANDATORY, NOT_SUPPORT, NEVER, NESTED가 있다.
11 |
12 | - MANDATORY: tx를 필요로 한다. 진행중인 tx가 없을경우 예외를 발생시킨다.
13 | - SUPPORTS: tx를 필요로하지 않는다. 진행중인 tx가 있다면 사용한다.
14 | - NOT_SUPPORTS: tx를 필요로 하지 않는다. 진행중인 tx가 있다면 중지하고 메서드가 종료된 후에 중지했던 tx를 다시 시작한다.
15 | - NEVER: tx를 필요로하지 않는다. 진행중인 tx가 있다면 예외를 발생시킨다.
16 | - NESTED: 진행중인 tx가 있다면 기존 tx에 중첩된 tx에서 메서드를 실행한다.
--------------------------------------------------------------------------------
/Back-End/jpa/queryfk.md:
--------------------------------------------------------------------------------
1 | # @Query 어노테이션에서 FK로 객체를 찾는 방법
2 |
3 | ```java
4 | class User {
5 | @Id
6 | private String username;
7 |
8 | @ManyToOne
9 | private School school;
10 | }
11 | ```
12 |
13 | ```java
14 | class Team {
15 | @Id
16 | private String teamName;
17 |
18 | @OneToMany
19 | private Set users;
20 |
21 | }
22 | ```
23 |
24 | ```java
25 | @Query(select u from User u where user.teamName = :team)
26 | List findByTeam(@Param('teamName')String teamName);
27 | ```
28 | 위 Repository interface는 얼핏 보면 그럴싸 해보이지만 실제로 구동을 시키면 500과 함께 application이 죽는다. 그 이유는 team은 객체로 매핑되어있기 때문에 실제로 작동을 시키려면
29 |
30 | ```java
31 | @Query(select u from User u where user.team.teamName = :team)
32 | List findByTeam(@Param('teamNmae')String teamName);
33 | ```
34 |
35 | 위와 같이 team객체 안에 있는 teamName으로 매핑을 해주어야 teamName으로 FK 객체의 값으로 찾을 수 있다.
--------------------------------------------------------------------------------
/Back-End/jpa/table/entity.md:
--------------------------------------------------------------------------------
1 | # 객체와 테이블 매핑
2 |
3 | ### 엔티티 매핑
4 | - 객체와 테이블 매핑 : @Entity, @Table
5 | - 필드와 컬럼 매핑 : @Column
6 | - 기본 키 매핑 : @Id
7 | - 연관관계 매핑 : @ManyToOne, @JoinColumn
8 |
9 | ### 객체와 테이블 매핑
10 |
11 | #### Entity
12 | - @Entity가 붙은 클래스는 JPA가 관리하면 엔티티라고한다.
13 | - JPA를 사용해서 테이블과 매핑할 클래스는 @Entity 필수
14 |
15 | 주의
16 | - 기본 생성자 필수 (파라미터가 없는 public 또는 protected 생성자)
17 | - final 클래스, enum, interface, inner 클래스 사용 X
18 | - 저장할 필드에 final 사용 X
19 |
20 | ### @Table
21 | - @Table은 엔티티와 매핑할 테이블 지정]
22 | - name : 매핑할 테이블 이름 (기본값 : 엔티티 이름을 사용)
23 | - catalog : 데이터베이스 catalog 매핑
24 | - schema : 데이터베이스 schema 매핑
25 | - uniqueConstraints(DDL) : DDL 생성 시에 유니크 제약 조건 생성
--------------------------------------------------------------------------------
/Back-End/jpa/table/util.md:
--------------------------------------------------------------------------------
1 | # 데이터베이스 스키마 자동 생성
2 | - DDL을 애플리케이션 실행 시점에 자동 생성
3 | - 테이블 중심 -> 객체 중심
4 | - 데이터베이스 방언을 활용해 데이터베이스에 맞는 적절한 DDL 생성
5 | - 이렇게 생성된 **DDL은 개발 장비에서만 사용**
6 | - 생성된 DDL은 운영서버에서는 사용하지 않거나 적절히 다듬은 후 사용
7 |
8 | ### 속성
9 | - create : 기존 테이블 삭제 후 다시 생성 DROP + CREATE
10 | - create-drop : create나 같으나 종료시 DROP
11 | - update : 변경분만 반영(운영 db에선 사용x)
12 | - validate : 엔티티와 테이블이 정상 매핑되었는지만 확인
13 | - none: 사용하지 않음
14 |
15 | ### 주의
16 | - 운영 장비에는 절대 create , create drop , update를 사용하면 안된다.
17 | - 개발 초기 단계는 create or update
18 | - 테스트 서버는 update or validate
19 | - 스테이징과 운영에는 validate or none
20 |
21 | ### DDL 생성 기능
22 | - 제약 조건 추가
23 | - @Column(nullable = false, legnth = 10)
24 | - 유니크 제약조건 추가
25 | - @Table(uniqueConstraints = {@UniqueConstraint( name = "NAME_AGE_UNIQUE" , columnNames = {"NAME", "AGE"}) })
26 | - DDL 생성 기능은 DDL을 자동 생성할 때만 사용되고 JPA의 실행 로직에는 영향을 주지 않는다.(데이터베이스 영향)
--------------------------------------------------------------------------------
/Back-End/kotlin/collection.md:
--------------------------------------------------------------------------------
1 | # 코틀린 컬렉션즈
2 |
3 | ## 컬렉션에서 맵 만들기
4 | 키 리스트가 있을 때 각각의 키와 생성한 값을 연관시켜 맵을 만들고 싶을 경우 associateWith 함수에 각 키에 대해 실행되는 람다를 제공해 사용할 수 있다.
5 | ```kotlin
6 | @Test
7 | @Test
8 | internal fun associateWith() {
9 | val keys = 'a'..'f'
10 | val associate = keys.associate {
11 | it to it.toString().repeat(5).capitalize()
12 | }
13 | println(associate)
14 | }
15 | ```
16 |
17 | ## 컬렉션이 빈 경우 기본값 리턴하기
18 | 컬렉션을 처리할 때 컬렉션의 모든 요소가 선택에서 제외되지만 기본 응답을 리턴하고 싶은 경우 ifEmpty, ifBlank 함수를 사용해 기본 값을 리턴할 수 있다.
19 | ```kotlin
20 | @Test
21 | internal fun ifEmpty() {
22 | val products = listOf(Product("goods", 1000.0, false))
23 | val joinToString = products.filter { it.onSale }
24 | .map { it.name }
25 | .ifEmpty { listOf("none") }
26 | .joinToString(separator = ", ")
27 |
28 | println(joinToString) // none
29 |
30 | }
31 | ```
32 |
--------------------------------------------------------------------------------
/Back-End/kotlin/companion_and_object.md:
--------------------------------------------------------------------------------
1 | # companion object와 object의 차이점은 무엇일까요?
2 |
3 | Kotlin에선 싱글톤에 대한 `object`가 있습니다. 그리고 companion object는 object의 개념의 변형입니다.
4 |
5 | 특정 클래스에 속하는 싱글톤 객체입니다. companion object는 클래스의 동반자 같은 것 입니다. companion object는 독립적으로 설 수 없습니다.
6 |
7 | 캥거루 주머니 속의 아기처럼. 특정 클래스의 동반자이기 때문에 외부 클래스 인스턴스를 통해 모든 개인 수준 메서드 및 속성에 액세스할 수 있습니다.
8 |
9 | ### 예시
10 |
11 | 여기 케이크 가게의 예시가 있습니다.
12 |
13 | 새 케이크가 구워질 때 마다 cakeCount를 증가시켜야하고 변수 cakeCount는 모든 케이크 인스턴스에 공유되어야합니다.
14 |
15 | ```kt
16 | class Cake(var flavour: String) {
17 |
18 | init {
19 | println("Baked with Love : $flavour cake ")
20 | incrementCakeCount()
21 | }
22 |
23 | private fun incrementCakeCount() {
24 | cakeCount += 1
25 | }
26 |
27 | companion object {
28 | var cakeCount = 0
29 | }
30 | }
31 |
32 | fun main() {
33 | val cake1 = Cake("Chocolate")
34 | val cake2 = Cake("Vanilla")
35 | val cake3 = Cake("Butterscotch")
36 |
37 | println(Cake.cakeCount)
38 | }
39 | ```
40 |
41 | 아이디어는 Java의 정적 내부 클래스와 거의 비슷합니다. 그러나 클래스는 여러 번 인스턴스화할 수있는 코틀린 클래스이며 object 키워드는 단일 인스턴스가 있는 실제 객체에 대한 것이고 모든 멤버는 인스턴스 멤버라는 것을 기억하세요
--------------------------------------------------------------------------------
/Back-End/kotlin/datapersist.md:
--------------------------------------------------------------------------------
1 | # data 클래스로 persistence 구현하기
2 |
3 | `kotlin-jpa` 플러그인을 빌드 파일에 추가하면 JPA를 쉽게 사용할 수 있다.
4 |
5 | ```kt
6 | data class Person(
7 | val name: String,
8 | val dob: LocalDate
9 | )
10 | ```
11 |
12 | JPA 관점에서 data클래스는 두 가지 문제가 있다.
13 | 1. JPA는 모든 속성에 기본값을 제공하지 않는 이상 기본 생성자가 필수지만 data 클래스에는 기본 생성자가 없다.
14 | 2. val 속성과 함께 data 클래스를 생성하면 불변 객체가 생성되는데, JPA 객체와 더불어 잘 동작하도록 설계되어 있지 않다.
15 |
16 |
17 | ## 기본 생성자 문제
18 | 코틀린은 기본 생성자 문제를 해결하기 위해 2가지 플러그인을 제공한다.
19 | `no-arg` 플러그인은 인자가 없는 생성자를 추가할 클래스를 선택할 수 있고, 기본 생성자 추가를 호출하는 어노테이션을 정의할 수 있다. `no-arg`플러그인은 코틀린 엔티티에 기본 생성자를 자동으로 구성한다.
20 |
21 | ```kts
22 | plugins {
23 | kotlin("plugin.jpa") version "1.3.72"
24 | }
25 |
26 | dependencies {
27 | implementation("org.springframework.boot:spring-boot-starter-data-jpa")
28 | }
29 | ```
30 |
31 | `kotlin-spring` 플러그인 처럼 빌드 파일에 필요한 문법을 추가해 `no-arg` 플러그인을 사용할 수 있다. 컴파일러 플러그인은 합성한 기본 연산자를 코틀린 클래스에 추가한다. 즉 자바나 코틀린에서는 합성 기본 연산자를 호출할 수 없다. 하지만 스프링에서는 리플렉션을 사용해 합성 기본 연산자를 호출할 수 있다.
32 |
33 | `kotlin-jpa` 플러그인이 `no-arg` 플러그인보다 사용하기 더 쉽다 `kotlin-jpa` 플러그인은 `no-arg` 플러그인을 기반으로 만들어졌다. `kotlin-jpa` 플러그인은 다음 어노테이션으로 자동 표시된 클래스에 기본 생성자를 추가한다.
34 |
35 | - @Entity
36 | - @Embeddable
37 | - @MappedSuperClass
38 |
39 | ## JPA 엔티티에 불변 클래스 사용의 어려움
40 | JPA 엔티티에 불변 클래스를 사용하고 싶지 않는다. 따라서 스프링 개발 팀은 엔티티로 사용하고 싶은 코틀린 클래스에 필드 값을 변경할 수 있는 속성을 var 타입으로 사용하는 단순 클래스를 추천한다.
--------------------------------------------------------------------------------
/Back-End/kotlin/dsl.md:
--------------------------------------------------------------------------------
1 | # Kotlin DSL
2 |
3 | ```gradle
4 | plugins {
5 | kotlin("jvm") version "1.3.72"
6 | }
7 | ```
8 |
9 | 그레이들 5.0 이상 버전에서는 코틀린 DSL을 사용할 수 있고, 그레이들 5.0 이상 버전에서는 그레이들 플러그인 리퍼지토리에 등록되어있는 `kotlin-gradle-plugin`이 사용 가능하다. 최신 문법을 사용 `repositories`블록 처럼 플러그인을 찾아야할 장소 언급을 할 필요가 없다. 이는 그레이들 플러그인 저장소에 등록된 모든 그레이들 플러그인에 해당하는 사항이다. 또한 plugins 블록을 사용하면 자동으로 플러그인이 적용되기 때문에 apply 문도 사용할 필요가 없다.
10 |
11 | > 그레이들에서 코틀린 DSL을 사용하는 기본 빌드 파일 이름은 settings.gradle.kts, build.gradle.kts이다.
12 |
13 | 그루비 DSL과 가장 큰 차이점은 다음과 같다.
14 | - 모든 문자열에 큰따옴 표를 사용한다.
15 | - 코틀린 DSL에서는 괄호 사용이 필수다.
16 | - 코틀린은 콜론 : 대신 등호 기호 = 을 사용해 값을 할당한다.
17 |
18 | `setting.gradle.kts` 파일 사용을 권장하지만 필수는 아니다. 그레이들 빌드 과정의 초기화 단계에서 그레이들이 어떤 프로젝트 빌드 파일을 분석해야 하는지 결정하는 순간에 `settings.gradle.kts`가 처리된다. 멀티프로젝트 빌드에서 루트의 하위 디렉토리가 그레이들 프로젝트인지에 대한 정보가 `settings.gradle.kts 파일에 담겨있다. 그레이들 설정 정보와 의존성을 하위 프로젝트 사이에서 공유할 수 있고. 하위 프로젝트가 다른 하위 프로젝트를 의존할 수 있으며, 심지어 하위 프로젝트를 병렬로 빌드할 수도 있다.
19 |
20 | ## 그레이들을 사용해 코틀린 프로젝트 빌드하기
21 |
22 | ```gradle
23 | plugins {
24 | `java-libray` // (1)
25 | kotlin("jvm") version "1.3.72" // (2)
26 | }
27 |
28 | repositoies {
29 | jcentet()
30 | }
31 |
32 | dependencies {
33 | implementations(kotlin("stdlib")) // (3)
34 | }
35 | ```
36 |
37 | 1. 자바 라이브러리 플러그인에서 그레이들 작업을 추가
38 | 2. 코틀린 플러그인을 그레이들에 추가
39 | 3. 코틀린 표준 라이브러리 프로젝트 컴파일 타임에 추가
--------------------------------------------------------------------------------
/Back-End/kotlin/fun.md:
--------------------------------------------------------------------------------
1 | # 코틀린의 함수형 프로그래밍
2 |
3 | ## 함수형 프로그래밍
4 | 함수형 프로그래밍이라는 용어는 **불변성**을 선호하고 순수 함수를 사용하는 경우에 **동시성**을 쉽게 구현할 수 있으며, 반복보다는 변형을 사용하고, 조건문보다는 필터를 사용하는 코딩 스타이을 지창한다.
5 |
6 | ## 알고리즘에서 fold 사용하기
7 |
8 | fold 함수를 사용해 시퀀스나 컬렉션을 하나의 값으로 축약시킨다.
9 | ```kt
10 | internal class Fold {
11 |
12 | @Test
13 | internal fun name() {
14 | val numbers = intArrayOf(1, 2, 3, 4)
15 | val sum = sum(*numbers)
16 | println(sum) // 10
17 | }
18 |
19 | fun sum(vararg nums: Int) =
20 | nums.fold(0) { acc, n -> acc + n }
21 | }
22 | ```
23 |
24 | fold는 2개의 인자를 받는다, 첫 번째는 누적자의 초기 값이며, 두 번째는 두 개의 인자를 받아 누적자를 위해 새로운 값을 리턴하는 함수이다.
25 |
26 | ## reduce 함수를 사용해 축약하기
27 |
28 | 비어있지 않은 컬렉션의 값을 축약하고 싶지만 누적자의 초기값을 설정하고 싶지 않을 경우 reduce를 사용할 수 있다.
29 | reduce 함수는 fold 함수랑 거의 같은데 사용 목적도 같다. reduce 함수에는 **누적자의 초기값 인자가 없다**는 것이 fold와 가장 큰 차이점이다.
30 |
31 | ```kotlin
32 | @Test
33 | internal fun `reduce sum`() {
34 | val numbers = intArrayOf(1, 2, 3, 4)
35 | val sum = sumReduce(*numbers)
36 | // acc: 1, i: 2
37 | // acc: 3, i: 3
38 | // acc: 6, i: 4
39 | }
40 |
41 |
42 | fun sumReduce(vararg nums: Int) =
43 | nums.reduce { acc, i ->
44 | println("acc: $acc, i: $i")
45 | acc + i
46 | }
47 | ```
48 |
49 |
50 |
--------------------------------------------------------------------------------
/Back-End/kotlin/kotlin_jpa.md:
--------------------------------------------------------------------------------
1 | # Kotlin, JPA가 서로 지향하는 방향의 차이
2 |
3 | 코틀린과 JPA가 서로 다른 방향을 지향하는 것을 알고 있는가
4 |
5 | 어째서 코틀린과 JPA는 맞지 않는 방향을 추구하고 있는지에 대해서 알아보겠다.
6 |
7 | ## 코틀린이 추구하는 방향
8 |
9 | 코틀린은 **불변성**을 지향하며, 변경 가능한 상태를 최소화하여 코드의 안정성을 높이려 한다.
10 |
11 | 이를 위해 `val 키워드`를 사용하여 변수를 선언하고, 데이터 클래스를 사용하여 불변 데이터 모델을 정의할 수 있다.
12 |
13 | ## JPA가 추구하는 방향
14 |
15 | 반면에 JPA는 객체와 데이터베이스 간의 매핑을 중심으로 설계되었으며, **데이터베이스의 상태를 변경**하는 것이 주요 목적이다.
16 |
17 | 따라서 JPA는 엔티티 클래스를 사용하여 변경 가능한 데이터 모델을 정의하고, `EntityManager`를 사용하여 데이터베이스와 상호작용한다.
18 |
19 | ## 결론
20 |
21 | 코틀린과 JPA는 객체의 변화 상태에 관해서 지향하는 방향이 다르다.
22 |
23 | 각각의 장단점을 고려해서 사용해야 하는 것이 좋겠다. -> 도메인과 엔티티의 분리
--------------------------------------------------------------------------------
/Back-End/kotlin/lombokcant.md:
--------------------------------------------------------------------------------
1 | # Kotlin에서는 왜 lombok 라이브러리를 사용할 수 없을까?
2 |
3 | ## 개요
4 |
5 | 자바로 개발을 할때 Lombok을 사용하지 않은 사람은 거의 없을 것이다.
6 | 코틀린으로 넘어와서는 data클래스때문에 Lombok을 사용하지 않는 줄 알았는데 그냥 아예 못쓰는거라니.. 오늘 한번 정리해보겠다.
7 |
8 | ## 자바와 코틀린을 같이 사용할 경우
9 | 코틀린 컴파일러 -> .class 생성 -> java 컴파일러 -> .class 생성 -> 어노테이션 프로세싱 -> .class 파일 생성
10 |
11 | 여기서 어노테이션 프로세싱이 일어나는 위치가 코틀린 컴파일러 이후 자바 컴파일을 할 때 일어나기 때문에 롬복을 코틀린에서 사용할 수 없습니다.
12 |
13 | ## data class
14 | 그래도 코틀린에서는 data class라는 친구가 있기때문에 사실상 롬복을 쓸 필요는 없어보입니다.
15 |
16 | 데이터 클래스가 제공하는 함수
17 | - equals()/hashCode() pair
18 | - toString() of the form "User(name=John, age=42)"
19 | - componentN() functions corresponding to the properties in their order of declaration.
20 | - copy() function (see below).
21 |
22 | ```kotlin
23 | data class JeongWoo(
24 | val name: String,
25 | val age: Int
26 | )
27 | ```
--------------------------------------------------------------------------------
/Back-End/kotlin/singleton.md:
--------------------------------------------------------------------------------
1 | # Kotlin에서 싱글톤 클래스를 어떻게 생성할까요?
2 |
3 | `object` 키워드를 사용하세요 그게 전부입니다!
4 |
5 | ```kt
6 | object ClassName {
7 | }
8 | ```
9 |
10 | 이제 이 코드가 의미하는 바에 대한 요지를 빠르게 알려드리겠습니다.
11 |
12 | 가볍게 생각하지 마세요, 싱글톤 패턴은 사용 언어에 관계없이 매우 중요한 소프트웨어 디자인 패턴이기 때문입니다.
13 |
14 | 우슨 그 의미를 이해해야 합니다.
15 |
16 | 싱글톤 클래스는 말 그대로 Single all the time을 의미합니다. 여러번 인스턴스화되는 것으로 제한되며 싱글톤 클래스의 인스턴스가 생성되면 애플리케이션/앱 전체에서 이 클래스의 유일한 인스턴스로 영원히 유지됩니다.
17 |
18 | 자바에서는 우리는 싱글톤 클래스를 생성하기 위한 몇가지 단계를 따릅니다.
19 |
20 | 1. private constructor
21 | 2. 정적인 메서드 getInstance()
22 | 1. if 클래스가 존재하는 경우 -> 하나 생성
23 | 2. else -> 기존 인스턴스 반환
24 | 3. 스레드 안정성을 보장하기 위해 getInstance() 메서드 동기화
25 |
26 | 이 과정은 많은 보일러플레이트 코드를 유발합니다. Kotlin에서는 모든 단계를 단일로 좁혀 개발자의 작업을 쉽게 만듭니다.
27 |
28 | 이제 아까 위의 코드를 백스테이지에서 무슨 일이 일어나는지 이해해보려면 코드를 디 컴파일 해볼까요?
29 |
30 | ```java
31 | public final class ClassName {
32 | @NotNull
33 | public static final ClassName INSTANCE;
34 | private ClassName() {
35 |
36 | }
37 |
38 | static {
39 | ClassName var0 = new ClassName()
40 | INSTANCE = var0
41 | }
42 | }
43 | ```
--------------------------------------------------------------------------------
/Back-End/kotlin/starpro.md:
--------------------------------------------------------------------------------
1 | # Kotlin Generics 스타 프로젝션, reified 자료형
2 |
3 | ## 스타 프로젝션
4 | 스타 프로젝션 `<*>`은 어떤 자료형이라도 들어올 수 있으나 구체적으로 자료형이 결정되고 난 후엔ㄴ 그 자료형과 하위 자료형의 요소만 담을 수 있도록 제한할 수 잇습니다.
5 |
6 | in으로 정의되어 있는 타입매개변수를 * 스타 프로젝션으로 받으면 in Nothing으로 간주하고,
7 |
8 | out으로 정의되어 있는 타입매개변수를 * 스타 프로젝션으로 받으면 outAny?인 것으로 간주합니다.
9 |
10 | 따라서 * 스타 프로젝션을 사용할 때 그 위치에 따라 메서드 호출이 제한될 수 있습니다.
11 |
12 | ```kt
13 | class InOut(t: T, u: U){
14 | val prop: U = u // U는 out 위치
15 |
16 | fun fuc(t: T){ // T는 in 위치
17 | print(t)
18 | }
19 | }
20 |
21 | fun starFuc(v: InOut<*,*>) {
22 | v.fuc(1) // 오류, Nothing으로 인자 처리
23 | print(v.prop)
24 | }
25 | ```
26 |
27 | ## reified 자료형
28 |
29 | 제네릭은 컴파일 후 런타임에는 삭제되기 때문에 제네릭 타입에 접근할 수 없다.
30 |
31 | 그래서 `c: Class`처럼 제네릭 타입을 함수의 매개변수로 전달해야 타입에 접근할 수 있다.
32 |
33 | 하지만 `reified`로 타입 매개변수 T를 지정하면 런타임에서도 접근할 수 있게되어 `c: Class`와 같은 매개변수를 넘겨주지 않아도 된다.
34 |
35 | 하지만 refieid 자료형은 인라인 함수에서만 사용할 수 있다.
36 |
37 | ```kt
38 | inline fun fuc() {
39 | print(T::class)
40 | }
41 | ```
--------------------------------------------------------------------------------
/Back-End/kotlin/toPair.md:
--------------------------------------------------------------------------------
1 | # mapOf(), to로 Pair 인스턴스 생성하기
2 |
3 | 코틀린은 Pair 인스턴스의 리스트로부터 맵을 생성하는 mapOf와 같은 맵 생성을 위한 최상위 함수를 몇가지 제공한다. 코틀린 표준 라이브러리에 있는 mapOf 함수의 시그니처는 다음과 같다.
4 |
5 | `fun mapOf(vararg pairs: Pair: Map)`
6 |
7 | Pair는 first, second라는 이름의 두 개의 원소를 갖는 데이터 클래스다. Pair 클래스의 시그니처는 다음과 같다.
8 |
9 | `data class Pair: Seriallizable`
10 | Pair 클래스의 first, second 속성은 A, B의 제네릭 값에 해당한다. 2개의 인자를 받는 생성자를 사용해서 Pair 클래스를 생성할 수 있지만 to 함수를 사용하는 것이 더 일반적이다.
11 |
12 | ```kotlin
13 | @Test
14 | internal fun `create map using to function`() {
15 | val mapOf = mapOf("a" to 1, "b" to 2, "c" to 2)
16 |
17 | then(mapOf).anySatisfy { key, value ->
18 | then(key).isIn("a", "b", "c")
19 | then(value).isIn(1, 2)
20 | }
21 | }
22 | ```
--------------------------------------------------------------------------------
/Back-End/kotlin/top_level.md:
--------------------------------------------------------------------------------
1 | # 클래스 외부의 함수(A package-level/ Top-level 함수)
2 |
3 | 자바와 달리 코틀린에서는 클래스 외부에 함수를 작성할 수 있다.
4 |
5 | 함수 논리가 클래스의 속성이나 목적과 무관한 경우 사라져야한다.
6 |
7 | 이것은 코틀린이 독점적으로 객체 지향 언어가 아니며 기능적으로도 사용될 수 있기 때문에 가능한 일이다.
8 |
9 | ```kt
10 | package com.example
11 |
12 | fun hello(){
13 | println("hello")
14 | }
15 | ```
16 |
17 | 위의 코드를 자바로 변환하면 다음과 같은 형태가 된다.
18 |
19 | ```java
20 | package com.example;
21 |
22 | public final class ExampleKt {
23 | public static void sayHello() {
24 | System.out.println("hello");
25 | }
26 | }
27 | ```
28 |
29 | 위의 코드에서 ExampleKt 클래스는 코틀린 파일의 이름에 따라 자동으로 생성되며, 패키지 레벨 함수는 해당 클래스 내에 정적 메서드로 생성된다.
30 |
31 | ### 자바로 변환할 때 클래스 이름 지정해주는 방법
32 |
33 | ```kt
34 | @file:JvmName("MyFunctions")
35 |
36 | package com.example
37 |
38 | fun hello(){
39 | println("hello")
40 | }
41 | ```
42 |
43 |
44 | 위의 코틀린 코드에서 @file:JvmName("MyFunctions") 어노테이션은 해당 파일에서 생성되는 클래스 이름 MyFunctions로 변경한다는 의미이다.
45 |
46 | ```java
47 | package com.example;
48 |
49 | public final class MyFunctions {
50 | public static void sayHello() {
51 | System.out.println("hello");
52 | }
53 | }
54 | ```
55 |
56 | 즉 `@file:JvmName("$ClassName")`을 사용해 지정해 줄 수 있다.
--------------------------------------------------------------------------------
/Back-End/kotlin/use.md:
--------------------------------------------------------------------------------
1 | # .close()가 필요한 클래스를 사용할 때, use로 효율적으로 사용하기
2 |
3 | 더 이상 필요하지 않을 때 `.close()` 메서드를 사용해 명시적으로 닫아야하는 클래스들이 있다.
4 |
5 | 예를 들면
6 | - InputStream, OutputStream
7 | - java.sql.Connection
8 | - java.io.Reader
9 | - java.new.Socket
10 | - java.util.Scanner
11 |
12 | 이러한 리소스들은 `AutoCloseable`을 상속받는 `Closeable` 인터페이스를 구현하고 있다.
13 |
14 | 이러한 모든 리소스는 최종적으로 리소스에 대한 레퍼런스가 없어질 때, 가비지 컬렉터가 처리한다.
15 |
16 | 하지만 이러한 방식은 굉장히 느리며 쉽게 처리되지 않기때문에 사용하는 클라이언트가 명시적으로 .close() 작업을 처리하는 것이다.
17 |
18 | 전통적으로 try catch finally에 이러한 방식을 사용한다.
19 |
20 | 그러나 이런식으로 작성하게되면 복잡할 뿐만 아니라 catch와 finally에서 예외가 발생하면 예외가 따로 처리되지 않아 블록 내부에서 **오류가 발생하면 둘 중 하나만 예외가 전파되는 문제**가 있다.
21 |
22 | 물론 둘 다 전파될 수 있도록 구현할 수 있지만 정말 복잡해진다.
23 |
24 | ```kt
25 | val reader = BufferdReader(FileReader(path))
26 | try {
27 | return reader.lineSequence().sumBy { it.length }
28 | } finally {
29 | reader.close()
30 | }
31 | ```
32 |
33 | 그러나 use 함수를 사용해 앞의 코드를 적절하게 변경하면 다음과 같다. 이러한 코드는 모든 Closealbe 객체에 이용될 수 있다.
34 |
35 | ```kt
36 | reader.use {
37 | return reader.lineSequence().sumBy { it.length }
38 | }
39 | ```
40 |
41 | > 추가로 파일을 리소스로 사용하는 경우가 많고, 파일을 한 줄씩 읽어들이는 경우에 제공하는 useLines도 제공한다.
42 |
43 |
44 | 마치 자바에서 `try catch resources`를 사용했던 것과 같다.
45 |
46 |
47 | ### 결론
48 |
49 | use를 사용하면 AutoCloseable/Closeable을 구현한 객체를 쉽고 아전하게 처리할 수 있다.
50 |
51 | 또한 파일을 처리할 때는 파일을 한 줄씩 읽어들이는 useLines를 사용하는 것을 추천한다.
--------------------------------------------------------------------------------
/Back-End/kyd.md:
--------------------------------------------------------------------------------
1 | # KISS, YAGNI, DRY
2 |
3 | 코드의 품질읠 위해, 좋은 소스코드를 작성하기 위해 알고 따르면 좋을 대표적인 원칙들을 알아보겠다.
4 |
5 | ### KISS - Keep It Simple Stupid
6 |
7 | Keep It Simple Stupid, Keep It Short and Simple 등의 첫글자를 따서 만든 약어로 이를 설명하면 소프트웨어를 설계하는 작업이나 코딩을 하는 행위에서 되도록이면 간단하고 단순하게 만드는 것이 좋다는 원리로 소스코드나 설계내용이 **불필요하게 장황하거나 복잡해지는 것을 경계**하라는 원칙이다.
8 |
9 | 단순할수록 이해하기 쉽고 이해하기 쉬울수록 버그트레킹이 쉬우며 발생 가능성도 줄어든다. 이는 곧 생산성 향상으로 연결되기 때문에 복잡해지는 것을 할상 경계해야한다.
10 |
11 |
12 |
13 | ### YAGNI - You Ain't Gonna Need It
14 |
15 | YAGNI 원칙은 풀어쓰자면 필요한 작업만 해라라는 원칙이다.
16 |
17 | 프로그램을 작성하면 현재는 사용하지 않지만 미래에 사용할 혹은 확장성을 고려해 미리 작업해놓은 것들이 있을 수 있다.
18 |
19 | 그런 작업들 하지마! 라고 하는 원칙이 바로 YAGNI다.
20 |
21 | 현재는 사용하지 않는, 미래 어느시점에 사용될지도 모르는 코드를 작성해놓으면 코드가 불필요하게 장황하며 게다가 설계나 환경이 변경되었을 때 수정해야하는 코드의 양이 늘어나게 된다, 설계나 환경이 바뀌었는데 이렇게 미리 작업해놓은 코드를 수정하지 않았다면? 나중에 그 코드에서 버그를 발생시킨다. 그러니 당장 필요한 작업에 집중하고 쓸데없는 작업은 하지 말라는 것이다.
22 |
23 |
24 |
25 | ### DRY - Do not Repeat Yoursefl
26 |
27 | DRY 원칙은 반복하지 마라 라는 원칙이다 소스 코드에서 동일한 코드가 반복이 된다는 것은 잠재적인 버그의 위협을 증가시킨다 반복되는 코드 내용이 변경될 필요가 있는 경우 반복되는 모든 코드에 찾아가서 수정을 하기도 해야한다. 이 과정에서 실수가 발생한다면 또 버그가 발생한다.
28 |
29 | 프로젝트 규모가 커질수록 반복되는 코드로 인한 유지보수 오버헤드가 매우 커지기 때문에 작은 프로젝트라도 코드를 반복해서 사용하지 않는 습관이 중요하다.
30 |
31 | 그렇다고 두어번 반복된다고 또 모든것을 분리하지는 말자 적절히 얼마나 발생할지 앞으로 더 필요할지 이쯤이면 너무 많이 반복된것같은지를 적절히 판단하자 필자는 3번이상 반복되면 분리하는 편이다.
--------------------------------------------------------------------------------
/Back-End/spring/batch_concurrency.md:
--------------------------------------------------------------------------------
1 | # Spring Batch 데이터 일관성 관리
2 |
3 |
4 | 스프링 배치 애플리케이션이 같은 데이터를 변경하는 배치가 두 개 동시에 돌때 해결하는 방법이 무엇이 있을까요?
5 |
6 | 면접에서 받은 질문인데 더 자세히 한 번 알아보도록 하겠습니다.
7 |
8 | ### 동시성 제어하기
9 |
10 | 데이터 row에 관해 lock을 걸어 동시성을 제어하는 방법이에요
11 |
12 | 간단하고 직관적인 방법이지만 락의 대기 시간이 길어질 수 있고 데드락이 발생할 수도 있습니다.
13 |
14 |
15 | ### 분산 락 사용
16 |
17 | 여러 애플리케이션이 동시에 데이터 업데이트를 시도할 때, 분산 락을 사용해 각 애플리케이션이 데이터를 업데이트하기 전에 락을 획득하도록 해요, 이를 통해 한 번에 하나의 애플리케이션만이 데이터를 업데이트할 수 있도록 해요
18 |
19 | 분산 환경에서도 동시성을 제어할 수 있는 강력한 방법이지만, 락 관리에 대한 복잡성과 오버헤드가 발생할 수 있으며, 락 관리에 대한 중앙화된 시스템이 필요합니다.
20 |
21 |
22 | ### 일괄처리
23 |
24 | 좀 당연한 방법이라고 생각할 수 있는데 서로가 동시에 실행되지 않도록 조정하는거에요. 스케쥴러를 통해서 데이터 업데이트가 겹치지 않고 순차적으로 이루어지도록 합니다.
25 |
26 |
27 | ### 버전 관리
28 |
29 | 업데이트할 데이터에 버전 관리를 도입해서, 동시에 업데이트를 시도하는 경우에는 각 애플리케이션이 데이터 현재 버전과 일치하는지 확인하고, 버전이 일치할 때에만 업데이트를 수행하도록해요
30 |
31 | 데이터 변경 이력을 추적할 수 있으며, 동시성 제어에 유용한 방법이에요 그러나 데이터베이스 스키마 변경이 필요할 수 있어 처음부터 도입하지 않으면 조금 어려우며 버전 관리를 위한 추가적인 로직이 필요하며 오버헤드가 발생할 수도 있어요
32 |
33 |
34 | 스프링 배치는 대용량 데이터를 일정한 주기에 실행할 수 있도록 사용되는 배치 애플리케이션을 만드는 목적을 가지고 있기 때문에 배치 특성상 같은 데이터에 대한 처리를 여러번 돌린다는게 살짝 어색한 감이 없지않아 있다고 생각되지만 실무에서는 빈번히 일어날 수도 있다고 생각한다.
35 |
36 | 아직 실무에서 배치를 그렇게 작성해본 적이 없어서 더욱 알아봐야겠다
--------------------------------------------------------------------------------
/Back-End/spring/beans.md:
--------------------------------------------------------------------------------
1 | # 애플리케이션 로직, 인프라 빈, 컨테이너 인프라 빈
2 |
3 |
4 | ## 빈의 종류
5 |
6 | 스프링에서 빈은 또 3가지의 종류로 구성이 된다.
7 |
8 | - 애플리케이션 로직 빈
9 | - 애플리케이션 인프라 빈
10 | - 컨테이너 인프라 빈
11 |
12 |
13 | ### 애플리케이션 로직 빈
14 | 애플리케이션이 동작하면서 생성되고 소멸되는 빈이다. 기본적인 백엔드 애플리케이션에서는
15 | 서비스, 컨트롤러와 같은 컴포넌트들이 이 역할을 한다.
16 |
17 | ### 애플리케이션 인프라 빈
18 | 이 빈도 애플리케이션 생명주기에 맞춰져있지만 다른점은 외부에서 생성된 빈이라는 점이다.
19 | 예를 들면 DataSource가 있다.
20 |
21 | 애플리케이션 인프라 빈은 애플리케이션 로직 빈의 작업 수행을 도와주는 역할을 한다.
22 |
23 | ### 컨테이너 인프라 빈
24 | 컨테이너 인프라빈은 스프링 컨테이너의 기능을 확장하여 사용되는 빈을 의미한다.
25 | 예를 들면 DefaultAdvisorAutoProxyCreator와 같은 클래스들이 있다.
26 |
27 | 이러한 클래스들은 빈 후처리와 같은 기능들을 통하여 컨테이너의 빈을 스캔하는 방법과 같이 확장된 기능들을 제공해준다.
28 |
29 | 예를들어 @Configuration 어노테이션을 달아놓은 클래스 내부에 @Bean 어노테이션으로 빈들을 정의했다고 해보자. @Configuration 어노테이션 자체가 이 빈들을 컨테이너에 등록하게 해주는 기능을 수행하는 것 같지만 그렇지 않다. 이 Configuration 클래스를 그냥 빈으로 등록하면 클래스 내부 빈들은 컨테이너에 등록되지 않는다.
30 |
31 | 그러나 스프링의 컨테이너 인프라 빈인 ConfigurationClassPostProcessor 클래스가 이 작업을 수행해준다. (xml에서는 <\annotation-config>와 같이 전용 태그로 묶어줄수도있다.)
32 |
33 | @Autowired가 달려있는 클래스들도 마찬가지로 AutowiredAnnotationBeanPostProcessor와 같은 컨테이너 인프라 빈이 @PostConstruct도 CommonAnnotationBeanPostProcessor와 같은 컨테이너 인프라 빈들이 처리를 해준다.
34 |
35 |
36 |
--------------------------------------------------------------------------------
/Back-End/spring/image-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/spring/image-1.png
--------------------------------------------------------------------------------
/Back-End/spring/image-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/spring/image-2.png
--------------------------------------------------------------------------------
/Back-End/spring/image-3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/spring/image-3.png
--------------------------------------------------------------------------------
/Back-End/spring/image-4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/spring/image-4.png
--------------------------------------------------------------------------------
/Back-End/spring/image.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/spring/image.png
--------------------------------------------------------------------------------
/Back-End/spring/image/DI.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/spring/image/DI.png
--------------------------------------------------------------------------------
/Back-End/spring/image/Token.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/spring/image/Token.png
--------------------------------------------------------------------------------
/Back-End/spring/image/ac.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/spring/image/ac.png
--------------------------------------------------------------------------------
/Back-End/spring/image/aop.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/spring/image/aop.png
--------------------------------------------------------------------------------
/Back-End/spring/image/bean.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/spring/image/bean.png
--------------------------------------------------------------------------------
/Back-End/spring/image/bean2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/spring/image/bean2.png
--------------------------------------------------------------------------------
/Back-End/spring/image/dao.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/spring/image/dao.png
--------------------------------------------------------------------------------
/Back-End/spring/image/jdbc.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/spring/image/jdbc.png
--------------------------------------------------------------------------------
/Back-End/spring/image/jwt.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/spring/image/jwt.png
--------------------------------------------------------------------------------
/Back-End/spring/image/jwttoken.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/spring/image/jwttoken.png
--------------------------------------------------------------------------------
/Back-End/spring/image/mvcp.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/spring/image/mvcp.png
--------------------------------------------------------------------------------
/Back-End/spring/image/springdto.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/spring/image/springdto.png
--------------------------------------------------------------------------------
/Back-End/spring/image/패키지구조.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Back-End/spring/image/패키지구조.png
--------------------------------------------------------------------------------
/Back-End/spring/indexing.md:
--------------------------------------------------------------------------------
1 | ### Spring boot에서 데이터베이스 인덱싱하는법
2 |
3 | ### 인덱싱 연산
4 | 인덱스 연산은 수정이 일어날 때는 굉장히 비효율 적이다. 참고 바란다.
5 |
6 | ### 인덱스 설정법
7 | 엔티티 클래스 위에
8 |
9 | `@Table(indexes = @Index(name = "인덱스 명", columnList = "인덱싱 할 컬럼"))`
10 | 이렇게 붙여주면 된다.
--------------------------------------------------------------------------------
/Back-End/spring/mvc.md:
--------------------------------------------------------------------------------
1 | # MVC 패턴이란 무엇일까?
2 |
3 | ### MVC 패턴
4 | `Model-View-Controller`의 약자로 개발을 할 때 3가지 형태로 역학을 나누어 개발하는 방법론이다.
5 |
6 |
7 | 
8 |
9 | - `Model` : 애플리케이션이 무엇을 할 것인지 정의하는 부분이다. 즉 데이터베이스와 연동하여 사용자가 입력한 데이터나 사용자에게 출력할 데이터를 다룹니다.
10 | - `View` : 사용자에게 시각적으로 보여주는 부분입니다. (UI)
11 | - `Controller` : Model이 데이터를 어떻게 처리할지 알려주는 역할입니다. 사용자에 의해 클라이언트가 보낸 데이터가 있으면 모델을 호출하기전에 적절히 가공을 하고 모델을 호출합니다. 그런다음 모델이 업무 수행을 완료하면 그 결과를 가지고 View에게 전달하는 역할을 합니다.
12 |
13 |
14 |
15 | ### MVC 패턴을 사용하는 이유
16 | - 사용자가 보는 페이지, 데이터처리, 그리고 이 2가지를 중간에서 제엏나느 컨트롤러, 이 3가지로 구성되는 하나의 애플리케이션을 만들면 각각 맡은바에만 집중을 할 수 있게 됩니다.
17 | - 즉 서로 분리되어 각자의 역할을 집중할 수 있게끔하여 개발을 하고 그렇게 애플리케이션을 만든다면 `유지보수성` , `애플리케이션의 확장성` , `유연성`이 증가하고 중복 코딩이라는 문제점 또한 사라집니다.
18 |
19 |
20 |
--------------------------------------------------------------------------------
/Back-End/spring/package.md:
--------------------------------------------------------------------------------
1 | # 스프링 패키지 구조(Spring Package Structure) - 계층형 vs 도메인형
2 |
3 | 패키지 구성은 크게 두 가지 유형이 있다.
4 | 1. 계층형
5 | 2. 도메인형
6 |
7 | ### 계층형 패키지 구조
8 | - 계층형으로 패키지를 설계하는 방식
9 | - 전체적인 구조를 빠르게 파악할 수 있는 장점이 있지만 디렉토리 클래스들이 너무 많이 모이게 되는 단점이 존재
10 |
11 | **장점**
12 | 1. 해당 프로젝트에 이해가 상대적으로 낮아도 전체적인 구조를 빠르게 파악 가능
13 |
14 | **단점**
15 | 1. 디렉토리에 클래스들이 너무 많이 모이게 됨
16 | 2. 모듈 단위로 분리 시 어려움이 있음
17 |
18 | ### 도메인형 패키지 구조
19 | - 도메인 단위로 디렉토리 구성
20 | - 도메인 구조는 관련된 코드들이 응집해 있는 장점이 있지만, 프로젝트에 대한 이해도가 낮을 경우 전체적인 구조를 파악하기 힘든 어려운 점이 있음
21 |
22 | **장점**
23 | - 관련된 코드들이 응집해 있음
24 | - 모듈 단위로 분리할 때 유리함
25 |
26 | **단점**
27 | - 프로젝트에 대한 이해도가 낮을 경우 전체적인 구조를 파악하기 어려움
28 | - 개발자의 성향에 따라 도메인을 구분하는 기준이 다를 수 있고, 내 예상과 다른 패키지에 존재하는 경우 관련 코드를 찾기 어려움
29 | - 패키지 간 순환 참조가 발생할 가능성이 있음
30 | - 같은 패키지 내부에 있어도 되는 파일인데도 불구하고 모듈별로 구분되어 있기 때문에 다른 패키지에 존재하게 되고, 서로를 참조할 수 있음
31 |
32 |
33 |
34 | ### 계층형, 도메인형 예시
35 |
36 | 
37 |
38 |
39 |
40 |
41 | ### 결론
42 |
43 |
44 | 복잡도가 높고 제공하는 기능이 많아 하나의 계층에 속하는 클래수 수가 많고,
45 | 제공하는 기능을 명학환 기준으로 분리할 수 있고,
46 | 추후에 모듈별로 별도 서비스로 쪼개질 가능성이 있는경우
47 | -> **도메인형 구조**
48 |
49 |
50 | 복잡도가 낮고 제공하는 기능이 적어 하나의 계층에 속하는 클래스 수가 적고,
51 | 제공하는 기능을 명확한 기준으로 분리하기가 애매하고,
52 | 추후에 모듈별로 분리하게 될 일이 없을 것 같은 작은 규모의 프로젝트 일 경우
53 | -> **계층형 구조**
54 |
55 | 로 방향을 잡을 것 같다.
--------------------------------------------------------------------------------
/Back-End/spring/resource.md:
--------------------------------------------------------------------------------
1 | # Spring Resource Interface, Resource 추상화와 구현체
2 |
3 | ## Resource
4 | java.net.URL의 한계 (classpath 내부 접근이나 상대경로 등)를 넘어서기 위해 스프링에서 추가로 구현
5 |
6 | ### Resource Interface
7 | ```java
8 | public interface Resource extends InutStreamSource {
9 | boolean exists();
10 | boolean isReadable();
11 | boolean isOpen();
12 | boolean isFile();
13 |
14 | URL getURL() throws IOException;
15 | URI getURI() throws IOEXception;
16 | File getFile() throws IOException;
17 | ReadableByteChannel readableChannel() throws IOException;
18 |
19 | long contentLength() throws IOException;
20 | long lastModified() throws IOException;
21 |
22 | Resouce createRelative(String relativaPath) throws IOException;
23 | String getFilename();
24 | String getDescription();
25 | }
26 | ```
27 |
28 | ## Resource 구현체
29 |
30 | ### UrlResource
31 | URL을 기준으로 리소스를 읽어들임.
32 |
33 | 지원하는 프로토콜은 http, https, ftp, file, jar
34 |
35 | ### ClassPathResource
36 | 지원하는 접두어가 classpath: 일 때, 클래스패스를 기준으로 리소스를 읽어들인다.
37 |
38 | ### FileSystemResource
39 | 파일 시스템을 기준으로 읽는다.
40 |
41 | ### ServeltContextResource
42 | 웹 애플리케이션 루트에서 상대 경로로 리소스를 찾는다.
43 |
44 | ### InputStreamResource, ByteArrayResource
45 | 말그대로 InputStream, ByteArrayInput을 가져오기 위한 구현체
46 |
47 |
--------------------------------------------------------------------------------
/Back-End/spring/security_strategy.md:
--------------------------------------------------------------------------------
1 | # SecurityContextHolderStrategy (ThreadLocal, InheritableThreadLocal, Global)
2 |
3 | ## TheradLocal
4 | WebMVC 기반으로 프로젝트를 만든다고 가정할 때, 요청 한 개당 스레드 한 개가 생성된다.
5 |
6 | 이때 ThreadLocal을 사용하면 스레드마다 고유한 공간을 만들 수 잇고, 그곳에 SecurityContext를 저장할 수 있다.
7 |
8 | - ThreadLocal로 SecurityContext를 관리하면, SecurityContext는 요청마다 독립적으로 관리된다.
9 | - `IngeritableThreadSecurityLocalSecurityContextHolderStrategy`를 사용한다.
10 |
11 | ## InheritableThreadLocal
12 |
13 | `InheritableThreadSecurityLocalContextHolderStrategy`를 사용하며 이를 사용해, 자식 스레드까지도 SecurityContext를 공유한다.
14 |
15 | ## Global
16 |
17 | `GlobalSecurityContextHolderStrategy`를 사용하며, 글로벌로 설정되어 application 전체에서 SecurityContext를 공유한다.
18 |
--------------------------------------------------------------------------------
/Back-End/spring/testsecurity.md:
--------------------------------------------------------------------------------
1 | # Spring Test시에 Spring Security인증을 할 수 있는 어노테이션
2 |
3 | ### @WithMockUser
4 | WithMockUser 어노테이션은 지정한 사용자 이름, 패스워드, 권한으로 UserDetails를 생성한 후 보안 컨텍스트를 로드한다. 값을 지정하지 않을 시에는 아래의 기본값을 갖는다.
5 |
6 | - username: user
7 | - roles: ROLE_USER
8 | - password: password
9 |
10 | ### @WithAnonymousUser
11 | 익명의 사용자로 테스트할 수 있음
12 |
13 | ### @WithUserDetails
14 | 지정한 사용자 이름으로 계정을 조회한 후 UserDetails 객체를 조회하여 보안 컨텍스트를 로드하게 된다.
15 |
16 | - value: 지정한 사용자 이름. Default User
17 | - userDetailsServiceBeanName: UserDetails 조회 서비스의 빈 이, 하나만 잇으면 기입하지 않아도 된다.
--------------------------------------------------------------------------------
/Back-End/spring/valid.md:
--------------------------------------------------------------------------------
1 | # Spring Validation을 이용한 유효성 검증
2 |
3 | ### Validation
4 | - 올바르지 않은 데이터를 걸러내고 보안을 유지하기 위해 데이터 검증은 여러 계층에 걸쳐서 적용됨.
5 | - Client의 데이터는 조작이 쉬울 뿐더러 모든 데이터가 정상적인 방식으로 들어오는 것도 아니기 때문에, `Client Side`뿐만 아니라 `Server Side`에서도 데이터 유효성을 검사해야 할 필요가 있습니다.
6 | - 스프링부트 프로젝트에서는 @Validated를 이용해 유효성을 검증할 수 있습니다.
7 |
8 | ### Bean Validation
9 | 스프링의 기본적인 validation인 Bean valiation은 클래스 필드에 특정 어노테이션을 적용하여 필드가 갖는 제약 조건을 정의하는 구조로 이루어진 검사입니다.
10 | validator가 어떠한 비즈니스적 로직에 대한 검증이 아닌, 그 클래스로 생성된 객체 자체의 필드에 대한 유효성 여부를 검증합니다.
11 |
12 |
13 |
14 | #### @Valid, @Validated 차이
15 | @Valid는 java에서 지원해주는 어노테이션이고, @Validated는 Spring에서 지원해주는 어노테이션입니다. @Validated는 @Valid의 기능을 포함하고, 유효성을 검토할 그룹을 지정할 수 있는 기능을 추가로 가지고 있습니다.
16 |
17 |
18 |
19 | ### @NotNull, @NotEmpty, @NotBlank
20 | - 단순하게 null이 아니고, 비어있지 않고, 공백이 아니다라고는 알고있다.
21 | - 그렇다면 String의 경우 null도 안되고, 비어있지도 않고, 공백도 아니여야 한다면 세가지 어노테이션을 다 달아줘야 할까?
22 |
23 |
24 | #### @NotNull
25 | 제한된 CharSequence, Collection, Map, Array는 null만 아니라면 유효하지만, 비어있을 수는 있다.
26 |
27 | #### @NotEmpty
28 | 제한된 CharSequence, Collection, Map, Array는 null이 아니고 size또는 length가 0보다 커야한다.
29 |
30 | #### @NotBlank
31 | String 은 null이 아니고 trimmed length가 0보다 커야한다.
--------------------------------------------------------------------------------
/Data-Structure/image/case1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/image/case1.png
--------------------------------------------------------------------------------
/Data-Structure/image/case23.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/image/case23.png
--------------------------------------------------------------------------------
/Data-Structure/image/deletecase2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/image/deletecase2.png
--------------------------------------------------------------------------------
/Data-Structure/image/deleteexam.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/image/deleteexam.png
--------------------------------------------------------------------------------
/Data-Structure/image/deleteexam2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/image/deleteexam2.png
--------------------------------------------------------------------------------
/Data-Structure/image/deleteexam3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/image/deleteexam3.png
--------------------------------------------------------------------------------
/Data-Structure/image/deleteexam4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/image/deleteexam4.png
--------------------------------------------------------------------------------
/Data-Structure/image/examplenode.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/image/examplenode.png
--------------------------------------------------------------------------------
/Data-Structure/image/math.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/image/math.png
--------------------------------------------------------------------------------
/Data-Structure/image/nilnode.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/image/nilnode.png
--------------------------------------------------------------------------------
/Data-Structure/image/nodetree.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/image/nodetree.png
--------------------------------------------------------------------------------
/Data-Structure/image/redblack.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/image/redblack.png
--------------------------------------------------------------------------------
/Data-Structure/image/rededge.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/image/rededge.png
--------------------------------------------------------------------------------
/Data-Structure/image/rotation.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/image/rotation.png
--------------------------------------------------------------------------------
/Data-Structure/image/violation.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/image/violation.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/graph/image/bfs2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/graph/image/bfs2.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/graph/image/bfsal.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/graph/image/bfsal.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/graph/image/bfsexam.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/graph/image/bfsexam.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/graph/image/bfsimpl.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/graph/image/bfsimpl.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/graph/image/dfs.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/graph/image/dfs.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/graph/image/differgraph.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/graph/image/differgraph.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/tree/image/LLcase.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/tree/image/LLcase.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/tree/image/avl.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/tree/image/avl.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/tree/image/bst.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/tree/image/bst.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/tree/image/bstdelete2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/tree/image/bstdelete2.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/tree/image/bstdelete3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/tree/image/bstdelete3.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/tree/image/bstdetail1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/tree/image/bstdetail1.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/tree/image/bstdetail2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/tree/image/bstdetail2.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/tree/image/bstinsert2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/tree/image/bstinsert2.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/tree/image/deletebst1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/tree/image/deletebst1.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/tree/image/express.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/tree/image/express.jpeg
--------------------------------------------------------------------------------
/Data-Structure/비선형/tree/image/insertbst.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/tree/image/insertbst.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/tree/image/linuxtree.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/tree/image/linuxtree.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/tree/image/lr.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/tree/image/lr.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/tree/image/rl.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/tree/image/rl.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/tree/image/rr.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/tree/image/rr.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/tree/image/tree.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/tree/image/tree.png
--------------------------------------------------------------------------------
/Data-Structure/비선형/tree/image/windowtree.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/비선형/tree/image/windowtree.gif
--------------------------------------------------------------------------------
/Data-Structure/선형/queue/image/queue.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Data-Structure/선형/queue/image/queue.png
--------------------------------------------------------------------------------
/DataBase/ACID.md:
--------------------------------------------------------------------------------
1 | ### 트랜잭션과 ACID
2 |
3 | ### 트랜잭션
4 | 여러작업들을 하나로 묶은 단위입니다. 한 덩어리의 작업들은 모두 실행되거나, 실행되지 않습니다.
5 |
6 | 
7 |
8 | #### 트랜잭션이 필요한 이유
9 | 예를 들면 A은행 -> B은행으로 돈을 보내기 위하여 출금하고 송금한다고 가정합니다. A은행에서 돈을 출금하고나서 B은행으로 송금하려고 하는데 갑자기 시스템이 멈추면 어떻게 될까요? 돈은 출금되었지만, 송금되지 않고 증발하게 되는 끔찍한 상황이 발생합니다.
10 |
11 | 트랜잭션은 이런 상황이 일어나지 않도록 보장해줍니다.
12 |
13 | 대부분의 데이터베이스는 송금이 되다가 마는 상황이 발생하지 않도록 여러가지 방법을 제공하지만, 공통적으로 제공하는 가장 기본적인 방법은 트랜잭션을 통하여 데이터의 유효성을 보장하는 것 입니다.
14 |
15 | ### ACID
16 | ACID는 무슨 뜻일까요? `산`인가요?
17 |
18 | - ACID는 데이터의 유효성을 보장하기 위한, 트랜잭션의 특징들의 앞글자를 딴 단어입니다.
19 |
20 | #### Atomicity(원자성)
21 | 모든 작업이 반영되거나 모두 롤백되는 특성입니다.
22 |
23 | #### Consistency(일관성)
24 | 데이터는 미리 정의된 규칙에서만 수정이 가능한 특성을 의미합니다. 숫자컬럼에 문자열값을 저장이 안되도록 보장해줍니다.
25 |
26 | #### Isolation(독립성 , 고립성)
27 | A와 B 두개의 트랜잭션이 실행되고 있을 때, A의 작업들이 B에게 보여지는 정도를 의미합니다.
28 |
29 | #### Durability(영구성)
30 | 한번 반영된 트랜잭션의 내용은 영원히 적용되는 특성을 의미합니다.
--------------------------------------------------------------------------------
/DataBase/Image/1정규화적용.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DataBase/Image/1정규화적용.png
--------------------------------------------------------------------------------
/DataBase/Image/BCNF적용.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DataBase/Image/BCNF적용.png
--------------------------------------------------------------------------------
/DataBase/Image/BCNF정규화.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DataBase/Image/BCNF정규화.png
--------------------------------------------------------------------------------
/DataBase/Image/btree.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DataBase/Image/btree.png
--------------------------------------------------------------------------------
/DataBase/Image/cap.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DataBase/Image/cap.png
--------------------------------------------------------------------------------
/DataBase/Image/index.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DataBase/Image/index.png
--------------------------------------------------------------------------------
/DataBase/Image/table.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DataBase/Image/table.png
--------------------------------------------------------------------------------
/DataBase/Image/transaction.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DataBase/Image/transaction.png
--------------------------------------------------------------------------------
/DataBase/Image/리플리케이션.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DataBase/Image/리플리케이션.png
--------------------------------------------------------------------------------
/DataBase/Image/제1정규화.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DataBase/Image/제1정규화.png
--------------------------------------------------------------------------------
/DataBase/Image/제2정규화.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DataBase/Image/제2정규화.png
--------------------------------------------------------------------------------
/DataBase/Image/제2정규화적용.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DataBase/Image/제2정규화적용.png
--------------------------------------------------------------------------------
/DataBase/Image/제3정규화.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DataBase/Image/제3정규화.png
--------------------------------------------------------------------------------
/DataBase/Image/제3정규화적용.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DataBase/Image/제3정규화적용.png
--------------------------------------------------------------------------------
/DataBase/Image/클러스터링.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DataBase/Image/클러스터링.png
--------------------------------------------------------------------------------
/DataBase/ORMs.md:
--------------------------------------------------------------------------------
1 | # ORM의 개념과 종류, 활용 방안
2 |
3 | ### ORM의 개념
4 | - ORM Object Relational Mapping은 객체로 연결을 해준다는 의미로, 어플리케이션과 데이터베이스 연결 시 SQL 언어가 아닌 어플리케이션 개발 언어로 데이터베이스를 접근할 수 있게 해주는 툴이다.
5 | - ORM은 SQL문법 대신 어플리케이션의 개발 언어를 그대로 사용할 수 있게 함으로써, 개발 언어의 일관성과 가독성을 높여준다.
6 |
7 |
8 | ### ORM의 활용 방향
9 | ORM은 백엔드 개발에 있어 개발언어의 일관성과 가독성을 높여주는 강력한 장점이 있다.
10 |
11 | 다만, ORM만으로는 SQL의 모든 부분을 다루기가 어렵기 때문에 백엔드 개발 시 SQL 쿼리에 대한 지식과 경험이 바탕이되어야 더 효과적인 백엔드 개발이 가능하다는점을 염두해주면 좋다.
12 |
13 |
14 |
15 | ### ORM 장점 😃
16 | - **객체 지향적 코드로 인해 더 직관적이고 비즈니스 로직에 집중할 수 있도록 도와준다.**
17 | - CRUD을 위한 긴 SQL 문장을 작성할 필요가 없다.
18 | - 각 객체(Model)별로 코드를 작성하여 가독성을 높여 준다.
19 | - SQL의 절차적 접근이 아닌 객체적인 접근으로 생산성을 높여준다.
20 | - **재사용 및 유지보수의 편리성이 증가한다.**
21 | - 매핑 정보가 명확해, ERD를 보는 것에 대한 의존도를 낮출 수 있다.
22 | - ORM은 독립적으로 작성되어 있고 해당 객체들은 재사용이 가능하다.
23 | - **DBMS에 대한 종속성이 줄어든다.**
24 | - 대부분의 ORM은 DB에 종속적이지 않다.
25 | - 개발자는 Object에 집중함으로써 DBMS를 교체하는 극단적인 작업에도 비교적 적은 리스크와 시간이 소요된다.
26 | - 종속적이지 않다는 것은 구현 방법 뿐만 아니라 많은 솔루션에서 자료형 타입까지 유효하다.
27 |
28 | > 종속성: 프로그램 구조가 데이터 구조에 영향을 받는 것을 의미함
29 |
30 | ### ORM 단점 🥲
31 | - **완벽한 ORM만으로는 구현하기가 어렵다.**
32 | - 사용하기엔 편하지만 설계에는 매우 신중해야 한다.
33 | - 프로젝트의 복잡성이 높아질 경우 난이도 또한 올라갈 수 있다.
34 | - 잘못 구현된 경우 속도 저하 및 심한 경우 일관성이 무너지는 문제점이 생길 수 있다.
35 | - **프로시저 많은 시스템에서는 ORM의 객체 지향적인 장점을 활용하기 어렵다.**
36 | - 이미 프로시저가 많은 시스템에서는 다시 객체로 바꿔야 하며, 그 과정에서 생산성 저하 혹은 리스크가 발생할 수 있다.
37 |
38 | > 프로시저: 특정 작업을 위한 프로그램 일부, 함수와 같은 의미
--------------------------------------------------------------------------------
/DataBase/clustering.md:
--------------------------------------------------------------------------------
1 | # Clustering (Active Clustering, Standby Clustering)
2 |
3 | ## Clustering
4 | 데이터베이스 분산 기법 중 하나로 DB 서버를 여러 개를 두어 서버 한 대가 죽었을 때 대비할 수 있는 기법
5 |
6 | ## Active Clustring
7 |
8 |
9 | 
10 |
11 | DB 서버를 여러 개 구성하는 데, 각 서버를 Active 상태로 둠
12 |
13 | ### 장점
14 | - 서버 하나가 죽더라도 다른 서버가 역할을 바로 수행하므로 서비스 중단이 없음
15 | - CPU와 메모리 이용률을 올릴 수 있음
16 |
17 | ### 단점
18 | - 저장소 하나를 공유하게 되면 병목현상이 발생할 수 있다.
19 | - 서버를 여러대 한꺼번에 운영하므로 비용이 더 발생한다.
20 |
21 |
22 | ## Standby Clustering
23 |
24 | 
25 |
26 | 서버를 하나만 운영하고 나머지 서버는 Standby상태로 둔다.
27 | 운영하고 있는 서버가 다운되었을 시에 Standby 상태의 서버를 Active상태로 전환한다.
28 |
29 | ### 장점
30 | - Active-Active 클러스터링에 비해 적은 비용이 든다.
31 |
32 | ### 단점
33 | - 서버가 다운되었을 때 Standby 상태의 서버를 Active 상태로 전환하는 시간이 필요하다.
--------------------------------------------------------------------------------
/DataBase/connectionp.md:
--------------------------------------------------------------------------------
1 | # 데이터베이스 커넥션 풀
2 |
3 | ## Connection Pool CP
4 |
5 | 일반적인 데이터 연동 과정은 웹 어플리케이션이 필요할 때 마다 데이터베이스에 연결해 작업하는 방식이다.
6 |
7 | 하지만 이런식으로 필요할 때마다 연동해서 작업할 경우 데이터베이스 연결에 시간이 많이 걸리는 문제가 발생한다.
8 |
9 | 예를 들어 거래소의 경우, 동시에 몇천명이 동시 거래 및 조회 기능을 사용하는데 매번 데이터베이스와 커넥션을 맺고 푸는 작업을 한다면 굉장히 비효율적이다.
10 |
11 | 이 문제를 해결하기 위해 현재는 웹 어플리케이션이 실행됨과 동시에 연동할 데이터베이스와의 연결을 미리 설정해두고, 필요할 때마다 미리 연결해 놓은 상태를 이용해 빠르게 데이터베이스와 연동하여 작업하는 방식을 사용한다.
12 |
13 | **이렇게 미리 데이터베이스와 연결시킨 상태를 유지하는 기술을 커넥션 풀(Connection Pool, CP)라고 한다.**
14 |
15 | ## 커넥션 풀 사이스 설정
16 | 이론적으로 필요한 최소한의 커넥션 풀 사이즈를 알아보면
17 | `PoolSize = Tn x (Cm - 1) + 1`
18 |
19 | > Tn: 전체 스레드의 갯수
20 | > Cm: 하나의 Task에서 동시에 필요한 Connection 수
21 |
22 | 위와 같은 식으로 설정을 한다면 데드락을 피할 수는 있겠지만 여유 커넥션풀이 하나 뿐이라 성능상 좋지 못하다.
23 |
24 | 따라서 커넥션풀의 여유를 주기위해 아래와 같은 식을 사용하는 것을 권장한다.
25 |
26 | `PoolSize - Tn x (Cm - 1) + (Tn / 2)`
27 |
--------------------------------------------------------------------------------
/DataBase/dbload.md:
--------------------------------------------------------------------------------
1 | # 데이터베이스 부하분산(파티셔닝, 샤딩, 레플리케이션)
2 |
3 |
4 | ## 파티셔닝
5 |
6 | 특정한 기준으로 테이블을 분리하는 것.
7 |
8 | 종류로는 column을 기준으로 분리하는 수직 파티셔닝과
9 | row를 기준으로 분리하는 수평 파티셔닝이 존재한다.
10 |
11 | 수평 파티셔닝 방식에서도 해쉬 파티셔닝과 범위 파티셔닝과 같은 것들이 존재한다.
12 |
13 | 파티셔닝을 진행할 때 특정한 데이터를 기준으로 파티셔닝 키를 지정한다. 그렇기에 가장 많이 조회될때 사용되는 데이터를 기준으로 파티셔닝 키를 정해야한다.
14 |
15 |
16 | ## 샤딩
17 |
18 | 샤딩은 간단히 말해 수평 파티셔닝에서 분리한 테이블을 각각의 다른 DB 서버에 저장하는 것이다.
19 |
20 | 여기서 파니셔닝 Key는 샤드 Key라고 부른다.
21 |
22 |
23 |
24 | ## 레플리케이션
25 |
26 | DB를 복제해서 여러 대의 DB 서버에 저장하는 방식이다.
27 |
28 | Master-Slave 구조를 가지고 설계되는게 보통이며 Master에는 Read/Write와 Slave는 Read 작업을 맡고 있다.
29 |
30 | Slave의 버전은 최소 Master의 버전보다 높아야 한다.
31 |
32 | 간단하게 알아보았고 각각의 방법에 대해서 자세히 더 알아볼 예정이다.
--------------------------------------------------------------------------------
/DataBase/mmr.md:
--------------------------------------------------------------------------------
1 | ### MRR, BKA
2 |
3 | MySQL 서버의 옵티마이저가 실행 계획을 수립할 때 통계 정버와 옵티마이저 옵션을 결합해서 최적의 실행 계획을 수립한다.
4 |
5 | **옵티마이저는 옵션은 크게 조인 관련 옵티마이저 옵션과 옵티마이저 스위치로 구분한다.**
6 |
7 | 이번 글에서는 옵티마이저가 조인의 성능을 최적화하는 기법중 하나인 MRR과 배치 키 엑세스를 알아보겠다.
8 |
9 |
10 |
11 | ### MRR(Multi Range Read)
12 |
13 | DS-MRR(Disk Sweep Multi Range Read)라고도 한다.
14 |
15 | MySQL 서버에서 지금까지 지원하던 조인 방식은 드라이빙 테이블에서 레코드를 한 건 읽어서 드리븐 테이블의 일치하는 레코드를 찾아 조인을 수행하는 것이다.
16 |
17 | 이는 네스티드 루프 조인(Nested Loop Join)이라고 한다. MySQL 서버의 내부 구조상 조인 처리는 MySQL 엔진이 처리하지만, 실제 레코드를 검색하고 읽는 부분은 스토리지 엔진이 담당한다.
18 |
19 | 이 때 드라이빙 테이블의 레코드 건 별로 드리븐 테이블의 레코드를 찾으면 레코드를 찾고 읽는 스토리지 엔진에서는 아무런 최적화를 할 수 없는 문제가 발생한다.
20 |
21 | 이러한 단점을 보완하기 위해 MySQL 서버는 **조인 버퍼**를 사용해 조인 대상 테이블 중 하나로부터 레코드를 읽어 그 값을 버퍼에 버퍼링하여 스토리지 엔진이 레코드를 읽을때 한 번에 요청하여 읽을 수 있도록 최소화한다. 이렇게 되면 정렬된 순서로 접근해 디스크의 데이터 페이지 읽기를 최소화할 수 있는 것이다.
22 |
23 | > 물론 데이터 페이지가 메모리에 있다해도 예를들면 InnoDB 버퍼풀 그래도 버퍼풀의 접근을 최소화할 수 있는 것이다.
24 |
25 | 이러한 읽기 방식을 MRR이라고 하며, 이를 응용해서 실행되는 조인 방식을 BKA(Batched Key Access) 조인이라고 한다.
26 |
27 | BKA 조인 최적화는 기본적으로 비활성화 되어있는데 이는 BKA 조인의 단점이 있기 때문이다.
28 |
29 | 쿼리의 특성에 따라 도움이 되는 경우도 있고 부가적인 정렬작업이 필요해 오히려 성능에 안좋은 영향을 미치는 경우도 있어 잘 고려하여 적용해야한다.
--------------------------------------------------------------------------------
/DataBase/modeling.md:
--------------------------------------------------------------------------------
1 | # 데이터 모델링과 데이터 성질에 따른 DB 종류
2 |
3 | ## 데이터 모델링
4 | 주어진 개념으로부터 논리적인 데이터 모델을 구성하는 작업이다.
5 |
6 | ### 데이터 모델링의 목적
7 | - 업무 정보를 구성하는 기초가 되는 정보들을 일정한 표기법에 의해 표현함으로써 정보 시스템 구축의 대상이 되는 업무 내용을 정확하게 분석하는 것
8 | - 분석된 모델을 가지고 실제 데이터베이스를 생성해 개발 및 데이터 관리에 사용하기 위함
9 |
10 | 데이터 모델링은 중복성, 유연성, 일관성을 고려해 수행되어야 한다.
11 |
12 | - **중복성** : 같은 데이터베이스 내의 데이터 혹은 속성의 중복으로 저장되는 것을 지양해야 한다.
13 |
14 | - **유연성** 빈번한 모델에 대한 수정/변경이 이루어지지 않도록 쿼리의 튜닝까지 고려해야한다.
15 |
16 | - **일관성** : 데이터 간의 연관된 정보를 무시하고 데이터가 갱신되는 경우를 피하고자 데이터 간 관계를 명확히 정의해야한다.
17 |
18 |
19 | ### 관계형 데이터베이스의 데이터 모델링 순서
20 | 1. 요구사항 파악
21 | 2. 개념적 데이터 모델 설계
22 | 3. 논리적 데이터 모델 설계
23 | 4. 물리적 데이터 모델 설계
24 |
25 |
--------------------------------------------------------------------------------
/DataBase/nosql/mongodb/document.md:
--------------------------------------------------------------------------------
1 | # Document Database
2 |
3 | Document Database는 다음과 같은 이점을 제공합니다.
4 |
5 | ### High Performance
6 |
7 | 몽고디비는 높은 성능의 데이터 지속성을 제공하고 있습니다.
8 |
9 | - 내장(Embeded) 데이터 모델은 데이터베이스 시스템의 I/O 활동을 감소시킵니다.
10 | - Index를 통한 빠른 쿼리와 keys를 내장 Document와 Array에 추가할 수 있습니다.
11 |
12 | ### Rich Query Language
13 |
14 | 몽고디비는 풍부한 쿼리 표현식을 제공하고 있습니다.
15 |
16 |
17 | ### High Availability
18 |
19 | replica set이라고 불리는 몽고디비의 replication은 다음 기능을 제공하고 있습니다.
20 |
21 | - automic failover(특정 노드에 결함이 발생하면 다른 노드가 작업을 대신 수행)
22 | - data redundancy(replica set은 몽고디비의 서버 그룹으로 동일한 데이터 모음을 제공하여 데이터의 신뢰성과 높은 데이터 가용성을 제공합니다.)
23 |
24 |
25 | ### Horizontal Scaleablity
26 |
27 | 몽고디비는 수평적 확장을 제공하고 다음의 핵심 기능을 제공해요
28 |
29 | - Sharding 머신들 간의 데이터 분산
30 | - 몽고디비는 3.4부터 shard key 기반의 zones를 생성합니다. 균형있는 클러스터 내에서는 몽고디비는 읽기와 쓰기 작업을 해당 shard의 zone에 직접 접근하여 작업하도록 합니다.
31 |
32 |
33 | ### Support for Multiple Storage Engines
34 | 몽고디비는 다양한 저장엔진을 제공합니다.
35 |
36 | - WiredTiger Storage Engine
37 | - MMAPv1 Storage Engine
38 |
39 | 이외에도 다양한 외부 엔진이 추가할 수 있습니다.
40 |
--------------------------------------------------------------------------------
/DataBase/nosql/redis/locksync.md:
--------------------------------------------------------------------------------
1 | # Redis failover시 데이터 손실 방지 방법
2 |
3 | 레디스 분산락을 적용하여 한 데이터에 대해 락 메커니즘을 적용했다고 가정해보자.
4 |
5 | 락을 취득한 상태로 레디스 마스터 노드가 다운이 되어, 레플리카 노드가 failover 되었다.
6 |
7 | 여기서 failover 된 레플리카 노드는 락 정보를 갖고있지 않아 락 정보가 없어지게 된다면 어떻게 될까?
8 |
9 | 당연히 다른 노드들도 락에 대한 정보를 인지하지 못해 동시성 이슈가 발생하게 될 것이다. (락 상태 손실)
10 |
11 | 그렇기 때문에 꼭 이러한 문제를 해결해야한다.
12 |
13 | ### RedLock
14 |
15 | RedLock은 여러 redis 노드가 락을 취득해 과반수 이상의 노드가 취득하게 되었다면 락을 획득하는 방식으로 작동하게 된다.
16 |
17 | 클라이언트는 **다수의 레디스 노드가 락을 획득해야만 성공한 것으로 간주**되며, 한 노드에 장애가 발생해도 다수의 노드가 락 상태를 유지하고 있으면 락이 유효하게 유지된다. 즉 가용성이 더욱 높아지는 것이다.
18 |
19 |
20 |
21 | ### 동기식 복제
22 |
23 | 동기 복제와 비동기 복제의 주요 차이점은 데이터가 복제본에 기록되는 방식이다.
24 |
25 | 대부분의 동기식 복제는 기본 스토리지와 복제본에 동시에 데이터를 쓰게 된다. 그렇기에 기본 복사본과 복제본은 항상 동기화된 상태를 유지한다.
26 |
27 | 대조적으로 비동기 복제는 기본 스토리지에 데이터를 쓴 다음 복제본에 데이터를 복사한다. 거의 실시간으로 반영되게 구현할 수 있지만, 예약된 방식으로 발생하는 것이 더 일반적이다.
28 |
29 | 비동기식 복제가 동기식 복제보다 비용이 훨씬 적게드는 경향이 존재한다. 복제 프로세스가 실시간으로 발생할 필요가 없기 때문이다.
30 |
31 | 동기 복제는 복제 비용이 많이 들지만 복제 노드들과 데이터들이 일관성있게 존재하므로 데이터의 복제 유지 일관성이 중요하게 된다면 **동기식 복제를 통해 레플리카를 구성해 둘 수 있을 것이다.**
32 |
33 |
34 |
35 |
36 | ### 클라이언트 측 복구
37 |
38 | 클라이언트에서 페일오버 중 락 손실이 발생했을 가능성을 감지하는 메커니즘을 구축하는 방식인데.
39 |
40 | 클라이언트가 페일오버를 하트비트나 타임아웃을 통해 감지하는 것이다. 감지하게 된다면 락을 수동으로 해제하거나 락의 만료 시간을 기다린 후에 다시 시도할 수 있다.
41 |
42 | 이러한 방식들을 사용해 레디스 클러스터 뿐만 아니라 클러스터 환경에서 페일오버시 데이터가 손실되는 문제를 해결해볼 수 있다.
43 |
--------------------------------------------------------------------------------
/DataBase/nosql/sql_nosql.md:
--------------------------------------------------------------------------------
1 | # SQL vs NoSQL
2 |
3 | ### RDB
4 |
5 | RDB에서는 효율적인 데이터 관리를 위해서 **정규화**를 사용한다.
6 |
7 | 데이터의 중복을 방지할 수 있으며 복잡하고 다양한 질의가 가능하다.
8 |
9 | 하지만 단점으로는 여러 테이블의 연관관계를 외래키를 통해 갖고있고 연관된 데이터를 조인해서 가져오기때문에 조회가 느리다.
10 |
11 | 그리고 확장성이 떨어진다는 단점이 있다.
12 |
13 | 스키마 변경에 대한 공수도 매우 크다.
14 |
15 | Scale-out 등의 기법은 고려하지 않고 만들어졌다고 볼 수 있다.
16 |
17 | ### NoSQL
18 |
19 | 관계형 데이터베이스에서 하지 못했거나 어려운 것들을 해결하기 위해 등장했다.
20 |
21 | 데이터의 가시성이 뛰어난다. JSON형태로 Document 내부에 Document를 두는 것이 가능하다.
22 |
23 | Join이 없이 데이터를 조회가 가능하므로 조회속도가 매우 빠르다
24 |
25 | 스키마가 유연해서 데이터 모델을 Application의 요구사항에 맞게 데이터를 수용할 수 있다.
26 |
27 | 스케일 아웃이 간편하다.
28 |
29 | 단점으로는 역정규화에 따라 데이터 중복이 많이 발생하고 스키마 설계를 못하면 성능 저하가 발생한다.
30 |
31 | > NoSQL은 진짜 No SQL이라는 뜻이 아니라 Not-Only SQL이라는 뜻이다 기본 SQL 뿐만 아니라 다양한 방법으로 지원을하고있다는 데이터베이스라고 생각하면 된다.
32 |
33 | 무조건 NoSQL이 좋은가? 이건 또 아니다. NoSQL에서 연관관계가 있는 데이터를 저장할때 데이터의 중복이 많기 때문이다. 적절한 상황에 맞춰서 사용하도록하자
--------------------------------------------------------------------------------
/DataBase/sql/date.md:
--------------------------------------------------------------------------------
1 | # SQL 날짜(DATE) 함수를 사용한 실습 + DUAL 테이블
2 |
3 | ## DUAL 테이블
4 | sql 에서 지원해주는 가상의 테이블이다.
5 |
6 | 아래와 같이 현재 시간을 가져올 수 있다.
7 | ```sql
8 | SELECT SYSDATE FROM DUAL;
9 | ```
10 |
11 | 현재 시간에서 n개월 후, 전을 구하는 방법은
12 | ```sql
13 | SELECT ADD_MONTHS(SYSDATE, 3) FROM DUAL; # 3개월 후
14 | SELECT ADD_MONTHS(SYSDATE, -3) FROM DUAL; # 3개월 전
15 | ```
16 |
17 | 시간 빼고 년도만 구하는 방법
18 | ```sql
19 | SELECT TRUNC(SYSDATE) FROM DUAL;
20 | ```
21 |
22 | TO_CHAR를 사용해 지정된 포멧 형식으로 DATE 출력
23 |
24 | ```sql
25 | SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD HH24:MI:SS') FROM DUAL
26 | ```
--------------------------------------------------------------------------------
/DataBase/sql/groupby.md:
--------------------------------------------------------------------------------
1 | # GROUP BY, 집계함수로 데이터 그룹별 집계 실습
2 |
3 | GROUP BY를 통해 여러 데이터를 집계해서 확인할 수 있다.
4 |
5 | 집계 함수를 통해 행의 개수, 최대,최소값, 평균, 표춘편차등 여러 값들을 집계할 수 있다.
6 |
7 | COUNT를 통해 행의 개수를 출력할 수 있다.
8 | > COUNT(*)은 null 값의 행을 집계하지만 COUNT(${COLUMN_NAME})은 집계하지 않는다.
9 |
10 | SUM을 통해 각 조건에 맞는 행들의 데이터의 합을 구할 수 있다.
11 |
12 | ```sql
13 | SELECT CATEGORY, COUNT(*) FROM NETFLIX GROUP BY CATEGORY;
14 |
15 | SELECT CATEGORY, SUM(*) FROM NETFLIX GROUP BY CATEGORY;
16 | ```
17 |
18 | MAX,MIN을 통해 각 행의 값들의 최댓값과 최솟값을 구할 수 있다.
19 |
20 | ```sql
21 | SELECT CATEGORY, MAX(VIEW_COUNT) FROM NETFLIX GROUP BY CATEGORY;
22 |
23 | SELECT CATEGORY, MAX(VIEW_COUNT) FROM NETFLIX GROUP BY CATEGORY ORDER BY MAX(VIEW_COUNT) DESC; # order by 를 사용해 정렬 조건을 추가 가능
24 |
25 | SELECT CATEGORY, MIN(VIEW_COUNT) FROM NETFLIX GROUP BY CATEGORY;
26 |
27 | SELECT CATEGORY, MAX(VIEW_COUNT), MIN(VIEW_COUNT) FROM NETFLIX GROUP BY CATEGORY;
28 | ```
29 |
30 | AVG를 통해 평균을 구하는 것도 가능하다. + (참고: STDEV 표준편차 VAR 분산, STRING_AGG 컬럼 합치기)
31 |
32 | ```sql
33 | SELECT CATEGORY, AVG(VIEW_COUNT) FROM NETFLIX GROUP BY CATEGORY;
34 | ```
35 |
36 |
37 |
--------------------------------------------------------------------------------
/DataBase/sql/null.md:
--------------------------------------------------------------------------------
1 | # SQL NULL 관련 함수 - NVL, NVL2, NULLIF, COALESCE
2 |
3 | ## SQL NULL 관련 함수
4 | SQL의 NULL 관련 함수인 NVL, NVL2, NULLIF, COALESCE를 한번 알아보자.
5 |
6 | ### NVL
7 | NULL이면 다른 값으로 변경하는 함수
8 |
9 | NVL(K, 0)은 K 컬럼이 NULL이면 0으로 바꿈
10 |
11 | ### NVL2
12 | NVL 함수와 DECODE 함수가 하나로 합쳐진 함수
13 | NVL2(K, 1, -1)은 K컬럼이 NULL이 아니면 1을 NULL이면 -1을 반환
14 |
15 | ### NULLIF
16 | 두개의 값이 같으면 NULL을 같지 않으면 첫번째 값을 반환하는 함수
17 |
18 | NULLIF(exp1, exp2)은 exp1과 exp2가 같으면 NULL을 같지 않으면 exp1을 반환
19 |
20 | ### COALESCE
21 | NULL이 아닌 최초의 인자 값을 반환하는 함수
22 |
23 | COALESCE(exp1, exp2, exp3, ...)은 exp1부터 그 뒤로 차례대로 NULL인지 확인, 만약 exp2가 최초의 NULL이 아닌 값이면 exp2를 반환
--------------------------------------------------------------------------------
/DataBase/sql/numberfun.md:
--------------------------------------------------------------------------------
1 | # 숫자함수 ROUND(), TRUNC(), CEIL() 실습
2 |
3 | ### ROUND()
4 |
5 | 입력한 데이터의 반올림을 한다.
6 |
7 | ```sql
8 | SELECT ROUND(3.16) FROM DUAL; # 3
9 | SELECT ROUND(3.76) FROM DUAL; # 4
10 |
11 | SELECT ROUND(3.16, 1) FROM DUAL; # 3.2 두번째 인자가 있으면 그 인자의 소숫점 자릿수까지 출력함
12 | ```
13 |
14 | ### TRUNC()
15 |
16 | 입력받은 데이터의 소숫점 자리수를 다 버림
17 |
18 | ```sql
19 | SELECT TRUNC(3.16) FROM DUAL; # 3
20 | SELECT TRUNC(3.76) FROM DUAL; # 3
21 |
22 | SELECT TRUNC(3.16, 1) # 3.1
23 | ```
24 |
25 | ### CEIL()
26 | 입력받은 데이터를 올림
27 |
28 | ```sql
29 | SELECT CEIL(3.16) FROM DUAL; # 4
30 | SELECT CEIL(3.76) FROM DUAL; # 4
31 | SELECT CEIL(-3.16) FROM DUAL; # 3
32 | ```
--------------------------------------------------------------------------------
/DataBase/sql/orderby.md:
--------------------------------------------------------------------------------
1 | # ORDER BY로 데이터 정렬하기 실습
2 |
3 | ORDER BY를 통해서 데이터를 정렬된 상태로 조회할 수 있다.
4 |
5 | `ASC`: 오름차순 정렬으로 기본 값이다
6 | `DESC`: 내림차순 정렬으로 지정을 해주어야한다.
7 |
8 | 조회수 오름차순으로 데이터를 조회한다.
9 | 아래의 두 구문은 같은 동작을 한다.
10 | ```sql
11 | SELECT * FROM NETFLIX ORDER BY VIEW_COUNT ASC;
12 | SELECT * FROM NETFLIX ORDER BY VIEW_COUNT;
13 | ```
14 |
15 | 내림차순으로 데이터를 조회한다.
16 | ```sql
17 | SELECT * FROM NETFLIX ORDER BY VIEW_COUNT DESC;
18 | ```
19 |
20 | 여러 컬럼에 정렬 조건을 줘 조회할 수 있다.
21 |
22 | ```sql
23 | SELECT * FROM NETFLIX ORDER BY VIDEO_NAME, VIEW_COUNT DESC;
24 | ```
25 |
26 | 비디오 제목을 기준으로 조회수를 내림차순으로 정렬하여 조회한다.
27 |
28 |
--------------------------------------------------------------------------------
/DataBase/sql/replace.md:
--------------------------------------------------------------------------------
1 | # REPLACE() 함수로 데이터 수정하기 실습
2 |
3 | REPLACE(A, B, C)
4 |
5 | A에는 바꿀 데이터의 정보
6 | B는 A에서 바꿀 문자를 고른다.
7 | C에서는 B에서 고른 문자를 바꿀 문자를 고른다.
8 |
9 | C는 입력이 필수가 아니며 입력하지 않으면 B에서 고른 문자가 NULL로 변환된다.
10 |
11 | ```sql
12 | SELECT REPLACE('코드라이언', '코드', 'CODE') FROM DUAL; # CODE라이언
13 | SELECT REPLACE('코드라이언','코드') FROM DUAL; # 라이언
14 | SELECT REPLACE('010-1111-1111','-');
15 | ```
16 |
17 | SQL에서는 줄바꿈을 특정 기호로 저장한다. 줄바꿈을 REPLACE를 사용해서 없애고 싶다면.
18 |
19 | ```sql
20 | SELECT
21 | '안녕하세요
22 | 코드라이언입니다.'
23 | FROM DUAL;
24 |
25 | SELECT REPLACE('안녕하세요
26 | 코드라이언입니다.', CHR(10), ' ') FROM DUAL;
27 | ```
28 |
29 | 보통 컬럼 값을 변경할 때 이런식으로 사용된다.
30 |
31 | ```sql
32 | SELECT * FROM NETFLIX_CAST;
33 | SELECT REPLACE(CAST_MEMBER, '이지은', '아이유') FROM NETFLIX_CAST # 이지은의 데이터를 아이유로 변경
34 | ```
--------------------------------------------------------------------------------
/DataBase/sql/substr.md:
--------------------------------------------------------------------------------
1 | # SUBSTR() 함수를 사용한 문자 데이터 자르기 실습
2 |
3 | SUBSTR을 사용해서 문자 데이터를 자를 수 있다.
4 |
5 | SUBSTR(문자, N, M)
6 | N은 앞에서부터 N번째 문자를 가져오고 M은 N부터 M까지를 잘라오겠다는 뜻이다.
7 | M은 생략할 수 있고 생략한다면 N부터 문자 끝까지 가져온다.
8 |
9 | ```sql
10 | SELECT SUBSTR('코드라이언',3,2) FROM DUAL; # 라이
11 | SELECT SUBSTR('코드라이언',3) FROM DUAL; # 라이언
12 |
13 | SELECT SUBSTR('코드라이언', -4) FROM DUAL; # 드라이언, 음수가 들어가면 앞에서부터가 아닌 뒤에서부터 N번째로 읽는다.
14 | ```
15 |
16 | 1. SUBSTR과 NETFLIX CAST 테이블을 사용해서 캐스트 멤버의 이름 가운데를 *로 대체해보겠다.
17 | 2. 긴 문자의 기사를 전부 출력하지말고 20번째 까지만 출력한 후 ....으로 대체해보겠다.
18 |
19 | ```sql
20 | SELECT SUBSTR(CAST_MEMBER,1,1) || '*' || SUBSTR(CAST_MEMBER,3) FROM NETFLIX_CAST;
21 |
22 | SELECT SUBSTR('어쨋든 겁나게 긴 문자 입니다 안녕하세요 저의 이름은 긴 문자입니다 실습을 위해서 조금 길게 써보겠습ㄴ.', 1, 20) || '......' FROM DUAL;
23 | ```
24 |
25 |
--------------------------------------------------------------------------------
/DataBase/sql/upperlower.md:
--------------------------------------------------------------------------------
1 | # UPPER(), LOWER() 함수를 사용한 대소문자 구분 실습
2 |
3 | ### UPPER()
4 | 입력받은 문자 데이터를 모두 대문자로 변환
5 |
6 | ```sql
7 | SELECT UPPER('CodeLion') FROM DUAL; # CODELION
8 | ```
9 |
10 | ### LOWER()
11 | 입력받은 문자 데이터를 모두 소문자로 변환
12 | ```sql
13 | SELECT LOWER('CodeLion') FROM DUAL; # codelion
14 | ```
15 |
16 | 대소문자를 구분하지 않고 아이디가 codelion인 멤버를 찾기
17 |
18 | ```sql
19 | SELECT * FROM MEMBER WHERE ID = UPPER('codelion')
20 | ```
--------------------------------------------------------------------------------
/DataBase/sql/프로시저_트리거.md:
--------------------------------------------------------------------------------
1 | # 프로시저와 트리거의 차이점
2 |
3 | ### 프로시저
4 | 저장 프로시저는 미리 데이터베이스 서버에 일련의 SQL 명령을 해 놓고, 프로시저를 실행하여 SQL 명령을 간단하게 실행할 수 있도록 할 수 있다.
5 |
6 | 프로시저 안에는 SQL 문장 뿐만 아니라 if, while 문 등의 제어 명령이나 반복 명령을 기술할 수 있기 때문에 일종의 프로그램도 만들 수 있다.
7 |
8 | ### 트리거
9 | 트리거는 테이블에 작성한다. 어떤 테이블에 행을 삽입한다든지, 행을 변경, 삭제 했을때에 트리거가 설정되어 있으면, 트리거의 SQL 문장이 자동으로 실행된다.
10 |
11 | 이 기능을 사용하면 데이터의 추가, 삭제, 변경과 함께 관계하는 테이블을 조작하여 데이터베이스로서 모순이 없는 상태를 자동적으로 생성할 수 있다.
12 |
13 | ### 차이점
14 | 프로시저
15 | - CREATE PROCEDURE 문법 사용
16 | - 생성하면 소스코드와 실행코드가 생성
17 | - EXECUTE 명령어로 실행
18 | - COMMIT, ROLLBACK 가능
19 |
20 | 트리거
21 | - CREATE TRIGGER 문법사용
22 | - 생성하면 소스코드와 실행코드가 생성
23 | - 생성 후 자동 실행
24 | - COMMIT, ROLLBACK 불가능
--------------------------------------------------------------------------------
/DataBase/반정규화.md:
--------------------------------------------------------------------------------
1 | # 반정규화 Denormalization
2 |
3 | 반정규화는 정규화된 엔터티, 속성, 관계에 대해 시스템의 성능향상과 개발과 운영의 단순화를 위해 중복,통합,분리 등을 수행하는 데이터 모델링 기법이다.
4 |
5 | 반정규화는 데이터를 중복하여 성능을 향상시키기 위한 기법이라고 정의할 수 있고 좀 더 넓은 의미와 반정규화는 성능을 향상시키기 위해 정규화된 데이터 모델에서 중복, 통합, 분리등을 수행하는 모든 과정을 의미한다.
6 |
7 | 데이터 무결성이 깨질 수 있는 위헙을 무릅쓰고 데이터를 중복하여 반정규화를 적용시키는 이유는 데이터를 조회할 때 디스크 I/O량이 많아 성능이 저하되거나 경로가 너무 멀어 조인으로 인한 성능저하가 에상되거나 컬럼을 계산하여 일긍ㄹ 때 성능이 저하될 것이 예상되는 경우 반 정규화를 수행한다.
8 |
9 | ## 테이블의 반 정규화
10 |
11 | - 테이블 명함
12 | - 1:1 관계 테이블 병합
13 | - 1:M 관계 테이블 병합
14 | - 테이블 분할
15 | - 수직 분할
16 | - 수평 분할
17 | - 테이블 추가
18 | - 중복 테이블 추가
19 | - 통계 테이블 추가
20 | - 이력 테이블 추가
21 | - 부분 테이블 추가
22 |
23 | ## 컬럼의 반 정규화 기법
24 | - 중복 컬럼 추가
25 | - 파생 컬럼 추가
26 | - 이력 테이블 컬럼 추가
27 | - PK에 의한 컬럼 추가
28 | - 응용 시스템 오작동을 위한 컬럼 추가
29 |
30 |
31 | ## 반정규화 절차
32 | 1. 반정규화 대상 조사
33 | - 범위 처리 빈도수 조사
34 | - 대량의 범위 처리 조사
35 | - 통계성 프로세스 조사
36 | - 테이블 조인 개수
37 | 2. 다른 방법 유도 검토
38 | - 뷰 테이블
39 | - 클러스터링 적용
40 | - 인덱스의 조정
41 | - 응용 애플리케이션
42 | 3. 반정규화 적용
43 | - 테이블 반정규화
44 | - 속성의 반정규화
45 | - 관계의 반정규화
46 |
47 | ## 반정규화의 대상에 대해 다른 방법으로 처리
48 | 지나치게 많은 조인이 걸려 데이터를 조회하는 작업이 기술적으로 어려울 경우 뷰를 사용하면 이를 해결할 수도 있다.
49 |
50 | 대량의 데이터처리나 부분처리에 의해 성능이 저하되는 경우 클러스터링을 적용하거나 인덱스를 조정함으로써 성능을 향상시킬 수 있다.
51 |
52 | 대량의 데이터는 Primary Key의 성격에 따라 부분적인 테이블로 분리할 수 있다. 즉, 파티셔닝 기법이 적용되어 성능 저하를 방지할 수 있다.
53 |
54 | 응용 애플리케이션에서 로직을 구사하는 방법을 변경하믕로써 성능을 향상시킬 수 있다.
--------------------------------------------------------------------------------
/Design-Pattern/image/proxy.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Design-Pattern/image/proxy.png
--------------------------------------------------------------------------------
/Design-Pattern/image/templete.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Design-Pattern/image/templete.png
--------------------------------------------------------------------------------
/Design-Pattern/구조/decorator.md:
--------------------------------------------------------------------------------
1 | # 데코레이터 패턴
2 |
3 | 주어진 상황 및 용도에 따라 어떤 객체에 책임(기능)을 동적으로 추가하는 패턴을 말한다.
4 |
5 | 데코레이터라는 말 그대로 장식이라고 생각하면 편하다.
6 |
7 | 기본 기능을 가지고 있는 클래스를 하나 만들어주고 추가할 수 있는 기능들을 추가하기 편하도록 설계하는 방식이다.
8 |
9 | 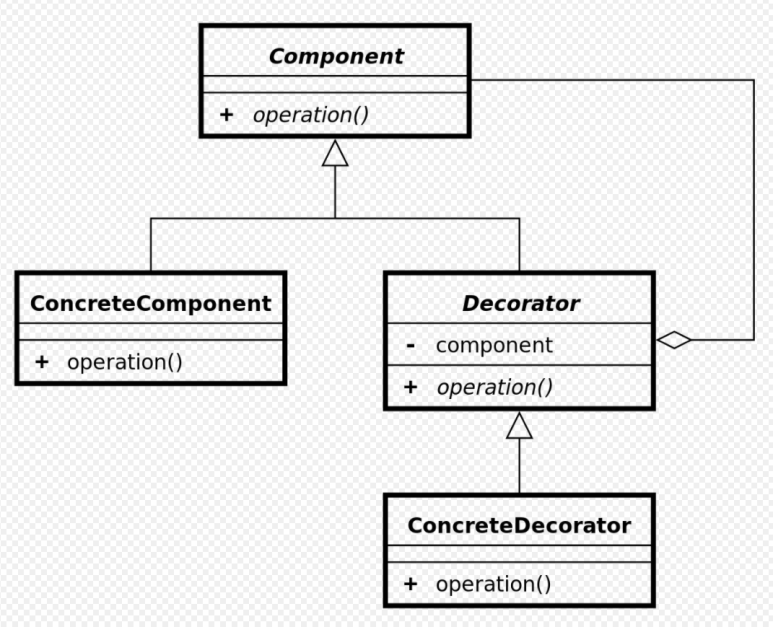
10 |
11 | - Component: 실질적인 인스턴스를 컨트롤 하는 역할
12 | - ConcreteComponent: Component의 실질적인 인스턴스의 부분으로 책임의 주체 역할
13 | - Decorator: Component와 ConcreteDecorator를 동일시 하게 해주는 역할
14 | - ConcreteDecorator: 실질적인 장식 인스턴스 및 정의이며 추가된 책임의 주체
15 |
16 | ## 데코레이터 패턴의 장단점
17 |
18 | ### 장점
19 | 1. 기존 코드를 수정하지 않고도 데코레이터 패턴을 통해 행동을 확장시킬 수 있다.
20 | 2. 구성과 위임을 통해서 실행중에 새로운 행동을 추가할 수 있다.
21 |
22 | ### 단점
23 | 1. 의미없는 객체들이 너무 많이 추가될 수 있다.
24 | 2. 데코레이터를 너무 많이 사용하면 코드가 필요 이상으로 복잡해질 수 있다.
25 |
26 | ### 아래와 같은 상황일 때 데코레이터 패턴 사용을 해주면 좋다.
27 |
28 | 1. 클래스의 요소들을 계속해서 수정하면서 사용하는 구조가 필요한 경우
29 | 2. 여러 요소들을 조합해서 사용하는 클래스 구조인 경우
--------------------------------------------------------------------------------
/Design-Pattern/생성/factory_method.md:
--------------------------------------------------------------------------------
1 | # 팩토리 메서드 패턴
2 |
3 | ## Factory Method Pattern
4 | 팩토리 메서드 패턴은 객체 생성을 공장(Factory) 클래스로 캡슐화 처리해 대신 생성하게 하는 디자인 패턴이다.
5 |
6 | 즉, 클라이언트에서 직접 new 연산자를 통해 제품 객체를 생성하는 것이 아닌, 제품 객체들을 도맡아 생성하는 공장 클래스르 만들고, 이를 상속하는 서브 공장 클래스의 메서드에서 여러가지 제품 객체 생성을 각각 책임지는 것이다.
7 |
8 | 또한 객체 생성에 필요한 과정을 템플릿 처럼 미리 구성해놓고, 객체 생성에 관한 전처리나 후처리를 통해 생성 과정을 다양하게 처리해 객체를 유연하게 정할 수 있는 특징도 있다.
9 |
10 | ## 팩토리 메서드 패턴 구조
11 |
12 | 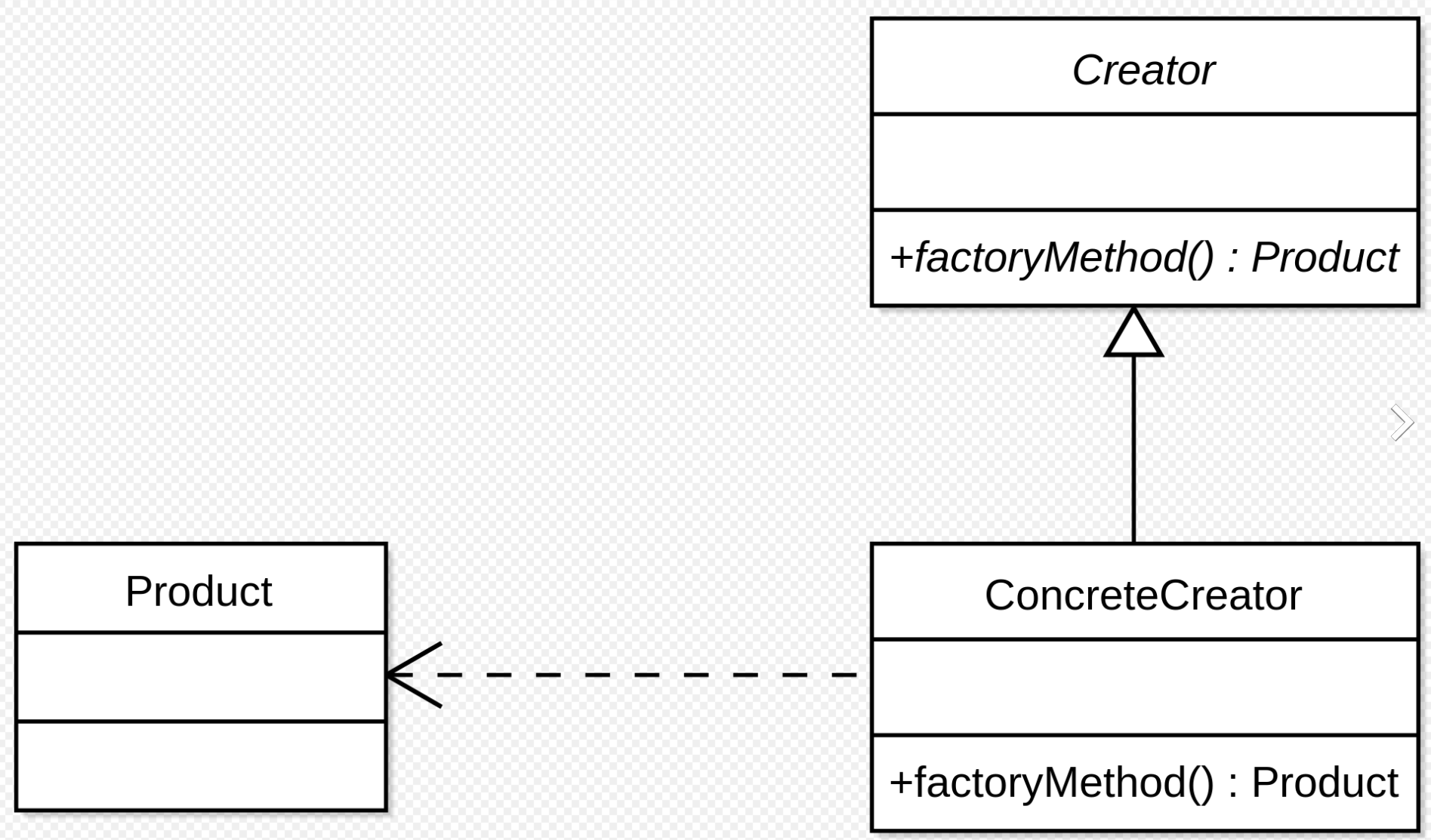
13 |
14 | - Creator
15 | - 최상위 공장 클래스로서, 팩토리 메서드를 추상화하여 서브 클래스로 하여금 구현하도록 한다.
16 | - **객체 생성 처리 메서드**: 객체 생성에 관한 전처리, 후처리를 템플릿화한 메소드
17 | - **팩토리 메서드**: 서브 공장 클래스에서 재정의할 객체 생성 추상 메서드
18 | - ConcreateCreator: 각 서브 공장 클래스들은 이에 맞는 제품 객체를 반환하도록 생성 추상 메소드를 재정의한다. 즉, 제품 객체 하나당 그에 걸맞는 생성 공장 객체가 위치된다.
19 | - Product: 제품 구현체를 추상화
20 | - ConcreateProduct: 제품 구현체
21 |
22 | 정리하자면, 팩토리 메서드 패턴은 객체를 만들어내는 공장을 만드는 패턴이라고 보면 된다. 그리고 어떤 클래스의 인스턴스를 만들지는 미리 정의한 공장 서브 클래스에서 결정한다.
23 |
24 | 겨우 객체 생성가지고 이런식으로 번거롭게 구성하는 이유는 객체간의 **결합도**가 낮아지고 유지보수에 용이해지기 때문이다.
25 |
26 | ## 템플릿 메서드 패턴과 팩토리 메서드 패턴의 관계
27 | 이름 구성이 비슷해서 어떠한 관계가 있을거라고 생각되는데, 템플릿 메서드는 `행동 패턴`이고 팩토리 메서드는 `생성 패턴`이라 둘은 전혀 다른 패턴이다. 다만 클래스 구조의 결은 둘이 같다고 보면 되는데, 인스턴스를 생성하는 공장을 Template Method 패턴으로 구성한 것이 Factory Method 패턴이 되기 때문이다. Template Method 패턴에서는 하위 클래스에서 구체적인 처리 알고리즘의 내용을 만들도록 추상 메소드를 상속 시켰었다. 이 로직을 알고리즘 내용이 아닌 인스턴스 생성에 적용한 것이 Factory Method 패턴인 것이다.
--------------------------------------------------------------------------------
/Design-Pattern/행동/Interpreter.md:
--------------------------------------------------------------------------------
1 | # 인터프리터 패턴
2 |
3 | 인터프리터 패턴은 **자주 사용되는 표현식 expression을 별개의 언어로 정의하고 재사용**하는 디자인 패턴이다.
4 |
5 | 간단한 언어(규칙)의 문법을 정의하고 해석하는 패턴이라고 볼 수 있다 (ex.정규식 분석)
6 |
7 |
8 |
9 | 
10 |
11 | - TerminalExpression은 문법 규칙에서의 기본 단위, 최하위 단위로 이 클래스는 해석할 문법 규칙의 최소 단위를 구한다.
12 | - NonTerminalExpression 복합 표현식의 구성 요소다. 이 클래스는 문법 규칙에서의 구성 요소를 해석한다. 문법의 구조를 나타내기 위해 사용된다.
13 |
14 | 예를 들면 사칙연산 후위 표기식을 보겠다 xyz+-에 대해서 x y z 자제는 TerminalExpression + -를 해석해 관련 TerminalExpression을 사용해 연산을 처리하는 Expression이 NonTerminalExpression이라고 보면 된다.
15 |
16 | > Expression 대표 인터페이스를 구현한 클래스들로 여러 Expression들을 구현할 수 있지만 자바 8부터 static 메서드를 사용해서 구현할 수도 있다.
17 |
18 |
19 |
20 | ### 예시
21 |
22 | 대표적으로 스프링에서도 찾아볼 수 있는데 `@Value("#{}")` 어노테이션이다. #{} 안에 SpEL 표기식을 사용해 properties를 참조할 수 있다. 마찬가지로 SpEL이라는 표현식(Expression)을 해석한 것이다.
23 |
24 | 그리고 정규표현식 Pattern 클래스를 사용해 regax를 검사하는 것도 인터프리터 패턴을 사용한 것으로 볼 수 있다.
25 |
26 |
27 |
28 | ### 장점
29 |
30 | 장점으로는 여러 패턴 표헌식에 대한 클래스를 만들어 자유로운 확장이 가능하다. OCP
31 |
32 | ### 단점
33 | 단점으로는 디버깅이 조금 어렵고, 복잡한 문법 또는 많은 표현식을 처리할 때 성능에 영향을 줄 수 있다. 그렇기 때문에 꼭 자주 사용되는 표현에서만 관련 패턴을 적용하도록 하자
34 |
--------------------------------------------------------------------------------
/Design-Pattern/행동/chain_of_resp.md:
--------------------------------------------------------------------------------
1 | # 책임 연쇄 패턴
2 |
3 | 책임 연쇄 패턴은 **핸들러들끼리 체인을 따라서 요청을 전달할 수 있게 해주는 디자인 패턴**입니다.
4 |
5 | 예를 들어 Request(유저 정보)객체를 인자로 받는, LoggingHandler(유저 정보를 로깅하는 핸들러), AuthHandler(로그인 여부 인증 핸들러)의 두개의 핸들러가 있다고 해봅시다.
6 |
7 | Client가 LoggingHandler를 통해 Request를 받아 정보를 로깅하기전 로그인 여부를 인증해야하는 과정을 밟아야한다면 클라이언트단에서 if문으로 검증해야할 것입니다. (혹은 데코레이터 패턴처럼 인자로 RequestHandler(핸들러들의 부모클래스)를 인자로 받아 생성하게 해서 인증 인가를 대신할 수도 있긴하다.) 그러니 이러한 Handler들이 여러개가 있다면 클라이언트단에서 핸들러를 사용하는 로직은 커질 수 밖에 없을 것 입니다.
8 |
9 | 여기서 해결 방법으로는 각 핸들러들은 chain(그 다음 행위를 수행할 핸들러)를 필드를 갖고(생성자를 통해 주입받음) 자신의 작업을 처리한 후 chain을 호출하는 방식을 사용할 수 있습니다.
10 |
11 | 이렇게된다면 원하는 작업들을 체인으로 마음대로 조정, 커스텀할 수 있습니다.
12 |
13 | ### 예제
14 |
15 | ```java
16 |
17 | class Client {
18 |
19 | fun main() {
20 | val requestHandler = LoggingHandler(AuthHandler(null))
21 | requestHandler.doWork()
22 | }
23 | }
24 |
25 | ```
26 |
27 | 위와 같이 마지막 핸들러에서는 null을 전달해 다음 체인을 지정하지 않게 할 수 있습니다.
28 |
29 | ### 장점
30 |
31 | 장점으로는 여러가지 로직들을 마음대로 커스텀, 구성할 수 있어 기능 추가에 용이합니다.
32 |
33 | 단점으로는 디버깅이 힘듭니다. (인자로 여러개의 핸들러들을 불규칙하게 넣기때문에)
34 |
35 |
36 |
37 |
38 | 스프링, 스프링부트에서 이러한 책임 연쇄 패턴을 찾아볼 수 있는데 대표적으로 Filter, SecurityConfig가 있습니다.
39 |
40 | Filter 클래스의 `chain.doFilter()`가 다음 작업으로 보내겠다는 뜻이며
41 |
42 | SecurityConfig에서 `http.어쩌구저쩌구.and().filterAfter()`와 같이 다음 필터들을 등록한다거나 그러한 로직도 책임 연쇄 패턴으로 볼 수 있습니다.
--------------------------------------------------------------------------------
/Design-Pattern/행동/command.md:
--------------------------------------------------------------------------------
1 | # 커맨드 패턴
2 |
3 | 커맨드패턴은 invoker(호출자)가 **여러 객체들을 직접 의존해 실행하는 것이 아닌 명령(Command)을 통해 행동을 수행하는 패턴**이다.
4 |
5 | 커맨드 패턴을 사용하면 요청을 캡슐화해서 커맨드 객체가 명령을 해야하는 객체들에 대한 의존성을 느슨하게 만들 수 있다.
6 |
7 |
8 | ### 문제와 예시
9 |
10 | 예를들어 버튼 클래스를 만들었다고 해보자. 그리고 그 버튼들은 엄청나게 많은 하위클래스가 있다고 생각해보자 여러 기능들을 하는 버튼들이 있고
11 |
12 | 이러한 버튼들을 사용하려면 호출자 Invoker에서 모든 버튼들을 의존하고 사용해야할 것이다.
13 |
14 | 그러나 여기서 문제가 있는데 기존 Button 클래스를 수정할 때마다 이러한 자식 클래스의 코드들을 깨트릴 위험이 생긴다.
15 |
16 | 그래픽 사용자 인터페이스 코드는 비즈니스 로직의 불안정한 코드에 어색하게 의존되어 있다.
17 |
18 | ### 해결책
19 | 올바른 해결책으로 관심사 분리의 원칙을 기반으로 한다.
20 |
21 | 버튼과 클라이언트는 서로 의존하게 만들며 Command도 함께 의존한다.
22 |
23 | 그리고 버튼(receiver)은 커맨드를 의존함으로써 결국 하나의 동작(execute 비즈니스로직)에 관련 로직들을 넣게되면
24 |
25 | 사용하는 입장에서는 변경이 일어나도 아무런 제약조건이 발생하지 않는 이점이 있다.
26 |
27 | 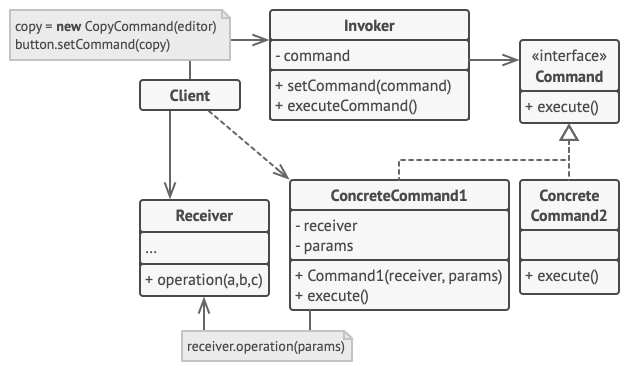
--------------------------------------------------------------------------------
/Design-Pattern/행동/iterator.md:
--------------------------------------------------------------------------------
1 | # 이터레이터 패턴
2 |
3 | 이터레이터 패턴이란 순회를 할 대상의 구체적인 **컬렉션타입을 알지 않고도 대상을 더욱 쉽게 순회할 수 있는 방법을 제공하는 디자인 패턴**이다.
4 |
5 | 대표적으로 자바의 Iterator 인터페이스 스프링의 CompositeIterator, StAX가 있다.
6 |
7 | ## 예시
8 |
9 | 예를 들어 Book 엔티티가 담겨있는 리스트가 있다고해보자. 이 엔티티를 시간순으로 정렬하고 싶다면 Collections.sort()를 이용해 조건을 넣고 정렬을 한 후 하나씩 for문으로 인덱스 참조 혹은 get 하여 출력해야할 것이다.
10 |
11 | 그러지 않고 RecentPostIterator와 같은 이터레이터 인터페이스를 구현해 다음과 같이 객체 순회 기능을 제공할 수 있다.
12 |
13 | ```java
14 | public class RecentPostIterator implements Iterator {
15 |
16 | private Iterator internalIterator;
17 |
18 | public RecentPostIterator(List posts) {
19 | Collections.sort(posts, (p1, p2) -> p2.getCreatedDateTime().compareTo(p1.getCreatedDateTime()));
20 | this.internalIterator = posts.iterator();
21 | }
22 |
23 | @Override
24 | public boolean hasNext() {
25 | return this.internalIterator.hasNext();
26 | }
27 |
28 | @Override
29 | public Post next() {
30 | return this.internalIterator.next();
31 | }
32 |
33 | }
34 | ```
35 |
36 | 이런식으로 이터레이터를 인터페이스를 사용한다면 구체적인 컬렉션(Set, List)를 알지 않고도 순회를 할 수 있어 순회하는 방식이 간단해진다.
37 |
38 | ### 장단점
39 |
40 |
41 | 물론 순회하는 방식마다 새로운 Iterator 클래스를 만들고 순회를 한다면 성능적으로도 느린 단점이 있지만,
42 |
43 | 더욱 유지보수가 쉽고 접근성이 가벼워지며, **객체를 순회한다는 책임을 이터레이 클래스에게 위임함으로써 응집도를 낮추어 더욱 확장성있는 코드 설계가 가능해진다.**
--------------------------------------------------------------------------------
/Design-Pattern/행동/mediator.md:
--------------------------------------------------------------------------------
1 | # 중재자 패턴
2 |
3 | 중재자 패턴이란 각 컴포넌트 간의 상호작용을 중재자에게 맡김으로써 상호 의존성을 낮줄 수 있게 해주는 디자인 패턴이다.
4 |
5 |
6 | ## 예시
7 |
8 | 예를 들어 Customer라는 클래스와 Restaurant, TowelService가 있다고 해보자.
9 |
10 | Customer는 restaurant에서 저녁을 먹을 수 있고 TowelService를 통해 수건을 받을 수 있다.
11 |
12 | 그렇다면 Customer는 저 두 클래스들을 의존하여 getTowel, dinner라는 메서드를 구현할 텐데 이렇게 되면 상호 의존성이 있기 때문에, 결합도가 올라간다.
13 |
14 | 여기서 FrontDesk라는 중재자를 둠으로써 customer를 인자로 받고 나머지 restaurant, towerService들을 사용해 customer 정보를 토대로 작업을 처리해준다면, customer와 다른 서비스들간의 의존성을 없앨 수 있다.
15 |
16 | 
17 |
18 | ### 장점
19 |
20 | 장점으로는 상호간 의존성을 떨어트리기 때문에 결합도가 낮은 코드를 작성할 수 있다.
21 |
22 | 여러가지 클래스들이 생기더라도 Client는 중재자 하나만 알고있으면 되기 때문에 확장이 용이하다.
23 |
24 | ### 단점
25 |
26 | 확장이 용이하고 결합도가 높은 클래스 구성도를 만들 수 있지만, 하나의 단점은 **중재자 클래스의 복잡성**이 있다. 중재자 클래스는 관련 서비스들에 대한 모든 의존성을 가지고 있기 때문이다.
27 |
28 | 그러나 이러한 문제와 중재자 패턴으로 얻을 수 있는 메리트를 비교해보았을때 중재자 패턴을 사용하는 것이 더욱 이점이 있다고 생각되기 때문에, 결국 중재자 패턴은 적용할 만한 패턴이라고 생각된다.
29 |
30 |
31 |
32 | ### 스프링에서 찾아보는 예시
33 |
34 | Spring에서 대표적으로 `DispatcherServlet`(front controller) 클래스가 이러한 패턴을 토대로 개발되었다.
35 |
36 | handlerMapping 과 같이 스프링 MVC에서 요청과 응답에 중재자 역할을 해준다.
--------------------------------------------------------------------------------
/Design-Pattern/행동/observer.md:
--------------------------------------------------------------------------------
1 | # 옵저버 패턴
2 |
3 | ## 옵저버 패턴이란
4 | 옵저버 패턴은 객체의 상태 변화를 관찰하는 관찬자들, 즉 옵저버들의 목록을 객체에 등록하여 상태 변화가 있을 때마다 메서드 등을 통해 객체가 직접 목록의 각 옵저버에게 통지하도록 하는 디자인 패턴이다. 주로 분산 이벤트 핸들링 시스템을 구현하는 데 사용된다. 발행/구독 모델로 알려져 있기도 하다.
5 |
6 | 아주 간단한 얘기를 해보자면 어떤 객체의 상태가 변할 때 그와 연관된 객체 들에게 알림을 보내느 디자인 패턴이 옵저버 패턴이라고 할 수 있다.
7 |
8 |
9 | 
10 |
11 | 옵저버 패턴에는 주체 객체와 상태 변경을 알아야하는 관찰 객체가 존재하며 이들의 관계는 1:1이 될수도 있고 1:N이 될 수도 있습니다.
12 |
13 | ## 옵저버의 장단점
14 |
15 | ### 장점
16 | 1. 실시간으로 한 객체의 변경사항을 다른 객체에 전파할 수 있다.
17 | 2. 느슨한 결합으로 시스템이 유연하고 객체간의 의존성을 제거할 수 있다.
18 |
19 | ### 단점
20 | 1. 너무 많이 사용하게 되면, 상태 관리가 힘들 수 있다.
21 | 2. 데이터 배분에 문제가 생기면 자칫 큰 문제로 이어질 수 있다.
22 |
23 |
24 |
--------------------------------------------------------------------------------
/Design-Pattern/행동/singleton.md:
--------------------------------------------------------------------------------
1 | # 싱글톤 패턴
2 |
3 | 객체의 인스턴스가 오직 1개만 생성되는 패턴을 의미
4 |
5 | ```java
6 | ublic class Singleton {
7 |
8 | private static Singleton instance = new Singleton();
9 |
10 | private Singleton() {
11 | // 생성자는 외부에서 호출못하게 private 으로 지정해야 한다.
12 | }
13 |
14 | public static Singleton getInstance() {
15 | return instance;
16 | }
17 |
18 | public void say() {
19 | System.out.println("hi, there");
20 | }
21 | }
22 | ```
23 |
24 | ## 싱글톤 패턴의 사용 이유
25 |
26 | ### 메모리 측면에서의 이점
27 | 최초 한번의 new 연산자를 통해 고정된 메모리 영역을 사용하기 때문에 추후 해당 객체 인스턴스에 접근할 때 메모리 낭비를 방지할 수 있다.
28 |
29 | ### 데이터 공유
30 | 클래스의 데이터간에 공유가 쉽다는 것이 또 하나의 이유다.
31 |
32 | 싱글턴 인스턴스가 전역으로 사용되는 인스턴스이기 때문에 다른 클래스의 인스턴스들이 접근하여 사용할 수 있다.
33 |
34 | 하지만 여러 클래스의 인스턴스에서 싱글톤 인스턴스에 데이터를 동시에 접근하게 되면 동시성 문제가 발생할 수 있으니 이점을 유의해서 설계해야한다.
35 |
36 | 이 외에도 도메인 관점에서 인스턴스가 한 개만 존재하는 것을 보증하고 싶은 경우 싱글톤 패턴을 사용해도 된다.
37 |
38 | ## 싱글턴 의문제점
39 |
40 | ### 구현하는 코드의 양
41 | 싱글톤 패턴을 구현하는 코드 자체가 많이 필요하다. 앞서 소개한 구현 방법 외에도 정적 팩토리 메서드에서 객체 생성을 확인하고 생성자를 호출하는 경우에 멀티 스레딩 환경에서 발생할 수 있는 동시성 문제를 해결하기 위해 `syncronized` 키워드를 사용해야한다.
42 |
43 | 두 번째는 테스트가 어렵다.
44 | 싱글톤 인스턴스는 자원을 공유하고 있기 때문에 테스트가 결정적으로 격리된 환경에서 수행되려면 매번 인스턴스의 상태를 초기화시켜주어야 한다. 그렇지 않으면 어플리케잇녀 전역에서 상태를 공유하기 때문에 테스트가 온전하게 수행되지 못한다.
45 |
46 | 세 번째로 의존 관계상 클라이언트가 구체 클래스에 의존하게 된다. new 키워드를 직접 사용하여 클래스에서 객체를 생서하고 있으므로, 이건 SOLID중 DIP를 위반하게 되고 OCP 원칙 또한 위반할 가능성이 높다.
47 |
48 |
--------------------------------------------------------------------------------
/DevOps/Docker/denied.md:
--------------------------------------------------------------------------------
1 | # permission denied while trying .. Docker demon socket 트러블 슈팅
2 |
3 | docker, docker compose를 사용해 Spring boot Application을 배포하기 위해 `sudo apt-get install docker, docker compose`를 해준 상황
4 |
5 | 그러나 `docker ps`를 입력하면
6 |
7 | ```
8 | permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Get "http://%2Fvar%2Frun%2Fdocker.sock/v1.24/containers/json": dial unix /var/run/docker.sock: connect: permission denied
9 | ```
10 |
11 | 이러한 오류메세지가 뜨게된 상황..
12 |
13 | 도커 권한 문제 때문에 docker 명령어가 먹지 않는 상황 문제는 루트가 아닌 사용자로 도커를 실행시키려고 했기 때문이다.
14 |
15 |
16 |
17 | ## 해결 방법
18 |
19 | ### docker 그룹 생성
20 |
21 | ```zsh
22 | $ sudo groupadd docker
23 | ```
24 |
25 |
26 | ### docker 그룹에 사용자 추가
27 | ```zsh
28 | $ sudo usermod -aG docker $USER
29 | ```
30 |
31 | ### 새 그룹에 로그인
32 |
33 | ```zsh
34 | $ newgrp docker
35 | ```
36 |
37 | 이렇게 하면 정상적으로 작동하는 것을 볼 수 있다.
--------------------------------------------------------------------------------
/DevOps/Docker/image/가상환경.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/Docker/image/가상환경.png
--------------------------------------------------------------------------------
/DevOps/Docker/image/격리.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/Docker/image/격리.png
--------------------------------------------------------------------------------
/DevOps/Docker/image/격리2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/Docker/image/격리2.png
--------------------------------------------------------------------------------
/DevOps/Docker/image/도커.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/Docker/image/도커.png
--------------------------------------------------------------------------------
/DevOps/Docker/image/도커한계.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/Docker/image/도커한계.png
--------------------------------------------------------------------------------
/DevOps/Docker/image/성능 비교.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/Docker/image/성능 비교.png
--------------------------------------------------------------------------------
/DevOps/Docker/image/성능비교2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/Docker/image/성능비교2.png
--------------------------------------------------------------------------------
/DevOps/Docker/image/스웜.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/Docker/image/스웜.png
--------------------------------------------------------------------------------
/DevOps/Docker/image/컨테이너.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/Docker/image/컨테이너.png
--------------------------------------------------------------------------------
/DevOps/Docker/이미지관련명령어.md:
--------------------------------------------------------------------------------
1 | # 이미지 관련 명령어
2 |
3 | ### 도커 이미지 목록
4 | docker pull 명령어를 통해 내려받은 도커 이미지들의 목록을 출력한다.
5 |
6 | ```
7 | $ docker images
8 | ```
9 |
10 | ### 도커 이미지 삭제
11 | 컨테이너도 더 이상 사용하지 않고 해당 이미지도 사용하지 않아 삭제하게 된다면 docker rmi 명령어를 통해 이미지를 삭제할 수 있다.
12 |
13 | ```
14 | # docker rmi IMAGE[:TAG]
15 | $ docker rmi ubuntu:16.04
16 | ```
17 |
18 | ### 도커 이미지 다운로드
19 | docker image pull [OPTION] imageName[:TagName]
20 |
21 | ```
22 | # CentOS의 이미지 취득
23 | docker image pull centos:7
24 |
25 | #CentOS의 모든 이미지 취득
26 | docker image pull -a centos
27 |
28 | # Ubuntu:latest 이미지 취득
29 | docker image pull ubuntu:latest
30 |
31 | # 텐서플로의 URL을 지정하여 이미지 취득
32 | docker iamge pull gcr.io.tensorflow/tensorflow
33 | ```
34 |
35 | ### 이미지 상세 정보 확인
36 | `docker image inspect [이미지]`
37 |
38 | `docker image inspect hello-world:latest`: hello-world 이미지 상세 정보 표시
--------------------------------------------------------------------------------
/DevOps/ELK.md:
--------------------------------------------------------------------------------
1 | # ELK와 로깅 구성
2 |
3 | 마이크로서비스 기반의 응용 프로그램을 설계할 때 고려해야하는 6가지 영역중
4 |
5 | Telemetry라는 영역이 있다. 혹은 Observation
6 |
7 | 이런 영역은 로깅, 모니터링, 트레이싱을 담당하며 각 기능은 다음과 같다.
8 |
9 | - 로깅 | 여러개로 분리된 서비스에서 생성되는 분산된 로그 파일에 대한 중앙화, 집중화 방안
10 | - 모니터링 | 다중화된 서비스에 대한 모니터링 방안
11 | - 트레이싱 | 클라이언트의 단일 요청에 대해 마이크로서비스간 다중 호출 관계가 있을 때 이에 대한 추적 방안
12 |
13 | 마이크로서비스에서 가장 많이 사용되는 로깅 방식은 ELK가 대표적이며 Elasticsearch, Logstash Kibana로 구성된다 (EFK는 Fluentd)
14 |
15 |
16 |
17 | ### ELK를 이용한 로깅 구성
18 |
19 | ELK의 각 솔루션별 기능을 보면 logstash를 통해 데이터를 집계하고 Elasticsearch를 통해 데이터 항목을 인덱싱하고 저장한 후 kibana를 통해 인덱싱된 데이터를 보여주는 시각화(Visualization) 구조를 가진다.
20 |
21 | 
22 |
23 | 위 그림을 보면 beats라는 추가 솔루션이 있는데, beats는 경량의 데이터 수집용 솔루션으로 데이터 수집을 위해 다양한 제품들로 구성되어있다.
24 |
25 | 
26 |
27 |
28 | 아래는 Beats + ELK로 구성할 수 있는 다양한 아키텍처들이다.
29 |
30 | 
--------------------------------------------------------------------------------
/DevOps/XaaS.md:
--------------------------------------------------------------------------------
1 | # IaaS, PaaS, SaaS 차이
2 |
3 | - `IaaS` : os 설치 전까지 VM 환경을 구성해 준다.
4 | - `PaaS` : 개발자가 운영할 수 있는 운영 환경까지 구성을 해준다.
5 | - `SaaS` : 사용자가 바로 사용할 수 있게 모든 환경을 제공해준다.
6 |
7 | ### IaaS (Infrastructure as a Service)
8 | - Infrastructure 레벨을 제공하는 서비스 (VM Hosting)
9 | - 서버, 스토리지, 데이터베이스 등과 같은 시스템이나 서비스를 구축하는데 필요한 IT 자원을 서비스 형태로 제공받아 사용
10 | - Amazon의 EC2(Amazon Elastic Computer Cloud) 서비스가 사용하는 방식
11 |
12 | ### PaaS (Platform as a Service)
13 | - 개발자가 응용 프로그램을 작성할 수 있도록 플랫폼 및 환경을 제공하는 클라우드 서비스
14 | - 사용자는 어플리케이션 서비스가 실행되는 실행 환경을 서비스 형태로 제공받아 사용
15 | - node.js, java와 같은 소프트웨어를 미리 구성해 놓아서, 사용자는 소스 코드가 입력하면 바로 서비스가 되는 방식
16 | - 사용자는 OS, Server H/W, Network등을 고려할 필요가 없음
17 | - 마이크로소프트 Azure Platform 서비스가 사용하는 방식
18 |
19 | ### SaaS(Software as a Service)
20 | - 사용자가 네트워크로 접속 해 메일, 워드 프로세스 같은 어플리케이션을 사용
21 | - 소프트웨어를 서비스 형태로 제공받는 방식
22 | - 모든 것이 소프트웨어 제공자에 의해 관리됨
23 |
24 | 
--------------------------------------------------------------------------------
/DevOps/apm.md:
--------------------------------------------------------------------------------
1 | # APM(Application Performance Management)
2 |
3 | ## APM
4 | 풀 네임 그대로 애플리케이션의 성능을 관리하는 서비스입니다.
5 |
6 | 웹 서비스를 제공하는데 있어 안정적으로 운영할 수 있도록 지원하는 서비스입니다.
7 |
8 | ### APM 도입시기
9 | 서비스 개발이 완료되고 테스트 단계부터 도입하여 운영하는 것이 효율적입니다.
10 |
11 | 다양한 어플리케이션 지원 | 모니터링 | 성능 관리 | 장애 관리
12 | --|--|--|--
13 | 오픈소스, 상용 어플리케이션과 연동 | 실시간 대쉬보드 제공, 사용자 정의에 따른 모니터링 제공, 통계 제공 | 연관 분석 기능, 응답속도 측정 후 분석 | 장애 발생 시 경보, 장애 발생 원인 정보 제공
14 |
15 | ### APM 구성
16 |
17 | 
18 |
19 | APM은 크게 3가지로 구성되어 있습니다.
20 | - APM Server: APM Agent로 부터 수집된 데이터를 분석하고 실제 동작하는 서버
21 | - APM Agent: APM Server에서 데이터를 수집하기위해 Agent가 설치된 어플리케이션 서버
22 | - APM Client: APM Server에서 수집 및 분석한 데이터를 사용자들에게 제공
23 |
24 | ### APM Solution
25 |
26 | Scouter, Prometheus, WhaTap 등의 모니터링 솔루션은 종류가 정말 많다
--------------------------------------------------------------------------------
/DevOps/aws/EC2Price.md:
--------------------------------------------------------------------------------
1 | # EC2의 가격 정책과 타입 종류
2 |
3 | ## On-Demand
4 | 실행하는 인스턴스에 따라 시간 또는 초당 컴퓨팅 파워로 측정된 가격을 지불
5 | - 약정은 필요 없다
6 | - 장기적인 수요 예측이 힘들거나 유연하게 EC2를 사용하고 싶을 때
7 | - 한번 써보고 싶을 때
8 |
9 | ## Stop Instance
10 | 경매 형식으로 시장에 남는 인스턴스를 저렴하게 구매해서 쓰는 방식
11 | - 최대 90% 정도 저렴
12 | - 단 언제 도로 내줘야 할지 모른다
13 | - 시작 종료가 자유롭거나 추가적인 컴퓨팅 파워가 필요한 경우
14 |
15 | ## 예약 인스턴스 Reserved Instance RI
16 | 미리 일정 기간 (1년 ~ 3년) 약정해서 쓰는 방식
17 | - 최대 75퍼센트까지 저렴 (On-Demand에 비해서)
18 | - 수요 예측이 확실할 때
19 | - 총 비용을 절감하기 위해 어느정도 기간의 약정이 가능한 사용자
20 |
21 | ## 전용 호스트
22 | 실제 물리적인 서버를 임대하는 방식
23 | - 라이센스 이슈( Windows Server등)
24 | - 규정에 따라 필요한 경우
25 |
26 | ## 타입 종류
27 | 
--------------------------------------------------------------------------------
/DevOps/aws/ELK.md:
--------------------------------------------------------------------------------
1 | # AWS ELK (Elastic Search Logstash Kibana)
2 |
3 | ## ELK
4 | ELK는 로그 데이터 분석 도구이다.
5 |
6 | ### Elastic Search
7 | Logstash를 통해 수신된 데이터를 저장소에 저장하는 역할
8 | **분산 검색 엔진이다.**
9 |
10 | ### Logstash
11 | 수집할 로그를 선정해, 지정된 서버에 인덱싱하여 전송하는 역할
12 |
13 | ### kibana
14 | 데이터를 시각적으로 탐색, 실시간으로 분석하는 역할
15 |
16 | ### ELK Stack
17 | 위의 ELK에 `Beats`가 추가된 것
18 |
19 | ### Beats
20 | 에이전트로 설치하여 다양한 유형의 데이터를 Elastic Search 또는 Logstash에 전송하는 데이터 발송자
21 |
--------------------------------------------------------------------------------
/DevOps/aws/SES.md:
--------------------------------------------------------------------------------
1 | # SES Simple Email Service
2 |
3 | Amazon Simple Email Servce(SES)는 개발자가 모든 애플리케이션 안에서 이메일을 보낼 수 있는 경제적이고 유연하며, 확장 가능한 이메일 서비스다.
4 |
5 | SES를 빠르게 구성하여 트랜잭션, 마케팅 또는 대량 이메일 커뮤니케이션을 포함한 다수의 이메일 사용 사례를 지원할 수 있다.
6 |
7 | ## 특징
8 | Email을 보내거나 받을 수 있는 서비스
9 |
10 | 이메일을 받을 때 여러 방법으로 처리 가능
11 | - Lambda 호출
12 | - SNS 호출
13 | - S3에 이메일 저장
14 |
15 | 대량의 이메일을 보내기 위해서는 샌드박스 모드 해제 필요(AWS Support 센터)
16 |
17 |
--------------------------------------------------------------------------------
/DevOps/aws/SNS.md:
--------------------------------------------------------------------------------
1 | # SNS SImple Notification Service
2 |
3 | ## 정의
4 | 구독중인 엔드포인트 또는 클라이언트에 메시지 전달을 조성 및 관리하는 웹 서비스이다.
5 | MOM을 구현한 Message Broker라고 보면 될 것 같다.
6 | 이벤트를 생상하는 쪽을 게시자 Publisher라고 하고, 이벤트를 구독하는 쪽을 구독자(Subscriber)라고 한다.
7 |
8 | 
9 |
10 | AWS SNS는 구독자 SQS/Lambda등에게 전송된 메시지 전달 상태에 log를 남겨준다.
--------------------------------------------------------------------------------
/DevOps/aws/SQS.md:
--------------------------------------------------------------------------------
1 | # SQS
2 |
3 | ## AWS SQS란
4 | - SQS는 Simple Queue Service의 약자
5 | - 애플리케이션 간의 메시지를 전달하기 위한 아주 간단한 Queue라고 생각하면 된다.
6 | - 지속성이 우수하고, 사용 가능한 보안 호스팅 대기열을 제공해, dead-letter queue, 표준 대기열, FIFO 대기열을 지원하고 있다.
7 |
8 | ## SQS와 MQ의 차이점
9 | - SQS는 이름 그대로 **'간단한' 큐 서비스**이다. 다른 MQ에 존재하는 message routin, fan-out, distribution lists를 지원하지 않는다. **메시지 생산자가 만들어낸 메시지를 메시지 소비자가 가져갈 수 있게 해주는 것이 전부다.**
10 | - Amazon MQ는 AMQP나 MQTT처럼 표준화된 여러 broadcast프로토콜을 완벽히 지원하는 fully managed 서비스이다. 복잡한 요구사항을 구현할 때 유용하며, AWS 외부에 있는 메시지 브로커를 AWS로 마이그레이션할 때 유용하다.
11 |
12 |
13 | ## SNS와 차이점
14 |
15 | ### SNS Simple Notification Service
16 | 1. publisher가 subscriber에게 메시지를 전송하는 관리형 서비스
17 | 2. publisher는 Topic에 메세지를 발행한다. Topic은 수 많은 Subscribers에게 전달될 수 있다. (fan out) 이때 전달 방식은 Lambda, SQS, Email 등 여러가지가 있다.
18 | 3. 다른 시스템들이 이벤트에 신경 쓰이는가? : Topic이 메세지를 publish하고 싶어하고, 사람들에게 발행됐다고 알리고 싶을 때
19 |
20 | ### SQS Simple Queue Service
21 | 1. 마이크로서비스, 분산 시스템 및 서버리스 애플리케이션을 쉽게 분리하고 확장할 수 있도록 지원하는 안전관리형 메세지 대기열 서비스
22 | 2. 시스템은 Queue로 부터 새로운 이벤트를 실시할 수 있다. Queue에 있는 메세지들은 한 명의 consumer 또는 하나의 서비스에서 실행된다.
23 | 3. 이 시스템이 이벤트에 신경쓰는가? : 내가 이벤트 수신자일 때.
--------------------------------------------------------------------------------
/DevOps/aws/as.md:
--------------------------------------------------------------------------------
1 | # 오토 스케일링 Auto Scaling
2 |
3 | ## Auto Scaling
4 | 애플리케이션을 모니터링하고 용량을 자동으로 조정하여, 최대한 저렴한 비용으로 안정적이고 예측 가능한 성능을 유지한다.
5 |
6 | AWS Auto Scaling을 사용하면 몇 분 만에 손쉽게 여러 서비스 전체에서 여러 리소스에 대해 애플리케이션 규모 조정을 설정할 수 있다.
7 |
8 | 
9 |
10 | ## Auto Scaling의 활용
11 | 최소한의 인스턴스를 사용
12 |
13 | 원하는 만큼의 인스턴스 개수를 목표로 유지
14 |
15 | 최대 인스턴스 개수 이하로 인스턴스 유지
16 |
17 | Avaliablity Zone에 골고루 분산될 수 있도록 인스턴스를 분배
18 |
19 | 항상 서비스가 유지될 수 있는 인스턴스 확보
20 |
21 | ### EC2 Auto Scaling 구성
22 | - Launch Configuration: 무엇을 어떻게 실행시킬 것인가?
23 | - EC2의 타입, 사이즈
24 | - AMI
25 | - Security Group, Key, IAM
26 | - User Data
27 | - Monitoring: 언제 실행시킬 것인가? + 상태 확인
28 | - 예: CPU 점유율이 일정 %를 넘어섰을 때 추가로 실행 or 2개 이상이 필요한 스택에서 EC2 하나가 죽었을 때
29 | - Cloud Watch (AND/OR) ELB와 연계
30 | - Desired Capacity: 얼만큼 실행 시킬 것인가?
31 | - 예 최소 1개 ~ 최대 3개
32 | - Lifecycle Hook: 인스턴스 시작/종료시 콜백
33 | - 다른 서비스와 연계하여 전/후 처리 가능 -> Cloud Watch Event / SNS / SQS
34 | - Terminationg: wait/Terminationg: Proceed 상태로 전환
35 | - 기본 3600초 동안 기다림 ( 기다리는 동안 이미지 백업이나 로그 백업 등의 작업을 할 수 있게끔 )
36 |
37 | ## EC2 Auto Scaling의 순서도
38 |
39 | 
--------------------------------------------------------------------------------
/DevOps/aws/cloudfront.md:
--------------------------------------------------------------------------------
1 | # Cloud Front
2 |
3 | AWS에서 제공하는 CDN 서비스다.
4 | 엣지 로케이션을 여러 개 두고, 가장 가까운 엣지 로케이션에 접근해서 지연시간을 최소화한다.
5 |
6 | > CDN(Content Delivery Network): 지연을 최소화하면서 사용자에게 콘텐츠를 배포하는 데 도움이 되는 서버 및 해당 데이터 센터의 지리적으로 분산된 네트워크
7 |
8 | ### 장점
9 | - 엣지 로케이션을 활용해 사용자에게 가장 가까운 엣지 로케이션에 접근해 지연시간을 최소화한다.
10 | - 캐싱을 활용해서 엣지 로케이션에 있는 정보면 S3에 다시 접근하지 않는다. 따라서 S3의 비용이 줄어든다.
11 |
12 | > 엣지 로케이션 Edge Location이란 : AWS의 CDN들의 여러 서비스들을 가장 빠른 속도로 제공(캐싱)하기 위한 거점이다.
--------------------------------------------------------------------------------
/DevOps/aws/ebs.md:
--------------------------------------------------------------------------------
1 | # EBS, Instance Storage, AMI
2 |
3 | ## EBS
4 | `Elastic Block Store`
5 |
6 | Amazon Elastice Block Store(EBS)는 AWS 클라우드의 Amazon EC2 인스턴스에서 사용할 영구 블록 스토리지 볼륨을 제공한다.
7 |
8 | 각 Amazon EBS 볼륨은 가용 영역 내에 자동으로 복제되어 구성요소 장애로부터 보호해주고, 고가용성 및 내구성을 제공한다.
9 |
10 | Amazon EBS 볼륨은 워크로드 실행에 필요한 지연 시간이 짧고 일관된 성능을 제공한다.
11 |
12 | Amazon EBS를 사용하면 단 몇 분 내에 사용량을 많게 또는 적게 확장할 수 있으며, 프로비저닝한 부분에 대해서만 저렴한 비용을 지불한다.
13 |
14 | 
15 |
16 | - `EBS Based`: 반 영구적인 파일의 저장 가능
17 | - Snapshot 가능
18 | - 인스턴스 업그레이드 가능
19 | - STOP이 가능함
20 | - `Instance Store`: 휘발성이 빠른 방식
21 | - 빠르지만 저장이 필요 없는 경우
22 | - STOP이 불가능하다.
23 |
24 |
25 | ## AMI
26 |
27 | Amazon Machine Image
28 |
29 | Amazon 머신 이미지 AMI는 인스턴스를 시작하는데 필요한 정보를 제공한다.
30 |
31 | 인스턴스를 시작할 때 AMI를 지정해야 한다.
32 |
33 | 동일한 구성의 인스턴스가 여러 개 필요할 때는 한 AMI에서 여러 인스턴스를 시작할 수 있다.
34 |
35 | 서로 다른 구성의 인스턴스가 필요할 때는 다양한 AMI를 사용하여 인스턴스를 시작하면 된다.
36 |
37 | ### 특징
38 | 
39 |
40 | AMI는 다음을 포함한다.
41 | 1. 1개 이상의 EBS 스냅샷 또는 인스턴스 저장 지원 AMI의 경우 인스턴스 루트 볼륨에 대한 템플릿 (예: 운영체제, 애플리케이션 서버, 애플리케이션)
42 | 2. AMI를 사용하여 인스턴스를 시작할 수 있는 AWS 계정을 제어하는 시작 권한
43 | 3. 시작될 때 인스턴스를 연결할 볼륨을 지정하는 블록 디바이스 매핑
--------------------------------------------------------------------------------
/DevOps/aws/elastic_ip.md:
--------------------------------------------------------------------------------
1 | # Elastic IP
2 |
3 | ## ENI
4 | Elastic Network Interface
5 |
6 | - Mac address
7 | - 원본/대상 확인
8 | - 한 개 이상의 보안 그룹
9 | - 한 개의 메인 프라이빗 IPv4
10 | - 한 개 이상의 보조 프라이빗 IPv4
11 | - 한 개 이상의 IPv6 주소
12 | - 하나의 퍼블릭 IPv4 주소
13 |
14 | EC2에는 여러대의 ENI를 붙일 수 있다. (EC2의 타입에 따라 붙일 수 있는 개수가 다르다)
15 | ENI에 부여된 public IP는 계속해서 바뀐다.
16 | Elastic IP Address는 고정된 public IP로 ENI에 붙일 수 있는 서비스다.
17 |
18 | 
19 |
20 | ## Elastic IP
21 | 사용은 무료
22 |
23 | 사용하지 않거나 ENI에 붙어있지 않을때만 사용료 지불
24 |
25 | EC2 뿐만 아니라, Network Load Balancer 혹은 Nat Gateway에도 고정 IP를 부여하는데 사용할 수 있다.
26 |
27 | 
--------------------------------------------------------------------------------
/DevOps/aws/iam.md:
--------------------------------------------------------------------------------
1 | # IAM(Identity and Access Management)
2 |
3 | IAM은 AWS 리소스에 대한 엑세스를 안전하게 제어할 수 있는 웹 서비스다.
4 |
5 | IAM을 사용하면 사용자가 엑세스할 수 있는 AWS 리소스를 제어하는 권한을 중앙에서 관리할 수 있다.
6 |
7 | IAM을 사용하여 리소스를 제어하는 권한을 중앙에서 관리할 수 잇다.
8 |
9 | IAM을 사용하여 리소스를 사용하도록 인증(로그인)및 권한 부여된 대상을 제어한다.
10 |
11 | ## IAM이 필요한 이유?
12 | IAM은 기업에서 보안을 강화하고, 업무 효율성을 높이기 위해 필요하다.
13 |
14 | IAM을 통해 사용자들의 권한을 관리하고, 인증 및 인가를 통해 보안을 관리할 수 있기 때문이다.
15 |
16 | 누구나 AWS의 리소스를 제어할 수 있는 권한을 가지고 있다면 한 계정만 털리더라도 시스템 전체가 해킹당할 수 있는 위험도 있다.
17 |
18 | root 계정으로 AWS리소스를 관리하는 것은 보안 측면상으로 굉장한 리스크를 안고가는 것이라고 생각한다.
19 |
20 | ## 실습
21 |
22 | ```
23 | [실습]
24 | 당신이 이번에 들어온 팀의 백엔드 엔지니어는 프로젝트 진행을 위해 AWS의 s3, ec2, rds, cloudwatch의 기능들을 활용하고 싶어합니다. 루트 계정을 지니고 있는 당신은 이 백엔드 엔지니어에게 IAM을 발급해주어야합니다. 문제에서 명시한 권한을 부여하여 IAM을 제작해 콘솔 로그인을 할 수 있는 아이디, 비밀번호를 부여하고 공유해주세요.
25 | (cloudwatch와 ec2는 readonly, rds와 s3는 Fullaccess를 부여하여야합니다. 이때 명시된 권한이 없다면 자신이 생각하였을때 최대한 비슷한 권한으로 부여해주세요.)
26 | ```
27 |
28 | .. 지금 aws 계정이 정지다 나중에 하겟다
--------------------------------------------------------------------------------
/DevOps/aws/natgateway.md:
--------------------------------------------------------------------------------
1 | # NAT, NAPT 그리고 AWS NAT Gateway
2 |
3 | ## NAT
4 |
5 | 대부분의 네트워크는 모든 호스트 중 일부만이 인터넷 통신을 수행한다.
6 |
7 | 따라서 대부분의 호스트는 private ip를 이용해 통신하고있기에 인터넷 통신을 수행할 때만 public ip를 사용하게 된다면 외부에 노출되는 public ip수를 크게 줄일 수 있다.
8 |
9 | private ip에서 인터넷으로 요청을 보낼 떄 요청이 nat을 제공하는 라우터를 통과하게되면
10 |
11 | **Nat 라우터는 주소 변환 테이블에 가지고 있던 private ip를 public ip로 ip 변환을 하여 요청을 보내고 변환 내용을 nat변환 테이블에 기록한다.**
12 |
13 | 이후 인터넷으로 보낸 응답이 도착하면 기록해두었던 nat 변환 테이블을 참조하여 요청을 보낸 private ip를 가진 호스트에게 응답을 반환한다.
14 |
15 | ## NAPT
16 |
17 | 네트워크에서는 여러 호스트가 고유한 private ip를 할당받고, 인터넷으로 요청을 보낼 때 public ip로 변환을 위해 nat을 통과할때 nat 변환 테이블은 private ip(요청 주소)와 nat으로 변환된 public ip(변환된 주소)를 기록합니다.
18 |
19 | private ip는 host마다 고유하지만 변환된 public ip는 네트워크의 대표 공인 ip이기에 동일할 수 있습니다.
20 |
21 | 따라서 인터넷에서 응답이 nat으로 돌아올 때 요청을 보낸 private ip를 구분하기 위해서 변환 테이블의 public ip와 private ip마다 각자 다른 port를 할당합니다.
22 |
23 | 이를 `Network Address Port Translation` NAPT라고 합니다.
24 |
25 | ## AWS NAT Gateway
26 |
27 | NAT 게이트웨이는 AWS에서 제공하는 NAT(Network Access Translation, 네트워크 주소 변환) 서비스입니다.
28 |
29 | NAT의 개념과 동일하게 private 서브넷의 인스턴스가 VPC 외부의 서비스(인터넷)에 연결할 수 있도록하고 외부 서비스에서 프라이빗 서브넷 내의 인스턴스와의 연결을 할 수 없도록 하기 위해 NAT 게이트웨이를 사용할 수 있습니다.
30 |
31 | 즉 프라이빗 서브넷 내의 EC2를 인터넷, AWS Service에 접근 가능하게 하고 외부에서는 해당 EC2에 대한 접근을 막기 위해 사용됩니다.
32 |
33 | 
--------------------------------------------------------------------------------
/DevOps/aws/securitygroup.md:
--------------------------------------------------------------------------------
1 | # AWS 보안 그룹 Security Group
2 |
3 | ## Security Group
4 |
5 | 
6 |
7 | 보안 그룹은 인스턴스에 대한 인바운드 및 아웃바운드 트래픽을 제어하는 가상 방화벽 역할을 한다.
8 |
9 | VPC에서 인스턴스를 시작할 때 최대 5개의 보안 그룹에 인스턴스를 할당할 수 있다.
10 |
11 | 보안 그룹은 **서브넷 수준이 아니라 인스턴스 수준에서 작동**하므로 VPC에 있는 서브넷의 각 인스턴스를 서로 다른 보안 그룹 세트에 할당할 수 있다.
12 |
13 | 시작할 때 특정 그룹을 지정하지 않으면 인스턴스가 자동으로 VPC의 기본 보안 그룹에 할당된다.
14 |
15 | ### 특징
16 |
17 | - 보안 장치
18 | - Network Access List(NACL)와 함께 방화벽의 역할을 하는 서비스
19 | - Port 허용
20 | - 트래픽이 지나갈 수 있는 Port, Source를 지정 가능
21 | - Deny는 불가능 -> NACL로 가능
22 | - 인스턴스 단위
23 | - 하나의 인스턴스에서 하나 이상의 SG 설정 가능
24 | - NACL의 경우 서브넷 단위
25 | - 설정된 인스턴스는 설정한 모든 SG의 룰을 적용 받음
26 |
27 | 
28 |
29 | - 설정된 모든 룰을 사용해서 필터링
30 | - NACL의 경우 적용된 룰의 순서대로 필터링
31 | - Stateful
32 | - Inbound로 들어온 트래픽이 별 다른 Outbound 설정 없이 나갈 수 있음
33 | - NACL은 Stateless
34 |
35 | 
--------------------------------------------------------------------------------
/DevOps/aws/session_manager.md:
--------------------------------------------------------------------------------
1 | # Systems Manager Session Manager
2 |
3 | ## Session Manager 탄생 배경
4 |
5 | 
6 |
7 | EC2의 개수가 늘어남에 따라 각각 다른 pem 파일들을 관리하기가 힘들어 진다.
8 |
9 | Bastion Host로 관리할지라도 매번 접속할 때 Bastion Host를 거쳐야 한다는 번거로움이 있다.
10 |
11 | 이것을 해결하기 위해서 나온 것이 Session Manager이다.
12 |
13 | ## Session Manager
14 | **Systems Manager Session Manager**
15 | - 완전 관리형 AWS 서비스로 EC2 및 온프레미스 인스턴스, 가상머신을 브라우저 기반의 쉘 혹은 AWS CLI로 관리할 수 있는 서비스
16 |
17 | ### System Manager
18 |
19 | 
20 |
21 | 원래는 위의 사진과 같이 굉장히 복잡하게 관리 했던 것들을 아래 사진으로 관리할 수 있는 것이 AWS System Manager 이다.
22 |
23 | 
24 |
25 | ### Session Manager의 장점.
26 | 1. 인스턴스에 대해 원클릭 엑세스를 제공하는 관리형 서비스
27 | 2. 인스턴스에 SSH연결 없이, 포트를 열 필요 없이, 배스천 호스트를 유지할 필요 없이 인스턴스에 로그인 가능
28 | 3. IAM 유저 단위로 제어 가능 (Key 파일로 제어할 필요 없음)
29 | - 예) 수백개의 인스턴스에 대해 일일이 로그인을 위한 키 파일을 관리해야 할 때
30 | - 개발자 별로 지정된 팀의 인스턴스만 로그인 할 수 있도록 하고 싶을 때
31 | 4. 웹브라우저 기반으로 OS와 무관하게 사용 가능
32 | 5. 로깅과 감사
33 | - 언제 어디서 누가 접속했는지 확인 가능(CloudTrail)
34 | - 접속 기록과 사용한 모든 커맨드 및 출력 내역을 S3 혹은 CloudWatch로 전송 가능
35 | - AWS의 서비스와 연동되어 있어 다양한 시나리오 구현 가능
36 | - 예: EventBridge 등과 연동하여 실시간으로 접그넹 대한 알림을 받기
37 |
38 |
--------------------------------------------------------------------------------
/DevOps/aws/고가용성_장애내구성.md:
--------------------------------------------------------------------------------
1 | # 고가용성과 장애내구성의 차이
2 |
3 | ### 고가용성 (High Availablity, HA)
4 | 장애 상황을 해결하고 서비스를 지속할 수 있는 능력으로 장애 상황을 위한 준비가 필요
5 |
6 | ### 장애 내구성 OR 내결함성(Fault Tolerance)
7 | 장애 상황에도 서비스를 지속할 수 있는 능력 장애 상황에 영향을 받지 않는 아키텍처가 필요
8 |
9 |
10 | 
11 |
12 | ### 재해 복구
13 | 말 그대로 장애 상황을 복구하는 것
14 |
15 | ## 확장성과 탄력성
16 |
17 | 
18 |
19 | ### 확장성 Scalable
20 | 쉽고 빠르게 규모를 늘릴 수 있는 능력
21 |
22 | 주로 수요에 따라 컴퓨팅 파워 혹은 용량 확장
23 |
24 | 
25 |
26 | ### 탄력성 Elastic
27 | 수요에 따라 컴퓨팅 파워/용량을 확장하거나 축소할 수 있는 능력
28 |
29 | 불필요한 자원을 사용하지 않고 비용 최적화에 필수적인 능력
--------------------------------------------------------------------------------
/DevOps/aws/라우팅테이블.md:
--------------------------------------------------------------------------------
1 | # AWS 라우팅 테이블
2 |
3 | ## 라우팅 테이블
4 |
5 | 라우팅 테이블은 VPC에서 사용되는 네트워크 구성요소다.
6 |
7 | 서므넷이나 게이트웨이의 네트워크 트래픽을 전송하는 위치를 결정하는 규칙 세트를 포함한다.
8 |
9 | **VPC 내에서 네트워크 트래픽을 효과적으로 라우팅하고 전달하기 위해 사용된다.**
10 |
11 | ### 기본 라우팅 테이블
12 | VPC와 함께 자동으로 제공되며, 다른 라우팅 테이블과 연결되지 않은 모든 서브넷의 라우팅을 제어한다.
13 |
14 | ### 사용자 지정 라우팅 테이블
15 | 사용자가 생성하는 VPC에 대한 라우팅 테이블이다. 트래픽의 대상과 해당 대상에 대한 전송 방법을 정의한다.
16 |
17 | ### 대상 (Destination, Target)
18 | 대상은 트래픽을 이동할 대상 IP 주소의 범위(CIDR)입니다.
19 | 트래픽을 전송할 때 사용할 게이트웨이, 네트워크 인터페이스 또는 연결을 지정합니다.
20 |
21 | > CIDR: 네트워크 주소와 서브넷 마스크를 조합하여 표현하는 방식으로, 기존의 클래스 기반 IP 주소 체계에서 더 유연한 주소 할당을 가능하게 한다. 클래스 기반 IP 주소 체계에는 A, B, C 클래스에 따라 주소를 할당했지만, CIDR에서는 더 작은 블록 단위로 IP주소를 할당할 수 있다.
22 |
23 | ### 라우팅 테이블 연결
24 | 라우팅 테이블과 서브넷, 인터넷 게이트웨이 또는 가상 프라이빗 게이트웨이 간의 연결이다.
25 |
26 | ### 서브넷 라우팅 테이블
27 | 특정 서브넷과 연결된 라우팅 테이블로, 해당 서므넷 내에서 트래픽을 라우팅한다.
28 |
29 | ### 로컬 라우팅
30 | VPC 내 통신을 위한 기본 라우팅 규칙이다.
31 |
32 | ### 전파
33 | 가상 프라이빗 게이트웨이와 연결하고 라우팅 전파를 활성화한 경우 VPN 연결을 위한 경로를 자동으로 서브넷 라우팅 테이블에 추가한다.
34 |
35 | ### 게이트웨이 라우팅 테이블
36 |
37 | 인터넷 게이트웨이 또는 가상 프라이빗 게이트웨이와 연결된 라우팅 테이블이다.
38 |
39 | ### 엣지 연결
40 | 인바운드 VPC 트래픽을 어플라이언스로 라우팅하는 데 사용하는 라우팅 테이블이다.
--------------------------------------------------------------------------------
/DevOps/blue_green.md:
--------------------------------------------------------------------------------
1 | # Blue/Green 배포와 아키텍처
2 |
3 | ### 무중단 배포
4 |
5 | 말 그대로 애플리케이션의 중단 없이 배포를 하는 것을 말한다.
6 |
7 | ## Blue/Green 배포
8 |
9 | 애플리케이션의 새로운 업데이트나 변경사항을 배포할 때 다운타임 없이 처리할 수 있는 배포 전략이다.
10 |
11 | 이전에 운영 중인 환경(블루)와 스테이징 환경(그린) 두 개의 동일한 환경을 생성하고 업데이트를 그린 환경에 배포하고 충분한 테스트를 거친 후 블루 환경에서 그린 환경으로 트래픽을 전환한다.
12 |
13 | 이렇게 하면 사용자가 배포 과정에서 다운타임이나 중단 현상을 경험하지 않도록 보장할 수 있다.
14 |
15 | 
16 |
17 | 
18 |
19 | 구버전과 같은 환경으로 신버전을 미리 준비한다.
20 |
21 | 로드밸런서의 라우팅을 한번에 전환시킨다.
22 |
23 | ### 장점
24 | - 구버전의 환경을 재활용하거나 롤백하기 쉽다.
25 | - 배포 과정에서 사용자가 다운타임이나 중단 현상을 경험하지 않도록 보장할 수 있다.
26 |
27 | ### 단점
28 | - 시스템의 자원이 두배로 든다.
29 |
30 |
31 | ## 블루그린 아키텍처
32 |
33 | 한번 블루그린 아키텍처를 짜보았다.
34 |
35 | 
--------------------------------------------------------------------------------
/DevOps/deploy.md:
--------------------------------------------------------------------------------
1 | # 배포 전략의 종류(롤링/블루 그린/카나리)
2 |
3 | ## 블루 그린 배포 (Blue Green)
4 |
5 | 
6 |
7 | 이전 버전 blue 환경으로, 새 버전은 green 환경으로 부를 수 있습니다.
8 |
9 | 한 번에 하나의 버전만 게시됩니다. 동일한 서버를 미리 구축한 뒤, 라우팅을 순간적으로 전환하여 새로운 버전을 배포하는 방식입니다.
10 |
11 | 빠른 롤백이 가능하다는 장점이 있고 운영 환경을 유지하며 새로 배포될 버전의 테스트도 가능하지만, 자원이 두배로 필요하니 비용이 많이 발생한다는 단점도 있습니다.
12 |
13 | ## 롤링 배포 (Rolling)
14 |
15 | 
16 |
17 | 롤링 배포는 애플리케이션이 실행 중인 인프라를 완전히 교체하여 이전 버전의 애플리케이션을 새로운 버전의 애플리케이션으로 서서히 교체하는 배포 전략입니다.
18 |
19 | 인스턴스를 정해놓은 단위로, 순차적으로 새로운 버전으로 교체됩니다.
20 |
21 | 가용 자원이 제한적일 경우에 사용됩니다.
22 |
23 | 이와 같은 방식은 서버 수의 제약이 있을 경우 유용하지만 배포 중 인스턴스 수가 감소되므로 서버 처리 용량을 미리 고려해놔야 합니다.
24 |
25 | ## 카나리 배포(Canary Deployment)
26 |
27 | 
28 |
29 | 전체 인프라에 새로운 소프트웨어 버전을 릴리즈하여 모든 사용자가 사용할 수 있도록 하기 전에 변경사항을 천천히 릴리즈함으로써 프로덕션 새로운 소프트웨어 버전을 도입하는 위험을 줄이는 기술입니다.
30 |
31 | 카나리아 새처럼 빠르게, 미리 위험을 감지하여 대응할 수 있도록 하는 배포 방식입니다. 구 버전의 서버와 새 버전의 서버들을 구성하고 일부 트래픽을 새 버전으로 분산하여 오류 여부를 판단하기 때문에 오류율 및 성능 모니터링에 유용하다고 합니다.
--------------------------------------------------------------------------------
/DevOps/exporter.md:
--------------------------------------------------------------------------------
1 | # Prometheus Exporter - 모니터링 에이전트
2 |
3 | ### Exporter
4 |
5 | 프로메테우스는 모니터링 대상의 메트릭을 수집한다.
6 |
7 | 그렇다면 그 모니터링 대상의 메트릭은 어디서 제공이 되는 것일까?
8 |
9 | 바로 Exporter에서 제공이 되는 것이다.
10 |
11 | Exporter는 모니터링 대상의 메트릭 데이터를 수집하고 프로메테우스가 접속했을 때 알려주는 역할을 한다. 호스트 서브의 cpu, memory 등을 수집하는 `node-exporter` 나 nginx의 데이터를 수집하는 `nginx-exporter` 도 있으며 다양한 데이터의 메트릭 내용을 제공하는 exporter들이 있다.
12 |
13 | > - 만약 Exporter를 쓰기 어려운 배치잡등은 push gateway를 사용하면 된다.
14 | > - 웹 애플리케이션 서버 같은 경우는 메트릭을 클라이언트 라이브러리를 이용해 메트릭을 만든 후 커스텀 Exporter를 사용할 수 있다.
15 |
16 | 즉 프로메테우스 서버는 Exporter가 열어놓은 HTTP 엔드포인트에 접속해서 메트릭을 수집한다.
17 |
18 | 그래서 이것을 **Pull 방식**이라고 부른다.
19 |
20 | Exporter들은 대표적으로
21 |
22 | - node-exporter
23 | - mysql-exporter
24 | - wmi-exporter
25 | - posgre-exporter
26 | - redis-exporter
27 | - kafka-exporter
28 | - jmx-exporter
29 |
30 | 등등이 있으며 [공식 홈페이지](https://prometheus.io/docs/instrumenting/exporters/)에 더 자세한 exporters 항목이 있다.
31 |
32 |
--------------------------------------------------------------------------------
/DevOps/hybrid.md:
--------------------------------------------------------------------------------
1 | # 하이브리드 클라우드 Hybrid Cloud
2 |
3 | ## 하이브리드 클라우드
4 |
5 | 클라우드는 그 서비스의 형태에 따라
6 | 1. 퍼블릭
7 | 2. 하이브리드
8 | 3. 프라이빗
9 | 4. 커뮤니티
10 |
11 | 로 나뉘어져 있습니다.
12 |
13 | 그중에서 하이브리드 클라우드는 **프라이빗 클라우드**와 **퍼블릭 클라우드**를 결합해 데이터와 애플리케이션을 공유할 수 있는 컴퓨팅 환경으로, 하이브리드 컴퓨팅은 컴퓨팅 및 처리 요구가 변동될 때 타사 데이터 센터에서 데이터 전체를 엑세스하지 않고도 **온프레미스 공용 클라우드로 원할하게 확장하여 오버플로를 처리할 수 있는 기능을 기업에게 제공**하는 것을 뜻합니다.
14 |
15 | 즉 이를 활용하면 고객은 중요한 비즈니스 애플리케이션 및 데이터를 회사 방화벽 뒤의 온 프레미스에 안전하게 보관하면서 기본 및 중요하지 않은 컴퓨팅 작업은 공용 클라우드에서 유연하게 컴퓨팅할 수 있습니다.
16 |
17 | ## 하이브리드 클라우드의 구조
18 | 
19 |
20 | - 온 프레미스에 구현되어 있는 기업 내부환경과 외부의 클라우드를 연동해 **내부적으로는 안전한 정보를 보관**하고, 기본 및 중**요하지 않은 정보는 클라우드를 활용**해 유연하게 컴퓨팅하는 기술입니다.
21 | - 이와 같이 하이브리드 클라우드를 사용하면 기업에서의 컴퓨팅 리소스를 확장할 수 있을 뿐 아니라, 단기간의 데이터의 처리가 급증하거나, 혹은 중요한 데이터와 로컬 리소스를 확보 해야할 때, 따로 자본을 지출할 필요가 없습니다.
22 | - 즉, 기업의 입장에서는 장기간 유휴 상태로 남아 있을 수 있는 **리소스들과 장비들을 적용할 수 있고**, 데이터의 노출을 위험을 최소화 하면서 클라우드 컴퓨팅의 모든 이점을 제공할 수 있는 최상의 플랫폼이라 할 수 있습니다.
--------------------------------------------------------------------------------
/DevOps/image/XaaS.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/image/XaaS.jpeg
--------------------------------------------------------------------------------
/DevOps/image/ami.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/image/ami.webp
--------------------------------------------------------------------------------
/DevOps/image/apm.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/image/apm.png
--------------------------------------------------------------------------------
/DevOps/image/aws.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/image/aws.png
--------------------------------------------------------------------------------
/DevOps/image/blue_green.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/image/blue_green.png
--------------------------------------------------------------------------------
/DevOps/image/cicd.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/image/cicd.png
--------------------------------------------------------------------------------
/DevOps/image/containers-101.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/image/containers-101.png
--------------------------------------------------------------------------------
/DevOps/image/ident.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/image/ident.webp
--------------------------------------------------------------------------------
/DevOps/image/instance.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/image/instance.webp
--------------------------------------------------------------------------------
/DevOps/image/instancestart.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/image/instancestart.webp
--------------------------------------------------------------------------------
/DevOps/image/nameins.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/image/nameins.webp
--------------------------------------------------------------------------------
/DevOps/image/publicinstance.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/image/publicinstance.webp
--------------------------------------------------------------------------------
/DevOps/image/start.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/image/start.webp
--------------------------------------------------------------------------------
/DevOps/image/startinstance.webp:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/image/startinstance.webp
--------------------------------------------------------------------------------
/DevOps/image/가상화.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/DevOps/image/가상화.jpeg
--------------------------------------------------------------------------------
/DevOps/k8s/dashboard.md:
--------------------------------------------------------------------------------
1 | # 쿠버네티스 대시보드 토큰 발행 및 접속
2 |
3 | > 대시보드를 실행하기 전 docker가 데몬에서 실행되어있어야하고 minikube를 실행해야합니다.
4 |
5 |
6 | ### Deploying the Dashboard UI
7 |
8 | `kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml`
9 |
10 | ### Command Line Proxy
11 |
12 | `kubectl proxy`
13 |
14 |
15 |
16 | ## 대시보드 사용자 만들기
17 | kubernetes-dashboard라는 네임스페이스에 admin-user라는 이름으로 서비스 계정을 생성할 것이다.
18 |
19 | ### ClusterRoleBinding
20 |
21 | ```sh
22 | cat <
51 |
52 | ## 대시보드 토큰 발행
53 |
54 | `kubectl -n kubernetes-dashboard create token admin-user`를 입력해 토큰을 발행해보자
55 |
56 | 아래와 같이 토큰이 발급되는 것을 볼 수 있다.
57 |
58 | 
--------------------------------------------------------------------------------
/DevOps/k8s/podstatus.md:
--------------------------------------------------------------------------------
1 | # Pod 생명주기, 재시작 정책
2 |
3 | Pod의 생명주기와 재시작 정책 그리고 컨테이너 상태 진단을 위한 Probe에 대해서 알아보겠다.
4 |
5 | ### Pod의 생명주기
6 |
7 | pod의 생명주기는 네 가지의 단계로 구분이 되어진다.
8 |
9 | 1. `PENDING`: 클러스터 내 파드가 승인이 되었지만 아직 컨테이너 내부가 시작되기 전이며 노드에 배치되지 않은 상태다.
10 | 2. `RUNNING`: 클러스터 내 파드가 승인되고 컨테이너가 시작되어 노드에 배치되어있는 상태다.
11 | 3. `SUCCEEDED`: 노드에 대한 유한한(정적인) 작업이 완료되었을때 나타내는 상태다. 노드를 종료할 때 나타내는 상태이며, 해당 작업을 정상적으로 마쳤다는 뜻이다.
12 | 4. `FAILED`: 노드에 대한 유한한(정적인) 작업이 완료되었을때 나타내는 상태다. 노드를 종료할 때 나타내는 상태이며, 해당 작업이 비정상 종료되었음을 의미한다.
13 |
14 | 이 외에도 특수한 경우에만 파드에 부여되는 상태 정보(`.status.phase`)가 추가로 존재한다.
15 | - `unknown`: 파드의 상태가 확인이 불가능할 경우다. 보통 노드 네트워크 문제로 발생한다.
16 | - `terminating`: 파드를 삭제시켰을 때 볼 수 있다. 일반적으로 파드는 삭제가되면 30초의 유예시간을 갖는다. 만약 이 유예시간없이 삭제시키고 싶다면 kubelet delete 옵션에 --force를 추가하면 된다.
17 |
18 | 파드의 생명 주기와 현재 상태는 **kubelet**이 주기적으로 모니터링한다. 이렇게 모니터링된 상태 정보는 `kubectl get pods`의 출력 결과 중 `STATUS` 필드에서 볼 수 있다. 해당 파드 오브젝트의 `.status.phase` 필드에서도 확인 가능하며, 이때 필요한 명령어는 다음과 같다.
19 |
20 | ```bash
21 | kubectl get pod <파드명> -o jsonpath='{.status.phase}'
22 | ```
23 |
24 |
25 |
26 | ### Pod 재시작 정책
27 |
28 | 파드에 포함된 컨테이너에는 오류가 생겼을때 재시작하기 위한 **정책**을 가지고 있다.
29 |
30 | 이 정책은 3가지로 분류되며 `spec.restartPolicy` 를 통해 직접 부여할 수 있다.
31 |
32 | 1. `Always`: 컨테이너가 정상/비정상 종료시 항상 재시작한다. default
33 | 2. `Onfailure`: 컨테이너가 비정상 종료시에만 재시작한다.
34 | 3. `Never`: 재시작하지 않는다.
35 |
36 | 컨테이너의 재시작 시도 주기는 최대 300초 한도로 10초 지수 단위로 진행된다.
37 |
38 | 10초후 20초후 40초후 80초후..
39 |
40 |
41 |
--------------------------------------------------------------------------------
/DevOps/k8s/process.md:
--------------------------------------------------------------------------------
1 | # 쿠버네티스의 동작 흐름
2 |
3 | 쿠버네티스에서는 새로운 pod을 만들기 위한 과정은 다음과 같다.
4 |
5 | 
6 |
7 | 1. Master Node의 kube-apiserver에 pod 생성을 요청한다.
8 |
9 |
10 | 2. kube-apiserver는 etcd에 새로운 상태를 저장한다.
11 | 3. kube-controller-manager에게 kube-apiserver가 etcd의 상태 변경을 확인하여, 새로운 pod 생성을 요청한다.
12 | 4. kube-controller-manager는 새로운 pod을 생성 (no assign)을 kube-apiserver에 전달하고, 이를 전달받은 kube-apiserver는 etcd에 저장
13 | 5. kube-scheduler는 kube-apiserver에 의해 pod(no assign)가 확인되면, 조건에 맞는 Worker Node를 찾아 해당 pod을 할당하기 위해 kube-apiserver는 etcd에 업데이트
14 | 6. 모든 WorkerNode의 kubelet은 자신의 Node에 할당되었지만, 생성되지 않은 pod이 있는지 체크하고 있다면 pod을 생성합니다.
15 | 7. 해당 Workder Node의 kubelet은 pod의 상태를 주기적으로 API 서버에 전달합니다.
16 |
17 | 흐름을 보면 각각의 컴포넌트들이 서로 개별적으로 통신하지 않고, API Server를 통해서 통신하는 것을 알 수 있습니다.
18 |
19 | 또한 컴포넌트들은 각기 현재 상태를 체크하고 독립적으로 동작하게 됩니다.
20 |
21 | ```zsh
22 | kubectl [command] [type] [name] [flags]
23 | ```
24 |
25 | ### command
26 | kubectl이 실행할 명령어. 예를 들어 `get`, `create`, `delete`, `apply` 등이 있다.
27 |
28 | ### type
29 | 명령어가 적용될 쿠버네티스의 오브젝트 유형. 예를 들어 pod, service, deployment 등이 있습니다.
30 |
31 | ### name
32 | 명령어가 적용될 쿠버네티스 오브젝트의 이름. 예를 들어 파드의 경우 파드의 이름을 지정합니다.
33 |
34 | ### flag
35 | 명령어 실행에 영향을 주는 옵션. 예를 들어 `--namespace`, `--selector`, `--output`등이 있습니다.
--------------------------------------------------------------------------------
/DevOps/vircon.md:
--------------------------------------------------------------------------------
1 | # 가상머신(Virtual Machine) vs 컨테이너(Container)
2 |
3 | ### 가상화 개념
4 | 가상화(Virtualization)는 물리적인 컴포넌트(Components, HW장치)를 논리적인 객체로 추상화 하는 것을 의미하는데, 마치 하나의 장치를 여러개처럼 동작 시키거나 반대로 여러개의 장채를 묶어 마치 하나의 장치인 것 처럼 사용자에게 공유자원으로 제공할 수 있어 클라우드 컴퓨팅 구현을 위한 핵심 기술이다.
5 |
6 | 가상화의 대상이 되는 컴퓨팅 자원은 프로세서(CPU), 메모리(Memory), 스토리지(Storage), 네트워크(Network)를 포함하며, 이들로 구성된 서버나 장치들을 가상화함으로써 높은 수준의 자원 사용률(물리서버 10 ~ 15퍼 , 가상화 70퍼 이상) vs 과 분산 처리 능력을 제공할 수 있다.
7 |
8 | 
9 |
10 |
11 |
12 | ### 가상 머신
13 |
14 | 가상화를 통해 구현되는 복제된 컴퓨팅 환경.
15 |
16 | **운영 목적**
17 | 1. 하나의 하드웨어 위에 동시에 여러 종류의 운영체제나 프로토콜 실행
18 | 2. 하나의 하드웨어 자원을 여러 사용자에게 분할
19 | 3. 가상화를 통해 분할된 시스템 간 상호 간섭이 없는 독립성을 보장
20 |
21 | ### 하이퍼 바이저
22 | 공용 컴퓨팅 자원을 관리하고 가상머신들을 컨트롤하는 중간 관리자
23 |
24 | ### 컨테이너
25 |
26 | 모듈화되고 격리된 컴퓨팅 공간 또는 컴퓨팅 환경을 의미하며, 시스템 환경 의존성을 탈피하고 안정적으로 구동.
27 |
28 | 컨테이너 기술의 등장 배경: 개발한 프로그램이 구동환경의 달라짐에 따라 예상하지 못한 각종 오류를 발생시키는 것을 해결하기 위함(= 컴퓨팅 환경 간 이식성 증가)
29 |
30 |
31 |
32 | ### 가상머신과 컨테이너의 차이점
33 |
34 | 1. 컨테이너는 가상화에서 하이퍼바이저와 게스트os 불필요
35 | 2. 대신, 컨테이너는 OS 레벨에서 프로세스를 격리해 모듈화된 프로그램 패키지로써 수행함
36 | 3. 따라서 컨테이너는 가상머신보다 가볍고 빠름
37 | 4. 이는 더 많은 응용프로그램을 더 쉽게 하나의 물리적 서버에서 구동시키는 것을 가능케 함
38 |
39 | 
40 |
41 |
--------------------------------------------------------------------------------
/DevOps/이중화.md:
--------------------------------------------------------------------------------
1 | # 서버 이중화 구조
2 |
3 | 서버 인프라를 설계하면 운영시에 서비스의 안정적인 운영을 위하여 서버 이중화를 구성한다.
4 |
5 | 물리적, 논리적 서버 또는 LAPR 등을 구성해 하나의 서비스가 장애가 발생하는 경우 다른 서버를 통해 서비스를 지속 가능하게 한다.
6 |
7 | 보통 서버의 이중화 구성은 `Active-Active`, `Active-Stand by` 구성으로 나누어 볼 수 있다.
8 |
9 |
10 | ### Active-Active
11 |
12 | Active-Active 구조는 L4 스위치 등의 부하분산(SLB Server Load Balancer) 로드밸런싱을 통해서 기능, 성격에 따라 1, 2번 서버로 나누어 처리하도록 구성한다.
13 |
14 | 웹 서버 이외에도 데이터베이스 서버에 필요한 경우에도 2개의 서버를 구성한다.
15 |
16 | 대부분의 웹 서버는 L4 스위치 SLB로 구성하고 DB서버는 Oracle RAC(Real Application Cluster)를 활용한다.
17 |
18 | 디스크 공유도 마찬가지로 Veritas CFS(Cluster File System)등으로 구성할 수 있다.
19 |
20 | 이러한 구성은 특정기기 장애시 1, 2번 서버로 따로 운영을 지속할 수 있고 다운타임이 존재하지 않는다.
21 |
22 |
23 |
24 | ### Active-Stand By
25 |
26 | 서버를 이중화하여 구성하지만 동시에 부하분선을 모든 기기에 서비스하는 것이 아니다.
27 |
28 | 장애시에 서비스를 이전하여 운영하는 형태로 구성된 것을 의미한다. (failover)
29 |
30 | 흔히 운영시스템이라고 부르는 운영시스템(메인서버) 서버가 장애시 서비스 장애를 인지하고 서브 서버로 서비스를 이전한다.
31 |
32 | 이러한 과정은 클러스터 하트비트 등으로 시스템 정상상태를 주기적으로 체킹하고
33 |
34 | > 클러스터 하트비트?
35 | > 클러스터 내의 각 노드가 정상적으로 작동하는지 (health check) 확인하기 위해 주기적으로 서로에게 신호를 보내는 것이다. 클러스터내의 안정성과 가용성을 유지하는 데 중요한 역할이다.
36 |
37 | 특이사항이 발생하는 경우 시스템 엔지니어 의사결정을 통해 수동으로 서브서버로 전환하거나, 크리티컬한 장애 발생시 자동으로 서비스를 전환한다.
38 |
39 | 결국 이러한 서버 이중화의 목적은 불가피한 장애 방지와 다운타임 최소화를 위해서다.
40 |
41 |
--------------------------------------------------------------------------------
/Front-End/JS/JSON.md:
--------------------------------------------------------------------------------
1 | # JSON
2 |
3 |
4 | ### JSON
5 | - 속성값 또는 키값으로 이루어진 데이터 오브젝트를 전달하기 위해 사람이 읽을 수 있는 텍스트를 사용하는 `개방형 표준` 포멧이다.
6 | - JSON의 공식 인터넷 미디어 타입은 `application / json` 이며, JSON의 파일 확장자는 `.json` 이다.
7 |
8 | > JSON에서 String은 큰따옴표("")만 사용한다.
9 |
10 |
11 | ex )
12 |
13 | ```json
14 | {
15 | "string" : "Huemang",
16 | "number" : 123,
17 | "boolean" : true,
18 | "null " : null,
19 | "object" : {},
20 | "array" : []
21 | }
22 | ```
23 |
24 | ```js
25 | import MyData from './myData'
26 |
27 | console.log(myData) // myData의 객체데이터 출력
28 | ```
29 |
30 | > JSON은 하나의 문자데이터다.
31 |
32 | > 통신을 하기 위한 용도나 가볍게 사용할 용도로는 적합하지않다.
33 |
34 | ### JSON.stringify()
35 |
36 | - 자바스크립트의 객체데이터를 문자 데이터로 바꾸어 주는 메서드
37 |
38 | ### JSON.parse()
39 |
40 | - 자바스크립트의 데이터를 분석하는 메서드
--------------------------------------------------------------------------------
/Front-End/JS/Object3.md:
--------------------------------------------------------------------------------
1 | # 객체 메소드
2 |
3 | ## Object.assign()
4 | - `Object.assign()` 메소드는 열거할 수 있는 하나 이상의 출처 객체로부터 대상 객체로 속성을 복사할 때 사용한다.
5 | - 대상 객체를 반환한다.
6 |
7 | **매개변수** :
8 | - `target` 대상객체.
9 |
10 | **반환 값**
11 | - 대상 객체.
12 |
13 | ```js
14 | const target = {a : 1, b : 2};
15 | const source = {b : 4, c : 5};
16 |
17 | const returnedTarget = Object.assign(target, source);
18 |
19 | console.log(target);
20 | // { a : 1 , b : 4 , c : 5 }
21 |
22 | console.log(returnedTarget);
23 | // { a : 1 , b : 4 , c : 5 }
24 | ```
25 |
26 | > `target` 과 `returnedTarget`은 같은 데이터다.
27 |
28 | > 객체는 생긴게 똑같아도 데이터는 다르다.
29 |
30 |
31 |
32 | ## keys()
33 | - `keys()` 객체의 값을 추출해서 배열로 만들어준다
34 |
35 | ```js
36 | const user ={
37 | name : "huemang",
38 | age : 17,
39 | email: "s22043@gsm.hs.kr"
40 | }
41 |
42 | const keys = Object.Keys(user);
43 | console.log(keys);
44 | // ['name' , 'age' , 'email']
45 |
46 | console.log(user['email']);
47 |
48 | const values = keys.map(key => user[key]);
49 | console.log(values);
50 | // ['huemang' , 17 , 's22043@gsm.hs.kr ]
51 | ```
52 |
53 | > 객체데이터에서 대괄호를 사용하는 `인덱싱` 방법을 사용했다. 나중에 더 알아보도록 하자.
--------------------------------------------------------------------------------
/Front-End/JS/Storage.md:
--------------------------------------------------------------------------------
1 | # Storage
2 |
3 | ## Local Storage
4 | - `localStorage`읽기 전용 속성을 사용하면 Document 출처의 Storage 객체에 접근할 수 있다.
5 | 저장한 데이터는 브라우저 세션 간에 공유됩니다.
6 |
7 |
8 |
9 | ### session Storage와 차이
10 | > localStorage는 데이터가 만료되지않고 session Storage의 데이터는 페이지 세션이 끝날 때. 사라지는 점이 다릅니다.
11 |
12 | ## 예제
13 | `Storage.setItem(Key , valuse)` : Storage에 값을 저장
14 | ```js
15 | localStorage.setItem('myCat', 'Tom');
16 | ```
17 |
18 | `Storage.getItme()` : Storage의 아이템 확인
19 |
20 | ```js
21 | const cat = localStorage.getItem('myCat');
22 | ```
23 |
24 | `Storage.removeItem()` : Storage의 아이템 제거
25 |
26 | ```js
27 | localStorage.removeItem('myCat');
28 | ```
29 |
30 |
--------------------------------------------------------------------------------
/Front-End/JS/ajax.md:
--------------------------------------------------------------------------------
1 | # ajax
2 | - ajax 는 http를 효과적으로 이용하는 기술입니다.
3 | - ajax 는 약속은 아닙니다 효과적으로 서버와 소통하기 위한 기술입니다.
4 |
5 | > ajax를 사용하면, 유저는 새로운 HTML 서버를 받는 것이 아닙니다.
6 | > 즉, 유저는 새로운 웹페이즈로 이동하는 것이 아니라 **동일한 웹페이지 내에서 DOM을 변경** 하게 됩니다.
7 |
8 |
9 |
10 | **이름과 자기소개를 하는 기능이 있다 해봅시다**
11 |
12 | 1. 요청 페이지에서 이름 칸에 '희망'을 쓰고, 내용에 '안녕하세요. 희망입니다' 라고 썼다 해봅시다.
13 | 2. 사용자는 이벤트로부터 JS는 해당 이름과 내용이 쓰여진 DOM을 읽습니다.
14 | 3. 그리고 XMLHttpRequest 객체를 통해 웹서버에 해당 이름과 내용을 전송합니다.
15 | 4. 웹서버는 요청을 처리하고 XML, Text 혹은 JSON을 XMLHttpRequest 객체에 전송합니다.
16 | 5. 그러면 , JavaScript가 해당 응답 정보를 DOM에 씁니다.
17 | 6. 그렇게 결과 페이지가 만들어집니다.
18 |
19 |
20 |
21 | AJAX를 사용하면, 새로운 HTML을 서버로부터 받아야 하는것이 아닙니다.
22 | 동일한 페이지의 일부를 수정할 수도 있는 가능성이 생깁니다. 결과적으로 사용자 입장에서 페이지 이동이 발생되지 않고 페이지 내부 변화만 일어나게 됩니다. HTML 페이지 전체를 다 바꿔야 하는 것이 아니라 부분만 바꿀 수 있게 되는 것입니다.
23 |
24 | ### XMLHttpRequest 객체
25 | Ajax 에 가장 핵심적인 구성 요소입니다.
26 | Ajax에서 XMLHttpRequest 객체는 **웹 브라우저가 서버와 데이터를 교환**할 때 사용됩니다.
27 | 웹 브라우저가 백그라운드에서 계쏙해서 서버와 통신할 수 있는 것은 바로 이 객체를 사용하기 때문입니다.
28 | ```js
29 | let httpRequest = new XMLHttpRequest();
30 | ```
--------------------------------------------------------------------------------
/Front-End/JS/destruct.md:
--------------------------------------------------------------------------------
1 | # 구조 분해 할당
2 |
3 | ### 구조 분해 할당이란 ?
4 | - 배열이나 객체의 속성을 해체하여 그 값을 개별 변수에 담을 수 있게 하는 JS 표현식 입니다.
5 |
6 | ```js
7 | const user = {
8 | name : `huemang`,
9 | age : 17,
10 | email : 's22043@gsm.hs.kr'
11 | }
12 |
13 | const { name , age , email, address} = user
14 |
15 | console.log(name);
16 | // humang
17 |
18 | console.log(age);
19 | // 17
20 |
21 | console.log(email);
22 | // s22043@gsm.hs.kr
23 |
24 | console.log(address);
25 | // undefined
26 |
27 | ```
28 | - 배열도 구조 분해 할당을 사용할 수 있다.
29 | - 만약 세번째 값만 추출 하고싶다면 값을 추출할 변수 뒤에 , 를 붙여주면 된다
30 |
31 | ```js
32 | const fruits = ['apple' , 'banana' , 'Cherry']
33 | const =[, , fruit] = fruits
34 |
35 | console.log(fruit);
36 | // Cherry
37 | ```
38 |
39 | - 변수에 기본값을 할당하면, 분해한 값이 `undefined`일 때 그 값을 대신 사용합니다.
40 |
41 | ```js
42 | let a, b;
43 |
44 | [a=5, b=7] = [1];
45 | console.log(a); // 1
46 | console.log(b); // 7
47 | ```
--------------------------------------------------------------------------------
/Front-End/JS/garbage.md:
--------------------------------------------------------------------------------
1 | # 가비지 컬렉션
2 | 자바스크립트는 눈에 보이지 않는 곳에서 메모리 관리를 수행합니다.
3 |
4 | 원시값, 객체, 함수 등 우리가 만드는 모든 것은 메모리를 차지합니다. 그렇다면 더는 쓸모 없어지게 된 것들은 어떻게 처리될까요? 지금부턴 자바스크립트 엔진이 어떻게 필요 없는 것을 찾아내 삭제하는지 알아보겠습니다.
5 |
6 |
7 |
8 | ## 가비지 컬렉션 기준
9 | 자바스크립트는 도달 가능성 이라는 개념을 사용해 메모리 관리를 수행합니다.
10 |
11 | `도달 가능한` 값은 쉽게 말해 어떻게든 접근하거나 사용할 수 있는 값을 의미합니다. 도달 가능한 값은 메모리에서 삭제되지 않습니다.
12 |
13 | 1. 아래 나온 값들은 그 태생부터 도달 가능하기 때문에, 명백한 이유 없이는 삭제되지 않습니다.
14 |
15 | - 현재 함수의 지역변수와 매개변수
16 | - 중첩 함수의 체인에 있는 함수에서 사용되는 변수와 매개변수
17 | - 전역 변수
18 | - 기타 등등
19 |
20 | 이런 값은 `root` 라고 합니다.
21 |
22 | 2. 루트가 참조하는 값이나 체이닝으로 루트에서 참조할 수 있는 값은 도달 가능한 값이 됩니다.
23 |
24 | 전역 변수에 객체가 저장되어있다고 가정해 봅시다. 이 객체의 프로퍼티가 또 다른 객체의 프로퍼티가 또 다른 객체를 참조하고 있다면, 프로퍼티가 참조하는 객체는 도달 가능한 값이 됩니다. 이 객체가 참조하는 다른 모든 것들도 도달 가능하다고 여겨집니다. 자세한 예씨는 아래에서 살펴보겠습니다.
25 |
26 | - 자바스크립트 엔진 내에선 `가비지 컬렉터`가 끊임없이 동작합니다. 가비지 컬렉터는 모든 객체를 모니터링하고, 도달할 수 없는 객체는 삭제합니다.
27 |
28 |
29 |
30 | ```js
31 | // user엔 객체 참조 값이 저장됩니다.
32 | let user = {
33 | name : "John"
34 | };
35 | ```
36 | 전역변수 `user`는 `{name : "John"}` 이라는 객체를 참조합니다. John의 프로퍼티 `name`은 원시값을 저장하고 있기 때문에 객체 안에 표현했습니다.
37 | `user`의 값을 다른 값으로 덮어쓰면 참조가 사라집니다.
38 | ```js
39 | user = null;
40 | ```
41 | 이제 John은 도달할 수 없는 상태가 되었습니다. John에 접근할 방법도, John을 참조하는 것도 모두 사라졌습니다. 가비지 컬렉터는 이제 John에 저장된 데이터를 삭제하고, John을 메모리에서도 삭제합니다.
42 |
43 |
44 |
--------------------------------------------------------------------------------
/Front-End/JS/import.md:
--------------------------------------------------------------------------------
1 | # import
2 |
3 | - 정적 `import`문은 다른 모듈에서 내보낸 바인딩을 가져올 때 사용합니다.
4 |
5 | ## 구문
6 | ```js
7 | import defaultExport from "module-name";
8 | import * as name from "module-name";
9 | import { export1 } from "module-name";
10 | import { export1 as alias1 } from "module-name";
11 | import { export1 , export2 } from "module-name";
12 | import { foo , bar } from "module-name/path/to/specific/un-exported/file";
13 | import { export1 , export2 as alias2 , [...] } from "module-name";
14 | import defaultExport, { export1 [ , [...] ] } from "module-name";
15 | import defaultExport, * as name from "module-name";
16 | import "module-name";
17 | let promise = import("module-name");
18 | ```
19 |
20 | - `defalutExport` : 모듈에서 가져온 기본 내보내기를 가리킬 이름.
21 |
22 | - `module-name` : 가져올 대상 모듈. 보통, 모듈을 담은 js파일로의 절대 또는 상대 경로
23 |
24 | - `name` : 가져온 대상에 접근할 때 일종의 이름공간으로 사용할, 모듈 객체의 이름.
25 |
26 | - `exportN` : 내보낸 대상 중 가져올 것의 이름.
27 | - `aliasN` : 가져온 유명 내보내기를 가리킬 이름.
28 |
29 | ## import 설명
30 |
31 | - 모듈 전체를 가져온다. export 한 모든 것들을 현재 범위 (스크립트 파일 하나로 구분되는 모듈 범위) 내에 `myModule`로 바인딩되어 들어갑니다.
32 |
33 | ```js
34 | import * as myModule from "my-module.js";
35 | ```
36 |
37 | 모듈에서 하나의 멤버만 가져옵니다. 현재 범위 내에 `myMember`이 들어갑니다.
38 |
39 | ```js
40 | import {myMember} from "my-module.js";
41 | ```
42 |
43 | 모듈에서 여러 멤버들을 가져옵니다. 현재 범위 내에 `foo` 와 `bar`이 들어갑니다.
44 |
45 | ```js
46 | import {foo, bar} from "my-module.js";
47 | ```
--------------------------------------------------------------------------------
/Front-End/TS/TypeScript.md:
--------------------------------------------------------------------------------
1 | # TypeScript
2 |
3 | ## TypeScript란 ?
4 | - 자바스크립트에 타입이라는 개념을 적용(확장)시킨 것이다.
5 | - 코드를 실행하기전에 에러를 잡아준다.
6 |
7 | > 타입스크립트는 Programing Language 언어 이다.
8 | > Compiled Language 이다
9 | > 자바스크립트 Interpreted Language 입니다
10 |
11 | ## Compiled와 Interpreted의 차이
12 |
13 | ### Compiled
14 | - 컴파일 필요 O
15 | - 컴파일러 필요 O
16 | - 컴파일하는 시점 O
17 | > 컴파일 타임
18 | - 컴파일 된 결과물을 실행
19 | - 컴파일된 결과물을 실행하는 시점
20 |
21 | ### Interpreted
22 | - 컴파일이 필요 X
23 | - 컴파일러가 필요 X
24 | - 컴파일하는 시점 X
25 | - 코드 자체를 실행
26 | - 코드를 실행하는 시점 o
27 |
28 | ## TypeScript vs JavaScript
29 |
30 | - TypeScript는 JavaScript 기반의 언어
31 | - JavaScript는 클라이언트 측 스크립팅 언어
32 | - TypeScript는 객체 지향 컴파일 언어
33 | - 객체 지향 프로그래밍 패러다임은 데이터 추상화에 중심
34 | > 객체와 클래스라는 두 주요 개념을 기반으로 함
--------------------------------------------------------------------------------
/Linux/df.md:
--------------------------------------------------------------------------------
1 | # df
2 |
3 | 
4 |
5 |
6 | 디스크 사용량 모니터링은 서버 모니터링에 있어 필수적이며 df는 **서버의 디스크 사용량, inode 공간을 확인할 수 있다.** `df -h`
7 |
8 | 디렉터리 별 사용량 확인은 du 명령을 통해 확인이 가능하다 `du -sh /*`
9 |
10 | 만약 용량 확보를 위해 파일삭제시 예상과 다르게 확보가 되지 않을 경우 lsof로 파일핸들러(사용자)를 조회해서 파일을 사용하는 프로세스를 종료해야한다.
11 |
12 | inode 파일이나 디렉터리 메타데이터를 가지고있는 구조체로서 파일과 디렉터리의 개수라고 바도 된다. inode 정보는 `df -i` 명령어로 확인이 가능하다.
13 |
14 | 정리하면 df 명령으로 서버의 디스크 상태를 체크할 수 있으며, 파일 마운트 포인트 기준으로 조회하기 때문에 아래 어떤 디렉터리가 용량이 많은지는 du를 통해 조회해 확인할 수 이다.
15 |
16 | 파일 혹은 디렉터리를 제거 했어도 용량이 반영되지 않았다면 파일 핸들러를 조회해봐야 한다. 파일 핸들은 프로세스가 파일을 열거나 참조할 때 파일 핸들이라는 상태가 생긴다. lsof를 통해 파일 핸들을 확인할 수 있으며 제거된 파일에 파일 핸들이 있다면 해당 프로세스를 kill하면 용량 개선이 반영된다.
17 |
18 | inode는 파일과 디렉터리에 대한 메타데이터로 파일과 디렉터리의 개수로 생각해도 된다.
19 |
--------------------------------------------------------------------------------
/Linux/netstat.md:
--------------------------------------------------------------------------------
1 | # netstat
2 |
3 | 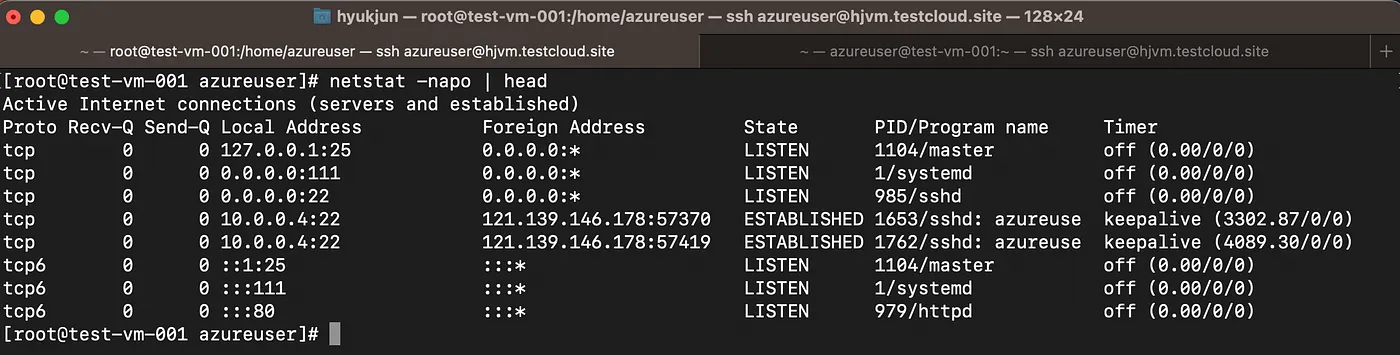
4 |
5 | 서버에 네트워크 연결 정보를 확인할 수 있다.
6 |
7 | tcp 3 way handshake, tcp 4 way handshake 진행 과정의 상태가 표현되기에 이를 매우 잘 이해해야한다.
8 |
9 | LISTEN, TIME_WAIT, ESTABLISHED 상태를 제일 많이 마주하게 되며 상태별로 다음과 같은 해석이 가능하다.
10 |
11 | - LISTEN: 프로세스가 소켓을 통해 요청을 듣고 있는 상태
12 | - ESTABLISHED: 커넥션이 맺어진 상태
13 | - TIME_WAIT: 커넥션이 종료되고 연결을 먼저 끊은쪽(active closer)에서 소켓을 정리하기 전 잠시 대기 하는 상태다
14 | - 이는 fin 과정 4 way hand shake에서 active closer가 마지막에 ack 패킷을 보내고 나서 패킷이 유실될 경우 다시 패킷을 보내 graceful하게 연결을 끊기 위함이다. (마지막 ack가 유실되면 passive closer는 ack를 못받았으므로 앞서 보낸 Fin을 다시 보내고 active closer는 time wait 상태이므로 소켓을 정리하기전에 fin을 다시 받을 수 있다. 이후 active closer는 ack를 보내 연결을 graceful하게 종료가 가능하다.)
15 |
16 | keepalive-timeout: nginx에 설정값중 하나로 매번 tcp 3 way handshake를 하게 되면 네트워크 성능 저하가 발생하기 때문에 연결을 유지하도록 하는 설정이다.
17 |
18 | http/1.0에서는 명시적인 connection: keep-alive 헤더를 추가하는 기법으로 구현되어 있지만 1.1 부터 스펙 자체에 persistence connections 개념이 도입되어 별도 헤더를 추가하지 않아도 된다.
19 |
20 | **CLOSE_WAIT**: fin 패킷을 수신하고 ack 요청을 만들기 전 상태로 이 상태가 계속 유지된다면, application 응답을 만들지 못하는 상황이므로 원인 분석 후 조치가 필요하다.
21 |
22 | 정리하면 netstat 명령을 통해 네트워크 연결 상태를 점검할 수 있다.
23 |
24 | 커넥션 종단간 ip port 정보등을 확인할 수 있으며 LISTEN, ESTABLISHED, TIME_WAIT등 소켓 상태 확인이 가능하다.
25 |
26 | CLOSE_WAIT 상태는 application이 소켓을 정리하지 못하고 응답을 만들어내지 못하는 경우이기 때문에 원인을 확인하고 조치가 필요한 상황으로 해석해야한다.
27 |
28 |
--------------------------------------------------------------------------------
/Linux/top.md:
--------------------------------------------------------------------------------
1 | # top
2 |
3 | 
4 |
5 | 서버에 구동되고 있는 프로세스들의 상태와, cpu, memory 사용률을 확인할 수 있다.
6 |
7 | hotkey: 1 -> 개별 cpu 확인, d -> 인터벌 변경(1로 하여 1초 간격으로 확인 가능)
8 |
9 | hotkey로 개발 cpu를 나타내 cpu들의 사용 불균형이 있는지 체크할 필요가 있다.
10 |
11 | 종합된 평균 사용량 cpu(s)은 정상이 아니지만 개별로 봤을 때 특정 cpu만 사용된다면 문제가 있는 상황으로 봐야한다.(싱글 스레드로 구동되는 app이 아닌 이상 비정상 상태) 이 경우 nginx의 worker=1 세팅 처럼 cpu를 모두 사용하지 못하는 경우등을 체크해야한다.
12 |
13 | cpu usage 중 주요 지표로 us/wa가 중요하다.
14 | - **us**: user 수준의 프로세스의 일반적인 cpu 사용량으로 us가 높다면 프로세스가 cpu를 많이 사용하는 것으로 해석된다.
15 | - **wa**: waiting, io작업을 대기하는 프로세스로 인해 사용되는 cpu사용량으로 해석한다.
16 |
17 | 프로세스 상태는 s 컬럼에서 (D R S Z) 확인 가능하다. (D, R은 Load Average에 영향을 준다.)
18 | - **D**: Uninterruptible, io가 대기중인 상태로 vmstat상 b 상태다
19 | - **R**: Running, cpu 사용중인 상태로 vmstat상태로 v상태다
20 | - **S**: Sleeping, 실제 작업을 하지 않고 잠자는 상태다
21 | - **Z**: Zombie, 실제 시스템 리소스를 사용하지 않지만, pid 고갈 문제를 일으킬 수 있다.
22 |
23 | top 명령으로 서버 내 프로세스들의 상태, cpu, memory 사용량을 확인할 수 있으며 cpu 사용량 중 us가 높다면 cpu를 많이 사용하는 프로세스, wa가 높다면 io를 많이 사용하는 프로세스로 해석할 수 있다.
24 |
25 | 보통 서버들은 멀티코어기 때문에 개별 cpu의 사용량을 확인해서 cpu 사용에 불균형이 있는지 확인해야한다.
26 |
27 | 프로세스의 상태는 D R S Z가 있고 혹시 서버에 좀비 프로세스가 많지는 않은지 확인해야한다.
28 |
29 |
30 |
31 |
--------------------------------------------------------------------------------
/MSA/ipc/ipc.md:
--------------------------------------------------------------------------------
1 | # 마이크로서비스 아키텍처 IPC
2 |
3 | IPC(Inter Process Communication)는 프로세스 간 통신이라는 프로세스들 사이에서 서로 데이터를 주고받는 행위 또는 그에 대한 방법이나 경로를 뜻하는 용어다.
4 |
5 | 애플리케이션이 여러개의 서비스로 구성되는 마이크로서비스 아키텍처에서 필수적이다. 보통은 JSON 기반의 REST가 많이 사용되지만 MSA가 아닌 일반적인 상황에서 여러가 지옵션을 잘 선택해야한다.
6 |
7 | ### 일대일/일대다 여부
8 | - 일대일: 각 클라이언트 요청은 정확한 한 서비스가 처리
9 | - 일대다: 각 클라이언트 요청을 여러 서비스가 협동하여 처리
10 |
11 | ### 동기/비동기 여부
12 | - 동기: 클라이언트는 서비스가 제시간에 응답하는 것을 가정하고 대기 도중 블로킹할 수 있음
13 | - 비동기: 클라이언트가 블로킹하지 않고, 응답은 즉시 전송되지 않아도 된다.
14 |
15 | ### 일대일 상호 작용
16 | - 요청/응답, 비동기 요청/응답, 단방향 알림
17 |
18 | ### 일대다 상호 작용
19 | - 발행/구독, 발행/비동기 응답
--------------------------------------------------------------------------------
/MSA/ipc/rpi.md:
--------------------------------------------------------------------------------
1 | # 동기 RPI 패턴 응용 통신
2 |
3 | RPI는 클라이언트가 서비스에 요청을 보내면, 서비스가 처리 후 응답을 회신하는 IPC이다. 종류는 다양할 수 있지만 REST, gRPC가 대표적이다.
4 |
5 | ## REST
6 | 웹 상 존재하는 자원을 url로 나타내고, 자원에 대한 행위를 HTTP 프로토콜의 메서드로 나타낸다. 데이터 형식은 대부분 JSON으로 나타낸다.
7 |
8 | ### 장점
9 | - 단순하고 익숙하다
10 | - 테스트가 간단하다
11 | - 중간 브로커가 필요가 없어서 시스템 아키텍처가 단순하다
12 |
13 | ### 단점
14 | - 요청/응답 스타일의 통신만 지원한다.
15 | - 가용성이 떨어진다.
16 | - 요청 한번으로 여러 리소스를 가져오기 힘들다.(데이터를 효율적으로 조회할 수 있게 grpahql이 떠오르고 있다.)
17 | - 다중 업데이트 작업을 HTTP 동사에 매핑하기 어려울 때가 많다(특정 데이터에 대한 행위가 여러 개 일 수 있으며 메서드에 다 할 수가 없다.)
18 |
19 |
20 |
21 | ## gRPC
22 | 바이너리 메시지 기반의 프로토콜이고, 프로토콜 버퍼를 IDL로 정의하여 프로토콜 버퍼 컴파일러로 클라이언트 쪽 스텁 및 서버쪽 스캘레톤을 생성할 수 있다.
23 |
24 | ### 장점
25 | - 다양한 업데이트 작업이 포함된 api 설계가 쉽다.
26 | - 큰 메시지를 교환할 때 컴팩트하고 효율적은 IPC
27 | - 양방향 스트리밍 덕분에, RPI, 메시징 두가지 통신 방식
--------------------------------------------------------------------------------
/MSA/pattern/cqrs.md:
--------------------------------------------------------------------------------
1 | # CQRS
2 |
3 | Event Sourcing과 함께 알아두어야 할 개념으로 CQRS가 있다.
4 |
5 | 간단히 설명하면 Command(Create, Update, Delete)와 Query(Read)의 책임을 분리하는 것이다.
6 |
7 | Event Sourcing과 연계시켜 생각해보면 Event는 Command 즉 상태가 변경되는 경우에만 발생하고 그 경우만 기록하면 된다.
8 |
9 | 단순 Query인 경우는 모델의 정보를 변화시키지 않기 때문에 그 기능을 분리하여 좀 더 손쉽게 Event Sourcing Pattern을 적용할 수 있다.
10 |
11 | 또한 Event Sourcing 개념에 의해 생성된 최신 데이터(snapshot)은 CQRS에서 Query의 개념으로 접근하여 조회하기 때문에 로직을 간략화하고 cache를 통해 조회속도를 손쉽게 개선할 수 있다.
12 |
13 | 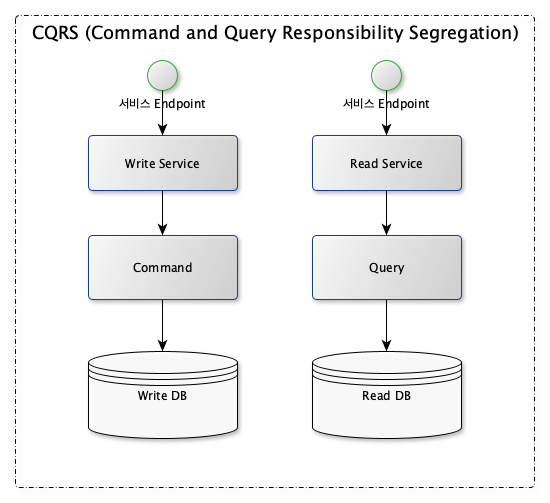
14 |
15 | ### 장점
16 | - 마이크로 서비스에서 데이터 처리 이점이 있다. 특정 api를 통해서만 데이터를 변경할 수 있고, 조회 api를 이용해서 데이터를 읽을 수 있도록 분리한다.
17 | - 읽기/쓰기 요청을 분리함으로 해서 성능을 개선할 수 있다.
18 | - 데이터 이상을 동시에 쓰는 방식보다 더 쉽게 찾을 수 있다.
19 | - 이벤트 소싱과 함께 사용되어 비동기 처리로 작업을 수행할 수 있다.
--------------------------------------------------------------------------------
/MSA/pattern/event_sourcing.md:
--------------------------------------------------------------------------------
1 | # Event Sourcing
2 |
3 | 애플리케이션의 모든 상태 변화를 순서대로 이벤트로 보관하여 처리하는 개념이다.
4 |
5 | 이렇게 모든 상태를 이벤트의 흐름으로 처리함으로써 애플리케이션의 개발을 간소화하고 분산 환경에 적절하게 대응할 수 있다.
6 |
7 | 모든 이벤트는 시간 순으로 기록이 되며 각 서비스들은 자신이 필요한 이벤트만 보고 있다가 최신의 상태를 유지하면 된다.
8 |
9 | 즉, 회원관리 서비스는 회원의 생성 삭제, 또는 변경 이벤트만 참조하여 회원의 최신정보(snapshot)을 가지고 최신 정보를 유지할 수 있으며, 상품 관련 서비스는 상품의 주문, 배송 등과 관련된 이벤트만 참조(Listening)하고 최신 상태를 유지한다.
10 |
11 | 이러한 EventSourcing이 완벽하게 동작하려면 모든 이벤트는 기록되어야 하고, 이벤트를 받지 못하는 서비스가 없도록 재전송이 가능해야한다.
12 |
13 | 또한 이벤트는 자신의 서비스 또는 WAS 내에서만 받을 수 있는 것이 아니라 브로드캐스팅이 되어야 분산된 환경에서도 완벽하게 동작할 수 있어야 한다.
14 |
15 | Event Sourcing의 이러한 특징 때문에 MSA 시스템을 적용할 때 Event 기반으로 구현하면 보다 손쉽게 구현이 가능하며, 각 서비스 간의 loosed coupling이 가능하다.
16 |
17 | 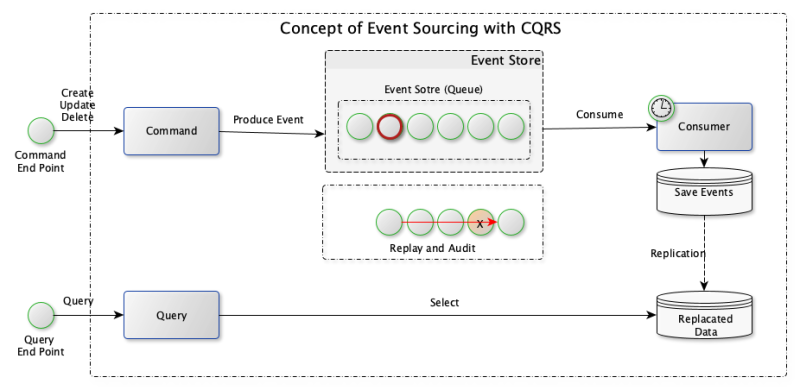
18 |
19 | 이벤트 소싱은 위와 같이 데이터를 변경하는 작업이 있을 때 데이터가 있는 서비스에 요청하는 방식은 동일하다.
20 |
21 | 그러나 한 가지 다른 점이 있다면 **데이터를 가진 서비스가 바로 데이터를 조작하지 않는다.**
22 |
23 | 위 그림을 보면 몇가지 요소가 있다.
24 | - Event Producer
25 | - Event Consumer
26 | - Event (Command)
27 | - Event Store (Queue)
28 | - Event Snapshot(빨간색 원)
29 |
30 | 대신에 위와 같은 이벤트를 발생시키고 Event Store에 저장한다.
31 |
32 | Kafka와 같은 메시지 브로커들이 Event Store가 될 수 있다. 그러면 이벤트 컨슈머가 해당 이벤트를 데이터베이스나 HDFS에 들어온 순서대로 적재를 한다.
33 |
34 | 그리고 필요한 데이터를 변경하거나 반영하게 된다.
--------------------------------------------------------------------------------
/MSA/service_discovery.md:
--------------------------------------------------------------------------------
1 | ### 서비스 디스커버리
2 |
3 | MSA에서는 서비스들 마다 다들 각자 다른 IP, Port를 가지고 있다.
4 |
5 | 이러한 서로 다른 서비스들의 IP와 Port의 정보들에 대해서 저장하고 관리할 필요가 있는데 이러한 메커니즘을 서비스 디스커버리라고 한다.
6 |
7 | 클라우드 기반 마이크로서비스 환경에서 견고한 서비스 디스커버리 메커니즘을 사용한다면 어떠한 이점이 있을까
8 |
9 | ### 고가용성
10 |
11 | 서비스 디스커버리는 클러스터 노드 간 서비스 검색 정보가 공유되는 핫 클러스터링 환경을 지원할 수 있어야한다.
12 |
13 | 한 노드가 가용하지 않으면 다른 노드가 그 역할을 대신 수행할 수 있다.
14 |
15 | > 클러스터는 서버와 인스턴스들의 그룹으로 정의할 수 있다.
16 |
17 | 이 경우 모든 인스턴스들은 고가용성, 안정성, 확장성을 제공하고자 동일한 구성을 가지고 협업한다.
18 |
19 | 로드 밸런서와 통합된 클러스터 서비스 중단을 방지하는 페일오버와 세션 데이터를 저장하는 세션 복제 기능을 제공할 수 있다.
20 |
21 |
22 | ### P2P (Peer to Peer)
23 |
24 | 서비스 디스커버리는 모든 노드들 간에 자신의 서비스 인스턴스 상태를 공유한다.
25 |
26 | ### 부하분산
27 |
28 | 서비스 디스커버리는 요청을 동적으로 분산시켜 관리하는 모든 인스턴스에 분배한다.
29 |
30 | 초창기 더 고정적이며 수동으로 관리되는 로드밸런서를 대체한다.
31 |
32 | ### 회복성
33 |
34 | 서비스 디스커버리 클라이언트는 서비스 정보를 로컬에 캐싱한다.
35 |
36 | 로컬 캐싱은 서비스 디스커버리 기능이 점진적으로 저하되는 것을 고려했기 때문에 생겨났다.
37 |
38 | 서비스 디스커버리가 서비스를 가용하지 않아도 애플리케이션은 여전히 작동할 수 있는 것이다.
39 |
40 | ### 결함내성
41 |
42 | 서비스 디스컵리가 비정상 서비스 인스턴스를 탐지하면 클라이언트 요청을 처리하는 가용 서비스 목록에서 해당 인스턴스를 제거해야한다.
43 |
44 | 서비스를 이용하여 이러한 결함을 탐지하고 사람의 개입 없이 조치되어야한다.
45 |
--------------------------------------------------------------------------------
/MSA/확장큐브.md:
--------------------------------------------------------------------------------
1 | # 확장 큐브로 보는 마이크로서비스
2 |
3 | `확장 큐브`의 개념으로 마이크로 서비스를 살펴보자.
4 |
5 | 확장 큐브는 애플리케이션을 확장하는 세 가지 방법을 정의한다.
6 |
7 | 1. X축 확장은 **동일한 다중 인스턴스에 들어온 요청을 부하분산**
8 | 2. Z축 확장은 **요청의 속성에 따라 요청을 라우팅**
9 | 3. Y축 확장은 **애플리케이션을 기능에 따라 서비스로 분해한다.**
10 |
11 | ### X축 확장: 다중 인스턴스에 고루 요청 분산
12 |
13 | X축 확장은 일반적인 모놀리식 애플리케이션의 확장 수단이다.
14 |
15 | 부하 분산기 뒷면에 애플리케이션 인스턴스를 N개 띄워놓고 부하 분산기는 들어온 요청을 이들 인스턴스에 고루 분배한다.
16 |
17 | 애플리케이션 능력과 가용성을 개선하기 위해 사용한다.
18 |
19 | 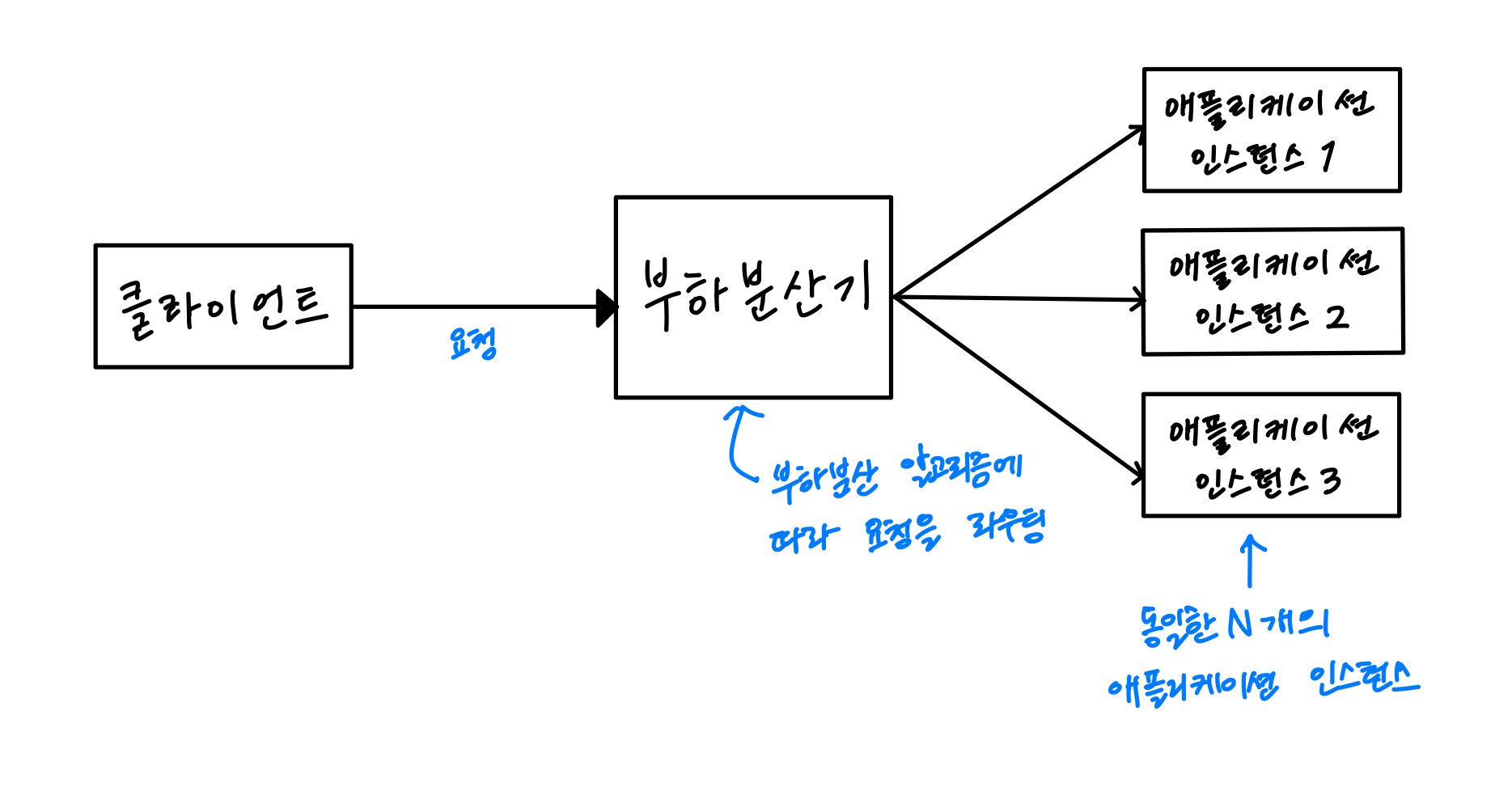
20 |
21 |
22 |
23 | ### Z축 확장: 요청 속성별 라우팅
24 |
25 | 모놀리식 애플리케이션의 다중 인스턴스를 실행하는 것은 X축 확장과 같지만, 인스턴스별로 주어진 데이터 하위집합만 처리하도록 하는 방법이다.
26 |
27 | 라우터는 요청의 속성에 알맞는 인스턴스로 요청을 라우팅한다.
28 |
29 | 각 애플리케이션 인스턴스는 자신에게 배정된 사용자 하위집단만 처리한다.
30 |
31 | 라우터는 요청헤더 Authorization에 포함된 userId를 보고 N개의 동일한 애플리케이션 인스턴스 중 하나를 선택한다.
32 |
33 | Z축 확장은 애플리케이션을 확장해서 **증가하는 트랜잭션 및 데이터 볼륨을 처리하기**좋은 수단이다.
34 |
35 | 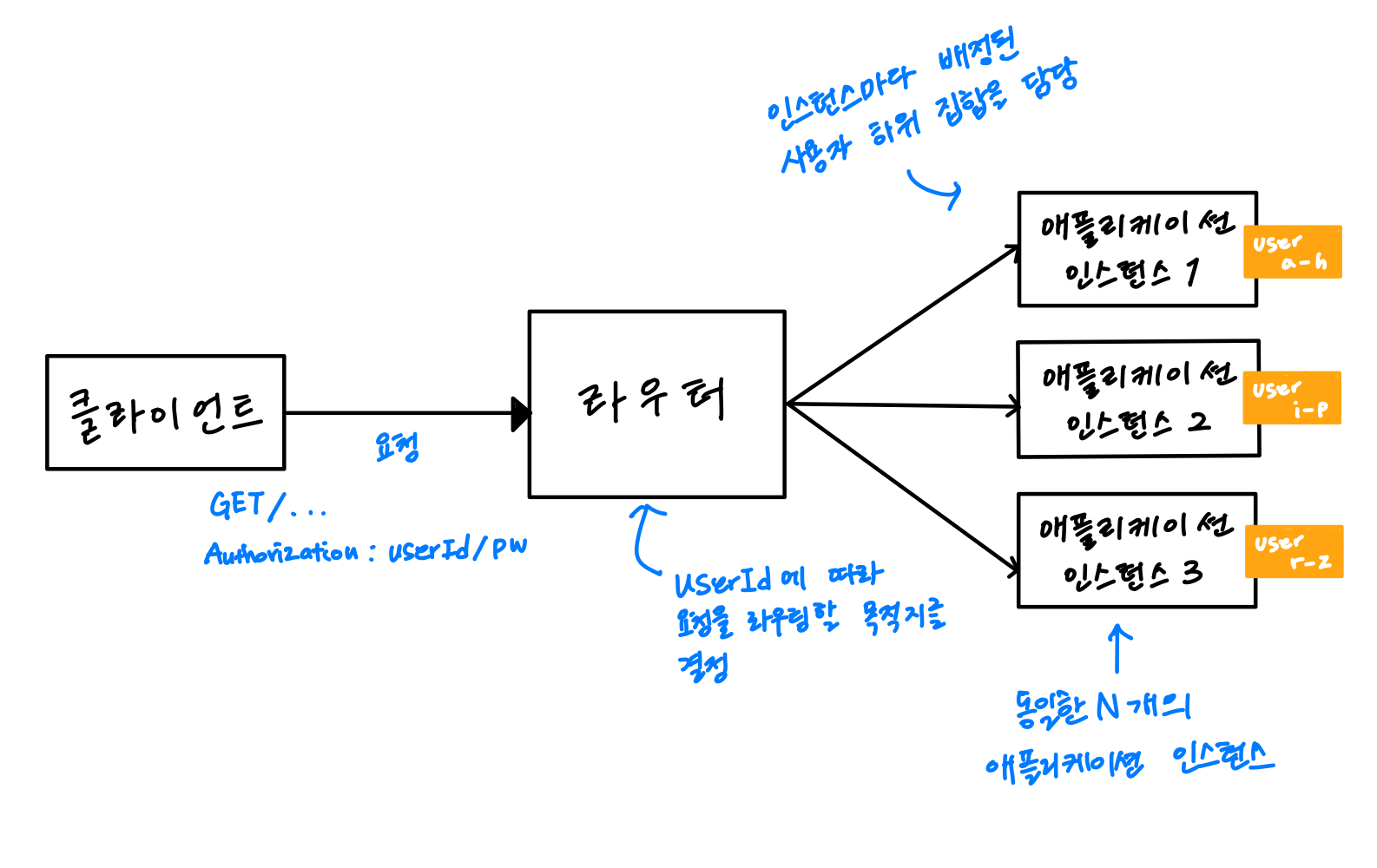
36 |
37 |
38 |
39 |
40 | ### Y축 확장: 기능에 따라 애플리케이션을 서비스로 분해
41 |
42 | X축/Z축 확장을 하면 애플리케이션 능력과 가용성은 개선되지만, 애플리케이션이 점점 더 복잡해진다. 따라서 여러 서비스로 쪼개기로 한다.
43 |
44 | 서비스는 주문 관리, 고객 관리 등 지엽적 기능이 구현된 미니 애플리케이션이며, 서비스에 따라 X축/Y축 확장도 가능하다.
45 |
46 | 예를 들어, 주문 서비스는 여러 서비스 인스턴스를 부하 분산하는 형태로 구성할 수 있다.
47 |
48 | 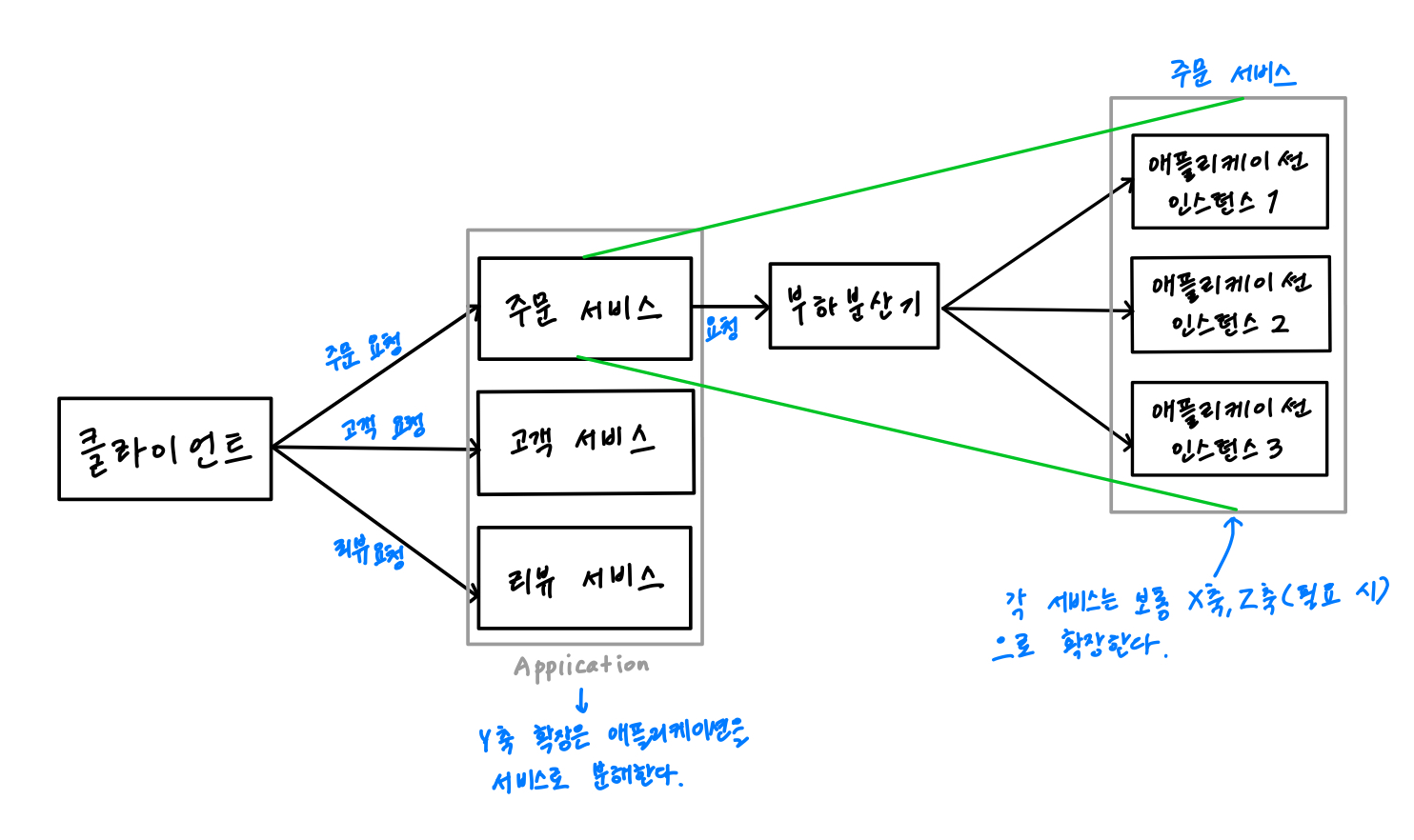
--------------------------------------------------------------------------------
/Network/et.md:
--------------------------------------------------------------------------------
1 | # Token Ring, Ethernet
2 |
3 | ### Token Ring
4 |
5 | 네트워크에서 데이터를 전송하고자 하는 PC는 이더넷 처럼 자기 맘대로 보내고 싶을 때 남들이 전송만 하지 않고 있으면 막 보내는게 아니라 네트워크 상에서 오직 **토큰을 가진 pc만 데이터를 실어 보낼 수 있는 방식**이다.
6 |
7 | 데이터를 다 보내면 토큰을 옆 pc에게 전달하고 이 전달방향은 단방향이다. 따라서 토큰링에서는 충돌이 발생하지 않고 네트워크에 대한 성능을 미리 예측하기도 쉽다.
8 |
9 | 그러나 내가 지금 보내야할 데이터가 있고 다른 pc들은 보낼 데이터가 하나도 없을때 토큰이 없으면 토큰을 기다려야하는 단점이 있다. 이런 토큰링 방식은 이더넷이 나오고 사라졌다.
10 |
11 | ### Ethernet
12 |
13 | 이더넷은 **네트워크를 구축하는 방식 중 하나**로 우리나라가 대부분 이 방식을 사용한다.
14 |
15 | 이더넷의 특징은 **CSMA/CD** 방식으로 통신하는 것이고 이 방식은 통신하고자 하는 컴퓨터가 네트워크를 살펴봐 아무도 사용 안하면 무조건 자기 데이터를 실어 보낸 후 잘갔는지 확인하는 방식이다.
16 | - CS(Carrier Sense): 네트워크 장치는 데이터를 전송하기 전에 네트워크가 사용하는 지 감지함.
17 | - MA(Multiple Acess): 여러 장치가 네트워크에 동시에 접근할 수 있음. 모든 장치는 동일한 통신 채널 공유
18 | - CD(Collision Detection): 데이터 전송 중 두 개 이상의 장치가 동시에 데이터를 전송하면 충돌이 나며 CSMA/CD는 이런 충돌을 감지하고 일정 시간후 다시 전송을 시도하는 방식으로 해소함.
19 |
20 | 만약 동시에 2개의 컴퓨터에서 자기 데이터를 실어 보내려고 하면 충돌이 발생하는데 이걸 collision이라고 하고 콜리전이 발생하면 이 pc는 자신이 보내려던 데이터를 랜덤하게 기다렸다가 다시 보낸다.
21 |
22 | 이로써 자신이 전송할 데이터가 있는데 토큰이 없어서 기다려야하는 상황은 더이상 발생하지 않는다.
23 |
24 |
--------------------------------------------------------------------------------
/Network/router.md:
--------------------------------------------------------------------------------
1 | # 라우터 Router
2 |
3 |
4 | 라우터는 OSI 7계층중 3계층에 속한 장비로 다른 네트워크에게 패킷을 전달하기위해 경로를 설정하고 데이터를 전달하는 역할을 한다.
5 |
6 | 라우터는 패킷을 보낼 때 목적지를 찾지 못하면 패킷을 드롭한다.
7 |
8 | 라우터는 목적지까지 한 번에 데이터를 보내기에는 경로를 탐색하는 과정이 너무 힘들기 때문에 근접한 라우터를 목적지로 지정하고 그 라우터에서 다시 경로를 탐색한다. 이 것을 **홉 바이 홉** 방식이라고 한다.
9 |
10 | 라우트할 목적지를 라우터는 테이블로 관리하고 있는데 이를 라우팅 테이블이라 하고 LPM 방식을 통해서 가장 가까운 목적지를 탐색한다. (롱기스트 프리픽스 매치)
11 |
12 | 라우터는 다음과 같은 3가지 기능을 한다.
13 |
14 | 1. 경로 지정: 다양한 경로 수집 후 최적의 경로에 패킷을 보낸다.
15 | 2. 브로드캐스트 컨트롤: 들어온 패킷의 목적지 주소가 라우팅 테이블에 없으면 패킷을 버린다.
16 | 3. 프로토콜 변환: 패킷 포워딩 과정에서 2계층의 헤더 정보를 제거 후 새롭게 만든다.
17 |
18 | ### 라우터의 경로 설정
19 |
20 | 라우터는 경로를 설정하는 방법이 3가지가 존재한다.
21 |
22 | #### 1. 다이렉트 커넥티드
23 |
24 | ip 주소를 입력하면 자연스럽게 인접 네트워크 정보를 얻는 방법이다.
25 |
26 | #### 2. 정적 라우팅
27 |
28 | 관리자가 직접 목적지 ip를 라우팅 테이블에 입력하는 방식이다.
29 |
30 | ### 3. 동적 라우팅
31 |
32 | 라우터 끼리 서로 경로 정보를 자동으로 교환하는 방법이다. 자신이 지금 패킷을 받을 수 있는 상태인지 아닌지에 대한 상태 교환으로 사용되기도한다.
33 |
34 |
35 |
36 | ### 브로드캐스트 컨트롤
37 |
38 | 라우터는 기본적으로 멀티캐스트로 정보를 습득하지 않고 브로드캐스트를 하지 않는다.
39 |
40 | 즉, 라우팅 테이블에 자신의 정보가 있어야만, 패킷을 보낼 수 있는 것이다.
41 |
42 | > 바로 연결되어 있는 네트워크는 정보가 없어도 보낼 수 있다.
43 |
44 | 이러한 기능을 `브로드캐스트/멀티캐스트 컨트롤`이라고 부른다.
45 |
46 |
47 |
48 |
49 | ### 프로토콜 변환
50 |
51 | 라우터의 또 다른 역할로 서로 다른 프로토콜로 구성된 네트워크를 연결하는 것이다. 근데 이 방법은 현재 대부분 네트워크가 이더넷을 사용하면서 줄어들었다. 예시로는 LAN, WAN이 있다.
52 |
53 | 라우터에 패킷이 들어오면 2계층까지의 헤더 정보를 벗기고 3계층 주소를 확인 후 2계층 헤더 정보를 새로 만들어서 외부로 보낸다.
54 |
55 |
--------------------------------------------------------------------------------
/Network/subn.md:
--------------------------------------------------------------------------------
1 | # Gateway, Subnet
2 |
3 | Local Network는 ARP 브로드 캐스트를 이용해서 MAC주소를 학습할 수 있고 이 MAC을 통해 직접 통신도 가능하다.
4 |
5 | 반면 Remote Network는 통신할 때 네트워크를 넘어 전달되지 못하는 브로드 캐스트의 성질 때문에 다른 네트워크 장비의 도움이 필요하다.
6 |
7 | 이 장비를 **Gateway**라고 하고 게이트웨이에 대한 정보를 pc, network 장비에게 설정하는 항목이 default gateway라는 옵션이다.
8 |
9 | 기본 게이트웨이는 3계층 장비가 수행하고 여러 네트워크와 연결되면서 적절한 경로를 지정해주는 역할을 한다.
10 |
11 | 출발지와 목적지 네트워크가 동일한 lan에서 통신하는 것인지 서로 다른 네트워크간의 통신하는 것인지 확인하기 위해서 출발지에서는 먼저 목적지가 자신이 속한 네트워크 범위인지를 체크해야한다. 이때 사용되는 범위 정보가 바로 **Subnet Mask**다.
12 | - 동일 네트워크 간의 통신과 다른 네트워크 간의 통신은 방식과 장비의 차이가 있다.
13 | - 로컬 통신은 ARP 요청으로 목적지를 찾아 통신할 수 있지만 원격 통신은 라우터를 넘어가지 못하는 브로드 캐스트를 위해 외부와 통신 가능한 장비의 도움이 필요하다.
14 | - **출발지와 목적지가 같은 네트워크인지를 확인하기 위해 사용되는 것이 서브넷 마스크다.** 즉 ip 주소의 네트워크 부분과 호스트 부분을 구분하기도 하며 식별할 수도 있는 것이다.
15 |
16 |
17 |
18 | ### Proxy ARP
19 |
20 | proxy arp는 arp를 대행해주는 기능으로 원격 통신은 기본 게이트웨이를 찾은 arp를 보내고 패킷을 기본 게이트웨이 쪽으로 보내야만 통신이 가능하다.
21 |
22 | 그러나 기본 게이트웨이에 프록시 arp가 활성화 되었다면 원격지라도 로컬에 arp 브로드 캐스트를 보낼 수가 있다.
23 | - 프록시 arp가 활성된 기본 게이트웨이(라우터)는 arp 브로드캐스트가 들어오면 자신이 대행 arp 응답을 해준다.
24 | - 이 경우, 패킷이 기본 게이트웨이 쪽으로 보내지므로 원격지 경로를 전달될 수 있다.
25 |
26 | proxy arp 기능은 라우터에 기본으로 활성화되어 있어, 사용자 몰래 동작하는 경우가 많다,
27 |
28 | 하지만 네트워크 설정 오류가 있거나 꼭 입력해야할 설정이 되어 있지 않아도 동작하는 경우가 있어 장애가 발생했을 때 쉽게 해결할 수 없게 만드는 **장애 요소**가 되기도 한다.
29 |
30 |
31 |
--------------------------------------------------------------------------------
/Operating-System/image/image-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Operating-System/image/image-1.png
--------------------------------------------------------------------------------
/Operating-System/image/image.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/Operating-System/image/image.png
--------------------------------------------------------------------------------
/Operating-System/swapping.md:
--------------------------------------------------------------------------------
1 | # OS에서의 스와핑 Swapping
2 |
3 | ## Swapping
4 | 프로세스가 실행되기 위해서는 프로세스의 명령어와 명령어가 접근하는 데이터가 메모리에 있어야 한다. 그러나 프로세스 또는 프로세스의 일부분은 실행 중에 임시로 백업 저장장치로 내보내졌다가 실행을 계속하기 위해 다시 메모리로 되돌아올 수 있다.
5 |
6 |
7 | 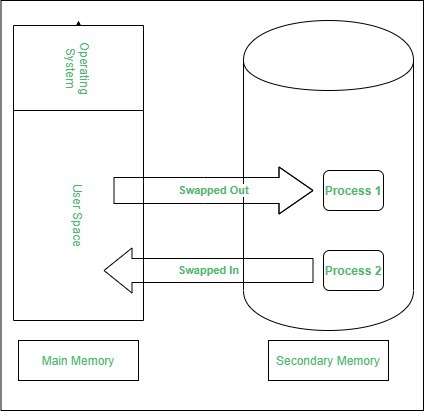
8 |
9 | Swapping을 통해서 물리 메모리의 제약을 덜 받을 수 있고 다중 프로그래밍 정도를 높일 수 있다. (degree of multiprogramming)
10 |
11 | - 메모리에서 나오는 것은 Swap out
12 | - 메모리로 들어가는 것은 Swap in
13 | 메모리 기준 in and out이다.
14 |
15 |
16 |
17 |
18 | ## 기본적인 스와핑
19 | 메인 메모리와 백업 저장장치 간에 전체 프로세스를 이동시킨다. (부분 스왑이 되는 경우도 있다.)
20 | 백업 저장장치는 저장 및 다시 접근해야하는 프로세스의 크기에 상관없이 수용할 수 있게 엄청 커야한다.
21 | 그리고 이러한 메모리 이미지에 직접 접근할 수 있어야 한다.
22 |
23 | 프로세스 또는 일부가 백업 저장장치로 스왑될 때 프로세스와 관련된 자료구조는 백업 저장장치에 기록되어야 한다.
24 |
25 | 표준 스와핑의 장점
26 | - 실제 물리 메모리보다 더 많은 프로세스를 수용할 수 있도록 물리 메모리가 초과 할당될 수 있다는 것이다.
27 | - 유휴 또는 대부분의 시간을 유휴 상태로 보내는 프로세스가 스와핑에 적합한 후보이다.
28 |
29 |
30 | ## 페이징에서 스와핑
31 | 사실 표준 스와핑은 현재 잘 사용하지 않는 경우가 태반이며
32 | 메모리와 저장장치 간에 프로세스 전체를 이동시키는 것이 힘들기 때문이다.
33 |
34 | 그래서 적은 수의 페이지만으로 이용하고는 한다.
35 |
36 | 
37 |
38 | ## 모바일 시스템에서 스와핑
39 | 모바일에서는 일반적으로 지원하지 않는다.
--------------------------------------------------------------------------------
/정보처리/Java.md:
--------------------------------------------------------------------------------
1 | # 객체지향
2 |
3 | ### 객체지향이란?
4 | - 우리가 실생활에서 쓰는 모든 것을 객체라 하며, 객체 지향 프로그래밍은
5 | 프로그램 구현에 필요한 객체를 파악하고 각각의 객체들의 역할이 무엇인지를 정의하여
6 | 객체들 간의 상호작용을 통해 프로그램을 만드는 것을 말한다
7 |
8 | ### 객체지향프로그래밍 언어의 구성요소
9 | 1. `클래스`
10 | > 같은 집단에 소속한 속성 행위를 정의 하는 것
11 |
12 | 2. `객체`
13 | > 클래스의 인스턴스로 자신 고유의 데이터를 가지며 클래스에서 정의한 행위를 수행 할 수 있다.
14 |
15 | 3. `메소드`
16 | > 클래스로 부터 생성된 객체를 사용하는 방법
17 |
18 | 4. `속성`
19 | >한 클래스내에 속한 객체들이 갖고있는 데이터값을 단위별로 정의 한 것
20 |
21 |
22 |
23 | ### 오버로딩이란 ?
24 | - 함수 이름은 같으나 매개변수, 숫자 타입을 다르게 사용
25 |
26 | ex )
27 | ```java
28 | class ExJava {
29 | int value = 0;
30 | int exov(int a){
31 | value = a;
32 | }
33 | int exov(int a , int b){
34 | value = a + b;
35 | }
36 | int exov(int a , int b , int c){
37 | value = a + b * c;
38 | }
39 | }
40 | ```
41 |
42 |
43 | ### 메소드 오버라이딩이란 ?
44 | - 슈퍼클래스로(하이클래스) 로부터 상속받은 메소드 재정의
45 |
46 |
47 |
48 |
49 |
50 | ### 접근 지정자
51 |
52 | 1. public : 모든 접근을 허용하는 접근자
53 | 2. protected : 자기 자신 클래스 및 상속받은 자식 클래스에서의 접근을 허용하는 접근자
54 | 3. private : 자기 자신 클래스 내부의 메소드만 접근을 허용하는 접근자
55 | 4. default : 같은 패키지에서는 모두 접근이 가능하지만 다른 패키지일때는 접근이 불가능한 접근자
56 |
57 |
58 |
59 | ###
60 |
61 |
--------------------------------------------------------------------------------
/정보처리/comrun.md:
--------------------------------------------------------------------------------
1 | # 런타임과 컴파일타임
2 |
3 | ### 런타임(Run time) 이란 ?
4 | - 컴파일 과정을 마친 응용 프로그램이 사용자에 의해서 실행되어 지는 때(time)를 의미한다.
5 |
6 | ### 런타임에러(Run time error)란?
7 | - 이미 컴파일이 완료되어 프로그램이 실행중임에도 불구하고, 의도치 않은 예외상황으로 인하여 프로그램 실행 중에 발생하는 오류 형태를 의미한다.
8 |
9 | ### 컴파일타임(Compile time) 이란?
10 | - 개발자에 의해 C , JAVA 등과 같은 개발 언어로 소스코드가 작성되며, 컴파일 과정을 통해 컴퓨터가 인식할 수 있는 기계어 코드로 변환되어 실행 가능한 프로그램이 되는 과정을 의미한다.
11 | - Template 프로그래밍을 모두 컴파일 타임에 결정 또는 실행된다.'
12 |
13 | ### 컴파일타임에러(Compile time error) 란?
14 | - 소스코드가 컴파일 되는 과정 중에 발생하는 Syntax error, 파일 참조 오류 등과 같은 문제들로 인해 컴파일이 방해되어 발생하는 오류들을 의미한다.
15 | - 컴파일에러 발생 시, 현재 문제가 되는 소스코드를 알려준다.
16 |
17 | **오류 유형**
18 | 런타임에러 | 컴파일타임 에러
19 | --|--
20 | 1, 0 나누기 오류 | 1. Syntax error
21 | 2, NULL 참조 오류 | 2. Type Check error
22 | 3, 메모리 부족 오류 |
--------------------------------------------------------------------------------
/정보처리/doker.md:
--------------------------------------------------------------------------------
1 | # 도커와 쿠버네티스
2 |
3 |
4 |
5 | ### Doker(도커)
6 |
7 | **컨테이너 기반의 오픈소스 가상화 플랫폼**
8 | - 하나의 큰 애플리케이션을 서비스 단위로 분할하여 빠른 배포 가능
9 | - 컨테이너끼리 서로에게 영향을 끼치지 않음
10 | - 도커는 기술적인 개념이자 도구이며 이미지를 컨테이너에 띄우고 실행하는 기술
11 | - 한 개의 컨테이너를 관리하는데 최적
12 |
13 | > `이미지 `: 컨테이너 실행에 필요한 파일과 설정값들을 포함하고 있는 것
14 | > `컨테이너` : 격리된 공간에서 프로세스가 동작하는 기술
15 |
16 |
17 |
18 | **가상 머신과 다른 점**
19 | 
20 |
21 | - `가상머신` : 서버 - Hypervisior 위에 VM들 올리기
22 | - `컨테이너` : 서버 - Hot Os - Doker Engine - Container 들 올리기
23 |
24 | **장점**
25 | 1. 필요한 자원만큼을 컨테이너에 할당하고 운영체제와 자원을 공유하므로 효율적이고 배포가 빠름
26 | 2. 또한 하나의 같은 서버에 다른 환경의 컨테이너를 설정할 수 있고 각각의 컨테이너는 독립돼있음!
27 |
28 |
29 |
30 |
31 | ### Kubernetes (쿠버네티스)
32 | **리눅스 컨테이너 작업을 자동화하는 오픈소스 플랫폼이며, 도커를 관리하는 오케스트레이션 툴**
33 | - 도커를 관리하는 툴
34 | - 도커를 기반으로 컨테이너를 관리하는 서비스
35 | - 여러 개의 컨테이너를 서비스 단위로 관리하는 데 최적화
36 |
37 | > 오케스트레이션 : 다수의 컨테이너 실행을 관리 및 조율하는 시스템 (스케쥴링 , 클러스터링, 서비스 디스커버리, 로드 밸런싱, 로깅 및 모니터링 등)
38 | 다른 오케스트레이션 툴 -도커 스웜, EC2, Nomad 등등
39 |
40 |
41 |
42 | ### 요약
43 | `도커` : 하나의 이미지를 컨테이너에 띄우고 실행하는 도구
44 | `쿠버네티스` : 도커를 기반으로 컨테이너를 관리하는 서비스
--------------------------------------------------------------------------------
/정보처리/image/doker.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/정보처리/image/doker.jpeg
--------------------------------------------------------------------------------
/정보처리/image/http-method.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/정보처리/image/http-method.png
--------------------------------------------------------------------------------
/정보처리/image/데드락.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/정보처리/image/데드락.png
--------------------------------------------------------------------------------
/정보처리/image/상태전이.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/정보처리/image/상태전이.png
--------------------------------------------------------------------------------
/정보처리/image/스케쥴링.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rlaope/estudy/565582d0d7aea7e8d3b881d7336c646cd9098273/정보처리/image/스케쥴링.png
--------------------------------------------------------------------------------
/정보처리/검토.md:
--------------------------------------------------------------------------------
1 | # 워크스루 , 인스팩션
2 |
3 | ### 워크스루
4 | - 개발 산출물을 `작성하는 중`에 산출물을 검토하고 결함을 찾아내는 기법
5 | - 주로 작성자의 요청에 의해 이루어지며, 중간 산출물을 대상으로 함
6 | - 후속작업에 대한 검사가 생각될 수 있음
7 | - 인스펙션에 비해 비형식적인 동료 검토 방법
8 |
9 |
10 |
11 | ### 인스펙션
12 | - 저자 외 다른 전문가가 검사하는 가장 공식적인 리뷰 기법
13 | - 문서화된 절차를 기반
14 | - 소프트웨어 명세를 만족하는지 검증
15 | - 코딩 전까지는 소요 인력의 2배 이상 필요하나 추후 인력 감소로 인해 결과적 품질 비용 감소, 개발 기간 단축
16 | - 인스펙션 구성원 중 경영자는 제외
--------------------------------------------------------------------------------
/정보처리/스레드.md:
--------------------------------------------------------------------------------
1 | # 스레드와 동시성
2 |
3 | ### 스레드
4 | - 어떠한 프로그램 내에서, 특시 프로세스 내에서 실행되는 흐름의 단위를 말한다.
5 | - 일반적으로 한 프로그램은 하나의 스레드를 가지고 있지만 ,프로그램 환경에따라 둘 이상의 스레드를 동시에 실행할 수 있다. 이러한 실행 방식을 멀티스레드라고 한다.
6 |
7 |
8 |
9 | ### 멀티 스레딩
10 | 멀티 스레드(multi thread)란 하나의 프로세스 내에서 둘 이상의 스레드가 동시에 작업을 수행하는 것을 의미한다. 멀티 스레드는 각 스레드가 자신이 속한 프로세스의 메모리를 공유한다.
11 |
12 |
13 |
14 | ### 멀티 스레드에서 동시성과 병렬성
15 | 동시성은 싱글 코어에서 멀티 스레드를 동작시키기 위한 방식으로 멀티 태스킹을 위해 여러개의 스레드를 번갈아가면서 실행되는 성질을 말한다. 동시성을 이용한 싱글 코어의 멀티 태스킹은 각 스레드들이 병렬적으로 실행되는 것처럼 보이지만 사실은 번갈아가면서 조금씩 실행되고 있는 것이다.
16 |
17 | 병렬성은 멀티 코어에서 멀티 스레드를 동작시키는 방식으로, 한 개 이상의 스레드를 포함하는 각 코어들이 동시에 실행되는 성질을 말한다. 병렬성은 데이터 병렬성과 작업 병렬성으로 구분된다.
18 | > **데이터 병렬성**
19 | > 전체 데이터를 쪼개 서브 데이터들로 만든 뒤, 서브 데이터들을 병렬처리하여 작업을 빠르게 수행하는 것을 말한다. 자바 8에서 지원하는 병렬 스트림이 데이터 병렬성을 구현한 것이다. 서브 데이는 멀티 코어의 수만큼 쪼개어 각각의 데이터들을 분리된 스레드에서 병렬 처리한다.
20 |
21 | > **작업 병렬성**
22 | > 서로 다른 작업을 병렬 처리하는 것을 말한다. 대표적인 예는 웹 서버로, 각각의 브라우저에서 요청한 내용을 개별 스레드에서 병렬로 처리한다.
--------------------------------------------------------------------------------
/정보처리/응용SW2.md:
--------------------------------------------------------------------------------
1 | # 응용SW_2( 컴퓨터 시스템 일반 학습지 )
2 |
3 | ### 데이터베이스중 관계형 데이터베이스 특징
4 | - 레코드의 집합으로 테이블이 구성됨
5 | - 데이터분류, 정렬, 탐색속도가 빠르고 데이터의 무결성이 보장됨.
6 | - 기존스키마 수정이 어렵고 대량데이터 처리가 비효율적임.
7 |
8 | ### 데이터 모델링
9 | - 시스템으로 구성하기 위한 데이터의 집합을 도출한 후 각 집합을 구성하는 세부 속성과 식별자를 정의하고 각 데이터 집합 간의 관계를 정해진 표기법으로 시각화 하는 과정
10 |
11 |
12 |
13 | ### Q ) 다음은 고객 테이블이다
14 |
15 | 고객번호 | 고객이름 | 주민번호
16 | |------|---|---|
17 | |5 |김동동|050102-4******|
18 | |3 |정봉봉|051218-4******|
19 | |8 |서징징|050711-4******|
20 |
21 | - 신규 고객이 들어왔다. 고객번호는 7, 고객이름은 '서봉동', 주민번호는 '050206-4******'이다. insert문을 사용하여 고객 테이블에 데이터를 삽입하는 명령문을 작성하시오.
22 |
23 |
24 |
25 |
26 | `answer )`
27 | ```
28 | INSERT
29 | INTO 고객(고객번호, 고객이름, 주민번호)
30 | VALUSE(7 , '서봉동' , 050206-4******);
31 | ```
32 |
33 | ### Q2 ) 고객이름이 서씨인 고객번호를 검색하는 명령문을 작성 하시오 (단, 고객이름은 3글자로 명시한다.)
34 |
35 | `answer )`
36 | ```
37 | SELECT 고객번호
38 | FROM 고객
39 | WHERE 고객이름 LIKE ('서__');
40 | ```
41 |
42 |
--------------------------------------------------------------------------------