├── .gitignore
├── LICENSE
├── Readme.md
├── configs
└── stable_diffusion_models.txt
├── docs
└── images
│ ├── diffusion_magic setting.PNG
│ ├── diffusion_magic.PNG
│ ├── diffusion_magic_3_sdxl.png
│ ├── diffusion_magic_depth_image.PNG
│ ├── diffusion_magic_image_variations.PNG
│ ├── diffusion_magic_image_variations_sdxl.PNG
│ ├── diffusion_magic_inpainting.PNG
│ ├── diffusion_magic_instruct_to_pix.PNG
│ ├── diffusion_magic_windows.PNG
│ ├── diffusionmagic-illusion-diffusion-color-image.jpg
│ ├── diffusionmagic-illusion-diffusion-pattern.jpg
│ └── diffusionmagic-illusion-diffusion-text.jpg
├── environment.yml
├── install-mac.sh
├── install.bat
├── install.sh
├── requirements.txt
├── src
├── app.py
├── backend
│ ├── computing.py
│ ├── controlnet
│ │ ├── ControlContext.py
│ │ └── controls
│ │ │ ├── canny_control.py
│ │ │ ├── control_interface.py
│ │ │ ├── depth_control.py
│ │ │ ├── hed_control.py
│ │ │ ├── image_control_factory.py
│ │ │ ├── line_control.py
│ │ │ ├── normal_control.py
│ │ │ ├── pose_control.py
│ │ │ ├── scribble_control.py
│ │ │ └── seg_control.py
│ ├── generate.py
│ ├── image_ops.py
│ ├── imagesaver.py
│ ├── stablediffusion
│ │ ├── depth_to_image.py
│ │ ├── inpainting.py
│ │ ├── instructpix.py
│ │ ├── modelmeta.py
│ │ ├── models
│ │ │ ├── scheduler_types.py
│ │ │ └── setting.py
│ │ ├── scheduler_factory.py
│ │ ├── scheduler_mixin.py
│ │ ├── stable_diffusion_types.py
│ │ ├── stablediffusion.py
│ │ └── stablediffusionxl.py
│ ├── upscaler.py
│ └── wuerstchen
│ │ ├── models
│ │ └── setting.py
│ │ └── wuerstchen.py
├── constants.py
├── frontend
│ └── web
│ │ ├── controlnet
│ │ └── controlnet_image_ui.py
│ │ ├── css
│ │ └── style.css
│ │ ├── depth_to_image_ui.py
│ │ ├── image_inpainting_ui.py
│ │ ├── image_inpainting_xl_ui.py
│ │ ├── image_to_image_ui.py
│ │ ├── image_to_image_xl_ui.py
│ │ ├── image_variations_ui.py
│ │ ├── image_variations_xl_ui.py
│ │ ├── instruct_pix_to_pix_ui.py
│ │ ├── settings_ui.py
│ │ ├── text_to_image_ui.py
│ │ ├── text_to_image_wuerstchen_ui.py
│ │ ├── text_to_image_xl_ui.py
│ │ └── ui.py
├── hf_models.py
├── models
│ └── configs.py
├── settings.py
└── utils.py
├── start.bat
└── start.sh
/.gitignore:
--------------------------------------------------------------------------------
1 | env
2 | *.bak
3 | *.pyc
4 | __pycache__
5 | results
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2023 Rupesh Sreeraman
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/Readme.md:
--------------------------------------------------------------------------------
1 | ## DiffusionMagic
2 | DiffusionMagic is simple to use Stable Diffusion workflows using [diffusers](https://github.com/huggingface/diffusers).
3 | DiffusionMagic focused on the following areas:
4 | - Easy to use
5 | - Cross-platform (Windows/Linux/Mac)
6 | - Modular design, latest best optimizations for speed and memory
7 |
8 | 
9 |
10 | ## Segmind Stable Diffusion 1B (SSD-1B)
11 | The Segmind Stable Diffusion Model (SSD-1B) is a smaller version of the Stable Diffusion XL (SDXL) that is 50% smaller but maintains high-quality text-to-image generation. It offers a 60% speedup compared to SDXL.
12 |
13 | You can run SSD-1B on Google Colab
14 |
15 | [](https://colab.research.google.com/drive/1z-3upaBQCqBw-QNeFYdNsLxbNE_pw1Rx?usp=sharing)
16 |
17 | ## Stable diffusion XL Colab
18 | You can run StableDiffusion XL 1.0 on Google Colab
19 |
20 | [](https://colab.research.google.com/drive/1eEZ_O-Fw87hoEsfSxUnGZhdqvMFEO5iV?usp=sharing)
21 |
22 | ## Würstchen Colab
23 | You can run Würstchen 2.0 on Google Colab
24 |
25 | [](https://colab.research.google.com/drive/1ib6W1CeK9V533Nc9MnoBe3TmU7Uaghtg?usp=sharing)
26 |
27 |
28 | ## Illusion Diffusion Colab (beta)
29 | You can run Illusion Diffusion on Google Colab
30 |
31 | [](https://colab.research.google.com/drive/1M3igyVklKkUh1Pgzy68JWms2KQy2z7s7?usp=sharing)
32 |
33 | Illusion diffusion supports following types of input images as illusion control :
34 | - Color images
35 | - Text images
36 | - Patterns
37 |
38 | You need to adjust the illusion strength to get desired result.
39 |
40 | 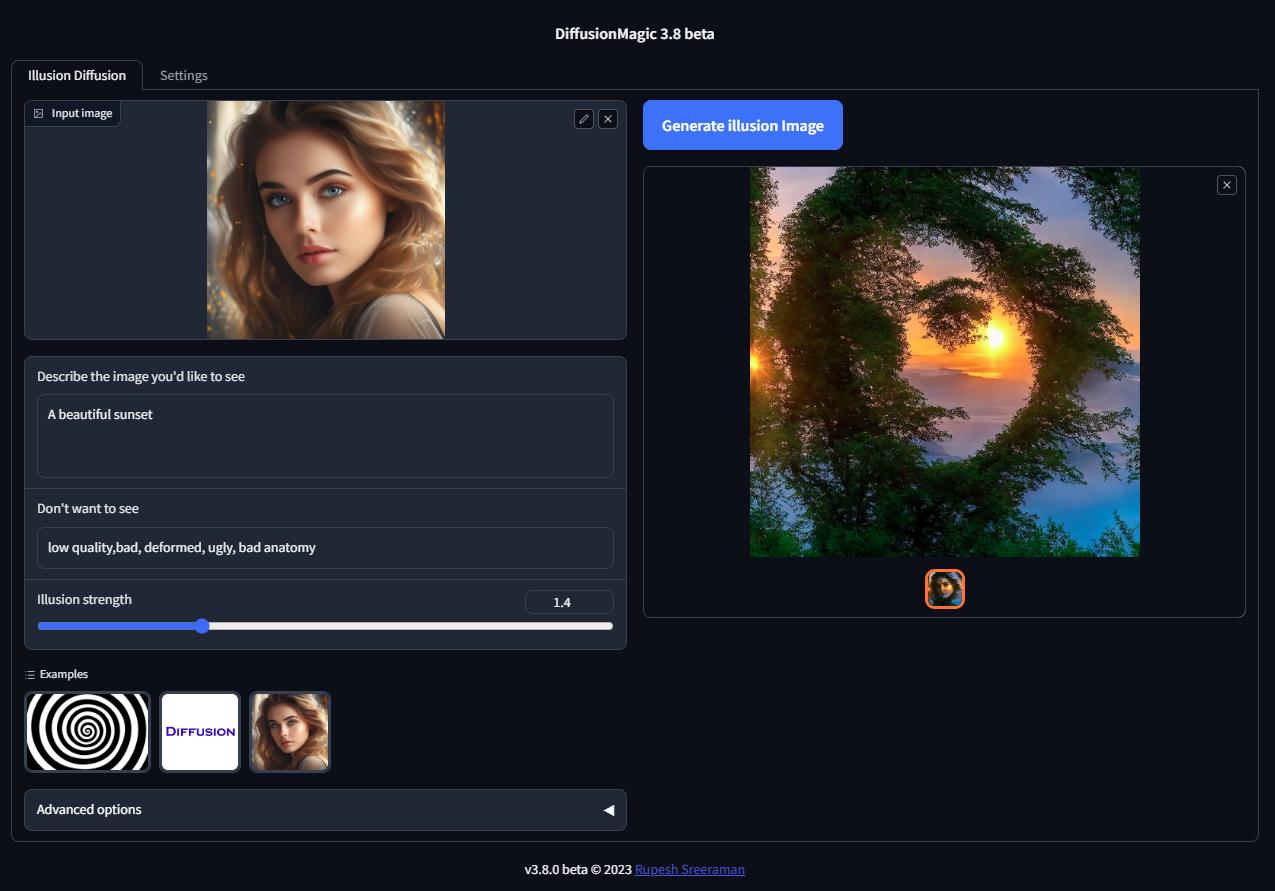
41 |
42 | 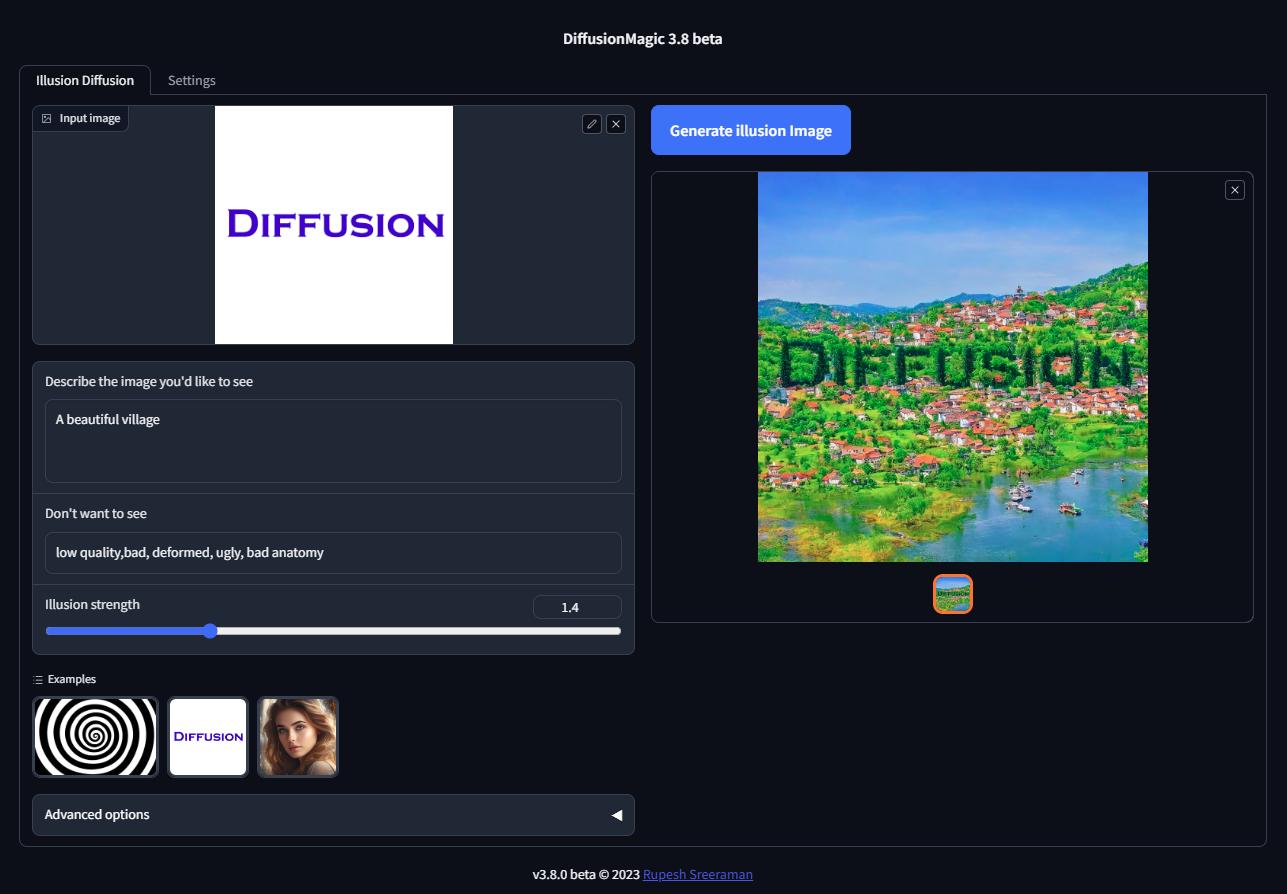
43 |
44 | 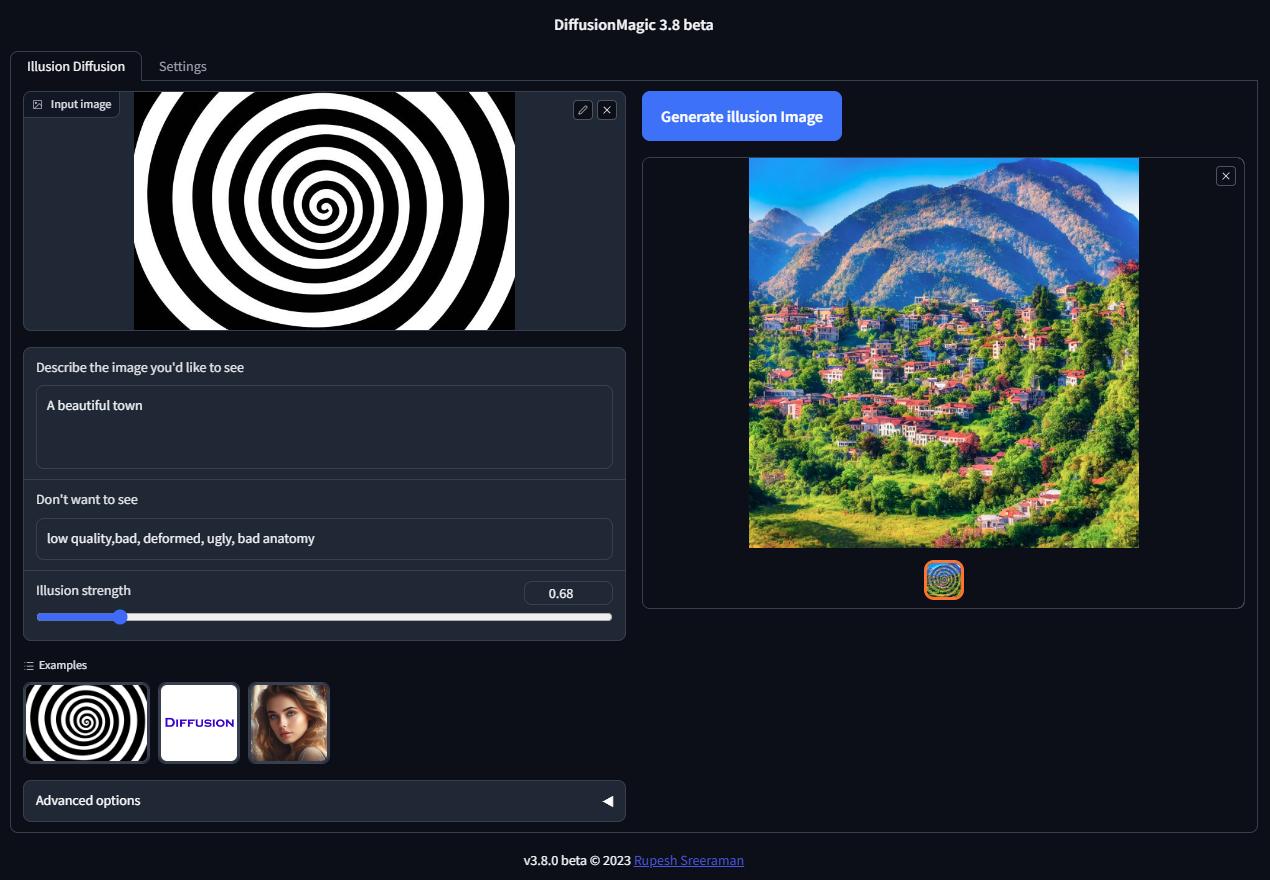
45 |
46 | ## Features
47 | - Supports Würstchen
48 | - Supports Stable diffusion XL
49 | - Supports various Stable Diffusion workflows
50 | - Text to Image
51 | - Image to Image
52 | - Image variations
53 | - Image Inpainting
54 | - Depth to Image
55 | - Instruction based image editing
56 | - Supports Controlnet workflows
57 | - Canny
58 | - MLSD (Line control)
59 | - Normal
60 | - HED
61 | - Pose
62 | - Depth
63 | - Scribble
64 | - Segmentation
65 | - Pytorch 2.0 support
66 | - Supports all stable diffusion Hugging Face models
67 | - Supports Stable diffusion v1 and v2 models, derived models
68 | - Works on Windows/Linux/Mac 64-bit
69 | - Works on CPU,GPU(Recent Nvidia GPU),Apple Silicon M1/M2 hardware
70 | - Supports DEIS scheduler for faster image generation (10 steps)
71 | - Supports 7 different samplers with latest DEIS sampler
72 | - LoRA(Low-Rank Adaptation of Large Language Models) models support (~3 MB size)
73 | - Easy to add new diffuser model by updating stable_diffusion_models.txt
74 | - Low VRAM mode supports GPU with RAM < 4 GB
75 | - Fast model loading
76 | - Supports Attention slicing and VAE slicing
77 | - Simple installation using install.bat/install.sh
78 |
79 | Please note that AMD GPUs are not supported.
80 | ## Screenshots
81 | ### Image variations
82 | 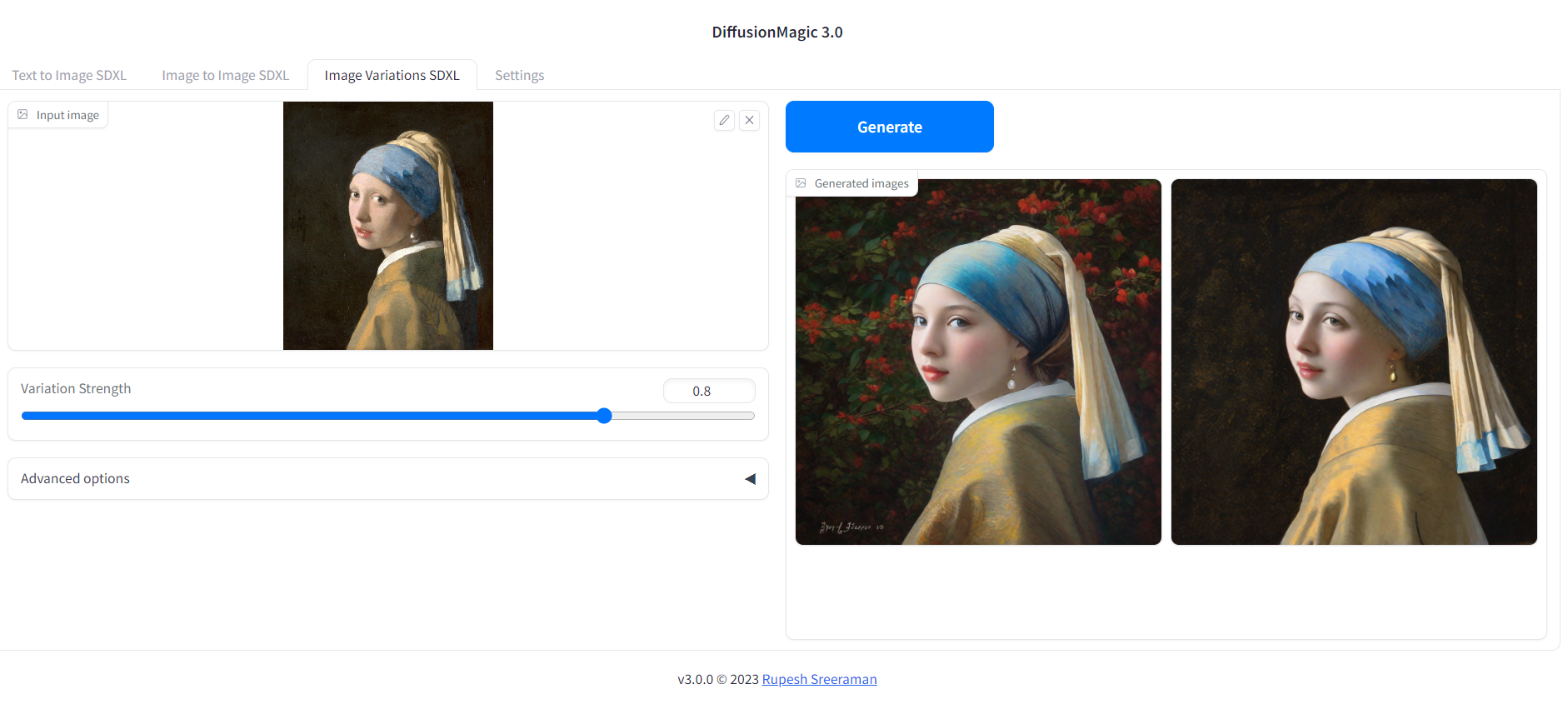
83 |
84 | ### Image Inpainting
85 | 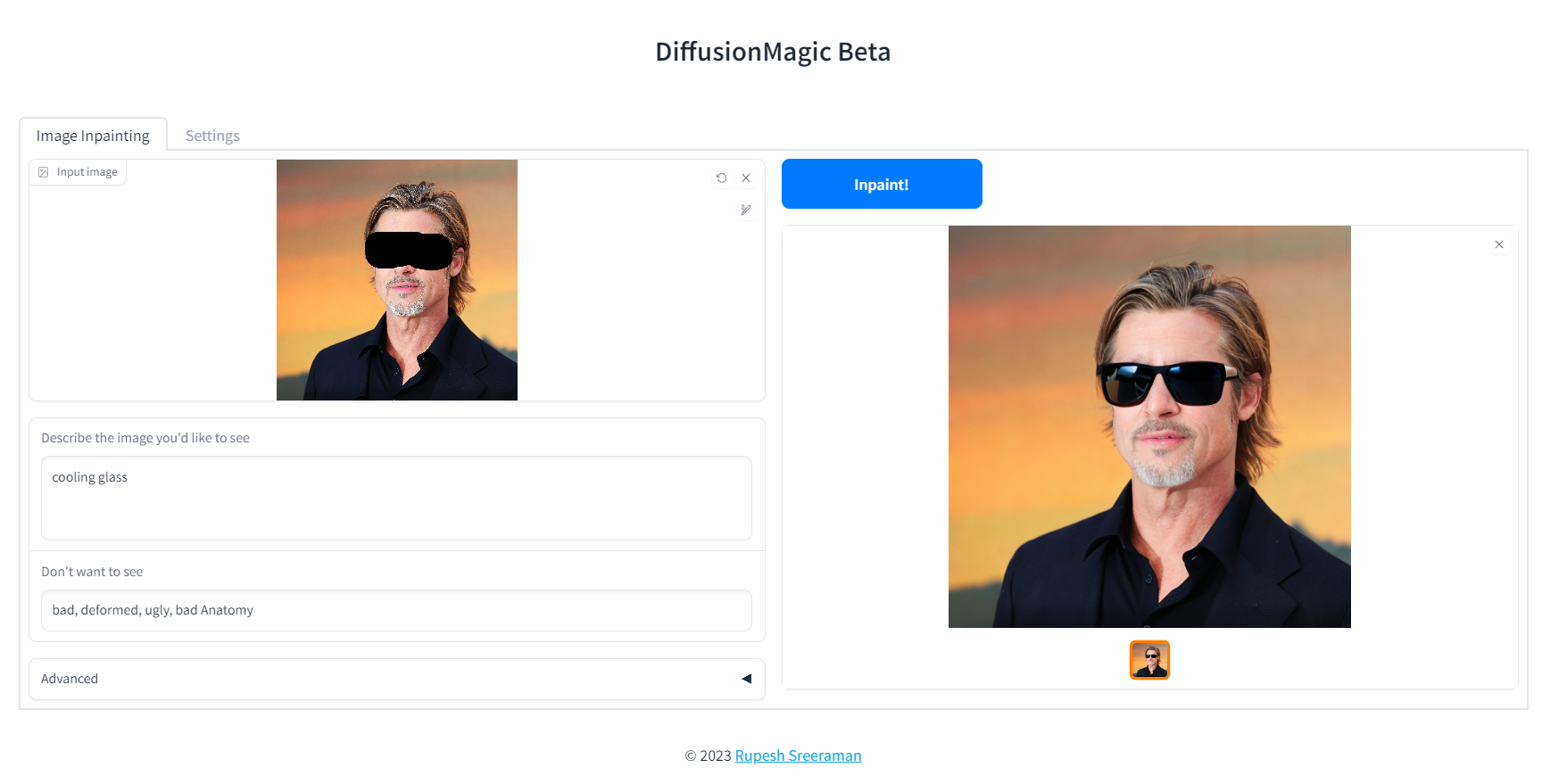
86 | ### Depth to Image
87 | 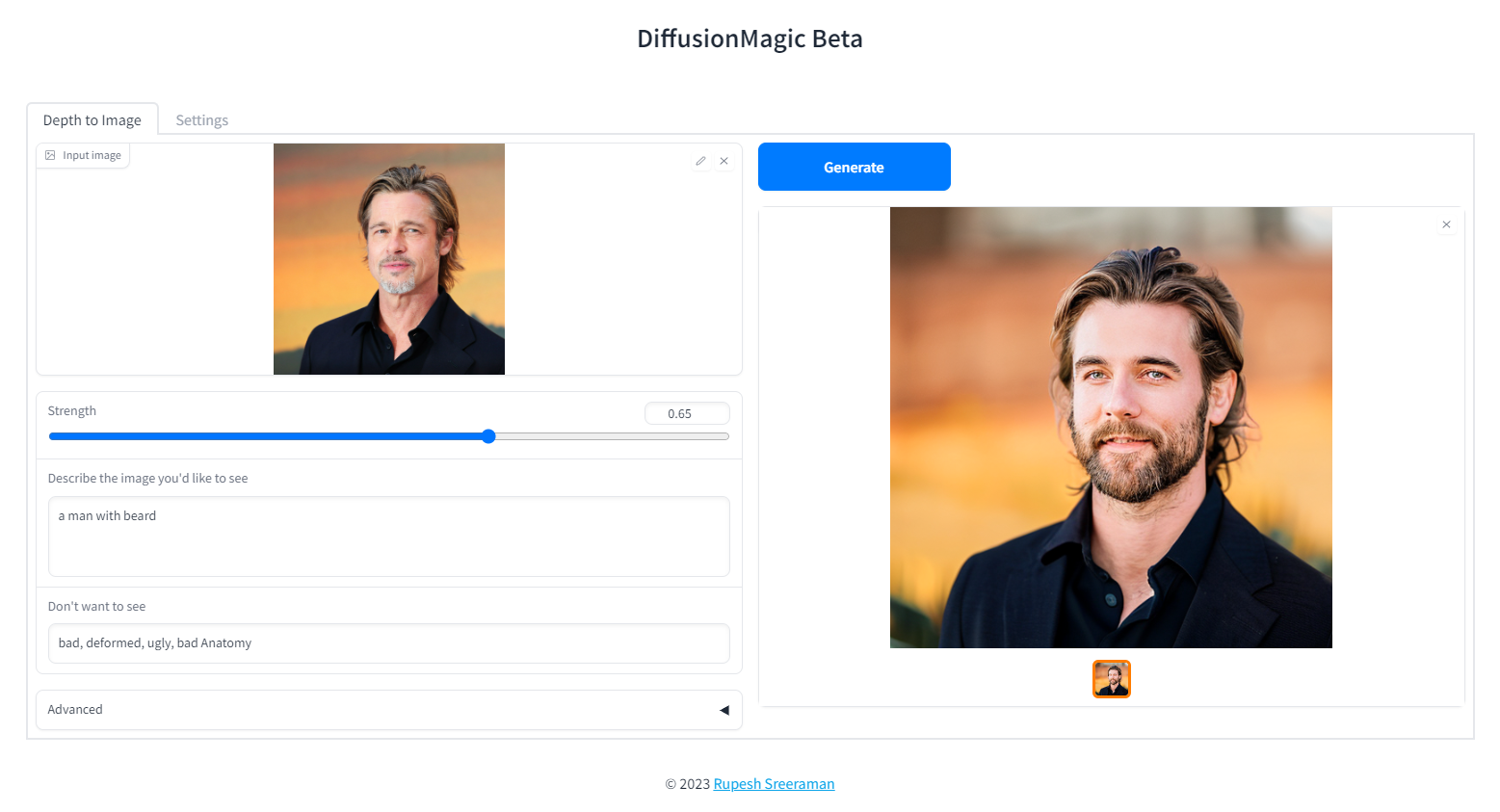
88 | ### Instruction based image editing
89 | 
91 | ## System Requirements:
92 | - Works on Windows/Linux/Mac 64-bit
93 | - Works on CPU,GPU,Apple Silicon M1/M2 hardware
94 | - 12 GB System RAM
95 | - ~11 GB disk space after installation (on SSD for best performance)
96 |
97 | ## Low VRAM mode < 4GB
98 | DiffusionMagic runs on low VRAM GPUs.
99 | [Here](https://nolowiz.com/easy-way-to-run-stable-diffusion-xl-on-low-vram-gpus/) is our guide to run StableDiffusion XL on low VRAM GPUs.
100 |
101 | ## Download Release
102 | Download release from the github DiffusionMagic [releases](https://github.com/rupeshs/diffusionmagic/releases/).
103 | ## How to install and run on Windows
104 | Follow the steps to install and run the Diffusion magic on Windows.
105 | - First we need to run(double click) the `install.bat` batch file it will install the necessary dependencies for DiffusionMagic.
106 | (It will take some time to install,depends on your internet speed)
107 | - Run the `install.bat` script.
108 | - To start DiffusionMagic double click `start.bat`
109 |
110 |
111 | 
112 | ## How to install and run on Linux
113 | Follow the steps to install and run the Diffusion magic on Linux.
114 |
115 | - Run the following command:
116 | `chmod +x install.sh`
117 | - Run the `install.sh` script.
118 | ` ./install.sh`
119 | - To start DiffusionMagic run:
120 | ` ./start.sh`
121 |
122 | ## How to install and run on Mac (Not tested)
123 | *Testers needed - If you have MacOS feel free to test and contribute*
124 |
125 | #### prerequisites
126 | - Mac computer with Apple silicon (M1/M2) hardware.
127 | - macOS 12.6 or later (13.0 or later recommended).
128 |
129 | Follow the steps to install and run the Diffusion magic on Mac (Apple Silicon M1/M2).
130 | - Run the following command:
131 | `chmod +x install-mac.sh`
132 | - Run the `install-mac.sh` script.
133 | `./install-mac.sh`
134 | - To start DiffusionMagic run:
135 | ` ./start.sh`
136 |
137 | Open the browser `http://localhost:7860/`
138 | ## Dark mode
139 | To get dark theme :
140 |
141 | `http://localhost:7860/?__theme=dark`
142 |
143 | ## How to switch models
144 | Diffusion magic will change UI based on the model selected.
145 | Follow the steps to switch the models() inpainting,depth to image or instruct pix to pix or any other hugging face stable diffusion model)
146 | - Start the Diffusion Magic app, open the settings tab and change the model
147 | 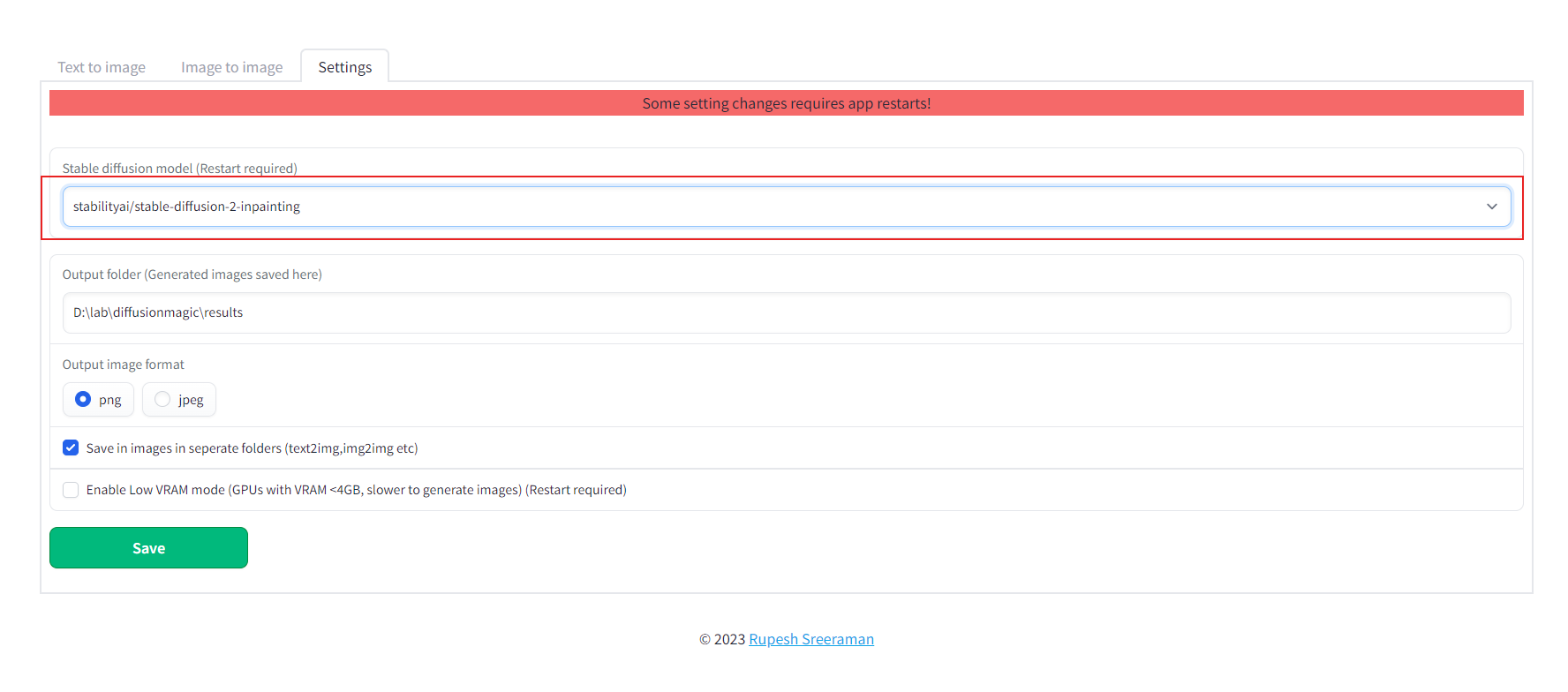
148 | - Save the settings
149 | - Close the app and start using start.bat/start.sh
150 | ## How to add new model
151 | We can add any Hugging Face stable diffusion model to DiffusionMagic by
152 | - Adding Hugging Face models id or local folder path to the configs/stable_diffusion_models.txt file
153 | E.g `https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0`
154 | Here model id is `dreamlike-art/dreamlike-diffusion-1.0`
155 | Or we can clone the model use the local folder path as model id.
156 | - Adding locally copied model path to configs/stable_diffusion_models.txt file
157 | ## Linting (Development)
158 | Run the following commands from src folder
159 |
160 | `mypy --ignore-missing-imports --explicit-package-bases .`
161 |
162 | `flake8 --max-line-length=100 .`
163 | ## Contribute
164 | Contributions are welcomed.
165 |
166 |
--------------------------------------------------------------------------------
/configs/stable_diffusion_models.txt:
--------------------------------------------------------------------------------
1 | stabilityai/stable-diffusion-2-1-base
2 | stabilityai/stable-diffusion-2-inpainting
3 | stabilityai/stable-diffusion-2-depth
4 | timbrooks/instruct-pix2pix
5 | runwayml/stable-diffusion-v1-5
6 | runwayml/stable-diffusion-inpainting
7 | CompVis/stable-diffusion-v1-4
8 | prompthero/openjourney-v2
9 | pcuenq/pokemon-lora
10 | sayakpaul/sd-model-finetuned-lora-t4
11 | prompthero/openjourney-v4
12 | lllyasviel/sd-controlnet-canny
13 | lllyasviel/sd-controlnet-mlsd
14 | lllyasviel/sd-controlnet-normal
15 | lllyasviel/sd-controlnet-hed
16 | lllyasviel/sd-controlnet-openpose
17 | lllyasviel/sd-controlnet-depth
18 | lllyasviel/sd-controlnet-scribble
19 | lllyasviel/sd-controlnet-seg
20 | stabilityai/stable-diffusion-xl-base-1.0
21 | warp-ai/wuerstchen
--------------------------------------------------------------------------------
/docs/images/diffusion_magic setting.PNG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rupeshs/diffusionmagic/4ce5c2c1bc7f3179832d58f2ca039b8f3b841795/docs/images/diffusion_magic setting.PNG
--------------------------------------------------------------------------------
/docs/images/diffusion_magic.PNG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rupeshs/diffusionmagic/4ce5c2c1bc7f3179832d58f2ca039b8f3b841795/docs/images/diffusion_magic.PNG
--------------------------------------------------------------------------------
/docs/images/diffusion_magic_3_sdxl.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rupeshs/diffusionmagic/4ce5c2c1bc7f3179832d58f2ca039b8f3b841795/docs/images/diffusion_magic_3_sdxl.png
--------------------------------------------------------------------------------
/docs/images/diffusion_magic_depth_image.PNG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rupeshs/diffusionmagic/4ce5c2c1bc7f3179832d58f2ca039b8f3b841795/docs/images/diffusion_magic_depth_image.PNG
--------------------------------------------------------------------------------
/docs/images/diffusion_magic_image_variations.PNG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rupeshs/diffusionmagic/4ce5c2c1bc7f3179832d58f2ca039b8f3b841795/docs/images/diffusion_magic_image_variations.PNG
--------------------------------------------------------------------------------
/docs/images/diffusion_magic_image_variations_sdxl.PNG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rupeshs/diffusionmagic/4ce5c2c1bc7f3179832d58f2ca039b8f3b841795/docs/images/diffusion_magic_image_variations_sdxl.PNG
--------------------------------------------------------------------------------
/docs/images/diffusion_magic_inpainting.PNG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rupeshs/diffusionmagic/4ce5c2c1bc7f3179832d58f2ca039b8f3b841795/docs/images/diffusion_magic_inpainting.PNG
--------------------------------------------------------------------------------
/docs/images/diffusion_magic_instruct_to_pix.PNG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rupeshs/diffusionmagic/4ce5c2c1bc7f3179832d58f2ca039b8f3b841795/docs/images/diffusion_magic_instruct_to_pix.PNG
--------------------------------------------------------------------------------
/docs/images/diffusion_magic_windows.PNG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rupeshs/diffusionmagic/4ce5c2c1bc7f3179832d58f2ca039b8f3b841795/docs/images/diffusion_magic_windows.PNG
--------------------------------------------------------------------------------
/docs/images/diffusionmagic-illusion-diffusion-color-image.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rupeshs/diffusionmagic/4ce5c2c1bc7f3179832d58f2ca039b8f3b841795/docs/images/diffusionmagic-illusion-diffusion-color-image.jpg
--------------------------------------------------------------------------------
/docs/images/diffusionmagic-illusion-diffusion-pattern.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rupeshs/diffusionmagic/4ce5c2c1bc7f3179832d58f2ca039b8f3b841795/docs/images/diffusionmagic-illusion-diffusion-pattern.jpg
--------------------------------------------------------------------------------
/docs/images/diffusionmagic-illusion-diffusion-text.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/rupeshs/diffusionmagic/4ce5c2c1bc7f3179832d58f2ca039b8f3b841795/docs/images/diffusionmagic-illusion-diffusion-text.jpg
--------------------------------------------------------------------------------
/environment.yml:
--------------------------------------------------------------------------------
1 | name: diffusionmagic-env
2 | channels:
3 | - conda-forge
4 | - pytorch
5 | - nvidia
6 | - defaults
7 | dependencies:
8 | - python=3.8.5
9 | - pip=23.2.1
10 | - pytorch-cuda=11.7
11 | - pytorch=2.0.1
12 | - torchvision=0.15.2
13 | - numpy=1.19.2
14 | - pip:
15 | - accelerate==0.23.0
16 | - diffusers==0.21.1
17 | - gradio==3.39.0
18 | - safetensors==0.3.1
19 | - scipy==1.10.0
20 | - transformers==4.33.2
21 | - pydantic==1.10.4
22 | - mypy==1.0.0
23 | - black==23.1.0
24 | - flake8==6.0.0
25 | - markupsafe==2.1.3
26 | - opencv-contrib-python==4.7.0.72
27 | - controlnet-aux==0.0.1
28 | - invisible-watermark==0.2.0
--------------------------------------------------------------------------------
/install-mac.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env bash
2 | echo Starting DiffusionMagic env installation...
3 | set -e
4 | PYTHON_COMMAND="python3"
5 |
6 | if ! command -v python3 &>/dev/null; then
7 | if ! command -v python &>/dev/null; then
8 | echo "Error: Python not found, please install python 3.8 or higher and try again"
9 | exit 1
10 | fi
11 | fi
12 |
13 | if command -v python &>/dev/null; then
14 | PYTHON_COMMAND="python"
15 | fi
16 |
17 | echo "Found $PYTHON_COMMAND command"
18 |
19 | python_version=$($PYTHON_COMMAND --version 2>&1 | awk '{print $2}')
20 | echo "Python version : $python_version"
21 |
22 | BASEDIR=$(pwd)
23 |
24 | $PYTHON_COMMAND -m venv "$BASEDIR/env"
25 | # shellcheck disable=SC1091
26 | source "$BASEDIR/env/bin/activate"
27 | pip install torch==2.0.1 torchvision==0.15.2
28 | pip install -r "$BASEDIR/requirements.txt"
29 | chmod +x "start.sh"
30 | read -n1 -r -p "DiffusionMagic installation completed,press any key to continue..." key
--------------------------------------------------------------------------------
/install.bat:
--------------------------------------------------------------------------------
1 |
2 | @echo off
3 | setlocal
4 | echo Starting DiffusionMagic env installation...
5 |
6 | set "PYTHON_COMMAND=python"
7 |
8 | call python --version > nul 2>&1
9 | if %errorlevel% equ 0 (
10 | echo Python command check :OK
11 | ) else (
12 | echo "Error: Python command not found,please install Python(Recommended : Python 3.10 or Python 3.11) and try again."
13 | pause
14 | exit /b 1
15 |
16 | )
17 |
18 | :check_python_version
19 | for /f "tokens=2" %%I in ('%PYTHON_COMMAND% --version 2^>^&1') do (
20 | set "python_version=%%I"
21 | )
22 |
23 | echo Python version: %python_version%
24 |
25 | %PYTHON_COMMAND% -m venv "%~dp0env"
26 | call "%~dp0env\Scripts\activate.bat" && pip install torch==2.0.1 torchvision==0.15.2 --index-url https://download.pytorch.org/whl/cu117
27 | call "%~dp0env\Scripts\activate.bat" && pip install -r "%~dp0requirements.txt"
28 | echo DiffusionMagic env installation completed.
29 | pause
--------------------------------------------------------------------------------
/install.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env bash
2 | echo Starting DiffusionMagic env installation...
3 | set -e
4 | PYTHON_COMMAND="python3"
5 |
6 | if ! command -v python3 &>/dev/null; then
7 | if ! command -v python &>/dev/null; then
8 | echo "Error: Python not found, please install python 3.8 or higher and try again"
9 | exit 1
10 | fi
11 | fi
12 |
13 | if command -v python &>/dev/null; then
14 | PYTHON_COMMAND="python"
15 | fi
16 |
17 | echo "Found $PYTHON_COMMAND command"
18 |
19 | python_version=$($PYTHON_COMMAND --version 2>&1 | awk '{print $2}')
20 | echo "Python version : $python_version"
21 |
22 | BASEDIR=$(pwd)
23 |
24 | $PYTHON_COMMAND -m venv "$BASEDIR/env"
25 | # shellcheck disable=SC1091
26 | source "$BASEDIR/env/bin/activate"
27 | pip install torch==2.0.1 torchvision==0.15.2 --index-url https://download.pytorch.org/whl/cu117
28 | pip install -r "$BASEDIR/requirements.txt"
29 | chmod +x "start.sh"
30 | read -n1 -r -p "DiffusionMagic installation completed,press any key to continue..." key
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | accelerate==0.23.0
2 | diffusers==0.21.1
3 | gradio==3.39.0
4 | safetensors==0.3.1
5 | scipy==1.10.0
6 | transformers==4.33.2
7 | pydantic==1.10.4
8 | mypy==1.0.0
9 | black==23.1.0
10 | flake8==6.0.0
11 | markupsafe==2.1.3
12 | opencv-contrib-python==4.7.0.72
13 | controlnet-aux==0.0.1
14 | invisible-watermark==0.2.0
--------------------------------------------------------------------------------
/src/app.py:
--------------------------------------------------------------------------------
1 | import argparse
2 |
3 | from backend.computing import Computing
4 | from backend.generate import Generate
5 | from frontend.web.ui import diffusionmagic_web_ui
6 | from settings import AppSettings
7 |
8 |
9 | def _get_model(model_id: str) -> str:
10 | if model_id == "":
11 | model_id = AppSettings().get_settings().model_settings.model_id
12 | return model_id
13 |
14 |
15 | if __name__ == "__main__":
16 | try:
17 | app_settings = AppSettings()
18 | app_settings.load()
19 | except Exception as ex:
20 | print(f"ERROR in loading application settings {ex}")
21 | print("Exiting...")
22 | exit()
23 | parser = argparse.ArgumentParser(description="DiffusionMagic")
24 | parser.add_argument(
25 | "-s", "--share", help="Shareable link", action="store_true", default=False
26 | )
27 | parser.add_argument(
28 | "-m",
29 | "--model",
30 | help="Model identifier,E.g. runwayml/stable-diffusion-v1-5",
31 | default="",
32 | )
33 | args = parser.parse_args()
34 | compute = Computing()
35 | model_id = _get_model(args.model)
36 |
37 | print(f"Model : {model_id}")
38 |
39 | generate = Generate(
40 | compute,
41 | model_id,
42 | )
43 |
44 | dm_web_ui = diffusionmagic_web_ui(
45 | generate,
46 | model_id,
47 | )
48 | if args.share:
49 | dm_web_ui.queue().launch(share=True)
50 | else:
51 | dm_web_ui.queue().launch()
52 |
--------------------------------------------------------------------------------
/src/backend/computing.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 |
4 | class Computing:
5 | __instance = None
6 | __fetch = True
7 |
8 | def __new__(cls):
9 | if Computing.__instance is None:
10 | Computing.__instance = super().__new__(cls)
11 | return Computing.__instance
12 |
13 | def __init__(self):
14 | if Computing.__fetch:
15 | self._device = self._detect_processor()
16 | self._torch_datatype = (
17 | torch.float32 if self._device == "cpu" or self._device == "mps" else torch.float16
18 | )
19 | Computing.__fetch = False
20 |
21 | @property
22 | def name(self):
23 | """Returns the device name CPU/CUDA/MPS"""
24 | return self._device
25 |
26 | @property
27 | def datatype(self):
28 | """Returns the optimal data type for interference"""
29 | return self._torch_datatype
30 |
31 | def _detect_processor(self) -> str:
32 | if torch.cuda.is_available():
33 | current_device_index = torch.cuda.current_device()
34 | gpu_name = torch.cuda.get_device_name(current_device_index)
35 | print(f"DEVICE: {gpu_name} ")
36 | return "cuda"
37 | elif hasattr(torch.backends, "mps") and torch.backends.mps.is_available():
38 | # Apple silicon (M1/M2) hardware
39 | print("DEVICE: MPS backend")
40 | return "mps"
41 | else:
42 | print("DEVICE: GPU not found,using CPU")
43 | return "cpu"
44 |
--------------------------------------------------------------------------------
/src/backend/controlnet/ControlContext.py:
--------------------------------------------------------------------------------
1 | from time import time
2 |
3 | import torch
4 | from diffusers import ControlNetModel, StableDiffusionControlNetPipeline
5 | from PIL import ImageOps
6 |
7 | from backend.computing import Computing
8 | from backend.controlnet.controls.image_control_factory import ImageControlFactory
9 | from backend.image_ops import resize_pil_image
10 | from backend.stablediffusion.models.scheduler_types import SchedulerType
11 | from backend.stablediffusion.models.setting import StableDiffusionControlnetSetting
12 | from backend.stablediffusion.scheduler_mixin import SamplerMixin
13 | from backend.stablediffusion.stable_diffusion_types import (
14 | StableDiffusionType,
15 | get_diffusion_type,
16 | )
17 |
18 |
19 | class ControlnetContext(SamplerMixin):
20 | def __init__(self, compute: Computing):
21 | self.compute = compute
22 | self.device = self.compute.name
23 | super().__init__()
24 |
25 | def init_control_to_image_pipleline(
26 | self,
27 | model_id: str = "lllyasviel/sd-controlnet-canny",
28 | stable_diffusion_model="runwayml/stable-diffusion-v1-5",
29 | low_vram_mode: bool = False,
30 | sampler: str = SchedulerType.UniPCMultistepScheduler.value,
31 | ):
32 | self.low_vram_mode = low_vram_mode
33 | self.controlnet_type = get_diffusion_type(model_id)
34 | image_control_factory = ImageControlFactory()
35 | self.image_control = image_control_factory.create_control(self.controlnet_type)
36 | print(f"StableDiffusion - {self.compute.name},{self.compute.datatype}")
37 | print(f"Controlnet - { self.controlnet_type }")
38 | print(f"Using ControlNet Model {model_id}")
39 | print(f"Using Stable diffusion Model {stable_diffusion_model}")
40 | self.control_net_model_id = model_id
41 | self.model_id = stable_diffusion_model
42 | self.default_sampler = self.find_sampler(
43 | sampler,
44 | self.model_id,
45 | )
46 |
47 | tic = time()
48 | self._load_model()
49 | delta = time() - tic
50 | print(f"Model loaded in {delta:.2f}s ")
51 | self._pipeline_to_device()
52 |
53 | def control_to_image(
54 | self,
55 | setting: StableDiffusionControlnetSetting,
56 | ):
57 | if setting.scheduler is None:
58 | raise Exception("Scheduler cannot be empty")
59 | print("Running controlnet image pipeline")
60 | self.controlnet_pipeline.scheduler = self.find_sampler(
61 | setting.scheduler,
62 | self.model_id,
63 | )
64 | generator = None
65 | if setting.seed != -1 and setting.seed:
66 | print(f"Using seed {setting.seed}")
67 | generator = torch.Generator(self.device).manual_seed(setting.seed)
68 |
69 | self._enable_slicing(setting)
70 | base_image = resize_pil_image(
71 | setting.image, setting.image_width, setting.image_height
72 | )
73 | control_img = self.image_control.get_control_image(base_image)
74 |
75 | images = self.controlnet_pipeline(
76 | prompt=setting.prompt,
77 | image=control_img,
78 | guidance_scale=setting.guidance_scale,
79 | num_inference_steps=setting.inference_steps,
80 | negative_prompt=setting.negative_prompt,
81 | num_images_per_prompt=setting.number_of_images,
82 | generator=generator,
83 | ).images
84 | if (
85 | self.controlnet_type == StableDiffusionType.controlnet_canny
86 | or self.controlnet_type == StableDiffusionType.controlnet_line
87 | ):
88 | inverted_image = ImageOps.invert(control_img)
89 | images.append(inverted_image)
90 | else:
91 | images.append(control_img)
92 |
93 | return images
94 |
95 | def _pipeline_to_device(self):
96 | if self.low_vram_mode:
97 | print("Running in low VRAM mode,slower to generate images")
98 | self.controlnet_pipeline.enable_sequential_cpu_offload()
99 | else:
100 | self.controlnet_pipeline.enable_model_cpu_offload()
101 |
102 | def _load_full_precision_model(self):
103 | self.controlnet = ControlNetModel.from_pretrained(self.control_net_model_id)
104 | self.controlnet_pipeline = StableDiffusionControlNetPipeline.from_pretrained(
105 | self.model_id,
106 | controlnet=self.controlnet,
107 | )
108 |
109 | def _load_model(self):
110 | print("Loading model...")
111 | if self.compute.name == "cuda":
112 | try:
113 | self.controlnet = ControlNetModel.from_pretrained(
114 | self.control_net_model_id,
115 | torch_dtype=torch.float16,
116 | )
117 | self.controlnet_pipeline = (
118 | StableDiffusionControlNetPipeline.from_pretrained(
119 | self.model_id,
120 | controlnet=self.controlnet,
121 | torch_dtype=torch.float16,
122 | revision="fp16",
123 | )
124 | )
125 | except Exception as ex:
126 | print(
127 | f" The fp16 of the model not found using full precision model, {ex}"
128 | )
129 | self._load_full_precision_model()
130 | else:
131 | self._load_full_precision_model()
132 |
133 | def _enable_slicing(self, setting: StableDiffusionControlnetSetting):
134 | if setting.attention_slicing:
135 | self.controlnet_pipeline.enable_attention_slicing()
136 | else:
137 | self.controlnet_pipeline.disable_attention_slicing()
138 |
139 | if setting.vae_slicing:
140 | self.controlnet_pipeline.enable_vae_slicing()
141 | else:
142 | self.controlnet_pipeline.disable_vae_slicing()
143 |
--------------------------------------------------------------------------------
/src/backend/controlnet/controls/canny_control.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from cv2 import Canny
3 | from PIL import Image
4 |
5 | from backend.controlnet.controls.control_interface import ControlInterface
6 |
7 |
8 | class CannyControl(ControlInterface):
9 | def get_control_image(self, image: Image) -> Image:
10 | low_threshold = 100
11 | high_threshold = 200
12 | image = np.array(image)
13 | image = Canny(image, low_threshold, high_threshold)
14 | image = image[:, :, None]
15 | image = np.concatenate([image, image, image], axis=2)
16 | return Image.fromarray(image)
17 |
--------------------------------------------------------------------------------
/src/backend/controlnet/controls/control_interface.py:
--------------------------------------------------------------------------------
1 | from abc import ABC, abstractmethod
2 |
3 | from PIL import Image
4 |
5 |
6 | class ControlInterface(ABC):
7 | @abstractmethod
8 | def get_control_image(
9 | self,
10 | image: Image,
11 | ) -> Image:
12 | pass
13 |
--------------------------------------------------------------------------------
/src/backend/controlnet/controls/depth_control.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from PIL import Image
3 | from transformers import pipeline
4 |
5 | from backend.controlnet.controls.control_interface import ControlInterface
6 |
7 |
8 | class DepthControl(ControlInterface):
9 | def get_control_image(self, image: Image) -> Image:
10 | depth_estimator = pipeline("depth-estimation")
11 | image = depth_estimator(image)["depth"]
12 | image = np.array(image)
13 | image = image[:, :, None]
14 | image = np.concatenate([image, image, image], axis=2)
15 | image = Image.fromarray(image)
16 | return image
17 |
--------------------------------------------------------------------------------
/src/backend/controlnet/controls/hed_control.py:
--------------------------------------------------------------------------------
1 | from PIL import Image
2 |
3 | from backend.controlnet.controls.control_interface import ControlInterface
4 | from controlnet_aux import HEDdetector
5 |
6 |
7 | class HedControl(ControlInterface):
8 | def get_control_image(self, image: Image) -> Image:
9 | hed = HEDdetector.from_pretrained("lllyasviel/ControlNet")
10 | image = hed(image)
11 | return image
12 |
--------------------------------------------------------------------------------
/src/backend/controlnet/controls/image_control_factory.py:
--------------------------------------------------------------------------------
1 | from backend.controlnet.controls.canny_control import CannyControl
2 | from backend.controlnet.controls.depth_control import DepthControl
3 | from backend.controlnet.controls.hed_control import HedControl
4 | from backend.controlnet.controls.line_control import LineControl
5 | from backend.controlnet.controls.normal_control import NormalControl
6 | from backend.controlnet.controls.pose_control import PoseControl
7 | from backend.controlnet.controls.scribble_control import ScribbleControl
8 | from backend.controlnet.controls.seg_control import SegControl
9 | from backend.stablediffusion.stable_diffusion_types import StableDiffusionType
10 |
11 |
12 | class ImageControlFactory:
13 | def create_control(self, controlnet_type: StableDiffusionType):
14 | if controlnet_type == StableDiffusionType.controlnet_canny:
15 | return CannyControl()
16 | elif controlnet_type == StableDiffusionType.controlnet_line:
17 | return LineControl()
18 | elif controlnet_type == StableDiffusionType.controlnet_normal:
19 | return NormalControl()
20 | elif controlnet_type == StableDiffusionType.controlnet_hed:
21 | return HedControl()
22 | elif controlnet_type == StableDiffusionType.controlnet_pose:
23 | return PoseControl()
24 | elif controlnet_type == StableDiffusionType.controlnet_depth:
25 | return DepthControl()
26 | elif controlnet_type == StableDiffusionType.controlnet_scribble:
27 | return ScribbleControl()
28 | elif controlnet_type == StableDiffusionType.controlnet_seg:
29 | return SegControl()
30 | else:
31 | print("Error: Control type not implemented!")
32 | raise Exception("Error: Control type not implemented!")
33 |
--------------------------------------------------------------------------------
/src/backend/controlnet/controls/line_control.py:
--------------------------------------------------------------------------------
1 | from PIL import Image
2 |
3 | from backend.controlnet.controls.control_interface import ControlInterface
4 | from controlnet_aux import MLSDdetector
5 |
6 |
7 | class LineControl(ControlInterface):
8 | def get_control_image(self, image: Image) -> Image:
9 | mlsd = MLSDdetector.from_pretrained("lllyasviel/ControlNet")
10 | image = mlsd(image)
11 | return image
12 |
--------------------------------------------------------------------------------
/src/backend/controlnet/controls/normal_control.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import numpy as np
3 | from PIL import Image
4 | from transformers import pipeline
5 |
6 | from backend.controlnet.controls.control_interface import ControlInterface
7 |
8 |
9 | class NormalControl(ControlInterface):
10 | def get_control_image(self, image: Image) -> Image:
11 | depth_estimator = pipeline("depth-estimation", model="Intel/dpt-hybrid-midas")
12 | image = depth_estimator(image)["predicted_depth"][0]
13 | image = image.numpy()
14 |
15 | image_depth = image.copy()
16 | image_depth -= np.min(image_depth)
17 | image_depth /= np.max(image_depth)
18 |
19 | bg_threhold = 0.4
20 |
21 | x = cv2.Sobel(image, cv2.CV_32F, 1, 0, ksize=3) # type: ignore
22 | x[image_depth < bg_threhold] = 0
23 |
24 | y = cv2.Sobel(image, cv2.CV_32F, 0, 1, ksize=3) # type: ignore
25 | y[image_depth < bg_threhold] = 0
26 |
27 | z = np.ones_like(x) * np.pi * 2.0
28 |
29 | image = np.stack([x, y, z], axis=2)
30 | image /= np.sum(image**2.0, axis=2, keepdims=True) ** 0.5
31 | image = (image * 127.5 + 127.5).clip(0, 255).astype(np.uint8)
32 | image = Image.fromarray(image)
33 | return image
34 |
--------------------------------------------------------------------------------
/src/backend/controlnet/controls/pose_control.py:
--------------------------------------------------------------------------------
1 | from controlnet_aux import OpenposeDetector
2 | from PIL import Image
3 |
4 | from backend.controlnet.controls.control_interface import ControlInterface
5 |
6 |
7 | class PoseControl(ControlInterface):
8 | def get_control_image(self, image: Image) -> Image:
9 | openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
10 | image = openpose(image)
11 | return image
12 |
--------------------------------------------------------------------------------
/src/backend/controlnet/controls/scribble_control.py:
--------------------------------------------------------------------------------
1 | from PIL import Image
2 |
3 | from backend.controlnet.controls.control_interface import ControlInterface
4 | from controlnet_aux import HEDdetector
5 |
6 |
7 | class ScribbleControl(ControlInterface):
8 | def get_control_image(self, image: Image) -> Image:
9 | hed = HEDdetector.from_pretrained("lllyasviel/ControlNet")
10 | image = hed(image, scribble=True)
11 | return image
12 |
--------------------------------------------------------------------------------
/src/backend/controlnet/controls/seg_control.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | from PIL import Image
4 | from transformers import AutoImageProcessor, UperNetForSemanticSegmentation
5 |
6 | from backend.controlnet.controls.control_interface import ControlInterface
7 |
8 | palette = np.asarray(
9 | [
10 | [0, 0, 0],
11 | [120, 120, 120],
12 | [180, 120, 120],
13 | [6, 230, 230],
14 | [80, 50, 50],
15 | [4, 200, 3],
16 | [120, 120, 80],
17 | [140, 140, 140],
18 | [204, 5, 255],
19 | [230, 230, 230],
20 | [4, 250, 7],
21 | [224, 5, 255],
22 | [235, 255, 7],
23 | [150, 5, 61],
24 | [120, 120, 70],
25 | [8, 255, 51],
26 | [255, 6, 82],
27 | [143, 255, 140],
28 | [204, 255, 4],
29 | [255, 51, 7],
30 | [204, 70, 3],
31 | [0, 102, 200],
32 | [61, 230, 250],
33 | [255, 6, 51],
34 | [11, 102, 255],
35 | [255, 7, 71],
36 | [255, 9, 224],
37 | [9, 7, 230],
38 | [220, 220, 220],
39 | [255, 9, 92],
40 | [112, 9, 255],
41 | [8, 255, 214],
42 | [7, 255, 224],
43 | [255, 184, 6],
44 | [10, 255, 71],
45 | [255, 41, 10],
46 | [7, 255, 255],
47 | [224, 255, 8],
48 | [102, 8, 255],
49 | [255, 61, 6],
50 | [255, 194, 7],
51 | [255, 122, 8],
52 | [0, 255, 20],
53 | [255, 8, 41],
54 | [255, 5, 153],
55 | [6, 51, 255],
56 | [235, 12, 255],
57 | [160, 150, 20],
58 | [0, 163, 255],
59 | [140, 140, 140],
60 | [250, 10, 15],
61 | [20, 255, 0],
62 | [31, 255, 0],
63 | [255, 31, 0],
64 | [255, 224, 0],
65 | [153, 255, 0],
66 | [0, 0, 255],
67 | [255, 71, 0],
68 | [0, 235, 255],
69 | [0, 173, 255],
70 | [31, 0, 255],
71 | [11, 200, 200],
72 | [255, 82, 0],
73 | [0, 255, 245],
74 | [0, 61, 255],
75 | [0, 255, 112],
76 | [0, 255, 133],
77 | [255, 0, 0],
78 | [255, 163, 0],
79 | [255, 102, 0],
80 | [194, 255, 0],
81 | [0, 143, 255],
82 | [51, 255, 0],
83 | [0, 82, 255],
84 | [0, 255, 41],
85 | [0, 255, 173],
86 | [10, 0, 255],
87 | [173, 255, 0],
88 | [0, 255, 153],
89 | [255, 92, 0],
90 | [255, 0, 255],
91 | [255, 0, 245],
92 | [255, 0, 102],
93 | [255, 173, 0],
94 | [255, 0, 20],
95 | [255, 184, 184],
96 | [0, 31, 255],
97 | [0, 255, 61],
98 | [0, 71, 255],
99 | [255, 0, 204],
100 | [0, 255, 194],
101 | [0, 255, 82],
102 | [0, 10, 255],
103 | [0, 112, 255],
104 | [51, 0, 255],
105 | [0, 194, 255],
106 | [0, 122, 255],
107 | [0, 255, 163],
108 | [255, 153, 0],
109 | [0, 255, 10],
110 | [255, 112, 0],
111 | [143, 255, 0],
112 | [82, 0, 255],
113 | [163, 255, 0],
114 | [255, 235, 0],
115 | [8, 184, 170],
116 | [133, 0, 255],
117 | [0, 255, 92],
118 | [184, 0, 255],
119 | [255, 0, 31],
120 | [0, 184, 255],
121 | [0, 214, 255],
122 | [255, 0, 112],
123 | [92, 255, 0],
124 | [0, 224, 255],
125 | [112, 224, 255],
126 | [70, 184, 160],
127 | [163, 0, 255],
128 | [153, 0, 255],
129 | [71, 255, 0],
130 | [255, 0, 163],
131 | [255, 204, 0],
132 | [255, 0, 143],
133 | [0, 255, 235],
134 | [133, 255, 0],
135 | [255, 0, 235],
136 | [245, 0, 255],
137 | [255, 0, 122],
138 | [255, 245, 0],
139 | [10, 190, 212],
140 | [214, 255, 0],
141 | [0, 204, 255],
142 | [20, 0, 255],
143 | [255, 255, 0],
144 | [0, 153, 255],
145 | [0, 41, 255],
146 | [0, 255, 204],
147 | [41, 0, 255],
148 | [41, 255, 0],
149 | [173, 0, 255],
150 | [0, 245, 255],
151 | [71, 0, 255],
152 | [122, 0, 255],
153 | [0, 255, 184],
154 | [0, 92, 255],
155 | [184, 255, 0],
156 | [0, 133, 255],
157 | [255, 214, 0],
158 | [25, 194, 194],
159 | [102, 255, 0],
160 | [92, 0, 255],
161 | ]
162 | )
163 |
164 |
165 | class SegControl(ControlInterface):
166 | def get_control_image(self, image: Image) -> Image:
167 | image_processor = AutoImageProcessor.from_pretrained(
168 | "openmmlab/upernet-convnext-small"
169 | )
170 | image_segmentor = UperNetForSemanticSegmentation.from_pretrained(
171 | "openmmlab/upernet-convnext-small"
172 | )
173 | pixel_values = image_processor(image, return_tensors="pt").pixel_values
174 | with torch.no_grad():
175 | outputs = image_segmentor(pixel_values)
176 | seg = image_processor.post_process_semantic_segmentation(
177 | outputs, target_sizes=[image.size[::-1]]
178 | )[0]
179 |
180 | color_seg = np.zeros((seg.shape[0], seg.shape[1], 3), dtype=np.uint8)
181 |
182 | for label, color in enumerate(palette):
183 | color_seg[seg == label, :] = color
184 | color_seg = color_seg.astype(np.uint8)
185 | image = Image.fromarray(color_seg)
186 | return image
187 |
--------------------------------------------------------------------------------
/src/backend/generate.py:
--------------------------------------------------------------------------------
1 | from typing import Any
2 |
3 | from backend.computing import Computing
4 | from backend.imagesaver import ImageSaver
5 | from backend.stablediffusion.depth_to_image import StableDiffusionDepthToImage
6 | from backend.stablediffusion.inpainting import StableDiffusionInpainting
7 | from backend.stablediffusion.instructpix import StableDiffusionInstructPixToPix
8 | from backend.stablediffusion.models.setting import (
9 | StableDiffusionImageDepthToImageSetting,
10 | StableDiffusionImageInpaintingSetting,
11 | StableDiffusionImageToImageSetting,
12 | StableDiffusionSetting,
13 | StableDiffusionImageInstructPixToPixSetting,
14 | StableDiffusionControlnetSetting,
15 | )
16 | from backend.wuerstchen.models.setting import WurstchenSetting
17 | from backend.controlnet.ControlContext import ControlnetContext
18 | from backend.stablediffusion.stablediffusion import StableDiffusion
19 | from backend.stablediffusion.stablediffusionxl import StableDiffusionXl
20 | from backend.wuerstchen.wuerstchen import Wuerstchen
21 | from settings import AppSettings
22 |
23 |
24 | class Generate:
25 | def __init__(
26 | self,
27 | compute: Computing,
28 | model_id: str,
29 | ):
30 | self.pipe_initialized = False
31 | self.inpaint_pipe_initialized = False
32 | self.depth_pipe_initialized = False
33 | self.pix_to_pix_initialized = False
34 | self.controlnet_initialized = False
35 | self.stable_diffusion = StableDiffusion(compute)
36 | self.stable_diffusion_inpainting = StableDiffusionInpainting(compute)
37 | self.stable_diffusion_depth = StableDiffusionDepthToImage(compute)
38 | self.stable_diffusion_pix_to_pix = StableDiffusionInstructPixToPix(compute)
39 | self.controlnet = ControlnetContext(compute)
40 | self.stable_diffusion_xl = StableDiffusionXl(compute)
41 | self.app_settings = AppSettings().get_settings()
42 | self.model_id = model_id
43 | self.low_vram_mode = self.app_settings.low_memory_mode
44 | self.wuerstchen = Wuerstchen(compute)
45 |
46 | def diffusion_text_to_image(
47 | self,
48 | prompt,
49 | neg_prompt,
50 | image_height,
51 | image_width,
52 | inference_steps,
53 | scheduler,
54 | guidance_scale,
55 | num_images,
56 | attention_slicing,
57 | vae_slicing,
58 | seed,
59 | ) -> Any:
60 | stable_diffusion_settings = StableDiffusionSetting(
61 | prompt=prompt,
62 | negative_prompt=neg_prompt,
63 | image_height=image_height,
64 | image_width=image_width,
65 | inference_steps=inference_steps,
66 | guidance_scale=guidance_scale,
67 | number_of_images=num_images,
68 | scheduler=scheduler,
69 | seed=seed,
70 | attention_slicing=attention_slicing,
71 | vae_slicing=vae_slicing,
72 | )
73 | self._init_stable_diffusion()
74 | images = self.stable_diffusion.text_to_image(stable_diffusion_settings)
75 | self._save_images(
76 | images,
77 | "TextToImage",
78 | )
79 | return images
80 |
81 | def _init_stable_diffusion(self):
82 | if not self.pipe_initialized:
83 | print("Initializing stable diffusion pipeline")
84 | self.stable_diffusion.get_text_to_image_pipleline(
85 | self.model_id,
86 | self.low_vram_mode,
87 | )
88 | self.pipe_initialized = True
89 |
90 | def _init_stable_diffusion_xl(self):
91 | if not self.pipe_initialized:
92 | print("Initializing stable diffusion xl pipeline")
93 | self.stable_diffusion_xl.get_text_to_image_xl_pipleline(
94 | self.model_id,
95 | self.low_vram_mode,
96 | )
97 | self.pipe_initialized = True
98 |
99 | def _init_wuerstchen(self):
100 | if not self.pipe_initialized:
101 | print("Initializing wuerstchen pipeline")
102 | self.wuerstchen.get_text_to_image_wuerstchen_pipleline(
103 | self.model_id,
104 | self.low_vram_mode,
105 | )
106 | self.pipe_initialized = True
107 |
108 | def diffusion_image_to_image(
109 | self,
110 | image,
111 | strength,
112 | prompt,
113 | neg_prompt,
114 | image_height,
115 | image_width,
116 | inference_steps,
117 | scheduler,
118 | guidance_scale,
119 | num_images,
120 | attention_slicing,
121 | seed,
122 | ) -> Any:
123 | stable_diffusion_image_settings = StableDiffusionImageToImageSetting(
124 | image=image,
125 | strength=strength,
126 | prompt=prompt,
127 | negative_prompt=neg_prompt,
128 | image_height=image_height,
129 | image_width=image_width,
130 | inference_steps=inference_steps,
131 | guidance_scale=guidance_scale,
132 | number_of_images=num_images,
133 | scheduler=scheduler,
134 | seed=seed,
135 | attention_slicing=attention_slicing,
136 | )
137 | self._init_stable_diffusion()
138 | images = self.stable_diffusion.image_to_image(stable_diffusion_image_settings)
139 |
140 | self._save_images(
141 | images,
142 | "ImageToImage",
143 | )
144 | return images
145 |
146 | def diffusion_image_inpainting(
147 | self,
148 | image,
149 | prompt,
150 | neg_prompt,
151 | image_height,
152 | image_width,
153 | inference_steps,
154 | scheduler,
155 | guidance_scale,
156 | num_images,
157 | attention_slicing,
158 | seed,
159 | ) -> Any:
160 | stable_diffusion_image_settings = StableDiffusionImageInpaintingSetting(
161 | image=image["image"],
162 | mask_image=image["mask"],
163 | prompt=prompt,
164 | negative_prompt=neg_prompt,
165 | image_height=image_height,
166 | image_width=image_width,
167 | inference_steps=inference_steps,
168 | guidance_scale=guidance_scale,
169 | number_of_images=num_images,
170 | scheduler=scheduler,
171 | seed=seed,
172 | attention_slicing=attention_slicing,
173 | )
174 |
175 | if not self.inpaint_pipe_initialized:
176 | print("Initializing stable diffusion inpainting pipeline")
177 | self.stable_diffusion_inpainting.get_inpainting_pipleline(
178 | self.model_id,
179 | self.low_vram_mode,
180 | )
181 | self.inpaint_pipe_initialized = True
182 |
183 | images = self.stable_diffusion_inpainting.image_inpainting(
184 | stable_diffusion_image_settings
185 | )
186 | self._save_images(
187 | images,
188 | "Inpainting",
189 | )
190 | return images
191 |
192 | def diffusion_depth_to_image(
193 | self,
194 | image,
195 | strength,
196 | prompt,
197 | neg_prompt,
198 | image_height,
199 | image_width,
200 | inference_steps,
201 | scheduler,
202 | guidance_scale,
203 | num_images,
204 | attention_slicing,
205 | seed,
206 | ) -> Any:
207 | stable_diffusion_image_settings = StableDiffusionImageDepthToImageSetting(
208 | image=image,
209 | strength=strength,
210 | prompt=prompt,
211 | negative_prompt=neg_prompt,
212 | image_height=image_height,
213 | image_width=image_width,
214 | inference_steps=inference_steps,
215 | guidance_scale=guidance_scale,
216 | number_of_images=num_images,
217 | scheduler=scheduler,
218 | seed=seed,
219 | attention_slicing=attention_slicing,
220 | )
221 |
222 | if not self.depth_pipe_initialized:
223 | print("Initializing stable diffusion depth to image pipeline")
224 |
225 | self.stable_diffusion_depth.get_depth_to_image_pipleline(
226 | self.model_id,
227 | self.low_vram_mode,
228 | )
229 | self.depth_pipe_initialized = True
230 | images = self.stable_diffusion_depth.depth_to_image(
231 | stable_diffusion_image_settings
232 | )
233 | self._save_images(
234 | images,
235 | "DepthToImage",
236 | )
237 | return images
238 |
239 | def _save_images(
240 | self,
241 | images: Any,
242 | folder: str,
243 | ):
244 | if AppSettings().get_settings().output_images.use_seperate_folders:
245 | ImageSaver.save_images(
246 | AppSettings().get_settings().output_images.path,
247 | images,
248 | folder,
249 | AppSettings().get_settings().output_images.format,
250 | )
251 | else:
252 | ImageSaver.save_images(
253 | AppSettings().get_settings().output_images.path,
254 | images,
255 | "",
256 | AppSettings().get_settings().output_images.format,
257 | )
258 |
259 | def diffusion_pix_to_pix(
260 | self,
261 | image,
262 | image_guidance,
263 | prompt,
264 | neg_prompt,
265 | image_height,
266 | image_width,
267 | inference_steps,
268 | scheduler,
269 | guidance_scale,
270 | num_images,
271 | attention_slicing,
272 | seed,
273 | ) -> Any:
274 | stable_diffusion_image_settings = StableDiffusionImageInstructPixToPixSetting(
275 | image=image,
276 | image_guidance=image_guidance,
277 | prompt=prompt,
278 | negative_prompt=neg_prompt,
279 | image_height=image_height,
280 | image_width=image_width,
281 | inference_steps=inference_steps,
282 | guidance_scale=guidance_scale,
283 | number_of_images=num_images,
284 | scheduler=scheduler,
285 | seed=seed,
286 | attention_slicing=attention_slicing,
287 | )
288 | if not self.pix_to_pix_initialized:
289 | print("Initializing stable diffusion instruct pix to pix pipeline")
290 | self.stable_diffusion_pix_to_pix.get_instruct_pix_to_pix_pipleline(
291 | self.model_id,
292 | self.low_vram_mode,
293 | )
294 | self.pix_to_pix_initialized = True
295 |
296 | images = self.stable_diffusion_pix_to_pix.instruct_pix_to_pix(
297 | stable_diffusion_image_settings
298 | )
299 | self._save_images(
300 | images,
301 | "InstructEditImage",
302 | )
303 | return images
304 |
305 | def diffusion_image_variations(
306 | self,
307 | image,
308 | strength,
309 | image_height,
310 | image_width,
311 | inference_steps,
312 | scheduler,
313 | guidance_scale,
314 | num_images,
315 | attention_slicing,
316 | seed,
317 | ) -> Any:
318 | stable_diffusion_image_settings = StableDiffusionImageToImageSetting(
319 | image=image,
320 | strength=strength,
321 | prompt="",
322 | negative_prompt="bad, deformed, ugly, bad anatomy",
323 | image_height=image_height,
324 | image_width=image_width,
325 | inference_steps=inference_steps,
326 | guidance_scale=guidance_scale,
327 | number_of_images=num_images,
328 | scheduler=scheduler,
329 | seed=seed,
330 | attention_slicing=attention_slicing,
331 | )
332 | self._init_stable_diffusion()
333 | images = self.stable_diffusion.image_to_image(stable_diffusion_image_settings)
334 |
335 | self._save_images(
336 | images,
337 | "ImageVariations",
338 | )
339 | return images
340 |
341 | def diffusion_control_to_image(
342 | self,
343 | image,
344 | prompt,
345 | neg_prompt,
346 | image_height,
347 | image_width,
348 | inference_steps,
349 | scheduler,
350 | guidance_scale,
351 | num_images,
352 | attention_slicing,
353 | vae_slicing,
354 | seed,
355 | ) -> Any:
356 | stable_diffusion_image_settings = StableDiffusionControlnetSetting(
357 | image=image,
358 | prompt=prompt,
359 | negative_prompt=neg_prompt,
360 | image_height=image_height,
361 | image_width=image_width,
362 | inference_steps=inference_steps,
363 | guidance_scale=guidance_scale,
364 | number_of_images=num_images,
365 | scheduler=scheduler,
366 | seed=seed,
367 | attention_slicing=attention_slicing,
368 | vae_slicing=vae_slicing,
369 | )
370 | if not self.controlnet_initialized:
371 | print("Initializing controlnet image pipeline")
372 | self.controlnet.init_control_to_image_pipleline(
373 | model_id=self.model_id,
374 | low_vram_mode=self.low_vram_mode,
375 | )
376 | self.controlnet_initialized = True
377 |
378 | images = self.controlnet.control_to_image(stable_diffusion_image_settings)
379 |
380 | self._save_images(
381 | images,
382 | "CannyToImage",
383 | )
384 | return images
385 |
386 | def diffusion_text_to_image_xl(
387 | self,
388 | prompt,
389 | neg_prompt,
390 | image_height,
391 | image_width,
392 | inference_steps,
393 | scheduler,
394 | guidance_scale,
395 | num_images,
396 | attention_slicing,
397 | vae_slicing,
398 | seed,
399 | ) -> Any:
400 | stable_diffusion_settings = StableDiffusionSetting(
401 | prompt=prompt,
402 | negative_prompt=neg_prompt,
403 | image_height=image_height,
404 | image_width=image_width,
405 | inference_steps=inference_steps,
406 | guidance_scale=guidance_scale,
407 | number_of_images=num_images,
408 | scheduler=scheduler,
409 | seed=seed,
410 | attention_slicing=attention_slicing,
411 | vae_slicing=vae_slicing,
412 | )
413 | self._init_stable_diffusion_xl()
414 | images = self.stable_diffusion_xl.text_to_image_xl(stable_diffusion_settings)
415 | self._save_images(
416 | images,
417 | "TextToImage",
418 | )
419 | return images
420 |
421 | def diffusion_image_to_image_xl(
422 | self,
423 | image,
424 | strength,
425 | prompt,
426 | neg_prompt,
427 | image_height,
428 | image_width,
429 | inference_steps,
430 | scheduler,
431 | guidance_scale,
432 | num_images,
433 | attention_slicing,
434 | seed,
435 | ) -> Any:
436 | stable_diffusion_image_settings = StableDiffusionImageToImageSetting(
437 | image=image,
438 | strength=strength,
439 | prompt=prompt,
440 | negative_prompt=neg_prompt,
441 | image_height=image_height,
442 | image_width=image_width,
443 | inference_steps=inference_steps,
444 | guidance_scale=guidance_scale,
445 | number_of_images=num_images,
446 | scheduler=scheduler,
447 | seed=seed,
448 | attention_slicing=attention_slicing,
449 | )
450 | self._init_stable_diffusion_xl()
451 | images = self.stable_diffusion_xl.image_to_image(
452 | stable_diffusion_image_settings
453 | )
454 |
455 | self._save_images(
456 | images,
457 | "ImageToImage",
458 | )
459 | return images
460 |
461 | def diffusion_image_variations_xl(
462 | self,
463 | image,
464 | strength,
465 | image_height,
466 | image_width,
467 | inference_steps,
468 | scheduler,
469 | guidance_scale,
470 | num_images,
471 | attention_slicing,
472 | seed,
473 | ) -> Any:
474 | stable_diffusion_image_settings = StableDiffusionImageToImageSetting(
475 | image=image,
476 | strength=strength,
477 | prompt="",
478 | negative_prompt="bad, deformed, ugly, bad anatomy",
479 | image_height=image_height,
480 | image_width=image_width,
481 | inference_steps=inference_steps,
482 | guidance_scale=guidance_scale,
483 | number_of_images=num_images,
484 | scheduler=scheduler,
485 | seed=seed,
486 | attention_slicing=attention_slicing,
487 | )
488 | self._init_stable_diffusion_xl()
489 | images = self.stable_diffusion_xl.image_to_image(
490 | stable_diffusion_image_settings
491 | )
492 |
493 | self._save_images(
494 | images,
495 | "ImageVariations",
496 | )
497 | return images
498 |
499 | def diffusion_text_to_image_wuerstchen(
500 | self,
501 | prompt,
502 | neg_prompt,
503 | image_height,
504 | image_width,
505 | guidance_scale,
506 | num_images,
507 | seed,
508 | ) -> Any:
509 | wurstchen_settings = WurstchenSetting(
510 | prompt=prompt,
511 | negative_prompt=neg_prompt,
512 | image_height=image_height,
513 | image_width=image_width,
514 | prior_guidance_scale=guidance_scale,
515 | number_of_images=num_images,
516 | seed=seed,
517 | )
518 | self._init_wuerstchen()
519 | images = self.wuerstchen.text_to_image_wuerstchen(wurstchen_settings)
520 | self._save_images(
521 | images,
522 | "TextToImage",
523 | )
524 | return images
525 |
--------------------------------------------------------------------------------
/src/backend/image_ops.py:
--------------------------------------------------------------------------------
1 | from PIL import Image
2 |
3 |
4 | def resize_pil_image(
5 | pil_image: Image,
6 | image_width,
7 | image_height,
8 | ):
9 | return pil_image.convert("RGB").resize(
10 | (
11 | image_width,
12 | image_height,
13 | ),
14 | Image.Resampling.LANCZOS,
15 | )
16 |
--------------------------------------------------------------------------------
/src/backend/imagesaver.py:
--------------------------------------------------------------------------------
1 | import os
2 | from typing import Any
3 | from uuid import uuid4
4 |
5 | from utils import join_paths
6 |
7 |
8 | class ImageSaver:
9 | @staticmethod
10 | def save_images(
11 | output_path: str,
12 | images: Any,
13 | folder_name: str = "",
14 | format: str = ".png",
15 | ) -> None:
16 | for image in images:
17 | image_id = uuid4()
18 | if not os.path.exists(output_path):
19 | os.mkdir(output_path)
20 |
21 | if folder_name:
22 | out_path = join_paths(
23 | output_path,
24 | folder_name,
25 | )
26 | else:
27 | out_path = output_path
28 |
29 | if not os.path.exists(out_path):
30 | os.mkdir(out_path)
31 |
32 | image.save(join_paths(out_path, f"{image_id}.{format}"))
33 |
--------------------------------------------------------------------------------
/src/backend/stablediffusion/depth_to_image.py:
--------------------------------------------------------------------------------
1 | from time import time
2 |
3 | import torch
4 | from diffusers import StableDiffusionDepth2ImgPipeline
5 | from PIL import Image
6 |
7 | from backend.computing import Computing
8 | from backend.stablediffusion.models.scheduler_types import SchedulerType
9 | from backend.stablediffusion.models.setting import (
10 | StableDiffusionImageDepthToImageSetting,
11 | )
12 | from backend.stablediffusion.scheduler_mixin import SamplerMixin
13 |
14 |
15 | class StableDiffusionDepthToImage(SamplerMixin):
16 | def __init__(self, compute: Computing):
17 | self.compute = compute
18 | self.device = self.compute.name
19 | super().__init__()
20 |
21 | def get_depth_to_image_pipleline(
22 | self,
23 | model_id: str = "stabilityai/stable-diffusion-2-depth",
24 | low_vram_mode: bool = False,
25 | sampler: str = SchedulerType.DPMSolverMultistepScheduler.value,
26 | ):
27 | self.low_vram_mode = low_vram_mode
28 | print(f"StableDiffusion - {self.compute.name},{self.compute.datatype}")
29 | print(f"using model {model_id}")
30 | self.model_id = model_id
31 | self.default_sampler = self.find_sampler(
32 | sampler,
33 | self.model_id,
34 | )
35 |
36 | tic = time()
37 | self._load_model()
38 | delta = time() - tic
39 | print(f"Model loaded in {delta:.2f}s ")
40 | self._pipeline_to_device()
41 |
42 | def depth_to_image(
43 | self,
44 | setting: StableDiffusionImageDepthToImageSetting,
45 | ):
46 | if setting.scheduler is None:
47 | raise Exception("Scheduler cannot be empty")
48 | print("Running depth to image pipeline")
49 | self.depth_pipeline.scheduler = self.find_sampler(
50 | setting.scheduler,
51 | self.model_id,
52 | )
53 | generator = None
54 | if setting.seed != -1 and setting.seed:
55 | print(f"Using seed {setting.seed}")
56 | generator = torch.Generator(self.device).manual_seed(setting.seed)
57 |
58 | if setting.attention_slicing:
59 | self.depth_pipeline.enable_attention_slicing()
60 | else:
61 | self.depth_pipeline.disable_attention_slicing()
62 |
63 | base_image = setting.image.convert("RGB").resize(
64 | (
65 | setting.image_width,
66 | setting.image_height,
67 | ),
68 | Image.Resampling.LANCZOS,
69 | )
70 | images = self.depth_pipeline(
71 | image=base_image,
72 | strength=setting.strength,
73 | prompt=setting.prompt,
74 | guidance_scale=setting.guidance_scale,
75 | num_inference_steps=setting.inference_steps,
76 | negative_prompt=setting.negative_prompt,
77 | num_images_per_prompt=setting.number_of_images,
78 | generator=generator,
79 | ).images
80 | return images
81 |
82 | def _pipeline_to_device(self):
83 | if self.low_vram_mode:
84 | print("Running in low VRAM mode,slower to generate images")
85 | self.depth_pipeline.enable_sequential_cpu_offload()
86 | else:
87 | if self.compute.name == "cuda":
88 | self.depth_pipeline = self.depth_pipeline.to("cuda")
89 | elif self.compute.name == "mps":
90 | self.depth_pipeline = self.depth_pipeline.to("mps")
91 |
92 | def _load_full_precision_model(self):
93 | self.depth_pipeline = StableDiffusionDepth2ImgPipeline.from_pretrained(
94 | self.model_id,
95 | torch_dtype=self.compute.datatype,
96 | scheduler=self.default_sampler,
97 | )
98 |
99 | def _load_model(self):
100 | print("Loading model...")
101 | if self.compute.name == "cuda":
102 | try:
103 | self.depth_pipeline = StableDiffusionDepth2ImgPipeline.from_pretrained(
104 | self.model_id,
105 | torch_dtype=self.compute.datatype,
106 | scheduler=self.default_sampler,
107 | revision="fp16",
108 | )
109 | except Exception as ex:
110 | print(
111 | f" The fp16 of the model not found using full precision model, {ex}"
112 | )
113 | self._load_full_precision_model()
114 | else:
115 | self._load_full_precision_model()
116 |
--------------------------------------------------------------------------------
/src/backend/stablediffusion/inpainting.py:
--------------------------------------------------------------------------------
1 | from time import time
2 |
3 | import torch
4 | from diffusers import StableDiffusionInpaintPipeline
5 | from PIL import Image
6 |
7 | from backend.computing import Computing
8 | from backend.stablediffusion.scheduler_mixin import SamplerMixin
9 | from backend.stablediffusion.models.scheduler_types import SchedulerType
10 | from backend.stablediffusion.models.setting import StableDiffusionImageInpaintingSetting
11 |
12 |
13 | class StableDiffusionInpainting(SamplerMixin):
14 | def __init__(self, compute: Computing):
15 | self.compute = compute
16 | self.device = self.compute.name
17 | super().__init__()
18 |
19 | def get_inpainting_pipleline(
20 | self,
21 | model_id: str = "stabilityai/stable-diffusion-2-inpainting",
22 | low_vram_mode: bool = False,
23 | sampler: str = SchedulerType.DPMSolverMultistepScheduler.value,
24 | ):
25 | self.model_id = model_id
26 | self.low_vram_mode = low_vram_mode
27 | print(f"StableDiffusion - {self.compute.name},{self.compute.datatype}")
28 | print(f"Using model {model_id}")
29 | self.default_sampler = self.find_sampler(
30 | sampler,
31 | self.model_id,
32 | )
33 |
34 | tic = time()
35 | self._load_model()
36 | delta = time() - tic
37 | print(f"Model loaded in {delta:.2f}s ")
38 | self._pipeline_to_device()
39 |
40 | def image_inpainting(self, setting: StableDiffusionImageInpaintingSetting):
41 | if setting.scheduler is None:
42 | raise Exception("Scheduler cannot be empty")
43 | print("Running image inpainting pipeline")
44 | self.inpainting_pipeline.scheduler = self.find_sampler(
45 | setting.scheduler,
46 | self.model_id,
47 | )
48 | generator = None
49 | if setting.seed != -1 and setting.seed:
50 | print(f"Using seed {setting.seed}")
51 | generator = torch.Generator(self.device).manual_seed(setting.seed)
52 |
53 | if setting.attention_slicing:
54 | self.inpainting_pipeline.enable_attention_slicing()
55 | else:
56 | self.inpainting_pipeline.disable_attention_slicing()
57 |
58 | base_image = setting.image.convert("RGB").resize(
59 | (
60 | setting.image_width,
61 | setting.image_height,
62 | ),
63 | Image.Resampling.LANCZOS,
64 | )
65 | mask_image = setting.mask_image.convert("RGB").resize(
66 | (
67 | setting.image_width,
68 | setting.image_height,
69 | ),
70 | Image.Resampling.LANCZOS,
71 | )
72 |
73 | images = self.inpainting_pipeline(
74 | image=base_image,
75 | mask_image=mask_image,
76 | height=setting.image_height,
77 | width=setting.image_width,
78 | prompt=setting.prompt,
79 | guidance_scale=setting.guidance_scale,
80 | num_inference_steps=setting.inference_steps,
81 | negative_prompt=setting.negative_prompt,
82 | num_images_per_prompt=setting.number_of_images,
83 | generator=generator,
84 | ).images
85 | return images
86 |
87 | def _pipeline_to_device(self):
88 | if self.low_vram_mode:
89 | print("Running in low VRAM mode,slower to generate images")
90 | self.inpainting_pipeline.enable_sequential_cpu_offload()
91 | else:
92 | if self.compute.name == "cuda":
93 | self.inpainting_pipeline = self.inpainting_pipeline.to("cuda")
94 | elif self.compute.name == "mps":
95 | self.inpainting_pipeline = self.inpainting_pipeline.to("mps")
96 |
97 | def _load_full_precision_model(self):
98 | self.inpainting_pipeline = StableDiffusionInpaintPipeline.from_pretrained(
99 | self.model_id,
100 | torch_dtype=self.compute.datatype,
101 | scheduler=self.default_sampler,
102 | )
103 |
104 | def _load_model(self):
105 | print("Loading model...")
106 | if self.compute.name == "cuda":
107 | try:
108 | self.inpainting_pipeline = (
109 | StableDiffusionInpaintPipeline.from_pretrained(
110 | self.model_id,
111 | torch_dtype=self.compute.datatype,
112 | scheduler=self.default_sampler,
113 | revision="fp16",
114 | )
115 | )
116 | except Exception as ex:
117 | print(
118 | f" The fp16 of the model not found using full precision model, {ex}"
119 | )
120 | self._load_full_precision_model()
121 | else:
122 | self._load_full_precision_model()
123 |
--------------------------------------------------------------------------------
/src/backend/stablediffusion/instructpix.py:
--------------------------------------------------------------------------------
1 | from time import time
2 |
3 | import torch
4 | from diffusers import StableDiffusionInstructPix2PixPipeline
5 | from PIL import Image
6 |
7 | from backend.computing import Computing
8 | from backend.stablediffusion.scheduler_mixin import SamplerMixin
9 | from backend.stablediffusion.models.scheduler_types import SchedulerType
10 | from backend.stablediffusion.models.setting import (
11 | StableDiffusionImageInstructPixToPixSetting,
12 | )
13 |
14 |
15 | class StableDiffusionInstructPixToPix(SamplerMixin):
16 | def __init__(self, compute: Computing):
17 | self.compute = compute
18 | self.device = self.compute.name
19 | super().__init__()
20 |
21 | def get_instruct_pix_to_pix_pipleline(
22 | self,
23 | model_id: str = "timbrooks/instruct-pix2pix",
24 | low_vram_mode: bool = False,
25 | sampler: str = SchedulerType.DPMSolverMultistepScheduler.value,
26 | ):
27 | print(f"StableDiffusion - {self.compute.name},{self.compute.datatype}")
28 | print(f"using model {model_id}")
29 | self.model_id = model_id
30 | self.low_vram_mode = low_vram_mode
31 | self.default_sampler = self.find_sampler(
32 | sampler,
33 | self.model_id,
34 | )
35 |
36 | tic = time()
37 | self._load_model()
38 | delta = time() - tic
39 | print(f"Model loaded in {delta:.2f}s ")
40 | self._pipeline_to_device()
41 |
42 | def instruct_pix_to_pix(self, setting: StableDiffusionImageInstructPixToPixSetting):
43 | if setting.scheduler is None:
44 | raise Exception("Scheduler cannot be empty")
45 | print("Running image to image pipeline")
46 | self.instruct_pix_pipeline.scheduler = self.find_sampler(
47 | setting.scheduler,
48 | self.model_id,
49 | )
50 | generator = None
51 | if setting.seed != -1 and setting.seed:
52 | print(f"Using seed {setting.seed}")
53 | generator = torch.Generator(self.device).manual_seed(setting.seed)
54 |
55 | if setting.attention_slicing:
56 | self.instruct_pix_pipeline.enable_attention_slicing()
57 | else:
58 | self.instruct_pix_pipeline.disable_attention_slicing()
59 |
60 | init_image = setting.image.resize(
61 | (
62 | setting.image_width,
63 | setting.image_height,
64 | ),
65 | Image.Resampling.LANCZOS,
66 | )
67 |
68 | images = self.instruct_pix_pipeline(
69 | image=init_image,
70 | image_guidance_scale=setting.image_guidance_scale,
71 | prompt=setting.prompt,
72 | guidance_scale=setting.guidance_scale,
73 | num_inference_steps=setting.inference_steps,
74 | negative_prompt=setting.negative_prompt,
75 | num_images_per_prompt=setting.number_of_images,
76 | generator=generator,
77 | ).images
78 | return images
79 |
80 | def _pipeline_to_device(self):
81 | if self.low_vram_mode:
82 | print("Running in low VRAM mode,slower to generate images")
83 | self.instruct_pix_pipeline.enable_sequential_cpu_offload()
84 | else:
85 | if self.compute.name == "cuda":
86 | self.instruct_pix_pipeline = self.instruct_pix_pipeline.to("cuda")
87 | elif self.compute.name == "mps":
88 | self.instruct_pix_pipeline = self.instruct_pix_pipeline.to("mps")
89 |
90 | def _load_full_precision_model(self):
91 | self.instruct_pix_pipeline = (
92 | StableDiffusionInstructPix2PixPipeline.from_pretrained(
93 | self.model_id,
94 | torch_dtype=self.compute.datatype,
95 | scheduler=self.default_sampler,
96 | )
97 | )
98 |
99 | def _load_model(self):
100 | print("Loading model...")
101 | if self.compute.name == "cuda":
102 | try:
103 | self.instruct_pix_pipeline = (
104 | StableDiffusionInstructPix2PixPipeline.from_pretrained(
105 | self.model_id,
106 | torch_dtype=self.compute.datatype,
107 | scheduler=self.default_sampler,
108 | revision="fp16",
109 | )
110 | )
111 | except Exception as ex:
112 | print(
113 | f" The fp16 of the model not found using full precision model, {ex}"
114 | )
115 | self._load_full_precision_model()
116 | else:
117 | self._load_full_precision_model()
118 |
--------------------------------------------------------------------------------
/src/backend/stablediffusion/modelmeta.py:
--------------------------------------------------------------------------------
1 | from huggingface_hub import model_info
2 |
3 |
4 | class ModelMeta:
5 | def __init__(self, model_path: str):
6 | self.model_path = model_path
7 |
8 | def is_loramodel(self):
9 | self.info = model_info(self.model_path)
10 | return self.info.cardData.get("base_model") is not None
11 |
12 | def get_lora_base_model(self):
13 | return self.info.cardData.get("base_model")
14 |
--------------------------------------------------------------------------------
/src/backend/stablediffusion/models/scheduler_types.py:
--------------------------------------------------------------------------------
1 | from enum import Enum
2 | from typing import Union
3 |
4 | from diffusers import (
5 | DDIMScheduler,
6 | DEISMultistepScheduler,
7 | DPMSolverMultistepScheduler,
8 | EulerAncestralDiscreteScheduler,
9 | EulerDiscreteScheduler,
10 | LMSDiscreteScheduler,
11 | PNDMScheduler,
12 | UniPCMultistepScheduler,
13 | KDPM2DiscreteScheduler,
14 | HeunDiscreteScheduler,
15 | KDPM2AncestralDiscreteScheduler,
16 | DPMSolverSinglestepScheduler,
17 | )
18 |
19 |
20 | class SchedulerType(Enum):
21 | """Diffuser schedulers"""
22 |
23 | # DDPMScheduler = "DDPM"
24 | DPMSolverMultistepScheduler = "DPMSolverMultistep"
25 | DDIMScheduler = "DDIM"
26 | EulerDiscreteScheduler = "EulerDiscrete"
27 | EulerAncestralDiscreteScheduler = "EulerAncestralDiscrete"
28 | LMSDiscreteScheduler = "LMSDiscrete"
29 | PNDMScheduler = "PNDM"
30 | DEISScheduler = "DEISMultistep"
31 | UniPCMultistepScheduler = "UniPCMultistep"
32 | KDPM2DiscreteScheduler = "KDPM2DiscreteScheduler"
33 | HeunDiscreteScheduler = "HeunDiscreteScheduler"
34 | KDPM2AncestralDiscreteScheduler = "KDPM2AncestralDiscreteScheduler"
35 | DPMSolverSinglestepScheduler = "DPMSolverSinglestepScheduler"
36 |
37 |
38 | Scheduler = Union[
39 | DDIMScheduler,
40 | DEISMultistepScheduler,
41 | DPMSolverMultistepScheduler,
42 | EulerAncestralDiscreteScheduler,
43 | EulerDiscreteScheduler,
44 | LMSDiscreteScheduler,
45 | PNDMScheduler,
46 | UniPCMultistepScheduler,
47 | KDPM2DiscreteScheduler,
48 | HeunDiscreteScheduler,
49 | KDPM2AncestralDiscreteScheduler,
50 | DPMSolverSinglestepScheduler,
51 | ]
52 |
53 |
54 | def get_sampler_names():
55 | samplers = [sampler.value for sampler in SchedulerType]
56 | return samplers
57 |
--------------------------------------------------------------------------------
/src/backend/stablediffusion/models/setting.py:
--------------------------------------------------------------------------------
1 | from typing import Optional, Any
2 |
3 | from pydantic import BaseModel
4 | from backend.stablediffusion.models.scheduler_types import SchedulerType
5 |
6 |
7 | class StableDiffusionSetting(BaseModel):
8 | prompt: str
9 | negative_prompt: Optional[str]
10 | image_height: Optional[int] = 512
11 | image_width: Optional[int] = 512
12 | inference_steps: Optional[int] = 20
13 | guidance_scale: Optional[float] = 7.5
14 | number_of_images: Optional[int] = 1
15 | scheduler: Optional[str] = SchedulerType.DPMSolverMultistepScheduler.value
16 | seed: Optional[int] = -1
17 | attention_slicing: Optional[bool] = True
18 | vae_slicing: Optional[bool] = True
19 |
20 |
21 | class StableDiffusionImageToImageSetting(StableDiffusionSetting):
22 | image: Any
23 | strength: Optional[float] = 0.75
24 |
25 |
26 | class StableDiffusionImageInpaintingSetting(StableDiffusionSetting):
27 | image: Any
28 | mask_image: Any
29 |
30 |
31 | class StableDiffusionImageDepthToImageSetting(StableDiffusionSetting):
32 | image: Any
33 | depth_image: Optional[Any]
34 | strength: Optional[float] = 0.8
35 |
36 |
37 | class StableDiffusionImageInstructPixToPixSetting(StableDiffusionSetting):
38 | image: Any
39 | image_guidance_scale: float = 1.5
40 |
41 |
42 | class StableDiffusionControlnetSetting(StableDiffusionSetting):
43 | image: Any
44 |
--------------------------------------------------------------------------------
/src/backend/stablediffusion/scheduler_factory.py:
--------------------------------------------------------------------------------
1 | from diffusers import (
2 | DDIMScheduler,
3 | DEISMultistepScheduler,
4 | DPMSolverMultistepScheduler,
5 | EulerAncestralDiscreteScheduler,
6 | EulerDiscreteScheduler,
7 | LMSDiscreteScheduler,
8 | PNDMScheduler,
9 | UniPCMultistepScheduler,
10 | KDPM2DiscreteScheduler,
11 | HeunDiscreteScheduler,
12 | KDPM2AncestralDiscreteScheduler,
13 | DPMSolverSinglestepScheduler,
14 | )
15 |
16 | from backend.stablediffusion.models.scheduler_types import SchedulerType, Scheduler
17 |
18 |
19 | class SchedulerFactory:
20 | def get_scheduler(
21 | self,
22 | scheduler_type: str,
23 | repo_id: str,
24 | ) -> Scheduler:
25 | if scheduler_type == SchedulerType.DDIMScheduler.value:
26 | return DDIMScheduler.from_pretrained(
27 | repo_id,
28 | subfolder="scheduler",
29 | )
30 | elif scheduler_type == SchedulerType.DEISScheduler.value:
31 | return DEISMultistepScheduler.from_pretrained(
32 | repo_id,
33 | subfolder="scheduler",
34 | )
35 | elif scheduler_type == SchedulerType.DPMSolverMultistepScheduler.value:
36 | return DPMSolverMultistepScheduler.from_pretrained(
37 | repo_id,
38 | subfolder="scheduler",
39 | )
40 | elif scheduler_type == SchedulerType.EulerAncestralDiscreteScheduler.value:
41 | return EulerAncestralDiscreteScheduler.from_pretrained(
42 | repo_id,
43 | subfolder="scheduler",
44 | )
45 | elif scheduler_type == SchedulerType.EulerDiscreteScheduler.value:
46 | return EulerDiscreteScheduler.from_pretrained(
47 | repo_id,
48 | subfolder="scheduler",
49 | )
50 | elif scheduler_type == SchedulerType.LMSDiscreteScheduler.value:
51 | return LMSDiscreteScheduler.from_pretrained(
52 | repo_id,
53 | subfolder="scheduler",
54 | )
55 | elif scheduler_type == SchedulerType.PNDMScheduler.value:
56 | return PNDMScheduler.from_pretrained(
57 | repo_id,
58 | subfolder="scheduler",
59 | )
60 | elif scheduler_type == SchedulerType.UniPCMultistepScheduler.value:
61 | return UniPCMultistepScheduler.from_pretrained(
62 | repo_id,
63 | subfolder="scheduler",
64 | )
65 | elif scheduler_type == SchedulerType.KDPM2DiscreteScheduler.value:
66 | return KDPM2DiscreteScheduler.from_pretrained(
67 | repo_id,
68 | subfolder="scheduler",
69 | )
70 | elif scheduler_type == SchedulerType.HeunDiscreteScheduler.value:
71 | return HeunDiscreteScheduler.from_pretrained(
72 | repo_id,
73 | subfolder="scheduler",
74 | )
75 | elif scheduler_type == SchedulerType.KDPM2AncestralDiscreteScheduler.value:
76 | return KDPM2AncestralDiscreteScheduler.from_pretrained(
77 | repo_id,
78 | subfolder="scheduler",
79 | )
80 | elif scheduler_type == SchedulerType.DPMSolverSinglestepScheduler.value:
81 | return DPMSolverSinglestepScheduler.from_pretrained(
82 | repo_id,
83 | subfolder="scheduler",
84 | )
85 | else:
86 | print(f"Scheduler {scheduler_type} not found")
87 | return None
88 |
--------------------------------------------------------------------------------
/src/backend/stablediffusion/scheduler_mixin.py:
--------------------------------------------------------------------------------
1 | from backend.stablediffusion.models.scheduler_types import Scheduler
2 | from backend.stablediffusion.scheduler_factory import SchedulerFactory
3 |
4 |
5 | class SamplerMixin:
6 | def __init__(self):
7 | self.samplers = {}
8 |
9 | def find_sampler(
10 | self,
11 | scheduler_name: str,
12 | repo_id: str,
13 | ) -> Scheduler:
14 | scheduler_factory = SchedulerFactory()
15 | if self.samplers.get(scheduler_name) is None:
16 | self.samplers[scheduler_name] = scheduler_factory.get_scheduler(
17 | scheduler_name,
18 | repo_id,
19 | )
20 | return self.samplers[scheduler_name]
21 |
--------------------------------------------------------------------------------
/src/backend/stablediffusion/stable_diffusion_types.py:
--------------------------------------------------------------------------------
1 | from enum import Enum
2 |
3 |
4 | class StableDiffusionType(str, Enum):
5 | """Stable diffusion types"""
6 |
7 | base = "Base"
8 | inpainting = "InPainting"
9 | depth2img = "DepthToImage"
10 | instruct_pix2pix = "InstructPixToPix"
11 | controlnet_canny = "controlnet_canny"
12 | controlnet_line = "controlnet_line"
13 | controlnet_normal = "controlnet_normal"
14 | controlnet_hed = "controlnet_hed"
15 | controlnet_pose = "controlnet_pose"
16 | controlnet_depth = "controlnet_depth"
17 | controlnet_scribble = "controlnet_scribble"
18 | controlnet_seg = "controlnet_seg"
19 | stable_diffusion_xl = "StableDiffusionXl"
20 | wuerstchen = "Wuerstchen"
21 |
22 |
23 | def get_diffusion_type(
24 | model_id: str,
25 | ) -> StableDiffusionType:
26 | stable_diffusion_type = StableDiffusionType.base
27 | model_id = model_id.lower()
28 | if "inpainting" in model_id:
29 | stable_diffusion_type = StableDiffusionType.inpainting
30 | elif "instruct-pix2pix" in model_id:
31 | stable_diffusion_type = StableDiffusionType.instruct_pix2pix
32 | elif "controlnet-canny" in model_id:
33 | stable_diffusion_type = StableDiffusionType.controlnet_canny
34 | elif "controlnet-mlsd" in model_id:
35 | stable_diffusion_type = StableDiffusionType.controlnet_line
36 | elif "controlnet-normal" in model_id:
37 | stable_diffusion_type = StableDiffusionType.controlnet_normal
38 | elif "controlnet-hed" in model_id:
39 | stable_diffusion_type = StableDiffusionType.controlnet_hed
40 | elif "controlnet-openpose" in model_id:
41 | stable_diffusion_type = StableDiffusionType.controlnet_pose
42 | elif "sd-controlnet-depth" in model_id:
43 | stable_diffusion_type = StableDiffusionType.controlnet_depth
44 | elif "depth" in model_id:
45 | stable_diffusion_type = StableDiffusionType.depth2img
46 | elif "controlnet-scribble" in model_id:
47 | stable_diffusion_type = StableDiffusionType.controlnet_scribble
48 | elif "controlnet-seg" in model_id:
49 | stable_diffusion_type = StableDiffusionType.controlnet_seg
50 | elif "stable-diffusion-xl" in model_id:
51 | stable_diffusion_type = StableDiffusionType.stable_diffusion_xl
52 | elif "wuerstchen" in model_id:
53 | stable_diffusion_type = StableDiffusionType.wuerstchen
54 | return stable_diffusion_type
55 |
--------------------------------------------------------------------------------
/src/backend/stablediffusion/stablediffusion.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from diffusers import StableDiffusionImg2ImgPipeline, StableDiffusionPipeline
3 | from PIL import Image
4 |
5 | from backend.computing import Computing
6 | from backend.stablediffusion.scheduler_mixin import SamplerMixin
7 | from backend.stablediffusion.models.scheduler_types import SchedulerType
8 | from backend.stablediffusion.models.setting import (
9 | StableDiffusionImageToImageSetting,
10 | StableDiffusionSetting,
11 | )
12 | from time import time
13 | from backend.stablediffusion.modelmeta import ModelMeta
14 |
15 |
16 | class StableDiffusion(SamplerMixin):
17 | def __init__(self, compute: Computing):
18 | self.compute = compute
19 | self.pipeline = None
20 | self.device = self.compute.name
21 |
22 | super().__init__()
23 |
24 | def get_text_to_image_pipleline(
25 | self,
26 | model_id: str = "stabilityai/stable-diffusion-2-1-base",
27 | low_vram_mode: bool = False,
28 | sampler: str = SchedulerType.DPMSolverMultistepScheduler.value,
29 | ):
30 | repo_id = model_id
31 | model_meta = ModelMeta(repo_id)
32 | is_lora_model = model_meta.is_loramodel()
33 | if is_lora_model:
34 | print("LoRA model detected")
35 | self.model_id = model_meta.get_lora_base_model()
36 | print(f"LoRA base model - {self.model_id}")
37 | else:
38 | self.model_id = model_id
39 |
40 | self.low_vram_mode = low_vram_mode
41 | print(f"StableDiffusion - {self.compute.name},{self.compute.datatype}")
42 | print(f"using model {model_id}")
43 | self.default_sampler = self.find_sampler(
44 | sampler,
45 | self.model_id,
46 | )
47 | tic = time()
48 | self._load_model()
49 | delta = time() - tic
50 | print(f"Model loaded in {delta:.2f}s ")
51 |
52 | if self.pipeline is None:
53 | raise Exception("Text to image pipeline not initialized")
54 | if is_lora_model:
55 | self.pipeline.unet.load_attn_procs(repo_id)
56 | self._pipeline_to_device()
57 | components = self.pipeline.components
58 | self.img_to_img_pipeline = StableDiffusionImg2ImgPipeline(**components)
59 |
60 | def text_to_image(self, setting: StableDiffusionSetting):
61 | if self.pipeline is None:
62 | raise Exception("Text to image pipeline not initialized")
63 |
64 | self.pipeline.scheduler = self.find_sampler(
65 | setting.scheduler,
66 | self.model_id,
67 | )
68 | generator = None
69 | if setting.seed != -1:
70 | print(f"Using seed {setting.seed}")
71 | generator = torch.Generator(self.device).manual_seed(setting.seed)
72 |
73 | if setting.attention_slicing:
74 | self.pipeline.enable_attention_slicing()
75 | else:
76 | self.pipeline.disable_attention_slicing()
77 |
78 | if setting.vae_slicing:
79 | self.pipeline.enable_vae_slicing()
80 | else:
81 | self.pipeline.disable_vae_slicing()
82 |
83 | images = self.pipeline(
84 | setting.prompt,
85 | guidance_scale=setting.guidance_scale,
86 | num_inference_steps=setting.inference_steps,
87 | height=setting.image_height,
88 | width=setting.image_width,
89 | negative_prompt=setting.negative_prompt,
90 | num_images_per_prompt=setting.number_of_images,
91 | generator=generator,
92 | ).images
93 | return images
94 |
95 | def image_to_image(self, setting: StableDiffusionImageToImageSetting):
96 | if setting.scheduler is None:
97 | raise Exception("Scheduler cannot be empty")
98 |
99 | print("Running image to image pipeline")
100 | self.img_to_img_pipeline.scheduler = self.find_sampler( # type: ignore
101 | setting.scheduler,
102 | self.model_id,
103 | )
104 | generator = None
105 | if setting.seed != -1 and setting.seed:
106 | print(f"Using seed {setting.seed}")
107 | generator = torch.Generator(self.device).manual_seed(setting.seed)
108 |
109 | if setting.attention_slicing:
110 | self.img_to_img_pipeline.enable_attention_slicing() # type: ignore
111 | else:
112 | self.img_to_img_pipeline.disable_attention_slicing() # type: ignore
113 |
114 | if setting.vae_slicing:
115 | self.pipeline.enable_vae_slicing() # type: ignore
116 | else:
117 | self.pipeline.disable_vae_slicing() # type: ignore
118 |
119 | init_image = setting.image.resize(
120 | (
121 | setting.image_width,
122 | setting.image_height,
123 | ),
124 | Image.Resampling.LANCZOS,
125 | )
126 | images = self.img_to_img_pipeline( # type: ignore
127 | image=init_image,
128 | strength=setting.strength,
129 | prompt=setting.prompt,
130 | guidance_scale=setting.guidance_scale,
131 | num_inference_steps=setting.inference_steps,
132 | negative_prompt=setting.negative_prompt,
133 | num_images_per_prompt=setting.number_of_images,
134 | generator=generator,
135 | ).images
136 | return images
137 |
138 | def _pipeline_to_device(self):
139 | if self.low_vram_mode:
140 | print("Running in low VRAM mode,slower to generate images")
141 | self.pipeline.enable_sequential_cpu_offload()
142 | else:
143 | if self.compute.name == "cuda":
144 | self.pipeline = self.pipeline.to("cuda")
145 | elif self.compute.name == "mps":
146 | self.pipeline = self.pipeline.to("mps")
147 |
148 | def _load_full_precision_model(self):
149 | self.pipeline = StableDiffusionPipeline.from_pretrained(
150 | self.model_id,
151 | torch_dtype=self.compute.datatype,
152 | scheduler=self.default_sampler,
153 | )
154 |
155 | def _load_model(self):
156 | if self.compute.name == "cuda":
157 | try:
158 | self.pipeline = StableDiffusionPipeline.from_pretrained(
159 | self.model_id,
160 | torch_dtype=self.compute.datatype,
161 | scheduler=self.default_sampler,
162 | revision="fp16",
163 | )
164 | except Exception as ex:
165 | print(
166 | f" The fp16 of the model not found using full precision model, {ex}"
167 | )
168 | self._load_full_precision_model()
169 | else:
170 | self._load_full_precision_model()
171 |
--------------------------------------------------------------------------------
/src/backend/stablediffusion/stablediffusionxl.py:
--------------------------------------------------------------------------------
1 | from time import time
2 |
3 | from torch import Generator
4 | from diffusers import (
5 | DiffusionPipeline,
6 | StableDiffusionXLImg2ImgPipeline,
7 | )
8 | from PIL import Image
9 |
10 | from backend.computing import Computing
11 | from backend.stablediffusion.modelmeta import ModelMeta
12 | from backend.stablediffusion.models.scheduler_types import SchedulerType
13 | from backend.stablediffusion.models.setting import (
14 | StableDiffusionImageToImageSetting,
15 | StableDiffusionSetting,
16 | )
17 | from backend.stablediffusion.scheduler_mixin import SamplerMixin
18 |
19 |
20 | class StableDiffusionXl(SamplerMixin):
21 | def __init__(self, compute: Computing):
22 | self.compute = compute
23 | self.pipeline = None
24 | self.device = self.compute.name
25 |
26 | super().__init__()
27 |
28 | def get_text_to_image_xl_pipleline(
29 | self,
30 | model_id: str = "stabilityai/stable-diffusion-xl-base-1.0",
31 | low_vram_mode: bool = False,
32 | sampler: str = SchedulerType.DPMSolverMultistepScheduler.value,
33 | ):
34 | repo_id = model_id
35 | model_meta = ModelMeta(repo_id)
36 | is_lora_model = model_meta.is_loramodel()
37 | if is_lora_model:
38 | print("LoRA model detected")
39 | self.model_id = model_meta.get_lora_base_model()
40 | print(f"LoRA base model - {self.model_id}")
41 | else:
42 | self.model_id = model_id
43 |
44 | self.low_vram_mode = low_vram_mode
45 | print(f"StableDiffusion - {self.compute.name},{self.compute.datatype}")
46 | print(f"using model {model_id}")
47 | self.default_sampler = self.find_sampler(
48 | sampler,
49 | self.model_id,
50 | )
51 | tic = time()
52 | self._load_model()
53 | delta = time() - tic
54 | print(f"Model loaded in {delta:.2f}s ")
55 |
56 | if self.pipeline is None:
57 | raise Exception("Text to image pipeline not initialized")
58 | if is_lora_model:
59 | self.pipeline.unet.load_attn_procs(repo_id)
60 | self._pipeline_to_device()
61 | components = self.pipeline.components
62 | self.img_to_img_pipeline = StableDiffusionXLImg2ImgPipeline(**components)
63 |
64 | def text_to_image_xl(self, setting: StableDiffusionSetting):
65 | if self.pipeline is None:
66 | raise Exception("Text to image pipeline not initialized")
67 |
68 | self.pipeline.scheduler = self.find_sampler(
69 | setting.scheduler,
70 | self.model_id,
71 | )
72 | generator = None
73 | if setting.seed != -1:
74 | print(f"Using seed {setting.seed}")
75 | generator = Generator(self.device).manual_seed(setting.seed)
76 |
77 | # if setting.attention_slicing:
78 | # self.pipeline.enable_attention_slicing()
79 | # else:
80 | # self.pipeline.disable_attention_slicing()
81 |
82 | if setting.vae_slicing:
83 | self.pipeline.enable_vae_slicing()
84 | else:
85 | self.pipeline.disable_vae_slicing()
86 |
87 | images = self.pipeline(
88 | setting.prompt,
89 | guidance_scale=setting.guidance_scale,
90 | num_inference_steps=setting.inference_steps,
91 | height=setting.image_height,
92 | width=setting.image_width,
93 | negative_prompt=setting.negative_prompt,
94 | num_images_per_prompt=setting.number_of_images,
95 | generator=generator,
96 | ).images
97 |
98 | # self.pipeline.unet = torch.compile(
99 | # self.pipeline.unet,
100 | # mode="reduce-overhead",
101 | # fullgraph=True,
102 | # )
103 | return images
104 |
105 | def _pipeline_to_device(self):
106 | if self.low_vram_mode:
107 | print("Running in low VRAM mode,slower to generate images")
108 | self.pipeline.enable_sequential_cpu_offload()
109 | else:
110 | if self.compute.name == "cuda":
111 | self.pipeline = self.pipeline.to("cuda")
112 | elif self.compute.name == "mps":
113 | self.pipeline = self.pipeline.to("mps")
114 |
115 | def _load_full_precision_model(self):
116 | self.pipeline = DiffusionPipeline.from_pretrained(
117 | self.model_id,
118 | torch_dtype=self.compute.datatype,
119 | scheduler=self.default_sampler,
120 | )
121 |
122 | def _load_model(self):
123 | if self.compute.name == "cuda":
124 | try:
125 | self.pipeline = DiffusionPipeline.from_pretrained(
126 | self.model_id,
127 | torch_dtype=self.compute.datatype,
128 | scheduler=self.default_sampler,
129 | use_safetensors=True,
130 | variant="fp16",
131 | )
132 | except Exception as ex:
133 | print(
134 | f" The fp16 of the model not found using full precision model, {ex}"
135 | )
136 | self._load_full_precision_model()
137 | else:
138 | self._load_full_precision_model()
139 |
140 | def image_to_image(self, setting: StableDiffusionImageToImageSetting):
141 | if setting.scheduler is None:
142 | raise Exception("Scheduler cannot be empty")
143 |
144 | print("Running image to image pipeline")
145 | self.img_to_img_pipeline.scheduler = self.find_sampler( # type: ignore
146 | setting.scheduler,
147 | self.model_id,
148 | )
149 | generator = None
150 | if setting.seed != -1 and setting.seed:
151 | print(f"Using seed {setting.seed}")
152 | generator = Generator(self.device).manual_seed(setting.seed)
153 |
154 | if setting.attention_slicing:
155 | self.img_to_img_pipeline.enable_attention_slicing() # type: ignore
156 | else:
157 | self.img_to_img_pipeline.disable_attention_slicing() # type: ignore
158 |
159 | if setting.vae_slicing:
160 | self.pipeline.enable_vae_slicing() # type: ignore
161 | else:
162 | self.pipeline.disable_vae_slicing() # type: ignore
163 |
164 | init_image = setting.image.resize(
165 | (
166 | setting.image_width,
167 | setting.image_height,
168 | ),
169 | Image.Resampling.LANCZOS,
170 | )
171 | images = self.img_to_img_pipeline( # type: ignore
172 | image=init_image,
173 | strength=setting.strength,
174 | prompt=setting.prompt,
175 | guidance_scale=setting.guidance_scale,
176 | num_inference_steps=setting.inference_steps,
177 | negative_prompt=setting.negative_prompt,
178 | num_images_per_prompt=setting.number_of_images,
179 | generator=generator,
180 | ).images
181 | return images
182 |
--------------------------------------------------------------------------------
/src/backend/upscaler.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from diffusers import StableDiffusionLatentUpscalePipeline
3 |
4 | # load model and scheduler
5 | # https://github.com/huggingface/diffusers/pull/2059
6 | upscale_model_id = "stabilityai/sd-x2-latent-upscaler"
7 | upscaler = StableDiffusionLatentUpscalePipeline.from_pretrained(
8 | upscale_model_id, torch_dtype=torch.float16
9 | )
10 | upscaler.to("cuda")
11 |
--------------------------------------------------------------------------------
/src/backend/wuerstchen/models/setting.py:
--------------------------------------------------------------------------------
1 | from pydantic import BaseModel
2 | from typing import Optional
3 |
4 |
5 | class WurstchenSetting(BaseModel):
6 | prompt: str
7 | negative_prompt: Optional[str]
8 | image_height: Optional[int] = 512
9 | image_width: Optional[int] = 512
10 | prior_guidance_scale: Optional[float] = 4.0
11 | number_of_images: Optional[int] = 1
12 | seed: Optional[int] = -1
13 |
--------------------------------------------------------------------------------
/src/backend/wuerstchen/wuerstchen.py:
--------------------------------------------------------------------------------
1 | from time import time
2 |
3 | from backend.computing import Computing
4 | from backend.wuerstchen.models.setting import WurstchenSetting
5 | from torch import Generator
6 | from diffusers.pipelines.wuerstchen import DEFAULT_STAGE_C_TIMESTEPS
7 | from diffusers import AutoPipelineForText2Image
8 |
9 |
10 | class Wuerstchen:
11 | def __init__(self, compute: Computing):
12 | self.compute = compute
13 | self.pipeline = None
14 | self.device = self.compute.name
15 | super().__init__()
16 |
17 | def get_text_to_image_wuerstchen_pipleline(
18 | self,
19 | model_id: str = "warp-ai/wuerstchen",
20 | low_vram_mode: bool = False,
21 | ):
22 | self.model_id = model_id
23 |
24 | self.low_vram_mode = low_vram_mode
25 | print(f"Wuerstchen - {self.compute.name},{self.compute.datatype}")
26 | print(f"using model {model_id}")
27 | tic = time()
28 | self._load_model()
29 | self._pipeline_to_device()
30 | delta = time() - tic
31 | print(f"Model loaded in {delta:.2f}s ")
32 |
33 | def text_to_image_wuerstchen(self, setting: WurstchenSetting):
34 | if self.pipeline is None:
35 | raise Exception("Text to image pipeline not initialized")
36 |
37 | generator = None
38 | if setting.seed != -1:
39 | print(f"Using seed {setting.seed}")
40 | generator = Generator(self.device).manual_seed(setting.seed)
41 |
42 | images = self.pipeline(
43 | setting.prompt,
44 | negative_prompt=setting.negative_prompt,
45 | height=setting.image_height,
46 | width=setting.image_width,
47 | prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS,
48 | prior_guidance_scale=setting.prior_guidance_scale,
49 | num_images_per_prompt=setting.number_of_images,
50 | generator=generator,
51 | ).images
52 |
53 | return images
54 |
55 | def _pipeline_to_device(self):
56 | if self.low_vram_mode:
57 | print("Running in low VRAM mode,slower to generate images")
58 | self.pipeline.enable_sequential_cpu_offload()
59 | else:
60 | if self.compute.name == "cuda":
61 | self.pipeline = self.pipeline.to("cuda")
62 | elif self.compute.name == "mps":
63 | self.pipeline = self.pipeline.to("mps")
64 |
65 | def _load_full_precision_model(self):
66 | self.pipeline = AutoPipelineForText2Image.from_pretrained(
67 | self.model_id,
68 | torch_dtype=self.compute.datatype,
69 | )
70 |
71 | def _load_model(self):
72 | if self.compute.name == "cuda":
73 | try:
74 | self.pipeline = AutoPipelineForText2Image.from_pretrained(
75 | self.model_id,
76 | torch_dtype=self.compute.datatype,
77 | )
78 | except Exception as ex:
79 | print(
80 | f" The fp16 of the model not found using full precision model, {ex}"
81 | )
82 | self._load_full_precision_model()
83 | else:
84 | self._load_full_precision_model()
85 |
--------------------------------------------------------------------------------
/src/constants.py:
--------------------------------------------------------------------------------
1 | VERSION = "3.6.0"
2 | STABLE_DIFFUSION_MODELS_FILE = "stable_diffusion_models.txt"
3 | APP_SETTINGS_FILE = "settings.yaml"
4 | CONFIG_DIRECTORY = "configs"
5 | RESULTS_DIRECTORY = "results"
6 |
--------------------------------------------------------------------------------
/src/frontend/web/controlnet/controlnet_image_ui.py:
--------------------------------------------------------------------------------
1 | from typing import Any
2 |
3 | import gradio as gr
4 |
5 | from backend.stablediffusion.models.scheduler_types import (
6 | SchedulerType,
7 | get_sampler_names,
8 | )
9 |
10 | random_enabled = True
11 |
12 |
13 | def get_controlnet_to_image_ui(generate_callback_fn: Any) -> None:
14 | with gr.Blocks():
15 | with gr.Row():
16 | with gr.Column():
17 |
18 | def random_seed():
19 | global random_enabled
20 | random_enabled = not random_enabled
21 | seed_val = -1
22 | if not random_enabled:
23 | seed_val = 42
24 |
25 | return gr.Number.update(
26 | interactive=not random_enabled, value=seed_val
27 | )
28 |
29 | input_image = gr.Image(label="Input image", type="pil")
30 |
31 | prompt = gr.Textbox(
32 | label="Describe the image you'd like to see",
33 | lines=3,
34 | placeholder="A fantasy landscape",
35 | )
36 |
37 | neg_prompt = gr.Textbox(
38 | label="Don't want to see",
39 | lines=1,
40 | placeholder="",
41 | value="bad, deformed, ugly, bad anatomy",
42 | )
43 | with gr.Accordion("Advanced options", open=False):
44 | image_height = gr.Slider(
45 | 512, 2048, value=512, step=64, label="Image Height"
46 | )
47 | image_width = gr.Slider(
48 | 512, 2048, value=512, step=64, label="Image Width"
49 | )
50 | num_inference_steps = gr.Slider(
51 | 1, 100, value=20, step=1, label="Inference Steps"
52 | )
53 | scheduler = gr.Dropdown(
54 | get_sampler_names(),
55 | value=SchedulerType.UniPCMultistepScheduler.value,
56 | label="Sampler",
57 | )
58 | guidance_scale = gr.Slider(
59 | 1.0,
60 | 30.0,
61 | value=7.5,
62 | step=0.5,
63 | label="Guidance Scale",
64 | )
65 | num_images = gr.Slider(
66 | 1,
67 | 50,
68 | value=1,
69 | step=1,
70 | label="Number of images to generate",
71 | )
72 | attn_slicing = gr.Checkbox(
73 | label="Attention slicing (Enable if low VRAM)",
74 | value=True,
75 | )
76 | vae_slicing = gr.Checkbox(
77 | label="VAE slicing (Enable if low VRAM)",
78 | value=True,
79 | )
80 | seed = gr.Number(
81 | label="Seed",
82 | value=-1,
83 | precision=0,
84 | interactive=False,
85 | )
86 | seed_checkbox = gr.Checkbox(
87 | label="Use random seed",
88 | value=True,
89 | interactive=True,
90 | )
91 |
92 | input_params = [
93 | input_image,
94 | prompt,
95 | neg_prompt,
96 | image_height,
97 | image_width,
98 | num_inference_steps,
99 | scheduler,
100 | guidance_scale,
101 | num_images,
102 | attn_slicing,
103 | vae_slicing,
104 | seed,
105 | ]
106 |
107 | with gr.Column():
108 | generate_btn = gr.Button("Generate", elem_id="generate_button")
109 | output = gr.Gallery(
110 | label="Generated images",
111 | show_label=True,
112 | elem_id="gallery",
113 | ).style(
114 | grid=2,
115 | )
116 | generate_btn.click(
117 | fn=generate_callback_fn,
118 | inputs=input_params,
119 | outputs=output,
120 | )
121 | seed_checkbox.change(fn=random_seed, outputs=seed)
122 |
--------------------------------------------------------------------------------
/src/frontend/web/css/style.css:
--------------------------------------------------------------------------------
1 | footer {
2 | visibility: hidden
3 | }
4 |
5 | #generate_button {
6 | color: white;
7 | border-color: #007bff;
8 | background: #007bff;
9 | width: 200px;
10 | height: 50px;
11 | }
12 |
13 | #save_button {
14 | color: white;
15 | border-color: #028b40;
16 | background: #01b97c;
17 | width: 200px;
18 | }
19 |
20 | #settings_header {
21 | background: rgb(245, 105, 105);
22 |
23 | }
--------------------------------------------------------------------------------
/src/frontend/web/depth_to_image_ui.py:
--------------------------------------------------------------------------------
1 | from typing import Any
2 |
3 | import gradio as gr
4 |
5 | from backend.stablediffusion.models.scheduler_types import (
6 | get_sampler_names,
7 | SchedulerType,
8 | )
9 |
10 | random_enabled = True
11 |
12 |
13 | def get_depth_to_image_ui(generate_callback_fn: Any) -> None:
14 | with gr.Blocks():
15 | with gr.Row():
16 | with gr.Column():
17 |
18 | def random_seed():
19 | global random_enabled
20 | random_enabled = not random_enabled
21 | seed_val = -1
22 | if not random_enabled:
23 | seed_val = 42
24 |
25 | return gr.Number.update(
26 | interactive=not random_enabled, value=seed_val
27 | )
28 |
29 | input_image = gr.Image(label="Input image", type="pil")
30 | strength = gr.Slider(
31 | 0.0,
32 | 1.0,
33 | value=0.8,
34 | step=0.05,
35 | label="Strength",
36 | )
37 |
38 | prompt = gr.Textbox(
39 | label="Describe the image you'd like to see",
40 | lines=3,
41 | placeholder="A fantasy landscape",
42 | )
43 |
44 | neg_prompt = gr.Textbox(
45 | label="Don't want to see",
46 | lines=1,
47 | placeholder="",
48 | value="bad, deformed, ugly, bad anatomy",
49 | )
50 | with gr.Accordion("Advanced options", open=False):
51 | image_height = gr.Slider(
52 | 512, 2048, value=512, step=64, label="Image Height"
53 | )
54 | image_width = gr.Slider(
55 | 512, 2048, value=512, step=64, label="Image Width"
56 | )
57 | num_inference_steps = gr.Slider(
58 | 1, 100, value=20, step=1, label="Inference Steps"
59 | )
60 | scheduler = gr.Dropdown(
61 | get_sampler_names(),
62 | value=SchedulerType.DPMSolverMultistepScheduler.value,
63 | label="Sampler",
64 | )
65 | guidance_scale = gr.Slider(
66 | 1.0,
67 | 30.0,
68 | value=7.5,
69 | step=0.5,
70 | label="Guidance Scale",
71 | )
72 | num_images = gr.Slider(
73 | 1,
74 | 50,
75 | value=1,
76 | step=1,
77 | label="Number of images to generate",
78 | )
79 | attn_slicing = gr.Checkbox(
80 | label="Attention slicing (Enable if low VRAM)",
81 | value=True,
82 | )
83 | seed = gr.Number(
84 | label="Seed",
85 | value=-1,
86 | precision=0,
87 | interactive=False,
88 | )
89 | seed_checkbox = gr.Checkbox(
90 | label="Use random seed",
91 | value=True,
92 | interactive=True,
93 | )
94 |
95 | input_params = [
96 | input_image,
97 | strength,
98 | prompt,
99 | neg_prompt,
100 | image_height,
101 | image_width,
102 | num_inference_steps,
103 | scheduler,
104 | guidance_scale,
105 | num_images,
106 | attn_slicing,
107 | seed,
108 | ]
109 |
110 | with gr.Column():
111 | generate_btn = gr.Button("Generate", elem_id="generate_button")
112 | output = gr.Gallery(
113 | label="Generated images",
114 | show_label=True,
115 | elem_id="gallery",
116 | columns=2,
117 | )
118 |
119 | generate_btn.click(
120 | fn=generate_callback_fn,
121 | inputs=input_params,
122 | outputs=output,
123 | )
124 | seed_checkbox.change(fn=random_seed, outputs=seed)
125 |
--------------------------------------------------------------------------------
/src/frontend/web/image_inpainting_ui.py:
--------------------------------------------------------------------------------
1 | from typing import Any
2 |
3 | import gradio as gr
4 |
5 | from backend.stablediffusion.models.scheduler_types import (
6 | SchedulerType,
7 | get_sampler_names,
8 | )
9 |
10 | random_enabled = True
11 |
12 |
13 | def get_image_inpainting_ui(generate_callback_fn: Any) -> None:
14 | with gr.Blocks():
15 | with gr.Row():
16 | with gr.Column():
17 |
18 | def random_seed():
19 | global random_enabled
20 | random_enabled = not random_enabled
21 | seed_val = -1
22 | if not random_enabled:
23 | seed_val = 42
24 |
25 | return gr.Number.update(
26 | interactive=not random_enabled, value=seed_val
27 | )
28 |
29 | input_image = gr.Image(label="Input image", type="pil", tool="sketch")
30 | prompt = gr.Textbox(
31 | label="Describe the image you'd like to see",
32 | lines=3,
33 | placeholder="A fantasy landscape",
34 | )
35 |
36 | neg_prompt = gr.Textbox(
37 | label="Don't want to see",
38 | lines=1,
39 | placeholder="",
40 | value="bad, deformed, ugly, bad anatomy",
41 | )
42 | with gr.Accordion("Advanced options", open=False):
43 | image_height = gr.Slider(
44 | 512, 2048, value=512, step=64, label="Image Height"
45 | )
46 | image_width = gr.Slider(
47 | 512, 2048, value=512, step=64, label="Image Width"
48 | )
49 | num_inference_steps = gr.Slider(
50 | 1, 100, value=20, step=1, label="Inference Steps"
51 | )
52 | scheduler = gr.Dropdown(
53 | get_sampler_names(),
54 | value=SchedulerType.DPMSolverMultistepScheduler.value,
55 | label="Sampler",
56 | )
57 | guidance_scale = gr.Slider(
58 | 1.0,
59 | 30.0,
60 | value=7.5,
61 | step=0.5,
62 | label="Guidance Scale",
63 | )
64 | num_images = gr.Slider(
65 | 1,
66 | 50,
67 | value=1,
68 | step=1,
69 | label="Number of images to generate",
70 | )
71 | attn_slicing = gr.Checkbox(
72 | label="Attention slicing (Not used)",
73 | value=True,
74 | )
75 | seed = gr.Number(
76 | label="Seed",
77 | value=-1,
78 | precision=0,
79 | interactive=False,
80 | )
81 | seed_checkbox = gr.Checkbox(
82 | label="Use random seed",
83 | value=True,
84 | interactive=True,
85 | )
86 |
87 | input_params = [
88 | input_image,
89 | prompt,
90 | neg_prompt,
91 | image_height,
92 | image_width,
93 | num_inference_steps,
94 | scheduler,
95 | guidance_scale,
96 | num_images,
97 | attn_slicing,
98 | seed,
99 | ]
100 |
101 | with gr.Column():
102 | generate_btn = gr.Button("Inpaint!", elem_id="generate_button")
103 | output = gr.Gallery(
104 | label="Generated images",
105 | show_label=True,
106 | elem_id="gallery",
107 | columns=2,
108 | )
109 | generate_btn.click(
110 | fn=generate_callback_fn,
111 | inputs=input_params,
112 | outputs=output,
113 | )
114 | seed_checkbox.change(fn=random_seed, outputs=seed)
115 |
--------------------------------------------------------------------------------
/src/frontend/web/image_inpainting_xl_ui.py:
--------------------------------------------------------------------------------
1 | from typing import Any
2 |
3 | import gradio as gr
4 |
5 | from backend.stablediffusion.models.scheduler_types import (
6 | SchedulerType,
7 | get_sampler_names,
8 | )
9 |
10 | random_enabled = True
11 |
12 |
13 | def get_image_inpainting_xl_ui(generate_callback_fn: Any) -> None:
14 | with gr.Blocks():
15 | with gr.Row():
16 | with gr.Column():
17 |
18 | def random_seed():
19 | global random_enabled
20 | random_enabled = not random_enabled
21 | seed_val = -1
22 | if not random_enabled:
23 | seed_val = 42
24 |
25 | return gr.Number.update(
26 | interactive=not random_enabled, value=seed_val
27 | )
28 |
29 | input_image = gr.Image(label="Input image", type="pil", tool="sketch")
30 | prompt = gr.Textbox(
31 | label="Describe the image you'd like to see",
32 | lines=3,
33 | placeholder="A fantasy landscape",
34 | )
35 |
36 | neg_prompt = gr.Textbox(
37 | label="Don't want to see",
38 | lines=1,
39 | placeholder="",
40 | value="bad, deformed, ugly, bad anatomy",
41 | )
42 | with gr.Accordion("Advanced options", open=False):
43 | image_height = gr.Slider(
44 | 1024, 2048, value=1024, step=64, label="Image Height"
45 | )
46 | image_width = gr.Slider(
47 | 1024, 2048, value=1024, step=64, label="Image Width"
48 | )
49 | num_inference_steps = gr.Slider(
50 | 1, 100, value=20, step=1, label="Inference Steps"
51 | )
52 | scheduler = gr.Dropdown(
53 | get_sampler_names(),
54 | value=SchedulerType.DPMSolverMultistepScheduler.value,
55 | label="Sampler",
56 | )
57 | guidance_scale = gr.Slider(
58 | 1.0,
59 | 30.0,
60 | value=7.5,
61 | step=0.5,
62 | label="Guidance Scale",
63 | )
64 | num_images = gr.Slider(
65 | 1,
66 | 50,
67 | value=1,
68 | step=1,
69 | label="Number of images to generate",
70 | )
71 | attn_slicing = gr.Checkbox(
72 | label="Attention slicing (Enable if low VRAM)",
73 | value=True,
74 | )
75 | seed = gr.Number(
76 | label="Seed",
77 | value=-1,
78 | precision=0,
79 | interactive=False,
80 | )
81 | seed_checkbox = gr.Checkbox(
82 | label="Use random seed",
83 | value=True,
84 | interactive=True,
85 | )
86 |
87 | input_params = [
88 | input_image,
89 | prompt,
90 | neg_prompt,
91 | image_height,
92 | image_width,
93 | num_inference_steps,
94 | scheduler,
95 | guidance_scale,
96 | num_images,
97 | attn_slicing,
98 | seed,
99 | ]
100 |
101 | with gr.Column():
102 | generate_btn = gr.Button("Inpaint!", elem_id="generate_button")
103 | output = gr.Gallery(
104 | label="Generated images",
105 | show_label=True,
106 | elem_id="gallery",
107 | columns=2,
108 | )
109 | generate_btn.click(
110 | fn=generate_callback_fn,
111 | inputs=input_params,
112 | outputs=output,
113 | )
114 | seed_checkbox.change(fn=random_seed, outputs=seed)
115 |
--------------------------------------------------------------------------------
/src/frontend/web/image_to_image_ui.py:
--------------------------------------------------------------------------------
1 | from typing import Any
2 |
3 | import gradio as gr
4 |
5 | from backend.stablediffusion.models.scheduler_types import (
6 | SchedulerType,
7 | get_sampler_names,
8 | )
9 |
10 | random_enabled = True
11 |
12 |
13 | def get_image_to_image_ui(generate_callback_fn: Any) -> None:
14 | with gr.Blocks():
15 | with gr.Row():
16 | with gr.Column():
17 |
18 | def random_seed():
19 | global random_enabled
20 | random_enabled = not random_enabled
21 | seed_val = -1
22 | if not random_enabled:
23 | seed_val = 42
24 |
25 | return gr.Number.update(
26 | interactive=not random_enabled, value=seed_val
27 | )
28 |
29 | input_image = gr.Image(label="Input image", type="pil")
30 | strength = gr.Slider(
31 | 0.0,
32 | 1.0,
33 | value=0.75,
34 | step=0.05,
35 | label="Strength",
36 | )
37 |
38 | prompt = gr.Textbox(
39 | label="Describe the image you'd like to see",
40 | lines=3,
41 | placeholder="A fantasy landscape",
42 | )
43 |
44 | neg_prompt = gr.Textbox(
45 | label="Don't want to see",
46 | lines=1,
47 | placeholder="",
48 | value="bad, deformed, ugly, bad anatomy",
49 | )
50 | with gr.Accordion("Advanced options", open=False):
51 | image_height = gr.Slider(
52 | 512, 2048, value=512, step=64, label="Image Height"
53 | )
54 | image_width = gr.Slider(
55 | 512, 2048, value=512, step=64, label="Image Width"
56 | )
57 | num_inference_steps = gr.Slider(
58 | 1, 100, value=20, step=1, label="Inference Steps"
59 | )
60 | scheduler = gr.Dropdown(
61 | get_sampler_names(),
62 | value=SchedulerType.DPMSolverMultistepScheduler.value,
63 | label="Sampler",
64 | )
65 | guidance_scale = gr.Slider(
66 | 1.0,
67 | 30.0,
68 | value=7.5,
69 | step=0.5,
70 | label="Guidance Scale",
71 | )
72 | num_images = gr.Slider(
73 | 1,
74 | 50,
75 | value=1,
76 | step=1,
77 | label="Number of images to generate",
78 | )
79 | attn_slicing = gr.Checkbox(
80 | label="Attention slicing (Enable if low VRAM)",
81 | value=True,
82 | )
83 | seed = gr.Number(
84 | label="Seed",
85 | value=-1,
86 | precision=0,
87 | interactive=False,
88 | )
89 | seed_checkbox = gr.Checkbox(
90 | label="Use random seed",
91 | value=True,
92 | interactive=True,
93 | )
94 |
95 | input_params = [
96 | input_image,
97 | strength,
98 | prompt,
99 | neg_prompt,
100 | image_height,
101 | image_width,
102 | num_inference_steps,
103 | scheduler,
104 | guidance_scale,
105 | num_images,
106 | attn_slicing,
107 | seed,
108 | ]
109 |
110 | with gr.Column():
111 | generate_btn = gr.Button("Generate", elem_id="generate_button")
112 | output = gr.Gallery(
113 | label="Generated images",
114 | show_label=True,
115 | elem_id="gallery",
116 | columns=2,
117 | )
118 | generate_btn.click(
119 | fn=generate_callback_fn,
120 | inputs=input_params,
121 | outputs=output,
122 | )
123 | seed_checkbox.change(fn=random_seed, outputs=seed)
124 |
--------------------------------------------------------------------------------
/src/frontend/web/image_to_image_xl_ui.py:
--------------------------------------------------------------------------------
1 | from typing import Any
2 |
3 | import gradio as gr
4 |
5 | from backend.stablediffusion.models.scheduler_types import (
6 | SchedulerType,
7 | get_sampler_names,
8 | )
9 |
10 | random_enabled = True
11 |
12 |
13 | def get_image_to_image_xl_ui(generate_callback_fn: Any) -> None:
14 | with gr.Blocks():
15 | with gr.Row():
16 | with gr.Column():
17 |
18 | def random_seed():
19 | global random_enabled
20 | random_enabled = not random_enabled
21 | seed_val = -1
22 | if not random_enabled:
23 | seed_val = 42
24 |
25 | return gr.Number.update(
26 | interactive=not random_enabled, value=seed_val
27 | )
28 |
29 | input_image = gr.Image(label="Input image", type="pil")
30 | strength = gr.Slider(
31 | 0.0,
32 | 1.0,
33 | value=0.75,
34 | step=0.05,
35 | label="Strength",
36 | )
37 |
38 | prompt = gr.Textbox(
39 | label="Describe the image you'd like to see",
40 | lines=3,
41 | placeholder="A fantasy landscape",
42 | )
43 |
44 | neg_prompt = gr.Textbox(
45 | label="Don't want to see",
46 | lines=1,
47 | placeholder="",
48 | value="bad, deformed, ugly, bad anatomy",
49 | )
50 | with gr.Accordion("Advanced options", open=False):
51 | image_height = gr.Slider(
52 | 768, 2048, value=1024, step=64, label="Image Height"
53 | )
54 | image_width = gr.Slider(
55 | 768, 2048, value=1024, step=64, label="Image Width"
56 | )
57 | num_inference_steps = gr.Slider(
58 | 1, 100, value=20, step=1, label="Inference Steps"
59 | )
60 | scheduler = gr.Dropdown(
61 | get_sampler_names(),
62 | value=SchedulerType.UniPCMultistepScheduler.value,
63 | label="Sampler",
64 | )
65 | guidance_scale = gr.Slider(
66 | 1.0,
67 | 30.0,
68 | value=7.5,
69 | step=0.5,
70 | label="Guidance Scale",
71 | )
72 | num_images = gr.Slider(
73 | 1,
74 | 50,
75 | value=1,
76 | step=1,
77 | label="Number of images to generate",
78 | )
79 | attn_slicing = gr.Checkbox(
80 | label="Attention slicing (Not supported)",
81 | value=False,
82 | interactive=False,
83 | )
84 | seed = gr.Number(
85 | label="Seed",
86 | value=-1,
87 | precision=0,
88 | interactive=False,
89 | )
90 | seed_checkbox = gr.Checkbox(
91 | label="Use random seed",
92 | value=True,
93 | interactive=True,
94 | )
95 |
96 | input_params = [
97 | input_image,
98 | strength,
99 | prompt,
100 | neg_prompt,
101 | image_height,
102 | image_width,
103 | num_inference_steps,
104 | scheduler,
105 | guidance_scale,
106 | num_images,
107 | attn_slicing,
108 | seed,
109 | ]
110 |
111 | with gr.Column():
112 | generate_btn = gr.Button("Generate", elem_id="generate_button")
113 | output = gr.Gallery(
114 | label="Generated images",
115 | show_label=True,
116 | elem_id="gallery",
117 | columns=2,
118 | )
119 | generate_btn.click(
120 | fn=generate_callback_fn,
121 | inputs=input_params,
122 | outputs=output,
123 | )
124 | seed_checkbox.change(fn=random_seed, outputs=seed)
125 |
--------------------------------------------------------------------------------
/src/frontend/web/image_variations_ui.py:
--------------------------------------------------------------------------------
1 | from typing import Any
2 |
3 | import gradio as gr
4 |
5 | from backend.stablediffusion.models.scheduler_types import (
6 | SchedulerType,
7 | get_sampler_names,
8 | )
9 |
10 | random_enabled = True
11 |
12 |
13 | def get_image_variations_ui(generate_callback_fn: Any) -> None:
14 | with gr.Blocks():
15 | with gr.Row():
16 | with gr.Column():
17 |
18 | def random_seed():
19 | global random_enabled
20 | random_enabled = not random_enabled
21 | seed_val = -1
22 | if not random_enabled:
23 | seed_val = 42
24 |
25 | return gr.Number.update(
26 | interactive=not random_enabled, value=seed_val
27 | )
28 |
29 | input_image = gr.Image(label="Input image", type="pil")
30 | strength = gr.Slider(
31 | 0.0,
32 | 1.0,
33 | value=0.65,
34 | step=0.05,
35 | label="Variation Strength",
36 | )
37 | with gr.Accordion("Advanced options", open=False):
38 | image_height = gr.Slider(
39 | 512, 2048, value=512, step=64, label="Image Height"
40 | )
41 | image_width = gr.Slider(
42 | 512, 2048, value=512, step=64, label="Image Width"
43 | )
44 | num_inference_steps = gr.Slider(
45 | 1, 100, value=20, step=1, label="Inference Steps"
46 | )
47 | scheduler = gr.Dropdown(
48 | get_sampler_names(),
49 | value=SchedulerType.UniPCMultistepScheduler.value,
50 | label="Sampler",
51 | )
52 | guidance_scale = gr.Slider(
53 | 1.0,
54 | 30.0,
55 | value=7.5,
56 | step=0.5,
57 | label="Guidance Scale",
58 | )
59 | num_images = gr.Slider(
60 | 1,
61 | 50,
62 | value=1,
63 | step=1,
64 | label="Number of images to generate",
65 | )
66 | attn_slicing = gr.Checkbox(
67 | label="Attention slicing (Enable if low VRAM)",
68 | value=True,
69 | )
70 | seed = gr.Number(
71 | label="Seed",
72 | value=-1,
73 | precision=0,
74 | interactive=False,
75 | )
76 | seed_checkbox = gr.Checkbox(
77 | label="Use random seed",
78 | value=True,
79 | interactive=True,
80 | )
81 |
82 | input_params = [
83 | input_image,
84 | strength,
85 | image_height,
86 | image_width,
87 | num_inference_steps,
88 | scheduler,
89 | guidance_scale,
90 | num_images,
91 | attn_slicing,
92 | seed,
93 | ]
94 |
95 | with gr.Column():
96 | generate_btn = gr.Button("Generate", elem_id="generate_button")
97 | output = gr.Gallery(
98 | label="Generated images",
99 | show_label=True,
100 | elem_id="gallery",
101 | columns=2,
102 | )
103 | generate_btn.click(
104 | fn=generate_callback_fn,
105 | inputs=input_params,
106 | outputs=output,
107 | )
108 | seed_checkbox.change(fn=random_seed, outputs=seed)
109 |
--------------------------------------------------------------------------------
/src/frontend/web/image_variations_xl_ui.py:
--------------------------------------------------------------------------------
1 | from typing import Any
2 |
3 | import gradio as gr
4 |
5 | from backend.stablediffusion.models.scheduler_types import (
6 | SchedulerType,
7 | get_sampler_names,
8 | )
9 |
10 | random_enabled = True
11 |
12 |
13 | def get_image_variations_xl_ui(generate_callback_fn: Any) -> None:
14 | with gr.Blocks():
15 | with gr.Row():
16 | with gr.Column():
17 |
18 | def random_seed():
19 | global random_enabled
20 | random_enabled = not random_enabled
21 | seed_val = -1
22 | if not random_enabled:
23 | seed_val = 42
24 |
25 | return gr.Number.update(
26 | interactive=not random_enabled, value=seed_val
27 | )
28 |
29 | input_image = gr.Image(label="Input image", type="pil")
30 | strength = gr.Slider(
31 | 0.0,
32 | 1.0,
33 | value=0.8,
34 | step=0.05,
35 | label="Variation Strength",
36 | )
37 | with gr.Accordion("Advanced options", open=False):
38 | image_height = gr.Slider(
39 | 768, 2048, value=1024, step=64, label="Image Height"
40 | )
41 | image_width = gr.Slider(
42 | 768, 2048, value=1024, step=64, label="Image Width"
43 | )
44 | num_inference_steps = gr.Slider(
45 | 1, 100, value=20, step=1, label="Inference Steps"
46 | )
47 | scheduler = gr.Dropdown(
48 | get_sampler_names(),
49 | value=SchedulerType.UniPCMultistepScheduler.value,
50 | label="Sampler",
51 | )
52 | guidance_scale = gr.Slider(
53 | 1.0,
54 | 30.0,
55 | value=7.5,
56 | step=0.5,
57 | label="Guidance Scale",
58 | )
59 | num_images = gr.Slider(
60 | 1,
61 | 50,
62 | value=2,
63 | step=1,
64 | label="Number of images to generate",
65 | )
66 | attn_slicing = gr.Checkbox(
67 | label="Attention slicing (Enable if low VRAM)",
68 | value=True,
69 | )
70 | seed = gr.Number(
71 | label="Seed",
72 | value=-1,
73 | precision=0,
74 | interactive=False,
75 | )
76 | seed_checkbox = gr.Checkbox(
77 | label="Use random seed",
78 | value=True,
79 | interactive=True,
80 | )
81 |
82 | input_params = [
83 | input_image,
84 | strength,
85 | image_height,
86 | image_width,
87 | num_inference_steps,
88 | scheduler,
89 | guidance_scale,
90 | num_images,
91 | attn_slicing,
92 | seed,
93 | ]
94 |
95 | with gr.Column():
96 | generate_btn = gr.Button("Generate", elem_id="generate_button")
97 | output = gr.Gallery(
98 | label="Generated images",
99 | show_label=True,
100 | elem_id="gallery",
101 | columns=2,
102 | )
103 | generate_btn.click(
104 | fn=generate_callback_fn,
105 | inputs=input_params,
106 | outputs=output,
107 | )
108 | seed_checkbox.change(fn=random_seed, outputs=seed)
109 |
--------------------------------------------------------------------------------
/src/frontend/web/instruct_pix_to_pix_ui.py:
--------------------------------------------------------------------------------
1 | from typing import Any
2 |
3 | import gradio as gr
4 |
5 | from backend.stablediffusion.models.scheduler_types import (
6 | SchedulerType,
7 | get_sampler_names,
8 | )
9 |
10 | random_enabled = True
11 |
12 |
13 | def get_instruct_pix_to_pix_ui(generate_callback_fn: Any) -> None:
14 | with gr.Blocks():
15 | with gr.Row():
16 | with gr.Column():
17 |
18 | def random_seed():
19 | global random_enabled
20 | random_enabled = not random_enabled
21 | seed_val = -1
22 | if not random_enabled:
23 | seed_val = 42
24 |
25 | return gr.Number.update(
26 | interactive=not random_enabled, value=seed_val
27 | )
28 |
29 | input_image = gr.Image(label="Input image", type="pil")
30 | image_guidance_scale = gr.Slider(
31 | 0.0,
32 | 2.0,
33 | value=1.5,
34 | step=0.05,
35 | label="Image Guidance Scale",
36 | )
37 |
38 | prompt = gr.Textbox(
39 | label="Edit Instruction",
40 | lines=3,
41 | placeholder="Add fireworks to the sky",
42 | )
43 |
44 | neg_prompt = gr.Textbox(
45 | label="Don't want to see",
46 | lines=1,
47 | placeholder="",
48 | value="bad, deformed, ugly, bad anatomy",
49 | )
50 | with gr.Accordion("Advanced options", open=False):
51 | image_height = gr.Slider(
52 | 512, 2048, value=512, step=64, label="Image Height"
53 | )
54 | image_width = gr.Slider(
55 | 512, 2048, value=512, step=64, label="Image Width"
56 | )
57 | num_inference_steps = gr.Slider(
58 | 1, 100, value=20, step=1, label="Inference Steps"
59 | )
60 | samplers = get_sampler_names()
61 | samplers.remove("DEISMultistep")
62 | scheduler = gr.Dropdown(
63 | samplers,
64 | value=SchedulerType.DPMSolverMultistepScheduler.value,
65 | label="Sampler",
66 | )
67 | guidance_scale = gr.Slider(
68 | 1.0,
69 | 30.0,
70 | value=7.5,
71 | step=0.5,
72 | label="Guidance Scale",
73 | )
74 | num_images = gr.Slider(
75 | 1,
76 | 50,
77 | value=1,
78 | step=1,
79 | label="Number of images to generate",
80 | )
81 | attn_slicing = gr.Checkbox(
82 | label="Attention slicing (Enable if low VRAM)",
83 | value=True,
84 | )
85 | seed = gr.Number(
86 | label="Seed",
87 | value=-1,
88 | precision=0,
89 | interactive=False,
90 | )
91 | seed_checkbox = gr.Checkbox(
92 | label="Use random seed",
93 | value=True,
94 | interactive=True,
95 | )
96 |
97 | input_params = [
98 | input_image,
99 | image_guidance_scale,
100 | prompt,
101 | neg_prompt,
102 | image_height,
103 | image_width,
104 | num_inference_steps,
105 | scheduler,
106 | guidance_scale,
107 | num_images,
108 | attn_slicing,
109 | seed,
110 | ]
111 |
112 | with gr.Column():
113 | generate_btn = gr.Button("Generate", elem_id="generate_button")
114 | output = gr.Gallery(
115 | label="Generated images",
116 | show_label=True,
117 | elem_id="gallery",
118 | columns=2,
119 | )
120 | generate_btn.click(
121 | fn=generate_callback_fn,
122 | inputs=input_params,
123 | outputs=output,
124 | )
125 | seed_checkbox.change(fn=random_seed, outputs=seed)
126 |
--------------------------------------------------------------------------------
/src/frontend/web/settings_ui.py:
--------------------------------------------------------------------------------
1 | import gradio as gr
2 | from hf_models import StableDiffusionModels
3 | from settings import AppSettings
4 | from datetime import datetime
5 |
6 |
7 | def save_app_settings(
8 | model_id,
9 | result_path,
10 | img_format,
11 | use_seperate_folder,
12 | enable_low_vram,
13 | ):
14 | app_settings = AppSettings()
15 | app_settings.get_settings().model_settings.model_id = model_id
16 | app_settings.get_settings().output_images.format = img_format
17 | app_settings.get_settings().output_images.path = result_path
18 | app_settings.get_settings().output_images.use_seperate_folders = use_seperate_folder
19 | app_settings.get_settings().low_memory_mode = enable_low_vram
20 | app_settings.save()
21 | now = datetime.now()
22 | current_time = now.strftime("%H:%M:%S")
23 | return "Settings last saved at " + current_time + ""
24 |
25 |
26 | def get_settings_ui() -> None:
27 | sd_models = StableDiffusionModels()
28 | sd_models.load_hf_models_from_text_file()
29 | app_settings = AppSettings().get_settings()
30 |
31 | with gr.Blocks():
32 | with gr.Row():
33 | with gr.Column():
34 | save_status = gr.HTML(
35 | "Some setting changes requires app restarts!
",
36 | elem_id="settings_header",
37 | )
38 | model_id = gr.Dropdown(
39 | sd_models.get_models(),
40 | value=app_settings.model_settings.model_id,
41 | label="Stable diffusion model (Restart required)",
42 | )
43 | result_path = gr.TextArea(
44 | label="Output folder (Generated images saved here)",
45 | value=app_settings.output_images.path,
46 | lines=1,
47 | )
48 | img_format = gr.Radio(
49 | label="Output image format",
50 | choices=["png", "jpeg"],
51 | value=app_settings.output_images.format,
52 | )
53 | use_seperate_folder = gr.Checkbox(
54 | label="Save in images in seperate folders (text2img,img2img etc)",
55 | value=app_settings.output_images.use_seperate_folders,
56 | )
57 | vram_label = (
58 | "Enable Low VRAM mode (GPUs with VRAM <4GB,"
59 | "slower to generate images) (Restart required)"
60 | )
61 | enable_low_vram = gr.Checkbox(
62 | label=vram_label,
63 | value=app_settings.low_memory_mode,
64 | )
65 | with gr.Column():
66 | save_button = gr.Button("Save", elem_id="save_button")
67 | save_status = gr.HTML("")
68 | save_button.click(
69 | fn=save_app_settings,
70 | inputs=[
71 | model_id,
72 | result_path,
73 | img_format,
74 | use_seperate_folder,
75 | enable_low_vram,
76 | ],
77 | outputs=save_status,
78 | )
79 |
--------------------------------------------------------------------------------
/src/frontend/web/text_to_image_ui.py:
--------------------------------------------------------------------------------
1 | from typing import Any
2 |
3 | import gradio as gr
4 |
5 | from backend.stablediffusion.models.scheduler_types import (
6 | SchedulerType,
7 | get_sampler_names,
8 | )
9 |
10 | random_enabled = True
11 |
12 |
13 | def get_text_to_image_ui(generate_callback_fn: Any) -> None:
14 | with gr.Blocks():
15 | with gr.Row():
16 | with gr.Column():
17 |
18 | def random_seed():
19 | global random_enabled
20 | random_enabled = not random_enabled
21 | seed_val = -1
22 | if not random_enabled:
23 | seed_val = 42
24 | return gr.Number.update(
25 | interactive=not random_enabled, value=seed_val
26 | )
27 |
28 | # with gr.Row():
29 | prompt = gr.Textbox(
30 | label="Describe the image you'd like to see",
31 | lines=3,
32 | placeholder="A fantasy landscape",
33 | )
34 | neg_prompt = gr.Textbox(
35 | label="Don't want to see",
36 | lines=1,
37 | placeholder="",
38 | value="bad, deformed, ugly, bad anatomy",
39 | )
40 | with gr.Accordion("Advanced options", open=False):
41 | image_height = gr.Slider(
42 | 512, 2048, value=512, step=64, label="Image Height"
43 | )
44 | image_width = gr.Slider(
45 | 512, 2048, value=512, step=64, label="Image Width"
46 | )
47 | num_inference_steps = gr.Slider(
48 | 1, 100, value=20, step=1, label="Inference Steps"
49 | )
50 | scheduler = gr.Dropdown(
51 | get_sampler_names(),
52 | value=SchedulerType.DPMSolverMultistepScheduler.value,
53 | label="Sampler",
54 | )
55 | guidance_scale = gr.Slider(
56 | 1.0, 30.0, value=7.5, step=0.5, label="Guidance Scale"
57 | )
58 | num_images = gr.Slider(
59 | 1,
60 | 50,
61 | value=1,
62 | step=1,
63 | label="Number of images to generate",
64 | )
65 | attn_slicing = gr.Checkbox(
66 | label="Attention slicing (Enable if low VRAM)",
67 | value=True,
68 | )
69 |
70 | vae_slicing = gr.Checkbox(
71 | label="VAE slicing (Enable if low VRAM)",
72 | value=True,
73 | )
74 | seed = gr.Number(
75 | label="Seed",
76 | value=-1,
77 | precision=0,
78 | interactive=False,
79 | )
80 | seed_checkbox = gr.Checkbox(
81 | label="Use random seed",
82 | value=True,
83 | interactive=True,
84 | )
85 |
86 | input_params = [
87 | prompt,
88 | neg_prompt,
89 | image_height,
90 | image_width,
91 | num_inference_steps,
92 | scheduler,
93 | guidance_scale,
94 | num_images,
95 | attn_slicing,
96 | vae_slicing,
97 | seed,
98 | ]
99 |
100 | with gr.Column():
101 | generate_btn = gr.Button("Generate", elem_id="generate_button")
102 | output = gr.Gallery(
103 | label="Generated images",
104 | show_label=True,
105 | elem_id="gallery",
106 | columns=2,
107 | )
108 | seed_checkbox.change(fn=random_seed, outputs=seed)
109 | generate_btn.click(
110 | fn=generate_callback_fn,
111 | inputs=input_params,
112 | outputs=output,
113 | )
114 |
--------------------------------------------------------------------------------
/src/frontend/web/text_to_image_wuerstchen_ui.py:
--------------------------------------------------------------------------------
1 | from typing import Any
2 | import gradio as gr
3 |
4 |
5 | random_enabled = True
6 |
7 |
8 | def get_text_to_image_wuerstchen_ui(generate_callback_fn: Any) -> None:
9 | with gr.Blocks():
10 | with gr.Row():
11 | with gr.Column():
12 |
13 | def random_seed():
14 | global random_enabled
15 | random_enabled = not random_enabled
16 | seed_val = -1
17 | if not random_enabled:
18 | seed_val = 42
19 | return gr.Number.update(
20 | interactive=not random_enabled, value=seed_val
21 | )
22 |
23 | # with gr.Row():
24 | prompt = gr.Textbox(
25 | label="Describe the image you'd like to see",
26 | lines=3,
27 | placeholder="A fantasy landscape",
28 | )
29 | neg_prompt = gr.Textbox(
30 | label="Don't want to see",
31 | lines=1,
32 | placeholder="",
33 | value="bad, deformed, ugly, bad anatomy",
34 | )
35 | with gr.Accordion("Advanced options", open=False):
36 | image_height = gr.Slider(
37 | 1024, 2048, value=1024, step=64, label="Image Height"
38 | )
39 | image_width = gr.Slider(
40 | 1024, 2048, value=1536, step=64, label="Image Width"
41 | )
42 | prior_guidance_scale = gr.Slider(
43 | 1.0, 10.0, value=4.0, step=0.5, label="Prior guidance Scale"
44 | )
45 | num_images = gr.Slider(
46 | 1,
47 | 50,
48 | value=1,
49 | step=1,
50 | label="Number of images to generate",
51 | )
52 | seed = gr.Number(
53 | label="Seed",
54 | value=-1,
55 | precision=0,
56 | interactive=False,
57 | )
58 | seed_checkbox = gr.Checkbox(
59 | label="Use random seed",
60 | value=True,
61 | interactive=True,
62 | )
63 |
64 | input_params = [
65 | prompt,
66 | neg_prompt,
67 | image_height,
68 | image_width,
69 | prior_guidance_scale,
70 | num_images,
71 | seed,
72 | ]
73 |
74 | with gr.Column():
75 | generate_btn = gr.Button("Generate", elem_id="generate_button")
76 | output = gr.Gallery(
77 | label="Generated images",
78 | show_label=True,
79 | elem_id="gallery",
80 | columns=2,
81 | )
82 | seed_checkbox.change(fn=random_seed, outputs=seed)
83 | generate_btn.click(
84 | fn=generate_callback_fn,
85 | inputs=input_params,
86 | outputs=output,
87 | )
88 |
--------------------------------------------------------------------------------
/src/frontend/web/text_to_image_xl_ui.py:
--------------------------------------------------------------------------------
1 | from typing import Any
2 |
3 | import gradio as gr
4 |
5 | from backend.stablediffusion.models.scheduler_types import (
6 | SchedulerType,
7 | get_sampler_names,
8 | )
9 |
10 | random_enabled = True
11 |
12 |
13 | def get_text_to_image_xl_ui(generate_callback_fn: Any) -> None:
14 | with gr.Blocks():
15 | with gr.Row():
16 | with gr.Column():
17 |
18 | def random_seed():
19 | global random_enabled
20 | random_enabled = not random_enabled
21 | seed_val = -1
22 | if not random_enabled:
23 | seed_val = 42
24 | return gr.Number.update(
25 | interactive=not random_enabled, value=seed_val
26 | )
27 |
28 | # with gr.Row():
29 | prompt = gr.Textbox(
30 | label="Describe the image you'd like to see",
31 | lines=3,
32 | placeholder="A fantasy landscape",
33 | )
34 | neg_prompt = gr.Textbox(
35 | label="Don't want to see",
36 | lines=1,
37 | placeholder="",
38 | value="bad, deformed, ugly, bad anatomy",
39 | )
40 | with gr.Accordion("Advanced options", open=False):
41 | image_height = gr.Slider(
42 | 768, 2048, value=1024, step=64, label="Image Height"
43 | )
44 | image_width = gr.Slider(
45 | 768, 2048, value=1024, step=64, label="Image Width"
46 | )
47 | num_inference_steps = gr.Slider(
48 | 1, 100, value=20, step=1, label="Inference Steps"
49 | )
50 | scheduler = gr.Dropdown(
51 | get_sampler_names(),
52 | value=SchedulerType.LMSDiscreteScheduler.value,
53 | label="Sampler",
54 | )
55 | guidance_scale = gr.Slider(
56 | 1.0, 30.0, value=7.5, step=0.5, label="Guidance Scale"
57 | )
58 | num_images = gr.Slider(
59 | 1,
60 | 50,
61 | value=1,
62 | step=1,
63 | label="Number of images to generate",
64 | )
65 | attn_slicing = gr.Checkbox(
66 | label="Attention slicing (Not supported)",
67 | value=False,
68 | interactive=False,
69 | )
70 |
71 | vae_slicing = gr.Checkbox(
72 | label="VAE slicing (Enable if low VRAM)",
73 | value=True,
74 | )
75 | seed = gr.Number(
76 | label="Seed",
77 | value=-1,
78 | precision=0,
79 | interactive=False,
80 | )
81 | seed_checkbox = gr.Checkbox(
82 | label="Use random seed",
83 | value=True,
84 | interactive=True,
85 | )
86 |
87 | input_params = [
88 | prompt,
89 | neg_prompt,
90 | image_height,
91 | image_width,
92 | num_inference_steps,
93 | scheduler,
94 | guidance_scale,
95 | num_images,
96 | attn_slicing,
97 | vae_slicing,
98 | seed,
99 | ]
100 |
101 | with gr.Column():
102 | generate_btn = gr.Button("Generate", elem_id="generate_button")
103 | output = gr.Gallery(
104 | label="Generated images",
105 | show_label=True,
106 | elem_id="gallery",
107 | columns=2,
108 | )
109 | seed_checkbox.change(fn=random_seed, outputs=seed)
110 | generate_btn.click(
111 | fn=generate_callback_fn,
112 | inputs=input_params,
113 | outputs=output,
114 | )
115 |
--------------------------------------------------------------------------------
/src/frontend/web/ui.py:
--------------------------------------------------------------------------------
1 | import gradio as gr
2 |
3 | from backend.generate import Generate
4 | from backend.stablediffusion.stable_diffusion_types import (
5 | StableDiffusionType,
6 | get_diffusion_type,
7 | )
8 | from constants import VERSION
9 | from frontend.web.controlnet.controlnet_image_ui import get_controlnet_to_image_ui
10 | from frontend.web.depth_to_image_ui import get_depth_to_image_ui
11 | from frontend.web.image_inpainting_ui import get_image_inpainting_ui
12 | from frontend.web.image_to_image_ui import get_image_to_image_ui
13 | from frontend.web.image_to_image_xl_ui import get_image_to_image_xl_ui
14 | from frontend.web.image_variations_ui import get_image_variations_ui
15 | from frontend.web.image_variations_xl_ui import get_image_variations_xl_ui
16 | from frontend.web.instruct_pix_to_pix_ui import get_instruct_pix_to_pix_ui
17 | from frontend.web.settings_ui import get_settings_ui
18 | from frontend.web.text_to_image_ui import get_text_to_image_ui
19 | from frontend.web.text_to_image_wuerstchen_ui import get_text_to_image_wuerstchen_ui
20 | from frontend.web.text_to_image_xl_ui import get_text_to_image_xl_ui
21 | from utils import DiffusionMagicPaths
22 |
23 |
24 | def _get_footer_message() -> str:
25 | version = f" v{VERSION} "
26 | footer_msg = version + (
27 | ' © 2023 '
28 | " Rupesh Sreeraman
"
29 | )
30 | return footer_msg
31 |
32 |
33 | def diffusionmagic_web_ui(
34 | generate: Generate,
35 | model_id: str,
36 | ) -> gr.Blocks:
37 | stable_diffusion_type = get_diffusion_type(model_id)
38 | with gr.Blocks(
39 | css=DiffusionMagicPaths.get_css_path(),
40 | title="DiffusionMagic",
41 | ) as diffusion_magic_ui:
42 | gr.HTML("DiffusionMagic 3.5
")
43 | with gr.Tabs():
44 | if stable_diffusion_type == StableDiffusionType.base:
45 | with gr.TabItem("Text to Image"):
46 | get_text_to_image_ui(generate.diffusion_text_to_image)
47 | with gr.TabItem("Image to Image"):
48 | get_image_to_image_ui(generate.diffusion_image_to_image)
49 | with gr.TabItem("Image Variations"):
50 | get_image_variations_ui(generate.diffusion_image_variations)
51 | elif stable_diffusion_type == StableDiffusionType.inpainting:
52 | with gr.TabItem("Image Inpainting"):
53 | get_image_inpainting_ui(generate.diffusion_image_inpainting)
54 | elif stable_diffusion_type == StableDiffusionType.depth2img:
55 | with gr.TabItem("Depth to Image"):
56 | get_depth_to_image_ui(generate.diffusion_depth_to_image)
57 | elif stable_diffusion_type == StableDiffusionType.instruct_pix2pix:
58 | with gr.TabItem("Instruct Pix to Pix"):
59 | get_instruct_pix_to_pix_ui(generate.diffusion_pix_to_pix)
60 | elif stable_diffusion_type == StableDiffusionType.controlnet_canny:
61 | with gr.TabItem("Controlnet Edge"):
62 | get_controlnet_to_image_ui(generate.diffusion_control_to_image)
63 | elif stable_diffusion_type == StableDiffusionType.controlnet_line:
64 | with gr.TabItem("Controlnet Lines"):
65 | get_controlnet_to_image_ui(generate.diffusion_control_to_image)
66 | elif stable_diffusion_type == StableDiffusionType.controlnet_normal:
67 | with gr.TabItem("Controlnet Normal"):
68 | get_controlnet_to_image_ui(generate.diffusion_control_to_image)
69 | elif stable_diffusion_type == StableDiffusionType.controlnet_hed:
70 | with gr.TabItem("Controlnet HED"):
71 | get_controlnet_to_image_ui(generate.diffusion_control_to_image)
72 | elif stable_diffusion_type == StableDiffusionType.controlnet_pose:
73 | with gr.TabItem("Controlnet Pose"):
74 | get_controlnet_to_image_ui(generate.diffusion_control_to_image)
75 | elif stable_diffusion_type == StableDiffusionType.controlnet_depth:
76 | with gr.TabItem("Controlnet Depth"):
77 | get_controlnet_to_image_ui(generate.diffusion_control_to_image)
78 | elif stable_diffusion_type == StableDiffusionType.controlnet_scribble:
79 | with gr.TabItem("Controlnet Scribble"):
80 | get_controlnet_to_image_ui(generate.diffusion_control_to_image)
81 | elif stable_diffusion_type == StableDiffusionType.controlnet_seg:
82 | with gr.TabItem("Controlnet Segmentation"):
83 | get_controlnet_to_image_ui(generate.diffusion_control_to_image)
84 | elif stable_diffusion_type == StableDiffusionType.stable_diffusion_xl:
85 | with gr.TabItem("Text to Image SDXL"):
86 | get_text_to_image_xl_ui(generate.diffusion_text_to_image_xl)
87 | with gr.TabItem("Image to Image SDXL"):
88 | get_image_to_image_xl_ui(generate.diffusion_image_to_image_xl)
89 | with gr.TabItem("Image Variations SDXL"):
90 | get_image_variations_xl_ui(generate.diffusion_image_variations_xl)
91 | elif stable_diffusion_type == StableDiffusionType.wuerstchen:
92 | with gr.TabItem("Text to Image Würstchen"):
93 | get_text_to_image_wuerstchen_ui(
94 | generate.diffusion_text_to_image_wuerstchen
95 | )
96 |
97 | elif stable_diffusion_type == StableDiffusionType.inpainting:
98 | get_image_variations_xl_ui
99 | with gr.TabItem("Settings"):
100 | get_settings_ui()
101 |
102 | gr.HTML(_get_footer_message())
103 | return diffusion_magic_ui
104 |
--------------------------------------------------------------------------------
/src/hf_models.py:
--------------------------------------------------------------------------------
1 | from utils import DiffusionMagicPaths
2 |
3 |
4 | class StableDiffusionModels:
5 | def __init__(self):
6 | self.config_path = DiffusionMagicPaths().get_models_config_path()
7 | self.__models = []
8 |
9 | def load_hf_models_from_text_file(self):
10 | """Loads hugging face stable diffusion models"""
11 | with open(self.config_path, "r") as file:
12 | lines = file.readlines()
13 | for repo_id in lines:
14 | if repo_id.strip() != "":
15 | self.__models.append(repo_id.strip())
16 |
17 | def get_models(self):
18 | return self.__models
19 |
--------------------------------------------------------------------------------
/src/models/configs.py:
--------------------------------------------------------------------------------
1 | from pydantic import BaseModel
2 | from utils import DiffusionMagicPaths
3 |
4 |
5 | class StableDiffusionModel(BaseModel):
6 | model_id: str = "stabilityai/stable-diffusion-xl-base-1.0"
7 | use_local: bool = False
8 |
9 |
10 | class OutputImages(BaseModel):
11 | path: str = DiffusionMagicPaths.get_results_path()
12 | format: str = "png"
13 | use_seperate_folders: bool = True
14 |
15 |
16 | class DiffusionMagicSettings(BaseModel):
17 | model_settings: StableDiffusionModel = StableDiffusionModel()
18 | output_images: OutputImages = OutputImages()
19 | low_memory_mode: bool = False
20 |
--------------------------------------------------------------------------------
/src/settings.py:
--------------------------------------------------------------------------------
1 | import yaml
2 |
3 | from models.configs import DiffusionMagicSettings
4 | from utils import DiffusionMagicPaths
5 | import os
6 |
7 |
8 | class AppSettings:
9 | __instance = None
10 |
11 | def __new__(cls):
12 | if AppSettings.__instance is None:
13 | AppSettings.__instance = super().__new__(cls)
14 | return AppSettings.__instance
15 |
16 | def __init__(self):
17 | self.config_path = DiffusionMagicPaths().get_app_settings_path()
18 |
19 | def load(self):
20 | if not os.path.exists(self.config_path):
21 | try:
22 | with open(self.config_path, "w") as file:
23 | yaml.dump(
24 | self.load_default(),
25 | file,
26 | )
27 | except Exception as ex:
28 | print(f"Error in creating settings : {ex}")
29 | try:
30 | with open(self.config_path) as file:
31 | settings_dict = yaml.safe_load(file)
32 | self._config = DiffusionMagicSettings.parse_obj(settings_dict)
33 | except Exception as ex:
34 | print(f"Error in loading settings : {ex}")
35 |
36 | def get_settings(self) -> DiffusionMagicSettings:
37 | return self._config
38 |
39 | def save(self):
40 | try:
41 | with open(self.config_path, "w") as file:
42 | yaml.dump(self._config.dict(), file)
43 | except Exception as ex:
44 | print(f"Error in saving settings : {ex}")
45 |
46 | def load_default(self):
47 | defult_config = DiffusionMagicSettings()
48 | return defult_config.dict()
49 |
--------------------------------------------------------------------------------
/src/utils.py:
--------------------------------------------------------------------------------
1 | import os
2 | import constants
3 |
4 |
5 | def join_paths(
6 | first_path: str,
7 | second_path: str,
8 | ) -> str:
9 | return os.path.join(first_path, second_path)
10 |
11 |
12 | def get_configs_path() -> str:
13 | app_dir = os.path.dirname(__file__)
14 | work_dir = os.path.dirname(app_dir)
15 | config_path = join_paths(work_dir, constants.CONFIG_DIRECTORY)
16 | return config_path
17 |
18 |
19 | class DiffusionMagicPaths:
20 | @staticmethod
21 | def get_models_config_path():
22 | configs_path = get_configs_path()
23 | models_config_path = join_paths(
24 | configs_path,
25 | constants.STABLE_DIFFUSION_MODELS_FILE,
26 | )
27 | return models_config_path
28 |
29 | @staticmethod
30 | def get_app_settings_path():
31 | configs_path = get_configs_path()
32 | settings_path = join_paths(
33 | configs_path,
34 | constants.APP_SETTINGS_FILE,
35 | )
36 | return settings_path
37 |
38 | @staticmethod
39 | def get_css_path():
40 | app_dir = os.path.dirname(__file__)
41 | css_path = os.path.join(
42 | app_dir,
43 | "frontend",
44 | "web",
45 | "css",
46 | "style.css",
47 | )
48 | return css_path
49 |
50 | @staticmethod
51 | def get_results_path():
52 | app_dir = os.path.dirname(__file__)
53 | work_dir = os.path.dirname(app_dir)
54 | config_path = join_paths(work_dir, constants.RESULTS_DIRECTORY)
55 | return config_path
56 |
--------------------------------------------------------------------------------
/start.bat:
--------------------------------------------------------------------------------
1 | @echo off
2 | setlocal
3 | echo Starting DiffusionMagic...
4 |
5 | set "PYTHON_COMMAND=python"
6 |
7 | call python --version > nul 2>&1
8 | if %errorlevel% equ 0 (
9 | echo Python command check :OK
10 | ) else (
11 | echo "Error: Python command not found, please install Python (Recommended : Python 3.10 or Python 3.11) and try again"
12 | pause
13 | exit /b 1
14 |
15 | )
16 |
17 | :check_python_version
18 | for /f "tokens=2" %%I in ('%PYTHON_COMMAND% --version 2^>^&1') do (
19 | set "python_version=%%I"
20 | )
21 |
22 | echo Python version: %python_version%
23 | call "%~dp0env\Scripts\activate.bat" && %PYTHON_COMMAND% "%~dp0\src\app.py"
--------------------------------------------------------------------------------
/start.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env bash
2 | echo Starting DiffusionMagic please wait...
3 | set -e
4 | PYTHON_COMMAND="python3"
5 |
6 | if ! command -v python3 &>/dev/null; then
7 | if ! command -v python &>/dev/null; then
8 | echo "Error: Python not found, please install python 3.8 or higher and try again"
9 | exit 1
10 | fi
11 | fi
12 |
13 | if command -v python &>/dev/null; then
14 | PYTHON_COMMAND="python"
15 | fi
16 |
17 | echo "Found $PYTHON_COMMAND command"
18 |
19 | python_version=$($PYTHON_COMMAND --version 2>&1 | awk '{print $2}')
20 | echo "Python version : $python_version"
21 |
22 | BASEDIR=$(pwd)
23 | # shellcheck disable=SC1091
24 | source "$BASEDIR/env/bin/activate"
25 | $PYTHON_COMMAND src/app.py
--------------------------------------------------------------------------------