├── tool
├── __init__.py
├── __pycache__
│ ├── utils.cpython-37.pyc
│ ├── __init__.cpython-37.pyc
│ ├── torch_utils.cpython-37.pyc
│ └── yolo_layer.cpython-37.pyc
├── torch_utils.py
├── utils_iou.py
├── utils.py
├── region_loss.py
├── config.py
└── yolo_layer.py
├── train.sh
├── requirements.txt
├── cfg.py
├── DATA_analysis.md
├── demo.py
├── README.md
├── models.py
├── cfg
└── yolov4.cfg
├── dataset.py
└── train.py
/tool/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/train.sh:
--------------------------------------------------------------------------------
1 | python train.py -g gpu_id -classes number of classes -dir 'data_dir' -pretrained 'pretrained_model.pth
2 |
--------------------------------------------------------------------------------
/tool/__pycache__/utils.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ry-eon/Bubble-Detector-YOLOv4/HEAD/tool/__pycache__/utils.cpython-37.pyc
--------------------------------------------------------------------------------
/tool/__pycache__/__init__.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ry-eon/Bubble-Detector-YOLOv4/HEAD/tool/__pycache__/__init__.cpython-37.pyc
--------------------------------------------------------------------------------
/tool/__pycache__/torch_utils.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ry-eon/Bubble-Detector-YOLOv4/HEAD/tool/__pycache__/torch_utils.cpython-37.pyc
--------------------------------------------------------------------------------
/tool/__pycache__/yolo_layer.cpython-37.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ry-eon/Bubble-Detector-YOLOv4/HEAD/tool/__pycache__/yolo_layer.cpython-37.pyc
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | numpy==1.18.2
2 | torch==1.4.0
3 | tensorboardX==2.0
4 | scikit_image==0.16.2
5 | matplotlib==2.2.3
6 | tqdm==4.43.0
7 | easydict==1.9
8 | Pillow==7.1.2
9 | skimage
10 | opencv_python
11 | pycocotools
--------------------------------------------------------------------------------
/cfg.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | '''
3 | @Time : 2020/05/06 21:05
4 | @Author : Tianxiaomo
5 | @File : Cfg.py
6 | @Noice :
7 | @Modificattion :
8 | @Author :
9 | @Time :
10 | @Detail :
11 |
12 | '''
13 | import os
14 | from easydict import EasyDict
15 |
16 |
17 | _BASE_DIR = os.path.dirname(os.path.abspath(__file__))
18 |
19 | Cfg = EasyDict()
20 |
21 | Cfg.use_darknet_cfg = False
22 | Cfg.cfgfile = os.path.join(_BASE_DIR, 'cfg', 'yolov4.cfg')
23 | Cfg.train_dir ='/home/ic-ai2/ry/datasets/bubble/'
24 |
25 | Cfg.batch = 16
26 | Cfg.subdivisions = 8
27 | Cfg.width = 608
28 | Cfg.height = 608
29 | Cfg.channels = 3
30 | Cfg.momentum = 0.949
31 | Cfg.decay = 0.0005
32 | Cfg.angle = 0
33 | Cfg.saturation = 1.5
34 | Cfg.exposure = 1.5
35 | Cfg.hue = .1
36 |
37 | Cfg.learning_rate = 0.00261
38 | Cfg.burn_in = 1000
39 | Cfg.max_batches = 4000
40 | Cfg.steps = [3200, 3600]
41 | Cfg.policy = Cfg.steps
42 | Cfg.scales = .1, .1
43 |
44 | Cfg.cutmix = 0
45 | Cfg.mosaic = 1
46 |
47 | Cfg.letter_box = 0
48 | Cfg.jitter = 0.2
49 | Cfg.classes = 1
50 | Cfg.track = 0
51 | Cfg.w = Cfg.width
52 | Cfg.h = Cfg.height
53 | Cfg.flip = 1
54 | Cfg.blur = 0
55 | Cfg.gaussian = 0
56 | Cfg.boxes = 60 # box num
57 | Cfg.TRAIN_EPOCHS = 300
58 | Cfg.train_label = os.path.join(_BASE_DIR, 'data', 'train.txt')
59 | Cfg.val_label = os.path.join(_BASE_DIR, 'data' ,'val.txt')
60 | Cfg.TRAIN_OPTIMIZER = 'adam'
61 | '''
62 | image_path1 x1,y1,x2,y2,id x1,y1,x2,y2,id x1,y1,x2,y2,id ...
63 | image_path2 x1,y1,x2,y2,id x1,y1,x2,y2,id x1,y1,x2,y2,id ...
64 | ...
65 | '''
66 |
67 | if Cfg.mosaic and Cfg.cutmix:
68 | Cfg.mixup = 4
69 | elif Cfg.cutmix:
70 | Cfg.mixup = 2
71 | elif Cfg.mosaic:
72 | Cfg.mixup = 3
73 |
74 | Cfg.checkpoints = os.path.join(_BASE_DIR, 'checkpoints')
75 | Cfg.TRAIN_TENSORBOARD_DIR = os.path.join(_BASE_DIR, 'log')
76 |
77 | Cfg.iou_type = 'iou' # 'giou', 'diou', 'ciou'
78 |
79 | Cfg.keep_checkpoint_max = 10
80 |
--------------------------------------------------------------------------------
/DATA_analysis.md:
--------------------------------------------------------------------------------
1 | # Data Distribution Update
2 |
3 | ### Data Distribution(2020.07.30)-4726
4 | 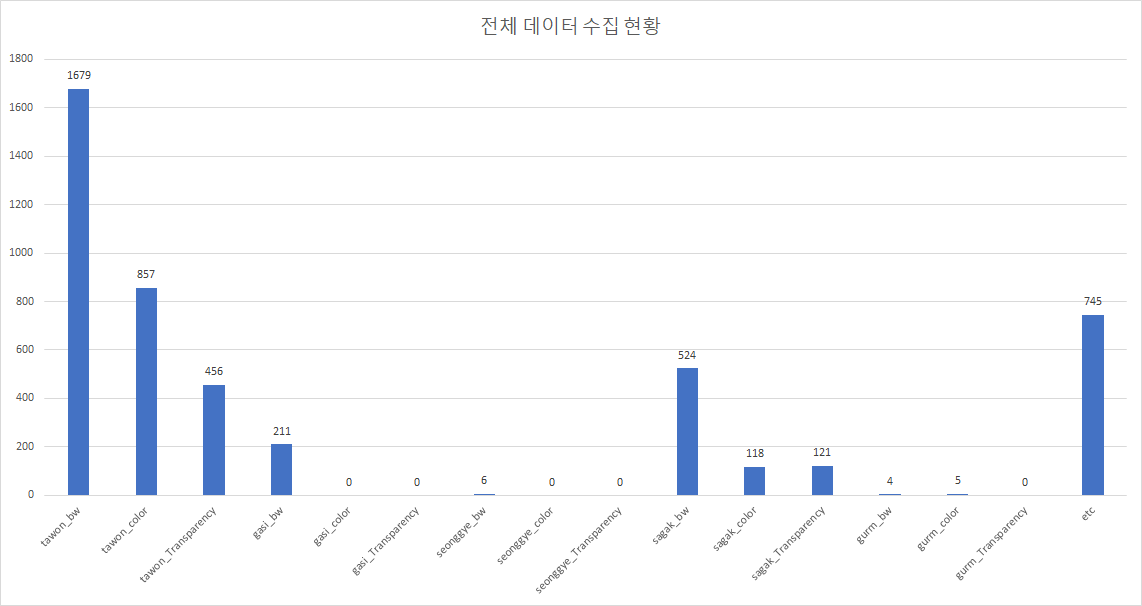
5 |
6 | Detail
7 | |Webtoon|Distribution|Explain|
8 | |------------------|------------|-------|
9 | |쿠베라(kubera)-1073|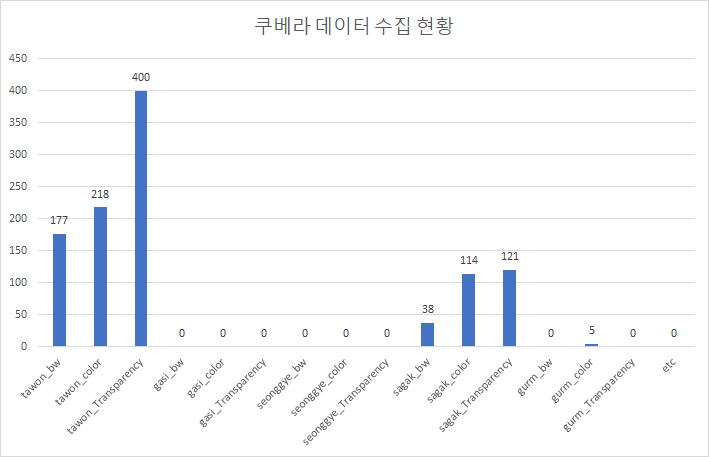|Kubera adds color to speech balloons to reveal the characteristics of the characters.|
10 | |헬퍼(Helper)-676|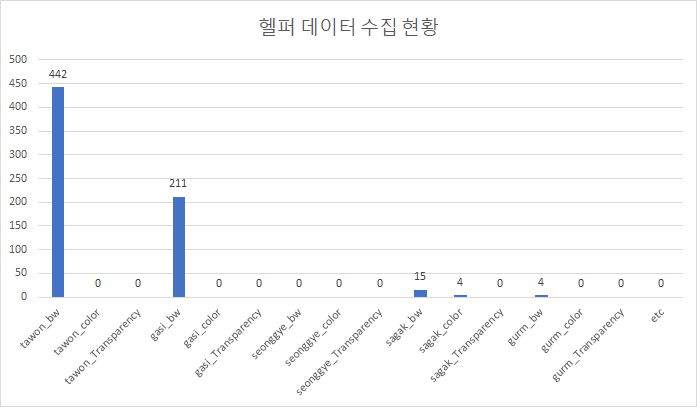|Although there is a slight frequency of use of gasi speech bubbles, most of them are black and white due to the nature of the helper.|
11 | |트럼프(Trump)-1157|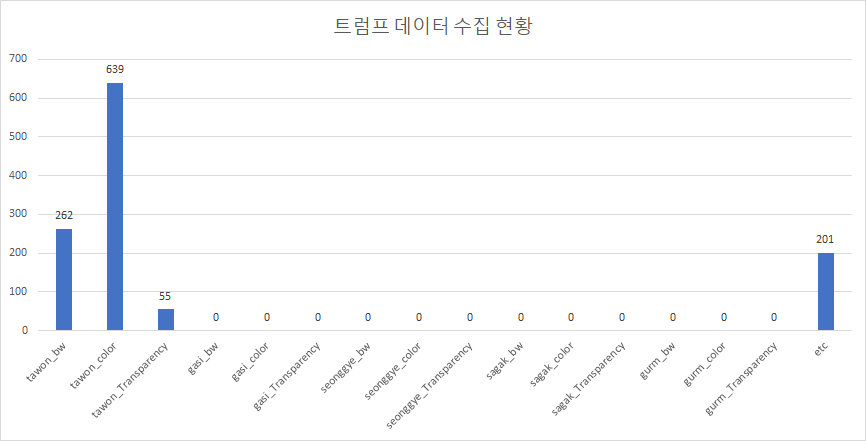|Trump adds color to speech balloons to reveal the characteristics of the characters.|
12 | |신의탑(tower of god)-1820|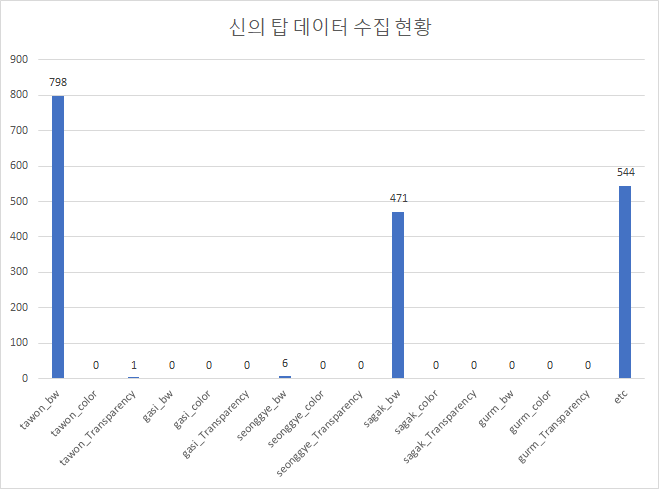|The Tower of God has many action scenes, so it uses a lot of dynamic speech bubbles. Therefore, there are many types of speech bubbles that are difficult to classify.|
13 |
14 |
15 |
16 | ### Data Distribution(2020.08.07)-8420
17 | 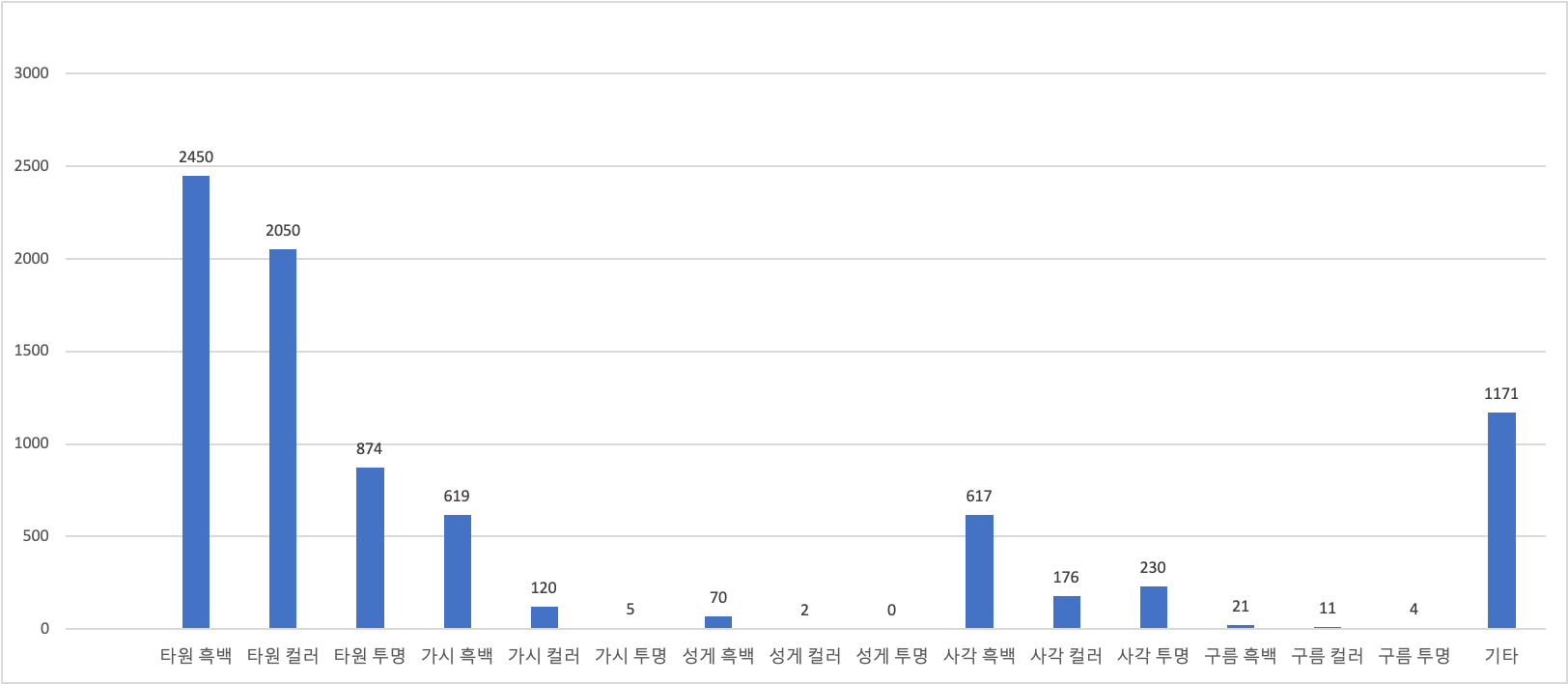
18 |
19 | **Webtoons used are Kubera, Trump, God of High School, The magic scroll merchant Gio, Golden Change, Underprin, Level up hard warrior, Empress remarried, and Wind breaker.**
20 |
21 | |Webtoon|Explain|
22 | |-------|-------|
23 | |God of High School|Many tawon-shaped transparency speech bubbles exist.|
24 | |The magic scroll merchant Gio|Among black and white, Many tawon-shaped transparency speech bubbles exist.|
25 | |Golden Change|Some tawon-shaped color speech bubbles exist.|
26 | |Underprin|Among the tawon-shaped speech bubbles, there is a speech bubble with white letters on a black background.|
27 | |Level up hard warrior| There are speech bubbles with patterns on the outer line.|
28 | |Empress remarried|There are speech bubbles with patterns on the outer line.|
29 | |Wind Breaker|Some tawon-shaped transparency speech bubbles exist.|
30 |
31 |
32 |
33 | ### Data Distribution(2020.08.11)-11832
34 | 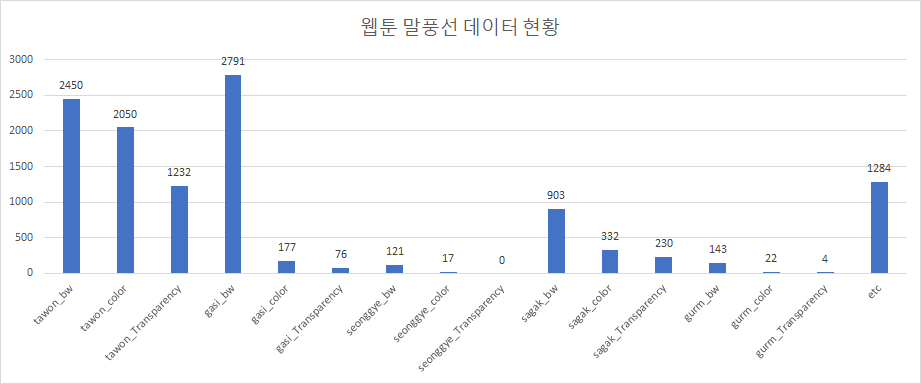
35 |
36 |
37 | ### Data Distribution(2020.08.19)-13582
38 | 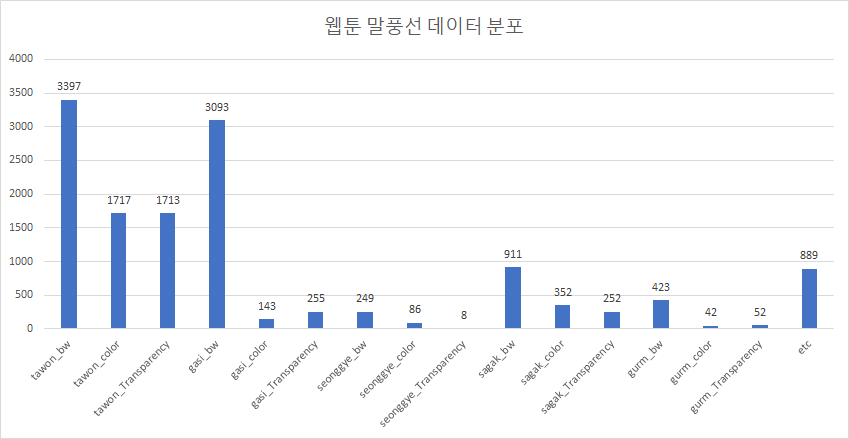
39 |
40 |
--------------------------------------------------------------------------------
/tool/torch_utils.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import os
3 | import time
4 | import math
5 | import torch
6 | import numpy as np
7 | from torch.autograd import Variable
8 |
9 | import itertools
10 | import struct # get_image_size
11 | import imghdr # get_image_size
12 |
13 | from tool import utils
14 |
15 |
16 | def bbox_ious(boxes1, boxes2, x1y1x2y2=True):
17 | if x1y1x2y2:
18 | mx = torch.min(boxes1[0], boxes2[0])
19 | Mx = torch.max(boxes1[2], boxes2[2])
20 | my = torch.min(boxes1[1], boxes2[1])
21 | My = torch.max(boxes1[3], boxes2[3])
22 | w1 = boxes1[2] - boxes1[0]
23 | h1 = boxes1[3] - boxes1[1]
24 | w2 = boxes2[2] - boxes2[0]
25 | h2 = boxes2[3] - boxes2[1]
26 | else:
27 | mx = torch.min(boxes1[0] - boxes1[2] / 2.0, boxes2[0] - boxes2[2] / 2.0)
28 | Mx = torch.max(boxes1[0] + boxes1[2] / 2.0, boxes2[0] + boxes2[2] / 2.0)
29 | my = torch.min(boxes1[1] - boxes1[3] / 2.0, boxes2[1] - boxes2[3] / 2.0)
30 | My = torch.max(boxes1[1] + boxes1[3] / 2.0, boxes2[1] + boxes2[3] / 2.0)
31 | w1 = boxes1[2]
32 | h1 = boxes1[3]
33 | w2 = boxes2[2]
34 | h2 = boxes2[3]
35 | uw = Mx - mx
36 | uh = My - my
37 | cw = w1 + w2 - uw
38 | ch = h1 + h2 - uh
39 | mask = ((cw <= 0) + (ch <= 0) > 0)
40 | area1 = w1 * h1
41 | area2 = w2 * h2
42 | carea = cw * ch
43 | carea[mask] = 0
44 | uarea = area1 + area2 - carea
45 | return carea / uarea
46 |
47 |
48 | def get_region_boxes(boxes_and_confs):
49 |
50 | # print('Getting boxes from boxes and confs ...')
51 |
52 | boxes_list = []
53 | confs_list = []
54 |
55 | for item in boxes_and_confs:
56 | boxes_list.append(item[0])
57 | confs_list.append(item[1])
58 |
59 | # boxes: [batch, num1 + num2 + num3, 1, 4]
60 | # confs: [batch, num1 + num2 + num3, num_classes]
61 | boxes = torch.cat(boxes_list, dim=1)
62 | confs = torch.cat(confs_list, dim=1)
63 |
64 | return [boxes, confs]
65 |
66 |
67 | def convert2cpu(gpu_matrix):
68 | return torch.FloatTensor(gpu_matrix.size()).copy_(gpu_matrix)
69 |
70 |
71 | def convert2cpu_long(gpu_matrix):
72 | return torch.LongTensor(gpu_matrix.size()).copy_(gpu_matrix)
73 |
74 |
75 |
76 | def do_detect(model, img, conf_thresh, nms_thresh, use_cuda=1):
77 | model.eval()
78 | t0 = time.time()
79 |
80 | if type(img) == np.ndarray and len(img.shape) == 3: # cv2 image
81 | img = torch.from_numpy(img.transpose(2, 0, 1)).float().div(255.0).unsqueeze(0)
82 | elif type(img) == np.ndarray and len(img.shape) == 4:
83 | img = torch.from_numpy(img.transpose(0, 3, 1, 2)).float().div(255.0)
84 | else:
85 | print("unknow image type")
86 | exit(-1)
87 |
88 | if use_cuda:
89 | img = img.cuda()
90 | img = torch.autograd.Variable(img)
91 |
92 | t1 = time.time()
93 |
94 | with torch.no_grad():
95 | output =model (img)
96 | t2 = time.time()
97 |
98 | # print('-----------------------------------')
99 | # print(' Preprocess : %f' % (t1 - t0))
100 | # print(' Model Inference : %f' % (t2 - t1))
101 | # print('-----------------------------------')
102 |
103 | return utils.post_processing(img, conf_thresh, nms_thresh, output)
104 |
105 |
--------------------------------------------------------------------------------
/demo.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | '''
3 | @Time : 20/04/25 15:49
4 | @Author : huguanghao
5 | @File : demo.py
6 | @Noice :
7 | @Modificattion :
8 | @Author :
9 | @Time :
10 | @Detail :
11 | '''
12 |
13 | # import sys
14 | # import time
15 | # from PIL import Image, ImageDraw
16 | # from models.tiny_yolo import TinyYoloNet
17 | from tool.utils import *
18 | from tool.torch_utils import *
19 | from tool.darknet2pytorch import Darknet
20 | import argparse
21 |
22 | """hyper parameters"""
23 | use_cuda = True
24 |
25 | def detect_cv2(cfgfile, weightfile, imgfile):
26 | import cv2
27 | m = Darknet(cfgfile)
28 |
29 | m.print_network()
30 | m.load_weights(weightfile)
31 | print('Loading weights from %s... Done!' % (weightfile))
32 |
33 | if use_cuda:
34 | m.cuda()
35 |
36 | num_classes = m.num_classes
37 | if num_classes == 20:
38 | namesfile = 'data/voc.names'
39 | elif num_classes == 80:
40 | namesfile = 'data/coco.names'
41 | else:
42 | namesfile = 'data/x.names'
43 | class_names = load_class_names(namesfile)
44 |
45 | img = cv2.imread(imgfile)
46 | sized = cv2.resize(img, (m.width, m.height))
47 | sized = cv2.cvtColor(sized, cv2.COLOR_BGR2RGB)
48 |
49 | for i in range(2):
50 | start = time.time()
51 | boxes = do_detect(m, sized, 0.4, 0.6, use_cuda)
52 | finish = time.time()
53 | if i == 1:
54 | print('%s: Predicted in %f seconds.' % (imgfile, (finish - start)))
55 |
56 | plot_boxes_cv2(img, boxes[0], savename='predictions.jpg', class_names=class_names)
57 |
58 |
59 | def detect_cv2_camera(cfgfile, weightfile):
60 | import cv2
61 | m = Darknet(cfgfile)
62 |
63 | m.print_network()
64 | m.load_weights(weightfile)
65 | print('Loading weights from %s... Done!' % (weightfile))
66 |
67 | if use_cuda:
68 | m.cuda()
69 |
70 | cap = cv2.VideoCapture(0)
71 | # cap = cv2.VideoCapture("./test.mp4")
72 | cap.set(3, 1280)
73 | cap.set(4, 720)
74 | print("Starting the YOLO loop...")
75 |
76 | num_classes = m.num_classes
77 | if num_classes == 20:
78 | namesfile = 'data/voc.names'
79 | elif num_classes == 80:
80 | namesfile = 'data/coco.names'
81 | else:
82 | namesfile = 'data/x.names'
83 | class_names = load_class_names(namesfile)
84 |
85 | while True:
86 | ret, img = cap.read()
87 | sized = cv2.resize(img, (m.width, m.height))
88 | sized = cv2.cvtColor(sized, cv2.COLOR_BGR2RGB)
89 |
90 | start = time.time()
91 | boxes = do_detect(m, sized, 0.4, 0.6, use_cuda)
92 | finish = time.time()
93 | print('Predicted in %f seconds.' % (finish - start))
94 |
95 | result_img = plot_boxes_cv2(img, boxes[0], savename=None, class_names=class_names)
96 |
97 | cv2.imshow('Yolo demo', result_img)
98 | cv2.waitKey(1)
99 |
100 | cap.release()
101 |
102 |
103 | def detect_skimage(cfgfile, weightfile, imgfile):
104 | from skimage import io
105 | from skimage.transform import resize
106 | m = Darknet(cfgfile)
107 |
108 | m.print_network()
109 | m.load_weights(weightfile)
110 | print('Loading weights from %s... Done!' % (weightfile))
111 |
112 | if use_cuda:
113 | m.cuda()
114 |
115 | num_classes = m.num_classes
116 | if num_classes == 20:
117 | namesfile = 'data/voc.names'
118 | elif num_classes == 80:
119 | namesfile = 'data/coco.names'
120 | else:
121 | namesfile = 'data/x.names'
122 | class_names = load_class_names(namesfile)
123 |
124 | img = io.imread(imgfile)
125 | sized = resize(img, (m.width, m.height)) * 255
126 |
127 | for i in range(2):
128 | start = time.time()
129 | boxes = do_detect(m, sized, 0.4, 0.4, use_cuda)
130 | finish = time.time()
131 | if i == 1:
132 | print('%s: Predicted in %f seconds.' % (imgfile, (finish - start)))
133 |
134 | plot_boxes_cv2(img, boxes, savename='predictions.jpg', class_names=class_names)
135 |
136 |
137 | def get_args():
138 | parser = argparse.ArgumentParser('Test your image or video by trained model.')
139 | parser.add_argument('-cfgfile', type=str, default='./cfg/yolov4.cfg',
140 | help='path of cfg file', dest='cfgfile')
141 | parser.add_argument('-weightfile', type=str,
142 | default='./checkpoints/Yolov4_epoch1.pth',
143 | help='path of trained model.', dest='weightfile')
144 | parser.add_argument('-imgfile', type=str,
145 | default='./data/mscoco2017/train2017/190109_180343_00154162.jpg',
146 | help='path of your image file.', dest='imgfile')
147 | args = parser.parse_args()
148 |
149 | return args
150 |
151 |
152 | if __name__ == '__main__':
153 | args = get_args()
154 | if args.imgfile:
155 | detect_cv2(args.cfgfile, args.weightfile, args.imgfile)
156 | # detect_imges(args.cfgfile, args.weightfile)
157 | # detect_cv2(args.cfgfile, args.weightfile, args.imgfile)
158 | # detect_skimage(args.cfgfile, args.weightfile, args.imgfile)
159 | else:
160 | detect_cv2_camera(args.cfgfile, args.weightfile)
161 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # bubble detector using YOLOv4
2 | ~~~
3 | Note : It's not the final version code. I will the refine and update the code.
4 | ~~~
5 |
6 | ## Overview
7 | Models detection speech bubble in webtoons or cartoons. I have referenced and implemented [pytorch-YOLOv4](https://github.com/Tianxiaomo/pytorch-YOLOv4) to detect speech bubble. The key point for improving performance is data analysis. In the case of speech bubbles, there are various forms. Therefore, I define the form of speech bubbles and present the results of training by considering the distribution of data.
8 |
9 |
10 |
11 | ### Definition of Speech Bubble
12 |
13 |
29 |
30 | #### Various speech bubble forms of real webtoons
31 | 
32 |
33 | + **In fact, there are various colors and various shapes of speech bubbles in webtoons.**
34 |
35 |
36 |
37 | ### New Definition
38 | **Key standard for Data Definition: Shape, Color, Form**
39 |
40 | `standard`
41 | + shape : Ellipse(tawon), Thorn(gasi), Sea_urchin(seonggye), Rectangle(sagak), Cloud(gurm)
42 | + Color : Black/white(bw), Colorful(color), Transparency(tran), Gradation
43 | + Form : Basic, Double Speech bubble, Multi-External, Scatter-type
44 | + example image 
45 |
46 | + **In this project, two categories are applied, shape and color, and form and Gradation are classified as ect.**
47 |
48 |
49 |
50 | ### classes
51 | **This class is not about detection, but about speech bubble data distribution.**
52 |
53 |
54 | 
55 |
56 |
61 |
62 |
63 | ### Install dependencies
64 |
65 | + **Pytorch Version**
66 | + Pytorch 1.4.0 for TensorRT 7.0 and higher
67 | + Pytorch 1.5.0 and 1.6.0 for TensorRT 7.1.2 and higher
68 |
69 | + **Install Dependencies Code**
70 | ~~~
71 | pip install onnxruntime numpy torch tensorboardX scikit_image tqdm easydict Pillow skimage opencv_python pycocotools
72 | ~~~
73 | or
74 | ~~~
75 | pip install -r requirements.txt
76 | ~~~
77 |
78 |
79 | ### Pretrained model
80 |
81 | |**Model**|**Link**|
82 | |---------|--------|
83 | |YOLOv4|[Link](https://drive.google.com/open?id=1fcbR0bWzYfIEdLJPzOsn4R5mlvR6IQyA)|
84 | |YOLOv4-bubble|[Link](https://drive.google.com/drive/u/2/folders/1hYGU8hPY1VH8P0DkKDnAfV4AOtRjKYhC)|
85 |
86 |
87 | ### Train
88 |
89 | + **1. Download weight**
90 |
91 | + **2. Train**
92 | ~~~
93 | python train.py -g gpu_id -classes number of classes -dir 'data_dir' -pretrained 'pretrained_model.pth'
94 | ~~~
95 | or
96 | ~~~
97 | Train.sh
98 | ~~~
99 |
100 | + **3. Config setting**
101 | + cfg.py
102 | + class = 1
103 | + learning_rate = 0.001
104 | + max_batches = 2000 (class * 2000)
105 | + steps = [1600, 1800], (max_batches * 0.8 , max_batches * 0.9)
106 | + train_dir = your dataset root
107 | + root tree

The image folder contains .jpg or .png image files. The XML folder contains .XML files(label).
108 |
109 | + cfg/yolov4.cfg
110 | + class 1
111 | + filter 18 (4 + 1 + class) * 3 (line: 961, 1049, 1137)
112 |
113 | **If you want to train custom dataset, use the information above.**
114 |
115 |
116 |
117 | ### Demo
118 |
119 | + **1. Download weight**
120 | + **2. Demo**
121 | ~~~
122 | python demp.py -cfgfile cfgfile -weightfile pretrained_model.pth -imgfile image_dir
123 | ~~~
124 | + defualt cfgfile is `./cfg/yolov4.cfg`
125 |
126 |
127 |
128 | ### Metric
129 |
130 | + **1. validation dataset**
131 |
132 |
133 | |tawon_bw|tawon_color|tawon_Transparency|gasi_bw|gasi_color|gasi_Transparency|seonggye_bw|seonggye_color|seonggye_Transparency|sagak_bw|sagak_color|sagak_Transparency|gurm_bw|gurm_color|gurm_Transparency|total|
134 | |----|----|-----|-----|-----|-----|-----|-----|-----|------|-----|-----|-----|-----|------|----|
135 | |116|70|68|65|29|59|51|43|44|42|33|69|47|2|12|750|
136 |
137 |
138 | + The above distribution is based on speech bubbles, not cuts.
139 | + The distribution is not constant because there are a number of speech bubbles inside a single cut. In addition, for some classes, examples are difficult to find, resulting in an unbalanced distribution as shown above.
140 |
--------------------------------------------------------------------------------
/tool/utils_iou.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | '''
3 |
4 | '''
5 | import torch
6 | import os, sys
7 | from torch.nn import functional as F
8 |
9 | import numpy as np
10 | from packaging import version
11 |
12 |
13 | __all__ = [
14 | "bboxes_iou",
15 | "bboxes_giou",
16 | "bboxes_diou",
17 | "bboxes_ciou",
18 | ]
19 |
20 |
21 | if version.parse(torch.__version__) >= version.parse('1.5.0'):
22 | def _true_divide(dividend, divisor):
23 | return torch.true_divide(dividend, divisor)
24 | else:
25 | def _true_divide(dividend, divisor):
26 | return dividend / divisor
27 |
28 | def bboxes_iou(bboxes_a, bboxes_b, fmt='voc', iou_type='iou'):
29 | """Calculate the Intersection of Unions (IoUs) between bounding boxes.
30 | IoU is calculated as a ratio of area of the intersection
31 | and area of the union.
32 |
33 | Args:
34 | bbox_a (array): An array whose shape is :math:`(N, 4)`.
35 | :math:`N` is the number of bounding boxes.
36 | The dtype should be :obj:`numpy.float32`.
37 | bbox_b (array): An array similar to :obj:`bbox_a`,
38 | whose shape is :math:`(K, 4)`.
39 | The dtype should be :obj:`numpy.float32`.
40 | Returns:
41 | array:
42 | An array whose shape is :math:`(N, K)`. \
43 | An element at index :math:`(n, k)` contains IoUs between \
44 | :math:`n` th bounding box in :obj:`bbox_a` and :math:`k` th bounding \
45 | box in :obj:`bbox_b`.
46 |
47 | from: https://github.com/chainer/chainercv
48 | """
49 | if bboxes_a.shape[1] != 4 or bboxes_b.shape[1] != 4:
50 | raise IndexError
51 |
52 | N, K = bboxes_a.shape[0], bboxes_b.shape[0]
53 |
54 | if fmt.lower() == 'voc': # xmin, ymin, xmax, ymax
55 | # top left
56 | tl_intersect = torch.max(
57 | bboxes_a[:, np.newaxis, :2],
58 | bboxes_b[:, :2]
59 | ) # of shape `(N,K,2)`
60 | # bottom right
61 | br_intersect = torch.min(
62 | bboxes_a[:, np.newaxis, 2:],
63 | bboxes_b[:, 2:]
64 | )
65 | bb_a = bboxes_a[:, 2:] - bboxes_a[:, :2]
66 | bb_b = bboxes_b[:, 2:] - bboxes_b[:, :2]
67 | # bb_* can also be seen vectors representing box_width, box_height
68 | elif fmt.lower() == 'yolo': # xcen, ycen, w, h
69 | # top left
70 | tl_intersect = torch.max(
71 | bboxes_a[:, np.newaxis, :2] - bboxes_a[:, np.newaxis, 2:] / 2,
72 | bboxes_b[:, :2] - bboxes_b[:, 2:] / 2
73 | )
74 | # bottom right
75 | br_intersect = torch.min(
76 | bboxes_a[:, np.newaxis, :2] + bboxes_a[:, np.newaxis, 2:] / 2,
77 | bboxes_b[:, :2] + bboxes_b[:, 2:] / 2
78 | )
79 | bb_a = bboxes_a[:, 2:]
80 | bb_b = bboxes_b[:, 2:]
81 | elif fmt.lower() == 'coco': # xmin, ymin, w, h
82 | # top left
83 | tl_intersect = torch.max(
84 | bboxes_a[:, np.newaxis, :2],
85 | bboxes_b[:, :2]
86 | )
87 | # bottom right
88 | br_intersect = torch.min(
89 | bboxes_a[:, np.newaxis, :2] + bboxes_a[:, np.newaxis, 2:],
90 | bboxes_b[:, :2] + bboxes_b[:, 2:]
91 | )
92 | bb_a = bboxes_a[:, 2:]
93 | bb_b = bboxes_b[:, 2:]
94 |
95 | area_a = torch.prod(bb_a, 1)
96 | area_b = torch.prod(bb_b, 1)
97 |
98 | # torch.prod(input, dim, keepdim=False, dtype=None) → Tensor
99 | # Returns the product of each row of the input tensor in the given dimension dim
100 | # if tl, br does not form a nondegenerate squre, then the corr. element in the `prod` would be 0
101 | en = (tl_intersect < br_intersect).type(tl_intersect.type()).prod(dim=2) # shape `(N,K,2)` ---> shape `(N,K)`
102 |
103 | area_intersect = torch.prod(br_intersect - tl_intersect, 2) * en # * ((tl < br).all())
104 | area_union = (area_a[:, np.newaxis] + area_b - area_intersect)
105 |
106 | iou = _true_divide(area_intersect, area_union)
107 |
108 | if iou_type.lower() == 'iou':
109 | return iou
110 |
111 | if fmt.lower() == 'voc': # xmin, ymin, xmax, ymax
112 | # top left
113 | tl_union = torch.min(
114 | bboxes_a[:, np.newaxis, :2],
115 | bboxes_b[:, :2]
116 | ) # of shape `(N,K,2)`
117 | # bottom right
118 | br_union = torch.max(
119 | bboxes_a[:, np.newaxis, 2:],
120 | bboxes_b[:, 2:]
121 | )
122 | elif fmt.lower() == 'yolo': # xcen, ycen, w, h
123 | # top left
124 | tl_union = torch.min(
125 | bboxes_a[:, np.newaxis, :2] - bboxes_a[:, np.newaxis, 2:] / 2,
126 | bboxes_b[:, :2] - bboxes_b[:, 2:] / 2
127 | )
128 | # bottom right
129 | br_union = torch.max(
130 | bboxes_a[:, np.newaxis, :2] + bboxes_a[:, np.newaxis, 2:] / 2,
131 | bboxes_b[:, :2] + bboxes_b[:, 2:] / 2
132 | )
133 | elif fmt.lower() == 'coco': # xmin, ymin, w, h
134 | # top left
135 | tl_union = torch.min(
136 | bboxes_a[:, np.newaxis, :2],
137 | bboxes_b[:, :2]
138 | )
139 | # bottom right
140 | br_union = torch.max(
141 | bboxes_a[:, np.newaxis, :2] + bboxes_a[:, np.newaxis, 2:],
142 | bboxes_b[:, :2] + bboxes_b[:, 2:]
143 | )
144 |
145 | # c for covering, of shape `(N,K,2)`
146 | # the last dim is box width, box hight
147 | bboxes_c = br_union - tl_union
148 |
149 | area_covering = torch.prod(bboxes_c, 2) # shape `(N,K)`
150 |
151 | giou = iou - _true_divide(area_covering - area_union, area_covering)
152 |
153 | if iou_type.lower() == 'giou':
154 | return giou
155 |
156 | if fmt.lower() == 'voc': # xmin, ymin, xmax, ymax
157 | centre_a = (bboxes_a[..., 2 :] + bboxes_a[..., : 2]) / 2
158 | centre_b = (bboxes_b[..., 2 :] + bboxes_b[..., : 2]) / 2
159 | elif fmt.lower() == 'yolo': # xcen, ycen, w, h
160 | centre_a = bboxes_a[..., : 2]
161 | centre_b = bboxes_b[..., : 2]
162 | elif fmt.lower() == 'coco': # xmin, ymin, w, h
163 | centre_a = bboxes_a[..., 2 :] + bboxes_a[..., : 2]/2
164 | centre_b = bboxes_b[..., 2 :] + bboxes_b[..., : 2]/2
165 |
166 | centre_dist = torch.norm(centre_a[:, np.newaxis] - centre_b, p='fro', dim=2)
167 | diag_len = torch.norm(bboxes_c, p='fro', dim=2)
168 |
169 | diou = iou - _true_divide(centre_dist.pow(2), diag_len.pow(2))
170 |
171 | if iou_type.lower() == 'diou':
172 | return diou
173 |
174 | """ the legacy custom cosine similarity:
175 |
176 | # bb_a of shape `(N,2)`, bb_b of shape `(K,2)`
177 | v = torch.einsum('nm,km->nk', bb_a, bb_b)
178 | v = _true_divide(v, (torch.norm(bb_a, p='fro', dim=1)[:,np.newaxis] * torch.norm(bb_b, p='fro', dim=1)))
179 | # avoid nan for torch.acos near \pm 1
180 | # https://github.com/pytorch/pytorch/issues/8069
181 | eps = 1e-7
182 | v = torch.clamp(v, -1+eps, 1-eps)
183 | """
184 | v = F.cosine_similarity(bb_a[:,np.newaxis,:], bb_b, dim=-1)
185 | v = (_true_divide(2*torch.acos(v), np.pi)).pow(2)
186 | with torch.no_grad():
187 | alpha = (_true_divide(v, 1-iou+v)) * ((iou>=0.5).type(iou.type()))
188 |
189 | ciou = diou - alpha * v
190 |
191 | if iou_type.lower() == 'ciou':
192 | return ciou
193 |
194 |
195 | def bboxes_giou(bboxes_a, bboxes_b, fmt='voc'):
196 | return bboxes_iou(bboxes_a, bboxes_b, fmt, 'giou')
197 |
198 |
199 | def bboxes_diou(bboxes_a, bboxes_b, fmt='voc'):
200 | return bboxes_iou(bboxes_a, bboxes_b, fmt, 'diou')
201 |
202 |
203 | def bboxes_ciou(bboxes_a, bboxes_b, fmt='voc'):
204 | return bboxes_iou(bboxes_a, bboxes_b, fmt, 'ciou')
205 |
--------------------------------------------------------------------------------
/tool/utils.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import os
3 | import time
4 | import math
5 | import numpy as np
6 |
7 | import itertools
8 | import struct # get_image_size
9 | import imghdr # get_image_size
10 |
11 |
12 | def sigmoid(x):
13 | return 1.0 / (np.exp(-x) + 1.)
14 |
15 |
16 | def softmax(x):
17 | x = np.exp(x - np.expand_dims(np.max(x, axis=1), axis=1))
18 | x = x / np.expand_dims(x.sum(axis=1), axis=1)
19 | return x
20 |
21 |
22 | def bbox_iou(box1, box2, x1y1x2y2=True):
23 |
24 | # print('iou box1:', box1)
25 | # print('iou box2:', box2)
26 |
27 | if x1y1x2y2:
28 | mx = min(box1[0], box2[0])
29 | Mx = max(box1[2], box2[2])
30 | my = min(box1[1], box2[1])
31 | My = max(box1[3], box2[3])
32 | w1 = box1[2] - box1[0]
33 | h1 = box1[3] - box1[1]
34 | w2 = box2[2] - box2[0]
35 | h2 = box2[3] - box2[1]
36 | else:
37 | w1 = box1[2]
38 | h1 = box1[3]
39 | w2 = box2[2]
40 | h2 = box2[3]
41 |
42 | mx = min(box1[0], box2[0])
43 | Mx = max(box1[0] + w1, box2[0] + w2)
44 | my = min(box1[1], box2[1])
45 | My = max(box1[1] + h1, box2[1] + h2)
46 | uw = Mx - mx
47 | uh = My - my
48 | cw = w1 + w2 - uw
49 | ch = h1 + h2 - uh
50 | carea = 0
51 | if cw <= 0 or ch <= 0:
52 | return 0.0
53 |
54 | area1 = w1 * h1
55 | area2 = w2 * h2
56 | carea = cw * ch
57 | uarea = area1 + area2 - carea
58 | return carea / uarea
59 |
60 |
61 | def nms_cpu(boxes, confs, nms_thresh=0.5, min_mode=False):
62 | # print(boxes.shape)
63 | x1 = boxes[:, 0]
64 | y1 = boxes[:, 1]
65 | x2 = boxes[:, 2]
66 | y2 = boxes[:, 3]
67 |
68 | areas = (x2 - x1) * (y2 - y1)
69 | order = confs.argsort()[::-1]
70 |
71 | keep = []
72 | while order.size > 0:
73 | idx_self = order[0]
74 | idx_other = order[1:]
75 |
76 | keep.append(idx_self)
77 |
78 | xx1 = np.maximum(x1[idx_self], x1[idx_other])
79 | yy1 = np.maximum(y1[idx_self], y1[idx_other])
80 | xx2 = np.minimum(x2[idx_self], x2[idx_other])
81 | yy2 = np.minimum(y2[idx_self], y2[idx_other])
82 |
83 | w = np.maximum(0.0, xx2 - xx1)
84 | h = np.maximum(0.0, yy2 - yy1)
85 | inter = w * h
86 |
87 | if min_mode:
88 | over = inter / np.minimum(areas[order[0]], areas[order[1:]])
89 | else:
90 | over = inter / (areas[order[0]] + areas[order[1:]] - inter)
91 |
92 | inds = np.where(over <= nms_thresh)[0]
93 | order = order[inds + 1]
94 |
95 | return np.array(keep)
96 |
97 |
98 |
99 | def plot_boxes_cv2(img, boxes, savename=None, class_names=None, color=None):
100 | import cv2
101 | img = np.copy(img)
102 | colors = np.array([[1, 0, 1], [0, 0, 1], [0, 1, 1], [0, 1, 0], [1, 1, 0], [1, 0, 0]], dtype=np.float32)
103 | imgs_cropped =[]
104 | bboxes_pts= []
105 |
106 | def get_color(c, x, max_val):
107 | ratio = float(x) / max_val * 5
108 | i = int(math.floor(ratio))
109 | j = int(math.ceil(ratio))
110 | ratio = ratio - i
111 | r = (1 - ratio) * colors[i][c] + ratio * colors[j][c]
112 | return int(r * 255)
113 |
114 | width = img.shape[1]
115 | height = img.shape[0]
116 | for i in range(len(boxes)):
117 | box = boxes[i]
118 | x1 = int(box[0] * width)
119 | y1 = int(box[1] * height)
120 | x2 = int(box[2] * width)
121 | y2 = int(box[3] * height)
122 |
123 | if color:
124 | rgb = color
125 | else:
126 | rgb = (255, 0, 0)
127 | if len(box) >= 7 and class_names:
128 | cls_conf = box[5]
129 | cls_id = box[6]
130 | print('%s: %f' % (class_names[cls_id], cls_conf))
131 | classes = len(class_names)
132 | offset = cls_id * 123457 % classes
133 | red = get_color(2, offset, classes)
134 | green = get_color(1, offset, classes)
135 | blue = get_color(0, offset, classes)
136 | if color is None:
137 | rgb = (red, green, blue)
138 | img = cv2.putText(img, class_names[cls_id], (x1, y1), cv2.FONT_HERSHEY_SIMPLEX, 1.2, rgb, 1)
139 |
140 | extend_w = int((x2 - x1) * 0.1)
141 | extend_h = int((y2 - y1) * 0.1)
142 | x1 = max(x1-extend_w , 0 )
143 | x2 = min(x2+extend_w, width-1)
144 | y1 = max(y1-extend_h , 0 )
145 | y2 = min(y2+extend_h, height-1)
146 | bbox_pts = []
147 | bbox_pts.append(x1)
148 | bbox_pts.append(y1)
149 | bbox_pts.append(x2)
150 | bbox_pts.append(y2)
151 | #print("x1 {} y1 {} x2 {} y2 {} ".format(x1,y1,x2,y2 ) )
152 | img_cropped = img[y1:y2, x1:x2]
153 | imgs_cropped.append(img_cropped)
154 | bboxes_pts.append(bbox_pts )
155 |
156 |
157 | img = cv2.rectangle(img, (x1, y1), (x2, y2), rgb, 1)
158 |
159 |
160 |
161 |
162 | '''
163 | if savename:
164 | print("save plot results to %s" % savename)
165 | cv2.imwrite(savename, img)
166 | '''
167 | return imgs_cropped, bboxes_pts , img
168 |
169 |
170 | def read_truths(lab_path):
171 | if not os.path.exists(lab_path):
172 | return np.array([])
173 | if os.path.getsize(lab_path):
174 | truths = np.loadtxt(lab_path)
175 | truths = truths.reshape(truths.size / 5, 5) # to avoid single truth problem
176 | return truths
177 | else:
178 | return np.array([])
179 |
180 |
181 | def load_class_names(namesfile):
182 | class_names = []
183 | with open(namesfile, 'r') as fp:
184 | lines = fp.readlines()
185 | for line in lines:
186 | line = line.rstrip()
187 | class_names.append(line)
188 | return class_names
189 |
190 |
191 |
192 | def post_processing(img, conf_thresh, nms_thresh, output):
193 |
194 | # anchors = [12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401]
195 | # num_anchors = 9
196 | # anchor_masks = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
197 | # strides = [8, 16, 32]
198 | # anchor_step = len(anchors) // num_anchors
199 |
200 | # [batch, num, 1, 4]
201 | box_array = output[0]
202 | # [batch, num, num_classes]
203 | confs = output[1]
204 |
205 | t1 = time.time()
206 |
207 | if type(box_array).__name__ != 'ndarray':
208 | box_array = box_array.cpu().detach().numpy()
209 | confs = confs.cpu().detach().numpy()
210 |
211 | num_classes = confs.shape[2]
212 |
213 | # [batch, num, 4]
214 | box_array = box_array[:, :, 0]
215 |
216 | # [batch, num, num_classes] --> [batch, num]
217 | max_conf = np.max(confs, axis=2)
218 | max_id = np.argmax(confs, axis=2)
219 |
220 | t2 = time.time()
221 |
222 | bboxes_batch = []
223 | for i in range(box_array.shape[0]):
224 |
225 | argwhere = max_conf[i] > conf_thresh
226 | l_box_array = box_array[i, argwhere, :]
227 | l_max_conf = max_conf[i, argwhere]
228 | l_max_id = max_id[i, argwhere]
229 |
230 | bboxes = []
231 | # nms for each class
232 | for j in range(num_classes):
233 |
234 | cls_argwhere = l_max_id == j
235 | ll_box_array = l_box_array[cls_argwhere, :]
236 | ll_max_conf = l_max_conf[cls_argwhere]
237 | ll_max_id = l_max_id[cls_argwhere]
238 |
239 | keep = nms_cpu(ll_box_array, ll_max_conf, nms_thresh)
240 |
241 | if (keep.size > 0):
242 | ll_box_array = ll_box_array[keep, :]
243 | ll_max_conf = ll_max_conf[keep]
244 | ll_max_id = ll_max_id[keep]
245 |
246 | for k in range(ll_box_array.shape[0]):
247 | bboxes.append([ll_box_array[k, 0], ll_box_array[k, 1], ll_box_array[k, 2], ll_box_array[k, 3], ll_max_conf[k], ll_max_conf[k], ll_max_id[k]])
248 |
249 | bboxes_batch.append(bboxes)
250 |
251 | t3 = time.time()
252 |
253 | #print('-----------------------------------')
254 | #print(' max and argmax : %f' % (t2 - t1))
255 | #print(' nms : %f' % (t3 - t2))
256 | #print('Post processing total : %f' % (t3 - t1))
257 | #print('-----------------------------------')
258 |
259 | return bboxes_batch
260 |
--------------------------------------------------------------------------------
/tool/region_loss.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 | import torch.nn.functional as F
3 | from tool.torch_utils import *
4 |
5 |
6 | def build_targets(pred_boxes, target, anchors, num_anchors, num_classes, nH, nW, noobject_scale, object_scale,
7 | sil_thresh, seen):
8 | nB = target.size(0)
9 | nA = num_anchors
10 | nC = num_classes
11 | anchor_step = len(anchors) / num_anchors
12 | conf_mask = torch.ones(nB, nA, nH, nW) * noobject_scale
13 | coord_mask = torch.zeros(nB, nA, nH, nW)
14 | cls_mask = torch.zeros(nB, nA, nH, nW)
15 | tx = torch.zeros(nB, nA, nH, nW)
16 | ty = torch.zeros(nB, nA, nH, nW)
17 | tw = torch.zeros(nB, nA, nH, nW)
18 | th = torch.zeros(nB, nA, nH, nW)
19 | tconf = torch.zeros(nB, nA, nH, nW)
20 | tcls = torch.zeros(nB, nA, nH, nW)
21 |
22 | nAnchors = nA * nH * nW
23 | nPixels = nH * nW
24 | for b in range(nB):
25 | cur_pred_boxes = pred_boxes[b * nAnchors:(b + 1) * nAnchors].t()
26 | cur_ious = torch.zeros(nAnchors)
27 | for t in range(50):
28 | if target[b][t * 5 + 1] == 0:
29 | break
30 | gx = target[b][t * 5 + 1] * nW
31 | gy = target[b][t * 5 + 2] * nH
32 | gw = target[b][t * 5 + 3] * nW
33 | gh = target[b][t * 5 + 4] * nH
34 | cur_gt_boxes = torch.FloatTensor([gx, gy, gw, gh]).repeat(nAnchors, 1).t()
35 | cur_ious = torch.max(cur_ious, bbox_ious(cur_pred_boxes, cur_gt_boxes, x1y1x2y2=False))
36 | conf_mask[b][cur_ious > sil_thresh] = 0
37 | if seen < 12800:
38 | if anchor_step == 4:
39 | tx = torch.FloatTensor(anchors).view(nA, anchor_step).index_select(1, torch.LongTensor([2])).view(1, nA, 1,
40 | 1).repeat(
41 | nB, 1, nH, nW)
42 | ty = torch.FloatTensor(anchors).view(num_anchors, anchor_step).index_select(1, torch.LongTensor([2])).view(
43 | 1, nA, 1, 1).repeat(nB, 1, nH, nW)
44 | else:
45 | tx.fill_(0.5)
46 | ty.fill_(0.5)
47 | tw.zero_()
48 | th.zero_()
49 | coord_mask.fill_(1)
50 |
51 | nGT = 0
52 | nCorrect = 0
53 | for b in range(nB):
54 | for t in range(50):
55 | if target[b][t * 5 + 1] == 0:
56 | break
57 | nGT = nGT + 1
58 | best_iou = 0.0
59 | best_n = -1
60 | min_dist = 10000
61 | gx = target[b][t * 5 + 1] * nW
62 | gy = target[b][t * 5 + 2] * nH
63 | gi = int(gx)
64 | gj = int(gy)
65 | gw = target[b][t * 5 + 3] * nW
66 | gh = target[b][t * 5 + 4] * nH
67 | gt_box = [0, 0, gw, gh]
68 | for n in range(nA):
69 | aw = anchors[anchor_step * n]
70 | ah = anchors[anchor_step * n + 1]
71 | anchor_box = [0, 0, aw, ah]
72 | iou = bbox_iou(anchor_box, gt_box, x1y1x2y2=False)
73 | if anchor_step == 4:
74 | ax = anchors[anchor_step * n + 2]
75 | ay = anchors[anchor_step * n + 3]
76 | dist = pow(((gi + ax) - gx), 2) + pow(((gj + ay) - gy), 2)
77 | if iou > best_iou:
78 | best_iou = iou
79 | best_n = n
80 | elif anchor_step == 4 and iou == best_iou and dist < min_dist:
81 | best_iou = iou
82 | best_n = n
83 | min_dist = dist
84 |
85 | gt_box = [gx, gy, gw, gh]
86 | pred_box = pred_boxes[b * nAnchors + best_n * nPixels + gj * nW + gi]
87 |
88 | coord_mask[b][best_n][gj][gi] = 1
89 | cls_mask[b][best_n][gj][gi] = 1
90 | conf_mask[b][best_n][gj][gi] = object_scale
91 | tx[b][best_n][gj][gi] = target[b][t * 5 + 1] * nW - gi
92 | ty[b][best_n][gj][gi] = target[b][t * 5 + 2] * nH - gj
93 | tw[b][best_n][gj][gi] = math.log(gw / anchors[anchor_step * best_n])
94 | th[b][best_n][gj][gi] = math.log(gh / anchors[anchor_step * best_n + 1])
95 | iou = bbox_iou(gt_box, pred_box, x1y1x2y2=False) # best_iou
96 | tconf[b][best_n][gj][gi] = iou
97 | tcls[b][best_n][gj][gi] = target[b][t * 5]
98 | if iou > 0.5:
99 | nCorrect = nCorrect + 1
100 |
101 | return nGT, nCorrect, coord_mask, conf_mask, cls_mask, tx, ty, tw, th, tconf, tcls
102 |
103 |
104 | class RegionLoss(nn.Module):
105 | def __init__(self, num_classes=0, anchors=[], num_anchors=1):
106 | super(RegionLoss, self).__init__()
107 | self.num_classes = num_classes
108 | self.anchors = anchors
109 | self.num_anchors = num_anchors
110 | self.anchor_step = len(anchors) / num_anchors
111 | self.coord_scale = 1
112 | self.noobject_scale = 1
113 | self.object_scale = 5
114 | self.class_scale = 1
115 | self.thresh = 0.6
116 | self.seen = 0
117 |
118 | def forward(self, output, target):
119 | # output : BxAs*(4+1+num_classes)*H*W
120 | t0 = time.time()
121 | nB = output.data.size(0)
122 | nA = self.num_anchors
123 | nC = self.num_classes
124 | nH = output.data.size(2)
125 | nW = output.data.size(3)
126 |
127 | output = output.view(nB, nA, (5 + nC), nH, nW)
128 | x = F.sigmoid(output.index_select(2, Variable(torch.cuda.LongTensor([0]))).view(nB, nA, nH, nW))
129 | y = F.sigmoid(output.index_select(2, Variable(torch.cuda.LongTensor([1]))).view(nB, nA, nH, nW))
130 | w = output.index_select(2, Variable(torch.cuda.LongTensor([2]))).view(nB, nA, nH, nW)
131 | h = output.index_select(2, Variable(torch.cuda.LongTensor([3]))).view(nB, nA, nH, nW)
132 | conf = F.sigmoid(output.index_select(2, Variable(torch.cuda.LongTensor([4]))).view(nB, nA, nH, nW))
133 | cls = output.index_select(2, Variable(torch.linspace(5, 5 + nC - 1, nC).long().cuda()))
134 | cls = cls.view(nB * nA, nC, nH * nW).transpose(1, 2).contiguous().view(nB * nA * nH * nW, nC)
135 | t1 = time.time()
136 |
137 | pred_boxes = torch.cuda.FloatTensor(4, nB * nA * nH * nW)
138 | grid_x = torch.linspace(0, nW - 1, nW).repeat(nH, 1).repeat(nB * nA, 1, 1).view(nB * nA * nH * nW).cuda()
139 | grid_y = torch.linspace(0, nH - 1, nH).repeat(nW, 1).t().repeat(nB * nA, 1, 1).view(nB * nA * nH * nW).cuda()
140 | anchor_w = torch.Tensor(self.anchors).view(nA, self.anchor_step).index_select(1, torch.LongTensor([0])).cuda()
141 | anchor_h = torch.Tensor(self.anchors).view(nA, self.anchor_step).index_select(1, torch.LongTensor([1])).cuda()
142 | anchor_w = anchor_w.repeat(nB, 1).repeat(1, 1, nH * nW).view(nB * nA * nH * nW)
143 | anchor_h = anchor_h.repeat(nB, 1).repeat(1, 1, nH * nW).view(nB * nA * nH * nW)
144 | pred_boxes[0] = x.data + grid_x
145 | pred_boxes[1] = y.data + grid_y
146 | pred_boxes[2] = torch.exp(w.data) * anchor_w
147 | pred_boxes[3] = torch.exp(h.data) * anchor_h
148 | pred_boxes = convert2cpu(pred_boxes.transpose(0, 1).contiguous().view(-1, 4))
149 | t2 = time.time()
150 |
151 | nGT, nCorrect, coord_mask, conf_mask, cls_mask, tx, ty, tw, th, tconf, tcls = build_targets(pred_boxes,
152 | target.data,
153 | self.anchors, nA,
154 | nC, \
155 | nH, nW,
156 | self.noobject_scale,
157 | self.object_scale,
158 | self.thresh,
159 | self.seen)
160 | cls_mask = (cls_mask == 1)
161 | nProposals = int((conf > 0.25).sum().data[0])
162 |
163 | tx = Variable(tx.cuda())
164 | ty = Variable(ty.cuda())
165 | tw = Variable(tw.cuda())
166 | th = Variable(th.cuda())
167 | tconf = Variable(tconf.cuda())
168 | tcls = Variable(tcls.view(-1)[cls_mask].long().cuda())
169 |
170 | coord_mask = Variable(coord_mask.cuda())
171 | conf_mask = Variable(conf_mask.cuda().sqrt())
172 | cls_mask = Variable(cls_mask.view(-1, 1).repeat(1, nC).cuda())
173 | cls = cls[cls_mask].view(-1, nC)
174 |
175 | t3 = time.time()
176 |
177 | loss_x = self.coord_scale * nn.MSELoss(reduction='sum')(x * coord_mask, tx * coord_mask) / 2.0
178 | loss_y = self.coord_scale * nn.MSELoss(reduction='sum')(y * coord_mask, ty * coord_mask) / 2.0
179 | loss_w = self.coord_scale * nn.MSELoss(reduction='sum')(w * coord_mask, tw * coord_mask) / 2.0
180 | loss_h = self.coord_scale * nn.MSELoss(reduction='sum')(h * coord_mask, th * coord_mask) / 2.0
181 | loss_conf = nn.MSELoss(reduction='sum')(conf * conf_mask, tconf * conf_mask) / 2.0
182 | loss_cls = self.class_scale * nn.CrossEntropyLoss(reduction='sum')(cls, tcls)
183 | loss = loss_x + loss_y + loss_w + loss_h + loss_conf + loss_cls
184 | t4 = time.time()
185 | if False:
186 | print('-----------------------------------')
187 | print(' activation : %f' % (t1 - t0))
188 | print(' create pred_boxes : %f' % (t2 - t1))
189 | print(' build targets : %f' % (t3 - t2))
190 | print(' create loss : %f' % (t4 - t3))
191 | print(' total : %f' % (t4 - t0))
192 | print('%d: nGT %d, recall %d, proposals %d, loss: x %f, y %f, w %f, h %f, conf %f, cls %f, total %f' % (
193 | self.seen, nGT, nCorrect, nProposals, loss_x.data[0], loss_y.data[0], loss_w.data[0], loss_h.data[0],
194 | loss_conf.data[0], loss_cls.data[0], loss.data[0]))
195 | return loss
196 |
--------------------------------------------------------------------------------
/tool/config.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from tool.torch_utils import convert2cpu
3 |
4 |
5 | def parse_cfg(cfgfile):
6 | blocks = []
7 | fp = open(cfgfile, 'r')
8 | block = None
9 | line = fp.readline()
10 | while line != '':
11 | line = line.rstrip()
12 | if line == '' or line[0] == '#':
13 | line = fp.readline()
14 | continue
15 | elif line[0] == '[':
16 | if block:
17 | blocks.append(block)
18 | block = dict()
19 | block['type'] = line.lstrip('[').rstrip(']')
20 | # set default value
21 | if block['type'] == 'convolutional':
22 | block['batch_normalize'] = 0
23 | else:
24 | key, value = line.split('=')
25 | key = key.strip()
26 | if key == 'type':
27 | key = '_type'
28 | value = value.strip()
29 | block[key] = value
30 | line = fp.readline()
31 |
32 | if block:
33 | blocks.append(block)
34 | fp.close()
35 | return blocks
36 |
37 |
38 | def print_cfg(blocks):
39 | print('layer filters size input output');
40 | prev_width = 416
41 | prev_height = 416
42 | prev_filters = 3
43 | out_filters = []
44 | out_widths = []
45 | out_heights = []
46 | ind = -2
47 | for block in blocks:
48 | ind = ind + 1
49 | if block['type'] == 'net':
50 | prev_width = int(block['width'])
51 | prev_height = int(block['height'])
52 | continue
53 | elif block['type'] == 'convolutional':
54 | filters = int(block['filters'])
55 | kernel_size = int(block['size'])
56 | stride = int(block['stride'])
57 | is_pad = int(block['pad'])
58 | pad = (kernel_size - 1) // 2 if is_pad else 0
59 | width = (prev_width + 2 * pad - kernel_size) // stride + 1
60 | height = (prev_height + 2 * pad - kernel_size) // stride + 1
61 | print('%5d %-6s %4d %d x %d / %d %3d x %3d x%4d -> %3d x %3d x%4d' % (
62 | ind, 'conv', filters, kernel_size, kernel_size, stride, prev_width, prev_height, prev_filters, width,
63 | height, filters))
64 | prev_width = width
65 | prev_height = height
66 | prev_filters = filters
67 | out_widths.append(prev_width)
68 | out_heights.append(prev_height)
69 | out_filters.append(prev_filters)
70 | elif block['type'] == 'maxpool':
71 | pool_size = int(block['size'])
72 | stride = int(block['stride'])
73 | width = prev_width // stride
74 | height = prev_height // stride
75 | print('%5d %-6s %d x %d / %d %3d x %3d x%4d -> %3d x %3d x%4d' % (
76 | ind, 'max', pool_size, pool_size, stride, prev_width, prev_height, prev_filters, width, height,
77 | filters))
78 | prev_width = width
79 | prev_height = height
80 | prev_filters = filters
81 | out_widths.append(prev_width)
82 | out_heights.append(prev_height)
83 | out_filters.append(prev_filters)
84 | elif block['type'] == 'avgpool':
85 | width = 1
86 | height = 1
87 | print('%5d %-6s %3d x %3d x%4d -> %3d' % (
88 | ind, 'avg', prev_width, prev_height, prev_filters, prev_filters))
89 | prev_width = width
90 | prev_height = height
91 | prev_filters = filters
92 | out_widths.append(prev_width)
93 | out_heights.append(prev_height)
94 | out_filters.append(prev_filters)
95 | elif block['type'] == 'softmax':
96 | print('%5d %-6s -> %3d' % (ind, 'softmax', prev_filters))
97 | out_widths.append(prev_width)
98 | out_heights.append(prev_height)
99 | out_filters.append(prev_filters)
100 | elif block['type'] == 'cost':
101 | print('%5d %-6s -> %3d' % (ind, 'cost', prev_filters))
102 | out_widths.append(prev_width)
103 | out_heights.append(prev_height)
104 | out_filters.append(prev_filters)
105 | elif block['type'] == 'reorg':
106 | stride = int(block['stride'])
107 | filters = stride * stride * prev_filters
108 | width = prev_width // stride
109 | height = prev_height // stride
110 | print('%5d %-6s / %d %3d x %3d x%4d -> %3d x %3d x%4d' % (
111 | ind, 'reorg', stride, prev_width, prev_height, prev_filters, width, height, filters))
112 | prev_width = width
113 | prev_height = height
114 | prev_filters = filters
115 | out_widths.append(prev_width)
116 | out_heights.append(prev_height)
117 | out_filters.append(prev_filters)
118 | elif block['type'] == 'upsample':
119 | stride = int(block['stride'])
120 | filters = prev_filters
121 | width = prev_width * stride
122 | height = prev_height * stride
123 | print('%5d %-6s * %d %3d x %3d x%4d -> %3d x %3d x%4d' % (
124 | ind, 'upsample', stride, prev_width, prev_height, prev_filters, width, height, filters))
125 | prev_width = width
126 | prev_height = height
127 | prev_filters = filters
128 | out_widths.append(prev_width)
129 | out_heights.append(prev_height)
130 | out_filters.append(prev_filters)
131 | elif block['type'] == 'route':
132 | layers = block['layers'].split(',')
133 | layers = [int(i) if int(i) > 0 else int(i) + ind for i in layers]
134 | if len(layers) == 1:
135 | print('%5d %-6s %d' % (ind, 'route', layers[0]))
136 | prev_width = out_widths[layers[0]]
137 | prev_height = out_heights[layers[0]]
138 | prev_filters = out_filters[layers[0]]
139 | elif len(layers) == 2:
140 | print('%5d %-6s %d %d' % (ind, 'route', layers[0], layers[1]))
141 | prev_width = out_widths[layers[0]]
142 | prev_height = out_heights[layers[0]]
143 | assert (prev_width == out_widths[layers[1]])
144 | assert (prev_height == out_heights[layers[1]])
145 | prev_filters = out_filters[layers[0]] + out_filters[layers[1]]
146 | elif len(layers) == 4:
147 | print('%5d %-6s %d %d %d %d' % (ind, 'route', layers[0], layers[1], layers[2], layers[3]))
148 | prev_width = out_widths[layers[0]]
149 | prev_height = out_heights[layers[0]]
150 | assert (prev_width == out_widths[layers[1]] == out_widths[layers[2]] == out_widths[layers[3]])
151 | assert (prev_height == out_heights[layers[1]] == out_heights[layers[2]] == out_heights[layers[3]])
152 | prev_filters = out_filters[layers[0]] + out_filters[layers[1]] + out_filters[layers[2]] + out_filters[
153 | layers[3]]
154 | else:
155 | print("route error !!! {} {} {}".format(sys._getframe().f_code.co_filename,
156 | sys._getframe().f_code.co_name, sys._getframe().f_lineno))
157 |
158 | out_widths.append(prev_width)
159 | out_heights.append(prev_height)
160 | out_filters.append(prev_filters)
161 | elif block['type'] in ['region', 'yolo']:
162 | print('%5d %-6s' % (ind, 'detection'))
163 | out_widths.append(prev_width)
164 | out_heights.append(prev_height)
165 | out_filters.append(prev_filters)
166 | elif block['type'] == 'shortcut':
167 | from_id = int(block['from'])
168 | from_id = from_id if from_id > 0 else from_id + ind
169 | print('%5d %-6s %d' % (ind, 'shortcut', from_id))
170 | prev_width = out_widths[from_id]
171 | prev_height = out_heights[from_id]
172 | prev_filters = out_filters[from_id]
173 | out_widths.append(prev_width)
174 | out_heights.append(prev_height)
175 | out_filters.append(prev_filters)
176 | elif block['type'] == 'connected':
177 | filters = int(block['output'])
178 | print('%5d %-6s %d -> %3d' % (ind, 'connected', prev_filters, filters))
179 | prev_filters = filters
180 | out_widths.append(1)
181 | out_heights.append(1)
182 | out_filters.append(prev_filters)
183 | else:
184 | print('unknown type %s' % (block['type']))
185 |
186 |
187 | def load_conv(buf, start, conv_model):
188 | num_w = conv_model.weight.numel()
189 | num_b = conv_model.bias.numel()
190 | conv_model.bias.data.copy_(torch.from_numpy(buf[start:start + num_b]));
191 | start = start + num_b
192 | conv_model.weight.data.copy_(torch.from_numpy(buf[start:start + num_w]).reshape(conv_model.weight.data.shape));
193 | start = start + num_w
194 | return start
195 |
196 |
197 | def save_conv(fp, conv_model):
198 | if conv_model.bias.is_cuda:
199 | convert2cpu(conv_model.bias.data).numpy().tofile(fp)
200 | convert2cpu(conv_model.weight.data).numpy().tofile(fp)
201 | else:
202 | conv_model.bias.data.numpy().tofile(fp)
203 | conv_model.weight.data.numpy().tofile(fp)
204 |
205 |
206 | def load_conv_bn(buf, start, conv_model, bn_model):
207 | num_w = conv_model.weight.numel()
208 | num_b = bn_model.bias.numel()
209 | bn_model.bias.data.copy_(torch.from_numpy(buf[start:start + num_b]));
210 | start = start + num_b
211 | bn_model.weight.data.copy_(torch.from_numpy(buf[start:start + num_b]));
212 | start = start + num_b
213 | bn_model.running_mean.copy_(torch.from_numpy(buf[start:start + num_b]));
214 | start = start + num_b
215 | bn_model.running_var.copy_(torch.from_numpy(buf[start:start + num_b]));
216 | start = start + num_b
217 | conv_model.weight.data.copy_(torch.from_numpy(buf[start:start + num_w]).reshape(conv_model.weight.data.shape));
218 | start = start + num_w
219 | return start
220 |
221 |
222 | def save_conv_bn(fp, conv_model, bn_model):
223 | if bn_model.bias.is_cuda:
224 | convert2cpu(bn_model.bias.data).numpy().tofile(fp)
225 | convert2cpu(bn_model.weight.data).numpy().tofile(fp)
226 | convert2cpu(bn_model.running_mean).numpy().tofile(fp)
227 | convert2cpu(bn_model.running_var).numpy().tofile(fp)
228 | convert2cpu(conv_model.weight.data).numpy().tofile(fp)
229 | else:
230 | bn_model.bias.data.numpy().tofile(fp)
231 | bn_model.weight.data.numpy().tofile(fp)
232 | bn_model.running_mean.numpy().tofile(fp)
233 | bn_model.running_var.numpy().tofile(fp)
234 | conv_model.weight.data.numpy().tofile(fp)
235 |
236 |
237 | def load_fc(buf, start, fc_model):
238 | num_w = fc_model.weight.numel()
239 | num_b = fc_model.bias.numel()
240 | fc_model.bias.data.copy_(torch.from_numpy(buf[start:start + num_b]));
241 | start = start + num_b
242 | fc_model.weight.data.copy_(torch.from_numpy(buf[start:start + num_w]));
243 | start = start + num_w
244 | return start
245 |
246 |
247 | def save_fc(fp, fc_model):
248 | fc_model.bias.data.numpy().tofile(fp)
249 | fc_model.weight.data.numpy().tofile(fp)
250 |
251 |
252 | if __name__ == '__main__':
253 | import sys
254 |
255 | blocks = parse_cfg('cfg/yolo.cfg')
256 | if len(sys.argv) == 2:
257 | blocks = parse_cfg(sys.argv[1])
258 | print_cfg(blocks)
259 |
--------------------------------------------------------------------------------
/tool/yolo_layer.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 | import torch.nn.functional as F
3 | from tool.torch_utils import *
4 |
5 | def yolo_forward(output, conf_thresh, num_classes, anchors, num_anchors, scale_x_y, only_objectness=1,
6 | validation=False):
7 | # Output would be invalid if it does not satisfy this assert
8 | # assert (output.size(1) == (5 + num_classes) * num_anchors)
9 |
10 | # print(output.size())
11 |
12 | # Slice the second dimension (channel) of output into:
13 | # [ 2, 2, 1, num_classes, 2, 2, 1, num_classes, 2, 2, 1, num_classes ]
14 | # And then into
15 | # bxy = [ 6 ] bwh = [ 6 ] det_conf = [ 3 ] cls_conf = [ num_classes * 3 ]
16 | batch = output.size(0)
17 | H = output.size(2)
18 | W = output.size(3)
19 |
20 | bxy_list = []
21 | bwh_list = []
22 | det_confs_list = []
23 | cls_confs_list = []
24 |
25 | for i in range(num_anchors):
26 | begin = i * (5 + num_classes)
27 | end = (i + 1) * (5 + num_classes)
28 |
29 | bxy_list.append(output[:, begin : begin + 2])
30 | bwh_list.append(output[:, begin + 2 : begin + 4])
31 | det_confs_list.append(output[:, begin + 4 : begin + 5])
32 | cls_confs_list.append(output[:, begin + 5 : end])
33 |
34 | # Shape: [batch, num_anchors * 2, H, W]
35 | bxy = torch.cat(bxy_list, dim=1)
36 | # Shape: [batch, num_anchors * 2, H, W]
37 | bwh = torch.cat(bwh_list, dim=1)
38 |
39 | # Shape: [batch, num_anchors, H, W]
40 | det_confs = torch.cat(det_confs_list, dim=1)
41 | # Shape: [batch, num_anchors * H * W]
42 | det_confs = det_confs.view(batch, num_anchors * H * W)
43 |
44 | # Shape: [batch, num_anchors * num_classes, H, W]
45 | cls_confs = torch.cat(cls_confs_list, dim=1)
46 | # Shape: [batch, num_anchors, num_classes, H * W]
47 | cls_confs = cls_confs.view(batch, num_anchors, num_classes, H * W)
48 | # Shape: [batch, num_anchors, num_classes, H * W] --> [batch, num_anchors * H * W, num_classes]
49 | cls_confs = cls_confs.permute(0, 1, 3, 2).reshape(batch, num_anchors * H * W, num_classes)
50 |
51 | # Apply sigmoid(), exp() and softmax() to slices
52 | #
53 | bxy = torch.sigmoid(bxy) * scale_x_y - 0.5 * (scale_x_y - 1)
54 | bwh = torch.exp(bwh)
55 | det_confs = torch.sigmoid(det_confs)
56 | cls_confs = torch.sigmoid(cls_confs)
57 |
58 | # Prepare C-x, C-y, P-w, P-h (None of them are torch related)
59 | grid_x = np.expand_dims(np.expand_dims(np.expand_dims(np.linspace(0, W - 1, W), axis=0).repeat(H, 0), axis=0), axis=0)
60 | grid_y = np.expand_dims(np.expand_dims(np.expand_dims(np.linspace(0, H - 1, H), axis=1).repeat(W, 1), axis=0), axis=0)
61 | # grid_x = torch.linspace(0, W - 1, W).reshape(1, 1, 1, W).repeat(1, 1, H, 1)
62 | # grid_y = torch.linspace(0, H - 1, H).reshape(1, 1, H, 1).repeat(1, 1, 1, W)
63 |
64 | anchor_w = []
65 | anchor_h = []
66 | for i in range(num_anchors):
67 | anchor_w.append(anchors[i * 2])
68 | anchor_h.append(anchors[i * 2 + 1])
69 |
70 | device = None
71 | cuda_check = output.is_cuda
72 | if cuda_check:
73 | device = output.get_device()
74 |
75 | bx_list = []
76 | by_list = []
77 | bw_list = []
78 | bh_list = []
79 |
80 | # Apply C-x, C-y, P-w, P-h
81 | for i in range(num_anchors):
82 | ii = i * 2
83 | # Shape: [batch, 1, H, W]
84 | bx = bxy[:, ii : ii + 1] + torch.tensor(grid_x, device=device, dtype=torch.float32) # grid_x.to(device=device, dtype=torch.float32)
85 | # Shape: [batch, 1, H, W]
86 | by = bxy[:, ii + 1 : ii + 2] + torch.tensor(grid_y, device=device, dtype=torch.float32) # grid_y.to(device=device, dtype=torch.float32)
87 | # Shape: [batch, 1, H, W]
88 | bw = bwh[:, ii : ii + 1] * anchor_w[i]
89 | # Shape: [batch, 1, H, W]
90 | bh = bwh[:, ii + 1 : ii + 2] * anchor_h[i]
91 |
92 | bx_list.append(bx)
93 | by_list.append(by)
94 | bw_list.append(bw)
95 | bh_list.append(bh)
96 |
97 |
98 | ########################################
99 | # Figure out bboxes from slices #
100 | ########################################
101 |
102 | # Shape: [batch, num_anchors, H, W]
103 | bx = torch.cat(bx_list, dim=1)
104 | # Shape: [batch, num_anchors, H, W]
105 | by = torch.cat(by_list, dim=1)
106 | # Shape: [batch, num_anchors, H, W]
107 | bw = torch.cat(bw_list, dim=1)
108 | # Shape: [batch, num_anchors, H, W]
109 | bh = torch.cat(bh_list, dim=1)
110 |
111 | # Shape: [batch, 2 * num_anchors, H, W]
112 | bx_bw = torch.cat((bx, bw), dim=1)
113 | # Shape: [batch, 2 * num_anchors, H, W]
114 | by_bh = torch.cat((by, bh), dim=1)
115 |
116 | # normalize coordinates to [0, 1]
117 | bx_bw /= W
118 | by_bh /= H
119 |
120 | # Shape: [batch, num_anchors * H * W, 1]
121 | bx = bx_bw[:, :num_anchors].view(batch, num_anchors * H * W, 1)
122 | by = by_bh[:, :num_anchors].view(batch, num_anchors * H * W, 1)
123 | bw = bx_bw[:, num_anchors:].view(batch, num_anchors * H * W, 1)
124 | bh = by_bh[:, num_anchors:].view(batch, num_anchors * H * W, 1)
125 |
126 | bx1 = bx - bw * 0.5
127 | by1 = by - bh * 0.5
128 | bx2 = bx1 + bw
129 | by2 = by1 + bh
130 |
131 | # Shape: [batch, num_anchors * h * w, 4] -> [batch, num_anchors * h * w, 1, 4]
132 | boxes = torch.cat((bx1, by1, bx2, by2), dim=2).view(batch, num_anchors * H * W, 1, 4)
133 | # boxes = boxes.repeat(1, 1, num_classes, 1)
134 |
135 | # boxes: [batch, num_anchors * H * W, 1, 4]
136 | # cls_confs: [batch, num_anchors * H * W, num_classes]
137 | # det_confs: [batch, num_anchors * H * W]
138 |
139 | det_confs = det_confs.view(batch, num_anchors * H * W, 1)
140 | confs = cls_confs * det_confs
141 |
142 | # boxes: [batch, num_anchors * H * W, 1, 4]
143 | # confs: [batch, num_anchors * H * W, num_classes]
144 |
145 | return boxes, confs
146 |
147 |
148 | def yolo_forward_dynamic(output, conf_thresh, num_classes, anchors, num_anchors, scale_x_y, only_objectness=1,
149 | validation=False):
150 | # Output would be invalid if it does not satisfy this assert
151 | # assert (output.size(1) == (5 + num_classes) * num_anchors)
152 |
153 | # print(output.size())
154 |
155 | # Slice the second dimension (channel) of output into:
156 | # [ 2, 2, 1, num_classes, 2, 2, 1, num_classes, 2, 2, 1, num_classes ]
157 | # And then into
158 | # bxy = [ 6 ] bwh = [ 6 ] det_conf = [ 3 ] cls_conf = [ num_classes * 3 ]
159 | # batch = output.size(0)
160 | # H = output.size(2)
161 | # W = output.size(3)
162 |
163 | bxy_list = []
164 | bwh_list = []
165 | det_confs_list = []
166 | cls_confs_list = []
167 |
168 | for i in range(num_anchors):
169 | begin = i * (5 + num_classes)
170 | end = (i + 1) * (5 + num_classes)
171 |
172 | bxy_list.append(output[:, begin : begin + 2])
173 | bwh_list.append(output[:, begin + 2 : begin + 4])
174 | det_confs_list.append(output[:, begin + 4 : begin + 5])
175 | cls_confs_list.append(output[:, begin + 5 : end])
176 |
177 | # Shape: [batch, num_anchors * 2, H, W]
178 | bxy = torch.cat(bxy_list, dim=1)
179 | # Shape: [batch, num_anchors * 2, H, W]
180 | bwh = torch.cat(bwh_list, dim=1)
181 |
182 | # Shape: [batch, num_anchors, H, W]
183 | det_confs = torch.cat(det_confs_list, dim=1)
184 | # Shape: [batch, num_anchors * H * W]
185 | det_confs = det_confs.view(output.size(0), num_anchors * output.size(2) * output.size(3))
186 |
187 | # Shape: [batch, num_anchors * num_classes, H, W]
188 | cls_confs = torch.cat(cls_confs_list, dim=1)
189 | # Shape: [batch, num_anchors, num_classes, H * W]
190 | cls_confs = cls_confs.view(output.size(0), num_anchors, num_classes, output.size(2) * output.size(3))
191 | # Shape: [batch, num_anchors, num_classes, H * W] --> [batch, num_anchors * H * W, num_classes]
192 | cls_confs = cls_confs.permute(0, 1, 3, 2).reshape(output.size(0), num_anchors * output.size(2) * output.size(3), num_classes)
193 |
194 | # Apply sigmoid(), exp() and softmax() to slices
195 | #
196 | bxy = torch.sigmoid(bxy) * scale_x_y - 0.5 * (scale_x_y - 1)
197 | bwh = torch.exp(bwh)
198 | det_confs = torch.sigmoid(det_confs)
199 | cls_confs = torch.sigmoid(cls_confs)
200 |
201 | # Prepare C-x, C-y, P-w, P-h (None of them are torch related)
202 | grid_x = np.expand_dims(np.expand_dims(np.expand_dims(np.linspace(0, output.size(3) - 1, output.size(3)), axis=0).repeat(output.size(2), 0), axis=0), axis=0)
203 | grid_y = np.expand_dims(np.expand_dims(np.expand_dims(np.linspace(0, output.size(2) - 1, output.size(2)), axis=1).repeat(output.size(3), 1), axis=0), axis=0)
204 | # grid_x = torch.linspace(0, W - 1, W).reshape(1, 1, 1, W).repeat(1, 1, H, 1)
205 | # grid_y = torch.linspace(0, H - 1, H).reshape(1, 1, H, 1).repeat(1, 1, 1, W)
206 |
207 | anchor_w = []
208 | anchor_h = []
209 | for i in range(num_anchors):
210 | anchor_w.append(anchors[i * 2])
211 | anchor_h.append(anchors[i * 2 + 1])
212 |
213 | device = None
214 | cuda_check = output.is_cuda
215 | if cuda_check:
216 | device = output.get_device()
217 |
218 | bx_list = []
219 | by_list = []
220 | bw_list = []
221 | bh_list = []
222 |
223 | # Apply C-x, C-y, P-w, P-h
224 | for i in range(num_anchors):
225 | ii = i * 2
226 | # Shape: [batch, 1, H, W]
227 | bx = bxy[:, ii : ii + 1] + torch.tensor(grid_x, device=device, dtype=torch.float32) # grid_x.to(device=device, dtype=torch.float32)
228 | # Shape: [batch, 1, H, W]
229 | by = bxy[:, ii + 1 : ii + 2] + torch.tensor(grid_y, device=device, dtype=torch.float32) # grid_y.to(device=device, dtype=torch.float32)
230 | # Shape: [batch, 1, H, W]
231 | bw = bwh[:, ii : ii + 1] * anchor_w[i]
232 | # Shape: [batch, 1, H, W]
233 | bh = bwh[:, ii + 1 : ii + 2] * anchor_h[i]
234 |
235 | bx_list.append(bx)
236 | by_list.append(by)
237 | bw_list.append(bw)
238 | bh_list.append(bh)
239 |
240 |
241 | ########################################
242 | # Figure out bboxes from slices #
243 | ########################################
244 |
245 | # Shape: [batch, num_anchors, H, W]
246 | bx = torch.cat(bx_list, dim=1)
247 | # Shape: [batch, num_anchors, H, W]
248 | by = torch.cat(by_list, dim=1)
249 | # Shape: [batch, num_anchors, H, W]
250 | bw = torch.cat(bw_list, dim=1)
251 | # Shape: [batch, num_anchors, H, W]
252 | bh = torch.cat(bh_list, dim=1)
253 |
254 | # Shape: [batch, 2 * num_anchors, H, W]
255 | bx_bw = torch.cat((bx, bw), dim=1)
256 | # Shape: [batch, 2 * num_anchors, H, W]
257 | by_bh = torch.cat((by, bh), dim=1)
258 |
259 | # normalize coordinates to [0, 1]
260 | bx_bw /= output.size(3)
261 | by_bh /= output.size(2)
262 |
263 | # Shape: [batch, num_anchors * H * W, 1]
264 | bx = bx_bw[:, :num_anchors].view(output.size(0), num_anchors * output.size(2) * output.size(3), 1)
265 | by = by_bh[:, :num_anchors].view(output.size(0), num_anchors * output.size(2) * output.size(3), 1)
266 | bw = bx_bw[:, num_anchors:].view(output.size(0), num_anchors * output.size(2) * output.size(3), 1)
267 | bh = by_bh[:, num_anchors:].view(output.size(0), num_anchors * output.size(2) * output.size(3), 1)
268 |
269 | bx1 = bx - bw * 0.5
270 | by1 = by - bh * 0.5
271 | bx2 = bx1 + bw
272 | by2 = by1 + bh
273 |
274 | # Shape: [batch, num_anchors * h * w, 4] -> [batch, num_anchors * h * w, 1, 4]
275 | boxes = torch.cat((bx1, by1, bx2, by2), dim=2).view(output.size(0), num_anchors * output.size(2) * output.size(3), 1, 4)
276 | # boxes = boxes.repeat(1, 1, num_classes, 1)
277 |
278 | # boxes: [batch, num_anchors * H * W, 1, 4]
279 | # cls_confs: [batch, num_anchors * H * W, num_classes]
280 | # det_confs: [batch, num_anchors * H * W]
281 |
282 | det_confs = det_confs.view(output.size(0), num_anchors * output.size(2) * output.size(3), 1)
283 | confs = cls_confs * det_confs
284 |
285 | # boxes: [batch, num_anchors * H * W, 1, 4]
286 | # confs: [batch, num_anchors * H * W, num_classes]
287 |
288 | return boxes, confs
289 |
290 | class YoloLayer(nn.Module):
291 | ''' Yolo layer
292 | model_out: while inference,is post-processing inside or outside the model
293 | true:outside
294 | '''
295 | def __init__(self, anchor_mask=[], num_classes=0, anchors=[], num_anchors=1, stride=32, model_out=False):
296 | super(YoloLayer, self).__init__()
297 | self.anchor_mask = anchor_mask
298 | self.num_classes = num_classes
299 | self.anchors = anchors
300 | self.num_anchors = num_anchors
301 | self.anchor_step = len(anchors) // num_anchors
302 | self.coord_scale = 1
303 | self.noobject_scale = 1
304 | self.object_scale = 5
305 | self.class_scale = 1
306 | self.thresh = 0.6
307 | self.stride = stride
308 | self.seen = 0
309 | self.scale_x_y = 1
310 |
311 | self.model_out = model_out
312 |
313 | def forward(self, output, target=None):
314 | if self.training:
315 | return output
316 | masked_anchors = []
317 | for m in self.anchor_mask:
318 | masked_anchors += self.anchors[m * self.anchor_step:(m + 1) * self.anchor_step]
319 | masked_anchors = [anchor / self.stride for anchor in masked_anchors]
320 |
321 | return yolo_forward_dynamic(output, self.thresh, self.num_classes, masked_anchors, len(self.anchor_mask),scale_x_y=self.scale_x_y)
322 |
323 |
--------------------------------------------------------------------------------
/models.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch import nn
3 | import torch.nn.functional as F
4 | from tool.torch_utils import *
5 | from tool.yolo_layer import YoloLayer
6 |
7 |
8 | class Mish(torch.nn.Module):
9 | def __init__(self):
10 | super().__init__()
11 |
12 | def forward(self, x):
13 | x = x * (torch.tanh(torch.nn.functional.softplus(x)))
14 | return x
15 |
16 |
17 | class Upsample(nn.Module):
18 | def __init__(self):
19 | super(Upsample, self).__init__()
20 |
21 | def forward(self, x, target_size, inference=False):
22 | assert (x.data.dim() == 4)
23 | # _, _, tH, tW = target_size
24 |
25 | if inference:
26 |
27 | #B = x.data.size(0)
28 | #C = x.data.size(1)
29 | #H = x.data.size(2)
30 | #W = x.data.size(3)
31 |
32 | return x.view(x.size(0), x.size(1), x.size(2), 1, x.size(3), 1).\
33 | expand(x.size(0), x.size(1), x.size(2), target_size[2] // x.size(2), x.size(3), target_size[3] // x.size(3)).\
34 | contiguous().view(x.size(0), x.size(1), target_size[2], target_size[3])
35 | else:
36 | return F.interpolate(x, size=(target_size[2], target_size[3]), mode='nearest')
37 |
38 |
39 | class Conv_Bn_Activation(nn.Module):
40 | def __init__(self, in_channels, out_channels, kernel_size, stride, activation, bn=True, bias=False):
41 | super().__init__()
42 | pad = (kernel_size - 1) // 2
43 |
44 | self.conv = nn.ModuleList()
45 | if bias:
46 | self.conv.append(nn.Conv2d(in_channels, out_channels, kernel_size, stride, pad))
47 | else:
48 | self.conv.append(nn.Conv2d(in_channels, out_channels, kernel_size, stride, pad, bias=False))
49 | if bn:
50 | self.conv.append(nn.BatchNorm2d(out_channels))
51 | if activation == "mish":
52 | self.conv.append(Mish())
53 | elif activation == "relu":
54 | self.conv.append(nn.ReLU(inplace=True))
55 | elif activation == "leaky":
56 | self.conv.append(nn.LeakyReLU(0.1, inplace=True))
57 | elif activation == "linear":
58 | pass
59 | else:
60 | print("activate error !!! {} {} {}".format(sys._getframe().f_code.co_filename,
61 | sys._getframe().f_code.co_name, sys._getframe().f_lineno))
62 |
63 | def forward(self, x):
64 | for l in self.conv:
65 | x = l(x)
66 | return x
67 |
68 |
69 | class ResBlock(nn.Module):
70 | """
71 | Sequential residual blocks each of which consists of \
72 | two convolution layers.
73 | Args:
74 | ch (int): number of input and output channels.
75 | nblocks (int): number of residual blocks.
76 | shortcut (bool): if True, residual tensor addition is enabled.
77 | """
78 |
79 | def __init__(self, ch, nblocks=1, shortcut=True):
80 | super().__init__()
81 | self.shortcut = shortcut
82 | self.module_list = nn.ModuleList()
83 | for i in range(nblocks):
84 | resblock_one = nn.ModuleList()
85 | resblock_one.append(Conv_Bn_Activation(ch, ch, 1, 1, 'mish'))
86 | resblock_one.append(Conv_Bn_Activation(ch, ch, 3, 1, 'mish'))
87 | self.module_list.append(resblock_one)
88 |
89 | def forward(self, x):
90 | for module in self.module_list:
91 | h = x
92 | for res in module:
93 | h = res(h)
94 | x = x + h if self.shortcut else h
95 | return x
96 |
97 |
98 | class DownSample1(nn.Module):
99 | def __init__(self):
100 | super().__init__()
101 | self.conv1 = Conv_Bn_Activation(3, 32, 3, 1, 'mish')
102 |
103 | self.conv2 = Conv_Bn_Activation(32, 64, 3, 2, 'mish')
104 | self.conv3 = Conv_Bn_Activation(64, 64, 1, 1, 'mish')
105 | # [route]
106 | # layers = -2
107 | self.conv4 = Conv_Bn_Activation(64, 64, 1, 1, 'mish')
108 |
109 | self.conv5 = Conv_Bn_Activation(64, 32, 1, 1, 'mish')
110 | self.conv6 = Conv_Bn_Activation(32, 64, 3, 1, 'mish')
111 | # [shortcut]
112 | # from=-3
113 | # activation = linear
114 |
115 | self.conv7 = Conv_Bn_Activation(64, 64, 1, 1, 'mish')
116 | # [route]
117 | # layers = -1, -7
118 | self.conv8 = Conv_Bn_Activation(128, 64, 1, 1, 'mish')
119 |
120 | def forward(self, input):
121 | x1 = self.conv1(input)
122 | x2 = self.conv2(x1)
123 | x3 = self.conv3(x2)
124 | # route -2
125 | x4 = self.conv4(x2)
126 | x5 = self.conv5(x4)
127 | x6 = self.conv6(x5)
128 | # shortcut -3
129 | x6 = x6 + x4
130 |
131 | x7 = self.conv7(x6)
132 | # [route]
133 | # layers = -1, -7
134 | x7 = torch.cat([x7, x3], dim=1)
135 | x8 = self.conv8(x7)
136 | return x8
137 |
138 |
139 | class DownSample2(nn.Module):
140 | def __init__(self):
141 | super().__init__()
142 | self.conv1 = Conv_Bn_Activation(64, 128, 3, 2, 'mish')
143 | self.conv2 = Conv_Bn_Activation(128, 64, 1, 1, 'mish')
144 | # r -2
145 | self.conv3 = Conv_Bn_Activation(128, 64, 1, 1, 'mish')
146 |
147 | self.resblock = ResBlock(ch=64, nblocks=2)
148 |
149 | # s -3
150 | self.conv4 = Conv_Bn_Activation(64, 64, 1, 1, 'mish')
151 | # r -1 -10
152 | self.conv5 = Conv_Bn_Activation(128, 128, 1, 1, 'mish')
153 |
154 | def forward(self, input):
155 | x1 = self.conv1(input)
156 | x2 = self.conv2(x1)
157 | x3 = self.conv3(x1)
158 |
159 | r = self.resblock(x3)
160 | x4 = self.conv4(r)
161 |
162 | x4 = torch.cat([x4, x2], dim=1)
163 | x5 = self.conv5(x4)
164 | return x5
165 |
166 |
167 | class DownSample3(nn.Module):
168 | def __init__(self):
169 | super().__init__()
170 | self.conv1 = Conv_Bn_Activation(128, 256, 3, 2, 'mish')
171 | self.conv2 = Conv_Bn_Activation(256, 128, 1, 1, 'mish')
172 | self.conv3 = Conv_Bn_Activation(256, 128, 1, 1, 'mish')
173 |
174 | self.resblock = ResBlock(ch=128, nblocks=8)
175 | self.conv4 = Conv_Bn_Activation(128, 128, 1, 1, 'mish')
176 | self.conv5 = Conv_Bn_Activation(256, 256, 1, 1, 'mish')
177 |
178 | def forward(self, input):
179 | x1 = self.conv1(input)
180 | x2 = self.conv2(x1)
181 | x3 = self.conv3(x1)
182 |
183 | r = self.resblock(x3)
184 | x4 = self.conv4(r)
185 |
186 | x4 = torch.cat([x4, x2], dim=1)
187 | x5 = self.conv5(x4)
188 | return x5
189 |
190 |
191 | class DownSample4(nn.Module):
192 | def __init__(self):
193 | super().__init__()
194 | self.conv1 = Conv_Bn_Activation(256, 512, 3, 2, 'mish')
195 | self.conv2 = Conv_Bn_Activation(512, 256, 1, 1, 'mish')
196 | self.conv3 = Conv_Bn_Activation(512, 256, 1, 1, 'mish')
197 |
198 | self.resblock = ResBlock(ch=256, nblocks=8)
199 | self.conv4 = Conv_Bn_Activation(256, 256, 1, 1, 'mish')
200 | self.conv5 = Conv_Bn_Activation(512, 512, 1, 1, 'mish')
201 |
202 | def forward(self, input):
203 | x1 = self.conv1(input)
204 | x2 = self.conv2(x1)
205 | x3 = self.conv3(x1)
206 |
207 | r = self.resblock(x3)
208 | x4 = self.conv4(r)
209 |
210 | x4 = torch.cat([x4, x2], dim=1)
211 | x5 = self.conv5(x4)
212 | return x5
213 |
214 |
215 | class DownSample5(nn.Module):
216 | def __init__(self):
217 | super().__init__()
218 | self.conv1 = Conv_Bn_Activation(512, 1024, 3, 2, 'mish')
219 | self.conv2 = Conv_Bn_Activation(1024, 512, 1, 1, 'mish')
220 | self.conv3 = Conv_Bn_Activation(1024, 512, 1, 1, 'mish')
221 |
222 | self.resblock = ResBlock(ch=512, nblocks=4)
223 | self.conv4 = Conv_Bn_Activation(512, 512, 1, 1, 'mish')
224 | self.conv5 = Conv_Bn_Activation(1024, 1024, 1, 1, 'mish')
225 |
226 | def forward(self, input):
227 | x1 = self.conv1(input)
228 | x2 = self.conv2(x1)
229 | x3 = self.conv3(x1)
230 |
231 | r = self.resblock(x3)
232 | x4 = self.conv4(r)
233 |
234 | x4 = torch.cat([x4, x2], dim=1)
235 | x5 = self.conv5(x4)
236 | return x5
237 |
238 |
239 | class Neck(nn.Module):
240 | def __init__(self, inference=False):
241 | super().__init__()
242 | self.inference = inference
243 |
244 | self.conv1 = Conv_Bn_Activation(1024, 512, 1, 1, 'leaky')
245 | self.conv2 = Conv_Bn_Activation(512, 1024, 3, 1, 'leaky')
246 | self.conv3 = Conv_Bn_Activation(1024, 512, 1, 1, 'leaky')
247 | # SPP
248 | self.maxpool1 = nn.MaxPool2d(kernel_size=5, stride=1, padding=5 // 2)
249 | self.maxpool2 = nn.MaxPool2d(kernel_size=9, stride=1, padding=9 // 2)
250 | self.maxpool3 = nn.MaxPool2d(kernel_size=13, stride=1, padding=13 // 2)
251 |
252 | # R -1 -3 -5 -6
253 | # SPP
254 | self.conv4 = Conv_Bn_Activation(2048, 512, 1, 1, 'leaky')
255 | self.conv5 = Conv_Bn_Activation(512, 1024, 3, 1, 'leaky')
256 | self.conv6 = Conv_Bn_Activation(1024, 512, 1, 1, 'leaky')
257 | self.conv7 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
258 | # UP
259 | self.upsample1 = Upsample()
260 | # R 85
261 | self.conv8 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
262 | # R -1 -3
263 | self.conv9 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
264 | self.conv10 = Conv_Bn_Activation(256, 512, 3, 1, 'leaky')
265 | self.conv11 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
266 | self.conv12 = Conv_Bn_Activation(256, 512, 3, 1, 'leaky')
267 | self.conv13 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
268 | self.conv14 = Conv_Bn_Activation(256, 128, 1, 1, 'leaky')
269 | # UP
270 | self.upsample2 = Upsample()
271 | # R 54
272 | self.conv15 = Conv_Bn_Activation(256, 128, 1, 1, 'leaky')
273 | # R -1 -3
274 | self.conv16 = Conv_Bn_Activation(256, 128, 1, 1, 'leaky')
275 | self.conv17 = Conv_Bn_Activation(128, 256, 3, 1, 'leaky')
276 | self.conv18 = Conv_Bn_Activation(256, 128, 1, 1, 'leaky')
277 | self.conv19 = Conv_Bn_Activation(128, 256, 3, 1, 'leaky')
278 | self.conv20 = Conv_Bn_Activation(256, 128, 1, 1, 'leaky')
279 |
280 | def forward(self, input, downsample4, downsample3, inference=False):
281 | x1 = self.conv1(input)
282 | x2 = self.conv2(x1)
283 | x3 = self.conv3(x2)
284 | # SPP
285 | m1 = self.maxpool1(x3)
286 | m2 = self.maxpool2(x3)
287 | m3 = self.maxpool3(x3)
288 | spp = torch.cat([m3, m2, m1, x3], dim=1)
289 | # SPP end
290 | x4 = self.conv4(spp)
291 | x5 = self.conv5(x4)
292 | x6 = self.conv6(x5)
293 | x7 = self.conv7(x6)
294 | # UP
295 | up = self.upsample1(x7, downsample4.size(), self.inference)
296 | # R 85
297 | x8 = self.conv8(downsample4)
298 | # R -1 -3
299 | x8 = torch.cat([x8, up], dim=1)
300 |
301 | x9 = self.conv9(x8)
302 | x10 = self.conv10(x9)
303 | x11 = self.conv11(x10)
304 | x12 = self.conv12(x11)
305 | x13 = self.conv13(x12)
306 | x14 = self.conv14(x13)
307 |
308 | # UP
309 | up = self.upsample2(x14, downsample3.size(), self.inference)
310 | # R 54
311 | x15 = self.conv15(downsample3)
312 | # R -1 -3
313 | x15 = torch.cat([x15, up], dim=1)
314 |
315 | x16 = self.conv16(x15)
316 | x17 = self.conv17(x16)
317 | x18 = self.conv18(x17)
318 | x19 = self.conv19(x18)
319 | x20 = self.conv20(x19)
320 | return x20, x13, x6
321 |
322 |
323 | class Yolov4Head(nn.Module):
324 | def __init__(self, output_ch, n_classes, inference=False):
325 | super().__init__()
326 | self.inference = inference
327 |
328 | self.conv1 = Conv_Bn_Activation(128, 256, 3, 1, 'leaky')
329 | self.conv2 = Conv_Bn_Activation(256, output_ch, 1, 1, 'linear', bn=False, bias=True)
330 |
331 | self.yolo1 = YoloLayer(
332 | anchor_mask=[0, 1, 2], num_classes=n_classes,
333 | anchors=[12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401],
334 | num_anchors=9, stride=8)
335 |
336 | # R -4
337 | self.conv3 = Conv_Bn_Activation(128, 256, 3, 2, 'leaky')
338 |
339 | # R -1 -16
340 | self.conv4 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
341 | self.conv5 = Conv_Bn_Activation(256, 512, 3, 1, 'leaky')
342 | self.conv6 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
343 | self.conv7 = Conv_Bn_Activation(256, 512, 3, 1, 'leaky')
344 | self.conv8 = Conv_Bn_Activation(512, 256, 1, 1, 'leaky')
345 | self.conv9 = Conv_Bn_Activation(256, 512, 3, 1, 'leaky')
346 | self.conv10 = Conv_Bn_Activation(512, output_ch, 1, 1, 'linear', bn=False, bias=True)
347 |
348 | self.yolo2 = YoloLayer(
349 | anchor_mask=[3, 4, 5], num_classes=n_classes,
350 | anchors=[12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401],
351 | num_anchors=9, stride=16)
352 |
353 | # R -4
354 | self.conv11 = Conv_Bn_Activation(256, 512, 3, 2, 'leaky')
355 |
356 | # R -1 -37
357 | self.conv12 = Conv_Bn_Activation(1024, 512, 1, 1, 'leaky')
358 | self.conv13 = Conv_Bn_Activation(512, 1024, 3, 1, 'leaky')
359 | self.conv14 = Conv_Bn_Activation(1024, 512, 1, 1, 'leaky')
360 | self.conv15 = Conv_Bn_Activation(512, 1024, 3, 1, 'leaky')
361 | self.conv16 = Conv_Bn_Activation(1024, 512, 1, 1, 'leaky')
362 | self.conv17 = Conv_Bn_Activation(512, 1024, 3, 1, 'leaky')
363 | self.conv18 = Conv_Bn_Activation(1024, output_ch, 1, 1, 'linear', bn=False, bias=True)
364 |
365 | self.yolo3 = YoloLayer(
366 | anchor_mask=[6, 7, 8], num_classes=n_classes,
367 | anchors=[12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401],
368 | num_anchors=9, stride=32)
369 |
370 | def forward(self, input1, input2, input3):
371 | x1 = self.conv1(input1)
372 | x2 = self.conv2(x1)
373 |
374 | x3 = self.conv3(input1)
375 | # R -1 -16
376 | x3 = torch.cat([x3, input2], dim=1)
377 | x4 = self.conv4(x3)
378 | x5 = self.conv5(x4)
379 | x6 = self.conv6(x5)
380 | x7 = self.conv7(x6)
381 | x8 = self.conv8(x7)
382 | x9 = self.conv9(x8)
383 | x10 = self.conv10(x9)
384 |
385 | # R -4
386 | x11 = self.conv11(x8)
387 | # R -1 -37
388 | x11 = torch.cat([x11, input3], dim=1)
389 |
390 | x12 = self.conv12(x11)
391 | x13 = self.conv13(x12)
392 | x14 = self.conv14(x13)
393 | x15 = self.conv15(x14)
394 | x16 = self.conv16(x15)
395 | x17 = self.conv17(x16)
396 | x18 = self.conv18(x17)
397 |
398 | if self.inference:
399 | y1 = self.yolo1(x2)
400 | y2 = self.yolo2(x10)
401 | y3 = self.yolo3(x18)
402 |
403 | return get_region_boxes([y1, y2, y3])
404 |
405 | else:
406 | return [x2, x10, x18]
407 |
408 |
409 | class Yolov4(nn.Module):
410 | def __init__(self, yolov4conv137weight=None, n_classes=80, inference=False):
411 | super().__init__()
412 |
413 | output_ch = (4 + 1 + n_classes) * 3
414 |
415 | # backbone
416 | self.down1 = DownSample1()
417 | self.down2 = DownSample2()
418 | self.down3 = DownSample3()
419 | self.down4 = DownSample4()
420 | self.down5 = DownSample5()
421 | # neck
422 | self.neek = Neck(inference)
423 | # yolov4conv137
424 | if yolov4conv137weight:
425 | _model = nn.Sequential(self.down1, self.down2, self.down3, self.down4, self.down5, self.neek)
426 | pretrained_dict = torch.load(yolov4conv137weight)
427 |
428 | model_dict = _model.state_dict()
429 | # 1. filter out unnecessary keys
430 | pretrained_dict = {k1: v for (k, v), k1 in zip(pretrained_dict.items(), model_dict)}
431 | # 2. overwrite entries in the existing state dict
432 | model_dict.update(pretrained_dict)
433 | _model.load_state_dict(model_dict)
434 |
435 | # head
436 | self.head = Yolov4Head(output_ch, n_classes, inference)
437 |
438 |
439 | def forward(self, input):
440 | d1 = self.down1(input)
441 | d2 = self.down2(d1)
442 | d3 = self.down3(d2)
443 | d4 = self.down4(d3)
444 | d5 = self.down5(d4)
445 |
446 | x20, x13, x6 = self.neek(d5, d4, d3)
447 |
448 | output = self.head(x20, x13, x6)
449 | return output
450 |
451 |
452 | if __name__ == "__main__":
453 | import sys
454 | import cv2
455 |
456 | namesfile = None
457 | if len(sys.argv) == 6:
458 | n_classes = int(sys.argv[1])
459 | weightfile = sys.argv[2]
460 | imgfile = sys.argv[3]
461 | height = int(sys.argv[4])
462 | width = int(sys.argv[5])
463 | elif len(sys.argv) == 7:
464 | n_classes = int(sys.argv[1])
465 | weightfile = sys.argv[2]
466 | imgfile = sys.argv[3]
467 | height = sys.argv[4]
468 | width = int(sys.argv[5])
469 | namesfile = int(sys.argv[6])
470 | else:
471 | print('Usage: ')
472 | print(' python models.py num_classes weightfile imgfile namefile')
473 |
474 | model = Yolov4(yolov4conv137weight=None, n_classes=n_classes, inference=True)
475 |
476 | pretrained_dict = torch.load(weightfile, map_location=torch.device('cuda'))
477 | model.load_state_dict(pretrained_dict)
478 |
479 | use_cuda = True
480 | if use_cuda:
481 | model.cuda()
482 |
483 | img = cv2.imread(imgfile)
484 |
485 | # Inference input size is 416*416 does not mean training size is the same
486 | # Training size could be 608*608 or even other sizes
487 | # Optional inference sizes:
488 | # Hight in {320, 416, 512, 608, ... 320 + 96 * n}
489 | # Width in {320, 416, 512, 608, ... 320 + 96 * m}
490 | sized = cv2.resize(img, (width, height))
491 | sized = cv2.cvtColor(sized, cv2.COLOR_BGR2RGB)
492 |
493 | from tool.utils import load_class_names, plot_boxes_cv2
494 | from tool.torch_utils import do_detect
495 |
496 | for i in range(2): # This 'for' loop is for speed check
497 | # Because the first iteration is usually longer
498 | boxes = do_detect(model, sized, 0.4, 0.6, use_cuda)
499 |
500 | if namesfile == None:
501 | if n_classes == 20:
502 | namesfile = 'data/voc.names'
503 | elif n_classes == 80:
504 | namesfile = 'data/coco.names'
505 | else:
506 | print("please give namefile")
507 |
508 | class_names = load_class_names(namesfile)
509 | plot_boxes_cv2(img, boxes[0], 'predictions.jpg', class_names)
510 |
--------------------------------------------------------------------------------
/cfg/yolov4.cfg:
--------------------------------------------------------------------------------
1 | [net]
2 | batch=64
3 | subdivisions=8
4 | # Training
5 | #width=512
6 | #height=512
7 | width=608
8 | height=608
9 | channels=3
10 | momentum=0.949
11 | decay=0.0005
12 | angle=0
13 | saturation = 1.5
14 | exposure = 1.5
15 | hue=.1
16 |
17 | learning_rate=0.0013
18 | burn_in=1000
19 | max_batches = 500500
20 | policy=steps
21 | steps=400000,450000
22 | scales=.1,.1
23 |
24 | #cutmix=1
25 | mosaic=1
26 |
27 | #:104x104 54:52x52 85:26x26 104:13x13 for 416
28 |
29 | [convolutional]
30 | batch_normalize=1
31 | filters=32
32 | size=3
33 | stride=1
34 | pad=1
35 | activation=mish
36 |
37 | # Downsample
38 |
39 | [convolutional]
40 | batch_normalize=1
41 | filters=64
42 | size=3
43 | stride=2
44 | pad=1
45 | activation=mish
46 |
47 | [convolutional]
48 | batch_normalize=1
49 | filters=64
50 | size=1
51 | stride=1
52 | pad=1
53 | activation=mish
54 |
55 | [route]
56 | layers = -2
57 |
58 | [convolutional]
59 | batch_normalize=1
60 | filters=64
61 | size=1
62 | stride=1
63 | pad=1
64 | activation=mish
65 |
66 | [convolutional]
67 | batch_normalize=1
68 | filters=32
69 | size=1
70 | stride=1
71 | pad=1
72 | activation=mish
73 |
74 | [convolutional]
75 | batch_normalize=1
76 | filters=64
77 | size=3
78 | stride=1
79 | pad=1
80 | activation=mish
81 |
82 | [shortcut]
83 | from=-3
84 | activation=linear
85 |
86 | [convolutional]
87 | batch_normalize=1
88 | filters=64
89 | size=1
90 | stride=1
91 | pad=1
92 | activation=mish
93 |
94 | [route]
95 | layers = -1,-7
96 |
97 | [convolutional]
98 | batch_normalize=1
99 | filters=64
100 | size=1
101 | stride=1
102 | pad=1
103 | activation=mish
104 |
105 | # Downsample
106 |
107 | [convolutional]
108 | batch_normalize=1
109 | filters=128
110 | size=3
111 | stride=2
112 | pad=1
113 | activation=mish
114 |
115 | [convolutional]
116 | batch_normalize=1
117 | filters=64
118 | size=1
119 | stride=1
120 | pad=1
121 | activation=mish
122 |
123 | [route]
124 | layers = -2
125 |
126 | [convolutional]
127 | batch_normalize=1
128 | filters=64
129 | size=1
130 | stride=1
131 | pad=1
132 | activation=mish
133 |
134 | [convolutional]
135 | batch_normalize=1
136 | filters=64
137 | size=1
138 | stride=1
139 | pad=1
140 | activation=mish
141 |
142 | [convolutional]
143 | batch_normalize=1
144 | filters=64
145 | size=3
146 | stride=1
147 | pad=1
148 | activation=mish
149 |
150 | [shortcut]
151 | from=-3
152 | activation=linear
153 |
154 | [convolutional]
155 | batch_normalize=1
156 | filters=64
157 | size=1
158 | stride=1
159 | pad=1
160 | activation=mish
161 |
162 | [convolutional]
163 | batch_normalize=1
164 | filters=64
165 | size=3
166 | stride=1
167 | pad=1
168 | activation=mish
169 |
170 | [shortcut]
171 | from=-3
172 | activation=linear
173 |
174 | [convolutional]
175 | batch_normalize=1
176 | filters=64
177 | size=1
178 | stride=1
179 | pad=1
180 | activation=mish
181 |
182 | [route]
183 | layers = -1,-10
184 |
185 | [convolutional]
186 | batch_normalize=1
187 | filters=128
188 | size=1
189 | stride=1
190 | pad=1
191 | activation=mish
192 |
193 | # Downsample
194 |
195 | [convolutional]
196 | batch_normalize=1
197 | filters=256
198 | size=3
199 | stride=2
200 | pad=1
201 | activation=mish
202 |
203 | [convolutional]
204 | batch_normalize=1
205 | filters=128
206 | size=1
207 | stride=1
208 | pad=1
209 | activation=mish
210 |
211 | [route]
212 | layers = -2
213 |
214 | [convolutional]
215 | batch_normalize=1
216 | filters=128
217 | size=1
218 | stride=1
219 | pad=1
220 | activation=mish
221 |
222 | [convolutional]
223 | batch_normalize=1
224 | filters=128
225 | size=1
226 | stride=1
227 | pad=1
228 | activation=mish
229 |
230 | [convolutional]
231 | batch_normalize=1
232 | filters=128
233 | size=3
234 | stride=1
235 | pad=1
236 | activation=mish
237 |
238 | [shortcut]
239 | from=-3
240 | activation=linear
241 |
242 | [convolutional]
243 | batch_normalize=1
244 | filters=128
245 | size=1
246 | stride=1
247 | pad=1
248 | activation=mish
249 |
250 | [convolutional]
251 | batch_normalize=1
252 | filters=128
253 | size=3
254 | stride=1
255 | pad=1
256 | activation=mish
257 |
258 | [shortcut]
259 | from=-3
260 | activation=linear
261 |
262 | [convolutional]
263 | batch_normalize=1
264 | filters=128
265 | size=1
266 | stride=1
267 | pad=1
268 | activation=mish
269 |
270 | [convolutional]
271 | batch_normalize=1
272 | filters=128
273 | size=3
274 | stride=1
275 | pad=1
276 | activation=mish
277 |
278 | [shortcut]
279 | from=-3
280 | activation=linear
281 |
282 | [convolutional]
283 | batch_normalize=1
284 | filters=128
285 | size=1
286 | stride=1
287 | pad=1
288 | activation=mish
289 |
290 | [convolutional]
291 | batch_normalize=1
292 | filters=128
293 | size=3
294 | stride=1
295 | pad=1
296 | activation=mish
297 |
298 | [shortcut]
299 | from=-3
300 | activation=linear
301 |
302 |
303 | [convolutional]
304 | batch_normalize=1
305 | filters=128
306 | size=1
307 | stride=1
308 | pad=1
309 | activation=mish
310 |
311 | [convolutional]
312 | batch_normalize=1
313 | filters=128
314 | size=3
315 | stride=1
316 | pad=1
317 | activation=mish
318 |
319 | [shortcut]
320 | from=-3
321 | activation=linear
322 |
323 | [convolutional]
324 | batch_normalize=1
325 | filters=128
326 | size=1
327 | stride=1
328 | pad=1
329 | activation=mish
330 |
331 | [convolutional]
332 | batch_normalize=1
333 | filters=128
334 | size=3
335 | stride=1
336 | pad=1
337 | activation=mish
338 |
339 | [shortcut]
340 | from=-3
341 | activation=linear
342 |
343 | [convolutional]
344 | batch_normalize=1
345 | filters=128
346 | size=1
347 | stride=1
348 | pad=1
349 | activation=mish
350 |
351 | [convolutional]
352 | batch_normalize=1
353 | filters=128
354 | size=3
355 | stride=1
356 | pad=1
357 | activation=mish
358 |
359 | [shortcut]
360 | from=-3
361 | activation=linear
362 |
363 | [convolutional]
364 | batch_normalize=1
365 | filters=128
366 | size=1
367 | stride=1
368 | pad=1
369 | activation=mish
370 |
371 | [convolutional]
372 | batch_normalize=1
373 | filters=128
374 | size=3
375 | stride=1
376 | pad=1
377 | activation=mish
378 |
379 | [shortcut]
380 | from=-3
381 | activation=linear
382 |
383 | [convolutional]
384 | batch_normalize=1
385 | filters=128
386 | size=1
387 | stride=1
388 | pad=1
389 | activation=mish
390 |
391 | [route]
392 | layers = -1,-28
393 |
394 | [convolutional]
395 | batch_normalize=1
396 | filters=256
397 | size=1
398 | stride=1
399 | pad=1
400 | activation=mish
401 |
402 | # Downsample
403 |
404 | [convolutional]
405 | batch_normalize=1
406 | filters=512
407 | size=3
408 | stride=2
409 | pad=1
410 | activation=mish
411 |
412 | [convolutional]
413 | batch_normalize=1
414 | filters=256
415 | size=1
416 | stride=1
417 | pad=1
418 | activation=mish
419 |
420 | [route]
421 | layers = -2
422 |
423 | [convolutional]
424 | batch_normalize=1
425 | filters=256
426 | size=1
427 | stride=1
428 | pad=1
429 | activation=mish
430 |
431 | [convolutional]
432 | batch_normalize=1
433 | filters=256
434 | size=1
435 | stride=1
436 | pad=1
437 | activation=mish
438 |
439 | [convolutional]
440 | batch_normalize=1
441 | filters=256
442 | size=3
443 | stride=1
444 | pad=1
445 | activation=mish
446 |
447 | [shortcut]
448 | from=-3
449 | activation=linear
450 |
451 |
452 | [convolutional]
453 | batch_normalize=1
454 | filters=256
455 | size=1
456 | stride=1
457 | pad=1
458 | activation=mish
459 |
460 | [convolutional]
461 | batch_normalize=1
462 | filters=256
463 | size=3
464 | stride=1
465 | pad=1
466 | activation=mish
467 |
468 | [shortcut]
469 | from=-3
470 | activation=linear
471 |
472 |
473 | [convolutional]
474 | batch_normalize=1
475 | filters=256
476 | size=1
477 | stride=1
478 | pad=1
479 | activation=mish
480 |
481 | [convolutional]
482 | batch_normalize=1
483 | filters=256
484 | size=3
485 | stride=1
486 | pad=1
487 | activation=mish
488 |
489 | [shortcut]
490 | from=-3
491 | activation=linear
492 |
493 |
494 | [convolutional]
495 | batch_normalize=1
496 | filters=256
497 | size=1
498 | stride=1
499 | pad=1
500 | activation=mish
501 |
502 | [convolutional]
503 | batch_normalize=1
504 | filters=256
505 | size=3
506 | stride=1
507 | pad=1
508 | activation=mish
509 |
510 | [shortcut]
511 | from=-3
512 | activation=linear
513 |
514 |
515 | [convolutional]
516 | batch_normalize=1
517 | filters=256
518 | size=1
519 | stride=1
520 | pad=1
521 | activation=mish
522 |
523 | [convolutional]
524 | batch_normalize=1
525 | filters=256
526 | size=3
527 | stride=1
528 | pad=1
529 | activation=mish
530 |
531 | [shortcut]
532 | from=-3
533 | activation=linear
534 |
535 |
536 | [convolutional]
537 | batch_normalize=1
538 | filters=256
539 | size=1
540 | stride=1
541 | pad=1
542 | activation=mish
543 |
544 | [convolutional]
545 | batch_normalize=1
546 | filters=256
547 | size=3
548 | stride=1
549 | pad=1
550 | activation=mish
551 |
552 | [shortcut]
553 | from=-3
554 | activation=linear
555 |
556 |
557 | [convolutional]
558 | batch_normalize=1
559 | filters=256
560 | size=1
561 | stride=1
562 | pad=1
563 | activation=mish
564 |
565 | [convolutional]
566 | batch_normalize=1
567 | filters=256
568 | size=3
569 | stride=1
570 | pad=1
571 | activation=mish
572 |
573 | [shortcut]
574 | from=-3
575 | activation=linear
576 |
577 | [convolutional]
578 | batch_normalize=1
579 | filters=256
580 | size=1
581 | stride=1
582 | pad=1
583 | activation=mish
584 |
585 | [convolutional]
586 | batch_normalize=1
587 | filters=256
588 | size=3
589 | stride=1
590 | pad=1
591 | activation=mish
592 |
593 | [shortcut]
594 | from=-3
595 | activation=linear
596 |
597 | [convolutional]
598 | batch_normalize=1
599 | filters=256
600 | size=1
601 | stride=1
602 | pad=1
603 | activation=mish
604 |
605 | [route]
606 | layers = -1,-28
607 |
608 | [convolutional]
609 | batch_normalize=1
610 | filters=512
611 | size=1
612 | stride=1
613 | pad=1
614 | activation=mish
615 |
616 | # Downsample
617 |
618 | [convolutional]
619 | batch_normalize=1
620 | filters=1024
621 | size=3
622 | stride=2
623 | pad=1
624 | activation=mish
625 |
626 | [convolutional]
627 | batch_normalize=1
628 | filters=512
629 | size=1
630 | stride=1
631 | pad=1
632 | activation=mish
633 |
634 | [route]
635 | layers = -2
636 |
637 | [convolutional]
638 | batch_normalize=1
639 | filters=512
640 | size=1
641 | stride=1
642 | pad=1
643 | activation=mish
644 |
645 | [convolutional]
646 | batch_normalize=1
647 | filters=512
648 | size=1
649 | stride=1
650 | pad=1
651 | activation=mish
652 |
653 | [convolutional]
654 | batch_normalize=1
655 | filters=512
656 | size=3
657 | stride=1
658 | pad=1
659 | activation=mish
660 |
661 | [shortcut]
662 | from=-3
663 | activation=linear
664 |
665 | [convolutional]
666 | batch_normalize=1
667 | filters=512
668 | size=1
669 | stride=1
670 | pad=1
671 | activation=mish
672 |
673 | [convolutional]
674 | batch_normalize=1
675 | filters=512
676 | size=3
677 | stride=1
678 | pad=1
679 | activation=mish
680 |
681 | [shortcut]
682 | from=-3
683 | activation=linear
684 |
685 | [convolutional]
686 | batch_normalize=1
687 | filters=512
688 | size=1
689 | stride=1
690 | pad=1
691 | activation=mish
692 |
693 | [convolutional]
694 | batch_normalize=1
695 | filters=512
696 | size=3
697 | stride=1
698 | pad=1
699 | activation=mish
700 |
701 | [shortcut]
702 | from=-3
703 | activation=linear
704 |
705 | [convolutional]
706 | batch_normalize=1
707 | filters=512
708 | size=1
709 | stride=1
710 | pad=1
711 | activation=mish
712 |
713 | [convolutional]
714 | batch_normalize=1
715 | filters=512
716 | size=3
717 | stride=1
718 | pad=1
719 | activation=mish
720 |
721 | [shortcut]
722 | from=-3
723 | activation=linear
724 |
725 | [convolutional]
726 | batch_normalize=1
727 | filters=512
728 | size=1
729 | stride=1
730 | pad=1
731 | activation=mish
732 |
733 | [route]
734 | layers = -1,-16
735 |
736 | [convolutional]
737 | batch_normalize=1
738 | filters=1024
739 | size=1
740 | stride=1
741 | pad=1
742 | activation=mish
743 |
744 | ##########################
745 |
746 | [convolutional]
747 | batch_normalize=1
748 | filters=512
749 | size=1
750 | stride=1
751 | pad=1
752 | activation=leaky
753 |
754 | [convolutional]
755 | batch_normalize=1
756 | size=3
757 | stride=1
758 | pad=1
759 | filters=1024
760 | activation=leaky
761 |
762 | [convolutional]
763 | batch_normalize=1
764 | filters=512
765 | size=1
766 | stride=1
767 | pad=1
768 | activation=leaky
769 |
770 | ### SPP ###
771 | [maxpool]
772 | stride=1
773 | size=5
774 |
775 | [route]
776 | layers=-2
777 |
778 | [maxpool]
779 | stride=1
780 | size=9
781 |
782 | [route]
783 | layers=-4
784 |
785 | [maxpool]
786 | stride=1
787 | size=13
788 |
789 | [route]
790 | layers=-1,-3,-5,-6
791 | ### End SPP ###
792 |
793 | [convolutional]
794 | batch_normalize=1
795 | filters=512
796 | size=1
797 | stride=1
798 | pad=1
799 | activation=leaky
800 |
801 | [convolutional]
802 | batch_normalize=1
803 | size=3
804 | stride=1
805 | pad=1
806 | filters=1024
807 | activation=leaky
808 |
809 | [convolutional]
810 | batch_normalize=1
811 | filters=512
812 | size=1
813 | stride=1
814 | pad=1
815 | activation=leaky
816 |
817 | [convolutional]
818 | batch_normalize=1
819 | filters=256
820 | size=1
821 | stride=1
822 | pad=1
823 | activation=leaky
824 |
825 | [upsample]
826 | stride=2
827 |
828 | [route]
829 | layers = 85
830 |
831 | [convolutional]
832 | batch_normalize=1
833 | filters=256
834 | size=1
835 | stride=1
836 | pad=1
837 | activation=leaky
838 |
839 | [route]
840 | layers = -1, -3
841 |
842 | [convolutional]
843 | batch_normalize=1
844 | filters=256
845 | size=1
846 | stride=1
847 | pad=1
848 | activation=leaky
849 |
850 | [convolutional]
851 | batch_normalize=1
852 | size=3
853 | stride=1
854 | pad=1
855 | filters=512
856 | activation=leaky
857 |
858 | [convolutional]
859 | batch_normalize=1
860 | filters=256
861 | size=1
862 | stride=1
863 | pad=1
864 | activation=leaky
865 |
866 | [convolutional]
867 | batch_normalize=1
868 | size=3
869 | stride=1
870 | pad=1
871 | filters=512
872 | activation=leaky
873 |
874 | [convolutional]
875 | batch_normalize=1
876 | filters=256
877 | size=1
878 | stride=1
879 | pad=1
880 | activation=leaky
881 |
882 | [convolutional]
883 | batch_normalize=1
884 | filters=128
885 | size=1
886 | stride=1
887 | pad=1
888 | activation=leaky
889 |
890 | [upsample]
891 | stride=2
892 |
893 | [route]
894 | layers = 54
895 |
896 | [convolutional]
897 | batch_normalize=1
898 | filters=128
899 | size=1
900 | stride=1
901 | pad=1
902 | activation=leaky
903 |
904 | [route]
905 | layers = -1, -3
906 |
907 | [convolutional]
908 | batch_normalize=1
909 | filters=128
910 | size=1
911 | stride=1
912 | pad=1
913 | activation=leaky
914 |
915 | [convolutional]
916 | batch_normalize=1
917 | size=3
918 | stride=1
919 | pad=1
920 | filters=256
921 | activation=leaky
922 |
923 | [convolutional]
924 | batch_normalize=1
925 | filters=128
926 | size=1
927 | stride=1
928 | pad=1
929 | activation=leaky
930 |
931 | [convolutional]
932 | batch_normalize=1
933 | size=3
934 | stride=1
935 | pad=1
936 | filters=256
937 | activation=leaky
938 |
939 | [convolutional]
940 | batch_normalize=1
941 | filters=128
942 | size=1
943 | stride=1
944 | pad=1
945 | activation=leaky
946 |
947 | ##########################
948 |
949 | [convolutional]
950 | batch_normalize=1
951 | size=3
952 | stride=1
953 | pad=1
954 | filters=256
955 | activation=leaky
956 |
957 | [convolutional]
958 | size=1
959 | stride=1
960 | pad=1
961 | filters=18
962 | activation=linear
963 |
964 |
965 | [yolo]
966 | mask = 0,1,2
967 | anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
968 | classes=1
969 | num=9
970 | jitter=.3
971 | ignore_thresh = .7
972 | truth_thresh = 1
973 | scale_x_y = 1.2
974 | iou_thresh=0.213
975 | cls_normalizer=1.0
976 | iou_normalizer=0.07
977 | iou_loss=ciou
978 | nms_kind=greedynms
979 | beta_nms=0.6
980 | max_delta=5
981 |
982 |
983 | [route]
984 | layers = -4
985 |
986 | [convolutional]
987 | batch_normalize=1
988 | size=3
989 | stride=2
990 | pad=1
991 | filters=256
992 | activation=leaky
993 |
994 | [route]
995 | layers = -1, -16
996 |
997 | [convolutional]
998 | batch_normalize=1
999 | filters=256
1000 | size=1
1001 | stride=1
1002 | pad=1
1003 | activation=leaky
1004 |
1005 | [convolutional]
1006 | batch_normalize=1
1007 | size=3
1008 | stride=1
1009 | pad=1
1010 | filters=512
1011 | activation=leaky
1012 |
1013 | [convolutional]
1014 | batch_normalize=1
1015 | filters=256
1016 | size=1
1017 | stride=1
1018 | pad=1
1019 | activation=leaky
1020 |
1021 | [convolutional]
1022 | batch_normalize=1
1023 | size=3
1024 | stride=1
1025 | pad=1
1026 | filters=512
1027 | activation=leaky
1028 |
1029 | [convolutional]
1030 | batch_normalize=1
1031 | filters=256
1032 | size=1
1033 | stride=1
1034 | pad=1
1035 | activation=leaky
1036 |
1037 | [convolutional]
1038 | batch_normalize=1
1039 | size=3
1040 | stride=1
1041 | pad=1
1042 | filters=512
1043 | activation=leaky
1044 |
1045 | [convolutional]
1046 | size=1
1047 | stride=1
1048 | pad=1
1049 | filters=18
1050 | activation=linear
1051 |
1052 |
1053 | [yolo]
1054 | mask = 3,4,5
1055 | anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
1056 | classes=1
1057 | num=9
1058 | jitter=.3
1059 | ignore_thresh = .7
1060 | truth_thresh = 1
1061 | scale_x_y = 1.1
1062 | iou_thresh=0.213
1063 | cls_normalizer=1.0
1064 | iou_normalizer=0.07
1065 | iou_loss=ciou
1066 | nms_kind=greedynms
1067 | beta_nms=0.6
1068 | max_delta=5
1069 |
1070 |
1071 | [route]
1072 | layers = -4
1073 |
1074 | [convolutional]
1075 | batch_normalize=1
1076 | size=3
1077 | stride=2
1078 | pad=1
1079 | filters=512
1080 | activation=leaky
1081 |
1082 | [route]
1083 | layers = -1, -37
1084 |
1085 | [convolutional]
1086 | batch_normalize=1
1087 | filters=512
1088 | size=1
1089 | stride=1
1090 | pad=1
1091 | activation=leaky
1092 |
1093 | [convolutional]
1094 | batch_normalize=1
1095 | size=3
1096 | stride=1
1097 | pad=1
1098 | filters=1024
1099 | activation=leaky
1100 |
1101 | [convolutional]
1102 | batch_normalize=1
1103 | filters=512
1104 | size=1
1105 | stride=1
1106 | pad=1
1107 | activation=leaky
1108 |
1109 | [convolutional]
1110 | batch_normalize=1
1111 | size=3
1112 | stride=1
1113 | pad=1
1114 | filters=1024
1115 | activation=leaky
1116 |
1117 | [convolutional]
1118 | batch_normalize=1
1119 | filters=512
1120 | size=1
1121 | stride=1
1122 | pad=1
1123 | activation=leaky
1124 |
1125 | [convolutional]
1126 | batch_normalize=1
1127 | size=3
1128 | stride=1
1129 | pad=1
1130 | filters=1024
1131 | activation=leaky
1132 |
1133 | [convolutional]
1134 | size=1
1135 | stride=1
1136 | pad=1
1137 | filters=18
1138 | activation=linear
1139 |
1140 |
1141 | [yolo]
1142 | mask = 6,7,8
1143 | anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
1144 | classes=1
1145 | num=9
1146 | jitter=.3
1147 | ignore_thresh = .7
1148 | truth_thresh = 1
1149 | random=1
1150 | scale_x_y = 1.05
1151 | iou_thresh=0.213
1152 | cls_normalizer=1.0
1153 | iou_normalizer=0.07
1154 | iou_loss=ciou
1155 | nms_kind=greedynms
1156 | beta_nms=0.6
1157 | max_delta=5
1158 |
--------------------------------------------------------------------------------
/dataset.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | '''
3 | @Time : 2020/05/06 21:09
4 | @Author : Tianxiaomo
5 | @File : dataset.py
6 | @Noice :
7 | @Modificattion :
8 | @Author :
9 | @Time :
10 | @Detail :
11 |
12 | '''
13 | import os
14 | import random
15 | import sys
16 |
17 | import cv2
18 | import numpy as np
19 |
20 | import torch
21 | from torch.utils.data.dataset import Dataset
22 | if sys.version_info[0] == 2:
23 | import xml.etree.cElementTree as ET
24 | else:
25 | import xml.etree.ElementTree as ET
26 |
27 |
28 | def rand_uniform_strong(min, max):
29 | if min > max:
30 | swap = min
31 | min = max
32 | max = swap
33 | return random.random() * (max - min) + min
34 |
35 |
36 | def rand_scale(s):
37 | scale = rand_uniform_strong(1, s)
38 | if random.randint(0, 1) % 2:
39 | return scale
40 | return 1. / scale
41 |
42 |
43 | def rand_precalc_random(min, max, random_part):
44 | if max < min:
45 | swap = min
46 | min = max
47 | max = swap
48 | return (random_part * (max - min)) + min
49 |
50 |
51 | def fill_truth_detection(bboxes, num_boxes, classes, flip, dx, dy, sx, sy, net_w, net_h):
52 | if bboxes.shape[0] == 0:
53 | return bboxes, 10000
54 | np.random.shuffle(bboxes)
55 | bboxes[:, 0] -= dx
56 | bboxes[:, 2] -= dx
57 | bboxes[:, 1] -= dy
58 | bboxes[:, 3] -= dy
59 |
60 | bboxes[:, 0] = np.clip(bboxes[:, 0], 0, sx)
61 | bboxes[:, 2] = np.clip(bboxes[:, 2], 0, sx)
62 |
63 | bboxes[:, 1] = np.clip(bboxes[:, 1], 0, sy)
64 | bboxes[:, 3] = np.clip(bboxes[:, 3], 0, sy)
65 |
66 | out_box = list(np.where(((bboxes[:, 1] == sy) & (bboxes[:, 3] == sy)) |
67 | ((bboxes[:, 0] == sx) & (bboxes[:, 2] == sx)) |
68 | ((bboxes[:, 1] == 0) & (bboxes[:, 3] == 0)) |
69 | ((bboxes[:, 0] == 0) & (bboxes[:, 2] == 0)))[0])
70 | list_box = list(range(bboxes.shape[0]))
71 | for i in out_box:
72 | list_box.remove(i)
73 | bboxes = bboxes[list_box]
74 |
75 | if bboxes.shape[0] == 0:
76 | return bboxes, 10000
77 |
78 | bboxes = bboxes[np.where((bboxes[:, 4] < classes) & (bboxes[:, 4] >= 0))[0]]
79 |
80 | if bboxes.shape[0] > num_boxes:
81 | bboxes = bboxes[:num_boxes]
82 |
83 | min_w_h = np.array([bboxes[:, 2] - bboxes[:, 0], bboxes[:, 3] - bboxes[:, 1]]).min()
84 |
85 | bboxes[:, 0] *= (net_w / sx)
86 | bboxes[:, 2] *= (net_w / sx)
87 | bboxes[:, 1] *= (net_h / sy)
88 | bboxes[:, 3] *= (net_h / sy)
89 |
90 | if flip:
91 | temp = net_w - bboxes[:, 0]
92 | bboxes[:, 0] = net_w - bboxes[:, 2]
93 | bboxes[:, 2] = temp
94 |
95 | return bboxes, min_w_h
96 |
97 |
98 | def rect_intersection(a, b):
99 | minx = max(a[0], b[0])
100 | miny = max(a[1], b[1])
101 |
102 | maxx = min(a[2], b[2])
103 | maxy = min(a[3], b[3])
104 | return [minx, miny, maxx, maxy]
105 |
106 |
107 | def image_data_augmentation(mat, w, h, pleft, ptop, swidth, sheight, flip, dhue, dsat, dexp, gaussian_noise, blur,
108 | truth):
109 | try:
110 | img = mat
111 | oh, ow, _ = img.shape
112 | pleft, ptop, swidth, sheight = int(pleft), int(ptop), int(swidth), int(sheight)
113 | # crop
114 | src_rect = [pleft, ptop, swidth + pleft, sheight + ptop] # x1,y1,x2,y2
115 | img_rect = [0, 0, ow, oh]
116 | new_src_rect = rect_intersection(src_rect, img_rect) # 交集
117 |
118 | dst_rect = [max(0, -pleft), max(0, -ptop), max(0, -pleft) + new_src_rect[2] - new_src_rect[0],
119 | max(0, -ptop) + new_src_rect[3] - new_src_rect[1]]
120 | # cv2.Mat sized
121 |
122 | if (src_rect[0] == 0 and src_rect[1] == 0 and src_rect[2] == img.shape[0] and src_rect[3] == img.shape[1]):
123 | sized = cv2.resize(img, (w, h), cv2.INTER_LINEAR)
124 | else:
125 | cropped = np.zeros([sheight, swidth, 3])
126 | cropped[:, :, ] = np.mean(img, axis=(0, 1))
127 |
128 | cropped[dst_rect[1]:dst_rect[3], dst_rect[0]:dst_rect[2]] = \
129 | img[new_src_rect[1]:new_src_rect[3], new_src_rect[0]:new_src_rect[2]]
130 |
131 | # resize
132 | sized = cv2.resize(cropped, (w, h), cv2.INTER_LINEAR)
133 |
134 | # flip
135 | if flip:
136 | # cv2.Mat cropped
137 | sized = cv2.flip(sized, 1) # 0 - x-axis, 1 - y-axis, -1 - both axes (x & y)
138 |
139 | # HSV augmentation
140 | # cv2.COLOR_BGR2HSV, cv2.COLOR_RGB2HSV, cv2.COLOR_HSV2BGR, cv2.COLOR_HSV2RGB
141 | if dsat != 1 or dexp != 1 or dhue != 0:
142 | if img.shape[2] >= 3:
143 | hsv_src = cv2.cvtColor(sized.astype(np.float32), cv2.COLOR_RGB2HSV) # RGB to HSV
144 | hsv = cv2.split(hsv_src)
145 | hsv[1] *= dsat
146 | hsv[2] *= dexp
147 | hsv[0] += 179 * dhue
148 | hsv_src = cv2.merge(hsv)
149 | sized = np.clip(cv2.cvtColor(hsv_src, cv2.COLOR_HSV2RGB), 0, 255) # HSV to RGB (the same as previous)
150 | else:
151 | sized *= dexp
152 |
153 | if blur:
154 | if blur == 1:
155 | dst = cv2.GaussianBlur(sized, (17, 17), 0)
156 | # cv2.bilateralFilter(sized, dst, 17, 75, 75)
157 | else:
158 | ksize = (blur / 2) * 2 + 1
159 | dst = cv2.GaussianBlur(sized, (ksize, ksize), 0)
160 |
161 | if blur == 1:
162 | img_rect = [0, 0, sized.cols, sized.rows]
163 | for b in truth:
164 | left = (b.x - b.w / 2.) * sized.shape[1]
165 | width = b.w * sized.shape[1]
166 | top = (b.y - b.h / 2.) * sized.shape[0]
167 | height = b.h * sized.shape[0]
168 | roi(left, top, width, height)
169 | roi = roi & img_rect
170 | dst[roi[0]:roi[0] + roi[2], roi[1]:roi[1] + roi[3]] = sized[roi[0]:roi[0] + roi[2],
171 | roi[1]:roi[1] + roi[3]]
172 |
173 | sized = dst
174 |
175 | if gaussian_noise:
176 | noise = np.array(sized.shape)
177 | gaussian_noise = min(gaussian_noise, 127)
178 | gaussian_noise = max(gaussian_noise, 0)
179 | cv2.randn(noise, 0, gaussian_noise) # mean and variance
180 | sized = sized + noise
181 | except:
182 | print("OpenCV can't augment image: " + str(w) + " x " + str(h))
183 | sized = mat
184 |
185 | return sized
186 |
187 |
188 | def filter_truth(bboxes, dx, dy, sx, sy, xd, yd):
189 | bboxes[:, 0] -= dx
190 | bboxes[:, 2] -= dx
191 | bboxes[:, 1] -= dy
192 | bboxes[:, 3] -= dy
193 |
194 | bboxes[:, 0] = np.clip(bboxes[:, 0], 0, sx)
195 | bboxes[:, 2] = np.clip(bboxes[:, 2], 0, sx)
196 |
197 | bboxes[:, 1] = np.clip(bboxes[:, 1], 0, sy)
198 | bboxes[:, 3] = np.clip(bboxes[:, 3], 0, sy)
199 |
200 | out_box = list(np.where(((bboxes[:, 1] == sy) & (bboxes[:, 3] == sy)) |
201 | ((bboxes[:, 0] == sx) & (bboxes[:, 2] == sx)) |
202 | ((bboxes[:, 1] == 0) & (bboxes[:, 3] == 0)) |
203 | ((bboxes[:, 0] == 0) & (bboxes[:, 2] == 0)))[0])
204 | list_box = list(range(bboxes.shape[0]))
205 | for i in out_box:
206 | list_box.remove(i)
207 | bboxes = bboxes[list_box]
208 |
209 | bboxes[:, 0] += xd
210 | bboxes[:, 2] += xd
211 | bboxes[:, 1] += yd
212 | bboxes[:, 3] += yd
213 |
214 | return bboxes
215 |
216 |
217 | def blend_truth_mosaic(out_img, img, bboxes, w, h, cut_x, cut_y, i_mixup,
218 | left_shift, right_shift, top_shift, bot_shift):
219 | left_shift = min(left_shift, w - cut_x)
220 | top_shift = min(top_shift, h - cut_y)
221 | right_shift = min(right_shift, cut_x)
222 | bot_shift = min(bot_shift, cut_y)
223 |
224 | if i_mixup == 0:
225 | bboxes = filter_truth(bboxes, left_shift, top_shift, cut_x, cut_y, 0, 0)
226 | out_img[:cut_y, :cut_x] = img[top_shift:top_shift + cut_y, left_shift:left_shift + cut_x]
227 | if i_mixup == 1:
228 | bboxes = filter_truth(bboxes, cut_x - right_shift, top_shift, w - cut_x, cut_y, cut_x, 0)
229 | out_img[:cut_y, cut_x:] = img[top_shift:top_shift + cut_y, cut_x - right_shift:w - right_shift]
230 | if i_mixup == 2:
231 | bboxes = filter_truth(bboxes, left_shift, cut_y - bot_shift, cut_x, h - cut_y, 0, cut_y)
232 | out_img[cut_y:, :cut_x] = img[cut_y - bot_shift:h - bot_shift, left_shift:left_shift + cut_x]
233 | if i_mixup == 3:
234 | bboxes = filter_truth(bboxes, cut_x - right_shift, cut_y - bot_shift, w - cut_x, h - cut_y, cut_x, cut_y)
235 | out_img[cut_y:, cut_x:] = img[cut_y - bot_shift:h - bot_shift, cut_x - right_shift:w - right_shift]
236 |
237 | return out_img, bboxes
238 |
239 |
240 | def draw_box(img, bboxes):
241 | for b in bboxes:
242 | img = cv2.rectangle(img, (b[0], b[1]), (b[2], b[3]), (0, 255, 0), 2)
243 | return img
244 |
245 |
246 | class Yolo_dataset(Dataset):
247 | def __init__(self, lable_path, cfg, train=True):
248 | super(Yolo_dataset, self).__init__()
249 | if cfg.mixup == 2:
250 | print("cutmix=1 - isn't supported for Detector")
251 | raise
252 | elif cfg.mixup == 2 and cfg.letter_box:
253 | print("Combination: letter_box=1 & mosaic=1 - isn't supported, use only 1 of these parameters")
254 | raise
255 |
256 | self.cfg = cfg
257 | self.train = train
258 |
259 | truth = {}
260 |
261 | # image, xml file path load
262 | self.ROOT = cfg.train_dir
263 | self.imgs = os.listdir(os.path.join(self.ROOT, 'image'))
264 | self.xmls = os.listdir(os.path.join(self.ROOT, 'XML'))
265 | self.imgs_name = [x.split('.')[0] for x in self.imgs]
266 | self.xmls = [x for x in self.xmls if x.split('.')[-1] == 'xml']
267 | self.xmls = [x for x in self.xmls if len(self.xml_bbox(os.path.join(self.ROOT, 'XML', x))) != 0]
268 | # xml 파일 기준으로 매칭되는 이미지가 있는지 검사
269 | self.xmls = [x for x in self.xmls if x.split('.')[0] in self.imgs_name]
270 | # image 파일 기준으로 매칭되는 xml파일이 있는 검사
271 | self.xmls_name = [x.split('.')[0] for x in self.xmls]
272 | self.imgs = [x for x in self.imgs if x.split('.')[0] in self.xmls_name]
273 |
274 | # image , xml file path sort
275 | self.imgs.sort()
276 | self.xmls.sort()
277 | for i in range(len(self.imgs)) :
278 | print("imgs:{} xml:{} ".format(self.imgs[i] , self.xmls[i]))
279 | assert len(self.imgs) == len(self.xmls) != 0, 'data number error!! imgs {} / xmls {}'.format(len(self.imgs), len(self.xmls))
280 |
281 | def __len__(self):
282 | return len(self.imgs)
283 |
284 | def __getitem__(self, index):
285 | if not self.train:
286 | return self._get_val_item(index)
287 |
288 | #img_path = self.imgs[index]
289 |
290 | img_path = os.path.join(self.ROOT, 'image', self.imgs[index])
291 | truth = self.xml_bbox(os.path.join(self.ROOT, 'XML', self.xmls[index]))
292 | bboxes = np.array(truth)
293 | #img_path = os.path.join(self.cfg.dataset_dir, img_path)
294 | use_mixup = self.cfg.mixup
295 | if random.randint(0, 1):
296 | use_mixup = 0
297 |
298 | if use_mixup == 3:
299 | min_offset = 0.2
300 | cut_x = random.randint(int(self.cfg.w * min_offset), int(self.cfg.w * (1 - min_offset)))
301 | cut_y = random.randint(int(self.cfg.h * min_offset), int(self.cfg.h * (1 - min_offset)))
302 |
303 | r1, r2, r3, r4, r_scale = 0, 0, 0, 0, 0
304 | dhue, dsat, dexp, flip, blur = 0, 0, 0, 0, 0
305 | gaussian_noise = 0
306 |
307 | out_img = np.zeros([self.cfg.h, self.cfg.w, 3])
308 | out_bboxes = []
309 |
310 | for i in range(use_mixup + 1):
311 | if i != 0:
312 | img_path = random.choice(self.imgs)
313 | #bboxes = np.array(self.truth.get(img_path), dtype=np.float)
314 | #img_path = os.path.join(self.cfg.dataset_dir, img_path)
315 |
316 | bboxes_path = os.path.join(self.ROOT, 'XML', img_path.split('.')[0] + '.xml')
317 | bboxes = self.xml_bbox(bboxes_path)
318 | img_path = os.path.join(self.ROOT, 'image', img_path)
319 |
320 | img = cv2.imread(img_path)
321 | img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
322 | if img is None:
323 | continue
324 | oh, ow, oc = img.shape
325 | dh, dw, dc = np.array(np.array([oh, ow, oc]) * self.cfg.jitter, dtype=np.int)
326 |
327 | dhue = rand_uniform_strong(-self.cfg.hue, self.cfg.hue)
328 | dsat = rand_scale(self.cfg.saturation)
329 | dexp = rand_scale(self.cfg.exposure)
330 |
331 | pleft = random.randint(-dw, dw)
332 | pright = random.randint(-dw, dw)
333 | ptop = random.randint(-dh, dh)
334 | pbot = random.randint(-dh, dh)
335 |
336 | flip = random.randint(0, 1) if self.cfg.flip else 0
337 |
338 | if (self.cfg.blur):
339 | tmp_blur = random.randint(0, 2) # 0 - disable, 1 - blur background, 2 - blur the whole image
340 | if tmp_blur == 0:
341 | blur = 0
342 | elif tmp_blur == 1:
343 | blur = 1
344 | else:
345 | blur = self.cfg.blur
346 |
347 | if self.cfg.gaussian and random.randint(0, 1):
348 | gaussian_noise = self.cfg.gaussian
349 | else:
350 | gaussian_noise = 0
351 |
352 | if self.cfg.letter_box:
353 | img_ar = ow / oh
354 | net_ar = self.cfg.w / self.cfg.h
355 | result_ar = img_ar / net_ar
356 | # print(" ow = %d, oh = %d, w = %d, h = %d, img_ar = %f, net_ar = %f, result_ar = %f \n", ow, oh, w, h, img_ar, net_ar, result_ar);
357 | if result_ar > 1: # sheight - should be increased
358 | oh_tmp = ow / net_ar
359 | delta_h = (oh_tmp - oh) / 2
360 | ptop = ptop - delta_h
361 | pbot = pbot - delta_h
362 | # print(" result_ar = %f, oh_tmp = %f, delta_h = %d, ptop = %f, pbot = %f \n", result_ar, oh_tmp, delta_h, ptop, pbot);
363 | else: # swidth - should be increased
364 | ow_tmp = oh * net_ar
365 | delta_w = (ow_tmp - ow) / 2
366 | pleft = pleft - delta_w
367 | pright = pright - delta_w
368 | # printf(" result_ar = %f, ow_tmp = %f, delta_w = %d, pleft = %f, pright = %f \n", result_ar, ow_tmp, delta_w, pleft, pright);
369 |
370 | swidth = ow - pleft - pright
371 | sheight = oh - ptop - pbot
372 |
373 | truth, min_w_h = fill_truth_detection(bboxes, self.cfg.boxes, self.cfg.classes, flip, pleft, ptop, swidth,
374 | sheight, self.cfg.w, self.cfg.h)
375 | if (min_w_h / 8) < blur and blur > 1: # disable blur if one of the objects is too small
376 | blur = min_w_h / 8
377 |
378 | ai = image_data_augmentation(img, self.cfg.w, self.cfg.h, pleft, ptop, swidth, sheight, flip,
379 | dhue, dsat, dexp, gaussian_noise, blur, truth)
380 |
381 | if use_mixup == 0:
382 | out_img = ai
383 | out_bboxes = truth
384 | if use_mixup == 1:
385 | if i == 0:
386 | old_img = ai.copy()
387 | old_truth = truth.copy()
388 | elif i == 1:
389 | out_img = cv2.addWeighted(ai, 0.5, old_img, 0.5)
390 | out_bboxes = np.concatenate([old_truth, truth], axis=0)
391 | elif use_mixup == 3:
392 | if flip:
393 | tmp = pleft
394 | pleft = pright
395 | pright = tmp
396 |
397 | left_shift = int(min(cut_x, max(0, (-int(pleft) * self.cfg.w / swidth))))
398 | top_shift = int(min(cut_y, max(0, (-int(ptop) * self.cfg.h / sheight))))
399 |
400 | right_shift = int(min((self.cfg.w - cut_x), max(0, (-int(pright) * self.cfg.w / swidth))))
401 | bot_shift = int(min(self.cfg.h - cut_y, max(0, (-int(pbot) * self.cfg.h / sheight))))
402 |
403 | out_img, out_bbox = blend_truth_mosaic(out_img, ai, truth.copy(), self.cfg.w, self.cfg.h, cut_x,
404 | cut_y, i, left_shift, right_shift, top_shift, bot_shift)
405 | out_bboxes.append(out_bbox)
406 | # print(img_path)
407 | if use_mixup == 3:
408 | out_bboxes = np.concatenate(out_bboxes, axis=0)
409 | out_bboxes1 = np.zeros([self.cfg.boxes, 5])
410 | out_bboxes1[:min(out_bboxes.shape[0], self.cfg.boxes)] = out_bboxes[:min(out_bboxes.shape[0], self.cfg.boxes)]
411 | return out_img, out_bboxes1
412 |
413 |
414 |
415 |
416 |
417 |
418 | def xml_bbox(self, xml_path):
419 | res = []
420 | target = ET.parse(xml_path).getroot()
421 | for obj in target.iter('object'):
422 | bbox = obj.find('bndbox')
423 | pts = ['xmin','ymin','xmax','ymax']
424 | bndbox = []
425 | for i , pt in enumerate(pts):
426 | cur_pt = float(bbox.find(pt).text)-1
427 | bndbox.append(cur_pt)
428 | label_idx = self.class_to_ind = 0
429 | bndbox.append(label_idx)
430 | res+=[bndbox]
431 | return np.array(res, dtype = np.float32)
432 |
433 |
434 |
435 |
436 |
437 | def _get_val_item(self, index):
438 | """
439 | """
440 | '''
441 | img_path = self.imgs[index]
442 | bboxes_with_cls_id = np.array(self.truth.get(img_path), dtype=np.float)
443 | '''
444 | img_path = os.path.join(self.ROOT, 'image', self.imgs[index])
445 | truth = self.xml_bbox(os.path.join(self.ROOT, 'XML', self.xmls[index]))
446 | bboxes_with_cls_id = np.array(truth, dtype=np.float)
447 |
448 |
449 |
450 | img = cv2.imread(img_path)
451 | # img_height, img_width = img.shape[:2]
452 | img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
453 | # img = cv2.resize(img, (self.cfg.w, self.cfg.h))
454 | # img = torch.from_numpy(img.transpose(2, 0, 1)).float().div(255.0).unsqueeze(0)
455 | num_objs = len(bboxes_with_cls_id)
456 | target = {}
457 | # boxes to coco format
458 | boxes = bboxes_with_cls_id[...,:4]
459 | boxes[..., 2:] = boxes[..., 2:] - boxes[..., :2] # box width, box height
460 | target['boxes'] = torch.as_tensor(boxes, dtype=torch.float32)
461 | target['labels'] = torch.as_tensor(bboxes_with_cls_id[...,-1].flatten(), dtype=torch.int64)
462 | #target['image_id'] = torch.tensor([get_image_id(img_path)])
463 | target['area'] = (target['boxes'][:,3])*(target['boxes'][:,2])
464 | target['iscrowd'] = torch.zeros((num_objs,), dtype=torch.int64)
465 | return img, target
466 |
467 |
468 | def get_image_id(filename:str) -> int:
469 | """
470 | Convert a string to a integer.
471 | Make sure that the images and the `image_id`s are in one-one correspondence.
472 | There are already `image_id`s in annotations of the COCO dataset,
473 | in which case this function is unnecessary.
474 | For creating one's own `get_image_id` function, one can refer to
475 | https://github.com/google/automl/blob/master/efficientdet/dataset/create_pascal_tfrecord.py#L86
476 | or refer to the following code (where the filenames are like 'level1_123.jpg')
477 | >>> lv, no = os.path.splitext(os.path.basename(filename))[0].split("_")
478 | >>> lv = lv.replace("level", "")
479 | >>> no = f"{int(no):04d}"
480 | >>> return int(lv+no)
481 | """
482 | raise NotImplementedError("Create your own 'get_image_id' function")
483 | lv, no = os.path.splitext(os.path.basename(filename))[0].split("_")
484 | lv = lv.replace("level", "")
485 | no = f"{int(no):04d}"
486 | return int(lv+no)
487 |
488 |
489 | if __name__ == "__main__":
490 | from cfg import Cfg
491 | import matplotlib.pyplot as plt
492 |
493 | random.seed(2020)
494 | np.random.seed(2020)
495 | Cfg.dataset_dir = '/mnt/e/Dataset'
496 | dataset = Yolo_dataset(Cfg.train_label, Cfg)
497 | for i in range(100):
498 | out_img, out_bboxes = dataset.__getitem__(i)
499 | a = draw_box(out_img.copy(), out_bboxes.astype(np.int32))
500 | plt.imshow(a.astype(np.int32))
501 | plt.show()
502 |
--------------------------------------------------------------------------------
/train.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | '''
3 | @Time : 2020/05/06 15:07
4 | @Author : Tianxiaomo
5 | @File : train.py
6 | @Noice :
7 | @Modificattion :
8 | @Author :
9 | @Time :
10 | @Detail :
11 |
12 | '''
13 | import time
14 | import logging
15 | import os, sys, math
16 | import argparse
17 | from collections import deque
18 | import datetime
19 |
20 | import cv2
21 | from tqdm import tqdm
22 | import numpy as np
23 | import torch
24 | import torch.nn as nn
25 | from torch.utils.data import DataLoader
26 | from torch import optim
27 | from torch.nn import functional as F
28 | from tensorboardX import SummaryWriter
29 | from easydict import EasyDict as edict
30 |
31 | from dataset import Yolo_dataset
32 | from cfg import Cfg
33 | from models import Yolov4
34 |
35 |
36 | def bboxes_iou(bboxes_a, bboxes_b, xyxy=True, GIoU=False, DIoU=False, CIoU=False):
37 | """Calculate the Intersection of Unions (IoUs) between bounding boxes.
38 | IoU is calculated as a ratio of area of the intersection
39 | and area of the union.
40 |
41 | Args:
42 | bbox_a (array): An array whose shape is :math:`(N, 4)`.
43 | :math:`N` is the number of bounding boxes.
44 | The dtype should be :obj:`numpy.float32`.
45 | bbox_b (array): An array similar to :obj:`bbox_a`,
46 | whose shape is :math:`(K, 4)`.
47 | The dtype should be :obj:`numpy.float32`.
48 | Returns:
49 | array:
50 | An array whose shape is :math:`(N, K)`. \
51 | An element at index :math:`(n, k)` contains IoUs between \
52 | :math:`n` th bounding box in :obj:`bbox_a` and :math:`k` th bounding \
53 | box in :obj:`bbox_b`.
54 |
55 | from: https://github.com/chainer/chainercv
56 | https://github.com/ultralytics/yolov3/blob/eca5b9c1d36e4f73bf2f94e141d864f1c2739e23/utils/utils.py#L262-L282
57 | """
58 | if bboxes_a.shape[1] != 4 or bboxes_b.shape[1] != 4:
59 | raise IndexError
60 |
61 | if xyxy:
62 | # intersection top left
63 | tl = torch.max(bboxes_a[:, None, :2], bboxes_b[:, :2])
64 | # intersection bottom right
65 | br = torch.min(bboxes_a[:, None, 2:], bboxes_b[:, 2:])
66 | # convex (smallest enclosing box) top left and bottom right
67 | con_tl = torch.min(bboxes_a[:, None, :2], bboxes_b[:, :2])
68 | con_br = torch.max(bboxes_a[:, None, 2:], bboxes_b[:, 2:])
69 | # centerpoint distance squared
70 | rho2 = ((bboxes_a[:, None, 0] + bboxes_a[:, None, 2]) - (bboxes_b[:, 0] + bboxes_b[:, 2])) ** 2 / 4 + (
71 | (bboxes_a[:, None, 1] + bboxes_a[:, None, 3]) - (bboxes_b[:, 1] + bboxes_b[:, 3])) ** 2 / 4
72 |
73 | w1 = bboxes_a[:, 2] - bboxes_a[:, 0]
74 | h1 = bboxes_a[:, 3] - bboxes_a[:, 1]
75 | w2 = bboxes_b[:, 2] - bboxes_b[:, 0]
76 | h2 = bboxes_b[:, 3] - bboxes_b[:, 1]
77 |
78 | area_a = torch.prod(bboxes_a[:, 2:] - bboxes_a[:, :2], 1)
79 | area_b = torch.prod(bboxes_b[:, 2:] - bboxes_b[:, :2], 1)
80 | else:
81 | # intersection top left
82 | tl = torch.max((bboxes_a[:, None, :2] - bboxes_a[:, None, 2:] / 2),
83 | (bboxes_b[:, :2] - bboxes_b[:, 2:] / 2))
84 | # intersection bottom right
85 | br = torch.min((bboxes_a[:, None, :2] + bboxes_a[:, None, 2:] / 2),
86 | (bboxes_b[:, :2] + bboxes_b[:, 2:] / 2))
87 |
88 | # convex (smallest enclosing box) top left and bottom right
89 | con_tl = torch.min((bboxes_a[:, None, :2] - bboxes_a[:, None, 2:] / 2),
90 | (bboxes_b[:, :2] - bboxes_b[:, 2:] / 2))
91 | con_br = torch.max((bboxes_a[:, None, :2] + bboxes_a[:, None, 2:] / 2),
92 | (bboxes_b[:, :2] + bboxes_b[:, 2:] / 2))
93 | # centerpoint distance squared
94 | rho2 = ((bboxes_a[:, None, :2] - bboxes_b[:, :2]) ** 2 / 4).sum(dim=-1)
95 |
96 | w1 = bboxes_a[:, 2]
97 | h1 = bboxes_a[:, 3]
98 | w2 = bboxes_b[:, 2]
99 | h2 = bboxes_b[:, 3]
100 |
101 | area_a = torch.prod(bboxes_a[:, 2:], 1)
102 | area_b = torch.prod(bboxes_b[:, 2:], 1)
103 | en = (tl < br).type(tl.type()).prod(dim=2)
104 | area_i = torch.prod(br - tl, 2) * en # * ((tl < br).all())
105 | area_u = area_a[:, None] + area_b - area_i
106 | iou = area_i / area_u
107 |
108 | if GIoU or DIoU or CIoU:
109 | if GIoU: # Generalized IoU https://arxiv.org/pdf/1902.09630.pdf
110 | area_c = torch.prod(con_br - con_tl, 2) # convex area
111 | return iou - (area_c - area_u) / area_c # GIoU
112 | if DIoU or CIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
113 | # convex diagonal squared
114 | c2 = torch.pow(con_br - con_tl, 2).sum(dim=2) + 1e-16
115 | if DIoU:
116 | return iou - rho2 / c2 # DIoU
117 | elif CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
118 | v = (4 / math.pi ** 2) * torch.pow(torch.atan(w1 / h1).unsqueeze(1) - torch.atan(w2 / h2), 2)
119 | with torch.no_grad():
120 | alpha = v / (1 - iou + v)
121 | return iou - (rho2 / c2 + v * alpha) # CIoU
122 | return iou
123 |
124 |
125 | class Yolo_loss(nn.Module):
126 | def __init__(self, n_classes=80, n_anchors=3, device=None, batch=2):
127 | super(Yolo_loss, self).__init__()
128 | self.device = device
129 | self.strides = [8, 16, 32]
130 | image_size = 608
131 | self.n_classes = n_classes
132 | self.n_anchors = n_anchors
133 |
134 | self.anchors = [[12, 16], [19, 36], [40, 28], [36, 75], [76, 55], [72, 146], [142, 110], [192, 243], [459, 401]]
135 | self.anch_masks = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
136 | self.ignore_thre = 0.5
137 |
138 | self.masked_anchors, self.ref_anchors, self.grid_x, self.grid_y, self.anchor_w, self.anchor_h = [], [], [], [], [], []
139 |
140 | for i in range(3):
141 | all_anchors_grid = [(w / self.strides[i], h / self.strides[i]) for w, h in self.anchors]
142 | masked_anchors = np.array([all_anchors_grid[j] for j in self.anch_masks[i]], dtype=np.float32)
143 | ref_anchors = np.zeros((len(all_anchors_grid), 4), dtype=np.float32)
144 | ref_anchors[:, 2:] = np.array(all_anchors_grid, dtype=np.float32)
145 | ref_anchors = torch.from_numpy(ref_anchors)
146 | # calculate pred - xywh obj cls
147 | fsize = image_size // self.strides[i]
148 | grid_x = torch.arange(fsize, dtype=torch.float).repeat(batch, 3, fsize, 1).to(device)
149 | grid_y = torch.arange(fsize, dtype=torch.float).repeat(batch, 3, fsize, 1).permute(0, 1, 3, 2).to(device)
150 | anchor_w = torch.from_numpy(masked_anchors[:, 0]).repeat(batch, fsize, fsize, 1).permute(0, 3, 1, 2).to(
151 | device)
152 | anchor_h = torch.from_numpy(masked_anchors[:, 1]).repeat(batch, fsize, fsize, 1).permute(0, 3, 1, 2).to(
153 | device)
154 |
155 | self.masked_anchors.append(masked_anchors)
156 | self.ref_anchors.append(ref_anchors)
157 | self.grid_x.append(grid_x)
158 | self.grid_y.append(grid_y)
159 | self.anchor_w.append(anchor_w)
160 | self.anchor_h.append(anchor_h)
161 |
162 | def build_target(self, pred, labels, batchsize, fsize, n_ch, output_id):
163 | # target assignment
164 | tgt_mask = torch.zeros(batchsize, self.n_anchors, fsize, fsize, 4 + self.n_classes).to(device=self.device)
165 | obj_mask = torch.ones(batchsize, self.n_anchors, fsize, fsize).to(device=self.device)
166 | tgt_scale = torch.zeros(batchsize, self.n_anchors, fsize, fsize, 2).to(self.device)
167 | target = torch.zeros(batchsize, self.n_anchors, fsize, fsize, n_ch).to(self.device)
168 |
169 | # labels = labels.cpu().data
170 | nlabel = (labels.sum(dim=2) > 0).sum(dim=1) # number of objects
171 |
172 | truth_x_all = (labels[:, :, 2] + labels[:, :, 0]) / (self.strides[output_id] * 2)
173 | truth_y_all = (labels[:, :, 3] + labels[:, :, 1]) / (self.strides[output_id] * 2)
174 | truth_w_all = (labels[:, :, 2] - labels[:, :, 0]) / self.strides[output_id]
175 | truth_h_all = (labels[:, :, 3] - labels[:, :, 1]) / self.strides[output_id]
176 | truth_i_all = truth_x_all.to(torch.int16).cpu().numpy()
177 | truth_j_all = truth_y_all.to(torch.int16).cpu().numpy()
178 |
179 | for b in range(batchsize):
180 | n = int(nlabel[b])
181 | if n == 0:
182 | continue
183 | truth_box = torch.zeros(n, 4).to(self.device)
184 | truth_box[:n, 2] = truth_w_all[b, :n]
185 | truth_box[:n, 3] = truth_h_all[b, :n]
186 | truth_i = truth_i_all[b, :n]
187 | truth_j = truth_j_all[b, :n]
188 |
189 | # calculate iou between truth and reference anchors
190 | anchor_ious_all = bboxes_iou(truth_box.cpu(), self.ref_anchors[output_id], CIoU=True)
191 |
192 | # temp = bbox_iou(truth_box.cpu(), self.ref_anchors[output_id])
193 |
194 | best_n_all = anchor_ious_all.argmax(dim=1)
195 | best_n = best_n_all % 3
196 | best_n_mask = ((best_n_all == self.anch_masks[output_id][0]) |
197 | (best_n_all == self.anch_masks[output_id][1]) |
198 | (best_n_all == self.anch_masks[output_id][2]))
199 |
200 | if sum(best_n_mask) == 0:
201 | continue
202 |
203 | truth_box[:n, 0] = truth_x_all[b, :n]
204 | truth_box[:n, 1] = truth_y_all[b, :n]
205 |
206 | pred_ious = bboxes_iou(pred[b].view(-1, 4), truth_box, xyxy=False)
207 | pred_best_iou, _ = pred_ious.max(dim=1)
208 | pred_best_iou = (pred_best_iou > self.ignore_thre)
209 | pred_best_iou = pred_best_iou.view(pred[b].shape[:3])
210 | # set mask to zero (ignore) if pred matches truth
211 | obj_mask[b] = ~ pred_best_iou
212 |
213 | for ti in range(best_n.shape[0]):
214 | if best_n_mask[ti] == 1:
215 | i, j = truth_i[ti], truth_j[ti]
216 | a = best_n[ti]
217 | obj_mask[b, a, j, i] = 1
218 | tgt_mask[b, a, j, i, :] = 1
219 | target[b, a, j, i, 0] = truth_x_all[b, ti] - truth_x_all[b, ti].to(torch.int16).to(torch.float)
220 | target[b, a, j, i, 1] = truth_y_all[b, ti] - truth_y_all[b, ti].to(torch.int16).to(torch.float)
221 | target[b, a, j, i, 2] = torch.log(
222 | truth_w_all[b, ti] / torch.Tensor(self.masked_anchors[output_id])[best_n[ti], 0] + 1e-16)
223 | target[b, a, j, i, 3] = torch.log(
224 | truth_h_all[b, ti] / torch.Tensor(self.masked_anchors[output_id])[best_n[ti], 1] + 1e-16)
225 | target[b, a, j, i, 4] = 1
226 | target[b, a, j, i, 5 + labels[b, ti, 4].to(torch.int16).cpu().numpy()] = 1
227 | tgt_scale[b, a, j, i, :] = torch.sqrt(2 - truth_w_all[b, ti] * truth_h_all[b, ti] / fsize / fsize)
228 | return obj_mask, tgt_mask, tgt_scale, target
229 |
230 | def forward(self, xin, labels=None):
231 | loss, loss_xy, loss_wh, loss_obj, loss_cls, loss_l2 = 0, 0, 0, 0, 0, 0
232 | for output_id, output in enumerate(xin):
233 | batchsize = output.shape[0]
234 | fsize = output.shape[2]
235 | n_ch = 5 + self.n_classes
236 |
237 | output = output.view(batchsize, self.n_anchors, n_ch, fsize, fsize)
238 | output = output.permute(0, 1, 3, 4, 2) # .contiguous()
239 |
240 | # logistic activation for xy, obj, cls
241 | output[..., np.r_[:2, 4:n_ch]] = torch.sigmoid(output[..., np.r_[:2, 4:n_ch]])
242 |
243 | pred = output[..., :4].clone()
244 | pred[..., 0] += self.grid_x[output_id]
245 | pred[..., 1] += self.grid_y[output_id]
246 | pred[..., 2] = torch.exp(pred[..., 2]) * self.anchor_w[output_id]
247 | pred[..., 3] = torch.exp(pred[..., 3]) * self.anchor_h[output_id]
248 |
249 | obj_mask, tgt_mask, tgt_scale, target = self.build_target(pred, labels, batchsize, fsize, n_ch, output_id)
250 |
251 | # loss calculation
252 | output[..., 4] *= obj_mask
253 | output[..., np.r_[0:4, 5:n_ch]] *= tgt_mask
254 | output[..., 2:4] *= tgt_scale
255 |
256 | target[..., 4] *= obj_mask
257 | target[..., np.r_[0:4, 5:n_ch]] *= tgt_mask
258 | target[..., 2:4] *= tgt_scale
259 |
260 | loss_xy += F.binary_cross_entropy(input=output[..., :2], target=target[..., :2],
261 | weight=tgt_scale * tgt_scale, reduction='sum')
262 | loss_wh += F.mse_loss(input=output[..., 2:4], target=target[..., 2:4], reduction='sum') / 2
263 | loss_obj += F.binary_cross_entropy(input=output[..., 4], target=target[..., 4], reduction='sum')
264 | loss_cls += F.binary_cross_entropy(input=output[..., 5:], target=target[..., 5:], reduction='sum')
265 | loss_l2 += F.mse_loss(input=output, target=target, reduction='sum')
266 |
267 | loss = loss_xy + loss_wh + loss_obj + loss_cls
268 |
269 | return loss, loss_xy, loss_wh, loss_obj, loss_cls, loss_l2
270 |
271 |
272 | def collate(batch):
273 | images = []
274 | bboxes = []
275 | for img, box in batch:
276 | images.append([img])
277 | bboxes.append([box])
278 | images = np.concatenate(images, axis=0)
279 | images = images.transpose(0, 3, 1, 2)
280 | images = torch.from_numpy(images).div(255.0)
281 | bboxes = np.concatenate(bboxes, axis=0)
282 | bboxes = torch.from_numpy(bboxes)
283 | return images, bboxes
284 |
285 |
286 | def train(model, device, config, epochs=5, batch_size=1, save_cp=True, log_step=20, img_scale=0.5):
287 | train_dataset = Yolo_dataset(config.train_label, config, train=True)
288 |
289 | n_train = len(train_dataset)
290 |
291 | train_loader = DataLoader(train_dataset, batch_size=config.batch // config.subdivisions, shuffle=True,
292 | num_workers=8, pin_memory=True, drop_last=True, collate_fn=collate)
293 |
294 | # writer.add_images('legend',
295 | # torch.from_numpy(train_dataset.label2colorlegend2(cfg.DATA_CLASSES).transpose([2, 0, 1])).to(
296 | # device).unsqueeze(0))
297 | max_itr = config.TRAIN_EPOCHS * n_train
298 | # global_step = cfg.TRAIN_MINEPOCH * n_train
299 | global_step = 0
300 | logging.info(f'''Starting training:
301 | Epochs: {epochs}
302 | Batch size: {config.batch}
303 | Subdivisions: {config.subdivisions}
304 | Learning rate: {config.learning_rate}
305 | Training size: {n_train}
306 | Checkpoints: {save_cp}
307 | Device: {device.type}
308 | Images size: {config.width}
309 | Optimizer: {config.TRAIN_OPTIMIZER}
310 | Dataset classes: {config.classes}
311 | Train label path:{config.train_label}
312 | Pretrained:
313 | ''')
314 |
315 | # learning rate setup
316 | def burnin_schedule(i):
317 | if i < config.burn_in:
318 | factor = pow(i / config.burn_in, 4)
319 | elif i < config.steps[0]:
320 | factor = 1.0
321 | elif i < config.steps[1]:
322 | factor = 0.1
323 | else:
324 | factor = 0.01
325 | return factor
326 |
327 | if config.TRAIN_OPTIMIZER.lower() == 'adam':
328 | optimizer = optim.Adam(
329 | model.parameters(),
330 | lr=config.learning_rate / config.batch,
331 | betas=(0.9, 0.999),
332 | eps=1e-08,
333 | )
334 | elif config.TRAIN_OPTIMIZER.lower() == 'sgd':
335 | optimizer = optim.SGD(
336 | params=model.parameters(),
337 | lr=config.learning_rate / config.batch,
338 | momentum=config.momentum,
339 | weight_decay=config.decay,
340 | )
341 | scheduler = optim.lr_scheduler.LambdaLR(optimizer, burnin_schedule)
342 |
343 | criterion = Yolo_loss(device=device, batch=config.batch // config.subdivisions, n_classes=config.classes)
344 | # scheduler = ReduceLROnPlateau(optimizer, mode='max', verbose=True, patience=6, min_lr=1e-7)
345 | # scheduler = CosineAnnealingWarmRestarts(optimizer, 0.001, 1e-6, 20)
346 |
347 | save_prefix = 'Yolov4_epoch'
348 | saved_models = deque()
349 | model.train()
350 | for epoch in range(epochs):
351 | # model.train()
352 | epoch_loss = 0
353 | epoch_step = 0
354 |
355 | with tqdm(total=n_train, desc=f'Epoch {epoch + 1}/{epochs}', unit='img', ncols=50) as pbar:
356 | for i, batch in enumerate(train_loader):
357 | global_step += 1
358 | epoch_step += 1
359 | images = batch[0]
360 | bboxes = batch[1]
361 |
362 | images = images.to(device=device, dtype=torch.float32)
363 | bboxes = bboxes.to(device=device)
364 |
365 | bboxes_pred = model(images)
366 | loss, loss_xy, loss_wh, loss_obj, loss_cls, loss_l2 = criterion(bboxes_pred, bboxes)
367 | # loss = loss / config.subdivisions
368 | loss.backward()
369 |
370 | epoch_loss += loss.item()
371 |
372 | if global_step % config.subdivisions == 0:
373 | optimizer.step()
374 | scheduler.step()
375 | model.zero_grad()
376 |
377 | if global_step % (log_step * config.subdivisions) == 0:
378 | writer.add_scalar('train/Loss', loss.item(), global_step)
379 | writer.add_scalar('train/loss_xy', loss_xy.item(), global_step)
380 | writer.add_scalar('train/loss_wh', loss_wh.item(), global_step)
381 | writer.add_scalar('train/loss_obj', loss_obj.item(), global_step)
382 | writer.add_scalar('train/loss_cls', loss_cls.item(), global_step)
383 | writer.add_scalar('train/loss_l2', loss_l2.item(), global_step)
384 | writer.add_scalar('lr', scheduler.get_lr()[0] * config.batch, global_step)
385 | pbar.set_postfix(**{'loss (batch)': loss.item(), 'loss_xy': loss_xy.item(),
386 | 'loss_wh': loss_wh.item(),
387 | 'loss_obj': loss_obj.item(),
388 | 'loss_cls': loss_cls.item(),
389 | 'loss_l2': loss_l2.item(),
390 | 'lr': scheduler.get_lr()[0] * config.batch
391 | })
392 | logging.debug('Train step_{}: loss : {},loss xy : {},loss wh : {},'
393 | 'loss obj : {},loss cls : {},loss l2 : {},lr : {}'
394 | .format(global_step, loss.item(), loss_xy.item(),
395 | loss_wh.item(), loss_obj.item(),
396 | loss_cls.item(), loss_l2.item(),
397 | scheduler.get_lr()[0] * config.batch))
398 |
399 | pbar.update(images.shape[0])
400 |
401 | if save_cp:
402 | if epoch % 15 == 0:
403 | try:
404 | # os.mkdir(config.checkpoints)
405 | os.makedirs(config.checkpoints, exist_ok=True)
406 | logging.info('Created checkpoint directory')
407 | except OSError:
408 | pass
409 | save_path = os.path.join(config.checkpoints, f'{save_prefix}{epoch + 1}.pth')
410 | torch.save(model.state_dict(), save_path)
411 | logging.info(f'Checkpoint {epoch + 1} saved !')
412 | saved_models.append(save_path)
413 | if len(saved_models) > config.keep_checkpoint_max > 0:
414 | model_to_remove = saved_models.popleft()
415 | try:
416 | os.remove(model_to_remove)
417 | except:
418 | logging.info(f'failed to remove {model_to_remove}')
419 |
420 |
421 |
422 |
423 |
424 |
425 |
426 |
427 |
428 |
429 | def get_args(**kwargs):
430 | cfg = kwargs
431 | parser = argparse.ArgumentParser(description='Train the Model on images and target masks',
432 | formatter_class=argparse.ArgumentDefaultsHelpFormatter)
433 | # parser.add_argument('-b', '--batch-size', metavar='B', type=int, nargs='?', default=2,
434 | # help='Batch size', dest='batchsize')
435 | parser.add_argument('-l', '--learning-rate', metavar='LR', type=float, nargs='?', default=0.001,
436 | help='Learning rate', dest='learning_rate')
437 | parser.add_argument('-f', '--load', dest='load', type=str, default=None,
438 | help='Load model from a .pth file')
439 | parser.add_argument('-g', '--gpu', metavar='G', type=str, default='-1',
440 | help='GPU', dest='gpu')
441 | parser.add_argument('-dir', '--data-dir', type=str, default=None,
442 | help='dataset dir', dest='dataset_dir')
443 | parser.add_argument('-pretrained', type=str, default=None, help='pretrained yolov4.conv.137')
444 | parser.add_argument('-classes', type=int, default=80, help='dataset classes')
445 | parser.add_argument(
446 | '-optimizer', type=str, default='adam',
447 | help='training optimizer',
448 | dest='TRAIN_OPTIMIZER')
449 | parser.add_argument(
450 | '-iou-type', type=str, default='iou',
451 | help='iou type (iou, giou, diou, ciou)',
452 | dest='iou_type')
453 | parser.add_argument(
454 | '-keep-checkpoint-max', type=int, default=10,
455 | help='maximum number of checkpoints to keep. If set 0, all checkpoints will be kept',
456 | dest='keep_checkpoint_max')
457 | args = vars(parser.parse_args())
458 |
459 | # for k in args.keys():
460 | # cfg[k] = args.get(k)
461 | cfg.update(args)
462 |
463 | return edict(cfg)
464 |
465 |
466 | def init_logger(log_file=None, log_dir=None, log_level=logging.INFO, mode='w', stdout=True):
467 | """
468 | log_dir: 日志文件的文件夹路径
469 | mode: 'a', append; 'w', 覆盖原文件写入.
470 | """
471 | def get_date_str():
472 | now = datetime.datetime.now()
473 | return now.strftime('%Y-%m-%d_%H-%M-%S')
474 |
475 | fmt = '%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s: %(message)s'
476 | if log_dir is None:
477 | log_dir = '~/temp/log/'
478 | if log_file is None:
479 | log_file = 'log_' + get_date_str() + '.txt'
480 | if not os.path.exists(log_dir):
481 | os.makedirs(log_dir)
482 | log_file = os.path.join(log_dir, log_file)
483 | # 此处不能使用logging输出
484 | print('log file path:' + log_file)
485 |
486 | logging.basicConfig(level=logging.DEBUG,
487 | format=fmt,
488 | filename=log_file,
489 | filemode=mode)
490 |
491 | if stdout:
492 | console = logging.StreamHandler(stream=sys.stdout)
493 | console.setLevel(log_level)
494 | formatter = logging.Formatter(fmt)
495 | console.setFormatter(formatter)
496 | logging.getLogger('').addHandler(console)
497 |
498 | return logging
499 |
500 |
501 | def _get_date_str():
502 | now = datetime.datetime.now()
503 | return now.strftime('%Y-%m-%d_%H-%M')
504 |
505 |
506 | if __name__ == "__main__":
507 | logging = init_logger(log_dir='log')
508 | cfg = get_args(**Cfg)
509 | os.environ["CUDA_VISIBLE_DEVICES"] = cfg.gpu
510 | device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
511 | logging.info(f'Using device {device}')
512 |
513 | model = Yolov4(cfg.pretrained, n_classes=cfg.classes)
514 |
515 | if torch.cuda.device_count() > 1:
516 | model = torch.nn.DataParallel(model)
517 | model.to(device=device)
518 |
519 | try:
520 | train(model=model,
521 | config=cfg,
522 | epochs=cfg.TRAIN_EPOCHS,
523 | device=device, )
524 | except KeyboardInterrupt:
525 | torch.save(model.state_dict(), 'INTERRUPTED.pth')
526 | logging.info('Saved interrupt')
527 | try:
528 | sys.exit(0)
529 | except SystemExit:
530 | os._exit(0)
531 |
--------------------------------------------------------------------------------