├── .env.example
├── .github
├── FUNDING.yml
└── workflows
│ └── main.yml
├── .gitignore
├── LICENSE
├── PTN
├── __init__.py
├── extras.py
├── parse.py
├── patterns.py
└── post.py
├── README.md
├── SECURITY.md
├── assets
├── delete.png
├── emby.png
├── favicon.ico
├── i.ico
├── jellyfin.png
├── logout.png
├── movie.png
├── plex.png
├── tmdb.svg
└── tv.png
├── fixarr.py
├── linux_&_osx_start.sh
├── requirements.txt
├── windows_start.bat
└── windows_start.vbs
/.env.example:
--------------------------------------------------------------------------------
1 | # Optional
2 |
3 | TMDB_API_KEY=
4 |
--------------------------------------------------------------------------------
/.github/FUNDING.yml:
--------------------------------------------------------------------------------
1 | # These are supported funding model platforms
2 |
3 | github: sachinsenal0x64
4 | patreon: # Replace with a single Patreon username
5 | open_collective: # Replace with a single Open Collective username
6 | ko_fi: # Replace with a single Ko-fi username
7 | tidelift: # Replace with a single Tidelift platform-name/package-name e.g., npm/babel
8 | community_bridge: # Replace with a single Community Bridge project-name e.g., cloud-foundry
9 | liberapay: # Replace with a single Liberapay username
10 | issuehunt: # Replace with a single IssueHunt username
11 | otechie: # Replace with a single Otechie username
12 | lfx_crowdfunding: # Replace with a single LFX Crowdfunding project-name e.g., cloud-foundry
13 | custom: # Replace with up to 4 custom sponsorship URLs e.g., ['link1', 'link2']
14 |
--------------------------------------------------------------------------------
/.github/workflows/main.yml:
--------------------------------------------------------------------------------
1 | name: Fixarr Builds
2 |
3 | # Controls when the workflow will run
4 | on:
5 | # Triggers the workflow on push or pull request events but only for the "main" branch
6 | push:
7 | branches: [ "main", "master" ]
8 | pull_request:
9 | branches: [ "main", "master" ]
10 |
11 | # Allows you to run this workflow manually from the Actions tab
12 | workflow_dispatch:
13 |
14 | jobs:
15 | build:
16 | strategy:
17 | matrix:
18 | os: [ubuntu-latest,windows-latest]
19 | runs-on: ${{ matrix.os }}
20 |
21 | steps:
22 | - name: Check-out repository
23 | uses: actions/checkout@v3
24 |
25 | - name: Setup Python
26 | uses: actions/setup-python@v4
27 | with:
28 | python-version: '3.10' # Version range or exact version of a Python version to use, using SemVer's version range syntax
29 | architecture: 'x64' # optional x64 or x86. Defaults to x64 if not specified
30 | cache: 'pip'
31 | cache-dependency-path: |
32 | **/requirements*.txt
33 |
34 | - name: Install Dependencies
35 | run: |
36 | pip install -r requirements.txt
37 |
38 | - name: Build Executable
39 | uses: Nuitka/Nuitka-Action@main
40 | with:
41 | nuitka-version: main
42 | script-name: fixarr.py
43 | onefile: true
44 | enable-plugins: tk-inter
45 | windows-icon-from-ico: assets/favicon.ico
46 | include-data-dir: assets=./assets
47 |
48 | - name: Upload Artifacts
49 | uses: actions/upload-artifact@v3
50 | with:
51 | name: ${{ runner.os }} Build
52 | path: |
53 | build/*.exe
54 | build/*.bin
55 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | pip-wheel-metadata/
24 | share/python-wheels/
25 | *.egg-info/
26 | .installed.cfg
27 | *.egg
28 | .vscode
29 | MANIFEST
30 |
31 | # PyInstaller
32 | # Usually these files are written by a python script from a template
33 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
34 | *.manifest
35 | *.spec
36 |
37 | # Installer logs
38 | pip-log.txt
39 | pip-delete-this-directory.txt
40 |
41 | # Unit test / coverage reports
42 | htmlcov/
43 | .tox/
44 | .nox/
45 | .coverage
46 | .coverage.*
47 | .cache
48 | nosetests.xml
49 | coverage.xml
50 | *.cover
51 | *.py,cover
52 | .hypothesis/
53 | .pytest_cache/
54 |
55 | # Translations
56 | *.mo
57 | *.pot
58 |
59 | # Django stuff:
60 | *.log
61 | local_settings.py
62 | db.sqlite3
63 | db.sqlite3-journal
64 |
65 | # Flask stuff:
66 | instance/
67 | .webassets-cache
68 |
69 | # Scrapy stuff:
70 | .scrapy
71 |
72 | # Sphinx documentation
73 | docs/_build/
74 |
75 | # PyBuilder
76 | target/
77 |
78 | # Jupyter Notebook
79 | .ipynb_checkpoints
80 |
81 | # IPython
82 | profile_default/
83 | ipython_config.py
84 |
85 | # pyenv
86 | .python-version
87 |
88 | # pipenv
89 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
90 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
91 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
92 | # install all needed dependencies.
93 | #Pipfile.lock
94 |
95 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
96 | __pypackages__/
97 |
98 | # Celery stuff
99 | celerybeat-schedule
100 | celerybeat.pid
101 |
102 | # SageMath parsed files
103 | *.sage.py
104 |
105 | # Environments
106 | .env
107 | .venv
108 | env/
109 | venv/
110 | ENV/
111 | env.bak/
112 | venv.bak/
113 |
114 | # Spyder project settings
115 | .spyderproject
116 | .spyproject
117 |
118 | # Rope project settings
119 | .ropeproject
120 |
121 | # mkdocs documentation
122 | /site
123 |
124 | # mypy
125 | .mypy_cache/
126 | .dmypy.json
127 | dmypy.json
128 |
129 | # Pyre type checker
130 | .pyre/
131 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2023 FIXARR
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/PTN/__init__.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 |
3 | import pkgutil
4 | import sys
5 |
6 | # Regex in python 2 is very slow so we check if the faster 'regex' library is available.
7 | faster_regex = pkgutil.find_loader("regex")
8 | if faster_regex is not None and sys.version_info[0] < 3:
9 | re = faster_regex.load_module("regex")
10 | else:
11 | re = pkgutil.find_loader("re").load_module("re")
12 |
13 | from .parse import PTN
14 |
15 | __author__ = "Giorgio Momigliano"
16 | __email__ = "gmomigliano@protonmail.com"
17 | __version__ = "2.5"
18 | __license__ = "MIT"
19 |
20 |
21 | # TODO change coherent_types default to True in 3.0
22 | def parse(name, standardise=True, coherent_types=False):
23 | return PTN().parse(name, standardise, coherent_types)
24 |
--------------------------------------------------------------------------------
/PTN/extras.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 |
3 | # Helper functions and constants for patterns.py
4 |
5 | delimiters = "[\.\s\-\+_\/(),]"
6 |
7 | langs = [
8 | ("rus(?:sian)?", "Russian"),
9 | ("(?:True)?fre?(?:nch)?", "French"),
10 | ("(?:nu)?ita(?:liano?)?", "Italian"),
11 | ("castellano|spa(?:nish)?|esp?", "Spanish"),
12 | ("swedish", "Swedish"),
13 | ("dk|dan(?:ish)?", "Danish"),
14 | ("ger(?:man)?|deu(?:tsch)?", "German"),
15 | ("nordic", "Nordic"),
16 | ("exyu", "ExYu"),
17 | ("chs|chi(?:nese)?", "Chinese"),
18 | ("hin(?:di)?", "Hindi"),
19 | ("polish|poland", "Polish"),
20 | ("mandarin", "Mandarin"),
21 | ("kor(?:ean)?", "Korean"),
22 | ("bengali|bangla", "Bengali"),
23 | ("kannada", "Kannada"),
24 | ("tam(?:il)?", "Tamil"),
25 | ("tel(?:ugu)?", "Telugu"),
26 | ("marathi", "Marathi"),
27 | ("mal(?:ayalam)?", "Malayalam"),
28 | ("japanese|ja?p", "Japanese"),
29 | ("interslavic", "Interslavic"),
30 | ("ara(?:bic)?", "Arabic"),
31 | ("urdu", "Urdu"),
32 | ("punjabi", "Punjabi"),
33 | ("portuguese", "Portuguese"),
34 | ("albanian?", "Albanian"),
35 | ("egypt(?:ian)?", "Egyptian"),
36 | ("en?(?:g(?:lish)?)?", "English"), # Must be at end, matches just an 'e'
37 | ]
38 |
39 | genres = [
40 | ("Sci-?Fi", "Sci-Fi"),
41 | ("Drama", "Drama"),
42 | ("Comedy", "Comedy"),
43 | ("West(?:\.|ern)?", "Western"),
44 | ("Action", "Action"),
45 | ("Adventure", "Adventure"),
46 | ("Thriller", "Thriller"),
47 | ]
48 |
49 | # Some titles just can't be parsed without breaking everything else, so here
50 | # are known those known exceptions. They are executed when the parsed_title and
51 | # incorrect_parse match within a .parse() dict, removing the latter, and replacing
52 | # the former with actual_title.
53 | exceptions = [
54 | {"parsed_title": "", "incorrect_parse": ("year", 1983), "actual_title": "1983"},
55 | {
56 | "parsed_title": "Marvel's Agents of S H I E L D",
57 | "incorrect_parse": ("title", "Marvel's Agents of S H I E L D"),
58 | "actual_title": "Marvel's Agents of S.H.I.E.L.D.",
59 | },
60 | {
61 | "parsed_title": "Marvels Agents of S H I E L D",
62 | "incorrect_parse": ("title", "Marvels Agents of S H I E L D"),
63 | "actual_title": "Marvel's Agents of S.H.I.E.L.D.",
64 | },
65 | {
66 | "parsed_title": "Magnum P I",
67 | "incorrect_parse": ("title", "Magnum P I"),
68 | "actual_title": "Magnum P.I.",
69 | },
70 | ]
71 |
72 | # Patterns that should only try to be matched after the 'title delimiter', either a year
73 | # or a season. So if we have a language in the title it won't cause issues by getting matched.
74 | # Empty list indicates to always do so, as opposed to matching specific regexes.
75 | patterns_ignore_title = {
76 | "language": [],
77 | "audio": ["LiNE"],
78 | "network": ["Hallmark"],
79 | "untouched": [],
80 | "internal": [],
81 | "limited": [],
82 | "proper": [],
83 | "extended": [],
84 | }
85 |
86 |
87 | channels = [(1, 0), (2, 0), (5, 1), (6, 1), (7, 1)]
88 |
89 |
90 | # Return tuple with regexes for audio name with appended channel types, and without any channels
91 | def get_channel_audio_options(patterns_with_names):
92 | options = []
93 | for audio_pattern, name in patterns_with_names:
94 | for speakers, subwoofers in channels:
95 | options.append(
96 | (
97 | "((?:{}){}*{}[. \-]?{}(?:ch)?)".format(
98 | audio_pattern, delimiters, speakers, subwoofers
99 | ),
100 | "{} {}.{}".format(name, speakers, subwoofers),
101 | )
102 | )
103 | options.append(
104 | ("({})".format(audio_pattern), name)
105 | ) # After for loop, would match first
106 |
107 | return options
108 |
109 |
110 | def prefix_pattern_with(prefixes, pattern_options, between="", optional=False):
111 | if optional:
112 | optional_char = "?"
113 | else:
114 | optional_char = ""
115 | options = []
116 | if not isinstance(prefixes, list):
117 | prefixes = [prefixes]
118 | for prefix in prefixes:
119 | if not isinstance(pattern_options, list):
120 | pattern_options = [pattern_options]
121 | for pattern_option in pattern_options:
122 | if isinstance(pattern_option, str):
123 | options.append(
124 | "(?:{}){}(?:{})?({})".format(
125 | prefix, optional_char, between, pattern_option
126 | )
127 | )
128 | else:
129 | options.append(
130 | (
131 | "(?:{}){}(?:{})?({})".format(
132 | prefix, optional_char, between, pattern_option[0]
133 | ),
134 | )
135 | + pattern_option[1:]
136 | )
137 |
138 | return options
139 |
140 |
141 | def suffix_pattern_with(suffixes, pattern_options, between="", optional=False):
142 | if optional:
143 | optional_char = "?"
144 | else:
145 | optional_char = ""
146 | options = []
147 | if not isinstance(suffixes, list):
148 | suffixes = [suffixes]
149 | for suffix in suffixes:
150 | if not isinstance(pattern_options, list):
151 | pattern_options = [pattern_options]
152 | for pattern_option in pattern_options:
153 | if isinstance(pattern_option, tuple):
154 | options.append(
155 | (
156 | "({})(?:{})?(?:{}){}".format(
157 | pattern_option[0], between, suffix, optional_char
158 | ),
159 | )
160 | + pattern_option[1:]
161 | )
162 | else:
163 | options.append(
164 | "({})(?:{})?(?:{}){}".format(
165 | pattern_option, between, suffix, optional_char
166 | )
167 | )
168 |
169 | return options
170 |
171 |
172 | # Link a regex-tuple list into a single regex (to be able to use elsewhere while
173 | # maintaining standardisation functionality).
174 | def link_patterns(pattern_options):
175 | if not isinstance(pattern_options, list):
176 | return pattern_options
177 | return (
178 | "(?:"
179 | + "|".join(
180 | [
181 | pattern_option[0]
182 | if isinstance(pattern_option, tuple)
183 | else pattern_option
184 | for pattern_option in pattern_options
185 | ]
186 | )
187 | + ")"
188 | )
189 |
--------------------------------------------------------------------------------
/PTN/parse.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | from . import re
3 | from .extras import exceptions, genres, langs, link_patterns, patterns_ignore_title
4 | from .patterns import delimiters, patterns, patterns_ordered, types
5 | from .post import post_processing_after_excess, post_processing_before_excess
6 |
7 |
8 | class PTN(object):
9 | def __init__(self):
10 | self.torrent_name = None
11 | self.parts = None
12 | self.part_slices = None
13 | self.match_slices = None
14 | self.standardise = None
15 | self.coherent_types = None
16 |
17 | self.post_title_pattern = "(?:{}|{})".format(
18 | link_patterns(patterns["season"]), link_patterns(patterns["year"])
19 | )
20 |
21 | def _part(self, name, match_slice, clean, overwrite=False):
22 | if overwrite or name not in self.parts:
23 | if self.coherent_types:
24 | if name not in ["title", "episodeName"] and not isinstance(clean, bool):
25 | if not isinstance(clean, list):
26 | clean = [clean]
27 | else:
28 | if isinstance(clean, list) and len(clean) == 1:
29 | clean = clean[0] # Avoids making a list if it only has 1 element
30 |
31 | self.parts[name] = clean
32 | self.part_slices[name] = match_slice
33 |
34 | # Ignored patterns will still be considered 'matched' to remove them from excess.
35 | if match_slice:
36 | self.match_slices.append(match_slice)
37 |
38 | @staticmethod
39 | def _clean_string(string):
40 | clean = re.sub(r"^( -|\(|\[)", "", string)
41 | if clean.find(" ") == -1 and clean.find(".") != -1:
42 | clean = re.sub(r"\.", " ", clean)
43 | clean = re.sub(r"_", " ", clean)
44 | clean = re.sub(r"([\[)_\]]|- )$", "", clean).strip()
45 | clean = clean.strip(" _-")
46 |
47 | return clean
48 |
49 | def parse(self, name, standardise, coherent_types):
50 | name = name.strip()
51 | self.parts = {}
52 | self.part_slices = {}
53 | self.torrent_name = name
54 | self.match_slices = []
55 | self.standardise = standardise
56 | self.coherent_types = coherent_types
57 |
58 | for key, pattern_options in [(key, patterns[key]) for key in patterns_ordered]:
59 | pattern_options = self.normalise_pattern_options(pattern_options)
60 |
61 | for pattern, replace, transforms in pattern_options:
62 | if key not in ("season", "episode", "site", "language", "genre"):
63 | pattern = r"\b(?:{})\b".format(pattern)
64 |
65 | clean_name = re.sub(r"_", " ", self.torrent_name)
66 | matches = self.get_matches(pattern, clean_name, key)
67 |
68 | if not matches:
69 | continue
70 |
71 | # With multiple matches, we will usually want to use the first match.
72 | # For 'year', we instead use the last instance of a year match since,
73 | # if a title includes a year, we don't want to use this for the year field.
74 | match_index = 0
75 | if key == "year":
76 | match_index = -1
77 |
78 | match = matches[match_index]["match"]
79 | match_start, match_end = (
80 | matches[match_index]["start"],
81 | matches[match_index]["end"],
82 | )
83 | if (
84 | key in self.parts
85 | ): # We can skip ahead if we already have a matched part
86 | self._part(key, (match_start, match_end), None, overwrite=False)
87 | continue
88 |
89 | index = self.get_match_indexes(match)
90 |
91 | if key in ("season", "episode"):
92 | clean = self.get_season_episode(match)
93 | elif key == "subtitles":
94 | clean = self.get_subtitles(match)
95 | elif key in ("language", "genre"):
96 | clean = self.split_multi(match)
97 | elif key in types.keys() and types[key] == "boolean":
98 | clean = True
99 | else:
100 | clean = match[index["clean"]]
101 | if key in types.keys() and types[key] == "integer":
102 | clean = int(clean)
103 |
104 | if self.standardise:
105 | clean = self.standardise_clean(clean, key, replace, transforms)
106 |
107 | self._part(key, (match_start, match_end), clean)
108 |
109 | self.process_title()
110 | self.fix_known_exceptions()
111 |
112 | unmatched = self.get_unmatched()
113 | for f in post_processing_before_excess:
114 | unmatched = f(self, unmatched)
115 |
116 | # clean_unmatched() depends on the before_excess methods adding more match slices.
117 | cleaned_unmatched = self.clean_unmatched()
118 | if cleaned_unmatched:
119 | self._part("excess", None, cleaned_unmatched)
120 |
121 | for f in post_processing_after_excess:
122 | f(self)
123 |
124 | return self.parts
125 |
126 | # Handles all the optional/missing tuple elements into a consistent list.
127 | @staticmethod
128 | def normalise_pattern_options(pattern_options):
129 | pattern_options_norm = []
130 |
131 | if isinstance(pattern_options, tuple):
132 | pattern_options = [pattern_options]
133 | elif not isinstance(pattern_options, list):
134 | pattern_options = [(pattern_options, None, None)]
135 | for options in pattern_options:
136 | if len(options) == 2: # No transformation
137 | pattern_options_norm.append(options + (None,))
138 | elif isinstance(options, tuple):
139 | if isinstance(options[2], tuple):
140 | pattern_options_norm.append(
141 | tuple(list(options[:2]) + [[options[2]]])
142 | )
143 | elif isinstance(options[2], list):
144 | pattern_options_norm.append(options)
145 | else:
146 | pattern_options_norm.append(
147 | tuple(list(options[:2]) + [[(options[2], [])]])
148 | )
149 |
150 | else:
151 | pattern_options_norm.append((options, None, None))
152 | pattern_options = pattern_options_norm
153 | return pattern_options
154 |
155 | def get_matches(self, pattern, clean_name, key):
156 | grouped_matches = []
157 | matches = list(re.finditer(pattern, clean_name, re.IGNORECASE))
158 | for m in matches:
159 | if m.start() < self.ignore_before_index(clean_name, key):
160 | continue
161 | groups = m.groups()
162 | if not groups:
163 | grouped_matches.append((m.group(), m.start(), m.end()))
164 | else:
165 | grouped_matches.append((groups, m.start(), m.end()))
166 |
167 | parsed_matches = []
168 | for match in grouped_matches:
169 | m = match[0]
170 | if isinstance(m, tuple):
171 | m = list(m)
172 | else:
173 | m = [m]
174 | parsed_matches.append({"match": m, "start": match[1], "end": match[2]})
175 | return parsed_matches
176 |
177 | # Only use part of the torrent name after the (guessed) title (split at a season or year)
178 | # to avoid matching certain patterns that could show up in a release title.
179 | def ignore_before_index(self, clean_name, key):
180 | match = None
181 | if key in patterns_ignore_title:
182 | patterns_ignored = patterns_ignore_title[key]
183 | if not patterns_ignored:
184 | match = re.search(self.post_title_pattern, clean_name, re.IGNORECASE)
185 | else:
186 | for ignore_pattern in patterns_ignored:
187 | if re.findall(ignore_pattern, clean_name, re.IGNORECASE):
188 | match = re.search(
189 | self.post_title_pattern, clean_name, re.IGNORECASE
190 | )
191 |
192 | if match:
193 | return match.start()
194 | return 0
195 |
196 | @staticmethod
197 | def get_match_indexes(match):
198 | index = {"raw": 0, "clean": 0}
199 |
200 | if len(match) > 1:
201 | # for season we might have it in index 1 or index 2
202 | # e.g. "5x09" TODO is this weirdness necessary
203 | for i in range(1, len(match)):
204 | if match[i]:
205 | index["clean"] = i
206 | break
207 |
208 | return index
209 |
210 | @staticmethod
211 | def get_season_episode(match):
212 | clean = None
213 | m = re.findall(r"[0-9]+", match[0])
214 | if m and len(m) > 1:
215 | clean = list(range(int(m[0]), int(m[-1]) + 1))
216 | elif m:
217 | clean = int(m[0])
218 | return clean
219 |
220 | @staticmethod
221 | def split_multi(match):
222 | # handle multi languages
223 | m = re.split(r"{}+".format(delimiters), match[0])
224 | clean = list(filter(None, m))
225 |
226 | return clean
227 |
228 | @staticmethod
229 | def get_subtitles(match):
230 | # handle multi subtitles
231 | m = re.split(r"{}+".format(delimiters), match[0])
232 | m = list(filter(None, m))
233 | clean = []
234 | # If it's only 1 result, it's fine if it's just 'subs'.
235 | if len(m) == 1:
236 | clean = m
237 | else:
238 | for x in m:
239 | if not re.match("subs?|soft", x, re.I):
240 | clean.append(x)
241 |
242 | return clean
243 |
244 | def standardise_clean(self, clean, key, replace, transforms):
245 | if replace:
246 | clean = replace
247 | if transforms:
248 | for transform in filter(lambda t: t[0], transforms):
249 | # For python2 compatibility, we're not able to simply pass functions as str.upper
250 | # means different things in 2.7 and 3.5.
251 | clean = getattr(clean, transform[0])(*transform[1])
252 | if key == "language" or key == "subtitles":
253 | clean = self.standardise_languages(clean)
254 | if not clean:
255 | clean = "Available"
256 | if key == "genre":
257 | clean = self.standardise_genres(clean)
258 | return clean
259 |
260 | @staticmethod
261 | def standardise_languages(clean):
262 | cleaned_langs = []
263 | for lang in clean:
264 | for lang_regex, lang_clean in langs:
265 | if re.match(
266 | lang_regex,
267 | re.sub(
268 | link_patterns(patterns["subtitles"][2:]), "", lang, flags=re.I
269 | ),
270 | re.IGNORECASE,
271 | ):
272 | cleaned_langs.append(lang_clean)
273 | break
274 | clean = cleaned_langs
275 | return clean
276 |
277 | @staticmethod
278 | def standardise_genres(clean):
279 | standard_genres = []
280 | for genre in clean:
281 | for regex, clean in genres:
282 | if re.match(regex, genre, re.IGNORECASE):
283 | standard_genres.append(clean)
284 | break
285 | return standard_genres
286 |
287 | # Merge all the match slices (such as when they overlap), then remove
288 | # them from excess.
289 | def merge_match_slices(self):
290 | matches = sorted(self.match_slices, key=lambda match: match[0])
291 |
292 | i = 0
293 | slices = []
294 | while i < len(matches):
295 | start, end = matches[i]
296 | i += 1
297 | for next_start, next_end in matches[i:]:
298 | if next_start <= end:
299 | end = max(end, next_end)
300 | i += 1
301 | else:
302 | break
303 | slices.append((start, end))
304 |
305 | self.match_slices = slices
306 |
307 | def process_title(self):
308 | unmatched = self.unmatched_list(keep_punctuation=False)
309 |
310 | # Use the first one as the title
311 | if unmatched:
312 | title_start, title_end = unmatched[0][0], unmatched[0][1]
313 |
314 | # If our unmatched is after the first 3 matches, we assume the title is missing
315 | # (or more likely got parsed as something else), as no torrents have it that
316 | # far away from the beginning of the release title.
317 | if (
318 | len(self.part_slices) > 3
319 | and title_start
320 | > sorted(self.part_slices.values(), key=lambda s: s[0])[3][0]
321 | ):
322 | self._part("title", None, "")
323 |
324 | raw = self.torrent_name[title_start:title_end]
325 | # Something in square brackets with 3 chars or less is too weird to be right.
326 | # If this seems too arbitrary, make it any square bracket, and Mother test
327 | # case will lose its translated title (which is mostly fine I think).
328 | m = re.search("\(|(?:\[(?:.{,3}\]|[^\]]*\d[^\]]*\]?))", raw, flags=re.I)
329 | if m:
330 | relative_title_end = m.start()
331 | raw = raw[:relative_title_end]
332 | title_end = relative_title_end + title_start
333 | # Similar logic as above, but looking at beginning of string unmatched brackets.
334 | m = re.search("^(?:\)|\[.*\])", raw)
335 | if m:
336 | relative_title_start = m.end()
337 | raw = raw[relative_title_start:]
338 | title_start = relative_title_start + title_start
339 | clean = self._clean_string(raw)
340 | # Re-add title_start to unrelative the index from raw to self.torrent_name
341 | self._part("title", (title_start, title_end), clean)
342 | else:
343 | self._part("title", None, "")
344 |
345 | def unmatched_list(self, keep_punctuation=True):
346 | self.merge_match_slices()
347 | unmatched = []
348 | prev_start = 0
349 | # A default so the last append won't crash if nothing has matched
350 | end = len(self.torrent_name)
351 | # Find all unmatched strings that aren't just punctuation
352 | for start, end in self.match_slices:
353 | if keep_punctuation or not re.match(
354 | delimiters + r"*\Z", self.torrent_name[prev_start:start]
355 | ):
356 | unmatched.append((prev_start, start))
357 | prev_start = end
358 |
359 | # Add the last unmatched slice
360 | if keep_punctuation or not re.match(
361 | delimiters + r"*\Z", self.torrent_name[end:]
362 | ):
363 | unmatched.append((end, len(self.torrent_name)))
364 |
365 | return unmatched
366 |
367 | def fix_known_exceptions(self):
368 | # Considerations for results that are known to cause issues, such
369 | # as media with years in them but without a release year.
370 | for exception in exceptions:
371 | incorrect_key, incorrect_value = exception["incorrect_parse"]
372 | if (
373 | self.parts["title"] == exception["parsed_title"]
374 | and incorrect_key in self.parts
375 | ):
376 | if self.parts[incorrect_key] == incorrect_value or (
377 | self.coherent_types and incorrect_value in self.parts[incorrect_key]
378 | ):
379 | self.parts.pop(incorrect_key)
380 | self._part("title", None, exception["actual_title"], overwrite=True)
381 |
382 | def get_unmatched(self):
383 | unmatched = ""
384 | for start, end in self.unmatched_list():
385 | unmatched += self.torrent_name[start:end]
386 |
387 | return unmatched
388 |
389 | def clean_unmatched(self):
390 | unmatched = []
391 | for start, end in self.unmatched_list():
392 | unmatched.append(self.torrent_name[start:end])
393 |
394 | unmatched_clean = []
395 | for raw in unmatched:
396 | clean = re.sub(r"(^[-_.\s(),]+)|([-.\s,]+$)", "", raw)
397 | clean = re.sub(r"[()/]", " ", clean)
398 | unmatched_clean += re.split(r"\.\.+|\s+", clean)
399 |
400 | filtered = []
401 | for extra in unmatched_clean:
402 | # re.fullmatch() is not available in python 2.7, so we manually do it with \Z.
403 | if not re.match(
404 | r"(?:Complete|Season|Full)?[\]\[,.+\- ]*(?:Complete|Season|Full)?\Z",
405 | extra,
406 | re.IGNORECASE,
407 | ):
408 | filtered.append(extra)
409 | return filtered
410 |
--------------------------------------------------------------------------------
/PTN/patterns.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 |
3 | # Patterns are either just a regex, or a tuple (or list of tuples) that contain the regex
4 | # to match, (optional) what it should be replaced with (None if to not replace), and
5 | # (optional) a string function's name to transform the value after everything (None if
6 | # to do nothing). The transform can also be a tuple (or list of tuples) with function names
7 | # and list of arguments.
8 | # The list of regexes all get matched, but only the first gets added to the returning info,
9 | # the rest are just matched to be removed from `excess`.
10 |
11 | from .extras import (
12 | delimiters,
13 | genres,
14 | get_channel_audio_options,
15 | langs,
16 | link_patterns,
17 | suffix_pattern_with,
18 | )
19 |
20 | season_range_pattern = (
21 | "(?:Complete"
22 | + delimiters
23 | + "*)?"
24 | + delimiters
25 | + "*(?:s(?:easons?)?)"
26 | + delimiters
27 | + "*(?:s?[0-9]{1,2}[\s]*(?:(?:\-|(?:\s*to\s*))[\s]*s?[0-9]{1,2})+)(?:"
28 | + delimiters
29 | + "*Complete)?"
30 | )
31 |
32 | year_pattern = "(?:19[0-9]|20[0-2])[0-9]"
33 | month_pattern = "0[1-9]|1[0-2]"
34 | day_pattern = "[0-2][0-9]|3[01]"
35 |
36 | episode_name_pattern = (
37 | "((?:[Pp](?:ar)?t"
38 | + delimiters
39 | + "*[0-9]|(?:[A-Za-z]|[0-9])[a-z]*(?:"
40 | + delimiters
41 | + "|$))+)"
42 | )
43 | pre_website_encoder_pattern = r"[^\s\.\[\]\-\(\)]+\)\s{0,2}\[[^\s\-]+\]|[^\s\.\[\]\-\(\)]+\s{0,2}(?:-\s)?[^\s\.\[\]\-]+$"
44 |
45 | # Forces an order to go by the regexes, as we want this to be deterministic (different
46 | # orders can generate different matchings). e.g. "doctor_who_2005..." in input.json
47 | patterns_ordered = [
48 | "season",
49 | "episode",
50 | "year",
51 | "month",
52 | "day",
53 | "resolution",
54 | "quality",
55 | "codec",
56 | "audio",
57 | "region",
58 | "extended",
59 | "hardcoded",
60 | "proper",
61 | "repack",
62 | "filetype",
63 | "widescreen",
64 | "site",
65 | "documentary",
66 | "language",
67 | "subtitles",
68 | "sbs",
69 | "unrated",
70 | "size",
71 | "bitDepth",
72 | "3d",
73 | "internal",
74 | "readnfo",
75 | "network",
76 | "fps",
77 | "hdr",
78 | "limited",
79 | "remastered",
80 | "directorsCut",
81 | "upscaled",
82 | "untouched",
83 | "remux",
84 | "internationalCut",
85 | "genre",
86 | ]
87 |
88 | patterns = {}
89 | patterns["episode"] = [
90 | "(? 1
155 | ):
156 | self._part("language", None, self.parts["subtitles"][0])
157 | self._part("subtitles", None, self.parts["subtitles"][1:], overwrite=True)
158 |
159 |
160 | # Language matches, to support multi-language releases that have the audio with each
161 | # language, will contain audio info (or simply extra strings like 'dub').
162 | # We remove non-lang matching items from this list.
163 | def filter_non_languages(self):
164 | if "language" in self.parts and isinstance(self.parts["language"], list):
165 | languages = list(self.parts["language"])
166 | for lang in self.parts["language"]:
167 | matched = False
168 | for lang_regex, lang_clean in langs:
169 | if re.match(lang_regex, lang, re.IGNORECASE):
170 | matched = True
171 | break
172 | if not matched:
173 | languages.remove(lang)
174 |
175 | self._part("language", self.part_slices["language"], languages, overwrite=True)
176 |
177 |
178 | def try_vague_season_episode(self):
179 | title = self.parts["title"]
180 | m = re.search("(\d{1,2})-(\d{1,2})$", title)
181 | if m:
182 | if "season" not in self.parts and "episode" not in self.parts:
183 | new_title = title[: m.start()]
184 | offset = self.part_slices["title"][0]
185 | # Setting the match slices here doesn't actually matter, but good practice.
186 | self._part(
187 | "season", (offset + m.start(1), offset + m.end(1)), int(m.group(1))
188 | )
189 | self._part(
190 | "episode", (offset + m.start(2), offset + m.end(2)), int(m.group(2))
191 | )
192 | self._part(
193 | "title",
194 | (offset, offset + len(new_title)),
195 | self._clean_string(new_title),
196 | overwrite=True,
197 | )
198 |
199 |
200 | post_processing_after_excess = [
201 | try_encoder,
202 | try_site,
203 | fix_same_subtitles_language_match,
204 | fix_subtitles_no_language,
205 | filter_non_languages,
206 | try_vague_season_episode,
207 | ]
208 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 |  4 |
4 |
5 |
6 | 🛠️ FIXARR
7 |
8 | 🍿 Ultimate Movie | TV | Anime Renamer with Backup Media Servers (Plex | Emby | Jellyfin)
9 |
10 |
11 |
12 | # 💕 Community
13 |
14 | > 🍻 Join the community: Discord
15 | > [](https://discord.gg/EbfftZ5Dd4)
16 |
17 |
18 |
19 | # 🖼️ GUI
20 |
21 | 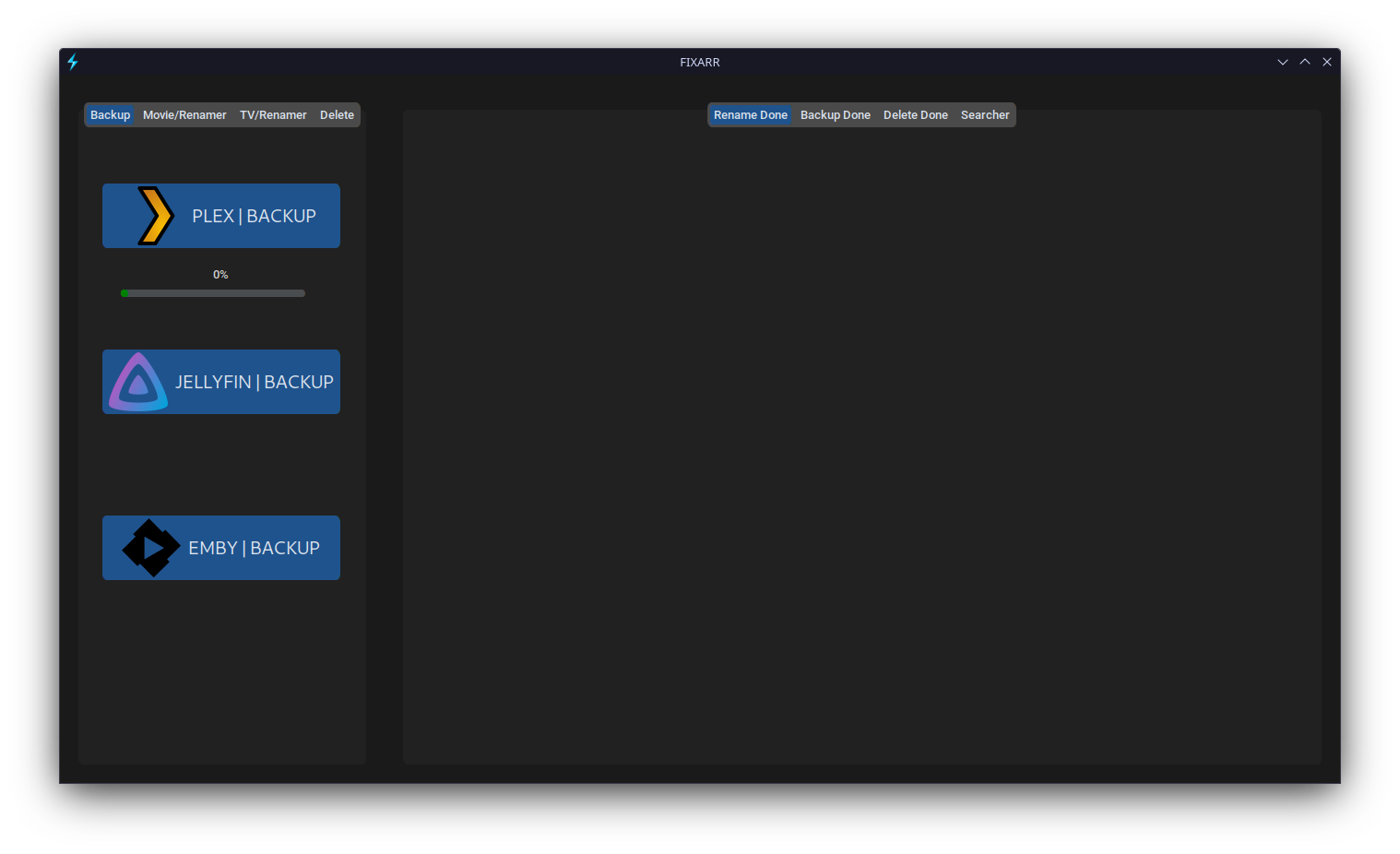
22 |
23 |
24 |
25 |
26 | ## 🚀 Features
27 |
28 | - 🎬 MOVIE RENAMER
29 | - 📺 TV RENAMER
30 | - 👧 ANIME RENAMER (⭕ in progress)
31 | - 🔺 PLEX BACKUP
32 | - ⚡️ MULTI THREADING
33 | - ♻ PURG UNNECESSARY FILES (NFO,SRT)
34 | - 🐟 JELLYFIN BACKUP (⭕ in progress)
35 | - ❄ EMBY BACKUP (⭕ in progress)
36 | - ⏬ MOVIE & TV SEACHER (⭕ in progress)
37 | - 💎 FALLBACK SERVERS
38 | - ✅ CROSS PLATFORM SUPPORT
39 |
40 |
41 |
42 | ## 💡 Pros
43 |
44 | - 🍕 Accurate Results (Even Torrent Movies Can Rename Without Any Issue)
45 | - 🆓 Fully Free And Open Source
46 | - 🧰 All in One Place
47 | - 🧾 Easy to Use
48 |
49 |
50 |
51 | ## 👎 Cons
52 |
53 | - 🐌 Slowly Develop
54 |
55 |
56 |
57 |
58 | # 📐 INSTALLATION
59 |
60 |
61 |
62 |
63 | # 💻 From Source [MODE: HARD]
64 |
65 |
66 |
67 | ## 🗝 .ENV SETUP (Optional):
68 |
69 |
70 |
71 | >Optional
72 |
73 | - Rename **.env.example** to **.env**
74 |
75 | - You can get api key from [THE MOVIE DB](https://www.themoviedb.org/settings/api?language=en-US) and its totally free.
76 |
77 | ```
78 | TMDB_API_KEY=tmdbkey
79 | ```
80 |
81 |
82 |
83 | 🐧For GNU/Linux :
84 |
85 | ```Terminal
86 |
87 | 🐧 Debian Based Distros :
88 |
89 | sudo apt-get install software-properties-common
90 | sudo apt-get install python3.10
91 |
92 |
93 | pip3 install customtkinter
94 | pip3 install -r requirements.txt
95 | python3 fixarr.py
96 |
97 |
98 | 🐧 Fedora Based Distros:
99 |
100 | sudo dnf install python3
101 | pip3 install customtkinter
102 |
103 | pip3 install -r requirements.txt
104 | python3 fixarr.py
105 |
106 |
107 | or just run .sh File
108 |
109 | ```
110 |
111 |
112 |
113 | 🍎 For macOS :
114 |
115 | ```Terminal
116 |
117 | For Mac OS With BREW:
118 |
119 | if you already not install brew then install its from offical site : https://brew.sh/#install
120 |
121 | brew install python3
122 | brew install python-tk
123 | pip3 install customtkinter
124 | pip3 install -r requirements.txt
125 | python3 fixarr.py
126 |
127 |
128 | or just run .sh File
129 |
130 | ```
131 |
132 |
133 |
134 | 🚪 For Windows:
135 |
136 | ```CMD
137 | First Install Python (python.org)
138 |
139 | pip install -r requirements.txt
140 | python fixarr.py
141 |
142 |
143 | or just run .bat File also you can create bat_shortcut
144 | ```
145 |
146 |
147 |
148 | ## 🏮 NOTE
149 |
150 |
151 |
152 | #### IF YOU WANT TO MAKE OWN STANDALONE APP (AKA .EXE or .BIN) USE NUITKA TO COMPILE SOURCE CODE INTO C
153 |
154 |
155 | ### WINDOWS
156 |
157 | ```compile
158 |
159 | [Install C Compiler (http://www.codeblocks.org/downloads/binaries/) and download (including compiler) setup & to work with this setup GCC env path (C:\Program Files\CodeBlocks\MinGW\bin) in your OS SYSTEM ENV ]
160 |
161 | open your cmd in Fixarr PATH
162 |
163 | pip -v install nuitka
164 |
165 | nuitka --mingw64 --standalone --windows-icon-from-ico=./assets/favicon.ico --include-data-dir=./assets=./assets --windows-company-name=FIXARR --product-name=FIXARR --product-version=0.1.0 --file-version=0.1.0 --plugin-enable=tk-inter fixarr.py
166 | ```
167 |
168 | ### GNU/LINUX
169 |
170 |
171 |
172 | ```
173 | nuitka3 --clang --standalone --windows-icon-from-ico=./assets/favicon.ico --include-data-dir=./assets=./assets --windows-company-name=FIXARR --product-name=FIXARR --product-version=0.1.0 --file-version=0.1.0 --plugin-enable=tk-inter -o fixarr.bin fixarr.py
174 |
175 | ```
176 |
177 |
178 |
179 |
180 | ## 💡 CREDITS
181 |
182 | #### MOVIE & TV API : [THEMOVIEDB.ORG](https://wwww.themoviedb.org)
183 | #### PARSER FOR TV SERIES: [PTN PROJECT](https://github.com/platelminto/parse-torrent-title)
184 |
185 |
186 |
187 |
188 |
189 |
190 |
191 |  192 |
193 |
192 |
193 |
194 |
195 | ## License
196 |
197 | MIT
198 |
--------------------------------------------------------------------------------
/SECURITY.md:
--------------------------------------------------------------------------------
1 | # Security Policy
2 |
3 | ## Supported Versions
4 |
5 | Use this section to tell people about which versions of your project are
6 | currently being supported with security updates.
7 |
8 | | Version | Supported |
9 | | ------- | --------- |
10 | | 5.1.x | ✅ |
11 | | 5.0.x | ❌ |
12 | | 4.0.x | ✅ |
13 | | < 4.0 | ❌ |
14 |
15 | ## Reporting a Vulnerability
16 |
17 | Use this section to tell people how to report a vulnerability.
18 |
19 | Tell them where to go, how often they can expect to get an update on a
20 | reported vulnerability, what to expect if the vulnerability is accepted or
21 | declined, etc.
22 |
--------------------------------------------------------------------------------
/assets/delete.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sachinsenal0x64/fixarr/e0b9d175322e092026b32fd8c4b4540d0a1e24dc/assets/delete.png
--------------------------------------------------------------------------------
/assets/emby.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sachinsenal0x64/fixarr/e0b9d175322e092026b32fd8c4b4540d0a1e24dc/assets/emby.png
--------------------------------------------------------------------------------
/assets/favicon.ico:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sachinsenal0x64/fixarr/e0b9d175322e092026b32fd8c4b4540d0a1e24dc/assets/favicon.ico
--------------------------------------------------------------------------------
/assets/i.ico:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sachinsenal0x64/fixarr/e0b9d175322e092026b32fd8c4b4540d0a1e24dc/assets/i.ico
--------------------------------------------------------------------------------
/assets/jellyfin.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sachinsenal0x64/fixarr/e0b9d175322e092026b32fd8c4b4540d0a1e24dc/assets/jellyfin.png
--------------------------------------------------------------------------------
/assets/logout.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sachinsenal0x64/fixarr/e0b9d175322e092026b32fd8c4b4540d0a1e24dc/assets/logout.png
--------------------------------------------------------------------------------
/assets/movie.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sachinsenal0x64/fixarr/e0b9d175322e092026b32fd8c4b4540d0a1e24dc/assets/movie.png
--------------------------------------------------------------------------------
/assets/plex.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sachinsenal0x64/fixarr/e0b9d175322e092026b32fd8c4b4540d0a1e24dc/assets/plex.png
--------------------------------------------------------------------------------
/assets/tmdb.svg:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/assets/tv.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sachinsenal0x64/fixarr/e0b9d175322e092026b32fd8c4b4540d0a1e24dc/assets/tv.png
--------------------------------------------------------------------------------
/fixarr.py:
--------------------------------------------------------------------------------
1 | __author__ = "sachinsenal"
2 |
3 | __version__ = "0.2.0"
4 |
5 |
6 | import datetime
7 | import json
8 | import os
9 | import pathlib
10 | import platform
11 | import re
12 | import shutil
13 | import signal
14 | import subprocess
15 | import sys
16 | import threading
17 | import time
18 | import tkinter as tk
19 | from concurrent.futures import ThreadPoolExecutor
20 | from itertools import islice
21 | from os import path
22 | from tkinter import filedialog, simpledialog
23 | from urllib.parse import urlencode
24 |
25 | import colorama
26 | import customtkinter as ctk
27 | import requests
28 | import rich
29 | from colorama import Back, Fore, Style
30 | from dotenv import load_dotenv
31 | from PIL import Image, ImageTk
32 | from rich.console import Console
33 | from rich.text import Text
34 | from thefuzz import fuzz, process
35 | from tqdm import tqdm
36 |
37 | import PTN
38 |
39 | ctk.set_appearance_mode("dark")
40 | ctk.set_default_color_theme("dark-blue")
41 |
42 |
43 | app = ctk.CTk()
44 |
45 | load_dotenv()
46 |
47 | tmdb = os.getenv("TMDB_API_KEY", "5740bd874a57b6d0814c98d36e1124b2")
48 |
49 |
50 | budle_dir = getattr(sys, "_MEIPASS", path.abspath(path.dirname(__file__)))
51 |
52 |
53 | path_to_app = path.join(budle_dir, "assets", "plex.png")
54 |
55 |
56 | path_to_app_1 = path.join(budle_dir, "assets", "i.ico")
57 |
58 |
59 | path_to_app_2 = path.join(budle_dir, "assets", "movie.png")
60 |
61 |
62 | path_to_app_3 = path.join(budle_dir, "assets", "tv.png")
63 |
64 |
65 | path_to_app_4 = path.join(budle_dir, "assets", "delete.png")
66 |
67 |
68 | path_to_app_5 = path.join(budle_dir, "assets", "jellyfin.png")
69 |
70 |
71 | path_to_app_6 = path.join(budle_dir, "assets", "emby.png")
72 |
73 |
74 | path_to_app_7 = path.join(budle_dir, "assets", "logout.png")
75 |
76 |
77 | WIDTH, HEIGHT = app.winfo_screenwidth(), app.winfo_screenheight()
78 |
79 |
80 | if os.name == "nt":
81 | if WIDTH == 3840 and HEIGHT == 2160:
82 | app.geometry("1500x900")
83 | ctk.set_widget_scaling(2.0)
84 |
85 | elif WIDTH == 2560 and HEIGHT == 1440:
86 | app.geometry("1388x800")
87 | ctk.set_widget_scaling(1.0)
88 |
89 | elif WIDTH == 1920 and HEIGHT == 1080:
90 | app.geometry("1388x768")
91 |
92 | elif WIDTH == 1600 and HEIGHT == 900:
93 | app.geometry("1350x580")
94 |
95 | elif WIDTH == 1280 and HEIGHT == 720:
96 | app.geometry("1230x490")
97 |
98 | else:
99 | app.geometry("1000x600")
100 |
101 | app.iconbitmap(path_to_app_1)
102 |
103 |
104 | if os.name == "posix":
105 | if WIDTH == 3840 and HEIGHT == 2160:
106 | app.geometry("1500x900")
107 | ctk.set_widget_scaling(2.0)
108 |
109 | elif WIDTH == 2560 and HEIGHT == 1440:
110 | app.geometry("1388x800")
111 | ctk.set_widget_scaling(1.0)
112 |
113 | elif WIDTH == 1920 and HEIGHT == 1080:
114 | app.geometry("1388x768")
115 |
116 | elif WIDTH == 1600 and HEIGHT == 900:
117 | app.geometry("1350x580")
118 |
119 | elif WIDTH == 1280 and HEIGHT == 720:
120 | app.geometry("1230x490")
121 |
122 | else:
123 | app.geometry("1000x600")
124 |
125 | log = Image.open(path_to_app_1)
126 | logo = ImageTk.PhotoImage(log)
127 |
128 | app.tk.call("wm", "iconphoto", app._w, logo)
129 |
130 |
131 | app.title("FIXARR")
132 |
133 | app.resizable(width=True, height=True)
134 |
135 |
136 | def clear():
137 | os.system("cls" if os.name == "nt" else "clear")
138 |
139 |
140 | __date__ = datetime.datetime.now().strftime("%Y-%m-%d_%I-%M-%S_%p")
141 | win_version = platform.win32_ver()[0]
142 | platform = platform.system() + " " + win_version
143 |
144 |
145 | tabview = ctk.CTkTabview(app)
146 | tabview_2 = ctk.CTkTabview(app)
147 |
148 | tabview.pack(fill="both", side="left", expand=True, padx=20, pady=20)
149 | tabview.configure()
150 |
151 |
152 | tabview_2.pack(fill="both", side="right", expand=True, padx=20, pady=20)
153 |
154 | tabview.columnconfigure(0, weight=1)
155 | tabview.rowconfigure(3, weight=1)
156 |
157 | tabview_2.columnconfigure(0, weight=1)
158 | tabview_2.rowconfigure(3, weight=1)
159 |
160 |
161 | image = ctk.CTkImage(
162 | light_image=Image.open(path_to_app),
163 | dark_image=Image.open(path_to_app),
164 | size=(64, 64),
165 | )
166 |
167 | image_2 = ctk.CTkImage(
168 | light_image=Image.open(path_to_app_2),
169 | dark_image=Image.open(path_to_app_2),
170 | size=(64, 64),
171 | )
172 |
173 | image_3 = ctk.CTkImage(
174 | light_image=Image.open(path_to_app_3),
175 | dark_image=Image.open(path_to_app_3),
176 | size=(64, 64),
177 | )
178 |
179 |
180 | image_4 = ctk.CTkImage(
181 | light_image=Image.open(path_to_app_4),
182 | dark_image=Image.open(path_to_app_4),
183 | size=(64, 64),
184 | )
185 |
186 |
187 | image_5 = ctk.CTkImage(
188 | light_image=Image.open(path_to_app_5),
189 | dark_image=Image.open(path_to_app_5),
190 | size=(64, 64),
191 | )
192 |
193 |
194 | image_6 = ctk.CTkImage(
195 | light_image=Image.open(path_to_app_6),
196 | dark_image=Image.open(path_to_app_6),
197 | size=(64, 64),
198 | )
199 |
200 |
201 | image_7 = ctk.CTkImage(
202 | light_image=Image.open(path_to_app_7),
203 | dark_image=Image.open(path_to_app_7),
204 | size=(24, 24),
205 | )
206 |
207 |
208 | bu = tabview.add("Backup")
209 | mv = tabview.add("Movie/Renamer")
210 | tv = tabview.add("TV/Renamer")
211 | de = tabview.add("Delete")
212 |
213 |
214 | out = tabview_2.add("Rename Done")
215 |
216 | done = tabview_2.add("Backup Done")
217 |
218 | rmf = tabview_2.add("Delete Done")
219 |
220 | fe = tabview_2.add("Searcher")
221 |
222 |
223 | class BrowseDialog(simpledialog.Dialog):
224 | def body(self, master):
225 | self.var = ctk.StringVar()
226 | self.var.set("Folder")
227 |
228 | choices = ["Folder"]
229 | combobox = ctk.CTkOptionMenu(master, values=choices, variable=self.var)
230 | combobox.pack(padx=20, pady=10)
231 |
232 | def apply(self):
233 | choice = self.var.get()
234 | if choice == "File":
235 | self.result = filedialog.askopenfilename()
236 | elif choice == "Folder":
237 | self.result = filedialog.askdirectory()
238 | else:
239 | self.result = None
240 |
241 |
242 | def remove_empty_directories(directory):
243 | for root, dirs, files in os.walk(directory, topdown=False):
244 | for dir_name in dirs:
245 | dir_path = os.path.join(root, dir_name)
246 | try:
247 | os.rmdir(dir_path)
248 | print(f"Deleted directory: {dir_path}")
249 | except OSError as e:
250 | print(f"Error deleting directory: {dir_path}, {e}")
251 | continue
252 |
253 |
254 | label_8 = ctk.CTkLabel(rmf, height=0, width=0)
255 | label = ctk.CTkLabel(out, height=0, width=0)
256 |
257 |
258 | def del_fi():
259 | result = filedialog.askdirectory()
260 | label_8.pack_forget()
261 | if result:
262 | if os.path.isfile(result):
263 | rem.configure(state="normal")
264 | rem.insert("end", result)
265 | rem.configure(state="disabled")
266 |
267 | elif os.path.isdir(result):
268 | for current_root, dirs, files in os.walk(result):
269 | for file in files:
270 | file_path = os.path.join(current_root, file)
271 | rem.configure(state="normal")
272 | # rem.delete("1.0", "end")
273 | rem.insert("end", file_path + "\n")
274 | rem.configure(state="disabled")
275 |
276 | deletes(result)
277 |
278 | return result
279 | return None
280 |
281 |
282 | def deletes(result):
283 | TOTAL_FILES_DELETED = 0
284 |
285 | ex = [
286 | ".txt",
287 | ".csv",
288 | ".xlsx",
289 | ".xls",
290 | ".pptx",
291 | ".ppt",
292 | ".jpg",
293 | ".jpeg",
294 | ".png",
295 | ".gif",
296 | ".bmp",
297 | ".pdf",
298 | ".doc",
299 | ".exe",
300 | ".srt",
301 | ".xml",
302 | ".rtf",
303 | ".nfo",
304 | ".src",
305 | ]
306 |
307 | # folders_to_delete = [
308 | # folder.lower()
309 | # for folder in input(
310 | # "Enter the name of the folders to delete, separated by commas: "
311 | # ).split(",")
312 | # ]
313 |
314 | for path, dirs, files in os.walk(result, topdown=False):
315 | for name in files:
316 | rename_path = pathlib.PurePath(path, name)
317 | print(rename_path)
318 |
319 | num_files = sum(
320 | [len(files) for path, dirs, files in os.walk(result, topdown=False)]
321 | )
322 |
323 | t = num_files
324 |
325 | for extension in ex:
326 | if name.endswith(extension):
327 | if not name.endswith(tuple(extension)):
328 | continue
329 | else:
330 | print(f"Deleting file: {os.path.join(path, name)}")
331 | os.remove(os.path.join(path, name))
332 | TOTAL_FILES_DELETED += 1
333 |
334 | for current_root, dirs, files in os.walk(result, topdown=False):
335 | for file in files:
336 | rem.configure(state="normal")
337 | file_path = os.path.join(current_root, file)
338 | # rem.delete("1.0", "end")
339 | rem.insert("end", file_path + "\n")
340 | rem.configure(state="disabled")
341 |
342 | label_8.configure(
343 | text=f"✅ TOTAL : {TOTAL_FILES_DELETED} FILES DELETED",
344 | font=("Segeo UI", 18),
345 | state="normal",
346 | text_color="#bf214b",
347 | )
348 | label_8.pack()
349 |
350 | # for folder in dirs:
351 | # if folder.lower() in folders_to_delete:
352 | # folder_path = os.path.join(root, folder)
353 | # print(f"Deleting folder: {folder_path}")
354 | # shutil.rmtree(folder_path)
355 | # TOTAL_FOLDERS_DELETED += 1
356 | # time.sleep(0.5)
357 |
358 |
359 | def browse():
360 | result = filedialog.askdirectory()
361 | label.pack_forget()
362 | if result:
363 | if os.path.isfile(result):
364 | file_folder_listbox.configure(state="normal")
365 | file_folder_listbox.insert("end", result)
366 | file_folder_listbox.configure(state="disabled")
367 |
368 | elif os.path.isdir(result):
369 | for current_root, dirs, files in os.walk(result):
370 | for file in files:
371 | file_path = os.path.join(current_root, file)
372 | file_folder_listbox.configure(state="normal")
373 | # file_folder_listbox.delete("1.0", "end")
374 | file_folder_listbox.insert("end", file_path + "\n")
375 | file_folder_listbox.configure(state="disabled")
376 |
377 | movie_renamer(result)
378 | return result
379 | return None
380 |
381 |
382 | def tv_browse():
383 | result = filedialog.askdirectory()
384 | if result:
385 | if os.path.isfile(result):
386 | file_folder_listbox.configure(state="normal")
387 | file_folder_listbox.insert("end", result)
388 | file_folder_listbox.configure(state="disabled")
389 |
390 | elif os.path.isdir(result):
391 | for current_root, dirs, files in os.walk(result):
392 | for file in files:
393 | file_path = os.path.join(current_root, file)
394 | file_folder_listbox.configure(state="normal")
395 | # file_folder_listbox.delete("1.0", "end")
396 | file_folder_listbox.insert("end", file_path + "\n")
397 | file_folder_listbox.configure(state="disabled")
398 |
399 | tv_renamer(result)
400 | return result
401 |
402 | return None
403 |
404 |
405 | # Movie Renamer
406 |
407 |
408 | def movie_renamer(file_or_folder):
409 | start_time = time.perf_counter()
410 |
411 | TOTAL_FILES_DELETED = 0
412 | TOTAL_FOLDERS_DELETED = 0
413 | TOTAL_FILES_ADDED = 0
414 | TOTAL_FILES_RENAMED = 0
415 |
416 | API_KEY = tmdb
417 |
418 | ext = [
419 | ".webm",
420 | ".mkv",
421 | ".flv",
422 | ".vob",
423 | ".ogv",
424 | ".ogg",
425 | ".rrc",
426 | ".gifv",
427 | ".mng",
428 | ".mov",
429 | ".avi",
430 | ".qt",
431 | ".wmv",
432 | ".yuv",
433 | ".rm",
434 | ".asf",
435 | ".amv",
436 | ".mp4",
437 | ".m4p",
438 | ".m4v",
439 | ".mpg",
440 | ".mp2",
441 | ".mpeg",
442 | ".mpe",
443 | ".mpv",
444 | ".m4v",
445 | ".svi",
446 | ".3gp",
447 | ".3g2",
448 | ".mxf",
449 | ".roq",
450 | ".nsv",
451 | ".flv",
452 | ".f4v",
453 | ".f4p",
454 | ".f4a",
455 | ".f4b",
456 | ".mod",
457 | ]
458 |
459 | for path, dirs, files in os.walk(file_or_folder):
460 | for name in files:
461 | rename_path = pathlib.PurePath(path, name)
462 | print(rename_path)
463 |
464 | num_files = sum(
465 | [len(files) for path, dirs, files in os.walk(file_or_folder)]
466 | )
467 |
468 | t = num_files
469 |
470 | # if ext not in name then dont do anything else rename
471 | if not name.endswith(tuple(ext)):
472 | continue
473 |
474 | else:
475 | # Extract the file name and extension from the file path
476 | base_name, ext = os.path.splitext(name)
477 |
478 | # Extract the year from the movie file name (assuming it is in the format 'Movie Title (YYYY)')
479 | year_match = re.search(
480 | r"^(.+?)(?=\s?(?:\()?(\d{4})(?:\))?\s?)", base_name, re.IGNORECASE
481 | )
482 |
483 | if year_match:
484 | # Extract the movie title and year from the file name
485 | movie_title = (
486 | year_match.group(1)
487 | .split("- ")[-1]
488 | .split("= ")[-1]
489 | .split(" – ")[-1]
490 | .replace(".", " ")
491 | .strip()
492 | .replace("_", " ")
493 | .strip()
494 | .replace("-", " ")
495 | .strip()
496 | )
497 |
498 | print(movie_title)
499 |
500 | year = year_match.group(2)
501 |
502 | rich.print(year)
503 |
504 | else:
505 | # If the year is not present, set it to an empty string
506 | year = ""
507 | movie_title = (
508 | base_name.replace(".", " ")
509 | .replace("_", " ")
510 | .replace(" - ", " ")
511 | .replace(" = ", " ")
512 | .strip()
513 | )
514 | rich.print(movie_title)
515 |
516 | # Add the year parameter to the movie db API URL
517 | url = f"https://api.themoviedb.org/3/search/movie?{urlencode({'api_key':API_KEY,'query':movie_title,'year':year,'include_adult':True,'with_genres':0})}"
518 |
519 | response = requests.get(url)
520 | print(json.dumps(response.json(), indent=4))
521 | data = response.json()
522 |
523 | if data["results"]:
524 | # Use the first search result as the movie title
525 | result = data["results"][0]["title"]
526 |
527 | err = {
528 | ":": " ",
529 | "/": " ",
530 | "\\": " ",
531 | "*": " ",
532 | "?": " ",
533 | '"': " ",
534 | "<": " ",
535 | ">": " ",
536 | "|": " ",
537 | ".": " ",
538 | "$": " ",
539 | }
540 |
541 | for old, new in err.items():
542 | result = result.replace(old, new)
543 |
544 | date = data["results"][0]["release_date"][:4]
545 | print(date)
546 |
547 | # Construct the new file name with the extracted movie title, release year, and original file extension
548 | new_name = (
549 | f"{result} ({date}){ext}" if year else f"{result} ({date}){ext}"
550 | )
551 |
552 | i = 1
553 |
554 | old_path = os.path.join(path, name)
555 | new_path = os.path.join(path, new_name)
556 | mov_progressbar.start()
557 | os.rename(old_path, new_path)
558 | mov_progressbar.stop()
559 |
560 | # create files for folders and rename
561 | folder_name = f"{result} ({date})" if year else f"{result} ({date})"
562 | folder_path = os.path.join(file_or_folder, folder_name)
563 |
564 | if not os.path.exists(folder_path):
565 | os.makedirs(folder_path)
566 |
567 | # move renamed file to folder
568 | dest_path = os.path.join(folder_path, new_name)
569 |
570 | try:
571 | shutil.move(new_path, dest_path)
572 | except shutil.Error:
573 | # failed to move file to folder, restore original filename
574 | os.rename(new_path, old_path)
575 |
576 | with tqdm(total=i, desc="Renaming : ", unit="Files") as pbar:
577 | time.sleep(1)
578 | pbar.update(1)
579 | mv_p = pbar.n / i * 100
580 | pbar.update(0)
581 | mv_per = str(int(mv_p))
582 | mv_precent.configure(text=mv_per + "%")
583 | mv_precent.update()
584 | mov_progressbar.set(pbar.n / i)
585 | mov_progressbar.update()
586 |
587 | TOTAL_FILES_RENAMED += 1
588 |
589 | remove_empty_directories(file_or_folder)
590 |
591 | for current_root, dirs, files in os.walk(file_or_folder, topdown=False):
592 | for file in files:
593 | file_folder_listbox.configure(state="normal")
594 | file_path = os.path.join(current_root, file)
595 | # rem.delete("1.0", "end")
596 | file_folder_listbox.insert("end", file_path + "\n")
597 | file_folder_listbox.configure(state="disabled")
598 |
599 | end_time = time.perf_counter()
600 |
601 | total_time = end_time - start_time
602 |
603 | console.print(f"Total Files Deleted: {TOTAL_FILES_DELETED}", style="bold red")
604 | console.print(
605 | f"Total Folders Deleted: {TOTAL_FOLDERS_DELETED}", style="bold red"
606 | )
607 | console.print(f"Total Files Added: {TOTAL_FILES_ADDED} ", style="bold green")
608 | console.print(
609 | f"Total Files Renamed: {TOTAL_FILES_RENAMED} ", style="bold green"
610 | )
611 | console.print(f"Total Time Spent: {total_time:.2f} seconds", style="blue")
612 |
613 | label.pack()
614 |
615 | label.configure(
616 | text=f"✅ TOTAL : {TOTAL_FILES_RENAMED} FILES RENAMED",
617 | font=("Segeo UI", 18),
618 | state="normal",
619 | text_color="Green",
620 | )
621 |
622 |
623 | # TV RENAMER
624 |
625 |
626 | def tv_renamer(file_or_folder):
627 | count = []
628 |
629 | start_time = time.perf_counter()
630 |
631 | TOTAL_FILES_DELETED = 0
632 | TOTAL_FOLDERS_DELETED = 0
633 | TOTAL_FILES_ADDED = 0
634 | TOTAL_FILES_RENAMED = 0
635 |
636 | ext = [
637 | ".webm",
638 | ".mkv",
639 | ".flv",
640 | ".vob",
641 | ".ogv",
642 | ".ogg",
643 | ".rrc",
644 | ".gifv",
645 | ".mng",
646 | ".mov",
647 | ".avi",
648 | ".qt",
649 | ".wmv",
650 | ".yuv",
651 | ".rm",
652 | ".asf",
653 | ".amv",
654 | ".mp4",
655 | ".m4p",
656 | ".m4v",
657 | ".mpg",
658 | ".mp2",
659 | ".mpeg",
660 | ".mpe",
661 | ".mpv",
662 | ".m4v",
663 | ".svi",
664 | ".3gp",
665 | ".3g2",
666 | ".mxf",
667 | ".roq",
668 | ".nsv",
669 | ".flv",
670 | ".f4v",
671 | ".f4p",
672 | ".f4a",
673 | ".f4b",
674 | ".mod",
675 | ]
676 |
677 | for path, dirs, files in os.walk(file_or_folder):
678 | for name in files:
679 | rename_path = pathlib.PurePath(path, name)
680 | print(rename_path)
681 |
682 | num_files = sum(
683 | [len(files) for path, dirs, files in os.walk(file_or_folder)]
684 | )
685 |
686 | len_file = num_files
687 |
688 | dib = dirs
689 |
690 | print(dib)
691 |
692 | # if ext not in name then dont do anything else rename
693 | if not name.endswith(tuple(ext)):
694 | continue
695 |
696 | else:
697 | # Extract the file name and extension from the file path
698 |
699 | year = None
700 |
701 | base_name, ext = os.path.splitext(name)
702 |
703 | max_similarity_ratio = 0
704 |
705 | match_3 = PTN.parse(base_name, standardise=False, coherent_types=True)
706 |
707 | if "title" in match_3:
708 | title = match_3["title"]
709 | rich.print("Title:", title)
710 |
711 | if "season" in match_3:
712 | season = match_3.get("season", [])[0]
713 | rich.print("Season:", season)
714 |
715 | if "episodeName" in match_3:
716 | episode = match_3.get("episodeName", [])
717 | rich.print("episodeName:", episode)
718 |
719 | if "year" in match_3:
720 | data = match_3
721 | year = data.get("year", [])[0]
722 | rich.print("Year:", year)
723 |
724 | if "episode" in match_3:
725 | episode = match_3.get("episode", [])[0]
726 | rich.print("Episode:", episode)
727 |
728 | if "documentary" in match_3:
729 | documentary = match_3.get("documentary", [])
730 | rich.print("Documentary:", documentary)
731 |
732 | if IndexError:
733 | pattern = r"^(\w+)\s(.+)$"
734 | match = re.search(pattern, base_name)
735 |
736 | if match:
737 | title = match.group(1)
738 | episode = match.group(2)
739 | print("Name:", name)
740 | print("Title:", title)
741 |
742 | query_params = {
743 | "api_key": tmdb,
744 | "query": title,
745 | "year": year,
746 | "include_adult": True,
747 | "with_genres": 0,
748 | }
749 |
750 | url = (
751 | f"https://api.themoviedb.org/3/search/tv?{urlencode(query_params)}"
752 | )
753 |
754 | response = requests.get(url)
755 |
756 | data = response.json()
757 |
758 | rich.print(data)
759 |
760 | try:
761 | t_name = data["results"][0]["name"]
762 | t_date = data["results"][0]["first_air_date"]
763 |
764 | t_date = t_date[:4]
765 |
766 | except:
767 | rich.print("Movie Skipped...")
768 |
769 | # Check if any TV show matches the search query
770 | if data.get("results"):
771 | # Get the ID of the first TV show in the search results (you can handle multiple results as needed)
772 | tv_show_id = data["results"][0]["id"]
773 |
774 | # Now, use the TV show ID to fetch information about its seasons
775 | season_url = (
776 | f"https://api.themoviedb.org/3/tv/{tv_show_id}?api_key={tmdb}"
777 | )
778 |
779 | season_response = requests.get(season_url)
780 | season_data = season_response.json()
781 |
782 | # Print information about seasons and episodes
783 | rich.print("Seasons:")
784 | for season in season_data["seasons"]:
785 | rich.print(
786 | f"Season {season['season_number']}: {season['name']}"
787 | )
788 |
789 | # Now, fetch information about episodes for each season
790 | episode_url = f"https://api.themoviedb.org/3/tv/{tv_show_id}/season/{season['season_number']}?api_key={tmdb}"
791 | episode_response = requests.get(episode_url)
792 | episode_data = episode_response.json()
793 | rich.print("Episodes:")
794 |
795 | for episode_i in episode_data["episodes"]:
796 | episode_number = episode_i["episode_number"]
797 | ep_n = episode_i["name"]
798 | print(episode_number)
799 |
800 | # Calculate similarity_ratio using fuzzywuzzy
801 | similarity_ratio = fuzz.ratio(str(episode), str(episode_number))
802 |
803 | if similarity_ratio > max_similarity_ratio:
804 | max_similarity_ratio = similarity_ratio
805 | episode_name = ep_n
806 | episode = episode_number
807 |
808 | print(
809 | "Similarity Ratio:",
810 | similarity_ratio,
811 | "BASE_NAME:",
812 | base_name,
813 | "API_ONE:",
814 | episode_name,
815 | )
816 |
817 | new_file_name = f"{t_name} - S{season['season_number']:02d}E{episode:02d} - {episode_name} ({t_date}){ext}"
818 | rich.print(new_file_name)
819 |
820 | tv_folder = f"{t_name} ({t_date})"
821 | season_folder = f"Season {season['season_number']:02d}"
822 |
823 | folder_path = os.path.join(file_or_folder, tv_folder)
824 | season_path = os.path.join(folder_path, season_folder)
825 |
826 | if not os.path.exists(folder_path):
827 | os.makedirs(folder_path)
828 |
829 | if not os.path.exists(season_path):
830 | os.makedirs(season_path)
831 |
832 | i = 1
833 |
834 | # Get the old file path
835 | old_file_path = os.path.join(path, name)
836 |
837 | # Create the new file path
838 | new_file_path = os.path.join(season_path, new_file_name)
839 |
840 | tv_progressbar.start()
841 |
842 | # Rename the file
843 |
844 | try:
845 | if not os.path.exists(new_file_path):
846 | os.rename(old_file_path, new_file_path)
847 |
848 | else:
849 | raise FileExistsError(
850 | "File already exists"
851 | ) # Raise the FileExistsError
852 | except FileExistsError as e:
853 | print(f"File already exists: {e}")
854 | # Handle the situation, maybe continue the loop or take other actions
855 | continue
856 | except OSError as e:
857 | print(f"An error occurred while renaming the file: {e}")
858 | continue
859 |
860 | with tqdm(total=i, desc="Renaming : ", unit="Files") as pbar:
861 | time.sleep(1)
862 | pbar.update(1)
863 | tv_p = pbar.n / i * 100
864 | pbar.update()
865 | tv_per = str(int(tv_p))
866 | tv_precent.configure(text=tv_per + "%")
867 | tv_precent.update()
868 | tv_progressbar.set(pbar.n / i)
869 | tv_progressbar.update()
870 | tv_progressbar.stop()
871 |
872 | TOTAL_FILES_RENAMED += 1
873 |
874 | remove_empty_directories(file_or_folder)
875 |
876 | end_time = time.perf_counter()
877 |
878 | for current_root, dirs, files in os.walk(file_or_folder, topdown=False):
879 | for file in files:
880 | file_folder_listbox.configure(state="normal")
881 | file_path = os.path.join(current_root, file)
882 | # rem.delete("1.0", "end")
883 | file_folder_listbox.insert("end", file_path + "\n")
884 | file_folder_listbox.configure(state="disabled")
885 |
886 | end_time = time.perf_counter()
887 |
888 | total_time = end_time - start_time
889 |
890 | console.print(f"Total Files Deleted: {TOTAL_FILES_DELETED}", style="bold red")
891 | console.print(
892 | f"Total Folders Deleted: {TOTAL_FOLDERS_DELETED}", style="bold red"
893 | )
894 | console.print(f"Total Files Added: {TOTAL_FILES_ADDED} ", style="bold green")
895 | console.print(
896 | f"Total Files Renamed: {TOTAL_FILES_RENAMED} ", style="bold green"
897 | )
898 | console.print(f"Total Time Spent: {total_time:.2f} seconds", style="blue")
899 |
900 | label.pack()
901 |
902 | label.configure(
903 | text=f"✅ TOTAL : {TOTAL_FILES_RENAMED} FILES RENAMED",
904 | font=("Segeo UI", 18),
905 | state="normal",
906 | text_color="Green",
907 | )
908 |
909 |
910 | def backup():
911 | start = time.perf_counter()
912 | TOTAL_BACKUP = 0
913 |
914 | # Find and backup the source folder
915 | try:
916 | for root, dirs, files in os.walk(src_root):
917 | if folder_name in dirs:
918 | src_folder = os.path.join(root, folder_name)
919 |
920 | now = datetime.datetime.now()
921 | timestamp_str = now.strftime("%Y-%m-%d_%I-%M-%S_%p")
922 |
923 | backup_name = f"{folder_name}-backup_{timestamp_str}"
924 |
925 | # Create the backup folder & backing up the source folder
926 | root_path = os.path.join(dst_root, backup_name)
927 | os.mkdir(root_path)
928 | update_path = os.path.join(root_path, folder_name)
929 |
930 | text = Text(f"Backup to: {update_path} \n")
931 | text.stylize("bold green", 0, 11)
932 | text.stylize("#ff00af", 11, 13)
933 | text.stylize("yellow3", 13, 120)
934 |
935 | console.print("Backing up Plex Media Server... \n", style="bold green")
936 | console.print(text)
937 |
938 | # Count the number of files and directories to be copied
939 | num_files = sum(
940 | [len(files) for root, dirs, files in os.walk(src_folder)]
941 | )
942 | # num_dirs = sum([len(dirs) for root, dirs, files in os.walk(src_folder)])
943 | total_files = num_files
944 | # TOTAL_BACKUP += 1
945 |
946 | with tqdm(total=total_files, desc="Backing up ", unit="File") as pbar:
947 |
948 | def copy_function(src, dst):
949 | if stop_flag:
950 | return
951 | if os.path.isdir(src):
952 | shutil.copytree(src, dst)
953 | else:
954 | shutil.copy2(src, dst)
955 |
956 | pbar.update(1)
957 | bak_ = pbar.n / total_files * 100
958 | per = str(int(bak_))
959 | bak_precent.configure(text=per + "%")
960 | bak_precent.update()
961 | bak_progressbar.set(pbar.n / total_files)
962 |
963 | shutil.copytree(
964 | src_folder,
965 | update_path,
966 | dirs_exist_ok=True,
967 | copy_function=copy_function,
968 | )
969 |
970 | # Export the registry key to a backup file
971 |
972 | console.print("\nExporting Plex registry key... \n", style="bold green")
973 |
974 | now = datetime.datetime.now()
975 | timestamp_str = now.strftime("%Y-%m-%d_%I-%M-%S_%p")
976 | backup_name = f"plex-registry-backup_{timestamp_str}.reg"
977 | update_name = f"plex-registry-backup_{timestamp_str}"
978 | reg_path = r"HKEY_CURRENT_USER\Software\Plex, Inc."
979 |
980 | backup_path = os.path.join(dst_root, update_name)
981 | os.mkdir(backup_path)
982 |
983 | backup_files = os.path.join(backup_path, backup_name)
984 |
985 | file = Text(f"Backup to: {backup_files} \n")
986 | file.stylize("bold green", 0, 10)
987 | file.stylize("#ff00af", 10, 13)
988 | file.stylize("yellow3", 13, 129)
989 |
990 | console.print(file)
991 |
992 | subprocess.call(
993 | ["REG", "EXPORT", reg_path, backup_files],
994 | stdout=subprocess.DEVNULL,
995 | )
996 |
997 | shutil.move(backup_path, root_path)
998 |
999 | end_file = shutil.move(root_path, nff)
1000 |
1001 | end = time.perf_counter()
1002 | TOTAL_BACKUP += 1
1003 | break
1004 |
1005 | console.print(f"Time taken: {end - start:.2f} seconds \n", style="bright_cyan")
1006 | console.print("Process Completed ! \n", style="#87ff00")
1007 | console.print(f"Total Backup Added: {TOTAL_BACKUP} ", style="bold green")
1008 |
1009 | label_2 = ctk.CTkLabel(done, text="", height=0, width=0)
1010 | label_2.pack()
1011 |
1012 | label_2.configure(
1013 | text=f"✅ Total Backup Added: {TOTAL_BACKUP}",
1014 | font=("Segeo UI", 18),
1015 | state="normal",
1016 | text_color="Green",
1017 | )
1018 |
1019 | label_3 = ctk.CTkLabel(done, height=0, width=0)
1020 | label_3.pack()
1021 |
1022 | label_3.configure(
1023 | text=f"{end_file}",
1024 | font=("Segeo UI", 20),
1025 | fg_color="#313131",
1026 | bg_color="#000000",
1027 | state="normal",
1028 | text_color="#a68017",
1029 | )
1030 |
1031 | except KeyboardInterrupt:
1032 | time.sleep(1)
1033 | console.print("Exiting...! \n", style="bold red")
1034 | sys.exit(1)
1035 |
1036 |
1037 | def signal_handler(x, y):
1038 | console.print("\nExiting... \n", style="bold red")
1039 | os._exit(0)
1040 |
1041 |
1042 | signal.signal(signal.SIGINT, signal_handler)
1043 |
1044 |
1045 | class ProcessingThread(threading.Thread):
1046 | def __init__(self, target_function):
1047 | super().__init__()
1048 | self.target_function = target_function
1049 | self.running = False
1050 |
1051 | def run(self):
1052 | self.running = True
1053 | self.target_function()
1054 |
1055 | def stop(self):
1056 | self.running = False
1057 |
1058 | def restart(self, target_function):
1059 | self.target_function = target_function
1060 | self.stop()
1061 | self.start()
1062 |
1063 |
1064 | processing_thread = None
1065 |
1066 |
1067 | def start_processing():
1068 | global processing_thread
1069 |
1070 | # check if a thread is already running
1071 | if processing_thread and processing_thread.running:
1072 | # if so, stop the thread
1073 | processing_thread.stop()
1074 |
1075 | # start a new thread for processing
1076 | processing_thread = ProcessingThread(target_function=browse)
1077 | processing_thread.start()
1078 |
1079 |
1080 | def start_processing_tv():
1081 | global processing_thread
1082 |
1083 | # check if a thread is already running
1084 | if processing_thread and processing_thread.running:
1085 | # if so, stop the thread
1086 | processing_thread.stop()
1087 |
1088 | # start a new thread for processing
1089 | processing_thread = ProcessingThread(target_function=tv_browse)
1090 | processing_thread.start()
1091 |
1092 |
1093 | def start_del():
1094 | global processing_thread
1095 | # check if a thread is already running
1096 | if processing_thread and processing_thread.running:
1097 | # if so, stop the thread
1098 | processing_thread.stop()
1099 |
1100 | # start a new thread for processing
1101 | processing_thread = ProcessingThread(target_function=del_fi)
1102 | processing_thread.start()
1103 |
1104 |
1105 | def bak_u():
1106 | global processing_thread
1107 |
1108 | # check if a thread is already running
1109 | if processing_thread and processing_thread.running:
1110 | # if so, stop the thread
1111 | processing_thread.stop()
1112 |
1113 | # start a new thread for processing
1114 | processing_thread = ProcessingThread(target_function=backup)
1115 | processing_thread.start()
1116 |
1117 |
1118 | # TEXT BOX
1119 |
1120 |
1121 | file_folder_listbox = ctk.CTkTextbox(out, height=650, width=1500)
1122 | file_folder_listbox.configure(
1123 | wrap="none",
1124 | font=("Segeo UI", 20),
1125 | fg_color="#212121",
1126 | bg_color="#212121",
1127 | state="disable",
1128 | text_color="#b37c25",
1129 | border_color="#212121",
1130 | corner_radius=3.2,
1131 | )
1132 | file_folder_listbox.pack(fill=ctk.BOTH, expand=True)
1133 |
1134 |
1135 | serc = ctk.CTkTextbox(fe, height=650, width=1500)
1136 | serc.configure(
1137 | wrap="none",
1138 | font=("Segeo UI", 20),
1139 | fg_color="#212121",
1140 | bg_color="#212121",
1141 | state="disable",
1142 | text_color="#b37c25",
1143 | border_color="#212121",
1144 | corner_radius=3.2,
1145 | )
1146 | serc.pack(fill=ctk.BOTH, expand=True)
1147 |
1148 |
1149 | serc = ctk.CTkLabel(fe, height=0, width=0)
1150 | serc.pack()
1151 |
1152 | serc.configure(
1153 | text=f"🛠 IN PROGRESS",
1154 | font=("Segeo UI", 18),
1155 | state="normal",
1156 | text_color="#d4af2a",
1157 | )
1158 |
1159 |
1160 | rem = ctk.CTkTextbox(rmf, height=650, width=1500)
1161 | rem.configure(
1162 | wrap="none",
1163 | font=("Segeo UI", 20),
1164 | fg_color="#212121",
1165 | bg_color="#212121",
1166 | state="disable",
1167 | text_color="#b37c25",
1168 | border_color="#212121",
1169 | corner_radius=3.2,
1170 | )
1171 | rem.pack(fill=ctk.BOTH, expand=True)
1172 |
1173 |
1174 | bak_ups = ctk.CTkTextbox(done, height=650, width=1500)
1175 | bak_ups.configure(
1176 | wrap="none",
1177 | font=("Segeo UI", 20),
1178 | fg_color="#212121",
1179 | bg_color="#212121",
1180 | state="disable",
1181 | text_color="#b37c25",
1182 | border_color="#212121",
1183 | corner_radius=3.2,
1184 | )
1185 | bak_ups.pack(fill=ctk.BOTH, expand=True)
1186 |
1187 |
1188 | button_2 = ctk.CTkButton(
1189 | tabview.tab("Movie/Renamer"),
1190 | text="MOVIE | TMDB",
1191 | image=image_2,
1192 | compound="left",
1193 | font=("Segeo UI", 20),
1194 | command=start_processing,
1195 | )
1196 |
1197 |
1198 | button_2.pack(side="left", padx=20, pady=20, expand=True)
1199 | button_2.grid(row=1, column=0, padx=25, pady=55, sticky="nsew")
1200 |
1201 |
1202 | button_3 = ctk.CTkButton(
1203 | tabview.tab("TV/Renamer"),
1204 | text="TV | TMDB ",
1205 | image=image_3,
1206 | compound="left",
1207 | font=("Segeo UI", 20),
1208 | command=start_processing_tv,
1209 | )
1210 |
1211 | button_3.pack(side="left", padx=20, pady=20, expand=True)
1212 | button_3.grid(row=1, column=0, padx=25, pady=55, ipadx=15, sticky="nsew")
1213 |
1214 |
1215 | button_4 = ctk.CTkButton(
1216 | tabview.tab("Delete"),
1217 | text="DELETE | FILES",
1218 | image=image_4,
1219 | compound="left",
1220 | font=("Segeo UI", 20),
1221 | command=start_del,
1222 | )
1223 |
1224 |
1225 | button_4.pack(side="left", padx=20, pady=20, expand=True)
1226 | button_4.grid(row=1, column=0, padx=25, pady=55, sticky="nsew")
1227 |
1228 |
1229 | button_1 = ctk.CTkButton(
1230 | tabview.tab("Backup"),
1231 | text="PLEX | BACKUP",
1232 | image=image,
1233 | compound="left",
1234 | font=("Segoe UI", 20),
1235 | command=bak_u,
1236 | )
1237 |
1238 |
1239 | button_1.grid(row=1, column=0, padx=20, pady=55, sticky="nsew")
1240 |
1241 |
1242 | button_5 = ctk.CTkButton(
1243 | tabview.tab("Backup"),
1244 | text="JELLYFIN | BACKUP",
1245 | image=image_5,
1246 | compound="left",
1247 | font=("Segoe UI", 20),
1248 | )
1249 |
1250 |
1251 | button_5.grid(row=2, column=0, padx=20, pady=55, sticky="nsew")
1252 |
1253 |
1254 | button_7 = ctk.CTkButton(
1255 | tabview.tab("Backup"),
1256 | text="EMBY | BACKUP",
1257 | image=image_6,
1258 | compound="left",
1259 | font=("Segoe UI", 20),
1260 | )
1261 |
1262 |
1263 | button_7.grid(row=3, column=0, padx=20, pady=55, sticky="nsew")
1264 |
1265 |
1266 | # PROGRESS BAR
1267 |
1268 |
1269 | bak_precent = ctk.CTkLabel(bu, text="0%")
1270 | bak_precent.place(x=140, y=140)
1271 |
1272 | bak_progressbar = ctk.CTkProgressBar(bu, orientation="horizontal", mode="determinate")
1273 | bak_progressbar.configure(progress_color="green")
1274 | bak_progressbar.place(x=40, y=170)
1275 |
1276 | bak_progressbar.set(0)
1277 |
1278 | mv_precent = ctk.CTkLabel(mv, text="0%")
1279 | mv_precent.place(x=140, y=140)
1280 |
1281 | mov_progressbar = ctk.CTkProgressBar(mv, orientation="horizontal", mode="determinate")
1282 | mov_progressbar.configure(progress_color="green")
1283 | mov_progressbar.place(x=40, y=170)
1284 |
1285 | mov_progressbar.set(0)
1286 |
1287 |
1288 | tv_precent = ctk.CTkLabel(tv, text="0%")
1289 | tv_precent.place(x=140, y=140)
1290 |
1291 | tv_progressbar = ctk.CTkProgressBar(tv, orientation="horizontal", mode="determinate")
1292 | tv_progressbar.configure(progress_color="green")
1293 | tv_progressbar.place(x=40, y=170)
1294 |
1295 | tv_progressbar.set(0)
1296 |
1297 |
1298 | del_precent = ctk.CTkLabel(de, text="0%")
1299 | del_precent.place(x=140, y=140)
1300 |
1301 |
1302 | del_progressbar = ctk.CTkProgressBar(de, orientation="horizontal", mode="determinate")
1303 | del_progressbar.configure(progress_color="green")
1304 | del_progressbar.place(x=40, y=170)
1305 |
1306 | del_progressbar.set(0)
1307 |
1308 |
1309 | if __name__ == "__main__":
1310 | colorama.init()
1311 | console = Console()
1312 | ver = Text("\nVersion: 0.2.0")
1313 | ver.stylize("bold yellow", 0, 8)
1314 | ver.stylize("yellow", 8, 15)
1315 | console.print("\nFIXARR", style="green_yellow")
1316 | console.print(ver)
1317 | console.print(f"\nDate: {__date__}", style="bright_cyan")
1318 | console.print(f"OS: {platform} \n", style="bright_cyan")
1319 |
1320 | YELLOW = "\x1b[1;33;40m"
1321 | RED = "\x1b[1;31;40m"
1322 |
1323 | nf = "PLEX BACKUPS"
1324 |
1325 | if os.name == "nt":
1326 | user_home = os.environ["USERPROFILE"]
1327 | src_root = os.path.join(user_home, "AppData", "Local")
1328 | dst_root = os.path.join(user_home, "Documents")
1329 |
1330 | nff = os.path.join(dst_root, nf)
1331 | if not os.path.exists(nff):
1332 | os.mkdir(nff)
1333 |
1334 | if platform == "Linux":
1335 | pass
1336 |
1337 | if platform == "Darwin":
1338 | pass
1339 |
1340 | folder_name = "Plex Media Server"
1341 | stop_flag = False
1342 |
1343 | app.mainloop()
1344 |
--------------------------------------------------------------------------------
/linux_&_osx_start.sh:
--------------------------------------------------------------------------------
1 | #!/bin/sh
2 |
3 | REPO_URL="https://github.com/sachinsenal0x64/FIXARR"
4 | CLONE_DIR="FIXARR"
5 |
6 | # Check if fixarr.py exists
7 | if [ -e "${CLONE_DIR}/fixarr.py" ]; then
8 | echo "fixarr.py already exists. Skipping Git clone."
9 | else
10 | echo "fixarr.py does not exist. Cloning Git repository..."
11 | git clone "${REPO_URL}" "${CLONE_DIR}"
12 | fi
13 |
14 | cd "${CLONE_DIR}"
15 | echo "Installing Packages......"
16 |
17 | # Create virtual environment
18 | python3 -m venv fixarr
19 |
20 | # Activate virtual environment
21 | source fixarr/bin/activate
22 |
23 | pip install -r requirements.txt
24 | chmod +x fixarr.py
25 | python fixarr.py
26 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | certifi==2023.7.22
2 | charset-normalizer==3.1.0
3 | colorama==0.4.6
4 | customtkinter==5.1.2
5 | darkdetect==0.8.0
6 | idna==3.7
7 | markdown-it-py==2.2.0
8 | mdurl==0.1.2
9 | Pillow==10.3.0
10 | Pygments==2.15.0
11 | requests==2.31.0
12 | rich==13.3.3
13 | tqdm==4.65.0
14 | urllib3==1.26.18
15 | ordered-set==4.1.0
16 | wheel==0.38.4
17 | zstandard==0.20.0
18 | python-dotenv==1.0.0
19 | thefuzz==0.20.0
20 |
--------------------------------------------------------------------------------
/windows_start.bat:
--------------------------------------------------------------------------------
1 | @echo off
2 | setlocal
3 |
4 | :: BatchGotAdmin
5 | :-------------------------------------
6 | REM --> Check for permissions
7 | >nul 2>&1 "%SYSTEMROOT%\system32\cacls.exe" "%SYSTEMROOT%\system32\config\system"
8 |
9 | REM --> If error flag set, we do not have admin.
10 | if '%errorlevel%' NEQ '0' (
11 | echo Requesting administrative privileges...
12 | goto UACPrompt
13 | ) else (
14 | goto gotAdmin
15 | )
16 |
17 | :UACPrompt
18 | echo Set UAC = CreateObject^("Shell.Application"^) > "%temp%\getadmin.vbs"
19 | echo UAC.ShellExecute "%~s0", "", "", "runas", 1 >> "%temp%\getadmin.vbs"
20 |
21 | "%temp%\getadmin.vbs"
22 | exit /B
23 |
24 | :gotAdmin
25 | if exist "%temp%\getadmin.vbs" (
26 | del "%temp%\getadmin.vbs"
27 | )
28 | pushd "%CD%"
29 | CD /D "%~dp0"
30 | goto :eof :: or use 'exit /b'
31 |
32 | :--------------------------------------
33 | set SCRIPT="%TEMP%\%RANDOM%-%RANDOM%-%RANDOM%-%RANDOM%.vbs"
34 |
35 | :: Define repository URL and clone directory
36 | set "repoURL=https://github.com/sachinsenal0x64/FIXARR"
37 | set "cloneDir=FIXARR"
38 |
39 | :: Check if fixarr.py exists
40 | if not exist "%cloneDir%\fixarr.py" (
41 | echo fixarr.py does not exist. Cloning Git repository...
42 | git clone %repoURL% %cloneDir%
43 | )
44 |
45 | :: Change to the clone directory
46 | cd /d %cloneDir%
47 |
48 | :: Print message and install packages
49 | echo Installing Packages......
50 | pip install -r requirements.txt
51 |
52 | :: Run fixarr.py without displaying the console window
53 | set python_path=python
54 | set code_file=fixarr.py
55 | start cmd.exe /k %python_path% %code_file%
56 |
57 | endlocal
58 | @REM @CMD.EXE
59 |
--------------------------------------------------------------------------------
/windows_start.vbs:
--------------------------------------------------------------------------------
1 | Set WshShell = CreateObject("WScript.Shell")
2 |
3 | ' Define repository URL and clone directory
4 | repoURL = "https://github.com/sachinsenal0x64/FIXARR"
5 | cloneDir = "FIXARR"
6 |
7 | ' Check if fixarr.py exists
8 | If Not objFSO.FileExists(cloneDir & "\fixarr.py") Then
9 | WScript.Echo "fixarr.py does not exist. Cloning Git repository..."
10 | WshShell.Run "git clone " & repoURL & " " & cloneDir, 0, True
11 | End If
12 |
13 | ' Change to the clone directory
14 | WshShell.CurrentDirectory = cloneDir
15 |
16 | ' Print message and install packages
17 | WScript.Echo "Installing Packages......"
18 | WshShell.Run "pip install -r requirements.txt", 0, True
19 |
20 | ' Run fixarr.py with displaying the console window
21 | WshShell.Run "python fixarr.py", 1, True
22 |
--------------------------------------------------------------------------------