├── new_metadata.xlsx
├── docs
├── Gen vs Real.jpg
├── GAN App demo.png
└── Omni BigGAN - Overview.jpg
├── requirements.txt
├── app
├── requirements.txt
├── gan_app.py
└── biggan.py
├── LICENSE
├── README.md
└── omni-loss-biggan.ipynb
/new_metadata.xlsx:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/safi842/Microstructure-GAN/HEAD/new_metadata.xlsx
--------------------------------------------------------------------------------
/docs/Gen vs Real.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/safi842/Microstructure-GAN/HEAD/docs/Gen vs Real.jpg
--------------------------------------------------------------------------------
/docs/GAN App demo.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/safi842/Microstructure-GAN/HEAD/docs/GAN App demo.png
--------------------------------------------------------------------------------
/docs/Omni BigGAN - Overview.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/safi842/Microstructure-GAN/HEAD/docs/Omni BigGAN - Overview.jpg
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | numpy==1.21.5
2 | pandas==1.4.4
3 | Pillow==9.4.0
4 | requests==2.28.1
5 | stqdm==0.0.5
6 | streamlit==1.17.0
7 | torch==1.13.1
8 | torchvision==0.14.1
9 |
--------------------------------------------------------------------------------
/app/requirements.txt:
--------------------------------------------------------------------------------
1 | numpy==1.21.5
2 | pandas==1.4.4
3 | Pillow==9.4.0
4 | requests==2.28.1
5 | stqdm==0.0.5
6 | streamlit==1.17.0
7 | torch==1.13.1
8 | torchvision==0.14.1
9 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2023 Mohammad Safiuddin
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | ## Microstructure-GAN — Pytorch Implementation
2 | [](https://safi842-microstructure-gan-appgan-app-32c049.streamlit.app/)
3 |
4 |
5 | 
6 |
7 | ### Establishing process-structure linkages using Generative Adversarial Networks
8 | Mohammad Safiuddin, Ch Likith Reddy, Ganesh Vasantada, CHJNS Harsha, Dr. Srinu Gangolu
9 |
10 | Paper: http://dx.doi.org/10.1007/978-981-97-6367-2_39
11 |
12 | [comment]: <> (Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila
)
13 | [comment]: <> (Paper: http://dx.doi.org/10.1007/978-981-97-6367-2_39
)
14 |
15 | Abstract: *The microstructure of a material strongly influences its mechanical properties
16 | and the microstructure itself is influenced by the processing conditions. Thus,
17 | establishing a Process-Structure-Property relationship is a crucial task in material design and is of interest in many engineering applications. In this work,
18 | the processing-structure relationship is modelled as deep learning based conditional image synthesis problem. This approach is devoid of feature engineering,
19 | needs little domain awareness, and can be applied to a wide variety of material
20 | systems. We develop a GAN (Generative Adversarial Network) to synthesize
21 | microstructures based on given processing conditions. Results show that our GAN model
22 | can produce high-fidelity multiphase microstructures which have a good correlation with the given processing conditions.*
23 |
24 | ### Results:
25 |
26 |
27 |  28 |
28 |
29 |
30 | #### File Overview
31 |
32 | The following files are included in this package:
33 |
34 | - `omni-loss-biggan.ipynb`: an Ipython notebook that contains the code used to train the model.
35 | - `new_metadata.xlsx`: an Excel workbook that holds the training image metadata.
36 | - `.\app`: a directory that contains the source code for the app. Further instructions on the app can be found below.
37 |
38 | ### Application
39 | [](https://safi842-microstructure-gan-appgan-app-32c049.streamlit.app/) \
40 | **If you want to run the app locally, follow the instructions below**
41 |
42 | 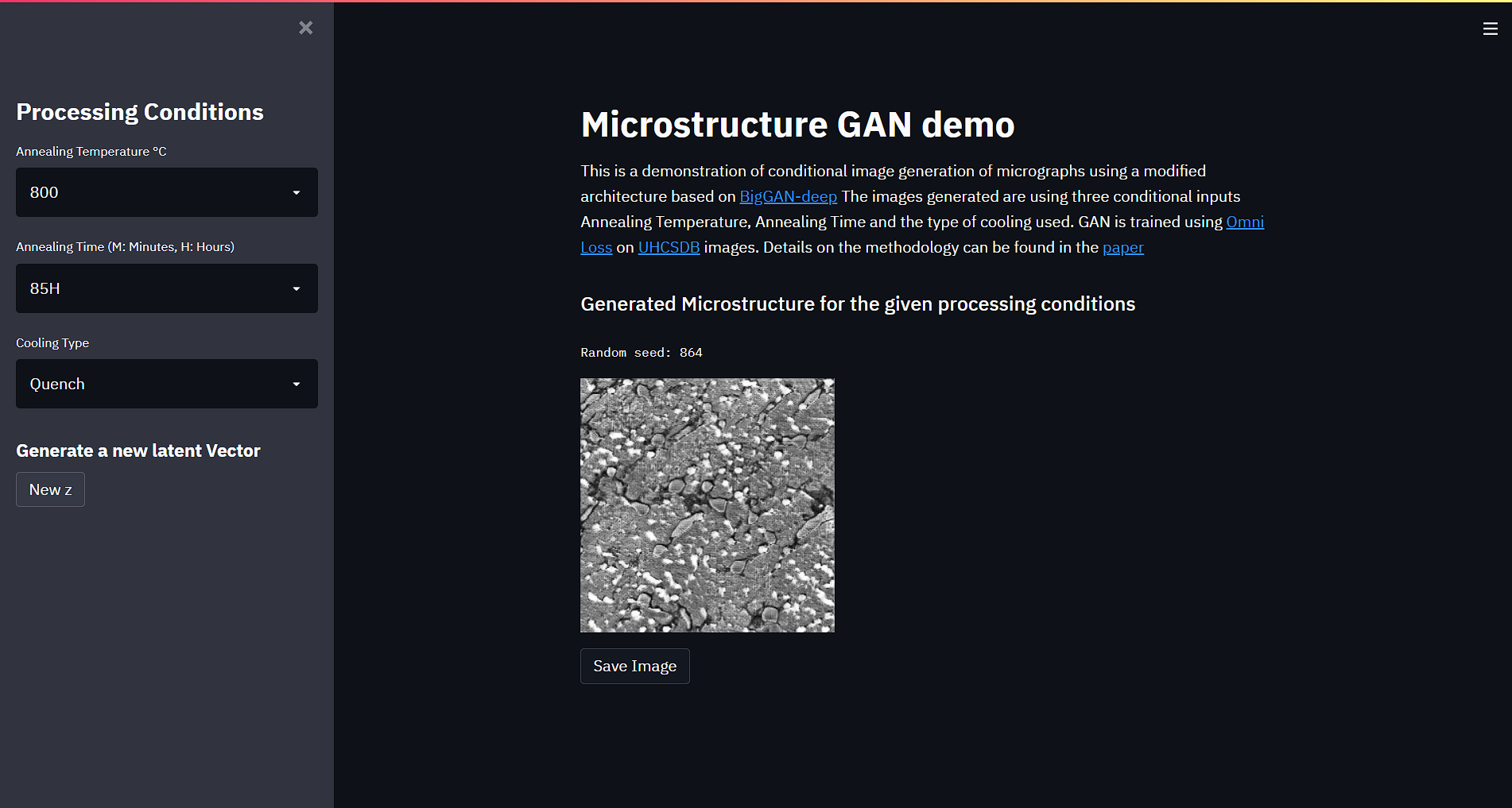 43 |
43 |
44 |
45 | To install the app, unzip the `.\Microstructure_GAN` folder. Next, navigate to the `.\Microstructure_GAN\app` directory in a terminal and run the following command to install the necessary packages:
46 |
47 | ```
48 | pip install requirements.txt
49 | ```
50 |
51 | Once the packages have been installed, run the following command to start the web app:
52 |
53 | ```
54 | streamlit run gan_app.py
55 | ```
56 |
57 | **Recreating Results:**
58 |
59 | Generated micrographs can be downloaded by clicking the "Download Micrograph" button. The file name of the saved image contains the processing conditions and seed value, for example: `800-85H-Quench-864.png`. To recreate the image, the latent vector can be generated using the `seed` as follows.
60 | ```
61 | seed = 864
62 | rng = np.random.RandomState(seed)
63 | latent_vector = rng.normal(0, 1, (1, 384))
64 | ```
65 |
--------------------------------------------------------------------------------
/app/gan_app.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from io import BytesIO
3 | import os
4 | import json
5 | import requests
6 | #import urllib.request
7 | from stqdm import stqdm
8 | from PIL import Image
9 | import pickle
10 | import streamlit as st
11 | import sys
12 | import urllib
13 | import torch
14 | import random
15 | import biggan
16 | from torchvision.utils import make_grid
17 | from io import BytesIO
18 | import base64
19 |
20 | class NumpyEncoder(json.JSONEncoder):
21 | def default(self, obj):
22 | if isinstance(obj, np.ndarray):
23 | return obj.tolist()
24 | return json.JSONEncoder.default(self, obj)
25 |
26 |
27 | def main():
28 | first_run = not os.path.exists('state.json')
29 | state = {}
30 | st.title("Microstructure GAN demo")
31 | """This is a demonstration of conditional image generation of micrographs using a modified architecture based on [BigGAN-deep](https://arxiv.org/abs/1809.11096)
32 | The images generated are using three conditional inputs Annealing Temperature, Annealing Time and the type of cooling used.
33 | GAN is trained using [Omni Loss](https://arxiv.org/abs/2011.13074) on [UHCSDB](http://uhcsdb.materials.cmu.edu/) images. Details on the methodology can be found in the [paper](https://arxiv.org/abs/2107.09402)"""
34 |
35 | st.sidebar.title('Processing Conditions',)
36 | state['anneal_temp'] = st.sidebar.selectbox('Annealing Temperature °C',[700,750,800,900,970,1000,1100])
37 | state['anneal_time'] = st.sidebar.selectbox('Annealing Time (M: Minutes, H: Hours)',['5M','90M','1H','3H','8H','24H','48H','85H'])
38 | state['cooling'] = st.sidebar.selectbox('Cooling Type',['Quench','Furnace Cool','Air Cool','650C-1H'])
39 | temp_dict = {970: 0, 800: 1, 900: 2, 1100: 3, 1000: 4, 700: 5, 750: 6}
40 | time_dict = {'90M': 0, '24H': 1, '3H': 2, '5M': 3, '8H': 4, '85H': 5, '1H': 6, '48H': 7}
41 | cool_dict = {'Quench': 0, 'Air Cool': 1, 'Furnace Cool': 2, '650C-1H': 3}
42 | model = load_gan()
43 | st.sidebar.subheader('Generate a new latent Vector')
44 | state['seed'] = 7
45 | if st.sidebar.button('New z'):
46 | state['seed'] = random.randint(0,1000)
47 | rng = np.random.RandomState(state['seed'])
48 | noise = torch.tensor(rng.normal(0, 1, (1, 384))).float()
49 | state['noise'] = noise.numpy()
50 | y_temp = temp_dict[state['anneal_temp']]
51 | y_time = time_dict[state['anneal_time']]
52 | y_cool = cool_dict[state['cooling']]
53 |
54 | state['image_out'] = generate_img(model, noise, y_temp, y_time, y_cool)
55 | st.subheader('Generated Microstructure for the given processing conditions')
56 | st.text("")
57 | st.text(f"Random seed: {state['seed']}")
58 | st.image(np.array(state['image_out']), use_column_width=False)
59 | im = Image.fromarray((np.array(state['image_out']).reshape(256,256) * 255).astype(np.uint8))
60 | buf = BytesIO()
61 | im.save(buf, format="PNG")
62 | byte_im = buf.getvalue()
63 | st.download_button(label = "Download Micrograph", data = byte_im , file_name = f"{state['anneal_temp']}-{state['anneal_time']}-{state['cooling']}-{state['seed']}.png", mime="image/png")
64 |
65 | with open('state.json', 'w') as fp:
66 | json.dump(state, fp, cls=NumpyEncoder)
67 |
68 | def download_model(url, filename):
69 | """
70 | Helper method handling downloading large files from `url` to `filename`. Returns a pointer to `filename`.
71 | """
72 | with st.spinner(text= f"Downloading {filename} ..."):
73 | chunkSize = 1024
74 | r = requests.get(url, stream=True)
75 | with open(filename, 'wb') as f:
76 | pbar = stqdm( unit="B", total=int( r.headers['Content-Length'] ) )
77 | for chunk in r.iter_content(chunk_size=chunkSize):
78 | if chunk: # filter out keep-alive new chunks
79 | pbar.update (len(chunk))
80 | f.write(chunk)
81 |
82 | @st.cache(suppress_st_warning=True)
83 | def load_gan():
84 | if not os.path.isfile("BigGAN-deep.pth"):
85 | url = "https://github.com/safi842/Microstructure-GAN/releases/download/v0/BigGAN-deep.pth"
86 | filename = "BigGAN-deep.pth"
87 | download_model(url, filename)
88 | st.write(f"Downloaded {filename}...")
89 | #filename, headers = urllib.request.urlretrieve(url,"BigGAN-deep.pth",MyProgressBar())
90 | model = biggan.Generator()
91 | model.load_state_dict(torch.load('BigGAN-deep.pth', map_location=torch.device('cpu')))
92 | return model
93 |
94 | @st.cache(suppress_st_warning=True)
95 | def generate_img(model,noise, y_temp, y_time, y_cool):
96 | y_temp = torch.tensor([y_temp])
97 | y_time = torch.tensor([y_time])
98 | y_cool = torch.tensor([y_cool])
99 | with torch.no_grad():
100 | synthetic = model(noise, y_temp, y_time, y_cool)[0]
101 | synthetic = 0.5 * synthetic + 0.5
102 | #synthetic = make_grid(synthetic, normalize=True)
103 | return np.transpose(synthetic.numpy() ,(1,2,0))
104 |
105 | main()
106 | st.markdown('Copyright (c) 2023 Mohammad Safiuddin
', unsafe_allow_html=True)
--------------------------------------------------------------------------------
/app/biggan.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pandas as pd
3 | import random
4 | import torch
5 | import torch.nn as nn
6 | import torch.nn.parallel
7 | import torch.backends.cudnn as cudnn
8 | import torch.optim as optim
9 | import torch.utils.data
10 | import torchvision.transforms as transforms
11 | import torchvision.utils as vutils
12 | from torch.utils.data import DataLoader, Dataset
13 | from torch.nn.utils import spectral_norm
14 | import torch.nn.functional as F
15 | import numpy as np
16 | from torchvision.utils import make_grid
17 |
18 | class ClassConditionalBN(nn.Module):
19 | def __init__(self, input_size, output_size, eps=1e-4, momentum=0.1):
20 | super(ClassConditionalBN, self).__init__()
21 | self.output_size, self.input_size = output_size, input_size
22 | # Prepare gain and bias layers
23 | self.gain = spectral_norm(nn.Linear(input_size, output_size, bias = False), eps = 1e-4)
24 | self.bias = spectral_norm(nn.Linear(input_size, output_size, bias = False), eps = 1e-4)
25 | # epsilon to avoid dividing by 0
26 | self.eps = eps
27 | # Momentum
28 | self.momentum = momentum
29 |
30 | self.register_buffer('stored_mean', torch.zeros(output_size))
31 | self.register_buffer('stored_var', torch.ones(output_size))
32 |
33 | def forward(self, x, y):
34 | # Calculate class-conditional gains and biases
35 | gain = (1 + self.gain(y)).view(y.size(0), -1, 1, 1)
36 | bias = self.bias(y).view(y.size(0), -1, 1, 1)
37 | out = F.batch_norm(x, self.stored_mean, self.stored_var, None, None,
38 | self.training, 0.1, self.eps)
39 | return out * gain + bias
40 |
41 | def extra_repr(self):
42 | s = 'out: {output_size}, in: {input_size},'
43 | return s.format(**self.__dict__)
44 |
45 | class Self_Attn(nn.Module):
46 | """ Self attention Layer"""
47 | def __init__(self,in_dim,activation = nn.ReLU(inplace = False)):
48 | super(Self_Attn,self).__init__()
49 | self.chanel_in = in_dim
50 | self.activation = activation
51 |
52 | self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
53 | self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
54 | self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)
55 | self.gamma = nn.Parameter(torch.zeros(1))
56 |
57 | self.softmax = nn.Softmax(dim=-1) #
58 | def forward(self,x):
59 | """
60 | inputs :
61 | x : input feature maps( B X C X W X H)
62 | returns :
63 | out : self attention value + input feature
64 | attention: B X N X N (N is Width*Height)
65 | """
66 | m_batchsize,C,width ,height = x.size()
67 | proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1) # B X CX(N)
68 | proj_key = self.key_conv(x).view(m_batchsize,-1,width*height) # B X C x (*W*H)
69 | energy = torch.bmm(proj_query,proj_key) # transpose check
70 | attention = self.softmax(energy) # BX (N) X (N)
71 | proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C X N
72 |
73 | out = torch.bmm(proj_value,attention.permute(0,2,1) )
74 | out = out.view(m_batchsize,C,width,height)
75 |
76 | out = self.gamma*out + x
77 | return out
78 |
79 | class GeneratorResBlock(nn.Module):
80 | def __init__(self, in_channels, out_channels, upsample = None, embed_dim = 128, dim_z = 384):
81 | super(GeneratorResBlock, self).__init__()
82 | self.in_channels = in_channels
83 | self.out_channels = out_channels
84 | self.hidden_channels = self.in_channels // 4
85 |
86 | self.conv1 = spectral_norm(nn.Conv2d(self.in_channels, self.hidden_channels, kernel_size = 1, padding = 0), eps = 1e-4)
87 | self.conv2 = spectral_norm(nn.Conv2d(self.hidden_channels, self.hidden_channels, kernel_size = 3, padding = 1), eps = 1e-4)
88 | self.conv3 = spectral_norm(nn.Conv2d(self.hidden_channels, self.hidden_channels, kernel_size = 3, padding = 1), eps = 1e-4)
89 | self.conv4 = spectral_norm(nn.Conv2d(self.hidden_channels, self.out_channels, kernel_size = 1, padding = 0), eps = 1e-4)
90 |
91 | self.bn1 = ClassConditionalBN((3 * embed_dim) + dim_z, self.in_channels)
92 | self.bn2 = ClassConditionalBN((3 * embed_dim) + dim_z, self.hidden_channels)
93 | self.bn3 = ClassConditionalBN((3 * embed_dim) + dim_z, self.hidden_channels)
94 | self.bn4 = ClassConditionalBN((3 * embed_dim) + dim_z, self.hidden_channels)
95 |
96 | self.activation = nn.ReLU(inplace=False)
97 |
98 | self.upsample = upsample
99 |
100 | def forward(self,x,y):
101 | # Project down to channel ratio
102 | h = self.conv1(self.activation(self.bn1(x, y)))
103 | # Apply next BN-ReLU
104 | h = self.activation(self.bn2(h, y))
105 | # Drop channels in x if necessary
106 | if self.in_channels != self.out_channels:
107 | x = x[:, :self.out_channels]
108 | # Upsample both h and x at this point
109 | if self.upsample:
110 | h = self.upsample(h)
111 | x = self.upsample(x)
112 | # 3x3 convs
113 | h = self.conv2(h)
114 | h = self.conv3(self.activation(self.bn3(h, y)))
115 | # Final 1x1 conv
116 | h = self.conv4(self.activation(self.bn4(h, y)))
117 | return h + x
118 |
119 | class Generator(nn.Module):
120 | def __init__(self, G_ch = 64, dim_z = 384, bottom_width=4, img_channels = 1,
121 | init = 'N02',n_classes_temp = 7, n_classes_time = 8, n_classes_cool = 4, embed_dim = 128):
122 | super(Generator, self).__init__()
123 | self.ch = G_ch
124 | self.dim_z = dim_z
125 | self.bottom_width = bottom_width
126 | self.init = init
127 | self.img_channels = img_channels
128 |
129 | self.embed_temp = nn.Embedding(n_classes_temp, embed_dim)
130 | self.embed_time = nn.Embedding(n_classes_time, embed_dim)
131 | self.embed_cool = nn.Embedding(n_classes_cool, embed_dim)
132 |
133 | self.linear = spectral_norm(nn.Linear(dim_z + (3 * embed_dim), 16 * self.ch * (self.bottom_width **2)), eps = 1e-4)
134 |
135 | self.blocks = nn.ModuleList([
136 | GeneratorResBlock(16*self.ch, 16*self.ch),
137 | GeneratorResBlock(16*self.ch, 16*self.ch, upsample = nn.Upsample(scale_factor = 2)),
138 | GeneratorResBlock(16*self.ch, 16*self.ch),
139 | GeneratorResBlock(16*self.ch, 8*self.ch, upsample = nn.Upsample(scale_factor = 2)),
140 | GeneratorResBlock(8*self.ch, 8*self.ch),
141 | GeneratorResBlock(8*self.ch, 8*self.ch, upsample = nn.Upsample(scale_factor = 2)),
142 | GeneratorResBlock(8*self.ch, 8*self.ch),
143 | GeneratorResBlock(8*self.ch, 4*self.ch, upsample = nn.Upsample(scale_factor = 2)),
144 | Self_Attn(4*self.ch),
145 | GeneratorResBlock(4*self.ch, 4*self.ch),
146 | GeneratorResBlock(4*self.ch, 2*self.ch, upsample = nn.Upsample(scale_factor = 2)),
147 | GeneratorResBlock(2*self.ch, 2*self.ch),
148 | GeneratorResBlock(2*self.ch, self.ch, upsample = nn.Upsample(scale_factor = 2))
149 | ])
150 |
151 | self.final_layer = nn.Sequential(
152 | nn.BatchNorm2d(self.ch),
153 | nn.ReLU(inplace = False),
154 | spectral_norm(nn.Conv2d(self.ch, self.img_channels, kernel_size = 3, padding = 1)),
155 | nn.Tanh()
156 | )
157 |
158 | self.init_weights()
159 |
160 | def init_weights(self):
161 | print(f"Weight initialization : {self.init}")
162 | self.param_count = 0
163 | for module in self.modules():
164 | if (isinstance(module, nn.Conv2d) or isinstance(module, nn.Linear) or isinstance(module, nn.Embedding)):
165 | if self.init == 'ortho':
166 | torch.nn.init.orthogonal_(module.weight)
167 | elif self.init == 'N02':
168 | torch.nn.init.normal_(module.weight, 0, 0.02)
169 | elif self.init in ['glorot', 'xavier']:
170 | torch.nn.init.xavier_uniform_(module.weight)
171 | else:
172 | print('Init style not recognized...')
173 | self.param_count += sum([p.data.nelement() for p in module.parameters()])
174 | #print("Param count for G's initialized parameters: %d Million" % (self.param_count/1000000))
175 |
176 |
177 | def forward(self,z , y_temp, y_time, y_cool):
178 | y_temp = self.embed_temp(y_temp)
179 | y_time = self.embed_time(y_time)
180 | y_cool = self.embed_cool(y_cool)
181 | z = torch.cat([z, y_temp, y_time, y_cool], 1)
182 | # First linear layer
183 | h = self.linear(z)
184 | # Reshape
185 | h = h.view(h.size(0), -1, self.bottom_width, self.bottom_width)
186 | # Loop over blocks
187 | for i, block in enumerate(self.blocks):
188 | if i != 8:
189 | h = block(h, z)
190 | else:
191 | h = block(h)
192 | # Apply batchnorm-relu-conv-tanh at output
193 | h = self.final_layer(h)
194 | return h
195 |
--------------------------------------------------------------------------------
/omni-loss-biggan.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "metadata": {
7 | "execution": {
8 | "iopub.execute_input": "2021-05-12T05:40:48.623112Z",
9 | "iopub.status.busy": "2021-05-12T05:40:48.621513Z",
10 | "iopub.status.idle": "2021-05-12T05:40:51.352905Z",
11 | "shell.execute_reply": "2021-05-12T05:40:51.352242Z"
12 | },
13 | "papermill": {
14 | "duration": 2.755864,
15 | "end_time": "2021-05-12T05:40:51.353059",
16 | "exception": false,
17 | "start_time": "2021-05-12T05:40:48.597195",
18 | "status": "completed"
19 | },
20 | "tags": []
21 | },
22 | "outputs": [],
23 | "source": [
24 | "import os\n",
25 | "import pandas as pd\n",
26 | "import random\n",
27 | "from collections import OrderedDict\n",
28 | "from PIL import Image\n",
29 | "import torch\n",
30 | "import torch.nn as nn\n",
31 | "import torch.nn.parallel\n",
32 | "import torch.backends.cudnn as cudnn\n",
33 | "import torch.optim as optim\n",
34 | "import torch.utils.data\n",
35 | "import torchvision.transforms as transforms\n",
36 | "import torchvision.utils as vutils\n",
37 | "from torch.utils.data import DataLoader, Dataset\n",
38 | "import pytorch_lightning as pl\n",
39 | "from torch.nn.utils import spectral_norm\n",
40 | "import torch.nn.functional as F\n",
41 | "import numpy as np\n",
42 | "import matplotlib.pyplot as plt\n",
43 | "import matplotlib.animation as animation\n",
44 | "from torchvision.utils import make_grid\n",
45 | "import warnings\n",
46 | "warnings.filterwarnings(\"ignore\")\n",
47 | "#from torchsummaryX import summary"
48 | ]
49 | },
50 | {
51 | "cell_type": "code",
52 | "execution_count": 2,
53 | "metadata": {
54 | "execution": {
55 | "iopub.execute_input": "2021-05-12T05:40:51.394016Z",
56 | "iopub.status.busy": "2021-05-12T05:40:51.393457Z",
57 | "iopub.status.idle": "2021-05-12T05:40:59.288763Z",
58 | "shell.execute_reply": "2021-05-12T05:40:59.288233Z"
59 | },
60 | "papermill": {
61 | "duration": 7.917559,
62 | "end_time": "2021-05-12T05:40:59.288929",
63 | "exception": false,
64 | "start_time": "2021-05-12T05:40:51.371370",
65 | "status": "completed"
66 | },
67 | "tags": []
68 | },
69 | "outputs": [
70 | {
71 | "name": "stdout",
72 | "output_type": "stream",
73 | "text": [
74 | "Collecting openpyxl\r\n",
75 | " Downloading openpyxl-3.0.7-py2.py3-none-any.whl (243 kB)\r\n",
76 | "\u001b[K |████████████████████████████████| 243 kB 1.2 MB/s \r\n",
77 | "\u001b[?25hCollecting et-xmlfile\r\n",
78 | " Downloading et_xmlfile-1.1.0-py3-none-any.whl (4.7 kB)\r\n",
79 | "Installing collected packages: et-xmlfile, openpyxl\r\n",
80 | "Successfully installed et-xmlfile-1.1.0 openpyxl-3.0.7\r\n"
81 | ]
82 | }
83 | ],
84 | "source": [
85 | "!pip install openpyxl"
86 | ]
87 | },
88 | {
89 | "cell_type": "markdown",
90 | "metadata": {
91 | "papermill": {
92 | "duration": 0.020651,
93 | "end_time": "2021-05-12T05:40:59.330619",
94 | "exception": false,
95 | "start_time": "2021-05-12T05:40:59.309968",
96 | "status": "completed"
97 | },
98 | "tags": []
99 | },
100 | "source": [
101 | "## Class Conditional Batch Normalization"
102 | ]
103 | },
104 | {
105 | "cell_type": "code",
106 | "execution_count": 3,
107 | "metadata": {
108 | "execution": {
109 | "iopub.execute_input": "2021-05-12T05:40:59.384025Z",
110 | "iopub.status.busy": "2021-05-12T05:40:59.383273Z",
111 | "iopub.status.idle": "2021-05-12T05:40:59.386077Z",
112 | "shell.execute_reply": "2021-05-12T05:40:59.385647Z"
113 | },
114 | "papermill": {
115 | "duration": 0.033907,
116 | "end_time": "2021-05-12T05:40:59.386189",
117 | "exception": false,
118 | "start_time": "2021-05-12T05:40:59.352282",
119 | "status": "completed"
120 | },
121 | "tags": []
122 | },
123 | "outputs": [],
124 | "source": [
125 | "class ClassConditionalBN(nn.Module):\n",
126 | " def __init__(self, input_size, output_size, eps=1e-4, momentum=0.1):\n",
127 | " super(ClassConditionalBN, self).__init__()\n",
128 | " self.output_size, self.input_size = output_size, input_size\n",
129 | " # Prepare gain and bias layers\n",
130 | " self.gain = spectral_norm(nn.Linear(input_size, output_size, bias = False), eps = 1e-4)\n",
131 | " self.bias = spectral_norm(nn.Linear(input_size, output_size, bias = False), eps = 1e-4)\n",
132 | " # epsilon to avoid dividing by 0\n",
133 | " self.eps = eps\n",
134 | " # Momentum\n",
135 | " self.momentum = momentum\n",
136 | " \n",
137 | " self.register_buffer('stored_mean', torch.zeros(output_size))\n",
138 | " self.register_buffer('stored_var', torch.ones(output_size))\n",
139 | " \n",
140 | " def forward(self, x, y):\n",
141 | " # Calculate class-conditional gains and biases\n",
142 | " gain = (1 + self.gain(y)).view(y.size(0), -1, 1, 1)\n",
143 | " bias = self.bias(y).view(y.size(0), -1, 1, 1)\n",
144 | " out = F.batch_norm(x, self.stored_mean, self.stored_var, None, None,\n",
145 | " self.training, 0.1, self.eps)\n",
146 | " return out * gain + bias\n",
147 | " \n",
148 | " def extra_repr(self):\n",
149 | " s = 'out: {output_size}, in: {input_size},'\n",
150 | " return s.format(**self.__dict__)"
151 | ]
152 | },
153 | {
154 | "cell_type": "markdown",
155 | "metadata": {
156 | "papermill": {
157 | "duration": 0.020582,
158 | "end_time": "2021-05-12T05:40:59.427620",
159 | "exception": false,
160 | "start_time": "2021-05-12T05:40:59.407038",
161 | "status": "completed"
162 | },
163 | "tags": []
164 | },
165 | "source": [
166 | "## Self Attention Module"
167 | ]
168 | },
169 | {
170 | "cell_type": "code",
171 | "execution_count": 4,
172 | "metadata": {
173 | "execution": {
174 | "iopub.execute_input": "2021-05-12T05:40:59.480572Z",
175 | "iopub.status.busy": "2021-05-12T05:40:59.479671Z",
176 | "iopub.status.idle": "2021-05-12T05:40:59.481743Z",
177 | "shell.execute_reply": "2021-05-12T05:40:59.482227Z"
178 | },
179 | "papermill": {
180 | "duration": 0.033732,
181 | "end_time": "2021-05-12T05:40:59.482365",
182 | "exception": false,
183 | "start_time": "2021-05-12T05:40:59.448633",
184 | "status": "completed"
185 | },
186 | "tags": []
187 | },
188 | "outputs": [],
189 | "source": [
190 | "class Self_Attn(nn.Module):\n",
191 | " \"\"\" Self attention Layer\"\"\"\n",
192 | " def __init__(self,in_dim,activation = nn.ReLU(inplace = False)):\n",
193 | " super(Self_Attn,self).__init__()\n",
194 | " self.chanel_in = in_dim\n",
195 | " self.activation = activation\n",
196 | " \n",
197 | " self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)\n",
198 | " self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)\n",
199 | " self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)\n",
200 | " self.gamma = nn.Parameter(torch.zeros(1))\n",
201 | "\n",
202 | " self.softmax = nn.Softmax(dim=-1) #\n",
203 | " def forward(self,x):\n",
204 | " \"\"\"\n",
205 | " inputs :\n",
206 | " x : input feature maps( B X C X W X H)\n",
207 | " returns :\n",
208 | " out : self attention value + input feature \n",
209 | " attention: B X N X N (N is Width*Height)\n",
210 | " \"\"\"\n",
211 | " m_batchsize,C,width ,height = x.size()\n",
212 | " proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1) # B X CX(N)\n",
213 | " proj_key = self.key_conv(x).view(m_batchsize,-1,width*height) # B X C x (*W*H)\n",
214 | " energy = torch.bmm(proj_query,proj_key) # transpose check\n",
215 | " attention = self.softmax(energy) # BX (N) X (N) \n",
216 | " proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C X N\n",
217 | "\n",
218 | " out = torch.bmm(proj_value,attention.permute(0,2,1) )\n",
219 | " out = out.view(m_batchsize,C,width,height)\n",
220 | " \n",
221 | " out = self.gamma*out + x\n",
222 | " return out"
223 | ]
224 | },
225 | {
226 | "cell_type": "markdown",
227 | "metadata": {
228 | "papermill": {
229 | "duration": 0.020504,
230 | "end_time": "2021-05-12T05:40:59.523763",
231 | "exception": false,
232 | "start_time": "2021-05-12T05:40:59.503259",
233 | "status": "completed"
234 | },
235 | "tags": []
236 | },
237 | "source": [
238 | "## Generator Resblock"
239 | ]
240 | },
241 | {
242 | "cell_type": "code",
243 | "execution_count": 5,
244 | "metadata": {
245 | "execution": {
246 | "iopub.execute_input": "2021-05-12T05:40:59.580342Z",
247 | "iopub.status.busy": "2021-05-12T05:40:59.579379Z",
248 | "iopub.status.idle": "2021-05-12T05:40:59.582130Z",
249 | "shell.execute_reply": "2021-05-12T05:40:59.581725Z"
250 | },
251 | "papermill": {
252 | "duration": 0.037638,
253 | "end_time": "2021-05-12T05:40:59.582245",
254 | "exception": false,
255 | "start_time": "2021-05-12T05:40:59.544607",
256 | "status": "completed"
257 | },
258 | "tags": []
259 | },
260 | "outputs": [],
261 | "source": [
262 | "class GeneratorResBlock(nn.Module):\n",
263 | " def __init__(self, in_channels, out_channels, upsample = None, embed_dim = 128, dim_z = 384):\n",
264 | " super(GeneratorResBlock, self).__init__()\n",
265 | " self.in_channels = in_channels\n",
266 | " self.out_channels = out_channels\n",
267 | " self.hidden_channels = self.in_channels // 4\n",
268 | " \n",
269 | " self.conv1 = spectral_norm(nn.Conv2d(self.in_channels, self.hidden_channels, kernel_size = 1, padding = 0), eps = 1e-4)\n",
270 | " self.conv2 = spectral_norm(nn.Conv2d(self.hidden_channels, self.hidden_channels, kernel_size = 3, padding = 1), eps = 1e-4)\n",
271 | " self.conv3 = spectral_norm(nn.Conv2d(self.hidden_channels, self.hidden_channels, kernel_size = 3, padding = 1), eps = 1e-4)\n",
272 | " self.conv4 = spectral_norm(nn.Conv2d(self.hidden_channels, self.out_channels, kernel_size = 1, padding = 0), eps = 1e-4)\n",
273 | " \n",
274 | " self.bn1 = ClassConditionalBN((3 * embed_dim) + dim_z, self.in_channels)\n",
275 | " self.bn2 = ClassConditionalBN((3 * embed_dim) + dim_z, self.hidden_channels)\n",
276 | " self.bn3 = ClassConditionalBN((3 * embed_dim) + dim_z, self.hidden_channels)\n",
277 | " self.bn4 = ClassConditionalBN((3 * embed_dim) + dim_z, self.hidden_channels)\n",
278 | " \n",
279 | " self.activation = nn.ReLU(inplace=False)\n",
280 | " \n",
281 | " self.upsample = upsample\n",
282 | " \n",
283 | " def forward(self,x,y):\n",
284 | " # Project down to channel ratio\n",
285 | " h = self.conv1(self.activation(self.bn1(x, y)))\n",
286 | " # Apply next BN-ReLU\n",
287 | " h = self.activation(self.bn2(h, y))\n",
288 | " # Drop channels in x if necessary\n",
289 | " if self.in_channels != self.out_channels:\n",
290 | " x = x[:, :self.out_channels] \n",
291 | " # Upsample both h and x at this point \n",
292 | " if self.upsample:\n",
293 | " h = self.upsample(h)\n",
294 | " x = self.upsample(x)\n",
295 | " # 3x3 convs\n",
296 | " h = self.conv2(h)\n",
297 | " h = self.conv3(self.activation(self.bn3(h, y)))\n",
298 | " # Final 1x1 conv\n",
299 | " h = self.conv4(self.activation(self.bn4(h, y)))\n",
300 | " return h + x"
301 | ]
302 | },
303 | {
304 | "cell_type": "markdown",
305 | "metadata": {
306 | "papermill": {
307 | "duration": 0.021846,
308 | "end_time": "2021-05-12T05:40:59.625610",
309 | "exception": false,
310 | "start_time": "2021-05-12T05:40:59.603764",
311 | "status": "completed"
312 | },
313 | "tags": []
314 | },
315 | "source": [
316 | "## BigGAN-deep Generator \n",
317 | "This version of the generator has a different input mechanism from that of the original version in the paper. This change was made to accomodate multiple conditional inputs."
318 | ]
319 | },
320 | {
321 | "cell_type": "code",
322 | "execution_count": 6,
323 | "metadata": {
324 | "execution": {
325 | "iopub.execute_input": "2021-05-12T05:40:59.691305Z",
326 | "iopub.status.busy": "2021-05-12T05:40:59.690418Z",
327 | "iopub.status.idle": "2021-05-12T05:40:59.692668Z",
328 | "shell.execute_reply": "2021-05-12T05:40:59.693070Z"
329 | },
330 | "papermill": {
331 | "duration": 0.04512,
332 | "end_time": "2021-05-12T05:40:59.693211",
333 | "exception": false,
334 | "start_time": "2021-05-12T05:40:59.648091",
335 | "status": "completed"
336 | },
337 | "tags": []
338 | },
339 | "outputs": [],
340 | "source": [
341 | "class Generator(nn.Module):\n",
342 | " def __init__(self, G_ch = 64, dim_z = 384, bottom_width=4, img_channels = 1,\n",
343 | " init = 'N02',n_classes_temp = 7, n_classes_time = 8, n_classes_cool = 4, embed_dim = 128):\n",
344 | " super(Generator, self).__init__()\n",
345 | " self.ch = G_ch\n",
346 | " self.dim_z = dim_z\n",
347 | " self.bottom_width = bottom_width\n",
348 | " self.init = init\n",
349 | " self.img_channels = img_channels\n",
350 | "\n",
351 | " self.embed_temp = nn.Embedding(n_classes_temp, embed_dim)\n",
352 | " self.embed_time = nn.Embedding(n_classes_time, embed_dim)\n",
353 | " self.embed_cool = nn.Embedding(n_classes_cool, embed_dim)\n",
354 | " \n",
355 | " self.linear = spectral_norm(nn.Linear(dim_z + (3 * embed_dim), 16 * self.ch * (self.bottom_width **2)), eps = 1e-4)\n",
356 | " \n",
357 | " self.blocks = nn.ModuleList([\n",
358 | " GeneratorResBlock(16*self.ch, 16*self.ch),\n",
359 | " GeneratorResBlock(16*self.ch, 16*self.ch, upsample = nn.Upsample(scale_factor = 2)),\n",
360 | " GeneratorResBlock(16*self.ch, 16*self.ch),\n",
361 | " GeneratorResBlock(16*self.ch, 8*self.ch, upsample = nn.Upsample(scale_factor = 2)),\n",
362 | " GeneratorResBlock(8*self.ch, 8*self.ch),\n",
363 | " GeneratorResBlock(8*self.ch, 8*self.ch, upsample = nn.Upsample(scale_factor = 2)),\n",
364 | " GeneratorResBlock(8*self.ch, 8*self.ch),\n",
365 | " GeneratorResBlock(8*self.ch, 4*self.ch, upsample = nn.Upsample(scale_factor = 2)),\n",
366 | " Self_Attn(4*self.ch),\n",
367 | " GeneratorResBlock(4*self.ch, 4*self.ch),\n",
368 | " GeneratorResBlock(4*self.ch, 2*self.ch, upsample = nn.Upsample(scale_factor = 2)),\n",
369 | " GeneratorResBlock(2*self.ch, 2*self.ch),\n",
370 | " GeneratorResBlock(2*self.ch, self.ch, upsample = nn.Upsample(scale_factor = 2))\n",
371 | " ])\n",
372 | " \n",
373 | " self.final_layer = nn.Sequential(\n",
374 | " nn.BatchNorm2d(self.ch),\n",
375 | " nn.ReLU(inplace = False),\n",
376 | " spectral_norm(nn.Conv2d(self.ch, self.img_channels, kernel_size = 3, padding = 1)),\n",
377 | " nn.Tanh()\n",
378 | " )\n",
379 | " \n",
380 | " self.init_weights()\n",
381 | " \n",
382 | " def init_weights(self):\n",
383 | " print(f\"Weight initialization : {self.init}\")\n",
384 | " self.param_count = 0\n",
385 | " for module in self.modules():\n",
386 | " if (isinstance(module, nn.Conv2d) or isinstance(module, nn.Linear) or isinstance(module, nn.Embedding)):\n",
387 | " if self.init == 'ortho':\n",
388 | " torch.nn.init.orthogonal_(module.weight)\n",
389 | " elif self.init == 'N02':\n",
390 | " torch.nn.init.normal_(module.weight, 0, 0.02)\n",
391 | " elif self.init in ['glorot', 'xavier']:\n",
392 | " torch.nn.init.xavier_uniform_(module.weight)\n",
393 | " else:\n",
394 | " print('Init style not recognized...')\n",
395 | " self.param_count += sum([p.data.nelement() for p in module.parameters()])\n",
396 | " print(\"Param count for G's initialized parameters: %d Million\" % (self.param_count/1000000))\n",
397 | " \n",
398 | " \n",
399 | " def forward(self,z , y_temp, y_time, y_cool):\n",
400 | " y_temp = self.embed_temp(y_temp)\n",
401 | " y_time = self.embed_time(y_time)\n",
402 | " y_cool = self.embed_cool(y_cool)\n",
403 | " z = torch.cat([z, y_temp, y_time, y_cool], 1) \n",
404 | " # First linear layer\n",
405 | " h = self.linear(z)\n",
406 | " # Reshape\n",
407 | " h = h.view(h.size(0), -1, self.bottom_width, self.bottom_width) \n",
408 | " # Loop over blocks\n",
409 | " for i, block in enumerate(self.blocks):\n",
410 | " if i != 8:\n",
411 | " h = block(h, z)\n",
412 | " else:\n",
413 | " h = block(h)\n",
414 | " # Apply batchnorm-relu-conv-tanh at output\n",
415 | " h = self.final_layer(h)\n",
416 | " return h"
417 | ]
418 | },
419 | {
420 | "cell_type": "markdown",
421 | "metadata": {
422 | "papermill": {
423 | "duration": 0.021752,
424 | "end_time": "2021-05-12T05:40:59.737083",
425 | "exception": false,
426 | "start_time": "2021-05-12T05:40:59.715331",
427 | "status": "completed"
428 | },
429 | "tags": []
430 | },
431 | "source": [
432 | "## Discriminator Resblock"
433 | ]
434 | },
435 | {
436 | "cell_type": "code",
437 | "execution_count": 7,
438 | "metadata": {
439 | "execution": {
440 | "iopub.execute_input": "2021-05-12T05:40:59.792117Z",
441 | "iopub.status.busy": "2021-05-12T05:40:59.791327Z",
442 | "iopub.status.idle": "2021-05-12T05:40:59.794226Z",
443 | "shell.execute_reply": "2021-05-12T05:40:59.793762Z"
444 | },
445 | "papermill": {
446 | "duration": 0.036436,
447 | "end_time": "2021-05-12T05:40:59.794341",
448 | "exception": false,
449 | "start_time": "2021-05-12T05:40:59.757905",
450 | "status": "completed"
451 | },
452 | "tags": []
453 | },
454 | "outputs": [],
455 | "source": [
456 | "class DiscriminatorResBlock(nn.Module):\n",
457 | " def __init__(self, in_channels, out_channels, preactivation=True, \n",
458 | " downsample=None,channel_ratio=4):\n",
459 | " super(DiscriminatorResBlock, self).__init__()\n",
460 | " self.in_channels, self.out_channels = in_channels, out_channels\n",
461 | " # If using wide D (as in SA-GAN and BigGAN), change the channel pattern\n",
462 | " self.hidden_channels = self.out_channels // channel_ratio\n",
463 | " self.preactivation = preactivation\n",
464 | " self.activation = nn.ReLU(inplace=False)\n",
465 | " self.downsample = downsample\n",
466 | " \n",
467 | " # Conv layers\n",
468 | " self.conv1 = spectral_norm(nn.Conv2d(self.in_channels, self.hidden_channels, \n",
469 | " kernel_size=1, padding=0), eps = 1e-4)\n",
470 | " self.conv2 = spectral_norm(nn.Conv2d(self.hidden_channels, self.hidden_channels, kernel_size = 3, padding = 1), eps = 1e-4)\n",
471 | " self.conv3 = spectral_norm(nn.Conv2d(self.hidden_channels, self.hidden_channels, kernel_size = 3, padding = 1), eps = 1e-4)\n",
472 | " self.conv4 = spectral_norm(nn.Conv2d(self.hidden_channels, self.out_channels, \n",
473 | " kernel_size=1, padding=0), eps = 1e-4)\n",
474 | " \n",
475 | " self.learnable_sc = True if (in_channels != out_channels) else False\n",
476 | " if self.learnable_sc:\n",
477 | " self.conv_sc = spectral_norm(nn.Conv2d(in_channels, out_channels - in_channels, \n",
478 | " kernel_size=1, padding=0), eps = 1e-4)\n",
479 | " \n",
480 | " def shortcut(self, x):\n",
481 | " if self.downsample:\n",
482 | " x = self.downsample(x)\n",
483 | " if self.learnable_sc:\n",
484 | " x = torch.cat([x, self.conv_sc(x)], 1) \n",
485 | " return x\n",
486 | " \n",
487 | " def forward(self, x):\n",
488 | " # 1x1 bottleneck conv\n",
489 | " h = self.conv1(F.relu(x))\n",
490 | " # 3x3 convs\n",
491 | " h = self.conv2(self.activation(h))\n",
492 | " h = self.conv3(self.activation(h))\n",
493 | " # relu before downsample\n",
494 | " h = self.activation(h)\n",
495 | " # downsample\n",
496 | " if self.downsample:\n",
497 | " h = self.downsample(h) \n",
498 | " # final 1x1 conv\n",
499 | " h = self.conv4(h)\n",
500 | " return h + self.shortcut(x)"
501 | ]
502 | },
503 | {
504 | "cell_type": "markdown",
505 | "metadata": {
506 | "papermill": {
507 | "duration": 0.020773,
508 | "end_time": "2021-05-12T05:40:59.836086",
509 | "exception": false,
510 | "start_time": "2021-05-12T05:40:59.815313",
511 | "status": "completed"
512 | },
513 | "tags": []
514 | },
515 | "source": [
516 | "## BigGAN-deep Discriminator\n",
517 | "The discriminator is modified to output a 21 dimensional vector and no class conditional information is provided"
518 | ]
519 | },
520 | {
521 | "cell_type": "code",
522 | "execution_count": 8,
523 | "metadata": {
524 | "execution": {
525 | "iopub.execute_input": "2021-05-12T05:40:59.892421Z",
526 | "iopub.status.busy": "2021-05-12T05:40:59.891385Z",
527 | "iopub.status.idle": "2021-05-12T05:40:59.896694Z",
528 | "shell.execute_reply": "2021-05-12T05:40:59.896271Z"
529 | },
530 | "papermill": {
531 | "duration": 0.039824,
532 | "end_time": "2021-05-12T05:40:59.896806",
533 | "exception": false,
534 | "start_time": "2021-05-12T05:40:59.856982",
535 | "status": "completed"
536 | },
537 | "tags": []
538 | },
539 | "outputs": [],
540 | "source": [
541 | "class Discriminator(nn.Module):\n",
542 | " def __init__(self, D_ch = 64, img_channels = 1, init = 'N02', n_classes_temp = 7, n_classes_time = 8, n_classes_cool = 4):\n",
543 | " super(Discriminator, self).__init__()\n",
544 | " self.ch = D_ch\n",
545 | " self.init = init\n",
546 | " self.img_channels = img_channels\n",
547 | " self.output_dim = n_classes_temp + n_classes_time + n_classes_cool + 2\n",
548 | " \n",
549 | " # Prepare model\n",
550 | " # Stem convolution\n",
551 | " self.input_conv = spectral_norm(nn.Conv2d(self.img_channels, self.ch, kernel_size = 3, padding = 1), eps = 1e-4)\n",
552 | " \n",
553 | " self.blocks = nn.Sequential(\n",
554 | " DiscriminatorResBlock(self.ch, 2*self.ch, downsample = nn.AvgPool2d(2)),\n",
555 | " DiscriminatorResBlock(2*self.ch, 2*self.ch),\n",
556 | " DiscriminatorResBlock(2*self.ch, 4*self.ch, downsample = nn.AvgPool2d(2)),\n",
557 | " DiscriminatorResBlock(4*self.ch, 4*self.ch),\n",
558 | " Self_Attn(4*self.ch),\n",
559 | " DiscriminatorResBlock(4*self.ch, 8*self.ch, downsample = nn.AvgPool2d(2)),\n",
560 | " DiscriminatorResBlock(8*self.ch, 8*self.ch),\n",
561 | " DiscriminatorResBlock(8*self.ch, 8*self.ch, downsample = nn.AvgPool2d(2)),\n",
562 | " DiscriminatorResBlock(8*self.ch, 8*self.ch),\n",
563 | " DiscriminatorResBlock(8*self.ch, 16*self.ch, downsample = nn.AvgPool2d(2)),\n",
564 | " DiscriminatorResBlock(16*self.ch, 16*self.ch),\n",
565 | " DiscriminatorResBlock(16*self.ch, 16*self.ch, downsample = nn.AvgPool2d(2)),\n",
566 | " DiscriminatorResBlock(16*self.ch, 16*self.ch),\n",
567 | " )\n",
568 | " # Linear output layer. The output dimension is typically 1, but may be\n",
569 | " # larger if we're e.g. turning this into a VAE with an inference output\n",
570 | " self.linear = spectral_norm(nn.Linear(16*self.ch, self.output_dim), eps = 1e-4)\n",
571 | " \n",
572 | " self.init_weights()\n",
573 | " \n",
574 | " def init_weights(self):\n",
575 | " print(f\"Weight initialization : {self.init}\")\n",
576 | " self.param_count = 0\n",
577 | " for module in self.modules():\n",
578 | " if (isinstance(module, nn.Conv2d) or isinstance(module, nn.Linear) or isinstance(module, nn.Embedding)):\n",
579 | " if self.init == 'ortho':\n",
580 | " torch.nn.init.orthogonal_(module.weight)\n",
581 | " elif self.init == 'N02':\n",
582 | " torch.nn.init.normal_(module.weight, 0, 0.02)\n",
583 | " elif self.init in ['glorot', 'xavier']:\n",
584 | " torch.nn.init.xavier_uniform_(module.weight)\n",
585 | " else:\n",
586 | " print('Init style not recognized...')\n",
587 | " self.param_count += sum([p.data.nelement() for p in module.parameters()])\n",
588 | " print(\"Param count for D's initialized parameters: %d Million\" % (self.param_count/1000000))\n",
589 | " \n",
590 | " def forward(self, x):\n",
591 | " # Run input conv\n",
592 | " h = self.input_conv(x)\n",
593 | " # Blocks\n",
594 | " h = self.blocks(h)\n",
595 | " # Apply global sum pooling as in SN-GAN\n",
596 | " h = torch.sum(nn.ReLU(inplace = False)(h), [2, 3])\n",
597 | " # Get initial class-unconditional output\n",
598 | " out = self.linear(h)\n",
599 | " # Get projection of final featureset onto class vectors and add to evidence\n",
600 | " #out = out + torch.sum(self.embed_temp(y_temp) * h, 1, keepdim=True) + torch.sum(self.embed_time(y_time) * h, 1, keepdim=True) + torch.sum(self.embed_cool(y_cool) * h, 1, keepdim=True)\n",
601 | " return out"
602 | ]
603 | },
604 | {
605 | "cell_type": "markdown",
606 | "metadata": {
607 | "papermill": {
608 | "duration": 0.020852,
609 | "end_time": "2021-05-12T05:40:59.938450",
610 | "exception": false,
611 | "start_time": "2021-05-12T05:40:59.917598",
612 | "status": "completed"
613 | },
614 | "tags": []
615 | },
616 | "source": [
617 | "## Differentiable Augmentation for GAN\n",
618 | "The implementation follows the Color-Translation-Cutout policy from this [paper](https://arxiv.org/pdf/2006.10738.pdf)"
619 | ]
620 | },
621 | {
622 | "cell_type": "code",
623 | "execution_count": 9,
624 | "metadata": {
625 | "execution": {
626 | "iopub.execute_input": "2021-05-12T05:41:00.003553Z",
627 | "iopub.status.busy": "2021-05-12T05:41:00.002673Z",
628 | "iopub.status.idle": "2021-05-12T05:41:00.005189Z",
629 | "shell.execute_reply": "2021-05-12T05:41:00.004788Z"
630 | },
631 | "papermill": {
632 | "duration": 0.045901,
633 | "end_time": "2021-05-12T05:41:00.005300",
634 | "exception": false,
635 | "start_time": "2021-05-12T05:40:59.959399",
636 | "status": "completed"
637 | },
638 | "tags": []
639 | },
640 | "outputs": [],
641 | "source": [
642 | "class DiffAugment:\n",
643 | " def __init__(self, policy='color,translation,cutout', channels_first=True):\n",
644 | " self.policy = policy\n",
645 | " print(f'Diff. Augment Policy : {policy}')\n",
646 | " self.channels_first = channels_first\n",
647 | " self.AUGMENT_FNS = {'color': [self.rand_brightness, self.rand_saturation, self.rand_contrast],\n",
648 | " 'translation': [self.rand_translation],\n",
649 | " 'cutout': [self.rand_cutout]}\n",
650 | " \n",
651 | " def __call__(self, x):\n",
652 | " if self.policy:\n",
653 | " if not self.channels_first:\n",
654 | " x = x.permute(0, 3, 1, 2)\n",
655 | " for p in self.policy.split(','):\n",
656 | " for f in self.AUGMENT_FNS[p]:\n",
657 | " x = f(x)\n",
658 | " if not self.channels_first:\n",
659 | " x = x.permute(0, 2, 3, 1)\n",
660 | " x = x.contiguous()\n",
661 | " return x\n",
662 | " \n",
663 | " \n",
664 | " def rand_brightness(self, x):\n",
665 | " x = x + (torch.rand(x.size(0), 1, 1, 1, dtype=x.dtype, device=x.device) - 0.5)\n",
666 | " return x\n",
667 | " \n",
668 | " def rand_saturation(self, x):\n",
669 | " x_mean = x.mean(dim=1, keepdim=True)\n",
670 | " x = (x - x_mean) * (torch.rand(x.size(0), 1, 1, 1, dtype=x.dtype, device=x.device) * 2) + x_mean\n",
671 | " return x\n",
672 | " \n",
673 | " def rand_contrast(self,x):\n",
674 | " x_mean = x.mean(dim=[1, 2, 3], keepdim=True)\n",
675 | " x = (x - x_mean) * (torch.rand(x.size(0), 1, 1, 1, dtype=x.dtype, device=x.device) + 0.5) + x_mean\n",
676 | " return x\n",
677 | " \n",
678 | " def rand_translation(self, x, ratio = 0.125):\n",
679 | " shift_x, shift_y = int(x.size(2) * ratio + 0.5), int(x.size(3) * ratio + 0.5)\n",
680 | " translation_x = torch.randint(-shift_x, shift_x + 1, size=[x.size(0), 1, 1], device=x.device)\n",
681 | " translation_y = torch.randint(-shift_y, shift_y + 1, size=[x.size(0), 1, 1], device=x.device)\n",
682 | " grid_batch, grid_x, grid_y = torch.meshgrid(\n",
683 | " torch.arange(x.size(0), dtype=torch.long, device=x.device),\n",
684 | " torch.arange(x.size(2), dtype=torch.long, device=x.device),\n",
685 | " torch.arange(x.size(3), dtype=torch.long, device=x.device),\n",
686 | " )\n",
687 | " grid_x = torch.clamp(grid_x + translation_x + 1, 0, x.size(2) + 1)\n",
688 | " grid_y = torch.clamp(grid_y + translation_y + 1, 0, x.size(3) + 1)\n",
689 | " x_pad = F.pad(x, [1, 1, 1, 1, 0, 0, 0, 0])\n",
690 | " x = x_pad.permute(0, 2, 3, 1).contiguous()[grid_batch, grid_x, grid_y].permute(0, 3, 1, 2)\n",
691 | " return x\n",
692 | " \n",
693 | " def rand_cutout(self, x, ratio=0.5):\n",
694 | " cutout_size = int(x.size(2) * ratio + 0.5), int(x.size(3) * ratio + 0.5)\n",
695 | " offset_x = torch.randint(0, x.size(2) + (1 - cutout_size[0] % 2), size=[x.size(0), 1, 1], device=x.device)\n",
696 | " offset_y = torch.randint(0, x.size(3) + (1 - cutout_size[1] % 2), size=[x.size(0), 1, 1], device=x.device)\n",
697 | " grid_batch, grid_x, grid_y = torch.meshgrid(\n",
698 | " torch.arange(x.size(0), dtype=torch.long, device=x.device),\n",
699 | " torch.arange(cutout_size[0], dtype=torch.long, device=x.device),\n",
700 | " torch.arange(cutout_size[1], dtype=torch.long, device=x.device),\n",
701 | " )\n",
702 | " grid_x = torch.clamp(grid_x + offset_x - cutout_size[0] // 2, min=0, max=x.size(2) - 1)\n",
703 | " grid_y = torch.clamp(grid_y + offset_y - cutout_size[1] // 2, min=0, max=x.size(3) - 1)\n",
704 | " mask = torch.ones(x.size(0), x.size(2), x.size(3), dtype=x.dtype, device=x.device)\n",
705 | " mask[grid_batch, grid_x, grid_y] = 0\n",
706 | " x = x * mask.unsqueeze(1)\n",
707 | " return x"
708 | ]
709 | },
710 | {
711 | "cell_type": "markdown",
712 | "metadata": {
713 | "papermill": {
714 | "duration": 0.020992,
715 | "end_time": "2021-05-12T05:41:00.047398",
716 | "exception": false,
717 | "start_time": "2021-05-12T05:41:00.026406",
718 | "status": "completed"
719 | },
720 | "tags": []
721 | },
722 | "source": [
723 | "## Custom sampler to balance the dataset "
724 | ]
725 | },
726 | {
727 | "cell_type": "code",
728 | "execution_count": 10,
729 | "metadata": {
730 | "execution": {
731 | "iopub.execute_input": "2021-05-12T05:41:00.099675Z",
732 | "iopub.status.busy": "2021-05-12T05:41:00.098826Z",
733 | "iopub.status.idle": "2021-05-12T05:41:00.101540Z",
734 | "shell.execute_reply": "2021-05-12T05:41:00.101057Z"
735 | },
736 | "papermill": {
737 | "duration": 0.033026,
738 | "end_time": "2021-05-12T05:41:00.101649",
739 | "exception": false,
740 | "start_time": "2021-05-12T05:41:00.068623",
741 | "status": "completed"
742 | },
743 | "tags": []
744 | },
745 | "outputs": [],
746 | "source": [
747 | "class ImbalancedDatasetSampler(torch.utils.data.sampler.Sampler):\n",
748 | " \"\"\"Samples elements randomly from a given list of indices for imbalanced dataset\n",
749 | " Arguments:\n",
750 | " indices (list, optional): a list of indices\n",
751 | " num_samples (int, optional): number of samples to draw\n",
752 | " callback_get_label func: a callback-like function which takes two arguments - dataset and index\n",
753 | " \"\"\"\n",
754 | " def __init__(self, dataset, indices=None, num_samples=None, callback_get_label=None):\n",
755 | " \n",
756 | " # if indices is not provided, \n",
757 | " # all elements in the dataset will be considered\n",
758 | " self.indices = list(range(len(dataset))) \\\n",
759 | " if indices is None else indices\n",
760 | " \n",
761 | " # define custom callback\n",
762 | " self.callback_get_label = callback_get_label\n",
763 | " \n",
764 | " # if num_samples is not provided, \n",
765 | " # draw `len(indices)` samples in each iteration\n",
766 | " self.num_samples = len(self.indices) \\\n",
767 | " if num_samples is None else num_samples\n",
768 | " \n",
769 | " # distribution of classes in the dataset for temp , time and cool \n",
770 | " label_to_count = {}\n",
771 | " for idx in self.indices:\n",
772 | " label = self._get_label(dataset, idx)\n",
773 | " if label in label_to_count:\n",
774 | " label_to_count[label] += 1\n",
775 | " else:\n",
776 | " label_to_count[label] = 1\n",
777 | " \n",
778 | " # weight for each sample\n",
779 | " weights = [1.0 / label_to_count[self._get_label(dataset, idx)]\n",
780 | " for idx in self.indices]\n",
781 | " weights = torch.DoubleTensor(weights)\n",
782 | " self.weights= weights\n",
783 | " \n",
784 | " def _get_label(self, dataset, idx):\n",
785 | " return dataset[idx][4]\n",
786 | " \n",
787 | " def __iter__(self):\n",
788 | " return (self.indices[i] for i in torch.multinomial(\n",
789 | " self.weights, self.num_samples, replacement=True))\n",
790 | " \n",
791 | " def __len__(self):\n",
792 | " return self.num_samples"
793 | ]
794 | },
795 | {
796 | "cell_type": "markdown",
797 | "metadata": {
798 | "papermill": {
799 | "duration": 0.021281,
800 | "end_time": "2021-05-12T05:41:00.143963",
801 | "exception": false,
802 | "start_time": "2021-05-12T05:41:00.122682",
803 | "status": "completed"
804 | },
805 | "tags": []
806 | },
807 | "source": [
808 | "## Custom dataset for UHCSDB"
809 | ]
810 | },
811 | {
812 | "cell_type": "code",
813 | "execution_count": 11,
814 | "metadata": {
815 | "execution": {
816 | "iopub.execute_input": "2021-05-12T05:41:00.197546Z",
817 | "iopub.status.busy": "2021-05-12T05:41:00.196765Z",
818 | "iopub.status.idle": "2021-05-12T05:41:00.199550Z",
819 | "shell.execute_reply": "2021-05-12T05:41:00.199131Z"
820 | },
821 | "papermill": {
822 | "duration": 0.034447,
823 | "end_time": "2021-05-12T05:41:00.199666",
824 | "exception": false,
825 | "start_time": "2021-05-12T05:41:00.165219",
826 | "status": "completed"
827 | },
828 | "tags": []
829 | },
830 | "outputs": [],
831 | "source": [
832 | "class MicrographDataset(Dataset):\n",
833 | " \"\"\"\n",
834 | " A custom Dataset class for Micrograph data which returns the following\n",
835 | " # Micrograph image\n",
836 | " # Inputs : Anneal Temperature , Anneal Time and Type of cooling used\n",
837 | " ------------------------------------------------------------------------------------\n",
838 | " Attributes\n",
839 | " \n",
840 | " df : pandas.core.frame.DataFrame\n",
841 | " A Dataframe that contains the proper entries (i.e. dataframe corresponding to new_metadata.xlsx)\n",
842 | " root_dir : str\n",
843 | " The path of the folder where the images are located\n",
844 | " transform : torchvision.transforms.transforms.Compose\n",
845 | " The transforms that are to be applied to the loaded images\n",
846 | " \"\"\"\n",
847 | " def __init__(self, df, root_dir, transform=None):\n",
848 | " self.df = df\n",
849 | " self.transform = transform\n",
850 | " self.root_dir = root_dir\n",
851 | " \n",
852 | " def __len__(self):\n",
853 | " return len(self.df) \n",
854 | " \n",
855 | " def __getitem__(self, idx):\n",
856 | " temp_dict = {970: 0, 800: 1, 900: 2, 1100: 3, 1000: 4, 700: 5, 750: 6}\n",
857 | " time_dict = {90: 0, 1440: 1, 180: 2, 5: 3, 480: 4, 5100: 5, 60: 6, 2880: 7}\n",
858 | " microconst_dict = {'spheroidite': 0, 'network' : 1,'spheroidite+widmanstatten' : 2, 'pearlite+spheroidite' : 3,\n",
859 | " 'pearlite' : 4,'pearlite+widmanstatten' : 5}\n",
860 | " cooling_dict = {'Q': 0, 'FC': 1, 'AR': 2, '650-1H': 3}\n",
861 | " row = self.df.loc[idx]\n",
862 | " img_name = row['path']\n",
863 | " img_path = self.root_dir + '/' + 'Cropped' + img_name\n",
864 | " anneal_temp = temp_dict[row['anneal_temperature']]\n",
865 | " if row['anneal_time_unit'] == 'H':\n",
866 | " anneal_time = int(row['anneal_time']) * 60\n",
867 | " else:\n",
868 | " anneal_time = row['anneal_time']\n",
869 | " anneal_time = time_dict[anneal_time]\n",
870 | " cooling_type = cooling_dict[row['cool_method']]\n",
871 | " microconst = microconst_dict[row['primary_microconstituent']]\n",
872 | " img = Image.open(img_path)\n",
873 | " img = img.convert('L')\n",
874 | " if self.transform:\n",
875 | " img = self.transform(img)\n",
876 | " return img , anneal_temp, anneal_time, cooling_type, microconst"
877 | ]
878 | },
879 | {
880 | "cell_type": "markdown",
881 | "metadata": {
882 | "papermill": {
883 | "duration": 0.022176,
884 | "end_time": "2021-05-12T05:41:00.244556",
885 | "exception": false,
886 | "start_time": "2021-05-12T05:41:00.222380",
887 | "status": "completed"
888 | },
889 | "tags": []
890 | },
891 | "source": [
892 | "## Lightining Module for GAN "
893 | ]
894 | },
895 | {
896 | "cell_type": "code",
897 | "execution_count": 12,
898 | "metadata": {
899 | "execution": {
900 | "iopub.execute_input": "2021-05-12T05:41:00.291050Z",
901 | "iopub.status.busy": "2021-05-12T05:41:00.290171Z",
902 | "iopub.status.idle": "2021-05-12T05:41:00.320279Z",
903 | "shell.execute_reply": "2021-05-12T05:41:00.319873Z"
904 | },
905 | "papermill": {
906 | "duration": 0.054443,
907 | "end_time": "2021-05-12T05:41:00.320388",
908 | "exception": false,
909 | "start_time": "2021-05-12T05:41:00.265945",
910 | "status": "completed"
911 | },
912 | "tags": []
913 | },
914 | "outputs": [],
915 | "source": [
916 | "class MicrographBigGAN(pl.LightningModule):\n",
917 | " def __init__(self, root_dir, df_dir, batch_size, augment_bool = True, lr = 0.0002,\n",
918 | " n_classes_temp = 7, n_classes_time = 8, n_classes_cool = 4):\n",
919 | " super().__init__()\n",
920 | " self.save_hyperparameters()\n",
921 | " self.root_dir = root_dir\n",
922 | " self.df_dir = df_dir\n",
923 | " self.generator = Generator(G_ch = 64)\n",
924 | " self.discriminator = Discriminator(D_ch = 64)\n",
925 | " self.diffaugment = DiffAugment()\n",
926 | " self.augment_bool = augment_bool\n",
927 | " self.batch_size = batch_size \n",
928 | " self.lr = lr\n",
929 | " self.n_classes_temp = n_classes_temp\n",
930 | " self.n_classes_time = n_classes_time\n",
931 | " self.n_classes_cool = n_classes_cool\n",
932 | " \n",
933 | " def forward(self, z, y_temp, y_time, y_cool):\n",
934 | " return self.generator(z, y_temp, y_time, y_cool)\n",
935 | " \n",
936 | " def multilabel_categorical_crossentropy(self, y_true, y_pred, margin=0., gamma=1.):\n",
937 | " \"\"\" y_true: positive=1, negative=0, ignore=-1\n",
938 | " \"\"\"\n",
939 | " y_true = y_true.clamp(-1, 1)\n",
940 | " if len(y_pred.shape) > 2:\n",
941 | " y_true = y_true.view(y_true.shape[0], 1, 1, -1)\n",
942 | " _, _, h, w = y_pred.shape\n",
943 | " y_true = y_true.expand(-1, h, w, -1)\n",
944 | " y_pred = y_pred.permute(0, 2, 3, 1)\n",
945 | "\n",
946 | " y_pred = y_pred + margin\n",
947 | " y_pred = y_pred * gamma\n",
948 | "\n",
949 | " y_pred[y_true == 1] = -1 * y_pred[y_true == 1]\n",
950 | " y_pred[y_true == -1] = -1e12\n",
951 | "\n",
952 | " y_pred_neg = y_pred.clone()\n",
953 | " y_pred_neg[y_true == 1] = -1e12\n",
954 | "\n",
955 | " y_pred_pos = y_pred.clone()\n",
956 | " y_pred_pos[y_true == 0] = -1e12\n",
957 | "\n",
958 | " zeros = torch.zeros_like(y_pred[..., :1])\n",
959 | " y_pred_neg = torch.cat([y_pred_neg, zeros], dim=-1)\n",
960 | " y_pred_pos = torch.cat([y_pred_pos, zeros], dim=-1)\n",
961 | " neg_loss = torch.logsumexp(y_pred_neg, dim=-1)\n",
962 | " pos_loss = torch.logsumexp(y_pred_pos, dim=-1)\n",
963 | " return neg_loss + pos_loss\n",
964 | " \n",
965 | " def Omni_Dloss(self,disc_real, disc_fake, y_temp_real, y_time_real, y_cool_real):\n",
966 | " b = y_temp_real.shape[0]\n",
967 | " y_temp = F.one_hot(y_temp_real, num_classes = self.n_classes_temp).to(self.device)\n",
968 | " y_time = F.one_hot(y_time_real, num_classes = self.n_classes_time).to(self.device)\n",
969 | " y_cool = F.one_hot(y_cool_real, num_classes = self.n_classes_cool).to(self.device)\n",
970 | " y_real = torch.cat([y_temp,y_time,y_cool,torch.tensor([1,0]).repeat(b,1).to(self.device)],1).float()\n",
971 | " y_real.requires_grad = True\n",
972 | " y_fake = torch.cat([torch.zeros((b, self.n_classes_temp + self.n_classes_time + self.n_classes_cool)),torch.tensor([0,1]).repeat(b,1)],1).float().to(self.device)\n",
973 | " y_fake.requires_grad = True\n",
974 | " d_loss_real = self.multilabel_categorical_crossentropy(y_true = y_real, y_pred = disc_real)\n",
975 | " d_loss_fake = self.multilabel_categorical_crossentropy(y_true = y_fake, y_pred = disc_fake)\n",
976 | " d_loss = d_loss_real.mean() + d_loss_fake.mean()\n",
977 | " return d_loss\n",
978 | " \n",
979 | " def Omni_Gloss(self, disc_fake, y_temp_fake, y_time_fake, y_cool_fake):\n",
980 | " b = y_temp_fake.shape[0]\n",
981 | " y_temp = F.one_hot(y_temp_fake, num_classes = self.n_classes_temp).to(self.device)\n",
982 | " y_time = F.one_hot(y_time_fake, num_classes = self.n_classes_time).to(self.device)\n",
983 | " y_cool = F.one_hot(y_cool_fake, num_classes = self.n_classes_cool).to(self.device)\n",
984 | " y_fake_g = torch.cat([y_temp,y_time,y_cool,torch.tensor([1,0]).repeat(b,1).to(self.device)],1).float()\n",
985 | " y_fake_g.requires_grad = True\n",
986 | " g_loss = self.multilabel_categorical_crossentropy(y_true = y_fake_g, y_pred = disc_fake)\n",
987 | " return g_loss.mean()\n",
988 | " \n",
989 | " def training_step(self, batch, batch_idx, optimizer_idx):\n",
990 | " real, y_temp_real, y_time_real, y_cool_real , _ = batch\n",
991 | " z = torch.randn(real.shape[0], 384)\n",
992 | " z = z.type_as(real)\n",
993 | " y_temp_fake = torch.randint(self.n_classes_temp,(real.shape[0],)).to(self.device)\n",
994 | " y_time_fake = torch.randint(self.n_classes_time,(real.shape[0],)).to(self.device)\n",
995 | " y_cool_fake = torch.randint(self.n_classes_cool,(real.shape[0],)).to(self.device)\n",
996 | " \n",
997 | " if optimizer_idx == 0:\n",
998 | " fake = self(z, y_temp_fake, y_time_fake, y_cool_fake)\n",
999 | " \n",
1000 | " if self.augment_bool:\n",
1001 | " disc_real = self.discriminator(self.diffaugment(real))\n",
1002 | " disc_fake = self.discriminator(self.diffaugment(fake))\n",
1003 | " else:\n",
1004 | " disc_real = self.discriminator(real)\n",
1005 | " disc_fake = self.discriminator(fake)\n",
1006 | " d_loss = self.Omni_Dloss(disc_real, disc_fake, y_temp_real, y_time_real, y_cool_real)\n",
1007 | " #print(d_loss.requires_grad)\n",
1008 | " tqdm_dict = {'d_loss': d_loss}\n",
1009 | " output = OrderedDict({\n",
1010 | " 'loss': d_loss,\n",
1011 | " 'progress_bar': tqdm_dict,\n",
1012 | " 'log': tqdm_dict\n",
1013 | " })\n",
1014 | " return output\n",
1015 | " \n",
1016 | " if optimizer_idx == 1:\n",
1017 | " fake = self(z,y_temp_fake, y_time_fake, y_cool_fake)\n",
1018 | " if self.augment_bool:\n",
1019 | " disc_fake = self.discriminator(self.diffaugment(fake))\n",
1020 | " else:\n",
1021 | " disc_fake = self.discriminator(fake)\n",
1022 | " g_loss = self.Omni_Gloss(disc_fake, y_temp_fake, y_time_fake, y_cool_fake)\n",
1023 | " #print(g_loss.requires_grad)\n",
1024 | " tqdm_dict = {'g_loss': g_loss}\n",
1025 | " output = OrderedDict({\n",
1026 | " 'loss': g_loss,\n",
1027 | " 'progress_bar': tqdm_dict,\n",
1028 | " 'log': tqdm_dict\n",
1029 | " })\n",
1030 | " return output\n",
1031 | " \n",
1032 | " def configure_optimizers(self):\n",
1033 | " opt_g = optim.Adam(self.generator.parameters(), lr = self.lr, weight_decay = 0.001)\n",
1034 | " opt_d = optim.Adam(self.discriminator.parameters(), lr = self.lr, weight_decay = 0.0005)\n",
1035 | " return (\n",
1036 | " {'optimizer': opt_d, 'frequency': 4},\n",
1037 | " {'optimizer': opt_g, 'frequency': 1}\n",
1038 | " )\n",
1039 | " \n",
1040 | " def train_dataloader(self):\n",
1041 | " img_transforms = transforms.Compose([\n",
1042 | " transforms.RandomCrop(256),\n",
1043 | " transforms.RandomHorizontalFlip(p=0.5),\n",
1044 | " transforms.RandomVerticalFlip(p=0.5),\n",
1045 | " transforms.Resize([256, 256]),\n",
1046 | " transforms.ToTensor(),\n",
1047 | " transforms.Normalize([0.5 for _ in range(1)],[0.5 for _ in range(1)]),\n",
1048 | " ])\n",
1049 | " df = pd.read_excel(self.df_dir,engine = 'openpyxl')\n",
1050 | " dataset = MicrographDataset(df,self.root_dir,transform = img_transforms)\n",
1051 | " return DataLoader(dataset, sampler = ImbalancedDatasetSampler(dataset), \n",
1052 | " batch_size=self.batch_size,shuffle=False)"
1053 | ]
1054 | },
1055 | {
1056 | "cell_type": "code",
1057 | "execution_count": 13,
1058 | "metadata": {
1059 | "execution": {
1060 | "iopub.execute_input": "2021-05-12T05:41:00.367953Z",
1061 | "iopub.status.busy": "2021-05-12T05:41:00.367205Z",
1062 | "iopub.status.idle": "2021-05-12T05:41:00.369515Z",
1063 | "shell.execute_reply": "2021-05-12T05:41:00.369901Z"
1064 | },
1065 | "papermill": {
1066 | "duration": 0.027684,
1067 | "end_time": "2021-05-12T05:41:00.370032",
1068 | "exception": false,
1069 | "start_time": "2021-05-12T05:41:00.342348",
1070 | "status": "completed"
1071 | },
1072 | "tags": []
1073 | },
1074 | "outputs": [],
1075 | "source": [
1076 | "ROOT_DIR = '../input/highcarbon-micrographs/For Training/Cropped'\n",
1077 | "DF_DIR = '../input/highcarbon-micrographs/new_metadata.xlsx'"
1078 | ]
1079 | },
1080 | {
1081 | "cell_type": "code",
1082 | "execution_count": 14,
1083 | "metadata": {
1084 | "execution": {
1085 | "iopub.execute_input": "2021-05-12T05:41:00.417973Z",
1086 | "iopub.status.busy": "2021-05-12T05:41:00.417450Z",
1087 | "iopub.status.idle": "2021-05-12T05:41:01.386394Z",
1088 | "shell.execute_reply": "2021-05-12T05:41:01.386953Z"
1089 | },
1090 | "papermill": {
1091 | "duration": 0.995368,
1092 | "end_time": "2021-05-12T05:41:01.387148",
1093 | "exception": false,
1094 | "start_time": "2021-05-12T05:41:00.391780",
1095 | "status": "completed"
1096 | },
1097 | "tags": []
1098 | },
1099 | "outputs": [
1100 | {
1101 | "name": "stdout",
1102 | "output_type": "stream",
1103 | "text": [
1104 | "Weight initialization : N02\n",
1105 | "Param count for G's initialized parameters: 39 Million\n",
1106 | "Weight initialization : N02\n",
1107 | "Param count for D's initialized parameters: 9 Million\n",
1108 | "Diff. Augment Policy : color,translation,cutout\n"
1109 | ]
1110 | }
1111 | ],
1112 | "source": [
1113 | "gan = MicrographBigGAN(ROOT_DIR,DF_DIR,batch_size=12)"
1114 | ]
1115 | },
1116 | {
1117 | "cell_type": "code",
1118 | "execution_count": 15,
1119 | "metadata": {
1120 | "execution": {
1121 | "iopub.execute_input": "2021-05-12T05:41:01.507288Z",
1122 | "iopub.status.busy": "2021-05-12T05:41:01.506408Z",
1123 | "iopub.status.idle": "2021-05-12T05:41:01.510356Z",
1124 | "shell.execute_reply": "2021-05-12T05:41:01.510902Z"
1125 | },
1126 | "papermill": {
1127 | "duration": 0.100204,
1128 | "end_time": "2021-05-12T05:41:01.511052",
1129 | "exception": false,
1130 | "start_time": "2021-05-12T05:41:01.410848",
1131 | "status": "completed"
1132 | },
1133 | "tags": []
1134 | },
1135 | "outputs": [],
1136 | "source": [
1137 | "trainer = pl.Trainer(max_epochs=600, gpus=1 if torch.cuda.is_available() else 0, accumulate_grad_batches=8)"
1138 | ]
1139 | },
1140 | {
1141 | "cell_type": "code",
1142 | "execution_count": 16,
1143 | "metadata": {
1144 | "execution": {
1145 | "iopub.execute_input": "2021-05-12T05:41:01.569751Z",
1146 | "iopub.status.busy": "2021-05-12T05:41:01.569230Z",
1147 | "iopub.status.idle": "2021-05-12T13:02:06.697914Z",
1148 | "shell.execute_reply": "2021-05-12T13:02:06.698424Z"
1149 | },
1150 | "papermill": {
1151 | "duration": 26465.164828,
1152 | "end_time": "2021-05-12T13:02:06.698628",
1153 | "exception": false,
1154 | "start_time": "2021-05-12T05:41:01.533800",
1155 | "status": "completed"
1156 | },
1157 | "tags": []
1158 | },
1159 | "outputs": [
1160 | {
1161 | "data": {
1162 | "application/vnd.jupyter.widget-view+json": {
1163 | "model_id": "b42a2f5cf39d48c385105398a2096934",
1164 | "version_major": 2,
1165 | "version_minor": 0
1166 | },
1167 | "text/plain": [
1168 | "Training: 0it [00:00, ?it/s]"
1169 | ]
1170 | },
1171 | "metadata": {},
1172 | "output_type": "display_data"
1173 | },
1174 | {
1175 | "data": {
1176 | "text/plain": [
1177 | "1"
1178 | ]
1179 | },
1180 | "execution_count": 16,
1181 | "metadata": {},
1182 | "output_type": "execute_result"
1183 | }
1184 | ],
1185 | "source": [
1186 | "trainer.fit(gan)"
1187 | ]
1188 | },
1189 | {
1190 | "cell_type": "code",
1191 | "execution_count": 17,
1192 | "metadata": {
1193 | "execution": {
1194 | "iopub.execute_input": "2021-05-12T13:02:06.795159Z",
1195 | "iopub.status.busy": "2021-05-12T13:02:06.750611Z",
1196 | "iopub.status.idle": "2021-05-12T13:02:08.948957Z",
1197 | "shell.execute_reply": "2021-05-12T13:02:08.949777Z"
1198 | },
1199 | "papermill": {
1200 | "duration": 2.226897,
1201 | "end_time": "2021-05-12T13:02:08.950022",
1202 | "exception": false,
1203 | "start_time": "2021-05-12T13:02:06.723125",
1204 | "status": "completed"
1205 | },
1206 | "tags": []
1207 | },
1208 | "outputs": [],
1209 | "source": [
1210 | "trainer.save_checkpoint(\"MicroGAN_checkpoint.ckpt\")"
1211 | ]
1212 | },
1213 | {
1214 | "cell_type": "markdown",
1215 | "metadata": {
1216 | "papermill": {
1217 | "duration": 0.040859,
1218 | "end_time": "2021-05-12T13:02:09.052123",
1219 | "exception": false,
1220 | "start_time": "2021-05-12T13:02:09.011264",
1221 | "status": "completed"
1222 | },
1223 | "tags": []
1224 | },
1225 | "source": [
1226 | "## For resuming the training \n",
1227 | "Add the saved checkpoint to the highcarbon-micrographs directory and then resume training. "
1228 | ]
1229 | },
1230 | {
1231 | "cell_type": "markdown",
1232 | "metadata": {
1233 | "papermill": {
1234 | "duration": 0.031489,
1235 | "end_time": "2021-05-12T13:02:09.132971",
1236 | "exception": false,
1237 | "start_time": "2021-05-12T13:02:09.101482",
1238 | "status": "completed"
1239 | },
1240 | "tags": []
1241 | },
1242 | "source": [
1243 | "new_gan = MicrographBigGAN.load_from_checkpoint(checkpoint_path=\"../input/microstrcuture-biggan-gpu/MicroGAN_checkpoint.ckpt\")"
1244 | ]
1245 | },
1246 | {
1247 | "cell_type": "markdown",
1248 | "metadata": {
1249 | "papermill": {
1250 | "duration": 0.022949,
1251 | "end_time": "2021-05-12T13:02:09.180732",
1252 | "exception": false,
1253 | "start_time": "2021-05-12T13:02:09.157783",
1254 | "status": "completed"
1255 | },
1256 | "tags": []
1257 | },
1258 | "source": [
1259 | "torch.save(new_gan.generator.state_dict(), 'BigGAN-deep.pth')"
1260 | ]
1261 | },
1262 | {
1263 | "cell_type": "markdown",
1264 | "metadata": {
1265 | "papermill": {
1266 | "duration": 0.023118,
1267 | "end_time": "2021-05-12T13:02:09.227021",
1268 | "exception": false,
1269 | "start_time": "2021-05-12T13:02:09.203903",
1270 | "status": "completed"
1271 | },
1272 | "tags": []
1273 | },
1274 | "source": [
1275 | "trainer = Trainer(resume_from_checkpoint='../input/highcarbon-micrographs/MicroGAN_checkpoint.ckpt')"
1276 | ]
1277 | },
1278 | {
1279 | "cell_type": "markdown",
1280 | "metadata": {
1281 | "papermill": {
1282 | "duration": 0.023173,
1283 | "end_time": "2021-05-12T13:02:09.274088",
1284 | "exception": false,
1285 | "start_time": "2021-05-12T13:02:09.250915",
1286 | "status": "completed"
1287 | },
1288 | "tags": []
1289 | },
1290 | "source": [
1291 | "trainer.fit(gan)"
1292 | ]
1293 | },
1294 | {
1295 | "cell_type": "code",
1296 | "execution_count": 18,
1297 | "metadata": {
1298 | "execution": {
1299 | "iopub.execute_input": "2021-05-12T13:02:09.325209Z",
1300 | "iopub.status.busy": "2021-05-12T13:02:09.324445Z",
1301 | "iopub.status.idle": "2021-05-12T13:02:09.593620Z",
1302 | "shell.execute_reply": "2021-05-12T13:02:09.594400Z"
1303 | },
1304 | "papermill": {
1305 | "duration": 0.297594,
1306 | "end_time": "2021-05-12T13:02:09.594673",
1307 | "exception": false,
1308 | "start_time": "2021-05-12T13:02:09.297079",
1309 | "status": "completed"
1310 | },
1311 | "tags": []
1312 | },
1313 | "outputs": [],
1314 | "source": [
1315 | "torch.save(gan.generator.state_dict(), 'BigGAN-deep.pth')"
1316 | ]
1317 | },
1318 | {
1319 | "cell_type": "code",
1320 | "execution_count": null,
1321 | "metadata": {
1322 | "papermill": {
1323 | "duration": 0.040898,
1324 | "end_time": "2021-05-12T13:02:09.695758",
1325 | "exception": false,
1326 | "start_time": "2021-05-12T13:02:09.654860",
1327 | "status": "completed"
1328 | },
1329 | "tags": []
1330 | },
1331 | "outputs": [],
1332 | "source": []
1333 | }
1334 | ],
1335 | "metadata": {
1336 | "kernelspec": {
1337 | "display_name": "Python 3",
1338 | "language": "python",
1339 | "name": "python3"
1340 | },
1341 | "language_info": {
1342 | "codemirror_mode": {
1343 | "name": "ipython",
1344 | "version": 3
1345 | },
1346 | "file_extension": ".py",
1347 | "mimetype": "text/x-python",
1348 | "name": "python",
1349 | "nbconvert_exporter": "python",
1350 | "pygments_lexer": "ipython3",
1351 | "version": "3.8.3"
1352 | },
1353 | "papermill": {
1354 | "default_parameters": {},
1355 | "duration": 26490.991864,
1356 | "end_time": "2021-05-12T13:02:12.461219",
1357 | "environment_variables": {},
1358 | "exception": null,
1359 | "input_path": "__notebook__.ipynb",
1360 | "output_path": "__notebook__.ipynb",
1361 | "parameters": {},
1362 | "start_time": "2021-05-12T05:40:41.469355",
1363 | "version": "2.3.3"
1364 | },
1365 | "widgets": {
1366 | "application/vnd.jupyter.widget-state+json": {
1367 | "state": {
1368 | "03955165e0e645319087ded469df198a": {
1369 | "model_module": "@jupyter-widgets/controls",
1370 | "model_module_version": "1.5.0",
1371 | "model_name": "ProgressStyleModel",
1372 | "state": {
1373 | "_model_module": "@jupyter-widgets/controls",
1374 | "_model_module_version": "1.5.0",
1375 | "_model_name": "ProgressStyleModel",
1376 | "_view_count": null,
1377 | "_view_module": "@jupyter-widgets/base",
1378 | "_view_module_version": "1.2.0",
1379 | "_view_name": "StyleView",
1380 | "bar_color": null,
1381 | "description_width": ""
1382 | }
1383 | },
1384 | "0a89a9c11093488180b029036a173df3": {
1385 | "model_module": "@jupyter-widgets/base",
1386 | "model_module_version": "1.2.0",
1387 | "model_name": "LayoutModel",
1388 | "state": {
1389 | "_model_module": "@jupyter-widgets/base",
1390 | "_model_module_version": "1.2.0",
1391 | "_model_name": "LayoutModel",
1392 | "_view_count": null,
1393 | "_view_module": "@jupyter-widgets/base",
1394 | "_view_module_version": "1.2.0",
1395 | "_view_name": "LayoutView",
1396 | "align_content": null,
1397 | "align_items": null,
1398 | "align_self": null,
1399 | "border": null,
1400 | "bottom": null,
1401 | "display": null,
1402 | "flex": null,
1403 | "flex_flow": null,
1404 | "grid_area": null,
1405 | "grid_auto_columns": null,
1406 | "grid_auto_flow": null,
1407 | "grid_auto_rows": null,
1408 | "grid_column": null,
1409 | "grid_gap": null,
1410 | "grid_row": null,
1411 | "grid_template_areas": null,
1412 | "grid_template_columns": null,
1413 | "grid_template_rows": null,
1414 | "height": null,
1415 | "justify_content": null,
1416 | "justify_items": null,
1417 | "left": null,
1418 | "margin": null,
1419 | "max_height": null,
1420 | "max_width": null,
1421 | "min_height": null,
1422 | "min_width": null,
1423 | "object_fit": null,
1424 | "object_position": null,
1425 | "order": null,
1426 | "overflow": null,
1427 | "overflow_x": null,
1428 | "overflow_y": null,
1429 | "padding": null,
1430 | "right": null,
1431 | "top": null,
1432 | "visibility": null,
1433 | "width": null
1434 | }
1435 | },
1436 | "207fc2d55d314763a543f4084c038f13": {
1437 | "model_module": "@jupyter-widgets/controls",
1438 | "model_module_version": "1.5.0",
1439 | "model_name": "HTMLModel",
1440 | "state": {
1441 | "_dom_classes": [],
1442 | "_model_module": "@jupyter-widgets/controls",
1443 | "_model_module_version": "1.5.0",
1444 | "_model_name": "HTMLModel",
1445 | "_view_count": null,
1446 | "_view_module": "@jupyter-widgets/controls",
1447 | "_view_module_version": "1.5.0",
1448 | "_view_name": "HTMLView",
1449 | "description": "",
1450 | "description_tooltip": null,
1451 | "layout": "IPY_MODEL_0a89a9c11093488180b029036a173df3",
1452 | "placeholder": "",
1453 | "style": "IPY_MODEL_91beed9008f34128ad4e23f0842758c7",
1454 | "value": " 50/50 [00:43<00:00, 1.14it/s, loss=5.77, v_num=0, d_loss=5.690, g_loss=6.650]"
1455 | }
1456 | },
1457 | "33fc35e21b5c4bacb6fbc4ab0aff8ce1": {
1458 | "model_module": "@jupyter-widgets/base",
1459 | "model_module_version": "1.2.0",
1460 | "model_name": "LayoutModel",
1461 | "state": {
1462 | "_model_module": "@jupyter-widgets/base",
1463 | "_model_module_version": "1.2.0",
1464 | "_model_name": "LayoutModel",
1465 | "_view_count": null,
1466 | "_view_module": "@jupyter-widgets/base",
1467 | "_view_module_version": "1.2.0",
1468 | "_view_name": "LayoutView",
1469 | "align_content": null,
1470 | "align_items": null,
1471 | "align_self": null,
1472 | "border": null,
1473 | "bottom": null,
1474 | "display": "inline-flex",
1475 | "flex": null,
1476 | "flex_flow": "row wrap",
1477 | "grid_area": null,
1478 | "grid_auto_columns": null,
1479 | "grid_auto_flow": null,
1480 | "grid_auto_rows": null,
1481 | "grid_column": null,
1482 | "grid_gap": null,
1483 | "grid_row": null,
1484 | "grid_template_areas": null,
1485 | "grid_template_columns": null,
1486 | "grid_template_rows": null,
1487 | "height": null,
1488 | "justify_content": null,
1489 | "justify_items": null,
1490 | "left": null,
1491 | "margin": null,
1492 | "max_height": null,
1493 | "max_width": null,
1494 | "min_height": null,
1495 | "min_width": null,
1496 | "object_fit": null,
1497 | "object_position": null,
1498 | "order": null,
1499 | "overflow": null,
1500 | "overflow_x": null,
1501 | "overflow_y": null,
1502 | "padding": null,
1503 | "right": null,
1504 | "top": null,
1505 | "visibility": null,
1506 | "width": "100%"
1507 | }
1508 | },
1509 | "4cc96cb6859640239a3f434bf7cc5402": {
1510 | "model_module": "@jupyter-widgets/controls",
1511 | "model_module_version": "1.5.0",
1512 | "model_name": "DescriptionStyleModel",
1513 | "state": {
1514 | "_model_module": "@jupyter-widgets/controls",
1515 | "_model_module_version": "1.5.0",
1516 | "_model_name": "DescriptionStyleModel",
1517 | "_view_count": null,
1518 | "_view_module": "@jupyter-widgets/base",
1519 | "_view_module_version": "1.2.0",
1520 | "_view_name": "StyleView",
1521 | "description_width": ""
1522 | }
1523 | },
1524 | "885f59260c8d4342a6c103b02963fa79": {
1525 | "model_module": "@jupyter-widgets/controls",
1526 | "model_module_version": "1.5.0",
1527 | "model_name": "FloatProgressModel",
1528 | "state": {
1529 | "_dom_classes": [],
1530 | "_model_module": "@jupyter-widgets/controls",
1531 | "_model_module_version": "1.5.0",
1532 | "_model_name": "FloatProgressModel",
1533 | "_view_count": null,
1534 | "_view_module": "@jupyter-widgets/controls",
1535 | "_view_module_version": "1.5.0",
1536 | "_view_name": "ProgressView",
1537 | "bar_style": "success",
1538 | "description": "",
1539 | "description_tooltip": null,
1540 | "layout": "IPY_MODEL_8f7728ba242f48b2b3aadf3a833eb75a",
1541 | "max": 50,
1542 | "min": 0,
1543 | "orientation": "horizontal",
1544 | "style": "IPY_MODEL_03955165e0e645319087ded469df198a",
1545 | "value": 50
1546 | }
1547 | },
1548 | "8f7728ba242f48b2b3aadf3a833eb75a": {
1549 | "model_module": "@jupyter-widgets/base",
1550 | "model_module_version": "1.2.0",
1551 | "model_name": "LayoutModel",
1552 | "state": {
1553 | "_model_module": "@jupyter-widgets/base",
1554 | "_model_module_version": "1.2.0",
1555 | "_model_name": "LayoutModel",
1556 | "_view_count": null,
1557 | "_view_module": "@jupyter-widgets/base",
1558 | "_view_module_version": "1.2.0",
1559 | "_view_name": "LayoutView",
1560 | "align_content": null,
1561 | "align_items": null,
1562 | "align_self": null,
1563 | "border": null,
1564 | "bottom": null,
1565 | "display": null,
1566 | "flex": "2",
1567 | "flex_flow": null,
1568 | "grid_area": null,
1569 | "grid_auto_columns": null,
1570 | "grid_auto_flow": null,
1571 | "grid_auto_rows": null,
1572 | "grid_column": null,
1573 | "grid_gap": null,
1574 | "grid_row": null,
1575 | "grid_template_areas": null,
1576 | "grid_template_columns": null,
1577 | "grid_template_rows": null,
1578 | "height": null,
1579 | "justify_content": null,
1580 | "justify_items": null,
1581 | "left": null,
1582 | "margin": null,
1583 | "max_height": null,
1584 | "max_width": null,
1585 | "min_height": null,
1586 | "min_width": null,
1587 | "object_fit": null,
1588 | "object_position": null,
1589 | "order": null,
1590 | "overflow": null,
1591 | "overflow_x": null,
1592 | "overflow_y": null,
1593 | "padding": null,
1594 | "right": null,
1595 | "top": null,
1596 | "visibility": null,
1597 | "width": null
1598 | }
1599 | },
1600 | "91beed9008f34128ad4e23f0842758c7": {
1601 | "model_module": "@jupyter-widgets/controls",
1602 | "model_module_version": "1.5.0",
1603 | "model_name": "DescriptionStyleModel",
1604 | "state": {
1605 | "_model_module": "@jupyter-widgets/controls",
1606 | "_model_module_version": "1.5.0",
1607 | "_model_name": "DescriptionStyleModel",
1608 | "_view_count": null,
1609 | "_view_module": "@jupyter-widgets/base",
1610 | "_view_module_version": "1.2.0",
1611 | "_view_name": "StyleView",
1612 | "description_width": ""
1613 | }
1614 | },
1615 | "b42a2f5cf39d48c385105398a2096934": {
1616 | "model_module": "@jupyter-widgets/controls",
1617 | "model_module_version": "1.5.0",
1618 | "model_name": "HBoxModel",
1619 | "state": {
1620 | "_dom_classes": [],
1621 | "_model_module": "@jupyter-widgets/controls",
1622 | "_model_module_version": "1.5.0",
1623 | "_model_name": "HBoxModel",
1624 | "_view_count": null,
1625 | "_view_module": "@jupyter-widgets/controls",
1626 | "_view_module_version": "1.5.0",
1627 | "_view_name": "HBoxView",
1628 | "box_style": "",
1629 | "children": [
1630 | "IPY_MODEL_c296a4a6337e482591115a2cae9bcab9",
1631 | "IPY_MODEL_885f59260c8d4342a6c103b02963fa79",
1632 | "IPY_MODEL_207fc2d55d314763a543f4084c038f13"
1633 | ],
1634 | "layout": "IPY_MODEL_33fc35e21b5c4bacb6fbc4ab0aff8ce1"
1635 | }
1636 | },
1637 | "c296a4a6337e482591115a2cae9bcab9": {
1638 | "model_module": "@jupyter-widgets/controls",
1639 | "model_module_version": "1.5.0",
1640 | "model_name": "HTMLModel",
1641 | "state": {
1642 | "_dom_classes": [],
1643 | "_model_module": "@jupyter-widgets/controls",
1644 | "_model_module_version": "1.5.0",
1645 | "_model_name": "HTMLModel",
1646 | "_view_count": null,
1647 | "_view_module": "@jupyter-widgets/controls",
1648 | "_view_module_version": "1.5.0",
1649 | "_view_name": "HTMLView",
1650 | "description": "",
1651 | "description_tooltip": null,
1652 | "layout": "IPY_MODEL_c36574edba584e488690901249d15ddc",
1653 | "placeholder": "",
1654 | "style": "IPY_MODEL_4cc96cb6859640239a3f434bf7cc5402",
1655 | "value": "Epoch 599: 100%"
1656 | }
1657 | },
1658 | "c36574edba584e488690901249d15ddc": {
1659 | "model_module": "@jupyter-widgets/base",
1660 | "model_module_version": "1.2.0",
1661 | "model_name": "LayoutModel",
1662 | "state": {
1663 | "_model_module": "@jupyter-widgets/base",
1664 | "_model_module_version": "1.2.0",
1665 | "_model_name": "LayoutModel",
1666 | "_view_count": null,
1667 | "_view_module": "@jupyter-widgets/base",
1668 | "_view_module_version": "1.2.0",
1669 | "_view_name": "LayoutView",
1670 | "align_content": null,
1671 | "align_items": null,
1672 | "align_self": null,
1673 | "border": null,
1674 | "bottom": null,
1675 | "display": null,
1676 | "flex": null,
1677 | "flex_flow": null,
1678 | "grid_area": null,
1679 | "grid_auto_columns": null,
1680 | "grid_auto_flow": null,
1681 | "grid_auto_rows": null,
1682 | "grid_column": null,
1683 | "grid_gap": null,
1684 | "grid_row": null,
1685 | "grid_template_areas": null,
1686 | "grid_template_columns": null,
1687 | "grid_template_rows": null,
1688 | "height": null,
1689 | "justify_content": null,
1690 | "justify_items": null,
1691 | "left": null,
1692 | "margin": null,
1693 | "max_height": null,
1694 | "max_width": null,
1695 | "min_height": null,
1696 | "min_width": null,
1697 | "object_fit": null,
1698 | "object_position": null,
1699 | "order": null,
1700 | "overflow": null,
1701 | "overflow_x": null,
1702 | "overflow_y": null,
1703 | "padding": null,
1704 | "right": null,
1705 | "top": null,
1706 | "visibility": null,
1707 | "width": null
1708 | }
1709 | }
1710 | },
1711 | "version_major": 2,
1712 | "version_minor": 0
1713 | }
1714 | }
1715 | },
1716 | "nbformat": 4,
1717 | "nbformat_minor": 5
1718 | }
1719 |
--------------------------------------------------------------------------------