├── .env.example
├── .gitignore
├── .project-root
├── LICENSE
├── README.md
├── assets
└── GotenNet_framework.png
├── gotennet
├── __init__.py
├── configs
│ ├── __init__.py
│ ├── callbacks
│ │ ├── default.yaml
│ │ └── none.yaml
│ ├── datamodule
│ │ └── qm9.yaml
│ ├── experiment
│ │ ├── qm9.yaml
│ │ └── qm9_u0.yaml
│ ├── hydra
│ │ ├── default.yaml
│ │ └── job_logging
│ │ │ └── logger.yaml
│ ├── local
│ │ └── .gitkeep
│ ├── logger
│ │ ├── comet.yaml
│ │ ├── csv.yaml
│ │ ├── default.yaml
│ │ ├── many_loggers.yaml
│ │ ├── mlflow.yaml
│ │ ├── neptune.yaml
│ │ ├── tensorboard.yaml
│ │ └── wandb.yaml
│ ├── model
│ │ └── gotennet.yaml
│ ├── paths
│ │ └── default.yaml
│ ├── test.yaml
│ ├── train.yaml
│ └── trainer
│ │ └── default.yaml
├── datamodules
│ ├── __init__.py
│ ├── components
│ │ ├── __init__.py
│ │ ├── qm9.py
│ │ └── utils.py
│ └── datamodule.py
├── models
│ ├── __init__.py
│ ├── components
│ │ ├── __init__.py
│ │ ├── layers.py
│ │ └── outputs.py
│ ├── goten_model.py
│ ├── representation
│ │ └── gotennet.py
│ └── tasks
│ │ ├── QM9Task.py
│ │ ├── Task.py
│ │ └── __init__.py
├── scripts
│ ├── __init__.py
│ ├── test.py
│ └── train.py
├── testing_pipeline.py
├── training_pipeline.py
├── utils
│ ├── __init__.py
│ ├── file.py
│ ├── logging_utils.py
│ └── utils.py
└── vendor
│ └── __init__.py
├── pyproject.toml
└── requirements.txt
/.env.example:
--------------------------------------------------------------------------------
1 | # example of file for storing private and user specific environment variables, like keys or system paths
2 | # rename it to ".env" (excluded from version control by default)
3 | # .env is loaded by train.py automatically
4 | # hydra allows you to reference variables in .yaml configs with special syntax: ${oc.env:MY_VAR}
5 |
6 | MY_VAR="/home/user/my/system/path"
7 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # OS
7 | .DS_Store
8 | .DS_Store?
9 |
10 | # C extensions
11 | *.so
12 |
13 | # Distribution / packaging
14 | .Python
15 | build/
16 | develop-eggs/
17 | dist/
18 | downloads/
19 | eggs/
20 | .eggs/
21 | lib/
22 | lib64/
23 | parts/
24 | sdist/
25 | var/
26 | wheels/
27 | pip-wheel-metadata/
28 | share/python-wheels/
29 | *.egg-info/
30 | .installed.cfg
31 | *.egg
32 | MANIFEST
33 |
34 | # PyInstaller
35 | # Usually these files are written by a python script from a template
36 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
37 | *.manifest
38 | *.spec
39 |
40 | # Installer logs
41 | pip-log.txt
42 | pip-delete-this-directory.txt
43 |
44 | # Unit test / coverage reports
45 | htmlcov/
46 | .tox/
47 | .nox/
48 | .coverage
49 | .coverage.*
50 | .cache
51 | nosetests.xml
52 | coverage.xml
53 | *.cover
54 | *.py,cover
55 | .hypothesis/
56 | .pytest_cache/
57 |
58 | # Translations
59 | *.mo
60 | *.pot
61 |
62 | # Django stuff:
63 | *.log
64 | local_settings.py
65 | db.sqlite3
66 | db.sqlite3-journal
67 |
68 | # Flask stuff:
69 | instance/
70 | .webassets-cache
71 |
72 | # Scrapy stuff:
73 | .scrapy
74 |
75 | # Sphinx documentation
76 | docs/_build/
77 |
78 | # PyBuilder
79 | target/
80 |
81 | # Jupyter Notebook
82 | .ipynb_checkpoints
83 |
84 | # IPython
85 | profile_default/
86 | ipython_config.py
87 |
88 | # pyenv
89 | .python-version
90 |
91 | # pipenv
92 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
93 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
94 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
95 | # install all needed dependencies.
96 | #Pipfile.lock
97 |
98 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
99 | __pypackages__/
100 |
101 | # Celery stuff
102 | celerybeat-schedule
103 | celerybeat.pid
104 |
105 | # SageMath parsed files
106 | *.sage.py
107 |
108 | # Environments
109 | .venv
110 | env/
111 | venv/
112 | ENV/
113 | env.bak/
114 | venv.bak/
115 |
116 | # Spyder project settings
117 | .spyderproject
118 | .spyproject
119 |
120 | # Rope project settings
121 | .ropeproject
122 |
123 | # mkdocs documentation
124 | /site
125 |
126 | # mypy
127 | .mypy_cache/
128 | .dmypy.json
129 | dmypy.json
130 |
131 | # Pyre type checker
132 | .pyre/
133 |
134 | ### VisualStudioCode
135 | .vscode/*
136 | !.vscode/settings.json
137 | !.vscode/tasks.json
138 | !.vscode/launch.json
139 | !.vscode/extensions.json
140 | *.code-workspace
141 | **/.vscode
142 |
143 | # JetBrains
144 | .idea/
145 |
146 | # Data & Models
147 | *.h5
148 | *.tar
149 | *.tar.gz
150 |
151 | # Lightning-Hydra-Template
152 | configs/local/default.yaml
153 | /data/
154 | /logs/
155 | .env
156 |
157 | # Aim logging
158 | .aim
159 |
--------------------------------------------------------------------------------
/.project-root:
--------------------------------------------------------------------------------
1 | # this file is required for inferring the project root directory
2 | # do not delete
3 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2025 Sarp Aykent
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # GotenNet: Rethinking Efficient 3D Equivariant Graph Neural Networks
2 |
3 |
4 |
5 | [](https://openreview.net/pdf?id=5wxCQDtbMo)
6 | [](https://www.sarpaykent.com/publications/gotennet/)
7 | [](LICENSE)
8 | [](https://pypi.org/project/gotennet/)
9 | [](https://pytorch.org/)
10 |
11 |
12 |
13 |
14 | 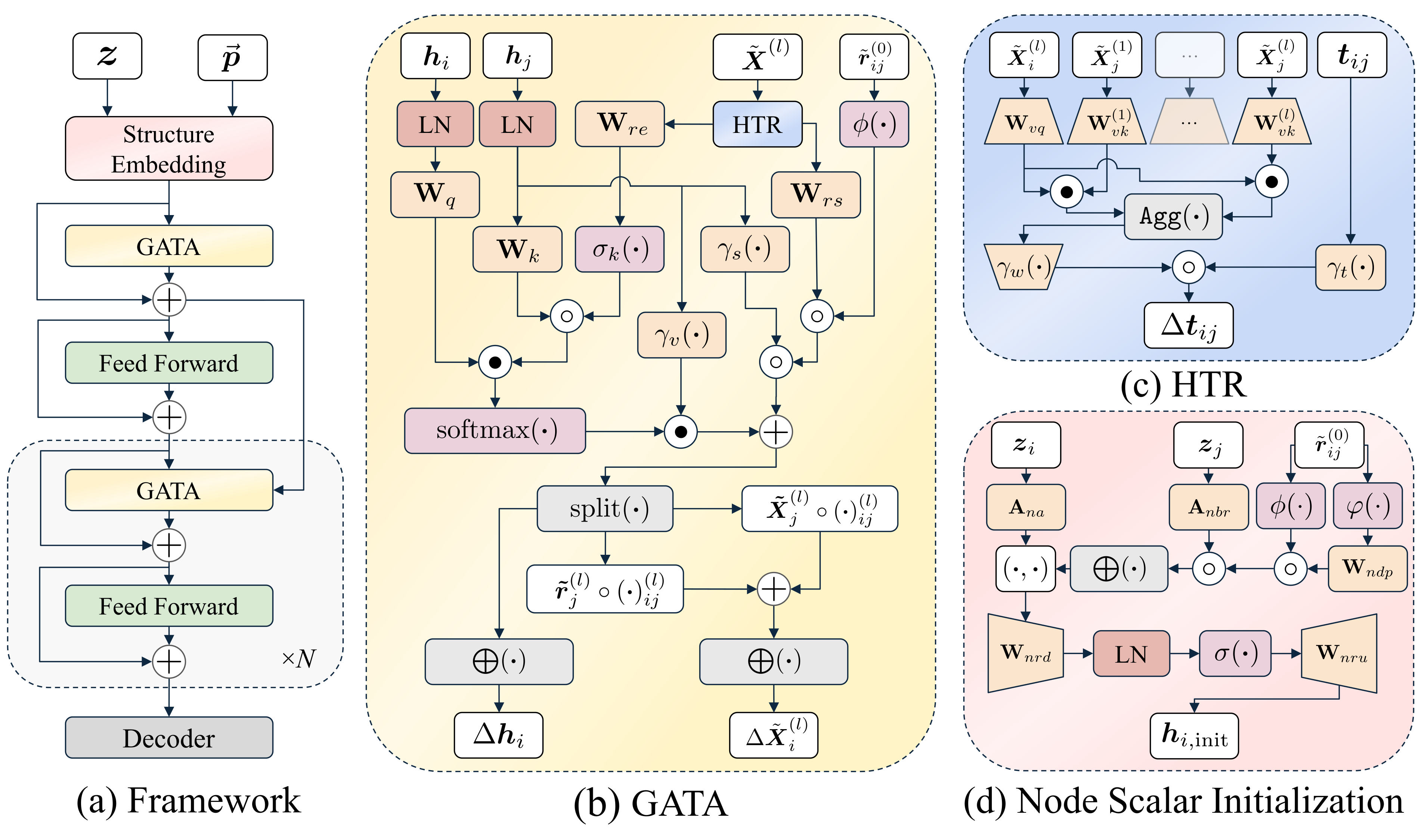 15 |
15 |
16 |
17 | ## Overview
18 |
19 | This is the official implementation of **"GotenNet: Rethinking Efficient 3D Equivariant Graph Neural Networks"** published at ICLR 2025.
20 |
21 | GotenNet introduces a novel framework for modeling 3D molecular structures that achieves state-of-the-art performance while maintaining computational efficiency. Our approach balances expressiveness and efficiency through innovative tensor-based representations and attention mechanisms.
22 |
23 | ## Table of Contents
24 | - [✨ Key Features](#-key-features)
25 | - [🚀 Installation](#-installation)
26 | - [📦 From PyPI (Recommended)](#-from-pypi-recommended)
27 | - [🔧 From Source](#🔧-from-source)
28 | - [🔬 Usage](#🔬-usage)
29 | - [Using the Model](#using-the-model)
30 | - [Loading Pre-trained Models Programmatically](#loading-pre-trained-models-programmatically)
31 | - [Training a Model](#training-a-model)
32 | - [Testing a Model](#testing-a-model)
33 | - [Configuration](#configuration)
34 | - [🤝 Contributing](#-contributing)
35 | - [📚 Citation](#-citation)
36 | - [📄 License](#-license)
37 | - [Acknowledgements](#acknowledgements)
38 |
39 | ## ✨ Key Features
40 |
41 | - 🔄 **Effective Geometric Tensor Representations**: Leverages geometric tensors without relying on irreducible representations or Clebsch-Gordan transforms
42 | - 🧩 **Unified Structural Embedding**: Introduces geometry-aware tensor attention for improved molecular representation
43 | - 📊 **Hierarchical Tensor Refinement**: Implements a flexible and efficient representation scheme
44 | - 🏆 **State-of-the-Art Performance**: Achieves superior results on QM9, rMD17, MD22, and Molecule3D datasets
45 | - 📈 **Load Pre-trained Models**: Easily load and use pre-trained model checkpoints by name, URL, or local path, with automatic download capabilities.
46 |
47 | ## 🚀 Installation
48 |
49 | ### 📦 From PyPI (Recommended)
50 |
51 | You can install it using pip:
52 |
53 | * **Core Model Only:** Installs only the essential dependencies required to use the `GotenNet` model.
54 | ```bash
55 | pip install gotennet
56 | ```
57 |
58 | * **Full Installation (Core + Training/Utilities):** Installs core dependencies plus libraries needed for training, data handling, logging, etc.
59 | ```bash
60 | pip install gotennet[full]
61 | ```
62 |
63 | ### 🔧 From Source
64 |
65 | 1. **Clone the repository:**
66 | ```bash
67 | git clone https://github.com/sarpaykent/gotennet.git
68 | cd gotennet
69 | ```
70 |
71 | 2. **Create and activate a virtual environment** (using conda or venv/uv):
72 | ```bash
73 | # Using conda
74 | conda create -n gotennet python=3.10
75 | conda activate gotennet
76 |
77 | # Or using venv/uv
78 | uv venv --python 3.10
79 | source .venv/bin/activate
80 | ```
81 |
82 | 3. **Install the package:**
83 | Choose the installation type based on your needs:
84 |
85 | * **Core Model Only:** Installs only the essential dependencies required to use the `GotenNet` model.
86 | ```bash
87 | pip install .
88 | ```
89 |
90 | * **Full Installation (Core + Training/Utilities):** Installs core dependencies plus libraries needed for training, data handling, logging, etc.
91 | ```bash
92 | pip install .[full]
93 | # Or for editable install:
94 | # pip install -e .[full]
95 | ```
96 | *(Note: `uv` can be used as a faster alternative to `pip` for installation, e.g., `uv pip install .[full]`)*
97 |
98 | ## 🔬 Usage
99 |
100 | ### Using the Model
101 |
102 | Once installed, you can import and use the `GotenNet` model directly in your Python code:
103 |
104 | ```python
105 | from gotennet import GotenNet
106 |
107 | # --- Using the base GotenNet model ---
108 | # Requires manual calculation of edge_index, edge_diff, edge_vec
109 |
110 | # Example instantiation
111 | model = GotenNet(
112 | n_atom_basis=256,
113 | n_interactions=4,
114 | # resf of the parameters
115 | )
116 |
117 | # Encoded representations can be computed with
118 | h, X = model(atomic_numbers, edge_index, edge_diff, edge_vec)
119 |
120 | # --- Using GotenNetWrapper (handles distance calculation) ---
121 | # Expects a PyTorch Geometric Data object or similar dict
122 | # with keys like 'z' (atomic_numbers), 'pos' (positions), 'batch'
123 |
124 | # Example instantiation
125 | from gotennet import GotenNetWrapper
126 | wrapped_model = GotenNetWrapper(
127 | n_atom_basis=256,
128 | n_interactions=4,
129 | # rest of the parameters
130 | )
131 |
132 | # Encoded representations can be computed with
133 | h, X = wrapped_model(data)
134 |
135 | ```
136 |
137 | ### Loading Pre-trained Models Programmatically
138 |
139 | You can easily load pre-trained `GotenModel` instances programmatically using the `from_pretrained` class method. This method can accept a model alias (which will be resolved to a download URL), a direct HTTPS URL to a checkpoint file, or a local file path. It handles automatic downloading and caching of checkpoints. Pre-trained model weights and aliases are hosted on the [GotenNet Hugging Face Model Hub](https://huggingface.co/sarpaykent/GotenNet).
140 |
141 | ```python
142 | from gotennet.models import GotenModel
143 |
144 | # Example 1: Load by model alias
145 | # This will automatically download from a known location if not found locally.
146 | # The format is {dataset}_{size}_{target}
147 | model_by_alias = GotenModel.from_pretrained("QM9_small_homo")
148 |
149 | # Example 2: Load from a direct URL
150 | model_url = "https://huggingface.co/sarpaykent/GotenNet/resolve/main/pretrained/qm9/small/gotennet_homo.ckpt" # Replace with an actual URL
151 | model_by_url = GotenModel.from_pretrained(model_url)
152 |
153 | # Example 3: Load from a local file path
154 | local_model_path = "/path/to/your/local_model.ckpt"
155 | model_by_path = GotenModel.from_pretrained(local_model_path)
156 |
157 | # After loading, the model is ready for inference:
158 | predictions = model_by_alias(data_input)
159 | ```
160 |
161 | For more advanced scenarios, if you only need to load the base `GotenNet` representation module from a local checkpoint (e.g., a checkpoint that only contains representation weights), you can use:
162 |
163 | ```python
164 | from gotennet.models.representation import GotenNet, GotenNetWrapper
165 |
166 | # Example: Load a GotenNet representation from a local file
167 | representation_checkpoint_path = "/path/to/your/local_model.ckpt"
168 | gotennet_model = GotenNet.load_from_checkpoint(representation_checkpoint_path)
169 | # or
170 | gotennet_wrapped = GotenNetWrapper.load_from_checkpoint(representation_checkpoint_path)
171 | ```
172 |
173 | ### Training a Model
174 |
175 | After installation, you can use the `train_gotennet` command:
176 |
177 | ```bash
178 | train_gotennet
179 | ```
180 |
181 | Or you can run the training script directly:
182 |
183 | ```bash
184 | python gotennet/scripts/train.py
185 | ```
186 |
187 | Both methods use Hydra for configuration. You can reproduce U0 target prediction on the QM9 dataset with the following command:
188 |
189 | ```bash
190 | train_gotennet experiment=qm9_u0.yaml
191 | ```
192 |
193 | ### Testing a Model
194 |
195 | To evaluate a trained model, you can use the `test_gotennet` script. When you provide a checkpoint, the script can infer necessary configurations (like dataset and task details) directly from the checkpoint file. This script leverages the `GotenModel.from_pretrained` capabilities, allowing you to specify the model to test by its alias, a direct URL, or a local file path, handling automatic downloads.
196 |
197 | Here's how you can use it:
198 |
199 | ```bash
200 | # Option 1: Test by model alias (e.g., QM9_small_homo)
201 | # The script will automatically download the checkpoint and infer configurations.
202 | test_gotennet checkpoint=QM9_small_homo
203 |
204 | # Option 2: Test with a direct checkpoint URL
205 | # The script will automatically download the checkpoint and infer configurations.
206 | test_gotennet checkpoint=https://huggingface.co/sarpaykent/GotenNet/resolve/main/pretrained/qm9/small/gotennet_homo.ckpt
207 |
208 | # Option 3: Test with a local checkpoint file path
209 | test_gotennet checkpoint=/path/to/your/local_model.ckpt
210 | ```
211 |
212 | The script uses [Hydra](https://hydra.cc/) for any additional or overriding configurations if needed, but for straightforward evaluation of a checkpoint, only the `checkpoint` argument is typically required.
213 |
214 | ### Configuration
215 |
216 | The project uses [Hydra](https://hydra.cc/) for configuration management. Configuration files are located in the `configs/` directory.
217 |
218 | Main configuration categories:
219 | - `datamodule`: Dataset configurations (md17, qm9, etc.)
220 | - `model`: Model configurations
221 | - `trainer`: Training parameters
222 | - `callbacks`: Callback configurations
223 | - `logger`: Logging configurations
224 |
225 | ## 🤝 Contributing
226 |
227 | We welcome contributions to GotenNet! Please feel free to submit a Pull Request.
228 |
229 |
230 | ## 📚 Citation
231 |
232 | Please consider citing our work below if this project is helpful:
233 |
234 |
235 | ```bibtex
236 | @inproceedings{aykent2025gotennet,
237 | author = {Aykent, Sarp and Xia, Tian},
238 | booktitle = {The Thirteenth International Conference on LearningRepresentations},
239 | year = {2025},
240 | title = {{GotenNet: Rethinking Efficient 3D Equivariant Graph Neural Networks}},
241 | url = {https://openreview.net/forum?id=5wxCQDtbMo},
242 | howpublished = {https://openreview.net/forum?id=5wxCQDtbMo},
243 | }
244 | ```
245 |
246 | ## 📄 License
247 |
248 | This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
249 |
250 | ## Acknowledgements
251 |
252 | GotenNet is proudly built on the innovative foundations provided by the projects below.
253 | - [e3nn](https://github.com/e3nn/e3nn)
254 | - [PyG](https://github.com/pyg-team/pytorch_geometric)
255 | - [PyTorch Lightning](https://github.com/Lightning-AI/pytorch-lightning)
256 |
--------------------------------------------------------------------------------
/assets/GotenNet_framework.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sarpaykent/GotenNet/c561c05a1120118004912b248c944f74022b30cc/assets/GotenNet_framework.png
--------------------------------------------------------------------------------
/gotennet/__init__.py:
--------------------------------------------------------------------------------
1 | """GotenNet: A machine learning model for molecular property prediction."""
2 |
3 | __version__ = "1.1.2"
4 |
5 | from gotennet.models.representation.gotennet import (
6 | EQFF, # noqa: F401
7 | GATA, # noqa: F401
8 | GotenNet, # noqa: F401
9 | GotenNetWrapper, # noqa: F401
10 | )
11 |
12 |
13 |
--------------------------------------------------------------------------------
/gotennet/configs/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sarpaykent/GotenNet/c561c05a1120118004912b248c944f74022b30cc/gotennet/configs/__init__.py
--------------------------------------------------------------------------------
/gotennet/configs/callbacks/default.yaml:
--------------------------------------------------------------------------------
1 | model_checkpoint:
2 | _target_: pytorch_lightning.callbacks.ModelCheckpoint
3 | monitor: "validation/val_loss" # name of the logged metric which determines when model is improving
4 | mode: "min" # "max" means higher metric value is better, can be also "min"
5 | save_top_k: 1 # save k best models (determined by above metric)
6 | save_last: True # additionaly always save model from last epoch
7 | verbose: False
8 | dirpath: ${paths.output_dir}/checkpoints
9 | filename: "epoch_{epoch:03d}"
10 | auto_insert_metric_name: False
11 |
12 | early_stopping:
13 | _target_: pytorch_lightning.callbacks.EarlyStopping
14 | monitor: "validation/ema_loss" # name of the logged metric which determines when model is improving
15 | mode: "min" # "max" means higher metric value is better, can be also "min"
16 | patience: 25 # how many validation epochs of not improving until training stops
17 | min_delta: 1e-6 # minimum change in the monitored metric needed to qualify as an improvement
18 |
19 | model_summary:
20 | _target_: pytorch_lightning.callbacks.RichModelSummary
21 | max_depth: 5
22 |
23 | rich_progress_bar:
24 | _target_: pytorch_lightning.callbacks.RichProgressBar
25 | refresh_rate: 1
26 |
27 | learning_rate_monitor:
28 | _target_: pytorch_lightning.callbacks.LearningRateMonitor
29 |
--------------------------------------------------------------------------------
/gotennet/configs/callbacks/none.yaml:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/gotennet/configs/datamodule/qm9.yaml:
--------------------------------------------------------------------------------
1 | _target_: gotennet.datamodules.datamodule.DataModule
2 |
3 | hparams:
4 | dataset: QM9
5 | dataset_arg:
6 | dataset_root: ${paths.data_dir} # data_path is specified in config.yaml
7 | derivative: false
8 | split_mode: null
9 | reload: 0
10 | batch_size: 32
11 | inference_batch_size: 128
12 | standardize: false
13 | splits: null
14 | train_size: 110000
15 | val_size: 10000
16 | test_size: null
17 | num_workers: 12
18 | seed: 1
19 | output_dir: ${paths.output_dir}
20 | ngpus: 1
21 | num_nodes: 1
22 | precision: 32
23 | task: train
24 | distributed_backend: ddp
25 | redirect: false
26 | accelerator: gpu
27 | test_interval: 10
28 | save_interval: 1
29 | prior_model: Atomref
30 | normalize_positions: false
31 |
--------------------------------------------------------------------------------
/gotennet/configs/experiment/qm9.yaml:
--------------------------------------------------------------------------------
1 | # @package _global_
2 |
3 | defaults:
4 | - override /datamodule: qm9.yaml
5 | - override /model: gotennet.yaml
6 | - override /callbacks: default.yaml
7 | - override /logger: wandb.yaml # set logger here or use command line (e.g. `python train.py logger=tensorboard`)
8 | - override /trainer: default.yaml
9 |
10 | datamodule:
11 | hparams:
12 | batch_size: 32
13 | seed: 1
14 | standardize: false
15 |
16 | model:
17 | lr: 0.0001
18 | lr_warmup_steps: 10000
19 | lr_monitor: "validation/val_loss"
20 | lr_minlr: 1.e-07
21 | lr_patience: 15
22 | weight_decay: 0.0
23 | task_config:
24 | task_loss: "MSELoss"
25 | representation:
26 | n_interactions: 4
27 | n_atom_basis: 256
28 | radial_basis: "expnorm"
29 | n_rbf: 64
30 | output:
31 | n_hidden: 256
32 |
33 | callbacks:
34 | early_stopping:
35 | monitor: "validation/val_loss" # name of the logged metric which determines when model is improving
36 | patience: 150 # how many validation epochs of not improving until training stops
37 | model_checkpoint:
38 | _target_: pytorch_lightning.callbacks.ModelCheckpoint
39 | monitor: "validation/MeanAbsoluteError_${label}" # name of the logged metric which determines when model is improving
40 |
--------------------------------------------------------------------------------
/gotennet/configs/experiment/qm9_u0.yaml:
--------------------------------------------------------------------------------
1 | # @package _global_
2 |
3 | defaults:
4 | - override /datamodule: qm9.yaml
5 | - override /model: gotennet.yaml
6 | - override /callbacks: default.yaml
7 | - override /logger: wandb.yaml # set logger here or use command line (e.g. `python train.py logger=tensorboard`)
8 | - override /trainer: default.yaml
9 |
10 | datamodule:
11 | hparams:
12 | batch_size: 32
13 | seed: 1
14 | standardize: false
15 |
16 | model:
17 | lr: 0.0001
18 | lr_warmup_steps: 10000
19 | lr_monitor: "validation/val_loss"
20 | lr_minlr: 1.e-07
21 | lr_patience: 15
22 | weight_decay: 0.0
23 | task_config:
24 | task_loss: "MSELoss"
25 | representation:
26 | n_interactions: 4
27 | n_atom_basis: 256
28 | radial_basis: "expnorm"
29 | n_rbf: 64
30 | output:
31 | n_hidden: 256
32 |
33 | callbacks:
34 | early_stopping:
35 | monitor: "validation/val_loss" # name of the logged metric which determines when model is improving
36 | patience: 150 # how many validation epochs of not improving until training stops
37 | model_checkpoint:
38 | _target_: pytorch_lightning.callbacks.ModelCheckpoint
39 | monitor: "validation/MeanAbsoluteError_${label}" # name of the logged metric which determines when model is improving
40 |
41 | label: "U0"
42 |
--------------------------------------------------------------------------------
/gotennet/configs/hydra/default.yaml:
--------------------------------------------------------------------------------
1 | # https://hydra.cc/docs/configure_hydra/intro/
2 |
3 | # enable color logging
4 | defaults:
5 | - override hydra_logging: colorlog
6 | - override job_logging: colorlog
7 | - override sweeper: optuna
8 | - override sweeper/sampler: grid
9 | # - override launcher: joblib
10 |
11 | # output directory, generated dynamically on each run
12 | run:
13 | dir: ${paths.log_dir}/${label}_${name}/runs/${now:%Y-%m-%d}_${now:%H-%M-%S}
14 | sweep:
15 | dir: ${paths.log_dir}/${name}/multiruns/${now:%Y-%m-%d}_${now:%H-%M-%S}
16 | subdir: 0
17 |
--------------------------------------------------------------------------------
/gotennet/configs/hydra/job_logging/logger.yaml:
--------------------------------------------------------------------------------
1 | # @package hydra.job_logging
2 | # python logging configuration for tasks
3 | version: 1
4 | formatters:
5 | simple:
6 | format: "[%(asctime)s][%(name)s][%(levelname)s] - %(message)s"
7 | colorlog:
8 | "()": "colorlog.ColoredFormatter"
9 | format: "[%(cyan)s%(asctime)s%(reset)s][%(blue)s%(name)s%(reset)s][%(log_color)s%(levelname)s%(reset)s] - %(message)s"
10 | log_colors:
11 | DEBUG: purple
12 | INFO: green
13 | WARNING: yellow
14 | ERROR: red
15 | CRITICAL: red
16 | handlers:
17 | console:
18 | class: rich.logging.RichHandler
19 | formatter: colorlog
20 | file:
21 | class: logging.FileHandler
22 | formatter: simple
23 | # relative to the job log directory
24 | filename: ${hydra.job.name}.log
25 | root:
26 | level: INFO
27 | handlers: [console, file]
28 |
29 | disable_existing_loggers: false
30 |
--------------------------------------------------------------------------------
/gotennet/configs/local/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sarpaykent/GotenNet/c561c05a1120118004912b248c944f74022b30cc/gotennet/configs/local/.gitkeep
--------------------------------------------------------------------------------
/gotennet/configs/logger/comet.yaml:
--------------------------------------------------------------------------------
1 | # https://www.comet.ml
2 |
3 | comet:
4 | _target_: pytorch_lightning.loggers.comet.CometLogger
5 | api_key: ${oc.env:COMET_API_TOKEN} # api key is loaded from environment variable
6 | project_name: "template-tests"
7 | experiment_name: ${name}
8 |
--------------------------------------------------------------------------------
/gotennet/configs/logger/csv.yaml:
--------------------------------------------------------------------------------
1 | # csv logger built in lightning
2 |
3 | csv:
4 | _target_: pytorch_lightning.loggers.csv_logs.CSVLogger
5 | save_dir: "."
6 | name: "csv/"
7 | prefix: ""
8 |
--------------------------------------------------------------------------------
/gotennet/configs/logger/default.yaml:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/gotennet/configs/logger/many_loggers.yaml:
--------------------------------------------------------------------------------
1 | # train with many loggers at once
2 |
3 | defaults:
4 | # - comet.yaml
5 | - csv.yaml
6 | # - mlflow.yaml
7 | # - neptune.yaml
8 | - tensorboard.yaml
9 | - wandb.yaml
10 |
--------------------------------------------------------------------------------
/gotennet/configs/logger/mlflow.yaml:
--------------------------------------------------------------------------------
1 | # https://mlflow.org
2 |
3 | mlflow:
4 | _target_: pytorch_lightning.loggers.mlflow.MLFlowLogger
5 | experiment_name: ${name}
6 | tracking_uri: ${original_work_dir}/logs/mlflow/mlruns # run `mlflow ui` command inside the `logs/mlflow/` dir to open the UI
7 | tags: null
8 | prefix: ""
9 | artifact_location: null
10 |
--------------------------------------------------------------------------------
/gotennet/configs/logger/neptune.yaml:
--------------------------------------------------------------------------------
1 | # https://neptune.ai
2 |
3 | neptune:
4 | _target_: pytorch_lightning.loggers.neptune.NeptuneLogger
5 | api_key: ${oc.env:NEPTUNE_API_TOKEN} # api key is loaded from environment variable
6 | project_name: your_name/template-tests
7 | close_after_fit: True
8 | offline_mode: False
9 | experiment_name: ${name}
10 | experiment_id: null
11 | prefix: ""
12 |
--------------------------------------------------------------------------------
/gotennet/configs/logger/tensorboard.yaml:
--------------------------------------------------------------------------------
1 | # https://www.tensorflow.org/tensorboard/
2 |
3 | tensorboard:
4 | _target_: pytorch_lightning.loggers.tensorboard.TensorBoardLogger
5 | save_dir: "tensorboard/"
6 | name: null
7 | version: ${name}
8 | log_graph: False
9 | default_hp_metric: True
10 | prefix: ""
11 |
--------------------------------------------------------------------------------
/gotennet/configs/logger/wandb.yaml:
--------------------------------------------------------------------------------
1 | # https://wandb.ai
2 |
3 | wandb:
4 | _target_: pytorch_lightning.loggers.wandb.WandbLogger
5 | project: ${project}
6 | name: ${name}
7 | save_dir: "."
8 | offline: False # set True to store all logs only locally
9 | id: null # pass correct id to resume experiment!
10 | entity: "" # set to name of your wandb team
11 | log_model: False
12 | prefix: ""
13 | job_type: "train"
14 | group: ""
15 | tags: []
16 |
--------------------------------------------------------------------------------
/gotennet/configs/model/gotennet.yaml:
--------------------------------------------------------------------------------
1 | _target_: gotennet.models.goten_model.GotenModel
2 | label: ${label}
3 | task: ${task}
4 |
5 | cutoff: 5.0
6 | lr: 0.0001
7 | lr_decay: 0.8
8 | lr_patience: 5
9 | lr_monitor: "validation/ema_loss"
10 | ema_decay: 0.9
11 | weight_decay: 0.01
12 |
13 | output:
14 | n_hidden: 256
15 |
16 | representation:
17 | __target__: gotennet.models.representation.gotennet.GotenNetWrapper
18 | n_atom_basis: 256
19 | n_interactions: 4
20 | n_rbf: 32
21 | cutoff_fn:
22 | __target__: gotennet.models.components.layers.CosineCutoff
23 | cutoff: 5.0
24 | radial_basis: "expnorm"
25 | activation: "swish"
26 | max_z: 100
27 | weight_init: "xavier_uniform"
28 | bias_init: "zeros"
29 | num_heads: 8
30 | attn_dropout: 0.1
31 | edge_updates: True
32 | lmax: 2
33 | aggr: "add"
34 | scale_edge: False
35 | evec_dim:
36 | emlp_dim:
37 | sep_htr: True
38 | sep_dir: True
39 | sep_tensor: True
40 | edge_ln: ""
41 |
42 | #task_config:
43 | # name: "Test"
44 |
--------------------------------------------------------------------------------
/gotennet/configs/paths/default.yaml:
--------------------------------------------------------------------------------
1 | # path to root directory
2 | # this requires PROJECT_ROOT environment variable to exist
3 | # PROJECT_ROOT is inferred and set by pyrootutils package in `train.py` and `eval.py`
4 | root_dir: ${oc.env:PROJECT_ROOT}
5 |
6 | # path to data directory
7 | data_dir: ${paths.root_dir}/data/
8 |
9 | # path to logging directory
10 | log_dir: ${paths.root_dir}/logs/
11 |
12 | # path to output directory, created dynamically by hydra
13 | # path generation pattern is specified in `configs/hydra/default.yaml`
14 | # use it to store all files generated during the run, like ckpts and metrics
15 | output_dir: ${hydra:runtime.output_dir}
16 |
--------------------------------------------------------------------------------
/gotennet/configs/test.yaml:
--------------------------------------------------------------------------------
1 | # @package _global_
2 |
3 | # specify here default evaluation configuration
4 | defaults:
5 | - _self_
6 | - datamodule: qm9.yaml
7 | - model: gotennet.yaml
8 | - callbacks: default.yaml
9 | - logger: default.yaml
10 | - trainer: default.yaml
11 |
12 | # experiment configs allow for version control of specific configurations
13 | # e.g. best hyperparameters for each combination of model and datamodule
14 | - experiment: null
15 |
16 | # config for hyperparameter optimization
17 | - hparams_search: null
18 |
19 | # optional local config for machine/user specific settings
20 | # it's optional since it doesn't need to exist and is excluded from version control
21 | - optional local: default.yaml
22 |
23 | # enable color logging
24 | - paths: default.yaml
25 | - hydra: default.yaml
26 | # - override /hydra/launcher: joblib
27 |
28 | original_work_dir: ${hydra:runtime.cwd}
29 |
30 | data_dir: ${original_work_dir}/data/
31 |
32 | print_config: True
33 |
34 | ignore_warnings: True
35 |
36 | seed: 42
37 | # default name for the experiment, determines logging folder path
38 | # (you can overwrite this name in experiment configs)
39 | name: "default"
40 | task: "QM9"
41 | exp: False
42 | project: "gotennet"
43 | label: -1
44 | label_str: -1
45 | # passing checkpoint path is necessary
46 | ckpt_path: null
47 | checkpoint: null
48 |
--------------------------------------------------------------------------------
/gotennet/configs/train.yaml:
--------------------------------------------------------------------------------
1 | # @package _global_
2 |
3 | # specify here default training configuration
4 | defaults:
5 | - _self_
6 | - datamodule: qm9.yaml
7 | - model: gotennet.yaml
8 | - callbacks: default.yaml
9 | - logger: default.yaml
10 | - trainer: default.yaml
11 |
12 | # experiment configs allow for version control of specific configurations
13 | # e.g. best hyperparameters for each combination of model and datamodule
14 | - experiment: null
15 |
16 | # config for hyperparameter optimization
17 | - hparams_search: null
18 |
19 | # optional local config for machine/user specific settings
20 | # it's optional since it doesn't need to exist and is excluded from version control
21 | - optional local: default.yaml
22 |
23 | # enable color logging
24 | - paths: default.yaml
25 | - hydra: default.yaml
26 |
27 | # pretty print config at the start of the run using Rich library
28 | print_config: True
29 |
30 | # disable python warnings if they annoy you
31 | ignore_warnings: True
32 |
33 | # set False to skip model training
34 | train: True
35 |
36 | # evaluate on test set, using best model weights achieved during training
37 | # lightning chooses best weights based on the metric specified in checkpoint callback
38 | test: True
39 |
40 | # seed for random number generators in pytorch, numpy and python.random
41 | seed: 42
42 |
43 | # default name for the experiment, determines logging folder path
44 | # (you can overwrite this name in experiment configs)
45 | name: "default"
46 | task: "QM9"
47 | exp: False
48 | project: "gotennet"
49 | label: -1
50 | label_str: -1
51 | ckpt_path: null
52 |
--------------------------------------------------------------------------------
/gotennet/configs/trainer/default.yaml:
--------------------------------------------------------------------------------
1 | _target_: pytorch_lightning.Trainer
2 |
3 | devices: 1
4 |
5 | min_epochs: 1
6 | max_epochs: 1000
7 | strategy: ddp_find_unused_parameters_false
8 | # number of validation steps to execute at the beginning of the training
9 | num_sanity_val_steps: 0
10 | gradient_clip_val: 5.0
11 |
--------------------------------------------------------------------------------
/gotennet/datamodules/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sarpaykent/GotenNet/c561c05a1120118004912b248c944f74022b30cc/gotennet/datamodules/__init__.py
--------------------------------------------------------------------------------
/gotennet/datamodules/components/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sarpaykent/GotenNet/c561c05a1120118004912b248c944f74022b30cc/gotennet/datamodules/components/__init__.py
--------------------------------------------------------------------------------
/gotennet/datamodules/components/qm9.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch_geometric.datasets import QM9 as QM9_geometric
3 | from torch_geometric.transforms import Compose
4 |
5 | qm9_target_dict = {
6 | 0: "mu",
7 | 1: "alpha",
8 | 2: "homo",
9 | 3: "lumo",
10 | 4: "gap",
11 | 5: "r2",
12 | 6: "zpve",
13 | 7: "U0",
14 | 8: "U",
15 | 9: "H",
16 | 10: "G",
17 | 11: "Cv",
18 | }
19 |
20 |
21 | class QM9(QM9_geometric):
22 | """
23 | QM9 dataset wrapper for PyTorch Geometric QM9 dataset.
24 |
25 | This class extends the PyTorch Geometric QM9 dataset to provide additional
26 | functionality for working with specific molecular properties.
27 | """
28 |
29 | mu = "mu"
30 | alpha = "alpha"
31 | homo = "homo"
32 | lumo = "lumo"
33 | gap = "gap"
34 | r2 = "r2"
35 | zpve = "zpve"
36 | U0 = "U0"
37 | U = "U"
38 | H = "H"
39 | G = "G"
40 | Cv = "Cv"
41 |
42 | available_properties = [
43 | mu,
44 | alpha,
45 | homo,
46 | lumo,
47 | gap,
48 | r2,
49 | zpve,
50 | U0,
51 | U,
52 | H,
53 | G,
54 | Cv,
55 | ]
56 |
57 | def __init__(
58 | self,
59 | root: str,
60 | transform=None,
61 | pre_transform=None,
62 | pre_filter=None,
63 | dataset_arg=None,
64 | ):
65 | """
66 | Initialize the QM9 dataset.
67 |
68 | Args:
69 | root (str): Root directory where the dataset should be saved.
70 | transform: Transform to be applied to each data object. If None,
71 | defaults to _filter_label.
72 | pre_transform: Transform to be applied to each data object before saving.
73 | pre_filter: Function that takes in a data object and returns a boolean,
74 | indicating whether the item should be included.
75 | dataset_arg (str): The property to train on. Must be one of the available
76 | properties defined in qm9_target_dict.
77 |
78 | Raises:
79 | AssertionError: If dataset_arg is None.
80 | """
81 | assert dataset_arg is not None, (
82 | "Please pass the desired property to "
83 | 'train on via "dataset_arg". Available '
84 | f'properties are {", ".join(qm9_target_dict.values())}.'
85 | )
86 |
87 | self.label = dataset_arg
88 | label2idx = dict(zip(qm9_target_dict.values(), qm9_target_dict.keys(), strict=False))
89 | self.label_idx = label2idx[self.label]
90 |
91 | if transform is None:
92 | transform = self._filter_label
93 | else:
94 | transform = Compose([transform, self._filter_label])
95 |
96 | super(QM9, self).__init__(
97 | root,
98 | transform=transform,
99 | pre_transform=pre_transform,
100 | pre_filter=pre_filter,
101 | )
102 |
103 |
104 | @staticmethod
105 | def label_to_idx(label: str) -> int:
106 | """
107 | Convert a property label to its corresponding index.
108 |
109 | Args:
110 | label (str): The property label to convert.
111 |
112 | Returns:
113 | int: The index corresponding to the property label.
114 | """
115 | label2idx = dict(zip(qm9_target_dict.values(), qm9_target_dict.keys(), strict=False))
116 | return label2idx[label]
117 |
118 | def mean(self, divide_by_atoms: bool = True) -> float:
119 | """
120 | Calculate the mean of the target property across the dataset.
121 |
122 | Args:
123 | divide_by_atoms (bool): Whether to normalize the property by the number
124 | of atoms in each molecule.
125 |
126 | Returns:
127 | float: The mean value of the target property.
128 | """
129 | if not divide_by_atoms:
130 | get_labels = lambda i: self.get(i).y
131 | else:
132 | get_labels = lambda i: self.get(i).y/self.get(i).pos.shape[0]
133 |
134 | y = torch.cat([get_labels(i) for i in range(len(self))], dim=0)
135 | assert len(y.shape) == 2
136 | if y.shape[1] != 1:
137 | y = y[:, self.label_idx]
138 | else:
139 | y = y[:, 0]
140 | return y.mean(axis=0)
141 | def min(self, divide_by_atoms: bool = True) -> float:
142 | """
143 | Calculate the minimum of the target property across the dataset.
144 |
145 | Args:
146 | divide_by_atoms (bool): Whether to normalize the property by the number
147 | of atoms in each molecule.
148 |
149 | Returns:
150 | float: The minimum value of the target property.
151 | """
152 | if not divide_by_atoms:
153 | get_labels = lambda i: self.get(i).y
154 | else:
155 | get_labels = lambda i: self.get(i).y/self.get(i).pos.shape[0]
156 |
157 | y = torch.cat([get_labels(i) for i in range(len(self))], dim=0)
158 | assert len(y.shape) == 2
159 | if y.shape[1] != 1:
160 | y = y[:, self.label_idx]
161 | else:
162 | y = y[:, 0]
163 | return y.min(axis=0)
164 |
165 | def std(self, divide_by_atoms: bool = True) -> float:
166 | """
167 | Calculate the standard deviation of the target property across the dataset.
168 |
169 | Args:
170 | divide_by_atoms (bool): Whether to normalize the property by the number
171 | of atoms in each molecule.
172 |
173 | Returns:
174 | float: The standard deviation of the target property.
175 | """
176 | if not divide_by_atoms:
177 | get_labels = lambda i: self.get(i).y
178 | else:
179 | get_labels = lambda i: self.get(i).y/self.get(i).pos.shape[0]
180 |
181 | y = torch.cat([get_labels(i) for i in range(len(self))], dim=0)
182 | assert len(y.shape) == 2
183 | if y.shape[1] != 1:
184 | y = y[:, self.label_idx]
185 | else:
186 | y = y[:, 0]
187 | return y.std(axis=0)
188 |
189 | def get_atomref(self, max_z: int = 100) -> torch.Tensor:
190 | """
191 | Get atomic reference values for the target property.
192 |
193 | Args:
194 | max_z (int): Maximum atomic number to consider.
195 |
196 | Returns:
197 | torch.Tensor: Tensor of atomic reference values, or None if not available.
198 | """
199 | atomref = self.atomref(self.label_idx)
200 | if atomref is None:
201 | return None
202 | if atomref.size(0) != max_z:
203 | tmp = torch.zeros(max_z).unsqueeze(1)
204 | idx = min(max_z, atomref.size(0))
205 | tmp[:idx] = atomref[:idx]
206 | return tmp
207 | return atomref
208 |
209 | def _filter_label(self, batch) -> torch.Tensor:
210 | """
211 | Filter the batch to only include the target property.
212 |
213 | Args:
214 | batch: A batch of data from the dataset.
215 |
216 | Returns:
217 | torch.Tensor: The filtered batch with only the target property.
218 | """
219 | batch.y = batch.y[:, self.label_idx].unsqueeze(1)
220 | return batch
221 |
--------------------------------------------------------------------------------
/gotennet/datamodules/components/utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | from pytorch_lightning.utilities import rank_zero_warn
4 |
5 |
6 | def train_val_test_split(
7 | dset_len: int,
8 | train_size: float or int or None,
9 | val_size: float or int or None,
10 | test_size: float or int or None,
11 | seed: int,
12 | ) -> tuple:
13 | """
14 | Split dataset indices into training, validation, and test sets.
15 |
16 | This function splits a dataset of length dset_len into training, validation,
17 | and test sets according to the specified sizes. The sizes can be specified as
18 | fractions of the dataset (float) or as absolute counts (int).
19 |
20 | Args:
21 | dset_len (int): Total length of the dataset.
22 | train_size (float or int or None): Size of the training set. If float, interpreted
23 | as a fraction of the dataset. If int, interpreted as an absolute count.
24 | If None, calculated as the remainder after val_size and test_size.
25 | val_size (float or int or None): Size of the validation set. If float, interpreted
26 | as a fraction of the dataset. If int, interpreted as an absolute count.
27 | If None, calculated as the remainder after train_size and test_size.
28 | test_size (float or int or None): Size of the test set. If float, interpreted
29 | as a fraction of the dataset. If int, interpreted as an absolute count.
30 | If None, calculated as the remainder after train_size and val_size.
31 | seed (int): Random seed for reproducibility.
32 |
33 | Returns:
34 | tuple: A tuple containing three numpy arrays (idx_train, idx_val, idx_test)
35 | with the indices for each split.
36 |
37 | Raises:
38 | AssertionError: If more than one of train_size, val_size, test_size is None,
39 | or if any split size is negative, or if the total split size exceeds
40 | the dataset length.
41 | """
42 | assert (train_size is None) + (val_size is None) + (test_size is None) <= 1, "Only one of train_size, val_size, test_size is allowed to be None."
43 |
44 | is_float = (isinstance(train_size, float), isinstance(val_size, float), isinstance(test_size, float))
45 |
46 | train_size = round(dset_len * train_size) if is_float[0] else train_size
47 | val_size = round(dset_len * val_size) if is_float[1] else val_size
48 | test_size = round(dset_len * test_size) if is_float[2] else test_size
49 |
50 | if train_size is None:
51 | train_size = dset_len - val_size - test_size
52 | elif val_size is None:
53 | val_size = dset_len - train_size - test_size
54 | elif test_size is None:
55 | test_size = dset_len - train_size - val_size
56 |
57 | # Adjust split sizes if they exceed the dataset length
58 | if train_size + val_size + test_size > dset_len:
59 | if is_float[2]:
60 | test_size -= 1
61 | elif is_float[1]:
62 | val_size -= 1
63 | elif is_float[0]:
64 | train_size -= 1
65 |
66 | assert train_size >= 0 and val_size >= 0 and test_size >= 0, (
67 | f"One of training ({train_size}), validation ({val_size}) or "
68 | f"testing ({test_size}) splits ended up with a negative size."
69 | )
70 |
71 | total = train_size + val_size + test_size
72 | assert dset_len >= total, f"The dataset ({dset_len}) is smaller than the combined split sizes ({total})."
73 |
74 | if total < dset_len:
75 | rank_zero_warn(f"{dset_len - total} samples were excluded from the dataset")
76 |
77 | # Generate random indices
78 | idxs = np.arange(dset_len, dtype=np.int64)
79 | idxs = np.random.default_rng(seed).permutation(idxs)
80 |
81 | # Split indices into train, validation, and test sets
82 | idx_train = idxs[:train_size]
83 | idx_val = idxs[train_size: train_size + val_size]
84 | idx_test = idxs[train_size + val_size: total]
85 |
86 | return np.array(idx_train), np.array(idx_val), np.array(idx_test)
87 |
88 |
89 | def make_splits(
90 | dataset_len: int,
91 | train_size: float or int or None,
92 | val_size: float or int or None,
93 | test_size: float or int or None,
94 | seed: int,
95 | filename: str = None,
96 | splits: str = None,
97 | ) -> tuple:
98 | """
99 | Create or load dataset splits and optionally save them to a file.
100 |
101 | This function either loads existing splits from a file or creates new splits
102 | using train_val_test_split. The resulting splits can be saved to a file.
103 |
104 | Args:
105 | dataset_len (int): Total length of the dataset.
106 | train_size (float or int or None): Size of the training set. See train_val_test_split.
107 | val_size (float or int or None): Size of the validation set. See train_val_test_split.
108 | test_size (float or int or None): Size of the test set. See train_val_test_split.
109 | seed (int): Random seed for reproducibility.
110 | filename (str, optional): If provided, the splits will be saved to this file.
111 | splits (str, optional): If provided, splits will be loaded from this file
112 | instead of being generated.
113 |
114 | Returns:
115 | tuple: A tuple containing three torch tensors (idx_train, idx_val, idx_test)
116 | with the indices for each split.
117 | """
118 | if splits is not None:
119 | splits = np.load(splits)
120 | idx_train = splits["idx_train"]
121 | idx_val = splits["idx_val"]
122 | idx_test = splits["idx_test"]
123 | else:
124 | idx_train, idx_val, idx_test = train_val_test_split(
125 | dataset_len,
126 | train_size,
127 | val_size,
128 | test_size,
129 | seed,
130 | )
131 |
132 | if filename is not None:
133 | np.savez(filename, idx_train=idx_train, idx_val=idx_val, idx_test=idx_test)
134 |
135 | return torch.from_numpy(idx_train), torch.from_numpy(idx_val), torch.from_numpy(idx_test)
136 |
137 |
138 | class MissingLabelException(Exception):
139 | """
140 | Exception raised when a required label is missing from the dataset.
141 |
142 | This exception is used to indicate that a required label or property
143 | is not available in the dataset being processed.
144 | """
145 | pass
146 |
--------------------------------------------------------------------------------
/gotennet/datamodules/datamodule.py:
--------------------------------------------------------------------------------
1 | from os.path import join
2 | from typing import Any, Dict, Optional, Union
3 |
4 | import torch
5 | from pytorch_lightning import LightningDataModule
6 | from pytorch_lightning.utilities import rank_zero_only, rank_zero_warn
7 | from torch_geometric.loader import DataLoader
8 | from torch_scatter import scatter
9 | from tqdm import tqdm
10 |
11 | from gotennet import utils
12 |
13 | from .components.qm9 import QM9
14 | from .components.utils import MissingLabelException, make_splits
15 |
16 | log = utils.get_logger(__name__)
17 |
18 |
19 | def normalize_positions(batch):
20 | """
21 | Normalize positions by subtracting center of mass.
22 |
23 | Args:
24 | batch: Data batch with position information.
25 |
26 | Returns:
27 | batch: Batch with normalized positions.
28 | """
29 | center = batch.center_of_mass
30 | batch.pos = batch.pos - center
31 | return batch
32 |
33 |
34 | class DataModule(LightningDataModule):
35 | """
36 | DataModule for handling various molecular datasets.
37 |
38 | This class provides a unified interface for loading, splitting, and
39 | standardizing different types of molecular datasets.
40 | """
41 |
42 | def __init__(self, hparams: Union[Dict, Any]):
43 | """
44 | Initialize the DataModule with configuration parameters.
45 |
46 | Args:
47 | hparams: Hyperparameters for the datamodule.
48 | """
49 | # Check if hparams is omegaconf.dictconfig.DictConfig
50 | if type(hparams) == "omegaconf.dictconfig.DictConfig":
51 | hparams = dict(hparams)
52 | super(DataModule, self).__init__()
53 | hparams = dict(hparams)
54 |
55 | # Update hyperparameters
56 | if hasattr(hparams, "__dict__"):
57 | self.hparams.update(hparams.__dict__)
58 | else:
59 | self.hparams.update(hparams)
60 |
61 | # Initialize attributes
62 | self._mean, self._std = None, None
63 | self._saved_dataloaders = dict()
64 | self.dataset = None
65 | self.loaded = False
66 |
67 | def get_metadata(self, label: Optional[str] = None) -> Dict:
68 | """
69 | Get metadata about the dataset.
70 |
71 | Args:
72 | label: Optional label to set as dataset_arg.
73 |
74 | Returns:
75 | Dict containing dataset metadata.
76 | """
77 | if label is not None:
78 | self.hparams["dataset_arg"] = label
79 |
80 | if self.loaded == False:
81 | self.prepare_dataset()
82 | self.loaded = True
83 |
84 | return {
85 | 'atomref': self.atomref,
86 | 'dataset': self.dataset,
87 | 'mean': self.mean,
88 | 'std': self.std
89 | }
90 |
91 | def prepare_dataset(self):
92 | """
93 | Prepare the dataset for training, validation, and testing.
94 |
95 | Loads the appropriate dataset based on the configuration and
96 | creates the train/val/test splits.
97 |
98 | Raises:
99 | AssertionError: If the specified dataset type is not supported.
100 | """
101 | dataset_type = self.hparams['dataset']
102 |
103 | # Validate dataset type is supported
104 | assert hasattr(self, f"_prepare_{dataset_type}"), \
105 | f"Dataset {dataset_type} not defined"
106 |
107 | # Call the appropriate dataset preparation method
108 | dataset_preparer = lambda t: getattr(self, f"_prepare_{t}")()
109 | self.idx_train, self.idx_val, self.idx_test = dataset_preparer(dataset_type)
110 |
111 | log.info(f"train {len(self.idx_train)}, val {len(self.idx_val)}, test {len(self.idx_test)}")
112 |
113 | # Set up dataset subsets
114 | self.train_dataset = self.dataset[self.idx_train]
115 | self.val_dataset = self.dataset[self.idx_val]
116 | self.test_dataset = self.dataset[self.idx_test]
117 |
118 | # Standardize if requested
119 | if self.hparams["standardize"]:
120 | self._standardize()
121 |
122 | def train_dataloader(self):
123 | """
124 | Get the training dataloader.
125 |
126 | Returns:
127 | DataLoader for training data.
128 | """
129 | return self._get_dataloader(self.train_dataset, "train")
130 |
131 | def val_dataloader(self):
132 | """
133 | Get the validation dataloader.
134 |
135 | Returns:
136 | DataLoader for validation data.
137 | """
138 | return self._get_dataloader(self.val_dataset, "val")
139 |
140 | def test_dataloader(self):
141 | """
142 | Get the test dataloader.
143 |
144 | Returns:
145 | DataLoader for test data.
146 | """
147 | return self._get_dataloader(self.test_dataset, "test")
148 |
149 | @property
150 | def atomref(self):
151 | """
152 | Get atom reference values if available.
153 |
154 | Returns:
155 | Atom reference values or None.
156 | """
157 | if hasattr(self.dataset, "get_atomref"):
158 | return self.dataset.get_atomref()
159 | return None
160 |
161 | @property
162 | def mean(self):
163 | """
164 | Get mean value for standardization.
165 |
166 | Returns:
167 | Mean value.
168 | """
169 | return self._mean
170 |
171 | @property
172 | def std(self):
173 | """
174 | Get standard deviation value for standardization.
175 |
176 | Returns:
177 | Standard deviation value.
178 | """
179 | return self._std
180 |
181 | def _get_dataloader(
182 | self,
183 | dataset,
184 | stage: str,
185 | store_dataloader: bool = True
186 | ):
187 | """
188 | Create a dataloader for the given dataset and stage.
189 |
190 | Args:
191 | dataset: The dataset to create a dataloader for.
192 | stage: The stage ('train', 'val', or 'test').
193 | store_dataloader: Whether to store the dataloader for reuse.
194 |
195 | Returns:
196 | DataLoader for the dataset.
197 | """
198 | store_dataloader = (store_dataloader and not self.hparams["reload"])
199 | if stage in self._saved_dataloaders and store_dataloader:
200 | return self._saved_dataloaders[stage]
201 |
202 | if stage == "train":
203 | batch_size = self.hparams["batch_size"]
204 | shuffle = True
205 | elif stage in ["val", "test"]:
206 | batch_size = self.hparams["inference_batch_size"]
207 | shuffle = False
208 |
209 | dl = DataLoader(
210 | dataset=dataset,
211 | batch_size=batch_size,
212 | shuffle=shuffle,
213 | num_workers=self.hparams["num_workers"],
214 | pin_memory=True,
215 | )
216 |
217 | if store_dataloader:
218 | self._saved_dataloaders[stage] = dl
219 | return dl
220 |
221 | @rank_zero_only
222 | def _standardize(self):
223 | """
224 | Standardize the dataset by computing mean and standard deviation.
225 |
226 | This method computes the mean and standard deviation of the dataset
227 | for standardization purposes. It handles different standardization
228 | approaches based on the configuration.
229 | """
230 | def get_label(batch, atomref):
231 | """
232 | Extract label from batch, accounting for atom references if provided.
233 | """
234 | if batch.y is None:
235 | raise MissingLabelException()
236 |
237 | dy = None
238 | if 'dy' in batch:
239 | dy = batch.dy.squeeze().clone()
240 |
241 | if atomref is None:
242 | return batch.y.clone(), dy
243 |
244 | atomref_energy = scatter(atomref[batch.z], batch.batch, dim=0)
245 | return (batch.y.squeeze() - atomref_energy.squeeze()).clone(), dy
246 |
247 | # Standard approach: compute mean and std from data
248 | data = tqdm(
249 | self._get_dataloader(self.train_dataset, "val", store_dataloader=False),
250 | desc="computing mean and std",
251 | )
252 | try:
253 | atomref = self.atomref if self.hparams.get("prior_model") == "Atomref" else None
254 | ys = [get_label(batch, atomref) for batch in data]
255 | # Convert array with n elements and each element contains 2 values
256 | # to array of two elements with n values
257 | ys, dys = zip(*ys, strict=False)
258 | ys = torch.cat(ys)
259 | except MissingLabelException:
260 | rank_zero_warn(
261 | "Standardize is true but failed to compute dataset mean and "
262 | "standard deviation. Maybe the dataset only contains forces."
263 | )
264 | return None
265 |
266 | self._mean = ys.mean(dim=0)[0].item()
267 | self._std = ys.std(dim=0)[0].item()
268 | log.info(f"mean: {self._mean}, std: {self._std}")
269 |
270 | def _prepare_QM9(self):
271 | """
272 | Load and prepare the QM9 dataset with appropriate splits.
273 |
274 | Returns:
275 | Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
276 | Indices for train, validation, and test splits.
277 | """
278 | # Apply position normalization if requested
279 | transform = normalize_positions if self.hparams["normalize_positions"] else None
280 | if transform:
281 | log.warning("Normalizing positions.")
282 |
283 | self.dataset = QM9(
284 | root=self.hparams["dataset_root"],
285 | dataset_arg=self.hparams["dataset_arg"],
286 | transform=transform
287 | )
288 |
289 | train_size = self.hparams["train_size"]
290 | val_size = self.hparams["val_size"]
291 |
292 | idx_train, idx_val, idx_test = make_splits(
293 | len(self.dataset),
294 | train_size,
295 | val_size,
296 | None,
297 | self.hparams["seed"],
298 | join(self.hparams["output_dir"], "splits.npz"),
299 | self.hparams["splits"],
300 | )
301 |
302 | return idx_train, idx_val, idx_test
303 |
--------------------------------------------------------------------------------
/gotennet/models/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sarpaykent/GotenNet/c561c05a1120118004912b248c944f74022b30cc/gotennet/models/__init__.py
--------------------------------------------------------------------------------
/gotennet/models/components/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sarpaykent/GotenNet/c561c05a1120118004912b248c944f74022b30cc/gotennet/models/components/__init__.py
--------------------------------------------------------------------------------
/gotennet/models/components/outputs.py:
--------------------------------------------------------------------------------
1 | from typing import Optional, Union
2 |
3 | import ase
4 | import torch
5 | import torch.nn.functional as F
6 | import torch_scatter
7 | from torch import nn
8 | from torch.autograd import grad
9 | from torch_geometric.utils import scatter
10 |
11 | from gotennet.models.components.layers import (
12 | Dense,
13 | GetItem,
14 | ScaleShift,
15 | SchnetMLP,
16 | shifted_softplus,
17 | str2act,
18 | )
19 | from gotennet.utils import get_logger
20 |
21 | log = get_logger(__name__)
22 |
23 |
24 | class GatedEquivariantBlock(nn.Module):
25 | """
26 | The gated equivariant block is used to obtain rotationally invariant and equivariant features to be used
27 | for tensorial prop.
28 | """
29 |
30 | def __init__(
31 | self,
32 | n_sin: int,
33 | n_vin: int,
34 | n_sout: int,
35 | n_vout: int,
36 | n_hidden: int,
37 | activation=F.silu,
38 | sactivation=None,
39 | ):
40 | """
41 | Initialize the GatedEquivariantBlock.
42 |
43 | Args:
44 | n_sin (int): Input dimension of scalar features.
45 | n_vin (int): Input dimension of vectorial features.
46 | n_sout (int): Output dimension of scalar features.
47 | n_vout (int): Output dimension of vectorial features.
48 | n_hidden (int): Size of hidden layers.
49 | activation: Activation of hidden layers.
50 | sactivation: Final activation to scalar features.
51 | """
52 | super().__init__()
53 | self.n_sin = n_sin
54 | self.n_vin = n_vin
55 | self.n_sout = n_sout
56 | self.n_vout = n_vout
57 | self.n_hidden = n_hidden
58 | self.mix_vectors = Dense(n_vin, 2 * n_vout, activation=None, bias=False)
59 | self.scalar_net = nn.Sequential(
60 | Dense(
61 | n_sin + n_vout, n_hidden, activation=activation
62 | ),
63 | Dense(n_hidden, n_sout + n_vout, activation=None),
64 | )
65 | self.sactivation = sactivation
66 |
67 | def forward(self, scalars: torch.Tensor, vectors: torch.Tensor):
68 | """
69 | Forward pass of the GatedEquivariantBlock.
70 |
71 | Args:
72 | scalars (torch.Tensor): Scalar input features.
73 | vectors (torch.Tensor): Vector input features.
74 |
75 | Returns:
76 | tuple: Tuple containing:
77 | - torch.Tensor: Output scalar features.
78 | - torch.Tensor: Output vector features.
79 | """
80 | vmix = self.mix_vectors(vectors)
81 | vectors_V, vectors_W = torch.split(vmix, self.n_vout, dim=-1)
82 | vectors_Vn = torch.norm(vectors_V, dim=-2)
83 |
84 | ctx = torch.cat([scalars, vectors_Vn], dim=-1)
85 | x = self.scalar_net(ctx)
86 | s_out, x = torch.split(x, [self.n_sout, self.n_vout], dim=-1)
87 | v_out = x.unsqueeze(-2) * vectors_W
88 |
89 | if self.sactivation:
90 | s_out = self.sactivation(s_out)
91 |
92 | return s_out, v_out
93 |
94 |
95 |
96 | class AtomwiseV3(nn.Module):
97 | """
98 | Atomwise prediction module V3 for predicting atomic properties.
99 | """
100 |
101 | def __init__(
102 | self,
103 | n_in: int,
104 | n_out: int = 1,
105 | aggregation_mode: Optional[str] = "sum",
106 | n_layers: int = 2,
107 | n_hidden: Optional[int] = None,
108 | activation = shifted_softplus,
109 | property: str = "y",
110 | contributions: Optional[str] = None,
111 | derivative: Optional[str] = None,
112 | negative_dr: bool = True,
113 | create_graph: bool = True,
114 | mean: Optional[Union[float, torch.Tensor]] = None,
115 | stddev: Optional[Union[float, torch.Tensor]] = None,
116 | atomref: Optional[torch.Tensor] = None,
117 | outnet: Optional[nn.Module] = None,
118 | return_vector: Optional[str] = None,
119 | standardize: bool = True,
120 | ):
121 | """
122 | Initialize the AtomwiseV3 module.
123 |
124 | Args:
125 | n_in (int): Input dimension of atomwise features.
126 | n_out (int): Output dimension of target property.
127 | aggregation_mode (Optional[str]): Aggregation method for atomic contributions.
128 | n_layers (int): Number of layers in the output network.
129 | n_hidden (Optional[int]): Size of hidden layers.
130 | activation: Activation function.
131 | property (str): Name of the target property.
132 | contributions (Optional[str]): Name of the atomic contributions.
133 | derivative (Optional[str]): Name of the property derivative.
134 | negative_dr (bool): If True, negative derivative of the energy.
135 | create_graph (bool): If True, create computational graph for derivatives.
136 | mean (Optional[Union[float, torch.Tensor]]): Mean of the property for standardization.
137 | stddev (Optional[Union[float, torch.Tensor]]): Standard deviation for standardization.
138 | atomref (Optional[torch.Tensor]): Reference single-atom properties.
139 | outnet (Optional[nn.Module]): Network for property prediction.
140 | return_vector (Optional[str]): Name of the vector property to return.
141 | standardize (bool): If True, standardize the output property.
142 | """
143 | super(AtomwiseV3, self).__init__()
144 |
145 | self.return_vector = return_vector
146 | self.n_layers = n_layers
147 | self.create_graph = create_graph
148 | self.property = property
149 | self.contributions = contributions
150 | self.derivative = derivative
151 | self.negative_dr = negative_dr
152 | self.standardize = standardize
153 |
154 |
155 | mean = 0.0 if mean is None else mean
156 | stddev = 1.0 if stddev is None else stddev
157 | self.mean = mean
158 | self.stddev = stddev
159 |
160 | if type(activation) is str:
161 | activation = str2act(activation)
162 |
163 | if atomref is not None:
164 | self.atomref = nn.Embedding.from_pretrained(
165 | atomref.type(torch.float32)
166 | )
167 | else:
168 | self.atomref = None
169 |
170 | if outnet is None:
171 | self.out_net = nn.Sequential(
172 | GetItem("representation"),
173 | SchnetMLP(n_in, n_out, n_hidden, n_layers, activation),
174 | )
175 | else:
176 | self.out_net = outnet
177 |
178 | # build standardization layer
179 | if self.standardize and (mean is not None and stddev is not None):
180 | self.standardize = ScaleShift(mean, stddev)
181 | else:
182 | self.standardize = nn.Identity()
183 |
184 | self.aggregation_mode = aggregation_mode
185 |
186 | def forward(self, inputs):
187 | """
188 | Predicts atomwise property.
189 |
190 | Args:
191 | inputs: Input data containing atomic representations.
192 |
193 | Returns:
194 | dict: Dictionary with predicted properties.
195 | """
196 | atomic_numbers = inputs.z
197 | result = {}
198 | yi = self.out_net(inputs)
199 | yi = yi * self.stddev
200 |
201 | if self.atomref is not None:
202 | y0 = self.atomref(atomic_numbers)
203 | yi = yi + y0
204 |
205 | if self.aggregation_mode is not None:
206 | y = torch_scatter.scatter(yi, inputs.batch, dim=0, reduce=self.aggregation_mode)
207 | else:
208 | y = yi
209 |
210 | y = y + self.mean
211 |
212 | # collect results
213 | result[self.property] = y
214 |
215 | if self.contributions:
216 | result[self.contributions] = yi
217 | if self.derivative:
218 | sign = -1.0 if self.negative_dr else 1.0
219 | dy = grad(
220 | outputs=result[self.property],
221 | inputs=[inputs.pos],
222 | grad_outputs=torch.ones_like(result[self.property]),
223 | create_graph=self.create_graph,
224 | retain_graph=True
225 | )[0]
226 |
227 | dy = sign * dy
228 | result[self.derivative] = dy
229 | return result
230 |
231 |
232 | class Atomwise(nn.Module):
233 | """
234 | Atomwise prediction module for predicting atomic properties.
235 | """
236 |
237 | def __init__(
238 | self,
239 | n_in: int,
240 | n_out: int = 1,
241 | aggregation_mode: Optional[str] = "sum",
242 | n_layers: int = 2,
243 | n_hidden: Optional[int] = None,
244 | activation = shifted_softplus,
245 | property: str = "y",
246 | contributions: Optional[str] = None,
247 | derivative: Optional[str] = None,
248 | negative_dr: bool = True,
249 | create_graph: bool = True,
250 | mean: Optional[torch.Tensor] = None,
251 | stddev: Optional[torch.Tensor] = None,
252 | atomref: Optional[torch.Tensor] = None,
253 | outnet: Optional[nn.Module] = None,
254 | return_vector: Optional[str] = None,
255 | standardize: bool = True,
256 | ):
257 | """
258 | Initialize the Atomwise module.
259 |
260 | Args:
261 | n_in (int): Input dimension of atomwise features.
262 | n_out (int): Output dimension of target property.
263 | aggregation_mode (Optional[str]): Aggregation method for atomic contributions.
264 | n_layers (int): Number of layers in the output network.
265 | n_hidden (Optional[int]): Size of hidden layers.
266 | activation: Activation function.
267 | property (str): Name of the target property.
268 | contributions (Optional[str]): Name of the atomic contributions.
269 | derivative (Optional[str]): Name of the property derivative.
270 | negative_dr (bool): If True, negative derivative of the energy.
271 | create_graph (bool): If True, create computational graph for derivatives.
272 | mean (Optional[torch.Tensor]): Mean of the property for standardization.
273 | stddev (Optional[torch.Tensor]): Standard deviation for standardization.
274 | atomref (Optional[torch.Tensor]): Reference single-atom properties.
275 | outnet (Optional[nn.Module]): Network for property prediction.
276 | return_vector (Optional[str]): Name of the vector property to return.
277 | standardize (bool): If True, standardize the output property.
278 | """
279 | super(Atomwise, self).__init__()
280 |
281 | self.return_vector = return_vector
282 | self.n_layers = n_layers
283 | self.create_graph = create_graph
284 | self.property = property
285 | self.contributions = contributions
286 | self.derivative = derivative
287 | self.negative_dr = negative_dr
288 | self.standardize = standardize
289 |
290 | mean = torch.FloatTensor([0.0]) if mean is None else mean
291 | stddev = torch.FloatTensor([1.0]) if stddev is None else stddev
292 |
293 | if type(activation) is str:
294 | activation = str2act(activation)
295 |
296 | # initialize single atom energies
297 | if atomref is not None:
298 | self.atomref = nn.Embedding.from_pretrained(
299 | atomref.type(torch.float32)
300 | )
301 | else:
302 | self.atomref = None
303 |
304 | self.equivariant = False
305 | # build output network
306 | if outnet is None:
307 | self.out_net = nn.Sequential(
308 | GetItem("representation"),
309 | SchnetMLP(n_in, n_out, n_hidden, n_layers, activation),
310 | )
311 | else:
312 | self.out_net = outnet
313 |
314 | # build standardization layer
315 | if self.standardize and (mean is not None and stddev is not None):
316 | log.info(f"Using standardization with mean {mean} and stddev {stddev}")
317 | self.standardize = ScaleShift(mean, stddev)
318 | else:
319 | self.standardize = nn.Identity()
320 |
321 | self.aggregation_mode = aggregation_mode
322 |
323 | def forward(self, inputs):
324 | """
325 | Predicts atomwise property.
326 |
327 | Args:
328 | inputs: Input data containing atomic representations.
329 |
330 | Returns:
331 | dict: Dictionary with predicted properties.
332 | """
333 | atomic_numbers = inputs.z
334 | result = {}
335 |
336 | if self.equivariant:
337 | l0 = inputs.representation
338 | l1 = inputs.vector_representation
339 | for eqlayer in self.out_net:
340 | l0, l1 = eqlayer(l0, l1)
341 |
342 | if self.return_vector:
343 | result[self.return_vector] = l1
344 | yi = l0
345 | else:
346 | yi = self.out_net(inputs)
347 | yi = self.standardize(yi)
348 |
349 | if self.atomref is not None:
350 | y0 = self.atomref(atomic_numbers)
351 | yi = yi + y0
352 |
353 |
354 | if self.aggregation_mode is not None:
355 | y = torch_scatter.scatter(yi, inputs.batch, dim=0, reduce=self.aggregation_mode)
356 | else:
357 | y = yi
358 |
359 | # collect results
360 | result[self.property] = y
361 |
362 | if self.contributions:
363 | result[self.contributions] = yi
364 |
365 | if self.derivative:
366 | sign = -1.0 if self.negative_dr else 1.0
367 | dy = grad(
368 | outputs=result[self.property],
369 | inputs=[inputs.pos],
370 | grad_outputs=torch.ones_like(result[self.property]),
371 | create_graph=self.create_graph,
372 | retain_graph=True
373 | )[0]
374 |
375 | result[self.derivative] = sign * dy
376 | return result
377 |
378 |
379 | class Dipole(nn.Module):
380 | """Output layer for dipole moment."""
381 |
382 | def __init__(
383 | self,
384 | n_in: int,
385 | n_hidden: Optional[int] = None,
386 | activation = F.silu,
387 | property: str = "dipole",
388 | predict_magnitude: bool = False,
389 | output_v: bool = True,
390 | mean: Optional[torch.Tensor] = None,
391 | stddev: Optional[torch.Tensor] = None,
392 | ):
393 | """
394 | Initialize the Dipole module.
395 |
396 | Args:
397 | n_in (int): Input dimension of atomwise features.
398 | n_hidden (Optional[int]): Size of hidden layers.
399 | activation: Activation function.
400 | property (str): Name of property to be predicted.
401 | predict_magnitude (bool): If true, calculate magnitude of dipole.
402 | output_v (bool): If true, output vector representation.
403 | mean (Optional[torch.Tensor]): Mean of the property for standardization.
404 | stddev (Optional[torch.Tensor]): Standard deviation for standardization.
405 | """
406 | super().__init__()
407 |
408 | self.stddev = stddev
409 | self.mean = mean
410 | self.output_v = output_v
411 | if n_hidden is None:
412 | n_hidden = n_in
413 |
414 | self.property = property
415 | self.derivative = None
416 | self.predict_magnitude = predict_magnitude
417 |
418 | self.equivariant_layers = nn.ModuleList(
419 | [
420 | GatedEquivariantBlock(n_sin=n_in, n_vin=n_in, n_sout=n_hidden, n_vout=n_hidden, n_hidden=n_hidden,
421 | activation=activation,
422 | sactivation=activation),
423 | GatedEquivariantBlock(n_sin=n_hidden, n_vin=n_hidden, n_sout=1, n_vout=1,
424 | n_hidden=n_hidden, activation=activation)
425 | ])
426 | self.requires_dr = False
427 | self.requires_stress = False
428 | self.aggregation_mode = 'sum'
429 |
430 | def forward(self, inputs):
431 | """
432 | Predicts dipole moment.
433 |
434 | Args:
435 | inputs: Input data containing atomic representations.
436 |
437 | Returns:
438 | dict: Dictionary with predicted dipole properties.
439 | """
440 | positions = inputs.pos
441 | l0 = inputs.representation
442 | l1 = inputs.vector_representation[:, :3, :]
443 |
444 |
445 | for eqlayer in self.equivariant_layers:
446 | l0, l1 = eqlayer(l0, l1)
447 |
448 | if self.stddev is not None:
449 | l0 = self.stddev * l0 + self.mean
450 |
451 | atomic_dipoles = torch.squeeze(l1, -1)
452 | charges = l0
453 | dipole_offsets = positions * charges
454 |
455 | y = atomic_dipoles + dipole_offsets
456 | # y = torch.sum(y, dim=1)
457 | y = torch_scatter.scatter(y, inputs.batch, dim=0, reduce=self.aggregation_mode)
458 | if self.output_v:
459 | y_vector = torch_scatter.scatter(l1, inputs.batch, dim=0, reduce=self.aggregation_mode)
460 |
461 |
462 | if self.predict_magnitude:
463 | y = torch.norm(y, dim=1, keepdim=True)
464 |
465 | result = {self.property: y}
466 | if self.output_v:
467 | result[self.property + "_vector"] = y_vector
468 | return result
469 |
470 |
471 | class ElectronicSpatialExtentV2(Atomwise):
472 | """Electronic spatial extent prediction module."""
473 |
474 | def __init__(
475 | self,
476 | n_in: int,
477 | n_layers: int = 2,
478 | n_hidden: Optional[int] = None,
479 | activation = shifted_softplus,
480 | property: str = "y",
481 | contributions: Optional[str] = None,
482 | mean: Optional[torch.Tensor] = None,
483 | stddev: Optional[torch.Tensor] = None,
484 | outnet: Optional[nn.Module] = None,
485 | ):
486 | """
487 | Initialize the ElectronicSpatialExtentV2 module.
488 |
489 | Args:
490 | n_in (int): Input dimension of atomwise features.
491 | n_layers (int): Number of layers in the output network.
492 | n_hidden (Optional[int]): Size of hidden layers.
493 | activation: Activation function.
494 | property (str): Name of the target property.
495 | contributions (Optional[str]): Name of the atomic contributions.
496 | mean (Optional[torch.Tensor]): Mean of the property for standardization.
497 | stddev (Optional[torch.Tensor]): Standard deviation for standardization.
498 | outnet (Optional[nn.Module]): Network for property prediction.
499 | """
500 | super(ElectronicSpatialExtentV2, self).__init__(
501 | n_in,
502 | 1,
503 | "sum",
504 | n_layers,
505 | n_hidden,
506 | activation=activation,
507 | mean=mean,
508 | stddev=stddev,
509 | outnet=outnet,
510 | property=property,
511 | contributions=contributions,
512 | )
513 | atomic_mass = torch.from_numpy(ase.data.atomic_masses).float()
514 | self.register_buffer("atomic_mass", atomic_mass)
515 |
516 | def forward(self, inputs):
517 | """
518 | Predicts the electronic spatial extent.
519 |
520 | Args:
521 | inputs: Input data containing atomic representations and positions.
522 |
523 | Returns:
524 | dict: Dictionary with predicted electronic spatial extent properties.
525 | """
526 | positions = inputs.pos
527 | x = self.out_net(inputs)
528 | mass = self.atomic_mass[inputs.z].view(-1, 1)
529 | c = scatter(mass * positions, inputs.batch, dim=0) / scatter(mass, inputs.batch, dim=0)
530 |
531 | yi = torch.norm(positions - c[inputs.batch], dim=1, keepdim=True)
532 | yi = yi ** 2 * x
533 |
534 | y = torch_scatter.scatter(yi, inputs.batch, dim=0, reduce=self.aggregation_mode)
535 |
536 | # collect results
537 | result = {self.property: y}
538 |
539 | if self.contributions:
540 | result[self.contributions] = x
541 |
542 | return result
543 |
--------------------------------------------------------------------------------
/gotennet/models/goten_model.py:
--------------------------------------------------------------------------------
1 | # Standard library imports
2 | from typing import Callable, Dict, Optional, TypeVar
3 |
4 | # Related third-party imports
5 | import pytorch_lightning as pl
6 | import torch
7 | import torch.nn as nn
8 | import torch.optim as opt
9 | from omegaconf import DictConfig
10 |
11 | from gotennet.utils import get_logger
12 |
13 | from ..utils.utils import get_function_name
14 |
15 | # Local application/library specific imports
16 | from .tasks import TASK_DICT
17 |
18 | BaseModuleType = TypeVar("BaseModelType", bound="nn.Module")
19 |
20 | log = get_logger(__name__)
21 |
22 |
23 | def lazy_instantiate(d):
24 | if isinstance(d, dict) or isinstance(d, DictConfig):
25 | for k, v in d.items():
26 | if k == "__target__":
27 | log.info(f"Lazy instantiation of {v} with hydra.utils.instantiate")
28 | d["_target_"] = d.pop("__target__")
29 | elif isinstance(v, dict) or isinstance(v, DictConfig):
30 | lazy_instantiate(v)
31 | return d
32 |
33 |
34 | class GotenModel(pl.LightningModule):
35 | """
36 | Atomistic model for molecular property prediction.
37 |
38 | This model combines a representation module with task-specific output modules
39 | to predict molecular properties.
40 | """
41 |
42 | def __init__(
43 | self,
44 | label: int,
45 | representation: nn.Module,
46 | task: str = "QM9",
47 | lr: float = 5e-4,
48 | lr_decay: float = 0.5,
49 | lr_patience: int = 100,
50 | lr_minlr: float = 1e-6,
51 | lr_monitor: str = "validation/ema_val_loss",
52 | weight_decay: float = 0.01,
53 | cutoff: float = 5.0,
54 | dataset_meta: Optional[Dict[str, Dict[int, torch.Tensor]]] = None,
55 | output: Optional[Dict] = None,
56 | scheduler: Optional[Callable] = None,
57 | save_predictions: Optional[bool] = None,
58 | task_config: Optional[Dict] = None,
59 | lr_warmup_steps: int = 0,
60 | use_ema: bool = False,
61 | **kwargs,
62 | ):
63 | """
64 | Initialize the atomistic model.
65 |
66 | Args:
67 | label: Target property index to predict.
68 | representation: Neural network module for atom/molecule representation.
69 | task: Task name, must be in TASK_DICT. Default is "QM9".
70 | lr: Learning rate. Default is 5e-4.
71 | lr_decay: Learning rate decay factor. Default is 0.5.
72 | lr_patience: Patience for learning rate scheduler. Default is 100.
73 | lr_minlr: Minimum learning rate. Default is 1e-6.
74 | lr_monitor: Metric to monitor for LR scheduling. Default is "validation/ema_val_loss".
75 | weight_decay: Weight decay for optimizer. Default is 0.01.
76 | cutoff: Cutoff distance for interactions. Default is 5.0.
77 | dataset_meta: Dataset metadata. Default is None.
78 | output: Output module configuration. Default is None.
79 | scheduler: Learning rate scheduler. Default is None.
80 | save_predictions: Whether to save predictions. Default is None.
81 | task_config: Task-specific configuration. Default is None.
82 | lr_warmup_steps: Number of warmup steps for learning rate. Default is 0.
83 | use_ema: Whether to use exponential moving average. Default is False.
84 | **kwargs: Additional keyword arguments.
85 | """
86 | super().__init__()
87 | self.use_ema = use_ema
88 | self.lr_warmup_steps = lr_warmup_steps
89 | self.lr_minlr = lr_minlr
90 |
91 | self.save_predictions = save_predictions
92 | if output is None:
93 | output = {}
94 |
95 | self.task = task
96 | self.label = label
97 |
98 | self.train_meta = []
99 | self.train_metrics = []
100 |
101 | self.cutoff = cutoff
102 | self.lr = lr
103 | self.lr_decay = lr_decay
104 | self.lr_patience = lr_patience
105 | self.lr_monitor = lr_monitor
106 | self.weight_decay = weight_decay
107 | self.dataset_meta = dataset_meta
108 | _dataset_obj = (
109 | dataset_meta.pop("dataset")
110 | if dataset_meta and "dataset" in dataset_meta
111 | else None
112 | )
113 |
114 | self.scheduler = scheduler
115 |
116 | self.save_hyperparameters()
117 |
118 | if isinstance(representation, DictConfig) and (
119 | "__target__" in representation or "_target_" in representation
120 | ):
121 | import hydra
122 |
123 | lazy_instantiate(representation)
124 | representation = hydra.utils.instantiate(representation)
125 |
126 | self.representation = representation
127 |
128 | if self.task in TASK_DICT:
129 | self.task_handler = TASK_DICT[self.task](
130 | representation, label, dataset_meta, task_config=task_config
131 | )
132 | self.evaluator = self.task_handler.get_evaluator()
133 | else:
134 | self.task_handler = None
135 | self.evaluator = None
136 |
137 | self.val_meta = self.get_metrics()
138 | self.val_metrics = nn.ModuleList([v["metric"]() for v in self.val_meta])
139 | self.test_meta = self.get_metrics()
140 | self.test_metrics = nn.ModuleList([v["metric"]() for v in self.test_meta])
141 |
142 | self.output_modules = self.get_output(output)
143 |
144 | self.loss_meta = self.get_losses()
145 | for loss in self.loss_meta:
146 | if "ema_rate" in loss:
147 | if "ema_stages" not in loss:
148 | loss["ema_stages"] = ["train", "validation"]
149 | self.loss_metrics = self.get_losses()
150 | self.loss_modules = nn.ModuleList([l["metric"]() for l in self.get_losses()])
151 |
152 | self.ema = {}
153 | for loss in self.get_losses():
154 | for stage in ["train", "validation", "test"]:
155 | self.ema[f"{stage}_{loss['target']}"] = None
156 |
157 | # For gradients
158 | self.requires_dr = any([om.derivative for om in self.output_modules])
159 |
160 | @classmethod
161 | def from_pretrained(
162 | cls,
163 | checkpoint_url: str, # Input is always a string
164 | ):
165 | from gotennet.utils.file import download_checkpoint
166 |
167 | ckpt_path = download_checkpoint(checkpoint_url)
168 | return cls.load_from_checkpoint(ckpt_path)
169 |
170 | def configure_model(self) -> None:
171 | """
172 | Configure the model. This method is called by PyTorch Lightning.
173 | """
174 | pass
175 |
176 | def get_losses(self) -> list:
177 | """
178 | Get loss functions for the model.
179 |
180 | Returns:
181 | list: List of loss function configurations.
182 |
183 | Raises:
184 | NotImplementedError: If task handler is not available.
185 | """
186 | if self.task_handler:
187 | return self.task_handler.get_losses()
188 | else:
189 | raise NotImplementedError()
190 |
191 | def get_metrics(self) -> list:
192 | """
193 | Get metrics for model evaluation.
194 |
195 | Returns:
196 | list: List of metric configurations.
197 |
198 | Raises:
199 | NotImplementedError: If task is not implemented.
200 | """
201 | if self.task_handler:
202 | return self.task_handler.get_metrics()
203 | else:
204 | raise NotImplementedError(f"Task not implemented {self.task}")
205 |
206 | def get_phase_metric(self, phase: str = "train") -> tuple:
207 | """
208 | Get metrics for a specific training phase.
209 |
210 | Args:
211 | phase: Training phase ('train', 'validation', or 'test'). Default is 'train'.
212 |
213 | Returns:
214 | tuple: Tuple of (metric_meta, metric_modules).
215 |
216 | Raises:
217 | NotImplementedError: If phase is not recognized.
218 | """
219 | if phase == "train":
220 | return self.train_meta, self.train_metrics
221 | elif phase == "validation":
222 | return self.val_meta, self.val_metrics
223 | elif phase == "test":
224 | return self.test_meta, self.test_metrics
225 |
226 | raise NotImplementedError()
227 |
228 | def get_output(self, output_config: Optional[Dict] = None) -> list:
229 | """
230 | Get output modules based on configuration.
231 |
232 | Args:
233 | output_config: Configuration for output modules. Default is None.
234 |
235 | Returns:
236 | list: List of output modules.
237 |
238 | Raises:
239 | NotImplementedError: If task is not implemented.
240 | """
241 | if self.task_handler:
242 | return self.task_handler.get_output(output_config)
243 | else:
244 | raise NotImplementedError("Task not implemented")
245 |
246 | def _get_num_graphs(self, batch) -> int:
247 | """
248 | Get the number of graphs in a batch.
249 |
250 | Args:
251 | batch: Batch of data.
252 |
253 | Returns:
254 | int: Number of graphs in the batch.
255 | """
256 | if type(batch) in [list, tuple]:
257 | batch = batch[0]
258 |
259 | return batch.num_graphs
260 |
261 | def calculate_output(self, batch) -> Dict:
262 | """
263 | Calculate model outputs for a batch.
264 |
265 | Args:
266 | batch: Batch of data.
267 |
268 | Returns:
269 | Dict: Dictionary of model outputs.
270 | """
271 | result = {}
272 | for output_model in self.output_modules:
273 | result.update(output_model(batch))
274 | return result
275 |
276 | def training_step(self, batch, batch_idx) -> torch.Tensor:
277 | """
278 | Perform a training step.
279 |
280 | Args:
281 | batch: Batch of data.
282 | batch_idx: Index of the batch.
283 |
284 | Returns:
285 | torch.Tensor: Loss value.
286 | """
287 | self._enable_grads(batch)
288 |
289 | batch.representation, batch.vector_representation = self.representation(batch)
290 |
291 | result = self.calculate_output(batch)
292 | loss = self.calculate_loss(batch, result, name="train")
293 | return loss
294 |
295 | def validation_step(self, batch, batch_idx, dataloader_idx: int = 0) -> Dict:
296 | """
297 | Perform a validation step.
298 |
299 | Args:
300 | batch: Batch of data.
301 | batch_idx: Index of the batch.
302 | dataloader_idx: Index of the dataloader. Default is 0.
303 |
304 | Returns:
305 | Dict: Dictionary of validation losses and outputs.
306 | """
307 | torch.set_grad_enabled(True)
308 | self._enable_grads(batch)
309 |
310 | batch.representation, batch.vector_representation = self.representation(batch)
311 |
312 | result = self.calculate_output(batch)
313 |
314 | torch.set_grad_enabled(False)
315 | val_loss = self.calculate_loss(batch, result, "validation").detach().item()
316 | self.log_metrics(batch, result, "validation")
317 | torch.set_grad_enabled(False)
318 |
319 | losses = {"val_loss": val_loss}
320 | self.log(
321 | "validation/val_loss",
322 | val_loss,
323 | prog_bar=True,
324 | on_step=False,
325 | on_epoch=True,
326 | batch_size=self._get_num_graphs(batch),
327 | )
328 | if self.evaluator:
329 | eval_keys = self.task_handler.get_evaluation_keys()
330 |
331 | losses["outputs"] = {
332 | "y_pred": result[eval_keys["pred"]].detach().cpu(),
333 | "y_true": batch[eval_keys["target"]].detach().cpu(),
334 | }
335 |
336 | return losses
337 |
338 | def test_step(self, batch, batch_idx, dataloader_idx: int = 0) -> Dict:
339 | """
340 | Perform a test step.
341 |
342 | Args:
343 | batch: Batch of data.
344 | batch_idx: Index of the batch.
345 | dataloader_idx: Index of the dataloader. Default is 0.
346 |
347 | Returns:
348 | Dict: Dictionary of test losses and outputs.
349 | """
350 | torch.set_grad_enabled(True)
351 | self._enable_grads(batch)
352 |
353 | batch.representation, batch.vector_representation = self.representation(batch)
354 |
355 | result = self.calculate_output(batch)
356 |
357 | torch.set_grad_enabled(False)
358 |
359 | _test_loss = self.calculate_loss(batch, result).detach().item()
360 | self.log_metrics(batch, result, "test")
361 | torch.set_grad_enabled(False)
362 |
363 | losses = {
364 | loss_dict["prediction"]: result[loss_dict["prediction"]].cpu()
365 | for loss_index, loss_dict in enumerate(self.loss_meta)
366 | }
367 |
368 | if self.evaluator:
369 | eval_keys = self.task_handler.get_evaluation_keys()
370 |
371 | losses["outputs"] = {
372 | "y_pred": result[eval_keys["pred"]].detach().cpu(),
373 | "y_true": batch[eval_keys["target"]].detach().cpu(),
374 | }
375 |
376 | return losses
377 |
378 | def encode(self, batch) -> object:
379 | """
380 | Encode a batch of data.
381 |
382 | Args:
383 | batch: Batch of data.
384 |
385 | Returns:
386 | batch: Batch with added representation.
387 | """
388 | torch.set_grad_enabled(True)
389 | self._enable_grads(batch)
390 | batch.representation, batch.vector_representation = self.representation(batch)
391 | return batch
392 |
393 | def forward(self, batch) -> Dict:
394 | """
395 | Forward pass through the model.
396 |
397 | Args:
398 | batch: Batch of data.
399 |
400 | Returns:
401 | Dict: Model outputs.
402 | """
403 | torch.set_grad_enabled(True)
404 | self._enable_grads(batch)
405 | batch.representation, batch.vector_representation = self.representation(batch)
406 |
407 | result = self.calculate_output(batch)
408 | torch.set_grad_enabled(False)
409 | return result
410 |
411 | def log_metrics(self, batch, result, mode: str) -> None:
412 | """
413 | Log metrics for a specific mode.
414 |
415 | Args:
416 | batch: Batch of data.
417 | result: Model outputs.
418 | mode: Mode ('train', 'validation', or 'test').
419 | """
420 | for idx, (metric_meta, metric_module) in enumerate(
421 | zip(*self.get_phase_metric(mode), strict=False)
422 | ):
423 | loss_fn = metric_module
424 |
425 | if "target" in metric_meta.keys():
426 | pred, targets = self.task_handler.process_outputs(
427 | batch, result, metric_meta, idx
428 | )
429 |
430 | pred = pred[:, :] if metric_meta["prediction"] == "force" else pred
431 | loss_i = loss_fn(pred, targets).detach().item()
432 | else:
433 | loss_i = loss_fn(result[metric_meta["prediction"]]).detach().item()
434 |
435 | lossname = get_function_name(loss_fn)
436 |
437 | if self.task_handler:
438 | var_name = self.task_handler.get_metric_names(metric_meta, idx)
439 |
440 | self.log(
441 | f"{mode}/{lossname}_{var_name}",
442 | loss_i,
443 | on_step=False,
444 | on_epoch=True,
445 | batch_size=self._get_num_graphs(batch),
446 | )
447 |
448 | def calculate_loss(self, batch, result, name: Optional[str] = None) -> torch.Tensor:
449 | """
450 | Calculate loss for a batch.
451 |
452 | Args:
453 | batch: Batch of data.
454 | result: Model outputs.
455 | name: Name of the phase ('train', 'validation', or 'test'). Default is None.
456 |
457 | Returns:
458 | torch.Tensor: Loss value.
459 | """
460 | loss = torch.tensor(0.0, device=self.device, dtype=self.dtype)
461 | if self.use_ema:
462 | og_loss = torch.tensor(0.0, device=self.device, dtype=self.dtype)
463 |
464 | for loss_index, loss_dict in enumerate(self.loss_meta):
465 | loss_fn = self.loss_modules[loss_index]
466 |
467 | if "target" in loss_dict.keys():
468 | pred, targets = self.task_handler.process_outputs(
469 | batch, result, loss_dict, loss_index
470 | )
471 | loss_i = loss_fn(pred, targets)
472 | else:
473 | loss_i = loss_fn(result[loss_dict["prediction"]])
474 |
475 | ema_addon = ""
476 | if self.use_ema:
477 | og_loss += loss_dict["loss_weight"] * loss_i
478 |
479 | # Check if EMA should be calculated
480 | if (
481 | "ema_rate" in loss_dict
482 | and name in loss_dict["ema_stages"]
483 | and (1.0 > loss_dict["ema_rate"] > 0.0)
484 | ):
485 | # Calculate EMA loss
486 | ema_key = f"{name}_{loss_dict['target']}"
487 | ema_addon = "_ema"
488 | if self.ema[ema_key] is None:
489 | self.ema[ema_key] = loss_i.detach()
490 | else:
491 | loss_ema = (
492 | loss_dict["ema_rate"] * loss_i
493 | + (1 - loss_dict["ema_rate"]) * self.ema[ema_key]
494 | )
495 | self.ema[ema_key] = loss_ema.detach()
496 | if self.use_ema:
497 | loss_i = loss_ema
498 |
499 | if name:
500 | self.log(
501 | f"{name}/{loss_dict['prediction']}{ema_addon}_loss",
502 | loss_i,
503 | on_step=True if name == "train" else False,
504 | on_epoch=True,
505 | prog_bar=True if name == "train" else False,
506 | batch_size=self._get_num_graphs(batch),
507 | )
508 | loss += loss_dict["loss_weight"] * loss_i
509 |
510 | if self.use_ema:
511 | self.log(
512 | f"{name}/val_loss_og",
513 | og_loss,
514 | on_step=True if name == "train" else False,
515 | on_epoch=True,
516 | batch_size=self._get_num_graphs(batch),
517 | )
518 |
519 | return loss
520 |
521 | def configure_optimizers(self) -> tuple:
522 | """
523 | Configure optimizers and learning rate schedulers.
524 |
525 | Returns:
526 | tuple: Tuple of (optimizers, schedulers).
527 | """
528 | optimizer = opt.AdamW(
529 | self.trainer.model.parameters(),
530 | lr=self.lr,
531 | weight_decay=self.weight_decay,
532 | # amsgrad=True, # changed based on gemnet
533 | eps=1e-7,
534 | )
535 |
536 | if self.scheduler:
537 | scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
538 | optimizer=optimizer, **self.scheduler
539 | )
540 | else:
541 | scheduler = opt.lr_scheduler.ReduceLROnPlateau(
542 | optimizer,
543 | factor=self.lr_decay,
544 | patience=self.lr_patience,
545 | min_lr=self.lr_minlr,
546 | )
547 |
548 | schedule = {
549 | "scheduler": scheduler,
550 | "monitor": self.lr_monitor,
551 | "interval": "epoch",
552 | "frequency": 1,
553 | "strict": True,
554 | }
555 |
556 | return [optimizer], [schedule]
557 |
558 | def optimizer_step(self, *args, **kwargs) -> None:
559 | """
560 | Perform an optimizer step with learning rate warmup.
561 |
562 | Args:
563 | *args: Variable length argument list.
564 | **kwargs: Arbitrary keyword arguments.
565 | """
566 | optimizer = kwargs["optimizer"] if "optimizer" in kwargs else args[2]
567 |
568 | if self.trainer.global_step < self.hparams.lr_warmup_steps:
569 | lr_scale = min(
570 | 1.0,
571 | float(self.trainer.global_step + 1)
572 | / float(self.hparams.lr_warmup_steps),
573 | )
574 | for pg in optimizer.param_groups:
575 | pg["lr"] = lr_scale * self.hparams.lr
576 |
577 | super().optimizer_step(*args, **kwargs)
578 | optimizer.zero_grad()
579 |
580 | def _enable_grads(self, batch) -> None:
581 | """
582 | Enable gradients for position tensor if derivatives are required.
583 |
584 | Args:
585 | batch: Batch of data.
586 | """
587 | if self.requires_dr:
588 | batch.pos.requires_grad_()
589 |
--------------------------------------------------------------------------------
/gotennet/models/representation/gotennet.py:
--------------------------------------------------------------------------------
1 | # Standard library imports
2 | from functools import partial
3 | from typing import Callable, List, Mapping, Optional, Tuple, Union
4 |
5 | # Related third-party imports
6 | import numpy as np
7 | import torch
8 | import torch.nn as nn
9 | import torch.nn.functional as F
10 | from torch import Tensor
11 | from torch_geometric.nn import MessagePassing
12 | from torch_geometric.typing import OptTensor
13 | from torch_geometric.utils import scatter, softmax
14 |
15 | # Local application/library specific imports
16 | import gotennet.utils as utils
17 | from gotennet.models.components.layers import (
18 | MLP,
19 | CosineCutoff,
20 | Dense,
21 | Distance,
22 | EdgeInit,
23 | NodeInit,
24 | TensorInit,
25 | TensorLayerNorm,
26 | get_weight_init_by_string,
27 | str2act,
28 | str2basis,
29 | )
30 |
31 | log = utils.get_logger(__name__)
32 |
33 | # num_nodes and hidden_dims are placeholder values, will be overwritten by actual data
34 | num_nodes = hidden_dims = 1
35 |
36 |
37 | def get_split_sizes_from_lmax(lmax: int, start: int = 1) -> List[int]:
38 | """
39 | Return split sizes for torch.split based on lmax.
40 |
41 | This function calculates the dimensions of spherical harmonic components
42 | for each angular momentum value from start to lmax.
43 |
44 | Args:
45 | lmax: Maximum angular momentum value
46 | start: Starting angular momentum value (default: 1)
47 |
48 | Returns:
49 | List of split sizes for torch.split (sizes of spherical harmonic components)
50 | """
51 | return [2 * l + 1 for l in range(start, lmax + 1)]
52 |
53 |
54 | def split_to_components(
55 | tensor: Tensor, lmax: int, start: int = 1, dim: int = -1
56 | ) -> List[Tensor]:
57 | """
58 | Split a tensor into its spherical harmonic components.
59 |
60 | This function splits a tensor containing concatenated spherical harmonic components
61 | into a list of separate tensors, each corresponding to a specific angular momentum.
62 |
63 | Args:
64 | tensor: The tensor to split [*, sum(2l+1 for l in range(start, lmax+1)), *]
65 | lmax: Maximum angular momentum value
66 | start: Starting angular momentum value (default: 1)
67 | dim: The dimension to split along (default: -1)
68 |
69 | Returns:
70 | List of tensors, each representing a spherical harmonic component
71 | """
72 | split_sizes = get_split_sizes_from_lmax(lmax, start=start)
73 | components = torch.split(tensor, split_sizes, dim=dim)
74 | return components
75 |
76 |
77 | class GATA(MessagePassing):
78 | def __init__(
79 | self,
80 | n_atom_basis: int,
81 | activation: Callable,
82 | weight_init: Callable = nn.init.xavier_uniform_,
83 | bias_init: Callable = nn.init.zeros_,
84 | aggr: str = "add",
85 | node_dim: int = 0,
86 | epsilon: float = 1e-7,
87 | layer_norm: str = "",
88 | steerable_norm: str = "",
89 | cutoff: float = 5.0,
90 | num_heads: int = 8,
91 | dropout: float = 0.0,
92 | edge_updates: Union[bool, str] = True,
93 | last_layer: bool = False,
94 | scale_edge: bool = True,
95 | evec_dim: Optional[int] = None,
96 | emlp_dim: Optional[int] = None,
97 | sep_htr: bool = True,
98 | sep_dir: bool = True,
99 | sep_tensor: bool = True,
100 | lmax: int = 2,
101 | edge_ln: str = "",
102 | ):
103 | """
104 | Graph Attention Transformer Architecture.
105 |
106 | Args:
107 | n_atom_basis: Number of features to describe atomic environments.
108 | activation: Activation function to be used. If None, no activation function is used.
109 | weight_init: Weight initialization function.
110 | bias_init: Bias initialization function.
111 | aggr: Aggregation method ('add', 'mean' or 'max').
112 | node_dim: The axis along which to aggregate.
113 | epsilon: Small constant for numerical stability.
114 | layer_norm: Type of layer normalization to use.
115 | steerable_norm: Type of steerable normalization to use.
116 | cutoff: Cutoff distance for interactions.
117 | num_heads: Number of attention heads.
118 | dropout: Dropout probability.
119 | edge_updates: Whether to update edge features.
120 | last_layer: Whether this is the last layer.
121 | scale_edge: Whether to scale edge features.
122 | evec_dim: Dimension of edge vector features.
123 | emlp_dim: Dimension of edge MLP features.
124 | sep_htr: Whether to separate vector features.
125 | sep_dir: Whether to separate direction features.
126 | sep_tensor: Whether to separate tensor features.
127 | lmax: Maximum angular momentum.
128 | """
129 | super(GATA, self).__init__(aggr=aggr, node_dim=node_dim)
130 | self.sep_htr = sep_htr
131 | self.epsilon = epsilon
132 | self.last_layer = last_layer
133 | self.edge_updates = edge_updates
134 | self.scale_edge = scale_edge
135 | self.activation = activation
136 | self.sep_dir = sep_dir
137 | self.sep_tensor = sep_tensor
138 |
139 | # Parse edge update configuration
140 | update_info = {
141 | "gated": False,
142 | "rej": True,
143 | "mlp": False,
144 | "mlpa": False,
145 | "lin_w": 0,
146 | "lin_ln": 0,
147 | }
148 |
149 | update_parts = edge_updates.split("_") if isinstance(edge_updates, str) else []
150 | allowed_parts = [
151 | "gated",
152 | "gatedt",
153 | "norej",
154 | "norm",
155 | "mlp",
156 | "mlpa",
157 | "act",
158 | "linw",
159 | "linwa",
160 | "ln",
161 | "postln",
162 | ]
163 |
164 | if not all([part in allowed_parts for part in update_parts]):
165 | raise ValueError(
166 | f"Invalid edge update parts. Allowed parts are {allowed_parts}"
167 | )
168 |
169 | if "gated" in update_parts:
170 | update_info["gated"] = "gated"
171 | if "gatedt" in update_parts:
172 | update_info["gated"] = "gatedt"
173 | if "act" in update_parts:
174 | update_info["gated"] = "act"
175 | if "norej" in update_parts:
176 | update_info["rej"] = False
177 | if "mlp" in update_parts:
178 | update_info["mlp"] = True
179 | if "mlpa" in update_parts:
180 | update_info["mlpa"] = True
181 | if "linw" in update_parts:
182 | update_info["lin_w"] = 1
183 | if "linwa" in update_parts:
184 | update_info["lin_w"] = 2
185 | if "ln" in update_parts:
186 | update_info["lin_ln"] = 1
187 | if "postln" in update_parts:
188 | update_info["lin_ln"] = 2
189 |
190 | self.update_info = update_info
191 | log.info(f"Edge updates: {update_info}")
192 |
193 | self.dropout = dropout
194 | self.n_atom_basis = n_atom_basis
195 | self.lmax = lmax
196 |
197 | # Calculate multiplier based on configuration
198 | multiplier = 3
199 | if self.sep_dir:
200 | multiplier += lmax - 1
201 | if self.sep_tensor:
202 | multiplier += lmax - 1
203 | self.multiplier = multiplier
204 |
205 | # Initialize layers
206 | InitDense = partial(Dense, weight_init=weight_init, bias_init=bias_init)
207 |
208 | # Implementation of gamma_s function
209 | self.gamma_s = nn.Sequential(
210 | InitDense(n_atom_basis, n_atom_basis, activation=activation),
211 | InitDense(n_atom_basis, multiplier * n_atom_basis, activation=None),
212 | )
213 |
214 | self.num_heads = num_heads
215 |
216 | # Query and key transformations
217 | self.W_q = InitDense(n_atom_basis, n_atom_basis, activation=None)
218 | self.W_k = InitDense(n_atom_basis, n_atom_basis, activation=None)
219 |
220 | # Value transformation
221 | self.gamma_v = nn.Sequential(
222 | InitDense(n_atom_basis, n_atom_basis, activation=activation),
223 | InitDense(n_atom_basis, multiplier * n_atom_basis, activation=None),
224 | )
225 |
226 | # Edge feature transformations
227 | self.W_re = InitDense(
228 | n_atom_basis,
229 | n_atom_basis,
230 | activation=activation,
231 | )
232 |
233 | # Initialize MLP for edge updates
234 | InitMLP = partial(MLP, weight_init=weight_init, bias_init=bias_init)
235 |
236 | self.edge_vec_dim = n_atom_basis if evec_dim is None else evec_dim
237 | self.edge_mlp_dim = n_atom_basis if emlp_dim is None else emlp_dim
238 |
239 | if not self.last_layer and self.edge_updates:
240 | if self.update_info["mlp"] or self.update_info["mlpa"]:
241 | dims = [n_atom_basis, self.edge_mlp_dim, n_atom_basis]
242 | else:
243 | dims = [n_atom_basis, n_atom_basis]
244 |
245 | self.gamma_t = InitMLP(
246 | dims,
247 | activation=activation,
248 | last_activation=None if self.update_info["mlp"] else self.activation,
249 | norm=edge_ln,
250 | )
251 |
252 | self.W_vq = InitDense(
253 | n_atom_basis, self.edge_vec_dim, activation=None, bias=False
254 | )
255 |
256 | if self.sep_htr:
257 | self.W_vk = nn.ModuleList(
258 | [
259 | InitDense(
260 | n_atom_basis, self.edge_vec_dim, activation=None, bias=False
261 | )
262 | for _i in range(self.lmax)
263 | ]
264 | )
265 | else:
266 | self.W_vk = InitDense(
267 | n_atom_basis, self.edge_vec_dim, activation=None, bias=False
268 | )
269 |
270 | modules = []
271 | if self.update_info["lin_w"] > 0:
272 | if self.update_info["lin_ln"] == 1:
273 | modules.append(nn.LayerNorm(self.edge_vec_dim))
274 | if self.update_info["lin_w"] % 10 == 2:
275 | modules.append(self.activation)
276 |
277 | self.W_edp = InitDense(
278 | self.edge_vec_dim,
279 | n_atom_basis,
280 | activation=None,
281 | norm="layer" if self.update_info["lin_ln"] == 2 else "",
282 | )
283 |
284 | modules.append(self.W_edp)
285 |
286 | if self.update_info["gated"] == "gatedt":
287 | modules.append(nn.Tanh())
288 | elif self.update_info["gated"] == "gated":
289 | modules.append(nn.Sigmoid())
290 | elif self.update_info["gated"] == "act":
291 | modules.append(nn.SiLU())
292 | self.gamma_w = nn.Sequential(*modules)
293 |
294 | # Cutoff function
295 | self.cutoff = CosineCutoff(cutoff)
296 | self._alpha = None
297 |
298 | # Spatial filter
299 | self.W_rs = InitDense(
300 | n_atom_basis,
301 | n_atom_basis * self.multiplier,
302 | activation=None,
303 | )
304 |
305 | # Normalization layers
306 | self.layernorm_ = layer_norm
307 | self.steerable_norm_ = steerable_norm
308 | self.layernorm = (
309 | nn.LayerNorm(n_atom_basis) if layer_norm != "" else nn.Identity()
310 | )
311 | self.tensor_layernorm = (
312 | TensorLayerNorm(n_atom_basis, trainable=False, lmax=self.lmax)
313 | if steerable_norm != ""
314 | else nn.Identity()
315 | )
316 |
317 | self.reset_parameters()
318 |
319 | def reset_parameters(self):
320 | """Reset all learnable parameters of the module."""
321 | if self.layernorm_:
322 | self.layernorm.reset_parameters()
323 |
324 | if self.steerable_norm_:
325 | self.tensor_layernorm.reset_parameters()
326 |
327 | for l in self.gamma_s:
328 | l.reset_parameters()
329 |
330 | self.W_q.reset_parameters()
331 | self.W_k.reset_parameters()
332 |
333 | for l in self.gamma_v:
334 | l.reset_parameters()
335 |
336 | self.W_rs.reset_parameters()
337 |
338 | if not self.last_layer and self.edge_updates:
339 | self.gamma_t.reset_parameters()
340 | self.W_vq.reset_parameters()
341 |
342 | if self.sep_htr:
343 | for w in self.W_vk:
344 | w.reset_parameters()
345 | else:
346 | self.W_vk.reset_parameters()
347 |
348 | if self.update_info["lin_w"] > 0:
349 | self.W_edp.reset_parameters()
350 |
351 | @staticmethod
352 | def vector_rejection(rep: Tensor, rl_ij: Tensor) -> Tensor:
353 | """
354 | Compute the vector rejection of vec onto rl_ij.
355 |
356 | Args:
357 | rep: Input tensor representation [num_edges, (L_max ** 2) - 1, hidden_dims]
358 | rl_ij: High-degree steerable feature tensor [num_edges, (L_max ** 2) - 1, 1]
359 |
360 | Returns:
361 | The component of vec orthogonal to rl_ij
362 | """
363 | vec_proj = (rep * rl_ij.unsqueeze(2)).sum(dim=1, keepdim=True)
364 | return rep - vec_proj * rl_ij.unsqueeze(2)
365 |
366 | def forward(
367 | self,
368 | edge_index: Tensor,
369 | h: Tensor,
370 | X: Tensor,
371 | rl_ij: Tensor,
372 | t_ij: Tensor,
373 | r_ij: Tensor,
374 | n_edges: Tensor,
375 | ) -> Tuple[Tensor, Tensor, Tensor]:
376 | """
377 | Compute interaction output for the GATA layer.
378 |
379 | This method processes node and edge features through the attention mechanism
380 | and updates both scalar and high-degree steerable features.
381 |
382 | Args:
383 | edge_index: Tensor describing graph connectivity [2, num_edges]
384 | h: Scalar input values [num_nodes, 1, hidden_dims]
385 | X: High-degree steerable features [num_nodes, (L_max ** 2) - 1, hidden_dims]
386 | rl_ij: Edge tensor representation [num_nodes, (L_max ** 2) - 1, 1]
387 | t_ij: Edge scalar features [num_nodes, 1, hidden_dims]
388 | r_ij: Edge scalar distance [num_nodes, 1]
389 | n_edges: Number of edges per node [num_edges, 1]
390 |
391 | Returns:
392 | Tuple containing:
393 | - Updated scalar values [num_nodes, 1, hidden_dims]
394 | - Updated high-degree steerable features [num_nodes, (L_max ** 2) - 1, hidden_dims]
395 | - Updated edge features [num_edges, 1, hidden_dims]
396 | """
397 | h = self.layernorm(h)
398 | X = self.tensor_layernorm(X)
399 |
400 | q = self.W_q(h).reshape(-1, self.num_heads, self.n_atom_basis // self.num_heads)
401 | k = self.W_k(h).reshape(-1, self.num_heads, self.n_atom_basis // self.num_heads)
402 |
403 | # inter-atomic
404 | x = self.gamma_s(h)
405 | v = self.gamma_v(h)
406 | t_ij_attn = self.W_re(t_ij)
407 | t_ij_filter = self.W_rs(t_ij)
408 |
409 | # propagate_type: (x: Tensor, q:Tensor, k:Tensor, v:Tensor, X: Tensor,
410 | # t_ij_filter: Tensor, t_ij_attn: Tensor, r_ij: Tensor,
411 | # rl_ij: Tensor, n_edges: Tensor)
412 | d_h, d_X = self.propagate(
413 | edge_index=edge_index,
414 | x=x,
415 | q=q,
416 | k=k,
417 | v=v,
418 | X=X,
419 | t_ij_filter=t_ij_filter,
420 | t_ij_attn=t_ij_attn,
421 | r_ij=r_ij,
422 | rl_ij=rl_ij,
423 | n_edges=n_edges,
424 | )
425 |
426 | h = h + d_h
427 | X = X + d_X
428 |
429 | if not self.last_layer and self.edge_updates:
430 | X_htr = X
431 |
432 | EQ = self.W_vq(X_htr)
433 | if self.sep_htr:
434 | X_split = torch.split(
435 | X_htr, get_split_sizes_from_lmax(self.lmax), dim=1
436 | )
437 | EK = torch.concat(
438 | [w(X_split[i]) for i, w in enumerate(self.W_vk)], dim=1
439 | )
440 | else:
441 | EK = self.W_vk(X_htr)
442 |
443 | # edge_updater_type: (EQ: Tensor, EK:Tensor, rl_ij: Tensor, t_ij: Tensor)
444 | dt_ij = self.edge_updater(edge_index, EQ=EQ, EK=EK, rl_ij=rl_ij, t_ij=t_ij)
445 | t_ij = t_ij + dt_ij
446 | self._alpha = None
447 | return h, X, t_ij
448 |
449 | self._alpha = None
450 | return h, X, t_ij
451 |
452 | def message(
453 | self,
454 | edge_index: Tensor,
455 | x_j: Tensor,
456 | q_i: Tensor,
457 | k_j: Tensor,
458 | v_j: Tensor,
459 | X_j: Tensor,
460 | t_ij_filter: Tensor,
461 | t_ij_attn: Tensor,
462 | r_ij: Tensor,
463 | rl_ij: Tensor,
464 | n_edges: Tensor,
465 | index: Tensor,
466 | ptr: OptTensor,
467 | dim_size: Optional[int],
468 | ) -> Tuple[Tensor, Tensor]:
469 | """
470 | Compute messages from source nodes to target nodes.
471 |
472 | This method implements the message passing mechanism for the GATA layer,
473 | combining attention-based and spatial filtering approaches.
474 |
475 | Args:
476 | edge_index: Edge connectivity tensor [2, num_edges]
477 | x_j: Source node features [num_edges, 1, hidden_dims]
478 | q_i: Target node query features [num_edges, num_heads, hidden_dims // num_heads]
479 | k_j: Source node key features [num_edges, num_heads, hidden_dims // num_heads]
480 | v_j: Source node value features [num_edges, num_heads, hidden_dims * multiplier // num_heads]
481 | X_j: Source node high-degree steerable features [num_edges, (L_max ** 2) - 1, hidden_dims]
482 | t_ij_filter: Edge scalar filter features [num_edges, 1, hidden_dims]
483 | t_ij_attn: Edge attention filter features [num_edges, 1, hidden_dims]
484 | r_ij: Edge scalar distance [num_edges, 1]
485 | rl_ij: Edge tensor representation [num_edges, (L_max ** 2) - 1, 1]
486 | n_edges: Number of edges per node [num_edges, 1]
487 | index: Index tensor for scatter operation
488 | ptr: Pointer tensor for scatter operation
489 | dim_size: Dimension size for scatter operation
490 |
491 | Returns:
492 | Tuple containing:
493 | - Scalar updates dh [num_edges, 1, hidden_dims]
494 | - High-degree steerable updates dX [num_edges, (L_max ** 2) - 1, hidden_dims]
495 | """
496 | # Reshape attention features
497 | t_ij_attn = t_ij_attn.reshape(
498 | -1, self.num_heads, self.n_atom_basis // self.num_heads
499 | )
500 |
501 | # Compute attention scores
502 | attn = (q_i * k_j * t_ij_attn).sum(dim=-1, keepdim=True)
503 | attn = softmax(attn, index, ptr, dim_size)
504 |
505 | # Normalize the attention scores
506 | if self.scale_edge:
507 | norm = torch.sqrt(n_edges.reshape(-1, 1, 1)) / np.sqrt(self.n_atom_basis)
508 | else:
509 | norm = 1.0 / np.sqrt(self.n_atom_basis)
510 |
511 | attn = attn * norm
512 | self._alpha = attn
513 | attn = F.dropout(attn, p=self.dropout, training=self.training)
514 |
515 | # Apply attention to values
516 | sea_ij = attn * v_j.reshape(
517 | -1, self.num_heads, (self.n_atom_basis * self.multiplier) // self.num_heads
518 | )
519 | sea_ij = sea_ij.reshape(-1, 1, self.n_atom_basis * self.multiplier)
520 |
521 | # Apply spatial filter
522 | spatial_attn = (
523 | t_ij_filter.unsqueeze(1)
524 | * x_j
525 | * self.cutoff(r_ij.unsqueeze(-1).unsqueeze(-1))
526 | )
527 |
528 | # Combine attention and spatial components
529 | outputs = spatial_attn + sea_ij
530 |
531 | # Split outputs into components
532 | components = torch.split(outputs, self.n_atom_basis, dim=-1)
533 |
534 | o_s_ij = components[0]
535 | components = components[1:]
536 |
537 | # Process direction components if enabled
538 | if self.sep_dir:
539 | o_d_l_ij, components = components[: self.lmax], components[self.lmax :]
540 | rl_ij_split = split_to_components(rl_ij[..., None], self.lmax, dim=1)
541 | dir_comps = [rl_ij_split[i] * o_d_l_ij[i] for i in range(self.lmax)]
542 | dX_R = torch.cat(dir_comps, dim=1)
543 | else:
544 | o_d_ij, components = components[0], components[1:]
545 | dX_R = o_d_ij * rl_ij[..., None]
546 |
547 | # Process tensor components if enabled
548 | if self.sep_tensor:
549 | o_t_l_ij = components[: self.lmax]
550 | X_j_split = split_to_components(X_j, self.lmax, dim=1)
551 | tensor_comps = [X_j_split[i] * o_t_l_ij[i] for i in range(self.lmax)]
552 | dX_X = torch.cat(tensor_comps, dim=1)
553 | else:
554 | o_t_ij = components[0]
555 | dX_X = o_t_ij * X_j
556 |
557 | # Combine components
558 | dX = dX_R + dX_X
559 | return o_s_ij, dX
560 |
561 | def edge_update(
562 | self, EQ_i: Tensor, EK_j: Tensor, rl_ij: Tensor, t_ij: Tensor
563 | ) -> Tensor:
564 | """
565 | Update edge features based on node features.
566 |
567 | This method computes updates to edge features by combining information from
568 | source and target nodes' high-degree steerable features, potentially applying
569 | vector rejection.
570 |
571 | Args:
572 | EQ_i: Source node high-degree steerable features [num_edges, (L_max ** 2) - 1, hidden_dims]
573 | EK_j: Target node high-degree steerable features [num_edges, (L_max ** 2) - 1, hidden_dims]
574 | rl_ij: Edge tensor representation [num_edges, (L_max ** 2) - 1, 1]
575 | t_ij: Edge scalar features [num_edges, 1, hidden_dims]
576 |
577 | Returns:
578 | Updated edge features [num_edges, 1, hidden_dims]
579 | """
580 | if self.sep_htr:
581 | EQ_i_split = split_to_components(EQ_i, self.lmax, dim=1)
582 | EK_j_split = split_to_components(EK_j, self.lmax, dim=1)
583 | rl_ij_split = split_to_components(rl_ij, self.lmax, dim=1)
584 |
585 | pairs = []
586 | for l in range(len(EQ_i_split)):
587 | if self.update_info["rej"]:
588 | EQ_i_l = self.vector_rejection(EQ_i_split[l], rl_ij_split[l])
589 | EK_j_l = self.vector_rejection(EK_j_split[l], -rl_ij_split[l])
590 | else:
591 | EQ_i_l = EQ_i_split[l]
592 | EK_j_l = EK_j_split[l]
593 | pairs.append((EQ_i_l, EK_j_l))
594 | elif not self.update_info["rej"]:
595 | pairs = [(EQ_i, EK_j)]
596 | else:
597 | EQr_i = self.vector_rejection(EQ_i, rl_ij)
598 | EKr_j = self.vector_rejection(EK_j, -rl_ij)
599 | pairs = [(EQr_i, EKr_j)]
600 |
601 | # Compute edge weights
602 | w_ij = None
603 | for el in pairs:
604 | EQ_i_l, EK_j_l = el
605 | w_l = (EQ_i_l * EK_j_l).sum(dim=1)
606 | if w_ij is None:
607 | w_ij = w_l
608 | else:
609 | w_ij = w_ij + w_l
610 |
611 | return self.gamma_t(t_ij) * self.gamma_w(w_ij)
612 |
613 | def aggregate(
614 | self,
615 | features: Tuple[Tensor, Tensor],
616 | index: Tensor,
617 | ptr: Optional[Tensor],
618 | dim_size: Optional[int],
619 | ) -> Tuple[Tensor, Tensor]:
620 | """
621 | Aggregate messages from source nodes to target nodes.
622 |
623 | This method implements the aggregation step of message passing, combining
624 | messages from neighboring nodes according to the specified aggregation method.
625 |
626 | Args:
627 | features: Tuple of scalar and vector features (h, X)
628 | index: Index tensor for scatter operation
629 | ptr: Pointer tensor for scatter operation
630 | dim_size: Dimension size for scatter operation
631 |
632 | Returns:
633 | Tuple containing:
634 | - Aggregated scalar features [num_nodes, 1, hidden_dims]
635 | - Aggregated high-degree steerable features [num_nodes, (L_max ** 2) - 1, hidden_dims]
636 | """
637 | h, X = features
638 | h = scatter(h, index, dim=self.node_dim, dim_size=dim_size, reduce=self.aggr)
639 | X = scatter(X, index, dim=self.node_dim, dim_size=dim_size, reduce=self.aggr)
640 | return h, X
641 |
642 | def update(self, inputs: Tuple[Tensor, Tensor]) -> Tuple[Tensor, Tensor]:
643 | """
644 | Update node features with aggregated messages.
645 |
646 | This method implements the update step of message passing. In this implementation,
647 | it simply passes through the aggregated features without additional processing.
648 |
649 | Args:
650 | inputs: Tuple of aggregated scalar and high-degree steerable features
651 |
652 | Returns:
653 | Tuple containing:
654 | - Updated scalar features [num_nodes, 1, hidden_dims]
655 | - Updated high-degree steerable features [num_nodes, (L_max ** 2) - 1, hidden_dims]
656 | """
657 | return inputs
658 |
659 |
660 | class EQFF(nn.Module):
661 | """
662 | Equivariant Feed-Forward (EQFF) Network for mixing atom features.
663 |
664 | This module facilitates efficient channel-wise interaction while maintaining equivariance.
665 | It separates scalar and high-degree steerable features, allowing for specialized processing
666 | of each feature type before combining them with non-linear mappings as described in the paper:
667 |
668 | EQFF(h, X^(l)) = (h + m_1, X^(l) + m_2 * (X^(l)W_{vu}))
669 | where m_1, m_2 = split_2(gamma_{m}(||X^(l)W_{vu}||_2, h))
670 | """
671 |
672 | def __init__(
673 | self,
674 | n_atom_basis: int,
675 | activation: Callable,
676 | lmax: int,
677 | epsilon: float = 1e-8,
678 | weight_init: Callable = nn.init.xavier_uniform_,
679 | bias_init: Callable = nn.init.zeros_,
680 | ):
681 | """
682 | Initialize EQFF module.
683 |
684 | Args:
685 | n_atom_basis: Number of features to describe atomic environments.
686 | activation: Activation function. If None, no activation function is used.
687 | lmax: Maximum angular momentum.
688 | epsilon: Stability constant added in norm to prevent numerical instabilities.
689 | weight_init: Weight initialization function.
690 | bias_init: Bias initialization function.
691 | """
692 | super(EQFF, self).__init__()
693 | self.lmax = lmax
694 | self.n_atom_basis = n_atom_basis
695 | self.epsilon = epsilon
696 |
697 | InitDense = partial(Dense, weight_init=weight_init, bias_init=bias_init)
698 |
699 | context_dim = 2 * n_atom_basis
700 | out_size = 2
701 |
702 | # gamma_m implementation
703 | self.gamma_m = nn.Sequential(
704 | InitDense(context_dim, n_atom_basis, activation=activation),
705 | InitDense(n_atom_basis, out_size * n_atom_basis, activation=None),
706 | )
707 |
708 | self.W_vu = InitDense(n_atom_basis, n_atom_basis, activation=None, bias=False)
709 |
710 | def reset_parameters(self):
711 | """Reset all learnable parameters of the module."""
712 | self.W_vu.reset_parameters()
713 | for l in self.gamma_m:
714 | l.reset_parameters()
715 |
716 | def forward(self, h: Tensor, X: Tensor) -> Tuple[Tensor, Tensor]:
717 | """
718 | Compute intraatomic mixing.
719 |
720 | Args:
721 | h: Scalar input values, [num_nodes, 1, hidden_dims].
722 | X: High-degree steerable features, [num_nodes, (L_max ** 2) - 1, hidden_dims].
723 |
724 | Returns:
725 | Tuple of updated scalar values and high-degree steerable features,
726 | each of shape [num_nodes, 1, hidden_dims] and [num_nodes, (L_max ** 2) - 1, hidden_dims].
727 | """
728 | X_p = self.W_vu(X)
729 |
730 | # Compute norm of X_V with numerical stability
731 | X_pn = torch.sqrt(torch.sum(X_p**2, dim=-2, keepdim=True) + self.epsilon)
732 |
733 | # Concatenate features for context
734 | channel_context = [h, X_pn]
735 | ctx = torch.cat(channel_context, dim=-1)
736 |
737 | # Apply gamma_m transformation
738 | x = self.gamma_m(ctx)
739 |
740 | # Split output into scalar and vector components
741 | m1, m2 = torch.split(x, self.n_atom_basis, dim=-1)
742 | dX_intra = m2 * X_p
743 |
744 | # Update features with residual connections
745 | h = h + m1
746 | X = X + dX_intra
747 |
748 | return h, X
749 |
750 |
751 | class GotenNet(nn.Module):
752 | """
753 | Graph Attention Transformer Network for atomic systems.
754 |
755 | GotenNet processes and updates two types of node features (invariant and steerable)
756 | and edge features (invariant) through three main mechanisms:
757 |
758 | 1. GATA (Graph Attention Transformer Architecture): A degree-wise attention-based
759 | message passing layer that updates both invariant and steerable features while
760 | preserving equivariance.
761 | 2. HTR (Hierarchical Tensor Refinement): Updates edge features across degrees with
762 | inner products of steerable features.
763 | 3. EQFF (Equivariant Feed-Forward): Further processes both types of node features
764 | while maintaining equivariance.
765 | """
766 |
767 | def __init__(
768 | self,
769 | n_atom_basis: int = 128,
770 | n_interactions: int = 8,
771 | radial_basis: Union[Callable, str] = "expnorm",
772 | n_rbf: int = 32,
773 | cutoff_fn: Optional[Union[Callable, str]] = None,
774 | activation: Optional[Union[Callable, str]] = F.silu,
775 | max_z: int = 100,
776 | epsilon: float = 1e-8,
777 | weight_init: Callable = nn.init.xavier_uniform_,
778 | bias_init: Callable = nn.init.zeros_,
779 | layernorm: str = "",
780 | steerable_norm: str = "",
781 | num_heads: int = 8,
782 | attn_dropout: float = 0.0,
783 | edge_updates: Union[bool, str] = True,
784 | scale_edge: bool = True,
785 | lmax: int = 1,
786 | aggr: str = "add",
787 | evec_dim: Optional[int] = None,
788 | emlp_dim: Optional[int] = None,
789 | sep_htr: bool = True,
790 | sep_dir: bool = False,
791 | sep_tensor: bool = False,
792 | edge_ln: str = "",
793 | ):
794 | """
795 | Initialize GotenNet model.
796 |
797 | Args:
798 | n_atom_basis: Number of features to describe atomic environments.
799 | This determines the size of each embedding vector; i.e. embeddings_dim.
800 | n_interactions: Number of interaction blocks.
801 | radial_basis: Layer for expanding interatomic distances in a basis set.
802 | n_rbf: Number of radial basis functions.
803 | cutoff_fn: Cutoff function.
804 | activation: Activation function.
805 | max_z: Maximum atomic number.
806 | epsilon: Stability constant added in norm to prevent numerical instabilities.
807 | weight_init: Weight initialization function.
808 | bias_init: Bias initialization function.
809 | max_num_neighbors: Maximum number of neighbors.
810 | layernorm: Type of layer normalization to use.
811 | steerable_norm: Type of steerable normalization to use.
812 | num_heads: Number of attention heads.
813 | attn_dropout: Dropout probability for attention.
814 | edge_updates: Whether to update edge features.
815 | scale_edge: Whether to scale edge features.
816 | lmax: Maximum angular momentum.
817 | aggr: Aggregation method ('add', 'mean' or 'max').
818 | evec_dim: Dimension of edge vector features.
819 | emlp_dim: Dimension of edge MLP features.
820 | sep_htr: Whether to separate vector features in interaction.
821 | sep_dir: Whether to separate direction features.
822 | sep_tensor: Whether to separate tensor features.
823 | """
824 | super(GotenNet, self).__init__()
825 |
826 | self.scale_edge = scale_edge
827 | if type(weight_init) == str:
828 | weight_init = get_weight_init_by_string(weight_init)
829 |
830 | if type(bias_init) == str:
831 | bias_init = get_weight_init_by_string(bias_init)
832 |
833 | if type(activation) is str:
834 | activation = str2act(activation)
835 |
836 | self.n_atom_basis = self.hidden_dim = n_atom_basis
837 | self.n_interactions = n_interactions
838 | self.cutoff_fn = cutoff_fn
839 | self.cutoff = cutoff_fn.cutoff
840 |
841 | self.node_init = NodeInit(
842 | [self.hidden_dim, self.hidden_dim],
843 | n_rbf,
844 | self.cutoff,
845 | max_z=max_z,
846 | weight_init=weight_init,
847 | bias_init=bias_init,
848 | proj_ln="layer",
849 | activation=activation,
850 | )
851 |
852 | self.edge_init = EdgeInit(n_rbf, self.hidden_dim)
853 |
854 | radial_basis = str2basis(radial_basis)
855 | self.radial_basis = radial_basis(cutoff=self.cutoff, n_rbf=n_rbf)
856 | self.A_na = nn.Embedding(max_z, n_atom_basis, padding_idx=0)
857 | self.sphere = TensorInit(l=lmax)
858 |
859 | self.gata_list = nn.ModuleList(
860 | [
861 | GATA(
862 | n_atom_basis=self.n_atom_basis,
863 | activation=activation,
864 | aggr=aggr,
865 | weight_init=weight_init,
866 | bias_init=bias_init,
867 | layer_norm=layernorm,
868 | steerable_norm=steerable_norm,
869 | cutoff=self.cutoff,
870 | epsilon=epsilon,
871 | num_heads=num_heads,
872 | dropout=attn_dropout,
873 | edge_updates=edge_updates,
874 | last_layer=(i == self.n_interactions - 1),
875 | scale_edge=scale_edge,
876 | evec_dim=evec_dim,
877 | emlp_dim=emlp_dim,
878 | sep_htr=sep_htr,
879 | sep_dir=sep_dir,
880 | sep_tensor=sep_tensor,
881 | lmax=lmax,
882 | edge_ln=edge_ln,
883 | )
884 | for i in range(self.n_interactions)
885 | ]
886 | )
887 |
888 | self.eqff_list = nn.ModuleList(
889 | [
890 | EQFF(
891 | n_atom_basis=self.n_atom_basis,
892 | activation=activation,
893 | lmax=lmax,
894 | epsilon=epsilon,
895 | weight_init=weight_init,
896 | bias_init=bias_init,
897 | )
898 | for i in range(self.n_interactions)
899 | ]
900 | )
901 |
902 | self.reset_parameters()
903 |
904 | @classmethod
905 | def load_from_checkpoint(cls, checkpoint_path: str, device="cpu") -> None:
906 | """
907 | Load model parameters from a checkpoint.
908 |
909 | Args:
910 | checkpoint: Dictionary containing model parameters.
911 | """
912 | if not os.path.exists(checkpoint_path):
913 | raise FileNotFoundError(
914 | f"Checkpoint file {checkpoint_path} does not exist."
915 | )
916 |
917 | checkpoint = torch.load(checkpoint_path, map_location=device)
918 |
919 | if "representation" in checkpoint:
920 | checkpoint = checkpoint["representation"]
921 |
922 | assert "hyper_parameters" in checkpoint, (
923 | "Checkpoint must contain 'hyper_parameters' key."
924 | )
925 | hyper_parameters = checkpoint["hyper_parameters"]
926 | assert "representation" in hyper_parameters, (
927 | "Hyperparameters must contain 'representation' key."
928 | )
929 | representation_config = hyper_parameters["representation"]
930 | _ = representation_config.pop("_target_", None)
931 |
932 | assert "state_dict" in checkpoint, "Checkpoint must contain 'state_dict' key."
933 | original_state_dict = checkpoint["state_dict"]
934 | new_state_dict = {}
935 | for k, v in original_state_dict.items():
936 | if k.startswith("output_modules."): # Skip output modules
937 | continue
938 | if k.startswith("representation."):
939 | new_k = k.replace("representation.", "")
940 | new_state_dict[new_k] = v
941 | else:
942 | new_state_dict[k] = v
943 |
944 | gotennet = cls(**representation_config)
945 | gotennet.load_state_dict(new_state_dict, strict=True)
946 | return gotennet
947 |
948 | def reset_parameters(self):
949 | self.node_init.reset_parameters()
950 | self.edge_init.reset_parameters()
951 | for l in self.gata_list:
952 | l.reset_parameters()
953 | for l in self.eqff_list:
954 | l.reset_parameters()
955 |
956 | def forward(
957 | self, atomic_numbers, edge_index, edge_diff, edge_vec
958 | ) -> Tuple[Tensor, Tensor]:
959 | """
960 | Compute atomic representations/embeddings.
961 |
962 | Args:
963 | atomic_numbers: Tensor of atomic numbers [num_nodes]
964 | edge_index: Tensor describing graph connectivity [2, num_edges]
965 | edge_diff: Tensor of edge distances [num_edges, 1]
966 | edge_vec: Tensor of edge direction vectors [num_edges, 3]
967 |
968 | Returns:
969 | Tuple containing:
970 | - Atomic representation [num_nodes, hidden_dims]
971 | - High-degree steerable features [num_nodes, (L_max ** 2) - 1, hidden_dims]
972 | """
973 | h = self.A_na(atomic_numbers)[:]
974 | phi_r0_ij = self.radial_basis(edge_diff)
975 |
976 | h = self.node_init(atomic_numbers, h, edge_index, edge_diff, phi_r0_ij)
977 | t_ij_init = self.edge_init(edge_index, phi_r0_ij, h)
978 | mask = edge_index[0] != edge_index[1]
979 | r0_ij = torch.norm(edge_vec[mask], dim=1).unsqueeze(1)
980 | edge_vec[mask] = edge_vec[mask] / r0_ij
981 |
982 | rl_ij = self.sphere(edge_vec)
983 |
984 | equi_dim = ((self.sphere.l + 1) ** 2) - 1
985 | # count number of edges for each node
986 | num_edges = scatter(
987 | torch.ones_like(edge_diff), edge_index[0], dim=0, reduce="sum"
988 | )
989 | n_edges = num_edges[edge_index[0]]
990 |
991 | hs = h.shape
992 | X = torch.zeros((hs[0], equi_dim, hs[1]), device=h.device)
993 | h.unsqueeze_(1)
994 | t_ij = t_ij_init
995 | for _i, (gata, eqff) in enumerate(
996 | zip(self.gata_list, self.eqff_list, strict=False)
997 | ):
998 | h, X, t_ij = gata(
999 | edge_index,
1000 | h,
1001 | X,
1002 | rl_ij=rl_ij,
1003 | t_ij=t_ij,
1004 | r_ij=edge_diff,
1005 | n_edges=n_edges,
1006 | ) # idx_i, idx_j, n_atoms, # , f_ij=f_ij
1007 | h, X = eqff(h, X)
1008 |
1009 | h = h.squeeze(1)
1010 | return h, X
1011 |
1012 |
1013 | class GotenNetWrapper(GotenNet):
1014 | """
1015 | The wrapper around GotenNet for processing atomistic data.
1016 | """
1017 |
1018 | def __init__(self, *args, max_num_neighbors=32, **kwargs):
1019 | super(GotenNetWrapper, self).__init__(*args, **kwargs)
1020 |
1021 | self.distance = Distance(
1022 | self.cutoff, max_num_neighbors=max_num_neighbors, loop=True
1023 | )
1024 | self.reset_parameters()
1025 |
1026 | def forward(self, inputs: Mapping[str, Tensor]) -> Tuple[Tensor, Tensor]:
1027 | """
1028 | Compute atomic representations/embeddings.
1029 |
1030 | Args:
1031 | inputs: Dictionary of input tensors containing atomic_numbers, pos, batch,
1032 | edge_index, r_ij, and dir_ij. Shape information:
1033 | - atomic_numbers: [num_nodes]
1034 | - pos: [num_nodes, 3]
1035 | - batch: [num_nodes]
1036 | - edge_index: [2, num_edges]
1037 |
1038 | Returns:
1039 | Tuple containing:
1040 | - Atomic representation [num_nodes, hidden_dims]
1041 | - High-degree steerable features [num_nodes, (L_max ** 2) - 1, hidden_dims]
1042 | """
1043 | atomic_numbers, pos, batch = inputs.z, inputs.pos, inputs.batch
1044 | edge_index, edge_diff, edge_vec = self.distance(pos, batch)
1045 | return super().forward(atomic_numbers, edge_index, edge_diff, edge_vec)
1046 |
--------------------------------------------------------------------------------
/gotennet/models/tasks/QM9Task.py:
--------------------------------------------------------------------------------
1 | """QM9 task implementation for quantum chemistry property prediction."""
2 |
3 | from __future__ import absolute_import, division, print_function
4 |
5 | import torch
6 | import torch.nn.functional as F
7 | import torchmetrics
8 | from torch.nn import L1Loss
9 |
10 | from gotennet.datamodules.components.qm9 import QM9
11 | from gotennet.models.components.outputs import (
12 | Atomwise,
13 | Dipole,
14 | ElectronicSpatialExtentV2,
15 | )
16 | from gotennet.models.tasks.Task import Task
17 |
18 |
19 | class QM9Task(Task):
20 | """
21 | Task for QM9 quantum chemistry dataset.
22 |
23 | This task predicts various quantum chemistry properties for small molecules.
24 | """
25 |
26 | name = "QM9"
27 |
28 | def __init__(
29 | self,
30 | representation: torch.nn.Module,
31 | label_key: str | int,
32 | dataset_meta: dict,
33 | task_config: dict | None = None,
34 | **kwargs
35 | ):
36 | """
37 | Initialize the QM9 task.
38 |
39 | Args:
40 | representation (torch.nn.Module): The representation model to use.
41 | label_key (str | int): The key or index for the label in the dataset.
42 | dataset_meta (dict): Metadata about the dataset (e.g., mean, std, atomref).
43 | task_config (dict, optional): Configuration for the task. Defaults to None.
44 | **kwargs: Additional keyword arguments.
45 | """
46 | super().__init__(
47 | representation,
48 | label_key,
49 | dataset_meta,
50 | task_config,
51 | **kwargs
52 | )
53 |
54 | if isinstance(label_key, str):
55 | self.label_key = QM9.available_properties.index(label_key)
56 | self.num_classes = 1
57 | self.task_loss = self.task_config.get("task_loss", "L1Loss")
58 | self.output_module = self.task_config.get("output_module", None)
59 |
60 | def process_outputs(
61 | self,
62 | batch,
63 | result: dict,
64 | metric_meta: dict,
65 | metric_idx: int
66 | ):
67 | """
68 | Process the outputs of the model for metric computation.
69 |
70 | Args:
71 | batch: The batch of data, expected to have a 'y' attribute for targets.
72 | result (dict): The dictionary containing model outputs (predictions).
73 | metric_meta (dict): Metadata about the metric, including 'prediction' and 'target' keys.
74 | metric_idx (int): Index of the metric.
75 |
76 | Returns:
77 | tuple[torch.Tensor, torch.Tensor]: A tuple containing the processed predictions and targets.
78 | """
79 | pred = result[metric_meta["prediction"]]
80 | if batch.y.shape[1] == 1:
81 | targets = batch.y
82 | else:
83 | targets = batch.y[:, metric_meta["target"]]
84 | pred = pred.reshape(targets.shape)
85 | if self.cast_to_float64:
86 | targets = targets.type(torch.float64)
87 | pred = pred.type(torch.float64)
88 |
89 | return pred, targets
90 |
91 | def get_metric_names(
92 | self,
93 | metric_meta: dict,
94 | metric_idx: int = 0
95 | ):
96 | """
97 | Get the names of the metrics.
98 |
99 | Args:
100 | metric_meta (dict): Metadata about the metric.
101 | metric_idx (int, optional): Index of the metric. Defaults to 0.
102 |
103 | Returns:
104 | str: The name of the metric, potentially including the property name.
105 | """
106 | if metric_meta["prediction"] == "property":
107 | return f"{QM9.available_properties[metric_meta['target']]}"
108 | return super(QM9Task, self).get_metric_names(metric_meta, metric_idx)
109 |
110 | def get_losses(self) -> list[dict]:
111 | """
112 | Get the loss functions for the QM9 task.
113 |
114 | Returns:
115 | list[dict]: A list of dictionaries, each containing loss function configuration.
116 | """
117 | if self.task_loss == "L1Loss":
118 | return [
119 | {
120 | "metric": L1Loss,
121 | "prediction": "property",
122 | "target": self.label_key,
123 | "loss_weight": 1.
124 | }
125 | ]
126 | elif self.task_loss == "MSELoss":
127 | return [
128 | {
129 | "metric": torch.nn.MSELoss,
130 | "prediction": "property",
131 | "target": self.label_key,
132 | "loss_weight": 1.
133 | }
134 | ]
135 |
136 | def get_metrics(self) -> list[dict]:
137 | """
138 | Get the metrics for the QM9 task.
139 |
140 | Returns:
141 | list[dict]: A list of dictionaries, each containing metric configuration.
142 | """
143 | return [
144 | {
145 | "metric": torchmetrics.MeanSquaredError,
146 | "prediction": "property",
147 | "target": self.label_key,
148 | },
149 | {
150 | "metric": torchmetrics.MeanAbsoluteError,
151 | "prediction": "property",
152 | "target": self.label_key,
153 | },
154 | ]
155 |
156 | def get_output(self, output_config: dict | None = None) -> torch.nn.ModuleList:
157 | """
158 | Get the output module for the QM9 task based on the target property.
159 |
160 | Args:
161 | output_config (dict | None): Configuration for the output module.
162 |
163 | Returns:
164 | torch.nn.ModuleList: A list containing the appropriate output module.
165 | """
166 | label_name = QM9.available_properties[self.label_key]
167 | output_config = output_config or {} # Ensure output_config is a dict
168 |
169 | if label_name == QM9.mu:
170 | mean = self.dataset_meta.get("mean", None)
171 | std = self.dataset_meta.get("std", None)
172 | outputs = Dipole(
173 | n_in=self.representation.hidden_dim,
174 | predict_magnitude=True,
175 | property="property",
176 | mean=mean,
177 | stddev=std,
178 | **output_config,
179 | )
180 | elif label_name == QM9.r2:
181 | outputs = ElectronicSpatialExtentV2(
182 | n_in=self.representation.hidden_dim,
183 | property="property",
184 | **output_config,
185 | )
186 | else:
187 | # Default to Atomwise for other properties
188 | mean = self.dataset_meta.get("mean", None)
189 | std = self.dataset_meta.get("std", None)
190 | outputs = Atomwise(
191 | n_in=self.representation.hidden_dim,
192 | mean=mean,
193 | stddev=std,
194 | atomref=self.dataset_meta.get('atomref'), # Use .get for safety
195 | property="property",
196 | activation=F.silu,
197 | **output_config,
198 | )
199 | return torch.nn.ModuleList([outputs])
200 |
201 | def get_evaluator(self) -> None:
202 | """
203 | Get the evaluator for the QM9 task.
204 |
205 | Returns:
206 | None: No special evaluator is needed for this task.
207 | """
208 | return None
209 |
210 | def get_dataloader_map(self) -> list[str]:
211 | """
212 | Get the dataloader map for the QM9 task.
213 |
214 | Returns:
215 | list[str]: A list containing 'test' as the only dataloader phase to use.
216 | """
217 | return ['test']
218 |
--------------------------------------------------------------------------------
/gotennet/models/tasks/Task.py:
--------------------------------------------------------------------------------
1 | """Base class for all tasks in the project."""
2 |
3 | from __future__ import absolute_import, division, print_function
4 |
5 | import torch
6 |
7 | from gotennet.utils import get_logger
8 |
9 | log = get_logger(__name__)
10 |
11 | class Task:
12 | """
13 | Base class for all tasks in the project.
14 |
15 | This class defines the interface for all tasks and provides common functionality.
16 | """
17 |
18 | name = None
19 |
20 | def __init__(
21 | self,
22 | representation,
23 | label_key,
24 | dataset_meta,
25 | task_config=None,
26 | task_defaults=None,
27 | **kwargs
28 | ):
29 | """
30 | Initialize a task.
31 |
32 | Args:
33 | representation: The representation model to use.
34 | label_key: The key for the label in the dataset.
35 | dataset_meta: Metadata about the dataset.
36 | task_config (dict, optional): Configuration for the task. Defaults to None.
37 | task_defaults (dict, optional): Default configuration for the task. Defaults to None.
38 | **kwargs: Additional keyword arguments.
39 | """
40 | if task_config is None:
41 | task_config = {}
42 | if task_defaults is None:
43 | task_defaults = {}
44 |
45 | self.task_config = task_config
46 | self.config = {**task_defaults, **task_config}
47 | log.info(f"Task config: {self.config}")
48 | self.representation = representation
49 | self.label_key = label_key
50 | self.dataset_meta = dataset_meta
51 | self.cast_to_float64 = True
52 |
53 | def process_outputs(
54 | self,
55 | batch,
56 | result,
57 | metric_meta,
58 | metric_idx
59 | ):
60 | """
61 | Process the outputs of the model for metric computation.
62 |
63 | Args:
64 | batch: The batch of data.
65 | result: The result of the model.
66 | metric_meta: Metadata about the metric.
67 | metric_idx: Index of the metric.
68 |
69 | Returns:
70 | tuple: A tuple containing the processed predictions and targets.
71 | """
72 | pred = result[metric_meta["prediction"]]
73 | targets = batch[metric_meta["target"]]
74 | pred = pred.reshape(targets.shape)
75 |
76 | if self.cast_to_float64:
77 | targets = targets.type(torch.float64)
78 | pred = pred.type(torch.float64)
79 |
80 | return pred, targets
81 |
82 | def get_metric_names(
83 | self,
84 | metric_meta,
85 | metric_idx=0
86 | ):
87 | """
88 | Get the names of the metrics.
89 |
90 | Args:
91 | metric_meta: Metadata about the metric.
92 | metric_idx (int, optional): Index of the metric. Defaults to 0.
93 |
94 | Returns:
95 | str: The name of the metric.
96 | """
97 | return f"{metric_meta['prediction']}"
98 |
99 | def get_losses(self):
100 | """
101 | Get the loss functions for the task.
102 |
103 | Returns:
104 | list: A list of dictionaries containing loss function configurations.
105 |
106 | Raises:
107 | NotImplementedError: This method must be implemented by subclasses.
108 | """
109 | raise NotImplementedError("get_losses() is not implemented")
110 |
111 | def get_metrics(self):
112 | """
113 | Get the metrics for the task.
114 |
115 | Returns:
116 | list: A list of dictionaries containing metric configurations.
117 |
118 | Raises:
119 | NotImplementedError: This method must be implemented by subclasses.
120 | """
121 | raise NotImplementedError("get_metrics() is not implemented")
122 |
123 | def get_output(self, output_config=None):
124 | """
125 | Get the output module for the task.
126 |
127 | Args:
128 | output_config: Configuration for the output module.
129 |
130 | Returns:
131 | torch.nn.Module: The output module.
132 |
133 | Raises:
134 | NotImplementedError: This method must be implemented by subclasses.
135 | """
136 | raise NotImplementedError("get_output() is not implemented")
137 |
138 | def get_evaluator(self):
139 | """
140 | Get the evaluator for the task.
141 |
142 | Returns:
143 | object: The evaluator for the task, or None if not needed.
144 | """
145 | return None
146 |
147 | def get_dataloader_map(self):
148 | """
149 | Get the dataloader map for the task.
150 |
151 | Returns:
152 | list: A list of dataloader names to use for the task.
153 | """
154 | return ['test']
155 |
--------------------------------------------------------------------------------
/gotennet/models/tasks/__init__.py:
--------------------------------------------------------------------------------
1 | """Task implementations for various molecular datasets."""
2 |
3 | from __future__ import absolute_import, division, print_function
4 |
5 | from gotennet.models.tasks.QM9Task import QM9Task
6 |
7 | # Dictionary mapping task names to their implementations
8 | TASK_DICT = {
9 | 'QM9': QM9Task, # QM9 quantum chemistry dataset
10 | }
11 |
--------------------------------------------------------------------------------
/gotennet/scripts/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sarpaykent/GotenNet/c561c05a1120118004912b248c944f74022b30cc/gotennet/scripts/__init__.py
--------------------------------------------------------------------------------
/gotennet/scripts/test.py:
--------------------------------------------------------------------------------
1 | import dotenv
2 | import hydra
3 | import torch
4 | from omegaconf import DictConfig
5 |
6 | from gotennet.utils.utils import find_config_directory # Import the utility function
7 |
8 | # Load environment variables from `.env` file if it exists
9 | # Recursively searches for `.env` in all folders starting from work dir
10 | dotenv.load_dotenv(override=True)
11 |
12 | # Find configs directory using the utility function
13 | config_dir = find_config_directory()
14 |
15 | # Disable TF32 precision for CUDA operations
16 | torch.backends.cuda.matmul.allow_tf32 = False
17 |
18 |
19 | @hydra.main(version_base="1.3", config_path=config_dir, config_name="test.yaml")
20 | def main(cfg: DictConfig) -> float:
21 | """
22 | Main testing function called by Hydra.
23 |
24 | This function serves as the entry point for the test process. It imports
25 | necessary modules, applies optional utilities, trains the model, and returns
26 | the optimized metric value.
27 |
28 | Args:
29 | cfg (DictConfig): Configuration composed by Hydra from command line arguments
30 | and config files. Contains all parameters for test.
31 |
32 | Returns:
33 | float: Value of the metric for tests.
34 | """
35 | # Imports can be nested inside @hydra.main to optimize tab completion
36 | # https://github.com/facebookresearch/hydra/issues/934
37 | from gotennet import utils
38 | from gotennet.testing_pipeline import test
39 |
40 | # Applies optional utilities
41 | utils.extras(cfg)
42 |
43 | # Train model
44 | metric_dict, _ = test(cfg)
45 |
46 | metric_value = utils.get_metric_value(
47 | metric_dict=metric_dict,
48 | metric_name=cfg.get("optimized_metric"),
49 | )
50 |
51 | # Return optimized metric
52 | return metric_value
53 |
54 |
55 | if __name__ == "__main__":
56 | main()
57 |
--------------------------------------------------------------------------------
/gotennet/scripts/train.py:
--------------------------------------------------------------------------------
1 | import dotenv
2 | import hydra
3 | import torch
4 | from omegaconf import DictConfig
5 |
6 | from gotennet.utils.utils import find_config_directory # Import the utility function
7 |
8 | # Load environment variables from `.env` file if it exists
9 | # Recursively searches for `.env` in all folders starting from work dir
10 | dotenv.load_dotenv(override=True)
11 |
12 | # Find configs directory using the utility function
13 | config_dir = find_config_directory()
14 |
15 | # Disable TF32 precision for CUDA operations
16 | torch.backends.cuda.matmul.allow_tf32 = False
17 |
18 |
19 | @hydra.main(version_base="1.3", config_path=config_dir, config_name="train.yaml")
20 | def main(cfg: DictConfig) -> float:
21 | """
22 | Main training function called by Hydra.
23 |
24 | This function serves as the entry point for the training process. It imports
25 | necessary modules, applies optional utilities, trains the model, and returns
26 | the optimized metric value.
27 |
28 | Args:
29 | cfg (DictConfig): Configuration composed by Hydra from command line arguments
30 | and config files. Contains all parameters for training.
31 |
32 | Returns:
33 | float: Value of the optimized metric for hyperparameter optimization.
34 | """
35 | # Imports can be nested inside @hydra.main to optimize tab completion
36 | # https://github.com/facebookresearch/hydra/issues/934
37 | from gotennet import utils
38 | from gotennet.training_pipeline import train
39 |
40 | # Applies optional utilities
41 | utils.extras(cfg)
42 |
43 | # Train model
44 | metric_dict, _ = train(cfg)
45 |
46 | # Safely retrieve metric value for hydra-based hyperparameter optimization
47 | metric_value = utils.get_metric_value(
48 | metric_dict=metric_dict,
49 | metric_name=cfg.get("optimized_metric"),
50 | )
51 |
52 | # Return optimized metric
53 | return metric_value
54 |
55 |
56 | if __name__ == "__main__":
57 | main()
58 |
--------------------------------------------------------------------------------
/gotennet/testing_pipeline.py:
--------------------------------------------------------------------------------
1 | from typing import List
2 |
3 | import hydra
4 | from lightning.pytorch.loggers import Logger
5 | from omegaconf import DictConfig
6 | from pytorch_lightning import (
7 | Callback,
8 | LightningDataModule,
9 | LightningModule,
10 | Trainer,
11 | seed_everything,
12 | )
13 |
14 | from gotennet import utils
15 |
16 | log = utils.get_logger(__name__)
17 |
18 | import torch
19 |
20 |
21 | @utils.task_wrapper
22 | def test(cfg: DictConfig) -> None:
23 | """Contains minimal example of the testing pipeline. Evaluates given checkpoint on a testset.
24 |
25 | Args:
26 | cfg (DictConfig): Configuration composed by Hydra.
27 |
28 | Returns:
29 | None
30 | """
31 | mm_prec = cfg.get("matmul_precision", "high")
32 | log.info(f"Running with {mm_prec} precision.")
33 | torch.set_float32_matmul_precision(mm_prec)
34 |
35 | # Set seed for random number generators in pytorch, numpy and python.random
36 | if cfg.get("seed"):
37 | seed_everything(cfg.seed, workers=True)
38 |
39 | if cfg.get("checkpoint"):
40 | from gotennet.models.goten_model import GotenModel
41 |
42 | model = GotenModel.from_pretrained(cfg.checkpoint)
43 | label = model.label
44 | if cfg.get("label", -1) == -1 and label is not None:
45 | cfg.label = label
46 | else:
47 | model = None
48 |
49 | # Init lightning datamodule
50 | log.info(f"Instantiating datamodule <{cfg.datamodule._target_}>")
51 | datamodule: LightningDataModule = hydra.utils.instantiate(cfg.datamodule)
52 |
53 | cfg.label_str = str(cfg.label)
54 | cfg.name = cfg.label_str + "_" + cfg.name
55 |
56 | if type(cfg.label) == str and hasattr(datamodule, "dataset_class"):
57 | cfg.label = datamodule.dataset_class().label_to_idx(cfg.label)
58 | log.info(f"Label {cfg.label} is mapped to index {cfg.label}")
59 |
60 | datamodule.label = cfg.label
61 |
62 | dataset_meta = (
63 | datamodule.get_metadata(cfg.label)
64 | if hasattr(datamodule, "get_metadata")
65 | else None
66 | )
67 |
68 | # Init lightning model
69 | log.info(f"Instantiating model <{cfg.model._target_}>")
70 | if model is None:
71 | model: LightningModule = hydra.utils.instantiate(
72 | cfg.model, dataset_meta=dataset_meta
73 | )
74 |
75 | print(model)
76 |
77 | callbacks: List[Callback] = []
78 | if "callbacks" in cfg:
79 | for name, cb_conf in cfg.callbacks.items():
80 | if name not in ["model_summary", "rich_progress_bar"]:
81 | continue
82 | if "_target_" in cb_conf:
83 | log.info(f"Instantiating callback <{cb_conf._target_}>")
84 | callbacks.append(hydra.utils.instantiate(cb_conf))
85 |
86 | # Init lightning loggers
87 | logger: List[Logger] = []
88 | if "logger" in cfg:
89 | for _, lg_conf in cfg.logger.items():
90 | if "_target_" in lg_conf:
91 | log.info(f"Instantiating logger <{lg_conf._target_}>")
92 | logger.append(hydra.utils.instantiate(lg_conf))
93 |
94 | # Init lightning trainer
95 | log.info(f"Instantiating trainer <{cfg.trainer._target_}>")
96 | trainer: Trainer = hydra.utils.instantiate(
97 | cfg.trainer, logger=logger, callbacks=callbacks
98 | )
99 |
100 | # Log hyperparameters
101 | if trainer.logger:
102 | trainer.logger.log_hyperparams({"ckpt_path": cfg.ckpt_path})
103 |
104 | log.info("Starting testing!")
105 |
106 | if cfg.get("ckpt_path"):
107 | ckpt_path = cfg.ckpt_path
108 | else:
109 | ckpt_path = None
110 | trainer.test(model=model, datamodule=datamodule, ckpt_path=ckpt_path)
111 |
112 | test_metrics = trainer.callback_metrics
113 | metric_dict = test_metrics
114 | return metric_dict
115 |
--------------------------------------------------------------------------------
/gotennet/training_pipeline.py:
--------------------------------------------------------------------------------
1 | import os
2 | from typing import List, Tuple
3 |
4 | import hydra
5 | import torch.multiprocessing
6 | from lightning import Trainer
7 | from lightning.pytorch.loggers import Logger
8 | from omegaconf import DictConfig
9 | from pytorch_lightning import (
10 | Callback,
11 | LightningDataModule,
12 | LightningModule,
13 | seed_everything,
14 | )
15 |
16 | import gotennet.utils.logging_utils
17 | from gotennet import utils
18 |
19 | log = utils.get_logger(__name__)
20 |
21 | import torch
22 |
23 |
24 | @utils.task_wrapper
25 | def train(cfg: DictConfig) -> Tuple[dict, dict]:
26 | """Contains the training pipeline. Can additionally evaluate model on a testset, using best
27 | weights achieved during training.
28 |
29 | Args:
30 | cfg (DictConfig): Configuration composed by Hydra.
31 |
32 | Returns:
33 | Optional[float]: Metric score for hyperparameter optimization.
34 | """
35 |
36 | mm_prec = cfg.get("matmul_precision", "highest")
37 | torch.set_float32_matmul_precision(mm_prec)
38 | log.info(f"Running with {mm_prec} precision.")
39 |
40 | # Set seed for random number generators in pytorch, numpy and python.random
41 | if cfg.get("seed"):
42 | seed_everything(cfg.seed, workers=True)
43 |
44 | ckpt_path = cfg.trainer.get("resume_from_checkpoint", None)
45 |
46 | # Convert relative ckpt path to absolute path if necessary
47 | if ckpt_path and not os.path.isabs(ckpt_path):
48 | cfg.trainer.resume_from_checkpoint = os.path.join(
49 | hydra.utils.get_original_cwd(), ckpt_path
50 | )
51 |
52 | # Init lightning datamodule
53 | log.info(f"Instantiating datamodule <{cfg.datamodule._target_}>")
54 | datamodule: LightningDataModule = hydra.utils.instantiate(cfg.datamodule)
55 |
56 | cfg.label_str = str(cfg.label)
57 | cfg.name = cfg.label_str + "_" + cfg.name
58 |
59 | log.info(f"Label string is: {cfg.label_str}")
60 |
61 | if type(cfg.label) == str and hasattr(datamodule, "dataset_class"):
62 | cfg.label = datamodule.dataset_class().label_to_idx(cfg.label)
63 | log.info(f"Label {cfg.label} is mapped to index {cfg.label}")
64 |
65 | datamodule.label = cfg.label
66 |
67 | dataset_meta = (
68 | datamodule.get_metadata(cfg.label)
69 | if hasattr(datamodule, "get_metadata")
70 | else None
71 | )
72 |
73 | # Init lightning model
74 | log.info(f"Instantiating model <{cfg.model._target_}>")
75 |
76 | model: LightningModule = hydra.utils.instantiate(
77 | cfg.model, dataset_meta=dataset_meta
78 | )
79 |
80 | # Init lightning callbacks
81 | callbacks: List[Callback] = []
82 | if "callbacks" in cfg:
83 | for name, cb_conf in cfg.callbacks.items():
84 | if cfg.exp and name in ["learning_rate_monitor"]:
85 | continue
86 | if "_target_" in cb_conf:
87 | log.info(f"Instantiating callback <{cb_conf._target_}>")
88 | callbacks.append(hydra.utils.instantiate(cb_conf))
89 |
90 | # Init lightning loggers
91 | logger: List[Logger] = []
92 | if "logger" in cfg and not cfg.exp:
93 | for _, lg_conf in cfg.logger.items():
94 | if "_target_" in lg_conf:
95 | log.info(f"Instantiating logger <{lg_conf._target_}>")
96 | logger.append(hydra.utils.instantiate(lg_conf))
97 |
98 | # Init lightning trainer
99 | log.info(f"Instantiating trainer <{cfg.trainer._target_}>")
100 |
101 | # profiler = PyTorchProfiler()
102 | trainer: Trainer = hydra.utils.instantiate(
103 | cfg.trainer,
104 | callbacks=callbacks,
105 | logger=logger,
106 | _convert_="partial",
107 | inference_mode=False,
108 | )
109 | # trainer = Trainer(barebones=True)
110 | datamodule.device = model.device
111 | print("Current device is: ", model.device)
112 | object_dict = {
113 | "cfg": cfg,
114 | "datamodule": datamodule,
115 | "model": model,
116 | "callbacks": callbacks,
117 | "logger": logger,
118 | "trainer": trainer,
119 | }
120 |
121 | # Send some parameters from config to all lightning loggers
122 | log.info("Logging hyperparameters!")
123 | gotennet.utils.logging_utils.log_hyperparameters(
124 | config=cfg,
125 | model=model,
126 | trainer=trainer,
127 | )
128 |
129 | # Train the model
130 | if cfg.get("train"):
131 | log.info("Starting training!")
132 | trainer.fit(model=model, datamodule=datamodule, ckpt_path=cfg.get("ckpt_path"))
133 |
134 | # Get metric score for hyperparameter optimization
135 | optimized_metric = cfg.get("optimized_metric")
136 | if optimized_metric and optimized_metric not in trainer.callback_metrics:
137 | raise Exception(
138 | "Metric for hyperparameter optimization not found! "
139 | "Make sure the `optimized_metric` in `hparams_search` config is correct!"
140 | )
141 |
142 | train_metrics = trainer.callback_metrics
143 |
144 | # Test the model
145 | if cfg.get("test"):
146 | # ckpt_path = "best"
147 | if cfg.get("train") and not cfg.trainer.get("fast_dev_run"):
148 | ckpt_path = trainer.checkpoint_callback.best_model_path
149 | if not cfg.get("train") or cfg.trainer.get("fast_dev_run"):
150 | if cfg.get("ckpt_path"):
151 | ckpt_path = cfg.ckpt_path
152 | else:
153 | ckpt_path = None
154 | log.info("Starting testing!")
155 | trainer.test(model=model, datamodule=datamodule, ckpt_path=ckpt_path)
156 |
157 | # Make sure everything closed properly
158 | log.info("Finalizing!")
159 |
160 | # Print path to best checkpoint
161 | if not cfg.trainer.get("fast_dev_run") and cfg.get("train"):
162 | log.info(f"Best model ckpt at {trainer.checkpoint_callback.best_model_path}")
163 |
164 | # Return metric score for hyperparameter optimization
165 | test_metrics = trainer.callback_metrics
166 | # merge train and test metrics
167 | metric_dict = {**train_metrics, **test_metrics}
168 |
169 | return metric_dict, object_dict
170 |
--------------------------------------------------------------------------------
/gotennet/utils/__init__.py:
--------------------------------------------------------------------------------
1 | import logging
2 | import warnings
3 | from typing import Sequence
4 |
5 | from omegaconf import DictConfig, OmegaConf
6 | from pytorch_lightning.utilities import rank_zero_only
7 |
8 |
9 | def humanbytes(B):
10 | """
11 | Return the given bytes as a human friendly KB, MB, GB, or TB string.
12 |
13 | Args:
14 | B: Number of bytes.
15 |
16 | Returns:
17 | str: Human-readable string representation of bytes.
18 | """
19 | B = float(B)
20 | KB = float(1024)
21 | MB = float(KB**2) # 1,048,576
22 | GB = float(KB**3) # 1,073,741,824
23 | TB = float(KB**4) # 1,099,511,627,776
24 |
25 | if B < KB:
26 | return "{0} {1}".format(B, "Bytes" if 0 == B > 1 else "Byte")
27 | elif KB <= B < MB:
28 | return "{0:.2f} KB".format(B / KB)
29 | elif MB <= B < GB:
30 | return "{0:.2f} MB".format(B / MB)
31 | elif GB <= B < TB:
32 | return "{0:.2f} GB".format(B / GB)
33 | elif TB <= B:
34 | return "{0:.2f} TB".format(B / TB)
35 |
36 |
37 | from gotennet.utils.logging_utils import log_hyperparameters as log_hyperparameters
38 | from gotennet.utils.utils import get_metric_value as get_metric_value
39 | from gotennet.utils.utils import task_wrapper as task_wrapper
40 |
41 |
42 | def get_logger(name=__name__) -> logging.Logger:
43 | """
44 | Initialize multi-GPU-friendly python command line logger.
45 |
46 | Args:
47 | name: Name of the logger, defaults to the module name.
48 |
49 | Returns:
50 | logging.Logger: Logger instance with rank zero only decorators.
51 | """
52 |
53 | logger = logging.getLogger(name)
54 |
55 | # this ensures all logging levels get marked with the rank zero decorator
56 | # otherwise logs would get multiplied for each GPU process in multi-GPU setup
57 | for level in (
58 | "debug",
59 | "info",
60 | "warning",
61 | "error",
62 | "exception",
63 | "fatal",
64 | "critical",
65 | ):
66 | setattr(logger, level, rank_zero_only(getattr(logger, level)))
67 |
68 | return logger
69 |
70 |
71 | log = get_logger(__name__)
72 |
73 |
74 | def extras(config: DictConfig) -> None:
75 | """
76 | Apply optional utilities, controlled by config flags.
77 |
78 | Utilities:
79 | - Ignoring python warnings
80 | - Rich config printing
81 |
82 | Args:
83 | config: DictConfig containing the hydra config.
84 | """
85 |
86 | # disable python warnings if
87 | if config.get("ignore_warnings"):
88 | log.info("Disabling python warnings! ")
89 | warnings.filterwarnings("ignore")
90 |
91 | # pretty print config tree using Rich library if
92 | if config.get("print_config"):
93 | log.info("Printing config tree with Rich! ")
94 | print_config(config, resolve=True)
95 |
96 |
97 | @rank_zero_only
98 | def print_config(
99 | config: DictConfig,
100 | print_order: Sequence[str] = (
101 | "datamodule",
102 | "model",
103 | "callbacks",
104 | "logger",
105 | "trainer",
106 | ),
107 | resolve: bool = True,
108 | ) -> None:
109 | """
110 | Print content of DictConfig using Rich library and its tree structure.
111 |
112 | Args:
113 | config: Configuration composed by Hydra.
114 | print_order: Determines in what order config components are printed.
115 | Defaults to ("datamodule", "model", "callbacks", "logger", "trainer").
116 | resolve: Whether to resolve reference fields of DictConfig. Defaults to True.
117 | """
118 | import rich.syntax
119 | import rich.tree
120 |
121 | style = "dim"
122 | tree = rich.tree.Tree("CONFIG", style=style, guide_style=style)
123 |
124 | quee = []
125 |
126 | for field in print_order:
127 | quee.append(field) if field in config else log.info(
128 | f"Field '{field}' not found in config"
129 | )
130 |
131 | for field in config:
132 | if field not in quee:
133 | quee.append(field)
134 |
135 | for field in quee:
136 | branch = tree.add(field, style=style, guide_style=style)
137 |
138 | config_group = config[field]
139 | if isinstance(config_group, DictConfig):
140 | branch_content = OmegaConf.to_yaml(config_group, resolve=resolve)
141 | else:
142 | branch_content = str(config_group)
143 |
144 | branch.add(rich.syntax.Syntax(branch_content, "yaml"))
145 |
146 | rich.print(tree)
147 |
148 | with open("config_tree.log", "w") as file:
149 | rich.print(tree, file=file)
150 |
--------------------------------------------------------------------------------
/gotennet/utils/file.py:
--------------------------------------------------------------------------------
1 | import os
2 | import shutil
3 | import urllib
4 | from pathlib import Path
5 | from typing import List
6 |
7 | import requests
8 |
9 | from gotennet.utils.logging_utils import get_logger
10 |
11 | log = get_logger(__name__)
12 |
13 | try:
14 | from tqdm.rich import tqdm as tqdm_rich_progress_bar
15 |
16 | tqdm_rich_available = True
17 | log.debug(
18 | "tqdm.rich and rich.progress components are available. Will use for downloads."
19 | )
20 | except ImportError:
21 | tqdm_rich_available = False
22 | log.debug(
23 | "tqdm.rich or necessary rich.progress components not available. Downloads will be silent."
24 | )
25 |
26 |
27 | def download_file(url: str, save_path: str) -> bool:
28 | """
29 | Downloads a file from a given URL and saves it to the specified path.
30 | It handles potential errors, ensures the target directory exists,
31 | and displays a progress bar using tqdm.rich's default Rich display if available.
32 |
33 | Args:
34 | url (str): The URL of the file to download.
35 | save_path (str): The local path (including filename) where the file should be saved.
36 |
37 | Returns:
38 | bool: True if download was successful, False otherwise.
39 | """
40 | save_path_opened_for_writing = False
41 | downloaded_size_final = 0
42 |
43 | try:
44 | directory = os.path.dirname(save_path)
45 | if directory and not os.path.exists(directory):
46 | os.makedirs(directory, exist_ok=True)
47 | log.info(f"Created directory: {directory}")
48 |
49 | log.info(f"Starting download from: {url} to {save_path}")
50 | response = urllib.request.urlopen(url)
51 |
52 | total_size_str = response.info().get("Content-Length")
53 | total_size = None
54 | if total_size_str:
55 | try:
56 | parsed_size = int(total_size_str)
57 | if parsed_size > 0:
58 | total_size = parsed_size
59 | else:
60 | log.warning(
61 | f"Content-Length is '{total_size_str}', treating as unknown size for progress bar."
62 | )
63 | except ValueError:
64 | log.warning(
65 | f"Could not parse Content-Length header: '{total_size_str}'. Treating as unknown size for progress bar."
66 | )
67 |
68 | if tqdm_rich_available:
69 | with open(save_path, "wb") as out_file:
70 | save_path_opened_for_writing = True
71 | # Using tqdm.rich with its default Rich display
72 | # No need to pass 'progress' or 'options' for custom columns
73 | with (
74 | tqdm_rich_progress_bar(
75 | total=total_size, # total=None is handled by tqdm (no percentage/ETA)
76 | desc=f"Downloading {os.path.basename(save_path)}",
77 | unit="B", # Unit for progress (Bytes)
78 | unit_scale=True, # Automatically scale to KB, MB, etc.
79 | unit_divisor=1024, # Use 1024 for binary units (KiB, MiB)
80 | # leave=True is default, keeps bar after completion
81 | ) as pbar
82 | ):
83 | chunk_size = 8192
84 | current_downloaded_size = 0
85 | while True:
86 | chunk = response.read(chunk_size)
87 | if not chunk:
88 | break
89 | out_file.write(chunk)
90 | pbar.update(
91 | len(chunk)
92 | ) # Update tqdm progress bar by bytes read
93 | current_downloaded_size += len(chunk)
94 | downloaded_size_final = current_downloaded_size
95 | pbar.refresh()
96 |
97 | if total_size is not None and downloaded_size_final != total_size:
98 | log.warning(
99 | f"Downloaded size {downloaded_size_final} does not match Content-Length {total_size} for {url}. "
100 | f"The file might be incomplete or the server reported an incorrect size."
101 | )
102 |
103 | else: # tqdm.rich not available, download silently
104 | log.info(
105 | f"Downloading {os.path.basename(save_path)} (tqdm.rich not found, progress bar disabled)"
106 | )
107 | with open(save_path, "wb") as out_file:
108 | save_path_opened_for_writing = True
109 | shutil.copyfileobj(response, out_file)
110 | if os.path.exists(save_path):
111 | downloaded_size_final = os.path.getsize(save_path)
112 | if total_size is not None and downloaded_size_final != total_size:
113 | log.warning(
114 | f"Downloaded size {downloaded_size_final} (silent download) does not match Content-Length {total_size} for {url}."
115 | )
116 |
117 | log.info(f"File downloaded successfully and saved to: {save_path}")
118 | return True
119 |
120 | except urllib.error.HTTPError as e:
121 | log.error(f"HTTP Error {e.code} ({e.reason}) while downloading {url}")
122 | except urllib.error.URLError as e:
123 | log.error(f"URL Error ({e.reason}) while downloading {url}")
124 | except OSError as e:
125 | log.error(
126 | f"OS Error ({e.errno}: {e.strerror}) while processing {url} for {save_path}"
127 | )
128 | except Exception as e:
129 | log.error(
130 | f"An unexpected error occurred during download of {url}: {e}", exc_info=True
131 | )
132 |
133 | if save_path_opened_for_writing and os.path.exists(save_path):
134 | try:
135 | log.warning(
136 | f"Attempting to remove partially downloaded or corrupted file: {save_path}"
137 | )
138 | os.remove(save_path)
139 | except OSError as rm_e:
140 | log.error(
141 | f"Could not remove partially downloaded/corrupted file {save_path}: {rm_e}"
142 | )
143 |
144 | return False
145 |
146 |
147 | def download_checkpoint(checkpoint_url: str) -> str:
148 | """
149 | Downloads a checkpoint file based on the provided identifier.
150 |
151 | Args:
152 | checkpoint_url (str): The identifier for the checkpoint. Can be a model name
153 | (e.g., "QM9_small_homo"), a direct URL, or a local file path.
154 |
155 | Returns:
156 | str: The local path to the downloaded checkpoint file.
157 |
158 | Raises:
159 | FileNotFoundError: If the checkpoint cannot be found or downloaded.
160 | ValueError: If the checkpoint name format is invalid or task/parameters are not supported.
161 | ImportError: If required modules for validation cannot be imported.
162 | """
163 | from gotennet.models.tasks import TASK_DICT
164 |
165 | urls_to_try: List[str] = []
166 | local_filename: str
167 |
168 | # 1. Determine the nature of checkpoint_url_str: Name, URL, or Path
169 | parts = checkpoint_url.split("_")
170 | is_potential_name = len(parts) == 3
171 | is_url = checkpoint_url.startswith(("http://", "https://"))
172 |
173 | # Condition for being a "name": matches pattern, is not a URL, and is not an existing file path
174 | # (to avoid misinterpreting a local file named 'task_size_label.ckpt' as a downloadable name)
175 | is_name_style = (
176 | is_potential_name and not is_url and not os.path.exists(checkpoint_url)
177 | )
178 |
179 | if is_name_style:
180 | task, size, label = parts[0], parts[1], parts[2]
181 |
182 | task = task.lower()
183 |
184 | # --- Validation logic for task, size, label (as in previous examples) ---
185 | # Example (ensure TASK_DICT etc. are properly defined and accessible):
186 |
187 | tasks = [k.lower() for k in list(TASK_DICT.keys())]
188 |
189 | if task not in tasks:
190 | raise ValueError(f"Task {task} is not supported or TASK_DICT not defined.")
191 |
192 | sizes = ["small", "base", "large"]
193 | if task == "rmd17":
194 | sizes = ["base"]
195 | if size not in sizes:
196 | raise ValueError(f"Size {size} is not supported.")
197 | if task == "qm9":
198 | try:
199 | from gotennet.datamodules.components.qm9 import qm9_target_dict
200 |
201 | label2idx = dict(
202 | zip(
203 | qm9_target_dict.values(),
204 | qm9_target_dict.keys(),
205 | strict=False,
206 | )
207 | )
208 | if label not in label2idx:
209 | raise ValueError(
210 | f"Label {label} is not valid for QM9 task. Available labels: {list(label2idx.keys())}"
211 | )
212 | except ImportError:
213 | raise ImportError(
214 | "Could not import qm9_target_dict for QM9 task validation."
215 | )
216 | # --- End of validation logic ---
217 |
218 | local_filename = (
219 | f"gotennet_{task}_{size}_{label}.ckpt" # Canonical local filename for this name
220 | )
221 | remote_filename = (
222 | f"gotennet_{label}.ckpt" # Canonical local filename for this name
223 | )
224 |
225 | # Generate list of URLs to try for this name
226 | # Primary URL (Hugging Face)
227 | primary_hf_url = f"https://huggingface.co/sarpaykent/GotenNet/resolve/main/pretrained/{task}/{size}/{remote_filename}"
228 | urls_to_try.append(primary_hf_url)
229 |
230 | if len(urls_to_try) == 1: # Only primary was added
231 | log.info(
232 | f"Interpreted '{checkpoint_url}' as a model name. Target URL: {urls_to_try[0]}, Local filename: {local_filename}"
233 | )
234 | else:
235 | log.info(
236 | f"Interpreted '{checkpoint_url}' as a model name. Will try {len(urls_to_try)} URLs. Local filename: {local_filename}"
237 | )
238 |
239 | elif is_url:
240 | # It's a direct URL
241 | urls_to_try.append(checkpoint_url)
242 | local_filename = os.path.basename(checkpoint_url)
243 | log.info(
244 | f"Interpreted '{checkpoint_url}' as a direct URL. Local filename: {local_filename}"
245 | )
246 | else:
247 | # urls_to_try remains empty; we'll only check for this path locally in the ckpt_dir
248 | log.info(
249 | f"Interpreted '{checkpoint_url}' as a potential local path identifier."
250 | )
251 | return checkpoint_url
252 |
253 | # 2. Construct local checkpoint path
254 |
255 | home_dir = Path.home()
256 | default_dir = os.path.join(home_dir, ".gotennet", "checkpoints")
257 | ckpt_dir = os.environ.get("CHECKPOINT_PATH", default_dir)
258 | os.makedirs(ckpt_dir, exist_ok=True)
259 | ckpt_path = os.path.join(ckpt_dir, local_filename)
260 |
261 | # 3. Check if file already exists locally and is valid
262 | if os.path.exists(ckpt_path):
263 | if os.path.getsize(ckpt_path) > 0:
264 | log.info(
265 | f"Using existing checkpoint '{local_filename}' found locally at '{ckpt_path}'."
266 | )
267 | return ckpt_path
268 | else:
269 | log.warning(
270 | f"Local checkpoint '{ckpt_path}' exists but is empty. Will attempt to (re-)download if URLs are available."
271 | )
272 | try:
273 | os.remove(ckpt_path) # Remove empty file
274 | except OSError as e:
275 | log.error(f"Could not remove empty local file '{ckpt_path}': {e}")
276 |
277 | # 4. Attempt to download if URLs are available
278 | if not urls_to_try:
279 | # This means input was treated as a local path that wasn't found (or was empty),
280 | # or it was a name for which no URLs were generated (should not happen if name logic is correct).
281 | raise FileNotFoundError(
282 | f"Checkpoint '{local_filename}' not found locally at '{ckpt_path}' and no download URLs were specified or derived."
283 | )
284 |
285 | download_successful = False
286 | last_error = None
287 |
288 | for i, url_to_attempt in enumerate(urls_to_try):
289 | log.info(
290 | f"Attempting download for '{local_filename}' from URL {i + 1}/{len(urls_to_try)}: {url_to_attempt}"
291 | )
292 | try:
293 | # Check URL accessibility
294 | response = requests.head(url_to_attempt, allow_redirects=True, timeout=10)
295 | response.raise_for_status() # Raises HTTPError for bad responses (4XX or 5XX)
296 | log.info(f"Remote URL is valid (HTTP Status: {response.status_code}).")
297 |
298 | # Attempt download
299 | log.warning(
300 | f"Downloading checkpoint to '{ckpt_path}' from '{url_to_attempt}'."
301 | ) # Matches original log level
302 | download_file(url_to_attempt, ckpt_path)
303 |
304 | # Verify download
305 | if not os.path.exists(ckpt_path):
306 | raise FileNotFoundError("Local file not found after download attempt.")
307 | if os.path.getsize(ckpt_path) == 0:
308 | if os.path.exists(ckpt_path):
309 | os.remove(ckpt_path) # Clean up empty file
310 | raise FileNotFoundError("Downloaded file is empty.")
311 |
312 | log.info(
313 | f"Successfully downloaded '{local_filename}' to '{ckpt_path}' from '{url_to_attempt}'."
314 | )
315 | download_successful = True
316 | break # Exit loop on successful download
317 |
318 | except requests.exceptions.HTTPError as e:
319 | log.warning(
320 | f"Failed to access '{url_to_attempt}' (HTTP status: {e.response.status_code})."
321 | )
322 | last_error = e
323 | except (
324 | requests.exceptions.RequestException
325 | ) as e: # Catches DNS errors, connection timeouts, etc.
326 | log.warning(f"Connection error for '{url_to_attempt}': {e}.")
327 | last_error = e
328 | except (
329 | FileNotFoundError
330 | ) as e: # From our own post-download checks or if download_file raises it
331 | log.warning(f"Download or verification failed for '{url_to_attempt}': {e}.")
332 | last_error = e
333 | if (
334 | os.path.exists(ckpt_path) and os.path.getsize(ckpt_path) == 0
335 | ): # Clean up if an empty file was created
336 | try:
337 | os.remove(ckpt_path)
338 | except OSError:
339 | pass
340 | except (
341 | Exception
342 | ) as e: # Catch other errors from download_file or unexpected issues
343 | log.warning(
344 | f"An unexpected error occurred during download from '{url_to_attempt}': {e}"
345 | )
346 | last_error = e
347 | if os.path.exists(ckpt_path): # Clean up potentially corrupt file
348 | try:
349 | os.remove(ckpt_path)
350 | except OSError:
351 | pass
352 |
353 | if i < len(urls_to_try) - 1: # If there are more URLs to try
354 | log.info("Trying next available URL...")
355 |
356 | if not download_successful:
357 | error_message = f"Failed to download checkpoint '{local_filename}' from all provided sources."
358 | if urls_to_try:
359 | error_message += f" Tried: {', '.join(urls_to_try)}."
360 | if last_error:
361 | log.error(f"{error_message} Last error: {last_error}")
362 | raise FileNotFoundError(error_message) from last_error
363 | else:
364 | log.error(error_message)
365 | raise FileNotFoundError(error_message)
366 |
367 | return ckpt_path
368 |
--------------------------------------------------------------------------------
/gotennet/utils/logging_utils.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import, division, print_function
2 |
3 | import logging
4 |
5 | import pytorch_lightning as pl
6 | from omegaconf import DictConfig
7 | from pytorch_lightning.utilities import rank_zero_only
8 |
9 |
10 | def get_logger(name=__name__) -> logging.Logger:
11 | """
12 | Initialize multi-GPU-friendly python command line logger.
13 |
14 | Args:
15 | name: Name of the logger, defaults to the module name.
16 |
17 | Returns:
18 | logging.Logger: Logger instance with rank zero only decorators.
19 | """
20 |
21 | logger = logging.getLogger(name)
22 |
23 | # this ensures all logging levels get marked with the rank zero decorator
24 | # otherwise logs would get multiplied for each GPU process in multi-GPU setup
25 | for level in (
26 | "debug",
27 | "info",
28 | "warning",
29 | "error",
30 | "exception",
31 | "fatal",
32 | "critical",
33 | ):
34 | setattr(logger, level, rank_zero_only(getattr(logger, level)))
35 |
36 | return logger
37 |
38 |
39 | @rank_zero_only
40 | def log_hyperparameters(
41 | config: DictConfig,
42 | model: pl.LightningModule,
43 | trainer: pl.Trainer,
44 | ) -> None:
45 | """
46 | Control which config parts are saved by Lightning loggers.
47 |
48 | Additionally saves:
49 | - number of model parameters (total, trainable, non-trainable)
50 |
51 | Args:
52 | config: DictConfig containing the hydra config.
53 | model: Lightning model.
54 | trainer: Lightning trainer.
55 | """
56 |
57 | if not trainer.logger:
58 | return
59 |
60 | hparams = {}
61 |
62 | # choose which parts of hydra config will be saved to loggers
63 | hparams["model"] = config["model"]
64 |
65 | # save number of model parameters
66 | hparams["model/params/total"] = sum(p.numel() for p in model.parameters())
67 | hparams["model/params/trainable"] = sum(
68 | p.numel() for p in model.parameters() if p.requires_grad
69 | )
70 | hparams["model/params/non_trainable"] = sum(
71 | p.numel() for p in model.parameters() if not p.requires_grad
72 | )
73 |
74 | hparams["datamodule"] = config["datamodule"]
75 | hparams["trainer"] = config["trainer"]
76 |
77 | if "seed" in config:
78 | hparams["seed"] = config["seed"]
79 | if "callbacks" in config:
80 | hparams["callbacks"] = config["callbacks"]
81 |
82 | # send hparams to all loggers
83 | trainer.logger.log_hyperparams(hparams)
84 |
--------------------------------------------------------------------------------
/gotennet/utils/utils.py:
--------------------------------------------------------------------------------
1 | """
2 | Utility functions for the GotenNet project.
3 | """
4 |
5 | from __future__ import absolute_import, division, print_function
6 |
7 | import os
8 | from importlib.util import find_spec
9 | from typing import Callable
10 |
11 | from omegaconf import DictConfig
12 |
13 | from gotennet.utils.logging_utils import get_logger
14 |
15 | log = get_logger(__name__)
16 |
17 |
18 | def find_config_directory() -> str:
19 | """
20 | Find the configs directory by searching in multiple locations.
21 |
22 | Returns:
23 | str: Absolute path to the configs directory.
24 |
25 | Raises:
26 | FileNotFoundError: If configs directory is not found in any search location.
27 | """
28 | package_location = os.path.dirname(
29 | os.path.realpath(__file__)
30 | ) # This will be utils.py's location
31 | current_dir = os.getcwd()
32 |
33 | # Define search paths in order of preference
34 | search_paths = [
35 | os.path.join(current_dir, "configs"), # Check for configs in CWD
36 | os.path.join(
37 | current_dir, "gotennet", "configs"
38 | ), # Check for gotennet/configs in CWD (e.g. running from project root)
39 | os.path.abspath(
40 | os.path.join(package_location, "..", "configs")
41 | ), # Check for ../configs relative to utils.py (i.e. gotennet/configs)
42 | ]
43 |
44 | # Search for configs directory
45 | for path in search_paths:
46 | if os.path.exists(path) and os.path.isdir(path):
47 | # Set PROJECT_ROOT environment variable based on current_dir
48 | # This assumes that if configs are found, current_dir is likely the project root.
49 | os.environ["PROJECT_ROOT"] = current_dir
50 | return os.path.abspath(path)
51 |
52 | # If no configs directory found, raise detailed error
53 | searched_paths_str = "\n".join(
54 | f" - {p}" for p in search_paths
55 | ) # Renamed variable to avoid conflict
56 | raise FileNotFoundError(
57 | f"Could not find 'configs' directory in any of the following locations:\n"
58 | f"{searched_paths_str}\n\n"
59 | f"Please ensure the 'configs' directory exists in one of these locations.\n"
60 | f"Current working directory: {current_dir}\n"
61 | f"Package location (of this util.py file): {package_location}"
62 | )
63 |
64 |
65 | def task_wrapper(task_func: Callable) -> Callable:
66 | """
67 | Optional decorator that controls the failure behavior when executing the task function.
68 |
69 | This wrapper can be used to:
70 | - make sure loggers are closed even if the task function raises an exception (prevents multirun failure)
71 | - save the exception to a `.log` file
72 | - mark the run as failed with a dedicated file in the `logs/` folder (so we can find and rerun it later)
73 | - etc. (adjust depending on your needs)
74 |
75 | Args:
76 | task_func: The task function to wrap.
77 |
78 | Returns:
79 | Callable: The wrapped function.
80 |
81 | Example:
82 | ```
83 | @utils.task_wrapper
84 | def train(cfg: DictConfig) -> Tuple[dict, dict]:
85 | ...
86 | return metric_dict, object_dict
87 | ```
88 | """
89 |
90 | def wrap(cfg: DictConfig):
91 | # execute the task
92 | try:
93 | metric_dict, object_dict = task_func(cfg=cfg)
94 |
95 | # things to do if exception occurs
96 | except Exception as ex:
97 | # save exception to `.log` file
98 | log.exception("")
99 |
100 | # some hyperparameter combinations might be invalid or cause out-of-memory errors
101 | # so when using hparam search plugins like Optuna, you might want to disable
102 | # raising the below exception to avoid multirun failure
103 | raise ex
104 |
105 | # things to always do after either success or exception
106 | finally:
107 | # display output dir path in terminal
108 | log.info(f"Output dir: {cfg.paths.output_dir}")
109 |
110 | # always close wandb run (even if exception occurs so multirun won't fail)
111 | if find_spec("wandb"): # check if wandb is installed
112 | import wandb
113 |
114 | if wandb.run:
115 | log.info("Closing wandb!")
116 | wandb.finish()
117 |
118 | return metric_dict, object_dict
119 |
120 | return wrap
121 |
122 |
123 | def get_metric_value(metric_dict: dict, metric_name: str) -> float | None:
124 | """
125 | Safely retrieves value of the metric logged in LightningModule.
126 |
127 | Args:
128 | metric_dict (dict): Dictionary containing metrics logged by LightningModule.
129 | metric_name (str): Name of the metric to retrieve.
130 |
131 | Returns:
132 | float | None: The value of the metric, or None if metric_name is empty.
133 |
134 | Raises:
135 | Exception: If the metric name is provided but not found in the metric dictionary.
136 | """
137 | if not metric_name:
138 | log.info("Metric name is None! Skipping metric value retrieval...")
139 | return None
140 |
141 | if metric_name not in metric_dict:
142 | raise Exception(
143 | f"Metric value not found! \n"
144 | "Make sure metric name logged in LightningModule is correct!\n"
145 | "Make sure `optimized_metric` name in `hparams_search` config is correct!"
146 | )
147 |
148 | metric_value = metric_dict[metric_name].item()
149 | log.info(f"Retrieved metric value! <{metric_name}={metric_value}>")
150 |
151 | return metric_value
152 |
153 |
154 | def get_function_name(func):
155 | if hasattr(func, "name"):
156 | func_name = func.name
157 | else:
158 | func_name = type(func).__name__.split(".")[-1]
159 | return func_name
160 |
--------------------------------------------------------------------------------
/gotennet/vendor/__init__.py:
--------------------------------------------------------------------------------
1 | # use this folder for storing third party code that cannot be installed using pip/conda
2 |
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [build-system]
2 | requires = ["hatchling>=1.18.0"]
3 | build-backend = "hatchling.build"
4 |
5 | [project]
6 | name = "gotennet"
7 | version = "1.1.2"
8 | description = "GotenNet: Rethinking Efficient 3D Equivariant Graph Neural Networks"
9 | readme = "README.md"
10 | requires-python = ">=3.10"
11 | license = { file = "LICENSE" }
12 | authors = [
13 | { name = "GotenNet Authors" },
14 | ]
15 | classifiers = [
16 | "Development Status :: 4 - Beta",
17 | "Intended Audience :: Science/Research",
18 | "License :: OSI Approved :: MIT License",
19 | "Programming Language :: Python :: 3",
20 | "Programming Language :: Python :: 3.10",
21 | "Topic :: Scientific/Engineering",
22 | "Topic :: Scientific/Engineering :: Artificial Intelligence",
23 | "Topic :: Scientific/Engineering :: Chemistry",
24 | ]
25 | # Core dependencies needed to import and use the GotenNet model
26 | dependencies = [
27 | "numpy",
28 | "torch>=2.5.0",
29 | "torch_geometric",
30 | "torch_scatter",
31 | "torch_sparse",
32 | "torch_cluster",
33 | "e3nn",
34 | "ase",
35 | ]
36 |
37 | [project.optional-dependencies]
38 | # Dependencies for training, data handling, logging, and utilities
39 | full = [
40 | "torchvision",
41 | "torchaudio",
42 | "pyg_lib",
43 | "torch_spline_conv",
44 | "lightning==2.2.5",
45 | "pytorch_lightning==2.2.5",
46 | "hydra-core",
47 | "python-dotenv",
48 | "pyrootutils",
49 | "wandb",
50 | "rich",
51 | "hydra-optuna-sweeper",
52 | "hydra-colorlog",
53 | "scikit-learn",
54 | "pandas",
55 | "rdkit",
56 | "omegaconf",
57 | ]
58 | dev = [
59 | "ruff",
60 | "black",
61 | "isort",
62 | "pytest",
63 | "pytest-cov",
64 | "mypy",
65 | ]
66 | docs = [
67 | "sphinx",
68 | "sphinx-rtd-theme",
69 | ]
70 |
71 | [project.urls]
72 | "Homepage" = "https://github.com/sarpaykent/gotennet"
73 | "Bug Tracker" = "https://github.com/sarpaykent/gotennet/issues"
74 |
75 | [project.scripts]
76 | train_gotennet = "gotennet.scripts.train:main"
77 | test_gotennet = "gotennet.scripts.test:main"
78 |
79 | [tool.hatch.build.targets.wheel]
80 | packages = ["gotennet"]
81 |
82 | [tool.hatch.build.targets.sdist]
83 | include = [
84 | "gotennet/**/*.py",
85 | "gotennet/**/*.yaml",
86 | "gotennet/**/*.yml",
87 | "LICENSE",
88 | "README.md",
89 | "pyproject.toml",
90 | "gotennet/scripts/train.py",
91 | "gotennet/configs/**/*.yaml",
92 | "gotennet/configs/**/*.yml",
93 | ]
94 |
95 | [tool.ruff]
96 | target-version = "py310"
97 | lint.select = ["F", "B", "I"]
98 | lint.ignore = []
99 |
100 | [tool.ruff.lint.isort]
101 | known-first-party = ["gotennet"]
102 |
103 | [tool.mypy]
104 | python_version = "3.10"
105 | warn_return_any = true
106 | warn_unused_configs = true
107 | disallow_untyped_defs = false
108 | disallow_incomplete_defs = false
109 |
110 | [[tool.mypy.overrides]]
111 | module = ["torch.*", "lightning.*", "hydra.*", "omegaconf.*", "wandb.*", "pyrootutils.*", "dotenv.*"]
112 | ignore_missing_imports = true
113 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | --find-links https://download.pytorch.org/whl/cu124
2 | torch==2.5.1
3 | torchvision==0.20.1
4 | torchaudio==2.5.1
5 |
6 | torch_geometric
7 |
8 | --find-links https://data.pyg.org/whl/torch-2.5.0+cu124.html
9 | pyg_lib
10 | torch_scatter
11 | torch_sparse
12 | torch_cluster
13 | torch_spline_conv
14 |
15 | lightning==2.2.5
16 | pytorch_lightning==2.2.5
17 |
18 | hydra-core
19 | python-dotenv
20 | pyrootutils
21 | wandb
22 | rich
23 | hydra-optuna-sweeper
24 | hydra-colorlog
25 | ase
26 | scikit-learn
27 | pandas
28 | rdkit
29 |
30 | e3nn
--------------------------------------------------------------------------------