├── PyPi Package
├── src
│ ├── denmune
│ │ ├── .idea
│ │ │ ├── .name
│ │ │ ├── .gitignore
│ │ │ ├── misc.xml
│ │ │ ├── inspectionProfiles
│ │ │ │ └── profiles_settings.xml
│ │ │ ├── modules.xml
│ │ │ └── denmune.iml
│ │ ├── __init__.py
│ │ └── denmune.py
│ └── denmune.egg-info
│ │ ├── dependency_links.txt
│ │ ├── top_level.txt
│ │ ├── requires.txt
│ │ ├── SOURCES.txt
│ │ └── PKG-INFO
├── MANIFEST.in
├── .vscode
│ └── settings.json
├── pyproject.toml
├── setup.py
├── setup.cfg
├── LICENSE
└── README.md
├── src
├── __init__.py
└── tests
│ └── test_denmune.py
├── images
├── denmune-illustration.png
└── denmune_propagation.png
├── requirements.txt
├── codecov.yml
├── .github
└── workflows
│ ├── python-package
│ └── codeql.yml
├── LICENSE
├── .circleci
└── config.yml
├── colab
└── iris_dataset.ipynb
├── README.md
└── kaggle
└── the-beauty-of-clusters-propagation.ipynb
/PyPi Package/src/denmune/.idea/.name:
--------------------------------------------------------------------------------
1 | denmune.py
--------------------------------------------------------------------------------
/PyPi Package/src/denmune.egg-info/dependency_links.txt:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/PyPi Package/src/denmune.egg-info/top_level.txt:
--------------------------------------------------------------------------------
1 | denmune
2 |
--------------------------------------------------------------------------------
/PyPi Package/MANIFEST.in:
--------------------------------------------------------------------------------
1 | recursive-include data *.ipynb *.py *.txt *.csv
--------------------------------------------------------------------------------
/PyPi Package/src/denmune/__init__.py:
--------------------------------------------------------------------------------
1 |
2 | from .denmune import DenMune
--------------------------------------------------------------------------------
/PyPi Package/.vscode/settings.json:
--------------------------------------------------------------------------------
1 | {
2 | "restructuredtext.confPath": ""
3 | }
--------------------------------------------------------------------------------
/src/__init__.py:
--------------------------------------------------------------------------------
1 | from .denmune import DenMune
2 |
3 | __all__ = ["DenMune"]
4 |
--------------------------------------------------------------------------------
/PyPi Package/src/denmune/.idea/.gitignore:
--------------------------------------------------------------------------------
1 | # Default ignored files
2 | /shelf/
3 | /workspace.xml
4 |
--------------------------------------------------------------------------------
/images/denmune-illustration.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/scikit-learn-contrib/denmune-clustering-algorithm/main/images/denmune-illustration.png
--------------------------------------------------------------------------------
/images/denmune_propagation.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/scikit-learn-contrib/denmune-clustering-algorithm/main/images/denmune_propagation.png
--------------------------------------------------------------------------------
/PyPi Package/pyproject.toml:
--------------------------------------------------------------------------------
1 | [build-system]
2 | requires = [
3 | "setuptools>=42",
4 | "wheel"
5 | ]
6 | build-backend = "setuptools.build_meta"
--------------------------------------------------------------------------------
/PyPi Package/src/denmune.egg-info/requires.txt:
--------------------------------------------------------------------------------
1 | numpy>=1.18.5
2 | pandas>=1.0.3
3 | matplotlib>=3.2.1
4 | scikit-learn>=0.22.1
5 | seaborn>=0.10.1
6 | ngt>=1.11.6
7 | anytree>=2.8.0
8 | treelib>=1.6.1
9 |
--------------------------------------------------------------------------------
/PyPi Package/src/denmune/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | ngt>=2.0.4
2 | numpy>=1.23.5
3 | pandas>=1.5.3
4 | matplotlib>=3.7.2
5 | scikit-learn>=1.2.2
6 | seaborn>=0.12.2
7 | anytree>=2.8
8 | treelib>=1.6.1
9 | pytest>=6.2.5
10 | coverage>=6.3.1
11 | treon
12 | testbook
13 | notebook
14 |
15 |
--------------------------------------------------------------------------------
/PyPi Package/src/denmune/.idea/inspectionProfiles/profiles_settings.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
--------------------------------------------------------------------------------
/PyPi Package/src/denmune/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/PyPi Package/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import setup
2 |
3 | setup(
4 | install_requires=[
5 |
6 | 'numpy==1.23.5',
7 | 'pandas==1.5.3',
8 | 'matplotlib==3.7.2',
9 | 'scikit-learn==1.2.2',
10 | 'seaborn==0.12.2',
11 | 'ngt==2.0.4',
12 | 'anytree==2.8',
13 | 'treelib==1.6.1',
14 | ]
15 |
16 | )
17 |
--------------------------------------------------------------------------------
/PyPi Package/src/denmune/.idea/denmune.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/PyPi Package/src/denmune.egg-info/SOURCES.txt:
--------------------------------------------------------------------------------
1 | LICENSE
2 | MANIFEST.in
3 | README.md
4 | pyproject.toml
5 | setup.cfg
6 | setup.py
7 | src/denmune/__init__.py
8 | src/denmune/denmune.py
9 | src/denmune.egg-info/PKG-INFO
10 | src/denmune.egg-info/SOURCES.txt
11 | src/denmune.egg-info/dependency_links.txt
12 | src/denmune.egg-info/requires.txt
13 | src/denmune.egg-info/top_level.txt
--------------------------------------------------------------------------------
/PyPi Package/setup.cfg:
--------------------------------------------------------------------------------
1 | [metadata]
2 | name = denmune
3 | version = 0.0.96
4 | author = Mohamed Ali Abbas
5 | author_email = mohamed.alyabbas@outlook.com
6 | description = This is the package for DenMune Clustering Algorithm published in paper https://doi.org/10.1016/j.patcog.2020.107589
7 | long_description = file: README.md
8 | long_description_content_type = text/markdown
9 | url = https://github.com/egy1st/denmune-clustering-algorithm
10 | project_urls =
11 | Bug Tracker = https://github.com/pypa/sampleproject/issues
12 | classifiers =
13 | Programming Language :: Python :: 3
14 | License :: OSI Approved :: BSD License
15 | Operating System :: OS Independent
16 |
17 | [options]
18 | package_dir =
19 | = src
20 | packages = find:
21 | python_requires = >=3.6
22 |
23 | [options.packages.find]
24 | where = src
25 |
--------------------------------------------------------------------------------
/codecov.yml:
--------------------------------------------------------------------------------
1 | codecov:
2 | require_ci_to_pass: yes
3 |
4 | coverage:
5 | precision: 2
6 | round: down
7 | range: "70...100"
8 |
9 | status:
10 | project:
11 | default: false # disable the default status that measures entire project
12 | tests: # declare a new status context "tests"
13 | target: 100% # we always want 100% coverage here
14 | paths: "tests/" # only include coverage in "tests/" folder
15 | jupyter: # declare a new status context "app"
16 | paths: "!tests/" # remove all files in "tests/"
17 |
18 | if_ci_failed: error #success, failure, error, ignore
19 | informational: true
20 |
21 | parsers:
22 | gcov:
23 | branch_detection:
24 | conditional: yes
25 | loop: yes
26 | method: no
27 | macro: no
28 |
29 | comment:
30 | layout: "reach,diff,flags,files,footer"
31 | behavior: default
32 | require_changes: no
33 |
34 |
--------------------------------------------------------------------------------
/.github/workflows/python-package:
--------------------------------------------------------------------------------
1 | name: workflow for codecov
2 | on: [push]
3 | jobs:
4 | run:
5 | runs-on: ${{ matrix.os }}
6 | strategy:
7 | matrix:
8 | os: [ubuntu-latest]
9 | python: ['3.6', '3.7', '3.8', '3.9']
10 | env:
11 | OS: ${{ matrix.os }}
12 | PYTHON: ${{ matrix.python }}
13 | steps:
14 | - uses: actions/checkout@master
15 | - name: Setup Python
16 | uses: actions/setup-python@master
17 | with:
18 | python-version: 3.7
19 | - name: Generate coverage report
20 | run: |
21 | pip install pytest
22 | pip install pytest-cov
23 | pip install numpy
24 | pip install -U scikit-learn
25 | pip install denmune
26 | pytest --cov=./ --cov-report=xml
27 | - name: Upload coverage to Codecov
28 | uses: codecov/codecov-action@v2
29 | with:
30 | token: 'fce1be95-36c5-4c80-83c1-fe9fa8539dae'
31 | files: ./coverage.xml
32 | env_vars: OS,PYTHON
33 | fail_ci_if_error: true
34 | flags: unittests
35 | name: codecov-umbrella
36 | verbose: true
37 |
--------------------------------------------------------------------------------
/PyPi Package/LICENSE:
--------------------------------------------------------------------------------
1 | Copyright (c) 2021, Mohamed Ali Abbas
2 | All rights reserved.
3 |
4 | Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
5 |
6 | 1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
7 |
8 | 2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
9 |
10 | 3. Neither the name of the copyright holder nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
11 |
12 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | BSD 3-Clause License
2 |
3 | Copyright (c) 2021, Mohamed Ali Abbas
4 | All rights reserved.
5 |
6 | Redistribution and use in source and binary forms, with or without
7 | modification, are permitted provided that the following conditions are met:
8 |
9 | 1. Redistributions of source code must retain the above copyright notice, this
10 | list of conditions and the following disclaimer.
11 |
12 | 2. Redistributions in binary form must reproduce the above copyright notice,
13 | this list of conditions and the following disclaimer in the documentation
14 | and/or other materials provided with the distribution.
15 |
16 | 3. Neither the name of the copyright holder nor the names of its
17 | contributors may be used to endorse or promote products derived from
18 | this software without specific prior written permission.
19 |
20 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
21 | AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
22 | IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
23 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
24 | FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
25 | DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
26 | SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
27 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
28 | OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
29 | OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
30 |
--------------------------------------------------------------------------------
/.github/workflows/codeql.yml:
--------------------------------------------------------------------------------
1 | # For most projects, this workflow file will not need changing; you simply need
2 | # to commit it to your repository.
3 | #
4 | # You may wish to alter this file to override the set of languages analyzed,
5 | # or to provide custom queries or build logic.
6 | #
7 | # ******** NOTE ********
8 | # We have attempted to detect the languages in your repository. Please check
9 | # the `language` matrix defined below to confirm you have the correct set of
10 | # supported CodeQL languages.
11 | #
12 | name: "CodeQL"
13 |
14 | on:
15 | push:
16 | branches: [ "main" ]
17 | pull_request:
18 | # The branches below must be a subset of the branches above
19 | branches: [ "main" ]
20 | schedule:
21 | - cron: '45 0 * * 6'
22 |
23 | jobs:
24 | analyze:
25 | name: Analyze
26 | runs-on: ubuntu-latest
27 | permissions:
28 | actions: read
29 | contents: read
30 | security-events: write
31 |
32 | strategy:
33 | fail-fast: false
34 | matrix:
35 | language: [ 'python' ]
36 | # CodeQL supports [ 'cpp', 'csharp', 'go', 'java', 'javascript', 'python', 'ruby' ]
37 | # Learn more about CodeQL language support at https://aka.ms/codeql-docs/language-support
38 |
39 | steps:
40 | - name: Checkout repository
41 | uses: actions/checkout@v3
42 |
43 | # Initializes the CodeQL tools for scanning.
44 | - name: Initialize CodeQL
45 | uses: github/codeql-action/init@v2
46 | with:
47 | languages: ${{ matrix.language }}
48 | # If you wish to specify custom queries, you can do so here or in a config file.
49 | # By default, queries listed here will override any specified in a config file.
50 | # Prefix the list here with "+" to use these queries and those in the config file.
51 |
52 | # Details on CodeQL's query packs refer to : https://docs.github.com/en/code-security/code-scanning/automatically-scanning-your-code-for-vulnerabilities-and-errors/configuring-code-scanning#using-queries-in-ql-packs
53 | # queries: security-extended,security-and-quality
54 |
55 |
56 | # Autobuild attempts to build any compiled languages (C/C++, C#, or Java).
57 | # If this step fails, then you should remove it and run the build manually (see below)
58 | - name: Autobuild
59 | uses: github/codeql-action/autobuild@v2
60 |
61 | # ℹ️ Command-line programs to run using the OS shell.
62 | # 📚 See https://docs.github.com/en/actions/using-workflows/workflow-syntax-for-github-actions#jobsjob_idstepsrun
63 |
64 | # If the Autobuild fails above, remove it and uncomment the following three lines.
65 | # modify them (or add more) to build your code if your project, please refer to the EXAMPLE below for guidance.
66 |
67 | # - run: |
68 | # echo "Run, Build Application using script"
69 | # ./location_of_script_within_repo/buildscript.sh
70 |
71 | - name: Perform CodeQL Analysis
72 | uses: github/codeql-action/analyze@v2
73 | with:
74 | category: "/language:${{matrix.language}}"
75 |
--------------------------------------------------------------------------------
/.circleci/config.yml:
--------------------------------------------------------------------------------
1 | # Use the latest 2.1 version of CircleCI pipeline process engine.
2 | # See: https://circleci.com/docs/2.0/configuration-reference
3 | version: 2.1
4 |
5 | # Orbs are reusable packages of CircleCI configuration that you may share across projects, enabling you to create encapsulated, parameterized commands, jobs, and executors that can be used across multiple projects.
6 | # See: https://circleci.com/docs/2.0/orb-intro/
7 | orbs:
8 | # The python orb contains a set of prepackaged CircleCI configuration you can use repeatedly in your configuration files
9 | # Orb commands and jobs help you with common scripting around a language/tool
10 | # so you dont have to copy and paste it everywhere.
11 | # See the orb documentation here: https://circleci.com/developer/orbs/orb/circleci/python
12 | codecov: codecov/codecov@3.0.0
13 | slack: circleci/slack@4.4.4
14 | python: circleci/python@2.1.1
15 |
16 |
17 | # Define a job to be invoked later in a workflow.
18 | # See: https://circleci.com/docs/2.0/configuration-reference/#jobs
19 | jobs:
20 | build-and-test: # This is the name of the job, feel free to change it to better match what you're trying to do!
21 | # These next lines defines a Docker executors: https://circleci.com/docs/2.0/executor-types/
22 | # You can specify an image from Dockerhub or use one of the convenience images from CircleCI's Developer Hub
23 | # A list of available CircleCI Docker convenience images are available here: https://circleci.com/developer/images/image/cimg/python
24 | # The executor is the environment in which the steps below will be executed - below will use a python 3.8 container
25 | # Change the version below to your required version of python
26 | docker:
27 | - image: cimg/python:3.10
28 |
29 |
30 | # Checkout the code as the first step. This is a dedicated CircleCI step.
31 | # The python orb's install-packages step will install the dependencies from a Pipfile via Pipenv by default.
32 | # Here we're making sure we use just use the system-wide pip. By default it uses the project root's requirements.txt.
33 | # Then run your tests!
34 | # CircleCI will report the results back to your VCS provider.
35 | steps:
36 | - checkout
37 | - python/install-packages:
38 | pkg-manager: pip
39 | # app-dir: ~/project/package-directory/ # If you're requirements.txt isn't in the root directory.
40 | # pip-dependency-file: test-requirements.txt # if you have a different name for your requirements file, maybe one that combines your runtime and test requirements.
41 |
42 | - run:
43 | name: Treon Test
44 | command: |
45 | cd colab
46 | # git clone https://github.com/egy1st/datasets
47 | # treon --threads=2
48 |
49 | - run:
50 | name: CodeCov pyTest
51 | command: |
52 | coverage run -m pytest
53 | coverage report
54 | coverage html
55 | coverage xml
56 | cp coverage.xml htmlcov/coverage.xml
57 |
58 | - codecov/upload
59 |
60 | - store_artifacts:
61 | path: htmlcov
62 |
63 | - slack/notify:
64 | template: basic_success_1
65 | channel: C0326UK1VFY
66 | # Invoke jobs via workflows
67 | # See: https://circleci.com/docs/2.0/configuration-reference/#workflows
68 | workflows:
69 | Python-3.10: # This is the name of the workflow, feel free to change it to better match your workflow.
70 | # Inside the workflow, you define the jobs you want to run.
71 | jobs:
72 | - build-and-test:
73 | context: Slack
74 |
75 |
--------------------------------------------------------------------------------
/src/tests/test_denmune.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from itertools import chain
3 | import pandas as pd
4 | import pytest
5 | from sklearn.datasets import make_blobs
6 | from sklearn.datasets import load_iris
7 | from src.denmune import DenMune
8 |
9 |
10 | # test DenMune's results
11 | X_cc, y_cc = make_blobs(
12 | n_samples=1000,
13 | centers=np.array([[-1, -1], [1, 1]]),
14 | random_state=0,
15 | shuffle=False,
16 | cluster_std=0.5,
17 | )
18 |
19 | knn = 10
20 |
21 | def test_DenMune_results():
22 | dm = DenMune(train_data=X_cc, train_truth=y_cc, k_nearest=knn)
23 | labels, validity = dm.fit_predict(show_analyzer=False)
24 | # This test use data that are not perfectly separable so the
25 | # accuracy is not 1. Accuracy around 0.90
26 | assert (np.mean(dm.labels_pred == y_cc) > 0.90) or (1 - np.mean(dm.labels_pred == y_cc) > 0.90)
27 |
28 |
29 | @pytest.mark.parametrize("train_data", [None, X_cc[:800] ])
30 | @pytest.mark.parametrize("train_truth", [None, y_cc[:800] ])
31 | @pytest.mark.parametrize("test_data", [None, X_cc[800:] ])
32 | @pytest.mark.parametrize("test_truth", [None, y_cc[800:] ])
33 | @pytest.mark.parametrize("validate", [True, False])
34 | @pytest.mark.parametrize("show_plots", [True, False])
35 | @pytest.mark.parametrize("show_noise", [True, False])
36 | @pytest.mark.parametrize("show_analyzer", [True, False])
37 | @pytest.mark.parametrize("prop_step", [0, 600])
38 |
39 | # all possible combinations will be tested over all parameters. Actually, 257 tests will be covered
40 | def test_parameters(train_data, train_truth, test_data, test_truth, validate, show_plots, show_noise, show_analyzer, prop_step):
41 | if not (train_data is None):
42 | if not (train_data is not None and train_truth is None and test_truth is not None):
43 | if not (train_data is not None and test_data is not None and train_truth is None):
44 | if not (train_data is not None and train_truth is not None and test_truth is not None and test_data is None):
45 | dm = DenMune(train_data=train_data, train_truth=train_truth, test_data=test_data, test_truth=test_truth, k_nearest=10,prop_step=prop_step)
46 | labels, validity = dm.fit_predict(validate=validate, show_plots=show_plots, show_noise=show_noise, show_analyzer=show_analyzer)
47 | # This test use data that are not perfectly separable so the
48 | # accuracy is not 1. Accuracy around 0.70
49 | assert ( np.mean(labels == y_cc) > 0.70 or (1 - np.mean( labels == y_cc) > 0.70) )
50 |
51 |
52 | def test_DenMune_propagation():
53 | snapshots = chain([0], range(2,5), range(5,50,5), range(50, 100, 10), range(100,500,50), range(500,1100, 100))
54 | for snapshot in snapshots:
55 | dm = DenMune(train_data=X_cc, k_nearest=knn, prop_step=snapshot)
56 | labels, validity = dm.fit_predict(show_analyzer=False, show_plots=False)
57 | # if snapshot iteration = 1000, this means we could propagate to the end properly
58 | assert (snapshot == 1000)
59 |
60 | # we are going to do some tests using iris data
61 | X_iris = load_iris()["data"]
62 | y_iris = load_iris()["target"]
63 |
64 | # we test t_SNE reduction by applying it on Iris dataset which has 4 dimentions.
65 | @pytest.mark.parametrize("file_2d", [None, 'iris_2d.csv'])
66 | @pytest.mark.parametrize("rgn_tsne", [True, False])
67 |
68 |
69 | def test_t_SNE(rgn_tsne, file_2d):
70 | dm = DenMune(train_data=X_iris, train_truth=y_iris, k_nearest=knn, rgn_tsne=rgn_tsne, file_2d=file_2d)
71 | labels, validity = dm.fit_predict(show_analyzer=False, show_plots=False)
72 | assert (dm.data.shape[1] == 2) # this means it was reduced properly to 2-d using t-SNE
73 |
74 | def test_knn():
75 | for k in range (5, 55, 5):
76 | dm = DenMune(train_data=X_iris, train_truth=y_iris, k_nearest=k, rgn_tsne=False)
77 | labels, validity = dm.fit_predict(show_analyzer=False, show_plots=False)
78 | #assert (k == 50) # this means we tested the algorithm works fine with several knn inputs
79 |
80 |
81 | data_file = 'https://raw.githubusercontent.com/egy1st/datasets/dd90854f92cb5ef73b4146606c1c158c32e69b94/denmune/shapes/aggr_rand.csv'
82 | data = pd.read_csv(data_file, sep=',', header=None)
83 | labels = data.iloc[:, -1]
84 | data = data.drop(data.columns[-1], axis=1)
85 | train_data = data [:555]
86 | test_data = data [555:]
87 | train_labels = labels [:555]
88 | test_labels = labels [555:]
89 |
90 | # check if data will be treated correctly when comes as dataframe
91 | def test_dataframe():
92 | knn = 11 # k-nearest neighbor, the only parameter required by the algorithm
93 | dm = DenMune(train_data=train_data, train_truth=train_labels, test_data=test_data, test_truth=test_labels, k_nearest=knn, rgn_tsne=True)
94 | labels, validity = dm.fit_predict(validate=True, show_noise=True, show_analyzer=True)
95 | assert ( np.mean(dm.labels_pred == labels) > 0.97 or (1 - np.mean( dm.labels_pred == labels) > 0.97) )
96 |
97 |
98 | def test_exceptions():
99 |
100 | with pytest.raises(Exception) as execinfo:
101 | dm = DenMune(train_data=None, k_nearest=10)
102 | #labels, validity = dm.fit_predict()
103 | #raise Exception('train data is None')
104 |
105 | with pytest.raises(Exception) as execinfo:
106 | dm = DenMune(train_data=train_data, test_truth=test_labels, k_nearest=10)
107 | #labels, validity = dm.fit_predict()
108 | #raise Exception('train_data is not None and train_truth is None and test_truth is not None')
109 |
110 | with pytest.raises(Exception) as execinfo:
111 | dm = DenMune(train_data=train_data, test_data=test_data, k_nearest=10)
112 | #labels, validity = dm.fit_predict()
113 | #raise Exception('train_data is not None and test_data is not None and train_truth is None')
114 |
115 | with pytest.raises(Exception) as execinfo:
116 | dm = DenMune(train_data=train_data, train_truth=train_labels, test_truth=test_labels, test_data=None, k_nearest=10)
117 | #labels, validity = dm.fit_predict()
118 | #raise Exception('train_data is not None and train_truth is not None and test_truth is not None and test_data is None')
119 | with pytest.raises(Exception) as execinfo:
120 |
121 | dm = DenMune(train_data=train_data, train_truth=train_labels, k_nearest=0) # default value for k_nearest is 1 which is valid
122 | #labels, validity = dm.fit_predict()
123 | #raise Exception('k-nearest neighbor should be at least 1')
124 |
--------------------------------------------------------------------------------
/PyPi Package/README.md:
--------------------------------------------------------------------------------
1 | DenMune: A density-peak clustering algorithm
2 | =============================================
3 |
4 | DenMune a clustering algorithm that can find clusters of arbitrary size, shapes and densities in two-dimensions. Higher dimensions are first reduced to 2-D using the t-sne. The algorithm relies on a single parameter K (the number of nearest neighbors). The results show the superiority of the algorithm. Enjoy the simplicity but the power of DenMune.
5 |
6 |
7 | []( https://pypi.org/project/denmune/)
8 | [](https://mybinder.org/v2/gh/egy1st/denmune-clustering-algorithm/HEAD)
9 | [](https://denmune.readthedocs.io/en/latest/?badge=latest)
10 | [](#colab)
11 | [](https://www.kaggle.com/egyfirst/denmune-clustering-iris-dataset?scriptVersionId=84775816)
12 | [](https://www.sciencedirect.com/science/article/abs/pii/S0031320320303927)
13 | [](https://data.mendeley.com/datasets/b73cw5n43r/4)
14 | [](https://choosealicense.com/licenses/bsd-3-clause/)
15 | [](https://circleci.com/gh/egy1st/denmune-clustering-algorithm/tree/main)
16 | [](https://codecov.io/gh/egy1st/denmune-clustering-algorithm)
17 |
18 | Based on the paper
19 | -------------------
20 |
21 | |Paper|Journal|
22 | |-------------------------------------------------------------------------------------------|-----------------------------|
23 | |Mohamed Abbas, Adel El-Zoghabi, Amin Ahoukry,
24 | |*DenMune: Density peak based clustering using mutual nearest neighbors*
25 | |In: Journal of Pattern Recognition, Elsevier,
26 | |volume 109, number 107589, January 2021
27 | |DOI: https://doi.org/10.1016/j.patcog.2020.107589
28 |
29 | Documentation:
30 | ---------------
31 | Documentation, including tutorials, are available on https://denmune.readthedocs.io
32 |
33 | [](https://denmune.readthedocs.io/en/latest/?badge=latest)
34 |
35 |
36 | Watch it in action
37 | -------------------
38 | This 30 seconds will tell you how a density-baased algorithm, DenMune propagates:
39 |
40 | [](https://colab.research.google.com/drive/1o-tP3uvDGjxBOGYkir1lnbr74sZ06e0U?usp=sharing)
41 |
42 | []()
43 |
44 |
45 |
46 | When less means more
47 | --------------------
48 | Most calssic clustering algorithms fail in detecting complex clusters where clusters are of different size, shape, density, and being exist in noisy data.
49 | Recently, a density-based algorithm named DenMune showed great ability in detecting complex shapes even in noisy data. it can detect number of clusters automatically, detect both pre-identified-noise and post-identified-noise automatically and removing them.
50 |
51 | It can achieve accuracy reach 100% in most classic pattern problems, achieve 97% in MNIST dataset. A great advantage of this algorithm is being single-parameter algorithm. All you need is to set number of k-nearest neighbor and the algorithm will care about the rest. Being Non-senstive to changes in k, make it robust and stable.
52 |
53 | Keep in mind, the algorithm reduce any N-D dataset to only 2-D dataset initially, so it is a good benefit of this algorithm is being always to plot your data and explore it which make this algorithm a good candidate for data exploration. Finally, the algorithm comes with neat package for visualizing data, validating it and analyze the whole clustering process.
54 |
55 | How to install DenMune
56 | ------------------------
57 | Simply install DenMune clustering algorithm using pip command from the official Python repository
58 |
59 | []( https://pypi.org/project/denmune/)
60 |
61 | From the shell run the command
62 |
63 | ```shell
64 | pip install denmune
65 | ```
66 |
67 | From jupyter notebook cell run the command
68 |
69 | ```ipython3
70 | !pip install denmune
71 | ```
72 |
73 | How to use DenMune
74 | --------------------
75 | Once DenMune is installed, you just need to import it
76 |
77 | ```python
78 | from denmune import DenMune
79 | ```
80 | ###### Please note that first denmune (the package) in small letters, while the other one(the class itself) has D and M in capital case.
81 |
82 |
83 | Read data
84 | -----------
85 |
86 | There are four possible cases of data:
87 | - only train data without labels
88 | - only labeld train data
89 | - labeled train data in addition to test data without labels
90 | - labeled train data in addition to labeled test data
91 |
92 |
93 | ```python
94 | #=============================================
95 | # First scenario: train data without labels
96 | # ============================================
97 |
98 | data_path = 'datasets/denmune/chameleon/'
99 | dataset = "t7.10k.csv"
100 | data_file = data_path + dataset
101 |
102 | # train data without labels
103 | X_train = pd.read_csv(data_file, sep=',', header=None)
104 |
105 | knn = 39 # k-nearest neighbor, the only parameter required by the algorithm
106 |
107 | dm = DenMune(train_data=X_train, k_nearest=knn)
108 | labels, validity = dm.fit_predict(show_analyzer=False, show_noise=True)
109 |
110 | ```
111 | This is an intutive dataset which has no groundtruth provided
112 |
113 | 
114 |
115 | ```python
116 | #=============================================
117 | # Second scenario: train data with labels
118 | # ============================================
119 |
120 | data_path = 'datasets/denmune/shapes/'
121 | dataset = "aggregation.csv"
122 | data_file = data_path + dataset
123 |
124 | # train data with labels
125 | X_train = pd.read_csv(data_file, sep=',', header=None)
126 | y_train = X_train.iloc[:, -1]
127 | X_train = X_train.drop(X_train.columns[-1], axis=1)
128 |
129 | knn = 6 # k-nearest neighbor, the only parameter required by the algorithm
130 |
131 | dm = DenMune(train_data=X_train, train_truth= y_train, k_nearest=knn)
132 | labels, validity = dm.fit_predict(show_analyzer=False, show_noise=True)
133 | ```
134 | Datset groundtruth
135 |
136 | 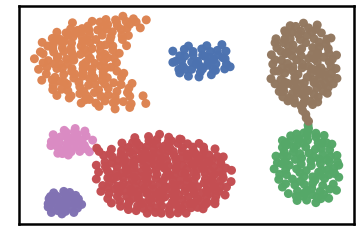
137 |
138 | Datset as detected by DenMune at k=6
139 |
140 | 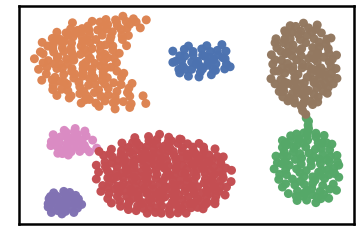
141 |
142 |
143 | ```python
144 | #=================================================================
145 | # Third scenario: train data with labels in addition to test data
146 | # ================================================================
147 |
148 | data_path = 'datasets/denmune/pendigits/'
149 | file_2d = data_path + 'pendigits-2d.csv'
150 |
151 | # train data with labels
152 | X_train = pd.read_csv(data_path + 'train.csv', sep=',', header=None)
153 | y_train = X_train.iloc[:, -1]
154 | X_train = X_train.drop(X_train.columns[-1], axis=1)
155 |
156 | # test data without labels
157 | X_test = pd.read_csv(data_path + 'test.csv', sep=',', header=None)
158 | X_test = X_test.drop(X_test.columns[-1], axis=1)
159 |
160 | knn = 50 # k-nearest neighbor, the only parameter required by the algorithm
161 |
162 | dm = DenMune(train_data=X_train, train_truth= y_train,
163 | test_data= X_test,
164 | k_nearest=knn)
165 | labels, validity = dm.fit_predict(show_analyzer=True, show_noise=True)
166 | ```
167 | dataset groundtruth
168 |
169 | 
170 |
171 |
172 | dataset as detected by DenMune at k=50
173 |
174 | 
175 |
176 | test data as predicted by DenMune on training the dataset at k=50
177 |
178 | 
179 |
180 |
181 | Algorithm's Parameters
182 | -----------------------
183 | 1. Parameters used within the initialization of the DenMune class
184 |
185 | ```python
186 | def __init__ (self,
187 | train_data=None, test_data=None,
188 | train_truth=None, test_truth=None,
189 | file_2d =None, k_nearest=None,
190 | rgn_tsne=False, prop_step=0,
191 | ):
192 | ```
193 |
194 | - train_data:
195 | - data used for training the algorithm
196 | - default: None. It should be provided by the use, otherwise an error will riase.
197 |
198 | - train_truth:
199 | - labels of training data
200 | - default: None
201 |
202 | - test_data:
203 | - data used for testing the algorithm
204 |
205 | - test_truth:
206 | - labels of testing data
207 | - default: None
208 |
209 | - k_nearest:
210 | - number of nearest neighbor
211 | - default: 0. the default is invalid. k-nearest neighbor should be at leat 1.
212 |
213 | - rgn_tsn:
214 | - when set to True: It will regenerate the reduced 2-D version of the N-D dataset each time the algorithm run.
215 | - when set to False: It will generate the reduced 2-D version of the N-D dataset first time only, then will reuse the saved exist file
216 | - default: True
217 |
218 | - file_2d: name (include location) of file used save/load the reduced 2-d version
219 | - if empty: the algorithm will create temporary file named '_temp_2d'
220 | - default: None
221 |
222 | - prop_step:
223 | - size of increment used in showing the clustering propagation.
224 | - leave this parameter set to 0, the default value, unless you are willing intentionally to enter the propagation mode.
225 | - default: 0
226 |
227 |
228 | 2. Parameters used within the fit_predict function:
229 |
230 | ```python
231 | def fit_predict(self,
232 | validate=True,
233 | show_plots=True,
234 | show_noise=True,
235 | show_analyzer=True
236 | ):
237 | ```
238 |
239 | - validate:
240 | - validate data on/off according to five measures integrated with DenMUne (Accuracy. F1-score, NMI index, AMI index, ARI index)
241 | - default: True
242 |
243 | - show_plots:
244 | - show/hide plotting of data
245 | - default: True
246 |
247 | - show_noise:
248 | - show/hide noise and outlier
249 | - default: True
250 |
251 | - show_analyzer:
252 | - show/hide the analyzer
253 | - default: True
254 |
255 | The Analyzer
256 | -------------
257 |
258 | The algorithm provide an intutive tool called analyzer, once called it will provide you with in-depth analysis on how your clustering results perform.
259 |
260 | 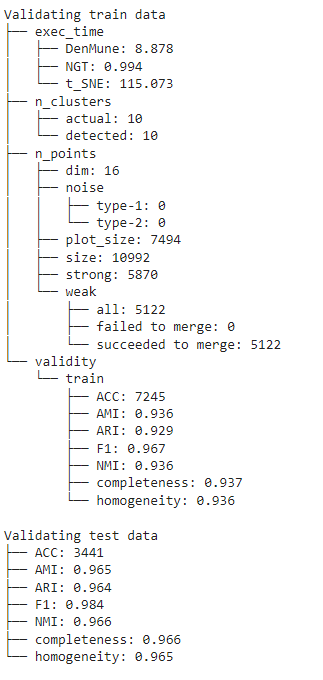
261 |
262 | Noise Detection
263 | ----------------
264 |
265 | DenMune detects noise and outlier automatically, no need to any further work from your side.
266 |
267 | - It plots pre-identified noise in black
268 | - It plots post-identified noise in light grey
269 |
270 | You can set show_noise parameter to False.
271 |
272 |
273 | ```python
274 |
275 | # let us show noise
276 |
277 | m = DenMune(train_data=X_train, k_nearest=knn)
278 | labels, validity = dm.fit_predict(show_noise=True)
279 | ```
280 |
281 | ```python
282 |
283 | # let us show clean data by removing noise
284 |
285 | m = DenMune(train_data=X_train, k_nearest=knn)
286 | labels, validity = dm.fit_predict(show_noise=False)
287 | ```
288 |
289 | | noisy data | clean data |
290 | ----------| ---------------------------------------------------------------------------------------------------|
291 | |  |  |
292 |
293 |
294 | Validatation
295 | --------------
296 | You can get your validation results using 3 methods
297 |
298 | - by showing the Analyzer
299 | - extract values from the validity returned list from fit_predict function
300 | - extract values from the Analyzer dictionary
301 | -
302 | There are five validity measures built-in the algorithm, which are:
303 |
304 | - ACC, Accuracy
305 | - F1 score
306 | - NMI index (Normalized Mutual Information)
307 | - AMI index (Adjusted Mutual Information)
308 | - ARI index (Adjusted Rand Index)
309 |
310 | 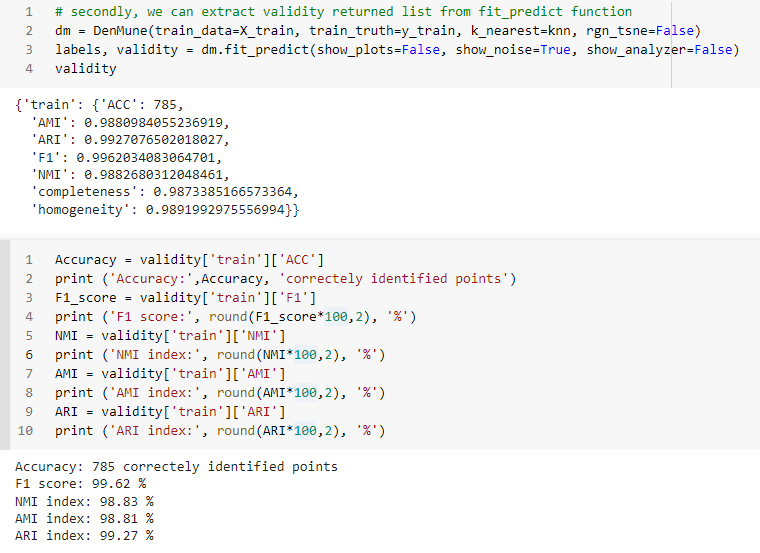
311 |
312 | K-nearest Evolution
313 | -------------------
314 | The following chart shows the evolution of pre and post identified noise in correspondence to increase of number of knn. Also, detected number of clusters is analyzed in the same chart in relation with both types of identified noise.
315 |
316 | 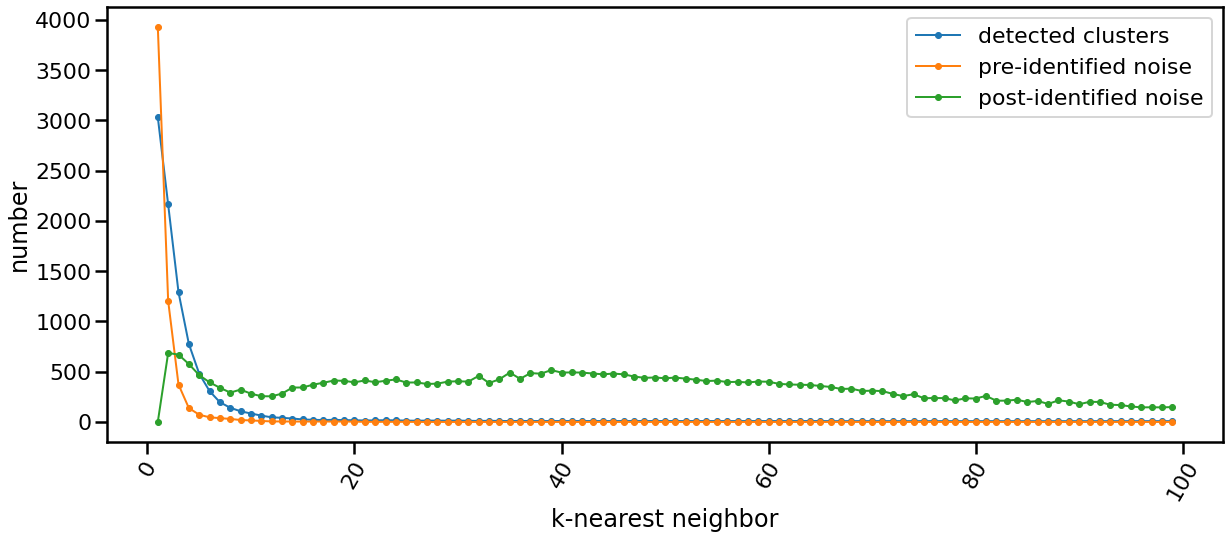
317 |
318 |
319 | The Scalability
320 | ----------------
321 | | data size | time |
322 | |------------------| ------------------- |
323 | | data size: 5000 | time: 2.3139 seconds |
324 | | data size: 10000 | time: 5.8752 seconds |
325 | | data size: 15000 | time: 12.4535 seconds |
326 | | data size: 20000 | time: 18.8466 seconds |
327 | | data size: 25000 | time: 28.992 seconds |
328 | | data size: 30000 | time: 39.3166 seconds |
329 | | data size: 35000 | time: 39.4842 seconds |
330 | | data size: 40000 | time: 63.7649 seconds |
331 | | data size: 45000 | time: 73.6828 seconds |
332 | | data size: 50000 | time: 86.9194 seconds |
333 | | data size: 55000 | time: 90.1077 seconds |
334 | | data size: 60000 | time: 125.0228 seconds |
335 | | data size: 65000 | time: 149.1858 seconds |
336 | | data size: 70000 | time: 177.4184 seconds |
337 | | data size: 75000 | time: 204.0712 seconds |
338 | | data size: 80000 | time: 220.502 seconds |
339 | | data size: 85000 | time: 251.7625 seconds |
340 | | data size: 100000 | time: 257.563 seconds |
341 |
342 | | 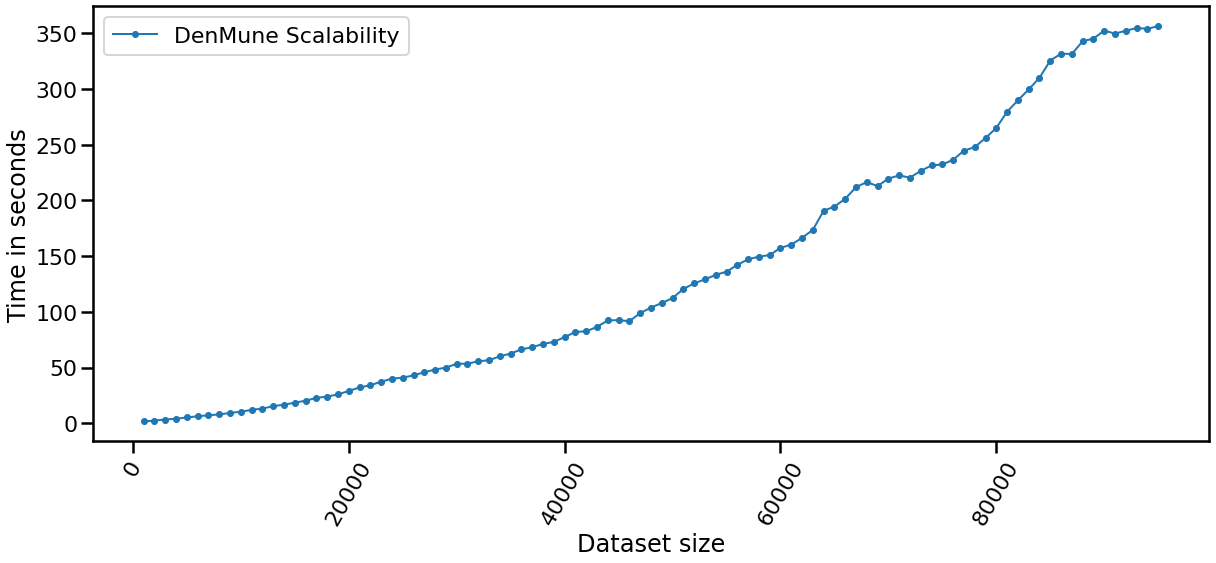
343 |
344 | The Stability
345 | --------------
346 |
347 | The algorithm is only single-parameter, even more it not sensitive to changes in that parameter, k. You may guess that from the following chart yourself. This is of greate benfit for you as a data exploration analyst. You can simply explore the dataset using an arbitrary k. Being Non-senstive to changes in k, make it robust and stable.
348 |
349 | 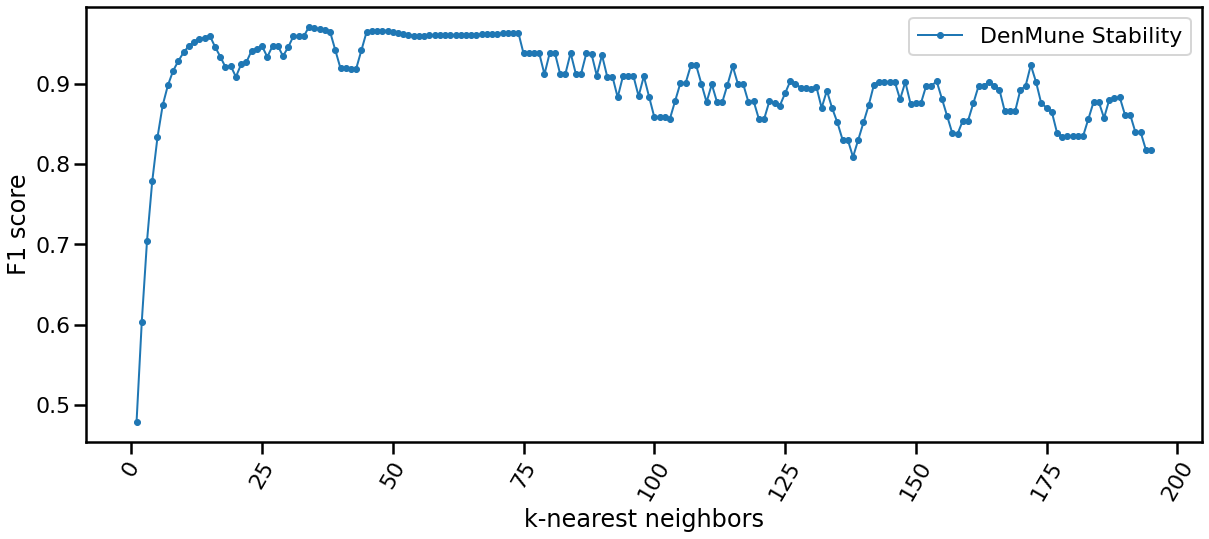
350 |
351 |
352 | Reveal the propagation
353 | -----------------------
354 |
355 | one of the top performing feature in this algorithm is enabling you to watch how your clusters propagate to construct the final output clusters.
356 | just use the parameter 'prop_step' as in the following example:
357 |
358 | ```python
359 | dataset = "t7.10k" #
360 | data_path = 'datasets/denmune/chameleon/'
361 |
362 | # train file
363 | data_file = data_path + dataset +'.csv'
364 | X_train = pd.read_csv(data_file, sep=',', header=None)
365 |
366 |
367 | from itertools import chain
368 |
369 | # Denmune's Paramaters
370 | knn = 39 # number of k-nearest neighbor, the only parameter required by the algorithm
371 |
372 | # create list of differnt snapshots of the propagation
373 | snapshots = chain(range(2,5), range(5,50,10), range(50, 100, 25), range(100,500,100), range(500,2000, 250), range(1000,5500, 500))
374 |
375 | from IPython.display import clear_output
376 | for snapshot in snapshots:
377 | print ("itration", snapshot )
378 | clear_output(wait=True)
379 | dm = DenMune(train_data=X_train, k_nearest=knn, rgn_tsne=False, prop_step=snapshot)
380 | labels, validity = dm.fit_predict(show_analyzer=False, show_noise=False)
381 | ```
382 |
383 | []()
384 |
385 | Interact with the algorithm
386 | ---------------------------
387 | [](https://colab.research.google.com/drive/1EUROd6TRwxW3A_XD3KTxL8miL2ias4Ue?usp=sharing)
388 |
389 | This notebook allows you interact with the algorithm in many asspects:
390 | - you can choose which dataset to cluster (among 4 chameleon datasets)
391 | - you can decide which number of k-nearest neighbor to use
392 | - show noise on/off; thus you can invesitigate noise detected by the algorithm
393 | - show analyzer on/off
394 |
395 | How to run and test
396 | --------------------
397 |
398 | 1. Launch Examples in Repo2Docker Binder
399 |
400 | Simply use our repo2docker offered by mybinder.org, which encapsulate the algorithm and all required data in one virtual machine instance. All jupter notebooks examples found in this repository will be also available to you in action to practice in this respo2docer. Thanks mybinder.org, you made it possible!
401 |
402 | [](https://mybinder.org/v2/gh/egy1st/denmune-clustering-algorithm/HEAD)
403 |
404 | 2. Launch each Example in Kaggle workspace
405 |
406 | If you are a kaggler like me, then Kaggle, the best workspace where data scientist meet, should fit you to test the algorithm with great experince.
407 |
408 | | Dataset | Kaggle URL |
409 | ----------| ---------------------------------------------------------------------------------------------------|
410 | |When less means more - kaggle |[]( https://www.kaggle.com/egyfirst/when-less-means-more) |
411 | |Non-groundtruth datasets - kaggle|[](https://www.kaggle.com/egyfirst/detecting-non-groundtruth-datasets) |
412 | |2D Shape datasets - kaggle|[](https://www.kaggle.com/egyfirst/detection-of-2d-shape-datasets) |
413 | |MNIST dataset kaggle|[](https://www.kaggle.com/egyfirst/get-97-using-simple-yet-one-parameter-algorithm) |
414 | |Iris dataset kaggle| [](https://www.kaggle.com/egyfirst/denmune-clustering-iris-dataset) |
415 | |Training MNIST to get 97%| []( https://www.kaggle.com/egyfirst/training-mnist-dataset-to-get-97) |
416 | |Noise detection - kaggle| []( https://www.kaggle.com/egyfirst/noise-detection) |
417 | |Validation - kaggle| [](https://www.kaggle.com/egyfirst/validate-in-5-built-in-validity-insexes) |
418 | |The beauty of propagation - kaggle| [](https://www.kaggle.com/egyfirst/the-beauty-of-clusters-propagation) |
419 | |The beauty of propagation part2 - kaggle | [](https://www.kaggle.com/egyfirst/the-beauty-of-propagation-part2) |
420 | |Snapshots of propagation -kaggle| [](https://www.kaggle.com/egyfirst/beauty-of-propagation-part3) |
421 | |Scalability kaggle| [](https://www.kaggle.com/egyfirst/scalability-vs-speed) |
422 | |Stability - kaggle| [](https://www.kaggle.com/egyfirst/stability-vs-number-of-nearest-neighbor) |
423 | |k-nearest-evolution - kaggle| [](https://www.kaggle.com/egyfirst/k-nearest-evolution) |
424 |
425 | 3. Launch each Example in Google Research, CoLab
426 |
427 | Need to test examples one by one, then here another option. Use colab offered by google research to test each example individually.
428 |
429 |
430 |
431 | Here is a list of Google CoLab URL to use the algorithm interactively
432 | ----------------------------------------------------------------------
433 |
434 |
435 | | Dataset | CoLab URL |
436 | ----------| ---------------------------------------------------------------------------------------------------|
437 | |How to use it - colab|[]( https://colab.research.google.com/drive/1J_uKdhZ3z1KeY0-wJ7Ruw2PZSY1orKQm)|
438 | |Chameleon datasets - colab|[](https://colab.research.google.com/drive/1EUROd6TRwxW3A_XD3KTxL8miL2ias4Ue?usp=sharing) |
439 | |2D Shape datasets - colab|[]( https://colab.research.google.com/drive/1EaqTPCRHSuTKB-qEbnWHpGKFj6XytMIk?usp=sharing) |
440 | |MNIST dataset - colab|[](https://colab.research.google.com/drive/1a9FGHRA6IPc5jhLOV46iEbpUeQXptSJp?usp=sharing) |
441 | |iris dataset - colab|[](https://colab.research.google.com/drive/1nKql57Xh7xVVu6NpTbg3vRdRg42R7hjm?usp=sharing) |
442 | |Get 97% by training MNIST dataset - colab|[]( https://colab.research.google.com/drive/1NeOtXEQY94oD98Ufbh3IhTHnnYwIA659) |
443 | |Non-groundtruth datasets - colab|[]( https://colab.research.google.com/drive/1d17ejQ83aUy0CZIeQ7bHTugSC9AjJ2mU?usp=sharing) |
444 | |Noise detection - colab|[]( https://colab.research.google.com/drive/1Bp3c-cJfjLWxupmrBJ_6Q4-nqIfZcII4) |
445 | |Validation - colab|[]( https://colab.research.google.com/drive/13_EVaQOv_QiNmQiMWJAcFFHPJHGCrQLe) |
446 | |How it propagates - colab|[](https://colab.research.google.com/drive/1o-tP3uvDGjxBOGYkir1lnbr74sZ06e0U?usp=sharing)|
447 | |Snapshots of propagation - colab|[](https://colab.research.google.com/drive/1vPXNKa8Rf3TnqDHSD3YSWl3g1iNSqjl2?usp=sharing)|
448 | |Scalability - colab|[](https://colab.research.google.com/drive/1d55wkBndLLapO7Yx1ePHhE8mL61j9-TH?usp=sharing)|
449 | |Stability vs number of nearest neighbors - colab|[](https://colab.research.google.com/drive/17VgVRMFBWvkSIH1yA3tMl6UQ7Eu68K2l?usp=sharing)|
450 | |k-nearest-evolution - colab|[]( https://colab.research.google.com/drive/1DZ-CQPV3WwJSiaV3-rjwPwmXw4RUh8Qj)|
451 |
452 |
453 |
454 | How to cite
455 | =====
456 | If you have used this codebase in a scientific publication and wish to cite it, please use the [Journal of Pattern Recognition article](https://www.sciencedirect.com/science/article/abs/pii/S0031320320303927)
457 |
458 | Mohamed Abbas McInnes, Adel El-Zoghaby, Amin Ahoukry, *DenMune: Density peak based clustering using mutual nearest neighbors*
459 | In: Journal of Pattern Recognition, Elsevier, volume 109, number 107589.
460 | January 2021
461 |
462 |
463 | ```bib
464 | @article{ABBAS2021107589,
465 | title = {DenMune: Density peak based clustering using mutual nearest neighbors},
466 | journal = {Pattern Recognition},
467 | volume = {109},
468 | pages = {107589},
469 | year = {2021},
470 | issn = {0031-3203},
471 | doi = {https://doi.org/10.1016/j.patcog.2020.107589},
472 | url = {https://www.sciencedirect.com/science/article/pii/S0031320320303927},
473 | author = {Mohamed Abbas and Adel El-Zoghabi and Amin Shoukry},
474 | keywords = {Clustering, Mutual neighbors, Dimensionality reduction, Arbitrary shapes, Pattern recognition, Nearest neighbors, Density peak},
475 | abstract = {Many clustering algorithms fail when clusters are of arbitrary shapes, of varying densities, or the data classes are unbalanced and close to each other, even in two dimensions. A novel clustering algorithm “DenMune” is presented to meet this challenge. It is based on identifying dense regions using mutual nearest neighborhoods of size K, where K is the only parameter required from the user, besides obeying the mutual nearest neighbor consistency principle. The algorithm is stable for a wide range of values of K. Moreover, it is able to automatically detect and remove noise from the clustering process as well as detecting the target clusters. It produces robust results on various low and high dimensional datasets relative to several known state of the art clustering algorithms.}
476 | }
477 | ```
478 |
479 | Licensing
480 | ------------
481 |
482 | The DenMune algorithm is 3-clause BSD licensed. Enjoy.
483 |
484 | [](https://choosealicense.com/licenses/bsd-3-clause/)
485 |
486 |
487 | Task List
488 | ------------
489 |
490 | - [x] Update Github with the DenMune sourcode
491 | - [x] create repo2docker repository
492 | - [x] Create pip Package
493 | - [x] create CoLab shared examples
494 | - [x] create documentation
495 | - [x] create Kaggle shared examples
496 | - [x] PEP8 compliant
497 | - [x] Continuous integration
498 | - [x] scikit-learn compatible
499 | - [X] Unit tests (coverage: 100%)
500 | - [ ] create conda package
501 |
502 |
--------------------------------------------------------------------------------
/PyPi Package/src/denmune.egg-info/PKG-INFO:
--------------------------------------------------------------------------------
1 | Metadata-Version: 2.1
2 | Name: denmune
3 | Version: 0.0.96
4 | Summary: This is the package for DenMune Clustering Algorithm published in paper https://doi.org/10.1016/j.patcog.2020.107589
5 | Home-page: https://github.com/egy1st/denmune-clustering-algorithm
6 | Author: Mohamed Ali Abbas
7 | Author-email: mohamed.alyabbas@outlook.com
8 | License: UNKNOWN
9 | Project-URL: Bug Tracker, https://github.com/pypa/sampleproject/issues
10 | Platform: UNKNOWN
11 | Classifier: Programming Language :: Python :: 3
12 | Classifier: License :: OSI Approved :: BSD License
13 | Classifier: Operating System :: OS Independent
14 | Requires-Python: >=3.6
15 | Description-Content-Type: text/markdown
16 | License-File: LICENSE
17 |
18 | DenMune: A density-peak clustering algorithm
19 | =============================================
20 |
21 | DenMune a clustering algorithm that can find clusters of arbitrary size, shapes and densities in two-dimensions. Higher dimensions are first reduced to 2-D using the t-sne. The algorithm relies on a single parameter K (the number of nearest neighbors). The results show the superiority of the algorithm. Enjoy the simplicity but the power of DenMune.
22 |
23 |
24 | []( https://pypi.org/project/denmune/)
25 | [](https://mybinder.org/v2/gh/egy1st/denmune-clustering-algorithm/HEAD)
26 | [](https://denmune.readthedocs.io/en/latest/?badge=latest)
27 | [](#colab)
28 | [](https://www.kaggle.com/egyfirst/denmune-clustering-iris-dataset?scriptVersionId=84775816)
29 | [](https://www.sciencedirect.com/science/article/abs/pii/S0031320320303927)
30 | [](https://data.mendeley.com/datasets/b73cw5n43r/4)
31 | [](https://choosealicense.com/licenses/bsd-3-clause/)
32 | [](https://circleci.com/gh/egy1st/denmune-clustering-algorithm/tree/main)
33 | [](https://codecov.io/gh/egy1st/denmune-clustering-algorithm)
34 | [](https://github.com/egy1st/denmune-clustering-algorithm/actions/workflows/python-package.yml)
35 |
36 | Based on the paper
37 | -------------------
38 |
39 | |Paper|Journal|
40 | |-------------------------------------------------------------------------------------------|-----------------------------|
41 | |Mohamed Abbas, Adel El-Zoghabi, Amin Ahoukry,
 ","metadata":{},"cell_type":"markdown","outputs":[],"execution_count":0},{"cell_type":"markdown","id":"e7d9b26d","metadata":{"papermill":{"duration":0.004085,"end_time":"2022-01-28T16:59:53.754281","exception":false,"start_time":"2022-01-28T16:59:53.750196","status":"completed"},"tags":[]},"source":["##### Have you ever wondered how a cluster propgate. It is time to reveal the beuty of clusters propgation. It as simple as\n","- running the next cell,\n","- wait,\n","- watch and\n","- ENJOY."]},{"cell_type":"code","execution_count":1,"id":"7d1fe6fe","metadata":{"execution":{"iopub.execute_input":"2022-01-28T16:59:53.765377Z","iopub.status.busy":"2022-01-28T16:59:53.764201Z","iopub.status.idle":"2022-01-28T17:03:36.326661Z","shell.execute_reply":"2022-01-28T17:03:36.325883Z","shell.execute_reply.started":"2022-01-24T22:08:58.752738Z"},"id":"FZgP6jwmzFtZ","papermill":{"duration":222.569057,"end_time":"2022-01-28T17:03:36.326871","exception":false,"start_time":"2022-01-28T16:59:53.757814","status":"completed"},"tags":[]},"outputs":[{"data":{"image/png":"iVBORw0KGgoAAAANSUhEUgAAAWkAAADzCAYAAABE8effAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMSwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/YYfK9AAAACXBIWXMAAAsTAAALEwEAmpwYAABqPElEQVR4nO29d5hcx3Wn/da9nXs6TM4ZGORIEMwEmIMCFahAyaIcZMnpc9i11+u1/azDyvK3/nbX62xJlmRZlkVJlERSzCQIigRJgMhxMAiDyTl1jvd+f/SE7pnuCUCHO8B9+QDE3K6pOp1+t+rUqXOEqqro6Ojo6GgTqdAG6Ojo6OhkRhdpHR0dHQ2ji7SOjo6OhtFFWkdHR0fDGLLVkRDiGNAM+ICL2epXR0dH5zpnDVAEdKqqumP+gyJb0R1CiEnAlZXOdHR0dG48plRVdc+/mLWZNIkZtMvlcrF9+/Ysdqujo6Nz/XL8+HGmpqYgoaELyKZIXwRqt2/fzv79+7PYrY6Ojs71y969e3nzzTchg5tY3zjU0dHR0TC6SOvo6OhomGy6O3R0dK5DFEVleNCLqqhUVDuQZX1ul090kdbR0cnI4Xeu8M4bl5iaDAFQVGRi913N3H5PK0KIjL/n94Y5dqiHkSEvRqPMxm01tLSV5cvs6wpdpG9gwoFxhrr2MzF4kng8gs1ZS0XDnZRUbSu0aToa4MC+i+x78XzKNZ8vwr4Xz+P3RXjwwxtTHotF47z203McO9RDNBJPeezoe93YHWY++pnttLSV59z2pVAUlQtnh+g4O0QsGkdVYXTYRzAQpaTMzk23NbBxW02hzQR0kb5hCfqG6Dj8T8Sigdlr/qluOk99l6C3j9q1jxbQOp1CEwpGefv19GfSVFXl0Fud2OxGyisdrFlfweiwl3/5vweIxZSMffq9Yb7zzwcpKjJRXe9mxy31rNlQgcEg5+pppLfDF+Y/vn6IgT4PqqpC0lERIcAzFeLKpTEud4zywU9szatt6dBF+galp/2ZFIFOZvDKmxRXbcfm0MZMQif/XDg3TGTebBiYFTVFVdn3wnmEAKvdRCgQRVGWdzDO54tw4dwwF84NA1Be5aBtYwXVdS7Wba5icjzAyKAPi81IQ3MJkpTZrZJMPKYQ8EcwWwyYzJml7dmnTjDQ55l+QvOfX0KoAY4d6qFtUyVtGyuXNX6u0EX6BiQcHMc7cWnRNmN9h7Gt/3CeLNLRGpFwbME1NY0IqyoEfJFrGmtk0MvIoBchQJYl4nFlVildbgv3f3ADG7ZWMzkeRJIEkiy4cnEMRVExmw3EYwqH3+2iu3MMVQFJEqzbXMmm7TWMDvsBlbUbKqiuczM24uNS+8i07RluKklKffS9bl2kdfJPNOxZsk0kPJUHS7JDyD/MUNdbeEYT/lNH6RoqG+7C6qgusGWrl6pa5+y/57sEcoWqMucuUVWEJJiaDPHDbx/FYJAWdaUkoygq504Ocu7k4Oy1/S91YLObaGh2oyzxfFRgZu4+OZZ+tZlPdJG+ATFZ3Eu2MSe1UZU4E8OnmRg8RiwawuqoorzuNqxFhZ1hAHjHL3Hx2DdRlOjstbH+I0wMHKdl2+dwlW8ooHWrl9qGYqrrnPR3F+5mnTxzX65AL0bAH6H99PCKfsfuMF/zuNeKLtI3ICaLG2dpG56xjoxtSmt3A6DEI1w8+g28k52zj/kmOxnteY/6DR+lvO6WnNubjKLEmBw6TcDbjySbGO19b06gVZWZKZKiqlw583223PXfkGRjXm1c7fT3THJg30WG+r2FNqUwqKCiIoBtu+oKbY0u0jcqDesf4/z7/0Q0svCLWNm0l/GBo4wPHCUS9oCqMLsAnPbVqaj0nPsxRe6mvMyoveMXGezcj3f8Iqoan7Mn47pVJRbxMdLzDpVNe3Jun9YZ6vcwNuLDZjfR2FKKyLAZd+n8CE99831i0Wufua5qpj0ib71+gep6F+WVjoKZoov0DYrZVsaGW3+T4e63GR88gRKPYHPWUVK1k4HLrxIOjiUaqjNfVnXuf0lCPdr7HvXrH8uprd3nfsRI78EkW5LsWYLBzv1UNN6FEDfmKbnRYR/PPnWCvu7J6ZdMxem28sjHNi/YEFMVlWe/d1wX6BkEjI8G+O7XDvGrv7dn0YiRXKKLtAZQlBgj3QcY7TtEJDiB0eKitGYXFQ13IRtMORvXaHZSu/bRlJjorrNPJwn00kIY9A1muD7EYOcbTI6cQVViFLkaqWi8C3fFphXZOD5wbFqgr27nKhb14xntwFW+HgDfZBeTw2dQlSh2dyPuis1I0vX5NfD7wnznn97D6wmlvHxTE0Ge+sb7PP7kTWzYmthcnZwI8NQ3DuP1hAtkrQaZ3kGcmgxy+lgfO29tLIgZ1+enUyMEfUPEYyEs9nIMRlvaNooSS/h8k0LiwsFx+i+9wtTIWdbe9EVkw9VtXkRCU4wPHCMW9WG2lVNStY1o2EM4MIbBVITVUU3A0weo2By1AIwPHk/x7S5ETRHMcHCCcwf/lljYi9HioqzmZsy2Mi4e/yZKfC40yzvZiXeyk+rme3GUrEGSTdicdYseLQYY6Xl3btyrxO/pxlHSyuUT/8bUWNIJup53MFncrNnxi5rYBM02R97tXiDQM6gq/OS7xykutbH/5Q4unB262vvgdc3M5uXLz5wl4I9wxz1rMrqKcoUu0itAiUdR4hFko3XR5bNnrIPejhcI+gYAkCQDJVXbqVv3IWSDJaXtaO/BjDHLfk8vw91vUd1yf8p1VYnjGbtANOLBbC2lqLglRexUVWHg8j4GO19HVZVZ0e0++8NEAyElCe3cN1OSTSnCuhwiwTEi0zPvSGgC/2QXkmxEiUdJJ6wDl19j4PJrICTM1lJq1zxEcdU2gt5BBjpfJ+QfwWh2UORqwu6uJ+AdWJE9qQgQAkky0tP+TKpAz9gfmuTi0X9h053/ZXZGHY+FmRg6SSQ0icniprhyy4L3bTXQcWZwUeGNRuP86z+8SyQc0wV6CaKROPteOM+7b17mc1+6hapad97G1kV6GQR9QwxcfjWxTFYVTGYX5fW3Utm4ByGlHmn1jF3k4rFvJsRxGkWJMdp/mKB/iHW7fjXld8b63k8dbJ54DncdwGQpJuQbZnTgCLGwhxTxExIms5PKpj0YTE5Geg7gm7i8+BNS0/scVyrQGTpfXj+qQjgwwuWT30Gcfgo1KYQu6AXPaPs12iFmfedFxS30X3o1Y8tIeIqJoZOUVu9kfPAE3WefJh6fW/b3nn+Ohg0fpaR6Qfk5TbOcsLVwaOGhFZ3MBP1Rvvq/32bbrjo+8IkteTnSrov0EgS9g5w//I/EY6HZa5HwFH0XX8Y/1UvLts+lzGL7L76YItDJ+Kd6mBg+nZLAKOXQSBo3Qyzq48rp72U2UFWIhCbpaX9mZU9MQyQL9LUzJ84ApTW7iEcD0xEhmfFNdGKxlnHl1H+gznsP4vEwV04/hclaTJG7KYu25o7xUX+hTbiuOXG4F4DHntie87FuzC3vFdB74fkUgU5mcuQMnqQldDg4jt/Tu2h/E4MnUn42ml2Jma2qkJdjXdc96uzrWeRqpH7dhxHL2BiUJANDXW/OCbSa6ntXURm68maujM4qnRdG+er/fovhwRs0zjlPnDrWx0QeTiTqIr0I0bBn0QMfAOP9R4HEjLv77I/nBHfGF5zyR8E7fpHOU9/DO34ZVYkTCU3k46nckPgmOzm+74/pOjPti5//3iThrtiEZ/zi7PuUuGGqKW2944vnO9ECsVicH//7MaLR+JKbsjrXhhJXOX86fXRTNtHdHYsQiwaXbBON+PBPdtNx9GsosfnhSwtnxvFYkPHBY4wPHJ3ewFt8Ga5zrahEQuNprycS6Ug4iltwlKyZ9qWnW83MtNW+6LWfGsTvT9oTEOgLtBxy8kgvt+5pyekY+kx6EUwWF5K0+JFis62Myye/gxILsexvw8xMTRfoguOu2ETr9s8TDk6gKotvollshU9WvxRjI6m+aO3fVlY3g32Jk5y5RJ9JL4JssFBStZ3RvoMZ2wS9/brLYhUzOXyGi+FvEl/G5mU4zfsc8Pbjn+pBko24ytZnjIfPFzZ70uEndYFXRycHnDjcy72PrM9Z/9e9SMcifkZ6DzI5fAolHsXuaqCi4XZszqUTp6iqkhKKlQ7/VFe2TNUpBKqCb3KJkMVpYmEPsWgQg9FKNOyh89R/TPup55TQWlRN0+ZPYXPW5sjgxdm0rYbXfnqOWExZEKWikxt6Lqdzp2WP61qkw8EJOg7/E5HQ5Oy1UGCE8YGjNG58nNLaXYk0nEOnZkXc5qqnrHY3JouLgUuvMTF4vGD262gTVVW4cPRfCHoHmO/iCvoGOHfwb2jZ8lmKqxaWXlJVlYCnh1gkgMVejtlWmlXbbEUm7nl4Ha/+9Jzui84TXl9uj9Jf1yLdfe5HKQI9g4pK17mnsTnruHLm+wS8fbOPTY2dZ+jKm9Sv/wgDna/n0Vqd1cCJ/X+CwWCdLj2WqbKHwpUz38dZ1pZyUnFqtJ3e888RCozOXnOWttG48ePLyvG9XG7d04LTbeGFp08R8GczBl0nHePDfiLhWM4SMF23G4fhwPii4XOqqtB56rspAj0TfqXEw3Sd+X7Gk3k6NzCqQiyaKMm0GEo8ksiDMs1w19tcPPoNQv7hlDBAz1gHHYe/mjEW/2rZuK2Gux5oy2qfOpnZ//LiobrXwvUr0sHRxRuo6lwGt5TY2NkGuTJN54ZAxTuWqLY91neYnvPPsPAzpU4fjx9lrP9w1i0Y0Q+z5I2uy2M563vVuTsiIQ/dZ3+IZ/wiqhJFMlgoq9lFzZqHUpaWBlPRMnqbqXWmC7JO9pkYOsmFI19PHJJZFJWx/qNUNNyZ1fEH+5euZamTHUYGvEyMBSguzX50z6qaSQd9Q5x++ytMjZ6bzfegxEIMd7/Nif1/xvjAsdm2NkcN1qI0hUhnj/suzAKno5Nd1ETagGXEwwd9Axlzvlwt4aDuj84XsZjCaz89l5O+V5VIXzr2zYwHDlQlSuep7zKQlO2sYf1jqQndk4/76uhoCFWJMXXNmf9SCYV0kc4XQhJ0nB0i4M9GJslUVo1IB70DcxVDFqH/8muJzRnA5qqnZdvncJau0zcBdTTP5PCZrPYXi+onWvOJoqj4vdkPx1s1Pumgf2jZbUd630MIibG+w4uHSunoaAjf+PIO1SwXJa5/7vOJLAmKnFdXRWkxNCXSvskuRnoOEPD0Ickmiiu3UlZ3KwajdfnHbVWF0d6DWUpgr6OTP8LBUcLBScxWd1b6M1kMRKP69yAfqKrK+i3VWG3Zr0mqGXfHcPcBzr//D4wPniAUGCXg7afv4ku0H/xbIqEpHMWtCLG8e4ou0Dqrlc5T/46qZMdNsWZdRVb60VkeTWuye3p0Bk2IdMg/Qu/559I+Fg6M0n7o7zn19v+LquqlfnSub/yTV+huf2a6RuS1ccvdzashu+p1gRCCl358huGB7Ic9akKkx/rfT58MZjoaIxqaIKpnmtO5QRjtfZeTb/45/ZdeW1ZO80wUOS164v9cI5itHh5XVA69fSXrQ2hCpEP+NKcD9WgMTWO0FBfahOuaeCzIwKWXOfWzLzPWd3WnESfHA6jMiYjO1SMErN2Y5D4STJfTTH1tuzuznxFPExuHxmWdDrw+UNMk+F1tsx2LvZJNd/wuSjzK1Gg7Q11v419muk+dlaHEw1w5831kkx13+YaUx3yTXQx1/Qzv+EUEAmfZOiqb9mBz1ABgL8r+JtaNyu33tLLnoTb+8r+9tDBHt6rOXovHsz+51MRMurRmV+IfyfUArzNUVU0r0DOPpV6YvqaqWY8elGRzomzX1SKMNG78+HRfRoort1Df9gH0GiC5ROXSsW/Rd+FFouGEz3N88Dgd7/8jk8OnicdCxGJBxgePc/7Q388mFisutVPfVIyqXH/fp3xisxvZcUsDxw72UFRkRlXU2e9n4t9zbSdGA3z/W4eJxbIXo66JmbSiRDGaimY/gNcbmcR5YUNSfPPq3MVlzbbtzmYcZa0EpnoIB8dR4pHECU0hMFlLKKu9mWjYx8ClVzL2UVyxnUhkCiUeJR4LEg17po/gC9wVm6luuW9BQnuzvRxJNqEo0WW6qWaeiy4ey0dhsHMfg1f2U7f2Awxcfi3tPo6ixOg68wM23/lfEZJMabmN7hwnpb+eqaxxsvehNr7xNwcIBqNzE8hM8ycB588Mse+F8zz44Y1ZsaHgIj010s6lE/86nbfg+quauRKBVoIxVG8MqdgEBpF4KcTMw2paoZZkEyVVO6hZ+/CSbiNVVTn91ldY7DWeGjvL9nv/HJE0247HIghJSj1in4TBaKWkegejfYeWfJqzCDFrhpAMVLfcj8VegSwb6Tn/PKHAvMNLyflW0iXFUlRMYz6kaIxYkYW41YRqKvjHO/uoCr0d05FQGVZEkekq9wZLM8cO9ubRuOuLX/m9u3E4LfzdV94gFJqOLBMCgZp+sZ/koz5+qIc9D7Zhtlz7Z7Cgn2JVVenteG4usYyY9sbfYJuGakxBmYoRfWEAvArIgFmGsAJmCbnRBrJAGQihTkaRqxyU3LyLqoceoKiyCUlO9T3Gw2EC3T0IWcbe1IiQEl9mJRZKWwQhGSUewTPagat8rmabbFjat1nX9kFC/hF8E5dZ9o1WCGSDhTU7foEid9Ps5eLJKwx0DoGqIvtCiLhC3GZGNUqgqoi4guwPI0ViSIEIRk8QOU2eCn9rBdFie8axVz2LVDCPhCZ58blTeTZodZGpvJiYnhk5nBZOvN87J9CzDcQCl+z8zdlwOMbwoJf6pmvfYC+oSAemehJVKq5DH/SixFTU8Qjx817iF/wJMU5+CeJAYNqnFYgTP5eaFzje52Gkbx+jz7+FvbkJe1MTVQ8/iL2pkZ7v/5DBF18i6k1UMLZUlFP70ceouO9eJNmEEBLqElnZgr6BFJFeDrLBTNuuLzLS8y497T9J0yLxITZZS3CUtMzWmyyt2YXBaE1pWV5/GxNHX8DUNYgUmZvBRErsBOpLcZzpRU6Tl2L+p8jaM0bUZYN00Q2LCNz1gMniprerp9BmaJbF6j+qqAgEE6MBeruWEfqb4WNkMGRny6+gIj012n5DzJqjrwwnlkJWGXUyitITzIpXR41G8XVcwNdxgaFXXsXW3ESgqzupgUpocIhL//hVLv3T13Bv24pxk52IezHfv0CeJ5rLRQiJioY7CAfHGe5+e8HjkmSgafMncRS3LNpPqOMY1ov9qCR9NtSEO8M45su42538XVEBKRLHfnGIQGsFqpz6W6ZRL5FiO8xcX5WCPe0YnWe7yezEWbYOIXSRvhbMVgNGo5z2sTST6RSKS2xU1TizYkfBRNo/2c1A575CDZ831MkoyiX/9A+5HSvQeSXxD0laGCWjqkyePIU4JTDcV4q8Nr3/WkgGiiu2XJMd9es+hNVewXD32wT9wwgErvL1VLXcj32JKu2qqjDx1vcTtiCBmN5Fn358uXOTGdkyeYIYT3QTKS1CkSWM3iByILEBZJzw42+tTMy0V+3MOul9FhKSkGnc+DhCSDS2lnD2+GBhzdMgKioKKtIiEUkRVDDJrN9SxcmjfQsbLKHSdz+4Nmvx6QUT6cEr+7jeNgnTITltGCqcxIa95O35ZgpjnBa7+DsepGYbYsFyTFDdch8GUwY/7gooq7uFsrpbiMdCCMmQcdNxPpGBy8Qmh6ftnZtJX8vHXSgq5pGFpaSMU0Fcx7qIuq1EypzEXNZVKtQJnKVt1K59ZDZOet3GyhtKpOe7MCZQsQFmJGLTwhxDRSAxBVgAd5p+FKAThf5RP5s2VlLX4Ka3e3JBOyEJauvdDPROoUx/3xxOM3sfWsfWmxafjKyEgoi0qqpMjZ6f/un6i+hIIKhb9yEqG+8ifPMoh3/5V/Pne19iHCUQoVTZgd/WRziQyNFttpVR1bSXsrrdWTUluaTZUsQ8Y0y+/3zeXGACEKqKeSKAaSLA5M4mkJNEOvl1XAXi7Z/qTonwuXBupIDWXBtCSmzfKcuM8Z4fujqESi8qAjATJ7XMb+LzJVCpRlCOwDj9iAfoQ8EPfOO50/yv37ybJ76wm5d+coazx/uJT9vjclu55+E2ttxUh2cyyGC/B5PZQENTMZKc3eMnBZpJq6kRHerc9VVJhlAo30QnlY13MfTaG6BowPeeJDQWUUrTHZ8lEhwHVEzW0oKefAwPdjLwH3+GEvQVZPyIyzq3wZhhFQJoWqzj0SAjvQepaX2ArktjnD0xUGiTrprWtjJu3dPC/pc66OuZBMBqM7J5Rw1mi5Ezx/sZH0m4ERVUelAxkthzH0dlJg+mCmSqw64C/agMoGKa/t3kOI6LPVM8+Scv84E7mlm7vZp7Hl3P6KAXk9lAXYN71p3hdFtxuq9uH2c5FESkhZAocjfjm+ycuTDzyHW1kSikxKZD3zPPFtiShViqqxBCYLblJr3iYiiREN6Tb+A78zZKOICpooFw/8WEQBfo/Z8N1VtsFaIoCX+/ZoVaZazvfSoa7+XH/35s2bNQrSFJgvs+sIHKGictbeVMTQSJRuO4S6wYDInv1D0Pr6Pr0ig//cEpzo14Gb6GCZ4KZKqnMuWP8N1XEqv+ihIbv/3pHbRmIaxuJRTsWHhV057UC6p6XQk0gLtiE13f/R5KIFBoUxLiMo2logL39m0FMSMe9NH/7T9i7JVvEO7rIDrai//MAWITgwV9/5dz8MU05MHSM4ZpxIMU0GbO8khoglMHvo3Xk2n+qG2EgA99ciuVSZERrmIrZRVFswI9Q2NrGb/+X+/hpr2teblvDo8H+O9ffYcX3ukkksfSZAXbOHSVb6B+3Yfp63geRY2zal0dGbAWVRE41E3vUz8otCkJpqMXDDYba3/nN1HCYfqeeY7hfW8QGRvHXFZGxf33UvPhDyKbs18CaIbxN75DZLgrZ/1fLWKpL52qYhmcQkpKoBNzWvG3lKMatXWyMR46S1HRTfh89qSFgVZn/9MIcBfbeORjm1m7YWXFCvpGfXnb7onGVP7x6ZN89+V2PvvQeh65vTnnYxb001XRcAclVdsZGzhK34UXMlYC1ypCMlK79lEGO/cRi/pnr7tK1yFOqXT96F8LaN08VJWaD3+Q6kcfxuh2c/qP/wTfxUuzD4eGh+n+7veYPHqMjX/yxzkRaiUcxHdmYfy0Fm7Q5lEv0dLMx+qNk4EUgQYweII4L40T3L6OiMbynddWD9PekSwgSTkGNERFVRF7HlqHrchEQ1PJisPWJn0hDp3OfwSLNxDln358CovZwD031ed0rIJPAQwmO+6KTfSe157fFiEtsgQX1Kx5kMrGOymvvxXv+CWUWBirs4ZI1yinfvxHeTV1OVhqarBUVdHzg6fxXbi40P8qBJ728wy+9DK1j3046+PHvGOo0exXU84GRm8occClzLHgMRGNY+lNn6RI8vlpqXoAY8M6JkfOEfT2MzVylmh4MscWL46jKN0GrPaEevddLWzYWn3Vv/8Hf3+goLf477/Wwd6ddTnddNdEqtKJwROFNmERpvOJJGG2ltK48eNUNe0FEifpXGXrKK7aisVWxtArr+XfzGUQ6E6cRux/9qeZIxhUleHX38jJ+LLVkT4SRiMbcbYro9iujCIHIonMgzEF07AH59k+5PDCVZ4AUFWm3nsWk8VJRf0tNG78KFv3/CHOsg0L2ucLIaCsdBJJyp/f9GqwF5nYeWvDVf/+28f76B0uTDTQzJ2hf9SfcxsKPpMeHzhO34UXC20GkDhtZzAWEQ1PzQnHzP+n35TKpj3Urn0kJUvcfELDw5rMR2KrqyXm8xPzLHIsXFUJj43lZHzZ7sLWso3ApWPzHtFGrLwg4fYwjy48+LIYod524v4pZLtr9lp53W48o+eybOHykSSVtWuucL6jtWA2LIYkwRNfuLaY/B++cSFL1qwcRZ1JIcxs7HSuKPhMeqDzdQr9BRWSkR33fpmd93+F9bf8BiaLO00jgc1ZS3XL/YsKNICppCQ3hl4jlQ8+wNh7B5dsZ7DmLuaz5N6fQ7Jc+4lGTaGq+M68NfejEsfubsZSVFVAo6CpfpBCf7cycdf9a6mpdy/ZLhqL0zPkZWQitdajoqh09hc+/7yqwpUc21HQmXQ4MErIN7R0w5wi2Lrnj5Gm03GaLC7W7f41+i++zMTQSRQlhmywUFp9EzWtDyAblt5QC/alOeuvAXq+/0OiE5NLtrM1NubMBlN5AzVP/g8m3/4h/vMHUeOxeQeatIcwWVEjixeEjXnGiISmGLj8GuODx1HiEQxGG7LBSjx29cVkrwVZjlNRPs7wSP5j4RdDkgV3P9C2aJtoTOF7r57n5feu4A0k0tCuayjm5x5Zz9Y15aTkLCkw//epo9RVFLFmGTedq6HA+aQLHxfdsv3zC1JlmixumjZ/ioYNHyUWDWIw2Zede2LghZfwX9Jmvb/ep36AZLMt2W7ZhQquElNZHRUf+W2UWAT/2XcYee5vczretbK4QIvETcZm5/z7/5CSrzsWDYCqJqrWxAsTV11WOpkk0trw/be2lS8ZxfFX3znMwTOpURvnuyf406+9xx//0i2cuTyGVs7qxBWVZ966xH/+zE056b+gIm22lU3PNApz2KO4chvFFZsyPi7JJkzy8ot5qvE4Xf/xvWyYljOWc7Bm8shRjnzp19nxd3+NZDQu2X7ZY0fDeN5/Hs+x14h5RpHMthQ/7qpECITBiM8WITIymfZxRYmBMICa/xBTWZ4ZUxsCDVBetTCCJpmTF0c4eGZwdrKQPGeIqipff+Z04TYMM3D6Um72caDAPmkhJMrqbinI2DZnHY2bHs9qn8G+fuKelW06aZXQ4CDnvvyXWetPiYYZ+O6fMf7Gd4lNDoESRwl6iY6u5vJOiVl06QO/wMT4vE3C2ULCyvSf/EdaCAEGg/bOHsSWODj0s2N904WbF3o0VBW6Br0536xbCbn2uhR847Cs7ta8j1lU3Mq63b++ogxtyyHXboJ8M3niJPFwduKaPe8/T7jvPJp2Pq8Qye6k+rP/HfuWPcST3RmqQuJ5Jj/X/D9vVYWqijHKy7R10ObQ21c4+l7mU6e+4MJSaFpnbDLIxelEUNmm4CI9cOnlvI5XXn87bTf98rJ9zCvBWnP1QfmaRFHwX+7MSlfeE/s0s9GTLcwVjVgbNiEbTJjM07kmNPYchYDGem1tZAtJsP+lDmKx9DPqpmqn1l7GJVGBP/7nAzmZqBVcpD1jF/M2VnHlNho2fHQ2O122GXnzraUbrTIk8/J98osRmxrNSj/aQWCp3zj7U1ntTMyv9tRl0rN4FflC4PdH6LyQ3o/7wO6rP+BSSHzB2ILNzmxQcJGORfIX6zgxdILTB/6KsYGjOel/+PV9KdnmVjuy1Yq9qSk7fTnym94x10hmK47t98/+XNm0lyJ37pPtrISZc1hF9iAL3S+FY2a2GZlfhXsaU4a6gquBQ9ejSEsriJ7IBmH/MFdOfY+By9mvrxgeG9PccvdaqPvk44gs3XQcOx/MSj9aQLIWUfWp/4Yh6cYjyUZat38eLUVRzGC3hhBiRrQ18PlUQVVULNb0Lkd/MKqVTAErxpyDG0zBRdpodi7dKAcMXH6VaDi7kRjm8vLrRqTrPv0J6j72kaz159r1KLKzPGv9FYqSB36Rhv/nq1jqF+bmMBitOMvWJfKTLHEqNV8IARZLGLM5eQNYG5/R558+RTBNXu5SlwWHLXuhn/nkA3e2ZL3Pgn+SZopm5pdE+a7xweNZ7bVk981Z7a9QNP3iz9P4xKez2qdkNFOy94ms9pl3hMB104NIxsynTqtb7kMIbS3XLZYo99x1iM0b22lb04ksFz7xkhCCqckQx99fGIJpNMg8sLsxafafiiTgkdtydyr2amlrLKauIvv+/4KLtKu8cNnCknNAZ4OS3buy2l9BkGUq7tmbk64NzrK5WeZqXM+qKsPP/9OiRQuK3E20bv88Jot28reMjjl599B2Tp9dz4VLzcTjEoWcTQtJzHqFOjL4cJ94aD1b15Ql2s/8ngBZEnzxI1v4tce3a2r7x11k4stfuj0nfRf8aRZXbsNsLUBuAVUhHstubmNLVWET6mQDySAjDLk5iGpp2ICxuHL6J6EZl8BK8J96k75v/QGBi0cytnGVrWPDbb+dP6MWYWLSzvtHtzDlST7lV9gbpKrMHPRRiUXTp4aYGvNT1OWhRZVwAQ6gXBVsRGKN28aUL6yJ2s4zbGwuxWLOzfem4N8SSTayZucvYSyAUI90v81w97tZ608IkTOBywuShBKNEezNzSlAISRKH/oCQk5+jVbZjFoI1FiUkZ/+PUoscz6OeJZXaVfL+QstqGq6r3mBhXpap/t7Jnnh6VPEk8uSReN86+/eIRKJU4JgLTLrkWlEwqLAD/71CL29UwW0fiFl11u18PlY7OVsufP3uXDka3jH85sjtqf9Rwxd2Q8CHMUtVDTcic1Ze9X9GZwOouPaOuG1KGnWjJIpdxE3tpbtVH/uz5l850eJ2aiiYKpeixqLEB2+krNxs0HcZCBU7SbqTiSpCr/7D9Ru/Rh211xcr6LEGO56i/6L+T2klY64IhifSBf6qJ0bo6rC4Xe6uHJxlI9/7iZMZpnOi2OEgpmPsyuKyoFXOvJo5dLkMrZbEyINiVnomp2/yOm3/jKRdD+PREKJ0khjwQnGBo7RvOXTlFRtv6q+DFYbUTQs0kIsGoFira3B1pjbwwSWmjVUPf5fUJU4qCpCNjDx7k+Y2Hclp+NeCzGLAe+GOpDnBM4b7OP8oX+gafrz4p/s5sLRrxGPaaNSt9+fboNTaKXGQgqjw37++X/9bNnte7rSlzMrBNVlNppqcpcorODujmQkycC63b9WQAtUUON0nvx3es//NJG9bIXI1uzmA8kq8ydQ8zbvhBA0PPHpnNZrSxlPkmddH6YS7R6pVwH/2qoUgU4gUFHpPvs0nvGLnH//HzQj0ABWSxTZMFPXUMxu2Obr/c0lUQ2tBn7n0ztRcpjwSVMiDWC2liTSOhaYoa43uXjk6yveXJSLtHcEd5aZmCYhMDgcCOPc62ypqGDt7/wWZXfcVhDTbGt3ITm0lZx+hpjDgmJOF7ebWJXEYyEuHfsWagEy3S1Gy9bH2LarmYyxbKsYLUVR/9d/OMCX/vI1frz/Yk7EuvBqmI4C5N1Nh3fiEif2/wklVdupWfNQ+rJa8zCXlS7pUigcAslkonzPXTR9/nMo0SiBK13IVitFa9dk7XThVVkmyVR+5LcYfOorS1ZByScxu5lgbRq/rhDA3GaXEtdWFXSzrZyK+tu4vzzGyJCXniupLjjNfkSXiRGBAyh0YuCZe9/wRJBvPX+WrkEPv/3pnVkdQ5sirSFUJcZY/xE8Yxeoar4X2WCmyN2E2ZZ+1ld2+20M79uvnW+ALFN+5x3UPv5RUBTM5eUY7HM1Bk3b3YWzbR7Whk3UfeH/w3PkJTwn9qOGCvsVDFW5CNali3fW/qx0Zk/FbDHw5K/cyvkzQ5w53k84HKO61oW7xMbzT5+arkKlkc/qClBRqUdwtpDx3oIFrqM3jvTy8K1NrG/KXpy8JkVaNlg05dsDlWh4ip72HwMJn567YjONmz6xICe1e8d2HOva8J5rL4ypMwiBubycLX/5PzCXatONkA5jcRWl9/88pff/PKP7/g3Puz/J6/gqECuyELMaCaUVaLSv0UKitGZuNifJEhu2VrNh65zfX1VUTh7pTcywV5lGz5jrL/AOaCbf/htHerIq0przSQNUNNxVaBMWIXGkfGLoFJdOfDvlkVg0yMTwKco/fW+BbEtCCJp+4clVJdAzREJTBH1Dec8oqJpMTG1rwLe+mlBj2cIGq8S36y7fhNmWxv4khCR44pduprpu9ZYvswHWAr0f0iI1Gqf82a1nqcmZdHXr/Qx07itIyaHlo+Idu8Dx/X+KxVpKJDhONJJYnquqinAZUKdic1/qmSVlHpyBhqIimn/pFyi7vTCbgFeLf6qbvo4X8E52ggoiHsPUUIq1dxyR5Q2Z+b2pBhlfaxmqybDw/VkFwpxMyD+MqiqIJU50mi1GfB4trVhXhh1YrwraBYRQc+5hFALcRWa8gciiRXDrKxav4bhSNDmTFkJiw+2/W2gzlkU84sM/1TUr0JBYBslbXNPLYjXx7kpS4o9IbN4ZchgFsvkv/pyKe/fmrP9c4J/qoePwVxMCDYCKKgnCFU58a6uytqhNl1U5XFrE1LZ64kXTrqukKJjVJdCJMLtQYISpkbNLth4a8OCdWn0infyOyECjmnBB5vKtsphkfvvTO/n6Hz7ArZszh4vKksj6wRZNijSA0WBB+86/zMhbncibZ9KwzsmCbDbT9rv/ie1//b+oeOA+hNkAZglRZkJUZc6utmwkiWCvNsolqUqcoHeAoG8IVV080ULfxRdRlPS17WIOC9Fi27XZAsQlQaTYTqSkiLjFSNRlxbuhlmBLxXVQrCH1hrKcikd+b3iV3YSSmbO7CKhVEkJdXpyb49mRmMKtm6swGWW++NEtabPdSULwax/fRkXJtX1W56NJdweQiDkVYlrfVtnOBonZtPHuMuSb3CiDIQwTJlSrinFjCaPyESTFRni7D3NbY0LApp+iGoojZAFGCVRQegLEDoyjTi6jOOf0F0625S6PwHJQVZWhrjcZ7np7doVhtpZQ1XwPJVXbmRw+QzTswWQtwV2+kVg0iHf80qJ9xuwWTBOBFX0SZr7GKhCqcBCqK03kuZxtsFoFammWc2CluNSWeI1WYTiemP47YbZKJYIdN9Xymce28IUvv5rVYraSEAhAlhM38mKHhb/6f+5i3+Ee3j7RTygSY219MY/e3kRzDk4ealakjWYnFls5ocDI6vsEJSHZDUitibuuAGL48Y1fwjctSinhTwKEVU75WWq0YaqzEvnxAOrI9IZEutdjemlucrtxbdm8pF1B3xBjfYcIBycwWVyU1t6ctdzefR3PM9SdWu8xHByn68wP6Wn/CYoyt9dgNDmoWfPQwk6EAHVu9141SESK7YQqnFh7xjDMSxY/c65u/jWAqMtKqKFsrt8bAGdp25JtikvtNK8t4/KF0VX7HRNJf3vbx9gnneXXHljHP7zSji9Dea6VMLNBuL2tPKXqis1i5IN3tvDBHCT5n49mRVoIQWXj3XSdezpxnHWJ5fKqZzHtkAWmhyuR34HA5V4Swa0zv5e6zG383GeQlsjEN3D5dfovvZJybbjnHSob91DX9uiKzE5EYgwiG8zYXQ1EQ1MMd789/aVf+MVX4tGUFKXRiJee9p8gy2bi8w+EzL7vKoos4W8pByHwbaxF9gSxDE0h4gqhajcxpw0pEsU07MU04UOKJG4EigT+NZVc/0x/JoTA5qhJVIhZBo9+fAv/9k/vMjkRXI0L1hR83jDHDvYAcLPDROveVt45P8qEN8TIRIBYfGVPUJr+XhkkwSfvX/qmlys0K9IAZXW7iYQnGex8Y3rGuco/RddCkYzykMA0WQthFeEwoHpjxHv9KL0hrFIZ9Z/+JGV33I537BKTo2cxmp2U19+OLM8dop0aaZ8T6NnXNPFhHOp6E5uzZvYgRDTiIxwYRTZYsRalCl0sGqD73I+ZHDqFOv2+mCxuilxNSx+PVtWUG4uixLDaSwn6hxaK+/R6PFZSlDLbizut+J2pbh3FbCRUX0KofjpGVVFT3RvXPSqO4laat3xmyciOGYpLbXzht+7iyHtdnDnez/BAoc/wZQefN8Kld3r477+/ly995fXER2H6s7Cco9szbqDKEhtf/MgWNjYXLpRVZOu0kRBiP7Bnz5497N+/Pyt9zhAJTTExeJxIaJLh7ndIPo57PbDc92C+n1FN8tcv7YOUgaVDGg0mByXVO/COXyLkG0wIsKpiMDmw2MspcjdQXLGVK2efJujt4+punAujJgxGG0LIS2dAvJbP63Xr6kg8L0k2suO+L19TT91XxvnW376TDaM0QcOt9fz40FwlHXl6wRFb5HMkS/Abn9xBZYmNTc2li8ZEZ4O9e/fy5ptvArypqure+Y9reiY9g8niorJpD56xCwx3Hyi0OYUhjcCImdv9slhezHks4mW4a2HKyFjEgy/iwTdxicHON5Y5ZiamM74nbe3FIr7l/Wq6OPPk12aV+lZXxvTzXXDTvvbJS0NTCa5iC1MTqy80Lx3HDiXcHyUqVKqCmbWXF0E/yoLcH7Ik+M+fuYm7dlx9TvlssypEGhKzzSunn+J6dHkIIZaYTYtVHIy4GFf5Xi42I850WOg6mEVLsmnap5/+uRS5m7Iyzu47m3n1uXNZ6avQ2BWVKqBm3jfIAbQhcREFUWTGaJTY3FLKh+9qZU29uxCmZmTViLR/qivvxQDyyfWQ41czXGevpc1ZR13bhwDoOPLPGdtVNGYnncJte1t567ULi1ZHWS2YWSjQMwigEQmzL8a6zZV89OPbMOWoTuG1sGoi+KPh62NDQ0dneQiKilvYeMfvseHW38JR0oKjpIWGDR9dsCkoENStfRR3+casjf7EL+3OWl+FZKk1qCnRiI6zw/z0ByfzYtNK0d5tIwOZUoOmcCOE6ulc10iyibabfw17hjqb5XW34i7fyFj/ESKhCYxmF6U1Ny0r13k64kqcw/0nOTl4DhXYVrWBXTVbqW8uYeetDRx9r/vqn8wqQCBm07WeOd5P45oydu6uR2goKmjViLTNUYPZVk44MJKxjaNkbaKQrS7UOquUxk2fyijQMxjNTqqa71l2n6FoiLe63+fCaCeSJLGjehO7arYyGfLwlZ/9Pb2egdm2+y4foNZZxR/c/et84PEtjI/5uXJh7KqfjxaYmU2rc4cL0s6vVRWe/+FJTh3p5YlfuhmzRRv1X1aNSAO0bHuS9oP/FzVN7UGDyUHD+o/SfuhvErmob/S4ap1ViMBdkT2Xxah/nH878SPe6zk6K1ACwf7Od6l31SALKUWgZ+jzDPJ/DnyNLz/w+zz+uZv427/YRzgUS+pj7u/VxHK333uuTPDyM2f58Ke25dii5bFqfNIANkcVm+74fZyl6xBS4v4iJCMl1bvYeNt/wmIvpbzu1kRjMV18U0dnleCu2IQkZWfeNOIf449e/yve7TmSNINMzCYVVaFnqo/LE5ldGZcmujk/eglMcTxbLhCXYkl9JPpRr+NJ0Jnj/QR82c0LfbWsqpk0gNnqZu1NX8j4eE3rg0RCk4wPHl/9hdx0bhhMtjKaNn86a/394PTzTAQzR0Mp098LVVUzRhZdGOvkYM8xLkntSDsuUtHThnO8Ejk2l61RRb2+AkSnD4jFYgrDgx6a1ixePCEfrDqRXgohyTRveYKqpr1MDJ0kHg9jc9Yx3HWAgOf63gTRWT1I02XXjGYnFfV3Ula7C0nOjg80Eo/ybu/RZbdX1YWzYoFAQuLNK+8BoBhiDDafZbD5LCImgSpQUSkbbKa8f+3s71wPqGoiv55WwvG0YUUOsDqqsTrmknN3nfnhXGIffWNRpyAkjsPLspnt9/5ZzkYJRoNE48tL1ZnJZaGi0usZwB9NrdyuqiqKPOf6GK67QMAxSc3lLRijlvndAKtTvIUQVNY4l26YB65bkZ6PLJuIxYJLN9TRyQVJsc3FlVtyOlSRyY7DZMcTXvyovSQklEUmLK9ffhtJkokri6cU8LtG6di+D7unFGPEQsQcwDVSS8nYTIWSdIlktY2iqgz1e6jRwOnDVbVxeC24c/zF0NGZQTZYkWQzM+WskgVaNliobNqb2/Elmb3Nty15inUxgYbpajZLCHSinQoC/K4xJsv7CDgnGGg9zXDNhdl+VhtCCOIxbay4bxiRrmrag8FQ2IolOjcGqqrQtutXcJS0ply3u+ppu+mLWOzlObfh45sepdFdl/NxFmOk7gKXt7zNRGU3akmA2gY3VTVOrHZtxB8vhtks6+6OfGO2ldG260t0t/8E30Qnq/P+rqN5hISiRJENJtp2fYmQf4RIaBKj2bkgJ3cusRjMfGLTB/ifb/9j3sZMR8jqZbDpLIPAH378/2KQE5IzNRng77+yn5hGZqvzqWsq0TcOC4HVUc26m3+VkH8E3+QVhrsPTOdETsVgtFO79hGKils49+5foyjaiJfU0QoSiZzm6eslCgSyMVGM1GIvz8vMORlv2EfXZB/vdB/J67jpmAnRS2TVnXuNJCFRVlnEYJ+nYLYthhLXzs3jhhLpGWa+OGW1NxMOjOIZu0A07EU2WnGWrMFSVDXrz6tZ+zC9HT/VTzDqAFDecAdWexXd7T/O2MZZ2obRtLCadK7onOhhf+e7jAbGGfAM0ecd1NwndXPlegxSokZgLBbn3796kJHhZeYQLwCRyPLyr+eDG1KkkzHbyii3ZQ5Yr2i4k2hokuHuA3PhSrpg37DUrnkUSTYwNXqOqdH2BY/LBgu1a1dWJ3IpPGEfr1x8k/d6jhGKhWgubuDhtXvZVNHGN44+xSsXE0UaltoILBRCCB5b/+Dsz2ePD2haoIGcV2NZCTe8SC+FEIK6dR+ivOEOJgZPEI+F8Ix1EPD2p/+FaQEvKm5BCBklHsE/1ZW+rc7qQkjIBhMALds+x1DnG4z0HiQa8SKEhLt8E9WtD2TV9zwaGOdP9/0fRgLjSdcmeL/vBLtrt3Oo73jawyhaQSD4jVs+z+bKucK4588MJf6h4dPAngnthOvqIr1MzNaS2cxj4eBYZpGezhnSsOFjs19W32QXHe//49IFWnVygmy0EY+GuNbamNaiqtl/S5KB6tYHqGq5j1gkgCSbZgU8m3zr6A9SBDpZkN9bwanCQiFLEmW2kpRrWvL3ZmJqKkQ8piAbCh8AV3gLViHu8s2LPm6xlafMpuyueoxmbYTz3GiU1uxi+z1/ys77/wKTpXg6ZvnqlrJNmz654JoQEkZzUU4EeiI4xdGB07M/K6qi2RlzJmJKnH889G8p5eEaWkoW+Q1tYJAlJFkbLg9dpK+C4sot2Bw1GR+vaX0w5WfPaAeR8NQ1CcSNjBAyZttKXQgCV/lGGjc+nvhJkmnd/vnpDb2VC11RcSu2JfI8Z5sR/9isn1mr/ublMOAd5uzIhdmfyzcYGWw9TfvWfZzfto++ppPE5HABLVxIdb1LMyXtdHfHVSAkmbU7v0DXuR8xNXxmdnZjMruoXfsIxVVbU9oH/YNJv5yUQnVZXzzB3LHa1TWLygYVjXdR2biHvgsvEA4MLdrW5qjDaHFhMFopqd6Jo2RNyhfN5qxl0x2/x5UzP2ByaLmlkgQl1Tto2vypa3gWV4fb6sr7mLlAReW59lcpt5cy6B3mrw78M9Hi6GwmvonyXsLmAM3nb9FMno+dtzYW2oRZdJG+SgwmO63bPkckNEnQO4BssGB3Ny6oPwdgmI6ZvWqEREX9HQAMd7/NjSHWEmt3/TLOkjUA2F0NjA8cI/NzF7Tt+iKycfFTpbLBQtPGxzk52o4SXyz+XWB3NdC260tZy063HFRVpX30IsO+MYqtLjaUr+Fc0ix0tXJs4Ay//cKfYJZNieRPAiQhZt0goaJJ4oYIhqQ0qIXCXWJly87MK+V8o4v0NWKyuJesL+eu2ExP+7MoymKZyTLPlGc2LY1mB0HfAN7xiwt/dzZ3torZVkE4MLyCZ7E0QjJisZdjdzUw1n8YVVVWHIooGSxUNd3LxOBxgr65jVchZGyuBmZeA3f5Biqb9qbMgktrbmLg8mvEIv60Y5bX376kQM8gG620bP05Lh77Zgb7E69ndct9eRXoi2NX+IdD36bfO7dicFucmGQToZi23AErRUUlrsTxK4HE4Zbp93b2PTaojFV3Utm7vuBzkLKKIs24OkAX6bxgMNqoaX2A3gsvZGgh5twgycInJMrrb6O6+T6MZgeQEGyvkKaT3s77IE33Ub/uQ5jtZUwNn0FR4pgsLlQ1jpAMWOyVdBz+p8QschnultYdv4TFVoLFXjH3fEx2BjvfWNFrUNl8DzWtDyaiIlruQYlHCQfHEMKAxb50YnXZYGHN9l/g4vFvEosGUsK3XOUbqGv7wIrscZVvoGnzp7hy5vtJr4OYfU2dJWtwlq3L3EGWGfSN8OWf/S3BaCjl+mTIgywknOaiJbPaaZ0Zt2CmQgFjNZ3Ue9YTyVyrIC9cbB/h8Dtd7LpdGy4PXaTzRGXTHgymIoau7CfoT8xyzbZyIqHJ1NC8aaEVQqJt15cocjel9GOd2bDMcKcXCKyOKkwWN5amPWnbtG57ks6T/04s6k/TQaq7xlHchGxIzRNc0/oQkmRi8PLryz8yryoppaEk2ZgS0rYc7O4GNt/5B0wMHsPv6UGSTRRXbl3wGi2XmSrbfRdexO/pARI3g7KaXdSseTit6ypXvNjxxgKBniGuKjQXN3BlogdP2LfqIjxWQiysoIV4hjdfauemWxs0UTVcF+k8UlpzE6U1NxEJTQIJV4l/qpsrp58iFBidbWcyu2jY8NG04lNavZP+S68kiu2mwVWxaUn3i7N0LZvv+m90nXmKiaGTzG5kzhN+Z8naBQKdaCaobrkXi62Myyf/bdGxpn9j2k1x7cgGE2V1t1DGLVnpz1HSyvpbfoNwcBwlFsFsK0GSsx9OtxRH+08t+vi5kQv8n0f+O984+hRHlmi7epir3g1gM1pRwoUXaAC/P8roiI/ySkehTdFFuhAki6jd1cDG238X38RlwsFxjGYHztK2jLO4hD/1c1w+8a/E52182YqqadzwsWXZIBtMNGx8nIC3n3BwfMHjQshUt96/aB/uik3IBivxZRRTyHeSoZVithY2djemxFMOqsy4A2Z8ozElzreP/fC6EejUkEIVSUj84s5Psu9AdvdSroVwKLZ0ozygi7QGEELgKGnFQevSjQFn6Ro23fFfGO07hH+yCyEbKa7YjLtyy4qqTRuMVtp2fYmus0/jGeuYvW61V1C37sNLuhGEJFO//iNcOf0fS7Yrrbl52XbdaPgifiLxyIKq3tP/QEVFFjIH+44XxsA8oKhKwv8uCeJxbbhzDEa50CYAukivWoxmB9Ut911zPyaLm7U7f4lwYJxQYASjyY7Nufxk8aU1O5kYOsHUyNkMLQRNmz41u/Gps5CvHv4u/mgg7WMzYh2/AVIKfPv40+wsepT4VOH9wABFjsKHA4IWPPQ6msBsK8FVtm5FAj1Dy9afo6x2NwiZ5BOVFnsl62/9LUqqt2fP0OuMUf847/edgLmsyzc0Xa5MN/v8IklCMyKtz6R1rhlJNtK46RNUtz6Id+ISAoGjZI0+e14GnZM9swc6hEgItTodhqmNRX9+mSjvpap7Y8FvWFp69XWR1skaJouL0uqdhTZjVWFOE0kihJg9Mn2jocgxFBFHVgsrTRaLduow6u4OHZ0CsrF8LU5zahWX1ZxM6VoRGnH7bNqunWPhq1KkVVUlGAwSjS52zFpHR/sYZAOf2PTB2Z9vZIGeQQtHsrVU0XxVuTtUVeXgwYMcPnyYcDiRy8BqtXLzzTdz8816iJfO6uSBNXchSxLfPv40gah2KoLkm5mcHs5SE96RwsYov/92F/c8vL6gNsywqmbSL7zwAgcOHJgVaIBgMMjPfvYzXnzxxQJapqNzbdzbcgcGoY243EIgEDjMdr646zPccsvaQptDKBjF79NGUqtVM5MeHh6mvX1h4c8Zzp49y65duygv1/bJNq0Qi8WQZRm/34/JZMJkyu9R6P7+fkZHRzGbzbS0tGA0amd5WQhG/eN4s3R0frVRU1TJE9seY0fVJkwGE29d6lj6l/JAwB/BXlT4MLxVI9InTpxYss2zzz7Lk08+mbcvfDwe58KFC3R0dBCNRqmsrGTr1q1YLBY6Ojrwer04nU7a2tpWZFMsFmNychJZlikuLs6avdFolMOHD3Pq1Cm8Xm/KY7Iss3v3bm6//fasjZeO8fFxXnjhBYaH547/ms1m7rjjDrZv357TsTWNSPhi1QJEdSSnDk3GarBkPGSTTfp9Q0TjMUzTJcgG+z05H3MpJEngdC0v9W2uWTUiPTo6umSbyclJfvzjH/P4448jSbn15ITDYZ5++mkGB+eqrnR1dXH48GGEEMTjcyfE9u/fz4MPPsjatYsv4xRF4d133+XkyZMEgwnfZFlZGbfffjtr1qy5JntjsRg/+tGP6OvrSysE8Xicd999F6/Xy0MPPXRNY81HURTOnDnDiRMnGB4eTokLhsRruW/fPsxmMxs2bMjq2KuFMlsJdc5qeqb68xajW2S0IYTAn8EPHogGkYSUl83Mbx39PrvrtmOSjZo4Fr5+axVmizbkcVX4pD0eD0NDi5dOmqG3t5dLly7l2CJ44403UgR6hng8TiwWSxHCcDjM888/n7Z9Mi+++CIHDx4kEAgkku2oKqOjozz33HOcP3/+muw9c+YMfX19S7Y7ffo0fn92lt2xWIyOjg6+853v8OqrrzI0NJTyusy/WRw6dGjZfQcCAQ4dOsQzzzzDCy+8wIULF1CU1R0Z8ZEND80eaEmHJKRrDk+b6b3Y4uJ/PvyH/Nl9v0tzcX1KG5fZwYbytXOJ+fMQEueN+Dk2XXTXXpT/LITzadu0sjS6uUQbt4olOHny5Iq+gOfPn19y1roS+vr6OHjwIGNjY1gsFjZt2pTWP77YUlVRFI4cOcIHPpA+OX1fX9+ifb711lu0tbVddXjSmTNnlrRxhvfee4/77ru2vCAXLlzgtddeIxBYfLmsqurscxobG2NqagqXa/Haft3d3Tz77LNEInNZANvb26mqquJjH/sYFsvC9KqrgTsbb8YT9vL90z8lFAvPvlc1jkqe2PoYgWgQk2zin9//N4JXUalFIDDJRm6t38knN3+QMlsi899XHvivXBy7Qq9nAIe5iG2VG/i7Q/8KkJKZL9dMhRJujlis8Dfbd9+4xNad+S08nIlVIdKdnZ3L9tXNxFAvhaIoxONxhBCMjo4ihKC8vHzWTRKLxRgbG+PIkSOcO3du9vc8Hk+KP3UldHd3z46Z7I7x+Xy8/vrriz6nqakpLl++TEtLC8FgkFAohMViYWhoiGg0SkVFBW63m2g0iizLSJI0K4CBQGCBD3oxJiYmFow//+YQDidEJJ0g9vb28txzz12Vf3XmZhyNRpEkiampKWRZnhXuUCjEc889lyLQMwwODvLyyy+zadMmDAYDdXV1GAyr4iM+y6Nt97K3+TYO953EF/FT76phc8W6lNd/3+W3OTmUZhN95vVOcyMXwMOOLWy2N9DSuI1Se2nK42tKm1hT2jT7c5O7joNdR3D6YggVvDaJmCG3M+p4r41vvfwOPZ0LU+fmm6F+D1MTQVzFhfdLi2xtVAgh9gN79uzZw/79+6+qD0VR6OrqwuPx4HA4aGpqQpIkvvWtbzE2NraivqqrqykpKSEcDlNUVMRtt92GzWbj7NmzHDhwAI9n4eaEEII1a9ZQUlKS4hfOFjPCKUkSDQ0NAPT09BCLLT8m1GAwEI/HUwRwZsPJYDDM9iVJEoqipFxbLtu3b2fLli28/vrrjIyMEI1GMZlMNDY20tDQwKlTp2ZvVDM3t3vvvZfa2sTM4+tf/zpTUyuvgWQ0GikrK2NkZCTFZiEExcXFGI1GxsbGlnw+M4JmtVq59dZb2bFjx4pt0TIdo5f5o9f/avZnW1BBUlV81iTv5ayrgtl0p9svRHAGEmXXmtdv44FPfRGTOSFCQb+XU+/to7vjFPFYDAwy/X2dGKb9w3EJhkpkLtUYIAfVShr7tuEcqEvYWniXNAAVVQ7u/9AG1qyvWLrxNbB3717efPNNgDdVVd07/3HNiHR3dzcvv/xyyozPbrdjsViWtWmoU3juvvtu1q1bx9e+9rWC2jF/1n/fffexbdu2AlmzkAsnD3HinVcZ7u3EYDDRuvkmdt79KMUV1cvu42/e+yYHut7H7Ymx8XKUmAHe32hGSXrqAjHrqrCFVHadT1p9CEHLxh088Mkvsv/H3+b8iXfTquP8KyNuifam7PqMrT43Ledunzd+/vzhmRCSQAj4xJM3sW5z7nzUS4m0JtaCo6Oj/OQnP1kwQ/L5fPh8q7v45o3Ez372sxWveHLBfPfMe++9x5YtW3Ie8bMc3nvlRxx58/nZn6PRMO3H3uHy2WN85Au/R3nN8oqf/sbuz1NTVEHPU08jAaYYtPTFuFRnmBXWGYGWFWjrmZdCQVW5fOYo3/yL3yESXv6KsXxSoSeo4rdmTzxt3uKM0+dMRWvzQWICK3j9hXbaNlUW7Li6JkT6yJEjCwS6EPGiOtfOzAZloUkWar/fz8DAwKw7plCMD/enCHQykXCQN5/9Do//yh8ueExVVXounOHku6/R39mBJMvUtW4gPNSPITb3PakZi2MLq/SWy3jsEragQt1IHJdPwZhhL24pgRYsnE2XT8XxW7MnHVFTOhtUKHCipdkN7RE/A71T1NS7C2KHJkS6s7Oz0CboXIckC3Vy3HqhaD96YNHHh3ouMz7cT0lFDUo8Tvuxd2g/eoDB7kso8dRJzMVT7wMLZcztU3D7shsdIQA1Sa2FAhbZRCi+zErxSxA3aD9RWihYuFwimhBpfdask0sMBgMVFbnd/FmKWDRCf2cH6kwoqUhzyk8Fz/gIY4O9vPXcvxPwFf7kHQBCIE3bqqLyibuewNpQy5++8ddZ6T79TLrwmfBmkCRBeWXR0g1zhCZEur6+no6OufP6umjrZJNNmzYVNHZ6uO8Kz3/7b/B7J+cuTh9Wmu9QeP7bf4OqsXSlsz5hAe6SSnbu3IskSZRY3YwHJ6+5/4g1wFjVFUoHm665r1ywfnMVDlfhPj+F30kBdu3aNbupowu0TjZpbW1lz549BRs/Eg7x03/9awK+qQwbYKmfd60JdCKpSOJfDncpH/jcb85+V3/5pieyNspgwzl6Wo8TcEyiSIV3TUFCi6pqnDzysc0FtUMTM+mqqioeffRRXn31VUKhUKHN0blOqK2t5bHHHiuoDR3H3yXonw4rFdN/rYKJiJBkNt+yF1QVRYlT07yONZtvRk46HHRu5GJWx/SUDuArG8Tsd9Jy+nYKXZz31rubuffR9RgMhU0hqwmRBmhra6O5uZl33nmHw4cPF9ocneuALVu2FNoEBrrmCdkqEOjKhlY++su/j8GQOXNjOBbh+fP7sj52k7ueeuM6xjSwyD91tI9b7mop+KnDwr8SSRiNRnbt2lVoM3SuEzZu3FhoE5CThG41uPKsRU4+8at/tKhAA/zvA18jTvbdEp/c9CGip5xZ7/dqCPijvPly4XNba0qkIXHKUE/cr3OtCCGyfqz/aqiobUJVlERUxyoQaUmaW9pHYhGO9p/m3Z4jDPlGZq9fmejh2ODp7I8tJMSIHa9XGxVRAM6c6CcWLayPXDPujmSs1sInNdFZ3cwkpbLZbAWzYXy4n/deebpg418NDnciM94LHfv40dkX8UXmshg6zUUYhAFPaPnJulbCTTVbUYLamjfGYgrhUAyDsXB+aU2K9FJ5l3V0lkO28mJfLe+9/DThUCCR7Ejjs+gZ60bs8I2jT/HyhTcXpCidDOU2bvtI/0kikgyqdnI522xGrLbClnbT1m1rmpVmbdPRSce1Fkq4FkIBH1fOnwQWJnzSEiqpQYAHRC8vXdiftxzSySiqwqn4McKmQEHGX4AK23fXo6gqPZ3jdF8eJ1oA14cmZ9KrYYNFR/sU0icdCvjnYp41+nmeb5XXJoiYCntDUVHpbzlJ/fldyIpMIU8eOt1m2k8P8u7+yyiKihBgtZm4+c4m7r5/LSIHKVvTocmZtBaylemsfqqqCrdstjvdGE1mVEVdFZMOFbhYV/iK7Soqfsc4lzceIGos7Abi1ESIsWE/ipJ4/1Q1UUH8Z69e4JVnz+bNDk2qoclU+BpnOquf1tbWgo1tNJmpblzLwvmq9lCBk61GfDZtyIGqqoStfgJFE0s3LgSqyuF3uvBM5melpo13ZR7FxcWFNkHnOqDQUUKjA90FHX8xZm4dQRO8v8GMx1HYU3WzJN3TTCF74exYBFUFRVVpP5WfAAdNivT8Gns6OlfD1ZTwyhZBnwe/Z7Jg42cieaMwMYM2ETZrZGMzSaAtPieWoKNwtiyDfG0iak6kx8bGNHEIQWf1MzIysnSjHNF1/lTBxs7EfMfLZJEgYtKcBAAgqRKK0FqyqSRUNW9FADT1DqmKSsgX1HTIks7qQAiB2Wwu2PhjQ70FGzsZlYVhdgARA3TUG7SUtjkJQcAxyXjlFW2E4qVBBapq83N8XRMheDF/hPF3e/CeGyYSiWBAIpqDvAA6Nw4zld8LRXH58ovK5gqPTTDslohLUDWu4AiqxCXorpDpLzckqq1ojjmjJsp7KBtsKaAti9N+apAdtzTkfJyCi3QsEKX3qVNEJxIuDhmJEhwMMVlYw3SujZkJUIGEoLm5uaAbhxZbYSp5VDevo6apjZ/1vs9x29zezlDpvIZaXK0KpmPKE7ZFLIGCFqJdilAoP4fuCi7Sk+/3zgq0jxCHOI9PTcoprc33RycT81enBRLrQsZIA5w78lbex1yzZTcPf+ZXAfjmMwchJLRQz/UqSBhtiJqQtOWRnUOFyur8bGwW/BXwnB0GQEHhIOfxq6HUz5Q2XVI6KyXP7+OJEycKVnxWVVW6L2Q/S1wmzFY7tz/yyVmBnghOzeXZWG0CLab/oOIerSuwMZmRZUHz2rK8jFXQmbSqqsSnq/AOMkFADWHDTBFWosSYwJdoV0gjdTCbzZSXl9Pbu/hmmFChmCLGp9+3+RhUmTpRCjVWugd7UJTc7d77/X7GxsYKVoA2nuP8M47iMh781Jew2otwl6WuGo4PnMnp2LlGIHDg0rQ/2uGy5i3AoaAiLYTA5LYQmQgypQbYTRvluJi5/QcIc5ZuBrlB4qYXuxvl4vMwf7zpMUwmE6qqYjabWbduHTt37sTpdNLV1cV7773H0NAQ0WgUIQQ2mw1ZlglNBbiN9TiwMYmPs/QQIYoFE2aMGJFpoxYLJpwllTg/8gEOHTrE8ePHc5ZQq1BRQkM9l3Pav8Fo4mNf/IPZtKLzuTKhjciSpZCEQFWZjeAQCOwmG2WT9Vja6zHEtHfyWIjEXxu25s+dVlCRjodjGFxmIuNB1jO3tJnRDhtmdrGG02oXZoz0MEqA6fP8Gb5/O3bsoKqqirNnz9Lf3080Gr1q+4QQKXkXzGoit0FYRCkrK8NutzM4OEgkEsFms9HY2EgwGKSnpwchBEIIIpHIomOYzWYsRgt+rw8ZiXJchIgwhZ84CkYMVFPMhC3IVGAuj+982wBsNht33XUXDoeD3t5eVFWlrKyMgYEBOjs7CQQChMPhzDeDaf/lBx58hJZ1CyMjGhsbaWxsBBLJi+LxOHa7Hf+lcQaebUdVFASCEhzcwYbU13LmDVMT0TxWq5XNmzdz5MiRRV+fq8XhcFBaOn+3LD/k1B8tBPF4jP4r51m3/ba0TUYD47kb/xqRxKw/A0iIniDxWf6NWz6PubeClw6c0dTyWQiRojcWi4Gb72jK2/gFE+l4OEbfU6cIjyzM+Ztc5F4g2EITKlBLGe/RnhDqNBsiQgg2bdpEZWXlbOmkAwcOcOjQoRUtrWdmYM3NzVRVVdF36BJN0XIcJBLIR80KtTvbKN5SjaqqxGIxjMaFyWm+//3v09PTs+hYzc3NbB6rIeJdPPexJBl5reh4So7k5JmiJEk8+eST2O2Jo7QzYgqwfv167rnnHgDeeukNDp0+OvuYERkViE2HPBpUGadn6RnMTOREdCrE4E/Pg5q6C7/YjrzJbUGNK1y6eHH2eWQ7CdHu3bsLlqjLN5W7ld/Mez7YdTGjSLss2ig/tVykuIx7pI5zzwQZG2zXlEAbjBLx+JxBZRVFPPbpbbhL8ldMomAiPXGwN0WgBSIlcH3+V1wAdszcxSZ6GKWfMSZVf0pDSZJwOFJ3XO+44w42b97MuXPnOH/+PKOjo8u2cceOHbjHTZTF4injmMMyo69cgrBC8a7atAIN0FTXtKRISwpEhpdOTq94o+x55G5efOWlVEFTE39tMDUSPjmGZbsJ2Zo5m9kaaungPHYstFKNc/rGM46XC/RRghPFs/zVx9TJQdT4ynzLnrMjTB4dYET0JS6IxYV6pSK+efNmtm3btiKbsomzOEcbSkk3ZTnDZw6gzKbd3DeKqiLNVE0HDBEzDe03YwkVMST8qIqGFBpoXVfOTbc14vOEKS6z0diS/9VZwUTac3powbX5Qj3/UVAxYqCFKlqoop1uxlUfk/hRBbRVNhO74mMq5iEWiBCdCKGEY0TGg5R6FHYqDbwj+fErwcyjCIEZI3fV70K8OcHIqD/jnX30zU78l8eRTBJGlwVDmY3YRIhYMIr/0jiuQAQ7ZvyE07pnBGA7v3x/bGt9Cx/72Mc4ePAgvT29gIoTO2uopjZYytg73XjOjVD7+CZ8F8bwnh0hOhVCGCTMlXbszSWEeqe4gw1ISClPqwQHt7IegGDvFDF/GIM99cSeGlfwnh/F1z5CPBLHVGLFf3lixTMfZTq+tBQnqNP+U1VgxEBcxFHmdSipAqdqR0ElQJioSP+aGQwG7r77bnbs2LEyg7LMmq27OfVe9itpJ6+cWjbuzNhub8vtfO/0s1kf/1qQhISqqqio00KdeC5VVzZiDhVp9pRxU2spa9YXZvN5hoKItBKNEw+mn63NLJNTZ9Vi9l/JirCBBlQgSoyIGqOoz8JQX+bqvhaM7GUz3YzQLvUSUWMYMWCQZKxuOy6Xi6qiciovGlG6Y0TUJWa4KgS7MyfxkZC4l20MMcFxtZMIc+IigCKsVJF+8ycdQy93ULm3hT3O7UyqVaioyKRmL4tOBLny9SMwb0YS8EUIXEosw+d+J7XNzOscGQnQ+Y/vY19bgrnUTswfQRglfB1jxH1zPvZQ77WVUypVHZTipEp1U0MpJozEVYV+xjhPHzFibKCBBsqRpm1TUBlUJzhDNzZM1FGOTZgoqnDTeu8mimq1MIvMwWwwScTq12yipqktY9MSq4vNFes4PVy4yjTJSCLhdhIiEbctCcHmyvUYI2bCU1WpB2tSv+IF53LHKLfcXdgok4KItGSUka3GjEINmX2a6WbbJgyYMCzrZJKERBOVNCmVKCiJYPl4Ytnlbqlj8lAvsUD2ko0LBJUUczd29nECIzINVFCBCxf2WfFZDsGuKXr+9djs80iLyrIrgSz1evkvjOO/kNtNqNumZ+8zGJCop5xK3EgkZtfJSAhqKKEK99xroIIYgoHvnaHktgZKb8/9Ud3FyEWOf0GiknfT+m3c8cgnM7Yb9Y/z3PnX6Jnqz74RV8H8z5gQAhX4zVt/gfHeMN/mvYWPa6hIwuWOEfy+MPaiwuWBKZi7w7mlkolD00vdFd49Uzeorp5koYt5w4y+dukaesuMQGDFxAPswDT9kmv1qGu+Sb9yAgum6SvpPxjzVxAzTcff7cZSVYS9ZfkrlGxTXtOAkCTULMaBO9ylxKIRLp89yuWzR6lrWc8tD3yMqoa5wgZ9nkH+9I3/gyecPk59xcwXywwuCWtIoXo0jsuvoAoYd8oMlMpEjSLtse4Sqxu7yUbInmkPQjsVx+KKysX2EbbtKtzBmoKdOCzeXYe5Iim/wXWuWYKEr1tM/6eTipj3X+La3N/z22ZEhcEXOlBihUlzqSoKJw68mr0Op4XRMzFKMDAnvr2X2/nJ1/8n/Vfm3HvfOvb93An0zLV5f4qnYuzsiFA7GqcoqOIIqDQOxtjZEcYWSrwHqqKk/GkJ2xjqukR5lYPqPGWSu2pUiBWg+GwyBRNp2Wyg7lObKb2zEWOxFckkYyjSXvC6TmFJRNUuFPDFUEIxBp87l3vj0vD289/j/X3PZm8WvciUMh6P8c6L3wdgxD/G6aEV+qDTiO7snwzYgyq7z4TZ2BmlbijGxisxpDRP1RSFdV1RmN4snPmv2BPHdOQiT3/1K7z61Fe5/0MbMBiSZEhVNTOLnqG+uXCrMijwYRbJZKDklnpKbqknNOhj8MXzZDhRrKOzIvyXJohMBDAV5y+e1Ts5xqmDbyR+yPaaPYOrYai3k8nRIcbxrWy/7WpsU1U2dEUxx8DsUShdYt+4KJiYVU84ZEwxlYrxOKUeZfY223HyIKXV9Tz5q7fxs1c6uNQxQg4zBVw1Lndhy7AVPMESQKBrkt7vnSQ6rldk0ckeE+/nd/Ps8tljqGpCZbLu0lpEVMNBP6XW4nmJyVSsQWWR2XHSvs68hwzxxJ/5FHtVrOGViXvjUJztFyNsvBKlLEmgZ+w59d4+auqcPPGF3dzzUJsm3Z6SXFijCp6qVFVVhl+9uOIDETo6SxHsncLfOYGpxIrRZcn5eLFI9qKC0qGq6oJ4Ylk24CqtwGIrYmvVBk4MnMXlibG2J0pMEhxdb0rugDkVTIikPaiw42KMiFHgN4EhpuAIJh6NGEFWoKdCZqhExh7K/nfUNzVOwO/F7nDR1zM1/fy04/JYs74co7GwRXoLLtLBnimiU6GlG+rorJDoeJD+H50BIbA3F1PxwJqc7ntU1jcn/ZQDlVHVBW6PtVt3zxYYuMvYQqf3JBuvRJEUMKNS4lEYdyYvmFPtcgRUJEXFElYxJ91jBGCZjpBtGYjTMhAnsgK1WO7cUwiB0Zh4TyRJzFzUTHjHnfetLbQJhRfpmG/xBEQ6OteMquK/PE7fD05T/9ltSKbczIxqWzZQUlHL+HBfTvqH1Nl0eXUDbdtv49DrzxCLRjjz7utsikVTNvLWdUVpbzIy4Ujv2SyfnGu8VCSsOemgZ7YktGHtZkyWhM+3bWMl504NJmyRhCaOiB/Yd5FnvucjEolTXedi951NeT+BWHCfdD6WoTo6AJHxAN5zuasgLoTgkc/++nTujtz4MU1mC5V1Ldz9oc9isdp59pv/i/f3PcvRn71INBJGVuby5gvAoMDmy1F2dERoHIhRPzSntMVeBbdveS6MdLl0lts2fSOBwWDi5vsem720cXs1ZUlhuUISKQsHs0XOe9WvC+eGmZwIEvBHuHR+hP/4l/d5+/WLebWh4CJtrXViKs3fDrzOjY3vwvITbF0N7rJKnvit/0Hr5l056T8SCjLYfZH3XvkR3ZfOLtl+RtOKgioNw3HqRuLICtSOxtnUGU0rvun+ZOp7OW2FkOZfoLKuhQ//4n+ism7ORWQwyHz2i7tpai1NaWuzm3j4o5v4/S8/gtWWObFUvnjjpfOMDHmXbpglCu7uAKh8eC19PzyDEo5p7uy+zvWFmodDLgajEWdJWU59q+FgIq/Mco5QJ28VCgVuORPGkK99eiGoaV7HQ5/+EvFYDJ9nHIutKGM1dafLyud+5VZGBr0M9E1hNhtoWTe3eSekPE+lM3D8UA8PfGhjXsbShEhbqhw0/Nx2Jo/24788TiwQRY0U9pSPzvWJJU/FQ0srazWXh0IABpX8ToJUlZaN27E5XAA4ipeX6rO8ykF51cL3qrzSgd87llUTFyOTe2VqIn/hwgV3d8xgdFsov7eFpi/sYs1v3oasgWWNzvWFMEi4tqWfwWWb1s03Y7UVLd3wOsdoMrN+551Z6691XXnW+loOiRDzhXc1Rx730jQj0vNxbc/Pl0nnOmf6+yUZZao+uA5kQaB7kvBwbo+2GoxGHvrMryEKVB1GK7hKKzFbs7fnFCtEThaVBZEm23fX5214Tbg70pHNDGI6NzACnJsqce+qYeztLvyX22f9xKYyO+X3NGNrcOdk6NrmdZRU1DI2uHh1nuuC+f736Rqfdmd283srilq48LzpOPXb9rRQWZ2/xFCavM1PvN/LxMHVUfFYR/sEuicZeLYd/6XxFCGJjPrp/9FZgn3XVrxgMQwGzc6DsooQAiFJc3+mnbnrtt+a1XFmylflJRRv3hhFTgsf+8wO7v/ghvTtc4TmRFqJxhl7p1uP8NDJGjFPmGiGjR41rjD+bnfOxvbmsCitVlgQYjdNTVMbrVuyG4rYvLY0kd40DyqduPHM/Vm/uZJNO2pyPu58NCfSvgtjqFHd1aGTPwLdU8RDy681uRLi8eUX9V2t3P+JL9C8YfusWFusdnbc+RAf/PxvI8vZXUkIIfjkL+yiutaZ93C8qlpXXsebQXNrscCV63/moZNHlrMiU9WcxU87XKWEA0tXg1+tbLv9AdbtuI11O24jHAwQDgWwO9zIOXTzOF1WvvDbd3Hx3DCvv3COof4cHSxJypVis5vYvKM2N+MsgeZm0prMVaizqpGsiwuG0WlBtucm5PPmez6Uk34LjdFs4eHP/Bp3fegzs9fMVhvO4rKcCnQyx9/vYXjQl3PPh8Vi4JM/vwtjjnK+LIXmZtKm0sIm2Na5/pCtRtRIPGNEgGtH9YIUoNmidcsumjZs58q54znpv1Cs3XYLa7bcXLDxh/o9s8mYcnWys765hHWbKtm+ux6rrXBVozQ3k3ZuqtCgVTqrmeh4EMlmQsgLP1jOzZW4b8rtZtAHn/wtKutacjpGvmnbektBx28/PTj771yd6vz453Zy297Wggo0aHAmbSgyU763hZF9lwttis51RNwXpmhdGeYyO5HxALLViGNDBZaq/JwKbN2yi6He6+MzbbJYqWvNbxjafOLTRUJUVc1ZJFjAH8HhLHyWTk3OWd07a6h4uPDJtnWuL/yXxnFtr6bq0XWU39OSN4EG2H7Hg0hSYSt8ZIv1N2XvmPfVUt80XRw2V6G62qk7oE2RBnBtrsS5tTIv+4jWBhfum2sxuMy5H0ynYKgxhZg3tyWuMiHJMnse+7mCjJ1VhKCpbWuhrWDNunLKyu256VyA02mholIbuVc0K9IAFfevoXhXLZJZXjyx7TTmqiIkm2HRBLjCJM32ZSxOJHWq/cRmyvc00/SFXdR/bjvWxtzGQ8pFJorWlyEsq3RmtZz4VAlsLcVLvmeldzVhqsjRl22GJBtkS+E8fJt27+WxL/wX3GVVBbPhmhCC4rIq6tduKrQlCEnw6Mc3Z6WfBX+E4JY9LUhp9jAKgeZ80skISVC2p5niW+sJD/rwto/gOTWU8YsvJEHzF29m4Jl2Ap0L461NZTbqPrU1cfY/piBZDSm7+kIILJVF1H1iC/FglIFn2wn2TF2F4dP/V8FS48DW6MZYbMVcbkfIEkaXeXYTK9g7Rd/TZ7J/gCf5NVrJsm2xfN4zfS4jb0LjL96E0WHmyr8cyTh7tTa4KbmlDu+54RUYuEKSXgdrgxuDo7Crpb5LZ/GMjyAkadXlp7E73Dz8mV/LWSTMSnGXLH1zt9qMqCqEw6mHlWx2E49+fDNvvHiesZG5OHZZSgj0bXu0s9GraZGeQTYbsDW6GXu3e9GZWWjAi/f8aOJATJp2kdEA4+92U35PCywR8yhbjRicV/mFni7KbCq3U/PRjcjWzDG41joX9qZifBeuIkdumudodFuJTl59rlthkDAWW4kMJx3AWKw0Rxokk4zBnoimqPnIBvqePks8kFrL0lRqo+qRxL6DwWkmMhpYhnHT/1/qHpHGLskkU3Z309Jj5JD2owc48uYLcxc0VHB1Kax2B0/89p9jseZ41bMCnG4LTpcFzyKFrDdur+bOe9dy5L0uOjtGEUKwZkM5O29tpMhhZv3mKi6dH2Gwz4PZbGD91ipNbBYmsypEepZlzOC8ZxevYec5O0zZnuZlHSldUU7rpBmosdSKe0cNzo0Vyyp66t5Vi+/S+LKe31IU31zL5NF+ImNJoreCajdqVElEQIwsckpuif4cGyqQpitpmCuKaPzFnXjPDhPs8YAkKGotoaitdHY1UdRWRuBydk6aFt9RjyRJTB0fJOYLIySBvaWEktsbMOfKh7lMjr/9SsrPWisKsBihgF9zNxQhBHc/uJaf/vBU2s+j0SRz1/1rcbqs3PvIengkfR9r1lfkvbjsSlhVIm2tcxEayHwE1FRsJeZbfGNICcVQQrFlCbBraxWT76+g8vO07pfe1oBj/fKTk1trnVQ+tJahVy/CYseTk+4rQhao8blPppAE7pvrcG2tAiEYfuVC+t9dzvdsCVeckCVcO6qZPLzwtTFXFFF6Z2PKNdlswL2jBneG5DSO9eWMvHZpeUezF7NfgK3Gha3RTfHuOuKBKJJRzll18JUQCYcYG1qY2XG1uD1UVaHjxEG23nZfoU1JYeetjXgmQ7y97yKKos6uYouKTDz++V04Xav/cNyqEmnXtiqmjg+gRNOX1nLvqsXXMUZ0PPNyXzLJiY3IZWAqtmKpdRJaKpVlinhKWOtXvvHo3FSBvbUE77kRwiN+IuOBxA1pRoiTN79sJuo+vZlgr5foeADJYsSxoQzj9DLNtaWSmCfExKHelFN2ktmAqcxGqHfx52N0WbA1uAl0T6Z93LWtivI9zdibi5k6PkBkLIhklnFsKMe5qXLFoigZJNw31TBxqHfl/vN5eM+NYGt0I4TAYC/sIYRkZFleVTPndAz1XAaNiTTA3ofXsfO2Bs4cHyAUjFJeUcT6rVUYDIW/OWeDVSXSRpeF6o9sYPC588RDc9nFkmeRkkkm0JV56ezYUJH25Fkmqh/bQM+3jxHzRdI3mCcUjk0VVy0OssWAe8dcRZrQoI+R1y8RGpxbPVjrXFTc34qp2IapOHPFi9I7GnFuqcR7boR4MIapxIpjfTnhYR+93zuV2QiRqDnp3lnD0EsXUnIwC1nCtbWSsj2JCs+2BnfWEuaX3t5AZDSA//J46gMzmrbMvap4ODfZ7K4V2WCkYe1mujoWvvarZTZtMGrnpjcfp8uqqc2+bLKqRBoSwtD0xV34zo8SGVs4iyxqK8N+fhT/xYUbccZiKyW3razsjcFmpOHJHUwc7sNzZph4IIJkNSJJgpg/SbiFwLG+PLEpmSUsVUXUf3Yb4VE/MV8Eo9OCqWT5yzej00LJLanP11rnwlxVRHgwTfkokVg92JoSM9GaxzYQmQgS7J1CSAJbU3HOZqdClqj+yAYCXZP42keIh+OYy2wJf3X3ZMJeSeBtH0msLjKItrkse6Wass2uez5E76VzxOMLbyR2pxtFUQj6cleA4Fpp3XRToU24IVl1Ig2JenXOzZVpHxOSoPpD65k6PsDUyUEi40EMNiOOjRUU76q9qgK3ss1I2d1NlN3dhKqqsyFIoUEvwZ4phCxhaynG5M6N/8tcZsdclr1Nr+oPb6D/6TNExlMjKgwOM9WPbUgJsTIVWzEV58evJ4TA3lSMvSm15FLyhp8QAs+ZofS/L0s4t2g3BrmqoZUPPPmb/OzZf2dybO45VDes4Z6P/QLO4lJe/M7fceX8yQJamZ4iV4km4qNvRFalSC+FkATunTW4d2Y/cU6ygFmqHFjSlJ3XOkanmYYnt+PtGE3Ek6uJU5eO9eWzURlapWxvM+FRP+Gh1JWAkCUqH16L8WrDJvNE/ZpNfOZ3vsxg9yWCPg+uskpKK+fyFH/w53+Ho2++wLG3XyYU8OXNDWK1O2jdvIuz7/8MRVFI9jMZzWYeeuJXNRMffaNxXYq0ztIIWcK5oQLnBu2GHqVDthio+/RWfB2j+M6PokTimCuLcG2rytuM/1oRQlDduCbj4zv3PMrarbdw9K0XuXT6CAHvZC6NwWg08ejnfpPqxjVsuOlOjh94hb7L55Ekiab129h2x4MUl2t3hXK9o4u0zqpDMkg4N1bg3Li6bjDL5cQ7r/HuSz9I+K5zHA1SUl7NfY//EpX1ib2UyvoWHvr0r+R0TJ2VoYu0jo6GuNJ+gref/4+5CzMuhhyJ9eZb750VaB1toou0jo6GOPbWSwuuJXzBAlVd2j9tslhp3bSLyvpmOs+doOv8iUXbjw7krlK6TnbQRVpHRyOoisLAlQvpHxQghITd4aZt+62MDvRgttqoaVpHyO8lFotQUdtE84YdSHJi83dybHhJkS5yFi/6uE7h0UVaR0criESqzEy1GCFxKOb2hz+xrO5aN+7keJqZeTLVTW0rMlEn/2gjYaqOjg5CCBrXbVu0TfOG7cvur7ppLWXVDRkfL66oKXgZLJ2l0UVaR0dD3LTnUWQ5/QLXbLGtOMHRIz/367hKKxIbkEl/HMVlPPpzv6HHPq8CdHeHjo6GqKxv4ZHP/gZvPvtveCfnUhsUT4fKOUuWn10RwFVSwRO/9ed0nDhI93TekPo1m2jbfitGk7YP/ugk0EVaR0djNK7bwuf+81/Se/kcfs8UrpJyqpuuvjCzwWhi46672LjrrixaqZMvdJHW0dEgQpKoX6PnytDRfdI6Ojo6mkYXaR0dHR0No4u0jo6OjoYR2SrnI4ToBWpdLhfbt2/PSp86Ojo61zvHjx9namoKoE9V1br5j2dTpCeBlRf309HR0dEBmFJV1T3/YjajOzqBZsAHXMxivzo6OjrXM2uAIhIauoCszaR1dHR0dLKPvnGoo6Ojo2F0kdbR0dHRMLpI6+jo6GgYXaR1dHR0NIwu0jo6OjoaRhdpHR0dHQ2ji7SOjo6OhtFFWkdHR0fD6CKto6Ojo2F0kdbR0dHRMLpI6+jo6GgYXaR1dHR0NIwu0jo6OjoaRhdpHR0dHQ2ji7SOjo6OhtFFWkdHR0fD/P/IvtmlE6m+LwAAAABJRU5ErkJggg==\n","text/plain":["
","metadata":{},"cell_type":"markdown","outputs":[],"execution_count":0},{"cell_type":"markdown","id":"e7d9b26d","metadata":{"papermill":{"duration":0.004085,"end_time":"2022-01-28T16:59:53.754281","exception":false,"start_time":"2022-01-28T16:59:53.750196","status":"completed"},"tags":[]},"source":["##### Have you ever wondered how a cluster propgate. It is time to reveal the beuty of clusters propgation. It as simple as\n","- running the next cell,\n","- wait,\n","- watch and\n","- ENJOY."]},{"cell_type":"code","execution_count":1,"id":"7d1fe6fe","metadata":{"execution":{"iopub.execute_input":"2022-01-28T16:59:53.765377Z","iopub.status.busy":"2022-01-28T16:59:53.764201Z","iopub.status.idle":"2022-01-28T17:03:36.326661Z","shell.execute_reply":"2022-01-28T17:03:36.325883Z","shell.execute_reply.started":"2022-01-24T22:08:58.752738Z"},"id":"FZgP6jwmzFtZ","papermill":{"duration":222.569057,"end_time":"2022-01-28T17:03:36.326871","exception":false,"start_time":"2022-01-28T16:59:53.757814","status":"completed"},"tags":[]},"outputs":[{"data":{"image/png":"iVBORw0KGgoAAAANSUhEUgAAAWkAAADzCAYAAABE8effAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMSwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/YYfK9AAAACXBIWXMAAAsTAAALEwEAmpwYAABqPElEQVR4nO29d5hcx3Wn/da9nXs6TM4ZGORIEMwEmIMCFahAyaIcZMnpc9i11+u1/azDyvK3/nbX62xJlmRZlkVJlERSzCQIigRJgMhxMAiDyTl1jvd+f/SE7pnuCUCHO8B9+QDE3K6pOp1+t+rUqXOEqqro6Ojo6GgTqdAG6Ojo6OhkRhdpHR0dHQ2ji7SOjo6OhtFFWkdHR0fDGLLVkRDiGNAM+ICL2epXR0dH5zpnDVAEdKqqumP+gyJb0R1CiEnAlZXOdHR0dG48plRVdc+/mLWZNIkZtMvlcrF9+/Ysdqujo6Nz/XL8+HGmpqYgoaELyKZIXwRqt2/fzv79+7PYrY6Ojs71y969e3nzzTchg5tY3zjU0dHR0TC6SOvo6OhomGy6O3R0dK5DFEVleNCLqqhUVDuQZX1ul090kdbR0cnI4Xeu8M4bl5iaDAFQVGRi913N3H5PK0KIjL/n94Y5dqiHkSEvRqPMxm01tLSV5cvs6wpdpG9gwoFxhrr2MzF4kng8gs1ZS0XDnZRUbSu0aToa4MC+i+x78XzKNZ8vwr4Xz+P3RXjwwxtTHotF47z203McO9RDNBJPeezoe93YHWY++pnttLSV59z2pVAUlQtnh+g4O0QsGkdVYXTYRzAQpaTMzk23NbBxW02hzQR0kb5hCfqG6Dj8T8Sigdlr/qluOk99l6C3j9q1jxbQOp1CEwpGefv19GfSVFXl0Fud2OxGyisdrFlfweiwl3/5vweIxZSMffq9Yb7zzwcpKjJRXe9mxy31rNlQgcEg5+pppLfDF+Y/vn6IgT4PqqpC0lERIcAzFeLKpTEud4zywU9szatt6dBF+galp/2ZFIFOZvDKmxRXbcfm0MZMQif/XDg3TGTebBiYFTVFVdn3wnmEAKvdRCgQRVGWdzDO54tw4dwwF84NA1Be5aBtYwXVdS7Wba5icjzAyKAPi81IQ3MJkpTZrZJMPKYQ8EcwWwyYzJml7dmnTjDQ55l+QvOfX0KoAY4d6qFtUyVtGyuXNX6u0EX6BiQcHMc7cWnRNmN9h7Gt/3CeLNLRGpFwbME1NY0IqyoEfJFrGmtk0MvIoBchQJYl4nFlVildbgv3f3ADG7ZWMzkeRJIEkiy4cnEMRVExmw3EYwqH3+2iu3MMVQFJEqzbXMmm7TWMDvsBlbUbKqiuczM24uNS+8i07RluKklKffS9bl2kdfJPNOxZsk0kPJUHS7JDyD/MUNdbeEYT/lNH6RoqG+7C6qgusGWrl6pa5+y/57sEcoWqMucuUVWEJJiaDPHDbx/FYJAWdaUkoygq504Ocu7k4Oy1/S91YLObaGh2oyzxfFRgZu4+OZZ+tZlPdJG+ATFZ3Eu2MSe1UZU4E8OnmRg8RiwawuqoorzuNqxFhZ1hAHjHL3Hx2DdRlOjstbH+I0wMHKdl2+dwlW8ooHWrl9qGYqrrnPR3F+5mnTxzX65AL0bAH6H99PCKfsfuMF/zuNeKLtI3ICaLG2dpG56xjoxtSmt3A6DEI1w8+g28k52zj/kmOxnteY/6DR+lvO6WnNubjKLEmBw6TcDbjySbGO19b06gVZWZKZKiqlw583223PXfkGRjXm1c7fT3THJg30WG+r2FNqUwqKCiIoBtu+oKbY0u0jcqDesf4/z7/0Q0svCLWNm0l/GBo4wPHCUS9oCqMLsAnPbVqaj0nPsxRe6mvMyoveMXGezcj3f8Iqoan7Mn47pVJRbxMdLzDpVNe3Jun9YZ6vcwNuLDZjfR2FKKyLAZd+n8CE99831i0Wufua5qpj0ib71+gep6F+WVjoKZoov0DYrZVsaGW3+T4e63GR88gRKPYHPWUVK1k4HLrxIOjiUaqjNfVnXuf0lCPdr7HvXrH8uprd3nfsRI78EkW5LsWYLBzv1UNN6FEDfmKbnRYR/PPnWCvu7J6ZdMxem28sjHNi/YEFMVlWe/d1wX6BkEjI8G+O7XDvGrv7dn0YiRXKKLtAZQlBgj3QcY7TtEJDiB0eKitGYXFQ13IRtMORvXaHZSu/bRlJjorrNPJwn00kIY9A1muD7EYOcbTI6cQVViFLkaqWi8C3fFphXZOD5wbFqgr27nKhb14xntwFW+HgDfZBeTw2dQlSh2dyPuis1I0vX5NfD7wnznn97D6wmlvHxTE0Ge+sb7PP7kTWzYmthcnZwI8NQ3DuP1hAtkrQaZ3kGcmgxy+lgfO29tLIgZ1+enUyMEfUPEYyEs9nIMRlvaNooSS/h8k0LiwsFx+i+9wtTIWdbe9EVkw9VtXkRCU4wPHCMW9WG2lVNStY1o2EM4MIbBVITVUU3A0weo2By1AIwPHk/x7S5ETRHMcHCCcwf/lljYi9HioqzmZsy2Mi4e/yZKfC40yzvZiXeyk+rme3GUrEGSTdicdYseLQYY6Xl3btyrxO/pxlHSyuUT/8bUWNIJup53MFncrNnxi5rYBM02R97tXiDQM6gq/OS7xykutbH/5Q4unB262vvgdc3M5uXLz5wl4I9wxz1rMrqKcoUu0itAiUdR4hFko3XR5bNnrIPejhcI+gYAkCQDJVXbqVv3IWSDJaXtaO/BjDHLfk8vw91vUd1yf8p1VYnjGbtANOLBbC2lqLglRexUVWHg8j4GO19HVZVZ0e0++8NEAyElCe3cN1OSTSnCuhwiwTEi0zPvSGgC/2QXkmxEiUdJJ6wDl19j4PJrICTM1lJq1zxEcdU2gt5BBjpfJ+QfwWh2UORqwu6uJ+AdWJE9qQgQAkky0tP+TKpAz9gfmuTi0X9h053/ZXZGHY+FmRg6SSQ0icniprhyy4L3bTXQcWZwUeGNRuP86z+8SyQc0wV6CaKROPteOM+7b17mc1+6hapad97G1kV6GQR9QwxcfjWxTFYVTGYX5fW3Utm4ByGlHmn1jF3k4rFvJsRxGkWJMdp/mKB/iHW7fjXld8b63k8dbJ54DncdwGQpJuQbZnTgCLGwhxTxExIms5PKpj0YTE5Geg7gm7i8+BNS0/scVyrQGTpfXj+qQjgwwuWT30Gcfgo1KYQu6AXPaPs12iFmfedFxS30X3o1Y8tIeIqJoZOUVu9kfPAE3WefJh6fW/b3nn+Ohg0fpaR6Qfk5TbOcsLVwaOGhFZ3MBP1Rvvq/32bbrjo+8IkteTnSrov0EgS9g5w//I/EY6HZa5HwFH0XX8Y/1UvLts+lzGL7L76YItDJ+Kd6mBg+nZLAKOXQSBo3Qyzq48rp72U2UFWIhCbpaX9mZU9MQyQL9LUzJ84ApTW7iEcD0xEhmfFNdGKxlnHl1H+gznsP4vEwV04/hclaTJG7KYu25o7xUX+hTbiuOXG4F4DHntie87FuzC3vFdB74fkUgU5mcuQMnqQldDg4jt/Tu2h/E4MnUn42ml2Jma2qkJdjXdc96uzrWeRqpH7dhxHL2BiUJANDXW/OCbSa6ntXURm68maujM4qnRdG+er/fovhwRs0zjlPnDrWx0QeTiTqIr0I0bBn0QMfAOP9R4HEjLv77I/nBHfGF5zyR8E7fpHOU9/DO34ZVYkTCU3k46nckPgmOzm+74/pOjPti5//3iThrtiEZ/zi7PuUuGGqKW2944vnO9ECsVicH//7MaLR+JKbsjrXhhJXOX86fXRTNtHdHYsQiwaXbBON+PBPdtNx9GsosfnhSwtnxvFYkPHBY4wPHJ3ewFt8Ga5zrahEQuNprycS6Ug4iltwlKyZ9qWnW83MtNW+6LWfGsTvT9oTEOgLtBxy8kgvt+5pyekY+kx6EUwWF5K0+JFis62Myye/gxILsexvw8xMTRfoguOu2ETr9s8TDk6gKotvollshU9WvxRjI6m+aO3fVlY3g32Jk5y5RJ9JL4JssFBStZ3RvoMZ2wS9/brLYhUzOXyGi+FvEl/G5mU4zfsc8Pbjn+pBko24ytZnjIfPFzZ70uEndYFXRycHnDjcy72PrM9Z/9e9SMcifkZ6DzI5fAolHsXuaqCi4XZszqUTp6iqkhKKlQ7/VFe2TNUpBKqCb3KJkMVpYmEPsWgQg9FKNOyh89R/TPup55TQWlRN0+ZPYXPW5sjgxdm0rYbXfnqOWExZEKWikxt6Lqdzp2WP61qkw8EJOg7/E5HQ5Oy1UGCE8YGjNG58nNLaXYk0nEOnZkXc5qqnrHY3JouLgUuvMTF4vGD262gTVVW4cPRfCHoHmO/iCvoGOHfwb2jZ8lmKqxaWXlJVlYCnh1gkgMVejtlWmlXbbEUm7nl4Ha/+9Jzui84TXl9uj9Jf1yLdfe5HKQI9g4pK17mnsTnruHLm+wS8fbOPTY2dZ+jKm9Sv/wgDna/n0Vqd1cCJ/X+CwWCdLj2WqbKHwpUz38dZ1pZyUnFqtJ3e888RCozOXnOWttG48ePLyvG9XG7d04LTbeGFp08R8GczBl0nHePDfiLhWM4SMF23G4fhwPii4XOqqtB56rspAj0TfqXEw3Sd+X7Gk3k6NzCqQiyaKMm0GEo8ksiDMs1w19tcPPoNQv7hlDBAz1gHHYe/mjEW/2rZuK2Gux5oy2qfOpnZ//LiobrXwvUr0sHRxRuo6lwGt5TY2NkGuTJN54ZAxTuWqLY91neYnvPPsPAzpU4fjx9lrP9w1i0Y0Q+z5I2uy2M563vVuTsiIQ/dZ3+IZ/wiqhJFMlgoq9lFzZqHUpaWBlPRMnqbqXWmC7JO9pkYOsmFI19PHJJZFJWx/qNUNNyZ1fEH+5euZamTHUYGvEyMBSguzX50z6qaSQd9Q5x++ytMjZ6bzfegxEIMd7/Nif1/xvjAsdm2NkcN1qI0hUhnj/suzAKno5Nd1ETagGXEwwd9Axlzvlwt4aDuj84XsZjCaz89l5O+V5VIXzr2zYwHDlQlSuep7zKQlO2sYf1jqQndk4/76uhoCFWJMXXNmf9SCYV0kc4XQhJ0nB0i4M9GJslUVo1IB70DcxVDFqH/8muJzRnA5qqnZdvncJau0zcBdTTP5PCZrPYXi+onWvOJoqj4vdkPx1s1Pumgf2jZbUd630MIibG+w4uHSunoaAjf+PIO1SwXJa5/7vOJLAmKnFdXRWkxNCXSvskuRnoOEPD0Ickmiiu3UlZ3KwajdfnHbVWF0d6DWUpgr6OTP8LBUcLBScxWd1b6M1kMRKP69yAfqKrK+i3VWG3Zr0mqGXfHcPcBzr//D4wPniAUGCXg7afv4ku0H/xbIqEpHMWtCLG8e4ou0Dqrlc5T/46qZMdNsWZdRVb60VkeTWuye3p0Bk2IdMg/Qu/559I+Fg6M0n7o7zn19v+LquqlfnSub/yTV+huf2a6RuS1ccvdzashu+p1gRCCl358huGB7Ic9akKkx/rfT58MZjoaIxqaIKpnmtO5QRjtfZeTb/45/ZdeW1ZO80wUOS164v9cI5itHh5XVA69fSXrQ2hCpEP+NKcD9WgMTWO0FBfahOuaeCzIwKWXOfWzLzPWd3WnESfHA6jMiYjO1SMErN2Y5D4STJfTTH1tuzuznxFPExuHxmWdDrw+UNMk+F1tsx2LvZJNd/wuSjzK1Gg7Q11v419muk+dlaHEw1w5831kkx13+YaUx3yTXQx1/Qzv+EUEAmfZOiqb9mBz1ABgL8r+JtaNyu33tLLnoTb+8r+9tDBHt6rOXovHsz+51MRMurRmV+IfyfUArzNUVU0r0DOPpV6YvqaqWY8elGRzomzX1SKMNG78+HRfRoort1Df9gH0GiC5ROXSsW/Rd+FFouGEz3N88Dgd7/8jk8OnicdCxGJBxgePc/7Q388mFisutVPfVIyqXH/fp3xisxvZcUsDxw72UFRkRlXU2e9n4t9zbSdGA3z/W4eJxbIXo66JmbSiRDGaimY/gNcbmcR5YUNSfPPq3MVlzbbtzmYcZa0EpnoIB8dR4pHECU0hMFlLKKu9mWjYx8ClVzL2UVyxnUhkCiUeJR4LEg17po/gC9wVm6luuW9BQnuzvRxJNqEo0WW6qWaeiy4ey0dhsHMfg1f2U7f2Awxcfi3tPo6ixOg68wM23/lfEZJMabmN7hwnpb+eqaxxsvehNr7xNwcIBqNzE8hM8ycB588Mse+F8zz44Y1ZsaHgIj010s6lE/86nbfg+quauRKBVoIxVG8MqdgEBpF4KcTMw2paoZZkEyVVO6hZ+/CSbiNVVTn91ldY7DWeGjvL9nv/HJE0247HIghJSj1in4TBaKWkegejfYeWfJqzCDFrhpAMVLfcj8VegSwb6Tn/PKHAvMNLyflW0iXFUlRMYz6kaIxYkYW41YRqKvjHO/uoCr0d05FQGVZEkekq9wZLM8cO9ubRuOuLX/m9u3E4LfzdV94gFJqOLBMCgZp+sZ/koz5+qIc9D7Zhtlz7Z7Cgn2JVVenteG4usYyY9sbfYJuGakxBmYoRfWEAvArIgFmGsAJmCbnRBrJAGQihTkaRqxyU3LyLqoceoKiyCUlO9T3Gw2EC3T0IWcbe1IiQEl9mJRZKWwQhGSUewTPagat8rmabbFjat1nX9kFC/hF8E5dZ9o1WCGSDhTU7foEid9Ps5eLJKwx0DoGqIvtCiLhC3GZGNUqgqoi4guwPI0ViSIEIRk8QOU2eCn9rBdFie8axVz2LVDCPhCZ58blTeTZodZGpvJiYnhk5nBZOvN87J9CzDcQCl+z8zdlwOMbwoJf6pmvfYC+oSAemehJVKq5DH/SixFTU8Qjx817iF/wJMU5+CeJAYNqnFYgTP5eaFzje52Gkbx+jz7+FvbkJe1MTVQ8/iL2pkZ7v/5DBF18i6k1UMLZUlFP70ceouO9eJNmEEBLqElnZgr6BFJFeDrLBTNuuLzLS8y497T9J0yLxITZZS3CUtMzWmyyt2YXBaE1pWV5/GxNHX8DUNYgUmZvBRErsBOpLcZzpRU6Tl2L+p8jaM0bUZYN00Q2LCNz1gMniprerp9BmaJbF6j+qqAgEE6MBeruWEfqb4WNkMGRny6+gIj012n5DzJqjrwwnlkJWGXUyitITzIpXR41G8XVcwNdxgaFXXsXW3ESgqzupgUpocIhL//hVLv3T13Bv24pxk52IezHfv0CeJ5rLRQiJioY7CAfHGe5+e8HjkmSgafMncRS3LNpPqOMY1ov9qCR9NtSEO8M45su42538XVEBKRLHfnGIQGsFqpz6W6ZRL5FiO8xcX5WCPe0YnWe7yezEWbYOIXSRvhbMVgNGo5z2sTST6RSKS2xU1TizYkfBRNo/2c1A575CDZ831MkoyiX/9A+5HSvQeSXxD0laGCWjqkyePIU4JTDcV4q8Nr3/WkgGiiu2XJMd9es+hNVewXD32wT9wwgErvL1VLXcj32JKu2qqjDx1vcTtiCBmN5Fn358uXOTGdkyeYIYT3QTKS1CkSWM3iByILEBZJzw42+tTMy0V+3MOul9FhKSkGnc+DhCSDS2lnD2+GBhzdMgKioKKtIiEUkRVDDJrN9SxcmjfQsbLKHSdz+4Nmvx6QUT6cEr+7jeNgnTITltGCqcxIa95O35ZgpjnBa7+DsepGYbYsFyTFDdch8GUwY/7gooq7uFsrpbiMdCCMmQcdNxPpGBy8Qmh6ftnZtJX8vHXSgq5pGFpaSMU0Fcx7qIuq1EypzEXNZVKtQJnKVt1K59ZDZOet3GyhtKpOe7MCZQsQFmJGLTwhxDRSAxBVgAd5p+FKAThf5RP5s2VlLX4Ka3e3JBOyEJauvdDPROoUx/3xxOM3sfWsfWmxafjKyEgoi0qqpMjZ6f/un6i+hIIKhb9yEqG+8ifPMoh3/5V/Pne19iHCUQoVTZgd/WRziQyNFttpVR1bSXsrrdWTUluaTZUsQ8Y0y+/3zeXGACEKqKeSKAaSLA5M4mkJNEOvl1XAXi7Z/qTonwuXBupIDWXBtCSmzfKcuM8Z4fujqESi8qAjATJ7XMb+LzJVCpRlCOwDj9iAfoQ8EPfOO50/yv37ybJ76wm5d+coazx/uJT9vjclu55+E2ttxUh2cyyGC/B5PZQENTMZKc3eMnBZpJq6kRHerc9VVJhlAo30QnlY13MfTaG6BowPeeJDQWUUrTHZ8lEhwHVEzW0oKefAwPdjLwH3+GEvQVZPyIyzq3wZhhFQJoWqzj0SAjvQepaX2ArktjnD0xUGiTrprWtjJu3dPC/pc66OuZBMBqM7J5Rw1mi5Ezx/sZH0m4ERVUelAxkthzH0dlJg+mCmSqw64C/agMoGKa/t3kOI6LPVM8+Scv84E7mlm7vZp7Hl3P6KAXk9lAXYN71p3hdFtxuq9uH2c5FESkhZAocjfjm+ycuTDzyHW1kSikxKZD3zPPFtiShViqqxBCYLblJr3iYiiREN6Tb+A78zZKOICpooFw/8WEQBfo/Z8N1VtsFaIoCX+/ZoVaZazvfSoa7+XH/35s2bNQrSFJgvs+sIHKGictbeVMTQSJRuO4S6wYDInv1D0Pr6Pr0ig//cEpzo14Gb6GCZ4KZKqnMuWP8N1XEqv+ihIbv/3pHbRmIaxuJRTsWHhV057UC6p6XQk0gLtiE13f/R5KIFBoUxLiMo2logL39m0FMSMe9NH/7T9i7JVvEO7rIDrai//MAWITgwV9/5dz8MU05MHSM4ZpxIMU0GbO8khoglMHvo3Xk2n+qG2EgA99ciuVSZERrmIrZRVFswI9Q2NrGb/+X+/hpr2teblvDo8H+O9ffYcX3ukkksfSZAXbOHSVb6B+3Yfp63geRY2zal0dGbAWVRE41E3vUz8otCkJpqMXDDYba3/nN1HCYfqeeY7hfW8QGRvHXFZGxf33UvPhDyKbs18CaIbxN75DZLgrZ/1fLWKpL52qYhmcQkpKoBNzWvG3lKMatXWyMR46S1HRTfh89qSFgVZn/9MIcBfbeORjm1m7YWXFCvpGfXnb7onGVP7x6ZN89+V2PvvQeh65vTnnYxb001XRcAclVdsZGzhK34UXMlYC1ypCMlK79lEGO/cRi/pnr7tK1yFOqXT96F8LaN08VJWaD3+Q6kcfxuh2c/qP/wTfxUuzD4eGh+n+7veYPHqMjX/yxzkRaiUcxHdmYfy0Fm7Q5lEv0dLMx+qNk4EUgQYweII4L40T3L6OiMbynddWD9PekSwgSTkGNERFVRF7HlqHrchEQ1PJisPWJn0hDp3OfwSLNxDln358CovZwD031ed0rIJPAQwmO+6KTfSe157fFiEtsgQX1Kx5kMrGOymvvxXv+CWUWBirs4ZI1yinfvxHeTV1OVhqarBUVdHzg6fxXbi40P8qBJ728wy+9DK1j3046+PHvGOo0exXU84GRm8occClzLHgMRGNY+lNn6RI8vlpqXoAY8M6JkfOEfT2MzVylmh4MscWL46jKN0GrPaEevddLWzYWn3Vv/8Hf3+goLf477/Wwd6ddTnddNdEqtKJwROFNmERpvOJJGG2ltK48eNUNe0FEifpXGXrKK7aisVWxtArr+XfzGUQ6E6cRux/9qeZIxhUleHX38jJ+LLVkT4SRiMbcbYro9iujCIHIonMgzEF07AH59k+5PDCVZ4AUFWm3nsWk8VJRf0tNG78KFv3/CHOsg0L2ucLIaCsdBJJyp/f9GqwF5nYeWvDVf/+28f76B0uTDTQzJ2hf9SfcxsKPpMeHzhO34UXC20GkDhtZzAWEQ1PzQnHzP+n35TKpj3Urn0kJUvcfELDw5rMR2KrqyXm8xPzLHIsXFUJj43lZHzZ7sLWso3ApWPzHtFGrLwg4fYwjy48+LIYod524v4pZLtr9lp53W48o+eybOHykSSVtWuucL6jtWA2LIYkwRNfuLaY/B++cSFL1qwcRZ1JIcxs7HSuKPhMeqDzdQr9BRWSkR33fpmd93+F9bf8BiaLO00jgc1ZS3XL/YsKNICppCQ3hl4jlQ8+wNh7B5dsZ7DmLuaz5N6fQ7Jc+4lGTaGq+M68NfejEsfubsZSVFVAo6CpfpBCf7cycdf9a6mpdy/ZLhqL0zPkZWQitdajoqh09hc+/7yqwpUc21HQmXQ4MErIN7R0w5wi2Lrnj5Gm03GaLC7W7f41+i++zMTQSRQlhmywUFp9EzWtDyAblt5QC/alOeuvAXq+/0OiE5NLtrM1NubMBlN5AzVP/g8m3/4h/vMHUeOxeQeatIcwWVEjixeEjXnGiISmGLj8GuODx1HiEQxGG7LBSjx29cVkrwVZjlNRPs7wSP5j4RdDkgV3P9C2aJtoTOF7r57n5feu4A0k0tCuayjm5x5Zz9Y15aTkLCkw//epo9RVFLFmGTedq6HA+aQLHxfdsv3zC1JlmixumjZ/ioYNHyUWDWIw2Zede2LghZfwX9Jmvb/ep36AZLMt2W7ZhQquElNZHRUf+W2UWAT/2XcYee5vczretbK4QIvETcZm5/z7/5CSrzsWDYCqJqrWxAsTV11WOpkk0trw/be2lS8ZxfFX3znMwTOpURvnuyf406+9xx//0i2cuTyGVs7qxBWVZ966xH/+zE056b+gIm22lU3PNApz2KO4chvFFZsyPi7JJkzy8ot5qvE4Xf/xvWyYljOWc7Bm8shRjnzp19nxd3+NZDQu2X7ZY0fDeN5/Hs+x14h5RpHMthQ/7qpECITBiM8WITIymfZxRYmBMICa/xBTWZ4ZUxsCDVBetTCCJpmTF0c4eGZwdrKQPGeIqipff+Z04TYMM3D6Um72caDAPmkhJMrqbinI2DZnHY2bHs9qn8G+fuKelW06aZXQ4CDnvvyXWetPiYYZ+O6fMf7Gd4lNDoESRwl6iY6u5vJOiVl06QO/wMT4vE3C2ULCyvSf/EdaCAEGg/bOHsSWODj0s2N904WbF3o0VBW6Br0536xbCbn2uhR847Cs7ta8j1lU3Mq63b++ogxtyyHXboJ8M3niJPFwduKaPe8/T7jvPJp2Pq8Qye6k+rP/HfuWPcST3RmqQuJ5Jj/X/D9vVYWqijHKy7R10ObQ21c4+l7mU6e+4MJSaFpnbDLIxelEUNmm4CI9cOnlvI5XXn87bTf98rJ9zCvBWnP1QfmaRFHwX+7MSlfeE/s0s9GTLcwVjVgbNiEbTJjM07kmNPYchYDGem1tZAtJsP+lDmKx9DPqpmqn1l7GJVGBP/7nAzmZqBVcpD1jF/M2VnHlNho2fHQ2O122GXnzraUbrTIk8/J98osRmxrNSj/aQWCp3zj7U1ntTMyv9tRl0rN4FflC4PdH6LyQ3o/7wO6rP+BSSHzB2ILNzmxQcJGORfIX6zgxdILTB/6KsYGjOel/+PV9KdnmVjuy1Yq9qSk7fTnym94x10hmK47t98/+XNm0lyJ37pPtrISZc1hF9iAL3S+FY2a2GZlfhXsaU4a6gquBQ9ejSEsriJ7IBmH/MFdOfY+By9mvrxgeG9PccvdaqPvk44gs3XQcOx/MSj9aQLIWUfWp/4Yh6cYjyUZat38eLUVRzGC3hhBiRrQ18PlUQVVULNb0Lkd/MKqVTAErxpyDG0zBRdpodi7dKAcMXH6VaDi7kRjm8vLrRqTrPv0J6j72kaz159r1KLKzPGv9FYqSB36Rhv/nq1jqF+bmMBitOMvWJfKTLHEqNV8IARZLGLM5eQNYG5/R558+RTBNXu5SlwWHLXuhn/nkA3e2ZL3Pgn+SZopm5pdE+a7xweNZ7bVk981Z7a9QNP3iz9P4xKez2qdkNFOy94ms9pl3hMB104NIxsynTqtb7kMIbS3XLZYo99x1iM0b22lb04ksFz7xkhCCqckQx99fGIJpNMg8sLsxafafiiTgkdtydyr2amlrLKauIvv+/4KLtKu8cNnCknNAZ4OS3buy2l9BkGUq7tmbk64NzrK5WeZqXM+qKsPP/9OiRQuK3E20bv88Jot28reMjjl599B2Tp9dz4VLzcTjEoWcTQtJzHqFOjL4cJ94aD1b15Ql2s/8ngBZEnzxI1v4tce3a2r7x11k4stfuj0nfRf8aRZXbsNsLUBuAVUhHstubmNLVWET6mQDySAjDLk5iGpp2ICxuHL6J6EZl8BK8J96k75v/QGBi0cytnGVrWPDbb+dP6MWYWLSzvtHtzDlST7lV9gbpKrMHPRRiUXTp4aYGvNT1OWhRZVwAQ6gXBVsRGKN28aUL6yJ2s4zbGwuxWLOzfem4N8SSTayZucvYSyAUI90v81w97tZ608IkTOBywuShBKNEezNzSlAISRKH/oCQk5+jVbZjFoI1FiUkZ/+PUoscz6OeJZXaVfL+QstqGq6r3mBhXpap/t7Jnnh6VPEk8uSReN86+/eIRKJU4JgLTLrkWlEwqLAD/71CL29UwW0fiFl11u18PlY7OVsufP3uXDka3jH85sjtqf9Rwxd2Q8CHMUtVDTcic1Ze9X9GZwOouPaOuG1KGnWjJIpdxE3tpbtVH/uz5l850eJ2aiiYKpeixqLEB2+krNxs0HcZCBU7SbqTiSpCr/7D9Ru/Rh211xcr6LEGO56i/6L+T2klY64IhifSBf6qJ0bo6rC4Xe6uHJxlI9/7iZMZpnOi2OEgpmPsyuKyoFXOvJo5dLkMrZbEyINiVnomp2/yOm3/jKRdD+PREKJ0khjwQnGBo7RvOXTlFRtv6q+DFYbUTQs0kIsGoFira3B1pjbwwSWmjVUPf5fUJU4qCpCNjDx7k+Y2Hclp+NeCzGLAe+GOpDnBM4b7OP8oX+gafrz4p/s5sLRrxGPaaNSt9+fboNTaKXGQgqjw37++X/9bNnte7rSlzMrBNVlNppqcpcorODujmQkycC63b9WQAtUUON0nvx3es//NJG9bIXI1uzmA8kq8ydQ8zbvhBA0PPHpnNZrSxlPkmddH6YS7R6pVwH/2qoUgU4gUFHpPvs0nvGLnH//HzQj0ABWSxTZMFPXUMxu2Obr/c0lUQ2tBn7n0ztRcpjwSVMiDWC2liTSOhaYoa43uXjk6yveXJSLtHcEd5aZmCYhMDgcCOPc62ypqGDt7/wWZXfcVhDTbGt3ITm0lZx+hpjDgmJOF7ebWJXEYyEuHfsWagEy3S1Gy9bH2LarmYyxbKsYLUVR/9d/OMCX/vI1frz/Yk7EuvBqmI4C5N1Nh3fiEif2/wklVdupWfNQ+rJa8zCXlS7pUigcAslkonzPXTR9/nMo0SiBK13IVitFa9dk7XThVVkmyVR+5LcYfOorS1ZByScxu5lgbRq/rhDA3GaXEtdWFXSzrZyK+tu4vzzGyJCXniupLjjNfkSXiRGBAyh0YuCZe9/wRJBvPX+WrkEPv/3pnVkdQ5sirSFUJcZY/xE8Yxeoar4X2WCmyN2E2ZZ+1ld2+20M79uvnW+ALFN+5x3UPv5RUBTM5eUY7HM1Bk3b3YWzbR7Whk3UfeH/w3PkJTwn9qOGCvsVDFW5CNali3fW/qx0Zk/FbDHw5K/cyvkzQ5w53k84HKO61oW7xMbzT5+arkKlkc/qClBRqUdwtpDx3oIFrqM3jvTy8K1NrG/KXpy8JkVaNlg05dsDlWh4ip72HwMJn567YjONmz6xICe1e8d2HOva8J5rL4ypMwiBubycLX/5PzCXatONkA5jcRWl9/88pff/PKP7/g3Puz/J6/gqECuyELMaCaUVaLSv0UKitGZuNifJEhu2VrNh65zfX1VUTh7pTcywV5lGz5jrL/AOaCbf/htHerIq0przSQNUNNxVaBMWIXGkfGLoFJdOfDvlkVg0yMTwKco/fW+BbEtCCJp+4clVJdAzREJTBH1Dec8oqJpMTG1rwLe+mlBj2cIGq8S36y7fhNmWxv4khCR44pduprpu9ZYvswHWAr0f0iI1Gqf82a1nqcmZdHXr/Qx07itIyaHlo+Idu8Dx/X+KxVpKJDhONJJYnquqinAZUKdic1/qmSVlHpyBhqIimn/pFyi7vTCbgFeLf6qbvo4X8E52ggoiHsPUUIq1dxyR5Q2Z+b2pBhlfaxmqybDw/VkFwpxMyD+MqiqIJU50mi1GfB4trVhXhh1YrwraBYRQc+5hFALcRWa8gciiRXDrKxav4bhSNDmTFkJiw+2/W2gzlkU84sM/1TUr0JBYBslbXNPLYjXx7kpS4o9IbN4ZchgFsvkv/pyKe/fmrP9c4J/qoePwVxMCDYCKKgnCFU58a6uytqhNl1U5XFrE1LZ64kXTrqukKJjVJdCJMLtQYISpkbNLth4a8OCdWn0infyOyECjmnBB5vKtsphkfvvTO/n6Hz7ArZszh4vKksj6wRZNijSA0WBB+86/zMhbncibZ9KwzsmCbDbT9rv/ie1//b+oeOA+hNkAZglRZkJUZc6utmwkiWCvNsolqUqcoHeAoG8IVV080ULfxRdRlPS17WIOC9Fi27XZAsQlQaTYTqSkiLjFSNRlxbuhlmBLxXVQrCH1hrKcikd+b3iV3YSSmbO7CKhVEkJdXpyb49mRmMKtm6swGWW++NEtabPdSULwax/fRkXJtX1W56NJdweQiDkVYlrfVtnOBonZtPHuMuSb3CiDIQwTJlSrinFjCaPyESTFRni7D3NbY0LApp+iGoojZAFGCVRQegLEDoyjTi6jOOf0F0625S6PwHJQVZWhrjcZ7np7doVhtpZQ1XwPJVXbmRw+QzTswWQtwV2+kVg0iHf80qJ9xuwWTBOBFX0SZr7GKhCqcBCqK03kuZxtsFoFammWc2CluNSWeI1WYTiemP47YbZKJYIdN9Xymce28IUvv5rVYraSEAhAlhM38mKHhb/6f+5i3+Ee3j7RTygSY219MY/e3kRzDk4ealakjWYnFls5ocDI6vsEJSHZDUitibuuAGL48Y1fwjctSinhTwKEVU75WWq0YaqzEvnxAOrI9IZEutdjemlucrtxbdm8pF1B3xBjfYcIBycwWVyU1t6ctdzefR3PM9SdWu8xHByn68wP6Wn/CYoyt9dgNDmoWfPQwk6EAHVu9141SESK7YQqnFh7xjDMSxY/c65u/jWAqMtKqKFsrt8bAGdp25JtikvtNK8t4/KF0VX7HRNJf3vbx9gnneXXHljHP7zSji9Dea6VMLNBuL2tPKXqis1i5IN3tvDBHCT5n49mRVoIQWXj3XSdezpxnHWJ5fKqZzHtkAWmhyuR34HA5V4Swa0zv5e6zG383GeQlsjEN3D5dfovvZJybbjnHSob91DX9uiKzE5EYgwiG8zYXQ1EQ1MMd789/aVf+MVX4tGUFKXRiJee9p8gy2bi8w+EzL7vKoos4W8pByHwbaxF9gSxDE0h4gqhajcxpw0pEsU07MU04UOKJG4EigT+NZVc/0x/JoTA5qhJVIhZBo9+fAv/9k/vMjkRXI0L1hR83jDHDvYAcLPDROveVt45P8qEN8TIRIBYfGVPUJr+XhkkwSfvX/qmlys0K9IAZXW7iYQnGex8Y3rGuco/RddCkYzykMA0WQthFeEwoHpjxHv9KL0hrFIZ9Z/+JGV33I537BKTo2cxmp2U19+OLM8dop0aaZ8T6NnXNPFhHOp6E5uzZvYgRDTiIxwYRTZYsRalCl0sGqD73I+ZHDqFOv2+mCxuilxNSx+PVtWUG4uixLDaSwn6hxaK+/R6PFZSlDLbizut+J2pbh3FbCRUX0KofjpGVVFT3RvXPSqO4laat3xmyciOGYpLbXzht+7iyHtdnDnez/BAoc/wZQefN8Kld3r477+/ly995fXER2H6s7Cco9szbqDKEhtf/MgWNjYXLpRVZOu0kRBiP7Bnz5497N+/Pyt9zhAJTTExeJxIaJLh7ndIPo57PbDc92C+n1FN8tcv7YOUgaVDGg0mByXVO/COXyLkG0wIsKpiMDmw2MspcjdQXLGVK2efJujt4+punAujJgxGG0LIS2dAvJbP63Xr6kg8L0k2suO+L19TT91XxvnW376TDaM0QcOt9fz40FwlHXl6wRFb5HMkS/Abn9xBZYmNTc2li8ZEZ4O9e/fy5ptvArypqure+Y9reiY9g8niorJpD56xCwx3Hyi0OYUhjcCImdv9slhezHks4mW4a2HKyFjEgy/iwTdxicHON5Y5ZiamM74nbe3FIr7l/Wq6OPPk12aV+lZXxvTzXXDTvvbJS0NTCa5iC1MTqy80Lx3HDiXcHyUqVKqCmbWXF0E/yoLcH7Ik+M+fuYm7dlx9TvlssypEGhKzzSunn+J6dHkIIZaYTYtVHIy4GFf5Xi42I850WOg6mEVLsmnap5/+uRS5m7Iyzu47m3n1uXNZ6avQ2BWVKqBm3jfIAbQhcREFUWTGaJTY3FLKh+9qZU29uxCmZmTViLR/qivvxQDyyfWQ41czXGevpc1ZR13bhwDoOPLPGdtVNGYnncJte1t567ULi1ZHWS2YWSjQMwigEQmzL8a6zZV89OPbMOWoTuG1sGoi+KPh62NDQ0dneQiKilvYeMfvseHW38JR0oKjpIWGDR9dsCkoENStfRR3+casjf7EL+3OWl+FZKk1qCnRiI6zw/z0ByfzYtNK0d5tIwOZUoOmcCOE6ulc10iyibabfw17hjqb5XW34i7fyFj/ESKhCYxmF6U1Ny0r13k64kqcw/0nOTl4DhXYVrWBXTVbqW8uYeetDRx9r/vqn8wqQCBm07WeOd5P45oydu6uR2goKmjViLTNUYPZVk44MJKxjaNkbaKQrS7UOquUxk2fyijQMxjNTqqa71l2n6FoiLe63+fCaCeSJLGjehO7arYyGfLwlZ/9Pb2egdm2+y4foNZZxR/c/et84PEtjI/5uXJh7KqfjxaYmU2rc4cL0s6vVRWe/+FJTh3p5YlfuhmzRRv1X1aNSAO0bHuS9oP/FzVN7UGDyUHD+o/SfuhvErmob/S4ap1ViMBdkT2Xxah/nH878SPe6zk6K1ACwf7Od6l31SALKUWgZ+jzDPJ/DnyNLz/w+zz+uZv427/YRzgUS+pj7u/VxHK333uuTPDyM2f58Ke25dii5bFqfNIANkcVm+74fZyl6xBS4v4iJCMl1bvYeNt/wmIvpbzu1kRjMV18U0dnleCu2IQkZWfeNOIf449e/yve7TmSNINMzCYVVaFnqo/LE5ldGZcmujk/eglMcTxbLhCXYkl9JPpRr+NJ0Jnj/QR82c0LfbWsqpk0gNnqZu1NX8j4eE3rg0RCk4wPHl/9hdx0bhhMtjKaNn86a/394PTzTAQzR0Mp098LVVUzRhZdGOvkYM8xLkntSDsuUtHThnO8Ejk2l61RRb2+AkSnD4jFYgrDgx6a1ixePCEfrDqRXgohyTRveYKqpr1MDJ0kHg9jc9Yx3HWAgOf63gTRWT1I02XXjGYnFfV3Ula7C0nOjg80Eo/ybu/RZbdX1YWzYoFAQuLNK+8BoBhiDDafZbD5LCImgSpQUSkbbKa8f+3s71wPqGoiv55WwvG0YUUOsDqqsTrmknN3nfnhXGIffWNRpyAkjsPLspnt9/5ZzkYJRoNE48tL1ZnJZaGi0usZwB9NrdyuqiqKPOf6GK67QMAxSc3lLRijlvndAKtTvIUQVNY4l26YB65bkZ6PLJuIxYJLN9TRyQVJsc3FlVtyOlSRyY7DZMcTXvyovSQklEUmLK9ffhtJkokri6cU8LtG6di+D7unFGPEQsQcwDVSS8nYTIWSdIlktY2iqgz1e6jRwOnDVbVxeC24c/zF0NGZQTZYkWQzM+WskgVaNliobNqb2/Elmb3Nty15inUxgYbpajZLCHSinQoC/K4xJsv7CDgnGGg9zXDNhdl+VhtCCOIxbay4bxiRrmrag8FQ2IolOjcGqqrQtutXcJS0ply3u+ppu+mLWOzlObfh45sepdFdl/NxFmOk7gKXt7zNRGU3akmA2gY3VTVOrHZtxB8vhtks6+6OfGO2ldG260t0t/8E30Qnq/P+rqN5hISiRJENJtp2fYmQf4RIaBKj2bkgJ3cusRjMfGLTB/ifb/9j3sZMR8jqZbDpLIPAH378/2KQE5IzNRng77+yn5hGZqvzqWsq0TcOC4HVUc26m3+VkH8E3+QVhrsPTOdETsVgtFO79hGKils49+5foyjaiJfU0QoSiZzm6eslCgSyMVGM1GIvz8vMORlv2EfXZB/vdB/J67jpmAnRS2TVnXuNJCFRVlnEYJ+nYLYthhLXzs3jhhLpGWa+OGW1NxMOjOIZu0A07EU2WnGWrMFSVDXrz6tZ+zC9HT/VTzDqAFDecAdWexXd7T/O2MZZ2obRtLCadK7onOhhf+e7jAbGGfAM0ecd1NwndXPlegxSokZgLBbn3796kJHhZeYQLwCRyPLyr+eDG1KkkzHbyii3ZQ5Yr2i4k2hokuHuA3PhSrpg37DUrnkUSTYwNXqOqdH2BY/LBgu1a1dWJ3IpPGEfr1x8k/d6jhGKhWgubuDhtXvZVNHGN44+xSsXE0UaltoILBRCCB5b/+Dsz2ePD2haoIGcV2NZCTe8SC+FEIK6dR+ivOEOJgZPEI+F8Ix1EPD2p/+FaQEvKm5BCBklHsE/1ZW+rc7qQkjIBhMALds+x1DnG4z0HiQa8SKEhLt8E9WtD2TV9zwaGOdP9/0fRgLjSdcmeL/vBLtrt3Oo73jawyhaQSD4jVs+z+bKucK4588MJf6h4dPAngnthOvqIr1MzNaS2cxj4eBYZpGezhnSsOFjs19W32QXHe//49IFWnVygmy0EY+GuNbamNaiqtl/S5KB6tYHqGq5j1gkgCSbZgU8m3zr6A9SBDpZkN9bwanCQiFLEmW2kpRrWvL3ZmJqKkQ8piAbCh8AV3gLViHu8s2LPm6xlafMpuyueoxmbYTz3GiU1uxi+z1/ys77/wKTpXg6ZvnqlrJNmz654JoQEkZzUU4EeiI4xdGB07M/K6qi2RlzJmJKnH889G8p5eEaWkoW+Q1tYJAlJFkbLg9dpK+C4sot2Bw1GR+vaX0w5WfPaAeR8NQ1CcSNjBAyZttKXQgCV/lGGjc+nvhJkmnd/vnpDb2VC11RcSu2JfI8Z5sR/9isn1mr/ublMOAd5uzIhdmfyzcYGWw9TfvWfZzfto++ppPE5HABLVxIdb1LMyXtdHfHVSAkmbU7v0DXuR8xNXxmdnZjMruoXfsIxVVbU9oH/YNJv5yUQnVZXzzB3LHa1TWLygYVjXdR2biHvgsvEA4MLdrW5qjDaHFhMFopqd6Jo2RNyhfN5qxl0x2/x5UzP2ByaLmlkgQl1Tto2vypa3gWV4fb6sr7mLlAReW59lcpt5cy6B3mrw78M9Hi6GwmvonyXsLmAM3nb9FMno+dtzYW2oRZdJG+SgwmO63bPkckNEnQO4BssGB3Ny6oPwdgmI6ZvWqEREX9HQAMd7/NjSHWEmt3/TLOkjUA2F0NjA8cI/NzF7Tt+iKycfFTpbLBQtPGxzk52o4SXyz+XWB3NdC260tZy063HFRVpX30IsO+MYqtLjaUr+Fc0ix0tXJs4Ay//cKfYJZNieRPAiQhZt0goaJJ4oYIhqQ0qIXCXWJly87MK+V8o4v0NWKyuJesL+eu2ExP+7MoymKZyTLPlGc2LY1mB0HfAN7xiwt/dzZ3torZVkE4MLyCZ7E0QjJisZdjdzUw1n8YVVVWHIooGSxUNd3LxOBxgr65jVchZGyuBmZeA3f5Biqb9qbMgktrbmLg8mvEIv60Y5bX376kQM8gG620bP05Lh77Zgb7E69ndct9eRXoi2NX+IdD36bfO7dicFucmGQToZi23AErRUUlrsTxK4HE4Zbp93b2PTaojFV3Utm7vuBzkLKKIs24OkAX6bxgMNqoaX2A3gsvZGgh5twgycInJMrrb6O6+T6MZgeQEGyvkKaT3s77IE33Ub/uQ5jtZUwNn0FR4pgsLlQ1jpAMWOyVdBz+p8QschnultYdv4TFVoLFXjH3fEx2BjvfWNFrUNl8DzWtDyaiIlruQYlHCQfHEMKAxb50YnXZYGHN9l/g4vFvEosGUsK3XOUbqGv7wIrscZVvoGnzp7hy5vtJr4OYfU2dJWtwlq3L3EGWGfSN8OWf/S3BaCjl+mTIgywknOaiJbPaaZ0Zt2CmQgFjNZ3Ue9YTyVyrIC9cbB/h8Dtd7LpdGy4PXaTzRGXTHgymIoau7CfoT8xyzbZyIqHJ1NC8aaEVQqJt15cocjel9GOd2bDMcKcXCKyOKkwWN5amPWnbtG57ks6T/04s6k/TQaq7xlHchGxIzRNc0/oQkmRi8PLryz8yryoppaEk2ZgS0rYc7O4GNt/5B0wMHsPv6UGSTRRXbl3wGi2XmSrbfRdexO/pARI3g7KaXdSseTit6ypXvNjxxgKBniGuKjQXN3BlogdP2LfqIjxWQiysoIV4hjdfauemWxs0UTVcF+k8UlpzE6U1NxEJTQIJV4l/qpsrp58iFBidbWcyu2jY8NG04lNavZP+S68kiu2mwVWxaUn3i7N0LZvv+m90nXmKiaGTzG5kzhN+Z8naBQKdaCaobrkXi62Myyf/bdGxpn9j2k1x7cgGE2V1t1DGLVnpz1HSyvpbfoNwcBwlFsFsK0GSsx9OtxRH+08t+vi5kQv8n0f+O984+hRHlmi7epir3g1gM1pRwoUXaAC/P8roiI/ySkehTdFFuhAki6jd1cDG238X38RlwsFxjGYHztK2jLO4hD/1c1w+8a/E52182YqqadzwsWXZIBtMNGx8nIC3n3BwfMHjQshUt96/aB/uik3IBivxZRRTyHeSoZVithY2djemxFMOqsy4A2Z8ozElzreP/fC6EejUkEIVSUj84s5Psu9AdvdSroVwKLZ0ozygi7QGEELgKGnFQevSjQFn6Ro23fFfGO07hH+yCyEbKa7YjLtyy4qqTRuMVtp2fYmus0/jGeuYvW61V1C37sNLuhGEJFO//iNcOf0fS7Yrrbl52XbdaPgifiLxyIKq3tP/QEVFFjIH+44XxsA8oKhKwv8uCeJxbbhzDEa50CYAukivWoxmB9Ut911zPyaLm7U7f4lwYJxQYASjyY7Nufxk8aU1O5kYOsHUyNkMLQRNmz41u/Gps5CvHv4u/mgg7WMzYh2/AVIKfPv40+wsepT4VOH9wABFjsKHA4IWPPQ6msBsK8FVtm5FAj1Dy9afo6x2NwiZ5BOVFnsl62/9LUqqt2fP0OuMUf847/edgLmsyzc0Xa5MN/v8IklCMyKtz6R1rhlJNtK46RNUtz6Id+ISAoGjZI0+e14GnZM9swc6hEgItTodhqmNRX9+mSjvpap7Y8FvWFp69XWR1skaJouL0uqdhTZjVWFOE0kihJg9Mn2jocgxFBFHVgsrTRaLduow6u4OHZ0CsrF8LU5zahWX1ZxM6VoRGnH7bNqunWPhq1KkVVUlGAwSjS52zFpHR/sYZAOf2PTB2Z9vZIGeQQtHsrVU0XxVuTtUVeXgwYMcPnyYcDiRy8BqtXLzzTdz8816iJfO6uSBNXchSxLfPv40gah2KoLkm5mcHs5SE96RwsYov/92F/c8vL6gNsywqmbSL7zwAgcOHJgVaIBgMMjPfvYzXnzxxQJapqNzbdzbcgcGoY243EIgEDjMdr646zPccsvaQptDKBjF79NGUqtVM5MeHh6mvX1h4c8Zzp49y65duygv1/bJNq0Qi8WQZRm/34/JZMJkyu9R6P7+fkZHRzGbzbS0tGA0amd5WQhG/eN4s3R0frVRU1TJE9seY0fVJkwGE29d6lj6l/JAwB/BXlT4MLxVI9InTpxYss2zzz7Lk08+mbcvfDwe58KFC3R0dBCNRqmsrGTr1q1YLBY6Ojrwer04nU7a2tpWZFMsFmNychJZlikuLs6avdFolMOHD3Pq1Cm8Xm/KY7Iss3v3bm6//fasjZeO8fFxXnjhBYaH547/ms1m7rjjDrZv357TsTWNSPhi1QJEdSSnDk3GarBkPGSTTfp9Q0TjMUzTJcgG+z05H3MpJEngdC0v9W2uWTUiPTo6umSbyclJfvzjH/P4448jSbn15ITDYZ5++mkGB+eqrnR1dXH48GGEEMTjcyfE9u/fz4MPPsjatYsv4xRF4d133+XkyZMEgwnfZFlZGbfffjtr1qy5JntjsRg/+tGP6OvrSysE8Xicd999F6/Xy0MPPXRNY81HURTOnDnDiRMnGB4eTokLhsRruW/fPsxmMxs2bMjq2KuFMlsJdc5qeqb68xajW2S0IYTAn8EPHogGkYSUl83Mbx39PrvrtmOSjZo4Fr5+axVmizbkcVX4pD0eD0NDi5dOmqG3t5dLly7l2CJ44403UgR6hng8TiwWSxHCcDjM888/n7Z9Mi+++CIHDx4kEAgkku2oKqOjozz33HOcP3/+muw9c+YMfX19S7Y7ffo0fn92lt2xWIyOjg6+853v8OqrrzI0NJTyusy/WRw6dGjZfQcCAQ4dOsQzzzzDCy+8wIULF1CU1R0Z8ZEND80eaEmHJKRrDk+b6b3Y4uJ/PvyH/Nl9v0tzcX1KG5fZwYbytXOJ+fMQEueN+Dk2XXTXXpT/LITzadu0sjS6uUQbt4olOHny5Iq+gOfPn19y1roS+vr6OHjwIGNjY1gsFjZt2pTWP77YUlVRFI4cOcIHPpA+OX1fX9+ifb711lu0tbVddXjSmTNnlrRxhvfee4/77ru2vCAXLlzgtddeIxBYfLmsqurscxobG2NqagqXa/Haft3d3Tz77LNEInNZANvb26mqquJjH/sYFsvC9KqrgTsbb8YT9vL90z8lFAvPvlc1jkqe2PoYgWgQk2zin9//N4JXUalFIDDJRm6t38knN3+QMlsi899XHvivXBy7Qq9nAIe5iG2VG/i7Q/8KkJKZL9dMhRJujlis8Dfbd9+4xNad+S08nIlVIdKdnZ3L9tXNxFAvhaIoxONxhBCMjo4ihKC8vHzWTRKLxRgbG+PIkSOcO3du9vc8Hk+KP3UldHd3z46Z7I7x+Xy8/vrriz6nqakpLl++TEtLC8FgkFAohMViYWhoiGg0SkVFBW63m2g0iizLSJI0K4CBQGCBD3oxJiYmFow//+YQDidEJJ0g9vb28txzz12Vf3XmZhyNRpEkiampKWRZnhXuUCjEc889lyLQMwwODvLyyy+zadMmDAYDdXV1GAyr4iM+y6Nt97K3+TYO953EF/FT76phc8W6lNd/3+W3OTmUZhN95vVOcyMXwMOOLWy2N9DSuI1Se2nK42tKm1hT2jT7c5O7joNdR3D6YggVvDaJmCG3M+p4r41vvfwOPZ0LU+fmm6F+D1MTQVzFhfdLi2xtVAgh9gN79uzZw/79+6+qD0VR6OrqwuPx4HA4aGpqQpIkvvWtbzE2NraivqqrqykpKSEcDlNUVMRtt92GzWbj7NmzHDhwAI9n4eaEEII1a9ZQUlKS4hfOFjPCKUkSDQ0NAPT09BCLLT8m1GAwEI/HUwRwZsPJYDDM9iVJEoqipFxbLtu3b2fLli28/vrrjIyMEI1GMZlMNDY20tDQwKlTp2ZvVDM3t3vvvZfa2sTM4+tf/zpTUyuvgWQ0GikrK2NkZCTFZiEExcXFGI1GxsbGlnw+M4JmtVq59dZb2bFjx4pt0TIdo5f5o9f/avZnW1BBUlV81iTv5ayrgtl0p9svRHAGEmXXmtdv44FPfRGTOSFCQb+XU+/to7vjFPFYDAwy/X2dGKb9w3EJhkpkLtUYIAfVShr7tuEcqEvYWniXNAAVVQ7u/9AG1qyvWLrxNbB3717efPNNgDdVVd07/3HNiHR3dzcvv/xyyozPbrdjsViWtWmoU3juvvtu1q1bx9e+9rWC2jF/1n/fffexbdu2AlmzkAsnD3HinVcZ7u3EYDDRuvkmdt79KMUV1cvu42/e+yYHut7H7Ymx8XKUmAHe32hGSXrqAjHrqrCFVHadT1p9CEHLxh088Mkvsv/H3+b8iXfTquP8KyNuifam7PqMrT43Ledunzd+/vzhmRCSQAj4xJM3sW5z7nzUS4m0JtaCo6Oj/OQnP1kwQ/L5fPh8q7v45o3Ez372sxWveHLBfPfMe++9x5YtW3Ie8bMc3nvlRxx58/nZn6PRMO3H3uHy2WN85Au/R3nN8oqf/sbuz1NTVEHPU08jAaYYtPTFuFRnmBXWGYGWFWjrmZdCQVW5fOYo3/yL3yESXv6KsXxSoSeo4rdmTzxt3uKM0+dMRWvzQWICK3j9hXbaNlUW7Li6JkT6yJEjCwS6EPGiOtfOzAZloUkWar/fz8DAwKw7plCMD/enCHQykXCQN5/9Do//yh8ueExVVXounOHku6/R39mBJMvUtW4gPNSPITb3PakZi2MLq/SWy3jsEragQt1IHJdPwZhhL24pgRYsnE2XT8XxW7MnHVFTOhtUKHCipdkN7RE/A71T1NS7C2KHJkS6s7Oz0CboXIckC3Vy3HqhaD96YNHHh3ouMz7cT0lFDUo8Tvuxd2g/eoDB7kso8dRJzMVT7wMLZcztU3D7shsdIQA1Sa2FAhbZRCi+zErxSxA3aD9RWihYuFwimhBpfdask0sMBgMVFbnd/FmKWDRCf2cH6kwoqUhzyk8Fz/gIY4O9vPXcvxPwFf7kHQBCIE3bqqLyibuewNpQy5++8ddZ6T79TLrwmfBmkCRBeWXR0g1zhCZEur6+no6OufP6umjrZJNNmzYVNHZ6uO8Kz3/7b/B7J+cuTh9Wmu9QeP7bf4OqsXSlsz5hAe6SSnbu3IskSZRY3YwHJ6+5/4g1wFjVFUoHm665r1ywfnMVDlfhPj+F30kBdu3aNbupowu0TjZpbW1lz549BRs/Eg7x03/9awK+qQwbYKmfd60JdCKpSOJfDncpH/jcb85+V3/5pieyNspgwzl6Wo8TcEyiSIV3TUFCi6pqnDzysc0FtUMTM+mqqioeffRRXn31VUKhUKHN0blOqK2t5bHHHiuoDR3H3yXonw4rFdN/rYKJiJBkNt+yF1QVRYlT07yONZtvRk46HHRu5GJWx/SUDuArG8Tsd9Jy+nYKXZz31rubuffR9RgMhU0hqwmRBmhra6O5uZl33nmHw4cPF9ocneuALVu2FNoEBrrmCdkqEOjKhlY++su/j8GQOXNjOBbh+fP7sj52k7ueeuM6xjSwyD91tI9b7mop+KnDwr8SSRiNRnbt2lVoM3SuEzZu3FhoE5CThG41uPKsRU4+8at/tKhAA/zvA18jTvbdEp/c9CGip5xZ7/dqCPijvPly4XNba0qkIXHKUE/cr3OtCCGyfqz/aqiobUJVlERUxyoQaUmaW9pHYhGO9p/m3Z4jDPlGZq9fmejh2ODp7I8tJMSIHa9XGxVRAM6c6CcWLayPXDPujmSs1sInNdFZ3cwkpbLZbAWzYXy4n/deebpg418NDnciM94LHfv40dkX8UXmshg6zUUYhAFPaPnJulbCTTVbUYLamjfGYgrhUAyDsXB+aU2K9FJ5l3V0lkO28mJfLe+9/DThUCCR7Ejjs+gZ60bs8I2jT/HyhTcXpCidDOU2bvtI/0kikgyqdnI522xGrLbClnbT1m1rmpVmbdPRSce1Fkq4FkIBH1fOnwQWJnzSEiqpQYAHRC8vXdiftxzSySiqwqn4McKmQEHGX4AK23fXo6gqPZ3jdF8eJ1oA14cmZ9KrYYNFR/sU0icdCvjnYp41+nmeb5XXJoiYCntDUVHpbzlJ/fldyIpMIU8eOt1m2k8P8u7+yyiKihBgtZm4+c4m7r5/LSIHKVvTocmZtBaylemsfqqqCrdstjvdGE1mVEVdFZMOFbhYV/iK7Soqfsc4lzceIGos7Abi1ESIsWE/ipJ4/1Q1UUH8Z69e4JVnz+bNDk2qoclU+BpnOquf1tbWgo1tNJmpblzLwvmq9lCBk61GfDZtyIGqqoStfgJFE0s3LgSqyuF3uvBM5melpo13ZR7FxcWFNkHnOqDQUUKjA90FHX8xZm4dQRO8v8GMx1HYU3WzJN3TTCF74exYBFUFRVVpP5WfAAdNivT8Gns6OlfD1ZTwyhZBnwe/Z7Jg42cieaMwMYM2ETZrZGMzSaAtPieWoKNwtiyDfG0iak6kx8bGNHEIQWf1MzIysnSjHNF1/lTBxs7EfMfLZJEgYtKcBAAgqRKK0FqyqSRUNW9FADT1DqmKSsgX1HTIks7qQAiB2Wwu2PhjQ70FGzsZlYVhdgARA3TUG7SUtjkJQcAxyXjlFW2E4qVBBapq83N8XRMheDF/hPF3e/CeGyYSiWBAIpqDvAA6Nw4zld8LRXH58ovK5gqPTTDslohLUDWu4AiqxCXorpDpLzckqq1ojjmjJsp7KBtsKaAti9N+apAdtzTkfJyCi3QsEKX3qVNEJxIuDhmJEhwMMVlYw3SujZkJUIGEoLm5uaAbhxZbYSp5VDevo6apjZ/1vs9x29zezlDpvIZaXK0KpmPKE7ZFLIGCFqJdilAoP4fuCi7Sk+/3zgq0jxCHOI9PTcoprc33RycT81enBRLrQsZIA5w78lbex1yzZTcPf+ZXAfjmMwchJLRQz/UqSBhtiJqQtOWRnUOFyur8bGwW/BXwnB0GQEHhIOfxq6HUz5Q2XVI6KyXP7+OJEycKVnxWVVW6L2Q/S1wmzFY7tz/yyVmBnghOzeXZWG0CLab/oOIerSuwMZmRZUHz2rK8jFXQmbSqqsSnq/AOMkFADWHDTBFWosSYwJdoV0gjdTCbzZSXl9Pbu/hmmFChmCLGp9+3+RhUmTpRCjVWugd7UJTc7d77/X7GxsYKVoA2nuP8M47iMh781Jew2otwl6WuGo4PnMnp2LlGIHDg0rQ/2uGy5i3AoaAiLYTA5LYQmQgypQbYTRvluJi5/QcIc5ZuBrlB4qYXuxvl4vMwf7zpMUwmE6qqYjabWbduHTt37sTpdNLV1cV7773H0NAQ0WgUIQQ2mw1ZlglNBbiN9TiwMYmPs/QQIYoFE2aMGJFpoxYLJpwllTg/8gEOHTrE8ePHc5ZQq1BRQkM9l3Pav8Fo4mNf/IPZtKLzuTKhjciSpZCEQFWZjeAQCOwmG2WT9Vja6zHEtHfyWIjEXxu25s+dVlCRjodjGFxmIuNB1jO3tJnRDhtmdrGG02oXZoz0MEqA6fP8Gb5/O3bsoKqqirNnz9Lf3080Gr1q+4QQKXkXzGoit0FYRCkrK8NutzM4OEgkEsFms9HY2EgwGKSnpwchBEIIIpHIomOYzWYsRgt+rw8ZiXJchIgwhZ84CkYMVFPMhC3IVGAuj+982wBsNht33XUXDoeD3t5eVFWlrKyMgYEBOjs7CQQChMPhzDeDaf/lBx58hJZ1CyMjGhsbaWxsBBLJi+LxOHa7Hf+lcQaebUdVFASCEhzcwYbU13LmDVMT0TxWq5XNmzdz5MiRRV+fq8XhcFBaOn+3LD/k1B8tBPF4jP4r51m3/ba0TUYD47kb/xqRxKw/A0iIniDxWf6NWz6PubeClw6c0dTyWQiRojcWi4Gb72jK2/gFE+l4OEbfU6cIjyzM+Ztc5F4g2EITKlBLGe/RnhDqNBsiQgg2bdpEZWXlbOmkAwcOcOjQoRUtrWdmYM3NzVRVVdF36BJN0XIcJBLIR80KtTvbKN5SjaqqxGIxjMaFyWm+//3v09PTs+hYzc3NbB6rIeJdPPexJBl5reh4So7k5JmiJEk8+eST2O2Jo7QzYgqwfv167rnnHgDeeukNDp0+OvuYERkViE2HPBpUGadn6RnMTOREdCrE4E/Pg5q6C7/YjrzJbUGNK1y6eHH2eWQ7CdHu3bsLlqjLN5W7ld/Mez7YdTGjSLss2ig/tVykuIx7pI5zzwQZG2zXlEAbjBLx+JxBZRVFPPbpbbhL8ldMomAiPXGwN0WgBSIlcH3+V1wAdszcxSZ6GKWfMSZVf0pDSZJwOFJ3XO+44w42b97MuXPnOH/+PKOjo8u2cceOHbjHTZTF4injmMMyo69cgrBC8a7atAIN0FTXtKRISwpEhpdOTq94o+x55G5efOWlVEFTE39tMDUSPjmGZbsJ2Zo5m9kaaungPHYstFKNc/rGM46XC/RRghPFs/zVx9TJQdT4ynzLnrMjTB4dYET0JS6IxYV6pSK+efNmtm3btiKbsomzOEcbSkk3ZTnDZw6gzKbd3DeKqiLNVE0HDBEzDe03YwkVMST8qIqGFBpoXVfOTbc14vOEKS6z0diS/9VZwUTac3powbX5Qj3/UVAxYqCFKlqoop1uxlUfk/hRBbRVNhO74mMq5iEWiBCdCKGEY0TGg5R6FHYqDbwj+fErwcyjCIEZI3fV70K8OcHIqD/jnX30zU78l8eRTBJGlwVDmY3YRIhYMIr/0jiuQAQ7ZvyE07pnBGA7v3x/bGt9Cx/72Mc4ePAgvT29gIoTO2uopjZYytg73XjOjVD7+CZ8F8bwnh0hOhVCGCTMlXbszSWEeqe4gw1ISClPqwQHt7IegGDvFDF/GIM99cSeGlfwnh/F1z5CPBLHVGLFf3lixTMfZTq+tBQnqNP+U1VgxEBcxFHmdSipAqdqR0ElQJioSP+aGQwG7r77bnbs2LEyg7LMmq27OfVe9itpJ6+cWjbuzNhub8vtfO/0s1kf/1qQhISqqqio00KdeC5VVzZiDhVp9pRxU2spa9YXZvN5hoKItBKNEw+mn63NLJNTZ9Vi9l/JirCBBlQgSoyIGqOoz8JQX+bqvhaM7GUz3YzQLvUSUWMYMWCQZKxuOy6Xi6qiciovGlG6Y0TUJWa4KgS7MyfxkZC4l20MMcFxtZMIc+IigCKsVJF+8ycdQy93ULm3hT3O7UyqVaioyKRmL4tOBLny9SMwb0YS8EUIXEosw+d+J7XNzOscGQnQ+Y/vY19bgrnUTswfQRglfB1jxH1zPvZQ77WVUypVHZTipEp1U0MpJozEVYV+xjhPHzFibKCBBsqRpm1TUBlUJzhDNzZM1FGOTZgoqnDTeu8mimq1MIvMwWwwScTq12yipqktY9MSq4vNFes4PVy4yjTJSCLhdhIiEbctCcHmyvUYI2bCU1WpB2tSv+IF53LHKLfcXdgok4KItGSUka3GjEINmX2a6WbbJgyYMCzrZJKERBOVNCmVKCiJYPl4Ytnlbqlj8lAvsUD2ko0LBJUUczd29nECIzINVFCBCxf2WfFZDsGuKXr+9djs80iLyrIrgSz1evkvjOO/kNtNqNumZ+8zGJCop5xK3EgkZtfJSAhqKKEK99xroIIYgoHvnaHktgZKb8/9Ud3FyEWOf0GiknfT+m3c8cgnM7Yb9Y/z3PnX6Jnqz74RV8H8z5gQAhX4zVt/gfHeMN/mvYWPa6hIwuWOEfy+MPaiwuWBKZi7w7mlkolD00vdFd49Uzeorp5koYt5w4y+dukaesuMQGDFxAPswDT9kmv1qGu+Sb9yAgum6SvpPxjzVxAzTcff7cZSVYS9ZfkrlGxTXtOAkCTULMaBO9ylxKIRLp89yuWzR6lrWc8tD3yMqoa5wgZ9nkH+9I3/gyecPk59xcwXywwuCWtIoXo0jsuvoAoYd8oMlMpEjSLtse4Sqxu7yUbInmkPQjsVx+KKysX2EbbtKtzBmoKdOCzeXYe5Iim/wXWuWYKEr1tM/6eTipj3X+La3N/z22ZEhcEXOlBihUlzqSoKJw68mr0Op4XRMzFKMDAnvr2X2/nJ1/8n/Vfm3HvfOvb93An0zLV5f4qnYuzsiFA7GqcoqOIIqDQOxtjZEcYWSrwHqqKk/GkJ2xjqukR5lYPqPGWSu2pUiBWg+GwyBRNp2Wyg7lObKb2zEWOxFckkYyjSXvC6TmFJRNUuFPDFUEIxBp87l3vj0vD289/j/X3PZm8WvciUMh6P8c6L3wdgxD/G6aEV+qDTiO7snwzYgyq7z4TZ2BmlbijGxisxpDRP1RSFdV1RmN4snPmv2BPHdOQiT3/1K7z61Fe5/0MbMBiSZEhVNTOLnqG+uXCrMijwYRbJZKDklnpKbqknNOhj8MXzZDhRrKOzIvyXJohMBDAV5y+e1Ts5xqmDbyR+yPaaPYOrYai3k8nRIcbxrWy/7WpsU1U2dEUxx8DsUShdYt+4KJiYVU84ZEwxlYrxOKUeZfY223HyIKXV9Tz5q7fxs1c6uNQxQg4zBVw1Lndhy7AVPMESQKBrkt7vnSQ6rldk0ckeE+/nd/Ps8tljqGpCZbLu0lpEVMNBP6XW4nmJyVSsQWWR2XHSvs68hwzxxJ/5FHtVrOGViXvjUJztFyNsvBKlLEmgZ+w59d4+auqcPPGF3dzzUJsm3Z6SXFijCp6qVFVVhl+9uOIDETo6SxHsncLfOYGpxIrRZcn5eLFI9qKC0qGq6oJ4Ylk24CqtwGIrYmvVBk4MnMXlibG2J0pMEhxdb0rugDkVTIikPaiw42KMiFHgN4EhpuAIJh6NGEFWoKdCZqhExh7K/nfUNzVOwO/F7nDR1zM1/fy04/JYs74co7GwRXoLLtLBnimiU6GlG+rorJDoeJD+H50BIbA3F1PxwJqc7ntU1jcn/ZQDlVHVBW6PtVt3zxYYuMvYQqf3JBuvRJEUMKNS4lEYdyYvmFPtcgRUJEXFElYxJ91jBGCZjpBtGYjTMhAnsgK1WO7cUwiB0Zh4TyRJzFzUTHjHnfetLbQJhRfpmG/xBEQ6OteMquK/PE7fD05T/9ltSKbczIxqWzZQUlHL+HBfTvqH1Nl0eXUDbdtv49DrzxCLRjjz7utsikVTNvLWdUVpbzIy4Ujv2SyfnGu8VCSsOemgZ7YktGHtZkyWhM+3bWMl504NJmyRhCaOiB/Yd5FnvucjEolTXedi951NeT+BWHCfdD6WoTo6AJHxAN5zuasgLoTgkc/++nTujtz4MU1mC5V1Ldz9oc9isdp59pv/i/f3PcvRn71INBJGVuby5gvAoMDmy1F2dERoHIhRPzSntMVeBbdveS6MdLl0lts2fSOBwWDi5vsem720cXs1ZUlhuUISKQsHs0XOe9WvC+eGmZwIEvBHuHR+hP/4l/d5+/WLebWh4CJtrXViKs3fDrzOjY3vwvITbF0N7rJKnvit/0Hr5l056T8SCjLYfZH3XvkR3ZfOLtl+RtOKgioNw3HqRuLICtSOxtnUGU0rvun+ZOp7OW2FkOZfoLKuhQ//4n+ism7ORWQwyHz2i7tpai1NaWuzm3j4o5v4/S8/gtWWObFUvnjjpfOMDHmXbpglCu7uAKh8eC19PzyDEo5p7uy+zvWFmodDLgajEWdJWU59q+FgIq/Mco5QJ28VCgVuORPGkK99eiGoaV7HQ5/+EvFYDJ9nHIutKGM1dafLyud+5VZGBr0M9E1hNhtoWTe3eSekPE+lM3D8UA8PfGhjXsbShEhbqhw0/Nx2Jo/24788TiwQRY0U9pSPzvWJJU/FQ0srazWXh0IABpX8ToJUlZaN27E5XAA4ipeX6rO8ykF51cL3qrzSgd87llUTFyOTe2VqIn/hwgV3d8xgdFsov7eFpi/sYs1v3oasgWWNzvWFMEi4tqWfwWWb1s03Y7UVLd3wOsdoMrN+551Z6691XXnW+loOiRDzhXc1Rx730jQj0vNxbc/Pl0nnOmf6+yUZZao+uA5kQaB7kvBwbo+2GoxGHvrMryEKVB1GK7hKKzFbs7fnFCtEThaVBZEm23fX5214Tbg70pHNDGI6NzACnJsqce+qYeztLvyX22f9xKYyO+X3NGNrcOdk6NrmdZRU1DI2uHh1nuuC+f736Rqfdmd283srilq48LzpOPXb9rRQWZ2/xFCavM1PvN/LxMHVUfFYR/sEuicZeLYd/6XxFCGJjPrp/9FZgn3XVrxgMQwGzc6DsooQAiFJc3+mnbnrtt+a1XFmylflJRRv3hhFTgsf+8wO7v/ghvTtc4TmRFqJxhl7p1uP8NDJGjFPmGiGjR41rjD+bnfOxvbmsCitVlgQYjdNTVMbrVuyG4rYvLY0kd40DyqduPHM/Vm/uZJNO2pyPu58NCfSvgtjqFHd1aGTPwLdU8RDy681uRLi8eUX9V2t3P+JL9C8YfusWFusdnbc+RAf/PxvI8vZXUkIIfjkL+yiutaZ93C8qlpXXsebQXNrscCV63/moZNHlrMiU9WcxU87XKWEA0tXg1+tbLv9AdbtuI11O24jHAwQDgWwO9zIOXTzOF1WvvDbd3Hx3DCvv3COof4cHSxJypVis5vYvKM2N+MsgeZm0prMVaizqpGsiwuG0WlBtucm5PPmez6Uk34LjdFs4eHP/Bp3fegzs9fMVhvO4rKcCnQyx9/vYXjQl3PPh8Vi4JM/vwtjjnK+LIXmZtKm0sIm2Na5/pCtRtRIPGNEgGtH9YIUoNmidcsumjZs58q54znpv1Cs3XYLa7bcXLDxh/o9s8mYcnWys765hHWbKtm+ux6rrXBVozQ3k3ZuqtCgVTqrmeh4EMlmQsgLP1jOzZW4b8rtZtAHn/wtKutacjpGvmnbektBx28/PTj771yd6vz453Zy297Wggo0aHAmbSgyU763hZF9lwttis51RNwXpmhdGeYyO5HxALLViGNDBZaq/JwKbN2yi6He6+MzbbJYqWvNbxjafOLTRUJUVc1ZJFjAH8HhLHyWTk3OWd07a6h4uPDJtnWuL/yXxnFtr6bq0XWU39OSN4EG2H7Hg0hSYSt8ZIv1N2XvmPfVUt80XRw2V6G62qk7oE2RBnBtrsS5tTIv+4jWBhfum2sxuMy5H0ynYKgxhZg3tyWuMiHJMnse+7mCjJ1VhKCpbWuhrWDNunLKyu256VyA02mholIbuVc0K9IAFfevoXhXLZJZXjyx7TTmqiIkm2HRBLjCJM32ZSxOJHWq/cRmyvc00/SFXdR/bjvWxtzGQ8pFJorWlyEsq3RmtZz4VAlsLcVLvmeldzVhqsjRl22GJBtkS+E8fJt27+WxL/wX3GVVBbPhmhCC4rIq6tduKrQlCEnw6Mc3Z6WfBX+E4JY9LUhp9jAKgeZ80skISVC2p5niW+sJD/rwto/gOTWU8YsvJEHzF29m4Jl2Ap0L461NZTbqPrU1cfY/piBZDSm7+kIILJVF1H1iC/FglIFn2wn2TF2F4dP/V8FS48DW6MZYbMVcbkfIEkaXeXYTK9g7Rd/TZ7J/gCf5NVrJsm2xfN4zfS4jb0LjL96E0WHmyr8cyTh7tTa4KbmlDu+54RUYuEKSXgdrgxuDo7Crpb5LZ/GMjyAkadXlp7E73Dz8mV/LWSTMSnGXLH1zt9qMqCqEw6mHlWx2E49+fDNvvHiesZG5OHZZSgj0bXu0s9GraZGeQTYbsDW6GXu3e9GZWWjAi/f8aOJATJp2kdEA4+92U35PCywR8yhbjRicV/mFni7KbCq3U/PRjcjWzDG41joX9qZifBeuIkdumudodFuJTl59rlthkDAWW4kMJx3AWKw0Rxokk4zBnoimqPnIBvqePks8kFrL0lRqo+qRxL6DwWkmMhpYhnHT/1/qHpHGLskkU3Z309Jj5JD2owc48uYLcxc0VHB1Kax2B0/89p9jseZ41bMCnG4LTpcFzyKFrDdur+bOe9dy5L0uOjtGEUKwZkM5O29tpMhhZv3mKi6dH2Gwz4PZbGD91ipNbBYmsypEepZlzOC8ZxevYec5O0zZnuZlHSldUU7rpBmosdSKe0cNzo0Vyyp66t5Vi+/S+LKe31IU31zL5NF+ImNJoreCajdqVElEQIwsckpuif4cGyqQpitpmCuKaPzFnXjPDhPs8YAkKGotoaitdHY1UdRWRuBydk6aFt9RjyRJTB0fJOYLIySBvaWEktsbMOfKh7lMjr/9SsrPWisKsBihgF9zNxQhBHc/uJaf/vBU2s+j0SRz1/1rcbqs3PvIengkfR9r1lfkvbjsSlhVIm2tcxEayHwE1FRsJeZbfGNICcVQQrFlCbBraxWT76+g8vO07pfe1oBj/fKTk1trnVQ+tJahVy/CYseTk+4rQhao8blPppAE7pvrcG2tAiEYfuVC+t9dzvdsCVeckCVcO6qZPLzwtTFXFFF6Z2PKNdlswL2jBneG5DSO9eWMvHZpeUezF7NfgK3Gha3RTfHuOuKBKJJRzll18JUQCYcYG1qY2XG1uD1UVaHjxEG23nZfoU1JYeetjXgmQ7y97yKKos6uYouKTDz++V04Xav/cNyqEmnXtiqmjg+gRNOX1nLvqsXXMUZ0PPNyXzLJiY3IZWAqtmKpdRJaKpVlinhKWOtXvvHo3FSBvbUE77kRwiN+IuOBxA1pRoiTN79sJuo+vZlgr5foeADJYsSxoQzj9DLNtaWSmCfExKHelFN2ktmAqcxGqHfx52N0WbA1uAl0T6Z93LWtivI9zdibi5k6PkBkLIhklnFsKMe5qXLFoigZJNw31TBxqHfl/vN5eM+NYGt0I4TAYC/sIYRkZFleVTPndAz1XAaNiTTA3ofXsfO2Bs4cHyAUjFJeUcT6rVUYDIW/OWeDVSXSRpeF6o9sYPC588RDc9nFkmeRkkkm0JV56ezYUJH25Fkmqh/bQM+3jxHzRdI3mCcUjk0VVy0OssWAe8dcRZrQoI+R1y8RGpxbPVjrXFTc34qp2IapOHPFi9I7GnFuqcR7boR4MIapxIpjfTnhYR+93zuV2QiRqDnp3lnD0EsXUnIwC1nCtbWSsj2JCs+2BnfWEuaX3t5AZDSA//J46gMzmrbMvap4ODfZ7K4V2WCkYe1mujoWvvarZTZtMGrnpjcfp8uqqc2+bLKqRBoSwtD0xV34zo8SGVs4iyxqK8N+fhT/xYUbccZiKyW3razsjcFmpOHJHUwc7sNzZph4IIJkNSJJgpg/SbiFwLG+PLEpmSUsVUXUf3Yb4VE/MV8Eo9OCqWT5yzej00LJLanP11rnwlxVRHgwTfkokVg92JoSM9GaxzYQmQgS7J1CSAJbU3HOZqdClqj+yAYCXZP42keIh+OYy2wJf3X3ZMJeSeBtH0msLjKItrkse6Wass2uez5E76VzxOMLbyR2pxtFUQj6cleA4Fpp3XRToU24IVl1Ig2JenXOzZVpHxOSoPpD65k6PsDUyUEi40EMNiOOjRUU76q9qgK3ss1I2d1NlN3dhKqqsyFIoUEvwZ4phCxhaynG5M6N/8tcZsdclr1Nr+oPb6D/6TNExlMjKgwOM9WPbUgJsTIVWzEV58evJ4TA3lSMvSm15FLyhp8QAs+ZofS/L0s4t2g3BrmqoZUPPPmb/OzZf2dybO45VDes4Z6P/QLO4lJe/M7fceX8yQJamZ4iV4km4qNvRFalSC+FkATunTW4d2Y/cU6ygFmqHFjSlJ3XOkanmYYnt+PtGE3Ek6uJU5eO9eWzURlapWxvM+FRP+Gh1JWAkCUqH16L8WrDJvNE/ZpNfOZ3vsxg9yWCPg+uskpKK+fyFH/w53+Ho2++wLG3XyYU8OXNDWK1O2jdvIuz7/8MRVFI9jMZzWYeeuJXNRMffaNxXYq0ztIIWcK5oQLnBu2GHqVDthio+/RWfB2j+M6PokTimCuLcG2rytuM/1oRQlDduCbj4zv3PMrarbdw9K0XuXT6CAHvZC6NwWg08ejnfpPqxjVsuOlOjh94hb7L55Ekiab129h2x4MUl2t3hXK9o4u0zqpDMkg4N1bg3Li6bjDL5cQ7r/HuSz9I+K5zHA1SUl7NfY//EpX1ib2UyvoWHvr0r+R0TJ2VoYu0jo6GuNJ+gref/4+5CzMuhhyJ9eZb750VaB1toou0jo6GOPbWSwuuJXzBAlVd2j9tslhp3bSLyvpmOs+doOv8iUXbjw7krlK6TnbQRVpHRyOoisLAlQvpHxQghITd4aZt+62MDvRgttqoaVpHyO8lFotQUdtE84YdSHJi83dybHhJkS5yFi/6uE7h0UVaR0criESqzEy1GCFxKOb2hz+xrO5aN+7keJqZeTLVTW0rMlEn/2gjYaqOjg5CCBrXbVu0TfOG7cvur7ppLWXVDRkfL66oKXgZLJ2l0UVaR0dD3LTnUWQ5/QLXbLGtOMHRIz/367hKKxIbkEl/HMVlPPpzv6HHPq8CdHeHjo6GqKxv4ZHP/gZvPvtveCfnUhsUT4fKOUuWn10RwFVSwRO/9ed0nDhI93TekPo1m2jbfitGk7YP/ugk0EVaR0djNK7bwuf+81/Se/kcfs8UrpJyqpuuvjCzwWhi46672LjrrixaqZMvdJHW0dEgQpKoX6PnytDRfdI6Ojo6mkYXaR0dHR0No4u0jo6OjoYR2SrnI4ToBWpdLhfbt2/PSp86Ojo61zvHjx9namoKoE9V1br5j2dTpCeBlRf309HR0dEBmFJV1T3/YjajOzqBZsAHXMxivzo6OjrXM2uAIhIauoCszaR1dHR0dLKPvnGoo6Ojo2F0kdbR0dHRMLpI6+jo6GgYXaR1dHR0NIwu0jo6OjoaRhdpHR0dHQ2ji7SOjo6OhtFFWkdHR0fD6CKto6Ojo2F0kdbR0dHRMLpI6+jo6GgYXaR1dHR0NIwu0jo6OjoaRhdpHR0dHQ2ji7SOjo6OhtFFWkdHR0fD/P/IvtmlE6m+LwAAAABJRU5ErkJggg==\n","text/plain":["