├── .gitignore
├── LICENSE
├── README.md
├── ckpt
└── .gitkeep
├── config.py
├── core
├── __init__.py
├── build.py
├── test_deblur.py
├── test_disp.py
├── test_stereodeblur.py
├── train_deblur.py
├── train_disp.py
└── train_stereodeblur.py
├── datasets
├── flyingthings3d.json
└── stereo_deblur_data.json
├── losses
├── __init__.py
└── multiscaleloss.py
├── models
├── DeblurNet.py
├── DispNet_Bi.py
├── StereoDeblurNet.py
├── VGG19.py
├── __init__.py
└── submodules.py
├── requirements.txt
├── runner.py
└── utils
├── __init__.py
├── data_loaders.py
├── data_transforms.py
├── imgio_gen.py
└── network_utils.py
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | env/
12 | build/
13 | develop-eggs/
14 | dist/
15 | downloads/
16 | eggs/
17 | .eggs/
18 | lib/
19 | lib64/
20 | parts/
21 | sdist/
22 | var/
23 | wheels/
24 | *.egg-info/
25 | .installed.cfg
26 | *.egg
27 |
28 | # PyInstaller
29 | # Usually these files are written by a python script from a template
30 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
31 | *.manifest
32 | *.spec
33 |
34 | # Installer logs
35 | pip-log.txt
36 | pip-delete-this-directory.txt
37 |
38 | # Unit test / coverage reports
39 | htmlcov/
40 | .tox/
41 | .coverage
42 | .coverage.*
43 | .cache
44 | nosetests.xml
45 | coverage.xml
46 | *.cover
47 | .hypothesis/
48 |
49 | # Translations
50 | *.mo
51 | *.pot
52 |
53 | # Django stuff:
54 | *.log
55 | local_settings.py
56 |
57 | # Flask stuff:
58 | instance/
59 | .webassets-cache
60 |
61 | # Scrapy stuff:
62 | .scrapy
63 |
64 | # Sphinx documentation
65 | docs/_build/
66 |
67 | # PyBuilder
68 | target/
69 |
70 | # Jupyter Notebook
71 | .ipynb_checkpoints
72 |
73 | # pyenv
74 | .python-version
75 |
76 | # celery beat schedule file
77 | celerybeat-schedule
78 |
79 | # SageMath parsed files
80 | *.sage.py
81 |
82 | # dotenv
83 | .env
84 |
85 | # virtualenv
86 | .venv
87 | venv/
88 | ENV/
89 |
90 | # Spyder project settings
91 | .spyderproject
92 | .spyproject
93 |
94 | # Rope project settings
95 | .ropeproject
96 |
97 | # mkdocs documentation
98 | /site
99 |
100 | # mypy
101 | .mypy_cache/
102 |
103 | # PyCharm
104 | .idea
105 |
106 | # Checkpoints
107 | ckpt/
108 |
109 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2018 Shangchen Zhou @ SenseTime
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # DAVANet
2 |
3 | Code repo for the paper "DAVANet: Stereo Deblurring with View Aggregation" (CVPR'19, Oral). [[Paper]](http://openaccess.thecvf.com/content_CVPR_2019/papers/Zhou_DAVANet_Stereo_Deblurring_With_View_Aggregation_CVPR_2019_paper.pdf) [[Project Page]](https://shangchenzhou.com/projects/davanet/)
4 |
5 |
6 | 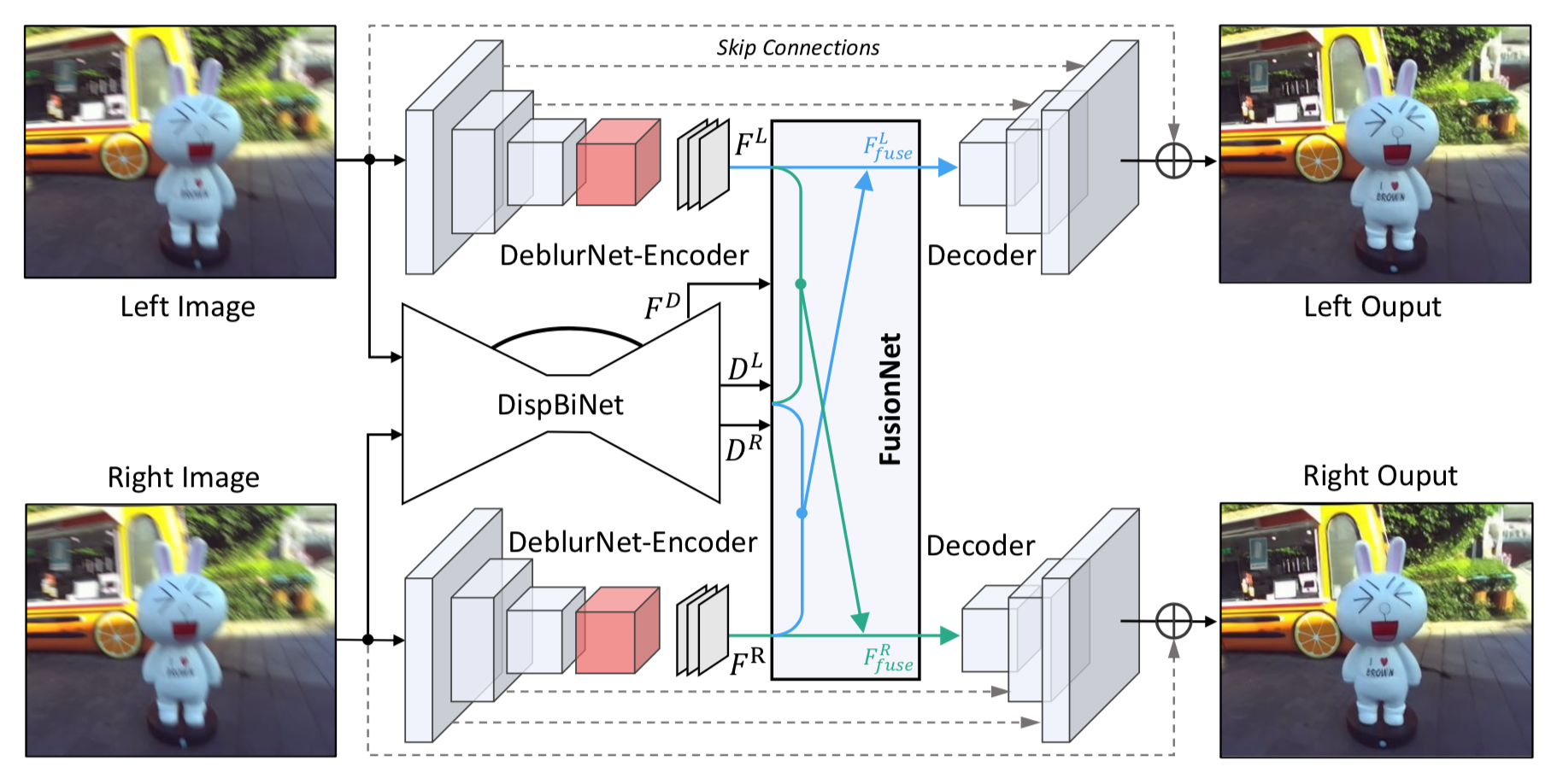 7 |
7 |
8 |
9 |
10 | ## Stereo Blur Dataset
11 |
12 |  13 |
13 |
14 |
15 | Download the dataset (192.5GB, unzipped 202.2GB) from [[Data Website]](https://stereoblur.shangchenzhou.com/).
16 |
17 | ## Pretrained Models
18 |
19 | You could download the pretrained model (34.8MB) of DAVANet from [[Here]](https://drive.google.com/file/d/1oVhKnPe_zrRa_JQUinW52ycJ2EGoAcHG/view?usp=sharing).
20 |
21 | (Note that the model does not need to unzip, just load it directly.)
22 |
23 | ## Prerequisites
24 |
25 | - Linux (tested on Ubuntu 14.04/16.04)
26 | - Python 2.7+
27 | - Pytorch 0.4.1
28 | - easydict
29 | - tensorboardX
30 | - pyexr
31 |
32 | #### Installation
33 |
34 | ```
35 | pip install -r requirements.txt
36 | ```
37 |
38 | ## Get Started
39 |
40 | Use the following command to train the neural network:
41 |
42 | ```
43 | python runner.py
44 | --phase 'train'\
45 | --data [dataset path]\
46 | --out [output path]
47 | ```
48 |
49 | Use the following command to test the neural network:
50 |
51 | ```
52 | python runner.py \
53 | --phase 'test'\
54 | --weights './ckpt/best-ckpt.pth.tar'\
55 | --data [dataset path]\
56 | --out [output path]
57 | ```
58 | Use the following command to resume training the neural network:
59 |
60 | ```
61 | python runner.py
62 | --phase 'resume'\
63 | --weights './ckpt/best-ckpt.pth.tar'\
64 | --data [dataset path]\
65 | --out [output path]
66 | ```
67 | You can also use the following simple command, with changing the settings in config.py:
68 |
69 | ```
70 | python runner.py
71 | ```
72 |
73 | ## Results on the testing dataset
74 |
75 |
76 |  77 |
77 |
78 |
79 | ## Citation
80 | If you find DAVANet, or Stereo Blur Dataset useful in your research, please consider citing:
81 |
82 | ```
83 | @inproceedings{zhou2019davanet,
84 | title={{DAVANet}: Stereo Deblurring with View Aggregation},
85 | author={Zhou, Shangchen and Zhang, Jiawei and Zuo, Wangmeng and Xie, Haozhe and Pan, Jinshan and Ren, Jimmy},
86 | booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
87 | year={2019}
88 | }
89 | ```
90 |
91 | ## Contact
92 |
93 | We are glad to hear if you have any suggestions and questions.
94 |
95 | Please send email to shangchenzhou@gmail.com
96 |
97 | ## Reference
98 | [1] Zhe Hu, Li Xu, and Ming-Hsuan Yang. Joint depth estimation and camera shake removal from single blurry image. In *CVPR*, 2014.
99 |
100 | [2] Seungjun Nah, Tae Hyun Kim, and Kyoung Mu Lee. Deep multi-scale convolutional neural network for dynamic scene deblurring. In *CVPR*, 2017.
101 |
102 | [3] Orest Kupyn, Volodymyr Budzan, Mykola Mykhailych, Dmytro Mishkin, and Jiri Matas. Deblurgan: Blind motion deblurring using conditional adversarial networks. In CVPR, 2018.
103 |
104 | [4] Jiawei Zhang, Jinshan Pan, Jimmy Ren, Yibing Song, Lin- chao Bao, Rynson WH Lau, and Ming-Hsuan Yang. Dynamic scene deblurring using spatially variant recurrent neural networks. In *CVPR*, 2018.
105 |
106 | [5] Xin Tao, Hongyun Gao, Xiaoyong Shen, Jue Wang, and Jiaya Jia. Scale-recurrent network for deep image deblurring. In *CVPR*, 2018.
107 |
108 | ## License
109 |
110 | This project is open sourced under MIT license.
111 |
--------------------------------------------------------------------------------
/ckpt/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sczhou/DAVANet/2bbe35ae01c0f1af718a1bc19272cda5ed3c320a/ckpt/.gitkeep
--------------------------------------------------------------------------------
/config.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | #
4 | # Developed by Shangchen Zhou
5 |
6 | from easydict import EasyDict as edict
7 | import socket
8 |
9 | __C = edict()
10 | cfg = __C
11 |
12 | #
13 | # Common
14 | #
15 | __C.CONST = edict()
16 | __C.CONST.DEVICE = 'all' # '0'
17 | __C.CONST.NUM_WORKER = 1 # number of data workers
18 | __C.CONST.WEIGHTS = '/data/code/StereodeblurNet-release/ckpt/best-ckpt.pth.tar'
19 | __C.CONST.TRAIN_BATCH_SIZE = 1
20 | __C.CONST.TEST_BATCH_SIZE = 1
21 |
22 |
23 | #
24 | # Dataset
25 | #
26 | __C.DATASET = edict()
27 | __C.DATASET.DATASET_NAME = 'StereoDeblur' # FlyingThings3D, StereoDeblur
28 | __C.DATASET.WITH_MASK = True
29 |
30 | if cfg.DATASET.DATASET_NAME == 'StereoDeblur':
31 | __C.DATASET.SPARSE = True
32 | else:
33 | __C.DATASET.SPARSE = False
34 |
35 | #
36 | # Directories
37 | #
38 | __C.DIR = edict()
39 | __C.DIR.OUT_PATH = '/data/code/StereodeblurNet/output'
40 |
41 | # For FlyingThings3D Dataset
42 | if cfg.DATASET.DATASET_NAME == 'FlyingThings3D':
43 | __C.DIR.DATASET_JSON_FILE_PATH = './datasets/flyingthings3d.json'
44 | __C.DIR.DATASET_ROOT = '/data/scene_flow/FlyingThings3D/'
45 | __C.DIR.IMAGE_LEFT_PATH = __C.DIR.DATASET_ROOT + '%s/%s/%s/%s/left/%s.png'
46 | __C.DIR.IMAGE_RIGHT_PATH = __C.DIR.DATASET_ROOT + '%s/%s/%s/%s/right/%s.png'
47 | __C.DIR.DISPARITY_LEFT_PATH = __C.DIR.DATASET_ROOT + 'disparity/%s/%s/%s/left/%s.pfm'
48 | __C.DIR.DISPARITY_RIGHT_PATH = __C.DIR.DATASET_ROOT + 'disparity/%s/%s/%s/right/%s.pfm'
49 |
50 | # For Stereo_Blur_Dataset
51 | elif cfg.DATASET.DATASET_NAME == 'StereoDeblur':
52 | __C.DIR.DATASET_JSON_FILE_PATH = './datasets/stereo_deblur_data.json'
53 | __C.DIR.DATASET_ROOT = '/data1/stereo_deblur_data_final_gamma/'
54 | __C.DIR.IMAGE_LEFT_BLUR_PATH = __C.DIR.DATASET_ROOT + '%s/image_left_blur_ga/%s.png'
55 | __C.DIR.IMAGE_LEFT_CLEAR_PATH = __C.DIR.DATASET_ROOT + '%s/image_left/%s.png'
56 | __C.DIR.IMAGE_RIGHT_BLUR_PATH = __C.DIR.DATASET_ROOT + '%s/image_right_blur_ga/%s.png'
57 | __C.DIR.IMAGE_RIGHT_CLEAR_PATH = __C.DIR.DATASET_ROOT + '%s/image_right/%s.png'
58 | __C.DIR.DISPARITY_LEFT_PATH = __C.DIR.DATASET_ROOT + '%s/disparity_left/%s.exr'
59 | __C.DIR.DISPARITY_RIGHT_PATH = __C.DIR.DATASET_ROOT + '%s/disparity_right/%s.exr'
60 |
61 | #
62 | # data augmentation
63 | #
64 | __C.DATA = edict()
65 | __C.DATA.STD = [255.0, 255.0, 255.0]
66 | __C.DATA.MEAN = [0.0, 0.0, 0.0]
67 | __C.DATA.DIV_DISP = 40.0 # 40.0 for disparity
68 | __C.DATA.CROP_IMG_SIZE = [256, 256] # Crop image size: height, width
69 | __C.DATA.GAUSSIAN = [0, 1e-4] # mu, std_var
70 | __C.DATA.COLOR_JITTER = [0.2, 0.15, 0.3, 0.1] # brightness, contrast, saturation, hue
71 |
72 | #
73 | # Network
74 | #
75 | __C.NETWORK = edict()
76 | __C.NETWORK.DISPNETARCH = 'DispNet_Bi' # available options: DispNet_Bi
77 | __C.NETWORK.DEBLURNETARCH = 'StereoDeblurNet' # available options: DeblurNet, StereoDeblurNet
78 | __C.NETWORK.LEAKY_VALUE = 0.1
79 | __C.NETWORK.BATCHNORM = False
80 | __C.NETWORK.PHASE = 'train' # available options: 'train', 'test', 'resume'
81 | __C.NETWORK.MODULE = 'all' # available options: 'dispnet', 'deblurnet', 'all'
82 | #
83 | # Training
84 | #
85 |
86 | __C.TRAIN = edict()
87 | __C.TRAIN.USE_PERCET_LOSS = True
88 | __C.TRAIN.NUM_EPOCHES = 400 # maximum number of epoches
89 | __C.TRAIN.BRIGHTNESS = .25
90 | __C.TRAIN.CONTRAST = .25
91 | __C.TRAIN.SATURATION = .25
92 | __C.TRAIN.HUE = .25
93 | __C.TRAIN.DISPNET_LEARNING_RATE = 1e-6
94 | __C.TRAIN.DEBLURNET_LEARNING_RATE = 1e-4
95 | __C.TRAIN.DISPNET_LR_MILESTONES = [100,200,300]
96 | __C.TRAIN.DEBLURNET_LR_MILESTONES = [80,160,240]
97 | __C.TRAIN.LEARNING_RATE_DECAY = 0.1 # Multiplicative factor of learning rate decay
98 | __C.TRAIN.MOMENTUM = 0.9
99 | __C.TRAIN.BETA = 0.999
100 | __C.TRAIN.BIAS_DECAY = 0.0 # regularization of bias, default: 0
101 | __C.TRAIN.WEIGHT_DECAY = 0.0 # regularization of weight, default: 0
102 | __C.TRAIN.PRINT_FREQ = 10
103 | __C.TRAIN.SAVE_FREQ = 5 # weights will be overwritten every save_freq epoch
104 |
105 | __C.LOSS = edict()
106 | __C.LOSS.MULTISCALE_WEIGHTS = [0.3, 0.3, 0.2, 0.1, 0.1]
107 |
108 | #
109 | # Testing options
110 | #
111 | __C.TEST = edict()
112 | __C.TEST.VISUALIZATION_NUM = 3
113 | __C.TEST.PRINT_FREQ = 5
114 | if __C.NETWORK.PHASE == 'test':
115 | __C.CONST.TEST_BATCH_SIZE = 1
116 |
--------------------------------------------------------------------------------
/core/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sczhou/DAVANet/2bbe35ae01c0f1af718a1bc19272cda5ed3c320a/core/__init__.py
--------------------------------------------------------------------------------
/core/build.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | #
4 | # Developed by Shangchen Zhou
5 |
6 | import os
7 | import sys
8 | import torch.backends.cudnn
9 | import torch.utils.data
10 |
11 | import utils.data_loaders
12 | import utils.data_transforms
13 | import utils.network_utils
14 | import models
15 | from models.DispNet_Bi import DispNet_Bi
16 | from models.DeblurNet import DeblurNet
17 | from models.StereoDeblurNet import StereoDeblurNet
18 |
19 | from datetime import datetime as dt
20 | from tensorboardX import SummaryWriter
21 | from core.train_disp import train_dispnet
22 | from core.test_disp import test_dispnet
23 | from core.train_deblur import train_deblurnet
24 | from core.test_deblur import test_deblurnet
25 | from core.train_stereodeblur import train_stereodeblurnet
26 | from core.test_stereodeblur import test_stereodeblurnet
27 | from losses.multiscaleloss import *
28 |
29 | def bulid_net(cfg):
30 |
31 | # Enable the inbuilt cudnn auto-tuner to find the best algorithm to use
32 | torch.backends.cudnn.benchmark = True
33 |
34 | # Set up data augmentation
35 | train_transforms = utils.data_transforms.Compose([
36 | utils.data_transforms.ColorJitter(cfg.DATA.COLOR_JITTER),
37 | utils.data_transforms.Normalize(mean=cfg.DATA.MEAN, std=cfg.DATA.STD, div_disp=cfg.DATA.DIV_DISP),
38 | utils.data_transforms.RandomCrop(cfg.DATA.CROP_IMG_SIZE),
39 | utils.data_transforms.RandomVerticalFlip(),
40 | utils.data_transforms.RandomColorChannel(),
41 | utils.data_transforms.RandomGaussianNoise(cfg.DATA.GAUSSIAN),
42 | utils.data_transforms.ToTensor(),
43 | ])
44 |
45 | test_transforms = utils.data_transforms.Compose([
46 | utils.data_transforms.Normalize(mean=cfg.DATA.MEAN, std=cfg.DATA.STD, div_disp=cfg.DATA.DIV_DISP),
47 | utils.data_transforms.ToTensor(),
48 | ])
49 |
50 | # Set up data loader
51 | dataset_loader = utils.data_loaders.DATASET_LOADER_MAPPING[cfg.DATASET.DATASET_NAME]()
52 | if cfg.NETWORK.PHASE in ['train', 'resume']:
53 | train_data_loader = torch.utils.data.DataLoader(
54 | dataset=dataset_loader.get_dataset(utils.data_loaders.DatasetType.TRAIN, train_transforms),
55 | batch_size=cfg.CONST.TRAIN_BATCH_SIZE,
56 | num_workers=cfg.CONST.NUM_WORKER, pin_memory=True, shuffle=True)
57 |
58 | test_data_loader = torch.utils.data.DataLoader(
59 | dataset=dataset_loader.get_dataset(utils.data_loaders.DatasetType.TEST, test_transforms),
60 | batch_size=cfg.CONST.TEST_BATCH_SIZE,
61 | num_workers=cfg.CONST.NUM_WORKER, pin_memory=True, shuffle=False)
62 |
63 | # Set up networks
64 | dispnet = models.__dict__[cfg.NETWORK.DISPNETARCH].__dict__[cfg.NETWORK.DISPNETARCH]()
65 | deblurnet = models.__dict__[cfg.NETWORK.DEBLURNETARCH].__dict__[cfg.NETWORK.DEBLURNETARCH]()
66 |
67 |
68 | print('[DEBUG] %s Parameters in %s: %d.' % (dt.now(), cfg.NETWORK.DISPNETARCH,
69 | utils.network_utils.count_parameters(dispnet)))
70 |
71 | print('[DEBUG] %s Parameters in %s: %d.' % (dt.now(), cfg.NETWORK.DEBLURNETARCH,
72 | utils.network_utils.count_parameters(deblurnet)))
73 |
74 | # Initialize weights of networks
75 | dispnet.apply(utils.network_utils.init_weights_kaiming)
76 | deblurnet.apply(utils.network_utils.init_weights_xavier)
77 | # Set up solver
78 | dispnet_solver = torch.optim.Adam(filter(lambda p: p.requires_grad, dispnet.parameters()), lr=cfg.TRAIN.DISPNET_LEARNING_RATE,
79 | betas=(cfg.TRAIN.MOMENTUM, cfg.TRAIN.BETA))
80 | deblurnet_solver = torch.optim.Adam(filter(lambda p: p.requires_grad, deblurnet.parameters()), lr=cfg.TRAIN.DEBLURNET_LEARNING_RATE,
81 | betas=(cfg.TRAIN.MOMENTUM, cfg.TRAIN.BETA))
82 |
83 | if torch.cuda.is_available():
84 | dispnet = torch.nn.DataParallel(dispnet).cuda()
85 | deblurnet = torch.nn.DataParallel(deblurnet).cuda()
86 |
87 | # Load pretrained model if exists
88 | init_epoch = 0
89 | Best_Epoch = -1
90 | Best_Disp_EPE = float('Inf')
91 | Best_Img_PSNR = 0
92 | if cfg.NETWORK.PHASE in ['test', 'resume']:
93 | print('[INFO] %s Recovering from %s ...' % (dt.now(), cfg.CONST.WEIGHTS))
94 | checkpoint = torch.load(cfg.CONST.WEIGHTS)
95 |
96 | if cfg.NETWORK.MODULE == 'dispnet':
97 | dispnet.load_state_dict(checkpoint['dispnet_state_dict'])
98 | init_epoch = checkpoint['epoch_idx']+1
99 | Best_Disp_EPE = checkpoint['Best_Disp_EPE']
100 | Best_Epoch = checkpoint['Best_Epoch']
101 | dispnet_solver.load_state_dict(checkpoint['dispnet_solver_state_dict'])
102 | print('[INFO] {0} Recover complete. Current epoch #{1}, Best_Disp_EPE = {2} at epoch #{3}.' \
103 | .format(dt.now(), init_epoch, Best_Disp_EPE, Best_Epoch))
104 | elif cfg.NETWORK.MODULE == 'deblurnet':
105 | deblurnet.load_state_dict(checkpoint['deblurnet_state_dict'])
106 | init_epoch = checkpoint['epoch_idx']+1
107 | Best_Img_PSNR = checkpoint['Best_Img_PSNR']
108 | Best_Epoch = checkpoint['Best_Epoch']
109 | deblurnet_solver.load_state_dict(checkpoint['deblurnet_solver_state_dict'])
110 | print('[INFO] {0} Recover complete. Current epoch #{1}, Best_Img_PSNR = {2} at epoch #{3}.' \
111 | .format(dt.now(), init_epoch, Best_Img_PSNR, Best_Epoch))
112 | init_epoch = 0
113 | elif cfg.NETWORK.MODULE == 'all':
114 | Best_Img_PSNR = checkpoint['Best_Img_PSNR']
115 | dispnet.load_state_dict(checkpoint['dispnet_state_dict'])
116 | deblurnet.load_state_dict(checkpoint['deblurnet_state_dict'])
117 | print('[INFO] {0} Recover complete. Best_Img_PSNR = {1}'.format(dt.now(), Best_Img_PSNR))
118 |
119 |
120 | # Set up learning rate scheduler to decay learning rates dynamically
121 | dispnet_lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(dispnet_solver,
122 | milestones=cfg.TRAIN.DISPNET_LR_MILESTONES,
123 | gamma=cfg.TRAIN.LEARNING_RATE_DECAY)
124 | deblurnet_lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(deblurnet_solver,
125 | milestones=cfg.TRAIN.DEBLURNET_LR_MILESTONES,
126 | gamma=cfg.TRAIN.LEARNING_RATE_DECAY)
127 |
128 | # Summary writer for TensorBoard
129 | if cfg.NETWORK.MODULE == 'dispnet':
130 | output_dir = os.path.join(cfg.DIR.OUT_PATH, dt.now().isoformat()+'_'+cfg.NETWORK.DISPNETARCH, '%s')
131 | elif cfg.NETWORK.MODULE == 'deblurnet':
132 | output_dir = os.path.join(cfg.DIR.OUT_PATH, dt.now().isoformat()+'_'+cfg.NETWORK.DEBLURNETARCH, '%s')
133 | elif cfg.NETWORK.MODULE == 'all':
134 | output_dir = os.path.join(cfg.DIR.OUT_PATH, dt.now().isoformat() + '_' + cfg.NETWORK.DEBLURNETARCH, '%s')
135 | log_dir = output_dir % 'logs'
136 | ckpt_dir = output_dir % 'checkpoints'
137 | train_writer = SummaryWriter(os.path.join(log_dir, 'train'))
138 | test_writer = SummaryWriter(os.path.join(log_dir, 'test'))
139 |
140 |
141 | if cfg.NETWORK.PHASE in ['train', 'resume']:
142 | # train and val
143 | if cfg.NETWORK.MODULE == 'dispnet':
144 | train_dispnet(cfg, init_epoch, train_data_loader, test_data_loader, dispnet, dispnet_solver,
145 | dispnet_lr_scheduler, ckpt_dir, train_writer, test_writer, Best_Disp_EPE, Best_Epoch)
146 | return
147 | elif cfg.NETWORK.MODULE == 'deblurnet':
148 | train_deblurnet(cfg, init_epoch, train_data_loader, test_data_loader, deblurnet, deblurnet_solver,
149 | deblurnet_lr_scheduler, ckpt_dir, train_writer, test_writer, Best_Img_PSNR, Best_Epoch)
150 | return
151 | elif cfg.NETWORK.MODULE == 'all':
152 | train_stereodeblurnet(cfg, init_epoch, train_data_loader, test_data_loader,
153 | dispnet, dispnet_solver, dispnet_lr_scheduler,
154 | deblurnet, deblurnet_solver, deblurnet_lr_scheduler,
155 | ckpt_dir, train_writer, test_writer,
156 | Best_Disp_EPE, Best_Img_PSNR, Best_Epoch)
157 |
158 | else:
159 | assert os.path.exists(cfg.CONST.WEIGHTS),'[FATAL] Please specify the file path of checkpoint!'
160 | if cfg.NETWORK.MODULE == 'dispnet':
161 | test_dispnet(cfg, init_epoch, test_data_loader, dispnet, test_writer)
162 | return
163 | elif cfg.NETWORK.MODULE == 'deblurnet':
164 | test_deblurnet(cfg, init_epoch, test_data_loader, deblurnet, test_writer)
165 | return
166 | elif cfg.NETWORK.MODULE == 'all':
167 | test_stereodeblurnet(cfg, init_epoch, test_data_loader, dispnet, deblurnet, test_writer)
168 |
--------------------------------------------------------------------------------
/core/test_deblur.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | #
4 | # Developed by Shangchen Zhou
5 | import os
6 | import sys
7 | import torch.backends.cudnn
8 | import torch.utils.data
9 | import numpy as np
10 | import utils.data_loaders
11 | import utils.data_transforms
12 | import utils.network_utils
13 | from losses.multiscaleloss import *
14 | from time import time
15 | import cv2
16 |
17 | def mkdir(path):
18 | if not os.path.isdir(path):
19 | mkdir(os.path.split(path)[0])
20 | else:
21 | return
22 | os.mkdir(path)
23 |
24 | def test_deblurnet(cfg, epoch_idx, test_data_loader, deblurnet, test_writer):
25 |
26 | # Testing loop
27 | n_batches = len(test_data_loader)
28 | test_epe = dict()
29 | # Batch average meterics
30 | batch_time = utils.network_utils.AverageMeter()
31 | data_time = utils.network_utils.AverageMeter()
32 | img_PSNRs = utils.network_utils.AverageMeter()
33 | batch_end_time = time()
34 |
35 | test_psnr = dict()
36 | g_names= 'init'
37 | save_num = 0
38 | for batch_idx, (names, images, DISPs, OCCs) in enumerate(test_data_loader):
39 | data_time.update(time() - batch_end_time)
40 | if not g_names == names:
41 | g_names = names
42 | save_num = 0
43 | save_num = save_num+1
44 | # Switch models to testing mode
45 | deblurnet.eval()
46 |
47 | if cfg.NETWORK.PHASE == 'test':
48 | assert (len(names) == 1)
49 | name = names[0]
50 | if not name in test_psnr:
51 | test_psnr[name] = {
52 | 'n_samples': 0,
53 | 'psnr': []
54 | }
55 |
56 | with torch.no_grad():
57 | # Get data from data loader
58 | imgs = [utils.network_utils.var_or_cuda(img) for img in images]
59 | img_blur_left, img_blur_right, img_clear_left, img_clear_right = imgs
60 |
61 | # Test the decoder
62 | output_img_clear_left = deblurnet(img_blur_left)
63 | output_img_clear_right = deblurnet(img_blur_right)
64 |
65 | # Append loss and accuracy to average metrics
66 | img_PSNR = PSNR(output_img_clear_left, img_clear_left) / 2 + PSNR(output_img_clear_right, img_clear_right) / 2
67 | img_PSNRs.update(img_PSNR.item(), cfg.CONST.TEST_BATCH_SIZE)
68 |
69 | if cfg.NETWORK.PHASE == 'test':
70 | test_psnr[name]['n_samples'] += 1
71 | test_psnr[name]['psnr'].append(img_PSNR)
72 |
73 | batch_time.update(time() - batch_end_time)
74 | batch_end_time = time()
75 |
76 | # Print result
77 | if (batch_idx+1) % cfg.TEST.PRINT_FREQ == 0:
78 | print('[TEST] [Epoch {0}/{1}][Batch {2}/{3}]\t BatchTime {4}\t DataTime {5}\t\t ImgPSNR {6}'
79 | .format(epoch_idx + 1, cfg.TRAIN.NUM_EPOCHES, batch_idx + 1, n_batches, batch_time, data_time, img_PSNRs))
80 |
81 | if batch_idx < cfg.TEST.VISUALIZATION_NUM:
82 | if epoch_idx == 0 or cfg.NETWORK.PHASE in ['test', 'resume']:
83 | test_writer.add_image('DeblurNet/IMG_BLUR_LEFT'+str(batch_idx+1),
84 | images[0][0][[2,1,0],:,:] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1), epoch_idx+1)
85 | test_writer.add_image('DeblurNet/IMG_BLUR_RIGHT'+str(batch_idx+1),
86 | images[1][0][[2,1,0],:,:] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1), epoch_idx+1)
87 | test_writer.add_image('DeblurNet/IMG_CLEAR_LEFT' + str(batch_idx + 1),
88 | images[2][0][[2,1,0],:,:] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1), epoch_idx + 1)
89 | test_writer.add_image('DeblurNet/IMG_CLEAR_RIGHT' + str(batch_idx + 1),
90 | images[3][0][[2,1,0],:,:] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1), epoch_idx + 1)
91 |
92 | test_writer.add_image('DeblurNet/OUT_IMG_CLEAR_LEFT'+str(batch_idx+1), output_img_clear_left[0][[2,1,0],:,:].cpu().clamp(0.0,1.0) + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1), epoch_idx+1)
93 | test_writer.add_image('DeblurNet/OUT_IMG_CLEAR_RIGHT'+str(batch_idx+1), output_img_clear_right[0][[2,1,0],:,:].cpu().clamp(0.0,1.0) + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1), epoch_idx+1)
94 |
95 | if cfg.NETWORK.PHASE == 'test':
96 | left_out_dir = os.path.join(cfg.DIR.OUT_PATH,'single',names[0],'left')
97 | right_out_dir = os.path.join(cfg.DIR.OUT_PATH,'single',names[0],'right')
98 | if not os.path.isdir(left_out_dir):
99 | mkdir(left_out_dir)
100 | if not os.path.isdir(right_out_dir):
101 | mkdir(right_out_dir)
102 | print(left_out_dir+'/'+str(save_num).zfill(4)+'.png')
103 | cv2.imwrite(left_out_dir+'/'+str(save_num).zfill(4)+'.png', (output_img_clear_left.clamp(0.0, 1.0)[0].cpu().numpy().transpose(1, 2, 0) * 255.0).astype(np.uint8),
104 | [int(cv2.IMWRITE_PNG_COMPRESSION), 5])
105 |
106 | cv2.imwrite(right_out_dir + '/' + str(save_num).zfill(4) + '.png',
107 | (output_img_clear_right.clamp(0.0, 1.0)[0].cpu().numpy().transpose(1, 2, 0) * 255.0).astype(np.uint8),[int(cv2.IMWRITE_PNG_COMPRESSION), 5])
108 |
109 | if cfg.NETWORK.PHASE == 'test':
110 |
111 | # Output test results
112 | print('============================ TEST RESULTS ============================')
113 | print('[TEST] Total_Mean_PSNR:' + str(img_PSNRs.avg))
114 | for name in test_psnr:
115 | test_psnr[name]['psnr'] = np.mean(test_psnr[name]['psnr'], axis=0)
116 | print('[TEST] Name: {0}\t Num: {1}\t Mean_PSNR: {2}'.format(name, test_psnr[name]['n_samples'],
117 | test_psnr[name]['psnr']))
118 |
119 | result_file = open(os.path.join(cfg.DIR.OUT_PATH, 'test_result.txt'), 'w')
120 | sys.stdout = result_file
121 | print('============================ TEST RESULTS ============================')
122 | print('[TEST] Total_Mean_PSNR:' + str(img_PSNRs.avg))
123 | for name in test_psnr:
124 | print('[TEST] Name: {0}\t Num: {1}\t Mean_PSNR: {2}'.format(name, test_psnr[name]['n_samples'],
125 | test_psnr[name]['psnr']))
126 | result_file.close()
127 | else:
128 | # Output val results
129 | print('============================ TEST RESULTS ============================')
130 | print('[TEST] Total_Mean_PSNR:' + str(img_PSNRs.avg))
131 | print('[TEST] [Epoch{0}]\t BatchTime_avg {1}\t DataTime_avg {2}\t ImgPSNR_avg {3}\n'
132 | .format(cfg.TRAIN.NUM_EPOCHES, batch_time.avg, data_time.avg, img_PSNRs.avg))
133 |
134 | # Add testing results to TensorBoard
135 | test_writer.add_scalar('DeblurNet/EpochPSNR_1_TEST', img_PSNRs.avg, epoch_idx + 1)
136 |
137 | return img_PSNRs.avg
--------------------------------------------------------------------------------
/core/test_disp.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | #
4 | # Developed by Shangchen Zhou
5 |
6 | import torch.backends.cudnn
7 | import torch.utils.data
8 |
9 | import utils.data_loaders
10 | import utils.data_transforms
11 | import utils.network_utils
12 | from losses.multiscaleloss import *
13 | import torchvision
14 |
15 | from time import time
16 |
17 | def test_dispnet(cfg, epoch_idx, test_data_loader, dispnet, test_writer):
18 |
19 | # Testing loop
20 | n_batches = len(test_data_loader)
21 | test_epe = dict()
22 | # Batch average meterics
23 | batch_time = utils.network_utils.AverageMeter()
24 | data_time = utils.network_utils.AverageMeter()
25 | disp_EPEs = utils.network_utils.AverageMeter()
26 | test_time = utils.network_utils.AverageMeter()
27 |
28 | batch_end_time = time()
29 | for batch_idx, (_, images, disps, occs) in enumerate(test_data_loader):
30 | data_time.update(time() - batch_end_time)
31 |
32 | # Switch models to testing mode
33 | dispnet.eval();
34 |
35 | with torch.no_grad():
36 | # Get data from data loader
37 | disparities = disps
38 | imgs = [utils.network_utils.var_or_cuda(img) for img in images]
39 | imgs = torch.cat(imgs, 1)
40 | ground_truth_disps = [utils.network_utils.var_or_cuda(disp) for disp in disparities]
41 | ground_truth_disps = torch.cat(ground_truth_disps, 1)
42 | occs = [utils.network_utils.var_or_cuda(occ) for occ in occs]
43 | occs = torch.cat(occs, 1)
44 |
45 | # Test the decoder
46 | torch.cuda.synchronize()
47 | test_time_start = time()
48 | output_disps = dispnet(imgs)
49 | torch.cuda.synchronize()
50 | test_time.update(time() - test_time_start)
51 | print('[TIME] {0}'.format(test_time))
52 |
53 | disp_EPE = cfg.DATA.DIV_DISP * realEPE(output_disps, ground_truth_disps, occs)
54 |
55 | # Append loss and accuracy to average metrics
56 | disp_EPEs.update(disp_EPE.item(), cfg.CONST.TEST_BATCH_SIZE)
57 |
58 | batch_time.update(time() - batch_end_time)
59 | batch_end_time = time()
60 |
61 | # Print result
62 | if (batch_idx+1) % cfg.TEST.PRINT_FREQ == 0:
63 | print('[TEST] [Epoch {0}/{1}][Batch {2}/{3}]\t BatchTime {4}\t DataTime {5}\t\t DispEPE {6}'
64 | .format(epoch_idx + 1, cfg.TRAIN.NUM_EPOCHES, batch_idx + 1, n_batches, batch_time, data_time, disp_EPEs))
65 |
66 | if batch_idx < cfg.TEST.VISUALIZATION_NUM:
67 |
68 | if epoch_idx == 0 or cfg.NETWORK.PHASE in ['test', 'resume']:
69 | test_writer.add_image('DispNet/IMG_LEFT'+str(batch_idx+1),
70 | images[0][0][[2,1,0],:,:] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1), epoch_idx+1)
71 | test_writer.add_image('DispNet/IMG_RIGHT'+str(batch_idx+1),
72 | images[1][0][[2,1,0],:,:] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1), epoch_idx+1)
73 |
74 | gt_disp_left, gt_disp_right = utils.network_utils.graybi2rgb(ground_truth_disps[0])
75 | test_writer.add_image('DispNet/DISP_GT_LEFT' +str(batch_idx + 1), gt_disp_left, epoch_idx + 1)
76 | test_writer.add_image('DispNet/DISP_GT_RIGHT'+str(batch_idx+1), gt_disp_right, epoch_idx+1)
77 |
78 | b, _, h, w = imgs.size()
79 | output_disps_up = torch.nn.functional.interpolate(output_disps, size=(h, w), mode = 'bilinear', align_corners=True)
80 | output_disp_up_left, output_disp_up_right = utils.network_utils.graybi2rgb(output_disps_up[0])
81 | test_writer.add_image('DispNet/DISP_OUT_LEFT_'+str(batch_idx+1), output_disp_up_left, epoch_idx+1)
82 | test_writer.add_image('DispNet/DISP_OUT_RIGHT_'+str(batch_idx+1), output_disp_up_right, epoch_idx+1)
83 |
84 |
85 |
86 | # Output testing results
87 | print('============================ TEST RESULTS ============================')
88 | print('[TEST] [Epoch{0}]\t BatchTime_avg {1}\t DataTime_avg {2}\t DispEPE_avg {3}\n'
89 | .format(cfg.TRAIN.NUM_EPOCHES, batch_time.avg, data_time.avg, disp_EPEs.avg))
90 |
91 | # Add testing results to TensorBoard
92 | test_writer.add_scalar('DispNet/EpochEPE_1_TEST', disp_EPEs.avg, epoch_idx+1)
93 | return disp_EPEs.avg
94 |
--------------------------------------------------------------------------------
/core/test_stereodeblur.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | #
4 | # Developed by Shangchen Zhou
5 |
6 | import torch.backends.cudnn
7 | import torch.utils.data
8 |
9 | import utils.data_loaders
10 | import utils.data_transforms
11 | import utils.network_utils
12 | from losses.multiscaleloss import *
13 | import torchvision
14 |
15 | from time import time
16 |
17 | def mkdir(path):
18 | if not os.path.isdir(path):
19 | mkdir(os.path.split(path)[0])
20 | else:
21 | return
22 | os.mkdir(path)
23 |
24 | def test_stereodeblurnet(cfg, epoch_idx, test_data_loader, dispnet, deblurnet, test_writer):
25 |
26 | # Testing loop
27 | n_batches = len(test_data_loader)
28 | # Batch average meterics
29 | batch_time = utils.network_utils.AverageMeter()
30 | test_time = utils.network_utils.AverageMeter()
31 | data_time = utils.network_utils.AverageMeter()
32 | disp_EPEs = utils.network_utils.AverageMeter()
33 | img_PSNRs = utils.network_utils.AverageMeter()
34 | batch_end_time = time()
35 | test_psnr = dict()
36 | g_names= 'init'
37 | save_num = 0
38 |
39 | for batch_idx, (names, images, disps, occs) in enumerate(test_data_loader):
40 | data_time.update(time() - batch_end_time)
41 | if not g_names == names:
42 | g_names = names
43 | save_num = 0
44 | save_num = save_num+1
45 | # Switch models to testing mode
46 | dispnet.eval()
47 | deblurnet.eval()
48 | if cfg.NETWORK.PHASE == 'test':
49 | assert (len(names) == 1)
50 | name = names[0]
51 | if not name in test_psnr:
52 | test_psnr[name] = {
53 | 'n_samples': 0,
54 | 'psnr': []
55 | }
56 |
57 | with torch.no_grad():
58 | # Get data from data loader
59 | disparities = disps
60 | imgs = [utils.network_utils.var_or_cuda(img) for img in images]
61 | img_blur_left, img_blur_right, img_clear_left, img_clear_right = imgs
62 | imgs_blur = torch.cat([img_blur_left, img_blur_right], 1)
63 |
64 | ground_truth_disps = [utils.network_utils.var_or_cuda(disp) for disp in disparities]
65 | ground_truth_disps = torch.cat(ground_truth_disps, 1)
66 | occs = [utils.network_utils.var_or_cuda(occ) for occ in occs]
67 | occs = torch.cat(occs, 1)
68 |
69 | # Test the dispnet
70 | # torch.cuda.synchronize()
71 | # test_time_start = time()
72 |
73 | output_disps = dispnet(imgs_blur)
74 |
75 | output_disp_feature = output_disps[1]
76 | output_disps = output_disps[0]
77 |
78 | # Test the deblurnet
79 | imgs_prd, output_diffs, output_masks= deblurnet(imgs_blur, output_disps, output_disp_feature)
80 |
81 | # torch.cuda.synchronize()
82 | # test_time.update(time() - test_time_start)
83 | # print('[TIME] {0}'.format(test_time))
84 | disp_EPE = cfg.DATA.DIV_DISP * realEPE(output_disps, ground_truth_disps, occs)
85 | disp_EPEs.update(disp_EPE.item(), cfg.CONST.TEST_BATCH_SIZE)
86 |
87 | img_PSNR = (PSNR(imgs_prd[0], img_clear_left) + PSNR(imgs_prd[1], img_clear_right)) / 2
88 | img_PSNRs.update(img_PSNR.item(), cfg.CONST.TRAIN_BATCH_SIZE)
89 |
90 | if cfg.NETWORK.PHASE == 'test':
91 | test_psnr[name]['n_samples'] += 1
92 | test_psnr[name]['psnr'].append(img_PSNR)
93 |
94 | batch_time.update(time() - batch_end_time)
95 | batch_end_time = time()
96 |
97 | # Print result
98 | if (batch_idx+1) % cfg.TEST.PRINT_FREQ == 0:
99 | print('[TEST] [Epoch {0}/{1}][Batch {2}/{3}]\t BatchTime {4}\t DataTime {5}\t DispEPE {6}\t imgPSNR {7}'
100 | .format(epoch_idx + 1, cfg.TRAIN.NUM_EPOCHES, batch_idx + 1, n_batches, batch_time, data_time, disp_EPEs, img_PSNRs))
101 |
102 | if batch_idx < cfg.TEST.VISUALIZATION_NUM and cfg.NETWORK.PHASE in ['train', 'resume']:
103 |
104 |
105 | if epoch_idx == 0 or cfg.NETWORK.PHASE in ['test', 'resume']:
106 | img_blur_left = images[0][0][[2, 1, 0], :, :] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
107 | img_blur_right = images[1][0][[2, 1, 0], :, :] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
108 | img_clear_left = images[2][0][[2, 1, 0], :, :] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
109 | img_clear_right = images[3][0][[2, 1, 0], :, :] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
110 | test_writer.add_image('StereoDeblurNet/IMG_BLUR' + str(batch_idx + 1),
111 | torch.cat([img_blur_left, img_blur_right], 2), epoch_idx + 1)
112 |
113 | test_writer.add_image('StereoDeblurNet/IMG_CLEAR' + str(batch_idx + 1),
114 | torch.cat([img_clear_left, img_clear_right], 2), epoch_idx + 1)
115 |
116 | gt_disp_left, gt_disp_right = utils.network_utils.graybi2rgb(ground_truth_disps[0])
117 | test_writer.add_image('StereoDeblurNet/DISP_GT' +str(batch_idx + 1),
118 | torch.cat([gt_disp_left, gt_disp_right], 2), epoch_idx + 1)
119 |
120 | b, _, h, w = imgs[0].size()
121 | diff_out_left, diff_out_right = utils.network_utils.graybi2rgb(torch.cat(output_diffs, 1)[0])
122 | output_masks = torch.nn.functional.interpolate(torch.cat(output_masks, 1), size=(h, w), mode='bilinear', align_corners=True)
123 | mask_out_left, mask_out_right = utils.network_utils.graybi2rgb(output_masks[0])
124 | disp_out_left, disp_out_right = utils.network_utils.graybi2rgb(output_disps[0])
125 | img_out_left = imgs_prd[0][0][[2, 1, 0], :, :].cpu().clamp(0.0, 1.0) + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
126 | img_out_right = imgs_prd[1][0][[2, 1, 0], :, :].cpu().clamp(0.0, 1.0) + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
127 | test_writer.add_image('StereoDeblurNet/IMG_OUT' + str(batch_idx + 1), torch.cat([img_out_left, img_out_right], 2), epoch_idx + 1)
128 | test_writer.add_image('StereoDeblurNet/DISP_OUT'+str(batch_idx+1), torch.cat([disp_out_left, disp_out_right], 2), epoch_idx+1)
129 | test_writer.add_image('StereoDeblurNet/DIFF_OUT'+str(batch_idx+1), torch.cat([diff_out_left, diff_out_right], 2), epoch_idx+1)
130 | test_writer.add_image('StereoDeblurNet/MAST_OUT'+str(batch_idx+1), torch.cat([mask_out_left, mask_out_right], 2), epoch_idx+1)
131 | if cfg.NETWORK.PHASE == 'test':
132 | img_left_dir = os.path.join(cfg.DIR.OUT_PATH,'stereo',names[0],'left')
133 | img_right_dir = os.path.join(cfg.DIR.OUT_PATH,'stereo',names[0],'right')
134 |
135 | if not os.path.isdir(img_left_dir):
136 | mkdir(img_left_dir)
137 | if not os.path.isdir(img_right_dir):
138 | mkdir(img_right_dir)
139 |
140 | print(img_left_dir + '/' + str(save_num).zfill(4) + '.png')
141 | cv2.imwrite(img_left_dir + '/' + str(save_num).zfill(4) + '.png',
142 | (imgs_prd[0].clamp(0.0, 1.0)[0].cpu().numpy().transpose(1, 2, 0) * 255.0).astype(
143 | np.uint8),
144 | [int(cv2.IMWRITE_PNG_COMPRESSION), 5])
145 |
146 | print(img_right_dir + '/' + str(save_num).zfill(4) + '.png')
147 | cv2.imwrite(img_right_dir + '/' + str(save_num).zfill(4) + '.png',
148 | (imgs_prd[1].clamp(0.0, 1.0)[0].cpu().numpy().transpose(1, 2, 0) * 255.0).astype(
149 | np.uint8), [int(cv2.IMWRITE_PNG_COMPRESSION), 5])
150 |
151 | # Output testing results
152 |
153 | if cfg.NETWORK.PHASE == 'test':
154 | # Output test results
155 | print('============================ TEST RESULTS ============================')
156 | print('[TEST] Total_Mean_PSNR:' + str(img_PSNRs.avg))
157 | for name in test_psnr:
158 | test_psnr[name]['psnr'] = np.mean(test_psnr[name]['psnr'], axis=0)
159 | print('[TEST] Name: {0}\t Num: {1}\t Mean_PSNR: {2}'.format(name, test_psnr[name]['n_samples'],
160 | test_psnr[name]['psnr']))
161 |
162 | result_file = open(os.path.join(cfg.DIR.OUT_PATH, 'test_result.txt'), 'w')
163 | sys.stdout = result_file
164 | print('============================ TEST RESULTS ============================')
165 | print('[TEST] Total_Mean_PSNR:' + str(img_PSNRs.avg))
166 | for name in test_psnr:
167 | print('[TEST] Name: {0}\t Num: {1}\t Mean_PSNR: {2}'.format(name, test_psnr[name]['n_samples'],
168 | test_psnr[name]['psnr']))
169 | result_file.close()
170 | else:
171 | # Output val results
172 | print('============================ TEST RESULTS ============================')
173 | print('[TEST] Total_Mean_PSNR:' + str(img_PSNRs.avg))
174 | print('[TEST] [Epoch{0}]\t BatchTime_avg {1}\t DataTime_avg {2}\t DispEPE_avg {3}\t ImgPSNR_avg {4}\n'
175 | .format(cfg.TRAIN.NUM_EPOCHES, batch_time.avg, data_time.avg, disp_EPEs.avg, img_PSNRs.avg))
176 |
177 | # Add testing results to TensorBoard
178 | test_writer.add_scalar('StereoDeblurNet/EpochEPE_1_TEST', disp_EPEs.avg, epoch_idx + 1)
179 | test_writer.add_scalar('StereoDeblurNet/EpochPSNR_1_TEST', img_PSNRs.avg, epoch_idx + 1)
180 |
181 | return disp_EPEs.avg, img_PSNRs.avg
--------------------------------------------------------------------------------
/core/train_deblur.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | #
4 | # Developed by Shangchen Zhou
5 |
6 | import os
7 | import torch.backends.cudnn
8 | import torch.utils.data
9 |
10 | import utils.data_loaders
11 | import utils.data_transforms
12 | import utils.network_utils
13 | import torchvision
14 |
15 | from losses.multiscaleloss import *
16 | from time import time
17 |
18 | from core.test_deblur import test_deblurnet
19 | from models.VGG19 import VGG19
20 |
21 |
22 | def train_deblurnet(cfg, init_epoch, train_data_loader, val_data_loader, deblurnet, deblurnet_solver,
23 | deblurnet_lr_scheduler, ckpt_dir, train_writer, val_writer, Best_Img_PSNR, Best_Epoch):
24 | # Training loop
25 | for epoch_idx in range(init_epoch, cfg.TRAIN.NUM_EPOCHES):
26 | # Tick / tock
27 | epoch_start_time = time()
28 |
29 | # Batch average meterics
30 | batch_time = utils.network_utils.AverageMeter()
31 | data_time = utils.network_utils.AverageMeter()
32 | test_time = utils.network_utils.AverageMeter()
33 | deblur_losses = utils.network_utils.AverageMeter()
34 | mse_losses = utils.network_utils.AverageMeter()
35 | if cfg.TRAIN.USE_PERCET_LOSS:
36 | percept_losses = utils.network_utils.AverageMeter()
37 | img_PSNRs = utils.network_utils.AverageMeter()
38 |
39 | # Adjust learning rate
40 | deblurnet_lr_scheduler.step()
41 |
42 | batch_end_time = time()
43 | n_batches = len(train_data_loader)
44 | if cfg.TRAIN.USE_PERCET_LOSS:
45 | vggnet = VGG19()
46 | if torch.cuda.is_available():
47 | vggnet = torch.nn.DataParallel(vggnet).cuda()
48 |
49 | for batch_idx, (_, images, DISPs, OCCs) in enumerate(train_data_loader):
50 | # Measure data time
51 |
52 | data_time.update(time() - batch_end_time)
53 | # Get data from data loader
54 | imgs = [utils.network_utils.var_or_cuda(img) for img in images]
55 | img_blur_left, img_blur_right, img_clear_left, img_clear_right = imgs
56 |
57 | # switch models to training mode
58 | deblurnet.train()
59 |
60 | output_img_clear_left = deblurnet(img_blur_left)
61 |
62 | mse_left_loss = mseLoss(output_img_clear_left, img_clear_left)
63 | if cfg.TRAIN.USE_PERCET_LOSS:
64 | percept_left_loss = perceptualLoss(output_img_clear_left, img_clear_left, vggnet)
65 | deblur_left_loss = mse_left_loss + 0.01 * percept_left_loss
66 | else:
67 | deblur_left_loss = mse_left_loss
68 |
69 | img_PSNR_left = PSNR(output_img_clear_left, img_clear_left)
70 |
71 | # Gradient decent
72 | deblurnet_solver.zero_grad()
73 | deblur_left_loss.backward()
74 |
75 | # For right
76 | output_img_clear_right = deblurnet(img_blur_right)
77 | mse_right_loss = mseLoss(output_img_clear_right, img_clear_right)
78 | if cfg.TRAIN.USE_PERCET_LOSS:
79 | percept_right_loss = perceptualLoss(output_img_clear_right, img_clear_right, vggnet)
80 | deblur_right_loss = mse_right_loss + 0.01 * percept_right_loss
81 | else:
82 | deblur_right_loss = mse_right_loss
83 |
84 | img_PSNR_right = PSNR(output_img_clear_right, img_clear_right)
85 |
86 | # Gradient decent
87 | deblurnet_solver.zero_grad()
88 | deblur_right_loss.backward()
89 | deblurnet_solver.step()
90 |
91 | mse_loss = (mse_left_loss + mse_right_loss) / 2
92 | mse_losses.update(mse_loss.item(), cfg.CONST.TRAIN_BATCH_SIZE)
93 | if cfg.TRAIN.USE_PERCET_LOSS:
94 | percept_loss = 0.01 *(percept_left_loss + percept_right_loss) / 2
95 | percept_losses.update(percept_loss.item(), cfg.CONST.TRAIN_BATCH_SIZE)
96 |
97 | deblur_loss = (deblur_left_loss + deblur_right_loss) / 2
98 | deblur_losses.update(deblur_loss.item(), cfg.CONST.TRAIN_BATCH_SIZE)
99 | img_PSNR = img_PSNR_left / 2 + img_PSNR_right / 2
100 | img_PSNRs.update(img_PSNR.item(), cfg.CONST.TRAIN_BATCH_SIZE)
101 |
102 | # Append loss to TensorBoard
103 | n_itr = epoch_idx * n_batches + batch_idx
104 | train_writer.add_scalar('DeblurNet/MSELoss_0_TRAIN', mse_loss.item(), n_itr)
105 | if cfg.TRAIN.USE_PERCET_LOSS:
106 | train_writer.add_scalar('DeblurNet/PerceptLoss_0_TRAIN', percept_loss.item(), n_itr)
107 | train_writer.add_scalar('DeblurNet/DeblurLoss_0_TRAIN', deblur_loss.item(), n_itr)
108 |
109 | # Tick / tock
110 | batch_time.update(time() - batch_end_time)
111 | batch_end_time = time()
112 |
113 | if (batch_idx + 1) % cfg.TRAIN.PRINT_FREQ == 0:
114 | if cfg.TRAIN.USE_PERCET_LOSS:
115 | print('[TRAIN] [Ech {0}/{1}][Bch {2}/{3}]\t BT {4}\t DT {5}\t Loss {6} [{7}, {8}]\t PSNR {9}'
116 | .format(epoch_idx + 1, cfg.TRAIN.NUM_EPOCHES, batch_idx + 1, n_batches, batch_time, data_time,
117 | deblur_losses, mse_losses, percept_losses, img_PSNRs))
118 | else:
119 | print('[TRAIN] [Ech {0}/{1}][Bch {2}/{3}]\t BT {4}\t DT {5}\t DeblurLoss {6} \t PSNR {7}'
120 | .format(epoch_idx + 1, cfg.TRAIN.NUM_EPOCHES, batch_idx + 1, n_batches, batch_time, data_time,
121 | deblur_losses, img_PSNRs))
122 |
123 | if batch_idx < cfg.TEST.VISUALIZATION_NUM:
124 |
125 | img_left_blur = images[0][0][[2, 1, 0], :, :] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
126 | img_right_blur = images[1][0][[2, 1, 0], :, :] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
127 | img_left_clear = images[2][0][[2, 1, 0], :, :] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
128 | img_right_clear = images[3][0][[2, 1, 0], :, :] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
129 | out_left = output_img_clear_left[0][[2,1,0],:,:].cpu().clamp(0.0,1.0) + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
130 | out_right = output_img_clear_right[0][[2,1,0],:,:].cpu().clamp(0.0,1.0) + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
131 | result = torch.cat([torch.cat([img_left_blur, img_right_blur], 2),torch.cat([img_left_clear, img_right_clear], 2),torch.cat([out_left, out_right], 2)],1)
132 | result = torchvision.utils.make_grid(result, nrow=1, normalize=True)
133 | train_writer.add_image('DeblurNet/TRAIN_RESULT' + str(batch_idx + 1), result, epoch_idx + 1)
134 |
135 |
136 | # Append epoch loss to TensorBoard
137 | train_writer.add_scalar('DeblurNet/EpochPSNR_0_TRAIN', img_PSNRs.avg, epoch_idx + 1)
138 |
139 | # Tick / tock
140 | epoch_end_time = time()
141 | print('[TRAIN] [Epoch {0}/{1}]\t EpochTime {2}\t DeblurLoss_avg {3}\t ImgPSNR_avg {4}'
142 | .format(epoch_idx + 1, cfg.TRAIN.NUM_EPOCHES, epoch_end_time - epoch_start_time, deblur_losses.avg,
143 | img_PSNRs.avg))
144 |
145 | # Validate the training models
146 | img_PSNR = test_deblurnet(cfg, epoch_idx, val_data_loader, deblurnet, val_writer)
147 |
148 | # Save weights to file
149 | if (epoch_idx + 1) % cfg.TRAIN.SAVE_FREQ == 0:
150 | if not os.path.exists(ckpt_dir):
151 | os.makedirs(ckpt_dir)
152 |
153 | utils.network_utils.save_deblur_checkpoints(os.path.join(ckpt_dir, 'ckpt-epoch-%04d.pth.tar' % (epoch_idx + 1)), \
154 | epoch_idx + 1, deblurnet, deblurnet_solver, Best_Img_PSNR,
155 | Best_Epoch)
156 | if img_PSNR > Best_Img_PSNR:
157 | if not os.path.exists(ckpt_dir):
158 | os.makedirs(ckpt_dir)
159 |
160 | Best_Img_PSNR = img_PSNR
161 | Best_Epoch = epoch_idx + 1
162 | utils.network_utils.save_deblur_checkpoints(os.path.join(ckpt_dir, 'best-ckpt.pth.tar'), \
163 | epoch_idx + 1, deblurnet, deblurnet_solver, Best_Img_PSNR,
164 | Best_Epoch)
165 |
166 | # Close SummaryWriter for TensorBoard
167 | train_writer.close()
168 | val_writer.close()
169 |
170 |
171 |
--------------------------------------------------------------------------------
/core/train_disp.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | #
4 | # Developed by Shangchen Zhou
5 |
6 | import os
7 | import torch.backends.cudnn
8 | import torch.utils.data
9 |
10 | import utils.data_loaders
11 | import utils.data_transforms
12 | import utils.network_utils
13 | import torchvision
14 |
15 | from losses.multiscaleloss import *
16 | from time import time
17 |
18 | from core.test_disp import test_dispnet
19 |
20 |
21 | def train_dispnet(cfg, init_epoch, train_data_loader, val_data_loader, dispnet, dispnet_solver,
22 | dispnet_lr_scheduler, ckpt_dir, train_writer, val_writer, Best_Disp_EPE, Best_Epoch):
23 | # Training loop
24 | Best_Disp_EPE = float('Inf')
25 | for epoch_idx in range(init_epoch, cfg.TRAIN.NUM_EPOCHES):
26 | # Tick / tock
27 | epoch_start_time = time()
28 |
29 | # Batch average meterics
30 | batch_time = utils.network_utils.AverageMeter()
31 | data_time = utils.network_utils.AverageMeter()
32 | disp_losses = utils.network_utils.AverageMeter()
33 | disp_EPEs = utils.network_utils.AverageMeter()
34 | disp_EPEs_blur = utils.network_utils.AverageMeter()
35 | disp_EPEs_clear = utils.network_utils.AverageMeter()
36 |
37 | # Adjust learning rate
38 | dispnet_lr_scheduler.step()
39 |
40 | batch_end_time = time()
41 | n_batches = len(train_data_loader)
42 |
43 | for batch_idx, (_, images, disps, occs) in enumerate(train_data_loader):
44 | # Measure data time
45 |
46 | data_time.update(time() - batch_end_time)
47 | # Get data from data loader
48 | disparities = disps
49 | imgs_blur = [utils.network_utils.var_or_cuda(img) for img in images[:2]]
50 | imgs_clear = [utils.network_utils.var_or_cuda(img) for img in images[2:]]
51 |
52 | imgs_blur = torch.cat(imgs_blur, 1)
53 | imgs_clear = torch.cat(imgs_clear, 1)
54 | ground_truth_disps = [utils.network_utils.var_or_cuda(disp) for disp in disparities]
55 | ground_truth_disps = torch.cat(ground_truth_disps, 1)
56 | occs = [utils.network_utils.var_or_cuda(occ) for occ in occs]
57 | occs = torch.cat(occs, 1)
58 |
59 | # switch models to training mode
60 | dispnet.train()
61 |
62 | # Train the model
63 | output_disps_blur = dispnet(imgs_blur)
64 |
65 | disp_loss_blur = multiscaleLoss(output_disps_blur, ground_truth_disps, imgs_blur, occs, cfg.LOSS.MULTISCALE_WEIGHTS)
66 | disp_EPE_blur = cfg.DATA.DIV_DISP * realEPE(output_disps_blur[0], ground_truth_disps, occs)
67 | disp_EPEs_blur.update(disp_EPE_blur.item(), cfg.CONST.TRAIN_BATCH_SIZE)
68 |
69 | output_disps_clear = dispnet(imgs_clear)
70 |
71 | disp_loss_clear = multiscaleLoss(output_disps_clear, ground_truth_disps, imgs_clear, occs, cfg.LOSS.MULTISCALE_WEIGHTS)
72 | disp_EPE_clear = cfg.DATA.DIV_DISP * realEPE(output_disps_clear[0], ground_truth_disps, occs)
73 | disp_EPEs_clear.update(disp_EPE_clear.item(), cfg.CONST.TRAIN_BATCH_SIZE)
74 |
75 | # Gradient decent
76 | dispnet_solver.zero_grad()
77 | disp_loss_clear.backward()
78 | dispnet_solver.step()
79 |
80 | disp_loss = (disp_loss_blur + disp_loss_clear) / 2.0
81 | disp_EPE = (disp_EPE_blur + disp_EPE_clear) / 2.0
82 | disp_losses.update(disp_loss.item(), cfg.CONST.TRAIN_BATCH_SIZE)
83 | disp_EPEs.update(disp_EPE.item(), cfg.CONST.TRAIN_BATCH_SIZE)
84 |
85 |
86 | # Append loss to TensorBoard
87 | n_itr = epoch_idx * n_batches + batch_idx
88 | train_writer.add_scalar('DispNet/BatchLoss_0_TRAIN', disp_loss.item(), n_itr)
89 |
90 | # Tick / tock
91 | batch_time.update(time() - batch_end_time)
92 | batch_end_time = time()
93 |
94 | if (batch_idx+1) % cfg.TRAIN.PRINT_FREQ == 0:
95 | print(
96 | '[TRAIN] [Epoch {0}/{1}][Batch {2}/{3}]\t BatchTime {4}\t DataTime {5}\t DispLoss {6}\t blurEPE {7}\t clearEPE {8}'
97 | .format(epoch_idx + 1, cfg.TRAIN.NUM_EPOCHES, batch_idx + 1, n_batches, batch_time, data_time,
98 | disp_losses, disp_EPEs_blur, disp_EPEs_clear))
99 |
100 | if batch_idx < cfg.TEST.VISUALIZATION_NUM:
101 | img_left_blur = images[0][0][[2, 1, 0], :, :] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
102 | img_right_blur = images[1][0][[2, 1, 0], :, :] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
103 | img_left_clear = images[2][0][[2, 1, 0], :, :] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
104 | img_right_clear = images[3][0][[2, 1, 0], :, :] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
105 | gt_disp_left, gt_disp_right = utils.network_utils.graybi2rgb(ground_truth_disps[0])
106 | b, _, h, w = imgs_clear.size()
107 | output_disps_up_blur = torch.nn.functional.interpolate(output_disps_blur[0], size=(h, w), mode='bilinear', align_corners=True)
108 | output_disps_up_clear = torch.nn.functional.interpolate(output_disps_clear[0], size=(h, w), mode='bilinear', align_corners=True)
109 | output_disp_up_left_blur, output_disp_up_right_blur = utils.network_utils.graybi2rgb(output_disps_up_blur[0])
110 | output_disp_up_left_clear, output_disp_up_right_clear = utils.network_utils.graybi2rgb(output_disps_up_clear[0])
111 | result = torch.cat([torch.cat([img_left_blur, img_right_blur], 2),
112 | torch.cat([img_left_clear, img_right_clear], 2),
113 | torch.cat([gt_disp_left, gt_disp_right], 2),
114 | torch.cat([output_disp_up_left_blur, output_disp_up_right_blur], 2),
115 | torch.cat([output_disp_up_left_clear, output_disp_up_right_clear], 2)],1)
116 | result = torchvision.utils.make_grid(result, nrow=1, normalize=True)
117 | train_writer.add_image('DispNet/TRAIN_RESULT' + str(batch_idx + 1), result, epoch_idx + 1)
118 |
119 | # Append epoch loss to TensorBoard
120 | train_writer.add_scalar('DispNet/EpochEPE_0_TRAIN', disp_EPEs.avg, epoch_idx + 1)
121 |
122 | # Tick / tock
123 | epoch_end_time = time()
124 | print('[TRAIN] [Epoch {0}/{1}]\t EpochTime {2}\t DispLoss_avg {3}\t DispEPE_avg {4}'
125 | .format(epoch_idx + 1, cfg.TRAIN.NUM_EPOCHES, epoch_end_time - epoch_start_time, disp_losses.avg,
126 | disp_EPEs.avg))
127 |
128 |
129 | # Save weights to file
130 | if (epoch_idx + 1) % cfg.TRAIN.SAVE_FREQ == 0:
131 | if not os.path.exists(ckpt_dir):
132 | os.makedirs(ckpt_dir)
133 |
134 | utils.network_utils.save_disp_checkpoints(os.path.join(ckpt_dir, 'ckpt-epoch-%04d.pth.tar' % (epoch_idx + 1)), \
135 | epoch_idx + 1, dispnet, dispnet_solver, Best_Disp_EPE,
136 | Best_Epoch)
137 | if disp_EPEs.avg < Best_Disp_EPE:
138 | if not os.path.exists(ckpt_dir):
139 | os.makedirs(ckpt_dir)
140 |
141 | Best_Disp_EPE = disp_EPEs.avg
142 | Best_Epoch = epoch_idx + 1
143 | utils.network_utils.save_disp_checkpoints(os.path.join(ckpt_dir, 'best-ckpt.pth.tar'), \
144 | epoch_idx + 1, dispnet, dispnet_solver, Best_Disp_EPE,
145 | Best_Epoch)
146 |
147 | # Close SummaryWriter for TensorBoard
148 | train_writer.close()
149 | val_writer.close()
150 |
151 |
--------------------------------------------------------------------------------
/core/train_stereodeblur.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | #
4 | # Developed by Shangchen Zhou
5 |
6 | import os
7 | import torch.backends.cudnn
8 | import torch.utils.data
9 |
10 | import utils.data_loaders
11 | import utils.data_transforms
12 | import utils.network_utils
13 | import torchvision
14 |
15 | from losses.multiscaleloss import *
16 | from time import time
17 |
18 | from core.test_stereodeblur import test_stereodeblurnet
19 | from models.VGG19 import VGG19
20 |
21 |
22 | def train_stereodeblurnet(cfg, init_epoch, train_data_loader, val_data_loader,
23 | dispnet, dispnet_solver, dispnet_lr_scheduler,
24 | deblurnet, deblurnet_solver, deblurnet_lr_scheduler,
25 | ckpt_dir, train_writer, val_writer,
26 | Disp_EPE, Best_Img_PSNR, Best_Epoch):
27 | # Training loop
28 | for epoch_idx in range(init_epoch, cfg.TRAIN.NUM_EPOCHES):
29 | # Tick / tock
30 | epoch_start_time = time()
31 |
32 | # Batch average meterics
33 | batch_time = utils.network_utils.AverageMeter()
34 | data_time = utils.network_utils.AverageMeter()
35 | disp_EPEs = utils.network_utils.AverageMeter()
36 | deblur_mse_losses = utils.network_utils.AverageMeter()
37 | if cfg.TRAIN.USE_PERCET_LOSS == True:
38 | deblur_percept_losses = utils.network_utils.AverageMeter()
39 | deblur_losses = utils.network_utils.AverageMeter()
40 | img_PSNRs = utils.network_utils.AverageMeter()
41 |
42 | # Adjust learning rate
43 | dispnet_lr_scheduler.step()
44 | deblurnet_lr_scheduler.step()
45 |
46 | batch_end_time = time()
47 | n_batches = len(train_data_loader)
48 |
49 | vggnet = VGG19()
50 | if torch.cuda.is_available():
51 | vggnet = torch.nn.DataParallel(vggnet).cuda()
52 |
53 | for batch_idx, (_, images, disps, occ_masks) in enumerate(train_data_loader):
54 | # Measure data time
55 |
56 | data_time.update(time() - batch_end_time)
57 | # Get data from data loader
58 | imgs = [utils.network_utils.var_or_cuda(img) for img in images]
59 | img_blur_left, img_blur_right, img_clear_left, img_clear_right = imgs
60 |
61 | imgs_blur = torch.cat([img_blur_left, img_blur_right], 1)
62 | ground_truth_disps = [utils.network_utils.var_or_cuda(disp) for disp in disps]
63 | ground_truth_disps = torch.cat(ground_truth_disps, 1)
64 | occ_masks = [utils.network_utils.var_or_cuda(occ_mask) for occ_mask in occ_masks]
65 | occ_masks = torch.cat(occ_masks, 1)
66 |
67 | # switch models to training mode
68 | dispnet.train()
69 | deblurnet.train()
70 |
71 | # Train the model
72 | output_disps = dispnet(imgs_blur)
73 |
74 | output_disp_feature = output_disps[-1]
75 | output_disps = output_disps[:-1]
76 | imgs_prd, output_diffs, output_masks = deblurnet(imgs_blur, output_disps[0], output_disp_feature)
77 |
78 | disp_EPE = cfg.DATA.DIV_DISP * realEPE(output_disps[0], ground_truth_disps, occ_masks)
79 | disp_EPEs.update(disp_EPE.item(), cfg.CONST.TRAIN_BATCH_SIZE)
80 |
81 | # deblur loss
82 | deblur_mse_left_loss = mseLoss(imgs_prd[0], img_clear_left)
83 | deblur_mse_right_loss = mseLoss(imgs_prd[1], img_clear_right)
84 | deblur_mse_loss = (deblur_mse_left_loss + deblur_mse_right_loss) / 2
85 | deblur_mse_losses.update(deblur_mse_loss.item(), cfg.CONST.TRAIN_BATCH_SIZE)
86 | if cfg.TRAIN.USE_PERCET_LOSS == True:
87 | deblur_percept_left_loss = perceptualLoss(imgs_prd[0], img_clear_left, vggnet)
88 | deblur_percept_right_loss = perceptualLoss(imgs_prd[1], img_clear_right, vggnet)
89 | deblur_percept_loss = (deblur_percept_left_loss + deblur_percept_right_loss) / 2
90 | deblur_percept_losses.update(deblur_percept_loss.item(), cfg.CONST.TRAIN_BATCH_SIZE)
91 | deblur_loss = deblur_mse_loss + 0.01 * deblur_percept_loss
92 | else:
93 | deblur_loss = deblur_mse_loss
94 | deblur_losses.update(deblur_loss.item(), cfg.CONST.TRAIN_BATCH_SIZE)
95 |
96 | img_PSNR = (PSNR(imgs_prd[0], img_clear_left) + PSNR(imgs_prd[1], img_clear_right)) / 2
97 | img_PSNRs.update(img_PSNR.item(), cfg.CONST.TRAIN_BATCH_SIZE)
98 |
99 | deblurnet_solver.zero_grad()
100 | deblurnet_loss = deblur_loss
101 | deblurnet_loss.backward()
102 | deblurnet_solver.step()
103 |
104 | # Append loss to TensorBoard
105 | n_itr = epoch_idx * n_batches + batch_idx
106 |
107 | train_writer.add_scalar('StereoDeblurNet/DeblurLoss_0_TRAIN', deblur_loss.item(), n_itr)
108 | train_writer.add_scalar('StereoDeblurNet/DeblurMSELoss_0_TRAIN', deblur_mse_loss.item(), n_itr)
109 | if cfg.TRAIN.USE_PERCET_LOSS == True:
110 | train_writer.add_scalar('StereoDeblurNet/DeblurPerceptLoss_0_TRAIN', deblur_percept_loss.item(), n_itr)
111 |
112 | # Tick / tock
113 | batch_time.update(time() - batch_end_time)
114 | batch_end_time = time()
115 |
116 | if (batch_idx + 1) % cfg.TRAIN.PRINT_FREQ == 0:
117 | print(
118 | '[TRAIN] [Ech {0}/{1}][Bch {2}/{3}] BT {4} DT {5} EPE {6} DeblurLoss {7} [{8}, {9}] PSNR {10}'
119 | .format(epoch_idx + 1, cfg.TRAIN.NUM_EPOCHES, batch_idx + 1, n_batches, batch_time, data_time,
120 | disp_EPEs, deblur_losses, deblur_mse_losses, deblur_percept_losses, img_PSNRs))
121 |
122 | if batch_idx < cfg.TEST.VISUALIZATION_NUM:
123 | img_blur_left = images[0][0][[2, 1, 0], :, :] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
124 | img_blur_right = images[1][0][[2, 1, 0], :, :] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
125 | img_clear_left = images[2][0][[2, 1, 0], :, :] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
126 | img_clear_right = images[3][0][[2, 1, 0], :, :] + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
127 | img_out_left = imgs_prd[0][0][[2, 1, 0], :, :].cpu().clamp(0.0, 1.0) + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
128 | img_out_right = imgs_prd[1][0][[2, 1, 0], :, :].cpu().clamp(0.0, 1.0) + torch.Tensor(cfg.DATA.MEAN).view(3, 1, 1)
129 | disp_gt_left, disp_gt_right = utils.network_utils.graybi2rgb(ground_truth_disps[0])
130 | b, _, h, w = imgs[0].shape
131 | diff_out_left, diff_out_right = utils.network_utils.graybi2rgb(torch.cat(output_diffs, 1)[0])
132 | output_masks = torch.nn.functional.interpolate(torch.cat(output_masks, 1), size=(h, w), mode='bilinear', align_corners=True)
133 | mask_out_left, mask_out_right = utils.network_utils.graybi2rgb(output_masks[0])
134 | disp_out_left, disp_out_right = utils.network_utils.graybi2rgb(output_disps[0][0])
135 | result = torch.cat([torch.cat([img_blur_left, img_blur_right], 2),
136 | torch.cat([img_clear_left, img_clear_right], 2),
137 | torch.cat([img_out_left, img_out_right], 2),
138 | torch.cat([disp_gt_left, disp_gt_right], 2),
139 | torch.cat([disp_out_left, disp_out_right], 2),
140 | torch.cat([diff_out_left, diff_out_right], 2),
141 | torch.cat([mask_out_left, mask_out_right], 2)], 1)
142 | result = torchvision.utils.make_grid(result, nrow=1, normalize=True)
143 | train_writer.add_image('StereoDeblurNet/TRAIN_RESULT' + str(batch_idx + 1), result, epoch_idx + 1)
144 |
145 | # Append epoch loss to TensorBoard
146 | train_writer.add_scalar('StereoDeblurNet/EpochEPE_0_TRAIN', disp_EPEs.avg, epoch_idx + 1)
147 | train_writer.add_scalar('StereoDeblurNet/EpochPSNR_0_TRAIN', img_PSNRs.avg, epoch_idx + 1)
148 |
149 | # Tick / tock
150 | epoch_end_time = time()
151 | print('[TRAIN] [Epoch {0}/{1}]\t EpochTime {2}\t DispEPE_avg {3}\t ImgPSNR_avg {4}'
152 | .format(epoch_idx + 1, cfg.TRAIN.NUM_EPOCHES, epoch_end_time - epoch_start_time, disp_EPEs.avg, img_PSNRs.avg))
153 |
154 | # Validate the training models
155 | Disp_EPE, img_PSNR = test_stereodeblurnet(cfg, epoch_idx, val_data_loader, dispnet, deblurnet, val_writer)
156 |
157 | # Save weights to file
158 | if (epoch_idx + 1) % cfg.TRAIN.SAVE_FREQ == 0:
159 | if not os.path.exists(ckpt_dir):
160 | os.makedirs(ckpt_dir)
161 |
162 | utils.network_utils.save_checkpoints(os.path.join(ckpt_dir, 'ckpt-epoch-%04d.pth.tar' % (epoch_idx + 1)), \
163 | epoch_idx + 1, dispnet, dispnet_solver, deblurnet, deblurnet_solver, \
164 | Disp_EPE, Best_Img_PSNR, Best_Epoch)
165 | if img_PSNR >= Best_Img_PSNR:
166 | if not os.path.exists(ckpt_dir):
167 | os.makedirs(ckpt_dir)
168 |
169 | Best_Img_PSNR = img_PSNR
170 | Best_Epoch = epoch_idx + 1
171 | utils.network_utils.save_checkpoints(os.path.join(ckpt_dir, 'best-ckpt.pth.tar'), \
172 | epoch_idx + 1, dispnet, dispnet_solver, deblurnet, deblurnet_solver, \
173 | Disp_EPE, Best_Img_PSNR, Best_Epoch)
174 |
175 | # Close SummaryWriter for TensorBoard
176 | train_writer.close()
177 | val_writer.close()
178 |
179 |
--------------------------------------------------------------------------------
/losses/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sczhou/DAVANet/2bbe35ae01c0f1af718a1bc19272cda5ed3c320a/losses/__init__.py
--------------------------------------------------------------------------------
/losses/multiscaleloss.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | from config import cfg
4 | from utils.network_utils import *
5 | #
6 | # Disparity Loss
7 | #
8 | def EPE(output, target, occ_mask):
9 | N = torch.sum(occ_mask)
10 | d_diff = output - target
11 | EPE_map = torch.abs(d_diff)
12 | EPE_map = torch.mul(EPE_map, occ_mask)
13 |
14 | EPE_mean = torch.sum(EPE_map)/N
15 | return EPE_mean
16 |
17 | def multiscaleLoss(outputs, target, img, occ_mask, weights):
18 |
19 | def one_scale(output, target, occ_mask):
20 | b, _, h, w = output.size()
21 | occ_mask = nn.functional.adaptive_max_pool2d(occ_mask, (h, w))
22 | if cfg.DATASET.SPARSE:
23 | target_scaled = nn.functional.adaptive_max_pool2d(target, (h, w))
24 | else:
25 | target_scaled = nn.functional.adaptive_avg_pool2d(target, (h, w))
26 | return EPE(output, target_scaled, occ_mask)
27 |
28 | if type(outputs) not in [tuple, list]:
29 | outputs = [outputs]
30 |
31 | assert(len(weights) == len(outputs))
32 |
33 | loss = 0
34 | for output, weight in zip(outputs, weights):
35 | loss += weight * one_scale(output, target, occ_mask)
36 | return loss
37 |
38 | def realEPE(output, target, occ_mask):
39 | b, _, h, w = target.size()
40 | upsampled_output = nn.functional.interpolate(output, size=(h,w), mode = 'bilinear', align_corners=True)
41 | return EPE(upsampled_output, target, occ_mask)
42 |
43 | #
44 | # Deblurring Loss
45 | #
46 | def mseLoss(output, target):
47 | mse_loss = nn.MSELoss(reduction ='elementwise_mean')
48 | MSE = mse_loss(output, target)
49 | return MSE
50 |
51 | def PSNR(output, target, max_val = 1.0):
52 | output = output.clamp(0.0,1.0)
53 | mse = torch.pow(target - output, 2).mean()
54 | if mse == 0:
55 | return torch.Tensor([100.0])
56 | return 10 * torch.log10(max_val**2 / mse)
57 |
58 |
59 | def perceptualLoss(fakeIm, realIm, vggnet):
60 | '''
61 | use vgg19 conv1_2, conv2_2, conv3_3 feature, before relu layer
62 | '''
63 |
64 | weights = [1, 0.2, 0.04]
65 | features_fake = vggnet(fakeIm)
66 | features_real = vggnet(realIm)
67 | features_real_no_grad = [f_real.detach() for f_real in features_real]
68 | mse_loss = nn.MSELoss(reduction='elementwise_mean')
69 |
70 | loss = 0
71 | for i in range(len(features_real)):
72 | loss_i = mse_loss(features_fake[i], features_real_no_grad[i])
73 | loss = loss + loss_i * weights[i]
74 |
75 | return loss
76 |
--------------------------------------------------------------------------------
/models/DeblurNet.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | #
4 | # Developed by Shangchen Zhou
5 |
6 | # from models.submodules import *
7 |
8 | from models.submodules import *
9 | class DeblurNet(nn.Module):
10 | def __init__(self):
11 | super(DeblurNet, self).__init__()
12 | # encoder
13 | ks = 3
14 | self.conv1_1 = conv(3, 32, kernel_size=ks, stride=1)
15 | self.conv1_2 = resnet_block(32, kernel_size=ks)
16 | self.conv1_3 = resnet_block(32, kernel_size=ks)
17 | self.conv1_4 = resnet_block(32, kernel_size=ks)
18 |
19 | self.conv2_1 = conv(32, 64, kernel_size=ks, stride=2)
20 | self.conv2_2 = resnet_block(64, kernel_size=ks)
21 | self.conv2_3 = resnet_block(64, kernel_size=ks)
22 | self.conv2_4 = resnet_block(64, kernel_size=ks)
23 |
24 |
25 | self.conv3_1 = conv(64, 128, kernel_size=ks, stride=2)
26 | self.conv3_2 = resnet_block(128, kernel_size=ks)
27 | self.conv3_3 = resnet_block(128, kernel_size=ks)
28 | self.conv3_4 = resnet_block(128, kernel_size=ks)
29 |
30 | dilation = [1,2,3,4]
31 | self.convd_1 = resnet_block(128, kernel_size=ks, dilation = [2, 1])
32 | self.convd_2 = resnet_block(128, kernel_size=ks, dilation = [3, 1])
33 | self.convd_3 = ms_dilate_block(128, kernel_size=ks, dilation = dilation)
34 |
35 | # decoder
36 | self.upconv3_i = conv(128, 128, kernel_size=ks,stride=1)
37 | self.upconv3_3 = resnet_block(128, kernel_size=ks)
38 | self.upconv3_2 = resnet_block(128, kernel_size=ks)
39 | self.upconv3_1 = resnet_block(128, kernel_size=ks)
40 |
41 | self.upconv2_u = upconv(128, 64)
42 | self.upconv2_i = conv(128, 64, kernel_size=ks,stride=1)
43 | self.upconv2_3 = resnet_block(64, kernel_size=ks)
44 | self.upconv2_2 = resnet_block(64, kernel_size=ks)
45 | self.upconv2_1 = resnet_block(64, kernel_size=ks)
46 |
47 | self.upconv1_u = upconv(64, 32)
48 | self.upconv1_i = conv(64, 32, kernel_size=ks,stride=1)
49 | self.upconv1_3 = resnet_block(32, kernel_size=ks)
50 | self.upconv1_2 = resnet_block(32, kernel_size=ks)
51 | self.upconv1_1 = resnet_block(32, kernel_size=ks)
52 |
53 | self.img_prd = conv(32, 3, kernel_size=ks, stride=1)
54 |
55 | def forward(self, x):
56 | # encoder
57 | conv1 = self.conv1_4(self.conv1_3(self.conv1_2(self.conv1_1(x))))
58 | conv2 = self.conv2_4(self.conv2_3(self.conv2_2(self.conv2_1(conv1))))
59 | conv3 = self.conv3_4(self.conv3_3(self.conv3_2(self.conv3_1(conv2))))
60 | convd = self.convd_3(self.convd_2(self.convd_1(conv3)))
61 |
62 | # decoder
63 | cat3 = self.upconv3_i(convd)
64 | upconv2 = self.upconv2_u(self.upconv3_1(self.upconv3_2(self.upconv3_3(cat3))))
65 | cat2 = self.upconv2_i(cat_with_crop(conv2, [conv2, upconv2]))
66 | upconv1 = self.upconv1_u(self.upconv2_1(self.upconv2_2(self.upconv2_3(cat2))))
67 | cat1 = self.upconv1_i(cat_with_crop(conv1, [conv1, upconv1]))
68 | img_prd = self.img_prd(self.upconv1_1(self.upconv1_2(self.upconv1_3(cat1))))
69 |
70 | return img_prd + x
71 |
--------------------------------------------------------------------------------
/models/DispNet_Bi.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | #
4 | # Developed by Shangchen Zhou
5 |
6 | from models.submodules import *
7 |
8 | class DispNet_Bi(nn.Module):
9 | def __init__(self):
10 | super(DispNet_Bi, self).__init__()
11 | # encoder
12 | ks = 3
13 | self.conv0 = conv(6, 48, kernel_size=ks, stride=1)
14 |
15 | self.conv1_1 = conv(48, 48, kernel_size=ks, stride=2)
16 | self.conv1_2 = conv(48, 48, kernel_size=ks, stride=1)
17 |
18 | self.conv2_1 = conv(48, 96, kernel_size=ks, stride=2)
19 | self.conv2_2 = conv(96, 96, kernel_size=ks, stride=1)
20 |
21 | self.conv3_1 = conv(96, 128, kernel_size=ks, stride=2)
22 | self.conv3_2 = conv(128, 128, kernel_size=ks, stride=1)
23 |
24 | self.conv4_1 = resnet_block(128, kernel_size=ks)
25 | self.conv4_2 = resnet_block(128, kernel_size=ks)
26 |
27 | self.convd_1 = resnet_block(128, kernel_size=ks, dilation=[2, 1])
28 | self.convd_2 = ms_dilate_block(128, kernel_size=ks, dilation=[1, 2, 3, 4])
29 |
30 | # decoder
31 | self.upconvd_i = conv(128, 128, kernel_size=ks, stride=1)
32 | self.dispd = predict_disp_bi(128)
33 |
34 | self.upconv3 = conv(128, 128, kernel_size=ks, stride=1)
35 | self.upconv3_i = conv(258, 128, kernel_size=ks, stride=1)
36 | self.upconv3_f = conv(128, 128, kernel_size=ks, stride=1)
37 | self.disp3 = predict_disp_bi(128)
38 |
39 | self.updisp3 = up_disp_bi()
40 | self.upconv2 = upconv(128, 96)
41 | self.upconv2_i = conv(194, 96, kernel_size=ks, stride=1)
42 | self.upconv2_f = conv(96, 96, kernel_size=ks, stride=1)
43 | self.disp2 = predict_disp_bi(96)
44 |
45 | self.updisp2 = up_disp_bi()
46 | self.upconv1 = upconv(96, 48)
47 | self.upconv1_i = conv(50, 48, kernel_size=ks, stride=1)
48 | self.upconv1_f = conv(48, 48, kernel_size=ks, stride=1)
49 | self.disp1 = predict_disp_bi(48)
50 |
51 | self.updisp1 = up_disp_bi()
52 | self.upconv0 = upconv(48, 32)
53 | self.upconv0_i = conv(34, 32, kernel_size=ks, stride=1)
54 | self.upconv0_f = conv(32, 32, kernel_size=ks, stride=1)
55 | self.disp0 = predict_disp_bi(32)
56 |
57 | def forward(self, x):
58 | # encoder
59 | conv0 = self.conv0(x)
60 | conv1 = self.conv1_2(self.conv1_1(conv0))
61 | conv2 = self.conv2_2(self.conv2_1(conv1))
62 | conv3 = self.conv3_2(self.conv3_1(conv2))
63 | conv4 = self.conv4_2(self.conv4_1(conv3))
64 | convd = self.convd_2(self.convd_1(conv4))
65 |
66 | # decoder
67 | upconvd_i = self.upconvd_i(convd)
68 | disp4 = self.dispd(upconvd_i)
69 |
70 | upconv3 = self.upconv3(upconvd_i)
71 | cat3 = torch.cat([conv3, upconv3, disp4], 1)
72 | upconv3_i = self.upconv3_f(self.upconv3_i(cat3))
73 | disp3 = self.disp3(upconv3_i) + disp4
74 |
75 | updisp3 = self.updisp3(disp3)
76 | upconv2 = self.upconv2(upconv3_i)
77 | cat2 = torch.cat([conv2, upconv2, updisp3], 1)
78 | upconv2_i = self.upconv2_f(self.upconv2_i(cat2))
79 | disp2 = self.disp2(upconv2_i) + updisp3
80 |
81 | updisp2 = self.updisp2(disp2)
82 | upconv1 = self.upconv1(upconv2_i)
83 | cat1 = torch.cat([upconv1, updisp2], 1)
84 | upconv1_i = self.upconv1_f(self.upconv1_i(cat1))
85 | disp1 = self.disp1(upconv1_i) + updisp2
86 |
87 | updisp1 = self.updisp1(disp1)
88 | upconv0 = self.upconv0(upconv1_i)
89 | cat0 = torch.cat([upconv0, updisp1], 1)
90 | upconv0_i = self.upconv0_f(self.upconv0_i(cat0))
91 | disp0 = self.disp0(upconv0_i) + updisp1
92 |
93 | # if self.training:
94 | # return disp0, disp1, disp2, disp3, disp4
95 | # else:
96 | # return disp0
97 |
98 | if self.training:
99 | return disp0, disp1, disp2, disp3, disp4, upconv0_i
100 | else:
101 | return disp0, upconv0_i
--------------------------------------------------------------------------------
/models/StereoDeblurNet.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | #
4 | # Developed by Shangchen Zhou
5 |
6 | from models.submodules import *
7 | from utils.network_utils import *
8 | from config import cfg
9 |
10 | class StereoDeblurNet(nn.Module):
11 | def __init__(self):
12 | super(StereoDeblurNet, self).__init__()
13 | # encoder
14 | ks = 3
15 | self.conv1_1 = conv(3, 32, kernel_size=ks, stride=1)
16 | self.conv1_2 = resnet_block(32, kernel_size=ks)
17 | self.conv1_3 = resnet_block(32, kernel_size=ks)
18 | self.conv1_4 = resnet_block(32, kernel_size=ks)
19 |
20 | self.conv2_1 = conv(32, 64, kernel_size=ks, stride=2)
21 | self.conv2_2 = resnet_block(64, kernel_size=ks)
22 | self.conv2_3 = resnet_block(64, kernel_size=ks)
23 | self.conv2_4 = resnet_block(64, kernel_size=ks)
24 |
25 | self.conv3_1 = conv(64, 128, kernel_size=ks, stride=2)
26 | self.conv3_2 = resnet_block(128, kernel_size=ks)
27 | self.conv3_3 = resnet_block(128, kernel_size=ks)
28 | self.conv3_4 = resnet_block(128, kernel_size=ks)
29 |
30 | dilation = [1,2,3,4]
31 | self.convd_1 = resnet_block(128, kernel_size=ks, dilation = [2, 1])
32 | self.convd_2 = resnet_block(128, kernel_size=ks, dilation = [3, 1])
33 | self.convd_3 = ms_dilate_block(128, kernel_size=ks, dilation = dilation)
34 |
35 | self.gatenet = gatenet()
36 |
37 | self.depth_sense_l = depth_sense(33, 32, kernel_size=ks)
38 | self.depth_sense_r = depth_sense(33, 32, kernel_size=ks)
39 |
40 | # decoder
41 | self.upconv3_i = conv(288, 128, kernel_size=ks,stride=1)
42 | self.upconv3_3 = resnet_block(128, kernel_size=ks)
43 | self.upconv3_2 = resnet_block(128, kernel_size=ks)
44 | self.upconv3_1 = resnet_block(128, kernel_size=ks)
45 |
46 | self.upconv2_u = upconv(128, 64)
47 | self.upconv2_i = conv(128, 64, kernel_size=ks,stride=1)
48 | self.upconv2_3 = resnet_block(64, kernel_size=ks)
49 | self.upconv2_2 = resnet_block(64, kernel_size=ks)
50 | self.upconv2_1 = resnet_block(64, kernel_size=ks)
51 |
52 | self.upconv1_u = upconv(64, 32)
53 | self.upconv1_i = conv(64, 32, kernel_size=ks,stride=1)
54 | self.upconv1_3 = resnet_block(32, kernel_size=ks)
55 | self.upconv1_2 = resnet_block(32, kernel_size=ks)
56 | self.upconv1_1 = resnet_block(32, kernel_size=ks)
57 |
58 | self.img_prd = conv(32, 3, kernel_size=ks, stride=1)
59 |
60 | def forward(self, imgs, disps_bi, disp_feature):
61 | img_left = imgs[:,:3]
62 | img_right = imgs[:,3:]
63 |
64 | disp_left = disps_bi[:, 0]
65 | disp_right = disps_bi[:, 1]
66 |
67 | # encoder-left
68 | conv1_left = self.conv1_4(self.conv1_3(self.conv1_2(self.conv1_1(img_left))))
69 | conv2_left = self.conv2_4(self.conv2_3(self.conv2_2(self.conv2_1(conv1_left))))
70 | conv3_left = self.conv3_4(self.conv3_3(self.conv3_2(self.conv3_1(conv2_left))))
71 | convd_left = self.convd_3(self.convd_2(self.convd_1(conv3_left)))
72 |
73 | # encoder-right
74 | conv1_right = self.conv1_4(self.conv1_3(self.conv1_2(self.conv1_1(img_right))))
75 | conv2_right = self.conv2_4(self.conv2_3(self.conv2_2(self.conv2_1(conv1_right))))
76 | conv3_right = self.conv3_4(self.conv3_3(self.conv3_2(self.conv3_1(conv2_right))))
77 | convd_right = self.convd_3(self.convd_2(self.convd_1(conv3_right)))
78 |
79 | b, c, h, w = convd_left.shape
80 |
81 | warp_img_left = disp_warp(img_right, -disp_left*cfg.DATA.DIV_DISP, cuda=True)
82 | warp_img_right = disp_warp(img_left, disp_right*cfg.DATA.DIV_DISP, cuda=True)
83 | diff_left = torch.sum(torch.abs(img_left - warp_img_left), 1).view(b,1,*warp_img_left.shape[-2:])
84 | diff_right = torch.sum(torch.abs(img_right - warp_img_right), 1).view(b,1,*warp_img_right.shape[-2:])
85 | diff_2_left = nn.functional.adaptive_avg_pool2d(diff_left, (h, w))
86 | diff_2_right = nn.functional.adaptive_avg_pool2d(diff_right, (h, w))
87 |
88 | disp_2_left = nn.functional.adaptive_avg_pool2d(disp_left, (h, w))
89 | disp_2_right = nn.functional.adaptive_avg_pool2d(disp_right, (h, w))
90 |
91 | disp_feature_2 = nn.functional.adaptive_avg_pool2d(disp_feature, (h, w))
92 |
93 | depth_aware_left = self.depth_sense_l(torch.cat([disp_feature_2, disp_2_left.view(b,1,h,w)], 1))
94 | depth_aware_right = self.depth_sense_r(torch.cat([disp_feature_2, disp_2_right.view(b,1,h,w)], 1))
95 |
96 | # the larger, the more accurate
97 | gate_left = self.gatenet(diff_2_left)
98 | gate_right = self.gatenet(diff_2_right)
99 |
100 | warp_convd_left = disp_warp(convd_right, -disp_2_left)
101 | warp_convd_right = disp_warp(convd_left, disp_2_right)
102 |
103 | # aggregate features
104 | agg_left = convd_left * (1.0-gate_left) + warp_convd_left * gate_left.repeat(1,c,1,1)
105 | agg_right = convd_right * (1.0-gate_right) + warp_convd_right * gate_right.repeat(1,c,1,1)
106 |
107 | # decoder-left
108 | cat3_left = self.upconv3_i(torch.cat([convd_left, agg_left, depth_aware_left], 1))
109 | upconv3_left = self.upconv3_1(self.upconv3_2(self.upconv3_3(cat3_left))) # upconv3 feature
110 |
111 | upconv2_u_left = self.upconv2_u(upconv3_left)
112 | cat2_left = self.upconv2_i(torch.cat([conv2_left, upconv2_u_left],1))
113 | upconv2_left = self.upconv2_1(self.upconv2_2(self.upconv2_3(cat2_left))) # upconv2 feature
114 | upconv1_u_left = self.upconv1_u(upconv2_left)
115 | cat1_left = self.upconv1_i(torch.cat([conv1_left, upconv1_u_left], 1))
116 |
117 | upconv1_left = self.upconv1_1(self.upconv1_2(self.upconv1_3(cat1_left))) # upconv1 feature
118 | img_prd_left = self.img_prd(upconv1_left) + img_left # predict img
119 |
120 | # decoder-right
121 | cat3_right = self.upconv3_i(torch.cat([convd_right, agg_right, depth_aware_right], 1))
122 | upconv3_right = self.upconv3_1(self.upconv3_2(self.upconv3_3(cat3_right))) # upconv3 feature
123 |
124 | upconv2_u_right = self.upconv2_u(upconv3_right)
125 | cat2_right = self.upconv2_i(torch.cat([conv2_right, upconv2_u_right], 1))
126 | upconv2_right = self.upconv2_1(self.upconv2_2(self.upconv2_3(cat2_right))) # upconv2 feature
127 | upconv1_u_right = self.upconv1_u(upconv2_right)
128 | cat1_right = self.upconv1_i(torch.cat([conv1_right, upconv1_u_right], 1))
129 |
130 | upconv1_right = self.upconv1_1(self.upconv1_2(self.upconv1_3(cat1_right))) # upconv1 feature
131 | img_prd_right = self.img_prd(upconv1_right) + img_right # predict img
132 |
133 | imgs_prd = [img_prd_left, img_prd_right]
134 |
135 | diff = [diff_left, diff_right]
136 | gate = [gate_left, gate_right]
137 |
138 | return imgs_prd, diff, gate
139 |
--------------------------------------------------------------------------------
/models/VGG19.py:
--------------------------------------------------------------------------------
1 | from models.submodules import *
2 | import torchvision.models
3 |
4 | class VGG19(nn.Module):
5 | def __init__(self):
6 | super(VGG19, self).__init__()
7 | '''
8 | use vgg19 conv1_2, conv2_2, conv3_3 feature, before relu layer
9 | '''
10 | self.feature_list = [2, 7, 14]
11 | vgg19 = torchvision.models.vgg19(pretrained=True)
12 |
13 | self.model = torch.nn.Sequential(*list(vgg19.features.children())[:self.feature_list[-1]+1])
14 |
15 |
16 | def forward(self, x):
17 | x = (x-0.5)/0.5
18 | features = []
19 | for i, layer in enumerate(list(self.model)):
20 | x = layer(x)
21 | if i in self.feature_list:
22 | features.append(x)
23 |
24 | return features
--------------------------------------------------------------------------------
/models/__init__.py:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/models/submodules.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | #
4 | # Developed by Shangchen Zhou
5 |
6 | import torch.nn as nn
7 | import torch
8 | import numpy as np
9 | from config import cfg
10 |
11 | def conv(in_channels, out_channels, kernel_size=3, stride=1,dilation=1, bias=True):
12 | return nn.Sequential(
13 | nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, dilation=dilation, padding=((kernel_size-1)//2)*dilation, bias=bias),
14 | nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE,inplace=True)
15 | )
16 |
17 | def predict_disp(in_channels):
18 | return nn.Conv2d(in_channels,1,kernel_size=3,stride=1,padding=1,bias=True)
19 |
20 | def predict_disp_bi(in_channels):
21 | return nn.Conv2d(in_channels,2,kernel_size=3,stride=1,padding=1,bias=True)
22 |
23 | def up_disp_bi():
24 | return nn.ConvTranspose2d(2, 2, 4, 2, 1, bias=False)
25 |
26 | def predict_occ(in_channels):
27 | return nn.Conv2d(in_channels,1,kernel_size=3,stride=1,padding=1,bias=True)
28 |
29 | def predict_occ_bi(in_channels):
30 | return nn.Conv2d(in_channels,2,kernel_size=3,stride=1,padding=1,bias=True)
31 |
32 | def upconv(in_channels, out_channels):
33 | return nn.Sequential(
34 | nn.ConvTranspose2d(in_channels, out_channels, kernel_size=4, stride=2, padding=1, bias=True),
35 | nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE,inplace=True)
36 | )
37 |
38 | def resnet_block(in_channels, kernel_size=3, dilation=[1,1], bias=True):
39 | return ResnetBlock(in_channels, kernel_size, dilation, bias=bias)
40 |
41 | class ResnetBlock(nn.Module):
42 | def __init__(self, in_channels, kernel_size, dilation, bias):
43 | super(ResnetBlock, self).__init__()
44 | self.stem = nn.Sequential(
45 | nn.Conv2d(in_channels, in_channels, kernel_size=kernel_size, stride=1, dilation=dilation[0], padding=((kernel_size-1)//2)*dilation[0], bias=bias),
46 | nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE, inplace=True),
47 | nn.Conv2d(in_channels, in_channels, kernel_size=kernel_size, stride=1, dilation=dilation[1], padding=((kernel_size-1)//2)*dilation[1], bias=bias),
48 | )
49 | def forward(self, x):
50 | out = self.stem(x) + x
51 | return out
52 |
53 |
54 | def gatenet(bias=True):
55 | return nn.Sequential(
56 | nn.Conv2d(1, 16, kernel_size=3, stride=1, dilation=1, padding=1, bias=bias),
57 | nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE,inplace=True),
58 | resnet_block(16, kernel_size=1),
59 | nn.Conv2d(16, 1, kernel_size=1, padding=0),
60 | nn.Sigmoid()
61 | )
62 |
63 | def depth_sense(in_channels, out_channels, kernel_size=3, dilation=1, bias=True):
64 | return nn.Sequential(
65 | nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=1, dilation=1,padding=((kernel_size - 1) // 2)*dilation, bias=bias),
66 | nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE, inplace=True),
67 | resnet_block(out_channels, kernel_size= 3),
68 | )
69 |
70 | def conv2x(in_channels, kernel_size=3,dilation=[1,1], bias=True):
71 | return nn.Sequential(
72 | nn.Conv2d(in_channels, in_channels, kernel_size=kernel_size, stride=1, dilation=dilation[0], padding=((kernel_size-1)//2)*dilation[0], bias=bias),
73 | nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE,inplace=True),
74 | nn.Conv2d(in_channels, in_channels, kernel_size=kernel_size, stride=1, dilation=dilation[1], padding=((kernel_size-1)//2)*dilation[1], bias=bias),
75 | nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE, inplace=True)
76 | )
77 |
78 |
79 | def ms_dilate_block(in_channels, kernel_size=3, dilation=[1,1,1,1], bias=True):
80 | return MSDilateBlock(in_channels, kernel_size, dilation, bias)
81 |
82 | class MSDilateBlock(nn.Module):
83 | def __init__(self, in_channels, kernel_size, dilation, bias):
84 | super(MSDilateBlock, self).__init__()
85 | self.conv1 = conv(in_channels, in_channels, kernel_size,dilation=dilation[0], bias=bias)
86 | self.conv2 = conv(in_channels, in_channels, kernel_size,dilation=dilation[1], bias=bias)
87 | self.conv3 = conv(in_channels, in_channels, kernel_size,dilation=dilation[2], bias=bias)
88 | self.conv4 = conv(in_channels, in_channels, kernel_size,dilation=dilation[3], bias=bias)
89 | self.convi = nn.Conv2d(in_channels*4, in_channels, kernel_size=kernel_size, stride=1, padding=(kernel_size-1)//2, bias=bias)
90 | def forward(self, x):
91 | conv1 = self.conv1(x)
92 | conv2 = self.conv2(x)
93 | conv3 = self.conv3(x)
94 | conv4 = self.conv4(x)
95 | cat = torch.cat([conv1, conv2, conv3, conv4], 1)
96 | out = self.convi(cat) + x
97 | return out
98 |
99 |
100 | def cat_with_crop(target, input):
101 | output = []
102 | for item in input:
103 | if item.size()[2:] == target.size()[2:]:
104 | output.append(item)
105 | else:
106 | output.append(item[:, :, :target.size(2), :target.size(3)])
107 | output = torch.cat(output,1)
108 | return output
109 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | argparse
2 | easydict
3 | numpy
4 | matplotlib
5 | scipy
6 | opencv-python==4.0.0.21
7 | torch==0.4.1
8 | torchvision==0.2.0
9 | tensorboardX
10 | OpenEXR
11 | pyexr
12 |
--------------------------------------------------------------------------------
/runner.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | #
4 | # Developed by Shangchen Zhou
5 |
6 | import matplotlib
7 | import os
8 | # Fix problem: no $DISPLAY environment variable
9 | matplotlib.use('Agg')
10 |
11 | from argparse import ArgumentParser
12 | from pprint import pprint
13 |
14 | from config import cfg
15 | from core.build import bulid_net
16 | import torch
17 |
18 | def get_args_from_command_line():
19 | parser = ArgumentParser(description='Parser of Runner of Network')
20 | parser.add_argument('--gpu', dest='gpu_id', help='GPU device id to use [cuda]', default=cfg.CONST.DEVICE, type=str)
21 | parser.add_argument('--phase', dest='phase', help='phase of CNN', default=cfg.NETWORK.PHASE, type=str)
22 | parser.add_argument('--weights', dest='weights', help='Initialize network from the weights file', default=cfg.CONST.WEIGHTS, type=str)
23 | parser.add_argument('--data', dest='data_path', help='Set dataset root_path', default=cfg.DIR.DATASET_ROOT, type=str)
24 | parser.add_argument('--out', dest='out_path', help='Set output path', default=cfg.DIR.OUT_PATH)
25 | args = parser.parse_args()
26 | return args
27 |
28 | def main():
29 | # Get args from command line
30 | args = get_args_from_command_line()
31 |
32 | if args.gpu_id is not None:
33 | cfg.CONST.DEVICE = args.gpu_id
34 | if args.phase is not None:
35 | cfg.NETWORK.PHASE = args.phase
36 | if args.weights is not None:
37 | cfg.CONST.WEIGHTS = args.weights
38 | if args.data_path is not None:
39 | cfg.DIR.DATASET_ROOT = args.data_path
40 | if args.out_path is not None:
41 | cfg.DIR.OUT_PATH = args.out_path
42 |
43 | # Print config
44 | print('Use config:')
45 | pprint(cfg)
46 |
47 | # Set GPU to use
48 | if type(cfg.CONST.DEVICE) == str and not cfg.CONST.DEVICE == 'all':
49 | os.environ["CUDA_VISIBLE_DEVICES"] = cfg.CONST.DEVICE
50 | print('CUDA DEVICES NUMBER: '+ str(torch.cuda.device_count()))
51 |
52 | # Setup Network & Start train/test process
53 | bulid_net(cfg)
54 |
55 | if __name__ == '__main__':
56 | main()
57 |
--------------------------------------------------------------------------------
/utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sczhou/DAVANet/2bbe35ae01c0f1af718a1bc19272cda5ed3c320a/utils/__init__.py
--------------------------------------------------------------------------------
/utils/data_loaders.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | #
4 | # Developed by Shangchen Zhou
5 |
6 | import cv2
7 | import json
8 | import numpy as np
9 | import os
10 | import io
11 | import random
12 | import scipy.io
13 | import sys
14 | import torch.utils.data.dataset
15 |
16 | from config import cfg
17 | from datetime import datetime as dt
18 | from enum import Enum, unique
19 | from utils.imgio_gen import readgen
20 | import utils.network_utils
21 |
22 | class DatasetType(Enum):
23 | TRAIN = 0
24 | TEST = 1
25 |
26 | class FlyingThings3DDataset(torch.utils.data.dataset.Dataset):
27 | """DrivingDataset class used for PyTorch DataLoader"""
28 |
29 | def __init__(self, file_list_with_metadata, transforms = None):
30 | self.file_list = file_list_with_metadata
31 | self.transforms = transforms
32 |
33 | def __len__(self):
34 | return len(self.file_list)
35 |
36 | def __getitem__(self, idx):
37 | imgs, disps = self.get_datum(idx)
38 | imgs, disps = self.transforms(imgs, disps)
39 | if cfg.DATASET.WITH_MASK:
40 | occs = utils.network_utils.get_occ([img.view(1, *img.shape) for img in imgs], [disp * cfg.DATA.DIV_DISP for disp in disps], cuda=False)
41 | else:
42 | _, H, W = imgs[0].shape
43 | occs = [torch.ones((1,H,W), dtype=torch.float32), torch.ones((1,H,W), dtype=torch.float32)]
44 | name = []
45 | return name, imgs, disps, occs
46 |
47 | def get_datum(self, idx):
48 | img_left_path = self.file_list[idx]['img_left']
49 | img_right_path = self.file_list[idx]['img_right']
50 | disp_left_path = self.file_list[idx]['disp_left']
51 | disp_right_path = self.file_list[idx]['disp_right']
52 |
53 | img_left = readgen(img_left_path).astype(np.float32)
54 | img_right = readgen(img_right_path).astype(np.float32)
55 | imgs = [img_left, img_right]
56 |
57 | disp_left = readgen(disp_left_path).astype(np.float32)
58 | disp_right = readgen(disp_right_path).astype(np.float32)
59 |
60 | disps = [disp_left, disp_right]
61 | return imgs, disps
62 | # //////////////////////////////// = End of FlyingThings3DDataset Class Definition = ///////////////////////////////// #
63 |
64 | class FlyingThings3DDataLoader:
65 | def __init__(self):
66 | self.img_left_path_template = cfg.DIR.IMAGE_LEFT_PATH
67 | self.img_right_path_template = cfg.DIR.IMAGE_RIGHT_PATH
68 | self.disp_left_path_template = cfg.DIR.DISPARITY_LEFT_PATH
69 | self.disp_right_path_template = cfg.DIR.DISPARITY_RIGHT_PATH
70 | # Load all files of the dataset
71 | with io.open(cfg.DIR.DATASET_JSON_FILE_PATH, encoding='utf-8') as file:
72 | self.files_list = json.loads(file.read())
73 |
74 | def get_dataset(self, dataset_type, transforms=None):
75 | files = []
76 | # Load data for each category
77 | for file in self.files_list:
78 | if dataset_type == DatasetType.TRAIN and (file['phase'] == 'TRAIN' or file['phase'] == 'TEST'):
79 | categories = file['categories']
80 | phase = file['phase']
81 | classes = file['classes']
82 | names = file['names']
83 | samples = file['sample']
84 | print('[INFO] %s Collecting files of Taxonomy [categories = %s, phase = %s, classes = %s, names = %s]' % (
85 | dt.now(), categories, phase, classes, names))
86 | files.extend(
87 | self.get_files_of_taxonomy(categories, phase, classes, names, samples))
88 | elif dataset_type == DatasetType.TEST and file['phase'] == 'TEST':
89 | categories = file['categories']
90 | phase = file['phase']
91 | classes = file['classes']
92 | names = file['names']
93 | samples = file['sample']
94 | print('[INFO] %s Collecting files of Taxonomy [categories = %s, phase = %s, classes = %s, names = %s]' % (
95 | dt.now(), categories, phase, classes, names))
96 | files.extend(
97 | self.get_files_of_taxonomy(categories, phase, classes, names, samples))
98 |
99 | print('[INFO] %s Complete collecting files of the dataset for %s. Total files: %d.' % (dt.now(), dataset_type.name, len(files)))
100 | return FlyingThings3DDataset(files, transforms)
101 |
102 | def get_files_of_taxonomy(self,categories, phase, classes, names, samples):
103 |
104 | # n_samples = len(samples)
105 | files_of_taxonomy = []
106 | for sample_idx, sample_name in enumerate(samples):
107 | # Get file path of img
108 | img_left_path = self.img_left_path_template % (categories, phase, classes, names, sample_name)
109 | img_right_path = self.img_right_path_template % (categories, phase, classes, names, sample_name)
110 | disp_left_path = self.disp_left_path_template % (phase, classes, names, sample_name)
111 | disp_right_path = self.disp_right_path_template % (phase, classes, names, sample_name)
112 |
113 | if os.path.exists(img_left_path) and os.path.exists(img_right_path) and os.path.exists(
114 | disp_left_path) and os.path.exists(disp_right_path):
115 | files_of_taxonomy.append({
116 | 'img_left': img_left_path,
117 | 'img_right': img_right_path,
118 | 'disp_left': disp_left_path,
119 | 'disp_right': disp_right_path,
120 | 'categories': categories,
121 | 'classes' : classes,
122 | 'names': names,
123 | 'sample_name': sample_name
124 | })
125 | return files_of_taxonomy
126 | # /////////////////////////////// = End of FlyingThings3DDataLoader Class Definition = /////////////////////////////// #
127 |
128 | class StereoDeblurDataset(torch.utils.data.dataset.Dataset):
129 | """StereoDeblurDataset class used for PyTorch DataLoader"""
130 |
131 | def __init__(self, file_list_with_metadata, transforms = None):
132 | self.file_list = file_list_with_metadata
133 | self.transforms = transforms
134 |
135 | def __len__(self):
136 | return len(self.file_list)
137 |
138 | def __getitem__(self, idx):
139 | name, imgs, disps = self.get_datum(idx)
140 | imgs, disps = self.transforms(imgs, disps)
141 | occs = utils.network_utils.get_occ([img.view(1, *img.shape) for img in imgs[-2:]], [disp * cfg.DATA.DIV_DISP for disp in disps], cuda=False)
142 | # remove nan and inf pixel
143 | disps[0][occs[0]==0] = 0
144 | disps[1][occs[1]==0] = 0
145 | return name, imgs, disps, occs
146 |
147 | def get_datum(self, idx):
148 |
149 | name = self.file_list[idx]['name']
150 | img_blur_left_path = self.file_list[idx]['img_blur_left']
151 | img_blur_right_path = self.file_list[idx]['img_blur_right']
152 | img_clear_left_path = self.file_list[idx]['img_clear_left']
153 | img_clear_right_path = self.file_list[idx]['img_clear_right']
154 | disp_left_path = self.file_list[idx]['disp_left']
155 | disp_right_path = self.file_list[idx]['disp_right']
156 |
157 | img_blur_left = readgen(img_blur_left_path).astype(np.float32)
158 | img_blur_right = readgen(img_blur_right_path).astype(np.float32)
159 | img_clear_left = readgen(img_clear_left_path).astype(np.float32)
160 | img_clear_right = readgen(img_clear_right_path).astype(np.float32)
161 | imgs = [img_blur_left, img_blur_right, img_clear_left, img_clear_right]
162 |
163 | disp_left = readgen(disp_left_path).astype(np.float32)
164 | disp_right = readgen(disp_right_path).astype(np.float32)
165 |
166 | disps = [disp_left, disp_right]
167 | return name, imgs, disps
168 | # //////////////////////////////// = End of StereoDeblurDataset Class Definition = ///////////////////////////////// #
169 |
170 | class StereoDeblurLoader:
171 | def __init__(self):
172 | self.img_left_blur_path_template = cfg.DIR.IMAGE_LEFT_BLUR_PATH
173 | self.img_left_clear_path_template = cfg.DIR.IMAGE_LEFT_CLEAR_PATH
174 | self.img_right_blur_path_template = cfg.DIR.IMAGE_RIGHT_BLUR_PATH
175 | self.img_right_clear_path_template = cfg.DIR.IMAGE_RIGHT_CLEAR_PATH
176 | self.disp_left_path_template = cfg.DIR.DISPARITY_LEFT_PATH
177 | self.disp_right_path_template = cfg.DIR.DISPARITY_RIGHT_PATH
178 | # Load all files of the dataset
179 | with io.open(cfg.DIR.DATASET_JSON_FILE_PATH, encoding='utf-8') as file:
180 | self.files_list = json.loads(file.read())
181 |
182 | def get_dataset(self, dataset_type, transforms=None):
183 | files = []
184 | # Load data for each sequence
185 | for file in self.files_list:
186 | if dataset_type == DatasetType.TRAIN and file['phase'] == 'Train':
187 | name = file['name']
188 | pair_num = file['pair_num']
189 | samples = file['sample']
190 | files_num_old = len(files)
191 | files.extend(self.get_files_of_taxonomy(name, samples))
192 | print('[INFO] %s Collecting files of Taxonomy [Name = %s, Pair Numbur = %s, Loaded = %r]' % (
193 | dt.now(), name, pair_num, pair_num == (len(files)-files_num_old)))
194 | elif dataset_type == DatasetType.TEST and file['phase'] == 'Test':
195 | name = file['name']
196 | pair_num = file['pair_num']
197 | samples = file['sample']
198 | files_num_old = len(files)
199 | files.extend(self.get_files_of_taxonomy(name, samples))
200 | print('[INFO] %s Collecting files of Taxonomy [Name = %s, Pair Numbur = %s, Loaded = %r]' % (
201 | dt.now(), name, pair_num, pair_num == (len(files)-files_num_old)))
202 |
203 | print('[INFO] %s Complete collecting files of the dataset for %s. Total Pair Numbur: %d.\n' % (dt.now(), dataset_type.name, len(files)))
204 | return StereoDeblurDataset(files, transforms)
205 |
206 | def get_files_of_taxonomy(self, name, samples):
207 |
208 | # n_samples = len(samples)
209 | files_of_taxonomy = []
210 | for sample_idx, sample_name in enumerate(samples):
211 | # Get file path of img
212 | img_left_clear_path = self.img_left_clear_path_template % (name, sample_name)
213 | img_right_clear_path = self.img_right_clear_path_template % (name, sample_name)
214 | img_left_blur_path = self.img_left_blur_path_template % (name, sample_name)
215 | img_right_blur_path = self.img_right_blur_path_template % (name, sample_name)
216 | disp_left_path = self.disp_left_path_template % (name, sample_name)
217 | disp_right_path = self.disp_right_path_template % (name, sample_name)
218 |
219 | if os.path.exists(img_left_blur_path) and os.path.exists(img_right_blur_path) and os.path.exists(
220 | img_left_clear_path) and os.path.exists(img_right_clear_path) and os.path.exists(
221 | disp_left_path) and os.path.exists(disp_right_path):
222 | files_of_taxonomy.append({
223 | 'name': name,
224 | 'img_blur_left': img_left_blur_path,
225 | 'img_blur_right': img_right_blur_path,
226 | 'img_clear_left': img_left_clear_path,
227 | 'img_clear_right': img_right_clear_path,
228 | 'disp_left': disp_left_path,
229 | 'disp_right': disp_right_path,
230 | })
231 | return files_of_taxonomy
232 | # /////////////////////////////// = End of StereoDeblurLoader Class Definition = /////////////////////////////// #
233 |
234 |
235 | DATASET_LOADER_MAPPING = {
236 | 'FlyingThings3D': FlyingThings3DDataLoader,
237 | 'StereoDeblur': StereoDeblurLoader,
238 | }
239 |
--------------------------------------------------------------------------------
/utils/data_transforms.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | #
4 | # Developed by Shangchen Zhou
5 | '''ref: http://pytorch.org/docs/master/torchvision/transforms.html'''
6 |
7 |
8 | import cv2
9 | import numpy as np
10 | import torch
11 | import torchvision.transforms.functional as F
12 | from config import cfg
13 | from PIL import Image
14 | import random
15 | import numbers
16 | class Compose(object):
17 | """ Composes several co_transforms together.
18 | For example:
19 | >>> transforms.Compose([
20 | >>> transforms.CenterCrop(10),
21 | >>> transforms.ToTensor(),
22 | >>> ])
23 | """
24 |
25 | def __init__(self, transforms):
26 | self.transforms = transforms
27 |
28 | def __call__(self, inputs, disps):
29 | for t in self.transforms:
30 | inputs,disps = t(inputs, disps)
31 | return inputs, disps
32 |
33 |
34 | class ColorJitter(object):
35 | def __init__(self, color_adjust_para):
36 | """brightness [max(0, 1 - brightness), 1 + brightness] or the given [min, max]"""
37 | """contrast [max(0, 1 - contrast), 1 + contrast] or the given [min, max]"""
38 | """saturation [max(0, 1 - saturation), 1 + saturation] or the given [min, max]"""
39 | """hue [-hue, hue] 0<= hue <= 0.5 or -0.5 <= min <= max <= 0.5"""
40 | '''Ajust brightness, contrast, saturation, hue'''
41 | '''Input: PIL Image, Output: PIL Image'''
42 | self.brightness, self.contrast, self.saturation, self.hue = color_adjust_para
43 |
44 | def __call__(self, inputs, disps):
45 | inputs = [Image.fromarray(np.uint8(inp)) for inp in inputs]
46 | if self.brightness > 0:
47 | brightness_factor = np.random.uniform(max(0, 1 - self.brightness), 1 + self.brightness)
48 | inputs = [F.adjust_brightness(inp, brightness_factor) for inp in inputs]
49 |
50 | if self.contrast > 0:
51 | contrast_factor = np.random.uniform(max(0, 1 - self.contrast), 1 + self.contrast)
52 | inputs = [F.adjust_contrast(inp, contrast_factor) for inp in inputs]
53 |
54 | if self.saturation > 0:
55 | saturation_factor = np.random.uniform(max(0, 1 - self.saturation), 1 + self.saturation)
56 | inputs = [F.adjust_saturation(inp, saturation_factor) for inp in inputs]
57 |
58 | if self.hue > 0:
59 | hue_factor = np.random.uniform(-self.hue, self.hue)
60 | inputs = [F.adjust_hue(inp, hue_factor) for inp in inputs]
61 |
62 | inputs = [np.asarray(inp) for inp in inputs]
63 | inputs = [inp.clip(0,255) for inp in inputs]
64 |
65 | return inputs, disps
66 |
67 | class RandomColorChannel(object):
68 | def __call__(self, inputs, disps):
69 | random_order = np.random.permutation(3)
70 | inputs = [inp[:,:,random_order] for inp in inputs]
71 |
72 | return inputs, disps
73 |
74 | class RandomGaussianNoise(object):
75 | def __init__(self, gaussian_para):
76 | self.mu = gaussian_para[0]
77 | self.std_var = gaussian_para[1]
78 |
79 | def __call__(self, inputs, disps):
80 |
81 | shape = inputs[0].shape
82 | gaussian_noise = np.random.normal(self.mu, self.std_var, shape)
83 | # only apply to blurry images
84 | inputs[0] = inputs[0]+gaussian_noise
85 | inputs[1] = inputs[1]+gaussian_noise
86 |
87 | inputs = [inp.clip(0, 1) for inp in inputs]
88 |
89 | return inputs, disps
90 |
91 | class Normalize(object):
92 | def __init__(self, mean, std, div_disp):
93 | self.mean = mean
94 | self.std = std
95 | self.div_disp = div_disp
96 | def __call__(self, inputs, disps):
97 | assert(all([isinstance(inp, np.ndarray) for inp in inputs]))
98 | inputs = [inp/self.std -self.mean for inp in inputs]
99 | disps = [d/self.div_disp for d in disps]
100 | return inputs, disps
101 |
102 | class CenterCrop(object):
103 |
104 | def __init__(self, crop_size):
105 | """Set the height and weight before and after cropping"""
106 |
107 | self.crop_size_h = crop_size[0]
108 | self.crop_size_w = crop_size[1]
109 |
110 | def __call__(self, inputs, disps):
111 | input_size_h, input_size_w, _ = inputs[0].shape
112 | x_start = int(round((input_size_w - self.crop_size_w) / 2.))
113 | y_start = int(round((input_size_h - self.crop_size_h) / 2.))
114 |
115 | inputs = [inp[y_start: y_start + self.crop_size_h, x_start: x_start + self.crop_size_w] for inp in inputs]
116 | disps = [disp[y_start: y_start + self.crop_size_h, x_start: x_start + self.crop_size_w] for disp in disps]
117 |
118 | return inputs, disps
119 |
120 | class RandomCrop(object):
121 |
122 | def __init__(self, crop_size):
123 | """Set the height and weight before and after cropping"""
124 | self.crop_size_h = crop_size[0]
125 | self.crop_size_w = crop_size[1]
126 |
127 | def __call__(self, inputs, disps):
128 | input_size_h, input_size_w, _ = inputs[0].shape
129 | x_start = random.randint(0, input_size_w - self.crop_size_w)
130 | y_start = random.randint(0, input_size_h - self.crop_size_h)
131 | inputs = [inp[y_start: y_start + self.crop_size_h, x_start: x_start + self.crop_size_w] for inp in inputs]
132 | disps = [disp[y_start: y_start + self.crop_size_h, x_start: x_start + self.crop_size_w] for disp in disps]
133 |
134 | return inputs, disps
135 |
136 | class RandomHorizontalFlip(object):
137 | """Randomly horizontally flips the given PIL.Image with a probability of 0.5 left-right"""
138 |
139 | def __call__(self, inputs, disps):
140 | if random.random() < 0.5:
141 | '''Change the order of 0 and 1, for keeping the net search direction'''
142 | inputs[0] = np.copy(np.fliplr(inputs[1]))
143 | inputs[1] = np.copy(np.fliplr(inputs[0]))
144 | inputs[2] = np.copy(np.fliplr(inputs[3]))
145 | inputs[3] = np.copy(np.fliplr(inputs[2]))
146 |
147 | disps[0] = np.copy(np.fliplr(disps[1]))
148 | disps[1] = np.copy(np.fliplr(disps[0]))
149 |
150 | return inputs, disps
151 |
152 |
153 | class RandomVerticalFlip(object):
154 | """Randomly vertically flips the given PIL.Image with a probability of 0.5 up-down"""
155 | def __call__(self, inputs, disps):
156 | if random.random() < 0.5:
157 | inputs = [np.copy(np.flipud(inp)) for inp in inputs]
158 | disps = [np.copy(np.flipud(disp)) for disp in disps]
159 | return inputs, disps
160 |
161 |
162 | class ToTensor(object):
163 | """Converts a numpy.ndarray (H x W x C) to a torch.FloatTensor of shape (C x H x W)."""
164 |
165 | def __call__(self, inputs, disps):
166 | assert(isinstance(inputs[0], np.ndarray) and isinstance(inputs[1], np.ndarray))
167 | inputs = [np.transpose(inp, (2, 0, 1)) for inp in inputs]
168 | inputs_tensor = [torch.from_numpy(inp).float() for inp in inputs]
169 |
170 | assert(isinstance(disps[0], np.ndarray) and isinstance(disps[1], np.ndarray))
171 | disps_tensor = [torch.from_numpy(d) for d in disps]
172 | disps_tensor = [d.view(1, d.size()[0],d.size()[1]).float() for d in disps_tensor]
173 | return inputs_tensor, disps_tensor
174 |
175 |
--------------------------------------------------------------------------------
/utils/imgio_gen.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3.4
2 |
3 | import os
4 | import re
5 | import numpy as np
6 | import uuid
7 | from scipy import misc
8 | import numpy as np
9 | import pyexr
10 | import sys
11 | import cv2
12 |
13 | def readgen(file):
14 | if file.endswith('.float3'): return readFloat(file)
15 | elif file.endswith('.flo'): return readFlow(file)
16 | elif file.endswith('.ppm'): return readImage(file)
17 | elif file.endswith('.pgm'): return readImage(file)
18 | elif file.endswith('.png'): return readImage(file)
19 | elif file.endswith('.jpg'): return readImage(file)
20 | elif file.endswith('.pfm'): return readPFM(file)[0]
21 | elif file.endswith('.exr'): return pyexr.open(file).get() #https://github.com/tvogels/pyexr
22 | else: raise Exception('don\'t know how to read %s' % file)
23 |
24 | def writegen(file, data):
25 | if file.endswith('.float3'): return writeFloat(file, data)
26 | elif file.endswith('.flo'): return writeFlow(file, data)
27 | elif file.endswith('.ppm'): return writeImage(file, data)
28 | elif file.endswith('.pgm'): return writeImage(file, data)
29 | elif file.endswith('.png'): return writeImage(file, data)
30 | elif file.endswith('.jpg'): return writeImage(file, data)
31 | elif file.endswith('.pfm'): return writePFM(file, data)
32 | elif file.endswith('.exr'): return pyexr.write(file, data) #https://github.com/tvogels/pyexr
33 | else: raise Exception('don\'t know how to write %s' % file)
34 |
35 | def readPFM(file):
36 | file = open(file, 'rb')
37 |
38 | color = None
39 | width = None
40 | height = None
41 | scale = None
42 | endian = None
43 |
44 | header = file.readline().rstrip()
45 | if header.decode("ascii") == 'PF':
46 | color = True
47 | elif header.decode("ascii") == 'Pf':
48 | color = False
49 | else:
50 | raise Exception('Not a PFM file.')
51 |
52 | dim_match = re.match(r'^(\d+)\s(\d+)\s$', file.readline().decode("ascii"))
53 | if dim_match:
54 | width, height = list(map(int, dim_match.groups()))
55 | else:
56 | raise Exception('Malformed PFM header.')
57 |
58 | scale = float(file.readline().decode("ascii").rstrip())
59 | if scale < 0: # little-endian
60 | endian = '<'
61 | scale = -scale
62 | else:
63 | endian = '>' # big-endian
64 |
65 | data = np.fromfile(file, endian + 'f')
66 | shape = (height, width, 3) if color else (height, width)
67 |
68 | data = np.reshape(data, shape)
69 | data = np.flipud(data)
70 | return data, scale
71 |
72 | def writePFM(file, image, scale=1):
73 | file = open(file, 'wb')
74 | color = None
75 | if image.dtype.name != 'float32':
76 | raise Exception('Image dtype must be float32.')
77 |
78 | image = np.flipud(image)
79 |
80 | if len(image.shape) == 3 and image.shape[2] == 3: # color image
81 | color = True
82 | elif len(image.shape) == 2 or len(image.shape) == 3 and image.shape[2] == 1: # greyscale
83 | color = False
84 | else:
85 | raise Exception('Image must have H x W x 3, H x W x 1 or H x W dimensions.')
86 |
87 | file.write('PF\n' if color else 'Pf\n'.encode())
88 | file.write('%d %d\n'.encode() % (image.shape[1], image.shape[0]))
89 |
90 | endian = image.dtype.byteorder
91 |
92 | if endian == '<' or endian == '=' and sys.byteorder == 'little':
93 | scale = -scale
94 |
95 | file.write('%f\n'.encode() % scale)
96 |
97 | image.tofile(file)
98 |
99 | def readFlow(name):
100 | if name.endswith('.pfm') or name.endswith('.PFM'):
101 | return readPFM(name)[0][:,:,0:2]
102 |
103 | f = open(name, 'rb')
104 |
105 | header = f.read(4)
106 | if header.decode("utf-8") != 'PIEH':
107 | raise Exception('Flow file header does not contain PIEH')
108 |
109 | width = np.fromfile(f, np.int32, 1).squeeze()
110 | height = np.fromfile(f, np.int32, 1).squeeze()
111 |
112 | flow = np.fromfile(f, np.float32, width * height * 2).reshape((height, width, 2))
113 |
114 | return flow.astype(np.float32)
115 |
116 | def readImage(name):
117 | if name.endswith('.pfm') or name.endswith('.PFM'):
118 | data = readPFM(name)[0]
119 | if len(data.shape)==3:
120 | return data[:,:,0:3]
121 | else:
122 | return data
123 |
124 | return cv2.imread(name)
125 |
126 | def writeImage(name, data):
127 | if name.endswith('.pfm') or name.endswith('.PFM'):
128 | return writePFM(name, data, 1)
129 |
130 | return misc.imsave(name, data)
131 |
132 | def writeFlow(name, flow):
133 | f = open(name, 'wb')
134 | f.write('PIEH'.encode('utf-8'))
135 | np.array([flow.shape[1], flow.shape[0]], dtype=np.int32).tofile(f)
136 | flow = flow.astype(np.float32)
137 | flow.tofile(f)
138 |
139 | def readFloat(name):
140 | f = open(name, 'rb')
141 |
142 | if(f.readline().decode("utf-8")) != 'float\n':
143 | raise Exception('float file %s did not contain keyword' % name)
144 |
145 | dim = int(f.readline())
146 |
147 | dims = []
148 | count = 1
149 | for i in range(0, dim):
150 | d = int(f.readline())
151 | dims.append(d)
152 | count *= d
153 |
154 | dims = list(reversed(dims))
155 |
156 | data = np.fromfile(f, np.float32, count).reshape(dims)
157 | if dim > 2:
158 | data = np.transpose(data, (2, 1, 0))
159 | data = np.transpose(data, (1, 0, 2))
160 |
161 | return data
162 |
163 | def writeFloat(name, data):
164 | f = open(name, 'wb')
165 |
166 | dim=len(data.shape)
167 | if dim>3:
168 | raise Exception('bad float file dimension: %d' % dim)
169 |
170 | f.write(('float\n').encode('ascii'))
171 | f.write(('%d\n' % dim).encode('ascii'))
172 |
173 | if dim == 1:
174 | f.write(('%d\n' % data.shape[0]).encode('ascii'))
175 | else:
176 | f.write(('%d\n' % data.shape[1]).encode('ascii'))
177 | f.write(('%d\n' % data.shape[0]).encode('ascii'))
178 | for i in range(2, dim):
179 | f.write(('%d\n' % data.shape[i]).encode('ascii'))
180 |
181 | data = data.astype(np.float32)
182 | if dim==2:
183 | data.tofile(f)
184 |
185 | else:
186 | np.transpose(data, (2, 0, 1)).tofile(f)
187 |
--------------------------------------------------------------------------------
/utils/network_utils.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/python
2 | # -*- coding: utf-8 -*-
3 | #
4 | # Developed by Shangchen Zhou
5 |
6 | import os
7 | import sys
8 | import torch
9 | import numpy as np
10 | from datetime import datetime as dt
11 | from config import cfg
12 | import torch.nn.functional as F
13 |
14 | import cv2
15 |
16 | def mkdir(path):
17 | if not os.path.isdir(path):
18 | mkdir(os.path.split(path)[0])
19 | else:
20 | return
21 | os.mkdir(path)
22 |
23 | def var_or_cuda(x):
24 | if torch.cuda.is_available():
25 | x = x.cuda(non_blocking=True)
26 | return x
27 |
28 |
29 | def init_weights_xavier(m):
30 | if isinstance(m, torch.nn.Conv2d) or isinstance(m, torch.nn.ConvTranspose2d):
31 | torch.nn.init.xavier_uniform_(m.weight)
32 | if m.bias is not None:
33 | torch.nn.init.constant_(m.bias, 0)
34 | elif type(m) == torch.nn.BatchNorm2d or type(m) == torch.nn.InstanceNorm2d:
35 | if m.weight is not None:
36 | torch.nn.init.constant_(m.weight, 1)
37 | torch.nn.init.constant_(m.bias, 0)
38 | elif type(m) == torch.nn.Linear:
39 | torch.nn.init.normal_(m.weight, 0, 0.01)
40 | torch.nn.init.constant_(m.bias, 0)
41 |
42 | def init_weights_kaiming(m):
43 | if isinstance(m, torch.nn.Conv2d) or isinstance(m, torch.nn.ConvTranspose2d):
44 | torch.nn.init.kaiming_normal_(m.weight)
45 | if m.bias is not None:
46 | torch.nn.init.constant_(m.bias, 0)
47 | elif type(m) == torch.nn.BatchNorm2d or type(m) == torch.nn.InstanceNorm2d:
48 | if m.weight is not None:
49 | torch.nn.init.constant_(m.weight, 1)
50 | torch.nn.init.constant_(m.bias, 0)
51 | elif type(m) == torch.nn.Linear:
52 | torch.nn.init.normal_(m.weight, 0, 0.01)
53 | torch.nn.init.constant_(m.bias, 0)
54 |
55 | def save_disp_checkpoints(file_path, epoch_idx, dispnet, dispnet_solver, Best_Disp_EPE, Best_Epoch):
56 | print('[INFO] %s Saving checkpoint to %s ...' % (dt.now(), file_path))
57 | checkpoint = {
58 | 'epoch_idx': epoch_idx,
59 | 'Best_Disp_EPE': Best_Disp_EPE,
60 | 'Best_Epoch': Best_Epoch,
61 | 'dispnet_state_dict': dispnet.state_dict(),
62 | 'dispnet_solver_state_dict': dispnet_solver.state_dict(),
63 | }
64 | torch.save(checkpoint, file_path)
65 |
66 | def save_deblur_checkpoints(file_path, epoch_idx, deblurnet, deblurnet_solver, Best_Img_PSNR, Best_Epoch):
67 | print('[INFO] %s Saving checkpoint to %s ...\n' % (dt.now(), file_path))
68 | checkpoint = {
69 | 'epoch_idx': epoch_idx,
70 | 'Best_Img_PSNR': Best_Img_PSNR,
71 | 'Best_Epoch': Best_Epoch,
72 | 'deblurnet_state_dict': deblurnet.state_dict(),
73 | 'deblurnet_solver_state_dict': deblurnet_solver.state_dict(),
74 | }
75 | torch.save(checkpoint, file_path)
76 |
77 | def save_checkpoints(file_path, epoch_idx, dispnet, dispnet_solver, deblurnet, deblurnet_solver, Disp_EPE, Best_Img_PSNR, Best_Epoch):
78 | print('[INFO] %s Saving checkpoint to %s ...' % (dt.now(), file_path))
79 | checkpoint = {
80 | 'epoch_idx': epoch_idx,
81 | 'Disp_EPE': Disp_EPE,
82 | 'Best_Img_PSNR': Best_Img_PSNR,
83 | 'Best_Epoch': Best_Epoch,
84 | 'dispnet_state_dict': dispnet.state_dict(),
85 | 'dispnet_solver_state_dict': dispnet_solver.state_dict(),
86 | 'deblurnet_state_dict': deblurnet.state_dict(),
87 | 'deblurnet_solver_state_dict': deblurnet_solver.state_dict(),
88 | }
89 | torch.save(checkpoint, file_path)
90 |
91 | def count_parameters(model):
92 | return sum(p.numel() for p in model.parameters())
93 |
94 | def get_weight_parameters(model):
95 | return [param for name, param in model.named_parameters() if ('weight' in name)]
96 |
97 | def get_bias_parameters(model):
98 | return [param for name, param in model.named_parameters() if ('bias' in name)]
99 |
100 | class AverageMeter(object):
101 | """Computes and stores the average and current value"""
102 | def __init__(self):
103 | self.reset()
104 |
105 | def reset(self):
106 | self.val = 0
107 | self.avg = 0
108 | self.sum = 0
109 | self.count = 0
110 |
111 | def update(self, val, n=1):
112 | self.val = val
113 | self.sum += val * n
114 | self.count += n
115 | self.avg = self.sum / self.count
116 |
117 | def __repr__(self):
118 | return '{:.5f} ({:.5f})'.format(self.val, self.avg)
119 |
120 | '''input Tensor: 2 H W'''
121 | def graybi2rgb(graybi):
122 | assert(isinstance(graybi, torch.Tensor))
123 | global args
124 | _, H, W = graybi.shape
125 | rgb_1 = torch.zeros((3,H,W))
126 | rgb_2 = torch.zeros((3,H,W))
127 | normalized_gray_map = graybi / (graybi.max())
128 | rgb_1[0] = normalized_gray_map[0]
129 | rgb_1[1] = normalized_gray_map[0]
130 | rgb_1[2] = normalized_gray_map[0]
131 |
132 | rgb_2[0] = normalized_gray_map[1]
133 | rgb_2[1] = normalized_gray_map[1]
134 | rgb_2[2] = normalized_gray_map[1]
135 | return rgb_1.clamp(0,1), rgb_2.clamp(0,1)
136 |
137 |
138 | def get_occ(imgs, disps, cuda = True):
139 | '''
140 | img: b, c, h, w
141 | disp: b, h, w
142 | '''
143 | assert(isinstance(imgs[0], torch.Tensor) and isinstance(imgs[1], torch.Tensor))
144 | assert(isinstance(disps[0], torch.Tensor) and isinstance(disps[1], torch.Tensor))
145 | if cuda == True:
146 | imgs = [var_or_cuda(img) for img in imgs]
147 | disps = [var_or_cuda(disp) for disp in disps]
148 | alpha = 0.001
149 | beta = 0.005
150 | B, _, H, W = imgs[0].shape
151 | disp_left = disps[0]
152 | disp_right = disps[1]
153 | mask0_lelf = ~np.logical_or(torch.isnan(disp_left), torch.isinf(disp_left))
154 | mask0_right = ~np.logical_or(torch.isnan(disp_right), torch.isinf(disp_right))
155 | disp_left[torch.isnan(disp_left)] = 0.0
156 | disp_right[torch.isnan(disp_right)] = 0.0
157 | disp_left[torch.isinf(disp_left)] = 0.0
158 | disp_right[torch.isinf(disp_right)] = 0.0
159 |
160 | img_warp_left = disp_warp(imgs[1], -disp_left, cuda = cuda)
161 | img_warp_right = disp_warp(imgs[0], disp_right, cuda = cuda)
162 |
163 | diff_left = (imgs[0] - img_warp_left)**2 - (alpha*(imgs[0]**2 + img_warp_left**2) + beta)
164 | mask1_left = torch.sum(diff_left, 1)<=0
165 | occ_left = torch.zeros((B,H,W), dtype=torch.float32)
166 | occ_left[np.logical_and(mask0_lelf, mask1_left)] = 1
167 |
168 | diff_right = (imgs[1] - img_warp_right)**2 - (alpha*(imgs[1]**2 + img_warp_right**2) + beta)
169 | mask1_right = torch.sum(diff_right, 1)<=0
170 | occ_right = torch.zeros((B,H,W), dtype=torch.float32)
171 | occ_right[np.logical_and(mask0_right, mask1_right)] = 1
172 |
173 | return [occ_left, occ_right]
174 |
175 |
176 | def disp_warp(img, disp, cuda=True):
177 | '''
178 | img.shape = b, c, h, w
179 | disp.shape = b, h, w
180 | '''
181 | b, c, h, w = img.shape
182 | if cuda == True:
183 | right_coor_x = (torch.arange(start=0, end=w, out=torch.cuda.FloatTensor())).repeat(b, h, 1)
184 | right_coor_y = (torch.arange(start=0, end=h, out=torch.cuda.FloatTensor())).repeat(b, w, 1).transpose(1, 2)
185 | else:
186 | right_coor_x = (torch.arange(start=0, end=w, out=torch.FloatTensor())).repeat(b, h, 1)
187 | right_coor_y = (torch.arange(start=0, end=h, out=torch.FloatTensor())).repeat(b, w, 1).transpose(1, 2)
188 | left_coor_x1 = right_coor_x + disp
189 | left_coor_norm1 = torch.stack((left_coor_x1 / (w - 1) * 2 - 1, right_coor_y / (h - 1) * 2 - 1), dim=1)
190 | ## backward warp
191 | warp_img = torch.nn.functional.grid_sample(img, left_coor_norm1.permute(0, 2, 3, 1))
192 |
193 | return warp_img
194 |
--------------------------------------------------------------------------------