├── Home.md
├── video
├── GOTO-2017-The-Many-Meanings-of-Event-Driven-Architecture-Martin-Fowler.md
├── Functional-programming-design-patterns-by-Scott-Wlaschin.md
├── GOTO 2014 Microservices Martin Fowler.md
├── AWS-re-Invent-2016-From-Resilience-to-Ubiquity.md
└── A-Netflix-Guide-to-Microservices-QCon2016.md
├── README.md
├── config.ru
├── edu
└── Architecting-on-AWS.md
├── scala.md
├── java9-jshell.md
├── agile_software_development_with_scrum.md
├── zuul.md
├── google_cloud_sql.md
├── book
├── advanced-analytics-with-spark.md
└── building-microservices.md
├── java_cachelock.md
├── galeracluster_for_mysql.md
└── 7-part_series_about_microservices.md
/Home.md:
--------------------------------------------------------------------------------
1 | # TIL(Today I Learned) Home
2 | 참고 url : [https://github.com/milooy/TIL](https://github.com/milooy/TIL)
--------------------------------------------------------------------------------
/video/GOTO-2017-The-Many-Meanings-of-Event-Driven-Architecture-Martin-Fowler.md:
--------------------------------------------------------------------------------
1 | https://www.youtube.com/watch?v=STKCRSUsyP0
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # study
2 | 공부합시다.
3 |
4 | * [7-part series about microservices](https://github.com/seongminwoo/study/blob/master/7-part_series_about_microservices.md)
5 | * [wiki 끄적끄적](https://github.com/seongminwoo/study/wiki)
6 |
--------------------------------------------------------------------------------
/config.ru:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env ruby
2 | require 'rubygems'
3 | require 'gollum/app'
4 |
5 | gollum_path = File.expand_path(File.dirname(__FILE__)) # CHANGE THIS TO POINT TO YOUR OWN WIKI REPO
6 | Precious::App.set(:gollum_path, gollum_path)
7 | Precious::App.set(:default_markup, :markdown) # set your favorite markup language
8 | Precious::App.set(:wiki_options, {
9 | :universal_toc => true,
10 | :mathjax => true,
11 | :live_preview => false,
12 | :css => true,
13 | :js => true
14 | })
15 | run Precious::App
16 |
--------------------------------------------------------------------------------
/edu/Architecting-on-AWS.md:
--------------------------------------------------------------------------------
1 | ## 교육 개요
2 | https://aws.amazon.com/ko/training/course-descriptions/architect/
3 |
4 | ### Course Outline
5 |
6 | #### Day 1
7 | * Core AWS Knowledge
8 | * Designing Your Environment
9 | * Making Your Environment Highly Available
10 | * Forklifting an Existing Application onto AWS
11 |
12 | #### Day 2
13 | * Event-Driven Scaling
14 | * Automating and Decoupling Your Infrastructure
15 | * Designing Storage at Scale
16 | * Hosting a New Web Application on AWS
17 |
18 | #### Day 3
19 | * The Four Pillars of the Well-Architected Framework
20 | * Disaster Recovery and Failover Strategies
21 | * Troubleshooting Your Environment
22 | * Large-Scale Design Patterns and Case Studies
23 |
24 | ## 정리
25 |
26 | ## 레퍼런스
27 | https://www.aws.training/
28 | https://online.vitalsource.com
29 | https://cloudcraft.co/
30 | https://aws.amazon.com/ko/architecture/
--------------------------------------------------------------------------------
/scala.md:
--------------------------------------------------------------------------------
1 | ### reference
2 | * http://seoh.blog/2015/01/18/transitioning-to-scala
3 | * http://www.scala-lang.org/old/node/8610
4 | * http://docs.scala-lang.org/ko/tutorials/tour/tour-of-scala.html
5 | * https://learnxinyminutes.com/docs/scala
6 | * https://twitter.github.io/scala_school/ko/index.html
7 | * https://slipp.net/wiki/display/java/Scala
8 | * http://stackoverflow.com/tags/scala/info
9 | * http://www.scala-lang.org/docu/files/ScalaByExample.pdf
10 | * http://www.scala-lang.org/api/current/
11 | * http://docs.scala-lang.org/glossary/
12 | * http://docs.scala-lang.org/cheatsheets/
13 |
14 | ### library
15 | https://github.com/scalaz/scalaz
16 | https://github.com/twitter/finagle
17 |
18 | ### online IDE
19 | https://www.tutorialspoint.com/compile_scala_online.php
20 |
21 | ### online judge
22 | http://www.spoj.com/
23 |
24 | ### video
25 | [Martin Odersky, "Working Hard to Keep It Simple" - OSCON Java 2011](https://www.youtube.com/watch?v=3jg1AheF4n0)
26 |
--------------------------------------------------------------------------------
/video/Functional-programming-design-patterns-by-Scott-Wlaschin.md:
--------------------------------------------------------------------------------
1 | https://www.youtube.com/watch?v=E8I19uA-wGY
2 |
3 |  4 |
4 |  5 |
5 |  6 |
6 |  7 |
7 |  8 |
8 |  9 |
9 |  10 |
--------------------------------------------------------------------------------
/java9-jshell.md:
--------------------------------------------------------------------------------
1 | ## Java 9 interpreter(REPL, Read Evaluate Print Loop)
2 | 드디어 자바에도 REPL(레플)이!!
3 | 프로젝트 생성없이 빠르게 코드 작성해서 테스트 및 실험 가능한 장점!!(quick feedback loop) 노클래스! 노메소드! 노컴파일!
4 |
5 | ## java9 설치 및 jenv로 멀티 자바 버전 관리
6 | ```
7 | brew, cask 없을 경우 설치
8 |
9 | brew, cask 업데이트
10 | $ brew update && brew cleanup && brew cask cleanup
11 |
12 | java 최신버전 설치하기(java9 출시되면서 아래 명령어로 java9 설치가능)
13 | $ brew cask install java
14 |
15 | ~~1.9-beta 설치하기 ~~
16 | ~~$ brew cask install java9-beta~~
17 |
18 | 사용해서 java version 관리하기
19 | $ brew install jenv
20 | $ echo 'export PATH="$HOME/.jenv/bin:$PATH"' >> ~/.bash_profile
21 | $ echo 'eval "$(jenv init -)"' >> ~/.bash_profile
22 | $ /usr/libexec/java_home -V
23 | $ jenv add /Library/Java/JavaVirtualMachines/jdk1.8.0_92.jdk/Contents/Home
24 | Or
25 | $ jenv add $(/usr/libexec/java_home -v1.8)
26 | $ jenv add /Library/Java/JavaVirtualMachines/jdk-9.jdk/Contents/Home
27 | Or
28 | $ jenny add $(/usr/libexec/java_home -v9)
29 | $ jenv versions
30 | $ jenv global oracle64-1.8.0.92
31 | Or
32 | $ jenv local oracle64-1.8.0.92
33 | ```
34 |
35 | ### reference
36 | * http://www.jenv.be/
37 | * http://davidcai.github.io/blog/posts/install-multiple-jdk-on-mac/
38 | * https://crazysalaryman.wordpress.com/2015/03/14/jenv-%EC%82%AC%EC%9A%A9%ED%95%98%EA%B8%B0/
39 |
40 | ## 기억해둘만한 내용
41 | [Exploring Java 9 by Venkat Subramaniam](https://www.youtube.com/watch?v=8XmYT89fBKg)
42 |
10 |
--------------------------------------------------------------------------------
/java9-jshell.md:
--------------------------------------------------------------------------------
1 | ## Java 9 interpreter(REPL, Read Evaluate Print Loop)
2 | 드디어 자바에도 REPL(레플)이!!
3 | 프로젝트 생성없이 빠르게 코드 작성해서 테스트 및 실험 가능한 장점!!(quick feedback loop) 노클래스! 노메소드! 노컴파일!
4 |
5 | ## java9 설치 및 jenv로 멀티 자바 버전 관리
6 | ```
7 | brew, cask 없을 경우 설치
8 |
9 | brew, cask 업데이트
10 | $ brew update && brew cleanup && brew cask cleanup
11 |
12 | java 최신버전 설치하기(java9 출시되면서 아래 명령어로 java9 설치가능)
13 | $ brew cask install java
14 |
15 | ~~1.9-beta 설치하기 ~~
16 | ~~$ brew cask install java9-beta~~
17 |
18 | 사용해서 java version 관리하기
19 | $ brew install jenv
20 | $ echo 'export PATH="$HOME/.jenv/bin:$PATH"' >> ~/.bash_profile
21 | $ echo 'eval "$(jenv init -)"' >> ~/.bash_profile
22 | $ /usr/libexec/java_home -V
23 | $ jenv add /Library/Java/JavaVirtualMachines/jdk1.8.0_92.jdk/Contents/Home
24 | Or
25 | $ jenv add $(/usr/libexec/java_home -v1.8)
26 | $ jenv add /Library/Java/JavaVirtualMachines/jdk-9.jdk/Contents/Home
27 | Or
28 | $ jenny add $(/usr/libexec/java_home -v9)
29 | $ jenv versions
30 | $ jenv global oracle64-1.8.0.92
31 | Or
32 | $ jenv local oracle64-1.8.0.92
33 | ```
34 |
35 | ### reference
36 | * http://www.jenv.be/
37 | * http://davidcai.github.io/blog/posts/install-multiple-jdk-on-mac/
38 | * https://crazysalaryman.wordpress.com/2015/03/14/jenv-%EC%82%AC%EC%9A%A9%ED%95%98%EA%B8%B0/
39 |
40 | ## 기억해둘만한 내용
41 | [Exploring Java 9 by Venkat Subramaniam](https://www.youtube.com/watch?v=8XmYT89fBKg)
42 |  43 |
44 |
43 |
44 |  45 |
46 |
45 |
46 |  47 |
48 |
47 |
48 |  49 |
50 |
49 |
50 |  51 |
52 |
51 |
52 |  53 |
54 |
53 |
54 |  55 |
56 |
55 |
56 |  57 |
58 |
59 | ## reference
60 | * http://jakubdziworski.github.io/java/2016/07/31/jshell-getting-started-examples.html
61 | * https://www.youtube.com/watch?v=8XmYT89fBKg
62 |
--------------------------------------------------------------------------------
/agile_software_development_with_scrum.md:
--------------------------------------------------------------------------------
1 | 책 정리 "Agile Software Development with Scrum" by 켄 슈와버, 마이크 버들
2 |
3 | ### 스크럼의 실천법
4 | #### 스크럼 마스터(Scrum Master)
5 | - 스크럼을 통해서 알려진 새로운 유형의 관리자다.
6 | - SM은 경영진에게는 팀의 입장을, 팀에게는 경영진의 입장을 대변한다.
7 | - 스크럼 마스터는 고객 및 관리자와 함께 제품 책임자(Product Owner)로 적합한 인물을 찾아내서 임명한다. 그후 관리자와 함께 상의해서 스크럼 팀을 조직한다.
8 | - 보통 팀 리더, 프로젝트 리더 혹은 프로젝트 관리자가 스크럼 마스터의 역할을 수행한다.
9 | - 어떻게 팀이 가능한 최고 수준의 생산성을 유지하게 할 수 있을까? 스크럼 마스터는 주로 결정을 내리고 장애 요소를 제거하는 방식으로 그와 같이 할 수 있다.
10 |
11 | #### 제품 백로그(Product Backlog)
12 | - 제품 백로그란 개발해야 할 기능들을 사업상의 중요도에 따라 구분한 목록으로서 개발 과정에서 끊임없이 진화한다.
13 | - 제품을 성장시켜 나가고 자신에게 필요한 것이 무엇인지에 대한 고객의 이해가 깊어짐에 따라 제품 백로그는 허술한 초기의 목록에서 시작해 점점 발전해 나간다.
14 | 제품 백로그는 우선순위에 따라 나열된다.
15 | - 우리에게 필요한 것은 단지 제품의 비전과 한 회의 반복 주기, 즉 스프린트를 시작할 수 있을 정도의 최우선 백로그 항목들뿐이다.
16 | - 제품 책임자(Product Owner)가 제품 백로그를 관리하고 통제할 권한을 가진다. 한 명이 아니라 여러 명이 되면, 팀은 허둥대고 질질 끄려다니다가 끊임없는 논쟁 끝에 결국 좌초하게 될 것이다.
17 | - 백로그가 만들어지면 제품 책임자는 다른 사람들과 함께 그것을 개발하는데 얼마나 걸릴지 추정한다.
18 |
19 | #### 스크럼 팀
20 | - 팀은 스크럼 목표를 달성하기 위해서 헌신한다. 팀은 목표를 달성하기 위해서 필요한 것이라면 무엇이든 할 수 있는 권한을 부여 받는다.
21 | - 팀의 크기는 7명이 이상적이며, 5명 미만이거나 9명을 초과해서는 안 된다.
22 | - 대부분의 개발 프로세스에서는 관리자가 각 팀원에게 무엇을 언제까지 해야 한다고 지시한다. 이런 방식으로 어떻게 관리자가 팀의 헌신을 이끌어낼 수 있을까?
23 | - 팀의 구성과 상관없이 분석에서부터 설계, 코딩, 테스트 및 사용자 문서 작성에 이르기 까지 필요한 모든 일을 팀 스스로 해내야 한다.
24 |
25 | #### 일일 스크럼 회의(Daily Scrum Meetings)
26 | - 15분짜리 현황 파악 회의
27 | - 소프트웨어 개발은 엄청난 의사소통을 필요로 하는 복잡한 프로세스다. 팀에게 있어서 일일 스크럼 회의는 의사소통의 장이다.
28 | - 스크럼 마스터는 규칙을 강조하고 사람들이 간결하게 말하도록 해서 일일 스크럼 회의가 길어지지 않도록 해야 한다.
29 | - 일일 스크럼 회의는 설계 회의가 아니며 작업 회의처럼 돌변해서도 안 된다.
30 | - 관리자들은 일일 스크럼 회의에서 오고 가는 이야기들에 주의를 기울임으로써 팀이 어떤 일을 하고 있고, 그것이 성공할 것 같은지 아닌지에 대한 감을 얻을 수 있다.
31 | - 팀원이 프로젝트에 흥미를 잃었는가? 가족 문제로 누군가가 일에서 손을 놓고 있지는 않은가? 어떤 사안에 대해서 팀 내에 불화가 있지는 않은가? 회의 중에 어떤 태도들을 보이는가? 등등 팀의상황을 지속적으로 관찰하기기 쉽다.
32 | ```
33 | 1) 지나 일일 스크럼 이후 무엇을 했는가?
34 | 2) 지금부터 다음 일일 스크럼까지 무엇을 하려고 하는가?
35 | 3) 업무를 하는데 무엇이 방해되는가?
36 | ```
37 |
38 | #### 스프린트 계획 회의
39 | - 고객, 사용자, 경영진, 제품 책임자의 스크럼 팀은 스프린트 계획 회의에서 다음 스프린트의 목표와 기능을 결정한다. 그 다음, 팀은 제품 증분을 개발하기 위해서 필요한 개별 태스크들을 도출한다.
40 | - 다음 스프린트의 목표 선정과 제품 백로그 확정, 스프린트 목표에 맞게 스프린트 백로그 정의하기.
41 |
42 | #### 스프린트(Sprint)
43 | - 개발팀은 스프린트라고 불리는 한정된 기간 동안 일을 한다. 30일이 적당. 그 이상이 되면 관리자가 참견하고 싶은 욕망을 억누르기 어렵기 때문이다.
44 | - 스크럼은 사람들에게 불가능한 복잡성으로부터 예측 가능한 제품을 쥐어 짜내도록 요구한다. 성공적으로 스크럼에 적응하는 사람들은 한 조직의 중핵을 담당할 만한 인물들이다. 스크럼은 이런 사람들을 판별하는데 도움이 된다.
45 | - 일단 창조적인 분위기로 흐르게 되면 팀의 창조성과 생산성이 급격히 상승한다.
46 | - 스프린트는 직원들이 할 일이 무엇인지 알고 그것을 해낼 수 있다는 것을 놓고 관리자와 내기를 하는 것 과 같다.
47 | - 일일 빌드(Daily product builds)는 팀의 진척도를 측정하는 훌륭한 수단이다.
48 |
49 | #### 스프린트 검토(Sprint Review)
50 | - 정보 전달을 위한 회의로 네 시간이 소요된다. 이 회의에서 팀은 경영진, 고객들, 사용자들과 제품 책임자에게 자신들이 이번 스프린트에서 개발한 제품 증분을 선보인다.
51 | - 30일 간의 스프린트 주기는 팀원들의 삶과 심지어 회사에서의 삶에 의미 있는 리듬을 제공해 준다. 30일마다 열리는 스프린트 검토 회의와 나머지 29일 동안 개발이 진행되는 식의 리듬 말이다.
52 | - 스프린트 검토 회의 동안, 참석한 모든 사람들은 시연중인 제품의 기능이 사용자 환경에서 어떻게 돌아갈지를 직접 보게 된다. 제품을직접 보면서, 다음 스프린트에는 어떤 기능이 추가되어야 할지를 고려하게 된다. 이런 제품 증분은 브레인스토밍에서 중심(focal point)이 된다.
53 |
--------------------------------------------------------------------------------
/zuul.md:
--------------------------------------------------------------------------------
1 | ## zuul
2 | https://github.com/Netflix/zuul/wiki
3 | https://medium.com/netflix-techblog/announcing-zuul-edge-service-in-the-cloud-ab3af5be08ee
4 |
5 | ### 개요
6 | netflix cloud gateway. proxy에 중점을 둔 심플 api gateway라고 보면 된다. netfix에는 별도로 api gateway가 안쪽 레이어에 존재한다.
7 | the front door to Netflix’s server infrastructure, handling traffic from all Netflix users around the world.
8 |
9 | 
10 |
11 | ### 아키텍쳐
12 | Zuul in Netflix’s Cloud Architecture
13 |
14 | 
15 |
16 | Zuul Core Architecture
17 |
18 | 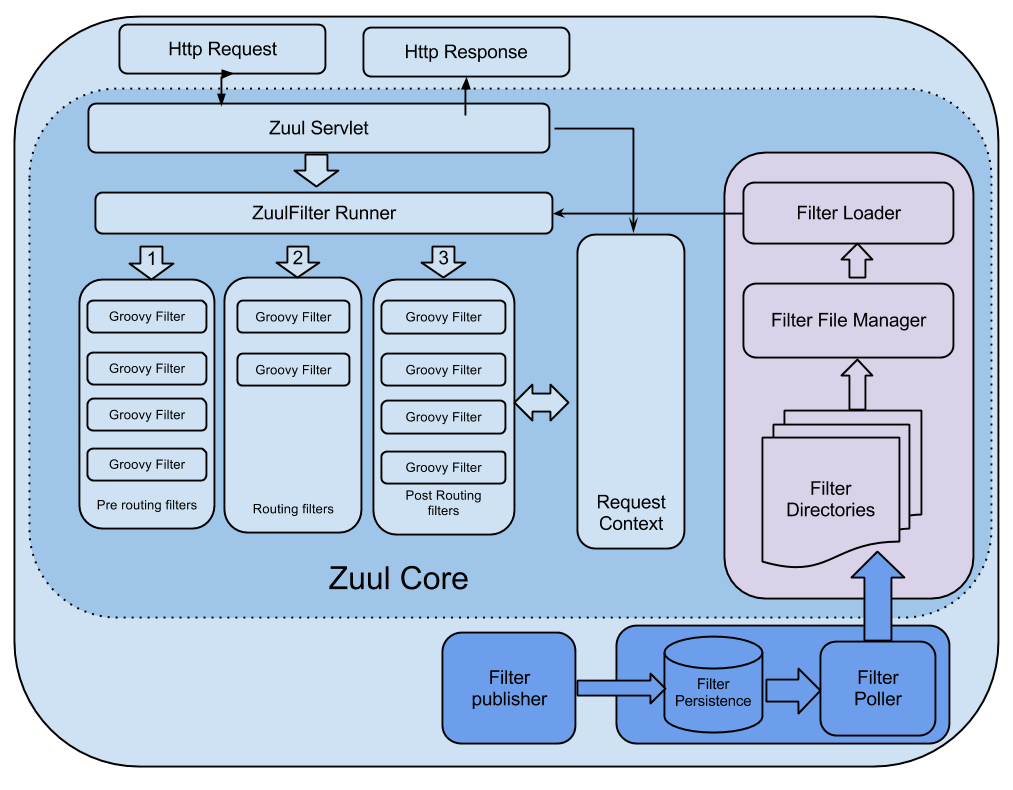
19 |
20 |
21 | Request Lifecycle
22 |
23 | 
24 |
25 |
26 | Netflix OSS libraries in Zuul
27 |
28 | 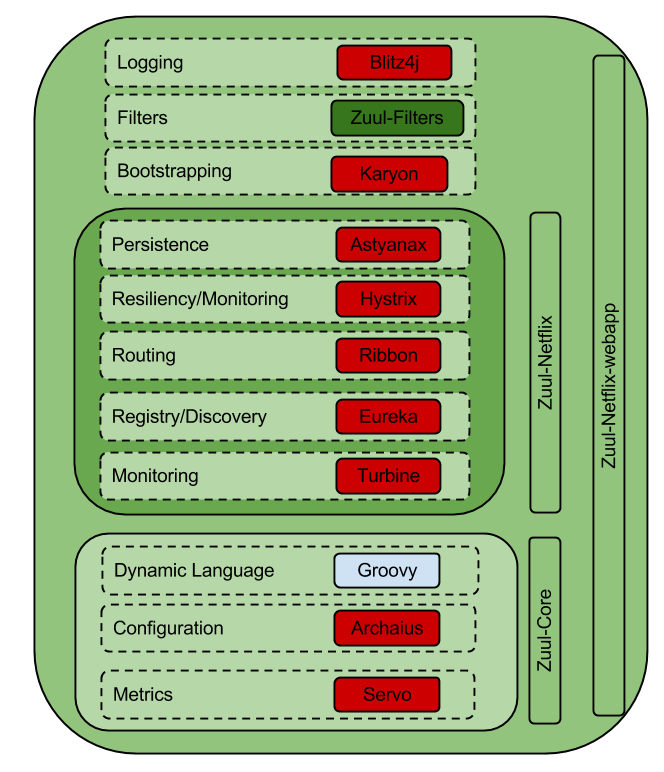
29 |
30 | 특정 고객 혹은 특정 디바이스에만 발생하는 문제를 디버깅하는 용도로 SurgicalDebugFilter를 사용하면 해당 고객 트래픽은 특정 인스턴스로만 가도록 해서 디버깅하기 편하다. 혹은 특정 페이지의 오류를 확인하거나 성능 튜닝을 할 때도 요긴하다.
31 |
32 | ## zuul2(비동기 버전)
33 | * https://medium.com/netflix-techblog/zuul-2-the-netflix-journey-to-asynchronous-non-blocking-systems-45947377fb5c
34 | * 한글 : http://chanwookpark.github.io/reactive/netflix/zuul/async/non-blocking/2016/11/21/zuul2-netflixjourney-to-asynchronous-non-blocking-systems/
35 |
36 | ### 개요
37 | zuul2는 기존 zuul과 달리 Netty를 사용한 비동기, 논블로킹 프레임워크 기반으로 동작한다.
38 |
39 | ### Differences Between Blocking vs. Non-Blocking Systems
40 |
41 | Multithreaded System Architecture
42 |
43 | 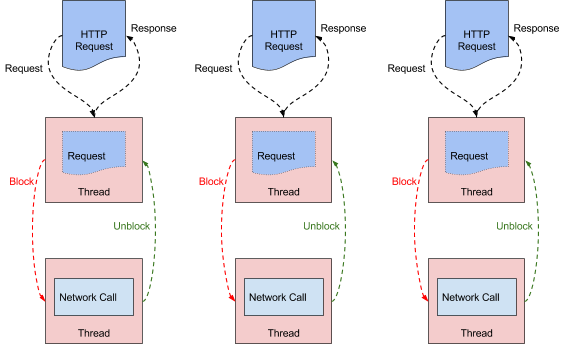
44 |
45 |
46 | Asynchronous and Non-blocking System Architecture
47 |
48 | 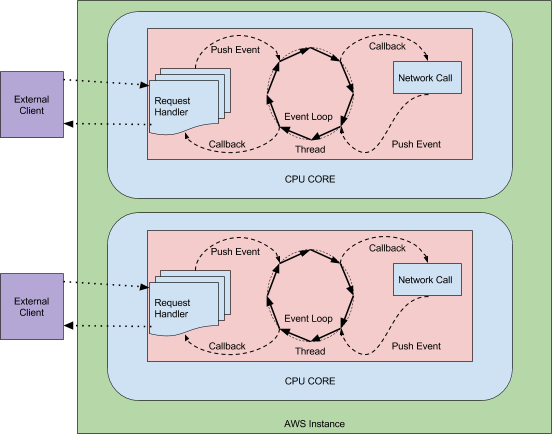
49 |
50 | 백엔드 latency가 느려지거나 retry storms(문제 발생시 재시도 현상) 발생시 커넥션과 이벤트가 큐에 적체가 되지만 이는 기존 쓰레드 기반의 블로킹 시스템에서 쓰레드가 쌓이는 것보다 시스템에 스트레스가 적다.
51 |
52 | ### Building Non-Blocking Zuul
53 | 스레드 로컬 변수는 동일한 스레드에서 여러 요청이 처리되는 비동기-논블로킹에서는 동작하지 않는다. 결과적으로 Zuul2를 구현하는데 따른 복잡성의 상당 부분은 스레드 로컬 변수가 사용되는 로직 수정에 있다.
54 |
55 | ### Results of Zuul 2 in Production
56 | * 비동기-논블로킹 사용으로 효율성을 크게 향상시킨건 아니지만 커넥션 확장(scaling)에서 이득을 취함.
57 | * 네트워크 커넥션 비용을 확 낮추면서 디바이스와의 push, 양방향 통신이 가능해짐.
58 | * 이를 통해 실시간 사용자 경험을 혁신 할 수 있으며, 푸시 알림을 통해 현재 API 트래픽의 상당 부분을 차지하는 (불필요한)API 요청을 대체함으로써 전체적인 클라우드 비용을 절감 할 수 있음.
59 | * 백엔드 latency 및 retry storms 이슈를 해결하는데도 이점이 있어 resiliency(탄력성) 장점.
60 | * CPU-bound 보다는 IO-bound에서 이점.
61 | * CPU-bound 이더라도 기존 servlet 기반 zuul보다는 netty기반 아키텍쳐를 통해 25%의 throughput 향상(25% CPU 사용 감소).
62 |
63 | ## 기타 링크
64 | * [배민 API GATEWAY - spring cloud zulu 적용기](http://woowabros.github.io/r&d/2017/06/13/apigateway.html)
65 | * [zuul-netflix-springone-platform](https://www.slideshare.net/MikeyCohen1/zuul-netflix-springone-platform)
66 | * [rethinking-cloud-proxies](https://www.slideshare.net/MikeyCohen1/rethinking-cloud-proxies-54923218)
67 |
--------------------------------------------------------------------------------
/google_cloud_sql.md:
--------------------------------------------------------------------------------
1 | ## Google Cloud SQL 개요
2 | ### https://cloud.google.com/sql/
3 | * MySQL database that lives in Google's cloud. 기존 MySQL에 비해 몇가지 추가기능과 제한사항이 있음.
4 | * Google handles replication(sync, async), patch management and database management.
5 | * fast, don’t run out of space, reliable storage.
6 | * Instances available up to 16GB RAM, 500GB storage.
7 | * pay-per-use model(pay for a database only when it’s being accessed) - SaaS 서비스 사업자에게 적합
8 | * data is replicated in many geographic locations ,failover automatically.(ISO/IEC 27001 compliant)
9 | * 사용자가 DB 인스턴스 설치 위치를 결정할 수 있다. ex) 미국IDC ,유럽 IDC 등
10 | * data is automatically encrypted.(ASE-256)
11 | * Easier Migration.
12 | * No Lock-in.
13 | * [web Console or a command-line interface.](https://cloud.google.com/sql/docs/getting-started)
14 | * [Google Cloud Platform Pricing Calculator](https://cloud.google.com/products/calculator/)
15 |
16 | ## 성능/확장성 측면에서 엔터프라이즈급으로 사용이 가능한 것인가 ?
17 | scale-up은 16GB of RAM and 500GB data storage가 max.
18 | 가이드에 ideal for small to medium-sized applications라고 나와 있는걸로 봐서 대규모 엔터프라이즈급에서는 사용하기 힘들어보임.
19 | 또한 유료 사용 Packages 등급에 메모리와 저장소 용량만 나오지 성능에 중요한 요소중 하나인 CPU 스펙이 나오질 않음.
20 | 고가용성과 사용성은 매우 우수.
21 | we cannot guarantee to restore instances larger than 250GB within 24 hours (smaller instances restore a lot faster).
22 |
23 | https://cloud.google.com/sql/docs/launch-checklist
24 | ```
25 | If you want the benefits of Google managing updates to MySQL, replicating your data automatically, and high availability, then Cloud SQL is likely the best choice for your application. If your goal is pure performance and you’re prepared to manage databases and data, then MySQL on a Google Compute Engine VM is likely a better choice for your application.
26 | ```
27 |
28 | https://cloud.google.com/sql/docs/introduction
29 | * Restrictions
30 | https://cloud.google.com/sql/faq#supportmysqlfeatures
31 | [Performance schema](https://dev.mysql.com/doc/refman/5.6/en/performance-schema.html)
32 | [InnoDB memcached plugin](https://dev.mysql.com/doc/refman/5.6/en/innodb-memcached.html)
33 |
34 | ## Google Cloud SQL을 지원하려면 어떻게 해야하냐?
35 | GCE 클라우드 안에서든 밖에서는 Cloud SQL을 설치하면 IP가 나오기 때문에 IP로 접근 가능.
36 | ```
37 | $ gcloud sql instances patch YOUR_INSTANCE_NAME --assign-ip
38 |
39 | In the output, find the "ipAddress" field. Use this as the IP address your applications or tools use to connect to the instance.
40 | ```
41 |
42 | ## FAQ
43 | ### https://cloud.google.com/sql/faq
44 | ### How does Google Cloud SQL failover work?
45 | 수 초간의 downtime은 있지만 auto failover. ip주소 인스턴스 이름 그대로 사용.
46 | ```
47 | Failover is designed to be transparent to your applications, so that after failover, an instance has the same instance name, IP address, and firewall rules. During the failover there will typically be a few seconds downtime as the instance starts up in a new zone. However, in some cases, the InnoDB crash-recovery process may take longer, delaying the time before the instance is up.
48 | ```
49 |
50 | ### Do I need to use the Google Developers Console to manage Google Cloud SQL?
51 | Console 뿐만 아니라 [Cloud SQL API](https://cloud.google.com/sql/docs/admin-api/)를 이용해서 애플리케이션에서 mysql 인스턴스를 동적으로 제어 가능.
52 |
--------------------------------------------------------------------------------
/book/advanced-analytics-with-spark.md:
--------------------------------------------------------------------------------
1 | ### Chapter3. 음악 추천과 Audioscrobbler 데이터셋
2 | #### 챕터 목적
3 | 음악 추천 모델 만들기 실습을 통해 스파크 MLlib를 적용해보고, 머신러닝 알고리즘의 기본을 이해한다.
4 |
5 | #### 3.1 데이터셋
6 | * [오디오스크로블러(Audioscrobbler)](https://ko.wikipedia.org/wiki/%EB%9D%BC%EC%8A%A4%ED%8A%B8_FM)에서 공개한 [데이터셋](https://storage.googleapis.com/aas-data-sets/profiledata_06-May-2005.tar.gz)
7 | * 오디오스크로블러는 인터넷 스트리밍 라디오 서비스를 제공한 [last.fm](https://www.last.fm/)의 첫번째 음악 추천 시스템
8 | * "개똥이가 소녀시대 음악을 들었어"와 같은 단순 재생 정보만을 기록한 데이터셋
9 | * 명시적인 '좋아요', '평점'이 아닌 음악 듣기(재생)를 통해 은연중에 사용자와 아티스트 사이의 관계가 드러나기 때문에 이런 종류의 데이터를 암묵적 피드백(Implicit Feedback)이라고 함
10 | * 데이터셋 구성
11 | - user_artist_data.txt : 2420만건의 음악 재생정보(사용자ID,아티스트ID,재생횟수)
12 | - artist_data.txt : 184만건의 아티스트 정보(아티스트ID,아티스트 이름)
13 | - artist_alias.txt : 19만건의 공식 아티스트ID 매핑정보(아티스트ID,아티스트대표ID)
14 |
15 | #### 3.2 교차 최소 제곱 추천 알고리즘(The Alternating Least Squares Recommender Algorithm)
16 | * 암묵적 피드백(Implicit Feedback) 데이터에 적합한 추천 알고리즘은?
17 | * 협업필터링(Collaborative Filtering) - A, B 두 사람이 재생한 노래가 유사하면 A의 노래를 B에게 추천.
18 | * [잠재요인(Latent-factor) 모델](https://en.wikipedia.org/wiki/Factor_analysis)로 분류할 수 있는 많은 알고리즘 중 하나를 사용하고자함.
19 | * 잠재요인 모델 : 다수의 사용자와 아이템 사이에서 관측된 상호작용을 상대적으로 적은 수의 관측되지 않은 숨은 원인으로(잠재특징) 설명하려 할 때 사용. => 특정 음반을 구입한 이유를 (직접 관측할 수 없고 데이터도 주어지지 않은) 음악 장르에 대한 개인 취향으로 설명하는것과 유사.
20 | * recommendation problem => maxtrix completion => matrix factorization
21 | * 행렬 분해(Matrix Factorization) 모델 사용.
22 | - 사용자가(i)가 아티스트(j)의 음악을 들었다면 A행렬의 i행 j열에 값이 존재한다고 표현
23 | - 사용자 - 아티스트의 가능한 모든 조합중 극히 일부만 데이터가 존재하기 때문에 A는 희소행렬(Sparse Matrix)
24 | - 행렬 A를 분해(행렬은 두 개의 낮은 차수로 이루어진 행렬로 분해가 가능하고, 이 분해된 행렬들끼리 다시 곱하면 원래의 행렬과 매우 유사한 단일 행렬이 되는 성질을 이용.)
25 | - A(i, j) = X(i, k) * Y(k, j) k는 상호작용하는 데이터를 설명하는 잠재요인(잠재 feature. 행렬의 차수)
26 | - 사용자-아티스트 행렬 근사치 = 사용자-특징 행렬 * 특징-아티스트 행렬
27 | 
28 | * 원래의 행렬 A는 매우 희소한 데 비해 행렬 곱 XY는 밀도가 매우 높아서 이 알고리즘을 행렬 채우기(Matrix Completion) 알고리즘이라고도 부름.
29 | * X와 Y를 계산하기 위해 이장에서는 교차 최소 제곱 알고리즘(ALS, Alternating Least Squares)을 사용
30 | - ["암묵적 피드백 데이터셋에 대한 협업 필터링"](http://yifanhu.net/PUB/cf.pdf), ["넷플릭스 프라이즈를 위한 대규모의 병렬 협업 필터링"](https://dl.acm.org/citation.cfm?id=1424269) 논문에서 아이디어.
31 | * 오차를 최소화하는 공식의 최적값을 구하기 위한 잘 알려진 알고리즘으로 딥러닝에서 많이 들어본 "확률적 경사하강법(SGD)", 교대최소제곱(ALS) 두가지 존재. 이중 ALS가 분산플랫폼에서 병렬화 용이([출처](http://rstatistics.tistory.com/29))
32 | - 주어진 objective가 pairwise optimization으로 생각하면 non-convex이지만, p나 q 중 하나를 고정하고 나머지에 대해 optimization을 하게 되면 convex, 그것도 closed form으로 계산된다는 점을 이용한 방법
33 | * ALS 알고리즘 장점(스파크 MLlib에 구현된 유일한 추천 알고리즘)
34 | - 입력 데이터 희소성의 장점 살림
35 | - 간단하고 최적화된 선형대수 기법 사용
36 | - 병렬처리가 가능해서 데이터가 많아져도 빠르게 처리 가능
37 | * 넷플릭스는 2006년 ‘넷플릭스 프라이즈’라는 기술 콘테스트를 개최. 넷플릭스의 추천 시스템인 ‘시네매치’의 품질을 10% 개선하는 사람에게 100만 달러(약 12억원) 상금. [출처](https://byline.network/2016/03/1-87/)
38 |
39 | #### 실습 예제) 3.3 데이터 준비하기 ~ 3.10 한 걸음 더 나아가기
40 |
41 | #### 볼만한 글들
42 | * [추천 엔진에 이용되는 데이터 마이닝 기법](http://rstatistics.tistory.com/29)
43 | * [Recommendation System (Matrix Completion)](http://sanghyukchun.github.io/73/)
44 | * [recommendation system with Implicit Feedback](http://sanghyukchun.github.io/95/)
45 | * [ch3 웹에 정리된 글](http://hyunje.com/data%20analysis/2015/07/13/advanced-analytics-with-spark-ch3-1/)
46 | * [추천 방식 장단 비교 및 추천 알고리즘 구현하기](https://proinlab.com/archives/2103)
47 | * [Spark ml Collaborative Filtering](https://spark.apache.org/docs/2.2.0/ml-collaborative-filtering.html)
48 |
--------------------------------------------------------------------------------
/video/GOTO 2014 Microservices Martin Fowler.md:
--------------------------------------------------------------------------------
1 | https://www.youtube.com/watch?v=wgdBVIX9ifA
2 |
3 |
57 |
58 |
59 | ## reference
60 | * http://jakubdziworski.github.io/java/2016/07/31/jshell-getting-started-examples.html
61 | * https://www.youtube.com/watch?v=8XmYT89fBKg
62 |
--------------------------------------------------------------------------------
/agile_software_development_with_scrum.md:
--------------------------------------------------------------------------------
1 | 책 정리 "Agile Software Development with Scrum" by 켄 슈와버, 마이크 버들
2 |
3 | ### 스크럼의 실천법
4 | #### 스크럼 마스터(Scrum Master)
5 | - 스크럼을 통해서 알려진 새로운 유형의 관리자다.
6 | - SM은 경영진에게는 팀의 입장을, 팀에게는 경영진의 입장을 대변한다.
7 | - 스크럼 마스터는 고객 및 관리자와 함께 제품 책임자(Product Owner)로 적합한 인물을 찾아내서 임명한다. 그후 관리자와 함께 상의해서 스크럼 팀을 조직한다.
8 | - 보통 팀 리더, 프로젝트 리더 혹은 프로젝트 관리자가 스크럼 마스터의 역할을 수행한다.
9 | - 어떻게 팀이 가능한 최고 수준의 생산성을 유지하게 할 수 있을까? 스크럼 마스터는 주로 결정을 내리고 장애 요소를 제거하는 방식으로 그와 같이 할 수 있다.
10 |
11 | #### 제품 백로그(Product Backlog)
12 | - 제품 백로그란 개발해야 할 기능들을 사업상의 중요도에 따라 구분한 목록으로서 개발 과정에서 끊임없이 진화한다.
13 | - 제품을 성장시켜 나가고 자신에게 필요한 것이 무엇인지에 대한 고객의 이해가 깊어짐에 따라 제품 백로그는 허술한 초기의 목록에서 시작해 점점 발전해 나간다.
14 | 제품 백로그는 우선순위에 따라 나열된다.
15 | - 우리에게 필요한 것은 단지 제품의 비전과 한 회의 반복 주기, 즉 스프린트를 시작할 수 있을 정도의 최우선 백로그 항목들뿐이다.
16 | - 제품 책임자(Product Owner)가 제품 백로그를 관리하고 통제할 권한을 가진다. 한 명이 아니라 여러 명이 되면, 팀은 허둥대고 질질 끄려다니다가 끊임없는 논쟁 끝에 결국 좌초하게 될 것이다.
17 | - 백로그가 만들어지면 제품 책임자는 다른 사람들과 함께 그것을 개발하는데 얼마나 걸릴지 추정한다.
18 |
19 | #### 스크럼 팀
20 | - 팀은 스크럼 목표를 달성하기 위해서 헌신한다. 팀은 목표를 달성하기 위해서 필요한 것이라면 무엇이든 할 수 있는 권한을 부여 받는다.
21 | - 팀의 크기는 7명이 이상적이며, 5명 미만이거나 9명을 초과해서는 안 된다.
22 | - 대부분의 개발 프로세스에서는 관리자가 각 팀원에게 무엇을 언제까지 해야 한다고 지시한다. 이런 방식으로 어떻게 관리자가 팀의 헌신을 이끌어낼 수 있을까?
23 | - 팀의 구성과 상관없이 분석에서부터 설계, 코딩, 테스트 및 사용자 문서 작성에 이르기 까지 필요한 모든 일을 팀 스스로 해내야 한다.
24 |
25 | #### 일일 스크럼 회의(Daily Scrum Meetings)
26 | - 15분짜리 현황 파악 회의
27 | - 소프트웨어 개발은 엄청난 의사소통을 필요로 하는 복잡한 프로세스다. 팀에게 있어서 일일 스크럼 회의는 의사소통의 장이다.
28 | - 스크럼 마스터는 규칙을 강조하고 사람들이 간결하게 말하도록 해서 일일 스크럼 회의가 길어지지 않도록 해야 한다.
29 | - 일일 스크럼 회의는 설계 회의가 아니며 작업 회의처럼 돌변해서도 안 된다.
30 | - 관리자들은 일일 스크럼 회의에서 오고 가는 이야기들에 주의를 기울임으로써 팀이 어떤 일을 하고 있고, 그것이 성공할 것 같은지 아닌지에 대한 감을 얻을 수 있다.
31 | - 팀원이 프로젝트에 흥미를 잃었는가? 가족 문제로 누군가가 일에서 손을 놓고 있지는 않은가? 어떤 사안에 대해서 팀 내에 불화가 있지는 않은가? 회의 중에 어떤 태도들을 보이는가? 등등 팀의상황을 지속적으로 관찰하기기 쉽다.
32 | ```
33 | 1) 지나 일일 스크럼 이후 무엇을 했는가?
34 | 2) 지금부터 다음 일일 스크럼까지 무엇을 하려고 하는가?
35 | 3) 업무를 하는데 무엇이 방해되는가?
36 | ```
37 |
38 | #### 스프린트 계획 회의
39 | - 고객, 사용자, 경영진, 제품 책임자의 스크럼 팀은 스프린트 계획 회의에서 다음 스프린트의 목표와 기능을 결정한다. 그 다음, 팀은 제품 증분을 개발하기 위해서 필요한 개별 태스크들을 도출한다.
40 | - 다음 스프린트의 목표 선정과 제품 백로그 확정, 스프린트 목표에 맞게 스프린트 백로그 정의하기.
41 |
42 | #### 스프린트(Sprint)
43 | - 개발팀은 스프린트라고 불리는 한정된 기간 동안 일을 한다. 30일이 적당. 그 이상이 되면 관리자가 참견하고 싶은 욕망을 억누르기 어렵기 때문이다.
44 | - 스크럼은 사람들에게 불가능한 복잡성으로부터 예측 가능한 제품을 쥐어 짜내도록 요구한다. 성공적으로 스크럼에 적응하는 사람들은 한 조직의 중핵을 담당할 만한 인물들이다. 스크럼은 이런 사람들을 판별하는데 도움이 된다.
45 | - 일단 창조적인 분위기로 흐르게 되면 팀의 창조성과 생산성이 급격히 상승한다.
46 | - 스프린트는 직원들이 할 일이 무엇인지 알고 그것을 해낼 수 있다는 것을 놓고 관리자와 내기를 하는 것 과 같다.
47 | - 일일 빌드(Daily product builds)는 팀의 진척도를 측정하는 훌륭한 수단이다.
48 |
49 | #### 스프린트 검토(Sprint Review)
50 | - 정보 전달을 위한 회의로 네 시간이 소요된다. 이 회의에서 팀은 경영진, 고객들, 사용자들과 제품 책임자에게 자신들이 이번 스프린트에서 개발한 제품 증분을 선보인다.
51 | - 30일 간의 스프린트 주기는 팀원들의 삶과 심지어 회사에서의 삶에 의미 있는 리듬을 제공해 준다. 30일마다 열리는 스프린트 검토 회의와 나머지 29일 동안 개발이 진행되는 식의 리듬 말이다.
52 | - 스프린트 검토 회의 동안, 참석한 모든 사람들은 시연중인 제품의 기능이 사용자 환경에서 어떻게 돌아갈지를 직접 보게 된다. 제품을직접 보면서, 다음 스프린트에는 어떤 기능이 추가되어야 할지를 고려하게 된다. 이런 제품 증분은 브레인스토밍에서 중심(focal point)이 된다.
53 |
--------------------------------------------------------------------------------
/zuul.md:
--------------------------------------------------------------------------------
1 | ## zuul
2 | https://github.com/Netflix/zuul/wiki
3 | https://medium.com/netflix-techblog/announcing-zuul-edge-service-in-the-cloud-ab3af5be08ee
4 |
5 | ### 개요
6 | netflix cloud gateway. proxy에 중점을 둔 심플 api gateway라고 보면 된다. netfix에는 별도로 api gateway가 안쪽 레이어에 존재한다.
7 | the front door to Netflix’s server infrastructure, handling traffic from all Netflix users around the world.
8 |
9 | 
10 |
11 | ### 아키텍쳐
12 | Zuul in Netflix’s Cloud Architecture
13 |
14 | 
15 |
16 | Zuul Core Architecture
17 |
18 | 
19 |
20 |
21 | Request Lifecycle
22 |
23 | 
24 |
25 |
26 | Netflix OSS libraries in Zuul
27 |
28 | 
29 |
30 | 특정 고객 혹은 특정 디바이스에만 발생하는 문제를 디버깅하는 용도로 SurgicalDebugFilter를 사용하면 해당 고객 트래픽은 특정 인스턴스로만 가도록 해서 디버깅하기 편하다. 혹은 특정 페이지의 오류를 확인하거나 성능 튜닝을 할 때도 요긴하다.
31 |
32 | ## zuul2(비동기 버전)
33 | * https://medium.com/netflix-techblog/zuul-2-the-netflix-journey-to-asynchronous-non-blocking-systems-45947377fb5c
34 | * 한글 : http://chanwookpark.github.io/reactive/netflix/zuul/async/non-blocking/2016/11/21/zuul2-netflixjourney-to-asynchronous-non-blocking-systems/
35 |
36 | ### 개요
37 | zuul2는 기존 zuul과 달리 Netty를 사용한 비동기, 논블로킹 프레임워크 기반으로 동작한다.
38 |
39 | ### Differences Between Blocking vs. Non-Blocking Systems
40 |
41 | Multithreaded System Architecture
42 |
43 | 
44 |
45 |
46 | Asynchronous and Non-blocking System Architecture
47 |
48 | 
49 |
50 | 백엔드 latency가 느려지거나 retry storms(문제 발생시 재시도 현상) 발생시 커넥션과 이벤트가 큐에 적체가 되지만 이는 기존 쓰레드 기반의 블로킹 시스템에서 쓰레드가 쌓이는 것보다 시스템에 스트레스가 적다.
51 |
52 | ### Building Non-Blocking Zuul
53 | 스레드 로컬 변수는 동일한 스레드에서 여러 요청이 처리되는 비동기-논블로킹에서는 동작하지 않는다. 결과적으로 Zuul2를 구현하는데 따른 복잡성의 상당 부분은 스레드 로컬 변수가 사용되는 로직 수정에 있다.
54 |
55 | ### Results of Zuul 2 in Production
56 | * 비동기-논블로킹 사용으로 효율성을 크게 향상시킨건 아니지만 커넥션 확장(scaling)에서 이득을 취함.
57 | * 네트워크 커넥션 비용을 확 낮추면서 디바이스와의 push, 양방향 통신이 가능해짐.
58 | * 이를 통해 실시간 사용자 경험을 혁신 할 수 있으며, 푸시 알림을 통해 현재 API 트래픽의 상당 부분을 차지하는 (불필요한)API 요청을 대체함으로써 전체적인 클라우드 비용을 절감 할 수 있음.
59 | * 백엔드 latency 및 retry storms 이슈를 해결하는데도 이점이 있어 resiliency(탄력성) 장점.
60 | * CPU-bound 보다는 IO-bound에서 이점.
61 | * CPU-bound 이더라도 기존 servlet 기반 zuul보다는 netty기반 아키텍쳐를 통해 25%의 throughput 향상(25% CPU 사용 감소).
62 |
63 | ## 기타 링크
64 | * [배민 API GATEWAY - spring cloud zulu 적용기](http://woowabros.github.io/r&d/2017/06/13/apigateway.html)
65 | * [zuul-netflix-springone-platform](https://www.slideshare.net/MikeyCohen1/zuul-netflix-springone-platform)
66 | * [rethinking-cloud-proxies](https://www.slideshare.net/MikeyCohen1/rethinking-cloud-proxies-54923218)
67 |
--------------------------------------------------------------------------------
/google_cloud_sql.md:
--------------------------------------------------------------------------------
1 | ## Google Cloud SQL 개요
2 | ### https://cloud.google.com/sql/
3 | * MySQL database that lives in Google's cloud. 기존 MySQL에 비해 몇가지 추가기능과 제한사항이 있음.
4 | * Google handles replication(sync, async), patch management and database management.
5 | * fast, don’t run out of space, reliable storage.
6 | * Instances available up to 16GB RAM, 500GB storage.
7 | * pay-per-use model(pay for a database only when it’s being accessed) - SaaS 서비스 사업자에게 적합
8 | * data is replicated in many geographic locations ,failover automatically.(ISO/IEC 27001 compliant)
9 | * 사용자가 DB 인스턴스 설치 위치를 결정할 수 있다. ex) 미국IDC ,유럽 IDC 등
10 | * data is automatically encrypted.(ASE-256)
11 | * Easier Migration.
12 | * No Lock-in.
13 | * [web Console or a command-line interface.](https://cloud.google.com/sql/docs/getting-started)
14 | * [Google Cloud Platform Pricing Calculator](https://cloud.google.com/products/calculator/)
15 |
16 | ## 성능/확장성 측면에서 엔터프라이즈급으로 사용이 가능한 것인가 ?
17 | scale-up은 16GB of RAM and 500GB data storage가 max.
18 | 가이드에 ideal for small to medium-sized applications라고 나와 있는걸로 봐서 대규모 엔터프라이즈급에서는 사용하기 힘들어보임.
19 | 또한 유료 사용 Packages 등급에 메모리와 저장소 용량만 나오지 성능에 중요한 요소중 하나인 CPU 스펙이 나오질 않음.
20 | 고가용성과 사용성은 매우 우수.
21 | we cannot guarantee to restore instances larger than 250GB within 24 hours (smaller instances restore a lot faster).
22 |
23 | https://cloud.google.com/sql/docs/launch-checklist
24 | ```
25 | If you want the benefits of Google managing updates to MySQL, replicating your data automatically, and high availability, then Cloud SQL is likely the best choice for your application. If your goal is pure performance and you’re prepared to manage databases and data, then MySQL on a Google Compute Engine VM is likely a better choice for your application.
26 | ```
27 |
28 | https://cloud.google.com/sql/docs/introduction
29 | * Restrictions
30 | https://cloud.google.com/sql/faq#supportmysqlfeatures
31 | [Performance schema](https://dev.mysql.com/doc/refman/5.6/en/performance-schema.html)
32 | [InnoDB memcached plugin](https://dev.mysql.com/doc/refman/5.6/en/innodb-memcached.html)
33 |
34 | ## Google Cloud SQL을 지원하려면 어떻게 해야하냐?
35 | GCE 클라우드 안에서든 밖에서는 Cloud SQL을 설치하면 IP가 나오기 때문에 IP로 접근 가능.
36 | ```
37 | $ gcloud sql instances patch YOUR_INSTANCE_NAME --assign-ip
38 |
39 | In the output, find the "ipAddress" field. Use this as the IP address your applications or tools use to connect to the instance.
40 | ```
41 |
42 | ## FAQ
43 | ### https://cloud.google.com/sql/faq
44 | ### How does Google Cloud SQL failover work?
45 | 수 초간의 downtime은 있지만 auto failover. ip주소 인스턴스 이름 그대로 사용.
46 | ```
47 | Failover is designed to be transparent to your applications, so that after failover, an instance has the same instance name, IP address, and firewall rules. During the failover there will typically be a few seconds downtime as the instance starts up in a new zone. However, in some cases, the InnoDB crash-recovery process may take longer, delaying the time before the instance is up.
48 | ```
49 |
50 | ### Do I need to use the Google Developers Console to manage Google Cloud SQL?
51 | Console 뿐만 아니라 [Cloud SQL API](https://cloud.google.com/sql/docs/admin-api/)를 이용해서 애플리케이션에서 mysql 인스턴스를 동적으로 제어 가능.
52 |
--------------------------------------------------------------------------------
/book/advanced-analytics-with-spark.md:
--------------------------------------------------------------------------------
1 | ### Chapter3. 음악 추천과 Audioscrobbler 데이터셋
2 | #### 챕터 목적
3 | 음악 추천 모델 만들기 실습을 통해 스파크 MLlib를 적용해보고, 머신러닝 알고리즘의 기본을 이해한다.
4 |
5 | #### 3.1 데이터셋
6 | * [오디오스크로블러(Audioscrobbler)](https://ko.wikipedia.org/wiki/%EB%9D%BC%EC%8A%A4%ED%8A%B8_FM)에서 공개한 [데이터셋](https://storage.googleapis.com/aas-data-sets/profiledata_06-May-2005.tar.gz)
7 | * 오디오스크로블러는 인터넷 스트리밍 라디오 서비스를 제공한 [last.fm](https://www.last.fm/)의 첫번째 음악 추천 시스템
8 | * "개똥이가 소녀시대 음악을 들었어"와 같은 단순 재생 정보만을 기록한 데이터셋
9 | * 명시적인 '좋아요', '평점'이 아닌 음악 듣기(재생)를 통해 은연중에 사용자와 아티스트 사이의 관계가 드러나기 때문에 이런 종류의 데이터를 암묵적 피드백(Implicit Feedback)이라고 함
10 | * 데이터셋 구성
11 | - user_artist_data.txt : 2420만건의 음악 재생정보(사용자ID,아티스트ID,재생횟수)
12 | - artist_data.txt : 184만건의 아티스트 정보(아티스트ID,아티스트 이름)
13 | - artist_alias.txt : 19만건의 공식 아티스트ID 매핑정보(아티스트ID,아티스트대표ID)
14 |
15 | #### 3.2 교차 최소 제곱 추천 알고리즘(The Alternating Least Squares Recommender Algorithm)
16 | * 암묵적 피드백(Implicit Feedback) 데이터에 적합한 추천 알고리즘은?
17 | * 협업필터링(Collaborative Filtering) - A, B 두 사람이 재생한 노래가 유사하면 A의 노래를 B에게 추천.
18 | * [잠재요인(Latent-factor) 모델](https://en.wikipedia.org/wiki/Factor_analysis)로 분류할 수 있는 많은 알고리즘 중 하나를 사용하고자함.
19 | * 잠재요인 모델 : 다수의 사용자와 아이템 사이에서 관측된 상호작용을 상대적으로 적은 수의 관측되지 않은 숨은 원인으로(잠재특징) 설명하려 할 때 사용. => 특정 음반을 구입한 이유를 (직접 관측할 수 없고 데이터도 주어지지 않은) 음악 장르에 대한 개인 취향으로 설명하는것과 유사.
20 | * recommendation problem => maxtrix completion => matrix factorization
21 | * 행렬 분해(Matrix Factorization) 모델 사용.
22 | - 사용자가(i)가 아티스트(j)의 음악을 들었다면 A행렬의 i행 j열에 값이 존재한다고 표현
23 | - 사용자 - 아티스트의 가능한 모든 조합중 극히 일부만 데이터가 존재하기 때문에 A는 희소행렬(Sparse Matrix)
24 | - 행렬 A를 분해(행렬은 두 개의 낮은 차수로 이루어진 행렬로 분해가 가능하고, 이 분해된 행렬들끼리 다시 곱하면 원래의 행렬과 매우 유사한 단일 행렬이 되는 성질을 이용.)
25 | - A(i, j) = X(i, k) * Y(k, j) k는 상호작용하는 데이터를 설명하는 잠재요인(잠재 feature. 행렬의 차수)
26 | - 사용자-아티스트 행렬 근사치 = 사용자-특징 행렬 * 특징-아티스트 행렬
27 | 
28 | * 원래의 행렬 A는 매우 희소한 데 비해 행렬 곱 XY는 밀도가 매우 높아서 이 알고리즘을 행렬 채우기(Matrix Completion) 알고리즘이라고도 부름.
29 | * X와 Y를 계산하기 위해 이장에서는 교차 최소 제곱 알고리즘(ALS, Alternating Least Squares)을 사용
30 | - ["암묵적 피드백 데이터셋에 대한 협업 필터링"](http://yifanhu.net/PUB/cf.pdf), ["넷플릭스 프라이즈를 위한 대규모의 병렬 협업 필터링"](https://dl.acm.org/citation.cfm?id=1424269) 논문에서 아이디어.
31 | * 오차를 최소화하는 공식의 최적값을 구하기 위한 잘 알려진 알고리즘으로 딥러닝에서 많이 들어본 "확률적 경사하강법(SGD)", 교대최소제곱(ALS) 두가지 존재. 이중 ALS가 분산플랫폼에서 병렬화 용이([출처](http://rstatistics.tistory.com/29))
32 | - 주어진 objective가 pairwise optimization으로 생각하면 non-convex이지만, p나 q 중 하나를 고정하고 나머지에 대해 optimization을 하게 되면 convex, 그것도 closed form으로 계산된다는 점을 이용한 방법
33 | * ALS 알고리즘 장점(스파크 MLlib에 구현된 유일한 추천 알고리즘)
34 | - 입력 데이터 희소성의 장점 살림
35 | - 간단하고 최적화된 선형대수 기법 사용
36 | - 병렬처리가 가능해서 데이터가 많아져도 빠르게 처리 가능
37 | * 넷플릭스는 2006년 ‘넷플릭스 프라이즈’라는 기술 콘테스트를 개최. 넷플릭스의 추천 시스템인 ‘시네매치’의 품질을 10% 개선하는 사람에게 100만 달러(약 12억원) 상금. [출처](https://byline.network/2016/03/1-87/)
38 |
39 | #### 실습 예제) 3.3 데이터 준비하기 ~ 3.10 한 걸음 더 나아가기
40 |
41 | #### 볼만한 글들
42 | * [추천 엔진에 이용되는 데이터 마이닝 기법](http://rstatistics.tistory.com/29)
43 | * [Recommendation System (Matrix Completion)](http://sanghyukchun.github.io/73/)
44 | * [recommendation system with Implicit Feedback](http://sanghyukchun.github.io/95/)
45 | * [ch3 웹에 정리된 글](http://hyunje.com/data%20analysis/2015/07/13/advanced-analytics-with-spark-ch3-1/)
46 | * [추천 방식 장단 비교 및 추천 알고리즘 구현하기](https://proinlab.com/archives/2103)
47 | * [Spark ml Collaborative Filtering](https://spark.apache.org/docs/2.2.0/ml-collaborative-filtering.html)
48 |
--------------------------------------------------------------------------------
/video/GOTO 2014 Microservices Martin Fowler.md:
--------------------------------------------------------------------------------
1 | https://www.youtube.com/watch?v=wgdBVIX9ifA
2 |
3 |  4 |
4 |  5 |
5 |  6 |
6 |  7 |
7 |  8 |
8 |  9 |
9 |  10 |
10 |  11 |
11 |  12 |
12 |  13 |
13 |  14 |
14 |  15 |
15 |  16 |
16 |  17 |
17 |  18 |
18 |  19 |
19 |  20 |
20 |  21 |
21 |  22 |
22 |  23 |
23 |  24 |
24 |  25 |
25 |  26 |
--------------------------------------------------------------------------------
/java_cachelock.md:
--------------------------------------------------------------------------------
1 | ## 개요
2 | nginx cache_lock 기능을 Global API-GATEWAY 프로젝트(java)에 구현하는 과정에서 고민하고 공부한 내용들을 남긴다.
3 |
4 | ## 고민
5 | lock 동기화 매커니즘 어떤걸 사용해야하나? 아래 몇가지 동기화 매커니즘들 중 readLock, writeLock 패턴이 가장 적합할거라 생각함.
6 | nginx cache lock 구현코드를 보면 단순히 wait 하면서 timer 걸어서 cache가 write 되었는지 polling 하는 구조로 보임(c 코드를 잘몰라서 확실하지는 않음)
7 | EHCache에서 제공하는 BlockingCache 구현체 코드를 보면 ReentrantReadWriteLock 사용.
8 |
9 | * Guarded Suspension 패턴(or Guarded timed)
10 | * 세마포어
11 | * readLock, writeLock
12 | * CountDownLatch
13 | * pub-sub 패턴
14 |
15 | nginx cache lock 구현 코드 : https://github.com/nginx/nginx/blob/645697f111983089fdcee0694d17480e0a05a3a5/src/http/ngx_http_file_cache.c
16 |
17 | ## 구현체들
18 | 1. 스프링 cache 추상화.
19 | 동기화 요구사항이 계속 있었음. Spring 4.3에서 sync=true 속성으로 지원. https://spring.io/blog/2016/03/04/core-container-refinements-in-spring-framework-4-3#cache-abstraction-refinements
20 | 스프링 커밋코드 : https://github.com/spring-projects/spring-framework/commit/19d97c425316801a767cf99178ef30af730b1570
21 |
22 | 2. EHCache BlockingCache
23 | BlockingCache Decorators로 cachelock 기능 제공. http://www.ehcache.org/documentation/2.8/apis/cache-decorators
24 | 코드 : http://grepcode.com/file/repo1.maven.org/maven2/net.sf.ehcache/ehcache/2.10.0/net/sf/ehcache/constructs/blocking/BlockingCache.java#BlockingCache
25 |
26 | ## 문제점
27 | 1. 프로젝트에서 Spring을 사용하지 않는다. cache 미존재시 put하는 로직이 복잡해서 Spring cache 추상화에서 제공하는 인터페이스로 던지기가 애매하다.
28 | 2. BlockingCache 구현체는 writeLock에 대한 lock은 get메소드에서 unlock은 put메소드에서 수행하게 되는데 이로 인해 혹여나 애플리케이션에서 put메소드 수행을 하지 않을 경우 lock이 unlock되지 않는 문제가 존재한다.
29 | 즉 lock 소유와 해제가 내부적으로 감춰져 있지 않고 애플리케이션으로 침투하게 되어 문제가 된다.
30 | 3. BlockingCache는 EHCache에 의존성을 가지고 있어서 redis 등에 cachelock 기능을 사용할수가 없다.
31 |
32 | ## 해결책
33 | BlockingCache 코드를 기본으로, 아래 스프링 코드처럼 get메소드 내에서 cache 미존재시 put까지 수행하고 writeLock을 해제하도록 코드 작성함.
34 | 스프링 참고 코드 : https://github.com/spring-projects/spring-framework/commit/19d97c425316801a767cf99178ef30af730b1570
35 | ```
36 | @SuppressWarnings("unchecked")
37 | @Override
38 | public T get(Object key, Callable valueLoader) {
39 | Element element = lookup(key);
40 | if (element != null) {
41 | return (T) element.getObjectValue();
42 | }
43 | else {
44 | this.cache.acquireWriteLockOnKey(key);
45 | try {
46 | element = lookup(key); // One more attempt with the write lock
47 | if (element != null) {
48 | return (T) element.getObjectValue();
49 | }
50 | else {
51 | return loadValue(key, valueLoader);
52 | }
53 | }
54 | finally {
55 | this.cache.releaseWriteLockOnKey(key);
56 | }
57 | }
58 |
59 | }
60 | ```
61 |
62 | ## 성능테스트
63 | https://oss.navercorp.com/api-gateway/gpop/issues/224#issuecomment-426905
64 |
65 | ## 성능테스트 문제점
66 | * vuser2000 + lock개수 다량(random.nextInt(4096))으로 성능테스트 수행하니 응답속도가 ~8초까지 느려지는 현상 발생.
67 | * 이유는 lock을 얻는데 오래걸리는 요청들이 생기면서 locktimeout5초 지연.
68 | * vuser1000->500->250개로 줄여보면 응답시간이 나아지긴하지만 여전히 lock 시간 지연.
69 |
70 | ## 성능 개선
71 | * ReentrantReadWriteLock 성능이 느리다는 보고들이 많고(writeLock starvation 문제), 최근 Java8에서는 ReentrantReadWriteLock을 개선한 StampedLock이 나옴.(http://stackoverflow.com/questions/26087738/performance-of-reentrantreadwritelock-read-lock)
72 | * Java8 쓰기는 좀 곤란하고 read와 write를 동시에 해도 문제가 없을 경우 readLock을 쓰지 말자는 글 발견.(http://blog.takipi.com/java-8-stampedlocks-vs-readwritelocks-and-synchronized/)
73 | * 최근 4.4에 커밋된 EhCacheCache 동기화 로직에서 보면 writeLock만 사용확인. 사실 캐시라서 가능하고, EHCache의 경우 오퍼레이션이 thread safe해서 괜찮.(https://github.com/spring-projects/spring-framework/commit/19d97c425316801a767cf99178ef30af730b1570)
74 |
75 |
76 | ## 동기화 관련 좋은 레퍼런스
77 | * BankAccount예제 : Synchronized vs Synchronized Volatile vs ReentrantLock vs ReentrantReadWriteLock vs StampedLock vs Immutable vs Atomic
78 | http://www.javaspecialists.eu/archive/Issue215.html
79 | * Starvation with ReadWriteLocks : http://www.javaspecialists.eu/archive/Issue165.html
80 | * Java 8 Concurrency Tutorial: Synchronization and Locks : http://winterbe.com/posts/2015/04/30/java8-concurrency-tutorial-synchronized-locks-examples/
81 |
--------------------------------------------------------------------------------
/video/AWS-re-Invent-2016-From-Resilience-to-Ubiquity.md:
--------------------------------------------------------------------------------
1 | https://www.youtube.com/watch?v=leqUbSY55hY
2 |
3 |
26 |
--------------------------------------------------------------------------------
/java_cachelock.md:
--------------------------------------------------------------------------------
1 | ## 개요
2 | nginx cache_lock 기능을 Global API-GATEWAY 프로젝트(java)에 구현하는 과정에서 고민하고 공부한 내용들을 남긴다.
3 |
4 | ## 고민
5 | lock 동기화 매커니즘 어떤걸 사용해야하나? 아래 몇가지 동기화 매커니즘들 중 readLock, writeLock 패턴이 가장 적합할거라 생각함.
6 | nginx cache lock 구현코드를 보면 단순히 wait 하면서 timer 걸어서 cache가 write 되었는지 polling 하는 구조로 보임(c 코드를 잘몰라서 확실하지는 않음)
7 | EHCache에서 제공하는 BlockingCache 구현체 코드를 보면 ReentrantReadWriteLock 사용.
8 |
9 | * Guarded Suspension 패턴(or Guarded timed)
10 | * 세마포어
11 | * readLock, writeLock
12 | * CountDownLatch
13 | * pub-sub 패턴
14 |
15 | nginx cache lock 구현 코드 : https://github.com/nginx/nginx/blob/645697f111983089fdcee0694d17480e0a05a3a5/src/http/ngx_http_file_cache.c
16 |
17 | ## 구현체들
18 | 1. 스프링 cache 추상화.
19 | 동기화 요구사항이 계속 있었음. Spring 4.3에서 sync=true 속성으로 지원. https://spring.io/blog/2016/03/04/core-container-refinements-in-spring-framework-4-3#cache-abstraction-refinements
20 | 스프링 커밋코드 : https://github.com/spring-projects/spring-framework/commit/19d97c425316801a767cf99178ef30af730b1570
21 |
22 | 2. EHCache BlockingCache
23 | BlockingCache Decorators로 cachelock 기능 제공. http://www.ehcache.org/documentation/2.8/apis/cache-decorators
24 | 코드 : http://grepcode.com/file/repo1.maven.org/maven2/net.sf.ehcache/ehcache/2.10.0/net/sf/ehcache/constructs/blocking/BlockingCache.java#BlockingCache
25 |
26 | ## 문제점
27 | 1. 프로젝트에서 Spring을 사용하지 않는다. cache 미존재시 put하는 로직이 복잡해서 Spring cache 추상화에서 제공하는 인터페이스로 던지기가 애매하다.
28 | 2. BlockingCache 구현체는 writeLock에 대한 lock은 get메소드에서 unlock은 put메소드에서 수행하게 되는데 이로 인해 혹여나 애플리케이션에서 put메소드 수행을 하지 않을 경우 lock이 unlock되지 않는 문제가 존재한다.
29 | 즉 lock 소유와 해제가 내부적으로 감춰져 있지 않고 애플리케이션으로 침투하게 되어 문제가 된다.
30 | 3. BlockingCache는 EHCache에 의존성을 가지고 있어서 redis 등에 cachelock 기능을 사용할수가 없다.
31 |
32 | ## 해결책
33 | BlockingCache 코드를 기본으로, 아래 스프링 코드처럼 get메소드 내에서 cache 미존재시 put까지 수행하고 writeLock을 해제하도록 코드 작성함.
34 | 스프링 참고 코드 : https://github.com/spring-projects/spring-framework/commit/19d97c425316801a767cf99178ef30af730b1570
35 | ```
36 | @SuppressWarnings("unchecked")
37 | @Override
38 | public T get(Object key, Callable valueLoader) {
39 | Element element = lookup(key);
40 | if (element != null) {
41 | return (T) element.getObjectValue();
42 | }
43 | else {
44 | this.cache.acquireWriteLockOnKey(key);
45 | try {
46 | element = lookup(key); // One more attempt with the write lock
47 | if (element != null) {
48 | return (T) element.getObjectValue();
49 | }
50 | else {
51 | return loadValue(key, valueLoader);
52 | }
53 | }
54 | finally {
55 | this.cache.releaseWriteLockOnKey(key);
56 | }
57 | }
58 |
59 | }
60 | ```
61 |
62 | ## 성능테스트
63 | https://oss.navercorp.com/api-gateway/gpop/issues/224#issuecomment-426905
64 |
65 | ## 성능테스트 문제점
66 | * vuser2000 + lock개수 다량(random.nextInt(4096))으로 성능테스트 수행하니 응답속도가 ~8초까지 느려지는 현상 발생.
67 | * 이유는 lock을 얻는데 오래걸리는 요청들이 생기면서 locktimeout5초 지연.
68 | * vuser1000->500->250개로 줄여보면 응답시간이 나아지긴하지만 여전히 lock 시간 지연.
69 |
70 | ## 성능 개선
71 | * ReentrantReadWriteLock 성능이 느리다는 보고들이 많고(writeLock starvation 문제), 최근 Java8에서는 ReentrantReadWriteLock을 개선한 StampedLock이 나옴.(http://stackoverflow.com/questions/26087738/performance-of-reentrantreadwritelock-read-lock)
72 | * Java8 쓰기는 좀 곤란하고 read와 write를 동시에 해도 문제가 없을 경우 readLock을 쓰지 말자는 글 발견.(http://blog.takipi.com/java-8-stampedlocks-vs-readwritelocks-and-synchronized/)
73 | * 최근 4.4에 커밋된 EhCacheCache 동기화 로직에서 보면 writeLock만 사용확인. 사실 캐시라서 가능하고, EHCache의 경우 오퍼레이션이 thread safe해서 괜찮.(https://github.com/spring-projects/spring-framework/commit/19d97c425316801a767cf99178ef30af730b1570)
74 |
75 |
76 | ## 동기화 관련 좋은 레퍼런스
77 | * BankAccount예제 : Synchronized vs Synchronized Volatile vs ReentrantLock vs ReentrantReadWriteLock vs StampedLock vs Immutable vs Atomic
78 | http://www.javaspecialists.eu/archive/Issue215.html
79 | * Starvation with ReadWriteLocks : http://www.javaspecialists.eu/archive/Issue165.html
80 | * Java 8 Concurrency Tutorial: Synchronization and Locks : http://winterbe.com/posts/2015/04/30/java8-concurrency-tutorial-synchronized-locks-examples/
81 |
--------------------------------------------------------------------------------
/video/AWS-re-Invent-2016-From-Resilience-to-Ubiquity.md:
--------------------------------------------------------------------------------
1 | https://www.youtube.com/watch?v=leqUbSY55hY
2 |
3 |  4 |
5 |
4 |
5 |  6 |
7 |
6 |
7 |  8 |
9 |
8 |
9 |  10 |
11 |
10 |
11 |  12 |
13 |
12 |
13 |  14 |
15 |
14 |
15 |  16 |
17 |
16 |
17 |  18 |
19 |
18 |
19 |  20 |
21 |
20 |
21 |  22 |
23 |
22 |
23 |  24 |
25 |
24 |
25 |  26 |
27 |
26 |
27 |  28 |
29 |
28 |
29 |  30 |
30 |  31 |
31 |  32 |
32 |  33 |
34 |
35 |
33 |
34 |
35 |  36 |
36 |  37 |
37 |  38 |
38 |  39 |
39 |  40 |
40 |  41 |
41 |  42 |
43 |
42 |
43 |  44 |
45 |
44 |
45 |  46 |
47 |
46 |
47 |  48 |
49 |
48 |
49 |  50 |
51 | 
52 |
53 |
50 |
51 | 
52 |
53 |  --------------------------------------------------------------------------------
/video/A-Netflix-Guide-to-Microservices-QCon2016.md:
--------------------------------------------------------------------------------
1 | https://www.youtube.com/watch?v=OczG5FQIcXw
2 |
3 | 
4 |
5 | 
6 |
7 | 
8 |
9 | 
10 |
11 | 
12 |
13 | 
14 |
15 | 
16 |
17 | 
18 |
19 | 
20 |
21 | 
22 |
23 | 
24 |
25 | 
26 |
27 | 
28 |
29 | 
30 |
31 | 
32 |
33 | 
34 |
35 | 
36 |
37 | 
38 |
39 | 
40 |
41 | 
42 |
43 | 
44 |
45 | 
46 |
47 | 
48 |
49 | 
50 |
51 | 
52 |
53 | 
54 |
55 | 
56 |
57 | 
58 |
59 | 
60 |
61 | 
62 |
63 | 
64 |
65 | 
66 |
67 | 
68 |
69 | 
70 |
71 | 
72 |
73 | 
74 |
75 | 
76 |
77 | 
78 |
79 | 
80 |
81 | 
82 |
83 | 
84 |
85 | 
--------------------------------------------------------------------------------
/galeracluster_for_mysql.md:
--------------------------------------------------------------------------------
1 | # GALERA CLUSTER FOR MYSQL
2 | synchronous replication에 기반한 MySQL Multimaster Cluster.
3 |
4 | ## What is Galera?
5 | 이탈리라어. 갤리(galley)선(특히 고대 그리스나 로마 시대 때 주로 노예들에게 노를 젓게 한 배)
6 | 갤리선이 빠르게 가기 위해선 수많은 선원들이 synchronously하게 노젓기를 할 수 있도록 해야하는데 galeracluster의 역할을 표현한다.
7 |
8 | ## 개요 및 특징
9 | http://galeracluster.com/products/
10 | write set replication (wsrep) interface의 구현체.
11 | 2007년 첫 릴리즈. open source.
12 | OpenStack에서도 사용. 가이드 : http://docs.openstack.org/high-availability-guide/content/ha-aa-db-mysql-galera.html
13 | * Synchronous replication => consistency.
14 | * Active-active multi-master topology => zero failover time.
15 | * Read and write to any cluster node
16 | * Automatic membership control, failed nodes drop from the cluster(elasticity)
17 | * Automatic node joining
18 | * True parallel replication, on row level
19 | * Direct client connections, native MySQL look & feel
20 | * No slave lag
21 | * No lost transactions
22 | * Both read and write scalability
23 | * Smaller client latencies
24 |
25 | ## WSREP?
26 | https://launchpad.net/wsrep/
27 | certification 기반의 multi-master replication을 위한 인터페이스.
28 | transaction (commit)write sets을 관리하는 애플리케이션 callback API와 replication plugin(library) call API를 정의한다.
29 | ```
30 | wsrep API defines a set of application callbacks and replication library calls necessary to implement synchronous writeset replication of transactional databases and similar applications. It aims to abstract and isolate replication implementation from application details. Although the main target of this interface is a certification-based multi-master replication, it is equally suitable for both asynchronous and synchronous master/slave replication.
31 | ```
32 |
33 | ## 설치 컴퍼넌트
34 | * wsrep(replication) provider
35 | * MySQL patch
36 |
37 | 최소 3대의 hosts애 설치 필요함.
38 | 클러스터에 먼저 한대(Primary Component) 띄우고
39 | `# service mysql start --wsrep-new-cluster`
40 | SHOW STATUS LIKE 'wsrep_cluster_size';
41 | ```
42 | +--------------------+-------+
43 | | Variable_name | Value |
44 | +--------------------+-------+
45 | | wsrep_cluster_size | 1 |
46 | +--------------------+-------+
47 | ```
48 | 나머지 노드들 띄우면 클러스터에 합류하게됨.
49 | `# service mysql start`
50 | ```
51 | +--------------------+-------+
52 | | Variable_name | Value |
53 | +--------------------+-------+
54 | | wsrep_cluster_size | 2 |
55 | +--------------------+-------+
56 | ```
57 |
58 | ## Why High Availability and Cloud are more difficult for databases?
59 | DB는 stateless 하지 않다. data가 크면 copy하는데 만 수시간. 스냅샷 포인트도 고려해야 하고, 서비스 중단없이 투입하려면 replication 기술이 요함.
60 |
61 | ## database clustering solutions vs Galera-Cluster-for-MySQL
62 | http://galeracluster.com/wp-content/uploads/2013/10/Minimizing-downtime-and-maximizing-elasticity-with-Galera-Cluster-for-MySQL.pdf
63 |
64 | * no scale-out benefit at all (active-passive)
65 | * can only scale read-only transactions (master-slave)
66 | * Well known database clustering solutions typically have at least two of the following
67 | downsides
68 | 1) risk of lost data due to asynchronous replication,
69 | 2) Up to 50% performance overhead,
70 | 3) downtime at planned and unplanned failovers may be up to several minutes,
71 | 4) poor compatibility compared to running with a non-clustered database,
72 | 5) prohibitively difficult to use
73 | 6) not suitable for Widea Area Network replication between datacenters/continents,
74 | 7) prohibitively expensive to use.
75 |
76 |
77 | 보통 Synchronous replication이 network latency에 취약한데, Galera는 certification-based replication를 통해 이를 해결했다고함. 심지어 여러 대륙간에 clustering 해도 문제없다고 함. Google Cloud SQL처럼 여러 대륙에 clustering 해서 재난 대비 및 end user에 response time 줄이는 효과.
78 |
79 | https://www.nginx.com/blog/mysql-high-availability-with-nginx-plus-and-galera-cluster/
80 | http://www.severalnines.com/mysql-load-balancing-haproxy-tutorial
81 | http://www.severalnines.com/clustercontrol
82 |
83 | ## CLUSTER DEPLOYMENT VARIANTS
84 | http://galeracluster.com/documentation-webpages/deploymentvariants.html
85 |
86 | ## DATABASE REPLICATION
87 | http://galeracluster.com/documentation-webpages/introduction.html
88 | ### ASYNCHRONOUS AND SYNCHRONOUS REPLICATION
89 | #### Advantages of Synchronous Replication
90 | High Availability - no data loss, consistent
91 | Improved Performance - transaction on all nodes in parallel.
92 | Causality across the Cluster - causality across the whole cluster.
93 |
94 | #### Disadvantages of Synchronous Replication
95 | m = n X o X t (n: number of nodes, o: number of operation, t: tps)
96 | 즉, nodes의 증가는 응답시간과 conflict, deadlock 발생확률의 기하급수적인 증가 야기.
97 |
98 | ### SOLVING THE ISSUES IN SYNCHRONOUS REPLICATION
99 | certification-based replication system.
100 |
101 | * Group Communication
102 | * Write-sets
103 | * Database State Machine
104 | * Transaction Reordering
105 |
106 | ## CERTIFICATION-BASED REPLICATION
107 | optimistic execution.
108 | 클러스터 내 모든 노드에 commit 복제시 certification test를 수행하는데 primary key 기반으로 conflicts을 체크 해서 빠른듯.
109 |
110 | http://galeracluster.com/documentation-webpages/certificationbasedreplication.html
111 |
112 | ### WHAT DB Features CERTIFICATION-BASED REPLICATION REQUIRES
113 | * Transactional Database
114 | * Atomic Changes
115 | * Global Ordering
116 |
117 | ### HOW CERTIFICATION-BASED REPLICATION WORKS
118 | http://galeracluster.com/documentation-webpages/certificationbasedreplication.html
119 |
120 | ## REPLICATION API
121 | http://galeracluster.com/documentation-webpages/architecture.html
122 | * Database Management System (DBMS) : The database server that runs on the individual node. Galera Cluster can use MySQL, MariaDB or Percona XtraDB.
123 | * wsrep API : The interface and the responsibilities for the database server and replication provider. It consists of:
124 | * wsrep hooks The integration with the database server engine for write-set replication.
125 | * dlopen() The function that makes the wsrep provider available to the wsrep hooks.
126 | * Galera Replication Plugin : The plugin that enables write-set replication service functionality.
127 | * Group Communication plugins : The various group communication systems available to Galera Cluster. For instance, gcomm and
128 |
129 | ## ISOLATION LEVELS
130 | The SNAPSHOT-ISOLATION : REPEATABLE-READ 와 SERIALIZABLE 중간
131 |
132 | ## STATE TRANSFERS
133 | State Snapshot Transfer, Incremental State Transfer
134 |
135 | ## 기타
136 | * 화이트페이퍼 : http://galeracluster.com/wp-content/uploads/2013/10/Minimizing-downtime-and-maximizing-elasticity-with-Galera-Cluster-for-MySQL.pdf
137 | * github : https://github.com/codership/galera
138 | * 용어 : http://galeracluster.com/documentation-webpages/glossary.html
139 |
--------------------------------------------------------------------------------
/book/building-microservices.md:
--------------------------------------------------------------------------------
1 | # "Building Microservices" by Sam Newman
2 |
3 | # 인상적인 문장들 정리
4 |
5 | ## 1장 마이크로서비스
6 | * 도메인 주도 설계(DDD), 지속적 배포(continuous delivery), 주문형 가상화(on-demand vitualization), 인프라스트럭쳐 자동화, 작고 자율적인 팀, 대규모 시스템 등의 분위기에 편승한 마이크로서비스는 실사용을 기반을 하나의 대세 내지는 패턴으로 부상했다.
7 | * 황금률은 '다른 변경없이 특정 서비스만 변경하고 배포할 수 있는가?'이다. 서비스를 잘 분리하려면(decoupling) 올바르게 모델링하고 API를 제대로 만들어야 한다.
8 | * 회복공학(resilence engineering)의 핵심은 격벽(bulkhead)이다. 즉 특정 컴포넌트에 장애가 발생하더라도 그 장애가 전파되지 않는다면 해당 문제를 격리하고 나머지 시스템을 계속 작동시킬 수 있다. 서비스의 경계야말로 명확한 격벽이다.
9 | * 하나의 큰 모놀리식 서비스에서는 항상 모든 것을 함께 확장해야 한다. 만약 작은 서비스들로 구성되어 있다면 필요한 서비스만 확장할 수 있다. 온라인 패션몰인 길트(Gilt)가 이런 이유로 마이크로서비스를 도입했다. 길트는 2007년 Ruby on Rails로 작성한 모놀리식 애플리케이션을 2009년 자바로 작성된 10개의 마이크로서비스로 변환했고, 2011년에 스칼라를 적용했다. 2014년 Node.js를 도입하여 수백 개 이상의 마이크로서비스를 운영하고 있다.
10 | * 마이크로서비스는 공짜도 은총알도 아니며, 황금 망치로 오인되는 일이 없어야 한다. 마이크로서비스는 분산 시스템과 연관된 모든 종류의 복잡성을 내포하고 있다. 마이크로서비스가 제공하는 혜택을 얻기 위해서는 배포, 테스트, 모니터링을 훨씬 더 잘 다루어야 할 것이다. 또한 시스템을 확대하고 회복력을 유지하는 방법에 대해 다르게 생각해야 할 것이다. 분산 트랜잭션이나 CAP 정리와 같은 것들이 골치 아플 수 있을 텐데 각오해야 할 것이다.
11 |
12 | ## 2장 진화적 아키텍트
13 | * IT 아키텍트의 역할을 잘 요약하는 다음의 비유를 좋아한다. 에릭 도넌버그는 아키텍트의 역할을 건축가보다는 도시 설계자에 가까운 의미로 접근해야 한다는 아이디어를 처음으로 필자와 공유했다. 도시 설계자의 역할은 다양한 정보 소스를 파악하고, 현재 시민의 요구에 부응함과 동시에 미래의 용도까지 고려하면서 도시 배치를 최적화 하는 것이다. 도시 설계자가 도시 발전에 영향을 미치는 방식은 흥미롭다. 그는 '특정 건물을 거기에 만들라'고 하는 대신 도시를 구역화한다.
14 | * 넷플릭스는 데이터 저장 기술을 대부분 카산드라(cassandra)로 통일 했다. 비록 모든 경우에 적합한 최선의 대응책은 아닐지라도, 넷플릭스는 카산드라와 관련된 도구 및 전문지식을 통해 얻는 가치야말로 몇몇 특정 태스크에 더 적합할 수 있는 다수의 이종 플랫폼 확장을 지원하고 운영하는 것보다 더 중요하다고 생각했다.
15 | * 만약 한 서비스는 HTTP 상에서 REST를 노출하고, 다른 서비스는 프로토콜 버퍼를, 또 다른 서비스는 자바 RMI를 사용하기로 결정한다면, 호출하는 서비스가 의사소통을 위한 다양한 스타일을 이해하고 지원해야 하므로 통합 작업은 악몽이 될 수 있다. 이것이 필자가 다이어그램 박스들 간에 벌어지는 이벤트를 걱정하고, 내부에서의 일에 대해서는 자유로워야 한다는 지침에 집착하는 이유다.
16 | * 시스템 설계상의 결정은 모두 trade-off와 관련된다. 의사결정을 구조화(framing)화 할 수 있는 가장 좋은 방법은 성취해야할 목표에 기반하여 일련의 원칙과 실천 사항을 정의하는 것이다.
17 | * 전략적 목표에서는 회사가 어디를 향해 나아가고 있는지, 그리고 고객을 행복하게 만들기 위해 어떻게 해야 할지 언급해야 한다. ex) '신규시장 개척을 위해 동남아시아로 영역 확장', '고객이 셀프서비스를 최대한 많이 사용하게 하자'
18 | * 원칙은 더 큰 목표를 위해 해야 할 일을 정렬하는 규칙으로, 때로는 변경 될 수 있다. 예를 들어 조직의 전략적 목표 중 하나가 새로운 제품의 시장 출시 시간(time to market)을 줄이는 것이라면, 제품 출시 팀이 소프트웨어의 수명주기 전반에 대한 통제권을 가지고, 제품이 준비될 때 마다 다른 팀과는 독립적으로 출시하도록 원칙을 정할 수 있다. 원칙의 수는 10개 미만인 것이 좋다. 클라우드 애플리케이션 플랫폼인 헤로쿠(heroku)의 12가지 요소(www.12factor.net)는 헤로쿠 플랫폼 상에서 잘 동작하는 애플리케이션을 작성하기 위해 정리된 일련의 설계 원칙으로, 다른 맥락에 적용해도 효과적이다.
19 | * 실천 사항(practice)은 원칙을 실행하는 방법으로, 업무 수행을 위한 자세하고도 실질적인 지침이다. 이것은 대개 기술 명세적이며, 어떤 개발자든 이해할 수 있도록 충분히 구체적이어야 한다.
20 | * 아키텍트는 많은 것에 대해 책임을 진다. 그들은 개발을 이끌 수 있는 일련의 원칙을 정하고, 원칙들이 조직의 전략과 일치하도록 보장할 뿐만 아니라 이 원칙들로 인해 개발자를 비참하게 만드는 실천 사항이 만들어지지 않도록 해야 한다.
21 | * 기술 리더의 역할은 사람들이 스스로 비전을 이해하도록 그들의 성장을 돕고, 비전을 결정하고 구현하는 데 적극적으로 참여할 수 있도록 만드는 것이다.
22 |
23 | ## 3장 서비스 모델링하기
24 | * 무엇이 좋은 서비스를 만드는가? 바로 느슨한 결합(loose coupling)과 강한 응집력(high cohesion)이다.
25 | * 서비스가 서로 느슨히 결합되어 있다면 하나의 서비스가 변경될 때 다른 서비스가 변경되는 일이 없다. 마이크로서비스의 요점은 특정 서비스를 쉽게 변경하고 배포할 수 있다는 것이다.
26 | * 특정 행위를 변경하고자 할 때는 한곳에서 변경하고(강한 응집력) 가능한 한 신속하게 릴리즈 할 수 있기를 원한다.
27 | * 모든 도메인은 다수의 경계가 있는 콘텍스트(bounded context)로 구성되며, 각 콘텍스트 내에는 외부와 통신할 필요가 없는 것과 콘텍스트 외부와 공유되는 것이 함께 존재한다. 경계가 있는 모든 콘텍스트에는 명백한 인터페이스가 존재하며 다른 콘텍스트와 공유되는 모델을 결정한다.
28 | * 경계가 있는 콘텍스트와 관련해서 필자가 좋아하는 또 다른 정의는 '명료한 경계에 의해 강제된 구체적인 책임'이다. 만약 여러분이 경계가 있는 콘텍스트로부터 정보를 원하거나 콘텍스트 내부의 기능을 요청하고자 한다면 모델을 이용하여 콘텍스트 경계와 의사소통해야 한다.
29 |
30 | ## 4장 통합
31 | * 통합(마이크로서비스간의 통신)에 대한 올바른 이해는 마이크로서비스 관련 기술에서 가장 중요한 요소다. 잘못 통합하면 재앙이다.
32 | * 마이크로서비스 간의 통신에 사용되는 API가 특정 기술에 종속되지 않도록 기술 중립성(technology-agnostic)을 유지하는 것을 매우 중요하게 생각하는 이유이기도 하다. 이는 마이크로서비스 구현에 기술 스택을 좌우하는 통합 기술을 회피하는 것을 의미한다.
33 | * 서비스 협업 방식 측면에서 우리가 내릴 수 있는 가장 중요한 결정 사항 중 하나인 동기(synchronous)와 비동기(asynchronous)방식을 논의해야 한다. 통신은 동기식이어야 하는가 비동기식이어야 하는가? 이 근원적인 선택은 필연적으로 우리를 특정 세부 구현으로 이끈다.
34 | * 서로 다른 이 두 통신 모드는 '요청/응답' 또는 '이벤트 기반'이라는 관용적인 두 가지 협력 방식을 가능하게 한다. 요청/응답 스타일은 클라이언트가 요청을 시작하고 응답을 기다리는 것이다. 이 모델은 동기 통신 방식과 명확히 일치하지만 비동기 통신에서도 잘 작동한다. 클라이언트는 작업 요청을 보내고 그 작업이 완료되었을 때 서버가 알려주도록 요청하는 콜백을 등록할 수 있다. 한편 이벤트 기반 협업에서는 모든 것이 뒤바뀐다. 클라이언트는 완료되어야 할 작업을 요청하는 대신 일(사건)이 발생했음을 알리고 다른 당사자들이 무엇을 해야 할지 알기 기대한다. 우리는 결코 다른 누구에게도 해야 할 일을 말하지 않는다. 이벤트 기반 시스템은 본질상 비동기적이다. 그리고 지능이 더 고르게 분산되어 있다. 즉, 비즈니스 로직이 핵심 두뇌로 집중화되기보다는 다양한 협업자들에 고르게 분배된다. 이벤트 기반 협업 역시 매우 결합도가 낮은 방식이다. 이벤트를 발산하는 클라이언트는 이벤트에 반응하는 대상이 누구인지 또는 무엇인지 전혀 알지 못한다. 이는 클라이언트 몰래 이벤트에 새로운 구독차를 추가할 수 있다는 의미다.
35 | * 필자는 코레오그래피 방식의 시스템이 전반적으로 더 느슨히 결합하고 유연하며 변경을 보다 쉽게 수용하는 것을 알게 되었다. 시스템 경계를 넘어 프로세스를 모니터링하고 추적하는 부가 작업이 필요하지만, 오케스트레이션 방식에 지나치게 의존하는 구현체는 매우 취약하고 높은 변경 비용을 수반한다. 이러한 면에서 필자는 각 서비스가 자신의 역할을 영리하게 인식하는 코레오그래피 방식의 시스템을 매우 선호한다.
36 | * 이벤트 기반의 비동기 통신시 고려해야 할 두 가지 주요 문제는 마이크로서비스가 이벤트를 발산하는 방법과 소비자가 생성된 이벤트를 찾는 방법이다. 전통적으로 RabbitMQ와 같은 메시지 브로커들은 두 문제를 모두 처리한다. 생산자는 API를 사용하여 브로커에 이벤트를 발행하고 브로커(중개자)는 이벤트가 도착하면 소비자에게 알릴 수 있도록 구독을 처리한다. 메시지 브로커 인프라스트럭쳐를 구축하고 운영하려면 부가적인 머신과 전문성이 요구되지만 일단 실현된다면 느슨히 결합된 이벤트 기반 아키텍처의 구현에 대단히 효과적인 방법이 된다. 이벤트를 전파하는 또 다른 대안은 HTTP를 사용하는 것이다. 아톰(ATOM)은 자원의 피드를 게시하기 위해 semantics를 정의한 REST 호환 사양서다. 고객 서비스는 변경될 때 해당 피드에 대한 이벤트만 발생하고, 고객 서비스의 소비자들은 단지 피드의 변경이 있는지 폴링만 하면 된다.
37 | * 분산 시스템은 호출 방법의 구현 세부 사항을 추상화하고 더 쉽게 추론하게 하므로 Rx(reactive extension) 구현체와 아주 잘 어울린다. Rx의 백미는 하위 서비스에 대해 동시에 발생하는 호출들을 훨씬 쉽게 처리하면서 다수의 호출을 함께 조합할 수 있다는 것이다.
38 | * 넷플릭스는 클라이언트 라이브러리를 특별히 강조한다. 사실 넷플릭스에서 사용되는 클라이언트 라이브러리는 시스템의 신뢰성과 확장성을 보장하려는 것이다. 넷플릭스의 클라이언트 라이브러리는 서비스 발견, 장애 모드(실패처리), 로깅, 그리고 실제로 서비스 자체의 본질과는 다른 측면들을 다룬다. 이러한 공유 클라이언트 없이는 넷플릭스의 대규모 확장 운영 상황에서 제대로 동작하는 각각의 클라이언트/서버 통신을 보장하기 어렵다. 그러나 넷플릭스의 한 관계자의 말에 따르면 시간이 지나면서 클라이언트 라이브러리는 클라이언트와 서버 사이에서 문제가 될 정도의 결합을 초래했다.
39 | * 관심 없는 데이터의 변경들을 무시할 수 있도록 독자(reader)를 구현하는 것이 바로 마틴 파울러가 말하는 '관대한 독자(tolerant reader)' 패턴이다. (ex) XPath를 사용해 필드의 저장 위치는 개의치 않고 필드 추출하기)
40 |
41 | ## 5장 모놀리스 분해하기
42 | * 스트럭쳐 101(Structure 101)과 같은 도구는 패키지 간의 의존성을 시각적으로 표현한다.
43 | * 보상 트랜잭션을 수동으로 통제하는 방식의 대안은 분산 트랜잭션(distributed transaction)의 사용이다. 트랜잭션 관리자가 하부 시스템에서 수행되는 다양한 트랜잭션을 통제, 조정한다. 분산 트랜잭션은 복잡성을 증가시킨다. 또한 재시도, 보상 로직을 최종 방법으로 사용하는 시스템은 추론하기 더 어려우며 데이터의 불일치를 고치기 위해 다른 보상 행위가 필요 할 수 있다. 트랜잭션 자체를 표현할 구체적인 개념을 만들어라. 이것은 보상 트랜잭션과 같은 다른 작업을 실행할 여지를 주고 시스템의 복잡한 개념들을 모니터링하고 관리할 수 있는 방법을 제공한다. 예를 들어 '진행 중인 주문' 같은 개념을 만들 수 있다.
44 |
45 | ## 6장 배포
46 | * 지속적 통합(CI)를 통한 핵심 목표는 모든 사람이 서로 동기를 맞추는 것이며, 그것은 새롭게 체크인된 코드가 기존 코드와 적절히 통합됨을 보장함으로써 달성할 수 있다. 이를 위해 CI 서버는 코드의 커밋을 감지하고, 체크아웃하고, 코드의 컴파일과 테스트 통과를 확인하는 것과 같은 몇가지 검증을 한다.
47 | * 지속적 배포(CD) 빌드 파이프라인(build pipeline)을 기반으로 모든 체크인의 실환경 준비에 대한 지속적인 피드백을 얻고, 나아가 모든 체크인을 빠짐없이 릴리스 후보로 여기는 접근 방법이다.
48 | * 우리가 배포하고자 하는 서비스는 모든 다양한 환경에서 동일해야 한다.
49 | * 대규모 마이크로서비스를 다룰 때 이용되는 다른 인기 있는 방법은 환경 구성을 제공하는 전용 시스템을 사용하는 것이다.
50 | * 사용하는 하부 플랫폼과 산출물이 어떤 것이든 간에 특정한 서비스를 배포하는 데 일관된 인터페이스를 유지하는 것은 필수다. 이 분야에서 오랜 기간 일하고 나서 필자는 어떤 배포도 실행시킬 수 있는 가장 타당한 방법은 매개 변수 전달이 가능한 한 줄의 명령행 호출임을 확신한다. 이것은 CI 도구에 의해 실행되는 스크립트로 또는 직접 입력함으로써 시작할 수 있다. 필자는 윈도우 배치부터 배쉬 쉘, 파이썬 패브릭 스크립트 등 다양한 기술 스택의 랩퍼 스크립트를 작성해왔다. 하지만 모든 명령행은 동일한 기본 포맷을 공유한다.
51 |
52 | ## 7장 테스팅
53 |
54 | ## 8장 모니터링
55 | * 필자는 서비스 스스로 기본적인 측정지표를 발산해야 한다고 강력히 제안한다. 웹 서비스라면 최소한 기본으로 응답시간과 에러율 같은 측정지표를 노출해야 한다. 만약 이러한 일을 대신하는 웹 서버가 여러분 서버 앞단에 없다면 그것은 필수다. 그러나 여러분은 더 나아가야 한다. 예를 들어 계정서비스(account service)는 고객이 과거 주문 내역을 본 횟수를 보여주거나 웹 쇼핑몰이 지난 하루 동안 얼마나 많은 돈을 벌었는지 기록하기 원할 수 있다.
56 | * 코다헤일(Codahale)의 측정지표 라이브러리는 JVM용 라이브러리의 한 예로 측정지표를 카운터, 타이머 또는 측정기로 저장하게 해준다. 예를 들어 시간 설정 측정지표(time-boxing metrics) 기능을 제공해서 최근 5분 동안의 주문수와 같은 측정지표를 지정할 수 있다.
57 |
58 | ## 9장 보안
59 |
60 | ## 10장 콘웨이의 법칙과 시스템 설계
61 | * 1968년 멜빈 콘웨이가 논문에서 다음과 같이 발표했다. "조직은 시스템(반드시 정보 시스템이라기보다는 더 넓은 의미의 시스템)을 설계할 때 필연적으로 그 조직의 의사소통 구조와 일치하도록 만든다."
62 | * 마이크로소프트는 조직 구조가 어떻게 그들의 특정 제품, 즉 윈도우 비스타의 소프트웨어 품질에 영향을 주는지 알아보기 위해 경험적 사례 연구를 진행했다. 코드 복잡도처럼 흔히 사용되는 소프트웨어 품질 지표를 포함하여 다수의 지표를 살펴본 후 그들은 조직 구조와 연관된 지표가 통계적으로 가장 밀접한 척도임을 발견했다.
63 | * 담담 서비스의 전체 수명주기를 소유하는 작은 팀의 추구는 아마존이 AWS를 만들 수 있었던 일등 공신이다. 넷플릭스는 아마존의 사례를 교훈삼아 처음부터 작고 독립적인 팀을 조직했고 그 결과 독립적인 서비스를 만들 수 있었다. 이를 통해 속도에 최적화된 시스템 아키텍쳐를 확보할 수 있었다.
64 | * 서비스 소유권(service ownership)이란 무엇일까? 이는 일반적으로 서비스를 소유한 팀이 해당 서비스의 변경을 책임지는 것을 말한다. 팀에 더 많은 권한과 자율성을 부여하지만 업무의 책임도 부여하면서 최선의 결정을 할 수 있는 사람이 결정하게 만든다.
65 | * "처음에 어떻게 보이든 항상 사람의 문제다" by 게리 와인버그(Gerry Weinberg) from '컨설팅의 비밀'
66 | * 마이크로서비스 세계에서 사람들의 책임을 명확히 구분해야 한다는 것을 이해하라.
67 | * 서비스 소유권(service ownership) = 동일 위치의 팀(collocated team) = bounded context.
68 |
69 | ## 11장 대규모 마이크로서비스
70 | * 마이크로서비스가 복잡하게 발전한다면? 분리된 많은 서비스의 장애를 처리하거나 수백 개의 서비스를 관리해야 한다면? 사람수보다 더 많은 마이크로 서비스가 있을 때의 대응 패턴은 무엇일까?
71 | * 장애는 대규모 환경에서 통계적으로 필연적이다.(하드디스크는 고장나고 소프트웨어는 오류가 발생하며 네트워크는 신뢰할 수 없다) 따라서 어떤 장애든 결국 발생한다는 것을 가정해야 한다.
72 | * 얼마나 많은 장애를 감내할 수 있는지와 얼마나 빠른 시스템이 되어야 하는지 아는 것은 사용자에 의해 좌우된다. 그것은 결국 가장 적합한 기술이 어떤 것인지 파악하는 데 도움이 된다.
73 | * 여러분은 응답시간/지연시간, 가용성, 데이터의 내구성과 같은 교차기능 요구사항에 대해 지속적이며 체계적으로 측정할 방법이 필요하다.
74 | * 고장나서 작동하지 않는 시스템보다 느리게 동작하는 시스템이 훨씬 다루기 힘들다는 것을 우리는 어렵게 습득했다. 분산 시스템에서 지연시간은 매우 중요하다. 결국 우리는 재발을 막기 위해 세 가지 조치를 취했다. 타임아웃을 올바르게 설정했고, 격벽(bulkhead)을 위해 커넥션 풀을 분리했으며, 정상 동작하지 않는 시스템은 애초에 호출하지 않도록 회로 차단기(Circuit Breaker)를 구현했다.
75 | * 넷플릭스가 전적으로 AWS 인프라스트럭쳐에 기반한다는 사실만큼 넷플릭스는 운영 규모로도 유명하다. 그리고 이 두 요소는 장애를 잘 수용해야 한다는 것을 의미한다. 넷플릭스는 장애에 강한 시스템을 보장하기 위해 실제로 장애을 조장하며 이를 극복했다.
76 | * 구글은 서버 장애를 흉내 내는 단순한 테스트 수준을 넘어 매년 진행하는 장애 복구 테스트(Disaster Recovery Test == DiRT) 훈련의 일부로 지진과 같은 대규모 재난까지 시뮬레이션한다. 넷플릭스 또한 장애를 유발하는 프로그램을 작성해서 하루 단위로 실환경에서 실행하는 더 공격적인 방법을 취한다.
77 | * 이들 프로그램 중 가장 유명한 카오스 몽키는 하루 중 특정 시간 동안 임의로 머신의 전원을 꺼버린다. 결국 실운영 환경에서 이런 사고의 발생 가능성을 인지하는 것은 시스템을 만드는 개발자들이 실제로 그 사고에 준비하게 만든다. 레이턴시 몽키는 머신간의 느린 네트워크 접속 상황을 시뮬레이션한다.
78 | * 장애를 줄이기 위한 분리의 일반적 형태는 모든 서비스를 데이터 센터의 단일 랙에서 실행하지 않거나 여러 데이터 센터로 분산하는 것이다. 여러분이 하부 서비스 제공자를 이용한다면 서비스 수준 계약(SLA)이 적절히 제공되고 계획될 수 있는지 여부가 중요하다. 여러분은 분기당 4시간 이하의 다운타임 보장이 필요하지만 호스팅 제공자가 분기당 8시간의 다운타임만 보장한다면 SLA를 변경하거나 대안을 마련해야 한다. 또한 컴퓨팅 서비스에 대해 AWS는 전체 리전에서 월간 99.95%의 가동시간만을 제공하므로 작업 부하를 리전 내 여러 가용 영역(availability zone)으로 분산하고 싶을 것이다.
79 | * 제프 딘(Jeff Dean)은 WSDM 2009 컨퍼런스에서 발표한 'Building Large-Scale Information Retrieval Systems'에서 10배 성장까지 고려해서 설계하고 100배 성장 전까지 재작성을 계획해야 한다고 강조했다. 특정 시점에서는 다음 단계의 성장을 지원하기 위해 매우 근본적인 것들을 해야 한다. 재설계는 길트가 한 것처럼 기존의 모놀리스를 나눠 쪼개는 것을 의미하거나 곧 살펴볼 내용인 부하를 더 잘 처리하기 위해 새로운 데이터 저장소를 선택하는 것일 수 있다. 그리고 재설계는 동기식 요청과 응답을 이벤트 기반의 시스템으로 전환하거나, 새로운 배포 플랫폼을 적용하거나, 전체 기술 스택을 교체하거나 그 중간에 있는 모든 것을 의미할 수도 있다.
80 | * 카산드라 같은 최근 시스템은 샤드 추가시 다운타임 없이 데이터의 재조정 수행이 가능하다.
81 | * 쓰기용 샤딩은 쓰기 볼륨을 확장할 수 있지만 회복성(resiliency)을 향상시키는 것은 아니다. 만약 고객 레코드 A부터 M까지는 항상 인스턴스 X에 저장될 때 인스턴스 X가 가용하지 못하면 그 레코드들을 잃어버릴 것이다. 하지만 카산드라는 카산드라 노드들의 집합인 링 내의 다수의 노드에 데이터를 복제하는 추가 기능을 제공한다.
82 | * CQRS(Command-Query Responsibility Segregation)는 다양한 종류의 확장을 가능하게 한다. 시스템에서 명령과 질의 부분은 다른 서비스나 다른 하드웨어에서 동작할 수 있고 근본적으로 다른 종류의 데이터 저장소를 사용할 수 있다. 이것은 확장을 다루는 수많은 방법을 가능하게 한다. 심지어 다양한 질의 구현을 통해 다양한 종류의 읽기 포맷을 지원할 수 있다. 예를 들어 그래프 기반의 데이터 표현이나 키/값 기반의 데이터 형태를 지원할 수 있다.
83 | * 캐시는 결과를 더 빠르게 제공하기 위해 데이터베이스나 다른 서비스까지의 불필요한 왕복을 제거한다. 잘 사용된다면 엄청난 성능 향상을 가져온다. 대규모 요청에도 HTTP가 확장을 매우 잘하는 이유는 캐싱의 개념이 내장되어 있기 때문이다. 분산 시스템에서는 일반적으로 캐싱을 클라이언트에 둘지 서버 측에 둘지 고민한다. 과연 어떤 것이 최선일까?
84 | * HTTP는 실제로 클라이언트와 서버 측에서 캐시할 수 있는 유용한 규약(콘트롤)을 제공한다. 이러한 규약들이 널리 사용되는 명세서에 포함된 사실은 캐시를 다루는 기존의 많은 소프트웨어의 이점을 이용할 수 있음을 의미한다. 스퀴드나 바니시 같은 리버스 프록시는 필요한 캐시된 콘텐츠를 저장하고 만료하면서 클라이언트와 서버 사이의 네트워크에 투명하게 배치될 수 있다. 이런 시스템들은 대규모 동시 요청을 아주 빠르게 처리하는 데 적합하며 공개용 웹사이트를 확장하는 데 있어 보편적인 방식이다. AWS의 클라우드프론트(CloudFront)나 아카마이(Akamai)와 같은 CDN은 트래픽이 세계 절반을 경유하지 않도록 해주며 호출한 클라이언트의 가까운 캐시로 요청을 라우팅한다. 그리고 현실적으로 HTTP 클라이언트 라이브러리와 클라언트 캐시는 우리를 대신해서 이러한 많은 작업을 처리할 수 있다.
85 | * 비록 여러분이 읽기용 캐싱을 더 자주 사용하더라도 쓰기용 캐싱이 적합한 사용 사례가 있다. 예를 들어 write-behind 캐시 방식을 사용한다면 로컬 캐시에 먼저 쓰고 데이터는 나중에 하위 소스에 플러시될 것이다. 이것은 대량 쓰기(burst of write)를 할 때나 동일한 데이터를 여러 번 쓸 때 유용하다. 버퍼와 잠재적으로 배치 쓰기에 사용될 경우 write-behind 캐시는 성능을 최적화하는 데 유용하다. 또한 버퍼링된 쓰기가 적절히 보존되면 하위 서비스를 사용할 수 없을 때도 쓰기를 큐에 추가하고 서비스가 다시 사용 가능해지면 보낼 수 있다.
86 | * 캐싱은 장애의 회복성을 구현하는 데 사용될 수 있다. 가디언 같은 경우 시스템이 중단된 경우에 제공할 수 있는 정적 버전의 웹사이트를 생성하기 위해 기존 라이브 사이트를 주기적으로 크롤링한다.
87 |
88 | ## 12장 종합정리(마이크로서비스의 원칙)
89 | * 비지니스 개념에 따른 모델(경계가 있는 콘텍스트)
90 | * 자동화 문화의 적용(자동화 테스팅, 지속적 배포, 환경 정의, 커스텀 이미지 생성, 불변 서버)
91 | * 내부 세부 구현의 은폐(기술 중립적 API)
92 | * 모든 것을 분권화(service owenership, 팀을 조직에 맞춰 조정, 코레오그래피)
93 | * 독립적인 배포(여러 버전의 엔드포인트 공존, blue/green 배포, 카나리배포, 소비자 주도 계약)
94 | * 장애 격리(안티프래질 사상, 타임아웃, 격벽, circuit breaker)
95 | * 매우 식별 가능한(유의적 모니터링, 로그, 통계, 상관관계 ID)
--------------------------------------------------------------------------------
/7-part_series_about_microservices.md:
--------------------------------------------------------------------------------
1 | # 개요
2 |
3 | [Chris Richardson](http://microservices.io/)이 포스팅하고 있는 "a 7-part series about designing, building, and deploying microservices." 시리즈 글들(총 7개)을 요약해본다.(2016-03-08 연재완료.)
4 |
5 | # 1. Introduction to Microservices
6 | 원본 글 : https://www.nginx.com/blog/introduction-to-microservices/
7 |
8 | ## Building Monolithic Applications
9 | 아래는 Uber같은 taxi-hailing app 아키텍쳐([hexagonal architecture](http://www.infoq.com/news/2014/10/exploring-hexagonal-architecture) = Ports and Adapters architecture.) 다이어그램이다.
10 | 논리적으로는 여러 모듈로 이루어져 있지만 단일(monolith) 애플리케이션으로 배포되는 특성상 개발, 테스트, 패키징, 배포 간편하고 쉬운 장점을 갖는다.
11 | 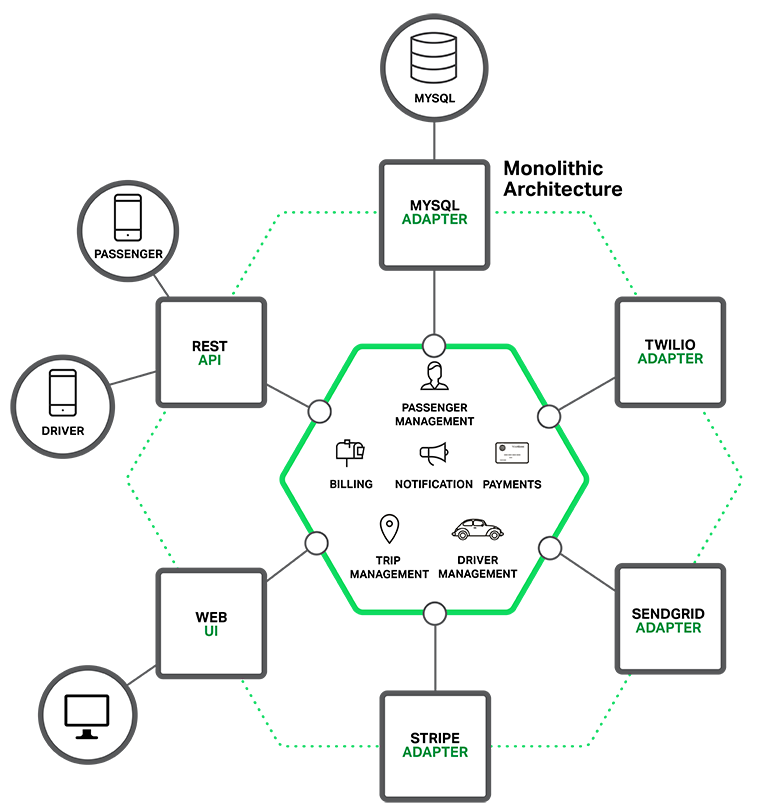
12 |
13 | ## Marching Towards Monolithic Hell
14 | 하지만 애플리케이션이 거대해질 경우 심플한 Monolithic 구조에서는 아래의 문제가 발생한다.
15 |
16 | * 생산성 - 수천개의 jars와 수백만 라인의 코드로 이루어진 beast 애플리케이션. Monolithic Hell. 복잡도가 증가하여 개발조직의 고통 시작, 배포시간도 오래걸림(수십분), 간단한 기능 추가에도 오래걸리는 배포 및 테스트로 인한 생산성 저하. CI에 역행. agile개발과 빠른 delivery의 어려움.
17 | * scale - CPU-intensive한 모듈과 in-memory 모듈이 함께 사용되는 경우처럼 리소스 요구사항이 상충될 때 확장성에 제약.
18 | * reliability - 앱이 하나의 프로세스로 돌기 때문에 한 모듈의 버그가 전면 장애로 이어짐.
19 | * adopt new tech speed - 새로운 언어, 프레임워크 기술 적용이 극도로 어려움.
20 | * hiring - 오래되고 비생산적인 기술 사용. 능력있는 인재 채용이 어려움.
21 |
22 | ## Microservices – Tackling the Complexity
23 | * Amazon, eBay, Netflix 등은 위 문제를 [MSA](http://microservices.io/patterns/microservices.html) 패턴을 도입해서 해결. 즉 monolithic 애플리케이션을 잘게 쪼개서 작은 서로 연결되는 서비스들로 구성.
24 | * 각 microservice는 독립적인 mini application.
25 | 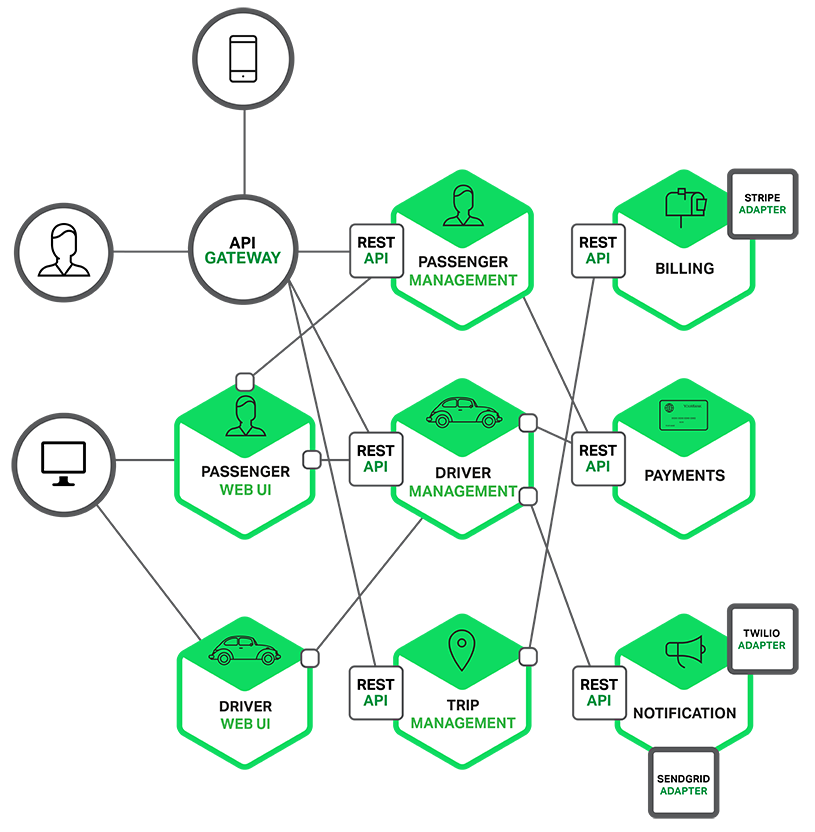
26 |
27 | * MSA 패턴은 Sacle Cube에서 Y축, 즉 different things를 분리해서 scale을 높이는 개념.
28 | 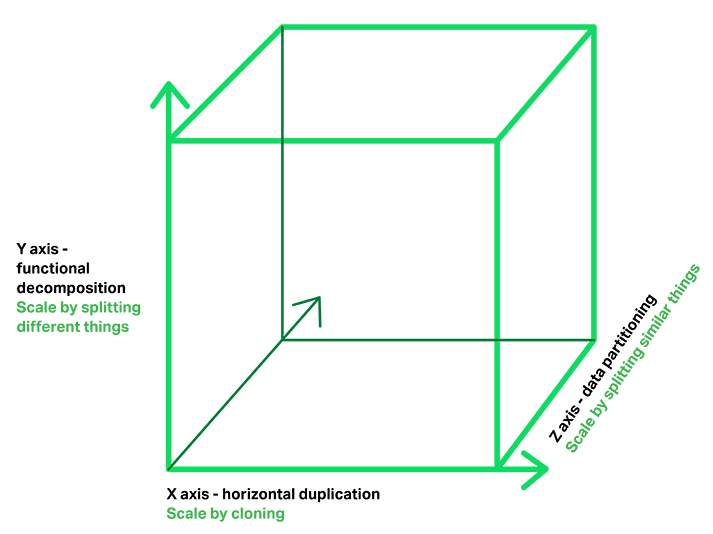
29 |
30 | * microservice마다 독립적인 database 스키마. data 중복의 단점은 있지만, 커플링은 낮추고 각 서비스에 효율적인 DB 사용이 가능해짐. ex) Driver Management 서비스는 Driver의 위치를 찾는데 효율적인 geo-queries 지원 DB 사용.
31 | 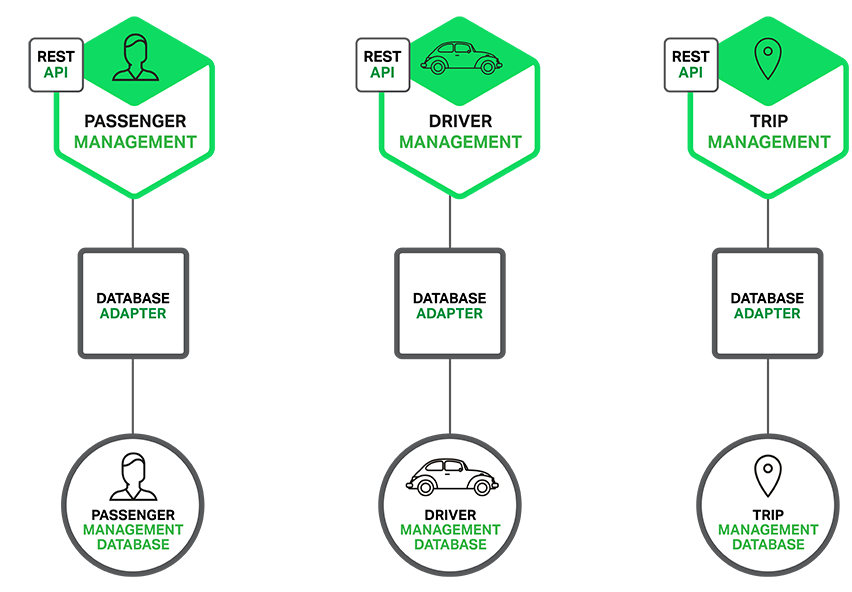
32 |
33 | * MSA VS SOA.
34 | * WSDL,SOAP vs REST
35 | * ESB vs APIGATEWAY
36 | * heavy vs simple, lightweight
37 |
38 | ## The Benefits of Microservices
39 | * 분리된 각 서비스는 개발이 빠르고 유지보수 및 이해하기 쉽다.
40 | * decompose complexity. 알고리즘으로 치면 divide and conquor 느낌. 분리된 서비스를 연결하는 RPC or message-driven API가 중요해짐.
41 | * 각 서비스에 집중하는 팀 구성 가능
42 | * 각 팀에서 자유롭게 기술을 선택할 수 있고 mini 서비스여서 기술 변경이 쉽다.
43 | * 요구사항을 구현하기위해 최적화된 언어와 아키텍처의 선택이 가능해진다.
44 | * CI의 현실화, 고속개발.
45 | * 각 서비스가 독립적으로 테스트, 배포되기 때문에 빠르고 좋은 품질 유지 가능.
46 | * 확장
47 | * 서비스 별로 독립적으로 확장 가능하고, 리소스 요구사항에 최적화된 장비 선택이 가능하다.
48 |
49 | ## The Drawbacks of Microservices
50 | 은탄환은 없다.
51 |
52 | * distributed system.
53 | * messaging or RPC. 부분실패(partial failure) 처리의 어려움, 롤백하기가 쉽지 않다.
54 | * partitioned database architecture
55 | * db 분산 트랜잭션 처리가 일상. NoSQL, messaging brokers에서는 strong consistency 만족시키기 어려움. eventual consistency.
56 | * 테스트
57 | * 한 서비스의 변경이 여러 서비스에 영향을 줌.
58 | * A -> B -> C depenency.
59 | * 배포
60 | * Hailo : 160, Netflix : 600 different services, 수많은 서비스 배포하려면 service discovery, 배포 자동화 도구들 필요. DevOps. ex) PaaS 서비스 이용 or 직접 구축(Mesos나 Kubernetes 이용.)
61 |
62 | * 팀간의 의사소통 어려움
63 | * 메모리 (중복)소비 증가. N x M services runs in its own JVM. own VM.
64 |
65 | # 2. Building Microservices: Using an API Gateway
66 | 원본 글 : https://www.nginx.com/blog/building-microservices-using-an-api-gateway/
67 |
68 | ## Introduction
69 | * 클라이언트가 접근하는 endpoint가 Monolithic 구조에서는 하나였다면 MSA 구조에서는 여러개 존재한다.
70 | 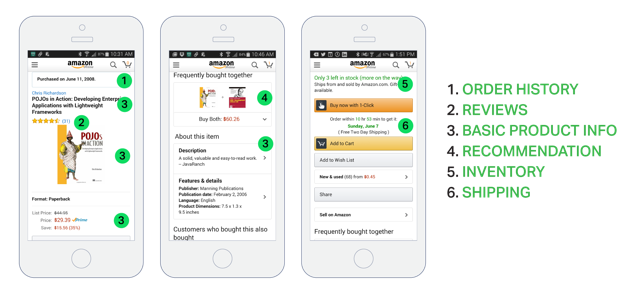
71 | * single REST call vs many REST call
72 | 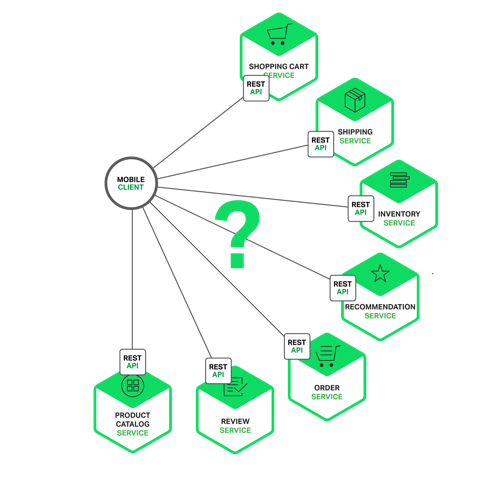
73 |
74 | ## Direct Client-to-Microservice Communication
75 | MSA 구조에서는 클라이언트가 접근하는 endpoint가 여러개 존재하고 아래와 같은 단점들로 인해 직접 호출하지 않는게 일반적인다.
76 |
77 | * public internet, mobile network에서 많은 요청은 비효율적.
78 | * 클라이언트 코드가 복잡해지고 리팩토링이 어려움.
79 | * microservices 에서 Thrift binary RPC, AMQP messaging protocol을 사용할 경우. 둘다 browser, 방화벽에 친화적이지 않고 내부 네트워크에서의 사용에 적합. 방확벽 밖에서는 HTTP나 WebSocket 프로토콜이 적합.
80 |
81 | ## Using an API Gateway
82 | * single entry point. OOP에서 Facade 패턴과 유사.
83 | * 내부 시스템 아키텍쳐를 캡슐화해서 클라이언트에 적합한 API를제공.
84 | * request routing, composition, and protocol translation. authentication, monitoring, load balancing, caching, request shaping and management, and static response handling.
85 | * Netflix API Gateway. 수십억 요청 처리.
86 | 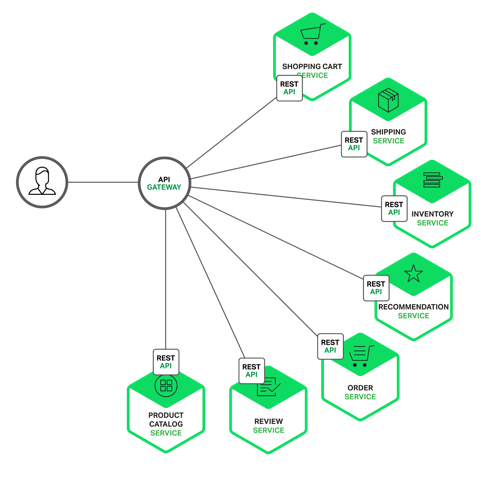
87 |
88 | ## Benefits and Drawbacks of an API Gateway
89 | ### Benefits
90 | * single endpoint(수많은 내부 서버 구조를 숨김).
91 | * 클라이언트와 서버사이의 round trip 횟수 감소.
92 | * 클라이언트 코드가 단순해짐.
93 | * 공통기능(인증, 캐싱, 통계, 프로토콜, 메시지 변환 등) 처리를 대신해줌.
94 |
95 | ### Drawbacks
96 | * 관리 포인트. API Gateway가 개발 병목이 될 수 있다.
97 | * API 탑재 프로세스(update)가 가벼워야 한다.
98 |
99 | ## Implementing an API Gateway
100 | API Gateway 구현시 아래 디자인 이슈를 고려 해야한다.
101 |
102 | * Performance and Scalability
103 | * 성능을 위해 API Gateway는 비동기, 논블로킹 I/O를 지원하는 플랫폼으로 개발 필요. ex) Netty, Vertx, Spring Reactor, or JBoss Undertow, Node.js, NGINX
104 |
105 | * Using a Reactive Programming Model(Future in Scala, CompletableFuture in Java 8, and Promise in JavaScript, Reactive Extensions)
106 | * simple yet efficient API Gateway code.
107 |
108 | * Service Invocation
109 | * microservice가 사용하는 다양한 통신 메커니즘 지원 필요. ex) asynchronous, messaging-based mechanism. JMS or AMQP, Zeromq. synchronous mechanism such as HTTP or Thrift.
110 |
111 | * Service Discovery
112 | * autoscaling and upgrades에 따른 service 주소가 dynamic하게 바뀌는 환경에서는 필수. Server-Side Discovery or Client-Side Discovery.
113 |
114 | * Handling Partial Failures
115 | * 백엔드 서비스가 실패 하더라도 (잘 바뀌지 않는 데이터라면)캐시 데이터 or 디폴트 데이터로 실패 처리 가능. cf) Netflix Hystrix
116 |
117 |
118 | # 3. Building Microservices: Inter-Process Communication in a Microservices Architecture
119 | 원본 글 : https://www.nginx.com/blog/building-microservices-inter-process-communication/
120 |
121 | ## Introduction
122 | language method call VS IPC(inter-process communication)
123 | 
124 |
125 | ## Interaction Styles
126 | MSA 각 서비스 컴퍼넌트들은 아래 다양한 IPC 방식의 조합을 사용하게 된다.
127 |
128 | | | One-to-One | One-to-Many |
129 | | ------------- |:-------------:| -----:|
130 | | Synchronous | Request/response | — |
131 | | Asynchronous | Notification, Request/async response | Publish/subscribe, Publish/async responses |
132 |
133 | * One-to-one – Each client request is processed by exactly one service instance.
134 | * One-to-many – Each request is processed by multiple service instances.
135 | * Synchronous – The client expects a timely response from the service and might even block while it waits.
136 | * Asynchronous – The client doesn’t block while waiting for a response, and the response, if any, isn’t necessarily sent immediately.
137 |
138 | ex) taxi-hailing(우버) app.
139 | 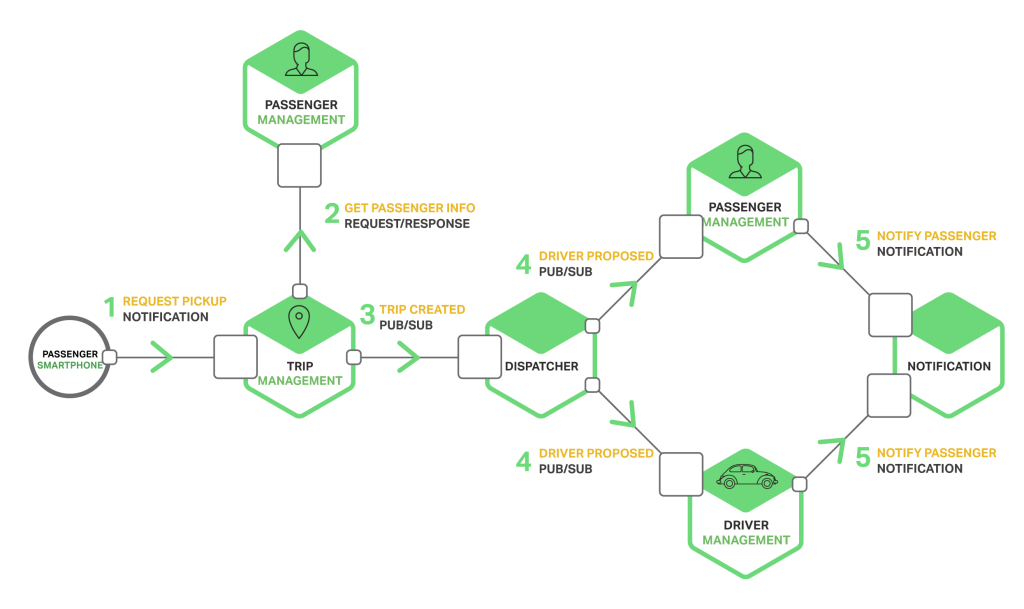
140 |
141 | ## Defining APIs
142 | * 서비스와 클라이언트간의 계약.
143 | * [API-first approach](http://www.programmableweb.com/news/how-to-design-great-apis-api-first-design-and-raml/how-to/2015/07/10)
144 | * IPC 메커니즘에 의존. ex) HTTP : URL, request and response formats.
145 |
146 |
147 | ## Evolving APIs
148 | * [Robustness principle.](https://en.wikipedia.org/wiki/Robustness_principle)
149 | - 서비스는 누락된 요청 속성에 대한 기본 값을 제공하고, 클라이언트는 별도로 추가된 응답 속성을 무시한다.
150 | * API 변경이 쉬운 IPC 메커니즘 및 메시지 포맷 사용.
151 | * API의 대격변에 대비해서 versioning 하는게 좋음.
152 |
153 | ## Handling Partial Failure
154 | 
155 | * [Netflix Hystrix](https://github.com/Netflix/Hystrix)
156 | * [described by Netflix](http://techblog.netflix.com/2012/02/fault-tolerance-in-high-volume.html)
157 | * Network timeouts – Never block indefinitely.
158 | * Limiting the number of outstanding requests – Throttling.
159 | * Circuit breaker pattern.
160 | * Provide fallbacks.
161 |
162 |
163 | ## IPC Technologies
164 | ### Asynchronous, Message-Based Communication
165 | 
166 | RabbitMQ, Apache Kafka,Apache ActiveMQ, and NSQ.
167 |
168 | #### 장점
169 | * Decouples the client from the service – The client is completely unaware of the service instances.
170 | * Message buffering – a message broker queues up the messages written to a channel until they can be processed by the consumer.
171 | * Flexible client-service interactions – Messaging supports all of the interaction styles described earlier.
172 | * Explicit inter-process communication. vs RPC
173 |
174 | #### 단점
175 | * Additional operational complexity.
176 | * Complexity of implementing request/response-based interaction – The client uses the correlation ID to match the response with the request.
177 |
178 | ### Synchronous, Request/Response IPC
179 | #### HTTP REST
180 | 
181 | [4단계의 REST 모델, maturity model for REST.](http://martinfowler.com/articles/richardsonMaturityModel.html)
182 | IDL tools : RAML and Swagger.
183 |
184 | ##### 장점
185 | * HTTP is simple and familiar.
186 | * You can test an HTTP API from within a browser using an extension such as Postman or from the command line using curl (assuming JSON or some other text format is used).
187 | * It directly supports request/response-style communication.
188 | * HTTP is, of course, firewall-friendly.
189 | * It doesn’t require an intermediate broker, which simplifies the system’s architecture.
190 |
191 | ##### 단점
192 | * It only directly supports the request/response style of interaction. You can use HTTP for notifications but the server must always send an HTTP response.
193 | * Because the client and service communicate directly (without an intermediary to buffer messages), they must both be running for the duration of the exchange.
194 | * The client must know the location (i.e., the URL) of each service instance.
195 |
196 |
197 | #### Thrift
198 | * a framework for writing cross-language RPCclients and servers.
199 | * Thrift provides a C-style IDL for defining your APIs. You use the Thrift compiler to generate client-side stubs and server-side skeletons. The compiler generates code for a variety of languages including C++, Java, Python, PHP, Ruby, Erlang, and Node.js.
200 | * supports JSON, binary, and compact binary message formats. transport protocols including raw TCP and HTTP.
201 |
202 | ### Message Formats
203 | * JSON and XML text message formats VS binary format.
204 | * [comparison of Thrift, Protocol Buffers, and Avro.](http://martin.kleppmann.com/2012/12/05/schema-evolution-in-avro-protocol-buffers-thrift.html)
205 |
206 | # 4. Service Discovery in a Microservices Architecture
207 | 원본 글 : https://www.nginx.com/blog/service-discovery-in-a-microservices-architecture/
208 |
209 | ## Why Use Service Discovery?
210 | 클라우드 환경에서의 microservices application은 auto-scaling, 장애, 업그레이드 등으로 인해 다이나믹하게 (IP주소가)변화한다.
211 | 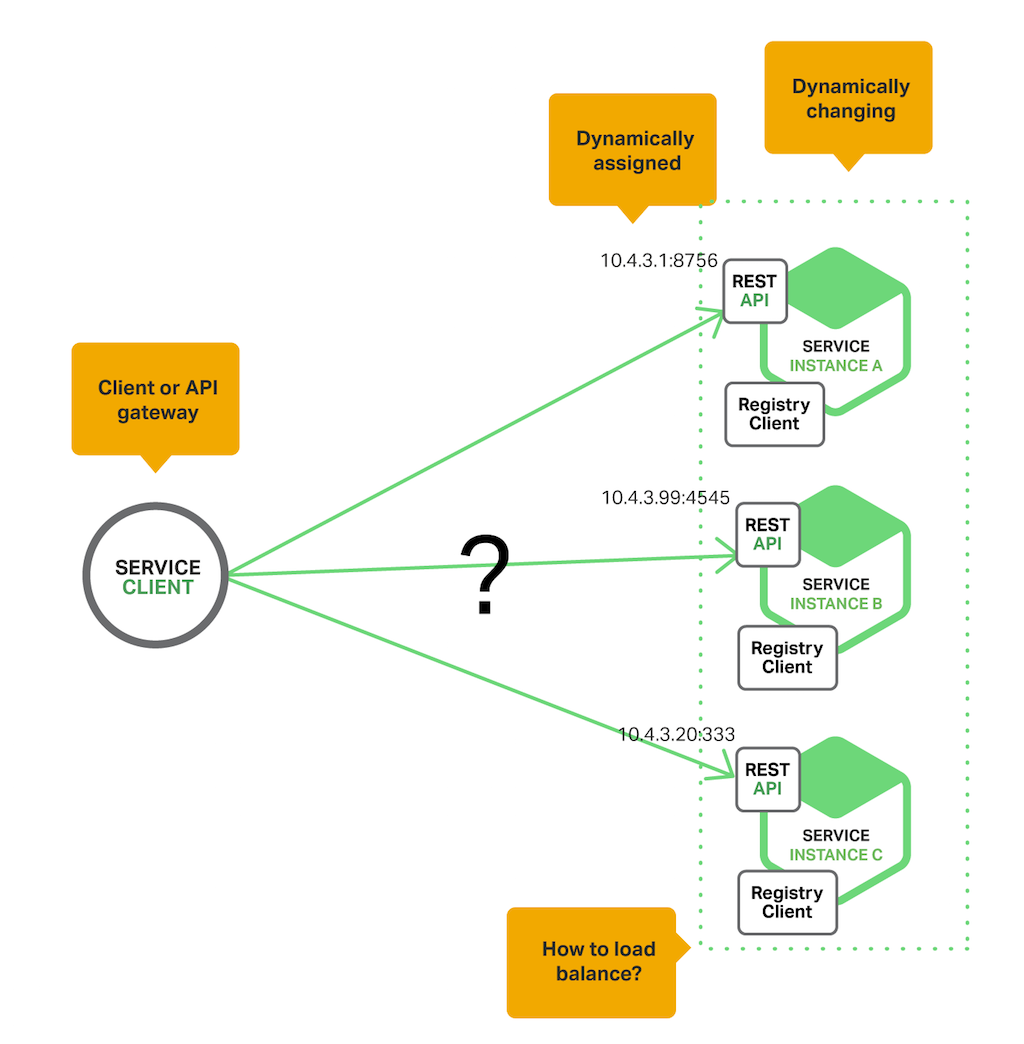
212 |
213 | ### The Client-Side Discovery Pattern
214 | 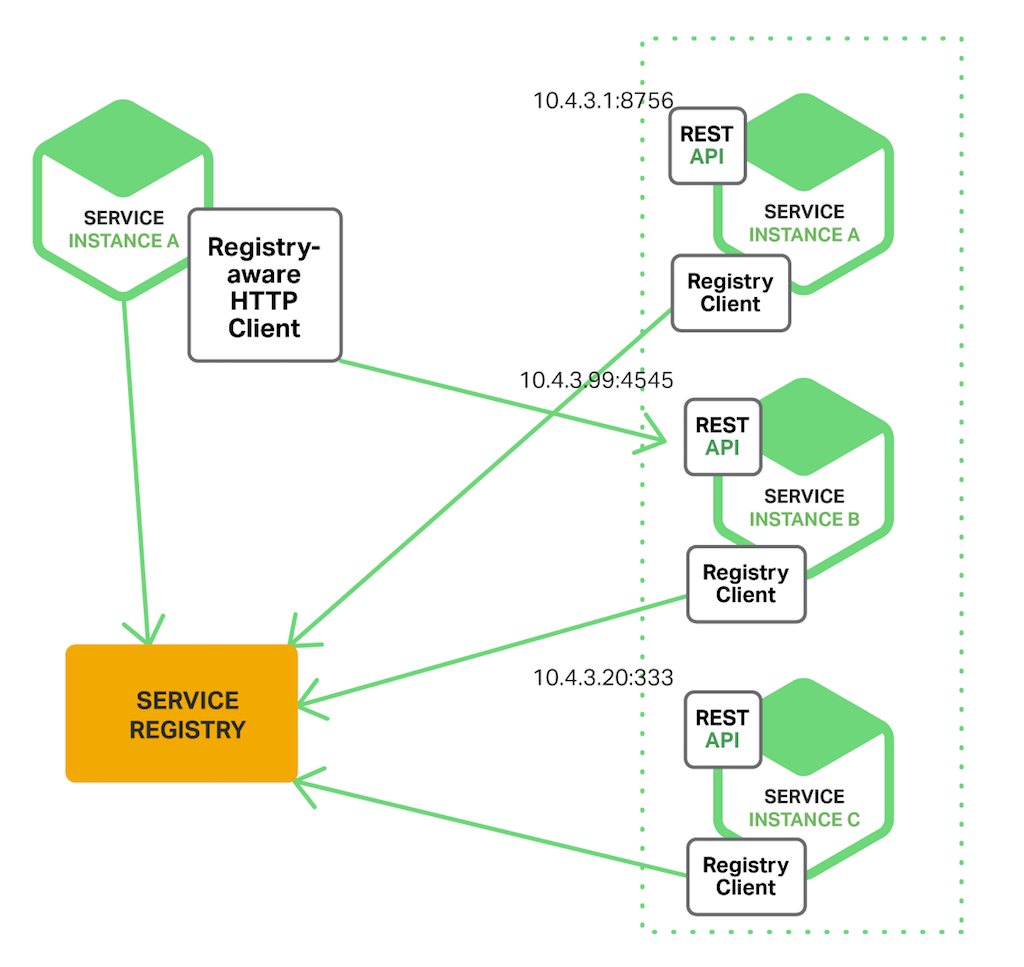
215 | Netflix OSS( Netflix Eureka, Netflix Ribbon)
216 |
217 | #### 장점
218 | client knows about the available services instances, it can make intelligent, application-specific load-balancing decisions such as using hashing consistently.
219 |
220 | #### 단점
221 | couples the client with the service registry. You must implement client-side service discovery logic for each programming language and framework used by your service clients.
222 |
223 | ### The Server-Side Discovery Pattern
224 | 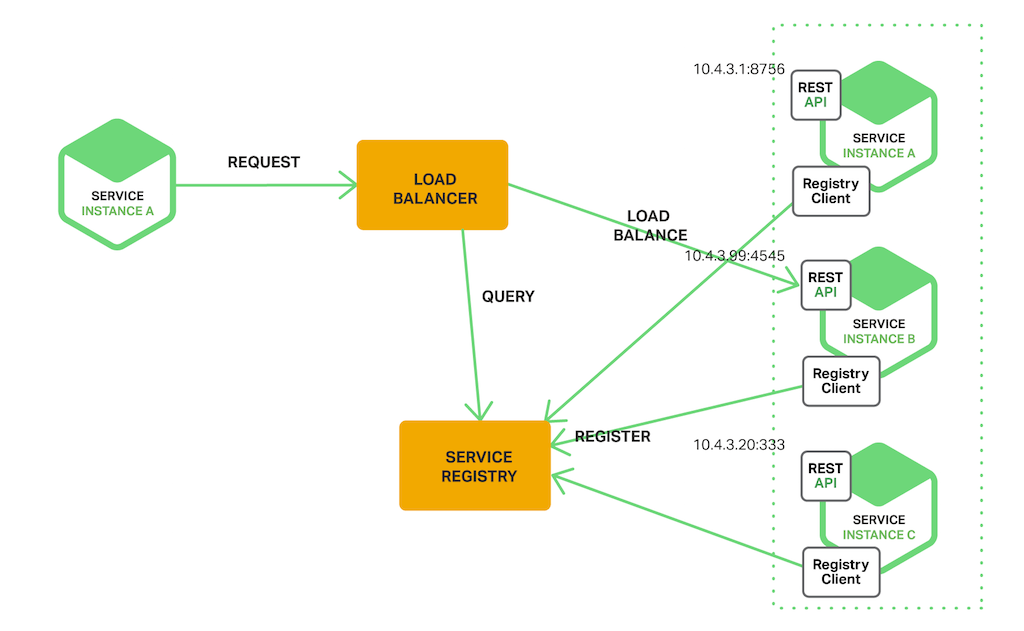
225 | AWS Elastic Load Balancer (ELB)
226 | * load balance external traffic from the Internet.
227 | * internal to a virtual private cloud (VPC)
228 |
229 | NGINX(with Consul, Consul Template)
230 |
231 | Kubernetes, Marathon - proxy 모듈
232 |
233 | #### 장점
234 | details of discovery are abstracted away from the client
235 |
236 | #### 단점
237 | highly available system component that need to set up and manage.
238 |
239 | ## The Service Registry
240 | 서비스 인스턴스의 네트워크 위치 정보를 저장하고있는 데이터베이스.
241 |
242 | * Netflix Eureka
243 | * etcd
244 | * consul
245 | * Apache Zookeeper
246 |
247 | Kubernetes, Marathon, and AWS의 경우 별도의 service registry가 존재하지 않고 인프라의 일부로 포함되어 있다.
248 |
249 |
250 | ## Service Registration Options
251 | ### The Self-Registration Pattern
252 | 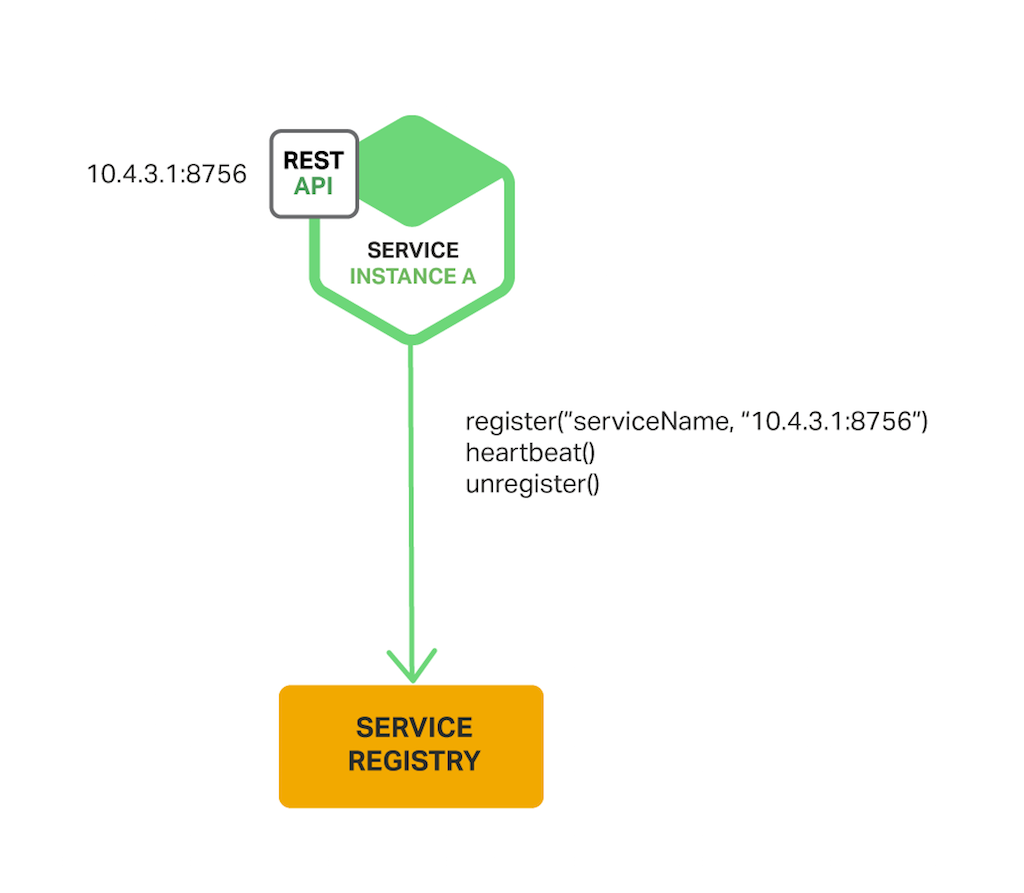
253 | Netflix OSS Eureka client. Spring Cloud project.(@EnableEurekaClient annotation)
254 |
255 | #### 장점
256 | relatively simple and doesn’t require any other system components.
257 |
258 | #### 단점
259 | couples the service instances to the service registry. You must implement the registration code in each programming language and framework used by your services.
260 |
261 | ### The Third-Party Registration Pattern
262 | 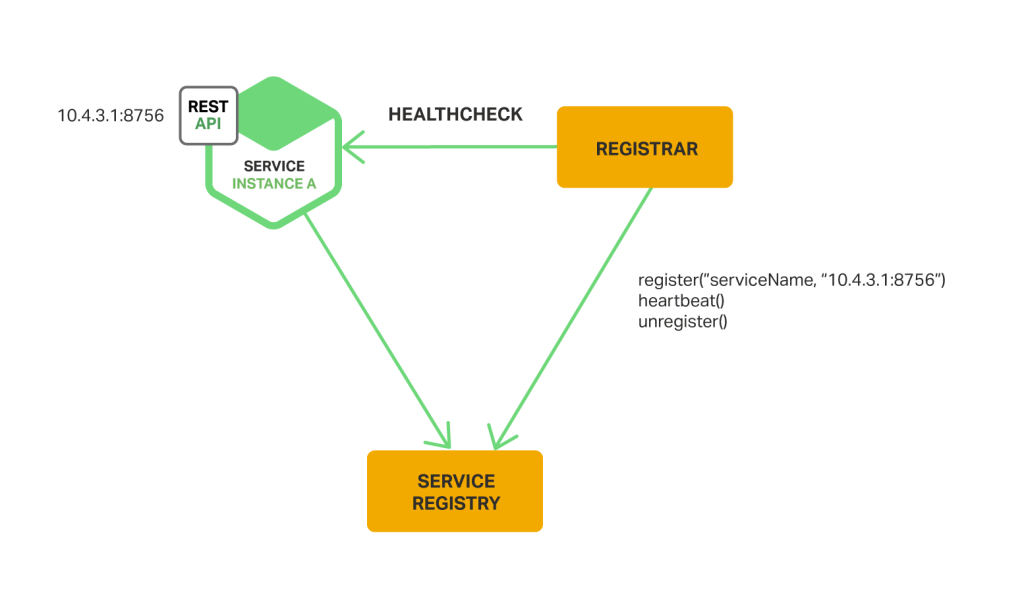
263 | Registrator - etcd or Consul with docker
264 |
265 | NetflixOSS Prana - Netflix Eureka.
266 |
267 | #### 장점
268 | services are decoupled from the service registry. You don’t need to implement service-registration logic for each programming language and framework used by your developers.
269 |
270 | #### 단점
271 | it is yet another highly available system component that you need to set up and manage.
272 |
273 |
274 | # 5. Event-Driven Data Management for Microservices
275 | 원본 글 : https://www.nginx.com/blog/event-driven-data-management-microservices/
276 |
277 | ## Microservices and the Problem of Distributed Data Management
278 | * MSA구조에서는 각 마이크로서비스마다 datastore를 가진다. 이러한 각 datastore에 대한 접근은 API를 통해서 이루어지고 따라서 여러 마이크로서비스간의 비지니스 트랜잭션 처리가 어려워진다.
279 | - consistency across multilpe services is not easy
280 | - query across multilpe services is not easy
281 |
282 | 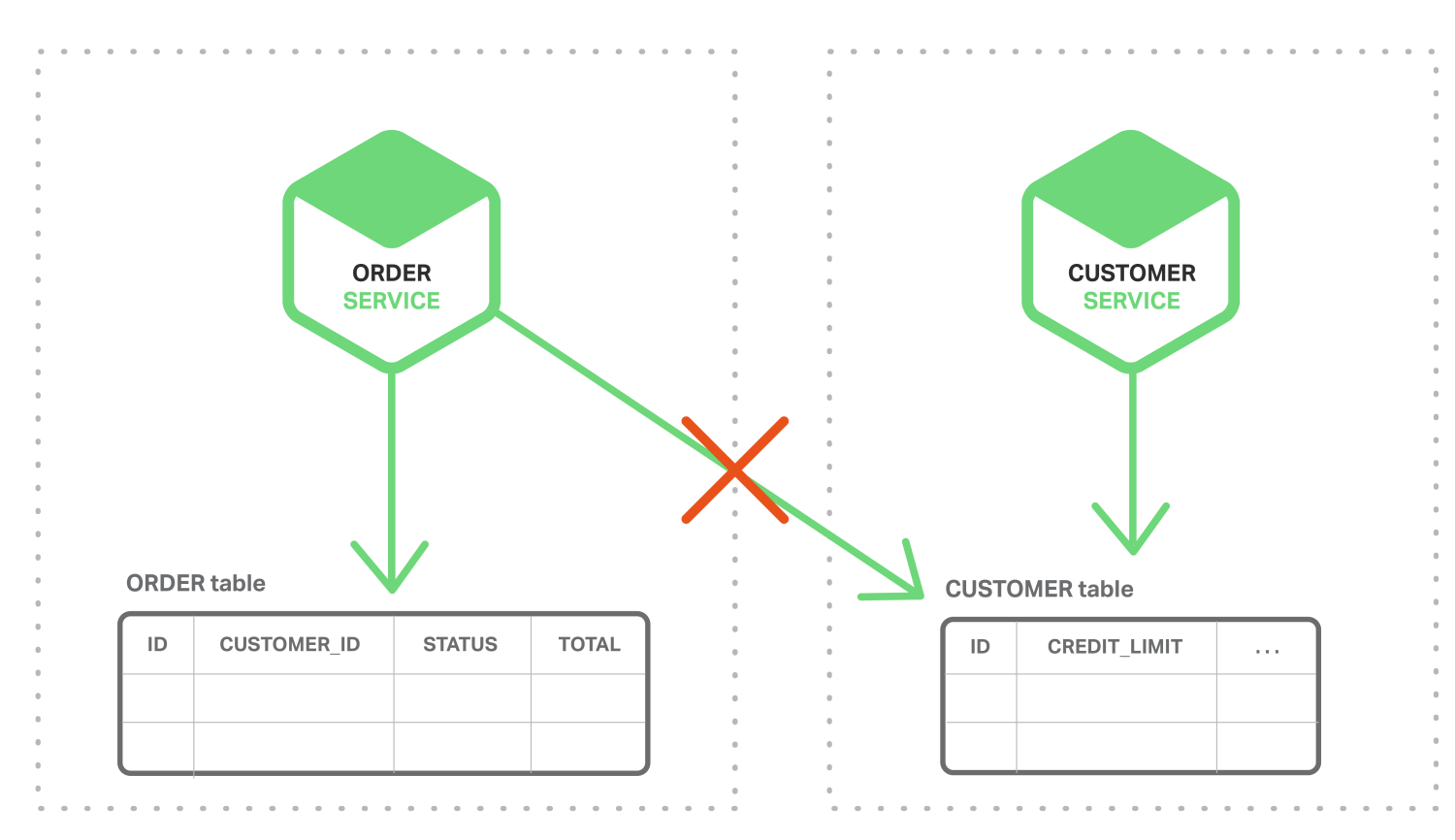
283 |
284 |
285 | ## Event-Driven Architecture
286 | 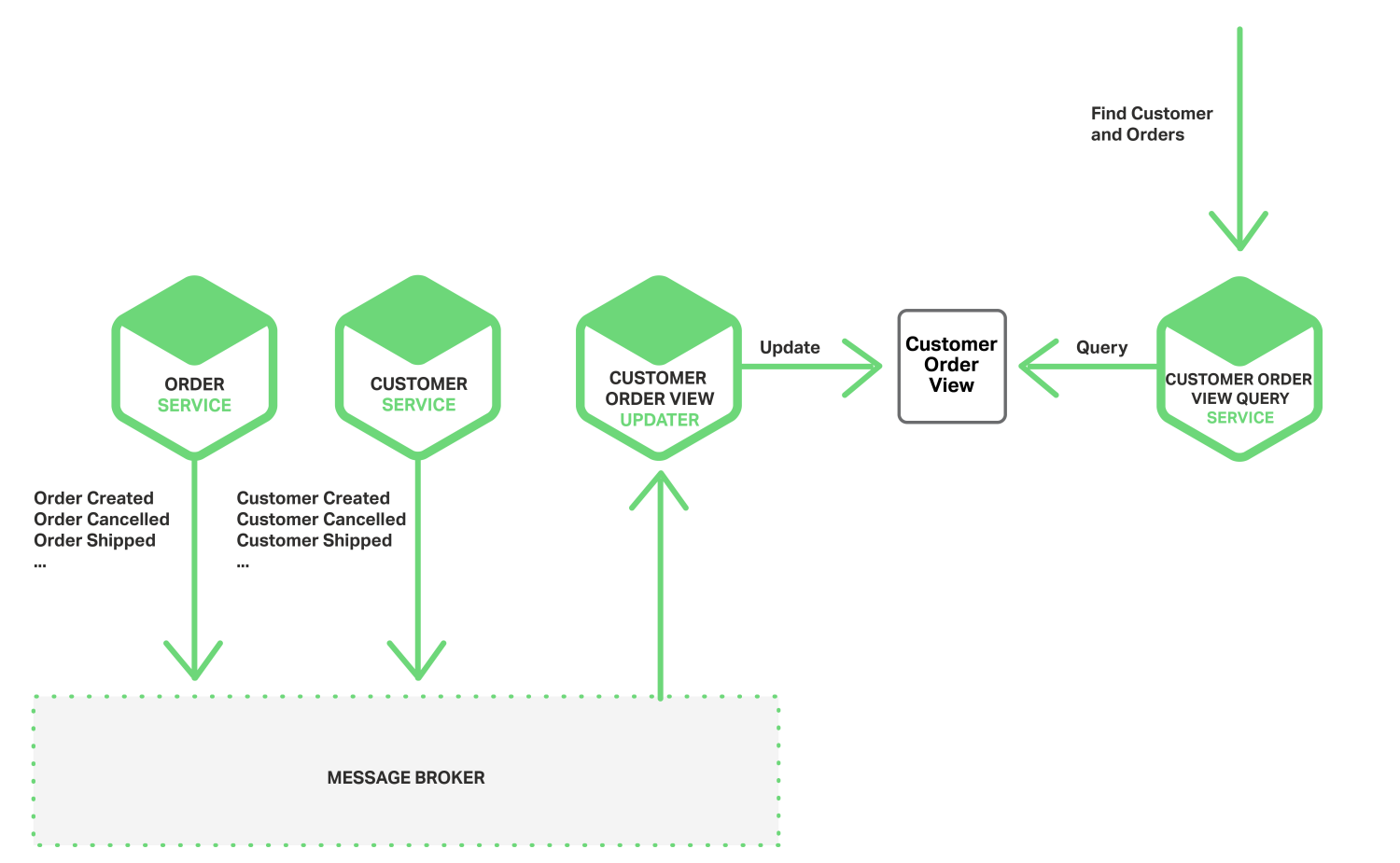
287 |
288 | #### 장점
289 | * 여러 서비스 간에 eventaul consistency 충족시킬 수 있다.
290 |
291 | #### 단점
292 | * ACID transaction 사용할 때 보다 프로그래밍 모델이 복잡해진다.
293 | * 애플리케이션에서 fail 발생시 fail에 대한 보상처리를 해줘야 한다.
294 | * isolation이 보장되지 않기 때문에 inconsistent한 데이터가 보일수 있음을 고려해야한다.
295 | * 중복 event 발생을 감지해서 무시할 수 있어야한다.
296 |
297 | - https://en.wikipedia.org/wiki/Eventual_consistency
298 | - http://queue.acm.org/detail.cfm?id=1394128
299 |
300 | ## Achieving Atomicity
301 | ### Publishing Events Using Local Transactions
302 | 2PC(Phase Commit)가 필요없음.
303 | 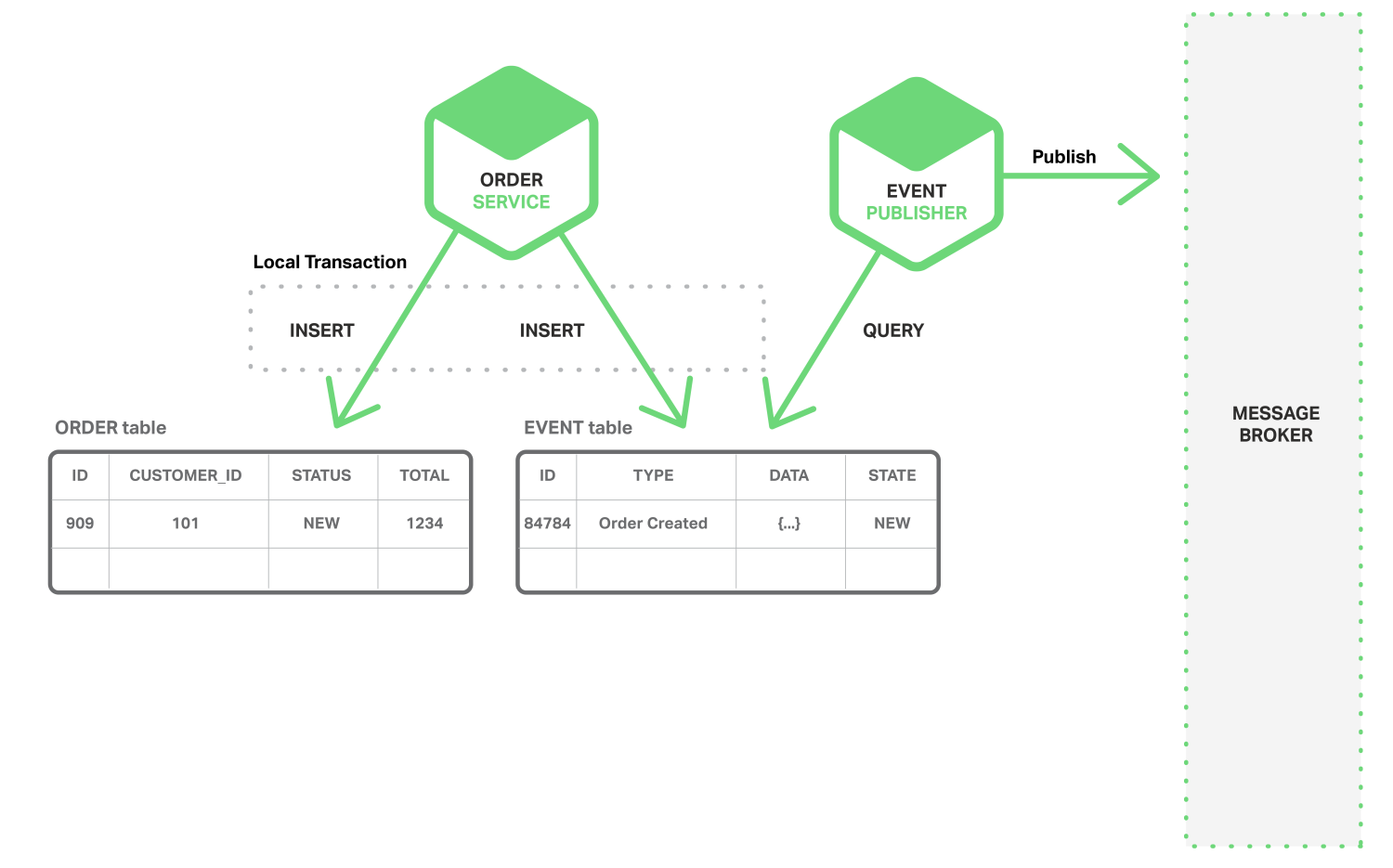
304 |
305 | ### Mining a Database Transaction Log
306 | 2PC(Phase Commit)가 필요없음. 이벤트 테이블도 필요없음. The Transaction Log Miner thread가 직접 트랜잭션로그 후킹.
307 | 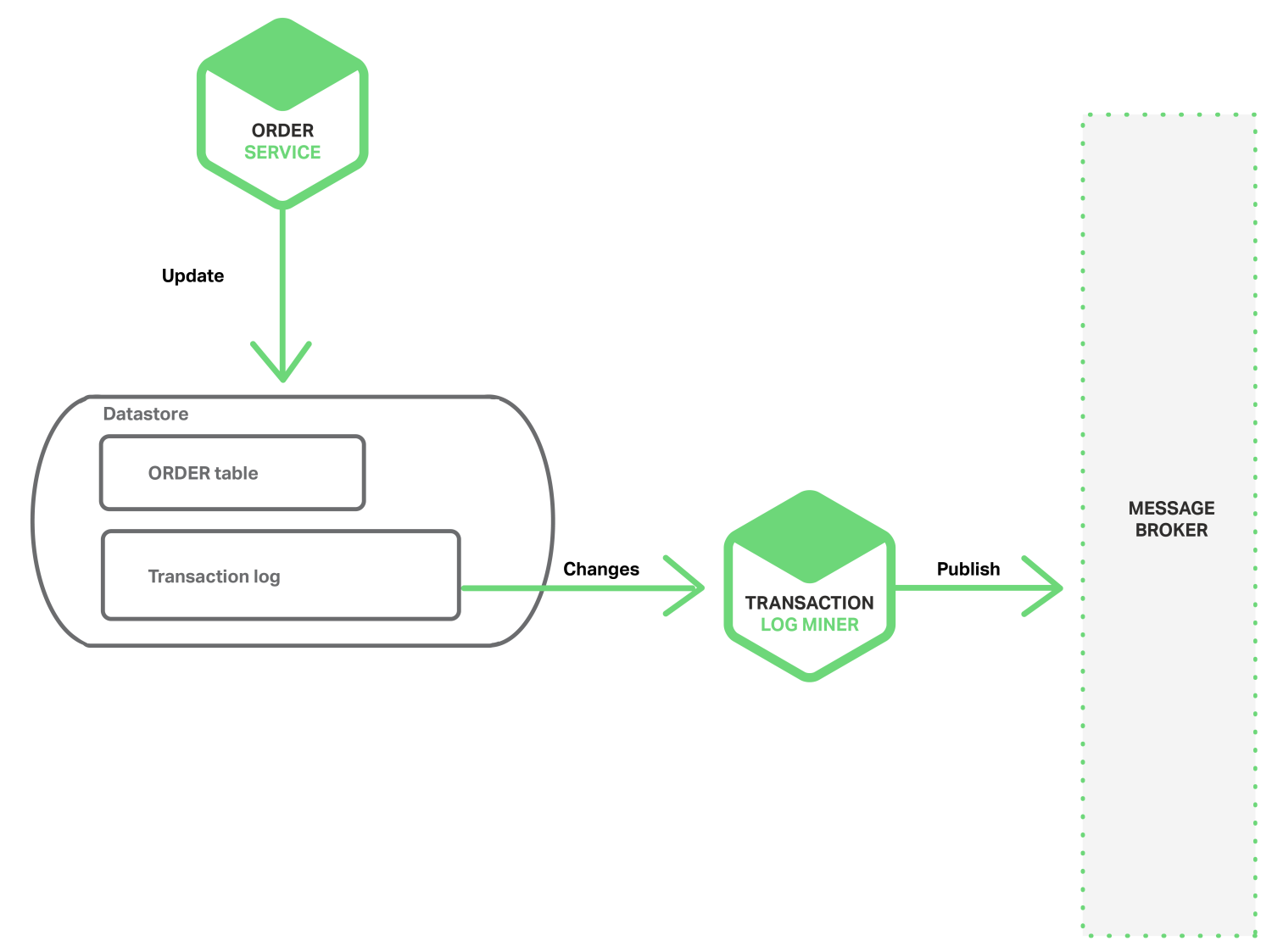
308 |
309 | ### Using Event Sourcing
310 | 2PC(Phase Commit)가 필요없음. 심지어 DB updates 없이 오직 evnets만을 사용해서 The Transaction Log Miner thread의 단점을 제거할수 있다. 또한 RDBMS와 ORM 사용시 발생하는 패러다임불일치 문제를 피할수 있는 장점이 있다. 다만 프로그래밍 모델이 복잡해서 러닝커브가 있고 CQRS 기법 사용을 강제하는 단점이 있다.
311 |
312 | 
313 |
314 | - https://github.com/cer/event-sourcing-examples/wiki/WhyEventSourcing
315 | - https://en.wikipedia.org/wiki/Object-relational_impedance_mismatch
316 | - https://github.com/cer/event-sourcing-examples/wiki
317 |
318 |
319 | # 6. Choosing a Microservices Deployment Strategy
320 | 원본 글 : https://www.nginx.com/blog/deploying-microservices/
321 |
322 | ## Motivations
323 | microservices 애플리케이션은 10, 100여개의 서비스들로 구성된다.
324 | 각 서비스는 적절한 CPU, memory, I/O 리소스를 제공받아야 하고 배포는 빠르고 안정적 효율적이어야한다.
325 |
326 | ## Multiple Service Instances per Host Pattern
327 | http://microservices.io/patterns/deployment/multiple-services-per-host.html
328 |
329 | 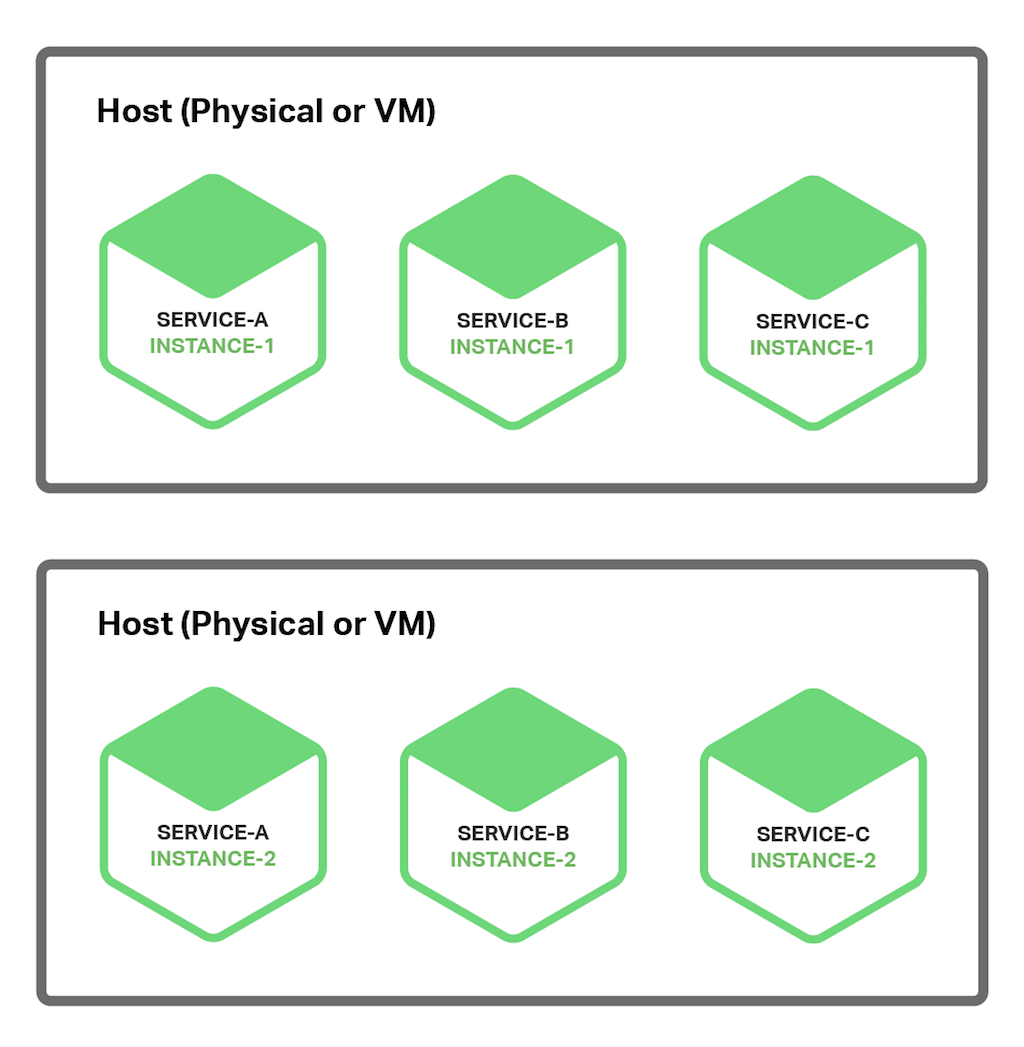
330 | ##### 장점
331 | * 자원 사용이 효율적이다.
332 | * 상대적으로 배포 속도가 빠르다. 서비스 시작속도도 빠르다.
333 |
334 | ##### 단점
335 | * 서비스 인스턴스가 동일한 프로세스에서 실행 될 경우 리소스 isolation 하기가 어렵다. cpu, 메모리를 한 서비스 인스턴스가 모두 사용하는 문제가 발생가능하다.
336 | * 운영팀(operations team)이 deploy하는 서비스들의 detail(언어, 프레임워크)을 잘 알아야 되고, 이는 배포 장애로 이어지는 위험요소가 된다.
337 |
338 |
339 | ## Service Instance per Host Pattern
340 | http://microservices.io/patterns/deployment/single-service-per-host.html
341 |
342 | ### Service Instance per Virtual Machine Pattern
343 | http://microservices.io/patterns/deployment/service-per-vm.html
344 | https://aws.amazon.com/ko/ec2/
345 |
346 | 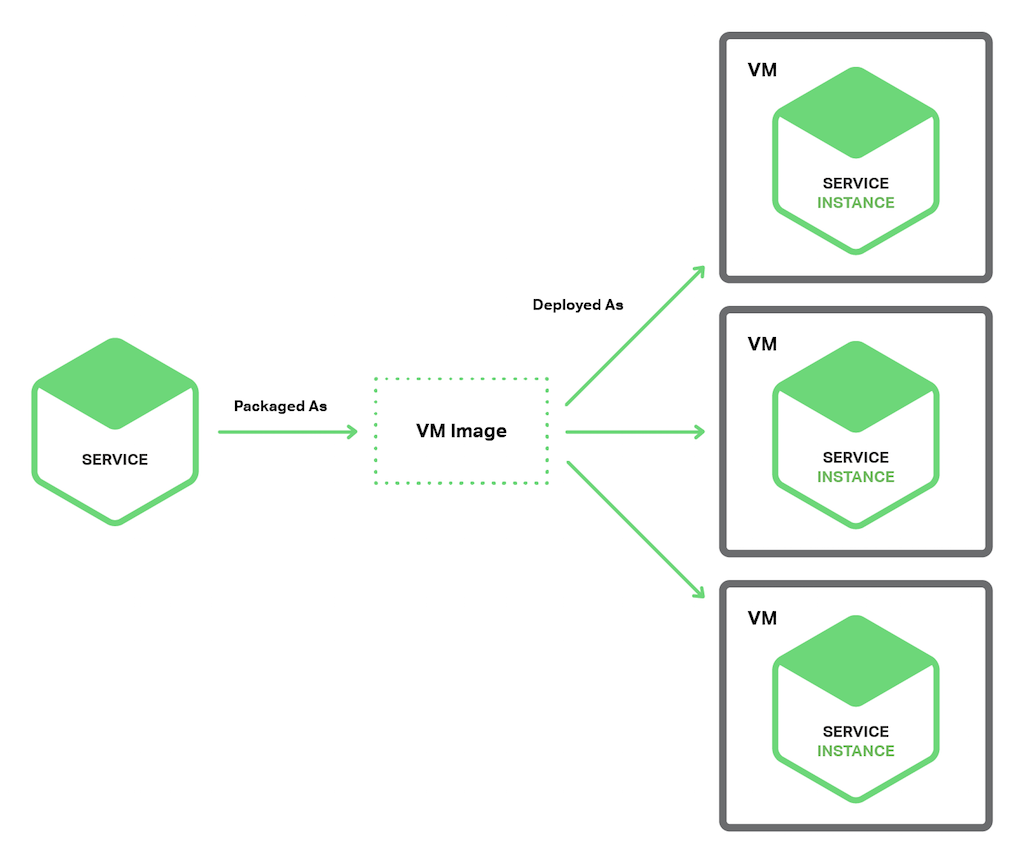
347 |
348 | Netfilx에서는 video streaming 서비스에 VM을 사용하는데 각 서비스를 Aminator를 사용해서 EC2 AMI(VM 이미지)로 패키지해서 EC2 인스턴스로 배포하고 있다.
349 |
350 | ##### 장점
351 | * 서비스마다 완벽한 isolation이 가능하다. 고정된 CPU와 메모리를 사용하고 다른 서비스에서 steal하지 않는다.
352 | * 성숙한 클라우드 인프라의 다양한 기능들 활용이 가능하다. ex) AWS load balancing and autoscaling.
353 | * 서비스 구현 기술과 관계없이 VM으로 캡슐화(black box) 가능하다. 이는 VM 관리 API로 단순화 추상화 되어서 쉽고 안정적인 배포를 가능하게한다.
354 |
355 | ##### 단점
356 | * 자원 사용이 비효율적이다. VM에 할당된 자원이 낭비된다.
357 | * 보통 public IaaS들은 VM이 미사용중이더라도 과금한다.
358 | http://techblog.netflix.com/2013/11/scryer-netflixs-predictive-auto-scaling.html
359 | * VM 이미지 빌드 및 실행이 오래 걸린다. 단 Boxfuse 같이 lightweight VM을 통한 해법이 존재한다.
360 | * VM 관리가 어렵다.
361 |
362 | ### Service Instance per Container Pattern
363 | http://microservices.io/patterns/deployment/service-per-container.html
364 | https://en.wikipedia.org/wiki/Operating-system-level_virtualization
365 |
366 | #### container technologies
367 | * docker
368 | * solaris zones
369 |
370 | #### cluster manager
371 | * kubernetes
372 | * marathon
373 |
374 | 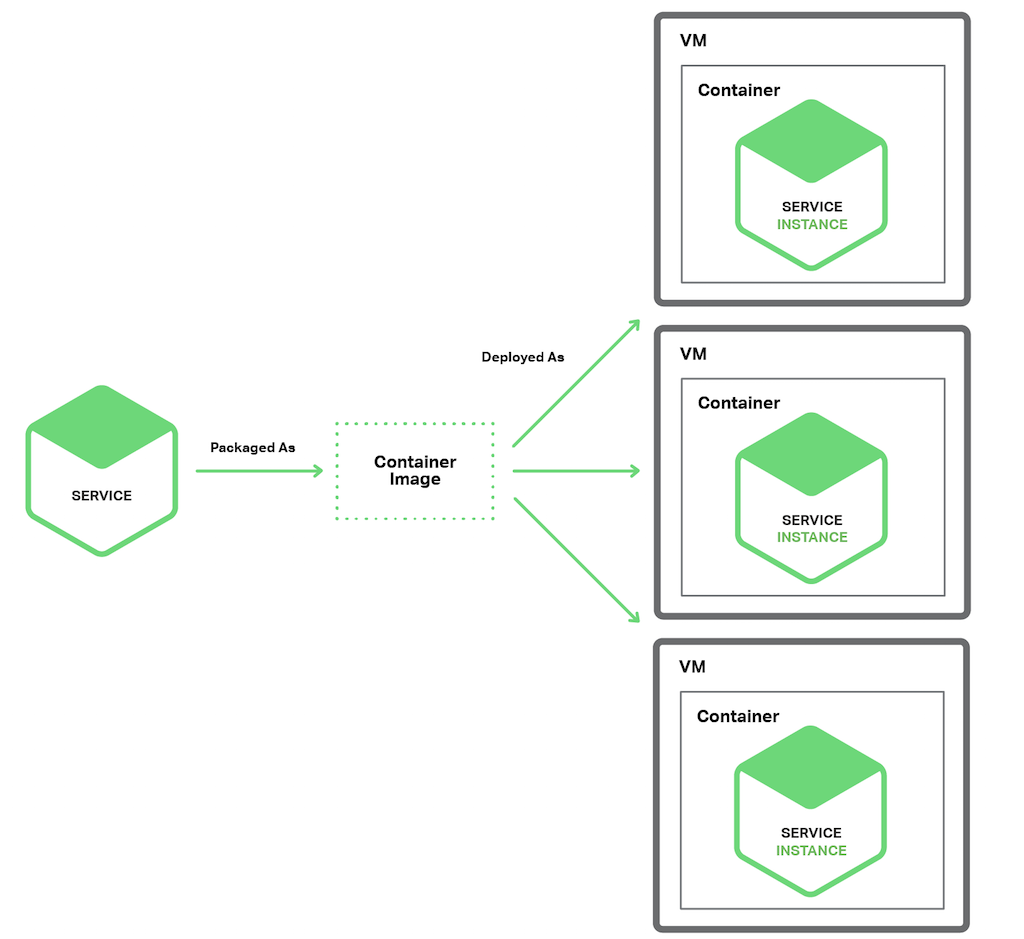
375 |
376 | ##### 장점
377 | * VM의 장점과 대부분 유사.
378 | * VM보다 가볍기 때문에 image 빌드 및 배포가 무척 빠름.
379 |
380 | ##### 단점
381 | * containers 인프라는 VM 인프라만큼 아직 성숙하지 못함.
382 | * 다른 container와 커널을 공유하기 때문에 VM 만큼 안전(secure)하지 못함
383 | * GCE(Google Container Engine)나 ECS(Amazon EC2 Container Service) 같은 솔루션을 사용하지 않을 경우 직접 인프라를 관리해야함.
384 |
385 | 사실 요즘엔 VM과 container 간의 구분이 흐릿해지고 있다.(Boxfuse VMs are fast to build and start. The Clear Containers project aims to create lightweight VMs. There is also growing interest in unikernels. Docker, Inc recently acquired Unikernel Systems.)
386 |
387 |
388 | ## Serverless Deployment(AWS Lambda)
389 | https://aws.amazon.com/lambda/
390 |
391 | * convenient way to deploy microservices.
392 | * automatically runs enough instances of your microservice to handle requests.
393 | * The request-based pricing.
394 |
395 | #### 제약사항
396 | * not intended to long-running services
397 | * Requests must complete within 300 seconds.
398 | * stateless
399 | * Services must also start quickly; otherwise, they might be timed out and terminated.
400 |
401 | #### Lambda 호출 4가지 방식
402 | * Directly, using a web service request
403 | * Automatically, in response to an event generated by an AWS service such as S3, DynamoDB, Kinesis, or Simple Email Service
404 | * Automatically, via an AWS API Gateway to handle HTTP requests from clients of the application
405 | * Periodically, according to a cron-like schedule
406 |
407 |
408 | # 7. Refactoring a Monolith into Microservices
409 | 원본 글 : https://www.nginx.com/blog/refactoring-a-monolith-into-microservices/
410 |
411 | monolithic 애플리케이션에서 microservices로 점진적으로 migration, refactoring 하는 전략 소개.
412 |
413 | ## Overview of Refactoring to Microservices
414 | * [application modernization](https://en.wikipedia.org/wiki/Software_modernization)
415 | * "Big Bang” rewrite는 위험하니점진적으로 refactoring 하는 전략을 취해야한다.
416 | * [Strangler Application](http://www.martinfowler.com/bliki/StranglerApplication.html)
417 |
418 | ## Strategy 1 – Stop Digging
419 | 신규 기능을 추가해야 할 경우 기존 MONOLITH가 아닌 별도의 신규 SERVICE를 만들어서 연동하라.
420 | 
421 |
422 | 신규 SERVICE가 MONOLITH 데이터에 접근하는 3가지 전략으로는 다음과 같다.
423 | * remote API 호출
424 | * database 직접 접근
425 | * database copy(동기화)
426 |
427 | glue code = anti-corruption layer(Eric Evans의 Domain Driven Design 책에서 소개된 패턴 용어.)
428 | SERVICE로 하여금 MONOLITH와 독립적인 domain 모델 사용가능하게 한다.
429 |
430 | MONOLITH의 문제점을 근본적으로 해결하는 방법은 아니다 MONOLITH를 break up 해야되는데 다음에서 그 전략을 설명한다.
431 |
432 | ## Strategy 2 – Split Frontend and Backend
433 | 
434 |
435 | Frontend와 Backend를 둘로 나눌 경우 아래 2가지 장점이 있지만 역시나 부분적인 솔루션이다.
436 |
437 | * 개발, 배포, 확장이 서로 독립적이다. 특히 Frontend 개발자는 빠르게 UI 작업 반복이 가능하고 A/B 테스팅을 쉽게 수행 가능해진다.
438 | * 자연스럽게 remote API 서버(Backend)가 생성된다.
439 |
440 |
441 | ## Strategy 3 – Extract Services
442 | 
443 |
444 | 추출(extraction) 전략은 아직 microserivce 경험이 없을 초반에는 추출하기 쉬운 모듈 먼저 진행 하고 그 후에는 이득이 되는 모듈에 우선순위를 두면된다. 이득이 되는 모듈이란 변경이 자주 발생하는 모듈이다. 추출하고 나면 개발, 배포가 독립적으로 이루어질 수 있어서 개발을 가속화 시키기 때문이다. 혹은 자원(CPU, 메모리) 요구사항이 특이한 케이스의 모듈을 대상으로 하는것도 좋다.
445 |
446 | * a pair of coarse-grained APIs 정의하기(inbound, outbound interfaces)
447 | * 모듈을 독립적인 서비스로 전환(IPC 사용). [Microservice Chassis framework](http://microservices.io/patterns/microservice-chassis.html) 사용.
448 |
449 | ## Summary
450 | * monolithic 애플리케이션에서 microservices로 전환은 한번에 할수는 없고 점진적으로 진행햐하는데, 3가지 전략이 있다.(new functionality as microservices, split Frontend and Backend, convert modules into services)
451 | * microservices가 증가함에 따라 개발팀의 기민함(agility)과 속도(velocity)가 증가할 것이다.
452 |
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
/video/A-Netflix-Guide-to-Microservices-QCon2016.md:
--------------------------------------------------------------------------------
1 | https://www.youtube.com/watch?v=OczG5FQIcXw
2 |
3 | 
4 |
5 | 
6 |
7 | 
8 |
9 | 
10 |
11 | 
12 |
13 | 
14 |
15 | 
16 |
17 | 
18 |
19 | 
20 |
21 | 
22 |
23 | 
24 |
25 | 
26 |
27 | 
28 |
29 | 
30 |
31 | 
32 |
33 | 
34 |
35 | 
36 |
37 | 
38 |
39 | 
40 |
41 | 
42 |
43 | 
44 |
45 | 
46 |
47 | 
48 |
49 | 
50 |
51 | 
52 |
53 | 
54 |
55 | 
56 |
57 | 
58 |
59 | 
60 |
61 | 
62 |
63 | 
64 |
65 | 
66 |
67 | 
68 |
69 | 
70 |
71 | 
72 |
73 | 
74 |
75 | 
76 |
77 | 
78 |
79 | 
80 |
81 | 
82 |
83 | 
84 |
85 | 
--------------------------------------------------------------------------------
/galeracluster_for_mysql.md:
--------------------------------------------------------------------------------
1 | # GALERA CLUSTER FOR MYSQL
2 | synchronous replication에 기반한 MySQL Multimaster Cluster.
3 |
4 | ## What is Galera?
5 | 이탈리라어. 갤리(galley)선(특히 고대 그리스나 로마 시대 때 주로 노예들에게 노를 젓게 한 배)
6 | 갤리선이 빠르게 가기 위해선 수많은 선원들이 synchronously하게 노젓기를 할 수 있도록 해야하는데 galeracluster의 역할을 표현한다.
7 |
8 | ## 개요 및 특징
9 | http://galeracluster.com/products/
10 | write set replication (wsrep) interface의 구현체.
11 | 2007년 첫 릴리즈. open source.
12 | OpenStack에서도 사용. 가이드 : http://docs.openstack.org/high-availability-guide/content/ha-aa-db-mysql-galera.html
13 | * Synchronous replication => consistency.
14 | * Active-active multi-master topology => zero failover time.
15 | * Read and write to any cluster node
16 | * Automatic membership control, failed nodes drop from the cluster(elasticity)
17 | * Automatic node joining
18 | * True parallel replication, on row level
19 | * Direct client connections, native MySQL look & feel
20 | * No slave lag
21 | * No lost transactions
22 | * Both read and write scalability
23 | * Smaller client latencies
24 |
25 | ## WSREP?
26 | https://launchpad.net/wsrep/
27 | certification 기반의 multi-master replication을 위한 인터페이스.
28 | transaction (commit)write sets을 관리하는 애플리케이션 callback API와 replication plugin(library) call API를 정의한다.
29 | ```
30 | wsrep API defines a set of application callbacks and replication library calls necessary to implement synchronous writeset replication of transactional databases and similar applications. It aims to abstract and isolate replication implementation from application details. Although the main target of this interface is a certification-based multi-master replication, it is equally suitable for both asynchronous and synchronous master/slave replication.
31 | ```
32 |
33 | ## 설치 컴퍼넌트
34 | * wsrep(replication) provider
35 | * MySQL patch
36 |
37 | 최소 3대의 hosts애 설치 필요함.
38 | 클러스터에 먼저 한대(Primary Component) 띄우고
39 | `# service mysql start --wsrep-new-cluster`
40 | SHOW STATUS LIKE 'wsrep_cluster_size';
41 | ```
42 | +--------------------+-------+
43 | | Variable_name | Value |
44 | +--------------------+-------+
45 | | wsrep_cluster_size | 1 |
46 | +--------------------+-------+
47 | ```
48 | 나머지 노드들 띄우면 클러스터에 합류하게됨.
49 | `# service mysql start`
50 | ```
51 | +--------------------+-------+
52 | | Variable_name | Value |
53 | +--------------------+-------+
54 | | wsrep_cluster_size | 2 |
55 | +--------------------+-------+
56 | ```
57 |
58 | ## Why High Availability and Cloud are more difficult for databases?
59 | DB는 stateless 하지 않다. data가 크면 copy하는데 만 수시간. 스냅샷 포인트도 고려해야 하고, 서비스 중단없이 투입하려면 replication 기술이 요함.
60 |
61 | ## database clustering solutions vs Galera-Cluster-for-MySQL
62 | http://galeracluster.com/wp-content/uploads/2013/10/Minimizing-downtime-and-maximizing-elasticity-with-Galera-Cluster-for-MySQL.pdf
63 |
64 | * no scale-out benefit at all (active-passive)
65 | * can only scale read-only transactions (master-slave)
66 | * Well known database clustering solutions typically have at least two of the following
67 | downsides
68 | 1) risk of lost data due to asynchronous replication,
69 | 2) Up to 50% performance overhead,
70 | 3) downtime at planned and unplanned failovers may be up to several minutes,
71 | 4) poor compatibility compared to running with a non-clustered database,
72 | 5) prohibitively difficult to use
73 | 6) not suitable for Widea Area Network replication between datacenters/continents,
74 | 7) prohibitively expensive to use.
75 |
76 |
77 | 보통 Synchronous replication이 network latency에 취약한데, Galera는 certification-based replication를 통해 이를 해결했다고함. 심지어 여러 대륙간에 clustering 해도 문제없다고 함. Google Cloud SQL처럼 여러 대륙에 clustering 해서 재난 대비 및 end user에 response time 줄이는 효과.
78 |
79 | https://www.nginx.com/blog/mysql-high-availability-with-nginx-plus-and-galera-cluster/
80 | http://www.severalnines.com/mysql-load-balancing-haproxy-tutorial
81 | http://www.severalnines.com/clustercontrol
82 |
83 | ## CLUSTER DEPLOYMENT VARIANTS
84 | http://galeracluster.com/documentation-webpages/deploymentvariants.html
85 |
86 | ## DATABASE REPLICATION
87 | http://galeracluster.com/documentation-webpages/introduction.html
88 | ### ASYNCHRONOUS AND SYNCHRONOUS REPLICATION
89 | #### Advantages of Synchronous Replication
90 | High Availability - no data loss, consistent
91 | Improved Performance - transaction on all nodes in parallel.
92 | Causality across the Cluster - causality across the whole cluster.
93 |
94 | #### Disadvantages of Synchronous Replication
95 | m = n X o X t (n: number of nodes, o: number of operation, t: tps)
96 | 즉, nodes의 증가는 응답시간과 conflict, deadlock 발생확률의 기하급수적인 증가 야기.
97 |
98 | ### SOLVING THE ISSUES IN SYNCHRONOUS REPLICATION
99 | certification-based replication system.
100 |
101 | * Group Communication
102 | * Write-sets
103 | * Database State Machine
104 | * Transaction Reordering
105 |
106 | ## CERTIFICATION-BASED REPLICATION
107 | optimistic execution.
108 | 클러스터 내 모든 노드에 commit 복제시 certification test를 수행하는데 primary key 기반으로 conflicts을 체크 해서 빠른듯.
109 |
110 | http://galeracluster.com/documentation-webpages/certificationbasedreplication.html
111 |
112 | ### WHAT DB Features CERTIFICATION-BASED REPLICATION REQUIRES
113 | * Transactional Database
114 | * Atomic Changes
115 | * Global Ordering
116 |
117 | ### HOW CERTIFICATION-BASED REPLICATION WORKS
118 | http://galeracluster.com/documentation-webpages/certificationbasedreplication.html
119 |
120 | ## REPLICATION API
121 | http://galeracluster.com/documentation-webpages/architecture.html
122 | * Database Management System (DBMS) : The database server that runs on the individual node. Galera Cluster can use MySQL, MariaDB or Percona XtraDB.
123 | * wsrep API : The interface and the responsibilities for the database server and replication provider. It consists of:
124 | * wsrep hooks The integration with the database server engine for write-set replication.
125 | * dlopen() The function that makes the wsrep provider available to the wsrep hooks.
126 | * Galera Replication Plugin : The plugin that enables write-set replication service functionality.
127 | * Group Communication plugins : The various group communication systems available to Galera Cluster. For instance, gcomm and
128 |
129 | ## ISOLATION LEVELS
130 | The SNAPSHOT-ISOLATION : REPEATABLE-READ 와 SERIALIZABLE 중간
131 |
132 | ## STATE TRANSFERS
133 | State Snapshot Transfer, Incremental State Transfer
134 |
135 | ## 기타
136 | * 화이트페이퍼 : http://galeracluster.com/wp-content/uploads/2013/10/Minimizing-downtime-and-maximizing-elasticity-with-Galera-Cluster-for-MySQL.pdf
137 | * github : https://github.com/codership/galera
138 | * 용어 : http://galeracluster.com/documentation-webpages/glossary.html
139 |
--------------------------------------------------------------------------------
/book/building-microservices.md:
--------------------------------------------------------------------------------
1 | # "Building Microservices" by Sam Newman
2 |
3 | # 인상적인 문장들 정리
4 |
5 | ## 1장 마이크로서비스
6 | * 도메인 주도 설계(DDD), 지속적 배포(continuous delivery), 주문형 가상화(on-demand vitualization), 인프라스트럭쳐 자동화, 작고 자율적인 팀, 대규모 시스템 등의 분위기에 편승한 마이크로서비스는 실사용을 기반을 하나의 대세 내지는 패턴으로 부상했다.
7 | * 황금률은 '다른 변경없이 특정 서비스만 변경하고 배포할 수 있는가?'이다. 서비스를 잘 분리하려면(decoupling) 올바르게 모델링하고 API를 제대로 만들어야 한다.
8 | * 회복공학(resilence engineering)의 핵심은 격벽(bulkhead)이다. 즉 특정 컴포넌트에 장애가 발생하더라도 그 장애가 전파되지 않는다면 해당 문제를 격리하고 나머지 시스템을 계속 작동시킬 수 있다. 서비스의 경계야말로 명확한 격벽이다.
9 | * 하나의 큰 모놀리식 서비스에서는 항상 모든 것을 함께 확장해야 한다. 만약 작은 서비스들로 구성되어 있다면 필요한 서비스만 확장할 수 있다. 온라인 패션몰인 길트(Gilt)가 이런 이유로 마이크로서비스를 도입했다. 길트는 2007년 Ruby on Rails로 작성한 모놀리식 애플리케이션을 2009년 자바로 작성된 10개의 마이크로서비스로 변환했고, 2011년에 스칼라를 적용했다. 2014년 Node.js를 도입하여 수백 개 이상의 마이크로서비스를 운영하고 있다.
10 | * 마이크로서비스는 공짜도 은총알도 아니며, 황금 망치로 오인되는 일이 없어야 한다. 마이크로서비스는 분산 시스템과 연관된 모든 종류의 복잡성을 내포하고 있다. 마이크로서비스가 제공하는 혜택을 얻기 위해서는 배포, 테스트, 모니터링을 훨씬 더 잘 다루어야 할 것이다. 또한 시스템을 확대하고 회복력을 유지하는 방법에 대해 다르게 생각해야 할 것이다. 분산 트랜잭션이나 CAP 정리와 같은 것들이 골치 아플 수 있을 텐데 각오해야 할 것이다.
11 |
12 | ## 2장 진화적 아키텍트
13 | * IT 아키텍트의 역할을 잘 요약하는 다음의 비유를 좋아한다. 에릭 도넌버그는 아키텍트의 역할을 건축가보다는 도시 설계자에 가까운 의미로 접근해야 한다는 아이디어를 처음으로 필자와 공유했다. 도시 설계자의 역할은 다양한 정보 소스를 파악하고, 현재 시민의 요구에 부응함과 동시에 미래의 용도까지 고려하면서 도시 배치를 최적화 하는 것이다. 도시 설계자가 도시 발전에 영향을 미치는 방식은 흥미롭다. 그는 '특정 건물을 거기에 만들라'고 하는 대신 도시를 구역화한다.
14 | * 넷플릭스는 데이터 저장 기술을 대부분 카산드라(cassandra)로 통일 했다. 비록 모든 경우에 적합한 최선의 대응책은 아닐지라도, 넷플릭스는 카산드라와 관련된 도구 및 전문지식을 통해 얻는 가치야말로 몇몇 특정 태스크에 더 적합할 수 있는 다수의 이종 플랫폼 확장을 지원하고 운영하는 것보다 더 중요하다고 생각했다.
15 | * 만약 한 서비스는 HTTP 상에서 REST를 노출하고, 다른 서비스는 프로토콜 버퍼를, 또 다른 서비스는 자바 RMI를 사용하기로 결정한다면, 호출하는 서비스가 의사소통을 위한 다양한 스타일을 이해하고 지원해야 하므로 통합 작업은 악몽이 될 수 있다. 이것이 필자가 다이어그램 박스들 간에 벌어지는 이벤트를 걱정하고, 내부에서의 일에 대해서는 자유로워야 한다는 지침에 집착하는 이유다.
16 | * 시스템 설계상의 결정은 모두 trade-off와 관련된다. 의사결정을 구조화(framing)화 할 수 있는 가장 좋은 방법은 성취해야할 목표에 기반하여 일련의 원칙과 실천 사항을 정의하는 것이다.
17 | * 전략적 목표에서는 회사가 어디를 향해 나아가고 있는지, 그리고 고객을 행복하게 만들기 위해 어떻게 해야 할지 언급해야 한다. ex) '신규시장 개척을 위해 동남아시아로 영역 확장', '고객이 셀프서비스를 최대한 많이 사용하게 하자'
18 | * 원칙은 더 큰 목표를 위해 해야 할 일을 정렬하는 규칙으로, 때로는 변경 될 수 있다. 예를 들어 조직의 전략적 목표 중 하나가 새로운 제품의 시장 출시 시간(time to market)을 줄이는 것이라면, 제품 출시 팀이 소프트웨어의 수명주기 전반에 대한 통제권을 가지고, 제품이 준비될 때 마다 다른 팀과는 독립적으로 출시하도록 원칙을 정할 수 있다. 원칙의 수는 10개 미만인 것이 좋다. 클라우드 애플리케이션 플랫폼인 헤로쿠(heroku)의 12가지 요소(www.12factor.net)는 헤로쿠 플랫폼 상에서 잘 동작하는 애플리케이션을 작성하기 위해 정리된 일련의 설계 원칙으로, 다른 맥락에 적용해도 효과적이다.
19 | * 실천 사항(practice)은 원칙을 실행하는 방법으로, 업무 수행을 위한 자세하고도 실질적인 지침이다. 이것은 대개 기술 명세적이며, 어떤 개발자든 이해할 수 있도록 충분히 구체적이어야 한다.
20 | * 아키텍트는 많은 것에 대해 책임을 진다. 그들은 개발을 이끌 수 있는 일련의 원칙을 정하고, 원칙들이 조직의 전략과 일치하도록 보장할 뿐만 아니라 이 원칙들로 인해 개발자를 비참하게 만드는 실천 사항이 만들어지지 않도록 해야 한다.
21 | * 기술 리더의 역할은 사람들이 스스로 비전을 이해하도록 그들의 성장을 돕고, 비전을 결정하고 구현하는 데 적극적으로 참여할 수 있도록 만드는 것이다.
22 |
23 | ## 3장 서비스 모델링하기
24 | * 무엇이 좋은 서비스를 만드는가? 바로 느슨한 결합(loose coupling)과 강한 응집력(high cohesion)이다.
25 | * 서비스가 서로 느슨히 결합되어 있다면 하나의 서비스가 변경될 때 다른 서비스가 변경되는 일이 없다. 마이크로서비스의 요점은 특정 서비스를 쉽게 변경하고 배포할 수 있다는 것이다.
26 | * 특정 행위를 변경하고자 할 때는 한곳에서 변경하고(강한 응집력) 가능한 한 신속하게 릴리즈 할 수 있기를 원한다.
27 | * 모든 도메인은 다수의 경계가 있는 콘텍스트(bounded context)로 구성되며, 각 콘텍스트 내에는 외부와 통신할 필요가 없는 것과 콘텍스트 외부와 공유되는 것이 함께 존재한다. 경계가 있는 모든 콘텍스트에는 명백한 인터페이스가 존재하며 다른 콘텍스트와 공유되는 모델을 결정한다.
28 | * 경계가 있는 콘텍스트와 관련해서 필자가 좋아하는 또 다른 정의는 '명료한 경계에 의해 강제된 구체적인 책임'이다. 만약 여러분이 경계가 있는 콘텍스트로부터 정보를 원하거나 콘텍스트 내부의 기능을 요청하고자 한다면 모델을 이용하여 콘텍스트 경계와 의사소통해야 한다.
29 |
30 | ## 4장 통합
31 | * 통합(마이크로서비스간의 통신)에 대한 올바른 이해는 마이크로서비스 관련 기술에서 가장 중요한 요소다. 잘못 통합하면 재앙이다.
32 | * 마이크로서비스 간의 통신에 사용되는 API가 특정 기술에 종속되지 않도록 기술 중립성(technology-agnostic)을 유지하는 것을 매우 중요하게 생각하는 이유이기도 하다. 이는 마이크로서비스 구현에 기술 스택을 좌우하는 통합 기술을 회피하는 것을 의미한다.
33 | * 서비스 협업 방식 측면에서 우리가 내릴 수 있는 가장 중요한 결정 사항 중 하나인 동기(synchronous)와 비동기(asynchronous)방식을 논의해야 한다. 통신은 동기식이어야 하는가 비동기식이어야 하는가? 이 근원적인 선택은 필연적으로 우리를 특정 세부 구현으로 이끈다.
34 | * 서로 다른 이 두 통신 모드는 '요청/응답' 또는 '이벤트 기반'이라는 관용적인 두 가지 협력 방식을 가능하게 한다. 요청/응답 스타일은 클라이언트가 요청을 시작하고 응답을 기다리는 것이다. 이 모델은 동기 통신 방식과 명확히 일치하지만 비동기 통신에서도 잘 작동한다. 클라이언트는 작업 요청을 보내고 그 작업이 완료되었을 때 서버가 알려주도록 요청하는 콜백을 등록할 수 있다. 한편 이벤트 기반 협업에서는 모든 것이 뒤바뀐다. 클라이언트는 완료되어야 할 작업을 요청하는 대신 일(사건)이 발생했음을 알리고 다른 당사자들이 무엇을 해야 할지 알기 기대한다. 우리는 결코 다른 누구에게도 해야 할 일을 말하지 않는다. 이벤트 기반 시스템은 본질상 비동기적이다. 그리고 지능이 더 고르게 분산되어 있다. 즉, 비즈니스 로직이 핵심 두뇌로 집중화되기보다는 다양한 협업자들에 고르게 분배된다. 이벤트 기반 협업 역시 매우 결합도가 낮은 방식이다. 이벤트를 발산하는 클라이언트는 이벤트에 반응하는 대상이 누구인지 또는 무엇인지 전혀 알지 못한다. 이는 클라이언트 몰래 이벤트에 새로운 구독차를 추가할 수 있다는 의미다.
35 | * 필자는 코레오그래피 방식의 시스템이 전반적으로 더 느슨히 결합하고 유연하며 변경을 보다 쉽게 수용하는 것을 알게 되었다. 시스템 경계를 넘어 프로세스를 모니터링하고 추적하는 부가 작업이 필요하지만, 오케스트레이션 방식에 지나치게 의존하는 구현체는 매우 취약하고 높은 변경 비용을 수반한다. 이러한 면에서 필자는 각 서비스가 자신의 역할을 영리하게 인식하는 코레오그래피 방식의 시스템을 매우 선호한다.
36 | * 이벤트 기반의 비동기 통신시 고려해야 할 두 가지 주요 문제는 마이크로서비스가 이벤트를 발산하는 방법과 소비자가 생성된 이벤트를 찾는 방법이다. 전통적으로 RabbitMQ와 같은 메시지 브로커들은 두 문제를 모두 처리한다. 생산자는 API를 사용하여 브로커에 이벤트를 발행하고 브로커(중개자)는 이벤트가 도착하면 소비자에게 알릴 수 있도록 구독을 처리한다. 메시지 브로커 인프라스트럭쳐를 구축하고 운영하려면 부가적인 머신과 전문성이 요구되지만 일단 실현된다면 느슨히 결합된 이벤트 기반 아키텍처의 구현에 대단히 효과적인 방법이 된다. 이벤트를 전파하는 또 다른 대안은 HTTP를 사용하는 것이다. 아톰(ATOM)은 자원의 피드를 게시하기 위해 semantics를 정의한 REST 호환 사양서다. 고객 서비스는 변경될 때 해당 피드에 대한 이벤트만 발생하고, 고객 서비스의 소비자들은 단지 피드의 변경이 있는지 폴링만 하면 된다.
37 | * 분산 시스템은 호출 방법의 구현 세부 사항을 추상화하고 더 쉽게 추론하게 하므로 Rx(reactive extension) 구현체와 아주 잘 어울린다. Rx의 백미는 하위 서비스에 대해 동시에 발생하는 호출들을 훨씬 쉽게 처리하면서 다수의 호출을 함께 조합할 수 있다는 것이다.
38 | * 넷플릭스는 클라이언트 라이브러리를 특별히 강조한다. 사실 넷플릭스에서 사용되는 클라이언트 라이브러리는 시스템의 신뢰성과 확장성을 보장하려는 것이다. 넷플릭스의 클라이언트 라이브러리는 서비스 발견, 장애 모드(실패처리), 로깅, 그리고 실제로 서비스 자체의 본질과는 다른 측면들을 다룬다. 이러한 공유 클라이언트 없이는 넷플릭스의 대규모 확장 운영 상황에서 제대로 동작하는 각각의 클라이언트/서버 통신을 보장하기 어렵다. 그러나 넷플릭스의 한 관계자의 말에 따르면 시간이 지나면서 클라이언트 라이브러리는 클라이언트와 서버 사이에서 문제가 될 정도의 결합을 초래했다.
39 | * 관심 없는 데이터의 변경들을 무시할 수 있도록 독자(reader)를 구현하는 것이 바로 마틴 파울러가 말하는 '관대한 독자(tolerant reader)' 패턴이다. (ex) XPath를 사용해 필드의 저장 위치는 개의치 않고 필드 추출하기)
40 |
41 | ## 5장 모놀리스 분해하기
42 | * 스트럭쳐 101(Structure 101)과 같은 도구는 패키지 간의 의존성을 시각적으로 표현한다.
43 | * 보상 트랜잭션을 수동으로 통제하는 방식의 대안은 분산 트랜잭션(distributed transaction)의 사용이다. 트랜잭션 관리자가 하부 시스템에서 수행되는 다양한 트랜잭션을 통제, 조정한다. 분산 트랜잭션은 복잡성을 증가시킨다. 또한 재시도, 보상 로직을 최종 방법으로 사용하는 시스템은 추론하기 더 어려우며 데이터의 불일치를 고치기 위해 다른 보상 행위가 필요 할 수 있다. 트랜잭션 자체를 표현할 구체적인 개념을 만들어라. 이것은 보상 트랜잭션과 같은 다른 작업을 실행할 여지를 주고 시스템의 복잡한 개념들을 모니터링하고 관리할 수 있는 방법을 제공한다. 예를 들어 '진행 중인 주문' 같은 개념을 만들 수 있다.
44 |
45 | ## 6장 배포
46 | * 지속적 통합(CI)를 통한 핵심 목표는 모든 사람이 서로 동기를 맞추는 것이며, 그것은 새롭게 체크인된 코드가 기존 코드와 적절히 통합됨을 보장함으로써 달성할 수 있다. 이를 위해 CI 서버는 코드의 커밋을 감지하고, 체크아웃하고, 코드의 컴파일과 테스트 통과를 확인하는 것과 같은 몇가지 검증을 한다.
47 | * 지속적 배포(CD) 빌드 파이프라인(build pipeline)을 기반으로 모든 체크인의 실환경 준비에 대한 지속적인 피드백을 얻고, 나아가 모든 체크인을 빠짐없이 릴리스 후보로 여기는 접근 방법이다.
48 | * 우리가 배포하고자 하는 서비스는 모든 다양한 환경에서 동일해야 한다.
49 | * 대규모 마이크로서비스를 다룰 때 이용되는 다른 인기 있는 방법은 환경 구성을 제공하는 전용 시스템을 사용하는 것이다.
50 | * 사용하는 하부 플랫폼과 산출물이 어떤 것이든 간에 특정한 서비스를 배포하는 데 일관된 인터페이스를 유지하는 것은 필수다. 이 분야에서 오랜 기간 일하고 나서 필자는 어떤 배포도 실행시킬 수 있는 가장 타당한 방법은 매개 변수 전달이 가능한 한 줄의 명령행 호출임을 확신한다. 이것은 CI 도구에 의해 실행되는 스크립트로 또는 직접 입력함으로써 시작할 수 있다. 필자는 윈도우 배치부터 배쉬 쉘, 파이썬 패브릭 스크립트 등 다양한 기술 스택의 랩퍼 스크립트를 작성해왔다. 하지만 모든 명령행은 동일한 기본 포맷을 공유한다.
51 |
52 | ## 7장 테스팅
53 |
54 | ## 8장 모니터링
55 | * 필자는 서비스 스스로 기본적인 측정지표를 발산해야 한다고 강력히 제안한다. 웹 서비스라면 최소한 기본으로 응답시간과 에러율 같은 측정지표를 노출해야 한다. 만약 이러한 일을 대신하는 웹 서버가 여러분 서버 앞단에 없다면 그것은 필수다. 그러나 여러분은 더 나아가야 한다. 예를 들어 계정서비스(account service)는 고객이 과거 주문 내역을 본 횟수를 보여주거나 웹 쇼핑몰이 지난 하루 동안 얼마나 많은 돈을 벌었는지 기록하기 원할 수 있다.
56 | * 코다헤일(Codahale)의 측정지표 라이브러리는 JVM용 라이브러리의 한 예로 측정지표를 카운터, 타이머 또는 측정기로 저장하게 해준다. 예를 들어 시간 설정 측정지표(time-boxing metrics) 기능을 제공해서 최근 5분 동안의 주문수와 같은 측정지표를 지정할 수 있다.
57 |
58 | ## 9장 보안
59 |
60 | ## 10장 콘웨이의 법칙과 시스템 설계
61 | * 1968년 멜빈 콘웨이가 논문에서 다음과 같이 발표했다. "조직은 시스템(반드시 정보 시스템이라기보다는 더 넓은 의미의 시스템)을 설계할 때 필연적으로 그 조직의 의사소통 구조와 일치하도록 만든다."
62 | * 마이크로소프트는 조직 구조가 어떻게 그들의 특정 제품, 즉 윈도우 비스타의 소프트웨어 품질에 영향을 주는지 알아보기 위해 경험적 사례 연구를 진행했다. 코드 복잡도처럼 흔히 사용되는 소프트웨어 품질 지표를 포함하여 다수의 지표를 살펴본 후 그들은 조직 구조와 연관된 지표가 통계적으로 가장 밀접한 척도임을 발견했다.
63 | * 담담 서비스의 전체 수명주기를 소유하는 작은 팀의 추구는 아마존이 AWS를 만들 수 있었던 일등 공신이다. 넷플릭스는 아마존의 사례를 교훈삼아 처음부터 작고 독립적인 팀을 조직했고 그 결과 독립적인 서비스를 만들 수 있었다. 이를 통해 속도에 최적화된 시스템 아키텍쳐를 확보할 수 있었다.
64 | * 서비스 소유권(service ownership)이란 무엇일까? 이는 일반적으로 서비스를 소유한 팀이 해당 서비스의 변경을 책임지는 것을 말한다. 팀에 더 많은 권한과 자율성을 부여하지만 업무의 책임도 부여하면서 최선의 결정을 할 수 있는 사람이 결정하게 만든다.
65 | * "처음에 어떻게 보이든 항상 사람의 문제다" by 게리 와인버그(Gerry Weinberg) from '컨설팅의 비밀'
66 | * 마이크로서비스 세계에서 사람들의 책임을 명확히 구분해야 한다는 것을 이해하라.
67 | * 서비스 소유권(service ownership) = 동일 위치의 팀(collocated team) = bounded context.
68 |
69 | ## 11장 대규모 마이크로서비스
70 | * 마이크로서비스가 복잡하게 발전한다면? 분리된 많은 서비스의 장애를 처리하거나 수백 개의 서비스를 관리해야 한다면? 사람수보다 더 많은 마이크로 서비스가 있을 때의 대응 패턴은 무엇일까?
71 | * 장애는 대규모 환경에서 통계적으로 필연적이다.(하드디스크는 고장나고 소프트웨어는 오류가 발생하며 네트워크는 신뢰할 수 없다) 따라서 어떤 장애든 결국 발생한다는 것을 가정해야 한다.
72 | * 얼마나 많은 장애를 감내할 수 있는지와 얼마나 빠른 시스템이 되어야 하는지 아는 것은 사용자에 의해 좌우된다. 그것은 결국 가장 적합한 기술이 어떤 것인지 파악하는 데 도움이 된다.
73 | * 여러분은 응답시간/지연시간, 가용성, 데이터의 내구성과 같은 교차기능 요구사항에 대해 지속적이며 체계적으로 측정할 방법이 필요하다.
74 | * 고장나서 작동하지 않는 시스템보다 느리게 동작하는 시스템이 훨씬 다루기 힘들다는 것을 우리는 어렵게 습득했다. 분산 시스템에서 지연시간은 매우 중요하다. 결국 우리는 재발을 막기 위해 세 가지 조치를 취했다. 타임아웃을 올바르게 설정했고, 격벽(bulkhead)을 위해 커넥션 풀을 분리했으며, 정상 동작하지 않는 시스템은 애초에 호출하지 않도록 회로 차단기(Circuit Breaker)를 구현했다.
75 | * 넷플릭스가 전적으로 AWS 인프라스트럭쳐에 기반한다는 사실만큼 넷플릭스는 운영 규모로도 유명하다. 그리고 이 두 요소는 장애를 잘 수용해야 한다는 것을 의미한다. 넷플릭스는 장애에 강한 시스템을 보장하기 위해 실제로 장애을 조장하며 이를 극복했다.
76 | * 구글은 서버 장애를 흉내 내는 단순한 테스트 수준을 넘어 매년 진행하는 장애 복구 테스트(Disaster Recovery Test == DiRT) 훈련의 일부로 지진과 같은 대규모 재난까지 시뮬레이션한다. 넷플릭스 또한 장애를 유발하는 프로그램을 작성해서 하루 단위로 실환경에서 실행하는 더 공격적인 방법을 취한다.
77 | * 이들 프로그램 중 가장 유명한 카오스 몽키는 하루 중 특정 시간 동안 임의로 머신의 전원을 꺼버린다. 결국 실운영 환경에서 이런 사고의 발생 가능성을 인지하는 것은 시스템을 만드는 개발자들이 실제로 그 사고에 준비하게 만든다. 레이턴시 몽키는 머신간의 느린 네트워크 접속 상황을 시뮬레이션한다.
78 | * 장애를 줄이기 위한 분리의 일반적 형태는 모든 서비스를 데이터 센터의 단일 랙에서 실행하지 않거나 여러 데이터 센터로 분산하는 것이다. 여러분이 하부 서비스 제공자를 이용한다면 서비스 수준 계약(SLA)이 적절히 제공되고 계획될 수 있는지 여부가 중요하다. 여러분은 분기당 4시간 이하의 다운타임 보장이 필요하지만 호스팅 제공자가 분기당 8시간의 다운타임만 보장한다면 SLA를 변경하거나 대안을 마련해야 한다. 또한 컴퓨팅 서비스에 대해 AWS는 전체 리전에서 월간 99.95%의 가동시간만을 제공하므로 작업 부하를 리전 내 여러 가용 영역(availability zone)으로 분산하고 싶을 것이다.
79 | * 제프 딘(Jeff Dean)은 WSDM 2009 컨퍼런스에서 발표한 'Building Large-Scale Information Retrieval Systems'에서 10배 성장까지 고려해서 설계하고 100배 성장 전까지 재작성을 계획해야 한다고 강조했다. 특정 시점에서는 다음 단계의 성장을 지원하기 위해 매우 근본적인 것들을 해야 한다. 재설계는 길트가 한 것처럼 기존의 모놀리스를 나눠 쪼개는 것을 의미하거나 곧 살펴볼 내용인 부하를 더 잘 처리하기 위해 새로운 데이터 저장소를 선택하는 것일 수 있다. 그리고 재설계는 동기식 요청과 응답을 이벤트 기반의 시스템으로 전환하거나, 새로운 배포 플랫폼을 적용하거나, 전체 기술 스택을 교체하거나 그 중간에 있는 모든 것을 의미할 수도 있다.
80 | * 카산드라 같은 최근 시스템은 샤드 추가시 다운타임 없이 데이터의 재조정 수행이 가능하다.
81 | * 쓰기용 샤딩은 쓰기 볼륨을 확장할 수 있지만 회복성(resiliency)을 향상시키는 것은 아니다. 만약 고객 레코드 A부터 M까지는 항상 인스턴스 X에 저장될 때 인스턴스 X가 가용하지 못하면 그 레코드들을 잃어버릴 것이다. 하지만 카산드라는 카산드라 노드들의 집합인 링 내의 다수의 노드에 데이터를 복제하는 추가 기능을 제공한다.
82 | * CQRS(Command-Query Responsibility Segregation)는 다양한 종류의 확장을 가능하게 한다. 시스템에서 명령과 질의 부분은 다른 서비스나 다른 하드웨어에서 동작할 수 있고 근본적으로 다른 종류의 데이터 저장소를 사용할 수 있다. 이것은 확장을 다루는 수많은 방법을 가능하게 한다. 심지어 다양한 질의 구현을 통해 다양한 종류의 읽기 포맷을 지원할 수 있다. 예를 들어 그래프 기반의 데이터 표현이나 키/값 기반의 데이터 형태를 지원할 수 있다.
83 | * 캐시는 결과를 더 빠르게 제공하기 위해 데이터베이스나 다른 서비스까지의 불필요한 왕복을 제거한다. 잘 사용된다면 엄청난 성능 향상을 가져온다. 대규모 요청에도 HTTP가 확장을 매우 잘하는 이유는 캐싱의 개념이 내장되어 있기 때문이다. 분산 시스템에서는 일반적으로 캐싱을 클라이언트에 둘지 서버 측에 둘지 고민한다. 과연 어떤 것이 최선일까?
84 | * HTTP는 실제로 클라이언트와 서버 측에서 캐시할 수 있는 유용한 규약(콘트롤)을 제공한다. 이러한 규약들이 널리 사용되는 명세서에 포함된 사실은 캐시를 다루는 기존의 많은 소프트웨어의 이점을 이용할 수 있음을 의미한다. 스퀴드나 바니시 같은 리버스 프록시는 필요한 캐시된 콘텐츠를 저장하고 만료하면서 클라이언트와 서버 사이의 네트워크에 투명하게 배치될 수 있다. 이런 시스템들은 대규모 동시 요청을 아주 빠르게 처리하는 데 적합하며 공개용 웹사이트를 확장하는 데 있어 보편적인 방식이다. AWS의 클라우드프론트(CloudFront)나 아카마이(Akamai)와 같은 CDN은 트래픽이 세계 절반을 경유하지 않도록 해주며 호출한 클라이언트의 가까운 캐시로 요청을 라우팅한다. 그리고 현실적으로 HTTP 클라이언트 라이브러리와 클라언트 캐시는 우리를 대신해서 이러한 많은 작업을 처리할 수 있다.
85 | * 비록 여러분이 읽기용 캐싱을 더 자주 사용하더라도 쓰기용 캐싱이 적합한 사용 사례가 있다. 예를 들어 write-behind 캐시 방식을 사용한다면 로컬 캐시에 먼저 쓰고 데이터는 나중에 하위 소스에 플러시될 것이다. 이것은 대량 쓰기(burst of write)를 할 때나 동일한 데이터를 여러 번 쓸 때 유용하다. 버퍼와 잠재적으로 배치 쓰기에 사용될 경우 write-behind 캐시는 성능을 최적화하는 데 유용하다. 또한 버퍼링된 쓰기가 적절히 보존되면 하위 서비스를 사용할 수 없을 때도 쓰기를 큐에 추가하고 서비스가 다시 사용 가능해지면 보낼 수 있다.
86 | * 캐싱은 장애의 회복성을 구현하는 데 사용될 수 있다. 가디언 같은 경우 시스템이 중단된 경우에 제공할 수 있는 정적 버전의 웹사이트를 생성하기 위해 기존 라이브 사이트를 주기적으로 크롤링한다.
87 |
88 | ## 12장 종합정리(마이크로서비스의 원칙)
89 | * 비지니스 개념에 따른 모델(경계가 있는 콘텍스트)
90 | * 자동화 문화의 적용(자동화 테스팅, 지속적 배포, 환경 정의, 커스텀 이미지 생성, 불변 서버)
91 | * 내부 세부 구현의 은폐(기술 중립적 API)
92 | * 모든 것을 분권화(service owenership, 팀을 조직에 맞춰 조정, 코레오그래피)
93 | * 독립적인 배포(여러 버전의 엔드포인트 공존, blue/green 배포, 카나리배포, 소비자 주도 계약)
94 | * 장애 격리(안티프래질 사상, 타임아웃, 격벽, circuit breaker)
95 | * 매우 식별 가능한(유의적 모니터링, 로그, 통계, 상관관계 ID)
--------------------------------------------------------------------------------
/7-part_series_about_microservices.md:
--------------------------------------------------------------------------------
1 | # 개요
2 |
3 | [Chris Richardson](http://microservices.io/)이 포스팅하고 있는 "a 7-part series about designing, building, and deploying microservices." 시리즈 글들(총 7개)을 요약해본다.(2016-03-08 연재완료.)
4 |
5 | # 1. Introduction to Microservices
6 | 원본 글 : https://www.nginx.com/blog/introduction-to-microservices/
7 |
8 | ## Building Monolithic Applications
9 | 아래는 Uber같은 taxi-hailing app 아키텍쳐([hexagonal architecture](http://www.infoq.com/news/2014/10/exploring-hexagonal-architecture) = Ports and Adapters architecture.) 다이어그램이다.
10 | 논리적으로는 여러 모듈로 이루어져 있지만 단일(monolith) 애플리케이션으로 배포되는 특성상 개발, 테스트, 패키징, 배포 간편하고 쉬운 장점을 갖는다.
11 | 
12 |
13 | ## Marching Towards Monolithic Hell
14 | 하지만 애플리케이션이 거대해질 경우 심플한 Monolithic 구조에서는 아래의 문제가 발생한다.
15 |
16 | * 생산성 - 수천개의 jars와 수백만 라인의 코드로 이루어진 beast 애플리케이션. Monolithic Hell. 복잡도가 증가하여 개발조직의 고통 시작, 배포시간도 오래걸림(수십분), 간단한 기능 추가에도 오래걸리는 배포 및 테스트로 인한 생산성 저하. CI에 역행. agile개발과 빠른 delivery의 어려움.
17 | * scale - CPU-intensive한 모듈과 in-memory 모듈이 함께 사용되는 경우처럼 리소스 요구사항이 상충될 때 확장성에 제약.
18 | * reliability - 앱이 하나의 프로세스로 돌기 때문에 한 모듈의 버그가 전면 장애로 이어짐.
19 | * adopt new tech speed - 새로운 언어, 프레임워크 기술 적용이 극도로 어려움.
20 | * hiring - 오래되고 비생산적인 기술 사용. 능력있는 인재 채용이 어려움.
21 |
22 | ## Microservices – Tackling the Complexity
23 | * Amazon, eBay, Netflix 등은 위 문제를 [MSA](http://microservices.io/patterns/microservices.html) 패턴을 도입해서 해결. 즉 monolithic 애플리케이션을 잘게 쪼개서 작은 서로 연결되는 서비스들로 구성.
24 | * 각 microservice는 독립적인 mini application.
25 | 
26 |
27 | * MSA 패턴은 Sacle Cube에서 Y축, 즉 different things를 분리해서 scale을 높이는 개념.
28 | 
29 |
30 | * microservice마다 독립적인 database 스키마. data 중복의 단점은 있지만, 커플링은 낮추고 각 서비스에 효율적인 DB 사용이 가능해짐. ex) Driver Management 서비스는 Driver의 위치를 찾는데 효율적인 geo-queries 지원 DB 사용.
31 | 
32 |
33 | * MSA VS SOA.
34 | * WSDL,SOAP vs REST
35 | * ESB vs APIGATEWAY
36 | * heavy vs simple, lightweight
37 |
38 | ## The Benefits of Microservices
39 | * 분리된 각 서비스는 개발이 빠르고 유지보수 및 이해하기 쉽다.
40 | * decompose complexity. 알고리즘으로 치면 divide and conquor 느낌. 분리된 서비스를 연결하는 RPC or message-driven API가 중요해짐.
41 | * 각 서비스에 집중하는 팀 구성 가능
42 | * 각 팀에서 자유롭게 기술을 선택할 수 있고 mini 서비스여서 기술 변경이 쉽다.
43 | * 요구사항을 구현하기위해 최적화된 언어와 아키텍처의 선택이 가능해진다.
44 | * CI의 현실화, 고속개발.
45 | * 각 서비스가 독립적으로 테스트, 배포되기 때문에 빠르고 좋은 품질 유지 가능.
46 | * 확장
47 | * 서비스 별로 독립적으로 확장 가능하고, 리소스 요구사항에 최적화된 장비 선택이 가능하다.
48 |
49 | ## The Drawbacks of Microservices
50 | 은탄환은 없다.
51 |
52 | * distributed system.
53 | * messaging or RPC. 부분실패(partial failure) 처리의 어려움, 롤백하기가 쉽지 않다.
54 | * partitioned database architecture
55 | * db 분산 트랜잭션 처리가 일상. NoSQL, messaging brokers에서는 strong consistency 만족시키기 어려움. eventual consistency.
56 | * 테스트
57 | * 한 서비스의 변경이 여러 서비스에 영향을 줌.
58 | * A -> B -> C depenency.
59 | * 배포
60 | * Hailo : 160, Netflix : 600 different services, 수많은 서비스 배포하려면 service discovery, 배포 자동화 도구들 필요. DevOps. ex) PaaS 서비스 이용 or 직접 구축(Mesos나 Kubernetes 이용.)
61 |
62 | * 팀간의 의사소통 어려움
63 | * 메모리 (중복)소비 증가. N x M services runs in its own JVM. own VM.
64 |
65 | # 2. Building Microservices: Using an API Gateway
66 | 원본 글 : https://www.nginx.com/blog/building-microservices-using-an-api-gateway/
67 |
68 | ## Introduction
69 | * 클라이언트가 접근하는 endpoint가 Monolithic 구조에서는 하나였다면 MSA 구조에서는 여러개 존재한다.
70 | 
71 | * single REST call vs many REST call
72 | 
73 |
74 | ## Direct Client-to-Microservice Communication
75 | MSA 구조에서는 클라이언트가 접근하는 endpoint가 여러개 존재하고 아래와 같은 단점들로 인해 직접 호출하지 않는게 일반적인다.
76 |
77 | * public internet, mobile network에서 많은 요청은 비효율적.
78 | * 클라이언트 코드가 복잡해지고 리팩토링이 어려움.
79 | * microservices 에서 Thrift binary RPC, AMQP messaging protocol을 사용할 경우. 둘다 browser, 방화벽에 친화적이지 않고 내부 네트워크에서의 사용에 적합. 방확벽 밖에서는 HTTP나 WebSocket 프로토콜이 적합.
80 |
81 | ## Using an API Gateway
82 | * single entry point. OOP에서 Facade 패턴과 유사.
83 | * 내부 시스템 아키텍쳐를 캡슐화해서 클라이언트에 적합한 API를제공.
84 | * request routing, composition, and protocol translation. authentication, monitoring, load balancing, caching, request shaping and management, and static response handling.
85 | * Netflix API Gateway. 수십억 요청 처리.
86 | 
87 |
88 | ## Benefits and Drawbacks of an API Gateway
89 | ### Benefits
90 | * single endpoint(수많은 내부 서버 구조를 숨김).
91 | * 클라이언트와 서버사이의 round trip 횟수 감소.
92 | * 클라이언트 코드가 단순해짐.
93 | * 공통기능(인증, 캐싱, 통계, 프로토콜, 메시지 변환 등) 처리를 대신해줌.
94 |
95 | ### Drawbacks
96 | * 관리 포인트. API Gateway가 개발 병목이 될 수 있다.
97 | * API 탑재 프로세스(update)가 가벼워야 한다.
98 |
99 | ## Implementing an API Gateway
100 | API Gateway 구현시 아래 디자인 이슈를 고려 해야한다.
101 |
102 | * Performance and Scalability
103 | * 성능을 위해 API Gateway는 비동기, 논블로킹 I/O를 지원하는 플랫폼으로 개발 필요. ex) Netty, Vertx, Spring Reactor, or JBoss Undertow, Node.js, NGINX
104 |
105 | * Using a Reactive Programming Model(Future in Scala, CompletableFuture in Java 8, and Promise in JavaScript, Reactive Extensions)
106 | * simple yet efficient API Gateway code.
107 |
108 | * Service Invocation
109 | * microservice가 사용하는 다양한 통신 메커니즘 지원 필요. ex) asynchronous, messaging-based mechanism. JMS or AMQP, Zeromq. synchronous mechanism such as HTTP or Thrift.
110 |
111 | * Service Discovery
112 | * autoscaling and upgrades에 따른 service 주소가 dynamic하게 바뀌는 환경에서는 필수. Server-Side Discovery or Client-Side Discovery.
113 |
114 | * Handling Partial Failures
115 | * 백엔드 서비스가 실패 하더라도 (잘 바뀌지 않는 데이터라면)캐시 데이터 or 디폴트 데이터로 실패 처리 가능. cf) Netflix Hystrix
116 |
117 |
118 | # 3. Building Microservices: Inter-Process Communication in a Microservices Architecture
119 | 원본 글 : https://www.nginx.com/blog/building-microservices-inter-process-communication/
120 |
121 | ## Introduction
122 | language method call VS IPC(inter-process communication)
123 | 
124 |
125 | ## Interaction Styles
126 | MSA 각 서비스 컴퍼넌트들은 아래 다양한 IPC 방식의 조합을 사용하게 된다.
127 |
128 | | | One-to-One | One-to-Many |
129 | | ------------- |:-------------:| -----:|
130 | | Synchronous | Request/response | — |
131 | | Asynchronous | Notification, Request/async response | Publish/subscribe, Publish/async responses |
132 |
133 | * One-to-one – Each client request is processed by exactly one service instance.
134 | * One-to-many – Each request is processed by multiple service instances.
135 | * Synchronous – The client expects a timely response from the service and might even block while it waits.
136 | * Asynchronous – The client doesn’t block while waiting for a response, and the response, if any, isn’t necessarily sent immediately.
137 |
138 | ex) taxi-hailing(우버) app.
139 | 
140 |
141 | ## Defining APIs
142 | * 서비스와 클라이언트간의 계약.
143 | * [API-first approach](http://www.programmableweb.com/news/how-to-design-great-apis-api-first-design-and-raml/how-to/2015/07/10)
144 | * IPC 메커니즘에 의존. ex) HTTP : URL, request and response formats.
145 |
146 |
147 | ## Evolving APIs
148 | * [Robustness principle.](https://en.wikipedia.org/wiki/Robustness_principle)
149 | - 서비스는 누락된 요청 속성에 대한 기본 값을 제공하고, 클라이언트는 별도로 추가된 응답 속성을 무시한다.
150 | * API 변경이 쉬운 IPC 메커니즘 및 메시지 포맷 사용.
151 | * API의 대격변에 대비해서 versioning 하는게 좋음.
152 |
153 | ## Handling Partial Failure
154 | 
155 | * [Netflix Hystrix](https://github.com/Netflix/Hystrix)
156 | * [described by Netflix](http://techblog.netflix.com/2012/02/fault-tolerance-in-high-volume.html)
157 | * Network timeouts – Never block indefinitely.
158 | * Limiting the number of outstanding requests – Throttling.
159 | * Circuit breaker pattern.
160 | * Provide fallbacks.
161 |
162 |
163 | ## IPC Technologies
164 | ### Asynchronous, Message-Based Communication
165 | 
166 | RabbitMQ, Apache Kafka,Apache ActiveMQ, and NSQ.
167 |
168 | #### 장점
169 | * Decouples the client from the service – The client is completely unaware of the service instances.
170 | * Message buffering – a message broker queues up the messages written to a channel until they can be processed by the consumer.
171 | * Flexible client-service interactions – Messaging supports all of the interaction styles described earlier.
172 | * Explicit inter-process communication. vs RPC
173 |
174 | #### 단점
175 | * Additional operational complexity.
176 | * Complexity of implementing request/response-based interaction – The client uses the correlation ID to match the response with the request.
177 |
178 | ### Synchronous, Request/Response IPC
179 | #### HTTP REST
180 | 
181 | [4단계의 REST 모델, maturity model for REST.](http://martinfowler.com/articles/richardsonMaturityModel.html)
182 | IDL tools : RAML and Swagger.
183 |
184 | ##### 장점
185 | * HTTP is simple and familiar.
186 | * You can test an HTTP API from within a browser using an extension such as Postman or from the command line using curl (assuming JSON or some other text format is used).
187 | * It directly supports request/response-style communication.
188 | * HTTP is, of course, firewall-friendly.
189 | * It doesn’t require an intermediate broker, which simplifies the system’s architecture.
190 |
191 | ##### 단점
192 | * It only directly supports the request/response style of interaction. You can use HTTP for notifications but the server must always send an HTTP response.
193 | * Because the client and service communicate directly (without an intermediary to buffer messages), they must both be running for the duration of the exchange.
194 | * The client must know the location (i.e., the URL) of each service instance.
195 |
196 |
197 | #### Thrift
198 | * a framework for writing cross-language RPCclients and servers.
199 | * Thrift provides a C-style IDL for defining your APIs. You use the Thrift compiler to generate client-side stubs and server-side skeletons. The compiler generates code for a variety of languages including C++, Java, Python, PHP, Ruby, Erlang, and Node.js.
200 | * supports JSON, binary, and compact binary message formats. transport protocols including raw TCP and HTTP.
201 |
202 | ### Message Formats
203 | * JSON and XML text message formats VS binary format.
204 | * [comparison of Thrift, Protocol Buffers, and Avro.](http://martin.kleppmann.com/2012/12/05/schema-evolution-in-avro-protocol-buffers-thrift.html)
205 |
206 | # 4. Service Discovery in a Microservices Architecture
207 | 원본 글 : https://www.nginx.com/blog/service-discovery-in-a-microservices-architecture/
208 |
209 | ## Why Use Service Discovery?
210 | 클라우드 환경에서의 microservices application은 auto-scaling, 장애, 업그레이드 등으로 인해 다이나믹하게 (IP주소가)변화한다.
211 | 
212 |
213 | ### The Client-Side Discovery Pattern
214 | 
215 | Netflix OSS( Netflix Eureka, Netflix Ribbon)
216 |
217 | #### 장점
218 | client knows about the available services instances, it can make intelligent, application-specific load-balancing decisions such as using hashing consistently.
219 |
220 | #### 단점
221 | couples the client with the service registry. You must implement client-side service discovery logic for each programming language and framework used by your service clients.
222 |
223 | ### The Server-Side Discovery Pattern
224 | 
225 | AWS Elastic Load Balancer (ELB)
226 | * load balance external traffic from the Internet.
227 | * internal to a virtual private cloud (VPC)
228 |
229 | NGINX(with Consul, Consul Template)
230 |
231 | Kubernetes, Marathon - proxy 모듈
232 |
233 | #### 장점
234 | details of discovery are abstracted away from the client
235 |
236 | #### 단점
237 | highly available system component that need to set up and manage.
238 |
239 | ## The Service Registry
240 | 서비스 인스턴스의 네트워크 위치 정보를 저장하고있는 데이터베이스.
241 |
242 | * Netflix Eureka
243 | * etcd
244 | * consul
245 | * Apache Zookeeper
246 |
247 | Kubernetes, Marathon, and AWS의 경우 별도의 service registry가 존재하지 않고 인프라의 일부로 포함되어 있다.
248 |
249 |
250 | ## Service Registration Options
251 | ### The Self-Registration Pattern
252 | 
253 | Netflix OSS Eureka client. Spring Cloud project.(@EnableEurekaClient annotation)
254 |
255 | #### 장점
256 | relatively simple and doesn’t require any other system components.
257 |
258 | #### 단점
259 | couples the service instances to the service registry. You must implement the registration code in each programming language and framework used by your services.
260 |
261 | ### The Third-Party Registration Pattern
262 | 
263 | Registrator - etcd or Consul with docker
264 |
265 | NetflixOSS Prana - Netflix Eureka.
266 |
267 | #### 장점
268 | services are decoupled from the service registry. You don’t need to implement service-registration logic for each programming language and framework used by your developers.
269 |
270 | #### 단점
271 | it is yet another highly available system component that you need to set up and manage.
272 |
273 |
274 | # 5. Event-Driven Data Management for Microservices
275 | 원본 글 : https://www.nginx.com/blog/event-driven-data-management-microservices/
276 |
277 | ## Microservices and the Problem of Distributed Data Management
278 | * MSA구조에서는 각 마이크로서비스마다 datastore를 가진다. 이러한 각 datastore에 대한 접근은 API를 통해서 이루어지고 따라서 여러 마이크로서비스간의 비지니스 트랜잭션 처리가 어려워진다.
279 | - consistency across multilpe services is not easy
280 | - query across multilpe services is not easy
281 |
282 | 
283 |
284 |
285 | ## Event-Driven Architecture
286 | 
287 |
288 | #### 장점
289 | * 여러 서비스 간에 eventaul consistency 충족시킬 수 있다.
290 |
291 | #### 단점
292 | * ACID transaction 사용할 때 보다 프로그래밍 모델이 복잡해진다.
293 | * 애플리케이션에서 fail 발생시 fail에 대한 보상처리를 해줘야 한다.
294 | * isolation이 보장되지 않기 때문에 inconsistent한 데이터가 보일수 있음을 고려해야한다.
295 | * 중복 event 발생을 감지해서 무시할 수 있어야한다.
296 |
297 | - https://en.wikipedia.org/wiki/Eventual_consistency
298 | - http://queue.acm.org/detail.cfm?id=1394128
299 |
300 | ## Achieving Atomicity
301 | ### Publishing Events Using Local Transactions
302 | 2PC(Phase Commit)가 필요없음.
303 | 
304 |
305 | ### Mining a Database Transaction Log
306 | 2PC(Phase Commit)가 필요없음. 이벤트 테이블도 필요없음. The Transaction Log Miner thread가 직접 트랜잭션로그 후킹.
307 | 
308 |
309 | ### Using Event Sourcing
310 | 2PC(Phase Commit)가 필요없음. 심지어 DB updates 없이 오직 evnets만을 사용해서 The Transaction Log Miner thread의 단점을 제거할수 있다. 또한 RDBMS와 ORM 사용시 발생하는 패러다임불일치 문제를 피할수 있는 장점이 있다. 다만 프로그래밍 모델이 복잡해서 러닝커브가 있고 CQRS 기법 사용을 강제하는 단점이 있다.
311 |
312 | 
313 |
314 | - https://github.com/cer/event-sourcing-examples/wiki/WhyEventSourcing
315 | - https://en.wikipedia.org/wiki/Object-relational_impedance_mismatch
316 | - https://github.com/cer/event-sourcing-examples/wiki
317 |
318 |
319 | # 6. Choosing a Microservices Deployment Strategy
320 | 원본 글 : https://www.nginx.com/blog/deploying-microservices/
321 |
322 | ## Motivations
323 | microservices 애플리케이션은 10, 100여개의 서비스들로 구성된다.
324 | 각 서비스는 적절한 CPU, memory, I/O 리소스를 제공받아야 하고 배포는 빠르고 안정적 효율적이어야한다.
325 |
326 | ## Multiple Service Instances per Host Pattern
327 | http://microservices.io/patterns/deployment/multiple-services-per-host.html
328 |
329 | 
330 | ##### 장점
331 | * 자원 사용이 효율적이다.
332 | * 상대적으로 배포 속도가 빠르다. 서비스 시작속도도 빠르다.
333 |
334 | ##### 단점
335 | * 서비스 인스턴스가 동일한 프로세스에서 실행 될 경우 리소스 isolation 하기가 어렵다. cpu, 메모리를 한 서비스 인스턴스가 모두 사용하는 문제가 발생가능하다.
336 | * 운영팀(operations team)이 deploy하는 서비스들의 detail(언어, 프레임워크)을 잘 알아야 되고, 이는 배포 장애로 이어지는 위험요소가 된다.
337 |
338 |
339 | ## Service Instance per Host Pattern
340 | http://microservices.io/patterns/deployment/single-service-per-host.html
341 |
342 | ### Service Instance per Virtual Machine Pattern
343 | http://microservices.io/patterns/deployment/service-per-vm.html
344 | https://aws.amazon.com/ko/ec2/
345 |
346 | 
347 |
348 | Netfilx에서는 video streaming 서비스에 VM을 사용하는데 각 서비스를 Aminator를 사용해서 EC2 AMI(VM 이미지)로 패키지해서 EC2 인스턴스로 배포하고 있다.
349 |
350 | ##### 장점
351 | * 서비스마다 완벽한 isolation이 가능하다. 고정된 CPU와 메모리를 사용하고 다른 서비스에서 steal하지 않는다.
352 | * 성숙한 클라우드 인프라의 다양한 기능들 활용이 가능하다. ex) AWS load balancing and autoscaling.
353 | * 서비스 구현 기술과 관계없이 VM으로 캡슐화(black box) 가능하다. 이는 VM 관리 API로 단순화 추상화 되어서 쉽고 안정적인 배포를 가능하게한다.
354 |
355 | ##### 단점
356 | * 자원 사용이 비효율적이다. VM에 할당된 자원이 낭비된다.
357 | * 보통 public IaaS들은 VM이 미사용중이더라도 과금한다.
358 | http://techblog.netflix.com/2013/11/scryer-netflixs-predictive-auto-scaling.html
359 | * VM 이미지 빌드 및 실행이 오래 걸린다. 단 Boxfuse 같이 lightweight VM을 통한 해법이 존재한다.
360 | * VM 관리가 어렵다.
361 |
362 | ### Service Instance per Container Pattern
363 | http://microservices.io/patterns/deployment/service-per-container.html
364 | https://en.wikipedia.org/wiki/Operating-system-level_virtualization
365 |
366 | #### container technologies
367 | * docker
368 | * solaris zones
369 |
370 | #### cluster manager
371 | * kubernetes
372 | * marathon
373 |
374 | 
375 |
376 | ##### 장점
377 | * VM의 장점과 대부분 유사.
378 | * VM보다 가볍기 때문에 image 빌드 및 배포가 무척 빠름.
379 |
380 | ##### 단점
381 | * containers 인프라는 VM 인프라만큼 아직 성숙하지 못함.
382 | * 다른 container와 커널을 공유하기 때문에 VM 만큼 안전(secure)하지 못함
383 | * GCE(Google Container Engine)나 ECS(Amazon EC2 Container Service) 같은 솔루션을 사용하지 않을 경우 직접 인프라를 관리해야함.
384 |
385 | 사실 요즘엔 VM과 container 간의 구분이 흐릿해지고 있다.(Boxfuse VMs are fast to build and start. The Clear Containers project aims to create lightweight VMs. There is also growing interest in unikernels. Docker, Inc recently acquired Unikernel Systems.)
386 |
387 |
388 | ## Serverless Deployment(AWS Lambda)
389 | https://aws.amazon.com/lambda/
390 |
391 | * convenient way to deploy microservices.
392 | * automatically runs enough instances of your microservice to handle requests.
393 | * The request-based pricing.
394 |
395 | #### 제약사항
396 | * not intended to long-running services
397 | * Requests must complete within 300 seconds.
398 | * stateless
399 | * Services must also start quickly; otherwise, they might be timed out and terminated.
400 |
401 | #### Lambda 호출 4가지 방식
402 | * Directly, using a web service request
403 | * Automatically, in response to an event generated by an AWS service such as S3, DynamoDB, Kinesis, or Simple Email Service
404 | * Automatically, via an AWS API Gateway to handle HTTP requests from clients of the application
405 | * Periodically, according to a cron-like schedule
406 |
407 |
408 | # 7. Refactoring a Monolith into Microservices
409 | 원본 글 : https://www.nginx.com/blog/refactoring-a-monolith-into-microservices/
410 |
411 | monolithic 애플리케이션에서 microservices로 점진적으로 migration, refactoring 하는 전략 소개.
412 |
413 | ## Overview of Refactoring to Microservices
414 | * [application modernization](https://en.wikipedia.org/wiki/Software_modernization)
415 | * "Big Bang” rewrite는 위험하니점진적으로 refactoring 하는 전략을 취해야한다.
416 | * [Strangler Application](http://www.martinfowler.com/bliki/StranglerApplication.html)
417 |
418 | ## Strategy 1 – Stop Digging
419 | 신규 기능을 추가해야 할 경우 기존 MONOLITH가 아닌 별도의 신규 SERVICE를 만들어서 연동하라.
420 | 
421 |
422 | 신규 SERVICE가 MONOLITH 데이터에 접근하는 3가지 전략으로는 다음과 같다.
423 | * remote API 호출
424 | * database 직접 접근
425 | * database copy(동기화)
426 |
427 | glue code = anti-corruption layer(Eric Evans의 Domain Driven Design 책에서 소개된 패턴 용어.)
428 | SERVICE로 하여금 MONOLITH와 독립적인 domain 모델 사용가능하게 한다.
429 |
430 | MONOLITH의 문제점을 근본적으로 해결하는 방법은 아니다 MONOLITH를 break up 해야되는데 다음에서 그 전략을 설명한다.
431 |
432 | ## Strategy 2 – Split Frontend and Backend
433 | 
434 |
435 | Frontend와 Backend를 둘로 나눌 경우 아래 2가지 장점이 있지만 역시나 부분적인 솔루션이다.
436 |
437 | * 개발, 배포, 확장이 서로 독립적이다. 특히 Frontend 개발자는 빠르게 UI 작업 반복이 가능하고 A/B 테스팅을 쉽게 수행 가능해진다.
438 | * 자연스럽게 remote API 서버(Backend)가 생성된다.
439 |
440 |
441 | ## Strategy 3 – Extract Services
442 | 
443 |
444 | 추출(extraction) 전략은 아직 microserivce 경험이 없을 초반에는 추출하기 쉬운 모듈 먼저 진행 하고 그 후에는 이득이 되는 모듈에 우선순위를 두면된다. 이득이 되는 모듈이란 변경이 자주 발생하는 모듈이다. 추출하고 나면 개발, 배포가 독립적으로 이루어질 수 있어서 개발을 가속화 시키기 때문이다. 혹은 자원(CPU, 메모리) 요구사항이 특이한 케이스의 모듈을 대상으로 하는것도 좋다.
445 |
446 | * a pair of coarse-grained APIs 정의하기(inbound, outbound interfaces)
447 | * 모듈을 독립적인 서비스로 전환(IPC 사용). [Microservice Chassis framework](http://microservices.io/patterns/microservice-chassis.html) 사용.
448 |
449 | ## Summary
450 | * monolithic 애플리케이션에서 microservices로 전환은 한번에 할수는 없고 점진적으로 진행햐하는데, 3가지 전략이 있다.(new functionality as microservices, split Frontend and Backend, convert modules into services)
451 | * microservices가 증가함에 따라 개발팀의 기민함(agility)과 속도(velocity)가 증가할 것이다.
452 |
--------------------------------------------------------------------------------