├── .actor
├── Dockerfile
├── README.md
├── actor.json
├── actor.sh
├── dataset_schema.json
└── input_schema.json
├── .dockerignore
├── .editorconfig
├── .github
├── CODEOWNERS
├── FUNDING.yml
├── ISSUE_TEMPLATE
│ ├── bug-report.yml
│ ├── config.yml
│ ├── false-negative.yml
│ ├── false-positive.yml
│ ├── feature-request.yml
│ └── site-request.yml
├── SECURITY.md
└── workflows
│ ├── regression.yml
│ └── update-site-list.yml
├── .gitignore
├── Dockerfile
├── LICENSE
├── devel
└── site-list.py
├── docs
├── CODE_OF_CONDUCT.md
├── README.md
├── images
│ ├── demo.png
│ └── sherlock-logo.png
├── pyproject
│ └── README.md
└── removed-sites.md
├── pyproject.toml
├── pytest.ini
├── sherlock_project
├── __init__.py
├── __main__.py
├── notify.py
├── py.typed
├── resources
│ ├── data.json
│ └── data.schema.json
├── result.py
├── sherlock.py
└── sites.py
├── tests
├── conftest.py
├── few_test_basic.py
├── sherlock_interactives.py
├── test_manifest.py
├── test_probes.py
├── test_ux.py
└── test_version.py
└── tox.ini
/.actor/Dockerfile:
--------------------------------------------------------------------------------
1 | FROM sherlock/sherlock as sherlock
2 |
3 | # Install Node.js
4 | RUN apt-get update; apt-get install curl gpg -y
5 | RUN mkdir -p /etc/apt/keyrings
6 | RUN curl -fsSL https://deb.nodesource.com/gpgkey/nodesource-repo.gpg.key | gpg --dearmor -o /etc/apt/keyrings/nodesource.gpg
7 | RUN echo "deb [signed-by=/etc/apt/keyrings/nodesource.gpg] https://deb.nodesource.com/node_20.x nodistro main" | tee /etc/apt/sources.list.d/nodesource.list
8 | RUN apt-get update && apt-get install -y curl bash git jq jo xz-utils nodejs
9 |
10 | # Install Apify CLI (node.js) for the Actor Runtime
11 | RUN npm -g install apify-cli
12 |
13 | # Install Dependencies for the Actor Shell Script
14 | RUN apt-get update && apt-get install -y bash jq jo xz-utils nodejs
15 |
16 | # Copy Actor dir with the actorization shell script
17 | COPY .actor/ .actor
18 |
19 | ENTRYPOINT [".actor/actor.sh"]
20 |
--------------------------------------------------------------------------------
/.actor/README.md:
--------------------------------------------------------------------------------
1 | # Sherlock Actor on Apify
2 |
3 | [](https://apify.com/netmilk/sherlock?fpr=sherlock)
4 |
5 | This Actor wraps the [Sherlock Project](https://sherlockproject.xyz/) to provide serverless username reconnaissance across social networks in the cloud. It helps you find usernames across multiple social media platforms without installing and running the tool locally.
6 |
7 | ## What are Actors?
8 | [Actors](https://docs.apify.com/platform/actors?fpr=sherlock) are serverless microservices running on the [Apify Platform](https://apify.com/?fpr=sherlock). They are based on the [Actor SDK](https://docs.apify.com/sdk/js?fpr=sherlock) and can be found in the [Apify Store](https://apify.com/store?fpr=sherlock). Learn more about Actors in the [Apify Whitepaper](https://whitepaper.actor?fpr=sherlock).
9 |
10 | ## Usage
11 |
12 | ### Apify Console
13 |
14 | 1. Go to the Apify Actor page
15 | 2. Click "Run"
16 | 3. In the input form, fill in **Username(s)** to search for
17 | 4. The Actor will run and produce its outputs in the default datastore
18 |
19 |
20 | ### Apify CLI
21 |
22 | ```bash
23 | apify call YOUR_USERNAME/sherlock --input='{
24 | "usernames": ["johndoe", "janedoe"]
25 | }'
26 | ```
27 |
28 | ### Using Apify API
29 |
30 | ```bash
31 | curl --request POST \
32 | --url "https://api.apify.com/v2/acts/YOUR_USERNAME~sherlock/run" \
33 | --header 'Content-Type: application/json' \
34 | --header 'Authorization: Bearer YOUR_API_TOKEN' \
35 | --data '{
36 | "usernames": ["johndoe", "janedoe"],
37 | }
38 | }'
39 | ```
40 |
41 | ## Input Parameters
42 |
43 | The Actor accepts a JSON schema with the following structure:
44 |
45 | | Field | Type | Required | Default | Description |
46 | |-------|------|----------|---------|-------------|
47 | | `usernames` | array | Yes | - | List of usernames to search for |
48 | | `usernames[]` | string | Yes | "json" | Username to search for |
49 |
50 |
51 | ### Example Input
52 |
53 | ```json
54 | {
55 | "usernames": ["techuser", "designuser"],
56 | }
57 | ```
58 |
59 | ## Output
60 |
61 | The Actor provides three types of outputs:
62 |
63 | ### Dataset Record*
64 |
65 | | Field | Type | Required | Description |
66 | |-------|------|----------|-------------|
67 | | `username` | string | Yes | Username the search was conducted for |
68 | | `links` | arrray | Yes | Array with found links to the social media |
69 | | `links[]`| string | No | URL to the account
70 |
71 | ### Example Dataset Item (JSON)
72 |
73 | ```json
74 | {
75 | "username": "johndoe",
76 | "links": [
77 | "https://github.com/johndoe"
78 | ]
79 | }
80 | ```
81 |
82 | ## Performance & Resources
83 |
84 | - **Memory Requirements**:
85 | - Minimum: 512 MB RAM
86 | - Recommended: 1 GB RAM for multiple usernames
87 | - **Processing Time**:
88 | - Single username: ~1-2 minutes
89 | - Multiple usernames: 2-5 minutes
90 | - Varies based on number of sites checked and response times
91 |
92 |
93 | For more help, check the [Sherlock Project documentation](https://github.com/sherlock-project/sherlock) or raise an issue in the Actor's repository.
94 |
--------------------------------------------------------------------------------
/.actor/actor.json:
--------------------------------------------------------------------------------
1 | {
2 | "actorSpecification": 1,
3 | "name": "sherlock",
4 | "version": "0.0",
5 | "buildTag": "latest",
6 | "environmentVariables": {},
7 | "dockerFile": "./Dockerfile",
8 | "dockerContext": "../",
9 | "input": "./input_schema.json",
10 | "storages": {
11 | "dataset": "./dataset_schema.json"
12 | }
13 | }
14 |
--------------------------------------------------------------------------------
/.actor/actor.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | INPUT=`apify actor:get-input | jq -r .usernames[] | xargs echo`
3 | echo "INPUT: $INPUT"
4 |
5 | sherlock $INPUT
6 |
7 | for username in $INPUT; do
8 | # escape the special meaning leading characters
9 | # https://github.com/jpmens/jo/blob/master/jo.md#description
10 | safe_username=$(echo $username | sed 's/^@/\\@/' | sed 's/^:/\\:/' | sed 's/%/\\%/')
11 | echo "pushing results for username: $username, content:"
12 | cat $username.txt
13 | sed '$d' $username.txt | jo -a | jo username=$safe_username links:=- | apify actor:push-data
14 | done
15 |
--------------------------------------------------------------------------------
/.actor/dataset_schema.json:
--------------------------------------------------------------------------------
1 | {
2 | "actorSpecification": 1,
3 | "fields":{
4 | "title": "Sherlock actor input",
5 | "description": "This is actor input schema",
6 | "type": "object",
7 | "schemaVersion": 1,
8 | "properties": {
9 | "links": {
10 | "title": "Links to accounts",
11 | "type": "array",
12 | "description": "A list of social media accounts found for the uername"
13 | },
14 | "username": {
15 | "title": "Lookup username",
16 | "type": "string",
17 | "description": "Username the lookup was performed for"
18 | }
19 | },
20 | "required": [
21 | "username",
22 | "links"
23 | ]
24 | },
25 | "views": {
26 | "overview": {
27 | "title": "Overview",
28 | "transformation": {
29 | "fields": [
30 | "username",
31 | "links"
32 | ],
33 | },
34 | "display": {
35 | "component": "table",
36 | "links": {
37 | "label": "Links"
38 | },
39 | "username":{
40 | "label": "Username"
41 | }
42 | }
43 | }
44 | }
45 | }
46 |
--------------------------------------------------------------------------------
/.actor/input_schema.json:
--------------------------------------------------------------------------------
1 | {
2 | "title": "Sherlock actor input",
3 | "description": "This is actor input schema",
4 | "type": "object",
5 | "schemaVersion": 1,
6 | "properties": {
7 | "usernames": {
8 | "title": "Usernames to hunt down",
9 | "type": "array",
10 | "description": "A list of usernames to be checked for existence across social media",
11 | "editor": "stringList",
12 | "prefill": ["johndoe"]
13 | }
14 | },
15 | "required": [
16 | "usernames"
17 | ]
18 | }
19 |
--------------------------------------------------------------------------------
/.dockerignore:
--------------------------------------------------------------------------------
1 | .git/
2 | .vscode/
3 | screenshot/
4 | tests/
5 | *.txt
6 | !/requirements.txt
7 | venv/
8 | devel/
--------------------------------------------------------------------------------
/.editorconfig:
--------------------------------------------------------------------------------
1 | root = true
2 |
3 | [*]
4 | indent_style = space
5 | indent_size = 2
6 | end_of_line = lf
7 | charset = utf-8
8 | trim_trailing_whitespace = true
9 | insert_final_newline = true
10 | curly_bracket_next_line = false
11 | spaces_around_operators = true
12 |
13 | [*.{markdown,md}]
14 | trim_trailing_whitespace = false
15 |
16 | [*.py]
17 | indent_size = 4
18 | quote_type = double
19 |
--------------------------------------------------------------------------------
/.github/CODEOWNERS:
--------------------------------------------------------------------------------
1 | ### REPOSITORY
2 | /.github/CODEOWNERS @sdushantha
3 | /.github/FUNDING.yml @sdushantha
4 | /LICENSE @sdushantha
5 |
6 | ### PACKAGING
7 | # Changes made to these items without code owner approval may negatively
8 | # impact packaging pipelines.
9 | /pyproject.toml @ppfeister @sdushantha
10 |
11 | ### REGRESSION
12 | /.github/workflows/regression.yml @ppfeister
13 | /tox.ini @ppfeister
14 | /pytest.ini @ppfeister
15 | /tests/ @ppfeister
16 |
--------------------------------------------------------------------------------
/.github/FUNDING.yml:
--------------------------------------------------------------------------------
1 | github: [ sdushantha, ppfeister, matheusfelipeog ]
2 |
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/bug-report.yml:
--------------------------------------------------------------------------------
1 | name: Bug report
2 | description: File a bug report
3 | labels: ["bug"]
4 | body:
5 | - type: dropdown
6 | id: package
7 | attributes:
8 | label: Installation method
9 | description: |
10 | Some packages are maintained by the community, rather than by the Sherlock Project.
11 | Knowing which packages are affected helps us diagnose package-specific bugs.
12 | options:
13 | - Select one
14 | - PyPI (via pip)
15 | - Homebrew
16 | - Docker
17 | - Kali repository (via apt)
18 | - Built from source
19 | - Other (indicate below)
20 | validations:
21 | required: true
22 | - type: input
23 | id: package-version
24 | attributes:
25 | label: Package version
26 | description: |
27 | Knowing the version of the package you are using can help us diagnose your issue more quickly.
28 | You can find the version by running `sherlock --version`.
29 | validations:
30 | required: true
31 | - type: textarea
32 | id: description
33 | attributes:
34 | label: Description
35 | description: |
36 | Detailed descriptions that help contributors understand and reproduce your bug are much more likely to lead to a fix.
37 | Please include the following information:
38 | - What you were trying to do
39 | - What you expected to happen
40 | - What actually happened
41 | placeholder: |
42 | When doing {action}, the expected result should be {expected result}.
43 | When doing {action}, however, the actual result was {actual result}.
44 | This is undesirable because {reason}.
45 | validations:
46 | required: true
47 | - type: textarea
48 | id: steps-to-reproduce
49 | attributes:
50 | label: Steps to reproduce
51 | description: Write a step by step list that will allow us to reproduce this bug.
52 | placeholder: |
53 | 1. Do something
54 | 2. Then do something else
55 | validations:
56 | required: true
57 | - type: textarea
58 | id: additional-info
59 | attributes:
60 | label: Additional information
61 | description: If you have some additional information, please write it here.
62 | validations:
63 | required: false
64 | - type: checkboxes
65 | id: terms
66 | attributes:
67 | label: Code of Conduct
68 | description: By submitting this issue, you agree to follow our [Code of Conduct](https://github.com/sherlock-project/sherlock/blob/master/docs/CODE_OF_CONDUCT.md).
69 | options:
70 | - label: I agree to follow this project's Code of Conduct
71 | required: true
72 |
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/config.yml:
--------------------------------------------------------------------------------
1 | blank_issues_enabled: false
2 |
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/false-negative.yml:
--------------------------------------------------------------------------------
1 | name: False negative
2 | description: Report a site that is returning false negative results
3 | title: "False negative for: "
4 | labels: ["false negative"]
5 | body:
6 | - type: markdown
7 | attributes:
8 | value: |
9 | Please include the site name in the title of your issue.
10 | Submit **one site per report** for faster resolution. If you have multiple sites in the same report, it often takes longer to fix.
11 | - type: textarea
12 | id: additional-info
13 | attributes:
14 | label: Additional info
15 | description: If you know why the site is returning false negatives, or noticed any patterns, please explain.
16 | placeholder: |
17 | Reddit is returning false negatives because...
18 | validations:
19 | required: false
20 | - type: checkboxes
21 | id: terms
22 | attributes:
23 | label: Code of Conduct
24 | description: By submitting this issue, you agree to follow our [Code of Conduct](https://github.com/sherlock-project/sherlock/blob/master/docs/CODE_OF_CONDUCT.md).
25 | options:
26 | - label: I agree to follow this project's Code of Conduct
27 | required: true
28 |
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/false-positive.yml:
--------------------------------------------------------------------------------
1 | name: False positive
2 | description: Report a site that is returning false positive results
3 | title: "False positive for: "
4 | labels: ["false positive"]
5 | body:
6 | - type: markdown
7 | attributes:
8 | value: |
9 | Please include the site name in the title of your issue.
10 | Submit **one site per report** for faster resolution. If you have multiple sites in the same report, it often takes longer to fix.
11 | - type: textarea
12 | id: additional-info
13 | attributes:
14 | label: Additional info
15 | description: If you know why the site is returning false positives, or noticed any patterns, please explain.
16 | placeholder: |
17 | Reddit is returning false positives because...
18 | False positives only occur after x searches...
19 | validations:
20 | required: false
21 | - type: checkboxes
22 | id: terms
23 | attributes:
24 | label: Code of Conduct
25 | description: By submitting this issue, you agree to follow our [Code of Conduct](https://github.com/sherlock-project/sherlock/blob/master/docs/CODE_OF_CONDUCT.md).
26 | options:
27 | - label: I agree to follow this project's Code of Conduct
28 | required: true
29 |
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/feature-request.yml:
--------------------------------------------------------------------------------
1 | name: Feature request
2 | description: Request a feature or enhancement
3 | labels: ["enhancement"]
4 | body:
5 | - type: markdown
6 | attributes:
7 | value: |
8 | Concise and thoughtful titles help other contributors find and add your requested feature.
9 | - type: textarea
10 | id: description
11 | attributes:
12 | label: Description
13 | description: Describe the feature you are requesting
14 | placeholder: I'd like Sherlock to be able to do xyz
15 | validations:
16 | required: true
17 | - type: checkboxes
18 | id: terms
19 | attributes:
20 | label: Code of Conduct
21 | description: By submitting this issue, you agree to follow our [Code of Conduct](https://github.com/sherlock-project/sherlock/blob/master/docs/CODE_OF_CONDUCT.md).
22 | options:
23 | - label: I agree to follow this project's Code of Conduct
24 | required: true
25 |
--------------------------------------------------------------------------------
/.github/ISSUE_TEMPLATE/site-request.yml:
--------------------------------------------------------------------------------
1 | name: Reuest a new website
2 | description: Request that Sherlock add support for a new website
3 | title: "Requesting support for: "
4 | labels: ["site support request"]
5 | body:
6 | - type: markdown
7 | attributes:
8 | value: |
9 | Ensure that the site name is in the title of your request. Requests without this information will be **closed**.
10 | - type: input
11 | id: site-url
12 | attributes:
13 | label: Site URL
14 | description: |
15 | What is the URL of the website indicated in your title?
16 | Websites sometimes have similar names. This helps constributors find the correct site.
17 | placeholder: https://reddit.com
18 | validations:
19 | required: true
20 | - type: textarea
21 | id: additional-info
22 | attributes:
23 | label: Additional info
24 | description: If you have suggestions on how Sherlock should detect for usernames, please explain below
25 | placeholder: Sherlock can detect if a username exists on Reddit by checking for...
26 | validations:
27 | required: false
28 | - type: checkboxes
29 | id: terms
30 | attributes:
31 | label: Code of Conduct
32 | description: By submitting this issue, you agree to follow our [Code of Conduct](https://github.com/sherlock-project/sherlock/blob/master/docs/CODE_OF_CONDUCT.md).
33 | options:
34 | - label: I agree to follow this project's Code of Conduct
35 | required: true
36 |
--------------------------------------------------------------------------------
/.github/SECURITY.md:
--------------------------------------------------------------------------------
1 | ## Security Policy
2 |
3 | ### Supported Versions
4 |
5 | Sherlock is a forward looking project. Only the latest and most current version is supported.
6 |
7 | ### Reporting a Vulnerability
8 |
9 | Security concerns can be submitted [__here__][report-url] without risk of exposing sensitive information. For issues that are low severity or unlikely to see exploitation, public issues are often acceptable.
10 |
11 | [report-url]: https://github.com/sherlock-project/sherlock/security/advisories/new
12 |
--------------------------------------------------------------------------------
/.github/workflows/regression.yml:
--------------------------------------------------------------------------------
1 | name: Regression Testing
2 |
3 | on:
4 | pull_request:
5 | branches:
6 | - master
7 | - release/**
8 | paths:
9 | - '.github/workflows/regression.yml'
10 | - '**/*.json'
11 | - '**/*.py'
12 | - '**/*.ini'
13 | - '**/*.toml'
14 | push:
15 | branches:
16 | - master
17 | - release/**
18 | paths:
19 | - '.github/workflows/regression.yml'
20 | - '**/*.json'
21 | - '**/*.py'
22 | - '**/*.ini'
23 | - '**/*.toml'
24 |
25 | jobs:
26 | tox-lint:
27 | # Linting is ran through tox to ensure that the same linter is used by local runners
28 | runs-on: ubuntu-latest
29 | steps:
30 | - uses: actions/checkout@v4
31 | - name: Set up linting environment
32 | uses: actions/setup-python@v5
33 | with:
34 | python-version: '3.x'
35 | - name: Install tox and related dependencies
36 | run: |
37 | python -m pip install --upgrade pip
38 | pip install tox
39 | - name: Run tox linting environment
40 | run: tox -e lint
41 | tox-matrix:
42 | runs-on: ${{ matrix.os }}
43 | strategy:
44 | fail-fast: false # We want to know what specicic versions it fails on
45 | matrix:
46 | os: [
47 | ubuntu-latest,
48 | windows-latest,
49 | macos-latest,
50 | ]
51 | python-version: [
52 | '3.9',
53 | '3.10',
54 | '3.11',
55 | '3.12',
56 | ]
57 | steps:
58 | - uses: actions/checkout@v4
59 | - name: Set up environment ${{ matrix.python-version }}
60 | uses: actions/setup-python@v5
61 | with:
62 | python-version: ${{ matrix.python-version }}
63 | - name: Install tox and related dependencies
64 | run: |
65 | python -m pip install --upgrade pip
66 | pip install tox
67 | pip install tox-gh-actions
68 | - name: Run tox
69 | run: tox
70 |
--------------------------------------------------------------------------------
/.github/workflows/update-site-list.yml:
--------------------------------------------------------------------------------
1 | name: Update Site List
2 |
3 | # Trigger the workflow when changes are pushed to the main branch
4 | # and the changes include the sherlock_project/resources/data.json file
5 | on:
6 | push:
7 | branches:
8 | - master
9 | paths:
10 | - sherlock_project/resources/data.json
11 |
12 | jobs:
13 | sync-json-data:
14 | # Use the latest version of Ubuntu as the runner environment
15 | runs-on: ubuntu-latest
16 |
17 | steps:
18 | # Check out the code at the specified pull request head commit
19 | - name: Checkout code
20 | uses: actions/checkout@v4
21 | with:
22 | ref: ${{ github.event.pull_request.head.sha }}
23 | fetch-depth: 0
24 |
25 | # Install Python 3
26 | - name: Install Python
27 | uses: actions/setup-python@v5
28 | with:
29 | python-version: '3.x'
30 |
31 | # Execute the site_list.py Python script
32 | - name: Execute site-list.py
33 | run: python devel/site-list.py
34 |
35 | - name: Pushes to another repository
36 | uses: sdushantha/github-action-push-to-another-repository@main
37 | env:
38 | SSH_DEPLOY_KEY: ${{ secrets.SSH_DEPLOY_KEY }}
39 | API_TOKEN_GITHUB: ${{ secrets.API_TOKEN_GITHUB }}
40 | with:
41 | source-directory: 'output'
42 | destination-github-username: 'sherlock-project'
43 | commit-message: 'Updated site list'
44 | destination-repository-name: 'sherlockproject.xyz'
45 | user-email: siddharth.dushantha@gmail.com
46 | target-branch: master
47 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Virtual Environments
2 | venv/
3 | bin/
4 | lib/
5 | pyvenv.cfg
6 | poetry.lock
7 |
8 | # Regression Testing
9 | .coverage
10 | .tox/
11 |
12 | # Editor Configurations
13 | .vscode/
14 | .idea/
15 |
16 | # Python
17 | __pycache__/
18 |
19 | # Pip
20 | src/
21 |
22 | # Devel, Build, and Installation
23 | *.egg-info/
24 | dist/**
25 |
26 | # Jupyter Notebook
27 | .ipynb_checkpoints
28 | *.ipynb
29 |
30 | # Output files, except requirements.txt
31 | *.txt
32 | !requirements.txt
33 |
34 | # Comma-Separated Values (CSV) Reports
35 | *.csv
36 |
37 | #XLSX Reports
38 | *.xlsx
39 |
40 | # Excluded sites list
41 | tests/.excluded_sites
42 |
43 | # MacOS Folder Metadata File
44 | .DS_Store
45 |
46 | # Vim swap files
47 | *.swp
48 |
--------------------------------------------------------------------------------
/Dockerfile:
--------------------------------------------------------------------------------
1 | # Release instructions:
2 | # 1. Update the version tag in the Dockerfile to match the version in sherlock/__init__.py
3 | # 2. Update the VCS_REF tag to match the tagged version's FULL commit hash
4 | # 3. Build image with BOTH latest and version tags
5 | # i.e. `docker build -t sherlock/sherlock:0.15.0 -t sherlock/sherlock:latest .`
6 |
7 | FROM python:3.12-slim-bullseye as build
8 | WORKDIR /sherlock
9 |
10 | RUN pip3 install --no-cache-dir --upgrade pip
11 |
12 | FROM python:3.12-slim-bullseye
13 | WORKDIR /sherlock
14 |
15 | ARG VCS_REF= # CHANGE ME ON UPDATE
16 | ARG VCS_URL="https://github.com/sherlock-project/sherlock"
17 | ARG VERSION_TAG= # CHANGE ME ON UPDATE
18 |
19 | ENV SHERLOCK_ENV=docker
20 |
21 | LABEL org.label-schema.vcs-ref=$VCS_REF \
22 | org.label-schema.vcs-url=$VCS_URL \
23 | org.label-schema.name="Sherlock" \
24 | org.label-schema.version=$VERSION_TAG \
25 | website="https://sherlockproject.xyz"
26 |
27 | RUN pip3 install --no-cache-dir sherlock-project==$VERSION_TAG
28 |
29 | WORKDIR /sherlock
30 |
31 | ENTRYPOINT ["sherlock"]
32 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2019 Sherlock Project
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/devel/site-list.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # This module generates the listing of supported sites which can be found in
3 | # sites.md. It also organizes all the sites in alphanumeric order
4 | import json
5 | import os
6 |
7 |
8 | DATA_REL_URI: str = "sherlock_project/resources/data.json"
9 |
10 | # Read the data.json file
11 | with open(DATA_REL_URI, "r", encoding="utf-8") as data_file:
12 | data: dict = json.load(data_file)
13 |
14 | # Removes schema-specific keywords for proper processing
15 | social_networks: dict = dict(data)
16 | social_networks.pop('$schema', None)
17 |
18 | # Sort the social networks in alphanumeric order
19 | social_networks: list = sorted(social_networks.items())
20 |
21 | # Make output dir where the site list will be written
22 | os.mkdir("output")
23 |
24 | # Write the list of supported sites to sites.md
25 | with open("output/sites.mdx", "w") as site_file:
26 | site_file.write("---\ntitle: 'List of supported sites'\nsidebarTitle: 'Supported sites'\nicon: 'globe'\ndescription: 'Sherlock currently supports **400+** sites'\n---\n\n")
27 | for social_network, info in social_networks:
28 | url_main = info["urlMain"]
29 | is_nsfw = "**(NSFW)**" if info.get("isNSFW") else ""
30 | site_file.write(f"1. [{social_network}]({url_main}) {is_nsfw}\n")
31 |
32 | # Overwrite the data.json file with sorted data
33 | with open(DATA_REL_URI, "w") as data_file:
34 | sorted_data = json.dumps(data, indent=2, sort_keys=True)
35 | data_file.write(sorted_data)
36 | data_file.write("\n")
37 |
38 | print("Finished updating supported site listing!")
39 |
40 |
--------------------------------------------------------------------------------
/docs/CODE_OF_CONDUCT.md:
--------------------------------------------------------------------------------
1 | # Contributor Covenant Code of Conduct
2 |
3 | ## Our Pledge
4 |
5 | We as members, contributors, and leaders pledge to make participation in our
6 | community a harassment-free experience for everyone, regardless of age, body
7 | size, visible or invisible disability, ethnicity, sex characteristics, gender
8 | identity and expression, level of experience, education, socio-economic status,
9 | nationality, personal appearance, race, caste, color, religion, or sexual
10 | identity and orientation.
11 |
12 | We pledge to act and interact in ways that contribute to an open, welcoming,
13 | diverse, inclusive, and healthy community.
14 | ## Our Standards
15 |
16 | Examples of behavior that contributes to a positive environment for our
17 | community include:
18 |
19 | * Demonstrating empathy and kindness toward other people
20 | * Being respectful of differing opinions, viewpoints, and experiences
21 | * Giving and gracefully accepting constructive feedback
22 | * Accepting responsibility and apologizing to those affected by our mistakes,
23 | and learning from the experience
24 | * Focusing on what is best not just for us as individuals, but for the overall
25 | community
26 |
27 | Examples of unacceptable behavior include:
28 |
29 | * The use of sexualized language or imagery, and sexual attention or advances of
30 | any kind
31 | * Trolling, insulting or derogatory comments, and personal or political attacks
32 | * Public or private harassment
33 | * Publishing others' private information, such as a physical or email address,
34 | without their explicit permission
35 | * Other conduct which could reasonably be considered inappropriate in a
36 | professional setting
37 |
38 | ## Enforcement Responsibilities
39 |
40 | Community leaders are responsible for clarifying and enforcing our standards of
41 | acceptable behavior and will take appropriate and fair corrective action in
42 | response to any behavior that they deem inappropriate, threatening, offensive,
43 | or harmful.
44 |
45 | Community leaders have the right and responsibility to remove, edit, or reject
46 | comments, commits, code, wiki edits, issues, and other contributions that are
47 | not aligned to this Code of Conduct, and will communicate reasons for moderation
48 | decisions when appropriate.
49 |
50 | ## Scope
51 |
52 | This Code of Conduct applies within all community spaces, and also applies when
53 | an individual is officially representing the community in public spaces.
54 | Examples of representing our community include using an official e-mail address,
55 | posting via an official social media account, or acting as an appointed
56 | representative at an online or offline event.
57 |
58 | ## Enforcement
59 |
60 | Instances of abusive, harassing, or otherwise unacceptable behavior may be
61 | reported to the community leaders responsible for enforcement at yahya.arbabi@gmail.com.
62 | All complaints will be reviewed and investigated promptly and fairly.
63 |
64 | All community leaders are obligated to respect the privacy and security of the
65 | reporter of any incident.
66 |
67 | ## Enforcement Guidelines
68 |
69 | Community leaders will follow these Community Impact Guidelines in determining
70 | the consequences for any action they deem in violation of this Code of Conduct:
71 |
72 | ### 1. Correction
73 |
74 | **Community Impact**: Use of inappropriate language or other behavior deemed
75 | unprofessional or unwelcome in the community.
76 |
77 | **Consequence**: A private, written warning from community leaders, providing
78 | clarity around the nature of the violation and an explanation of why the
79 | behavior was inappropriate. A public apology may be requested.
80 |
81 | ### 2. Warning
82 |
83 | **Community Impact**: A violation through a single incident or series of
84 | actions.
85 |
86 | **Consequence**: A warning with consequences for continued behavior. No
87 | interaction with the people involved, including unsolicited interaction with
88 | those enforcing the Code of Conduct, for a specified period of time. This
89 | includes avoiding interactions in community spaces as well as external channels
90 | like social media. Violating these terms may lead to a temporary or permanent
91 | ban.
92 |
93 | ### 3. Temporary Ban
94 |
95 | **Community Impact**: A serious violation of community standards, including
96 | sustained inappropriate behavior.
97 |
98 | **Consequence**: A temporary ban from any sort of interaction or public
99 | communication with the community for a specified period of time. No public or
100 | private interaction with the people involved, including unsolicited interaction
101 | with those enforcing the Code of Conduct, is allowed during this period.
102 | Violating these terms may lead to a permanent ban.
103 |
104 | ### 4. Permanent Ban
105 |
106 | **Community Impact**: Demonstrating a pattern of violation of community
107 | standards, including sustained inappropriate behavior, harassment of an
108 | individual, or aggression toward or disparagement of classes of individuals.
109 |
110 | **Consequence**: A permanent ban from any sort of public interaction within the
111 | community.
112 |
113 | ## Attribution
114 |
115 | This Code of Conduct is adapted from the [Contributor Covenant][homepage],
116 | version 2.1, available at
117 | [https://www.contributor-covenant.org/version/2/1/code_of_conduct.html][v2.1].
118 |
119 | Community Impact Guidelines were inspired by
120 | [Mozilla's code of conduct enforcement ladder][Mozilla CoC].
121 |
122 | For answers to common questions about this code of conduct, see the FAQ at
123 | [https://www.contributor-covenant.org/faq][FAQ]. Translations are available at
124 | [https://www.contributor-covenant.org/translations][translations].
125 |
126 | [homepage]: https://www.contributor-covenant.org
127 | [v2.1]: https://www.contributor-covenant.org/version/2/1/code_of_conduct.html
128 | [Mozilla CoC]: https://github.com/mozilla/diversity
129 | [FAQ]: https://www.contributor-covenant.org/faq
130 | [translations]: https://www.contributor-covenant.org/translations
--------------------------------------------------------------------------------
/docs/README.md:
--------------------------------------------------------------------------------
1 |
2 | Hunt down social media accounts by username across 400+ social networks
6 |
8 |
9 |
10 | Installation
11 | •
12 | Usage
13 | •
14 | Contributing
15 |
16 |
17 |
18 |
21 |
22 |
23 | ## Installation
24 |
25 | > [!WARNING]
26 | > Packages for ParrotOS and Ubuntu 24.04, maintained by a third party, appear to be __broken__.
27 | > Users of these systems should defer to pipx/pip or Docker.
28 |
29 | | Method | Notes |
30 | | - | - |
31 | | `pipx install sherlock-project` | `pip` may be used in place of `pipx` |
32 | | `docker run -it --rm sherlock/sherlock` |
33 | | `dnf install sherlock-project` | |
34 |
35 | Community-maintained packages are available for Debian (>= 13), Ubuntu (>= 22.10), Homebrew, Kali, and BlackArch. These packages are not directly supported or maintained by the Sherlock Project.
36 |
37 | See all alternative installation methods [here](https://sherlockproject.xyz/installation)
38 |
39 | ## General usage
40 |
41 | To search for only one user:
42 | ```bash
43 | sherlock user123
44 | ```
45 |
46 | To search for more than one user:
47 | ```bash
48 | sherlock user1 user2 user3
49 | ```
50 |
51 | Accounts found will be stored in an individual text file with the corresponding username (e.g ```user123.txt```).
52 |
53 | ```console
54 | $ sherlock --help
55 | usage: sherlock [-h] [--version] [--verbose] [--folderoutput FOLDEROUTPUT]
56 | [--output OUTPUT] [--tor] [--unique-tor] [--csv] [--xlsx]
57 | [--site SITE_NAME] [--proxy PROXY_URL] [--json JSON_FILE]
58 | [--timeout TIMEOUT] [--print-all] [--print-found] [--no-color]
59 | [--browse] [--local] [--nsfw]
60 | USERNAMES [USERNAMES ...]
61 |
62 | Sherlock: Find Usernames Across Social Networks (Version 0.14.3)
63 |
64 | positional arguments:
65 | USERNAMES One or more usernames to check with social networks.
66 | Check similar usernames using {?} (replace to '_', '-', '.').
67 |
68 | optional arguments:
69 | -h, --help show this help message and exit
70 | --version Display version information and dependencies.
71 | --verbose, -v, -d, --debug
72 | Display extra debugging information and metrics.
73 | --folderoutput FOLDEROUTPUT, -fo FOLDEROUTPUT
74 | If using multiple usernames, the output of the results will be
75 | saved to this folder.
76 | --output OUTPUT, -o OUTPUT
77 | If using single username, the output of the result will be saved
78 | to this file.
79 | --tor, -t Make requests over Tor; increases runtime; requires Tor to be
80 | installed and in system path.
81 | --unique-tor, -u Make requests over Tor with new Tor circuit after each request;
82 | increases runtime; requires Tor to be installed and in system
83 | path.
84 | --csv Create Comma-Separated Values (CSV) File.
85 | --xlsx Create the standard file for the modern Microsoft Excel
86 | spreadsheet (xlsx).
87 | --site SITE_NAME Limit analysis to just the listed sites. Add multiple options to
88 | specify more than one site.
89 | --proxy PROXY_URL, -p PROXY_URL
90 | Make requests over a proxy. e.g. socks5://127.0.0.1:1080
91 | --json JSON_FILE, -j JSON_FILE
92 | Load data from a JSON file or an online, valid, JSON file.
93 | --timeout TIMEOUT Time (in seconds) to wait for response to requests (Default: 60)
94 | --print-all Output sites where the username was not found.
95 | --print-found Output sites where the username was found.
96 | --no-color Don't color terminal output
97 | --browse, -b Browse to all results on default browser.
98 | --local, -l Force the use of the local data.json file.
99 | --nsfw Include checking of NSFW sites from default list.
100 | ```
101 | ## Apify Actor Usage [](https://apify.com/netmilk/sherlock?fpr=sherlock)
102 |
103 |
125 |
127 |
128 | ## Star history
129 |
130 |
131 |
135 |
136 | ## License
137 |
138 | MIT © Sherlock Project
4 | Hunt down social media accounts by username across 400+ social networks Additional documentation can be found at our GitHub repository
10 |
12 |
13 | ## Usage
14 |
15 | ```console
16 | $ sherlock --help
17 | usage: sherlock [-h] [--version] [--verbose] [--folderoutput FOLDEROUTPUT]
18 | [--output OUTPUT] [--tor] [--unique-tor] [--csv] [--xlsx]
19 | [--site SITE_NAME] [--proxy PROXY_URL] [--json JSON_FILE]
20 | [--timeout TIMEOUT] [--print-all] [--print-found] [--no-color]
21 | [--browse] [--local] [--nsfw]
22 | USERNAMES [USERNAMES ...]
23 | ```
24 |
25 | To search for only one user:
26 | ```bash
27 | $ sherlock user123
28 | ```
29 |
30 | To search for more than one user:
31 | ```bash
32 | $ sherlock user1 user2 user3
33 | ```
34 |
40 |
43 |
--------------------------------------------------------------------------------
/docs/removed-sites.md:
--------------------------------------------------------------------------------
1 | # List Of Sites Removed From Sherlock
2 |
3 | This is a list of sites implemented in such a way that the current design of
4 | Sherlock is not capable of determining if a given username exists or not.
5 | They are listed here in the hope that things may change in the future
6 | so they may be re-included.
7 |
8 |
9 | ## gpodder.net
10 |
11 | As of 2020-05-25, all usernames are reported as available.
12 |
13 | The server is returning a HTTP Status 500 (Internal server error)
14 | for all queries.
15 |
16 | ```json
17 | "gpodder.net": {
18 | "errorType": "status_code",
19 | "rank": 2013984,
20 | "url": "https://gpodder.net/user/{}",
21 | "urlMain": "https://gpodder.net/",
22 | "username_claimed": "blue",
23 | "username_unclaimed": "noonewouldeverusethis7"
24 | },
25 | ```
26 |
27 |
28 | ## Investing.com
29 |
30 | As of 2020-05-25, all usernames are reported as claimed.
31 |
32 | Any query against a user seems to be redirecting to a general
33 | information page at https://www.investing.com/brokers/. Probably
34 | required login before access.
35 |
36 | ```json
37 | "Investing.com": {
38 | "errorType": "status_code",
39 | "rank": 196,
40 | "url": "https://www.investing.com/traders/{}",
41 | "urlMain": "https://www.investing.com/",
42 | "username_claimed": "jenny",
43 | "username_unclaimed": "noonewouldeverusethis7"
44 | },
45 | ```
46 |
47 | ## AdobeForums
48 |
49 | As of 2020-04-12, all usernames are reported as available.
50 |
51 | When I went to the site to see what was going on, usernames that I know
52 | existed were redirecting to the main page.
53 |
54 | I was able to see user profiles without logging in, but the URL was not
55 | related to their user name. For example, user "tomke" went to
56 | https://community.adobe.com/t5/user/viewprofilepage/user-id/10882613.
57 | This can be detected, but it requires a different detection method.
58 |
59 | ```json
60 | "AdobeForums": {
61 | "errorType": "status_code",
62 | "rank": 59,
63 | "url": "https://forums.adobe.com/people/{}",
64 | "urlMain": "https://forums.adobe.com/",
65 | "username_claimed": "jack",
66 | "username_unclaimed": "noonewouldeverusethis77777"
67 | },
68 | ```
69 |
70 | ## Basecamp
71 |
72 | As of 2020-02-23, all usernames are reported as not existing.
73 |
74 |
75 | ```json
76 | "Basecamp": {
77 | "errorMsg": "The account you were looking for doesn't exist",
78 | "errorType": "message",
79 | "rank": 4914,
80 | "url": "https://{}.basecamphq.com",
81 | "urlMain": "https://basecamp.com/",
82 | "username_claimed": "blue",
83 | "username_unclaimed": "noonewouldeverusethis7"
84 | },
85 | ```
86 |
87 | ## Canva
88 |
89 | As of 2020-02-23, all usernames are reported as not existing.
90 |
91 | ```json
92 | "Canva": {
93 | "errorType": "response_url",
94 | "errorUrl": "https://www.canva.com/{}",
95 | "rank": 128,
96 | "url": "https://www.canva.com/{}",
97 | "urlMain": "https://www.canva.com/",
98 | "username_claimed": "jenny",
99 | "username_unclaimed": "xgtrq"
100 | },
101 | ```
102 |
103 | ## Pixabay
104 |
105 | As of 2020-01-21, all usernames are reported as not existing.
106 |
107 | ```json
108 | "Pixabay": {
109 | "errorType": "status_code",
110 | "rank": 378,
111 | "url": "https://pixabay.com/en/users/{}",
112 | "urlMain": "https://pixabay.com/",
113 | "username_claimed": "blue",
114 | "username_unclaimed": "noonewouldeverusethis7"
115 | },
116 | ```
117 |
118 | ## NPM-Packages
119 |
120 | NPM-Packages are not users.
121 |
122 | ```json
123 | "NPM-Package": {
124 | "errorType": "status_code",
125 | "url": "https://www.npmjs.com/package/{}",
126 | "urlMain": "https://www.npmjs.com/",
127 | "username_claimed": "blue",
128 | "username_unclaimed": "noonewouldeverusethis7"
129 | },
130 | ```
131 |
132 | ## Pexels
133 |
134 | As of 2020-01-21, all usernames are reported as not existing.
135 |
136 | ```json
137 | "Pexels": {
138 | "errorType": "status_code",
139 | "rank": 745,
140 | "url": "https://www.pexels.com/@{}",
141 | "urlMain": "https://www.pexels.com/",
142 | "username_claimed": "bruno",
143 | "username_unclaimed": "noonewouldeverusethis7"
144 | },
145 | ```
146 |
147 | ## RamblerDating
148 |
149 | As of 2019-12-31, site always times out.
150 |
151 | ```json
152 | "RamblerDating": {
153 | "errorType": "response_url",
154 | "errorUrl": "https://dating.rambler.ru/page/{}",
155 | "rank": 322,
156 | "url": "https://dating.rambler.ru/page/{}",
157 | "urlMain": "https://dating.rambler.ru/",
158 | "username_claimed": "blue",
159 | "username_unclaimed": "noonewouldeverusethis7"
160 | },
161 | ```
162 |
163 | ## YandexMarket
164 |
165 | As of 2019-12-31, all usernames are reported as existing.
166 |
167 | ```json
168 | "YandexMarket": {
169 | "errorMsg": "\u0422\u0443\u0442 \u043d\u0438\u0447\u0435\u0433\u043e \u043d\u0435\u0442",
170 | "errorType": "message",
171 | "rank": 47,
172 | "url": "https://market.yandex.ru/user/{}/achievements",
173 | "urlMain": "https://market.yandex.ru/",
174 | "username_claimed": "blue",
175 | "username_unclaimed": "noonewouldeverusethis7"
176 | },
177 | ```
178 |
179 | ## Codementor
180 |
181 | As of 2019-12-31, usernames that exist are not detected.
182 |
183 | ```json
184 | "Codementor": {
185 | "errorType": "status_code",
186 | "rank": 10252,
187 | "url": "https://www.codementor.io/@{}",
188 | "urlMain": "https://www.codementor.io/",
189 | "username_claimed": "blue",
190 | "username_unclaimed": "noonewouldeverusethis7"
191 | },
192 | ```
193 |
194 | ## KiwiFarms
195 |
196 | As of 2019-12-31, the site gives a 403 for all usernames. You have to
197 | be logged into see a profile.
198 |
199 | ```json
200 | "KiwiFarms": {
201 | "errorMsg": "The specified member cannot be found",
202 | "errorType": "message",
203 | "rank": 38737,
204 | "url": "https://kiwifarms.net/members/?username={}",
205 | "urlMain": "https://kiwifarms.net/",
206 | "username_claimed": "blue",
207 | "username_unclaimed": "noonewouldeverusethis"
208 | },
209 | ```
210 |
211 | ## Teknik
212 |
213 | As of 2019-11-30, the site causes Sherlock to just hang.
214 |
215 | ```json
216 | "Teknik": {
217 | "errorMsg": "The user does not exist",
218 | "errorType": "message",
219 | "rank": 357163,
220 | "url": "https://user.teknik.io/{}",
221 | "urlMain": "https://teknik.io/",
222 | "username_claimed": "red",
223 | "username_unclaimed": "noonewouldeverusethis7"
224 | }
225 | ```
226 |
227 | ## Shockwave
228 |
229 | As of 2019-11-28, usernames that exist give a 503 "Service Unavailable"
230 | HTTP Status.
231 |
232 | ```json
233 | "Shockwave": {
234 | "errorMsg": "Oh no! You just finished all of the games on the internet!",
235 | "errorType": "message",
236 | "rank": 35916,
237 | "url": "http://www.shockwave.com/member/profiles/{}.jsp",
238 | "urlMain": "http://www.shockwave.com/",
239 | "username_claimed": "blue",
240 | "username_unclaimed": "noonewouldeverusethis"
241 | },
242 | ```
243 |
244 | ## Foursquare
245 |
246 | When usage of automated tool is detected. Whole IP is banned from future requests.
247 | There is an error message:
248 |
249 | > Please verify you are a human
250 | > Access to this page has been denied because we believe you are using automation tools to browse the website.
251 |
252 | ```json
253 | "Foursquare": {
254 | "errorType": "status_code",
255 | "rank": 1843,
256 | "url": "https://foursquare.com/{}",
257 | "urlMain": "https://foursquare.com/",
258 | "username_claimed": "dens",
259 | "username_unclaimed": "noonewouldeverusethis7"
260 | },
261 | ```
262 |
263 | ## Khan Academy
264 |
265 | Usernames that don't exist are detected. First noticed 2019-10-25.
266 |
267 | ```json
268 | "Khan Academy": {
269 | "errorType": "status_code",
270 | "rank": 377,
271 | "url": "https://www.khanacademy.org/profile/{}",
272 | "urlMain": "https://www.khanacademy.org/",
273 | "username_claimed": "blue",
274 | "username_unclaimed": "noonewouldeverusethis7"
275 | },
276 | ```
277 |
278 |
279 | ## EVE Online
280 |
281 | Usernames that exist are not detected.
282 |
283 | ```json
284 | "EVE Online": {
285 | "errorType": "response_url",
286 | "errorUrl": "https://eveonline.com",
287 | "rank": 15347,
288 | "url": "https://evewho.com/pilot/{}/",
289 | "urlMain": "https://eveonline.com",
290 | "username_claimed": "blue",
291 | "username_unclaimed": "noonewouldeverusethis7"
292 | },
293 | ```
294 |
295 | ## AngelList
296 |
297 | Usernames that exist are not detected. Forbidden Request 403 Error.
298 |
299 | ```json
300 | "AngelList": {
301 | "errorType": "status_code",
302 | "rank": 5767,
303 | "url": "https://angel.co/u/{}",
304 | "urlMain": "https://angel.co/",
305 | "username_claimed": "blue",
306 | "username_unclaimed": "noonewouldeverusethis7"
307 | },
308 | ```
309 |
310 | ## PowerShell Gallery
311 |
312 | Accidentally merged even though the original pull request showed that all
313 | user names were available.
314 |
315 | ```json
316 | "PowerShell Gallery": {
317 | "errorType": "status_code",
318 | "rank": 163562,
319 | "url": "https://www.powershellgallery.com/profiles/{}",
320 | "urlMain": "https://www.powershellgallery.com",
321 | "username_claimed": "powershellteam",
322 | "username_unclaimed": "noonewouldeverusethis7"
323 | },
324 | ```
325 |
326 | ## StreamMe
327 |
328 | On 2019-04-07, I get a Timed Out message from the website. It has not
329 | been working earlier either (for some weeks). It takes about 21s before
330 | the site finally times out, so it really makes getting the results from
331 | Sherlock a pain.
332 |
333 | If the site becomes available in the future, we can put it back in.
334 |
335 | ```json
336 | "StreamMe": {
337 | "errorType": "status_code",
338 | "rank": 31702,
339 | "url": "https://www.stream.me/{}",
340 | "urlMain": "https://www.stream.me/",
341 | "username_claimed": "blue",
342 | "username_unclaimed": "noonewouldeverusethis7"
343 | },
344 | ```
345 |
346 | ## BlackPlanet
347 |
348 | This site has always returned a false positive. The site returns the exact
349 | same text for a claimed or an unclaimed username. The site must be rendering
350 | all of the different content using Javascript in the browser. So, there is
351 | no way distinguish between the results with the current design of Sherlock.
352 |
353 | ```json
354 | "BlackPlanet": {
355 | "errorMsg": "My Hits",
356 | "errorType": "message",
357 | "rank": 110021,
358 | "url": "http://blackplanet.com/{}",
359 | "urlMain": "http://blackplanet.com/"
360 | },
361 | ```
362 |
363 | ## Fotolog
364 |
365 | Around 2019-02-09, I get a 502 HTTP error (bad gateway) for any access. On
366 | 2019-03-10, the site is up, but it is in maintenance mode.
367 |
368 | It does not seem to be working, so there is no sense in including it in
369 | Sherlock.
370 |
371 | ```json
372 | "Fotolog": {
373 | "errorType": "status_code",
374 | "rank": 47777,
375 | "url": "https://fotolog.com/{}",
376 | "urlMain": "https://fotolog.com/"
377 | },
378 | ```
379 |
380 | ## Google Plus
381 |
382 | On 2019-04-02, Google shutdown Google Plus. While the content for some
383 | users is available after that point, it is going away. And, no one will
384 | be able to create a new account. So, there is no value is keeping it in
385 | Sherlock.
386 |
387 | Good-bye [Google Plus](https://en.wikipedia.org/wiki/Google%2B)...
388 |
389 | ```json
390 | "Google Plus": {
391 | "errorType": "status_code",
392 | "rank": 1,
393 | "url": "https://plus.google.com/+{}",
394 | "urlMain": "https://plus.google.com/",
395 | "username_claimed": "davidbrin1",
396 | "username_unclaimed": "noonewouldeverusethis7"
397 | },
398 | ```
399 |
400 |
401 | ## InsaneJournal
402 |
403 | As of 2020-02-23, InsaneJournal returns false positive, when providing a username which contains a period.
404 | Since we were not able to find the criteria for a valid username, the best thing to do now is to remove it.
405 |
406 | ```json
407 | "InsaneJournal": {
408 | "errorMsg": "Unknown user",
409 | "errorType": "message",
410 | "rank": 29728,
411 | "url": "http://{}.insanejournal.com/profile",
412 | "urlMain": "insanejournal.com",
413 | "username_claimed": "blue",
414 | "username_unclaimed": "dlyr6cd"
415 | },
416 | ```
417 |
418 | ## Sports Tracker
419 |
420 | As of 2020-04-02, Sports Tracker returns false positives. Checking with `errorMsg` and `response_url`
421 | did not seem to work.
422 |
423 | ```
424 | "SportsTracker": {
425 | "errorUrl": "https://www.sports-tracker.com/page-not-found",
426 | "errorType": "response_url",
427 | "rank": 93950,
428 | "url": "https://www.sports-tracker.com/view_profile/{}",
429 | "urlMain": "https://www.sports-tracker.com/",
430 | "username_claimed": "blue",
431 | "username_unclaimed": "noonewouldeveruse"
432 | },
433 | ```
434 |
435 | ## Trip
436 |
437 | As of 2020-04-02, Trip by Skyscanner seems to not work beceause it keeps on
438 | redirecting to skyscanner.com whether the username exists or not.
439 |
440 | ```json
441 | "Trip": {
442 | "errorType": "status_code",
443 | "rank": 2847,
444 | "url": "https://www.trip.skyscanner.com/user/{}",
445 | "urlMain": "https://www.trip.skyscanner.com/",
446 | "username_claimed": "blue",
447 | "username_unclaimed": "noonewouldeverusethis7"
448 | },
449 |
450 | ```
451 |
452 | ## boingboing.net
453 |
454 | As of 2020-04-02, boingboing.net requires a login to check if a user exits or not.
455 |
456 | ```
457 | "boingboing.net": {
458 | "errorType": "status_code",
459 | "rank": 5821,
460 | "url": "https://bbs.boingboing.net/u/{}",
461 | "urlMain": "https://boingboing.net/",
462 | "username_claimed": "admin",
463 | "username_unclaimed": "noonewouldeverusethis7"
464 | },
465 | ```
466 |
467 | ## elwoRU
468 | As of 2020-04-04, elwoRu does not exist anymore. I confirmed using
469 | downforeveryoneorjustme.com that the website is down.
470 |
471 | ```json
472 | "elwoRU": {
473 | "errorMsg": "\u041f\u043e\u043b\u044c\u0437\u043e\u0432\u0430\u0442\u0435\u043b\u044c \u043d\u0435 \u043d\u0430\u0439\u0434\u0435\u043d",
474 | "errorType": "message",
475 | "rank": 254810,
476 | "url": "https://elwo.ru/index/8-0-{}",
477 | "urlMain": "https://elwo.ru/",
478 | "username_claimed": "red",
479 | "username_unclaimed": "noonewouldeverusethis7"
480 | },
481 | ```
482 |
483 | ## ingvarr.net.ru
484 |
485 | As of 2020-04-04, ingvarr.net.ru does not exist anymore. I confirmed using
486 | downforeveryoneorjustme.com that the website is down.
487 |
488 | ```json
489 | "ingvarr.net.ru": {
490 | "errorMsg": "\u041f\u043e\u043b\u044c\u0437\u043e\u0432\u0430\u0442\u0435\u043b\u044c \u043d\u0435 \u043d\u0430\u0439\u0434\u0435\u043d",
491 | "errorType": "message",
492 | "rank": 107721,
493 | "url": "http://ingvarr.net.ru/index/8-0-{}",
494 | "urlMain": "http://ingvarr.net.ru/",
495 | "username_claimed": "red",
496 | "username_unclaimed": "noonewouldeverusethis7"
497 | },
498 | ```
499 |
500 | ## Redsun.tf
501 |
502 | As of 2020-06-20, Redsun.tf seems to be adding random digits to the end of the usernames which makes it pretty much impossible
503 | for Sherlock to check for usernames on this particular website.
504 |
505 | ```json
506 | "Redsun.tf": {
507 | "errorMsg": "The specified member cannot be found",
508 | "errorType": "message",
509 | "rank": 3796657,
510 | "url": "https://forum.redsun.tf/members/?username={}",
511 | "urlMain": "https://redsun.tf/",
512 | "username_claimed": "dan",
513 | "username_unclaimed": "noonewouldeverusethis"
514 | },
515 | ```
516 |
517 | ## Creative Market
518 |
519 | As of 2020-06-20, Creative Market has a captcha to prove that you are a human, and because of this
520 | Sherlock is unable to check for username on this site because we will always get a page which asks
521 | us to prove that we are not a robot.
522 |
523 | ```json
524 | "CreativeMarket": {
525 | "errorType": "status_code",
526 | "rank": 1896,
527 | "url": "https://creativemarket.com/users/{}",
528 | "urlMain": "https://creativemarket.com/",
529 | "username_claimed": "blue",
530 | "username_unclaimed": "noonewouldeverusethis7"
531 | },
532 | ```
533 |
534 | ## pvpru
535 |
536 | As of 2020-06-20, pvpru uses CloudFlair, and because of this we get a "Access denied" error whenever
537 | we try to check for a username.
538 |
539 | ```json
540 | "pvpru": {
541 | "errorType": "status_code",
542 | "rank": 405547,
543 | "url": "https://pvpru.com/board/member.php?username={}&tab=aboutme#aboutme",
544 | "urlMain": "https://pvpru.com/",
545 | "username_claimed": "blue",
546 | "username_unclaimed": "noonewouldeverusethis7"
547 | },
548 | ```
549 |
550 | ## easyen
551 | As of 2020-06-21, easyen returns false positives when using a username which contains
552 | a period. Since we could not find the criteria for the usernames for this site, it will be
553 | removed
554 |
555 | ```json
556 | "easyen": {
557 | "errorMsg": "\u041f\u043e\u043b\u044c\u0437\u043e\u0432\u0430\u0442\u0435\u043b\u044c \u043d\u0435 \u043d\u0430\u0439\u0434\u0435\u043d",
558 | "errorType": "message",
559 | "rank": 11564,
560 | "url": "https://easyen.ru/index/8-0-{}",
561 | "urlMain": "https://easyen.ru/",
562 | "username_claimed": "wd",
563 | "username_unclaimed": "noonewouldeverusethis7"
564 | },
565 | ```
566 |
567 | ## pedsovet
568 | As of 2020-06-21, pedsovet returns false positives when using a username which contains
569 | a period. Since we could not find the criteria for the usernames for this site, it will be
570 | removed
571 |
572 | ```json
573 | "pedsovet": {
574 | "errorMsg": "\u041f\u043e\u043b\u044c\u0437\u043e\u0432\u0430\u0442\u0435\u043b\u044c \u043d\u0435 \u043d\u0430\u0439\u0434\u0435\u043d",
575 | "errorType": "message",
576 | "rank": 6776,
577 | "url": "http://pedsovet.su/index/8-0-{}",
578 | "urlMain": "http://pedsovet.su/",
579 | "username_claimed": "blue",
580 | "username_unclaimed": "noonewouldeverusethis7"
581 | },
582 | ```
583 |
584 |
585 | ## radioskot
586 | As of 2020-06-21, radioskot returns false positives when using a username which contains
587 | a period. Since we could not find the criteria for the usernames for this site, it will be
588 | removed
589 | ```json
590 | "radioskot": {
591 | "errorMsg": "\u041f\u043e\u043b\u044c\u0437\u043e\u0432\u0430\u0442\u0435\u043b\u044c \u043d\u0435 \u043d\u0430\u0439\u0434\u0435\u043d",
592 | "errorType": "message",
593 | "rank": 105878,
594 | "url": "https://radioskot.ru/index/8-0-{}",
595 | "urlMain": "https://radioskot.ru/",
596 | "username_claimed": "red",
597 | "username_unclaimed": "noonewouldeverusethis7"
598 | },
599 | ```
600 |
601 |
602 |
603 | ## Coderwall
604 | As of 2020-07-06, Coderwall returns false positives when checking for an username which contains a period.
605 | I have tried to find out what Coderwall's criteria is for a valid username, but unfortunately I have not been able to
606 | find it and because of this, the best thing we can do now is to remove it.
607 | ```json
608 | "Coderwall": {
609 | "errorMsg": "404! Our feels when that url is used",
610 | "errorType": "message",
611 | "rank": 11256,
612 | "url": "https://coderwall.com/{}",
613 | "urlMain": "https://coderwall.com/",
614 | "username_claimed": "jenny",
615 | "username_unclaimed": "noonewouldeverusethis7"
616 | }
617 | ```
618 |
619 |
620 | ## TamTam
621 | As of 2020-07-06, TamTam returns false positives when given a username which contains a period
622 | ```json
623 | "TamTam": {
624 | "errorType": "response_url",
625 | "errorUrl": "https://tamtam.chat/",
626 | "rank": 87903,
627 | "url": "https://tamtam.chat/{}",
628 | "urlMain": "https://tamtam.chat/",
629 | "username_claimed": "blue",
630 | "username_unclaimed": "noonewouldeverusethis7"
631 | },
632 | ```
633 |
634 | ## Zomato
635 | As of 2020-07-24, Zomato seems to be unstable. Majority of the time, Zomato takes a very long time to respond.
636 | ```json
637 | "Zomato": {
638 | "errorType": "status_code",
639 | "headers": {
640 | "Accept-Language": "en-US,en;q=0.9"
641 | },
642 | "rank": 1920,
643 | "url": "https://www.zomato.com/pl/{}/foodjourney",
644 | "urlMain": "https://www.zomato.com/",
645 | "username_claimed": "deepigoyal",
646 | "username_unclaimed": "noonewouldeverusethis7"
647 | },
648 | ```
649 |
650 | ## Mixer
651 | As of 2020-07-22, the Mixer service has closed down.
652 | ```json
653 | "mixer.com": {
654 | "errorType": "status_code",
655 | "rank": 1544,
656 | "url": "https://mixer.com/{}",
657 | "urlMain": "https://mixer.com/",
658 | "urlProbe": "https://mixer.com/api/v1/channels/{}",
659 | "username_claimed": "blue",
660 | "username_unclaimed": "noonewouldeverusethis7"
661 | },
662 | ```
663 |
664 |
665 | ## KanoWorld
666 | As of 2020-07-22, KanoWorld's api.kano.me subdomain no longer exists which makes it not possible for us check for usernames.
667 | If an alternative way to check for usernames is found then it will added.
668 | ```json
669 | "KanoWorld": {
670 | "errorType": "status_code",
671 | "rank": 181933,
672 | "url": "https://api.kano.me/progress/user/{}",
673 | "urlMain": "https://world.kano.me/",
674 | "username_claimed": "blue",
675 | "username_unclaimed": "noonewouldeverusethis7"
676 | },
677 | ```
678 |
679 | ## YandexCollection
680 | As of 2020-08-11, YandexCollection presents us with a recaptcha which prevents us from checking for usernames
681 | ```json
682 | "YandexCollection": {
683 | "errorType": "status_code",
684 | "url": "https://yandex.ru/collections/user/{}/",
685 | "urlMain": "https://yandex.ru/collections/",
686 | "username_claimed": "blue",
687 | "username_unclaimed": "noonewouldeverusethis7"
688 | },
689 | ```
690 |
691 | ## PayPal
692 |
693 | As of 2020-08-24, PayPal now returns false positives, which was found when running the tests, but will most likley be added again in the near
694 | future once we find a better error detecting method.
695 | ```json
696 | "PayPal": {
697 | "errorMsg": "Cent ",
1023 | "errorType": "message",
1024 | "url": "https://beta.cent.co/@{}",
1025 | "urlMain": "https://cent.co/",
1026 | "username_claimed": "blue",
1027 | "username_unclaimed": "noonewouldeverusethis7"
1028 | },
1029 | ```
1030 |
1031 | ## Anobii
1032 |
1033 | As of 2021-06-27, Anobii returns false positives and there is no stable way of checking usernames.
1034 | ```
1035 |
1036 | "Anobii": {
1037 | "errorType": "response_url",
1038 | "url": "https://www.anobii.com/{}/profile",
1039 | "urlMain": "https://www.anobii.com/",
1040 | "username_claimed": "blue",
1041 | "username_unclaimed": "noonewouldeverusethis7"
1042 | }
1043 | ```
1044 |
1045 | ## Kali Community
1046 |
1047 | As of 2021-06-27, Kali Community requires us to be logged in order to check if a user exists on their forum.
1048 |
1049 | ```json
1050 | "Kali community": {
1051 | "errorMsg": "This user has not registered and therefore does not have a profile to view.",
1052 | "errorType": "message",
1053 | "url": "https://forums.kali.org/member.php?username={}",
1054 | "urlMain": "https://forums.kali.org/",
1055 | "username_claimed": "blue",
1056 | "username_unclaimed": "noonewouldeverusethis7"
1057 | }
1058 | ```
1059 |
1060 | ## NameMC
1061 |
1062 | As of 2021-06-27, NameMC uses captcha through CloudFlare which prevents us from checking if usernames exists on the site.
1063 |
1064 | ```json
1065 | "NameMC (Minecraft.net skins)": {
1066 | "errorMsg": "Profiles: 0 results",
1067 | "errorType": "message",
1068 | "url": "https://namemc.com/profile/{}",
1069 | "urlMain": "https://namemc.com/",
1070 | "username_claimed": "blue",
1071 | "username_unclaimed": "noonewouldeverusethis7"
1072 | },
1073 | ```
1074 |
1075 | ## SteamID
1076 |
1077 | As of 2021-06-27, Steam uses captcha through CloudFlare which prevents us from checking if usernames exists on the site.
1078 | ```json
1079 | "Steamid": {
1080 | "errorMsg": "No results found
",
1222 | "errorType": "message",
1223 | "regexCheck": "^[a-zA-z][a-zA-Z0-9_]{2,79}$",
1224 | "url": "https://www.capfriendly.com/users/{}",
1225 | "urlMain": "https://www.capfriendly.com/",
1226 | "username_claimed": "thisactuallyexists",
1227 | "username_unclaimed": "noonewouldeverusethis7"
1228 | },
1229 | ```
1230 |
1231 | ## Gab
1232 |
1233 | As of 2022-05-01, Gab returns false positives because they now use CloudFlare
1234 | ```json
1235 | "Gab": {
1236 | "errorMsg": "The page you are looking for isn't here.",
1237 | "errorType": "message",
1238 | "url": "https://gab.com/{}",
1239 | "urlMain": "https://gab.com",
1240 | "username_claimed": "a",
1241 | "username_unclaimed": "noonewouldeverusethis"
1242 | },
1243 | ```
1244 |
1245 | ## FanCentro
1246 |
1247 | As of 2022-05-1, FanCentro returns false positives. Will later in new version of Sherlock.
1248 |
1249 | ```json
1250 | "FanCentro": {
1251 | "errorMsg": "var environment",
1252 | "errorType": "message",
1253 | "url": "https://fancentro.com/{}",
1254 | "urlMain": "https://fancentro.com/",
1255 | "username_claimed": "nielsrosanna",
1256 | "username_unclaimed": "noonewouldeverusethis7"
1257 | },
1258 | ```
1259 |
1260 | ## Smashcast
1261 | As og 2022-05-01, Smashcast is down
1262 | ```json
1263 | "Smashcast": {
1264 | "errorType": "status_code",
1265 | "url": "https://www.smashcast.tv/api/media/live/{}",
1266 | "urlMain": "https://www.smashcast.tv/",
1267 | "username_claimed": "hello",
1268 | "username_unclaimed": "noonewouldeverusethis7"
1269 | },
1270 | ```
1271 |
1272 | ## Countable
1273 |
1274 | As og 2022-05-01, Countable returns false positives
1275 | ```json
1276 | "Countable": {
1277 | "errorType": "status_code",
1278 | "url": "https://www.countable.us/{}",
1279 | "urlMain": "https://www.countable.us/",
1280 | "username_claimed": "blue",
1281 | "username_unclaimed": "noonewouldeverusethis7"
1282 | },
1283 | ```
1284 |
1285 | ## Raidforums
1286 |
1287 | Raidforums is [now run by the FBI](https://twitter.com/janomine/status/1499453777648234501?s=21)
1288 | ```json
1289 | "Raidforums": {
1290 | "errorType": "status_code",
1291 | "url": "https://raidforums.com/User-{}",
1292 | "urlMain": "https://raidforums.com/",
1293 | "username_claimed": "red",
1294 | "username_unclaimed": "noonewouldeverusethis7"
1295 | },
1296 | ```
1297 |
1298 | ## Pinterest
1299 | Removed due to false positive
1300 |
1301 | ```json
1302 | "Pinterest": {
1303 | "errorType": "status_code",
1304 | "url": "https://www.pinterest.com/{}/",
1305 | "urlMain": "https://www.pinterest.com/",
1306 | "username_claimed": "blue",
1307 | "username_unclaimed": "noonewouldeverusethis76543"
1308 | }
1309 | ```
1310 |
1311 | ## PCPartPicker
1312 | As of 17-07-2022, PCPartPicker requires us to login in order to check if a user exits
1313 |
1314 | ```json
1315 | "PCPartPicker": {
1316 | "errorType": "status_code",
1317 | "url": "https://pcpartpicker.com/user/{}",
1318 | "urlMain": "https://pcpartpicker.com",
1319 | "username_claimed": "blue",
1320 | "username_unclaimed": "noonewouldeverusethis7"
1321 | },
1322 | ```
1323 |
1324 | ## Ebay
1325 | As of 17-07-2022, Ebay is very slow to respond. It was also reported that it returned false positives. So this is something that has been investigated further later.
1326 |
1327 | ```json
1328 | "eBay.com": {
1329 | "errorMsg": "The User ID you entered was not found. Please check the User ID and try again.",
1330 | "errorType": "message",
1331 | "url": "https://www.ebay.com/usr/{}",
1332 | "urlMain": "https://www.ebay.com/",
1333 | "username_claimed": "blue",
1334 | "username_unclaimed": "noonewouldeverusethis7"
1335 | },
1336 | "eBay.de": {
1337 | "errorMsg": "Der eingegebene Nutzername wurde nicht gefunden. Bitte pr\u00fcfen Sie den Nutzernamen und versuchen Sie es erneut.",
1338 | "errorType": "message",
1339 | "url": "https://www.ebay.de/usr/{}",
1340 | "urlMain": "https://www.ebay.de/",
1341 | "username_claimed": "blue",
1342 | "username_unclaimed": "noonewouldeverusethis7"
1343 | },
1344 | ```
1345 |
1346 | ## Ghost
1347 | As of 17-07-2022, Ghost returns false positives
1348 |
1349 | ```json
1350 | "Ghost": {
1351 | "errorMsg": "Domain Error",
1352 | "errorType": "message",
1353 | "url": "https://{}.ghost.io/",
1354 | "urlMain": "https://ghost.org/",
1355 | "username_claimed": "troyhunt",
1356 | "username_unclaimed": "noonewouldeverusethis7"
1357 | }
1358 | ```
1359 |
1360 | ## Atom Discussions
1361 | As of 25-07-2022, Atom Discussions seems to not work beceause it keeps on
1362 | redirecting to github discussion tab which does not exist and is not specific to a username
1363 |
1364 | ```json
1365 | "Atom Discussions": {
1366 | "errorMsg": "Oops! That page doesn\u2019t exist or is private.",
1367 | "errorType": "message",
1368 | "url": "https://discuss.atom.io/u/{}/summary",
1369 | "urlMain": "https://discuss.atom.io",
1370 | "username_claimed": "blue",
1371 | "username_unclaimed": "noonewouldeverusethis"
1372 | }
1373 | ```
1374 |
1375 | ## Gam1ng
1376 | As of 25-07-2022, Gam1ng has been permanently moved and is no longer functional
1377 |
1378 | ```json
1379 | "Gam1ng": {
1380 | "errorType": "status_code",
1381 | "url": "https://gam1ng.com.br/user/{}",
1382 | "urlMain": "https://gam1ng.com.br",
1383 | "username_claimed": "PinKgirl",
1384 | "username_unclaimed": "noonewouldeverusethis77777"
1385 | }
1386 | ```
1387 |
1388 | ## OGUsers
1389 | As of 25-07-2022, OGUsers is now no longer functional
1390 |
1391 | ```json
1392 | "OGUsers": {
1393 | "errorType": "status_code",
1394 | "url": "https://ogusers.com/{}",
1395 | "urlMain": "https://ogusers.com/",
1396 | "username_claimed": "ogusers",
1397 | "username_unclaimed": "noonewouldeverusethis7"
1398 | }
1399 | ```
1400 |
1401 | ## Otzovik
1402 | As of 25-07-2022, Otzovik is now no longer functional
1403 |
1404 | ```json
1405 | "Otzovik": {
1406 | "errorType": "status_code",
1407 | "url": "https://otzovik.com/profile/{}",
1408 | "urlMain": "https://otzovik.com/",
1409 | "username_claimed": "blue",
1410 | "username_unclaimed": "noonewouldeverusethis7"
1411 | }
1412 | ```
1413 |
1414 | ## radio_echo_msk
1415 | As of 25-07-2022, radio_echo_msk is now no longer functional
1416 |
1417 | ```json
1418 | "radio_echo_msk": {
1419 | "errorType": "status_code",
1420 | "url": "https://echo.msk.ru/users/{}",
1421 | "urlMain": "https://echo.msk.ru/",
1422 | "username_claimed": "blue",
1423 | "username_unclaimed": "noonewouldeverusethis7"
1424 | }
1425 | ```
1426 | ## Ello
1427 | As of 06.09.2022, Ello is now behind CloudFlare
1428 | ```json
1429 | "Ello": {
1430 | "errorMsg": "We couldn't find the page you're looking for",
1431 | "errorType": "message",
1432 | "url": "https://ello.co/{}",
1433 | "urlMain": "https://ello.co/",
1434 | "username_claimed": "blue",
1435 | "username_unclaimed": "noonewouldeverusethis7"
1436 | }
1437 | ```
1438 |
1439 | ## GitHub Support Community
1440 | As of 06.09.2022, GitHub Support Community's endpoint just redirects to the main community page
1441 | ```json
1442 | "GitHub Support Community": {
1443 | "errorMsg": "Oops! That page doesn\u2019t exist or is private.",
1444 | "errorType": "message",
1445 | "url": "https://github.community/u/{}/summary",
1446 | "urlMain": "https://github.community",
1447 | "username_claimed": "jperl",
1448 | "username_unclaimed": "noonewouldusethis298"
1449 | }
1450 | ```
1451 |
1452 | ## GuruShots
1453 | As of 08.09.2022, GuruShots returns false positives because it just returns a blank page. Need to look further into it so that it can be added back.
1454 |
1455 | ```json
1456 | "GuruShots": {
1457 | "errorType": "status_code",
1458 | "url": "https://gurushots.com/{}/photos",
1459 | "urlMain": "https://gurushots.com/",
1460 | "username_claimed": "blue",
1461 | "username_unclaimed": "noonewouldeverusethis7"
1462 | },
1463 | ```
1464 |
1465 | ## Google Developer
1466 | As of 09.10.2022, Google Developer returns false positives. The site is dynamic so we're not abl to get any proper results
1467 |
1468 | ```json
1469 | "Google Developer": {
1470 | "errorMsg": "Sorry, the profile was not found.",
1471 | "errorType": "message",
1472 | "url": "https://g.dev/{}",
1473 | "urlMain": "https://g.dev/",
1474 | "username_claimed": "blue",
1475 | "username_unclaimed": "noonewouldeverusethis7"
1476 | },
1477 | ```
1478 |
1479 | ## mastodon.technology
1480 | As of 18.12.2022, mastodon.technology has no A/AAAA records and the [website was shut down by the owner](https://ashfurrow.com/blog/mastodon-technology-shutdown/).
1481 |
1482 | ```json
1483 | "mastodon.technology": {
1484 | "errorType": "status_code",
1485 | "url": "https://mastodon.technology/@{}",
1486 | "urlMain": "https://mastodon.xyz/",
1487 | "username_claimed": "ashfurrow",
1488 | "username_unclaimed": "noonewouldeverusethis7"
1489 | },
1490 | ```
1491 |
1492 |
1493 | ## Aruino
1494 | As of 04.02.2023, Arduino returns false positives. Finding a fix is doable but takes some time. Will be fixed later
1495 |
1496 | ```json
1497 | "Arduino": {
1498 | "errorMsg":"Arduino Cloud ",
1499 | "errorType": "message",
1500 | "regexCheck": "^(?![_-])[A-Za-z0-9_-]{3,}$",
1501 | "url": "https://projecthub.arduino.cc/{}",
1502 | "urlMain": "https://www.arduino.cc/",
1503 | "username_claimed": "blue",
1504 | "username_unclaimed": "noonewould"
1505 | },
1506 |
1507 | ```
1508 |
1509 | ## Zoomit
1510 | As of 04.02.2023, Zoomit return false positves. An attempt at finding a fix was made but a lot of time was used without luck. Therefore, it wont be prioritized at the moment.
1511 | ```json
1512 | "zoomit": {
1513 | "errorMsg": "\u0645\u062a\u0627\u0633\u0641\u0627\u0646\u0647 \u0635\u0641\u062d\u0647 \u06cc\u0627\u0641\u062a \u0646\u0634\u062f",
1514 | "errorType": "message",
1515 | "url": "https://www.zoomit.ir/user/{}",
1516 | "urlMain": "https://www.zoomit.ir",
1517 | "username_claimed": "kossher",
1518 | "username_unclaimed": "noonewouldeverusethis7"
1519 | },
1520 | ```
1521 |
1522 | ## Facebook
1523 | As of 04.02.2023, Facebook returns false positives because we get prompted with the login screen to view the data
1524 | ```json
1525 | "Facebook": {
1526 | "errorType": "status_code",
1527 | "regexCheck": "^[a-zA-Z0-9\\.]{3,49}(?Tinder | Dating, Make Friends & Meet New People",
1594 | "Tinder | Match. Chat. Date. "
1595 | ],
1596 | "errorType": "message",
1597 | "url": "https://www.tinder.com/@{}",
1598 | "urlMain": "https://tinder.com/",
1599 | "username_claimed": "blue"
1600 | },
1601 | ```
1602 |
1603 |
1604 | ## Coil
1605 | As of 2023.03.15, Coil has been discontinued. All accounts were deleted and any requests return a 404.
1606 |
1607 | ```json
1608 | "Coil": {
1609 | "errorMsg": "User not found",
1610 | "errorType": "message",
1611 | "request_method": "POST",
1612 | "request_payload": {
1613 | "operationName": "getCreator",
1614 | "query": "query getCreator($userShortName:String!){getCreator(userShortName:$userShortName){id}}",
1615 | "variables": {
1616 | "userShortName": "{}"
1617 | }
1618 | },
1619 | "url": "https://coil.com/u/{}",
1620 | "urlMain": "https://coil.com/",
1621 | "urlProbe": "https://coil.com/gateway",
1622 | "username_claimed": "adam"
1623 | }
1624 | ```
1625 |
1626 | ## OnlyFans
1627 | As of 2023.04.20, OnlyFans returns false negatives on checking usernames with the API endpoint and directly through their website.
1628 |
1629 | ```json
1630 | "OnlyFans": {
1631 | "errorType": "status_code",
1632 | "isNSFW": true,
1633 | "url": "https://onlyfans.com/{}",
1634 | "urlMain": "https://onlyfans.com/",
1635 | "urlProbe": "https://onlyfans.com/api2/v2/users/{}",
1636 | "username_claimed": "theemilylynne"
1637 | }
1638 | ```
1639 |
1640 | ## OK
1641 | As of 2023.04.21, Ok.ru returns false positives
1642 | ```json
1643 | "OK": {
1644 | "errorType": "status_code",
1645 | "regexCheck": "^[a-zA-Z][a-zA-Z0-9_.-]*$",
1646 | "url": "https://ok.ru/{}",
1647 | "urlMain": "https://ok.ru/",
1648 | "username_claimed": "ok"
1649 | }
1650 | ```
1651 |
1652 | ## ForumhouseRU
1653 | As of 2023.04.21, ForumhouseRU returns false positives
1654 | ```json
1655 | "forumhouseRU": {
1656 | "errorMsg": "\u0423\u043a\u0430\u0437\u0430\u043d\u043d\u044b\u0439 \u043f\u043e\u043b\u044c\u0437\u043e\u0432\u0430\u0442\u0435\u043b\u044c \u043d\u0435 \u043d\u0430\u0439\u0434\u0435\u043d. \u041f\u043e\u0436\u0430\u043b\u0443\u0439\u0441\u0442\u0430, \u0432\u0432\u0435\u0434\u0438\u0442\u0435 \u0434\u0440\u0443\u0433\u043e\u0435 \u0438\u043c\u044f.",
1657 | "errorType": "message",
1658 | "url": "https://www.forumhouse.ru/members/?username={}",
1659 | "urlMain": "https://www.forumhouse.ru/",
1660 | "username_claimed": "red"
1661 | }
1662 | ```
1663 |
1664 | ## Enjin
1665 | As of 2023.08.29, Enjin has closed down.
1666 |
1667 | ```json
1668 | "Enjin": {
1669 | "errorMsg": "Yikes, there seems to have been an error. We've taken note and will check out the problem right away!",
1670 | "errorType": "message",
1671 | "url": "https://www.enjin.com/profile/{}",
1672 | "urlMain": "https://www.enjin.com/",
1673 | "username_claimed": "blue"
1674 | },
1675 | ```
1676 |
1677 | ## IRL
1678 | As of 2023.08.29, IRL has shut down
1679 | ```json
1680 | "IRL": {
1681 | "errorType": "status_code",
1682 | "url": "https://www.irl.com/{}",
1683 | "urlMain": "https://www.irl.com/",
1684 | "username_claimed": "hacker"
1685 | }
1686 | ```
1687 |
1688 | ## Munzee
1689 | As of 2023.08.29, Munzee requires us to be logged into the site in order to check if a user exists or not
1690 | ```json
1691 | "Munzee": {
1692 | "errorType": "status_code",
1693 | "url": "https://www.munzee.com/m/{}",
1694 | "urlMain": "https://www.munzee.com/",
1695 | "username_claimed": "blue"
1696 | }
1697 | ```
1698 |
1699 | ## Quizlet
1700 | As of 2023.08.29 Quizlet requires us to enable JavaScript to check if a user exsits on the website
1701 |
1702 | ```json
1703 | "Quizlet": {
1704 | "errorMsg": "Page Unavailable",
1705 | "errorType": "message",
1706 | "url": "https://quizlet.com/{}",
1707 | "urlMain": "https://quizlet.com",
1708 | "username_claimed": "blue"
1709 | }
1710 | ```
1711 |
1712 | ## GunsAndAmmo
1713 | As of 2023.08.29, GunsAndAmmo responds with 404 from time to time
1714 | ```json
1715 | "GunsAndAmmo": {
1716 | "errorType": "status_code",
1717 | "url": "https://forums.gunsandammo.com/profile/{}",
1718 | "urlMain": "https://gunsandammo.com/",
1719 | "username_claimed": "adam"
1720 | }
1721 | ```
1722 |
1723 | ## TikTok
1724 | As of 2023.12.21, TikTok returns false positives. This is because the webpage returns a somewhat blank page. This prevents us from being able to check for the existence of usernames. Proxitok does not work either.
1725 |
1726 | ```json
1727 | "TikTok": {
1728 | "errorType": "status_code",
1729 | "url": "https://tiktok.com/@{}",
1730 | "urlMain": "https://tiktok.com/",
1731 | "username_claimed": "red"
1732 | },
1733 | ```
1734 |
1735 | ## Lolchess
1736 | As of 2023.12.21, Lolchess returns false positives.
1737 | ```json
1738 | "Lolchess": {
1739 | "errorMsg": "No search results",
1740 | "errorType": "message",
1741 | "url": "https://lolchess.gg/profile/na/{}",
1742 | "urlMain": "https://lolchess.gg/",
1743 | "username_claimed": "blue"
1744 | },
1745 | ```
1746 |
1747 | ## Virgool
1748 | As of 2023.12.21, Virgool returns false positives.
1749 | ```json
1750 | "Virgool": {
1751 | "errorMsg": "\u06f4\u06f0\u06f4",
1752 | "errorType": "message",
1753 | "url": "https://virgool.io/@{}",
1754 | "urlMain": "https://virgool.io/",
1755 | "username_claimed": "blue"
1756 | },
1757 | ```
1758 |
1759 | ## Whonix Forum
1760 | As of 2023.12.21, Whonix Forum returns false positives.
1761 | ```json
1762 | "Whonix Forum": {
1763 | "errorType": "status_code",
1764 | "url": "https://forums.whonix.org/u/{}/summary",
1765 | "urlMain": "https://forums.whonix.org/",
1766 | "username_claimed": "red"
1767 | },
1768 | ```
1769 |
1770 | ## Ebio
1771 | As of 2023.12.21, Ebio returns false positives.
1772 | ```json
1773 | "ebio.gg": {
1774 | "errorType": "status_code",
1775 | "url": "https://ebio.gg/{}",
1776 | "urlMain": "https:/ebio.gg",
1777 | "username_claimed": "dev"
1778 | },
1779 | ```
1780 |
1781 | ## HexRPG
1782 | __2024-04-07 :__ HexRPG behind authentication wall. Unable to check usernames without logging in.
1783 | ```json
1784 | "HexRPG": {
1785 | "errorMsg": "Error : User ",
1786 | "errorType": "message",
1787 | "regexCheck": "^[a-zA-Z0-9_ ]{3,20}$",
1788 | "url": "https://www.hexrpg.com/userinfo/{}",
1789 | "urlMain": "https://www.hexrpg.com/",
1790 | "username_claimed": "blue"
1791 | }
1792 | ```
1793 |
1794 | ## Oracle Communities
1795 | __2024-04-07 :__ Oracle Communities behind authentication wall. Unable to check usernames without logging in.
1796 | ```json
1797 | "Oracle Communities": {
1798 | "errorType": "status_code",
1799 | "url": "https://community.oracle.com/people/{}",
1800 | "urlMain": "https://community.oracle.com",
1801 | "username_claimed": "dev"
1802 | }
1803 | ```
1804 |
1805 | ## Metacritic
1806 | __2024-04-07 :__ Non-existent users seemingly displayed as real users with no activity. Needs adjustment.
1807 | ```json
1808 | "metacritic": {
1809 | "errorMsg": "User not found",
1810 | "errorType": "message",
1811 | "regexCheck": "^(?![-_].)[A-Za-z0-9-_]{3,15}$",
1812 | "url": "https://www.metacritic.com/user/{}",
1813 | "urlMain": "https://www.metacritic.com/",
1814 | "username_claimed": "blue"
1815 | }
1816 | ```
1817 |
1818 | ## G2G
1819 | __2024-04-10 :__ Seems to be loading profiles with some wierd javascript setup that sherlock doesn't like, leading to difficult to control false positives
1820 | ```json
1821 | "G2G": {
1822 | "errorType": "response_url",
1823 | "errorUrl": "https://www.g2g.com/{}",
1824 | "regexCheck": "^[A-Za-z][A-Za-z0-9_]{2,11}$",
1825 | "url": "https://www.g2g.com/{}",
1826 | "urlMain": "https://www.g2g.com/",
1827 | "username_claimed": "user"
1828 | }
1829 | ```
1830 |
1831 | ## Bitcoin Forum
1832 | __2024-04-24 :__ BCF seems to have gone defunct. Uncertain.
1833 | ```json
1834 | "BitCoinForum": {
1835 | "errorMsg": "The user whose profile you are trying to view does not exist.",
1836 | "errorType": "message",
1837 | "url": "https://bitcoinforum.com/profile/{}",
1838 | "urlMain": "https://bitcoinforum.com",
1839 | "username_claimed": "bitcoinforum.com"
1840 | }
1841 | ```
1842 |
1843 | ## Zhihu
1844 | As of 24.06.2024, Zhihu returns false positives as they obfuscate the code thats returned. Checking for patterns may allow us to find a way to detect the existans of a user, this will be need to be worked on later
1845 | ```json
1846 |
1847 | "Zhihu": {
1848 | "errorMsg": "用户不存在",
1849 | "errorType": "message",
1850 | "url": "https://www.zhihu.com/people/{}",
1851 | "urlMain": "https://www.zhihu.com/",
1852 | "username_claimed": "blue"
1853 | }
1854 | ```
1855 |
1856 | ## Penetestit
1857 |
1858 | As of 24.06.2024, Pentestit returns a 403. This is most likely due to a new site structures
1859 |
1860 | ```json
1861 | "labpentestit": {
1862 | "errorType": "response_url",
1863 | "errorUrl": "https://lab.pentestit.ru/{}",
1864 | "url": "https://lab.pentestit.ru/profile/{}",
1865 | "urlMain": "https://lab.pentestit.ru/",
1866 | "username_claimed": "CSV"
1867 | }
1868 | ```
1869 |
1870 |
1871 | ## Euw
1872 | __2024-06-09 :__ errorMsg detection doesn't work anymore, because the error message is included in HTTP request body, even in successful search
1873 | ```json
1874 | "Euw": {
1875 | "errorMsg": "This summoner is not registered at OP.GG. Please check spelling.",
1876 | "errorType": "message",
1877 | "url": "https://euw.op.gg/summoner/userName={}",
1878 | "urlMain": "https://euw.op.gg/",
1879 | "username_claimed": "blue"
1880 | }
1881 | ```
1882 |
1883 | ## Etsy
1884 | __2024-06-10 :__ Http request returns 403 forbidden, and tries to verify the connection, so it doesn't work anymore
1885 | ```json
1886 | "Etsy": {
1887 | "errorType": "status_code",
1888 | "url": "https://www.etsy.com/shop/{}",
1889 | "urlMain": "https://www.etsy.com/",
1890 | "username_claimed": "JennyKrafts"
1891 | }
1892 | ```
1893 |
1894 | ## Alik.cz
1895 | __2024-07-21 :__ Target is now BLACKLISTED from the default manifest due to the site recieving unnecessarily high traffic from Sherlock (by request of the site owners). This target is not permitted to be reactivited. Inclusion in unrelated manifests is not impacted, but it is discouraged.
1896 |
1897 | ## 8tracks
1898 | __2025-02-02 :__ Might be dead again. Nobody knows for sure.
1899 | ```json
1900 | "8tracks": {
1901 | "errorType": "message",
1902 | "errorMsg": "\"available\":true",
1903 | "headers": {
1904 | "Accept-Language": "en-US,en;q=0.5"
1905 | },
1906 | "url": "https://8tracks.com/{}",
1907 | "urlProbe": "https://8tracks.com/users/check_username?login={}&format=jsonh",
1908 | "urlMain": "https://8tracks.com/",
1909 | "username_claimed": "blue"
1910 | }
1911 | ```
1912 |
1913 | ## Shpock
1914 | __2025-02-02 :__ Can likely be added back with a new endpoint (source username availability endpoint from mobile app reg flow?)
1915 | ```json
1916 | "Shpock": {
1917 | "errorType": "status_code",
1918 | "url": "https://www.shpock.com/shop/{}/items",
1919 | "urlMain": "https://www.shpock.com/",
1920 | "username_claimed": "user"
1921 | }
1922 | ```
1923 |
1924 | ## Twitch
1925 | __2025-02-02 :__
1926 | ```json
1927 | "Twitch": {
1928 | "errorType": "message",
1929 | "errorMsg": "components.availability-tracking.warn-unavailable.component",
1930 | "url": "https://www.twitch.tv/{}",
1931 | "urlMain": "https://www.twitch.tv/",
1932 | "urlProbe": "https://m.twitch.tv/{}",
1933 | "username_claimed": "jenny"
1934 | }
1935 | ```
1936 |
1937 | ## Fiverr
1938 | __2025-02-02 :__ Fiverr added CSRF protections that messed with this test
1939 | ```json
1940 | "Fiverr": {
1941 | "errorMsg": "\"status\":\"success\"",
1942 | "errorType": "message",
1943 | "headers": {
1944 | "Content-Type": "application/json",
1945 | "Accept-Language": "en-US,en;q=0.9"
1946 | },
1947 | "regexCheck": "^[A-Za-z][A-Za-z\\d_]{5,14}$",
1948 | "request_method": "POST",
1949 | "request_payload": {
1950 | "username": "{}"
1951 | },
1952 | "url": "https://www.fiverr.com/{}",
1953 | "urlMain": "https://www.fiverr.com/",
1954 | "urlProbe": "https://www.fiverr.com/validate_username",
1955 | "username_claimed": "blueman"
1956 | }
1957 | ```
1958 |
1959 | ## BabyRU
1960 | __2025-02-02 :__ Just being problematic (possibly related to errorMsg encoding?)
1961 | ```json
1962 | "babyRU": {
1963 | "errorMsg": [
1964 | "\u0421\u0442\u0440\u0430\u043d\u0438\u0446\u0430, \u043a\u043e\u0442\u043e\u0440\u0443\u044e \u0432\u044b \u0438\u0441\u043a\u0430\u043b\u0438, \u043d\u0435 \u043d\u0430\u0439\u0434\u0435\u043d\u0430",
1965 | "Доступ с вашего IP-адреса временно ограничен"
1966 | ],
1967 | "errorType": "message",
1968 | "url": "https://www.baby.ru/u/{}/",
1969 | "urlMain": "https://www.baby.ru/",
1970 | "username_claimed": "blue"
1971 | }
1972 | ```
1973 |
1974 | ## v0.dev
1975 | __2025-02-16 :__ Unsure if any way to view profiles exists now
1976 | ```json
1977 | "v0.dev": {
1978 | "errorType": "message",
1979 | "errorMsg": "v0 by Vercel ",
1980 | "url": "https://v0.dev/{}",
1981 | "urlMain": "https://v0.dev",
1982 | "username_claimed": "t3dotgg"
1983 | }
1984 | ```
1985 |
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [build-system]
2 | requires = [ "poetry-core>=1.2.0" ]
3 | build-backend = "poetry.core.masonry.api"
4 | # poetry-core 1.8 not available in .fc39. Can upgrade to 1.8.0 at .fc39 EOL
5 |
6 | [tool.poetry-version-plugin]
7 | source = "init"
8 |
9 | [tool.poetry]
10 | name = "sherlock-project"
11 | # single source of truth for version is __init__.py
12 | version = "0"
13 | description = "Hunt down social media accounts by username across social networks"
14 | license = "MIT"
15 | authors = [
16 | "Siddharth Dushantha "
17 | ]
18 | maintainers = [
19 | "Paul Pfeister ",
20 | "Matheus Felipe ",
21 | "Sondre Karlsen Dyrnes "
22 | ]
23 | readme = "docs/pyproject/README.md"
24 | packages = [ { include = "sherlock_project"} ]
25 | keywords = [ "osint", "reconnaissance", "information gathering" ]
26 | classifiers = [
27 | "Development Status :: 5 - Production/Stable",
28 | "Intended Audience :: Developers",
29 | "Intended Audience :: Information Technology",
30 | "Natural Language :: English",
31 | "Operating System :: OS Independent",
32 | "Programming Language :: Python :: 3",
33 | "Topic :: Security"
34 | ]
35 | homepage = "https://sherlockproject.xyz/"
36 | repository = "https://github.com/sherlock-project/sherlock"
37 |
38 |
39 | [tool.poetry.urls]
40 | "Bug Tracker" = "https://github.com/sherlock-project/sherlock/issues"
41 |
42 | [tool.poetry.dependencies]
43 | python = "^3.9"
44 | certifi = ">=2019.6.16"
45 | colorama = "^0.4.1"
46 | PySocks = "^1.7.0"
47 | requests = "^2.22.0"
48 | requests-futures = "^1.0.0"
49 | stem = "^1.8.0"
50 | torrequest = "^0.1.0"
51 | pandas = "^2.2.1"
52 | openpyxl = "^3.0.10"
53 |
54 | [tool.poetry.extras]
55 | tor = ["torrequest"]
56 |
57 | [tool.poetry.group.dev.dependencies]
58 | jsonschema = "^4.0.0"
59 |
60 | [tool.poetry.scripts]
61 | sherlock = 'sherlock_project.sherlock:main'
62 |
--------------------------------------------------------------------------------
/pytest.ini:
--------------------------------------------------------------------------------
1 | [pytest]
2 | addopts = --strict-markers
3 | markers =
4 | online: mark tests are requiring internet access.
5 |
--------------------------------------------------------------------------------
/sherlock_project/__init__.py:
--------------------------------------------------------------------------------
1 | """ Sherlock Module
2 |
3 | This module contains the main logic to search for usernames at social
4 | networks.
5 |
6 | """
7 |
8 | # This variable is only used to check for ImportErrors induced by users running as script rather than as module or package
9 | import_error_test_var = None
10 |
11 | __shortname__ = "Sherlock"
12 | __longname__ = "Sherlock: Find Usernames Across Social Networks"
13 | __version__ = "0.15.0"
14 |
15 | forge_api_latest_release = "https://api.github.com/repos/sherlock-project/sherlock/releases/latest"
16 |
--------------------------------------------------------------------------------
/sherlock_project/__main__.py:
--------------------------------------------------------------------------------
1 | #! /usr/bin/env python3
2 |
3 | """
4 | Sherlock: Find Usernames Across Social Networks Module
5 |
6 | This module contains the main logic to search for usernames at social
7 | networks.
8 | """
9 |
10 | import sys
11 |
12 |
13 | if __name__ == "__main__":
14 | # Check if the user is using the correct version of Python
15 | python_version = sys.version.split()[0]
16 |
17 | if sys.version_info < (3, 9):
18 | print(f"Sherlock requires Python 3.9+\nYou are using Python {python_version}, which is not supported by Sherlock.")
19 | sys.exit(1)
20 |
21 | from sherlock_project import sherlock
22 | sherlock.main()
23 |
--------------------------------------------------------------------------------
/sherlock_project/notify.py:
--------------------------------------------------------------------------------
1 | """Sherlock Notify Module
2 |
3 | This module defines the objects for notifying the caller about the
4 | results of queries.
5 | """
6 | from sherlock_project.result import QueryStatus
7 | from colorama import Fore, Style
8 | import webbrowser
9 |
10 | # Global variable to count the number of results.
11 | globvar = 0
12 |
13 |
14 | class QueryNotify:
15 | """Query Notify Object.
16 |
17 | Base class that describes methods available to notify the results of
18 | a query.
19 | It is intended that other classes inherit from this base class and
20 | override the methods to implement specific functionality.
21 | """
22 |
23 | def __init__(self, result=None):
24 | """Create Query Notify Object.
25 |
26 | Contains information about a specific method of notifying the results
27 | of a query.
28 |
29 | Keyword Arguments:
30 | self -- This object.
31 | result -- Object of type QueryResult() containing
32 | results for this query.
33 |
34 | Return Value:
35 | Nothing.
36 | """
37 |
38 | self.result = result
39 |
40 | # return
41 |
42 | def start(self, message=None):
43 | """Notify Start.
44 |
45 | Notify method for start of query. This method will be called before
46 | any queries are performed. This method will typically be
47 | overridden by higher level classes that will inherit from it.
48 |
49 | Keyword Arguments:
50 | self -- This object.
51 | message -- Object that is used to give context to start
52 | of query.
53 | Default is None.
54 |
55 | Return Value:
56 | Nothing.
57 | """
58 |
59 | # return
60 |
61 | def update(self, result):
62 | """Notify Update.
63 |
64 | Notify method for query result. This method will typically be
65 | overridden by higher level classes that will inherit from it.
66 |
67 | Keyword Arguments:
68 | self -- This object.
69 | result -- Object of type QueryResult() containing
70 | results for this query.
71 |
72 | Return Value:
73 | Nothing.
74 | """
75 |
76 | self.result = result
77 |
78 | # return
79 |
80 | def finish(self, message=None):
81 | """Notify Finish.
82 |
83 | Notify method for finish of query. This method will be called after
84 | all queries have been performed. This method will typically be
85 | overridden by higher level classes that will inherit from it.
86 |
87 | Keyword Arguments:
88 | self -- This object.
89 | message -- Object that is used to give context to start
90 | of query.
91 | Default is None.
92 |
93 | Return Value:
94 | Nothing.
95 | """
96 |
97 | # return
98 |
99 | def __str__(self):
100 | """Convert Object To String.
101 |
102 | Keyword Arguments:
103 | self -- This object.
104 |
105 | Return Value:
106 | Nicely formatted string to get information about this object.
107 | """
108 | return str(self.result)
109 |
110 |
111 | class QueryNotifyPrint(QueryNotify):
112 | """Query Notify Print Object.
113 |
114 | Query notify class that prints results.
115 | """
116 |
117 | def __init__(self, result=None, verbose=False, print_all=False, browse=False):
118 | """Create Query Notify Print Object.
119 |
120 | Contains information about a specific method of notifying the results
121 | of a query.
122 |
123 | Keyword Arguments:
124 | self -- This object.
125 | result -- Object of type QueryResult() containing
126 | results for this query.
127 | verbose -- Boolean indicating whether to give verbose output.
128 | print_all -- Boolean indicating whether to only print all sites, including not found.
129 | browse -- Boolean indicating whether to open found sites in a web browser.
130 |
131 | Return Value:
132 | Nothing.
133 | """
134 |
135 | super().__init__(result)
136 | self.verbose = verbose
137 | self.print_all = print_all
138 | self.browse = browse
139 |
140 | return
141 |
142 | def start(self, message):
143 | """Notify Start.
144 |
145 | Will print the title to the standard output.
146 |
147 | Keyword Arguments:
148 | self -- This object.
149 | message -- String containing username that the series
150 | of queries are about.
151 |
152 | Return Value:
153 | Nothing.
154 | """
155 |
156 | title = "Checking username"
157 |
158 | print(Style.BRIGHT + Fore.GREEN + "[" +
159 | Fore.YELLOW + "*" +
160 | Fore.GREEN + f"] {title}" +
161 | Fore.WHITE + f" {message}" +
162 | Fore.GREEN + " on:")
163 | # An empty line between first line and the result(more clear output)
164 | print('\r')
165 |
166 | return
167 |
168 | def countResults(self):
169 | """This function counts the number of results. Every time the function is called,
170 | the number of results is increasing.
171 |
172 | Keyword Arguments:
173 | self -- This object.
174 |
175 | Return Value:
176 | The number of results by the time we call the function.
177 | """
178 | global globvar
179 | globvar += 1
180 | return globvar
181 |
182 | def update(self, result):
183 | """Notify Update.
184 |
185 | Will print the query result to the standard output.
186 |
187 | Keyword Arguments:
188 | self -- This object.
189 | result -- Object of type QueryResult() containing
190 | results for this query.
191 |
192 | Return Value:
193 | Nothing.
194 | """
195 | self.result = result
196 |
197 | response_time_text = ""
198 | if self.result.query_time is not None and self.verbose is True:
199 | response_time_text = f" [{round(self.result.query_time * 1000)}ms]"
200 |
201 | # Output to the terminal is desired.
202 | if result.status == QueryStatus.CLAIMED:
203 | self.countResults()
204 | print(Style.BRIGHT + Fore.WHITE + "[" +
205 | Fore.GREEN + "+" +
206 | Fore.WHITE + "]" +
207 | response_time_text +
208 | Fore.GREEN +
209 | f" {self.result.site_name}: " +
210 | Style.RESET_ALL +
211 | f"{self.result.site_url_user}")
212 | if self.browse:
213 | webbrowser.open(self.result.site_url_user, 2)
214 |
215 | elif result.status == QueryStatus.AVAILABLE:
216 | if self.print_all:
217 | print(Style.BRIGHT + Fore.WHITE + "[" +
218 | Fore.RED + "-" +
219 | Fore.WHITE + "]" +
220 | response_time_text +
221 | Fore.GREEN + f" {self.result.site_name}:" +
222 | Fore.YELLOW + " Not Found!")
223 |
224 | elif result.status == QueryStatus.UNKNOWN:
225 | if self.print_all:
226 | print(Style.BRIGHT + Fore.WHITE + "[" +
227 | Fore.RED + "-" +
228 | Fore.WHITE + "]" +
229 | Fore.GREEN + f" {self.result.site_name}:" +
230 | Fore.RED + f" {self.result.context}" +
231 | Fore.YELLOW + " ")
232 |
233 | elif result.status == QueryStatus.ILLEGAL:
234 | if self.print_all:
235 | msg = "Illegal Username Format For This Site!"
236 | print(Style.BRIGHT + Fore.WHITE + "[" +
237 | Fore.RED + "-" +
238 | Fore.WHITE + "]" +
239 | Fore.GREEN + f" {self.result.site_name}:" +
240 | Fore.YELLOW + f" {msg}")
241 |
242 | elif result.status == QueryStatus.WAF:
243 | if self.print_all:
244 | print(Style.BRIGHT + Fore.WHITE + "[" +
245 | Fore.RED + "-" +
246 | Fore.WHITE + "]" +
247 | Fore.GREEN + f" {self.result.site_name}:" +
248 | Fore.RED + " Blocked by bot detection" +
249 | Fore.YELLOW + " (proxy may help)")
250 |
251 | else:
252 | # It should be impossible to ever get here...
253 | raise ValueError(
254 | f"Unknown Query Status '{result.status}' for site '{self.result.site_name}'"
255 | )
256 |
257 | return
258 |
259 | def finish(self, message="The processing has been finished."):
260 | """Notify Start.
261 | Will print the last line to the standard output.
262 | Keyword Arguments:
263 | self -- This object.
264 | message -- The 2 last phrases.
265 | Return Value:
266 | Nothing.
267 | """
268 | NumberOfResults = self.countResults() - 1
269 |
270 | print(Style.BRIGHT + Fore.GREEN + "[" +
271 | Fore.YELLOW + "*" +
272 | Fore.GREEN + "] Search completed with" +
273 | Fore.WHITE + f" {NumberOfResults} " +
274 | Fore.GREEN + "results" + Style.RESET_ALL
275 | )
276 |
277 | def __str__(self):
278 | """Convert Object To String.
279 |
280 | Keyword Arguments:
281 | self -- This object.
282 |
283 | Return Value:
284 | Nicely formatted string to get information about this object.
285 | """
286 | return str(self.result)
287 |
--------------------------------------------------------------------------------
/sherlock_project/py.typed:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/sherlock-project/sherlock/4423230c117a5c931a1c854d722609160bf5fcb3/sherlock_project/py.typed
--------------------------------------------------------------------------------
/sherlock_project/resources/data.schema.json:
--------------------------------------------------------------------------------
1 | {
2 | "$schema": "https://json-schema.org/draft/2020-12/schema",
3 | "title": "Sherlock Target Manifest",
4 | "description": "Social media targets to probe for the existence of known usernames",
5 | "type": "object",
6 | "properties": {
7 | "$schema": { "type": "string" }
8 | },
9 | "patternProperties": {
10 | "^(?!\\$).*?$": {
11 | "type": "object",
12 | "description": "Target name and associated information (key should be human readable name)",
13 | "required": [ "url", "urlMain", "errorType", "username_claimed" ],
14 | "properties": {
15 | "url": { "type": "string" },
16 | "urlMain": { "type": "string" },
17 | "urlProbe": { "type": "string" },
18 | "username_claimed": { "type": "string" },
19 | "regexCheck": { "type": "string" },
20 | "isNSFW": { "type": "boolean" },
21 | "headers": { "type": "object" },
22 | "request_payload": { "type": "object" },
23 | "__comment__": {
24 | "type": "string",
25 | "description": "Used to clarify important target information if (and only if) a commit message would not suffice.\nThis key should not be parsed anywhere within Sherlock."
26 | },
27 | "tags": {
28 | "oneOf": [
29 | { "$ref": "#/$defs/tag" },
30 | { "type": "array", "items": { "$ref": "#/$defs/tag" } }
31 | ]
32 | },
33 | "request_method": {
34 | "type": "string",
35 | "enum": [ "GET", "POST", "HEAD", "PUT" ]
36 | },
37 | "errorType": {
38 | "type": "string",
39 | "enum": [ "message", "response_url", "status_code" ]
40 | },
41 | "errorMsg": {
42 | "oneOf": [
43 | { "type": "string" },
44 | { "type": "array", "items": { "type": "string" } }
45 | ]
46 | },
47 | "errorCode": {
48 | "oneOf": [
49 | { "type": "integer" },
50 | { "type": "array", "items": { "type": "integer" } }
51 | ]
52 | },
53 | "errorUrl": { "type": "string" },
54 | "response_url": { "type": "string" }
55 | },
56 | "dependencies": {
57 | "errorMsg": {
58 | "properties" : { "errorType": { "const": "message" } }
59 | },
60 | "errorUrl": {
61 | "properties": { "errorType": { "const": "response_url" } }
62 | },
63 | "errorCode": {
64 | "properties": { "errorType": { "const": "status_code" } }
65 | }
66 | },
67 | "if": { "properties": { "errorType": { "const": "message" } } },
68 | "then": { "required": [ "errorMsg" ] },
69 | "else": {
70 | "if": { "properties": { "errorType": { "const": "response_url" } } },
71 | "then": { "required": [ "errorUrl" ] }
72 | },
73 | "additionalProperties": false
74 | }
75 | },
76 | "additionalProperties": false,
77 | "$defs": {
78 | "tag": { "type": "string", "enum": [ "adult", "gaming" ] }
79 | }
80 | }
81 |
--------------------------------------------------------------------------------
/sherlock_project/result.py:
--------------------------------------------------------------------------------
1 | """Sherlock Result Module
2 |
3 | This module defines various objects for recording the results of queries.
4 | """
5 | from enum import Enum
6 |
7 |
8 | class QueryStatus(Enum):
9 | """Query Status Enumeration.
10 |
11 | Describes status of query about a given username.
12 | """
13 | CLAIMED = "Claimed" # Username Detected
14 | AVAILABLE = "Available" # Username Not Detected
15 | UNKNOWN = "Unknown" # Error Occurred While Trying To Detect Username
16 | ILLEGAL = "Illegal" # Username Not Allowable For This Site
17 | WAF = "WAF" # Request blocked by WAF (i.e. Cloudflare)
18 |
19 | def __str__(self):
20 | """Convert Object To String.
21 |
22 | Keyword Arguments:
23 | self -- This object.
24 |
25 | Return Value:
26 | Nicely formatted string to get information about this object.
27 | """
28 | return self.value
29 |
30 | class QueryResult():
31 | """Query Result Object.
32 |
33 | Describes result of query about a given username.
34 | """
35 | def __init__(self, username, site_name, site_url_user, status,
36 | query_time=None, context=None):
37 | """Create Query Result Object.
38 |
39 | Contains information about a specific method of detecting usernames on
40 | a given type of web sites.
41 |
42 | Keyword Arguments:
43 | self -- This object.
44 | username -- String indicating username that query result
45 | was about.
46 | site_name -- String which identifies site.
47 | site_url_user -- String containing URL for username on site.
48 | NOTE: The site may or may not exist: this
49 | just indicates what the name would
50 | be, if it existed.
51 | status -- Enumeration of type QueryStatus() indicating
52 | the status of the query.
53 | query_time -- Time (in seconds) required to perform query.
54 | Default of None.
55 | context -- String indicating any additional context
56 | about the query. For example, if there was
57 | an error, this might indicate the type of
58 | error that occurred.
59 | Default of None.
60 |
61 | Return Value:
62 | Nothing.
63 | """
64 |
65 | self.username = username
66 | self.site_name = site_name
67 | self.site_url_user = site_url_user
68 | self.status = status
69 | self.query_time = query_time
70 | self.context = context
71 |
72 | return
73 |
74 | def __str__(self):
75 | """Convert Object To String.
76 |
77 | Keyword Arguments:
78 | self -- This object.
79 |
80 | Return Value:
81 | Nicely formatted string to get information about this object.
82 | """
83 | status = str(self.status)
84 | if self.context is not None:
85 | # There is extra context information available about the results.
86 | # Append it to the normal response text.
87 | status += f" ({self.context})"
88 |
89 | return status
90 |
--------------------------------------------------------------------------------
/sherlock_project/sherlock.py:
--------------------------------------------------------------------------------
1 | #! /usr/bin/env python3
2 |
3 | """
4 | Sherlock: Find Usernames Across Social Networks Module
5 |
6 | This module contains the main logic to search for usernames at social
7 | networks.
8 | """
9 |
10 | import sys
11 |
12 | try:
13 | from sherlock_project.__init__ import import_error_test_var # noqa: F401
14 | except ImportError:
15 | print("Did you run Sherlock with `python3 sherlock/sherlock.py ...`?")
16 | print("This is an outdated method. Please see https://sherlockproject.xyz/installation for up to date instructions.")
17 | sys.exit(1)
18 |
19 | import csv
20 | import signal
21 | import pandas as pd
22 | import os
23 | import re
24 | from argparse import ArgumentParser, RawDescriptionHelpFormatter
25 | from json import loads as json_loads
26 | from time import monotonic
27 | from typing import Optional
28 |
29 | import requests
30 | from requests_futures.sessions import FuturesSession
31 |
32 | from sherlock_project.__init__ import (
33 | __longname__,
34 | __shortname__,
35 | __version__,
36 | forge_api_latest_release,
37 | )
38 |
39 | from sherlock_project.result import QueryStatus
40 | from sherlock_project.result import QueryResult
41 | from sherlock_project.notify import QueryNotify
42 | from sherlock_project.notify import QueryNotifyPrint
43 | from sherlock_project.sites import SitesInformation
44 | from colorama import init
45 | from argparse import ArgumentTypeError
46 |
47 |
48 | class SherlockFuturesSession(FuturesSession):
49 | def request(self, method, url, hooks=None, *args, **kwargs):
50 | """Request URL.
51 |
52 | This extends the FuturesSession request method to calculate a response
53 | time metric to each request.
54 |
55 | It is taken (almost) directly from the following Stack Overflow answer:
56 | https://github.com/ross/requests-futures#working-in-the-background
57 |
58 | Keyword Arguments:
59 | self -- This object.
60 | method -- String containing method desired for request.
61 | url -- String containing URL for request.
62 | hooks -- Dictionary containing hooks to execute after
63 | request finishes.
64 | args -- Arguments.
65 | kwargs -- Keyword arguments.
66 |
67 | Return Value:
68 | Request object.
69 | """
70 | # Record the start time for the request.
71 | if hooks is None:
72 | hooks = {}
73 | start = monotonic()
74 |
75 | def response_time(resp, *args, **kwargs):
76 | """Response Time Hook.
77 |
78 | Keyword Arguments:
79 | resp -- Response object.
80 | args -- Arguments.
81 | kwargs -- Keyword arguments.
82 |
83 | Return Value:
84 | Nothing.
85 | """
86 | resp.elapsed = monotonic() - start
87 |
88 | return
89 |
90 | # Install hook to execute when response completes.
91 | # Make sure that the time measurement hook is first, so we will not
92 | # track any later hook's execution time.
93 | try:
94 | if isinstance(hooks["response"], list):
95 | hooks["response"].insert(0, response_time)
96 | elif isinstance(hooks["response"], tuple):
97 | # Convert tuple to list and insert time measurement hook first.
98 | hooks["response"] = list(hooks["response"])
99 | hooks["response"].insert(0, response_time)
100 | else:
101 | # Must have previously contained a single hook function,
102 | # so convert to list.
103 | hooks["response"] = [response_time, hooks["response"]]
104 | except KeyError:
105 | # No response hook was already defined, so install it ourselves.
106 | hooks["response"] = [response_time]
107 |
108 | return super(SherlockFuturesSession, self).request(
109 | method, url, hooks=hooks, *args, **kwargs
110 | )
111 |
112 |
113 | def get_response(request_future, error_type, social_network):
114 | # Default for Response object if some failure occurs.
115 | response = None
116 |
117 | error_context = "General Unknown Error"
118 | exception_text = None
119 | try:
120 | response = request_future.result()
121 | if response.status_code:
122 | # Status code exists in response object
123 | error_context = None
124 | except requests.exceptions.HTTPError as errh:
125 | error_context = "HTTP Error"
126 | exception_text = str(errh)
127 | except requests.exceptions.ProxyError as errp:
128 | error_context = "Proxy Error"
129 | exception_text = str(errp)
130 | except requests.exceptions.ConnectionError as errc:
131 | error_context = "Error Connecting"
132 | exception_text = str(errc)
133 | except requests.exceptions.Timeout as errt:
134 | error_context = "Timeout Error"
135 | exception_text = str(errt)
136 | except requests.exceptions.RequestException as err:
137 | error_context = "Unknown Error"
138 | exception_text = str(err)
139 |
140 | return response, error_context, exception_text
141 |
142 |
143 | def interpolate_string(input_object, username):
144 | if isinstance(input_object, str):
145 | return input_object.replace("{}", username)
146 | elif isinstance(input_object, dict):
147 | return {k: interpolate_string(v, username) for k, v in input_object.items()}
148 | elif isinstance(input_object, list):
149 | return [interpolate_string(i, username) for i in input_object]
150 | return input_object
151 |
152 |
153 | def check_for_parameter(username):
154 | """checks if {?} exists in the username
155 | if exist it means that sherlock is looking for more multiple username"""
156 | return "{?}" in username
157 |
158 |
159 | checksymbols = ["_", "-", "."]
160 |
161 |
162 | def multiple_usernames(username):
163 | """replace the parameter with with symbols and return a list of usernames"""
164 | allUsernames = []
165 | for i in checksymbols:
166 | allUsernames.append(username.replace("{?}", i))
167 | return allUsernames
168 |
169 |
170 | def sherlock(
171 | username: str,
172 | site_data: dict,
173 | query_notify: QueryNotify,
174 | tor: bool = False,
175 | unique_tor: bool = False,
176 | dump_response: bool = False,
177 | proxy: Optional[str] = None,
178 | timeout: int = 60,
179 | ):
180 | """Run Sherlock Analysis.
181 |
182 | Checks for existence of username on various social media sites.
183 |
184 | Keyword Arguments:
185 | username -- String indicating username that report
186 | should be created against.
187 | site_data -- Dictionary containing all of the site data.
188 | query_notify -- Object with base type of QueryNotify().
189 | This will be used to notify the caller about
190 | query results.
191 | tor -- Boolean indicating whether to use a tor circuit for the requests.
192 | unique_tor -- Boolean indicating whether to use a new tor circuit for each request.
193 | proxy -- String indicating the proxy URL
194 | timeout -- Time in seconds to wait before timing out request.
195 | Default is 60 seconds.
196 |
197 | Return Value:
198 | Dictionary containing results from report. Key of dictionary is the name
199 | of the social network site, and the value is another dictionary with
200 | the following keys:
201 | url_main: URL of main site.
202 | url_user: URL of user on site (if account exists).
203 | status: QueryResult() object indicating results of test for
204 | account existence.
205 | http_status: HTTP status code of query which checked for existence on
206 | site.
207 | response_text: Text that came back from request. May be None if
208 | there was an HTTP error when checking for existence.
209 | """
210 |
211 | # Notify caller that we are starting the query.
212 | query_notify.start(username)
213 | # Create session based on request methodology
214 | if tor or unique_tor:
215 | try:
216 | from torrequest import TorRequest # noqa: E402
217 | except ImportError:
218 | print("Important!")
219 | print("> --tor and --unique-tor are now DEPRECATED, and may be removed in a future release of Sherlock.")
220 | print("> If you've installed Sherlock via pip, you can include the optional dependency via `pip install 'sherlock-project[tor]'`.")
221 | print("> Other packages should refer to their documentation, or install it separately with `pip install torrequest`.\n")
222 | sys.exit(query_notify.finish())
223 |
224 | print("Important!")
225 | print("> --tor and --unique-tor are now DEPRECATED, and may be removed in a future release of Sherlock.")
226 |
227 | # Requests using Tor obfuscation
228 | try:
229 | underlying_request = TorRequest()
230 | except OSError:
231 | print("Tor not found in system path. Unable to continue.\n")
232 | sys.exit(query_notify.finish())
233 |
234 | underlying_session = underlying_request.session
235 | else:
236 | # Normal requests
237 | underlying_session = requests.session()
238 | underlying_request = requests.Request()
239 |
240 | # Limit number of workers to 20.
241 | # This is probably vastly overkill.
242 | if len(site_data) >= 20:
243 | max_workers = 20
244 | else:
245 | max_workers = len(site_data)
246 |
247 | # Create multi-threaded session for all requests.
248 | session = SherlockFuturesSession(
249 | max_workers=max_workers, session=underlying_session
250 | )
251 |
252 | # Results from analysis of all sites
253 | results_total = {}
254 |
255 | # First create futures for all requests. This allows for the requests to run in parallel
256 | for social_network, net_info in site_data.items():
257 | # Results from analysis of this specific site
258 | results_site = {"url_main": net_info.get("urlMain")}
259 |
260 | # Record URL of main site
261 |
262 | # A user agent is needed because some sites don't return the correct
263 | # information since they think that we are bots (Which we actually are...)
264 | headers = {
265 | "User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:129.0) Gecko/20100101 Firefox/129.0",
266 | }
267 |
268 | if "headers" in net_info:
269 | # Override/append any extra headers required by a given site.
270 | headers.update(net_info["headers"])
271 |
272 | # URL of user on site (if it exists)
273 | url = interpolate_string(net_info["url"], username.replace(' ', '%20'))
274 |
275 | # Don't make request if username is invalid for the site
276 | regex_check = net_info.get("regexCheck")
277 | if regex_check and re.search(regex_check, username) is None:
278 | # No need to do the check at the site: this username is not allowed.
279 | results_site["status"] = QueryResult(
280 | username, social_network, url, QueryStatus.ILLEGAL
281 | )
282 | results_site["url_user"] = ""
283 | results_site["http_status"] = ""
284 | results_site["response_text"] = ""
285 | query_notify.update(results_site["status"])
286 | else:
287 | # URL of user on site (if it exists)
288 | results_site["url_user"] = url
289 | url_probe = net_info.get("urlProbe")
290 | request_method = net_info.get("request_method")
291 | request_payload = net_info.get("request_payload")
292 | request = None
293 |
294 | if request_method is not None:
295 | if request_method == "GET":
296 | request = session.get
297 | elif request_method == "HEAD":
298 | request = session.head
299 | elif request_method == "POST":
300 | request = session.post
301 | elif request_method == "PUT":
302 | request = session.put
303 | else:
304 | raise RuntimeError(f"Unsupported request_method for {url}")
305 |
306 | if request_payload is not None:
307 | request_payload = interpolate_string(request_payload, username)
308 |
309 | if url_probe is None:
310 | # Probe URL is normal one seen by people out on the web.
311 | url_probe = url
312 | else:
313 | # There is a special URL for probing existence separate
314 | # from where the user profile normally can be found.
315 | url_probe = interpolate_string(url_probe, username)
316 |
317 | if request is None:
318 | if net_info["errorType"] == "status_code":
319 | # In most cases when we are detecting by status code,
320 | # it is not necessary to get the entire body: we can
321 | # detect fine with just the HEAD response.
322 | request = session.head
323 | else:
324 | # Either this detect method needs the content associated
325 | # with the GET response, or this specific website will
326 | # not respond properly unless we request the whole page.
327 | request = session.get
328 |
329 | if net_info["errorType"] == "response_url":
330 | # Site forwards request to a different URL if username not
331 | # found. Disallow the redirect so we can capture the
332 | # http status from the original URL request.
333 | allow_redirects = False
334 | else:
335 | # Allow whatever redirect that the site wants to do.
336 | # The final result of the request will be what is available.
337 | allow_redirects = True
338 |
339 | # This future starts running the request in a new thread, doesn't block the main thread
340 | if proxy is not None:
341 | proxies = {"http": proxy, "https": proxy}
342 | future = request(
343 | url=url_probe,
344 | headers=headers,
345 | proxies=proxies,
346 | allow_redirects=allow_redirects,
347 | timeout=timeout,
348 | json=request_payload,
349 | )
350 | else:
351 | future = request(
352 | url=url_probe,
353 | headers=headers,
354 | allow_redirects=allow_redirects,
355 | timeout=timeout,
356 | json=request_payload,
357 | )
358 |
359 | # Store future in data for access later
360 | net_info["request_future"] = future
361 |
362 | # Reset identify for tor (if needed)
363 | if unique_tor:
364 | underlying_request.reset_identity()
365 |
366 | # Add this site's results into final dictionary with all the other results.
367 | results_total[social_network] = results_site
368 |
369 | # Open the file containing account links
370 | # Core logic: If tor requests, make them here. If multi-threaded requests, wait for responses
371 | for social_network, net_info in site_data.items():
372 | # Retrieve results again
373 | results_site = results_total.get(social_network)
374 |
375 | # Retrieve other site information again
376 | url = results_site.get("url_user")
377 | status = results_site.get("status")
378 | if status is not None:
379 | # We have already determined the user doesn't exist here
380 | continue
381 |
382 | # Get the expected error type
383 | error_type = net_info["errorType"]
384 |
385 | # Retrieve future and ensure it has finished
386 | future = net_info["request_future"]
387 | r, error_text, exception_text = get_response(
388 | request_future=future, error_type=error_type, social_network=social_network
389 | )
390 |
391 | # Get response time for response of our request.
392 | try:
393 | response_time = r.elapsed
394 | except AttributeError:
395 | response_time = None
396 |
397 | # Attempt to get request information
398 | try:
399 | http_status = r.status_code
400 | except Exception:
401 | http_status = "?"
402 | try:
403 | response_text = r.text.encode(r.encoding or "UTF-8")
404 | except Exception:
405 | response_text = ""
406 |
407 | query_status = QueryStatus.UNKNOWN
408 | error_context = None
409 |
410 | # As WAFs advance and evolve, they will occasionally block Sherlock and
411 | # lead to false positives and negatives. Fingerprints should be added
412 | # here to filter results that fail to bypass WAFs. Fingerprints should
413 | # be highly targetted. Comment at the end of each fingerprint to
414 | # indicate target and date fingerprinted.
415 | WAFHitMsgs = [
416 | r'.loading-spinner{visibility:hidden}body.no-js .challenge-running{display:none}body.dark{background-color:#222;color:#d9d9d9}body.dark a{color:#fff}body.dark a:hover{color:#ee730a;text-decoration:underline}body.dark .lds-ring div{border-color:#999 transparent transparent}body.dark .font-red{color:#b20f03}body.dark', # 2024-05-13 Cloudflare
417 | r'', # 2024-11-11 Cloudflare error page
418 | r'AwsWafIntegration.forceRefreshToken', # 2024-11-11 Cloudfront (AWS)
419 | r'{return l.onPageView}}),Object.defineProperty(r,"perimeterxIdentifiers",{enumerable:' # 2024-04-09 PerimeterX / Human Security
420 | ]
421 |
422 | if error_text is not None:
423 | error_context = error_text
424 |
425 | elif any(hitMsg in r.text for hitMsg in WAFHitMsgs):
426 | query_status = QueryStatus.WAF
427 |
428 | elif error_type == "message":
429 | # error_flag True denotes no error found in the HTML
430 | # error_flag False denotes error found in the HTML
431 | error_flag = True
432 | errors = net_info.get("errorMsg")
433 | # errors will hold the error message
434 | # it can be string or list
435 | # by isinstance method we can detect that
436 | # and handle the case for strings as normal procedure
437 | # and if its list we can iterate the errors
438 | if isinstance(errors, str):
439 | # Checks if the error message is in the HTML
440 | # if error is present we will set flag to False
441 | if errors in r.text:
442 | error_flag = False
443 | else:
444 | # If it's list, it will iterate all the error message
445 | for error in errors:
446 | if error in r.text:
447 | error_flag = False
448 | break
449 | if error_flag:
450 | query_status = QueryStatus.CLAIMED
451 | else:
452 | query_status = QueryStatus.AVAILABLE
453 | elif error_type == "status_code":
454 | error_codes = net_info.get("errorCode")
455 | query_status = QueryStatus.CLAIMED
456 |
457 | # Type consistency, allowing for both singlets and lists in manifest
458 | if isinstance(error_codes, int):
459 | error_codes = [error_codes]
460 |
461 | if error_codes is not None and r.status_code in error_codes:
462 | query_status = QueryStatus.AVAILABLE
463 | elif r.status_code >= 300 or r.status_code < 200:
464 | query_status = QueryStatus.AVAILABLE
465 | elif error_type == "response_url":
466 | # For this detection method, we have turned off the redirect.
467 | # So, there is no need to check the response URL: it will always
468 | # match the request. Instead, we will ensure that the response
469 | # code indicates that the request was successful (i.e. no 404, or
470 | # forward to some odd redirect).
471 | if 200 <= r.status_code < 300:
472 | query_status = QueryStatus.CLAIMED
473 | else:
474 | query_status = QueryStatus.AVAILABLE
475 | else:
476 | # It should be impossible to ever get here...
477 | raise ValueError(
478 | f"Unknown Error Type '{error_type}' for " f"site '{social_network}'"
479 | )
480 |
481 | if dump_response:
482 | print("+++++++++++++++++++++")
483 | print(f"TARGET NAME : {social_network}")
484 | print(f"USERNAME : {username}")
485 | print(f"TARGET URL : {url}")
486 | print(f"TEST METHOD : {error_type}")
487 | try:
488 | print(f"STATUS CODES : {net_info['errorCode']}")
489 | except KeyError:
490 | pass
491 | print("Results...")
492 | try:
493 | print(f"RESPONSE CODE : {r.status_code}")
494 | except Exception:
495 | pass
496 | try:
497 | print(f"ERROR TEXT : {net_info['errorMsg']}")
498 | except KeyError:
499 | pass
500 | print(">>>>> BEGIN RESPONSE TEXT")
501 | try:
502 | print(r.text)
503 | except Exception:
504 | pass
505 | print("<<<<< END RESPONSE TEXT")
506 | print("VERDICT : " + str(query_status))
507 | print("+++++++++++++++++++++")
508 |
509 | # Notify caller about results of query.
510 | result = QueryResult(
511 | username=username,
512 | site_name=social_network,
513 | site_url_user=url,
514 | status=query_status,
515 | query_time=response_time,
516 | context=error_context,
517 | )
518 | query_notify.update(result)
519 |
520 | # Save status of request
521 | results_site["status"] = result
522 |
523 | # Save results from request
524 | results_site["http_status"] = http_status
525 | results_site["response_text"] = response_text
526 |
527 | # Add this site's results into final dictionary with all of the other results.
528 | results_total[social_network] = results_site
529 |
530 | return results_total
531 |
532 |
533 | def timeout_check(value):
534 | """Check Timeout Argument.
535 |
536 | Checks timeout for validity.
537 |
538 | Keyword Arguments:
539 | value -- Time in seconds to wait before timing out request.
540 |
541 | Return Value:
542 | Floating point number representing the time (in seconds) that should be
543 | used for the timeout.
544 |
545 | NOTE: Will raise an exception if the timeout in invalid.
546 | """
547 |
548 | float_value = float(value)
549 |
550 | if float_value <= 0:
551 | raise ArgumentTypeError(
552 | f"Invalid timeout value: {value}. Timeout must be a positive number."
553 | )
554 |
555 | return float_value
556 |
557 |
558 | def handler(signal_received, frame):
559 | """Exit gracefully without throwing errors
560 |
561 | Source: https://www.devdungeon.com/content/python-catch-sigint-ctrl-c
562 | """
563 | sys.exit(0)
564 |
565 |
566 | def main():
567 | parser = ArgumentParser(
568 | formatter_class=RawDescriptionHelpFormatter,
569 | description=f"{__longname__} (Version {__version__})",
570 | )
571 | parser.add_argument(
572 | "--version",
573 | action="version",
574 | version=f"{__shortname__} v{__version__}",
575 | help="Display version information and dependencies.",
576 | )
577 | parser.add_argument(
578 | "--verbose",
579 | "-v",
580 | "-d",
581 | "--debug",
582 | action="store_true",
583 | dest="verbose",
584 | default=False,
585 | help="Display extra debugging information and metrics.",
586 | )
587 | parser.add_argument(
588 | "--folderoutput",
589 | "-fo",
590 | dest="folderoutput",
591 | help="If using multiple usernames, the output of the results will be saved to this folder.",
592 | )
593 | parser.add_argument(
594 | "--output",
595 | "-o",
596 | dest="output",
597 | help="If using single username, the output of the result will be saved to this file.",
598 | )
599 | parser.add_argument(
600 | "--tor",
601 | "-t",
602 | action="store_true",
603 | dest="tor",
604 | default=False,
605 | help="Make requests over Tor; increases runtime; requires Tor to be installed and in system path.",
606 | )
607 | parser.add_argument(
608 | "--unique-tor",
609 | "-u",
610 | action="store_true",
611 | dest="unique_tor",
612 | default=False,
613 | help="Make requests over Tor with new Tor circuit after each request; increases runtime; requires Tor to be installed and in system path.",
614 | )
615 | parser.add_argument(
616 | "--csv",
617 | action="store_true",
618 | dest="csv",
619 | default=False,
620 | help="Create Comma-Separated Values (CSV) File.",
621 | )
622 | parser.add_argument(
623 | "--xlsx",
624 | action="store_true",
625 | dest="xlsx",
626 | default=False,
627 | help="Create the standard file for the modern Microsoft Excel spreadsheet (xlsx).",
628 | )
629 | parser.add_argument(
630 | "--site",
631 | action="append",
632 | metavar="SITE_NAME",
633 | dest="site_list",
634 | default=[],
635 | help="Limit analysis to just the listed sites. Add multiple options to specify more than one site.",
636 | )
637 | parser.add_argument(
638 | "--proxy",
639 | "-p",
640 | metavar="PROXY_URL",
641 | action="store",
642 | dest="proxy",
643 | default=None,
644 | help="Make requests over a proxy. e.g. socks5://127.0.0.1:1080",
645 | )
646 | parser.add_argument(
647 | "--dump-response",
648 | action="store_true",
649 | dest="dump_response",
650 | default=False,
651 | help="Dump the HTTP response to stdout for targeted debugging.",
652 | )
653 | parser.add_argument(
654 | "--json",
655 | "-j",
656 | metavar="JSON_FILE",
657 | dest="json_file",
658 | default=None,
659 | help="Load data from a JSON file or an online, valid, JSON file. Upstream PR numbers also accepted.",
660 | )
661 | parser.add_argument(
662 | "--timeout",
663 | action="store",
664 | metavar="TIMEOUT",
665 | dest="timeout",
666 | type=timeout_check,
667 | default=60,
668 | help="Time (in seconds) to wait for response to requests (Default: 60)",
669 | )
670 | parser.add_argument(
671 | "--print-all",
672 | action="store_true",
673 | dest="print_all",
674 | default=False,
675 | help="Output sites where the username was not found.",
676 | )
677 | parser.add_argument(
678 | "--print-found",
679 | action="store_true",
680 | dest="print_found",
681 | default=True,
682 | help="Output sites where the username was found (also if exported as file).",
683 | )
684 | parser.add_argument(
685 | "--no-color",
686 | action="store_true",
687 | dest="no_color",
688 | default=False,
689 | help="Don't color terminal output",
690 | )
691 | parser.add_argument(
692 | "username",
693 | nargs="+",
694 | metavar="USERNAMES",
695 | action="store",
696 | help="One or more usernames to check with social networks. Check similar usernames using {?} (replace to '_', '-', '.').",
697 | )
698 | parser.add_argument(
699 | "--browse",
700 | "-b",
701 | action="store_true",
702 | dest="browse",
703 | default=False,
704 | help="Browse to all results on default browser.",
705 | )
706 |
707 | parser.add_argument(
708 | "--local",
709 | "-l",
710 | action="store_true",
711 | default=False,
712 | help="Force the use of the local data.json file.",
713 | )
714 |
715 | parser.add_argument(
716 | "--nsfw",
717 | action="store_true",
718 | default=False,
719 | help="Include checking of NSFW sites from default list.",
720 | )
721 |
722 | parser.add_argument(
723 | "--no-txt",
724 | action="store_true",
725 | dest="no_txt",
726 | default=False,
727 | help="Disable creation of a txt file",
728 | )
729 |
730 | args = parser.parse_args()
731 |
732 | # If the user presses CTRL-C, exit gracefully without throwing errors
733 | signal.signal(signal.SIGINT, handler)
734 |
735 | # Check for newer version of Sherlock. If it exists, let the user know about it
736 | try:
737 | latest_release_raw = requests.get(forge_api_latest_release).text
738 | latest_release_json = json_loads(latest_release_raw)
739 | latest_remote_tag = latest_release_json["tag_name"]
740 |
741 | if latest_remote_tag[1:] != __version__:
742 | print(
743 | f"Update available! {__version__} --> {latest_remote_tag[1:]}"
744 | f"\n{latest_release_json['html_url']}"
745 | )
746 |
747 | except Exception as error:
748 | print(f"A problem occurred while checking for an update: {error}")
749 |
750 | # Argument check
751 | # TODO regex check on args.proxy
752 | if args.tor and (args.proxy is not None):
753 | raise Exception("Tor and Proxy cannot be set at the same time.")
754 |
755 | # Make prompts
756 | if args.proxy is not None:
757 | print("Using the proxy: " + args.proxy)
758 |
759 | if args.tor or args.unique_tor:
760 | print("Using Tor to make requests")
761 |
762 | print(
763 | "Warning: some websites might refuse connecting over Tor, so note that using this option might increase connection errors."
764 | )
765 |
766 | if args.no_color:
767 | # Disable color output.
768 | init(strip=True, convert=False)
769 | else:
770 | # Enable color output.
771 | init(autoreset=True)
772 |
773 | # Check if both output methods are entered as input.
774 | if args.output is not None and args.folderoutput is not None:
775 | print("You can only use one of the output methods.")
776 | sys.exit(1)
777 |
778 | # Check validity for single username output.
779 | if args.output is not None and len(args.username) != 1:
780 | print("You can only use --output with a single username")
781 | sys.exit(1)
782 |
783 | # Create object with all information about sites we are aware of.
784 | try:
785 | if args.local:
786 | sites = SitesInformation(
787 | os.path.join(os.path.dirname(__file__), "resources/data.json")
788 | )
789 | else:
790 | json_file_location = args.json_file
791 | if args.json_file:
792 | # If --json parameter is a number, interpret it as a pull request number
793 | if args.json_file.isnumeric():
794 | pull_number = args.json_file
795 | pull_url = f"https://api.github.com/repos/sherlock-project/sherlock/pulls/{pull_number}"
796 | pull_request_raw = requests.get(pull_url).text
797 | pull_request_json = json_loads(pull_request_raw)
798 |
799 | # Check if it's a valid pull request
800 | if "message" in pull_request_json:
801 | print(f"ERROR: Pull request #{pull_number} not found.")
802 | sys.exit(1)
803 |
804 | head_commit_sha = pull_request_json["head"]["sha"]
805 | json_file_location = f"https://raw.githubusercontent.com/sherlock-project/sherlock/{head_commit_sha}/sherlock_project/resources/data.json"
806 |
807 | sites = SitesInformation(json_file_location)
808 | except Exception as error:
809 | print(f"ERROR: {error}")
810 | sys.exit(1)
811 |
812 | if not args.nsfw:
813 | sites.remove_nsfw_sites(do_not_remove=args.site_list)
814 |
815 | # Create original dictionary from SitesInformation() object.
816 | # Eventually, the rest of the code will be updated to use the new object
817 | # directly, but this will glue the two pieces together.
818 | site_data_all = {site.name: site.information for site in sites}
819 | if args.site_list == []:
820 | # Not desired to look at a sub-set of sites
821 | site_data = site_data_all
822 | else:
823 | # User desires to selectively run queries on a sub-set of the site list.
824 | # Make sure that the sites are supported & build up pruned site database.
825 | site_data = {}
826 | site_missing = []
827 | for site in args.site_list:
828 | counter = 0
829 | for existing_site in site_data_all:
830 | if site.lower() == existing_site.lower():
831 | site_data[existing_site] = site_data_all[existing_site]
832 | counter += 1
833 | if counter == 0:
834 | # Build up list of sites not supported for future error message.
835 | site_missing.append(f"'{site}'")
836 |
837 | if site_missing:
838 | print(f"Error: Desired sites not found: {', '.join(site_missing)}.")
839 |
840 | if not site_data:
841 | sys.exit(1)
842 |
843 | # Create notify object for query results.
844 | query_notify = QueryNotifyPrint(
845 | result=None, verbose=args.verbose, print_all=args.print_all, browse=args.browse
846 | )
847 |
848 | # Run report on all specified users.
849 | all_usernames = []
850 | for username in args.username:
851 | if check_for_parameter(username):
852 | for name in multiple_usernames(username):
853 | all_usernames.append(name)
854 | else:
855 | all_usernames.append(username)
856 | for username in all_usernames:
857 | results = sherlock(
858 | username,
859 | site_data,
860 | query_notify,
861 | tor=args.tor,
862 | unique_tor=args.unique_tor,
863 | dump_response=args.dump_response,
864 | proxy=args.proxy,
865 | timeout=args.timeout,
866 | )
867 |
868 | if args.output:
869 | result_file = args.output
870 | elif args.folderoutput:
871 | # The usernames results should be stored in a targeted folder.
872 | # If the folder doesn't exist, create it first
873 | os.makedirs(args.folderoutput, exist_ok=True)
874 | result_file = os.path.join(args.folderoutput, f"{username}.txt")
875 | else:
876 | result_file = f"{username}.txt"
877 |
878 | if not args.no_txt:
879 | with open(result_file, "w", encoding="utf-8") as file:
880 | exists_counter = 0
881 | for website_name in results:
882 | dictionary = results[website_name]
883 | if dictionary.get("status").status == QueryStatus.CLAIMED:
884 | exists_counter += 1
885 | file.write(dictionary["url_user"] + "\n")
886 | file.write(f"Total Websites Username Detected On : {exists_counter}\n")
887 |
888 | if args.csv:
889 | result_file = f"{username}.csv"
890 | if args.folderoutput:
891 | # The usernames results should be stored in a targeted folder.
892 | # If the folder doesn't exist, create it first
893 | os.makedirs(args.folderoutput, exist_ok=True)
894 | result_file = os.path.join(args.folderoutput, result_file)
895 |
896 | with open(result_file, "w", newline="", encoding="utf-8") as csv_report:
897 | writer = csv.writer(csv_report)
898 | writer.writerow(
899 | [
900 | "username",
901 | "name",
902 | "url_main",
903 | "url_user",
904 | "exists",
905 | "http_status",
906 | "response_time_s",
907 | ]
908 | )
909 | for site in results:
910 | if (
911 | args.print_found
912 | and not args.print_all
913 | and results[site]["status"].status != QueryStatus.CLAIMED
914 | ):
915 | continue
916 |
917 | response_time_s = results[site]["status"].query_time
918 | if response_time_s is None:
919 | response_time_s = ""
920 | writer.writerow(
921 | [
922 | username,
923 | site,
924 | results[site]["url_main"],
925 | results[site]["url_user"],
926 | str(results[site]["status"].status),
927 | results[site]["http_status"],
928 | response_time_s,
929 | ]
930 | )
931 | if args.xlsx:
932 | usernames = []
933 | names = []
934 | url_main = []
935 | url_user = []
936 | exists = []
937 | http_status = []
938 | response_time_s = []
939 |
940 | for site in results:
941 | if (
942 | args.print_found
943 | and not args.print_all
944 | and results[site]["status"].status != QueryStatus.CLAIMED
945 | ):
946 | continue
947 |
948 | if response_time_s is None:
949 | response_time_s.append("")
950 | else:
951 | response_time_s.append(results[site]["status"].query_time)
952 | usernames.append(username)
953 | names.append(site)
954 | url_main.append(results[site]["url_main"])
955 | url_user.append(results[site]["url_user"])
956 | exists.append(str(results[site]["status"].status))
957 | http_status.append(results[site]["http_status"])
958 |
959 | DataFrame = pd.DataFrame(
960 | {
961 | "username": usernames,
962 | "name": names,
963 | "url_main": url_main,
964 | "url_user": url_user,
965 | "exists": exists,
966 | "http_status": http_status,
967 | "response_time_s": response_time_s,
968 | }
969 | )
970 | DataFrame.to_excel(f"{username}.xlsx", sheet_name="sheet1", index=False)
971 |
972 | print()
973 | query_notify.finish()
974 |
975 |
976 | if __name__ == "__main__":
977 | main()
978 |
--------------------------------------------------------------------------------
/sherlock_project/sites.py:
--------------------------------------------------------------------------------
1 | """Sherlock Sites Information Module
2 |
3 | This module supports storing information about websites.
4 | This is the raw data that will be used to search for usernames.
5 | """
6 | import json
7 | import requests
8 | import secrets
9 |
10 | class SiteInformation:
11 | def __init__(self, name, url_home, url_username_format, username_claimed,
12 | information, is_nsfw, username_unclaimed=secrets.token_urlsafe(10)):
13 | """Create Site Information Object.
14 |
15 | Contains information about a specific website.
16 |
17 | Keyword Arguments:
18 | self -- This object.
19 | name -- String which identifies site.
20 | url_home -- String containing URL for home of site.
21 | url_username_format -- String containing URL for Username format
22 | on site.
23 | NOTE: The string should contain the
24 | token "{}" where the username should
25 | be substituted. For example, a string
26 | of "https://somesite.com/users/{}"
27 | indicates that the individual
28 | usernames would show up under the
29 | "https://somesite.com/users/" area of
30 | the website.
31 | username_claimed -- String containing username which is known
32 | to be claimed on website.
33 | username_unclaimed -- String containing username which is known
34 | to be unclaimed on website.
35 | information -- Dictionary containing all known information
36 | about website.
37 | NOTE: Custom information about how to
38 | actually detect the existence of the
39 | username will be included in this
40 | dictionary. This information will
41 | be needed by the detection method,
42 | but it is only recorded in this
43 | object for future use.
44 | is_nsfw -- Boolean indicating if site is Not Safe For Work.
45 |
46 | Return Value:
47 | Nothing.
48 | """
49 |
50 | self.name = name
51 | self.url_home = url_home
52 | self.url_username_format = url_username_format
53 |
54 | self.username_claimed = username_claimed
55 | self.username_unclaimed = secrets.token_urlsafe(32)
56 | self.information = information
57 | self.is_nsfw = is_nsfw
58 |
59 | return
60 |
61 | def __str__(self):
62 | """Convert Object To String.
63 |
64 | Keyword Arguments:
65 | self -- This object.
66 |
67 | Return Value:
68 | Nicely formatted string to get information about this object.
69 | """
70 |
71 | return f"{self.name} ({self.url_home})"
72 |
73 |
74 | class SitesInformation:
75 | def __init__(self, data_file_path=None):
76 | """Create Sites Information Object.
77 |
78 | Contains information about all supported websites.
79 |
80 | Keyword Arguments:
81 | self -- This object.
82 | data_file_path -- String which indicates path to data file.
83 | The file name must end in ".json".
84 |
85 | There are 3 possible formats:
86 | * Absolute File Format
87 | For example, "c:/stuff/data.json".
88 | * Relative File Format
89 | The current working directory is used
90 | as the context.
91 | For example, "data.json".
92 | * URL Format
93 | For example,
94 | "https://example.com/data.json", or
95 | "http://example.com/data.json".
96 |
97 | An exception will be thrown if the path
98 | to the data file is not in the expected
99 | format, or if there was any problem loading
100 | the file.
101 |
102 | If this option is not specified, then a
103 | default site list will be used.
104 |
105 | Return Value:
106 | Nothing.
107 | """
108 |
109 | if not data_file_path:
110 | # The default data file is the live data.json which is in the GitHub repo. The reason why we are using
111 | # this instead of the local one is so that the user has the most up-to-date data. This prevents
112 | # users from creating issue about false positives which has already been fixed or having outdated data
113 | data_file_path = "https://raw.githubusercontent.com/sherlock-project/sherlock/master/sherlock_project/resources/data.json"
114 |
115 | # Ensure that specified data file has correct extension.
116 | if not data_file_path.lower().endswith(".json"):
117 | raise FileNotFoundError(f"Incorrect JSON file extension for data file '{data_file_path}'.")
118 |
119 | # if "http://" == data_file_path[:7].lower() or "https://" == data_file_path[:8].lower():
120 | if data_file_path.lower().startswith("http"):
121 | # Reference is to a URL.
122 | try:
123 | response = requests.get(url=data_file_path)
124 | except Exception as error:
125 | raise FileNotFoundError(
126 | f"Problem while attempting to access data file URL '{data_file_path}': {error}"
127 | )
128 |
129 | if response.status_code != 200:
130 | raise FileNotFoundError(f"Bad response while accessing "
131 | f"data file URL '{data_file_path}'."
132 | )
133 | try:
134 | site_data = response.json()
135 | except Exception as error:
136 | raise ValueError(
137 | f"Problem parsing json contents at '{data_file_path}': {error}."
138 | )
139 |
140 | else:
141 | # Reference is to a file.
142 | try:
143 | with open(data_file_path, "r", encoding="utf-8") as file:
144 | try:
145 | site_data = json.load(file)
146 | except Exception as error:
147 | raise ValueError(
148 | f"Problem parsing json contents at '{data_file_path}': {error}."
149 | )
150 |
151 | except FileNotFoundError:
152 | raise FileNotFoundError(f"Problem while attempting to access "
153 | f"data file '{data_file_path}'."
154 | )
155 |
156 | site_data.pop('$schema', None)
157 |
158 | self.sites = {}
159 |
160 | # Add all site information from the json file to internal site list.
161 | for site_name in site_data:
162 | try:
163 |
164 | self.sites[site_name] = \
165 | SiteInformation(site_name,
166 | site_data[site_name]["urlMain"],
167 | site_data[site_name]["url"],
168 | site_data[site_name]["username_claimed"],
169 | site_data[site_name],
170 | site_data[site_name].get("isNSFW",False)
171 |
172 | )
173 | except KeyError as error:
174 | raise ValueError(
175 | f"Problem parsing json contents at '{data_file_path}': Missing attribute {error}."
176 | )
177 | except TypeError:
178 | print(f"Encountered TypeError parsing json contents for target '{site_name}' at {data_file_path}\nSkipping target.\n")
179 |
180 | return
181 |
182 | def remove_nsfw_sites(self, do_not_remove: list = []):
183 | """
184 | Remove NSFW sites from the sites, if isNSFW flag is true for site
185 |
186 | Keyword Arguments:
187 | self -- This object.
188 |
189 | Return Value:
190 | None
191 | """
192 | sites = {}
193 | do_not_remove = [site.casefold() for site in do_not_remove]
194 | for site in self.sites:
195 | if self.sites[site].is_nsfw and site.casefold() not in do_not_remove:
196 | continue
197 | sites[site] = self.sites[site]
198 | self.sites = sites
199 |
200 | def site_name_list(self):
201 | """Get Site Name List.
202 |
203 | Keyword Arguments:
204 | self -- This object.
205 |
206 | Return Value:
207 | List of strings containing names of sites.
208 | """
209 |
210 | return sorted([site.name for site in self], key=str.lower)
211 |
212 | def __iter__(self):
213 | """Iterator For Object.
214 |
215 | Keyword Arguments:
216 | self -- This object.
217 |
218 | Return Value:
219 | Iterator for sites object.
220 | """
221 |
222 | for site_name in self.sites:
223 | yield self.sites[site_name]
224 |
225 | def __len__(self):
226 | """Length For Object.
227 |
228 | Keyword Arguments:
229 | self -- This object.
230 |
231 | Return Value:
232 | Length of sites object.
233 | """
234 | return len(self.sites)
235 |
--------------------------------------------------------------------------------
/tests/conftest.py:
--------------------------------------------------------------------------------
1 | import os
2 | import json
3 | import urllib
4 | import pytest
5 | from sherlock_project.sites import SitesInformation
6 |
7 | @pytest.fixture()
8 | def sites_obj():
9 | sites_obj = SitesInformation(data_file_path=os.path.join(os.path.dirname(__file__), "../sherlock_project/resources/data.json"))
10 | yield sites_obj
11 |
12 | @pytest.fixture(scope="session")
13 | def sites_info():
14 | sites_obj = SitesInformation(data_file_path=os.path.join(os.path.dirname(__file__), "../sherlock_project/resources/data.json"))
15 | sites_iterable = {site.name: site.information for site in sites_obj}
16 | yield sites_iterable
17 |
18 | @pytest.fixture(scope="session")
19 | def remote_schema():
20 | schema_url: str = 'https://raw.githubusercontent.com/sherlock-project/sherlock/master/sherlock_project/resources/data.schema.json'
21 | with urllib.request.urlopen(schema_url) as remoteschema:
22 | schemadat = json.load(remoteschema)
23 | yield schemadat
24 |
--------------------------------------------------------------------------------
/tests/few_test_basic.py:
--------------------------------------------------------------------------------
1 | import sherlock_project
2 |
3 | #from sherlock.sites import SitesInformation
4 | #local_manifest = data_file_path=os.path.join(os.path.dirname(__file__), "../sherlock/resources/data.json")
5 |
6 | def test_username_via_message():
7 | sherlock_project.__main__("--version")
8 |
--------------------------------------------------------------------------------
/tests/sherlock_interactives.py:
--------------------------------------------------------------------------------
1 | import os
2 | import platform
3 | import re
4 | import subprocess
5 |
6 | class Interactives:
7 | def run_cli(args:str = "") -> str:
8 | """Pass arguments to Sherlock as a normal user on the command line"""
9 | # Adapt for platform differences (Windows likes to be special)
10 | if platform.system() == "Windows":
11 | command:str = f"py -m sherlock_project {args}"
12 | else:
13 | command:str = f"sherlock {args}"
14 |
15 | proc_out:str = ""
16 | try:
17 | proc_out = subprocess.check_output(command, shell=True, stderr=subprocess.STDOUT)
18 | return proc_out.decode()
19 | except subprocess.CalledProcessError as e:
20 | raise InteractivesSubprocessError(e.output.decode())
21 |
22 |
23 | def walk_sherlock_for_files_with(pattern: str) -> list[str]:
24 | """Check all files within the Sherlock package for matching patterns"""
25 | pattern:re.Pattern = re.compile(pattern)
26 | matching_files:list[str] = []
27 | for root, dirs, files in os.walk("sherlock_project"):
28 | for file in files:
29 | file_path = os.path.join(root,file)
30 | if "__pycache__" in file_path:
31 | continue
32 | with open(file_path, 'r', errors='ignore') as f:
33 | if pattern.search(f.read()):
34 | matching_files.append(file_path)
35 | return matching_files
36 |
37 | class InteractivesSubprocessError(Exception):
38 | pass
39 |
--------------------------------------------------------------------------------
/tests/test_manifest.py:
--------------------------------------------------------------------------------
1 | import os
2 | import json
3 | import pytest
4 | from jsonschema import validate
5 |
6 | def test_validate_manifest_against_local_schema():
7 | """Ensures that the manifest matches the local schema, for situations where the schema is being changed."""
8 | json_relative: str = '../sherlock_project/resources/data.json'
9 | schema_relative: str = '../sherlock_project/resources/data.schema.json'
10 |
11 | json_path: str = os.path.join(os.path.dirname(__file__), json_relative)
12 | schema_path: str = os.path.join(os.path.dirname(__file__), schema_relative)
13 |
14 | with open(json_path, 'r') as f:
15 | jsondat = json.load(f)
16 | with open(schema_path, 'r') as f:
17 | schemadat = json.load(f)
18 |
19 | validate(instance=jsondat, schema=schemadat)
20 |
21 |
22 | @pytest.mark.online
23 | def test_validate_manifest_against_remote_schema(remote_schema):
24 | """Ensures that the manifest matches the remote schema, so as to not unexpectedly break clients."""
25 | json_relative: str = '../sherlock_project/resources/data.json'
26 | json_path: str = os.path.join(os.path.dirname(__file__), json_relative)
27 |
28 | with open(json_path, 'r') as f:
29 | jsondat = json.load(f)
30 |
31 | validate(instance=jsondat, schema=remote_schema)
32 |
33 | # Ensure that the expected values are beind returned by the site list
34 | @pytest.mark.parametrize("target_name,target_expected_err_type", [
35 | ('GitHub', 'status_code'),
36 | ('GitLab', 'message'),
37 | ])
38 | def test_site_list_iterability (sites_info, target_name, target_expected_err_type):
39 | assert sites_info[target_name]['errorType'] == target_expected_err_type
40 |
--------------------------------------------------------------------------------
/tests/test_probes.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | import random
3 | import string
4 | import re
5 | from sherlock_project.sherlock import sherlock
6 | from sherlock_project.notify import QueryNotify
7 | from sherlock_project.result import QueryStatus
8 | #from sherlock_interactives import Interactives
9 |
10 |
11 | def simple_query(sites_info: dict, site: str, username: str) -> QueryStatus:
12 | query_notify = QueryNotify()
13 | site_data: dict = {}
14 | site_data[site] = sites_info[site]
15 | return sherlock(
16 | username=username,
17 | site_data=site_data,
18 | query_notify=query_notify,
19 | )[site]['status'].status
20 |
21 |
22 | @pytest.mark.online
23 | class TestLiveTargets:
24 | """Actively test probes against live and trusted targets"""
25 | # Known positives should only use sites trusted to be reliable and unchanging
26 | @pytest.mark.parametrize('site,username',[
27 | ('GitLab', 'ppfeister'),
28 | ('AllMyLinks', 'blue'),
29 | ])
30 | def test_known_positives_via_message(self, sites_info, site, username):
31 | assert simple_query(sites_info=sites_info, site=site, username=username) is QueryStatus.CLAIMED
32 |
33 |
34 | # Known positives should only use sites trusted to be reliable and unchanging
35 | @pytest.mark.parametrize('site,username',[
36 | ('GitHub', 'ppfeister'),
37 | ('GitHub', 'sherlock-project'),
38 | ('Docker Hub', 'ppfeister'),
39 | ('Docker Hub', 'sherlock'),
40 | ])
41 | def test_known_positives_via_status_code(self, sites_info, site, username):
42 | assert simple_query(sites_info=sites_info, site=site, username=username) is QueryStatus.CLAIMED
43 |
44 |
45 | # Known positives should only use sites trusted to be reliable and unchanging
46 | @pytest.mark.parametrize('site,username',[
47 | ('Keybase', 'blue'),
48 | ('devRant', 'blue'),
49 | ])
50 | def test_known_positives_via_response_url(self, sites_info, site, username):
51 | assert simple_query(sites_info=sites_info, site=site, username=username) is QueryStatus.CLAIMED
52 |
53 |
54 | # Randomly generate usernames of high length and test for positive availability
55 | # Randomly generated usernames should be simple alnum for simplicity and high
56 | # compatibility. Several attempts may be made ~just in case~ a real username is
57 | # generated.
58 | @pytest.mark.parametrize('site,random_len',[
59 | ('GitLab', 255),
60 | ('Codecademy', 30)
61 | ])
62 | def test_likely_negatives_via_message(self, sites_info, site, random_len):
63 | num_attempts: int = 3
64 | attempted_usernames: list[str] = []
65 | status: QueryStatus = QueryStatus.CLAIMED
66 | for i in range(num_attempts):
67 | acceptable_types = string.ascii_letters + string.digits
68 | random_handle = ''.join(random.choice(acceptable_types) for _ in range (random_len))
69 | attempted_usernames.append(random_handle)
70 | status = simple_query(sites_info=sites_info, site=site, username=random_handle)
71 | if status is QueryStatus.AVAILABLE:
72 | break
73 | assert status is QueryStatus.AVAILABLE, f"Could not validate available username after {num_attempts} attempts with randomly generated usernames {attempted_usernames}."
74 |
75 |
76 | # Randomly generate usernames of high length and test for positive availability
77 | # Randomly generated usernames should be simple alnum for simplicity and high
78 | # compatibility. Several attempts may be made ~just in case~ a real username is
79 | # generated.
80 | @pytest.mark.parametrize('site,random_len',[
81 | ('GitHub', 39),
82 | ('Docker Hub', 30)
83 | ])
84 | def test_likely_negatives_via_status_code(self, sites_info, site, random_len):
85 | num_attempts: int = 3
86 | attempted_usernames: list[str] = []
87 | status: QueryStatus = QueryStatus.CLAIMED
88 | for i in range(num_attempts):
89 | acceptable_types = string.ascii_letters + string.digits
90 | random_handle = ''.join(random.choice(acceptable_types) for _ in range (random_len))
91 | attempted_usernames.append(random_handle)
92 | status = simple_query(sites_info=sites_info, site=site, username=random_handle)
93 | if status is QueryStatus.AVAILABLE:
94 | break
95 | assert status is QueryStatus.AVAILABLE, f"Could not validate available username after {num_attempts} attempts with randomly generated usernames {attempted_usernames}."
96 |
97 |
98 | def test_username_illegal_regex(sites_info):
99 | site: str = 'BitBucket'
100 | invalid_handle: str = '*#$Y&*JRE'
101 | pattern = re.compile(sites_info[site]['regexCheck'])
102 | # Ensure that the username actually fails regex before testing sherlock
103 | assert pattern.match(invalid_handle) is None
104 | assert simple_query(sites_info=sites_info, site=site, username=invalid_handle) is QueryStatus.ILLEGAL
105 |
106 |
--------------------------------------------------------------------------------
/tests/test_ux.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from sherlock_project import sherlock
3 | from sherlock_interactives import Interactives
4 | from sherlock_interactives import InteractivesSubprocessError
5 |
6 | def test_remove_nsfw(sites_obj):
7 | nsfw_target: str = 'Pornhub'
8 | assert nsfw_target in {site.name: site.information for site in sites_obj}
9 | sites_obj.remove_nsfw_sites()
10 | assert nsfw_target not in {site.name: site.information for site in sites_obj}
11 |
12 |
13 | # Parametrized sites should *not* include Motherless, which is acting as the control
14 | @pytest.mark.parametrize('nsfwsites', [
15 | ['Pornhub'],
16 | ['Pornhub', 'Xvideos'],
17 | ])
18 | def test_nsfw_explicit_selection(sites_obj, nsfwsites):
19 | for site in nsfwsites:
20 | assert site in {site.name: site.information for site in sites_obj}
21 | sites_obj.remove_nsfw_sites(do_not_remove=nsfwsites)
22 | for site in nsfwsites:
23 | assert site in {site.name: site.information for site in sites_obj}
24 | assert 'Motherless' not in {site.name: site.information for site in sites_obj}
25 |
26 | def test_wildcard_username_expansion():
27 | assert sherlock.check_for_parameter('test{?}test') is True
28 | assert sherlock.check_for_parameter('test{.}test') is False
29 | assert sherlock.check_for_parameter('test{}test') is False
30 | assert sherlock.check_for_parameter('testtest') is False
31 | assert sherlock.check_for_parameter('test{?test') is False
32 | assert sherlock.check_for_parameter('test?}test') is False
33 | assert sherlock.multiple_usernames('test{?}test') == ["test_test" , "test-test" , "test.test"]
34 |
35 |
36 | @pytest.mark.parametrize('cliargs', [
37 | '',
38 | '--site urghrtuight --egiotr',
39 | '--',
40 | ])
41 | def test_no_usernames_provided(cliargs):
42 | with pytest.raises(InteractivesSubprocessError, match=r"error: the following arguments are required: USERNAMES"):
43 | Interactives.run_cli(cliargs)
44 |
--------------------------------------------------------------------------------
/tests/test_version.py:
--------------------------------------------------------------------------------
1 | import os
2 | from sherlock_interactives import Interactives
3 | import sherlock_project
4 |
5 | def test_versioning() -> None:
6 | # Ensure __version__ matches version presented to the user
7 | assert sherlock_project.__version__ in Interactives.run_cli("--version")
8 | # Ensure __init__ is single source of truth for __version__ in package
9 | # Temporarily allows sherlock.py so as to not trigger early upgrades
10 | found:list = Interactives.walk_sherlock_for_files_with(r'__version__ *= *')
11 | expected:list = [
12 | # Normalization is REQUIRED for Windows ( / vs \ )
13 | os.path.normpath("sherlock_project/__init__.py"),
14 | ]
15 | # Sorting is REQUIRED for Mac
16 | assert sorted(found) == sorted(expected)
17 |
--------------------------------------------------------------------------------
/tox.ini:
--------------------------------------------------------------------------------
1 | [tox]
2 | requires =
3 | tox >= 3
4 | envlist =
5 | lint
6 | py313
7 | py312
8 | py311
9 | py310
10 | py39
11 | py38
12 |
13 | [testenv]
14 | description = Attempt to build and install the package
15 | deps =
16 | coverage
17 | jsonschema
18 | pytest
19 | allowlist_externals = coverage
20 | commands =
21 | coverage run --source=sherlock_project --module pytest -v
22 | coverage report --show-missing
23 |
24 | [testenv:offline]
25 | deps =
26 | jsonschema
27 | pytest
28 | commands =
29 | pytest -v -m "not online"
30 |
31 | [testenv:lint]
32 | description = Lint with Ruff
33 | deps =
34 | ruff
35 | commands =
36 | ruff check
37 |
38 | [gh-actions]
39 | python =
40 | 3.12: py312
41 | 3.11: py311
42 | 3.10: py310
43 | 3.9: py39
44 |
--------------------------------------------------------------------------------
 19 |
20 |
19 |
20 | 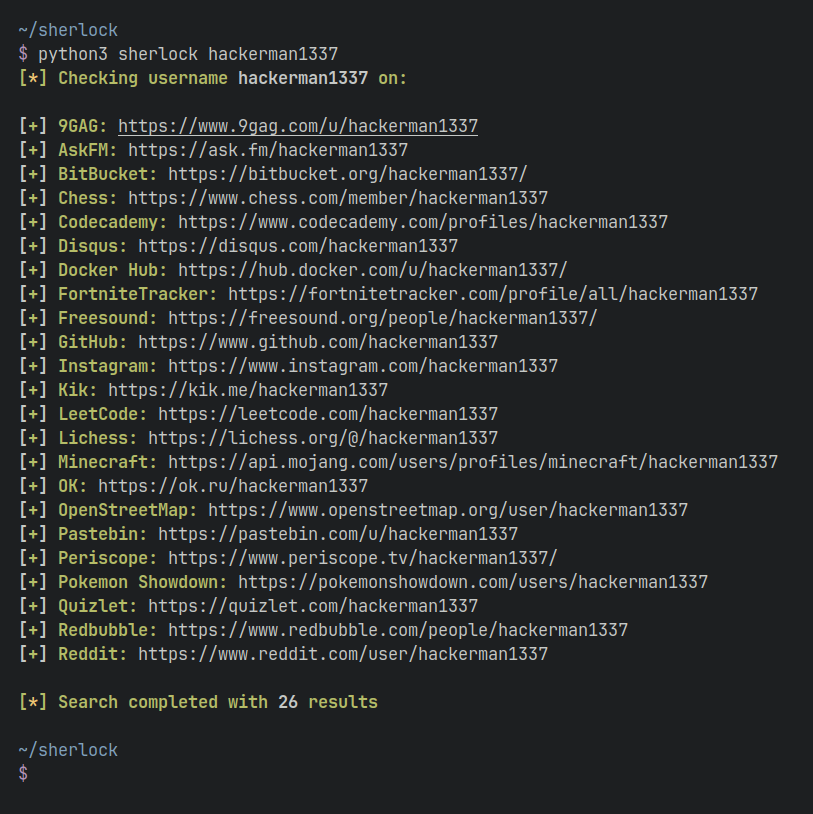 41 |
42 |
41 |
42 |