├── .gitignore
├── Data
├── VisualGenome
│ ├── LICENSE.txt
│ ├── __init__.py
│ ├── api.py
│ ├── local.py
│ ├── models.py
│ └── utils.py
└── __init__.py
├── FilesManager
├── FilesManager.py
├── LanguageModule
│ ├── object_embeddings.p
│ └── predicate_embeddings.p
├── __init__.py
├── files.yaml
└── module
│ ├── params.yaml
│ ├── saver
│ └── __init__.py
│ └── tf_logs
│ └── __init__.py
├── Module
├── Eval.py
├── Module.py
├── Train.py
└── __init__.py
├── README.md
├── Run.py
├── Utils
├── Logger.py
├── Singleton.py
└── __init__.py
├── __init__.py
├── qualitive_results_att_boxes.png
├── requirements.txt
├── sg_example_final.png
└── sgp_arch_git.png
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | env/
12 | build/
13 | develop-eggs/
14 | dist/
15 | downloads/
16 | eggs/
17 | .eggs/
18 | lib/
19 | lib64/
20 | parts/
21 | sdist/
22 | var/
23 | wheels/
24 | *.egg-info/
25 | .installed.cfg
26 | *.egg
27 |
28 | # PyInstaller
29 | # Usually these files are written by a python script from a template
30 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
31 | *.manifest
32 | *.spec
33 |
34 | # Installer logs
35 | pip-log.txt
36 | pip-delete-this-directory.txt
37 |
38 | # Unit test / coverage reports
39 | htmlcov/
40 | .tox/
41 | .coverage
42 | .coverage.*
43 | .cache
44 | nosetests.xml
45 | coverage.xml
46 | *.cover
47 | .hypothesis/
48 |
49 | # Translations
50 | *.mo
51 | *.pot
52 |
53 | # Django stuff:
54 | *.log
55 | local_settings.py
56 |
57 | # Flask stuff:
58 | instance/
59 | .webassets-cache
60 |
61 | # Scrapy stuff:
62 | .scrapy
63 |
64 | # Sphinx documentation
65 | docs/_build/
66 |
67 | # PyBuilder
68 | target/
69 |
70 | # Jupyter Notebook
71 | .ipynb_checkpoints
72 |
73 | # pyenv
74 | .python-version
75 |
76 | # celery beat schedule file
77 | celerybeat-schedule
78 |
79 | # SageMath parsed files
80 | *.sage.py
81 |
82 | # dotenv
83 | .env
84 |
85 | # virtualenv
86 | .venv
87 | venv/
88 | ENV/
89 |
90 | # Spyder project settings
91 | .spyderproject
92 | .spyproject
93 |
94 | # Rope project settings
95 | .ropeproject
96 |
97 | # mkdocs documentation
98 | /site
99 |
100 | # mypy
101 | .mypy_cache/
102 |
103 | #additional
104 | FilesManager/module/tf_logs/
105 | FilesManager/module/saver/
106 |
--------------------------------------------------------------------------------
/Data/VisualGenome/LICENSE.txt:
--------------------------------------------------------------------------------
1 | Copyright (c) 2015 Ranjay Krishna
2 |
3 |
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 |
13 |
14 | The above copyright notice and this permission notice shall be included in
15 | all copies or substantial portions of the Software.
16 |
17 |
18 |
19 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
20 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
21 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
22 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
23 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
24 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
25 | THE SOFTWARE.
26 |
--------------------------------------------------------------------------------
/Data/VisualGenome/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/shikorab/SceneGraph/d2dc960a0d3728e7d2b0eaceb9d0fdaedb2a47d5/Data/VisualGenome/__init__.py
--------------------------------------------------------------------------------
/Data/VisualGenome/api.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 | import utils
3 |
4 |
5 | def GetAllImageIds():
6 | """
7 | Get all Image ids.
8 | """
9 | page = 1
10 | next = '/api/v0/images/all?page=' + str(page)
11 | ids = []
12 | while True:
13 | data = utils.RetrieveData(next)
14 | ids.extend(data['results'])
15 | if data['next'] is None:
16 | break
17 | page += 1
18 | next = '/api/v0/images/all?page=' + str(page)
19 | return ids
20 |
21 |
22 | def GetImageIdsInRange(startIndex=0, endIndex=99):
23 | """
24 | Get Image ids from startIndex to endIndex.
25 | """
26 | idsPerPage = 1000
27 | startPage = startIndex / idsPerPage + 1
28 | endPage = endIndex / idsPerPage + 1
29 | ids = []
30 | for page in range(startPage, endPage + 1):
31 | data = utils.RetrieveData('/api/v0/images/all?page=' + str(page))
32 | ids.extend(data['results'])
33 | ids = ids[startIndex % 100:]
34 | ids = ids[:endIndex - startIndex + 1]
35 | return ids
36 |
37 |
38 | def GetImageData(id=61512):
39 | """
40 | Get data about an image.
41 | """
42 | data = utils.RetrieveData('/api/v0/images/' + str(id))
43 | if 'detail' in data and data['detail'] == 'Not found.':
44 | return None
45 | image = utils.ParseImageData(data)
46 | return image
47 |
48 |
49 | def GetRegionDescriptionsOfImage(id=61512):
50 | """
51 | Get the region descriptions of an image.
52 | """
53 | image = GetImageData(id=id)
54 | data = utils.RetrieveData('/api/v0/images/' + str(id) + '/regions')
55 | if 'detail' in data and data['detail'] == 'Not found.':
56 | return None
57 | return utils.ParseRegionDescriptions(data, image)
58 |
59 |
60 | def GetRegionGraphOfRegion(image_id=61512, region_id=1):
61 | """
62 | Get Region Graph of a particular Region in an image.
63 | """
64 | image = GetImageData(id=image_id)
65 | data = utils.RetrieveData('/api/v0/images/' + str(image_id) + '/regions/' + str(region_id))
66 | if 'detail' in data and data['detail'] == 'Not found.':
67 | return None
68 | return utils.ParseGraph(data[0], image)
69 |
70 |
71 | def GetSceneGraphOfImage(id=61512):
72 | """
73 | Get Scene Graph of an image.
74 | """
75 | image = GetImageData(id=id)
76 | data = utils.RetrieveData('/api/v0/images/' + str(id) + '/graph')
77 | if 'detail' in data and data['detail'] == 'Not found.':
78 | return None
79 | return utils.ParseGraph(data, image)
80 |
81 |
82 | def GetAllQAs(qtotal=100):
83 | """
84 | Gets all the QA from the dataset.
85 | qtotal int total number of QAs to return. Set to None if all QAs should be returned
86 | """
87 | page = 1
88 | next = '/api/v0/qa/all?page=' + str(page)
89 | qas = []
90 | image_map = {}
91 | while True:
92 | data = utils.RetrieveData(next)
93 | for d in data['results']:
94 | if d['image'] not in image_map:
95 | image_map[d['image']] = GetImageData(id=d['image'])
96 | qas.extend(utils.ParseQA(data['results'], image_map))
97 | if qtotal is not None and len(qas) > qtotal:
98 | return qas
99 | if data['next'] is None:
100 | break
101 | page += 1
102 | next = '/api/v0/qa/all?page=' + str(page)
103 | return qas
104 |
105 |
106 | def GetQAofType(qtype='why', qtotal=100):
107 | """
108 | Get all QA's of a particular type - example, 'why'
109 | qtype string possible values: what, where, when, why, who, how.
110 | qtotal int total number of QAs to return. Set to None if all QAs should be returned
111 | """
112 | page = 1
113 | next = '/api/v0/qa/' + qtype + '?page=' + str(page)
114 | qas = []
115 | image_map = {}
116 | while True:
117 | data = utils.RetrieveData(next)
118 | for d in data['results']:
119 | if d['image'] not in image_map:
120 | image_map[d['image']] = GetImageData(id=d['image'])
121 | qas.extend(utils.ParseQA(data['results'], image_map))
122 | if qtotal is not None and len(qas) > qtotal:
123 | return qas
124 | if data['next'] is None:
125 | break
126 | page += 1
127 | next = '/api/v0/qa/' + qtype + '?page=' + str(page)
128 | return qas
129 |
130 |
131 | def GetQAofImage(id=61512):
132 | """
133 | Get all QAs for a particular image.
134 | """
135 | page = 1
136 | next = '/api/v0/image/' + str(id) + '/qa?page=' + str(page)
137 | qas = []
138 | image_map = {}
139 | while True:
140 | data = utils.RetrieveData(next)
141 | for d in data['results']:
142 | if d['image'] not in image_map:
143 | image_map[d['image']] = GetImageData(id=d['image'])
144 | qas.extend(utils.ParseQA(data['results'], image_map))
145 | if data['next'] is None:
146 | break
147 | page += 1
148 | next = '/api/v0/image/' + str(id) + '/qa?page=' + str(page)
149 | return qas
150 |
151 |
--------------------------------------------------------------------------------
/Data/VisualGenome/local.py:
--------------------------------------------------------------------------------
1 | import gc
2 | import json
3 | import os
4 |
5 | import utils
6 | from models import Graph, Synset
7 | from models import Image, Object, Attribute, Relationship
8 |
9 |
10 | def GetAllImageData(dataDir=None):
11 | """
12 | Get Image ids from startIndex to endIndex.
13 | """
14 |
15 | if dataDir is None:
16 | dataDir = utils.GetDataDir()
17 | dataFile = os.path.join(dataDir, 'image_data.json')
18 | data = json.load(open(dataFile))
19 | return [utils.ParseImageData(image) for image in data]
20 |
21 |
22 | def GetAllRegionDescriptions(dataDir=None):
23 | """
24 | Get all region descriptions.
25 | """
26 | if dataDir is None:
27 | dataDir = utils.GetDataDir()
28 | dataFile = os.path.join(dataDir, 'region_descriptions.json')
29 | imageData = GetAllImageData(dataDir)
30 | imageMap = {}
31 | for d in imageData:
32 | imageMap[d.id] = d
33 | images = json.load(open(dataFile))
34 | output = []
35 | for image in images:
36 | output.append(utils.ParseRegionDescriptions(image['regions'], imageMap[image['id']]))
37 | return output
38 |
39 |
40 | def GetAllQAs(dataDir=None):
41 | """
42 | Get all question answers.
43 | """
44 | if dataDir is None:
45 | dataDir = utils.GetDataDir()
46 | dataFile = os.path.join(dataDir, 'question_answers.json')
47 | imageData = GetAllImageData(dataDir)
48 | imageMap = {}
49 | for d in imageData:
50 | imageMap[d.id] = d
51 | images = json.load(open(dataFile))
52 | output = []
53 | for image in images:
54 | output.append(utils.ParseQA(image['qas'], imageMap))
55 | return output
56 |
57 |
58 | # --------------------------------------------------------------------------------------------------
59 | # GetSceneGraphs and sub-methods
60 |
61 |
62 | def GetSceneGraph(image_id, images='data/', imageDataDir='data/by-id/', synsetFile='data/synsets.json'):
63 | """
64 | Load a single scene graph from a .json file.
65 | """
66 | if type(images) is str:
67 | # Instead of a string, we can pass this dict as the argument `images`
68 | images = {img.id: img for img in GetAllImageData(images)}
69 |
70 | fname = str(image_id) + '.json'
71 | image = images[image_id]
72 | data = json.load(open(imageDataDir + fname, 'r'))
73 |
74 | scene_graph = ParseGraphLocal(data, image)
75 | scene_graph = InitSynsets(scene_graph, synsetFile)
76 | return scene_graph
77 |
78 |
79 | def GetSceneGraphs(startIndex=0, endIndex=-1,
80 | dataDir='data/', imageDataDir='data/by-id/',
81 | minRels=0, maxRels=100):
82 | """
83 | Get scene graphs given locally stored .json files; requires `SaveSceneGraphsById`.
84 |
85 | startIndex, endIndex : get scene graphs listed by image, from startIndex through endIndex
86 | dataDir : directory with `image_data.json` and `synsets.json`
87 | imageDataDir : directory of scene graph jsons saved by image id (see `SaveSceneGraphsById`)
88 | minRels, maxRels: only get scene graphs with at least / less than this number of relationships
89 | """
90 | images = {img.id: img for img in GetAllImageData(dataDir)}
91 | scene_graphs = []
92 |
93 | img_fnames = os.listdir(imageDataDir)
94 | if endIndex < 1:
95 | endIndex = len(img_fnames)
96 |
97 | for fname in img_fnames[startIndex: endIndex]:
98 | image_id = int(fname.split('.')[0])
99 | scene_graph = GetSceneGraph(image_id, images, imageDataDir, dataDir + 'synsets.json')
100 | n_rels = len(scene_graph.relationships)
101 | if minRels <= n_rels <= maxRels:
102 | scene_graphs.append(scene_graph)
103 |
104 | return scene_graphs
105 |
106 |
107 | def MapObject(object_map, obj):
108 | """
109 | Use object ids as hashes to `src.models.Object` instances. If item not
110 | in table, create new `Object`. Used when building scene graphs from json.
111 | """
112 | oid = obj['object_id']
113 | obj['id'] = oid
114 | del obj['object_id']
115 |
116 | if oid in object_map:
117 | object_ = object_map[oid]
118 |
119 | else:
120 | if 'attributes' in obj:
121 | attrs = obj['attributes']
122 | del obj['attributes']
123 | else:
124 | attrs = []
125 | if 'w' in obj:
126 | obj['width'] = obj['w']
127 | obj['height'] = obj['h']
128 | del obj['w'], obj['h']
129 |
130 | object_ = Object(**obj)
131 |
132 | object_.attributes = attrs
133 | object_map[oid] = object_
134 |
135 | return object_map, object_
136 |
137 |
138 | global count_skips
139 | count_skips = [0, 0]
140 |
141 |
142 | def ParseGraphLocal(data, image, verbose=False):
143 | """
144 | Modified version of `utils.ParseGraph`.
145 | """
146 |
147 | global count_skips
148 | objects = []
149 | object_map = {}
150 | relationships = []
151 | attributes = []
152 |
153 | for obj in data['objects']:
154 | object_map, o_ = MapObject(object_map, obj)
155 | objects.append(o_)
156 | for rel in data['relationships']:
157 | if rel['subject_id'] in object_map and rel['object_id'] in object_map:
158 | object_map, s = MapObject(object_map, {'object_id': rel['subject_id']})
159 | v = rel['predicate']
160 | object_map, o = MapObject(object_map, {'object_id': rel['object_id']})
161 | rid = rel['relationship_id']
162 | relationships.append(Relationship(rid, s, v, o, rel['synsets']))
163 | else:
164 | # Skip this relationship if we don't have the subject and object in
165 | # the object_map for this scene graph. Some data is missing in this way.
166 | count_skips[0] += 1
167 | if 'attributes' in data:
168 | for attr in data['attributes']:
169 | a = attr['attribute']
170 | if a['object_id'] in object_map:
171 | attributes.append(Attribute(attr['attribute_id'], a['object_id'], a['names'], a['synsets']))
172 | else:
173 | count_skips[1] += 1
174 | if verbose:
175 | print 'Skipped {} rels, {} attrs total'.format(*count_skips)
176 | return Graph(image, objects, relationships, attributes)
177 |
178 |
179 | def InitSynsets(scene_graph, synset_file):
180 | """
181 | Convert synsets in a scene graph from strings to Synset objects.
182 | """
183 |
184 | syn_data = json.load(open(synset_file, 'r'))
185 | syn_class = {s['synset_name']: Synset(s['synset_name'], s['synset_definition']) for s in syn_data}
186 |
187 | for obj in scene_graph.objects:
188 | obj.synsets = [syn_class[sn] for sn in obj.synsets]
189 | for rel in scene_graph.relationships:
190 | rel.synset = [syn_class[sn] for sn in rel.synset]
191 | for attr in scene_graph.attributes:
192 | obj.synset = [syn_class[sn] for sn in attr.synset]
193 |
194 | return scene_graph
195 |
196 |
197 | # --------------------------------------------------------------------------------------------------
198 | # This is a pre-processing step that only needs to be executed once.
199 | # You can download .jsons segmented with these methods from:
200 | # https://drive.google.com/file/d/0Bygumy5BKFtcQ1JrcFpyQWdaQWM
201 |
202 |
203 | def SaveSceneGraphsById(dataDir='data/', imageDataDir='data/by-id/'):
204 | """
205 | Save a separate .json file for each image id in `imageDataDir`.
206 |
207 | Notes
208 | -----
209 | - If we don't save .json's by id, `scene_graphs.json` is >6G in RAM
210 | - Separated .json files are ~1.1G on disk
211 | - Run `AddAttrsToSceneGraphs` before `ParseGraphLocal` will work
212 | - Attributes are only present in objects, and do not have synset info
213 |
214 | Each output .json has the following keys:
215 | - "id"
216 | - "objects"
217 | - "relationships"
218 | """
219 |
220 | if not os.path.exists(imageDataDir):
221 | os.mkdir(imageDataDir)
222 |
223 | all_data = json.load(open(os.path.join(dataDir, 'scene_graphs.json')))
224 | for sg_data in all_data:
225 | img_fname = str(sg_data['image_id']) + '.json'
226 | with open(os.path.join(imageDataDir, img_fname), 'w') as f:
227 | json.dump(sg_data, f)
228 |
229 | del all_data
230 | gc.collect() # clear memory
231 |
232 |
233 | def AddAttrsToSceneGraphs(dataDir='data/'):
234 | """
235 | Add attributes to `scene_graph.json`, extracted from `attributes.json`.
236 |
237 | This also adds a unique id to each attribute, and separates individual
238 | attibutes for each object (these are grouped in `attributes.json`).
239 | """
240 |
241 | attr_data = json.load(open(os.path.join(dataDir, 'attributes.json')))
242 | with open(os.path.join(dataDir, 'scene_graphs.json')) as f:
243 | sg_dict = {sg['image_id']: sg for sg in json.load(f)}
244 |
245 | id_count = 0
246 | for img_attrs in attr_data:
247 | attrs = []
248 | for attribute in img_attrs['attributes']:
249 | a = img_attrs.copy()
250 | del a['attributes']
251 | a['attribute'] = attribute
252 | a['attribute_id'] = id_count
253 | attrs.append(a)
254 | id_count += 1
255 | iid = img_attrs['image_id']
256 | sg_dict[iid]['attributes'] = attrs
257 |
258 | with open(os.path.join(dataDir, 'scene_graphs.json'), 'w') as f:
259 | json.dump(sg_dict.values(), f)
260 | del attr_data, sg_dict
261 | gc.collect()
262 |
263 |
264 | # --------------------------------------------------------------------------------------------------
265 | # For info on VRD dataset, see:
266 | # http://cs.stanford.edu/people/ranjaykrishna/vrd/
267 |
268 | def GetSceneGraphsVRD(json_file='data/vrd/json/test.json'):
269 | """
270 | Load VRD dataset into scene graph format.
271 | """
272 |
273 | scene_graphs = []
274 | with open(json_file, 'r') as f:
275 | D = json.load(f)
276 |
277 | scene_graphs = [ParseGraphVRD(d) for d in D]
278 | return scene_graphs
279 |
280 |
281 | def ParseGraphVRD(d):
282 | image = Image(d['photo_id'], d['filename'], d['width'], d['height'], '', '')
283 |
284 | id2obj = {}
285 | objs = []
286 | rels = []
287 | atrs = []
288 |
289 | for i, o in enumerate(d['objects']):
290 | b = o['bbox']
291 | obj = Object(i, b['x'], b['y'], b['w'], b['h'], o['names'], [])
292 | id2obj[i] = obj
293 | objs.append(obj)
294 |
295 | for j, a in enumerate(o['attributes']):
296 | atrs.append(Attribute(j, obj, a['attribute'], []))
297 |
298 | for i, r in enumerate(d['relationships']):
299 | s = id2obj[r['objects'][0]]
300 | o = id2obj[r['objects'][1]]
301 | v = r['relationship']
302 | rels.append(Relationship(i, s, v, o, []))
303 |
304 | return Graph(image, objs, rels, atrs)
305 |
306 |
307 | if __name__ == '__main__':
308 | # AddAttrsToSceneGraphs()
309 | # SaveSceneGraphsById()
310 | image_data = GetAllImageData()
311 | region_interest = GetAllRegionDescriptions()
312 | qas = GetAllQAs()
313 | tt = GetSceneGraph(1)
314 | print("We got an image")
315 |
--------------------------------------------------------------------------------
/Data/VisualGenome/models.py:
--------------------------------------------------------------------------------
1 | """
2 | Visual Genome Python API wrapper, models
3 | """
4 |
5 |
6 | class Image:
7 | """
8 | Image.
9 | ID int
10 | url hyperlink string
11 | width int
12 | height int
13 | """
14 |
15 | def __init__(self, id, url, width, height, coco_id, flickr_id):
16 | """
17 |
18 | :param id: ID int
19 | :param url: url hyperlink string
20 | :param width: width int
21 | :param height: height int
22 | :param coco_id:
23 | :param flickr_id:
24 | """
25 | self.id = id
26 | self.url = url
27 | self.width = width
28 | self.height = height
29 | self.coco_id = coco_id
30 | self.flickr_id = flickr_id
31 |
32 | def __str__(self):
33 | return 'id: %d, coco_id: %d, flickr_id: %d, width: %d, url: %s' \
34 | % (
35 | self.id, -1 if self.coco_id is None else self.coco_id,
36 | -1 if self.flickr_id is None else self.flickr_id,
37 | self.width, self.url)
38 |
39 | def __repr__(self):
40 | return str(self)
41 |
42 |
43 | class Region:
44 | """
45 | Region.
46 | image int
47 | phrase string
48 | x int
49 | y int
50 | width int
51 | height int
52 | """
53 |
54 | def __init__(self, id, image, phrase, x, y, width, height):
55 | """
56 |
57 | :param id:
58 | :param image: image int
59 | :param phrase: phrase string
60 | :param x: x int
61 | :param y: y int
62 | :param width: width int
63 | :param height: height int
64 | """
65 | self.id = id
66 | self.image = image
67 | self.phrase = phrase
68 | self.x = x
69 | self.y = y
70 | self.width = width
71 | self.height = height
72 |
73 | def __str__(self):
74 | return 'id: %d, x: %d, y: %d, width: %d, height: %d, phrase: %s, image: %d' % \
75 | (self.id, self.x, self.y, self.width, self.height, self.phrase, self.image.id)
76 |
77 | def __repr__(self):
78 | return str(self)
79 |
80 |
81 | class Graph:
82 | """
83 | Graphs contain objects, relationships and attributes
84 | image Image
85 | bboxes Object array
86 | relationships Relationship array
87 | attributes Attribute array
88 | """
89 |
90 | def __init__(self, image, objects, relationships, attributes):
91 | self.image = image
92 | self.objects = objects
93 | self.relationships = relationships
94 | self.attributes = attributes
95 |
96 |
97 | class Object:
98 | """
99 | Objects.
100 | id int
101 | x int
102 | y int
103 | width int
104 | height int
105 | names string array
106 | synsets Synset array
107 | """
108 |
109 | def __init__(self, id, x, y, width, height, names, synsets):
110 | self.id = id
111 | self.x = x
112 | self.y = y
113 | self.width = width
114 | self.height = height
115 | self.names = names
116 | self.synsets = synsets
117 |
118 | def __str__(self):
119 | name = self.names[0] if len(self.names) != 0 else 'None'
120 | return '%s' % (name)
121 |
122 | def __repr__(self):
123 | return str(self)
124 |
125 |
126 | class Relationship:
127 | """
128 | Relationships. Ex, 'man - jumping over - fire hydrant'.
129 | subject int
130 | predicate string
131 | object int
132 | rel_canon Synset
133 | """
134 |
135 | def __init__(self, id, subject, predicate, object, synset):
136 | self.id = id
137 | self.subject = subject
138 | self.predicate = predicate
139 | self.object = object
140 | self.synset = synset
141 |
142 | def __str__(self):
143 | return "%d: %s %s %s" % (self.id, self.subject, self.predicate, self.object)
144 |
145 | def __repr__(self):
146 | return str(self)
147 |
148 |
149 | class Attribute:
150 | """
151 | Attributes. Ex, 'man - old'.
152 | subject Object
153 | attribute string
154 | synset Synset
155 | """
156 | def __init__(self, id, subject, attribute, synset):
157 | self.id = id
158 | self.subject = subject
159 | self.attribute = attribute
160 | self.synset = synset
161 |
162 | def __str__(self):
163 | return "%d: %s is %s" % (self.id, self.subject, self.attribute)
164 |
165 | def __repr__(self):
166 | return str(self)
167 |
168 |
169 | class QA:
170 | """
171 | Question Answer Pairs.
172 | ID int
173 | image int
174 | question string
175 | answer string
176 | q_objects QAObject array
177 | a_objects QAObject array
178 | """
179 |
180 | def __init__(self, id, image, question, answer, question_objects, answer_objects):
181 | self.id = id
182 | self.image = image
183 | self.question = question
184 | self.answer = answer
185 | self.q_objects = question_objects
186 | self.a_objects = answer_objects
187 |
188 | def __str__(self):
189 | return 'id: %d, image: %d, question: %s, answer: %s' \
190 | % (self.id, self.image.id, self.question, self.answer)
191 |
192 | def __repr__(self):
193 | return str(self)
194 |
195 |
196 | class QAObject:
197 | """
198 | Question Answer Objects are localized in the image and refer to a part
199 | of the question text or the answer text.
200 | start_idx int
201 | end_idx int
202 | name string
203 | synset_name string
204 | synset_definition string
205 | """
206 |
207 | def __init__(self, start_idx, end_idx, name, synset):
208 | self.start_idx = start_idx
209 | self.end_idx = end_idx
210 | self.name = name
211 | self.synset = synset
212 |
213 | def __repr__(self):
214 | return str(self)
215 |
216 |
217 | class Synset:
218 | """
219 | Wordnet Synsets.
220 | name string
221 | definition string
222 | """
223 |
224 | def __init__(self, name, definition):
225 | self.name = name
226 | self.definition = definition
227 |
228 | def __str__(self):
229 | return '{} - {}'.format(self.name, self.definition)
230 |
231 | def __repr__(self):
232 | return str(self)
233 |
234 |
235 | class ObjectMapping(object):
236 | """
237 | This class inherits Object and adds a url field for mapping between an object and the img url
238 | Objects Mapping.
239 | id int
240 | x int
241 | y int
242 | width int
243 | height int
244 | names string array
245 | synsets Synset array
246 | url hyperlink string
247 | """
248 |
249 | def __init__(self, id, x, y, width, height, names, synsets, url):
250 | self.url = url
251 | self.id = id
252 | self.x = x
253 | self.y = y
254 | self.width = width
255 | self.height = height
256 | self.names = names
257 | self.synsets = synsets
258 |
259 | def __str__(self):
260 | name = self.names[0] if len(self.names) != 0 else 'None'
261 | return '%s' % (name)
262 |
263 | def __repr__(self):
264 | return str(self)
265 |
266 |
267 | class RelationshipMapping(object):
268 | """
269 | Relationships. Ex, 'man - jumping over - fire hydrant'.
270 | subject int
271 | predicate string
272 | object int
273 | rel_canon Synset
274 | """
275 |
276 | def __init__(self, id, subject, predicate, object, synset, url, filtered_id):
277 | self.id = id
278 | self.subject = subject
279 | self.predicate = predicate
280 | self.object = object
281 | self.synset = synset
282 | self.url = url
283 | self.filtered_id = filtered_id
284 |
285 | def __str__(self):
286 | return "%d: %s %s %s" % (self.id, self.subject, self.predicate, self.object)
287 |
288 | def __repr__(self):
289 | return str(self)
290 |
291 |
292 | class ImageMapping(object):
293 | """
294 | Image.
295 | ID int
296 | url hyperlink string
297 | width int
298 | height int
299 | """
300 |
301 | def __init__(self, id, url, width, height, coco_id, flickr_id, width_org, height_org, img_ind):
302 | """
303 |
304 | :param id: ID int
305 | :param url: url hyperlink string
306 | :param width: width from images_1024 int
307 | :param height: height from images_1024 int
308 | :param coco_id:
309 | :param flickr_id:
310 | """
311 |
312 | self.img_ind = img_ind
313 | self.height_org = height_org
314 | self.width_org = width_org
315 | self.id = id
316 | self.url = url
317 | self.width = width
318 | self.height = height
319 | self.coco_id = coco_id
320 | self.flickr_id = flickr_id
321 |
322 | def __str__(self):
323 | return 'id: %d, coco_id: %d, flickr_id: %d, width: %d, url: %s' \
324 | % (
325 | self.id, -1 if self.coco_id is None else self.coco_id,
326 | -1 if self.flickr_id is None else self.flickr_id,
327 | self.width, self.url)
328 |
329 | def __repr__(self):
330 | return str(self)
331 |
332 |
--------------------------------------------------------------------------------
/Data/VisualGenome/utils.py:
--------------------------------------------------------------------------------
1 | from models import Image, Object, Attribute, Relationship
2 | from models import Region, Graph, QA, QAObject, Synset
3 | import httplib
4 | import json
5 |
6 |
7 | def GetDataDir():
8 | """
9 | Get the local directory where the Visual Genome data is locally stored.
10 | """
11 | from os.path import dirname, realpath, join
12 | dataDir = join(dirname(realpath('__file__')), 'data')
13 | return dataDir
14 |
15 |
16 | def RetrieveData(request):
17 | """
18 | Helper Method used to get all data from request string.
19 | """
20 | connection = httplib.HTTPSConnection("visualgenome.org", '443')
21 | connection.request("GET", request)
22 | response = connection.getresponse()
23 | jsonString = response.read()
24 | data = json.loads(jsonString)
25 | return data
26 |
27 |
28 | def ParseSynset(canon):
29 | """
30 | Helper to Extract Synset from canon object.
31 | """
32 | if len(canon) == 0:
33 | return None
34 | return Synset(canon[0]['synset_name'], canon[0]['synset_definition'])
35 |
36 |
37 | def ParseGraph(data, image):
38 | """
39 | Helper to parse a Graph object from API data.
40 | """
41 |
42 | objects = []
43 | object_map = {}
44 | relationships = []
45 | attributes = []
46 | # Create the Objects
47 | for obj in data['bounding_boxes']:
48 | names = []
49 | synsets = []
50 | for s in obj['boxed_objects']:
51 | names.append(s['name'])
52 | synsets.append(ParseSynset(s['object_canon']))
53 | object_ = Object(obj['id'], obj['x'], obj['y'], obj['width'], obj['height'], names, synsets)
54 | object_map[obj['id']] = object_
55 | objects.append(object_)
56 | # Create the Relationships
57 | for rel in data['relationships']:
58 | relationships.append(Relationship(rel['id'], object_map[rel['subject']], \
59 | rel['predicate'], object_map[rel['object']],
60 | ParseSynset(rel['relationship_canon'])))
61 | # Create the Attributes
62 | for atr in data['attributes']:
63 | attributes.append(Attribute(atr['id'], object_map[atr['subject']], \
64 | atr['attribute'], ParseSynset(atr['attribute_canon'])))
65 | return Graph(image, objects, relationships, attributes)
66 |
67 |
68 | def ParseImageData(data):
69 | """
70 | Helper to parse the image data for one image.
71 | """
72 |
73 | img_id = data['id'] if 'id' in data else data['image_id']
74 | url = data['url']
75 | width = data['width']
76 | height = data['height']
77 | coco_id = data['coco_id']
78 | flickr_id = data['flickr_id']
79 | image = Image(img_id, url, width, height, coco_id, flickr_id)
80 | return image
81 |
82 |
83 | def ParseRegionDescriptions(data, image):
84 | """
85 | Helper to parse region descriptions.
86 | """
87 |
88 | regions = []
89 | if data[0].has_key('region_id'):
90 | region_id_key = 'region_id'
91 | else:
92 | region_id_key = 'id'
93 | for d in data:
94 | regions.append(Region(d[region_id_key], image, d['phrase'], d['x'], d['y'], d['width'], d['height']))
95 | return regions
96 |
97 |
98 | def ParseQA(data, image_map):
99 | """
100 | Helper to parse a list of question answers.
101 | """
102 |
103 | qas = []
104 | for d in data:
105 | qos = []
106 | aos = []
107 | if 'question_objects' in d:
108 | for qo in d['question_objects']:
109 | synset = Synset(qo['synset_name'], qo['synset_definition'])
110 | qos.append(QAObject(qo['entity_idx_start'], qo['entity_idx_end'], qo['entity_name'], synset))
111 | if 'answer_objects' in d:
112 | for ao in d['answer_objects']:
113 | synset = Synset(o['synset_name'], ao['synset_definition'])
114 | aos.append(QAObject(ao['entity_idx_start'], ao['entity_idx_end'], ao['entity_name'], synset))
115 | qas.append(QA(d['qa_id'], image_map[d['image_id']], d['question'], d['answer'], qos, aos))
116 | return qas
117 |
--------------------------------------------------------------------------------
/Data/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/shikorab/SceneGraph/d2dc960a0d3728e7d2b0eaceb9d0fdaedb2a47d5/Data/__init__.py
--------------------------------------------------------------------------------
/FilesManager/FilesManager.py:
--------------------------------------------------------------------------------
1 | import os
2 | import os.path
3 | import sys
4 |
5 | sys.path.append("..")
6 | from Utils.Singleton import Singleton
7 | import cPickle
8 | import yaml
9 | import copy
10 | import json
11 | import h5py
12 |
13 | FILE_MANAGER_PATH = os.path.abspath(os.path.dirname(__file__))
14 | FILE_MANAGER_FILENAME = "files.yaml"
15 |
16 |
17 | class FilesManager(object):
18 | """
19 | Files Manager used to load and save any kind of files
20 | """
21 | __metaclass__ = Singleton
22 |
23 | def __init__(self, overrides_filename=None):
24 | """
25 | Constructor for FilesManager
26 | :param overrides_filename: "*.yaml file used to override paths to files
27 | """
28 | # save input data
29 | self.overrides_filename = overrides_filename
30 | # prints
31 | self.log = lambda x: self.log_str(x)
32 |
33 | # load file paths
34 | stream = file(os.path.join(FILE_MANAGER_PATH, FILE_MANAGER_FILENAME), 'r')
35 | self.files = yaml.load(stream)
36 |
37 | # override file paths
38 | if overrides_filename != None:
39 | print("FilesManager: overrides files according to " + str(overrides_filename))
40 | # read yaml file
41 | stream = file(os.path.join(FILE_MANAGER_PATH, overrides_filename), 'r')
42 | overrides = yaml.load(stream)
43 | # override
44 | self.override(self.files, overrides)
45 |
46 | def load_file(self, tokens, version=None):
47 | """
48 | load file given file tokens
49 | :param tokens: tokens delimited with '.' (each toked is a level in files.yaml)
50 | :param version: useful if old version is required (according to numbers in files.yaml)
51 | :return: data read from file according to file type
52 | """
53 | # get file path
54 | fileinfo = self.get_file_info(tokens, version)
55 | filetype = fileinfo["type"]
56 | filename = os.path.join(FILE_MANAGER_PATH, fileinfo["name"])
57 |
58 | # load data per file type
59 | if filetype == "pickle":
60 | self.log("FilesManager: Load pickle file: %s=%s" % (tokens, filename))
61 | picklefile = open(filename, "rb")
62 |
63 | # get number of objects stored in the pickle file
64 | nof_objects = 1
65 | if "nof_objects" in fileinfo:
66 | nof_objects = fileinfo["nof_objects"]
67 |
68 | # load data
69 | if nof_objects == 1:
70 | data = cPickle.load(picklefile)
71 | else:
72 | data = []
73 | for i in range(nof_objects):
74 | data.append(cPickle.load(picklefile))
75 |
76 | picklefile.close()
77 | return data
78 | elif filetype == "yaml":
79 | self.log("FilesManager: Load yaml file: %s=%s" % (tokens, filename))
80 | stream = open(filename, 'r')
81 | data = yaml.load(stream)
82 | return data
83 | elif filetype == "json":
84 | self.log("FilesManager: Load json file: %s=%s" % (tokens, filename))
85 | f = open(filename, 'r')
86 | data = json.load(f)
87 | return data
88 | elif filetype == "h5py":
89 | self.log("FilesManager: Load h5py file: %s=%s" % (tokens, filename))
90 | data = h5py.File(filename, 'r')
91 | return data
92 | elif filetype == "text":
93 | self.log("FilesManager: Load text file: %s=%s" % (tokens, filename))
94 | with open(filename) as f:
95 | lines = f.readlines()
96 | return lines
97 |
98 | def save_file(self, tokens, data, version=None):
99 | """
100 | save file given tokens in pickle format
101 | :param tokens: tokens delimited with '.' (each toked is a level in files.yaml)
102 | :param version: useful if old version is required (according to numbers in files.yaml)
103 | :param data: data to save
104 | :return: void
105 | """
106 | # get file path
107 | fileinfo = self.get_file_info(tokens, version)
108 | filename = os.path.join(FILE_MANAGER_PATH, fileinfo["name"])
109 |
110 | self.log("FilesManager: Save pickle file: " + filename)
111 |
112 | # load data
113 | picklefile = open(filename, "wb")
114 | # get number of objects stored in the pickle file
115 | nof_objects = 1
116 | if "nof_objects" in fileinfo:
117 | nof_objects = fileinfo["nof_objects"]
118 | if nof_objects == 1:
119 | cPickle.dump(data, picklefile)
120 | else:
121 | for elem in data:
122 | cPickle.dump(elem, picklefile)
123 |
124 | picklefile.close()
125 |
126 | def file_exist(self, tokens, version=None):
127 | """
128 | check if file exists given tokens
129 | :param tokens: tokens delimited with '.' (each toked is a level in files.yaml)
130 | :param version: useful if old version is required (according to numbers in files.yaml)
131 | :return: True if file exist
132 | """
133 | # get file path
134 | fileinfo = self.get_file_info(tokens, version)
135 | filename = os.path.join(FILE_MANAGER_PATH, fileinfo["name"])
136 |
137 | return os.path.exists(filename)
138 |
139 | def get_file_info(self, tokens, version=None):
140 |
141 | """
142 | get file name given file tokens
143 | :param tokens: tokens delimited with '.' (each toked is a level in files.yaml)
144 | :param version: useful if old version is required (according to numbers in files.yaml)
145 | :return: dictionary with file info
146 | """
147 | # get list of tokens
148 | tokens_lst = tokens.split(".")
149 |
150 | # get filename
151 | fileinfo = self.files
152 | for token in tokens_lst:
153 | if fileinfo.has_key(token):
154 | fileinfo = fileinfo[token]
155 | else:
156 | raise Exception("unknown name token {0} for name {1}".format(token, tokens))
157 |
158 | # make sure fileinfo was extracted
159 | if not "name" in fileinfo:
160 | raise Exception("uncomplete file tokens", tokens)
161 |
162 | # handle versions
163 | if version is not None:
164 | if "versions" in fileinfo:
165 | versions = fileinfo["versions"]
166 | if version in versions:
167 | # deep copy to be able to override info
168 | fileinfo = copy.deepcopy(fileinfo)
169 | fileinfo["name"] = versions[version]["name"]
170 | self.log("FilesManager: %s - Use Old Version %d" % (tokens, version))
171 | if "doc" in versions[version]:
172 | self.log("FilesManager: Version %d doc - %s" % (version, versions[version]["doc"]))
173 | else:
174 | raise Exception("FilesManager: %s version num %d wasn't found" % (tokens, version))
175 | else:
176 | raise Exception("FilesManager: %s versions token wasn't found" % (tokens))
177 |
178 | return fileinfo
179 |
180 |
181 | def get_file_path(self, tokens, version=None):
182 | """
183 | return full path to file
184 | :param tokens: tokens delimited with '.' (each toked is a level in files.yaml)
185 | :param version: useful if old version is required (according to numbers in files.yaml)
186 | :return: path to file
187 | """
188 | # get file path
189 | fileinfo = self.get_file_info(tokens, version)
190 | filename = os.path.join(FILE_MANAGER_PATH, fileinfo["name"])
191 |
192 | self.log("FilesManager: file path : %s=%s" % (tokens, filename))
193 | return filename
194 |
195 | def override(self, files_db, overrides):
196 | """
197 | Overrides files data base according to overrides data base
198 | :param files_db:
199 | :param overrides:
200 | :return: void
201 | """
202 | for elem in overrides:
203 | if elem in files_db:
204 | if type(overrides[elem]) == str:
205 | files_db[elem] = overrides[elem]
206 |
207 | else:
208 | self.override(files_db[elem], overrides[elem])
209 | else:
210 | files_db[elem] = overrides[elem]
211 |
212 | def add_logger(self, logger):
213 | """
214 | Log all prints to file
215 | :return:
216 | """
217 | self.log = lambda x: logger.log(x)
218 |
219 | def log_str(self, x):
220 | print(x)
221 |
--------------------------------------------------------------------------------
/FilesManager/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/shikorab/SceneGraph/d2dc960a0d3728e7d2b0eaceb9d0fdaedb2a47d5/FilesManager/__init__.py
--------------------------------------------------------------------------------
/FilesManager/files.yaml:
--------------------------------------------------------------------------------
1 | # the file holds the paths to default files that will be loaded or saved
2 | logs:
3 | name: "logs"
4 | type: "dir"
5 | doc: "default folder for logs"
6 |
7 | sg_module:
8 | train:
9 | tf_logs:
10 | name: "module/tf_logs"
11 | type: "dir"
12 | doc: "holds tensor flow log"
13 | saver:
14 | name: "module/saver"
15 | type: "dir"
16 | doc: "stores module weights"
17 | params:
18 | name: "module/params.yaml"
19 | type: "yaml"
20 | doc: "train parameters"
21 |
22 | language_module:
23 | word2vec:
24 | object_embeddings:
25 | name: "LanguageModule/object_embeddings.p"
26 | type: "pickle"
27 | doc: "Testing Language Model Word2vec trained"
28 | predicate_embeddings:
29 | name: "LanguageModule/predicate_embeddings.p"
30 | type: "pickle"
31 | doc: "Testing Language Model Word2vec trained"
32 |
33 | data:
34 | visual_genome:
35 | train:
36 | name: "../Module/data/train"
37 | type: "dir"
38 | doc: "dir with entities files. each file inclues 1000 entities"
39 | train_baseline:
40 | name: "../Module/data/train/baseline"
41 | type: "dir"
42 | doc: "dir with baseline confidence per each relation and entity"
43 | test:
44 | name: "../Module/data/test"
45 | type: "dir"
46 | doc: "dir with entities files. each file inclues 1000 entities"
47 | test_baseline:
48 | name: "../Module/data/test/baseline"
49 | type: "dir"
50 | doc: "dir with baseline confidence per each relation and entity"
51 | data:
52 | name: "../Module"
53 | type: "dir"
54 | doc: "dir with zip file and data folder"
55 |
--------------------------------------------------------------------------------
/FilesManager/module/params.yaml:
--------------------------------------------------------------------------------
1 | name: gpi_ling_new
2 | nof_iterations: 10000
3 | learning_rate: 0.0001
4 | learning_rate_steps: 1000
5 | learning_rate_decay: 0.5
6 | load_model_name: "gpi_ling_new_best_module.ckpt"
7 | use_saved_model: False
8 | batch_size: 20
9 | predicate_pos_neg_ratio: 10
10 | lr_object_coeff: 4
11 | layers: [500, 500, 500]
12 | gpu: 0
13 |
14 |
--------------------------------------------------------------------------------
/FilesManager/module/saver/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/shikorab/SceneGraph/d2dc960a0d3728e7d2b0eaceb9d0fdaedb2a47d5/FilesManager/module/saver/__init__.py
--------------------------------------------------------------------------------
/FilesManager/module/tf_logs/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/shikorab/SceneGraph/d2dc960a0d3728e7d2b0eaceb9d0fdaedb2a47d5/FilesManager/module/tf_logs/__init__.py
--------------------------------------------------------------------------------
/Module/Eval.py:
--------------------------------------------------------------------------------
1 | import inspect
2 | import os
3 | import sys
4 |
5 | sys.path.append("..")
6 |
7 | from FilesManager.FilesManager import FilesManager
8 | from Module import Module
9 | from Utils.Logger import Logger
10 | import tensorflow as tf
11 | import numpy as np
12 | from Train import test, NOF_OBJECTS, NOF_PREDICATES
13 | import cPickle
14 | import matplotlib.pyplot
15 | matplotlib.pyplot.switch_backend('agg')
16 | import time
17 |
18 | def iou(box_a, box_b):
19 | union_area = (max(box_a[2], box_b[2]) - min(box_a[0], box_b[0]) + 1) * (max(box_a[3], box_b[3]) - min(box_a[1], box_b[1]) + 1)
20 | overlap_w = min(box_a[2], box_b[2]) - max(box_a[0], box_b[0]) + 1
21 | if overlap_w <= 0:
22 | return 0
23 | overlap_h = min(box_a[3], box_b[3]) - max(box_a[1], box_b[1]) + 1
24 | if overlap_h <= 0:
25 | return 0
26 | return float(overlap_w * overlap_h) / union_area
27 |
28 | def eval_image(entity, labels_relation, labels_entity, out_confidence_relation_val, out_confidence_entity_val, k=100):
29 | """
30 | Scene Graph Classification -
31 | R@k metric (measures the fraction of ground truth relationships
32 | triplets that appear among the k most confident triplet prediction in an image)
33 | :param labels_relation: labels of image predicates (each one is one hot vector) - shape (N, N, NOF_PREDICATES)
34 | :param labels_entity: labels of image objects (each one is one hot vector) - shape (N, NOF_OBJECTS)
35 | :param out_confidence_relation_val: confidence of image predicates - shape (N, N, NOF_PREDICATES)
36 | :param out_confidence_entity_val: confidence of image objects - shape (N, NOF_OBJECTS)
37 | :param k: k most confident predictions to consider
38 | :return: image score, number of the gt triplets that appear in the k most confident predictions,
39 | number of the gt triplets
40 | """
41 | # iterate over each relation to predict and find k highest predictions
42 | top_predictions = np.zeros((0, 12))
43 |
44 | # results per relation
45 | per_relation_correct = np.zeros(NOF_PREDICATES)
46 | per_relation_total = np.zeros(NOF_PREDICATES)
47 |
48 | N = labels_entity.shape[0]
49 | if N == 1:
50 | return 0, 0, 0, per_relation_correct, per_relation_total
51 |
52 | relation_pred = np.argmax(out_confidence_relation_val[:, :, :NOF_PREDICATES - 1], axis=2)
53 | relation_scores = np.max(out_confidence_relation_val[:, :, :NOF_PREDICATES - 1], axis=2)
54 | entity_pred = np.argmax(out_confidence_entity_val, axis=1)
55 | entity_scores = np.max(out_confidence_entity_val, axis=1)
56 |
57 | # get list of the top k most confident triplets predictions
58 | for subject_index in range(N):
59 | for object_index in range(N):
60 | # filter if subject equals to object
61 | if subject_index == object_index:
62 | continue
63 |
64 | # create entry with the scores
65 | triplet_prediction = np.zeros((1, 12))
66 | triplet_prediction[0][0] = entity.objects[subject_index].x
67 | triplet_prediction[0][1] = entity.objects[subject_index].y
68 | triplet_prediction[0][2] = entity.objects[subject_index].x + entity.objects[subject_index].width
69 | triplet_prediction[0][3] = entity.objects[subject_index].y + entity.objects[subject_index].height
70 | triplet_prediction[0][4] = entity.objects[object_index].x
71 | triplet_prediction[0][5] = entity.objects[object_index].y
72 | triplet_prediction[0][6] = entity.objects[object_index].x + entity.objects[object_index].width
73 | triplet_prediction[0][7] = entity.objects[object_index].y + entity.objects[object_index].height
74 |
75 | triplet_prediction[0][8] = entity_pred[subject_index]
76 | triplet_prediction[0][9] = relation_pred[subject_index][object_index]
77 | triplet_prediction[0][10] = entity_pred[object_index]
78 | triplet_prediction[0][11] = relation_scores[subject_index][object_index] * entity_scores[subject_index] * \
79 | entity_scores[object_index]
80 |
81 | # append to the list of highest predictions
82 | top_predictions = np.concatenate((top_predictions, triplet_prediction))
83 |
84 | # get k highest confidence
85 | top_k_indices = np.argsort(top_predictions[:, 11])[-k:]
86 | sub_boxes = top_predictions[top_k_indices, :4]
87 | obj_boxes = top_predictions[top_k_indices, 4:8]
88 | sub_pred = top_predictions[top_k_indices, 8]
89 | relation_pred = top_predictions[top_k_indices, 9]
90 | obj_pred = top_predictions[top_k_indices, 10]
91 |
92 | relations_gt = np.argmax(labels_relation, axis=2)
93 | entities_gt = np.argmax(labels_entity, axis=1)
94 |
95 | img_score = 0
96 | nof_pos_relationship = 0
97 | for subject_index in range(N):
98 | for object_index in range(N):
99 | # filter if subject equals to object
100 | if subject_index == object_index:
101 | continue
102 | # filter negative relationship
103 | if relations_gt[subject_index, object_index] == NOF_PREDICATES - 1:
104 | continue
105 |
106 | gt_sub_box = np.zeros((4))
107 | gt_sub_box[0] = entity.objects[subject_index].x
108 | gt_sub_box[1] = entity.objects[subject_index].y
109 | gt_sub_box[2] = entity.objects[subject_index].x + entity.objects[subject_index].width
110 | gt_sub_box[3] = entity.objects[subject_index].y + entity.objects[subject_index].height
111 |
112 | gt_obj_box = np.zeros((4))
113 | gt_obj_box[0] = entity.objects[object_index].x
114 | gt_obj_box[1] = entity.objects[object_index].y
115 | gt_obj_box[2] = entity.objects[object_index].x + entity.objects[object_index].width
116 | gt_obj_box[3] = entity.objects[object_index].y + entity.objects[object_index].height
117 |
118 | predicate_id = relations_gt[subject_index][object_index]
119 | sub_id = entities_gt[subject_index]
120 | obj_id = entities_gt[object_index]
121 |
122 | nof_pos_relationship += 1
123 | per_relation_total[predicate_id] += 1
124 |
125 | # filter according to iou
126 | found = False
127 | for top_k_i in range(k):
128 | if sub_id != sub_pred[top_k_i] or obj_id != obj_pred[top_k_i] or predicate_id !=relation_pred[top_k_i]:
129 | continue
130 | iou_sub_val = iou(gt_sub_box, sub_boxes[top_k_i])
131 | if iou_sub_val < 0.5:
132 | continue
133 | iou_obj_val = iou(gt_obj_box, obj_boxes[top_k_i])
134 | if iou_obj_val < 0.5:
135 | continue
136 |
137 | found = True
138 | break
139 |
140 | if found:
141 | img_score += 1
142 | per_relation_correct[predicate_id] += 1
143 | else:
144 | img_score = img_score
145 |
146 | if nof_pos_relationship != 0:
147 | img_score_percent = float(img_score) / float(nof_pos_relationship)
148 | else:
149 | img_score_percent = 0
150 |
151 | return img_score_percent, img_score, nof_pos_relationship, per_relation_correct, per_relation_total
152 |
153 |
154 | def eval(load_module_name=None, k=100, layers=[500, 500, 500], gpu=1):
155 | """
156 | Evaluate module:
157 | - Scene Graph Classification - R@k metric (measures the fraction of ground truth relationships
158 | triplets that appear among the k most confident triplet prediction in an image)
159 | :param load_module_name: name of the module to load
160 | :param k: see description
161 | :param layers: hidden layers of relation and entity classifier
162 | :param gpu: gpu number to use
163 | :return: nothing - output to logger instead
164 | """
165 | gpi_type = "Linguistic"
166 | k_recall = True
167 | filesmanager = FilesManager()
168 | # create logger
169 | logger = Logger()
170 |
171 | # print eval params
172 | frame = inspect.currentframe()
173 | args, _, _, values = inspect.getargvalues(frame)
174 | logger.log('function name "%s"' % inspect.getframeinfo(frame)[2])
175 | for i in args:
176 | logger.log(" %s = %s" % (i, values[i]))
177 |
178 | # set gpu
179 | if gpu != None:
180 | os.environ["CUDA_VISIBLE_DEVICES"] = str(gpu)
181 | logger.log("os.environ[\"CUDA_VISIBLE_DEVICES\"] = " + str(gpu))
182 |
183 | # create module
184 | module = Module(gpi_type=gpi_type, nof_predicates=NOF_PREDICATES, nof_objects=NOF_OBJECTS,
185 | is_train=False, layers=layers, including_object=True)
186 |
187 | # get input place holders
188 | confidence_relation_ph, confidence_entity_ph, bb_ph, word_embed_relations_ph, word_embed_entities_ph = module.get_in_ph()
189 | # get module output
190 | out_relation_probes, out_entity_probes = module.get_output()
191 |
192 | # Initialize the Computational Graph
193 | init = tf.global_variables_initializer()
194 | # Add ops to save and restore all the variables.
195 | saver = tf.train.Saver()
196 |
197 | # read data
198 | entities_path = filesmanager.get_file_path("data.visual_genome.test")
199 |
200 | test_files_list = range(35)
201 |
202 | # embeddings
203 | embed_obj = FilesManager().load_file("language_module.word2vec.object_embeddings")
204 | embed_pred = FilesManager().load_file("language_module.word2vec.predicate_embeddings")
205 | embed_pred = np.concatenate((embed_pred, np.zeros(embed_pred[:1].shape)), axis=0) # concat negative represntation
206 | accum_results = None
207 | with tf.Session() as sess:
208 | if load_module_name is not None:
209 | # Restore variables from disk.
210 | if load_module_name=="gpi_linguistic_pretrained":
211 | module_path = os.path.join(filesmanager.get_file_path("data.visual_genome.data"), "data")
212 | else:
213 | module_path = filesmanager.get_file_path("sg_module.train.saver")
214 | module_path_load = os.path.join(module_path, load_module_name + "_module.ckpt")
215 | if os.path.exists(module_path_load + ".index"):
216 | saver.restore(sess, module_path_load)
217 | logger.log("Model restored.")
218 | else:
219 | raise Exception("Module not found")
220 | else:
221 | sess.run(init)
222 | # eval module
223 |
224 | nof = 0
225 | total = 0
226 | correct_all = 0
227 | total_all = 0
228 |
229 | # create one hot vector for null relation
230 | relation_neg = np.zeros(NOF_PREDICATES)
231 | relation_neg[NOF_PREDICATES - 1] = 1
232 |
233 | index = 0
234 | basline_path = filesmanager.get_file_path("data.visual_genome.test_baseline")
235 | for file_name in test_files_list:
236 | file_path = os.path.join(entities_path, str(file_name) + ".p")
237 | file_handle = open(file_path, "rb")
238 | test_entities = cPickle.load(file_handle)
239 | file_handle.close()
240 |
241 | for entity in test_entities:
242 | file_path = os.path.join(basline_path, str(entity.image.id) + ".p")
243 | if not os.path.exists(file_path):
244 | continue
245 | file_handle = open(file_path, "rb")
246 | detector_data = cPickle.load(file_handle)
247 | file_handle.close()
248 |
249 | entity.predicates_outputs_with_no_activation = detector_data["rel_dist_mapped"]
250 | entity.objects_outputs_with_no_activations = detector_data["obj_dist_mapped"]
251 | # set diagonal to be negative relation
252 | N = entity.predicates_outputs_with_no_activation.shape[0]
253 | indices = np.arange(N)
254 | entity.predicates_outputs_with_no_activation[indices, indices, :] = relation_neg
255 | entity.predicates_labels[indices, indices, :] = relation_neg
256 |
257 | # create bounding box info per object
258 | obj_bb = np.zeros((len(entity.objects), 14))
259 | for obj_id in range(len(entity.objects)):
260 | obj_bb[obj_id][0] = entity.objects[obj_id].x / 1200.0
261 | obj_bb[obj_id][1] = entity.objects[obj_id].y / 1200.0
262 | obj_bb[obj_id][2] = (entity.objects[obj_id].x + entity.objects[obj_id].width) / 1200.0
263 | obj_bb[obj_id][3] = (entity.objects[obj_id].y + entity.objects[obj_id].height) / 1200.0
264 | obj_bb[obj_id][4] = entity.objects[obj_id].x
265 | obj_bb[obj_id][5] = -1 * entity.objects[obj_id].x
266 | obj_bb[obj_id][6] = entity.objects[obj_id].y
267 | obj_bb[obj_id][7] = -1 * entity.objects[obj_id].y
268 | obj_bb[obj_id][8] = entity.objects[obj_id].width * entity.objects[obj_id].height
269 | obj_bb[obj_id][9] = -1 * entity.objects[obj_id].width * entity.objects[obj_id].height
270 | obj_bb[:, 4] = np.argsort(obj_bb[:, 4])
271 | obj_bb[:, 5] = np.argsort(obj_bb[:, 5])
272 | obj_bb[:, 6] = np.argsort(obj_bb[:, 6])
273 | obj_bb[:, 7] = np.argsort(obj_bb[:, 7])
274 | obj_bb[:, 8] = np.argsort(obj_bb[:, 8])
275 | obj_bb[:, 9] = np.argsort(obj_bb[:, 9])
276 | obj_bb[:, 10] = np.argsort(np.max(entity.objects_outputs_with_no_activations, axis=1))
277 | obj_bb[:, 11] = np.argsort(-1 * np.max(entity.objects_outputs_with_no_activations, axis=1))
278 | obj_bb[:, 12] = np.arange(obj_bb.shape[0])
279 | obj_bb[:, 13] = np.arange(obj_bb.shape[0], 0, -1)
280 |
281 | # filter images with no positive relations
282 | relations_neg_labels = entity.predicates_labels[:, :, NOF_PREDICATES - 1:]
283 | if np.sum(entity.predicates_labels[:, :, :NOF_PREDICATES - 1]) == 0:
284 | continue
285 |
286 | # use object class labels for pred class (multiply be some factor to convert to confidence)
287 | in_entity_confidence = entity.objects_outputs_with_no_activations
288 |
289 | # create the feed dictionary
290 | feed_dict = {confidence_relation_ph: entity.predicates_outputs_with_no_activation,
291 | confidence_entity_ph: in_entity_confidence,
292 | bb_ph: obj_bb,
293 | module.phase_ph: False,
294 | word_embed_entities_ph: embed_obj, word_embed_relations_ph: embed_pred}
295 |
296 | out_relation_probes_val, out_entity_probes_val = \
297 | sess.run([out_relation_probes, out_entity_probes],
298 | feed_dict=feed_dict)
299 |
300 | out_relation_probes_val[indices, indices, :] = relation_neg
301 |
302 | results = test(entity.predicates_labels, entity.objects_labels, out_relation_probes_val,
303 | out_entity_probes_val)
304 |
305 | # accumulate results
306 | if accum_results is None:
307 | accum_results = results
308 | else:
309 | for key in results:
310 | accum_results[key] += results[key]
311 |
312 | # eval image
313 | k_metric_res, correct_image, total_image, img_per_relation_correct, img_per_relation_total = eval_image(entity,
314 | entity.predicates_labels,
315 | entity.objects_labels, out_relation_probes_val, out_entity_probes_val, k=min(k, N * N - N))
316 | # filter images without positive relations
317 | if total_image == 0:
318 | continue
319 |
320 | nof += 1
321 | total += k_metric_res
322 | total_score = float(total) / nof
323 | correct_all += correct_image
324 | total_all += total_image
325 | logger.log("\rresult %d - %f (%d / %d) - total %f (%d)" % (
326 | index, k_metric_res, correct_image, total_image, total_score, entity.image.id))
327 |
328 | index += 1
329 |
330 | relation_accuracy = float(accum_results['entity_correct']) / accum_results['entity_total']
331 | relation_pos_accuracy = float(accum_results['relations_pos_correct']) / accum_results[
332 | 'relations_pos_total']
333 | relationships_pos_accuracy = float(accum_results['relationships_pos_correct']) / accum_results[
334 | 'relations_pos_total']
335 | logger.log("entity %f - positive relation %f - positive triplet %f" %
336 | (relation_accuracy, relation_pos_accuracy, relationships_pos_accuracy))
337 |
338 | time.sleep(3)
339 |
340 |
341 | logger.log("(%s) Final Result for k=%d - %f" % (load_module_name, k, total_score))
342 |
343 |
344 | if __name__ == "__main__":
345 | k_recall = True
346 | gpu = 1
347 | layers = [500, 500, 500]
348 |
349 | load_module_name = "gpi_linguistic_pretrained"
350 | k = 100
351 | eval(load_module_name, k, layers, gpu)
352 | exit()
353 |
--------------------------------------------------------------------------------
/Module/Module.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | import sys
3 |
4 | sys.path.append("..")
5 | from Utils.Logger import Logger
6 |
7 |
8 | class Module(object):
9 | """
10 | SGP Module which gets as an input the confidence of relations (predicates) and entities (objects)
11 | and outputs an improved confidence for predicates and objects
12 | """
13 |
14 | def __init__(self, gpi_type="Linguistic", nof_predicates=51, nof_objects=150, rnn_steps=2, is_train=True,
15 | learning_rate=0.0001,
16 | learning_rate_steps=1000, learning_rate_decay=0.5,
17 | including_object=False, layers=[500, 500, 500], reg_factor=0.0, lr_object_coeff=4):
18 | """
19 | Construct module:
20 | - create input placeholders
21 | - apply SGP rnn_steps times
22 | - create labels placeholders
23 | - create module loss and train_step
24 |
25 | :type gpi_type: "Linguistic", "FeatureAttention", "NeighbourAttention"
26 | :param nof_predicates: nof predicate labels
27 | :param nof_objects: nof object labels
28 | :param rnn_steps: number of time to apply SGP
29 | :param is_train: whether the module will be used to train or eval
30 | """
31 | # save input
32 | self.learning_rate_decay = learning_rate_decay
33 | self.learning_rate_steps = learning_rate_steps
34 | self.learning_rate = learning_rate
35 | self.nof_predicates = nof_predicates
36 | self.nof_objects = nof_objects
37 | self.is_train = is_train
38 | self.rnn_steps = rnn_steps
39 | self.embed_size = 300
40 | self.gpi_type = gpi_type
41 |
42 | self.including_object = including_object
43 | self.lr_object_coeff = lr_object_coeff
44 | self.layers = layers
45 | self.reg_factor = reg_factor
46 | self.activation_fn = tf.nn.relu
47 | self.reuse = None
48 | # logging module
49 | logger = Logger()
50 |
51 | ##
52 | # module input
53 | self.phase_ph = tf.placeholder(tf.bool, name='phase')
54 |
55 | # confidence
56 | self.confidence_relation_ph = tf.placeholder(dtype=tf.float32, shape=(None, None, self.nof_predicates),
57 | name="confidence_relation")
58 | #self.confidence_relation_ph = tf.contrib.layers.dropout(self.confidence_relation_ph, keep_prob=0.9, is_training=self.phase_ph)
59 | self.confidence_entity_ph = tf.placeholder(dtype=tf.float32, shape=(None, self.nof_objects),
60 | name="confidence_entity")
61 | #self.confidence_entity_ph = tf.contrib.layers.dropout(self.confidence_entity_ph, keep_prob=0.9, is_training=self.phase_ph)
62 | # spatial features
63 | self.entity_bb_ph = tf.placeholder(dtype=tf.float32, shape=(None, 14), name="obj_bb")
64 |
65 | # word embeddings
66 | self.word_embed_entities_ph = tf.placeholder(dtype=tf.float32, shape=(self.nof_objects, self.embed_size),
67 | name="word_embed_objects")
68 | self.word_embed_relations_ph = tf.placeholder(dtype=tf.float32, shape=(self.nof_predicates, self.embed_size),
69 | name="word_embed_predicates")
70 |
71 | # labels
72 | if self.is_train:
73 | self.labels_relation_ph = tf.placeholder(dtype=tf.float32, shape=(None, None, self.nof_predicates),
74 | name="labels_predicate")
75 | self.labels_entity_ph = tf.placeholder(dtype=tf.float32, shape=(None, self.nof_objects),
76 | name="labels_object")
77 | self.labels_coeff_loss_ph = tf.placeholder(dtype=tf.float32, shape=(None), name="labels_coeff_loss")
78 |
79 | # store all the outputs of of rnn steps
80 | self.out_confidence_entity_lst = []
81 | self.out_confidence_relation_lst = []
82 | # rnn stage module
83 | confidence_relation = self.confidence_relation_ph
84 | confidence_entity = self.confidence_entity_ph
85 |
86 | # features msg
87 | for step in range(self.rnn_steps):
88 | confidence_relation, confidence_entity_temp = \
89 | self.sgp(in_confidence_relation=confidence_relation,
90 | in_confidence_entity=confidence_entity,
91 | scope_name="deep_graph")
92 | # store the confidence
93 | self.out_confidence_relation_lst.append(confidence_relation)
94 | if self.including_object:
95 | confidence_entity = confidence_entity_temp
96 | # store the confidence
97 | self.out_confidence_entity_lst.append(confidence_entity_temp)
98 | self.reuse = True
99 |
100 | #confidence_entity = confidence_entity_temp
101 | self.out_confidence_relation = confidence_relation
102 | self.out_confidence_entity = confidence_entity
103 | reshaped_relation_confidence = tf.reshape(confidence_relation, (-1, self.nof_predicates))
104 | self.reshaped_relation_probes = tf.nn.softmax(reshaped_relation_confidence)
105 | self.out_relation_probes = tf.reshape(self.reshaped_relation_probes, tf.shape(confidence_relation),
106 | name="out_relation_probes")
107 | self.out_entity_probes = tf.nn.softmax(confidence_entity, name="out_entity_probes")
108 |
109 | # loss
110 | if self.is_train:
111 | # Learning rate
112 | self.lr_ph = tf.placeholder(dtype=tf.float32, shape=[], name="lr_ph")
113 |
114 | self.loss, self.gradients, self.grad_placeholder, self.train_step = self.module_loss()
115 |
116 | def nn(self, features, layers, out, scope_name, seperated_layer=False, last_activation=None):
117 | """
118 | simple nn to convert features to confidence
119 | :param features: list of features tensor
120 | :param layers: hidden layers
121 | :param seperated_layer: First run FC one each feature tensor seperately
122 | :param out: output shape (used to reshape to required output shape)
123 | :param scope_name: tensorflow scope name
124 | :param last_activation: activation function for the last layer (None means no activation)
125 | :return: confidence
126 | """
127 | with tf.variable_scope(scope_name) as scopevar:
128 |
129 | # first layer each feature seperatly
130 | features_h_lst = []
131 | index = 0
132 | for feature in features:
133 | if seperated_layer:
134 | in_size = feature.shape[-1]._value
135 | scope = str(index)
136 | h = tf.contrib.layers.fully_connected(feature, in_size, reuse=self.reuse, scope=scope,
137 | activation_fn=self.activation_fn)
138 | index += 1
139 | features_h_lst.append(h)
140 | else:
141 | features_h_lst.append(feature)
142 |
143 | h = tf.concat(features_h_lst, axis=-1)
144 | h = tf.contrib.layers.dropout(h, keep_prob=0.9, is_training=self.phase_ph)
145 | for layer in layers:
146 | scope = str(index)
147 | h = tf.contrib.layers.fully_connected(h, layer, reuse=self.reuse, scope=scope,
148 | activation_fn=self.activation_fn)
149 | h = tf.contrib.layers.dropout(h, keep_prob=0.9, is_training=self.phase_ph)
150 | index += 1
151 |
152 | scope = str(index)
153 | y = tf.contrib.layers.fully_connected(h, out, reuse=self.reuse, scope=scope, activation_fn=last_activation)
154 | return y
155 |
156 | def sgp(self, in_confidence_relation, in_confidence_entity, scope_name="rnn_cell"):
157 | """
158 | SGP step - which get as an input a confidence of the predicates and objects and return an improved confidence of the predicates and the objects
159 | :return:
160 | :param in_confidence_relation: in relation confidence
161 | :param in_confidence_entity: in entity confidence
162 | :param scope_name: sgp step scope
163 | :return: improved relatiob probabilities, improved relation confidence, improved entity probabilities and improved entity confidence
164 | """
165 | with tf.variable_scope(scope_name):
166 |
167 | # relation features normalization
168 | self.in_confidence_predicate_actual = in_confidence_relation
169 | relation_probes = tf.nn.softmax(in_confidence_relation)
170 | self.relation_probes = relation_probes
171 | relation_features = tf.log(relation_probes + tf.constant(1e-10))
172 |
173 | # entity features normalization
174 | self.in_confidence_entity_actual = in_confidence_entity
175 | entity_probes = tf.nn.softmax(in_confidence_entity)
176 | self.entity_probes = entity_probes
177 | entity_features_conf = tf.log(entity_probes + tf.constant(1e-10))
178 | entity_features = tf.concat((entity_features_conf, self.entity_bb_ph), axis=1)
179 |
180 | # word embeddings
181 | # expand object word embed
182 | N = tf.slice(tf.shape(self.confidence_relation_ph), [0], [1], name="N")
183 | if self.gpi_type == "Linguistic":
184 | self.entity_prediction = tf.argmax(self.entity_probes, axis=1)
185 | self.entity_prediction_val = tf.reduce_max(self.entity_probes, axis=1)
186 | self.embed_entities = tf.gather(self.word_embed_entities_ph, self.entity_prediction)
187 | self.embed_entities = tf.transpose(
188 | tf.multiply(tf.transpose(self.embed_entities), self.entity_prediction_val))
189 | in_extended_confidence_embed_shape = tf.concat((N, tf.shape(self.embed_entities)), 0)
190 | entity_features = tf.concat((self.embed_entities, entity_features), axis=1)
191 |
192 | self.relation_prediction = tf.argmax(self.relation_probes[:, :, :self.nof_predicates - 1], axis=2)
193 | self.relation_prediction_val = tf.reduce_max(self.relation_probes[:, :, :self.nof_predicates - 1], axis=2)
194 | self.embed_relations = tf.gather(self.word_embed_relations_ph, tf.reshape(self.relation_prediction, [-1]))
195 | self.embed_relations = tf.transpose(
196 | tf.multiply(tf.transpose(self.embed_relations), tf.reshape(self.relation_prediction_val, [-1])))
197 | self.embed_relations = tf.reshape(self.embed_relations, in_extended_confidence_embed_shape)
198 | relation_features = tf.concat((relation_features, self.embed_relations), axis=2)
199 |
200 | # append relations in both directions
201 | self.relation_features = tf.concat((relation_features, tf.transpose(relation_features, perm=[1, 0, 2])), axis=2)
202 |
203 | # expand object confidence
204 | self.extended_confidence_entity_shape = tf.concat((N, tf.shape(entity_features)), 0)
205 | self.expand_object_features = tf.add(tf.zeros(self.extended_confidence_entity_shape),
206 | entity_features,
207 | name="expand_object_features")
208 | # expand subject confidence
209 | self.expand_subject_features = tf.transpose(self.expand_object_features, perm=[1, 0, 2],
210 | name="expand_subject_features")
211 |
212 | ##
213 | # Node Neighbours
214 | self.object_ngbrs = [self.expand_object_features, self.expand_subject_features, relation_features]
215 | # apply phi
216 | self.object_ngbrs_phi = self.nn(features=self.object_ngbrs, layers=[], out=500, scope_name="nn_phi")
217 | # Attention mechanism
218 | if self.gpi_type == "FeatureAttention" or self.gpi_type == "Linguistic":
219 | self.object_ngbrs_scores = self.nn(features=self.object_ngbrs, layers=[], out=500,
220 | scope_name="nn_phi_atten")
221 | self.object_ngbrs_weights = tf.nn.softmax(self.object_ngbrs_scores, dim=1)
222 | self.object_ngbrs_phi_all = tf.reduce_sum(tf.multiply(self.object_ngbrs_phi, self.object_ngbrs_weights),
223 | axis=1)
224 |
225 | elif self.gpi_type == "NeighbourAttention":
226 | self.object_ngbrs_scores = self.nn(features=self.object_ngbrs, layers=[], out=1,
227 | scope_name="nn_phi_atten")
228 | self.object_ngbrs_weights = tf.nn.softmax(self.object_ngbrs_scores, dim=1)
229 | self.object_ngbrs_phi_all = tf.reduce_sum(tf.multiply(self.object_ngbrs_phi, self.object_ngbrs_weights),
230 | axis=1)
231 | else:
232 | self.object_ngbrs_phi_all = tf.reduce_mean(self.object_ngbrs_phi, axis=1)
233 |
234 | ##
235 | # Nodes
236 | self.object_ngbrs2 = [entity_features, self.object_ngbrs_phi_all]
237 | # apply alpha
238 | self.object_ngbrs2_alpha = self.nn(features=self.object_ngbrs2, layers=[], out=500, scope_name="nn_phi2")
239 | # Attention mechanism
240 | if self.gpi_type == "FeatureAttention" or self.gpi_type == "Linguistic":
241 | self.object_ngbrs2_scores = self.nn(features=self.object_ngbrs2, layers=[], out=500,
242 | scope_name="nn_phi2_atten")
243 | self.object_ngbrs2_weights = tf.nn.softmax(self.object_ngbrs2_scores, dim=0)
244 | self.object_ngbrs2_alpha_all = tf.reduce_sum(
245 | tf.multiply(self.object_ngbrs2_alpha, self.object_ngbrs2_weights), axis=0)
246 | elif self.gpi_type == "NeighbourAttention":
247 | self.object_ngbrs2_scores = self.nn(features=self.object_ngbrs2, layers=[], out=1,
248 | scope_name="nn_phi2_atten")
249 | self.object_ngbrs2_weights = tf.nn.softmax(self.object_ngbrs2_scores, dim=0)
250 | self.object_ngbrs2_alpha_all = tf.reduce_sum(
251 | tf.multiply(self.object_ngbrs2_alpha, self.object_ngbrs2_weights), axis=0)
252 | else:
253 | self.object_ngbrs2_alpha_all = tf.reduce_mean(self.object_ngbrs2_alpha, axis=0)
254 |
255 | expand_graph_shape = tf.concat((N, N, tf.shape(self.object_ngbrs2_alpha_all)), 0)
256 | expand_graph = tf.add(tf.zeros(expand_graph_shape), self.object_ngbrs2_alpha_all)
257 |
258 | ##
259 | # rho relation (relation prediction)
260 | # The input is object features, subject features, relation features and the representation of the graph
261 | self.expand_obj_ngbrs_phi_all = tf.add(tf.zeros_like(self.object_ngbrs_phi), self.object_ngbrs_phi_all)
262 | self.expand_sub_ngbrs_phi_all = tf.transpose(self.expand_obj_ngbrs_phi_all, perm=[1, 0, 2])
263 | self.relation_all_features = [relation_features, self.expand_object_features, self.expand_subject_features, expand_graph]
264 |
265 | pred_delta = self.nn(features=self.relation_all_features, layers=self.layers, out=self.nof_predicates,
266 | scope_name="nn_pred")
267 | pred_forget_gate = self.nn(features=self.relation_all_features, layers=[], out=1,
268 | scope_name="nn_pred_forgate", last_activation=tf.nn.sigmoid)
269 | out_confidence_relation = pred_delta + pred_forget_gate * in_confidence_relation
270 |
271 | ##
272 | # rho entity (entity prediction)
273 | # The input is entity features, entity neighbour features and the representation of the graph
274 | if self.including_object:
275 | self.object_all_features = [entity_features, expand_graph[0], self.object_ngbrs_phi_all]
276 | obj_delta = self.nn(features=self.object_all_features, layers=self.layers, out=self.nof_objects,
277 | scope_name="nn_obj")
278 | obj_forget_gate = self.nn(features=self.object_all_features, layers=[], out=self.nof_objects,
279 | scope_name="nn_obj_forgate", last_activation=tf.nn.sigmoid)
280 | out_confidence_object = obj_delta + obj_forget_gate * in_confidence_entity
281 | else:
282 | out_confidence_object = in_confidence_entity
283 |
284 | return out_confidence_relation, out_confidence_object
285 |
286 | def module_loss(self, scope_name="loss"):
287 | """
288 | SGP loss
289 | :param scope_name: tensor flow scope name
290 | :return: loss and train step
291 | """
292 | with tf.variable_scope(scope_name):
293 | # reshape to batch like shape
294 | shaped_labels_predicate = tf.reshape(self.labels_relation_ph, (-1, self.nof_predicates))
295 |
296 | # relation gt
297 | self.gt = tf.argmax(shaped_labels_predicate, axis=1)
298 |
299 | loss = 0
300 |
301 | for rnn_step in range(self.rnn_steps):
302 |
303 | shaped_confidence_predicate = tf.reshape(self.out_confidence_relation_lst[rnn_step],
304 | (-1, self.nof_predicates))
305 |
306 | # set predicate loss
307 | self.relation_ce_loss = tf.nn.softmax_cross_entropy_with_logits(labels=shaped_labels_predicate,
308 | logits=shaped_confidence_predicate,
309 | name="relation_ce_loss")
310 |
311 | self.loss_relation = self.relation_ce_loss
312 | self.loss_relation_weighted = tf.multiply(self.loss_relation, self.labels_coeff_loss_ph)
313 |
314 | loss += tf.reduce_sum(self.loss_relation_weighted)
315 |
316 | # set object loss
317 | if self.including_object:
318 | self.object_ce_loss = tf.nn.softmax_cross_entropy_with_logits(labels=self.labels_entity_ph,
319 | logits=self.out_confidence_entity_lst[
320 | rnn_step],
321 | name="object_ce_loss")
322 |
323 | loss += self.lr_object_coeff * tf.reduce_sum(self.object_ce_loss)
324 |
325 | # reg
326 | trainable_vars = tf.trainable_variables()
327 | lossL2 = tf.add_n([tf.nn.l2_loss(v) for v in trainable_vars]) * self.reg_factor
328 | loss += lossL2
329 |
330 | # minimize
331 | #opt = tf.train.GradientDescentOptimizer(self.lr_ph)
332 | opt = tf.train.AdamOptimizer(self.lr_ph)
333 | # opt = tf.train.MomentumOptimizer(self.lr_ph, 0.9, use_nesterov=True)
334 | gradients = opt.compute_gradients(loss)
335 | # create placeholder to minimize in a batch
336 | grad_placeholder = [(tf.placeholder("float", shape=grad[0].get_shape()), grad[1]) for grad in gradients]
337 |
338 | train_step = opt.apply_gradients(grad_placeholder)
339 | return loss, gradients, grad_placeholder, train_step
340 |
341 | def get_in_ph(self):
342 | """
343 | get input place holders
344 | """
345 | return self.confidence_relation_ph, self.confidence_entity_ph, self.entity_bb_ph, self.word_embed_relations_ph, self.word_embed_entities_ph
346 |
347 | def get_output(self):
348 | """
349 | get module output
350 | """
351 | return self.out_relation_probes, self.out_entity_probes
352 |
353 | def get_labels_ph(self):
354 | """
355 | get module labels ph (used for train)
356 | """
357 | return self.labels_relation_ph, self.labels_entity_ph, self.labels_coeff_loss_ph
358 |
359 | def get_module_loss(self):
360 | """
361 | get module loss and train step
362 | """
363 | return self.loss, self.gradients, self.grad_placeholder, self.train_step
364 |
--------------------------------------------------------------------------------
/Module/Train.py:
--------------------------------------------------------------------------------
1 | import sys
2 | sys.path.append("..")
3 |
4 | import math
5 | import inspect
6 |
7 | from Data.VisualGenome.models import *
8 | from FilesManager.FilesManager import FilesManager
9 | from Module import Module
10 | import tensorflow as tf
11 | import numpy as np
12 | import os
13 | import cPickle
14 | from random import shuffle
15 |
16 | from Utils.Logger import Logger
17 |
18 | # feature sizes
19 | NOF_PREDICATES = 51
20 | NOF_OBJECTS = 150
21 |
22 | # save model every number of iterations
23 | SAVE_MODEL_ITERATIONS = 5
24 |
25 | # test every number of iterations
26 | TEST_ITERATIONS = 1
27 |
28 |
29 | def test(labels_relation, labels_entity, out_confidence_relation_val, out_confidence_entity_val):
30 | """
31 | returns a dictionary with statistics about object, predicate and relationship accuracy in this image
32 | :param labels_relation: labels of image predicates (each one is one hot vector) - shape (N, N, NOF_PREDICATES)
33 | :param labels_entity: labels of image objects (each one is one hot vector) - shape (N, NOF_OBJECTS)
34 | :param out_confidence_relation_val: confidence of image predicates - shape (N, N, NOF_PREDICATES)
35 | :param out_confidence_entity_val: confidence of image objects - shape (N, NOF_OBJECTS)
36 | :return: see description
37 | """
38 | relation_gt = np.argmax(labels_relation, axis=2)
39 | entity_gt = np.argmax(labels_entity, axis=1)
40 | relation_pred = np.argmax(out_confidence_relation_val, axis=2)
41 | relations_pred_no_neg = np.argmax(out_confidence_relation_val[:, :, :NOF_PREDICATES - 1], axis=2)
42 | entities_pred = np.argmax(out_confidence_entity_val, axis=1)
43 |
44 | # noinspection PyDictCreation
45 | results = {}
46 | # number of objects
47 | results["entity_total"] = entity_gt.shape[0]
48 | # number of predicates / relationships
49 | results["relations_total"] = relation_gt.shape[0] * relation_gt.shape[1]
50 | # number of positive predicates / relationships
51 | pos_indices = np.where(relation_gt != NOF_PREDICATES - 1)
52 | results["relations_pos_total"] = pos_indices[0].shape[0]
53 |
54 | # number of object correct predictions
55 | results["entity_correct"] = np.sum(entity_gt == entities_pred)
56 | # number of correct predicate
57 | results["relations_correct"] = np.sum(relation_gt == relation_pred)
58 | # number of correct positive predicates
59 | relations_gt_pos = relation_gt[pos_indices]
60 | relations_pred_pos = relations_pred_no_neg[pos_indices]
61 | results["relations_pos_correct"] = np.sum(relations_gt_pos == relations_pred_pos)
62 | # number of correct relationships
63 | entity_true_indices = np.where(entity_gt == entities_pred)
64 | relations_gt_true = relation_gt[entity_true_indices[0], :][:, entity_true_indices[0]]
65 | relations_pred_true = relation_pred[entity_true_indices[0], :][:, entity_true_indices[0]]
66 | relations_pred_true_pos = relations_pred_no_neg[entity_true_indices[0], :][:, entity_true_indices[0]]
67 | results["relationships_correct"] = np.sum(relations_gt_true == relations_pred_true)
68 | # number of correct positive relationships
69 | pos_true_indices = np.where(relations_gt_true != NOF_PREDICATES - 1)
70 | relations_gt_pos_true = relations_gt_true[pos_true_indices]
71 | relations_pred_pos_true = relations_pred_true_pos[pos_true_indices]
72 | results["relationships_pos_correct"] = np.sum(relations_gt_pos_true == relations_pred_pos_true)
73 |
74 | return results
75 |
76 |
77 | def train(name="module",
78 | nof_iterations=100,
79 | learning_rate=0.0001,
80 | learning_rate_steps=1000,
81 | learning_rate_decay=0.5,
82 | load_module_name="module.ckpt",
83 | use_saved_module=False,
84 | batch_size=20,
85 | pred_pos_neg_ratio=10,
86 | lr_object_coeff=4,
87 | layers=[500, 500, 500],
88 | gpu=0):
89 | """
90 | Train SGP module given train parameters and module hyper-parameters
91 | :param name: name of the train session
92 | :param nof_iterations: number of epochs
93 | :param learning_rate:
94 | :param learning_rate_steps: decay after number of steps
95 | :param learning_rate_decay: the factor to decay the learning rate
96 | :param load_module_name: name of already trained module weights to load
97 | :param use_saved_module: start from already train module
98 | :param batch_size: number of images in each mini-batch
99 | :param pred_pos_neg_ratio: Set the loss ratio between positive and negatives (not labeled) predicates
100 | :param lr_object_coeff: Set the loss ratio between objects and predicates
101 | :param layers: list of sizes of the hidden layer of the predicate and object classifier
102 | :param gpu: gpu number to use for the training
103 | :return: nothing
104 | """
105 | gpi_type = "Linguistic"
106 | including_object = True
107 | # get filesmanager
108 | filesmanager = FilesManager()
109 |
110 | # create logger
111 | logger_path = filesmanager.get_file_path("logs")
112 | logger_path = os.path.join(logger_path, name)
113 | logger = Logger(name, logger_path)
114 |
115 | # print train params
116 | frame = inspect.currentframe()
117 | args, _, _, values = inspect.getargvalues(frame)
118 | logger.log('function name "%s"' % inspect.getframeinfo(frame)[2])
119 | for i in args:
120 | logger.log(" %s = %s" % (i, values[i]))
121 |
122 | # set gpu
123 | if gpu != None:
124 | os.environ["CUDA_VISIBLE_DEVICES"] = str(gpu)
125 | logger.log("os.environ[\"CUDA_VISIBLE_DEVICES\"] = " + str(gpu))
126 |
127 | # create module
128 | module = Module(gpi_type=gpi_type, nof_predicates=NOF_PREDICATES, nof_objects=NOF_OBJECTS,
129 | is_train=True,
130 | learning_rate=learning_rate, learning_rate_steps=learning_rate_steps,
131 | learning_rate_decay=learning_rate_decay,
132 | lr_object_coeff=lr_object_coeff,
133 | including_object=including_object,
134 | layers=layers)
135 |
136 | ##
137 | # get module place holders
138 | #
139 | # get input place holders
140 | confidence_relation_ph, confidence_entity_ph, bb_ph, word_embed_relations_ph, word_embed_entities_ph = module.get_in_ph()
141 | # get labels place holders
142 | labels_relation_ph, labels_entity_ph, labels_coeff_loss_ph = module.get_labels_ph()
143 | # get loss and train step
144 | loss, gradients, grad_placeholder, train_step = module.get_module_loss()
145 |
146 | ##
147 | # get module output
148 | out_relation_probes, out_entity_probes = module.get_output()
149 |
150 | # Initialize the Computational Graph
151 | init = tf.global_variables_initializer()
152 | # Add ops to save and restore all the variables.
153 | variables = tf.contrib.slim.get_variables_to_restore()
154 | variables_to_restore = variables
155 | saver = tf.train.Saver(variables_to_restore)
156 |
157 | with tf.Session() as sess:
158 | # Restore variables from disk.
159 | module_path = filesmanager.get_file_path("sg_module.train.saver")
160 | module_path_load = os.path.join(module_path, load_module_name)
161 | if os.path.exists(module_path_load + ".index") and use_saved_module:
162 | saver.restore(sess, module_path_load)
163 | logger.log("Model restored.")
164 | else:
165 | sess.run(init)
166 |
167 | # train images
168 | vg_train_path = filesmanager.get_file_path("data.visual_genome.train")
169 | # list of train files
170 | train_files_list = range(2, 72)
171 | shuffle(train_files_list)
172 |
173 | # Actual validation is 5 files.
174 | # After tunning the hyper parameters, use just 2 files for early stopping.
175 | validation_files_list = range(2)
176 |
177 | # create one hot vector for predicate_negative (i.e. not labeled)
178 | relation_neg = np.zeros(NOF_PREDICATES)
179 | relation_neg[NOF_PREDICATES - 1] = 1
180 |
181 | # object embedding
182 | embed_obj = FilesManager().load_file("language_module.word2vec.object_embeddings")
183 | embed_pred = FilesManager().load_file("language_module.word2vec.predicate_embeddings")
184 | embed_pred = np.concatenate((embed_pred, np.zeros(embed_pred[:1].shape)),
185 | axis=0) # concat negative represntation
186 |
187 | # train module
188 | lr = learning_rate
189 | best_test_loss = -1
190 | baseline_path = filesmanager.get_file_path("data.visual_genome.train_baseline")
191 | for epoch in xrange(1, nof_iterations):
192 | accum_results = None
193 | total_loss = 0
194 | steps = []
195 | # read data
196 | file_index = -1
197 | for file_name in train_files_list:
198 |
199 | file_index += 1
200 |
201 | # load data from file
202 | file_path = os.path.join(vg_train_path, str(file_name) + ".p")
203 | file_handle = open(file_path, "rb")
204 | train_images = cPickle.load(file_handle)
205 | file_handle.close()
206 | shuffle(train_images)
207 |
208 | for image in train_images:
209 | # load initial belief by baseline detector
210 | file_path = os.path.join(baseline_path, str(image.image.id) + ".p")
211 | if not os.path.exists(file_path):
212 | continue
213 | file_handle = open(file_path, "rb")
214 | decetctor_data = cPickle.load(file_handle)
215 | file_handle.close()
216 | image.predicates_outputs_with_no_activation = decetctor_data["rel_dist_mapped"]
217 | image.objects_outputs_with_no_activations = decetctor_data["obj_dist_mapped"]
218 |
219 | # set diagonal to be negative predicate (no relation for a single object)
220 | indices = np.arange(image.predicates_outputs_with_no_activation.shape[0])
221 | image.predicates_outputs_with_no_activation[indices, indices, :] = relation_neg
222 | image.predicates_labels[indices, indices, :] = relation_neg
223 |
224 | # spatial features
225 | entity_bb = np.zeros((len(image.objects), 14))
226 | for obj_id in range(len(image.objects)):
227 | entity_bb[obj_id][0] = image.objects[obj_id].x / 1200.0
228 | entity_bb[obj_id][1] = image.objects[obj_id].y / 1200.0
229 | entity_bb[obj_id][2] = (image.objects[obj_id].x + image.objects[obj_id].width) / 1200.0
230 | entity_bb[obj_id][3] = (image.objects[obj_id].y + image.objects[obj_id].height) / 1200.0
231 | entity_bb[obj_id][4] = image.objects[obj_id].x
232 | entity_bb[obj_id][5] = -1 * image.objects[obj_id].x
233 | entity_bb[obj_id][6] = image.objects[obj_id].y
234 | entity_bb[obj_id][7] = -1 * image.objects[obj_id].y
235 | entity_bb[obj_id][8] = image.objects[obj_id].width * image.objects[obj_id].height
236 | entity_bb[obj_id][9] = -1 * image.objects[obj_id].width * image.objects[obj_id].height
237 | entity_bb[:, 4] = np.argsort(entity_bb[:, 4])
238 | entity_bb[:, 5] = np.argsort(entity_bb[:, 5])
239 | entity_bb[:, 6] = np.argsort(entity_bb[:, 6])
240 | entity_bb[:, 7] = np.argsort(entity_bb[:, 7])
241 | entity_bb[:, 8] = np.argsort(entity_bb[:, 8])
242 | entity_bb[:, 9] = np.argsort(entity_bb[:, 9])
243 | entity_bb[:, 10] = np.argsort(np.max(image.objects_outputs_with_no_activations, axis=1))
244 | entity_bb[:, 11] = np.argsort(-1 * np.max(image.objects_outputs_with_no_activations, axis=1))
245 | entity_bb[:, 12] = np.arange(entity_bb.shape[0])
246 | entity_bb[:, 13] = np.arange(entity_bb.shape[0], 0, -1)
247 |
248 | # filter non mixed cases
249 | relations_neg_labels = image.predicates_labels[:, :, NOF_PREDICATES - 1:]
250 | if np.sum(image.predicates_labels[:, :, :NOF_PREDICATES - 1]) == 0:
251 | continue
252 |
253 | if including_object:
254 | in_entity_confidence = image.objects_outputs_with_no_activations
255 | else:
256 | in_entity_confidence = image.objects_labels * 1000
257 |
258 | # give lower weight to negatives
259 | coeff_factor = np.ones(relations_neg_labels.shape)
260 | factor = float(np.sum(image.predicates_labels[:, :, :NOF_PREDICATES - 2])) / np.sum(
261 | relations_neg_labels) / pred_pos_neg_ratio
262 | coeff_factor[relations_neg_labels == 1] *= factor
263 |
264 | coeff_factor[indices, indices] = 0
265 |
266 | # create the feed dictionary
267 | feed_dict = {confidence_relation_ph: image.predicates_outputs_with_no_activation,
268 | confidence_entity_ph: in_entity_confidence,
269 | bb_ph : entity_bb,
270 | module.phase_ph: True,
271 | word_embed_entities_ph: embed_obj, word_embed_relations_ph: embed_pred,
272 | labels_relation_ph: image.predicates_labels, labels_entity_ph: image.objects_labels,
273 | labels_coeff_loss_ph: coeff_factor.reshape((-1)), module.lr_ph: lr}
274 |
275 | # run the network
276 | out_relation_probes_val, out_entity_probes_val, loss_val, gradients_val = \
277 | sess.run([out_relation_probes, out_entity_probes, loss, gradients],
278 | feed_dict=feed_dict)
279 | if math.isnan(loss_val):
280 | print("NAN")
281 | continue
282 |
283 | # set diagonal to be neg (in order not to take into account in statistics)
284 | out_relation_probes_val[indices, indices, :] = relation_neg
285 |
286 | # append gradient to list (will be applied as a batch of entities)
287 | steps.append(gradients_val)
288 |
289 | # statistic
290 | total_loss += loss_val
291 |
292 | results = test(image.predicates_labels, image.objects_labels, out_relation_probes_val,
293 | out_entity_probes_val)
294 |
295 | # accumulate results
296 | if accum_results is None:
297 | accum_results = results
298 | else:
299 | for key in results:
300 | accum_results[key] += results[key]
301 |
302 | if len(steps) == batch_size:
303 | # apply steps
304 | step = steps[0]
305 | feed_grad_apply_dict = {grad_placeholder[j][0]: step[j][0] for j in
306 | xrange(len(grad_placeholder))}
307 | for i in xrange(1, len(steps)):
308 | step = steps[i]
309 | for j in xrange(len(grad_placeholder)):
310 | feed_grad_apply_dict[grad_placeholder[j][0]] += step[j][0]
311 |
312 | feed_grad_apply_dict[module.lr_ph] = lr
313 | sess.run([train_step], feed_dict=feed_grad_apply_dict)
314 | steps = []
315 | # print stat - per file just for the first epoch - disabled!!
316 | if epoch == 1:
317 | obj_accuracy = float(accum_results['entity_correct']) / accum_results['entity_total']
318 | predicate_pos_accuracy = float(accum_results['relations_pos_correct']) / accum_results[
319 | 'relations_pos_total']
320 | relationships_pos_accuracy = float(accum_results['relationships_pos_correct']) / accum_results[
321 | 'relations_pos_total']
322 | logger.log("iter %d.%d - obj %f - pred %f - relation %f" %
323 | (epoch, file_index, obj_accuracy, predicate_pos_accuracy, relationships_pos_accuracy))
324 |
325 | # print stat per epoch
326 | obj_accuracy = float(accum_results['entity_correct']) / accum_results['entity_total']
327 | predicate_pos_accuracy = float(accum_results['relations_pos_correct']) / accum_results[
328 | 'relations_pos_total']
329 | predicate_all_accuracy = float(accum_results['relations_correct']) / accum_results['relations_total']
330 | relationships_pos_accuracy = float(accum_results['relationships_pos_correct']) / accum_results[
331 | 'relations_pos_total']
332 | relationships_all_accuracy = float(accum_results['relationships_correct']) / accum_results[
333 | 'relations_total']
334 |
335 | logger.log("iter %d - loss %f - obj %f - pred %f - rela %f - all_pred %f - all rela %f - lr %f" %
336 | (epoch, total_loss, obj_accuracy, predicate_pos_accuracy, relationships_pos_accuracy,
337 | predicate_all_accuracy, relationships_all_accuracy, lr))
338 |
339 | # run validation
340 | if epoch % TEST_ITERATIONS == 0:
341 | total_test_loss = 0
342 | accum_test_results = None
343 |
344 | for file_name in validation_files_list:
345 | # load data from file
346 | file_path = os.path.join(vg_train_path, str(file_name) + ".p")
347 | file_handle = open(file_path, "rb")
348 | validation_images = cPickle.load(file_handle)
349 | file_handle.close()
350 |
351 | for image in validation_images:
352 | file_path = os.path.join(baseline_path, str(image.image.id) + ".p")
353 | if not os.path.exists(file_path):
354 | continue
355 | file_handle = open(file_path, "rb")
356 | detector_data = cPickle.load(file_handle)
357 | file_handle.close()
358 |
359 | image.predicates_outputs_with_no_activation = detector_data["rel_dist_mapped"]
360 | image.objects_outputs_with_no_activations = detector_data["obj_dist_mapped"]
361 | # set diagonal to be neg
362 | indices = np.arange(image.predicates_outputs_with_no_activation.shape[0])
363 | image.predicates_outputs_with_no_activation[indices, indices, :] = relation_neg
364 | image.predicates_labels[indices, indices, :] = relation_neg
365 |
366 | # get shape of extended object to be used by the module
367 | extended_confidence_object_shape = np.asarray(image.predicates_outputs_with_no_activation.shape)
368 | extended_confidence_object_shape[2] = NOF_OBJECTS
369 |
370 | # spatial features
371 | entity_bb = np.zeros((len(image.objects), 14))
372 | for obj_id in range(len(image.objects)):
373 | entity_bb[obj_id][0] = image.objects[obj_id].x / 1200.0
374 | entity_bb[obj_id][1] = image.objects[obj_id].y / 1200.0
375 | entity_bb[obj_id][2] = (image.objects[obj_id].x + image.objects[obj_id].width) / 1200.0
376 | entity_bb[obj_id][3] = (image.objects[obj_id].y + image.objects[obj_id].height) / 1200.0
377 | entity_bb[obj_id][4] = image.objects[obj_id].x
378 | entity_bb[obj_id][5] = -1 * image.objects[obj_id].x
379 | entity_bb[obj_id][6] = image.objects[obj_id].y
380 | entity_bb[obj_id][7] = -1 * image.objects[obj_id].y
381 | entity_bb[obj_id][8] = image.objects[obj_id].width * image.objects[obj_id].height
382 | entity_bb[obj_id][9] = -1 * image.objects[obj_id].width * image.objects[obj_id].height
383 | entity_bb[:, 4] = np.argsort(entity_bb[:, 4])
384 | entity_bb[:, 5] = np.argsort(entity_bb[:, 5])
385 | entity_bb[:, 6] = np.argsort(entity_bb[:, 6])
386 | entity_bb[:, 7] = np.argsort(entity_bb[:, 7])
387 | entity_bb[:, 8] = np.argsort(entity_bb[:, 8])
388 | entity_bb[:, 9] = np.argsort(entity_bb[:, 9])
389 | entity_bb[:, 10] = np.argsort(np.max(image.objects_outputs_with_no_activations, axis=1))
390 | entity_bb[:, 11] = np.argsort(-1 * np.max(image.objects_outputs_with_no_activations, axis=1))
391 | entity_bb[:, 12] = np.arange(entity_bb.shape[0])
392 | entity_bb[:, 13] = np.arange(entity_bb.shape[0], 0, -1)
393 |
394 | # filter non mixed cases
395 | relations_neg_labels = image.predicates_labels[:, :, NOF_PREDICATES - 1:]
396 | if np.sum(image.predicates_labels[:, :, :NOF_PREDICATES - 1]) == 0:
397 | continue
398 |
399 | # give lower weight to negatives
400 | coeff_factor = np.ones(relations_neg_labels.shape)
401 | factor = float(np.sum(image.predicates_labels[:, :, :NOF_PREDICATES - 2])) / np.sum(
402 | relations_neg_labels) / pred_pos_neg_ratio
403 | coeff_factor[relations_neg_labels == 1] *= factor
404 | coeff_factor[indices, indices] = 0
405 | coeff_factor[relations_neg_labels == 1] = 0
406 |
407 | if including_object:
408 | in_entity_confidence = image.objects_outputs_with_no_activations
409 | else:
410 | in_entity_confidence = image.objects_labels * 1000
411 |
412 | # create the feed dictionary
413 | feed_dict = {confidence_relation_ph: image.predicates_outputs_with_no_activation,
414 | confidence_entity_ph: in_entity_confidence,
415 | module.entity_bb_ph: entity_bb,
416 | module.word_embed_entities_ph: embed_obj,
417 | module.phase_ph: False,
418 | module.word_embed_relations_ph: embed_pred,
419 | labels_relation_ph: image.predicates_labels,
420 | labels_entity_ph: image.objects_labels,
421 | labels_coeff_loss_ph: coeff_factor.reshape((-1))}
422 |
423 | # run the network
424 | out_relation_probes_val, out_entity_probes_val, loss_val = sess.run(
425 | [out_relation_probes, out_entity_probes, loss],
426 | feed_dict=feed_dict)
427 |
428 | # set diagonal to be neg (in order not to take into account in statistics)
429 | out_relation_probes_val[indices, indices, :] = relation_neg
430 |
431 | # statistic
432 | total_test_loss += loss_val
433 |
434 | # statistics
435 | results = test(image.predicates_labels, image.objects_labels,
436 | out_relation_probes_val, out_entity_probes_val)
437 |
438 | # accumulate results
439 | if accum_test_results is None:
440 | accum_test_results = results
441 | else:
442 | for key in results:
443 | accum_test_results[key] += results[key]
444 |
445 |
446 | # print stat
447 | obj_accuracy = float(accum_test_results['entity_correct']) / accum_test_results['entity_total']
448 | predicate_pos_accuracy = float(accum_test_results['relations_pos_correct']) / accum_test_results[
449 | 'relations_pos_total']
450 | predicate_all_accuracy = float(accum_test_results['relations_correct']) / accum_test_results[
451 | 'relations_total']
452 | relationships_pos_accuracy = float(accum_test_results['relationships_pos_correct']) / \
453 | accum_test_results[
454 | 'relations_pos_total']
455 | relationships_all_accuracy = float(accum_test_results['relationships_correct']) / accum_test_results[
456 | 'relations_total']
457 |
458 | logger.log("VALIDATION - loss %f - obj %f - pred %f - rela %f - all_pred %f - all rela %f" %
459 | (total_test_loss, obj_accuracy, predicate_pos_accuracy, relationships_pos_accuracy,
460 | predicate_all_accuracy, relationships_all_accuracy))
461 |
462 | # save best module so far
463 | if best_test_loss == -1 or total_test_loss < best_test_loss:
464 | module_path_save = os.path.join(module_path, name + "_best_module.ckpt")
465 | save_path = saver.save(sess, module_path_save)
466 | logger.log("Model saved in file: %s" % save_path)
467 | best_test_loss = total_test_loss
468 |
469 | # save module
470 | if epoch % SAVE_MODEL_ITERATIONS == 0:
471 | module_path_save = os.path.join(module_path, name + "_module.ckpt")
472 | save_path = saver.save(sess, module_path_save)
473 | logger.log("Model saved in file: %s" % save_path)
474 |
475 | # learning rate decay
476 | if (epoch % learning_rate_steps) == 0:
477 | lr *= learning_rate_decay
478 |
479 |
480 | if __name__ == "__main__":
481 | filemanager = FilesManager()
482 |
483 | params = filemanager.load_file("sg_module.train.params")
484 |
485 | name = params["name"]
486 | learning_rate = params["learning_rate"]
487 | learning_rate_steps = params["learning_rate_steps"]
488 | learning_rate_decay = params["learning_rate_decay"]
489 | nof_iterations = params["nof_iterations"]
490 | load_model_name = params["load_model_name"]
491 | use_saved_model = params["use_saved_model"]
492 | batch_size = params["batch_size"]
493 | predicate_pos_neg_ratio = params["predicate_pos_neg_ratio"]
494 | lr_object_coeff = params["lr_object_coeff"]
495 | layers = params["layers"]
496 | gpu = params["gpu"]
497 |
498 | train(name, nof_iterations, learning_rate, learning_rate_steps, learning_rate_decay, load_model_name,
499 | use_saved_model, batch_size, predicate_pos_neg_ratio, lr_object_coeff, layers,
500 | gpu)
501 |
--------------------------------------------------------------------------------
/Module/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/shikorab/SceneGraph/d2dc960a0d3728e7d2b0eaceb9d0fdaedb2a47d5/Module/__init__.py
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Mapping Images to Scene Graphs with Permutation-Invariant Structured Prediction
2 | #### [Roei Herzig*](https://roeiherz.github.io/) , Moshiko Raboh*, [Gal Chechik](https://chechiklab.biu.ac.il/~gal/), [Jonathan Berant](http://www.cs.tau.ac.il/~joberant/), [Amir Globerson](http://www.cs.tau.ac.il/~gamir/) 3 |
4 |
5 | ## Introduction
6 | Scene graph prediction is the task of mapping an image into a set of bounding boxes, along with their categories and relations (e.g., see [2, 3, 4, 5, 6]).
7 |
8 |
9 | In the paper [Scene Graphs with Permutation-Invariant Structured Prediction](https://arxiv.org/abs/1802.05451) (2018) [1] we present a new architecture for graph inference that has the **following structural property**:
10 | on the one hand, the architecture is invariant to input permutations;
11 | on the other hand, every permutation-invariant function can be implemented via this architecture.
12 |
13 | In this repository, we share our architecture implementation for the task of scene graph prediction.
14 |
15 | ## Model implementation
16 | **Scene Graph Predictor (SGP)** gets as an input inital confidience distributions per entity and relation and processes these to obtain new labels. SGP satisfies the graph permutation invariance property intoduced in the paper.
17 | The model is implemented in [TensorFlow](https://www.tensorflow.org/).
18 | For the initial confidence distributions per entity and relation, we simply re-use features learned by the baseline model from Zellers et al. (2017). (git repository https://github.com/rowanz/neural-motifs)
19 |
20 |
21 |
22 | ## SGP architecture
23 | Our SGP implementation is using an iteratively RNN to process predictions. Each step outputs an improved predictions.
24 |
25 |
3 |
4 |
5 | ## Introduction
6 | Scene graph prediction is the task of mapping an image into a set of bounding boxes, along with their categories and relations (e.g., see [2, 3, 4, 5, 6]).
7 |
8 |
9 | In the paper [Scene Graphs with Permutation-Invariant Structured Prediction](https://arxiv.org/abs/1802.05451) (2018) [1] we present a new architecture for graph inference that has the **following structural property**:
10 | on the one hand, the architecture is invariant to input permutations;
11 | on the other hand, every permutation-invariant function can be implemented via this architecture.
12 |
13 | In this repository, we share our architecture implementation for the task of scene graph prediction.
14 |
15 | ## Model implementation
16 | **Scene Graph Predictor (SGP)** gets as an input inital confidience distributions per entity and relation and processes these to obtain new labels. SGP satisfies the graph permutation invariance property intoduced in the paper.
17 | The model is implemented in [TensorFlow](https://www.tensorflow.org/).
18 | For the initial confidence distributions per entity and relation, we simply re-use features learned by the baseline model from Zellers et al. (2017). (git repository https://github.com/rowanz/neural-motifs)
19 |
20 |
21 |
22 | ## SGP architecture
23 | Our SGP implementation is using an iteratively RNN to process predictions. Each step outputs an improved predictions.
24 |
25 |  26 |
27 | A schematic representation of the architecture. Given an image, a Label predictor outputs initial predictions . Then, our SGP model, computes each  element wise. Next, they are summed to create vector 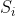, which is concatenated with . Then, 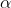 is applied, and another summation creates the graph representation. Finally,  classifies objects and  classifies relation. The process of SGP could be repeated iteratively (in the paper we repeat it 3 times).
28 |
29 | For more information, please look at the code (Module/Module.py file) and the paper.
30 |
31 |
32 | ## Attention with SGP architecture
33 | Our SGP architecture uses attention at the feature-level for each node during inference.
34 | We weight the significance of each feature per node, such that the network can choose which features from adjacent nodes contributes the most information.
35 |
36 |
26 |
27 | A schematic representation of the architecture. Given an image, a Label predictor outputs initial predictions . Then, our SGP model, computes each  element wise. Next, they are summed to create vector , which is concatenated with . Then,  is applied, and another summation creates the graph representation. Finally,  classifies objects and  classifies relation. The process of SGP could be repeated iteratively (in the paper we repeat it 3 times).
28 |
29 | For more information, please look at the code (Module/Module.py file) and the paper.
30 |
31 |
32 | ## Attention with SGP architecture
33 | Our SGP architecture uses attention at the feature-level for each node during inference.
34 | We weight the significance of each feature per node, such that the network can choose which features from adjacent nodes contributes the most information.
35 |
36 |  37 |
38 | An example of attention per entities and global attention over all nodes. The size and location of objects provide a key signal to the attention mechanism. The model assigns higher confidence for the label "tie" when the label "shirt" is detected (third panel from the left). Similarly, the model assigns a higher confidence for the label "eye" when it is located near "hair".
39 |
40 | ## Dependencies
41 | To get started with the framework, install the following dependencies:
42 | - [Python 2.7](https://www.python.org/)
43 | - [tensorflow-gpu 1.0.1](https://www.tensorflow.org/)
44 | - [matplotlib 2.0.2](http://matplotlib.org/)
45 | - [h5py 2.7.0](http://www.h5py.org/)
46 | - [numpy 1.12.1](http://www.numpy.org/)
47 | - [pyyaml 3.12](https://pypi.python.org/pypi/PyYAML)
48 |
49 | Run `"pip install -r requirements.txt"` - to install all the requirements.
50 |
51 |
52 | ## Usage
53 | 1. Run `"python Run.py download"` to download and extract train, validation and test data. The data already contains the result of applying the baseline detecor over the VisualGenome data.
54 | 2. Run `"python Run.py eval gpi_linguistic_pretrained "` to evaluate the pre-trained model of our best variant, linguistic with multi-head attention. (recall@100 SG Classification).
55 | 3. Run `"python Run.py train gpi_linguistic "` to train a new model (linguistic with multi-head attention).
56 | 4. Run `"python Run.py eval gpi_linguistic_best "` to evaluate the new model. (recall@100 SG Classification).
57 |
58 |
59 | ## About this repository
60 | This repository contains an implementation of our best variant (Linguistic with multi-head attention) of the Scene Graph Prediction (SGP) model introduced in the paper [Scene Graphs with Permutation-Invariant Structured Prediction](https://arxiv.org/abs/1802.05451).
61 | (The repsitory updated for version 1 of the paper - the results of latest version will be published ×in the future).
62 | Specifically, the repository allow to run scene-graph classification (recall@100) evaluation script on our pre-trained model or alternatively (1) train an SGP model (2) evaluate the trained model using scene-graph classification (recall@100) evaluation script.
63 |
64 |
65 | ## References
66 | [1] Roei Herzig, Moshiko Raboh, Gal Chechik, Jonathan Berant, Amir Globerson, [Mapping Images to Scene Graphs with Permutation-Invariant Structured Prediction](https://arxiv.org/abs/1802.05451), 2018.
67 |
68 | [2] Justin Johnson, Ranjay Krishna, Michael Stark, Li Jia Li, David A. Shamma, Michael S. Bernstein, Fei Fei Li, [Image Retrieval using Scene Graphs](http://hci.stanford.edu/publications/2015/scenegraphs/JohnsonCVPR2015.pdf), CVPR, 2015.
69 |
70 | [3] Cewu Lu, Ranjay Krishna, Michael S. Bernstein, Fei Fei Li, [Visual Relationship Detection with Language Priors](https://cs.stanford.edu/people/ranjaykrishna/vrd/vrd.pdf), ECCV, 2016.
71 |
72 | [4] Xu, Danfei and Zhu, Yuke and Choy, Christopher and Fei-Fei, Li, [Scene Graph Generation by Iterative Message Passing](https://arxiv.org/pdf/1701.02426.pdf), CVPR, 2017.
73 |
74 | [5] Alejandro Newell and Jia Deng, [Pixels to Graphs by Associative Embedding](https://papers.nips.cc/paper/6812-pixels-to-graphs-by-associative-embedding.pdf), NIPS, 2017.
75 |
76 | [6] Rowan Zellers, Mark Yatskar, Sam Thomson, Yejin Choi, [Neural Motifs: Scene Graph Parsing with Global Context](https://arxiv.org/pdf/1711.06640.pdf), CVPR, 2018.
77 |
78 | ## Cite
79 | Please cite our paper if you use this code in your own work:
80 | ```
81 | @inproceedings{hr18perminvimg2sg,
82 | author = {Roei Herzig and
83 | Moshiko Raboh and
84 | Gal Chechik and
85 | Jonathan Berant and
86 | Amir Globerson},
87 | title = {Mapping Images to Scene Graphs with Permutation-Invariant Structured
88 | Prediction},
89 | booktitle = {Advances in Neural Information Processing Systems (NIPS)},
90 | year = {2018}
91 | }
92 | ```
93 |
--------------------------------------------------------------------------------
/Run.py:
--------------------------------------------------------------------------------
1 | import sys
2 | from Module.Train import train
3 | from Module.Eval import eval
4 | import zipfile
5 | import os
6 | from FilesManager.FilesManager import FilesManager
7 | from Utils.Logger import Logger
8 | import urllib
9 |
10 | if __name__ == "__main__":
11 | version_filename_flag = '.data_ver2'
12 |
13 | # create logger
14 | logger = Logger()
15 |
16 | application = None
17 | name = None
18 | gpu = None
19 |
20 | ## get input parameters
21 | # application
22 | if len(sys.argv) > 1:
23 | application = sys.argv[1]
24 |
25 | # module name
26 | if len(sys.argv) > 2:
27 | name = sys.argv[2]
28 |
29 | # gpu number
30 | if len(sys.argv) > 3:
31 | gpu = sys.argv[3]
32 |
33 | if application == "train":
34 | # check if requried data version downloaded
35 | if not os.path.isfile(version_filename_flag):
36 | print("Error: Data wasn't downloaded. Type python Run.py for instructions how to download\n\n")
37 | exit()
38 | logger.log("Command: Train(module_name=%s, gpu=%s" % (name, str(gpu)))
39 | train(name=name, gpu=gpu)
40 |
41 | elif application == "eval":
42 | # check if requried data version downloaded
43 | if not os.path.isfile(version_filename_flag):
44 | print("Error: Data wasn't downloaded. Type python Run.py for instructions how to download\n\n")
45 | exit()
46 |
47 | logger.log("Command: Eval(module_name=%s, gpu=%s" % (name, str(gpu)))
48 | eval(load_module_name=name, gpu=gpu)
49 |
50 | elif application == "download":
51 | logger.log("Command: Download()")
52 |
53 | filesmanager = FilesManager()
54 | path = filesmanager.get_file_path("data.visual_genome.data")
55 | file_name = os.path.join(path, "data.zip")
56 |
57 | # Download Data
58 | logger.log("Download Data ...")
59 | url = "http://www.cs.tau.ac.il/~taunlp/scene_graph/data.zip"
60 | urllib.urlretrieve(url, file_name)
61 |
62 | # Extract data
63 | logger.log("Extract ZIP file ...")
64 | zip_ref = zipfile.ZipFile(file_name, 'r')
65 | zip_ref.extractall(path)
66 | zip_ref.close()
67 |
68 | # mark data version downloaded
69 | open(version_filename_flag, "wb").close()
70 |
71 | else:
72 | # print usage
73 | print("Error: unexpected usage\n\n")
74 | print("SGP Runner")
75 | print("----------")
76 | print("Download data: \"python Run.py download\"")
77 | print(" Should be run just once, on the first time the module used")
78 | print("Train Module: \"python Run.py train \"")
79 | print(" Train lingustic SGP")
80 | print(" Module weights with the highest score over the validation set will be saved as \"_best\"")
81 | print(" Module weights of the last epoch will be saved as \"\"")
82 | print("Eval Module: \"python Run.py eval \"")
83 | print(" Scene graph classification (recall@100) evaluation for the trained module.")
84 | print(" Use 'gpi_ling_orig_best' for a pre-trained module")
85 | print(" Use \"_best\" for a self-trained module")
86 |
--------------------------------------------------------------------------------
/Utils/Logger.py:
--------------------------------------------------------------------------------
1 | import os
2 | import os.path
3 | import sys
4 | from FilesManager.FilesManager import FilesManager
5 | import time
6 | sys.path.append("..")
7 | from Utils.Singleton import Singleton
8 |
9 |
10 | class Logger(object):
11 | """
12 | Logger class
13 | """
14 | __metaclass__ = Singleton
15 |
16 | def __init__(self, name="", path=None):
17 | """
18 | Creating logger, the name of the logger will be printed at each line and log will be saved in path
19 | :param name: name of the logger
20 | :param path: path to log file
21 | """
22 | self.name = name
23 | if self.name != "":
24 | self.prefix = self.name + ": "
25 | else:
26 | self.prefix = ""
27 |
28 | self.path = path
29 |
30 | # create dir
31 | if self.path is not None:
32 | if not os.path.exists(self.path):
33 | os.makedirs(self.path)
34 |
35 | # create file to log
36 | self.log_file = open(self.path + "/logger.log", "w")
37 | else:
38 | self.log_file = None
39 |
40 | # add logger to file manager
41 | filesmanager = FilesManager()
42 | filesmanager.add_logger(self)
43 |
44 | # default log file
45 | if self.log_file is None:
46 | self.path = filesmanager.get_file_path("logs")
47 | if not os.path.exists(self.path):
48 | os.makedirs(self.path)
49 | self.log_file = open(self.path + "/logger-%s.log" % time.strftime("%c"), "w")
50 | self.log("Start %s" % time.strftime("%c"))
51 |
52 | def log(self, str):
53 | """
54 | This function write str to the logger
55 | :param str: a string to be written
56 | """
57 | if self.log_file is not None:
58 | self.log_file.write(self.name + ": " + str + "\n")
59 | self.log_file.flush()
60 | print(self.prefix + str)
61 |
62 | def get_dir(self):
63 | """
64 | Get the path of the dir
65 | :return: path of the dir
66 | """
67 | return self.path
68 |
69 | @classmethod
70 | def get_logger(cls):
71 | """
72 | This function returns the logger
73 | :return: return the cls logger
74 | """
75 | return cls
76 |
--------------------------------------------------------------------------------
/Utils/Singleton.py:
--------------------------------------------------------------------------------
1 | class Singleton(type):
2 | """
3 | Singleton metaclass
4 | """
5 |
6 | _instances = {}
7 |
8 | def __call__(cls, *args, **kwargs):
9 | if cls not in cls._instances:
10 | cls._instances[cls] = super(Singleton, cls).__call__(*args, **kwargs)
11 | return cls._instances[cls]
12 |
13 |
14 | class Visitor(object):
15 | """
16 | This class is a base class for the visitor design pattern,
17 | a subclass can implement visit methods for specific types
18 | for example, given two classes A and B, a visitor need to create two functions
19 | visit_A and visit_B and dynamically the visit method will route to the correct visit method
20 | given a subject of type A or B
21 | """
22 |
23 | def visit(self, subject):
24 | method_name = 'visit_' + type(subject).__name__
25 | method = getattr(self, method_name)
26 | if method is None:
27 | method = self.generic_visit
28 | return method(subject)
29 |
30 | def generic_visit(self, subject):
31 | print('Class {0} does not have a visit function in {1}'.format(type(subject).__name__,
32 | type(self).__name__))
--------------------------------------------------------------------------------
/Utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/shikorab/SceneGraph/d2dc960a0d3728e7d2b0eaceb9d0fdaedb2a47d5/Utils/__init__.py
--------------------------------------------------------------------------------
/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/shikorab/SceneGraph/d2dc960a0d3728e7d2b0eaceb9d0fdaedb2a47d5/__init__.py
--------------------------------------------------------------------------------
/qualitive_results_att_boxes.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/shikorab/SceneGraph/d2dc960a0d3728e7d2b0eaceb9d0fdaedb2a47d5/qualitive_results_att_boxes.png
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | tensorflow_gpu==1.0.1
2 | matplotlib==2.0.2
3 | h5py==2.7.0
4 | numpy==1.13.1
5 | PyYAML==3.12
6 |
--------------------------------------------------------------------------------
/sg_example_final.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/shikorab/SceneGraph/d2dc960a0d3728e7d2b0eaceb9d0fdaedb2a47d5/sg_example_final.png
--------------------------------------------------------------------------------
/sgp_arch_git.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/shikorab/SceneGraph/d2dc960a0d3728e7d2b0eaceb9d0fdaedb2a47d5/sgp_arch_git.png
--------------------------------------------------------------------------------
37 |
38 | An example of attention per entities and global attention over all nodes. The size and location of objects provide a key signal to the attention mechanism. The model assigns higher confidence for the label "tie" when the label "shirt" is detected (third panel from the left). Similarly, the model assigns a higher confidence for the label "eye" when it is located near "hair".
39 |
40 | ## Dependencies
41 | To get started with the framework, install the following dependencies:
42 | - [Python 2.7](https://www.python.org/)
43 | - [tensorflow-gpu 1.0.1](https://www.tensorflow.org/)
44 | - [matplotlib 2.0.2](http://matplotlib.org/)
45 | - [h5py 2.7.0](http://www.h5py.org/)
46 | - [numpy 1.12.1](http://www.numpy.org/)
47 | - [pyyaml 3.12](https://pypi.python.org/pypi/PyYAML)
48 |
49 | Run `"pip install -r requirements.txt"` - to install all the requirements.
50 |
51 |
52 | ## Usage
53 | 1. Run `"python Run.py download"` to download and extract train, validation and test data. The data already contains the result of applying the baseline detecor over the VisualGenome data.
54 | 2. Run `"python Run.py eval gpi_linguistic_pretrained "` to evaluate the pre-trained model of our best variant, linguistic with multi-head attention. (recall@100 SG Classification).
55 | 3. Run `"python Run.py train gpi_linguistic "` to train a new model (linguistic with multi-head attention).
56 | 4. Run `"python Run.py eval gpi_linguistic_best "` to evaluate the new model. (recall@100 SG Classification).
57 |
58 |
59 | ## About this repository
60 | This repository contains an implementation of our best variant (Linguistic with multi-head attention) of the Scene Graph Prediction (SGP) model introduced in the paper [Scene Graphs with Permutation-Invariant Structured Prediction](https://arxiv.org/abs/1802.05451).
61 | (The repsitory updated for version 1 of the paper - the results of latest version will be published ×in the future).
62 | Specifically, the repository allow to run scene-graph classification (recall@100) evaluation script on our pre-trained model or alternatively (1) train an SGP model (2) evaluate the trained model using scene-graph classification (recall@100) evaluation script.
63 |
64 |
65 | ## References
66 | [1] Roei Herzig, Moshiko Raboh, Gal Chechik, Jonathan Berant, Amir Globerson, [Mapping Images to Scene Graphs with Permutation-Invariant Structured Prediction](https://arxiv.org/abs/1802.05451), 2018.
67 |
68 | [2] Justin Johnson, Ranjay Krishna, Michael Stark, Li Jia Li, David A. Shamma, Michael S. Bernstein, Fei Fei Li, [Image Retrieval using Scene Graphs](http://hci.stanford.edu/publications/2015/scenegraphs/JohnsonCVPR2015.pdf), CVPR, 2015.
69 |
70 | [3] Cewu Lu, Ranjay Krishna, Michael S. Bernstein, Fei Fei Li, [Visual Relationship Detection with Language Priors](https://cs.stanford.edu/people/ranjaykrishna/vrd/vrd.pdf), ECCV, 2016.
71 |
72 | [4] Xu, Danfei and Zhu, Yuke and Choy, Christopher and Fei-Fei, Li, [Scene Graph Generation by Iterative Message Passing](https://arxiv.org/pdf/1701.02426.pdf), CVPR, 2017.
73 |
74 | [5] Alejandro Newell and Jia Deng, [Pixels to Graphs by Associative Embedding](https://papers.nips.cc/paper/6812-pixels-to-graphs-by-associative-embedding.pdf), NIPS, 2017.
75 |
76 | [6] Rowan Zellers, Mark Yatskar, Sam Thomson, Yejin Choi, [Neural Motifs: Scene Graph Parsing with Global Context](https://arxiv.org/pdf/1711.06640.pdf), CVPR, 2018.
77 |
78 | ## Cite
79 | Please cite our paper if you use this code in your own work:
80 | ```
81 | @inproceedings{hr18perminvimg2sg,
82 | author = {Roei Herzig and
83 | Moshiko Raboh and
84 | Gal Chechik and
85 | Jonathan Berant and
86 | Amir Globerson},
87 | title = {Mapping Images to Scene Graphs with Permutation-Invariant Structured
88 | Prediction},
89 | booktitle = {Advances in Neural Information Processing Systems (NIPS)},
90 | year = {2018}
91 | }
92 | ```
93 |
--------------------------------------------------------------------------------
/Run.py:
--------------------------------------------------------------------------------
1 | import sys
2 | from Module.Train import train
3 | from Module.Eval import eval
4 | import zipfile
5 | import os
6 | from FilesManager.FilesManager import FilesManager
7 | from Utils.Logger import Logger
8 | import urllib
9 |
10 | if __name__ == "__main__":
11 | version_filename_flag = '.data_ver2'
12 |
13 | # create logger
14 | logger = Logger()
15 |
16 | application = None
17 | name = None
18 | gpu = None
19 |
20 | ## get input parameters
21 | # application
22 | if len(sys.argv) > 1:
23 | application = sys.argv[1]
24 |
25 | # module name
26 | if len(sys.argv) > 2:
27 | name = sys.argv[2]
28 |
29 | # gpu number
30 | if len(sys.argv) > 3:
31 | gpu = sys.argv[3]
32 |
33 | if application == "train":
34 | # check if requried data version downloaded
35 | if not os.path.isfile(version_filename_flag):
36 | print("Error: Data wasn't downloaded. Type python Run.py for instructions how to download\n\n")
37 | exit()
38 | logger.log("Command: Train(module_name=%s, gpu=%s" % (name, str(gpu)))
39 | train(name=name, gpu=gpu)
40 |
41 | elif application == "eval":
42 | # check if requried data version downloaded
43 | if not os.path.isfile(version_filename_flag):
44 | print("Error: Data wasn't downloaded. Type python Run.py for instructions how to download\n\n")
45 | exit()
46 |
47 | logger.log("Command: Eval(module_name=%s, gpu=%s" % (name, str(gpu)))
48 | eval(load_module_name=name, gpu=gpu)
49 |
50 | elif application == "download":
51 | logger.log("Command: Download()")
52 |
53 | filesmanager = FilesManager()
54 | path = filesmanager.get_file_path("data.visual_genome.data")
55 | file_name = os.path.join(path, "data.zip")
56 |
57 | # Download Data
58 | logger.log("Download Data ...")
59 | url = "http://www.cs.tau.ac.il/~taunlp/scene_graph/data.zip"
60 | urllib.urlretrieve(url, file_name)
61 |
62 | # Extract data
63 | logger.log("Extract ZIP file ...")
64 | zip_ref = zipfile.ZipFile(file_name, 'r')
65 | zip_ref.extractall(path)
66 | zip_ref.close()
67 |
68 | # mark data version downloaded
69 | open(version_filename_flag, "wb").close()
70 |
71 | else:
72 | # print usage
73 | print("Error: unexpected usage\n\n")
74 | print("SGP Runner")
75 | print("----------")
76 | print("Download data: \"python Run.py download\"")
77 | print(" Should be run just once, on the first time the module used")
78 | print("Train Module: \"python Run.py train \"")
79 | print(" Train lingustic SGP")
80 | print(" Module weights with the highest score over the validation set will be saved as \"_best\"")
81 | print(" Module weights of the last epoch will be saved as \"\"")
82 | print("Eval Module: \"python Run.py eval \"")
83 | print(" Scene graph classification (recall@100) evaluation for the trained module.")
84 | print(" Use 'gpi_ling_orig_best' for a pre-trained module")
85 | print(" Use \"_best\" for a self-trained module")
86 |
--------------------------------------------------------------------------------
/Utils/Logger.py:
--------------------------------------------------------------------------------
1 | import os
2 | import os.path
3 | import sys
4 | from FilesManager.FilesManager import FilesManager
5 | import time
6 | sys.path.append("..")
7 | from Utils.Singleton import Singleton
8 |
9 |
10 | class Logger(object):
11 | """
12 | Logger class
13 | """
14 | __metaclass__ = Singleton
15 |
16 | def __init__(self, name="", path=None):
17 | """
18 | Creating logger, the name of the logger will be printed at each line and log will be saved in path
19 | :param name: name of the logger
20 | :param path: path to log file
21 | """
22 | self.name = name
23 | if self.name != "":
24 | self.prefix = self.name + ": "
25 | else:
26 | self.prefix = ""
27 |
28 | self.path = path
29 |
30 | # create dir
31 | if self.path is not None:
32 | if not os.path.exists(self.path):
33 | os.makedirs(self.path)
34 |
35 | # create file to log
36 | self.log_file = open(self.path + "/logger.log", "w")
37 | else:
38 | self.log_file = None
39 |
40 | # add logger to file manager
41 | filesmanager = FilesManager()
42 | filesmanager.add_logger(self)
43 |
44 | # default log file
45 | if self.log_file is None:
46 | self.path = filesmanager.get_file_path("logs")
47 | if not os.path.exists(self.path):
48 | os.makedirs(self.path)
49 | self.log_file = open(self.path + "/logger-%s.log" % time.strftime("%c"), "w")
50 | self.log("Start %s" % time.strftime("%c"))
51 |
52 | def log(self, str):
53 | """
54 | This function write str to the logger
55 | :param str: a string to be written
56 | """
57 | if self.log_file is not None:
58 | self.log_file.write(self.name + ": " + str + "\n")
59 | self.log_file.flush()
60 | print(self.prefix + str)
61 |
62 | def get_dir(self):
63 | """
64 | Get the path of the dir
65 | :return: path of the dir
66 | """
67 | return self.path
68 |
69 | @classmethod
70 | def get_logger(cls):
71 | """
72 | This function returns the logger
73 | :return: return the cls logger
74 | """
75 | return cls
76 |
--------------------------------------------------------------------------------
/Utils/Singleton.py:
--------------------------------------------------------------------------------
1 | class Singleton(type):
2 | """
3 | Singleton metaclass
4 | """
5 |
6 | _instances = {}
7 |
8 | def __call__(cls, *args, **kwargs):
9 | if cls not in cls._instances:
10 | cls._instances[cls] = super(Singleton, cls).__call__(*args, **kwargs)
11 | return cls._instances[cls]
12 |
13 |
14 | class Visitor(object):
15 | """
16 | This class is a base class for the visitor design pattern,
17 | a subclass can implement visit methods for specific types
18 | for example, given two classes A and B, a visitor need to create two functions
19 | visit_A and visit_B and dynamically the visit method will route to the correct visit method
20 | given a subject of type A or B
21 | """
22 |
23 | def visit(self, subject):
24 | method_name = 'visit_' + type(subject).__name__
25 | method = getattr(self, method_name)
26 | if method is None:
27 | method = self.generic_visit
28 | return method(subject)
29 |
30 | def generic_visit(self, subject):
31 | print('Class {0} does not have a visit function in {1}'.format(type(subject).__name__,
32 | type(self).__name__))
--------------------------------------------------------------------------------
/Utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/shikorab/SceneGraph/d2dc960a0d3728e7d2b0eaceb9d0fdaedb2a47d5/Utils/__init__.py
--------------------------------------------------------------------------------
/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/shikorab/SceneGraph/d2dc960a0d3728e7d2b0eaceb9d0fdaedb2a47d5/__init__.py
--------------------------------------------------------------------------------
/qualitive_results_att_boxes.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/shikorab/SceneGraph/d2dc960a0d3728e7d2b0eaceb9d0fdaedb2a47d5/qualitive_results_att_boxes.png
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | tensorflow_gpu==1.0.1
2 | matplotlib==2.0.2
3 | h5py==2.7.0
4 | numpy==1.13.1
5 | PyYAML==3.12
6 |
--------------------------------------------------------------------------------
/sg_example_final.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/shikorab/SceneGraph/d2dc960a0d3728e7d2b0eaceb9d0fdaedb2a47d5/sg_example_final.png
--------------------------------------------------------------------------------
/sgp_arch_git.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/shikorab/SceneGraph/d2dc960a0d3728e7d2b0eaceb9d0fdaedb2a47d5/sgp_arch_git.png
--------------------------------------------------------------------------------