stocksight is an open source stock analysis software that uses Elasticsearch to store Twitter and news headlines data for stocks. stocksight analyzes the emotions of what the author writes and does sentiment analysis on the text to determine how the author "feels" about a stock.
23 | -------------------------------------------------------------------------------- /CHANGELOG.md: -------------------------------------------------------------------------------- 1 | # stocksight Change Log 2 | 3 | ## [0.1-b.12] = 2020-06-08 4 | ### changed 5 | - removed --noelasticsearch cli arg option 6 | 7 | ## [0.1-b.11] = 2020-05-24 8 | ### changed 9 | - removed stocksight web site uploading capability, site has been removed 10 | 11 | ## [0.1-b.10] = 2020-03-29 12 | ### added 13 | - Dockerfile and docker-compose.yml for running in docker 14 | ### changed 15 | - added random time delay between fetching tweets to reduce chance of getting Twitter 420 code (throttled/backoff) 16 | ### fixed 17 | - using -k keywords no longer causes twitter user id's to be looked up 18 | - fatal error when looking up and using twitter user ids 19 | 20 | ## [0.1-b.9] = 2019-10-27 21 | ### added 22 | - -l --linksentiment cli arg - follow any tweet link urls and run sentiment analysis on those web pages 23 | - requirement for newspaper3k python module to requirements.txt, install with pip 24 | 25 | ## [0.1-b.8] = 2019-10-25 26 | ### added 27 | - -w --websentiment cli arg - Get sentiment results from text processing website 28 | - improved nltk token processing - no longed needed to provide multiple case in nltk tokens in config 29 | - requirement for nltk stopwords, install with python -c "import nltk; nltk.download('stopwords')" 30 | ### changed 31 | - getting web sentiment results from text processing website is no longer default 32 | - improved tweet text cleaning, sentiment algorithm and stocksight sentiment upload values 33 | 34 | ## [0.1-b.7] = 2019-10-24 35 | ### added 36 | - check if running Python 3 37 | - -U --upload - uploads sentiment to stocksight website (BETA) https://stocksight.diskoverspace.com/ 38 | - stocksight_token in config.py.sample, used for auth to upload to stocksight website, copy to your config 39 | - nltk_min_tokens in config.py.sample, used to set minimum number of tokens required, copy to your config 40 | - tweet/news headline count/filtered/ratio log output 41 | - --noelasticsearch cli arg for not adding new docs to Elasticsearch 42 | - -s stock symbol cli arg (required arg), this is the stock symbol name and also used as the "tag name" on the stocksight webiste when uploading sentiment data 43 | - --overridetokensreq and --overridetokensignore cli args 44 | - -a --addtokens cli arg to add nltk required tokens from config to keywords 45 | ### changed 46 | - --newsheadlines no longer requires stock symbol, use -s to provide stock symbol 47 | - nltk required tokens from config now do not automatically get added to keywords, use -a or --addtokens to add them 48 | ### fixed 49 | - 'NoneType' object is not iterable Can't get sentiment from url caused by 400 Form Validation Errors text: This field is required traceback error when tweet with no text passed to sentiment_analysis 50 | 51 | ## [0.1-b.6] = 2019-07-15 52 | ### fixed 53 | - "TypeError: sequence item 0: expected str instance, int found" traceback error when running with -f twitteruserids.txt 54 | 55 | ## [0.1-b.5] = 2019-01-11 56 | ### changed 57 | - set encoding to utf-8 and checked for bytes when writing to twitteruserids.txt 58 | 59 | ## [0.1-b.4] = 2018-12-10 60 | ### fixed 61 | - TypeError: can't concat str to bytes when writing to twitteruserids.txt 62 | 63 | ## [0.1-b.3] = 2018-11-23 64 | ### added 65 | - requirements.txt for installing python requirements with pip 66 | - config.py.sample has new setting for specifying elasticsearch host/ip, port, username and password, copy to your config file 67 | 68 | ## [0.1-b.2] = 2018-10-10 69 | ### added 70 | - cli option -n --newsheadlines to fetch and analyze stock symbol headlines from yahoo finance website instead of twitter 71 | - cli option --frequency to control how often news headlines are retrieved 72 | - cli option --followlinks to follow any links in news headlines and scrape any relevant text on landing page 73 | - additional mappings for newsheadline docs in elasticsearch indices 74 | ### changed 75 | - code cleanup 76 | 77 | ## [0.1-b.1] = 2018-10-09 78 | ### note 79 | - first release 80 | -------------------------------------------------------------------------------- /README.md: -------------------------------------------------------------------------------- 1 | 2 |
3 | [](./LICENSE)
4 | [](https://github.com/shirosaidev/stocksight/releases/latest)
5 | [](https://www.patreon.com/shirosaidev)
6 | [](https://www.paypal.com/cgi-bin/webscr?cmd=_s-xclick&hosted_button_id=CLF223XAS4W72)
7 |
8 | # stocksight
9 | Stock market analyzer and stock predictor using Elasticsearch, Twitter, News headlines and Python natural language processing and sentiment analysis. How much do emotions on Twitter and news headlines affect a stock's price? Let's find out...
10 |
11 | ## About
12 | stocksight is an open source stock market analysis software that uses Elasticsearch to store Twitter and news headlines data for stocks. stocksight analyzes the emotions of what the author writes and does sentiment analysis on the text to determine how the author "feels" about a stock. It could be used for more than finding sentiment of just stocks, it could be used to find sentiment of anything...
13 |
14 |
15 | ## Slack workspace
16 | Join the conversation, get support, etc on [stocksight Slack](https://join.slack.com/t/stocksightworkspace/shared_invite/enQtNzk1ODI0NjA3MTM4LTA3ZDA0YzllOGNiM2I5ZjAzYWM2MjNmMjI0OTRlY2ZjYTk1NmM5YmEwMmMwOTE2OTNiMGZlNzdjZmZkM2RjM2U).
17 |
18 |
19 | ## Requirements
20 | - Python 3.x
21 | - Elasticsearch 5.x
22 | - Kibana 5.x
23 | - elasticsearch python module
24 | - nltk python module
25 | - requests python module
26 | - tweepy python module
27 | - beautifulsoup4 python module
28 | - textblob python module
29 | - vaderSentiment python module
30 | - newspaper3k python module
31 |
32 | ### Download
33 |
34 | ```shell
35 | $ git clone https://github.com/shirosaidev/stocksight.git
36 | $ cd stocksight
37 | ```
38 | [Download latest version](https://github.com/shirosaidev/stocksight/releases/latest)
39 |
40 | ## Screenshot
41 | Stocksight Kibana dashboard
42 |
2 |
3 | [](./LICENSE)
4 | [](https://github.com/shirosaidev/stocksight/releases/latest)
5 | [](https://www.patreon.com/shirosaidev)
6 | [](https://www.paypal.com/cgi-bin/webscr?cmd=_s-xclick&hosted_button_id=CLF223XAS4W72)
7 |
8 | # stocksight
9 | Stock market analyzer and stock predictor using Elasticsearch, Twitter, News headlines and Python natural language processing and sentiment analysis. How much do emotions on Twitter and news headlines affect a stock's price? Let's find out...
10 |
11 | ## About
12 | stocksight is an open source stock market analysis software that uses Elasticsearch to store Twitter and news headlines data for stocks. stocksight analyzes the emotions of what the author writes and does sentiment analysis on the text to determine how the author "feels" about a stock. It could be used for more than finding sentiment of just stocks, it could be used to find sentiment of anything...
13 |
14 |
15 | ## Slack workspace
16 | Join the conversation, get support, etc on [stocksight Slack](https://join.slack.com/t/stocksightworkspace/shared_invite/enQtNzk1ODI0NjA3MTM4LTA3ZDA0YzllOGNiM2I5ZjAzYWM2MjNmMjI0OTRlY2ZjYTk1NmM5YmEwMmMwOTE2OTNiMGZlNzdjZmZkM2RjM2U).
17 |
18 |
19 | ## Requirements
20 | - Python 3.x
21 | - Elasticsearch 5.x
22 | - Kibana 5.x
23 | - elasticsearch python module
24 | - nltk python module
25 | - requests python module
26 | - tweepy python module
27 | - beautifulsoup4 python module
28 | - textblob python module
29 | - vaderSentiment python module
30 | - newspaper3k python module
31 |
32 | ### Download
33 |
34 | ```shell
35 | $ git clone https://github.com/shirosaidev/stocksight.git
36 | $ cd stocksight
37 | ```
38 | [Download latest version](https://github.com/shirosaidev/stocksight/releases/latest)
39 |
40 | ## Screenshot
41 | Stocksight Kibana dashboard
42 | 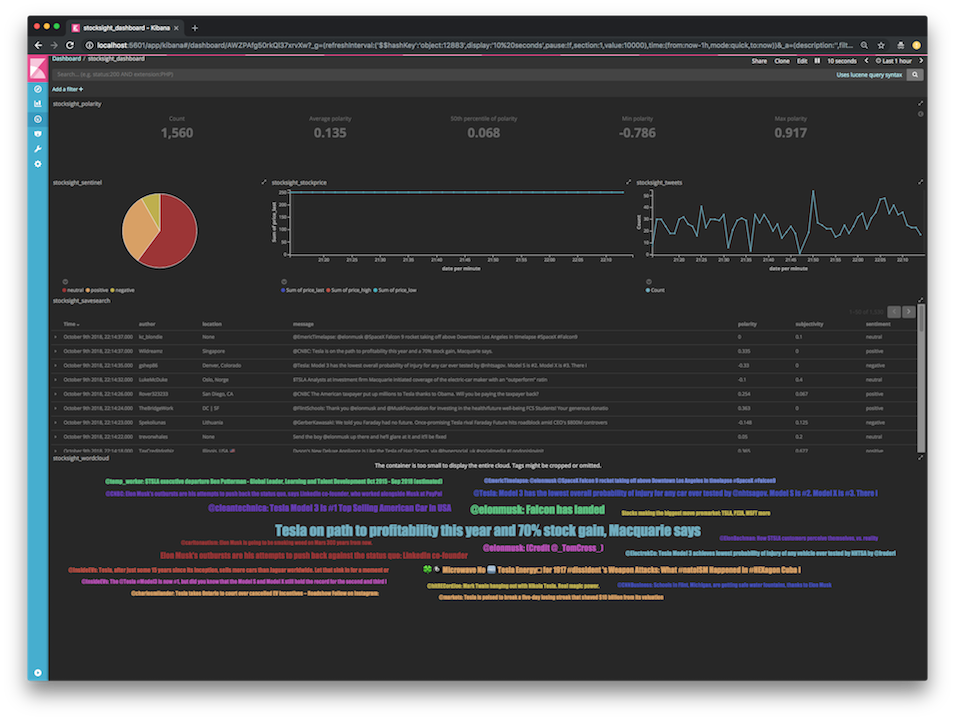 43 |
44 |
45 | ## Install - Docker
46 |
47 | *** **See [how to use](#how-to-use) below before building the Docker containers** ***
48 |
49 | 1) Download/clone stocksight repo with git.
50 | 2) Set up stocksight, elasticsearch and kibana containers using Docker compose
51 | ```
52 | cd stocksight
53 | cp config.py.sample config.py
54 | ***see how to use below for config.py (stocksight config) changes***
55 | docker-compose build && docker-compose up
56 | ```
57 | **This will volume mount config.py (stocksight settings) and twitteruserids.txt to those files in your local git cloned "stocksight" directory**
58 |
59 | 3) Once all the containers have started up, shell into the container
60 |
61 | `docker exec -it stocksight_stocksight_1 bash`
62 |
63 | 4) See examples below for running stocksight.
64 |
65 | ## Install - local
66 |
67 | **Recommended to install Elasticsearch and Kibana in local machine or other machine/vm/docker**
68 |
69 | 1) Install python requirements using pip
70 |
71 | `pip install -r requirements.txt`
72 |
73 | 2) Install python nltk data
74 |
75 | `python -c "import nltk; nltk.download('punkt'); nltk.download('stopwords')"`
76 |
77 |
78 | ## How to use
79 | 1) Create a new twitter application and generate your consumer key and access token. https://developer.twitter.com/en/docs/basics/developer-portal/guides/apps.html
80 | https://developer.twitter.com/en/docs/basics/authentication/guides/access-tokens.html
81 |
82 | 2) Copy config.py.sample to config.py (stocksight config file)
83 |
84 | 3) Set elasticsearch settings in config.py for your env (for Docker, set `elasticsearch_host = "elasticsearch"`)
85 |
86 | 4) Add twitter consumer key/access token and secrets to config.py
87 |
88 | 5) Edit config.py and modify NLTK tokens required/ignored and twitter feeds you want to mine. NLTK tokens required are keywords which must be in tweet before adding it to Elasticsearch (whitelist). NLTK tokens ignored are keywords which if are found in tweet, it will not be added to Elasticsearch (blacklist).
89 |
90 | ### Examples
91 |
92 | Run sentiment.py to create 'stocksight' index in Elasticsearch and start mining and analyzing Tweets using keywords and the stock symbol TSLA
93 |
94 | ```sh
95 | $ python sentiment.py -s TSLA -k 'Elon Musk',Musk,Tesla,SpaceX --debug
96 | ```
97 |
98 | Start mining and analyzing Tweets using keywords and the stock symbol TSLA and follow any url links in tweets and performing sentiment analysis on the link web page as well as the tweet
99 |
100 | ```sh
101 | $ python sentiment.py -s TSLA -k 'Elon Musk',Musk,Tesla,SpaceX -l --debug
102 | ```
103 |
104 | Start mining and analyzing Tweets from feeds in config using cached user ids from file (if you change any of the twitter feeds in the config file, you need to delete this file and recreate it without -f)
105 |
106 | ```sh
107 | $ python sentiment.py -s TSLA -f twitteruserids.txt --debug
108 | ```
109 |
110 | Start mining and analyzing News headlines and following headline links and scraping relevant text on landing page
111 |
112 | ```sh
113 | $ python sentiment.py -s TSLA --followlinks --debug
114 | ```
115 |
116 | Run stockprice.py to add stock prices to 'stocksight' index in Elasticsearch
117 |
118 | ```sh
119 | $ python stockprice.py -s TSLA --debug
120 | ```
121 |
122 | ### Kibana
123 |
124 | Load 'stocksight' index in Kibana. For index pattern you can use 'stocksight' if you only have the single index or 'stocksight-*', etc. For time-field name you will want to use the date/time field 'date'.
125 |
126 | To import the saved exported visualizations/dashboard, go to Kibana, click on management, click on saved objects, click on the import button and import the export.json file.
127 |
128 |
129 | ### CLI options
130 |
131 | ```
132 | usage: sentiment.py [-h] [-i INDEX] [-d] -s SYMBOL [-k KEYWORDS] [-a] [-u URL]
133 | [-f FILE] [-l] [-n] [--frequency FREQUENCY]
134 | [--followlinks] [-w]
135 | [--overridetokensreq TOKEN [TOKEN ...]]
136 | [--overridetokensignore TOKEN [TOKEN ...]] [-v] [--debug]
137 | [-q] [-V]
138 |
139 | optional arguments:
140 | -h, --help show this help message and exit
141 | -i INDEX, --index INDEX
142 | Index name for Elasticsearch (default: stocksight)
143 | -d, --delindex Delete existing Elasticsearch index first
144 | -s SYMBOL, --symbol SYMBOL
145 | Stock symbol you are interesed in searching for,
146 | example: TSLA
147 | -k KEYWORDS, --keywords KEYWORDS
148 | Use keywords to search for in Tweets instead of feeds.
149 | Separated by comma, case insensitive, spaces are ANDs
150 | commas are ORs. Example: TSLA,'Elon
151 | Musk',Musk,Tesla,SpaceX
152 | -a, --addtokens Add nltk tokens required from config to keywords
153 | -u URL, --url URL Use twitter users from any links in web page at url
154 | -f FILE, --file FILE Use twitter user ids from file
155 | -l, --linksentiment Follow any link url in tweets and analyze sentiment on
156 | web page
157 | -n, --newsheadlines Get news headlines instead of Twitter using stock
158 | symbol from -s
159 | --frequency FREQUENCY
160 | How often in seconds to retrieve news headlines
161 | (default: 120 sec)
162 | --followlinks Follow links on news headlines and scrape relevant
163 | text from landing page
164 | -w, --websentiment Get sentiment results from text processing website
165 | --overridetokensreq TOKEN [TOKEN ...]
166 | Override nltk required tokens from config, separate
167 | with space
168 | --overridetokensignore TOKEN [TOKEN ...]
169 | Override nltk ignore tokens from config, separate with
170 | space
171 | -v, --verbose Increase output verbosity
172 | --debug Debug message output
173 | -q, --quiet Run quiet with no message output
174 | -V, --version Prints version and exits
175 |
176 |
177 | usage: stockprice.py [-h] [-i INDEX] [-d] [-s SYMBOL] [-f FREQUENCY] [-v]
178 | [--debug] [-q] [-V]
179 |
180 | optional arguments:
181 | -h, --help show this help message and exit
182 | -i INDEX, --index INDEX
183 | Index name for Elasticsearch (default: stocksight)
184 | -d, --delindex Delete existing Elasticsearch index first
185 | -s SYMBOL, --symbol SYMBOL
186 | Stock symbol to use, example: TSLA
187 | -f FREQUENCY, --frequency FREQUENCY
188 | How often in seconds to retrieve stock data (default:
189 | 120 sec)
190 | -v, --verbose Increase output verbosity
191 | --debug Debug message output
192 | -q, --quiet Run quiet with no message output
193 | -V, --version Prints version and exits
194 | ```
195 |
196 |
197 | ## Disclaimer
198 |
199 | This software is for educational purposes only. USE THE SOFTWARE AT YOUR OWN RISK. THE AUTHORS AND ALL AFFILIATES ASSUME NO RESPONSIBILITY FOR YOUR TRADING RESULTS. Do not risk money which you are afraid to lose. There might be bugs in the code - this software DOES NOT come with ANY warranty.
200 |
--------------------------------------------------------------------------------
/export.json:
--------------------------------------------------------------------------------
1 | [
2 | {
3 | "_id": "AWZPAfg50rkQl37xrvXw",
4 | "_type": "dashboard",
5 | "_source": {
6 | "title": "stocksight_dashboard",
7 | "hits": 0,
8 | "description": "",
9 | "panelsJSON": "[{\"col\":1,\"id\":\"AWZO7a1n0rkQl37xrvXK\",\"panelIndex\":1,\"row\":3,\"size_x\":3,\"size_y\":3,\"type\":\"visualization\"},{\"col\":9,\"id\":\"AWZO8wUR0rkQl37xrvXV\",\"panelIndex\":2,\"row\":3,\"size_x\":4,\"size_y\":3,\"type\":\"visualization\"},{\"col\":1,\"columns\":[\"author\",\"location\",\"message\",\"polarity\",\"subjectivity\",\"sentiment\"],\"id\":\"AWZO_6iv0rkQl37xrvXt\",\"panelIndex\":3,\"row\":6,\"size_x\":12,\"size_y\":4,\"sort\":[\"date\",\"desc\"],\"type\":\"search\"},{\"col\":1,\"id\":\"AWZW6DNS0rkQl37xrvcg\",\"panelIndex\":4,\"row\":10,\"size_x\":12,\"size_y\":4,\"type\":\"visualization\"},{\"col\":4,\"id\":\"AWZYOrcih4RzKn4w3M7J\",\"panelIndex\":5,\"row\":3,\"size_x\":5,\"size_y\":3,\"type\":\"visualization\"},{\"col\":1,\"id\":\"AWZY6Xtjh4RzKn4w3NXT\",\"panelIndex\":6,\"row\":1,\"size_x\":12,\"size_y\":2,\"type\":\"visualization\"}]",
10 | "optionsJSON": "{\"darkTheme\":true}",
11 | "uiStateJSON": "{\"P-2\":{\"vis\":{\"legendOpen\":true}},\"P-6\":{\"vis\":{\"defaultColors\":{\"0 - 1\":\"rgb(0,104,55)\"}}}}",
12 | "version": 1,
13 | "timeRestore": false,
14 | "kibanaSavedObjectMeta": {
15 | "searchSourceJSON": "{\"filter\":[{\"query\":{\"match_all\":{}}}],\"highlightAll\":true,\"version\":true}"
16 | }
17 | }
18 | },
19 | {
20 | "_id": "AWZO_6iv0rkQl37xrvXt",
21 | "_type": "search",
22 | "_source": {
23 | "title": "stocksight_savesearch",
24 | "description": "",
25 | "hits": 0,
26 | "columns": [
27 | "author",
28 | "location",
29 | "message",
30 | "polarity",
31 | "subjectivity",
32 | "sentiment"
33 | ],
34 | "sort": [
35 | "date",
36 | "desc"
37 | ],
38 | "version": 1,
39 | "kibanaSavedObjectMeta": {
40 | "searchSourceJSON": "{\"index\":\"stocksight\",\"highlightAll\":true,\"version\":true,\"query\":{\"match_all\":{}},\"filter\":[{\"meta\":{\"index\":\"stocksight\",\"negate\":false,\"disabled\":false,\"alias\":null,\"type\":\"phrase\",\"key\":\"_type\",\"value\":\"tweet\"},\"query\":{\"match\":{\"_type\":{\"query\":\"tweet\",\"type\":\"phrase\"}}},\"$state\":{\"store\":\"appState\"}}]}"
41 | }
42 | }
43 | },
44 | {
45 | "_id": "AWZY6Xtjh4RzKn4w3NXT",
46 | "_type": "visualization",
47 | "_source": {
48 | "title": "stocksight_polarity",
49 | "visState": "{\"title\":\"stocksight_polarity\",\"type\":\"metric\",\"params\":{\"addTooltip\":true,\"addLegend\":false,\"type\":\"gauge\",\"gauge\":{\"verticalSplit\":false,\"autoExtend\":false,\"percentageMode\":false,\"gaugeType\":\"Metric\",\"gaugeStyle\":\"Full\",\"backStyle\":\"Full\",\"orientation\":\"vertical\",\"colorSchema\":\"Green to Red\",\"gaugeColorMode\":\"None\",\"useRange\":false,\"colorsRange\":[{\"from\":0,\"to\":1}],\"invertColors\":false,\"labels\":{\"show\":true,\"color\":\"black\"},\"scale\":{\"show\":false,\"labels\":false,\"color\":\"#333\",\"width\":2},\"type\":\"simple\",\"style\":{\"fontSize\":\"24\",\"bgColor\":false,\"labelColor\":false,\"subText\":\"\"},\"extendRange\":false}},\"aggs\":[{\"id\":\"5\",\"enabled\":true,\"type\":\"count\",\"schema\":\"metric\",\"params\":{}},{\"id\":\"1\",\"enabled\":true,\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"polarity\"}},{\"id\":\"4\",\"enabled\":true,\"type\":\"median\",\"schema\":\"metric\",\"params\":{\"field\":\"polarity\",\"percents\":[50]}},{\"id\":\"2\",\"enabled\":true,\"type\":\"min\",\"schema\":\"metric\",\"params\":{\"field\":\"polarity\"}},{\"id\":\"3\",\"enabled\":true,\"type\":\"max\",\"schema\":\"metric\",\"params\":{\"field\":\"polarity\"}}],\"listeners\":{}}",
50 | "uiStateJSON": "{\"vis\":{\"defaultColors\":{\"0 - 1\":\"rgb(0,104,55)\"}}}",
51 | "description": "",
52 | "version": 1,
53 | "kibanaSavedObjectMeta": {
54 | "searchSourceJSON": "{\"index\":\"stocksight\",\"query\":{\"match_all\":{}},\"filter\":[]}"
55 | }
56 | }
57 | },
58 | {
59 | "_id": "AWZO7a1n0rkQl37xrvXK",
60 | "_type": "visualization",
61 | "_source": {
62 | "title": "stocksight_sentinel",
63 | "visState": "{\"title\":\"stocksight_sentinel\",\"type\":\"pie\",\"params\":{\"addLegend\":true,\"addTooltip\":true,\"isDonut\":false,\"legendPosition\":\"bottom\",\"type\":\"pie\"},\"aggs\":[{\"id\":\"1\",\"enabled\":true,\"type\":\"count\",\"schema\":\"metric\",\"params\":{}},{\"id\":\"2\",\"enabled\":true,\"type\":\"terms\",\"schema\":\"segment\",\"params\":{\"field\":\"sentiment.keyword\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\"}}],\"listeners\":{}}",
64 | "uiStateJSON": "{}",
65 | "description": "",
66 | "version": 1,
67 | "kibanaSavedObjectMeta": {
68 | "searchSourceJSON": "{\"index\":\"stocksight\",\"query\":{\"match_all\":{}},\"filter\":[]}"
69 | }
70 | }
71 | },
72 | {
73 | "_id": "AWZYOrcih4RzKn4w3M7J",
74 | "_type": "visualization",
75 | "_source": {
76 | "title": "stocksight_stockprice",
77 | "visState": "{\"title\":\"stocksight_stockprice\",\"type\":\"line\",\"params\":{\"grid\":{\"categoryLines\":false,\"style\":{\"color\":\"#eee\"}},\"categoryAxes\":[{\"id\":\"CategoryAxis-1\",\"type\":\"category\",\"position\":\"bottom\",\"show\":true,\"style\":{},\"scale\":{\"type\":\"linear\"},\"labels\":{\"show\":true,\"truncate\":100},\"title\":{\"text\":\"date per 30 seconds\"}}],\"valueAxes\":[{\"id\":\"ValueAxis-1\",\"name\":\"LeftAxis-1\",\"type\":\"value\",\"position\":\"left\",\"show\":true,\"style\":{},\"scale\":{\"type\":\"linear\",\"mode\":\"normal\"},\"labels\":{\"show\":true,\"rotate\":0,\"filter\":false,\"truncate\":100},\"title\":{\"text\":\"Sum of price_last\"}}],\"seriesParams\":[{\"show\":\"true\",\"type\":\"line\",\"mode\":\"normal\",\"data\":{\"label\":\"Sum of price_last\",\"id\":\"1\"},\"valueAxis\":\"ValueAxis-1\",\"drawLinesBetweenPoints\":true,\"showCircles\":true},{\"show\":true,\"mode\":\"normal\",\"type\":\"line\",\"drawLinesBetweenPoints\":true,\"showCircles\":true,\"data\":{\"id\":\"3\",\"label\":\"Sum of price_high\"},\"valueAxis\":\"ValueAxis-1\"},{\"show\":true,\"mode\":\"normal\",\"type\":\"line\",\"drawLinesBetweenPoints\":true,\"showCircles\":true,\"data\":{\"id\":\"4\",\"label\":\"Sum of price_low\"},\"valueAxis\":\"ValueAxis-1\"}],\"addTooltip\":true,\"addLegend\":true,\"legendPosition\":\"bottom\",\"times\":[],\"addTimeMarker\":false,\"type\":\"line\"},\"aggs\":[{\"id\":\"1\",\"enabled\":true,\"type\":\"sum\",\"schema\":\"metric\",\"params\":{\"field\":\"price_last\"}},{\"id\":\"2\",\"enabled\":true,\"type\":\"date_histogram\",\"schema\":\"segment\",\"params\":{\"field\":\"date\",\"interval\":\"auto\",\"customInterval\":\"2h\",\"min_doc_count\":1,\"extended_bounds\":{}}},{\"id\":\"3\",\"enabled\":true,\"type\":\"sum\",\"schema\":\"metric\",\"params\":{\"field\":\"price_high\"}},{\"id\":\"4\",\"enabled\":true,\"type\":\"sum\",\"schema\":\"metric\",\"params\":{\"field\":\"price_low\"}}],\"listeners\":{}}",
78 | "uiStateJSON": "{}",
79 | "description": "",
80 | "version": 1,
81 | "kibanaSavedObjectMeta": {
82 | "searchSourceJSON": "{\"index\":\"stocksight\",\"query\":{\"match_all\":{}},\"filter\":[{\"meta\":{\"index\":\"stocksight\",\"negate\":false,\"disabled\":false,\"alias\":null,\"type\":\"phrase\",\"key\":\"_type\",\"value\":\"stock\"},\"query\":{\"match\":{\"_type\":{\"query\":\"stock\",\"type\":\"phrase\"}}},\"$state\":{\"store\":\"appState\"}}]}"
83 | }
84 | }
85 | },
86 | {
87 | "_id": "AWZO8wUR0rkQl37xrvXV",
88 | "_type": "visualization",
89 | "_source": {
90 | "title": "stocksight_tweets",
91 | "visState": "{\"title\":\"stocksight_tweets\",\"type\":\"line\",\"params\":{\"grid\":{\"categoryLines\":false,\"style\":{\"color\":\"#eee\"}},\"categoryAxes\":[{\"id\":\"CategoryAxis-1\",\"type\":\"category\",\"position\":\"bottom\",\"show\":true,\"style\":{},\"scale\":{\"type\":\"linear\"},\"labels\":{\"show\":true,\"truncate\":100},\"title\":{\"text\":\"date per 30 seconds\"}}],\"valueAxes\":[{\"id\":\"ValueAxis-1\",\"name\":\"LeftAxis-1\",\"type\":\"value\",\"position\":\"left\",\"show\":true,\"style\":{},\"scale\":{\"type\":\"linear\",\"mode\":\"normal\"},\"labels\":{\"show\":true,\"rotate\":0,\"filter\":false,\"truncate\":100},\"title\":{\"text\":\"Count\"}}],\"seriesParams\":[{\"show\":\"true\",\"type\":\"line\",\"mode\":\"normal\",\"data\":{\"label\":\"Count\",\"id\":\"1\"},\"valueAxis\":\"ValueAxis-1\",\"drawLinesBetweenPoints\":true,\"showCircles\":true,\"interpolate\":\"linear\"}],\"addTooltip\":true,\"addLegend\":true,\"legendPosition\":\"bottom\",\"times\":[],\"addTimeMarker\":false,\"type\":\"line\"},\"aggs\":[{\"id\":\"1\",\"enabled\":true,\"type\":\"count\",\"schema\":\"metric\",\"params\":{\"customLabel\":\"\"}},{\"id\":\"2\",\"enabled\":true,\"type\":\"date_histogram\",\"schema\":\"segment\",\"params\":{\"field\":\"date\",\"interval\":\"auto\",\"customInterval\":\"2h\",\"min_doc_count\":1,\"extended_bounds\":{}}}],\"listeners\":{}}",
92 | "uiStateJSON": "{}",
93 | "description": "",
94 | "version": 1,
95 | "kibanaSavedObjectMeta": {
96 | "searchSourceJSON": "{\"index\":\"stocksight\",\"query\":{\"match_all\":{}},\"filter\":[]}"
97 | }
98 | }
99 | },
100 | {
101 | "_id": "AWZW6DNS0rkQl37xrvcg",
102 | "_type": "visualization",
103 | "_source": {
104 | "title": "stocksight_wordcloud",
105 | "visState": "{\n \"title\": \"stocksight_wordcloud\",\n \"type\": \"tagcloud\",\n \"params\": {\n \"scale\": \"linear\",\n \"orientation\": \"single\",\n \"minFontSize\": 14,\n \"maxFontSize\": 36,\n \"type\": \"tagcloud\"\n },\n \"aggs\": [\n {\n \"id\": \"1\",\n \"enabled\": true,\n \"type\": \"count\",\n \"schema\": \"metric\",\n \"params\": {}\n },\n {\n \"id\": \"2\",\n \"enabled\": true,\n \"type\": \"terms\",\n \"schema\": \"segment\",\n \"params\": {\n \"field\": \"message.keyword\",\n \"size\": 25,\n \"order\": \"desc\",\n \"orderBy\": \"1\"\n }\n }\n ],\n \"listeners\": {}\n}",
106 | "uiStateJSON": "{}",
107 | "description": "",
108 | "version": 1,
109 | "kibanaSavedObjectMeta": {
110 | "searchSourceJSON": "{\n \"index\": \"stocksight\",\n \"query\": {\n \"match_all\": {}\n },\n \"filter\": []\n}"
111 | }
112 | }
113 | }
114 | ]
--------------------------------------------------------------------------------
/stockprice.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | """stockprice.py - get stock price from Yahoo and add to
4 | Elasticsearch.
5 | See README.md or https://github.com/shirosaidev/stocksight
6 | for more information.
7 |
8 | Copyright (C) Chris Park 2018-2020
9 | stocksight is released under the Apache 2.0 license. See
10 | LICENSE for the full license text.
11 | """
12 |
13 | import time
14 | import requests
15 | import re
16 | import argparse
17 | import logging
18 | import sys
19 | from elasticsearch import Elasticsearch
20 | from random import randint
21 |
22 | # import elasticsearch host
23 | from config import elasticsearch_host, elasticsearch_port, elasticsearch_user, elasticsearch_password
24 |
25 | from sentiment import STOCKSIGHT_VERSION
26 | __version__ = STOCKSIGHT_VERSION
27 |
28 | # url to fetch stock price from, SYMBOL will be replaced with symbol from cli args
29 | url = "https://query1.finance.yahoo.com/v8/finance/chart/SYMBOL?region=US&lang=en-US&includePrePost=false&interval=2m&range=5d&corsDomain=finance.yahoo.com&.tsrc=finance"
30 |
31 | # create instance of elasticsearch
32 | es = Elasticsearch(hosts=[{'host': elasticsearch_host, 'port': elasticsearch_port}],
33 | http_auth=(elasticsearch_user, elasticsearch_password))
34 |
35 | class GetStock:
36 |
37 | def get_price(self, url, symbol):
38 | import re
39 |
40 | while True:
41 |
42 | logger.info("Grabbing stock data for symbol %s..." % symbol)
43 |
44 | try:
45 |
46 | # add stock symbol to url
47 | url = re.sub("SYMBOL", symbol, url)
48 | # get stock data (json) from url
49 | try:
50 | r = requests.get(url)
51 | data = r.json()
52 | except (requests.HTTPError, requests.ConnectionError, requests.ConnectTimeout) as re:
53 | logger.error("Exception: exception getting stock data from url caused by %s" % re)
54 | raise
55 | logger.debug(data)
56 | # build dict to store stock info
57 | try:
58 | D = {}
59 | D['symbol'] = symbol
60 | D['last'] = data['chart']['result'][0]['indicators']['quote'][0]['close'][-1]
61 | if D['last'] is None:
62 | D['last'] = data['chart']['result'][0]['indicators']['quote'][0]['close'][-2]
63 | D['date'] = time.strftime('%Y-%m-%dT%H:%M:%S', time.gmtime()) # time now in gmt (utc)
64 | try:
65 | D['change'] = (data['chart']['result'][0]['indicators']['quote'][0]['close'][-1] -
66 | data['chart']['result'][0]['indicators']['quote'][0]['close'][-2]) / \
67 | data['chart']['result'][0]['indicators']['quote'][0]['close'][-2] * 100
68 | except TypeError:
69 | D['change'] = (data['chart']['result'][0]['indicators']['quote'][0]['close'][-2] -
70 | data['chart']['result'][0]['indicators']['quote'][0]['close'][-3]) / \
71 | data['chart']['result'][0]['indicators']['quote'][0]['close'][-3] * 100
72 | pass
73 | D['high'] = data['chart']['result'][0]['indicators']['quote'][0]['high'][-1]
74 | if D['high'] is None:
75 | D['high'] = data['chart']['result'][0]['indicators']['quote'][0]['high'][-2]
76 | D['low'] = data['chart']['result'][0]['indicators']['quote'][0]['low'][-1]
77 | if D['low'] is None:
78 | D['low'] = data['chart']['result'][0]['indicators']['quote'][0]['low'][-2]
79 | D['vol'] = data['chart']['result'][0]['indicators']['quote'][0]['volume'][-1]
80 | if D['vol'] is None:
81 | D['vol'] = data['chart']['result'][0]['indicators']['quote'][0]['volume'][-2]
82 | logger.debug(D)
83 | except KeyError as e:
84 | logger.error("Exception: exception getting stock data caused by %s" % e)
85 | raise
86 |
87 | # check before adding to ES
88 | if D['last'] is not None and D['high'] is not None and D['low'] is not None:
89 | logger.info("Adding stock data to Elasticsearch...")
90 | # add stock price info to elasticsearch
91 | es.index(index=args.index,
92 | doc_type="stock",
93 | body={"symbol": D['symbol'],
94 | "price_last": D['last'],
95 | "date": D['date'],
96 | "change": D['change'],
97 | "price_high": D['high'],
98 | "price_low": D['low'],
99 | "vol": D['vol']
100 | })
101 | else:
102 | logger.warning("Some stock data had null values, not adding to Elasticsearch")
103 |
104 | except Exception as e:
105 | logger.error("Exception: can't get stock data, trying again later, reason is %s" % e)
106 | pass
107 |
108 | logger.info("Will get stock data again in %s sec..." % args.frequency)
109 | time.sleep(args.frequency)
110 |
111 |
112 | if __name__ == '__main__':
113 |
114 | # parse cli args
115 | parser = argparse.ArgumentParser()
116 | parser.add_argument("-i", "--index", metavar="INDEX", default="stocksight",
117 | help="Index name for Elasticsearch (default: stocksight)")
118 | parser.add_argument("-d", "--delindex", action="store_true",
119 | help="Delete existing Elasticsearch index first")
120 | parser.add_argument("-s", "--symbol", metavar="SYMBOL",
121 | help="Stock symbol to use, example: TSLA")
122 | parser.add_argument("-f", "--frequency", metavar="FREQUENCY", default=120, type=int,
123 | help="How often in seconds to retrieve stock data (default: 120 sec)")
124 | parser.add_argument("-v", "--verbose", action="store_true",
125 | help="Increase output verbosity")
126 | parser.add_argument("--debug", action="store_true",
127 | help="Debug message output")
128 | parser.add_argument("-q", "--quiet", action="store_true",
129 | help="Run quiet with no message output")
130 | parser.add_argument("-V", "--version", action="version",
131 | version="stocksight v%s" % STOCKSIGHT_VERSION,
132 | help="Prints version and exits")
133 | args = parser.parse_args()
134 |
135 | # set up logging
136 | logger = logging.getLogger('stocksight')
137 | logger.setLevel(logging.INFO)
138 | eslogger = logging.getLogger('elasticsearch')
139 | eslogger.setLevel(logging.WARNING)
140 | requestslogger = logging.getLogger('requests')
141 | requestslogger.setLevel(logging.WARNING)
142 | logging.addLevelName(
143 | logging.INFO, "\033[1;32m%s\033[1;0m"
144 | % logging.getLevelName(logging.INFO))
145 | logging.addLevelName(
146 | logging.WARNING, "\033[1;31m%s\033[1;0m"
147 | % logging.getLevelName(logging.WARNING))
148 | logging.addLevelName(
149 | logging.ERROR, "\033[1;41m%s\033[1;0m"
150 | % logging.getLevelName(logging.ERROR))
151 | logging.addLevelName(
152 | logging.DEBUG, "\033[1;33m%s\033[1;0m"
153 | % logging.getLevelName(logging.DEBUG))
154 | logformatter = '%(asctime)s [%(levelname)s][%(name)s] %(message)s'
155 | loglevel = logging.INFO
156 | logging.basicConfig(format=logformatter, level=loglevel)
157 | if args.verbose:
158 | logger.setLevel(logging.INFO)
159 | eslogger.setLevel(logging.INFO)
160 | requestslogger.setLevel(logging.INFO)
161 | if args.debug:
162 | logger.setLevel(logging.DEBUG)
163 | eslogger.setLevel(logging.DEBUG)
164 | requestslogger.setLevel(logging.DEBUG)
165 | if args.quiet:
166 | logger.disabled = True
167 | eslogger.disabled = True
168 | requestslogger.disabled = True
169 |
170 | # print banner
171 | if not args.quiet:
172 | c = randint(1, 4)
173 | if c == 1:
174 | color = '31m'
175 | elif c == 2:
176 | color = '32m'
177 | elif c == 3:
178 | color = '33m'
179 | elif c == 4:
180 | color = '35m'
181 |
182 | banner = """\033[%s
183 | _ _
184 | _| |_ _ _ _| |_ _ _ _
185 | | __| |_ ___ ___| |_| __|_|___| |_| |_
186 | |__ | _| . | _| '_|__ | | . | | _|
187 | |_ _|_| |___|___|_,_|_ _|_|_ |_|_|_|
188 | |_| |_| |___|
189 | :) = +$ :( = -$ v%s
190 | https://github.com/shirosaidev/stocksight
191 | \033[0m""" % (color, STOCKSIGHT_VERSION)
192 | print(banner + '\n')
193 |
194 | # set up elasticsearch mappings and create index
195 | mappings = {
196 | "mappings": {
197 | "stock": {
198 | "properties": {
199 | "symbol": {
200 | "type": "keyword"
201 | },
202 | "price_last": {
203 | "type": "float"
204 | },
205 | "date": {
206 | "type": "date"
207 | },
208 | "change": {
209 | "type": "float"
210 | },
211 | "price_high": {
212 | "type": "float"
213 | },
214 | "price_low": {
215 | "type": "float"
216 | },
217 | "vol": {
218 | "type": "integer"
219 | }
220 | }
221 | }
222 | }
223 | }
224 |
225 | if args.symbol is None:
226 | print("No stock symbol, see -h for help.")
227 | sys.exit(1)
228 |
229 | if args.delindex:
230 | logger.info('Deleting existing Elasticsearch index ' + args.index)
231 | es.indices.delete(index=args.index, ignore=[400, 404])
232 |
233 | logger.info('Creating new Elasticsearch index or using existing ' + args.index)
234 | es.indices.create(index=args.index, body=mappings, ignore=[400, 404])
235 |
236 | # create instance of GetStock
237 | stockprice = GetStock()
238 |
239 | try:
240 | # get stock price
241 | stockprice.get_price(symbol=args.symbol, url=url)
242 | except Exception as e:
243 | logger.warning("Exception: Failed to get stock data caused by: %s" % e)
244 | except KeyboardInterrupt:
245 | print("Ctrl-c keyboard interrupt, exiting...")
246 | sys.exit(0)
247 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "{}"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright 2017-2019 Chris Park
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/sentiment.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | """sentiment.py - analyze tweets on Twitter and add
4 | relevant tweets and their sentiment values to
5 | Elasticsearch.
6 | See README.md or https://github.com/shirosaidev/stocksight
7 | for more information.
8 |
9 | Copyright (C) Chris Park 2018-2020
10 | stocksight is released under the Apache 2.0 license. See
11 | LICENSE for the full license text.
12 | """
13 |
14 | import sys
15 | import json
16 | import time
17 | import re
18 | import requests
19 | import nltk
20 | import argparse
21 | import logging
22 | import string
23 | try:
24 | import urllib.parse as urlparse
25 | except ImportError:
26 | import urlparse
27 | from tweepy.streaming import StreamListener
28 | from tweepy import API, Stream, OAuthHandler, TweepError
29 | from textblob import TextBlob
30 | from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
31 | from bs4 import BeautifulSoup
32 | from elasticsearch import Elasticsearch
33 | from random import randint, randrange
34 | from datetime import datetime
35 | from newspaper import Article, ArticleException
36 |
37 | # import elasticsearch host, twitter keys and tokens
38 | from config import *
39 |
40 |
41 | STOCKSIGHT_VERSION = '0.1-b.12'
42 | __version__ = STOCKSIGHT_VERSION
43 |
44 | IS_PY3 = sys.version_info >= (3, 0)
45 |
46 | if not IS_PY3:
47 | print("Sorry, stocksight requires Python 3.")
48 | sys.exit(1)
49 |
50 | # sentiment text-processing url
51 | sentimentURL = 'http://text-processing.com/api/sentiment/'
52 |
53 | # tweet id list
54 | tweet_ids = []
55 |
56 | # file to hold twitter user ids
57 | twitter_users_file = './twitteruserids.txt'
58 |
59 | prev_time = time.time()
60 | sentiment_avg = [0.0,0.0,0.0]
61 |
62 |
63 | class TweetStreamListener(StreamListener):
64 |
65 | def __init__(self):
66 | self.count = 0
67 | self.count_filtered = 0
68 | self.filter_ratio = 0
69 |
70 | # on success
71 | def on_data(self, data):
72 | try:
73 | self.count+=1
74 | # decode json
75 | dict_data = json.loads(data)
76 |
77 | print("\n------------------------------> (tweets: %s, filtered: %s, filter-ratio: %s)" \
78 | % (self.count, self.count_filtered, str(round(self.count_filtered/self.count*100,2))+"%"))
79 | logger.debug('tweet data: ' + str(dict_data))
80 |
81 | text = dict_data["text"]
82 | if text is None:
83 | logger.info("Tweet has no relevant text, skipping")
84 | self.count_filtered+=1
85 | return True
86 |
87 | # grab html links from tweet
88 | tweet_urls = []
89 | if args.linksentiment:
90 | tweet_urls = re.findall(r'(https?://[^\s]+)', text)
91 |
92 | # clean up tweet text
93 | textclean = clean_text(text)
94 |
95 | # check if tweet has no valid text
96 | if textclean == "":
97 | logger.info("Tweet does not cotain any valid text after cleaning, not adding")
98 | self.count_filtered+=1
99 | return True
100 |
101 | # get date when tweet was created
102 | created_date = time.strftime(
103 | '%Y-%m-%dT%H:%M:%S', time.strptime(dict_data['created_at'], '%a %b %d %H:%M:%S +0000 %Y'))
104 |
105 | # store dict_data into vars
106 | screen_name = str(dict_data.get("user", {}).get("screen_name"))
107 | location = str(dict_data.get("user", {}).get("location"))
108 | language = str(dict_data.get("user", {}).get("lang"))
109 | friends = int(dict_data.get("user", {}).get("friends_count"))
110 | followers = int(dict_data.get("user", {}).get("followers_count"))
111 | statuses = int(dict_data.get("user", {}).get("statuses_count"))
112 | text_filtered = str(textclean)
113 | tweetid = int(dict_data.get("id"))
114 | text_raw = str(dict_data.get("text"))
115 |
116 | # output twitter data
117 | print("\n<------------------------------")
118 | print("Tweet Date: " + created_date)
119 | print("Screen Name: " + screen_name)
120 | print("Location: " + location)
121 | print("Language: " + language)
122 | print("Friends: " + str(friends))
123 | print("Followers: " + str(followers))
124 | print("Statuses: " + str(statuses))
125 | print("Tweet ID: " + str(tweetid))
126 | print("Tweet Raw Text: " + text_raw)
127 | print("Tweet Filtered Text: " + text_filtered)
128 |
129 | # create tokens of words in text using nltk
130 | text_for_tokens = re.sub(
131 | r"[\%|\$|\.|\,|\!|\:|\@]|\(|\)|\#|\+|(``)|('')|\?|\-", "", text_filtered)
132 | tokens = nltk.word_tokenize(text_for_tokens)
133 | # convert to lower case
134 | tokens = [w.lower() for w in tokens]
135 | # remove punctuation from each word
136 | table = str.maketrans('', '', string.punctuation)
137 | stripped = [w.translate(table) for w in tokens]
138 | # remove remaining tokens that are not alphabetic
139 | tokens = [w for w in stripped if w.isalpha()]
140 | # filter out stop words
141 | stop_words = set(nltk.corpus.stopwords.words('english'))
142 | tokens = [w for w in tokens if not w in stop_words]
143 | # remove words less than 3 characters
144 | tokens = [w for w in tokens if not len(w) < 3]
145 | print("NLTK Tokens: " + str(tokens))
146 |
147 | # check for min token length
148 | if len(tokens) < 5:
149 | logger.info("Tweet does not contain min. number of tokens, not adding")
150 | self.count_filtered+=1
151 | return True
152 |
153 | # do some checks before adding to elasticsearch and crawling urls in tweet
154 | if friends == 0 or \
155 | followers == 0 or \
156 | statuses == 0 or \
157 | text == "" or \
158 | tweetid in tweet_ids:
159 | logger.info("Tweet doesn't meet min requirements, not adding")
160 | self.count_filtered+=1
161 | return True
162 |
163 | # check ignored tokens from config
164 | for t in nltk_tokens_ignored:
165 | if t in tokens:
166 | logger.info("Tweet contains token from ignore list, not adding")
167 | self.count_filtered+=1
168 | return True
169 | # check required tokens from config
170 | tokenspass = False
171 | tokensfound = 0
172 | for t in nltk_tokens_required:
173 | if t in tokens:
174 | tokensfound += 1
175 | if tokensfound == nltk_min_tokens:
176 | tokenspass = True
177 | break
178 | if not tokenspass:
179 | logger.info("Tweet does not contain token from required list or min required, not adding")
180 | self.count_filtered+=1
181 | return True
182 |
183 | # clean text for sentiment analysis
184 | text_clean = clean_text_sentiment(text_filtered)
185 |
186 | # check if tweet has no valid text
187 | if text_clean == "":
188 | logger.info("Tweet does not cotain any valid text after cleaning, not adding")
189 | self.count_filtered+=1
190 | return True
191 |
192 | print("Tweet Clean Text (sentiment): " + text_clean)
193 |
194 | # get sentiment values
195 | polarity, subjectivity, sentiment = sentiment_analysis(text_clean)
196 |
197 | # add tweet_id to list
198 | tweet_ids.append(dict_data["id"])
199 |
200 | # get sentiment for tweet
201 | if len(tweet_urls) > 0:
202 | tweet_urls_polarity = 0
203 | tweet_urls_subjectivity = 0
204 | for url in tweet_urls:
205 | res = tweeklink_sentiment_analysis(url)
206 | if res is None:
207 | continue
208 | pol, sub, sen = res
209 | tweet_urls_polarity = (tweet_urls_polarity + pol) / 2
210 | tweet_urls_subjectivity = (tweet_urls_subjectivity + sub) / 2
211 | if sentiment == "positive" or sen == "positive":
212 | sentiment = "positive"
213 | elif sentiment == "negative" or sen == "negative":
214 | sentiment = "negative"
215 | else:
216 | sentiment = "neutral"
217 |
218 | # calculate average polarity and subjectivity from tweet and tweet links
219 | if tweet_urls_polarity > 0:
220 | polarity = (polarity + tweet_urls_polarity) / 2
221 | if tweet_urls_subjectivity > 0:
222 | subjectivity = (subjectivity + tweet_urls_subjectivity) / 2
223 |
224 |
225 | logger.info("Adding tweet to elasticsearch")
226 | # add twitter data and sentiment info to elasticsearch
227 | es.index(index=args.index,
228 | doc_type="tweet",
229 | body={"author": screen_name,
230 | "location": location,
231 | "language": language,
232 | "friends": friends,
233 | "followers": followers,
234 | "statuses": statuses,
235 | "date": created_date,
236 | "message": text_filtered,
237 | "tweet_id": tweetid,
238 | "polarity": polarity,
239 | "subjectivity": subjectivity,
240 | "sentiment": sentiment})
241 |
242 | # randomly sleep to stagger request time
243 | time.sleep(randrange(2,5))
244 | return True
245 |
246 | except Exception as e:
247 | logger.warning("Exception: exception caused by: %s" % e)
248 | raise
249 |
250 | # on failure
251 | def on_error(self, status_code):
252 | logger.error("Got an error with status code: %s (will try again later)" % status_code)
253 | # randomly sleep to stagger request time
254 | time.sleep(randrange(2,30))
255 | return True
256 |
257 | # on timeout
258 | def on_timeout(self):
259 | logger.warning("Timeout... (will try again later)")
260 | # randomly sleep to stagger request time
261 | time.sleep(randrange(2,30))
262 | return True
263 |
264 |
265 | class NewsHeadlineListener:
266 |
267 | def __init__(self, url=None, frequency=120):
268 | self.url = url
269 | self.headlines = []
270 | self.followedlinks = []
271 | self.frequency = frequency
272 | self.count = 0
273 | self.count_filtered = 0
274 | self.filter_ratio = 0
275 |
276 | while True:
277 | new_headlines = self.get_news_headlines(self.url)
278 |
279 | # add any new headlines
280 | for htext, htext_url in new_headlines:
281 | if htext not in self.headlines:
282 | self.headlines.append(htext)
283 | self.count+=1
284 |
285 | datenow = datetime.utcnow().isoformat()
286 | # output news data
287 | print("\n------------------------------> (news headlines: %s, filtered: %s, filter-ratio: %s)" \
288 | % (self.count, self.count_filtered, str(round(self.count_filtered/self.count*100,2))+"%"))
289 | print("Date: " + datenow)
290 | print("News Headline: " + htext)
291 | print("Location (url): " + htext_url)
292 |
293 | # create tokens of words in text using nltk
294 | text_for_tokens = re.sub(
295 | r"[\%|\$|\.|\,|\!|\:|\@]|\(|\)|\#|\+|(``)|('')|\?|\-", "", htext)
296 | tokens = nltk.word_tokenize(text_for_tokens)
297 | print("NLTK Tokens: " + str(tokens))
298 |
299 | # check for min token length
300 | if len(tokens) < 5:
301 | logger.info("Text does not contain min. number of tokens, not adding")
302 | self.count_filtered+=1
303 | continue
304 |
305 | # check ignored tokens from config
306 | for t in nltk_tokens_ignored:
307 | if t in tokens:
308 | logger.info("Text contains token from ignore list, not adding")
309 | self.count_filtered+=1
310 | continue
311 | # check required tokens from config
312 | tokenspass = False
313 | for t in nltk_tokens_required:
314 | if t in tokens:
315 | tokenspass = True
316 | break
317 | if not tokenspass:
318 | logger.info("Text does not contain token from required list, not adding")
319 | self.count_filtered+=1
320 | continue
321 |
322 | # get sentiment values
323 | polarity, subjectivity, sentiment = sentiment_analysis(htext)
324 |
325 | logger.info("Adding news headline to elasticsearch")
326 | # add news headline data and sentiment info to elasticsearch
327 | es.index(index=args.index,
328 | doc_type="newsheadline",
329 | body={"date": datenow,
330 | "location": htext_url,
331 | "message": htext,
332 | "polarity": polarity,
333 | "subjectivity": subjectivity,
334 | "sentiment": sentiment})
335 |
336 | logger.info("Will get news headlines again in %s sec..." % self.frequency)
337 | time.sleep(self.frequency)
338 |
339 | def get_news_headlines(self, url):
340 |
341 | latestheadlines = []
342 | latestheadlines_links = []
343 | parsed_uri = urlparse.urljoin(url, '/')
344 |
345 | try:
346 |
347 | req = requests.get(url)
348 | html = req.text
349 | soup = BeautifulSoup(html, 'html.parser')
350 | html = soup.findAll('h3')
351 | links = soup.findAll('a')
352 |
353 | logger.debug(html)
354 | logger.debug(links)
355 |
356 | if html:
357 | for i in html:
358 | latestheadlines.append((i.next.next.next.next, url))
359 | logger.debug(latestheadlines)
360 |
361 | if args.followlinks:
362 | if links:
363 | for i in links:
364 | if '/news/' in i['href']:
365 | l = parsed_uri.rstrip('/') + i['href']
366 | if l not in self.followedlinks:
367 | latestheadlines_links.append(l)
368 | self.followedlinks.append(l)
369 | logger.debug(latestheadlines_links)
370 |
371 | logger.info("Following any new links and grabbing text from page...")
372 |
373 | for linkurl in latestheadlines_links:
374 | for p in get_page_text(linkurl):
375 | latestheadlines.append((p, linkurl))
376 | logger.debug(latestheadlines)
377 |
378 | except requests.exceptions.RequestException as re:
379 | logger.warning("Exception: can't crawl web site (%s)" % re)
380 | pass
381 |
382 | return latestheadlines
383 |
384 |
385 | def get_page_text(url):
386 |
387 | max_paragraphs = 10
388 |
389 | try:
390 | logger.debug(url)
391 | req = requests.get(url)
392 | html = req.text
393 | soup = BeautifulSoup(html, 'html.parser')
394 | html_p = soup.findAll('p')
395 |
396 | logger.debug(html_p)
397 |
398 | if html_p:
399 | n = 1
400 | for i in html_p:
401 | if n <= max_paragraphs:
402 | if i.string is not None:
403 | logger.debug(i.string)
404 | yield i.string
405 | n += 1
406 |
407 | except requests.exceptions.RequestException as re:
408 | logger.warning("Exception: can't crawl web site (%s)" % re)
409 | pass
410 |
411 |
412 | def clean_text(text):
413 | # clean up text
414 | text = text.replace("\n", " ")
415 | text = re.sub(r"https?\S+", "", text)
416 | text = re.sub(r"&.*?;", "", text)
417 | text = re.sub(r"<.*?>", "", text)
418 | text = text.replace("RT", "")
419 | text = text.replace(u"…", "")
420 | text = text.strip()
421 | return text
422 |
423 |
424 | def clean_text_sentiment(text):
425 | # clean up text for sentiment analysis
426 | text = re.sub(r"[#|@]\S+", "", text)
427 | text = text.strip()
428 | return text
429 |
430 |
431 | def get_sentiment_from_url(text, sentimentURL):
432 | # get sentiment from text processing website
433 | payload = {'text': text}
434 |
435 | try:
436 | #logger.debug(text)
437 | post = requests.post(sentimentURL, data=payload)
438 | #logger.debug(post.status_code)
439 | #logger.debug(post.text)
440 | except requests.exceptions.RequestException as re:
441 | logger.error("Exception: requests exception getting sentiment from url caused by %s" % re)
442 | raise
443 |
444 | # return None if we are getting throttled or other connection problem
445 | if post.status_code != 200:
446 | logger.warning("Can't get sentiment from url caused by %s %s" % (post.status_code, post.text))
447 | return None
448 |
449 | response = post.json()
450 |
451 | neg = response['probability']['neg']
452 | pos = response['probability']['pos']
453 | neu = response['probability']['neutral']
454 | label = response['label']
455 |
456 | # determine if sentiment is positive, negative, or neutral
457 | if label == "neg":
458 | sentiment = "negative"
459 | elif label == "neutral":
460 | sentiment = "neutral"
461 | else:
462 | sentiment = "positive"
463 |
464 | return sentiment, neg, pos, neu
465 |
466 |
467 | def sentiment_analysis(text):
468 | """Determine if sentiment is positive, negative, or neutral
469 | algorithm to figure out if sentiment is positive, negative or neutral
470 | uses sentiment polarity from TextBlob, VADER Sentiment and
471 | sentiment from text-processing URL
472 | could be made better :)
473 | """
474 |
475 | # pass text into sentiment url
476 | if args.websentiment:
477 | ret = get_sentiment_from_url(text, sentimentURL)
478 | if ret is None:
479 | sentiment_url = None
480 | else:
481 | sentiment_url, neg_url, pos_url, neu_url = ret
482 | else:
483 | sentiment_url = None
484 |
485 | # pass text into TextBlob
486 | text_tb = TextBlob(text)
487 |
488 | # pass text into VADER Sentiment
489 | analyzer = SentimentIntensityAnalyzer()
490 | text_vs = analyzer.polarity_scores(text)
491 |
492 | # determine sentiment from our sources
493 | if sentiment_url is None:
494 | if text_tb.sentiment.polarity < 0 and text_vs['compound'] <= -0.05:
495 | sentiment = "negative"
496 | elif text_tb.sentiment.polarity > 0 and text_vs['compound'] >= 0.05:
497 | sentiment = "positive"
498 | else:
499 | sentiment = "neutral"
500 | else:
501 | if text_tb.sentiment.polarity < 0 and text_vs['compound'] <= -0.05 and sentiment_url == "negative":
502 | sentiment = "negative"
503 | elif text_tb.sentiment.polarity > 0 and text_vs['compound'] >= 0.05 and sentiment_url == "positive":
504 | sentiment = "positive"
505 | else:
506 | sentiment = "neutral"
507 |
508 | # calculate average polarity from TextBlob and VADER
509 | polarity = (text_tb.sentiment.polarity + text_vs['compound']) / 2
510 |
511 | # output sentiment polarity
512 | print("************")
513 | print("Sentiment Polarity: " + str(round(polarity, 3)))
514 |
515 | # output sentiment subjectivity (TextBlob)
516 | print("Sentiment Subjectivity: " + str(round(text_tb.sentiment.subjectivity, 3)))
517 |
518 | # output sentiment
519 | print("Sentiment (url): " + str(sentiment_url))
520 | print("Sentiment (algorithm): " + str(sentiment))
521 | print("Overall sentiment (textblob): ", text_tb.sentiment)
522 | print("Overall sentiment (vader): ", text_vs)
523 | print("sentence was rated as ", round(text_vs['neg']*100, 3), "% Negative")
524 | print("sentence was rated as ", round(text_vs['neu']*100, 3), "% Neutral")
525 | print("sentence was rated as ", round(text_vs['pos']*100, 3), "% Positive")
526 | print("************")
527 |
528 | return polarity, text_tb.sentiment.subjectivity, sentiment
529 |
530 |
531 | def tweeklink_sentiment_analysis(url):
532 | # get text summary of tweek link web page and run sentiment analysis on it
533 | try:
534 | logger.info('Following tweet link %s to get sentiment..' % url)
535 | article = Article(url)
536 | article.download()
537 | article.parse()
538 | # check if twitter web page
539 | if "Tweet with a location" in article.text:
540 | logger.info('Link to Twitter web page, skipping')
541 | return None
542 | article.nlp()
543 | tokens = article.keywords
544 | print("Tweet link nltk tokens:", tokens)
545 |
546 | # check for min token length
547 | if len(tokens) < 5:
548 | logger.info("Tweet link does not contain min. number of tokens, not adding")
549 | return None
550 | # check ignored tokens from config
551 | for t in nltk_tokens_ignored:
552 | if t in tokens:
553 | logger.info("Tweet link contains token from ignore list, not adding")
554 | return None
555 | # check required tokens from config
556 | tokenspass = False
557 | tokensfound = 0
558 | for t in nltk_tokens_required:
559 | if t in tokens:
560 | tokensfound += 1
561 | if tokensfound == nltk_min_tokens:
562 | tokenspass = True
563 | break
564 | if not tokenspass:
565 | logger.info("Tweet link does not contain token from required list or min required, not adding")
566 | return None
567 |
568 | summary = article.summary
569 | if summary == '':
570 | logger.info('No text found in tweet link url web page')
571 | return None
572 | summary_clean = clean_text(summary)
573 | summary_clean = clean_text_sentiment(summary_clean)
574 | print("Tweet link Clean Summary (sentiment): " + summary_clean)
575 | polarity, subjectivity, sentiment = sentiment_analysis(summary_clean)
576 |
577 | return polarity, subjectivity, sentiment
578 |
579 | except ArticleException as e:
580 | logger.warning('Exception: error getting text on Twitter link caused by: %s' % e)
581 | return None
582 |
583 |
584 | def get_twitter_users_from_url(url):
585 | twitter_users = []
586 | logger.info("Grabbing any twitter users from url %s" % url)
587 | try:
588 | twitter_urls = ("http://twitter.com/", "http://www.twitter.com/",
589 | "https://twitter.com/", "https://www.twitter.com/")
590 | # req_header = {'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Safari/604.1.38"}
591 | req = requests.get(url)
592 | html = req.text
593 | soup = BeautifulSoup(html, 'html.parser')
594 | html_links = []
595 | for link in soup.findAll('a'):
596 | html_links.append(link.get('href'))
597 | if html_links:
598 | for link in html_links:
599 | # check if twitter_url in link
600 | parsed_uri = urlparse.urljoin(link, '/')
601 | # get twitter user name from link and add to list
602 | if parsed_uri in twitter_urls and "=" not in link and "?" not in link:
603 | user = link.split('/')[3]
604 | twitter_users.append(u'@' + user)
605 | logger.debug(twitter_users)
606 | except requests.exceptions.RequestException as re:
607 | logger.warning("Requests exception: can't crawl web site caused by: %s" % re)
608 | pass
609 | return twitter_users
610 |
611 |
612 | def get_twitter_users_from_file(file):
613 | # get twitter user ids from text file
614 | twitter_users = []
615 | logger.info("Grabbing any twitter user ids from file %s" % file)
616 | try:
617 | f = open(file, "rt", encoding='utf-8')
618 | for line in f.readlines():
619 | u = line.strip()
620 | twitter_users.append(u)
621 | logger.debug(twitter_users)
622 | f.close()
623 | except (IOError, OSError) as e:
624 | logger.warning("Exception: error opening file caused by: %s" % e)
625 | pass
626 | return twitter_users
627 |
628 |
629 | if __name__ == '__main__':
630 | # parse cli args
631 | parser = argparse.ArgumentParser()
632 | parser.add_argument("-i", "--index", metavar="INDEX", default="stocksight",
633 | help="Index name for Elasticsearch (default: stocksight)")
634 | parser.add_argument("-d", "--delindex", action="store_true",
635 | help="Delete existing Elasticsearch index first")
636 | parser.add_argument("-s", "--symbol", metavar="SYMBOL", required=True,
637 | help="Stock symbol you are interesed in searching for, example: TSLA")
638 | parser.add_argument("-k", "--keywords", metavar="KEYWORDS",
639 | help="Use keywords to search for in Tweets instead of feeds. "
640 | "Separated by comma, case insensitive, spaces are ANDs commas are ORs. "
641 | "Example: TSLA,'Elon Musk',Musk,Tesla,SpaceX")
642 | parser.add_argument("-a", "--addtokens", action="store_true",
643 | help="Add nltk tokens required from config to keywords")
644 | parser.add_argument("-u", "--url", metavar="URL",
645 | help="Use twitter users from any links in web page at url")
646 | parser.add_argument("-f", "--file", metavar="FILE",
647 | help="Use twitter user ids from file")
648 | parser.add_argument("-l", "--linksentiment", action="store_true",
649 | help="Follow any link url in tweets and analyze sentiment on web page")
650 | parser.add_argument("-n", "--newsheadlines", action="store_true",
651 | help="Get news headlines instead of Twitter using stock symbol from -s")
652 | parser.add_argument("--frequency", metavar="FREQUENCY", default=120, type=int,
653 | help="How often in seconds to retrieve news headlines (default: 120 sec)")
654 | parser.add_argument("--followlinks", action="store_true",
655 | help="Follow links on news headlines and scrape relevant text from landing page")
656 | parser.add_argument("-w", "--websentiment", action="store_true",
657 | help="Get sentiment results from text processing website")
658 | parser.add_argument("--overridetokensreq", metavar="TOKEN", nargs="+",
659 | help="Override nltk required tokens from config, separate with space")
660 | parser.add_argument("--overridetokensignore", metavar="TOKEN", nargs="+",
661 | help="Override nltk ignore tokens from config, separate with space")
662 | parser.add_argument("-v", "--verbose", action="store_true",
663 | help="Increase output verbosity")
664 | parser.add_argument("--debug", action="store_true",
665 | help="Debug message output")
666 | parser.add_argument("-q", "--quiet", action="store_true",
667 | help="Run quiet with no message output")
668 | parser.add_argument("-V", "--version", action="version",
669 | version="stocksight v%s" % STOCKSIGHT_VERSION,
670 | help="Prints version and exits")
671 | args = parser.parse_args()
672 |
673 | # set up logging
674 | logger = logging.getLogger('stocksight')
675 | logger.setLevel(logging.INFO)
676 | eslogger = logging.getLogger('elasticsearch')
677 | eslogger.setLevel(logging.WARNING)
678 | tweepylogger = logging.getLogger('tweepy')
679 | tweepylogger.setLevel(logging.INFO)
680 | requestslogger = logging.getLogger('requests')
681 | requestslogger.setLevel(logging.INFO)
682 | logging.addLevelName(
683 | logging.INFO, "\033[1;32m%s\033[1;0m"
684 | % logging.getLevelName(logging.INFO))
685 | logging.addLevelName(
686 | logging.WARNING, "\033[1;31m%s\033[1;0m"
687 | % logging.getLevelName(logging.WARNING))
688 | logging.addLevelName(
689 | logging.ERROR, "\033[1;41m%s\033[1;0m"
690 | % logging.getLevelName(logging.ERROR))
691 | logging.addLevelName(
692 | logging.DEBUG, "\033[1;33m%s\033[1;0m"
693 | % logging.getLevelName(logging.DEBUG))
694 | logformatter = '%(asctime)s [%(levelname)s][%(name)s] %(message)s'
695 | loglevel = logging.INFO
696 | logging.basicConfig(format=logformatter, level=loglevel)
697 | if args.verbose:
698 | logger.setLevel(logging.INFO)
699 | eslogger.setLevel(logging.INFO)
700 | tweepylogger.setLevel(logging.INFO)
701 | requestslogger.setLevel(logging.INFO)
702 | if args.debug:
703 | logger.setLevel(logging.DEBUG)
704 | eslogger.setLevel(logging.DEBUG)
705 | tweepylogger.setLevel(logging.DEBUG)
706 | requestslogger.setLevel(logging.DEBUG)
707 | if args.quiet:
708 | logger.disabled = True
709 | eslogger.disabled = True
710 | tweepylogger.disabled = True
711 | requestslogger.disabled = True
712 |
713 | # print banner
714 | if not args.quiet:
715 | c = randint(1, 4)
716 | if c == 1:
717 | color = '31m'
718 | elif c == 2:
719 | color = '32m'
720 | elif c == 3:
721 | color = '33m'
722 | elif c == 4:
723 | color = '35m'
724 |
725 | banner = """\033[%s
726 | _ _
727 | _| |_ _ _ _| |_ _ _ _
728 | | __| |_ ___ ___| |_| __|_|___| |_| |_
729 | |__ | _| . | _| '_|__ | | . | | _|
730 | |_ _|_| |___|___|_,_|_ _|_|_ |_|_|_|
731 | |_| |_| |___|
732 | :) = +$ :( = -$ v%s
733 | https://github.com/shirosaidev/stocksight
734 | \033[0m""" % (color, STOCKSIGHT_VERSION)
735 | print(banner + '\n')
736 |
737 | # create instance of elasticsearch
738 | es = Elasticsearch(hosts=[{'host': elasticsearch_host, 'port': elasticsearch_port}],
739 | http_auth=(elasticsearch_user, elasticsearch_password))
740 |
741 | # set up elasticsearch mappings and create index
742 | mappings = {
743 | "mappings": {
744 | "tweet": {
745 | "properties": {
746 | "author": {
747 | "type": "string",
748 | "fields": {
749 | "keyword": {
750 | "type": "keyword"
751 | }
752 | }
753 | },
754 | "location": {
755 | "type": "string",
756 | "fields": {
757 | "keyword": {
758 | "type": "keyword"
759 | }
760 | }
761 | },
762 | "language": {
763 | "type": "string",
764 | "fields": {
765 | "keyword": {
766 | "type": "keyword"
767 | }
768 | }
769 | },
770 | "friends": {
771 | "type": "long"
772 | },
773 | "followers": {
774 | "type": "long"
775 | },
776 | "statuses": {
777 | "type": "long"
778 | },
779 | "date": {
780 | "type": "date"
781 | },
782 | "message": {
783 | "type": "string",
784 | "fields": {
785 | "english": {
786 | "type": "string",
787 | "analyzer": "english"
788 | },
789 | "keyword": {
790 | "type": "keyword"
791 | }
792 | }
793 | },
794 | "tweet_id": {
795 | "type": "long"
796 | },
797 | "polarity": {
798 | "type": "float"
799 | },
800 | "subjectivity": {
801 | "type": "float"
802 | },
803 | "sentiment": {
804 | "type": "string",
805 | "fields": {
806 | "keyword": {
807 | "type": "keyword"
808 | }
809 | }
810 | }
811 | }
812 | },
813 | "newsheadline": {
814 | "properties": {
815 | "date": {
816 | "type": "date"
817 | },
818 | "location": {
819 | "type": "string",
820 | "fields": {
821 | "keyword": {
822 | "type": "keyword"
823 | }
824 | }
825 | },
826 | "message": {
827 | "type": "string",
828 | "fields": {
829 | "english": {
830 | "type": "string",
831 | "analyzer": "english"
832 | },
833 | "keyword": {
834 | "type": "keyword"
835 | }
836 | }
837 | },
838 | "polarity": {
839 | "type": "float"
840 | },
841 | "subjectivity": {
842 | "type": "float"
843 | },
844 | "sentiment": {
845 | "type": "string",
846 | "fields": {
847 | "keyword": {
848 | "type": "keyword"
849 | }
850 | }
851 | }
852 | }
853 | }
854 | }
855 | }
856 |
857 | if args.delindex:
858 | logger.info('Deleting existing Elasticsearch index ' + args.index)
859 | es.indices.delete(index=args.index, ignore=[400, 404])
860 |
861 | logger.info('Creating new Elasticsearch index or using existing ' + args.index)
862 | es.indices.create(index=args.index, body=mappings, ignore=[400, 404])
863 |
864 | # check if we need to override any tokens
865 | if args.overridetokensreq:
866 | nltk_tokens_required = tuple(args.overridetokensreq)
867 | if args.overridetokensignore:
868 | nltk_tokens_ignored = tuple(args.overridetokensignore)
869 |
870 | # are we grabbing news headlines from yahoo finance or twitter
871 | if args.newsheadlines:
872 | try:
873 | url = "https://finance.yahoo.com/quote/%s/?p=%s" % (args.symbol, args.symbol)
874 |
875 | logger.info('NLTK tokens required: ' + str(nltk_tokens_required))
876 | logger.info('NLTK tokens ignored: ' + str(nltk_tokens_ignored))
877 | logger.info("Scraping news for %s from %s ..." % (args.symbol, url))
878 |
879 | # create instance of NewsHeadlineListener
880 | newslistener = NewsHeadlineListener(url, args.frequency)
881 | except KeyboardInterrupt:
882 | print("Ctrl-c keyboard interrupt, exiting...")
883 | sys.exit(0)
884 |
885 | else:
886 | # create instance of the tweepy tweet stream listener
887 | tweetlistener = TweetStreamListener()
888 |
889 | # set twitter keys/tokens
890 | auth = OAuthHandler(consumer_key, consumer_secret)
891 | auth.set_access_token(access_token, access_token_secret)
892 | api = API(auth)
893 |
894 | # create instance of the tweepy stream
895 | stream = Stream(auth, tweetlistener)
896 |
897 | # grab any twitter users from links in web page at url
898 | if args.url:
899 | twitter_users = get_twitter_users_from_url(args.url)
900 | if len(twitter_users) > 0:
901 | twitter_feeds = twitter_users
902 | else:
903 | logger.info("No twitter users found in links on web page, exiting")
904 | sys.exit(1)
905 |
906 | # grab twitter users from file
907 | if args.file:
908 | twitter_users = get_twitter_users_from_file(args.file)
909 | if len(twitter_users) > 0:
910 | useridlist = twitter_users
911 | else:
912 | logger.info("No twitter users found in file, exiting")
913 | sys.exit(1)
914 | elif args.keywords is None:
915 | # build user id list from user names
916 | logger.info("Looking up Twitter user ids from usernames... (use -f twitteruserids.txt for cached user ids)")
917 | useridlist = []
918 | while True:
919 | for u in twitter_feeds:
920 | try:
921 | # get user id from screen name using twitter api
922 | user = api.get_user(screen_name=u)
923 | uid = str(user.id)
924 | if uid not in useridlist:
925 | useridlist.append(uid)
926 | time.sleep(randrange(2, 5))
927 | except TweepError as te:
928 | # sleep a bit in case twitter suspends us
929 | logger.warning("Tweepy exception: twitter api error caused by: %s" % te)
930 | logger.info("Sleeping for a random amount of time and retrying...")
931 | time.sleep(randrange(2,30))
932 | continue
933 | except KeyboardInterrupt:
934 | logger.info("Ctrl-c keyboard interrupt, exiting...")
935 | stream.disconnect()
936 | sys.exit(0)
937 | break
938 |
939 | if len(useridlist) > 0:
940 | logger.info('Writing twitter user ids to text file %s' % twitter_users_file)
941 | try:
942 | f = open(twitter_users_file, "wt", encoding='utf-8')
943 | for i in useridlist:
944 | line = str(i) + "\n"
945 | if type(line) is bytes:
946 | line = line.decode('utf-8')
947 | f.write(line)
948 | f.close()
949 | except (IOError, OSError) as e:
950 | logger.warning("Exception: error writing to file caused by: %s" % e)
951 | pass
952 | except Exception as e:
953 | raise
954 |
955 | try:
956 | # search twitter for keywords
957 | logger.info('Stock symbol: ' + str(args.symbol))
958 | logger.info('NLTK tokens required: ' + str(nltk_tokens_required))
959 | logger.info('NLTK tokens ignored: ' + str(nltk_tokens_ignored))
960 | logger.info('Listening for Tweets (ctrl-c to exit)...')
961 | if args.keywords is None:
962 | logger.info('No keywords entered, following Twitter users...')
963 | logger.info('Twitter Feeds: ' + str(twitter_feeds))
964 | logger.info('Twitter User Ids: ' + str(useridlist))
965 | stream.filter(follow=useridlist, languages=['en'])
966 | else:
967 | # keywords to search on twitter
968 | # add keywords to list
969 | keywords = args.keywords.split(',')
970 | if args.addtokens:
971 | # add tokens to keywords to list
972 | for f in nltk_tokens_required:
973 | keywords.append(f)
974 | logger.info('Searching Twitter for keywords...')
975 | logger.info('Twitter keywords: ' + str(keywords))
976 | stream.filter(track=keywords, languages=['en'])
977 | except TweepError as te:
978 | logger.debug("Tweepy Exception: Failed to get tweets caused by: %s" % te)
979 | except KeyboardInterrupt:
980 | print("Ctrl-c keyboard interrupt, exiting...")
981 | stream.disconnect()
982 | sys.exit(0)
983 |
--------------------------------------------------------------------------------
43 |
44 |
45 | ## Install - Docker
46 |
47 | *** **See [how to use](#how-to-use) below before building the Docker containers** ***
48 |
49 | 1) Download/clone stocksight repo with git.
50 | 2) Set up stocksight, elasticsearch and kibana containers using Docker compose
51 | ```
52 | cd stocksight
53 | cp config.py.sample config.py
54 | ***see how to use below for config.py (stocksight config) changes***
55 | docker-compose build && docker-compose up
56 | ```
57 | **This will volume mount config.py (stocksight settings) and twitteruserids.txt to those files in your local git cloned "stocksight" directory**
58 |
59 | 3) Once all the containers have started up, shell into the container
60 |
61 | `docker exec -it stocksight_stocksight_1 bash`
62 |
63 | 4) See examples below for running stocksight.
64 |
65 | ## Install - local
66 |
67 | **Recommended to install Elasticsearch and Kibana in local machine or other machine/vm/docker**
68 |
69 | 1) Install python requirements using pip
70 |
71 | `pip install -r requirements.txt`
72 |
73 | 2) Install python nltk data
74 |
75 | `python -c "import nltk; nltk.download('punkt'); nltk.download('stopwords')"`
76 |
77 |
78 | ## How to use
79 | 1) Create a new twitter application and generate your consumer key and access token. https://developer.twitter.com/en/docs/basics/developer-portal/guides/apps.html
80 | https://developer.twitter.com/en/docs/basics/authentication/guides/access-tokens.html
81 |
82 | 2) Copy config.py.sample to config.py (stocksight config file)
83 |
84 | 3) Set elasticsearch settings in config.py for your env (for Docker, set `elasticsearch_host = "elasticsearch"`)
85 |
86 | 4) Add twitter consumer key/access token and secrets to config.py
87 |
88 | 5) Edit config.py and modify NLTK tokens required/ignored and twitter feeds you want to mine. NLTK tokens required are keywords which must be in tweet before adding it to Elasticsearch (whitelist). NLTK tokens ignored are keywords which if are found in tweet, it will not be added to Elasticsearch (blacklist).
89 |
90 | ### Examples
91 |
92 | Run sentiment.py to create 'stocksight' index in Elasticsearch and start mining and analyzing Tweets using keywords and the stock symbol TSLA
93 |
94 | ```sh
95 | $ python sentiment.py -s TSLA -k 'Elon Musk',Musk,Tesla,SpaceX --debug
96 | ```
97 |
98 | Start mining and analyzing Tweets using keywords and the stock symbol TSLA and follow any url links in tweets and performing sentiment analysis on the link web page as well as the tweet
99 |
100 | ```sh
101 | $ python sentiment.py -s TSLA -k 'Elon Musk',Musk,Tesla,SpaceX -l --debug
102 | ```
103 |
104 | Start mining and analyzing Tweets from feeds in config using cached user ids from file (if you change any of the twitter feeds in the config file, you need to delete this file and recreate it without -f)
105 |
106 | ```sh
107 | $ python sentiment.py -s TSLA -f twitteruserids.txt --debug
108 | ```
109 |
110 | Start mining and analyzing News headlines and following headline links and scraping relevant text on landing page
111 |
112 | ```sh
113 | $ python sentiment.py -s TSLA --followlinks --debug
114 | ```
115 |
116 | Run stockprice.py to add stock prices to 'stocksight' index in Elasticsearch
117 |
118 | ```sh
119 | $ python stockprice.py -s TSLA --debug
120 | ```
121 |
122 | ### Kibana
123 |
124 | Load 'stocksight' index in Kibana. For index pattern you can use 'stocksight' if you only have the single index or 'stocksight-*', etc. For time-field name you will want to use the date/time field 'date'.
125 |
126 | To import the saved exported visualizations/dashboard, go to Kibana, click on management, click on saved objects, click on the import button and import the export.json file.
127 |
128 |
129 | ### CLI options
130 |
131 | ```
132 | usage: sentiment.py [-h] [-i INDEX] [-d] -s SYMBOL [-k KEYWORDS] [-a] [-u URL]
133 | [-f FILE] [-l] [-n] [--frequency FREQUENCY]
134 | [--followlinks] [-w]
135 | [--overridetokensreq TOKEN [TOKEN ...]]
136 | [--overridetokensignore TOKEN [TOKEN ...]] [-v] [--debug]
137 | [-q] [-V]
138 |
139 | optional arguments:
140 | -h, --help show this help message and exit
141 | -i INDEX, --index INDEX
142 | Index name for Elasticsearch (default: stocksight)
143 | -d, --delindex Delete existing Elasticsearch index first
144 | -s SYMBOL, --symbol SYMBOL
145 | Stock symbol you are interesed in searching for,
146 | example: TSLA
147 | -k KEYWORDS, --keywords KEYWORDS
148 | Use keywords to search for in Tweets instead of feeds.
149 | Separated by comma, case insensitive, spaces are ANDs
150 | commas are ORs. Example: TSLA,'Elon
151 | Musk',Musk,Tesla,SpaceX
152 | -a, --addtokens Add nltk tokens required from config to keywords
153 | -u URL, --url URL Use twitter users from any links in web page at url
154 | -f FILE, --file FILE Use twitter user ids from file
155 | -l, --linksentiment Follow any link url in tweets and analyze sentiment on
156 | web page
157 | -n, --newsheadlines Get news headlines instead of Twitter using stock
158 | symbol from -s
159 | --frequency FREQUENCY
160 | How often in seconds to retrieve news headlines
161 | (default: 120 sec)
162 | --followlinks Follow links on news headlines and scrape relevant
163 | text from landing page
164 | -w, --websentiment Get sentiment results from text processing website
165 | --overridetokensreq TOKEN [TOKEN ...]
166 | Override nltk required tokens from config, separate
167 | with space
168 | --overridetokensignore TOKEN [TOKEN ...]
169 | Override nltk ignore tokens from config, separate with
170 | space
171 | -v, --verbose Increase output verbosity
172 | --debug Debug message output
173 | -q, --quiet Run quiet with no message output
174 | -V, --version Prints version and exits
175 |
176 |
177 | usage: stockprice.py [-h] [-i INDEX] [-d] [-s SYMBOL] [-f FREQUENCY] [-v]
178 | [--debug] [-q] [-V]
179 |
180 | optional arguments:
181 | -h, --help show this help message and exit
182 | -i INDEX, --index INDEX
183 | Index name for Elasticsearch (default: stocksight)
184 | -d, --delindex Delete existing Elasticsearch index first
185 | -s SYMBOL, --symbol SYMBOL
186 | Stock symbol to use, example: TSLA
187 | -f FREQUENCY, --frequency FREQUENCY
188 | How often in seconds to retrieve stock data (default:
189 | 120 sec)
190 | -v, --verbose Increase output verbosity
191 | --debug Debug message output
192 | -q, --quiet Run quiet with no message output
193 | -V, --version Prints version and exits
194 | ```
195 |
196 |
197 | ## Disclaimer
198 |
199 | This software is for educational purposes only. USE THE SOFTWARE AT YOUR OWN RISK. THE AUTHORS AND ALL AFFILIATES ASSUME NO RESPONSIBILITY FOR YOUR TRADING RESULTS. Do not risk money which you are afraid to lose. There might be bugs in the code - this software DOES NOT come with ANY warranty.
200 |
--------------------------------------------------------------------------------
/export.json:
--------------------------------------------------------------------------------
1 | [
2 | {
3 | "_id": "AWZPAfg50rkQl37xrvXw",
4 | "_type": "dashboard",
5 | "_source": {
6 | "title": "stocksight_dashboard",
7 | "hits": 0,
8 | "description": "",
9 | "panelsJSON": "[{\"col\":1,\"id\":\"AWZO7a1n0rkQl37xrvXK\",\"panelIndex\":1,\"row\":3,\"size_x\":3,\"size_y\":3,\"type\":\"visualization\"},{\"col\":9,\"id\":\"AWZO8wUR0rkQl37xrvXV\",\"panelIndex\":2,\"row\":3,\"size_x\":4,\"size_y\":3,\"type\":\"visualization\"},{\"col\":1,\"columns\":[\"author\",\"location\",\"message\",\"polarity\",\"subjectivity\",\"sentiment\"],\"id\":\"AWZO_6iv0rkQl37xrvXt\",\"panelIndex\":3,\"row\":6,\"size_x\":12,\"size_y\":4,\"sort\":[\"date\",\"desc\"],\"type\":\"search\"},{\"col\":1,\"id\":\"AWZW6DNS0rkQl37xrvcg\",\"panelIndex\":4,\"row\":10,\"size_x\":12,\"size_y\":4,\"type\":\"visualization\"},{\"col\":4,\"id\":\"AWZYOrcih4RzKn4w3M7J\",\"panelIndex\":5,\"row\":3,\"size_x\":5,\"size_y\":3,\"type\":\"visualization\"},{\"col\":1,\"id\":\"AWZY6Xtjh4RzKn4w3NXT\",\"panelIndex\":6,\"row\":1,\"size_x\":12,\"size_y\":2,\"type\":\"visualization\"}]",
10 | "optionsJSON": "{\"darkTheme\":true}",
11 | "uiStateJSON": "{\"P-2\":{\"vis\":{\"legendOpen\":true}},\"P-6\":{\"vis\":{\"defaultColors\":{\"0 - 1\":\"rgb(0,104,55)\"}}}}",
12 | "version": 1,
13 | "timeRestore": false,
14 | "kibanaSavedObjectMeta": {
15 | "searchSourceJSON": "{\"filter\":[{\"query\":{\"match_all\":{}}}],\"highlightAll\":true,\"version\":true}"
16 | }
17 | }
18 | },
19 | {
20 | "_id": "AWZO_6iv0rkQl37xrvXt",
21 | "_type": "search",
22 | "_source": {
23 | "title": "stocksight_savesearch",
24 | "description": "",
25 | "hits": 0,
26 | "columns": [
27 | "author",
28 | "location",
29 | "message",
30 | "polarity",
31 | "subjectivity",
32 | "sentiment"
33 | ],
34 | "sort": [
35 | "date",
36 | "desc"
37 | ],
38 | "version": 1,
39 | "kibanaSavedObjectMeta": {
40 | "searchSourceJSON": "{\"index\":\"stocksight\",\"highlightAll\":true,\"version\":true,\"query\":{\"match_all\":{}},\"filter\":[{\"meta\":{\"index\":\"stocksight\",\"negate\":false,\"disabled\":false,\"alias\":null,\"type\":\"phrase\",\"key\":\"_type\",\"value\":\"tweet\"},\"query\":{\"match\":{\"_type\":{\"query\":\"tweet\",\"type\":\"phrase\"}}},\"$state\":{\"store\":\"appState\"}}]}"
41 | }
42 | }
43 | },
44 | {
45 | "_id": "AWZY6Xtjh4RzKn4w3NXT",
46 | "_type": "visualization",
47 | "_source": {
48 | "title": "stocksight_polarity",
49 | "visState": "{\"title\":\"stocksight_polarity\",\"type\":\"metric\",\"params\":{\"addTooltip\":true,\"addLegend\":false,\"type\":\"gauge\",\"gauge\":{\"verticalSplit\":false,\"autoExtend\":false,\"percentageMode\":false,\"gaugeType\":\"Metric\",\"gaugeStyle\":\"Full\",\"backStyle\":\"Full\",\"orientation\":\"vertical\",\"colorSchema\":\"Green to Red\",\"gaugeColorMode\":\"None\",\"useRange\":false,\"colorsRange\":[{\"from\":0,\"to\":1}],\"invertColors\":false,\"labels\":{\"show\":true,\"color\":\"black\"},\"scale\":{\"show\":false,\"labels\":false,\"color\":\"#333\",\"width\":2},\"type\":\"simple\",\"style\":{\"fontSize\":\"24\",\"bgColor\":false,\"labelColor\":false,\"subText\":\"\"},\"extendRange\":false}},\"aggs\":[{\"id\":\"5\",\"enabled\":true,\"type\":\"count\",\"schema\":\"metric\",\"params\":{}},{\"id\":\"1\",\"enabled\":true,\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"polarity\"}},{\"id\":\"4\",\"enabled\":true,\"type\":\"median\",\"schema\":\"metric\",\"params\":{\"field\":\"polarity\",\"percents\":[50]}},{\"id\":\"2\",\"enabled\":true,\"type\":\"min\",\"schema\":\"metric\",\"params\":{\"field\":\"polarity\"}},{\"id\":\"3\",\"enabled\":true,\"type\":\"max\",\"schema\":\"metric\",\"params\":{\"field\":\"polarity\"}}],\"listeners\":{}}",
50 | "uiStateJSON": "{\"vis\":{\"defaultColors\":{\"0 - 1\":\"rgb(0,104,55)\"}}}",
51 | "description": "",
52 | "version": 1,
53 | "kibanaSavedObjectMeta": {
54 | "searchSourceJSON": "{\"index\":\"stocksight\",\"query\":{\"match_all\":{}},\"filter\":[]}"
55 | }
56 | }
57 | },
58 | {
59 | "_id": "AWZO7a1n0rkQl37xrvXK",
60 | "_type": "visualization",
61 | "_source": {
62 | "title": "stocksight_sentinel",
63 | "visState": "{\"title\":\"stocksight_sentinel\",\"type\":\"pie\",\"params\":{\"addLegend\":true,\"addTooltip\":true,\"isDonut\":false,\"legendPosition\":\"bottom\",\"type\":\"pie\"},\"aggs\":[{\"id\":\"1\",\"enabled\":true,\"type\":\"count\",\"schema\":\"metric\",\"params\":{}},{\"id\":\"2\",\"enabled\":true,\"type\":\"terms\",\"schema\":\"segment\",\"params\":{\"field\":\"sentiment.keyword\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\"}}],\"listeners\":{}}",
64 | "uiStateJSON": "{}",
65 | "description": "",
66 | "version": 1,
67 | "kibanaSavedObjectMeta": {
68 | "searchSourceJSON": "{\"index\":\"stocksight\",\"query\":{\"match_all\":{}},\"filter\":[]}"
69 | }
70 | }
71 | },
72 | {
73 | "_id": "AWZYOrcih4RzKn4w3M7J",
74 | "_type": "visualization",
75 | "_source": {
76 | "title": "stocksight_stockprice",
77 | "visState": "{\"title\":\"stocksight_stockprice\",\"type\":\"line\",\"params\":{\"grid\":{\"categoryLines\":false,\"style\":{\"color\":\"#eee\"}},\"categoryAxes\":[{\"id\":\"CategoryAxis-1\",\"type\":\"category\",\"position\":\"bottom\",\"show\":true,\"style\":{},\"scale\":{\"type\":\"linear\"},\"labels\":{\"show\":true,\"truncate\":100},\"title\":{\"text\":\"date per 30 seconds\"}}],\"valueAxes\":[{\"id\":\"ValueAxis-1\",\"name\":\"LeftAxis-1\",\"type\":\"value\",\"position\":\"left\",\"show\":true,\"style\":{},\"scale\":{\"type\":\"linear\",\"mode\":\"normal\"},\"labels\":{\"show\":true,\"rotate\":0,\"filter\":false,\"truncate\":100},\"title\":{\"text\":\"Sum of price_last\"}}],\"seriesParams\":[{\"show\":\"true\",\"type\":\"line\",\"mode\":\"normal\",\"data\":{\"label\":\"Sum of price_last\",\"id\":\"1\"},\"valueAxis\":\"ValueAxis-1\",\"drawLinesBetweenPoints\":true,\"showCircles\":true},{\"show\":true,\"mode\":\"normal\",\"type\":\"line\",\"drawLinesBetweenPoints\":true,\"showCircles\":true,\"data\":{\"id\":\"3\",\"label\":\"Sum of price_high\"},\"valueAxis\":\"ValueAxis-1\"},{\"show\":true,\"mode\":\"normal\",\"type\":\"line\",\"drawLinesBetweenPoints\":true,\"showCircles\":true,\"data\":{\"id\":\"4\",\"label\":\"Sum of price_low\"},\"valueAxis\":\"ValueAxis-1\"}],\"addTooltip\":true,\"addLegend\":true,\"legendPosition\":\"bottom\",\"times\":[],\"addTimeMarker\":false,\"type\":\"line\"},\"aggs\":[{\"id\":\"1\",\"enabled\":true,\"type\":\"sum\",\"schema\":\"metric\",\"params\":{\"field\":\"price_last\"}},{\"id\":\"2\",\"enabled\":true,\"type\":\"date_histogram\",\"schema\":\"segment\",\"params\":{\"field\":\"date\",\"interval\":\"auto\",\"customInterval\":\"2h\",\"min_doc_count\":1,\"extended_bounds\":{}}},{\"id\":\"3\",\"enabled\":true,\"type\":\"sum\",\"schema\":\"metric\",\"params\":{\"field\":\"price_high\"}},{\"id\":\"4\",\"enabled\":true,\"type\":\"sum\",\"schema\":\"metric\",\"params\":{\"field\":\"price_low\"}}],\"listeners\":{}}",
78 | "uiStateJSON": "{}",
79 | "description": "",
80 | "version": 1,
81 | "kibanaSavedObjectMeta": {
82 | "searchSourceJSON": "{\"index\":\"stocksight\",\"query\":{\"match_all\":{}},\"filter\":[{\"meta\":{\"index\":\"stocksight\",\"negate\":false,\"disabled\":false,\"alias\":null,\"type\":\"phrase\",\"key\":\"_type\",\"value\":\"stock\"},\"query\":{\"match\":{\"_type\":{\"query\":\"stock\",\"type\":\"phrase\"}}},\"$state\":{\"store\":\"appState\"}}]}"
83 | }
84 | }
85 | },
86 | {
87 | "_id": "AWZO8wUR0rkQl37xrvXV",
88 | "_type": "visualization",
89 | "_source": {
90 | "title": "stocksight_tweets",
91 | "visState": "{\"title\":\"stocksight_tweets\",\"type\":\"line\",\"params\":{\"grid\":{\"categoryLines\":false,\"style\":{\"color\":\"#eee\"}},\"categoryAxes\":[{\"id\":\"CategoryAxis-1\",\"type\":\"category\",\"position\":\"bottom\",\"show\":true,\"style\":{},\"scale\":{\"type\":\"linear\"},\"labels\":{\"show\":true,\"truncate\":100},\"title\":{\"text\":\"date per 30 seconds\"}}],\"valueAxes\":[{\"id\":\"ValueAxis-1\",\"name\":\"LeftAxis-1\",\"type\":\"value\",\"position\":\"left\",\"show\":true,\"style\":{},\"scale\":{\"type\":\"linear\",\"mode\":\"normal\"},\"labels\":{\"show\":true,\"rotate\":0,\"filter\":false,\"truncate\":100},\"title\":{\"text\":\"Count\"}}],\"seriesParams\":[{\"show\":\"true\",\"type\":\"line\",\"mode\":\"normal\",\"data\":{\"label\":\"Count\",\"id\":\"1\"},\"valueAxis\":\"ValueAxis-1\",\"drawLinesBetweenPoints\":true,\"showCircles\":true,\"interpolate\":\"linear\"}],\"addTooltip\":true,\"addLegend\":true,\"legendPosition\":\"bottom\",\"times\":[],\"addTimeMarker\":false,\"type\":\"line\"},\"aggs\":[{\"id\":\"1\",\"enabled\":true,\"type\":\"count\",\"schema\":\"metric\",\"params\":{\"customLabel\":\"\"}},{\"id\":\"2\",\"enabled\":true,\"type\":\"date_histogram\",\"schema\":\"segment\",\"params\":{\"field\":\"date\",\"interval\":\"auto\",\"customInterval\":\"2h\",\"min_doc_count\":1,\"extended_bounds\":{}}}],\"listeners\":{}}",
92 | "uiStateJSON": "{}",
93 | "description": "",
94 | "version": 1,
95 | "kibanaSavedObjectMeta": {
96 | "searchSourceJSON": "{\"index\":\"stocksight\",\"query\":{\"match_all\":{}},\"filter\":[]}"
97 | }
98 | }
99 | },
100 | {
101 | "_id": "AWZW6DNS0rkQl37xrvcg",
102 | "_type": "visualization",
103 | "_source": {
104 | "title": "stocksight_wordcloud",
105 | "visState": "{\n \"title\": \"stocksight_wordcloud\",\n \"type\": \"tagcloud\",\n \"params\": {\n \"scale\": \"linear\",\n \"orientation\": \"single\",\n \"minFontSize\": 14,\n \"maxFontSize\": 36,\n \"type\": \"tagcloud\"\n },\n \"aggs\": [\n {\n \"id\": \"1\",\n \"enabled\": true,\n \"type\": \"count\",\n \"schema\": \"metric\",\n \"params\": {}\n },\n {\n \"id\": \"2\",\n \"enabled\": true,\n \"type\": \"terms\",\n \"schema\": \"segment\",\n \"params\": {\n \"field\": \"message.keyword\",\n \"size\": 25,\n \"order\": \"desc\",\n \"orderBy\": \"1\"\n }\n }\n ],\n \"listeners\": {}\n}",
106 | "uiStateJSON": "{}",
107 | "description": "",
108 | "version": 1,
109 | "kibanaSavedObjectMeta": {
110 | "searchSourceJSON": "{\n \"index\": \"stocksight\",\n \"query\": {\n \"match_all\": {}\n },\n \"filter\": []\n}"
111 | }
112 | }
113 | }
114 | ]
--------------------------------------------------------------------------------
/stockprice.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | """stockprice.py - get stock price from Yahoo and add to
4 | Elasticsearch.
5 | See README.md or https://github.com/shirosaidev/stocksight
6 | for more information.
7 |
8 | Copyright (C) Chris Park 2018-2020
9 | stocksight is released under the Apache 2.0 license. See
10 | LICENSE for the full license text.
11 | """
12 |
13 | import time
14 | import requests
15 | import re
16 | import argparse
17 | import logging
18 | import sys
19 | from elasticsearch import Elasticsearch
20 | from random import randint
21 |
22 | # import elasticsearch host
23 | from config import elasticsearch_host, elasticsearch_port, elasticsearch_user, elasticsearch_password
24 |
25 | from sentiment import STOCKSIGHT_VERSION
26 | __version__ = STOCKSIGHT_VERSION
27 |
28 | # url to fetch stock price from, SYMBOL will be replaced with symbol from cli args
29 | url = "https://query1.finance.yahoo.com/v8/finance/chart/SYMBOL?region=US&lang=en-US&includePrePost=false&interval=2m&range=5d&corsDomain=finance.yahoo.com&.tsrc=finance"
30 |
31 | # create instance of elasticsearch
32 | es = Elasticsearch(hosts=[{'host': elasticsearch_host, 'port': elasticsearch_port}],
33 | http_auth=(elasticsearch_user, elasticsearch_password))
34 |
35 | class GetStock:
36 |
37 | def get_price(self, url, symbol):
38 | import re
39 |
40 | while True:
41 |
42 | logger.info("Grabbing stock data for symbol %s..." % symbol)
43 |
44 | try:
45 |
46 | # add stock symbol to url
47 | url = re.sub("SYMBOL", symbol, url)
48 | # get stock data (json) from url
49 | try:
50 | r = requests.get(url)
51 | data = r.json()
52 | except (requests.HTTPError, requests.ConnectionError, requests.ConnectTimeout) as re:
53 | logger.error("Exception: exception getting stock data from url caused by %s" % re)
54 | raise
55 | logger.debug(data)
56 | # build dict to store stock info
57 | try:
58 | D = {}
59 | D['symbol'] = symbol
60 | D['last'] = data['chart']['result'][0]['indicators']['quote'][0]['close'][-1]
61 | if D['last'] is None:
62 | D['last'] = data['chart']['result'][0]['indicators']['quote'][0]['close'][-2]
63 | D['date'] = time.strftime('%Y-%m-%dT%H:%M:%S', time.gmtime()) # time now in gmt (utc)
64 | try:
65 | D['change'] = (data['chart']['result'][0]['indicators']['quote'][0]['close'][-1] -
66 | data['chart']['result'][0]['indicators']['quote'][0]['close'][-2]) / \
67 | data['chart']['result'][0]['indicators']['quote'][0]['close'][-2] * 100
68 | except TypeError:
69 | D['change'] = (data['chart']['result'][0]['indicators']['quote'][0]['close'][-2] -
70 | data['chart']['result'][0]['indicators']['quote'][0]['close'][-3]) / \
71 | data['chart']['result'][0]['indicators']['quote'][0]['close'][-3] * 100
72 | pass
73 | D['high'] = data['chart']['result'][0]['indicators']['quote'][0]['high'][-1]
74 | if D['high'] is None:
75 | D['high'] = data['chart']['result'][0]['indicators']['quote'][0]['high'][-2]
76 | D['low'] = data['chart']['result'][0]['indicators']['quote'][0]['low'][-1]
77 | if D['low'] is None:
78 | D['low'] = data['chart']['result'][0]['indicators']['quote'][0]['low'][-2]
79 | D['vol'] = data['chart']['result'][0]['indicators']['quote'][0]['volume'][-1]
80 | if D['vol'] is None:
81 | D['vol'] = data['chart']['result'][0]['indicators']['quote'][0]['volume'][-2]
82 | logger.debug(D)
83 | except KeyError as e:
84 | logger.error("Exception: exception getting stock data caused by %s" % e)
85 | raise
86 |
87 | # check before adding to ES
88 | if D['last'] is not None and D['high'] is not None and D['low'] is not None:
89 | logger.info("Adding stock data to Elasticsearch...")
90 | # add stock price info to elasticsearch
91 | es.index(index=args.index,
92 | doc_type="stock",
93 | body={"symbol": D['symbol'],
94 | "price_last": D['last'],
95 | "date": D['date'],
96 | "change": D['change'],
97 | "price_high": D['high'],
98 | "price_low": D['low'],
99 | "vol": D['vol']
100 | })
101 | else:
102 | logger.warning("Some stock data had null values, not adding to Elasticsearch")
103 |
104 | except Exception as e:
105 | logger.error("Exception: can't get stock data, trying again later, reason is %s" % e)
106 | pass
107 |
108 | logger.info("Will get stock data again in %s sec..." % args.frequency)
109 | time.sleep(args.frequency)
110 |
111 |
112 | if __name__ == '__main__':
113 |
114 | # parse cli args
115 | parser = argparse.ArgumentParser()
116 | parser.add_argument("-i", "--index", metavar="INDEX", default="stocksight",
117 | help="Index name for Elasticsearch (default: stocksight)")
118 | parser.add_argument("-d", "--delindex", action="store_true",
119 | help="Delete existing Elasticsearch index first")
120 | parser.add_argument("-s", "--symbol", metavar="SYMBOL",
121 | help="Stock symbol to use, example: TSLA")
122 | parser.add_argument("-f", "--frequency", metavar="FREQUENCY", default=120, type=int,
123 | help="How often in seconds to retrieve stock data (default: 120 sec)")
124 | parser.add_argument("-v", "--verbose", action="store_true",
125 | help="Increase output verbosity")
126 | parser.add_argument("--debug", action="store_true",
127 | help="Debug message output")
128 | parser.add_argument("-q", "--quiet", action="store_true",
129 | help="Run quiet with no message output")
130 | parser.add_argument("-V", "--version", action="version",
131 | version="stocksight v%s" % STOCKSIGHT_VERSION,
132 | help="Prints version and exits")
133 | args = parser.parse_args()
134 |
135 | # set up logging
136 | logger = logging.getLogger('stocksight')
137 | logger.setLevel(logging.INFO)
138 | eslogger = logging.getLogger('elasticsearch')
139 | eslogger.setLevel(logging.WARNING)
140 | requestslogger = logging.getLogger('requests')
141 | requestslogger.setLevel(logging.WARNING)
142 | logging.addLevelName(
143 | logging.INFO, "\033[1;32m%s\033[1;0m"
144 | % logging.getLevelName(logging.INFO))
145 | logging.addLevelName(
146 | logging.WARNING, "\033[1;31m%s\033[1;0m"
147 | % logging.getLevelName(logging.WARNING))
148 | logging.addLevelName(
149 | logging.ERROR, "\033[1;41m%s\033[1;0m"
150 | % logging.getLevelName(logging.ERROR))
151 | logging.addLevelName(
152 | logging.DEBUG, "\033[1;33m%s\033[1;0m"
153 | % logging.getLevelName(logging.DEBUG))
154 | logformatter = '%(asctime)s [%(levelname)s][%(name)s] %(message)s'
155 | loglevel = logging.INFO
156 | logging.basicConfig(format=logformatter, level=loglevel)
157 | if args.verbose:
158 | logger.setLevel(logging.INFO)
159 | eslogger.setLevel(logging.INFO)
160 | requestslogger.setLevel(logging.INFO)
161 | if args.debug:
162 | logger.setLevel(logging.DEBUG)
163 | eslogger.setLevel(logging.DEBUG)
164 | requestslogger.setLevel(logging.DEBUG)
165 | if args.quiet:
166 | logger.disabled = True
167 | eslogger.disabled = True
168 | requestslogger.disabled = True
169 |
170 | # print banner
171 | if not args.quiet:
172 | c = randint(1, 4)
173 | if c == 1:
174 | color = '31m'
175 | elif c == 2:
176 | color = '32m'
177 | elif c == 3:
178 | color = '33m'
179 | elif c == 4:
180 | color = '35m'
181 |
182 | banner = """\033[%s
183 | _ _
184 | _| |_ _ _ _| |_ _ _ _
185 | | __| |_ ___ ___| |_| __|_|___| |_| |_
186 | |__ | _| . | _| '_|__ | | . | | _|
187 | |_ _|_| |___|___|_,_|_ _|_|_ |_|_|_|
188 | |_| |_| |___|
189 | :) = +$ :( = -$ v%s
190 | https://github.com/shirosaidev/stocksight
191 | \033[0m""" % (color, STOCKSIGHT_VERSION)
192 | print(banner + '\n')
193 |
194 | # set up elasticsearch mappings and create index
195 | mappings = {
196 | "mappings": {
197 | "stock": {
198 | "properties": {
199 | "symbol": {
200 | "type": "keyword"
201 | },
202 | "price_last": {
203 | "type": "float"
204 | },
205 | "date": {
206 | "type": "date"
207 | },
208 | "change": {
209 | "type": "float"
210 | },
211 | "price_high": {
212 | "type": "float"
213 | },
214 | "price_low": {
215 | "type": "float"
216 | },
217 | "vol": {
218 | "type": "integer"
219 | }
220 | }
221 | }
222 | }
223 | }
224 |
225 | if args.symbol is None:
226 | print("No stock symbol, see -h for help.")
227 | sys.exit(1)
228 |
229 | if args.delindex:
230 | logger.info('Deleting existing Elasticsearch index ' + args.index)
231 | es.indices.delete(index=args.index, ignore=[400, 404])
232 |
233 | logger.info('Creating new Elasticsearch index or using existing ' + args.index)
234 | es.indices.create(index=args.index, body=mappings, ignore=[400, 404])
235 |
236 | # create instance of GetStock
237 | stockprice = GetStock()
238 |
239 | try:
240 | # get stock price
241 | stockprice.get_price(symbol=args.symbol, url=url)
242 | except Exception as e:
243 | logger.warning("Exception: Failed to get stock data caused by: %s" % e)
244 | except KeyboardInterrupt:
245 | print("Ctrl-c keyboard interrupt, exiting...")
246 | sys.exit(0)
247 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "{}"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright 2017-2019 Chris Park
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/sentiment.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | """sentiment.py - analyze tweets on Twitter and add
4 | relevant tweets and their sentiment values to
5 | Elasticsearch.
6 | See README.md or https://github.com/shirosaidev/stocksight
7 | for more information.
8 |
9 | Copyright (C) Chris Park 2018-2020
10 | stocksight is released under the Apache 2.0 license. See
11 | LICENSE for the full license text.
12 | """
13 |
14 | import sys
15 | import json
16 | import time
17 | import re
18 | import requests
19 | import nltk
20 | import argparse
21 | import logging
22 | import string
23 | try:
24 | import urllib.parse as urlparse
25 | except ImportError:
26 | import urlparse
27 | from tweepy.streaming import StreamListener
28 | from tweepy import API, Stream, OAuthHandler, TweepError
29 | from textblob import TextBlob
30 | from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
31 | from bs4 import BeautifulSoup
32 | from elasticsearch import Elasticsearch
33 | from random import randint, randrange
34 | from datetime import datetime
35 | from newspaper import Article, ArticleException
36 |
37 | # import elasticsearch host, twitter keys and tokens
38 | from config import *
39 |
40 |
41 | STOCKSIGHT_VERSION = '0.1-b.12'
42 | __version__ = STOCKSIGHT_VERSION
43 |
44 | IS_PY3 = sys.version_info >= (3, 0)
45 |
46 | if not IS_PY3:
47 | print("Sorry, stocksight requires Python 3.")
48 | sys.exit(1)
49 |
50 | # sentiment text-processing url
51 | sentimentURL = 'http://text-processing.com/api/sentiment/'
52 |
53 | # tweet id list
54 | tweet_ids = []
55 |
56 | # file to hold twitter user ids
57 | twitter_users_file = './twitteruserids.txt'
58 |
59 | prev_time = time.time()
60 | sentiment_avg = [0.0,0.0,0.0]
61 |
62 |
63 | class TweetStreamListener(StreamListener):
64 |
65 | def __init__(self):
66 | self.count = 0
67 | self.count_filtered = 0
68 | self.filter_ratio = 0
69 |
70 | # on success
71 | def on_data(self, data):
72 | try:
73 | self.count+=1
74 | # decode json
75 | dict_data = json.loads(data)
76 |
77 | print("\n------------------------------> (tweets: %s, filtered: %s, filter-ratio: %s)" \
78 | % (self.count, self.count_filtered, str(round(self.count_filtered/self.count*100,2))+"%"))
79 | logger.debug('tweet data: ' + str(dict_data))
80 |
81 | text = dict_data["text"]
82 | if text is None:
83 | logger.info("Tweet has no relevant text, skipping")
84 | self.count_filtered+=1
85 | return True
86 |
87 | # grab html links from tweet
88 | tweet_urls = []
89 | if args.linksentiment:
90 | tweet_urls = re.findall(r'(https?://[^\s]+)', text)
91 |
92 | # clean up tweet text
93 | textclean = clean_text(text)
94 |
95 | # check if tweet has no valid text
96 | if textclean == "":
97 | logger.info("Tweet does not cotain any valid text after cleaning, not adding")
98 | self.count_filtered+=1
99 | return True
100 |
101 | # get date when tweet was created
102 | created_date = time.strftime(
103 | '%Y-%m-%dT%H:%M:%S', time.strptime(dict_data['created_at'], '%a %b %d %H:%M:%S +0000 %Y'))
104 |
105 | # store dict_data into vars
106 | screen_name = str(dict_data.get("user", {}).get("screen_name"))
107 | location = str(dict_data.get("user", {}).get("location"))
108 | language = str(dict_data.get("user", {}).get("lang"))
109 | friends = int(dict_data.get("user", {}).get("friends_count"))
110 | followers = int(dict_data.get("user", {}).get("followers_count"))
111 | statuses = int(dict_data.get("user", {}).get("statuses_count"))
112 | text_filtered = str(textclean)
113 | tweetid = int(dict_data.get("id"))
114 | text_raw = str(dict_data.get("text"))
115 |
116 | # output twitter data
117 | print("\n<------------------------------")
118 | print("Tweet Date: " + created_date)
119 | print("Screen Name: " + screen_name)
120 | print("Location: " + location)
121 | print("Language: " + language)
122 | print("Friends: " + str(friends))
123 | print("Followers: " + str(followers))
124 | print("Statuses: " + str(statuses))
125 | print("Tweet ID: " + str(tweetid))
126 | print("Tweet Raw Text: " + text_raw)
127 | print("Tweet Filtered Text: " + text_filtered)
128 |
129 | # create tokens of words in text using nltk
130 | text_for_tokens = re.sub(
131 | r"[\%|\$|\.|\,|\!|\:|\@]|\(|\)|\#|\+|(``)|('')|\?|\-", "", text_filtered)
132 | tokens = nltk.word_tokenize(text_for_tokens)
133 | # convert to lower case
134 | tokens = [w.lower() for w in tokens]
135 | # remove punctuation from each word
136 | table = str.maketrans('', '', string.punctuation)
137 | stripped = [w.translate(table) for w in tokens]
138 | # remove remaining tokens that are not alphabetic
139 | tokens = [w for w in stripped if w.isalpha()]
140 | # filter out stop words
141 | stop_words = set(nltk.corpus.stopwords.words('english'))
142 | tokens = [w for w in tokens if not w in stop_words]
143 | # remove words less than 3 characters
144 | tokens = [w for w in tokens if not len(w) < 3]
145 | print("NLTK Tokens: " + str(tokens))
146 |
147 | # check for min token length
148 | if len(tokens) < 5:
149 | logger.info("Tweet does not contain min. number of tokens, not adding")
150 | self.count_filtered+=1
151 | return True
152 |
153 | # do some checks before adding to elasticsearch and crawling urls in tweet
154 | if friends == 0 or \
155 | followers == 0 or \
156 | statuses == 0 or \
157 | text == "" or \
158 | tweetid in tweet_ids:
159 | logger.info("Tweet doesn't meet min requirements, not adding")
160 | self.count_filtered+=1
161 | return True
162 |
163 | # check ignored tokens from config
164 | for t in nltk_tokens_ignored:
165 | if t in tokens:
166 | logger.info("Tweet contains token from ignore list, not adding")
167 | self.count_filtered+=1
168 | return True
169 | # check required tokens from config
170 | tokenspass = False
171 | tokensfound = 0
172 | for t in nltk_tokens_required:
173 | if t in tokens:
174 | tokensfound += 1
175 | if tokensfound == nltk_min_tokens:
176 | tokenspass = True
177 | break
178 | if not tokenspass:
179 | logger.info("Tweet does not contain token from required list or min required, not adding")
180 | self.count_filtered+=1
181 | return True
182 |
183 | # clean text for sentiment analysis
184 | text_clean = clean_text_sentiment(text_filtered)
185 |
186 | # check if tweet has no valid text
187 | if text_clean == "":
188 | logger.info("Tweet does not cotain any valid text after cleaning, not adding")
189 | self.count_filtered+=1
190 | return True
191 |
192 | print("Tweet Clean Text (sentiment): " + text_clean)
193 |
194 | # get sentiment values
195 | polarity, subjectivity, sentiment = sentiment_analysis(text_clean)
196 |
197 | # add tweet_id to list
198 | tweet_ids.append(dict_data["id"])
199 |
200 | # get sentiment for tweet
201 | if len(tweet_urls) > 0:
202 | tweet_urls_polarity = 0
203 | tweet_urls_subjectivity = 0
204 | for url in tweet_urls:
205 | res = tweeklink_sentiment_analysis(url)
206 | if res is None:
207 | continue
208 | pol, sub, sen = res
209 | tweet_urls_polarity = (tweet_urls_polarity + pol) / 2
210 | tweet_urls_subjectivity = (tweet_urls_subjectivity + sub) / 2
211 | if sentiment == "positive" or sen == "positive":
212 | sentiment = "positive"
213 | elif sentiment == "negative" or sen == "negative":
214 | sentiment = "negative"
215 | else:
216 | sentiment = "neutral"
217 |
218 | # calculate average polarity and subjectivity from tweet and tweet links
219 | if tweet_urls_polarity > 0:
220 | polarity = (polarity + tweet_urls_polarity) / 2
221 | if tweet_urls_subjectivity > 0:
222 | subjectivity = (subjectivity + tweet_urls_subjectivity) / 2
223 |
224 |
225 | logger.info("Adding tweet to elasticsearch")
226 | # add twitter data and sentiment info to elasticsearch
227 | es.index(index=args.index,
228 | doc_type="tweet",
229 | body={"author": screen_name,
230 | "location": location,
231 | "language": language,
232 | "friends": friends,
233 | "followers": followers,
234 | "statuses": statuses,
235 | "date": created_date,
236 | "message": text_filtered,
237 | "tweet_id": tweetid,
238 | "polarity": polarity,
239 | "subjectivity": subjectivity,
240 | "sentiment": sentiment})
241 |
242 | # randomly sleep to stagger request time
243 | time.sleep(randrange(2,5))
244 | return True
245 |
246 | except Exception as e:
247 | logger.warning("Exception: exception caused by: %s" % e)
248 | raise
249 |
250 | # on failure
251 | def on_error(self, status_code):
252 | logger.error("Got an error with status code: %s (will try again later)" % status_code)
253 | # randomly sleep to stagger request time
254 | time.sleep(randrange(2,30))
255 | return True
256 |
257 | # on timeout
258 | def on_timeout(self):
259 | logger.warning("Timeout... (will try again later)")
260 | # randomly sleep to stagger request time
261 | time.sleep(randrange(2,30))
262 | return True
263 |
264 |
265 | class NewsHeadlineListener:
266 |
267 | def __init__(self, url=None, frequency=120):
268 | self.url = url
269 | self.headlines = []
270 | self.followedlinks = []
271 | self.frequency = frequency
272 | self.count = 0
273 | self.count_filtered = 0
274 | self.filter_ratio = 0
275 |
276 | while True:
277 | new_headlines = self.get_news_headlines(self.url)
278 |
279 | # add any new headlines
280 | for htext, htext_url in new_headlines:
281 | if htext not in self.headlines:
282 | self.headlines.append(htext)
283 | self.count+=1
284 |
285 | datenow = datetime.utcnow().isoformat()
286 | # output news data
287 | print("\n------------------------------> (news headlines: %s, filtered: %s, filter-ratio: %s)" \
288 | % (self.count, self.count_filtered, str(round(self.count_filtered/self.count*100,2))+"%"))
289 | print("Date: " + datenow)
290 | print("News Headline: " + htext)
291 | print("Location (url): " + htext_url)
292 |
293 | # create tokens of words in text using nltk
294 | text_for_tokens = re.sub(
295 | r"[\%|\$|\.|\,|\!|\:|\@]|\(|\)|\#|\+|(``)|('')|\?|\-", "", htext)
296 | tokens = nltk.word_tokenize(text_for_tokens)
297 | print("NLTK Tokens: " + str(tokens))
298 |
299 | # check for min token length
300 | if len(tokens) < 5:
301 | logger.info("Text does not contain min. number of tokens, not adding")
302 | self.count_filtered+=1
303 | continue
304 |
305 | # check ignored tokens from config
306 | for t in nltk_tokens_ignored:
307 | if t in tokens:
308 | logger.info("Text contains token from ignore list, not adding")
309 | self.count_filtered+=1
310 | continue
311 | # check required tokens from config
312 | tokenspass = False
313 | for t in nltk_tokens_required:
314 | if t in tokens:
315 | tokenspass = True
316 | break
317 | if not tokenspass:
318 | logger.info("Text does not contain token from required list, not adding")
319 | self.count_filtered+=1
320 | continue
321 |
322 | # get sentiment values
323 | polarity, subjectivity, sentiment = sentiment_analysis(htext)
324 |
325 | logger.info("Adding news headline to elasticsearch")
326 | # add news headline data and sentiment info to elasticsearch
327 | es.index(index=args.index,
328 | doc_type="newsheadline",
329 | body={"date": datenow,
330 | "location": htext_url,
331 | "message": htext,
332 | "polarity": polarity,
333 | "subjectivity": subjectivity,
334 | "sentiment": sentiment})
335 |
336 | logger.info("Will get news headlines again in %s sec..." % self.frequency)
337 | time.sleep(self.frequency)
338 |
339 | def get_news_headlines(self, url):
340 |
341 | latestheadlines = []
342 | latestheadlines_links = []
343 | parsed_uri = urlparse.urljoin(url, '/')
344 |
345 | try:
346 |
347 | req = requests.get(url)
348 | html = req.text
349 | soup = BeautifulSoup(html, 'html.parser')
350 | html = soup.findAll('h3')
351 | links = soup.findAll('a')
352 |
353 | logger.debug(html)
354 | logger.debug(links)
355 |
356 | if html:
357 | for i in html:
358 | latestheadlines.append((i.next.next.next.next, url))
359 | logger.debug(latestheadlines)
360 |
361 | if args.followlinks:
362 | if links:
363 | for i in links:
364 | if '/news/' in i['href']:
365 | l = parsed_uri.rstrip('/') + i['href']
366 | if l not in self.followedlinks:
367 | latestheadlines_links.append(l)
368 | self.followedlinks.append(l)
369 | logger.debug(latestheadlines_links)
370 |
371 | logger.info("Following any new links and grabbing text from page...")
372 |
373 | for linkurl in latestheadlines_links:
374 | for p in get_page_text(linkurl):
375 | latestheadlines.append((p, linkurl))
376 | logger.debug(latestheadlines)
377 |
378 | except requests.exceptions.RequestException as re:
379 | logger.warning("Exception: can't crawl web site (%s)" % re)
380 | pass
381 |
382 | return latestheadlines
383 |
384 |
385 | def get_page_text(url):
386 |
387 | max_paragraphs = 10
388 |
389 | try:
390 | logger.debug(url)
391 | req = requests.get(url)
392 | html = req.text
393 | soup = BeautifulSoup(html, 'html.parser')
394 | html_p = soup.findAll('p')
395 |
396 | logger.debug(html_p)
397 |
398 | if html_p:
399 | n = 1
400 | for i in html_p:
401 | if n <= max_paragraphs:
402 | if i.string is not None:
403 | logger.debug(i.string)
404 | yield i.string
405 | n += 1
406 |
407 | except requests.exceptions.RequestException as re:
408 | logger.warning("Exception: can't crawl web site (%s)" % re)
409 | pass
410 |
411 |
412 | def clean_text(text):
413 | # clean up text
414 | text = text.replace("\n", " ")
415 | text = re.sub(r"https?\S+", "", text)
416 | text = re.sub(r"&.*?;", "", text)
417 | text = re.sub(r"<.*?>", "", text)
418 | text = text.replace("RT", "")
419 | text = text.replace(u"…", "")
420 | text = text.strip()
421 | return text
422 |
423 |
424 | def clean_text_sentiment(text):
425 | # clean up text for sentiment analysis
426 | text = re.sub(r"[#|@]\S+", "", text)
427 | text = text.strip()
428 | return text
429 |
430 |
431 | def get_sentiment_from_url(text, sentimentURL):
432 | # get sentiment from text processing website
433 | payload = {'text': text}
434 |
435 | try:
436 | #logger.debug(text)
437 | post = requests.post(sentimentURL, data=payload)
438 | #logger.debug(post.status_code)
439 | #logger.debug(post.text)
440 | except requests.exceptions.RequestException as re:
441 | logger.error("Exception: requests exception getting sentiment from url caused by %s" % re)
442 | raise
443 |
444 | # return None if we are getting throttled or other connection problem
445 | if post.status_code != 200:
446 | logger.warning("Can't get sentiment from url caused by %s %s" % (post.status_code, post.text))
447 | return None
448 |
449 | response = post.json()
450 |
451 | neg = response['probability']['neg']
452 | pos = response['probability']['pos']
453 | neu = response['probability']['neutral']
454 | label = response['label']
455 |
456 | # determine if sentiment is positive, negative, or neutral
457 | if label == "neg":
458 | sentiment = "negative"
459 | elif label == "neutral":
460 | sentiment = "neutral"
461 | else:
462 | sentiment = "positive"
463 |
464 | return sentiment, neg, pos, neu
465 |
466 |
467 | def sentiment_analysis(text):
468 | """Determine if sentiment is positive, negative, or neutral
469 | algorithm to figure out if sentiment is positive, negative or neutral
470 | uses sentiment polarity from TextBlob, VADER Sentiment and
471 | sentiment from text-processing URL
472 | could be made better :)
473 | """
474 |
475 | # pass text into sentiment url
476 | if args.websentiment:
477 | ret = get_sentiment_from_url(text, sentimentURL)
478 | if ret is None:
479 | sentiment_url = None
480 | else:
481 | sentiment_url, neg_url, pos_url, neu_url = ret
482 | else:
483 | sentiment_url = None
484 |
485 | # pass text into TextBlob
486 | text_tb = TextBlob(text)
487 |
488 | # pass text into VADER Sentiment
489 | analyzer = SentimentIntensityAnalyzer()
490 | text_vs = analyzer.polarity_scores(text)
491 |
492 | # determine sentiment from our sources
493 | if sentiment_url is None:
494 | if text_tb.sentiment.polarity < 0 and text_vs['compound'] <= -0.05:
495 | sentiment = "negative"
496 | elif text_tb.sentiment.polarity > 0 and text_vs['compound'] >= 0.05:
497 | sentiment = "positive"
498 | else:
499 | sentiment = "neutral"
500 | else:
501 | if text_tb.sentiment.polarity < 0 and text_vs['compound'] <= -0.05 and sentiment_url == "negative":
502 | sentiment = "negative"
503 | elif text_tb.sentiment.polarity > 0 and text_vs['compound'] >= 0.05 and sentiment_url == "positive":
504 | sentiment = "positive"
505 | else:
506 | sentiment = "neutral"
507 |
508 | # calculate average polarity from TextBlob and VADER
509 | polarity = (text_tb.sentiment.polarity + text_vs['compound']) / 2
510 |
511 | # output sentiment polarity
512 | print("************")
513 | print("Sentiment Polarity: " + str(round(polarity, 3)))
514 |
515 | # output sentiment subjectivity (TextBlob)
516 | print("Sentiment Subjectivity: " + str(round(text_tb.sentiment.subjectivity, 3)))
517 |
518 | # output sentiment
519 | print("Sentiment (url): " + str(sentiment_url))
520 | print("Sentiment (algorithm): " + str(sentiment))
521 | print("Overall sentiment (textblob): ", text_tb.sentiment)
522 | print("Overall sentiment (vader): ", text_vs)
523 | print("sentence was rated as ", round(text_vs['neg']*100, 3), "% Negative")
524 | print("sentence was rated as ", round(text_vs['neu']*100, 3), "% Neutral")
525 | print("sentence was rated as ", round(text_vs['pos']*100, 3), "% Positive")
526 | print("************")
527 |
528 | return polarity, text_tb.sentiment.subjectivity, sentiment
529 |
530 |
531 | def tweeklink_sentiment_analysis(url):
532 | # get text summary of tweek link web page and run sentiment analysis on it
533 | try:
534 | logger.info('Following tweet link %s to get sentiment..' % url)
535 | article = Article(url)
536 | article.download()
537 | article.parse()
538 | # check if twitter web page
539 | if "Tweet with a location" in article.text:
540 | logger.info('Link to Twitter web page, skipping')
541 | return None
542 | article.nlp()
543 | tokens = article.keywords
544 | print("Tweet link nltk tokens:", tokens)
545 |
546 | # check for min token length
547 | if len(tokens) < 5:
548 | logger.info("Tweet link does not contain min. number of tokens, not adding")
549 | return None
550 | # check ignored tokens from config
551 | for t in nltk_tokens_ignored:
552 | if t in tokens:
553 | logger.info("Tweet link contains token from ignore list, not adding")
554 | return None
555 | # check required tokens from config
556 | tokenspass = False
557 | tokensfound = 0
558 | for t in nltk_tokens_required:
559 | if t in tokens:
560 | tokensfound += 1
561 | if tokensfound == nltk_min_tokens:
562 | tokenspass = True
563 | break
564 | if not tokenspass:
565 | logger.info("Tweet link does not contain token from required list or min required, not adding")
566 | return None
567 |
568 | summary = article.summary
569 | if summary == '':
570 | logger.info('No text found in tweet link url web page')
571 | return None
572 | summary_clean = clean_text(summary)
573 | summary_clean = clean_text_sentiment(summary_clean)
574 | print("Tweet link Clean Summary (sentiment): " + summary_clean)
575 | polarity, subjectivity, sentiment = sentiment_analysis(summary_clean)
576 |
577 | return polarity, subjectivity, sentiment
578 |
579 | except ArticleException as e:
580 | logger.warning('Exception: error getting text on Twitter link caused by: %s' % e)
581 | return None
582 |
583 |
584 | def get_twitter_users_from_url(url):
585 | twitter_users = []
586 | logger.info("Grabbing any twitter users from url %s" % url)
587 | try:
588 | twitter_urls = ("http://twitter.com/", "http://www.twitter.com/",
589 | "https://twitter.com/", "https://www.twitter.com/")
590 | # req_header = {'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Safari/604.1.38"}
591 | req = requests.get(url)
592 | html = req.text
593 | soup = BeautifulSoup(html, 'html.parser')
594 | html_links = []
595 | for link in soup.findAll('a'):
596 | html_links.append(link.get('href'))
597 | if html_links:
598 | for link in html_links:
599 | # check if twitter_url in link
600 | parsed_uri = urlparse.urljoin(link, '/')
601 | # get twitter user name from link and add to list
602 | if parsed_uri in twitter_urls and "=" not in link and "?" not in link:
603 | user = link.split('/')[3]
604 | twitter_users.append(u'@' + user)
605 | logger.debug(twitter_users)
606 | except requests.exceptions.RequestException as re:
607 | logger.warning("Requests exception: can't crawl web site caused by: %s" % re)
608 | pass
609 | return twitter_users
610 |
611 |
612 | def get_twitter_users_from_file(file):
613 | # get twitter user ids from text file
614 | twitter_users = []
615 | logger.info("Grabbing any twitter user ids from file %s" % file)
616 | try:
617 | f = open(file, "rt", encoding='utf-8')
618 | for line in f.readlines():
619 | u = line.strip()
620 | twitter_users.append(u)
621 | logger.debug(twitter_users)
622 | f.close()
623 | except (IOError, OSError) as e:
624 | logger.warning("Exception: error opening file caused by: %s" % e)
625 | pass
626 | return twitter_users
627 |
628 |
629 | if __name__ == '__main__':
630 | # parse cli args
631 | parser = argparse.ArgumentParser()
632 | parser.add_argument("-i", "--index", metavar="INDEX", default="stocksight",
633 | help="Index name for Elasticsearch (default: stocksight)")
634 | parser.add_argument("-d", "--delindex", action="store_true",
635 | help="Delete existing Elasticsearch index first")
636 | parser.add_argument("-s", "--symbol", metavar="SYMBOL", required=True,
637 | help="Stock symbol you are interesed in searching for, example: TSLA")
638 | parser.add_argument("-k", "--keywords", metavar="KEYWORDS",
639 | help="Use keywords to search for in Tweets instead of feeds. "
640 | "Separated by comma, case insensitive, spaces are ANDs commas are ORs. "
641 | "Example: TSLA,'Elon Musk',Musk,Tesla,SpaceX")
642 | parser.add_argument("-a", "--addtokens", action="store_true",
643 | help="Add nltk tokens required from config to keywords")
644 | parser.add_argument("-u", "--url", metavar="URL",
645 | help="Use twitter users from any links in web page at url")
646 | parser.add_argument("-f", "--file", metavar="FILE",
647 | help="Use twitter user ids from file")
648 | parser.add_argument("-l", "--linksentiment", action="store_true",
649 | help="Follow any link url in tweets and analyze sentiment on web page")
650 | parser.add_argument("-n", "--newsheadlines", action="store_true",
651 | help="Get news headlines instead of Twitter using stock symbol from -s")
652 | parser.add_argument("--frequency", metavar="FREQUENCY", default=120, type=int,
653 | help="How often in seconds to retrieve news headlines (default: 120 sec)")
654 | parser.add_argument("--followlinks", action="store_true",
655 | help="Follow links on news headlines and scrape relevant text from landing page")
656 | parser.add_argument("-w", "--websentiment", action="store_true",
657 | help="Get sentiment results from text processing website")
658 | parser.add_argument("--overridetokensreq", metavar="TOKEN", nargs="+",
659 | help="Override nltk required tokens from config, separate with space")
660 | parser.add_argument("--overridetokensignore", metavar="TOKEN", nargs="+",
661 | help="Override nltk ignore tokens from config, separate with space")
662 | parser.add_argument("-v", "--verbose", action="store_true",
663 | help="Increase output verbosity")
664 | parser.add_argument("--debug", action="store_true",
665 | help="Debug message output")
666 | parser.add_argument("-q", "--quiet", action="store_true",
667 | help="Run quiet with no message output")
668 | parser.add_argument("-V", "--version", action="version",
669 | version="stocksight v%s" % STOCKSIGHT_VERSION,
670 | help="Prints version and exits")
671 | args = parser.parse_args()
672 |
673 | # set up logging
674 | logger = logging.getLogger('stocksight')
675 | logger.setLevel(logging.INFO)
676 | eslogger = logging.getLogger('elasticsearch')
677 | eslogger.setLevel(logging.WARNING)
678 | tweepylogger = logging.getLogger('tweepy')
679 | tweepylogger.setLevel(logging.INFO)
680 | requestslogger = logging.getLogger('requests')
681 | requestslogger.setLevel(logging.INFO)
682 | logging.addLevelName(
683 | logging.INFO, "\033[1;32m%s\033[1;0m"
684 | % logging.getLevelName(logging.INFO))
685 | logging.addLevelName(
686 | logging.WARNING, "\033[1;31m%s\033[1;0m"
687 | % logging.getLevelName(logging.WARNING))
688 | logging.addLevelName(
689 | logging.ERROR, "\033[1;41m%s\033[1;0m"
690 | % logging.getLevelName(logging.ERROR))
691 | logging.addLevelName(
692 | logging.DEBUG, "\033[1;33m%s\033[1;0m"
693 | % logging.getLevelName(logging.DEBUG))
694 | logformatter = '%(asctime)s [%(levelname)s][%(name)s] %(message)s'
695 | loglevel = logging.INFO
696 | logging.basicConfig(format=logformatter, level=loglevel)
697 | if args.verbose:
698 | logger.setLevel(logging.INFO)
699 | eslogger.setLevel(logging.INFO)
700 | tweepylogger.setLevel(logging.INFO)
701 | requestslogger.setLevel(logging.INFO)
702 | if args.debug:
703 | logger.setLevel(logging.DEBUG)
704 | eslogger.setLevel(logging.DEBUG)
705 | tweepylogger.setLevel(logging.DEBUG)
706 | requestslogger.setLevel(logging.DEBUG)
707 | if args.quiet:
708 | logger.disabled = True
709 | eslogger.disabled = True
710 | tweepylogger.disabled = True
711 | requestslogger.disabled = True
712 |
713 | # print banner
714 | if not args.quiet:
715 | c = randint(1, 4)
716 | if c == 1:
717 | color = '31m'
718 | elif c == 2:
719 | color = '32m'
720 | elif c == 3:
721 | color = '33m'
722 | elif c == 4:
723 | color = '35m'
724 |
725 | banner = """\033[%s
726 | _ _
727 | _| |_ _ _ _| |_ _ _ _
728 | | __| |_ ___ ___| |_| __|_|___| |_| |_
729 | |__ | _| . | _| '_|__ | | . | | _|
730 | |_ _|_| |___|___|_,_|_ _|_|_ |_|_|_|
731 | |_| |_| |___|
732 | :) = +$ :( = -$ v%s
733 | https://github.com/shirosaidev/stocksight
734 | \033[0m""" % (color, STOCKSIGHT_VERSION)
735 | print(banner + '\n')
736 |
737 | # create instance of elasticsearch
738 | es = Elasticsearch(hosts=[{'host': elasticsearch_host, 'port': elasticsearch_port}],
739 | http_auth=(elasticsearch_user, elasticsearch_password))
740 |
741 | # set up elasticsearch mappings and create index
742 | mappings = {
743 | "mappings": {
744 | "tweet": {
745 | "properties": {
746 | "author": {
747 | "type": "string",
748 | "fields": {
749 | "keyword": {
750 | "type": "keyword"
751 | }
752 | }
753 | },
754 | "location": {
755 | "type": "string",
756 | "fields": {
757 | "keyword": {
758 | "type": "keyword"
759 | }
760 | }
761 | },
762 | "language": {
763 | "type": "string",
764 | "fields": {
765 | "keyword": {
766 | "type": "keyword"
767 | }
768 | }
769 | },
770 | "friends": {
771 | "type": "long"
772 | },
773 | "followers": {
774 | "type": "long"
775 | },
776 | "statuses": {
777 | "type": "long"
778 | },
779 | "date": {
780 | "type": "date"
781 | },
782 | "message": {
783 | "type": "string",
784 | "fields": {
785 | "english": {
786 | "type": "string",
787 | "analyzer": "english"
788 | },
789 | "keyword": {
790 | "type": "keyword"
791 | }
792 | }
793 | },
794 | "tweet_id": {
795 | "type": "long"
796 | },
797 | "polarity": {
798 | "type": "float"
799 | },
800 | "subjectivity": {
801 | "type": "float"
802 | },
803 | "sentiment": {
804 | "type": "string",
805 | "fields": {
806 | "keyword": {
807 | "type": "keyword"
808 | }
809 | }
810 | }
811 | }
812 | },
813 | "newsheadline": {
814 | "properties": {
815 | "date": {
816 | "type": "date"
817 | },
818 | "location": {
819 | "type": "string",
820 | "fields": {
821 | "keyword": {
822 | "type": "keyword"
823 | }
824 | }
825 | },
826 | "message": {
827 | "type": "string",
828 | "fields": {
829 | "english": {
830 | "type": "string",
831 | "analyzer": "english"
832 | },
833 | "keyword": {
834 | "type": "keyword"
835 | }
836 | }
837 | },
838 | "polarity": {
839 | "type": "float"
840 | },
841 | "subjectivity": {
842 | "type": "float"
843 | },
844 | "sentiment": {
845 | "type": "string",
846 | "fields": {
847 | "keyword": {
848 | "type": "keyword"
849 | }
850 | }
851 | }
852 | }
853 | }
854 | }
855 | }
856 |
857 | if args.delindex:
858 | logger.info('Deleting existing Elasticsearch index ' + args.index)
859 | es.indices.delete(index=args.index, ignore=[400, 404])
860 |
861 | logger.info('Creating new Elasticsearch index or using existing ' + args.index)
862 | es.indices.create(index=args.index, body=mappings, ignore=[400, 404])
863 |
864 | # check if we need to override any tokens
865 | if args.overridetokensreq:
866 | nltk_tokens_required = tuple(args.overridetokensreq)
867 | if args.overridetokensignore:
868 | nltk_tokens_ignored = tuple(args.overridetokensignore)
869 |
870 | # are we grabbing news headlines from yahoo finance or twitter
871 | if args.newsheadlines:
872 | try:
873 | url = "https://finance.yahoo.com/quote/%s/?p=%s" % (args.symbol, args.symbol)
874 |
875 | logger.info('NLTK tokens required: ' + str(nltk_tokens_required))
876 | logger.info('NLTK tokens ignored: ' + str(nltk_tokens_ignored))
877 | logger.info("Scraping news for %s from %s ..." % (args.symbol, url))
878 |
879 | # create instance of NewsHeadlineListener
880 | newslistener = NewsHeadlineListener(url, args.frequency)
881 | except KeyboardInterrupt:
882 | print("Ctrl-c keyboard interrupt, exiting...")
883 | sys.exit(0)
884 |
885 | else:
886 | # create instance of the tweepy tweet stream listener
887 | tweetlistener = TweetStreamListener()
888 |
889 | # set twitter keys/tokens
890 | auth = OAuthHandler(consumer_key, consumer_secret)
891 | auth.set_access_token(access_token, access_token_secret)
892 | api = API(auth)
893 |
894 | # create instance of the tweepy stream
895 | stream = Stream(auth, tweetlistener)
896 |
897 | # grab any twitter users from links in web page at url
898 | if args.url:
899 | twitter_users = get_twitter_users_from_url(args.url)
900 | if len(twitter_users) > 0:
901 | twitter_feeds = twitter_users
902 | else:
903 | logger.info("No twitter users found in links on web page, exiting")
904 | sys.exit(1)
905 |
906 | # grab twitter users from file
907 | if args.file:
908 | twitter_users = get_twitter_users_from_file(args.file)
909 | if len(twitter_users) > 0:
910 | useridlist = twitter_users
911 | else:
912 | logger.info("No twitter users found in file, exiting")
913 | sys.exit(1)
914 | elif args.keywords is None:
915 | # build user id list from user names
916 | logger.info("Looking up Twitter user ids from usernames... (use -f twitteruserids.txt for cached user ids)")
917 | useridlist = []
918 | while True:
919 | for u in twitter_feeds:
920 | try:
921 | # get user id from screen name using twitter api
922 | user = api.get_user(screen_name=u)
923 | uid = str(user.id)
924 | if uid not in useridlist:
925 | useridlist.append(uid)
926 | time.sleep(randrange(2, 5))
927 | except TweepError as te:
928 | # sleep a bit in case twitter suspends us
929 | logger.warning("Tweepy exception: twitter api error caused by: %s" % te)
930 | logger.info("Sleeping for a random amount of time and retrying...")
931 | time.sleep(randrange(2,30))
932 | continue
933 | except KeyboardInterrupt:
934 | logger.info("Ctrl-c keyboard interrupt, exiting...")
935 | stream.disconnect()
936 | sys.exit(0)
937 | break
938 |
939 | if len(useridlist) > 0:
940 | logger.info('Writing twitter user ids to text file %s' % twitter_users_file)
941 | try:
942 | f = open(twitter_users_file, "wt", encoding='utf-8')
943 | for i in useridlist:
944 | line = str(i) + "\n"
945 | if type(line) is bytes:
946 | line = line.decode('utf-8')
947 | f.write(line)
948 | f.close()
949 | except (IOError, OSError) as e:
950 | logger.warning("Exception: error writing to file caused by: %s" % e)
951 | pass
952 | except Exception as e:
953 | raise
954 |
955 | try:
956 | # search twitter for keywords
957 | logger.info('Stock symbol: ' + str(args.symbol))
958 | logger.info('NLTK tokens required: ' + str(nltk_tokens_required))
959 | logger.info('NLTK tokens ignored: ' + str(nltk_tokens_ignored))
960 | logger.info('Listening for Tweets (ctrl-c to exit)...')
961 | if args.keywords is None:
962 | logger.info('No keywords entered, following Twitter users...')
963 | logger.info('Twitter Feeds: ' + str(twitter_feeds))
964 | logger.info('Twitter User Ids: ' + str(useridlist))
965 | stream.filter(follow=useridlist, languages=['en'])
966 | else:
967 | # keywords to search on twitter
968 | # add keywords to list
969 | keywords = args.keywords.split(',')
970 | if args.addtokens:
971 | # add tokens to keywords to list
972 | for f in nltk_tokens_required:
973 | keywords.append(f)
974 | logger.info('Searching Twitter for keywords...')
975 | logger.info('Twitter keywords: ' + str(keywords))
976 | stream.filter(track=keywords, languages=['en'])
977 | except TweepError as te:
978 | logger.debug("Tweepy Exception: Failed to get tweets caused by: %s" % te)
979 | except KeyboardInterrupt:
980 | print("Ctrl-c keyboard interrupt, exiting...")
981 | stream.disconnect()
982 | sys.exit(0)
983 |
--------------------------------------------------------------------------------