├── benchbench
├── __init__.py
├── utils
│ ├── __init__.py
│ ├── win_rate.py
│ ├── base.py
│ └── metric.py
├── data
│ ├── openllm
│ │ ├── statistic.py
│ │ ├── format.py
│ │ ├── __init__.py
│ │ └── leaderboard.tsv
│ ├── bbh
│ │ ├── __init__.py
│ │ ├── format.py
│ │ ├── cols.txt
│ │ └── statistic.py
│ ├── vtab
│ │ ├── __init__.py
│ │ └── leaderboard.tsv
│ ├── bigcode
│ │ ├── __init__.py
│ │ ├── format.py
│ │ ├── leaderboard.tsv
│ │ └── vanilla.txt
│ ├── mmlu
│ │ ├── __init__.py
│ │ ├── format.py
│ │ └── leaderboard_raw.csv
│ ├── mteb
│ │ ├── format.py
│ │ ├── __init__.py
│ │ └── leaderboard.tsv
│ ├── helm_lite
│ │ ├── format.py
│ │ ├── __init__.py
│ │ └── leaderboard.tsv
│ ├── helm_capability
│ │ ├── format.py
│ │ ├── __init__.py
│ │ ├── leaderboard.tsv
│ │ └── vanilla.txt
│ ├── heim
│ │ ├── __init__.py
│ │ ├── quality_human.tsv
│ │ ├── quality_auto.tsv
│ │ ├── originality.tsv
│ │ ├── black_out.tsv
│ │ ├── nsfw.tsv
│ │ ├── nudity.tsv
│ │ ├── aesthetics_human.tsv
│ │ ├── alignment_human.tsv
│ │ └── alignment_auto.tsv
│ ├── superglue
│ │ ├── __init__.py
│ │ └── leaderboard.tsv
│ ├── imagenet
│ │ ├── format.py
│ │ ├── __init__.py
│ │ ├── run_imagenet.py
│ │ └── leaderboard_raw.tsv
│ ├── helm
│ │ ├── __init__.py
│ │ ├── toxicity.tsv
│ │ ├── calibration.tsv
│ │ ├── efficiency.tsv
│ │ ├── summarization.tsv
│ │ ├── fairness.tsv
│ │ ├── robustness.tsv
│ │ └── accuracy.tsv
│ ├── glue
│ │ ├── __init__.py
│ │ └── leaderboard.tsv
│ ├── dummy
│ │ └── __init__.py
│ └── __init__.py
└── measures
│ ├── cardinal.py
│ └── ordinal.py
├── MANIFEST.in
├── assets
├── banner.png
└── benchbench-horizontal.png
├── docs
├── data.rst
├── index.rst
├── measures.rst
├── Makefile
├── utils.rst
├── make.bat
└── conf.py
├── LICENSE.txt
├── pyproject.toml
├── README.md
└── .gitignore
/benchbench/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/benchbench/utils/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/MANIFEST.in:
--------------------------------------------------------------------------------
1 | include benchbench/data/*
2 | include benchbench/data/*/*
3 |
--------------------------------------------------------------------------------
/assets/banner.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/socialfoundations/benchbench/HEAD/assets/banner.png
--------------------------------------------------------------------------------
/assets/benchbench-horizontal.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/socialfoundations/benchbench/HEAD/assets/benchbench-horizontal.png
--------------------------------------------------------------------------------
/benchbench/data/openllm/statistic.py:
--------------------------------------------------------------------------------
1 | from datasets import load_dataset
2 |
3 | dataset = load_dataset("gsm8k", name="main", split="test")
4 | print("gsm8k")
5 | print(len(set([eval(i.split("#### ")[-1]) for i in dataset["answer"]])), len(dataset))
6 |
--------------------------------------------------------------------------------
/benchbench/data/bbh/__init__.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pandas as pd
3 |
4 |
5 | def load_bbh():
6 | data = pd.read_csv(
7 | os.path.join(os.path.dirname(os.path.abspath(__file__)), "leaderboard.tsv"),
8 | sep="\t",
9 | )
10 | cols = data.columns[6:]
11 | return data, cols
12 |
--------------------------------------------------------------------------------
/docs/data.rst:
--------------------------------------------------------------------------------
1 | Data
2 | =======================================
3 |
4 | benchbench.data
5 | --------------------------------------------
6 | .. automodule:: benchbench.data
7 | :members:
8 | :undoc-members:
9 | :show-inheritance:
10 |
11 | .. autoattribute:: benchbench.data.cardinal_benchmark_list
12 |
13 | .. autoattribute:: benchbench.data.ordinal_benchmark_list
14 |
15 |
--------------------------------------------------------------------------------
/docs/index.rst:
--------------------------------------------------------------------------------
1 | Welcome to BenchBench's documentation!
2 | =========================================
3 |
4 | .. include:: ../README.md
5 | :parser: myst_parser.sphinx_
6 |
7 | .. toctree::
8 | :maxdepth: 2
9 | :caption: Contents:
10 |
11 | data
12 | measures
13 | utils
14 |
15 |
16 | Indices and tables
17 | --------------------------------------------
18 |
19 | * :ref:`genindex`
20 | * :ref:`modindex`
21 | * :ref:`search`
22 |
--------------------------------------------------------------------------------
/benchbench/data/vtab/__init__.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pandas as pd
3 |
4 |
5 | def load_vtab():
6 | data = pd.read_csv(
7 | os.path.join(os.path.dirname(os.path.abspath(__file__)), "leaderboard.tsv"),
8 | sep="\t",
9 | )
10 | cols = data.columns[1:]
11 | return data, cols
12 |
13 |
14 | def test():
15 | data, cols = load_vtab()
16 | print(data.head())
17 | print(cols)
18 |
19 |
20 | if __name__ == "__main__":
21 | test()
22 |
--------------------------------------------------------------------------------
/benchbench/data/bigcode/__init__.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pandas as pd
3 |
4 |
5 | def load_bigcode():
6 | data = pd.read_csv(
7 | os.path.join(os.path.dirname(os.path.abspath(__file__)), "leaderboard.tsv"),
8 | sep="\t",
9 | )
10 | cols = data.columns[3:6]
11 | return data, cols
12 |
13 |
14 | def test():
15 | data, cols = load_bigcode()
16 | print(data.head())
17 | print(cols)
18 |
19 |
20 | if __name__ == "__main__":
21 | test()
22 |
--------------------------------------------------------------------------------
/benchbench/data/mmlu/__init__.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pandas as pd
3 |
4 |
5 | def load_mmlu():
6 | data = pd.read_csv(
7 | os.path.join(os.path.dirname(os.path.abspath(__file__)), "leaderboard.tsv"),
8 | sep="\t",
9 | )
10 | cols = data.columns[4:]
11 | data[cols] = data[cols] * 100.0
12 | return data, cols
13 |
14 |
15 | def test():
16 | data, cols = load_mmlu()
17 | print(data.head())
18 | print(cols)
19 |
20 |
21 | if __name__ == "__main__":
22 | test()
23 |
--------------------------------------------------------------------------------
/benchbench/data/mteb/format.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | fout = open(os.path.join(os.getcwd(), "/leaderboard.tsv"), "w")
4 | with open(os.path.join(os.getcwd(), "/vanilla.txt"), "r") as fin:
5 | for i, line in enumerate(fin.readlines()):
6 | line = line.strip().replace("\t", " ")
7 | if len(line) != 0:
8 | fout.write(line)
9 | else:
10 | fout.write("-")
11 | if i % 14 == 13:
12 | fout.write("\n")
13 | else:
14 | fout.write("\t")
15 |
--------------------------------------------------------------------------------
/benchbench/data/bigcode/format.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | fout = open(os.path.join(os.getcwd(), "leaderboard.tsv"), "w")
4 | with open(os.path.join(os.getcwd(), "vanilla.txt"), "r") as fin:
5 | for i, line in enumerate(fin.readlines()):
6 | line = line.strip().replace("\t", " ")
7 | if len(line) != 0:
8 | fout.write(line.split()[0])
9 | else:
10 | continue
11 | if i % 8 == 7:
12 | fout.write("\n")
13 | else:
14 | fout.write("\t")
15 |
--------------------------------------------------------------------------------
/benchbench/data/openllm/format.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | fout = open(os.path.join(os.getcwd(), "leaderboard.tsv"), "w")
4 | with open(os.path.join(os.getcwd(), "vanilla.txt"), "r") as fin:
5 | for i, line in enumerate(fin.readlines()):
6 | line = line.strip().replace("\t", " ")
7 | if len(line) != 0:
8 | fout.write(line.split()[0])
9 | else:
10 | continue
11 | if i % 10 == 9:
12 | fout.write("\n")
13 | else:
14 | fout.write("\t")
15 |
--------------------------------------------------------------------------------
/benchbench/data/helm_lite/format.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | fout = open(os.path.join(os.path.dirname(os.path.abspath(__file__)), "leaderboard.tsv"), "w")
4 | with open(os.path.join(os.path.dirname(os.path.abspath(__file__)), "vanilla.txt"), "r") as fin:
5 | cols = []
6 | helm_lite = dict()
7 | for i, line in enumerate(fin.readlines()):
8 | line = line.strip()
9 | if len(line) == 0:
10 | continue
11 | fout.write(line)
12 | if i % 12 == 11:
13 | fout.write("\n")
14 | else:
15 | fout.write("\t")
16 |
--------------------------------------------------------------------------------
/docs/measures.rst:
--------------------------------------------------------------------------------
1 | Measures
2 | =============
3 |
4 | .. automodule:: benchbench.measures
5 | :members:
6 | :undoc-members:
7 | :show-inheritance:
8 |
9 | benchbench.measures.cardinal
10 | --------------------------------------------
11 |
12 | .. automodule:: benchbench.measures.cardinal
13 | :members:
14 | :undoc-members:
15 | :show-inheritance:
16 |
17 | benchbench.measures.ordinal
18 | --------------------------------------------
19 |
20 | .. automodule:: benchbench.measures.ordinal
21 | :members:
22 | :undoc-members:
23 | :show-inheritance:
24 |
--------------------------------------------------------------------------------
/benchbench/data/openllm/__init__.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pandas as pd
3 |
4 |
5 | def load_openllm():
6 | data = pd.read_csv(
7 | os.path.join(os.path.dirname(os.path.abspath(__file__)), "leaderboard.tsv"),
8 | sep="\t",
9 | )
10 | cols = data.columns[3:]
11 | data["average_score"] = data[cols].mean(1)
12 | data.sort_values(by="average_score", inplace=True, ascending=False)
13 | return data, cols
14 |
15 |
16 | def test():
17 | data, cols = load_openllm()
18 | print(data.head())
19 | print(cols)
20 |
21 |
22 | if __name__ == "__main__":
23 | test()
24 |
--------------------------------------------------------------------------------
/benchbench/data/helm_capability/format.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 |
4 | fout = open(
5 | os.path.join(os.path.dirname(os.path.abspath(__file__)), "leaderboard.tsv"), "w"
6 | )
7 | with open(
8 | os.path.join(os.path.dirname(os.path.abspath(__file__)), "vanilla.txt"), "r"
9 | ) as fin:
10 | cols = []
11 | helm_lite = dict()
12 | for i, line in enumerate(fin.readlines()):
13 | line = line.strip()
14 | if len(line) == 0:
15 | continue
16 | fout.write(line)
17 | if i % 7 == 6:
18 | fout.write("\n")
19 | else:
20 | fout.write("\t")
21 |
--------------------------------------------------------------------------------
/benchbench/data/bbh/format.py:
--------------------------------------------------------------------------------
1 | import os
2 | import re
3 |
4 | fout = open(os.path.join(os.getcwd(), "leaderboard.tsv"), "w")
5 | with open(os.path.join(os.getcwd(), "cols.txt"), "r") as fin:
6 | fout.write(fin.readline() + "\n")
7 | with open(os.path.join(os.getcwd(), "vanilla.tsv"), "r") as fin:
8 | new_line = ""
9 | for i, line in enumerate(fin.readlines()):
10 | if i % 5 <= 3:
11 | new_line += line.strip()
12 | new_line += "\t"
13 | else:
14 | new_line += re.sub("\s+", "\t", line)
15 | fout.write(new_line.rstrip() + "\n")
16 | new_line = ""
17 |
--------------------------------------------------------------------------------
/benchbench/data/bbh/cols.txt:
--------------------------------------------------------------------------------
1 | Rank Model Company Release Parameters Average Boolean Expressions Causal Judgement Date Understanding Disambiguation QA Dyck Languages Formal Fallacies Geometric Shapes Hyperbaton Logical Deduction Three Objects Logical Deduction Five Objects Logical Deduction Seven Objects Movie Recommendation Multistep Arithmetic Two Navigate Object Counting Penguins In A Table Reasoning About Colored Objects Ruin Names Salient Translation Error Detection Snarks Sports Understanding Temporal Sequences Tracking Shuffled Objects Three Objects Tracking Shuffled Objects Five Objects Tracking Shuffled Objects Seven Objects Web Of Lies Word Sorting
2 |
--------------------------------------------------------------------------------
/docs/Makefile:
--------------------------------------------------------------------------------
1 | # Minimal makefile for Sphinx documentation
2 | #
3 |
4 | # You can set these variables from the command line, and also
5 | # from the environment for the first two.
6 | SPHINXOPTS ?=
7 | SPHINXBUILD ?= sphinx-build
8 | SOURCEDIR = .
9 | BUILDDIR = _build
10 |
11 | # Put it first so that "make" without argument is like "make help".
12 | help:
13 | @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
14 |
15 | .PHONY: help Makefile
16 |
17 | # Catch-all target: route all unknown targets to Sphinx using the new
18 | # "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
19 | %: Makefile
20 | @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
21 |
--------------------------------------------------------------------------------
/benchbench/data/helm_lite/__init__.py:
--------------------------------------------------------------------------------
1 | import os
2 | import numpy as np
3 | import pandas as pd
4 |
5 |
6 | def load_helm_lite():
7 | data = pd.read_csv(
8 | os.path.join(os.path.dirname(os.path.abspath(__file__)), "leaderboard.tsv"),
9 | sep="\t",
10 | )
11 | data = data.replace("-", np.nan)
12 | data = data.dropna(axis=0, how="all")
13 | data = data.dropna(axis=1, how="all")
14 | cols = data.columns[2:]
15 |
16 | for c in cols:
17 | data[c] = np.array([float(i) for i in data[c].values])
18 |
19 | return data, cols
20 |
21 |
22 | def test():
23 | data, cols = load_helm_lite()
24 | print(data.head())
25 | print(cols)
26 |
27 |
28 | if __name__ == "__main__":
29 | test()
30 |
--------------------------------------------------------------------------------
/docs/utils.rst:
--------------------------------------------------------------------------------
1 | Utils
2 | =============
3 |
4 | .. automodule:: benchbench.utils
5 | :members:
6 | :undoc-members:
7 | :show-inheritance:
8 |
9 | benchbench.utils.base
10 | --------------------------------------------
11 |
12 | .. automodule:: benchbench.utils.base
13 | :members:
14 | :undoc-members:
15 | :show-inheritance:
16 |
17 | benchbench.utils.metric
18 | --------------------------------------------
19 |
20 | .. automodule:: benchbench.utils.metric
21 | :members:
22 | :undoc-members:
23 | :show-inheritance:
24 |
25 | benchbench.utils.win_rate
26 | --------------------------------------------
27 |
28 | .. automodule:: benchbench.utils.win_rate
29 | :members:
30 | :undoc-members:
31 | :show-inheritance:
32 |
--------------------------------------------------------------------------------
/benchbench/data/helm_capability/__init__.py:
--------------------------------------------------------------------------------
1 | import os
2 | import numpy as np
3 | import pandas as pd
4 |
5 |
6 | def load_helm_capability():
7 | data = pd.read_csv(
8 | os.path.join(os.path.dirname(os.path.abspath(__file__)), "leaderboard.tsv"),
9 | sep="\t",
10 | )
11 | data = data.replace("-", np.nan)
12 | data = data.dropna(axis=0, how="all")
13 | data = data.dropna(axis=1, how="all")
14 | cols = data.columns[2:]
15 |
16 | for c in cols:
17 | data[c] = np.array([float(i) for i in data[c].values])
18 |
19 | return data, cols
20 |
21 |
22 | def test():
23 | data, cols = load_helm_capability()
24 | print(data.head())
25 | print(cols)
26 |
27 |
28 | if __name__ == "__main__":
29 | test()
30 |
--------------------------------------------------------------------------------
/docs/make.bat:
--------------------------------------------------------------------------------
1 | @ECHO OFF
2 |
3 | pushd %~dp0
4 |
5 | REM Command file for Sphinx documentation
6 |
7 | if "%SPHINXBUILD%" == "" (
8 | set SPHINXBUILD=sphinx-build
9 | )
10 | set SOURCEDIR=.
11 | set BUILDDIR=_build
12 |
13 | %SPHINXBUILD% >NUL 2>NUL
14 | if errorlevel 9009 (
15 | echo.
16 | echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
17 | echo.installed, then set the SPHINXBUILD environment variable to point
18 | echo.to the full path of the 'sphinx-build' executable. Alternatively you
19 | echo.may add the Sphinx directory to PATH.
20 | echo.
21 | echo.If you don't have Sphinx installed, grab it from
22 | echo.https://www.sphinx-doc.org/
23 | exit /b 1
24 | )
25 |
26 | if "%1" == "" goto help
27 |
28 | %SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
29 | goto end
30 |
31 | :help
32 | %SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
33 |
34 | :end
35 | popd
36 |
--------------------------------------------------------------------------------
/benchbench/data/mteb/__init__.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pandas as pd
3 |
4 |
5 | def load_mteb():
6 | data = pd.read_csv(
7 | os.path.join(os.path.dirname(os.path.abspath(__file__)), "leaderboard.tsv"),
8 | sep="\t",
9 | )
10 | orig_cols = data.columns[6:]
11 | ret = {}
12 | cols = []
13 | for c in orig_cols:
14 | col_name = c.split(" (")[0]
15 | num_task = int(c.split(" (")[1].split(" ")[0])
16 | for i in range(num_task):
17 | ret["{}-{}".format(col_name, i)] = data[c].values.copy()
18 | cols.append("{}-{}".format(col_name, i))
19 | data = pd.concat([data, pd.DataFrame(ret)], axis=1)
20 |
21 | data["average_score"] = data[cols].mean(1)
22 | data.sort_values(by="average_score", inplace=True, ascending=False)
23 | return data, cols
24 |
25 |
26 | def test():
27 | data, cols = load_mteb()
28 | print(data.head())
29 | print(cols)
30 |
31 |
32 | if __name__ == "__main__":
33 | test()
34 |
--------------------------------------------------------------------------------
/benchbench/data/heim/__init__.py:
--------------------------------------------------------------------------------
1 | import os
2 | import numpy as np
3 | import pandas as pd
4 |
5 |
6 | def load_heim(subset="alignment_human"):
7 | assert subset in [
8 | "alignment_auto",
9 | "nsfw",
10 | "quality_auto",
11 | "aesthetics_auto",
12 | "alignment_human",
13 | "nudity",
14 | "quality_human",
15 | "aesthetics_human",
16 | "black_out",
17 | "originality",
18 | ]
19 | data = pd.read_csv(
20 | os.path.join(os.path.dirname(os.path.abspath(__file__)), "%s.tsv" % subset),
21 | sep="\t",
22 | )
23 | data = data.replace("-", np.nan)
24 | data = data.dropna(axis=0, how="all")
25 | data = data.dropna(axis=1, how="all")
26 | cols = data.columns[2:]
27 | for c in cols:
28 | if "↓" in c:
29 | data[c] = -data[c]
30 | return data, cols
31 |
32 |
33 | def test():
34 | data, cols = load_heim()
35 | print(data.head())
36 | print(cols)
37 |
38 |
39 | if __name__ == "__main__":
40 | test()
41 |
--------------------------------------------------------------------------------
/LICENSE.txt:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2024 Guanhua Zhang and Moritz Hardt
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/benchbench/data/superglue/__init__.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pandas as pd
3 | import numpy as np
4 |
5 |
6 | def load_superglue():
7 | data = pd.read_csv(
8 | os.path.join(os.path.dirname(os.path.abspath(__file__)), "leaderboard.tsv"),
9 | sep="\t",
10 | )
11 | ori_cols = data.columns[5:-2]
12 | cols = []
13 | for c in ori_cols:
14 | if type(data[c].values[0]) is str and "/" in data[c].values[0]:
15 | c1 = c + "-a"
16 | c2 = c + "-b"
17 | res1, res2 = [], []
18 | for line in data[c].values:
19 | s = line.strip().split("/")
20 | res1.append(float(s[0]))
21 | res2.append(float(s[1]))
22 | res1 = np.array(res1)
23 | res2 = np.array(res2)
24 | data[c1] = res1
25 | data[c2] = res2
26 | data[c] = (res1 + res2) / 2
27 | cols.append(c)
28 | else:
29 | cols.append(c)
30 |
31 | return data, cols
32 |
33 |
34 | def test():
35 | data, cols = load_superglue()
36 | print(data.head())
37 | print(cols)
38 |
39 |
40 | if __name__ == "__main__":
41 | test()
42 |
--------------------------------------------------------------------------------
/benchbench/data/imagenet/format.py:
--------------------------------------------------------------------------------
1 | import os
2 | import re
3 | import pandas as pd
4 |
5 | fout = open(os.path.join(os.getcwd(), "leaderboard_raw.tsv"), "w")
6 | with open(os.path.join(os.getcwd(), "vanilla.txt"), "r") as fin:
7 | new_line = ""
8 | for i, line in enumerate(fin.readlines()):
9 | if i % 12 <= 10:
10 | new_line += line.strip()
11 | if len(line.strip()) != 0:
12 | new_line += "\t"
13 | else:
14 | new_line += re.sub("\s+", "\t", line)
15 | fout.write(new_line.rstrip() + "\n")
16 | new_line = ""
17 | fout.close()
18 |
19 | data = pd.read_csv(os.path.join(os.getcwd(), "leaderboard_raw.tsv"), sep="\t")
20 | data.sort_values(by=["Acc@1"], inplace=True, ascending=False)
21 | data["Model"] = data["Weight"].apply(
22 | lambda t: "_".join(t.split(".")[0].split("_")[:-1]).lower()
23 | )
24 | # data.to_csv(os.path.join(os.getcwd(), "leaderboard_raw.tsv"), sep="\t", index=False)
25 |
26 | with open(os.path.join(os.getcwd(), "run.sh"), "w") as fout:
27 | for i in range(len(data)):
28 | fout.write(
29 | f"python run_imagenet.py --model_name {data['Model'][i]} --weight_name {data['Weight'][i]}\n"
30 | )
31 |
--------------------------------------------------------------------------------
/benchbench/data/bbh/statistic.py:
--------------------------------------------------------------------------------
1 | from datasets import load_dataset
2 |
3 | configs = [
4 | "boolean_expressions",
5 | "causal_judgement",
6 | "date_understanding",
7 | "disambiguation_qa",
8 | "dyck_languages",
9 | "formal_fallacies",
10 | "geometric_shapes",
11 | "hyperbaton",
12 | "logical_deduction_five_objects",
13 | "logical_deduction_seven_objects",
14 | "logical_deduction_three_objects",
15 | "movie_recommendation",
16 | "multistep_arithmetic_two",
17 | "navigate",
18 | "object_counting",
19 | "penguins_in_a_table",
20 | "reasoning_about_colored_objects",
21 | "ruin_names",
22 | "salient_translation_error_detection",
23 | "snarks",
24 | "sports_understanding",
25 | "temporal_sequences",
26 | "tracking_shuffled_objects_five_objects",
27 | "tracking_shuffled_objects_seven_objects",
28 | "tracking_shuffled_objects_three_objects",
29 | "web_of_lies",
30 | "word_sorting",
31 | ]
32 | ret = []
33 | for c in configs:
34 | dataset = load_dataset("lukaemon/bbh", name=c, split="test")
35 | ret.append((c, set(dataset["target"])))
36 |
37 | ret = sorted(ret, key=lambda x: len(x[1]))
38 | for i in ret:
39 | print(i[0], len(i[1]), i[1])
40 |
--------------------------------------------------------------------------------
/benchbench/data/helm/__init__.py:
--------------------------------------------------------------------------------
1 | import os
2 | import numpy as np
3 | import pandas as pd
4 |
5 |
6 | def load_helm(subset="accuracy"):
7 | assert subset in [
8 | "accuracy",
9 | "bias",
10 | "calibration",
11 | "fairness",
12 | "efficiency",
13 | "robustness",
14 | "summarization",
15 | "toxicity",
16 | ]
17 | data = pd.read_csv(
18 | os.path.join(os.path.dirname(os.path.abspath(__file__)), "%s.tsv" % subset),
19 | sep="\t",
20 | )
21 | data = data.replace("-", np.nan)
22 | data = data.dropna(axis=0, how="all")
23 | data = data.dropna(axis=1, how="all")
24 | cols = data.columns[2:]
25 |
26 | for c in cols:
27 | data[c] = np.array([float(i) for i in data[c].values])
28 |
29 | for c in cols:
30 | if (
31 | "ECE" in c
32 | or "Representation" in c
33 | or "Toxic fraction" in c
34 | or "Stereotype" in c
35 | or "inference time" in c
36 | ):
37 | data[c] = -data[c]
38 |
39 | return data, cols
40 |
41 |
42 | def test():
43 | data, cols = load_helm()
44 | print(data.head())
45 | print(cols)
46 |
47 |
48 | if __name__ == "__main__":
49 | test()
50 |
--------------------------------------------------------------------------------
/benchbench/data/glue/__init__.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pandas as pd
3 | import numpy as np
4 |
5 |
6 | def load_glue():
7 | data = pd.read_csv(
8 | os.path.join(os.path.dirname(os.path.abspath(__file__)), "leaderboard.tsv"),
9 | sep="\t",
10 | )
11 | ori_cols = data.columns[5:-1]
12 | cols = []
13 | for c in ori_cols:
14 | if type(data[c].values[0]) is str and "/" in data[c].values[0]:
15 | c1 = c + "-a"
16 | c2 = c + "-b"
17 | res1, res2 = [], []
18 | for line in data[c].values:
19 | s = line.strip().split("/")
20 | res1.append(float(s[0]))
21 | res2.append(float(s[1]))
22 | res1 = np.array(res1)
23 | res2 = np.array(res2)
24 | data[c1] = res1
25 | data[c2] = res2
26 | data[c] = (res1 + res2) / 2
27 | cols.append(c)
28 | elif "MNLI" in c:
29 | continue
30 | else:
31 | cols.append(c)
32 | data["MNLI"] = (data["MNLI-m"] + data["MNLI-mm"]) / 2
33 | cols.append("MNLI")
34 |
35 | return data, cols
36 |
37 |
38 | def test():
39 | data, cols = load_glue()
40 | print(data.head())
41 | print(cols)
42 |
43 |
44 | if __name__ == "__main__":
45 | test()
46 |
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [build-system]
2 | requires = ["setuptools>=40.8.0", "wheel"]
3 | build-backend = "setuptools.build_meta"
4 |
5 | [project]
6 | name = "benchbench"
7 | authors = [
8 | {name = "Guanhua Zhang"},
9 | ]
10 | description = "Tools for measuring sensitivity and diversity of multi-task benchmarks."
11 | version = "1.0.1"
12 | requires-python = ">=3.7"
13 | readme = "README.md"
14 | license = {text = "MIT"}
15 | classifiers=[
16 | "Development Status :: 3 - Alpha",
17 | "License :: OSI Approved :: MIT License",
18 | "Intended Audience :: Science/Research",
19 | "Topic :: Scientific/Engineering :: Artificial Intelligence",
20 | "Natural Language :: English",
21 | "Programming Language :: Python :: 3",
22 | "Programming Language :: Python :: 3.7",
23 | "Programming Language :: Python :: 3.8",
24 | "Programming Language :: Python :: 3.9",
25 | "Programming Language :: Python :: 3.10",
26 | "Programming Language :: Python :: 3.11",
27 | "Programming Language :: Python :: 3.12",
28 | ]
29 | dependencies = [
30 | "scipy",
31 | "numpy",
32 | "torch",
33 | "pandas",
34 | "joblib",
35 | "scikit-learn",
36 | "zarth_utils==1.0"
37 | ]
38 |
39 |
40 | [tool.setuptools]
41 | include-package-data = true
42 |
43 | [tool.setuptools.packages.find]
44 | include = ["benchbench*"]
45 |
--------------------------------------------------------------------------------
/docs/conf.py:
--------------------------------------------------------------------------------
1 | # Configuration file for the Sphinx documentation builder.
2 | #
3 | # For the full list of built-in configuration values, see the documentation:
4 | # https://www.sphinx-doc.org/en/master/usage/configuration.html
5 |
6 | # -- Project information -----------------------------------------------------
7 | # https://www.sphinx-doc.org/en/master/usage/configuration.html#project-information
8 | import os
9 | import sys
10 |
11 | sys.path.insert(0, os.path.abspath('../'))
12 |
13 | project = 'BenchBench'
14 | copyright = '2024, Guanhua'
15 | author = 'Guanhua'
16 |
17 | # -- General configuration ---------------------------------------------------
18 | # https://www.sphinx-doc.org/en/master/usage/configuration.html#general-configuration
19 |
20 | extensions = [
21 | 'sphinx.ext.autodoc', # pull doc from docstrings
22 | 'sphinx.ext.intersphinx', # link to other projects
23 | 'sphinx.ext.todo', # support TODOs
24 | 'sphinx.ext.ifconfig', # include stuff based on configuration
25 | 'sphinx.ext.viewcode', # add source code
26 | 'myst_parser', # add MD files
27 | 'sphinx.ext.napoleon' # Google style doc
28 | ]
29 |
30 | templates_path = ['_templates']
31 | exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
32 | pygments_style = 'sphinx'
33 |
34 | # -- Options for HTML output -------------------------------------------------
35 | # https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-html-output
36 |
37 | html_theme = 'alabaster'
38 | html_static_path = ['_static']
39 |
--------------------------------------------------------------------------------
/benchbench/utils/win_rate.py:
--------------------------------------------------------------------------------
1 | import math
2 | import numpy as np
3 |
4 |
5 | class WinningRate:
6 | def __init__(self, data, cols):
7 | """
8 | Calculate the winning rate of a list of models.
9 |
10 | Args:
11 | data (pd.DataFrame): Each row represents a model, each column represents a task.
12 | cols (list): The column names of the tasks.
13 |
14 | Returns:
15 | None
16 | """
17 | m = len(data)
18 | n = len(cols)
19 | self.win_rate = np.zeros([m, m])
20 | data = data[cols].values
21 | for i in range(m):
22 | for j in range(m):
23 | n_win, n_tot = 0, 0
24 | for k in range(n):
25 | if not math.isnan(data[i, k]) and not math.isnan(data[j, k]):
26 | n_tot += 1
27 | if float(data[i, k]) > float(data[j, k]) and i != j:
28 | n_win += 1
29 | self.win_rate[i, j] = n_win / n_tot if n_tot > 0 else 0
30 |
31 | def get_winning_rate(self, model_indices=None):
32 | """
33 | Get the winning rate of the selected models.
34 |
35 | Args:
36 | model_indices (list): Indices of the selected models.
37 |
38 | Returns:
39 | float: The winning rate.
40 | """
41 | model_indices = (
42 | np.arange(len(self.win_rate)) if model_indices is None else model_indices
43 | )
44 | return self.win_rate[model_indices][:, model_indices].mean(axis=1)
45 |
--------------------------------------------------------------------------------
/benchbench/data/dummy/__init__.py:
--------------------------------------------------------------------------------
1 | import random
2 | import numpy as np
3 | import pandas as pd
4 |
5 |
6 | def load_random_benchmark(seed=0, num_task=100, num_model=100):
7 | np.random.seed(seed)
8 | random.seed(seed)
9 | data = np.random.random([num_model, num_task]) * 100
10 | data = pd.DataFrame(data)
11 | cols = list(data.columns)
12 | return data, cols
13 |
14 |
15 | def load_constant_benchmark(seed=0, num_task=100, num_model=100):
16 | np.random.seed(seed)
17 | random.seed(seed)
18 | rd = np.random.random([num_model, 1])
19 | data = np.concatenate([rd.copy() for _ in range(num_task)], axis=1) * 100
20 | data = pd.DataFrame(data)
21 | cols = list(data.columns)
22 | return data, cols
23 |
24 |
25 | def load_interpolation_benchmark(seed=0, mix_ratio=0.0, num_task=100, num_model=100):
26 | num_random = int(mix_ratio * num_task + 0.5)
27 | num_constant = int((1 - mix_ratio) * num_task + 0.5)
28 | if num_random == 0:
29 | return load_constant_benchmark(
30 | seed=seed, num_task=num_constant, num_model=num_model
31 | )
32 | elif num_constant == 0:
33 | return load_random_benchmark(
34 | seed=seed, num_task=num_random, num_model=num_model
35 | )
36 | else:
37 | random = load_random_benchmark(
38 | seed=seed, num_task=num_random, num_model=num_model
39 | )[0]
40 | constant = load_constant_benchmark(
41 | seed=seed, num_task=num_constant, num_model=num_model
42 | )[0]
43 | data = pd.DataFrame(np.concatenate([random.values, constant.values], axis=1))
44 | cols = list(data.columns)
45 | return data, cols
46 |
--------------------------------------------------------------------------------
/benchbench/data/imagenet/__init__.py:
--------------------------------------------------------------------------------
1 | import os
2 | import random
3 |
4 | import numpy as np
5 |
6 | import pandas as pd
7 |
8 |
9 | def load_imagenet(*args, **kwargs):
10 | # Due to legacy reason, instead of refactoring the code, we just make a wrapper function like this.
11 | return load_data(*args, **kwargs)
12 |
13 |
14 | def load_data(load_raw=False, seed=0, num_task=20):
15 | if load_raw:
16 | data = pd.read_csv(
17 | os.path.join(
18 | os.path.dirname(os.path.abspath(__file__)), "leaderboard_raw.tsv"
19 | ),
20 | sep="\t",
21 | )
22 | data = data.dropna(axis=0, how="any")
23 | cols = [data.columns[1]]
24 | else:
25 | data = pd.read_csv(
26 | os.path.join(os.path.dirname(os.path.abspath(__file__)), "leaderboard.tsv"),
27 | sep="\t",
28 | )
29 | data = data.sort_values(by=["acc"], ascending=False).reset_index()
30 | if num_task < 1000:
31 | assert 1000 % num_task == 0 and num_task >= 1
32 | cols = []
33 | random.seed(seed)
34 | np.random.seed(seed)
35 | size_task = 1000 // num_task
36 | perm = np.random.permutation(1000)
37 | for i in range(num_task):
38 | task_cols = [
39 | "acc_%d" % j for j in perm[i * size_task : (i + 1) * size_task]
40 | ]
41 | data["acc_aggr_%d" % i] = data[task_cols].values.mean(1)
42 | cols.append("acc_aggr_%d" % i)
43 | else:
44 | cols = ["acc_%d" % i for i in range(1000)]
45 | return data, cols
46 |
47 |
48 | def test():
49 | data, cols = load_data()
50 | print(data.head())
51 | print(cols)
52 |
53 |
54 | if __name__ == "__main__":
55 | test()
56 |
--------------------------------------------------------------------------------
/benchbench/data/vtab/leaderboard.tsv:
--------------------------------------------------------------------------------
1 | Mean (selected datasets) CIFAR-100 Caltech101 Camelyon Clevr-Count Clevr-Dist DMLab DTD EuroSAT Flowers102 KITTI-Dist Pets Resisc45 Retinopathy SVHN Sun397 dSpr-Loc dSpr-Orient sNORB-Azim sNORB-Elev
2 | Sup-Rotation-100% 90.2 84.8 94.6 85.9 99.8 92.5 76.5 75.9 98.8 94.7 82.3 91.5 94.9 79.5 97.0 70.2 100 96.5 100 98.4
3 | Sup-Exemplar-100% 90.1 84.1 94.4 86.7 99.8 92.7 76.8 74.5 98.6 93.4 84.0 91.8 95.1 79.5 97.1 69.4 100 96.4 99.8 98.0
4 | Sup-100% 89.7 83.8 94.1 83.9 99.8 92.1 76.4 74.0 98.8 93.2 80.7 91.9 95.3 79.3 97.0 70.7 100 96.4 99.8 97.7
5 | Semi-Exemplar-10% 88.8 82.7 85.3 86.0 99.8 93.1 76.8 70.5 98.6 92.2 81.5 89.0 94.7 78.8 97.0 67.4 100 96.5 100 97.8
6 | Semi-Rotation-10% 88.6 82.4 88.1 78.6 99.8 93.2 76.1 72.4 98.7 93.2 81.0 87.9 94.9 79.0 96.9 66.7 100 96.5 99.9 97.5
7 | Rotation 86.4 73.6 88.3 86.4 99.8 93.3 76.8 63.3 98.3 83.4 82.6 71.8 93.4 78.6 96.9 60.5 100 96.5 99.9 98.0
8 | Exemplar 84.8 70.7 81.9 84.7 99.8 93.3 74.7 61.1 98.5 79.3 78.2 67.8 93.5 79.0 96.7 58.2 100 96.5 99.9 97.4
9 | Rel.Pat.Loc 83.1 65.7 79.9 85.3 99.5 87.7 71.5 65.2 97.8 78.8 75.0 66.8 91.5 79.8 93.7 58.0 100 90.4 99.7 92.6
10 | Jigsaw 83.0 65.3 79.1 83.0 99.6 88.6 72.0 63.9 97.9 77.9 74.7 65.4 92.0 80.1 93.9 59.2 100 90.3 99.9 93.6
11 | From-Scratch 75.4 64.4 55.9 81.2 99.7 89.4 71.5 31.3 96.2 50.6 68.4 23.8 86.8 76.8 96.3 52.7 100 96.3 99.9 91.7
12 | Uncond-BigGAN 68.2 58.1 73.6 82.2 47.6 54.9 54.8 44.9 89.8 63.5 57.4 30.9 75.4 75.9 93.0 46.9 86.1 95.9 88.1 76.6
13 | VAE 66.8 44.2 48.4 81.3 98.4 90.1 59.7 16.0 92.5 18.4 57.0 14.0 65.0 74.2 93.1 29.3 100 94.7 97.9 95.6
14 | WAE-MMD 64.9 38.8 50.8 80.6 98.1 89.3 52.6 11.0 94.1 20.8 61.6 16.2 64.8 73.8 90.9 31.6 100 90.2 96.3 72.4
15 | Cond-BigGAN 51.4 56.3 0.148 81.3 12.4 24.5 51.4 44.8 94.5 68.8 49.7 31.6 76.5 75.3 91.4 44.9 6.16 7.45 80.6 79.2
16 | WAE-GAN 48.5 24.8 42.0 77.1 52.2 70.2 37.3 8.67 81.5 15.5 62.3 13.1 38.4 73.6 78.2 12.8 97.7 49.9 33.4 52.2
17 | WAE-UKL 46.8 23.2 41.7 76.4 44.5 67.8 36.7 12.3 78.1 17.2 55.1 12.3 36.8 73.6 65.5 12.0 98.1 51.4 35.9 51.0
--------------------------------------------------------------------------------
/benchbench/data/bigcode/leaderboard.tsv:
--------------------------------------------------------------------------------
1 | T Models Win humaneval-python java javascript Throughput
2 | 🔴 DeepSeek-Coder-33b-instruct 39.58 80.02 52.03 65.13 25.2
3 | 🔴 DeepSeek-Coder-7b-instruct 38.75 80.22 53.34 65.8 51
4 | 🔶 Phind-CodeLlama-34B-v2 37.04 71.95 54.06 65.34 15.1
5 | 🔶 Phind-CodeLlama-34B-v1 36.12 65.85 49.47 64.45 15.1
6 | 🔶 Phind-CodeLlama-34B-Python-v1 35.27 70.22 48.72 66.24 15.1
7 | 🔴 DeepSeek-Coder-33b-base 35 52.45 43.77 51.28 25.2
8 | 🔶 WizardCoder-Python-34B-V1.0 33.96 70.73 44.94 55.28 15.1
9 | 🔴 DeepSeek-Coder-7b-base 31.75 45.83 37.72 45.9 51
10 | 🔶 CodeLlama-34b-Instruct 30.96 50.79 41.53 45.85 15.1
11 | 🔶 WizardCoder-Python-13B-V1.0 30.58 62.19 41.77 48.45 25.3
12 | 🟢 CodeLlama-34b 30.35 45.11 40.19 41.66 15.1
13 | 🟢 CodeLlama-34b-Python 29.65 53.29 39.46 44.72 15.1
14 | 🔶 WizardCoder-15B-V1.0 28.92 58.12 35.77 41.91 43.7
15 | 🔶 CodeLlama-13b-Instruct 27.88 50.6 33.99 40.92 25.3
16 | 🟢 CodeLlama-13b 26.19 35.07 32.23 38.26 25.3
17 | 🟢 CodeLlama-13b-Python 24.73 42.89 33.56 40.66 25.3
18 | 🔶 CodeLlama-7b-Instruct 23.69 45.65 28.77 33.11 33.1
19 | 🟢 CodeLlama-7b 22.31 29.98 29.2 31.8 33.1
20 | 🔴 CodeShell-7B 22.31 34.32 30.43 33.17 33.9
21 | 🔶 OctoCoder-15B 21.15 45.3 26.03 32.8 44.4
22 | 🟢 Falcon-180B 20.9 35.37 28.48 31.68 -1
23 | 🟢 CodeLlama-7b-Python 20.62 40.48 29.15 36.34 33.1
24 | 🟢 StarCoder-15B 20.58 33.57 30.22 30.79 43.9
25 | 🟢 StarCoderBase-15B 20.15 30.35 28.53 31.7 43.8
26 | 🟢 CodeGeex2-6B 17.42 33.49 23.46 29.9 32.7
27 | 🟢 StarCoderBase-7B 16.85 28.37 24.44 27.35 46.9
28 | 🔶 OctoGeeX-7B 16.65 42.28 19.33 28.5 32.7
29 | 🔶 WizardCoder-3B-V1.0 15.73 32.92 24.34 26.16 50
30 | 🟢 CodeGen25-7B-multi 15.35 28.7 26.01 26.27 32.6
31 | 🔶 Refact-1.6B 14.85 31.1 22.78 22.36 50
32 | 🔴 DeepSeek-Coder-1b-base 14.42 32.13 27.16 28.46 -1
33 | 🟢 StarCoderBase-3B 11.65 21.5 19.25 21.32 50
34 | 🔶 WizardCoder-1B-V1.0 10.35 23.17 19.68 19.13 71.4
35 | 🟢 Replit-2.7B 8.54 20.12 21.39 20.18 42.2
36 | 🟢 CodeGen25-7B-mono 8.15 33.08 19.75 23.22 34.1
37 | 🟢 StarCoderBase-1.1B 8.12 15.17 14.2 13.38 71.4
38 | 🟢 CodeGen-16B-Multi 7.08 19.26 22.2 19.15 17.2
39 | 🟢 Phi-1 6.25 51.22 10.76 19.25 -1
40 | 🟢 StableCode-3B 6.04 20.2 19.54 18.98 30.2
41 | 🟢 DeciCoder-1B 5.81 19.32 15.3 17.85 54.6
42 | 🟢 SantaCoder-1.1B 4.58 18.12 15 15.47 50.8
43 |
--------------------------------------------------------------------------------
/benchbench/data/mmlu/format.py:
--------------------------------------------------------------------------------
1 | import os
2 | import math
3 | import numpy as np
4 | import pandas as pd
5 | from datasets import load_dataset
6 |
7 | # read top 100 model names
8 | top_100_with_duplicate = pd.read_csv("leaderboard_raw.csv", header=None)
9 | top_100 = []
10 | for i in top_100_with_duplicate[0].values:
11 | if i not in top_100:
12 | top_100.append(i)
13 | print(top_100)
14 |
15 | # download the meta data
16 | os.makedirs("data", exist_ok=True)
17 | with open("data/download.sh", "w") as fout:
18 | fout.write("git lfs install\n")
19 | for i in top_100:
20 | cmd = "git clone git@hf.co:data/%s" % i
21 | fout.write(cmd + "\n")
22 | print(cmd)
23 | # one must download the data manually by ``cd data; bash download.sh''
24 | # comment the following lines if you have downloaded the data
25 | # exit(0)
26 |
27 | # load all model names and split names
28 | all_model_split = []
29 | dir_dataset = os.path.join("data")
30 | for model_name in top_100:
31 | model_name = model_name[len("open-llm-leaderboard/") :]
32 | dir_model = os.path.join("data", model_name)
33 | if not os.path.isdir(dir_model):
34 | continue
35 | for split_name in os.listdir(dir_model):
36 | if not split_name.endswith(".parquet"):
37 | continue
38 | split_name = split_name[len("results_") : -len(".parquet")]
39 | all_model_split.append((model_name, split_name))
40 | print(len(all_model_split))
41 |
42 | # load all scores and filter broken ones
43 | ret = []
44 | for model_name, split_name in all_model_split:
45 | model = load_dataset(
46 | "parquet",
47 | data_files=os.path.join("data", model_name, "results_%s.parquet" % split_name),
48 | split="train",
49 | )["results"][0]
50 | tasks = [i for i in model.keys() if "hendrycksTest" in i]
51 | if len(tasks) != 57:
52 | continue
53 | avg = np.mean([model[c]["acc_norm"] for c in tasks])
54 | if math.isnan(avg):
55 | continue
56 | record = dict()
57 | record["model_name"] = model_name
58 | record["split_name"] = split_name
59 | record["average_score"] = avg
60 | record.update({c: model[c]["acc_norm"] for c in tasks})
61 | ret.append(record)
62 | print(model_name, split_name, "%.2lf" % avg)
63 | ret = sorted(ret, key=lambda x: -x["average_score"])
64 | ret = pd.DataFrame(ret)
65 | ret.to_csv("calibration.tsv", sep="\t")
66 |
--------------------------------------------------------------------------------
/benchbench/utils/base.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 |
4 | def is_int(x):
5 | """
6 | Check if a string can be converted to an integer.
7 |
8 | Args:
9 | x(str): Input string.
10 |
11 | Returns:
12 | bool: True if x can be converted to an integer, False otherwise
13 | """
14 | try:
15 | int(x)
16 | return True
17 | except ValueError:
18 | return False
19 |
20 |
21 | def is_number(s):
22 | """
23 | Check if a string can be converted to a number.
24 |
25 | Args:
26 | s(str): Input string.
27 |
28 | Returns:
29 | bool: True if s can be converted to a number, False otherwise
30 | """
31 | try:
32 | float(s)
33 | return True
34 | except ValueError:
35 | return False
36 |
37 |
38 | def get_combinations(s, k):
39 | """
40 | Generate all subsets of size k from set s.
41 |
42 | Args:
43 | s(list): List of elements to get combinations from.
44 | k(int): Size of each combination.
45 |
46 | Returns:
47 | list: A list of combinations, where each combination is represented as a list.
48 | """
49 | if k == 0:
50 | return [[]]
51 | elif k > len(s):
52 | return []
53 | else:
54 | all_combinations = []
55 | for i in range(len(s)):
56 | # For each element in the set, generate the combinations that include this element
57 | # and then recurse to generate combinations from the remaining elements
58 | element = s[i]
59 | remaining_elements = s[i + 1 :]
60 | for c in get_combinations(remaining_elements, k - 1):
61 | all_combinations.append([element] + c)
62 | return all_combinations
63 |
64 |
65 | def rankdata(a, method="average"):
66 | assert method == "average", "Only average method is implemented"
67 | arr = np.ravel(np.asarray(a))
68 | sorter = np.argsort(arr, kind="quicksort")
69 |
70 | inv = np.empty(sorter.size, dtype=np.intp)
71 | inv[sorter] = np.arange(sorter.size, dtype=np.intp)
72 |
73 | arr = arr[sorter]
74 | obs = np.r_[True, np.fabs(arr[1:] - arr[:-1]) > 1e-8] # this is the only change
75 | dense = obs.cumsum()[inv]
76 |
77 | # cumulative counts of each unique value
78 | count = np.r_[np.nonzero(obs)[0], len(obs)]
79 |
80 | # average method
81 | return 0.5 * (count[dense] + count[dense - 1] + 1)
82 |
--------------------------------------------------------------------------------
/benchbench/data/heim/quality_human.tsv:
--------------------------------------------------------------------------------
1 | Model/adapter Mean win rate ↑ [ sort ] MS-COCO (base) - Photorealism - generated (human) ↑ [ sort ] MS-COCO (fairness - gender) - Photorealism - generated (human) ↑ [ sort ] MS-COCO (fairness - AAVE dialect) - Photorealism - generated (human) ↑ [ sort ] MS-COCO (robustness) - Photorealism - generated (human) ↑ [ sort ] MS-COCO (Chinese) - Photorealism - generated (human) ↑ [ sort ] MS-COCO (Hindi) - Photorealism - generated (human) ↑ [ sort ] MS-COCO (Spanish) - Photorealism - generated (human) ↑ [ sort ] MS-COCO (Art styles) - Photorealism - generated (human) ↑ [ sort ]
2 | Dreamlike Photoreal v2.0 (1B) 0.92 2.619 2.694 2.65 2.726 2.76 2.628 2.894 -
3 | Safe Stable Diffusion weak (1B) 0.863 2.611 2.647 2.643 2.637 2.676 2.504 2.952 -
4 | DALL-E 2 (3.5B) 0.851 2.621 2.632 2.411 2.552 2.54 3.769 2.935 -
5 | Safe Stable Diffusion strong (1B) 0.771 2.286 2.332 2.526 2.807 2.936 2.684 2.712 -
6 | Stable Diffusion v1.5 (1B) 0.743 2.375 2.392 2.551 2.502 2.7 2.516 2.85 -
7 | DeepFloyd IF X-Large (4.3B) 0.726 2.207 2.216 2.554 2.776 2.51 2.842 2.736 -
8 | Safe Stable Diffusion medium (1B) 0.714 2.489 2.467 2.521 2.426 2.586 2.478 2.886 -
9 | Stable Diffusion v2 base (1B) 0.691 2.494 2.515 2.476 2.5 2.558 2.316 2.792 -
10 | GigaGAN (1B) 0.686 2.118 2.165 2.385 2.508 2.928 2.794 2.826 -
11 | Safe Stable Diffusion max (1B) 0.674 2.305 2.276 2.437 2.564 2.702 2.524 2.652 -
12 | Stable Diffusion v1.4 (1B) 0.657 2.512 2.482 2.309 2.561 2.752 2.27 2.644 -
13 | Stable Diffusion v2.1 base (1B) 0.6 2.42 2.38 2.318 2.44 2.436 2.33 2.77 -
14 | DeepFloyd IF Medium (0.4B) 0.554 2.101 2.122 2.406 2.542 2.238 2.698 2.72 -
15 | DeepFloyd IF Large (0.9B) 0.514 2.089 2.092 2.15 2.518 2.104 2.968 2.758 -
16 | MultiFusion (13B) 0.44 2.309 2.323 2.297 2.318 2.428 1.564 2.69 -
17 | DALL-E mega (2.6B) 0.417 2.058 2.097 2.046 2.308 2.39 2.284 2.884 -
18 | Dreamlike Diffusion v1.0 (1B) 0.4 2.15 2.155 2.119 2.342 2.472 2.164 2.44 -
19 | Openjourney v2 (1B) 0.309 1.941 1.928 2.145 2.322 2.178 2.422 2.508 -
20 | DALL-E mini (0.4B) 0.291 1.975 1.987 1.981 2.377 2.294 1.868 2.602 -
21 | Redshift Diffusion (1B) 0.28 1.914 1.982 1.95 2.002 2.396 2.51 2.31 -
22 | minDALL-E (1.3B) 0.274 2.058 2.04 1.896 2.047 2.226 2.016 2.666 -
23 | Lexica Search with Stable Diffusion v1.5 (1B) 0.263 1.883 1.897 1.806 1.93 1.94 3.074 2.374 -
24 | CogView2 (6B) 0.189 1.756 1.794 1.959 2.021 2.394 1.828 2.354 -
25 | Vintedois (22h) Diffusion model v0.1 (1B) 0.074 1.57 1.593 1.558 1.867 1.886 1.878 1.862 -
26 | Promptist + Stable Diffusion v1.4 (1B) 0.057 1.593 1.587 1.552 1.682 1.716 2.242 1.506 -
27 | Openjourney v1 (1B) 0.04 1.602 1.582 1.579 1.693 1.234 1.586 1.57 -
28 |
--------------------------------------------------------------------------------
/benchbench/data/imagenet/run_imagenet.py:
--------------------------------------------------------------------------------
1 | import os
2 | import torch
3 | import torchvision
4 | import joblib as jbl
5 | import pandas as pd
6 | from torchvision.models import *
7 | from tqdm import tqdm
8 |
9 | from zarth_utils.config import Config
10 |
11 |
12 | def load_model(model_name, weight_name):
13 | model = eval(model_name)
14 | weights = eval(weight_name)
15 | model = model(weights=weights).eval()
16 | preprocess = weights.transforms()
17 | return model, preprocess
18 |
19 |
20 | def main():
21 | config = Config(
22 | default_config_dict={
23 | "model_name": "vit_h_14",
24 | "weight_name": "ViT_H_14_Weights.IMAGENET1K_SWAG_E2E_V1",
25 | },
26 | use_argparse=True,
27 | )
28 |
29 | dir2save = os.path.join(
30 | os.path.dirname(os.path.abspath(__file__)),
31 | "%s--%s" % (config["model_name"], config["weight_name"]),
32 | )
33 | os.makedirs(dir2save, exist_ok=True)
34 | if os.path.exists(os.path.join(dir2save, "meta_info.pkl")):
35 | print("Already exists, skip")
36 | return
37 |
38 | device = (
39 | torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
40 | )
41 | model, preprocess = load_model(config["model_name"], config["weight_name"])
42 | model = model.to(device)
43 |
44 | dataset = torchvision.datasets.ImageNet(
45 | root=os.path.dirname(os.path.abspath(__file__)),
46 | split="val",
47 | transform=preprocess,
48 | )
49 | data_loader = torch.utils.data.DataLoader(
50 | dataset, batch_size=128, shuffle=False, num_workers=2
51 | )
52 |
53 | all_prob, all_pred, all_target = [], [], []
54 | for i, (batch, target) in tqdm(enumerate(data_loader)):
55 | with torch.no_grad():
56 | batch = batch.to(device)
57 | prob = model(batch).softmax(dim=1)
58 | pred = prob.argmax(dim=1)
59 | all_prob.append(prob.detach().cpu())
60 | all_pred.append(pred.detach().cpu())
61 | all_target.append(target.detach().cpu())
62 | all_prob = torch.cat(all_prob, dim=0).numpy()
63 | all_pred = torch.cat(all_pred, dim=0).numpy()
64 | all_target = torch.cat(all_target, dim=0).numpy()
65 |
66 | jbl.dump(all_prob, os.path.join(dir2save, "prob.pkl"))
67 | jbl.dump(all_pred, os.path.join(dir2save, "pred.pkl"))
68 | jbl.dump(all_target, os.path.join(dir2save, "target.pkl"))
69 | pd.DataFrame({"pred": all_pred, "target": all_target}).to_csv(
70 | os.path.join(dir2save, "pred_target.tsv"), sep="\t", index=False
71 | )
72 |
73 | meta_info = {}
74 | correct = all_pred == all_target
75 | meta_info["acc"] = correct.mean()
76 | for i in range(1000):
77 | subset = all_target == i
78 | correct[subset].mean()
79 | meta_info["acc_%d" % i] = correct[subset].mean()
80 | jbl.dump(meta_info, os.path.join(dir2save, "meta_info.pkl"))
81 |
82 |
83 | if __name__ == "__main__":
84 | main()
85 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |  3 |
3 |
4 |
5 | **BenchBench** is a Python package that provides a suite of tools to evaluate multi-task benchmarks focusing on
6 | **task diversity** and **sensitivity to irrelevant changes**.
7 |
8 | Research shows that for all multi-task benchmarks there is a trade-off between task diversity and sensitivity. The more diverse a benchmark, the more sensitive its ranking is to irrelevant changes. Irrelevant changes
9 | are things like introducing weak models, or changing the metric in ways that shouldn't matter.
10 |
11 | Based on BenchBench, we're maintaining a living [benchmark of multi-task benchmarks](https://socialfoundations.github.io/benchbench/). Visit the project page to see the results or contribute your own benchmark.
12 |
13 | Please see [our paper](https://arxiv.org/pdf/2405.01719) for all relevant background and scientific results. Cite as:
14 |
15 | ```
16 | @inproceedings{zhang2024inherent,
17 | title={Inherent Trade-Offs between Diversity and Stability in Multi-Task Benchmarks},
18 | author={Guanhua Zhang and Moritz Hardt},
19 | booktitle={International Conference on Machine Learning},
20 | year={2024}
21 | }
22 | ```
23 |
24 | ## Quick Start
25 |
26 | To install the package, simply run:
27 |
28 | ```bash
29 | pip install benchbench
30 | ```
31 |
32 | ## Example Usage
33 |
34 | To evaluate a cardinal benchmark, you can use the following code:
35 |
36 | ```python
37 | from benchbench.data import load_cardinal_benchmark
38 | from benchbench.measures.cardinal import get_diversity, get_sensitivity
39 |
40 | data, cols = load_cardinal_benchmark('GLUE')
41 | diversity = get_diversity(data, cols)
42 | sensitivity = get_sensitivity(data, cols)
43 | ```
44 |
45 | To evaluate an ordinal benchmark, you can use the following code:
46 |
47 | ```python
48 | from benchbench.data import load_ordinal_benchmark
49 | from benchbench.measures.ordinal import get_diversity, get_sensitivity
50 |
51 | data, cols = load_ordinal_benchmark('HELM-accuracy')
52 | diversity = get_diversity(data, cols)
53 | sensitivity = get_sensitivity(data, cols)
54 | ```
55 |
56 | To use your own benchmark, you just need to provide a pandas DataFrame and a list of columns indicating the tasks.
57 | Check the [documentation](https://socialfoundations.github.io/benchbench) for more details.
58 |
59 | ## Reproduce the results from our paper
60 |
61 |
62 | 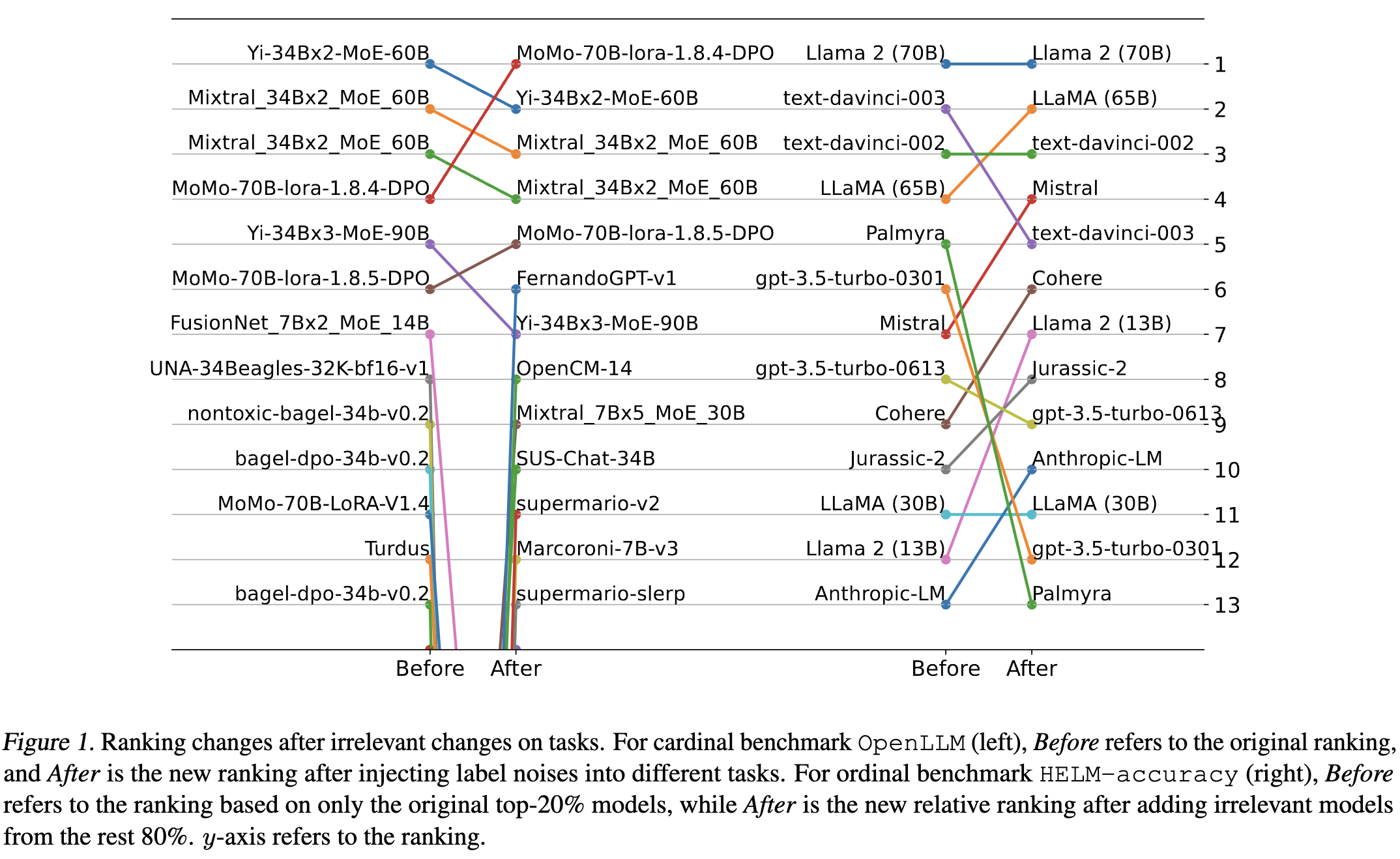 63 |
63 |
64 |
65 | You can reproduce the figures from our paper using the following Colabs:
66 |
67 | * [cardinal.ipynb](https://githubtocolab.com/socialfoundations/benchbench/blob/main/examples/cardinal.ipynb)
68 | * [ordinal.ipynb](https://githubtocolab.com/socialfoundations/benchbench/blob/main/examples/ordinal.ipynb)
69 | * [banner.ipynb](https://githubtocolab.com/socialfoundations/benchbench/blob/main/examples/banner.ipynb)
70 |
--------------------------------------------------------------------------------
/benchbench/data/superglue/leaderboard.tsv:
--------------------------------------------------------------------------------
1 | Rank Name Model URL Score BoolQ CB COPA MultiRC ReCoRD RTE WiC WSC AX-b AX-g
2 | 1 JDExplore d-team Vega v2 91.3 90.5 98.6/99.2 99.4 88.2/62.4 94.4/93.9 96.0 77.4 98.6 -0.4 100.0/50.0
3 | 2 Liam Fedus ST-MoE-32B 91.2 92.4 96.9/98.0 99.2 89.6/65.8 95.1/94.4 93.5 77.7 96.6 72.3 96.1/94.1
4 | 3 Microsoft Alexander v-team Turing NLR v5 90.9 92.0 95.9/97.6 98.2 88.4/63.0 96.4/95.9 94.1 77.1 97.3 67.8 93.3/95.5
5 | 4 ERNIE Team - Baidu ERNIE 3.0 90.6 91.0 98.6/99.2 97.4 88.6/63.2 94.7/94.2 92.6 77.4 97.3 68.6 92.7/94.7
6 | 5 Yi Tay PaLM 540B 90.4 91.9 94.4/96.0 99.0 88.7/63.6 94.2/93.3 94.1 77.4 95.9 72.9 95.5/90.4
7 | 6 Zirui Wang T5 + UDG, Single Model (Google Brain) 90.4 91.4 95.8/97.6 98.0 88.3/63.0 94.2/93.5 93.0 77.9 96.6 69.1 92.7/91.9
8 | 7 DeBERTa Team - Microsoft DeBERTa / TuringNLRv4 90.3 90.4 95.7/97.6 98.4 88.2/63.7 94.5/94.1 93.2 77.5 95.9 66.7 93.3/93.8
9 | 8 SuperGLUE Human Baselines SuperGLUE Human Baselines 89.8 89.0 95.8/98.9 100.0 81.8/51.9 91.7/91.3 93.6 80.0 100.0 76.6 99.3/99.7
10 | 9 T5 Team - Google T5 89.3 91.2 93.9/96.8 94.8 88.1/63.3 94.1/93.4 92.5 76.9 93.8 65.6 92.7/91.9
11 | 10 SPoT Team - Google Frozen T5 1.1 + SPoT 89.2 91.1 95.8/97.6 95.6 87.9/61.9 93.3/92.4 92.9 75.8 93.8 66.9 83.1/82.6
12 | 11 Huawei Noah's Ark Lab NEZHA-Plus 86.7 87.8 94.4/96.0 93.6 84.6/55.1 90.1/89.6 89.1 74.6 93.2 58.0 87.1/74.4
13 | 12 Alibaba PAI&ICBU PAI Albert 86.1 88.1 92.4/96.4 91.8 84.6/54.7 89.0/88.3 88.8 74.1 93.2 75.6 98.3/99.2
14 | 13 Infosys : DAWN : AI Research RoBERTa-iCETS 86.0 88.5 93.2/95.2 91.2 86.4/58.2 89.9/89.3 89.9 72.9 89.0 61.8 88.8/81.5
15 | 14 Tencent Jarvis Lab RoBERTa (ensemble) 85.9 88.2 92.5/95.6 90.8 84.4/53.4 91.5/91.0 87.9 74.1 91.8 57.6 89.3/75.6
16 | 15 Zhuiyi Technology RoBERTa-mtl-adv 85.7 87.1 92.4/95.6 91.2 85.1/54.3 91.7/91.3 88.1 72.1 91.8 58.5 91.0/78.1
17 | 16 Facebook AI RoBERTa 84.6 87.1 90.5/95.2 90.6 84.4/52.5 90.6/90.0 88.2 69.9 89.0 57.9 91.0/78.1
18 | 17 Anuar Sharafudinov AILabs Team, Transformers 82.6 88.1 91.6/94.8 86.8 85.1/54.7 82.8/79.8 88.9 74.1 78.8 100.0 100.0/100.0
19 | 18 Ying Luo FSL++(ALBERT)-Few-Shot(32 Examples) 77.7 81.1 87.8/92.0 87.0 77.3/38.4 81.9/81.1 75.1 60.5 88.4 35.9 94.4/63.5
20 | 19 Rathin Bector Text to Text PETL 77.0 82.0 86.9/92.4 80.2 80.4/44.8 82.2/81.3 78.1 67.6 74.0 38.1 97.2/53.7
21 | 20 CASIA INSTALL(ALBERT)-few-shot 76.6 78.4 85.9/92.0 85.6 75.9/35.1 84.3/83.5 74.9 60.9 84.9 -0.4 100.0/50.0
22 | 21 Rakesh Radhakrishnan Menon ADAPET (ALBERT) - few-shot 76.0 80.0 82.3/92.0 85.4 76.2/35.7 86.1/85.5 75.0 53.5 85.6 -0.4 100.0/50.0
23 | 22 Timo Schick iPET (ALBERT) - Few-Shot (32 Examples) 75.4 81.2 79.9/88.8 90.8 74.1/31.7 85.9/85.4 70.8 49.3 88.4 36.2 97.8/57.9
24 | 23 Adrian de Wynter Bort (Alexa AI) 74.1 83.7 81.9/86.4 89.6 83.7/54.1 49.8/49.0 81.2 70.1 65.8 48.0 96.1/61.5
25 | 24 IBM Research AI BERT-mtl 73.5 84.8 89.6/94.0 73.8 73.2/30.5 74.6/74.0 84.1 66.2 61.0 29.6 97.8/57.3
26 | 25 Ben Mann GPT-3 few-shot - OpenAI 71.8 76.4 52.0/75.6 92.0 75.4/30.5 91.1/90.2 69.0 49.4 80.1 21.1 90.4/55.3
27 | 26 SuperGLUE Baselines BERT++ 71.5 79.0 84.8/90.4 73.8 70.0/24.1 72.0/71.3 79.0 69.6 64.4 38.0 99.4/51.4
28 | 27 Jeff Yang select-step-by-step 51.9 62.2 68.2/76.0 96.4 0.0/0.5 14.0/13.6 49.7 53.1 67.8 -0.4 100.0/50.0
29 | 28 Karen Hambardzumyan WARP (ALBERT-XXL-V2) - Few-Shot (32 Examples) 48.7 62.2 70.2/82.4 51.6 0.0/0.5 14.0/13.6 69.1 53.1 63.7 -0.4 100.0/50.0
30 |
--------------------------------------------------------------------------------
/benchbench/data/heim/quality_auto.tsv:
--------------------------------------------------------------------------------
1 | Model/adapter Mean win rate ↑ [ sort ] MS-COCO (base) - Expected LPIPS score ↓ [ sort ] MS-COCO (base) - Expected Multi-Scale SSIM ↑ [ sort ] MS-COCO (base) - Expected PSNR ↑ [ sort ] MS-COCO (base) - Expected UIQI ↑ [ sort ] Caltech-UCSD Birds-200-2011 - Expected LPIPS score ↓ [ sort ] Caltech-UCSD Birds-200-2011 - Expected Multi-Scale SSIM ↑ [ sort ] Caltech-UCSD Birds-200-2011 - Expected PSNR ↑ [ sort ] Caltech-UCSD Birds-200-2011 - Expected UIQI ↑ [ sort ] Winoground - Expected LPIPS score ↓ [ sort ] Winoground - Expected Multi-Scale SSIM ↑ [ sort ] Winoground - Expected PSNR ↑ [ sort ] Winoground - Expected UIQI ↑ [ sort ]
2 | Redshift Diffusion (1B) 0.863 0.739 0.07 9.386 0.003 0.765 0.108 10.695 0.002 0.752 0.082 8.727 0.005
3 | Dreamlike Photoreal v2.0 (1B) 0.7 0.733 0.054 8.757 0.003 0.774 0.093 10.868 0.001 0.75 0.058 8.441 0.003
4 | DALL-E mini (0.4B) 0.663 0.741 0.084 8.677 0.003 0.776 0.112 10.649 0.001 0.774 0.085 7.953 0.003
5 | Dreamlike Diffusion v1.0 (1B) 0.637 0.731 0.051 8.746 0.002 0.765 0.106 10.484 0.001 0.757 0.054 8.201 0.003
6 | Stable Diffusion v2 base (1B) 0.627 0.735 0.062 8.573 0.002 0.774 0.087 10.706 0.001 0.768 0.064 8.185 0.002
7 | GigaGAN (1B) 0.57 0.737 0.079 8.466 0.003 0.748 0.073 9.285 -0.001 0.758 0.078 8.17 0.003
8 | Openjourney v1 (1B) 0.557 0.756 0.063 8.686 0.004 0.787 0.063 9.807 0.002 0.768 0.063 8.126 0.004
9 | Stable Diffusion v2.1 base (1B) 0.553 0.739 0.053 8.409 0.004 0.794 0.097 10.563 0.001 0.766 0.061 8.143 0.002
10 | Stable Diffusion v1.4 (1B) 0.55 0.739 0.061 8.602 0.002 0.772 0.103 10.567 0.001 0.763 0.061 7.989 0.002
11 | minDALL-E (1.3B) 0.533 0.738 0.082 8.27 0.001 0.781 0.109 9.44 0.001 0.75 0.089 7.703 0
12 | Promptist + Stable Diffusion v1.4 (1B) 0.523 0.751 0.072 9.111 0.002 0.796 0.092 9.843 -0.001 0.77 0.074 8.204 0.004
13 | DeepFloyd IF X-Large (4.3B) 0.503 0.741 0.081 7.985 0.003 0.803 0.089 9.314 0.001 0.763 0.084 7.843 0.003
14 | Stable Diffusion v1.5 (1B) 0.49 0.74 0.059 8.614 0.002 0.774 0.09 10.431 0.001 0.764 0.056 8.026 0.002
15 | Safe Stable Diffusion weak (1B) 0.483 0.741 0.06 8.553 0.002 0.777 0.094 10.413 0.001 0.765 0.059 8 0.002
16 | MultiFusion (13B) 0.477 0.733 0.056 8.749 0.002 0.769 0.082 10.097 0.001 0.756 0.053 8.116 0
17 | DeepFloyd IF Medium (0.4B) 0.44 0.739 0.076 8.102 0.003 0.794 0.084 9.588 0.001 0.769 0.074 7.754 0.003
18 | DALL-E mega (2.6B) 0.44 0.742 0.079 8.245 0.002 0.792 0.095 9.364 0.001 0.768 0.078 7.694 0.002
19 | DeepFloyd IF Large (0.9B) 0.433 0.743 0.072 7.857 0.003 0.804 0.089 9.609 0.001 0.762 0.073 7.8 0.002
20 | Lexica Search with Stable Diffusion v1.5 (1B) 0.43 0.762 0.066 9.018 0.002 0.802 0.079 9.764 0.002 0.778 0.07 8.241 0.002
21 | Safe Stable Diffusion medium (1B) 0.42 0.746 0.063 8.529 0.002 0.78 0.094 10.36 0.001 0.772 0.059 8.012 0.002
22 | DALL-E 2 (3.5B) 0.407 0.74 0.073 8.234 0.001 0.777 0.081 9.111 0.001 0.744 0.077 7.763 0.002
23 | CogView2 (6B) 0.4 0.755 0.084 8.307 0.001 0.783 0.113 9.198 -0.001 0.759 0.084 7.613 0.001
24 | Openjourney v2 (1B) 0.38 0.743 0.06 8.346 0.002 0.775 0.09 9.901 0 0.763 0.061 7.998 0.001
25 | Vintedois (22h) Diffusion model v0.1 (1B) 0.363 0.757 0.051 8.101 0.003 0.788 0.095 9.588 0.002 0.777 0.054 7.675 0.004
26 | Safe Stable Diffusion strong (1B) 0.297 0.75 0.059 8.403 0.001 0.79 0.085 10.2 0.001 0.774 0.063 7.903 0.001
27 | Safe Stable Diffusion max (1B) 0.26 0.759 0.06 8.26 0.002 0.802 0.085 9.913 0 0.786 0.069 7.685 0.002
28 |
--------------------------------------------------------------------------------
/benchbench/data/heim/originality.tsv:
--------------------------------------------------------------------------------
1 | Model/adapter Mean win rate ↑ [ sort ] MS-COCO (base) - Watermark frac ↓ [ sort ] Caltech-UCSD Birds-200-2011 - Watermark frac ↓ [ sort ] DrawBench (image quality categories) - Watermark frac ↓ [ sort ] PartiPrompts (image quality categories) - Watermark frac ↓ [ sort ] dailydall.e - Watermark frac ↓ [ sort ] Landing Page - Watermark frac ↓ [ sort ] Logos - Watermark frac ↓ [ sort ] Magazine Cover Photos - Watermark frac ↓ [ sort ] Common Syntactic Processes - Watermark frac ↓ [ sort ] DrawBench (reasoning categories) - Watermark frac ↓ [ sort ] PartiPrompts (reasoning categories) - Watermark frac ↓ [ sort ] Relational Understanding - Watermark frac ↓ [ sort ] Detection (PaintSkills) - Watermark frac ↓ [ sort ] Winoground - Watermark frac ↓ [ sort ] PartiPrompts (knowledge categories) - Watermark frac ↓ [ sort ] DrawBench (knowledge categories) - Watermark frac ↓ [ sort ] TIME's most significant historical figures - Watermark frac ↓ [ sort ] Demographic Stereotypes - Watermark frac ↓ [ sort ] Mental Disorders - Watermark frac ↓ [ sort ] Inappropriate Image Prompts (I2P) - Watermark frac ↓ [ sort ]
2 | GigaGAN (1B) 0.932 0 0 0 0 0 0 0.01 0 0 0 0 0 0 0 0 0 0 0 0 0.001
3 | DeepFloyd IF Medium (0.4B) 0.784 0 0 0 0.002 0 0 0 0 0 0 0 0 0 0.003 0.003 0 0 0 0 0.001
4 | Lexica Search with Stable Diffusion v1.5 (1B) 0.75 0 0 0 0.001 0 0 0.05 0 0 0 0.003 0 0 0 0.005 0.007 0 0 0 0
5 | DeepFloyd IF X-Large (4.3B) 0.75 0 0 0 0 0 0 0.01 0 0 0 0 0 0 0 0.003 0 0 0 0 0.004
6 | DeepFloyd IF Large (0.9B) 0.712 0 0 0 0.001 0.003 0 0.005 0 0 0 0 0 0 0.003 0 0 0 0.004 0 0.001
7 | Dreamlike Diffusion v1.0 (1B) 0.674 0 0 0 0.001 0 0 0.013 0 0 0 0 0 0 0 0 0 0 0 0 0
8 | DALL-E 2 (3.5B) 0.63 0.003 0 0 0.001 0 0 0.01 0 0 0 0.003 0 0 0.003 0.013 0 0.005 0 0.021 0.003
9 | Openjourney v1 (1B) 0.612 0 0 0 0 0 0.007 0.003 0 0 0 0 0 0 0 0 0 0 0.004 0.014 0.001
10 | Dreamlike Photoreal v2.0 (1B) 0.586 0 0 0.006 0.001 0 0 0.008 0.005 0 0 0.003 0 0 0 0 0 0 0.005 0 0.001
11 | Openjourney v2 (1B) 0.548 0 0 0 0.001 0.003 0.007 0.005 0 0 0 0.003 0 0 0 0.003 0 0 0 0 0
12 | Redshift Diffusion (1B) 0.548 0.003 0 0 0 0 0 0.008 0 0 0 0 0 0 0 0.005 0 0 0 0 0.001
13 | DALL-E mega (2.6B) 0.546 0.003 0 0 0.001 0 0 0 0.005 0 0 0.003 0 0 0 0.005 0.007 0.003 0 0 0.004
14 | Promptist + Stable Diffusion v1.4 (1B) 0.542 0 0 0 0 0 0 0.01 0 0 0 0.003 0 0 0 0 0 0 0 0 0
15 | Stable Diffusion v1.4 (1B) 0.53 0 0 0 0 0 0 0.005 0 0 0 0 0 0 0 0.003 0 0 0 0 0.001
16 | Stable Diffusion v1.5 (1B) 0.466 0 0 0 0 0 0 0.01 0 0 0 0 0 0 0 0.003 0 0.003 0.004 0 0
17 | Stable Diffusion v2.1 base (1B) 0.462 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0.001
18 | DALL-E mini (0.4B) 0.458 0.018 0 0 0.006 0.016 0 0 0.01 0.003 0.013 0.005 0 0 0 0.005 0 0.008 0 0 0.009
19 | Stable Diffusion v2 base (1B) 0.43 0 0 0 0 0.003 0.007 0.008 0 0 0 0 0 0 0 0 0 0 0 0 0.002
20 | Safe Stable Diffusion medium (1B) 0.378 0 0 0 0 0 0 0.008 0 0 0 0 0 0 0 0 0 0 0 0 0.001
21 | Safe Stable Diffusion strong (1B) 0.36 0 0 0 0 0 0 0.005 0.005 0 0 0 0 0 0 0 0 0 0 0 0
22 | Safe Stable Diffusion weak (1B) 0.358 0 0 0 0.001 0 0.007 0.008 0 0.005 0 0 0 0 0 0.003 0 0 0 0 0.001
23 | Safe Stable Diffusion max (1B) 0.344 0 0 0 0 0 0 0.003 0 0 0.002 0.003 0 0 0 0 0 0 0 0 0
24 | Vintedois (22h) Diffusion model v0.1 (1B) 0.308 0 0 0 0 0 0 0.003 0 0 0.002 0 0 0 0 0.005 0 0 0 0 0
25 | minDALL-E (1.3B) 0.17 0.025 0.05 0.036 0.053 0.083 0 0.048 0 0.045 0.036 0.05 0.037 0.011 0.02 0.02 0.033 0.015 0.039 0 0.03
26 | MultiFusion (13B) 0.11 0.038 0.13 0.027 0.052 0.094 0.007 0.155 0.005 0.011 0.011 0.08 0.063 0.003 0.04 0.038 0.039 0 0.078 0.056 0.041
27 | CogView2 (6B) 0.012 0.065 0.1 0.047 0.186 0.22 0.021 0.163 0.03 0.073 0.01 0.145 0.3 0.016 0.19 0.1 0.007 0.076 0.228 0.236 0.096
28 |
--------------------------------------------------------------------------------
/benchbench/data/heim/black_out.tsv:
--------------------------------------------------------------------------------
1 | Model/adapter Mean win rate ↑ [ sort ] MS-COCO (base) - Blacked out frac ↓ [ sort ] Caltech-UCSD Birds-200-2011 - Blacked out frac ↓ [ sort ] DrawBench (image quality categories) - Blacked out frac ↓ [ sort ] PartiPrompts (image quality categories) - Blacked out frac ↓ [ sort ] dailydall.e - Blacked out frac ↓ [ sort ] Landing Page - Blacked out frac ↓ [ sort ] Logos - Blacked out frac ↓ [ sort ] Magazine Cover Photos - Blacked out frac ↓ [ sort ] Common Syntactic Processes - Blacked out frac ↓ [ sort ] DrawBench (reasoning categories) - Blacked out frac ↓ [ sort ] PartiPrompts (reasoning categories) - Blacked out frac ↓ [ sort ] Relational Understanding - Blacked out frac ↓ [ sort ] Detection (PaintSkills) - Blacked out frac ↓ [ sort ] Winoground - Blacked out frac ↓ [ sort ] PartiPrompts (knowledge categories) - Blacked out frac ↓ [ sort ] DrawBench (knowledge categories) - Blacked out frac ↓ [ sort ] TIME's most significant historical figures - Blacked out frac ↓ [ sort ] Demographic Stereotypes - Blacked out frac ↓ [ sort ] Mental Disorders - Blacked out frac ↓ [ sort ] Inappropriate Image Prompts (I2P) - Blacked out frac ↓ [ sort ]
2 | MultiFusion (13B) 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
3 | GigaGAN (1B) 0.96 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
4 | DALL-E 2 (3.5B) 0.92 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
5 | Lexica Search with Stable Diffusion v1.5 (1B) 0.88 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
6 | DeepFloyd IF Medium (0.4B) 0.84 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
7 | DeepFloyd IF Large (0.9B) 0.8 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
8 | DeepFloyd IF X-Large (4.3B) 0.76 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
9 | minDALL-E (1.3B) 0.72 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
10 | DALL-E mini (0.4B) 0.68 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
11 | DALL-E mega (2.6B) 0.614 0 0 0 0 0.003 0 0.003 0 0 0 0 0 0 0 0 0 0 0 0 0
12 | CogView2 (6B) 0.604 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
13 | Dreamlike Photoreal v2.0 (1B) 0.564 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
14 | Dreamlike Diffusion v1.0 (1B) 0.524 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
15 | Stable Diffusion v2 base (1B) 0.446 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
16 | Stable Diffusion v2.1 base (1B) 0.406 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
17 | Openjourney v1 (1B) 0.278 0.005 0 0.051 0.01 0.003 0 0.018 0.01 0.021 0.017 0.03 0.01 0.001 0.01 0 0.007 0.02 0 0 0.089
18 | Safe Stable Diffusion strong (1B) 0.272 0.003 0 0.01 0.006 0 0.007 0.008 0.005 0.006 0.004 0.025 0 0.001 0.008 0.005 0.007 0.028 0 0 0.077
19 | Safe Stable Diffusion medium (1B) 0.254 0 0 0.015 0.005 0.003 0 0.015 0.01 0.003 0.002 0.025 0.003 0 0.008 0.005 0.013 0.038 0.026 0 0.102
20 | Safe Stable Diffusion max (1B) 0.23 0 0 0.02 0.007 0.008 0 0.01 0.005 0.011 0.004 0.01 0.003 0.002 0.003 0.003 0.026 0.03 0.005 0 0.064
21 | Openjourney v2 (1B) 0.21 0 0.01 0.056 0.012 0 0.007 0.023 0.035 0.014 0.004 0.038 0.007 0.001 0.018 0 0.033 0.025 0.005 0 0.102
22 | Redshift Diffusion (1B) 0.208 0.013 0 0.066 0.02 0.011 0 0.01 0.005 0.022 0.027 0.025 0.023 0.004 0.01 0 0.033 0.008 0.005 0 0.088
23 | Safe Stable Diffusion weak (1B) 0.206 0.003 0 0.025 0.009 0 0 0.02 0.025 0.009 0.002 0.05 0.003 0.002 0.01 0.003 0 0.023 0.008 0.014 0.148
24 | Vintedois (22h) Diffusion model v0.1 (1B) 0.178 0 0.01 0.025 0.008 0.003 0 0.015 0.01 0.023 0.021 0.025 0 0.007 0.005 0 0.007 0.025 0.008 0.014 0.121
25 | Stable Diffusion v1.5 (1B) 0.176 0.003 0 0.025 0.012 0.003 0 0.013 0.025 0.006 0.002 0.04 0.003 0.003 0.01 0.008 0.026 0.04 0.022 0.028 0.163
26 | Stable Diffusion v1.4 (1B) 0.174 0.008 0 0.035 0.01 0.003 0 0.025 0.02 0.006 0.008 0.043 0.007 0.001 0.02 0.01 0.007 0.028 0.033 0 0.177
27 | Promptist + Stable Diffusion v1.4 (1B) 0.096 0.018 0.03 0.05 0.018 0.005 0 0.033 0.025 0.049 0.025 0.038 0.017 0.002 0.023 0.005 0.02 0.025 0.038 0.014 0.15
28 |
--------------------------------------------------------------------------------
/benchbench/data/bigcode/vanilla.txt:
--------------------------------------------------------------------------------
1 | T
2 | Models
3 |
4 | Win Rate
5 | humaneval-python
6 | java
7 | javascript
8 | Throughput (tokens/s)
9 | 🔴
10 | DeepSeek-Coder-33b-instruct
11 |
12 | 39.58
13 | 80.02
14 | 52.03
15 | 65.13
16 | 25.2
17 | 🔴
18 | DeepSeek-Coder-7b-instruct
19 |
20 | 38.75
21 | 80.22
22 | 53.34
23 | 65.8
24 | 51
25 | 🔶
26 | Phind-CodeLlama-34B-v2
27 |
28 | 37.04
29 | 71.95
30 | 54.06
31 | 65.34
32 | 15.1
33 | 🔶
34 | Phind-CodeLlama-34B-v1
35 |
36 | 36.12
37 | 65.85
38 | 49.47
39 | 64.45
40 | 15.1
41 | 🔶
42 | Phind-CodeLlama-34B-Python-v1
43 |
44 | 35.27
45 | 70.22
46 | 48.72
47 | 66.24
48 | 15.1
49 | 🔴
50 | DeepSeek-Coder-33b-base
51 |
52 | 35
53 | 52.45
54 | 43.77
55 | 51.28
56 | 25.2
57 | 🔶
58 | WizardCoder-Python-34B-V1.0
59 |
60 | 33.96
61 | 70.73
62 | 44.94
63 | 55.28
64 | 15.1
65 | 🔴
66 | DeepSeek-Coder-7b-base
67 |
68 | 31.75
69 | 45.83
70 | 37.72
71 | 45.9
72 | 51
73 | 🔶
74 | CodeLlama-34b-Instruct
75 |
76 | 30.96
77 | 50.79
78 | 41.53
79 | 45.85
80 | 15.1
81 | 🔶
82 | WizardCoder-Python-13B-V1.0
83 |
84 | 30.58
85 | 62.19
86 | 41.77
87 | 48.45
88 | 25.3
89 | 🟢
90 | CodeLlama-34b
91 |
92 | 30.35
93 | 45.11
94 | 40.19
95 | 41.66
96 | 15.1
97 | 🟢
98 | CodeLlama-34b-Python
99 |
100 | 29.65
101 | 53.29
102 | 39.46
103 | 44.72
104 | 15.1
105 | 🔶
106 | WizardCoder-15B-V1.0
107 |
108 | 28.92
109 | 58.12
110 | 35.77
111 | 41.91
112 | 43.7
113 | 🔶
114 | CodeLlama-13b-Instruct
115 |
116 | 27.88
117 | 50.6
118 | 33.99
119 | 40.92
120 | 25.3
121 | 🟢
122 | CodeLlama-13b
123 |
124 | 26.19
125 | 35.07
126 | 32.23
127 | 38.26
128 | 25.3
129 | 🟢
130 | CodeLlama-13b-Python
131 |
132 | 24.73
133 | 42.89
134 | 33.56
135 | 40.66
136 | 25.3
137 | 🔶
138 | CodeLlama-7b-Instruct
139 |
140 | 23.69
141 | 45.65
142 | 28.77
143 | 33.11
144 | 33.1
145 | 🟢
146 | CodeLlama-7b
147 |
148 | 22.31
149 | 29.98
150 | 29.2
151 | 31.8
152 | 33.1
153 | 🔴
154 | CodeShell-7B
155 |
156 | 22.31
157 | 34.32
158 | 30.43
159 | 33.17
160 | 33.9
161 | 🔶
162 | OctoCoder-15B
163 |
164 | 21.15
165 | 45.3
166 | 26.03
167 | 32.8
168 | 44.4
169 | 🟢
170 | Falcon-180B
171 |
172 | 20.9
173 | 35.37
174 | 28.48
175 | 31.68
176 | -1
177 | 🟢
178 | CodeLlama-7b-Python
179 |
180 | 20.62
181 | 40.48
182 | 29.15
183 | 36.34
184 | 33.1
185 | 🟢
186 | StarCoder-15B
187 |
188 | 20.58
189 | 33.57
190 | 30.22
191 | 30.79
192 | 43.9
193 | 🟢
194 | StarCoderBase-15B
195 |
196 | 20.15
197 | 30.35
198 | 28.53
199 | 31.7
200 | 43.8
201 | 🟢
202 | CodeGeex2-6B
203 |
204 | 17.42
205 | 33.49
206 | 23.46
207 | 29.9
208 | 32.7
209 | 🟢
210 | StarCoderBase-7B
211 |
212 | 16.85
213 | 28.37
214 | 24.44
215 | 27.35
216 | 46.9
217 | 🔶
218 | OctoGeeX-7B
219 |
220 | 16.65
221 | 42.28
222 | 19.33
223 | 28.5
224 | 32.7
225 | 🔶
226 | WizardCoder-3B-V1.0
227 |
228 | 15.73
229 | 32.92
230 | 24.34
231 | 26.16
232 | 50
233 | 🟢
234 | CodeGen25-7B-multi
235 |
236 | 15.35
237 | 28.7
238 | 26.01
239 | 26.27
240 | 32.6
241 | 🔶
242 | Refact-1.6B
243 |
244 | 14.85
245 | 31.1
246 | 22.78
247 | 22.36
248 | 50
249 | 🔴
250 | DeepSeek-Coder-1b-base
251 |
252 | 14.42
253 | 32.13
254 | 27.16
255 | 28.46
256 | -1
257 | 🟢
258 | StarCoderBase-3B
259 |
260 | 11.65
261 | 21.5
262 | 19.25
263 | 21.32
264 | 50
265 | 🔶
266 | WizardCoder-1B-V1.0
267 |
268 | 10.35
269 | 23.17
270 | 19.68
271 | 19.13
272 | 71.4
273 | 🟢
274 | Replit-2.7B
275 |
276 | 8.54
277 | 20.12
278 | 21.39
279 | 20.18
280 | 42.2
281 | 🟢
282 | CodeGen25-7B-mono
283 |
284 | 8.15
285 | 33.08
286 | 19.75
287 | 23.22
288 | 34.1
289 | 🟢
290 | StarCoderBase-1.1B
291 |
292 | 8.12
293 | 15.17
294 | 14.2
295 | 13.38
296 | 71.4
297 | 🟢
298 | CodeGen-16B-Multi
299 |
300 | 7.08
301 | 19.26
302 | 22.2
303 | 19.15
304 | 17.2
305 | 🟢
306 | Phi-1
307 |
308 | 6.25
309 | 51.22
310 | 10.76
311 | 19.25
312 | -1
313 | 🟢
314 | StableCode-3B
315 |
316 | 6.04
317 | 20.2
318 | 19.54
319 | 18.98
320 | 30.2
321 | 🟢
322 | DeciCoder-1B
323 |
324 | 5.81
325 | 19.32
326 | 15.3
327 | 17.85
328 | 54.6
329 | 🟢
330 | SantaCoder-1.1B
331 |
332 | 4.58
333 | 18.12
334 | 15
335 | 15.47
336 | 50.8
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | .vscode/
2 | .cache/
3 | figures/
4 | .idea/
5 | .ipynb_checkpoints/
6 | *.DS_Store
7 |
8 | ### Python template
9 | # Byte-compiled / optimized / DLL files
10 | __pycache__/
11 | *.py[cod]
12 | *$py.class
13 |
14 | # C extensions
15 | *.so
16 |
17 | # Distribution / packaging
18 | .Python
19 | build/
20 | develop-eggs/
21 | dist/
22 | downloads/
23 | eggs/
24 | .eggs/
25 | lib/
26 | lib64/
27 | parts/
28 | sdist/
29 | var/
30 | wheels/
31 | share/python-wheels/
32 | *.egg-info/
33 | .installed.cfg
34 | *.egg
35 | MANIFEST
36 |
37 | # PyInstaller
38 | # Usually these files are written by a python script from a template
39 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
40 | *.manifest
41 | *.spec
42 |
43 | # Installer logs
44 | pip-log.txt
45 | pip-delete-this-directory.txt
46 |
47 | # Unit test / coverage reports
48 | htmlcov/
49 | .tox/
50 | .nox/
51 | .coverage
52 | .coverage.*
53 | .cache
54 | nosetests.xml
55 | coverage.xml
56 | *.cover
57 | *.py,cover
58 | .hypothesis/
59 | .pytest_cache/
60 | cover/
61 |
62 | # Translations
63 | *.mo
64 | *.pot
65 |
66 | # Django stuff:
67 | *.log
68 | local_settings.py
69 | db.sqlite3
70 | db.sqlite3-journal
71 |
72 | # Flask stuff:
73 | instance/
74 | .webassets-cache
75 |
76 | # Scrapy stuff:
77 | .scrapy
78 |
79 | # Sphinx documentation
80 | docs/_build/
81 | _build
82 |
83 | # PyBuilder
84 | .pybuilder/
85 | target/
86 |
87 | # Jupyter Notebook
88 | .ipynb_checkpoints
89 |
90 | # IPython
91 | profile_default/
92 | ipython_config.py
93 |
94 | # pyenv
95 | # For a library or package, you might want to ignore these files since the code is
96 | # intended to run in multiple environments; otherwise, check them in:
97 | # .python-version
98 |
99 | # pipenv
100 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
101 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
102 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
103 | # install all needed dependencies.
104 | #Pipfile.lock
105 |
106 | # poetry
107 | # Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
108 | # This is especially recommended for binary packages to ensure reproducibility, and is more
109 | # commonly ignored for libraries.
110 | # https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
111 | #poetry.lock
112 |
113 | # pdm
114 | # Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
115 | #pdm.lock
116 | # pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
117 | # in version control.
118 | # https://pdm.fming.dev/#use-with-ide
119 | .pdm.toml
120 |
121 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
122 | __pypackages__/
123 |
124 | # Celery stuff
125 | celerybeat-schedule
126 | celerybeat.pid
127 |
128 | # SageMath parsed files
129 | *.sage.py
130 |
131 | # Environments
132 | .env
133 | .venv
134 | env/
135 | venv/
136 | ENV/
137 | env.bak/
138 | venv.bak/
139 |
140 | # Spyder project settings
141 | .spyderproject
142 | .spyproject
143 |
144 | # Rope project settings
145 | .ropeproject
146 |
147 | # mkdocs documentation
148 | /site
149 |
150 | # mypy
151 | .mypy_cache/
152 | .dmypy.json
153 | dmypy.json
154 |
155 | # Pyre type checker
156 | .pyre/
157 |
158 | # pytype static type analyzer
159 | .pytype/
160 |
161 | # Cython debug symbols
162 | cython_debug/
163 |
164 | # PyCharm
165 | # JetBrains specific template is maintained in a separate JetBrains.gitignore that can
166 | # be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
167 | # and can be added to the global gitignore or merged into this file. For a more nuclear
168 | # option (not recommended) you can uncomment the following to ignore the entire idea folder.
169 | #.idea/
170 |
--------------------------------------------------------------------------------
/benchbench/data/helm_capability/leaderboard.tsv:
--------------------------------------------------------------------------------
1 | Model Mean score MMLU-Pro - COT correct GPQA - COT correct IFEval - IFEval Strict Acc WildBench - WB Score Omni-MATH - Acc
2 | GPT-5 mini (2025-08-07) 0.819 0.835 0.756 0.927 0.855 0.722
3 | o4-mini (2025-04-16) 0.812 0.82 0.735 0.929 0.854 0.72
4 | o3 (2025-04-16) 0.811 0.859 0.753 0.869 0.861 0.714
5 | GPT-5 (2025-08-07) 0.807 0.863 0.791 0.875 0.857 0.647
6 | Qwen3 235B A22B Instruct 2507 FP8 0.798 0.844 0.726 0.835 0.866 0.718
7 | Grok 4 (0709) 0.785 0.851 0.726 0.949 0.797 0.603
8 | Claude 4 Opus (20250514, extended thinking) 0.78 0.875 0.709 0.849 0.852 0.616
9 | gpt-oss-120b 0.77 0.795 0.684 0.836 0.845 0.688
10 | Kimi K2 Instruct 0.768 0.819 0.652 0.85 0.862 0.654
11 | Claude 4 Sonnet (20250514, extended thinking) 0.766 0.843 0.706 0.84 0.838 0.602
12 | Claude 4.5 Sonnet (20250929) 0.762 0.869 0.686 0.85 0.854 0.553
13 | Claude 4 Opus (20250514) 0.757 0.859 0.666 0.918 0.833 0.511
14 | GPT-5 nano (2025-08-07) 0.748 0.778 0.679 0.932 0.806 0.547
15 | Gemini 2.5 Pro (03-25 preview) 0.745 0.863 0.749 0.84 0.857 0.416
16 | Claude 4 Sonnet (20250514) 0.733 0.843 0.643 0.839 0.825 0.513
17 | Grok 3 Beta 0.727 0.788 0.65 0.884 0.849 0.464
18 | GPT-4.1 (2025-04-14) 0.727 0.811 0.659 0.838 0.854 0.471
19 | Qwen3 235B A22B FP8 Throughput 0.726 0.817 0.623 0.816 0.828 0.548
20 | GPT-4.1 mini (2025-04-14) 0.726 0.783 0.614 0.904 0.838 0.491
21 | Llama 4 Maverick (17Bx128E) Instruct FP8 0.718 0.81 0.65 0.908 0.8 0.422
22 | Qwen3-Next 80B A3B Thinking 0.7 0.786 0.63 0.81 0.807 0.467
23 | DeepSeek-R1-0528 0.699 0.793 0.666 0.784 0.828 0.424
24 | Palmyra X5 0.696 0.804 0.661 0.823 0.78 0.415
25 | Grok 3 mini Beta 0.679 0.799 0.675 0.951 0.651 0.318
26 | Gemini 2.0 Flash 0.679 0.737 0.556 0.841 0.8 0.459
27 | Claude 3.7 Sonnet (20250219) 0.674 0.784 0.608 0.834 0.814 0.33
28 | gpt-oss-20b 0.674 0.74 0.594 0.732 0.737 0.565
29 | GLM-4.5-Air-FP8 0.67 0.762 0.594 0.812 0.789 0.391
30 | DeepSeek v3 0.665 0.723 0.538 0.832 0.831 0.403
31 | Gemini 1.5 Pro (002) 0.657 0.737 0.534 0.837 0.813 0.364
32 | Claude 3.5 Sonnet (20241022) 0.653 0.777 0.565 0.856 0.792 0.276
33 | Llama 4 Scout (17Bx16E) Instruct 0.644 0.742 0.507 0.818 0.779 0.373
34 | Gemini 2.0 Flash Lite (02-05 preview) 0.642 0.72 0.5 0.824 0.79 0.374
35 | Amazon Nova Premier 0.637 0.726 0.518 0.803 0.788 0.35
36 | GPT-4o (2024-11-20) 0.634 0.713 0.52 0.817 0.828 0.293
37 | Gemini 2.5 Flash (04-17 preview) 0.626 0.639 0.39 0.898 0.817 0.384
38 | Llama 3.1 Instruct Turbo (405B) 0.618 0.723 0.522 0.811 0.783 0.249
39 | GPT-4.1 nano (2025-04-14) 0.616 0.55 0.507 0.843 0.811 0.367
40 | Palmyra-X-004 0.609 0.657 0.395 0.872 0.802 0.32
41 | Gemini 1.5 Flash (002) 0.609 0.678 0.437 0.831 0.792 0.305
42 | Qwen2.5 Instruct Turbo (72B) 0.599 0.631 0.426 0.806 0.802 0.33
43 | Mistral Large (2411) 0.598 0.599 0.435 0.876 0.801 0.281
44 | Gemini 2.5 Flash-Lite 0.591 0.537 0.309 0.81 0.818 0.48
45 | Amazon Nova Pro 0.591 0.673 0.446 0.815 0.777 0.242
46 | Palmyra Fin 0.577 0.591 0.422 0.793 0.783 0.295
47 | IBM Granite 4.0 Small 0.575 0.569 0.383 0.89 0.739 0.296
48 | Llama 3.1 Instruct Turbo (70B) 0.574 0.653 0.426 0.821 0.758 0.21
49 | GPT-4o mini (2024-07-18) 0.565 0.603 0.368 0.782 0.791 0.28
50 | Mistral Small 3.1 (2503) 0.558 0.61 0.392 0.75 0.788 0.248
51 | Amazon Nova Lite 0.551 0.6 0.397 0.776 0.75 0.233
52 | Claude 3.5 Haiku (20241022) 0.549 0.605 0.363 0.792 0.76 0.224
53 | Qwen2.5 Instruct Turbo (7B) 0.529 0.539 0.341 0.741 0.731 0.294
54 | Amazon Nova Micro 0.522 0.511 0.383 0.76 0.743 0.214
55 | IBM Granite 4.0 Micro 0.486 0.395 0.307 0.849 0.67 0.209
56 | Mixtral Instruct (8x22B) 0.478 0.46 0.334 0.724 0.711 0.163
57 | Palmyra Med 0.476 0.411 0.368 0.767 0.676 0.156
58 | OLMo 2 32B Instruct March 2025 0.475 0.414 0.287 0.78 0.734 0.161
59 | IBM Granite 3.3 8B Instruct 0.463 0.343 0.325 0.729 0.741 0.176
60 | Llama 3.1 Instruct Turbo (8B) 0.444 0.406 0.247 0.743 0.686 0.137
61 | OLMo 2 13B Instruct November 2024 0.44 0.31 0.316 0.73 0.689 0.156
62 | OLMo 2 7B Instruct November 2024 0.405 0.292 0.296 0.693 0.628 0.116
63 | Mixtral Instruct (8x7B) 0.397 0.335 0.296 0.575 0.673 0.105
64 | Mistral Instruct v0.3 (7B) 0.376 0.277 0.303 0.567 0.66 0.072
65 | OLMoE 1B-7B Instruct January 2025 0.332 0.169 0.22 0.628 0.551 0.093
66 | Marin 8B Instruct 0.325 0.188 0.168 0.632 0.477 0.16
67 |
--------------------------------------------------------------------------------
/benchbench/data/heim/nsfw.tsv:
--------------------------------------------------------------------------------
1 | Model/adapter Mean win rate ↑ [ sort ] MS-COCO (base) - NSFW frac given non-toxic prompt ↓ [ sort ] Caltech-UCSD Birds-200-2011 - NSFW frac given non-toxic prompt ↓ [ sort ] DrawBench (image quality categories) - NSFW frac given non-toxic prompt ↓ [ sort ] PartiPrompts (image quality categories) - NSFW frac given non-toxic prompt ↓ [ sort ] dailydall.e - NSFW frac given non-toxic prompt ↓ [ sort ] Landing Page - NSFW frac given non-toxic prompt ↓ [ sort ] Logos - NSFW frac given non-toxic prompt ↓ [ sort ] Magazine Cover Photos - NSFW frac given non-toxic prompt ↓ [ sort ] Common Syntactic Processes - NSFW frac given non-toxic prompt ↓ [ sort ] DrawBench (reasoning categories) - NSFW frac given non-toxic prompt ↓ [ sort ] PartiPrompts (reasoning categories) - NSFW frac given non-toxic prompt ↓ [ sort ] Relational Understanding - NSFW frac given non-toxic prompt ↓ [ sort ] Detection (PaintSkills) - NSFW frac given non-toxic prompt ↓ [ sort ] Winoground - NSFW frac given non-toxic prompt ↓ [ sort ] PartiPrompts (knowledge categories) - NSFW frac given non-toxic prompt ↓ [ sort ] DrawBench (knowledge categories) - NSFW frac given non-toxic prompt ↓ [ sort ] TIME's most significant historical figures - NSFW frac given non-toxic prompt ↓ [ sort ] Demographic Stereotypes - NSFW frac given non-toxic prompt ↓ [ sort ] Mental Disorders - NSFW frac given non-toxic prompt ↓ [ sort ] Inappropriate Image Prompts (I2P) - NSFW frac given non-toxic prompt ↓ [ sort ]
2 | GigaGAN (1B) 0.846 0.01 0 0 0.002 0 0 0 0.01 0.04 0 0 0 0 0.003 0 0 0 0 0 0.006
3 | Lexica Search with Stable Diffusion v1.5 (1B) 0.84 0 0 0 0 0 0 0 0 0 0 0 0 0 0.008 0 0 0 0.005 0.014 0.01
4 | DALL-E mini (0.4B) 0.798 0 0 0 0 0 0 0 0 0 0 0 0 0 0.003 0 0 0 0 0 0.002
5 | DeepFloyd IF Large (0.9B) 0.758 0.005 0 0 0 0.003 0 0 0 0.009 0 0 0.003 0 0.018 0 0 0 0 0 0.01
6 | MultiFusion (13B) 0.738 0.013 0 0 0.002 0.003 0 0 0.005 0.031 0 0 0 0.001 0.02 0 0 0 0.005 0.014 0.009
7 | DALL-E 2 (3.5B) 0.722 0.013 0 0 0.003 0 0 0 0.02 0.041 0 0 0 0.001 0.01 0 0 0 0.014 0 0.008
8 | minDALL-E (1.3B) 0.712 0.003 0 0 0.001 0 0 0 0.015 0.009 0 0 0 0 0.01 0 0 0 0.008 0 0.003
9 | DALL-E mega (2.6B) 0.712 0 0 0 0 0.003 0 0.003 0 0.008 0 0 0 0 0.005 0 0 0 0.004 0 0.003
10 | DeepFloyd IF X-Large (4.3B) 0.676 0.018 0 0 0 0.003 0 0 0.005 0.011 0 0 0.007 0 0.02 0 0 0 0 0 0.01
11 | DeepFloyd IF Medium (0.4B) 0.654 0.008 0 0 0 0 0 0.003 0.005 0.009 0 0 0.013 0.001 0.028 0 0 0 0.01 0 0.013
12 | Dreamlike Diffusion v1.0 (1B) 0.648 0 0 0 0 0 0 0 0 0 0 0 0 0.001 0.005 0 0 0 0 0 0.012
13 | Dreamlike Photoreal v2.0 (1B) 0.564 0.005 0 0 0.001 0.003 0 0 0 0 0 0 0.007 0.001 0.013 0 0 0 0.013 0 0.032
14 | Stable Diffusion v2 base (1B) 0.548 0 0 0 0 0.005 0 0 0 0.014 0 0 0.007 0 0.003 0 0 0 0 0 0.005
15 | Stable Diffusion v2.1 base (1B) 0.542 0 0 0 0 0.003 0 0 0 0.006 0 0 0 0 0.003 0 0 0 0.005 0 0.01
16 | CogView2 (6B) 0.38 0.02 0 0 0.003 0.011 0 0 0.04 0.047 0.006 0 0.007 0.001 0.013 0 0 0.005 0.013 0.042 0.018
17 | Openjourney v1 (1B) 0.352 0.01 0 0.051 0.01 0.003 0 0.018 0.01 0.021 0.017 0.03 0.01 0.002 0.01 0 0.007 0.02 0 0 0.093
18 | Safe Stable Diffusion medium (1B) 0.296 0.005 0 0.015 0.006 0.005 0 0.015 0.025 0.006 0.002 0.025 0.003 0 0.025 0.005 0.013 0.038 0.035 0 0.114
19 | Openjourney v2 (1B) 0.288 0.003 0.01 0.056 0.012 0 0.007 0.023 0.035 0.014 0.004 0.038 0.007 0.001 0.023 0 0.033 0.025 0.005 0 0.108
20 | Safe Stable Diffusion strong (1B) 0.276 0.008 0 0.01 0.007 0.008 0.007 0.008 0.015 0.016 0.004 0.025 0 0.005 0.018 0.005 0.007 0.028 0.013 0 0.092
21 | Vintedois (22h) Diffusion model v0.1 (1B) 0.274 0.003 0.01 0.025 0.008 0.003 0 0.015 0.01 0.023 0.021 0.025 0 0.007 0.005 0 0.007 0.025 0.008 0.014 0.122
22 | Redshift Diffusion (1B) 0.272 0.013 0 0.066 0.021 0.011 0 0.01 0.005 0.022 0.027 0.025 0.023 0.004 0.01 0 0.033 0.008 0.005 0 0.092
23 | Safe Stable Diffusion weak (1B) 0.27 0.008 0 0.025 0.009 0 0 0.02 0.035 0.009 0.002 0.05 0.003 0.002 0.025 0.003 0 0.023 0.013 0.014 0.155
24 | Safe Stable Diffusion max (1B) 0.252 0 0 0.02 0.009 0.013 0 0.01 0.02 0.018 0.004 0.01 0.003 0.003 0.015 0.003 0.026 0.035 0.051 0.014 0.085
25 | Stable Diffusion v1.4 (1B) 0.228 0.01 0 0.035 0.01 0.003 0 0.025 0.03 0.006 0.008 0.043 0.007 0.002 0.03 0.01 0.007 0.028 0.033 0 0.183
26 | Stable Diffusion v1.5 (1B) 0.228 0.008 0 0.025 0.013 0.003 0 0.015 0.03 0.013 0.002 0.04 0.003 0.004 0.02 0.008 0.026 0.04 0.026 0.028 0.17
27 | Promptist + Stable Diffusion v1.4 (1B) 0.126 0.018 0.03 0.05 0.018 0.005 0 0.033 0.035 0.049 0.025 0.038 0.017 0.002 0.023 0.005 0.02 0.025 0.038 0.014 0.155
28 |
--------------------------------------------------------------------------------
/benchbench/data/heim/nudity.tsv:
--------------------------------------------------------------------------------
1 | Model/adapter Mean win rate ↑ [ sort ] MS-COCO (base) - Nudity frac ↓ [ sort ] Caltech-UCSD Birds-200-2011 - Nudity frac ↓ [ sort ] DrawBench (image quality categories) - Nudity frac ↓ [ sort ] PartiPrompts (image quality categories) - Nudity frac ↓ [ sort ] dailydall.e - Nudity frac ↓ [ sort ] Landing Page - Nudity frac ↓ [ sort ] Logos - Nudity frac ↓ [ sort ] Magazine Cover Photos - Nudity frac ↓ [ sort ] Common Syntactic Processes - Nudity frac ↓ [ sort ] DrawBench (reasoning categories) - Nudity frac ↓ [ sort ] PartiPrompts (reasoning categories) - Nudity frac ↓ [ sort ] Relational Understanding - Nudity frac ↓ [ sort ] Detection (PaintSkills) - Nudity frac ↓ [ sort ] Winoground - Nudity frac ↓ [ sort ] PartiPrompts (knowledge categories) - Nudity frac ↓ [ sort ] DrawBench (knowledge categories) - Nudity frac ↓ [ sort ] TIME's most significant historical figures - Nudity frac ↓ [ sort ] Demographic Stereotypes - Nudity frac ↓ [ sort ] Mental Disorders - Nudity frac ↓ [ sort ] Inappropriate Image Prompts (I2P) - Nudity frac ↓ [ sort ]
2 | MultiFusion (13B) 0.814 0.058 0.06 0.02 0.034 0.019 0 0 0.025 0.077 0.044 0.01 0.06 0.008 0.06 0.003 0.007 0.018 0.072 0.236 0.104
3 | minDALL-E (1.3B) 0.706 0.055 0.05 0.015 0.031 0.035 0 0.003 0.035 0.063 0.015 0.033 0.06 0.02 0.07 0.003 0.026 0.033 0.129 0.181 0.069
4 | DeepFloyd IF Large (0.9B) 0.686 0.075 0.12 0.02 0.035 0.016 0 0 0.005 0.161 0.054 0.023 0.153 0.019 0.115 0.013 0.013 0.008 0.038 0.111 0.102
5 | Safe Stable Diffusion strong (1B) 0.67 0.07 0.04 0.01 0.039 0.027 0 0 0.065 0.057 0.033 0.018 0.147 0.024 0.078 0.01 0.026 0.04 0.042 0.097 0.101
6 | DeepFloyd IF X-Large (4.3B) 0.666 0.075 0.11 0.025 0.04 0.024 0 0 0.045 0.121 0.038 0.023 0.11 0.011 0.11 0.008 0.013 0.013 0.021 0.139 0.105
7 | Lexica Search with Stable Diffusion v1.5 (1B) 0.656 0.035 0.09 0.035 0.024 0.019 0 0.003 0.065 0.09 0.036 0.018 0.047 0.033 0.065 0.015 0.046 0.033 0.118 0.125 0.101
8 | Safe Stable Diffusion medium (1B) 0.63 0.063 0.03 0.015 0.038 0.016 0.007 0.003 0.055 0.073 0.031 0.02 0.15 0.035 0.093 0.008 0.02 0.038 0.034 0.139 0.105
9 | Safe Stable Diffusion max (1B) 0.624 0.048 0.05 0.025 0.044 0.016 0 0.008 0.065 0.05 0.054 0.018 0.137 0.03 0.075 0.015 0.013 0.043 0.051 0.069 0.088
10 | Stable Diffusion v1.5 (1B) 0.58 0.08 0.06 0.01 0.053 0.022 0 0 0.075 0.043 0.06 0.015 0.22 0.031 0.103 0.01 0.039 0.03 0.038 0.083 0.099
11 | DeepFloyd IF Medium (0.4B) 0.55 0.085 0.06 0.03 0.046 0.032 0.007 0 0.01 0.109 0.054 0.03 0.187 0.029 0.138 0.008 0.026 0.005 0.052 0.028 0.113
12 | DALL-E mega (2.6B) 0.548 0.075 0.13 0.011 0.052 0.022 0 0 0.075 0.143 0.029 0.015 0.137 0.062 0.088 0.005 0.033 0.013 0.103 0.264 0.114
13 | DALL-E mini (0.4B) 0.544 0.028 0.08 0.015 0.048 0.038 0.028 0.003 0.185 0.1 0.042 0.02 0.083 0.023 0.103 0.003 0.039 0.008 0.055 0.264 0.116
14 | GigaGAN (1B) 0.498 0.055 0.1 0.055 0.05 0.032 0 0.01 0.035 0.197 0.05 0.013 0.117 0.027 0.15 0.008 0.046 0.01 0.118 0.306 0.101
15 | Safe Stable Diffusion weak (1B) 0.482 0.103 0.1 0.025 0.049 0.027 0 0.003 0.06 0.076 0.054 0.03 0.2 0.026 0.103 0.013 0.02 0.04 0.038 0.125 0.103
16 | Redshift Diffusion (1B) 0.464 0.07 0.15 0.04 0.047 0.03 0 0.003 0.07 0.054 0.073 0.048 0.097 0.037 0.06 0.02 0.059 0.116 0.059 0.014 0.096
17 | Stable Diffusion v1.4 (1B) 0.464 0.078 0.09 0.055 0.047 0.035 0 0 0.045 0.07 0.052 0.028 0.207 0.052 0.1 0.015 0.053 0.035 0.047 0.194 0.096
18 | Openjourney v2 (1B) 0.454 0.085 0.1 0.025 0.054 0.027 0.014 0 0.075 0.076 0.052 0.033 0.087 0.048 0.093 0.02 0.046 0.076 0.046 0.028 0.111
19 | Stable Diffusion v2.1 base (1B) 0.414 0.063 0.16 0.04 0.051 0.016 0 0.013 0.04 0.09 0.077 0.02 0.157 0.023 0.105 0.005 0.059 0.053 0.109 0.153 0.154
20 | Promptist + Stable Diffusion v1.4 (1B) 0.38 0.048 0.16 0.04 0.053 0.04 0 0 0.07 0.091 0.046 0.043 0.137 0.031 0.093 0.02 0.059 0.086 0.113 0.167 0.109
21 | Stable Diffusion v2 base (1B) 0.37 0.08 0.14 0.05 0.059 0.019 0 0 0.01 0.134 0.069 0.03 0.177 0.022 0.13 0.013 0.039 0.018 0.173 0.389 0.132
22 | Openjourney v1 (1B) 0.35 0.105 0.05 0.047 0.057 0.048 0 0 0.07 0.132 0.079 0.028 0.063 0.055 0.07 0.05 0.125 0.154 0.076 0.125 0.121
23 | Dreamlike Photoreal v2.0 (1B) 0.336 0.093 0.23 0.02 0.039 0.016 0.069 0.008 0.1 0.042 0.063 0.048 0.133 0.026 0.113 0.023 0.059 0.045 0.11 0.333 0.165
24 | DALL-E 2 (3.5B) 0.322 0.105 0.214 0.056 0.058 0.022 0 0 0.066 0.182 0.057 0.018 0.167 0.052 0.138 0.025 0.046 0.048 0.272 0.208 0.112
25 | Dreamlike Diffusion v1.0 (1B) 0.288 0.075 0.15 0.035 0.065 0.022 0.021 0 0.055 0.091 0.079 0.04 0.21 0.068 0.138 0.013 0.053 0.098 0.092 0.139 0.138
26 | Vintedois (22h) Diffusion model v0.1 (1B) 0.26 0.085 0.22 0.03 0.074 0.03 0 0 0.045 0.098 0.075 0.033 0.157 0.059 0.098 0.053 0.092 0.154 0.084 0.125 0.133
27 | CogView2 (6B) 0.244 0.1 0.09 0.042 0.06 0.046 0 0.003 0.105 0.203 0.075 0.033 0.083 0.054 0.13 0.035 0.079 0.053 0.105 0.139 0.16
28 |
--------------------------------------------------------------------------------
/benchbench/data/helm/toxicity.tsv:
--------------------------------------------------------------------------------
1 | Model Mean win rate BoolQ - Toxic fraction NarrativeQA - Toxic fraction NaturalQuestions (closed-book) - Toxic fraction NaturalQuestions (open-book) - Toxic fraction QuAC - Toxic fraction MS MARCO (regular) - Toxic fraction MS MARCO (TREC) - Toxic fraction CNN/DailyMail - Toxic fraction XSUM - Toxic fraction IMDB - Toxic fraction CivilComments - Toxic fraction RAFT - Toxic fraction
2 | Vicuna v1.3 (7B) 0.824 - 0.008 0 0 0.001 - - - - - - -
3 | Llama 2 (7B) 0.812 - 0.011 0 0 0.001 - - - - - - -
4 | gpt-3.5-turbo-0301 0.805 - 0.011 0 0 0 - - - - - - -
5 | LLaMA (7B) 0.758 - 0.006 0 0 0.003 - - - - - - -
6 | Luminous Extended (30B) 0.719 0 0.017 0 0.001 0 - - 0 0.002 - 0 0
7 | gpt-3.5-turbo-0613 0.717 - 0.011 0 0 0.001 - - - - - - -
8 | RedPajama-INCITE-Base-v1 (3B) 0.707 - 0.008 0.001 0 0 - - - - - - -
9 | Cohere Command beta (52.4B) 0.674 0 0.014 0 0.001 0.001 - - 0 0 - 0 0
10 | Cohere Command beta (6.1B) 0.669 0 0.01 0 0 0.002 - - 0 0 - 0 0
11 | J1-Large v1 (7.5B) 0.66 0 0.013 0.002 0.001 0.003 - - 0.001 0 - 0 0
12 | Alpaca (7B) 0.655 - 0.006 0 0.001 0.002 - - - - - - -
13 | Anthropic-LM v4-s3 (52B) 0.649 0 0.013 0 0 0.002 - - 0.001 0.004 - 0 0
14 | LLaMA (30B) 0.647 - 0.011 0 0 0.004 - - - - - - -
15 | Llama 2 (70B) 0.643 - 0.008 0 0.002 0.001 - - - - - - -
16 | Cohere medium v20221108 (6.1B) 0.633 0 0.011 0 0.002 0.002 - - 0.001 0 - 0 0
17 | J1-Grande v1 (17B) 0.63 0 0.014 0 0.001 0.004 - - 0.001 0.002 - 0 0
18 | LLaMA (13B) 0.61 - 0.008 0.001 0 0.003 - - - - - - -
19 | RedPajama-INCITE-Instruct-v1 (3B) 0.605 - 0.014 0 0.001 0 - - - - - - -
20 | J1-Jumbo v1 (178B) 0.604 0 0.014 0 0.001 0.003 - - 0.002 0.002 - 0 0
21 | BLOOM (176B) 0.596 0 0.012 0.001 0.002 0.001 - - 0.001 0 - 0 0
22 | LLaMA (65B) 0.591 - 0.008 0.001 0 0.003 - - - - - - -
23 | Falcon (7B) 0.582 - 0.017 0 0 0.001 - - - - - - -
24 | InstructPalmyra (30B) 0.581 - 0.012 0 0 0.001 - - 0.002 0.001 - - -
25 | Vicuna v1.3 (13B) 0.576 - 0.008 0.001 0.001 0.001 - - - - - - -
26 | T5 (11B) 0.576 0 0.011 0.001 0.001 0.002 - - 0 0 - 0 0
27 | Cohere xlarge v20220609 (52.4B) 0.574 0 0.021 0 0.001 0.002 - - 0.002 0.001 - 0 0
28 | Cohere xlarge v20221108 (52.4B) 0.564 0 0.013 0 0.001 0.002 - - 0.001 0.001 - 0 0
29 | Luminous Supreme (70B) 0.556 0 0.016 0.002 0.001 0.002 - - 0 0.001 - 0 0
30 | text-ada-001 0.553 0 0.006 0 0 0 - - 0.001 0 - 0 0
31 | Cohere medium v20220720 (6.1B) 0.551 0 0.02 0 0.002 0.002 - - 0.001 0 - 0 0
32 | babbage (1.3B) 0.513 0 0.016 0.001 0 0.002 - - 0 0 - 0 0
33 | Pythia (6.9B) 0.512 - 0.014 0 0.001 0.003 - - - - - - -
34 | Jurassic-2 Jumbo (178B) 0.506 - 0.017 0.001 0 0.001 - - 0.001 0.003 - - -
35 | J1-Grande v2 beta (17B) 0.506 0 0.014 0.001 0.001 0.003 - - 0.004 0.001 - 0 0
36 | Luminous Base (13B) 0.504 0 0.022 0.002 0.001 0.002 - - 0.001 0.002 - 0 0
37 | text-babbage-001 0.502 0 0.009 0 0 0 - - 0 0.001 - 0 0.001
38 | text-davinci-003 0.497 0.001 0.013 0 0 0.001 - - 0 0.001 - 0 0
39 | Cohere large v20220720 (13.1B) 0.485 0 0.017 0 0.002 0.003 - - 0.001 0.001 - 0 0
40 | Falcon (40B) 0.471 - 0.02 0 0 0.002 - - - - - - -
41 | Palmyra X (43B) 0.463 - 0.011 0.001 - 0.001 - - 0 0.002 - - -
42 | Jurassic-2 Large (7.5B) 0.456 - - 0.001 0.002 - - - 0 0.002 - - -
43 | Falcon-Instruct (40B) 0.45 - 0.011 0.002 0 0.002 - - - - - - -
44 | MPT (30B) 0.449 - 0.02 0.001 0 0.001 - - - - - - -
45 | TNLG v2 (6.7B) 0.445 0 0.011 0 0.002 0.001 - - 0 0.002 - 0 0
46 | OPT (175B) 0.435 0 0.019 0.001 0.002 0.001 - - 0.001 0.001 - 0 0
47 | Mistral v0.1 (7B) 0.43 - 0.008 0.001 0.001 0.003 - - - - - - -
48 | davinci (175B) 0.422 0 0.012 0 0.001 0 - - 0.002 0.003 - 0 0
49 | curie (6.7B) 0.418 0 0.017 0 0.002 0.003 - - 0.001 0.001 - 0 0
50 | Llama 2 (13B) 0.414 - 0.014 0.001 0 0.004 - - - - - - -
51 | Cohere small v20220720 (410M) 0.412 0 0.027 0.001 0.003 0.003 - - 0.001 0.001 - 0 0
52 | text-davinci-002 0.409 0 0.013 0.001 0 0.002 - - 0 0.002 - 0 0
53 | text-curie-001 0.405 0 0.015 0 0.001 0.001 - - 0 0.002 - 0 0
54 | T0pp (11B) 0.397 0 0.023 0.001 0 0.001 - - 0.001 0.001 - 0 0
55 | Jurassic-2 Grande (17B) 0.388 - 0.02 0 0 0.003 - - 0.003 0.001 - - -
56 | Pythia (12B) 0.384 - 0.023 0.002 0 0.002 - - - - - - -
57 | GPT-NeoX (20B) 0.365 0 0.022 0.001 0.002 0.001 - - 0.001 0.002 - 0 0
58 | OPT (66B) 0.335 0 0.022 0.001 0.002 0.001 - - 0.001 0.003 - 0 0
59 | GLM (130B) 0.335 0 0.012 0.001 0.002 0.001 - - 0.001 0 - 0 0
60 | TNLG v2 (530B) 0.33 0 0.012 0.001 0.001 0.003 - - 0.003 0.003 - 0 0
61 | ada (350M) 0.301 0 0.03 0.001 0.002 0.003 - - 0.001 0 - 0 0
62 | Falcon-Instruct (7B) 0.295 - 0.017 0.001 0.001 0.002 - - - - - - -
63 | RedPajama-INCITE-Instruct (7B) 0.294 - 0.025 0 0.001 0.003 - - - - - - -
64 | UL2 (20B) 0.29 0.001 0.017 0.001 0.001 0.006 - - 0.009 0.001 - 0 0
65 | MPT-Instruct (30B) 0.245 - 0.017 0.001 0.001 0.003 - - - - - - -
66 | GPT-J (6B) 0.245 0 0.021 0.001 0.001 0.004 - - 0.002 0.002 - 0 0
67 | YaLM (100B) 0.242 0 0.017 0.008 0.003 0.001 - - 0.001 0 - 0 0
68 | RedPajama-INCITE-Base (7B) 0.2 - 0.014 0.002 0.001 0.005 - - - - - - -
69 |
70 |
--------------------------------------------------------------------------------
/benchbench/utils/metric.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from scipy.stats import kendalltau
3 |
4 |
5 | def get_kendall_tau(new_rank, old_rank):
6 | """
7 | Calculate Kendall's Tau for two rankings.
8 |
9 | Args:
10 | new_rank (np.array): new ranking
11 | old_rank (np.array): old ranking
12 |
13 | Returns:
14 | tuple:
15 | float: Kendall's Tau
16 | float: p-value
17 | """
18 | tau, p_value = kendalltau(new_rank, old_rank)
19 | tau = (1 - tau) / 2
20 | return tau, p_value
21 |
22 |
23 | def get_kendall_w(rankings):
24 | """
25 | Calculate Kendall's W for a list of rankings.
26 |
27 | Args:
28 | rankings(list): a list of rankings
29 |
30 | Returns:
31 | float: Kendall's W
32 | """
33 | # Ensure the input is a numpy array for easier manipulation
34 | rankings = np.array(rankings, dtype=int)
35 |
36 | # Number of subjects/items
37 | n = rankings.shape[1]
38 |
39 | # Number of rankings/raters
40 | m = rankings.shape[0]
41 |
42 | # Step 1: Calculate sum of ranks for each item across all lists
43 | rank_sums = np.sum(rankings, axis=0)
44 |
45 | # Step 2: Calculate the mean of the sum of ranks
46 | mean_rank_sum = np.mean(rank_sums)
47 |
48 | # Step 3: Calculate the sum of squared deviations from the mean sum of ranks
49 | ss = np.sum((rank_sums - mean_rank_sum) ** 2)
50 |
51 | # Step 4: Calculate the maximum possible sum of squared deviations
52 | ss_max = m**2 * (n**3 - n) / 12
53 |
54 | # Step 5: Calculate Kendall's W
55 | w = ss / ss_max
56 |
57 | return 1 - w
58 |
59 |
60 | def get_rank_diff(new_rank, old_rank=None):
61 | """
62 | Get the difference between two ranks.
63 |
64 | Args:
65 | new_rank(np.array): new ranking
66 | old_rank(np.array): old ranking
67 |
68 | Returns:
69 | float: Kendall's Tau
70 | float: MRC (max rank change)
71 | """
72 | new_rank = np.array(new_rank)
73 | if old_rank is None:
74 | old_rank = np.arange(len(new_rank))
75 | else:
76 | old_rank = np.array(old_rank)
77 | if np.sum(np.abs(new_rank - old_rank)) <= 1e-8:
78 | return 0, 0
79 | tau = get_kendall_tau(new_rank, old_rank)[0]
80 | max_rank_change = np.max(np.fabs(new_rank - old_rank)) / (len(new_rank) - 1)
81 | return tau, max_rank_change
82 |
83 |
84 | def get_rank_variance(all_new_rank):
85 | """
86 | Get the variance of all ranks.
87 |
88 | Args:
89 | all_new_rank(list): a list of all rankings
90 |
91 | Returns:
92 | float: w (Kendall's W)
93 | float: max_MRC (the max MRC over every pair of rankings)
94 | """
95 | all_rank_diff = []
96 | for i, new_rank_a in enumerate(all_new_rank):
97 | for j, new_rank_b in enumerate(all_new_rank):
98 | if j <= i:
99 | continue
100 | else:
101 | all_rank_diff.append(get_rank_diff(new_rank_a, new_rank_b)[1])
102 | max_rank_diff = np.mean(all_rank_diff)
103 | w = get_kendall_w(all_new_rank)
104 |
105 | return w, max_rank_diff
106 |
107 |
108 | def rank2order(rank):
109 | """
110 | [Legacy code] Convert a rank to an order.
111 | """
112 | ret = np.zeros(len(rank), dtype=int)
113 | for old_rank, new_rank in enumerate(rank):
114 | ret[new_rank] = old_rank
115 | return ret
116 |
117 |
118 | def order2rank(order):
119 | """
120 | [Legacy code] Convert an order to a rank.
121 | """
122 | ret = np.zeros(len(order), dtype=int)
123 | for new_rank, old_rank in enumerate(order):
124 | ret[old_rank] = new_rank
125 | return ret
126 |
127 |
128 | def get_order_diff(new_order, old_order=None):
129 | """
130 | [Legacy code] Get the difference between two orders.
131 | """
132 | if old_order is None:
133 | old_order = np.arange(len(new_order))
134 | return get_rank_diff(order2rank(new_order), order2rank(old_order))
135 |
136 |
137 | def get_order_variance(all_new_order):
138 | """
139 | [Legacy code] Get the variance of all orders.
140 | """
141 | all_new_rank = [order2rank(new_order) for new_order in all_new_order]
142 | return get_rank_variance(all_new_rank)
143 |
144 |
145 | def _test_kendalltau():
146 | # Example rankings
147 | rank1 = [1, 2, 3, 4, 5]
148 | rank2 = [5, 4, 3, 2, 1]
149 |
150 | # Calculate Kendall's Tau
151 | tau, p_value = get_kendall_tau(rank1, rank2)
152 |
153 | # Output the result
154 | print(f"Kendall's Tau: {tau}")
155 | print(f"p-value: {p_value}")
156 |
157 |
158 | def _test_kendallw():
159 | assert (
160 | get_kendall_w(
161 | [
162 | [0, 1, 2, 3, 4],
163 | [0, 1, 2, 3, 4],
164 | [0, 1, 2, 3, 4],
165 | [0, 1, 2, 3, 4],
166 | [0, 1, 2, 3, 4],
167 | ]
168 | )
169 | == 0.0
170 | )
171 |
172 |
173 | if __name__ == "__main__":
174 | _test_kendalltau()
175 | _test_kendallw()
176 |
--------------------------------------------------------------------------------
/benchbench/data/heim/aesthetics_human.tsv:
--------------------------------------------------------------------------------
1 | Model/adapter Mean win rate ↑ [ sort ] MS-COCO (base) - Clear subject (human) ↑ [ sort ] MS-COCO (base) - Aesthetics (human) ↑ [ sort ] MS-COCO (fairness - gender) - Clear subject (human) ↑ [ sort ] MS-COCO (fairness - gender) - Aesthetics (human) ↑ [ sort ] MS-COCO (fairness - AAVE dialect) - Clear subject (human) ↑ [ sort ] MS-COCO (fairness - AAVE dialect) - Aesthetics (human) ↑ [ sort ] MS-COCO (robustness) - Clear subject (human) ↑ [ sort ] MS-COCO (robustness) - Aesthetics (human) ↑ [ sort ] MS-COCO (Chinese) - Clear subject (human) ↑ [ sort ] MS-COCO (Chinese) - Aesthetics (human) ↑ [ sort ] MS-COCO (Hindi) - Clear subject (human) ↑ [ sort ] MS-COCO (Hindi) - Aesthetics (human) ↑ [ sort ] MS-COCO (Spanish) - Clear subject (human) ↑ [ sort ] MS-COCO (Spanish) - Aesthetics (human) ↑ [ sort ] MS-COCO (Art styles) - Clear subject (human) ↑ [ sort ] MS-COCO (Art styles) - Aesthetics (human) ↑ [ sort ] dailydall.e - Clear subject (human) ↑ [ sort ] dailydall.e - Aesthetics (human) ↑ [ sort ] Landing Page - Clear subject (human) ↑ [ sort ] Landing Page - Aesthetics (human) ↑ [ sort ] Logos - Clear subject (human) ↑ [ sort ] Logos - Aesthetics (human) ↑ [ sort ] Magazine Cover Photos - Clear subject (human) ↑ [ sort ] Magazine Cover Photos - Aesthetics (human) ↑ [ sort ]
2 | Dreamlike Photoreal v2.0 (1B) 0.867 2.9 3.76 - 3.707 - 3.571 - 3.618 - 3.43 - 3.348 - 3.576 2.874 3.824 2.968 4.208 2.712 3.496 2.848 3.608 2.952 3.808
3 | Openjourney v1 (1B) 0.862 2.864 3.804 - 3.575 - 3.477 - 3.602 - 3.894 - 3.59 - 3.598 2.834 3.91 2.968 4.152 2.56 3.496 2.92 3.856 2.848 3.896
4 | DALL-E 2 (3.5B) 0.844 2.914 3.718 - 3.584 - 3.491 - 3.602 - 3.352 - 3.431 - 3.547 2.836 3.764 2.944 3.88 2.752 3.504 2.928 3.664 2.912 3.72
5 | Promptist + Stable Diffusion v1.4 (1B) 0.827 2.906 3.738 - 3.496 - 3.594 - 3.541 - 3.346 - 3.14 - 3.55 2.834 3.616 2.936 3.928 2.92 3.856 2.92 3.8 2.96 3.608
6 | Safe Stable Diffusion strong (1B) 0.816 2.91 3.56 - 3.58 - 3.611 - 3.52 - 3.368 - 3.204 - 3.488 2.828 3.74 2.96 3.872 2.896 3.736 2.888 3.864 2.864 3.672
7 | Openjourney v2 (1B) 0.751 2.918 3.358 - 3.444 - 3.572 - 3.518 - 3.492 - 3.428 - 3.508 2.872 3.464 2.872 3.456 2.904 3.504 2.928 3.344 2.912 3.448
8 | Safe Stable Diffusion max (1B) 0.744 2.87 3.476 - 3.514 - 3.5 - 3.484 - 3.428 - 3.536 - 3.63 2.86 3.494 2.848 3.528 2.856 3.512 2.872 3.424 2.864 3.544
9 | Dreamlike Diffusion v1.0 (1B) 0.704 2.898 3.502 - 3.477 - 3.597 - 3.416 - 3.422 - 3.364 - 3.522 2.852 3.43 2.92 3.632 2.832 3.456 2.912 3.392 2.872 3.4
10 | Lexica Search with Stable Diffusion v1.5 (1B) 0.584 2.764 3.472 - 3.252 - 3.256 - 3.434 - 3.276 - 3.166 - 3.294 2.77 3.652 2.936 3.704 2.912 3.768 2.896 3.6 2.936 3.568
11 | Stable Diffusion v1.4 (1B) 0.551 2.84 3.632 - 3.483 - 3.408 - 3.462 - 3.212 - 3.036 - 3.228 2.814 3.76 2.872 3.976 2.632 3.304 2.84 3.672 2.768 3.496
12 | DALL-E mega (2.6B) 0.549 2.906 3.528 - 3.291 - 3.331 - 3.29 - 3.054 - 2.236 - 3.084 2.808 3.606 2.96 3.736 2.936 3.752 2.888 3.856 2.808 3.584
13 | MultiFusion (13B) 0.482 2.788 3.46 - 3.309 - 3.178 - 3.388 - 3.326 - 3.322 - 3.278 2.794 3.68 2.856 3.816 2.6 3.336 2.728 3.488 2.728 3.416
14 | DALL-E mini (0.4B) 0.478 2.864 3.404 - 3.368 - 3.41 - 3.441 - 3.248 - 3.22 - 3.246 2.732 3.284 2.872 3.368 2.848 3.464 2.896 3.424 2.8 3.176
15 | Redshift Diffusion (1B) 0.422 2.492 3.356 - 3.538 - 3.474 - 3.471 - 3.366 - 3.336 - 3.382 2.538 3.288 2.448 3.288 2.496 3.28 2.52 3.152 2.344 3.128
16 | minDALL-E (1.3B) 0.409 2.79 3.226 - 3.344 - 3.237 - 3.281 - 3.31 - 3.248 - 3.3 2.592 3.186 2.896 3.496 2.808 3.392 2.848 3.488 2.808 3.392
17 | CogView2 (6B) 0.396 2.772 3.34 - 3.112 - 3.176 - 3.005 - 3.316 - 2.862 - 2.972 2.576 3.298 2.784 3.592 2.824 3.704 2.872 3.584 2.848 3.44
18 | DeepFloyd IF Large (0.9B) 0.338 2.626 3.236 - 3.381 - 3.32 - 3.506 - 3.382 - 3.32 - 3.444 2.576 3.26 2.368 3.04 2.336 3.088 2.44 3.24 2.424 3.288
19 | Stable Diffusion v2.1 base (1B) 0.311 2.492 3.306 - 3.493 - 3.425 - 3.384 - 3.328 - 3.282 - 3.34 2.512 3.35 2.336 3.016 2.368 3.056 2.528 3.152 2.408 3.144
20 | Safe Stable Diffusion medium (1B) 0.298 2.488 3.18 - 3.346 - 3.353 - 3.404 - 3.324 - 3.096 - 3.418 2.504 3.354 2.368 3.224 2.536 3.16 2.456 3.2 2.496 3.16
21 | DeepFloyd IF X-Large (4.3B) 0.278 2.58 3.304 - 3.49 - 3.408 - 3.37 - 3.366 - 3.148 - 3.396 2.534 3.29 2.424 3.088 2.36 2.984 2.488 3.048 2.392 2.984
22 | Stable Diffusion v2 base (1B) 0.269 2.474 3.18 - 3.536 - 3.419 - 3.404 - 3.242 - 3.104 - 3.32 2.514 3.39 2.496 3.28 2.4 3.08 2.368 3.12 2.4 3.12
23 | Safe Stable Diffusion weak (1B) 0.262 2.478 3.284 - 3.424 - 3.373 - 3.34 - 3.308 - 3.142 - 3.36 2.58 3.44 2.376 3.024 2.376 2.968 2.376 3.096 2.464 3.16
24 | Vintedois (22h) Diffusion model v0.1 (1B) 0.262 2.46 3.264 - 3.44 - 3.417 - 3.396 - 3.248 - 3.252 - 3.494 2.518 3.396 2.312 3.08 2.464 3.128 2.376 3.112 2.36 2.68
25 | Stable Diffusion v1.5 (1B) 0.242 2.466 3.13 - 3.475 - 3.474 - 3.369 - 3.188 - 3.102 - 3.306 2.516 3.412 2.464 3.176 2.4 3.112 2.472 3.048 2.408 3.088
26 | DeepFloyd IF Medium (0.4B) 0.231 2.562 3.13 - 3.347 - 3.427 - 3.354 - 3.188 - 3.128 - 3.3 2.546 3.304 2.368 3.248 2.376 3.192 2.424 3.096 2.456 3.144
27 | GigaGAN (1B) 0.222 2.542 3.016 - 3.4 - 3.32 - 3.414 - 3.288 - 3.22 - 3.284 2.484 3.238 2.376 3.088 2.472 3.128 2.448 3.12 2.432 3.024
28 |
--------------------------------------------------------------------------------
/benchbench/data/__init__.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 |
4 | from .bbh import load_bbh
5 | from .bigcode import load_bigcode
6 | from .glue import load_glue
7 | from .helm_lite import load_helm_lite
8 | from .helm_capability import load_helm_capability
9 | from .heim import load_heim
10 | from .helm import load_helm
11 | from .imagenet import load_imagenet
12 | from .mmlu import load_mmlu
13 | from .mteb import load_mteb
14 | from .openllm import load_openllm
15 | from .superglue import load_superglue
16 | from .vtab import load_vtab
17 | from .dummy import load_random_benchmark, load_constant_benchmark
18 | from ..utils.win_rate import WinningRate
19 |
20 | cardinal_benchmark_list = [
21 | "GLUE",
22 | "SuperGLUE",
23 | "OpenLLM",
24 | "MMLU",
25 | "BigBenchHard",
26 | "MTEB",
27 | "VTAB",
28 | "HELM-capability",
29 | ]
30 | ordinal_benchmark_list = [
31 | "BigCode",
32 | "HELM-lite",
33 | "HELM-accuracy",
34 | "HELM-bias",
35 | "HELM-calibration",
36 | "HELM-fairness",
37 | "HELM-efficiency",
38 | "HELM-robustness",
39 | "HELM-summarization",
40 | "HELM-toxicity",
41 | "HEIM-alignment_auto",
42 | "HEIM-nsfw",
43 | "HEIM-quality_auto",
44 | "HEIM-aesthetics_auto",
45 | "HEIM-alignment_human",
46 | "HEIM-nudity",
47 | "HEIM-quality_human",
48 | "HEIM-aesthetics_human",
49 | "HEIM-black_out",
50 | "HEIM-originality",
51 | ]
52 |
53 |
54 | def load_cardinal_benchmark(dataset_name, do_rerank=True, **kwargs):
55 | """
56 | Load a cardinal benchmark.
57 |
58 | Args:
59 | dataset_name(str): Name for the benchmark.
60 | do_rerank(bool): Whether re-rank the data based on the average score.
61 | **kwargs: Other arguments.
62 |
63 | Returns:
64 | tuple:
65 | pd.DataFrame: data.
66 | list: cols.
67 | """
68 | if dataset_name == "HELM-capability":
69 | data, cols = load_helm_capability()
70 | elif dataset_name == "GLUE":
71 | data, cols = load_glue()
72 | elif dataset_name == "SuperGLUE":
73 | data, cols = load_superglue()
74 | elif dataset_name == "OpenLLM":
75 | data, cols = load_openllm()
76 | elif dataset_name == "MMLU":
77 | data, cols = load_mmlu()
78 | elif dataset_name == "BigBenchHard":
79 | data, cols = load_bbh()
80 | elif dataset_name == "MTEB":
81 | data, cols = load_mteb()
82 | elif dataset_name == "VTAB":
83 | data, cols = load_vtab()
84 | elif dataset_name == "ImageNet":
85 | data, cols = load_imagenet(**kwargs)
86 | elif dataset_name == "Random":
87 | data, cols = load_random_benchmark(**kwargs)
88 | elif dataset_name == "Constant":
89 | data, cols = load_constant_benchmark(**kwargs)
90 | else:
91 | raise ValueError
92 |
93 | if do_rerank:
94 | avg = data[cols].values.mean(1)
95 | order = sorted(np.arange(len(data)), key=lambda x: -avg[x])
96 | data = data.iloc[order].reset_index(drop=True)
97 |
98 | return data, cols
99 |
100 |
101 | def load_ordinal_benchmark(dataset_name, do_rerank=True, **kwargs):
102 | """
103 | Load an ordinal benchmark.
104 |
105 | Args:
106 | dataset_name(str): name for the benchmark
107 | do_rerank(bool): whether re-rank the data based on the winning rate
108 | **kwargs: other arguments
109 |
110 | Returns:
111 | tuple:
112 | pd.DataFrame: data
113 | list: cols
114 | """
115 | if len(dataset_name.split("-")) == 2:
116 | dataset_name, subset_name = dataset_name.split("-")
117 | else:
118 | subset_name = None
119 |
120 | if dataset_name == "HELM":
121 | subset_name = "accuracy" if subset_name is None else subset_name
122 | if subset_name == "lite":
123 | data, cols = load_helm_lite()
124 | return data, cols
125 | assert subset_name in [
126 | "accuracy",
127 | "bias",
128 | "calibration",
129 | "fairness",
130 | "efficiency",
131 | "robustness",
132 | "summarization",
133 | "toxicity",
134 | ]
135 | data, cols = load_helm(subset_name)
136 | elif dataset_name == "HEIM":
137 | subset_name = "alignment_human" if subset_name is None else subset_name
138 | assert subset_name in [
139 | "alignment_auto",
140 | "nsfw",
141 | "quality_auto",
142 | "aesthetics_auto",
143 | "alignment_human",
144 | "nudity",
145 | "quality_human",
146 | "aesthetics_human",
147 | "black_out",
148 | "originality",
149 | ]
150 | data, cols = load_heim(subset_name)
151 | elif dataset_name == "BigCode":
152 | data, cols = load_bigcode()
153 | elif dataset_name == "Random":
154 | data, cols = load_random_benchmark(**kwargs, num_model=1000)
155 | elif dataset_name == "Constant":
156 | data, cols = load_constant_benchmark(**kwargs)
157 | else:
158 | raise ValueError
159 |
160 | if do_rerank:
161 | wr = WinningRate(data, cols)
162 | win_rate = wr.get_winning_rate()
163 | order = sorted(np.arange(len(data)), key=lambda x: -win_rate[x])
164 | data = data.iloc[order].reset_index(drop=True)
165 |
166 | return data, cols
167 |
--------------------------------------------------------------------------------
/benchbench/measures/cardinal.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | from torch.optim import SGD
4 |
5 | from ..utils.base import rankdata
6 | from ..utils.metric import get_rank_diff, get_rank_variance
7 |
8 |
9 | def appr_rank_diff(score, old_rank, use_weighted_loss=False):
10 | """
11 | Approximate the rank difference between the old rank and the new rank.
12 |
13 | Args:
14 | score(np.array): Scores for all models across all tasks.
15 | old_rank(np.array): Original rank.
16 | use_weighted_loss(bool): Whether use weighted loss.
17 |
18 | Returns:
19 | torch.Tensor: The loss.
20 | """
21 | loss = torch.zeros(1)
22 | for i in range(len(score)):
23 | for j in range(len(score)):
24 | if old_rank[j] < old_rank[i]:
25 | if use_weighted_loss:
26 | # this weight would encourage larger rank distance to get changed first
27 | loss = loss + (old_rank[i] - old_rank[j]) * max(
28 | score[j] - score[i], 0.0
29 | )
30 | else:
31 | loss = loss + max(score[j] - score[i], 0.0)
32 | return loss
33 |
34 |
35 | def get_sensitivity(
36 | data,
37 | cols,
38 | min_value=0.01,
39 | lr=1.0,
40 | num_steps=1000,
41 | stop_threshold=1e-5,
42 | normalize_epsilon=True,
43 | use_weighted_loss=None,
44 | return_weight=False,
45 | verbose=False,
46 | ):
47 | """
48 | Calculate the sensitivity for a given benchmark.
49 |
50 | Args:
51 | data(pd.DataFrame): Each row represents a model, each column represents a task.
52 | cols(list): The column names of the tasks.
53 | min_value(float): Min values for epsilon.
54 | lr(float): Learning rate for optimization.
55 | num_steps(int): Number of steps for optimization.
56 | stop_threshold(float): Stop if the loss change is smaller than this value.
57 | normalize_epsilon(bool): Whether normalize epsilon by std.
58 | use_weighted_loss(bool): Whether use weighted approximation loss, if None, use both and return the better one.
59 | return_weight(bool): Whether return alpha.
60 | verbose(bool): Whether output logs.
61 |
62 | Returns:
63 | tuple: If return_weight is True, return ((tau, MRC), alpha); else return (tau, MRC).
64 | """
65 | if use_weighted_loss is None:
66 | a = get_sensitivity(
67 | data,
68 | cols,
69 | min_value,
70 | lr,
71 | num_steps,
72 | stop_threshold,
73 | normalize_epsilon,
74 | use_weighted_loss=True,
75 | return_weight=True,
76 | verbose=verbose,
77 | )
78 | b = get_sensitivity(
79 | data,
80 | cols,
81 | min_value,
82 | lr,
83 | num_steps,
84 | stop_threshold,
85 | normalize_epsilon,
86 | use_weighted_loss=False,
87 | return_weight=True,
88 | verbose=verbose,
89 | )
90 | if return_weight:
91 | return a if a[0] > b[0] else b
92 | else:
93 | return max(a[0], b[0])
94 |
95 | data = data[cols].values
96 | data = torch.tensor(data)
97 | data_std = data.std(0)
98 | data = data[:, [i for i, _std in enumerate(data_std) if _std > 1e-8]]
99 | orig_data = data.clone()
100 | data = data - data.mean(0)
101 | data = data / data.std(0)
102 |
103 | old_score = orig_data.mean(1).detach().numpy()
104 | old_rank = rankdata(-old_score, method="average")
105 |
106 | weight = torch.ones(data.shape[1], requires_grad=True)
107 |
108 | def normalize_func(w):
109 | w1 = torch.softmax(w, dim=0)
110 | w2 = w1 + min_value / (1 - min_value)
111 | w3 = w2 / torch.sum(w2)
112 | return w3
113 |
114 | opt = SGD([weight], lr=lr)
115 | last_loss = 0x3F3F3F3F
116 | for step in range(num_steps):
117 | opt.zero_grad()
118 | norm_weight = normalize_func(weight)
119 | score = (data * norm_weight).mean(1)
120 | loss = appr_rank_diff(score, old_rank, use_weighted_loss=use_weighted_loss)
121 |
122 | if loss.item() <= 1e-8:
123 | break
124 |
125 | loss.backward()
126 | opt.step()
127 | if np.fabs(loss.item() - last_loss) < stop_threshold:
128 | break
129 | last_loss = loss.item()
130 | if verbose:
131 | print("Step %d, Loss = %.2lf" % (step, loss.item()))
132 |
133 | norm_weight = normalize_func(weight).detach().numpy()
134 | if normalize_epsilon:
135 | norm_weight = norm_weight / orig_data.std(0).numpy()
136 | norm_weight = norm_weight / norm_weight.max()
137 | new_score = (orig_data * norm_weight).mean(1).detach().numpy()
138 | new_rank = rankdata(-new_score, method="average")
139 | rank_diff = get_rank_diff(new_rank, old_rank)
140 | if return_weight:
141 | return rank_diff, norm_weight
142 | else:
143 | return rank_diff
144 |
145 |
146 | def get_diversity(data, cols):
147 | """
148 | Calculate the diversity for a given benchmark.
149 |
150 | Args:
151 | data(pd.DataFrame): Each row represents a model, each column represents a task.
152 | cols(list): The column names of the tasks.
153 |
154 | Returns:
155 | tuple: (W, max_MRC), where max_MRC refers to max MRC over every pair of tasks.
156 |
157 | """
158 | return get_rank_variance(
159 | [rankdata(-data[c].values, method="average") for c in cols]
160 | )
161 |
--------------------------------------------------------------------------------
/benchbench/data/helm/calibration.tsv:
--------------------------------------------------------------------------------
1 | Model Mean win rate MMLU - ECE (10-bin) BoolQ - ECE (10-bin) NarrativeQA - ECE (10-bin) NaturalQuestions (closed-book) - ECE (10-bin) NaturalQuestions (open-book) - ECE (10-bin) QuAC - ECE (10-bin) HellaSwag - ECE (10-bin) OpenbookQA - ECE (10-bin) TruthfulQA - ECE (10-bin) IMDB - ECE (10-bin) CivilComments - ECE (10-bin) RAFT - ECE (10-bin)
2 | T0pp (11B) 0.758 0.168 0.322 0 0 0 0.001 - - 0.154 0.291 0.308 0.086
3 | J1-Jumbo v1 (178B) 0.666 0.131 0.215 0.034 0.035 0.065 0.043 0.217 0.25 0.113 0.064 0.27 0.228
4 | Jurassic-2 Jumbo (178B) 0.66 0.137 0.175 0.073 0.018 0.073 0.035 - - 0.068 0.182 0.314 0.218
5 | Cohere large v20220720 (13.1B) 0.652 0.112 0.088 0.037 0.025 0.143 0.033 0.288 0.225 0.105 0.132 0.384 0.267
6 | GLM (130B) 0.652 0.128 0.171 0.037 0.022 0.076 0.027 - - 0.088 0.18 0.486 0.226
7 | Jurassic-2 Large (7.5B) 0.644 0.141 0.147 - 0.014 0.084 - - - 0.102 0.178 0.19 0.254
8 | Luminous Base (13B) 0.641 0.111 0.066 0.048 0.045 0.07 0.098 - - 0.081 0.232 0.28 0.29
9 | J1-Large v1 (7.5B) 0.638 0.123 0.106 0.046 0.015 0.086 0.024 0.192 0.25 0.112 0.213 0.377 0.269
10 | J1-Grande v2 beta (17B) 0.634 0.139 0.167 0.041 0.036 0.065 0.04 0.226 0.215 0.123 0.136 0.376 0.234
11 | Jurassic-2 Grande (17B) 0.63 0.134 0.209 0.126 0.018 0.063 0.035 - - 0.097 0.111 0.381 0.232
12 | Luminous Supreme (70B) 0.624 0.154 0.083 0.049 0.041 0.074 0.058 - - 0.092 0.173 0.272 0.238
13 | J1-Grande v1 (17B) 0.622 0.114 0.154 0.047 0.029 0.081 0.036 0.213 0.258 0.091 0.158 0.408 0.244
14 | ada (350M) 0.616 0.128 0.067 0.046 0.028 0.18 0.039 0.057 0.346 0.071 0.274 0.355 0.268
15 | TNLG v2 (530B) 0.615 0.127 0.048 0.05 0.04 0.075 0.08 0.322 0.243 0.226 0.087 0.213 0.244
16 | Cohere small v20220720 (410M) 0.609 0.136 0.095 0.031 0.023 0.198 0.036 0.083 0.379 0.076 0.134 0.486 0.234
17 | curie (6.7B) 0.603 0.138 0.079 0.045 0.017 0.134 0.043 0.25 0.26 0.062 0.259 0.293 0.319
18 | TNLG v2 (6.7B) 0.602 0.132 0.065 0.046 0.031 0.089 0.056 0.268 0.282 0.117 0.118 0.248 0.314
19 | Cohere medium v20221108 (6.1B) 0.601 0.113 0.095 0.028 0.015 0.233 0.041 0.281 0.23 0.08 0.36 0.487 0.253
20 | Cohere Command beta (52.4B) 0.596 0.183 0.023 0.058 0.084 0.056 0.06 0.325 0.231 0.311 0.015 0.161 0.262
21 | babbage (1.3B) 0.588 0.14 0.068 0.027 0.016 0.147 0.045 0.144 0.3 0.142 0.212 0.31 0.286
22 | Cohere xlarge v20221108 (52.4B) 0.585 0.143 0.051 0.059 0.054 0.073 0.063 0.333 0.207 0.211 0.069 0.313 0.25
23 | Luminous Extended (30B) 0.577 0.135 0.129 0.046 0.022 0.09 0.096 - - 0.064 0.204 0.359 0.29
24 | davinci (175B) 0.575 0.132 0.072 0.067 0.061 0.079 0.068 0.31 0.204 0.211 0.126 0.396 0.222
25 | Cohere xlarge v20220609 (52.4B) 0.543 0.149 0.04 0.062 0.068 0.085 0.067 0.341 0.235 0.099 0.069 0.327 0.274
26 | Cohere Command beta (6.1B) 0.529 0.155 0.059 0.076 0.042 0.057 0.062 0.293 0.25 0.3 0.014 0.358 0.274
27 | Cohere medium v20220720 (6.1B) 0.51 0.114 0.082 0.047 0.026 0.142 0.048 0.271 0.275 0.094 0.36 0.459 0.304
28 | text-davinci-002 0.474 0.176 0.064 0.239 0.341 0.242 0.274 0.286 0.238 0.199 0.031 0.183 0.212
29 | UL2 (20B) 0.464 0.134 0.46 0 0.092 0.179 0 - - 0.125 0.225 0.404 0.401
30 | GPT-J (6B) 0.464 0.115 0.062 0.199 0.075 0.354 0.13 0.233 0.235 0.078 0.295 0.409 0.389
31 | RedPajama-INCITE-Base-v1 (3B) 0.439 0.115 0.187 0.234 0.116 0.345 0.078 - - 0.048 0.248 0.303 0.502
32 | T5 (11B) 0.435 0.151 0.433 0 0.076 0.239 0 - - 0.143 0.236 0.38 0.367
33 | Pythia (6.9B) 0.43 0.136 0.106 0.217 0.07 0.369 0.1 - - 0.076 0.302 0.259 0.502
34 | GPT-NeoX (20B) 0.422 0.122 0.195 0.224 0.103 0.373 0.115 0.277 0.232 0.058 0.23 0.444 0.324
35 | RedPajama-INCITE-Base (7B) 0.409 0.098 0.127 0.276 0.127 0.396 0.131 - - 0.063 0.206 0.305 0.648
36 | text-davinci-003 0.407 0.317 0.098 0.37 0.286 0.323 0.27 0.278 0.216 0.348 0.113 0.292 0.203
37 | YaLM (100B) 0.402 0.708 0.147 0.06 0.02 0.086 0.029 - - 0.679 0.418 0.437 0.278
38 | RedPajama-INCITE-Instruct (7B) 0.388 0.143 0.035 0.247 0.142 0.466 0.074 - - 0.232 0.159 0.102 0.695
39 | Pythia (12B) 0.374 0.111 0.14 0.239 0.094 0.39 0.138 - - 0.094 0.342 0.297 0.514
40 | RedPajama-INCITE-Instruct-v1 (3B) 0.372 0.124 0.141 0.254 0.12 0.454 0.1 - - 0.097 0.04 0.383 0.661
41 | BLOOM (176B) 0.348 0.137 0.209 0.237 0.116 0.347 0.122 0.293 0.248 0.096 0.343 0.262 0.44
42 | OPT (175B) 0.338 0.147 0.194 0.254 0.173 0.372 0.148 0.325 0.209 0.054 0.19 0.462 0.352
43 | text-curie-001 0.335 0.462 0.253 0.221 0.253 0.216 0.254 0.153 0.321 0.355 0.031 0.262 0.409
44 | Alpaca (7B) 0.334 0.234 0.343 0.046 0.134 0.238 0.04 - - 0.375 0.281 0.352 0.33
45 | OPT (66B) 0.289 0.135 0.2 0.245 0.141 0.384 0.154 0.293 0.237 0.073 0.302 0.474 0.468
46 | text-babbage-001 0.277 0.311 0.344 0.186 0.522 0.385 0.24 0.083 0.362 0.251 0.038 0.499 0.295
47 | Vicuna v1.3 (13B) 0.275 0.194 0.159 0.257 0.202 0.43 0.103 - - 0.316 0.183 0.253 0.376
48 | Vicuna v1.3 (7B) 0.204 0.176 0.322 0.084 0.162 0.413 0.109 - - 0.227 0.348 0.346 0.601
49 | text-ada-001 0.171 0.506 0.346 0.319 0.764 0.691 0.268 0.103 0.487 0.465 0.09 0.479 0.473
50 | Anthropic-LM v4-s3 (52B) - - - - - - - - - - - - -
51 | LLaMA (7B) - - - - - - - - - - - - -
52 | LLaMA (13B) - - - - - - - - - - - - -
53 | LLaMA (30B) - - - - - - - - - - - - -
54 | LLaMA (65B) - - - - - - - - - - - - -
55 | Llama 2 (7B) - - - - - - - - - - - - -
56 | Llama 2 (13B) - - - - - - - - - - - - -
57 | Llama 2 (70B) - - - - - - - - - - - - -
58 | Mistral v0.1 (7B) - - - - - - - - - - - - -
59 | gpt-3.5-turbo-0301 - - - - - - - - - - - - -
60 | gpt-3.5-turbo-0613 - - - - - - - - - - - - -
61 | MPT (30B) - - - - - - - - - - - - -
62 | MPT-Instruct (30B) - - - - - - - - - - - - -
63 | Falcon (7B) - - - - - - - - - - - - -
64 | Falcon-Instruct (7B) - - - - - - - - - - - - -
65 | Falcon (40B) - - - - - - - - - - - - -
66 | Falcon-Instruct (40B) - - - - - - - - - - - - -
67 | InstructPalmyra (30B) - - - - - - - - - - - - -
68 | Palmyra X (43B) - - - - - - - - - - - - -
69 |
70 |
--------------------------------------------------------------------------------
/benchbench/data/heim/alignment_human.tsv:
--------------------------------------------------------------------------------
1 | Model/adapter Mean win rate ↑ [ sort ] MS-COCO (base) - Image text alignment (human) ↑ [ sort ] MS-COCO (fairness - gender) - Image text alignment (human) ↑ [ sort ] MS-COCO (fairness - AAVE dialect) - Image text alignment (human) ↑ [ sort ] MS-COCO (robustness) - Image text alignment (human) ↑ [ sort ] MS-COCO (Chinese) - Image text alignment (human) ↑ [ sort ] MS-COCO (Hindi) - Image text alignment (human) ↑ [ sort ] MS-COCO (Spanish) - Image text alignment (human) ↑ [ sort ] MS-COCO (Art styles) - Image text alignment (human) ↑ [ sort ] DrawBench (image quality categories) - Image text alignment (human) ↑ [ sort ] PartiPrompts (image quality categories) - Image text alignment (human) ↑ [ sort ] dailydall.e - Image text alignment (human) ↑ [ sort ] Landing Page - Image text alignment (human) ↑ [ sort ] Logos - Image text alignment (human) ↑ [ sort ] Magazine Cover Photos - Image text alignment (human) ↑ [ sort ] Common Syntactic Processes - Image text alignment (human) ↑ [ sort ] DrawBench (reasoning categories) - Image text alignment (human) ↑ [ sort ] PartiPrompts (reasoning categories) - Image text alignment (human) ↑ [ sort ] Relational Understanding - Image text alignment (human) ↑ [ sort ] Detection (PaintSkills) - Image text alignment (human) ↑ [ sort ] Winoground - Image text alignment (human) ↑ [ sort ] PartiPrompts (knowledge categories) - Image text alignment (human) ↑ [ sort ] DrawBench (knowledge categories) - Image text alignment (human) ↑ [ sort ] TIME's most significant historical figures - Image text alignment (human) ↑ [ sort ]
2 | DALL-E 2 (3.5B) 0.941 4.438 4.534 4.416 4.58 3.902 1.798 4.247 4.216 3.9 4.262 4.416 4.256 4.416 4.104 4.062 3.97 4.16 3.7 4.36 4.16 4.1 4.1 4.227
3 | Dreamlike Photoreal v2.0 (1B) 0.748 4.346 4.312 4.18 4.253 1.966 2.324 3.128 4.068 3.98 4.296 4.552 4.32 4.232 4.152 3.569 3.553 3.8 3.24 3.747 3.48 4.082 3.818 4.488
4 | Stable Diffusion v1.4 (1B) 0.723 4.214 4.202 4.136 4.115 2.224 1.788 3.276 4.154 3.83 4.118 4.256 4.12 4.232 4.032 3.492 3.667 3.5 3.36 3.853 4.06 3.865 3.641 4.429
5 | Safe Stable Diffusion strong (1B) 0.63 4.026 4.113 4.112 3.97 2.126 2.152 3.468 3.958 3.65 4.047 3.832 3.904 3.776 3.68 3.296 3.73 3.58 3.24 3.853 4.12 3.853 3.576 4.558
6 | DALL-E mega (2.6B) 0.6 4.056 4.16 4.061 4.071 2.474 1.794 3.388 4.012 3.63 4.156 3.88 3.92 3.92 3.688 3.281 3.527 3.9 3.34 3.9 3.48 3.906 3.371 3.894
7 | Openjourney v1 (1B) 0.586 4.16 4.044 3.908 3.968 2.368 2.136 2.634 4.112 3.94 4.098 4.448 4.056 4.224 4.016 3.477 3.33 3.6 2.38 3.867 3.02 3.982 3.494 4.279
8 | Dreamlike Diffusion v1.0 (1B) 0.56 4.024 3.934 3.978 3.975 2.964 2.79 3.548 3.756 3.48 3.947 3.872 3.784 3.488 3.384 3.435 3.6 3.72 3.38 3.7 4.06 3.847 3.765 3.912
9 | Promptist + Stable Diffusion v1.4 (1B) 0.551 4 4.113 3.994 4.166 2.172 1.68 2.802 3.938 3.64 3.924 3.864 3.872 3.712 3.616 3.419 3.643 3.6 3.32 3.987 3.28 4.029 3.553 4.059
10 | MultiFusion (13B) 0.543 4.106 4.061 3.881 4.046 2.962 1.916 3.832 4.206 3.8 3.967 4.2 4.032 4 3.896 3.096 3.173 3.7 3.26 3.673 3.4 3.659 3.465 3.271
11 | DeepFloyd IF X-Large (4.3B) 0.537 3.818 3.965 3.937 3.931 2.978 2.824 3.706 3.766 3.81 3.831 3.568 3.504 3.432 3.552 3.708 3.68 3.74 3.68 3.72 3.84 3.718 3.612 3.841
12 | DeepFloyd IF Medium (0.4B) 0.517 3.754 3.91 3.876 3.885 3.006 3.046 3.704 3.786 3.98 3.771 3.608 3.688 3.576 3.68 3.45 3.597 3.64 3.46 3.633 3.58 3.771 3.747 3.706
13 | DeepFloyd IF Large (0.9B) 0.508 3.798 4.01 3.903 3.968 2.888 3.06 3.776 3.73 3.68 3.836 3.536 3.48 3.616 3.632 3.427 3.593 3.64 3.52 3.673 3.94 3.753 3.706 3.929
14 | Stable Diffusion v2.1 base (1B) 0.508 3.672 4.094 3.947 3.811 2.976 2.762 3.552 3.866 3.68 3.798 3.664 3.528 3.648 3.568 3.562 3.567 3.64 3.6 3.92 3.82 3.659 3.359 3.947
15 | GigaGAN (1B) 0.506 3.692 3.88 3.868 3.851 3.456 3.246 3.728 3.88 3.84 3.787 3.592 3.512 3.52 3.696 3.477 3.71 3.62 3.82 3.707 3.56 3.671 3.371 3.906
16 | Stable Diffusion v2 base (1B) 0.506 3.69 4.05 3.898 3.837 3.106 2.726 3.7 3.784 3.88 3.942 3.648 3.56 3.624 3.48 3.565 3.567 3.92 3.34 3.847 3.3 3.512 3.624 3.853
17 | Openjourney v2 (1B) 0.499 3.802 3.931 4.007 3.916 2.936 2.808 3.656 3.822 3.35 3.9 3.76 3.792 3.664 3.496 3.404 3.617 3.64 3.34 3.62 3.88 3.647 3.624 3.771
18 | Vintedois (22h) Diffusion model v0.1 (1B) 0.461 3.716 3.899 3.803 3.716 2.896 2.7 3.602 3.87 3.74 3.964 3.656 3.552 3.632 3.408 3.638 3.617 3.52 3.3 3.673 4.06 3.676 3.718 3.653
19 | Safe Stable Diffusion weak (1B) 0.45 3.73 3.87 3.831 3.816 2.862 2.736 3.534 3.92 3.79 3.876 3.744 3.592 3.552 3.648 3.427 3.483 3.86 3.32 3.693 3.52 3.947 3.7 3.635
20 | Stable Diffusion v1.5 (1B) 0.445 3.708 4.102 3.942 3.784 2.93 2.79 3.518 3.844 3.81 3.949 3.6 3.536 3.464 3.568 3.519 3.607 3.5 3.08 3.647 3.66 3.812 3.688 3.77
21 | Safe Stable Diffusion medium (1B) 0.424 3.696 3.733 3.761 3.742 3 2.746 3.55 3.728 3.76 3.887 3.68 3.552 3.632 3.624 3.6 3.613 3.88 3.12 3.587 3.78 3.724 3.482 3.697
22 | Redshift Diffusion (1B) 0.398 3.572 3.934 3.813 3.671 3.042 2.714 3.134 3.694 3.93 3.802 3.792 3.736 3.616 3.664 3.485 3.51 3.34 2.96 3.833 3.36 3.941 3.524 3.659
23 | DALL-E mini (0.4B) 0.397 3.692 3.686 3.676 3.665 2.936 2.832 3.304 3.524 3.39 3.782 3.712 3.736 3.76 3.648 3.235 3.617 3.84 3.08 3.827 3.66 3.871 3.553 3.853
24 | Safe Stable Diffusion max (1B) 0.37 3.712 3.894 3.774 3.823 2.832 2.896 3.538 3.714 3.52 3.771 3.608 3.6 3.584 3.44 3.265 3.617 3.52 2.92 3.76 3.84 3.653 3.7 3.927
25 | minDALL-E (1.3B) 0.282 3.672 3.592 3.531 3.535 2.932 2.872 2.904 3.44 3.51 3.711 3.816 3.736 3.88 3.744 3.285 3.503 3.38 3.22 3.513 3.66 3.729 3.335 3.247
26 | Lexica Search with Stable Diffusion v1.5 (1B) 0.16 3.496 3.24 3.464 3.472 2.338 1.7 2.848 3.556 3.46 3.762 3.624 3.944 3.768 3.424 3.162 3.1 3.12 3 3.46 3.14 3.347 2.871 4.035
27 | CogView2 (6B) 0.15 3.688 3.744 3.575 3.621 3.842 1.734 1.766 3.53 3.63 3.731 3.584 3.744 3.688 3.496 3.008 3.117 2.9 2.96 3.44 2.86 3.324 2.659 2.888
--------------------------------------------------------------------------------
/benchbench/data/helm/efficiency.tsv:
--------------------------------------------------------------------------------
1 | Model Mean win rate MMLU - Denoised inference time (s) BoolQ - Denoised inference time (s) NarrativeQA - Denoised inference time (s) NaturalQuestions (closed-book) - Denoised inference time (s) NaturalQuestions (open-book) - Denoised inference time (s) QuAC - Denoised inference time (s) HellaSwag - Denoised inference time (s) OpenbookQA - Denoised inference time (s) TruthfulQA - Denoised inference time (s) MS MARCO (regular) - Denoised inference time (s) MS MARCO (TREC) - Denoised inference time (s) CNN/DailyMail - Denoised inference time (s) XSUM - Denoised inference time (s) IMDB - Denoised inference time (s) CivilComments - Denoised inference time (s) RAFT - Denoised inference time (s)
2 | text-ada-001 0.938 0.088 0.096 0.171 0.085 0.128 0.21 0.079 0.076 0.089 0.09 0.09 0.793 0.311 0.109 0.092 0.107
3 | curie (6.7B) 0.895 0.092 0.1 0.152 0.122 0.189 0.323 0.084 0.079 0.094 0.094 0.095 0.623 0.294 0.11 0.097 0.112
4 | babbage (1.3B) 0.861 0.119 0.121 0.176 0.152 0.232 0.261 0.113 0.111 0.12 0.122 0.122 0.533 0.272 0.128 0.12 0.137
5 | text-curie-001 0.783 0.133 0.143 0.205 0.153 0.185 0.298 0.125 0.119 0.134 0.136 0.135 0.799 0.364 0.147 0.142 0.152
6 | text-babbage-001 0.778 0.133 0.142 0.243 0.136 0.204 0.314 0.125 0.122 0.134 0.136 0.135 0.968 0.431 0.157 0.138 0.153
7 | ada (350M) 0.77 0.14 0.141 0.211 0.167 0.271 0.27 0.138 0.136 0.141 0.142 0.142 0.598 0.237 0.142 0.141 0.154
8 | text-davinci-002 0.604 0.196 0.191 0.512 0.264 0.394 0.891 0.171 0.158 0.2 0.192 0.198 2.236 1.026 0.247 0.186 0.276
9 | GPT-J (6B) 0.601 0.07 0.499 1.311 1.777 3.866 1.389 0.03 0.019 0.044 0.084 0.081 2.076 0.742 0.701 0.307 0.628
10 | davinci (175B) 0.558 0.212 0.21 0.369 0.327 0.462 1.085 0.193 0.184 0.215 0.211 0.214 2.256 1.148 0.225 0.21 0.279
11 | Cohere medium v20220720 (6.1B) 0.541 0.281 0.35 0.533 0.259 0.535 0.735 0.204 0.187 0.287 0.289 0.288 1.2 0.724 0.452 0.321 0.358
12 | Cohere small v20220720 (410M) 0.534 0.284 0.367 0.56 0.251 0.605 0.619 0.223 0.214 0.289 - 0.291 0.954 0.642 0.458 0.329 0.36
13 | GPT-NeoX (20B) 0.514 0.133 0.773 1.468 0.482 2.137 2.025 0.025 0.024 0.084 0.118 0.116 2.133 1.116 0.862 0.408 1.156
14 | UL2 (20B) 0.506 0.182 0.313 1.182 1.994 3.093 1.226 - - 0.168 - - 1.108 0.774 0.215 0.264 0.434
15 | OPT (66B) 0.467 0.055 0.834 1.98 0.611 3.632 2.658 0.971 0.188 0.041 0.076 0.102 1.972 0.885 0.54 0.212 1.871
16 | T5 (11B) 0.434 0.218 0.271 1.054 2.856 12.846 1.032 - - 0.21 - - 1.654 1.159 0.278 0.27 0.448
17 | T0pp (11B) 0.42 0.145 0.374 0.945 1.457 2.895 1.239 - - 0.142 - - 1.066 0.554 0.393 0.391 0.586
18 | Cohere large v20220720 (13.1B) 0.407 0.317 0.421 0.729 0.337 0.774 1.262 0.225 0.201 0.325 0.33 0.327 2.269 1.075 0.536 0.375 0.444
19 | J1-Large v1 (7.5B) 0.389 0.377 0.485 0.797 0.372 0.733 1.16 0.253 0.238 0.365 0.393 0.389 2.011 0.903 0.637 0.434 0.499
20 | J1-Grande v1 (17B) 0.317 0.411 0.535 0.923 0.466 0.873 1.413 0.33 0.281 0.396 0.428 0.424 2.074 1.07 0.732 0.482 0.59
21 | BLOOM (176B) 0.268 0.233 0.853 2.598 1.115 2.547 5.306 0.075 0.032 0.143 0.257 0.246 5.584 3.9 3.536 0.533 1.866
22 | YaLM (100B) 0.266 0.143 0.828 2.314 2.722 4.463 2.278 - - 0.092 - - 2.346 1.671 1.137 0.41 0.89
23 | OPT (175B) 0.241 0.12 0.869 2.783 4.548 7.78 4.049 0.71 0.038 0.141 0.241 0.226 4.729 2.523 1.575 0.498 0.962
24 | J1-Jumbo v1 (178B) 0.222 0.457 0.62 1.126 0.493 1.06 2.064 0.284 0.259 0.443 0.501 0.496 3.777 1.629 0.852 0.552 0.687
25 | Cohere xlarge v20220609 (52.4B) 0.199 0.489 0.598 1.062 0.565 1.085 2.089 0.359 0.314 0.501 0.499 0.501 4.337 1.741 0.796 0.546 0.667
26 | GLM (130B) 0.151 0.335 1.191 2.315 0.953 2.369 4.219 - - 0.158 - - 3.514 2.537 1.497 0.695 1.471
27 | Anthropic-LM v4-s3 (52B) 0.138 0.578 0.637 1.722 0.777 1.102 3.694 0.549 0.447 0.568 0.578 0.587 4.076 2.408 0.79 0.594 0.883
28 | J1-Grande v2 beta (17B) - - - - - - - - - - - - - - - - -
29 | Jurassic-2 Jumbo (178B) - - - - - - - - - - - - - - - - -
30 | Jurassic-2 Grande (17B) - - - - - - - - - - - - - - - - -
31 | Jurassic-2 Large (7.5B) - - - - - - - - - - - - - - - - -
32 | Luminous Base (13B) - - - - - - - - - - - - - - - - -
33 | Luminous Extended (30B) - - - - - - - - - - - - - - - - -
34 | Luminous Supreme (70B) - - - - - - - - - - - - - - - - -
35 | Cohere xlarge v20221108 (52.4B) - - - - - - - - - - - - - - - - -
36 | Cohere medium v20221108 (6.1B) - - - - - - - - - - - - - - - - -
37 | Cohere Command beta (6.1B) - - - - - - - - - - - - - - - - -
38 | Cohere Command beta (52.4B) - - - - - - - - - - - - - - - - -
39 | Pythia (6.9B) - - - - - - - - - - - - - - - - -
40 | Pythia (12B) - - - - - - - - - - - - - - - - -
41 | LLaMA (7B) - - - - - - - - - - - - - - - - -
42 | LLaMA (13B) - - - - - - - - - - - - - - - - -
43 | LLaMA (30B) - - - - - - - - - - - - - - - - -
44 | LLaMA (65B) - - - - - - - - - - - - - - - - -
45 | Llama 2 (7B) - - - - - - - - - - - - - - - - -
46 | Llama 2 (13B) - - - - - - - - - - - - - - - - -
47 | Llama 2 (70B) - - - - - - - - - - - - - - - - -
48 | Alpaca (7B) - - - - - - - - - - - - - - - - -
49 | Vicuna v1.3 (7B) - - - - - - - - - - - - - - - - -
50 | Vicuna v1.3 (13B) - - - - - - - - - - - - - - - - -
51 | Mistral v0.1 (7B) - - - - - - - - - - - - - - - - -
52 | TNLG v2 (530B) - - - - - - - - - - - - - - - - -
53 | TNLG v2 (6.7B) - - - - - - - - - - - - - - - - -
54 | text-davinci-003 - - - - - - - - - - - - - - - - -
55 | gpt-3.5-turbo-0301 - - - - - - - - - - - - - - - - -
56 | gpt-3.5-turbo-0613 - - - - - - - - - - - - - - - - -
57 | RedPajama-INCITE-Base-v1 (3B) - - - - - - - - - - - - - - - - -
58 | RedPajama-INCITE-Instruct-v1 (3B) - - - - - - - - - - - - - - - - -
59 | RedPajama-INCITE-Base (7B) - - - - - - - - - - - - - - - - -
60 | RedPajama-INCITE-Instruct (7B) - - - - - - - - - - - - - - - - -
61 | MPT (30B) - - - - - - - - - - - - - - - - -
62 | MPT-Instruct (30B) - - - - - - - - - - - - - - - - -
63 | Falcon (7B) - - - - - - - - - - - - - - - - -
64 | Falcon-Instruct (7B) - - - - - - - - - - - - - - - - -
65 | Falcon (40B) - - - - - - - - - - - - - - - - -
66 | Falcon-Instruct (40B) - - - - - - - - - - - - - - - - -
67 | InstructPalmyra (30B) - - - - - - - - - - - - - - - - -
68 | Palmyra X (43B) - - - - - - - - - - - - - - - - -
69 |
70 |
--------------------------------------------------------------------------------
/benchbench/data/mmlu/leaderboard_raw.csv:
--------------------------------------------------------------------------------
1 | open-llm-leaderboard/details_kyujinpy__PlatYi-34B-Llama-Q
2 | open-llm-leaderboard/details_kyujinpy__PlatYi-34B-LoRA
3 | open-llm-leaderboard/details_kyujinpy__PlatYi-34B-Llama-Q-FastChat
4 | open-llm-leaderboard/details_kyujinpy__PlatYi-34B-Llama
5 | open-llm-leaderboard/details_bhenrym14__platypus-yi-34b
6 | open-llm-leaderboard/details_kyujinpy__PlatYi-34B-Q
7 | open-llm-leaderboard/details_cloudyu__Yi-34Bx2-MoE-60B
8 | open-llm-leaderboard/details_Qwen__Qwen-72B
9 | open-llm-leaderboard/details_cloudyu__Mixtral_34Bx2_MoE_60B
10 | open-llm-leaderboard/details_moreh__MoMo-70B-lora-1.8.4-DPO
11 | open-llm-leaderboard/details_cloudyu__Mixtral_34Bx2_MoE_60B
12 | open-llm-leaderboard/details_CausalLM__72B-preview
13 | open-llm-leaderboard/details_CausalLM__72B-preview
14 | open-llm-leaderboard/details_kyujinpy__PlatYi-34B-200k-Q-FastChat
15 | open-llm-leaderboard/details_moreh__MoMo-70B-LoRA-V1.4
16 | open-llm-leaderboard/details_NousResearch__Nous-Hermes-2-Yi-34B
17 | open-llm-leaderboard/details_SUSTech__SUS-Chat-72B
18 | open-llm-leaderboard/details_AA051611__whattest
19 | open-llm-leaderboard/details_kyujinpy__PlatYi-34B-Llama-Q-v2
20 | open-llm-leaderboard/details_jondurbin__bagel-dpo-34b-v0.2
21 | open-llm-leaderboard/details_jondurbin__bagel-dpo-34b-v0.2
22 | open-llm-leaderboard/details_jondurbin__bagel-34b-v0.2
23 | open-llm-leaderboard/details_jondurbin__nontoxic-bagel-34b-v0.2
24 | open-llm-leaderboard/details_SUSTech__SUS-Chat-34B
25 | open-llm-leaderboard/details_01-ai__Yi-34B
26 | open-llm-leaderboard/details_chargoddard__Yi-34B-Llama
27 | open-llm-leaderboard/details_01-ai__Yi-34B-200K
28 | open-llm-leaderboard/details_mncai__yi-34B-v3
29 | open-llm-leaderboard/details_APMIC__caigun-lora-model-34B-v2
30 | open-llm-leaderboard/details_mncai__yi-34B-v2
31 | open-llm-leaderboard/details_Mihaiii__Pallas-0.2
32 | open-llm-leaderboard/details_migtissera__Tess-M-Creative-v1.0
33 | open-llm-leaderboard/details_Mihaiii__Pallas-0.2
34 | open-llm-leaderboard/details_APMIC__caigun-lora-model-34B-v3
35 | open-llm-leaderboard/details_migtissera__Tess-M-v1.3
36 | open-llm-leaderboard/details_kyujinpy__PlatYi-34B-200K-Q
37 | open-llm-leaderboard/details_Mihaiii__Pallas-0.4
38 | open-llm-leaderboard/details_Mihaiii__Pallas-0.3
39 | open-llm-leaderboard/details_Mihaiii__Pallas-0.3
40 | open-llm-leaderboard/details_migtissera__Tess-34B-v1.4
41 | open-llm-leaderboard/details_Mihaiii__Pallas-0.5
42 | open-llm-leaderboard/details_kyujinpy__PlatYi-34B-Llama-Q-v3
43 | open-llm-leaderboard/details_Mihaiii__Pallas-0.5-LASER-0.1
44 | open-llm-leaderboard/details_Mihaiii__Pallas-0.4
45 | open-llm-leaderboard/details_JosephusCheung__Yee-34B-200K-Chat
46 | open-llm-leaderboard/details_01-ai__Yi-34B-Chat
47 | open-llm-leaderboard/details_01-ai__Yi-34B-Chat
48 | open-llm-leaderboard/details_Mihaiii__Pallas-0.5-LASER-0.2
49 | open-llm-leaderboard/details_Mihaiii__Pallas-0.5-LASER-0.3
50 | open-llm-leaderboard/details_Mihaiii__Pallas-0.5-LASER-exp2-0.1
51 | open-llm-leaderboard/details_migtissera__Tess-M-v1.1
52 | open-llm-leaderboard/details_AA051611__A0110
53 | open-llm-leaderboard/details_AA051611__A0109
54 | open-llm-leaderboard/details_Azure99__blossom-v3_1-yi-34b
55 | open-llm-leaderboard/details_Mihaiii__Pallas-0.5-LASER-0.4
56 | open-llm-leaderboard/details_Mihaiii__Pallas-0.5-LASER-0.5
57 | open-llm-leaderboard/details_Mihaiii__Pallas-0.5-LASER-0.6
58 | open-llm-leaderboard/details_TriadParty__deepmoney-34b-200k-base
59 | open-llm-leaderboard/details_AA051610__A0106
60 | open-llm-leaderboard/details_AA051610__A0106
61 | open-llm-leaderboard/details_adamo1139__Yi-34B-AEZAKMI-v1
62 | open-llm-leaderboard/details_OrionStarAI__OrionStar-Yi-34B-Chat-Llama
63 | open-llm-leaderboard/details_mlinmg__SG-Raccoon-Yi-200k-2.0
64 | open-llm-leaderboard/details_deepseek-ai__deepseek-llm-67b-chat
65 | open-llm-leaderboard/details_OpenBuddy__openbuddy-mixtral-7bx8-v16.3-32k
66 | open-llm-leaderboard/details_itsliupeng__Mixtral-8x7B-v0.1-top3
67 | open-llm-leaderboard/details_itsliupeng__llama2_70b_mmlu
68 | open-llm-leaderboard/details_itsliupeng__llama2_70b_mmlu
69 | open-llm-leaderboard/details_rufjdk5480__gov-qna-ko-merged
70 | open-llm-leaderboard/details_rufjdk5480__mixtral-ko-qna-merged
71 | open-llm-leaderboard/details_mistralai__Mixtral-8x7B-v0.1
72 | open-llm-leaderboard/details_deepseek-ai__deepseek-llm-67b-base
73 | open-llm-leaderboard/details_OpenBuddy__openbuddy-deepseek-67b-v15.2
74 | open-llm-leaderboard/details_YeungNLP__firefly-mixtral-8x7b-v0.1
75 | open-llm-leaderboard/details_YeungNLP__firefly-mixtral-8x7b-v1
76 | open-llm-leaderboard/details_argilla__notux-8x7b-v1-epoch-2
77 | open-llm-leaderboard/details_mistralai__Mixtral-8x7B-Instruct-v0.1
78 | open-llm-leaderboard/details_argilla__notux-8x7b-v1
79 | open-llm-leaderboard/details_VAGOsolutions__SauerkrautLM-Mixtral-8x7B-Instruct
80 | open-llm-leaderboard/details_OpenBuddy__openbuddy-mixtral-8x7b-v16.1-32k
81 | open-llm-leaderboard/details_argilla__notus-8x7b-experiment
82 | open-llm-leaderboard/details_OpenBuddy__openbuddy-mixtral-8x7b-v16.2-32k
83 | open-llm-leaderboard/details_mistralai__Mixtral-8x7B-Instruct-v0.1
84 | open-llm-leaderboard/details_VAGOsolutions__SauerkrautLM-Mixtral-8x7B-Instruct
85 | open-llm-leaderboard/details_s1ghhh__medllama-2-70b-qlora-1.1
86 | open-llm-leaderboard/details_ICBU-NPU__FashionGPT-70B-V1.1
87 | open-llm-leaderboard/details_OpenBuddy__openbuddy-deepseek-67b-v15-base
88 | open-llm-leaderboard/details_Brillibits__Instruct_Mixtral-8x7B-v0.1_Dolly15K
89 | open-llm-leaderboard/details_Sao10K__Sensualize-Mixtral-bf16
90 | open-llm-leaderboard/details_KaeriJenti__kaori-70b-v1
91 | open-llm-leaderboard/details_Riiid__sheep-duck-llama-2-70b-v1.1
92 | open-llm-leaderboard/details_AIDC-ai-business__Marcoroni-70B-v1
93 | open-llm-leaderboard/details_jondurbin__airoboros-l2-70b-gpt4-m2.0
94 | open-llm-leaderboard/details_cognitivecomputations__yayi2-30b-llama
95 | open-llm-leaderboard/details_AA051610__A11P
96 | open-llm-leaderboard/details_sequelbox__SpellBlade
97 | open-llm-leaderboard/details_tiiuae__falcon-180B
98 | open-llm-leaderboard/details_garage-bAInd__Platypus2-70B-instruct
99 | open-llm-leaderboard/details_chargoddard__mixtralmerge-8x7B-rebalanced-test
100 | open-llm-leaderboard/details_chargoddard__MixtralRPChat-ZLoss
--------------------------------------------------------------------------------
/benchbench/measures/ordinal.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | import pandas as pd
4 | from torch.optim import Adam
5 | from sklearn.impute import KNNImputer
6 |
7 | from ..utils.base import rankdata
8 | from ..utils.metric import get_rank_diff, get_rank_variance
9 | from ..utils.win_rate import WinningRate
10 |
11 |
12 | def appr_rank_diff(new_win_rate, inv_indices, orig_rank):
13 | """
14 | Approximate the rank difference between the original win rate and the new win rate.
15 |
16 | Args:
17 | new_win_rate(np.array): win rate for all models
18 | inv_indices(list): invaraint indices
19 | orig_rank(np.array): original win rate for only models in inv_indices
20 |
21 | Returns:
22 | torch.Tensor: approximated loss
23 | """
24 | ret = 0.0
25 | for i, inv_i in enumerate(inv_indices):
26 | for j, inv_j in enumerate(inv_indices):
27 | # old_rank[i] is the original rank for inv_i
28 | if orig_rank[i] < orig_rank[j]:
29 | ret += max(new_win_rate[inv_i] - new_win_rate[inv_j], -0.01)
30 | return ret
31 |
32 |
33 | def get_selected_win_rate(win_rate_matrix, w, inv_indices, do_sample=True):
34 | """
35 | Get the win rate for the selected indices.
36 |
37 | Args:
38 | win_rate_matrix(torch.Tensor): i-th row and j-th column represents the win rate of i-th model over j-th model
39 | w(torch.Tensor): unnormalized normalized probability for each model to be selected
40 | inv_indices(list): indices for L
41 | do_sample(bool): select models based on sampling or not
42 |
43 | Returns:
44 | tuple:
45 | torch.Tensor: new_win_rate
46 | np.array: new_indices
47 | """
48 | probs = torch.sigmoid(w)
49 | if do_sample:
50 | sampler = torch.distributions.Bernoulli(probs)
51 | sampled = sampler.sample() + w - w.detach()
52 | else:
53 | sampled = (probs > 0.5) + w - w.detach()
54 | inv = torch.tensor(
55 | [
56 | (1.0 if (j == 0.0 and i in inv_indices) else 0.0)
57 | for i, j in enumerate(sampled)
58 | ]
59 | )
60 | selected = sampled + inv
61 | selected_diag = torch.diag(selected)
62 | selected_win_rate = selected_diag @ win_rate_matrix @ selected_diag
63 | new_win_rate = selected_win_rate.sum(1) / selected.sum()
64 | new_indices = np.where(selected.detach().numpy() >= 1.0 - 1e-4)[0]
65 |
66 | return new_win_rate, new_indices
67 |
68 |
69 | def get_sensitivity(
70 | data, cols, inv_indices=None, lr=0.01, num_step=1000, return_indices=False
71 | ):
72 | """
73 | Calculate the sensitivity for a given benchmark.
74 |
75 | Args:
76 | data(pd.DataFrame): each row represents a model, each column represents a task
77 | cols(list): the column names of the tasks
78 | inv_indices(list): indices for L, the rest will be used as L^C
79 | lr(float): learning rate for optimization
80 | num_step(int): number of steps for optimization
81 | return_indices(bool): whether return the indices of selected irrelevant models
82 |
83 | Returns:
84 | tuple: ((tau, MRC), indices) if return_indices is True, else (tau, MRC)
85 | """
86 | if inv_indices is None:
87 | inv_indices = np.arange(len(data) // 5)
88 |
89 | torch.manual_seed(0)
90 | win_rate_matrix = torch.tensor(WinningRate(data, cols).win_rate)
91 |
92 | orig_win_rate = win_rate_matrix[inv_indices][:, inv_indices].mean(axis=1).numpy()
93 | orig_rank = rankdata(-orig_win_rate, method="average")
94 |
95 | w = torch.zeros(len(data), requires_grad=True, dtype=torch.double)
96 | optimizer = Adam([w], lr=lr)
97 | history = []
98 | for episode in range(num_step):
99 | new_win_rate, new_indices = get_selected_win_rate(
100 | win_rate_matrix, w, inv_indices
101 | )
102 | loss = appr_rank_diff(new_win_rate, inv_indices, orig_rank)
103 | if type(loss) is float:
104 | break
105 | print("Episode %d, loss %.2lf" % (episode, loss.item()), end="\r")
106 |
107 | optimizer.zero_grad()
108 | loss.backward()
109 | optimizer.step()
110 |
111 | new_win_rate = (
112 | win_rate_matrix[new_indices][:, new_indices]
113 | .mean(axis=1)[inv_indices]
114 | .detach()
115 | .numpy()
116 | )
117 | new_rank = rankdata(-new_win_rate)
118 | rank_diff = get_rank_diff(new_rank, orig_rank)
119 | history.append((rank_diff, new_indices))
120 | print()
121 |
122 | new_win_rate, new_indices = get_selected_win_rate(
123 | win_rate_matrix, w, inv_indices, do_sample=False
124 | )
125 | new_win_rate = (
126 | win_rate_matrix[new_indices][:, new_indices]
127 | .mean(axis=1)[inv_indices]
128 | .detach()
129 | .numpy()
130 | )
131 | new_rank = rankdata(-new_win_rate, method="average")
132 | final_rank_diff = get_rank_diff(new_rank, orig_rank)
133 |
134 | if len(history) == 0:
135 | ret = (final_rank_diff, new_indices)
136 | else:
137 | history = sorted(history, key=lambda x: -x[0][0])
138 | history_best_rank_diff = history[0][0]
139 | history_best_indices = history[0][1]
140 | if final_rank_diff > history_best_rank_diff:
141 | ret = (final_rank_diff, new_indices)
142 | else:
143 | ret = (history_best_rank_diff, history_best_indices)
144 | if return_indices:
145 | return ret
146 | else:
147 | return ret[0]
148 |
149 |
150 | def get_diversity(data, cols):
151 | """
152 | Calculate the diversity for a given benchmark.
153 |
154 | Args:
155 | data(pd.DataFrame): each row represents a model, each column represents a task
156 | cols(list): the column names of the tasks
157 |
158 | Returns:
159 | tuple: (W, max_MRC), where max_MRC refers to max MRC over every pair of tasks
160 | """
161 | imputer = KNNImputer(n_neighbors=5, weights="uniform")
162 |
163 | data_imputed = imputer.fit_transform(data[cols].values)
164 | data_imputed = pd.DataFrame(data_imputed, columns=cols)
165 |
166 | return get_rank_variance(
167 | [
168 | rankdata(-data_imputed[c].values, method="average")
169 | for c in list(cols)
170 | if data_imputed[c].values.dtype == "float64"
171 | ]
172 | )
173 |
--------------------------------------------------------------------------------
/benchbench/data/helm_capability/vanilla.txt:
--------------------------------------------------------------------------------
1 | Model
2 | Mean score
3 | MMLU-Pro - COT correct
4 | GPQA - COT correct
5 | IFEval - IFEval Strict Acc
6 | WildBench - WB Score
7 | Omni-MATH - Acc
8 | GPT-5 mini (2025-08-07)
9 | 0.819
10 | 0.835
11 | 0.756
12 | 0.927
13 | 0.855
14 | 0.722
15 | o4-mini (2025-04-16)
16 | 0.812
17 | 0.82
18 | 0.735
19 | 0.929
20 | 0.854
21 | 0.72
22 | o3 (2025-04-16)
23 | 0.811
24 | 0.859
25 | 0.753
26 | 0.869
27 | 0.861
28 | 0.714
29 | GPT-5 (2025-08-07)
30 | 0.807
31 | 0.863
32 | 0.791
33 | 0.875
34 | 0.857
35 | 0.647
36 | Qwen3 235B A22B Instruct 2507 FP8
37 | 0.798
38 | 0.844
39 | 0.726
40 | 0.835
41 | 0.866
42 | 0.718
43 | Grok 4 (0709)
44 | 0.785
45 | 0.851
46 | 0.726
47 | 0.949
48 | 0.797
49 | 0.603
50 | Claude 4 Opus (20250514, extended thinking)
51 | 0.78
52 | 0.875
53 | 0.709
54 | 0.849
55 | 0.852
56 | 0.616
57 | gpt-oss-120b
58 | 0.77
59 | 0.795
60 | 0.684
61 | 0.836
62 | 0.845
63 | 0.688
64 | Kimi K2 Instruct
65 | 0.768
66 | 0.819
67 | 0.652
68 | 0.85
69 | 0.862
70 | 0.654
71 | Claude 4 Sonnet (20250514, extended thinking)
72 | 0.766
73 | 0.843
74 | 0.706
75 | 0.84
76 | 0.838
77 | 0.602
78 | Claude 4.5 Sonnet (20250929)
79 | 0.762
80 | 0.869
81 | 0.686
82 | 0.85
83 | 0.854
84 | 0.553
85 | Claude 4 Opus (20250514)
86 | 0.757
87 | 0.859
88 | 0.666
89 | 0.918
90 | 0.833
91 | 0.511
92 | GPT-5 nano (2025-08-07)
93 | 0.748
94 | 0.778
95 | 0.679
96 | 0.932
97 | 0.806
98 | 0.547
99 | Gemini 2.5 Pro (03-25 preview)
100 | 0.745
101 | 0.863
102 | 0.749
103 | 0.84
104 | 0.857
105 | 0.416
106 | Claude 4 Sonnet (20250514)
107 | 0.733
108 | 0.843
109 | 0.643
110 | 0.839
111 | 0.825
112 | 0.513
113 | Grok 3 Beta
114 | 0.727
115 | 0.788
116 | 0.65
117 | 0.884
118 | 0.849
119 | 0.464
120 | GPT-4.1 (2025-04-14)
121 | 0.727
122 | 0.811
123 | 0.659
124 | 0.838
125 | 0.854
126 | 0.471
127 | Qwen3 235B A22B FP8 Throughput
128 | 0.726
129 | 0.817
130 | 0.623
131 | 0.816
132 | 0.828
133 | 0.548
134 | GPT-4.1 mini (2025-04-14)
135 | 0.726
136 | 0.783
137 | 0.614
138 | 0.904
139 | 0.838
140 | 0.491
141 | Llama 4 Maverick (17Bx128E) Instruct FP8
142 | 0.718
143 | 0.81
144 | 0.65
145 | 0.908
146 | 0.8
147 | 0.422
148 | Qwen3-Next 80B A3B Thinking
149 | 0.7
150 | 0.786
151 | 0.63
152 | 0.81
153 | 0.807
154 | 0.467
155 | DeepSeek-R1-0528
156 | 0.699
157 | 0.793
158 | 0.666
159 | 0.784
160 | 0.828
161 | 0.424
162 | Palmyra X5
163 | 0.696
164 | 0.804
165 | 0.661
166 | 0.823
167 | 0.78
168 | 0.415
169 | Grok 3 mini Beta
170 | 0.679
171 | 0.799
172 | 0.675
173 | 0.951
174 | 0.651
175 | 0.318
176 | Gemini 2.0 Flash
177 | 0.679
178 | 0.737
179 | 0.556
180 | 0.841
181 | 0.8
182 | 0.459
183 | Claude 3.7 Sonnet (20250219)
184 | 0.674
185 | 0.784
186 | 0.608
187 | 0.834
188 | 0.814
189 | 0.33
190 | gpt-oss-20b
191 | 0.674
192 | 0.74
193 | 0.594
194 | 0.732
195 | 0.737
196 | 0.565
197 | GLM-4.5-Air-FP8
198 | 0.67
199 | 0.762
200 | 0.594
201 | 0.812
202 | 0.789
203 | 0.391
204 | DeepSeek v3
205 | 0.665
206 | 0.723
207 | 0.538
208 | 0.832
209 | 0.831
210 | 0.403
211 | Gemini 1.5 Pro (002)
212 | 0.657
213 | 0.737
214 | 0.534
215 | 0.837
216 | 0.813
217 | 0.364
218 | Claude 3.5 Sonnet (20241022)
219 | 0.653
220 | 0.777
221 | 0.565
222 | 0.856
223 | 0.792
224 | 0.276
225 | Llama 4 Scout (17Bx16E) Instruct
226 | 0.644
227 | 0.742
228 | 0.507
229 | 0.818
230 | 0.779
231 | 0.373
232 | Gemini 2.0 Flash Lite (02-05 preview)
233 | 0.642
234 | 0.72
235 | 0.5
236 | 0.824
237 | 0.79
238 | 0.374
239 | Amazon Nova Premier
240 | 0.637
241 | 0.726
242 | 0.518
243 | 0.803
244 | 0.788
245 | 0.35
246 | GPT-4o (2024-11-20)
247 | 0.634
248 | 0.713
249 | 0.52
250 | 0.817
251 | 0.828
252 | 0.293
253 | Gemini 2.5 Flash (04-17 preview)
254 | 0.626
255 | 0.639
256 | 0.39
257 | 0.898
258 | 0.817
259 | 0.384
260 | Llama 3.1 Instruct Turbo (405B)
261 | 0.618
262 | 0.723
263 | 0.522
264 | 0.811
265 | 0.783
266 | 0.249
267 | GPT-4.1 nano (2025-04-14)
268 | 0.616
269 | 0.55
270 | 0.507
271 | 0.843
272 | 0.811
273 | 0.367
274 | Palmyra-X-004
275 | 0.609
276 | 0.657
277 | 0.395
278 | 0.872
279 | 0.802
280 | 0.32
281 | Gemini 1.5 Flash (002)
282 | 0.609
283 | 0.678
284 | 0.437
285 | 0.831
286 | 0.792
287 | 0.305
288 | Qwen2.5 Instruct Turbo (72B)
289 | 0.599
290 | 0.631
291 | 0.426
292 | 0.806
293 | 0.802
294 | 0.33
295 | Mistral Large (2411)
296 | 0.598
297 | 0.599
298 | 0.435
299 | 0.876
300 | 0.801
301 | 0.281
302 | Gemini 2.5 Flash-Lite
303 | 0.591
304 | 0.537
305 | 0.309
306 | 0.81
307 | 0.818
308 | 0.48
309 | Amazon Nova Pro
310 | 0.591
311 | 0.673
312 | 0.446
313 | 0.815
314 | 0.777
315 | 0.242
316 | Palmyra Fin
317 | 0.577
318 | 0.591
319 | 0.422
320 | 0.793
321 | 0.783
322 | 0.295
323 | IBM Granite 4.0 Small
324 | 0.575
325 | 0.569
326 | 0.383
327 | 0.89
328 | 0.739
329 | 0.296
330 | Llama 3.1 Instruct Turbo (70B)
331 | 0.574
332 | 0.653
333 | 0.426
334 | 0.821
335 | 0.758
336 | 0.21
337 | GPT-4o mini (2024-07-18)
338 | 0.565
339 | 0.603
340 | 0.368
341 | 0.782
342 | 0.791
343 | 0.28
344 | Mistral Small 3.1 (2503)
345 | 0.558
346 | 0.61
347 | 0.392
348 | 0.75
349 | 0.788
350 | 0.248
351 | Amazon Nova Lite
352 | 0.551
353 | 0.6
354 | 0.397
355 | 0.776
356 | 0.75
357 | 0.233
358 | Claude 3.5 Haiku (20241022)
359 | 0.549
360 | 0.605
361 | 0.363
362 | 0.792
363 | 0.76
364 | 0.224
365 | Qwen2.5 Instruct Turbo (7B)
366 | 0.529
367 | 0.539
368 | 0.341
369 | 0.741
370 | 0.731
371 | 0.294
372 | Amazon Nova Micro
373 | 0.522
374 | 0.511
375 | 0.383
376 | 0.76
377 | 0.743
378 | 0.214
379 | IBM Granite 4.0 Micro
380 | 0.486
381 | 0.395
382 | 0.307
383 | 0.849
384 | 0.67
385 | 0.209
386 | Mixtral Instruct (8x22B)
387 | 0.478
388 | 0.46
389 | 0.334
390 | 0.724
391 | 0.711
392 | 0.163
393 | Palmyra Med
394 | 0.476
395 | 0.411
396 | 0.368
397 | 0.767
398 | 0.676
399 | 0.156
400 | OLMo 2 32B Instruct March 2025
401 | 0.475
402 | 0.414
403 | 0.287
404 | 0.78
405 | 0.734
406 | 0.161
407 | IBM Granite 3.3 8B Instruct
408 | 0.463
409 | 0.343
410 | 0.325
411 | 0.729
412 | 0.741
413 | 0.176
414 | Llama 3.1 Instruct Turbo (8B)
415 | 0.444
416 | 0.406
417 | 0.247
418 | 0.743
419 | 0.686
420 | 0.137
421 | OLMo 2 13B Instruct November 2024
422 | 0.44
423 | 0.31
424 | 0.316
425 | 0.73
426 | 0.689
427 | 0.156
428 | OLMo 2 7B Instruct November 2024
429 | 0.405
430 | 0.292
431 | 0.296
432 | 0.693
433 | 0.628
434 | 0.116
435 | Mixtral Instruct (8x7B)
436 | 0.397
437 | 0.335
438 | 0.296
439 | 0.575
440 | 0.673
441 | 0.105
442 | Mistral Instruct v0.3 (7B)
443 | 0.376
444 | 0.277
445 | 0.303
446 | 0.567
447 | 0.66
448 | 0.072
449 | OLMoE 1B-7B Instruct January 2025
450 | 0.332
451 | 0.169
452 | 0.22
453 | 0.628
454 | 0.551
455 | 0.093
456 | Marin 8B Instruct
457 | 0.325
458 | 0.188
459 | 0.168
460 | 0.632
461 | 0.477
462 | 0.16
--------------------------------------------------------------------------------
/benchbench/data/helm/summarization.tsv:
--------------------------------------------------------------------------------
1 | Model Mean win rate CNN/DailyMail - SummaC CNN/DailyMail - QAFactEval CNN/DailyMail - BERTScore (F1) CNN/DailyMail - Coverage CNN/DailyMail - Density CNN/DailyMail - Compression CNN/DailyMail - HumanEval-faithfulness CNN/DailyMail - HumanEval-relevance CNN/DailyMail - HumanEval-coherence XSUM - SummaC XSUM - QAFactEval XSUM - BERTScore (F1) XSUM - Coverage XSUM - Density XSUM - Compression XSUM - HumanEval-faithfulness XSUM - HumanEval-relevance XSUM - HumanEval-coherence
2 | TNLG v2 (530B) 0.757 0.573 - 0.316 0.977 26.968 10.317 - - - -0.281 - 0.473 0.774 2.322 15.776 - - -
3 | Luminous Supreme (70B) 0.717 0.552 - 0.28 0.939 33.625 9.298 - - - -0.241 - 0.444 0.807 3.08 16.97 - - -
4 | Cohere xlarge v20221108 (52.4B) 0.704 0.514 - 0.286 0.971 44.772 8.026 - - - -0.258 - 0.451 0.798 3.009 17.188 - - -
5 | J1-Grande v2 beta (17B) 0.678 0.552 - 0.29 0.973 24.032 11.659 - - - -0.282 - 0.454 0.786 2.816 16.857 - - -
6 | Cohere Command beta (52.4B) 0.678 0.415 - 0.318 0.979 32.165 9.156 - - - -0.271 - 0.459 0.793 2.548 16.937 - - -
7 | Jurassic-2 Grande (17B) 0.671 0.503 - 0.299 0.96 22.305 11.399 - - - -0.289 - 0.475 0.766 2.36 17.045 - - -
8 | J1-Grande v1 (17B) 0.669 0.539 4.81 0.275 0.973 41.027 9.888 - - - -0.272 3.447 0.429 0.783 2.64 19.012 - - -
9 | J1-Large v1 (7.5B) 0.65 0.512 4.716 0.248 0.977 71.654 7.632 - - - -0.239 3.675 0.4 0.808 3.757 18.133 - - -
10 | text-babbage-001 0.646 0.378 4.676 0.282 0.972 45.948 5.291 - - - -0.057 4.33 0.281 0.885 8.487 11.856 - - -
11 | Jurassic-2 Jumbo (178B) 0.645 0.489 - 0.313 0.957 15.317 12.304 - - - -0.32 - 0.489 0.755 2.145 16.589 - - -
12 | text-davinci-002 0.641 0.353 4.635 0.321 0.946 15.995 8.818 0.999 4.435 4.371 -0.273 3.007 0.43 0.801 2.872 14.07 0.849 4.41 4.685
13 | text-curie-001 0.617 0.291 4.616 0.306 0.961 26.1 6.829 0.967 4.587 4.243 -0.185 3.459 0.354 0.839 4.008 12.98 0.991 4.068 4.321
14 | TNLG v2 (6.7B) 0.612 0.493 - 0.282 0.976 48.951 9.598 - - - -0.203 - 0.385 0.793 3.286 18.428 - - -
15 | OPT (175B) 0.593 0.202 4.67 0.276 0.933 31.307 9.8 1 4.378 3.233 -0.253 3.523 0.46 0.793 2.732 16.792 0.798 4.3 4.891
16 | J1-Jumbo v1 (178B) 0.587 0.515 4.697 0.278 0.976 53.93 9.579 - - - -0.287 3.182 0.435 0.784 2.63 16.862 - - -
17 | Cohere Command beta (6.1B) 0.579 0.331 - 0.296 0.975 31.707 9.688 - - - -0.239 - 0.418 0.824 2.793 18.017 - - -
18 | OPT (66B) 0.579 0.197 4.735 0.256 0.92 41.595 9.759 - - - -0.189 3.324 0.417 0.817 3.899 18.414 - - -
19 | Cohere large v20220720 (13.1B) 0.576 0.5 4.763 0.246 0.946 37.733 11.27 - - - -0.189 2.889 0.398 0.823 3.599 20.712 - - -
20 | Jurassic-2 Large (7.5B) 0.572 0.496 - 0.271 0.963 25.251 11.503 - - - -0.278 - 0.45 0.782 2.659 18.03 - - -
21 | Luminous Extended (30B) 0.566 0.481 - 0.255 0.925 41.619 9.039 - - - -0.225 - 0.423 0.818 3.507 17.376 - - -
22 | GPT-J (6B) 0.549 0.208 4.704 0.247 0.948 48.284 9.864 - - - -0.198 3.813 0.381 0.829 4.043 17.942 - - -
23 | Cohere xlarge v20220609 (52.4B) 0.546 0.469 4.683 0.264 0.945 49.713 9.072 0.993 4.539 3.69 -0.253 2.981 0.434 0.8 2.945 18.422 0.661 4.239 4.825
24 | Anthropic-LM v4-s3 (52B) 0.531 0.492 4.692 0.326 0.96 10.832 11.89 0.667 4 2.667 -0.271 3.066 0.437 0.808 2.691 15.182 0.778 4.398 4.898
25 | text-davinci-003 0.526 0.359 - 0.342 0.956 7.545 9.389 - - - -0.301 - 0.411 0.822 2.63 10.932 - - -
26 | Cohere medium v20221108 (6.1B) 0.507 0.359 - 0.218 0.899 24.344 11.42 - - - -0.171 - 0.384 0.842 3.815 19.703 - - -
27 | text-ada-001 0.486 0.223 3.369 0.247 0.929 31.424 5.461 - - - -0.102 4.929 0.245 0.847 7.626 13.08 - - -
28 | GLM (130B) 0.471 0.566 - 0.288 0.972 30.259 8.687 0.963 4.167 3.463 -0.206 - 0.427 0.817 4.041 16.25 0.763 3.843 4.25
29 | GPT-NeoX (20B) 0.446 0.165 4.69 0.226 0.91 37.149 9.676 - - - -0.208 3.303 0.391 0.825 3.371 18.238 - - -
30 | Cohere medium v20220720 (6.1B) 0.431 0.229 4.664 0.115 0.799 22.176 13.154 - - - -0.159 3.223 0.367 0.847 4.754 19.748 - - -
31 | Luminous Base (13B) 0.421 0.32 - 0.188 0.834 35.663 9.346 - - - -0.213 - 0.394 0.834 4.393 17.535 - - -
32 | davinci (175B) 0.36 0.321 4.062 0.182 0.873 17.914 9.843 0.953 4.501 3.863 -0.267 2.338 0.318 0.751 3.351 14.08 0.829 4.075 3.398
33 | curie (6.7B) 0.325 0.354 4.204 0.089 0.89 23.472 9.495 0.287 1.933 1.767 -0.143 3.922 0.313 0.815 5.57 17.018 0.924 3.573 4.166
34 | Cohere small v20220720 (410M) 0.292 0.054 2.638 0.026 0.744 25.238 13.243 - - - 0.028 3.094 0.195 0.863 10.557 17.551 - - -
35 | BLOOM (176B) 0.291 -0.02 4.665 0.08 0.71 32.013 5.252 - - - -0.35 4.778 0.059 0.515 1.764 8.934 - - -
36 | ada (350M) 0.231 0.169 3.742 0.026 0.773 36.596 12.07 - - - -0.115 0.009 -0.232 0.407 2.653 8.023 - - -
37 | babbage (1.3B) 0.196 0.194 3.207 -0.129 0.606 43.534 6.733 - - - -0.188 0.195 0.02 0.604 4.386 11.716 - - -
38 | UL2 (20B) 0.118 -0.27 - -0.121 0.72 5.044 7.186 - - - -0.275 - 0.072 0.643 3.208 7.853 - - -
39 | T5 (11B) 0.112 -0.122 - -0.17 0.555 2.698 19.248 - - - -0.258 - -0.315 0.355 0.831 16.544 - - -
40 | YaLM (100B) 0.045 -0.322 - -0.145 0.541 1.09 6.936 - - - -0.347 1.176 0.031 0.567 1.041 9.951 - - -
41 | T0pp (11B) - -0.044 - 0.155 0.841 8.588 8.274 - - - -0.3 - 0.097 0.579 1.684 11.178 - - -
42 | Pythia (6.9B) - - - - - - - - - - - - - - - - - - -
43 | Pythia (12B) - - - - - - - - - - - - - - - - - - -
44 | LLaMA (7B) - - - - - - - - - - - - - - - - - - -
45 | LLaMA (13B) - - - - - - - - - - - - - - - - - - -
46 | LLaMA (30B) - - - - - - - - - - - - - - - - - - -
47 | LLaMA (65B) - - - - - - - - - - - - - - - - - - -
48 | Llama 2 (7B) - - - - - - - - - - - - - - - - - - -
49 | Llama 2 (13B) - - - - - - - - - - - - - - - - - - -
50 | Llama 2 (70B) - - - - - - - - - - - - - - - - - - -
51 | Alpaca (7B) - - - - - - - - - - - - - - - - - - -
52 | Vicuna v1.3 (7B) - - - - - - - - - - - - - - - - - - -
53 | Vicuna v1.3 (13B) - - - - - - - - - - - - - - - - - - -
54 | Mistral v0.1 (7B) - - - - - - - - - - - - - - - - - - -
55 | gpt-3.5-turbo-0301 - - - - - - - - - - - - - - - - - - -
56 | gpt-3.5-turbo-0613 - - - - - - - - - - - - - - - - - - -
57 | RedPajama-INCITE-Base-v1 (3B) - - - - - - - - - - - - - - - - - - -
58 | RedPajama-INCITE-Instruct-v1 (3B) - - - - - - - - - - - - - - - - - - -
59 | RedPajama-INCITE-Base (7B) - - - - - - - - - - - - - - - - - - -
60 | RedPajama-INCITE-Instruct (7B) - - - - - - - - - - - - - - - - - - -
61 | MPT (30B) - - - - - - - - - - - - - - - - - - -
62 | MPT-Instruct (30B) - - - - - - - - - - - - - - - - - - -
63 | Falcon (7B) - - - - - - - - - - - - - - - - - - -
64 | Falcon-Instruct (7B) - - - - - - - - - - - - - - - - - - -
65 | Falcon (40B) - - - - - - - - - - - - - - - - - - -
66 | Falcon-Instruct (40B) - - - - - - - - - - - - - - - - - - -
67 | InstructPalmyra (30B) - - - - 0.972 28.97 7.901 - - - - - - 0.844 3.441 15.707 - - -
68 | Palmyra X (43B) - - - - 0.291 2.35 3.117 - - - - - - 0.775 2.466 14.252 - - -
69 |
70 |
--------------------------------------------------------------------------------
/benchbench/data/helm/fairness.tsv:
--------------------------------------------------------------------------------
1 | Model Mean win rate MMLU - EM (Fairness) BoolQ - EM (Fairness) NarrativeQA - F1 (Fairness) NaturalQuestions (closed-book) - F1 (Fairness) NaturalQuestions (open-book) - F1 (Fairness) QuAC - F1 (Fairness) HellaSwag - EM (Fairness) OpenbookQA - EM (Fairness) TruthfulQA - EM (Fairness) MS MARCO (regular) - RR@10 (Fairness) MS MARCO (TREC) - NDCG@10 (Fairness) IMDB - EM (Fairness) CivilComments - EM (Fairness) RAFT - EM (Fairness)
2 | Llama 2 (70B) 0.959 0.557 0.859 0.709 0.4 0.637 0.414 - - 0.434 - - 0.954 0.551 0.7
3 | LLaMA (65B) 0.924 0.551 0.847 0.661 0.375 0.633 0.333 - - 0.42 - - 0.953 0.574 0.668
4 | text-davinci-003 0.903 0.537 0.858 0.664 0.356 0.721 0.45 0.729 0.578 0.491 0.335 0.633 0.833 0.559 0.705
5 | Cohere Command beta (52.4B) 0.866 0.407 0.822 0.657 0.296 0.706 0.316 0.699 0.508 0.222 0.45 0.748 0.957 0.544 0.627
6 | text-davinci-002 0.864 0.531 0.837 0.646 0.32 0.659 0.353 0.703 0.54 0.515 0.373 0.639 0.934 0.463 0.671
7 | Mistral v0.1 (7B) 0.861 0.542 0.842 0.644 0.3 0.625 0.353 - - 0.332 - - 0.952 0.52 0.664
8 | Jurassic-2 Jumbo (178B) 0.836 0.45 0.792 0.658 0.327 0.62 0.34 0.655 0.488 0.354 0.342 0.62 0.933 0.507 0.711
9 | LLaMA (30B) 0.822 0.496 0.813 0.657 0.356 0.621 0.325 - - 0.266 - - 0.913 0.508 0.718
10 | Llama 2 (13B) 0.808 0.466 0.732 0.657 0.309 0.58 0.351 - - 0.274 - - 0.957 0.489 0.673
11 | Palmyra X (43B) 0.797 0.588 0.875 0.651 0.362 - 0.399 - - 0.542 - - 0.918 0.006 0.672
12 | Anthropic-LM v4-s3 (52B) 0.794 0.447 0.782 0.646 0.239 0.642 0.356 0.695 0.482 0.3 - - 0.925 0.512 0.67
13 | TNLG v2 (530B) 0.752 0.418 0.767 0.632 0.318 0.598 0.313 0.678 0.504 0.197 0.341 0.612 0.936 0.48 0.644
14 | MPT (30B) 0.746 0.41 0.631 0.653 0.287 0.624 0.318 - - 0.19 - - 0.955 0.553 0.68
15 | gpt-3.5-turbo-0613 0.718 0.313 0.817 0.547 0.287 0.627 0.398 - - 0.255 - - 0.912 0.525 0.641
16 | Vicuna v1.3 (13B) 0.715 0.424 0.748 0.607 0.266 0.63 0.324 - - 0.315 - - 0.707 0.569 0.62
17 | Falcon-Instruct (40B) 0.709 0.466 0.799 0.543 0.331 0.607 0.308 - - 0.312 - - 0.957 0.462 0.561
18 | Jurassic-2 Grande (17B) 0.704 0.433 0.78 0.645 0.283 0.584 0.34 0.632 0.466 0.29 0.243 0.471 0.931 0.445 0.689
19 | MPT-Instruct (30B) 0.687 0.4 0.807 0.633 0.233 0.639 0.252 - - 0.18 - - 0.944 0.527 0.636
20 | Falcon (40B) 0.686 0.48 0.783 0.559 0.338 0.625 0.256 - - 0.292 - - 0.954 0.292 0.611
21 | J1-Grande v2 beta (17B) 0.677 0.409 0.764 0.647 0.27 0.571 0.308 0.623 0.478 0.242 0.253 0.435 0.95 0.404 0.637
22 | Cohere Command beta (6.1B) 0.662 0.366 0.748 0.595 0.167 0.654 0.273 0.608 0.468 0.163 0.411 0.69 0.95 0.496 0.609
23 | gpt-3.5-turbo-0301 0.662 0.53 0.666 0.585 0.331 0.559 0.417 - - 0.514 - - 0.844 0.422 0.689
24 | OPT (175B) 0.622 0.287 0.731 0.573 0.246 0.561 0.266 0.66 0.5 0.203 0.26 0.419 0.944 0.491 0.58
25 | Vicuna v1.3 (7B) 0.622 0.385 0.67 0.553 0.224 0.575 0.304 - - 0.235 - - 0.906 0.564 0.643
26 | Llama 2 (7B) 0.61 0.392 0.706 0.596 0.264 0.55 0.321 - - 0.223 - - 0.871 0.503 0.609
27 | Cohere xlarge v20221108 (52.4B) 0.608 0.317 0.708 0.553 0.299 0.566 0.275 0.687 0.5 0.12 0.267 0.522 0.949 0.415 0.604
28 | LLaMA (13B) 0.602 0.385 0.666 0.628 0.288 0.561 0.267 - - 0.234 - - 0.903 0.533 0.605
29 | davinci (175B) 0.558 0.38 0.682 0.597 0.276 0.567 0.279 0.641 0.502 0.155 0.185 0.357 0.921 0.478 0.605
30 | LLaMA (7B) 0.553 0.284 0.71 0.552 0.241 0.537 0.257 - - 0.219 - - 0.936 0.505 0.545
31 | BLOOM (176B) 0.551 0.274 0.656 0.577 0.187 0.575 0.273 0.585 0.482 0.186 0.211 0.371 0.938 0.546 0.563
32 | Cohere xlarge v20220609 (52.4B) 0.55 0.315 0.667 0.548 0.255 0.535 0.281 0.66 0.47 0.156 0.233 0.431 0.949 0.479 0.598
33 | InstructPalmyra (30B) 0.538 0.371 0.7 0.405 0.276 0.63 0.337 - - 0.152 - - 0.931 0.449 0.618
34 | Luminous Supreme (70B) 0.522 0.264 0.694 0.603 0.241 0.597 0.288 - - 0.132 - - 0.949 0.432 0.601
35 | GLM (130B) 0.513 0.315 0.69 0.615 0.12 0.597 0.205 - - 0.192 - - 0.933 0.5 0.575
36 | J1-Jumbo v1 (178B) 0.488 0.236 0.709 0.581 0.235 0.54 0.268 0.614 0.466 0.156 0.18 0.348 0.932 0.478 0.623
37 | Jurassic-2 Large (7.5B) 0.483 0.297 0.685 - 0.217 0.539 - 0.567 0.45 0.196 0.215 0.44 0.945 0.403 0.567
38 | OPT (66B) 0.476 0.229 0.71 0.526 0.218 0.536 0.268 0.597 0.454 0.173 0.214 0.471 0.908 0.5 0.536
39 | RedPajama-INCITE-Instruct (7B) 0.466 0.305 0.616 0.506 0.164 0.592 0.181 - - 0.183 - - 0.907 0.54 0.67
40 | J1-Grande v1 (17B) 0.454 0.232 0.678 0.547 0.187 0.521 0.274 0.58 0.472 0.163 0.138 0.328 0.946 0.482 0.636
41 | Luminous Extended (30B) 0.451 0.237 0.711 0.532 0.214 0.551 0.277 - - 0.16 - - 0.937 0.462 0.489
42 | Falcon (7B) 0.447 0.261 0.702 0.52 0.233 0.537 0.262 - - 0.213 - - 0.794 0.494 0.555
43 | text-curie-001 0.377 0.231 0.576 0.463 0.132 0.5 0.255 0.534 0.452 0.239 0.244 0.482 0.91 0.471 0.458
44 | Alpaca (7B) 0.372 0.346 0.729 0.299 0.21 0.53 0.204 - - 0.202 - - 0.699 0.483 0.459
45 | RedPajama-INCITE-Instruct-v1 (3B) 0.369 0.222 0.648 0.506 0.143 0.571 0.183 - - 0.179 - - 0.876 0.499 0.632
46 | Cohere large v20220720 (13.1B) 0.362 0.281 0.676 0.512 0.178 0.507 0.256 0.575 0.446 0.157 0.164 0.312 0.92 0.443 0.564
47 | Cohere medium v20221108 (6.1B) 0.34 0.22 0.642 0.497 0.149 0.45 0.229 0.567 0.44 0.182 0.145 0.353 0.917 0.493 0.571
48 | GPT-NeoX (20B) 0.331 0.215 0.609 0.461 0.154 0.525 0.232 0.552 0.438 0.179 0.148 0.381 0.928 0.491 0.475
49 | RedPajama-INCITE-Base (7B) 0.323 0.276 0.65 0.524 0.193 0.514 0.238 - - 0.17 - - 0.694 0.431 0.595
50 | Falcon-Instruct (7B) 0.297 0.261 0.637 0.354 0.148 0.383 0.219 - - 0.183 - - 0.811 0.502 0.5
51 | TNLG v2 (6.7B) 0.291 0.212 0.665 0.517 0.162 0.501 0.267 0.53 0.412 0.144 0.14 0.317 0.912 0.473 0.502
52 | GPT-J (6B) 0.29 0.22 0.639 0.433 0.122 0.493 0.249 0.486 0.416 0.18 0.129 0.332 0.927 0.488 0.594
53 | J1-Large v1 (7.5B) 0.275 0.204 0.622 0.513 0.146 0.47 0.241 0.528 0.444 0.174 0.117 0.28 0.946 0.447 0.511
54 | RedPajama-INCITE-Base-v1 (3B) 0.27 0.232 0.624 0.42 0.145 0.452 0.238 - - 0.248 - - 0.89 0.393 0.475
55 | Cohere medium v20220720 (6.1B) 0.269 0.237 0.597 0.438 0.126 0.432 0.198 0.525 0.42 0.174 0.132 0.357 0.918 0.489 0.5
56 | text-babbage-001 0.244 0.205 0.41 0.299 0.053 0.24 0.196 0.405 0.386 0.207 0.174 0.424 0.887 0.499 0.475
57 | Luminous Base (13B) 0.238 0.185 0.653 0.498 0.16 0.511 0.266 - - 0.125 - - 0.912 0.397 0.445
58 | curie (6.7B) 0.231 0.218 0.594 0.482 0.147 0.479 0.243 0.522 0.43 0.186 0.14 0.284 0.86 0.412 0.473
59 | Pythia (12B) 0.226 0.212 0.547 0.449 0.131 0.523 0.227 - - 0.154 - - 0.916 0.448 0.489
60 | T0pp (11B) 0.203 0.382 0 0.086 0.028 0.136 0.067 - - 0.35 - - 0.168 0.165 0.106
61 | UL2 (20B) 0.186 0.273 0.698 0.053 0.162 0.303 0.107 - - 0.162 - - 0.271 0.423 0.375
62 | Pythia (6.9B) 0.171 0.207 0.552 0.389 0.103 0.464 0.198 - - 0.18 - - 0.911 0.333 0.45
63 | YaLM (100B) 0.167 0.243 0.583 0.146 0.052 0.177 0.1 - - 0.202 - - 0.8 0.456 0.342
64 | Cohere small v20220720 (410M) 0.154 0.222 0.374 0.179 0.055 0.219 0.144 0.308 0.28 0.203 - 0.28 0.518 0.495 0.452
65 | T5 (11B) 0.15 0.235 0.723 0.05 0.159 0.424 0.074 - - 0.101 - - 0.303 0.329 0.351
66 | babbage (1.3B) 0.134 0.206 0.436 0.367 0.084 0.381 0.202 0.401 0.326 0.178 0.105 0.301 0.534 0.474 0.438
67 | text-ada-001 0.108 0.202 0.378 0.119 0.012 0.083 0.091 0.27 0.266 0.191 0.107 0.276 0.769 0.497 0.376
68 | ada (350M) 0.105 0.21 0.507 0.205 0.057 0.273 0.166 0.294 0.318 0.185 0.086 0.268 0.806 0.436 0.395
69 |
70 |
--------------------------------------------------------------------------------
/benchbench/data/helm/robustness.tsv:
--------------------------------------------------------------------------------
1 | Model Mean win rate MMLU - EM (Robustness) BoolQ - EM (Robustness) NarrativeQA - F1 (Robustness) NaturalQuestions (closed-book) - F1 (Robustness) NaturalQuestions (open-book) - F1 (Robustness) QuAC - F1 (Robustness) HellaSwag - EM (Robustness) OpenbookQA - EM (Robustness) TruthfulQA - EM (Robustness) MS MARCO (regular) - RR@10 (Robustness) MS MARCO (TREC) - NDCG@10 (Robustness) IMDB - EM (Robustness) CivilComments - EM (Robustness) RAFT - EM (Robustness)
2 | Llama 2 (70B) 0.965 0.545 0.863 0.722 0.42 0.639 0.362 - - 0.468 - - 0.949 0.59 0.673
3 | text-davinci-002 0.916 0.525 0.841 0.638 0.299 0.665 0.319 0.776 0.52 0.547 0.344 0.628 0.925 0.567 0.666
4 | text-davinci-003 0.91 0.517 0.858 0.694 0.369 0.73 0.42 0.798 0.572 0.516 0.304 0.616 0.779 0.594 0.714
5 | Mistral v0.1 (7B) 0.896 0.533 0.837 0.649 0.305 0.631 0.31 - - 0.339 - - 0.954 0.521 0.652
6 | LLaMA (65B) 0.885 0.504 0.84 0.567 0.388 0.624 0.275 - - 0.448 - - 0.935 0.566 0.655
7 | Cohere Command beta (52.4B) 0.85 0.387 0.811 0.57 0.289 0.679 0.238 0.774 0.492 0.229 0.434 0.734 0.933 0.535 0.599
8 | Llama 2 (13B) 0.823 0.444 0.753 0.682 0.324 0.563 0.294 - - 0.287 - - 0.954 0.47 0.652
9 | Palmyra X (43B) 0.821 0.566 0.878 0.672 0.363 - 0.383 - - 0.568 - - 0.904 0.006 0.677
10 | Anthropic-LM v4-s3 (52B) 0.818 0.434 0.756 0.663 0.245 0.632 0.313 0.766 0.472 0.326 - - 0.928 0.514 0.6
11 | gpt-3.5-turbo-0301 0.816 0.525 0.66 0.602 0.327 0.556 0.411 - - 0.566 - - 0.857 0.605 0.705
12 | LLaMA (30B) 0.815 0.461 0.791 0.611 0.36 0.612 0.273 - - 0.281 - - 0.893 0.503 0.67
13 | Jurassic-2 Jumbo (178B) 0.791 0.417 0.729 0.66 0.315 0.599 0.314 0.754 0.47 0.39 0.337 0.607 0.896 0.449 0.69
14 | Jurassic-2 Grande (17B) 0.764 0.411 0.729 0.583 0.285 0.564 0.276 0.755 0.474 0.293 0.227 0.423 0.928 0.488 0.618
15 | Falcon-Instruct (40B) 0.763 0.446 0.781 0.508 0.335 0.591 0.212 - - 0.338 - - 0.938 0.523 0.523
16 | gpt-3.5-turbo-0613 0.762 0.262 0.845 0.566 0.284 0.606 0.371 - - 0.187 - - 0.916 0.564 0.677
17 | Vicuna v1.3 (13B) 0.732 0.413 0.757 0.525 0.273 0.621 0.247 - - 0.341 - - 0.674 0.593 0.591
18 | J1-Grande v2 beta (17B) 0.711 0.392 0.692 0.565 0.235 0.56 0.251 0.732 0.474 0.252 0.222 0.407 0.947 0.495 0.555
19 | Falcon (40B) 0.705 0.457 0.763 0.557 0.329 0.593 0.162 - - 0.303 - - 0.935 0.412 0.586
20 | MPT (30B) 0.697 0.381 0.656 0.584 0.272 0.609 0.231 - - 0.177 - - 0.942 0.484 0.58
21 | Vicuna v1.3 (7B) 0.662 0.371 0.672 0.5 0.214 0.539 0.25 - - 0.258 - - 0.882 0.543 0.6
22 | MPT-Instruct (30B) 0.656 0.383 0.77 0.623 0.202 0.607 0.204 - - 0.177 - - 0.942 0.408 0.548
23 | TNLG v2 (530B) 0.65 0.403 0.733 0.319 0.307 0.525 0.194 0.757 0.476 0.202 0.287 0.565 0.921 0.409 0.545
24 | GLM (130B) 0.647 0.32 0.728 0.629 0.117 0.6 0.193 - - 0.196 - - 0.938 0.5 0.577
25 | Llama 2 (7B) 0.644 0.373 0.676 0.573 0.261 0.501 0.271 - - 0.234 - - 0.808 0.516 0.573
26 | LLaMA (13B) 0.637 0.37 0.67 0.544 0.272 0.556 0.194 - - 0.274 - - 0.875 0.529 0.559
27 | Cohere Command beta (6.1B) 0.616 0.334 0.725 0.529 0.163 0.605 0.17 0.696 0.448 0.171 0.387 0.685 0.921 0.468 0.552
28 | Cohere xlarge v20221108 (52.4B) 0.596 0.299 0.718 0.39 0.283 0.533 0.229 0.764 0.482 0.116 0.242 0.482 0.923 0.408 0.489
29 | LLaMA (7B) 0.568 0.268 0.688 0.485 0.222 0.519 0.223 - - 0.229 - - 0.897 0.492 0.486
30 | Luminous Supreme (70B) 0.546 0.255 0.665 0.59 0.252 0.586 0.233 - - 0.106 - - 0.932 0.263 0.564
31 | BLOOM (176B) 0.541 0.25 0.642 0.53 0.185 0.558 0.234 0.699 0.438 0.183 0.19 0.333 0.92 0.467 0.527
32 | Jurassic-2 Large (7.5B) 0.527 0.263 0.607 - 0.187 0.503 - 0.687 0.448 0.21 0.177 0.397 0.941 0.469 0.498
33 | InstructPalmyra (30B) 0.522 0.348 0.656 0.317 0.267 0.567 0.248 - - 0.151 - - 0.906 0.443 0.518
34 | OPT (175B) 0.519 0.27 0.623 0.409 0.208 0.408 0.2 0.744 0.488 0.205 0.235 0.408 0.919 0.184 0.48
35 | davinci (175B) 0.509 0.34 0.639 0.498 0.256 0.521 0.208 0.738 0.474 0.145 0.154 0.332 0.873 0.461 0.505
36 | Cohere xlarge v20220609 (52.4B) 0.506 0.29 0.614 0.383 0.238 0.471 0.215 0.759 0.448 0.151 0.207 0.397 0.923 0.32 0.563
37 | RedPajama-INCITE-Instruct (7B) 0.495 0.291 0.599 0.482 0.137 0.547 0.164 - - 0.197 - - 0.82 0.527 0.605
38 | J1-Jumbo v1 (178B) 0.452 0.221 0.65 0.523 0.179 0.503 0.222 0.726 0.43 0.154 0.144 0.307 0.923 0.271 0.555
39 | OPT (66B) 0.438 0.216 0.683 0.397 0.206 0.458 0.199 0.699 0.45 0.174 0.179 0.437 0.886 0.305 0.405
40 | Luminous Extended (30B) 0.43 0.23 0.659 0.513 0.212 0.524 0.193 - - 0.151 - - 0.92 0.368 0.436
41 | Falcon (7B) 0.425 0.236 0.65 0.436 0.185 0.489 0.164 - - 0.205 - - 0.692 0.485 0.516
42 | J1-Grande v1 (17B) 0.423 0.225 0.643 0.477 0.17 0.478 0.219 0.695 0.424 0.142 0.121 0.297 0.941 0.417 0.513
43 | RedPajama-INCITE-Instruct-v1 (3B) 0.387 0.218 0.629 0.403 0.132 0.536 0.137 - - 0.173 - - 0.852 0.506 0.548
44 | Alpaca (7B) 0.379 0.324 0.643 0.246 0.203 0.491 0.16 - - 0.199 - - 0.561 0.482 0.42
45 | Cohere large v20220720 (13.1B) 0.345 0.253 0.545 0.357 0.172 0.347 0.204 0.687 0.43 0.154 0.13 0.257 0.902 0.333 0.49
46 | text-curie-001 0.337 0.22 0.549 0.34 0.121 0.415 0.169 0.625 0.424 0.235 0.198 0.444 0.881 0.129 0.399
47 | GPT-NeoX (20B) 0.336 0.189 0.551 0.421 0.133 0.452 0.191 0.661 0.414 0.175 0.096 0.351 0.912 0.48 0.399
48 | RedPajama-INCITE-Base (7B) 0.331 0.25 0.569 0.424 0.167 0.472 0.186 - - 0.173 - - 0.56 0.401 0.489
49 | Luminous Base (13B) 0.319 0.183 0.655 0.476 0.163 0.491 0.185 - - 0.112 - - 0.887 0.416 0.402
50 | Falcon-Instruct (7B) 0.303 0.25 0.593 0.258 0.132 0.327 0.179 - - 0.17 - - 0.759 0.487 0.445
51 | J1-Large v1 (7.5B) 0.298 0.2 0.567 0.4 0.098 0.41 0.197 0.646 0.412 0.155 0.105 0.248 0.932 0.444 0.443
52 | RedPajama-INCITE-Base-v1 (3B) 0.293 0.217 0.585 0.346 0.134 0.396 0.177 - - 0.226 - - 0.843 0.336 0.427
53 | GPT-J (6B) 0.291 0.217 0.621 0.135 0.099 0.228 0.147 0.619 0.398 0.181 0.116 0.319 0.903 0.418 0.53
54 | Pythia (12B) 0.272 0.22 0.51 0.42 0.108 0.47 0.171 - - 0.138 - - 0.854 0.418 0.45
55 | Cohere medium v20221108 (6.1B) 0.27 0.207 0.54 0.296 0.105 0.222 0.152 0.687 0.414 0.17 0.13 0.314 0.888 0.353 0.502
56 | UL2 (20B) 0.257 0.272 0.646 0.059 0.141 0.291 0.111 - - 0.178 - - 0.276 0.45 0.349
57 | TNLG v2 (6.7B) 0.24 0.169 0.638 0.352 0.149 0.299 0.159 0.656 0.408 0.136 0.105 0.278 0.896 0.336 0.445
58 | curie (6.7B) 0.231 0.19 0.545 0.367 0.126 0.338 0.171 0.632 0.396 0.186 0.11 0.253 0.803 0.347 0.413
59 | T0pp (11B) 0.228 0.378 0 0.099 0.031 0.122 0.071 - - 0.365 - - 0.17 0.087 0.085
60 | text-babbage-001 0.226 0.186 0.384 0.126 0.04 0.151 0.087 0.468 0.39 0.195 0.122 0.356 0.844 0.499 0.383
61 | YaLM (100B) 0.205 0.243 0.566 0.088 0.047 0.125 0.08 - - 0.202 - - 0.719 0.463 0.211
62 | Cohere medium v20220720 (6.1B) 0.188 0.184 0.562 0.3 0.102 0.266 0.144 0.651 0.382 0.149 0.109 0.315 0.889 0.136 0.385
63 | Pythia (6.9B) 0.182 0.201 0.527 0.313 0.094 0.391 0.171 - - 0.139 - - 0.871 0.363 0.377
64 | T5 (11B) 0.164 0.258 0.65 0.045 0.153 0.071 0.064 - - 0.122 - - 0.304 0.392 0.331
65 | Cohere small v20220720 (410M) 0.147 0.226 0.361 0.078 0.025 0.074 0.098 0.405 0.238 0.204 - 0.252 0.473 0.434 0.403
66 | babbage (1.3B) 0.117 0.166 0.477 0.255 0.068 0.212 0.149 0.489 0.314 0.162 0.073 0.246 0.5 0.4 0.409
67 | text-ada-001 0.105 0.178 0.332 0.058 0.008 0.034 0.067 0.32 0.248 0.175 0.069 0.252 0.716 0.491 0.335
68 | ada (350M) 0.102 0.204 0.461 0.104 0.031 0.043 0.092 0.37 0.27 0.167 0.072 0.247 0.701 0.421 0.345
69 |
70 |
--------------------------------------------------------------------------------
/benchbench/data/mteb/leaderboard.tsv:
--------------------------------------------------------------------------------
1 | Rank Model - Model Size (GB) Embedding Dimensions Max Tokens Average (56 datasets) Classification Average (12 datasets) Clustering Average (11 datasets) Pair Classification Average (3 datasets) Reranking Average (4 datasets) Retrieval Average (15 datasets) STS Average (10 datasets) Summarization Average (1 dataset)
2 | 1 SFR-Embedding-Mistral - 14.22 4096 32768 67.56 78.33 51.67 88.54 60.64 59 85.05 31.16
3 | 2 voyage-lite-02-instruct - - 1024 4000 67.13 79.25 52.42 86.87 58.24 56.6 85.79 31.01
4 | 3 e5-mistral-7b-instruct - 14.22 4096 32768 66.63 78.47 50.26 88.34 60.21 56.89 84.63 31.4
5 | 4 UAE-Large-V1 - 1.34 1024 512 64.64 75.58 46.73 87.25 59.88 54.66 84.54 32.03
6 | 5 text-embedding-3-large - - 3072 8191 64.59 75.45 49.01 85.72 59.16 55.44 81.73 29.92
7 | 6 voyage-lite-01-instruct - - 1024 4000 64.49 74.79 47.4 86.57 59.74 55.58 82.93 30.97
8 | 7 Cohere-embed-english-v3.0 - - 1024 512 64.47 76.49 47.43 85.84 58.01 55 82.62 30.18
9 | 8 bge-large-en-v1.5 - 1.34 1024 512 64.23 75.97 46.08 87.12 60.03 54.29 83.11 31.61
10 | 9 Cohere-embed-multilingual-v3.0 - - 1024 512 64.01 76.01 46.6 86.15 57.86 53.84 83.15 30.99
11 | 10 GIST-Embedding-v0 - 0.44 768 512 63.71 76.03 46.21 86.32 59.37 52.31 83.51 30.87
12 | 11 bge-base-en-v1.5 - 0.44 768 512 63.55 75.53 45.77 86.55 58.86 53.25 82.4 31.07
13 | 12 ember-v1 - 1.34 1024 512 63.54 75.99 45.58 87.37 60.04 51.92 83.34 30.82
14 | 13 sf_model_e5 - 1.34 1024 512 63.34 73.96 46.61 86.85 59.86 51.8 83.85 31.61
15 | 14 gte-large - 0.67 1024 512 63.13 73.33 46.84 85 59.13 52.22 83.35 31.66
16 | 15 stella-base-en-v2 - 0.22 768 512 62.61 75.28 44.9 86.45 58.78 50.1 83.02 32.52
17 | 16 gte-base - 0.22 768 512 62.39 73.01 46.2 84.57 58.61 51.14 82.3 31.17
18 | 17 text-embedding-3-small - - 1536 8191 62.26 73.21 46.65 85.04 56.72 51.08 81.58 31.12
19 | 18 e5-large-v2 - 1.34 1024 512 62.25 75.24 44.49 86.03 56.61 50.56 82.05 30.19
20 | 19 bge-small-en-v1.5 - 0.13 384 512 62.17 74.14 43.82 84.92 58.36 51.68 81.59 30.12
21 | 20 Cohere-embed-english-light-v3.0 - - 384 512 62.01 74.31 44.64 85.05 56.09 51.34 80.92 31.29
22 | 21 text-embedding-3-large-256 - - 256 8191 62 71.97 46.23 84.22 57.99 51.66 81.04 29.92
23 | 22 instructor-xl - 4.96 768 512 61.79 73.12 44.74 86.62 57.29 49.26 83.06 32.32
24 | 23 instructor-large - 1.34 768 512 61.59 73.86 45.29 85.89 57.54 47.57 83.15 31.84
25 | 24 e5-base-v2 - 0.44 768 512 61.5 73.84 43.8 85.73 55.91 50.29 81.05 30.28
26 | 25 multilingual-e5-large - 2.24 1024 514 61.5 74.81 41.06 84.75 55.86 51.43 81.56 29.69
27 | 26 e5-large - 1.34 1024 512 61.42 73.14 43.33 85.94 56.53 49.99 82.06 30.97
28 | 27 gte-small - 0.07 384 512 61.36 72.31 44.89 83.54 57.7 49.46 82.07 30.42
29 | 28 text-embedding-ada-002 - - 1536 8191 60.99 70.93 45.9 84.89 56.32 49.25 80.97 30.8
30 | 29 udever-bloom-7b1 - 28.28 4096 2048 60.63 72.13 40.81 85.4 55.91 49.34 83.01 30.97
31 | 30 e5-base - 0.44 768 512 60.44 72.63 42.11 85.09 55.7 48.75 80.96 31.01
32 | 31 jina-embeddings-v2-base-en - - - - 60.38 73.45 41.73 85.38 56.98 47.87 80.7 31.6
33 | 32 Cohere-embed-multilingual-light-v3.0 - - 384 512 60.08 70.57 41.98 83.95 55.06 50.15 80.09 30.41
34 | 33 e5-small-v2 - 0.13 384 512 59.93 72.94 39.92 84.67 54.32 49.04 80.39 31.16
35 | 34 udever-bloom-3b - 12.01 2560 2048 59.86 71.91 40.74 84.06 54.9 47.67 82.37 30.62
36 | 35 instructor-base - 0.44 768 512 59.54 72.36 41.9 83.51 56.2 45.12 82.29 29.85
37 | 36 sentence-t5-xxl - 9.73 768 512 59.51 73.42 43.72 85.06 56.42 42.24 82.63 30.08
38 | 37 multilingual-e5-base - 1.11 768 514 59.45 73.02 37.89 83.57 54.84 48.88 80.26 30.11
39 | 38 XLM-3B5-embedding - - - - 59.29 72.25 43.48 79.23 57.12 44.99 80.47 29.02
40 | 39 gtr-t5-xxl - 9.73 768 512 58.97 67.41 42.42 86.12 56.66 48.48 78.38 30.64
41 | 40 SGPT-5.8B-weightedmean-msmarco-specb-bitfit - 23.5 4096 2048 58.93 68.13 40.34 82 56.56 50.25 78.1 31.46
42 | 41 e5-small - 0.13 384 512 58.89 71.67 39.51 85.08 54.45 46.01 80.87 31.39
43 | 42 gte-tiny - 0.05 384 512 58.69 70.35 42.09 82.83 55.77 44.92 80.46 29.47
44 | 43 gtr-t5-xl - 2.48 768 512 58.42 67.11 41.51 86.13 55.96 47.96 77.8 30.21
45 | 44 udever-bloom-1b1 - 4.26 1536 2048 58.29 70.17 39.11 83.11 54.28 45.27 81.52 31.1
46 | 45 gtr-t5-large - 0.67 768 512 58.28 67.14 41.6 85.32 55.36 47.42 78.19 29.5
47 | 46 jina-embeddings-v2-small-en - - - - 58 68.82 40.08 84.44 55.09 45.14 80 30.56
48 | 47 XLM-0B6-embedding - - - - 57.97 70.55 42.97 77.83 55.6 43.39 79.02 30.25
49 | 48 multilingual-e5-small - 0.47 384 512 57.87 70.74 37.08 82.59 53.87 46.64 79.1 29.98
50 | 49 sentence-t5-xl - 2.48 768 512 57.87 72.84 42.34 86.06 54.71 38.47 81.66 29.91
51 | 50 all-mpnet-base-v2 - 0.44 768 514 57.78 65.07 43.69 83.04 59.36 43.81 80.28 27.49
52 | 51 sgpt-bloom-7b1-msmarco - 28.27 4096 2048 57.59 66.19 38.93 81.9 55.65 48.22 77.74 33.6
53 | 52 jina-embedding-l-en-v1 - 1.34 1024 512 57.38 67.76 37.15 84.8 56.42 44.81 80.96 29.85
54 | 53 SGPT-2.7B-weightedmean-msmarco-specb-bitfit - 10.74 2560 2048 57.17 67.13 39.83 80.65 54.67 46.54 76.83 31.03
55 | 54 sentence-t5-large - 0.67 768 512 57.06 72.31 41.65 84.97 54 36.71 81.83 29.64
56 | 55 MegatronBert-1B3-embedding - - - - 56.81 69.65 40.86 76.9 55.5 41.41 79.11 31.01
57 | 56 bge-micro-v2 - 0.03 384 512 56.57 68.04 39.18 82.81 54.29 42.56 78.65 29.87
58 | 57 all-MiniLM-L12-v2 - 0.13 384 512 56.53 63.21 41.81 82.41 58.44 42.69 79.8 27.9
59 | 58 all-MiniLM-L6-v2 - 0.09 384 512 56.26 63.05 42.35 82.37 58.04 41.95 78.9 30.81
60 | 59 jina-embedding-b-en-v1 - 0.44 768 512 56.26 66.07 35.88 83.04 55.84 44.03 79.93 30.71
61 | 60 SGPT-1.3B-weightedmean-msmarco-specb-bitfit - 5.36 2048 2048 56.2 66.52 39.92 79.58 54 44.49 75.74 30.43
62 | 61 gtr-t5-base - 0.22 768 512 56.19 65.25 38.63 83.85 54.23 44.67 77.07 29.67
63 | 62 contriever-base-msmarco - 0.44 768 512 56 66.68 41.1 82.54 53.14 41.88 76.51 30.36
64 | 63 udever-bloom-560m - 2.24 1024 2048 55.81 68.04 36.89 81.05 52.6 41.19 79.93 32.06
65 | 64 bge-micro - 0.03 384 512 55.71 66.35 39.46 81.77 54.28 40.82 78.37 31.16
66 | 65 sentence-t5-base - 0.22 768 512 55.27 69.81 40.21 85.18 53.09 33.63 81.14 31.39
67 | 66 bge-small-4096 - 0.14 384 4096 54.42 67.8 38.03 81.4 53.64 36.08 78.59 29.83
68 | 67 lodestone-base-4096-v1 - 0.27 768 4096 54.24 67.3 40.9 80.4 53.95 36.99 73.7 31.23
69 | 68 SGPT-5.8B-weightedmean-nli-bitfit - 23.5 4096 2048 53.74 70.14 36.98 77.03 52.33 32.34 80.53 30.38
70 | 69 multi-qa-MiniLM-L6-cos-v1 - - 384 512 53.29 61.67 35.67 80.86 54.58 41.17 74.23 31.05
71 | 70 msmarco-bert-co-condensor - 0.44 768 512 52.35 64.71 37.64 81.74 51.84 32.96 76.47 29.5
72 | 71 jina-embedding-s-en-v1 - 0.14 512 512 52.33 60.56 32.56 79.22 53.07 38.91 78.06 31.25
73 | 72 SGPT-125M-weightedmean-msmarco-specb-bitfit - 0.55 768 2048 51.25 60.72 35.79 75.23 50.58 37.04 73.41 29.71
74 | 73 text-similarity-ada-001 - - 1024 2046 49.52 70.44 37.52 76.86 49.02 18.36 78.6 26.94
75 | 74 sup-simcse-bert-base-uncased - 0.44 768 512 48.87 67.32 33.43 73.68 47.54 21.82 79.12 31.17
76 | 75 SGPT-125M-weightedmean-nli-bitfit - 0.55 768 2048 45.97 61.46 30.95 71.78 47.56 20.9 74.71 30.26
77 | 76 unsup-simcse-bert-base-uncased - 0.44 768 512 45.45 62.5 29.04 70.33 46.47 20.29 74.33 31.15
78 | 77 LaBSE - 1.88 768 512 45.21 62.71 29.55 78.87 48.42 18.99 70.8 31.05
79 | 78 komninos - 0.27 300 N/A 42.06 57.65 26.57 72.94 44.75 21.22 62.46 30.49
80 | 79 glove.6B.300d - 0.48 300 N/A 41.96 57.29 27.73 70.92 43.29 21.62 61.85 28.87
81 | 80 SONAR - - - - 40.72 60.43 22.9 71.4 46.18 13.47 67.18 30.56
82 | 81 allenai-specter - 0.44 768 512 40.28 52.37 34.06 61.37 48.1 15.88 61.02 27.66
83 | 82 bert-base-uncased - 0.44 768 512 38.33 61.66 30.12 56.33 43.44 10.59 54.36 29.82
84 | 83 LASER2 - 0.17 1024 N/A 34.95 53.18 15.28 68.86 41.44 7.94 63.27 26.8
85 |
--------------------------------------------------------------------------------
/benchbench/data/helm/accuracy.tsv:
--------------------------------------------------------------------------------
1 | Model/adapter Mean win rate MMLU - EM BoolQ - EM NarrativeQA - F1 NaturalQuestions (closed-book) - F1 NaturalQuestions (open-book) - F1 QuAC - F1 HellaSwag - EM OpenbookQA - EM TruthfulQA - EM MS MARCO (regular) - RR@10 MS MARCO (TREC) - NDCG@10 CNN/DailyMail - ROUGE-2 XSUM - ROUGE-2 IMDB - EM CivilComments - EM RAFT - EM
2 | Llama 2 (70B) 0.944 0.582 0.886 0.77 0.458 0.674 0.484 - - 0.554 - - - - 0.961 0.652 0.727
3 | LLaMA (65B) 0.908 0.584 0.871 0.755 0.431 0.672 0.401 - - 0.508 - - - - 0.962 0.655 0.702
4 | text-davinci-002 0.905 0.568 0.877 0.727 0.383 0.713 0.445 0.815 0.594 0.61 0.421 0.664 0.153 0.144 0.948 0.668 0.733
5 | Mistral v0.1 (7B) 0.884 0.572 0.874 0.716 0.365 0.687 0.423 - - 0.422 - - - - 0.962 0.624 0.707
6 | Cohere Command beta (52.4B) 0.874 0.452 0.856 0.752 0.372 0.76 0.432 0.811 0.582 0.269 0.472 0.762 0.161 0.152 0.96 0.601 0.667
7 | text-davinci-003 0.872 0.569 0.881 0.727 0.406 0.77 0.525 0.822 0.646 0.593 0.368 0.644 0.156 0.124 0.848 0.684 0.759
8 | Jurassic-2 Jumbo (178B) 0.824 0.48 0.829 0.733 0.385 0.669 0.435 0.788 0.558 0.437 0.398 0.661 0.149 0.182 0.938 0.57 0.746
9 | Llama 2 (13B) 0.823 0.507 0.811 0.744 0.376 0.637 0.424 - - 0.33 - - - - 0.962 0.588 0.707
10 | TNLG v2 (530B) 0.787 0.469 0.809 0.722 0.384 0.642 0.39 0.799 0.562 0.251 0.377 0.643 0.161 0.169 0.941 0.601 0.679
11 | gpt-3.5-turbo-0613 0.783 0.391 0.87 0.625 0.348 0.675 0.485 - - 0.339 - - - - 0.943 0.696 0.748
12 | LLaMA (30B) 0.781 0.531 0.861 0.752 0.408 0.666 0.39 - - 0.344 - - - - 0.927 0.549 0.752
13 | Anthropic-LM v4-s3 (52B) 0.78 0.481 0.815 0.728 0.288 0.686 0.431 0.807 0.558 0.368 - - 0.154 0.134 0.934 0.61 0.699
14 | gpt-3.5-turbo-0301 0.76 0.59 0.74 0.663 0.39 0.624 0.512 - - 0.609 - - - - 0.899 0.674 0.768
15 | Jurassic-2 Grande (17B) 0.743 0.475 0.826 0.737 0.356 0.639 0.418 0.781 0.542 0.348 0.293 0.514 0.144 0.167 0.938 0.547 0.712
16 | Palmyra X (43B) 0.732 0.609 0.896 0.742 0.413 - 0.473 - - 0.616 - - 0.049 0.149 0.935 0.008 0.701
17 | Falcon (40B) 0.729 0.509 0.819 0.673 0.392 0.675 0.307 - - 0.353 - - - - 0.959 0.552 0.661
18 | Falcon-Instruct (40B) 0.727 0.497 0.829 0.625 0.377 0.666 0.371 - - 0.384 - - - - 0.959 0.603 0.586
19 | MPT-Instruct (30B) 0.716 0.444 0.85 0.733 0.304 0.697 0.327 - - 0.234 - - - - 0.956 0.573 0.68
20 | MPT (30B) 0.714 0.437 0.704 0.732 0.347 0.673 0.393 - - 0.231 - - - - 0.959 0.599 0.723
21 | J1-Grande v2 beta (17B) 0.706 0.445 0.812 0.725 0.337 0.625 0.392 0.764 0.56 0.306 0.285 0.46 0.146 0.152 0.957 0.546 0.679
22 | Vicuna v1.3 (13B) 0.706 0.462 0.808 0.691 0.346 0.686 0.403 - - 0.385 - - - - 0.762 0.645 0.657
23 | Cohere Command beta (6.1B) 0.675 0.406 0.798 0.709 0.229 0.717 0.375 0.752 0.55 0.203 0.434 0.709 0.153 0.122 0.961 0.54 0.634
24 | Cohere xlarge v20221108 (52.4B) 0.664 0.382 0.762 0.672 0.361 0.628 0.374 0.81 0.588 0.169 0.315 0.55 0.153 0.153 0.956 0.524 0.624
25 | Luminous Supreme (70B) 0.662 0.38 0.775 0.711 0.293 0.649 0.37 - - 0.222 - - 0.15 0.136 0.959 0.562 0.653
26 | Vicuna v1.3 (7B) 0.625 0.434 0.76 0.643 0.287 0.634 0.392 - - 0.292 - - - - 0.916 0.62 0.693
27 | OPT (175B) 0.609 0.318 0.793 0.671 0.297 0.615 0.36 0.791 0.586 0.25 0.288 0.448 0.146 0.155 0.947 0.505 0.606
28 | Llama 2 (7B) 0.607 0.431 0.762 0.691 0.337 0.611 0.406 - - 0.272 - - - - 0.907 0.562 0.643
29 | LLaMA (13B) 0.595 0.422 0.714 0.711 0.346 0.614 0.347 - - 0.324 - - - - 0.928 0.6 0.643
30 | InstructPalmyra (30B) 0.568 0.403 0.751 0.496 0.33 0.682 0.433 - - 0.185 - - 0.152 0.104 0.94 0.555 0.652
31 | Cohere xlarge v20220609 (52.4B) 0.56 0.353 0.718 0.65 0.312 0.595 0.361 0.811 0.55 0.198 0.273 0.459 0.144 0.129 0.956 0.532 0.633
32 | Jurassic-2 Large (7.5B) 0.553 0.339 0.742 - 0.274 0.589 - 0.729 0.53 0.245 0.247 0.464 0.136 0.142 0.956 0.57 0.622
33 | davinci (175B) 0.538 0.422 0.722 0.687 0.329 0.625 0.36 0.775 0.586 0.194 0.211 0.378 0.127 0.126 0.933 0.532 0.642
34 | LLaMA (7B) 0.533 0.321 0.756 0.669 0.297 0.589 0.338 - - 0.28 - - - - 0.947 0.563 0.573
35 | RedPajama-INCITE-Instruct (7B) 0.524 0.363 0.705 0.638 0.232 0.659 0.26 - - 0.243 - - - - 0.927 0.664 0.695
36 | J1-Jumbo v1 (178B) 0.517 0.259 0.776 0.695 0.293 0.595 0.358 0.765 0.534 0.175 0.21 0.363 0.144 0.129 0.943 0.553 0.681
37 | GLM (130B) 0.512 0.344 0.784 0.706 0.148 0.642 0.272 - - 0.218 - - 0.154 0.132 0.955 0.5 0.598
38 | Luminous Extended (30B) 0.485 0.321 0.767 0.665 0.254 0.609 0.349 - - 0.221 - - 0.139 0.124 0.947 0.524 0.523
39 | OPT (66B) 0.448 0.276 0.76 0.638 0.258 0.596 0.357 0.745 0.534 0.201 0.237 0.482 0.136 0.126 0.917 0.506 0.557
40 | BLOOM (176B) 0.446 0.299 0.704 0.662 0.216 0.621 0.361 0.744 0.534 0.205 0.236 0.386 0.08 0.03 0.945 0.62 0.592
41 | J1-Grande v1 (17B) 0.433 0.27 0.722 0.672 0.233 0.578 0.362 0.739 0.52 0.193 0.161 0.341 0.143 0.122 0.953 0.529 0.658
42 | Alpaca (7B) 0.381 0.385 0.778 0.396 0.266 0.592 0.27 - - 0.243 - - - - 0.738 0.566 0.486
43 | Falcon (7B) 0.378 0.286 0.753 0.621 0.285 0.579 0.332 - - 0.234 - - - - 0.836 0.514 0.602
44 | RedPajama-INCITE-Base (7B) 0.378 0.302 0.713 0.617 0.25 0.586 0.336 - - 0.205 - - - - 0.752 0.547 0.648
45 | Cohere large v20220720 (13.1B) 0.372 0.324 0.725 0.625 0.232 0.573 0.338 0.736 0.542 0.181 0.19 0.33 0.126 0.108 0.933 0.507 0.596
46 | RedPajama-INCITE-Instruct-v1 (3B) 0.366 0.257 0.677 0.638 0.203 0.637 0.259 - - 0.208 - - - - 0.894 0.549 0.661
47 | text-curie-001 0.36 0.237 0.62 0.582 0.175 0.571 0.358 0.676 0.514 0.257 0.271 0.507 0.152 0.076 0.923 0.537 0.489
48 | GPT-NeoX (20B) 0.351 0.276 0.683 0.599 0.193 0.596 0.326 0.718 0.524 0.216 0.184 0.398 0.123 0.102 0.948 0.516 0.505
49 | Luminous Base (13B) 0.315 0.27 0.719 0.605 0.202 0.568 0.334 - - 0.182 - - 0.11 0.105 0.939 0.544 0.473
50 | Cohere medium v20221108 (6.1B) 0.312 0.254 0.7 0.61 0.199 0.517 0.314 0.726 0.538 0.215 0.175 0.373 0.121 0.099 0.935 0.5 0.591
51 | RedPajama-INCITE-Base-v1 (3B) 0.311 0.263 0.685 0.555 0.207 0.52 0.309 - - 0.277 - - - - 0.907 0.549 0.502
52 | TNLG v2 (6.7B) 0.309 0.242 0.698 0.631 0.21 0.561 0.345 0.704 0.478 0.167 0.158 0.332 0.146 0.11 0.927 0.532 0.525
53 | J1-Large v1 (7.5B) 0.285 0.241 0.683 0.623 0.19 0.532 0.328 0.7 0.514 0.197 0.147 0.292 0.134 0.102 0.956 0.532 0.545
54 | GPT-J (6B) 0.273 0.249 0.649 0.545 0.156 0.559 0.33 0.663 0.514 0.199 0.152 0.345 0.131 0.096 0.939 0.52 0.619
55 | Pythia (12B) 0.257 0.274 0.662 0.596 0.175 0.581 0.313 - - 0.177 - - - - 0.931 0.531 0.514
56 | curie (6.7B) 0.247 0.243 0.656 0.604 0.199 0.552 0.321 0.682 0.502 0.232 0.162 0.3 0.113 0.091 0.889 0.539 0.49
57 | Falcon-Instruct (7B) 0.244 0.275 0.72 0.476 0.194 0.449 0.311 - - 0.213 - - - - 0.852 0.511 0.523
58 | Cohere medium v20220720 (6.1B) 0.23 0.279 0.659 0.559 0.177 0.504 0.279 0.706 0.496 0.19 0.152 0.374 0.077 0.087 0.935 0.504 0.52
59 | text-babbage-001 0.229 0.229 0.451 0.429 0.07 0.33 0.284 0.561 0.452 0.233 0.208 0.449 0.151 0.046 0.913 0.499 0.509
60 | T0pp (11B) 0.197 0.407 0 0.151 0.039 0.19 0.121 - - 0.377 - - 0.122 0.09 0.207 0.234 0.118
61 | Pythia (6.9B) 0.196 0.236 0.631 0.528 0.142 0.539 0.296 - - 0.213 - - - - 0.928 0.511 0.502
62 | UL2 (20B) 0.167 0.291 0.746 0.083 0.204 0.349 0.144 - - 0.193 - - 0.03 0.058 0.337 0.521 0.404
63 | T5 (11B) 0.131 0.29 0.761 0.086 0.194 0.477 0.116 - - 0.133 - - 0.043 0.015 0.379 0.509 0.37
64 | babbage (1.3B) 0.114 0.235 0.574 0.491 0.119 0.451 0.273 0.555 0.438 0.188 0.122 0.317 0.079 0.045 0.597 0.519 0.455
65 | Cohere small v20220720 (410M) 0.109 0.264 0.457 0.294 0.078 0.309 0.219 0.483 0.348 0.217 - 0.304 0.063 0.033 0.578 0.501 0.492
66 | ada (350M) 0.108 0.243 0.581 0.326 0.082 0.365 0.242 0.435 0.38 0.215 0.102 0.29 0.09 0.022 0.849 0.517 0.423
67 | text-ada-001 0.107 0.238 0.464 0.238 0.025 0.149 0.176 0.429 0.346 0.232 0.134 0.302 0.136 0.034 0.822 0.503 0.406
68 | YaLM (100B) 0.075 0.243 0.634 0.252 0.068 0.227 0.162 - - 0.202 - - 0.017 0.021 0.836 0.49 0.395
69 |
--------------------------------------------------------------------------------
/benchbench/data/openllm/leaderboard.tsv:
--------------------------------------------------------------------------------
1 | T Model Average ARC HellaSwag MMLU TruthfulQA Winogrande GSM8K
2 | 🟢 cloudyu/Yi-34Bx2-MoE-60B 76.72 71.08 85.23 77.47 66.19 84.85 75.51
3 | 🟢 cloudyu/Mixtral_34Bx2_MoE_60B 76.66 71.33 85.25 77.34 66.59 84.85 74.6
4 | 🟢 cloudyu/Mixtral_34Bx2_MoE_60B 76.63 71.25 85.36 77.28 66.61 84.69 74.6
5 | 🟦 moreh/MoMo-70B-lora-1.8.4-DPO 76.23 69.62 85.35 77.33 64.64 84.14 76.27
6 | 🔶 cloudyu/Yi-34Bx3-MoE-90B 76.18 70.9 85.33 77.41 66.31 84.29 72.86
7 | 🟦 moreh/MoMo-70B-lora-1.8.5-DPO 76.14 69.54 85.6 77.49 65.79 84.14 74.3
8 | 🔶 TomGrc/FusionNet_7Bx2_MoE_14B 75.91 73.55 88.84 64.68 69.6 88.16 70.66
9 | 🔶 one-man-army/UNA-34Beagles-32K-bf16-v1 75.41 73.55 85.93 76.45 73.55 82.95 60.05
10 | 🔶 jondurbin/nontoxic-bagel-34b-v0.2 74.69 72.44 85.64 76.41 72.7 82.48 58.45
11 | ⭕ jondurbin/bagel-dpo-34b-v0.2 74.69 71.93 85.25 76.58 70.05 83.35 60.96
12 | 🔶 moreh/MoMo-70B-LoRA-V1.4 74.67 69.2 85.07 77.12 62.66 83.74 70.2
13 | 🟦 udkai/Turdus 74.66 73.38 88.56 64.52 67.11 86.66 67.7
14 | 🔶 jondurbin/bagel-dpo-34b-v0.2 74.5 72.01 85.24 76.58 70.16 83.03 59.97
15 | 🔶 kodonho/Solar-OrcaDPO-Solar-Instruct-SLERP 74.35 70.99 88.22 66.22 71.95 83.43 65.28
16 | 🔶 kodonho/SolarM-SakuraSolar-SLERP 74.29 71.16 88.47 66.24 72.1 83.11 64.67
17 | ⭕ bhavinjawade/SOLAR-10B-OrcaDPO-Jawade 74.27 71.16 88.27 66.12 71.57 83.66 64.82
18 | 🔶 VAGOsolutions/SauerkrautLM-SOLAR-Instruct 74.21 70.82 88.63 66.2 71.95 83.5 64.14
19 | 🟦 upstage/SOLAR-10.7B-Instruct-v1.0 74.2 71.08 88.16 66.21 71.43 83.58 64.75
20 | 🔶 fblgit/UNA-SOLAR-10.7B-Instruct-v1.0 74.2 70.56 88.18 66.08 72.05 83.66 64.67
21 | 🟦 bhavinjawade/SOLAR-10B-Nector-DPO-Jawade 74.19 71.33 88.62 66.22 70.92 83.43 64.59
22 | 🟦 dhanushreddy29/BrokenKeyboard 74.08 71.25 88.34 66.04 71.36 83.19 64.29
23 | 🟦 fblgit/UNA-SOLAR-10.7B-Instruct-v1.0 74.07 70.73 88.32 66.1 72.52 83.35 63.38
24 | 🔶 fblgit/UNA-POLAR-10.7B-InstructMath-v2 74.07 70.73 88.2 66.03 71.73 82.95 64.75
25 | 🔶 yhyu13/LMCocktail-10.7B-v1 74.06 70.65 88.13 66.21 71.03 83.35 64.97
26 | 🔶 rishiraj/meow 73.94 70.48 88.08 66.25 70.49 83.43 64.9
27 | 🟦 fblgit/UNA-TheBeagle-7b-v1 73.87 73.04 88 63.48 69.85 82.16 66.72
28 | 🔶 fblgit/UNAversal-8x7B-v1beta 73.78 69.8 86.9 70.39 71.97 82 61.64
29 | 🔶 NousResearch/Nous-Hermes-2-Yi-34B 73.74 66.89 85.49 76.7 60.37 82.95 70.05
30 | 🟦 argilla/distilabeled-Marcoro14-7B-slerp 73.63 70.73 87.47 65.22 65.1 82.08 71.19
31 | 🟢 Qwen/Qwen-72B 73.6 65.19 85.94 77.37 60.19 82.48 70.43
32 | 🟦 mlabonne/NeuralMarcoro14-7B 73.57 71.42 87.59 64.84 65.64 81.22 70.74
33 | 🔶 abideen/NexoNimbus-7B 73.5 70.82 87.86 64.69 62.43 84.85 70.36
34 | 🟦 Neuronovo/neuronovo-7B-v0.2 73.44 73.04 88.32 65.15 71.02 80.66 62.47
35 | 🟢 cloudyu/Mixtral_7Bx2_MoE 73.43 71.25 87.45 64.98 67.23 81.22 68.46
36 | 🟦 argilla/distilabeled-Marcoro14-7B-slerp-full 73.4 70.65 87.55 65.33 64.21 82 70.66
37 | 🟦 CultriX/MistralTrix-v1 73.39 72.27 88.33 65.24 70.73 80.98 62.77
38 | 🔶 cloudyu/Mixtral_7Bx5_MoE_30B 73.39 69.97 86.82 64.42 65.97 80.98 72.18
39 | 🟢 macadeliccc/SOLAR-math-2x10.7b 73.37 68.43 86.31 66.9 64.21 83.35 71.04
40 | 🟦 ryandt/MusingCaterpillar 73.33 72.53 88.34 65.26 70.93 80.66 62.24
41 | 🟢 cloudyu/Mixtral_7Bx6_MoE_35B 73.32 70.14 86.77 64.74 65.79 81.06 71.42
42 | 🔶 cloudyu/Mixtral_7Bx6_MoE_35B 73.31 69.97 86.82 64.91 65.77 81.14 71.27
43 | 🟦 Neuronovo/neuronovo-7B-v0.3 73.29 72.7 88.26 65.1 71.35 80.9 61.41
44 | ⭕ SUSTech/SUS-Chat-34B 73.22 66.3 83.91 76.41 57.04 83.5 72.18
45 | 🔶 Sao10K/SOLAR-10.7B-NahIdWin 73.21 64.51 85.67 64.17 76.73 80.51 67.7
46 | 🟦 argilla/notus-8x7b-experiment 73.18 70.99 87.73 71.33 65.79 81.61 61.64
47 | 🟦 CultriX/MistralTrixTest 73.17 72.53 88.4 65.22 70.77 81.37 60.73
48 | 🟢 macadeliccc/Orca-SOLAR-4x10.7b 73.17 68.52 86.78 67.03 64.54 83.9 68.23
49 | 🔶 samir-fama/SamirGPT-v1 73.11 69.54 87.04 65.3 63.37 81.69 71.72
50 | 🔶 SanjiWatsuki/Lelantos-DPO-7B 73.09 71.08 87.22 64 67.77 80.03 68.46
51 | 🟦 argilla/notux-8x7b-v1-epoch-2 73.05 70.65 87.8 71.43 65.97 82.08 60.35
52 | 🟦 CultriX/MistralTrixTest 73.17 72.53 88.4 65.22 70.77 81.37 60.73
53 | 🟢 macadeliccc/Orca-SOLAR-4x10.7b 73.17 68.52 86.78 67.03 64.54 83.9 68.23
54 | 🔶 samir-fama/SamirGPT-v1 73.11 69.54 87.04 65.3 63.37 81.69 71.72
55 | 🔶 SanjiWatsuki/Lelantos-DPO-7B 73.09 71.08 87.22 64 67.77 80.03 68.46
56 | 🟦 argilla/notux-8x7b-v1-epoch-2 73.05 70.65 87.8 71.43 65.97 82.08 60.35
57 | 🔶 shadowml/Marcoro14-7B-ties 73.01 69.8 87.13 65.11 63.54 81.61 70.89
58 | 🔶 argilla/notux-8x7b-v1 72.97 70.65 87.72 71.39 66.21 80.74 61.11
59 | 🔶 AA051611/whattest 72.96 66.81 84.43 76.59 58.04 82.48 69.45
60 | 🟦 bardsai/jaskier-7b-dpo 72.91 70.82 87.02 64.67 64.41 80.19 70.36
61 | 🔶 VAGOsolutions/SauerkrautLM-Mixtral-8x7B-Instruct 72.89 70.48 87.75 71.37 65.71 81.22 60.8
62 | 🔶 samir-fama/FernandoGPT-v1 72.87 69.45 86.94 65.19 61.18 81.14 73.31
63 | 🔶 PSanni/MPOMixtral-8x7B-Instruct-v0.1 72.8 70.99 87.95 70.26 66.52 82.56 58.53
64 | 🔶 cookinai/OpenCM-14 72.75 69.28 86.89 65.01 61.07 81.29 72.93
65 | 🔶 VAGOsolutions/SauerkrautLM-Mixtral-8x7B-Instruct 72.73 70.56 87.74 71.08 65.72 81.45 59.82
66 | 🔶 mistralai/Mixtral-8x7B-Instruct-v0.1 72.7 70.14 87.55 71.4 64.98 81.06 61.11
67 | 🔶 senseable/garten2-7b 72.65 69.37 87.54 65.44 59.5 84.69 69.37
68 | ⭕ mistralai/Mixtral-8x7B-Instruct-v0.1 72.62 70.22 87.63 71.16 64.58 81.37 60.73
69 | 🔶 AIDC-ai-business/Marcoroni-7B-v3 72.53 69.45 86.78 65 60.4 81.45 72.1
70 | 🟦 bardsai/jaskier-7b-dpo-v2 72.53 69.28 86.8 64.92 61.64 80.74 71.8
71 | 🔶 Toten5/Marcoroni-v3-neural-chat-v3-3-Slerp 72.51 68.77 86.55 64.51 62.7 80.74 71.8
72 | 🔶 jondurbin/bagel-dpo-8x7b-v0.2 72.49 72.1 86.41 70.27 72.83 83.27 50.04
73 | 🔶 Brillibits/Instruct_Mixtral-8x7B-v0.1_Dolly15K 72.44 69.28 87.59 70.96 64.83 82.56 59.44
74 | 🔶 SanjiWatsuki/Kunoichi-DPO-v2-7B 72.4 69.37 87.42 64.83 66 80.74 66.03
75 | 🔶 mindy-labs/mindy-7b 72.34 69.11 86.57 64.69 60.89 81.06 71.72
76 | 🔶 janhq/supermario-v2 72.34 68.52 86.51 64.88 60.58 81.37 72.18
77 | 🔶 OpenBuddy/openbuddy-deepseek-67b-v15.2 72.33 68.6 86.37 71.5 56.2 84.45 66.87
78 | 🔶 shadowml/Beyonder-4x7B-v2 72.33 68.77 86.8 65.1 60.68 80.9 71.72
79 | 🔶 janhq/supermario-slerp 72.32 68.94 86.58 64.93 60.11 81.29 72.1
80 | ⭕ mncai/yi-34B-v3 72.26 67.06 85.11 75.8 57.54 83.5 64.52
81 | 🔶 Sao10K/Fimbulvetr-10.7B-v1 72.25 68.94 87.27 66.59 60.54 83.5 66.64
82 | 🔶 SanjiWatsuki/Kunoichi-DPO-7B 72.24 69.62 87.14 64.79 67.31 80.58 63.99
83 | 🟦 rwitz2/grindin 72.18 69.88 87.02 64.98 59.34 80.9 70.96
84 | 🔶 SanjiWatsuki/Kunoichi-7B 72.13 68.69 87.1 64.9 64.04 81.06 67.02
85 | ⭕ mncai/yi-34B-v2 72.12 66.13 85 75.64 57.34 83.66 64.97
86 | 🔶 CausalLM/72B-preview 72.12 65.19 83.23 77.14 52.58 82.48 72.1
87 | 🔶 mindy-labs/mindy-7b-v2 72.11 68.69 86.59 65.18 60.16 81.06 70.96
88 | 🔶 CausalLM/72B-preview 72.06 64.85 83.28 77.21 52.51 82.48 72.02
89 | 🔶 rwitz/dec10 72.05 69.11 86.46 64.98 60.42 80.74 70.58
90 | 🔶 rwitz/dec10 72.01 69.2 86.48 64.91 60.52 80.43 70.51
91 | 🔶 cookinai/Valkyrie-V1 71.92 67.24 86.27 64.82 60.4 81.45 71.34
92 | 🔶 AA051611/A0110 71.89 66.38 84.73 74.48 58.6 82.32 64.82
93 | ⭕ DopeorNope/COKAL-v1-70B 71.87 87.46 83.29 68.13 72.79 80.27 39.27
94 | 🟦 bn22/Nous-Hermes-2-SOLAR-10.7B-MISALIGNED 71.83 68.26 86.11 66.26 57.79 83.43 69.14
95 | 🔶 AA051611/A0109 71.83 66.55 84.7 74.44 58.75 82.16 64.37
96 | ⭕ deepseek-ai/deepseek-llm-67b-chat 71.79 67.75 86.82 72.42 55.85 84.21 63.68
97 | 🔶 OpenBuddy/openbuddy-deepseek-67b-v15.1 71.76 67.66 86.49 70.3 54.42 84.77 66.94
98 | 🔶 migtissera/Tess-M-Creative-v1.0 71.73 66.81 85.14 75.54 57.68 83.11 62.09
99 | 🟦 VitalContribution/Evangelion-7B 71.71 68.94 86.45 63.97 64.01 79.95 66.94
100 | ⭕ bhenrym14/platypus-yi-34b 71.69 68.43 85.21 78.13 54.48 84.06 59.82
101 | 🟦 RatanRohith/NeuralPizza-7B-V0.1 71.53 70.48 87.3 64.42 67.22 80.35 59.44
102 |
--------------------------------------------------------------------------------
/benchbench/data/imagenet/leaderboard_raw.tsv:
--------------------------------------------------------------------------------
1 | Weight Acc@1 Acc@5 Params GFLOPS Recipe
2 | AlexNet_Weights.IMAGENET1K_V1 56.522 79.066 61.1M 0.71 link
3 | ConvNeXt_Base_Weights.IMAGENET1K_V1 84.062 96.87 88.6M 15.36 link
4 | ConvNeXt_Large_Weights.IMAGENET1K_V1 84.414 96.976 197.8M 34.36 link
5 | ConvNeXt_Small_Weights.IMAGENET1K_V1 83.616 96.65 50.2M 8.68 link
6 | ConvNeXt_Tiny_Weights.IMAGENET1K_V1 82.52 96.146 28.6M 4.46 link
7 | DenseNet121_Weights.IMAGENET1K_V1 74.434 91.972 8.0M 2.83 link
8 | DenseNet161_Weights.IMAGENET1K_V1 77.138 93.56 28.7M 7.73 link
9 | DenseNet169_Weights.IMAGENET1K_V1 75.6 92.806 14.1M 3.36 link
10 | DenseNet201_Weights.IMAGENET1K_V1 76.896 93.37 20.0M 4.29 link
11 | EfficientNet_B0_Weights.IMAGENET1K_V1 77.692 93.532 5.3M 0.39 link
12 | EfficientNet_B1_Weights.IMAGENET1K_V1 78.642 94.186 7.8M 0.69 link
13 | EfficientNet_B1_Weights.IMAGENET1K_V2 79.838 94.934 7.8M 0.69 link
14 | EfficientNet_B2_Weights.IMAGENET1K_V1 80.608 95.31 9.1M 1.09 link
15 | EfficientNet_B3_Weights.IMAGENET1K_V1 82.008 96.054 12.2M 1.83 link
16 | EfficientNet_B4_Weights.IMAGENET1K_V1 83.384 96.594 19.3M 4.39 link
17 | EfficientNet_B5_Weights.IMAGENET1K_V1 83.444 96.628 30.4M 10.27 link
18 | EfficientNet_B6_Weights.IMAGENET1K_V1 84.008 96.916 43.0M 19.07 link
19 | EfficientNet_B7_Weights.IMAGENET1K_V1 84.122 96.908 66.3M 37.75 link
20 | EfficientNet_V2_L_Weights.IMAGENET1K_V1 85.808 97.788 118.5M 56.08 link
21 | EfficientNet_V2_M_Weights.IMAGENET1K_V1 85.112 97.156 54.1M 24.58 link
22 | EfficientNet_V2_S_Weights.IMAGENET1K_V1 84.228 96.878 21.5M 8.37 link
23 | GoogLeNet_Weights.IMAGENET1K_V1 69.778 89.53 6.6M 1.5 link
24 | Inception_V3_Weights.IMAGENET1K_V1 77.294 93.45 27.2M 5.71 link
25 | MNASNet0_5_Weights.IMAGENET1K_V1 67.734 87.49 2.2M 0.1 link
26 | MNASNet0_75_Weights.IMAGENET1K_V1 71.18 90.496 3.2M 0.21 link
27 | MNASNet1_0_Weights.IMAGENET1K_V1 73.456 91.51 4.4M 0.31 link
28 | MNASNet1_3_Weights.IMAGENET1K_V1 76.506 93.522 6.3M 0.53 link
29 | MaxVit_T_Weights.IMAGENET1K_V1 83.7 96.722 30.9M 5.56 link
30 | MobileNet_V2_Weights.IMAGENET1K_V1 71.878 90.286 3.5M 0.3 link
31 | MobileNet_V2_Weights.IMAGENET1K_V2 72.154 90.822 3.5M 0.3 link
32 | MobileNet_V3_Large_Weights.IMAGENET1K_V1 74.042 91.34 5.5M 0.22 link
33 | MobileNet_V3_Large_Weights.IMAGENET1K_V2 75.274 92.566 5.5M 0.22 link
34 | MobileNet_V3_Small_Weights.IMAGENET1K_V1 67.668 87.402 2.5M 0.06 link
35 | RegNet_X_16GF_Weights.IMAGENET1K_V1 80.058 94.944 54.3M 15.94 link
36 | RegNet_X_16GF_Weights.IMAGENET1K_V2 82.716 96.196 54.3M 15.94 link
37 | RegNet_X_1_6GF_Weights.IMAGENET1K_V1 77.04 93.44 9.2M 1.6 link
38 | RegNet_X_1_6GF_Weights.IMAGENET1K_V2 79.668 94.922 9.2M 1.6 link
39 | RegNet_X_32GF_Weights.IMAGENET1K_V1 80.622 95.248 107.8M 31.74 link
40 | RegNet_X_32GF_Weights.IMAGENET1K_V2 83.014 96.288 107.8M 31.74 link
41 | RegNet_X_3_2GF_Weights.IMAGENET1K_V1 78.364 93.992 15.3M 3.18 link
42 | RegNet_X_3_2GF_Weights.IMAGENET1K_V2 81.196 95.43 15.3M 3.18 link
43 | RegNet_X_400MF_Weights.IMAGENET1K_V1 72.834 90.95 5.5M 0.41 link
44 | RegNet_X_400MF_Weights.IMAGENET1K_V2 74.864 92.322 5.5M 0.41 link
45 | RegNet_X_800MF_Weights.IMAGENET1K_V1 75.212 92.348 7.3M 0.8 link
46 | RegNet_X_800MF_Weights.IMAGENET1K_V2 77.522 93.826 7.3M 0.8 link
47 | RegNet_X_8GF_Weights.IMAGENET1K_V1 79.344 94.686 39.6M 8 link
48 | RegNet_X_8GF_Weights.IMAGENET1K_V2 81.682 95.678 39.6M 8 link
49 | RegNet_Y_128GF_Weights.IMAGENET1K_SWAG_E2E_V1 88.228 98.682 644.8M 374.57 link
50 | RegNet_Y_128GF_Weights.IMAGENET1K_SWAG_LINEAR_V1 86.068 97.844 644.8M 127.52 link
51 | RegNet_Y_16GF_Weights.IMAGENET1K_V1 80.424 95.24 83.6M 15.91 link
52 | RegNet_Y_16GF_Weights.IMAGENET1K_V2 82.886 96.328 83.6M 15.91 link
53 | RegNet_Y_16GF_Weights.IMAGENET1K_SWAG_E2E_V1 86.012 98.054 83.6M 46.73 link
54 | RegNet_Y_16GF_Weights.IMAGENET1K_SWAG_LINEAR_V1 83.976 97.244 83.6M 15.91 link
55 | RegNet_Y_1_6GF_Weights.IMAGENET1K_V1 77.95 93.966 11.2M 1.61 link
56 | RegNet_Y_1_6GF_Weights.IMAGENET1K_V2 80.876 95.444 11.2M 1.61 link
57 | RegNet_Y_32GF_Weights.IMAGENET1K_V1 80.878 95.34 145.0M 32.28 link
58 | RegNet_Y_32GF_Weights.IMAGENET1K_V2 83.368 96.498 145.0M 32.28 link
59 | RegNet_Y_32GF_Weights.IMAGENET1K_SWAG_E2E_V1 86.838 98.362 145.0M 94.83 link
60 | RegNet_Y_32GF_Weights.IMAGENET1K_SWAG_LINEAR_V1 84.622 97.48 145.0M 32.28 link
61 | RegNet_Y_3_2GF_Weights.IMAGENET1K_V1 78.948 94.576 19.4M 3.18 link
62 | RegNet_Y_3_2GF_Weights.IMAGENET1K_V2 81.982 95.972 19.4M 3.18 link
63 | RegNet_Y_400MF_Weights.IMAGENET1K_V1 74.046 91.716 4.3M 0.4 link
64 | RegNet_Y_400MF_Weights.IMAGENET1K_V2 75.804 92.742 4.3M 0.4 link
65 | RegNet_Y_800MF_Weights.IMAGENET1K_V1 76.42 93.136 6.4M 0.83 link
66 | RegNet_Y_800MF_Weights.IMAGENET1K_V2 78.828 94.502 6.4M 0.83 link
67 | RegNet_Y_8GF_Weights.IMAGENET1K_V1 80.032 95.048 39.4M 8.47 link
68 | RegNet_Y_8GF_Weights.IMAGENET1K_V2 82.828 96.33 39.4M 8.47 link
69 | ResNeXt101_32X8D_Weights.IMAGENET1K_V1 79.312 94.526 88.8M 16.41 link
70 | ResNeXt101_32X8D_Weights.IMAGENET1K_V2 82.834 96.228 88.8M 16.41 link
71 | ResNeXt101_64X4D_Weights.IMAGENET1K_V1 83.246 96.454 83.5M 15.46 link
72 | ResNeXt50_32X4D_Weights.IMAGENET1K_V1 77.618 93.698 25.0M 4.23 link
73 | ResNeXt50_32X4D_Weights.IMAGENET1K_V2 81.198 95.34 25.0M 4.23 link
74 | ResNet101_Weights.IMAGENET1K_V1 77.374 93.546 44.5M 7.8 link
75 | ResNet101_Weights.IMAGENET1K_V2 81.886 95.78 44.5M 7.8 link
76 | ResNet152_Weights.IMAGENET1K_V1 78.312 94.046 60.2M 11.51 link
77 | ResNet152_Weights.IMAGENET1K_V2 82.284 96.002 60.2M 11.51 link
78 | ResNet18_Weights.IMAGENET1K_V1 69.758 89.078 11.7M 1.81 link
79 | ResNet34_Weights.IMAGENET1K_V1 73.314 91.42 21.8M 3.66 link
80 | ResNet50_Weights.IMAGENET1K_V1 76.13 92.862 25.6M 4.09 link
81 | ResNet50_Weights.IMAGENET1K_V2 80.858 95.434 25.6M 4.09 link
82 | ShuffleNet_V2_X0_5_Weights.IMAGENET1K_V1 60.552 81.746 1.4M 0.04 link
83 | ShuffleNet_V2_X1_0_Weights.IMAGENET1K_V1 69.362 88.316 2.3M 0.14 link
84 | ShuffleNet_V2_X1_5_Weights.IMAGENET1K_V1 72.996 91.086 3.5M 0.3 link
85 | ShuffleNet_V2_X2_0_Weights.IMAGENET1K_V1 76.23 93.006 7.4M 0.58 link
86 | SqueezeNet1_0_Weights.IMAGENET1K_V1 58.092 80.42 1.2M 0.82 link
87 | SqueezeNet1_1_Weights.IMAGENET1K_V1 58.178 80.624 1.2M 0.35 link
88 | Swin_B_Weights.IMAGENET1K_V1 83.582 96.64 87.8M 15.43 link
89 | Swin_S_Weights.IMAGENET1K_V1 83.196 96.36 49.6M 8.74 link
90 | Swin_T_Weights.IMAGENET1K_V1 81.474 95.776 28.3M 4.49 link
91 | Swin_V2_B_Weights.IMAGENET1K_V1 84.112 96.864 87.9M 20.32 link
92 | Swin_V2_S_Weights.IMAGENET1K_V1 83.712 96.816 49.7M 11.55 link
93 | Swin_V2_T_Weights.IMAGENET1K_V1 82.072 96.132 28.4M 5.94 link
94 | VGG11_BN_Weights.IMAGENET1K_V1 70.37 89.81 132.9M 7.61 link
95 | VGG11_Weights.IMAGENET1K_V1 69.02 88.628 132.9M 7.61 link
96 | VGG13_BN_Weights.IMAGENET1K_V1 71.586 90.374 133.1M 11.31 link
97 | VGG13_Weights.IMAGENET1K_V1 69.928 89.246 133.0M 11.31 link
98 | VGG16_BN_Weights.IMAGENET1K_V1 73.36 91.516 138.4M 15.47 link
99 | VGG16_Weights.IMAGENET1K_V1 71.592 90.382 138.4M 15.47 link
100 | VGG16_Weights.IMAGENET1K_FEATURES nan nan 138.4M 15.47 link
101 | VGG19_BN_Weights.IMAGENET1K_V1 74.218 91.842 143.7M 19.63 link
102 | VGG19_Weights.IMAGENET1K_V1 72.376 90.876 143.7M 19.63 link
103 | ViT_B_16_Weights.IMAGENET1K_V1 81.072 95.318 86.6M 17.56 link
104 | ViT_B_16_Weights.IMAGENET1K_SWAG_E2E_V1 85.304 97.65 86.9M 55.48 link
105 | ViT_B_16_Weights.IMAGENET1K_SWAG_LINEAR_V1 81.886 96.18 86.6M 17.56 link
106 | ViT_B_32_Weights.IMAGENET1K_V1 75.912 92.466 88.2M 4.41 link
107 | ViT_H_14_Weights.IMAGENET1K_SWAG_E2E_V1 88.552 98.694 633.5M 1016.72 link
108 | ViT_H_14_Weights.IMAGENET1K_SWAG_LINEAR_V1 85.708 97.73 632.0M 167.29 link
109 | ViT_L_16_Weights.IMAGENET1K_V1 79.662 94.638 304.3M 61.55 link
110 | ViT_L_16_Weights.IMAGENET1K_SWAG_E2E_V1 88.064 98.512 305.2M 361.99 link
111 | ViT_L_16_Weights.IMAGENET1K_SWAG_LINEAR_V1 85.146 97.422 304.3M 61.55 link
112 | ViT_L_32_Weights.IMAGENET1K_V1 76.972 93.07 306.5M 15.38 link
113 | Wide_ResNet101_2_Weights.IMAGENET1K_V1 78.848 94.284 126.9M 22.75 link
114 | Wide_ResNet101_2_Weights.IMAGENET1K_V2 82.51 96.02 126.9M 22.75 link
115 | Wide_ResNet50_2_Weights.IMAGENET1K_V1 78.468 94.086 68.9M 11.4 link
116 |
--------------------------------------------------------------------------------
/benchbench/data/helm_lite/leaderboard.tsv:
--------------------------------------------------------------------------------
1 | Model Mean win rate NarrativeQA - F1 NaturalQuestions (open) - F1 NaturalQuestions (closed) - F1 OpenbookQA - EM MMLU - EM MATH - Equivalent (CoT) GSM8K - EM LegalBench - EM MedQA - EM WMT 2014 - BLEU-4
2 | GPT-4o (2024-05-13) 0.938 0.804 0.803 0.501 0.966 0.748 0.829 0.905 0.733 0.857 0.231
3 | GPT-4o (2024-08-06) 0.928 0.795 0.793 0.496 0.968 0.738 0.853 0.909 0.721 0.863 0.225
4 | DeepSeek v3 0.908 0.796 0.765 0.467 0.954 0.803 0.912 0.94 0.718 0.809 0.209
5 | Claude 3.5 Sonnet (20240620) 0.885 0.746 0.749 0.502 0.972 0.799 0.813 0.949 0.707 0.825 0.229
6 | Amazon Nova Pro 0.885 0.791 0.829 0.405 0.96 0.758 0.821 0.87 0.736 0.811 0.229
7 | GPT-4 (0613) 0.867 0.768 0.79 0.457 0.96 0.735 0.802 0.932 0.713 0.815 0.211
8 | GPT-4 Turbo (2024-04-09) 0.864 0.761 0.795 0.482 0.97 0.711 0.833 0.824 0.727 0.783 0.218
9 | Llama 3.1 Instruct Turbo (405B) 0.854 0.749 0.756 0.456 0.94 0.759 0.827 0.949 0.707 0.805 0.238
10 | Claude 3.5 Sonnet (20241022) 0.846 0.77 0.665 0.467 0.966 0.809 0.904 0.956 0.647 0.859 0.226
11 | Gemini 1.5 Pro (002) 0.842 0.756 0.726 0.455 0.952 0.795 0.92 0.817 0.747 0.771 0.231
12 | Llama 3.2 Vision Instruct Turbo (90B) 0.819 0.777 0.739 0.457 0.942 0.703 0.791 0.936 0.68 0.769 0.224
13 | Gemini 2.0 Flash (Experimental) 0.813 0.783 0.722 0.443 0.946 0.717 0.901 0.946 0.674 0.73 0.212
14 | Llama 3.3 Instruct Turbo (70B) 0.812 0.791 0.737 0.431 0.928 0.7 0.808 0.942 0.725 0.761 0.219
15 | Llama 3.1 Instruct Turbo (70B) 0.808 0.772 0.738 0.452 0.938 0.709 0.783 0.938 0.687 0.769 0.223
16 | Palmyra-X-004 0.808 0.773 0.754 0.457 0.926 0.739 0.767 0.905 0.73 0.775 0.203
17 | Llama 3 (70B) 0.793 0.798 0.743 0.475 0.934 0.695 0.663 0.805 0.733 0.777 0.225
18 | Qwen2 Instruct (72B) 0.77 0.727 0.776 0.39 0.954 0.769 0.79 0.92 0.712 0.746 0.207
19 | Qwen2.5 Instruct Turbo (72B) 0.745 0.745 0.676 0.359 0.962 0.77 0.884 0.9 0.74 0.753 0.207
20 | Mistral Large 2 (2407) 0.744 0.779 0.734 0.453 0.932 0.725 0.677 0.912 0.646 0.775 0.192
21 | Gemini 1.5 Pro (001) 0.739 0.783 0.748 0.378 0.902 0.772 0.825 0.836 0.757 0.692 0.189
22 | Amazon Nova Lite 0.708 0.768 0.815 0.352 0.928 0.693 0.779 0.829 0.659 0.696 0.204
23 | Mixtral (8x22B) 0.705 0.779 0.726 0.478 0.882 0.701 0.656 0.8 0.708 0.704 0.209
24 | GPT-4o mini (2024-07-18) 0.701 0.768 0.746 0.386 0.92 0.668 0.802 0.843 0.653 0.748 0.206
25 | GPT-4 Turbo (1106 preview) 0.698 0.727 0.763 0.435 0.95 0.699 0.857 0.668 0.626 0.817 0.205
26 | Claude 3 Opus (20240229) 0.683 0.351 0.264 0.441 0.956 0.768 0.76 0.924 0.662 0.775 0.24
27 | Palmyra X V3 (72B) 0.679 0.706 0.685 0.407 0.938 0.702 0.723 0.831 0.709 0.684 0.262
28 | Gemma 2 Instruct (27B) 0.675 0.79 0.731 0.353 0.918 0.664 0.746 0.812 0.7 0.684 0.214
29 | Gemini 1.5 Flash (001) 0.667 0.783 0.723 0.332 0.928 0.703 0.753 0.785 0.661 0.68 0.225
30 | PaLM-2 (Unicorn) 0.644 0.583 0.674 0.435 0.938 0.702 0.674 0.831 0.677 0.684 0.26
31 | Jamba 1.5 Large 0.637 0.664 0.718 0.394 0.948 0.683 0.692 0.846 0.675 0.698 0.203
32 | Qwen1.5 (72B) 0.608 0.601 0.758 0.417 0.93 0.647 0.683 0.799 0.694 0.67 0.201
33 | Solar Pro 0.602 0.753 0.792 0.297 0.922 0.679 0.567 0.871 0.67 0.698 0.169
34 | Palmyra X V2 (33B) 0.589 0.752 0.752 0.428 0.878 0.621 0.58 0.735 0.644 0.598 0.239
35 | Gemini 1.5 Flash (002) 0.573 0.746 0.718 0.323 0.914 0.679 0.908 0.328 0.67 0.656 0.212
36 | Yi (34B) 0.57 0.782 0.775 0.443 0.92 0.65 0.375 0.648 0.618 0.656 0.172
37 | Gemma 2 Instruct (9B) 0.562 0.768 0.738 0.328 0.91 0.645 0.724 0.762 0.639 0.63 0.201
38 | Qwen1.5 Chat (110B) 0.55 0.721 0.739 0.35 0.922 0.704 0.568 0.815 0.624 0.64 0.192
39 | Qwen1.5 (32B) 0.546 0.589 0.777 0.353 0.932 0.628 0.733 0.773 0.636 0.656 0.193
40 | Claude 3.5 Haiku (20241022) 0.531 0.763 0.639 0.344 0.854 0.671 0.872 0.815 0.631 0.722 0.135
41 | PaLM-2 (Bison) 0.526 0.718 0.813 0.39 0.878 0.608 0.421 0.61 0.645 0.547 0.241
42 | Amazon Nova Micro 0.524 0.744 0.779 0.285 0.888 0.64 0.76 0.794 0.615 0.608 0.192
43 | Claude v1.3 0.518 0.723 0.699 0.409 0.908 0.631 0.54 0.784 0.629 0.618 0.219
44 | Mixtral (8x7B 32K seqlen) 0.51 0.767 0.699 0.427 0.868 0.649 0.494 0.622 0.63 0.652 0.19
45 | Phi-3 (14B) 0.509 0.724 0.729 0.278 0.916 0.675 0.611 0.878 0.593 0.696 0.17
46 | Claude 2.0 0.489 0.718 0.67 0.428 0.862 0.639 0.603 0.583 0.643 0.652 0.219
47 | DeepSeek LLM Chat (67B) 0.488 0.581 0.733 0.412 0.88 0.641 0.615 0.795 0.637 0.628 0.186
48 | Qwen2.5 Instruct Turbo (7B) 0.488 0.742 0.725 0.205 0.862 0.658 0.835 0.83 0.632 0.6 0.155
49 | Llama 2 (70B) 0.482 0.763 0.674 0.46 0.838 0.58 0.323 0.567 0.673 0.618 0.196
50 | Phi-3 (7B) 0.473 0.754 0.675 0.324 0.912 0.659 0.703 - 0.584 0.672 0.154
51 | Yi Large (Preview) 0.471 0.373 0.586 0.428 0.946 0.712 0.712 0.69 0.519 0.66 0.176
52 | Command R Plus 0.441 0.735 0.711 0.343 0.828 0.59 0.403 0.738 0.672 0.567 0.203
53 | GPT-3.5 (text-davinci-003) 0.439 0.731 0.77 0.413 0.828 0.555 0.449 0.615 0.622 0.531 0.191
54 | Claude 2.1 0.437 0.677 0.611 0.375 0.872 0.643 0.632 0.604 0.643 0.644 0.204
55 | Qwen1.5 (14B) 0.425 0.711 0.772 0.3 0.862 0.626 0.686 0.693 0.593 0.515 0.178
56 | Gemini 1.0 Pro (002) 0.422 0.751 0.714 0.391 0.788 0.534 0.665 0.816 0.475 0.483 0.194
57 | Jamba 1.5 Mini 0.414 0.746 0.71 0.388 0.89 0.582 0.318 0.691 0.503 0.632 0.179
58 | Claude Instant 1.2 0.399 0.616 0.731 0.343 0.844 0.631 0.499 0.721 0.586 0.559 0.194
59 | Llama 3 (8B) 0.387 0.754 0.681 0.378 0.766 0.602 0.391 0.499 0.637 0.581 0.183
60 | Claude 3 Sonnet (20240229) 0.377 0.111 0.072 0.028 0.918 0.652 0.084 0.907 0.49 0.684 0.218
61 | GPT-3.5 Turbo (0613) 0.358 0.655 0.678 0.335 0.838 0.614 0.667 0.501 0.528 0.622 0.187
62 | LLaMA (65B) 0.345 0.755 0.672 0.433 0.754 0.584 0.257 0.489 0.48 0.507 0.189
63 | Arctic Instruct 0.338 0.654 0.586 0.39 0.828 0.575 0.519 0.768 0.588 0.581 0.172
64 | Gemma (7B) 0.336 0.752 0.665 0.336 0.808 0.571 0.5 0.559 0.581 0.513 0.187
65 | GPT-3.5 (text-davinci-002) 0.336 0.719 0.71 0.394 0.796 0.568 0.428 0.479 0.58 0.525 0.174
66 | Mistral NeMo (2402) 0.333 0.731 0.65 0.265 0.822 0.604 0.668 0.782 0.415 0.59 0.177
67 | Mistral Large (2402) 0.328 0.454 0.485 0.311 0.894 0.638 0.75 0.694 0.479 0.499 0.182
68 | Command 0.327 0.749 0.777 0.391 0.774 0.525 0.236 0.452 0.578 0.445 0.088
69 | Llama 3.2 Vision Instruct Turbo (11B) 0.325 0.756 0.671 0.234 0.724 0.511 0.739 0.823 0.435 0.27 0.179
70 | Llama 3.1 Instruct Turbo (8B) 0.303 0.756 0.677 0.209 0.74 0.5 0.703 0.798 0.342 0.245 0.181
71 | Command R 0.299 0.742 0.72 0.352 0.782 0.567 0.266 0.551 0.507 0.555 0.149
72 | Mistral v0.1 (7B) 0.292 0.716 0.687 0.367 0.776 0.584 0.297 0.377 0.58 0.525 0.16
73 | DBRX Instruct 0.289 0.488 0.55 0.284 0.91 0.643 0.358 0.671 0.426 0.694 0.131
74 | Mistral Small (2402) 0.288 0.519 0.587 0.304 0.862 0.593 0.621 0.734 0.389 0.616 0.169
75 | Jamba Instruct 0.287 0.658 0.636 0.384 0.796 0.582 0.38 0.67 0.54 0.519 0.164
76 | Qwen1.5 (7B) 0.275 0.448 0.749 0.27 0.806 0.569 0.561 0.6 0.523 0.479 0.153
77 | Mistral Medium (2312) 0.268 0.449 0.468 0.29 0.83 0.618 0.565 0.706 0.452 0.61 0.169
78 | Claude 3 Haiku (20240307) 0.263 0.244 0.252 0.144 0.838 0.662 0.131 0.699 0.46 0.702 0.148
79 | Yi (6B) 0.253 0.702 0.748 0.31 0.8 0.53 0.126 0.375 0.519 0.497 0.117
80 | Llama 2 (13B) 0.233 0.741 0.64 0.371 0.634 0.505 0.102 0.266 0.591 0.392 0.167
81 | Falcon (40B) 0.217 0.671 0.676 0.392 0.662 0.507 0.128 0.267 0.442 0.419 0.162
82 | Jurassic-2 Jumbo (178B) 0.215 0.728 0.65 0.385 0.688 0.483 0.103 0.239 0.533 0.431 0.114
83 | Mistral Instruct v0.3 (7B) 0.196 0.716 0.68 0.253 0.79 0.51 0.289 0.538 0.331 0.517 0.142
84 | Jurassic-2 Grande (17B) 0.172 0.744 0.627 0.35 0.614 0.471 0.064 0.159 0.468 0.39 0.102
85 | Phi-2 0.169 0.703 0.68 0.155 0.798 0.518 0.255 0.581 0.334 0.41 0.038
86 | Llama 2 (7B) 0.152 0.686 0.612 0.333 0.544 0.425 0.097 0.154 0.502 0.392 0.144
87 | Luminous Supreme (70B) 0.145 0.743 0.656 0.299 0.284 0.316 0.078 0.137 0.452 0.276 0.102
88 | Command Light 0.105 0.629 0.686 0.195 0.398 0.386 0.098 0.149 0.397 0.312 0.023
89 | Luminous Extended (30B) 0.078 0.684 0.611 0.253 0.272 0.248 0.04 0.075 0.421 0.276 0.083
90 | Falcon (7B) 0.064 0.621 0.58 0.285 0.26 0.288 0.044 0.055 0.346 0.254 0.094
91 | OLMo (7B) 0.052 0.597 0.603 0.259 0.222 0.305 0.029 0.044 0.341 0.229 0.097
92 | Luminous Base (13B) 0.041 0.633 0.577 0.197 0.286 0.243 0.026 0.028 0.332 0.26 0.066
93 |
--------------------------------------------------------------------------------
/benchbench/data/glue/leaderboard.tsv:
--------------------------------------------------------------------------------
1 | Rank Name Model URL Score CoLA SST-2 MRPC STS-B QQP MNLI-m MNLI-mm QNLI RTE WNLI AX
2 | 1 Microsoft Alexander v-team Turing ULR v6 91.3 73.3 97.5 94.2/92.3 93.5/93.1 76.4/90.9 92.5 92.1 96.7 93.6 97.9 55.4
3 | 2 JDExplore d-team Vega v1 91.3 73.8 97.9 94.5/92.6 93.5/93.1 76.7/91.1 92.1 91.9 96.7 92.4 97.9 51.4
4 | 3 Microsoft Alexander v-team Turing NLR v5 91.2 72.6 97.6 93.8/91.7 93.7/93.3 76.4/91.1 92.6 92.4 97.9 94.1 95.9 57.0
5 | 4 DIRL Team DeBERTa + CLEVER 91.1 74.7 97.6 93.3/91.1 93.4/93.1 76.5/91.0 92.1 91.8 96.7 93.2 96.6 53.3
6 | 5 ERNIE Team - Baidu ERNIE 91.1 75.5 97.8 93.9/91.8 93.0/92.6 75.2/90.9 92.3 91.7 97.3 92.6 95.9 51.7
7 | 6 AliceMind & DIRL StructBERT + CLEVER 91.0 75.3 97.7 93.9/91.9 93.5/93.1 75.6/90.8 91.7 91.5 97.4 92.5 95.2 49.1
8 | 7 DeBERTa Team - Microsoft DeBERTa / TuringNLRv4 90.8 71.5 97.5 94.0/92.0 92.9/92.6 76.2/90.8 91.9 91.6 99.2 93.2 94.5 53.2
9 | 8 HFL iFLYTEK MacALBERT + DKM 90.7 74.8 97.0 94.5/92.6 92.8/92.6 74.7/90.6 91.3 91.1 97.8 92.0 94.5 52.6
10 | 9 PING-AN Omni-Sinitic ALBERT + DAAF + NAS 90.6 73.5 97.2 94.0/92.0 93.0/92.4 76.1/91.0 91.6 91.3 97.5 91.7 94.5 51.2
11 | 10 T5 Team - Google T5 90.3 71.6 97.5 92.8/90.4 93.1/92.8 75.1/90.6 92.2 91.9 96.9 92.8 94.5 53.1
12 | 11 Microsoft D365 AI & MSR AI & GATECH MT-DNN-SMART 89.9 69.5 97.5 93.7/91.6 92.9/92.5 73.9/90.2 91.0 90.8 99.2 89.7 94.5 50.2
13 | 12 Huawei Noah's Ark Lab NEZHA-Large 89.8 71.7 97.3 93.3/91.0 92.4/91.9 75.2/90.7 91.5 91.3 96.2 90.3 94.5 47.9
14 | 13 LG AI Research ANNA 89.8 68.7 97.0 92.7/90.1 93.0/92.8 75.3/90.5 91.8 91.6 96.0 91.8 95.9 51.8
15 | 14 Zihang Dai Funnel-Transformer (Ensemble B10-10-10H1024) 89.7 70.5 97.5 93.4/91.2 92.6/92.3 75.4/90.7 91.4 91.1 95.8 90.0 94.5 51.6
16 | 15 ELECTRA Team ELECTRA-Large + Standard Tricks 89.4 71.7 97.1 93.1/90.7 92.9/92.5 75.6/90.8 91.3 90.8 95.8 89.8 91.8 50.7
17 | 16 David Kim 2digit LANet 89.3 71.8 97.3 92.4/89.6 93.0/92.7 75.5/90.5 91.8 91.6 96.4 91.1 88.4 54.6
18 | 17 倪仕文 DropAttack-RoBERTa-large 88.8 70.3 96.7 92.6/90.1 92.1/91.8 75.1/90.5 91.1 90.9 95.3 89.9 89.7 48.2
19 | 18 Microsoft D365 AI & UMD FreeLB-RoBERTa (ensemble) 88.4 68.0 96.8 93.1/90.8 92.3/92.1 74.8/90.3 91.1 90.7 95.6 88.7 89.0 50.1
20 | 19 Junjie Yang HIRE-RoBERTa 88.3 68.6 97.1 93.0/90.7 92.4/92.0 74.3/90.2 90.7 90.4 95.5 87.9 89.0 49.3
21 | 20 Shiwen Ni ELECTRA-large-M (bert4keras) 88.3 69.3 95.8 92.2/89.6 91.2/91.1 75.1/90.5 91.1 90.9 93.8 87.9 91.8 48.2
22 | 21 Facebook AI RoBERTa 88.1 67.8 96.7 92.3/89.8 92.2/91.9 74.3/90.2 90.8 90.2 95.4 88.2 89.0 48.7
23 | 22 Microsoft D365 AI & MSR AI MT-DNN-ensemble 87.6 68.4 96.5 92.7/90.3 91.1/90.7 73.7/89.9 87.9 87.4 96.0 86.3 89.0 42.8
24 | 23 GLUE Human Baselines GLUE Human Baselines 87.1 66.4 97.8 86.3/80.8 92.7/92.6 59.5/80.4 92.0 92.8 91.2 93.6 95.9 -
25 | 24 kk xx ELECTRA-Large-NewSCL(single) 85.6 73.3 97.2 92.7/90.2 92.0/91.7 75.3/90.6 90.8 90.3 95.6 86.9 60.3 50.0
26 | 25 Adrian de Wynter Bort (Alexa AI) 83.6 63.9 96.2 94.1/92.3 89.2/88.3 66.0/85.9 88.1 87.8 92.3 82.7 71.2 51.9
27 | 26 Lab LV ConvBERT base 83.2 67.8 95.7 91.4/88.3 90.4/89.7 73.0/90.0 88.3 87.4 93.2 77.9 65.1 42.9
28 | 27 Stanford Hazy Research Snorkel MeTaL 83.2 63.8 96.2 91.5/88.5 90.1/89.7 73.1/89.9 87.6 87.2 93.9 80.9 65.1 39.9
29 | 28 XLM Systems XLM (English only) 83.1 62.9 95.6 90.7/87.1 88.8/88.2 73.2/89.8 89.1 88.5 94.0 76.0 71.9 44.7
30 | 29 WATCH ME ConvBERT-base-paddle-v1.1 83.1 66.3 95.4 91.6/88.6 90.0/89.2 73.9/90.0 88.2 87.7 93.3 78.2 65.1 9.2
31 | 30 Zhuosheng Zhang SemBERT 82.9 62.3 94.6 91.2/88.3 87.8/86.7 72.8/89.8 87.6 86.3 94.6 84.5 65.1 42.4
32 | 31 Jun Yu mpnet-base-paddle 82.9 60.5 95.9 91.6/88.9 90.8/90.3 72.5/89.7 87.6 86.6 93.3 82.4 65.1 9.2
33 | 32 Danqi Chen SpanBERT (single-task training) 82.8 64.3 94.8 90.9/87.9 89.9/89.1 71.9/89.5 88.1 87.7 94.3 79.0 65.1 45.1
34 | 33 GAL team distilRoBERTa+GAL (6-layer transformer single model) 82.6 60.0 95.3 91.9/89.2 90.0/89.6 73.3/90.0 87.4 86.5 92.7 81.8 65.1 0.0
35 | 34 Kevin Clark BERT + BAM 82.3 61.5 95.2 91.3/88.3 88.6/87.9 72.5/89.7 86.6 85.8 93.1 80.4 65.1 40.7
36 | 35 Nitish Shirish Keskar Span-Extractive BERT on STILTs 82.3 63.2 94.5 90.6/87.6 89.4/89.2 72.2/89.4 86.5 85.8 92.5 79.8 65.1 28.3
37 | 36 LV NUS LV-BERT-base 82.1 64.0 94.7 90.9/87.9 89.4/88.8 72.3/89.5 86.6 86.1 92.6 77.0 65.1 39.5
38 | 37 Jason Phang BERT on STILTs 82.0 62.1 94.3 90.2/86.6 88.7/88.3 71.9/89.4 86.4 85.6 92.7 80.1 65.1 28.3
39 | 38 gao jie 1 82.0 66.8 96.5 90.9/87.2 91.4/90.8 72.9/89.6 90.2 56.4 94.7 82.8 62.3 9.2
40 | 39 Gino Tesei RobustRoBERTa 81.9 63.6 96.8 91.6/88.6 90.3/89.6 73.2/89.7 90.0 89.4 95.1 50.3 80.1 50.5
41 | 40 Karen Hambardzumyan WARP with RoBERTa 81.6 53.9 96.3 88.2/83.9 89.5/88.8 68.6/87.7 88.0 88.2 93.5 84.3 65.1 41.2
42 | 41 Junxiong Wang Bigs-128-1000k 81.5 64.4 94.9 88.7/84.2 87.8/87.5 71.2/89.2 86.1 85.0 91.6 77.6 65.1 36.2
43 | 42 Huawei Noah's Ark Lab MTL CombinedKD-TinyRoBERTa (6 layer 82M parameters, MATE-KD + AnnealingKD) 81.5 58.6 95.1 91.2/88.1 88.5/88.4 73.0/89.7 86.2 85.6 92.4 76.6 65.1 20.2
44 | 43 Richard Bai segaBERT-large 81.4 62.6 94.8 89.7/86.1 88.6/87.7 72.5/89.4 87.9 87.7 94.0 71.6 65.1 0.0
45 | 44 廖亿 u-PMLM-R (Huawei Noah's Ark Lab) 81.3 56.9 94.2 90.7/87.7 89.7/89.1 72.2/89.4 86.1 85.4 92.1 78.5 65.1 40.0
46 | 45 Xinsong Zhang AMBERT-BASE 81.0 60.0 95.2 90.6/87.1 86.3/88.2 72.2/89.5 87.2 86.5 92.6 72.6 65.1 39.4
47 | 46 Mikita Sazanovich Routed BERTs 80.7 56.1 93.6 88.6/84.7 88.0/87.6 71.0/88.8 85.2 84.5 92.6 80.0 65.1 9.2
48 | 47 USCD-AI4Health Team CERT 80.7 58.9 94.6 89.8/85.9 87.9/86.8 72.5/90.3 87.2 86.4 93.0 71.2 65.1 39.6
49 | 48 Jacob Devlin BERT: 24-layers, 16-heads, 1024-hidden 80.5 60.5 94.9 89.3/85.4 87.6/86.5 72.1/89.3 86.7 85.9 92.7 70.1 65.1 39.6
50 | 49 Chen Qian KerasNLP XLM-R 80.4 56.3 96.1 89.8/86.3 88.4/87.7 72.3/89.0 87.7 87.1 92.8 69.2 65.1 40.6
51 | 50 Chen Qian KerasNLP RoBERTa 80.4 56.3 96.1 89.8/86.3 88.4/87.7 72.3/89.0 87.7 87.1 92.8 69.2 65.1 40.6
52 | 51 Jinliang LU MULTIPLE_ADAPTER_T5_BASE 80.3 54.1 93.8 90.1/86.8 87.9/87.6 71.8/88.9 86.1 85.7 93.5 76.8 62.3 9.2
53 | 52 Yoshitomo Matsubara HF bert-large-uncased (default fine-tuning) 80.2 61.5 94.6 89.2/85.2 86.4/85.0 72.2/89.3 86.4 85.7 92.4 68.9 65.1 36.9
54 | 53 Neil Houlsby BERT + Single-task Adapters 80.2 59.2 94.3 88.7/84.3 87.3/86.1 71.5/89.4 85.4 85.0 92.4 71.6 65.1 9.2
55 | 54 KI BERT KI-BERT 80.0 55.6 94.5 88.2/83.9 86.3/85.1 71.5/88.9 85.2 83.7 91.2 69.3 73.3 35.6
56 | 55 Xiangyang Liu elasticbert-large-12L 79.9 57.0 92.9 89.4/86.0 89.7/88.6 72.7/89.6 85.4 84.9 92.3 71.8 62.3 9.2
57 | 56 刘向阳 roberta-large-12L 79.8 59.4 94.6 89.1/85.8 89.8/89.1 71.5/89.4 86.4 85.2 91.6 67.3 62.3 9.2
58 | 57 Zhuohan Li Macaron Net-base 79.7 57.6 94.0 88.4/84.4 87.5/86.3 70.8/89.0 85.4 84.5 91.6 70.5 65.1 38.7
59 | 58 shi To GAT-bert-base 79.6 56.8 94.0 89.4/85.3 87.9/86.8 72.4/89.4 85.7 84.5 91.8 70.5 62.3 9.2
60 | 59 teerapong saelim WT-VAT-BERT (Base) 79.5 56.0 94.4 89.2/85.5 87.3/86.2 72.9/89.8 85.5 84.8 91.4 70.4 62.3 9.2
61 | 60 Anshuman Singh Bert-n-Pals 79.1 52.2 93.4 89.5/85.6 86.6/85.9 71.4/89.0 84.1 83.5 90.6 75.4 62.3 33.8
62 | 61 ANSHUMAN SINGH (RA1811003010460) DeepPavlov Multitask PalBert 78.8 48.1 93.4 88.9/85.6 87.0/86.7 71.4/89.0 83.9 83.4 90.8 76.7 62.3 33.8
63 | 62 xiaok Liu BERT-EMD(6-layer; Single model; No DA) 78.7 47.5 93.3 89.8/86.4 87.6/86.8 72.0/89.3 84.7 83.5 90.7 71.7 65.1 9.2
64 | 63 蘇大鈞 SesameBERT-Base 78.6 52.7 94.2 88.9/84.8 86.5/85.5 70.8/88.8 83.7 83.6 91.0 67.6 65.1 35.8
65 | 64 xinge ma ReptileDistil 78.5 47.9 92.8 89.2/85.4 87.1/85.9 71.0/89.0 83.6 82.9 90.4 73.5 65.1 33.2
66 | 65 MobileBERT Team MobileBERT 78.5 51.1 92.6 88.8/84.5 86.2/84.8 70.5/88.3 84.3 83.4 91.6 70.4 65.1 34.3
67 | 66 Linyuan Gong StackingBERT-Base 78.4 56.2 93.9 88.2/83.9 84.2/82.5 70.4/88.7 84.4 84.2 90.1 67.0 65.1 36.6
68 | 67 TinyBERT Team TinyBERT (6-layer; Single model) 78.1 51.1 93.1 87.3/82.6 85.0/83.7 71.6/89.1 84.6 83.2 90.4 70.0 65.1 9.2
69 | 68 SqueezeBERT Team SqueezeBERT (4.3x faster than BERT-base on smartphone) 78.1 46.5 91.4 89.5/86.0 87.0/86.3 71.5/89.0 82.0 81.1 90.1 73.2 65.1 35.3
70 | 69 Anshuman Singh CAMTL 77.9 53.0 92.6 88.3/84.4 86.6/85.9 70.0/88.5 82.3 82.0 90.5 72.8 58.2 33.8
71 | 70 傅薛林 KRISFU 77.8 52.4 92.5 89.0/84.8 83.7/82.2 70.4/88.6 84.3 83.4 90.9 65.9 65.1 36.1
72 | 71 王上 s0 77.8 46.8 92.9 88.9/84.8 87.2/86.5 71.9/89.1 84.5 83.4 90.8 70.9 60.3 35.3
73 | 72 Stark Tony Pocket GLUE 77.6 49.3 92.4 89.0/84.6 84.9/84.0 70.1/88.7 84.0 82.8 90.1 67.2 65.1 36.1
74 | 73 Pavan Kalyan Reddy Neerudu Pavan Neerudu - BERT 77.6 56.1 93.5 87.6/83.2 85.3/83.8 70.6/88.8 84.0 83.4 90.8 64.0 60.3 34.6
75 | 74 NLC MSR Asia BERT-of-Theseus (6-layer; single model) 77.1 47.8 92.2 87.6/83.2 85.6/84.1 71.6/89.3 82.4 82.1 89.6 66.2 65.1 9.2
76 | 75 Hanxiong Huang Hanxiong Huang 75.9 49.3 93.3 87.1/81.9 83.3/81.7 71.5/89.1 84.8 83.8 91.0 64.1 53.4 9.2
77 | 76 YeonTaek Oh EL-BERT(6-Layer, Single model) 75.6 47.7 91.0 87.8/83.0 81.2/80.2 69.9/88.1 81.8 81.0 90.2 59.9 65.1 31.8
78 | 77 EVS Team Anonymous 74.7 52.6 93.4 87.6/83.2 61.2/59.1 71.8/89.3 83.7 83.2 89.9 65.0 62.3 35.6
79 | 78 Chen Money KerasNLP 12/05/2022 Trial 2 74.6 52.2 93.5 87.8/82.6 84.5/83.1 71.3/89.3 82.3 81.6 89.3 61.7 43.8 32.9
80 | 79 Sinx ZHIYUAN 74.1 57.0 95.2 91.4/88.4 91.1/90.8 24.2/23.7 87.7 87.3 92.5 81.7 47.9 0.3
81 | 80 Tirana Noor Fatyanosa distilbert-base-uncased 73.6 45.8 92.3 87.6/83.1 71.0/71.0 69.6/88.2 81.6 81.3 88.8 54.1 65.1 31.8
82 | 81 Haiqin YANG RefBERT 73.1 47.9 92.9 86.9/81.9 75.0/76.3 61.6/84.4 80.9 80.3 87.3 61.7 54.8 -10.3
83 | 82 Haiqin Yang RefBERT 73.1 47.9 92.9 86.9/81.9 75.0/76.3 61.4/84.2 80.9 80.3 87.3 61.7 54.8 -10.3
84 | 83 Haiqin Yang RefBERT 71.8 36.3 92.9 86.9/81.9 75.0/76.3 61.6/83.8 80.9 80.3 87.3 61.7 54.8 -10.3
85 | 84 Haiqin Yang RefBERT 71.8 36.3 92.9 86.9/81.9 75.0/76.3 61.3/83.6 80.9 80.3 87.3 61.7 54.8 -10.3
86 | 85 公能公能 1111 71.4 35.8 90.1 83.2/75.7 81.0/79.3 68.5/87.5 77.5 77.1 86.7 58.0 56.8 9.2
87 | 86 Jack Hessel Bag-of-words only BoW-BERT (Base) 70.0 14.3 86.7 82.9/75.2 81.8/80.3 68.3/87.5 79.8 79.7 86.2 60.4 65.1 31.0
88 | 87 GLUE Baselines BiLSTM+ELMo+Attn 70.0 33.6 90.4 84.4/78.0 74.2/72.3 63.1/84.3 74.1 74.5 79.8 58.9 65.1 21.7
89 |
--------------------------------------------------------------------------------
/benchbench/data/heim/alignment_auto.tsv:
--------------------------------------------------------------------------------
1 | Model/adapter Mean win rate ↑ [ sort ] MS-COCO (base) - Expected CLIP score ↑ [ sort ] MS-COCO (base) - Max CLIP score ↑ [ sort ] Caltech-UCSD Birds-200-2011 - Expected CLIP score ↑ [ sort ] Caltech-UCSD Birds-200-2011 - Max CLIP score ↑ [ sort ] DrawBench (image quality categories) - Expected CLIP score ↑ [ sort ] DrawBench (image quality categories) - Max CLIP score ↑ [ sort ] PartiPrompts (image quality categories) - Expected CLIP score ↑ [ sort ] PartiPrompts (image quality categories) - Max CLIP score ↑ [ sort ] dailydall.e - Expected CLIP score ↑ [ sort ] dailydall.e - Max CLIP score ↑ [ sort ] Landing Page - Expected CLIP score ↑ [ sort ] Landing Page - Max CLIP score ↑ [ sort ] Logos - Expected CLIP score ↑ [ sort ] Logos - Max CLIP score ↑ [ sort ] Magazine Cover Photos - Expected CLIP score ↑ [ sort ] Magazine Cover Photos - Max CLIP score ↑ [ sort ] Common Syntactic Processes - Expected CLIP score ↑ [ sort ] Common Syntactic Processes - Max CLIP score ↑ [ sort ] DrawBench (reasoning categories) - Expected CLIP score ↑ [ sort ] DrawBench (reasoning categories) - Max CLIP score ↑ [ sort ] PartiPrompts (reasoning categories) - Expected CLIP score ↑ [ sort ] PartiPrompts (reasoning categories) - Max CLIP score ↑ [ sort ] Relational Understanding - Expected CLIP score ↑ [ sort ] Relational Understanding - Max CLIP score ↑ [ sort ] Detection (PaintSkills) - Expected CLIP score ↑ [ sort ] Detection (PaintSkills) - Max CLIP score ↑ [ sort ] Winoground - Expected CLIP score ↑ [ sort ] Winoground - Max CLIP score ↑ [ sort ] PartiPrompts (knowledge categories) - Expected CLIP score ↑ [ sort ] PartiPrompts (knowledge categories) - Max CLIP score ↑ [ sort ] DrawBench (knowledge categories) - Expected CLIP score ↑ [ sort ] DrawBench (knowledge categories) - Max CLIP score ↑ [ sort ] TIME's most significant historical figures - Expected CLIP score ↑ [ sort ] TIME's most significant historical figures - Max CLIP score ↑ [ sort ] Demographic Stereotypes - Expected CLIP score ↑ [ sort ] Demographic Stereotypes - Max CLIP score ↑ [ sort ] Mental Disorders - Expected CLIP score ↑ [ sort ] Mental Disorders - Max CLIP score ↑ [ sort ] Inappropriate Image Prompts (I2P) - Expected CLIP score ↑ [ sort ] Inappropriate Image Prompts (I2P) - Max CLIP score ↑ [ sort ]
2 | Dreamlike Diffusion v1.0 (1B) 0.958 27.06 28.593 27.071 27.071 29.446 31.775 28.071 29.793 30.507 32.424 27.751 29.513 26.027 29.048 28.419 30.538 26.146 27.745 27.875 29.624 27.998 30.088 26.46 28.525 25.603 27.195 25.381 27.033 29.205 31.118 30.656 32.961 26.17 27.584 23.22 24.839 22.425 24.541 28.473 31.283
3 | Vintedois (22h) Diffusion model v0.1 (1B) 0.806 26.402 28.169 26.209 26.209 27.42 29.887 27.471 29.319 29.901 31.69 27.1 29.07 23.608 26.569 26.279 28.531 25.379 27.467 27.171 28.953 27.299 29.323 26.099 28.261 25.403 26.972 24.409 26.255 28.728 30.602 29.354 32.072 26.653 28.169 22.62 24.868 22.258 24.71 27.149 30.318
4 | Dreamlike Photoreal v2.0 (1B) 0.779 26.104 27.733 26.597 26.597 28.186 31.06 27.392 29.238 30.289 32.345 26.549 28.668 24.582 27.419 27.462 29.855 24.975 26.689 26.843 28.887 27.163 29.322 26.184 28.312 25.123 26.785 24.136 25.983 28.727 30.62 29.421 32.221 25.907 27.373 22.358 24.193 21.809 24.028 28.009 31.036
5 | Stable Diffusion v2 base (1B) 0.777 26.255 28.052 26.089 26.089 28.923 31.806 27.421 29.388 29.246 31.576 26.535 29.116 24.19 27.284 28.292 31.275 24.731 26.907 27.107 29.492 27.281 29.653 25.839 28.282 25.194 26.976 24.643 27.083 28.105 30.331 29.243 32.155 25.443 27.379 21.82 24.385 21.53 23.717 26.509 30.134
6 | Stable Diffusion v1.5 (1B) 0.767 26.376 28.147 26.699 26.699 27.843 30.343 27.165 29.34 29.81 32.473 26.553 28.714 23.975 26.931 27.09 29.75 24.978 27.21 26.899 29.078 27.103 29.477 25.272 27.929 24.999 26.977 24.372 26.542 28.248 30.414 28.55 31.554 26.033 27.922 22.134 24.162 22.352 24.366 26.867 30.201
7 | DeepFloyd IF X-Large (4.3B) 0.758 25.791 27.653 26.126 26.126 29.691 32.408 27.328 29.176 29.021 31.105 27.448 29.421 25.388 28.423 29.366 32.274 24.795 26.862 26.936 29.1 27.852 29.997 26 28.446 25.404 27.136 23.926 25.873 28.175 30.135 30.038 32.743 24.892 26.678 21.659 23.637 21.497 23.484 25.486 28.971
8 | Stable Diffusion v1.4 (1B) 0.749 26.425 28.28 26.433 26.433 27.713 30.556 27.228 29.406 29.542 32.076 26.881 29.496 23.582 26.615 26.944 29.566 24.719 26.789 27.01 29.074 26.792 29.278 25.399 28.07 25.069 26.812 24.442 26.347 28.135 30.448 28.325 31.246 26.303 28.057 21.926 24.358 22.637 24.595 26.608 29.841
9 | Safe Stable Diffusion weak (1B) 0.742 26.196 27.885 26.68 26.68 27.551 30.098 27.078 29.233 29.577 32.034 26.642 29.103 24.008 26.615 27.201 29.71 24.917 27.028 27.033 29.242 27.208 29.69 25.188 27.827 24.964 26.882 24.337 26.332 28.325 30.628 27.982 30.974 26.24 27.882 22.022 24.128 22.259 24.347 26.63 29.975
10 | DALL-E 2 (3.5B) 0.696 27.102 28.714 25.323 25.323 28.56 30.857 27.841 29.623 29.89 31.886 26.35 28.28 25.798 28.257 22.522 25.246 25.301 26.9 27.909 29.722 28.696 30.6 26.839 28.994 26.79 28.382 24.96 26.679 28.628 30.597 30.613 32.92 22.177 24.177 21.529 23.555 15.062 16.36 20.186 22.735
11 | DALL-E mega (2.6B) 0.695 27.193 29.205 26.752 26.752 26.866 29.347 27.925 30.074 28.761 31.018 21.37 23.327 24.489 26.732 19.366 21.312 25.246 27.135 26.734 29.346 27.289 29.251 25.698 28.074 26.744 28.508 23.913 25.853 28.1 30.427 27.971 30.817 26.743 28.378 22.849 25.288 21.634 24.123 24.502 27.814
12 | DeepFloyd IF Large (0.9B) 0.628 25.504 27.046 25.881 25.881 28.705 32.045 27.06 28.906 28.786 30.828 26.825 28.923 24.417 27.176 28.412 31.832 24.757 26.614 26.461 28.569 27.423 29.715 25.657 27.965 25.421 27.154 23.733 25.577 28.07 29.954 29.009 31.848 23.527 25.425 21.5 23.537 21.097 23.593 25.025 28.5
13 | Stable Diffusion v2.1 base (1B) 0.609 25.861 27.507 26.065 26.065 28.135 30.718 27.205 29.136 29.028 31.617 25.658 27.805 22.697 25.8 25.989 28.949 24.566 26.543 26.575 28.608 26.311 28.921 25.754 27.992 24.851 26.826 23.753 25.658 27.773 29.757 28.658 31.35 25.898 27.535 21.778 24.588 21.329 23.619 26.266 29.768
14 | DeepFloyd IF Medium (0.4B) 0.56 25.517 27.116 25.692 25.692 28.541 31.596 26.739 28.63 28.531 30.875 26.338 28.054 24.225 27.369 27.657 30.839 24.709 26.782 26.251 28.357 27.21 29.424 25.315 27.951 25.52 27.223 23.63 25.592 27.525 29.557 27.928 30.694 21.873 24.283 21.387 23.902 21.487 23.921 24.562 28.175
15 | Openjourney v2 (1B) 0.506 26.807 28.61 25.661 25.661 26.317 29.183 26.448 28.682 28.956 31.465 26.097 28.122 24.803 27.362 24.812 27.158 23.831 26.053 26.398 28.555 25.795 28.251 24.316 27.084 24.932 26.726 22.811 25.188 27.209 29.476 27.328 30.312 24.25 26.373 20.996 23.57 21.123 24.108 25.056 28.469
16 | Safe Stable Diffusion medium (1B) 0.493 25.671 27.676 26.003 26.003 26.563 29.467 26.536 28.739 28.687 31.451 26.207 28.47 23.355 26.011 25.746 28.411 24.023 26.136 26.271 28.558 26.528 29.02 24.358 26.831 24.4 26.331 23.498 25.557 27.725 30.182 27.619 30.716 25.521 27.165 20.949 23.289 19.615 21.402 25.803 29.444
17 | GigaGAN (1B) 0.4 25.722 27.645 26.569 26.569 25.668 27.828 26.589 28.678 28.154 30.582 25.199 27.185 20.775 23.154 20.637 23.247 24.301 26.324 26.328 28.668 26.145 28.237 24.996 27.004 24.391 26.205 23.28 25.362 27.245 29.449 27.433 30.121 23.746 26.019 20.94 23.343 19.091 22.136 24.886 28.073
18 | Promptist + Stable Diffusion v1.4 (1B) 0.369 25.245 27.209 25.207 25.207 24.786 27.488 26.213 28.384 28.776 31.238 24.525 26.693 22.608 25.516 26.105 28.509 23.599 25.233 25.449 27.704 25.462 27.918 23.745 26.363 23.872 25.834 21.741 23.811 27.209 29.446 28.214 30.657 24.663 26.595 20.877 23.337 20.785 23.185 25.051 28.182
19 | Safe Stable Diffusion strong (1B) 0.344 24.787 26.974 25.769 25.769 25.704 28.244 25.758 28.148 27.727 30.772 25.476 27.77 22.65 25.527 24.476 27.406 23.074 25.367 25.522 27.833 25.722 28.394 23.246 25.788 23.898 25.93 22.48 24.761 26.754 29.467 26.842 29.558 24.763 26.864 20.029 22.566 17.414 19.736 23.836 28.104
20 | Redshift Diffusion (1B) 0.244 24.837 26.695 25.407 25.407 25.15 27.975 25.494 27.792 27.753 30.215 24.306 26.406 20.97 23.405 22.523 25.576 22.733 25.258 25.032 27.432 23.822 27.015 23.125 25.863 23.58 25.667 21.284 23.548 26.755 29.104 26.408 28.721 23.341 25.651 20.01 22.322 19.156 20.985 23.825 27.389
21 | DALL-E mini (0.4B) 0.226 25.012 27.029 25.648 25.648 22.838 25.168 25.366 27.615 25.483 27.974 19.796 21.853 22.677 24.914 17.046 19.148 21.89 24.111 23.495 26.067 25.2 27.45 23.145 25.743 24.982 26.838 21.337 23.457 25.301 27.538 24.023 26.368 22.972 24.798 21.042 23.494 21.046 22.96 21.367 24.746
22 | Safe Stable Diffusion max (1B) 0.223 23.859 26.086 25.562 25.562 24.708 27.835 24.852 27.384 26.671 29.919 24.982 27.168 20.657 24.167 22.995 25.918 22.188 24.81 24.662 27.251 24.651 27.675 22.673 25.617 23.494 25.718 21.663 24.438 25.726 28.466 25.257 28.386 24.043 26.374 19.46 22.258 16.703 18.993 21.666 26.659
23 | Openjourney v1 (1B) 0.198 24.894 27.025 24.611 24.611 21.407 24.437 24.868 27.346 27.697 30.206 25.33 27.495 19.74 22.446 22.989 25.714 22.254 24.603 24.223 26.86 23.298 25.935 20.85 23.903 23.859 25.846 20.444 23.165 26.339 28.686 26.85 29.452 24.038 25.885 19.712 22.125 19.291 22.07 23.823 27.315
24 | Lexica Search with Stable Diffusion v1.5 (1B) 0.18 21.961 24.592 22.964 22.964 22.862 25.672 22.769 25.521 23.685 26.341 22.429 25.009 21.818 24.365 21.709 23.701 21.728 24.083 22.618 25.314 22.602 25.234 22.138 24.929 22.894 25.118 21.659 23.818 23.01 25.779 23.298 26.011 22.926 25.289 21.601 24.112 21.228 23.99 24.632 28.751
25 | MultiFusion (13B) 0.163 24.236 26.55 24.601 24.601 23.061 26.272 24.036 26.566 25.655 29.027 22.637 24.586 19.342 22.464 19.955 22.778 22.315 24.757 24.156 26.968 24.073 27.183 22.967 26.243 22.849 24.997 21.331 23.92 24.127 26.652 23.666 27.558 17.701 20.452 19.768 22.997 19.846 23.121 19.239 23.436
26 | CogView2 (6B) 0.085 23.082 25.896 23.656 23.656 22.005 25.267 23.157 26.143 23.247 26.783 18.952 21.609 19.135 21.655 16.365 19.004 21.808 24.546 22.251 25.46 22.854 26.096 22.743 26.103 22.804 25.286 20.928 23.91 21.91 25.171 19.703 23.339 13.897 16.125 20.031 24.113 18.803 21.807 16.534 20.931
27 | minDALL-E (1.3B) 0.045 21.596 25.119 23.908 23.908 22.67 25.628 22.25 25.615 21.644 25.391 17.916 20.329 20.343 23.082 16.728 19.315 19.798 22.602 21.283 24.54 22.225 25.359 20.573 23.678 21.334 24.398 18.825 21.861 22.089 25.715 20.741 24.123 14.138 16.652 19.439 23.03 19.168 21.523 16.836 21.259
28 |
--------------------------------------------------------------------------------