├── .gitingore
├── LICENSE
├── README.md
└── transformer.py
/.gitingore:
--------------------------------------------------------------------------------
1 | *.idea
2 | *.pyc
3 | .idea.ipynb_checkpoints
4 | data/csv/*
5 | *.zip
6 | __pycache__/*
7 | .idea/
8 | .idea/*
9 | *.bin
10 | *.zip
11 | *.idea
12 | docs/training
13 | docs/training/*
14 | __pycache__/
15 | data/*
16 | *.pyc
17 | .idea
18 | .ipynb_checkpoints
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright [yyyy] [name of copyright owner]
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # transformer
2 |
3 | A PyTorch Implementation of Transformer in [Attention Is All You Need](https://arxiv.org/abs/1706.03762).
4 | This repository focused on implementing the contents of the paper as much as possible.
5 |
6 | ## Intro
7 |
8 | 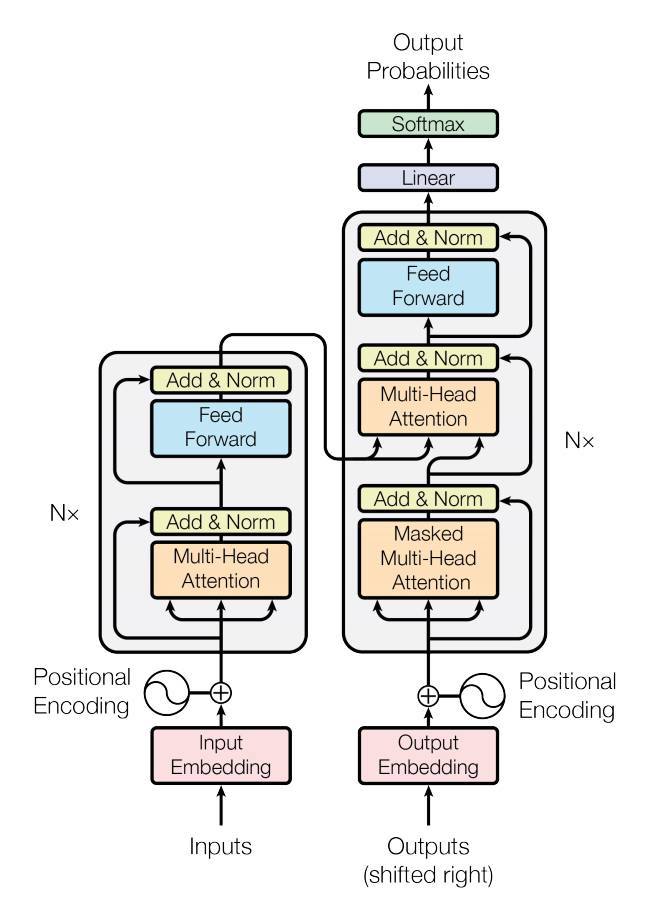 9 |
10 | This repository focused on implementing the contents of the paper as much as possible,
11 | while at the same time striving for a readable code. To improve readability,
12 | I designed the model structure to fit as much as possible to the blocks in the above Transformers figure.
13 |
14 | ## Installation
15 | This project recommends Python 3.7 or higher.
16 | We recommend creating a new virtual environment for this project (using virtual env or conda).
17 |
18 | ### Prerequisites
19 | * Numpy: `pip install numpy` (Refer [here](https://github.com/numpy/numpy) for problem installing Numpy).
20 | * Pytorch: Refer to [PyTorch website](http://pytorch.org/) to install the version w.r.t. your environment.
21 |
22 | ### Install from source
23 | Currently we only support installation from source code using setuptools. Checkout the source code and run the
24 | following commands:
25 |
26 | ```
27 | pip install -e .
28 | ```
29 |
30 | ## Usage
31 |
32 | ```python
33 | import torch
34 | import torch.nn as nn
35 | from transformer import Transformer
36 |
37 | BATCH_SIZE, SEQ_LENGTH, D_MODEL = 3, 10, 64
38 |
39 | cuda = torch.cuda.is_available()
40 | device = torch.device('cuda' if cuda else 'cpu')
41 |
42 | inputs = torch.zeros(BATCH_SIZE, SEQ_LENGTH).long().to(device)
43 | input_lengths = torch.LongTensor([12345, 12300, 12000])
44 | targets = torch.LongTensor([[1, 3, 3, 3, 3, 3, 4, 5, 6, 2],
45 | [1, 3, 3, 3, 3, 3, 4, 5, 2, 0],
46 | [1, 3, 3, 3, 3, 3, 4, 2, 0, 0]]).to(device)
47 | target_lengths = torch.LongTensor([9, 8, 7])
48 |
49 | model = nn.DataParallel(Transformer(num_input_embeddings=30, num_output_embeddings=50,
50 | d_model=64,
51 | num_encoder_layers=3, num_decoder_layers=3)).to(device)
52 |
53 | # Forward propagate
54 | outputs = model(inputs, input_lengths, targets, target_lengths)
55 |
56 | # Inference
57 | outputs = model(inputs, input_lengths)
58 | ```
59 |
60 | ## Troubleshoots and Contributing
61 | If you have any questions, bug reports, and feature requests, please [open an issue](https://github.com/sooftware/conformer/issues) on github or
62 | contacts sh951011@gmail.com please.
63 |
64 | I appreciate any kind of feedback or contribution. Feel free to proceed with small issues like bug fixes, documentation improvement. For major contributions and new features, please discuss with the collaborators in corresponding issues.
65 |
66 | ## Code Style
67 | I follow [PEP-8](https://www.python.org/dev/peps/pep-0008/) for code style. Especially the style of docstrings is important to generate documentation.
68 |
69 | ## Author
70 |
71 | * Soohwan Kim [@sooftware](https://github.com/sooftware)
72 | * Contacts: sh951011@gmail.com
--------------------------------------------------------------------------------
/transformer.py:
--------------------------------------------------------------------------------
1 | import math
2 | import torch
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 | import numpy as np
6 | from torch import Tensor
7 | from typing import Optional, Tuple
8 |
9 |
10 | def get_attn_pad_mask(inputs, input_lengths, expand_length):
11 | """ mask position is set to 1 """
12 |
13 | def get_transformer_non_pad_mask(inputs: Tensor, input_lengths: Tensor) -> Tensor:
14 | """ Padding position is set to 0, either use input_lengths or pad_id """
15 | batch_size = inputs.size(0)
16 |
17 | if len(inputs.size()) == 2:
18 | non_pad_mask = inputs.new_ones(inputs.size()) # B x T
19 | elif len(inputs.size()) == 3:
20 | non_pad_mask = inputs.new_ones(inputs.size()[:-1]) # B x T
21 | else:
22 | raise ValueError(f"Unsupported input shape {inputs.size()}")
23 |
24 | for i in range(batch_size):
25 | non_pad_mask[i, input_lengths[i]:] = 0
26 |
27 | return non_pad_mask
28 |
29 | non_pad_mask = get_transformer_non_pad_mask(inputs, input_lengths)
30 | pad_mask = non_pad_mask.lt(1)
31 | attn_pad_mask = pad_mask.unsqueeze(1).expand(-1, expand_length, -1)
32 | return attn_pad_mask
33 |
34 |
35 | def get_attn_subsequent_mask(seq):
36 | assert seq.dim() == 2
37 | attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
38 | subsequent_mask = torch.triu(torch.ones(attn_shape), diagonal=1)
39 |
40 | if seq.is_cuda:
41 | subsequent_mask = subsequent_mask.cuda()
42 |
43 | return subsequent_mask
44 |
45 |
46 | class PositionalEncoding(nn.Module):
47 | """
48 | Positional Encoding proposed in "Attention Is All You Need".
49 | Since transformer contains no recurrence and no convolution, in order for the model to make
50 | use of the order of the sequence, we must add some positional information.
51 |
52 | "Attention Is All You Need" use sine and cosine functions of different frequencies:
53 | PE_(pos, 2i) = sin(pos / power(10000, 2i / d_model))
54 | PE_(pos, 2i+1) = cos(pos / power(10000, 2i / d_model))
55 | """
56 | def __init__(self, d_model: int = 80, max_len: int = 5000) -> None:
57 | super(PositionalEncoding, self).__init__()
58 | pe = torch.zeros(max_len, d_model, requires_grad=False)
59 | position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1).float()
60 | div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
61 | pe[:, 0::2] = torch.sin(position * div_term)
62 | pe[:, 1::2] = torch.cos(position * div_term)
63 | pe = pe.unsqueeze(0)
64 | self.register_buffer('pe', pe)
65 |
66 | def forward(self, length: int) -> Tensor:
67 | return self.pe[:, :length]
68 |
69 |
70 | class Embedding(nn.Module):
71 | """
72 | Embedding layer. Similarly to other sequence transduction models, transformer use learned embeddings
73 | to convert the input tokens and output tokens to vectors of dimension d_model.
74 | In the embedding layers, transformer multiply those weights by sqrt(d_model)
75 | """
76 | def __init__(self, num_embeddings: int, pad_id: int, d_model: int = 512) -> None:
77 | super(Embedding, self).__init__()
78 | self.sqrt_dim = math.sqrt(d_model)
79 | self.embedding = nn.Embedding(num_embeddings, d_model, padding_idx=pad_id)
80 |
81 | def forward(self, inputs: Tensor) -> Tensor:
82 | return self.embedding(inputs) * self.sqrt_dim
83 |
84 |
85 | class AddNorm(nn.Module):
86 | """
87 | Add & Normalization layer proposed in "Attention Is All You Need".
88 | Transformer employ a residual connection around each of the two sub-layers,
89 | (Multi-Head Attention & Feed-Forward) followed by layer normalization.
90 | """
91 | def __init__(self, sublayer: nn.Module, d_model: int = 512) -> None:
92 | super(AddNorm, self).__init__()
93 | self.sublayer = sublayer
94 | self.layer_norm = nn.LayerNorm(d_model)
95 |
96 | def forward(self, *args):
97 | residual = args[0]
98 | output = self.sublayer(*args)
99 |
100 | if isinstance(output, tuple):
101 | return self.layer_norm(output[0] + residual), output[1]
102 | else:
103 | return self.layer_norm(output + residual)
104 |
105 |
106 | class ScaledDotProductAttention(nn.Module):
107 | """
108 | Scaled Dot-Product Attention proposed in "Attention Is All You Need"
109 | Compute the dot products of the query with all keys, divide each by sqrt(dim),
110 | and apply a softmax function to obtain the weights on the values
111 |
112 | Args: dim, mask
113 | dim (int): dimention of attention
114 | mask (torch.Tensor): tensor containing indices to be masked
115 |
116 | Inputs: query, key, value, mask
117 | - **query** (batch, q_len, d_model): tensor containing projection vector for decoder.
118 | - **key** (batch, k_len, d_model): tensor containing projection vector for encoder.
119 | - **value** (batch, v_len, d_model): tensor containing features of the encoded input sequence.
120 | - **mask** (-): tensor containing indices to be masked
121 |
122 | Returns: context, attn
123 | - **context**: tensor containing the context vector from attention mechanism.
124 | - **attn**: tensor containing the attention (alignment) from the encoder outputs.
125 | """
126 | def __init__(self, dim: int) -> None:
127 | super(ScaledDotProductAttention, self).__init__()
128 | self.sqrt_dim = np.sqrt(dim)
129 |
130 | def forward(self, query: Tensor, key: Tensor, value: Tensor, mask: Optional[Tensor] = None) -> Tuple[Tensor, Tensor]:
131 | score = torch.bmm(query, key.transpose(1, 2)) / self.sqrt_dim
132 |
133 | if mask is not None:
134 | score.masked_fill_(mask.view(score.size()), -float('Inf'))
135 |
136 | attn = F.softmax(score, -1)
137 | context = torch.bmm(attn, value)
138 | return context, attn
139 |
140 |
141 | class MultiHeadAttention(nn.Module):
142 | """
143 | Multi-Head Attention proposed in "Attention Is All You Need"
144 | Instead of performing a single attention function with d_model-dimensional keys, values, and queries,
145 | project the queries, keys and values h times with different, learned linear projections to d_head dimensions.
146 | These are concatenated and once again projected, resulting in the final values.
147 | Multi-head attention allows the model to jointly attend to information from different representation
148 | subspaces at different positions.
149 |
150 | MultiHead(Q, K, V) = Concat(head_1, ..., head_h) · W_o
151 | where head_i = Attention(Q · W_q, K · W_k, V · W_v)
152 |
153 | Args:
154 | d_model (int): The dimension of keys / values / quries (default: 512)
155 | num_heads (int): The number of attention heads. (default: 8)
156 |
157 | Inputs: query, key, value, mask
158 | - **query** (batch, q_len, d_model): In transformer, three different ways:
159 | Case 1: come from previoys decoder layer
160 | Case 2: come from the input embedding
161 | Case 3: come from the output embedding (masked)
162 |
163 | - **key** (batch, k_len, d_model): In transformer, three different ways:
164 | Case 1: come from the output of the encoder
165 | Case 2: come from the input embeddings
166 | Case 3: come from the output embedding (masked)
167 |
168 | - **value** (batch, v_len, d_model): In transformer, three different ways:
169 | Case 1: come from the output of the encoder
170 | Case 2: come from the input embeddings
171 | Case 3: come from the output embedding (masked)
172 |
173 | - **mask** (-): tensor containing indices to be masked
174 |
175 | Returns: output, attn
176 | - **output** (batch, output_len, dimensions): tensor containing the attended output features.
177 | - **attn** (batch * num_heads, v_len): tensor containing the attention (alignment) from the encoder outputs.
178 | """
179 | def __init__(self, d_model: int = 512, num_heads: int = 8) -> None:
180 | super(MultiHeadAttention, self).__init__()
181 |
182 | assert d_model % num_heads == 0, "d_model % num_heads should be zero."
183 |
184 | self.d_head = int(d_model / num_heads)
185 | self.num_heads = num_heads
186 | self.scaled_dot_attn = ScaledDotProductAttention(self.d_head)
187 | self.linear_q = nn.Linear(d_model, self.d_head * num_heads)
188 | self.linear_k = nn.Linear(d_model, self.d_head * num_heads)
189 | self.linear_v = nn.Linear(d_model, self.d_head * num_heads)
190 | self.linear = nn.Linear(d_model, d_model)
191 |
192 | def forward(self, query: Tensor, key: Tensor, value: Tensor, mask: Optional[Tensor] = None) -> Tuple[Tensor, Tensor]:
193 | batch_size = value.size(0)
194 |
195 | query = self.linear_q(query).view(batch_size, -1, self.num_heads, self.d_head) # BxQ_LENxNxD
196 | key = self.linear_k(key).view(batch_size, -1, self.num_heads, self.d_head) # BxK_LENxNxD
197 | value = self.linear_v(value).view(batch_size, -1, self.num_heads, self.d_head) # BxV_LENxNxD
198 |
199 | query = query.permute(2, 0, 1, 3).contiguous().view(batch_size * self.num_heads, -1, self.d_head) # BNxQ_LENxD
200 | key = key.permute(2, 0, 1, 3).contiguous().view(batch_size * self.num_heads, -1, self.d_head) # BNxK_LENxD
201 | value = value.permute(2, 0, 1, 3).contiguous().view(batch_size * self.num_heads, -1, self.d_head) # BNxV_LENxD
202 |
203 | if mask is not None:
204 | mask = mask.unsqueeze(1).repeat(1, self.num_heads, 1, 1) # BxNxQ_LENxK_LEN
205 |
206 | context, attn = self.scaled_dot_attn(query, key, value, mask)
207 | context = context.view(self.num_heads, batch_size, -1, self.d_head)
208 | context = context.permute(1, 2, 0, 3).contiguous().view(batch_size, -1, self.num_heads * self.d_head) # BxTxND
209 |
210 | return self.linear(context)
211 |
212 |
213 | class PoswiseFeedForwardNet(nn.Module):
214 | """
215 | Position-wise Feedforward Networks proposed in "Attention Is All You Need".
216 | Fully connected feed-forward network, which is applied to each position separately and identically.
217 | This consists of two linear transformations with a ReLU activation in between.
218 | Another way of describing this is as two convolutions with kernel size 1.
219 | """
220 | def __init__(self, d_model: int = 512, d_ff: int = 2048, dropout_p: float = 0.3) -> None:
221 | super(PoswiseFeedForwardNet, self).__init__()
222 | self.feed_forward = nn.Sequential(
223 | nn.Linear(d_model, d_ff),
224 | nn.Dropout(dropout_p),
225 | nn.ReLU(),
226 | nn.Linear(d_ff, d_model),
227 | nn.Dropout(dropout_p)
228 | )
229 |
230 | def forward(self, inputs: Tensor) -> Tensor:
231 | return self.feed_forward(inputs)
232 |
233 |
234 | class TransformerEncoderLayer(nn.Module):
235 | """
236 | EncoderLayer is made up of self-attention and feedforward network.
237 | This standard encoder layer is based on the paper "Attention Is All You Need".
238 | """
239 | def __init__(
240 | self,
241 | d_model: int = 512,
242 | num_heads: int = 8,
243 | d_ff: int = 2048,
244 | dropout_p: float = 0.3,
245 | ) -> None:
246 | super(TransformerEncoderLayer, self).__init__()
247 | self.self_attention = AddNorm(MultiHeadAttention(d_model, num_heads), d_model)
248 | self.feed_forward = AddNorm(PoswiseFeedForwardNet(d_model, d_ff, dropout_p), d_model)
249 |
250 | def forward(
251 | self,
252 | inputs: Tensor,
253 | self_attn_mask: Optional[Tensor] = None,
254 | ) -> Tuple[Tensor, Tensor]:
255 | output = self.self_attention(inputs, inputs, inputs, self_attn_mask)
256 | output = self.feed_forward(output)
257 | return output
258 |
259 |
260 | class TransformerEncoder(nn.Module):
261 | """
262 | The TransformerEncoder is composed of a stack of N identical layers.
263 | Each layer has two sub-layers. The first is a multi-head self-attention mechanism,
264 | and the second is a simple, position-wise fully connected feed-forward network.
265 | """
266 | def __init__(
267 | self,
268 | num_embeddings: int,
269 | d_model: int = 512,
270 | d_ff: int = 2048,
271 | num_layers: int = 6,
272 | num_heads: int = 8,
273 | dropout_p: float = 0.1,
274 | pad_id: int = 0,
275 | ) -> None:
276 | super(TransformerEncoder, self).__init__()
277 | self.d_model = d_model
278 | self.num_layers = num_layers
279 | self.num_heads = num_heads
280 | self.pad_id = pad_id
281 | self.embedding = Embedding(num_embeddings, pad_id, d_model)
282 | self.pos_encoding = PositionalEncoding(d_model)
283 | self.input_dropout = nn.Dropout(p=dropout_p)
284 | self.layers = nn.ModuleList(
285 | [TransformerEncoderLayer(d_model, num_heads, d_ff, dropout_p) for _ in range(num_layers)]
286 | )
287 |
288 | def forward(self, inputs: Tensor, input_lengths: Tensor = None):
289 | length = inputs.size(1)
290 |
291 | output = self.input_dropout(self.embedding(inputs) + self.pos_encoding(length))
292 | self_attn_mask = get_attn_pad_mask(inputs, input_lengths, length)
293 |
294 | for layer in self.layers:
295 | output = layer(output, self_attn_mask)
296 |
297 | return output
298 |
299 |
300 | class TransformerDecoderLayer(nn.Module):
301 | r"""
302 | DecoderLayer is made up of self-attention, multi-head attention and feedforward network.
303 | This standard decoders layer is based on the paper "Attention Is All You Need".
304 |
305 | Args:
306 | d_model: dimension of model (default: 512)
307 | num_heads: number of attention heads (default: 8)
308 | d_ff: dimension of feed forward network (default: 2048)
309 | dropout_p: probability of dropout (default: 0.3)
310 |
311 | Inputs:
312 | inputs (torch.FloatTensor): input sequence of transformer decoder layer
313 | encoder_outputs (torch.FloatTensor): outputs of encoder
314 | self_attn_mask (torch.BoolTensor): mask of self attention
315 | encoder_output_mask (torch.BoolTensor): mask of encoder outputs
316 |
317 | Returns:
318 | (Tensor, Tensor, Tensor)
319 | * outputs (torch.FloatTensor): output of transformer decoder layer
320 | * self_attn (torch.FloatTensor): output of self attention
321 | * encoder_attn (torch.FloatTensor): output of encoder attention
322 |
323 | Reference:
324 | Ashish Vaswani et al.: Attention Is All You Need
325 | https://arxiv.org/abs/1706.03762
326 | """
327 | def __init__(
328 | self,
329 | d_model: int = 512,
330 | num_heads: int = 8,
331 | d_ff: int = 2048,
332 | dropout_p: float = 0.3,
333 | ) -> None:
334 | super(TransformerDecoderLayer, self).__init__()
335 | self.self_attention_prenorm = nn.LayerNorm(d_model)
336 | self.decoder_attention_prenorm = nn.LayerNorm(d_model)
337 | self.feed_forward_prenorm = nn.LayerNorm(d_model)
338 | self.self_attention = MultiHeadAttention(d_model, num_heads)
339 | self.decoder_attention = MultiHeadAttention(d_model, num_heads)
340 | self.feed_forward = PoswiseFeedForwardNet(d_model, d_ff, dropout_p)
341 |
342 | def forward(
343 | self,
344 | inputs: Tensor,
345 | encoder_outputs: Tensor,
346 | self_attn_mask: Optional[Tensor] = None,
347 | encoder_attn_mask: Optional[Tensor] = None,
348 | ) -> Tuple[Tensor, Tensor, Tensor]:
349 | r"""
350 | Forward propagate transformer decoder layer.
351 |
352 | Inputs:
353 | inputs (torch.FloatTensor): input sequence of transformer decoder layer
354 | encoder_outputs (torch.FloatTensor): outputs of encoder
355 | self_attn_mask (torch.BoolTensor): mask of self attention
356 | encoder_output_mask (torch.BoolTensor): mask of encoder outputs
357 |
358 | Returns:
359 | outputs (torch.FloatTensor): output of transformer decoder layer
360 | self_attn (torch.FloatTensor): output of self attention
361 | encoder_attn (torch.FloatTensor): output of encoder attention
362 | """
363 | residual = inputs
364 | inputs = self.self_attention_prenorm(inputs)
365 | outputs = self.self_attention(inputs, inputs, inputs, self_attn_mask)
366 | outputs += residual
367 |
368 | residual = outputs
369 | outputs = self.decoder_attention_prenorm(outputs)
370 | outputs = self.decoder_attention(outputs, encoder_outputs, encoder_outputs, encoder_attn_mask)
371 | outputs += residual
372 |
373 | residual = outputs
374 | outputs = self.feed_forward_prenorm(outputs)
375 | outputs = self.feed_forward(outputs)
376 | outputs += residual
377 |
378 | return outputs
379 |
380 |
381 | class TransformerDecoder(nn.Module):
382 | r"""
383 | The TransformerDecoder is composed of a stack of N identical layers.
384 | Each layer has three sub-layers. The first is a multi-head self-attention mechanism,
385 | and the second is a multi-head attention mechanism, third is a feed-forward network.
386 |
387 | Args:
388 | num_classes: umber of classes
389 | d_model: dimension of model
390 | d_ff: dimension of feed forward network
391 | num_layers: number of layers
392 | num_heads: number of attention heads
393 | dropout_p: probability of dropout
394 | pad_id (int, optional): index of the pad symbol (default: 0)
395 | sos_id (int, optional): index of the start of sentence symbol (default: 1)
396 | eos_id (int, optional): index of the end of sentence symbol (default: 2)
397 | max_length (int): max decoding length
398 | """
399 |
400 | def __init__(
401 | self,
402 | num_classes: int,
403 | d_model: int = 512,
404 | d_ff: int = 512,
405 | num_layers: int = 6,
406 | num_heads: int = 8,
407 | dropout_p: float = 0.3,
408 | pad_id: int = 0,
409 | sos_id: int = 1,
410 | eos_id: int = 2,
411 | max_length: int = 512,
412 | ) -> None:
413 | super(TransformerDecoder, self).__init__()
414 | self.d_model = d_model
415 | self.num_layers = num_layers
416 | self.num_heads = num_heads
417 | self.max_length = max_length
418 | self.pad_id = pad_id
419 | self.sos_id = sos_id
420 | self.eos_id = eos_id
421 |
422 | self.embedding = Embedding(num_classes, pad_id, d_model)
423 | self.positional_encoding = PositionalEncoding(d_model)
424 | self.input_dropout = nn.Dropout(p=dropout_p)
425 | self.layers = nn.ModuleList([
426 | TransformerDecoderLayer(
427 | d_model=d_model,
428 | num_heads=num_heads,
429 | d_ff=d_ff,
430 | dropout_p=dropout_p,
431 | ) for _ in range(num_layers)
432 | ])
433 | self.fc = nn.Linear(d_model, num_classes, bias=False)
434 |
435 | def forward_step(
436 | self,
437 | decoder_inputs: torch.Tensor,
438 | decoder_input_lengths: torch.Tensor,
439 | encoder_outputs: torch.Tensor,
440 | encoder_output_lengths: torch.Tensor,
441 | positional_encoding_length: int,
442 | ) -> torch.Tensor:
443 | dec_self_attn_pad_mask = get_attn_pad_mask(
444 | decoder_inputs, decoder_input_lengths, decoder_inputs.size(1)
445 | )
446 | dec_self_attn_subsequent_mask = get_attn_subsequent_mask(decoder_inputs)
447 | self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0)
448 |
449 | encoder_attn_mask = get_attn_pad_mask(encoder_outputs, encoder_output_lengths, decoder_inputs.size(1))
450 |
451 | outputs = self.embedding(decoder_inputs) + self.positional_encoding(positional_encoding_length)
452 | outputs = self.input_dropout(outputs)
453 |
454 | for layer in self.layers:
455 | outputs = layer(
456 | inputs=outputs,
457 | encoder_outputs=encoder_outputs,
458 | self_attn_mask=self_attn_mask,
459 | encoder_attn_mask=encoder_attn_mask,
460 | )
461 |
462 | return outputs
463 |
464 | def forward(
465 | self,
466 | encoder_outputs: torch.Tensor,
467 | targets: Optional[torch.LongTensor] = None,
468 | encoder_output_lengths: torch.Tensor = None,
469 | target_lengths: torch.Tensor = None,
470 | ) -> torch.Tensor:
471 | r"""
472 | Forward propagate a `encoder_outputs` for training.
473 |
474 | Args:
475 | targets (torch.LongTensor): A target sequence passed to decoders. `IntTensor` of size
476 | ``(batch, seq_length)``
477 | encoder_outputs (torch.FloatTensor): A output sequence of encoders. `FloatTensor` of size
478 | ``(batch, seq_length, dimension)``
479 | encoder_output_lengths (torch.LongTensor): The length of encoders outputs. ``(batch)``
480 |
481 | Returns:
482 | * logits (torch.FloatTensor): Log probability of model predictions.
483 | """
484 | logits = list()
485 | batch_size = encoder_outputs.size(0)
486 |
487 | if targets is not None:
488 | targets = targets[targets != self.eos_id].view(batch_size, -1)
489 | target_length = targets.size(1)
490 |
491 | step_outputs = self.forward_step(
492 | decoder_inputs=targets,
493 | decoder_input_lengths=target_lengths,
494 | encoder_outputs=encoder_outputs,
495 | encoder_output_lengths=encoder_output_lengths,
496 | positional_encoding_length=target_length,
497 | )
498 | step_outputs = self.fc(step_outputs).log_softmax(dim=-1)
499 |
500 | for di in range(step_outputs.size(1)):
501 | step_output = step_outputs[:, di, :]
502 | logits.append(step_output)
503 |
504 | # Inference
505 | else:
506 | input_var = encoder_outputs.new_zeros(batch_size, self.max_length).long()
507 | input_var = input_var.fill_(self.pad_id)
508 | input_var[:, 0] = self.sos_id
509 |
510 | for di in range(1, self.max_length):
511 | input_lengths = torch.IntTensor(batch_size).fill_(di)
512 |
513 | outputs = self.forward_step(
514 | decoder_inputs=input_var[:, :di],
515 | decoder_input_lengths=input_lengths,
516 | encoder_outputs=encoder_outputs,
517 | encoder_output_lengths=encoder_output_lengths,
518 | positional_encoding_length=di,
519 | )
520 | step_output = self.fc(outputs).log_softmax(dim=-1)
521 | logits.append(step_output[:, -1, :])
522 | input_var[:, di] = logits[-1].topk(1)[1].squeeze()
523 |
524 | return torch.stack(logits, dim=1)
525 |
526 |
527 | class Transformer(nn.Module):
528 | """
529 | A Transformer model. User is able to modify the attributes as needed.
530 | The architecture is based on the paper "Attention Is All You Need".
531 |
532 | Args:
533 | pad_id (int): identification of
534 | num_input_embeddings (int): dimension of input embeddings
535 | num_output_embeddings (int): dimenstion of output embeddings
536 | d_model (int): dimension of model (default: 512)
537 | d_ff (int): dimension of feed forward network (default: 2048)
538 | num_encoder_layers (int): number of encoder layers (default: 6)
539 | num_decoder_layers (int): number of decoder layers (default: 6)
540 | num_heads (int): number of attention heads (default: 8)
541 | dropout_p (float): dropout probability (default: 0.3)
542 |
543 | Inputs: inputs, targets
544 | - **inputs** (batch, input_length): tensor containing input sequences
545 | - **targets** (batch, target_length): tensor contatining target sequences
546 |
547 | Returns: output
548 | - **output**: tensor containing the outputs
549 | """
550 | def __init__(
551 | self,
552 | num_input_embeddings: int,
553 | num_output_embeddings: int,
554 | d_model: int = 512,
555 | d_ff: int = 2048,
556 | num_heads: int = 8,
557 | num_encoder_layers: int = 6,
558 | num_decoder_layers: int = 6,
559 | dropout_p: float = 0.1,
560 | pad_id: int = 0,
561 | sos_id: int = 1,
562 | eos_id: int = 2,
563 | max_length: int = 512,
564 | ) -> None:
565 | super(Transformer, self).__init__()
566 | self.pad_id = pad_id
567 | self.encoder = TransformerEncoder(
568 | num_embeddings=num_input_embeddings,
569 | d_model=d_model,
570 | d_ff=d_ff,
571 | num_layers=num_encoder_layers,
572 | num_heads=num_heads,
573 | dropout_p=dropout_p,
574 | pad_id=pad_id,
575 | )
576 | self.decoder = TransformerDecoder(
577 | num_classes=num_output_embeddings,
578 | d_model=d_model,
579 | d_ff=d_ff,
580 | num_layers=num_decoder_layers,
581 | num_heads=num_heads,
582 | dropout_p=dropout_p,
583 | pad_id=pad_id,
584 | sos_id=sos_id,
585 | eos_id=eos_id,
586 | max_length=max_length,
587 | )
588 |
589 | def forward(
590 | self,
591 | inputs: Tensor,
592 | input_lengths: Tensor,
593 | targets: Optional[Tensor] = None,
594 | target_lengths: Optional[Tensor] = None,
595 | ) -> Tuple[Tensor, Tensor, Tensor, Tensor]:
596 | encoder_outputs = self.encoder(inputs, input_lengths)
597 | return self.decoder(encoder_outputs, targets, input_lengths, target_lengths)
598 |
--------------------------------------------------------------------------------
9 |
10 | This repository focused on implementing the contents of the paper as much as possible,
11 | while at the same time striving for a readable code. To improve readability,
12 | I designed the model structure to fit as much as possible to the blocks in the above Transformers figure.
13 |
14 | ## Installation
15 | This project recommends Python 3.7 or higher.
16 | We recommend creating a new virtual environment for this project (using virtual env or conda).
17 |
18 | ### Prerequisites
19 | * Numpy: `pip install numpy` (Refer [here](https://github.com/numpy/numpy) for problem installing Numpy).
20 | * Pytorch: Refer to [PyTorch website](http://pytorch.org/) to install the version w.r.t. your environment.
21 |
22 | ### Install from source
23 | Currently we only support installation from source code using setuptools. Checkout the source code and run the
24 | following commands:
25 |
26 | ```
27 | pip install -e .
28 | ```
29 |
30 | ## Usage
31 |
32 | ```python
33 | import torch
34 | import torch.nn as nn
35 | from transformer import Transformer
36 |
37 | BATCH_SIZE, SEQ_LENGTH, D_MODEL = 3, 10, 64
38 |
39 | cuda = torch.cuda.is_available()
40 | device = torch.device('cuda' if cuda else 'cpu')
41 |
42 | inputs = torch.zeros(BATCH_SIZE, SEQ_LENGTH).long().to(device)
43 | input_lengths = torch.LongTensor([12345, 12300, 12000])
44 | targets = torch.LongTensor([[1, 3, 3, 3, 3, 3, 4, 5, 6, 2],
45 | [1, 3, 3, 3, 3, 3, 4, 5, 2, 0],
46 | [1, 3, 3, 3, 3, 3, 4, 2, 0, 0]]).to(device)
47 | target_lengths = torch.LongTensor([9, 8, 7])
48 |
49 | model = nn.DataParallel(Transformer(num_input_embeddings=30, num_output_embeddings=50,
50 | d_model=64,
51 | num_encoder_layers=3, num_decoder_layers=3)).to(device)
52 |
53 | # Forward propagate
54 | outputs = model(inputs, input_lengths, targets, target_lengths)
55 |
56 | # Inference
57 | outputs = model(inputs, input_lengths)
58 | ```
59 |
60 | ## Troubleshoots and Contributing
61 | If you have any questions, bug reports, and feature requests, please [open an issue](https://github.com/sooftware/conformer/issues) on github or
62 | contacts sh951011@gmail.com please.
63 |
64 | I appreciate any kind of feedback or contribution. Feel free to proceed with small issues like bug fixes, documentation improvement. For major contributions and new features, please discuss with the collaborators in corresponding issues.
65 |
66 | ## Code Style
67 | I follow [PEP-8](https://www.python.org/dev/peps/pep-0008/) for code style. Especially the style of docstrings is important to generate documentation.
68 |
69 | ## Author
70 |
71 | * Soohwan Kim [@sooftware](https://github.com/sooftware)
72 | * Contacts: sh951011@gmail.com
--------------------------------------------------------------------------------
/transformer.py:
--------------------------------------------------------------------------------
1 | import math
2 | import torch
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 | import numpy as np
6 | from torch import Tensor
7 | from typing import Optional, Tuple
8 |
9 |
10 | def get_attn_pad_mask(inputs, input_lengths, expand_length):
11 | """ mask position is set to 1 """
12 |
13 | def get_transformer_non_pad_mask(inputs: Tensor, input_lengths: Tensor) -> Tensor:
14 | """ Padding position is set to 0, either use input_lengths or pad_id """
15 | batch_size = inputs.size(0)
16 |
17 | if len(inputs.size()) == 2:
18 | non_pad_mask = inputs.new_ones(inputs.size()) # B x T
19 | elif len(inputs.size()) == 3:
20 | non_pad_mask = inputs.new_ones(inputs.size()[:-1]) # B x T
21 | else:
22 | raise ValueError(f"Unsupported input shape {inputs.size()}")
23 |
24 | for i in range(batch_size):
25 | non_pad_mask[i, input_lengths[i]:] = 0
26 |
27 | return non_pad_mask
28 |
29 | non_pad_mask = get_transformer_non_pad_mask(inputs, input_lengths)
30 | pad_mask = non_pad_mask.lt(1)
31 | attn_pad_mask = pad_mask.unsqueeze(1).expand(-1, expand_length, -1)
32 | return attn_pad_mask
33 |
34 |
35 | def get_attn_subsequent_mask(seq):
36 | assert seq.dim() == 2
37 | attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
38 | subsequent_mask = torch.triu(torch.ones(attn_shape), diagonal=1)
39 |
40 | if seq.is_cuda:
41 | subsequent_mask = subsequent_mask.cuda()
42 |
43 | return subsequent_mask
44 |
45 |
46 | class PositionalEncoding(nn.Module):
47 | """
48 | Positional Encoding proposed in "Attention Is All You Need".
49 | Since transformer contains no recurrence and no convolution, in order for the model to make
50 | use of the order of the sequence, we must add some positional information.
51 |
52 | "Attention Is All You Need" use sine and cosine functions of different frequencies:
53 | PE_(pos, 2i) = sin(pos / power(10000, 2i / d_model))
54 | PE_(pos, 2i+1) = cos(pos / power(10000, 2i / d_model))
55 | """
56 | def __init__(self, d_model: int = 80, max_len: int = 5000) -> None:
57 | super(PositionalEncoding, self).__init__()
58 | pe = torch.zeros(max_len, d_model, requires_grad=False)
59 | position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1).float()
60 | div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
61 | pe[:, 0::2] = torch.sin(position * div_term)
62 | pe[:, 1::2] = torch.cos(position * div_term)
63 | pe = pe.unsqueeze(0)
64 | self.register_buffer('pe', pe)
65 |
66 | def forward(self, length: int) -> Tensor:
67 | return self.pe[:, :length]
68 |
69 |
70 | class Embedding(nn.Module):
71 | """
72 | Embedding layer. Similarly to other sequence transduction models, transformer use learned embeddings
73 | to convert the input tokens and output tokens to vectors of dimension d_model.
74 | In the embedding layers, transformer multiply those weights by sqrt(d_model)
75 | """
76 | def __init__(self, num_embeddings: int, pad_id: int, d_model: int = 512) -> None:
77 | super(Embedding, self).__init__()
78 | self.sqrt_dim = math.sqrt(d_model)
79 | self.embedding = nn.Embedding(num_embeddings, d_model, padding_idx=pad_id)
80 |
81 | def forward(self, inputs: Tensor) -> Tensor:
82 | return self.embedding(inputs) * self.sqrt_dim
83 |
84 |
85 | class AddNorm(nn.Module):
86 | """
87 | Add & Normalization layer proposed in "Attention Is All You Need".
88 | Transformer employ a residual connection around each of the two sub-layers,
89 | (Multi-Head Attention & Feed-Forward) followed by layer normalization.
90 | """
91 | def __init__(self, sublayer: nn.Module, d_model: int = 512) -> None:
92 | super(AddNorm, self).__init__()
93 | self.sublayer = sublayer
94 | self.layer_norm = nn.LayerNorm(d_model)
95 |
96 | def forward(self, *args):
97 | residual = args[0]
98 | output = self.sublayer(*args)
99 |
100 | if isinstance(output, tuple):
101 | return self.layer_norm(output[0] + residual), output[1]
102 | else:
103 | return self.layer_norm(output + residual)
104 |
105 |
106 | class ScaledDotProductAttention(nn.Module):
107 | """
108 | Scaled Dot-Product Attention proposed in "Attention Is All You Need"
109 | Compute the dot products of the query with all keys, divide each by sqrt(dim),
110 | and apply a softmax function to obtain the weights on the values
111 |
112 | Args: dim, mask
113 | dim (int): dimention of attention
114 | mask (torch.Tensor): tensor containing indices to be masked
115 |
116 | Inputs: query, key, value, mask
117 | - **query** (batch, q_len, d_model): tensor containing projection vector for decoder.
118 | - **key** (batch, k_len, d_model): tensor containing projection vector for encoder.
119 | - **value** (batch, v_len, d_model): tensor containing features of the encoded input sequence.
120 | - **mask** (-): tensor containing indices to be masked
121 |
122 | Returns: context, attn
123 | - **context**: tensor containing the context vector from attention mechanism.
124 | - **attn**: tensor containing the attention (alignment) from the encoder outputs.
125 | """
126 | def __init__(self, dim: int) -> None:
127 | super(ScaledDotProductAttention, self).__init__()
128 | self.sqrt_dim = np.sqrt(dim)
129 |
130 | def forward(self, query: Tensor, key: Tensor, value: Tensor, mask: Optional[Tensor] = None) -> Tuple[Tensor, Tensor]:
131 | score = torch.bmm(query, key.transpose(1, 2)) / self.sqrt_dim
132 |
133 | if mask is not None:
134 | score.masked_fill_(mask.view(score.size()), -float('Inf'))
135 |
136 | attn = F.softmax(score, -1)
137 | context = torch.bmm(attn, value)
138 | return context, attn
139 |
140 |
141 | class MultiHeadAttention(nn.Module):
142 | """
143 | Multi-Head Attention proposed in "Attention Is All You Need"
144 | Instead of performing a single attention function with d_model-dimensional keys, values, and queries,
145 | project the queries, keys and values h times with different, learned linear projections to d_head dimensions.
146 | These are concatenated and once again projected, resulting in the final values.
147 | Multi-head attention allows the model to jointly attend to information from different representation
148 | subspaces at different positions.
149 |
150 | MultiHead(Q, K, V) = Concat(head_1, ..., head_h) · W_o
151 | where head_i = Attention(Q · W_q, K · W_k, V · W_v)
152 |
153 | Args:
154 | d_model (int): The dimension of keys / values / quries (default: 512)
155 | num_heads (int): The number of attention heads. (default: 8)
156 |
157 | Inputs: query, key, value, mask
158 | - **query** (batch, q_len, d_model): In transformer, three different ways:
159 | Case 1: come from previoys decoder layer
160 | Case 2: come from the input embedding
161 | Case 3: come from the output embedding (masked)
162 |
163 | - **key** (batch, k_len, d_model): In transformer, three different ways:
164 | Case 1: come from the output of the encoder
165 | Case 2: come from the input embeddings
166 | Case 3: come from the output embedding (masked)
167 |
168 | - **value** (batch, v_len, d_model): In transformer, three different ways:
169 | Case 1: come from the output of the encoder
170 | Case 2: come from the input embeddings
171 | Case 3: come from the output embedding (masked)
172 |
173 | - **mask** (-): tensor containing indices to be masked
174 |
175 | Returns: output, attn
176 | - **output** (batch, output_len, dimensions): tensor containing the attended output features.
177 | - **attn** (batch * num_heads, v_len): tensor containing the attention (alignment) from the encoder outputs.
178 | """
179 | def __init__(self, d_model: int = 512, num_heads: int = 8) -> None:
180 | super(MultiHeadAttention, self).__init__()
181 |
182 | assert d_model % num_heads == 0, "d_model % num_heads should be zero."
183 |
184 | self.d_head = int(d_model / num_heads)
185 | self.num_heads = num_heads
186 | self.scaled_dot_attn = ScaledDotProductAttention(self.d_head)
187 | self.linear_q = nn.Linear(d_model, self.d_head * num_heads)
188 | self.linear_k = nn.Linear(d_model, self.d_head * num_heads)
189 | self.linear_v = nn.Linear(d_model, self.d_head * num_heads)
190 | self.linear = nn.Linear(d_model, d_model)
191 |
192 | def forward(self, query: Tensor, key: Tensor, value: Tensor, mask: Optional[Tensor] = None) -> Tuple[Tensor, Tensor]:
193 | batch_size = value.size(0)
194 |
195 | query = self.linear_q(query).view(batch_size, -1, self.num_heads, self.d_head) # BxQ_LENxNxD
196 | key = self.linear_k(key).view(batch_size, -1, self.num_heads, self.d_head) # BxK_LENxNxD
197 | value = self.linear_v(value).view(batch_size, -1, self.num_heads, self.d_head) # BxV_LENxNxD
198 |
199 | query = query.permute(2, 0, 1, 3).contiguous().view(batch_size * self.num_heads, -1, self.d_head) # BNxQ_LENxD
200 | key = key.permute(2, 0, 1, 3).contiguous().view(batch_size * self.num_heads, -1, self.d_head) # BNxK_LENxD
201 | value = value.permute(2, 0, 1, 3).contiguous().view(batch_size * self.num_heads, -1, self.d_head) # BNxV_LENxD
202 |
203 | if mask is not None:
204 | mask = mask.unsqueeze(1).repeat(1, self.num_heads, 1, 1) # BxNxQ_LENxK_LEN
205 |
206 | context, attn = self.scaled_dot_attn(query, key, value, mask)
207 | context = context.view(self.num_heads, batch_size, -1, self.d_head)
208 | context = context.permute(1, 2, 0, 3).contiguous().view(batch_size, -1, self.num_heads * self.d_head) # BxTxND
209 |
210 | return self.linear(context)
211 |
212 |
213 | class PoswiseFeedForwardNet(nn.Module):
214 | """
215 | Position-wise Feedforward Networks proposed in "Attention Is All You Need".
216 | Fully connected feed-forward network, which is applied to each position separately and identically.
217 | This consists of two linear transformations with a ReLU activation in between.
218 | Another way of describing this is as two convolutions with kernel size 1.
219 | """
220 | def __init__(self, d_model: int = 512, d_ff: int = 2048, dropout_p: float = 0.3) -> None:
221 | super(PoswiseFeedForwardNet, self).__init__()
222 | self.feed_forward = nn.Sequential(
223 | nn.Linear(d_model, d_ff),
224 | nn.Dropout(dropout_p),
225 | nn.ReLU(),
226 | nn.Linear(d_ff, d_model),
227 | nn.Dropout(dropout_p)
228 | )
229 |
230 | def forward(self, inputs: Tensor) -> Tensor:
231 | return self.feed_forward(inputs)
232 |
233 |
234 | class TransformerEncoderLayer(nn.Module):
235 | """
236 | EncoderLayer is made up of self-attention and feedforward network.
237 | This standard encoder layer is based on the paper "Attention Is All You Need".
238 | """
239 | def __init__(
240 | self,
241 | d_model: int = 512,
242 | num_heads: int = 8,
243 | d_ff: int = 2048,
244 | dropout_p: float = 0.3,
245 | ) -> None:
246 | super(TransformerEncoderLayer, self).__init__()
247 | self.self_attention = AddNorm(MultiHeadAttention(d_model, num_heads), d_model)
248 | self.feed_forward = AddNorm(PoswiseFeedForwardNet(d_model, d_ff, dropout_p), d_model)
249 |
250 | def forward(
251 | self,
252 | inputs: Tensor,
253 | self_attn_mask: Optional[Tensor] = None,
254 | ) -> Tuple[Tensor, Tensor]:
255 | output = self.self_attention(inputs, inputs, inputs, self_attn_mask)
256 | output = self.feed_forward(output)
257 | return output
258 |
259 |
260 | class TransformerEncoder(nn.Module):
261 | """
262 | The TransformerEncoder is composed of a stack of N identical layers.
263 | Each layer has two sub-layers. The first is a multi-head self-attention mechanism,
264 | and the second is a simple, position-wise fully connected feed-forward network.
265 | """
266 | def __init__(
267 | self,
268 | num_embeddings: int,
269 | d_model: int = 512,
270 | d_ff: int = 2048,
271 | num_layers: int = 6,
272 | num_heads: int = 8,
273 | dropout_p: float = 0.1,
274 | pad_id: int = 0,
275 | ) -> None:
276 | super(TransformerEncoder, self).__init__()
277 | self.d_model = d_model
278 | self.num_layers = num_layers
279 | self.num_heads = num_heads
280 | self.pad_id = pad_id
281 | self.embedding = Embedding(num_embeddings, pad_id, d_model)
282 | self.pos_encoding = PositionalEncoding(d_model)
283 | self.input_dropout = nn.Dropout(p=dropout_p)
284 | self.layers = nn.ModuleList(
285 | [TransformerEncoderLayer(d_model, num_heads, d_ff, dropout_p) for _ in range(num_layers)]
286 | )
287 |
288 | def forward(self, inputs: Tensor, input_lengths: Tensor = None):
289 | length = inputs.size(1)
290 |
291 | output = self.input_dropout(self.embedding(inputs) + self.pos_encoding(length))
292 | self_attn_mask = get_attn_pad_mask(inputs, input_lengths, length)
293 |
294 | for layer in self.layers:
295 | output = layer(output, self_attn_mask)
296 |
297 | return output
298 |
299 |
300 | class TransformerDecoderLayer(nn.Module):
301 | r"""
302 | DecoderLayer is made up of self-attention, multi-head attention and feedforward network.
303 | This standard decoders layer is based on the paper "Attention Is All You Need".
304 |
305 | Args:
306 | d_model: dimension of model (default: 512)
307 | num_heads: number of attention heads (default: 8)
308 | d_ff: dimension of feed forward network (default: 2048)
309 | dropout_p: probability of dropout (default: 0.3)
310 |
311 | Inputs:
312 | inputs (torch.FloatTensor): input sequence of transformer decoder layer
313 | encoder_outputs (torch.FloatTensor): outputs of encoder
314 | self_attn_mask (torch.BoolTensor): mask of self attention
315 | encoder_output_mask (torch.BoolTensor): mask of encoder outputs
316 |
317 | Returns:
318 | (Tensor, Tensor, Tensor)
319 | * outputs (torch.FloatTensor): output of transformer decoder layer
320 | * self_attn (torch.FloatTensor): output of self attention
321 | * encoder_attn (torch.FloatTensor): output of encoder attention
322 |
323 | Reference:
324 | Ashish Vaswani et al.: Attention Is All You Need
325 | https://arxiv.org/abs/1706.03762
326 | """
327 | def __init__(
328 | self,
329 | d_model: int = 512,
330 | num_heads: int = 8,
331 | d_ff: int = 2048,
332 | dropout_p: float = 0.3,
333 | ) -> None:
334 | super(TransformerDecoderLayer, self).__init__()
335 | self.self_attention_prenorm = nn.LayerNorm(d_model)
336 | self.decoder_attention_prenorm = nn.LayerNorm(d_model)
337 | self.feed_forward_prenorm = nn.LayerNorm(d_model)
338 | self.self_attention = MultiHeadAttention(d_model, num_heads)
339 | self.decoder_attention = MultiHeadAttention(d_model, num_heads)
340 | self.feed_forward = PoswiseFeedForwardNet(d_model, d_ff, dropout_p)
341 |
342 | def forward(
343 | self,
344 | inputs: Tensor,
345 | encoder_outputs: Tensor,
346 | self_attn_mask: Optional[Tensor] = None,
347 | encoder_attn_mask: Optional[Tensor] = None,
348 | ) -> Tuple[Tensor, Tensor, Tensor]:
349 | r"""
350 | Forward propagate transformer decoder layer.
351 |
352 | Inputs:
353 | inputs (torch.FloatTensor): input sequence of transformer decoder layer
354 | encoder_outputs (torch.FloatTensor): outputs of encoder
355 | self_attn_mask (torch.BoolTensor): mask of self attention
356 | encoder_output_mask (torch.BoolTensor): mask of encoder outputs
357 |
358 | Returns:
359 | outputs (torch.FloatTensor): output of transformer decoder layer
360 | self_attn (torch.FloatTensor): output of self attention
361 | encoder_attn (torch.FloatTensor): output of encoder attention
362 | """
363 | residual = inputs
364 | inputs = self.self_attention_prenorm(inputs)
365 | outputs = self.self_attention(inputs, inputs, inputs, self_attn_mask)
366 | outputs += residual
367 |
368 | residual = outputs
369 | outputs = self.decoder_attention_prenorm(outputs)
370 | outputs = self.decoder_attention(outputs, encoder_outputs, encoder_outputs, encoder_attn_mask)
371 | outputs += residual
372 |
373 | residual = outputs
374 | outputs = self.feed_forward_prenorm(outputs)
375 | outputs = self.feed_forward(outputs)
376 | outputs += residual
377 |
378 | return outputs
379 |
380 |
381 | class TransformerDecoder(nn.Module):
382 | r"""
383 | The TransformerDecoder is composed of a stack of N identical layers.
384 | Each layer has three sub-layers. The first is a multi-head self-attention mechanism,
385 | and the second is a multi-head attention mechanism, third is a feed-forward network.
386 |
387 | Args:
388 | num_classes: umber of classes
389 | d_model: dimension of model
390 | d_ff: dimension of feed forward network
391 | num_layers: number of layers
392 | num_heads: number of attention heads
393 | dropout_p: probability of dropout
394 | pad_id (int, optional): index of the pad symbol (default: 0)
395 | sos_id (int, optional): index of the start of sentence symbol (default: 1)
396 | eos_id (int, optional): index of the end of sentence symbol (default: 2)
397 | max_length (int): max decoding length
398 | """
399 |
400 | def __init__(
401 | self,
402 | num_classes: int,
403 | d_model: int = 512,
404 | d_ff: int = 512,
405 | num_layers: int = 6,
406 | num_heads: int = 8,
407 | dropout_p: float = 0.3,
408 | pad_id: int = 0,
409 | sos_id: int = 1,
410 | eos_id: int = 2,
411 | max_length: int = 512,
412 | ) -> None:
413 | super(TransformerDecoder, self).__init__()
414 | self.d_model = d_model
415 | self.num_layers = num_layers
416 | self.num_heads = num_heads
417 | self.max_length = max_length
418 | self.pad_id = pad_id
419 | self.sos_id = sos_id
420 | self.eos_id = eos_id
421 |
422 | self.embedding = Embedding(num_classes, pad_id, d_model)
423 | self.positional_encoding = PositionalEncoding(d_model)
424 | self.input_dropout = nn.Dropout(p=dropout_p)
425 | self.layers = nn.ModuleList([
426 | TransformerDecoderLayer(
427 | d_model=d_model,
428 | num_heads=num_heads,
429 | d_ff=d_ff,
430 | dropout_p=dropout_p,
431 | ) for _ in range(num_layers)
432 | ])
433 | self.fc = nn.Linear(d_model, num_classes, bias=False)
434 |
435 | def forward_step(
436 | self,
437 | decoder_inputs: torch.Tensor,
438 | decoder_input_lengths: torch.Tensor,
439 | encoder_outputs: torch.Tensor,
440 | encoder_output_lengths: torch.Tensor,
441 | positional_encoding_length: int,
442 | ) -> torch.Tensor:
443 | dec_self_attn_pad_mask = get_attn_pad_mask(
444 | decoder_inputs, decoder_input_lengths, decoder_inputs.size(1)
445 | )
446 | dec_self_attn_subsequent_mask = get_attn_subsequent_mask(decoder_inputs)
447 | self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0)
448 |
449 | encoder_attn_mask = get_attn_pad_mask(encoder_outputs, encoder_output_lengths, decoder_inputs.size(1))
450 |
451 | outputs = self.embedding(decoder_inputs) + self.positional_encoding(positional_encoding_length)
452 | outputs = self.input_dropout(outputs)
453 |
454 | for layer in self.layers:
455 | outputs = layer(
456 | inputs=outputs,
457 | encoder_outputs=encoder_outputs,
458 | self_attn_mask=self_attn_mask,
459 | encoder_attn_mask=encoder_attn_mask,
460 | )
461 |
462 | return outputs
463 |
464 | def forward(
465 | self,
466 | encoder_outputs: torch.Tensor,
467 | targets: Optional[torch.LongTensor] = None,
468 | encoder_output_lengths: torch.Tensor = None,
469 | target_lengths: torch.Tensor = None,
470 | ) -> torch.Tensor:
471 | r"""
472 | Forward propagate a `encoder_outputs` for training.
473 |
474 | Args:
475 | targets (torch.LongTensor): A target sequence passed to decoders. `IntTensor` of size
476 | ``(batch, seq_length)``
477 | encoder_outputs (torch.FloatTensor): A output sequence of encoders. `FloatTensor` of size
478 | ``(batch, seq_length, dimension)``
479 | encoder_output_lengths (torch.LongTensor): The length of encoders outputs. ``(batch)``
480 |
481 | Returns:
482 | * logits (torch.FloatTensor): Log probability of model predictions.
483 | """
484 | logits = list()
485 | batch_size = encoder_outputs.size(0)
486 |
487 | if targets is not None:
488 | targets = targets[targets != self.eos_id].view(batch_size, -1)
489 | target_length = targets.size(1)
490 |
491 | step_outputs = self.forward_step(
492 | decoder_inputs=targets,
493 | decoder_input_lengths=target_lengths,
494 | encoder_outputs=encoder_outputs,
495 | encoder_output_lengths=encoder_output_lengths,
496 | positional_encoding_length=target_length,
497 | )
498 | step_outputs = self.fc(step_outputs).log_softmax(dim=-1)
499 |
500 | for di in range(step_outputs.size(1)):
501 | step_output = step_outputs[:, di, :]
502 | logits.append(step_output)
503 |
504 | # Inference
505 | else:
506 | input_var = encoder_outputs.new_zeros(batch_size, self.max_length).long()
507 | input_var = input_var.fill_(self.pad_id)
508 | input_var[:, 0] = self.sos_id
509 |
510 | for di in range(1, self.max_length):
511 | input_lengths = torch.IntTensor(batch_size).fill_(di)
512 |
513 | outputs = self.forward_step(
514 | decoder_inputs=input_var[:, :di],
515 | decoder_input_lengths=input_lengths,
516 | encoder_outputs=encoder_outputs,
517 | encoder_output_lengths=encoder_output_lengths,
518 | positional_encoding_length=di,
519 | )
520 | step_output = self.fc(outputs).log_softmax(dim=-1)
521 | logits.append(step_output[:, -1, :])
522 | input_var[:, di] = logits[-1].topk(1)[1].squeeze()
523 |
524 | return torch.stack(logits, dim=1)
525 |
526 |
527 | class Transformer(nn.Module):
528 | """
529 | A Transformer model. User is able to modify the attributes as needed.
530 | The architecture is based on the paper "Attention Is All You Need".
531 |
532 | Args:
533 | pad_id (int): identification of
534 | num_input_embeddings (int): dimension of input embeddings
535 | num_output_embeddings (int): dimenstion of output embeddings
536 | d_model (int): dimension of model (default: 512)
537 | d_ff (int): dimension of feed forward network (default: 2048)
538 | num_encoder_layers (int): number of encoder layers (default: 6)
539 | num_decoder_layers (int): number of decoder layers (default: 6)
540 | num_heads (int): number of attention heads (default: 8)
541 | dropout_p (float): dropout probability (default: 0.3)
542 |
543 | Inputs: inputs, targets
544 | - **inputs** (batch, input_length): tensor containing input sequences
545 | - **targets** (batch, target_length): tensor contatining target sequences
546 |
547 | Returns: output
548 | - **output**: tensor containing the outputs
549 | """
550 | def __init__(
551 | self,
552 | num_input_embeddings: int,
553 | num_output_embeddings: int,
554 | d_model: int = 512,
555 | d_ff: int = 2048,
556 | num_heads: int = 8,
557 | num_encoder_layers: int = 6,
558 | num_decoder_layers: int = 6,
559 | dropout_p: float = 0.1,
560 | pad_id: int = 0,
561 | sos_id: int = 1,
562 | eos_id: int = 2,
563 | max_length: int = 512,
564 | ) -> None:
565 | super(Transformer, self).__init__()
566 | self.pad_id = pad_id
567 | self.encoder = TransformerEncoder(
568 | num_embeddings=num_input_embeddings,
569 | d_model=d_model,
570 | d_ff=d_ff,
571 | num_layers=num_encoder_layers,
572 | num_heads=num_heads,
573 | dropout_p=dropout_p,
574 | pad_id=pad_id,
575 | )
576 | self.decoder = TransformerDecoder(
577 | num_classes=num_output_embeddings,
578 | d_model=d_model,
579 | d_ff=d_ff,
580 | num_layers=num_decoder_layers,
581 | num_heads=num_heads,
582 | dropout_p=dropout_p,
583 | pad_id=pad_id,
584 | sos_id=sos_id,
585 | eos_id=eos_id,
586 | max_length=max_length,
587 | )
588 |
589 | def forward(
590 | self,
591 | inputs: Tensor,
592 | input_lengths: Tensor,
593 | targets: Optional[Tensor] = None,
594 | target_lengths: Optional[Tensor] = None,
595 | ) -> Tuple[Tensor, Tensor, Tensor, Tensor]:
596 | encoder_outputs = self.encoder(inputs, input_lengths)
597 | return self.decoder(encoder_outputs, targets, input_lengths, target_lengths)
598 |
--------------------------------------------------------------------------------