├── .gitignore
├── .travis.yml
├── LICENSE
├── Makefile
├── README.md
├── demo.sh
├── eval
├── matlab
│ ├── WordLookup.m
│ ├── evaluate_vectors.m
│ └── read_and_evaluate.m
├── octave
│ ├── WordLookup_octave.m
│ ├── evaluate_vectors_octave.m
│ └── read_and_evaluate_octave.m
├── python
│ ├── distance.py
│ ├── evaluate.py
│ └── word_analogy.py
└── question-data
│ ├── capital-common-countries.txt
│ ├── capital-world.txt
│ ├── city-in-state.txt
│ ├── currency.txt
│ ├── family.txt
│ ├── gram1-adjective-to-adverb.txt
│ ├── gram2-opposite.txt
│ ├── gram3-comparative.txt
│ ├── gram4-superlative.txt
│ ├── gram5-present-participle.txt
│ ├── gram6-nationality-adjective.txt
│ ├── gram7-past-tense.txt
│ ├── gram8-plural.txt
│ └── gram9-plural-verbs.txt
├── randomization.test.sh
└── src
├── README.md
├── common.c
├── common.h
├── cooccur.c
├── glove.c
├── shuffle.c
└── vocab_count.c
/.gitignore:
--------------------------------------------------------------------------------
1 | # Object files
2 | *.o
3 | *.ko
4 | *.obj
5 | *.elf
6 |
7 | # Precompiled Headers
8 | *.gch
9 | *.pch
10 |
11 | # Libraries
12 | *.lib
13 | *.a
14 | *.la
15 | *.lo
16 |
17 | # Shared objects (inc. Windows DLLs)
18 | *.dll
19 | *.so
20 | *.so.*
21 | *.dylib
22 |
23 | # Executables
24 | *.exe
25 | *.out
26 | *.app
27 | *.i*86
28 | *.x86_64
29 | *.hex
30 |
31 | # Debug files
32 | *.dSYM/
33 |
34 |
35 | build/*
36 | *.swp
37 |
38 | # OS X stuff
39 | ._*
40 |
41 | # demo.sh-produced artifacts
42 | /cooccurrence.bin
43 | /cooccurrence.shuf.bin
44 | /text8
45 | /vectors.bin
46 | /vectors.txt
47 | /vocab.txt
48 |
--------------------------------------------------------------------------------
/.travis.yml:
--------------------------------------------------------------------------------
1 | language: c
2 | dist: trusty
3 | sudo: required
4 | before_install:
5 | - sudo apt-get install python2.7 python-numpy python-pip
6 | script: pip install numpy && ./demo.sh | tee results.txt && [[ `cat results.txt | egrep "Total accuracy. 2[23]" | wc -l` = "1" ]] && echo test-passed
7 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 |
2 | Apache License
3 | Version 2.0, January 2004
4 | http://www.apache.org/licenses/
5 |
6 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
7 |
8 | 1. Definitions.
9 |
10 | "License" shall mean the terms and conditions for use, reproduction,
11 | and distribution as defined by Sections 1 through 9 of this document.
12 |
13 | "Licensor" shall mean the copyright owner or entity authorized by
14 | the copyright owner that is granting the License.
15 |
16 | "Legal Entity" shall mean the union of the acting entity and all
17 | other entities that control, are controlled by, or are under common
18 | control with that entity. For the purposes of this definition,
19 | "control" means (i) the power, direct or indirect, to cause the
20 | direction or management of such entity, whether by contract or
21 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
22 | outstanding shares, or (iii) beneficial ownership of such entity.
23 |
24 | "You" (or "Your") shall mean an individual or Legal Entity
25 | exercising permissions granted by this License.
26 |
27 | "Source" form shall mean the preferred form for making modifications,
28 | including but not limited to software source code, documentation
29 | source, and configuration files.
30 |
31 | "Object" form shall mean any form resulting from mechanical
32 | transformation or translation of a Source form, including but
33 | not limited to compiled object code, generated documentation,
34 | and conversions to other media types.
35 |
36 | "Work" shall mean the work of authorship, whether in Source or
37 | Object form, made available under the License, as indicated by a
38 | copyright notice that is included in or attached to the work
39 | (an example is provided in the Appendix below).
40 |
41 | "Derivative Works" shall mean any work, whether in Source or Object
42 | form, that is based on (or derived from) the Work and for which the
43 | editorial revisions, annotations, elaborations, or other modifications
44 | represent, as a whole, an original work of authorship. For the purposes
45 | of this License, Derivative Works shall not include works that remain
46 | separable from, or merely link (or bind by name) to the interfaces of,
47 | the Work and Derivative Works thereof.
48 |
49 | "Contribution" shall mean any work of authorship, including
50 | the original version of the Work and any modifications or additions
51 | to that Work or Derivative Works thereof, that is intentionally
52 | submitted to Licensor for inclusion in the Work by the copyright owner
53 | or by an individual or Legal Entity authorized to submit on behalf of
54 | the copyright owner. For the purposes of this definition, "submitted"
55 | means any form of electronic, verbal, or written communication sent
56 | to the Licensor or its representatives, including but not limited to
57 | communication on electronic mailing lists, source code control systems,
58 | and issue tracking systems that are managed by, or on behalf of, the
59 | Licensor for the purpose of discussing and improving the Work, but
60 | excluding communication that is conspicuously marked or otherwise
61 | designated in writing by the copyright owner as "Not a Contribution."
62 |
63 | "Contributor" shall mean Licensor and any individual or Legal Entity
64 | on behalf of whom a Contribution has been received by Licensor and
65 | subsequently incorporated within the Work.
66 |
67 | 2. Grant of Copyright License. Subject to the terms and conditions of
68 | this License, each Contributor hereby grants to You a perpetual,
69 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
70 | copyright license to reproduce, prepare Derivative Works of,
71 | publicly display, publicly perform, sublicense, and distribute the
72 | Work and such Derivative Works in Source or Object form.
73 |
74 | 3. Grant of Patent License. Subject to the terms and conditions of
75 | this License, each Contributor hereby grants to You a perpetual,
76 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
77 | (except as stated in this section) patent license to make, have made,
78 | use, offer to sell, sell, import, and otherwise transfer the Work,
79 | where such license applies only to those patent claims licensable
80 | by such Contributor that are necessarily infringed by their
81 | Contribution(s) alone or by combination of their Contribution(s)
82 | with the Work to which such Contribution(s) was submitted. If You
83 | institute patent litigation against any entity (including a
84 | cross-claim or counterclaim in a lawsuit) alleging that the Work
85 | or a Contribution incorporated within the Work constitutes direct
86 | or contributory patent infringement, then any patent licenses
87 | granted to You under this License for that Work shall terminate
88 | as of the date such litigation is filed.
89 |
90 | 4. Redistribution. You may reproduce and distribute copies of the
91 | Work or Derivative Works thereof in any medium, with or without
92 | modifications, and in Source or Object form, provided that You
93 | meet the following conditions:
94 |
95 | (a) You must give any other recipients of the Work or
96 | Derivative Works a copy of this License; and
97 |
98 | (b) You must cause any modified files to carry prominent notices
99 | stating that You changed the files; and
100 |
101 | (c) You must retain, in the Source form of any Derivative Works
102 | that You distribute, all copyright, patent, trademark, and
103 | attribution notices from the Source form of the Work,
104 | excluding those notices that do not pertain to any part of
105 | the Derivative Works; and
106 |
107 | (d) If the Work includes a "NOTICE" text file as part of its
108 | distribution, then any Derivative Works that You distribute must
109 | include a readable copy of the attribution notices contained
110 | within such NOTICE file, excluding those notices that do not
111 | pertain to any part of the Derivative Works, in at least one
112 | of the following places: within a NOTICE text file distributed
113 | as part of the Derivative Works; within the Source form or
114 | documentation, if provided along with the Derivative Works; or,
115 | within a display generated by the Derivative Works, if and
116 | wherever such third-party notices normally appear. The contents
117 | of the NOTICE file are for informational purposes only and
118 | do not modify the License. You may add Your own attribution
119 | notices within Derivative Works that You distribute, alongside
120 | or as an addendum to the NOTICE text from the Work, provided
121 | that such additional attribution notices cannot be construed
122 | as modifying the License.
123 |
124 | You may add Your own copyright statement to Your modifications and
125 | may provide additional or different license terms and conditions
126 | for use, reproduction, or distribution of Your modifications, or
127 | for any such Derivative Works as a whole, provided Your use,
128 | reproduction, and distribution of the Work otherwise complies with
129 | the conditions stated in this License.
130 |
131 | 5. Submission of Contributions. Unless You explicitly state otherwise,
132 | any Contribution intentionally submitted for inclusion in the Work
133 | by You to the Licensor shall be under the terms and conditions of
134 | this License, without any additional terms or conditions.
135 | Notwithstanding the above, nothing herein shall supersede or modify
136 | the terms of any separate license agreement you may have executed
137 | with Licensor regarding such Contributions.
138 |
139 | 6. Trademarks. This License does not grant permission to use the trade
140 | names, trademarks, service marks, or product names of the Licensor,
141 | except as required for reasonable and customary use in describing the
142 | origin of the Work and reproducing the content of the NOTICE file.
143 |
144 | 7. Disclaimer of Warranty. Unless required by applicable law or
145 | agreed to in writing, Licensor provides the Work (and each
146 | Contributor provides its Contributions) on an "AS IS" BASIS,
147 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
148 | implied, including, without limitation, any warranties or conditions
149 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
150 | PARTICULAR PURPOSE. You are solely responsible for determining the
151 | appropriateness of using or redistributing the Work and assume any
152 | risks associated with Your exercise of permissions under this License.
153 |
154 | 8. Limitation of Liability. In no event and under no legal theory,
155 | whether in tort (including negligence), contract, or otherwise,
156 | unless required by applicable law (such as deliberate and grossly
157 | negligent acts) or agreed to in writing, shall any Contributor be
158 | liable to You for damages, including any direct, indirect, special,
159 | incidental, or consequential damages of any character arising as a
160 | result of this License or out of the use or inability to use the
161 | Work (including but not limited to damages for loss of goodwill,
162 | work stoppage, computer failure or malfunction, or any and all
163 | other commercial damages or losses), even if such Contributor
164 | has been advised of the possibility of such damages.
165 |
166 | 9. Accepting Warranty or Additional Liability. While redistributing
167 | the Work or Derivative Works thereof, You may choose to offer,
168 | and charge a fee for, acceptance of support, warranty, indemnity,
169 | or other liability obligations and/or rights consistent with this
170 | License. However, in accepting such obligations, You may act only
171 | on Your own behalf and on Your sole responsibility, not on behalf
172 | of any other Contributor, and only if You agree to indemnify,
173 | defend, and hold each Contributor harmless for any liability
174 | incurred by, or claims asserted against, such Contributor by reason
175 | of your accepting any such warranty or additional liability.
176 |
177 | END OF TERMS AND CONDITIONS
178 |
179 | APPENDIX: How to apply the Apache License to your work.
180 |
181 | To apply the Apache License to your work, attach the following
182 | boilerplate notice, with the fields enclosed by brackets "[]"
183 | replaced with your own identifying information. (Don't include
184 | the brackets!) The text should be enclosed in the appropriate
185 | comment syntax for the file format. We also recommend that a
186 | file or class name and description of purpose be included on the
187 | same "printed page" as the copyright notice for easier
188 | identification within third-party archives.
189 |
190 | Copyright 2014 The Board of Trustees of The Leland Stanford Junior University
191 |
192 | Licensed under the Apache License, Version 2.0 (the "License");
193 | you may not use this file except in compliance with the License.
194 | You may obtain a copy of the License at
195 |
196 | http://www.apache.org/licenses/LICENSE-2.0
197 |
198 | Unless required by applicable law or agreed to in writing, software
199 | distributed under the License is distributed on an "AS IS" BASIS,
200 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
201 | See the License for the specific language governing permissions and
202 | limitations under the License.
203 |
--------------------------------------------------------------------------------
/Makefile:
--------------------------------------------------------------------------------
1 | CC = gcc
2 | #For older gcc, use -O3 or -O2 instead of -Ofast
3 | # CFLAGS = -lm -pthread -Ofast -march=native -funroll-loops -Wno-unused-result
4 |
5 | # Use -Ofast with caution. It speeds up training, but the checks for NaN will not work
6 | # (-Ofast turns on --fast-math, which turns on -ffinite-math-only,
7 | # which assumes everything is NOT NaN or +-Inf, so checks for NaN always return false
8 | # see https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html)
9 | # CFLAGS = -lm -pthread -Ofast -march=native -funroll-loops -Wall -Wextra -Wpedantic
10 |
11 | CPU_ARCHITECTURE = $(shell uname -m)
12 | OS = $(shell uname -o)
13 | # Non-empty string if Apple Silicon, empty string otherwise.
14 | APPLE_SILICON = $(and $(filter Darwin,$(OS)),$(filter arm64,$(CPU_ARCHITECTURE)))
15 |
16 | # clang (which masquerades as gcc on macOS) doesn't support this option, at least
17 | # not the Apple-provided clang on Apple Silicon as of macOS 13.2.1.
18 | ifeq ($(APPLE_SILICON),)
19 | CPU_ARCHITECTURE_FLAGS = -march=native
20 | endif
21 |
22 | CFLAGS = -lm -pthread -O3 $(CPU_ARCHITECTURE_FLAGS) -funroll-loops -Wall -Wextra -Wpedantic
23 | BUILDDIR := build
24 | SRCDIR := src
25 | OBJDIR := $(BUILDDIR)
26 |
27 | OBJ := $(OBJDIR)/vocab_count.o $(OBJDIR)/cooccur.o $(OBJDIR)/shuffle.o $(OBJDIR)/glove.o
28 | HEADERS := $(SRCDIR)/common.h
29 | MODULES := $(BUILDDIR)/vocab_count $(BUILDDIR)/cooccur $(BUILDDIR)/shuffle $(BUILDDIR)/glove
30 |
31 |
32 | all: dir $(OBJ) $(MODULES)
33 | dir :
34 | mkdir -p $(BUILDDIR)
35 | $(BUILDDIR)/glove : $(OBJDIR)/glove.o $(OBJDIR)/common.o
36 | $(CC) $^ -o $@ $(CFLAGS)
37 | $(BUILDDIR)/shuffle : $(OBJDIR)/shuffle.o $(OBJDIR)/common.o
38 | $(CC) $^ -o $@ $(CFLAGS)
39 | $(BUILDDIR)/cooccur : $(OBJDIR)/cooccur.o $(OBJDIR)/common.o
40 | $(CC) $^ -o $@ $(CFLAGS)
41 | $(BUILDDIR)/vocab_count : $(OBJDIR)/vocab_count.o $(OBJDIR)/common.o
42 | $(CC) $^ -o $@ $(CFLAGS)
43 | $(OBJDIR)/%.o : $(SRCDIR)/%.c $(HEADERS)
44 | $(CC) -c $< -o $@ $(CFLAGS)
45 | .PHONY: clean
46 | clean:
47 | rm -rf $(BUILDDIR)
48 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | ## GloVe: Global Vectors for Word Representation
2 |
3 |
4 | | nearest neighbors of
frog | Litoria | Leptodactylidae | Rana | Eleutherodactylus |
5 | | --- | ------------------------------- | ------------------- | ---------------- | ------------------- |
6 | | Pictures |  |
|  |
|  |
|  |
7 |
8 | | Comparisons | man -> woman | city -> zip | comparative -> superlative |
9 | | --- | ------------------------|-------------------------|-------------------------|
10 | | GloVe Geometry |
|
7 |
8 | | Comparisons | man -> woman | city -> zip | comparative -> superlative |
9 | | --- | ------------------------|-------------------------|-------------------------|
10 | | GloVe Geometry | 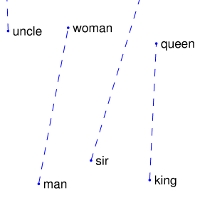 |
| 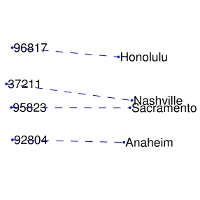 |
| 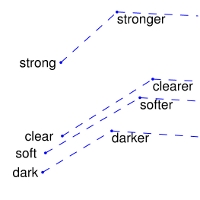 |
11 |
12 | We provide an implementation of the GloVe model for learning word representations, and describe how to download web-dataset vectors or train your own. See the [project page](https://nlp.stanford.edu/projects/glove/) or the [paper](https://nlp.stanford.edu/pubs/glove.pdf) for more information on glove vectors.
13 |
14 | ## Download pre-trained word vectors
15 | The links below contain word vectors obtained from the respective corpora. If you want word vectors trained on massive web datasets, you need only download one of these text files! Pre-trained word vectors are made available under the Public Domain Dedication and License.
16 |
|
11 |
12 | We provide an implementation of the GloVe model for learning word representations, and describe how to download web-dataset vectors or train your own. See the [project page](https://nlp.stanford.edu/projects/glove/) or the [paper](https://nlp.stanford.edu/pubs/glove.pdf) for more information on glove vectors.
13 |
14 | ## Download pre-trained word vectors
15 | The links below contain word vectors obtained from the respective corpora. If you want word vectors trained on massive web datasets, you need only download one of these text files! Pre-trained word vectors are made available under the Public Domain Dedication and License.
16 |
17 |
18 | - Common Crawl (42B tokens, 1.9M vocab, uncased, 300d vectors, 1.75 GB download): glove.42B.300d.zip [mirror]
19 | - Common Crawl (840B tokens, 2.2M vocab, cased, 300d vectors, 2.03 GB download): glove.840B.300d.zip [mirror]
20 | - Wikipedia 2014 + Gigaword 5 (6B tokens, 400K vocab, uncased, 300d vectors, 822 MB download): glove.6B.zip [mirror]
21 | - Twitter (2B tweets, 27B tokens, 1.2M vocab, uncased, 200d vectors, 1.42 GB download): glove.twitter.27B.zip [mirror]
22 |
23 |
 28 |
29 | If the web datasets above don't match the semantics of your end use case, you can train word vectors on your own corpus.
30 |
31 | $ git clone https://github.com/stanfordnlp/glove
32 | $ cd glove && make
33 | $ ./demo.sh
34 |
35 | Make sure you have the following prerequisites installed when running the steps above:
36 |
37 | * GNU Make
38 | * GCC (Clang pretending to be GCC is fine)
39 | * Python and NumPy
40 |
41 | The demo.sh script downloads a small corpus, consisting of the first 100M characters of Wikipedia. It collects unigram counts, constructs and shuffles cooccurrence data, and trains a simple version of the GloVe model. It also runs a word analogy evaluation script in python to verify word vector quality. More details about training on your own corpus can be found by reading [demo.sh](https://github.com/stanfordnlp/GloVe/blob/master/demo.sh) or the [src/README.md](https://github.com/stanfordnlp/GloVe/tree/master/src)
42 |
43 | ### License
44 | All work contained in this package is licensed under the Apache License, Version 2.0. See the include LICENSE file.
45 |
--------------------------------------------------------------------------------
/demo.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -e
3 |
4 | # Makes programs, downloads sample data, trains a GloVe model, and then evaluates it.
5 | # One optional argument can specify the language used for eval script: matlab, octave or [default] python
6 |
7 | make
8 | if [ ! -e text8 ]; then
9 | if hash wget 2>/dev/null; then
10 | wget http://mattmahoney.net/dc/text8.zip
11 | else
12 | curl -O http://mattmahoney.net/dc/text8.zip
13 | fi
14 | unzip text8.zip
15 | rm text8.zip
16 | fi
17 |
18 | CORPUS=text8
19 | VOCAB_FILE=vocab.txt
20 | COOCCURRENCE_FILE=cooccurrence.bin
21 | COOCCURRENCE_SHUF_FILE=cooccurrence.shuf.bin
22 | BUILDDIR=build
23 | SAVE_FILE=vectors
24 | VERBOSE=2
25 | MEMORY=4.0
26 | VOCAB_MIN_COUNT=5
27 | VECTOR_SIZE=50
28 | MAX_ITER=15
29 | WINDOW_SIZE=15
30 | BINARY=2
31 | NUM_THREADS=8
32 | X_MAX=10
33 | if hash python 2>/dev/null; then
34 | PYTHON=python
35 | else
36 | PYTHON=python3
37 | fi
38 |
39 | echo
40 | echo "$ $BUILDDIR/vocab_count -min-count $VOCAB_MIN_COUNT -verbose $VERBOSE < $CORPUS > $VOCAB_FILE"
41 | $BUILDDIR/vocab_count -min-count $VOCAB_MIN_COUNT -verbose $VERBOSE < $CORPUS > $VOCAB_FILE
42 | echo "$ $BUILDDIR/cooccur -memory $MEMORY -vocab-file $VOCAB_FILE -verbose $VERBOSE -window-size $WINDOW_SIZE < $CORPUS > $COOCCURRENCE_FILE"
43 | $BUILDDIR/cooccur -memory $MEMORY -vocab-file $VOCAB_FILE -verbose $VERBOSE -window-size $WINDOW_SIZE < $CORPUS > $COOCCURRENCE_FILE
44 | echo "$ $BUILDDIR/shuffle -memory $MEMORY -verbose $VERBOSE < $COOCCURRENCE_FILE > $COOCCURRENCE_SHUF_FILE"
45 | $BUILDDIR/shuffle -memory $MEMORY -verbose $VERBOSE < $COOCCURRENCE_FILE > $COOCCURRENCE_SHUF_FILE
46 | echo "$ $BUILDDIR/glove -save-file $SAVE_FILE -threads $NUM_THREADS -input-file $COOCCURRENCE_SHUF_FILE -x-max $X_MAX -iter $MAX_ITER -vector-size $VECTOR_SIZE -binary $BINARY -vocab-file $VOCAB_FILE -verbose $VERBOSE"
47 | $BUILDDIR/glove -save-file $SAVE_FILE -threads $NUM_THREADS -input-file $COOCCURRENCE_SHUF_FILE -x-max $X_MAX -iter $MAX_ITER -vector-size $VECTOR_SIZE -binary $BINARY -vocab-file $VOCAB_FILE -verbose $VERBOSE
48 | if [ "$CORPUS" = 'text8' ]; then
49 | if [ "$1" = 'matlab' ]; then
50 | matlab -nodisplay -nodesktop -nojvm -nosplash < ./eval/matlab/read_and_evaluate.m 1>&2
51 | elif [ "$1" = 'octave' ]; then
52 | octave < ./eval/octave/read_and_evaluate_octave.m 1>&2
53 | else
54 | echo "$ $PYTHON eval/python/evaluate.py"
55 | $PYTHON eval/python/evaluate.py
56 | fi
57 | fi
58 |
--------------------------------------------------------------------------------
/eval/matlab/WordLookup.m:
--------------------------------------------------------------------------------
1 | function index = WordLookup(InputString)
2 | global wordMap
3 | if wordMap.isKey(InputString)
4 | index = wordMap(InputString);
5 | elseif wordMap.isKey('')
6 | index = wordMap('');
7 | else
8 | index = 0;
9 | end
10 |
--------------------------------------------------------------------------------
/eval/matlab/evaluate_vectors.m:
--------------------------------------------------------------------------------
1 | function [BB] = evaluate_vectors(W)
2 |
3 | global wordMap
4 |
5 | filenames = {'capital-common-countries' 'capital-world' 'currency' 'city-in-state' 'family' 'gram1-adjective-to-adverb' ...
6 | 'gram2-opposite' 'gram3-comparative' 'gram4-superlative' 'gram5-present-participle' 'gram6-nationality-adjective' ...
7 | 'gram7-past-tense' 'gram8-plural' 'gram9-plural-verbs'};
8 | path = './eval/question-data/';
9 |
10 | split_size = 100; %to avoid memory overflow, could be increased/decreased depending on system and vocab size
11 |
12 | correct_sem = 0; %count correct semantic questions
13 | correct_syn = 0; %count correct syntactic questions
14 | correct_tot = 0; %count correct questions
15 | count_sem = 0; %count all semantic questions
16 | count_syn = 0; %count all syntactic questions
17 | count_tot = 0; %count all questions
18 | full_count = 0; %count all questions, including those with unknown words
19 |
20 | if wordMap.isKey('')
21 | unkkey = wordMap('');
22 | else
23 | unkkey = 0;
24 | end
25 |
26 | for j=1:length(filenames);
27 |
28 | clear dist;
29 |
30 | fid=fopen([path filenames{j} '.txt']);
31 | temp=textscan(fid,'%s%s%s%s');
32 | fclose(fid);
33 | ind1 = cellfun(@WordLookup,temp{1}); %indices of first word in analogy
34 | ind2 = cellfun(@WordLookup,temp{2}); %indices of second word in analogy
35 | ind3 = cellfun(@WordLookup,temp{3}); %indices of third word in analogy
36 | ind4 = cellfun(@WordLookup,temp{4}); %indices of answer word in analogy
37 | full_count = full_count + length(ind1);
38 | ind = (ind1 ~= unkkey) & (ind2 ~= unkkey) & (ind3 ~= unkkey) & (ind4 ~= unkkey); %only look at those questions which have no unknown words
39 | ind1 = ind1(ind);
40 | ind2 = ind2(ind);
41 | ind3 = ind3(ind);
42 | ind4 = ind4(ind);
43 | disp([filenames{j} ':']);
44 | mx = zeros(1,length(ind1));
45 | num_iter = ceil(length(ind1)/split_size);
46 | for jj=1:num_iter
47 | range = (jj-1)*split_size+1:min(jj*split_size,length(ind1));
48 | dist = full(W * (W(ind2(range),:)' - W(ind1(range),:)' + W(ind3(range),:)')); %cosine similarity if input W has been normalized
49 | for i=1:length(range)
50 | dist(ind1(range(i)),i) = -Inf;
51 | dist(ind2(range(i)),i) = -Inf;
52 | dist(ind3(range(i)),i) = -Inf;
53 | end
54 | [~, mx(range)] = max(dist); %predicted word index
55 | end
56 |
57 | val = (ind4 == mx'); %correct predictions
58 | count_tot = count_tot + length(ind1);
59 | correct_tot = correct_tot + sum(val);
60 | disp(['ACCURACY TOP1: ' num2str(mean(val)*100,'%-2.2f') '% (' num2str(sum(val)) '/' num2str(length(val)) ')']);
61 | if j < 6
62 | count_sem = count_sem + length(ind1);
63 | correct_sem = correct_sem + sum(val);
64 | else
65 | count_syn = count_syn + length(ind1);
66 | correct_syn = correct_syn + sum(val);
67 | end
68 |
69 | disp(['Total accuracy: ' num2str(100*correct_tot/count_tot,'%-2.2f') '% Semantic accuracy: ' num2str(100*correct_sem/count_sem,'%-2.2f') '% Syntactic accuracy: ' num2str(100*correct_syn/count_syn,'%-2.2f') '%']);
70 |
71 | end
72 | disp('________________________________________________________________________________');
73 | disp(['Questions seen/total: ' num2str(100*count_tot/full_count,'%-2.2f') '% (' num2str(count_tot) '/' num2str(full_count) ')']);
74 | disp(['Semantic Accuracy: ' num2str(100*correct_sem/count_sem,'%-2.2f') '% (' num2str(correct_sem) '/' num2str(count_sem) ')']);
75 | disp(['Syntactic Accuracy: ' num2str(100*correct_syn/count_syn,'%-2.2f') '% (' num2str(correct_syn) '/' num2str(count_syn) ')']);
76 | disp(['Total Accuracy: ' num2str(100*correct_tot/count_tot,'%-2.2f') '% (' num2str(correct_tot) '/' num2str(count_tot) ')']);
77 | BB = [100*correct_sem/count_sem 100*correct_syn/count_syn 100*correct_tot/count_tot];
78 |
79 | end
80 |
--------------------------------------------------------------------------------
/eval/matlab/read_and_evaluate.m:
--------------------------------------------------------------------------------
1 | addpath('./eval/matlab');
2 | if(~exist('vocab_file'))
3 | vocab_file = 'vocab.txt';
4 | end
5 | if(~exist('vectors_file'))
6 | vectors_file = 'vectors.bin';
7 | end
8 |
9 | fid = fopen(vocab_file, 'r');
10 | words = textscan(fid, '%s %f');
11 | fclose(fid);
12 | words = words{1};
13 | vocab_size = length(words);
14 | global wordMap
15 | wordMap = containers.Map(words(1:vocab_size),1:vocab_size);
16 |
17 | fid = fopen(vectors_file,'r');
18 | fseek(fid,0,'eof');
19 | vector_size = ftell(fid)/16/vocab_size - 1;
20 | frewind(fid);
21 | WW = fread(fid, [vector_size+1 2*vocab_size], 'double')';
22 | fclose(fid);
23 |
24 | W1 = WW(1:vocab_size, 1:vector_size); % word vectors
25 | W2 = WW(vocab_size+1:end, 1:vector_size); % context (tilde) word vectors
26 |
27 | W = W1 + W2; %Evaluate on sum of word vectors
28 | W = bsxfun(@rdivide,W,sqrt(sum(W.*W,2))); %normalize vectors before evaluation
29 | evaluate_vectors(W);
30 | exit
31 |
32 |
--------------------------------------------------------------------------------
/eval/octave/WordLookup_octave.m:
--------------------------------------------------------------------------------
1 | function index = WordLookup_octave(InputString)
2 | global wordMap
3 |
4 | if isfield(wordMap, InputString)
5 | index = wordMap.(InputString);
6 | elseif isfield(wordMap, '')
7 | index = wordMap.('');
8 | else
9 | index = 0;
10 | end
11 |
--------------------------------------------------------------------------------
/eval/octave/evaluate_vectors_octave.m:
--------------------------------------------------------------------------------
1 | function [BB] = evaluate_vectors_octave(W)
2 |
3 | global wordMap
4 |
5 | filenames = {'capital-common-countries' 'capital-world' 'currency' 'city-in-state' 'family' 'gram1-adjective-to-adverb' ...
6 | 'gram2-opposite' 'gram3-comparative' 'gram4-superlative' 'gram5-present-participle' 'gram6-nationality-adjective' ...
7 | 'gram7-past-tense' 'gram8-plural' 'gram9-plural-verbs'};
8 | path = './eval/question-data/';
9 |
10 | split_size = 100; %to avoid memory overflow, could be increased/decreased depending on system and vocab size
11 |
12 | correct_sem = 0; %count correct semantic questions
13 | correct_syn = 0; %count correct syntactic questions
14 | correct_tot = 0; %count correct questions
15 | count_sem = 0; %count all semantic questions
16 | count_syn = 0; %count all syntactic questions
17 | count_tot = 0; %count all questions
18 | full_count = 0; %count all questions, including those with unknown words
19 |
20 |
21 | if isfield(wordMap, '')
22 | unkkey = wordMap.('');
23 | else
24 | unkkey = 0;
25 | end
26 |
27 | for j=1:length(filenames);
28 |
29 | clear dist;
30 |
31 | fid=fopen([path filenames{j} '.txt']);
32 | temp=textscan(fid,'%s%s%s%s');
33 | fclose(fid);
34 | ind1 = cellfun(@WordLookup_octave,temp{1}); %indices of first word in analogy
35 | ind2 = cellfun(@WordLookup_octave,temp{2}); %indices of second word in analogy
36 | ind3 = cellfun(@WordLookup_octave,temp{3}); %indices of third word in analogy
37 | ind4 = cellfun(@WordLookup_octave,temp{4}); %indices of answer word in analogy
38 | full_count = full_count + length(ind1);
39 | ind = (ind1 ~= unkkey) & (ind2 ~= unkkey) & (ind3 ~= unkkey) & (ind4 ~= unkkey); %only look at those questions which have no unknown words
40 | ind1 = ind1(ind);
41 | ind2 = ind2(ind);
42 | ind3 = ind3(ind);
43 | ind4 = ind4(ind);
44 | disp([filenames{j} ':']);
45 | mx = zeros(1,length(ind1));
46 | num_iter = ceil(length(ind1)/split_size);
47 | for jj=1:num_iter
48 | range = (jj-1)*split_size+1:min(jj*split_size,length(ind1));
49 | dist = full(W * (W(ind2(range),:)' - W(ind1(range),:)' + W(ind3(range),:)')); %cosine similarity if input W has been normalized
50 | for i=1:length(range)
51 | dist(ind1(range(i)),i) = -Inf;
52 | dist(ind2(range(i)),i) = -Inf;
53 | dist(ind3(range(i)),i) = -Inf;
54 | end
55 | [~, mx(range)] = max(dist); %predicted word index
56 | end
57 |
58 | val = (ind4 == mx'); %correct predictions
59 | count_tot = count_tot + length(ind1);
60 | correct_tot = correct_tot + sum(val);
61 | disp(['ACCURACY TOP1: ' num2str(mean(val)*100,'%-2.2f') '% (' num2str(sum(val)) '/' num2str(length(val)) ')']);
62 | if j < 6
63 | count_sem = count_sem + length(ind1);
64 | correct_sem = correct_sem + sum(val);
65 | else
66 | count_syn = count_syn + length(ind1);
67 | correct_syn = correct_syn + sum(val);
68 | end
69 |
70 | disp(['Total accuracy: ' num2str(100*correct_tot/count_tot,'%-2.2f') '% Semantic accuracy: ' num2str(100*correct_sem/count_sem,'%-2.2f') '% Syntactic accuracy: ' num2str(100*correct_syn/count_syn,'%-2.2f') '%']);
71 |
72 | end
73 | disp('________________________________________________________________________________');
74 | disp(['Questions seen/total: ' num2str(100*count_tot/full_count,'%-2.2f') '% (' num2str(count_tot) '/' num2str(full_count) ')']);
75 | disp(['Semantic Accuracy: ' num2str(100*correct_sem/count_sem,'%-2.2f') '% (' num2str(correct_sem) '/' num2str(count_sem) ')']);
76 | disp(['Syntactic Accuracy: ' num2str(100*correct_syn/count_syn,'%-2.2f') '% (' num2str(correct_syn) '/' num2str(count_syn) ')']);
77 | disp(['Total Accuracy: ' num2str(100*correct_tot/count_tot,'%-2.2f') '% (' num2str(correct_tot) '/' num2str(count_tot) ')']);
78 | BB = [100*correct_sem/count_sem 100*correct_syn/count_syn 100*correct_tot/count_tot];
79 |
80 | end
81 |
--------------------------------------------------------------------------------
/eval/octave/read_and_evaluate_octave.m:
--------------------------------------------------------------------------------
1 | addpath('./eval/octave');
2 | if(~exist('vocab_file'))
3 | vocab_file = 'vocab.txt';
4 | end
5 | if(~exist('vectors_file'))
6 | vectors_file = 'vectors.bin';
7 | end
8 |
9 | fid = fopen(vocab_file, 'r');
10 | words = textscan(fid, '%s %f');
11 | fclose(fid);
12 | words = words{1};
13 | vocab_size = length(words);
14 | global wordMap
15 |
16 | wordMap = struct();
17 | for i=1:numel(words)
18 | wordMap.(words{i}) = i;
19 | end
20 |
21 | fid = fopen(vectors_file,'r');
22 | fseek(fid,0,'eof');
23 | vector_size = ftell(fid)/16/vocab_size - 1;
24 | frewind(fid);
25 | WW = fread(fid, [vector_size+1 2*vocab_size], 'double')';
26 | fclose(fid);
27 |
28 | W1 = WW(1:vocab_size, 1:vector_size); % word vectors
29 | W2 = WW(vocab_size+1:end, 1:vector_size); % context (tilde) word vectors
30 |
31 | W = W1 + W2; %Evaluate on sum of word vectors
32 | W = bsxfun(@rdivide,W,sqrt(sum(W.*W,2))); %normalize vectors before evaluation
33 | evaluate_vectors_octave(W);
34 | exit
35 |
36 |
--------------------------------------------------------------------------------
/eval/python/distance.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import numpy as np
3 | import sys
4 |
5 | def generate():
6 | parser = argparse.ArgumentParser()
7 | parser.add_argument('--vocab_file', default='vocab.txt', type=str)
8 | parser.add_argument('--vectors_file', default='vectors.txt', type=str)
9 | args = parser.parse_args()
10 |
11 | with open(args.vocab_file, 'r') as f:
12 | words = [x.rstrip().split(' ')[0] for x in f.readlines()]
13 | with open(args.vectors_file, 'r') as f:
14 | vectors = {}
15 | for line in f:
16 | vals = line.rstrip().split(' ')
17 | vectors[vals[0]] = [float(x) for x in vals[1:]]
18 |
19 | vocab_size = len(words)
20 | vocab = {w: idx for idx, w in enumerate(words)}
21 | ivocab = {idx: w for idx, w in enumerate(words)}
22 |
23 | vector_dim = len(vectors[ivocab[0]])
24 | W = np.zeros((vocab_size, vector_dim))
25 | for word, v in vectors.items():
26 | if word == '':
27 | continue
28 | W[vocab[word], :] = v
29 |
30 | # normalize each word vector to unit variance
31 | W_norm = np.zeros(W.shape)
32 | d = (np.sum(W ** 2, 1) ** (0.5))
33 | W_norm = (W.T / d).T
34 | return (W_norm, vocab, ivocab)
35 |
36 |
37 | def distance(W, vocab, ivocab, input_term):
38 | for idx, term in enumerate(input_term.split(' ')):
39 | if term in vocab:
40 | print('Word: %s Position in vocabulary: %i' % (term, vocab[term]))
41 | if idx == 0:
42 | vec_result = np.copy(W[vocab[term], :])
43 | else:
44 | vec_result += W[vocab[term], :]
45 | else:
46 | print('Word: %s Out of dictionary!\n' % term)
47 | return
48 |
49 | vec_norm = np.zeros(vec_result.shape)
50 | d = (np.sum(vec_result ** 2,) ** (0.5))
51 | vec_norm = (vec_result.T / d).T
52 |
53 | dist = np.dot(W, vec_norm.T)
54 |
55 | for term in input_term.split(' '):
56 | index = vocab[term]
57 | dist[index] = -np.Inf
58 |
59 | a = np.argsort(-dist)[:N]
60 |
61 | print("\n Word Cosine distance\n")
62 | print("---------------------------------------------------------\n")
63 | for x in a:
64 | print("%35s\t\t%f\n" % (ivocab[x], dist[x]))
65 |
66 |
67 | if __name__ == "__main__":
68 | N = 100 # number of closest words that will be shown
69 | W, vocab, ivocab = generate()
70 | while True:
71 | input_term = input("\nEnter word or sentence (EXIT to break): ")
72 | if input_term == 'EXIT':
73 | break
74 | else:
75 | distance(W, vocab, ivocab, input_term)
76 |
--------------------------------------------------------------------------------
/eval/python/evaluate.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import numpy as np
3 |
4 | def main():
5 | parser = argparse.ArgumentParser()
6 | parser.add_argument('--vocab_file', default='vocab.txt', type=str)
7 | parser.add_argument('--vectors_file', default='vectors.txt', type=str)
8 | args = parser.parse_args()
9 |
10 | with open(args.vocab_file, 'r') as f:
11 | words = [x.rstrip().split(' ')[0] for x in f.readlines()]
12 | with open(args.vectors_file, 'r') as f:
13 | vectors = {}
14 | for line in f:
15 | vals = line.rstrip().split(' ')
16 | vectors[vals[0]] = [float(x) for x in vals[1:]]
17 |
18 | vocab_size = len(words)
19 | vocab = {w: idx for idx, w in enumerate(words)}
20 | ivocab = {idx: w for idx, w in enumerate(words)}
21 |
22 | vector_dim = len(vectors[ivocab[0]])
23 | W = np.zeros((vocab_size, vector_dim))
24 | for word, v in vectors.items():
25 | if word == '':
26 | continue
27 | W[vocab[word], :] = v
28 |
29 | # normalize each word vector to unit length
30 | W_norm = np.zeros(W.shape)
31 | d = (np.sum(W ** 2, 1) ** (0.5))
32 | W_norm = (W.T / d).T
33 | evaluate_vectors(W_norm, vocab)
34 |
35 | def evaluate_vectors(W, vocab):
36 | """Evaluate the trained word vectors on a variety of tasks"""
37 |
38 | filenames = [
39 | 'capital-common-countries.txt', 'capital-world.txt', 'currency.txt',
40 | 'city-in-state.txt', 'family.txt', 'gram1-adjective-to-adverb.txt',
41 | 'gram2-opposite.txt', 'gram3-comparative.txt', 'gram4-superlative.txt',
42 | 'gram5-present-participle.txt', 'gram6-nationality-adjective.txt',
43 | 'gram7-past-tense.txt', 'gram8-plural.txt', 'gram9-plural-verbs.txt',
44 | ]
45 | prefix = './eval/question-data/'
46 |
47 | # to avoid memory overflow, could be increased/decreased
48 | # depending on system and vocab size
49 | split_size = 100
50 |
51 | correct_sem = 0; # count correct semantic questions
52 | correct_syn = 0; # count correct syntactic questions
53 | correct_tot = 0 # count correct questions
54 | count_sem = 0; # count all semantic questions
55 | count_syn = 0; # count all syntactic questions
56 | count_tot = 0 # count all questions
57 | full_count = 0 # count all questions, including those with unknown words
58 |
59 | for i in range(len(filenames)):
60 | with open('%s/%s' % (prefix, filenames[i]), 'r') as f:
61 | full_data = [line.rstrip().split(' ') for line in f]
62 | full_count += len(full_data)
63 | data = [x for x in full_data if all(word in vocab for word in x)]
64 |
65 | if len(data) == 0:
66 | print("ERROR: no lines of vocab kept for %s !" % filenames[i])
67 | print("Example missing line:", full_data[0])
68 | continue
69 |
70 | indices = np.array([[vocab[word] for word in row] for row in data])
71 | ind1, ind2, ind3, ind4 = indices.T
72 |
73 | predictions = np.zeros((len(indices),))
74 | num_iter = int(np.ceil(len(indices) / float(split_size)))
75 | for j in range(num_iter):
76 | subset = np.arange(j*split_size, min((j + 1)*split_size, len(ind1)))
77 |
78 | pred_vec = (W[ind2[subset], :] - W[ind1[subset], :]
79 | + W[ind3[subset], :])
80 | #cosine similarity if input W has been normalized
81 | dist = np.dot(W, pred_vec.T)
82 |
83 | for k in range(len(subset)):
84 | dist[ind1[subset[k]], k] = -np.inf
85 | dist[ind2[subset[k]], k] = -np.inf
86 | dist[ind3[subset[k]], k] = -np.inf
87 |
88 | # predicted word index
89 | predictions[subset] = np.argmax(dist, 0).flatten()
90 |
91 | val = (ind4 == predictions) # correct predictions
92 | count_tot = count_tot + len(ind1)
93 | correct_tot = correct_tot + sum(val)
94 | if i < 5:
95 | count_sem = count_sem + len(ind1)
96 | correct_sem = correct_sem + sum(val)
97 | else:
98 | count_syn = count_syn + len(ind1)
99 | correct_syn = correct_syn + sum(val)
100 |
101 | print("%s:" % filenames[i])
102 | print('ACCURACY TOP1: %.2f%% (%d/%d)' %
103 | (np.mean(val) * 100, np.sum(val), len(val)))
104 |
105 | print('Questions seen/total: %.2f%% (%d/%d)' %
106 | (100 * count_tot / float(full_count), count_tot, full_count))
107 | print('Semantic accuracy: %.2f%% (%i/%i)' %
108 | (100 * correct_sem / float(count_sem), correct_sem, count_sem))
109 | print('Syntactic accuracy: %.2f%% (%i/%i)' %
110 | (100 * correct_syn / float(count_syn), correct_syn, count_syn))
111 | print('Total accuracy: %.2f%% (%i/%i)' % (100 * correct_tot / float(count_tot), correct_tot, count_tot))
112 |
113 |
114 | if __name__ == "__main__":
115 | main()
116 |
--------------------------------------------------------------------------------
/eval/python/word_analogy.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import numpy as np
3 |
4 | def generate():
5 | parser = argparse.ArgumentParser()
6 | parser.add_argument('--vocab_file', default='vocab.txt', type=str)
7 | parser.add_argument('--vectors_file', default='vectors.txt', type=str)
8 | args = parser.parse_args()
9 |
10 | with open(args.vocab_file, 'r') as f:
11 | words = [x.rstrip().split(' ')[0] for x in f.readlines()]
12 | with open(args.vectors_file, 'r') as f:
13 | vectors = {}
14 | for line in f:
15 | vals = line.rstrip().split(' ')
16 | vectors[vals[0]] = [float(x) for x in vals[1:]]
17 |
18 | vocab_size = len(words)
19 | vocab = {w: idx for idx, w in enumerate(words)}
20 | ivocab = {idx: w for idx, w in enumerate(words)}
21 |
22 | vector_dim = len(vectors[ivocab[0]])
23 | W = np.zeros((vocab_size, vector_dim))
24 | for word, v in vectors.items():
25 | if word == '':
26 | continue
27 | W[vocab[word], :] = v
28 |
29 | # normalize each word vector to unit variance
30 | W_norm = np.zeros(W.shape)
31 | d = (np.sum(W ** 2, 1) ** (0.5))
32 | W_norm = (W.T / d).T
33 | return (W_norm, vocab, ivocab)
34 |
35 |
36 | def distance(W, vocab, ivocab, input_term):
37 | vecs = {}
38 | if len(input_term.split(' ')) < 3:
39 | print("Only %i words were entered.. three words are needed at the input to perform the calculation\n" % len(input_term.split(' ')))
40 | return
41 | else:
42 | for idx, term in enumerate(input_term.split(' ')):
43 | if term in vocab:
44 | print('Word: %s Position in vocabulary: %i' % (term, vocab[term]))
45 | vecs[idx] = W[vocab[term], :]
46 | else:
47 | print('Word: %s Out of dictionary!\n' % term)
48 | return
49 |
50 | vec_result = vecs[1] - vecs[0] + vecs[2]
51 |
52 | vec_norm = np.zeros(vec_result.shape)
53 | d = (np.sum(vec_result ** 2,) ** (0.5))
54 | vec_norm = (vec_result.T / d).T
55 |
56 | dist = np.dot(W, vec_norm.T)
57 |
58 | for term in input_term.split(' '):
59 | index = vocab[term]
60 | dist[index] = -np.Inf
61 |
62 | a = np.argsort(-dist)[:N]
63 |
64 | print("\n Word Cosine distance\n")
65 | print("---------------------------------------------------------\n")
66 | for x in a:
67 | print("%35s\t\t%f\n" % (ivocab[x], dist[x]))
68 |
69 |
70 | if __name__ == "__main__":
71 | N = 100; # number of closest words that will be shown
72 | W, vocab, ivocab = generate()
73 | while True:
74 | input_term = input("\nEnter three words (EXIT to break): ")
75 | if input_term == 'EXIT':
76 | break
77 | else:
78 | distance(W, vocab, ivocab, input_term)
79 |
80 |
--------------------------------------------------------------------------------
/eval/question-data/capital-common-countries.txt:
--------------------------------------------------------------------------------
1 | athens greece baghdad iraq
2 | athens greece bangkok thailand
3 | athens greece beijing china
4 | athens greece berlin germany
5 | athens greece bern switzerland
6 | athens greece cairo egypt
7 | athens greece canberra australia
8 | athens greece hanoi vietnam
9 | athens greece havana cuba
10 | athens greece helsinki finland
11 | athens greece islamabad pakistan
12 | athens greece kabul afghanistan
13 | athens greece london england
14 | athens greece madrid spain
15 | athens greece moscow russia
16 | athens greece oslo norway
17 | athens greece ottawa canada
18 | athens greece paris france
19 | athens greece rome italy
20 | athens greece stockholm sweden
21 | athens greece tehran iran
22 | athens greece tokyo japan
23 | baghdad iraq bangkok thailand
24 | baghdad iraq beijing china
25 | baghdad iraq berlin germany
26 | baghdad iraq bern switzerland
27 | baghdad iraq cairo egypt
28 | baghdad iraq canberra australia
29 | baghdad iraq hanoi vietnam
30 | baghdad iraq havana cuba
31 | baghdad iraq helsinki finland
32 | baghdad iraq islamabad pakistan
33 | baghdad iraq kabul afghanistan
34 | baghdad iraq london england
35 | baghdad iraq madrid spain
36 | baghdad iraq moscow russia
37 | baghdad iraq oslo norway
38 | baghdad iraq ottawa canada
39 | baghdad iraq paris france
40 | baghdad iraq rome italy
41 | baghdad iraq stockholm sweden
42 | baghdad iraq tehran iran
43 | baghdad iraq tokyo japan
44 | baghdad iraq athens greece
45 | bangkok thailand beijing china
46 | bangkok thailand berlin germany
47 | bangkok thailand bern switzerland
48 | bangkok thailand cairo egypt
49 | bangkok thailand canberra australia
50 | bangkok thailand hanoi vietnam
51 | bangkok thailand havana cuba
52 | bangkok thailand helsinki finland
53 | bangkok thailand islamabad pakistan
54 | bangkok thailand kabul afghanistan
55 | bangkok thailand london england
56 | bangkok thailand madrid spain
57 | bangkok thailand moscow russia
58 | bangkok thailand oslo norway
59 | bangkok thailand ottawa canada
60 | bangkok thailand paris france
61 | bangkok thailand rome italy
62 | bangkok thailand stockholm sweden
63 | bangkok thailand tehran iran
64 | bangkok thailand tokyo japan
65 | bangkok thailand athens greece
66 | bangkok thailand baghdad iraq
67 | beijing china berlin germany
68 | beijing china bern switzerland
69 | beijing china cairo egypt
70 | beijing china canberra australia
71 | beijing china hanoi vietnam
72 | beijing china havana cuba
73 | beijing china helsinki finland
74 | beijing china islamabad pakistan
75 | beijing china kabul afghanistan
76 | beijing china london england
77 | beijing china madrid spain
78 | beijing china moscow russia
79 | beijing china oslo norway
80 | beijing china ottawa canada
81 | beijing china paris france
82 | beijing china rome italy
83 | beijing china stockholm sweden
84 | beijing china tehran iran
85 | beijing china tokyo japan
86 | beijing china athens greece
87 | beijing china baghdad iraq
88 | beijing china bangkok thailand
89 | berlin germany bern switzerland
90 | berlin germany cairo egypt
91 | berlin germany canberra australia
92 | berlin germany hanoi vietnam
93 | berlin germany havana cuba
94 | berlin germany helsinki finland
95 | berlin germany islamabad pakistan
96 | berlin germany kabul afghanistan
97 | berlin germany london england
98 | berlin germany madrid spain
99 | berlin germany moscow russia
100 | berlin germany oslo norway
101 | berlin germany ottawa canada
102 | berlin germany paris france
103 | berlin germany rome italy
104 | berlin germany stockholm sweden
105 | berlin germany tehran iran
106 | berlin germany tokyo japan
107 | berlin germany athens greece
108 | berlin germany baghdad iraq
109 | berlin germany bangkok thailand
110 | berlin germany beijing china
111 | bern switzerland cairo egypt
112 | bern switzerland canberra australia
113 | bern switzerland hanoi vietnam
114 | bern switzerland havana cuba
115 | bern switzerland helsinki finland
116 | bern switzerland islamabad pakistan
117 | bern switzerland kabul afghanistan
118 | bern switzerland london england
119 | bern switzerland madrid spain
120 | bern switzerland moscow russia
121 | bern switzerland oslo norway
122 | bern switzerland ottawa canada
123 | bern switzerland paris france
124 | bern switzerland rome italy
125 | bern switzerland stockholm sweden
126 | bern switzerland tehran iran
127 | bern switzerland tokyo japan
128 | bern switzerland athens greece
129 | bern switzerland baghdad iraq
130 | bern switzerland bangkok thailand
131 | bern switzerland beijing china
132 | bern switzerland berlin germany
133 | cairo egypt canberra australia
134 | cairo egypt hanoi vietnam
135 | cairo egypt havana cuba
136 | cairo egypt helsinki finland
137 | cairo egypt islamabad pakistan
138 | cairo egypt kabul afghanistan
139 | cairo egypt london england
140 | cairo egypt madrid spain
141 | cairo egypt moscow russia
142 | cairo egypt oslo norway
143 | cairo egypt ottawa canada
144 | cairo egypt paris france
145 | cairo egypt rome italy
146 | cairo egypt stockholm sweden
147 | cairo egypt tehran iran
148 | cairo egypt tokyo japan
149 | cairo egypt athens greece
150 | cairo egypt baghdad iraq
151 | cairo egypt bangkok thailand
152 | cairo egypt beijing china
153 | cairo egypt berlin germany
154 | cairo egypt bern switzerland
155 | canberra australia hanoi vietnam
156 | canberra australia havana cuba
157 | canberra australia helsinki finland
158 | canberra australia islamabad pakistan
159 | canberra australia kabul afghanistan
160 | canberra australia london england
161 | canberra australia madrid spain
162 | canberra australia moscow russia
163 | canberra australia oslo norway
164 | canberra australia ottawa canada
165 | canberra australia paris france
166 | canberra australia rome italy
167 | canberra australia stockholm sweden
168 | canberra australia tehran iran
169 | canberra australia tokyo japan
170 | canberra australia athens greece
171 | canberra australia baghdad iraq
172 | canberra australia bangkok thailand
173 | canberra australia beijing china
174 | canberra australia berlin germany
175 | canberra australia bern switzerland
176 | canberra australia cairo egypt
177 | hanoi vietnam havana cuba
178 | hanoi vietnam helsinki finland
179 | hanoi vietnam islamabad pakistan
180 | hanoi vietnam kabul afghanistan
181 | hanoi vietnam london england
182 | hanoi vietnam madrid spain
183 | hanoi vietnam moscow russia
184 | hanoi vietnam oslo norway
185 | hanoi vietnam ottawa canada
186 | hanoi vietnam paris france
187 | hanoi vietnam rome italy
188 | hanoi vietnam stockholm sweden
189 | hanoi vietnam tehran iran
190 | hanoi vietnam tokyo japan
191 | hanoi vietnam athens greece
192 | hanoi vietnam baghdad iraq
193 | hanoi vietnam bangkok thailand
194 | hanoi vietnam beijing china
195 | hanoi vietnam berlin germany
196 | hanoi vietnam bern switzerland
197 | hanoi vietnam cairo egypt
198 | hanoi vietnam canberra australia
199 | havana cuba helsinki finland
200 | havana cuba islamabad pakistan
201 | havana cuba kabul afghanistan
202 | havana cuba london england
203 | havana cuba madrid spain
204 | havana cuba moscow russia
205 | havana cuba oslo norway
206 | havana cuba ottawa canada
207 | havana cuba paris france
208 | havana cuba rome italy
209 | havana cuba stockholm sweden
210 | havana cuba tehran iran
211 | havana cuba tokyo japan
212 | havana cuba athens greece
213 | havana cuba baghdad iraq
214 | havana cuba bangkok thailand
215 | havana cuba beijing china
216 | havana cuba berlin germany
217 | havana cuba bern switzerland
218 | havana cuba cairo egypt
219 | havana cuba canberra australia
220 | havana cuba hanoi vietnam
221 | helsinki finland islamabad pakistan
222 | helsinki finland kabul afghanistan
223 | helsinki finland london england
224 | helsinki finland madrid spain
225 | helsinki finland moscow russia
226 | helsinki finland oslo norway
227 | helsinki finland ottawa canada
228 | helsinki finland paris france
229 | helsinki finland rome italy
230 | helsinki finland stockholm sweden
231 | helsinki finland tehran iran
232 | helsinki finland tokyo japan
233 | helsinki finland athens greece
234 | helsinki finland baghdad iraq
235 | helsinki finland bangkok thailand
236 | helsinki finland beijing china
237 | helsinki finland berlin germany
238 | helsinki finland bern switzerland
239 | helsinki finland cairo egypt
240 | helsinki finland canberra australia
241 | helsinki finland hanoi vietnam
242 | helsinki finland havana cuba
243 | islamabad pakistan kabul afghanistan
244 | islamabad pakistan london england
245 | islamabad pakistan madrid spain
246 | islamabad pakistan moscow russia
247 | islamabad pakistan oslo norway
248 | islamabad pakistan ottawa canada
249 | islamabad pakistan paris france
250 | islamabad pakistan rome italy
251 | islamabad pakistan stockholm sweden
252 | islamabad pakistan tehran iran
253 | islamabad pakistan tokyo japan
254 | islamabad pakistan athens greece
255 | islamabad pakistan baghdad iraq
256 | islamabad pakistan bangkok thailand
257 | islamabad pakistan beijing china
258 | islamabad pakistan berlin germany
259 | islamabad pakistan bern switzerland
260 | islamabad pakistan cairo egypt
261 | islamabad pakistan canberra australia
262 | islamabad pakistan hanoi vietnam
263 | islamabad pakistan havana cuba
264 | islamabad pakistan helsinki finland
265 | kabul afghanistan london england
266 | kabul afghanistan madrid spain
267 | kabul afghanistan moscow russia
268 | kabul afghanistan oslo norway
269 | kabul afghanistan ottawa canada
270 | kabul afghanistan paris france
271 | kabul afghanistan rome italy
272 | kabul afghanistan stockholm sweden
273 | kabul afghanistan tehran iran
274 | kabul afghanistan tokyo japan
275 | kabul afghanistan athens greece
276 | kabul afghanistan baghdad iraq
277 | kabul afghanistan bangkok thailand
278 | kabul afghanistan beijing china
279 | kabul afghanistan berlin germany
280 | kabul afghanistan bern switzerland
281 | kabul afghanistan cairo egypt
282 | kabul afghanistan canberra australia
283 | kabul afghanistan hanoi vietnam
284 | kabul afghanistan havana cuba
285 | kabul afghanistan helsinki finland
286 | kabul afghanistan islamabad pakistan
287 | london england madrid spain
288 | london england moscow russia
289 | london england oslo norway
290 | london england ottawa canada
291 | london england paris france
292 | london england rome italy
293 | london england stockholm sweden
294 | london england tehran iran
295 | london england tokyo japan
296 | london england athens greece
297 | london england baghdad iraq
298 | london england bangkok thailand
299 | london england beijing china
300 | london england berlin germany
301 | london england bern switzerland
302 | london england cairo egypt
303 | london england canberra australia
304 | london england hanoi vietnam
305 | london england havana cuba
306 | london england helsinki finland
307 | london england islamabad pakistan
308 | london england kabul afghanistan
309 | madrid spain moscow russia
310 | madrid spain oslo norway
311 | madrid spain ottawa canada
312 | madrid spain paris france
313 | madrid spain rome italy
314 | madrid spain stockholm sweden
315 | madrid spain tehran iran
316 | madrid spain tokyo japan
317 | madrid spain athens greece
318 | madrid spain baghdad iraq
319 | madrid spain bangkok thailand
320 | madrid spain beijing china
321 | madrid spain berlin germany
322 | madrid spain bern switzerland
323 | madrid spain cairo egypt
324 | madrid spain canberra australia
325 | madrid spain hanoi vietnam
326 | madrid spain havana cuba
327 | madrid spain helsinki finland
328 | madrid spain islamabad pakistan
329 | madrid spain kabul afghanistan
330 | madrid spain london england
331 | moscow russia oslo norway
332 | moscow russia ottawa canada
333 | moscow russia paris france
334 | moscow russia rome italy
335 | moscow russia stockholm sweden
336 | moscow russia tehran iran
337 | moscow russia tokyo japan
338 | moscow russia athens greece
339 | moscow russia baghdad iraq
340 | moscow russia bangkok thailand
341 | moscow russia beijing china
342 | moscow russia berlin germany
343 | moscow russia bern switzerland
344 | moscow russia cairo egypt
345 | moscow russia canberra australia
346 | moscow russia hanoi vietnam
347 | moscow russia havana cuba
348 | moscow russia helsinki finland
349 | moscow russia islamabad pakistan
350 | moscow russia kabul afghanistan
351 | moscow russia london england
352 | moscow russia madrid spain
353 | oslo norway ottawa canada
354 | oslo norway paris france
355 | oslo norway rome italy
356 | oslo norway stockholm sweden
357 | oslo norway tehran iran
358 | oslo norway tokyo japan
359 | oslo norway athens greece
360 | oslo norway baghdad iraq
361 | oslo norway bangkok thailand
362 | oslo norway beijing china
363 | oslo norway berlin germany
364 | oslo norway bern switzerland
365 | oslo norway cairo egypt
366 | oslo norway canberra australia
367 | oslo norway hanoi vietnam
368 | oslo norway havana cuba
369 | oslo norway helsinki finland
370 | oslo norway islamabad pakistan
371 | oslo norway kabul afghanistan
372 | oslo norway london england
373 | oslo norway madrid spain
374 | oslo norway moscow russia
375 | ottawa canada paris france
376 | ottawa canada rome italy
377 | ottawa canada stockholm sweden
378 | ottawa canada tehran iran
379 | ottawa canada tokyo japan
380 | ottawa canada athens greece
381 | ottawa canada baghdad iraq
382 | ottawa canada bangkok thailand
383 | ottawa canada beijing china
384 | ottawa canada berlin germany
385 | ottawa canada bern switzerland
386 | ottawa canada cairo egypt
387 | ottawa canada canberra australia
388 | ottawa canada hanoi vietnam
389 | ottawa canada havana cuba
390 | ottawa canada helsinki finland
391 | ottawa canada islamabad pakistan
392 | ottawa canada kabul afghanistan
393 | ottawa canada london england
394 | ottawa canada madrid spain
395 | ottawa canada moscow russia
396 | ottawa canada oslo norway
397 | paris france rome italy
398 | paris france stockholm sweden
399 | paris france tehran iran
400 | paris france tokyo japan
401 | paris france athens greece
402 | paris france baghdad iraq
403 | paris france bangkok thailand
404 | paris france beijing china
405 | paris france berlin germany
406 | paris france bern switzerland
407 | paris france cairo egypt
408 | paris france canberra australia
409 | paris france hanoi vietnam
410 | paris france havana cuba
411 | paris france helsinki finland
412 | paris france islamabad pakistan
413 | paris france kabul afghanistan
414 | paris france london england
415 | paris france madrid spain
416 | paris france moscow russia
417 | paris france oslo norway
418 | paris france ottawa canada
419 | rome italy stockholm sweden
420 | rome italy tehran iran
421 | rome italy tokyo japan
422 | rome italy athens greece
423 | rome italy baghdad iraq
424 | rome italy bangkok thailand
425 | rome italy beijing china
426 | rome italy berlin germany
427 | rome italy bern switzerland
428 | rome italy cairo egypt
429 | rome italy canberra australia
430 | rome italy hanoi vietnam
431 | rome italy havana cuba
432 | rome italy helsinki finland
433 | rome italy islamabad pakistan
434 | rome italy kabul afghanistan
435 | rome italy london england
436 | rome italy madrid spain
437 | rome italy moscow russia
438 | rome italy oslo norway
439 | rome italy ottawa canada
440 | rome italy paris france
441 | stockholm sweden tehran iran
442 | stockholm sweden tokyo japan
443 | stockholm sweden athens greece
444 | stockholm sweden baghdad iraq
445 | stockholm sweden bangkok thailand
446 | stockholm sweden beijing china
447 | stockholm sweden berlin germany
448 | stockholm sweden bern switzerland
449 | stockholm sweden cairo egypt
450 | stockholm sweden canberra australia
451 | stockholm sweden hanoi vietnam
452 | stockholm sweden havana cuba
453 | stockholm sweden helsinki finland
454 | stockholm sweden islamabad pakistan
455 | stockholm sweden kabul afghanistan
456 | stockholm sweden london england
457 | stockholm sweden madrid spain
458 | stockholm sweden moscow russia
459 | stockholm sweden oslo norway
460 | stockholm sweden ottawa canada
461 | stockholm sweden paris france
462 | stockholm sweden rome italy
463 | tehran iran tokyo japan
464 | tehran iran athens greece
465 | tehran iran baghdad iraq
466 | tehran iran bangkok thailand
467 | tehran iran beijing china
468 | tehran iran berlin germany
469 | tehran iran bern switzerland
470 | tehran iran cairo egypt
471 | tehran iran canberra australia
472 | tehran iran hanoi vietnam
473 | tehran iran havana cuba
474 | tehran iran helsinki finland
475 | tehran iran islamabad pakistan
476 | tehran iran kabul afghanistan
477 | tehran iran london england
478 | tehran iran madrid spain
479 | tehran iran moscow russia
480 | tehran iran oslo norway
481 | tehran iran ottawa canada
482 | tehran iran paris france
483 | tehran iran rome italy
484 | tehran iran stockholm sweden
485 | tokyo japan athens greece
486 | tokyo japan baghdad iraq
487 | tokyo japan bangkok thailand
488 | tokyo japan beijing china
489 | tokyo japan berlin germany
490 | tokyo japan bern switzerland
491 | tokyo japan cairo egypt
492 | tokyo japan canberra australia
493 | tokyo japan hanoi vietnam
494 | tokyo japan havana cuba
495 | tokyo japan helsinki finland
496 | tokyo japan islamabad pakistan
497 | tokyo japan kabul afghanistan
498 | tokyo japan london england
499 | tokyo japan madrid spain
500 | tokyo japan moscow russia
501 | tokyo japan oslo norway
502 | tokyo japan ottawa canada
503 | tokyo japan paris france
504 | tokyo japan rome italy
505 | tokyo japan stockholm sweden
506 | tokyo japan tehran iran
507 |
--------------------------------------------------------------------------------
/eval/question-data/currency.txt:
--------------------------------------------------------------------------------
1 | algeria dinar angola kwanza
2 | algeria dinar argentina peso
3 | algeria dinar armenia dram
4 | algeria dinar brazil real
5 | algeria dinar bulgaria lev
6 | algeria dinar cambodia riel
7 | algeria dinar canada dollar
8 | algeria dinar croatia kuna
9 | algeria dinar denmark krone
10 | algeria dinar europe euro
11 | algeria dinar hungary forint
12 | algeria dinar india rupee
13 | algeria dinar iran rial
14 | algeria dinar japan yen
15 | algeria dinar korea won
16 | algeria dinar latvia lats
17 | algeria dinar lithuania litas
18 | algeria dinar macedonia denar
19 | algeria dinar malaysia ringgit
20 | algeria dinar mexico peso
21 | algeria dinar nigeria naira
22 | algeria dinar poland zloty
23 | algeria dinar romania leu
24 | algeria dinar russia ruble
25 | algeria dinar sweden krona
26 | algeria dinar thailand baht
27 | algeria dinar ukraine hryvnia
28 | algeria dinar usa dollar
29 | algeria dinar vietnam dong
30 | angola kwanza argentina peso
31 | angola kwanza armenia dram
32 | angola kwanza brazil real
33 | angola kwanza bulgaria lev
34 | angola kwanza cambodia riel
35 | angola kwanza canada dollar
36 | angola kwanza croatia kuna
37 | angola kwanza denmark krone
38 | angola kwanza europe euro
39 | angola kwanza hungary forint
40 | angola kwanza india rupee
41 | angola kwanza iran rial
42 | angola kwanza japan yen
43 | angola kwanza korea won
44 | angola kwanza latvia lats
45 | angola kwanza lithuania litas
46 | angola kwanza macedonia denar
47 | angola kwanza malaysia ringgit
48 | angola kwanza mexico peso
49 | angola kwanza nigeria naira
50 | angola kwanza poland zloty
51 | angola kwanza romania leu
52 | angola kwanza russia ruble
53 | angola kwanza sweden krona
54 | angola kwanza thailand baht
55 | angola kwanza ukraine hryvnia
56 | angola kwanza usa dollar
57 | angola kwanza vietnam dong
58 | angola kwanza algeria dinar
59 | argentina peso armenia dram
60 | argentina peso brazil real
61 | argentina peso bulgaria lev
62 | argentina peso cambodia riel
63 | argentina peso canada dollar
64 | argentina peso croatia kuna
65 | argentina peso denmark krone
66 | argentina peso europe euro
67 | argentina peso hungary forint
68 | argentina peso india rupee
69 | argentina peso iran rial
70 | argentina peso japan yen
71 | argentina peso korea won
72 | argentina peso latvia lats
73 | argentina peso lithuania litas
74 | argentina peso macedonia denar
75 | argentina peso malaysia ringgit
76 | argentina peso nigeria naira
77 | argentina peso poland zloty
78 | argentina peso romania leu
79 | argentina peso russia ruble
80 | argentina peso sweden krona
81 | argentina peso thailand baht
82 | argentina peso ukraine hryvnia
83 | argentina peso usa dollar
84 | argentina peso vietnam dong
85 | argentina peso algeria dinar
86 | argentina peso angola kwanza
87 | armenia dram brazil real
88 | armenia dram bulgaria lev
89 | armenia dram cambodia riel
90 | armenia dram canada dollar
91 | armenia dram croatia kuna
92 | armenia dram denmark krone
93 | armenia dram europe euro
94 | armenia dram hungary forint
95 | armenia dram india rupee
96 | armenia dram iran rial
97 | armenia dram japan yen
98 | armenia dram korea won
99 | armenia dram latvia lats
100 | armenia dram lithuania litas
101 | armenia dram macedonia denar
102 | armenia dram malaysia ringgit
103 | armenia dram mexico peso
104 | armenia dram nigeria naira
105 | armenia dram poland zloty
106 | armenia dram romania leu
107 | armenia dram russia ruble
108 | armenia dram sweden krona
109 | armenia dram thailand baht
110 | armenia dram ukraine hryvnia
111 | armenia dram usa dollar
112 | armenia dram vietnam dong
113 | armenia dram algeria dinar
114 | armenia dram angola kwanza
115 | armenia dram argentina peso
116 | brazil real bulgaria lev
117 | brazil real cambodia riel
118 | brazil real canada dollar
119 | brazil real croatia kuna
120 | brazil real denmark krone
121 | brazil real europe euro
122 | brazil real hungary forint
123 | brazil real india rupee
124 | brazil real iran rial
125 | brazil real japan yen
126 | brazil real korea won
127 | brazil real latvia lats
128 | brazil real lithuania litas
129 | brazil real macedonia denar
130 | brazil real malaysia ringgit
131 | brazil real mexico peso
132 | brazil real nigeria naira
133 | brazil real poland zloty
134 | brazil real romania leu
135 | brazil real russia ruble
136 | brazil real sweden krona
137 | brazil real thailand baht
138 | brazil real ukraine hryvnia
139 | brazil real usa dollar
140 | brazil real vietnam dong
141 | brazil real algeria dinar
142 | brazil real angola kwanza
143 | brazil real argentina peso
144 | brazil real armenia dram
145 | bulgaria lev cambodia riel
146 | bulgaria lev canada dollar
147 | bulgaria lev croatia kuna
148 | bulgaria lev denmark krone
149 | bulgaria lev europe euro
150 | bulgaria lev hungary forint
151 | bulgaria lev india rupee
152 | bulgaria lev iran rial
153 | bulgaria lev japan yen
154 | bulgaria lev korea won
155 | bulgaria lev latvia lats
156 | bulgaria lev lithuania litas
157 | bulgaria lev macedonia denar
158 | bulgaria lev malaysia ringgit
159 | bulgaria lev mexico peso
160 | bulgaria lev nigeria naira
161 | bulgaria lev poland zloty
162 | bulgaria lev romania leu
163 | bulgaria lev russia ruble
164 | bulgaria lev sweden krona
165 | bulgaria lev thailand baht
166 | bulgaria lev ukraine hryvnia
167 | bulgaria lev usa dollar
168 | bulgaria lev vietnam dong
169 | bulgaria lev algeria dinar
170 | bulgaria lev angola kwanza
171 | bulgaria lev argentina peso
172 | bulgaria lev armenia dram
173 | bulgaria lev brazil real
174 | cambodia riel canada dollar
175 | cambodia riel croatia kuna
176 | cambodia riel denmark krone
177 | cambodia riel europe euro
178 | cambodia riel hungary forint
179 | cambodia riel india rupee
180 | cambodia riel iran rial
181 | cambodia riel japan yen
182 | cambodia riel korea won
183 | cambodia riel latvia lats
184 | cambodia riel lithuania litas
185 | cambodia riel macedonia denar
186 | cambodia riel malaysia ringgit
187 | cambodia riel mexico peso
188 | cambodia riel nigeria naira
189 | cambodia riel poland zloty
190 | cambodia riel romania leu
191 | cambodia riel russia ruble
192 | cambodia riel sweden krona
193 | cambodia riel thailand baht
194 | cambodia riel ukraine hryvnia
195 | cambodia riel usa dollar
196 | cambodia riel vietnam dong
197 | cambodia riel algeria dinar
198 | cambodia riel angola kwanza
199 | cambodia riel argentina peso
200 | cambodia riel armenia dram
201 | cambodia riel brazil real
202 | cambodia riel bulgaria lev
203 | canada dollar croatia kuna
204 | canada dollar denmark krone
205 | canada dollar europe euro
206 | canada dollar hungary forint
207 | canada dollar india rupee
208 | canada dollar iran rial
209 | canada dollar japan yen
210 | canada dollar korea won
211 | canada dollar latvia lats
212 | canada dollar lithuania litas
213 | canada dollar macedonia denar
214 | canada dollar malaysia ringgit
215 | canada dollar mexico peso
216 | canada dollar nigeria naira
217 | canada dollar poland zloty
218 | canada dollar romania leu
219 | canada dollar russia ruble
220 | canada dollar sweden krona
221 | canada dollar thailand baht
222 | canada dollar ukraine hryvnia
223 | canada dollar vietnam dong
224 | canada dollar algeria dinar
225 | canada dollar angola kwanza
226 | canada dollar argentina peso
227 | canada dollar armenia dram
228 | canada dollar brazil real
229 | canada dollar bulgaria lev
230 | canada dollar cambodia riel
231 | croatia kuna denmark krone
232 | croatia kuna europe euro
233 | croatia kuna hungary forint
234 | croatia kuna india rupee
235 | croatia kuna iran rial
236 | croatia kuna japan yen
237 | croatia kuna korea won
238 | croatia kuna latvia lats
239 | croatia kuna lithuania litas
240 | croatia kuna macedonia denar
241 | croatia kuna malaysia ringgit
242 | croatia kuna mexico peso
243 | croatia kuna nigeria naira
244 | croatia kuna poland zloty
245 | croatia kuna romania leu
246 | croatia kuna russia ruble
247 | croatia kuna sweden krona
248 | croatia kuna thailand baht
249 | croatia kuna ukraine hryvnia
250 | croatia kuna usa dollar
251 | croatia kuna vietnam dong
252 | croatia kuna algeria dinar
253 | croatia kuna angola kwanza
254 | croatia kuna argentina peso
255 | croatia kuna armenia dram
256 | croatia kuna brazil real
257 | croatia kuna bulgaria lev
258 | croatia kuna cambodia riel
259 | croatia kuna canada dollar
260 | denmark krone europe euro
261 | denmark krone hungary forint
262 | denmark krone india rupee
263 | denmark krone iran rial
264 | denmark krone japan yen
265 | denmark krone korea won
266 | denmark krone latvia lats
267 | denmark krone lithuania litas
268 | denmark krone macedonia denar
269 | denmark krone malaysia ringgit
270 | denmark krone mexico peso
271 | denmark krone nigeria naira
272 | denmark krone poland zloty
273 | denmark krone romania leu
274 | denmark krone russia ruble
275 | denmark krone sweden krona
276 | denmark krone thailand baht
277 | denmark krone ukraine hryvnia
278 | denmark krone usa dollar
279 | denmark krone vietnam dong
280 | denmark krone algeria dinar
281 | denmark krone angola kwanza
282 | denmark krone argentina peso
283 | denmark krone armenia dram
284 | denmark krone brazil real
285 | denmark krone bulgaria lev
286 | denmark krone cambodia riel
287 | denmark krone canada dollar
288 | denmark krone croatia kuna
289 | europe euro hungary forint
290 | europe euro india rupee
291 | europe euro iran rial
292 | europe euro japan yen
293 | europe euro korea won
294 | europe euro latvia lats
295 | europe euro lithuania litas
296 | europe euro macedonia denar
297 | europe euro malaysia ringgit
298 | europe euro mexico peso
299 | europe euro nigeria naira
300 | europe euro poland zloty
301 | europe euro romania leu
302 | europe euro russia ruble
303 | europe euro sweden krona
304 | europe euro thailand baht
305 | europe euro ukraine hryvnia
306 | europe euro usa dollar
307 | europe euro vietnam dong
308 | europe euro algeria dinar
309 | europe euro angola kwanza
310 | europe euro argentina peso
311 | europe euro armenia dram
312 | europe euro brazil real
313 | europe euro bulgaria lev
314 | europe euro cambodia riel
315 | europe euro canada dollar
316 | europe euro croatia kuna
317 | europe euro denmark krone
318 | hungary forint india rupee
319 | hungary forint iran rial
320 | hungary forint japan yen
321 | hungary forint korea won
322 | hungary forint latvia lats
323 | hungary forint lithuania litas
324 | hungary forint macedonia denar
325 | hungary forint malaysia ringgit
326 | hungary forint mexico peso
327 | hungary forint nigeria naira
328 | hungary forint poland zloty
329 | hungary forint romania leu
330 | hungary forint russia ruble
331 | hungary forint sweden krona
332 | hungary forint thailand baht
333 | hungary forint ukraine hryvnia
334 | hungary forint usa dollar
335 | hungary forint vietnam dong
336 | hungary forint algeria dinar
337 | hungary forint angola kwanza
338 | hungary forint argentina peso
339 | hungary forint armenia dram
340 | hungary forint brazil real
341 | hungary forint bulgaria lev
342 | hungary forint cambodia riel
343 | hungary forint canada dollar
344 | hungary forint croatia kuna
345 | hungary forint denmark krone
346 | hungary forint europe euro
347 | india rupee iran rial
348 | india rupee japan yen
349 | india rupee korea won
350 | india rupee latvia lats
351 | india rupee lithuania litas
352 | india rupee macedonia denar
353 | india rupee malaysia ringgit
354 | india rupee mexico peso
355 | india rupee nigeria naira
356 | india rupee poland zloty
357 | india rupee romania leu
358 | india rupee russia ruble
359 | india rupee sweden krona
360 | india rupee thailand baht
361 | india rupee ukraine hryvnia
362 | india rupee usa dollar
363 | india rupee vietnam dong
364 | india rupee algeria dinar
365 | india rupee angola kwanza
366 | india rupee argentina peso
367 | india rupee armenia dram
368 | india rupee brazil real
369 | india rupee bulgaria lev
370 | india rupee cambodia riel
371 | india rupee canada dollar
372 | india rupee croatia kuna
373 | india rupee denmark krone
374 | india rupee europe euro
375 | india rupee hungary forint
376 | iran rial japan yen
377 | iran rial korea won
378 | iran rial latvia lats
379 | iran rial lithuania litas
380 | iran rial macedonia denar
381 | iran rial malaysia ringgit
382 | iran rial mexico peso
383 | iran rial nigeria naira
384 | iran rial poland zloty
385 | iran rial romania leu
386 | iran rial russia ruble
387 | iran rial sweden krona
388 | iran rial thailand baht
389 | iran rial ukraine hryvnia
390 | iran rial usa dollar
391 | iran rial vietnam dong
392 | iran rial algeria dinar
393 | iran rial angola kwanza
394 | iran rial argentina peso
395 | iran rial armenia dram
396 | iran rial brazil real
397 | iran rial bulgaria lev
398 | iran rial cambodia riel
399 | iran rial canada dollar
400 | iran rial croatia kuna
401 | iran rial denmark krone
402 | iran rial europe euro
403 | iran rial hungary forint
404 | iran rial india rupee
405 | japan yen korea won
406 | japan yen latvia lats
407 | japan yen lithuania litas
408 | japan yen macedonia denar
409 | japan yen malaysia ringgit
410 | japan yen mexico peso
411 | japan yen nigeria naira
412 | japan yen poland zloty
413 | japan yen romania leu
414 | japan yen russia ruble
415 | japan yen sweden krona
416 | japan yen thailand baht
417 | japan yen ukraine hryvnia
418 | japan yen usa dollar
419 | japan yen vietnam dong
420 | japan yen algeria dinar
421 | japan yen angola kwanza
422 | japan yen argentina peso
423 | japan yen armenia dram
424 | japan yen brazil real
425 | japan yen bulgaria lev
426 | japan yen cambodia riel
427 | japan yen canada dollar
428 | japan yen croatia kuna
429 | japan yen denmark krone
430 | japan yen europe euro
431 | japan yen hungary forint
432 | japan yen india rupee
433 | japan yen iran rial
434 | korea won latvia lats
435 | korea won lithuania litas
436 | korea won macedonia denar
437 | korea won malaysia ringgit
438 | korea won mexico peso
439 | korea won nigeria naira
440 | korea won poland zloty
441 | korea won romania leu
442 | korea won russia ruble
443 | korea won sweden krona
444 | korea won thailand baht
445 | korea won ukraine hryvnia
446 | korea won usa dollar
447 | korea won vietnam dong
448 | korea won algeria dinar
449 | korea won angola kwanza
450 | korea won argentina peso
451 | korea won armenia dram
452 | korea won brazil real
453 | korea won bulgaria lev
454 | korea won cambodia riel
455 | korea won canada dollar
456 | korea won croatia kuna
457 | korea won denmark krone
458 | korea won europe euro
459 | korea won hungary forint
460 | korea won india rupee
461 | korea won iran rial
462 | korea won japan yen
463 | latvia lats lithuania litas
464 | latvia lats macedonia denar
465 | latvia lats malaysia ringgit
466 | latvia lats mexico peso
467 | latvia lats nigeria naira
468 | latvia lats poland zloty
469 | latvia lats romania leu
470 | latvia lats russia ruble
471 | latvia lats sweden krona
472 | latvia lats thailand baht
473 | latvia lats ukraine hryvnia
474 | latvia lats usa dollar
475 | latvia lats vietnam dong
476 | latvia lats algeria dinar
477 | latvia lats angola kwanza
478 | latvia lats argentina peso
479 | latvia lats armenia dram
480 | latvia lats brazil real
481 | latvia lats bulgaria lev
482 | latvia lats cambodia riel
483 | latvia lats canada dollar
484 | latvia lats croatia kuna
485 | latvia lats denmark krone
486 | latvia lats europe euro
487 | latvia lats hungary forint
488 | latvia lats india rupee
489 | latvia lats iran rial
490 | latvia lats japan yen
491 | latvia lats korea won
492 | lithuania litas macedonia denar
493 | lithuania litas malaysia ringgit
494 | lithuania litas mexico peso
495 | lithuania litas nigeria naira
496 | lithuania litas poland zloty
497 | lithuania litas romania leu
498 | lithuania litas russia ruble
499 | lithuania litas sweden krona
500 | lithuania litas thailand baht
501 | lithuania litas ukraine hryvnia
502 | lithuania litas usa dollar
503 | lithuania litas vietnam dong
504 | lithuania litas algeria dinar
505 | lithuania litas angola kwanza
506 | lithuania litas argentina peso
507 | lithuania litas armenia dram
508 | lithuania litas brazil real
509 | lithuania litas bulgaria lev
510 | lithuania litas cambodia riel
511 | lithuania litas canada dollar
512 | lithuania litas croatia kuna
513 | lithuania litas denmark krone
514 | lithuania litas europe euro
515 | lithuania litas hungary forint
516 | lithuania litas india rupee
517 | lithuania litas iran rial
518 | lithuania litas japan yen
519 | lithuania litas korea won
520 | lithuania litas latvia lats
521 | macedonia denar malaysia ringgit
522 | macedonia denar mexico peso
523 | macedonia denar nigeria naira
524 | macedonia denar poland zloty
525 | macedonia denar romania leu
526 | macedonia denar russia ruble
527 | macedonia denar sweden krona
528 | macedonia denar thailand baht
529 | macedonia denar ukraine hryvnia
530 | macedonia denar usa dollar
531 | macedonia denar vietnam dong
532 | macedonia denar algeria dinar
533 | macedonia denar angola kwanza
534 | macedonia denar argentina peso
535 | macedonia denar armenia dram
536 | macedonia denar brazil real
537 | macedonia denar bulgaria lev
538 | macedonia denar cambodia riel
539 | macedonia denar canada dollar
540 | macedonia denar croatia kuna
541 | macedonia denar denmark krone
542 | macedonia denar europe euro
543 | macedonia denar hungary forint
544 | macedonia denar india rupee
545 | macedonia denar iran rial
546 | macedonia denar japan yen
547 | macedonia denar korea won
548 | macedonia denar latvia lats
549 | macedonia denar lithuania litas
550 | malaysia ringgit mexico peso
551 | malaysia ringgit nigeria naira
552 | malaysia ringgit poland zloty
553 | malaysia ringgit romania leu
554 | malaysia ringgit russia ruble
555 | malaysia ringgit sweden krona
556 | malaysia ringgit thailand baht
557 | malaysia ringgit ukraine hryvnia
558 | malaysia ringgit usa dollar
559 | malaysia ringgit vietnam dong
560 | malaysia ringgit algeria dinar
561 | malaysia ringgit angola kwanza
562 | malaysia ringgit argentina peso
563 | malaysia ringgit armenia dram
564 | malaysia ringgit brazil real
565 | malaysia ringgit bulgaria lev
566 | malaysia ringgit cambodia riel
567 | malaysia ringgit canada dollar
568 | malaysia ringgit croatia kuna
569 | malaysia ringgit denmark krone
570 | malaysia ringgit europe euro
571 | malaysia ringgit hungary forint
572 | malaysia ringgit india rupee
573 | malaysia ringgit iran rial
574 | malaysia ringgit japan yen
575 | malaysia ringgit korea won
576 | malaysia ringgit latvia lats
577 | malaysia ringgit lithuania litas
578 | malaysia ringgit macedonia denar
579 | mexico peso nigeria naira
580 | mexico peso poland zloty
581 | mexico peso romania leu
582 | mexico peso russia ruble
583 | mexico peso sweden krona
584 | mexico peso thailand baht
585 | mexico peso ukraine hryvnia
586 | mexico peso usa dollar
587 | mexico peso vietnam dong
588 | mexico peso algeria dinar
589 | mexico peso angola kwanza
590 | mexico peso armenia dram
591 | mexico peso brazil real
592 | mexico peso bulgaria lev
593 | mexico peso cambodia riel
594 | mexico peso canada dollar
595 | mexico peso croatia kuna
596 | mexico peso denmark krone
597 | mexico peso europe euro
598 | mexico peso hungary forint
599 | mexico peso india rupee
600 | mexico peso iran rial
601 | mexico peso japan yen
602 | mexico peso korea won
603 | mexico peso latvia lats
604 | mexico peso lithuania litas
605 | mexico peso macedonia denar
606 | mexico peso malaysia ringgit
607 | nigeria naira poland zloty
608 | nigeria naira romania leu
609 | nigeria naira russia ruble
610 | nigeria naira sweden krona
611 | nigeria naira thailand baht
612 | nigeria naira ukraine hryvnia
613 | nigeria naira usa dollar
614 | nigeria naira vietnam dong
615 | nigeria naira algeria dinar
616 | nigeria naira angola kwanza
617 | nigeria naira argentina peso
618 | nigeria naira armenia dram
619 | nigeria naira brazil real
620 | nigeria naira bulgaria lev
621 | nigeria naira cambodia riel
622 | nigeria naira canada dollar
623 | nigeria naira croatia kuna
624 | nigeria naira denmark krone
625 | nigeria naira europe euro
626 | nigeria naira hungary forint
627 | nigeria naira india rupee
628 | nigeria naira iran rial
629 | nigeria naira japan yen
630 | nigeria naira korea won
631 | nigeria naira latvia lats
632 | nigeria naira lithuania litas
633 | nigeria naira macedonia denar
634 | nigeria naira malaysia ringgit
635 | nigeria naira mexico peso
636 | poland zloty romania leu
637 | poland zloty russia ruble
638 | poland zloty sweden krona
639 | poland zloty thailand baht
640 | poland zloty ukraine hryvnia
641 | poland zloty usa dollar
642 | poland zloty vietnam dong
643 | poland zloty algeria dinar
644 | poland zloty angola kwanza
645 | poland zloty argentina peso
646 | poland zloty armenia dram
647 | poland zloty brazil real
648 | poland zloty bulgaria lev
649 | poland zloty cambodia riel
650 | poland zloty canada dollar
651 | poland zloty croatia kuna
652 | poland zloty denmark krone
653 | poland zloty europe euro
654 | poland zloty hungary forint
655 | poland zloty india rupee
656 | poland zloty iran rial
657 | poland zloty japan yen
658 | poland zloty korea won
659 | poland zloty latvia lats
660 | poland zloty lithuania litas
661 | poland zloty macedonia denar
662 | poland zloty malaysia ringgit
663 | poland zloty mexico peso
664 | poland zloty nigeria naira
665 | romania leu russia ruble
666 | romania leu sweden krona
667 | romania leu thailand baht
668 | romania leu ukraine hryvnia
669 | romania leu usa dollar
670 | romania leu vietnam dong
671 | romania leu algeria dinar
672 | romania leu angola kwanza
673 | romania leu argentina peso
674 | romania leu armenia dram
675 | romania leu brazil real
676 | romania leu bulgaria lev
677 | romania leu cambodia riel
678 | romania leu canada dollar
679 | romania leu croatia kuna
680 | romania leu denmark krone
681 | romania leu europe euro
682 | romania leu hungary forint
683 | romania leu india rupee
684 | romania leu iran rial
685 | romania leu japan yen
686 | romania leu korea won
687 | romania leu latvia lats
688 | romania leu lithuania litas
689 | romania leu macedonia denar
690 | romania leu malaysia ringgit
691 | romania leu mexico peso
692 | romania leu nigeria naira
693 | romania leu poland zloty
694 | russia ruble sweden krona
695 | russia ruble thailand baht
696 | russia ruble ukraine hryvnia
697 | russia ruble usa dollar
698 | russia ruble vietnam dong
699 | russia ruble algeria dinar
700 | russia ruble angola kwanza
701 | russia ruble argentina peso
702 | russia ruble armenia dram
703 | russia ruble brazil real
704 | russia ruble bulgaria lev
705 | russia ruble cambodia riel
706 | russia ruble canada dollar
707 | russia ruble croatia kuna
708 | russia ruble denmark krone
709 | russia ruble europe euro
710 | russia ruble hungary forint
711 | russia ruble india rupee
712 | russia ruble iran rial
713 | russia ruble japan yen
714 | russia ruble korea won
715 | russia ruble latvia lats
716 | russia ruble lithuania litas
717 | russia ruble macedonia denar
718 | russia ruble malaysia ringgit
719 | russia ruble mexico peso
720 | russia ruble nigeria naira
721 | russia ruble poland zloty
722 | russia ruble romania leu
723 | sweden krona thailand baht
724 | sweden krona ukraine hryvnia
725 | sweden krona usa dollar
726 | sweden krona vietnam dong
727 | sweden krona algeria dinar
728 | sweden krona angola kwanza
729 | sweden krona argentina peso
730 | sweden krona armenia dram
731 | sweden krona brazil real
732 | sweden krona bulgaria lev
733 | sweden krona cambodia riel
734 | sweden krona canada dollar
735 | sweden krona croatia kuna
736 | sweden krona denmark krone
737 | sweden krona europe euro
738 | sweden krona hungary forint
739 | sweden krona india rupee
740 | sweden krona iran rial
741 | sweden krona japan yen
742 | sweden krona korea won
743 | sweden krona latvia lats
744 | sweden krona lithuania litas
745 | sweden krona macedonia denar
746 | sweden krona malaysia ringgit
747 | sweden krona mexico peso
748 | sweden krona nigeria naira
749 | sweden krona poland zloty
750 | sweden krona romania leu
751 | sweden krona russia ruble
752 | thailand baht ukraine hryvnia
753 | thailand baht usa dollar
754 | thailand baht vietnam dong
755 | thailand baht algeria dinar
756 | thailand baht angola kwanza
757 | thailand baht argentina peso
758 | thailand baht armenia dram
759 | thailand baht brazil real
760 | thailand baht bulgaria lev
761 | thailand baht cambodia riel
762 | thailand baht canada dollar
763 | thailand baht croatia kuna
764 | thailand baht denmark krone
765 | thailand baht europe euro
766 | thailand baht hungary forint
767 | thailand baht india rupee
768 | thailand baht iran rial
769 | thailand baht japan yen
770 | thailand baht korea won
771 | thailand baht latvia lats
772 | thailand baht lithuania litas
773 | thailand baht macedonia denar
774 | thailand baht malaysia ringgit
775 | thailand baht mexico peso
776 | thailand baht nigeria naira
777 | thailand baht poland zloty
778 | thailand baht romania leu
779 | thailand baht russia ruble
780 | thailand baht sweden krona
781 | ukraine hryvnia usa dollar
782 | ukraine hryvnia vietnam dong
783 | ukraine hryvnia algeria dinar
784 | ukraine hryvnia angola kwanza
785 | ukraine hryvnia argentina peso
786 | ukraine hryvnia armenia dram
787 | ukraine hryvnia brazil real
788 | ukraine hryvnia bulgaria lev
789 | ukraine hryvnia cambodia riel
790 | ukraine hryvnia canada dollar
791 | ukraine hryvnia croatia kuna
792 | ukraine hryvnia denmark krone
793 | ukraine hryvnia europe euro
794 | ukraine hryvnia hungary forint
795 | ukraine hryvnia india rupee
796 | ukraine hryvnia iran rial
797 | ukraine hryvnia japan yen
798 | ukraine hryvnia korea won
799 | ukraine hryvnia latvia lats
800 | ukraine hryvnia lithuania litas
801 | ukraine hryvnia macedonia denar
802 | ukraine hryvnia malaysia ringgit
803 | ukraine hryvnia mexico peso
804 | ukraine hryvnia nigeria naira
805 | ukraine hryvnia poland zloty
806 | ukraine hryvnia romania leu
807 | ukraine hryvnia russia ruble
808 | ukraine hryvnia sweden krona
809 | ukraine hryvnia thailand baht
810 | usa dollar vietnam dong
811 | usa dollar algeria dinar
812 | usa dollar angola kwanza
813 | usa dollar argentina peso
814 | usa dollar armenia dram
815 | usa dollar brazil real
816 | usa dollar bulgaria lev
817 | usa dollar cambodia riel
818 | usa dollar croatia kuna
819 | usa dollar denmark krone
820 | usa dollar europe euro
821 | usa dollar hungary forint
822 | usa dollar india rupee
823 | usa dollar iran rial
824 | usa dollar japan yen
825 | usa dollar korea won
826 | usa dollar latvia lats
827 | usa dollar lithuania litas
828 | usa dollar macedonia denar
829 | usa dollar malaysia ringgit
830 | usa dollar mexico peso
831 | usa dollar nigeria naira
832 | usa dollar poland zloty
833 | usa dollar romania leu
834 | usa dollar russia ruble
835 | usa dollar sweden krona
836 | usa dollar thailand baht
837 | usa dollar ukraine hryvnia
838 | vietnam dong algeria dinar
839 | vietnam dong angola kwanza
840 | vietnam dong argentina peso
841 | vietnam dong armenia dram
842 | vietnam dong brazil real
843 | vietnam dong bulgaria lev
844 | vietnam dong cambodia riel
845 | vietnam dong canada dollar
846 | vietnam dong croatia kuna
847 | vietnam dong denmark krone
848 | vietnam dong europe euro
849 | vietnam dong hungary forint
850 | vietnam dong india rupee
851 | vietnam dong iran rial
852 | vietnam dong japan yen
853 | vietnam dong korea won
854 | vietnam dong latvia lats
855 | vietnam dong lithuania litas
856 | vietnam dong macedonia denar
857 | vietnam dong malaysia ringgit
858 | vietnam dong mexico peso
859 | vietnam dong nigeria naira
860 | vietnam dong poland zloty
861 | vietnam dong romania leu
862 | vietnam dong russia ruble
863 | vietnam dong sweden krona
864 | vietnam dong thailand baht
865 | vietnam dong ukraine hryvnia
866 | vietnam dong usa dollar
867 |
--------------------------------------------------------------------------------
/eval/question-data/family.txt:
--------------------------------------------------------------------------------
1 | boy girl brother sister
2 | boy girl brothers sisters
3 | boy girl dad mom
4 | boy girl father mother
5 | boy girl grandfather grandmother
6 | boy girl grandpa grandma
7 | boy girl grandson granddaughter
8 | boy girl groom bride
9 | boy girl he she
10 | boy girl his her
11 | boy girl husband wife
12 | boy girl king queen
13 | boy girl man woman
14 | boy girl nephew niece
15 | boy girl policeman policewoman
16 | boy girl prince princess
17 | boy girl son daughter
18 | boy girl sons daughters
19 | boy girl stepbrother stepsister
20 | boy girl stepfather stepmother
21 | boy girl stepson stepdaughter
22 | boy girl uncle aunt
23 | brother sister brothers sisters
24 | brother sister dad mom
25 | brother sister father mother
26 | brother sister grandfather grandmother
27 | brother sister grandpa grandma
28 | brother sister grandson granddaughter
29 | brother sister groom bride
30 | brother sister he she
31 | brother sister his her
32 | brother sister husband wife
33 | brother sister king queen
34 | brother sister man woman
35 | brother sister nephew niece
36 | brother sister policeman policewoman
37 | brother sister prince princess
38 | brother sister son daughter
39 | brother sister sons daughters
40 | brother sister stepbrother stepsister
41 | brother sister stepfather stepmother
42 | brother sister stepson stepdaughter
43 | brother sister uncle aunt
44 | brother sister boy girl
45 | brothers sisters dad mom
46 | brothers sisters father mother
47 | brothers sisters grandfather grandmother
48 | brothers sisters grandpa grandma
49 | brothers sisters grandson granddaughter
50 | brothers sisters groom bride
51 | brothers sisters he she
52 | brothers sisters his her
53 | brothers sisters husband wife
54 | brothers sisters king queen
55 | brothers sisters man woman
56 | brothers sisters nephew niece
57 | brothers sisters policeman policewoman
58 | brothers sisters prince princess
59 | brothers sisters son daughter
60 | brothers sisters sons daughters
61 | brothers sisters stepbrother stepsister
62 | brothers sisters stepfather stepmother
63 | brothers sisters stepson stepdaughter
64 | brothers sisters uncle aunt
65 | brothers sisters boy girl
66 | brothers sisters brother sister
67 | dad mom father mother
68 | dad mom grandfather grandmother
69 | dad mom grandpa grandma
70 | dad mom grandson granddaughter
71 | dad mom groom bride
72 | dad mom he she
73 | dad mom his her
74 | dad mom husband wife
75 | dad mom king queen
76 | dad mom man woman
77 | dad mom nephew niece
78 | dad mom policeman policewoman
79 | dad mom prince princess
80 | dad mom son daughter
81 | dad mom sons daughters
82 | dad mom stepbrother stepsister
83 | dad mom stepfather stepmother
84 | dad mom stepson stepdaughter
85 | dad mom uncle aunt
86 | dad mom boy girl
87 | dad mom brother sister
88 | dad mom brothers sisters
89 | father mother grandfather grandmother
90 | father mother grandpa grandma
91 | father mother grandson granddaughter
92 | father mother groom bride
93 | father mother he she
94 | father mother his her
95 | father mother husband wife
96 | father mother king queen
97 | father mother man woman
98 | father mother nephew niece
99 | father mother policeman policewoman
100 | father mother prince princess
101 | father mother son daughter
102 | father mother sons daughters
103 | father mother stepbrother stepsister
104 | father mother stepfather stepmother
105 | father mother stepson stepdaughter
106 | father mother uncle aunt
107 | father mother boy girl
108 | father mother brother sister
109 | father mother brothers sisters
110 | father mother dad mom
111 | grandfather grandmother grandpa grandma
112 | grandfather grandmother grandson granddaughter
113 | grandfather grandmother groom bride
114 | grandfather grandmother he she
115 | grandfather grandmother his her
116 | grandfather grandmother husband wife
117 | grandfather grandmother king queen
118 | grandfather grandmother man woman
119 | grandfather grandmother nephew niece
120 | grandfather grandmother policeman policewoman
121 | grandfather grandmother prince princess
122 | grandfather grandmother son daughter
123 | grandfather grandmother sons daughters
124 | grandfather grandmother stepbrother stepsister
125 | grandfather grandmother stepfather stepmother
126 | grandfather grandmother stepson stepdaughter
127 | grandfather grandmother uncle aunt
128 | grandfather grandmother boy girl
129 | grandfather grandmother brother sister
130 | grandfather grandmother brothers sisters
131 | grandfather grandmother dad mom
132 | grandfather grandmother father mother
133 | grandpa grandma grandson granddaughter
134 | grandpa grandma groom bride
135 | grandpa grandma he she
136 | grandpa grandma his her
137 | grandpa grandma husband wife
138 | grandpa grandma king queen
139 | grandpa grandma man woman
140 | grandpa grandma nephew niece
141 | grandpa grandma policeman policewoman
142 | grandpa grandma prince princess
143 | grandpa grandma son daughter
144 | grandpa grandma sons daughters
145 | grandpa grandma stepbrother stepsister
146 | grandpa grandma stepfather stepmother
147 | grandpa grandma stepson stepdaughter
148 | grandpa grandma uncle aunt
149 | grandpa grandma boy girl
150 | grandpa grandma brother sister
151 | grandpa grandma brothers sisters
152 | grandpa grandma dad mom
153 | grandpa grandma father mother
154 | grandpa grandma grandfather grandmother
155 | grandson granddaughter groom bride
156 | grandson granddaughter he she
157 | grandson granddaughter his her
158 | grandson granddaughter husband wife
159 | grandson granddaughter king queen
160 | grandson granddaughter man woman
161 | grandson granddaughter nephew niece
162 | grandson granddaughter policeman policewoman
163 | grandson granddaughter prince princess
164 | grandson granddaughter son daughter
165 | grandson granddaughter sons daughters
166 | grandson granddaughter stepbrother stepsister
167 | grandson granddaughter stepfather stepmother
168 | grandson granddaughter stepson stepdaughter
169 | grandson granddaughter uncle aunt
170 | grandson granddaughter boy girl
171 | grandson granddaughter brother sister
172 | grandson granddaughter brothers sisters
173 | grandson granddaughter dad mom
174 | grandson granddaughter father mother
175 | grandson granddaughter grandfather grandmother
176 | grandson granddaughter grandpa grandma
177 | groom bride he she
178 | groom bride his her
179 | groom bride husband wife
180 | groom bride king queen
181 | groom bride man woman
182 | groom bride nephew niece
183 | groom bride policeman policewoman
184 | groom bride prince princess
185 | groom bride son daughter
186 | groom bride sons daughters
187 | groom bride stepbrother stepsister
188 | groom bride stepfather stepmother
189 | groom bride stepson stepdaughter
190 | groom bride uncle aunt
191 | groom bride boy girl
192 | groom bride brother sister
193 | groom bride brothers sisters
194 | groom bride dad mom
195 | groom bride father mother
196 | groom bride grandfather grandmother
197 | groom bride grandpa grandma
198 | groom bride grandson granddaughter
199 | he she his her
200 | he she husband wife
201 | he she king queen
202 | he she man woman
203 | he she nephew niece
204 | he she policeman policewoman
205 | he she prince princess
206 | he she son daughter
207 | he she sons daughters
208 | he she stepbrother stepsister
209 | he she stepfather stepmother
210 | he she stepson stepdaughter
211 | he she uncle aunt
212 | he she boy girl
213 | he she brother sister
214 | he she brothers sisters
215 | he she dad mom
216 | he she father mother
217 | he she grandfather grandmother
218 | he she grandpa grandma
219 | he she grandson granddaughter
220 | he she groom bride
221 | his her husband wife
222 | his her king queen
223 | his her man woman
224 | his her nephew niece
225 | his her policeman policewoman
226 | his her prince princess
227 | his her son daughter
228 | his her sons daughters
229 | his her stepbrother stepsister
230 | his her stepfather stepmother
231 | his her stepson stepdaughter
232 | his her uncle aunt
233 | his her boy girl
234 | his her brother sister
235 | his her brothers sisters
236 | his her dad mom
237 | his her father mother
238 | his her grandfather grandmother
239 | his her grandpa grandma
240 | his her grandson granddaughter
241 | his her groom bride
242 | his her he she
243 | husband wife king queen
244 | husband wife man woman
245 | husband wife nephew niece
246 | husband wife policeman policewoman
247 | husband wife prince princess
248 | husband wife son daughter
249 | husband wife sons daughters
250 | husband wife stepbrother stepsister
251 | husband wife stepfather stepmother
252 | husband wife stepson stepdaughter
253 | husband wife uncle aunt
254 | husband wife boy girl
255 | husband wife brother sister
256 | husband wife brothers sisters
257 | husband wife dad mom
258 | husband wife father mother
259 | husband wife grandfather grandmother
260 | husband wife grandpa grandma
261 | husband wife grandson granddaughter
262 | husband wife groom bride
263 | husband wife he she
264 | husband wife his her
265 | king queen man woman
266 | king queen nephew niece
267 | king queen policeman policewoman
268 | king queen prince princess
269 | king queen son daughter
270 | king queen sons daughters
271 | king queen stepbrother stepsister
272 | king queen stepfather stepmother
273 | king queen stepson stepdaughter
274 | king queen uncle aunt
275 | king queen boy girl
276 | king queen brother sister
277 | king queen brothers sisters
278 | king queen dad mom
279 | king queen father mother
280 | king queen grandfather grandmother
281 | king queen grandpa grandma
282 | king queen grandson granddaughter
283 | king queen groom bride
284 | king queen he she
285 | king queen his her
286 | king queen husband wife
287 | man woman nephew niece
288 | man woman policeman policewoman
289 | man woman prince princess
290 | man woman son daughter
291 | man woman sons daughters
292 | man woman stepbrother stepsister
293 | man woman stepfather stepmother
294 | man woman stepson stepdaughter
295 | man woman uncle aunt
296 | man woman boy girl
297 | man woman brother sister
298 | man woman brothers sisters
299 | man woman dad mom
300 | man woman father mother
301 | man woman grandfather grandmother
302 | man woman grandpa grandma
303 | man woman grandson granddaughter
304 | man woman groom bride
305 | man woman he she
306 | man woman his her
307 | man woman husband wife
308 | man woman king queen
309 | nephew niece policeman policewoman
310 | nephew niece prince princess
311 | nephew niece son daughter
312 | nephew niece sons daughters
313 | nephew niece stepbrother stepsister
314 | nephew niece stepfather stepmother
315 | nephew niece stepson stepdaughter
316 | nephew niece uncle aunt
317 | nephew niece boy girl
318 | nephew niece brother sister
319 | nephew niece brothers sisters
320 | nephew niece dad mom
321 | nephew niece father mother
322 | nephew niece grandfather grandmother
323 | nephew niece grandpa grandma
324 | nephew niece grandson granddaughter
325 | nephew niece groom bride
326 | nephew niece he she
327 | nephew niece his her
328 | nephew niece husband wife
329 | nephew niece king queen
330 | nephew niece man woman
331 | policeman policewoman prince princess
332 | policeman policewoman son daughter
333 | policeman policewoman sons daughters
334 | policeman policewoman stepbrother stepsister
335 | policeman policewoman stepfather stepmother
336 | policeman policewoman stepson stepdaughter
337 | policeman policewoman uncle aunt
338 | policeman policewoman boy girl
339 | policeman policewoman brother sister
340 | policeman policewoman brothers sisters
341 | policeman policewoman dad mom
342 | policeman policewoman father mother
343 | policeman policewoman grandfather grandmother
344 | policeman policewoman grandpa grandma
345 | policeman policewoman grandson granddaughter
346 | policeman policewoman groom bride
347 | policeman policewoman he she
348 | policeman policewoman his her
349 | policeman policewoman husband wife
350 | policeman policewoman king queen
351 | policeman policewoman man woman
352 | policeman policewoman nephew niece
353 | prince princess son daughter
354 | prince princess sons daughters
355 | prince princess stepbrother stepsister
356 | prince princess stepfather stepmother
357 | prince princess stepson stepdaughter
358 | prince princess uncle aunt
359 | prince princess boy girl
360 | prince princess brother sister
361 | prince princess brothers sisters
362 | prince princess dad mom
363 | prince princess father mother
364 | prince princess grandfather grandmother
365 | prince princess grandpa grandma
366 | prince princess grandson granddaughter
367 | prince princess groom bride
368 | prince princess he she
369 | prince princess his her
370 | prince princess husband wife
371 | prince princess king queen
372 | prince princess man woman
373 | prince princess nephew niece
374 | prince princess policeman policewoman
375 | son daughter sons daughters
376 | son daughter stepbrother stepsister
377 | son daughter stepfather stepmother
378 | son daughter stepson stepdaughter
379 | son daughter uncle aunt
380 | son daughter boy girl
381 | son daughter brother sister
382 | son daughter brothers sisters
383 | son daughter dad mom
384 | son daughter father mother
385 | son daughter grandfather grandmother
386 | son daughter grandpa grandma
387 | son daughter grandson granddaughter
388 | son daughter groom bride
389 | son daughter he she
390 | son daughter his her
391 | son daughter husband wife
392 | son daughter king queen
393 | son daughter man woman
394 | son daughter nephew niece
395 | son daughter policeman policewoman
396 | son daughter prince princess
397 | sons daughters stepbrother stepsister
398 | sons daughters stepfather stepmother
399 | sons daughters stepson stepdaughter
400 | sons daughters uncle aunt
401 | sons daughters boy girl
402 | sons daughters brother sister
403 | sons daughters brothers sisters
404 | sons daughters dad mom
405 | sons daughters father mother
406 | sons daughters grandfather grandmother
407 | sons daughters grandpa grandma
408 | sons daughters grandson granddaughter
409 | sons daughters groom bride
410 | sons daughters he she
411 | sons daughters his her
412 | sons daughters husband wife
413 | sons daughters king queen
414 | sons daughters man woman
415 | sons daughters nephew niece
416 | sons daughters policeman policewoman
417 | sons daughters prince princess
418 | sons daughters son daughter
419 | stepbrother stepsister stepfather stepmother
420 | stepbrother stepsister stepson stepdaughter
421 | stepbrother stepsister uncle aunt
422 | stepbrother stepsister boy girl
423 | stepbrother stepsister brother sister
424 | stepbrother stepsister brothers sisters
425 | stepbrother stepsister dad mom
426 | stepbrother stepsister father mother
427 | stepbrother stepsister grandfather grandmother
428 | stepbrother stepsister grandpa grandma
429 | stepbrother stepsister grandson granddaughter
430 | stepbrother stepsister groom bride
431 | stepbrother stepsister he she
432 | stepbrother stepsister his her
433 | stepbrother stepsister husband wife
434 | stepbrother stepsister king queen
435 | stepbrother stepsister man woman
436 | stepbrother stepsister nephew niece
437 | stepbrother stepsister policeman policewoman
438 | stepbrother stepsister prince princess
439 | stepbrother stepsister son daughter
440 | stepbrother stepsister sons daughters
441 | stepfather stepmother stepson stepdaughter
442 | stepfather stepmother uncle aunt
443 | stepfather stepmother boy girl
444 | stepfather stepmother brother sister
445 | stepfather stepmother brothers sisters
446 | stepfather stepmother dad mom
447 | stepfather stepmother father mother
448 | stepfather stepmother grandfather grandmother
449 | stepfather stepmother grandpa grandma
450 | stepfather stepmother grandson granddaughter
451 | stepfather stepmother groom bride
452 | stepfather stepmother he she
453 | stepfather stepmother his her
454 | stepfather stepmother husband wife
455 | stepfather stepmother king queen
456 | stepfather stepmother man woman
457 | stepfather stepmother nephew niece
458 | stepfather stepmother policeman policewoman
459 | stepfather stepmother prince princess
460 | stepfather stepmother son daughter
461 | stepfather stepmother sons daughters
462 | stepfather stepmother stepbrother stepsister
463 | stepson stepdaughter uncle aunt
464 | stepson stepdaughter boy girl
465 | stepson stepdaughter brother sister
466 | stepson stepdaughter brothers sisters
467 | stepson stepdaughter dad mom
468 | stepson stepdaughter father mother
469 | stepson stepdaughter grandfather grandmother
470 | stepson stepdaughter grandpa grandma
471 | stepson stepdaughter grandson granddaughter
472 | stepson stepdaughter groom bride
473 | stepson stepdaughter he she
474 | stepson stepdaughter his her
475 | stepson stepdaughter husband wife
476 | stepson stepdaughter king queen
477 | stepson stepdaughter man woman
478 | stepson stepdaughter nephew niece
479 | stepson stepdaughter policeman policewoman
480 | stepson stepdaughter prince princess
481 | stepson stepdaughter son daughter
482 | stepson stepdaughter sons daughters
483 | stepson stepdaughter stepbrother stepsister
484 | stepson stepdaughter stepfather stepmother
485 | uncle aunt boy girl
486 | uncle aunt brother sister
487 | uncle aunt brothers sisters
488 | uncle aunt dad mom
489 | uncle aunt father mother
490 | uncle aunt grandfather grandmother
491 | uncle aunt grandpa grandma
492 | uncle aunt grandson granddaughter
493 | uncle aunt groom bride
494 | uncle aunt he she
495 | uncle aunt his her
496 | uncle aunt husband wife
497 | uncle aunt king queen
498 | uncle aunt man woman
499 | uncle aunt nephew niece
500 | uncle aunt policeman policewoman
501 | uncle aunt prince princess
502 | uncle aunt son daughter
503 | uncle aunt sons daughters
504 | uncle aunt stepbrother stepsister
505 | uncle aunt stepfather stepmother
506 | uncle aunt stepson stepdaughter
507 |
--------------------------------------------------------------------------------
/eval/question-data/gram9-plural-verbs.txt:
--------------------------------------------------------------------------------
1 | decrease decreases describe describes
2 | decrease decreases eat eats
3 | decrease decreases enhance enhances
4 | decrease decreases estimate estimates
5 | decrease decreases find finds
6 | decrease decreases generate generates
7 | decrease decreases go goes
8 | decrease decreases implement implements
9 | decrease decreases increase increases
10 | decrease decreases listen listens
11 | decrease decreases play plays
12 | decrease decreases predict predicts
13 | decrease decreases provide provides
14 | decrease decreases say says
15 | decrease decreases scream screams
16 | decrease decreases search searches
17 | decrease decreases see sees
18 | decrease decreases shuffle shuffles
19 | decrease decreases sing sings
20 | decrease decreases sit sits
21 | decrease decreases slow slows
22 | decrease decreases speak speaks
23 | decrease decreases swim swims
24 | decrease decreases talk talks
25 | decrease decreases think thinks
26 | decrease decreases vanish vanishes
27 | decrease decreases walk walks
28 | decrease decreases work works
29 | decrease decreases write writes
30 | describe describes eat eats
31 | describe describes enhance enhances
32 | describe describes estimate estimates
33 | describe describes find finds
34 | describe describes generate generates
35 | describe describes go goes
36 | describe describes implement implements
37 | describe describes increase increases
38 | describe describes listen listens
39 | describe describes play plays
40 | describe describes predict predicts
41 | describe describes provide provides
42 | describe describes say says
43 | describe describes scream screams
44 | describe describes search searches
45 | describe describes see sees
46 | describe describes shuffle shuffles
47 | describe describes sing sings
48 | describe describes sit sits
49 | describe describes slow slows
50 | describe describes speak speaks
51 | describe describes swim swims
52 | describe describes talk talks
53 | describe describes think thinks
54 | describe describes vanish vanishes
55 | describe describes walk walks
56 | describe describes work works
57 | describe describes write writes
58 | describe describes decrease decreases
59 | eat eats enhance enhances
60 | eat eats estimate estimates
61 | eat eats find finds
62 | eat eats generate generates
63 | eat eats go goes
64 | eat eats implement implements
65 | eat eats increase increases
66 | eat eats listen listens
67 | eat eats play plays
68 | eat eats predict predicts
69 | eat eats provide provides
70 | eat eats say says
71 | eat eats scream screams
72 | eat eats search searches
73 | eat eats see sees
74 | eat eats shuffle shuffles
75 | eat eats sing sings
76 | eat eats sit sits
77 | eat eats slow slows
78 | eat eats speak speaks
79 | eat eats swim swims
80 | eat eats talk talks
81 | eat eats think thinks
82 | eat eats vanish vanishes
83 | eat eats walk walks
84 | eat eats work works
85 | eat eats write writes
86 | eat eats decrease decreases
87 | eat eats describe describes
88 | enhance enhances estimate estimates
89 | enhance enhances find finds
90 | enhance enhances generate generates
91 | enhance enhances go goes
92 | enhance enhances implement implements
93 | enhance enhances increase increases
94 | enhance enhances listen listens
95 | enhance enhances play plays
96 | enhance enhances predict predicts
97 | enhance enhances provide provides
98 | enhance enhances say says
99 | enhance enhances scream screams
100 | enhance enhances search searches
101 | enhance enhances see sees
102 | enhance enhances shuffle shuffles
103 | enhance enhances sing sings
104 | enhance enhances sit sits
105 | enhance enhances slow slows
106 | enhance enhances speak speaks
107 | enhance enhances swim swims
108 | enhance enhances talk talks
109 | enhance enhances think thinks
110 | enhance enhances vanish vanishes
111 | enhance enhances walk walks
112 | enhance enhances work works
113 | enhance enhances write writes
114 | enhance enhances decrease decreases
115 | enhance enhances describe describes
116 | enhance enhances eat eats
117 | estimate estimates find finds
118 | estimate estimates generate generates
119 | estimate estimates go goes
120 | estimate estimates implement implements
121 | estimate estimates increase increases
122 | estimate estimates listen listens
123 | estimate estimates play plays
124 | estimate estimates predict predicts
125 | estimate estimates provide provides
126 | estimate estimates say says
127 | estimate estimates scream screams
128 | estimate estimates search searches
129 | estimate estimates see sees
130 | estimate estimates shuffle shuffles
131 | estimate estimates sing sings
132 | estimate estimates sit sits
133 | estimate estimates slow slows
134 | estimate estimates speak speaks
135 | estimate estimates swim swims
136 | estimate estimates talk talks
137 | estimate estimates think thinks
138 | estimate estimates vanish vanishes
139 | estimate estimates walk walks
140 | estimate estimates work works
141 | estimate estimates write writes
142 | estimate estimates decrease decreases
143 | estimate estimates describe describes
144 | estimate estimates eat eats
145 | estimate estimates enhance enhances
146 | find finds generate generates
147 | find finds go goes
148 | find finds implement implements
149 | find finds increase increases
150 | find finds listen listens
151 | find finds play plays
152 | find finds predict predicts
153 | find finds provide provides
154 | find finds say says
155 | find finds scream screams
156 | find finds search searches
157 | find finds see sees
158 | find finds shuffle shuffles
159 | find finds sing sings
160 | find finds sit sits
161 | find finds slow slows
162 | find finds speak speaks
163 | find finds swim swims
164 | find finds talk talks
165 | find finds think thinks
166 | find finds vanish vanishes
167 | find finds walk walks
168 | find finds work works
169 | find finds write writes
170 | find finds decrease decreases
171 | find finds describe describes
172 | find finds eat eats
173 | find finds enhance enhances
174 | find finds estimate estimates
175 | generate generates go goes
176 | generate generates implement implements
177 | generate generates increase increases
178 | generate generates listen listens
179 | generate generates play plays
180 | generate generates predict predicts
181 | generate generates provide provides
182 | generate generates say says
183 | generate generates scream screams
184 | generate generates search searches
185 | generate generates see sees
186 | generate generates shuffle shuffles
187 | generate generates sing sings
188 | generate generates sit sits
189 | generate generates slow slows
190 | generate generates speak speaks
191 | generate generates swim swims
192 | generate generates talk talks
193 | generate generates think thinks
194 | generate generates vanish vanishes
195 | generate generates walk walks
196 | generate generates work works
197 | generate generates write writes
198 | generate generates decrease decreases
199 | generate generates describe describes
200 | generate generates eat eats
201 | generate generates enhance enhances
202 | generate generates estimate estimates
203 | generate generates find finds
204 | go goes implement implements
205 | go goes increase increases
206 | go goes listen listens
207 | go goes play plays
208 | go goes predict predicts
209 | go goes provide provides
210 | go goes say says
211 | go goes scream screams
212 | go goes search searches
213 | go goes see sees
214 | go goes shuffle shuffles
215 | go goes sing sings
216 | go goes sit sits
217 | go goes slow slows
218 | go goes speak speaks
219 | go goes swim swims
220 | go goes talk talks
221 | go goes think thinks
222 | go goes vanish vanishes
223 | go goes walk walks
224 | go goes work works
225 | go goes write writes
226 | go goes decrease decreases
227 | go goes describe describes
228 | go goes eat eats
229 | go goes enhance enhances
230 | go goes estimate estimates
231 | go goes find finds
232 | go goes generate generates
233 | implement implements increase increases
234 | implement implements listen listens
235 | implement implements play plays
236 | implement implements predict predicts
237 | implement implements provide provides
238 | implement implements say says
239 | implement implements scream screams
240 | implement implements search searches
241 | implement implements see sees
242 | implement implements shuffle shuffles
243 | implement implements sing sings
244 | implement implements sit sits
245 | implement implements slow slows
246 | implement implements speak speaks
247 | implement implements swim swims
248 | implement implements talk talks
249 | implement implements think thinks
250 | implement implements vanish vanishes
251 | implement implements walk walks
252 | implement implements work works
253 | implement implements write writes
254 | implement implements decrease decreases
255 | implement implements describe describes
256 | implement implements eat eats
257 | implement implements enhance enhances
258 | implement implements estimate estimates
259 | implement implements find finds
260 | implement implements generate generates
261 | implement implements go goes
262 | increase increases listen listens
263 | increase increases play plays
264 | increase increases predict predicts
265 | increase increases provide provides
266 | increase increases say says
267 | increase increases scream screams
268 | increase increases search searches
269 | increase increases see sees
270 | increase increases shuffle shuffles
271 | increase increases sing sings
272 | increase increases sit sits
273 | increase increases slow slows
274 | increase increases speak speaks
275 | increase increases swim swims
276 | increase increases talk talks
277 | increase increases think thinks
278 | increase increases vanish vanishes
279 | increase increases walk walks
280 | increase increases work works
281 | increase increases write writes
282 | increase increases decrease decreases
283 | increase increases describe describes
284 | increase increases eat eats
285 | increase increases enhance enhances
286 | increase increases estimate estimates
287 | increase increases find finds
288 | increase increases generate generates
289 | increase increases go goes
290 | increase increases implement implements
291 | listen listens play plays
292 | listen listens predict predicts
293 | listen listens provide provides
294 | listen listens say says
295 | listen listens scream screams
296 | listen listens search searches
297 | listen listens see sees
298 | listen listens shuffle shuffles
299 | listen listens sing sings
300 | listen listens sit sits
301 | listen listens slow slows
302 | listen listens speak speaks
303 | listen listens swim swims
304 | listen listens talk talks
305 | listen listens think thinks
306 | listen listens vanish vanishes
307 | listen listens walk walks
308 | listen listens work works
309 | listen listens write writes
310 | listen listens decrease decreases
311 | listen listens describe describes
312 | listen listens eat eats
313 | listen listens enhance enhances
314 | listen listens estimate estimates
315 | listen listens find finds
316 | listen listens generate generates
317 | listen listens go goes
318 | listen listens implement implements
319 | listen listens increase increases
320 | play plays predict predicts
321 | play plays provide provides
322 | play plays say says
323 | play plays scream screams
324 | play plays search searches
325 | play plays see sees
326 | play plays shuffle shuffles
327 | play plays sing sings
328 | play plays sit sits
329 | play plays slow slows
330 | play plays speak speaks
331 | play plays swim swims
332 | play plays talk talks
333 | play plays think thinks
334 | play plays vanish vanishes
335 | play plays walk walks
336 | play plays work works
337 | play plays write writes
338 | play plays decrease decreases
339 | play plays describe describes
340 | play plays eat eats
341 | play plays enhance enhances
342 | play plays estimate estimates
343 | play plays find finds
344 | play plays generate generates
345 | play plays go goes
346 | play plays implement implements
347 | play plays increase increases
348 | play plays listen listens
349 | predict predicts provide provides
350 | predict predicts say says
351 | predict predicts scream screams
352 | predict predicts search searches
353 | predict predicts see sees
354 | predict predicts shuffle shuffles
355 | predict predicts sing sings
356 | predict predicts sit sits
357 | predict predicts slow slows
358 | predict predicts speak speaks
359 | predict predicts swim swims
360 | predict predicts talk talks
361 | predict predicts think thinks
362 | predict predicts vanish vanishes
363 | predict predicts walk walks
364 | predict predicts work works
365 | predict predicts write writes
366 | predict predicts decrease decreases
367 | predict predicts describe describes
368 | predict predicts eat eats
369 | predict predicts enhance enhances
370 | predict predicts estimate estimates
371 | predict predicts find finds
372 | predict predicts generate generates
373 | predict predicts go goes
374 | predict predicts implement implements
375 | predict predicts increase increases
376 | predict predicts listen listens
377 | predict predicts play plays
378 | provide provides say says
379 | provide provides scream screams
380 | provide provides search searches
381 | provide provides see sees
382 | provide provides shuffle shuffles
383 | provide provides sing sings
384 | provide provides sit sits
385 | provide provides slow slows
386 | provide provides speak speaks
387 | provide provides swim swims
388 | provide provides talk talks
389 | provide provides think thinks
390 | provide provides vanish vanishes
391 | provide provides walk walks
392 | provide provides work works
393 | provide provides write writes
394 | provide provides decrease decreases
395 | provide provides describe describes
396 | provide provides eat eats
397 | provide provides enhance enhances
398 | provide provides estimate estimates
399 | provide provides find finds
400 | provide provides generate generates
401 | provide provides go goes
402 | provide provides implement implements
403 | provide provides increase increases
404 | provide provides listen listens
405 | provide provides play plays
406 | provide provides predict predicts
407 | say says scream screams
408 | say says search searches
409 | say says see sees
410 | say says shuffle shuffles
411 | say says sing sings
412 | say says sit sits
413 | say says slow slows
414 | say says speak speaks
415 | say says swim swims
416 | say says talk talks
417 | say says think thinks
418 | say says vanish vanishes
419 | say says walk walks
420 | say says work works
421 | say says write writes
422 | say says decrease decreases
423 | say says describe describes
424 | say says eat eats
425 | say says enhance enhances
426 | say says estimate estimates
427 | say says find finds
428 | say says generate generates
429 | say says go goes
430 | say says implement implements
431 | say says increase increases
432 | say says listen listens
433 | say says play plays
434 | say says predict predicts
435 | say says provide provides
436 | scream screams search searches
437 | scream screams see sees
438 | scream screams shuffle shuffles
439 | scream screams sing sings
440 | scream screams sit sits
441 | scream screams slow slows
442 | scream screams speak speaks
443 | scream screams swim swims
444 | scream screams talk talks
445 | scream screams think thinks
446 | scream screams vanish vanishes
447 | scream screams walk walks
448 | scream screams work works
449 | scream screams write writes
450 | scream screams decrease decreases
451 | scream screams describe describes
452 | scream screams eat eats
453 | scream screams enhance enhances
454 | scream screams estimate estimates
455 | scream screams find finds
456 | scream screams generate generates
457 | scream screams go goes
458 | scream screams implement implements
459 | scream screams increase increases
460 | scream screams listen listens
461 | scream screams play plays
462 | scream screams predict predicts
463 | scream screams provide provides
464 | scream screams say says
465 | search searches see sees
466 | search searches shuffle shuffles
467 | search searches sing sings
468 | search searches sit sits
469 | search searches slow slows
470 | search searches speak speaks
471 | search searches swim swims
472 | search searches talk talks
473 | search searches think thinks
474 | search searches vanish vanishes
475 | search searches walk walks
476 | search searches work works
477 | search searches write writes
478 | search searches decrease decreases
479 | search searches describe describes
480 | search searches eat eats
481 | search searches enhance enhances
482 | search searches estimate estimates
483 | search searches find finds
484 | search searches generate generates
485 | search searches go goes
486 | search searches implement implements
487 | search searches increase increases
488 | search searches listen listens
489 | search searches play plays
490 | search searches predict predicts
491 | search searches provide provides
492 | search searches say says
493 | search searches scream screams
494 | see sees shuffle shuffles
495 | see sees sing sings
496 | see sees sit sits
497 | see sees slow slows
498 | see sees speak speaks
499 | see sees swim swims
500 | see sees talk talks
501 | see sees think thinks
502 | see sees vanish vanishes
503 | see sees walk walks
504 | see sees work works
505 | see sees write writes
506 | see sees decrease decreases
507 | see sees describe describes
508 | see sees eat eats
509 | see sees enhance enhances
510 | see sees estimate estimates
511 | see sees find finds
512 | see sees generate generates
513 | see sees go goes
514 | see sees implement implements
515 | see sees increase increases
516 | see sees listen listens
517 | see sees play plays
518 | see sees predict predicts
519 | see sees provide provides
520 | see sees say says
521 | see sees scream screams
522 | see sees search searches
523 | shuffle shuffles sing sings
524 | shuffle shuffles sit sits
525 | shuffle shuffles slow slows
526 | shuffle shuffles speak speaks
527 | shuffle shuffles swim swims
528 | shuffle shuffles talk talks
529 | shuffle shuffles think thinks
530 | shuffle shuffles vanish vanishes
531 | shuffle shuffles walk walks
532 | shuffle shuffles work works
533 | shuffle shuffles write writes
534 | shuffle shuffles decrease decreases
535 | shuffle shuffles describe describes
536 | shuffle shuffles eat eats
537 | shuffle shuffles enhance enhances
538 | shuffle shuffles estimate estimates
539 | shuffle shuffles find finds
540 | shuffle shuffles generate generates
541 | shuffle shuffles go goes
542 | shuffle shuffles implement implements
543 | shuffle shuffles increase increases
544 | shuffle shuffles listen listens
545 | shuffle shuffles play plays
546 | shuffle shuffles predict predicts
547 | shuffle shuffles provide provides
548 | shuffle shuffles say says
549 | shuffle shuffles scream screams
550 | shuffle shuffles search searches
551 | shuffle shuffles see sees
552 | sing sings sit sits
553 | sing sings slow slows
554 | sing sings speak speaks
555 | sing sings swim swims
556 | sing sings talk talks
557 | sing sings think thinks
558 | sing sings vanish vanishes
559 | sing sings walk walks
560 | sing sings work works
561 | sing sings write writes
562 | sing sings decrease decreases
563 | sing sings describe describes
564 | sing sings eat eats
565 | sing sings enhance enhances
566 | sing sings estimate estimates
567 | sing sings find finds
568 | sing sings generate generates
569 | sing sings go goes
570 | sing sings implement implements
571 | sing sings increase increases
572 | sing sings listen listens
573 | sing sings play plays
574 | sing sings predict predicts
575 | sing sings provide provides
576 | sing sings say says
577 | sing sings scream screams
578 | sing sings search searches
579 | sing sings see sees
580 | sing sings shuffle shuffles
581 | sit sits slow slows
582 | sit sits speak speaks
583 | sit sits swim swims
584 | sit sits talk talks
585 | sit sits think thinks
586 | sit sits vanish vanishes
587 | sit sits walk walks
588 | sit sits work works
589 | sit sits write writes
590 | sit sits decrease decreases
591 | sit sits describe describes
592 | sit sits eat eats
593 | sit sits enhance enhances
594 | sit sits estimate estimates
595 | sit sits find finds
596 | sit sits generate generates
597 | sit sits go goes
598 | sit sits implement implements
599 | sit sits increase increases
600 | sit sits listen listens
601 | sit sits play plays
602 | sit sits predict predicts
603 | sit sits provide provides
604 | sit sits say says
605 | sit sits scream screams
606 | sit sits search searches
607 | sit sits see sees
608 | sit sits shuffle shuffles
609 | sit sits sing sings
610 | slow slows speak speaks
611 | slow slows swim swims
612 | slow slows talk talks
613 | slow slows think thinks
614 | slow slows vanish vanishes
615 | slow slows walk walks
616 | slow slows work works
617 | slow slows write writes
618 | slow slows decrease decreases
619 | slow slows describe describes
620 | slow slows eat eats
621 | slow slows enhance enhances
622 | slow slows estimate estimates
623 | slow slows find finds
624 | slow slows generate generates
625 | slow slows go goes
626 | slow slows implement implements
627 | slow slows increase increases
628 | slow slows listen listens
629 | slow slows play plays
630 | slow slows predict predicts
631 | slow slows provide provides
632 | slow slows say says
633 | slow slows scream screams
634 | slow slows search searches
635 | slow slows see sees
636 | slow slows shuffle shuffles
637 | slow slows sing sings
638 | slow slows sit sits
639 | speak speaks swim swims
640 | speak speaks talk talks
641 | speak speaks think thinks
642 | speak speaks vanish vanishes
643 | speak speaks walk walks
644 | speak speaks work works
645 | speak speaks write writes
646 | speak speaks decrease decreases
647 | speak speaks describe describes
648 | speak speaks eat eats
649 | speak speaks enhance enhances
650 | speak speaks estimate estimates
651 | speak speaks find finds
652 | speak speaks generate generates
653 | speak speaks go goes
654 | speak speaks implement implements
655 | speak speaks increase increases
656 | speak speaks listen listens
657 | speak speaks play plays
658 | speak speaks predict predicts
659 | speak speaks provide provides
660 | speak speaks say says
661 | speak speaks scream screams
662 | speak speaks search searches
663 | speak speaks see sees
664 | speak speaks shuffle shuffles
665 | speak speaks sing sings
666 | speak speaks sit sits
667 | speak speaks slow slows
668 | swim swims talk talks
669 | swim swims think thinks
670 | swim swims vanish vanishes
671 | swim swims walk walks
672 | swim swims work works
673 | swim swims write writes
674 | swim swims decrease decreases
675 | swim swims describe describes
676 | swim swims eat eats
677 | swim swims enhance enhances
678 | swim swims estimate estimates
679 | swim swims find finds
680 | swim swims generate generates
681 | swim swims go goes
682 | swim swims implement implements
683 | swim swims increase increases
684 | swim swims listen listens
685 | swim swims play plays
686 | swim swims predict predicts
687 | swim swims provide provides
688 | swim swims say says
689 | swim swims scream screams
690 | swim swims search searches
691 | swim swims see sees
692 | swim swims shuffle shuffles
693 | swim swims sing sings
694 | swim swims sit sits
695 | swim swims slow slows
696 | swim swims speak speaks
697 | talk talks think thinks
698 | talk talks vanish vanishes
699 | talk talks walk walks
700 | talk talks work works
701 | talk talks write writes
702 | talk talks decrease decreases
703 | talk talks describe describes
704 | talk talks eat eats
705 | talk talks enhance enhances
706 | talk talks estimate estimates
707 | talk talks find finds
708 | talk talks generate generates
709 | talk talks go goes
710 | talk talks implement implements
711 | talk talks increase increases
712 | talk talks listen listens
713 | talk talks play plays
714 | talk talks predict predicts
715 | talk talks provide provides
716 | talk talks say says
717 | talk talks scream screams
718 | talk talks search searches
719 | talk talks see sees
720 | talk talks shuffle shuffles
721 | talk talks sing sings
722 | talk talks sit sits
723 | talk talks slow slows
724 | talk talks speak speaks
725 | talk talks swim swims
726 | think thinks vanish vanishes
727 | think thinks walk walks
728 | think thinks work works
729 | think thinks write writes
730 | think thinks decrease decreases
731 | think thinks describe describes
732 | think thinks eat eats
733 | think thinks enhance enhances
734 | think thinks estimate estimates
735 | think thinks find finds
736 | think thinks generate generates
737 | think thinks go goes
738 | think thinks implement implements
739 | think thinks increase increases
740 | think thinks listen listens
741 | think thinks play plays
742 | think thinks predict predicts
743 | think thinks provide provides
744 | think thinks say says
745 | think thinks scream screams
746 | think thinks search searches
747 | think thinks see sees
748 | think thinks shuffle shuffles
749 | think thinks sing sings
750 | think thinks sit sits
751 | think thinks slow slows
752 | think thinks speak speaks
753 | think thinks swim swims
754 | think thinks talk talks
755 | vanish vanishes walk walks
756 | vanish vanishes work works
757 | vanish vanishes write writes
758 | vanish vanishes decrease decreases
759 | vanish vanishes describe describes
760 | vanish vanishes eat eats
761 | vanish vanishes enhance enhances
762 | vanish vanishes estimate estimates
763 | vanish vanishes find finds
764 | vanish vanishes generate generates
765 | vanish vanishes go goes
766 | vanish vanishes implement implements
767 | vanish vanishes increase increases
768 | vanish vanishes listen listens
769 | vanish vanishes play plays
770 | vanish vanishes predict predicts
771 | vanish vanishes provide provides
772 | vanish vanishes say says
773 | vanish vanishes scream screams
774 | vanish vanishes search searches
775 | vanish vanishes see sees
776 | vanish vanishes shuffle shuffles
777 | vanish vanishes sing sings
778 | vanish vanishes sit sits
779 | vanish vanishes slow slows
780 | vanish vanishes speak speaks
781 | vanish vanishes swim swims
782 | vanish vanishes talk talks
783 | vanish vanishes think thinks
784 | walk walks work works
785 | walk walks write writes
786 | walk walks decrease decreases
787 | walk walks describe describes
788 | walk walks eat eats
789 | walk walks enhance enhances
790 | walk walks estimate estimates
791 | walk walks find finds
792 | walk walks generate generates
793 | walk walks go goes
794 | walk walks implement implements
795 | walk walks increase increases
796 | walk walks listen listens
797 | walk walks play plays
798 | walk walks predict predicts
799 | walk walks provide provides
800 | walk walks say says
801 | walk walks scream screams
802 | walk walks search searches
803 | walk walks see sees
804 | walk walks shuffle shuffles
805 | walk walks sing sings
806 | walk walks sit sits
807 | walk walks slow slows
808 | walk walks speak speaks
809 | walk walks swim swims
810 | walk walks talk talks
811 | walk walks think thinks
812 | walk walks vanish vanishes
813 | work works write writes
814 | work works decrease decreases
815 | work works describe describes
816 | work works eat eats
817 | work works enhance enhances
818 | work works estimate estimates
819 | work works find finds
820 | work works generate generates
821 | work works go goes
822 | work works implement implements
823 | work works increase increases
824 | work works listen listens
825 | work works play plays
826 | work works predict predicts
827 | work works provide provides
828 | work works say says
829 | work works scream screams
830 | work works search searches
831 | work works see sees
832 | work works shuffle shuffles
833 | work works sing sings
834 | work works sit sits
835 | work works slow slows
836 | work works speak speaks
837 | work works swim swims
838 | work works talk talks
839 | work works think thinks
840 | work works vanish vanishes
841 | work works walk walks
842 | write writes decrease decreases
843 | write writes describe describes
844 | write writes eat eats
845 | write writes enhance enhances
846 | write writes estimate estimates
847 | write writes find finds
848 | write writes generate generates
849 | write writes go goes
850 | write writes implement implements
851 | write writes increase increases
852 | write writes listen listens
853 | write writes play plays
854 | write writes predict predicts
855 | write writes provide provides
856 | write writes say says
857 | write writes scream screams
858 | write writes search searches
859 | write writes see sees
860 | write writes shuffle shuffles
861 | write writes sing sings
862 | write writes sit sits
863 | write writes slow slows
864 | write writes speak speaks
865 | write writes swim swims
866 | write writes talk talks
867 | write writes think thinks
868 | write writes vanish vanishes
869 | write writes walk walks
870 | write writes work works
871 |
--------------------------------------------------------------------------------
/randomization.test.sh:
--------------------------------------------------------------------------------
1 | # Tests for ensuring randomization is being controlled
2 |
3 | make
4 |
5 | if [ ! -e text8 ]; then
6 | if hash wget 2>/dev/null; then
7 | wget http://mattmahoney.net/dc/text8.zip
8 | else
9 | curl -O http://mattmahoney.net/dc/text8.zip
10 | fi
11 | unzip text8.zip
12 | rm text8.zip
13 | fi
14 |
15 | # Global constants
16 | CORPUS=text8
17 | VERBOSE=2
18 | BUILDDIR=build
19 | MEMORY=4.0
20 | VOCAB_MIN_COUNT=20
21 |
22 | # Re-used files
23 | VOCAB_FILE=$(mktemp vocab.test.txt.XXXXXX)
24 | COOCCURRENCE_FILE=$(mktemp cooccurrence.test.bin.XXXXXX)
25 | COOCCURRENCE_SHUF_FILE=$(mktemp cooccurrence_shuf.test.bin.XXXXXX)
26 |
27 | # Make vocab
28 | $BUILDDIR/vocab_count -min-count $VOCAB_MIN_COUNT -verbose $VERBOSE < $CORPUS > $VOCAB_FILE
29 |
30 | # Make Coocurrences
31 | $BUILDDIR/cooccur -memory $MEMORY -vocab-file $VOCAB_FILE -verbose $VERBOSE -window-size 5 < $CORPUS > $COOCCURRENCE_FILE
32 |
33 | # Shuffle Coocurrences
34 | $BUILDDIR/shuffle -memory $MEMORY -verbose $VERBOSE -seed 1 < $COOCCURRENCE_FILE > $COOCCURRENCE_SHUF_FILE
35 |
36 | # Keep track of failure
37 | num_failed=0
38 |
39 | check_exit() {
40 | eval $2
41 | failed=$(( $1 != $? ))
42 | num_failed=$(( $num_failed + $failed ))
43 | if [[ $failed -eq 0 ]]; then
44 | echo PASSED
45 | else
46 | echo FAILED
47 | fi
48 | }
49 |
50 | # Test control of random seed in shuffle
51 | printf "\n\n--- TEST SET: Control of random seed in shuffle\n"
52 | TEST_FILE=$(mktemp cooc_shuf.test.bin.XXXXXX)
53 |
54 | printf "\n- TEST: Using the same seed should get the same shuffle\n"
55 | $BUILDDIR/shuffle -memory $MEMORY -verbose 0 -seed 1 < $COOCCURRENCE_FILE > $TEST_FILE
56 | check_exit 0 "cmp --quiet $COOCCURRENCE_SHUF_FILE $TEST_FILE"
57 |
58 | printf "\n- TEST: Changing the seed should change the shuffle\n"
59 | $BUILDDIR/shuffle -memory $MEMORY -verbose 0 -seed 2 < $COOCCURRENCE_FILE > $TEST_FILE
60 | check_exit 1 "cmp --quiet $COOCCURRENCE_SHUF_FILE $TEST_FILE"
61 |
62 | rm $TEST_FILE # Clean up
63 | # ---
64 |
65 | # Control randomization in GloVe
66 | printf "\n\n--- TEST SET: Control of random seed in glove\n"
67 | # Note "-threads" must equal 1 for these to pass, since order in which results come back from individual threads is uncontrolled
68 | BASE_PREFIX=$(mktemp base_vectors.XXXXXX)
69 | TEST_PREFIX=$(mktemp test_vectors.XXXXXX)
70 |
71 | printf "\n- TEST: Reusing seed should give the same vectors\n"
72 | $BUILDDIR/glove -save-file $BASE_PREFIX -threads 1 -input-file $COOCCURRENCE_SHUF_FILE -iter 3 -vector-size 10 -binary 1 -vocab-file $VOCAB_FILE -verbose 0 -seed 1
73 | $BUILDDIR/glove -save-file $TEST_PREFIX -threads 1 -input-file $COOCCURRENCE_SHUF_FILE -iter 3 -vector-size 10 -binary 1 -vocab-file $VOCAB_FILE -verbose 0 -seed 1
74 | check_exit 0 "cmp --quiet $BASE_PREFIX.bin $TEST_PREFIX.bin"
75 |
76 | printf "\n- TEST: Changing seed should change the learned vectors\n"
77 | $BUILDDIR/glove -save-file $TEST_PREFIX -threads 1 -input-file $COOCCURRENCE_SHUF_FILE -iter 3 -vector-size 10 -binary 1 -vocab-file $VOCAB_FILE -verbose 0 -seed 2
78 | check_exit 1 "cmp --quiet $BASE_PREFIX.bin $TEST_PREFIX.bin"
79 |
80 | printf "\n- TEST: Should be able to save/load initial parameters\n"
81 | $BUILDDIR/glove -save-file $BASE_PREFIX -threads 1 -input-file $COOCCURRENCE_SHUF_FILE -iter 3 -vector-size 10 -binary 1 -vocab-file $VOCAB_FILE -verbose 0 -save-init-param 1
82 | $BUILDDIR/glove -save-file $TEST_PREFIX -threads 1 -input-file $COOCCURRENCE_SHUF_FILE -iter 3 -vector-size 10 -binary 1 -vocab-file $VOCAB_FILE -verbose 0 -save-init-param 1 -load-init-param 1 -init-param-file "$BASE_PREFIX.000.bin"
83 | check_exit 0 "cmp --quiet $BASE_PREFIX.000.bin $TEST_PREFIX.000.bin && cmp --quiet $BASE_PREFIX.bin $TEST_PREFIX.bin"
84 |
85 | rm "$BASE_PREFIX.000.bin" "$TEST_PREFIX.000.bin" "$BASE_PREFIX.bin" "$TEST_PREFIX.bin" # Clean up
86 | rm $BASE_PREFIX $TEST_PREFIX
87 |
88 | # ----
89 |
90 | printf "\n- TEST: Should be able to save/load initial parameters and gradsq\n"
91 | # note: the seed will be randomly assigned and should not matter
92 | $BUILDDIR/glove -save-file $BASE_PREFIX -gradsq-file $BASE_PREFIX.gradsq -threads 1 -input-file $COOCCURRENCE_SHUF_FILE -iter 6 -vector-size 10 -binary 1 -vocab-file $VOCAB_FILE -verbose 0 -checkpoint-every 2
93 |
94 | $BUILDDIR/glove -save-file $TEST_PREFIX -gradsq-file $TEST_PREFIX.gradsq -threads 1 -input-file $COOCCURRENCE_SHUF_FILE -iter 4 -vector-size 10 -binary 1 -vocab-file $VOCAB_FILE -verbose 0 -checkpoint-every 2 -load-init-param 1 -init-param-file "$BASE_PREFIX.002.bin" -load-init-gradsq 1 -init-gradsq-file "$BASE_PREFIX.gradsq.002.bin"
95 |
96 | echo "Compare vectors before & after load gradsq - 2 iterations"
97 | check_exit 0 "cmp --quiet $BASE_PREFIX.004.bin $TEST_PREFIX.002.bin"
98 | echo "Compare vectors before & after load gradsq - 4 iterations"
99 | check_exit 0 "cmp --quiet $BASE_PREFIX.006.bin $TEST_PREFIX.004.bin"
100 | echo "Compare vectors before & after load gradsq - final"
101 | check_exit 0 "cmp --quiet $BASE_PREFIX.bin $TEST_PREFIX.bin"
102 |
103 | echo "Compare gradsq before & after load gradsq - 2 iterations"
104 | check_exit 0 "cmp --quiet $BASE_PREFIX.gradsq.004.bin $TEST_PREFIX.gradsq.002.bin"
105 | echo "Compare gradsq before & after load gradsq - 4 iterations"
106 | check_exit 0 "cmp --quiet $BASE_PREFIX.gradsq.006.bin $TEST_PREFIX.gradsq.004.bin"
107 | echo "Compare gradsq before & after load gradsq - final"
108 | check_exit 0 "cmp --quiet $BASE_PREFIX.gradsq.bin $TEST_PREFIX.gradsq.bin"
109 |
110 | echo "Cleaning up files"
111 | check_exit 0 "rm $BASE_PREFIX.002.bin $BASE_PREFIX.004.bin $BASE_PREFIX.006.bin $BASE_PREFIX.bin"
112 | check_exit 0 "rm $BASE_PREFIX.gradsq.002.bin $BASE_PREFIX.gradsq.004.bin $BASE_PREFIX.gradsq.006.bin $BASE_PREFIX.gradsq.bin"
113 | check_exit 0 "rm $TEST_PREFIX.002.bin $TEST_PREFIX.004.bin $TEST_PREFIX.bin"
114 | check_exit 0 "rm $TEST_PREFIX.gradsq.002.bin $TEST_PREFIX.gradsq.004.bin $TEST_PREFIX.gradsq.bin"
115 | check_exit 0 "rm $VOCAB_FILE $COOCCURRENCE_FILE $COOCCURRENCE_SHUF_FILE"
116 |
117 | echo
118 | echo SUMMARY:
119 | if [[ $num_failed -gt 0 ]]; then
120 | echo $num_failed tests failed.
121 | exit 1
122 | else
123 | echo All tests passed.
124 | exit 0
125 | fi
126 |
127 |
128 |
--------------------------------------------------------------------------------
/src/README.md:
--------------------------------------------------------------------------------
1 | ### Package Contents
2 |
3 | To train your own GloVe vectors, first you'll need to prepare your corpus as a single text file with all words separated by one or more spaces or tabs. If your corpus has multiple documents, the documents (only) should be separated by new line characters. Cooccurrence contexts for words do not extend past newline characters. Once you create your corpus, you can train GloVe vectors using the following 4 tools. An example is included in `demo.sh`, which you can modify as necessary.
4 |
5 | The four main tools in this package are:
6 |
7 | #### 1) vocab_count
8 | This tool requires an input corpus that should already consist of whitespace-separated tokens. Use something like the [Stanford Tokenizer](https://nlp.stanford.edu/software/tokenizer.html) first on raw text. From the corpus, it constructs unigram counts from a corpus, and optionally thresholds the resulting vocabulary based on total vocabulary size or minimum frequency count.
9 |
10 | #### 2) cooccur
11 | Constructs word-word cooccurrence statistics from a corpus. The user should supply a vocabulary file, as produced by `vocab_count`, and may specify a variety of parameters, as described by running `./build/cooccur`.
12 |
13 | #### 3) shuffle
14 | Shuffles the binary file of cooccurrence statistics produced by `cooccur`. For large files, the file is automatically split into chunks, each of which is shuffled and stored on disk before being merged and shuffled together. The user may specify a number of parameters, as described by running `./build/shuffle`.
15 |
16 | #### 4) glove
17 | Train the GloVe model on the specified cooccurrence data, which typically will be the output of the `shuffle` tool. The user should supply a vocabulary file, as given by `vocab_count`, and may specify a number of other parameters, which are described by running `./build/glove`.
18 |
--------------------------------------------------------------------------------
/src/common.c:
--------------------------------------------------------------------------------
1 | // Common code for cooccur.c, vocab_count.c,
2 | // glove.c and shuffle.c
3 | //
4 | // GloVe: Global Vectors for Word Representation
5 | // Copyright (c) 2014 The Board of Trustees of
6 | // The Leland Stanford Junior University. All Rights Reserved.
7 | //
8 | // Licensed under the Apache License, Version 2.0 (the "License");
9 | // you may not use this file except in compliance with the License.
10 | // You may obtain a copy of the License at
11 | //
12 | // http://www.apache.org/licenses/LICENSE-2.0
13 | //
14 | // Unless required by applicable law or agreed to in writing, software
15 | // distributed under the License is distributed on an "AS IS" BASIS,
16 | // WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | // See the License for the specific language governing permissions and
18 | // limitations under the License.
19 | //
20 | //
21 | // For more information, bug reports, fixes, contact:
22 | // Jeffrey Pennington (jpennin@stanford.edu)
23 | // Christopher Manning (manning@cs.stanford.edu)
24 | // https://github.com/stanfordnlp/GloVe/
25 | // GlobalVectors@googlegroups.com
26 | // http://nlp.stanford.edu/projects/glove/
27 |
28 | #include
29 | #include
30 | #include
31 | #include "common.h"
32 |
33 | #ifdef _MSC_VER
34 | #define STRERROR(ERRNO, BUF, BUFSIZE) strerror_s((BUF), (BUFSIZE), (ERRNO))
35 | #else
36 | #define STRERROR(ERRNO, BUF, BUFSIZE) strerror_r((ERRNO), (BUF), (BUFSIZE))
37 | #endif
38 |
39 | /* Efficient string comparison */
40 | int scmp( char *s1, char *s2 ) {
41 | while (*s1 != '\0' && *s1 == *s2) {s1++; s2++;}
42 | return (*s1 - *s2);
43 | }
44 |
45 | /* Move-to-front hashing and hash function from Hugh Williams, http://www.seg.rmit.edu.au/code/zwh-ipl/ */
46 |
47 | /* Simple bitwise hash function */
48 | unsigned int bitwisehash(char *word, int tsize, unsigned int seed) {
49 | char c;
50 | unsigned int h;
51 | h = seed;
52 | for ( ; (c = *word) != '\0'; word++) h ^= ((h << 5) + c + (h >> 2));
53 | return (unsigned int)((h & 0x7fffffff) % tsize);
54 | }
55 |
56 | /* Create hash table, initialise pointers to NULL */
57 | HASHREC ** inithashtable() {
58 | int i;
59 | HASHREC **ht;
60 | ht = (HASHREC **) malloc( sizeof(HASHREC *) * TSIZE );
61 | for (i = 0; i < TSIZE; i++) ht[i] = (HASHREC *) NULL;
62 | return ht;
63 | }
64 |
65 | /* Read word from input stream. Return 1 when encounter '\n' or EOF (but separate from word), 0 otherwise.
66 | Words can be separated by space(s), tab(s), or newline(s). Carriage return characters are just ignored.
67 | (Okay for Windows, but not for Mac OS 9-. Ignored even if by themselves or in words.)
68 | A newline is taken as indicating a new document (contexts won't cross newline).
69 | Argument word array is assumed to be of size MAX_STRING_LENGTH.
70 | words will be truncated if too long. They are truncated with some care so that they
71 | cannot truncate in the middle of a utf-8 character, but
72 | still little to no harm will be done for other encodings like iso-8859-1.
73 | (This function appears identically copied in vocab_count.c and cooccur.c.)
74 | */
75 | int get_word(char *word, FILE *fin) {
76 | int i = 0, ch;
77 | for ( ; ; ) {
78 | ch = fgetc(fin);
79 | if (ch == '\r') continue;
80 | if (i == 0 && ((ch == '\n') || (ch == EOF))) {
81 | word[i] = 0;
82 | return 1;
83 | }
84 | if (i == 0 && ((ch == ' ') || (ch == '\t'))) continue; // skip leading space
85 | if ((ch == EOF) || (ch == ' ') || (ch == '\t') || (ch == '\n')) {
86 | if (ch == '\n') ungetc(ch, fin); // return the newline next time as document ender
87 | break;
88 | }
89 | if (i < MAX_STRING_LENGTH - 1)
90 | word[i++] = ch; // don't allow words to exceed MAX_STRING_LENGTH
91 | }
92 | word[i] = 0; //null terminate
93 | // avoid truncation destroying a multibyte UTF-8 char except if only thing on line (so the i > x tests won't overwrite word[0])
94 | // see https://en.wikipedia.org/wiki/UTF-8#Description
95 | if (i == MAX_STRING_LENGTH - 1 && (word[i-1] & 0x80) == 0x80) {
96 | if ((word[i-1] & 0xC0) == 0xC0) {
97 | word[i-1] = '\0';
98 | } else if (i > 2 && (word[i-2] & 0xE0) == 0xE0) {
99 | word[i-2] = '\0';
100 | } else if (i > 3 && (word[i-3] & 0xF8) == 0xF0) {
101 | word[i-3] = '\0';
102 | }
103 | }
104 | return 0;
105 | }
106 |
107 | int find_arg(char *str, int argc, char **argv) {
108 | int i;
109 | for (i = 1; i < argc; i++) {
110 | if (!scmp(str, argv[i])) {
111 | if (i == argc - 1) {
112 | printf("No argument given for %s\n", str);
113 | exit(1);
114 | }
115 | return i;
116 | }
117 | }
118 | return -1;
119 | }
120 |
121 | void free_table(HASHREC **ht) {
122 | int i;
123 | HASHREC* current;
124 | HASHREC* tmp;
125 | for (i = 0; i < TSIZE; i++) {
126 | current = ht[i];
127 | while (current != NULL) {
128 | tmp = current;
129 | current = current->next;
130 | free(tmp->word);
131 | free(tmp);
132 | }
133 | }
134 | free(ht);
135 | }
136 |
137 | void free_fid(FILE **fid, const int num) {
138 | int i;
139 | for(i = 0; i < num; i++) {
140 | if(fid[i] != NULL)
141 | fclose(fid[i]);
142 | }
143 | free(fid);
144 | }
145 |
146 |
147 | int log_file_loading_error(char *file_description, char *file_name) {
148 | fprintf(stderr, "Unable to open %s %s.\n", file_description, file_name);
149 | fprintf(stderr, "Errno: %d\n", errno);
150 | char error[MAX_STRING_LENGTH];
151 | STRERROR(errno, error, MAX_STRING_LENGTH);
152 | fprintf(stderr, "Error description: %s\n", error);
153 | return errno;
154 | }
155 |
--------------------------------------------------------------------------------
/src/common.h:
--------------------------------------------------------------------------------
1 | #ifndef COMMON_H
2 | #define COMMON_H
3 |
4 | // Common code for cooccur.c, vocab_count.c,
5 | // glove.c and shuffle.c
6 | //
7 | // GloVe: Global Vectors for Word Representation
8 | // Copyright (c) 2014 The Board of Trustees of
9 | // The Leland Stanford Junior University. All Rights Reserved.
10 | //
11 | // Licensed under the Apache License, Version 2.0 (the "License");
12 | // you may not use this file except in compliance with the License.
13 | // You may obtain a copy of the License at
14 | //
15 | // http://www.apache.org/licenses/LICENSE-2.0
16 | //
17 | // Unless required by applicable law or agreed to in writing, software
18 | // distributed under the License is distributed on an "AS IS" BASIS,
19 | // WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
20 | // See the License for the specific language governing permissions and
21 | // limitations under the License.
22 | //
23 | //
24 | // For more information, bug reports, fixes, contact:
25 | // Jeffrey Pennington (jpennin@stanford.edu)
26 | // Christopher Manning (manning@cs.stanford.edu)
27 | // https://github.com/stanfordnlp/GloVe/
28 | // GlobalVectors@googlegroups.com
29 | // http://nlp.stanford.edu/projects/glove/
30 |
31 | #include
32 |
33 | #define MAX_STRING_LENGTH 1000
34 | #define TSIZE 1048576
35 | #define SEED 1159241
36 | #define HASHFN bitwisehash
37 |
38 | typedef double real;
39 | typedef struct cooccur_rec {
40 | int word1;
41 | int word2;
42 | real val;
43 | } CREC;
44 | typedef struct hashrec {
45 | char *word;
46 | long long num; //count or id
47 | struct hashrec *next;
48 | } HASHREC;
49 |
50 |
51 | int scmp( char *s1, char *s2 );
52 | unsigned int bitwisehash(char *word, int tsize, unsigned int seed);
53 | HASHREC **inithashtable();
54 | int get_word(char *word, FILE *fin);
55 | void free_table(HASHREC **ht);
56 | int find_arg(char *str, int argc, char **argv);
57 | void free_fid(FILE **fid, const int num);
58 |
59 | // logs errors when loading files. call after a failed load
60 | int log_file_loading_error(char *file_description, char *file_name);
61 |
62 | #endif /* COMMON_H */
63 |
64 |
--------------------------------------------------------------------------------
/src/cooccur.c:
--------------------------------------------------------------------------------
1 | // Tool to calculate word-word cooccurrence statistics
2 | //
3 | // Copyright (c) 2014, 2018 The Board of Trustees of
4 | // The Leland Stanford Junior University. All Rights Reserved.
5 | //
6 | // Licensed under the Apache License, Version 2.0 (the "License");
7 | // you may not use this file except in compliance with the License.
8 | // You may obtain a copy of the License at
9 | //
10 | // http://www.apache.org/licenses/LICENSE-2.0
11 | //
12 | // Unless required by applicable law or agreed to in writing, software
13 | // distributed under the License is distributed on an "AS IS" BASIS,
14 | // WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
15 | // See the License for the specific language governing permissions and
16 | // limitations under the License.
17 | //
18 | //
19 | // For more information, bug reports, fixes, contact:
20 | // Jeffrey Pennington (jpennin@stanford.edu)
21 | // Christopher Manning (manning@cs.stanford.edu)
22 | // https://github.com/stanfordnlp/GloVe/
23 | // GlobalVectors@googlegroups.com
24 | // http://nlp.stanford.edu/projects/glove/
25 |
26 | #include
27 | #include
28 | #include
29 | #include
30 | #include "common.h"
31 |
32 | typedef struct cooccur_rec_id {
33 | int word1;
34 | int word2;
35 | real val;
36 | int id;
37 | } CRECID;
38 |
39 | int verbose = 2; // 0, 1, or 2
40 | long long max_product; // Cutoff for product of word frequency ranks below which cooccurrence counts will be stored in a compressed full array
41 | long long overflow_length; // Number of cooccurrence records whose product exceeds max_product to store in memory before writing to disk
42 | int window_size = 15; // default context window size
43 | int symmetric = 1; // 0: asymmetric, 1: symmetric
44 | real memory_limit = 3; // soft limit, in gigabytes, used to estimate optimal array sizes
45 | int distance_weighting = 1; // Flag to control the distance weighting of cooccurrence counts
46 | char *vocab_file, *file_head;
47 |
48 | /* Search hash table for given string, return record if found, else NULL */
49 | HASHREC *hashsearch(HASHREC **ht, char *w) {
50 | HASHREC *htmp, *hprv;
51 | unsigned int hval = HASHFN(w, TSIZE, SEED);
52 | for (hprv = NULL, htmp=ht[hval]; htmp != NULL && scmp(htmp->word, w) != 0; hprv = htmp, htmp = htmp->next);
53 | if ( htmp != NULL && hprv!=NULL ) { // move to front on access
54 | hprv->next = htmp->next;
55 | htmp->next = ht[hval];
56 | ht[hval] = htmp;
57 | }
58 | return(htmp);
59 | }
60 |
61 | /* Insert string in hash table, check for duplicates which should be absent */
62 | void hashinsert(HASHREC **ht, char *w, long long id) {
63 | HASHREC *htmp, *hprv;
64 | unsigned int hval = HASHFN(w, TSIZE, SEED);
65 | for (hprv = NULL, htmp = ht[hval]; htmp != NULL && scmp(htmp->word, w) != 0; hprv = htmp, htmp = htmp->next);
66 | if (htmp == NULL) {
67 | htmp = (HASHREC *) malloc(sizeof(HASHREC));
68 | htmp->word = (char *) malloc(strlen(w) + 1);
69 | strcpy(htmp->word, w);
70 | htmp->num = id;
71 | htmp->next = NULL;
72 | if (hprv == NULL) ht[hval] = htmp;
73 | else hprv->next = htmp;
74 | }
75 | else fprintf(stderr, "Error, duplicate entry located: %s.\n",htmp->word);
76 | return;
77 | }
78 |
79 | /* Write sorted chunk of cooccurrence records to file, accumulating duplicate entries */
80 | int write_chunk(CREC *cr, long long length, FILE *fout) {
81 | if (length == 0) return 0;
82 |
83 | long long a = 0;
84 | CREC old = cr[a];
85 |
86 | for (a = 1; a < length; a++) {
87 | if (cr[a].word1 == old.word1 && cr[a].word2 == old.word2) {
88 | old.val += cr[a].val;
89 | continue;
90 | }
91 | fwrite(&old, sizeof(CREC), 1, fout);
92 | old = cr[a];
93 | }
94 | fwrite(&old, sizeof(CREC), 1, fout);
95 | return 0;
96 | }
97 |
98 | /* Check if two cooccurrence records are for the same two words, used for qsort */
99 | int compare_crec(const void *a, const void *b) {
100 | int c;
101 | if ( (c = ((CREC *) a)->word1 - ((CREC *) b)->word1) != 0) return c;
102 | else return (((CREC *) a)->word2 - ((CREC *) b)->word2);
103 |
104 | }
105 |
106 | /* Check if two cooccurrence records are for the same two words */
107 | int compare_crecid(CRECID a, CRECID b) {
108 | int c;
109 | if ( (c = a.word1 - b.word1) != 0) return c;
110 | else return a.word2 - b.word2;
111 | }
112 |
113 | /* Swap two entries of priority queue */
114 | void swap_entry(CRECID *pq, int i, int j) {
115 | CRECID temp = pq[i];
116 | pq[i] = pq[j];
117 | pq[j] = temp;
118 | }
119 |
120 | /* Insert entry into priority queue */
121 | void insert(CRECID *pq, CRECID new, int size) {
122 | int j = size - 1, p;
123 | pq[j] = new;
124 | while ( (p=(j-1)/2) >= 0 ) {
125 | if (compare_crecid(pq[p],pq[j]) > 0) {swap_entry(pq,p,j); j = p;}
126 | else break;
127 | }
128 | }
129 |
130 | /* Delete entry from priority queue */
131 | void delete(CRECID *pq, int size) {
132 | int j, p = 0;
133 | pq[p] = pq[size - 1];
134 | while ( (j = 2*p+1) < size - 1 ) {
135 | if (j == size - 2) {
136 | if (compare_crecid(pq[p],pq[j]) > 0) swap_entry(pq,p,j);
137 | return;
138 | }
139 | else {
140 | if (compare_crecid(pq[j], pq[j+1]) < 0) {
141 | if (compare_crecid(pq[p],pq[j]) > 0) {swap_entry(pq,p,j); p = j;}
142 | else return;
143 | }
144 | else {
145 | if (compare_crecid(pq[p],pq[j+1]) > 0) {swap_entry(pq,p,j+1); p = j + 1;}
146 | else return;
147 | }
148 | }
149 | }
150 | }
151 |
152 | /* Write top node of priority queue to file, accumulating duplicate entries */
153 | int merge_write(CRECID new, CRECID *old, FILE *fout) {
154 | if (new.word1 == old->word1 && new.word2 == old->word2) {
155 | old->val += new.val;
156 | return 0; // Indicates duplicate entry
157 | }
158 | fwrite(old, sizeof(CREC), 1, fout);
159 | *old = new;
160 | return 1; // Actually wrote to file
161 | }
162 |
163 | /* Merge [num] sorted files of cooccurrence records */
164 | int merge_files(int num) {
165 | int i, size;
166 | long long counter = 0;
167 | CRECID *pq, new, old;
168 | char filename[200];
169 | FILE **fid, *fout;
170 | fid = calloc(num, sizeof(FILE));
171 | pq = malloc(sizeof(CRECID) * num);
172 | fout = stdout;
173 | if (verbose > 1) fprintf(stderr, "Merging cooccurrence files: processed 0 lines.");
174 |
175 | /* Open all files and add first entry of each to priority queue */
176 | for (i = 0; i < num; i++) {
177 | sprintf(filename,"%s_%04d.bin",file_head,i);
178 | fid[i] = fopen(filename,"rb");
179 | if (fid[i] == NULL) {log_file_loading_error("file", filename); free_fid(fid, num); free(pq); return 1;}
180 | fread(&new, sizeof(CREC), 1, fid[i]);
181 | new.id = i;
182 | insert(pq,new,i+1);
183 | }
184 |
185 | /* Pop top node, save it in old to see if the next entry is a duplicate */
186 | size = num;
187 | old = pq[0];
188 | i = pq[0].id;
189 | delete(pq, size);
190 | fread(&new, sizeof(CREC), 1, fid[i]);
191 | if (feof(fid[i])) size--;
192 | else {
193 | new.id = i;
194 | insert(pq, new, size);
195 | }
196 |
197 | /* Repeatedly pop top node and fill priority queue until files have reached EOF */
198 | while (size > 0) {
199 | counter += merge_write(pq[0], &old, fout); // Only count the lines written to file, not duplicates
200 | if ((counter%100000) == 0) if (verbose > 1) fprintf(stderr,"\033[39G%lld lines.",counter);
201 | i = pq[0].id;
202 | delete(pq, size);
203 | fread(&new, sizeof(CREC), 1, fid[i]);
204 | if (feof(fid[i])) size--;
205 | else {
206 | new.id = i;
207 | insert(pq, new, size);
208 | }
209 | }
210 | fwrite(&old, sizeof(CREC), 1, fout);
211 | fprintf(stderr,"\033[0GMerging cooccurrence files: processed %lld lines.\n",++counter);
212 | for (i=0;i 0) {
244 | fprintf(stderr, "window size: %d\n", window_size);
245 | if (symmetric == 0) fprintf(stderr, "context: asymmetric\n");
246 | else fprintf(stderr, "context: symmetric\n");
247 | }
248 | if (verbose > 1) fprintf(stderr, "max product: %lld\n", max_product);
249 | if (verbose > 1) fprintf(stderr, "overflow length: %lld\n", overflow_length);
250 | sprintf(format,"%%%ds %%lld", MAX_STRING_LENGTH); // Format to read from vocab file, which has (irrelevant) frequency data
251 | if (verbose > 1) fprintf(stderr, "Reading vocab from file \"%s\"...", vocab_file);
252 | fid = fopen(vocab_file,"r");
253 | if (fid == NULL) {
254 | log_file_loading_error("vocab file", vocab_file);
255 | free_resources(vocab_hash, cr, lookup, history, bigram_table);
256 | return 1;
257 | }
258 | while (fscanf(fid, format, str, &id) != EOF) hashinsert(vocab_hash, str, ++j); // Here id is not used: inserting vocab words into hash table with their frequency rank, j
259 | fclose(fid);
260 | vocab_size = j;
261 | j = 0;
262 | if (verbose > 1) fprintf(stderr, "loaded %lld words.\nBuilding lookup table...", vocab_size);
263 |
264 | /* Build auxiliary lookup table used to index into bigram_table */
265 | lookup = (long long *)calloc( vocab_size + 1, sizeof(long long) );
266 | if (lookup == NULL) {
267 | fprintf(stderr, "Couldn't allocate memory!");
268 | free_resources(vocab_hash, cr, lookup, history, bigram_table);
269 | return 1;
270 | }
271 | lookup[0] = 1;
272 | for (a = 1; a <= vocab_size; a++) {
273 | if ((lookup[a] = max_product / a) < vocab_size) lookup[a] += lookup[a-1];
274 | else lookup[a] = lookup[a-1] + vocab_size;
275 | }
276 | if (verbose > 1) fprintf(stderr, "table contains %lld elements.\n",lookup[a-1]);
277 |
278 | /* Allocate memory for full array which will store all cooccurrence counts for words whose product of frequency ranks is less than max_product */
279 | bigram_table = (real *)calloc( lookup[a-1] , sizeof(real) );
280 | if (bigram_table == NULL) {
281 | fprintf(stderr, "Couldn't allocate memory!");
282 | free_resources(vocab_hash, cr, lookup, history, bigram_table);
283 | return 1;
284 | }
285 |
286 | fid = stdin;
287 | // sprintf(format,"%%%ds",MAX_STRING_LENGTH);
288 | sprintf(filename,"%s_%04d.bin", file_head, fidcounter);
289 | foverflow = fopen(filename,"wb");
290 | if (verbose > 1) fprintf(stderr,"Processing token: 0");
291 |
292 | // if symmetric > 0, we can increment ind twice per iteration,
293 | // meaning up to 2x window_size in one loop
294 | long long const overflow_threshold = symmetric == 0 ? overflow_length - window_size : overflow_length - 2 * window_size;
295 |
296 | /* For each token in input stream, calculate a weighted cooccurrence sum within window_size */
297 | while (1) {
298 | if (ind >= overflow_threshold) {
299 | // If overflow buffer is (almost) full, sort it and write it to temporary file
300 | qsort(cr, ind, sizeof(CREC), compare_crec);
301 | write_chunk(cr,ind,foverflow);
302 | fclose(foverflow);
303 | fidcounter++;
304 | sprintf(filename,"%s_%04d.bin",file_head,fidcounter);
305 | foverflow = fopen(filename,"wb");
306 | ind = 0;
307 | }
308 | flag = get_word(str, fid);
309 | if (verbose > 2) fprintf(stderr, "Maybe processing token: %s\n", str);
310 | if (flag == 1) {
311 | // Newline, reset line index (j); maybe eof.
312 | if (feof(fid)) {
313 | if (verbose > 2) fprintf(stderr, "Not getting coocurs as at eof\n");
314 | break;
315 | }
316 | j = 0;
317 | if (verbose > 2) fprintf(stderr, "Not getting coocurs as at newline\n");
318 | continue;
319 | }
320 | counter++;
321 | if ((counter%100000) == 0) if (verbose > 1) fprintf(stderr,"\033[19G%lld",counter);
322 | htmp = hashsearch(vocab_hash, str);
323 | if (htmp == NULL) {
324 | if (verbose > 2) fprintf(stderr, "Not getting coocurs as word not in vocab\n");
325 | continue; // Skip out-of-vocabulary words
326 | }
327 | w2 = htmp->num; // Target word (frequency rank)
328 | for (k = j - 1; k >= ( (j > window_size) ? j - window_size : 0 ); k--) { // Iterate over all words to the left of target word, but not past beginning of line
329 | w1 = history[k % window_size]; // Context word (frequency rank)
330 | if (verbose > 2) fprintf(stderr, "Adding cooccur between words %lld and %lld.\n", w1, w2);
331 | if ( w1 < max_product/w2 ) { // Product is small enough to store in a full array
332 | bigram_table[lookup[w1-1] + w2 - 2] += distance_weighting ? 1.0/((real)(j-k)) : 1.0; // Weight by inverse of distance between words if needed
333 | if (symmetric > 0) bigram_table[lookup[w2-1] + w1 - 2] += distance_weighting ? 1.0/((real)(j-k)) : 1.0; // If symmetric context is used, exchange roles of w2 and w1 (ie look at right context too)
334 | }
335 | else { // Product is too big, data is likely to be sparse. Store these entries in a temporary buffer to be sorted, merged (accumulated), and written to file when it gets full.
336 | cr[ind].word1 = w1;
337 | cr[ind].word2 = w2;
338 | cr[ind].val = distance_weighting ? 1.0/((real)(j-k)) : 1.0;
339 | ind++; // Keep track of how full temporary buffer is
340 | if (symmetric > 0) { // Symmetric context
341 | cr[ind].word1 = w2;
342 | cr[ind].word2 = w1;
343 | cr[ind].val = distance_weighting ? 1.0/((real)(j-k)) : 1.0;
344 | ind++;
345 | }
346 | }
347 | }
348 | history[j % window_size] = w2; // Target word is stored in circular buffer to become context word in the future
349 | j++;
350 | }
351 |
352 | /* Write out temp buffer for the final time (it may not be full) */
353 | if (verbose > 1) fprintf(stderr,"\033[0GProcessed %lld tokens.\n",counter);
354 | qsort(cr, ind, sizeof(CREC), compare_crec);
355 | write_chunk(cr,ind,foverflow);
356 | sprintf(filename,"%s_0000.bin",file_head);
357 |
358 | /* Write out full bigram_table, skipping zeros */
359 | if (verbose > 1) fprintf(stderr, "Writing cooccurrences to disk");
360 | fid = fopen(filename,"wb");
361 | j = 1e6;
362 | for (x = 1; x <= vocab_size; x++) {
363 | if ( (long long) (0.75*log(vocab_size / x)) < j) {
364 | j = (long long) (0.75*log(vocab_size / x));
365 | if (verbose > 1) fprintf(stderr,".");
366 | } // log's to make it look (sort of) pretty
367 | for (y = 1; y <= (lookup[x] - lookup[x-1]); y++) {
368 | if ((r = bigram_table[lookup[x-1] - 2 + y]) != 0) {
369 | fwrite(&x, sizeof(int), 1, fid);
370 | fwrite(&y, sizeof(int), 1, fid);
371 | fwrite(&r, sizeof(real), 1, fid);
372 | }
373 | }
374 | }
375 |
376 | if (verbose > 1) fprintf(stderr,"%d files in total.\n",fidcounter + 1);
377 | fclose(fid);
378 | fclose(foverflow);
379 | free_resources(vocab_hash, cr, lookup, history, bigram_table);
380 | return merge_files(fidcounter + 1); // Merge the sorted temporary files
381 | }
382 |
383 | int main(int argc, char **argv) {
384 | int i;
385 | real rlimit, n = 1e5;
386 | vocab_file = malloc(sizeof(char) * MAX_STRING_LENGTH);
387 | file_head = malloc(sizeof(char) * MAX_STRING_LENGTH);
388 |
389 | if (argc == 1) {
390 | printf("Tool to calculate word-word cooccurrence statistics\n");
391 | printf("Author: Jeffrey Pennington (jpennin@stanford.edu)\n\n");
392 | printf("Usage options:\n");
393 | printf("\t-verbose \n");
394 | printf("\t\tSet verbosity: 0, 1, 2 (default), or 3\n");
395 | printf("\t-symmetric \n");
396 | printf("\t\tIf = 0, only use left context; if = 1 (default), use left and right\n");
397 | printf("\t-window-size \n");
398 | printf("\t\tNumber of context words to the left (and to the right, if symmetric = 1); default 15\n");
399 | printf("\t-vocab-file \n");
400 | printf("\t\tFile containing vocabulary (truncated unigram counts, produced by 'vocab_count'); default vocab.txt\n");
401 | printf("\t-memory \n");
402 | printf("\t\tSoft limit for memory consumption, in GB -- based on simple heuristic, so not extremely accurate; default 4.0\n");
403 | printf("\t-max-product \n");
404 | printf("\t\tLimit the size of dense cooccurrence array by specifying the max product of the frequency counts of the two cooccurring words.\n\t\tThis value overrides that which is automatically produced by '-memory'. Typically only needs adjustment for use with very large corpora.\n");
405 | printf("\t-overflow-length \n");
406 | printf("\t\tLimit to length the sparse overflow array, which buffers cooccurrence data that does not fit in the dense array, before writing to disk. \n\t\tThis value overrides that which is automatically produced by '-memory'. Typically only needs adjustment for use with very large corpora.\n");
407 | printf("\t-overflow-file \n");
408 | printf("\t\tFilename, excluding extension, for temporary files; default overflow\n");
409 | printf("\t-distance-weighting \n");
410 | printf("\t\tIf = 0, do not weight cooccurrence count by distance between words; if = 1 (default), weight the cooccurrence count by inverse of distance between words\n");
411 |
412 | printf("\nExample usage:\n");
413 | printf("./cooccur -verbose 2 -symmetric 0 -window-size 10 -vocab-file vocab.txt -memory 8.0 -overflow-file tempoverflow < corpus.txt > cooccurrences.bin\n\n");
414 | free(vocab_file);
415 | free(file_head);
416 | return 0;
417 | }
418 |
419 | if ((i = find_arg((char *)"-verbose", argc, argv)) > 0) verbose = atoi(argv[i + 1]);
420 | if ((i = find_arg((char *)"-symmetric", argc, argv)) > 0) symmetric = atoi(argv[i + 1]);
421 | if ((i = find_arg((char *)"-window-size", argc, argv)) > 0) window_size = atoi(argv[i + 1]);
422 | if ((i = find_arg((char *)"-vocab-file", argc, argv)) > 0) strcpy(vocab_file, argv[i + 1]);
423 | else strcpy(vocab_file, (char *)"vocab.txt");
424 | if ((i = find_arg((char *)"-overflow-file", argc, argv)) > 0) strcpy(file_head, argv[i + 1]);
425 | else strcpy(file_head, (char *)"overflow");
426 | if ((i = find_arg((char *)"-memory", argc, argv)) > 0) memory_limit = atof(argv[i + 1]);
427 | if ((i = find_arg((char *)"-distance-weighting", argc, argv)) > 0) distance_weighting = atoi(argv[i + 1]);
428 |
429 | /* The memory_limit determines a limit on the number of elements in bigram_table and the overflow buffer */
430 | /* Estimate the maximum value that max_product can take so that this limit is still satisfied */
431 | rlimit = 0.85 * (real)memory_limit * 1073741824/(sizeof(CREC));
432 | while (fabs(rlimit - n * (log(n) + 0.1544313298)) > 1e-3) n = rlimit / (log(n) + 0.1544313298);
433 | max_product = (long long) n;
434 | overflow_length = (long long) rlimit/6; // 0.85 + 1/6 ~= 1
435 |
436 | /* Override estimates by specifying limits explicitly on the command line */
437 | if ((i = find_arg((char *)"-max-product", argc, argv)) > 0) max_product = atoll(argv[i + 1]);
438 | if ((i = find_arg((char *)"-overflow-length", argc, argv)) > 0) overflow_length = atoll(argv[i + 1]);
439 |
440 | const int returned_value = get_cooccurrence();
441 | free(vocab_file);
442 | free(file_head);
443 | return returned_value;
444 | }
445 |
446 |
--------------------------------------------------------------------------------
/src/glove.c:
--------------------------------------------------------------------------------
1 | // GloVe: Global Vectors for Word Representation
2 | //
3 | // Copyright (c) 2014 The Board of Trustees of
4 | // The Leland Stanford Junior University. All Rights Reserved.
5 | //
6 | // Licensed under the Apache License, Version 2.0 (the "License");
7 | // you may not use this file except in compliance with the License.
8 | // You may obtain a copy of the License at
9 | //
10 | // http://www.apache.org/licenses/LICENSE-2.0
11 | //
12 | // Unless required by applicable law or agreed to in writing, software
13 | // distributed under the License is distributed on an "AS IS" BASIS,
14 | // WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
15 | // See the License for the specific language governing permissions and
16 | // limitations under the License.
17 | //
18 | //
19 | // For more information, bug reports, fixes, contact:
20 | // Jeffrey Pennington (jpennin@stanford.edu)
21 | // GlobalVectors@googlegroups.com
22 | // http://nlp.stanford.edu/projects/glove/
23 |
24 | // silence the many complaints from visual studio
25 | #define _CRT_SECURE_NO_WARNINGS
26 |
27 | #include
28 | #include
29 | #include
30 | #include
31 | #include
32 | #include
33 |
34 | // windows pthread.h is buggy, but this #define fixes it
35 | #define HAVE_STRUCT_TIMESPEC
36 | #include
37 |
38 | #include "common.h"
39 |
40 | #define _FILE_OFFSET_BITS 64
41 |
42 | int write_header=0; //0=no, 1=yes; writes vocab_size/vector_size as first line for use with some libraries, such as gensim.
43 | int verbose = 2; // 0, 1, or 2
44 | int seed = 0;
45 | int use_unk_vec = 1; // 0 or 1
46 | int num_threads = 8; // pthreads
47 | int num_iter = 25; // Number of full passes through cooccurrence matrix
48 | int vector_size = 50; // Word vector size
49 | int save_gradsq = 0; // By default don't save squared gradient values
50 | int use_binary = 0; // 0: save as text files; 1: save as binary; 2: both. For binary, save both word and context word vectors.
51 | int model = 2; // For text file output only. 0: concatenate word and context vectors (and biases) i.e. save everything; 1: Just save word vectors (no bias); 2: Save (word + context word) vectors (no biases)
52 | int checkpoint_every = 0; // checkpoint the model for every checkpoint_every iterations. Do nothing if checkpoint_every <= 0
53 | int load_init_param = 0; // if 1 initial paramters are loaded from -init-param-file
54 | int save_init_param = 0; // if 1 initial paramters are saved (i.e., in the 0 checkpoint)
55 | int load_init_gradsq = 0; // if 1 initial squared gradients are loaded from -init-gradsq-file
56 | real eta = 0.05; // Initial learning rate
57 | real alpha = 0.75, x_max = 100.0; // Weighting function parameters, not extremely sensitive to corpus, though may need adjustment for very small or very large corpora
58 | real grad_clip_value = 100.0; // Clipping parameter for gradient components. Values will be clipped to [-grad_clip_value, grad_clip_value] interval.
59 | real *W, *gradsq, *cost;
60 | long long num_lines, *lines_per_thread, vocab_size;
61 | char vocab_file[MAX_STRING_LENGTH];
62 | char input_file[MAX_STRING_LENGTH];
63 | char save_W_file[MAX_STRING_LENGTH];
64 | char save_gradsq_file[MAX_STRING_LENGTH];
65 | char init_param_file[MAX_STRING_LENGTH];
66 | char init_gradsq_file[MAX_STRING_LENGTH];
67 |
68 | /**
69 | * Loads a save file for use as the initial values for the parameters or gradsq
70 | * Return value: 0 if success, -1 if fail
71 | */
72 | int load_init_file(char *file_name, real *array, long long array_size) {
73 | FILE *fin;
74 | long long a;
75 | fin = fopen(file_name, "rb");
76 | if (fin == NULL) {
77 | log_file_loading_error("init file", file_name);
78 | return -1;
79 | }
80 | for (a = 0; a < array_size; a++) {
81 | if (feof(fin)) {
82 | fprintf(stderr, "EOF reached before data fully loaded in %s.\n", file_name);
83 | fclose(fin);
84 | return -1;
85 | }
86 | fread(&array[a], sizeof(real), 1, fin);
87 | }
88 | fclose(fin);
89 | return 0;
90 | }
91 |
92 | void initialize_parameters() {
93 | // TODO: return an error code when an error occurs, clean up in the calling routine
94 | if (seed == 0) {
95 | seed = time(0);
96 | }
97 | fprintf(stderr, "Using random seed %d\n", seed);
98 | srand(seed);
99 | long long a;
100 | long long W_size = 2 * vocab_size * (vector_size + 1); // +1 to allocate space for bias
101 |
102 | /* Allocate space for word vectors and context word vectors, and correspodning gradsq */
103 | a = posix_memalign((void **)&W, 128, W_size * sizeof(real)); // Might perform better than malloc
104 | if (W == NULL) {
105 | fprintf(stderr, "Error allocating memory for W\n");
106 | exit(1);
107 | }
108 | a = posix_memalign((void **)&gradsq, 128, W_size * sizeof(real)); // Might perform better than malloc
109 | if (gradsq == NULL) {
110 | fprintf(stderr, "Error allocating memory for gradsq\n");
111 | free(W);
112 | exit(1);
113 | }
114 | if (load_init_param) {
115 | // Load existing parameters
116 | fprintf(stderr, "\nLoading initial parameters from %s \n", init_param_file);
117 | if (load_init_file(init_param_file, W, W_size)) {
118 | free(W);
119 | free(gradsq);
120 | exit(1);
121 | }
122 | } else {
123 | // Initialize new parameters
124 | for (a = 0; a < W_size; ++a) {
125 | W[a] = (rand() / (real)RAND_MAX - 0.5) / vector_size;
126 | }
127 | }
128 |
129 | if (load_init_gradsq) {
130 | // Load existing squared gradients
131 | fprintf(stderr, "\nLoading initial squared gradients from %s \n", init_gradsq_file);
132 | if (load_init_file(init_gradsq_file, gradsq, W_size)) {
133 | free(W);
134 | free(gradsq);
135 | exit(1);
136 | }
137 | } else {
138 | // Initialize new squared gradients
139 | for (a = 0; a < W_size; ++a) {
140 | gradsq[a] = 1.0; // So initial value of eta is equal to initial learning rate
141 | }
142 | }
143 | }
144 |
145 | static inline real check_nan(real update) {
146 | if (isnan(update) || isinf(update)) {
147 | fprintf(stderr,"\ncaught NaN in update");
148 | return 0.;
149 | } else {
150 | return update;
151 | }
152 | }
153 |
154 | /* Train the GloVe model */
155 | void *glove_thread(void *vid) {
156 | long long a, b ,l1, l2;
157 | long long id = *(long long*)vid;
158 | CREC cr;
159 | real diff, fdiff, temp1, temp2;
160 | FILE *fin;
161 | fin = fopen(input_file, "rb");
162 | if (fin == NULL) {
163 | // TODO: exit all the threads or somehow mark that glove failed
164 | log_file_loading_error("input file", input_file);
165 | pthread_exit(NULL);
166 | }
167 | fseeko(fin, (num_lines / num_threads * id) * (sizeof(CREC)), SEEK_SET); //Threads spaced roughly equally throughout file
168 | cost[id] = 0;
169 |
170 | real* W_updates1 = (real*)malloc(vector_size * sizeof(real));
171 | if (NULL == W_updates1){
172 | fclose(fin);
173 | pthread_exit(NULL);
174 | }
175 | real* W_updates2 = (real*)malloc(vector_size * sizeof(real));
176 | if (NULL == W_updates2){
177 | fclose(fin);
178 | free(W_updates1);
179 | pthread_exit(NULL);
180 | }
181 | for (a = 0; a < lines_per_thread[id]; a++) {
182 | fread(&cr, sizeof(CREC), 1, fin);
183 | if (feof(fin)) break;
184 | if (cr.word1 < 1 || cr.word2 < 1) { continue; }
185 |
186 | /* Get location of words in W & gradsq */
187 | l1 = (cr.word1 - 1LL) * (vector_size + 1); // cr word indices start at 1
188 | l2 = ((cr.word2 - 1LL) + vocab_size) * (vector_size + 1); // shift by vocab_size to get separate vectors for context words
189 |
190 | /* Calculate cost, save diff for gradients */
191 | diff = 0;
192 | for (b = 0; b < vector_size; b++) diff += W[b + l1] * W[b + l2]; // dot product of word and context word vector
193 | diff += W[vector_size + l1] + W[vector_size + l2] - log(cr.val); // add separate bias for each word
194 | fdiff = (cr.val > x_max) ? diff : pow(cr.val / x_max, alpha) * diff; // multiply weighting function (f) with diff
195 |
196 | // Check for NaN and inf() in the diffs.
197 | if (isnan(diff) || isnan(fdiff) || isinf(diff) || isinf(fdiff)) {
198 | fprintf(stderr,"Caught NaN in diff for kdiff for thread. Skipping update");
199 | continue;
200 | }
201 |
202 | cost[id] += 0.5 * fdiff * diff; // weighted squared error
203 |
204 | /* Adaptive gradient updates */
205 | real W_updates1_sum = 0;
206 | real W_updates2_sum = 0;
207 | for (b = 0; b < vector_size; b++) {
208 | // learning rate times gradient for word vectors
209 | temp1 = fmin(fmax(fdiff * W[b + l2], -grad_clip_value), grad_clip_value) * eta;
210 | temp2 = fmin(fmax(fdiff * W[b + l1], -grad_clip_value), grad_clip_value) * eta;
211 | // adaptive updates
212 | W_updates1[b] = temp1 / sqrt(gradsq[b + l1]);
213 | W_updates2[b] = temp2 / sqrt(gradsq[b + l2]);
214 | W_updates1_sum += W_updates1[b];
215 | W_updates2_sum += W_updates2[b];
216 | gradsq[b + l1] += temp1 * temp1;
217 | gradsq[b + l2] += temp2 * temp2;
218 | }
219 | if (!isnan(W_updates1_sum) && !isinf(W_updates1_sum) && !isnan(W_updates2_sum) && !isinf(W_updates2_sum)) {
220 | for (b = 0; b < vector_size; b++) {
221 | W[b + l1] -= W_updates1[b];
222 | W[b + l2] -= W_updates2[b];
223 | }
224 | }
225 |
226 | // updates for bias terms
227 | W[vector_size + l1] -= check_nan(fdiff / sqrt(gradsq[vector_size + l1]));
228 | W[vector_size + l2] -= check_nan(fdiff / sqrt(gradsq[vector_size + l2]));
229 | fdiff *= fdiff;
230 | gradsq[vector_size + l1] += fdiff;
231 | gradsq[vector_size + l2] += fdiff;
232 |
233 | }
234 | free(W_updates1);
235 | free(W_updates2);
236 |
237 | fclose(fin);
238 | pthread_exit(NULL);
239 | }
240 |
241 | /* Save params to file */
242 | int save_params(int nb_iter) {
243 | /*
244 | * nb_iter is the number of iteration (= a full pass through the cooccurrence matrix).
245 | * nb_iter > 0 => checkpointing the intermediate parameters, so nb_iter is in the filename of output file.
246 | * nb_iter == 0 => checkpointing the initial parameters
247 | * else => saving the final paramters, so nb_iter is ignored.
248 | */
249 |
250 | long long a, b;
251 | char format[20];
252 | char output_file[MAX_STRING_LENGTH+20], output_file_gsq[MAX_STRING_LENGTH+20];
253 | char *word = malloc(sizeof(char) * MAX_STRING_LENGTH + 1);
254 | if (NULL == word) {
255 | return 1;
256 | }
257 | FILE *fid, *fout;
258 | FILE *fgs = NULL;
259 |
260 | if (use_binary > 0 || nb_iter == 0) {
261 | // Save parameters in binary file
262 | // note: always save initial parameters in binary, as the reading code expects binary
263 | if (nb_iter < 0)
264 | sprintf(output_file,"%s.bin",save_W_file);
265 | else
266 | sprintf(output_file,"%s.%03d.bin",save_W_file,nb_iter);
267 |
268 | fout = fopen(output_file,"wb");
269 | if (fout == NULL) {log_file_loading_error("weights file", save_W_file); free(word); return 1;}
270 | for (a = 0; a < 2 * vocab_size * (vector_size + 1); a++) fwrite(&W[a], sizeof(real), 1,fout);
271 | fclose(fout);
272 | if (save_gradsq > 0) {
273 | if (nb_iter < 0)
274 | sprintf(output_file_gsq,"%s.bin",save_gradsq_file);
275 | else
276 | sprintf(output_file_gsq,"%s.%03d.bin",save_gradsq_file,nb_iter);
277 |
278 | fgs = fopen(output_file_gsq,"wb");
279 | if (fgs == NULL) {log_file_loading_error("gradsq file", save_gradsq_file); free(word); return 1;}
280 | for (a = 0; a < 2 * vocab_size * (vector_size + 1); a++) fwrite(&gradsq[a], sizeof(real), 1,fgs);
281 | fclose(fgs);
282 | }
283 | }
284 | if (use_binary != 1) { // Save parameters in text file
285 | if (nb_iter < 0)
286 | sprintf(output_file,"%s.txt",save_W_file);
287 | else
288 | sprintf(output_file,"%s.%03d.txt",save_W_file,nb_iter);
289 | if (save_gradsq > 0) {
290 | if (nb_iter < 0)
291 | sprintf(output_file_gsq,"%s.txt",save_gradsq_file);
292 | else
293 | sprintf(output_file_gsq,"%s.%03d.txt",save_gradsq_file,nb_iter);
294 |
295 | fgs = fopen(output_file_gsq,"wb");
296 | if (fgs == NULL) {log_file_loading_error("gradsq file", save_gradsq_file); free(word); return 1;}
297 | }
298 | fout = fopen(output_file,"wb");
299 | if (fout == NULL) {log_file_loading_error("weights file", save_W_file); free(word); return 1;}
300 | fid = fopen(vocab_file, "r");
301 | sprintf(format,"%%%ds",MAX_STRING_LENGTH);
302 | if (fid == NULL) {log_file_loading_error("vocab file", vocab_file); free(word); fclose(fout); return 1;}
303 | if (write_header) fprintf(fout, "%lld %d\n", vocab_size, vector_size);
304 | for (a = 0; a < vocab_size; a++) {
305 | if (fscanf(fid,format,word) == 0) {free(word); fclose(fid); fclose(fout); return 1;}
306 | // input vocab cannot contain special keyword
307 | if (strcmp(word, "") == 0) {free(word); fclose(fid); fclose(fout); return 1;}
308 | fprintf(fout, "%s",word);
309 | if (model == 0) { // Save all parameters (including bias)
310 | for (b = 0; b < (vector_size + 1); b++) fprintf(fout," %lf", W[a * (vector_size + 1) + b]);
311 | for (b = 0; b < (vector_size + 1); b++) fprintf(fout," %lf", W[(vocab_size + a) * (vector_size + 1) + b]);
312 | }
313 | if (model == 1) // Save only "word" vectors (without bias)
314 | for (b = 0; b < vector_size; b++) fprintf(fout," %lf", W[a * (vector_size + 1) + b]);
315 | if (model == 2) // Save "word + context word" vectors (without bias)
316 | for (b = 0; b < vector_size; b++) fprintf(fout," %lf", W[a * (vector_size + 1) + b] + W[(vocab_size + a) * (vector_size + 1) + b]);
317 | if (model == 3) { // Save "word" and "context" vectors (without bias; row-concatenated)
318 | for (b = 0; b < vector_size; b++) fprintf(fout," %lf", W[a * (vector_size + 1) + b]);
319 | for (b = 0; b < vector_size; b++) fprintf(fout," %lf", W[(vocab_size + a) * (vector_size + 1) + b]);
320 | }
321 | fprintf(fout,"\n");
322 | if (save_gradsq > 0) { // Save gradsq
323 | fprintf(fgs, "%s",word);
324 | for (b = 0; b < (vector_size + 1); b++) fprintf(fgs," %lf", gradsq[a * (vector_size + 1) + b]);
325 | for (b = 0; b < (vector_size + 1); b++) fprintf(fgs," %lf", gradsq[(vocab_size + a) * (vector_size + 1) + b]);
326 | fprintf(fgs,"\n");
327 | }
328 | if (fscanf(fid,format,word) == 0) {
329 | // Eat irrelevant frequency entry
330 | fclose(fout);
331 | fclose(fid);
332 | free(word);
333 | return 1;
334 | }
335 | }
336 |
337 | if (use_unk_vec) {
338 | real* unk_vec = (real*)calloc((vector_size + 1), sizeof(real));
339 | real* unk_context = (real*)calloc((vector_size + 1), sizeof(real));
340 | strcpy(word, "");
341 |
342 | long long num_rare_words = vocab_size < 100 ? vocab_size : 100;
343 |
344 | for (a = vocab_size - num_rare_words; a < vocab_size; a++) {
345 | for (b = 0; b < (vector_size + 1); b++) {
346 | unk_vec[b] += W[a * (vector_size + 1) + b] / num_rare_words;
347 | unk_context[b] += W[(vocab_size + a) * (vector_size + 1) + b] / num_rare_words;
348 | }
349 | }
350 |
351 | fprintf(fout, "%s",word);
352 | if (model == 0) { // Save all parameters (including bias)
353 | for (b = 0; b < (vector_size + 1); b++) fprintf(fout," %lf", unk_vec[b]);
354 | for (b = 0; b < (vector_size + 1); b++) fprintf(fout," %lf", unk_context[b]);
355 | }
356 | if (model == 1) // Save only "word" vectors (without bias)
357 | for (b = 0; b < vector_size; b++) fprintf(fout," %lf", unk_vec[b]);
358 | if (model == 2) // Save "word + context word" vectors (without bias)
359 | for (b = 0; b < vector_size; b++) fprintf(fout," %lf", unk_vec[b] + unk_context[b]);
360 | if (model == 3) { // Save "word" and "context" vectors (without bias; row-concatenated)
361 | for (b = 0; b < vector_size; b++) fprintf(fout," %lf", unk_vec[b]);
362 | for (b = 0; b < vector_size; b++) fprintf(fout," %lf", unk_context[b]);
363 | }
364 | fprintf(fout,"\n");
365 |
366 | free(unk_vec);
367 | free(unk_context);
368 | }
369 |
370 | fclose(fid);
371 | fclose(fout);
372 | if (save_gradsq > 0) fclose(fgs);
373 | }
374 | free(word);
375 | return 0;
376 | }
377 |
378 | /* Train model */
379 | int train_glove() {
380 | long long a, file_size;
381 | int save_params_return_code;
382 | int b;
383 | FILE *fin;
384 | real total_cost = 0;
385 |
386 | fprintf(stderr, "TRAINING MODEL\n");
387 |
388 | fin = fopen(input_file, "rb");
389 | if (fin == NULL) {log_file_loading_error("cooccurrence file", input_file); return 1;}
390 | fseeko(fin, 0, SEEK_END);
391 | file_size = ftello(fin);
392 | num_lines = file_size/(sizeof(CREC)); // Assuming the file isn't corrupt and consists only of CREC's
393 | fclose(fin);
394 | fprintf(stderr,"Read %lld lines.\n", num_lines);
395 | if (verbose > 1) fprintf(stderr,"Initializing parameters...");
396 | initialize_parameters();
397 | if (verbose > 1) fprintf(stderr,"done.\n");
398 | if (save_init_param) {
399 | if (verbose > 1) fprintf(stderr,"Saving initial parameters... ");
400 | save_params_return_code = save_params(0);
401 | if (save_params_return_code != 0)
402 | return save_params_return_code;
403 | if (verbose > 1) fprintf(stderr,"done.\n");
404 | }
405 | if (verbose > 0) fprintf(stderr,"vector size: %d\n", vector_size);
406 | if (verbose > 0) fprintf(stderr,"vocab size: %lld\n", vocab_size);
407 | if (verbose > 0) fprintf(stderr,"x_max: %lf\n", x_max);
408 | if (verbose > 0) fprintf(stderr,"alpha: %lf\n", alpha);
409 | pthread_t *pt = (pthread_t *)malloc(num_threads * sizeof(pthread_t));
410 | lines_per_thread = (long long *) malloc(num_threads * sizeof(long long));
411 |
412 | time_t rawtime;
413 | struct tm *info;
414 | char time_buffer[80];
415 | // Lock-free asynchronous SGD
416 | for (b = 0; b < num_iter; b++) {
417 | total_cost = 0;
418 | for (a = 0; a < num_threads - 1; a++) lines_per_thread[a] = num_lines / num_threads;
419 | lines_per_thread[a] = num_lines / num_threads + num_lines % num_threads;
420 | long long *thread_ids = (long long*)malloc(sizeof(long long) * num_threads);
421 | for (a = 0; a < num_threads; a++) thread_ids[a] = a;
422 | for (a = 0; a < num_threads; a++) pthread_create(&pt[a], NULL, glove_thread, (void *)&thread_ids[a]);
423 | for (a = 0; a < num_threads; a++) pthread_join(pt[a], NULL);
424 | for (a = 0; a < num_threads; a++) total_cost += cost[a];
425 | free(thread_ids);
426 |
427 | time(&rawtime);
428 | info = localtime(&rawtime);
429 | strftime(time_buffer,80,"%x - %I:%M.%S%p", info);
430 | fprintf(stderr, "%s, iter: %03d, cost: %lf\n", time_buffer, b+1, total_cost/num_lines);
431 |
432 | if (checkpoint_every > 0 && (b + 1) % checkpoint_every == 0) {
433 | fprintf(stderr," saving intermediate parameters for iter %03d...", b+1);
434 | save_params_return_code = save_params(b+1);
435 | if (save_params_return_code != 0) {
436 | free(pt);
437 | free(lines_per_thread);
438 | return save_params_return_code;
439 | }
440 | fprintf(stderr,"done.\n");
441 | }
442 | }
443 | free(pt);
444 | free(lines_per_thread);
445 | return save_params(-1);
446 | }
447 |
448 | int main(int argc, char **argv) {
449 | int i;
450 | FILE *fid;
451 | int result = 0;
452 |
453 | if (argc == 1) {
454 | printf("GloVe: Global Vectors for Word Representation, v0.2\n");
455 | printf("Author: Jeffrey Pennington (jpennin@stanford.edu)\n\n");
456 | printf("Usage options:\n");
457 | printf("\t-verbose \n");
458 | printf("\t\tSet verbosity: 0, 1, or 2 (default)\n");
459 | printf("\t-write-header \n");
460 | printf("\t\tIf 1, write vocab_size/vector_size as first line. Do nothing if 0 (default).\n");
461 | printf("\t-vector-size \n");
462 | printf("\t\tDimension of word vector representations (excluding bias term); default 50\n");
463 | printf("\t-threads \n");
464 | printf("\t\tNumber of threads; default 8\n");
465 | printf("\t-iter \n");
466 | printf("\t\tNumber of training iterations; default 25\n");
467 | printf("\t-eta \n");
468 | printf("\t\tInitial learning rate; default 0.05\n");
469 | printf("\t-alpha \n");
470 | printf("\t\tParameter in exponent of weighting function; default 0.75\n");
471 | printf("\t-x-max \n");
472 | printf("\t\tParameter specifying cutoff in weighting function; default 100.0\n");
473 | printf("\t-grad-clip\n");
474 | printf("\t\tGradient components clipping parameter. Values will be clipped to [-grad-clip, grad-clip] interval\n");
475 | printf("\t-binary \n");
476 | printf("\t\tSave output in binary format (0: text, 1: binary, 2: both); default 0\n");
477 | printf("\t-model \n");
478 | printf("\t\tModel for word vector output (for text output only); default 2\n");
479 | printf("\t\t 0: output all data, for both word and context word vectors, including bias terms\n");
480 | printf("\t\t 1: output word vectors, excluding bias terms\n");
481 | printf("\t\t 2: output word vectors + context word vectors, excluding bias terms\n");
482 | printf("\t\t 3: output word vectors and context word vectors, excluding bias terms; context word vectors are row-concatenated to the word vectors\n");
483 | printf("\t-input-file \n");
484 | printf("\t\tBinary input file of shuffled cooccurrence data (produced by 'cooccur' and 'shuffle'); default cooccurrence.shuf.bin\n");
485 | printf("\t-vocab-file \n");
486 | printf("\t\tFile containing vocabulary (truncated unigram counts, produced by 'vocab_count'); default vocab.txt\n");
487 | printf("\t-save-file \n");
488 | printf("\t\tFilename, excluding extension, for word vector output; default vectors\n");
489 | printf("\t-gradsq-file \n");
490 | printf("\t\tFilename, excluding extension, for squared gradient output; default gradsq\n");
491 | printf("\t-save-gradsq \n");
492 | printf("\t\tSave accumulated squared gradients; default 0 (off); ignored if gradsq-file is specified\n");
493 | printf("\t-checkpoint-every \n");
494 | printf("\t\tCheckpoint a model every iterations; default 0 (off)\n");
495 | printf("\t-load-init-param \n");
496 | printf("\t\tLoad initial parameters from -init-param-file; default 0 (false)\n");
497 | printf("\t-save-init-param \n");
498 | printf("\t\tSave initial parameters (i.e., checkpoint the model before any training); default 0 (false)\n");
499 | printf("\t-init-param-file \n");
500 | printf("\t\tBinary initial parameters file to be loaded if -load-init-params is 1; (default is to look for vectors.000.bin)\n");
501 | printf("\t-load-init-gradsq \n");
502 | printf("\t\tLoad initial squared gradients from -init-gradsq-file; default 0 (false)\n");
503 | printf("\t-init-gradsq-file \n");
504 | printf("\t\tBinary initial squared gradients file to be loaded if -load-init-gradsq is 1; (default is to look for gradsq.000.bin)\n");
505 | printf("\t-seed \n");
506 | printf("\t\tRandom seed to use. If not set, will be randomized using current time.");
507 | printf("\nExample usage:\n");
508 | printf("./glove -input-file cooccurrence.shuf.bin -vocab-file vocab.txt -save-file vectors -gradsq-file gradsq -verbose 2 -vector-size 100 -threads 16 -alpha 0.75 -x-max 100.0 -eta 0.05 -binary 2 -model 2\n\n");
509 | result = 0;
510 | } else {
511 | if ((i = find_arg((char *)"-write-header", argc, argv)) > 0) write_header = atoi(argv[i + 1]);
512 | if ((i = find_arg((char *)"-verbose", argc, argv)) > 0) verbose = atoi(argv[i + 1]);
513 | if ((i = find_arg((char *)"-vector-size", argc, argv)) > 0) vector_size = atoi(argv[i + 1]);
514 | if ((i = find_arg((char *)"-iter", argc, argv)) > 0) num_iter = atoi(argv[i + 1]);
515 | if ((i = find_arg((char *)"-threads", argc, argv)) > 0) num_threads = atoi(argv[i + 1]);
516 | cost = malloc(sizeof(real) * num_threads);
517 | if ((i = find_arg((char *)"-alpha", argc, argv)) > 0) alpha = atof(argv[i + 1]);
518 | if ((i = find_arg((char *)"-x-max", argc, argv)) > 0) x_max = atof(argv[i + 1]);
519 | if ((i = find_arg((char *)"-eta", argc, argv)) > 0) eta = atof(argv[i + 1]);
520 | if ((i = find_arg((char *)"-grad-clip", argc, argv)) > 0) grad_clip_value = atof(argv[i + 1]);
521 | if ((i = find_arg((char *)"-binary", argc, argv)) > 0) use_binary = atoi(argv[i + 1]);
522 | if ((i = find_arg((char *)"-model", argc, argv)) > 0) model = atoi(argv[i + 1]);
523 | if (model != 0 && model != 1) model = 2;
524 | if ((i = find_arg((char *)"-save-gradsq", argc, argv)) > 0) save_gradsq = atoi(argv[i + 1]);
525 | if ((i = find_arg((char *)"-vocab-file", argc, argv)) > 0) strcpy(vocab_file, argv[i + 1]);
526 | else strcpy(vocab_file, (char *)"vocab.txt");
527 | if ((i = find_arg((char *)"-save-file", argc, argv)) > 0) strcpy(save_W_file, argv[i + 1]);
528 | else strcpy(save_W_file, (char *)"vectors");
529 | if ((i = find_arg((char *)"-gradsq-file", argc, argv)) > 0) {
530 | strcpy(save_gradsq_file, argv[i + 1]);
531 | save_gradsq = 1;
532 | }
533 | else if (save_gradsq > 0) strcpy(save_gradsq_file, (char *)"gradsq");
534 | if ((i = find_arg((char *)"-input-file", argc, argv)) > 0) strcpy(input_file, argv[i + 1]);
535 | else strcpy(input_file, (char *)"cooccurrence.shuf.bin");
536 | if ((i = find_arg((char *)"-checkpoint-every", argc, argv)) > 0) checkpoint_every = atoi(argv[i + 1]);
537 | if ((i = find_arg((char *)"-init-param-file", argc, argv)) > 0) strcpy(init_param_file, argv[i + 1]);
538 | else strcpy(init_param_file, (char *)"vectors.000.bin");
539 | if ((i = find_arg((char *)"-load-init-param", argc, argv)) > 0) load_init_param = atoi(argv[i + 1]);
540 | if ((i = find_arg((char *)"-save-init-param", argc, argv)) > 0) save_init_param = atoi(argv[i + 1]);
541 | if ((i = find_arg((char *)"-init-gradsq-file", argc, argv)) > 0) strcpy(init_gradsq_file, argv[i + 1]);
542 | else strcpy(init_gradsq_file, (char *)"gradsq.000.bin");
543 | if ((i = find_arg((char *)"-load-init-gradsq", argc, argv)) > 0) load_init_gradsq = atoi(argv[i + 1]);
544 | if ((i = find_arg((char *)"-seed", argc, argv)) > 0) seed = atoi(argv[i + 1]);
545 |
546 | vocab_size = 0;
547 | fid = fopen(vocab_file, "r");
548 | if (fid == NULL) {log_file_loading_error("vocab file", vocab_file); free(cost); return 1;}
549 | while ((i = getc(fid)) != EOF) if (i == '\n') vocab_size++; // Count number of entries in vocab_file
550 | fclose(fid);
551 | if (vocab_size == 0) {fprintf(stderr, "Unable to find any vocab entries in vocab file %s.\n", vocab_file); free(cost); return 1;}
552 | result = train_glove();
553 | free(cost);
554 | }
555 | free(W);
556 | free(gradsq);
557 |
558 | return result;
559 | }
560 |
--------------------------------------------------------------------------------
/src/shuffle.c:
--------------------------------------------------------------------------------
1 | // Tool to shuffle entries of word-word cooccurrence files
2 | //
3 | // Copyright (c) 2014 The Board of Trustees of
4 | // The Leland Stanford Junior University. All Rights Reserved.
5 | //
6 | // Licensed under the Apache License, Version 2.0 (the "License");
7 | // you may not use this file except in compliance with the License.
8 | // You may obtain a copy of the License at
9 | //
10 | // http://www.apache.org/licenses/LICENSE-2.0
11 | //
12 | // Unless required by applicable law or agreed to in writing, software
13 | // distributed under the License is distributed on an "AS IS" BASIS,
14 | // WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
15 | // See the License for the specific language governing permissions and
16 | // limitations under the License.
17 | //
18 | //
19 | // For more information, bug reports, fixes, contact:
20 | // Jeffrey Pennington (jpennin@stanford.edu)
21 | // GlobalVectors@googlegroups.com
22 | // http://nlp.stanford.edu/projects/glove/
23 |
24 | #include
25 | #include
26 | #include
27 | #include
28 | #include "common.h"
29 |
30 |
31 | static const long LRAND_MAX = ((long) RAND_MAX + 2) * (long)RAND_MAX;
32 |
33 | int verbose = 2; // 0, 1, or 2
34 | int seed = 0;
35 | long long array_size = 2000000; // size of chunks to shuffle individually
36 | char *file_head; // temporary file string
37 | real memory_limit = 2.0; // soft limit, in gigabytes
38 |
39 | /* Generate uniformly distributed random long ints */
40 | static long rand_long(long n) {
41 | long limit = LRAND_MAX - LRAND_MAX % n;
42 | long rnd;
43 | do {
44 | rnd = ((long)RAND_MAX + 1) * (long)rand() + (long)rand();
45 | } while (rnd >= limit);
46 | return rnd % n;
47 | }
48 |
49 | /* Write contents of array to binary file */
50 | int write_chunk(CREC *array, long size, FILE *fout) {
51 | long i = 0;
52 | for (i = 0; i < size; i++) fwrite(&array[i], sizeof(CREC), 1, fout);
53 | return 0;
54 | }
55 |
56 | /* Fisher-Yates shuffle */
57 | void shuffle(CREC *array, long n) {
58 | long i, j;
59 | CREC tmp;
60 | for (i = n - 1; i > 0; i--) {
61 | j = rand_long(i + 1);
62 | tmp = array[j];
63 | array[j] = array[i];
64 | array[i] = tmp;
65 | }
66 | }
67 |
68 | /* Merge shuffled temporary files; doesn't necessarily produce a perfect shuffle, but good enough */
69 | int shuffle_merge(int num) {
70 | long i, j, k, l = 0;
71 | int fidcounter = 0;
72 | CREC *array;
73 | char filename[MAX_STRING_LENGTH];
74 | FILE **fid, *fout = stdout;
75 |
76 | array = malloc(sizeof(CREC) * array_size);
77 | fid = calloc(num, sizeof(FILE));
78 | for (fidcounter = 0; fidcounter < num; fidcounter++) { //num = number of temporary files to merge
79 | sprintf(filename,"%s_%04d.bin",file_head, fidcounter);
80 | fid[fidcounter] = fopen(filename, "rb");
81 | if (fid[fidcounter] == NULL) {
82 | log_file_loading_error("temp file", filename);
83 | free(array);
84 | free_fid(fid, num);
85 | return 1;
86 | }
87 | }
88 | if (verbose > 0) fprintf(stderr, "Merging temp files: processed %ld lines.", l);
89 |
90 | while (1) { //Loop until EOF in all files
91 | i = 0;
92 | //Read at most array_size values into array, roughly array_size/num from each temp file
93 | for (j = 0; j < num; j++) {
94 | if (feof(fid[j])) continue;
95 | for (k = 0; k < array_size / num; k++){
96 | fread(&array[i], sizeof(CREC), 1, fid[j]);
97 | if (feof(fid[j])) break;
98 | i++;
99 | }
100 | }
101 | if (i == 0) break;
102 | l += i;
103 | shuffle(array, i-1); // Shuffles lines between temp files
104 | write_chunk(array,i,fout);
105 | if (verbose > 0) fprintf(stderr, "\033[31G%ld lines.", l);
106 | }
107 | fprintf(stderr, "\033[0GMerging temp files: processed %ld lines.", l);
108 | for (fidcounter = 0; fidcounter < num; fidcounter++) {
109 | fclose(fid[fidcounter]);
110 | sprintf(filename,"%s_%04d.bin",file_head, fidcounter);
111 | remove(filename);
112 | }
113 | fprintf(stderr, "\n\n");
114 | free(array);
115 | free(fid);
116 | return 0;
117 | }
118 |
119 | /* Shuffle large input stream by splitting into chunks */
120 | int shuffle_by_chunks() {
121 | if (seed == 0) {
122 | seed = time(0);
123 | }
124 | fprintf(stderr, "Using random seed %d\n", seed);
125 | srand(seed);
126 | long i = 0, l = 0;
127 | int fidcounter = 0;
128 | char filename[MAX_STRING_LENGTH];
129 | CREC *array;
130 | FILE *fin = stdin, *fid;
131 | array = malloc(sizeof(CREC) * array_size);
132 |
133 | fprintf(stderr,"SHUFFLING COOCCURRENCES\n");
134 | if (verbose > 0) fprintf(stderr,"array size: %lld\n", array_size);
135 | sprintf(filename,"%s_%04d.bin",file_head, fidcounter);
136 | fid = fopen(filename,"w");
137 | if (fid == NULL) {
138 | log_file_loading_error("file", filename);
139 | free(array);
140 | return 1;
141 | }
142 | if (verbose > 1) fprintf(stderr, "Shuffling by chunks: processed 0 lines.");
143 |
144 | while (1) { //Continue until EOF
145 | if (i >= array_size) {// If array is full, shuffle it and save to temporary file
146 | shuffle(array, i-2);
147 | l += i;
148 | if (verbose > 1) fprintf(stderr, "\033[22Gprocessed %ld lines.", l);
149 | write_chunk(array,i,fid);
150 | fclose(fid);
151 | fidcounter++;
152 | sprintf(filename,"%s_%04d.bin",file_head, fidcounter);
153 | fid = fopen(filename,"w");
154 | if (fid == NULL) {
155 | log_file_loading_error("file", filename);
156 | free(array);
157 | return 1;
158 | }
159 | i = 0;
160 | }
161 | fread(&array[i], sizeof(CREC), 1, fin);
162 | if (feof(fin)) break;
163 | i++;
164 | }
165 | shuffle(array, i-2); //Last chunk may be smaller than array_size
166 | write_chunk(array,i,fid);
167 | l += i;
168 | if (verbose > 1) fprintf(stderr, "\033[22Gprocessed %ld lines.\n", l);
169 | if (verbose > 1) fprintf(stderr, "Wrote %d temporary file(s).\n", fidcounter + 1);
170 | fclose(fid);
171 | free(array);
172 | return shuffle_merge(fidcounter + 1); // Merge and shuffle together temporary files
173 | }
174 |
175 | int main(int argc, char **argv) {
176 | int i;
177 |
178 | if (argc == 2 &&
179 | (!scmp(argv[1], "-h") || !scmp(argv[1], "-help") || !scmp(argv[1], "--help"))) {
180 | printf("Tool to shuffle entries of word-word cooccurrence files\n");
181 | printf("Author: Jeffrey Pennington (jpennin@stanford.edu)\n\n");
182 | printf("Usage options:\n");
183 | printf("\t-verbose \n");
184 | printf("\t\tSet verbosity: 0, 1, or 2 (default)\n");
185 | printf("\t-memory \n");
186 | printf("\t\tSoft limit for memory consumption, in GB; default 4.0\n");
187 | printf("\t-array-size \n");
188 | printf("\t\tLimit to length the buffer which stores chunks of data to shuffle before writing to disk. \n\t\tThis value overrides that which is automatically produced by '-memory'.\n");
189 | printf("\t-temp-file \n");
190 | printf("\t\tFilename, excluding extension, for temporary files; default temp_shuffle\n");
191 | printf("\t-seed \n");
192 | printf("\t\tRandom seed to use. If not set, will be randomized using current time.");
193 | printf("\nExample usage: (assuming 'cooccurrence.bin' has been produced by 'coccur')\n");
194 | printf("./shuffle -verbose 2 -memory 8.0 < cooccurrence.bin > cooccurrence.shuf.bin\n");
195 | return 0;
196 | }
197 |
198 | file_head = malloc(sizeof(char) * MAX_STRING_LENGTH);
199 | if ((i = find_arg((char *)"-verbose", argc, argv)) > 0) verbose = atoi(argv[i + 1]);
200 | if ((i = find_arg((char *)"-temp-file", argc, argv)) > 0) strcpy(file_head, argv[i + 1]);
201 | else strcpy(file_head, (char *)"temp_shuffle");
202 | if ((i = find_arg((char *)"-memory", argc, argv)) > 0) memory_limit = atof(argv[i + 1]);
203 | array_size = (long long) (0.95 * (real)memory_limit * 1073741824/(sizeof(CREC)));
204 | if ((i = find_arg((char *)"-array-size", argc, argv)) > 0) array_size = atoll(argv[i + 1]);
205 | if ((i = find_arg((char *)"-seed", argc, argv)) > 0) seed = atoi(argv[i + 1]);
206 | const int returned_value = shuffle_by_chunks();
207 | free(file_head);
208 | return returned_value;
209 | }
210 |
211 |
--------------------------------------------------------------------------------
/src/vocab_count.c:
--------------------------------------------------------------------------------
1 | // Tool to extract unigram counts
2 | //
3 | // GloVe: Global Vectors for Word Representation
4 | // Copyright (c) 2014 The Board of Trustees of
5 | // The Leland Stanford Junior University. All Rights Reserved.
6 | //
7 | // Licensed under the Apache License, Version 2.0 (the "License");
8 | // you may not use this file except in compliance with the License.
9 | // You may obtain a copy of the License at
10 | //
11 | // http://www.apache.org/licenses/LICENSE-2.0
12 | //
13 | // Unless required by applicable law or agreed to in writing, software
14 | // distributed under the License is distributed on an "AS IS" BASIS,
15 | // WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
16 | // See the License for the specific language governing permissions and
17 | // limitations under the License.
18 | //
19 | //
20 | // For more information, bug reports, fixes, contact:
21 | // Jeffrey Pennington (jpennin@stanford.edu)
22 | // Christopher Manning (manning@cs.stanford.edu)
23 | // https://github.com/stanfordnlp/GloVe/
24 | // GlobalVectors@googlegroups.com
25 | // http://nlp.stanford.edu/projects/glove/
26 |
27 | #include
28 | #include
29 | #include
30 | #include "common.h"
31 |
32 | typedef struct vocabulary {
33 | char *word;
34 | long long count;
35 | } VOCAB;
36 |
37 | int verbose = 2; // 0, 1, or 2
38 | long long min_count = 1; // min occurrences for inclusion in vocab
39 | long long max_vocab = 0; // max_vocab = 0 for no limit
40 |
41 |
42 | /* Vocab frequency comparison; break ties alphabetically */
43 | int CompareVocabTie(const void *a, const void *b) {
44 | long long c;
45 | if ( (c = ((VOCAB *) b)->count - ((VOCAB *) a)->count) != 0) return ( c > 0 ? 1 : -1 );
46 | else return (scmp(((VOCAB *) a)->word,((VOCAB *) b)->word));
47 |
48 | }
49 |
50 | /* Vocab frequency comparison; no tie-breaker */
51 | int CompareVocab(const void *a, const void *b) {
52 | long long c;
53 | if ( (c = ((VOCAB *) b)->count - ((VOCAB *) a)->count) != 0) return ( c > 0 ? 1 : -1 );
54 | else return 0;
55 | }
56 |
57 | /* Search hash table for given string, insert if not found */
58 | void hashinsert(HASHREC **ht, char *w) {
59 | HASHREC *htmp, *hprv;
60 | unsigned int hval = HASHFN(w, TSIZE, SEED);
61 |
62 | for (hprv = NULL, htmp = ht[hval]; htmp != NULL && scmp(htmp->word, w) != 0; hprv = htmp, htmp = htmp->next);
63 | if (htmp == NULL) {
64 | htmp = (HASHREC *) malloc( sizeof(HASHREC) );
65 | htmp->word = (char *) malloc( strlen(w) + 1 );
66 | strcpy(htmp->word, w);
67 | htmp->num = 1;
68 | htmp->next = NULL;
69 | if ( hprv==NULL )
70 | ht[hval] = htmp;
71 | else
72 | hprv->next = htmp;
73 | }
74 | else {
75 | /* new records are not moved to front */
76 | htmp->num++;
77 | if (hprv != NULL) {
78 | /* move to front on access */
79 | hprv->next = htmp->next;
80 | htmp->next = ht[hval];
81 | ht[hval] = htmp;
82 | }
83 | }
84 | return;
85 | }
86 |
87 | int get_counts() {
88 | long long i = 0, j = 0, vocab_size = 12500;
89 | // char format[20];
90 | char str[MAX_STRING_LENGTH + 1];
91 | HASHREC **vocab_hash = inithashtable();
92 | HASHREC *htmp;
93 | VOCAB *vocab;
94 | FILE *fid = stdin;
95 |
96 | fprintf(stderr, "BUILDING VOCABULARY\n");
97 | if (verbose > 1) fprintf(stderr, "Processed %lld tokens.", i);
98 | // sprintf(format,"%%%ds",MAX_STRING_LENGTH);
99 | while ( ! feof(fid)) {
100 | // Insert all tokens into hashtable
101 | int nl = get_word(str, fid);
102 | if (nl) continue; // just a newline marker or feof
103 | if (strcmp(str, "") == 0) {
104 | fprintf(stderr, "\nError, vector found in corpus.\nPlease remove s from your corpus (e.g. cat text8 | sed -e 's///g' > text8.new)");
105 | free_table(vocab_hash);
106 | return 1;
107 | }
108 | hashinsert(vocab_hash, str);
109 | if (((++i)%100000) == 0) if (verbose > 1) fprintf(stderr,"\033[11G%lld tokens.", i);
110 | }
111 | if (verbose > 1) fprintf(stderr, "\033[0GProcessed %lld tokens.\n", i);
112 | vocab = malloc(sizeof(VOCAB) * vocab_size);
113 | for (i = 0; i < TSIZE; i++) { // Migrate vocab to array
114 | htmp = vocab_hash[i];
115 | while (htmp != NULL) {
116 | vocab[j].word = htmp->word;
117 | vocab[j].count = htmp->num;
118 | j++;
119 | if (j>=vocab_size) {
120 | vocab_size += 2500;
121 | vocab = (VOCAB *)realloc(vocab, sizeof(VOCAB) * vocab_size);
122 | }
123 | htmp = htmp->next;
124 | }
125 | }
126 | if (verbose > 1) fprintf(stderr, "Counted %lld unique words.\n", j);
127 | if (max_vocab > 0 && max_vocab < j)
128 | // If the vocabulary exceeds limit, first sort full vocab by frequency without alphabetical tie-breaks.
129 | // This results in pseudo-random ordering for words with same frequency, so that when truncated, the words span whole alphabet
130 | qsort(vocab, j, sizeof(VOCAB), CompareVocab);
131 | else max_vocab = j;
132 | qsort(vocab, max_vocab, sizeof(VOCAB), CompareVocabTie); //After (possibly) truncating, sort (possibly again), breaking ties alphabetically
133 |
134 | for (i = 0; i < max_vocab; i++) {
135 | if (vocab[i].count < min_count) { // If a minimum frequency cutoff exists, truncate vocabulary
136 | if (verbose > 0) fprintf(stderr, "Truncating vocabulary at min count %lld.\n",min_count);
137 | break;
138 | }
139 | printf("%s %lld\n",vocab[i].word,vocab[i].count);
140 | }
141 |
142 | if (i == max_vocab && max_vocab < j) if (verbose > 0) fprintf(stderr, "Truncating vocabulary at size %lld.\n", max_vocab);
143 | fprintf(stderr, "Using vocabulary of size %lld.\n\n", i);
144 | free_table(vocab_hash);
145 | free(vocab);
146 | return 0;
147 | }
148 |
149 | int main(int argc, char **argv) {
150 | if (argc == 2 &&
151 | (!scmp(argv[1], "-h") || !scmp(argv[1], "-help") || !scmp(argv[1], "--help"))) {
152 | printf("Simple tool to extract unigram counts\n");
153 | printf("Author: Jeffrey Pennington (jpennin@stanford.edu)\n\n");
154 | printf("Usage options:\n");
155 | printf("\t-verbose \n");
156 | printf("\t\tSet verbosity: 0, 1, or 2 (default)\n");
157 | printf("\t-max-vocab \n");
158 | printf("\t\tUpper bound on vocabulary size, i.e. keep the most frequent words. The minimum frequency words are randomly sampled so as to obtain an even distribution over the alphabet.\n");
159 | printf("\t-min-count \n");
160 | printf("\t\tLower limit such that words which occur fewer than times are discarded.\n");
161 | printf("\nExample usage:\n");
162 | printf("./vocab_count -verbose 2 -max-vocab 100000 -min-count 10 < corpus.txt > vocab.txt\n");
163 | return 0;
164 | }
165 |
166 | int i;
167 | if ((i = find_arg((char *)"-verbose", argc, argv)) > 0) verbose = atoi(argv[i + 1]);
168 | if ((i = find_arg((char *)"-max-vocab", argc, argv)) > 0) max_vocab = atoll(argv[i + 1]);
169 | if ((i = find_arg((char *)"-min-count", argc, argv)) > 0) min_count = atoll(argv[i + 1]);
170 | return get_counts();
171 | }
172 |
173 |
--------------------------------------------------------------------------------
28 |
29 | If the web datasets above don't match the semantics of your end use case, you can train word vectors on your own corpus.
30 |
31 | $ git clone https://github.com/stanfordnlp/glove
32 | $ cd glove && make
33 | $ ./demo.sh
34 |
35 | Make sure you have the following prerequisites installed when running the steps above:
36 |
37 | * GNU Make
38 | * GCC (Clang pretending to be GCC is fine)
39 | * Python and NumPy
40 |
41 | The demo.sh script downloads a small corpus, consisting of the first 100M characters of Wikipedia. It collects unigram counts, constructs and shuffles cooccurrence data, and trains a simple version of the GloVe model. It also runs a word analogy evaluation script in python to verify word vector quality. More details about training on your own corpus can be found by reading [demo.sh](https://github.com/stanfordnlp/GloVe/blob/master/demo.sh) or the [src/README.md](https://github.com/stanfordnlp/GloVe/tree/master/src)
42 |
43 | ### License
44 | All work contained in this package is licensed under the Apache License, Version 2.0. See the include LICENSE file.
45 |
--------------------------------------------------------------------------------
/demo.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | set -e
3 |
4 | # Makes programs, downloads sample data, trains a GloVe model, and then evaluates it.
5 | # One optional argument can specify the language used for eval script: matlab, octave or [default] python
6 |
7 | make
8 | if [ ! -e text8 ]; then
9 | if hash wget 2>/dev/null; then
10 | wget http://mattmahoney.net/dc/text8.zip
11 | else
12 | curl -O http://mattmahoney.net/dc/text8.zip
13 | fi
14 | unzip text8.zip
15 | rm text8.zip
16 | fi
17 |
18 | CORPUS=text8
19 | VOCAB_FILE=vocab.txt
20 | COOCCURRENCE_FILE=cooccurrence.bin
21 | COOCCURRENCE_SHUF_FILE=cooccurrence.shuf.bin
22 | BUILDDIR=build
23 | SAVE_FILE=vectors
24 | VERBOSE=2
25 | MEMORY=4.0
26 | VOCAB_MIN_COUNT=5
27 | VECTOR_SIZE=50
28 | MAX_ITER=15
29 | WINDOW_SIZE=15
30 | BINARY=2
31 | NUM_THREADS=8
32 | X_MAX=10
33 | if hash python 2>/dev/null; then
34 | PYTHON=python
35 | else
36 | PYTHON=python3
37 | fi
38 |
39 | echo
40 | echo "$ $BUILDDIR/vocab_count -min-count $VOCAB_MIN_COUNT -verbose $VERBOSE < $CORPUS > $VOCAB_FILE"
41 | $BUILDDIR/vocab_count -min-count $VOCAB_MIN_COUNT -verbose $VERBOSE < $CORPUS > $VOCAB_FILE
42 | echo "$ $BUILDDIR/cooccur -memory $MEMORY -vocab-file $VOCAB_FILE -verbose $VERBOSE -window-size $WINDOW_SIZE < $CORPUS > $COOCCURRENCE_FILE"
43 | $BUILDDIR/cooccur -memory $MEMORY -vocab-file $VOCAB_FILE -verbose $VERBOSE -window-size $WINDOW_SIZE < $CORPUS > $COOCCURRENCE_FILE
44 | echo "$ $BUILDDIR/shuffle -memory $MEMORY -verbose $VERBOSE < $COOCCURRENCE_FILE > $COOCCURRENCE_SHUF_FILE"
45 | $BUILDDIR/shuffle -memory $MEMORY -verbose $VERBOSE < $COOCCURRENCE_FILE > $COOCCURRENCE_SHUF_FILE
46 | echo "$ $BUILDDIR/glove -save-file $SAVE_FILE -threads $NUM_THREADS -input-file $COOCCURRENCE_SHUF_FILE -x-max $X_MAX -iter $MAX_ITER -vector-size $VECTOR_SIZE -binary $BINARY -vocab-file $VOCAB_FILE -verbose $VERBOSE"
47 | $BUILDDIR/glove -save-file $SAVE_FILE -threads $NUM_THREADS -input-file $COOCCURRENCE_SHUF_FILE -x-max $X_MAX -iter $MAX_ITER -vector-size $VECTOR_SIZE -binary $BINARY -vocab-file $VOCAB_FILE -verbose $VERBOSE
48 | if [ "$CORPUS" = 'text8' ]; then
49 | if [ "$1" = 'matlab' ]; then
50 | matlab -nodisplay -nodesktop -nojvm -nosplash < ./eval/matlab/read_and_evaluate.m 1>&2
51 | elif [ "$1" = 'octave' ]; then
52 | octave < ./eval/octave/read_and_evaluate_octave.m 1>&2
53 | else
54 | echo "$ $PYTHON eval/python/evaluate.py"
55 | $PYTHON eval/python/evaluate.py
56 | fi
57 | fi
58 |
--------------------------------------------------------------------------------
/eval/matlab/WordLookup.m:
--------------------------------------------------------------------------------
1 | function index = WordLookup(InputString)
2 | global wordMap
3 | if wordMap.isKey(InputString)
4 | index = wordMap(InputString);
5 | elseif wordMap.isKey('')
6 | index = wordMap('');
7 | else
8 | index = 0;
9 | end
10 |
--------------------------------------------------------------------------------
/eval/matlab/evaluate_vectors.m:
--------------------------------------------------------------------------------
1 | function [BB] = evaluate_vectors(W)
2 |
3 | global wordMap
4 |
5 | filenames = {'capital-common-countries' 'capital-world' 'currency' 'city-in-state' 'family' 'gram1-adjective-to-adverb' ...
6 | 'gram2-opposite' 'gram3-comparative' 'gram4-superlative' 'gram5-present-participle' 'gram6-nationality-adjective' ...
7 | 'gram7-past-tense' 'gram8-plural' 'gram9-plural-verbs'};
8 | path = './eval/question-data/';
9 |
10 | split_size = 100; %to avoid memory overflow, could be increased/decreased depending on system and vocab size
11 |
12 | correct_sem = 0; %count correct semantic questions
13 | correct_syn = 0; %count correct syntactic questions
14 | correct_tot = 0; %count correct questions
15 | count_sem = 0; %count all semantic questions
16 | count_syn = 0; %count all syntactic questions
17 | count_tot = 0; %count all questions
18 | full_count = 0; %count all questions, including those with unknown words
19 |
20 | if wordMap.isKey('')
21 | unkkey = wordMap('');
22 | else
23 | unkkey = 0;
24 | end
25 |
26 | for j=1:length(filenames);
27 |
28 | clear dist;
29 |
30 | fid=fopen([path filenames{j} '.txt']);
31 | temp=textscan(fid,'%s%s%s%s');
32 | fclose(fid);
33 | ind1 = cellfun(@WordLookup,temp{1}); %indices of first word in analogy
34 | ind2 = cellfun(@WordLookup,temp{2}); %indices of second word in analogy
35 | ind3 = cellfun(@WordLookup,temp{3}); %indices of third word in analogy
36 | ind4 = cellfun(@WordLookup,temp{4}); %indices of answer word in analogy
37 | full_count = full_count + length(ind1);
38 | ind = (ind1 ~= unkkey) & (ind2 ~= unkkey) & (ind3 ~= unkkey) & (ind4 ~= unkkey); %only look at those questions which have no unknown words
39 | ind1 = ind1(ind);
40 | ind2 = ind2(ind);
41 | ind3 = ind3(ind);
42 | ind4 = ind4(ind);
43 | disp([filenames{j} ':']);
44 | mx = zeros(1,length(ind1));
45 | num_iter = ceil(length(ind1)/split_size);
46 | for jj=1:num_iter
47 | range = (jj-1)*split_size+1:min(jj*split_size,length(ind1));
48 | dist = full(W * (W(ind2(range),:)' - W(ind1(range),:)' + W(ind3(range),:)')); %cosine similarity if input W has been normalized
49 | for i=1:length(range)
50 | dist(ind1(range(i)),i) = -Inf;
51 | dist(ind2(range(i)),i) = -Inf;
52 | dist(ind3(range(i)),i) = -Inf;
53 | end
54 | [~, mx(range)] = max(dist); %predicted word index
55 | end
56 |
57 | val = (ind4 == mx'); %correct predictions
58 | count_tot = count_tot + length(ind1);
59 | correct_tot = correct_tot + sum(val);
60 | disp(['ACCURACY TOP1: ' num2str(mean(val)*100,'%-2.2f') '% (' num2str(sum(val)) '/' num2str(length(val)) ')']);
61 | if j < 6
62 | count_sem = count_sem + length(ind1);
63 | correct_sem = correct_sem + sum(val);
64 | else
65 | count_syn = count_syn + length(ind1);
66 | correct_syn = correct_syn + sum(val);
67 | end
68 |
69 | disp(['Total accuracy: ' num2str(100*correct_tot/count_tot,'%-2.2f') '% Semantic accuracy: ' num2str(100*correct_sem/count_sem,'%-2.2f') '% Syntactic accuracy: ' num2str(100*correct_syn/count_syn,'%-2.2f') '%']);
70 |
71 | end
72 | disp('________________________________________________________________________________');
73 | disp(['Questions seen/total: ' num2str(100*count_tot/full_count,'%-2.2f') '% (' num2str(count_tot) '/' num2str(full_count) ')']);
74 | disp(['Semantic Accuracy: ' num2str(100*correct_sem/count_sem,'%-2.2f') '% (' num2str(correct_sem) '/' num2str(count_sem) ')']);
75 | disp(['Syntactic Accuracy: ' num2str(100*correct_syn/count_syn,'%-2.2f') '% (' num2str(correct_syn) '/' num2str(count_syn) ')']);
76 | disp(['Total Accuracy: ' num2str(100*correct_tot/count_tot,'%-2.2f') '% (' num2str(correct_tot) '/' num2str(count_tot) ')']);
77 | BB = [100*correct_sem/count_sem 100*correct_syn/count_syn 100*correct_tot/count_tot];
78 |
79 | end
80 |
--------------------------------------------------------------------------------
/eval/matlab/read_and_evaluate.m:
--------------------------------------------------------------------------------
1 | addpath('./eval/matlab');
2 | if(~exist('vocab_file'))
3 | vocab_file = 'vocab.txt';
4 | end
5 | if(~exist('vectors_file'))
6 | vectors_file = 'vectors.bin';
7 | end
8 |
9 | fid = fopen(vocab_file, 'r');
10 | words = textscan(fid, '%s %f');
11 | fclose(fid);
12 | words = words{1};
13 | vocab_size = length(words);
14 | global wordMap
15 | wordMap = containers.Map(words(1:vocab_size),1:vocab_size);
16 |
17 | fid = fopen(vectors_file,'r');
18 | fseek(fid,0,'eof');
19 | vector_size = ftell(fid)/16/vocab_size - 1;
20 | frewind(fid);
21 | WW = fread(fid, [vector_size+1 2*vocab_size], 'double')';
22 | fclose(fid);
23 |
24 | W1 = WW(1:vocab_size, 1:vector_size); % word vectors
25 | W2 = WW(vocab_size+1:end, 1:vector_size); % context (tilde) word vectors
26 |
27 | W = W1 + W2; %Evaluate on sum of word vectors
28 | W = bsxfun(@rdivide,W,sqrt(sum(W.*W,2))); %normalize vectors before evaluation
29 | evaluate_vectors(W);
30 | exit
31 |
32 |
--------------------------------------------------------------------------------
/eval/octave/WordLookup_octave.m:
--------------------------------------------------------------------------------
1 | function index = WordLookup_octave(InputString)
2 | global wordMap
3 |
4 | if isfield(wordMap, InputString)
5 | index = wordMap.(InputString);
6 | elseif isfield(wordMap, '')
7 | index = wordMap.('');
8 | else
9 | index = 0;
10 | end
11 |
--------------------------------------------------------------------------------
/eval/octave/evaluate_vectors_octave.m:
--------------------------------------------------------------------------------
1 | function [BB] = evaluate_vectors_octave(W)
2 |
3 | global wordMap
4 |
5 | filenames = {'capital-common-countries' 'capital-world' 'currency' 'city-in-state' 'family' 'gram1-adjective-to-adverb' ...
6 | 'gram2-opposite' 'gram3-comparative' 'gram4-superlative' 'gram5-present-participle' 'gram6-nationality-adjective' ...
7 | 'gram7-past-tense' 'gram8-plural' 'gram9-plural-verbs'};
8 | path = './eval/question-data/';
9 |
10 | split_size = 100; %to avoid memory overflow, could be increased/decreased depending on system and vocab size
11 |
12 | correct_sem = 0; %count correct semantic questions
13 | correct_syn = 0; %count correct syntactic questions
14 | correct_tot = 0; %count correct questions
15 | count_sem = 0; %count all semantic questions
16 | count_syn = 0; %count all syntactic questions
17 | count_tot = 0; %count all questions
18 | full_count = 0; %count all questions, including those with unknown words
19 |
20 |
21 | if isfield(wordMap, '')
22 | unkkey = wordMap.('');
23 | else
24 | unkkey = 0;
25 | end
26 |
27 | for j=1:length(filenames);
28 |
29 | clear dist;
30 |
31 | fid=fopen([path filenames{j} '.txt']);
32 | temp=textscan(fid,'%s%s%s%s');
33 | fclose(fid);
34 | ind1 = cellfun(@WordLookup_octave,temp{1}); %indices of first word in analogy
35 | ind2 = cellfun(@WordLookup_octave,temp{2}); %indices of second word in analogy
36 | ind3 = cellfun(@WordLookup_octave,temp{3}); %indices of third word in analogy
37 | ind4 = cellfun(@WordLookup_octave,temp{4}); %indices of answer word in analogy
38 | full_count = full_count + length(ind1);
39 | ind = (ind1 ~= unkkey) & (ind2 ~= unkkey) & (ind3 ~= unkkey) & (ind4 ~= unkkey); %only look at those questions which have no unknown words
40 | ind1 = ind1(ind);
41 | ind2 = ind2(ind);
42 | ind3 = ind3(ind);
43 | ind4 = ind4(ind);
44 | disp([filenames{j} ':']);
45 | mx = zeros(1,length(ind1));
46 | num_iter = ceil(length(ind1)/split_size);
47 | for jj=1:num_iter
48 | range = (jj-1)*split_size+1:min(jj*split_size,length(ind1));
49 | dist = full(W * (W(ind2(range),:)' - W(ind1(range),:)' + W(ind3(range),:)')); %cosine similarity if input W has been normalized
50 | for i=1:length(range)
51 | dist(ind1(range(i)),i) = -Inf;
52 | dist(ind2(range(i)),i) = -Inf;
53 | dist(ind3(range(i)),i) = -Inf;
54 | end
55 | [~, mx(range)] = max(dist); %predicted word index
56 | end
57 |
58 | val = (ind4 == mx'); %correct predictions
59 | count_tot = count_tot + length(ind1);
60 | correct_tot = correct_tot + sum(val);
61 | disp(['ACCURACY TOP1: ' num2str(mean(val)*100,'%-2.2f') '% (' num2str(sum(val)) '/' num2str(length(val)) ')']);
62 | if j < 6
63 | count_sem = count_sem + length(ind1);
64 | correct_sem = correct_sem + sum(val);
65 | else
66 | count_syn = count_syn + length(ind1);
67 | correct_syn = correct_syn + sum(val);
68 | end
69 |
70 | disp(['Total accuracy: ' num2str(100*correct_tot/count_tot,'%-2.2f') '% Semantic accuracy: ' num2str(100*correct_sem/count_sem,'%-2.2f') '% Syntactic accuracy: ' num2str(100*correct_syn/count_syn,'%-2.2f') '%']);
71 |
72 | end
73 | disp('________________________________________________________________________________');
74 | disp(['Questions seen/total: ' num2str(100*count_tot/full_count,'%-2.2f') '% (' num2str(count_tot) '/' num2str(full_count) ')']);
75 | disp(['Semantic Accuracy: ' num2str(100*correct_sem/count_sem,'%-2.2f') '% (' num2str(correct_sem) '/' num2str(count_sem) ')']);
76 | disp(['Syntactic Accuracy: ' num2str(100*correct_syn/count_syn,'%-2.2f') '% (' num2str(correct_syn) '/' num2str(count_syn) ')']);
77 | disp(['Total Accuracy: ' num2str(100*correct_tot/count_tot,'%-2.2f') '% (' num2str(correct_tot) '/' num2str(count_tot) ')']);
78 | BB = [100*correct_sem/count_sem 100*correct_syn/count_syn 100*correct_tot/count_tot];
79 |
80 | end
81 |
--------------------------------------------------------------------------------
/eval/octave/read_and_evaluate_octave.m:
--------------------------------------------------------------------------------
1 | addpath('./eval/octave');
2 | if(~exist('vocab_file'))
3 | vocab_file = 'vocab.txt';
4 | end
5 | if(~exist('vectors_file'))
6 | vectors_file = 'vectors.bin';
7 | end
8 |
9 | fid = fopen(vocab_file, 'r');
10 | words = textscan(fid, '%s %f');
11 | fclose(fid);
12 | words = words{1};
13 | vocab_size = length(words);
14 | global wordMap
15 |
16 | wordMap = struct();
17 | for i=1:numel(words)
18 | wordMap.(words{i}) = i;
19 | end
20 |
21 | fid = fopen(vectors_file,'r');
22 | fseek(fid,0,'eof');
23 | vector_size = ftell(fid)/16/vocab_size - 1;
24 | frewind(fid);
25 | WW = fread(fid, [vector_size+1 2*vocab_size], 'double')';
26 | fclose(fid);
27 |
28 | W1 = WW(1:vocab_size, 1:vector_size); % word vectors
29 | W2 = WW(vocab_size+1:end, 1:vector_size); % context (tilde) word vectors
30 |
31 | W = W1 + W2; %Evaluate on sum of word vectors
32 | W = bsxfun(@rdivide,W,sqrt(sum(W.*W,2))); %normalize vectors before evaluation
33 | evaluate_vectors_octave(W);
34 | exit
35 |
36 |
--------------------------------------------------------------------------------
/eval/python/distance.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import numpy as np
3 | import sys
4 |
5 | def generate():
6 | parser = argparse.ArgumentParser()
7 | parser.add_argument('--vocab_file', default='vocab.txt', type=str)
8 | parser.add_argument('--vectors_file', default='vectors.txt', type=str)
9 | args = parser.parse_args()
10 |
11 | with open(args.vocab_file, 'r') as f:
12 | words = [x.rstrip().split(' ')[0] for x in f.readlines()]
13 | with open(args.vectors_file, 'r') as f:
14 | vectors = {}
15 | for line in f:
16 | vals = line.rstrip().split(' ')
17 | vectors[vals[0]] = [float(x) for x in vals[1:]]
18 |
19 | vocab_size = len(words)
20 | vocab = {w: idx for idx, w in enumerate(words)}
21 | ivocab = {idx: w for idx, w in enumerate(words)}
22 |
23 | vector_dim = len(vectors[ivocab[0]])
24 | W = np.zeros((vocab_size, vector_dim))
25 | for word, v in vectors.items():
26 | if word == '':
27 | continue
28 | W[vocab[word], :] = v
29 |
30 | # normalize each word vector to unit variance
31 | W_norm = np.zeros(W.shape)
32 | d = (np.sum(W ** 2, 1) ** (0.5))
33 | W_norm = (W.T / d).T
34 | return (W_norm, vocab, ivocab)
35 |
36 |
37 | def distance(W, vocab, ivocab, input_term):
38 | for idx, term in enumerate(input_term.split(' ')):
39 | if term in vocab:
40 | print('Word: %s Position in vocabulary: %i' % (term, vocab[term]))
41 | if idx == 0:
42 | vec_result = np.copy(W[vocab[term], :])
43 | else:
44 | vec_result += W[vocab[term], :]
45 | else:
46 | print('Word: %s Out of dictionary!\n' % term)
47 | return
48 |
49 | vec_norm = np.zeros(vec_result.shape)
50 | d = (np.sum(vec_result ** 2,) ** (0.5))
51 | vec_norm = (vec_result.T / d).T
52 |
53 | dist = np.dot(W, vec_norm.T)
54 |
55 | for term in input_term.split(' '):
56 | index = vocab[term]
57 | dist[index] = -np.Inf
58 |
59 | a = np.argsort(-dist)[:N]
60 |
61 | print("\n Word Cosine distance\n")
62 | print("---------------------------------------------------------\n")
63 | for x in a:
64 | print("%35s\t\t%f\n" % (ivocab[x], dist[x]))
65 |
66 |
67 | if __name__ == "__main__":
68 | N = 100 # number of closest words that will be shown
69 | W, vocab, ivocab = generate()
70 | while True:
71 | input_term = input("\nEnter word or sentence (EXIT to break): ")
72 | if input_term == 'EXIT':
73 | break
74 | else:
75 | distance(W, vocab, ivocab, input_term)
76 |
--------------------------------------------------------------------------------
/eval/python/evaluate.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import numpy as np
3 |
4 | def main():
5 | parser = argparse.ArgumentParser()
6 | parser.add_argument('--vocab_file', default='vocab.txt', type=str)
7 | parser.add_argument('--vectors_file', default='vectors.txt', type=str)
8 | args = parser.parse_args()
9 |
10 | with open(args.vocab_file, 'r') as f:
11 | words = [x.rstrip().split(' ')[0] for x in f.readlines()]
12 | with open(args.vectors_file, 'r') as f:
13 | vectors = {}
14 | for line in f:
15 | vals = line.rstrip().split(' ')
16 | vectors[vals[0]] = [float(x) for x in vals[1:]]
17 |
18 | vocab_size = len(words)
19 | vocab = {w: idx for idx, w in enumerate(words)}
20 | ivocab = {idx: w for idx, w in enumerate(words)}
21 |
22 | vector_dim = len(vectors[ivocab[0]])
23 | W = np.zeros((vocab_size, vector_dim))
24 | for word, v in vectors.items():
25 | if word == '':
26 | continue
27 | W[vocab[word], :] = v
28 |
29 | # normalize each word vector to unit length
30 | W_norm = np.zeros(W.shape)
31 | d = (np.sum(W ** 2, 1) ** (0.5))
32 | W_norm = (W.T / d).T
33 | evaluate_vectors(W_norm, vocab)
34 |
35 | def evaluate_vectors(W, vocab):
36 | """Evaluate the trained word vectors on a variety of tasks"""
37 |
38 | filenames = [
39 | 'capital-common-countries.txt', 'capital-world.txt', 'currency.txt',
40 | 'city-in-state.txt', 'family.txt', 'gram1-adjective-to-adverb.txt',
41 | 'gram2-opposite.txt', 'gram3-comparative.txt', 'gram4-superlative.txt',
42 | 'gram5-present-participle.txt', 'gram6-nationality-adjective.txt',
43 | 'gram7-past-tense.txt', 'gram8-plural.txt', 'gram9-plural-verbs.txt',
44 | ]
45 | prefix = './eval/question-data/'
46 |
47 | # to avoid memory overflow, could be increased/decreased
48 | # depending on system and vocab size
49 | split_size = 100
50 |
51 | correct_sem = 0; # count correct semantic questions
52 | correct_syn = 0; # count correct syntactic questions
53 | correct_tot = 0 # count correct questions
54 | count_sem = 0; # count all semantic questions
55 | count_syn = 0; # count all syntactic questions
56 | count_tot = 0 # count all questions
57 | full_count = 0 # count all questions, including those with unknown words
58 |
59 | for i in range(len(filenames)):
60 | with open('%s/%s' % (prefix, filenames[i]), 'r') as f:
61 | full_data = [line.rstrip().split(' ') for line in f]
62 | full_count += len(full_data)
63 | data = [x for x in full_data if all(word in vocab for word in x)]
64 |
65 | if len(data) == 0:
66 | print("ERROR: no lines of vocab kept for %s !" % filenames[i])
67 | print("Example missing line:", full_data[0])
68 | continue
69 |
70 | indices = np.array([[vocab[word] for word in row] for row in data])
71 | ind1, ind2, ind3, ind4 = indices.T
72 |
73 | predictions = np.zeros((len(indices),))
74 | num_iter = int(np.ceil(len(indices) / float(split_size)))
75 | for j in range(num_iter):
76 | subset = np.arange(j*split_size, min((j + 1)*split_size, len(ind1)))
77 |
78 | pred_vec = (W[ind2[subset], :] - W[ind1[subset], :]
79 | + W[ind3[subset], :])
80 | #cosine similarity if input W has been normalized
81 | dist = np.dot(W, pred_vec.T)
82 |
83 | for k in range(len(subset)):
84 | dist[ind1[subset[k]], k] = -np.inf
85 | dist[ind2[subset[k]], k] = -np.inf
86 | dist[ind3[subset[k]], k] = -np.inf
87 |
88 | # predicted word index
89 | predictions[subset] = np.argmax(dist, 0).flatten()
90 |
91 | val = (ind4 == predictions) # correct predictions
92 | count_tot = count_tot + len(ind1)
93 | correct_tot = correct_tot + sum(val)
94 | if i < 5:
95 | count_sem = count_sem + len(ind1)
96 | correct_sem = correct_sem + sum(val)
97 | else:
98 | count_syn = count_syn + len(ind1)
99 | correct_syn = correct_syn + sum(val)
100 |
101 | print("%s:" % filenames[i])
102 | print('ACCURACY TOP1: %.2f%% (%d/%d)' %
103 | (np.mean(val) * 100, np.sum(val), len(val)))
104 |
105 | print('Questions seen/total: %.2f%% (%d/%d)' %
106 | (100 * count_tot / float(full_count), count_tot, full_count))
107 | print('Semantic accuracy: %.2f%% (%i/%i)' %
108 | (100 * correct_sem / float(count_sem), correct_sem, count_sem))
109 | print('Syntactic accuracy: %.2f%% (%i/%i)' %
110 | (100 * correct_syn / float(count_syn), correct_syn, count_syn))
111 | print('Total accuracy: %.2f%% (%i/%i)' % (100 * correct_tot / float(count_tot), correct_tot, count_tot))
112 |
113 |
114 | if __name__ == "__main__":
115 | main()
116 |
--------------------------------------------------------------------------------
/eval/python/word_analogy.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import numpy as np
3 |
4 | def generate():
5 | parser = argparse.ArgumentParser()
6 | parser.add_argument('--vocab_file', default='vocab.txt', type=str)
7 | parser.add_argument('--vectors_file', default='vectors.txt', type=str)
8 | args = parser.parse_args()
9 |
10 | with open(args.vocab_file, 'r') as f:
11 | words = [x.rstrip().split(' ')[0] for x in f.readlines()]
12 | with open(args.vectors_file, 'r') as f:
13 | vectors = {}
14 | for line in f:
15 | vals = line.rstrip().split(' ')
16 | vectors[vals[0]] = [float(x) for x in vals[1:]]
17 |
18 | vocab_size = len(words)
19 | vocab = {w: idx for idx, w in enumerate(words)}
20 | ivocab = {idx: w for idx, w in enumerate(words)}
21 |
22 | vector_dim = len(vectors[ivocab[0]])
23 | W = np.zeros((vocab_size, vector_dim))
24 | for word, v in vectors.items():
25 | if word == '':
26 | continue
27 | W[vocab[word], :] = v
28 |
29 | # normalize each word vector to unit variance
30 | W_norm = np.zeros(W.shape)
31 | d = (np.sum(W ** 2, 1) ** (0.5))
32 | W_norm = (W.T / d).T
33 | return (W_norm, vocab, ivocab)
34 |
35 |
36 | def distance(W, vocab, ivocab, input_term):
37 | vecs = {}
38 | if len(input_term.split(' ')) < 3:
39 | print("Only %i words were entered.. three words are needed at the input to perform the calculation\n" % len(input_term.split(' ')))
40 | return
41 | else:
42 | for idx, term in enumerate(input_term.split(' ')):
43 | if term in vocab:
44 | print('Word: %s Position in vocabulary: %i' % (term, vocab[term]))
45 | vecs[idx] = W[vocab[term], :]
46 | else:
47 | print('Word: %s Out of dictionary!\n' % term)
48 | return
49 |
50 | vec_result = vecs[1] - vecs[0] + vecs[2]
51 |
52 | vec_norm = np.zeros(vec_result.shape)
53 | d = (np.sum(vec_result ** 2,) ** (0.5))
54 | vec_norm = (vec_result.T / d).T
55 |
56 | dist = np.dot(W, vec_norm.T)
57 |
58 | for term in input_term.split(' '):
59 | index = vocab[term]
60 | dist[index] = -np.Inf
61 |
62 | a = np.argsort(-dist)[:N]
63 |
64 | print("\n Word Cosine distance\n")
65 | print("---------------------------------------------------------\n")
66 | for x in a:
67 | print("%35s\t\t%f\n" % (ivocab[x], dist[x]))
68 |
69 |
70 | if __name__ == "__main__":
71 | N = 100; # number of closest words that will be shown
72 | W, vocab, ivocab = generate()
73 | while True:
74 | input_term = input("\nEnter three words (EXIT to break): ")
75 | if input_term == 'EXIT':
76 | break
77 | else:
78 | distance(W, vocab, ivocab, input_term)
79 |
80 |
--------------------------------------------------------------------------------
/eval/question-data/capital-common-countries.txt:
--------------------------------------------------------------------------------
1 | athens greece baghdad iraq
2 | athens greece bangkok thailand
3 | athens greece beijing china
4 | athens greece berlin germany
5 | athens greece bern switzerland
6 | athens greece cairo egypt
7 | athens greece canberra australia
8 | athens greece hanoi vietnam
9 | athens greece havana cuba
10 | athens greece helsinki finland
11 | athens greece islamabad pakistan
12 | athens greece kabul afghanistan
13 | athens greece london england
14 | athens greece madrid spain
15 | athens greece moscow russia
16 | athens greece oslo norway
17 | athens greece ottawa canada
18 | athens greece paris france
19 | athens greece rome italy
20 | athens greece stockholm sweden
21 | athens greece tehran iran
22 | athens greece tokyo japan
23 | baghdad iraq bangkok thailand
24 | baghdad iraq beijing china
25 | baghdad iraq berlin germany
26 | baghdad iraq bern switzerland
27 | baghdad iraq cairo egypt
28 | baghdad iraq canberra australia
29 | baghdad iraq hanoi vietnam
30 | baghdad iraq havana cuba
31 | baghdad iraq helsinki finland
32 | baghdad iraq islamabad pakistan
33 | baghdad iraq kabul afghanistan
34 | baghdad iraq london england
35 | baghdad iraq madrid spain
36 | baghdad iraq moscow russia
37 | baghdad iraq oslo norway
38 | baghdad iraq ottawa canada
39 | baghdad iraq paris france
40 | baghdad iraq rome italy
41 | baghdad iraq stockholm sweden
42 | baghdad iraq tehran iran
43 | baghdad iraq tokyo japan
44 | baghdad iraq athens greece
45 | bangkok thailand beijing china
46 | bangkok thailand berlin germany
47 | bangkok thailand bern switzerland
48 | bangkok thailand cairo egypt
49 | bangkok thailand canberra australia
50 | bangkok thailand hanoi vietnam
51 | bangkok thailand havana cuba
52 | bangkok thailand helsinki finland
53 | bangkok thailand islamabad pakistan
54 | bangkok thailand kabul afghanistan
55 | bangkok thailand london england
56 | bangkok thailand madrid spain
57 | bangkok thailand moscow russia
58 | bangkok thailand oslo norway
59 | bangkok thailand ottawa canada
60 | bangkok thailand paris france
61 | bangkok thailand rome italy
62 | bangkok thailand stockholm sweden
63 | bangkok thailand tehran iran
64 | bangkok thailand tokyo japan
65 | bangkok thailand athens greece
66 | bangkok thailand baghdad iraq
67 | beijing china berlin germany
68 | beijing china bern switzerland
69 | beijing china cairo egypt
70 | beijing china canberra australia
71 | beijing china hanoi vietnam
72 | beijing china havana cuba
73 | beijing china helsinki finland
74 | beijing china islamabad pakistan
75 | beijing china kabul afghanistan
76 | beijing china london england
77 | beijing china madrid spain
78 | beijing china moscow russia
79 | beijing china oslo norway
80 | beijing china ottawa canada
81 | beijing china paris france
82 | beijing china rome italy
83 | beijing china stockholm sweden
84 | beijing china tehran iran
85 | beijing china tokyo japan
86 | beijing china athens greece
87 | beijing china baghdad iraq
88 | beijing china bangkok thailand
89 | berlin germany bern switzerland
90 | berlin germany cairo egypt
91 | berlin germany canberra australia
92 | berlin germany hanoi vietnam
93 | berlin germany havana cuba
94 | berlin germany helsinki finland
95 | berlin germany islamabad pakistan
96 | berlin germany kabul afghanistan
97 | berlin germany london england
98 | berlin germany madrid spain
99 | berlin germany moscow russia
100 | berlin germany oslo norway
101 | berlin germany ottawa canada
102 | berlin germany paris france
103 | berlin germany rome italy
104 | berlin germany stockholm sweden
105 | berlin germany tehran iran
106 | berlin germany tokyo japan
107 | berlin germany athens greece
108 | berlin germany baghdad iraq
109 | berlin germany bangkok thailand
110 | berlin germany beijing china
111 | bern switzerland cairo egypt
112 | bern switzerland canberra australia
113 | bern switzerland hanoi vietnam
114 | bern switzerland havana cuba
115 | bern switzerland helsinki finland
116 | bern switzerland islamabad pakistan
117 | bern switzerland kabul afghanistan
118 | bern switzerland london england
119 | bern switzerland madrid spain
120 | bern switzerland moscow russia
121 | bern switzerland oslo norway
122 | bern switzerland ottawa canada
123 | bern switzerland paris france
124 | bern switzerland rome italy
125 | bern switzerland stockholm sweden
126 | bern switzerland tehran iran
127 | bern switzerland tokyo japan
128 | bern switzerland athens greece
129 | bern switzerland baghdad iraq
130 | bern switzerland bangkok thailand
131 | bern switzerland beijing china
132 | bern switzerland berlin germany
133 | cairo egypt canberra australia
134 | cairo egypt hanoi vietnam
135 | cairo egypt havana cuba
136 | cairo egypt helsinki finland
137 | cairo egypt islamabad pakistan
138 | cairo egypt kabul afghanistan
139 | cairo egypt london england
140 | cairo egypt madrid spain
141 | cairo egypt moscow russia
142 | cairo egypt oslo norway
143 | cairo egypt ottawa canada
144 | cairo egypt paris france
145 | cairo egypt rome italy
146 | cairo egypt stockholm sweden
147 | cairo egypt tehran iran
148 | cairo egypt tokyo japan
149 | cairo egypt athens greece
150 | cairo egypt baghdad iraq
151 | cairo egypt bangkok thailand
152 | cairo egypt beijing china
153 | cairo egypt berlin germany
154 | cairo egypt bern switzerland
155 | canberra australia hanoi vietnam
156 | canberra australia havana cuba
157 | canberra australia helsinki finland
158 | canberra australia islamabad pakistan
159 | canberra australia kabul afghanistan
160 | canberra australia london england
161 | canberra australia madrid spain
162 | canberra australia moscow russia
163 | canberra australia oslo norway
164 | canberra australia ottawa canada
165 | canberra australia paris france
166 | canberra australia rome italy
167 | canberra australia stockholm sweden
168 | canberra australia tehran iran
169 | canberra australia tokyo japan
170 | canberra australia athens greece
171 | canberra australia baghdad iraq
172 | canberra australia bangkok thailand
173 | canberra australia beijing china
174 | canberra australia berlin germany
175 | canberra australia bern switzerland
176 | canberra australia cairo egypt
177 | hanoi vietnam havana cuba
178 | hanoi vietnam helsinki finland
179 | hanoi vietnam islamabad pakistan
180 | hanoi vietnam kabul afghanistan
181 | hanoi vietnam london england
182 | hanoi vietnam madrid spain
183 | hanoi vietnam moscow russia
184 | hanoi vietnam oslo norway
185 | hanoi vietnam ottawa canada
186 | hanoi vietnam paris france
187 | hanoi vietnam rome italy
188 | hanoi vietnam stockholm sweden
189 | hanoi vietnam tehran iran
190 | hanoi vietnam tokyo japan
191 | hanoi vietnam athens greece
192 | hanoi vietnam baghdad iraq
193 | hanoi vietnam bangkok thailand
194 | hanoi vietnam beijing china
195 | hanoi vietnam berlin germany
196 | hanoi vietnam bern switzerland
197 | hanoi vietnam cairo egypt
198 | hanoi vietnam canberra australia
199 | havana cuba helsinki finland
200 | havana cuba islamabad pakistan
201 | havana cuba kabul afghanistan
202 | havana cuba london england
203 | havana cuba madrid spain
204 | havana cuba moscow russia
205 | havana cuba oslo norway
206 | havana cuba ottawa canada
207 | havana cuba paris france
208 | havana cuba rome italy
209 | havana cuba stockholm sweden
210 | havana cuba tehran iran
211 | havana cuba tokyo japan
212 | havana cuba athens greece
213 | havana cuba baghdad iraq
214 | havana cuba bangkok thailand
215 | havana cuba beijing china
216 | havana cuba berlin germany
217 | havana cuba bern switzerland
218 | havana cuba cairo egypt
219 | havana cuba canberra australia
220 | havana cuba hanoi vietnam
221 | helsinki finland islamabad pakistan
222 | helsinki finland kabul afghanistan
223 | helsinki finland london england
224 | helsinki finland madrid spain
225 | helsinki finland moscow russia
226 | helsinki finland oslo norway
227 | helsinki finland ottawa canada
228 | helsinki finland paris france
229 | helsinki finland rome italy
230 | helsinki finland stockholm sweden
231 | helsinki finland tehran iran
232 | helsinki finland tokyo japan
233 | helsinki finland athens greece
234 | helsinki finland baghdad iraq
235 | helsinki finland bangkok thailand
236 | helsinki finland beijing china
237 | helsinki finland berlin germany
238 | helsinki finland bern switzerland
239 | helsinki finland cairo egypt
240 | helsinki finland canberra australia
241 | helsinki finland hanoi vietnam
242 | helsinki finland havana cuba
243 | islamabad pakistan kabul afghanistan
244 | islamabad pakistan london england
245 | islamabad pakistan madrid spain
246 | islamabad pakistan moscow russia
247 | islamabad pakistan oslo norway
248 | islamabad pakistan ottawa canada
249 | islamabad pakistan paris france
250 | islamabad pakistan rome italy
251 | islamabad pakistan stockholm sweden
252 | islamabad pakistan tehran iran
253 | islamabad pakistan tokyo japan
254 | islamabad pakistan athens greece
255 | islamabad pakistan baghdad iraq
256 | islamabad pakistan bangkok thailand
257 | islamabad pakistan beijing china
258 | islamabad pakistan berlin germany
259 | islamabad pakistan bern switzerland
260 | islamabad pakistan cairo egypt
261 | islamabad pakistan canberra australia
262 | islamabad pakistan hanoi vietnam
263 | islamabad pakistan havana cuba
264 | islamabad pakistan helsinki finland
265 | kabul afghanistan london england
266 | kabul afghanistan madrid spain
267 | kabul afghanistan moscow russia
268 | kabul afghanistan oslo norway
269 | kabul afghanistan ottawa canada
270 | kabul afghanistan paris france
271 | kabul afghanistan rome italy
272 | kabul afghanistan stockholm sweden
273 | kabul afghanistan tehran iran
274 | kabul afghanistan tokyo japan
275 | kabul afghanistan athens greece
276 | kabul afghanistan baghdad iraq
277 | kabul afghanistan bangkok thailand
278 | kabul afghanistan beijing china
279 | kabul afghanistan berlin germany
280 | kabul afghanistan bern switzerland
281 | kabul afghanistan cairo egypt
282 | kabul afghanistan canberra australia
283 | kabul afghanistan hanoi vietnam
284 | kabul afghanistan havana cuba
285 | kabul afghanistan helsinki finland
286 | kabul afghanistan islamabad pakistan
287 | london england madrid spain
288 | london england moscow russia
289 | london england oslo norway
290 | london england ottawa canada
291 | london england paris france
292 | london england rome italy
293 | london england stockholm sweden
294 | london england tehran iran
295 | london england tokyo japan
296 | london england athens greece
297 | london england baghdad iraq
298 | london england bangkok thailand
299 | london england beijing china
300 | london england berlin germany
301 | london england bern switzerland
302 | london england cairo egypt
303 | london england canberra australia
304 | london england hanoi vietnam
305 | london england havana cuba
306 | london england helsinki finland
307 | london england islamabad pakistan
308 | london england kabul afghanistan
309 | madrid spain moscow russia
310 | madrid spain oslo norway
311 | madrid spain ottawa canada
312 | madrid spain paris france
313 | madrid spain rome italy
314 | madrid spain stockholm sweden
315 | madrid spain tehran iran
316 | madrid spain tokyo japan
317 | madrid spain athens greece
318 | madrid spain baghdad iraq
319 | madrid spain bangkok thailand
320 | madrid spain beijing china
321 | madrid spain berlin germany
322 | madrid spain bern switzerland
323 | madrid spain cairo egypt
324 | madrid spain canberra australia
325 | madrid spain hanoi vietnam
326 | madrid spain havana cuba
327 | madrid spain helsinki finland
328 | madrid spain islamabad pakistan
329 | madrid spain kabul afghanistan
330 | madrid spain london england
331 | moscow russia oslo norway
332 | moscow russia ottawa canada
333 | moscow russia paris france
334 | moscow russia rome italy
335 | moscow russia stockholm sweden
336 | moscow russia tehran iran
337 | moscow russia tokyo japan
338 | moscow russia athens greece
339 | moscow russia baghdad iraq
340 | moscow russia bangkok thailand
341 | moscow russia beijing china
342 | moscow russia berlin germany
343 | moscow russia bern switzerland
344 | moscow russia cairo egypt
345 | moscow russia canberra australia
346 | moscow russia hanoi vietnam
347 | moscow russia havana cuba
348 | moscow russia helsinki finland
349 | moscow russia islamabad pakistan
350 | moscow russia kabul afghanistan
351 | moscow russia london england
352 | moscow russia madrid spain
353 | oslo norway ottawa canada
354 | oslo norway paris france
355 | oslo norway rome italy
356 | oslo norway stockholm sweden
357 | oslo norway tehran iran
358 | oslo norway tokyo japan
359 | oslo norway athens greece
360 | oslo norway baghdad iraq
361 | oslo norway bangkok thailand
362 | oslo norway beijing china
363 | oslo norway berlin germany
364 | oslo norway bern switzerland
365 | oslo norway cairo egypt
366 | oslo norway canberra australia
367 | oslo norway hanoi vietnam
368 | oslo norway havana cuba
369 | oslo norway helsinki finland
370 | oslo norway islamabad pakistan
371 | oslo norway kabul afghanistan
372 | oslo norway london england
373 | oslo norway madrid spain
374 | oslo norway moscow russia
375 | ottawa canada paris france
376 | ottawa canada rome italy
377 | ottawa canada stockholm sweden
378 | ottawa canada tehran iran
379 | ottawa canada tokyo japan
380 | ottawa canada athens greece
381 | ottawa canada baghdad iraq
382 | ottawa canada bangkok thailand
383 | ottawa canada beijing china
384 | ottawa canada berlin germany
385 | ottawa canada bern switzerland
386 | ottawa canada cairo egypt
387 | ottawa canada canberra australia
388 | ottawa canada hanoi vietnam
389 | ottawa canada havana cuba
390 | ottawa canada helsinki finland
391 | ottawa canada islamabad pakistan
392 | ottawa canada kabul afghanistan
393 | ottawa canada london england
394 | ottawa canada madrid spain
395 | ottawa canada moscow russia
396 | ottawa canada oslo norway
397 | paris france rome italy
398 | paris france stockholm sweden
399 | paris france tehran iran
400 | paris france tokyo japan
401 | paris france athens greece
402 | paris france baghdad iraq
403 | paris france bangkok thailand
404 | paris france beijing china
405 | paris france berlin germany
406 | paris france bern switzerland
407 | paris france cairo egypt
408 | paris france canberra australia
409 | paris france hanoi vietnam
410 | paris france havana cuba
411 | paris france helsinki finland
412 | paris france islamabad pakistan
413 | paris france kabul afghanistan
414 | paris france london england
415 | paris france madrid spain
416 | paris france moscow russia
417 | paris france oslo norway
418 | paris france ottawa canada
419 | rome italy stockholm sweden
420 | rome italy tehran iran
421 | rome italy tokyo japan
422 | rome italy athens greece
423 | rome italy baghdad iraq
424 | rome italy bangkok thailand
425 | rome italy beijing china
426 | rome italy berlin germany
427 | rome italy bern switzerland
428 | rome italy cairo egypt
429 | rome italy canberra australia
430 | rome italy hanoi vietnam
431 | rome italy havana cuba
432 | rome italy helsinki finland
433 | rome italy islamabad pakistan
434 | rome italy kabul afghanistan
435 | rome italy london england
436 | rome italy madrid spain
437 | rome italy moscow russia
438 | rome italy oslo norway
439 | rome italy ottawa canada
440 | rome italy paris france
441 | stockholm sweden tehran iran
442 | stockholm sweden tokyo japan
443 | stockholm sweden athens greece
444 | stockholm sweden baghdad iraq
445 | stockholm sweden bangkok thailand
446 | stockholm sweden beijing china
447 | stockholm sweden berlin germany
448 | stockholm sweden bern switzerland
449 | stockholm sweden cairo egypt
450 | stockholm sweden canberra australia
451 | stockholm sweden hanoi vietnam
452 | stockholm sweden havana cuba
453 | stockholm sweden helsinki finland
454 | stockholm sweden islamabad pakistan
455 | stockholm sweden kabul afghanistan
456 | stockholm sweden london england
457 | stockholm sweden madrid spain
458 | stockholm sweden moscow russia
459 | stockholm sweden oslo norway
460 | stockholm sweden ottawa canada
461 | stockholm sweden paris france
462 | stockholm sweden rome italy
463 | tehran iran tokyo japan
464 | tehran iran athens greece
465 | tehran iran baghdad iraq
466 | tehran iran bangkok thailand
467 | tehran iran beijing china
468 | tehran iran berlin germany
469 | tehran iran bern switzerland
470 | tehran iran cairo egypt
471 | tehran iran canberra australia
472 | tehran iran hanoi vietnam
473 | tehran iran havana cuba
474 | tehran iran helsinki finland
475 | tehran iran islamabad pakistan
476 | tehran iran kabul afghanistan
477 | tehran iran london england
478 | tehran iran madrid spain
479 | tehran iran moscow russia
480 | tehran iran oslo norway
481 | tehran iran ottawa canada
482 | tehran iran paris france
483 | tehran iran rome italy
484 | tehran iran stockholm sweden
485 | tokyo japan athens greece
486 | tokyo japan baghdad iraq
487 | tokyo japan bangkok thailand
488 | tokyo japan beijing china
489 | tokyo japan berlin germany
490 | tokyo japan bern switzerland
491 | tokyo japan cairo egypt
492 | tokyo japan canberra australia
493 | tokyo japan hanoi vietnam
494 | tokyo japan havana cuba
495 | tokyo japan helsinki finland
496 | tokyo japan islamabad pakistan
497 | tokyo japan kabul afghanistan
498 | tokyo japan london england
499 | tokyo japan madrid spain
500 | tokyo japan moscow russia
501 | tokyo japan oslo norway
502 | tokyo japan ottawa canada
503 | tokyo japan paris france
504 | tokyo japan rome italy
505 | tokyo japan stockholm sweden
506 | tokyo japan tehran iran
507 |
--------------------------------------------------------------------------------
/eval/question-data/currency.txt:
--------------------------------------------------------------------------------
1 | algeria dinar angola kwanza
2 | algeria dinar argentina peso
3 | algeria dinar armenia dram
4 | algeria dinar brazil real
5 | algeria dinar bulgaria lev
6 | algeria dinar cambodia riel
7 | algeria dinar canada dollar
8 | algeria dinar croatia kuna
9 | algeria dinar denmark krone
10 | algeria dinar europe euro
11 | algeria dinar hungary forint
12 | algeria dinar india rupee
13 | algeria dinar iran rial
14 | algeria dinar japan yen
15 | algeria dinar korea won
16 | algeria dinar latvia lats
17 | algeria dinar lithuania litas
18 | algeria dinar macedonia denar
19 | algeria dinar malaysia ringgit
20 | algeria dinar mexico peso
21 | algeria dinar nigeria naira
22 | algeria dinar poland zloty
23 | algeria dinar romania leu
24 | algeria dinar russia ruble
25 | algeria dinar sweden krona
26 | algeria dinar thailand baht
27 | algeria dinar ukraine hryvnia
28 | algeria dinar usa dollar
29 | algeria dinar vietnam dong
30 | angola kwanza argentina peso
31 | angola kwanza armenia dram
32 | angola kwanza brazil real
33 | angola kwanza bulgaria lev
34 | angola kwanza cambodia riel
35 | angola kwanza canada dollar
36 | angola kwanza croatia kuna
37 | angola kwanza denmark krone
38 | angola kwanza europe euro
39 | angola kwanza hungary forint
40 | angola kwanza india rupee
41 | angola kwanza iran rial
42 | angola kwanza japan yen
43 | angola kwanza korea won
44 | angola kwanza latvia lats
45 | angola kwanza lithuania litas
46 | angola kwanza macedonia denar
47 | angola kwanza malaysia ringgit
48 | angola kwanza mexico peso
49 | angola kwanza nigeria naira
50 | angola kwanza poland zloty
51 | angola kwanza romania leu
52 | angola kwanza russia ruble
53 | angola kwanza sweden krona
54 | angola kwanza thailand baht
55 | angola kwanza ukraine hryvnia
56 | angola kwanza usa dollar
57 | angola kwanza vietnam dong
58 | angola kwanza algeria dinar
59 | argentina peso armenia dram
60 | argentina peso brazil real
61 | argentina peso bulgaria lev
62 | argentina peso cambodia riel
63 | argentina peso canada dollar
64 | argentina peso croatia kuna
65 | argentina peso denmark krone
66 | argentina peso europe euro
67 | argentina peso hungary forint
68 | argentina peso india rupee
69 | argentina peso iran rial
70 | argentina peso japan yen
71 | argentina peso korea won
72 | argentina peso latvia lats
73 | argentina peso lithuania litas
74 | argentina peso macedonia denar
75 | argentina peso malaysia ringgit
76 | argentina peso nigeria naira
77 | argentina peso poland zloty
78 | argentina peso romania leu
79 | argentina peso russia ruble
80 | argentina peso sweden krona
81 | argentina peso thailand baht
82 | argentina peso ukraine hryvnia
83 | argentina peso usa dollar
84 | argentina peso vietnam dong
85 | argentina peso algeria dinar
86 | argentina peso angola kwanza
87 | armenia dram brazil real
88 | armenia dram bulgaria lev
89 | armenia dram cambodia riel
90 | armenia dram canada dollar
91 | armenia dram croatia kuna
92 | armenia dram denmark krone
93 | armenia dram europe euro
94 | armenia dram hungary forint
95 | armenia dram india rupee
96 | armenia dram iran rial
97 | armenia dram japan yen
98 | armenia dram korea won
99 | armenia dram latvia lats
100 | armenia dram lithuania litas
101 | armenia dram macedonia denar
102 | armenia dram malaysia ringgit
103 | armenia dram mexico peso
104 | armenia dram nigeria naira
105 | armenia dram poland zloty
106 | armenia dram romania leu
107 | armenia dram russia ruble
108 | armenia dram sweden krona
109 | armenia dram thailand baht
110 | armenia dram ukraine hryvnia
111 | armenia dram usa dollar
112 | armenia dram vietnam dong
113 | armenia dram algeria dinar
114 | armenia dram angola kwanza
115 | armenia dram argentina peso
116 | brazil real bulgaria lev
117 | brazil real cambodia riel
118 | brazil real canada dollar
119 | brazil real croatia kuna
120 | brazil real denmark krone
121 | brazil real europe euro
122 | brazil real hungary forint
123 | brazil real india rupee
124 | brazil real iran rial
125 | brazil real japan yen
126 | brazil real korea won
127 | brazil real latvia lats
128 | brazil real lithuania litas
129 | brazil real macedonia denar
130 | brazil real malaysia ringgit
131 | brazil real mexico peso
132 | brazil real nigeria naira
133 | brazil real poland zloty
134 | brazil real romania leu
135 | brazil real russia ruble
136 | brazil real sweden krona
137 | brazil real thailand baht
138 | brazil real ukraine hryvnia
139 | brazil real usa dollar
140 | brazil real vietnam dong
141 | brazil real algeria dinar
142 | brazil real angola kwanza
143 | brazil real argentina peso
144 | brazil real armenia dram
145 | bulgaria lev cambodia riel
146 | bulgaria lev canada dollar
147 | bulgaria lev croatia kuna
148 | bulgaria lev denmark krone
149 | bulgaria lev europe euro
150 | bulgaria lev hungary forint
151 | bulgaria lev india rupee
152 | bulgaria lev iran rial
153 | bulgaria lev japan yen
154 | bulgaria lev korea won
155 | bulgaria lev latvia lats
156 | bulgaria lev lithuania litas
157 | bulgaria lev macedonia denar
158 | bulgaria lev malaysia ringgit
159 | bulgaria lev mexico peso
160 | bulgaria lev nigeria naira
161 | bulgaria lev poland zloty
162 | bulgaria lev romania leu
163 | bulgaria lev russia ruble
164 | bulgaria lev sweden krona
165 | bulgaria lev thailand baht
166 | bulgaria lev ukraine hryvnia
167 | bulgaria lev usa dollar
168 | bulgaria lev vietnam dong
169 | bulgaria lev algeria dinar
170 | bulgaria lev angola kwanza
171 | bulgaria lev argentina peso
172 | bulgaria lev armenia dram
173 | bulgaria lev brazil real
174 | cambodia riel canada dollar
175 | cambodia riel croatia kuna
176 | cambodia riel denmark krone
177 | cambodia riel europe euro
178 | cambodia riel hungary forint
179 | cambodia riel india rupee
180 | cambodia riel iran rial
181 | cambodia riel japan yen
182 | cambodia riel korea won
183 | cambodia riel latvia lats
184 | cambodia riel lithuania litas
185 | cambodia riel macedonia denar
186 | cambodia riel malaysia ringgit
187 | cambodia riel mexico peso
188 | cambodia riel nigeria naira
189 | cambodia riel poland zloty
190 | cambodia riel romania leu
191 | cambodia riel russia ruble
192 | cambodia riel sweden krona
193 | cambodia riel thailand baht
194 | cambodia riel ukraine hryvnia
195 | cambodia riel usa dollar
196 | cambodia riel vietnam dong
197 | cambodia riel algeria dinar
198 | cambodia riel angola kwanza
199 | cambodia riel argentina peso
200 | cambodia riel armenia dram
201 | cambodia riel brazil real
202 | cambodia riel bulgaria lev
203 | canada dollar croatia kuna
204 | canada dollar denmark krone
205 | canada dollar europe euro
206 | canada dollar hungary forint
207 | canada dollar india rupee
208 | canada dollar iran rial
209 | canada dollar japan yen
210 | canada dollar korea won
211 | canada dollar latvia lats
212 | canada dollar lithuania litas
213 | canada dollar macedonia denar
214 | canada dollar malaysia ringgit
215 | canada dollar mexico peso
216 | canada dollar nigeria naira
217 | canada dollar poland zloty
218 | canada dollar romania leu
219 | canada dollar russia ruble
220 | canada dollar sweden krona
221 | canada dollar thailand baht
222 | canada dollar ukraine hryvnia
223 | canada dollar vietnam dong
224 | canada dollar algeria dinar
225 | canada dollar angola kwanza
226 | canada dollar argentina peso
227 | canada dollar armenia dram
228 | canada dollar brazil real
229 | canada dollar bulgaria lev
230 | canada dollar cambodia riel
231 | croatia kuna denmark krone
232 | croatia kuna europe euro
233 | croatia kuna hungary forint
234 | croatia kuna india rupee
235 | croatia kuna iran rial
236 | croatia kuna japan yen
237 | croatia kuna korea won
238 | croatia kuna latvia lats
239 | croatia kuna lithuania litas
240 | croatia kuna macedonia denar
241 | croatia kuna malaysia ringgit
242 | croatia kuna mexico peso
243 | croatia kuna nigeria naira
244 | croatia kuna poland zloty
245 | croatia kuna romania leu
246 | croatia kuna russia ruble
247 | croatia kuna sweden krona
248 | croatia kuna thailand baht
249 | croatia kuna ukraine hryvnia
250 | croatia kuna usa dollar
251 | croatia kuna vietnam dong
252 | croatia kuna algeria dinar
253 | croatia kuna angola kwanza
254 | croatia kuna argentina peso
255 | croatia kuna armenia dram
256 | croatia kuna brazil real
257 | croatia kuna bulgaria lev
258 | croatia kuna cambodia riel
259 | croatia kuna canada dollar
260 | denmark krone europe euro
261 | denmark krone hungary forint
262 | denmark krone india rupee
263 | denmark krone iran rial
264 | denmark krone japan yen
265 | denmark krone korea won
266 | denmark krone latvia lats
267 | denmark krone lithuania litas
268 | denmark krone macedonia denar
269 | denmark krone malaysia ringgit
270 | denmark krone mexico peso
271 | denmark krone nigeria naira
272 | denmark krone poland zloty
273 | denmark krone romania leu
274 | denmark krone russia ruble
275 | denmark krone sweden krona
276 | denmark krone thailand baht
277 | denmark krone ukraine hryvnia
278 | denmark krone usa dollar
279 | denmark krone vietnam dong
280 | denmark krone algeria dinar
281 | denmark krone angola kwanza
282 | denmark krone argentina peso
283 | denmark krone armenia dram
284 | denmark krone brazil real
285 | denmark krone bulgaria lev
286 | denmark krone cambodia riel
287 | denmark krone canada dollar
288 | denmark krone croatia kuna
289 | europe euro hungary forint
290 | europe euro india rupee
291 | europe euro iran rial
292 | europe euro japan yen
293 | europe euro korea won
294 | europe euro latvia lats
295 | europe euro lithuania litas
296 | europe euro macedonia denar
297 | europe euro malaysia ringgit
298 | europe euro mexico peso
299 | europe euro nigeria naira
300 | europe euro poland zloty
301 | europe euro romania leu
302 | europe euro russia ruble
303 | europe euro sweden krona
304 | europe euro thailand baht
305 | europe euro ukraine hryvnia
306 | europe euro usa dollar
307 | europe euro vietnam dong
308 | europe euro algeria dinar
309 | europe euro angola kwanza
310 | europe euro argentina peso
311 | europe euro armenia dram
312 | europe euro brazil real
313 | europe euro bulgaria lev
314 | europe euro cambodia riel
315 | europe euro canada dollar
316 | europe euro croatia kuna
317 | europe euro denmark krone
318 | hungary forint india rupee
319 | hungary forint iran rial
320 | hungary forint japan yen
321 | hungary forint korea won
322 | hungary forint latvia lats
323 | hungary forint lithuania litas
324 | hungary forint macedonia denar
325 | hungary forint malaysia ringgit
326 | hungary forint mexico peso
327 | hungary forint nigeria naira
328 | hungary forint poland zloty
329 | hungary forint romania leu
330 | hungary forint russia ruble
331 | hungary forint sweden krona
332 | hungary forint thailand baht
333 | hungary forint ukraine hryvnia
334 | hungary forint usa dollar
335 | hungary forint vietnam dong
336 | hungary forint algeria dinar
337 | hungary forint angola kwanza
338 | hungary forint argentina peso
339 | hungary forint armenia dram
340 | hungary forint brazil real
341 | hungary forint bulgaria lev
342 | hungary forint cambodia riel
343 | hungary forint canada dollar
344 | hungary forint croatia kuna
345 | hungary forint denmark krone
346 | hungary forint europe euro
347 | india rupee iran rial
348 | india rupee japan yen
349 | india rupee korea won
350 | india rupee latvia lats
351 | india rupee lithuania litas
352 | india rupee macedonia denar
353 | india rupee malaysia ringgit
354 | india rupee mexico peso
355 | india rupee nigeria naira
356 | india rupee poland zloty
357 | india rupee romania leu
358 | india rupee russia ruble
359 | india rupee sweden krona
360 | india rupee thailand baht
361 | india rupee ukraine hryvnia
362 | india rupee usa dollar
363 | india rupee vietnam dong
364 | india rupee algeria dinar
365 | india rupee angola kwanza
366 | india rupee argentina peso
367 | india rupee armenia dram
368 | india rupee brazil real
369 | india rupee bulgaria lev
370 | india rupee cambodia riel
371 | india rupee canada dollar
372 | india rupee croatia kuna
373 | india rupee denmark krone
374 | india rupee europe euro
375 | india rupee hungary forint
376 | iran rial japan yen
377 | iran rial korea won
378 | iran rial latvia lats
379 | iran rial lithuania litas
380 | iran rial macedonia denar
381 | iran rial malaysia ringgit
382 | iran rial mexico peso
383 | iran rial nigeria naira
384 | iran rial poland zloty
385 | iran rial romania leu
386 | iran rial russia ruble
387 | iran rial sweden krona
388 | iran rial thailand baht
389 | iran rial ukraine hryvnia
390 | iran rial usa dollar
391 | iran rial vietnam dong
392 | iran rial algeria dinar
393 | iran rial angola kwanza
394 | iran rial argentina peso
395 | iran rial armenia dram
396 | iran rial brazil real
397 | iran rial bulgaria lev
398 | iran rial cambodia riel
399 | iran rial canada dollar
400 | iran rial croatia kuna
401 | iran rial denmark krone
402 | iran rial europe euro
403 | iran rial hungary forint
404 | iran rial india rupee
405 | japan yen korea won
406 | japan yen latvia lats
407 | japan yen lithuania litas
408 | japan yen macedonia denar
409 | japan yen malaysia ringgit
410 | japan yen mexico peso
411 | japan yen nigeria naira
412 | japan yen poland zloty
413 | japan yen romania leu
414 | japan yen russia ruble
415 | japan yen sweden krona
416 | japan yen thailand baht
417 | japan yen ukraine hryvnia
418 | japan yen usa dollar
419 | japan yen vietnam dong
420 | japan yen algeria dinar
421 | japan yen angola kwanza
422 | japan yen argentina peso
423 | japan yen armenia dram
424 | japan yen brazil real
425 | japan yen bulgaria lev
426 | japan yen cambodia riel
427 | japan yen canada dollar
428 | japan yen croatia kuna
429 | japan yen denmark krone
430 | japan yen europe euro
431 | japan yen hungary forint
432 | japan yen india rupee
433 | japan yen iran rial
434 | korea won latvia lats
435 | korea won lithuania litas
436 | korea won macedonia denar
437 | korea won malaysia ringgit
438 | korea won mexico peso
439 | korea won nigeria naira
440 | korea won poland zloty
441 | korea won romania leu
442 | korea won russia ruble
443 | korea won sweden krona
444 | korea won thailand baht
445 | korea won ukraine hryvnia
446 | korea won usa dollar
447 | korea won vietnam dong
448 | korea won algeria dinar
449 | korea won angola kwanza
450 | korea won argentina peso
451 | korea won armenia dram
452 | korea won brazil real
453 | korea won bulgaria lev
454 | korea won cambodia riel
455 | korea won canada dollar
456 | korea won croatia kuna
457 | korea won denmark krone
458 | korea won europe euro
459 | korea won hungary forint
460 | korea won india rupee
461 | korea won iran rial
462 | korea won japan yen
463 | latvia lats lithuania litas
464 | latvia lats macedonia denar
465 | latvia lats malaysia ringgit
466 | latvia lats mexico peso
467 | latvia lats nigeria naira
468 | latvia lats poland zloty
469 | latvia lats romania leu
470 | latvia lats russia ruble
471 | latvia lats sweden krona
472 | latvia lats thailand baht
473 | latvia lats ukraine hryvnia
474 | latvia lats usa dollar
475 | latvia lats vietnam dong
476 | latvia lats algeria dinar
477 | latvia lats angola kwanza
478 | latvia lats argentina peso
479 | latvia lats armenia dram
480 | latvia lats brazil real
481 | latvia lats bulgaria lev
482 | latvia lats cambodia riel
483 | latvia lats canada dollar
484 | latvia lats croatia kuna
485 | latvia lats denmark krone
486 | latvia lats europe euro
487 | latvia lats hungary forint
488 | latvia lats india rupee
489 | latvia lats iran rial
490 | latvia lats japan yen
491 | latvia lats korea won
492 | lithuania litas macedonia denar
493 | lithuania litas malaysia ringgit
494 | lithuania litas mexico peso
495 | lithuania litas nigeria naira
496 | lithuania litas poland zloty
497 | lithuania litas romania leu
498 | lithuania litas russia ruble
499 | lithuania litas sweden krona
500 | lithuania litas thailand baht
501 | lithuania litas ukraine hryvnia
502 | lithuania litas usa dollar
503 | lithuania litas vietnam dong
504 | lithuania litas algeria dinar
505 | lithuania litas angola kwanza
506 | lithuania litas argentina peso
507 | lithuania litas armenia dram
508 | lithuania litas brazil real
509 | lithuania litas bulgaria lev
510 | lithuania litas cambodia riel
511 | lithuania litas canada dollar
512 | lithuania litas croatia kuna
513 | lithuania litas denmark krone
514 | lithuania litas europe euro
515 | lithuania litas hungary forint
516 | lithuania litas india rupee
517 | lithuania litas iran rial
518 | lithuania litas japan yen
519 | lithuania litas korea won
520 | lithuania litas latvia lats
521 | macedonia denar malaysia ringgit
522 | macedonia denar mexico peso
523 | macedonia denar nigeria naira
524 | macedonia denar poland zloty
525 | macedonia denar romania leu
526 | macedonia denar russia ruble
527 | macedonia denar sweden krona
528 | macedonia denar thailand baht
529 | macedonia denar ukraine hryvnia
530 | macedonia denar usa dollar
531 | macedonia denar vietnam dong
532 | macedonia denar algeria dinar
533 | macedonia denar angola kwanza
534 | macedonia denar argentina peso
535 | macedonia denar armenia dram
536 | macedonia denar brazil real
537 | macedonia denar bulgaria lev
538 | macedonia denar cambodia riel
539 | macedonia denar canada dollar
540 | macedonia denar croatia kuna
541 | macedonia denar denmark krone
542 | macedonia denar europe euro
543 | macedonia denar hungary forint
544 | macedonia denar india rupee
545 | macedonia denar iran rial
546 | macedonia denar japan yen
547 | macedonia denar korea won
548 | macedonia denar latvia lats
549 | macedonia denar lithuania litas
550 | malaysia ringgit mexico peso
551 | malaysia ringgit nigeria naira
552 | malaysia ringgit poland zloty
553 | malaysia ringgit romania leu
554 | malaysia ringgit russia ruble
555 | malaysia ringgit sweden krona
556 | malaysia ringgit thailand baht
557 | malaysia ringgit ukraine hryvnia
558 | malaysia ringgit usa dollar
559 | malaysia ringgit vietnam dong
560 | malaysia ringgit algeria dinar
561 | malaysia ringgit angola kwanza
562 | malaysia ringgit argentina peso
563 | malaysia ringgit armenia dram
564 | malaysia ringgit brazil real
565 | malaysia ringgit bulgaria lev
566 | malaysia ringgit cambodia riel
567 | malaysia ringgit canada dollar
568 | malaysia ringgit croatia kuna
569 | malaysia ringgit denmark krone
570 | malaysia ringgit europe euro
571 | malaysia ringgit hungary forint
572 | malaysia ringgit india rupee
573 | malaysia ringgit iran rial
574 | malaysia ringgit japan yen
575 | malaysia ringgit korea won
576 | malaysia ringgit latvia lats
577 | malaysia ringgit lithuania litas
578 | malaysia ringgit macedonia denar
579 | mexico peso nigeria naira
580 | mexico peso poland zloty
581 | mexico peso romania leu
582 | mexico peso russia ruble
583 | mexico peso sweden krona
584 | mexico peso thailand baht
585 | mexico peso ukraine hryvnia
586 | mexico peso usa dollar
587 | mexico peso vietnam dong
588 | mexico peso algeria dinar
589 | mexico peso angola kwanza
590 | mexico peso armenia dram
591 | mexico peso brazil real
592 | mexico peso bulgaria lev
593 | mexico peso cambodia riel
594 | mexico peso canada dollar
595 | mexico peso croatia kuna
596 | mexico peso denmark krone
597 | mexico peso europe euro
598 | mexico peso hungary forint
599 | mexico peso india rupee
600 | mexico peso iran rial
601 | mexico peso japan yen
602 | mexico peso korea won
603 | mexico peso latvia lats
604 | mexico peso lithuania litas
605 | mexico peso macedonia denar
606 | mexico peso malaysia ringgit
607 | nigeria naira poland zloty
608 | nigeria naira romania leu
609 | nigeria naira russia ruble
610 | nigeria naira sweden krona
611 | nigeria naira thailand baht
612 | nigeria naira ukraine hryvnia
613 | nigeria naira usa dollar
614 | nigeria naira vietnam dong
615 | nigeria naira algeria dinar
616 | nigeria naira angola kwanza
617 | nigeria naira argentina peso
618 | nigeria naira armenia dram
619 | nigeria naira brazil real
620 | nigeria naira bulgaria lev
621 | nigeria naira cambodia riel
622 | nigeria naira canada dollar
623 | nigeria naira croatia kuna
624 | nigeria naira denmark krone
625 | nigeria naira europe euro
626 | nigeria naira hungary forint
627 | nigeria naira india rupee
628 | nigeria naira iran rial
629 | nigeria naira japan yen
630 | nigeria naira korea won
631 | nigeria naira latvia lats
632 | nigeria naira lithuania litas
633 | nigeria naira macedonia denar
634 | nigeria naira malaysia ringgit
635 | nigeria naira mexico peso
636 | poland zloty romania leu
637 | poland zloty russia ruble
638 | poland zloty sweden krona
639 | poland zloty thailand baht
640 | poland zloty ukraine hryvnia
641 | poland zloty usa dollar
642 | poland zloty vietnam dong
643 | poland zloty algeria dinar
644 | poland zloty angola kwanza
645 | poland zloty argentina peso
646 | poland zloty armenia dram
647 | poland zloty brazil real
648 | poland zloty bulgaria lev
649 | poland zloty cambodia riel
650 | poland zloty canada dollar
651 | poland zloty croatia kuna
652 | poland zloty denmark krone
653 | poland zloty europe euro
654 | poland zloty hungary forint
655 | poland zloty india rupee
656 | poland zloty iran rial
657 | poland zloty japan yen
658 | poland zloty korea won
659 | poland zloty latvia lats
660 | poland zloty lithuania litas
661 | poland zloty macedonia denar
662 | poland zloty malaysia ringgit
663 | poland zloty mexico peso
664 | poland zloty nigeria naira
665 | romania leu russia ruble
666 | romania leu sweden krona
667 | romania leu thailand baht
668 | romania leu ukraine hryvnia
669 | romania leu usa dollar
670 | romania leu vietnam dong
671 | romania leu algeria dinar
672 | romania leu angola kwanza
673 | romania leu argentina peso
674 | romania leu armenia dram
675 | romania leu brazil real
676 | romania leu bulgaria lev
677 | romania leu cambodia riel
678 | romania leu canada dollar
679 | romania leu croatia kuna
680 | romania leu denmark krone
681 | romania leu europe euro
682 | romania leu hungary forint
683 | romania leu india rupee
684 | romania leu iran rial
685 | romania leu japan yen
686 | romania leu korea won
687 | romania leu latvia lats
688 | romania leu lithuania litas
689 | romania leu macedonia denar
690 | romania leu malaysia ringgit
691 | romania leu mexico peso
692 | romania leu nigeria naira
693 | romania leu poland zloty
694 | russia ruble sweden krona
695 | russia ruble thailand baht
696 | russia ruble ukraine hryvnia
697 | russia ruble usa dollar
698 | russia ruble vietnam dong
699 | russia ruble algeria dinar
700 | russia ruble angola kwanza
701 | russia ruble argentina peso
702 | russia ruble armenia dram
703 | russia ruble brazil real
704 | russia ruble bulgaria lev
705 | russia ruble cambodia riel
706 | russia ruble canada dollar
707 | russia ruble croatia kuna
708 | russia ruble denmark krone
709 | russia ruble europe euro
710 | russia ruble hungary forint
711 | russia ruble india rupee
712 | russia ruble iran rial
713 | russia ruble japan yen
714 | russia ruble korea won
715 | russia ruble latvia lats
716 | russia ruble lithuania litas
717 | russia ruble macedonia denar
718 | russia ruble malaysia ringgit
719 | russia ruble mexico peso
720 | russia ruble nigeria naira
721 | russia ruble poland zloty
722 | russia ruble romania leu
723 | sweden krona thailand baht
724 | sweden krona ukraine hryvnia
725 | sweden krona usa dollar
726 | sweden krona vietnam dong
727 | sweden krona algeria dinar
728 | sweden krona angola kwanza
729 | sweden krona argentina peso
730 | sweden krona armenia dram
731 | sweden krona brazil real
732 | sweden krona bulgaria lev
733 | sweden krona cambodia riel
734 | sweden krona canada dollar
735 | sweden krona croatia kuna
736 | sweden krona denmark krone
737 | sweden krona europe euro
738 | sweden krona hungary forint
739 | sweden krona india rupee
740 | sweden krona iran rial
741 | sweden krona japan yen
742 | sweden krona korea won
743 | sweden krona latvia lats
744 | sweden krona lithuania litas
745 | sweden krona macedonia denar
746 | sweden krona malaysia ringgit
747 | sweden krona mexico peso
748 | sweden krona nigeria naira
749 | sweden krona poland zloty
750 | sweden krona romania leu
751 | sweden krona russia ruble
752 | thailand baht ukraine hryvnia
753 | thailand baht usa dollar
754 | thailand baht vietnam dong
755 | thailand baht algeria dinar
756 | thailand baht angola kwanza
757 | thailand baht argentina peso
758 | thailand baht armenia dram
759 | thailand baht brazil real
760 | thailand baht bulgaria lev
761 | thailand baht cambodia riel
762 | thailand baht canada dollar
763 | thailand baht croatia kuna
764 | thailand baht denmark krone
765 | thailand baht europe euro
766 | thailand baht hungary forint
767 | thailand baht india rupee
768 | thailand baht iran rial
769 | thailand baht japan yen
770 | thailand baht korea won
771 | thailand baht latvia lats
772 | thailand baht lithuania litas
773 | thailand baht macedonia denar
774 | thailand baht malaysia ringgit
775 | thailand baht mexico peso
776 | thailand baht nigeria naira
777 | thailand baht poland zloty
778 | thailand baht romania leu
779 | thailand baht russia ruble
780 | thailand baht sweden krona
781 | ukraine hryvnia usa dollar
782 | ukraine hryvnia vietnam dong
783 | ukraine hryvnia algeria dinar
784 | ukraine hryvnia angola kwanza
785 | ukraine hryvnia argentina peso
786 | ukraine hryvnia armenia dram
787 | ukraine hryvnia brazil real
788 | ukraine hryvnia bulgaria lev
789 | ukraine hryvnia cambodia riel
790 | ukraine hryvnia canada dollar
791 | ukraine hryvnia croatia kuna
792 | ukraine hryvnia denmark krone
793 | ukraine hryvnia europe euro
794 | ukraine hryvnia hungary forint
795 | ukraine hryvnia india rupee
796 | ukraine hryvnia iran rial
797 | ukraine hryvnia japan yen
798 | ukraine hryvnia korea won
799 | ukraine hryvnia latvia lats
800 | ukraine hryvnia lithuania litas
801 | ukraine hryvnia macedonia denar
802 | ukraine hryvnia malaysia ringgit
803 | ukraine hryvnia mexico peso
804 | ukraine hryvnia nigeria naira
805 | ukraine hryvnia poland zloty
806 | ukraine hryvnia romania leu
807 | ukraine hryvnia russia ruble
808 | ukraine hryvnia sweden krona
809 | ukraine hryvnia thailand baht
810 | usa dollar vietnam dong
811 | usa dollar algeria dinar
812 | usa dollar angola kwanza
813 | usa dollar argentina peso
814 | usa dollar armenia dram
815 | usa dollar brazil real
816 | usa dollar bulgaria lev
817 | usa dollar cambodia riel
818 | usa dollar croatia kuna
819 | usa dollar denmark krone
820 | usa dollar europe euro
821 | usa dollar hungary forint
822 | usa dollar india rupee
823 | usa dollar iran rial
824 | usa dollar japan yen
825 | usa dollar korea won
826 | usa dollar latvia lats
827 | usa dollar lithuania litas
828 | usa dollar macedonia denar
829 | usa dollar malaysia ringgit
830 | usa dollar mexico peso
831 | usa dollar nigeria naira
832 | usa dollar poland zloty
833 | usa dollar romania leu
834 | usa dollar russia ruble
835 | usa dollar sweden krona
836 | usa dollar thailand baht
837 | usa dollar ukraine hryvnia
838 | vietnam dong algeria dinar
839 | vietnam dong angola kwanza
840 | vietnam dong argentina peso
841 | vietnam dong armenia dram
842 | vietnam dong brazil real
843 | vietnam dong bulgaria lev
844 | vietnam dong cambodia riel
845 | vietnam dong canada dollar
846 | vietnam dong croatia kuna
847 | vietnam dong denmark krone
848 | vietnam dong europe euro
849 | vietnam dong hungary forint
850 | vietnam dong india rupee
851 | vietnam dong iran rial
852 | vietnam dong japan yen
853 | vietnam dong korea won
854 | vietnam dong latvia lats
855 | vietnam dong lithuania litas
856 | vietnam dong macedonia denar
857 | vietnam dong malaysia ringgit
858 | vietnam dong mexico peso
859 | vietnam dong nigeria naira
860 | vietnam dong poland zloty
861 | vietnam dong romania leu
862 | vietnam dong russia ruble
863 | vietnam dong sweden krona
864 | vietnam dong thailand baht
865 | vietnam dong ukraine hryvnia
866 | vietnam dong usa dollar
867 |
--------------------------------------------------------------------------------
/eval/question-data/family.txt:
--------------------------------------------------------------------------------
1 | boy girl brother sister
2 | boy girl brothers sisters
3 | boy girl dad mom
4 | boy girl father mother
5 | boy girl grandfather grandmother
6 | boy girl grandpa grandma
7 | boy girl grandson granddaughter
8 | boy girl groom bride
9 | boy girl he she
10 | boy girl his her
11 | boy girl husband wife
12 | boy girl king queen
13 | boy girl man woman
14 | boy girl nephew niece
15 | boy girl policeman policewoman
16 | boy girl prince princess
17 | boy girl son daughter
18 | boy girl sons daughters
19 | boy girl stepbrother stepsister
20 | boy girl stepfather stepmother
21 | boy girl stepson stepdaughter
22 | boy girl uncle aunt
23 | brother sister brothers sisters
24 | brother sister dad mom
25 | brother sister father mother
26 | brother sister grandfather grandmother
27 | brother sister grandpa grandma
28 | brother sister grandson granddaughter
29 | brother sister groom bride
30 | brother sister he she
31 | brother sister his her
32 | brother sister husband wife
33 | brother sister king queen
34 | brother sister man woman
35 | brother sister nephew niece
36 | brother sister policeman policewoman
37 | brother sister prince princess
38 | brother sister son daughter
39 | brother sister sons daughters
40 | brother sister stepbrother stepsister
41 | brother sister stepfather stepmother
42 | brother sister stepson stepdaughter
43 | brother sister uncle aunt
44 | brother sister boy girl
45 | brothers sisters dad mom
46 | brothers sisters father mother
47 | brothers sisters grandfather grandmother
48 | brothers sisters grandpa grandma
49 | brothers sisters grandson granddaughter
50 | brothers sisters groom bride
51 | brothers sisters he she
52 | brothers sisters his her
53 | brothers sisters husband wife
54 | brothers sisters king queen
55 | brothers sisters man woman
56 | brothers sisters nephew niece
57 | brothers sisters policeman policewoman
58 | brothers sisters prince princess
59 | brothers sisters son daughter
60 | brothers sisters sons daughters
61 | brothers sisters stepbrother stepsister
62 | brothers sisters stepfather stepmother
63 | brothers sisters stepson stepdaughter
64 | brothers sisters uncle aunt
65 | brothers sisters boy girl
66 | brothers sisters brother sister
67 | dad mom father mother
68 | dad mom grandfather grandmother
69 | dad mom grandpa grandma
70 | dad mom grandson granddaughter
71 | dad mom groom bride
72 | dad mom he she
73 | dad mom his her
74 | dad mom husband wife
75 | dad mom king queen
76 | dad mom man woman
77 | dad mom nephew niece
78 | dad mom policeman policewoman
79 | dad mom prince princess
80 | dad mom son daughter
81 | dad mom sons daughters
82 | dad mom stepbrother stepsister
83 | dad mom stepfather stepmother
84 | dad mom stepson stepdaughter
85 | dad mom uncle aunt
86 | dad mom boy girl
87 | dad mom brother sister
88 | dad mom brothers sisters
89 | father mother grandfather grandmother
90 | father mother grandpa grandma
91 | father mother grandson granddaughter
92 | father mother groom bride
93 | father mother he she
94 | father mother his her
95 | father mother husband wife
96 | father mother king queen
97 | father mother man woman
98 | father mother nephew niece
99 | father mother policeman policewoman
100 | father mother prince princess
101 | father mother son daughter
102 | father mother sons daughters
103 | father mother stepbrother stepsister
104 | father mother stepfather stepmother
105 | father mother stepson stepdaughter
106 | father mother uncle aunt
107 | father mother boy girl
108 | father mother brother sister
109 | father mother brothers sisters
110 | father mother dad mom
111 | grandfather grandmother grandpa grandma
112 | grandfather grandmother grandson granddaughter
113 | grandfather grandmother groom bride
114 | grandfather grandmother he she
115 | grandfather grandmother his her
116 | grandfather grandmother husband wife
117 | grandfather grandmother king queen
118 | grandfather grandmother man woman
119 | grandfather grandmother nephew niece
120 | grandfather grandmother policeman policewoman
121 | grandfather grandmother prince princess
122 | grandfather grandmother son daughter
123 | grandfather grandmother sons daughters
124 | grandfather grandmother stepbrother stepsister
125 | grandfather grandmother stepfather stepmother
126 | grandfather grandmother stepson stepdaughter
127 | grandfather grandmother uncle aunt
128 | grandfather grandmother boy girl
129 | grandfather grandmother brother sister
130 | grandfather grandmother brothers sisters
131 | grandfather grandmother dad mom
132 | grandfather grandmother father mother
133 | grandpa grandma grandson granddaughter
134 | grandpa grandma groom bride
135 | grandpa grandma he she
136 | grandpa grandma his her
137 | grandpa grandma husband wife
138 | grandpa grandma king queen
139 | grandpa grandma man woman
140 | grandpa grandma nephew niece
141 | grandpa grandma policeman policewoman
142 | grandpa grandma prince princess
143 | grandpa grandma son daughter
144 | grandpa grandma sons daughters
145 | grandpa grandma stepbrother stepsister
146 | grandpa grandma stepfather stepmother
147 | grandpa grandma stepson stepdaughter
148 | grandpa grandma uncle aunt
149 | grandpa grandma boy girl
150 | grandpa grandma brother sister
151 | grandpa grandma brothers sisters
152 | grandpa grandma dad mom
153 | grandpa grandma father mother
154 | grandpa grandma grandfather grandmother
155 | grandson granddaughter groom bride
156 | grandson granddaughter he she
157 | grandson granddaughter his her
158 | grandson granddaughter husband wife
159 | grandson granddaughter king queen
160 | grandson granddaughter man woman
161 | grandson granddaughter nephew niece
162 | grandson granddaughter policeman policewoman
163 | grandson granddaughter prince princess
164 | grandson granddaughter son daughter
165 | grandson granddaughter sons daughters
166 | grandson granddaughter stepbrother stepsister
167 | grandson granddaughter stepfather stepmother
168 | grandson granddaughter stepson stepdaughter
169 | grandson granddaughter uncle aunt
170 | grandson granddaughter boy girl
171 | grandson granddaughter brother sister
172 | grandson granddaughter brothers sisters
173 | grandson granddaughter dad mom
174 | grandson granddaughter father mother
175 | grandson granddaughter grandfather grandmother
176 | grandson granddaughter grandpa grandma
177 | groom bride he she
178 | groom bride his her
179 | groom bride husband wife
180 | groom bride king queen
181 | groom bride man woman
182 | groom bride nephew niece
183 | groom bride policeman policewoman
184 | groom bride prince princess
185 | groom bride son daughter
186 | groom bride sons daughters
187 | groom bride stepbrother stepsister
188 | groom bride stepfather stepmother
189 | groom bride stepson stepdaughter
190 | groom bride uncle aunt
191 | groom bride boy girl
192 | groom bride brother sister
193 | groom bride brothers sisters
194 | groom bride dad mom
195 | groom bride father mother
196 | groom bride grandfather grandmother
197 | groom bride grandpa grandma
198 | groom bride grandson granddaughter
199 | he she his her
200 | he she husband wife
201 | he she king queen
202 | he she man woman
203 | he she nephew niece
204 | he she policeman policewoman
205 | he she prince princess
206 | he she son daughter
207 | he she sons daughters
208 | he she stepbrother stepsister
209 | he she stepfather stepmother
210 | he she stepson stepdaughter
211 | he she uncle aunt
212 | he she boy girl
213 | he she brother sister
214 | he she brothers sisters
215 | he she dad mom
216 | he she father mother
217 | he she grandfather grandmother
218 | he she grandpa grandma
219 | he she grandson granddaughter
220 | he she groom bride
221 | his her husband wife
222 | his her king queen
223 | his her man woman
224 | his her nephew niece
225 | his her policeman policewoman
226 | his her prince princess
227 | his her son daughter
228 | his her sons daughters
229 | his her stepbrother stepsister
230 | his her stepfather stepmother
231 | his her stepson stepdaughter
232 | his her uncle aunt
233 | his her boy girl
234 | his her brother sister
235 | his her brothers sisters
236 | his her dad mom
237 | his her father mother
238 | his her grandfather grandmother
239 | his her grandpa grandma
240 | his her grandson granddaughter
241 | his her groom bride
242 | his her he she
243 | husband wife king queen
244 | husband wife man woman
245 | husband wife nephew niece
246 | husband wife policeman policewoman
247 | husband wife prince princess
248 | husband wife son daughter
249 | husband wife sons daughters
250 | husband wife stepbrother stepsister
251 | husband wife stepfather stepmother
252 | husband wife stepson stepdaughter
253 | husband wife uncle aunt
254 | husband wife boy girl
255 | husband wife brother sister
256 | husband wife brothers sisters
257 | husband wife dad mom
258 | husband wife father mother
259 | husband wife grandfather grandmother
260 | husband wife grandpa grandma
261 | husband wife grandson granddaughter
262 | husband wife groom bride
263 | husband wife he she
264 | husband wife his her
265 | king queen man woman
266 | king queen nephew niece
267 | king queen policeman policewoman
268 | king queen prince princess
269 | king queen son daughter
270 | king queen sons daughters
271 | king queen stepbrother stepsister
272 | king queen stepfather stepmother
273 | king queen stepson stepdaughter
274 | king queen uncle aunt
275 | king queen boy girl
276 | king queen brother sister
277 | king queen brothers sisters
278 | king queen dad mom
279 | king queen father mother
280 | king queen grandfather grandmother
281 | king queen grandpa grandma
282 | king queen grandson granddaughter
283 | king queen groom bride
284 | king queen he she
285 | king queen his her
286 | king queen husband wife
287 | man woman nephew niece
288 | man woman policeman policewoman
289 | man woman prince princess
290 | man woman son daughter
291 | man woman sons daughters
292 | man woman stepbrother stepsister
293 | man woman stepfather stepmother
294 | man woman stepson stepdaughter
295 | man woman uncle aunt
296 | man woman boy girl
297 | man woman brother sister
298 | man woman brothers sisters
299 | man woman dad mom
300 | man woman father mother
301 | man woman grandfather grandmother
302 | man woman grandpa grandma
303 | man woman grandson granddaughter
304 | man woman groom bride
305 | man woman he she
306 | man woman his her
307 | man woman husband wife
308 | man woman king queen
309 | nephew niece policeman policewoman
310 | nephew niece prince princess
311 | nephew niece son daughter
312 | nephew niece sons daughters
313 | nephew niece stepbrother stepsister
314 | nephew niece stepfather stepmother
315 | nephew niece stepson stepdaughter
316 | nephew niece uncle aunt
317 | nephew niece boy girl
318 | nephew niece brother sister
319 | nephew niece brothers sisters
320 | nephew niece dad mom
321 | nephew niece father mother
322 | nephew niece grandfather grandmother
323 | nephew niece grandpa grandma
324 | nephew niece grandson granddaughter
325 | nephew niece groom bride
326 | nephew niece he she
327 | nephew niece his her
328 | nephew niece husband wife
329 | nephew niece king queen
330 | nephew niece man woman
331 | policeman policewoman prince princess
332 | policeman policewoman son daughter
333 | policeman policewoman sons daughters
334 | policeman policewoman stepbrother stepsister
335 | policeman policewoman stepfather stepmother
336 | policeman policewoman stepson stepdaughter
337 | policeman policewoman uncle aunt
338 | policeman policewoman boy girl
339 | policeman policewoman brother sister
340 | policeman policewoman brothers sisters
341 | policeman policewoman dad mom
342 | policeman policewoman father mother
343 | policeman policewoman grandfather grandmother
344 | policeman policewoman grandpa grandma
345 | policeman policewoman grandson granddaughter
346 | policeman policewoman groom bride
347 | policeman policewoman he she
348 | policeman policewoman his her
349 | policeman policewoman husband wife
350 | policeman policewoman king queen
351 | policeman policewoman man woman
352 | policeman policewoman nephew niece
353 | prince princess son daughter
354 | prince princess sons daughters
355 | prince princess stepbrother stepsister
356 | prince princess stepfather stepmother
357 | prince princess stepson stepdaughter
358 | prince princess uncle aunt
359 | prince princess boy girl
360 | prince princess brother sister
361 | prince princess brothers sisters
362 | prince princess dad mom
363 | prince princess father mother
364 | prince princess grandfather grandmother
365 | prince princess grandpa grandma
366 | prince princess grandson granddaughter
367 | prince princess groom bride
368 | prince princess he she
369 | prince princess his her
370 | prince princess husband wife
371 | prince princess king queen
372 | prince princess man woman
373 | prince princess nephew niece
374 | prince princess policeman policewoman
375 | son daughter sons daughters
376 | son daughter stepbrother stepsister
377 | son daughter stepfather stepmother
378 | son daughter stepson stepdaughter
379 | son daughter uncle aunt
380 | son daughter boy girl
381 | son daughter brother sister
382 | son daughter brothers sisters
383 | son daughter dad mom
384 | son daughter father mother
385 | son daughter grandfather grandmother
386 | son daughter grandpa grandma
387 | son daughter grandson granddaughter
388 | son daughter groom bride
389 | son daughter he she
390 | son daughter his her
391 | son daughter husband wife
392 | son daughter king queen
393 | son daughter man woman
394 | son daughter nephew niece
395 | son daughter policeman policewoman
396 | son daughter prince princess
397 | sons daughters stepbrother stepsister
398 | sons daughters stepfather stepmother
399 | sons daughters stepson stepdaughter
400 | sons daughters uncle aunt
401 | sons daughters boy girl
402 | sons daughters brother sister
403 | sons daughters brothers sisters
404 | sons daughters dad mom
405 | sons daughters father mother
406 | sons daughters grandfather grandmother
407 | sons daughters grandpa grandma
408 | sons daughters grandson granddaughter
409 | sons daughters groom bride
410 | sons daughters he she
411 | sons daughters his her
412 | sons daughters husband wife
413 | sons daughters king queen
414 | sons daughters man woman
415 | sons daughters nephew niece
416 | sons daughters policeman policewoman
417 | sons daughters prince princess
418 | sons daughters son daughter
419 | stepbrother stepsister stepfather stepmother
420 | stepbrother stepsister stepson stepdaughter
421 | stepbrother stepsister uncle aunt
422 | stepbrother stepsister boy girl
423 | stepbrother stepsister brother sister
424 | stepbrother stepsister brothers sisters
425 | stepbrother stepsister dad mom
426 | stepbrother stepsister father mother
427 | stepbrother stepsister grandfather grandmother
428 | stepbrother stepsister grandpa grandma
429 | stepbrother stepsister grandson granddaughter
430 | stepbrother stepsister groom bride
431 | stepbrother stepsister he she
432 | stepbrother stepsister his her
433 | stepbrother stepsister husband wife
434 | stepbrother stepsister king queen
435 | stepbrother stepsister man woman
436 | stepbrother stepsister nephew niece
437 | stepbrother stepsister policeman policewoman
438 | stepbrother stepsister prince princess
439 | stepbrother stepsister son daughter
440 | stepbrother stepsister sons daughters
441 | stepfather stepmother stepson stepdaughter
442 | stepfather stepmother uncle aunt
443 | stepfather stepmother boy girl
444 | stepfather stepmother brother sister
445 | stepfather stepmother brothers sisters
446 | stepfather stepmother dad mom
447 | stepfather stepmother father mother
448 | stepfather stepmother grandfather grandmother
449 | stepfather stepmother grandpa grandma
450 | stepfather stepmother grandson granddaughter
451 | stepfather stepmother groom bride
452 | stepfather stepmother he she
453 | stepfather stepmother his her
454 | stepfather stepmother husband wife
455 | stepfather stepmother king queen
456 | stepfather stepmother man woman
457 | stepfather stepmother nephew niece
458 | stepfather stepmother policeman policewoman
459 | stepfather stepmother prince princess
460 | stepfather stepmother son daughter
461 | stepfather stepmother sons daughters
462 | stepfather stepmother stepbrother stepsister
463 | stepson stepdaughter uncle aunt
464 | stepson stepdaughter boy girl
465 | stepson stepdaughter brother sister
466 | stepson stepdaughter brothers sisters
467 | stepson stepdaughter dad mom
468 | stepson stepdaughter father mother
469 | stepson stepdaughter grandfather grandmother
470 | stepson stepdaughter grandpa grandma
471 | stepson stepdaughter grandson granddaughter
472 | stepson stepdaughter groom bride
473 | stepson stepdaughter he she
474 | stepson stepdaughter his her
475 | stepson stepdaughter husband wife
476 | stepson stepdaughter king queen
477 | stepson stepdaughter man woman
478 | stepson stepdaughter nephew niece
479 | stepson stepdaughter policeman policewoman
480 | stepson stepdaughter prince princess
481 | stepson stepdaughter son daughter
482 | stepson stepdaughter sons daughters
483 | stepson stepdaughter stepbrother stepsister
484 | stepson stepdaughter stepfather stepmother
485 | uncle aunt boy girl
486 | uncle aunt brother sister
487 | uncle aunt brothers sisters
488 | uncle aunt dad mom
489 | uncle aunt father mother
490 | uncle aunt grandfather grandmother
491 | uncle aunt grandpa grandma
492 | uncle aunt grandson granddaughter
493 | uncle aunt groom bride
494 | uncle aunt he she
495 | uncle aunt his her
496 | uncle aunt husband wife
497 | uncle aunt king queen
498 | uncle aunt man woman
499 | uncle aunt nephew niece
500 | uncle aunt policeman policewoman
501 | uncle aunt prince princess
502 | uncle aunt son daughter
503 | uncle aunt sons daughters
504 | uncle aunt stepbrother stepsister
505 | uncle aunt stepfather stepmother
506 | uncle aunt stepson stepdaughter
507 |
--------------------------------------------------------------------------------
/eval/question-data/gram9-plural-verbs.txt:
--------------------------------------------------------------------------------
1 | decrease decreases describe describes
2 | decrease decreases eat eats
3 | decrease decreases enhance enhances
4 | decrease decreases estimate estimates
5 | decrease decreases find finds
6 | decrease decreases generate generates
7 | decrease decreases go goes
8 | decrease decreases implement implements
9 | decrease decreases increase increases
10 | decrease decreases listen listens
11 | decrease decreases play plays
12 | decrease decreases predict predicts
13 | decrease decreases provide provides
14 | decrease decreases say says
15 | decrease decreases scream screams
16 | decrease decreases search searches
17 | decrease decreases see sees
18 | decrease decreases shuffle shuffles
19 | decrease decreases sing sings
20 | decrease decreases sit sits
21 | decrease decreases slow slows
22 | decrease decreases speak speaks
23 | decrease decreases swim swims
24 | decrease decreases talk talks
25 | decrease decreases think thinks
26 | decrease decreases vanish vanishes
27 | decrease decreases walk walks
28 | decrease decreases work works
29 | decrease decreases write writes
30 | describe describes eat eats
31 | describe describes enhance enhances
32 | describe describes estimate estimates
33 | describe describes find finds
34 | describe describes generate generates
35 | describe describes go goes
36 | describe describes implement implements
37 | describe describes increase increases
38 | describe describes listen listens
39 | describe describes play plays
40 | describe describes predict predicts
41 | describe describes provide provides
42 | describe describes say says
43 | describe describes scream screams
44 | describe describes search searches
45 | describe describes see sees
46 | describe describes shuffle shuffles
47 | describe describes sing sings
48 | describe describes sit sits
49 | describe describes slow slows
50 | describe describes speak speaks
51 | describe describes swim swims
52 | describe describes talk talks
53 | describe describes think thinks
54 | describe describes vanish vanishes
55 | describe describes walk walks
56 | describe describes work works
57 | describe describes write writes
58 | describe describes decrease decreases
59 | eat eats enhance enhances
60 | eat eats estimate estimates
61 | eat eats find finds
62 | eat eats generate generates
63 | eat eats go goes
64 | eat eats implement implements
65 | eat eats increase increases
66 | eat eats listen listens
67 | eat eats play plays
68 | eat eats predict predicts
69 | eat eats provide provides
70 | eat eats say says
71 | eat eats scream screams
72 | eat eats search searches
73 | eat eats see sees
74 | eat eats shuffle shuffles
75 | eat eats sing sings
76 | eat eats sit sits
77 | eat eats slow slows
78 | eat eats speak speaks
79 | eat eats swim swims
80 | eat eats talk talks
81 | eat eats think thinks
82 | eat eats vanish vanishes
83 | eat eats walk walks
84 | eat eats work works
85 | eat eats write writes
86 | eat eats decrease decreases
87 | eat eats describe describes
88 | enhance enhances estimate estimates
89 | enhance enhances find finds
90 | enhance enhances generate generates
91 | enhance enhances go goes
92 | enhance enhances implement implements
93 | enhance enhances increase increases
94 | enhance enhances listen listens
95 | enhance enhances play plays
96 | enhance enhances predict predicts
97 | enhance enhances provide provides
98 | enhance enhances say says
99 | enhance enhances scream screams
100 | enhance enhances search searches
101 | enhance enhances see sees
102 | enhance enhances shuffle shuffles
103 | enhance enhances sing sings
104 | enhance enhances sit sits
105 | enhance enhances slow slows
106 | enhance enhances speak speaks
107 | enhance enhances swim swims
108 | enhance enhances talk talks
109 | enhance enhances think thinks
110 | enhance enhances vanish vanishes
111 | enhance enhances walk walks
112 | enhance enhances work works
113 | enhance enhances write writes
114 | enhance enhances decrease decreases
115 | enhance enhances describe describes
116 | enhance enhances eat eats
117 | estimate estimates find finds
118 | estimate estimates generate generates
119 | estimate estimates go goes
120 | estimate estimates implement implements
121 | estimate estimates increase increases
122 | estimate estimates listen listens
123 | estimate estimates play plays
124 | estimate estimates predict predicts
125 | estimate estimates provide provides
126 | estimate estimates say says
127 | estimate estimates scream screams
128 | estimate estimates search searches
129 | estimate estimates see sees
130 | estimate estimates shuffle shuffles
131 | estimate estimates sing sings
132 | estimate estimates sit sits
133 | estimate estimates slow slows
134 | estimate estimates speak speaks
135 | estimate estimates swim swims
136 | estimate estimates talk talks
137 | estimate estimates think thinks
138 | estimate estimates vanish vanishes
139 | estimate estimates walk walks
140 | estimate estimates work works
141 | estimate estimates write writes
142 | estimate estimates decrease decreases
143 | estimate estimates describe describes
144 | estimate estimates eat eats
145 | estimate estimates enhance enhances
146 | find finds generate generates
147 | find finds go goes
148 | find finds implement implements
149 | find finds increase increases
150 | find finds listen listens
151 | find finds play plays
152 | find finds predict predicts
153 | find finds provide provides
154 | find finds say says
155 | find finds scream screams
156 | find finds search searches
157 | find finds see sees
158 | find finds shuffle shuffles
159 | find finds sing sings
160 | find finds sit sits
161 | find finds slow slows
162 | find finds speak speaks
163 | find finds swim swims
164 | find finds talk talks
165 | find finds think thinks
166 | find finds vanish vanishes
167 | find finds walk walks
168 | find finds work works
169 | find finds write writes
170 | find finds decrease decreases
171 | find finds describe describes
172 | find finds eat eats
173 | find finds enhance enhances
174 | find finds estimate estimates
175 | generate generates go goes
176 | generate generates implement implements
177 | generate generates increase increases
178 | generate generates listen listens
179 | generate generates play plays
180 | generate generates predict predicts
181 | generate generates provide provides
182 | generate generates say says
183 | generate generates scream screams
184 | generate generates search searches
185 | generate generates see sees
186 | generate generates shuffle shuffles
187 | generate generates sing sings
188 | generate generates sit sits
189 | generate generates slow slows
190 | generate generates speak speaks
191 | generate generates swim swims
192 | generate generates talk talks
193 | generate generates think thinks
194 | generate generates vanish vanishes
195 | generate generates walk walks
196 | generate generates work works
197 | generate generates write writes
198 | generate generates decrease decreases
199 | generate generates describe describes
200 | generate generates eat eats
201 | generate generates enhance enhances
202 | generate generates estimate estimates
203 | generate generates find finds
204 | go goes implement implements
205 | go goes increase increases
206 | go goes listen listens
207 | go goes play plays
208 | go goes predict predicts
209 | go goes provide provides
210 | go goes say says
211 | go goes scream screams
212 | go goes search searches
213 | go goes see sees
214 | go goes shuffle shuffles
215 | go goes sing sings
216 | go goes sit sits
217 | go goes slow slows
218 | go goes speak speaks
219 | go goes swim swims
220 | go goes talk talks
221 | go goes think thinks
222 | go goes vanish vanishes
223 | go goes walk walks
224 | go goes work works
225 | go goes write writes
226 | go goes decrease decreases
227 | go goes describe describes
228 | go goes eat eats
229 | go goes enhance enhances
230 | go goes estimate estimates
231 | go goes find finds
232 | go goes generate generates
233 | implement implements increase increases
234 | implement implements listen listens
235 | implement implements play plays
236 | implement implements predict predicts
237 | implement implements provide provides
238 | implement implements say says
239 | implement implements scream screams
240 | implement implements search searches
241 | implement implements see sees
242 | implement implements shuffle shuffles
243 | implement implements sing sings
244 | implement implements sit sits
245 | implement implements slow slows
246 | implement implements speak speaks
247 | implement implements swim swims
248 | implement implements talk talks
249 | implement implements think thinks
250 | implement implements vanish vanishes
251 | implement implements walk walks
252 | implement implements work works
253 | implement implements write writes
254 | implement implements decrease decreases
255 | implement implements describe describes
256 | implement implements eat eats
257 | implement implements enhance enhances
258 | implement implements estimate estimates
259 | implement implements find finds
260 | implement implements generate generates
261 | implement implements go goes
262 | increase increases listen listens
263 | increase increases play plays
264 | increase increases predict predicts
265 | increase increases provide provides
266 | increase increases say says
267 | increase increases scream screams
268 | increase increases search searches
269 | increase increases see sees
270 | increase increases shuffle shuffles
271 | increase increases sing sings
272 | increase increases sit sits
273 | increase increases slow slows
274 | increase increases speak speaks
275 | increase increases swim swims
276 | increase increases talk talks
277 | increase increases think thinks
278 | increase increases vanish vanishes
279 | increase increases walk walks
280 | increase increases work works
281 | increase increases write writes
282 | increase increases decrease decreases
283 | increase increases describe describes
284 | increase increases eat eats
285 | increase increases enhance enhances
286 | increase increases estimate estimates
287 | increase increases find finds
288 | increase increases generate generates
289 | increase increases go goes
290 | increase increases implement implements
291 | listen listens play plays
292 | listen listens predict predicts
293 | listen listens provide provides
294 | listen listens say says
295 | listen listens scream screams
296 | listen listens search searches
297 | listen listens see sees
298 | listen listens shuffle shuffles
299 | listen listens sing sings
300 | listen listens sit sits
301 | listen listens slow slows
302 | listen listens speak speaks
303 | listen listens swim swims
304 | listen listens talk talks
305 | listen listens think thinks
306 | listen listens vanish vanishes
307 | listen listens walk walks
308 | listen listens work works
309 | listen listens write writes
310 | listen listens decrease decreases
311 | listen listens describe describes
312 | listen listens eat eats
313 | listen listens enhance enhances
314 | listen listens estimate estimates
315 | listen listens find finds
316 | listen listens generate generates
317 | listen listens go goes
318 | listen listens implement implements
319 | listen listens increase increases
320 | play plays predict predicts
321 | play plays provide provides
322 | play plays say says
323 | play plays scream screams
324 | play plays search searches
325 | play plays see sees
326 | play plays shuffle shuffles
327 | play plays sing sings
328 | play plays sit sits
329 | play plays slow slows
330 | play plays speak speaks
331 | play plays swim swims
332 | play plays talk talks
333 | play plays think thinks
334 | play plays vanish vanishes
335 | play plays walk walks
336 | play plays work works
337 | play plays write writes
338 | play plays decrease decreases
339 | play plays describe describes
340 | play plays eat eats
341 | play plays enhance enhances
342 | play plays estimate estimates
343 | play plays find finds
344 | play plays generate generates
345 | play plays go goes
346 | play plays implement implements
347 | play plays increase increases
348 | play plays listen listens
349 | predict predicts provide provides
350 | predict predicts say says
351 | predict predicts scream screams
352 | predict predicts search searches
353 | predict predicts see sees
354 | predict predicts shuffle shuffles
355 | predict predicts sing sings
356 | predict predicts sit sits
357 | predict predicts slow slows
358 | predict predicts speak speaks
359 | predict predicts swim swims
360 | predict predicts talk talks
361 | predict predicts think thinks
362 | predict predicts vanish vanishes
363 | predict predicts walk walks
364 | predict predicts work works
365 | predict predicts write writes
366 | predict predicts decrease decreases
367 | predict predicts describe describes
368 | predict predicts eat eats
369 | predict predicts enhance enhances
370 | predict predicts estimate estimates
371 | predict predicts find finds
372 | predict predicts generate generates
373 | predict predicts go goes
374 | predict predicts implement implements
375 | predict predicts increase increases
376 | predict predicts listen listens
377 | predict predicts play plays
378 | provide provides say says
379 | provide provides scream screams
380 | provide provides search searches
381 | provide provides see sees
382 | provide provides shuffle shuffles
383 | provide provides sing sings
384 | provide provides sit sits
385 | provide provides slow slows
386 | provide provides speak speaks
387 | provide provides swim swims
388 | provide provides talk talks
389 | provide provides think thinks
390 | provide provides vanish vanishes
391 | provide provides walk walks
392 | provide provides work works
393 | provide provides write writes
394 | provide provides decrease decreases
395 | provide provides describe describes
396 | provide provides eat eats
397 | provide provides enhance enhances
398 | provide provides estimate estimates
399 | provide provides find finds
400 | provide provides generate generates
401 | provide provides go goes
402 | provide provides implement implements
403 | provide provides increase increases
404 | provide provides listen listens
405 | provide provides play plays
406 | provide provides predict predicts
407 | say says scream screams
408 | say says search searches
409 | say says see sees
410 | say says shuffle shuffles
411 | say says sing sings
412 | say says sit sits
413 | say says slow slows
414 | say says speak speaks
415 | say says swim swims
416 | say says talk talks
417 | say says think thinks
418 | say says vanish vanishes
419 | say says walk walks
420 | say says work works
421 | say says write writes
422 | say says decrease decreases
423 | say says describe describes
424 | say says eat eats
425 | say says enhance enhances
426 | say says estimate estimates
427 | say says find finds
428 | say says generate generates
429 | say says go goes
430 | say says implement implements
431 | say says increase increases
432 | say says listen listens
433 | say says play plays
434 | say says predict predicts
435 | say says provide provides
436 | scream screams search searches
437 | scream screams see sees
438 | scream screams shuffle shuffles
439 | scream screams sing sings
440 | scream screams sit sits
441 | scream screams slow slows
442 | scream screams speak speaks
443 | scream screams swim swims
444 | scream screams talk talks
445 | scream screams think thinks
446 | scream screams vanish vanishes
447 | scream screams walk walks
448 | scream screams work works
449 | scream screams write writes
450 | scream screams decrease decreases
451 | scream screams describe describes
452 | scream screams eat eats
453 | scream screams enhance enhances
454 | scream screams estimate estimates
455 | scream screams find finds
456 | scream screams generate generates
457 | scream screams go goes
458 | scream screams implement implements
459 | scream screams increase increases
460 | scream screams listen listens
461 | scream screams play plays
462 | scream screams predict predicts
463 | scream screams provide provides
464 | scream screams say says
465 | search searches see sees
466 | search searches shuffle shuffles
467 | search searches sing sings
468 | search searches sit sits
469 | search searches slow slows
470 | search searches speak speaks
471 | search searches swim swims
472 | search searches talk talks
473 | search searches think thinks
474 | search searches vanish vanishes
475 | search searches walk walks
476 | search searches work works
477 | search searches write writes
478 | search searches decrease decreases
479 | search searches describe describes
480 | search searches eat eats
481 | search searches enhance enhances
482 | search searches estimate estimates
483 | search searches find finds
484 | search searches generate generates
485 | search searches go goes
486 | search searches implement implements
487 | search searches increase increases
488 | search searches listen listens
489 | search searches play plays
490 | search searches predict predicts
491 | search searches provide provides
492 | search searches say says
493 | search searches scream screams
494 | see sees shuffle shuffles
495 | see sees sing sings
496 | see sees sit sits
497 | see sees slow slows
498 | see sees speak speaks
499 | see sees swim swims
500 | see sees talk talks
501 | see sees think thinks
502 | see sees vanish vanishes
503 | see sees walk walks
504 | see sees work works
505 | see sees write writes
506 | see sees decrease decreases
507 | see sees describe describes
508 | see sees eat eats
509 | see sees enhance enhances
510 | see sees estimate estimates
511 | see sees find finds
512 | see sees generate generates
513 | see sees go goes
514 | see sees implement implements
515 | see sees increase increases
516 | see sees listen listens
517 | see sees play plays
518 | see sees predict predicts
519 | see sees provide provides
520 | see sees say says
521 | see sees scream screams
522 | see sees search searches
523 | shuffle shuffles sing sings
524 | shuffle shuffles sit sits
525 | shuffle shuffles slow slows
526 | shuffle shuffles speak speaks
527 | shuffle shuffles swim swims
528 | shuffle shuffles talk talks
529 | shuffle shuffles think thinks
530 | shuffle shuffles vanish vanishes
531 | shuffle shuffles walk walks
532 | shuffle shuffles work works
533 | shuffle shuffles write writes
534 | shuffle shuffles decrease decreases
535 | shuffle shuffles describe describes
536 | shuffle shuffles eat eats
537 | shuffle shuffles enhance enhances
538 | shuffle shuffles estimate estimates
539 | shuffle shuffles find finds
540 | shuffle shuffles generate generates
541 | shuffle shuffles go goes
542 | shuffle shuffles implement implements
543 | shuffle shuffles increase increases
544 | shuffle shuffles listen listens
545 | shuffle shuffles play plays
546 | shuffle shuffles predict predicts
547 | shuffle shuffles provide provides
548 | shuffle shuffles say says
549 | shuffle shuffles scream screams
550 | shuffle shuffles search searches
551 | shuffle shuffles see sees
552 | sing sings sit sits
553 | sing sings slow slows
554 | sing sings speak speaks
555 | sing sings swim swims
556 | sing sings talk talks
557 | sing sings think thinks
558 | sing sings vanish vanishes
559 | sing sings walk walks
560 | sing sings work works
561 | sing sings write writes
562 | sing sings decrease decreases
563 | sing sings describe describes
564 | sing sings eat eats
565 | sing sings enhance enhances
566 | sing sings estimate estimates
567 | sing sings find finds
568 | sing sings generate generates
569 | sing sings go goes
570 | sing sings implement implements
571 | sing sings increase increases
572 | sing sings listen listens
573 | sing sings play plays
574 | sing sings predict predicts
575 | sing sings provide provides
576 | sing sings say says
577 | sing sings scream screams
578 | sing sings search searches
579 | sing sings see sees
580 | sing sings shuffle shuffles
581 | sit sits slow slows
582 | sit sits speak speaks
583 | sit sits swim swims
584 | sit sits talk talks
585 | sit sits think thinks
586 | sit sits vanish vanishes
587 | sit sits walk walks
588 | sit sits work works
589 | sit sits write writes
590 | sit sits decrease decreases
591 | sit sits describe describes
592 | sit sits eat eats
593 | sit sits enhance enhances
594 | sit sits estimate estimates
595 | sit sits find finds
596 | sit sits generate generates
597 | sit sits go goes
598 | sit sits implement implements
599 | sit sits increase increases
600 | sit sits listen listens
601 | sit sits play plays
602 | sit sits predict predicts
603 | sit sits provide provides
604 | sit sits say says
605 | sit sits scream screams
606 | sit sits search searches
607 | sit sits see sees
608 | sit sits shuffle shuffles
609 | sit sits sing sings
610 | slow slows speak speaks
611 | slow slows swim swims
612 | slow slows talk talks
613 | slow slows think thinks
614 | slow slows vanish vanishes
615 | slow slows walk walks
616 | slow slows work works
617 | slow slows write writes
618 | slow slows decrease decreases
619 | slow slows describe describes
620 | slow slows eat eats
621 | slow slows enhance enhances
622 | slow slows estimate estimates
623 | slow slows find finds
624 | slow slows generate generates
625 | slow slows go goes
626 | slow slows implement implements
627 | slow slows increase increases
628 | slow slows listen listens
629 | slow slows play plays
630 | slow slows predict predicts
631 | slow slows provide provides
632 | slow slows say says
633 | slow slows scream screams
634 | slow slows search searches
635 | slow slows see sees
636 | slow slows shuffle shuffles
637 | slow slows sing sings
638 | slow slows sit sits
639 | speak speaks swim swims
640 | speak speaks talk talks
641 | speak speaks think thinks
642 | speak speaks vanish vanishes
643 | speak speaks walk walks
644 | speak speaks work works
645 | speak speaks write writes
646 | speak speaks decrease decreases
647 | speak speaks describe describes
648 | speak speaks eat eats
649 | speak speaks enhance enhances
650 | speak speaks estimate estimates
651 | speak speaks find finds
652 | speak speaks generate generates
653 | speak speaks go goes
654 | speak speaks implement implements
655 | speak speaks increase increases
656 | speak speaks listen listens
657 | speak speaks play plays
658 | speak speaks predict predicts
659 | speak speaks provide provides
660 | speak speaks say says
661 | speak speaks scream screams
662 | speak speaks search searches
663 | speak speaks see sees
664 | speak speaks shuffle shuffles
665 | speak speaks sing sings
666 | speak speaks sit sits
667 | speak speaks slow slows
668 | swim swims talk talks
669 | swim swims think thinks
670 | swim swims vanish vanishes
671 | swim swims walk walks
672 | swim swims work works
673 | swim swims write writes
674 | swim swims decrease decreases
675 | swim swims describe describes
676 | swim swims eat eats
677 | swim swims enhance enhances
678 | swim swims estimate estimates
679 | swim swims find finds
680 | swim swims generate generates
681 | swim swims go goes
682 | swim swims implement implements
683 | swim swims increase increases
684 | swim swims listen listens
685 | swim swims play plays
686 | swim swims predict predicts
687 | swim swims provide provides
688 | swim swims say says
689 | swim swims scream screams
690 | swim swims search searches
691 | swim swims see sees
692 | swim swims shuffle shuffles
693 | swim swims sing sings
694 | swim swims sit sits
695 | swim swims slow slows
696 | swim swims speak speaks
697 | talk talks think thinks
698 | talk talks vanish vanishes
699 | talk talks walk walks
700 | talk talks work works
701 | talk talks write writes
702 | talk talks decrease decreases
703 | talk talks describe describes
704 | talk talks eat eats
705 | talk talks enhance enhances
706 | talk talks estimate estimates
707 | talk talks find finds
708 | talk talks generate generates
709 | talk talks go goes
710 | talk talks implement implements
711 | talk talks increase increases
712 | talk talks listen listens
713 | talk talks play plays
714 | talk talks predict predicts
715 | talk talks provide provides
716 | talk talks say says
717 | talk talks scream screams
718 | talk talks search searches
719 | talk talks see sees
720 | talk talks shuffle shuffles
721 | talk talks sing sings
722 | talk talks sit sits
723 | talk talks slow slows
724 | talk talks speak speaks
725 | talk talks swim swims
726 | think thinks vanish vanishes
727 | think thinks walk walks
728 | think thinks work works
729 | think thinks write writes
730 | think thinks decrease decreases
731 | think thinks describe describes
732 | think thinks eat eats
733 | think thinks enhance enhances
734 | think thinks estimate estimates
735 | think thinks find finds
736 | think thinks generate generates
737 | think thinks go goes
738 | think thinks implement implements
739 | think thinks increase increases
740 | think thinks listen listens
741 | think thinks play plays
742 | think thinks predict predicts
743 | think thinks provide provides
744 | think thinks say says
745 | think thinks scream screams
746 | think thinks search searches
747 | think thinks see sees
748 | think thinks shuffle shuffles
749 | think thinks sing sings
750 | think thinks sit sits
751 | think thinks slow slows
752 | think thinks speak speaks
753 | think thinks swim swims
754 | think thinks talk talks
755 | vanish vanishes walk walks
756 | vanish vanishes work works
757 | vanish vanishes write writes
758 | vanish vanishes decrease decreases
759 | vanish vanishes describe describes
760 | vanish vanishes eat eats
761 | vanish vanishes enhance enhances
762 | vanish vanishes estimate estimates
763 | vanish vanishes find finds
764 | vanish vanishes generate generates
765 | vanish vanishes go goes
766 | vanish vanishes implement implements
767 | vanish vanishes increase increases
768 | vanish vanishes listen listens
769 | vanish vanishes play plays
770 | vanish vanishes predict predicts
771 | vanish vanishes provide provides
772 | vanish vanishes say says
773 | vanish vanishes scream screams
774 | vanish vanishes search searches
775 | vanish vanishes see sees
776 | vanish vanishes shuffle shuffles
777 | vanish vanishes sing sings
778 | vanish vanishes sit sits
779 | vanish vanishes slow slows
780 | vanish vanishes speak speaks
781 | vanish vanishes swim swims
782 | vanish vanishes talk talks
783 | vanish vanishes think thinks
784 | walk walks work works
785 | walk walks write writes
786 | walk walks decrease decreases
787 | walk walks describe describes
788 | walk walks eat eats
789 | walk walks enhance enhances
790 | walk walks estimate estimates
791 | walk walks find finds
792 | walk walks generate generates
793 | walk walks go goes
794 | walk walks implement implements
795 | walk walks increase increases
796 | walk walks listen listens
797 | walk walks play plays
798 | walk walks predict predicts
799 | walk walks provide provides
800 | walk walks say says
801 | walk walks scream screams
802 | walk walks search searches
803 | walk walks see sees
804 | walk walks shuffle shuffles
805 | walk walks sing sings
806 | walk walks sit sits
807 | walk walks slow slows
808 | walk walks speak speaks
809 | walk walks swim swims
810 | walk walks talk talks
811 | walk walks think thinks
812 | walk walks vanish vanishes
813 | work works write writes
814 | work works decrease decreases
815 | work works describe describes
816 | work works eat eats
817 | work works enhance enhances
818 | work works estimate estimates
819 | work works find finds
820 | work works generate generates
821 | work works go goes
822 | work works implement implements
823 | work works increase increases
824 | work works listen listens
825 | work works play plays
826 | work works predict predicts
827 | work works provide provides
828 | work works say says
829 | work works scream screams
830 | work works search searches
831 | work works see sees
832 | work works shuffle shuffles
833 | work works sing sings
834 | work works sit sits
835 | work works slow slows
836 | work works speak speaks
837 | work works swim swims
838 | work works talk talks
839 | work works think thinks
840 | work works vanish vanishes
841 | work works walk walks
842 | write writes decrease decreases
843 | write writes describe describes
844 | write writes eat eats
845 | write writes enhance enhances
846 | write writes estimate estimates
847 | write writes find finds
848 | write writes generate generates
849 | write writes go goes
850 | write writes implement implements
851 | write writes increase increases
852 | write writes listen listens
853 | write writes play plays
854 | write writes predict predicts
855 | write writes provide provides
856 | write writes say says
857 | write writes scream screams
858 | write writes search searches
859 | write writes see sees
860 | write writes shuffle shuffles
861 | write writes sing sings
862 | write writes sit sits
863 | write writes slow slows
864 | write writes speak speaks
865 | write writes swim swims
866 | write writes talk talks
867 | write writes think thinks
868 | write writes vanish vanishes
869 | write writes walk walks
870 | write writes work works
871 |
--------------------------------------------------------------------------------
/randomization.test.sh:
--------------------------------------------------------------------------------
1 | # Tests for ensuring randomization is being controlled
2 |
3 | make
4 |
5 | if [ ! -e text8 ]; then
6 | if hash wget 2>/dev/null; then
7 | wget http://mattmahoney.net/dc/text8.zip
8 | else
9 | curl -O http://mattmahoney.net/dc/text8.zip
10 | fi
11 | unzip text8.zip
12 | rm text8.zip
13 | fi
14 |
15 | # Global constants
16 | CORPUS=text8
17 | VERBOSE=2
18 | BUILDDIR=build
19 | MEMORY=4.0
20 | VOCAB_MIN_COUNT=20
21 |
22 | # Re-used files
23 | VOCAB_FILE=$(mktemp vocab.test.txt.XXXXXX)
24 | COOCCURRENCE_FILE=$(mktemp cooccurrence.test.bin.XXXXXX)
25 | COOCCURRENCE_SHUF_FILE=$(mktemp cooccurrence_shuf.test.bin.XXXXXX)
26 |
27 | # Make vocab
28 | $BUILDDIR/vocab_count -min-count $VOCAB_MIN_COUNT -verbose $VERBOSE < $CORPUS > $VOCAB_FILE
29 |
30 | # Make Coocurrences
31 | $BUILDDIR/cooccur -memory $MEMORY -vocab-file $VOCAB_FILE -verbose $VERBOSE -window-size 5 < $CORPUS > $COOCCURRENCE_FILE
32 |
33 | # Shuffle Coocurrences
34 | $BUILDDIR/shuffle -memory $MEMORY -verbose $VERBOSE -seed 1 < $COOCCURRENCE_FILE > $COOCCURRENCE_SHUF_FILE
35 |
36 | # Keep track of failure
37 | num_failed=0
38 |
39 | check_exit() {
40 | eval $2
41 | failed=$(( $1 != $? ))
42 | num_failed=$(( $num_failed + $failed ))
43 | if [[ $failed -eq 0 ]]; then
44 | echo PASSED
45 | else
46 | echo FAILED
47 | fi
48 | }
49 |
50 | # Test control of random seed in shuffle
51 | printf "\n\n--- TEST SET: Control of random seed in shuffle\n"
52 | TEST_FILE=$(mktemp cooc_shuf.test.bin.XXXXXX)
53 |
54 | printf "\n- TEST: Using the same seed should get the same shuffle\n"
55 | $BUILDDIR/shuffle -memory $MEMORY -verbose 0 -seed 1 < $COOCCURRENCE_FILE > $TEST_FILE
56 | check_exit 0 "cmp --quiet $COOCCURRENCE_SHUF_FILE $TEST_FILE"
57 |
58 | printf "\n- TEST: Changing the seed should change the shuffle\n"
59 | $BUILDDIR/shuffle -memory $MEMORY -verbose 0 -seed 2 < $COOCCURRENCE_FILE > $TEST_FILE
60 | check_exit 1 "cmp --quiet $COOCCURRENCE_SHUF_FILE $TEST_FILE"
61 |
62 | rm $TEST_FILE # Clean up
63 | # ---
64 |
65 | # Control randomization in GloVe
66 | printf "\n\n--- TEST SET: Control of random seed in glove\n"
67 | # Note "-threads" must equal 1 for these to pass, since order in which results come back from individual threads is uncontrolled
68 | BASE_PREFIX=$(mktemp base_vectors.XXXXXX)
69 | TEST_PREFIX=$(mktemp test_vectors.XXXXXX)
70 |
71 | printf "\n- TEST: Reusing seed should give the same vectors\n"
72 | $BUILDDIR/glove -save-file $BASE_PREFIX -threads 1 -input-file $COOCCURRENCE_SHUF_FILE -iter 3 -vector-size 10 -binary 1 -vocab-file $VOCAB_FILE -verbose 0 -seed 1
73 | $BUILDDIR/glove -save-file $TEST_PREFIX -threads 1 -input-file $COOCCURRENCE_SHUF_FILE -iter 3 -vector-size 10 -binary 1 -vocab-file $VOCAB_FILE -verbose 0 -seed 1
74 | check_exit 0 "cmp --quiet $BASE_PREFIX.bin $TEST_PREFIX.bin"
75 |
76 | printf "\n- TEST: Changing seed should change the learned vectors\n"
77 | $BUILDDIR/glove -save-file $TEST_PREFIX -threads 1 -input-file $COOCCURRENCE_SHUF_FILE -iter 3 -vector-size 10 -binary 1 -vocab-file $VOCAB_FILE -verbose 0 -seed 2
78 | check_exit 1 "cmp --quiet $BASE_PREFIX.bin $TEST_PREFIX.bin"
79 |
80 | printf "\n- TEST: Should be able to save/load initial parameters\n"
81 | $BUILDDIR/glove -save-file $BASE_PREFIX -threads 1 -input-file $COOCCURRENCE_SHUF_FILE -iter 3 -vector-size 10 -binary 1 -vocab-file $VOCAB_FILE -verbose 0 -save-init-param 1
82 | $BUILDDIR/glove -save-file $TEST_PREFIX -threads 1 -input-file $COOCCURRENCE_SHUF_FILE -iter 3 -vector-size 10 -binary 1 -vocab-file $VOCAB_FILE -verbose 0 -save-init-param 1 -load-init-param 1 -init-param-file "$BASE_PREFIX.000.bin"
83 | check_exit 0 "cmp --quiet $BASE_PREFIX.000.bin $TEST_PREFIX.000.bin && cmp --quiet $BASE_PREFIX.bin $TEST_PREFIX.bin"
84 |
85 | rm "$BASE_PREFIX.000.bin" "$TEST_PREFIX.000.bin" "$BASE_PREFIX.bin" "$TEST_PREFIX.bin" # Clean up
86 | rm $BASE_PREFIX $TEST_PREFIX
87 |
88 | # ----
89 |
90 | printf "\n- TEST: Should be able to save/load initial parameters and gradsq\n"
91 | # note: the seed will be randomly assigned and should not matter
92 | $BUILDDIR/glove -save-file $BASE_PREFIX -gradsq-file $BASE_PREFIX.gradsq -threads 1 -input-file $COOCCURRENCE_SHUF_FILE -iter 6 -vector-size 10 -binary 1 -vocab-file $VOCAB_FILE -verbose 0 -checkpoint-every 2
93 |
94 | $BUILDDIR/glove -save-file $TEST_PREFIX -gradsq-file $TEST_PREFIX.gradsq -threads 1 -input-file $COOCCURRENCE_SHUF_FILE -iter 4 -vector-size 10 -binary 1 -vocab-file $VOCAB_FILE -verbose 0 -checkpoint-every 2 -load-init-param 1 -init-param-file "$BASE_PREFIX.002.bin" -load-init-gradsq 1 -init-gradsq-file "$BASE_PREFIX.gradsq.002.bin"
95 |
96 | echo "Compare vectors before & after load gradsq - 2 iterations"
97 | check_exit 0 "cmp --quiet $BASE_PREFIX.004.bin $TEST_PREFIX.002.bin"
98 | echo "Compare vectors before & after load gradsq - 4 iterations"
99 | check_exit 0 "cmp --quiet $BASE_PREFIX.006.bin $TEST_PREFIX.004.bin"
100 | echo "Compare vectors before & after load gradsq - final"
101 | check_exit 0 "cmp --quiet $BASE_PREFIX.bin $TEST_PREFIX.bin"
102 |
103 | echo "Compare gradsq before & after load gradsq - 2 iterations"
104 | check_exit 0 "cmp --quiet $BASE_PREFIX.gradsq.004.bin $TEST_PREFIX.gradsq.002.bin"
105 | echo "Compare gradsq before & after load gradsq - 4 iterations"
106 | check_exit 0 "cmp --quiet $BASE_PREFIX.gradsq.006.bin $TEST_PREFIX.gradsq.004.bin"
107 | echo "Compare gradsq before & after load gradsq - final"
108 | check_exit 0 "cmp --quiet $BASE_PREFIX.gradsq.bin $TEST_PREFIX.gradsq.bin"
109 |
110 | echo "Cleaning up files"
111 | check_exit 0 "rm $BASE_PREFIX.002.bin $BASE_PREFIX.004.bin $BASE_PREFIX.006.bin $BASE_PREFIX.bin"
112 | check_exit 0 "rm $BASE_PREFIX.gradsq.002.bin $BASE_PREFIX.gradsq.004.bin $BASE_PREFIX.gradsq.006.bin $BASE_PREFIX.gradsq.bin"
113 | check_exit 0 "rm $TEST_PREFIX.002.bin $TEST_PREFIX.004.bin $TEST_PREFIX.bin"
114 | check_exit 0 "rm $TEST_PREFIX.gradsq.002.bin $TEST_PREFIX.gradsq.004.bin $TEST_PREFIX.gradsq.bin"
115 | check_exit 0 "rm $VOCAB_FILE $COOCCURRENCE_FILE $COOCCURRENCE_SHUF_FILE"
116 |
117 | echo
118 | echo SUMMARY:
119 | if [[ $num_failed -gt 0 ]]; then
120 | echo $num_failed tests failed.
121 | exit 1
122 | else
123 | echo All tests passed.
124 | exit 0
125 | fi
126 |
127 |
128 |
--------------------------------------------------------------------------------
/src/README.md:
--------------------------------------------------------------------------------
1 | ### Package Contents
2 |
3 | To train your own GloVe vectors, first you'll need to prepare your corpus as a single text file with all words separated by one or more spaces or tabs. If your corpus has multiple documents, the documents (only) should be separated by new line characters. Cooccurrence contexts for words do not extend past newline characters. Once you create your corpus, you can train GloVe vectors using the following 4 tools. An example is included in `demo.sh`, which you can modify as necessary.
4 |
5 | The four main tools in this package are:
6 |
7 | #### 1) vocab_count
8 | This tool requires an input corpus that should already consist of whitespace-separated tokens. Use something like the [Stanford Tokenizer](https://nlp.stanford.edu/software/tokenizer.html) first on raw text. From the corpus, it constructs unigram counts from a corpus, and optionally thresholds the resulting vocabulary based on total vocabulary size or minimum frequency count.
9 |
10 | #### 2) cooccur
11 | Constructs word-word cooccurrence statistics from a corpus. The user should supply a vocabulary file, as produced by `vocab_count`, and may specify a variety of parameters, as described by running `./build/cooccur`.
12 |
13 | #### 3) shuffle
14 | Shuffles the binary file of cooccurrence statistics produced by `cooccur`. For large files, the file is automatically split into chunks, each of which is shuffled and stored on disk before being merged and shuffled together. The user may specify a number of parameters, as described by running `./build/shuffle`.
15 |
16 | #### 4) glove
17 | Train the GloVe model on the specified cooccurrence data, which typically will be the output of the `shuffle` tool. The user should supply a vocabulary file, as given by `vocab_count`, and may specify a number of other parameters, which are described by running `./build/glove`.
18 |
--------------------------------------------------------------------------------
/src/common.c:
--------------------------------------------------------------------------------
1 | // Common code for cooccur.c, vocab_count.c,
2 | // glove.c and shuffle.c
3 | //
4 | // GloVe: Global Vectors for Word Representation
5 | // Copyright (c) 2014 The Board of Trustees of
6 | // The Leland Stanford Junior University. All Rights Reserved.
7 | //
8 | // Licensed under the Apache License, Version 2.0 (the "License");
9 | // you may not use this file except in compliance with the License.
10 | // You may obtain a copy of the License at
11 | //
12 | // http://www.apache.org/licenses/LICENSE-2.0
13 | //
14 | // Unless required by applicable law or agreed to in writing, software
15 | // distributed under the License is distributed on an "AS IS" BASIS,
16 | // WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | // See the License for the specific language governing permissions and
18 | // limitations under the License.
19 | //
20 | //
21 | // For more information, bug reports, fixes, contact:
22 | // Jeffrey Pennington (jpennin@stanford.edu)
23 | // Christopher Manning (manning@cs.stanford.edu)
24 | // https://github.com/stanfordnlp/GloVe/
25 | // GlobalVectors@googlegroups.com
26 | // http://nlp.stanford.edu/projects/glove/
27 |
28 | #include
29 | #include
30 | #include
31 | #include "common.h"
32 |
33 | #ifdef _MSC_VER
34 | #define STRERROR(ERRNO, BUF, BUFSIZE) strerror_s((BUF), (BUFSIZE), (ERRNO))
35 | #else
36 | #define STRERROR(ERRNO, BUF, BUFSIZE) strerror_r((ERRNO), (BUF), (BUFSIZE))
37 | #endif
38 |
39 | /* Efficient string comparison */
40 | int scmp( char *s1, char *s2 ) {
41 | while (*s1 != '\0' && *s1 == *s2) {s1++; s2++;}
42 | return (*s1 - *s2);
43 | }
44 |
45 | /* Move-to-front hashing and hash function from Hugh Williams, http://www.seg.rmit.edu.au/code/zwh-ipl/ */
46 |
47 | /* Simple bitwise hash function */
48 | unsigned int bitwisehash(char *word, int tsize, unsigned int seed) {
49 | char c;
50 | unsigned int h;
51 | h = seed;
52 | for ( ; (c = *word) != '\0'; word++) h ^= ((h << 5) + c + (h >> 2));
53 | return (unsigned int)((h & 0x7fffffff) % tsize);
54 | }
55 |
56 | /* Create hash table, initialise pointers to NULL */
57 | HASHREC ** inithashtable() {
58 | int i;
59 | HASHREC **ht;
60 | ht = (HASHREC **) malloc( sizeof(HASHREC *) * TSIZE );
61 | for (i = 0; i < TSIZE; i++) ht[i] = (HASHREC *) NULL;
62 | return ht;
63 | }
64 |
65 | /* Read word from input stream. Return 1 when encounter '\n' or EOF (but separate from word), 0 otherwise.
66 | Words can be separated by space(s), tab(s), or newline(s). Carriage return characters are just ignored.
67 | (Okay for Windows, but not for Mac OS 9-. Ignored even if by themselves or in words.)
68 | A newline is taken as indicating a new document (contexts won't cross newline).
69 | Argument word array is assumed to be of size MAX_STRING_LENGTH.
70 | words will be truncated if too long. They are truncated with some care so that they
71 | cannot truncate in the middle of a utf-8 character, but
72 | still little to no harm will be done for other encodings like iso-8859-1.
73 | (This function appears identically copied in vocab_count.c and cooccur.c.)
74 | */
75 | int get_word(char *word, FILE *fin) {
76 | int i = 0, ch;
77 | for ( ; ; ) {
78 | ch = fgetc(fin);
79 | if (ch == '\r') continue;
80 | if (i == 0 && ((ch == '\n') || (ch == EOF))) {
81 | word[i] = 0;
82 | return 1;
83 | }
84 | if (i == 0 && ((ch == ' ') || (ch == '\t'))) continue; // skip leading space
85 | if ((ch == EOF) || (ch == ' ') || (ch == '\t') || (ch == '\n')) {
86 | if (ch == '\n') ungetc(ch, fin); // return the newline next time as document ender
87 | break;
88 | }
89 | if (i < MAX_STRING_LENGTH - 1)
90 | word[i++] = ch; // don't allow words to exceed MAX_STRING_LENGTH
91 | }
92 | word[i] = 0; //null terminate
93 | // avoid truncation destroying a multibyte UTF-8 char except if only thing on line (so the i > x tests won't overwrite word[0])
94 | // see https://en.wikipedia.org/wiki/UTF-8#Description
95 | if (i == MAX_STRING_LENGTH - 1 && (word[i-1] & 0x80) == 0x80) {
96 | if ((word[i-1] & 0xC0) == 0xC0) {
97 | word[i-1] = '\0';
98 | } else if (i > 2 && (word[i-2] & 0xE0) == 0xE0) {
99 | word[i-2] = '\0';
100 | } else if (i > 3 && (word[i-3] & 0xF8) == 0xF0) {
101 | word[i-3] = '\0';
102 | }
103 | }
104 | return 0;
105 | }
106 |
107 | int find_arg(char *str, int argc, char **argv) {
108 | int i;
109 | for (i = 1; i < argc; i++) {
110 | if (!scmp(str, argv[i])) {
111 | if (i == argc - 1) {
112 | printf("No argument given for %s\n", str);
113 | exit(1);
114 | }
115 | return i;
116 | }
117 | }
118 | return -1;
119 | }
120 |
121 | void free_table(HASHREC **ht) {
122 | int i;
123 | HASHREC* current;
124 | HASHREC* tmp;
125 | for (i = 0; i < TSIZE; i++) {
126 | current = ht[i];
127 | while (current != NULL) {
128 | tmp = current;
129 | current = current->next;
130 | free(tmp->word);
131 | free(tmp);
132 | }
133 | }
134 | free(ht);
135 | }
136 |
137 | void free_fid(FILE **fid, const int num) {
138 | int i;
139 | for(i = 0; i < num; i++) {
140 | if(fid[i] != NULL)
141 | fclose(fid[i]);
142 | }
143 | free(fid);
144 | }
145 |
146 |
147 | int log_file_loading_error(char *file_description, char *file_name) {
148 | fprintf(stderr, "Unable to open %s %s.\n", file_description, file_name);
149 | fprintf(stderr, "Errno: %d\n", errno);
150 | char error[MAX_STRING_LENGTH];
151 | STRERROR(errno, error, MAX_STRING_LENGTH);
152 | fprintf(stderr, "Error description: %s\n", error);
153 | return errno;
154 | }
155 |
--------------------------------------------------------------------------------
/src/common.h:
--------------------------------------------------------------------------------
1 | #ifndef COMMON_H
2 | #define COMMON_H
3 |
4 | // Common code for cooccur.c, vocab_count.c,
5 | // glove.c and shuffle.c
6 | //
7 | // GloVe: Global Vectors for Word Representation
8 | // Copyright (c) 2014 The Board of Trustees of
9 | // The Leland Stanford Junior University. All Rights Reserved.
10 | //
11 | // Licensed under the Apache License, Version 2.0 (the "License");
12 | // you may not use this file except in compliance with the License.
13 | // You may obtain a copy of the License at
14 | //
15 | // http://www.apache.org/licenses/LICENSE-2.0
16 | //
17 | // Unless required by applicable law or agreed to in writing, software
18 | // distributed under the License is distributed on an "AS IS" BASIS,
19 | // WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
20 | // See the License for the specific language governing permissions and
21 | // limitations under the License.
22 | //
23 | //
24 | // For more information, bug reports, fixes, contact:
25 | // Jeffrey Pennington (jpennin@stanford.edu)
26 | // Christopher Manning (manning@cs.stanford.edu)
27 | // https://github.com/stanfordnlp/GloVe/
28 | // GlobalVectors@googlegroups.com
29 | // http://nlp.stanford.edu/projects/glove/
30 |
31 | #include
32 |
33 | #define MAX_STRING_LENGTH 1000
34 | #define TSIZE 1048576
35 | #define SEED 1159241
36 | #define HASHFN bitwisehash
37 |
38 | typedef double real;
39 | typedef struct cooccur_rec {
40 | int word1;
41 | int word2;
42 | real val;
43 | } CREC;
44 | typedef struct hashrec {
45 | char *word;
46 | long long num; //count or id
47 | struct hashrec *next;
48 | } HASHREC;
49 |
50 |
51 | int scmp( char *s1, char *s2 );
52 | unsigned int bitwisehash(char *word, int tsize, unsigned int seed);
53 | HASHREC **inithashtable();
54 | int get_word(char *word, FILE *fin);
55 | void free_table(HASHREC **ht);
56 | int find_arg(char *str, int argc, char **argv);
57 | void free_fid(FILE **fid, const int num);
58 |
59 | // logs errors when loading files. call after a failed load
60 | int log_file_loading_error(char *file_description, char *file_name);
61 |
62 | #endif /* COMMON_H */
63 |
64 |
--------------------------------------------------------------------------------
/src/cooccur.c:
--------------------------------------------------------------------------------
1 | // Tool to calculate word-word cooccurrence statistics
2 | //
3 | // Copyright (c) 2014, 2018 The Board of Trustees of
4 | // The Leland Stanford Junior University. All Rights Reserved.
5 | //
6 | // Licensed under the Apache License, Version 2.0 (the "License");
7 | // you may not use this file except in compliance with the License.
8 | // You may obtain a copy of the License at
9 | //
10 | // http://www.apache.org/licenses/LICENSE-2.0
11 | //
12 | // Unless required by applicable law or agreed to in writing, software
13 | // distributed under the License is distributed on an "AS IS" BASIS,
14 | // WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
15 | // See the License for the specific language governing permissions and
16 | // limitations under the License.
17 | //
18 | //
19 | // For more information, bug reports, fixes, contact:
20 | // Jeffrey Pennington (jpennin@stanford.edu)
21 | // Christopher Manning (manning@cs.stanford.edu)
22 | // https://github.com/stanfordnlp/GloVe/
23 | // GlobalVectors@googlegroups.com
24 | // http://nlp.stanford.edu/projects/glove/
25 |
26 | #include
27 | #include
28 | #include
29 | #include
30 | #include "common.h"
31 |
32 | typedef struct cooccur_rec_id {
33 | int word1;
34 | int word2;
35 | real val;
36 | int id;
37 | } CRECID;
38 |
39 | int verbose = 2; // 0, 1, or 2
40 | long long max_product; // Cutoff for product of word frequency ranks below which cooccurrence counts will be stored in a compressed full array
41 | long long overflow_length; // Number of cooccurrence records whose product exceeds max_product to store in memory before writing to disk
42 | int window_size = 15; // default context window size
43 | int symmetric = 1; // 0: asymmetric, 1: symmetric
44 | real memory_limit = 3; // soft limit, in gigabytes, used to estimate optimal array sizes
45 | int distance_weighting = 1; // Flag to control the distance weighting of cooccurrence counts
46 | char *vocab_file, *file_head;
47 |
48 | /* Search hash table for given string, return record if found, else NULL */
49 | HASHREC *hashsearch(HASHREC **ht, char *w) {
50 | HASHREC *htmp, *hprv;
51 | unsigned int hval = HASHFN(w, TSIZE, SEED);
52 | for (hprv = NULL, htmp=ht[hval]; htmp != NULL && scmp(htmp->word, w) != 0; hprv = htmp, htmp = htmp->next);
53 | if ( htmp != NULL && hprv!=NULL ) { // move to front on access
54 | hprv->next = htmp->next;
55 | htmp->next = ht[hval];
56 | ht[hval] = htmp;
57 | }
58 | return(htmp);
59 | }
60 |
61 | /* Insert string in hash table, check for duplicates which should be absent */
62 | void hashinsert(HASHREC **ht, char *w, long long id) {
63 | HASHREC *htmp, *hprv;
64 | unsigned int hval = HASHFN(w, TSIZE, SEED);
65 | for (hprv = NULL, htmp = ht[hval]; htmp != NULL && scmp(htmp->word, w) != 0; hprv = htmp, htmp = htmp->next);
66 | if (htmp == NULL) {
67 | htmp = (HASHREC *) malloc(sizeof(HASHREC));
68 | htmp->word = (char *) malloc(strlen(w) + 1);
69 | strcpy(htmp->word, w);
70 | htmp->num = id;
71 | htmp->next = NULL;
72 | if (hprv == NULL) ht[hval] = htmp;
73 | else hprv->next = htmp;
74 | }
75 | else fprintf(stderr, "Error, duplicate entry located: %s.\n",htmp->word);
76 | return;
77 | }
78 |
79 | /* Write sorted chunk of cooccurrence records to file, accumulating duplicate entries */
80 | int write_chunk(CREC *cr, long long length, FILE *fout) {
81 | if (length == 0) return 0;
82 |
83 | long long a = 0;
84 | CREC old = cr[a];
85 |
86 | for (a = 1; a < length; a++) {
87 | if (cr[a].word1 == old.word1 && cr[a].word2 == old.word2) {
88 | old.val += cr[a].val;
89 | continue;
90 | }
91 | fwrite(&old, sizeof(CREC), 1, fout);
92 | old = cr[a];
93 | }
94 | fwrite(&old, sizeof(CREC), 1, fout);
95 | return 0;
96 | }
97 |
98 | /* Check if two cooccurrence records are for the same two words, used for qsort */
99 | int compare_crec(const void *a, const void *b) {
100 | int c;
101 | if ( (c = ((CREC *) a)->word1 - ((CREC *) b)->word1) != 0) return c;
102 | else return (((CREC *) a)->word2 - ((CREC *) b)->word2);
103 |
104 | }
105 |
106 | /* Check if two cooccurrence records are for the same two words */
107 | int compare_crecid(CRECID a, CRECID b) {
108 | int c;
109 | if ( (c = a.word1 - b.word1) != 0) return c;
110 | else return a.word2 - b.word2;
111 | }
112 |
113 | /* Swap two entries of priority queue */
114 | void swap_entry(CRECID *pq, int i, int j) {
115 | CRECID temp = pq[i];
116 | pq[i] = pq[j];
117 | pq[j] = temp;
118 | }
119 |
120 | /* Insert entry into priority queue */
121 | void insert(CRECID *pq, CRECID new, int size) {
122 | int j = size - 1, p;
123 | pq[j] = new;
124 | while ( (p=(j-1)/2) >= 0 ) {
125 | if (compare_crecid(pq[p],pq[j]) > 0) {swap_entry(pq,p,j); j = p;}
126 | else break;
127 | }
128 | }
129 |
130 | /* Delete entry from priority queue */
131 | void delete(CRECID *pq, int size) {
132 | int j, p = 0;
133 | pq[p] = pq[size - 1];
134 | while ( (j = 2*p+1) < size - 1 ) {
135 | if (j == size - 2) {
136 | if (compare_crecid(pq[p],pq[j]) > 0) swap_entry(pq,p,j);
137 | return;
138 | }
139 | else {
140 | if (compare_crecid(pq[j], pq[j+1]) < 0) {
141 | if (compare_crecid(pq[p],pq[j]) > 0) {swap_entry(pq,p,j); p = j;}
142 | else return;
143 | }
144 | else {
145 | if (compare_crecid(pq[p],pq[j+1]) > 0) {swap_entry(pq,p,j+1); p = j + 1;}
146 | else return;
147 | }
148 | }
149 | }
150 | }
151 |
152 | /* Write top node of priority queue to file, accumulating duplicate entries */
153 | int merge_write(CRECID new, CRECID *old, FILE *fout) {
154 | if (new.word1 == old->word1 && new.word2 == old->word2) {
155 | old->val += new.val;
156 | return 0; // Indicates duplicate entry
157 | }
158 | fwrite(old, sizeof(CREC), 1, fout);
159 | *old = new;
160 | return 1; // Actually wrote to file
161 | }
162 |
163 | /* Merge [num] sorted files of cooccurrence records */
164 | int merge_files(int num) {
165 | int i, size;
166 | long long counter = 0;
167 | CRECID *pq, new, old;
168 | char filename[200];
169 | FILE **fid, *fout;
170 | fid = calloc(num, sizeof(FILE));
171 | pq = malloc(sizeof(CRECID) * num);
172 | fout = stdout;
173 | if (verbose > 1) fprintf(stderr, "Merging cooccurrence files: processed 0 lines.");
174 |
175 | /* Open all files and add first entry of each to priority queue */
176 | for (i = 0; i < num; i++) {
177 | sprintf(filename,"%s_%04d.bin",file_head,i);
178 | fid[i] = fopen(filename,"rb");
179 | if (fid[i] == NULL) {log_file_loading_error("file", filename); free_fid(fid, num); free(pq); return 1;}
180 | fread(&new, sizeof(CREC), 1, fid[i]);
181 | new.id = i;
182 | insert(pq,new,i+1);
183 | }
184 |
185 | /* Pop top node, save it in old to see if the next entry is a duplicate */
186 | size = num;
187 | old = pq[0];
188 | i = pq[0].id;
189 | delete(pq, size);
190 | fread(&new, sizeof(CREC), 1, fid[i]);
191 | if (feof(fid[i])) size--;
192 | else {
193 | new.id = i;
194 | insert(pq, new, size);
195 | }
196 |
197 | /* Repeatedly pop top node and fill priority queue until files have reached EOF */
198 | while (size > 0) {
199 | counter += merge_write(pq[0], &old, fout); // Only count the lines written to file, not duplicates
200 | if ((counter%100000) == 0) if (verbose > 1) fprintf(stderr,"\033[39G%lld lines.",counter);
201 | i = pq[0].id;
202 | delete(pq, size);
203 | fread(&new, sizeof(CREC), 1, fid[i]);
204 | if (feof(fid[i])) size--;
205 | else {
206 | new.id = i;
207 | insert(pq, new, size);
208 | }
209 | }
210 | fwrite(&old, sizeof(CREC), 1, fout);
211 | fprintf(stderr,"\033[0GMerging cooccurrence files: processed %lld lines.\n",++counter);
212 | for (i=0;i 0) {
244 | fprintf(stderr, "window size: %d\n", window_size);
245 | if (symmetric == 0) fprintf(stderr, "context: asymmetric\n");
246 | else fprintf(stderr, "context: symmetric\n");
247 | }
248 | if (verbose > 1) fprintf(stderr, "max product: %lld\n", max_product);
249 | if (verbose > 1) fprintf(stderr, "overflow length: %lld\n", overflow_length);
250 | sprintf(format,"%%%ds %%lld", MAX_STRING_LENGTH); // Format to read from vocab file, which has (irrelevant) frequency data
251 | if (verbose > 1) fprintf(stderr, "Reading vocab from file \"%s\"...", vocab_file);
252 | fid = fopen(vocab_file,"r");
253 | if (fid == NULL) {
254 | log_file_loading_error("vocab file", vocab_file);
255 | free_resources(vocab_hash, cr, lookup, history, bigram_table);
256 | return 1;
257 | }
258 | while (fscanf(fid, format, str, &id) != EOF) hashinsert(vocab_hash, str, ++j); // Here id is not used: inserting vocab words into hash table with their frequency rank, j
259 | fclose(fid);
260 | vocab_size = j;
261 | j = 0;
262 | if (verbose > 1) fprintf(stderr, "loaded %lld words.\nBuilding lookup table...", vocab_size);
263 |
264 | /* Build auxiliary lookup table used to index into bigram_table */
265 | lookup = (long long *)calloc( vocab_size + 1, sizeof(long long) );
266 | if (lookup == NULL) {
267 | fprintf(stderr, "Couldn't allocate memory!");
268 | free_resources(vocab_hash, cr, lookup, history, bigram_table);
269 | return 1;
270 | }
271 | lookup[0] = 1;
272 | for (a = 1; a <= vocab_size; a++) {
273 | if ((lookup[a] = max_product / a) < vocab_size) lookup[a] += lookup[a-1];
274 | else lookup[a] = lookup[a-1] + vocab_size;
275 | }
276 | if (verbose > 1) fprintf(stderr, "table contains %lld elements.\n",lookup[a-1]);
277 |
278 | /* Allocate memory for full array which will store all cooccurrence counts for words whose product of frequency ranks is less than max_product */
279 | bigram_table = (real *)calloc( lookup[a-1] , sizeof(real) );
280 | if (bigram_table == NULL) {
281 | fprintf(stderr, "Couldn't allocate memory!");
282 | free_resources(vocab_hash, cr, lookup, history, bigram_table);
283 | return 1;
284 | }
285 |
286 | fid = stdin;
287 | // sprintf(format,"%%%ds",MAX_STRING_LENGTH);
288 | sprintf(filename,"%s_%04d.bin", file_head, fidcounter);
289 | foverflow = fopen(filename,"wb");
290 | if (verbose > 1) fprintf(stderr,"Processing token: 0");
291 |
292 | // if symmetric > 0, we can increment ind twice per iteration,
293 | // meaning up to 2x window_size in one loop
294 | long long const overflow_threshold = symmetric == 0 ? overflow_length - window_size : overflow_length - 2 * window_size;
295 |
296 | /* For each token in input stream, calculate a weighted cooccurrence sum within window_size */
297 | while (1) {
298 | if (ind >= overflow_threshold) {
299 | // If overflow buffer is (almost) full, sort it and write it to temporary file
300 | qsort(cr, ind, sizeof(CREC), compare_crec);
301 | write_chunk(cr,ind,foverflow);
302 | fclose(foverflow);
303 | fidcounter++;
304 | sprintf(filename,"%s_%04d.bin",file_head,fidcounter);
305 | foverflow = fopen(filename,"wb");
306 | ind = 0;
307 | }
308 | flag = get_word(str, fid);
309 | if (verbose > 2) fprintf(stderr, "Maybe processing token: %s\n", str);
310 | if (flag == 1) {
311 | // Newline, reset line index (j); maybe eof.
312 | if (feof(fid)) {
313 | if (verbose > 2) fprintf(stderr, "Not getting coocurs as at eof\n");
314 | break;
315 | }
316 | j = 0;
317 | if (verbose > 2) fprintf(stderr, "Not getting coocurs as at newline\n");
318 | continue;
319 | }
320 | counter++;
321 | if ((counter%100000) == 0) if (verbose > 1) fprintf(stderr,"\033[19G%lld",counter);
322 | htmp = hashsearch(vocab_hash, str);
323 | if (htmp == NULL) {
324 | if (verbose > 2) fprintf(stderr, "Not getting coocurs as word not in vocab\n");
325 | continue; // Skip out-of-vocabulary words
326 | }
327 | w2 = htmp->num; // Target word (frequency rank)
328 | for (k = j - 1; k >= ( (j > window_size) ? j - window_size : 0 ); k--) { // Iterate over all words to the left of target word, but not past beginning of line
329 | w1 = history[k % window_size]; // Context word (frequency rank)
330 | if (verbose > 2) fprintf(stderr, "Adding cooccur between words %lld and %lld.\n", w1, w2);
331 | if ( w1 < max_product/w2 ) { // Product is small enough to store in a full array
332 | bigram_table[lookup[w1-1] + w2 - 2] += distance_weighting ? 1.0/((real)(j-k)) : 1.0; // Weight by inverse of distance between words if needed
333 | if (symmetric > 0) bigram_table[lookup[w2-1] + w1 - 2] += distance_weighting ? 1.0/((real)(j-k)) : 1.0; // If symmetric context is used, exchange roles of w2 and w1 (ie look at right context too)
334 | }
335 | else { // Product is too big, data is likely to be sparse. Store these entries in a temporary buffer to be sorted, merged (accumulated), and written to file when it gets full.
336 | cr[ind].word1 = w1;
337 | cr[ind].word2 = w2;
338 | cr[ind].val = distance_weighting ? 1.0/((real)(j-k)) : 1.0;
339 | ind++; // Keep track of how full temporary buffer is
340 | if (symmetric > 0) { // Symmetric context
341 | cr[ind].word1 = w2;
342 | cr[ind].word2 = w1;
343 | cr[ind].val = distance_weighting ? 1.0/((real)(j-k)) : 1.0;
344 | ind++;
345 | }
346 | }
347 | }
348 | history[j % window_size] = w2; // Target word is stored in circular buffer to become context word in the future
349 | j++;
350 | }
351 |
352 | /* Write out temp buffer for the final time (it may not be full) */
353 | if (verbose > 1) fprintf(stderr,"\033[0GProcessed %lld tokens.\n",counter);
354 | qsort(cr, ind, sizeof(CREC), compare_crec);
355 | write_chunk(cr,ind,foverflow);
356 | sprintf(filename,"%s_0000.bin",file_head);
357 |
358 | /* Write out full bigram_table, skipping zeros */
359 | if (verbose > 1) fprintf(stderr, "Writing cooccurrences to disk");
360 | fid = fopen(filename,"wb");
361 | j = 1e6;
362 | for (x = 1; x <= vocab_size; x++) {
363 | if ( (long long) (0.75*log(vocab_size / x)) < j) {
364 | j = (long long) (0.75*log(vocab_size / x));
365 | if (verbose > 1) fprintf(stderr,".");
366 | } // log's to make it look (sort of) pretty
367 | for (y = 1; y <= (lookup[x] - lookup[x-1]); y++) {
368 | if ((r = bigram_table[lookup[x-1] - 2 + y]) != 0) {
369 | fwrite(&x, sizeof(int), 1, fid);
370 | fwrite(&y, sizeof(int), 1, fid);
371 | fwrite(&r, sizeof(real), 1, fid);
372 | }
373 | }
374 | }
375 |
376 | if (verbose > 1) fprintf(stderr,"%d files in total.\n",fidcounter + 1);
377 | fclose(fid);
378 | fclose(foverflow);
379 | free_resources(vocab_hash, cr, lookup, history, bigram_table);
380 | return merge_files(fidcounter + 1); // Merge the sorted temporary files
381 | }
382 |
383 | int main(int argc, char **argv) {
384 | int i;
385 | real rlimit, n = 1e5;
386 | vocab_file = malloc(sizeof(char) * MAX_STRING_LENGTH);
387 | file_head = malloc(sizeof(char) * MAX_STRING_LENGTH);
388 |
389 | if (argc == 1) {
390 | printf("Tool to calculate word-word cooccurrence statistics\n");
391 | printf("Author: Jeffrey Pennington (jpennin@stanford.edu)\n\n");
392 | printf("Usage options:\n");
393 | printf("\t-verbose \n");
394 | printf("\t\tSet verbosity: 0, 1, 2 (default), or 3\n");
395 | printf("\t-symmetric \n");
396 | printf("\t\tIf = 0, only use left context; if = 1 (default), use left and right\n");
397 | printf("\t-window-size \n");
398 | printf("\t\tNumber of context words to the left (and to the right, if symmetric = 1); default 15\n");
399 | printf("\t-vocab-file \n");
400 | printf("\t\tFile containing vocabulary (truncated unigram counts, produced by 'vocab_count'); default vocab.txt\n");
401 | printf("\t-memory \n");
402 | printf("\t\tSoft limit for memory consumption, in GB -- based on simple heuristic, so not extremely accurate; default 4.0\n");
403 | printf("\t-max-product \n");
404 | printf("\t\tLimit the size of dense cooccurrence array by specifying the max product of the frequency counts of the two cooccurring words.\n\t\tThis value overrides that which is automatically produced by '-memory'. Typically only needs adjustment for use with very large corpora.\n");
405 | printf("\t-overflow-length \n");
406 | printf("\t\tLimit to length the sparse overflow array, which buffers cooccurrence data that does not fit in the dense array, before writing to disk. \n\t\tThis value overrides that which is automatically produced by '-memory'. Typically only needs adjustment for use with very large corpora.\n");
407 | printf("\t-overflow-file \n");
408 | printf("\t\tFilename, excluding extension, for temporary files; default overflow\n");
409 | printf("\t-distance-weighting \n");
410 | printf("\t\tIf = 0, do not weight cooccurrence count by distance between words; if = 1 (default), weight the cooccurrence count by inverse of distance between words\n");
411 |
412 | printf("\nExample usage:\n");
413 | printf("./cooccur -verbose 2 -symmetric 0 -window-size 10 -vocab-file vocab.txt -memory 8.0 -overflow-file tempoverflow < corpus.txt > cooccurrences.bin\n\n");
414 | free(vocab_file);
415 | free(file_head);
416 | return 0;
417 | }
418 |
419 | if ((i = find_arg((char *)"-verbose", argc, argv)) > 0) verbose = atoi(argv[i + 1]);
420 | if ((i = find_arg((char *)"-symmetric", argc, argv)) > 0) symmetric = atoi(argv[i + 1]);
421 | if ((i = find_arg((char *)"-window-size", argc, argv)) > 0) window_size = atoi(argv[i + 1]);
422 | if ((i = find_arg((char *)"-vocab-file", argc, argv)) > 0) strcpy(vocab_file, argv[i + 1]);
423 | else strcpy(vocab_file, (char *)"vocab.txt");
424 | if ((i = find_arg((char *)"-overflow-file", argc, argv)) > 0) strcpy(file_head, argv[i + 1]);
425 | else strcpy(file_head, (char *)"overflow");
426 | if ((i = find_arg((char *)"-memory", argc, argv)) > 0) memory_limit = atof(argv[i + 1]);
427 | if ((i = find_arg((char *)"-distance-weighting", argc, argv)) > 0) distance_weighting = atoi(argv[i + 1]);
428 |
429 | /* The memory_limit determines a limit on the number of elements in bigram_table and the overflow buffer */
430 | /* Estimate the maximum value that max_product can take so that this limit is still satisfied */
431 | rlimit = 0.85 * (real)memory_limit * 1073741824/(sizeof(CREC));
432 | while (fabs(rlimit - n * (log(n) + 0.1544313298)) > 1e-3) n = rlimit / (log(n) + 0.1544313298);
433 | max_product = (long long) n;
434 | overflow_length = (long long) rlimit/6; // 0.85 + 1/6 ~= 1
435 |
436 | /* Override estimates by specifying limits explicitly on the command line */
437 | if ((i = find_arg((char *)"-max-product", argc, argv)) > 0) max_product = atoll(argv[i + 1]);
438 | if ((i = find_arg((char *)"-overflow-length", argc, argv)) > 0) overflow_length = atoll(argv[i + 1]);
439 |
440 | const int returned_value = get_cooccurrence();
441 | free(vocab_file);
442 | free(file_head);
443 | return returned_value;
444 | }
445 |
446 |
--------------------------------------------------------------------------------
/src/glove.c:
--------------------------------------------------------------------------------
1 | // GloVe: Global Vectors for Word Representation
2 | //
3 | // Copyright (c) 2014 The Board of Trustees of
4 | // The Leland Stanford Junior University. All Rights Reserved.
5 | //
6 | // Licensed under the Apache License, Version 2.0 (the "License");
7 | // you may not use this file except in compliance with the License.
8 | // You may obtain a copy of the License at
9 | //
10 | // http://www.apache.org/licenses/LICENSE-2.0
11 | //
12 | // Unless required by applicable law or agreed to in writing, software
13 | // distributed under the License is distributed on an "AS IS" BASIS,
14 | // WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
15 | // See the License for the specific language governing permissions and
16 | // limitations under the License.
17 | //
18 | //
19 | // For more information, bug reports, fixes, contact:
20 | // Jeffrey Pennington (jpennin@stanford.edu)
21 | // GlobalVectors@googlegroups.com
22 | // http://nlp.stanford.edu/projects/glove/
23 |
24 | // silence the many complaints from visual studio
25 | #define _CRT_SECURE_NO_WARNINGS
26 |
27 | #include
28 | #include
29 | #include
30 | #include
31 | #include
32 | #include
33 |
34 | // windows pthread.h is buggy, but this #define fixes it
35 | #define HAVE_STRUCT_TIMESPEC
36 | #include
37 |
38 | #include "common.h"
39 |
40 | #define _FILE_OFFSET_BITS 64
41 |
42 | int write_header=0; //0=no, 1=yes; writes vocab_size/vector_size as first line for use with some libraries, such as gensim.
43 | int verbose = 2; // 0, 1, or 2
44 | int seed = 0;
45 | int use_unk_vec = 1; // 0 or 1
46 | int num_threads = 8; // pthreads
47 | int num_iter = 25; // Number of full passes through cooccurrence matrix
48 | int vector_size = 50; // Word vector size
49 | int save_gradsq = 0; // By default don't save squared gradient values
50 | int use_binary = 0; // 0: save as text files; 1: save as binary; 2: both. For binary, save both word and context word vectors.
51 | int model = 2; // For text file output only. 0: concatenate word and context vectors (and biases) i.e. save everything; 1: Just save word vectors (no bias); 2: Save (word + context word) vectors (no biases)
52 | int checkpoint_every = 0; // checkpoint the model for every checkpoint_every iterations. Do nothing if checkpoint_every <= 0
53 | int load_init_param = 0; // if 1 initial paramters are loaded from -init-param-file
54 | int save_init_param = 0; // if 1 initial paramters are saved (i.e., in the 0 checkpoint)
55 | int load_init_gradsq = 0; // if 1 initial squared gradients are loaded from -init-gradsq-file
56 | real eta = 0.05; // Initial learning rate
57 | real alpha = 0.75, x_max = 100.0; // Weighting function parameters, not extremely sensitive to corpus, though may need adjustment for very small or very large corpora
58 | real grad_clip_value = 100.0; // Clipping parameter for gradient components. Values will be clipped to [-grad_clip_value, grad_clip_value] interval.
59 | real *W, *gradsq, *cost;
60 | long long num_lines, *lines_per_thread, vocab_size;
61 | char vocab_file[MAX_STRING_LENGTH];
62 | char input_file[MAX_STRING_LENGTH];
63 | char save_W_file[MAX_STRING_LENGTH];
64 | char save_gradsq_file[MAX_STRING_LENGTH];
65 | char init_param_file[MAX_STRING_LENGTH];
66 | char init_gradsq_file[MAX_STRING_LENGTH];
67 |
68 | /**
69 | * Loads a save file for use as the initial values for the parameters or gradsq
70 | * Return value: 0 if success, -1 if fail
71 | */
72 | int load_init_file(char *file_name, real *array, long long array_size) {
73 | FILE *fin;
74 | long long a;
75 | fin = fopen(file_name, "rb");
76 | if (fin == NULL) {
77 | log_file_loading_error("init file", file_name);
78 | return -1;
79 | }
80 | for (a = 0; a < array_size; a++) {
81 | if (feof(fin)) {
82 | fprintf(stderr, "EOF reached before data fully loaded in %s.\n", file_name);
83 | fclose(fin);
84 | return -1;
85 | }
86 | fread(&array[a], sizeof(real), 1, fin);
87 | }
88 | fclose(fin);
89 | return 0;
90 | }
91 |
92 | void initialize_parameters() {
93 | // TODO: return an error code when an error occurs, clean up in the calling routine
94 | if (seed == 0) {
95 | seed = time(0);
96 | }
97 | fprintf(stderr, "Using random seed %d\n", seed);
98 | srand(seed);
99 | long long a;
100 | long long W_size = 2 * vocab_size * (vector_size + 1); // +1 to allocate space for bias
101 |
102 | /* Allocate space for word vectors and context word vectors, and correspodning gradsq */
103 | a = posix_memalign((void **)&W, 128, W_size * sizeof(real)); // Might perform better than malloc
104 | if (W == NULL) {
105 | fprintf(stderr, "Error allocating memory for W\n");
106 | exit(1);
107 | }
108 | a = posix_memalign((void **)&gradsq, 128, W_size * sizeof(real)); // Might perform better than malloc
109 | if (gradsq == NULL) {
110 | fprintf(stderr, "Error allocating memory for gradsq\n");
111 | free(W);
112 | exit(1);
113 | }
114 | if (load_init_param) {
115 | // Load existing parameters
116 | fprintf(stderr, "\nLoading initial parameters from %s \n", init_param_file);
117 | if (load_init_file(init_param_file, W, W_size)) {
118 | free(W);
119 | free(gradsq);
120 | exit(1);
121 | }
122 | } else {
123 | // Initialize new parameters
124 | for (a = 0; a < W_size; ++a) {
125 | W[a] = (rand() / (real)RAND_MAX - 0.5) / vector_size;
126 | }
127 | }
128 |
129 | if (load_init_gradsq) {
130 | // Load existing squared gradients
131 | fprintf(stderr, "\nLoading initial squared gradients from %s \n", init_gradsq_file);
132 | if (load_init_file(init_gradsq_file, gradsq, W_size)) {
133 | free(W);
134 | free(gradsq);
135 | exit(1);
136 | }
137 | } else {
138 | // Initialize new squared gradients
139 | for (a = 0; a < W_size; ++a) {
140 | gradsq[a] = 1.0; // So initial value of eta is equal to initial learning rate
141 | }
142 | }
143 | }
144 |
145 | static inline real check_nan(real update) {
146 | if (isnan(update) || isinf(update)) {
147 | fprintf(stderr,"\ncaught NaN in update");
148 | return 0.;
149 | } else {
150 | return update;
151 | }
152 | }
153 |
154 | /* Train the GloVe model */
155 | void *glove_thread(void *vid) {
156 | long long a, b ,l1, l2;
157 | long long id = *(long long*)vid;
158 | CREC cr;
159 | real diff, fdiff, temp1, temp2;
160 | FILE *fin;
161 | fin = fopen(input_file, "rb");
162 | if (fin == NULL) {
163 | // TODO: exit all the threads or somehow mark that glove failed
164 | log_file_loading_error("input file", input_file);
165 | pthread_exit(NULL);
166 | }
167 | fseeko(fin, (num_lines / num_threads * id) * (sizeof(CREC)), SEEK_SET); //Threads spaced roughly equally throughout file
168 | cost[id] = 0;
169 |
170 | real* W_updates1 = (real*)malloc(vector_size * sizeof(real));
171 | if (NULL == W_updates1){
172 | fclose(fin);
173 | pthread_exit(NULL);
174 | }
175 | real* W_updates2 = (real*)malloc(vector_size * sizeof(real));
176 | if (NULL == W_updates2){
177 | fclose(fin);
178 | free(W_updates1);
179 | pthread_exit(NULL);
180 | }
181 | for (a = 0; a < lines_per_thread[id]; a++) {
182 | fread(&cr, sizeof(CREC), 1, fin);
183 | if (feof(fin)) break;
184 | if (cr.word1 < 1 || cr.word2 < 1) { continue; }
185 |
186 | /* Get location of words in W & gradsq */
187 | l1 = (cr.word1 - 1LL) * (vector_size + 1); // cr word indices start at 1
188 | l2 = ((cr.word2 - 1LL) + vocab_size) * (vector_size + 1); // shift by vocab_size to get separate vectors for context words
189 |
190 | /* Calculate cost, save diff for gradients */
191 | diff = 0;
192 | for (b = 0; b < vector_size; b++) diff += W[b + l1] * W[b + l2]; // dot product of word and context word vector
193 | diff += W[vector_size + l1] + W[vector_size + l2] - log(cr.val); // add separate bias for each word
194 | fdiff = (cr.val > x_max) ? diff : pow(cr.val / x_max, alpha) * diff; // multiply weighting function (f) with diff
195 |
196 | // Check for NaN and inf() in the diffs.
197 | if (isnan(diff) || isnan(fdiff) || isinf(diff) || isinf(fdiff)) {
198 | fprintf(stderr,"Caught NaN in diff for kdiff for thread. Skipping update");
199 | continue;
200 | }
201 |
202 | cost[id] += 0.5 * fdiff * diff; // weighted squared error
203 |
204 | /* Adaptive gradient updates */
205 | real W_updates1_sum = 0;
206 | real W_updates2_sum = 0;
207 | for (b = 0; b < vector_size; b++) {
208 | // learning rate times gradient for word vectors
209 | temp1 = fmin(fmax(fdiff * W[b + l2], -grad_clip_value), grad_clip_value) * eta;
210 | temp2 = fmin(fmax(fdiff * W[b + l1], -grad_clip_value), grad_clip_value) * eta;
211 | // adaptive updates
212 | W_updates1[b] = temp1 / sqrt(gradsq[b + l1]);
213 | W_updates2[b] = temp2 / sqrt(gradsq[b + l2]);
214 | W_updates1_sum += W_updates1[b];
215 | W_updates2_sum += W_updates2[b];
216 | gradsq[b + l1] += temp1 * temp1;
217 | gradsq[b + l2] += temp2 * temp2;
218 | }
219 | if (!isnan(W_updates1_sum) && !isinf(W_updates1_sum) && !isnan(W_updates2_sum) && !isinf(W_updates2_sum)) {
220 | for (b = 0; b < vector_size; b++) {
221 | W[b + l1] -= W_updates1[b];
222 | W[b + l2] -= W_updates2[b];
223 | }
224 | }
225 |
226 | // updates for bias terms
227 | W[vector_size + l1] -= check_nan(fdiff / sqrt(gradsq[vector_size + l1]));
228 | W[vector_size + l2] -= check_nan(fdiff / sqrt(gradsq[vector_size + l2]));
229 | fdiff *= fdiff;
230 | gradsq[vector_size + l1] += fdiff;
231 | gradsq[vector_size + l2] += fdiff;
232 |
233 | }
234 | free(W_updates1);
235 | free(W_updates2);
236 |
237 | fclose(fin);
238 | pthread_exit(NULL);
239 | }
240 |
241 | /* Save params to file */
242 | int save_params(int nb_iter) {
243 | /*
244 | * nb_iter is the number of iteration (= a full pass through the cooccurrence matrix).
245 | * nb_iter > 0 => checkpointing the intermediate parameters, so nb_iter is in the filename of output file.
246 | * nb_iter == 0 => checkpointing the initial parameters
247 | * else => saving the final paramters, so nb_iter is ignored.
248 | */
249 |
250 | long long a, b;
251 | char format[20];
252 | char output_file[MAX_STRING_LENGTH+20], output_file_gsq[MAX_STRING_LENGTH+20];
253 | char *word = malloc(sizeof(char) * MAX_STRING_LENGTH + 1);
254 | if (NULL == word) {
255 | return 1;
256 | }
257 | FILE *fid, *fout;
258 | FILE *fgs = NULL;
259 |
260 | if (use_binary > 0 || nb_iter == 0) {
261 | // Save parameters in binary file
262 | // note: always save initial parameters in binary, as the reading code expects binary
263 | if (nb_iter < 0)
264 | sprintf(output_file,"%s.bin",save_W_file);
265 | else
266 | sprintf(output_file,"%s.%03d.bin",save_W_file,nb_iter);
267 |
268 | fout = fopen(output_file,"wb");
269 | if (fout == NULL) {log_file_loading_error("weights file", save_W_file); free(word); return 1;}
270 | for (a = 0; a < 2 * vocab_size * (vector_size + 1); a++) fwrite(&W[a], sizeof(real), 1,fout);
271 | fclose(fout);
272 | if (save_gradsq > 0) {
273 | if (nb_iter < 0)
274 | sprintf(output_file_gsq,"%s.bin",save_gradsq_file);
275 | else
276 | sprintf(output_file_gsq,"%s.%03d.bin",save_gradsq_file,nb_iter);
277 |
278 | fgs = fopen(output_file_gsq,"wb");
279 | if (fgs == NULL) {log_file_loading_error("gradsq file", save_gradsq_file); free(word); return 1;}
280 | for (a = 0; a < 2 * vocab_size * (vector_size + 1); a++) fwrite(&gradsq[a], sizeof(real), 1,fgs);
281 | fclose(fgs);
282 | }
283 | }
284 | if (use_binary != 1) { // Save parameters in text file
285 | if (nb_iter < 0)
286 | sprintf(output_file,"%s.txt",save_W_file);
287 | else
288 | sprintf(output_file,"%s.%03d.txt",save_W_file,nb_iter);
289 | if (save_gradsq > 0) {
290 | if (nb_iter < 0)
291 | sprintf(output_file_gsq,"%s.txt",save_gradsq_file);
292 | else
293 | sprintf(output_file_gsq,"%s.%03d.txt",save_gradsq_file,nb_iter);
294 |
295 | fgs = fopen(output_file_gsq,"wb");
296 | if (fgs == NULL) {log_file_loading_error("gradsq file", save_gradsq_file); free(word); return 1;}
297 | }
298 | fout = fopen(output_file,"wb");
299 | if (fout == NULL) {log_file_loading_error("weights file", save_W_file); free(word); return 1;}
300 | fid = fopen(vocab_file, "r");
301 | sprintf(format,"%%%ds",MAX_STRING_LENGTH);
302 | if (fid == NULL) {log_file_loading_error("vocab file", vocab_file); free(word); fclose(fout); return 1;}
303 | if (write_header) fprintf(fout, "%lld %d\n", vocab_size, vector_size);
304 | for (a = 0; a < vocab_size; a++) {
305 | if (fscanf(fid,format,word) == 0) {free(word); fclose(fid); fclose(fout); return 1;}
306 | // input vocab cannot contain special keyword
307 | if (strcmp(word, "") == 0) {free(word); fclose(fid); fclose(fout); return 1;}
308 | fprintf(fout, "%s",word);
309 | if (model == 0) { // Save all parameters (including bias)
310 | for (b = 0; b < (vector_size + 1); b++) fprintf(fout," %lf", W[a * (vector_size + 1) + b]);
311 | for (b = 0; b < (vector_size + 1); b++) fprintf(fout," %lf", W[(vocab_size + a) * (vector_size + 1) + b]);
312 | }
313 | if (model == 1) // Save only "word" vectors (without bias)
314 | for (b = 0; b < vector_size; b++) fprintf(fout," %lf", W[a * (vector_size + 1) + b]);
315 | if (model == 2) // Save "word + context word" vectors (without bias)
316 | for (b = 0; b < vector_size; b++) fprintf(fout," %lf", W[a * (vector_size + 1) + b] + W[(vocab_size + a) * (vector_size + 1) + b]);
317 | if (model == 3) { // Save "word" and "context" vectors (without bias; row-concatenated)
318 | for (b = 0; b < vector_size; b++) fprintf(fout," %lf", W[a * (vector_size + 1) + b]);
319 | for (b = 0; b < vector_size; b++) fprintf(fout," %lf", W[(vocab_size + a) * (vector_size + 1) + b]);
320 | }
321 | fprintf(fout,"\n");
322 | if (save_gradsq > 0) { // Save gradsq
323 | fprintf(fgs, "%s",word);
324 | for (b = 0; b < (vector_size + 1); b++) fprintf(fgs," %lf", gradsq[a * (vector_size + 1) + b]);
325 | for (b = 0; b < (vector_size + 1); b++) fprintf(fgs," %lf", gradsq[(vocab_size + a) * (vector_size + 1) + b]);
326 | fprintf(fgs,"\n");
327 | }
328 | if (fscanf(fid,format,word) == 0) {
329 | // Eat irrelevant frequency entry
330 | fclose(fout);
331 | fclose(fid);
332 | free(word);
333 | return 1;
334 | }
335 | }
336 |
337 | if (use_unk_vec) {
338 | real* unk_vec = (real*)calloc((vector_size + 1), sizeof(real));
339 | real* unk_context = (real*)calloc((vector_size + 1), sizeof(real));
340 | strcpy(word, "");
341 |
342 | long long num_rare_words = vocab_size < 100 ? vocab_size : 100;
343 |
344 | for (a = vocab_size - num_rare_words; a < vocab_size; a++) {
345 | for (b = 0; b < (vector_size + 1); b++) {
346 | unk_vec[b] += W[a * (vector_size + 1) + b] / num_rare_words;
347 | unk_context[b] += W[(vocab_size + a) * (vector_size + 1) + b] / num_rare_words;
348 | }
349 | }
350 |
351 | fprintf(fout, "%s",word);
352 | if (model == 0) { // Save all parameters (including bias)
353 | for (b = 0; b < (vector_size + 1); b++) fprintf(fout," %lf", unk_vec[b]);
354 | for (b = 0; b < (vector_size + 1); b++) fprintf(fout," %lf", unk_context[b]);
355 | }
356 | if (model == 1) // Save only "word" vectors (without bias)
357 | for (b = 0; b < vector_size; b++) fprintf(fout," %lf", unk_vec[b]);
358 | if (model == 2) // Save "word + context word" vectors (without bias)
359 | for (b = 0; b < vector_size; b++) fprintf(fout," %lf", unk_vec[b] + unk_context[b]);
360 | if (model == 3) { // Save "word" and "context" vectors (without bias; row-concatenated)
361 | for (b = 0; b < vector_size; b++) fprintf(fout," %lf", unk_vec[b]);
362 | for (b = 0; b < vector_size; b++) fprintf(fout," %lf", unk_context[b]);
363 | }
364 | fprintf(fout,"\n");
365 |
366 | free(unk_vec);
367 | free(unk_context);
368 | }
369 |
370 | fclose(fid);
371 | fclose(fout);
372 | if (save_gradsq > 0) fclose(fgs);
373 | }
374 | free(word);
375 | return 0;
376 | }
377 |
378 | /* Train model */
379 | int train_glove() {
380 | long long a, file_size;
381 | int save_params_return_code;
382 | int b;
383 | FILE *fin;
384 | real total_cost = 0;
385 |
386 | fprintf(stderr, "TRAINING MODEL\n");
387 |
388 | fin = fopen(input_file, "rb");
389 | if (fin == NULL) {log_file_loading_error("cooccurrence file", input_file); return 1;}
390 | fseeko(fin, 0, SEEK_END);
391 | file_size = ftello(fin);
392 | num_lines = file_size/(sizeof(CREC)); // Assuming the file isn't corrupt and consists only of CREC's
393 | fclose(fin);
394 | fprintf(stderr,"Read %lld lines.\n", num_lines);
395 | if (verbose > 1) fprintf(stderr,"Initializing parameters...");
396 | initialize_parameters();
397 | if (verbose > 1) fprintf(stderr,"done.\n");
398 | if (save_init_param) {
399 | if (verbose > 1) fprintf(stderr,"Saving initial parameters... ");
400 | save_params_return_code = save_params(0);
401 | if (save_params_return_code != 0)
402 | return save_params_return_code;
403 | if (verbose > 1) fprintf(stderr,"done.\n");
404 | }
405 | if (verbose > 0) fprintf(stderr,"vector size: %d\n", vector_size);
406 | if (verbose > 0) fprintf(stderr,"vocab size: %lld\n", vocab_size);
407 | if (verbose > 0) fprintf(stderr,"x_max: %lf\n", x_max);
408 | if (verbose > 0) fprintf(stderr,"alpha: %lf\n", alpha);
409 | pthread_t *pt = (pthread_t *)malloc(num_threads * sizeof(pthread_t));
410 | lines_per_thread = (long long *) malloc(num_threads * sizeof(long long));
411 |
412 | time_t rawtime;
413 | struct tm *info;
414 | char time_buffer[80];
415 | // Lock-free asynchronous SGD
416 | for (b = 0; b < num_iter; b++) {
417 | total_cost = 0;
418 | for (a = 0; a < num_threads - 1; a++) lines_per_thread[a] = num_lines / num_threads;
419 | lines_per_thread[a] = num_lines / num_threads + num_lines % num_threads;
420 | long long *thread_ids = (long long*)malloc(sizeof(long long) * num_threads);
421 | for (a = 0; a < num_threads; a++) thread_ids[a] = a;
422 | for (a = 0; a < num_threads; a++) pthread_create(&pt[a], NULL, glove_thread, (void *)&thread_ids[a]);
423 | for (a = 0; a < num_threads; a++) pthread_join(pt[a], NULL);
424 | for (a = 0; a < num_threads; a++) total_cost += cost[a];
425 | free(thread_ids);
426 |
427 | time(&rawtime);
428 | info = localtime(&rawtime);
429 | strftime(time_buffer,80,"%x - %I:%M.%S%p", info);
430 | fprintf(stderr, "%s, iter: %03d, cost: %lf\n", time_buffer, b+1, total_cost/num_lines);
431 |
432 | if (checkpoint_every > 0 && (b + 1) % checkpoint_every == 0) {
433 | fprintf(stderr," saving intermediate parameters for iter %03d...", b+1);
434 | save_params_return_code = save_params(b+1);
435 | if (save_params_return_code != 0) {
436 | free(pt);
437 | free(lines_per_thread);
438 | return save_params_return_code;
439 | }
440 | fprintf(stderr,"done.\n");
441 | }
442 | }
443 | free(pt);
444 | free(lines_per_thread);
445 | return save_params(-1);
446 | }
447 |
448 | int main(int argc, char **argv) {
449 | int i;
450 | FILE *fid;
451 | int result = 0;
452 |
453 | if (argc == 1) {
454 | printf("GloVe: Global Vectors for Word Representation, v0.2\n");
455 | printf("Author: Jeffrey Pennington (jpennin@stanford.edu)\n\n");
456 | printf("Usage options:\n");
457 | printf("\t-verbose \n");
458 | printf("\t\tSet verbosity: 0, 1, or 2 (default)\n");
459 | printf("\t-write-header \n");
460 | printf("\t\tIf 1, write vocab_size/vector_size as first line. Do nothing if 0 (default).\n");
461 | printf("\t-vector-size \n");
462 | printf("\t\tDimension of word vector representations (excluding bias term); default 50\n");
463 | printf("\t-threads \n");
464 | printf("\t\tNumber of threads; default 8\n");
465 | printf("\t-iter \n");
466 | printf("\t\tNumber of training iterations; default 25\n");
467 | printf("\t-eta \n");
468 | printf("\t\tInitial learning rate; default 0.05\n");
469 | printf("\t-alpha \n");
470 | printf("\t\tParameter in exponent of weighting function; default 0.75\n");
471 | printf("\t-x-max \n");
472 | printf("\t\tParameter specifying cutoff in weighting function; default 100.0\n");
473 | printf("\t-grad-clip\n");
474 | printf("\t\tGradient components clipping parameter. Values will be clipped to [-grad-clip, grad-clip] interval\n");
475 | printf("\t-binary \n");
476 | printf("\t\tSave output in binary format (0: text, 1: binary, 2: both); default 0\n");
477 | printf("\t-model \n");
478 | printf("\t\tModel for word vector output (for text output only); default 2\n");
479 | printf("\t\t 0: output all data, for both word and context word vectors, including bias terms\n");
480 | printf("\t\t 1: output word vectors, excluding bias terms\n");
481 | printf("\t\t 2: output word vectors + context word vectors, excluding bias terms\n");
482 | printf("\t\t 3: output word vectors and context word vectors, excluding bias terms; context word vectors are row-concatenated to the word vectors\n");
483 | printf("\t-input-file \n");
484 | printf("\t\tBinary input file of shuffled cooccurrence data (produced by 'cooccur' and 'shuffle'); default cooccurrence.shuf.bin\n");
485 | printf("\t-vocab-file \n");
486 | printf("\t\tFile containing vocabulary (truncated unigram counts, produced by 'vocab_count'); default vocab.txt\n");
487 | printf("\t-save-file \n");
488 | printf("\t\tFilename, excluding extension, for word vector output; default vectors\n");
489 | printf("\t-gradsq-file \n");
490 | printf("\t\tFilename, excluding extension, for squared gradient output; default gradsq\n");
491 | printf("\t-save-gradsq \n");
492 | printf("\t\tSave accumulated squared gradients; default 0 (off); ignored if gradsq-file is specified\n");
493 | printf("\t-checkpoint-every \n");
494 | printf("\t\tCheckpoint a model every iterations; default 0 (off)\n");
495 | printf("\t-load-init-param \n");
496 | printf("\t\tLoad initial parameters from -init-param-file; default 0 (false)\n");
497 | printf("\t-save-init-param \n");
498 | printf("\t\tSave initial parameters (i.e., checkpoint the model before any training); default 0 (false)\n");
499 | printf("\t-init-param-file \n");
500 | printf("\t\tBinary initial parameters file to be loaded if -load-init-params is 1; (default is to look for vectors.000.bin)\n");
501 | printf("\t-load-init-gradsq \n");
502 | printf("\t\tLoad initial squared gradients from -init-gradsq-file; default 0 (false)\n");
503 | printf("\t-init-gradsq-file \n");
504 | printf("\t\tBinary initial squared gradients file to be loaded if -load-init-gradsq is 1; (default is to look for gradsq.000.bin)\n");
505 | printf("\t-seed \n");
506 | printf("\t\tRandom seed to use. If not set, will be randomized using current time.");
507 | printf("\nExample usage:\n");
508 | printf("./glove -input-file cooccurrence.shuf.bin -vocab-file vocab.txt -save-file vectors -gradsq-file gradsq -verbose 2 -vector-size 100 -threads 16 -alpha 0.75 -x-max 100.0 -eta 0.05 -binary 2 -model 2\n\n");
509 | result = 0;
510 | } else {
511 | if ((i = find_arg((char *)"-write-header", argc, argv)) > 0) write_header = atoi(argv[i + 1]);
512 | if ((i = find_arg((char *)"-verbose", argc, argv)) > 0) verbose = atoi(argv[i + 1]);
513 | if ((i = find_arg((char *)"-vector-size", argc, argv)) > 0) vector_size = atoi(argv[i + 1]);
514 | if ((i = find_arg((char *)"-iter", argc, argv)) > 0) num_iter = atoi(argv[i + 1]);
515 | if ((i = find_arg((char *)"-threads", argc, argv)) > 0) num_threads = atoi(argv[i + 1]);
516 | cost = malloc(sizeof(real) * num_threads);
517 | if ((i = find_arg((char *)"-alpha", argc, argv)) > 0) alpha = atof(argv[i + 1]);
518 | if ((i = find_arg((char *)"-x-max", argc, argv)) > 0) x_max = atof(argv[i + 1]);
519 | if ((i = find_arg((char *)"-eta", argc, argv)) > 0) eta = atof(argv[i + 1]);
520 | if ((i = find_arg((char *)"-grad-clip", argc, argv)) > 0) grad_clip_value = atof(argv[i + 1]);
521 | if ((i = find_arg((char *)"-binary", argc, argv)) > 0) use_binary = atoi(argv[i + 1]);
522 | if ((i = find_arg((char *)"-model", argc, argv)) > 0) model = atoi(argv[i + 1]);
523 | if (model != 0 && model != 1) model = 2;
524 | if ((i = find_arg((char *)"-save-gradsq", argc, argv)) > 0) save_gradsq = atoi(argv[i + 1]);
525 | if ((i = find_arg((char *)"-vocab-file", argc, argv)) > 0) strcpy(vocab_file, argv[i + 1]);
526 | else strcpy(vocab_file, (char *)"vocab.txt");
527 | if ((i = find_arg((char *)"-save-file", argc, argv)) > 0) strcpy(save_W_file, argv[i + 1]);
528 | else strcpy(save_W_file, (char *)"vectors");
529 | if ((i = find_arg((char *)"-gradsq-file", argc, argv)) > 0) {
530 | strcpy(save_gradsq_file, argv[i + 1]);
531 | save_gradsq = 1;
532 | }
533 | else if (save_gradsq > 0) strcpy(save_gradsq_file, (char *)"gradsq");
534 | if ((i = find_arg((char *)"-input-file", argc, argv)) > 0) strcpy(input_file, argv[i + 1]);
535 | else strcpy(input_file, (char *)"cooccurrence.shuf.bin");
536 | if ((i = find_arg((char *)"-checkpoint-every", argc, argv)) > 0) checkpoint_every = atoi(argv[i + 1]);
537 | if ((i = find_arg((char *)"-init-param-file", argc, argv)) > 0) strcpy(init_param_file, argv[i + 1]);
538 | else strcpy(init_param_file, (char *)"vectors.000.bin");
539 | if ((i = find_arg((char *)"-load-init-param", argc, argv)) > 0) load_init_param = atoi(argv[i + 1]);
540 | if ((i = find_arg((char *)"-save-init-param", argc, argv)) > 0) save_init_param = atoi(argv[i + 1]);
541 | if ((i = find_arg((char *)"-init-gradsq-file", argc, argv)) > 0) strcpy(init_gradsq_file, argv[i + 1]);
542 | else strcpy(init_gradsq_file, (char *)"gradsq.000.bin");
543 | if ((i = find_arg((char *)"-load-init-gradsq", argc, argv)) > 0) load_init_gradsq = atoi(argv[i + 1]);
544 | if ((i = find_arg((char *)"-seed", argc, argv)) > 0) seed = atoi(argv[i + 1]);
545 |
546 | vocab_size = 0;
547 | fid = fopen(vocab_file, "r");
548 | if (fid == NULL) {log_file_loading_error("vocab file", vocab_file); free(cost); return 1;}
549 | while ((i = getc(fid)) != EOF) if (i == '\n') vocab_size++; // Count number of entries in vocab_file
550 | fclose(fid);
551 | if (vocab_size == 0) {fprintf(stderr, "Unable to find any vocab entries in vocab file %s.\n", vocab_file); free(cost); return 1;}
552 | result = train_glove();
553 | free(cost);
554 | }
555 | free(W);
556 | free(gradsq);
557 |
558 | return result;
559 | }
560 |
--------------------------------------------------------------------------------
/src/shuffle.c:
--------------------------------------------------------------------------------
1 | // Tool to shuffle entries of word-word cooccurrence files
2 | //
3 | // Copyright (c) 2014 The Board of Trustees of
4 | // The Leland Stanford Junior University. All Rights Reserved.
5 | //
6 | // Licensed under the Apache License, Version 2.0 (the "License");
7 | // you may not use this file except in compliance with the License.
8 | // You may obtain a copy of the License at
9 | //
10 | // http://www.apache.org/licenses/LICENSE-2.0
11 | //
12 | // Unless required by applicable law or agreed to in writing, software
13 | // distributed under the License is distributed on an "AS IS" BASIS,
14 | // WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
15 | // See the License for the specific language governing permissions and
16 | // limitations under the License.
17 | //
18 | //
19 | // For more information, bug reports, fixes, contact:
20 | // Jeffrey Pennington (jpennin@stanford.edu)
21 | // GlobalVectors@googlegroups.com
22 | // http://nlp.stanford.edu/projects/glove/
23 |
24 | #include
25 | #include
26 | #include
27 | #include
28 | #include "common.h"
29 |
30 |
31 | static const long LRAND_MAX = ((long) RAND_MAX + 2) * (long)RAND_MAX;
32 |
33 | int verbose = 2; // 0, 1, or 2
34 | int seed = 0;
35 | long long array_size = 2000000; // size of chunks to shuffle individually
36 | char *file_head; // temporary file string
37 | real memory_limit = 2.0; // soft limit, in gigabytes
38 |
39 | /* Generate uniformly distributed random long ints */
40 | static long rand_long(long n) {
41 | long limit = LRAND_MAX - LRAND_MAX % n;
42 | long rnd;
43 | do {
44 | rnd = ((long)RAND_MAX + 1) * (long)rand() + (long)rand();
45 | } while (rnd >= limit);
46 | return rnd % n;
47 | }
48 |
49 | /* Write contents of array to binary file */
50 | int write_chunk(CREC *array, long size, FILE *fout) {
51 | long i = 0;
52 | for (i = 0; i < size; i++) fwrite(&array[i], sizeof(CREC), 1, fout);
53 | return 0;
54 | }
55 |
56 | /* Fisher-Yates shuffle */
57 | void shuffle(CREC *array, long n) {
58 | long i, j;
59 | CREC tmp;
60 | for (i = n - 1; i > 0; i--) {
61 | j = rand_long(i + 1);
62 | tmp = array[j];
63 | array[j] = array[i];
64 | array[i] = tmp;
65 | }
66 | }
67 |
68 | /* Merge shuffled temporary files; doesn't necessarily produce a perfect shuffle, but good enough */
69 | int shuffle_merge(int num) {
70 | long i, j, k, l = 0;
71 | int fidcounter = 0;
72 | CREC *array;
73 | char filename[MAX_STRING_LENGTH];
74 | FILE **fid, *fout = stdout;
75 |
76 | array = malloc(sizeof(CREC) * array_size);
77 | fid = calloc(num, sizeof(FILE));
78 | for (fidcounter = 0; fidcounter < num; fidcounter++) { //num = number of temporary files to merge
79 | sprintf(filename,"%s_%04d.bin",file_head, fidcounter);
80 | fid[fidcounter] = fopen(filename, "rb");
81 | if (fid[fidcounter] == NULL) {
82 | log_file_loading_error("temp file", filename);
83 | free(array);
84 | free_fid(fid, num);
85 | return 1;
86 | }
87 | }
88 | if (verbose > 0) fprintf(stderr, "Merging temp files: processed %ld lines.", l);
89 |
90 | while (1) { //Loop until EOF in all files
91 | i = 0;
92 | //Read at most array_size values into array, roughly array_size/num from each temp file
93 | for (j = 0; j < num; j++) {
94 | if (feof(fid[j])) continue;
95 | for (k = 0; k < array_size / num; k++){
96 | fread(&array[i], sizeof(CREC), 1, fid[j]);
97 | if (feof(fid[j])) break;
98 | i++;
99 | }
100 | }
101 | if (i == 0) break;
102 | l += i;
103 | shuffle(array, i-1); // Shuffles lines between temp files
104 | write_chunk(array,i,fout);
105 | if (verbose > 0) fprintf(stderr, "\033[31G%ld lines.", l);
106 | }
107 | fprintf(stderr, "\033[0GMerging temp files: processed %ld lines.", l);
108 | for (fidcounter = 0; fidcounter < num; fidcounter++) {
109 | fclose(fid[fidcounter]);
110 | sprintf(filename,"%s_%04d.bin",file_head, fidcounter);
111 | remove(filename);
112 | }
113 | fprintf(stderr, "\n\n");
114 | free(array);
115 | free(fid);
116 | return 0;
117 | }
118 |
119 | /* Shuffle large input stream by splitting into chunks */
120 | int shuffle_by_chunks() {
121 | if (seed == 0) {
122 | seed = time(0);
123 | }
124 | fprintf(stderr, "Using random seed %d\n", seed);
125 | srand(seed);
126 | long i = 0, l = 0;
127 | int fidcounter = 0;
128 | char filename[MAX_STRING_LENGTH];
129 | CREC *array;
130 | FILE *fin = stdin, *fid;
131 | array = malloc(sizeof(CREC) * array_size);
132 |
133 | fprintf(stderr,"SHUFFLING COOCCURRENCES\n");
134 | if (verbose > 0) fprintf(stderr,"array size: %lld\n", array_size);
135 | sprintf(filename,"%s_%04d.bin",file_head, fidcounter);
136 | fid = fopen(filename,"w");
137 | if (fid == NULL) {
138 | log_file_loading_error("file", filename);
139 | free(array);
140 | return 1;
141 | }
142 | if (verbose > 1) fprintf(stderr, "Shuffling by chunks: processed 0 lines.");
143 |
144 | while (1) { //Continue until EOF
145 | if (i >= array_size) {// If array is full, shuffle it and save to temporary file
146 | shuffle(array, i-2);
147 | l += i;
148 | if (verbose > 1) fprintf(stderr, "\033[22Gprocessed %ld lines.", l);
149 | write_chunk(array,i,fid);
150 | fclose(fid);
151 | fidcounter++;
152 | sprintf(filename,"%s_%04d.bin",file_head, fidcounter);
153 | fid = fopen(filename,"w");
154 | if (fid == NULL) {
155 | log_file_loading_error("file", filename);
156 | free(array);
157 | return 1;
158 | }
159 | i = 0;
160 | }
161 | fread(&array[i], sizeof(CREC), 1, fin);
162 | if (feof(fin)) break;
163 | i++;
164 | }
165 | shuffle(array, i-2); //Last chunk may be smaller than array_size
166 | write_chunk(array,i,fid);
167 | l += i;
168 | if (verbose > 1) fprintf(stderr, "\033[22Gprocessed %ld lines.\n", l);
169 | if (verbose > 1) fprintf(stderr, "Wrote %d temporary file(s).\n", fidcounter + 1);
170 | fclose(fid);
171 | free(array);
172 | return shuffle_merge(fidcounter + 1); // Merge and shuffle together temporary files
173 | }
174 |
175 | int main(int argc, char **argv) {
176 | int i;
177 |
178 | if (argc == 2 &&
179 | (!scmp(argv[1], "-h") || !scmp(argv[1], "-help") || !scmp(argv[1], "--help"))) {
180 | printf("Tool to shuffle entries of word-word cooccurrence files\n");
181 | printf("Author: Jeffrey Pennington (jpennin@stanford.edu)\n\n");
182 | printf("Usage options:\n");
183 | printf("\t-verbose \n");
184 | printf("\t\tSet verbosity: 0, 1, or 2 (default)\n");
185 | printf("\t-memory \n");
186 | printf("\t\tSoft limit for memory consumption, in GB; default 4.0\n");
187 | printf("\t-array-size \n");
188 | printf("\t\tLimit to length the buffer which stores chunks of data to shuffle before writing to disk. \n\t\tThis value overrides that which is automatically produced by '-memory'.\n");
189 | printf("\t-temp-file \n");
190 | printf("\t\tFilename, excluding extension, for temporary files; default temp_shuffle\n");
191 | printf("\t-seed \n");
192 | printf("\t\tRandom seed to use. If not set, will be randomized using current time.");
193 | printf("\nExample usage: (assuming 'cooccurrence.bin' has been produced by 'coccur')\n");
194 | printf("./shuffle -verbose 2 -memory 8.0 < cooccurrence.bin > cooccurrence.shuf.bin\n");
195 | return 0;
196 | }
197 |
198 | file_head = malloc(sizeof(char) * MAX_STRING_LENGTH);
199 | if ((i = find_arg((char *)"-verbose", argc, argv)) > 0) verbose = atoi(argv[i + 1]);
200 | if ((i = find_arg((char *)"-temp-file", argc, argv)) > 0) strcpy(file_head, argv[i + 1]);
201 | else strcpy(file_head, (char *)"temp_shuffle");
202 | if ((i = find_arg((char *)"-memory", argc, argv)) > 0) memory_limit = atof(argv[i + 1]);
203 | array_size = (long long) (0.95 * (real)memory_limit * 1073741824/(sizeof(CREC)));
204 | if ((i = find_arg((char *)"-array-size", argc, argv)) > 0) array_size = atoll(argv[i + 1]);
205 | if ((i = find_arg((char *)"-seed", argc, argv)) > 0) seed = atoi(argv[i + 1]);
206 | const int returned_value = shuffle_by_chunks();
207 | free(file_head);
208 | return returned_value;
209 | }
210 |
211 |
--------------------------------------------------------------------------------
/src/vocab_count.c:
--------------------------------------------------------------------------------
1 | // Tool to extract unigram counts
2 | //
3 | // GloVe: Global Vectors for Word Representation
4 | // Copyright (c) 2014 The Board of Trustees of
5 | // The Leland Stanford Junior University. All Rights Reserved.
6 | //
7 | // Licensed under the Apache License, Version 2.0 (the "License");
8 | // you may not use this file except in compliance with the License.
9 | // You may obtain a copy of the License at
10 | //
11 | // http://www.apache.org/licenses/LICENSE-2.0
12 | //
13 | // Unless required by applicable law or agreed to in writing, software
14 | // distributed under the License is distributed on an "AS IS" BASIS,
15 | // WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
16 | // See the License for the specific language governing permissions and
17 | // limitations under the License.
18 | //
19 | //
20 | // For more information, bug reports, fixes, contact:
21 | // Jeffrey Pennington (jpennin@stanford.edu)
22 | // Christopher Manning (manning@cs.stanford.edu)
23 | // https://github.com/stanfordnlp/GloVe/
24 | // GlobalVectors@googlegroups.com
25 | // http://nlp.stanford.edu/projects/glove/
26 |
27 | #include
28 | #include
29 | #include
30 | #include "common.h"
31 |
32 | typedef struct vocabulary {
33 | char *word;
34 | long long count;
35 | } VOCAB;
36 |
37 | int verbose = 2; // 0, 1, or 2
38 | long long min_count = 1; // min occurrences for inclusion in vocab
39 | long long max_vocab = 0; // max_vocab = 0 for no limit
40 |
41 |
42 | /* Vocab frequency comparison; break ties alphabetically */
43 | int CompareVocabTie(const void *a, const void *b) {
44 | long long c;
45 | if ( (c = ((VOCAB *) b)->count - ((VOCAB *) a)->count) != 0) return ( c > 0 ? 1 : -1 );
46 | else return (scmp(((VOCAB *) a)->word,((VOCAB *) b)->word));
47 |
48 | }
49 |
50 | /* Vocab frequency comparison; no tie-breaker */
51 | int CompareVocab(const void *a, const void *b) {
52 | long long c;
53 | if ( (c = ((VOCAB *) b)->count - ((VOCAB *) a)->count) != 0) return ( c > 0 ? 1 : -1 );
54 | else return 0;
55 | }
56 |
57 | /* Search hash table for given string, insert if not found */
58 | void hashinsert(HASHREC **ht, char *w) {
59 | HASHREC *htmp, *hprv;
60 | unsigned int hval = HASHFN(w, TSIZE, SEED);
61 |
62 | for (hprv = NULL, htmp = ht[hval]; htmp != NULL && scmp(htmp->word, w) != 0; hprv = htmp, htmp = htmp->next);
63 | if (htmp == NULL) {
64 | htmp = (HASHREC *) malloc( sizeof(HASHREC) );
65 | htmp->word = (char *) malloc( strlen(w) + 1 );
66 | strcpy(htmp->word, w);
67 | htmp->num = 1;
68 | htmp->next = NULL;
69 | if ( hprv==NULL )
70 | ht[hval] = htmp;
71 | else
72 | hprv->next = htmp;
73 | }
74 | else {
75 | /* new records are not moved to front */
76 | htmp->num++;
77 | if (hprv != NULL) {
78 | /* move to front on access */
79 | hprv->next = htmp->next;
80 | htmp->next = ht[hval];
81 | ht[hval] = htmp;
82 | }
83 | }
84 | return;
85 | }
86 |
87 | int get_counts() {
88 | long long i = 0, j = 0, vocab_size = 12500;
89 | // char format[20];
90 | char str[MAX_STRING_LENGTH + 1];
91 | HASHREC **vocab_hash = inithashtable();
92 | HASHREC *htmp;
93 | VOCAB *vocab;
94 | FILE *fid = stdin;
95 |
96 | fprintf(stderr, "BUILDING VOCABULARY\n");
97 | if (verbose > 1) fprintf(stderr, "Processed %lld tokens.", i);
98 | // sprintf(format,"%%%ds",MAX_STRING_LENGTH);
99 | while ( ! feof(fid)) {
100 | // Insert all tokens into hashtable
101 | int nl = get_word(str, fid);
102 | if (nl) continue; // just a newline marker or feof
103 | if (strcmp(str, "") == 0) {
104 | fprintf(stderr, "\nError, vector found in corpus.\nPlease remove s from your corpus (e.g. cat text8 | sed -e 's///g' > text8.new)");
105 | free_table(vocab_hash);
106 | return 1;
107 | }
108 | hashinsert(vocab_hash, str);
109 | if (((++i)%100000) == 0) if (verbose > 1) fprintf(stderr,"\033[11G%lld tokens.", i);
110 | }
111 | if (verbose > 1) fprintf(stderr, "\033[0GProcessed %lld tokens.\n", i);
112 | vocab = malloc(sizeof(VOCAB) * vocab_size);
113 | for (i = 0; i < TSIZE; i++) { // Migrate vocab to array
114 | htmp = vocab_hash[i];
115 | while (htmp != NULL) {
116 | vocab[j].word = htmp->word;
117 | vocab[j].count = htmp->num;
118 | j++;
119 | if (j>=vocab_size) {
120 | vocab_size += 2500;
121 | vocab = (VOCAB *)realloc(vocab, sizeof(VOCAB) * vocab_size);
122 | }
123 | htmp = htmp->next;
124 | }
125 | }
126 | if (verbose > 1) fprintf(stderr, "Counted %lld unique words.\n", j);
127 | if (max_vocab > 0 && max_vocab < j)
128 | // If the vocabulary exceeds limit, first sort full vocab by frequency without alphabetical tie-breaks.
129 | // This results in pseudo-random ordering for words with same frequency, so that when truncated, the words span whole alphabet
130 | qsort(vocab, j, sizeof(VOCAB), CompareVocab);
131 | else max_vocab = j;
132 | qsort(vocab, max_vocab, sizeof(VOCAB), CompareVocabTie); //After (possibly) truncating, sort (possibly again), breaking ties alphabetically
133 |
134 | for (i = 0; i < max_vocab; i++) {
135 | if (vocab[i].count < min_count) { // If a minimum frequency cutoff exists, truncate vocabulary
136 | if (verbose > 0) fprintf(stderr, "Truncating vocabulary at min count %lld.\n",min_count);
137 | break;
138 | }
139 | printf("%s %lld\n",vocab[i].word,vocab[i].count);
140 | }
141 |
142 | if (i == max_vocab && max_vocab < j) if (verbose > 0) fprintf(stderr, "Truncating vocabulary at size %lld.\n", max_vocab);
143 | fprintf(stderr, "Using vocabulary of size %lld.\n\n", i);
144 | free_table(vocab_hash);
145 | free(vocab);
146 | return 0;
147 | }
148 |
149 | int main(int argc, char **argv) {
150 | if (argc == 2 &&
151 | (!scmp(argv[1], "-h") || !scmp(argv[1], "-help") || !scmp(argv[1], "--help"))) {
152 | printf("Simple tool to extract unigram counts\n");
153 | printf("Author: Jeffrey Pennington (jpennin@stanford.edu)\n\n");
154 | printf("Usage options:\n");
155 | printf("\t-verbose \n");
156 | printf("\t\tSet verbosity: 0, 1, or 2 (default)\n");
157 | printf("\t-max-vocab \n");
158 | printf("\t\tUpper bound on vocabulary size, i.e. keep the most frequent words. The minimum frequency words are randomly sampled so as to obtain an even distribution over the alphabet.\n");
159 | printf("\t-min-count \n");
160 | printf("\t\tLower limit such that words which occur fewer than times are discarded.\n");
161 | printf("\nExample usage:\n");
162 | printf("./vocab_count -verbose 2 -max-vocab 100000 -min-count 10 < corpus.txt > vocab.txt\n");
163 | return 0;
164 | }
165 |
166 | int i;
167 | if ((i = find_arg((char *)"-verbose", argc, argv)) > 0) verbose = atoi(argv[i + 1]);
168 | if ((i = find_arg((char *)"-max-vocab", argc, argv)) > 0) max_vocab = atoll(argv[i + 1]);
169 | if ((i = find_arg((char *)"-min-count", argc, argv)) > 0) min_count = atoll(argv[i + 1]);
170 | return get_counts();
171 | }
172 |
173 |
--------------------------------------------------------------------------------