├── .gitignore
├── README.md
├── experiments
├── __init__.py
├── classification_ensembles.py
├── classification_imagenet.py
├── classification_ue.py
├── classification_ue_ood.py
├── configs.py
├── data
│ ├── .gitignore
│ ├── al
│ │ └── .gitkeep
│ ├── detector
│ │ └── .gitkeep
│ ├── models
│ │ └── .gitkeep
│ ├── ood
│ │ └── .gitkeep
│ ├── regression
│ │ └── .gitkeep
│ └── xor
│ │ └── .gitkeep
├── deprecated
│ ├── __init__.py
│ ├── active_learning_debug.py
│ ├── active_learning_mnist.py
│ ├── active_learning_svhn.py
│ ├── al_rosenbrock_experiment.py
│ ├── classification_active_learning.py
│ ├── classification_active_learning_fasetai.py
│ ├── classification_bench_masks.ipynb
│ ├── classification_error_detection.py
│ ├── classification_error_detection_fastai.py
│ ├── classification_image.py
│ ├── classification_ood_detection.py
│ ├── classification_visual.ipynb
│ ├── classification_xor.ipynb
│ ├── dpp.ipynb
│ ├── ensemble-datasets.ipynb
│ ├── ensemble-masks.ipynb
│ ├── ensemble_debug.py
│ ├── ensembles.ipynb
│ ├── ensembles_2.ipynb
│ ├── ensembles_3.ipynb
│ ├── ensembles_4.ipynb
│ ├── ensembles_5.ipynb
│ ├── move.py
│ ├── plot_df.py
│ ├── plot_df_al.py
│ ├── print_confidence_accuracy_multi_ack.py
│ ├── print_histogram.py
│ ├── print_it.py
│ ├── print_ll.py
│ ├── regression_2_prfm2.ipynb
│ ├── regression_3_dolan-more.ipynb
│ ├── regression_active_learning.ipynb
│ ├── regression_bench_ue.ipynb
│ ├── regression_dm_big_exper_train.ipynb
│ ├── regression_dm_dolan-more.ipynb
│ ├── regression_dm_produce_results_from_models.ipynb
│ ├── regression_masks.ipynb
│ ├── regression_visual-circles.ipynb
│ ├── regression_visual.ipynb
│ ├── small_eigen_debug.ipynb
│ ├── uq_proc (2).ipynb
│ └── utils
│ │ ├── __init__.py
│ │ ├── data.py
│ │ └── fastai.py
├── logs
│ └── .gitignore
├── models.py
├── move_chest.py
├── print_confidence_accuracy.py
├── print_ood.py
├── regression_1_big_exper_train-clean.ipynb
├── regression_2_ll_on_trained_models.ipynb
├── regression_3_ood_w_training.ipynb
└── visual_datasets.py
├── figures
├── 2d_toy.png
├── active_learning_mnist.png
├── benchmark.png
├── convergence.png
├── dolan_acc_ens.png
├── dolan_acc_single.png
├── dpp_ring_contour.png
├── error_detector_cifar.png
├── error_detector_mnist.png
├── error_detector_svhn.png
├── ood_mnist.png
└── ring_results.png
└── requirements.txt
/.gitignore:
--------------------------------------------------------------------------------
1 | .idea
2 | .ipynb_checkpoints
3 | *.pyc
4 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Uncertainty estimation via decorrelation and DPP
2 | Code for paper "Dropout Strikes Back: Improved Uncertainty
3 | Estimation via Diversity Sampling" by Kirill Fedyanin, Evgenii Tsymbalov, Maxim Panov published in [Recent Trends in Analysis of Images, Social Networks and Texts](https://link.springer.com/chapter/10.1007/978-3-031-15168-2_11) by Springer. You can cite this paper by bibtex provided below.
4 |
5 | Main code with implemented methods (DPP, k-DPP, leverages masks for dropout) are in our [alpaca library](https://github.com/stat-ml/alpaca)
6 |
7 |
8 | ### Motivation
9 |
10 |
11 | For regression tasks, it could be useful to know not just a prediction but also a confidence interval. It's hard to do it in the close form for deep learning, but to estimate, you can you so-called [ensembles](https://arxiv.org/abs/1612.01474) of several models. To avoid training and keeping several models, you could use [monte-carlo dropout](https://arxiv.org/abs/1506.02142) on inference.
12 |
13 | To use MC dropout, you need multiple forward passes; converging requires tens or even hundreds of forward passes.
14 |
15 |
16 | 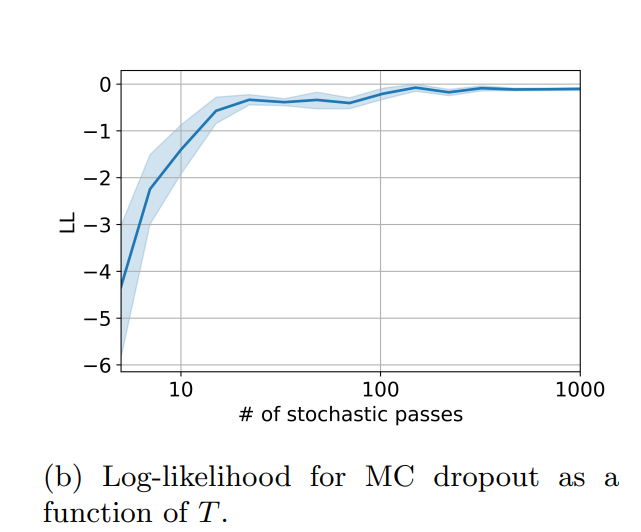 17 |
17 |
18 |
19 | We propose to force the diversity of forward passes by hiring determinantal point processes. See how it improves the log-likelihood metric across various UCI datasets for the different numbers of stochastic passes T = 10, 30, 100.
20 |
21 | 
22 |
23 |
24 | ### Paper
25 |
26 | You can read full paper here [https://link.springer.com/chapter/10.1007/978-3-031-15168-2_11](https://link.springer.com/chapter/10.1007/978-3-031-15168-2_11)
27 |
28 | For the citation, please use
29 |
30 | ```bibtex
31 | @InProceedings{Fedyanin2021DropoutSB,
32 | author="Fedyanin, Kirill
33 | and Tsymbalov, Evgenii
34 | and Panov, Maxim",
35 | title="Dropout Strikes Back: Improved Uncertainty Estimation via Diversity Sampling",
36 | booktitle="Recent Trends in Analysis of Images, Social Networks and Texts",
37 | year="2022",
38 | publisher="Springer International Publishing",
39 | pages="125--137",
40 | isbn="978-3-031-15168-2"
41 | }
42 | ```
43 |
44 |
45 | ## Install dependency
46 | ```
47 | pip install -r requirements.txt
48 | ```
49 |
50 | ## Regression
51 | To get the experiment results from the paper, run the following notebooks
52 | - `experiments/regression_1_big_exper_train-clean.ipynb` to train the models
53 | - `experiments/regression_2_ll_on_trained_models.ipynb` to get the ll values for different datasets
54 | - `experiments/regression_3_ood_w_training.ipynb` for the OOD experiments
55 |
56 | ## Classification
57 |
58 | From the experiment folder run the following scripts. They goes in pairs, first script trains models and estimate the uncertainty, second just print the results.
59 |
60 | #### Accuracy experiment on MNIST
61 | ```bash
62 | python classification_ue.py mnist
63 | python print_confidence_accuracy.py mnist
64 | ```
65 | #### Accuracy experiment on CIFAR
66 | ```bash
67 | python classification_ue.py cifar
68 | python print_confidence_accuracy.py cifar
69 | ```
70 | #### Accuracy experiment on ImageNet
71 | For the imagenet you need to manually download validation dataset (version ILSVRC2012) and put images to the `experiments/data/imagenet/valid` folder
72 | ```bash
73 | python classification_imagenet.py
74 | python print_confidence_accuracy.py imagenet
75 | ```
76 | #### OOD experiment on MNIST
77 | ```bash
78 | python classification_ue_ood.py mnist
79 | python print_ood.py mnist
80 | ```
81 | #### OOD experiment on CIFAR
82 | ```bash
83 | python classification_ue_ood.py cifar
84 | python print_ood.py cifar
85 | ```
86 | #### OOD experiment on ImageNet
87 | ```bash
88 | python classification_imagenet.py --ood
89 | python print_ood.py imagenet
90 | ```
91 |
92 | You can change the uncertainty estimation function for mnist/cifar by adding `-a=var_ratio` or `-a=max_prob` keys to the scripts.
93 |
--------------------------------------------------------------------------------
/experiments/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/experiments/__init__.py
--------------------------------------------------------------------------------
/experiments/classification_ensembles.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pickle
3 | from argparse import ArgumentParser
4 | from collections import OrderedDict
5 | from copy import deepcopy
6 | from pathlib import Path
7 |
8 | import numpy as np
9 | import torch
10 | from sklearn.model_selection import train_test_split
11 | from catalyst.dl import SupervisedRunner
12 | from catalyst.dl.callbacks import AccuracyCallback, EarlyStoppingCallback
13 | from catalyst.utils import set_global_seed
14 |
15 | from alpaca.uncertainty_estimator.bald import bald as bald_score
16 |
17 | from configs import base_config, experiment_config
18 | from deprecated.classification_active_learning import loader
19 | from classification_ue_ood import get_data as get_data_ood
20 | from classification_ue import get_data, train
21 |
22 |
23 | def parse_arguments():
24 | parser = ArgumentParser()
25 | parser.add_argument('name')
26 | parser.add_argument('--acquisition', '-a', type=str, default='bald')
27 | parser.add_argument('--ood', dest='ood', action='store_true')
28 | args = parser.parse_args()
29 |
30 | config = deepcopy(base_config)
31 | config.update(experiment_config[args.name])
32 | config['name'] = args.name
33 | config['acquisition'] = args.acquisition
34 | config['ood'] = args.ood
35 |
36 | return config
37 |
38 |
39 | def bench_uncertainty(ensemble, x_val_tensor, y_val, config):
40 | probabilities, max_prob, bald, var_ratio_ue = ensemble.estimate(x_val_tensor)
41 | uncertainties = {
42 | 'ensemble_max_prob': np.array(max_prob),
43 | 'ensemble_bald': np.array(bald),
44 | 'ensemble_var_ratio': np.array(var_ratio_ue)
45 | }
46 | record = {
47 | 'y_val': y_val,
48 | 'uncertainties': uncertainties,
49 | 'probabilities': probabilities,
50 | 'estimators': list(uncertainties.keys()),
51 | }
52 |
53 | ood_str = '_ood' if config['ood'] else ''
54 | with open(ensemble.logdir / f"ue_ensemble{ood_str}.pickle", 'wb') as f:
55 | pickle.dump(record, f)
56 |
57 |
58 | class Ensemble:
59 | def __init__(self, logbase, n_models, config, loaders, start_i=0):
60 | self.models = []
61 | self.n_models = n_models
62 | self.logdir = Path(f"{logbase}/{config['name']}_{start_i}")
63 |
64 | for i in range(start_i, start_i + n_models):
65 | set_global_seed(i + 42)
66 | logdir = Path(f"{logbase}/{config['name']}_{i}")
67 | print(logdir)
68 |
69 | possible_checkpoint = logdir / 'checkpoints' / 'best.pth'
70 | if os.path.exists(possible_checkpoint):
71 | checkpoint = possible_checkpoint
72 | else:
73 | checkpoint = None
74 |
75 | self.models.append(train(config, loaders, logdir, checkpoint))
76 |
77 | def estimate(self, X_pool):
78 | mcd_realizations = torch.zeros((len(X_pool), self.n_models, 10))
79 |
80 | with torch.no_grad():
81 | for i, model in enumerate(self.models):
82 | model.cuda()
83 | prediction = model(X_pool.cuda())
84 | prediction = prediction.to('cpu')
85 | # mcd_realizations.append(prediction)
86 | mcd_realizations[:, i, :] = torch.softmax(prediction, dim=-1)
87 |
88 | # mcd_realizations = torch.cat(mcd_realizations, dim=0)
89 | probabilities = mcd_realizations.mean(dim=1)
90 | max_class = torch.argmax(probabilities, dim=-1)
91 | max_prob_ens = mcd_realizations[np.arange(len(X_pool)), :, max_class]
92 | max_prob_ue = -max_prob_ens.mean(dim=-1) + 1
93 | bald = bald_score(mcd_realizations.numpy())
94 | var_ratio_ue = var_ratio_score(mcd_realizations, max_class, self.n_models)
95 | return probabilities, max_prob_ue, bald, var_ratio_ue
96 |
97 |
98 | def var_ratio_score(mcd_realizations, max_class, n_models):
99 | reps = max_class.unsqueeze(dim=-1).repeat(1, n_models)
100 | tops = torch.argmax(mcd_realizations, axis=-1)
101 | incorrects = (reps != tops).float()
102 | ue = torch.sum(incorrects, dim=-1) / n_models
103 | return ue
104 |
105 |
106 | if __name__ == '__main__':
107 | config = parse_arguments()
108 | set_global_seed(42)
109 | logbase = 'logs/classification_ensembles'
110 | n_models = config['n_models']
111 |
112 | if config['ood']:
113 | loaders, ood_loader, x_train, y_train, x_val, y_val, x_ood, y_ood = get_data_ood(config)
114 | x_ood_tensor = torch.cat([batch[0] for batch in ood_loader])
115 | for j in range(config['repeats']):
116 | ensemble = Ensemble(logbase, n_models, config, loaders, j * n_models)
117 | bench_uncertainty(ensemble, x_ood_tensor, y_val, config)
118 | else:
119 | loaders, x_train, y_train, x_val, y_val = get_data(config)
120 | x_val_tensor = torch.cat([batch[0] for batch in loaders['valid']])
121 |
122 | for j in range(config['repeats']):
123 | ensemble = Ensemble(logbase, n_models, config, loaders, j * n_models)
124 | bench_uncertainty(ensemble, x_val_tensor, y_val, config)
125 |
126 |
--------------------------------------------------------------------------------
/experiments/classification_imagenet.py:
--------------------------------------------------------------------------------
1 | from time import time
2 | from collections import defaultdict
3 | import os
4 | import pickle
5 | from argparse import ArgumentParser
6 | from copy import deepcopy
7 | from pathlib import Path
8 |
9 | from torch.utils.data import Dataset, DataLoader
10 | from torchvision import transforms
11 | from PIL import Image
12 |
13 | import numpy as np
14 | import torch
15 | from catalyst.utils import set_global_seed
16 |
17 | from alpaca.active_learning.simple_update import entropy
18 | from alpaca.uncertainty_estimator import build_estimator
19 |
20 | from configs import base_config, experiment_config
21 | from models import resnet_dropout
22 |
23 |
24 | def parse_arguments():
25 | parser = ArgumentParser()
26 | parser.add_argument('--acquisition', '-a', type=str, default='bald')
27 | parser.add_argument('--dataset-folder', type=str, default='data/imagenet')
28 | parser.add_argument('--bs', type=int, default=250)
29 | parser.add_argument('--ood', dest='ood', action='store_true')
30 | args = parser.parse_args()
31 | args.name ='imagenet'
32 |
33 | config = deepcopy(base_config)
34 | config.update(experiment_config[args.name])
35 |
36 |
37 | if args.ood:
38 | args.dataset_folder = 'data/chest'
39 |
40 | for param in ['name', 'acquisition', 'bs', 'dataset_folder', 'ood']:
41 | config[param] = getattr(args, param)
42 |
43 |
44 | return config
45 |
46 |
47 | def bench_uncertainty(model, val_loader, y_val, acquisition, config, logdir):
48 | ood_str = '_ood' if config['ood'] else ''
49 | logfile = logdir / f"ue{ood_str}_{config['acquisition']}.pickle"
50 | print(logfile)
51 |
52 | probabilities = get_probabilities(model, val_loader).astype(np.single)
53 |
54 | estimators = ['max_prob', 'mc_dropout', 'ht_dpp', 'cov_k_dpp']
55 | # estimators = ['mc_dropout']
56 |
57 | print(estimators)
58 |
59 | uncertainties = {}
60 | times = defaultdict(list)
61 | for estimator_name in estimators:
62 | print(estimator_name)
63 | t0 = time()
64 | ue = calc_ue(model, val_loader, probabilities, config['dropout_rate'], estimator_name, nn_runs=config['nn_runs'], acquisition=acquisition)
65 | times[estimator_name].append(time() - t0)
66 | print('time', time() - t0)
67 | uncertainties[estimator_name] = ue
68 |
69 | record = {
70 | 'y_val': y_val,
71 | 'uncertainties': uncertainties,
72 | 'probabilities': probabilities,
73 | 'estimators': estimators,
74 | 'times': times
75 | }
76 | with open(logfile, 'wb') as f:
77 | pickle.dump(record, f)
78 |
79 | return probabilities, uncertainties, estimators
80 |
81 |
82 | def calc_ue(model, val_loader, probabilities, dropout_rate, estimator_type='max_prob', nn_runs=150, acquisition='bald'):
83 | if estimator_type == 'max_prob':
84 | ue = 1 - np.max(probabilities, axis=-1)
85 | elif estimator_type == 'max_entropy':
86 | ue = entropy(probabilities)
87 | else:
88 | acquisition_param = 'var_ratio' if acquisition == 'max_prob' else acquisition
89 |
90 | estimator = build_estimator(
91 | 'bald_masked', model, dropout_mask=estimator_type, num_classes=1000,
92 | nn_runs=nn_runs, keep_runs=False, acquisition=acquisition_param,
93 | dropout_rate=dropout_rate
94 | )
95 | ue = estimator.estimate(val_loader)
96 |
97 | return ue
98 |
99 |
100 | def get_probabilities(model, loader):
101 | model.eval().cuda()
102 |
103 | results = []
104 |
105 | with torch.no_grad():
106 | for i, batch in enumerate(loader):
107 | print(i)
108 | probabilities = torch.softmax(model(batch.cuda()), dim=-1)
109 | results.extend(list(probabilities.cpu().numpy()))
110 | return np.array(results)
111 |
112 |
113 |
114 | image_transforms = transforms.Compose([
115 | transforms.Resize(256),
116 | transforms.CenterCrop(224),
117 | transforms.ToTensor(),
118 | transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
119 | ])
120 |
121 |
122 | class ImageDataset(Dataset):
123 | def __init__(self, folder):
124 | self.folder = Path(folder)
125 | files = sorted(os.listdir(folder))
126 | self.files = files[:downsample]
127 |
128 | def __len__(self):
129 | return len(self.files)
130 |
131 | def __getitem__(self, idx):
132 | img_path = self.folder / self.files[idx]
133 | image = Image.open(img_path).convert('RGB')
134 |
135 | image = image_transforms(image).double()
136 |
137 | return image
138 |
139 |
140 | def get_data(config):
141 | label_file = Path(config['dataset_folder'])/'val.txt'
142 |
143 | with open(label_file, 'r') as f:
144 | y_val = np.array([int(line.split()[1]) for line in f.readlines()])[:downsample]
145 |
146 | valid_folder = Path(config['dataset_folder']) / 'valid'
147 |
148 | dataset = ImageDataset(valid_folder)
149 | val_loader = DataLoader(dataset, batch_size=config['bs'])
150 | val_loader.shape = (downsample, 3, 224, 224)
151 |
152 | return val_loader, y_val
153 |
154 |
155 | if __name__ == '__main__':
156 | downsample = 50_000
157 |
158 | config = parse_arguments()
159 | print(config)
160 | set_global_seed(42)
161 | val_loader, y_val = get_data(config)
162 |
163 | for i in range(config['repeats']):
164 | set_global_seed(i + 42)
165 | logdir = Path(f"logs/classification/{config['name']}_{i}")
166 |
167 | model = resnet_dropout(dropout_rate=config['dropout_rate']).double()
168 |
169 | bench_uncertainty(model, val_loader, y_val, config['acquisition'], config, logdir)
170 |
--------------------------------------------------------------------------------
/experiments/classification_ue.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pickle
3 | from argparse import ArgumentParser
4 | from collections import OrderedDict
5 | from copy import deepcopy
6 | from pathlib import Path
7 |
8 | import numpy as np
9 | import torch
10 | from sklearn.model_selection import train_test_split
11 | from sklearn.metrics import roc_curve, roc_auc_score
12 | from scipy.special import softmax
13 | import matplotlib.pyplot as plt
14 | import seaborn as sns
15 | import pandas as pd
16 | from catalyst.dl import SupervisedRunner
17 | from catalyst.dl.callbacks import AccuracyCallback, EarlyStoppingCallback
18 | from catalyst.utils import set_global_seed
19 |
20 | from alpaca.active_learning.simple_update import entropy
21 | from alpaca.uncertainty_estimator import build_estimator
22 | from alpaca.uncertainty_estimator.masks import DEFAULT_MASKS
23 |
24 | from configs import base_config, experiment_config
25 | from visual_datasets import loader
26 |
27 |
28 | def parse_arguments():
29 | parser = ArgumentParser()
30 | parser.add_argument('name')
31 | parser.add_argument('--acquisition', '-a', type=str, default='bald')
32 | args = parser.parse_args()
33 |
34 | config = deepcopy(base_config)
35 | config.update(experiment_config[args.name])
36 | config['name'] = args.name
37 | config['acquisition'] = args.acquisition
38 |
39 | return config
40 |
41 |
42 | def train(config, loaders, logdir, checkpoint=None):
43 | model = config['model_class'](dropout_rate=config['dropout_rate']).double()
44 |
45 | if checkpoint is not None:
46 | model.load_state_dict(torch.load(checkpoint)['model_state_dict'])
47 | model.eval()
48 | else:
49 | criterion = torch.nn.CrossEntropyLoss()
50 | optimizer = torch.optim.Adam(model.parameters())
51 | callbacks = [AccuracyCallback(num_classes=10), EarlyStoppingCallback(config['patience'])]
52 |
53 | runner = SupervisedRunner()
54 | runner.train(
55 | model, criterion, optimizer, loaders,
56 | logdir=logdir, num_epochs=config['epochs'], verbose=True,
57 | callbacks=callbacks
58 | )
59 |
60 | return model
61 |
62 |
63 | def bench_uncertainty(model, model_checkpoint, loaders, x_val, y_val, acquisition, config):
64 | runner = SupervisedRunner()
65 | logits = runner.predict_loader(model, loaders['valid'])
66 | probabilities = softmax(logits, axis=-1)
67 |
68 | if config['acquisition'] in ['bald', 'var_ratio']:
69 | estimators = ['mc_dropout', 'ht_dpp', 'ht_k_dpp', 'cov_dpp', 'cov_k_dpp']
70 | elif config['acquisition'] == 'max_prob':
71 | estimators = ['max_prob', 'mc_dropout', 'ht_dpp', 'ht_k_dpp', 'cov_dpp', 'cov_k_dpp']
72 | else:
73 | raise ValueError
74 |
75 | print(estimators)
76 |
77 | uncertainties = {}
78 | lls = {}
79 | for estimator_name in estimators:
80 | # try:
81 | print(estimator_name)
82 | ue, ll = calc_ue(model, x_val, y_val, probabilities, estimator_name, nn_runs=config['nn_runs'], acquisition=acquisition)
83 | uncertainties[estimator_name] = ue
84 | lls[estimator_name] = ll
85 | # except Exception as e:
86 | # print(e)
87 |
88 | record = {
89 | 'checkpoint': model_checkpoint,
90 | 'y_val': y_val,
91 | 'uncertainties': uncertainties,
92 | 'probabilities': probabilities,
93 | 'logits': logits,
94 | 'estimators': estimators,
95 | 'lls': lls
96 | }
97 | with open(logdir / f"ue_{config['acquisition']}.pickle", 'wb') as f:
98 | pickle.dump(record, f)
99 |
100 | return probabilities, uncertainties, estimators
101 |
102 |
103 | def log_likelihood(probabilities, y):
104 | try:
105 | ll = np.mean(np.log(probabilities[np.arange(len(probabilities)), y]))
106 | except FloatingPointError:
107 | import ipdb; ipdb.set_trace()
108 | return ll
109 |
110 |
111 | def calc_ue(model, datapoints, y_val, probabilities, estimator_type='max_prob', nn_runs=100, acquisition='bald'):
112 | if estimator_type == 'max_prob':
113 | ue = 1 - np.max(probabilities, axis=-1)
114 | ll = log_likelihood(probabilities, y_val)
115 | elif estimator_type == 'max_entropy':
116 | ue = entropy(probabilities)
117 | ll = log_likelihood(probabilities, y_val)
118 | else:
119 | acquisition_param = 'var_ratio' if acquisition == 'max_prob' else acquisition
120 |
121 | estimator = build_estimator(
122 | 'bald_masked', model, dropout_mask=estimator_type, num_classes=10,
123 | nn_runs=nn_runs, keep_runs=True, acquisition=acquisition_param)
124 | ue = estimator.estimate(torch.DoubleTensor(datapoints).cuda())
125 | probs = softmax(estimator.last_mcd_runs(), axis=-1)
126 | probs = np.mean(probs, axis=-2)
127 |
128 | ll = log_likelihood(probs, y_val)
129 |
130 | if acquisition == 'max_prob':
131 | ue = 1 - np.max(probs, axis=-1)
132 |
133 | return ue, ll
134 |
135 |
136 | def misclassfication_detection(y_val, probabilities, uncertainties, estimators):
137 | results = []
138 | predictions = np.argmax(probabilities, axis=-1)
139 | errors = (predictions != y_val)
140 | for estimator_name in estimators:
141 | fpr, tpr, _ = roc_curve(errors, uncertainties[estimator_name])
142 | roc_auc = roc_auc_score(errors, uncertainties[estimator_name])
143 | results.append((estimator_name, roc_auc))
144 |
145 | return results
146 |
147 |
148 | def get_data(config):
149 | x_train, y_train, x_val, y_val, train_tfms = config['prepare_dataset'](config)
150 |
151 | if len(x_train) > config['train_size']:
152 | x_train, _, y_train, _ = train_test_split(
153 | x_train, y_train, train_size=config['train_size'], stratify=y_train
154 | )
155 |
156 | loaders = OrderedDict({
157 | 'train': loader(x_train, y_train, config['batch_size'], tfms=train_tfms, train=True),
158 | 'valid': loader(x_val, y_val, config['batch_size'])
159 | })
160 | return loaders, x_train, y_train, x_val, y_val
161 |
162 |
163 | if __name__ == '__main__':
164 | config = parse_arguments()
165 | set_global_seed(42)
166 | loaders, x_train, y_train, x_val, y_val = get_data(config)
167 | print(y_train[:5])
168 |
169 | rocaucs = []
170 | for i in range(config['repeats']):
171 | set_global_seed(i + 42)
172 | logdir = Path(f"logs/classification/{config['name']}_{i}")
173 | print(logdir)
174 |
175 | possible_checkpoint = logdir / 'checkpoints' / 'best.pth'
176 | if os.path.exists(possible_checkpoint):
177 | checkpoint = possible_checkpoint
178 | else:
179 | checkpoint = None
180 |
181 | model = train(config, loaders, logdir, checkpoint)
182 | x_val_tensor = torch.cat([batch[0] for batch in loaders['valid']])
183 |
184 | bench_uncertainty(
185 | model, checkpoint, loaders, x_val_tensor, y_val, config['acquisition'], config)
186 |
187 |
188 |
--------------------------------------------------------------------------------
/experiments/classification_ue_ood.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pickle
3 | from argparse import ArgumentParser
4 | from collections import OrderedDict
5 | from copy import deepcopy
6 | from pathlib import Path
7 |
8 | import numpy as np
9 | import torch
10 | from sklearn.model_selection import train_test_split
11 | from scipy.special import softmax
12 | from catalyst.dl import SupervisedRunner
13 | from catalyst.utils import set_global_seed
14 |
15 | from alpaca.active_learning.simple_update import entropy
16 | from alpaca.uncertainty_estimator import build_estimator
17 | from alpaca.uncertainty_estimator.masks import DEFAULT_MASKS
18 |
19 | from configs import base_config, experiment_ood_config
20 | from visual_datasets import loader
21 |
22 | from classification_ue import train
23 |
24 |
25 | def parse_arguments():
26 | parser = ArgumentParser()
27 | parser.add_argument('name')
28 | parser.add_argument('--acquisition', '-a', type=str, default='bald')
29 | args = parser.parse_args()
30 |
31 | config = deepcopy(base_config)
32 | config.update(experiment_ood_config[args.name])
33 | config['name'] = args.name
34 | config['acquisition'] = args.acquisition
35 |
36 | return config
37 |
38 |
39 | def bench_uncertainty(model, model_checkpoint, ood_loader, x_ood, acquisition, nn_runs):
40 | runner = SupervisedRunner()
41 | logits = runner.predict_loader(model, ood_loader)
42 | probabilities = softmax(logits, axis=-1)
43 |
44 | if config['acquisition'] in ['bald', 'var_ratio']:
45 | estimators = ['mc_dropout', 'ht_dpp', 'ht_k_dpp', 'cov_dpp', 'cov_k_dpp']
46 | elif config['acquisition'] == 'max_prob':
47 | estimators = ['max_prob', 'mc_dropout', 'ht_dpp', 'ht_k_dpp', 'cov_dpp', 'cov_k_dpp']
48 | else:
49 | raise ValueError
50 |
51 |
52 | uncertainties = {}
53 | for estimator_name in estimators:
54 | print(estimator_name)
55 | ue = calc_ue(model, x_ood, probabilities, estimator_name, nn_runs=nn_runs, acquisition=acquisition)
56 | uncertainties[estimator_name] = ue
57 | print(ue)
58 |
59 | record = {
60 | 'checkpoint': model_checkpoint,
61 | 'uncertainties': uncertainties,
62 | 'probabilities': probabilities,
63 | 'logits': logits,
64 | 'estimators': estimators
65 | }
66 |
67 | file_name = logdir / f"ue_ood_{config['acquisition']}.pickle"
68 | with open(file_name, 'wb') as f:
69 | pickle.dump(record, f)
70 |
71 | return probabilities, uncertainties, estimators
72 |
73 |
74 | def calc_ue(model, datapoints, probabilities, estimator_type='max_prob', nn_runs=100, acquisition='bald'):
75 | if estimator_type == 'max_prob':
76 | ue = 1 - np.max(probabilities, axis=-1)
77 | elif estimator_type == 'max_entropy':
78 | ue = entropy(probabilities)
79 | else:
80 | acquisition_param = 'var_ratio' if acquisition == 'max_prob' else acquisition
81 |
82 | estimator = build_estimator(
83 | 'bald_masked', model, dropout_mask=estimator_type, num_classes=10,
84 | nn_runs=nn_runs, keep_runs=True, acquisition=acquisition_param)
85 | ue = estimator.estimate(torch.DoubleTensor(datapoints).cuda())
86 |
87 | if acquisition == 'max_prob':
88 | probs = softmax(estimator.last_mcd_runs(), axis=-1)
89 | probs = np.mean(probs, axis=-2)
90 | ue = 1 - np.max(probs, axis=-1)
91 |
92 | return ue
93 |
94 |
95 | def get_data(config):
96 | x_train, y_train, x_val, y_val, train_tfms = config['prepare_dataset'](config)
97 |
98 | if len(x_train) > config['train_size']:
99 | x_train, _, y_train, _ = train_test_split(
100 | x_train, y_train, train_size=config['train_size'], stratify=y_train
101 | )
102 |
103 | _, _, x_ood, y_ood, _ = config['prepare_dataset'](config)
104 | ood_loader = loader(x_ood, y_ood, config['batch_size'])
105 |
106 | loaders = OrderedDict({
107 | 'train': loader(x_train, y_train, config['batch_size'], tfms=train_tfms, train=True),
108 | 'valid': loader(x_val, y_val, config['batch_size']),
109 | })
110 | return loaders, ood_loader, x_train, y_train, x_val, y_val, x_ood, y_ood
111 |
112 |
113 | if __name__ == '__main__':
114 | config = parse_arguments()
115 | print(config)
116 | set_global_seed(42)
117 | loaders, ood_loader, x_train, y_train, x_val, y_val, x_ood, y_ood = get_data(config)
118 | print(y_train[:5])
119 |
120 | for i in range(config['repeats']):
121 | set_global_seed(i + 42)
122 | logdir = Path(f"logs/classification/{config['name']}_{i}")
123 | print(logdir)
124 |
125 | possible_checkpoint = logdir / 'checkpoints' / 'best.pth'
126 | if os.path.exists(possible_checkpoint):
127 | checkpoint = possible_checkpoint
128 | else:
129 | checkpoint = None
130 |
131 | model = train(config, loaders, logdir, checkpoint)
132 | print(model)
133 | x_ood_tensor = torch.cat([batch[0] for batch in ood_loader])
134 |
135 | probabilities, uncertainties, estimators = bench_uncertainty(
136 | model, checkpoint, ood_loader, x_ood_tensor, config['acquisition'], config['nn_runs'])
137 |
138 |
--------------------------------------------------------------------------------
/experiments/configs.py:
--------------------------------------------------------------------------------
1 | from copy import deepcopy
2 |
3 | from visual_datasets import prepare_cifar, prepare_mnist, prepare_svhn
4 | from models import SimpleConv, StrongConv
5 |
6 | base_config = {
7 | 'train_size': 50_000,
8 | 'val_size': 10_000,
9 | 'prepare_dataset': prepare_mnist,
10 | 'model_class': SimpleConv,
11 | 'epochs': 50,
12 | 'patience': 3,
13 | 'batch_size': 128,
14 | 'repeats': 3,
15 | 'dropout_rate': 0.5,
16 | 'nn_runs': 100
17 | }
18 |
19 |
20 | experiment_config = {
21 | 'mnist': {
22 | 'train_size': 500,
23 | 'dropout_rate': 0.5,
24 | 'n_models': 20
25 | },
26 | 'cifar': {
27 | 'prepare_dataset': prepare_cifar,
28 | 'model_class': StrongConv,
29 | 'n_models': 20,
30 | },
31 | 'imagenet': {
32 | 'dropout_rate': 0.5,
33 | 'repeats': 1,
34 | }
35 | }
36 |
37 | experiment_ood_config = {
38 | 'mnist': {
39 | 'train_size': 500,
40 | 'ood_dataset': prepare_mnist
41 | },
42 | 'svhn': {
43 | 'prepare_dataset': prepare_svhn,
44 | 'model_class': StrongConv,
45 | 'repeats': 3,
46 | },
47 | 'cifar': {
48 | 'prepare_dataset': prepare_cifar,
49 | 'model_class': StrongConv,
50 | 'repeats': 3
51 | }
52 | }
53 |
54 |
55 | al_config = deepcopy(base_config)
56 | al_config.update({
57 | 'pool_size': 10_000,
58 | 'val_size': 10_000,
59 | 'repeats': 5,
60 | 'methods': ['random', 'mc_dropout', 'decorrelating_sc', 'dpp', 'ht_dpp', 'k_dpp', 'ht_k_dpp'],
61 | 'steps': 50
62 | })
63 |
64 | al_experiments = {
65 | 'mnist': {
66 | 'start_size': 200,
67 | 'step_size': 10,
68 | },
69 | 'cifar': {
70 | 'start_size': 2000,
71 | 'step_size': 30,
72 | 'prepare_dataset': prepare_cifar,
73 | 'model_class': StrongConv,
74 | 'repeats': 3
75 | },
76 | 'svhn': {
77 | 'start_size': 2000,
78 | 'step_size': 30,
79 | 'prepare_dataset': prepare_svhn,
80 | 'model_class': StrongConv,
81 | 'repeats': 3
82 | }
83 | }
84 |
--------------------------------------------------------------------------------
/experiments/data/.gitignore:
--------------------------------------------------------------------------------
1 | *.csv
2 | *.png
3 | *.pkl
4 |
--------------------------------------------------------------------------------
/experiments/data/al/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/experiments/data/al/.gitkeep
--------------------------------------------------------------------------------
/experiments/data/detector/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/experiments/data/detector/.gitkeep
--------------------------------------------------------------------------------
/experiments/data/models/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/experiments/data/models/.gitkeep
--------------------------------------------------------------------------------
/experiments/data/ood/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/experiments/data/ood/.gitkeep
--------------------------------------------------------------------------------
/experiments/data/regression/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/experiments/data/regression/.gitkeep
--------------------------------------------------------------------------------
/experiments/data/xor/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/experiments/data/xor/.gitkeep
--------------------------------------------------------------------------------
/experiments/deprecated/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/experiments/deprecated/__init__.py
--------------------------------------------------------------------------------
/experiments/deprecated/active_learning_debug.py:
--------------------------------------------------------------------------------
1 | import sys
2 | sys.path.append('..')
3 |
4 | import torch
5 | import numpy as np
6 | import matplotlib.pyplot as plt
7 |
8 | from fastai.vision import rand_pad, flip_lr, ImageDataBunch
9 |
10 | from model.cnn import AnotherConv
11 | from dataloader.builder import build_dataset
12 | from deprecated.utils import ImageArrayDS
13 |
14 | # == Place to develop, experiment and debug new methods of active learning == #
15 |
16 | # torch.cuda.set_device(1)
17 |
18 |
19 | total_size = 60_000
20 | val_size = 10_000
21 | start_size = 1_000
22 | step_size = 10
23 | steps = 8
24 | reload = True
25 | nn_runs = 100
26 |
27 | pool_size = 200
28 |
29 |
30 | # Load data
31 | dataset = build_dataset('cifar_10', val_size=val_size)
32 | x_set, y_set = dataset.dataset('train')
33 | x_val, y_val = dataset.dataset('val')
34 |
35 | shape = (-1, 3, 32, 32)
36 | x_set = ((x_set - 128)/128).reshape(shape)
37 | x_val = ((x_val - 128)/128).reshape(shape)
38 |
39 | # x_pool, x_train, y_pool, y_train = train_test_split(x_set, y_set, test_size=start_size, stratify=y_set)
40 | x_train, y_train = x_set, y_set
41 |
42 | train_tfms = [*rand_pad(4, 32), flip_lr(p=0.5)]
43 | train_ds = ImageArrayDS(x_train, y_train, train_tfms)
44 | val_ds = ImageArrayDS(x_val, y_val)
45 | data = ImageDataBunch.create(train_ds, val_ds, bs=256)
46 |
47 |
48 | loss_func = torch.nn.CrossEntropyLoss()
49 |
50 | np.set_printoptions(threshold=sys.maxsize, suppress=True)
51 |
52 | model = AnotherConv()
53 | # model = resnet_masked(pretrained=True)
54 | # model = resnet_linear(pretrained=True, dropout_rate=0.5, freeze=False)
55 |
56 | # learner = Learner(data, model, metrics=accuracy, loss_func=loss_func)
57 | #
58 | # model_path = "experiments/data/model.pt"
59 | # if reload and os.path.exists(model_path):
60 | # model.load_state_dict(torch.load(model_path))
61 | # else:
62 | # learner.fit(10, 1e-3, wd=0.02)
63 | # torch.save(model.state_dict(), model_path)
64 | #
65 | # images = torch.FloatTensor(x_val)# .to('cuda')
66 | #
67 | # inferencer = Inferencer(model)
68 | # predictions = F.softmax(inferencer(images), dim=1).detach().cpu().numpy()[:10]
69 |
70 |
71 | repeats = 3
72 | methods = ['goy', 'mus', 'cosher']
73 | from random import random
74 |
75 | results = []
76 | for _ in range(repeats):
77 | start = 0.1 * random()
78 | for method in methods:
79 | accuracies = [start]
80 | current = start
81 | for i in range(10):
82 | current += 0.1*random()
83 | accuracies.append(current)
84 | records = list(zip(accuracies, range(len(accuracies)), [method] * len(accuracies)))
85 | results.extend(records)
86 |
87 | import pandas as pd
88 | import seaborn as sns
89 | df = pd.DataFrame(results, columns=['accuracy', 'step', 'method'])
90 | sns.lineplot('step', 'accuracy', hue='method', data=df)
91 | plt.show()
92 |
93 |
94 | # idxs = np.argsort(entropies)[::-1][:10]
95 | # print(idxs)
96 |
97 | # mask = build_mask('k_dpp')
98 | # estimator = BaldMasked(inferencer, dropout_mask=mask, num_classes=10, nn_runs=nn_runs)
99 | # estimations = estimator.estimate(images)
100 | # print(estimations)
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
--------------------------------------------------------------------------------
/experiments/deprecated/active_learning_mnist.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import torch
3 |
4 | sys.path.append('..')
5 | from dataloader.builder import build_dataset
6 | from uncertainty_estimator.masks import DEFAULT_MASKS
7 | from active_learning import main
8 |
9 | torch.cuda.set_device(1)
10 | torch.backends.cudnn.benchmark = True
11 |
12 |
13 | def prepare_mnist(config):
14 | dataset = build_dataset('mnist', val_size=config['val_size'])
15 | x_set, y_set = dataset.dataset('train')
16 | x_val, y_val = dataset.dataset('val')
17 |
18 | shape = (-1, 1, 28, 28)
19 | x_set = ((x_set - 128) / 128).reshape(shape)
20 | x_val = ((x_val - 128) / 128).reshape(shape)
21 |
22 | train_tfms = []
23 |
24 | return x_set, y_set, x_val, y_val, train_tfms
25 |
26 |
27 | mnist_config = {
28 | 'repeats': 5,
29 | 'start_size': 100,
30 | 'step_size': 20,
31 | 'val_size': 10_000,
32 | 'pool_size': 10_000,
33 | 'steps': 30,
34 | 'methods': ['random', 'error_oracle', 'max_entropy', *DEFAULT_MASKS],
35 | 'epochs': 30,
36 | 'patience': 2,
37 | 'model_type': 'simple_conv',
38 | 'nn_runs': 100,
39 | 'batch_size': 32,
40 | 'start_lr': 5e-4,
41 | 'weight_decay': 0.2,
42 | 'prepare_dataset': prepare_mnist,
43 | 'name': 'mnist_beauty_2'
44 | }
45 |
46 |
47 | if __name__ == '__main__':
48 | main(mnist_config)
49 |
--------------------------------------------------------------------------------
/experiments/deprecated/active_learning_svhn.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import torch
3 | import numpy as np
4 | from fastai.vision import (rand_pad, flip_lr)
5 |
6 | sys.path.append('..')
7 | from dataloader.builder import build_dataset
8 | from uncertainty_estimator.masks import DEFAULT_MASKS
9 | from active_learning import main
10 |
11 | torch.cuda.set_device(1)
12 | torch.backends.cudnn.benchmark = True
13 |
14 |
15 | def prepare_svhn(config):
16 | dataset = build_dataset('svhn', val_size=config['val_size'])
17 | x_set, y_set = dataset.dataset('train')
18 | x_val, y_val = dataset.dataset('val')
19 | y_set[y_set == 10] = 0
20 | y_val[y_val == 10] = 0
21 |
22 | shape = (-1, 32, 32, 3)
23 | x_set = ((x_set - 128) / 128).reshape(shape)
24 | x_val = ((x_val - 128) / 128).reshape(shape)
25 | x_set = np.rollaxis(x_set, 3, 1)
26 | x_val = np.rollaxis(x_val, 3, 1)
27 |
28 | train_tfms = [*rand_pad(4, 32), flip_lr(p=0.5)] # Transformation to augment images
29 |
30 | return x_set, y_set, x_val, y_val, train_tfms
31 |
32 |
33 | svhn_config = {
34 | 'repeats': 3,
35 | 'start_size': 5_000,
36 | 'step_size': 50,
37 | 'val_size': 10_000,
38 | 'pool_size': 12_000,
39 | 'steps': 30,
40 | 'methods': ['random', 'error_oracle', 'max_entropy', *DEFAULT_MASKS],
41 | 'epochs': 30,
42 | 'patience': 2,
43 | 'model_type': 'resnet',
44 | 'nn_runs': 100,
45 | 'batch_size': 256,
46 | 'start_lr': 5e-4,
47 | 'weight_decay': 0.2,
48 | 'prepare_dataset': prepare_svhn,
49 | 'name': 'svhn'
50 | }
51 |
52 | experiment = 4
53 |
54 | if experiment == 2:
55 | svhn_config['pool_size'] = 5000
56 | svhn_config['start_size'] = 2000
57 | svhn_config['step_size'] = 20
58 | svhn_config['model'] = 'conv'
59 | elif experiment == 3:
60 | svhn_config['pool_size'] = 20_000
61 | svhn_config['start_size'] = 10_000
62 | svhn_config['step_size'] = 100
63 | svhn_config['model'] = 'resent'
64 | elif experiment == 4:
65 | svhn_config['pool_size'] = 5_000
66 | svhn_config['start_size'] = 1_000
67 | svhn_config['step_size'] = 30
68 | svhn_config['model'] = 'resent'
69 | svhn_config['repeats'] = 10
70 |
71 |
72 | if __name__ == '__main__':
73 | main(svhn_config)
74 |
--------------------------------------------------------------------------------
/experiments/deprecated/al_rosenbrock_experiment.py:
--------------------------------------------------------------------------------
1 | import random
2 | import argparse
3 |
4 | import numpy as np
5 | import matplotlib.pyplot as plt
6 | import torch
7 |
8 | from model.mlp import MLP
9 | from dataloader.rosen import RosenData
10 | from uncertainty_estimator.nngp import NNGPRegression
11 | from uncertainty_estimator.mcdue import MCDUE
12 | from uncertainty_estimator.random_estimator import RandomEstimator
13 | from sample_selector.eager import EagerSampleSelector
14 | from oracle.identity import IdentityOracle
15 | from active_learning.al_trainer import ALTrainer
16 |
17 |
18 | def run_experiment(config):
19 | """
20 | Run active learning for the 10D rosenbrock function data
21 | It starts from small train dataset and then extends it with points from pool
22 |
23 | We compare three sampling methods:
24 | - Random datapoints
25 | - Points with highest uncertainty by MCDUE
26 | - Points with highest uncertainty by NNGP (proposed method)
27 | """
28 | rmses = {}
29 |
30 | for estimator_name in config['estimators']:
31 | print("\nEstimator:", estimator_name)
32 |
33 | # load data
34 |
35 | rosen = RosenData(
36 | config['n_dim'], config['data_size'], config['data_split'],
37 | use_cache=config['use_cache'])
38 | x_train, y_train = rosen.dataset('train')
39 | x_val, y_val = rosen.dataset('train')
40 | x_pool, y_pool = rosen.dataset('pool')
41 |
42 | # Build neural net and set random seed
43 | set_random(config['random_seed'])
44 | model = MLP(config['layers'])
45 |
46 | estimator = build_estimator(estimator_name, model) # to estimate uncertainties
47 | oracle = IdentityOracle(y_pool) # generate y for X from pool
48 | sampler = EagerSampleSelector() # sample X and y from pool by uncertainty estimations
49 |
50 | # Active learning training
51 | trainer = ALTrainer(
52 | model, estimator, sampler, oracle, config['al_iterations'],
53 | config['update_size'], verbose=config['verbose'])
54 | rmses[estimator_name] = trainer.train(x_train, y_train, x_val, y_val, x_pool)
55 |
56 | visualize(rmses)
57 |
58 |
59 | def set_random(random_seed):
60 | # Setting seeds for reproducibility
61 | if random_seed is not None:
62 | torch.manual_seed(random_seed)
63 | np.random.seed(random_seed)
64 | random.seed(random_seed)
65 |
66 |
67 | def build_estimator(name, model):
68 | if name == 'nngp':
69 | estimator = NNGPRegression(model)
70 | elif name == 'random':
71 | estimator = RandomEstimator()
72 | elif name == 'mcdue':
73 | estimator = MCDUE(model)
74 | else:
75 | raise ValueError("Wrong estimator name")
76 | return estimator
77 |
78 |
79 | def visualize(rmses):
80 | print(rmses)
81 | plt.figure(figsize=(12, 9))
82 | plt.xlabel('Active learning iteration')
83 | plt.ylabel('Validation RMSE')
84 | for estimator_name, rmse in rmses.items():
85 | plt.plot(rmse, label=estimator_name, marker='.')
86 |
87 | plt.title('RMS Error by active learning iterations')
88 | plt.legend()
89 |
90 | plt.show()
91 |
92 |
93 | def parse_arguments():
94 | parser = argparse.ArgumentParser(description='Change experiment parameters')
95 | parser.add_argument(
96 | '--estimators', choices=['nngp', 'mcdue', 'random'], default=['nngp', 'mcdue', 'random'],
97 | nargs='+', help='Estimator types for the experiment')
98 | parser.add_argument(
99 | '--random-seed', type=int, default=None,
100 | help='Set the seed to make result reproducible')
101 | parser.add_argument(
102 | '--n-dim', type=int, default=10, help='Rosenbrock function dimentions')
103 | parser.add_argument(
104 | '--data-size', type=int, default=2000, help='Size of dataset')
105 | parser.add_argument(
106 | '--data-split', type=int, default=[0.1, 0.1, 0.1, 0.7], help='Size of dataset')
107 | parser.add_argument(
108 | '--update-size', type=int, default=100,
109 | help='Amount of samples to take from pool per iteration')
110 | parser.add_argument(
111 | '--al-iterations', '-i', type=int, default=10, help='Number of learning iterations')
112 | parser.add_argument('--verbose', action='store_true')
113 | parser.add_argument(
114 | '--no-use-cache', dest='use_cache', action='store_false',
115 | help='To generate new sample points for rosenbrock function')
116 | parser.add_argument(
117 | '--layers', type=int, nargs='+', default=[10, 128, 64, 32, 1],
118 | help='Size of the layers in neural net')
119 |
120 | return vars(parser.parse_args())
121 |
122 |
123 | if __name__ == '__main__':
124 | config = parse_arguments()
125 | run_experiment(config)
126 |
127 |
128 | config = {
129 | 'estimators': ['nngp', 'mcdue', 'random'],
130 | 'random_seed': None,
131 | 'n_dim': 9,
132 | 'data_size': 2400,
133 | 'data_split': [0.2, 0.1, 0.1, 0.6],
134 | 'update_size': 99,
135 | 'al_iterations': 9,
136 | 'verbose': False,
137 | 'use_cache': True,
138 | 'layers': [9, 128, 64, 32, 1]
139 | }
140 |
--------------------------------------------------------------------------------
/experiments/deprecated/classification_active_learning.py:
--------------------------------------------------------------------------------
1 | from argparse import ArgumentParser
2 | from collections import OrderedDict
3 | from copy import deepcopy
4 | from pathlib import Path
5 |
6 | import numpy as np
7 | import torch
8 | from torch.utils.data import DataLoader
9 | from sklearn.model_selection import train_test_split
10 | import matplotlib.pyplot as plt
11 | import seaborn as sns
12 | import pandas as pd
13 | from catalyst.dl import SupervisedRunner
14 | from catalyst.dl.callbacks import AccuracyCallback, EarlyStoppingCallback
15 | from catalyst.utils import set_global_seed
16 |
17 | from alpaca.active_learning.simple_update import update_set
18 |
19 | from configs import al_config, al_experiments
20 | from visual_datasets import ImageDataset
21 |
22 |
23 | def parse_arguments():
24 | parser = ArgumentParser()
25 | parser.add_argument('name')
26 | name = parser.parse_args().name
27 | config = deepcopy(al_config)
28 | config.update(al_experiments[name])
29 | config['name'] = name
30 |
31 | return config
32 |
33 |
34 | def active_train(config, i):
35 | set_global_seed(i + 42)
36 | # Load data
37 | x_set, y_set, x_val, y_val, train_tfms = config['prepare_dataset'](config)
38 | print(x_set.shape)
39 |
40 | # Initial data split
41 | x_set, x_train_init, y_set, y_train_init = train_test_split(x_set, y_set, test_size=config['start_size'], stratify=y_set)
42 | _, x_pool_init, _, y_pool_init = train_test_split(x_set, y_set, test_size=config['pool_size'], stratify=y_set)
43 |
44 | model_init = config['model_class']().double()
45 | val_accuracy = []
46 | # Active learning
47 | for method in config['methods']:
48 | model = deepcopy(model_init)
49 | print(f"== {method} ==")
50 | logdir = f"logs/al/{config['name']}_{method}_{i}"
51 | x_pool, y_pool = np.copy(x_pool_init), np.copy(y_pool_init)
52 | x_train, y_train = np.copy(x_train_init), np.copy(y_train_init)
53 |
54 | criterion = torch.nn.CrossEntropyLoss()
55 | optimizer = torch.optim.Adam(model.parameters())
56 |
57 | accuracies = []
58 |
59 | for j in range(config['steps']):
60 | print(f"Step {j+1}, train size: {len(x_train)}")
61 |
62 | loaders = get_loaders(x_train, y_train, x_val, y_val, config['batch_size'], train_tfms)
63 |
64 | runner = SupervisedRunner()
65 | callbacks = [AccuracyCallback(num_classes=10), EarlyStoppingCallback(config['patience'])]
66 | runner.train(
67 | model, criterion, optimizer, loaders,
68 | logdir=logdir, num_epochs=config['epochs'], verbose=False,
69 | callbacks=callbacks
70 | )
71 |
72 | accuracies.append(runner.state.best_valid_metrics['accuracy01'])
73 |
74 | if i != config['steps'] - 1:
75 | samples = next(iter(loader(x_pool, y_pool, batch_size=len(x_pool))))[0].cuda()
76 | print('Samples!', samples.shape)
77 | x_pool, x_train, y_pool, y_train = update_set(
78 | x_pool, x_train, y_pool, y_train, config['step_size'],
79 | method=method, model=model, samples=samples)
80 | print('Metric', accuracies)
81 |
82 | records = list(zip(accuracies, range(len(accuracies)), [method] * len(accuracies)))
83 | val_accuracy.extend(records)
84 |
85 | return val_accuracy
86 |
87 |
88 | def get_loaders(x_train, y_train, x_val, y_val, batch_size, tfms):
89 | loaders = OrderedDict({
90 | 'train': loader(x_train, y_train, batch_size, tfms=tfms, train=True),
91 | 'valid': loader(x_val, y_val, batch_size)
92 | })
93 | return loaders
94 |
95 |
96 | # Set initial datas
97 | def loader(x, y, batch_size=128, tfms=None, train=False):
98 | # ds = TensorDataset(torch.DoubleTensor(x), torch.LongTensor(y))
99 | ds = ImageDataset(x, y, train=train, tfms=tfms)
100 | _loader = DataLoader(ds, batch_size=batch_size, num_workers=4, shuffle=train)
101 | return _loader
102 |
103 |
104 | def plot_metric(metrics, config, title=None):
105 | df = pd.DataFrame(metrics, columns=['Accuracy', 'Step', 'Method'])
106 |
107 | filename = f"ht_{config['name']}_{config['start_size']}_{config['step_size']}"
108 | dir = Path(__file__).parent.absolute() / 'data' / 'al'
109 | df.to_csv(dir / (filename + '.csv'))
110 |
111 | try:
112 | sns.lineplot('Step', 'Accuracy', hue='Method', data=df)
113 | plt.legend(loc='upper left')
114 | plt.figure(figsize=(8, 6))
115 | default_title = f"Validation accuracy, start size {config['start_size']}, "
116 | default_title += f"step size {config['step_size']}"
117 | title = title or default_title
118 | plt.title(title)
119 | file = dir / filename
120 | plt.savefig(file)
121 | except Exception as e:
122 | print(e)
123 |
124 |
125 | if __name__ == '__main__':
126 | config = parse_arguments()
127 | results = []
128 | for i in range(config['repeats']):
129 | print(f"======{i}======")
130 | accuracies = active_train(config, i)
131 | results.extend(accuracies)
132 |
133 | print(results)
134 |
135 | plot_metric(results, config)
136 |
137 |
--------------------------------------------------------------------------------
/experiments/deprecated/classification_active_learning_fasetai.py:
--------------------------------------------------------------------------------
1 | import random
2 |
3 | import numpy as np
4 | import matplotlib.pyplot as plt
5 | from sklearn.model_selection import train_test_split
6 | import seaborn as sns
7 | import pandas as pd
8 |
9 | import torch
10 | from torch import nn
11 |
12 | from fastai.vision import (ImageDataBunch, Learner, accuracy)
13 | from fastai.callbacks import EarlyStoppingCallback
14 |
15 | from alpaca.model.cnn import AnotherConv, SimpleConv
16 | from alpaca.model.resnet import resnet_masked
17 | from alpaca.active_learning.simple_update import update_set
18 | from deprecated.utils import ImageArrayDS
19 | from visual_datasets import prepare_mnist, prepare_cifar, prepare_svhn
20 |
21 |
22 | """
23 | Active learning experiment for computer vision tasks (MNIST, CIFAR, SVHN)
24 | """
25 |
26 |
27 | SEED = 43
28 | torch.manual_seed(SEED)
29 | np.random.seed(SEED)
30 | random.seed(SEED)
31 |
32 | if torch.cuda.is_available():
33 | torch.cuda.set_device(0)
34 | torch.backends.cudnn.deterministic = True
35 | torch.backends.cudnn.benchmark = False
36 | device = 'cuda'
37 | else:
38 | device = 'cpu'
39 |
40 | experiment_label = 'ht'
41 |
42 |
43 | def main(config):
44 | # Load data
45 | x_set, y_set, x_val, y_val, train_tfms = config['prepare_dataset'](config)
46 |
47 | val_accuracy = []
48 | for _ in range(config['repeats']): # more repЕсли кнопочный, то есть вот прямо бабушкофон. Ещё его можно забрать из пассажа на фрунзе.eats for robust results
49 | # Initial data split
50 | x_set, x_train_init, y_set, y_train_init = train_test_split(x_set, y_set, test_size=config['start_size'], stratify=y_set)
51 | _, x_pool_init, _, y_pool_init = train_test_split(x_set, y_set, test_size=config['pool_size'], stratify=y_set)
52 |
53 | # Active learning
54 | for method in config['methods']:
55 | print(f"== {method} ==")
56 | x_pool, y_pool = np.copy(x_pool_init), np.copy(y_pool_init)
57 | x_train, y_train = np.copy(x_train_init), np.copy(y_train_init)
58 |
59 | model = build_model(config['model_type'])
60 | accuracies = []
61 |
62 | for i in range(config['steps']):
63 | print(f"Step {i+1}, train size: {len(x_train)}")
64 |
65 | learner = train_classifier(model, config, x_train, y_train, x_val, y_val, train_tfms)
66 | accuracies.append(learner.recorder.metrics[-1][0].item())
67 |
68 | if i != config['steps'] - 1:
69 | x_pool, x_train, y_pool, y_train = update_set(
70 | x_pool, x_train, y_pool, y_train, config['step_size'], method=method, model=model)
71 |
72 | records = list(zip(accuracies, range(len(accuracies)), [method] * len(accuracies)))
73 | val_accuracy.extend(records)
74 |
75 | # Display results
76 | try:
77 | plot_metric(val_accuracy, config)
78 | except:
79 | import ipdb; ipdb.set_trace()
80 |
81 |
82 | def train_classifier(model, config, x_train, y_train, x_val, y_val, train_tfms=None):
83 | loss_func = torch.nn.CrossEntropyLoss()
84 |
85 | if train_tfms is None:
86 | train_tfms = []
87 | train_ds = ImageArrayDS(x_train, y_train, train_tfms)
88 | val_ds = ImageArrayDS(x_val, y_val)
89 | data = ImageDataBunch.create(train_ds, val_ds, bs=config['batch_size'])
90 |
91 | callbacks = [partial(EarlyStoppingCallback, min_delta=1e-3, patience=config['patience'])]
92 | learner = Learner(data, model, metrics=accuracy, loss_func=loss_func, callback_fns=callbacks)
93 | learner.fit(config['epochs'], config['start_lr'], wd=config['weight_decay'])
94 |
95 | return learner
96 |
97 |
98 | def plot_metric(metrics, config, title=None):
99 | plt.figure(figsize=(8, 6))
100 | default_title = f"Validation accuracy, start size {config['start_size']}, "
101 | default_title += f"step size {config['step_size']}, model {config['model_type']}"
102 | title = title or default_title
103 | plt.title(title)
104 |
105 | df = pd.DataFrame(metrics, columns=['Accuracy', 'Step', 'Method'])
106 | sns.lineplot('Step', 'Accuracy', hue='Method', data=df)
107 | # plt.legend(loc='upper left')
108 |
109 | filename = f"{experiment_label}_{config['name']}_{config['model_type']}_{config['start_size']}_{config['step_size']}"
110 | dir = Path(__file__).parent.absolute() / 'data' / 'al'
111 | file = dir / filename
112 | plt.savefig(file)
113 | df.to_csv(dir / (filename + '.csv'))
114 | # plt.show()
115 |
116 |
117 | class Model21(nn.Module):
118 | def __init__(self):
119 | super().__init__()
120 | base = 16
121 | self.conv = nn.Sequential(
122 | nn.Conv2d(3, base, 3, padding=1, bias=False),
123 | nn.BatchNorm2d(base),
124 | nn.CELU(),
125 | nn.Conv2d(base, base, 3, padding=1, bias=False),
126 | nn.CELU(),
127 | nn.MaxPool2d(2, 2),
128 | nn.Dropout2d(0.2),
129 | nn.Conv2d(base, 2*base, 3, padding=1, bias=False),
130 | nn.BatchNorm2d(2*base),
131 | nn.CELU(),
132 | nn.Conv2d(2 * base, 2 * base, 3, padding=1, bias=False),
133 | nn.CELU(),
134 | nn.Dropout2d(0.3),
135 | nn.MaxPool2d(2, 2),
136 | nn.Conv2d(2*base, 4*base, 3, padding=1, bias=False),
137 | nn.BatchNorm2d(4*base),
138 | nn.CELU(),
139 | nn.Conv2d(4*base, 4*base, 3, padding=1, bias=False),
140 | nn.CELU(),
141 | nn.Dropout2d(0.4),
142 | nn.MaxPool2d(2, 2),
143 | )
144 | self.linear_size = 8 * 8 * base
145 | self.linear = nn.Sequential(
146 | nn.Linear(self.linear_size, 8*base),
147 | nn.CELU(),
148 | )
149 | self.dropout = nn.Dropout(0.3)
150 | self.fc = nn.Linear(8*base, 10)
151 |
152 | def forward(self, x, dropout_rate=0.5, dropout_mask=None):
153 | x = self.conv(x)
154 | x = x.reshape(-1, self.linear_size)
155 | x = self.linear(x)
156 | if dropout_mask is None:
157 | x = self.dropout(x)
158 | else:
159 | x = x * dropout_mask(x, 0.3, 0)
160 | return self.fc(x)
161 |
162 |
163 | def build_model(model_type):
164 | if model_type == 'conv':
165 | model = AnotherConv()
166 | elif model_type == 'resnet':
167 | model = resnet_masked(pretrained=True)
168 | elif model_type == 'simple_conv':
169 | model = SimpleConv()
170 | elif model_type == 'strong_conv':
171 | print('piu!')
172 | model = Model21()
173 | return model
174 |
175 |
176 | config_cifar = {
177 | 'val_size': 10_000,
178 | 'pool_size': 15_000,
179 | 'start_size': 7_000,
180 | 'step_size': 50,
181 | 'steps': 50,
182 | # 'methods': ['random', 'error_oracle', 'max_entropy', *DEFAULT_MASKS, 'ht_dpp'],
183 | 'methods': ['random', 'error_oracle', 'max_entropy', 'mc_dropout', 'ht_dpp'],
184 | 'epochs': 30,
185 | 'patience': 2,
186 | 'model_type': 'strong_conv',
187 | 'repeats': 3,
188 | 'nn_runs': 100,
189 | 'batch_size': 128,
190 | 'start_lr': 5e-4,
191 | 'weight_decay': 0.0002,
192 | 'prepare_dataset': prepare_cifar,
193 | 'name': 'cifar'
194 | }
195 |
196 | config_svhn = deepcopy(config_cifar)
197 | config_svhn.update({
198 | 'prepare_dataset': prepare_svhn,
199 | 'name': 'svhn',
200 | 'model_type': 'strong_conv',
201 | 'repeats': 3,
202 | 'epochs': 30,
203 | 'methods': ['random', 'error_oracle', 'max_entropy', 'mc_dropout', 'ht_dpp']
204 | })
205 |
206 | config_mnist = deepcopy(config_cifar)
207 | config_mnist.update({
208 | 'start_size': 100,
209 | 'step_size': 20,
210 | 'model_type': 'simple_conv',
211 | 'methods': ['ht_dpp'],
212 | 'prepare_dataset': prepare_mnist,
213 | 'batch_size': 32,
214 | 'name': 'mnist',
215 | 'steps': 50
216 | })
217 |
218 | # configs = [config_mnist, config_cifar, config_svhn]
219 |
220 | configs = [config_mnist]
221 |
222 | if __name__ == '__main__':
223 | for config in configs:
224 | print(config)
225 | main(config)
--------------------------------------------------------------------------------
/experiments/deprecated/classification_error_detection.py:
--------------------------------------------------------------------------------
1 | from argparse import ArgumentParser
2 | from collections import OrderedDict, defaultdict
3 | from copy import deepcopy
4 | from pathlib import Path
5 |
6 | import numpy as np
7 | import torch
8 | from torch.utils.data import TensorDataset, DataLoader
9 | from sklearn.model_selection import train_test_split
10 | from sklearn.preprocessing import StandardScaler
11 | from sklearn.metrics import roc_curve, roc_auc_score
12 | from scipy.special import softmax
13 | import matplotlib.pyplot as plt
14 | import seaborn as sns
15 | import pandas as pd
16 | from catalyst.dl import SupervisedRunner
17 | from catalyst.dl.callbacks import AccuracyCallback, EarlyStoppingCallback
18 | from catalyst.utils import set_global_seed
19 |
20 | from alpaca.active_learning.simple_update import entropy
21 | from alpaca.uncertainty_estimator import build_estimator
22 |
23 | from configs import base_config, experiment_config
24 |
25 |
26 | def parse_arguments():
27 | parser = ArgumentParser()
28 | parser.add_argument('name')
29 | name = parser.parse_args().name
30 |
31 | config = deepcopy(base_config)
32 | config.update(experiment_config[name])
33 | config['name'] = name
34 |
35 | return config
36 |
37 |
38 | def train(config, loaders, logdir, checkpoint=None):
39 | model = config['model_class']().double()
40 |
41 | if checkpoint is not None:
42 | model.load_state_dict(torch.load(checkpoint)['model_state_dict'])
43 | model.eval()
44 | else:
45 | criterion = torch.nn.CrossEntropyLoss()
46 | optimizer = torch.optim.Adam(model.parameters())
47 | callbacks = [AccuracyCallback(num_classes=10), EarlyStoppingCallback(config['patience'])]
48 |
49 | runner = SupervisedRunner()
50 | runner.train(
51 | model, criterion, optimizer, loaders,
52 | logdir=logdir, num_epochs=config['epochs'], verbose=False,
53 | callbacks=callbacks
54 | )
55 |
56 | return model
57 |
58 |
59 | def bench_error_detection(model, estimators, loaders, x_val, y_val):
60 | runner = SupervisedRunner()
61 | logits = runner.predict_loader(model, loaders['valid'])
62 | probabilities = softmax(logits, axis=-1)
63 |
64 | estimators = [
65 | # 'max_entropy', 'max_prob',
66 | 'mc_dropout', 'decorrelating_sc',
67 | 'dpp', 'ht_dpp', 'k_dpp', 'ht_k_dpp']
68 |
69 | uncertainties = {}
70 | for estimator_name in estimators:
71 | print(estimator_name)
72 | ue = calc_ue(model, x_val, probabilities, estimator_name, nn_runs=150)
73 | uncertainties[estimator_name] = ue
74 |
75 | predictions = np.argmax(probabilities, axis=-1)
76 | errors = (predictions != y_val).astype(np.int)
77 |
78 | results = []
79 | for estimator_name in estimators:
80 | fpr, tpr, _ = roc_curve(errors, uncertainties[estimator_name])
81 | roc_auc = roc_auc_score(errors, uncertainties[estimator_name])
82 | results.append((estimator_name, roc_auc))
83 |
84 | return results
85 |
86 |
87 | def get_data(config):
88 | x_train, y_train, x_val, y_val, train_tfms = config['prepare_dataset'](config)
89 |
90 | if len(x_train) > config['train_size']:
91 | x_train, _, y_train, _ = train_test_split(
92 | x_train, y_train, train_size=config['train_size'], stratify=y_train
93 | )
94 |
95 | loaders = OrderedDict({
96 | 'train': loader(x_train, y_train, config['batch_size'], shuffle=True),
97 | 'valid': loader(x_val, y_val, config['batch_size'])
98 | })
99 | return loaders, x_train, y_train, x_val, y_val
100 |
101 |
102 | def calc_ue(model, datapoints, probabilities, estimator_type='max_prob', nn_runs=150):
103 | if estimator_type == 'max_prob':
104 | ue = 1 - probabilities[np.arange(len(probabilities)), np.argmax(probabilities, axis=-1)]
105 | elif estimator_type == 'max_entropy':
106 | ue = entropy(probabilities)
107 | else:
108 | estimator = build_estimator(
109 | 'bald_masked', model, dropout_mask=estimator_type, num_classes=10,
110 | nn_runs=nn_runs, keep_runs=True, acquisition='var_ratio')
111 | ue = estimator.estimate(torch.DoubleTensor(datapoints).cuda())
112 | return ue
113 |
114 |
115 | # Set initial datas
116 | def loader(x, y, batch_size=128, shuffle=False):
117 | ds = TensorDataset(torch.DoubleTensor(x), torch.LongTensor(y))
118 | _loader = DataLoader(ds, batch_size=batch_size, num_workers=4, shuffle=shuffle)
119 | return _loader
120 |
121 |
122 | if __name__ == '__main__':
123 | config = parse_arguments()
124 | print(config)
125 | loaders, x_train, y_train, x_val, y_val = get_data(config)
126 |
127 | rocaucs = []
128 | for i in range(config['repeats']):
129 | set_global_seed(i + 42)
130 | logdir = f"logs/ht/{config['name']}_{i}"
131 | model = train(config, loaders, logdir)
132 | rocaucs.extend(bench_error_detection(model, config, loaders, x_val, y_val))
133 |
134 | df = pd.DataFrame(rocaucs, columns=['Estimator', 'ROC-AUCs'])
135 | plt.figure(figsize=(9, 6))
136 | plt.title(f"Error detection for {config['name']}")
137 | sns.boxplot('Estimator', 'ROC-AUCs', data=df)
138 | plt.savefig(f"data/ed/{config['name']}.png", dpi=150)
139 | plt.show()
140 |
141 | df.to_csv(f"logs/{config['name']}_ed.csv")
142 |
--------------------------------------------------------------------------------
/experiments/deprecated/classification_error_detection_fastai.py:
--------------------------------------------------------------------------------
1 | from copy import deepcopy
2 | import sys
3 | from functools import partial
4 | import random
5 |
6 | import numpy as np
7 | import matplotlib.pyplot as plt
8 | from sklearn.model_selection import train_test_split
9 |
10 | import torch
11 | import torch.nn.functional as F
12 | from fastai.vision import (ImageDataBunch, Learner, accuracy)
13 | from fastai.callbacks import EarlyStoppingCallback
14 |
15 | from alpaca.uncertainty_estimator import build_estimator
16 | from alpaca.active_learning.simple_update import entropy
17 |
18 | from deprecated.utils import ImageArrayDS
19 | from deprecated.classification_active_learning import build_model
20 | from visual_datasets import prepare_cifar, prepare_mnist, prepare_svhn
21 |
22 |
23 | """
24 | Experiment to detect errors by uncertainty estimation quantification
25 | It provided on MNIST, CIFAR and SVHN datasets (see config below)
26 | We report results as a boxplot ROC-AUC figure on multiple runs
27 | """
28 |
29 | label = 'ue_accuracy'
30 |
31 | SEED = 42
32 | torch.manual_seed(SEED)
33 | np.random.seed(SEED)
34 | random.seed(SEED)
35 |
36 | if torch.cuda.is_available():
37 | torch.cuda.set_device(1)
38 | torch.backends.cudnn.deterministic = True
39 | torch.backends.cudnn.benchmark = False
40 | device = 'cuda'
41 | else:
42 | device = 'cpu'
43 |
44 |
45 | def accuracy_curve(mistake, ue):
46 | accuracy_ = lambda x: 1 - sum(x) / len(x)
47 | thresholds = np.arange(0.1, 1.1, 0.1)
48 | accuracy_by_ue = [accuracy_(mistake[ue < t]) for t in thresholds]
49 | return thresholds, accuracy_by_ue
50 |
51 |
52 | def benchmark_uncertainty(config):
53 | results = []
54 | plt.figure(figsize=(10, 8))
55 | for i in range(config['repeats']):
56 | # Load data
57 | x_set, y_set, x_val, y_val, train_tfms = config['prepare_dataset'](config)
58 |
59 | if len(x_set) > config['train_size']:
60 | _, x_train, _, y_train = train_test_split(
61 | x_set, y_set, test_size=config['train_size'], stratify=y_set)
62 | else:
63 | x_train, y_train = x_set, y_set
64 |
65 | train_ds = ImageArrayDS(x_train, y_train, train_tfms)
66 | val_ds = ImageArrayDS(x_val, y_val)
67 | data = ImageDataBunch.create(train_ds, val_ds, bs=config['batch_size'])
68 |
69 | # Train model
70 | loss_func = torch.nn.CrossEntropyLoss()
71 | np.set_printoptions(threshold=sys.maxsize, suppress=True)
72 |
73 | model = build_model(config['model_type'])
74 | callbacks = [partial(EarlyStoppingCallback, min_delta=1e-3, patience=config['patience'])]
75 | learner = Learner(data, model, metrics=accuracy, loss_func=loss_func, callback_fns=callbacks)
76 | learner.fit(config['epochs'], config['start_lr'], wd=config['weight_decay'])
77 |
78 | # Evaluate different estimators
79 | images = torch.FloatTensor(x_val).to(device)
80 | logits = model(images)
81 | probabilities = F.softmax(logits, dim=1).detach().cpu().numpy()
82 | predictions = np.argmax(probabilities, axis=-1)
83 | print('Logits average', np.average(logits))
84 |
85 | for estimator_name in config['estimators']:
86 | print(estimator_name)
87 | ue = calc_ue(model, images, probabilities, estimator_name, config['nn_runs'])
88 | mistake = 1 - (predictions == y_val).astype(np.int)
89 |
90 | # roc_auc = roc_auc_score(mistake, ue)
91 | # print(estimator_name, roc_auc)
92 | # results.append((estimator_name, roc_auc))
93 |
94 | # ue_thresholds, ue_accuracy = accuracy_curve(mistake, ue)
95 | # results.extend([(t, accu, estimator_name) for t, accu in zip(ue_thresholds, ue_accuracy)])
96 | # plt.plot(ue_thresholds, ue_accuracy, label=estimator_name, alpha=0.8)
97 |
98 | # if i == config['repeats'] - 1:
99 | # fpr, tpr, thresholds = roc_curve(mistake, ue, pos_label=1)
100 | # plt.plot(fpr, tpr, label=name, alpha=0.8)
101 | # plt.xlabel('FPR')
102 | # plt.ylabel('TPR')
103 |
104 | # if i == config['repeats'] - 1:
105 | # ue_thresholds, ue_accuracy = accuracy_curve(mistake, ue)
106 | # plt.plot(ue_thresholds, ue_accuracy, label=name, alpha=0.8)
107 | # Plot the results and generate figures
108 | # plt.figure(dpi=150)
109 | # dir = Path(__file__).parent.absolute() / 'data' / 'detector'
110 | # # plt.legend()
111 | # df = pd.DataFrame(results, columns=['ue', 'accuracy', 'estimator_name'])
112 | #
113 | # sns.lineplot('ue', 'accuracy', hue='estimator_name', data=df)
114 | # plt.title(f"Uncertainty vs accuracy, {config['name']}")
115 | # plt.xlabel('Uncertaint thresholds, t')
116 | # plt.ylabel('Accuracy for points where ue(t) < t ')
117 | # file = f"{label}_{config['name']}_{config['train_size']}_{config['nn_runs']}"
118 | # plt.savefig(dir / file, dpi=150)
119 | # plt.show()
120 |
121 | # # Plot the results and generate figures
122 | # dir = Path(__file__).parent.absolute() / 'data' / 'detector'
123 | # plt.title(f"{config['name']} uncertainty ROC")
124 | # plt.legend()
125 | # file = f"var_{label}_roc_{config['name']}_{config['train_size']}_{config['nn_runs']}"
126 | # plt.savefig(dir / file)
127 | # # plt.show()
128 | #
129 | # df = pd.DataFrame(results, columns=['Estimator type', 'ROC-AUC score'])
130 | # df = df.replace('mc_dropout', 'MC dropout')
131 | # df = df.replace('decorrelating_sc', 'decorrelation')
132 | # df = df[df['Estimator type'] != 'k_dpp_noisereg']
133 | # print(df)
134 | # fig, ax = plt.subplots(figsize=(8, 6))
135 | # plt.subplots_adjust(left=0.2)
136 | #
137 | # with sns.axes_style('whitegrid'):
138 | # sns.boxplot(data=df, y='ROC-AUC score', x='Estimator type', ax=ax)
139 | #
140 | # ax.yaxis.grid(True)
141 | # ax.xaxis.grid(True)
142 | #
143 | # plt.title(f'{config["name"]} wrong prediction ROC-AUC')
144 |
145 | # file = f"var_{label}_boxplot_{config['name']}_{config['train_size']}_{config['nn_runs']}"
146 | # plt.savefig(dir / file)
147 | # df.to_csv(dir / (file + '.csv'))
148 |
149 |
150 | def calc_ue(model, images, probabilities, estimator_type='max_prob', nn_runs=100):
151 | if estimator_type == 'max_prob':
152 | ue = 1 - probabilities[np.arange(len(probabilities)), np.argmax(probabilities, axis=-1)]
153 | elif estimator_type == 'max_entropy':
154 | ue = entropy(probabilities)
155 | else:
156 | estimator = build_estimator(
157 | 'bald_masked', model, dropout_mask=estimator_type, num_classes=10,
158 | nn_runs=nn_runs, keep_runs=True)
159 | # try:
160 | ue = estimator.estimate(images)
161 | # except:
162 | # import ipdb; ipdb.set_trace()
163 |
164 | print(np.average(estimator.last_mcd_runs()))
165 |
166 | # import ipdb; ipdb.set_trace()
167 | # print(ue[:20])
168 | return ue
169 |
170 |
171 | config_mnist = {
172 | 'train_size': 3_000,
173 | 'val_size': 10_000,
174 | 'model_type': 'simple_conv',
175 | 'batch_size': 256,
176 | 'patience': 3,
177 | 'epochs': 100,
178 | 'start_lr': 1e-3,
179 | 'weight_decay': 0.1,
180 | 'reload': False,
181 | 'nn_runs': 150,
182 | 'estimators': ['mc_dropout', 'decorrelating_sc', 'dpp', 'k_dpp', 'ht_dpp', 'ht_k_dpp'],
183 | 'repeats': 5,
184 | 'name': 'MNIST',
185 | 'prepare_dataset': prepare_mnist,
186 | }
187 | # config_mnist.update({
188 | # 'epochs': 20,
189 | # # 'estimators': ['decorrelating_sc', 'mc_dropout'],
190 | # 'repeats': 5,
191 | # 'train_size': 3000
192 | # })
193 |
194 | config_cifar = deepcopy(config_mnist)
195 | config_cifar.update({
196 | 'train_size': 60_000,
197 | 'val_size': 10_000,
198 | 'model_type': 'resnet',
199 | 'name': 'CIFAR-10',
200 | 'prepare_dataset': prepare_cifar
201 | })
202 |
203 | config_svhn = deepcopy(config_mnist)
204 | config_svhn.update({
205 | 'train_size': 60_000,
206 | 'val_size': 10_000,
207 | 'model_type': 'resnet',
208 | 'name': 'SVHN',
209 | 'prepare_dataset': prepare_svhn
210 | })
211 |
212 | # configs = [config_mnist, config_cifar, config_svhn]
213 | configs = [config_mnist]
214 |
215 |
216 | # # TODO: for debug, remove
217 | # config_mnist.update({
218 | # 'epochs': 20,
219 | # # 'estimators': ['decorrelating_sc', 'mc_dropout'],
220 | # 'repeats': 1,
221 | # 'train_size': 3000
222 | # })
223 |
224 |
225 | if __name__ == '__main__':
226 | for config in configs:
227 | print(config)
228 | benchmark_uncertainty(config)
229 |
--------------------------------------------------------------------------------
/experiments/deprecated/classification_image.py:
--------------------------------------------------------------------------------
1 | from functools import partial
2 |
3 | import matplotlib.pyplot as plt
4 | import numpy as np
5 | import pandas as pd
6 | import seaborn as sns
7 |
8 | import torch
9 | from fastai.vision import rand_pad, flip_lr, ImageDataBunch, Learner, accuracy
10 | from fastai.callbacks import EarlyStoppingCallback
11 |
12 |
13 | from dataloader.builder import build_dataset
14 | from deprecated.utils import ImageArrayDS, Inferencer
15 | from model.cnn import AnotherConv
16 | from model.resnet import resnet_linear, resnet_masked
17 | from experiments.experiment_setup import build_estimator
18 | from uncertainty_estimator.masks import build_masks, DEFAULT_MASKS
19 | from analysis.metrics import uq_ndcg
20 |
21 |
22 | torch.backends.cudnn.benchmark = True
23 |
24 | val_size = 30_000
25 | lr = 1e-3
26 | weight_decay = 1e-3
27 |
28 | config = {
29 | 'model_runs': 3,
30 | 'repeat_runs': 3,
31 | 'nn_runs': 150,
32 | 'dropout_uq': 0.5,
33 | 'num_classes': 10
34 | }
35 |
36 |
37 | def ll(trainer, x, y):
38 | trainer.eval()
39 | logits = trainer(x).detach().cpu()
40 | probs = torch.softmax(logits, axis=-1).numpy()[np.arange(len(x)), y]
41 | return np.log(probs)
42 |
43 |
44 | def main():
45 | data, x_train, y_train, x_val, y_val = load_data()
46 | loss_func = torch.nn.CrossEntropyLoss()
47 |
48 | models = {
49 | 'cnn': AnotherConv(),
50 | 'resnet': resnet_masked(pretrained=True),
51 | 'resnet_multiple': resnet_linear(pretrained=True)
52 | }
53 |
54 | estimation_samples = 5_000
55 | ndcgs, estimator_type, model_types = [], [], []
56 | accuracies = []
57 |
58 | for i in range(config['model_runs']):
59 | print('==models run==', i+1)
60 | for name, model in models.items():
61 | callbacks = [partial(EarlyStoppingCallback, patience=3, min_delta=1e-2, monitor='valid_loss')]
62 | learner = Learner(data, model, loss_func=loss_func, metrics=[accuracy], callback_fns=callbacks)
63 | learner.fit(100, lr, wd=weight_decay)
64 | inferencer = Inferencer(model)
65 | masks = build_masks(DEFAULT_MASKS)
66 |
67 | for j in range(config['repeat_runs']):
68 | idxs = np.random.choice(len(x_val), estimation_samples, replace=False)
69 | x_current = x_val[idxs]
70 | y_current = y_val[idxs]
71 |
72 | # masks
73 | current_ll = ll(inferencer, x_current, y_current)
74 | for mask_name, mask in masks.items():
75 | print(mask_name)
76 | estimator = build_estimator(
77 | 'bald_masked', inferencer, nn_runs=config['nn_runs'], dropout_mask=mask,
78 | dropout_rate=config['dropout_uq'], num_classes=config['num_classes'])
79 | uq = estimator.estimate(x_current)
80 | estimator.reset()
81 | ndcgs.append(uq_ndcg(-current_ll, uq))
82 | estimator_type.append(mask_name)
83 | estimator.reset()
84 | model_types.append(name)
85 | accuracies.append(learner.recorder.metrics[-1][0].item())
86 | try:
87 | plt.figure(figsize=(12, 8))
88 | plt.title(f"NDCG on different train samples")
89 |
90 | df = pd.DataFrame({
91 | 'ndcg': ndcgs,
92 | 'estimator_type': estimator_type,
93 | 'model': model_types
94 | })
95 | sns.boxplot(data=df, x='estimator_type', y='ndcg', hue='model')
96 | plt.show()
97 |
98 | plt.figure(figsize=(12, 8))
99 | plt.title('Accuracies')
100 | df = pd.DataFrame({
101 | 'accuracy': accuracies,
102 | 'model': model_types
103 | })
104 | sns.boxplot(data=df, y='accuracy', x='model')
105 | plt.show()
106 | except Exception as e:
107 | print(e)
108 | import ipdb; ipdb.set_trace()
109 |
110 |
111 | def load_data():
112 | dataset = build_dataset('cifar_10', val_size=val_size)
113 | x_train, y_train = dataset.dataset('train')
114 | x_val, y_val = dataset.dataset('val')
115 |
116 | shape = (-1, 3, 32, 32)
117 | x_train = ((x_train - 128)/128).reshape(shape)
118 | x_val = ((x_val - 128)/128).reshape(shape)
119 |
120 | train_tfms = [*rand_pad(4, 32), flip_lr(p=0.5)]
121 | train_ds = ImageArrayDS(x_train, y_train, train_tfms)
122 | val_ds = ImageArrayDS(x_val, y_val)
123 | data = ImageDataBunch.create(train_ds, val_ds, bs=256)
124 | return data, x_train, y_train, x_val, y_val
125 |
126 |
127 | if __name__ == '__main__':
128 | main()
129 |
130 |
--------------------------------------------------------------------------------
/experiments/deprecated/classification_ood_detection.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import random
3 | from copy import deepcopy
4 | from functools import partial
5 | from pathlib import Path
6 |
7 | import numpy as np
8 | import matplotlib.pyplot as plt
9 | import seaborn as sns
10 | import pandas as pd
11 | from sklearn.model_selection import train_test_split
12 | from sklearn.metrics import roc_auc_score, roc_curve
13 |
14 | import torch
15 | import torch.nn.functional as F
16 |
17 | from fastai.vision import (ImageDataBunch, Learner, accuracy)
18 | from fastai.callbacks import EarlyStoppingCallback
19 |
20 | from alpaca.uncertainty_estimator.masks import DEFAULT_MASKS
21 | from alpaca.uncertainty_estimator import build_estimator
22 | from alpaca.active_learning.simple_update import entropy
23 |
24 | from deprecated.utils import ImageArrayDS
25 | from visual_datasets import prepare_cifar, prepare_mnist, prepare_svhn, prepare_fashion_mnist
26 | from deprecated.classification_active_learning import build_model
27 |
28 |
29 | """
30 | Experiment to detect out-of-distribution samples (OOD) by uncertainty estimation quantification
31 | Results are provided on MNIST/Fashion-MNIST and CIFAR/SVHN pairs (see config below)
32 | We report results as a boxplot ROC-AUC figure for multiple runs
33 | """
34 |
35 | label = 'ratio'
36 |
37 | SEED = 42
38 | torch.manual_seed(SEED)
39 | np.random.seed(SEED)
40 | random.seed(SEED)
41 |
42 | if torch.cuda.is_available():
43 | torch.cuda.set_device(0)
44 | torch.backends.cudnn.deterministic = True
45 | torch.backends.cudnn.benchmark = False
46 | device = 'cuda'
47 | else:
48 | device = 'cpu'
49 |
50 |
51 | def benchmark_ood(config):
52 | results = []
53 | plt.figure(figsize=(10, 8))
54 | for i in range(config['repeats']):
55 | # Load data
56 | x_set, y_set, x_val, y_val, train_tfms = config['prepare_dataset'](config)
57 |
58 | if len(x_set) > config['train_size']:
59 | _, x_train, _, y_train = train_test_split(
60 | x_set, y_set, test_size=config['train_size'], stratify=y_set)
61 | else:
62 | x_train, y_train = x_set, y_set
63 |
64 | _, _, x_alt, y_alt, _ = config['alternative_dataset'](config)
65 |
66 | train_ds = ImageArrayDS(x_train, y_train, train_tfms)
67 | val_ds = ImageArrayDS(x_val, y_val)
68 | data = ImageDataBunch.create(train_ds, val_ds, bs=config['batch_size'])
69 |
70 | # Train model
71 | loss_func = torch.nn.CrossEntropyLoss()
72 | np.set_printoptions(threshold=sys.maxsize, suppress=True)
73 |
74 | model = build_model(config['model_type'])
75 | callbacks = [partial(EarlyStoppingCallback, min_delta=1e-3, patience=config['patience'])]
76 | learner = Learner(data, model, metrics=accuracy, loss_func=loss_func, callback_fns=callbacks)
77 | learner.fit(config['epochs'], config['start_lr'], wd=config['weight_decay'])
78 |
79 | # Get data for binary classification of OOD detector
80 | original_images = torch.FloatTensor(x_val)
81 | alt_images = torch.FloatTensor(x_alt)
82 | images = torch.cat((original_images, alt_images)).to(device)
83 | y = np.array([0]*len(original_images) + [1]*len(alt_images))
84 |
85 | probabilities = F.softmax(model(images), dim=1).detach().cpu().numpy()
86 |
87 | # Calculate uncertainty and generate ROC data for OOD detection
88 | for name in config['estimators']:
89 | ue = calc_ue(model, images, probabilities, name, config['nn_runs'])
90 |
91 | roc_auc = roc_auc_score(y, ue)
92 | print(name, roc_auc)
93 | results.append((name, roc_auc))
94 |
95 | if i == config['repeats'] - 1:
96 | fpr, tpr, thresholds = roc_curve(y, ue, pos_label=1)
97 | plt.plot(fpr, tpr, label=name, alpha=0.8)
98 | plt.xlabel('FPR')
99 | plt.ylabel('TPR')
100 |
101 | # Plot the results and save figures
102 | dir = Path(__file__).parent.absolute() / 'data' / 'ood'
103 | plt.title(f"{config['name']} ood detection ROC")
104 | plt.legend()
105 | plt.savefig(dir / f"var_{label}_ood_roc_{config['name']}_{config['train_size']}_{config['nn_runs']}")
106 | # plt.show()
107 |
108 | plt.figure(figsize=(10, 8))
109 | plt.title(f"{config['name']} ood detection ROC-AUC")
110 | df = pd.DataFrame(results, columns=['Estimator type', 'ROC-AUC score'])
111 | sns.boxplot('Estimator type', 'ROC-AUC score', data=df)
112 | plt.savefig(dir / f"var_{label}_ood_boxplot_{config['name']}_{config['train_size']}_{config['nn_runs']}")
113 | # plt.show()
114 |
115 |
116 | def calc_ue(model, images, probabilities, estimator_type='max_prob', nn_runs=100):
117 | if estimator_type == 'max_prob':
118 | ue = 1 - probabilities[np.arange(len(probabilities)), np.argmax(probabilities, axis=-1)]
119 | elif estimator_type == 'max_entropy':
120 | ue = entropy(probabilities)
121 | else:
122 | estimator = build_estimator(
123 | 'bald_masked', model, dropout_mask=estimator_type, num_classes=10, nn_runs=nn_runs)
124 | ue = estimator.estimate(images)
125 | print(ue[:10])
126 |
127 | return ue
128 |
129 |
130 | config_mnist = {
131 | 'train_size': 50_000,
132 | 'val_size': 5_000,
133 | 'model_type': 'simple_conv',
134 | 'batch_size': 256,
135 | 'patience': 3,
136 | 'epochs': 50,
137 | 'start_lr': 1e-3,
138 | 'weight_decay': 0.1,
139 | 'reload': False,
140 | 'nn_runs': 150,
141 | 'estimators': DEFAULT_MASKS,
142 | 'repeats': 5,
143 | 'name': 'MNIST',
144 | 'prepare_dataset': prepare_mnist,
145 | 'alternative_dataset': prepare_fashion_mnist,
146 | }
147 |
148 |
149 | # # TODO: for debug, remove
150 | # config_mnist.update({
151 | # 'epochs': 2,
152 | # 'estimators': ['decorrelating_sc', 'mc_dropout'],
153 | # 'repeats': 1
154 | # })
155 |
156 | config_cifar = deepcopy(config_mnist)
157 | config_cifar.update({
158 | 'train_size': 50_000,
159 | 'val_size': 5_000,
160 | 'model_type': 'resnet',
161 | 'name': 'CIFAR-10',
162 | 'prepare_dataset': prepare_cifar,
163 | 'alternative_dataset': prepare_svhn,
164 | })
165 |
166 |
167 | configs = [config_mnist, config_cifar]
168 |
169 |
170 | if __name__ == '__main__':
171 | for config in configs:
172 | print(config)
173 | benchmark_ood(config)
174 |
--------------------------------------------------------------------------------
/experiments/deprecated/classification_xor.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {
7 | "collapsed": true,
8 | "pycharm": {
9 | "is_executing": false
10 | }
11 | },
12 | "outputs": [],
13 | "source": [
14 | "import torch\n",
15 | "from torch.utils.data import TensorDataset\n",
16 | "import numpy as np\n",
17 | "import matplotlib.pyplot as plt\n",
18 | "\n",
19 | "from fastai.vision import Learner, accuracy\n",
20 | "from fastai.basic_data import DataBunch\n",
21 | "\n",
22 | "from alpaca.model.dense import Dense\n",
23 | "from alpaca.uncertainty_estimator import build_estimator\n",
24 | "from alpaca.uncertainty_estimator.masks import DEFAULT_MASKS\n"
25 | ]
26 | },
27 | {
28 | "cell_type": "code",
29 | "execution_count": null,
30 | "outputs": [],
31 | "source": [
32 | "border = 1.2\n",
33 | "dots = 300\n",
34 | "xx, yy = np.meshgrid(np.linspace(-border, border, dots), np.linspace(-border, border, dots))\n",
35 | "x_mesh = np.vstack((xx.ravel(), yy.ravel())).T\n",
36 | "epochs = 10 \n",
37 | "layers = (2, 100, 100, 100, 2)\n"
38 | ],
39 | "metadata": {
40 | "collapsed": false,
41 | "pycharm": {
42 | "name": "#%%\n",
43 | "is_executing": false
44 | }
45 | }
46 | },
47 | {
48 | "cell_type": "code",
49 | "execution_count": null,
50 | "outputs": [],
51 | "source": [
52 | "device = 'cuda' if torch.cuda.is_available() else 'cpu'\n",
53 | "\n",
54 | "def xor(points, noise_level=0.):\n",
55 | " rng = np.random\n",
56 | " x = 2*rng.random((points, 2)) - 1\n",
57 | " noised_x = x + noise_level * (2*rng.random((points, 2)) - 1)\n",
58 | " y = np.logical_xor(noised_x[:, 0] > 0, noised_x[:, 1] > 0)\n",
59 | " return x, y\n",
60 | "\n",
61 | "\n",
62 | "def train(x, y, x_val, y_val):\n",
63 | " loss_func = torch.nn.CrossEntropyLoss()\n",
64 | " model = Dense(layers, dropout_rate=0.5)\n",
65 | "\n",
66 | " train_ds = TensorDataset(torch.FloatTensor(x), torch.LongTensor(y))\n",
67 | " val_ds = TensorDataset(torch.FloatTensor(x_val), torch.LongTensor(y_val))\n",
68 | " data = DataBunch.create(train_ds, val_ds, bs=10)\n",
69 | "\n",
70 | " learner = Learner(data, model, metrics=accuracy, loss_func=loss_func)\n",
71 | "\n",
72 | " learner.fit_one_cycle(epochs)\n",
73 | " return model\n",
74 | "\n",
75 | "\n",
76 | "def eval(model, x, y, method='basic_bern', noise_level=0):\n",
77 | " t_mesh = torch.FloatTensor(x_mesh).to(device)\n",
78 | " estimator = build_estimator('bald_masked', model, dropout_mask=method, num_classes=2, dropout_rate=0.5, keep_runs=True)\n",
79 | " # estimations = sigmoid(estimator.estimate(t_val))\n",
80 | " estimations = model(t_mesh)[:, 0].detach()\n",
81 | " plot(x, y, estimations, noise_level, 'prediction')\n",
82 | " estimations = estimator.estimate(t_mesh)\n",
83 | " estimations = estimations\n",
84 | " plot(x, y, estimations, noise_level, method)\n",
85 | " \n",
86 | " \n",
87 | "def plot(x, y, estimations, noise_level, method):\n",
88 | " Z = estimations.reshape(xx.shape)\n",
89 | " plt.figure(figsize=(12, 9))\n",
90 | " plt.scatter(x[:, 0], x[:, 1], s=50, c=y, cmap=plt.cm.gray, edgecolors=(0, 0, 0))\n",
91 | " plt.imshow(Z, interpolation='nearest',\n",
92 | " extent=(xx.min(), xx.max(), yy.min(), yy.max()),\n",
93 | " aspect='auto', origin='lower', cmap=plt.cm.RdBu_r)\n",
94 | " plt.title(f\"{method} with noise {noise_level}\")\n",
95 | " plt.colorbar() \n",
96 | " plt.savefig(f\"data/xor/{method}_{noise_level}.png\")\n",
97 | " plt.show()\n"
98 | ],
99 | "metadata": {
100 | "collapsed": false,
101 | "pycharm": {
102 | "name": "#%%\n",
103 | "is_executing": false
104 | }
105 | }
106 | },
107 | {
108 | "cell_type": "markdown",
109 | "source": [
110 | "### Plot for all masks\n"
111 | ],
112 | "metadata": {
113 | "collapsed": false,
114 | "pycharm": {
115 | "name": "#%% md\n",
116 | "is_executing": true
117 | }
118 | }
119 | },
120 | {
121 | "cell_type": "code",
122 | "execution_count": null,
123 | "outputs": [],
124 | "source": [
125 | "for noise_level in np.arange(0, 1, 0.1):\n",
126 | " noise_level = round(noise_level, 1)\n",
127 | " print(noise_level)\n",
128 | " x, y = xor(500, noise_level)\n",
129 | " x_val, y_val = xor(500, noise_level)\n",
130 | " model = train(x, y, x_val, y_val)\n",
131 | " for mask_name in DEFAULT_MASKS:\n",
132 | " eval(model, x, y, mask_name, noise_level)"
133 | ],
134 | "metadata": {
135 | "collapsed": false,
136 | "pycharm": {
137 | "name": "#%%\n",
138 | "is_executing": false
139 | }
140 | }
141 | },
142 | {
143 | "cell_type": "code",
144 | "execution_count": null,
145 | "outputs": [],
146 | "source": [
147 | "\n"
148 | ],
149 | "metadata": {
150 | "collapsed": false,
151 | "pycharm": {
152 | "name": "#%%\n"
153 | }
154 | }
155 | }
156 | ],
157 | "metadata": {
158 | "kernelspec": {
159 | "display_name": "Python 3",
160 | "language": "python",
161 | "name": "python3"
162 | },
163 | "language_info": {
164 | "codemirror_mode": {
165 | "name": "ipython",
166 | "version": 2
167 | },
168 | "file_extension": ".py",
169 | "mimetype": "text/x-python",
170 | "name": "python",
171 | "nbconvert_exporter": "python",
172 | "pygments_lexer": "ipython2",
173 | "version": "2.7.6"
174 | },
175 | "pycharm": {
176 | "stem_cell": {
177 | "cell_type": "raw",
178 | "source": [],
179 | "metadata": {
180 | "collapsed": false
181 | }
182 | }
183 | }
184 | },
185 | "nbformat": 4,
186 | "nbformat_minor": 0
187 | }
--------------------------------------------------------------------------------
/experiments/deprecated/dpp.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "metadata": {
7 | "collapsed": true,
8 | "pycharm": {
9 | "is_executing": false
10 | }
11 | },
12 | "outputs": [],
13 | "source": [
14 | "import numpy as np\n",
15 | "from dppy.finite_dpps import FiniteDPP"
16 | ]
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": 2,
21 | "outputs": [],
22 | "source": [
23 | "correlations = np.eye(5)\n",
24 | "dpp = FiniteDPP('correlation', **{'K': correlations})\n",
25 | "\n"
26 | ],
27 | "metadata": {
28 | "collapsed": false,
29 | "pycharm": {
30 | "name": "#%%\n",
31 | "is_executing": false
32 | }
33 | }
34 | },
35 | {
36 | "cell_type": "code",
37 | "execution_count": 3,
38 | "outputs": [
39 | {
40 | "data": {
41 | "text/plain": "[array([0, 3, 2, 1, 4])]"
42 | },
43 | "metadata": {},
44 | "output_type": "execute_result",
45 | "execution_count": 3
46 | }
47 | ],
48 | "source": [
49 | "dpp.sample_exact()\n",
50 | "dpp.list_of_samples"
51 | ],
52 | "metadata": {
53 | "collapsed": false,
54 | "pycharm": {
55 | "name": "#%%\n",
56 | "is_executing": false
57 | }
58 | }
59 | },
60 | {
61 | "cell_type": "code",
62 | "execution_count": 3,
63 | "outputs": [],
64 | "source": [
65 | "\n"
66 | ],
67 | "metadata": {
68 | "collapsed": false,
69 | "pycharm": {
70 | "name": "#%%\n",
71 | "is_executing": false
72 | }
73 | }
74 | }
75 | ],
76 | "metadata": {
77 | "kernelspec": {
78 | "name": "python3",
79 | "language": "python",
80 | "display_name": "Python 3"
81 | },
82 | "language_info": {
83 | "codemirror_mode": {
84 | "name": "ipython",
85 | "version": 2
86 | },
87 | "file_extension": ".py",
88 | "mimetype": "text/x-python",
89 | "name": "python",
90 | "nbconvert_exporter": "python",
91 | "pygments_lexer": "ipython2",
92 | "version": "2.7.6"
93 | },
94 | "pycharm": {
95 | "stem_cell": {
96 | "cell_type": "raw",
97 | "source": [],
98 | "metadata": {
99 | "collapsed": false
100 | }
101 | }
102 | }
103 | },
104 | "nbformat": 4,
105 | "nbformat_minor": 0
106 | }
--------------------------------------------------------------------------------
/experiments/deprecated/ensemble_debug.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pickle
3 | import random
4 | from pathlib import Path
5 |
6 | import seaborn as sns
7 | import pandas as pd
8 | import torch
9 | from torch.nn.functional import elu
10 | import numpy as np
11 | import matplotlib.pyplot as plt
12 |
13 | from alpaca.uncertainty_estimator.masks import build_masks, DEFAULT_MASKS
14 | from alpaca.analysis.metrics import uq_ll
15 | from alpaca.model.ensemble import MLPEnsemble
16 | from alpaca.uncertainty_estimator import build_estimator
17 | from alpaca.analysis.metrics import get_uq_metrics
18 |
19 | plt.rcParams['figure.facecolor'] = 'white'
20 |
21 | SEED = 10
22 | torch.manual_seed(SEED)
23 | np.random.seed(SEED)
24 | random.seed(SEED)
25 |
26 | torch.cuda.set_device(0)
27 | torch.backends.cudnn.deterministic = True
28 | torch.backends.cudnn.benchmark = False
29 |
30 | folder = Path('./data/regression')
31 | files = sorted([file for file in os.listdir(folder) if file.endswith('.pickle')])
32 | files = [file for file in files if file.startswith('bos')]
33 |
34 |
35 | def load_setup(file):
36 | print(file)
37 | with open(folder / 'log_exp.log', 'w') as f:
38 | f.write(f'{cnt} / {len(files)}')
39 | with open(folder / file, 'rb') as f:
40 | dct = pickle.load(f)
41 | config = dct['config']
42 | config['n_ue_runs'] = 1
43 | config['acc_percentile'] = .1
44 | state_dict = dct['state_dict']
45 | x_train, y_train, x_val, y_val, x_scaler, y_scaler = dct['data']
46 |
47 | ensemble = MLPEnsemble(
48 | config['layers'], n_models=config['n_ens'], activation = elu,
49 | reduction='mean')
50 | ensemble.load_state_dict(state_dict)
51 |
52 | model = ensemble.models[2]
53 | return model, ensemble, x_train, y_train, x_val, y_val, x_scaler, y_scaler
54 |
55 |
56 | accumulate_ll = []
57 | data = []
58 |
59 |
60 | # np.random.shuffle(files)
61 | for cnt, file in enumerate(files[:1]):
62 | model, ensemble, x_train, y_train, x_val, y_val, x_scaler, y_scaler = load_setup(file)
63 |
64 | x_val_tensor = torch.tensor(x_val)
65 | unscale = lambda y : y_scaler.inverse_transform(y)
66 |
67 | predictions = model(x_val_tensor.cuda()).cpu().detach().numpy()
68 | errors = predictions - y_val
69 | # rmse_single = np.sqrt(np.mean(np.square(errors)))
70 | # accumulate.append([file[:4], 'single', rmse_single])
71 |
72 | # predictions = ensemble(x_val_tensor.cuda()).cpu().detach().numpy()
73 | # errors = predictions - y_val
74 | # rmse_single = np.sqrt(np.mean(np.square(errors)))
75 | # accumulate.append([file[:4], 'ensemble', rmse_single])
76 |
77 | for mask_name in DEFAULT_MASKS:
78 | estimator = build_estimator(
79 | 'mcdue_masked', model, nn_runs=100, keep_runs=True,
80 | dropout_mask=mask_name)
81 | ue =estimator.estimate(torch.Tensor(x_val).double().cuda())
82 | runs = estimator.last_mcd_runs()
83 | predictions = np.mean(estimator.last_mcd_runs(), axis=-1)
84 | errors = predictions - y_val[:, 0]
85 | rmse_mask = np.sqrt(np.mean(np.square(errors)))
86 | # accumulate.append([file[:4], mask_name, rmse_mask])
87 | ll = uq_ll(errors, ue)
88 | accumulate_ll.append([file[:4], mask_name, ll])
89 |
90 |
91 | plt.figure(figsize=(10, 6))
92 |
93 | accumulate2 = [record for record in accumulate_ll if record[1] !='decorrelating_sc']
94 | df = pd.DataFrame(accumulate2, columns=['dataset', 'type', 'LL'])
95 | sns.boxplot('dataset', 'LL', hue='type', data=df)
96 | plt.savefig('ll_masks.png', dpi=150)
97 |
98 |
--------------------------------------------------------------------------------
/experiments/deprecated/ensembles.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "outputs": [],
7 | "source": [
8 | "import sys\n",
9 | "sys.path.append('..')\n",
10 | "%load_ext autoreload\n",
11 | "%autoreload 2\n"
12 | ],
13 | "metadata": {
14 | "collapsed": false,
15 | "pycharm": {
16 | "name": "#%%\n"
17 | }
18 | }
19 | },
20 | {
21 | "cell_type": "code",
22 | "execution_count": null,
23 | "outputs": [],
24 | "source": [
25 | "import os\n",
26 | "from pathlib import Path\n",
27 | "import random\n",
28 | "\n",
29 | "import matplotlib.pyplot as plt\n",
30 | "import pickle\n",
31 | "import torch\n",
32 | "import numpy as np\n",
33 | "\n",
34 | "# from experiment_setup import get_model, set_random, build_estimator\n",
35 | "from alpaca.model.ensemble import MLPEnsemble\n",
36 | "from alpaca.model.mlp import MLP\n",
37 | "from alpaca.dataloader.builder import build_dataset\n",
38 | "from alpaca.uncertainty_estimator import build_estimator\n",
39 | "from alpaca.analysis.metrics import uq_ll\n",
40 | "\n",
41 | "from experiments.utils.data import scale, multiple_kfold\n",
42 | "\n",
43 | "plt.rcParams['figure.facecolor'] = 'white'"
44 | ],
45 | "metadata": {
46 | "collapsed": false,
47 | "pycharm": {
48 | "name": "#%%\n"
49 | }
50 | }
51 | },
52 | {
53 | "cell_type": "code",
54 | "execution_count": null,
55 | "outputs": [],
56 | "source": [
57 | "SEED = 10\n",
58 | "torch.manual_seed(SEED)\n",
59 | "np.random.seed(SEED)\n",
60 | "random.seed(SEED)\n",
61 | "\n",
62 | "torch.cuda.set_device(0)\n",
63 | "torch.backends.cudnn.deterministic = True\n",
64 | "torch.backends.cudnn.benchmark = False\n",
65 | "\n"
66 | ],
67 | "metadata": {
68 | "collapsed": false,
69 | "pycharm": {
70 | "name": "#%%\n"
71 | }
72 | }
73 | },
74 | {
75 | "cell_type": "code",
76 | "execution_count": null,
77 | "outputs": [],
78 | "source": [
79 | "config = {\n",
80 | " 'nn_runs': 100,\n",
81 | " 'runs': 2,\n",
82 | " 'max_runs': 20,\n",
83 | " # Our train config\n",
84 | " 'layers': [8, 128, 128, 64, 1],\n",
85 | " 'epochs': 10_000,\n",
86 | " 'validation_step': 100,\n",
87 | "\n",
88 | " 'patience': 10,\n",
89 | " 'dropout_rate': 0.5,\n",
90 | " 'dropout_uq': 0.5,\n",
91 | " 'batch_size': 256,\n",
92 | " 'l2_reg': 1e-5,\n",
93 | "\n",
94 | " 'optimizer': {'type': 'Adam', 'lr': 0.01, 'weight_decay':1e-5},\n",
95 | " 'n_split_runs': 3,\n",
96 | " 'n_model_runs': 3,\n",
97 | " 'n_ens': 20,\n",
98 | " 'n_ue_runs': 5,\n",
99 | " 'k_folds': 10,\n",
100 | " 'verbose': False,\n",
101 | "}\n"
102 | ],
103 | "metadata": {
104 | "collapsed": false,
105 | "pycharm": {
106 | "name": "#%%\n"
107 | }
108 | }
109 | },
110 | {
111 | "cell_type": "code",
112 | "execution_count": null,
113 | "outputs": [],
114 | "source": [
115 | "train_opts = ['patience', 'dropout_rate', 'epochs', 'batch_size', 'validation_step', 'verbose']\n",
116 | "config['train_opts'] = {k: config[k] for k in config if k in train_opts}\n"
117 | ],
118 | "metadata": {
119 | "collapsed": false,
120 | "pycharm": {
121 | "name": "#%%\n"
122 | }
123 | }
124 | },
125 | {
126 | "cell_type": "code",
127 | "execution_count": null,
128 | "outputs": [],
129 | "source": [
130 | "# datasets = [\n",
131 | "# 'boston_housing', 'concrete', 'energy_efficiency',\n",
132 | "# 'kin8nm', 'naval_propulsion', 'ccpp', 'red_wine',\n",
133 | "# 'yacht_hydrodynamics'\n",
134 | "# ]"
135 | ],
136 | "metadata": {
137 | "collapsed": false,
138 | "pycharm": {
139 | "name": "#%%\n"
140 | }
141 | }
142 | },
143 | {
144 | "cell_type": "code",
145 | "execution_count": null,
146 | "outputs": [],
147 | "source": [
148 | "# dataset_name = 'kin8nm'\n",
149 | "dataset_name = 'ccpp'\n",
150 | "dataset = build_dataset(dataset_name, val_split=0.2)\n",
151 | "x_train, y_train = dataset.dataset('train')\n",
152 | "x_val, y_val = dataset.dataset('val')\n",
153 | "\n",
154 | "x_train, x_val, x_scaler = scale(x_train, x_val)\n",
155 | "y_train, y_val, y_scaler = scale(y_train, y_val)\n",
156 | "\n",
157 | "print(dataset_name, x_train.shape)\n",
158 | "config['layers'][0] = x_train.shape[-1]\n"
159 | ],
160 | "metadata": {
161 | "collapsed": false,
162 | "pycharm": {
163 | "name": "#%%\n"
164 | }
165 | }
166 | },
167 | {
168 | "cell_type": "code",
169 | "execution_count": null,
170 | "outputs": [],
171 | "source": [
172 | "model = MLP(config['layers'])\n"
173 | ],
174 | "metadata": {
175 | "collapsed": false,
176 | "pycharm": {
177 | "name": "#%%\n"
178 | }
179 | }
180 | },
181 | {
182 | "cell_type": "code",
183 | "execution_count": null,
184 | "outputs": [],
185 | "source": [
186 | "model.fit((x_train, y_train), (x_val, y_val))\n"
187 | ],
188 | "metadata": {
189 | "collapsed": false,
190 | "pycharm": {
191 | "name": "#%%\n"
192 | }
193 | }
194 | },
195 | {
196 | "cell_type": "code",
197 | "execution_count": null,
198 | "outputs": [],
199 | "source": [
200 | "x_val_tensor = torch.tensor(x_val)\n",
201 | "predictions = model(x_val_tensor.cuda()).cpu().detach().numpy()\n"
202 | ],
203 | "metadata": {
204 | "collapsed": false,
205 | "pycharm": {
206 | "name": "#%%\n"
207 | }
208 | }
209 | },
210 | {
211 | "cell_type": "code",
212 | "execution_count": null,
213 | "outputs": [],
214 | "source": [
215 | "unscale = lambda y : y_scaler.inverse_transform(y)\n",
216 | "\n",
217 | "scaled_errors = unscale(predictions) - unscale(y_val)\n",
218 | "rmse_single = np.sqrt(np.mean(np.square(scaled_errors)))"
219 | ],
220 | "metadata": {
221 | "collapsed": false,
222 | "pycharm": {
223 | "name": "#%%\n"
224 | }
225 | }
226 | },
227 | {
228 | "cell_type": "code",
229 | "execution_count": null,
230 | "outputs": [],
231 | "source": [
232 | "train_opts = ['patience', 'dropout_rate', 'epochs', 'batch_size', 'validation_step', 'verbose']\n",
233 | "config['train_opts'] = {k: config[k] for k in config if k in train_opts}"
234 | ],
235 | "metadata": {
236 | "collapsed": false,
237 | "pycharm": {
238 | "name": "#%%\n"
239 | }
240 | }
241 | },
242 | {
243 | "cell_type": "code",
244 | "execution_count": null,
245 | "outputs": [],
246 | "source": [
247 | "\n",
248 | "train_opts = config['train_opts'].copy()\n",
249 | "ensemble = MLPEnsemble(config['layers'],\n",
250 | " n_models=config['n_ens'],\n",
251 | " reduction='mean')\n",
252 | "ensemble.fit((x_train, y_train),\n",
253 | " (x_val, y_val),\n",
254 | " **train_opts)\n",
255 | "\n",
256 | "\n",
257 | "estimator_ensemble = build_estimator('emcdue', ensemble, nn_runs=100)\n",
258 | "estimator_single = build_estimator('mcdue', model, nn_runs=100)\n",
259 | "\n",
260 | "x_val_tensor = torch.tensor(x_val)\n",
261 | "unscale = lambda y : y_scaler.inverse_transform(y)\n",
262 | "\n",
263 | "predictions = model(x_val_tensor.cuda()).cpu().detach().numpy()\n",
264 | "errors = predictions - y_val\n",
265 | "ue_single = estimator_single.estimate(torch.Tensor(x_val).double().cuda())\n",
266 | "ll_single = uq_ll(errors, ue_single)\n",
267 | "\n",
268 | "\n",
269 | "predictions = ensemble(x_val_tensor.cuda()).cpu().detach().numpy()\n",
270 | "errors = predictions - y_val\n",
271 | "ue_ensemble = estimator_ensemble.estimate(torch.Tensor(x_val).double().cuda())\n",
272 | "ll_ensemble = uq_ll(errors, ue_ensemble)\n",
273 | "\n",
274 | "# accumulate.append([file[:4], 'single', ll_single])\n",
275 | "# accumulate.append([file[:4], 'ensemble', ll_ensemble])\n"
276 | ],
277 | "metadata": {
278 | "collapsed": false,
279 | "pycharm": {
280 | "name": "#%%\n"
281 | }
282 | }
283 | },
284 | {
285 | "cell_type": "code",
286 | "execution_count": null,
287 | "outputs": [],
288 | "source": [
289 | "ll_single\n",
290 | "ll_ensemble\n",
291 | "\n"
292 | ],
293 | "metadata": {
294 | "collapsed": false,
295 | "pycharm": {
296 | "name": "#%%\n"
297 | }
298 | }
299 | }
300 | ],
301 | "metadata": {
302 | "kernelspec": {
303 | "name": "python3",
304 | "language": "python",
305 | "display_name": "Python 3"
306 | },
307 | "language_info": {
308 | "codemirror_mode": {
309 | "name": "ipython",
310 | "version": 2
311 | },
312 | "file_extension": ".py",
313 | "mimetype": "text/x-python",
314 | "name": "python",
315 | "nbconvert_exporter": "python",
316 | "pygments_lexer": "ipython2",
317 | "version": "2.7.6"
318 | }
319 | },
320 | "nbformat": 4,
321 | "nbformat_minor": 0
322 | }
--------------------------------------------------------------------------------
/experiments/deprecated/ensembles_2.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "outputs": [],
7 | "source": [
8 | "%load_ext autoreload\n",
9 | "%autoreload 2"
10 | ],
11 | "metadata": {
12 | "collapsed": false,
13 | "pycharm": {
14 | "name": "#%%\n"
15 | }
16 | }
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": null,
21 | "outputs": [],
22 | "source": [
23 | "import os\n",
24 | "import pickle\n",
25 | "import random\n",
26 | "from pathlib import Path\n",
27 | "\n",
28 | "import pandas as pd\n",
29 | "import torch\n",
30 | "from torch.nn.functional import elu\n",
31 | "import numpy as np\n",
32 | "import matplotlib.pyplot as plt\n",
33 | "\n",
34 | "from alpaca.uncertainty_estimator.masks import build_masks, DEFAULT_MASKS\n",
35 | "from alpaca.model.ensemble import MLPEnsemble\n",
36 | "from alpaca.uncertainty_estimator import build_estimator\n",
37 | "from alpaca.analysis.metrics import get_uq_metrics\n",
38 | "\n",
39 | "plt.rcParams['figure.facecolor'] = 'white'\n"
40 | ],
41 | "metadata": {
42 | "collapsed": false,
43 | "pycharm": {
44 | "name": "#%%\n"
45 | }
46 | }
47 | },
48 | {
49 | "cell_type": "code",
50 | "execution_count": null,
51 | "outputs": [],
52 | "source": [
53 | "SEED = 10\n",
54 | "torch.manual_seed(SEED)\n",
55 | "np.random.seed(SEED)\n",
56 | "random.seed(SEED)\n",
57 | "\n",
58 | "torch.cuda.set_device(0)\n",
59 | "torch.backends.cudnn.deterministic = True\n",
60 | "torch.backends.cudnn.benchmark = False\n"
61 | ],
62 | "metadata": {
63 | "collapsed": false,
64 | "pycharm": {
65 | "name": "#%%\n"
66 | }
67 | }
68 | },
69 | {
70 | "cell_type": "code",
71 | "execution_count": null,
72 | "outputs": [],
73 | "source": [
74 | "folder = Path('./data/regression')\n",
75 | "files = [file for file in os.listdir(folder) if file.endswith('.pickle')]\n",
76 | "# files = [file for file in files if file.startswith('kin8')]\n"
77 | ],
78 | "metadata": {
79 | "collapsed": false,
80 | "pycharm": {
81 | "name": "#%%\n"
82 | }
83 | }
84 | },
85 | {
86 | "cell_type": "code",
87 | "execution_count": null,
88 | "outputs": [],
89 | "source": [
90 | "\n",
91 | "accumulate = []"
92 | ],
93 | "metadata": {
94 | "collapsed": false,
95 | "pycharm": {
96 | "name": "#%%\n"
97 | }
98 | }
99 | },
100 | {
101 | "cell_type": "code",
102 | "execution_count": null,
103 | "outputs": [],
104 | "source": [
105 | "data = []\n",
106 | "for cnt, file in enumerate(files):\n",
107 | " print(file)\n",
108 | " with open(folder / 'log_exp.log', 'w') as f:\n",
109 | " f.write(f'{cnt} / {len(files)}')\n",
110 | " with open(folder / file, 'rb') as f:\n",
111 | " dct = pickle.load(f)\n",
112 | " print(file)\n",
113 | " config = dct['config']\n",
114 | " config['n_ue_runs'] = 1\n",
115 | " config['acc_percentile'] = .1\n",
116 | " state_dict = dct['state_dict']\n",
117 | " x_train, y_train, x_val, y_val, x_scaler, y_scaler = dct['data']\n",
118 | "\n",
119 | " ensemble = MLPEnsemble(\n",
120 | " config['layers'], n_models=config['n_ens'], activation = elu,\n",
121 | " reduction='mean')\n",
122 | " ensemble.load_state_dict(state_dict)\n",
123 | "\n",
124 | " model = ensemble.models[2]\n",
125 | "\n",
126 | " x_val_tensor = torch.tensor(x_val)\n",
127 | " predictions = model(x_val_tensor.cuda()).cpu().detach().numpy()\n",
128 | " unscale = lambda y : y_scaler.inverse_transform(y)\n",
129 | " # unscale = lambda y : y\n",
130 | "\n",
131 | " scaled_errors = unscale(predictions) - unscale(y_val)\n",
132 | " rmse_single = np.sqrt(np.mean(np.square(scaled_errors)))\n",
133 | " #%%\n",
134 | " predictions = ensemble(x_val_tensor.cuda()).cpu().detach().numpy()\n",
135 | " scaled_errors = unscale(predictions) - unscale(y_val)\n",
136 | " rmse_ensemble = np.sqrt(np.mean(np.square(scaled_errors)))\n",
137 | "\n",
138 | " #%%\n",
139 | " accumulate.append([file[:4], 'single', rmse_single])\n",
140 | " accumulate.append([file[:4], 'ensemble', rmse_ensemble])\n",
141 | "\n",
142 | " print(file)\n",
143 | " print('Single', rmse_single)\n",
144 | " print('Ensemble', rmse_ensemble)\n",
145 | "\n"
146 | ],
147 | "metadata": {
148 | "collapsed": false,
149 | "pycharm": {
150 | "name": "#%%\n"
151 | }
152 | }
153 | },
154 | {
155 | "cell_type": "code",
156 | "execution_count": null,
157 | "outputs": [],
158 | "source": [
159 | "import seaborn as sns\n",
160 | "import pandas as pd"
161 | ],
162 | "metadata": {
163 | "collapsed": false,
164 | "pycharm": {
165 | "name": "#%%\n"
166 | }
167 | }
168 | },
169 | {
170 | "cell_type": "code",
171 | "execution_count": null,
172 | "outputs": [],
173 | "source": [
174 | "df = pd.DataFrame(accumulate, columns=['dataset', 'type', 'rmse'])\n",
175 | "df"
176 | ],
177 | "metadata": {
178 | "collapsed": false,
179 | "pycharm": {
180 | "name": "#%%\n"
181 | }
182 | }
183 | },
184 | {
185 | "cell_type": "code",
186 | "execution_count": null,
187 | "outputs": [],
188 | "source": [
189 | "sns.boxplot('dataset', 'rmse', hue='type', data=df)\n",
190 | "plt.savefig('rmse.png', dpi=150)\n"
191 | ],
192 | "metadata": {
193 | "collapsed": false,
194 | "pycharm": {
195 | "name": "#%%\n"
196 | }
197 | }
198 | }
199 | ],
200 | "metadata": {
201 | "kernelspec": {
202 | "name": "python3",
203 | "language": "python",
204 | "display_name": "Python 3"
205 | },
206 | "language_info": {
207 | "codemirror_mode": {
208 | "name": "ipython",
209 | "version": 2
210 | },
211 | "file_extension": ".py",
212 | "mimetype": "text/x-python",
213 | "name": "python",
214 | "nbconvert_exporter": "python",
215 | "pygments_lexer": "ipython2",
216 | "version": "2.7.6"
217 | }
218 | },
219 | "nbformat": 4,
220 | "nbformat_minor": 0
221 | }
--------------------------------------------------------------------------------
/experiments/deprecated/ensembles_3.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "outputs": [],
7 | "source": [
8 | "%load_ext autoreload\n",
9 | "%autoreload 2"
10 | ],
11 | "metadata": {
12 | "collapsed": false,
13 | "pycharm": {
14 | "name": "#%%\n"
15 | }
16 | }
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": null,
21 | "outputs": [],
22 | "source": [
23 | "import os\n",
24 | "import pickle\n",
25 | "import random\n",
26 | "from pathlib import Path\n",
27 | "\n",
28 | "import seaborn as sns\n",
29 | "import pandas as pd\n",
30 | "import torch\n",
31 | "from torch.nn.functional import elu\n",
32 | "import numpy as np\n",
33 | "import matplotlib.pyplot as plt\n",
34 | "\n",
35 | "from alpaca.uncertainty_estimator.masks import build_masks, DEFAULT_MASKS\n",
36 | "from alpaca.analysis.metrics import uq_ll\n",
37 | "from alpaca.model.ensemble import MLPEnsemble\n",
38 | "from alpaca.uncertainty_estimator import build_estimator\n",
39 | "from alpaca.analysis.metrics import get_uq_metrics\n",
40 | "\n",
41 | "plt.rcParams['figure.facecolor'] = 'white'\n"
42 | ],
43 | "metadata": {
44 | "collapsed": false,
45 | "pycharm": {
46 | "name": "#%%\n"
47 | }
48 | }
49 | },
50 | {
51 | "cell_type": "code",
52 | "execution_count": null,
53 | "outputs": [],
54 | "source": [
55 | "SEED = 10\n",
56 | "torch.manual_seed(SEED)\n",
57 | "np.random.seed(SEED)\n",
58 | "random.seed(SEED)\n",
59 | "\n",
60 | "torch.cuda.set_device(0)\n",
61 | "torch.backends.cudnn.deterministic = True\n",
62 | "torch.backends.cudnn.benchmark = False\n"
63 | ],
64 | "metadata": {
65 | "collapsed": false,
66 | "pycharm": {
67 | "name": "#%%\n"
68 | }
69 | }
70 | },
71 | {
72 | "cell_type": "code",
73 | "execution_count": null,
74 | "outputs": [],
75 | "source": [
76 | "folder = Path('./data/regression')\n",
77 | "files = sorted([file for file in os.listdir(folder) if file.endswith('.pickle')])\n",
78 | "# files = [file for file in files if file.startswith('kin8')]\n",
79 | "\n"
80 | ],
81 | "metadata": {
82 | "collapsed": false,
83 | "pycharm": {
84 | "name": "#%%\n"
85 | }
86 | }
87 | },
88 | {
89 | "cell_type": "code",
90 | "execution_count": null,
91 | "outputs": [],
92 | "source": [
93 | "def load_setup(file):\n",
94 | " print(file)\n",
95 | " with open(folder / 'log_exp.log', 'w') as f:\n",
96 | " f.write(f'{cnt} / {len(files)}')\n",
97 | " with open(folder / file, 'rb') as f:\n",
98 | " dct = pickle.load(f)\n",
99 | " print(file)\n",
100 | " config = dct['config']\n",
101 | " config['n_ue_runs'] = 1\n",
102 | " config['acc_percentile'] = .1\n",
103 | " state_dict = dct['state_dict']\n",
104 | " x_train, y_train, x_val, y_val, x_scaler, y_scaler = dct['data']\n",
105 | "\n",
106 | " ensemble = MLPEnsemble(\n",
107 | " config['layers'], n_models=config['n_ens'], activation = elu,\n",
108 | " reduction='mean')\n",
109 | " ensemble.load_state_dict(state_dict)\n",
110 | "\n",
111 | " model = ensemble.models[2]\n",
112 | " return model, ensemble, x_train, y_train, x_val, y_val, x_scaler, y_scaler\n"
113 | ],
114 | "metadata": {
115 | "collapsed": false,
116 | "pycharm": {
117 | "name": "#%%\n"
118 | }
119 | }
120 | },
121 | {
122 | "cell_type": "code",
123 | "execution_count": null,
124 | "outputs": [],
125 | "source": [
126 | "accumulate = []\n",
127 | "data = []\n",
128 | "\n",
129 | "for cnt, file in enumerate(files):\n",
130 | " model, ensemble, x_train, y_train, x_val, y_val, x_scaler, y_scaler = load_setup(file)\n",
131 | " estimator_ensemble = build_estimator('emcdue', ensemble, nn_runs=100)\n",
132 | " estimator_single = build_estimator('mcdue', model, nn_runs=100)\n",
133 | "\n",
134 | " x_val_tensor = torch.tensor(x_val)\n",
135 | " unscale = lambda y : y_scaler.inverse_transform(y)\n",
136 | "\n",
137 | " predictions = model(x_val_tensor.cuda()).cpu().detach().numpy()\n",
138 | " errors = predictions - y_val\n",
139 | " ue_single = estimator_single.estimate(torch.Tensor(x_val).double().cuda())\n",
140 | " ll_single = uq_ll(errors, ue_single)\n",
141 | "\n",
142 | "\n",
143 | " predictions = ensemble(x_val_tensor.cuda()).cpu().detach().numpy()\n",
144 | " errors = predictions - y_val\n",
145 | " ue_ensemble = estimator_ensemble.estimate(torch.Tensor(x_val).double().cuda())\n",
146 | " ll_ensemble = uq_ll(errors, ue_ensemble)\n",
147 | "\n",
148 | " accumulate.append([file[:4], 'single', ll_single])\n",
149 | " accumulate.append([file[:4], 'ensemble', ll_ensemble])\n",
150 | " #\n",
151 | " # print(file)\n",
152 | " # print('Single', rmse_single)\n",
153 | " # print('Ensemble', rmse_ensemble)\n",
154 | "\n"
155 | ],
156 | "metadata": {
157 | "collapsed": false,
158 | "pycharm": {
159 | "name": "#%%\n"
160 | }
161 | }
162 | },
163 | {
164 | "cell_type": "code",
165 | "execution_count": null,
166 | "outputs": [],
167 | "source": [
168 | "df = pd.DataFrame(accumulate, columns=['dataset', 'type', 'll'])\n",
169 | "sns.boxplot('dataset', 'll', hue='type', data=df)\n",
170 | "plt.savefig('ll_emcdue.png', dpi=150)\n",
171 | "\n",
172 | "\n",
173 | "\n"
174 | ],
175 | "metadata": {
176 | "collapsed": false,
177 | "pycharm": {
178 | "name": "#%%\n"
179 | }
180 | }
181 | }
182 | ],
183 | "metadata": {
184 | "kernelspec": {
185 | "name": "python3",
186 | "language": "python",
187 | "display_name": "Python 3"
188 | },
189 | "language_info": {
190 | "codemirror_mode": {
191 | "name": "ipython",
192 | "version": 2
193 | },
194 | "file_extension": ".py",
195 | "mimetype": "text/x-python",
196 | "name": "python",
197 | "nbconvert_exporter": "python",
198 | "pygments_lexer": "ipython2",
199 | "version": "2.7.6"
200 | }
201 | },
202 | "nbformat": 4,
203 | "nbformat_minor": 0
204 | }
--------------------------------------------------------------------------------
/experiments/deprecated/ensembles_4.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "outputs": [],
7 | "source": [
8 | "%load_ext autoreload\n",
9 | "%autoreload 2"
10 | ],
11 | "metadata": {
12 | "collapsed": false,
13 | "pycharm": {
14 | "name": "#%%\n"
15 | }
16 | }
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": null,
21 | "outputs": [],
22 | "source": [
23 | "import os\n",
24 | "import pickle\n",
25 | "import random\n",
26 | "from pathlib import Path\n",
27 | "\n",
28 | "import seaborn as sns\n",
29 | "import pandas as pd\n",
30 | "import torch\n",
31 | "from torch.nn.functional import elu\n",
32 | "import numpy as np\n",
33 | "import matplotlib.pyplot as plt\n",
34 | "\n",
35 | "from alpaca.uncertainty_estimator.masks import build_masks, DEFAULT_MASKS\n",
36 | "from alpaca.analysis.metrics import uq_ll\n",
37 | "from alpaca.model.ensemble import MLPEnsemble\n",
38 | "from alpaca.uncertainty_estimator import build_estimator\n",
39 | "from alpaca.analysis.metrics import get_uq_metrics\n",
40 | "\n",
41 | "plt.rcParams['figure.facecolor'] = 'white'\n"
42 | ],
43 | "metadata": {
44 | "collapsed": false,
45 | "pycharm": {
46 | "name": "#%%\n"
47 | }
48 | }
49 | },
50 | {
51 | "cell_type": "code",
52 | "execution_count": null,
53 | "outputs": [],
54 | "source": [
55 | "SEED = 10\n",
56 | "torch.manual_seed(SEED)\n",
57 | "np.random.seed(SEED)\n",
58 | "random.seed(SEED)\n",
59 | "\n",
60 | "torch.cuda.set_device(0)\n",
61 | "torch.backends.cudnn.deterministic = True\n",
62 | "torch.backends.cudnn.benchmark = False\n"
63 | ],
64 | "metadata": {
65 | "collapsed": false,
66 | "pycharm": {
67 | "name": "#%%\n"
68 | }
69 | }
70 | },
71 | {
72 | "cell_type": "code",
73 | "execution_count": null,
74 | "outputs": [],
75 | "source": [
76 | "folder = Path('./data/regression')\n",
77 | "files = sorted([file for file in os.listdir(folder) if file.endswith('.pickle')])\n",
78 | "# files = [file for file in files if file.startswith('kin8')]\n",
79 | "\n"
80 | ],
81 | "metadata": {
82 | "collapsed": false,
83 | "pycharm": {
84 | "name": "#%%\n"
85 | }
86 | }
87 | },
88 | {
89 | "cell_type": "code",
90 | "execution_count": null,
91 | "outputs": [],
92 | "source": [
93 | "def load_setup(file):\n",
94 | " print(file)\n",
95 | " with open(folder / 'log_exp.log', 'w') as f:\n",
96 | " f.write(f'{cnt} / {len(files)}')\n",
97 | " with open(folder / file, 'rb') as f:\n",
98 | " dct = pickle.load(f)\n",
99 | " config = dct['config']\n",
100 | " config['n_ue_runs'] = 1\n",
101 | " config['acc_percentile'] = .1\n",
102 | " state_dict = dct['state_dict']\n",
103 | " x_train, y_train, x_val, y_val, x_scaler, y_scaler = dct['data']\n",
104 | "\n",
105 | " ensemble = MLPEnsemble(\n",
106 | " config['layers'], n_models=config['n_ens'], activation = elu,\n",
107 | " reduction='mean')\n",
108 | " ensemble.load_state_dict(state_dict)\n",
109 | "\n",
110 | " model = ensemble.models[2]\n",
111 | " return model, ensemble, x_train, y_train, x_val, y_val, x_scaler, y_scaler\n"
112 | ],
113 | "metadata": {
114 | "collapsed": false,
115 | "pycharm": {
116 | "name": "#%%\n"
117 | }
118 | }
119 | },
120 | {
121 | "cell_type": "code",
122 | "execution_count": null,
123 | "outputs": [],
124 | "source": [
125 | "accumulate_ll = []\n",
126 | "data = []\n",
127 | "\n",
128 | "\n",
129 | "# np.random.shuffle(files)\n",
130 | "for cnt, file in enumerate(files):\n",
131 | " model, ensemble, x_train, y_train, x_val, y_val, x_scaler, y_scaler = load_setup(file)\n",
132 | "\n",
133 | " x_val_tensor = torch.tensor(x_val)\n",
134 | " unscale = lambda y : y_scaler.inverse_transform(y)\n",
135 | "\n",
136 | " predictions = model(x_val_tensor.cuda()).cpu().detach().numpy()\n",
137 | " errors = predictions - y_val\n",
138 | " # rmse_single = np.sqrt(np.mean(np.square(errors)))\n",
139 | " # accumulate.append([file[:4], 'single', rmse_single])\n",
140 | "\n",
141 | " # predictions = ensemble(x_val_tensor.cuda()).cpu().detach().numpy()\n",
142 | " # errors = predictions - y_val\n",
143 | " # rmse_single = np.sqrt(np.mean(np.square(errors)))\n",
144 | " # accumulate.append([file[:4], 'ensemble', rmse_single])\n",
145 | "\n",
146 | " for mask_name in DEFAULT_MASKS:\n",
147 | " estimator = build_estimator(\n",
148 | " 'mcdue_masked', model, nn_runs=100, keep_runs=True,\n",
149 | " dropout_mask=mask_name)\n",
150 | " ue =estimator.estimate(torch.Tensor(x_val).double().cuda())\n",
151 | " runs = estimator.last_mcd_runs()\n",
152 | " predictions = np.mean(estimator.last_mcd_runs(), axis=-1)\n",
153 | " errors = predictions - y_val[:, 0]\n",
154 | " rmse_mask = np.sqrt(np.mean(np.square(errors)))\n",
155 | " # accumulate.append([file[:4], mask_name, rmse_mask])\n",
156 | " ll = uq_ll(errors, ue)\n",
157 | " accumulate_ll.append([file[:4], mask_name, ll])\n",
158 | "\n",
159 | "\n",
160 | "\n"
161 | ],
162 | "metadata": {
163 | "collapsed": false,
164 | "pycharm": {
165 | "name": "#%%\n"
166 | }
167 | }
168 | },
169 | {
170 | "cell_type": "code",
171 | "execution_count": null,
172 | "outputs": [],
173 | "source": [
174 | "plt.figure(figsize=(10, 6))\n",
175 | "\n",
176 | "accumulate2 = [record for record in accumulate_ll if record[1] !='decorrelating_sc']\n",
177 | "df = pd.DataFrame(accumulate2, columns=['dataset', 'type', 'LL'])\n",
178 | "sns.boxplot('dataset', 'LL', hue='type', data=df)\n",
179 | "plt.savefig('ll_masks.png', dpi=150)\n",
180 | "\n"
181 | ],
182 | "metadata": {
183 | "collapsed": false,
184 | "pycharm": {
185 | "name": "#%%\n"
186 | }
187 | }
188 | },
189 | {
190 | "cell_type": "code",
191 | "execution_count": null,
192 | "outputs": [],
193 | "source": [
194 | "\n"
195 | ],
196 | "metadata": {
197 | "collapsed": false,
198 | "pycharm": {
199 | "name": "#%%\n"
200 | }
201 | }
202 | },
203 | {
204 | "cell_type": "code",
205 | "execution_count": null,
206 | "outputs": [],
207 | "source": [
208 | "\n"
209 | ],
210 | "metadata": {
211 | "collapsed": false,
212 | "pycharm": {
213 | "name": "#%%\n"
214 | }
215 | }
216 | }
217 | ],
218 | "metadata": {
219 | "kernelspec": {
220 | "name": "python3",
221 | "language": "python",
222 | "display_name": "Python 3"
223 | },
224 | "language_info": {
225 | "codemirror_mode": {
226 | "name": "ipython",
227 | "version": 2
228 | },
229 | "file_extension": ".py",
230 | "mimetype": "text/x-python",
231 | "name": "python",
232 | "nbconvert_exporter": "python",
233 | "pygments_lexer": "ipython2",
234 | "version": "2.7.6"
235 | }
236 | },
237 | "nbformat": 4,
238 | "nbformat_minor": 0
239 | }
--------------------------------------------------------------------------------
/experiments/deprecated/ensembles_5.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "outputs": [],
7 | "source": [
8 | "%load_ext autoreload\n",
9 | "%autoreload 2"
10 | ],
11 | "metadata": {
12 | "collapsed": false,
13 | "pycharm": {
14 | "name": "#%%\n"
15 | }
16 | }
17 | },
18 | {
19 | "cell_type": "code",
20 | "execution_count": null,
21 | "outputs": [],
22 | "source": [
23 | "import os\n",
24 | "import pickle\n",
25 | "import random\n",
26 | "from pathlib import Path\n",
27 | "\n",
28 | "import seaborn as sns\n",
29 | "import pandas as pd\n",
30 | "import torch\n",
31 | "from torch.nn.functional import elu\n",
32 | "import numpy as np\n",
33 | "import matplotlib.pyplot as plt\n",
34 | "\n",
35 | "from alpaca.uncertainty_estimator.masks import build_masks, DEFAULT_MASKS\n",
36 | "from alpaca.analysis.metrics import uq_ll\n",
37 | "from alpaca.model.ensemble import MLPEnsemble\n",
38 | "from alpaca.uncertainty_estimator import build_estimator\n",
39 | "from alpaca.analysis.metrics import get_uq_metrics\n",
40 | "\n",
41 | "plt.rcParams['figure.facecolor'] = 'white'\n"
42 | ],
43 | "metadata": {
44 | "collapsed": false,
45 | "pycharm": {
46 | "name": "#%%\n"
47 | }
48 | }
49 | },
50 | {
51 | "cell_type": "code",
52 | "execution_count": null,
53 | "outputs": [],
54 | "source": [
55 | "SEED = 10\n",
56 | "torch.manual_seed(SEED)\n",
57 | "np.random.seed(SEED)\n",
58 | "random.seed(SEED)\n",
59 | "\n",
60 | "torch.cuda.set_device(0)\n",
61 | "torch.backends.cudnn.deterministic = True\n",
62 | "torch.backends.cudnn.benchmark = False\n"
63 | ],
64 | "metadata": {
65 | "collapsed": false,
66 | "pycharm": {
67 | "name": "#%%\n"
68 | }
69 | }
70 | },
71 | {
72 | "cell_type": "code",
73 | "execution_count": null,
74 | "outputs": [],
75 | "source": [
76 | "folder = Path('./data/regression')\n",
77 | "files = sorted([file for file in os.listdir(folder) if file.endswith('.pickle')])\n",
78 | "# files = [file for file in files if file.startswith('kin8')]\n",
79 | "\n"
80 | ],
81 | "metadata": {
82 | "collapsed": false,
83 | "pycharm": {
84 | "name": "#%%\n"
85 | }
86 | }
87 | },
88 | {
89 | "cell_type": "code",
90 | "execution_count": null,
91 | "outputs": [],
92 | "source": [
93 | "def load_setup(file):\n",
94 | " print(file)\n",
95 | " with open(folder / 'log_exp.log', 'w') as f:\n",
96 | " f.write(f'{cnt} / {len(files)}')\n",
97 | " with open(folder / file, 'rb') as f:\n",
98 | " dct = pickle.load(f)\n",
99 | " config = dct['config']\n",
100 | " config['n_ue_runs'] = 1\n",
101 | " config['acc_percentile'] = .1\n",
102 | " state_dict = dct['state_dict']\n",
103 | " x_train, y_train, x_val, y_val, x_scaler, y_scaler = dct['data']\n",
104 | "\n",
105 | " ensemble = MLPEnsemble(\n",
106 | " config['layers'], n_models=config['n_ens'], activation = elu,\n",
107 | " reduction='mean')\n",
108 | " ensemble.load_state_dict(state_dict)\n",
109 | "\n",
110 | " model = ensemble.models[2]\n",
111 | " return model, ensemble, x_train, y_train, x_val, y_val, x_scaler, y_scaler\n"
112 | ],
113 | "metadata": {
114 | "collapsed": false,
115 | "pycharm": {
116 | "name": "#%%\n"
117 | }
118 | }
119 | },
120 | {
121 | "cell_type": "code",
122 | "execution_count": null,
123 | "outputs": [],
124 | "source": [
125 | "accumulate_ll = []\n",
126 | "data = []\n",
127 | "\n",
128 | "\n",
129 | "np.random.shuffle(files)\n",
130 | "for cnt, file in enumerate(files[:3]):\n",
131 | " model, ensemble, x_train, y_train, x_val, y_val, x_scaler, y_scaler = load_setup(file)\n",
132 | "\n",
133 | " x_val_tensor = torch.tensor(x_val)\n",
134 | " unscale = lambda y : y_scaler.inverse_transform(y)\n",
135 | "\n",
136 | " predictions = model(x_val_tensor.cuda()).cpu().detach().numpy()\n",
137 | " errors = predictions - y_val\n",
138 | "\n",
139 | " # mask_names = ['mc_dropout', 'ht_decorrelating', 'ht_dpp', 'cov_dpp', 'ht_k_dpp', 'cov_k_dpp']\n",
140 | " mask_names = ['k_dpp', 'ht_k_dpp', 'cov_k_dpp']\n",
141 | " for mask_name in mask_names:\n",
142 | " try:\n",
143 | " estimator = build_estimator(\n",
144 | " 'mcdue_masked', model, nn_runs=100, keep_runs=True,\n",
145 | " dropout_mask=mask_name, dropout_rate=0.5)\n",
146 | " ue =estimator.estimate(torch.Tensor(x_val).double().cuda())\n",
147 | " runs = estimator.last_mcd_runs()\n",
148 | " predictions = np.mean(estimator.last_mcd_runs(), axis=-1)\n",
149 | " errors = predictions - y_val[:, 0]\n",
150 | " rmse_mask = np.sqrt(np.mean(np.square(errors)))\n",
151 | " ll = uq_ll(errors, ue)\n",
152 | " accumulate_ll.append([file[:4], mask_name, ll])\n",
153 | " print(estimator, ll)\n",
154 | " continue\n"
155 | ],
156 | "metadata": {
157 | "collapsed": false,
158 | "pycharm": {
159 | "name": "#%%\n",
160 | "is_executing": true
161 | }
162 | }
163 | },
164 | {
165 | "cell_type": "code",
166 | "execution_count": null,
167 | "outputs": [],
168 | "source": [
169 | "plt.figure(figsize=(14, 6))\n",
170 | "\n",
171 | "accumulate2 = [record for record in accumulate_ll if record[1] !='decorrelating_sc']\n",
172 | "df = pd.DataFrame(accumulate2, columns=['dataset', 'type', 'LL'])\n",
173 | "sns.boxplot('dataset', 'LL', hue='type', data=df)\n",
174 | "plt.savefig('ll_masks.png', dpi=150)\n",
175 | "\n"
176 | ],
177 | "metadata": {
178 | "collapsed": false,
179 | "pycharm": {
180 | "name": "#%%\n"
181 | }
182 | }
183 | },
184 | {
185 | "cell_type": "code",
186 | "execution_count": null,
187 | "outputs": [],
188 | "source": [
189 | "\n"
190 | ],
191 | "metadata": {
192 | "collapsed": false,
193 | "pycharm": {
194 | "name": "#%%\n"
195 | }
196 | }
197 | },
198 | {
199 | "cell_type": "code",
200 | "execution_count": null,
201 | "outputs": [],
202 | "source": [
203 | "\n"
204 | ],
205 | "metadata": {
206 | "collapsed": false,
207 | "pycharm": {
208 | "name": "#%%\n"
209 | }
210 | }
211 | }
212 | ],
213 | "metadata": {
214 | "kernelspec": {
215 | "name": "python3",
216 | "language": "python",
217 | "display_name": "Python 3"
218 | },
219 | "language_info": {
220 | "codemirror_mode": {
221 | "name": "ipython",
222 | "version": 2
223 | },
224 | "file_extension": ".py",
225 | "mimetype": "text/x-python",
226 | "name": "python",
227 | "nbconvert_exporter": "python",
228 | "pygments_lexer": "ipython2",
229 | "version": "2.7.6"
230 | }
231 | },
232 | "nbformat": 4,
233 | "nbformat_minor": 0
234 | }
--------------------------------------------------------------------------------
/experiments/deprecated/move.py:
--------------------------------------------------------------------------------
1 | import os
2 | from shutil import copyfile
3 |
4 |
5 |
6 | for ack in ['max_prob']:
7 | for i in range(3):
8 | file_from = f"logs/{ack}/cifar_{i}/ue.pickle"
9 | file_to = f"logs/classification/cifar_{i}/ue_{ack}.pickle"
10 | copyfile(file_from, file_to)
11 | print(file_from)
12 | print(file_to)
13 |
14 |
--------------------------------------------------------------------------------
/experiments/deprecated/plot_df.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | import matplotlib.pyplot as plt
3 | import seaborn as sns
4 | from experiments.experiment_setup import ROOT_DIR
5 | from pathlib import Path
6 | import matplotlib
7 |
8 | matplotlib.rcParams['savefig.dpi'] = 150
9 |
10 | #
11 | # dataset = 'MNIST'
12 | # dataset = 'CIFAR-10'
13 | # dataset = 'SVHN'
14 |
15 | file = Path(ROOT_DIR) / 'experiments'/ 'data'/ f'var_ratio_4_boxplot_{dataset}_50000_150.csv'
16 | df = pd.read_csv(file)
17 | df = df.replace('mc_dropout', 'MC dropout')
18 | df = df.replace('decorrelating_sc', 'decorrelation')
19 | df = df[df['Estimator type'] != 'k_dpp_noisereg']
20 | print(df)
21 | fig, ax = plt.subplots(figsize=(6, 6))
22 | plt.subplots_adjust(right=.95)
23 |
24 | with sns.axes_style('whitegrid'):
25 | sns.boxplot(data=df, y='ROC-AUC score', x='Estimator type', ax=ax)
26 | plt.title(f'{dataset} wrong prediction ROC-AUC')
27 |
28 | ax.yaxis.grid(True)
29 | ax.xaxis.grid(True)
30 |
31 |
32 | plt.savefig(f'experiments/data/results/rocauc_{dataset}_4.png')
33 | plt.show()
34 |
35 |
--------------------------------------------------------------------------------
/experiments/deprecated/plot_df_al.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | import matplotlib.pyplot as plt
3 | import seaborn as sns
4 | from experiments.experiment_setup import ROOT_DIR
5 | from pathlib import Path
6 | import matplotlib
7 |
8 | matplotlib.rcParams['savefig.dpi'] = 600
9 | # matplotlib.rcParams['savefig.dpi'] = 2 * matplotlib.rcParams['savefig.dpi']
10 |
11 | #
12 | # dataset = 'MNIST'
13 | # dataset = 'CIFAR-10'
14 | dataset = 'SVHN'
15 |
16 | file = Path(ROOT_DIR) / 'experiments' / 'data' / f'mnist_beauty_simple_conv_100_20.csv'
17 | df = pd.read_csv(file)
18 | df = df.replace('mc_dropout', 'MC dropout')
19 | df = df.replace('decorrelating_sc', 'decorrelation')
20 | print(df)
21 | df = df[df['Method'] != 'k_dpp_noisereg']
22 | df2 = df[df.Method.isin(['random', 'error_oracle', 'max_entropy'])]
23 | df3 = df[~df.Method.isin(['random', 'error_oracle', 'max_entropy'])]
24 | df4 = pd.concat((df3, df2))
25 |
26 | fig, ax = plt.subplots(figsize=(8, 5))
27 | plt.subplots_adjust(left=0.1, right=0.95)
28 |
29 | with sns.axes_style('whitegrid'):
30 | sns.lineplot('Step', 'Accuracy', hue='Method', data=df4)
31 | plt.title(f'Active learning on MNIST')
32 |
33 | ax.yaxis.grid(True)
34 | ax.xaxis.grid(True)
35 | plt.savefig(f'experiments/data/results/al.png')
36 | plt.show()
--------------------------------------------------------------------------------
/experiments/deprecated/print_confidence_accuracy_multi_ack.py:
--------------------------------------------------------------------------------
1 | import pickle
2 | import os
3 | import argparse
4 |
5 | import numpy as np
6 | import pandas as pd
7 | import matplotlib.pyplot as plt
8 | import seaborn as sns
9 |
10 |
11 | parser = argparse.ArgumentParser()
12 | parser.add_argument('name', type=str)
13 | parser.add_argument('repeats', type=int)
14 | # parser.add_argument('--acquisition', '-a', type=str, default='bald')
15 | parser.add_argument('--covariance', dest='covariance', action='store_true')
16 | args = parser.parse_args()
17 |
18 |
19 | acc_conf = []
20 | count_conf = []
21 |
22 | method = 'ht_k_dpp'
23 |
24 |
25 | covariance_str = '_covar' if args.covariance else ''
26 |
27 |
28 |
29 | # method = 'ht_dpp'
30 | approaches = [
31 | ('ensemble_max_prob', 'ensemble'),
32 | ('mc_dropout', 'bald'),
33 | ('ht_dpp', 'bald'),
34 | ('ensemble_bald', 'ensemble'),
35 | ('max_prob', '')
36 | ]
37 |
38 | # file_name = f'logs/classification/mnist_0/ue.pickle'
39 | #
40 | #
41 | # with open(file_name, 'rb') as f:
42 | # record = pickle.load(f)
43 | #
44 | # print(record)
45 | #
46 | #
47 | # import ipdb; ipdb.set_trace()
48 |
49 | # for ack in ['var_ratio', 'bald_n', 'max_prob']:
50 | for estimator_name, ack in approaches:
51 | args.acquisition = ack
52 | acquisition_str = 'bald' if args.acquisition in ['bald_n', ''] else args.acquisition
53 |
54 | for i in range(args.repeats):
55 | file_name = f'logs/classification/{args.name}_{i}/ue_{acquisition_str}{covariance_str}.pickle'
56 | print(file_name)
57 |
58 | with open(file_name, 'rb') as f:
59 | record = pickle.load(f)
60 |
61 | prediction = np.argmax(np.array(record['probabilities']), axis=-1)
62 | # import ipdb; ipdb.set_trace()
63 | is_correct = (prediction == record['y_val']).astype(np.int)
64 |
65 | # bins = np.concatenate((np.arange(0, 0.9, 0.1), np.arange(0.9, 1, 0.01)))
66 | bins = np.arange(0, 1, 0.1)
67 |
68 | print(record['uncertainties'].keys())
69 | ue = record['uncertainties'][estimator_name]
70 |
71 | print(estimator_name)
72 | print(min(ue), max(ue))
73 | if args.acquisition == 'bald_n':
74 | ue = ue / max(ue)
75 |
76 | for confidence_level in bins:
77 | point_confidences = 1 - ue
78 | bin_correct = is_correct[point_confidences > confidence_level]
79 | if len(bin_correct) > 0:
80 | accuracy = sum(bin_correct) / len(bin_correct)
81 | else:
82 | accuracy = None
83 | acc_conf.append((confidence_level, accuracy, estimator_name+'_'+ack))
84 | count_conf.append((confidence_level, len(bin_correct), estimator_name+' '+ack))
85 |
86 |
87 | plt.figure(figsize=(12, 6))
88 |
89 | plt.subplot(1, 2, 1)
90 | plt.title(f"Confidence-accuracy {args.name} {args.acquisition} {covariance_str}")
91 | df = pd.DataFrame(acc_conf, columns=['Confidence level', 'Accuracy', 'Estimator'])
92 | sns.lineplot('Confidence level', 'Accuracy', data=df, hue='Estimator')
93 | # plt.savefig(f"data/conf_accuracy_{args.name}_{args.acquisition}", dpi=150)
94 |
95 | plt.subplot(1, 2, 2)
96 | # plt.figure(figsize=(8, 6))
97 | plt.title(f"Confidence-count {args.name} {args.acquisition} {covariance_str}")
98 | df = pd.DataFrame(count_conf, columns=['Confidence level', 'Count', 'Estimator'])
99 | sns.lineplot('Confidence level', 'Count', data=df, hue='Estimator')
100 | plt.savefig(f"data/conf_ackquisition_{args.name}_{method}", dpi=150)
101 | # plt.savefig(f"data/conf_count_{args.name}_{args.acquisition}", dpi=150)
102 | plt.show()
103 |
104 |
--------------------------------------------------------------------------------
/experiments/deprecated/print_histogram.py:
--------------------------------------------------------------------------------
1 | import pickle
2 | import os
3 | import argparse
4 |
5 | import numpy as np
6 | import pandas as pd
7 | import matplotlib.pyplot as plt
8 | import seaborn as sns
9 |
10 |
11 | parser = argparse.ArgumentParser()
12 | parser.add_argument('name', type=str)
13 | parser.add_argument('repeats', type=int)
14 | parser.add_argument('--group', type=str, default='ht')
15 | args = parser.parse_args()
16 |
17 |
18 | acc_conf = []
19 | count_conf = []
20 |
21 |
22 | for i in range(args.repeats):
23 | file_name = f'logs/{args.group}/{args.name}_{i}/ue.pickle'
24 |
25 | with open(file_name, 'rb') as f:
26 | record = pickle.load(f)
27 |
28 | prediction = np.argmax(record['probabilities'], axis=-1)
29 | is_correct = (prediction == record['y_val']).astype(np.int)
30 |
31 | fig = plt.figure(figsize=(12, 8))
32 | fig.suptitle(args.group)
33 |
34 | for i, estimator in enumerate(record['estimators']):
35 | if estimator in ['max_entropy']:
36 | continue
37 | ue = record['uncertainties'][estimator]
38 | print(ue.shape)
39 | print(estimator)
40 | print(min(ue), max(ue))
41 | ax = plt.subplot(2, 3, i)
42 | ax.set_title(estimator)
43 | plt.hist(ue)
44 |
45 | plt.show()
46 |
47 |
48 |
49 |
--------------------------------------------------------------------------------
/experiments/deprecated/print_it.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | import matplotlib.pyplot as plt
3 | import seaborn as sns
4 |
5 |
6 | # df = pd.read_csv('data/al/ht_mnist_200_10.csv', names=['id', 'accuracy', 'step', 'method'], index_col='id', skiprows=1)
7 | #
8 | #
9 | # plt.figure(figsize=(8, 6))
10 | # plt.title('MNIST')
11 | # sns.lineplot('step', 'accuracy', hue='method', data=df)
12 | # plt.savefig('data/al/al_ht_mnist_200_10')
13 | # plt.show()
14 |
15 |
16 | config = {
17 | 'name': 'cifar'
18 | }
19 | # df = pd.DataFrame(rocaucs, columns=['Estimator', 'ROC-AUCs'])
20 | df = pd.read_csv(f"logs/{config['name']}_ed.csv", names=['id', 'ROC-AUCs', 'Estimator'], index_col='id', skiprows=1)
21 | plt.figure(figsize=(9, 6))
22 | sns.boxplot('Estimator', 'ROC-AUCs', data=df)
23 | plt.title(f"Error detection for {config['name']}")
24 | plt.savefig(f"data/ed/{config['name']}.png", dpi=150)
25 | plt.show()
26 |
27 | df.to_csv(f"logs/{config['name']}_ed.csv")
28 |
--------------------------------------------------------------------------------
/experiments/deprecated/print_ll.py:
--------------------------------------------------------------------------------
1 | import pickle
2 | import os
3 | import argparse
4 |
5 | import numpy as np
6 | import pandas as pd
7 | import matplotlib.pyplot as plt
8 | import seaborn as sns
9 |
10 |
11 | parser = argparse.ArgumentParser()
12 | parser.add_argument('name', type=str)
13 | parser.add_argument('repeats', type=int)
14 | parser.add_argument('--acquisition', '-a', type=str, default='bald')
15 | parser.add_argument('--covariance', dest='covariance', action='store_true')
16 | args = parser.parse_args()
17 |
18 |
19 |
20 | covariance_str = '_covar' if args.covariance else ''
21 | acquisition_str = 'bald' if args.acquisition == 'bald_n' else args.acquisition
22 |
23 |
24 | ll_records = []
25 |
26 | for i in range(args.repeats):
27 | file_name = f'logs/classification/{args.name}_{i}/ue_{acquisition_str}{covariance_str}.pickle'
28 | print(file_name)
29 |
30 | with open(file_name, 'rb') as f:
31 | record = pickle.load(f)
32 |
33 | print(i)
34 | print(record['lls'])
35 |
36 | ll_records.extend(record['lls'].items())
37 |
38 | len_val = 10_000
39 |
40 | ll_records = [(record[0], record[1] / len_val) for record in ll_records]
41 | print(ll_records)
42 |
43 | df = pd.DataFrame(ll_records, columns=['method', 'log_likelihood'])
44 | plt.title(args.name)
45 | sns.boxplot('method', 'log_likelihood', data=df)
46 | plt.show()
47 |
48 |
49 | # prediction = np.argmax(record['probabilities'], axis=-1)
50 | # is_correct = (prediction == record['y_val']).astype(np.int)
51 | #
52 | # # bins = np.concatenate((np.arange(0, 0.9, 0.1), np.arange(0.9, 1, 0.01)))
53 | # bins = np.arange(0, 1, 0.1)
54 | #
55 | # for i, estimator in enumerate(record['estimators']):
56 | # if estimator in ['max_entropy']:
57 | # continue
58 | # ue = record['uncertainties'][estimator]
59 | #
60 | # print(estimator)
61 | # print(min(ue), max(ue))
62 | # if args.acquisition == 'bald_n':
63 | # ue = ue / max(ue)
64 | #
65 | # for confidence_level in bins:
66 | # point_confidences = 1 - ue
67 | # bin_correct = is_correct[point_confidences > confidence_level]
68 | # if len(bin_correct) > 0:
69 | # accuracy = sum(bin_correct) / len(bin_correct)
70 | # else:
71 | # accuracy = None
72 | # acc_conf.append((confidence_level, accuracy, estimator))
73 | # count_conf.append((confidence_level, len(bin_correct), estimator))
74 |
75 |
76 | # plt.figure(figsize=(12, 6))
77 | #
78 | # plt.subplot(1, 2, 1)
79 | # plt.title(f"Confidence-accuracy {args.name} {args.acquisition} {covariance_str}")
80 | # df = pd.DataFrame(acc_conf, columns=['Confidence level', 'Accuracy', 'Estimator'])
81 | # sns.lineplot('Confidence level', 'Accuracy', data=df, hue='Estimator')
82 | # # plt.savefig(f"data/conf_accuracy_{args.name}_{args.acquisition}", dpi=150)
83 | #
84 | # plt.subplot(1, 2, 2)
85 | # # plt.figure(figsize=(8, 6))
86 | # plt.title(f"Confidence-count {args.name} {args.acquisition} {covariance_str}")
87 | # df = pd.DataFrame(count_conf, columns=['Confidence level', 'Count', 'Estimator'])
88 | # sns.lineplot('Confidence level', 'Count', data=df, hue='Estimator')
89 | # plt.savefig(f"data/conf_accuracy_{args.name}_{args.acquisition}{covariance_str}", dpi=150)
90 | # # plt.savefig(f"data/conf_count_{args.name}_{args.acquisition}", dpi=150)
91 | # plt.show()
92 | #
93 |
--------------------------------------------------------------------------------
/experiments/deprecated/regression_2_prfm2.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": [
9 | "%load_ext autoreload\n",
10 | "%autoreload 2"
11 | ]
12 | },
13 | {
14 | "cell_type": "code",
15 | "execution_count": null,
16 | "metadata": {},
17 | "outputs": [],
18 | "source": [
19 | "import os\n",
20 | "import pickle\n",
21 | "import random\n",
22 | "from pathlib import Path\n",
23 | "\n",
24 | "import pandas as pd\n",
25 | "import torch\n",
26 | "from torch.nn.functional import elu\n",
27 | "import numpy as np\n",
28 | "import matplotlib.pyplot as plt\n",
29 | "\n",
30 | "from alpaca.uncertainty_estimator.masks import build_masks, DEFAULT_MASKS\n",
31 | "from alpaca.model.ensemble import MLPEnsemble\n",
32 | "from alpaca.uncertainty_estimator import build_estimator\n",
33 | "from alpaca.analysis.metrics import get_uq_metrics\n",
34 | "\n",
35 | "plt.rcParams['figure.facecolor'] = 'white'\n"
36 | ]
37 | },
38 | {
39 | "cell_type": "code",
40 | "execution_count": null,
41 | "metadata": {},
42 | "outputs": [],
43 | "source": [
44 | "SEED = 10 \n",
45 | "torch.manual_seed(SEED)\n",
46 | "np.random.seed(SEED)\n",
47 | "random.seed(SEED)\n",
48 | "\n",
49 | "torch.cuda.set_device(0)\n",
50 | "torch.backends.cudnn.deterministic = True\n",
51 | "torch.backends.cudnn.benchmark = False\n"
52 | ]
53 | },
54 | {
55 | "cell_type": "code",
56 | "execution_count": null,
57 | "metadata": {},
58 | "outputs": [],
59 | "source": [
60 | "def construct_estimator(model, model_type, name):\n",
61 | " if model_type == 'mask': \n",
62 | " mask = masks[name]\n",
63 | " msk = build_estimator(\n",
64 | " 'mcdue_masked', model, nn_runs=config['nn_runs'], dropout_mask=mask,\n",
65 | " dropout_rate=config['dropout_uq'])\n",
66 | " msk.tol_level=1e-5\n",
67 | " return msk\n",
68 | " elif model_type == 'emask': \n",
69 | " mask = emasks[name]\n",
70 | " msk = build_estimator(\n",
71 | " 'emcdue_masked', model, nn_runs=config['nn_runs'], dropout_mask=mask,\n",
72 | " dropout_rate=config['dropout_uq'])\n",
73 | " msk.tol_level=1e-5\n",
74 | " return msk\n",
75 | " else:\n",
76 | " return build_estimator(name, model)\n",
77 | "\n",
78 | "\n",
79 | "class Evaluator: \n",
80 | " def __init__(self, x_test, y_test, y_scaler, tag='standard'):\n",
81 | " self.x_test = torch.DoubleTensor(x_test).cuda()\n",
82 | " self.y_test = y_test\n",
83 | " self.unscale = lambda y : y_scaler.inverse_transform(y) \n",
84 | " self.tag = tag\n",
85 | " self.results = []\n",
86 | "\n",
87 | " def bench(self, model, name, model_type='mask'): \n",
88 | " predictions = model(self.x_test).cpu().detach().numpy()\n",
89 | " \n",
90 | " errors = np.abs(predictions - self.y_test)\n",
91 | " \n",
92 | " scaled_errors = self.unscale(predictions) - self.unscale(self.y_test)\n",
93 | " rmse = np.sqrt(np.mean(np.square(scaled_errors)))\n",
94 | "\n",
95 | " estimator = construct_estimator(model, model_type, name)\n",
96 | " if model_type == 'emask':\n",
97 | " name = 'e_' + name\n",
98 | " \n",
99 | " for run in range(config['n_ue_runs']):\n",
100 | " estimations = estimator.estimate(self.x_test)\n",
101 | " acc, ndcg, ll = get_uq_metrics(estimations, errors, \n",
102 | " config['acc_percentile'],\n",
103 | " bins = [80, 95, 99]\n",
104 | " )\n",
105 | " self.results.append([acc, ndcg, ll, rmse, name, self.tag])\n",
106 | " if hasattr(estimator, 'reset'):\n",
107 | " estimator.reset()"
108 | ]
109 | },
110 | {
111 | "cell_type": "code",
112 | "execution_count": null,
113 | "metadata": {},
114 | "outputs": [],
115 | "source": [
116 | "folder = Path('./data/regression')\n",
117 | "files = [file for file in os.listdir(folder) if file.endswith('.pickle')]"
118 | ]
119 | },
120 | {
121 | "cell_type": "code",
122 | "execution_count": null,
123 | "metadata": {},
124 | "outputs": [],
125 | "source": [
126 | "data = []\n",
127 | "for cnt, file in enumerate(files[:1]):\n",
128 | " with open(folder / 'log_exp.log', 'w') as f:\n",
129 | " f.write(f'{cnt} / {len(files)}')\n",
130 | " with open(folder / file, 'rb') as f:\n",
131 | " dct = pickle.load(f)\n",
132 | " print(file)\n",
133 | " config = dct['config']\n",
134 | " config['n_ue_runs'] = 1\n",
135 | " config['acc_percentile'] = .1\n",
136 | " state_dict = dct['state_dict']\n",
137 | " x_train, y_train, x_val, y_val, x_scaler, y_scaler = dct['data']\n",
138 | "\n",
139 | " model = MLPEnsemble(\n",
140 | " config['layers'], n_models=config['n_ens'], activation = elu,\n",
141 | " reduction='mean')\n",
142 | " model.load_state_dict(state_dict)\n",
143 | "\n",
144 | " standard_evaluator = Evaluator(x_val, y_val, y_scaler, 'standard')\n",
145 | " masks = build_masks(DEFAULT_MASKS)\n",
146 | " emasks = []\n",
147 | " for i in range(config['n_ens']):\n",
148 | " msk = build_masks(DEFAULT_MASKS)\n",
149 | " emasks.append(msk)\n",
150 | " emasks = {key: [e[key] for e in emasks] for key in masks.keys()}\n",
151 | "\n",
152 | "\n",
153 | " #\n",
154 | " single_model = model.models[2]\n",
155 | " # for name in masks:\n",
156 | " # print(name, end = '|')\n",
157 | " # standard_evaluator.bench(single_model, name, 'mask')\n",
158 | " # standard_evaluator.bench(model, 'eue', 'ensemble')\n",
159 | " # for name in emasks:\n",
160 | " # print(name, end = '*|')\n",
161 | " # standard_evaluator.bench(model, name, 'emask')\n",
162 | " # mask_df = pd.DataFrame(standard_evaluator.results,\n",
163 | " # columns=['Acc', 'NDCG', 'LL',\n",
164 | " # 'RMSE', 'Mask', 'Tag'])\n",
165 | " # mask_df['fname'] = file\n",
166 | " # data.append(mask_df)\n",
167 | " # pd.concat(data).to_csv(folder/'experiment_results.csv', index = None)\n"
168 | ]
169 | },
170 | {
171 | "cell_type": "code",
172 | "execution_count": null,
173 | "metadata": {},
174 | "outputs": [],
175 | "source": [
176 | "'finished'"
177 | ]
178 | },
179 | {
180 | "cell_type": "code",
181 | "execution_count": null,
182 | "outputs": [],
183 | "source": [
184 | "\n"
185 | ],
186 | "metadata": {
187 | "collapsed": false,
188 | "pycharm": {
189 | "name": "#%%\n"
190 | }
191 | }
192 | }
193 | ],
194 | "metadata": {
195 | "kernelspec": {
196 | "display_name": "Python 3",
197 | "language": "python",
198 | "name": "python3"
199 | },
200 | "language_info": {
201 | "codemirror_mode": {
202 | "name": "ipython",
203 | "version": 3
204 | },
205 | "file_extension": ".py",
206 | "mimetype": "text/x-python",
207 | "name": "python",
208 | "nbconvert_exporter": "python",
209 | "pygments_lexer": "ipython3",
210 | "version": "3.6.7"
211 | }
212 | },
213 | "nbformat": 4,
214 | "nbformat_minor": 2
215 | }
--------------------------------------------------------------------------------
/experiments/deprecated/regression_3_dolan-more.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "outputs": [],
7 | "source": [
8 | "# Let's build Dolan-More curves, see:\n",
9 | "# http://abelsiqueira.github.io/blog/introduction-to-performance-profile/"
10 | ],
11 | "metadata": {
12 | "collapsed": false,
13 | "pycharm": {
14 | "name": "#%%\n",
15 | "is_executing": false
16 | }
17 | }
18 | },
19 | {
20 | "cell_type": "code",
21 | "execution_count": null,
22 | "metadata": {
23 | "pycharm": {
24 | "is_executing": false
25 | }
26 | },
27 | "outputs": [],
28 | "source": [
29 | "from pathlib import Path\n",
30 | "import random\n",
31 | "\n",
32 | "import seaborn as sns\n",
33 | "import pandas as pd\n",
34 | "import numpy as np\n",
35 | "import matplotlib.pyplot as plt\n",
36 | "import torch\n",
37 | "%matplotlib inline"
38 | ]
39 | },
40 | {
41 | "cell_type": "code",
42 | "execution_count": null,
43 | "outputs": [],
44 | "source": [
45 | "SEED = 10\n",
46 | "torch.manual_seed(SEED)\n",
47 | "np.random.seed(SEED)\n",
48 | "random.seed(SEED)\n",
49 | "\n",
50 | "torch.cuda.set_device(0)\n",
51 | "torch.backends.cudnn.deterministic = True\n",
52 | "torch.backends.cudnn.benchmark = False\n"
53 | ],
54 | "metadata": {
55 | "collapsed": false,
56 | "pycharm": {
57 | "name": "#%%\n",
58 | "is_executing": false
59 | }
60 | }
61 | },
62 | {
63 | "cell_type": "code",
64 | "execution_count": null,
65 | "metadata": {
66 | "pycharm": {
67 | "is_executing": false
68 | }
69 | },
70 | "outputs": [],
71 | "source": [
72 | "folder = Path('./data/regression')\n",
73 | "df = pd.read_csv(folder / 'experiment_results.csv').drop_duplicates()"
74 | ]
75 | },
76 | {
77 | "cell_type": "code",
78 | "execution_count": null,
79 | "metadata": {
80 | "pycharm": {
81 | "is_executing": false
82 | }
83 | },
84 | "outputs": [],
85 | "source": [
86 | "emasks = []\n",
87 | "masks = []\n",
88 | "for msk in df.Mask.unique():\n",
89 | " if msk[:2] == 'e_':\n",
90 | " emasks.append(msk)\n",
91 | " elif msk != 'eue':\n",
92 | " masks.append(msk)\n",
93 | "print(masks)\n",
94 | "print(emasks)"
95 | ]
96 | },
97 | {
98 | "cell_type": "code",
99 | "execution_count": null,
100 | "metadata": {
101 | "pycharm": {
102 | "is_executing": false
103 | }
104 | },
105 | "outputs": [],
106 | "source": [
107 | "dsets = []\n",
108 | "for fname in df.fname:\n",
109 | " dsets.append(fname.split('_')[0])\n",
110 | "df['dset'] = dsets"
111 | ]
112 | },
113 | {
114 | "cell_type": "code",
115 | "execution_count": null,
116 | "metadata": {
117 | "pycharm": {
118 | "is_executing": false
119 | }
120 | },
121 | "outputs": [],
122 | "source": []
123 | },
124 | {
125 | "cell_type": "code",
126 | "execution_count": null,
127 | "outputs": [],
128 | "source": [
129 | "# %%time\n",
130 | "large_data = []\n",
131 | "metric = 'Acc'\n",
132 | "for fname, df_temp in df.groupby('fname'):\n",
133 | " data = []\n",
134 | " assert len(df_temp[df_temp.Mask == 'eue']) == 1\n",
135 | " eue_performance = df_temp[df_temp.Mask == 'eue'][metric].values[0]\n",
136 | " dct_single = {'eue': eue_performance}\n",
137 | " for mask in masks:\n",
138 | " perf = df_temp[df_temp.Mask == mask][metric].values[0]\n",
139 | " dct_single[mask] = perf\n",
140 | " dct_single = {k: 1./v for k, v in dct_single.items()}\n",
141 | " data.append(dct_single)\n",
142 | " \n",
143 | " df_res = pd.DataFrame(data)\n",
144 | " normalized_values = df_res.values/df_res.min(axis = 1).values[:,None]\n",
145 | " df_res = pd.DataFrame(normalized_values, columns = df_res.columns)\n",
146 | " large_data.append(df_res)"
147 | ],
148 | "metadata": {
149 | "collapsed": false,
150 | "pycharm": {
151 | "name": "#%%\n",
152 | "is_executing": false
153 | }
154 | }
155 | },
156 | {
157 | "cell_type": "code",
158 | "execution_count": null,
159 | "metadata": {
160 | "pycharm": {
161 | "is_executing": false
162 | }
163 | },
164 | "outputs": [],
165 | "source": [
166 | "df_res = pd.concat(large_data)"
167 | ]
168 | },
169 | {
170 | "cell_type": "code",
171 | "execution_count": null,
172 | "metadata": {
173 | "pycharm": {
174 | "is_executing": false
175 | }
176 | },
177 | "outputs": [],
178 | "source": [
179 | "def make_dm_plot(df_res, masks, emasks,\n",
180 | " metric = 'some metric', \n",
181 | " exper = 'some exper',\n",
182 | " taus = np.linspace(1, 3, 101),\n",
183 | " plotter = plt.plot,\n",
184 | " **kwargs\n",
185 | " ):\n",
186 | " npp = len(df_res)\n",
187 | " for msk in masks:\n",
188 | " if 'eue' == msk:\n",
189 | " continue\n",
190 | " pas = []\n",
191 | " for tau in taus:\n",
192 | " pas.append(sum(df_res[msk].values <= tau)/npp)\n",
193 | " print(f'{msk}, {pas[0]:.2f}')\n",
194 | " plotter(taus, pas, label = msk,**kwargs)\n",
195 | " for msk in emasks:\n",
196 | " if 'eue' == msk:\n",
197 | " continue\n",
198 | " pas = []\n",
199 | " for tau in taus:\n",
200 | " pas.append(sum(df_res[msk].values <= tau)/npp)\n",
201 | " print(f'{msk}, {pas[0]:.2f}')\n",
202 | " plotter(taus, pas, label = msk,**kwargs)\n",
203 | " pas = []\n",
204 | " for tau in taus:\n",
205 | " pas.append(sum(df_res['eue'].values <= tau)/npp)\n",
206 | " print(f'{msk}, {pas[0]:.2f}')\n",
207 | " plotter(taus, pas, 'k', label = 'eue',**kwargs)\n",
208 | "\n",
209 | " plt.legend()\n",
210 | " plt.title(metric + '|' + exper)"
211 | ]
212 | },
213 | {
214 | "cell_type": "code",
215 | "execution_count": null,
216 | "metadata": {
217 | "pycharm": {
218 | "is_executing": false
219 | }
220 | },
221 | "outputs": [],
222 | "source": [
223 | "plt.figure(figsize=(8,6))\n",
224 | "masks = ['mc_dropout', 'decorrelating_sc', 'dpp', 'k_dpp', \n",
225 | " 'eue']\n",
226 | "make_dm_plot(df_res[masks], masks, [], metric, f' ', \n",
227 | " taus = np.linspace(1, 3, 101),lw=3, alpha=.8)\n",
228 | "plt.grid()\n",
229 | "plt.title('Accuracy for single NN UE')\n",
230 | "plt.legend(['MC dropout',\n",
231 | " 'decorrelation',\n",
232 | " 'dpp', 'k_dpp', 'ensemble'\n",
233 | " ])\n",
234 | "plt.xlabel(r'$\\tau$')\n",
235 | "plt.ylabel(r'$\\rho_a(\\tau$)')\n",
236 | "plt.xlim(1, 3)\n",
237 | "plt.savefig('../figures/dolan_acc_single.png', dpi = 600)\n"
238 | ]
239 | },
240 | {
241 | "cell_type": "code",
242 | "execution_count": null,
243 | "metadata": {
244 | "pycharm": {
245 | "is_executing": false
246 | }
247 | },
248 | "outputs": [],
249 | "source": [
250 | "import seaborn as sns\n",
251 | "cnt = 1\n",
252 | "names_as_in_paper = [\n",
253 | " 'boston', 'concrete', 'energy', 'kin8nm',\n",
254 | " 'naval', 'ccpp', 'naval', 'red wine', 'yacht'\n",
255 | "]\n",
256 | "\n",
257 | "\n",
258 | "plt.figure(figsize=(10,20))\n",
259 | "for dset in df.dset.unique():\n",
260 | " plt.subplot(4,2,cnt)\n",
261 | " dfx = df[(df.dset == dset)]\n",
262 | " g=sns.boxplot(x = 'LL', y = 'Mask', data = dfx)#, hue = 'dset')\n",
263 | " if cnt % 2 == 0:\n",
264 | " g.set(yticklabels=[])\n",
265 | " plt.grid()\n",
266 | " plt.title(names_as_in_paper[cnt-1])\n",
267 | " cnt += 1\n",
268 | "plt.tight_layout()\n"
269 | ]
270 | },
271 | {
272 | "cell_type": "code",
273 | "execution_count": null,
274 | "metadata": {
275 | "pycharm": {
276 | "is_executing": false
277 | }
278 | },
279 | "outputs": [],
280 | "source": [
281 | "import seaborn as sns\n",
282 | "cnt = 1\n",
283 | "names_as_in_paper = [\n",
284 | " 'boston', 'concrete', 'energy', 'kin8nm',\n",
285 | " 'naval', 'ccpp', 'naval', 'red wine', 'yacht'\n",
286 | "]\n",
287 | "\n",
288 | "plt.figure(figsize=(10,12))\n",
289 | "for dset in df.dset.unique():\n",
290 | " plt.subplot(4,2,cnt)\n",
291 | " dfx = df[(df.dset == dset) & (df.Mask.isin(masks))]\n",
292 | " g=sns.boxplot(x = 'LL', y = 'Mask', data = dfx)\n",
293 | " print(dset)\n",
294 | " g.set(ylabel='')\n",
295 | " if cnt % 2 == 0:\n",
296 | " g.set(yticklabels=[])\n",
297 | " else:\n",
298 | " g.set(yticklabels=['MC dropout', 'decorrelation', 'dpp', 'k_dpp', 'eue'])\n",
299 | " plt.grid()\n",
300 | " plt.title(names_as_in_paper[cnt-1])\n",
301 | " cnt += 1\n",
302 | "plt.tight_layout()\n",
303 | "plt.savefig('../figures/LL_UCI_single.png', dpi = 600)"
304 | ]
305 | },
306 | {
307 | "cell_type": "code",
308 | "execution_count": null,
309 | "outputs": [],
310 | "source": [
311 | "cnt = 1\n",
312 | "names_as_in_paper = [\n",
313 | " 'boston', 'concrete', 'energy', 'kin8nm',\n",
314 | " 'naval', 'ccpp', 'naval', 'red wine', 'yacht'\n",
315 | "]\n",
316 | "\n",
317 | "plt.figure(figsize=(10,12))\n",
318 | "\n",
319 | "for dset in df.dset.unique():\n",
320 | " plt.subplot(4,2,cnt)\n",
321 | " dfx = df[(df.dset == dset) & (df.Mask.isin(emasks))]\n",
322 | " g=sns.boxplot(x = 'LL', y = 'Mask', data = dfx)\n",
323 | " g.set(ylabel='')\n",
324 | " if cnt % 2 == 0:\n",
325 | " g.set(yticklabels=[])\n",
326 | " else:\n",
327 | " g.set(yticklabels=['MC dropout', 'decorrelation', 'dpp', 'k_dpp'])\n",
328 | " plt.grid()\n",
329 | " plt.title(names_as_in_paper[cnt-1])\n",
330 | " cnt += 1\n",
331 | "plt.tight_layout()\n",
332 | "plt.savefig('../figures/LL_UCI_ens.png', dpi = 600)"
333 | ],
334 | "metadata": {
335 | "collapsed": false,
336 | "pycharm": {
337 | "name": "#%%\n",
338 | "is_executing": false
339 | }
340 | }
341 | },
342 | {
343 | "cell_type": "code",
344 | "execution_count": null,
345 | "outputs": [],
346 | "source": [
347 | "\n"
348 | ],
349 | "metadata": {
350 | "collapsed": false,
351 | "pycharm": {
352 | "name": "#%%\n"
353 | }
354 | }
355 | }
356 | ],
357 | "metadata": {
358 | "kernelspec": {
359 | "display_name": "Python 3",
360 | "language": "python",
361 | "name": "python3"
362 | },
363 | "language_info": {
364 | "codemirror_mode": {
365 | "name": "ipython",
366 | "version": 3
367 | },
368 | "file_extension": ".py",
369 | "mimetype": "text/x-python",
370 | "name": "python",
371 | "nbconvert_exporter": "python",
372 | "pygments_lexer": "ipython3",
373 | "version": "3.6.7"
374 | },
375 | "pycharm": {
376 | "stem_cell": {
377 | "cell_type": "raw",
378 | "source": [],
379 | "metadata": {
380 | "collapsed": false
381 | }
382 | }
383 | }
384 | },
385 | "nbformat": 4,
386 | "nbformat_minor": 2
387 | }
--------------------------------------------------------------------------------
/experiments/deprecated/regression_dm_produce_results_from_models.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": 1,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": [
9 | "import sys\n",
10 | "sys.path.append('..')\n",
11 | "%load_ext autoreload\n",
12 | "%autoreload 2"
13 | ]
14 | },
15 | {
16 | "cell_type": "code",
17 | "execution_count": 2,
18 | "metadata": {},
19 | "outputs": [],
20 | "source": [
21 | "sys.path = ['/home/etsymbalov/.local/lib/python3.6/site-packages'] + sys.path"
22 | ]
23 | },
24 | {
25 | "cell_type": "code",
26 | "execution_count": 3,
27 | "metadata": {},
28 | "outputs": [],
29 | "source": [
30 | "import numpy as np\n",
31 | "import matplotlib.pyplot as plt\n",
32 | "\n",
33 | "from experiment_setup import get_model, set_random, build_estimator\n",
34 | "from uncertainty_estimator.masks import build_masks, DEFAULT_MASKS\n",
35 | "from dataloader.toy import ToyQubicData, ToySinData\n",
36 | "from model.mlp import MLP\n",
37 | "from model.ensemble import MLPEnsemble\n",
38 | "import pickle\n",
39 | "\n",
40 | "plt.rcParams['figure.facecolor'] = 'white'"
41 | ]
42 | },
43 | {
44 | "cell_type": "code",
45 | "execution_count": 4,
46 | "metadata": {},
47 | "outputs": [],
48 | "source": [
49 | "from dataloader.builder import build_dataset\n",
50 | "from model.mlp import MLP\n",
51 | "from uncertainty_estimator.masks import build_masks \n",
52 | "from experiment_setup import build_estimator\n",
53 | "from analysis.metrics import get_uq_metrics\n",
54 | "from experiments.utils.data import scale, split_ood, multiple_kfold"
55 | ]
56 | },
57 | {
58 | "cell_type": "code",
59 | "execution_count": 8,
60 | "metadata": {},
61 | "outputs": [],
62 | "source": [
63 | "import os\n",
64 | "import pickle\n",
65 | "import pandas as pd"
66 | ]
67 | },
68 | {
69 | "cell_type": "code",
70 | "execution_count": 15,
71 | "metadata": {},
72 | "outputs": [],
73 | "source": [
74 | "def construct_estimator(model, model_type, name):\n",
75 | " if model_type == 'mask': \n",
76 | " mask = masks[name]\n",
77 | " return build_estimator(\n",
78 | " 'mcdue_masked', model, nn_runs=config['nn_runs'], dropout_mask=mask,\n",
79 | " dropout_rate=config['dropout_uq'])\n",
80 | " elif model_type == 'emask': \n",
81 | " mask = emasks[name]\n",
82 | " return build_estimator(\n",
83 | " 'emcdue_masked', model, nn_runs=config['nn_runs'], dropout_mask=mask,\n",
84 | " dropout_rate=config['dropout_uq'])\n",
85 | " else:\n",
86 | " return build_estimator(name, model)\n",
87 | "\n",
88 | "\n",
89 | "class Evaluator: \n",
90 | " def __init__(self, x_test, y_test, y_scaler, tag='standard'):\n",
91 | " self.x_test = x_test\n",
92 | " self.y_test = y_test\n",
93 | " self.unscale = lambda y : y_scaler.inverse_transform(y) \n",
94 | " self.tag = tag\n",
95 | " self.results = []\n",
96 | "\n",
97 | " def bench(self, model, name, model_type='mask'): \n",
98 | " predictions = model(self.x_test).cpu().numpy()\n",
99 | " \n",
100 | " errors = np.abs(predictions - self.y_test)\n",
101 | " \n",
102 | " scaled_errors = self.unscale(predictions) - self.unscale(self.y_test)\n",
103 | " rmse = np.sqrt(np.mean(np.square(scaled_errors)))\n",
104 | "\n",
105 | " estimator = construct_estimator(model, model_type, name)\n",
106 | " if model_type == 'emask':\n",
107 | " name = 'e_' + name\n",
108 | " \n",
109 | " for run in range(config['n_ue_runs']):\n",
110 | " estimations = estimator.estimate(self.x_test)\n",
111 | " acc, ndcg, ll = get_uq_metrics(estimations, errors, \n",
112 | " config['acc_percentile'],\n",
113 | " bins = [80, 95, 99]\n",
114 | " )\n",
115 | " self.results.append([acc, ndcg, ll, rmse, name, self.tag])\n",
116 | " if hasattr(estimator, 'reset'):\n",
117 | " estimator.reset()"
118 | ]
119 | },
120 | {
121 | "cell_type": "code",
122 | "execution_count": 16,
123 | "metadata": {},
124 | "outputs": [],
125 | "source": [
126 | "folder = './exp1/'\n",
127 | "files = os.listdir(folder)"
128 | ]
129 | },
130 | {
131 | "cell_type": "code",
132 | "execution_count": null,
133 | "metadata": {},
134 | "outputs": [],
135 | "source": [
136 | "data = []\n",
137 | "for cnt, file in enumerate(files):\n",
138 | " with open('log_exp.log', 'w') as f:\n",
139 | " f.write(f'{cnt} / {len(files)}')\n",
140 | " with open(folder + file, 'rb') as f:\n",
141 | " dct = pickle.load(f)\n",
142 | "# print(file)\n",
143 | " config = dct['config']\n",
144 | " config['n_ue_runs'] = 1\n",
145 | " config['acc_percentile'] = .1\n",
146 | " state_dict = dct['state_dict']\n",
147 | " x_train, y_train, x_val, y_val, x_scaler, y_scaler = dct['data']\n",
148 | " \n",
149 | " model = MLPEnsemble(config['layers'], \n",
150 | " n_models=config['n_ens'], \n",
151 | " reduction='mean')\n",
152 | " model.load_state_dict(state_dict)\n",
153 | " \n",
154 | " standard_evaluator = Evaluator(x_val, y_val, y_scaler, 'standard')\n",
155 | " masks = build_masks(DEFAULT_MASKS)\n",
156 | " emasks = [build_masks(DEFAULT_MASKS) for i in range(config['n_ens'])]\n",
157 | " emasks = {key: [e[key] for e in emasks] for key in masks.keys()}\n",
158 | "\n",
159 | " single_model = model.models[2]\n",
160 | " for name in masks: \n",
161 | "# print(name, end = '|')\n",
162 | " standard_evaluator.bench(single_model, name, 'mask')\n",
163 | " standard_evaluator.bench(model, 'eue', 'ensemble') \n",
164 | " for name in emasks: \n",
165 | "# print(name, end = '*|')\n",
166 | " standard_evaluator.bench(model, name, 'emask')\n",
167 | " mask_df = pd.DataFrame(standard_evaluator.results, \n",
168 | " columns=['Acc', 'NDCG', 'LL', 'RMSE', 'Mask', 'Tag'])\n",
169 | " mask_df['fname'] = file\n",
170 | " data.append(mask_df)\n",
171 | " pd.concat(data).to_csv('exper1_results.csv', index = None)"
172 | ]
173 | },
174 | {
175 | "cell_type": "code",
176 | "execution_count": null,
177 | "metadata": {},
178 | "outputs": [],
179 | "source": []
180 | }
181 | ],
182 | "metadata": {
183 | "kernelspec": {
184 | "display_name": "Python 3",
185 | "language": "python",
186 | "name": "python3"
187 | },
188 | "language_info": {
189 | "codemirror_mode": {
190 | "name": "ipython",
191 | "version": 3
192 | },
193 | "file_extension": ".py",
194 | "mimetype": "text/x-python",
195 | "name": "python",
196 | "nbconvert_exporter": "python",
197 | "pygments_lexer": "ipython3",
198 | "version": "3.6.7"
199 | }
200 | },
201 | "nbformat": 4,
202 | "nbformat_minor": 2
203 | }
204 |
--------------------------------------------------------------------------------
/experiments/deprecated/regression_visual.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {
7 | "collapsed": false,
8 | "jupyter": {
9 | "outputs_hidden": false
10 | },
11 | "pycharm": {
12 | "is_executing": false,
13 | "name": "#%%\n"
14 | }
15 | },
16 | "outputs": [],
17 | "source": [
18 | "import sys\n",
19 | "sys.path.append('..')\n",
20 | "%load_ext autoreload\n",
21 | "%autoreload 2"
22 | ]
23 | },
24 | {
25 | "cell_type": "code",
26 | "execution_count": null,
27 | "metadata": {
28 | "collapsed": false,
29 | "jupyter": {
30 | "outputs_hidden": false
31 | },
32 | "pycharm": {
33 | "is_executing": false,
34 | "name": "#%%\n"
35 | }
36 | },
37 | "outputs": [],
38 | "source": [
39 | "from itertools import product\n",
40 | "\n",
41 | "import numpy as np\n",
42 | "import matplotlib.pyplot as plt\n",
43 | "import seaborn as sns\n",
44 | "\n",
45 | "\n",
46 | "from dataloader.builder import build_dataset\n",
47 | "from model.mlp import MLP\n",
48 | "from uncertainty_estimator.masks import build_masks, DEFAULT_MASKS\n",
49 | "from experiment_setup import build_estimator, get_model\n",
50 | "from experiments.utils.data import scale, split_ood, multiple_kfold\n",
51 | "import torch\n",
52 | "\n",
53 | "from analysis.autoencoder import AutoEncoder \n",
54 | "\n",
55 | "plt.rcParams['figure.facecolor'] = 'white'\n",
56 | "torch.cuda.set_device(1)\n"
57 | ]
58 | },
59 | {
60 | "cell_type": "code",
61 | "execution_count": null,
62 | "metadata": {
63 | "collapsed": false,
64 | "jupyter": {
65 | "outputs_hidden": false
66 | },
67 | "pycharm": {
68 | "is_executing": false,
69 | "name": "#%%\n"
70 | }
71 | },
72 | "outputs": [],
73 | "source": [
74 | "config = {\n",
75 | " 'nn_runs': 100,\n",
76 | " 'runs': 2,\n",
77 | " 'max_runs': 20,\n",
78 | " 'k_folds': 10,\n",
79 | " 'verbose': False,\n",
80 | " 'layers': [8, 256, 256, 128, 1],\n",
81 | " 'epochs': 10_000,\n",
82 | " 'validation_step': 50,\n",
83 | " 'acc_percentile': 0.1,\n",
84 | " 'patience': 3,\n",
85 | " 'dropout_rate': 0.2,\n",
86 | " 'dropout_uq': 0.5,\n",
87 | " 'batch_size': 256,\n",
88 | " # 'dataset': 'kin8nm',\n",
89 | " 'dataset': 'naval_propulsion',\n",
90 | " 'ood_percentile': 90,\n",
91 | " 'with_ensembles': True,\n",
92 | " 'optimizer': {'type': 'Adadelta', 'weight_decay':1e-3}\n",
93 | "}"
94 | ]
95 | },
96 | {
97 | "cell_type": "code",
98 | "execution_count": null,
99 | "metadata": {
100 | "collapsed": false,
101 | "jupyter": {
102 | "outputs_hidden": false
103 | },
104 | "pycharm": {
105 | "is_executing": false,
106 | "name": "#%%\n"
107 | }
108 | },
109 | "outputs": [],
110 | "source": [
111 | "# Load dataset\n",
112 | "dataset = build_dataset(config['dataset'])\n",
113 | "\n",
114 | "x_train, y_train = dataset.dataset('train')\n",
115 | "x_val, y_val = dataset.dataset('val')\n",
116 | "config['layers'][0] = x_train.shape[-1]\n"
117 | ]
118 | },
119 | {
120 | "cell_type": "code",
121 | "execution_count": null,
122 | "metadata": {
123 | "collapsed": false,
124 | "jupyter": {
125 | "outputs_hidden": false
126 | },
127 | "pycharm": {
128 | "is_executing": false,
129 | "name": "#%%\n"
130 | }
131 | },
132 | "outputs": [],
133 | "source": [
134 | "x_train, x_val, x_scaler = scale(x_train, x_val)\n",
135 | "y_train, y_val, y_scaler = scale(y_train, y_val)"
136 | ]
137 | },
138 | {
139 | "cell_type": "code",
140 | "execution_count": null,
141 | "metadata": {
142 | "collapsed": false,
143 | "jupyter": {
144 | "outputs_hidden": false
145 | },
146 | "pycharm": {
147 | "is_executing": false,
148 | "name": "#%%\n"
149 | }
150 | },
151 | "outputs": [],
152 | "source": [
153 | "autoencoder = AutoEncoder(config['layers'][0], 128, 2, lr=1e-2)\n",
154 | "autoencoder.train()\n",
155 | "for e in range(500):\n",
156 | " loss = autoencoder.fit(x_train)\n",
157 | " if (e+1) % 5 == 0:\n",
158 | " print(e+1, loss)\n"
159 | ]
160 | },
161 | {
162 | "cell_type": "code",
163 | "execution_count": null,
164 | "metadata": {
165 | "collapsed": false,
166 | "jupyter": {
167 | "outputs_hidden": false
168 | },
169 | "pycharm": {
170 | "is_executing": false,
171 | "name": "#%%\n"
172 | }
173 | },
174 | "outputs": [],
175 | "source": [
176 | "autoencoder.eval()\n",
177 | "def encode(x):\n",
178 | " samples = torch.DoubleTensor(x).to('cuda')\n",
179 | " encoded = autoencoder.encode(samples)\n",
180 | " return encoded.cpu().detach().numpy()\n",
181 | "\n",
182 | "def decode(x):\n",
183 | " samples = torch.DoubleTensor(x).to('cuda')\n",
184 | " encoded = autoencoder.decode(samples)\n",
185 | " return encoded.cpu().detach().numpy()\n"
186 | ]
187 | },
188 | {
189 | "cell_type": "code",
190 | "execution_count": null,
191 | "metadata": {
192 | "collapsed": false,
193 | "jupyter": {
194 | "outputs_hidden": false
195 | },
196 | "pycharm": {
197 | "is_executing": false,
198 | "name": "#%%\n"
199 | }
200 | },
201 | "outputs": [],
202 | "source": [
203 | "encoded_train = encode(x_train)\n",
204 | "plt.figure(figsize=(12, 10))\n",
205 | "sns.scatterplot(\n",
206 | " x=encoded_train[:, 0], y=encoded_train[:, 1], hue=y_train.squeeze(),\n",
207 | " palette=\"Accent\")\n"
208 | ]
209 | },
210 | {
211 | "cell_type": "code",
212 | "execution_count": null,
213 | "metadata": {
214 | "collapsed": false,
215 | "jupyter": {
216 | "outputs_hidden": false
217 | },
218 | "pycharm": {
219 | "is_executing": false,
220 | "name": "#%%\n"
221 | }
222 | },
223 | "outputs": [],
224 | "source": [
225 | "# Train or load model\n",
226 | "model = MLP(config['layers'], optimizer=config['optimizer'])\n",
227 | "model_path = f\"experiments/data/model_{config['dataset']}.ckpt\"\n",
228 | "model = get_model(model, model_path, (x_train, y_train), (x_val, y_val))\n"
229 | ]
230 | },
231 | {
232 | "cell_type": "code",
233 | "execution_count": null,
234 | "metadata": {
235 | "collapsed": false,
236 | "jupyter": {
237 | "outputs_hidden": false
238 | },
239 | "pycharm": {
240 | "is_executing": false,
241 | "name": "#%%\n"
242 | }
243 | },
244 | "outputs": [],
245 | "source": [
246 | "ngridx = 150\n",
247 | "ngridy = 150\n",
248 | "x = encoded_train[:, 0]\n",
249 | "y = encoded_train[:, 1]\n",
250 | "\n",
251 | "x1, x2 = 3*min(x), 3*max(x)\n",
252 | "y1, y2 = 3*min(y), 3*max(y)\n",
253 | "\n",
254 | "xi = np.linspace(x1, x2, ngridx)\n",
255 | "yi = np.linspace(y1, y2, ngridy)\n",
256 | "\n",
257 | "# Countour coord; for some reason they are ortogonal to usual coord in pyplot\n",
258 | "points = np.array(list(product(yi, xi)))\n",
259 | "x_grid = decode(points)\n",
260 | "x_grid.shape"
261 | ]
262 | },
263 | {
264 | "cell_type": "code",
265 | "execution_count": null,
266 | "metadata": {
267 | "collapsed": false,
268 | "jupyter": {
269 | "outputs_hidden": false
270 | },
271 | "pycharm": {
272 | "is_executing": false,
273 | "name": "#%%\n"
274 | }
275 | },
276 | "outputs": [],
277 | "source": [
278 | "\n",
279 | "# UE\n",
280 | "masks = build_masks(DEFAULT_MASKS)\n",
281 | "for name, mask in masks.items():\n",
282 | " estimator = build_estimator('mcdue_masked', model, dropout_mask=mask)\n",
283 | " estimations = estimator.estimate(x_grid)\n",
284 | " zi = estimations.reshape((ngridx, ngridy))\n",
285 | "\n",
286 | " fig, ax1 = plt.subplots(figsize=(16, 12))\n",
287 | " ax1.contour(xi, yi, zi, levels=14, linewidths=0.5, colors='k')\n",
288 | " cntr1 = ax1.contourf(xi, yi, zi, levels=14, cmap=\"gray\")\n",
289 | " fig.colorbar(cntr1, ax=ax1)\n",
290 | "\n",
291 | " ax1.scatter(x, y, c=y_train.squeeze(), alpha=0.5)\n",
292 | " ax1.set(xlim=(x1, x2), ylim=(y1, y2))\n",
293 | " ax1.set_title('%s grid and contour (%d points, %d grid points)' %\n",
294 | " (name, len(x), ngridx * ngridy))"
295 | ]
296 | },
297 | {
298 | "cell_type": "code",
299 | "execution_count": null,
300 | "metadata": {
301 | "collapsed": false,
302 | "jupyter": {
303 | "outputs_hidden": false
304 | },
305 | "pycharm": {
306 | "is_executing": false,
307 | "name": "#%%\n"
308 | }
309 | },
310 | "outputs": [],
311 | "source": [
312 | "decode(np.array([[10, 0.7]]))\n"
313 | ]
314 | },
315 | {
316 | "cell_type": "code",
317 | "execution_count": null,
318 | "metadata": {
319 | "collapsed": false,
320 | "jupyter": {
321 | "outputs_hidden": false
322 | },
323 | "pycharm": {
324 | "is_executing": false,
325 | "name": "#%%\n"
326 | }
327 | },
328 | "outputs": [],
329 | "source": [
330 | "\n"
331 | ]
332 | }
333 | ],
334 | "metadata": {
335 | "kernelspec": {
336 | "display_name": "Python 3",
337 | "language": "python",
338 | "name": "python3"
339 | },
340 | "language_info": {
341 | "codemirror_mode": {
342 | "name": "ipython",
343 | "version": 3
344 | },
345 | "file_extension": ".py",
346 | "mimetype": "text/x-python",
347 | "name": "python",
348 | "nbconvert_exporter": "python",
349 | "pygments_lexer": "ipython3",
350 | "version": "3.7.3"
351 | },
352 | "pycharm": {
353 | "stem_cell": {
354 | "cell_type": "raw",
355 | "source": [],
356 | "metadata": {
357 | "collapsed": false
358 | }
359 | }
360 | }
361 | },
362 | "nbformat": 4,
363 | "nbformat_minor": 4
364 | }
--------------------------------------------------------------------------------
/experiments/deprecated/uq_proc (2).ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {},
7 | "outputs": [],
8 | "source": [
9 | "import sys\n",
10 | "sys.path = ['/home/etsymbalov/.local/lib/python3.6/site-packages'] + sys.path\n",
11 | "import torch\n",
12 | "from torch.nn.functional import elu"
13 | ]
14 | },
15 | {
16 | "cell_type": "code",
17 | "execution_count": null,
18 | "metadata": {},
19 | "outputs": [],
20 | "source": [
21 | "# !python -m pip install torch==1.5.0+cu92 torchvision==0.6.0+cu92 -f https://download.pytorch.org/whl/torch_stable.html --user"
22 | ]
23 | },
24 | {
25 | "cell_type": "code",
26 | "execution_count": null,
27 | "metadata": {},
28 | "outputs": [],
29 | "source": [
30 | "torch.__version__"
31 | ]
32 | },
33 | {
34 | "cell_type": "code",
35 | "execution_count": null,
36 | "metadata": {},
37 | "outputs": [],
38 | "source": [
39 | "# !python -m pip install alpaca-ml --user --upgrade --force\n",
40 | "# я и руками ставил"
41 | ]
42 | },
43 | {
44 | "cell_type": "code",
45 | "execution_count": null,
46 | "metadata": {},
47 | "outputs": [],
48 | "source": [
49 | "from torch.nn.functional import leaky_relu"
50 | ]
51 | },
52 | {
53 | "cell_type": "code",
54 | "execution_count": null,
55 | "metadata": {},
56 | "outputs": [],
57 | "source": []
58 | },
59 | {
60 | "cell_type": "code",
61 | "execution_count": null,
62 | "metadata": {},
63 | "outputs": [],
64 | "source": [
65 | "import os\n",
66 | "import pickle\n",
67 | "import random\n",
68 | "from pathlib import Path\n",
69 | "\n",
70 | "import pandas as pd\n",
71 | "# import torch\n",
72 | "# from torch.nn.functional import elu\n",
73 | "import numpy as np\n",
74 | "import matplotlib.pyplot as plt\n",
75 | "\n",
76 | "from alpaca.uncertainty_estimator.masks import build_masks, DEFAULT_MASKS\n",
77 | "from alpaca.model.ensemble import MLPEnsemble\n",
78 | "from alpaca.uncertainty_estimator import build_estimator\n",
79 | "from alpaca.analysis.metrics import get_uq_metrics\n",
80 | "\n",
81 | "plt.rcParams['figure.facecolor'] = 'white'"
82 | ]
83 | },
84 | {
85 | "cell_type": "code",
86 | "execution_count": null,
87 | "metadata": {},
88 | "outputs": [],
89 | "source": [
90 | "SEED = 10 \n",
91 | "torch.manual_seed(SEED)\n",
92 | "np.random.seed(SEED)\n",
93 | "random.seed(SEED)\n",
94 | "\n",
95 | "torch.cuda.set_device(0)\n",
96 | "torch.backends.cudnn.deterministic = True\n",
97 | "torch.backends.cudnn.benchmark = False"
98 | ]
99 | },
100 | {
101 | "cell_type": "code",
102 | "execution_count": null,
103 | "metadata": {},
104 | "outputs": [],
105 | "source": [
106 | "def construct_estimator(model, model_type, name):\n",
107 | " if model_type == 'mask': \n",
108 | " mask = masks[name]\n",
109 | " msk = build_estimator(\n",
110 | " 'mcdue_masked', model, nn_runs=config['nn_runs'], dropout_mask=mask,\n",
111 | " dropout_rate=config['dropout_uq'])\n",
112 | " msk.tol_level=1e-5\n",
113 | " return msk\n",
114 | " elif model_type == 'emask': \n",
115 | " mask = emasks[name]\n",
116 | " msk = build_estimator(\n",
117 | " 'emcdue_masked', model, nn_runs=config['nn_runs'], dropout_mask=mask,\n",
118 | " dropout_rate=config['dropout_uq'])\n",
119 | " msk.tol_level=1e-5\n",
120 | " return msk\n",
121 | " else:\n",
122 | " return build_estimator(name, model)\n",
123 | "\n",
124 | "\n",
125 | "class Evaluator: \n",
126 | " def __init__(self, x_test, y_test, y_scaler, tag='standard'):\n",
127 | " self.x_test = torch.DoubleTensor(x_test).cuda()\n",
128 | " self.y_test = y_test\n",
129 | " self.unscale = lambda y : y_scaler.inverse_transform(y) \n",
130 | " self.tag = tag\n",
131 | " self.results = []\n",
132 | "\n",
133 | " def bench(self, model, name, model_type='mask'): \n",
134 | " predictions = model(self.x_test).cpu().detach().numpy()\n",
135 | " \n",
136 | " errors = np.abs(predictions - self.y_test)\n",
137 | " \n",
138 | " scaled_errors = self.unscale(predictions) - self.unscale(self.y_test)\n",
139 | " rmse = np.sqrt(np.mean(np.square(scaled_errors)))\n",
140 | "\n",
141 | " estimator = construct_estimator(model, model_type, name)\n",
142 | " if model_type == 'emask':\n",
143 | " name = 'e_' + name\n",
144 | " \n",
145 | " for run in range(config['n_ue_runs']):\n",
146 | " estimations = estimator.estimate(self.x_test)\n",
147 | " acc, ndcg, ll = get_uq_metrics(estimations, errors, \n",
148 | " config['acc_percentile'],\n",
149 | " bins = [80, 95, 99]\n",
150 | " )\n",
151 | " self.results.append([acc, ndcg, ll, rmse, name, self.tag])\n",
152 | " if hasattr(estimator, 'reset'):\n",
153 | " estimator.reset()\n"
154 | ]
155 | },
156 | {
157 | "cell_type": "code",
158 | "execution_count": null,
159 | "metadata": {},
160 | "outputs": [],
161 | "source": [
162 | "# folder = Path('./experiments/exp5_smot')\n",
163 | "folder = Path('data/regression_2')\n",
164 | "files = [file for file in os.listdir(folder) if file.endswith('.pickle')]\n"
165 | ]
166 | },
167 | {
168 | "cell_type": "code",
169 | "execution_count": null,
170 | "outputs": [],
171 | "source": [
172 | "files\n"
173 | ],
174 | "metadata": {
175 | "collapsed": false,
176 | "pycharm": {
177 | "name": "#%%\n"
178 | }
179 | }
180 | },
181 | {
182 | "cell_type": "code",
183 | "execution_count": null,
184 | "metadata": {},
185 | "outputs": [],
186 | "source": [
187 | "# with open(folder / file, 'rb') as f:\n",
188 | "# dct = pickle.load(f)\n",
189 | "# with open('./paper_upgrade/A_log_exp.log', 'w') as f:\n",
190 | "# f.write(f'{cnt} / {len(files)}')"
191 | ]
192 | },
193 | {
194 | "cell_type": "code",
195 | "execution_count": null,
196 | "metadata": {},
197 | "outputs": [],
198 | "source": [
199 | "DEFAULT_MASKS2 = DEFAULT_MASKS + ['decorrelating_sc', 'dpp']#, 'k_dpp']"
200 | ]
201 | },
202 | {
203 | "cell_type": "code",
204 | "execution_count": null,
205 | "metadata": {},
206 | "outputs": [],
207 | "source": [
208 | "DEFAULT_MASKS"
209 | ]
210 | },
211 | {
212 | "cell_type": "code",
213 | "execution_count": null,
214 | "metadata": {},
215 | "outputs": [],
216 | "source": [
217 | "data = []\n",
218 | "errs = []\n",
219 | "for cnt, file in enumerate(files[:3]):\n",
220 | "# if cnt < 235:\n",
221 | "# continue\n",
222 | " try:\n",
223 | " with open(folder / file, 'rb') as f:\n",
224 | " dct = pickle.load(f)\n",
225 | " with open('./A_log_exp.log', 'w') as f:\n",
226 | " f.write(f'{cnt} / {len(files)}')\n",
227 | " print(file)\n",
228 | " config = dct['config']\n",
229 | " config['n_ue_runs'] = 1\n",
230 | " config['acc_percentile'] = .1\n",
231 | " state_dict = dct['state_dict']\n",
232 | " x_train, y_train, x_val, y_val, x_scaler, y_scaler = dct['data']\n",
233 | "\n",
234 | " model = MLPEnsemble(\n",
235 | " config['layers'], n_models=config['n_ens'], activation = elu,\n",
236 | " reduction='mean')\n",
237 | " model.load_state_dict(state_dict)\n",
238 | "\n",
239 | " standard_evaluator = Evaluator(x_val, y_val, y_scaler, 'standard')\n",
240 | " masks = build_masks(DEFAULT_MASKS2)\n",
241 | " emasks = []\n",
242 | " for i in range(config['n_ens']):\n",
243 | " msk = build_masks(DEFAULT_MASKS2)\n",
244 | " emasks.append(msk)\n",
245 | " emasks = {key: [e[key] for e in emasks] for key in masks.keys()}\n",
246 | "\n",
247 | " single_model = model.models[2]\n",
248 | " for name in masks: \n",
249 | " print(name, end = '|')\n",
250 | " standard_evaluator.bench(single_model, name, 'mask')\n",
251 | " standard_evaluator.bench(model, 'eue', 'ensemble') \n",
252 | " for name in emasks: \n",
253 | " print(name, end = '*|')\n",
254 | " standard_evaluator.bench(model, name, 'emask')\n",
255 | " mask_df = pd.DataFrame(standard_evaluator.results, \n",
256 | " columns=['Acc', 'NDCG', 'LL',\n",
257 | " 'RMSE', 'Mask', 'Tag'])\n",
258 | " mask_df['fname'] = file\n",
259 | " data.append(mask_df)\n",
260 | " pd.concat(data).to_csv('./AAAA_experiment_results.csv', index = None)\n",
261 | " except Exception as e:\n",
262 | " errs.append([e,cnt,file])"
263 | ]
264 | },
265 | {
266 | "cell_type": "code",
267 | "execution_count": null,
268 | "metadata": {},
269 | "outputs": [],
270 | "source": [
271 | "pd.concat(data).head(50)"
272 | ]
273 | },
274 | {
275 | "cell_type": "code",
276 | "execution_count": null,
277 | "metadata": {},
278 | "outputs": [],
279 | "source": []
280 | }
281 | ],
282 | "metadata": {
283 | "kernelspec": {
284 | "display_name": "Python 3",
285 | "language": "python",
286 | "name": "python3"
287 | },
288 | "language_info": {
289 | "codemirror_mode": {
290 | "name": "ipython",
291 | "version": 3
292 | },
293 | "file_extension": ".py",
294 | "mimetype": "text/x-python",
295 | "name": "python",
296 | "nbconvert_exporter": "python",
297 | "pygments_lexer": "ipython3",
298 | "version": "3.6.7"
299 | }
300 | },
301 | "nbformat": 4,
302 | "nbformat_minor": 2
303 | }
--------------------------------------------------------------------------------
/experiments/deprecated/utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/experiments/deprecated/utils/__init__.py
--------------------------------------------------------------------------------
/experiments/deprecated/utils/data.py:
--------------------------------------------------------------------------------
1 | from sklearn.preprocessing import StandardScaler
2 | import numpy as np
3 | from sklearn.model_selection import KFold
4 |
5 |
6 | def scale(train, val):
7 | scaler = StandardScaler()
8 | scaler.fit(train)
9 | train = scaler.transform(train)
10 | val = scaler.transform(val)
11 | return train, val, scaler
12 |
13 |
14 | def split_ood(x_all, y_all, percentile=10):
15 | threshold = np.percentile(y_all, percentile)
16 | ood_idx = np.argwhere(y_all > threshold)[:, 0]
17 | x_ood, y_ood = x_all[ood_idx], y_all[ood_idx]
18 | train_idx = np.argwhere(y_all <= threshold)[:, 0]
19 | x_train, y_train = x_all[train_idx], y_all[train_idx]
20 |
21 | return x_train, y_train, x_ood, y_ood
22 |
23 |
24 | def multiple_kfold(k, data_size, max_iterations):
25 | kfold = KFold(k)
26 | for i in range(max_iterations):
27 | if i % k == 0:
28 | data_idx = np.random.permutation(data_size)
29 | idx_generator = kfold.split(data_idx)
30 | train_idx, val_idx = next(idx_generator)
31 | yield data_idx[train_idx], data_idx[val_idx]
32 |
--------------------------------------------------------------------------------
/experiments/deprecated/utils/fastai.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | from torch.utils.data import Dataset, TensorDataset, DataLoader
4 | import fastai
5 | from fastai.vision import Image
6 |
7 | # For fastai pbar work in notebooks in vscode and pycharm
8 | from fastprogress.fastprogress import force_console_behavior
9 | master_bar, progress_bar = force_console_behavior()
10 | fastai.basic_train.master_bar, fastai.basic_train.progress_bar = master_bar, progress_bar
11 |
12 |
13 | class ImageArrayDS(Dataset):
14 | def __init__(self, images, labels, tfms=None):
15 | self.images = torch.FloatTensor(images)
16 | self.labels = torch.LongTensor(labels)
17 | self.tfms = tfms
18 |
19 | def __getitem__(self, idx):
20 | image = Image(self.images[idx])
21 | if self.tfms is not None:
22 | image = image.apply_tfms(self.tfms)
23 | return image, self.labels[idx]
24 |
25 | def __len__(self):
26 | return len(self.images)
27 |
28 |
29 | class Inferencer:
30 | def __init__(self, model, batch_size=8192):
31 | self.model = model
32 | self.batch_size = batch_size
33 |
34 | def __call__(self, x, dropout_rate=0.5, dropout_mask=None):
35 | predictions = []
36 | self.model.eval()
37 |
38 | if isinstance(x, np.ndarray):
39 | x = torch.Tensor(x)
40 |
41 | for batch in DataLoader(TensorDataset(x), batch_size=self.batch_size):
42 | batch = batch[0].cuda()
43 | prediction = self.model(batch, dropout_rate=dropout_rate, dropout_mask=dropout_mask).detach().cpu() #.numpy()
44 |
45 | predictions.append(prediction)
46 |
47 | if predictions:
48 | return torch.cat(predictions)
49 | else:
50 | return torch.Tensor([])
51 |
52 | def train(self):
53 | self.model.train()
54 |
55 | def eval(self):
56 | self.model.eval()
57 |
58 |
--------------------------------------------------------------------------------
/experiments/logs/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/experiments/models.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from torch import nn
3 | import torch.nn.functional as F
4 | from torchvision.models.resnet import ResNet, BasicBlock, conv3x3, conv1x1, Bottleneck
5 | from torch.hub import load_state_dict_from_url
6 | from alpaca.model.cnn import SimpleConv
7 |
8 | model_urls = {
9 | 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
10 | }
11 |
12 | class StrongConv(nn.Module):
13 | def __init__(self, dropout_rate=0.5):
14 | super().__init__()
15 | base = 16
16 | self.conv = nn.Sequential(
17 | nn.Conv2d(3, base, 3, padding=1, bias=False),
18 | nn.BatchNorm2d(base),
19 | nn.CELU(),
20 | nn.Conv2d(base, base, 3, padding=1, bias=False),
21 | nn.CELU(),
22 | nn.MaxPool2d(2, 2),
23 | nn.Dropout2d(0.2),
24 | nn.Conv2d(base, 2*base, 3, padding=1, bias=False),
25 | nn.BatchNorm2d(2*base),
26 | nn.CELU(),
27 | nn.Conv2d(2 * base, 2 * base, 3, padding=1, bias=False),
28 | nn.CELU(),
29 | nn.Dropout2d(0.3),
30 | nn.MaxPool2d(2, 2),
31 | nn.Conv2d(2*base, 4*base, 3, padding=1, bias=False),
32 | nn.BatchNorm2d(4*base),
33 | nn.CELU(),
34 | nn.Conv2d(4*base, 4*base, 3, padding=1, bias=False),
35 | nn.CELU(),
36 | nn.Dropout2d(0.4),
37 | nn.MaxPool2d(2, 2),
38 | )
39 | self.linear_size = 8 * 8 * base
40 | self.linear = nn.Sequential(
41 | nn.Linear(self.linear_size, 8*base),
42 | nn.CELU(),
43 | )
44 | self.dropout = nn.Dropout(0.5)
45 | self.fc = nn.Linear(8*base, 10)
46 |
47 | def forward(self, x, dropout_rate=0.5, dropout_mask=None):
48 | x = self.conv(x)
49 | x = x.reshape(-1, self.linear_size)
50 | x = self.linear(x)
51 | if dropout_mask is None:
52 | x = self.dropout(x)
53 | else:
54 | x = x * dropout_mask(x, dropout_rate, 0)
55 | return self.fc(x)
56 |
57 |
58 | class ResNetMasked(ResNet):
59 | def forward(self, x, dropout_rate=0.3, dropout_mask=None, make_conv=True):
60 | if make_conv:
61 | x = self.conv1(x)
62 | x = self.bn1(x)
63 | x = self.relu(x)
64 | x = self.maxpool(x)
65 |
66 | x = self.layer1(x)
67 | x = self.layer2(x)
68 | x = self.layer3(x)
69 | x = self.layer4(x)
70 |
71 | x = self.avgpool(x)
72 | x = torch.flatten(x, 1)
73 | self.middle_x = x.detach().cpu().clone()
74 | if dropout_mask is not None:
75 | x = x * dropout_mask(x, dropout_rate, 0)
76 | else:
77 | x = self.dropout(x)
78 | x = self.fc(x)
79 |
80 | return x
81 |
82 |
83 | def resnet_masked(pretrained=True, dropout_rate=0.3):
84 | base = resnet18(pretrained=pretrained)
85 | base.dropout = nn.Dropout(dropout_rate)
86 | base.fc = nn.Linear(512, 10)
87 |
88 | return base
89 |
90 |
91 | def resnet_dropout(pretrained=True, dropout_rate=0.3):
92 | base = resnet18(pretrained=pretrained)
93 | base.dropout = nn.Dropout(dropout_rate)
94 | # base.fc = nn.Linear(512, 10)
95 |
96 | return base
97 |
98 |
99 |
100 | def _resnet(arch, block, layers, pretrained, progress, **kwargs):
101 | model = ResNetMasked(block, layers, **kwargs)
102 |
103 | if pretrained:
104 | state_dict = load_state_dict_from_url(model_urls[arch],
105 | progress=progress)
106 | model.load_state_dict(state_dict)
107 | return model
108 |
109 |
110 | def resnet18(pretrained=False, progress=True, **kwargs):
111 | r"""ResNet-18 model from
112 | `"Deep Residual Learning for Image Recognition" `_
113 |
114 | Args:
115 | pretrained (bool): If True, returns a model pre-trained on ImageNet
116 | progress (bool): If True, displays a progress bar of the download to stderr
117 | """
118 | return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, progress,
119 | **kwargs)
120 |
--------------------------------------------------------------------------------
/experiments/move_chest.py:
--------------------------------------------------------------------------------
1 | import os
2 | from pathlib import Path
3 | from shutil import copy
4 |
5 | from PIL import Image
6 |
7 | ## The script to make Chexpert directory style similar to the ImageNet
8 | root_dir = Path('data/chest')
9 | source = root_dir / 'CheXpert-v1.0-small' / 'train'
10 | target = root_dir / 'train'
11 |
12 |
13 | folder_list = sorted(os.listdir(source))
14 |
15 | for folder in folder_list:
16 | with_images = source/folder/'study1'
17 |
18 | if os.path.exists(with_images / 'view1_frontal.jpg'):
19 | file_path = with_images / 'view1_frontal.jpg'
20 | else:
21 | file_path = with_images / 'view1_lateral.jpg'
22 | image = Image.open(file_path)
23 |
24 | copy(file_path, target/f"{folder}.jpg")
25 |
26 | print(image.size, folder)
27 |
28 |
29 |
30 |
--------------------------------------------------------------------------------
/experiments/print_confidence_accuracy.py:
--------------------------------------------------------------------------------
1 | import pickle
2 | import os
3 | import argparse
4 |
5 | import numpy as np
6 | import pandas as pd
7 | import matplotlib.pyplot as plt
8 | import seaborn as sns
9 |
10 |
11 | def estimator_name(estimator):
12 | return {
13 | 'max_prob': 'Max probability',
14 | 'mc_dropout': 'MC dropout',
15 | 'ht_decorrelating': 'decorrelation',
16 | 'ht_dpp': 'DPP',
17 | 'ht_k_dpp': 'k-DPP',
18 | 'cov_dpp': 'DPP (cov)',
19 | 'cov_k_dpp': 'k-DPP (cov)',
20 | 'ensemble_max_prob': 'Ensemble (max prob)',
21 | 'ensemble_bald': 'Ensemble (bald)',
22 | 'ensemble_var_ratio': 'Ensemble (var ratio)',
23 | }[estimator]
24 |
25 |
26 | def print_confidence():
27 | parser = argparse.ArgumentParser()
28 | parser.add_argument('name', type=str)
29 | parser.add_argument('--acquisition', '-a', type=str, default='bald')
30 | parser.add_argument('--covariance', dest='covariance', action='store_true')
31 | args = parser.parse_args()
32 |
33 | args.repeats = {'mnist': 3, 'cifar': 3, 'imagenet': 1}[args.name]
34 |
35 | acc_conf = []
36 | count_conf = []
37 |
38 | covariance_str = '_covar' if args.covariance else ''
39 | acquisition_str = args.acquisition
40 |
41 | for i in range(args.repeats):
42 | file_name = f'logs/classification/{args.name}_{i}/ue_{acquisition_str}.pickle'
43 | if os.path.exists(file_name):
44 | process_file(file_name, args.acquisition, acc_conf, count_conf, ['mc_dropout', 'ht_dpp', 'cov_k_dpp', 'cov_dpp', 'ht_k_dpp', 'max_prob'])
45 |
46 | if args.acquisition == 'max_prob':
47 | ensemble_method = f"ensemble_{args.acquisition}"
48 | ensemble_file = f'logs/classification/{args.name}_{i}/ue_ensemble.pickle'
49 | if os.path.exists(ensemble_file):
50 | process_file(ensemble_file, args.acquisition, acc_conf, count_conf, [ensemble_method])
51 |
52 |
53 | plt.rcParams.update({'font.size': 13})
54 | plt.rc('grid', linestyle="--")
55 | plt.figure(figsize=(7, 5))
56 |
57 | if args.acquisition == 'bald':
58 | metric = 'UE'
59 | else:
60 | metric = 'Confidence'
61 |
62 | plt.title(f"{metric}-accuracy {args.name} {args.acquisition} {covariance_str}")
63 | df = pd.DataFrame(acc_conf, columns=[f'{metric} level', 'Accuracy', 'Estimator'])
64 | sns.lineplot(f'{metric} level', 'Accuracy', data=df, hue='Estimator')
65 | # plt.subplots_adjust(right=0.7)
66 | # plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
67 | sign = '<' if args.acquisition == 'bald' else '<'
68 | plt.ylabel(fr"Accuracy for samples, {metric} {sign} $\tau$")
69 | plt.xlabel(r"$\tau$")
70 | plt.grid()
71 |
72 | plt.savefig(f"data/conf_accuracy_{args.name}_{args.acquisition}{covariance_str}", dpi=150)
73 | plt.show()
74 |
75 |
76 | def process_file(file_name, acquisition, acc_conf, count_conf, methods):
77 | if acquisition == 'bald':
78 | process_file_bald(file_name, acquisition, acc_conf, count_conf, methods)
79 | return
80 |
81 | with open(file_name, 'rb') as f:
82 | record = pickle.load(f)
83 |
84 | prediction = np.argmax(np.array(record['probabilities']), axis=-1)
85 | is_correct = (prediction == record['y_val']).astype(np.int)
86 |
87 | bins = np.concatenate((np.arange(0, 1, 0.1), [0.98, 0.99, 0.999]))
88 |
89 | for estimator in methods:
90 | if estimator not in record['uncertainties'].keys():
91 | continue
92 |
93 | ue = record['uncertainties'][estimator]
94 | print(estimator)
95 | ue = ue / max(ue)
96 |
97 | for confidence_level in bins:
98 | point_confidences = 1 - ue
99 | bin_correct = is_correct[point_confidences > confidence_level]
100 | if len(bin_correct) > 0:
101 | accuracy = sum(bin_correct) / len(bin_correct)
102 | else:
103 | accuracy = None
104 |
105 | acc_conf.append((confidence_level, accuracy, estimator_name(estimator)))
106 | count_conf.append((confidence_level, len(bin_correct), estimator_name(estimator)))
107 |
108 |
109 | def process_file_bald(file_name, acquisition, acc_conf, count_conf, methods):
110 | with open(file_name, 'rb') as f:
111 | record = pickle.load(f)
112 |
113 | prediction = np.argmax(np.array(record['probabilities']), axis=-1)
114 | is_correct = (prediction == record['y_val']).astype(np.int)
115 |
116 | if 'mnist' in file_name:
117 | bins = np.concatenate(([0, 0.01, 0.02, 0.03, 0.04, 0.05], np.arange(0.1, 1.4, 0.1)))
118 | elif 'cifar' in file_name:
119 | bins = np.concatenate(([0, 0.01, 0.02, 0.03, 0.04, 0.05], np.arange(0.1, 1, 0.1)))
120 | else:
121 | bins = np.concatenate(([0.05], np.arange(0.3, 3, 0.3)))
122 |
123 | for estimator in methods:
124 | if estimator not in record['uncertainties'].keys():
125 | continue
126 | ue = record['uncertainties'][estimator]
127 |
128 | for ue_level in bins:
129 | bin_correct = is_correct[ue < ue_level]
130 |
131 | if len(bin_correct) > 0:
132 | accuracy = sum(bin_correct) / len(bin_correct)
133 | else:
134 | accuracy = None
135 |
136 | acc_conf.append((ue_level, accuracy, estimator_name(estimator)))
137 | count_conf.append((ue_level, len(bin_correct), estimator_name(estimator)))
138 |
139 |
140 | if __name__ == '__main__':
141 | print_confidence()
142 |
--------------------------------------------------------------------------------
/experiments/print_ood.py:
--------------------------------------------------------------------------------
1 | import pickle
2 | import os
3 | import argparse
4 |
5 | import numpy as np
6 | import pandas as pd
7 | import matplotlib.pyplot as plt
8 | import seaborn as sns
9 | from print_confidence_accuracy import estimator_name
10 |
11 |
12 | parser = argparse.ArgumentParser()
13 | parser.add_argument('name', type=str)
14 | parser.add_argument('--acquisition', '-a', type=str, default='bald')
15 | args = parser.parse_args()
16 | args.repeats = {'mnist': 3, 'cifar': 3, 'imagenet': 1}[args.name]
17 |
18 |
19 | def process_file(file_name, count_conf, args, methods):
20 |
21 | with open(file_name, 'rb') as f:
22 | record = pickle.load(f)
23 |
24 | if args.acquisition == 'bald':
25 | process_file_bald(record, count_conf, args, methods)
26 | return
27 |
28 | bins = np.concatenate((np.arange(0, 1, 0.1), [0.98, 0.99, 0.999]))
29 | for estimator in methods:
30 | if estimator not in record['uncertainties'].keys():
31 | continue
32 | ue = record['uncertainties'][estimator]
33 |
34 | print(estimator)
35 | print(min(ue), max(ue))
36 | if args.acquisition == 'bald':
37 | ue = ue / max(ue)
38 |
39 | for confidence_level in bins:
40 | point_confidences = 1 - ue
41 | level_count = np.sum(point_confidences > confidence_level)
42 | count_conf.append((confidence_level, level_count, estimator_name(estimator)))
43 |
44 |
45 | def process_file_bald(record, count_conf, args, methods):
46 | # bins = np.concatenate((np.arange(0, 1, 0.1), [0.98, 0.99, 0.999]))
47 |
48 | max_ue = {
49 | 'mnist': 1.4, 'cifar': 1, 'imagenet': 1.1
50 | }[args.name]
51 |
52 | bins = np.concatenate(([0, 0.02, 0.04, 0.06], np.arange(0.1, max_ue, 0.02)))
53 |
54 | for estimator in methods:
55 | if estimator not in record['uncertainties'].keys():
56 | continue
57 | ue = record['uncertainties'][estimator]
58 |
59 | print(estimator)
60 | if args.acquisition == 'bald':
61 | ue = ue / max(ue)
62 |
63 | for ue_level in bins:
64 | level_count = np.sum(ue < ue_level)
65 | count_conf.append((ue_level, level_count, estimator_name(estimator)))
66 |
67 |
68 | count_conf = []
69 |
70 | for i in range(args.repeats):
71 | file_name = f'logs/classification/{args.name}_{i}/ue_ood_{args.acquisition}.pickle'
72 | if args.acquisition == 'max_prob':
73 | methods = ['mc_dropout', 'ht_dpp', 'cov_k_dpp', 'cov_dpp', 'ht_k_dpp', 'max_prob']
74 | else:
75 | methods = ['mc_dropout', 'ht_dpp', 'cov_k_dpp', 'cov_dpp', 'ht_k_dpp']
76 |
77 |
78 | process_file(file_name, count_conf, args, methods)
79 |
80 | if args.acquisition == 'max_prob':
81 | ensemble_method = f"ensemble_{args.acquisition}"
82 | file_name = f'logs/classification/{args.name}_{i}/ue_ensemble_ood.pickle'
83 | if os.path.exists(file_name):
84 | process_file(file_name, count_conf, args, [ensemble_method])
85 |
86 |
87 |
88 | if args.acquisition == 'bald':
89 | metric = 'UE'
90 | else:
91 | metric = 'Confidence'
92 |
93 | plt.rcParams.update({'font.size': 13})
94 | plt.rc('grid', linestyle="--")
95 | plt.figure(figsize=(7, 5))
96 | plt.title(f"{metric}-count for OOD {args.name} {args.acquisition}")
97 | df = pd.DataFrame(count_conf, columns=[f'{metric} level', 'Count', 'Estimator'])
98 | sns.lineplot(f'{metric} level', 'Count', data=df, hue='Estimator')
99 | plt.subplots_adjust(left=0.15)
100 | # plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
101 |
102 | sign = '<' if args.acquisition == 'bald' else '>'
103 | plt.ylabel(rf"Number of samples, {metric} {sign} $\tau$")
104 | plt.xlabel(rf"$\tau$")
105 | plt.grid()
106 | plt.savefig(f"data/conf_ood_{args.name}_{args.acquisition}", dpi=150)
107 | plt.show()
108 |
109 |
--------------------------------------------------------------------------------
/experiments/regression_1_big_exper_train-clean.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "metadata": {
7 | "pycharm": {
8 | "is_executing": false
9 | }
10 | },
11 | "outputs": [],
12 | "source": [
13 | "# 1) pick dataset\n",
14 | "# 2) make n_split_runs=3 runs of 5-kfold\n",
15 | "# 3) for n_model_runs=3 \n",
16 | "# 4) train an ensemble of n_ens=5 models\n",
17 | "# 5) for each single-nn model make n_ue_runs=5 UE runs\n",
18 | "# 6) for EUE make a UE run\n",
19 | "# 7) for ensemble-UE make n_ue_runs=5 UE runs\n",
20 | "# 8) save data for a future"
21 | ]
22 | },
23 | {
24 | "cell_type": "code",
25 | "execution_count": null,
26 | "metadata": {
27 | "pycharm": {
28 | "is_executing": false
29 | }
30 | },
31 | "outputs": [],
32 | "source": [
33 | "import sys\n",
34 | "sys.path.append('..')\n",
35 | "%load_ext autoreload\n",
36 | "%autoreload 2\n"
37 | ]
38 | },
39 | {
40 | "cell_type": "code",
41 | "execution_count": null,
42 | "metadata": {
43 | "pycharm": {
44 | "is_executing": false
45 | }
46 | },
47 | "outputs": [],
48 | "source": [
49 | "import os\n",
50 | "from pathlib import Path\n",
51 | "import random\n",
52 | "\n",
53 | "import matplotlib.pyplot as plt\n",
54 | "import pickle\n",
55 | "import torch\n",
56 | "import numpy as np\n",
57 | "\n",
58 | "# from experiment_setup import get_model, set_random, build_estimator\n",
59 | "from alpaca.model.ensemble import MLPEnsemble\n",
60 | "from alpaca.dataloader.builder import build_dataset\n",
61 | "from experiments.utils.data import scale, multiple_kfold\n",
62 | "\n",
63 | "plt.rcParams['figure.facecolor'] = 'white'"
64 | ]
65 | },
66 | {
67 | "cell_type": "code",
68 | "execution_count": null,
69 | "metadata": {
70 | "pycharm": {
71 | "is_executing": false
72 | }
73 | },
74 | "outputs": [],
75 | "source": [
76 | "SEED = 10 \n",
77 | "torch.manual_seed(SEED)\n",
78 | "np.random.seed(SEED)\n",
79 | "random.seed(SEED)\n",
80 | "\n",
81 | "torch.cuda.set_device(0)\n",
82 | "torch.backends.cudnn.deterministic = True\n",
83 | "torch.backends.cudnn.benchmark = False\n",
84 | "\n"
85 | ]
86 | },
87 | {
88 | "cell_type": "code",
89 | "execution_count": null,
90 | "metadata": {
91 | "pycharm": {
92 | "is_executing": false
93 | }
94 | },
95 | "outputs": [],
96 | "source": [
97 | "config = {\n",
98 | " 'nn_runs': 100,\n",
99 | " 'runs': 2,\n",
100 | " 'max_runs': 20,\n",
101 | " # Our train config\n",
102 | " 'layers': [8, 128, 128, 64, 1],\n",
103 | "# 'layers': [8, 256, 256, 128, 1],\n",
104 | " #'layers': [8, 2048, 2048, 1024, 1],\n",
105 | " 'epochs': 10_000,\n",
106 | " 'validation_step': 100,\n",
107 | " \n",
108 | " # Our train config\n",
109 | " 'nll_layers': [8, 256, 256, 128, 2],\n",
110 | " 'nll_epochs': 400,\n",
111 | " 'nll_validation_step': 50,\n",
112 | " \n",
113 | " 'acc_percentile': 0.1,\n",
114 | " 'patience': 10,\n",
115 | " 'dropout_rate': 0.2,\n",
116 | " 'dropout_uq': 0.5,\n",
117 | " 'batch_size': 256,\n",
118 | " 'dataset': 'kin8nm',\n",
119 | " 'l2_reg': 1e-5,\n",
120 | " 'ood_percentile': 90,\n",
121 | " \n",
122 | " 'optimizer': {'type': 'Adam', 'lr': 0.01, 'weight_decay':1e-5},\n",
123 | " 'n_split_runs': 3,\n",
124 | " 'n_model_runs': 3,\n",
125 | " 'n_ens': 5,\n",
126 | " 'n_ue_runs': 5,\n",
127 | " 'k_folds': 10,\n",
128 | " 'verbose': False,\n",
129 | "}\n"
130 | ]
131 | },
132 | {
133 | "cell_type": "code",
134 | "execution_count": null,
135 | "metadata": {
136 | "pycharm": {
137 | "is_executing": false
138 | }
139 | },
140 | "outputs": [],
141 | "source": [
142 | "train_opts = ['patience', 'dropout_rate', 'epochs', 'batch_size', 'validation_step', 'verbose']\n",
143 | "config['train_opts'] = {k: config[k] for k in config if k in train_opts}\n"
144 | ]
145 | },
146 | {
147 | "cell_type": "code",
148 | "execution_count": null,
149 | "metadata": {
150 | "pycharm": {
151 | "is_executing": false
152 | }
153 | },
154 | "outputs": [],
155 | "source": [
156 | "datasets = [\n",
157 | " 'boston_housing', 'concrete', 'energy_efficiency',\n",
158 | " 'kin8nm', 'naval_propulsion', 'ccpp', 'red_wine', \n",
159 | " 'yacht_hydrodynamics'\n",
160 | "]"
161 | ]
162 | },
163 | {
164 | "cell_type": "code",
165 | "execution_count": null,
166 | "metadata": {
167 | "pycharm": {
168 | "is_executing": false
169 | }
170 | },
171 | "outputs": [],
172 | "source": [
173 | "for dataset_name in datasets:\n",
174 | " dataset = build_dataset(dataset_name, val_split=0.0) \n",
175 | " x_set, y_set = dataset.dataset('train')\n",
176 | " print(dataset_name, x_set.shape)\n",
177 | " config['layers'][0] = x_set.shape[-1]"
178 | ]
179 | },
180 | {
181 | "cell_type": "code",
182 | "execution_count": null,
183 | "metadata": {
184 | "pycharm": {
185 | "is_executing": true
186 | }
187 | },
188 | "outputs": [
189 | {
190 | "name": "stdout",
191 | "text": [
192 | "Fit [3/5] model:\n",
193 | "Fit [4/5] model:\n",
194 | "Fit [5/5] model:\n",
195 | "Fit [1/5] model:\n",
196 | "Fit [2/5] model:\n",
197 | "Fit [3/5] model:\n",
198 | "Fit [4/5] model:\n"
199 | ],
200 | "output_type": "stream"
201 | }
202 | ],
203 | "source": [
204 | "# over datasets\n",
205 | "for dataset_name in datasets:\n",
206 | " print(f'=={dataset_name}==')\n",
207 | " dataset = build_dataset(dataset_name, val_split=0.0) \n",
208 | " x_set, y_set = dataset.dataset('train')\n",
209 | " config['layers'][0] = x_set.shape[-1]\n",
210 | " # over different splits\n",
211 | " for split_cnt in range(config['n_split_runs']):\n",
212 | " kfold_iterator = multiple_kfold(config['k_folds'], \n",
213 | " len(x_set), \n",
214 | " config['k_folds'])\n",
215 | " # within one split\n",
216 | " for kfold_cnt, (val_idx, train_idx) in enumerate(kfold_iterator): \n",
217 | " # MIND THE ORDER\n",
218 | " x_train, y_train = x_set[train_idx], y_set[train_idx]\n",
219 | " x_val, y_val = x_set[val_idx], y_set[val_idx]\n",
220 | " x_train, x_val, x_scaler = scale(x_train, x_val)\n",
221 | " y_train, y_val, y_scaler = scale(y_train, y_val)\n",
222 | " \n",
223 | " train_opts = config['train_opts'].copy()\n",
224 | " # over model runs\n",
225 | " for model_cnt in range(config['n_split_runs']):\n",
226 | " model = MLPEnsemble(config['layers'], \n",
227 | " n_models=config['n_ens'], \n",
228 | " reduction='mean')\n",
229 | " model.fit((x_train, y_train),\n",
230 | " (x_val, y_val),\n",
231 | " **train_opts)\n",
232 | " \n",
233 | " fname = f'{dataset_name[:4]}_split={split_cnt}_kfold={kfold_cnt}_model={model_cnt}'\n",
234 | " dct = {\n",
235 | " 'config': config,\n",
236 | " 'state_dict': model.state_dict(),\n",
237 | " 'data': (x_train, y_train, x_val, y_val, x_scaler, y_scaler)\n",
238 | " }\n",
239 | " dir = Path(os.getcwd()) / 'data' / 'regression'\n",
240 | " with open(dir / f'{fname}.pickle', 'wb') as f:\n",
241 | " pickle.dump(dct, f)"
242 | ]
243 | },
244 | {
245 | "cell_type": "code",
246 | "execution_count": null,
247 | "metadata": {
248 | "pycharm": {
249 | "is_executing": true
250 | }
251 | },
252 | "outputs": [],
253 | "source": [
254 | "x_train.shape, x_val.shape"
255 | ]
256 | },
257 | {
258 | "cell_type": "code",
259 | "execution_count": null,
260 | "outputs": [],
261 | "source": [
262 | "\n"
263 | ],
264 | "metadata": {
265 | "collapsed": false,
266 | "pycharm": {
267 | "name": "#%%\n",
268 | "is_executing": true
269 | }
270 | }
271 | }
272 | ],
273 | "metadata": {
274 | "kernelspec": {
275 | "display_name": "Python 3",
276 | "language": "python",
277 | "name": "python3"
278 | },
279 | "language_info": {
280 | "codemirror_mode": {
281 | "name": "ipython",
282 | "version": 3
283 | },
284 | "file_extension": ".py",
285 | "mimetype": "text/x-python",
286 | "name": "python",
287 | "nbconvert_exporter": "python",
288 | "pygments_lexer": "ipython3",
289 | "version": "3.6.7"
290 | },
291 | "pycharm": {
292 | "stem_cell": {
293 | "cell_type": "raw",
294 | "source": [],
295 | "metadata": {
296 | "collapsed": false
297 | }
298 | }
299 | }
300 | },
301 | "nbformat": 4,
302 | "nbformat_minor": 2
303 | }
--------------------------------------------------------------------------------
/experiments/visual_datasets.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from torch.utils.data import Dataset
3 | from torch.utils.data import DataLoader
4 | from albumentations import (
5 | HorizontalFlip, CLAHE, ShiftScaleRotate, Blur, HueSaturationValue,
6 | RandomBrightnessContrast, Compose, Normalize, ToFloat
7 | )
8 | from albumentations.pytorch.transforms import ToTensorV2
9 | import matplotlib.pyplot as plt
10 |
11 | from alpaca.dataloader.builder import build_dataset
12 |
13 | def loader(x, y, batch_size=128, tfms=None, train=False):
14 | # ds = TensorDataset(torch.DoubleTensor(x), torch.LongTensor(y))
15 | ds = ImageDataset(x, y, train=train, tfms=tfms)
16 | _loader = DataLoader(ds, batch_size=batch_size, num_workers=4, shuffle=train)
17 | return _loader
18 |
19 |
20 | augmentations = Compose([])
21 |
22 | post_aug = Compose([
23 | Normalize(),
24 | ToTensorV2(),
25 | ])
26 |
27 |
28 | def prepare_cifar(config):
29 | dataset = build_dataset('cifar_10', val_size=config['val_size'])
30 |
31 | x_set, y_set = dataset.dataset('train')
32 | x_val, y_val = dataset.dataset('val')
33 |
34 | shape = (-1, 3, 32, 32)
35 | x_set = np.moveaxis(x_set.reshape(shape), 1, 3).astype(np.uint8)
36 | x_val = np.moveaxis(x_val.reshape(shape), 1, 3).astype(np.uint8)
37 |
38 | # x_set = ((x_set - 128) / 128).reshape(shape)
39 | # x_val = ((x_val - 128) / 128).reshape(shape)
40 |
41 | train_tfms = augmentations
42 |
43 | return x_set, y_set, x_val, y_val, train_tfms
44 |
45 |
46 | def prepare_mnist(config):
47 | dataset = build_dataset('mnist', val_size=config['val_size'])
48 | x_set, y_set = dataset.dataset('train')
49 | x_val, y_val = dataset.dataset('val')
50 |
51 | shape = (-1, 1, 28, 28)
52 | x_set = ((x_set - 128) / 128).reshape(shape)
53 | x_val = ((x_val - 128) / 128).reshape(shape)
54 |
55 | train_tfms = []
56 |
57 | return x_set, y_set, x_val, y_val, train_tfms
58 |
59 |
60 | def prepare_svhn(config):
61 | dataset = build_dataset('svhn', val_size=config['val_size'])
62 |
63 | x_set, y_set = dataset.dataset('train')
64 | x_val, y_val = dataset.dataset('val')
65 | y_set[y_set == 10] = 0
66 | y_val[y_val == 10] = 0
67 |
68 | shape = (-1, 32, 32, 3)
69 | x_set = x_set.reshape(shape).astype(np.uint8)
70 | x_val = x_val.reshape(shape).astype(np.uint8)
71 | train_tfms = augmentations
72 |
73 | return x_set, y_set, x_val, y_val, train_tfms
74 |
75 |
76 | def prepare_fashion_mnist(config):
77 | dataset = build_dataset('fashion_mnist', val_size=config['val_size'])
78 | x_set, y_set = dataset.dataset('train')
79 | x_val, y_val = dataset.dataset('val')
80 | print(x_set.shape)
81 |
82 | shape = (-1, 1, 28, 28)
83 | x_set = ((x_set - 128) / 128).reshape(shape)
84 | x_val = ((x_val - 128) / 128).reshape(shape)
85 |
86 | train_tfms = []
87 |
88 | return x_set, y_set, x_val, y_val, train_tfms
89 |
90 |
91 | class ImageDataset(Dataset):
92 | def __init__(self, x, y, train=False, tfms=None):
93 | self.x = x
94 | self.y = y
95 | self.train = train
96 | self.tfms = tfms
97 |
98 | def __len__(self):
99 | return len(self.y)
100 |
101 | def __getitem__(self, idx):
102 | return self.load_img(idx), self.y[idx]
103 |
104 | def load_img(self, idx):
105 | image = self.x[idx]
106 | if self.tfms:
107 | image = self.tfms(image=image)['image']
108 | if image.shape[2] == 3:
109 | image = post_aug(image=image)['image'].double()
110 | return image
111 |
--------------------------------------------------------------------------------
/figures/2d_toy.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/figures/2d_toy.png
--------------------------------------------------------------------------------
/figures/active_learning_mnist.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/figures/active_learning_mnist.png
--------------------------------------------------------------------------------
/figures/benchmark.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/figures/benchmark.png
--------------------------------------------------------------------------------
/figures/convergence.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/figures/convergence.png
--------------------------------------------------------------------------------
/figures/dolan_acc_ens.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/figures/dolan_acc_ens.png
--------------------------------------------------------------------------------
/figures/dolan_acc_single.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/figures/dolan_acc_single.png
--------------------------------------------------------------------------------
/figures/dpp_ring_contour.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/figures/dpp_ring_contour.png
--------------------------------------------------------------------------------
/figures/error_detector_cifar.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/figures/error_detector_cifar.png
--------------------------------------------------------------------------------
/figures/error_detector_mnist.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/figures/error_detector_mnist.png
--------------------------------------------------------------------------------
/figures/error_detector_svhn.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/figures/error_detector_svhn.png
--------------------------------------------------------------------------------
/figures/ood_mnist.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/figures/ood_mnist.png
--------------------------------------------------------------------------------
/figures/ring_results.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/stat-ml/dpp-dropout-uncertainty/3e0ac89c6717be0ce1dc322ccd3cfb1f06e0e952/figures/ring_results.png
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | pandas>=0.25.1
2 | seaborn>=0.9.0
3 | alpaca-ml==0.8.0
4 | torch>=1.2.0
5 | torchvision=
6 | catalyst==20.3
7 | matplotlib>=3.0.0
8 | albumentations==0.4.3
9 |
10 |
--------------------------------------------------------------------------------